\n",
"\n",
"\n",
" \n",
"
\n",
"
"
],
"text/plain": [
" Population, total Surface area (sq. km) \\\n",
"country date \n",
"Afghanistan 1960-01-01 8996351.0 NaN \n",
" 1961-01-01 9166764.0 652860.0 \n",
" 1962-01-01 9345868.0 652860.0 \n",
"... ... ... \n",
"Zimbabwe 2015-01-01 15777451.0 390760.0 \n",
" 2016-01-01 16150362.0 390760.0 \n",
" 2017-01-01 16529904.0 390760.0 \n",
"\n",
" Land area (sq. km) Arable land (% of land area) \n",
"country date \n",
"Afghanistan 1960-01-01 NaN NaN \n",
" 1961-01-01 652860.0 11.717673 \n",
" 1962-01-01 652860.0 11.794259 \n",
"... ... ... \n",
"Zimbabwe 2015-01-01 386850.0 10.339925 \n",
" 2016-01-01 386850.0 NaN \n",
" 2017-01-01 386850.0 NaN \n",
"\n",
"[15312 rows x 4 columns]"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"indicators = {'SP.POP.TOTL': 'Population, total',\n",
" 'AG.SRF.TOTL.K2': 'Surface area (sq. km)',\n",
" 'AG.LND.TOTL.K2': 'Land area (sq. km)',\n",
" 'AG.LND.ARBL.ZS': 'Arable land (% of land area)'}\n",
"data = wb.get_dataframe(indicators, convert_date=True).sort_index()\n",
"data"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"World is one of the countries"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"| \n", " | \n", " | Population, total | \n", "Surface area (sq. km) | \n", "Land area (sq. km) | \n", "Arable land (% of land area) | \n", "
|---|---|---|---|---|---|
| country | \n", "date | \n", "\n", " | \n", " | \n", " | \n", " |
| Afghanistan | \n", "1960-01-01 | \n", "8996351.0 | \n", "NaN | \n", "NaN | \n", "NaN | \n", "
| 1961-01-01 | \n", "9166764.0 | \n", "652860.0 | \n", "652860.0 | \n", "11.717673 | \n", "|
| 1962-01-01 | \n", "9345868.0 | \n", "652860.0 | \n", "652860.0 | \n", "11.794259 | \n", "|
| ... | \n", "... | \n", "... | \n", "... | \n", "... | \n", "... | \n", "
| Zimbabwe | \n", "2015-01-01 | \n", "15777451.0 | \n", "390760.0 | \n", "386850.0 | \n", "10.339925 | \n", "
| 2016-01-01 | \n", "16150362.0 | \n", "390760.0 | \n", "386850.0 | \n", "NaN | \n", "|
| 2017-01-01 | \n", "16529904.0 | \n", "390760.0 | \n", "386850.0 | \n", "NaN | \n", "
15312 rows × 4 columns
\n", "\n",
"\n",
"\n",
" \n",
"
\n",
"
"
],
"text/plain": [
" Population, total Surface area (sq. km) Land area (sq. km) \\\n",
"date \n",
"1960-01-01 3.032160e+09 NaN NaN \n",
"1961-01-01 3.073369e+09 134043190.4 129721455.4 \n",
"1962-01-01 3.126510e+09 134043190.4 129721435.4 \n",
"... ... ... ... \n",
"2015-01-01 7.357559e+09 134325130.2 129732901.8 \n",
"2016-01-01 7.444157e+09 134325130.2 129733172.7 \n",
"2017-01-01 7.530360e+09 134325130.2 129733172.7 \n",
"\n",
" Arable land (% of land area) \n",
"date \n",
"1960-01-01 NaN \n",
"1961-01-01 9.693086 \n",
"1962-01-01 9.726105 \n",
"... ... \n",
"2015-01-01 10.991288 \n",
"2016-01-01 NaN \n",
"2017-01-01 NaN \n",
"\n",
"[58 rows x 4 columns]"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"data.loc['World']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Can we classify over continents?"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"Index(['Iran, Islamic Rep.', 'Congo, Dem. Rep.', 'Germany', 'Vietnam',\n",
" 'Egypt, Arab Rep.', 'Central Europe and the Baltics', 'Philippines',\n",
" 'Ethiopia', 'Japan', 'Mexico', 'Russian Federation', 'Bangladesh',\n",
" 'Nigeria', 'Pakistan', 'Brazil', 'Indonesia', 'United States',\n",
" 'Euro area', 'North America',\n",
" 'Middle East & North Africa (IDA & IBRD countries)',\n",
" 'Middle East & North Africa (excluding high income)', 'Arab World',\n",
" 'Europe & Central Asia (excluding high income)',\n",
" 'Middle East & North Africa',\n",
" 'Europe & Central Asia (IDA & IBRD countries)',\n",
" 'Fragile and conflict affected situations', 'European Union',\n",
" 'IDA blend', 'Latin America & Caribbean (excluding high income)',\n",
" 'Latin America & the Caribbean (IDA & IBRD countries)',\n",
" 'Latin America & Caribbean', 'Low income',\n",
" 'Heavily indebted poor countries (HIPC)', 'Pre-demographic dividend',\n",
" 'Europe & Central Asia', 'Least developed countries: UN classification',\n",
" 'Sub-Saharan Africa (excluding high income)',\n",
" 'Sub-Saharan Africa (IDA & IBRD countries)', 'Sub-Saharan Africa',\n",
" 'IDA only', 'Post-demographic dividend', 'High income', 'OECD members',\n",
" 'India', 'China', 'IDA total', 'South Asia (IDA & IBRD)', 'South Asia',\n",
" 'East Asia & Pacific (IDA & IBRD countries)',\n",
" 'East Asia & Pacific (excluding high income)',\n",
" 'Late-demographic dividend', 'East Asia & Pacific',\n",
" 'Upper middle income', 'Lower middle income',\n",
" 'Early-demographic dividend', 'IBRD only', 'Middle income',\n",
" 'Low & middle income', 'IDA & IBRD total', 'World'],\n",
" dtype='object', name='country')"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"data.loc[(slice(None), '2017-01-01'), :]['Population, total'].dropna(\n",
").sort_values().tail(60).index.get_level_values('country')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Extract zones manually (in order of increasing population)"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"zones = ['North America', 'Middle East & North Africa',\n",
" 'Latin America & Caribbean', 'Europe & Central Asia',\n",
" 'Sub-Saharan Africa', 'South Asia',\n",
" 'East Asia & Pacific'][::-1]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And extract population information (and check total is right)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
"population = data.loc[zones]['Population, total'].swaplevel().unstack()\n",
"population = population[zones]\n",
"assert all(data.loc['World']['Population, total'] == population.sum(axis=1))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Stacked area plot with matplotlib"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"| \n", " | Population, total | \n", "Surface area (sq. km) | \n", "Land area (sq. km) | \n", "Arable land (% of land area) | \n", "
|---|---|---|---|---|
| date | \n", "\n", " | \n", " | \n", " | \n", " |
| 1960-01-01 | \n", "3.032160e+09 | \n", "NaN | \n", "NaN | \n", "NaN | \n", "
| 1961-01-01 | \n", "3.073369e+09 | \n", "134043190.4 | \n", "129721455.4 | \n", "9.693086 | \n", "
| 1962-01-01 | \n", "3.126510e+09 | \n", "134043190.4 | \n", "129721435.4 | \n", "9.726105 | \n", "
| ... | \n", "... | \n", "... | \n", "... | \n", "... | \n", "
| 2015-01-01 | \n", "7.357559e+09 | \n", "134325130.2 | \n", "129732901.8 | \n", "10.991288 | \n", "
| 2016-01-01 | \n", "7.444157e+09 | \n", "134325130.2 | \n", "129733172.7 | \n", "NaN | \n", "
| 2017-01-01 | \n", "7.530360e+09 | \n", "134325130.2 | \n", "129733172.7 | \n", "NaN | \n", "
58 rows × 4 columns
\n", ""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAA0QAAAGoCAYAAABmACX+AAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAAPYQAAD2EBqD+naQAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMi4yLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvhp/UCwAAIABJREFUeJzs3Xlc1NX6wPHPdxj2fVNEUVDEfb1Uaq4393K3XDJDUzMzr9dcsq7lUm65e6/aTRSzRbPUn1m5S26ZS6Ii4IIgLgiyDesAw8zvD2KuCCquw8jzfr14vZjvcs4zX8J45pzzHMVgMCCEEEIIIYQQFZHK1AEIIYQQQgghhKlIQiSEEEIIIYSosCQhEkIIIYQQQlRYkhAJIYQQQgghKixJiIQQQgghhBAVliREQgghhBBCiApLEiIhhBBCCCFEhSUJkRBCCCGEEKLCkoRICCGEEEIIUWFJQiSEEEIIIYSosCQhEkIIIYQQQlRYalMH8CgURVEAbyDD1LEIIYQQQgghTM4RuGEwGAxlvcGsEyIKk6Frpg5CCCGEEEIIUW5UA66X9WJzT4gyAK5evYqTk5OpYxFCCCGEEEKYSHp6Oj4+PvCAs8fMPSECwMnJSRIiIYQQQgghxAOTogpCCCGEEEKICksSIiGEEEIIIUSFJQmREEIIIYQQosJ6JtYQ3U9BQQH5+fmmDkMIcQ9WVlaoVPIZjRBCCCGermc6ITIYDNy8eZO0tDRThyKEuA+VSoWfnx9WVlamDkUIIYQQFcgznRAVJUOVKlXCzs6Own1chRDljV6v58aNG8THx1O9enX5XRVCCCHEU/PMJkQFBQXGZMjd3d3U4Qgh7sPT05MbN26g0+mwtLQ0dThCCCGEqCCe2Qn7RWuG7OzsTByJEKIsiqbKFRQUmDgSIYQQQlQkz2xCVESm3ghhHuR3VQghhBCm8MwnREIIIYQQQghxN5IQiSeqffv2jB8/3tRhPFGKorB161bj66ioKFq0aIGNjQ1NmzYlNjYWRVEICwszYZRCCCGEEKI0z2xRhXvx/eDnp9ZX7NyXH/ieoKAg1q1bV+J4ly5d2LFjxyPHFBoaSocOHUhNTcXFxaVM99SpU4eYmBhiYmKoWrVqmfvavHnzY1kgv2PHDqZOnUpUVBRubm706tWLFStW3Pe+25+lWq3Gx8eHvn37MmPGDOzt7R85LoD4+HhcXV2Nrz/55BPs7e05f/48Dg4OuLi4EB8fj4eHx2PpTwghhBBCPD4yQlROde3alfj4+GJf3333nUliOXToEFqtlldffZWQkJAHutfNzQ1HR8dH6l+r1dK3b18aN27M2bNn+fnnn2natGmZ7y96lpcvX+bTTz9lxYoVTJw48ZFiup2XlxfW1tbG19HR0bRu3ZoaNWrg7u6OhYUFXl5eqNUV8vMHIYQQQohyTRKicsra2hovL69iX7ePQixatIhGjRphb2+Pj48PY8aMITMz03j+ypUr9OjRA1dXV+zt7WnQoAG//PILsbGxdOjQAQBXV1cURSEoKOiesQQHBzN48GDeeOMN1qxZg8FgKHZ+xYoV1K5dGxsbGypXrkz//v2N5+6cMvf1118TGBiIo6MjXl5eDB48mMTExPs+DwsLC15//XX8/f1p2rQpo0aNuu89RYqepY+PD4MHD+b11183TnErKCjgrbfews/PD1tbW+rUqcPSpUtLtLFmzRoaNGiAtbU1VapUYezYscZzt0+ZUxSFkydPMnPmTBRFYfr06aVOmTt37hwvv/wyTk5OODo60qZNG6Kjo8v8noQQQgghxOMhH1mbKZVKxbJly/D19SUmJoYxY8YwefJk4zSyd999l7y8PA4cOIC9vT0RERE4ODjg4+PDjz/+SL9+/Th//jxOTk7Y2tretZ+MjAw2bdrEH3/8Qd26dcnKyjJOuQM4ceIE48aNY/369bRq1YqUlBQOHjx41/by8vKYNWsWderUITExkX/+858EBQXxyy+/3PUeGxsbunTpwuTJkwkMDMTNze0hn1ohW1tbY1l2vV5PtWrV+P777/Hw8ODIkSOMGjWKKlWq8NprrwGwcuVKJkyYwNy5c+nWrRsajYbDhw+X2nZ8fDwdO3aka9euTJw4EQcHB5KSkopdc/36ddq2bUv79u3Zt28fTk5OHD58GJ1O90jvSwghhBDiaSvIyMPC0crUYTwSSYjKqe3bt+Pg4FDs2JQpU5g2bRpAsVEXPz8/Zs2axTvvvGNMiOLi4ujXrx+NGjUCoGbNmsbrixKKSpUq3XcN0YYNG6hduzYNGjQAYODAgQQHBxsTori4OOzt7XnllVdwdHSkRo0aNGvW7K7tDR8+3Ph9zZo1WbZsGc8//zyZmZkl3m+RGTNmcOrUKQYNGkS7du3YuXMn3t7eAIwdO5YrV67w008/3fN9FDl27BjffvstL730EgCWlpbMmDHDeN7Pz48jR47w/fffGxOiTz/9lPfff59//OMfxuuee+65Utsvmhrn4OCAl5cXQImE6D//+Q/Ozs5s2LDBuL4qICCgTPELIYQQQpiaLi2XnLNJ5Jy9hS45B+9pLU0d0iORhKic6tChAytXrix27PaRkf379zN79mwiIiJIT09Hp9Oh1WrJysrC3t6ecePG8c4777Br1y46duxIv379aNy48QPHERwczJAhQ4yvhwwZQtu2bUlLS8PFxYVOnTpRo0YNatasSdeuXenatSt9+vS564a4p06dYvr06YSFhZGSkoJerwcKE6v69euXuD41NZU5c+awefNmunfvjkql4sUXX2TXrl3Url2b8PBwunXrds/3UJRc6nQ68vPz6dWrF8uXLzeeX7VqFatXr+bKlSvk5OSQl5dnXKOUmJjIjRs3jAnU4xAWFkabNm0eS7EJIYQQQoin4fYkKO9qBvy1gkJlZ/7phKwhKqfs7e3x9/cv9lWUEF25coXu3bvTsGFDfvzxR06ePMl//vMfAONUsBEjRnD58mXeeOMNzp49S2BgYLEkoCwiIiL4448/mDx5Mmq1GrVaTYsWLcjJyTEWeHB0dOTPP//ku+++o0qVKnz88cc0adKEtLS0Eu1lZWXRuXNnHBwc+Prrrzl+/DhbtmwBCqfSleb8+fPk5uYaR51mzpxJr169aN26Nd999x1Hjx4tlrCVpkOHDoSFhXH+/Hm0Wi2bN2+mUqVKAHz//ff885//ZPjw4ezatYuwsDCGDRtmjOde0wkf1pNoUwghhBDicdOlack4eI3EFWHcnHcMzc+XyYv7XzL0rJCEyAydOHECnU7HwoULadGiBQEBAdy4caPEdT4+PowePZrNmzfz/vvv8+WXXwJgZVU4z7OgoOCe/QQHB9O2bVtOnz5NWFiY8Wvy5MkEBwcbr1Or1XTs2JH58+dz5swZYmNj2bdvX4n2oqKiSEpKYu7cubRp04a6devet6BCUYnvAwcOGI8tXryYHj16MHjwYN5+++37lgEvSi5r1KhRYlTm4MGDtGrVijFjxtCsWTP8/f2LFTdwdHTE19eXvXv33rOPB9G4cWMOHjxoTF6FEEIIIcoLXZqWjAPXSPxPGDfnHUfzc8wzmQTdzvzHuJ5Rubm53Lx5s9gxtVqNh4cHtWrVQqfTsXz5cnr06MHhw4dZtWpVsWvHjx9Pt27dCAgIIDU1lX379lGvXj0AatSogaIobN++ne7du2Nra1ti/U5+fj7r169n5syZNGzYsNi5ESNGMH/+fE6fPs3Vq1e5fPkybdu2xdXVlV9++QW9Xk+dOnVKvKfq1atjZWXF8uXLGT16NOHh4cyaNeuez8HHx4eBAwfy7rvvkpuby4svvsjly5c5c+YM9vb2bNu2jY8++sg44vOg/P39+eqrr9i5cyd+fn6sX7+e48eP4+fnZ7xm+vTpjB49mkqVKtGtWzcyMjI4fPgw77333kP1OXbsWJYvX87AgQOZOnUqzs7OHD16lOeff77U5yaEEEII8STp0rTknEki52xS4XS4CqZCJkQPs1nq07Zjxw6qVKlS7FidOnWIioqiadOmLFq0iHnz5jF16lTatm3LnDlzGDp0qPHagoIC3n33Xa5du4aTkxNdu3Zl8eLFQOGoy4wZM/jggw8YNmwYQ4cOLbG/0LZt20hOTqZPnz4lYqtduzaNGjUiODiY1157jc2bNzN9+nS0Wi21a9fmu+++MxZhuJ2npychISF8+OGHLFu2jObNm7NgwQJ69ux5z2exbt06Pv/8cz777DOuXLlC1apVGTJkCL/++isvvfQSPXv2ZP/+/Q81FW306NGEhYUxYMAAFEVh0KBBjBkzhl9//dV4zZtvvolWq2Xx4sVMnDgRDw+PYqXFH5S7uzv79u1j0qRJtGvXDgsLC5o2bcqLL7740G0KIYQQQjyIwjVBt/6XBD3DI0D3o9y5p4w5URTFCdBoNBqcnJyKndNqtcTExODn54eNjY1pAhRClJn8zgohhBBPlk6T+9dI0K3HlgSp7NR4f1w+qsylp6fj7OwM4GwwGNLLel+FHCESQgghhBCiIijQ5JJ99q/pcHHpFXok6G4kIRJCCCGEEOIZIknQg5GESAghhBBCCDMnSdDDk4RICCGEEEIIMyRJ0OMhCZEQQgghhBBmQpKgx08SIiGEEEIIIcoxSYKeLEmIhBBCCCGEKGckCXp6JCESQgghhBCiHNBpcsmRJOipk4RICCGEEEIIE5EkyPRUpg5AlC+hoaEoikJaWtpT7Xf69Ok0bdr0qfYphBBCCGEKurRcMg5eJ3HlaW7OPYZm+2XyrkgyZCoVc4RouvNT7EvzwLckJiYybdo0fv31VxISEnB1daVJkyZMnz6dli1bPrbQ2rdvT9OmTVmyZMlja3PUqFEEBwfzzTffMHDgwDLfN3HiRN57773HFocQQgghRHmiS9GSE/7XSNC1DLNPfhRXSzQ2ycSkhePN4/v71BQqZkJUzvXr14/8/HzWrVtHzZo1SUhIYO/evaSkpJg6tHvKzs5m48aNTJo0ieDg4AdKiBwcHHBwcHiC0QkhhBBCPF265BxywpPIPptE/rVMU4fz6DzUpKoTiYg7zLU/IwCwcXA0cVCPTqbMlTNpaWkcOnSIefPm0aFDB2rUqMHzzz/P1KlTefnll43XxcXF0atXLxwcHHBycuK1114jISHBeD4oKIjevXsXa3v8+PG0b9/eeP63335j6dKlKIqCoijExsYarz158iSBgYHY2dnRqlUrzp8/f9/YN23aRP369Zk6dSqHDx8u1h4UTsd7/vnnsbe3x8XFhRdffJErV64AJafMHT9+nE6dOuHh4YGzszPt2rXjzz//LOtjFEIIIYQwCV1SDun7r5Kw/BQ3Pz+B5tdY802GFKCSmqTKCYRm/cDG45+x6/cvuXY9wtSRPVaSEJUzRSMlW7duJTc3t9RrDAYDvXv3JiUlhd9++43du3cTHR3NgAEDytzP0qVLadmyJSNHjiQ+Pp74+Hh8fHyM5z/66CMWLlzIiRMnUKvVDB8+/L5tBgcHM2TIEJydnenevTtr1641ntPpdPTu3Zt27dpx5swZfv/9d0aNGoWiKKW2lZGRwZtvvsnBgwc5evQotWvXpnv37mRkZJT5PQohhBBCPA35idmk740jYemf3FxwgvSdseRfN9MkSKWg97Lgpuc1dqeuZ+Mfn7H3aAgJidGmjuyJMemUOUVRYoEapZxaYTAY3n3K4ZQLarWakJAQRo4cyapVq2jevDnt2rVj4MCBNG7cGIA9e/Zw5swZYmJijEnM+vXradCgAcePH+e55567bz/Ozs5YWVlhZ2eHl5dXifOfffYZ7dq1A+CDDz7g5ZdfRqvVYmNjU2p7Fy9e5OjRo2zevBmAIUOGMG7cOD755BNUKhXp6eloNBpeeeUVatWqBUC9evXuGt/f//73Yq+/+OILXF1d+e2333jllVfu+/6EEEIIIZ6k/JtZxn2CdInZpg7n0agVCjwV4nMvc+bCXjKik0wd0VNl6hGi54Aqt311+uv4JpNFVA7069ePGzdusG3bNrp06UJoaCjNmzcnJCQEgMjISHx8fIqN6NSvXx8XFxciIyMfSwxFyRdAlSpVgMJiD3cTHBxMly5d8PDwAKB79+5kZWWxZ88eANzc3AgKCqJLly706NGDpUuXEh8ff9f2EhMTGT16NAEBATg7O+Ps7ExmZiZxcXGP4+0JIYQQQjywvOuZaHbEcnPBCRKW/EnG3jjzTYYsVei84YrLRX66vpIfjszh8MmNZGRUrGQITDxCZDAYbt3+WlGUD4Bo4DfTRFR+2NjY0KlTJzp16sTHH3/MiBEj+OSTTwgKCsJgMJQ61ez24yqVCoOhePmS/Pz8MvdvaWlp/L6oTb1eX+q1BQUFfPXVV9y8eRO1Wl3seHBwMJ07dwZg7dq1jBs3jh07drBx40b+9a9/sXv3blq0aFGizaCgIG7dusWSJUuoUaMG1tbWtGzZkry8vDK/ByGEEEKIR5Ubl15YHS48mYIUranDeSSKtYo8dx1XM6M4c34fuReyTB1SuVBuqswpimIFDAEWGe78S/5/11gD1rcdMv+yFmVUv359tm7davw+Li6Oq1evGkeJIiIi0Gg0xmlonp6ehIeHF2sjLCysWKJjZWVFQUHBI8f2yy+/kJGRwalTp7CwsDAej4qK4vXXXyc5ORl3d3cAmjVrRrNmzZg6dSotW7bk22+/LTUhOnjwICtWrKB79+4AXL16laSkiveJhRBCCCGeLoPeQF6shpxzyeScS6YgrfQ13eZCsbVA65bLFc05wqNCyY8y76TuSSg3CRHQG3ABQu5xzVTgk6cSjYkkJyfz6quvMnz4cBo3boyjoyMnTpxg/vz59OrVC4COHTvSuHFjXn/9dZYsWYJOp2PMmDG0a9eOwMBAoHANzueff85XX31Fy5Yt+frrrwkPD6dZs2bGvnx9ffnjjz+IjY3FwcEBNze3h4o5ODiYl19+mSZNmhQ73qBBA8aPH8/XX39Nz549+e9//0vPnj3x9vbm/PnzXLhwgaFDh5bapr+/P+vXrycwMJD09HQmTZqEra3tQ8UnhBBCCHEvBp0e7aU0csKT0EamoM8q+6ya8kixV5Ptkk1M8mkizh+goEBn6pDKtfKUEL0F/GowGG7c45o5wKLbXjsC1x64p4fYLPVpcXBw4IUXXmDx4sVER0eTn5+Pj48PI0eO5MMPPwQKp7Bt3bqV9957j7Zt26JSqejatSvLly83ttOlSxemTZvG5MmT0Wq1DB8+nKFDh3L27FnjNRMnTuTNN9+kfv365OTkEBMT88DxJiQk8PPPP/Ptt9+WOKcoCn379jXuSRQVFcW6detITk6mSpUqjB07lrfffrvUdtesWcOoUaNo1qwZ1atXZ/bs2UycOPGB4xNCCCGEKI0+V4c2KpWcc0loz6diyH30WTOmpDipyXTM4FLCn5w/dwSDofSlDqIk5S6z055uEIpSA7gM9DUYDP/3APc5ARqNRoOTk1Oxc1qtlpiYGPz8/O5aGU0IUX7I76wQQognrSAzD21kCjnnktFeSgWd6f8OfhSKiyXpdqmcv/EH0TEnTBKDjYMj7wZ/Z5K+75Seno6zszOAs8FgSC/rfeVlhGgYkAj8bOpAhBBCCCHEs0OnyTUWRci7ogEzHzhR3C1JtbpFZNxh4k6F3/8GcV8mT4gURVFRmBCtMxgMMsFRCCGEEEI8El1SDtnhSeSEJxVukGrOA0EK4KEmWXWTc7EHiD9x0dQRPXNMnhABHYHqwBpTByKEEEIIIcxT0Uap2nNJ5N80072BiqjA4GnBLcM1zkaHknRZ9mF8kkyeEBkMhl0U5r5CCCGEEEKUWd7VjMLpcOeS0SXlmDqcR2OhoPdUuKmL5cyFfWiiE0wdUYVh8oRICCGEEEKIsjDuERT+1x5BGvPeIwhLFQWeBq7nXOLshb1kXko1dUQVkiREQgghhBCi3DLo9Gij09CGJ5MTmYw+08z3CLJWkeeu42rmec6e34f2QqapQ6rwJCESQgghhBDlij6vgNwLqWSHJ6GNSsGgNfM9guwsyHHN5UrqWcLPh6KLyjN1SOI2khAJIYQQQgiT02t15ESmkBOeRO6FVAz55l0fW3FUk+WYSXTSKaIiD6PXm3dS9yyThEgIIYQQQphEQWYeORHJ5IQnkxudBgXmXB/7r41SbVO5EH+cS2eOmTocUUYVMiFqtK7RU+vr7Jtnn1pftwsNDaVDhw6kpqbi4uLyVPuOjY3Fz8+PU6dO0bRp06fa95NmMBh4++23+eGHH0hNTb3ne1QUhS1bttC7d++nHKUQQghRfunS/too9VwSeVfSzX6jVDzUpKpvEXX1iGyUaqYqZEJU3iUmJjJt2jR+/fVXEhIScHV1pUmTJkyfPp2WLVs+0b4LCgqYP38+69at48qVK9ja2hIQEMDbb7/NsGHDnmjf5UXnzp3Zu3cvhw8fpkWLFsXO7dixg5CQEEJDQ6lZsyYeHh53bSc+Ph5XV9cnHa4QQghR7uUn5RQmQeFJ5F8z8yICt+0RFB59gFsxsaaOyCQsbWzw8KmHrUtdU4fyyCQhKof69etHfn4+69ato2bNmiQkJLB3715SUlKeeN/Tp0/nv//9L//+978JDAwkPT2dEydOkJpq+jKQeXl5WFlZPdE+4uLi+P333xk7dizBwcElEqLo6GiqVKlCq1at7hunl5fXE41VCCGEKM/ybmT+b4+gBDPfKFWtUOAJ8bkxnLm4j4zoW6aOyCScPL1wrlyPAn11UhNdSE2yIDvH/NMJlakDEMWlpaVx6NAh5s2bR4cOHahRowbPP/88U6dO5eWXXwYKp6QpikJYWFix+xRFITQ0tFh7hw8fpkmTJtjY2PDCCy9w9uy9p/D99NNPjBkzhldffRU/Pz+aNGnCW2+9xYQJE4zX7Nixg9atW+Pi4oK7uzuvvPIK0dHRJdq6fPkyHTp0wM7OjiZNmvD7778bzyUnJzNo0CCqVauGnZ0djRo14rvvvit2f/v27Rk7diwTJkzAw8ODTp06AbBo0SIaNWqEvb09Pj4+jBkzhszM/33aFBISgouLCzt37qRevXo4ODjQtWtX4uPj7/P0Ye3atbzyyiu88847bNy4kaysLOO5oKAg3nvvPeLi4lAUBV9f33vGqSgKW7duNd5/7do1Bg4ciJubG/b29gQGBvLHH38AhYlWr169qFy5Mg4ODjz33HPs2bPnvvEKIYQQ5YVBbyA3VkPaz5eJ//w4ictOkbHvqtkmQ4q1Bfneei47RfB/V//ND0fmcvjkRjLSK04yZKFWU8mvPtUb98Kj5jvk6QZz63ozUuLdMRRYmDq8x0YSonLGwcEBBwcHtm7dSm7uo282NmnSJBYsWMDx48epVKkSPXv2JD//7vX7vby82LdvH7du3f2XPSsriwkTJnD8+HH27t2LSqWiT58+6PXFJwF/9NFHTJw4kbCwMAICAhg0aBA6nQ4ArVbL3/72N7Zv3054eDijRo3ijTfeMCYIRdatW4darebw4cN88cUXAKhUKpYtW0Z4eDjr1q1j3759TJ48udh92dnZLFiwgPXr13PgwAHi4uKYOHHiPZ+VwWBg7dq1DBkyhLp16xIQEMD3339vPL906VJmzpxJtWrViI+P5/jx4/eM83aZmZm0a9eOGzdusG3bNk6fPs3kyZONzywzM5Pu3buzZ88eTp06RZcuXejRowdxcXH3jFkIIYQwJYNOj/Z8CqmbLxI/+w9urTpD5sHrFCRrTR3aQ1Gc1GRXzeWczTE2XVzA5sOfc/z0T2i1Zj7N7wHYObtSrX5rqjUcgq37u6SndSXxai0yU21NHdoTY/5jXM8YtVpNSEgII0eOZNWqVTRv3px27doxcOBAGjdu/MDtffLJJ8YRi3Xr1lGtWjW2bNnCa6+9Vur1ixYton///nh5edGgQQNatWpFr1696Natm/Gafv36FbsnODiYSpUqERERQcOGDY3HJ06caBzVmjFjBg0aNODSpUvUrVuXqlWrFktQ3nvvPXbs2MGmTZt44YUXjMf9/f2ZP39+sf7Gjx9v/N7Pz49Zs2bxzjvvsGLFCuPx/Px8Vq1aRa1atQAYO3YsM2fOvOez2rNnD9nZ2XTp0gWAIUOGEBwcbFw75ezsjKOjIxYWFiWmw5UW5+2+/fZbbt26xfHjx3FzczPeU6RJkyY0adLE+PrTTz9ly5YtbNu2jbFjx94zbiGEEOJp0ucWoD2fQs655MI9gnLNu5y04mFJquUtLlz/g5jTYfe/4VmjKLhXq4m9awC5OT6kJdmTFK+YOqqnSkaIyqF+/foZRxK6dOlCaGgozZs3JyQk5IHbur0Ig5ubG3Xq1CEyMhL432iUg4MDo0ePBqB+/fqEh4dz9OhRhg0bRkJCAj169GDEiBHGdqKjoxk8eDA1a9bEyckJPz8/gBKjGbcncFWqVAEKC0ZAYfGGzz77jMaNG+Pu7o6DgwO7du0q0UZgYGCJ97R//346depE1apVcXR0ZOjQoSQnJxeb3mZnZ2dMhor6L+r7boKDgxkwYABqdeHnBIMGDeKPP/7g/Pnz97zvbnHeLiwsjGbNmhmToTtlZWUxefJk6tevj4uLCw4ODkRFRckIkRBCiHKhIDOPrOM3SQo5x41Zv5PybRQ5p2+ZZzJkoaD3UnHT8zp7M75jw/FP2XnkC2KuVJxkyMrWDu86gVRv9BrO3u+SldmLxKv10CQ5oFCxkiGQEaJyy8bGhk6dOtGpUyc+/vhjRowYwSeffEJQUBAqVWEeazD8r1b/vabB3UlRCv9Dv30NkpOTk/F7lUrFc889x3PPPcc///lPvv76a9544w0++ugj/Pz86NGjBz4+Pnz55Zd4e3uj1+tp2LAheXnFd122tLQs0WfRFLGFCxeyePFilixZYlwPNH78+BJt2NvbF3t95coVunfvzujRo5k1axZubm4cOnSIt956q9gzuL3vov5vf153SklJYevWreTn57Ny5Urj8YKCAtasWcO8efPuem9pcd7J1vbew8yTJk1i586dLFiwAH9/f2xtbenfv3+J5yGEEEI8LboULTnnksiJSDb78tiKjQV5bvlcy7pA+IVQsi9pTB3SU+dcyRunSvUoKPAhNdGFlEQZFykiCZGZqF8KCg5wAAAgAElEQVS/vnGBvqenJ1BY1rlZs2ZA8eTmdkePHqV69eoApKamcuHCBerWLSyPePuUrfv1DYWjGMnJyURGRvLFF1/Qpk0bAA4dOvTA7+fgwYP06tWLIUOGAIWJ0sWLF6lXr9497ztx4gQ6nY6FCxcaE8Pb1/k8rG+++YZq1aoVK4IAsHfvXubMmcNnn31mHDl6GI0bN2b16tWkpKSUOkp08OBBgoKC6NOnD1C4pig2Nvah+xNCCCEeRt6NzMKpcOeSyb+Zdf8byjHFUU2WYxYxKaeJvHCQggKdqUN6qiwsLfGoXgdre38y073J1thw67qpoyqfJCEqZ5KTk3n11VcZPnw4jRs3xtHRkRMnTjB//nx69eoFFI42tGjRgrlz5+Lr60tSUhL/+te/Sm1v5syZuLu7U7lyZT766CM8PDzuuVFo//79efHFF2nVqhVeXl7ExMQwdepUAgICqFu3LiqVCnd3d/773/9SpUoV4uLi+OCDDx74ffr7+/Pjjz9y5MgRXF1dWbRoETdv3rxvQlSrVi10Oh3Lly+nR48eHD58mFWrVj1w/3cKDg6mf//+xdZAAdSoUYMpU6bw888/G5//wxg0aBCzZ8+md+/ezJkzhypVqnDq1Cm8vb1p2bIl/v7+bN68mR49eqAoCtOmTStRpEIIIYR43Ax6A3mxGnLOJZMTkUxB6qMXdDIlxV1NmlUKF24c4/KZk6YO56mzd3HD1bs+qHxJTXRHk2IBT37XFrNXIROis2/eu/S0KTk4OPDCCy+wePFioqOjyc/Px8fHh5EjR/Lhhx8ar1uzZg3Dhw8nMDCQOnXqMH/+fDp37lyivblz5/KPf/yDixcv0qRJE7Zt23bPvXy6dOnCd999x5w5c9BoNHh5efH3v/+d6dOnG0dINmzYwLhx42jYsCF16tRh2bJltG/f/oHe57Rp04iJiaFLly7Y2dkxatQoevfujUZz7yHspk2bsmjRIubNm8fUqVNp27Ytc+bMYejQoQ/U/+1OnjzJ6dOn+fLLL0ucc3R0pHPnzgQHBz9SQmRlZcWuXbt4//336d69Ozqdjvr16/Of//wHgMWLFzN8+HBatWqFh4cHU6ZMIT09/aH7E0IIIe7GkK9HezH1r6IIyeizzHjk5K9NUpMM1zkXc4iEmJLbgDzLFJUKDx9/bJ1ro82uSnqyA0n332VE3EG517qK8k5RFCdAo9Foiq2BgcKyzjExMfj5+WFjY2OaAIUQZSa/s0II8eQUZOWjjSqsDJd7MRVDvvnOQlAsVeg89dzQXubsxdAKtS8QgI2DI27V6mNh6Udasif5OZb3v+kJsrZXM2JhW5PGUCQ9PR1nZ2cAZ4PBUOZPlivkCJEQQgghxLOusChC8l9FETTmXRTBXk2OSw5xmgjORf1G3oUcU4f0VLl618DRvQ55eT6k3XIiJaHiVYJ7kiQhEkIIIYR4RuRdyyAnIhltRDL5N7NNHc4jUVwtSbdN41LCSS6e+wODwYwzugdkaWODh099LG1rkpFSmZwsa3KumTqqZ5ckREIIIYQQZspQoCf3suavJCiFAo0ZF0VQAE81yUo8kXFHuP5nlKkjeqqcK1X5qyx2dVJvuZCaJGWxnxZJiIQQQgghzIheq0N7PrUwCTqfgkFrhpujFrFUUeBh4GZeLOGXQkm7fNPUET01t5fFzkqvQpbGVspim4gkREIIIYQQ5ZxOk4s2onA9UO5lDRSYcVEsWwu0bnlcTY8k/EIouRfMe7+jB+Hg5olrlXroqU7aLSmLXV5IQiSEEEIIUQ7l38wyFkXIv55p6nAeieJiSaadhuhbYZyPOoJeb8ajWg9AZaHGo3ptbBxrk51ZhcxUe27dMHVU4k6SEAkhhBBClAOGAgO5sZrCkaDIFApStKYO6eEpgIeaFItEzl/9nbhT4aaO6Km5fXPUtFvupKdZkJ5m6qjEvUhCJIQQQghhIvrcwvVA2ohktBdS0Web8Sapf60HSsi/wrnoA6RcrhgLYlQWFrj7+GPrVBtttrdsjmqGJCESQgghhHiKCjS55EQmkxORQm50mnmvB7JXo3XR/rUe6LcKsx7of6NANdDccidDoyZDY+qoxMOqkAlRZN16T62velGRT60vUf6EhobSoUMHUlNTcXFxeSJ9hISEMH78eNLSZDxeCCHKq7wbmcapcGa/HshNTbpNGpdunuTCuT/AYL4JXVmpLNR4+NTGxskfbXYVGQV6xkiB83IoKCgIRVFKfHXt2tXUoT0SvV7PlClT8Pb2xtbWlsaNG/N///d/Zb5///79dO/eHXd3d+zs7Khfvz7vv/8+168/viH52NhYFEUhLCzssbVZVrNnz8bCwoK5c+c+0H0DBgzgwoULTygqIYQQD8NQoEd7MZW0bdHEzz1G4rJTpO+JM89kSKVgqGxBYqWb/Jb9AxtOfsYvh//Dheijz3QyZO/qQbUGbajWYAh2Hu+SrulG4tXapCc7mDo08ZhVyBEic9C1a1fWrl1b7Ji1tfVDt2cwGCgoKECtNt2P/Ouvv2bx4sV89dVXtGjRgkuXLpX53i+++IIxY8bw5ptv8uOPP+Lr60tcXBxfffUVCxcuZNGiRU8w8pLy8vKwsrJ6rG2uXbuWyZMns2bNGj744IMy32dra4utre1jjUUIIcSD02t1aKNSyIlMMfv9gRQbC/Lc8rmedZHwi7+RFZ1q6pCeOLWVNR7V62BlV5OcTC8yUu1IkopwFYKMEJVT1tbWeHl5FftydXUFSh/FSEtLQ1EUQkNDgcKpWoqisHPnTgIDA7G2tubgwYMArFy5klq1amFlZUWdOnVYv359sb4VRWHlypV069YNW1tb/Pz82LRpU7Frrl+/zoABA3B1dcXd3Z1evXoRGxt7z/ekUqnw9PRk4MCB+Pr60rFjRzp27HjfZ3Ht2jXGjRvHuHHjWLNmDe3bt8fX15e2bduyevVqPv74Y+O1R44coW3bttja2uLj48O4cePIyvrffGZfX19mz57N8OHDcXR0pHr16vz3v/81nvfz8wOgWbNmKIpC+/btgcJRu969ezNnzhy8vb0JCAgACpO8wMBAHB0d8fLyYvDgwSQmJt73Pd3pt99+Iycnh5kzZ5KVlcWBAweKnT99+jQdOnTA0dERJycn/va3v3HixAmgcMrc7dPxoqOj6dWrF5UrV8bBwYHnnnuOPXv2PHBMQggh7k+XqiXj8HVurT7LjVlHSdlwnpzTt8wyGVJcLMnyzuas1e9sujCfzYc/54+wrWRlPaPJkKLg6l2D6o06UaXeMKyc3iEtuSOJV2uSkWpn6ujEUyQJ0TNu8uTJzJkzh8jISBo3bsyWLVv4xz/+wfvvv094eDhvv/02w4YNY//+/cXumzZtGv369eP06dMMGTKEQYMGERlZuB4qOzubDh064ODgwIEDBzh06BAODg507dqVvLy8u8by0ksvodFomDZt2gO9h02bNpGXl8fkyZNLPV+UDJw9e5YuXbrQt29fzpw5w8aNGzl06BBjx44tdv3ChQsJDAzk1KlTjBkzhnfeeYeoqCgAjh07BsCePXuIj49n8+bNxvv27t1LZGQku3fvZvv27UDhSNGsWbM4ffo0W7duJSYmhqCgoAd6fwDBwcEMGjQIS0tLBg0aRHBwcLHzr7/+OtWqVeP48eOcPHmSDz74AEtLy1LbyszMpHv37uzZs4dTp07RpUsXevToQVxc3APHJYQQojiDwUDetQw0u2JJWPInN+cdR/PTZXIvmWFxBBVQWU2S1y0O5W1jw6lP2X54ORHnD1BQYMbV7u7B1smFqnVb4NN4AM5Vx5KT04/Ea41IvemKvkD+LK6oZMpcObV9+3YcHIrPUZ0yZcoDJxMzZ86kU6dOxtcLFiwgKCiIMWPGADBhwgSOHj3KggUL6NChg/G6V199lREjRgAwa9Ysdu/ezfLly1mxYgUbNmxApVKxevVqFEUBCqd7ubi4EBoaSufOnUvEkZ2dTadOnRg8eDC7d+8mOzubBQsWGO93cnJi7dq19OvXr8S9Fy9exMnJiSpVqtzzvX7++ecMHjyY8ePHA1C7dm2WLVtGu3btWLlyJTY2NgB0797d+P6nTJnC4sWLCQ0NpW7dunh6egLg7u6Ol5dXsfbt7e1ZvXp1salyw4cPN35fs2ZNli1bxvPPP09mZmaJn9/dpKen8+OPP3LkyBEAhgwZwosvvsjy5ctxcnICIC4ujkmTJlG3bl3je7ubJk2a0KRJE+PrTz/9lC1btrBt27YSyaEQQoj7M+j0aKPTCktjR6ZQkH73D//KO8Xagnz3Am7kRBN+MZSM6CRTh/REGYshONdCm+2NJsme5ATF1GGJckYSonKqQ4cOrFy5stgxNze3B24nMDCw2OvIyEhGjRpV7NiLL77I0qVLix1r2bJliddFU/ROnjzJpUuXcHR0LHaNVqslOjq61DhCQkJIS0vj3//+N1lZWbRv356goCCCg4O5du0amZmZtGrVqtR7DQaDMXG6l6K4vvnmm2L36vV6YmJiqFevsLpg48aNjecVRcHLy6tM09waNWpUYt3QqVOnmD59OmFhYaSkpKDX64HCBKZ+/fr3bRPg22+/pWbNmsYkpmnTptSsWZMNGzYYf1YTJkxgxIgRrF+/no4dO/Lqq69Sq1atUtvLyspixowZbN++nRs3bqDT6cjJyZERIiGEeAD67HxyolLQRqagvZCKIdf8psAVUVwsybRPJybpDFEXj1AQZb4JXVk4eVTGuXJd9FRHc8uNdI0F6X+VxJZUSJRGEqJyyt7eHn9//1LPqVSFQ7qG2yq75Ofn37WdO92ZXJQ14Si6Rq/X87e//a1Y4lGkaITlTmfOnKFBgwZYWVlhZWXF7t27adOmDX369KF27dp07dr1riNAAQEBaDQa4uPj7zlKpNfrefvttxk3blyJc9WrVzd+f+dUM0VRjInMvdz5LLOysujcuTOdO3fm66+/xtPTk7i4OLp06XLPqYN3WrNmDefOnStW8EKv1xMcHGxMiKZPn87gwYP5+eef+fXXX/nkk0/YsGEDffr0KdHepEmT2LlzJwsWLMDf3x9bW1v69+//QDEJIURFpEvOIScihZyIZPKupIPezKbAFVEpGDxVJHOTqLjfuX7q2d4CxNLaBnefwmIImeleZGtsuSXFEMQDkITIDBUlHfHx8TRr1gygzGWi69Wrx6FDhxg6dKjx2JEjR4yjJ0WOHj1a7JqjR48a+2revDkbN26kUqVKxild91O1alW2bNlCRkYGjo6OVKpUiT179tCmTRu2b9/OyZMn73pv//79+eCDD5g/fz6LFy8ucT4tLQ0XFxeaN2/OuXPn7ppIlkXRCFBBwf0/CYyKiiIpKYm5c+fi4+MDYCx0UFZnz57lxIkThIaGFhsBTEtLo23btoSHh9OwYUOgMDEMCAjgn//8J4MGDWLt2rWlJkQHDx4kKCjIeC4zM/O+BS+EEKIiMhgM5F3NQBtZmATpErJNHdJDU2wtyHPN53r2JSIuHiAjOtnUIT1Rrt41cHQPQKerSuotF9KSVfBsv2XxBElCVE7l5uZy8+bNYsfUajUeHh7Y2trSokUL5s6di6+vL0lJSfzrX/8qU7uTJk3itddeo3nz5rz00kv89NNPbN68uUQVsk2bNhEYGEjr1q355ptvOHbsmHGh/+uvv87nn39Or169mDlzJtWqVSMuLo7NmzczadIkqlWrVqLft956i6VLl9KzZ08+++wz3N3d2bNnD2lpadjZ2bF69WpWrFhRasw+Pj4sXryYsWPHkp6eztChQ/H19eXatWt89dVXODg4sHDhQqZMmUKLFi149913GTlyJPb29sYiCMuXLy/T86lUqRK2trbs2LGDatWqYWNjg7Ozc6nXVq9eHSsrK5YvX87o0aMJDw9n1qxZZeqnSHBwMM8//zxt27Ytca5ly5YEBwcze/ZsJk2aRP/+/fHz8+PatWscP3681PVWAP7+/mzevJkePXqgKArTpk0r0wiYEEJUBAadHu2lNOMmqfoM8x09V1wtybBNK5wKF3UYvd58p/Xdj62jE25V66Gy8iUjxZOcLCtyrpk6KvGsqJAJUb2o8j90vGPHjhLTw+rUqWOshrZmzRqGDx9OYGAgderUYf78+aUWM7hT7969Wbp0KZ9//jnjxo3Dz8+PtWvXGstLF5kxYwYbNmxgzJgxeHl58c033xjXxNjZ2XHgwAGmTJlC3759ycjIoGrVqrz00kt3HTHy9vbm2LFjxnvS09P529/+xrfffoudnR2dOnXC39+fCRMmlHr/mDFjCAgIYMGCBfTp04ecnBx8fX155ZVXjPc0btyY3377jY8++og2bdpgMBioVasWAwYMuO9zKaJWq1m2bBkzZ87k448/pk2bNsZS5nfy9PQkJCSEDz/8kGXLltG8eXMWLFhAz549y9RXXl4eX3/9NVOmTCn1fL9+/ZgzZw7z5s0jOTmZoUOHkpCQgIeHB3379mXGjBml3rd48WKGDx9Oq1at8PDwYMqUKaSnp5cpJiGEeBYZ1wNFJKO9kIYhz0wTBwsFvaeKJP11Iq8c5mZM2ffzMzcqCzXuPrWwdfInN8ebtCQHKYYgnhjFYOIdhhVFqQrMA7oBtsAF4C2DwXD3OVT/u9cJ0Gg0mhJ/iGu1WmJiYvDz8zNWFxNloygKW7ZsoXfv3qYORVQg8jsrhHicdClaciKS0UYkkxtrvuuBFDs1Whct1zMvcO7ib2RnP7sfcDl6VMalch0MSnXSbrmjy7MwdUjiLqxtLajsmo9bRjTOV0/QcMOXpg4JKKzc+9fMHmeDwVDmXxaTjhApiuIKHAb2U5gQJQK1gDRTxiWEEEII85N3LcOYBOXfNN/1QLir0VilEJ3wJxcjjoGJP7x+UixtbHD3qYuVrR9Z6V5kSTGEcstCreDpoeCRfx2n6CNYH/gN5a8pmhZ3WVpgTkw9ZW4KcNVgMAy77VisiWIRQgghhBkxFOjJvawh51wy2shkCjRmuh7IUkWBh4HE/DgiYg6RFPOMbpOgKLhWqV5YDCG/KqlJLqQlyWao5ZICbu5qKqmTcb72J7bHd6HKenZHJ02dEPUEdiqKsgloB1wHVhgMhlLH3RRFsQasbzvkWNp14tGYehqlEEIIcTf63AK05wurwmmjUjFodaYO6aEojmqyHbOJSztHxIWD5F3IMXVIT4SxGIKlL+mplcjJspRiCOWUvZOayg5ZuCVHYH9qFxaJz2hiXgpTJ0Q1gXeARcBs4HlgmaIouQaD4atSrp8KfPIU4xNCCCGEiRVk5Bmnwmmj00Bnhh/cKYCnmhRVIhevHyP2zGlTR/REFBZD8L+tGIK9FEMop6xsLKjspsMt6zKOEaFYhf5p6pBMxtQJkQo4YTAYPvzr9SlFURpQmCSVlhDNoTB5KuIIyOcMQgghxDMmPykH7blkcs4lkXc1A8wxB7KxIM9NR3zOZSIuHUBzOdHUIT0RzpW8caoUgN7gg+aWGxkaCzI0heckFSo/VCoFT08VHvp4nGKOYn1oPyqdmU4zfcxMnRDFAxF3HIsESt1gxWAw5AK5Ra8VRX7NhBBCiGdF3rUMcs4lk3MuGV2ieRZFuH1voPMXjlBQYJ5T+u7F2t4B92p1UVv5kqmpTHaGNbeumzoqURoXNzWVrNNwiT+N3fEdqDJSTB1SuWTqhOgwUOeOYwHAFRPEIoQQQoinyKA3kBujKRwJikimIC33/jeVN2oFvYfCrYLrRF05zM2YaFNH9NipLCxwr1YLW2d/crXeaG45kpIoH0qXR3aOaio7ZuOWeh7707tQ37hs6pDMgqkTosXAEUVRPgS+p3AN0ai/voQQQgjxjDHk69FeTC2sDBeVjD7L/EZQFAc1Oc45XEs/z7kLv6G9mGnqkB47J08vnCvVQY8P6UluZKSryXh2i4yZLUtrFZXd9LjlxOIY9RvWocdMHZJZMmlCZDAYjiuK0ofCtUEfAzHAeIPB8I0p4xJCCCHE46PX6tBGpZATnoT2QiqGPL2pQ3owCuChJk2dxMX4E1wO//OZ2xvI2s4et2p1Udv4kp1emSyNjewJVA6pLBQ8PYrWAf2B9aF9sg7oMTD1CBEGg2E7sP1p9vmf0fueWl/vrvr7U+vrfnx9fRk/fjzjx483dSiPVVBQEGlpaWzdutXUoZjEnT9XRVHYsmULvXv3LvX62NhY/Pz8OHXqFE2bNn2aoQohKpCCzDzjeqDc6DQoMK8EQrFSke+h56Y2lnPRB0i7HG/qkB4rRaXCvVot7JxrkZdXlbRbTqTekmlw5ZGrhyWe6mRc4sOw+2Mnqsw0U4f0zDF5QiRKetQ/8ENCQhg/fjxpacV/YY4fP469vf3jCJFvv/2WN954g5EjR7Jq1arH0ubDWrp06VPZO2nhwoUsX76chIQEqlevzvvvv8+oUWWb3Xnq1Clmz57NgQMH0Gg0VK9enXbt2jFp0iQCAgIeKa7H+XMVQohHoUvVkhP+V2W4K+lmVxlOcbEk0y6d2JSzRF44TMH5Z+uTd0ePyrhUroNB8UGT5EFmhgWZGaaOStzJwVlNJfssXJMjsQ/bhTpBltY/aZIQVSCenp6Pra01a9YwefJkVq5cyaJFi7Czs3tsbZdVQUEBiqLg7Oz8xPs6cOAAEydOZNmyZfTo0YOrV6+SlJRUpnu3b99Ov3796NKlC9988w21atUiMTGRTZs2MW3aNDZu3PhQMeXl5WFlZfVYf65CCPGg8hOyCpOgiGTyr5vZWhoLBYOHiiRucD7ud66fOm/qiB6romlwljY1yEqvTJbGVqbBlUPWthZUds3HLTMah3P7sQp9NveoKs9Upg5APLhFixbRqFEj7O3t8fHxYcyYMWRmFv5PKDQ0lGHDhqHRaFAUBUVRmD59OlA4tWrJkiXGdhRFYfXq1fTp0wc7Oztq167Ntm3b7tt/bGwsR44c4YMPPqBu3br88MMPxc6HhITg4uLC9u3bqVOnDnZ2dvTv35+srCzWrVuHr68vrq6uvPfeexQUFBjvy8vLY/LkyVStWhV7e3teeOEFQkNDS223fv36WFtbc+XKFYKCgopND9Pr9cybNw9/f3+sra2pXr06n332mfH8lClTCAgIwM7Ojpo1azJt2jTy8/Pv+Z5VKhUWFha89dZb+Pr60qZNG/r06XPfZ5Wdnc2wYcPo3r0727Zto2PHjvj5+fHCCy+wYMECvvjiC6AwuXvrrbfw8/PD1taWOnXqsHTp0mJtFb3POXPm4O3tbRxZuvPnChAfH0+3bt2wtbXFz8+PTZs2lYgtKiqKVq1aYWNjQ4MGDYo9a4CIiAi6d++Og4MDlStX5o033iiWBO7YsYPWrVvj4uKCu7s7r7zyCtHR/6uuFBsbi6IobN68mQ4dOmBnZ0eTJk34/fff7/vchBDlW97VDDQ7Yrm58AQJi/8kffcVs0mGFDs1ed4FXHaK5KcbK/n+6Gz2HQ3h+g3zT4ZUFhZ41AigeuNueAW8hWIzitRb7Ui86kuWxtbU4Ym/qC1VVKmi0Mj9Oq3SfqDVznfx//Y93LYtwSpakiFTkBEiM6RSqVi2bBm+vr7ExMQwZswYJk+ezIoVK2jVqhVLlizh448/5vz5wn/cHRwc7trWjBkzmD9/Pp9//jnLly/n9ddf58qVK7i5ud31njVr1vDyyy/j7OzMkCFDCA4OZujQocWuyc7OZtmyZWzYsIGMjAz69u1L3759cXFx4ZdffuHy5cv069eP1q1bM2DAAACGDRtGbGwsGzZswNvbmy1bttC1a1fOnj1L7dq1je3OmTOH1atX4+7uTqVKlUrEN3XqVL788ksWL15M69atiY+PJyoqynje0dGRkJAQvL29OXv2LCNHjsTR0ZHJkyff9T03a9aMqlWrMmbMGNasWYNKVbbPEnbu3ElSUtJd23ZxcQEKk7hq1arx/fff4+HhwZEjRxg1ahRVqlThtddeM16/d+9enJyc2L179z2nCU6bNo25c+eydOlS1q9fz6BBg2jYsCH16tUzXjNp0iSWLFlC/fr1WbRoET179iQmJgZ3d3fi4+Np164dI0eOZNGiReTk5DBlyhRee+019u0rXIOXlZXFhAkTaNSoEVlZWXz88cf06dOHsLCwYs/no48+YsGCBdSuXZuPPvqIQYMGcenSJdRq+edHCHNh0BvIi9UYR4LMrjy2hyUay2SiE/7kYsSxZ6oggpNnFZwrBRirwWWmq8mUanDlikql4O6pwtOQgFPcCWx/34OSm2PqsMRt5C8SM3R7UQQ/Pz9mzZrFO++8w4oVK7CyssLZ2RlFUfDy8rpvW0FBQQwaNAiA2bNns3z5co4dO0bXrl1LvV6v1xMSEsLy5csBGDhwIBMmTODSpUv4+/sbr8vPz2flypXUqlULgP79+7N+/XoSEhJwcHCgfv36dOjQgf379zNgwACio6P57rvvuHbtGt7e3gBMnDiRHTt2sHbtWmbPnm1sd8WKFTRp0qTU+DIyMli6dCn//ve/efPNNwGoVasWrVu3Nl7zr3/9y/i9r68v77//Phs3brxr0qLX6+nVqxdNmjQhLS2NwYMH89VXX2FlZQVAw4YNGTZsGO+//36Jey9evAhA3bp1S227iKWlJTNmzDC+9vPz48iRI3z//ffFEiJ7e3tWr15t7PtuXn31VUaMGAHArFmz2L17N8uXL2fFihXGa8aOHUu/foV7IK9cuZIdO3YQHBxsnArZvHlz43OHwkTYx8eHCxcuEBAQYLy3SHBwMJUqVSIiIoKGDRsaj0+cOJGXX34ZKEzAGzRowKVLl+77TIQQpmXQ6dFGp6ENTyYnMhl95r1H0ssVSxUFHgYS8q8QcfkQyTFXTR3RY2PcFNXal0xNJbLTpRpcuaOAm7saT3UKLvGnsT2+SzZELeckITJD+/fvZ/bs2URERJCeno5Op0Or1ZKVlfXAi+sbN25s/N7e3h5HR0cSE2uif0oAACAASURBVBPvev2uXbvIysqiW7duAHh4eNC5c2fWrFlT7I9nOzs7YzIEULlyZXx9fYuNVlWuXNnY159//onBYChRYCA3Nxd3d3fjaysrq2Ix3ykyMpLc3Fxeeumlu17zww8/sGTJEi5dukRmZiY6nQ4nJ6e7Xr9jxw4OHz7M9evXsbe355VXXqFHjx5s3rwZCwsLoqOjiyVct3uQYg+rVq1i9erVXLlyhZycHPLy8kpUgWvUqNH/s3ff4VFW+f//n2daZtIzMwlJSKUXdZVlZdFVsaywimL5KXaBtbDIj7WsYllExBVRQUW3uH5AXNQP635E17IWqtKigIT0QkihZ5JMSZmSzNzfP4ZkCQlJCCEzIedxXVwXc8993/NKQpn3nHPep9NiCGD8+PFtHmdmZp70HI1Gw9ixY8nPzwdg165dbNy4sd3RxZKSEoYNG0ZJSQnz5s0jIyODqqoqfD5/G92KiopWBdHxP6+EhAQAKisrZUEkSUHI5/HiKrTizK3CVVCD4vJ2flGQEJEaGiLqKbfmkV+0GU/R2fEJvEqtObYp6mC5KWoQi4zWEGuoI6Y6l7DMdagrKwIdSToFsiDqY8rLy7nmmmuYOXMmCxcuxGg0smXLFn772992ug6mPVqtttVjIUTLG9v2rFixgpqamlZNFHw+H7t372bhwoWo1eqT3rej1/L5fKjVanbt2tVyj2bHvyk3GAwIcfL/CAyGjudIZ2RkcNttt7FgwQImTpxIVFQUq1evZsmSJSe9Jisri5SUlJZphJ9++ilXX301V155JTfccAODBg3iwgsvbPfa5gKvoKCgTZFyvI8++ohHHnmEJUuWMH78eCIiInjllVf44YcfWp13Ot3kOvq+nXiOz+fjuuuuY/HixW3OaS5qrrvuOpKTk3nnnXdITEzE5/Nxzjnn4PG07sp0/M/9+PtLkhQcmvcIasiuwl1kRWnsI38/BRCroUZ1lKIDP1K+JyvQiXpMVFwikXHD8ClJ2C0mah1quSlqkAmL1BAX3kCMtYiw3A1oK/r+GrT+TBZEfczOnTtpampiyZIlLes0Pvroo1bn6HS6Vs0Kekp1dTX//ve/Wb16NaNHj2457vP5uOSSS/jqq6+YPHlyt+59wQUX4PV6qays5JJLLul2xqFDh2IwGFi/fn3LlLHjbd26ldTUVJ555pmWY+XlHbezHDhwIKWlpRw4cICkpCTCwsL4z3/+w+WXX85TTz3FmjVrTlpsXH311ZjNZl5++WU++eSTNs/bbDaio6PZvHkzF110EbNmzWp57vgGBacqIyOj1bqujIwMLrjggjbnXHrppQA0NTWxa9cuZs+eDcCYMWP4+OOPSUtLa3etT3V1Nfn5+bz99tstP68tW7Z0O68kSb3L52zCmVeNM7sK114rNPWNNTUiREWjycdh1z5yi7/Dvu/kMxr6En14BMaB/mlwtbZYnLV6LAcDnUo6nj5Mw4AoNzG1JYTnbZLND84ysiAKUna7vc0UJ6PRyODBg2lqauLNN9/kuuuuY+vWrW32AUpLS6Ouro7169fzs5/9jNDQ0B5pi71q1SpMJhO33HJLm6YCkydPZvny5d0uiIYNG8add97JPffcw5IlS7jggguoqqpiw4YNnHvuuVxzzTVduo9er2fu3Lk88cQT6HQ6Lr74YiwWC7m5ufz2t79lyJAhVFRUsHr1an7xi1/w5ZdftluoHO/mm29mwYIFXHvttSxZsoS0tDQyMjI4fPgwYWFhrFixgilTprTbaKF5zc8tt9zC9ddfz5w5cxgyZAhVVVV89NFHLVmGDBnCP/7xD7755hvS09NZtWoVO3bsID09vVvfz3/961+MHTuWX/3qV3zwwQf8+OOPLF++vNU5f/7znxk6dCgjR47ktddew2q1MmPGDAAeeugh3nnnHW6//XYef/xxzGYze/fuZfXq1bzzzjvExMRgMpn4+9//TkJCAhUVFTz55JPdyipJUu/w1jfiyqv2jwT1oY1SRZSWurBaymuyySvagreg7+8NpNZoMCUNRR856Ng0uHA5DS7IhBjUxMU0EdNQTmThZrQFPyDOomYcUmv9siB66G9XBDpCpzZt2tTmE/17772XlStXsnTpUhYvXsxTTz3FpZdeyqJFi1qNBlx00UXMnDmTqVOnUl1dzfz581tab5+OFStWcOONN7b7xv/mm29m6tSpHD16tNv3f/fdd3nhhRd47LHHOHjwICaTifHjx3e5GGo2b948NBoNzz77LIcOHSIhIYGZM2cCMGXKFB555BFmz56N2+3m2muvZd68eR1+f0JDQ9m2bRtPPfUU06dPx2KxMHr0aF5++WXGjh3LuHHjePjhh1m2bFm710+ZMoVt27axaNEi7rjjDhwOB8nJyVxxxRW88MILAMycOZPMzEymTp2KEILbb7+dWbNm8dVXX53S195swYIFrF69mlmzZhEfH88HH3zAqFGjWp3z0ksvsXjxYnbv3s3gwYP597//jdlsBiAxMZGtW7cyd+5cJk6ciNvtJjU1lUmTJqFSqRBCsHr1aubMmcM555zD8OHDWbZsGRMmTOhWXkmSzgxvnQdnbjXOnCrcJXbw9YE3dCrArKFadYTCigz2Z+YGOlGPiBowkMhY/zQ4m8WIw67GYQ90KqmZPlRNbLS/AIrYux1d3naEr++soZNOjziVRd/BRggRCdjtdnubRfEul4vS0lLS09PR6/WBCShJUpfJv7OS1DO8Dg/O3Cqc2VW4y+zQB5YECZ2KRvNxU+EcfX8qnD48EmPSCNS6NOpssThrQwIdSTqOPkxDXJSHmPoyIoq3oc3PkCNA3aSOimLYDxmBjgGAw+EgKioKIEpRlC6vvOuXI0SSJEmSdDZpsrlwZvtHgjwVDugD7+tEhIaGyHrKanLIK/qepsK+PRVOrdViSh6KPnwQLmcC9qpwao7KaXDBorkAMtaXEl60FW3Bj7IAklrIgkiSJEmS+qDGKifOnCqcOVU0HqgLdJzOCcCswaaxUHTwR0qzMju9JNjFJKQQbh6K15uE3RKNw6rGYfU/J0uhwPrvCFApEbIAkjohCyJJkiRJ6iMaj9T/twg60hDoOJ3TCLyxgqON5eSWfEfNvr7dOi00MpqYgSNQaVOprYnFWa/DeSDQqSRoXgPUiLGhnIjCLbIJgnRKZEEkSZIkSUHMc6AWZ45/OlxTVfBvNipC1bii3RyoLSCn6DtcxX1g9OokNDodpuThhISl46yPp7YmnOojgU4lQesucBHFW/1NEGQBJHWTLIgkSZIkKci4KxzHRoKq8da4Ah2nUyJGi8NgY9/R3RTmbUdR+kAnh/YIQUxCChGmYTR5B2KrjMZeo4KaQAeTWhVAe7ejy92G6Kt/zqSgIwsiSZIkSQowRVHwVNTizPZPh/Pa3IGO1LFjrbGrxGEKKrZx8KeCQCfqttBoIzEJw1FpUnHUmHE2yGlwwUAWQFJvkgWRJEmSJAWA4lPwlDla1gR5HcHdZU1oVTTF+jjU3Bq7pG+2xtboQo5NgxuEs34AtTVhchpcEJAFkBRIsiCSJEmSpF6i+BTc++z+Iii3Cl9tY6AjdUiEa3BGOSm35ZJb+B2NRcE/fa8NITAmphFuHEJT00CsFjkNLhjIAkgKJrIgkiRJkqQzSPH6cO+10ZBdhSu/Gl99U6AjdUgYNTj0NoqP7KQ450fogwvVw2JMxCSMAHUKjmozDQ1aGvpAU76zWUiomrjo5iYI29DlbZNNEKSg0S8LoiVTJ/faaz32zy/O+GtMmDCB888/n9dff/2k56SlpfHwww/z8MMPn/QcIQSffPIJN9xwA2VlZaSnp7N7927OP//8MxFb6kRXfq7dVVBQwLRp08jMzGTEiBFkZra/H8jKlSt5+OGHsdlsPZ5Bks5mSqMPV7HVPxKUV4PiCuIiSAXEarBwkLyyLRzZtTfQiU6ZNkSPKXkYutBBNNTFU2cNpepwoFP1b7IAkvoSVaADSG1NmzYNIQQzZ85s89ysWbMQQjBt2rSWY2vWrGHhwoW9mLBrNm3ahBCi3V9HjvTMhO20tLQuFwzvv/8+I0aMQK/Xk5aW1uXv2YQJExBCsHr16lbHX3/9ddLS0k41chvN36eeLDoOHDiATqdjxIgR7T4/f/58wsLCKCwsZP369Se9z9SpUykqKuqxXJJ0NvN5vDRkW6j+MJ9DCzOo/kceDT9VBmcxpBF4EwQHTeV8bXmXf2b8iQ0ZKzlypI8UQ0JgHJhG8rm/JmHkNDQRM7FVX0Xl/kHUWUMDna5f0odpSEn08bPoUi62fMBFX/2OoR/OxvzpK4TkbpXFkBTUTmmESAgxHLgduARIA0IBC7Ab+Ab4WFGUIG+N0zckJyezevVqXnvtNQwGAwAul4v//d//JSUlpdW5RqMxEBG7rLCwkMjIyFbH4uLiejVDWVkZ99xzD0888QQPPvggFovllN7o6/V6/vjHP3LzzTej1Wp7LFdj45lZP7By5UpuvfVWvv/+e7Zu3crFF1/c6vmSkhKuvfZaUlNTO8xmMBha/vxJktSWz+3FlV9NQ3YV7iIrSmPwroEQIWo8pkYO1BWSVbQJV7Ej0JFOScumqJo0HDVmGhp0chpcAIWGa4iNdBNTV0p40Ra0hTtl0SP1WV0aIRJCXCCEWAvsAS4FdgCvA/OA9wEB/Ak4JISYK4QIOUN5+40xY8aQkpLCmjVrWo6tWbOG5ORkLrjgglbnTpgwodVUuMrKSq677joMBgPp6el88MEHbe5fXFzMpZdeil6vZ9SoUaxdu7bTTHl5eVxzzTWEh4czYMAA7r77bqqqqjq9Li4ujvj4+Fa/VCr/H70dO3bw61//GrPZTFRUFJdddhk//fRTq+ufe+45UlJSCAkJITExkTlz5rR83eXl5TzyyCMtI08n0/z8jBkzSE9P58ILL+Suu+7qNHuz22+/HbvdzjvvvNPheX/9618ZPHgwOp2O4cOHs2rVqjY5/va3vzFlyhTCwsK47777uPzyywGIiYlpM/rn8/l44oknMBqNxMfH89xzz3WaVVEU3n33Xe6++27uuOMOli9f3ibDrl27eP755xFC8Nxzz1FWVoYQgo8++ogJEyag1+t5//33WblyJdHR0a2u/+yzzxg7dix6vR6z2cxNN93U8tz777/P2LFjiYiIID4+njvuuIPKyr7ZiUqSTsbn8dKwx0LVqjwOLcygZnUhrtzqoCyGRLgG10AP+YZd/Kv4VdZsfYUf93yGyxn8xZBaqyVu0ChSzrueuMEP4FVPp/rIRVgOJOJu0AU6Xr8TFqkhLbGJC8ILueTA//DLLx5k8IdzMH72GrqCHbIYkvq0ro4QfQq8AkxVFOWkfVmEEOOBR4DHgBdPP17/Nn36dN59913uvPNOAFasWMGMGTPYtGlTh9dNmzaN/fv3s2HDBnQ6HXPmzGn1ptTn83HTTTdhNpvJyMjA4XB0uLYI4PDhw1x22WXcf//9LF26FKfTydy5c7n11lvZsGFDt7/G2tpa7r33XpYtWwbAkiVLuOaaayguLiYiIoL/+7//47XXXmP16tWMHj2aI0eOsGfPHsBfIP7sZz/jgQce4P777+/wdQYOHMjYsWOZPXs2n332GXq9/pRyRkZG8vTTT/P8889z7733EhYW1uacTz75hN///ve8/vrrXHXVVXzxxRdMnz6dpKSklqIH/NPVFi1axGuvvYZarWbKlCncfPPNLSNpx4/IvPfeezz66KP88MMPbN++nWnTpnHxxRfz61//+qRZN27cSENDA1dddRVJSUmMGzeON954g4iICMD/s7zqqquYNGkSf/jDHwgPD28pbOfOncuSJUt49913CQkJ4dtvv2117y+//JKbbrqJZ555hlWrVuHxePjyyy9bnvd4PCxcuJDhw4dTWVnJI488wrRp0/jPf/5zSt9vSQo2SqMXZ0ENzqwqXAU1QVn8NBPRWhyhNvYe3UlRzg99qilCZFwCUXEj8PqSsVfF4LCqcVj9z538Iy/pTAiP0hIbVk+0fS/h+ZvR7ssKdCRJOmO6WhANVRSl0w0SFEXZDmwXQsiPbnrA3XffzVNPPdXy6f3WrVtZvXp1hwVRUVERX331FRkZGYwbNw6A5cuXM3LkyJZz1q1bR35+PmVlZSQlJQHw4osv8pvf/Oak9/3rX//KmDFjePHF/9a5K1asIDk5maKiIoYNG3bSa5tfo9nAgQMpLCwE4Iorrmj13Ntvv01MTAzfffcdkydPpqKigvj4eK666iq0Wi0pKSlceOGFgH+qoFqtbhmN6Mj999+PoigMGjSISZMm8dlnn7VM45s8eTLp6em8+eabHd5j1qxZvPHGGyxdupR58+a1ef7VV19l2rRpzJo1C4BHH32UjIwMXn311VYF0R133MGMGTNaHpeWlgL+kbQTR2POO+885s+fD8DQoUN56623WL9+fYcF0fLly7nttttQq9WMHj2aIUOG8M9//pP77rsPgPj4eDQaDeHh4S3ft+aC6OGHH2414nOiP/3pT9x2220sWLCg5djPfvazlt8f/3UNGjSIZcuWceGFF1JXV0d4ePhJ7ytJwUhp8uEqrKEhqwpXfg2KxxvoSO0TgFlDtfooBRXbOLA7L9CJukyrN2BOGYlWn0adPZ4Ghx7LwUCn6p8iY7TEGmqJthYRmrsJbUVhoCNJUq/pUkHUlWLodM6X2mc2m7n22mt57733UBSFa6+9FrPZ3OE1+fn5aDQaxo4d23JsxIgRrd5o5+fnk5KS0qpQGT9+fIf33bVrFxs3bmz3TW1JSUmHBdHmzZtbRicANJr//rGrrKzk2WefZcOGDRw9ehSv10tDQwMVFRUA3HLLLbz++usthcw111zDdddd1+oencnLy2PlypXk5uYycuRIpk+fzoQJE/j666+Ji4sjNzeXu+++u9P7hISE8PzzzzN79mx+97vftXk+Pz+fBx54oNWxiy++mDfeeKPVseN/Np0577zzWj1OSEjocAqazWZjzZo1bNmypeXYXXfdxYoVK1oKoo50li0zM7PD0bjdu3fz3HPPkZmZSU1NDT6f/1P0iooKRo0a1enrS1KgKU3HusNlVeHMq0ZxB2kRpBH4YgVHG8vJKfmOmn19pIo4tidQmHEoTY1J2CyRWC2yv1MgRBm1xIY4iK4pIDR7A5pD+wIdSZIC5lSbKkQAw4BCRVHqhBBjgIcBA/CpoihtF6tIp2XGjBnMnj0bgD//+c+dnq8cmxrR0XoapZ3pEx2dD/5pdtdddx2LFy9u81xCQkKH16anp7cZ+Wg2bdo0LBYLr7/+OqmpqYSEhDB+/Hg8Hn9NnZycTGFhIWvXrmXdunXMmjWLV155he+++67LzQ2ysrLQ6XQtb8iXL1/O1KlTufjii3n88cepra3l+uuv79K97rrrLl599VVeeOGFdjvMnfh9VBSlzbH2ptudzIlfoxCipchoz4cffojL5WoZHWzO4PP5yMvL67Qo6SxbRw0W6uvrufrqq7n66qt5//33iY2NpaKigokTJ7b8PCUpGCk+BXepHWemhYacKhRnEHaFA4RejcfYyIH6InKKNtLQR5oi6MMjMSaNRK1Nw1ETK5shBIKAGJMGs9ZOtCWP0KwNqCsrAp1KkoJGlwsiIcSlwBdAOGAVQtwO/B9wEPACNwkhQhVF6XjVuXRKJk2a1PJmcuLEiZ2eP3LkSJqamti5c2fL1LLCwsJWLZ1HjRpFRUUFhw4dIjExEYDt27d3eN8xY8bw8ccfk5aWdkqjM53ZvHkzf/nLX7jmmmsA2L9/f5tGDQaDgeuvv57rr7+ehx56iBEjRpCdnc2YMWPQ6XR4vR1/gjtw4EA8Hg8//PAD48aNQ61W8+GHHzJlyhQefPBBli5d2uVOaiqVihdffJGbb765zSjRyJEj2bJlC/fcc0/LsW3btrWartgenc4/w7Szr6Mrli9fzmOPPdaqMQPAnDlzWLFiBa+++upp3f+8885j/fr1TJ8+vc1zBQUFVFVV8dJLL5GcnAzAzp07T+v1JOlM8uyvpWGPhYYsCz5HcBbtIlxDQ1Q9pdVZ5BVtwesNzpzHEyoVpqTBhEYPxe1KxG6JoOaoXAHUm4QKjCYNZnUNkUdzCNuzHlVNz2x3IUlno1N5Z/sC8C9gPjAd+CfwlqIoTwMIIf4IPATIgqgHqdVq8vPzW37fmeHDhzNp0iTuv/9+/v73v6PRaHj44YdbveG/6qqrGD58OPfccw9LlizB4XDwzDPPdHjfhx56iHfeeYfbb7+dxx9/HLPZzN69e1m9ejXvvPNOh9kqKytxuVytjplMJrRaLUOGDGHVqlWMHTsWh8PB448/3irrypUr8Xq9jBs3jtDQUFatWoXBYGhpF52Wlsb333/PbbfdRkhISLtTCn/1q19x0UUXMXXqVF5//XXOPfdcsrOz2bdvH2FhYXz44Yc8+OCDhIZ2be+KyZMnM27cON5++20GDBjQcvzxxx/n1ltvZcyYMVx55ZV8/vnnrFmzhnXr1nV4v9TUVIQQfPHFF1xzzTUYDIZurbfJzMzkp59+4oMPPmiz/9Dtt9/OM888w6JFi06rbfj8+fO58sorGTx4MLfddhtNTU189dVXPPHEE6SkpKDT6XjzzTeZOXMmOTk5Qbk/ltS/NVY20JBZiXOPhaZqV+cXBICI0eIwWCk6tIO9OTv6RFOE0GgjMYkjEKo0HNVm6mo11NUGOlX/oVILTGYVZqqIOJRF6E/rUTmqAx1LkvqMUymIzgMeUBTlgBBiMfAc/qKo2Wpgbg9mO2Me++cXgY5wSk7cw6cz7777Lvfddx+XXXYZAwYM4IUXXmjVBEClUvHJJ5/w29/+lgsvvJC0tDSWLVvGpEmTTnrPxMREtm7dyty5c5k4cSJut5vU1FQmTZrU0kL7ZIYPH97m2Pbt2/nlL3/JihUreOCBB7jgggtISUnhxRdf5A9/+EPLedHR0bz00ks8+uijeL1ezj33XD7//HNMJhMAzz//PA8++CCDBw/G7XafdDrg119/zXPPPcejjz7KwYMHGTJkCL/73e+49dZbGTduHHfeeScff/xxp19Ls8WLF3PRRRe1OnbDDTfwxhtv8MorrzBnzhzS09N59913mTBhQof3GjhwIAsWLODJJ59k+vTp3HPPPaxcubJLOY63fPlyRo0a1e5mrDfccAO/+93v+PzzzztsmtCZCRMm8K9//YuFCxfy0ksvERkZyaWXXgpAbGwsK1eu5Omnn2bZsmWMGTOGV199tcvTESXpTGmyuXHuqaQh00Lj4fpAx2mrpSnCEfLLt3Lwp4JAJ+qUSq3BnDwUfeRgXA0DcVSHUX040Kn6D7VWhdkEJt9RIg9kot+zAVV935hCKUnBSLT3BrLdE4XwAfGKolQee1wL/ExRlH3HHg8ADimK0vkwRg8RQkQCdrvd3qZocLlclJaWkp6efsotliVJ6n3y76zUk7y1HpzZVTRkWfCUOyDYBlnUx5oiNJWTs3cTNdZDgU7UqXCjmeiEUUAKtioTTZ5e++++39PoVMSaFIyNh4ms2IV+z0aE2xnoWJIEgDoqimE/ZAQ6BgAOh4OoqCiAKEVRuvwpwamMECm0/i/lxMeSJEmSFDC+hkacOdU0ZFlw77NBkG0VJEJUeExeDjYUk124gYa99kBH6pBaq8WcPIyQiCE01CZQZw2lKvjrtrOCTq8mNsaL0XOQ8NIfCcnZjMrjDnQsSWqXMrDjrU/6glMpiASwXgjR3H4nFPhcCNG8wrPnVtpLkiRJUhf43E04c6tx7rHg2msDb3B9TifCNTRENlBmzSav6HuaCoK7KUKEeQDRA0agkILVYsRuVYM10KnOfvpQNbHRTcQ4K4goyUCXsxXhC9KW71K/J5IHUj0ynqwUhW9iDlAVVsWWzi8LaqdSxCw44fG/2znn49PIIkmSJEmdUhq9OPNrcO6x4Cy0QlNwDQUJowa73krxoZ1B3xRBrdVhThlOSNhgGuoSqLMasMhRoDPOEK4hLtJNTH0Z4UXb0Bb8gAjiPydS/yYGJmAdlUh2isLXxoMUa44CR1uejyIqcOF6SJcLIkVRTiyIJEmSJKlXKE0+XEVWGrIsuPJqUDxB9Om5AGI1VIlD5JVt4fCu4kAn6lCkeQBR8SPxKSnYLDHYa9RQE+hUZ7ewSA2x4U5iHPsIK9iMbu/uQEeSpJMSCQOwjU4iJwXWGg+Rp7UAlkDHOqPkNDdJkiQpKCleBXeJjYY9Fpy51SiuINow9VhThCNNZWQVbcC+72jn1wRIu6NABwOd6uwWGaPFbKgj2lpMWP73aMtyAx1Jkk5KDIjDfk4SucmCteYj5GiPAv2rbXuXCiIhxNfA84qibOvkvAhgFlCnKMqfu3Df5/Dva3S8o4qi9P3VWZIkSdIpU3wKnjK7vwjKqcZX3xjoSP+lEXhj4ZBrL1lF66nbG7yLayLMA4iOH3FsFMgoR4HOsGiTFrPOTnR1IaG5m9Ac3BvoSJJ0UmJALPZRyeSnqlhrOkSWrpL+/g9EV0eI/gV8dKzV9mfATuAQ4AJigFHAr4BrgC+Ax08hQy5w1XGPg2gehCRJktQb3BUOnHssNGRX4XMET+MBoVPhMXs5UF9IVsF6XMV1gY7UrpaOcOFD/R3hbHIU6EwRAmJMGsxaK1GVeYRmbUBtORDoWJJ0UiLWjGN0MgVpataajpCpO4LsltJalwoiRVGWCyFWAf8fMBW4H4hufhrIA74Bfq4oSuEpZmhSFOXIKV4jSZIk9XGeQ3U4syw0ZFXhrXEFOk4LoVfjNnkod+SRk78RT2Fw7vcSbowlJmEkPlL9o0CyI9wZoVIJTGYVJlFN5JFsDHs2oLZWBjqWJJ1USwGUqma96Sg/hRwGbIGOFdROpamCB/jw2C+EEFGAAahWFOV05jQMFUIcAtzAD8DTzZu9nkgIEQKEHHco4jReV5IkSepljUfr/dPhsqpoqgqeQkPozy3U/QAAIABJREFU1bhMHkqtWeQUbMLrDZ5RqmYqtQZzyjD0EUOOrQUKkx3hzgC1RmA2C4y+SqIOZqLfswFVXXDvGSX1byLOjGOULIBOR7ebKiiKYgdO91+IH4B7gCJgAPBHYJsQYrSiKO2t5nqKtmuOTtmBJzef7i26LOmlS3rttU7XtGnTsNlsfPrpp4GOclo2bdrE5ZdfjtVqJTo6uvMLJEk6oxotDTizqmjIstB0tCHQcVqIEBVuUyNl9hyyCzbQlB98RVBYtJGYxFGgSsNmMeGwqXHI9zk9SqNTEWtSMDYeJqJiF4Y9GxHu4CnWJelEzQVQfpqadS1T4OQ/DKcjoF3mFEX56riH2UKI7UAJcC+wtJ1LFp1wPAI46ybuTps2jffee49Fixbx5JNPthz/9NNPufHGG1FOc6+CsrIy0tPT2b17N+eff/7pxgXA6XSSmJiIEIKDBw9iMBh65L7dcdFFF3H48GGiovp+X3xJ6quaqp00ZFXhzLLQeLg+0HFa+NcENVFem0tW/gYaC4Jnqh6AUKkwJQ8hNGoYrvpEHDXhVB0OdKqzi86gJi7GS4zrABFlO9BlfY+qKfiKYUlqJgbEYR+VREGqivWmo+zWyRGgnhZUbbcVRakXQmQDQ0/yvBv/1DoAhBC9Fa3X6fV6Fi9ezIMPPkhMTEyP3dfjOTP/6H/88cecc845KIrCmjVruPPOO8/I63SmsbERnU5HfLxsVChJva3J5moZCWo8EDzNB4RWhSfWS8WxIijY1gTpwyMxJY9CaNJxVMVS59BQ5wh0qrOHIUxDbJSHmPpywksy0OVtR/hk/yYpeIn4OOyjk8hLFqwzHZZd4HqBKtABjndsjdBIoN9/HnbVVVcRHx/PokWLOjzv448/ZvTo0YSEhJCWlsaSJUtaPZ+WlsYLL7zAtGnTiIqK4v777yc9PR2ACy64ACEEEyZMaHXNq6++SkJCAiaTiYceeojGxs6XiC1fvpy77rqLu+66i+XLl7d5XgjB22+/zeTJkwkNDWXkyJFs376dvXv3MmHCBMLCwhg/fjwlJSWtrvv888/5+c9/jl6vZ9CgQSxYsICmpqZW9/3b3/7GlClTCAsL44UXXmDTpk0IIbDZ/vvpydatW7nssssIDQ0lJiaGiRMnYrX6Vx9//fXX/OpXvyI6OhqTycTkyZPb5JAkqX1NVhe13x+g8s+ZHFm8A/t/SoOiGBJaFY2JCvsi81hT9gZrtr7Mzqwv8TQGQTEkBMaB6aScN4kBw+4D7W+pPnIRVQcS8LiC6nPKPiksUkNaYhPnRxTxq0PvMv7LBxny4f+P6d+vEpKzRRZDUtARCQOwXzmG7dN/zsLHErlleg33XZjF0oQ9x4oh6UwL6L+8QohXgc+BCiAO/xqiSOC9QOYKBmq1mhdffJE77riDOXPmkJSU1OacXbt2ceutt/Lcc88xdepUtm3bxqxZszCZTEybNq3lvFdeeYV58+bxxz/+EYDZs2dz4YUXsm7dOkaPHo1Op2s5d+PGjSQkJLBx40b27t3L1KlTOf/887n//vtPmrWkpITt27ezZs0aFEXh4YcfZt++fQwaNKjVeQsXLmTp0qUsXbqUuXPncscddzBo0CCeeuopUlJSmDFjBrNnz+arr/wzKb/55hvuuusuli1bxiWXXEJJSQkPPPAAAPPn/3cp2fz581m0aBGvvfYaarWa0tLSVq+bmZnJlVdeyYwZM1i2bBkajYaNGzfi9fr/U6yvr+fRRx/l3HPPpb6+nmeffZYbb7yRzMxMVKqg+sxAkoJCU40LZ3YVDdlBNhJ0rEX2/rp89uSvx1MUPOuVtHoDsSmjUOsHU1sTR0O9jobgidenRURriQ2tJ9p2bBPU0pxAR5KkDonkRKwjEshNhnUxh8nVVdLfNkINNqdcEAkh9gG/OLHpgRAiGvhJUZRB7V/ZriTgfwEzYAEygF8qilJ+qrnORjfeeCPnn38+8+fPb3fUZenSpVx55ZXMmzcPgGHDhpGXl8crr7zSqiC64oor+MMf/tDyuKysDACTydRmallMTAxvvfUWarWaESNGcO2117J+/foOC6IVK1bwm9/8pmVq36RJk1ixYgUvvPBCq/OmT5/OrbfeCsDcuXMZP3488+bNY+LEiQD8/ve/Z/r06S3n/+lPf+LJJ5/k3nvvBWDQoEEsXLiQJ554olVBdMcddzBjxoyWxycWRC+//DJjx47lL3/5S8ux0aNHt/z+5ptvbnX+8uXLiYuLIy8vj3POOeekX7ck9Sf+Isi/T1DQFUGxXioceWQVbMBTGDxVRlRcApFxI2nypmCrjKbGIj9g6QlRRi1mfS3RNYWE5X6HZv+p7vYhSb1LpCVTNXwA2ck+1kYfpFhbCciRn2DSnRGiNEDdzvEQYOCp3EhRlNu68fr9yuLFi7niiit47LHH2jyXn5/PlClTWh27+OKLef311/F6vajV/h/T2LFju/x6o0ePbrkOICEhgezs7JOe7/V6ee+993jjjTdajt1111088sgjLFiwoNW9zjvvvJbfDxgwAIBzzz231TGXy4XD4SAyMpJdu3axY8cO/vSnP7V6PZfLRUNDA6GhoV36+jIzM7nllltO+nxJSQnz5s0jIyODqqoqfD4fABUVFbIgkvq1pmonDdlVOLOraDwYZEWQuYny2jyyg2hNkFqjwZwynJDwIdQ7Eqm3y81RT5uAaKOG2BAHUVX5hGVvRH24tPPrJClQhIDBqVQOjyUrsZFvog9QrjmMXA0S3LpcEAkhrj/u4UQhxPEtt9XAlUBZD+WSjrn00kuZOHEiTz/9dKtRHwBFUdo0lmivA11YWFiXX0+r1bZ6LIRoKRDa880333Dw4EGmTp3a6rjX6+Xbb7/lN7/5Tbv3bs7d3rHm1/P5fCxYsICbbrqpzevq9fqW33f29XXW8e66664jOTmZd955h8TERHw+H+ecc84Za0AhScGs8Ug9zpwqnLnVQdodLriKoNDIaIxJo0GVjs1ikpujni4BMUYNZp2N6Mo8QrPWo7acdc1kpbOJWo0yNI0jQ43sTnTzTdR+DqsPcBY2QT6rncoIUfPmNApt1/g04i+G2g5jSKdt0aJFXHDBBQwbNqzV8VGjRrFly5ZWx7Zt28awYcNajcycqHnNUPMamtOxfPlybrvtNp555plWx1966SWWL1/eqiA6VWPGjKGwsJAhQ4acVsbzzjuP9evXs2DBgjbPVVdXk5+fz9tvv80ll/j3jDrxeypJZzvP/lqcuVU4c6qDa7PUIC2CjAPTCDeNwO1KwmaJoOrw2dvx9IwTEGPSEKuxEWXJJXTPetRVclhNCmJaLb7h6RwcGs2ueCffRJZTrSoH5GqPvqzLBZGiKCoAIUQp/jVEVWcsldTKeeedx5133smbb77Z6vhjjz3GL37xCxYuXMjUqVPZvn07b731Vqu1Mu2Ji4vDYDDw9ddfk5SUhF6v79aePRaLhc8//5zPPvuszdSye++9l2uvvRaLxUJsbOwp3xvg2WefZfLkySQnJ3PLLbegUqnIysoiOzu7zfqkjjz11FOce+65zJo1i5kzZ6LT6di4cSO33HILRqMRk8nE3//+dxISEqioqGi195MknY0Un4KnzI4zpxpnXjVem7vzi3pJMBZBGl0I5tSR6AxDcFjjaaj7b0MEWQqdIgFGkwaz1kZUZS6hmWtRV8upRFLwEno9jSPT2T8ogh8T6vk2rIxa1b5Ax5J62CmvIVIUJf1MBOlNSS9dEugIp2zhwoV89NFHrY6NGTOGjz76iGeffZaFCxeSkJDA888/32Zq3Yk0Gg3Lli3j+eef59lnn+WSSy5h06ZNp5zpH//4B2FhYVx55ZVtnrv88suJiIhg1apVPProo6d8b4CJEyfyxRdf8Pzzz/Pyyy+j1WoZMWIE99133yndZ9iwYXz77bc8/fTTXHjhhRgMBsaNG8ftt9+OSqVi9erVzJkzh3POOYfhw4ezbNmyNq3IJamvU7w+3CV2/3S4vGp8dZ230+8twVgEhcWYMSaOwkca1kojtirZEKFbmkeAtDaiKnMI270WVc2RQKeSpJMSEeG4RqZRnh5KRpyDdWFluERxoGNJZ5hob81JpxcJcSX+NUNxnLCXkaIoM9q96AwQQkQCdrvdTmRkZKvnXC4XpaWlpKent1pvIklScJJ/Z3uez+PFVViDM7caV0ENiit49l8RISo8puOKoEDvDyQEpoHphBlH4moYiKM6PLB5+qpWa4DkCJAU/IQxhvpRKZSkhbDZXM1mQwVeTv29cX8WFRLFltuCY7mBw+FonvUUpShKl7e47k7b7fnAs8BO/C0z5J8aSZKkIOGtb8SVV+0vgvbaoOnkTVF6mwhR4zZ5KHPkklOwkcYCV0DzaHQ6zKmj0On9U+Hq63XUB08fib6huQuczk508xog2QRBCmIiMR77iEQKU1RsMlayI+QQkBvoWFKAdaft9kxgmqIoq3o6jCRJknTqmqwunLn+IshTbofgqYEQejUuk4cyWzY5BRtpKghs90Z/V7hzUEQ6tkojtqqTN6CR2hdt0hKrs/nbYGeulQWQFLyEgPRkqofFkTPQx/qYQxRoqwC5DF5qrTsFkQ7Y1tNBJEmSpK5rPFrf0hQhmPYIAhAGNS6jm1JrNjkFm/B6A1sExSSkEGEeidudLLvCdUNUjJZYvYPo6jxC96xHc1R205KClEaDb1gaR4YYyUx0801kBYfVh4BDgU4mBbnuFET/A9wBLOzhLJIkSdJJKIpyrD12Na7c4GqPDSBCNThjnJTWZJFbuAmvtylgWVRqDeaUYegjh1NnTaShNgTnsUEMWQp1LjJaQ2xoHdHVBYRlr0dzSHbUkoKTMBjwjEpn/6BwdgyoZ114OXZRhtwWUzpV3SmI9MADQoirgCz8exC1UBSley3FzpDuNI2QJKn3yb+rbSleBfc+m386XF41PkdwbRYsIjTUR9RRUrWb/LwtKErg5uqFhIZhThmN0A7GbonDYVPjsAUsTp8SHqUlLqyOGGshYdkb0ByQHbWk4CSMMTSMTGZfagjbzXY2hZbjEUWBjiWdBbpTEJ0HZB77/TknPBc072i0Wi0ADQ0NGAyGAKeRJKkzHo//zX5Hmwr3B0qjF1eR1T8drqAGxRm4kZb2iGgtjlAbxYd/pDh7BwSwkI0wxRGdMJombxq2o9FUH5XjP10RFqkhLtxJtL2YiJyNaMrzAh1JktolkhKwDU+gMFnFdy0NEOSfV6nndWcfosvPRJCeplariY6OprKyEoDQ0FCEkP9ZSlIw8vl8WCwWQkND0Wi68zlN3+ZzNuEsqMGZU4W7yIrSGERdEQBh1GILqSL/wHbKd+8JYBCBKWkQYTEjcNYPpLYmHMvBwMXpKwxhGuKi3MTUlhCR9x3akszOL5Kk3qZWowxOwTLUTFZiI+ujD1GisQCWQCeT+oGz+p1HfHw8QEtRJElS8FKpVKSkpPSbDy68djfOY+2x3aV28AbNALt/oY1ZQ7X6KPnlmzm4qzBgUdRaHbGpI9GFDsVRE099nY764OohEXRCQtUMiG4kpr6UiMLN6Ap2BDqSJLUh9HqahqdxYHAku+IbWBtRQbVqP7A/0NGkfqg7+xBtpIOpcYqiXHFaiXqQEIKEhATi4uJobAyeXdklSWpLp9OhUqk6P7EPa6xsONYeu8rfGS6IaiDUAl+s4GhTOTkl31GzL3BDL/rwSEzJ54AqHZvFjK1aDdUBixP0dHo1cUYvRmcFEXu3oftuC0KuyZOCjIiKxDkylbI0A9vjbGwMrcAl9gY6liQB3RshOnGsXQucj3890XunnegMUKvV/X5dgiRJva+5M5zrWFOEJkuQdYYLUeMxNXGgvoicog007O3ypt49LiougcgBo2nypGCtjKL6SP8YKewOjU5FnEnB5DlIxL4MQjZ/hwhgVz9Jao+Ij8MxciBFyRq+N1nICDmAIvIDHUuS2tWdNUSPtHdcCPEcEH66gSRJkvoypcmHe5/dPx0uGDvDhWtoiGygzJpNbuH3eAO0UapQqTAnD8EQNZyG2iTqbAbk/p7tU2sEsWYVJu8hIst3ot+2AeFxBTqWJP2XSgWDU7AMMZOb6GNDywaoNYFOJkld0pNriN4HfgT+0IP3lCRJCnre+kZcBTW48qtxFdtQ3N5AR2pFGDU49DaKj+ykOOfHgHWG0+oNmFNGodEPwV4VR61DS23gBqWCllCB2azGjIWoA7vQZ6xF5aoPdCxJatG8/ufgoEh+ineyLmI/leoDgPxUQ+qberIgGg/Ij6wkSeoXGisbcOZV48qvwVPhCK71QCpQYtVUcYi8si0c2RW4efrhRjMxiaPx+tKwVsZgtZzd68S6RYDRpCFWU0PU4T2E7lyLyiEXTUnBQ8RE0zAihbJUPRlxdjaEluGW63+ks0h3miqsOfEQkACMBRb2RChJkqRgo3gV3GV2XHn+/YG81cH1+Y/QqWg0+zjsLCG7eBO1JVUBCiIwDUwnzDgCV0MSjmrZGrs9UTFa4gx2oitzCM1ch7pKfpOk4CEG+vf/KUpRsSmmkh16uf+PdHbrzgiR/YTHPqAQeFZRlG9PP5IkSVJw8DU04iq04iyowVVoRXEF18J1EabBGe2k3JpDbtH3NBYGpkjThugxp4xEaxjsb41dr6NezvBqxb8ZagNGayFhWevQHJSfrktBQqWCIalUDjWTndDEhuhDFGvl/j9S/9KdpgrTz0QQSZKkYNB4pN5fABUcmwoXXHukIoxa7Poa9h7eSXHujoCtB4owDyA6fiReXyq2yhisVXIq3PFCDGoGxDRirN9HeN536Db9FOhIkgS03v/np/gG1kbsp0ru/yP1c91eQySE+DkwEv/M+TxFUXb3WCpJkqReojT5cJXY/E0RCmrwWt2BjtRa83og5RB55YFbD6RSqzElD8UQOYyGukTqrKFyKtxxNFoVsWYFs+cAEXu3EfL9ZoQvuJprSP2TXP8jSZ3rzhqiOGA1MAGw4V9DFHVsw9bbFEWRY6ySJAU1r8ONM99fALlLbCie4BoGCpb1QP4NUkeh0gzCXmWm1q6h9sRJ0/2UUIHJrCFWHCWqYieG7WsR7uDaZ0rqn0SSf/1PYbKK7+T6H0nqku6MEL0JRAKjFUXJBxBCjMK/Kesy4PaeiydJknT6FN+xDVKPjQI1Hg6+BS4iXIMzykm5LZfcwu8Csh5ICBXGpHTCYobhdg3EbomQG6QeJypGS5zeRvTRbEJ3f4PaWhnoSFJ/p1ajDEmlcoiJ7MRG1kUfZJ9Grv+RpFPVnYJoEnBVczEEoChKnhDiIUA2VZAkKSj4GhpxFVtxFVhxFdXgqw+uhghwbD1QSDV7j+yiOCcw64EMEZEYk0ah0qRhr46lvk5LfV2vxwhKhnANAyJdGG2FhGevR7O/MNCRpH5OGAx4RqZxID2CnfH1rAuvwKqqACoCHU2S+rTuFEQqoLGd443HnpMkSQqIYG+IgFqgmFVYlIPklW7haGlJr0cQQoUpaRChMUPlKNAJNDoVA8w+TM5yIgu+R7cpI9CRpH5OmIzUj0xmX4qObbFWvjfsxyOKAx1Lks463SmINgBvCCFuVxTlEIAQYiDwGrC+J8NJkiR1xOfx4m5uiFBoxWsLsoYIgNCr8RibONhQTE7RJur3Wns9gyEyGuPAEag06dirYqmr01AnR4EQAkyxGmKpJKriRwzb1iI8wbW/lNS/iJSBWIfHk58EG41HydQdAXIDHUuSznrdKYhmA/8GyoQQ+/F3mUsBsoG7ejCbJElSG42VDbgK/dPg3KV2aApM2+mOiCgt9WG1lNZkkV+0Fa/X06uv7+8INwRD5FBczgTsVeFyFOiY8CgNA8LqiLHkEPbT16irDwc6ktRfaTQoQ1M5OtjInoGNrI06QIX6KHA00Mkkqd/pzj5E+4ExQohfAyPwd5nLUxRlXU+HkyRJ8nm8uPfacBVZcRUGYVtsaJkKV80RCvdncCCz9zs6hRtjiY4fgSJScFSZWnWE68+lkDZExQCTD1P9PiJyN6DbJHeIkAJDGAx4RqWzPz2cXXH1fBtRjl1VDpQHOpok9Xvd3odIUZS1wNoezCJJkgQcNwpUWIO7LEhHgcI0uKJdHKwtIrf4exr29m4/arVWhzl5GCHhg2moS6DOGkqVHOxomQYXx1EiyzLQb1uPyhOERbR01hPGGOpHprAv9fj1P0WBjiVJUju6sw/RMmCvoijLTjg+GxiiKMrDPRVOkqT+wedu+u8oUJE1OEeBBGDWYNNUUXL4J/bm7uz1rnCRcQlExY3A50vGZonBblVD7y9JCjphkRriw/3T4MJ3fYWq5kigI0n9kEhKxDY8nsJkFZuMlewMOYRc/yNJfUN3RohuBq5v5/g24ElAFkSSJHVIURQaD9UfK4Bq8FTUgjcIR4H0ahqNXo64ysgt+R7bvt4dgtHq9ZiSR6AzDKbeMYB6ux7LwV6NEJQ0umPT4JxlROZtRLdpZ6AjSf2NSgWDU6kcZiY7oYl1MQcp0VQCcm8qSeqLulMQmYD25oY4APPpxZEk6WzlrW/EXWz1T4UrtuKra697f4AJwKTFoa2h1LKHosIMfD5vr0aIjk8mInY4TU1J2CzR2KrkbgYIMJk1xKosRO/fiWHb17IbnNSrhE5H04h0Dg2K4qcEJ2sj9lOp3g/sD3Q0SZJ6QHcKor34N2d964TjvwH2nXYiSZLOCopPwVPhaJkG13iwzt+TMsgcPwqUv28zNfsO9errh4SGYUoeiSYkHYd1AK46Ha4DvRohKIVGaBgQ0YCxOp/w3V+jrpQbT0q9R4SH4R6ZTnl6KD/E1bIurIwGVe/vGyZJUu/oTkG0FHhLCBGLf08igCuBx5DT5SSpX/Pa3S0FkKvYhuJqCnSkto6NAtXqrJRa9lBYuL1XR4GEUGFMSicsZigedyI2SxQ1lf25D5yfWqsizqxgdlcQVfAduk3bAx1J6kf8G6CmUJKmY4u5hs36CppEQaBjSZLUS7rTdnuFECIEeAaYd+xwGfA7RVH+0YPZJEkKckqTD3eZA1eRf2PUpqMNgY7ULmFQ44lp4oirlIJ9W3t9FCg0MhrjwJEIdSr26jjq6zTUy41RiTFridNUE31gJ4aMr1G56gMdSeonxMAEbCMSKEhWscl0lF26w0BOoGNJUp8gEMTqTaSGxJCi0jOUkEBHOm1COY0uScdGiZyKogTkv3YhRCRgt9vtREZGBiKCJPU7TTUuXIU1uIqsuEvsKJ7eXWPTJcc6wtk11ew7mknxvh9RFF+vvbxKrcGcPBR91GCc9Yk4qsMQ/Xo3IL/QcA0DIp0YrfmEZ36L+nBpoCNJ/YEQMCgFy7BYcgb6WBd9kGJtdaBTSVLQM4XEkKo3kaIykOpVSHHWkeqwkFJTjsFz3AeghhiYWxawnMdzOBxERUUBRCmK4ujqdd3ehwhAURTL6Vx/PCHEU8CLwBuydbckBQ+lyYe71I6rwF8ENVmcgY7ULhGmwR3t5lB9CXklW6jd12P/PHVJdHwyEeah+JQkbJYYHHY1jn6+MaqmeRqcq5zIwu+R0+CkXqHR4BuezpEhMexOcPFNZAVH1AcB2aJRkk4UqYsgTR9LijqUVC+kuhtIcVSRWlNBuKv/rN08rYKopwghfgE8AGQFOoskSdBkc/tHgQpqgncUSC1QzCqswkLJ4Z/Yl/tTr+4LFBoVQ0zicFSaVGqtsbjqdbj6+/utE7vBbf8G4Q7OAlo6ewiDnsYR6ewfFMGO+HrWRpRjF6WAHIGUJIBQTSiphlhSNOGk+lSkup2k1lWTWr2f6Ib+U/R0JOAFkRAiHPgAuB/4YyfnhkCriYoRZzCaJPUbilfBU+7AeawICtq1QNFa6kPrOGAvIL9kG669XR4NP23aED2m5GHoQgfhrB9AbU0Y1XL/TyJjtMQZHERbcgnb/S3qqv5eFUpnmoiIwDUqjdJ0A9vjbGwILcctigMdS5ICKkQdQrIhjlRtBCmKmjS3m5R6K6nWA8Q6KgDZJKQjAS+IgD8DXyqKsk4I0WFBBDwFzO+FTJJ01vPWefx7AhXUBG1HuOaW2BbPfgrLf+Boae+1vVWp1RgHDiI0ejCNnkRslkhs1Sro50sPDGEa4qJcGB3FRGRvQLMpL9CRpLOcvwNcMsXHOsBtMVTgJT/QsSSp12lUGpIMcaRqo0hBS2qjh9R6G6m2w8Rb9yKQHwx0V0ALIiHEbcDPgbFdvGQR/rbfzSIAuWOHJHWR52AdroIanAU1NB6oDb59gVSAyd8MobQyi+LCH3q1JbZ/HdAQFCUJW5WRulo1dbW99vJBSRuiIs7kw+QsJ7JwM9r8DEQvTk2U+h8xIA77qCQKU1VsNFayM+QQkBvoWJLUK1RCRbze7O/gJnSkNXpJabCTZjtMorUCjU9u+XkmdKsgEkJciX/voTj8b2FaKIoyo4v3SAbeAK5WFKVLW44riuIG3Mfdo6uRJalfUhq9uIpt/lGgwhq8dk+gI7UhorQ0hNdzyFFMwb6t1JVYe+21w41mouKHoVKnUGs1y3VANO8HBMamQ0SW7SBkywZUTcH350Y6e4ikRKwjEshLhnWmI+RojwI1gY4lSWeUOcRIqt5EqkpPapOPVGcdqY6jpFSVo/OWBTpev3PKBZEQYj7wLLATOEz3P2P+Of6CatdxhY0auFQIMRsIURQlCFdyS1Jwa7K5cOUfa4iwz47S2Hvtprvi+GlwRRU/cKQXp8HpwyMwDhyOJiSVekcc9XYD1Yd77eWDklojMJsFZu8RIst3ot+zQTZCkM4okZZE1fB4cpK8fGs8RLGmEqgMdCxJ6nFRukhS9bGkqg3+Dm6u+mNtq/cT5pbNDIJJd0aIZgLTFEVZdZqvvR4494Rj7+Jf9bVYFkOS1DWKT8FT4cBV4F8P1HgkyDa3VAswq7EKC6WVe9hbsKPX9gT6byOENFzOeOxVYdRU9u+RZZVaYDbFolrkAAAgAElEQVSrMCtHiTywG/0P61A55S6x0hnSvAfQ8Dj2DGzkm+gDlGuOALIjiXR2aO7glqoJJ8WnIs3tJKW2mrSaCqJkB7c+ozsFkQ7YdrovrChKLSdsCy2EqAeqFUWR20VLUge89Y24i6w4C2twF1nxNQRXQwQRraE+rI4DtsJe7Qan1mgwJg3GEDmIRncCtqrWjRD6YymkUgtMZhVmqog8uBvDznWo6uyBjiWdrVQqGJLK0WFmdic28k10BQflHkBSH6dT6UgOjSNVG0mqoibV4yalzkqa9aDs4HaW6E5B9D/AHcDCHs4iSVIHPIfqju0NZMWz3wFBNBNOGNR4YpqodFdQWJbx/9i78xhJ8zyv7+/f8zxx30feVXlf1T2sFgMyBswhIYyQDGZtfMnyslq81uLV2gYZ7wokDmu8kjELCHZBAgQLi7CQvVyCWZbpOfqc6bu6u46svO8jMiPjviMe/5FZPTVN90xVdmZGZMbnJaUq48nMeL45R1V84vf7fb9k1jeu577GIjE6QSg5Q6c9Ru44TjFvU+zj1/tPV4BSbuY8AL2iACRXx7Zx5yfZn0vx/midX49tcGRtA9vdrkzkhTjGYTQwwLg3xqTxMt5oMlHJM3G6x0huDctd6XaJcoUuEoj8wE8ZY34/Z4NUm89+0XXdP3XRYlzX/b0X/VmR26bTaFNf6dGGCOdDUXNWhrX9+6w+evd6tsEZQ2L4LuHUDB13jGI2SaXiUOnNsUnX4tMAxBGxnQ/wv/MKVvn65jNJn3EcOgtT7M0leHe0yr+NbHJibQKb3a5M5IcyGIYDaca9CSYtH+PNNpOVAuOFQ8ZOtvCog1vfukgg+hHgw/PPv/KZr6kXq8iX0DqtnbXFfnTWEIFW7ywDmbjnfBvc9Q5FjQ2NEknPgrlDIZuiWvVQ7ePdN5+eAeKIyPb7BO5/QwFIro7HQ2dxit3ZOG8PV/j16AZ5ax1Y73ZlIl8o7Usy7k8yaQUYb3WYrJYYLxwxfrKJr6XwLv++Fw5Eruv+vqsoRKQffa8hwlkIah32zlKH8Vq0Ui6Z1jZLm9+5tm5wkfQQscE5jH3n01bY9b1ruXVP0gqQXCfj9dJanGJnLsbbw2V+I7JJ3uhdc+k9UW+ESf8A43bwvINbhYlihomTLXVwkxf2pQazGmPuAK7run38fq3Ii+nUWtSenJ61xn6SpVPukYYIBkh5KHpO2Tj5mKWV79BeuvptepHUINGhWSz7LqV8mmrRx3Eft8JWAJLrZLxeWvem2Z6N8p2REr8R3qBkrq8VvsgPErD93A0MMuGJMNmxmKjXmCidMHGyRUId3OQSXWQOkQX8OeBPA+Hza0XgrwBfda+rn67IDdI8rp4FoEcn1DcL0O6N3aVnzRCaHFTXebj2Brm1q08i4eQAsaE5LOcO5fwAlaKvr2cBfS8AZc4D0NcVgOTKGJ+P5kvTbM1G+M5Qkd8IbVCxdFhcuscxDmPBASY8cSZwmGw0mCifMnG6x1B+GcOTbpcofeAiK0RfBX4S+DngDc7eV/6dwF/grOHCn72s4kRuKrfj0tjIU32cpfYoSyvTI4MuDZB2yDsnrB5+wMqjq58JFE6mzwKQ5y7lXJpK0c9JH48gsWzDQNoi5R4R2dEZILlaxu+n+dI0mzNh3hoq8vXQBhVrudtlSR9K+5JM+FNMWn4mW20mKyUm8vvcUTMD6QEXCUQ/DvwJ13X/5TPX7htjdoFfRoFI+lSn2qL25OwsUG3pFLfaG1vhnq4C7VfXebj6Gvm1wyu9XzCeJDE8h+0dp1xIU84H+joA2c75ClDngOjOh/g/0CBUuTom4KdxHoDeHCrw9dAGNaN32OV6PB1SOulEmOgYJmsVJgsZJrJbhGva4ia96yKBKMnnT6B6fP41kb5xthXuhNqjLPWNAnR6YCucAVIOeW+WtcMPWH709pWuAgUiMRKj8zi+u1RKQ5ROA5xcbebqaY7HIp2CZPuQ6Pb7+D98BatW7nZZckuZQIDGy9NszIR4YzDPK6EN6gpAcoVsYzMaGGDSm2ACh6lmk8nSKROnOwzlH6MhpXITXSQQ3Qd+BvjZz1z/mfOvidxabrtDfeOsK1ztce9shXs6GPWwtsGD1deu9CyQLxQmObaAxz9OtTxIMRsie3Rlt+t5voDNQKJNorZDZONdvJ+8itWod7ssuaVMKET9pUnWZ0K8OZjnleAGDbPU7bLkFop5o0z5B5i0g0ydt66ezO9z92QLT1tt1+V2uUgg+jPAvz4fzPoWZ7OHfgdwF/hDl1ibSE9oFxvUls4CUG05h1tvd7ukZ84CZVk7+oCVx+/Q6VxNXR6fn+SdOXyhKWrVIfLHYU4z5krudROEog4D4Rrx0gbh5bfwPP4uxu2BlUG5lUw4RO2lKdang7w+eMo3gpu0FIDkkjxtaDDljTPpOkzV60wWT5jKbpEoa4ub9I+LzCH6tjFmHvifgEXOXpr9GvDLruv28bQQuS1c16W5UzpriLCUpblb6omRwyZoU483Oaiu8XD19Ss7C2TZDsk70wRjMzQbI+QyUfJZC7LndVzJXXuUgXjSQ8pXJH76hNDD13A2H3a7KrnFTDRK9eVJVqf8vD6Y5dv+LVpGW5Dky4l4wkwGBpmyg0y1XaYqJaby+9w93lRDAxEuOIfoPPioeYLcGp/OBnqcpfbklE6p2e2SwALSDjn7mNX9D1h9+O7VnAUyhsTIOJHULO3OGPlMglLBptSHjc9sx5BKWSQ5Jnr4gOD9b2Jl+7gjhFw5E49ReXmSlUkvrw5keT2wRRuFbnlxBsNIYIApX5IpPEw1GkyVTpnKbpEuboH+dyXyhZ4rEBljfgT4xHXdzvnnX8h13Y8upTKRK9Y8KH+6CtTYLPZEQwQTdKjH6+xVVnm48hrF1eMruU84mSY+vIix71LIpqlWPFR3ruRWPc0ftEnH2yTqu4Q338f/8bcx9d44Fya3k0kmKL80wZNJD98eOOZN3zauedDtsuQG8VpeJoLDTHkiTHcspmtlpvJHTJxsEGhsdrs8kRvpeVeIPgSGgaPzz10+f+eMC9iXU5rI5erU29RXTqktnVJbytLON7pd0qdngXLO2SrQysN34ArOo3j8AdJ3F/AEpqiUhimdBjjuw2Go0YSHdKBMrLBG6MlbeJbf0/kfuVImlaT08jhPJj18M3XEd/y7wCfdLktugIgnzHRgiGk7yFSrzXSlyNTpLmPZdWxXw3RFLtPzBqIpIPPM5yI3QvOo8uk2uPp6Htrdf/H7dC7QXmWVR6uvk1+7/BZtxrJI3ZkhGJ+lWR8ll4lyetxXp3+wbEMqbZEyWSJHDwl+8ir2kQ4Jy9Wy0kmKL43zeNLhm+kMb/sUgOQHG/AnmfalmTZ+ppsNZkqnTB1vki5pm5vIdXmuQOS67rNrsBPAm67rft/USWOMw1m3Oa3XStd06i3qq3lqy2crQe1srdslfW8ukOdq5wJFB0aIDc7jcpf8SYpS0aZUvPTb9Kzv2/62/SG+j76t+T9y5ax0ksLL4zyecPhm+oh3fHsoAMlnGQyjwQGmvSmmcZip15kqHjN9vE60qjdqRLrtIk0VvgmMcLZ97lmx869py5xcG7fj0tgpUl/OUVs+pbFd7I1VIL9NI9nioLbOw9XXyK1d/sF8fzhKcmwBxzdJKTdIpegj0y99Hg3EEg5pf5loYY3Qk+9o+5tcC5NMUPrKBEuTHl5JHfKOXwFIvscyFmOBQWa8SWawmalVmckfMnW8rvM9Ij3sIoHI8PlNiFOA3o6VK9fK1c62wC3nqK/m6FRaP/yHroFJeSh4T1k/vs/S0luXPhfI9nhJ353HF56iVh0mfxwme9Qf2+Acr0U6CclOhvDBJwQ++TZ29mrajos8y8RjlL8yyZNJL98cyPCWfwcFILGMxZ3AEDO+BDOdp8HngKnjdfzNjW6XJyIv6LkDkTHm184/dYF/YIx5dhS7DfwI8OYl1iYCnDdDWD1bAaov52gd90YXMOO1aKU6HDS2eLT+Oifr25f7/MYiMTpBKDlLuz1GLhMnf2rB6fnXL/VuvSUSd0gFa8TLmwTX3sH38C1MuzeCr9xuJhql8pVJVqZ8fGvwhNd9W+oC18cMhrHgELPeJLPYzFSrzOYPmMqs4WttdLs8EbkkL7JClD//0wBF4NlXpQ3gO8DfuaS6pI/16jY4AJNyKPjybJ58wuPlN2kvXW6nulAiTWJkEWPdJX8yQKXiUKlc6i16juOxSKUMCU6IHD0i8Oh1nP2NbpclfcKEQ9RenmZlJsCrg1leDWxqDlAfejrDZ8aXYhaHmVqN2fwh08dr2uom0geeOxC5rvsTAMaYDeD/dl1X2+Pk0rROqtSWc9SXT6mt5nFrvbEaYPw2zWSbg/oGj9fe4GT9cof1ePx+UncW8IamqRSGKOWCt74d9tPVn1h5i/DGe3gevInV6oEW6NIXTCBA/SvTrM+EeH0oxyuBDVrmUbfLkmuU9iWZDaSZxcdcvc5sIcNMZo1QXcFHpF+98Bki13X/4lUUIv2lU2lSW82drQKt5HqjGxx8Ohco72RZP/qQ5aW3L/UskDEWyTtThOKzNJqj5DMxcicWnFzaLXqK47VIJQ0J95hI5jGBB6/hHOpFh1wf4/fTfGmajdkwbwwV+HponbpZ6nZZcg2i3gizgSFmrQCzjSazxRPmMuvEK+rqJiLf7yJNFTDG/BfAfwmMA95nv+a67n9wCXXJLeO2OzQ2i2ftsFdyNHeKn9+aowtM0KGeaLBfvpq5QOFkmvjwIljj5LMpyiUP5dKl3qJnhGMOqVCNeGWb0Pq7eLX6I9fN46H90jRbczHeHCny74IbVKwn3a5KrpDf9jEdHGHOiTDX6jBXzDJ7sslg4QGg818i8sO9cCAyxvws8FXgV4A/Avx9YAb4bcAvXWp1cqM1jyqfNkKor+VxG5fbde3CbIObtjg1GVb332ft4ftwie2aP90GF5ymUhymlAvcym1wlm1IpSyS1inR48cEHr6Gs7fW7bKk3zgOncVpdubjfHekzK+HNyhaq92uSq6AZSzGg8PMeRPMdSzmKgXmsrvcPVnFcpe7XZ6I3GAXWSH6k8BPua77T4wxPw78X67rrhlj/hKQvNzy5CZpl5vUV77XDa6dr//wH7omJupQjVTYKTzh0crrVFbyP/yHnve5P+0GN0erOUbu+HZugwuEHNKxJonaDqHN9/F/8hqm3hsd/6SP2Dbu/BS780neGavybyLr5C0F8dsm6UswHxhgHj9z9RpzuQNmMqtqaS0iV+IigWic77XXrgKR88//EWed5n7mEuqSG8BttqlvFKiv5qktn9LcK/XMNjg8Fp0UHHf2eLLzNrv3L/fQdCiRIj6ygLEnKJykqVQ8t64bXCzpkPaXiOVWCS69gXf1frdLkn5kWTA7wf5CmvfGGvyb2AbH1gaw0eXC5DJ4LA/ToVHmnQjzrQ7zxVPmM+ukS/r7RkSuz0UC0QFnQ1g3zz9+O3AfmOJ2j0bpe27bpbF9FoDqqznqWwVo9UgCOm+GUHRybJ0+5MnKd2g8ubzVC28gSOrOAp7A5Kfb4E5u0TY4yzak0hYpc0Lk8CHBj7+Ffbzb7bKkHxkDU+Mc3Rvk/bEGX4tvsm9vA5c750uu34A/ybx/kHk8zFcrzJ/uMZVZw9PRFkcR6a6LBKJvAP8p8D7w94C/et5k4bcCv/aDflBuFrfj0twvn4Wf1Rz19ULvnAMCTNxDJVRir7DC0tpbFNcub4+aZTuk7swQiE3TqI+Sy0Q5Pb49ed/rtxlIdEg09whvvY//o29j1dRJX7rDTNzh+N4w9++2+Vp8m01nF1Agv6kcy2EmNMaCE2W+1WGheML80RrJsrq7iUhvukgg+inAAnBd928bY7LA7wL+FfC3L7E26YLmUYX66lkr7MZ6nk6lN+YBAZiQQz3W4Ki2ydLmdzhev9x/XOPDd4ik5+m4Y+QzSYoFm2LhUm/RNf6Qw0CsSaK6RWT1u3gfvIFp985/t9JfzN1RsvdG+Piuy79N7LLsOeBs84HcNElfnPnAEAv4WKhVmD/dZ/poBU9H57pE5Oa4yByiDtB55vE/Bf7pZRYl16eZqVBfy59/5OgUm90u6VPGZ9NKdjhp77O6+x5bn3xyqc8fSqSID89jOeMUTweolb3Ubsmb0qGow0C4Rry4Tnj5DTxL72IusZOeyIswYyOcvjTKx+Muv5HYY8lzBFxue3u5WpaxmAiOsOCNs9CCxXKOhcw6A4WPul2aiMiX9lyByBjzI8/7hK7r6m/HHtY6qZ6Fn9WzVtjtQg/NiPFYuEnDqcmwcfQRq0/evdShqN9/DmiIUi7IyS15Uzqa8DAQKBHLrRB6+CqejcsNjyIvwowOc/rSGJ+Mw28kd3nsyQCZbpclzynoBJkLjrBoBVloNFjIHzJ3tEKgsdHt0kRErsTzrhB9yFn/sB92iMIF7C9VkVyqVq72vSYIa3naud5phY1lIG1TsLNsnTzkydp3aT6pXdrT245D6s4c/ug0jfoIuUzkVpwDMgaSaYeUkyOWeUTgwbdw9je6XZb0MXN3lNPFER7cha8n9nngPQKOu12WPIdBf4oF/wCLroeFapHFk23Gj5cwPO52aSIi1+Z5A9HUlVYhl6aVr38afupredrZywsYX5oBk/RQ8hfYzT9hafVNKquXd0jHsm0So5ME49N02qPkjuMU8jaFyxs51BW2Y0inLJJkiOx9TPD+K1iFWzbkSG4OY2DyDscLQ3x8p83X43ssawtcz7ONzURwmEVvgsVWh4VilkU1OhARAZ4zELmuu3nVhcjFtAsN6mu5s1WgtRytkx4KQICJOVTDVQ5Kazxef4v82uGlPff3B6AR8scJyiWbcunSbtEVHp/FQNIl2dwnsvUe/vvf1ABU6R7LgpkJDufT3B9r8uuxbXacfeAW9Z2/ZQJOgPng6Kdb3hZzB8wdreBvrne7NBGRnvTCTRWMMf/9D/q667r/8OLlyA/TLp4HoLU89dU8rePeeqFsQg6NWIOj+jZPtr7L0frl/QP8NACF4tO02yPkT25HAPIGbAYTbRK1bSLr7+D9+DWsVg+d7ZK+YrxeWguT7E/H+GC0zr+NbHGkOUA9K+VLsBgYYhEPi5USC9kdJo6XsdylbpcmInJjXKTt9l//zGMPEAQaQAVQILoknXqLxk6J5k6Jxm6Rxk6pt7bAcbWd4CzbJjk6RTA+dasCUCDkMBBrkKhsEl5+C++j72AusXmEyIsw0Si1exNsTAZ4e7DAK8FNKpZaJvcag2E8NMKCN8FiGxZLORYzawwU7ne7NBGRG+8ibbcTn71mjJkD/hbwly+jqH7kNjs09ko0d86CT2OneLb602Odko3fppXokO0csHHwMetLH3DWif3Lsx2HxNg0wegUrfYw+eM4pZJN6YYHoO9rgb30Ot4n73a7JOljZmSIwsIoT8ZtXk+d8KZvG9c86nZZ8gyf7WMmOMI9J8JCo8liPsP80Qqhunavi4hchYusEP17XNddNsb8HPCrwOLz/pwx5qeBnwYmzy89AP6S67pfu4y6elW72KB5VKGVqdDcLdPYKdI8rECnx9IPYAI2rUSbk9YBGwf32Xj80eUFII+H5NgMgegkzeYIheMopYJN6YYPQw3HHAZCFeL5FcKPXsOzpk700iW2DTPjZGbTPBht8434Ho89x4CacvSKuDfGQmCIReNjoVph8XSPqcwqTme526WJiPSNSwlE59rA6Av+zA7wc8DK+eMfB/6FMeY3u6774BJru3Zux6WVrdF6GnyOqp/+6dZa3S7vC5mgTTPe5qS5z/rBfTYffQSXNNDT8XpJjs3gj0zSbAyTP45RzFsUb3gXuKczgOKnTwg9+BbOltrVSneYUIjG4gQ7U2HeG6rwSniLE0vnf3rFWHCIRV+KxbbFvXKehcw6w/mPgY+7XZqISF+7SFOFP/zZS8AI8DPAGy/yXK7r/qvPXPqz56tGv52z1aIbpfJRhurHx2erPydVaPXeis9nmYhDI9LguLHL+t6HbK8/vLTndry+8wA0RbMxRO44SiFnUchd2i2un4F40kPaWyCefUzwk2/h7K788J8TuQJmaJDi4hgrdx3eTGd53b9Nyzzpdll9zzY2U6FRFj0xFlsu9wrHLBwuE6uqxbWISC+6yArRP//MY5ezEeTfAP70RQsxxtjAHwNCwFtf8D0+wPfMpchF73cVakunVD/u7WGEJuZQC9c4qm6xuv0+h+url/bcHp+f5NgMvvAkjfow+ePIjQ9AlmVIpm1SVpbo0QOC91/BPlG7YekCyzrb/jY3wIORNt9IPN3+lu12ZX3NZ/uYC41yzw6zWG9wL3/I3OGyWlyLiNwgF2mqYF1mAcaY38RZAPIDJeCPuq77RcsUPw/8+cu8/61mwCQ8VAJlDkrrrGy9Q3Z999Ke3hsIkhidxRcap1EbIn8SIX9qweml3eLa2R6LdAqSnSNiu/fx3/8GVukGJzq5sUzAT3Nxit2pCO8PV/l3kS2OrR3OdhpLNwRsP/OhMe5ZQV6q13kpu8vM0bLO+4iI3HBf6gyRMcYAuO6XOmSyBPwoEAf+c+BXjDG/5wtC0S8Av/jM4wh6dfA9loGUTclTYL+4yvL62xTXLm/FKpRIERuawfHeoVZJUzgJkc+aG/0GtddvM5Bsk6zvEd58D/9H38I0equ1ufQHk0pSXrzL+oSPt9KnfCu4RcPohXa3BJ0gi6FRXrKC3KtWeCm7y9TRCrarLYkiIrfNhQKRMeYngf8VmDt/vAz8Ndd1/+6LPpfrug2+11ThXWPMbwP+Z+B//JzvrQP1Z+p48eJvE8fgpiwK1im7p0ssr79NbfWSelQbQ3xojHBqGmONUsonqRb9ZA8v5+m7JRhxGIjUiZc3Ca9+F+/DtzQDSK6fMTB1l+zcII/GXL6dOORD7wE38OjkrRBygiyGxnjJBHipWual7DaTmSdYrhqkiIj0g4s0Vfg/OAtDf4PvnfX5j4C/aoyZdF33z33Jmgzff05IzpmATTvuknMzbGcesbL+Dq3lxqU8t+3xkhydJBCdoNMZppBNUKs51PYu5em75mkHuFhuhdDj19UCW7rC+P20FibZm47ywXCNr0e2OLD3gBv+f7Ab6Hvhx8/L1QovnWwxmVnCoPAjItKvLrJC9NPA/+C67j955tq/NMZ8xFlIeu5AZIz5P4GvcdYTNgL818DvBf7gBeq6VUzEoRVuUyJHprTF1t5DMusbl/b8gUiM+MgMHv8dGvUB8icRigWL4g2eAWTZhlTKJmFliR0vEXjwLZz9jW6XJX3IDKQpL9xhbdzDdwfyfCuwSd2oG+F1U/gREZHncZFAZAPvfs719y7wfEPAP+KsbXce+Aj4g67r/rsL1HUzGTAxD41gg0Iny1F+g82dj8ivH13iPc63vyUnsexRysUU5XyA08zl3aIbghGHdKRBvLZLaOsD/B+/iqlXu12W9Bnj99OaG+doMsaD4Sbfju2z5DkB1IzjOn165scEeLla5aWTTSaPte1NRER+uIsEol/lbJXoT33m+k8B//hFnsh13Z+8wP1vJOOxIGrT9DWpuEUK9WOO8zts731CZe1yl2Ucr4/k6DT+yF3anWGK2fjZ9rcb3C3asg3JlE3SzhE9eULg8Rt4NABVusDcHSM/N8TqmM13k6e8HtimYda6XVZfCTiBT8/8vFyr8tLJNlM68yMiIhd00S5zP2mM+QPAd84f/3bgLvAPjTGfdoFzXfezoelWcy0Xk/TQ8reoUqLQOOGksMthZo2T7NU1wwslUsQGp3F8Y9RrAxSOwxTyhkL+ym555Z6u/sRqe4R37uP7+FWs6iU1jBB5TiYeoz53h73xEB8OVvhmZJd9+xC44d1FbhC/7WM+NMbLVoiXazVezu6cd3tb6nZpIiJyS1wkEH0FeP/885nzPzPnH1955vu+TCvuG+mdw6/x4L2vX+k9jGWRGJkglJgAM0Ipnzjr/naJO+yum2UbUmmLhDklerJMYOkNPFt6sSPXy/h8tGfHyUzGeTTS5o3oIfd9h5xNBpDr4LE8zIfv8LIdPg8/e5rzIyIiV+4ig1l/31UUIv8+j99PbPAu/sgIlj1Aox6ndBqmUrGpVLpd3cWFog7pcJ1YdYfw5gf4Hryusz9yvSwLM3GH0+k0a6M2bydPeSOwTd2sd7uyvuFYDnOhMV5yorxUb/Dy6R7zh8t42qvdLk1ERPrMlx3Meoezuay7l1RPfzKGSGqQcGIMT2CITidJpRSjnPdRKhpKxW4XeHG2Y0ilLBImS/R4icDD13D2dN5CrpcZGqAyO8rWHR8fpst8O7zDsaW219fFMQ6z4fPw02jy8uk+8wdP8Lb1d4GIiHTfReYQWZy11v7TQPj8WhH4K8BXXdftXGqFt4gvGCKUGMAfTmN7ExgTo1GPUcqFaTZsTo+///tv4tjZcMwhFaoTq2wT3nwf34M3MI1at8uSPmIiERrzd9kfD/PJYI3XogesOlngtNul9QXHOEyHRnnZEzsLP7kD5g+e4Gsp/IiISG+6yArRV4GfBH4OeIOz1+2/E/gLgB/4s5dV3E1jLEM4mSYYG8AbSGE5cdxOhEYjTKXop1nzUKlwo7e7PcvxWqSShgRZIpklAo+0+iPX6+m5n+PJOEvDbd6MZXjfu49rnnS7tL7gtbzMhka550S412hyL3fIwsGSwo+IiNwoFwlEPw78Cdd1/+Uz1+4bY3aBX6aPA5ET/AO03N9EIcetG0FiWYZEyibhFIkU1gmtv49n6R1Mu9Xt0qRfOA7u9F1Op1KsDsM7iVPe9O/Q0LmfaxFwAiwER7lnBblXr3PvvOGBp6OBsyIicrNdJBAl4XPHfD8+/1r/cm9JYz0D0biHZKBKtLJDePs+3odvqu21XB/Lgokx8tMDrI/YvJfM80Zwh5LZBra7Xd2tl/DGmA8Mcc/4WayWuHeyzTt0v3gAACAASURBVOTxMpZaXYuIyC10kUB0H/gZ4Gc/c/1nzr8mN0wo6pAMN4g1DgnvP8T36A3srOasyDUxBjM+RmFqgK1RDx+mirwa3OHU2gdu8DThG8BgGA+NMO9NsNg2LJZyLByvM5T/GPi42+WJiIhci4sEoj8D/GtjzO8H3uJs3tDv4Gww6x+6xNrkCgTDDslIi1jriNDRYwKP3sI+2up2WdIvjMHcGaU4PcDWqJf7ySKvhfc4tg6Ag25Xd6v5bR9zoTHm7RCLjSaL+SPmj1YI1je7XZqIiEhXXWQO0beNMQvAnwQWOWuq8GvAL7uuqx62PcQftEnGOsQ7x4QyTwgsfQdnV/v95fqYsRFKM0NsjXr5KF3mteAuR/YhoBXIqzToT7PgH2ABh4VKiYXsDhPHq1iuBpyKiIh81oXmEJ3PHerb5gm9yOu3ScVdYu4J4ZMVAstv49l82O2ypI+Y4UHKMyPsjPn4KF3m1fAuB3YGyHS7tFvLY3mYCY0y70RZaLZZKJ2wcLhKvKJVXxERkef13IHIGBME/jLwnwEe4OvAz7que/wDf1AuncdnkUxAnByR7Cr+1XfwrH2EuS1NHaTnWekUldlR9u4E+HigyuvhfTadLJDtdmm3VswbZTEwzILxsVirspDdYyqziqez2u3SREREbrQXWSH6i8AfB/4xUAP+G+BvAX/s8ssSOJvzE41aRLw1ws0sgdwW/q1P8Cy/j+m0u12e9AkTCdOYH2d/PMyDwTqvRfZZ8WSBfLdLu5UMhrHgEIu+JAtti8VynsXjDYZznwCfdLs8ERGRW+dFAtGPAT/puu7/A2CM+VXgDWOM7bquXp1/CYGwQzTcIWKVCFaOCByv4936BGd7Sas+cr08HtzZcY4nEyyNuLwVz/Cud0+DTq+Iz/YxGxplwQ4z32yxmM+wcLRCuKZGByIiItflRQLRXeC1pw9c133bGNMCRtFgkC9k2YZg2CHk7xCw6/jbJXy1U7ylQzwnO3g2H2CfHnW7TOlH5+2u8zODrI3avJvM8Wpwm5rZBPSC/LIlfQkWA4Ms4GWhWmHhdJepo1VsNToQERHpqhcJRDbQ+My11gs+x602ZB3gi6/jLRziye7gHK5jH2xqlUd6golGqS/cZXc8xP3BKt+IbHNgq931ZXOMw0RomHlPnIWWy0LplMXMOumixrSJiIj0ohcJMwb4B8aY+jPX/MDfNsaUn15wXffHLqu4myb58OvY//yfdbsMEbBtmL7LyXSapVGXN+IZ3vXt4Zqlbld2q4wEBpjzpZnDYbZaYS53wHRmFU97rduliYiIyHN6kUD0K59z7VcvqxARuTgrnaI8P8b2XT/vpYt8I7xN3toBdrpd2q0Q80aZCwwxZwLMNurMF46ZzawSrqm9tYiIyE333IHIdd2fuMpCROT5GL+f1twER1MxHg41eS12wENPBnV9+/LCnhAzgWFm7SCzzTYzpSxzx5uki+rwJiIiclvp/I9ILztvfJCbHWRtzOa7iVNeD2zTMJo982UEbD/ToRFm7TCzrTaz5TyzJ1sM5x4Bj7pdnoiIiFwjBSKRHvK08cHOxFnjg1ciWxxZanxwUT7bx1RwmBknwmzbZbZcZCa7xZ3sMga1EhcREREFIpHu+Wzjg8TTmT9qfPCiHMthMjjMrCfGTNswWykym9vj7vGa2lqLiIjID6RAJHJNTDJBdeEOW+MBNT64oLPgM8K0J8psx2K6WmT29IDx43U8HXV2ExERkRenQCRyFWwbd2ac49k0j0bavBo/4CPvETqf8nw8loeJ4DAznigzHYuZSpHZ3D7jx+s4Cj4iIiJyiRSIRC6BiceoLY6frf4MlngltEXe2ga2u11aT/PZPiaDQ0w7UWbaMFMtMp3bZ/x4A6ejxhEiIiK9yDU2ri9K2xulER4l1O2CviQFIpEXZdswdZeTmbOzP68ljnjPt49Wf75YwAkwFRhixgkz3XKZqRSYOd3lTnYVS2d8RERErpXrDdHxRml5ojQ9Yep2mKodpmxClE2QvBui0Alw2glw0vZz3PRx1PBz2PCyX/dx0vBA9ey54iUPH3b31/nSFIhEfggrnaQ8d4etcT8fDJT4ZmibU539+VxBJ8h0cIgZO8xsq8N0OcdsdpeR0ycY1CxCRETky3IdP643QssboemJ0rBD1OwwFROibEIUCVJwA+Q6AbJtPyctP0cNP0dNHwf1s0DTrJlu/xo9RYFI5BnG66U9N8HRVJyHwy1ejR3w0JsBHna7tJ4ScALMBIeZscPMtNrMlAvMZncYOV3C8Ljb5YmIiPQk1/KcbzWL0PKEadjhszBjhamY4HmYCZJzA5y2nq7OnIeZ2lmYKdesbv8at44CkfQ1c3eUwuwQ62MObydzvBrcpmbWu11Wz3Ash6ngKHOeKHNtmC/lmMnuMKoVHxER6TOu7cX1noWZpidMwwlTs8JUrRAVE6REiIIbIN8JcNrxk237yTT9ZJpeDus+9ute8jUHKt3+TeSzFIikb5hYlPr8OHvjQe4PVvlWZJdd+wg46nZpPWEkMMCcL80cDnPVCnOne0xl1tTOWkREbjzXG6LjidD2Rmg44U+3mVWtEGUClM63meU7AU7bZ2HmpOkj0/RxUPexX/dQrDlQ7vZvIldBgUhuJ48Hd3ac46kkj0c6vBk/4j3vPmg7FwEnwFxwlAU7yEKjyXw+w2xmjUhtq9uliYiIfB/XcnC9ETreCE1PhKYTOmsAYIWomuBZkCFIoeMn/+mZGR/HTR+HDR+HdQ9HDZ2ZkR9MgUhuPseB6bucTiZZH7Z4P57n9cA2FWsT2Ox2dV01FEiz4BtgwXVYqJZYONlm/GQZy9V2NxERuVrfd17GCVP3RD53i1mu4/+0AcCzW8wO615OtcVMroECkdwsHg/u9F1OJ5KsDxveS+R4079Dpc9n/ngsD9OhERacGAvNNgvFYxaO1ohXtOojIiIv7tkw0/REdF5GbjUFIulZxuulM32X04kEa8PwXiLHG/4damYL6N8X+klfgoXAIAv4mK9VWMjuMZVZxaNBpiIicu5szkyMlidCwxOhboeonrdmLhEiT/A8zATItgIct87mzDxty6yVGeknCkTSE0wwSGvmDifjMVYGO7wXP+W7vl0apn+3vTnGYTI0wrwnxkLLZaF0ykJmnXTxfrdLExGRK+QaC7xh2t4oTW+UhhM5bwAQpvQ00LgBcp0gJ+3A2ZyZ5tnQzLMGADozI/IiFIjk2plolObMGJk7YZ4Mtng7esL7/n3a9G83s5ATZD44woIV5F69zkJun7nDFbzt/v3PRETkJnMdPx1fjJY3RsMTpW6HqdgRyiZEgTB5N8jpeaA5bvk5agTYr/vYa/g4qHlwqwo0Itelq4HIGPPzwI8Bi0AVeBP4311XJ75vC5OIU58d43AsxNJAg+9Ej/jIewQsd7u0rhn0p1jwD7DoelioFrl3ss3dYw00FRHpNa6xcf1noabpjVFzYpTtKCUTpkiYUzdIthPkpB3kqOlnvx5gt+5np+Y9a9Fc6vZvICLPo9srRL8H+CXgnfNavgr8hjHmJdd11en9hjEDaWozI+yPBXiYrvFW5IglzzH06QBPg2E8NMKiN8G9FtwrnbJwtEqq9EG3SxMR6SuusXB9Mdq+BHVvjJonRtmKUjQRcoTJuiFOWiGO2gEOGkF26z52an72a16t1Ij0ga4GItd1/+Czj40xP8HZlMzfArzalaLkh3McuDtCaTzF3pCXx6kar4f32HByQK7b1XWFYxymQiPc88S512xxL3/M4uETQvX+PP8kInJVXMtDJ5Cg5U1Q88apODFKVow8YbJuhONOiKNWiP1mkN16gK2qj92al3bV6nbpItKjur1C9Fmx8z+zn/dFY4wP8D1zKXLlFfU5k0zQmBrheDTEerrDh7Ecb/v2qFj7wH63y+sKv+1jLjTGoh1isd7gpdwBc4fL+Fo67yMi8qJcX4SWP0Xdm6DqSVC0YuSsGCedKJlOiMNWiL1GkO1agM1qgP2KV93PRORS9UwgMsYY4BeB113X/eQLvu3ngT9/fVX1D+P305kYpXAnzu6gzcNEhe+GDtl0ckCx2+V1TcIbYyE4xD18LFTLLGZ3mcysYbv9ewZKROQHcT0h2oEUdV+SiidJwYqTMzGO3ShH7TB7rRDbtTCbtQBrVT/lmg35blctIv2sZwIR8DeBHwF+1w/4nl/gLDQ9FQF2rrKoW8e2MXdGKN9NczDsZSXZ4IPwCR/6DmjTv/N9DIax4BCLviSLbYvFUo7F4w2G8h8DH3e7PBGRrnEth04gSdOfPlvBcRLkrTjHboyjdoS9ZpjtRoiNWpD1SuBsfk3/vo8mIjdQTwQiY8zfAP4w8Ltd1/3CgOO6bh2oP/Nz11DdzWWGBqlPDJIZCbKeavFRNH++3e0AOOh2eV3js33MBEdYdCLMN1ss5jMsHK0Qrum8j4j0B9cJ0A6mqftSlD0pCnacU2Jk3Bj77TC7jTAbtRDrlQAbVT9uRf/eisjt1e222wb4G8AfBX6v67rr3aznpjKJOM2JYbKjYbYG4JNokXcDhxzZWb7gOFbfSPrizAcGWcTHQrXKwukuU5lVnI62vInI7eJ6Q7QCA9R9KUqeJHkrQZY4R50oe60I240Qm7UQy5UgRyWPWkKLiJzr9grRLwH/LfBHgKIxZvj8et513Wr3yupNJh6jPTZIfizKzoDF41iFtz8957PS7fK6ymf7mAoOM+tEmG25zJXzLGbWGCx81O3SREQuzPWGaQUGqPlSlD0J8laCE+IcuVH2mhG2GmHWqiGWy0FOCw4Uul2xiMjN0+1A9NPnf37rM9d/AvgH11pJDzCRCO5ImupAhHzCx1EctsN1VvwFHvuynFhloL8X0Wxjczc4xJw3zmzbYrZaYu50l/FjNToQkZvB9UVoBgaoeVOUPUnyVpwT4hyer+Rs1c9DTiVAXiFHROTKdXsO0e3flGzbmGgE4lFa0SD1iJ9K2KEUssgHXPaCDdaCJR55TziyS8B2tyvuCQbDaHCQWW+SGRxma1XmTg+Yzqzibfd3KBSR3uPaXtrBAeq+NBVviryd4IQEh26UvWaUjUaE1UqIJ5Ug+byjrmoiIj2k2ytEt8pH/2GapYEf5chb58BbYdcpcmAXaVNCm7W/2HBggFlfilm8zNRrzOYPmc6sEWyoyYGIdNfToFPzD1LypDm1U2RIsNeOs9mMsFqN8qQcZLPiwy3f/vf4RERuIwWiS/R6Osu/yH/RCCUZ8CeZ8aeZxc9cvcZMMcNMZp1wrT9bfYtI97jGohNI0QgOUfIOngedJLudOFuNGKu1MI9LITYqfgUdEZFbToFILl3cG2MmMMis5Weu0WSmcMLc8RqxioKPiFw91wnQCg1T8Q9R8KQ5NikO3ATbrTir9ShL5TCPSwFqVbvfG3GKiAgKRPIlxL0xJv1pZuwgM802s6Usc8ebpIsaZCoiV6PjT9AIDlH2DXHqpMmQYrcdZ6MZZ7ka4UEpzE7Jp13KIiLy3BSI5Aeyjc1YYJApb5wpPEzWa0wVT5g62SShFR8RuSQuBjeYoh4YpugbJGsPcEiSnXaC1XqMpUqET0ph8jkHct2uVkREbhMFIgEg6o0w6R9g0g4x2XaZrBaZyh8ycbyBR13dRORLcI1NJzhALTBE0TvIiZ3mgBTbrQTr9SiPKmEelMKUs3a3SxURkT6kQNRHvJaXu8FBJj1RJjo2k406k8UTJrJbJMta7RGRF3d2XmeIqm+AgneAE5Ni302y1YqzUovxqBzmcTlEs6rGBCIi0psUiG4Zg2E4kGbCl2DS+Jlstpgo55jM7TF6uoblrnS7RBG5AZ6u6tQDQxS9aXJ2miMS7LYTbDYjrFSjPCwF2S35dV5HRERuNAWiG+psi9sgk3aAiTZM1kpM5I6YyG7ib2p+j4h8PtcTpBUYoOYfoORJcWolyRDnoB1juxllrRZmuRJireKjXbW6Xa6IiMiVUyDqQR7Lw6A/yaAnwoDlY9C1GWq3GWhUGS3nmcxukShvAQ+6XaqI9AAXgxtI0QikqXjTFJwkWZPkyI2x34qy2YiwXguxVA5xUPRCsdsVi4iI9A4FomsQcAJEnBARx0/Y8hGxPESMQwRDqu0y2GoyWCszVM4xUDwkUc5iWO122SLSZWfb1tLUA4OUvQPk7CQZkhx0Ymw3Y6zVw6xWgiyXg9RrFpx2u2IREZGbR4HoEv13LR9/2B0iUi8TbpSJVAuEa0WcTqvbpYlID3kadBr+AUreAXJOihMS7HXinwadpXKY5bJf29ZERESumALRJVrM7cPGO90uQ0S6xLU8Z40I/CkqnhQ5J8UxSfY/XdGJ8KQcYrkSVNc1ERGRHqFAJCLyA5yFnDQNX4qKN0XBSZAlTsaNsd+Ost0Is1ELs1IJsF314VYUdERERG4SBSIR6TuuN0wrkKbuS1F2EhTsBFliZNwo+60wO40IG7Ugq5UgOxUfVLpdsYiIiFwVBSIRuRVcX4xmIE3Nl6LkJMlbcU6IcdSJstuMstUIsV4NsVwJkC84UOh2xSIiItILFIhEpCe5xsYNJGn401S9SUpOgpyJcUyco3aEvVaYzXqYjWqQ5UqAcs2GfLerFhERkZtGgUhEro3r+GkHUjR8acreJEUrzqmJk3GjHLSj7DTDbNVCrFYCbFQ1GFRERESungKRiHwpru2lE0hT96cpe1LknSRZ4hx2Yuy1omw1wmzUQqxUAhyWvFDqdsUiIiIi36NAJCKfy7V9tENDVP2DFDwDZK0khyTZbcXYbkRYr4VYqQTZqvhwy+qsJiIiIjeTApFIH3J9UeqhUcq+IU6dNBlS7HXibDRjrFQjPC6FWC8HoNztSkVERESulgKRyC3jWh7a4REqgWFyniGOTJrtToq1ZoKlSpSPihEO8l41IBARERFBgUjkxukEUtSDIxR8wxzbA+yTZrOZYKkW50E5wuNSgHZFzQhEREREnocCkUgPcS0PrfAo5eAop54hDhhgu51kpRHnUSXGR8Uw+VMHTrtdqYiIiMjtoEAkco1cx08zPErZP8KJZ5h9BlhvpViqJfioFOVhKajVHREREZFrpEAkcolcY9MOj1AO3uHEM8KeGWStleZhLcn9YozH5QBuSR3ZRERERHqFApHIC+oE01RDdzj1jXJohtjspHlcT3K/lODDQpi6homKiIiI3BgKRCKf0fEnqIXvkPeNcGQPsdUeYKWZ5ONynA8KUU6zDmS7XaWIiIiIXAYFIuk7ri9GLXyHwnng2XEHWGmkeFCN834hylHOA7luVykiIiIi10GBSG4d1xejHhqh4B8jYw+y4w6w2kzxoJLgg2KEvbxPM3hEREREBFAgkhvG9QRphkYo+4fJOQMcmgF22klWmzGWKjE+LobJ5D0KPCIiIiLyXBSIpGe4jp9WaISKf4icZ5CMlWa3nWCjmWCpGuWTUpitoh+K3a5URERERG4LBSK5Fq7loR0eoRIYJucZImPS7LoJNpsJlipRHpYjrJX8UOp2pSIiIiLSTxSI5EtzMXSCaerBUQreQY7tQfbcFJutBE9qMT4pRXlS9mvgqIiIiIj0HAUi+YFcb5hmcJiKf4CCk+bEJDlw4+y0YqzXoyxXwjwshyhnbbWiFhEREZEbR4GoT7m+KM3AIFVfmoInRdZKctRJsNuOsVkPs1KL8LgUIlPwQKHb1YqIiIiIXA0Folum40/QDAxS8aXJO2dB57ATZ7cVY7MRZrkS5lE5RD7vqBObiIiIiPS9rgYiY8zvBv434LcAI8AfdV33n3ezpl7jOn5cb5i2J0LTE6bmxCg4KU5MkkM3xk4rzno9zHIlwlI5QDHnaKioiIiIiMhz6vYKUQi4D/x94P/rci1f2kbwN9G5+2O0sehg08Y6/9yihU37mWtnHzYl10u+HeC07eek5eOk6eeo6SFT93LU8FGuqRGBiIiIiMhV6Wogcl33a8DXAIwx3SzlUvzN/O/g/10e73YZIiIiIiLynLq9QvRCjDE+wPfMpUi3ahERERERkZvvpu3H+nnOWgE8/djpbjkiIiIiInKT3bRA9AtA7JmPO90tR0REREREbrIbtWXOdd06UH/6+DacOxIRERERke65aStEIiIiIiIil6bbc4jCwOwzl6aMMT8KZF3X3epSWSIiIiIi0ie6vWXutwLffObxL57/+SvAH7/2akREREREpK90ew7RtwAdBBIRERERka7QGSIREREREelbCkQiIiIiItK3FIhERERERKRvKRCJiIiIiEjfUiASEREREZG+pUAkIiIiIiJ9S4FIRERERET6lgKRiIiIiIj0LQUiERERERHpWwpEIiIiIiLStxSIRERERESkbykQiYiIiIhI31IgEhERERGRvqVAJCIiIiIifUuBSERERERE+pYCkYiIiIiI9C0FIhERERER6VsKRCIiIiIi0rcUiEREREREpG8pEImIiIiISN9SIBIRERERkb6lQCQiIiIiIn1LgUhERERERPqWApGIiIiIiPQtBSIREREREelbCkQiIiIiItK3FIhERERERKRvKRCJiIiIiEjfUiASEREREZG+pUAkIiIiIiJ9S4FIRERERET6lgKRiIiIiIj0LQUiERERERHpWwpEIiIiIiLStxSIRERERESkbykQiYiIiIhI31IgEhERERGRvtUTgcgY8yeNMevGmJox5j1jzH/c7ZpEREREROT263ogMsb8V8BfA74K/GbgNeBrxpjxrhYmIiIiIiK3ntPtAoA/Bfw913X/7vnj/8UY858APw38/LPfaIzxAb5nLkUACoXCddT5Q9UrJTr1SrfLEBERERG5Fm3L6ZnX4hetw7iue8mlvMDNjfECFeCPua77z565/teBH3Vd9/d85vv/AvDnr7VIERERERG5Se64rrv7vN/c7RWiNGADh5+5fggMf873/wLwi5+5lgSy/3979x8jR1nHcfz94UcrP8svC0VsqgVqULQEUCsV8QKIRqWENkVNFcGYiEqCAcSoQIMREEERSCBNFa1BwahNixEbaiqSgrGFooQDIlERKz9apJRie7R8/eN5tjcMe9e9293u3s7nlUz2buaZeZ657z63+8zzzDOtL1pl7QM8BRwGbOxwWay9HOtqcbyrxfGuDse6WhzvHdsHWDuSHTrdIKopd1OpzjoiYguwpbS6O/roeoSk2o8bI8J/2x7mWFeL410tjnd1ONbV4ng3ZMR/l05PqrAO2Mbre4Mm8vpeIzMzMzMzs5bqaIMoIgaA1cAppU2nACt3fonMzMzMzKxKumHI3HXAIkmrgPuAzwOTgZs7Wqrq2gLM5/VDE633ONbV4nhXi+NdHY51tTjebdDRWea2F0I6D7gYmAQ8DFwQEfd0tlRmZmZmZtbruqJBZGZmZmZm1gmdnlTBzMzMzMysY9wgMjMzMzOzynKDyMzMzMzMKssNIjMzMzMzqyw3iHqQpBMlLZW0VlJImlXafrCkW/P2lyXdJemIOseZIen3kjZJekHSCkl71Ek3XtKanNf0dp6bvVazsZY0Je9Xb5lTJ78DJT2Vt++3M87RBrWibks6RNIiSU/nuv2ApNlD5Oe63UEtivdUSb+W9JykFyXdIengIfJzvDtE0tck/VnSRknPSlosaVopzXhJN0hal+vuEkmHldJMzu+ZTTndDySNGyLPEyRtlbSmnedmr9XCWF8vabWkLTuKoaTDc34vtOOceoEbRL1pL+Ah4EvlDZIELAbeCpwOHAP8E7hb0l6FdDOAu4BlwLuB44EbgVfr5PcdYG1rT8Ea1Gys/0Wa7r64XAZsAn5bJ7+FwF9aewo2Ak3XbWARMA34OHA08CvgdknH1MnPdbuzmop3fl0GBNAHnACMA5ZKqvf573h3zgeAm4D3kh5OvxuwrFR3vw+cAZwFzAT2Bu6UtCtAfv0N6X0zM6c7E7i2nJmkCcBPgOVtOh8bWtOxzgT8ELh9uMwk7Q78DPhjq06gJ0WElx5eSB+Eswq/H5nXvb2wbldgPfC5wrr7gSsaOP6HgX7gqHzc6Z0+56ouo411neM8CCyss/4LwArSF6sA9uv0OVd5aaJuvwTMKx1rPXBuaZ3rdhcto4k3cCqwDdi3kGb/vN/Jjnf3LsAbcxxOzL9PAAaAuYU0h+b4fqgQw23AoYU0ZwGbi++BvP7nwBXA5cCaTp9vlZfRxLq0/7AxBK4mXQg7G3ih0+fbrYt7iKpnfH7dXFsREdtIlW8mgKSJwHuAZyWtlPSMpD9Imlk8UB52sQCYB7y8MwpvI7LDWJdJOhaYTuoJKq4/CrgU+DT1ewmt8xqN973AXEkHSNpF0ll53xW1BK7bY0Ij8R5P+qJVfKL9ZlId3v6ecLy70oT8+nx+PRbYndTjB0BErCU9zP59edUM4OG8vuZ3pPfBsbUVkj4LTAXmt6XkNlKjiXVDJPUBc4AvNl/M3uYGUfU8ShpWcaWk/SWNk3QJcAhpuBSkIRiQrjosAE4DHgCW18an5+EatwI3R8SqnVd8G4FGYl12LtAfEStrKySNJ3W3XxQRT7a70DZqjcZ7LmmIxnrSF+VbgDMi4glw3R5DGon3/aThr1dL2jMPybmG9Nk/CRzvbpRjch1wb0Q8nFcfAgxExH9LyZ/J22ppniluzOkHamnyZ/hVwKciYmt7zsAa1USsGzn2gaS6fXZEvNiC4vY0N4gqJiJeIY0pPpJ0NeJl4CTS/SLbcrLa++KWiPhRRDwYERcAjwHn5G1fBvYFrtxJRbcRajDW2ylNmPFJSr1DpBj3R8RP21lea84I4v0t0rCpk4HjSB/Gv5B0dN7uuj0GNBLviHiOdHX4Y6ShkhtIV6MfYPA94Xh3nxuBdwKfaCCtSL2ANTFUmnz/yW3AZRHxeNOltFZoJtY7sgC4LSLuGU3BqsYNogqKiNURMR3YD5gUEacBBwJ/z0n+k18fKe3aD0zOP/eRbgjcImkrYl3oNAAAA1RJREFU8Le8fpWkH7et8DYiDcS6aDawJ+lG26I+YE6ejWgrgzfhrpPkIRddZEfxljSVdIP+ORGxPCIeioj5wCoGh1S4bo8RjdTviFgWEVOBicBBETEPeFMhjePdRSTdQJrw5IMR8VRh09PAOEn7l3aZyGCv0NOUehBy+t1zmn1IF0FuLPw/vxR4V/69r+UnZENqMtaN6AMuLMR6ITAh/37ODvatnN06XQDrnIjYANu70I8Dvpk3/YM009C00i5HMjjz2PnANwrbDiWNVZ4L/Kk9JbbRGibWRecCS/JV5aIzgeJ068eTZrZ5P/BE60trzRom3nvm1/J9YNsYvEDmuj3GNFK/I2JdTtNH+mK1JG9yvLtAHjp1A2lmsZMionzRajXwCmlWsjvyPpOAdwAX5zT3AV+XNCkiahc2TyUNjV1N6iU8mtc6j/TFeTb1L5RZi7Uo1o2YQZpopeZ04Kuk+5D+ParC9zA3iHqQpL2Bwwur3qL0TInnI+JJpefLPAc8SfrneD2wOCKWAURESLoGmC/pIWAN8BngbaR/mpTvJZH0Uv7xidKVDmujZmNdOM7hwInAR8p51O4tKaQ9KP/YHxF+psFO1IJ4P0rqAbhF0oWk+4hmkT54Pwqu292kFfU730Dfn9PNyGm+FxGPgePdRW4iDVk+HdgoqdbTsyEi/hcRGyQtBK6VtJ40TPK7wF+Bu3PaZaSRHYskXQQckNMsKNxDUrtPBQBJzwKbC/evWPu1Ita1z+29Sb2Ce2jw2WGPRMRARPQXM5V0HPCqYz2ETk9z56X1C2kcedRZbs3bzyc9f2aAdFPuFcC4Ose5JKfbBKwEZg6T5xQ8VetYjvW3c7pdRpCnp90eg/EGjgB+SRp6sYn0nJt5w+Tpuj22430VaQjOAPA48BVAjnd3LUPEOUg3xNfSvIHUs7CedM/YUuDNpeNMBu7M29fn9OOHyfdyPO32WI31iiGOM2WIfM/G024PuSj/kczMzMzMzCrHkyqYmZmZmVlluUFkZmZmZmaV5QaRmZmZmZlVlhtEZmZmZmZWWW4QmZmZmZlZZblBZGZmZmZmleUGkZmZmZmZVZYbRGZmZmZmVlluEJmZmZmZWWW5QWRmZmZmZpXlBpGZmZmZmVXW/wE5O5e0BsRxRgAAAABJRU5ErkJggg==\n",
"text/plain": [
"
"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"plt.clf()\n",
"plt.figure(figsize=(10, 5), dpi=100)\n",
"plt.stackplot(population.index, population.values.T / 1e9)\n",
"plt.legend(population.columns, loc='upper left')\n",
"plt.ylabel('Population count (B)')\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Stacked bar plot with plotly"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
""
],
"text/vnd.plotly.v1+html": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"import plotly.offline as offline\n",
"import plotly.graph_objs as go\n",
"\n",
"offline.init_notebook_mode()"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.plotly.v1+json": {
"data": [
{
"name": "East Asia & Pacific",
"stackgroup": "World",
"type": "scatter",
"uid": "e5b08b9e-fcb8-4246-87db-4cb5b960bdf4",
"x": [
"1960-01-01",
"1961-01-01",
"1962-01-01",
"1963-01-01",
"1964-01-01",
"1965-01-01",
"1966-01-01",
"1967-01-01",
"1968-01-01",
"1969-01-01",
"1970-01-01",
"1971-01-01",
"1972-01-01",
"1973-01-01",
"1974-01-01",
"1975-01-01",
"1976-01-01",
"1977-01-01",
"1978-01-01",
"1979-01-01",
"1980-01-01",
"1981-01-01",
"1982-01-01",
"1983-01-01",
"1984-01-01",
"1985-01-01",
"1986-01-01",
"1987-01-01",
"1988-01-01",
"1989-01-01",
"1990-01-01",
"1991-01-01",
"1992-01-01",
"1993-01-01",
"1994-01-01",
"1995-01-01",
"1996-01-01",
"1997-01-01",
"1998-01-01",
"1999-01-01",
"2000-01-01",
"2001-01-01",
"2002-01-01",
"2003-01-01",
"2004-01-01",
"2005-01-01",
"2006-01-01",
"2007-01-01",
"2008-01-01",
"2009-01-01",
"2010-01-01",
"2011-01-01",
"2012-01-01",
"2013-01-01",
"2014-01-01",
"2015-01-01",
"2016-01-01",
"2017-01-01"
],
"y": [
1039944591,
1043546747,
1058028199,
1083802299,
1109204182,
1135650895,
1165517894,
1194424326,
1223721283,
1256501008,
1289258962,
1322942750,
1354794332,
1385052014,
1415128313,
1442241325,
1466464716,
1489361661,
1512159741,
1535391301,
1558178982,
1581806986,
1607731269,
1633628203,
1658253758,
1683448851,
1710171170,
1738276268,
1766656203,
1794408755,
1821481246,
1847530233,
1871898268,
1895356643,
1918771287,
1941918800,
1964635058,
1986799861,
2008140141,
2028095314,
2047150745,
2065521836,
2082953527,
2099545576,
2115557365,
2131363078,
2147029631,
2162104019,
2177421759,
2192352319,
2207154641,
2221934584,
2237082761,
2252311022,
2267745366,
2283108073,
2298726779,
2314364990
]
},
{
"name": "South Asia",
"stackgroup": "World",
"type": "scatter",
"uid": "5ccdb42f-dbf4-4abc-a1de-851c1114c31b",
"x": [
"1960-01-01",
"1961-01-01",
"1962-01-01",
"1963-01-01",
"1964-01-01",
"1965-01-01",
"1966-01-01",
"1967-01-01",
"1968-01-01",
"1969-01-01",
"1970-01-01",
"1971-01-01",
"1972-01-01",
"1973-01-01",
"1974-01-01",
"1975-01-01",
"1976-01-01",
"1977-01-01",
"1978-01-01",
"1979-01-01",
"1980-01-01",
"1981-01-01",
"1982-01-01",
"1983-01-01",
"1984-01-01",
"1985-01-01",
"1986-01-01",
"1987-01-01",
"1988-01-01",
"1989-01-01",
"1990-01-01",
"1991-01-01",
"1992-01-01",
"1993-01-01",
"1994-01-01",
"1995-01-01",
"1996-01-01",
"1997-01-01",
"1998-01-01",
"1999-01-01",
"2000-01-01",
"2001-01-01",
"2002-01-01",
"2003-01-01",
"2004-01-01",
"2005-01-01",
"2006-01-01",
"2007-01-01",
"2008-01-01",
"2009-01-01",
"2010-01-01",
"2011-01-01",
"2012-01-01",
"2013-01-01",
"2014-01-01",
"2015-01-01",
"2016-01-01",
"2017-01-01"
],
"y": [
571835666,
583894094,
596413939,
609391805,
622822615,
636701820,
651036352,
665826653,
681054882,
696697198,
712740919,
729173562,
746012374,
763310561,
781140577,
799553306,
818560436,
838142287,
858277856,
878933031,
900076467,
921696915,
943781613,
966293643,
989188965,
1012429641,
1035982524,
1059829211,
1083963380,
1108386444,
1133089464,
1158058109,
1183253534,
1208612942,
1234059205,
1259530819,
1284978193,
1310387887,
1335777637,
1361185289,
1386625845,
1412104373,
1437568227,
1462906674,
1487975237,
1512670560,
1536943534,
1560818860,
1584359049,
1607663899,
1630806784,
1653798614,
1676615491,
1699310450,
1721847786,
1744199944,
1766393714,
1788388852
]
},
{
"name": "Sub-Saharan Africa",
"stackgroup": "World",
"type": "scatter",
"uid": "d81b1f54-9dcc-475b-9517-2127417ea48f",
"x": [
"1960-01-01",
"1961-01-01",
"1962-01-01",
"1963-01-01",
"1964-01-01",
"1965-01-01",
"1966-01-01",
"1967-01-01",
"1968-01-01",
"1969-01-01",
"1970-01-01",
"1971-01-01",
"1972-01-01",
"1973-01-01",
"1974-01-01",
"1975-01-01",
"1976-01-01",
"1977-01-01",
"1978-01-01",
"1979-01-01",
"1980-01-01",
"1981-01-01",
"1982-01-01",
"1983-01-01",
"1984-01-01",
"1985-01-01",
"1986-01-01",
"1987-01-01",
"1988-01-01",
"1989-01-01",
"1990-01-01",
"1991-01-01",
"1992-01-01",
"1993-01-01",
"1994-01-01",
"1995-01-01",
"1996-01-01",
"1997-01-01",
"1998-01-01",
"1999-01-01",
"2000-01-01",
"2001-01-01",
"2002-01-01",
"2003-01-01",
"2004-01-01",
"2005-01-01",
"2006-01-01",
"2007-01-01",
"2008-01-01",
"2009-01-01",
"2010-01-01",
"2011-01-01",
"2012-01-01",
"2013-01-01",
"2014-01-01",
"2015-01-01",
"2016-01-01",
"2017-01-01"
],
"y": [
228586005,
234008580,
239647139,
245503266,
251576403,
257868609,
264386171,
271139271,
278138996,
285397999,
292929074,
300737023,
308831549,
317234127,
325972033,
335064879,
344522341,
354343159,
364515830,
375034981,
385885281,
397065556,
408577033,
420413518,
432573431,
445048059,
457835414,
470938971,
484357710,
498102752,
512177101,
526599014,
541365685,
556451898,
571828603,
587469624,
603385639,
619607956,
636182577,
653179863,
670649638,
688615995,
707099850,
726140617,
745788118,
766080507,
787035792,
808660166,
830965556,
853953657,
877628367,
901989926,
927039875,
952734072,
979017918,
1005850049,
1033212743,
1061107721
]
},
{
"name": "Europe & Central Asia",
"stackgroup": "World",
"type": "scatter",
"uid": "41d2b519-5c2e-4f44-a2bf-af5275db6ae1",
"x": [
"1960-01-01",
"1961-01-01",
"1962-01-01",
"1963-01-01",
"1964-01-01",
"1965-01-01",
"1966-01-01",
"1967-01-01",
"1968-01-01",
"1969-01-01",
"1970-01-01",
"1971-01-01",
"1972-01-01",
"1973-01-01",
"1974-01-01",
"1975-01-01",
"1976-01-01",
"1977-01-01",
"1978-01-01",
"1979-01-01",
"1980-01-01",
"1981-01-01",
"1982-01-01",
"1983-01-01",
"1984-01-01",
"1985-01-01",
"1986-01-01",
"1987-01-01",
"1988-01-01",
"1989-01-01",
"1990-01-01",
"1991-01-01",
"1992-01-01",
"1993-01-01",
"1994-01-01",
"1995-01-01",
"1996-01-01",
"1997-01-01",
"1998-01-01",
"1999-01-01",
"2000-01-01",
"2001-01-01",
"2002-01-01",
"2003-01-01",
"2004-01-01",
"2005-01-01",
"2006-01-01",
"2007-01-01",
"2008-01-01",
"2009-01-01",
"2010-01-01",
"2011-01-01",
"2012-01-01",
"2013-01-01",
"2014-01-01",
"2015-01-01",
"2016-01-01",
"2017-01-01"
],
"y": [
667246384,
674972972,
682938669,
690962675,
698905664,
706609007,
713341112,
719879789,
726161895,
732317863,
737948178,
743607439,
749815857,
755867961,
761701324,
767332578,
772838318,
778094845,
783298994,
788525199,
793937090,
799215272,
803972967,
808524728,
813281381,
818146882,
823155058,
828213790,
833315236,
838462813,
842848473,
846178276,
849656745,
852762016,
854723055,
856352860,
857652705,
859112733,
860236341,
861380108,
862304086,
863615632,
865196877,
867457664,
870030756,
872661616,
875343235,
878465990,
881965815,
885591814,
889016507,
891098854,
894679968,
898881448,
903123160,
907426233,
911686319,
915545801
]
},
{
"name": "Latin America & Caribbean",
"stackgroup": "World",
"type": "scatter",
"uid": "dd6bc133-ee5c-4ca8-8457-ddf476dc6ab2",
"x": [
"1960-01-01",
"1961-01-01",
"1962-01-01",
"1963-01-01",
"1964-01-01",
"1965-01-01",
"1966-01-01",
"1967-01-01",
"1968-01-01",
"1969-01-01",
"1970-01-01",
"1971-01-01",
"1972-01-01",
"1973-01-01",
"1974-01-01",
"1975-01-01",
"1976-01-01",
"1977-01-01",
"1978-01-01",
"1979-01-01",
"1980-01-01",
"1981-01-01",
"1982-01-01",
"1983-01-01",
"1984-01-01",
"1985-01-01",
"1986-01-01",
"1987-01-01",
"1988-01-01",
"1989-01-01",
"1990-01-01",
"1991-01-01",
"1992-01-01",
"1993-01-01",
"1994-01-01",
"1995-01-01",
"1996-01-01",
"1997-01-01",
"1998-01-01",
"1999-01-01",
"2000-01-01",
"2001-01-01",
"2002-01-01",
"2003-01-01",
"2004-01-01",
"2005-01-01",
"2006-01-01",
"2007-01-01",
"2008-01-01",
"2009-01-01",
"2010-01-01",
"2011-01-01",
"2012-01-01",
"2013-01-01",
"2014-01-01",
"2015-01-01",
"2016-01-01",
"2017-01-01"
],
"y": [
220434662,
226564469,
232897323,
239401268,
246016368,
252710310,
259468669,
266295880,
273209036,
280225795,
287361389,
294620137,
301984430,
309446959,
316987646,
324590837,
332247800,
339956419,
347735305,
355593111,
363543431,
371580994,
379697683,
387868173,
396059351,
404246768,
412413602,
420560827,
428701267,
436857131,
445044474,
453251622,
461466819,
469673465,
477832467,
485913138,
493920488,
501837820,
509664957,
517324344,
524829251,
532172709,
539372044,
546478662,
553563090,
560673962,
567821716,
574994397,
582179826,
589349327,
596478519,
603537118,
610547919,
617495658,
624335544,
631062657,
637663890,
644137666
]
},
{
"name": "Middle East & North Africa",
"stackgroup": "World",
"type": "scatter",
"uid": "ed1e8fae-72d2-495c-b82c-946c6c4a74bd",
"x": [
"1960-01-01",
"1961-01-01",
"1962-01-01",
"1963-01-01",
"1964-01-01",
"1965-01-01",
"1966-01-01",
"1967-01-01",
"1968-01-01",
"1969-01-01",
"1970-01-01",
"1971-01-01",
"1972-01-01",
"1973-01-01",
"1974-01-01",
"1975-01-01",
"1976-01-01",
"1977-01-01",
"1978-01-01",
"1979-01-01",
"1980-01-01",
"1981-01-01",
"1982-01-01",
"1983-01-01",
"1984-01-01",
"1985-01-01",
"1986-01-01",
"1987-01-01",
"1988-01-01",
"1989-01-01",
"1990-01-01",
"1991-01-01",
"1992-01-01",
"1993-01-01",
"1994-01-01",
"1995-01-01",
"1996-01-01",
"1997-01-01",
"1998-01-01",
"1999-01-01",
"2000-01-01",
"2001-01-01",
"2002-01-01",
"2003-01-01",
"2004-01-01",
"2005-01-01",
"2006-01-01",
"2007-01-01",
"2008-01-01",
"2009-01-01",
"2010-01-01",
"2011-01-01",
"2012-01-01",
"2013-01-01",
"2014-01-01",
"2015-01-01",
"2016-01-01",
"2017-01-01"
],
"y": [
105488678,
108374227,
111385940,
114471415,
117671617,
120973578,
124374455,
127947266,
131566224,
135279930,
139083819,
142950993,
146887303,
150999871,
155259901,
159722643,
164407528,
169318424,
174493349,
180000521,
185843847,
192015875,
198499602,
205229901,
212102793,
219095273,
226161475,
233285188,
240367135,
247283550,
255989130,
262659662,
267020622,
273204804,
279279333,
286917385,
292934005,
298982946,
305001541,
311053183,
317129227,
323196354,
329289435,
335522845,
342046777,
348956287,
356287693,
363996317,
371999662,
380192587,
388376106,
396573248,
404783020,
412953000,
421030035,
428974903,
436738031,
444322417
]
},
{
"name": "North America",
"stackgroup": "World",
"type": "scatter",
"uid": "1664abd5-63da-48bf-a458-41469dab41cb",
"x": [
"1960-01-01",
"1961-01-01",
"1962-01-01",
"1963-01-01",
"1964-01-01",
"1965-01-01",
"1966-01-01",
"1967-01-01",
"1968-01-01",
"1969-01-01",
"1970-01-01",
"1971-01-01",
"1972-01-01",
"1973-01-01",
"1974-01-01",
"1975-01-01",
"1976-01-01",
"1977-01-01",
"1978-01-01",
"1979-01-01",
"1980-01-01",
"1981-01-01",
"1982-01-01",
"1983-01-01",
"1984-01-01",
"1985-01-01",
"1986-01-01",
"1987-01-01",
"1988-01-01",
"1989-01-01",
"1990-01-01",
"1991-01-01",
"1992-01-01",
"1993-01-01",
"1994-01-01",
"1995-01-01",
"1996-01-01",
"1997-01-01",
"1998-01-01",
"1999-01-01",
"2000-01-01",
"2001-01-01",
"2002-01-01",
"2003-01-01",
"2004-01-01",
"2005-01-01",
"2006-01-01",
"2007-01-01",
"2008-01-01",
"2009-01-01",
"2010-01-01",
"2011-01-01",
"2012-01-01",
"2013-01-01",
"2014-01-01",
"2015-01-01",
"2016-01-01",
"2017-01-01"
],
"y": [
198624409,
202007500,
205198600,
208253700,
211262900,
214031100,
216659000,
219176000,
221503000,
223759000,
226431000,
229361135,
231943831,
234332208,
236681487,
239235000,
241606200,
244088400,
246674600,
249385800,
251872670,
254421050,
256921449,
259303930,
261583423,
263922898,
266394382,
268896849,
271452347,
274256841,
277473326,
281211703,
285092192,
288811320,
292297226,
295691746,
299126029,
302704697,
306162843,
309600485,
312993944,
316113359,
319050105,
321847258,
324864038,
327892753,
331014940,
334184023,
337405012,
340465736,
343408819,
346051624,
348808615,
351451876,
354223012,
356937591,
359735880,
362492702
]
}
],
"layout": {
"title": "World population"
}
},
"text/html": [
""
],
"text/vnd.plotly.v1+html": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"data = [go.Scatter(x=population.index, y=population[zone], name=zone, stackgroup='World')\n",
" for zone in zones]\n",
"fig = go.Figure(data=data,\n",
" layout=go.Layout(title='World population'))\n",
"offline.iplot(fig)"
]
}
],
"metadata": {
"jupytext": {
"cell_markers": "region,endregion",
"formats": "ipynb,.pct.py:percent,.lgt.py:light,.spx.py:sphinx,md,Rmd,.pandoc.md:pandoc"
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.3"
},
"toc": {
"base_numbering": 1,
"nav_menu": {},
"number_sections": true,
"sideBar": true,
"skip_h1_title": false,
"title_cell": "Table of Contents",
"title_sidebar": "Contents",
"toc_cell": false,
"toc_position": {},
"toc_section_display": true,
"toc_window_display": false
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: demo/World population.lgt.py
================================================
# ---
# jupyter:
# jupytext:
# cell_markers: region,endregion
# formats: ipynb,.pct.py:percent,.lgt.py:light,.spx.py:sphinx,md,Rmd,.pandoc.md:pandoc
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.4'
# jupytext_version: 1.1.0
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # A quick insight at world population
#
# ## Collecting population data
#
# In the below we retrieve population data from the
# [World Bank](http://www.worldbank.org/)
# using the [wbdata](https://github.com/OliverSherouse/wbdata) python package
# region
import pandas as pd
import wbdata as wb
pd.options.display.max_rows = 6
pd.options.display.max_columns = 20
# endregion
# Corresponding indicator is found using search method - or, directly,
# the World Bank site.
wb.search_indicators('Population, total') # SP.POP.TOTL
# wb.search_indicators('area')
# => https://data.worldbank.org/indicator is easier to use
# Now we download the population data
indicators = {'SP.POP.TOTL': 'Population, total',
'AG.SRF.TOTL.K2': 'Surface area (sq. km)',
'AG.LND.TOTL.K2': 'Land area (sq. km)',
'AG.LND.ARBL.ZS': 'Arable land (% of land area)'}
data = wb.get_dataframe(indicators, convert_date=True).sort_index()
data
# World is one of the countries
data.loc['World']
# Can we classify over continents?
data.loc[(slice(None), '2017-01-01'), :]['Population, total'].dropna(
).sort_values().tail(60).index.get_level_values('country')
# Extract zones manually (in order of increasing population)
zones = ['North America', 'Middle East & North Africa',
'Latin America & Caribbean', 'Europe & Central Asia',
'Sub-Saharan Africa', 'South Asia',
'East Asia & Pacific'][::-1]
# And extract population information (and check total is right)
population = data.loc[zones]['Population, total'].swaplevel().unstack()
population = population[zones]
assert all(data.loc['World']['Population, total'] == population.sum(axis=1))
# ## Stacked area plot with matplotlib
import matplotlib.pyplot as plt
plt.clf()
plt.figure(figsize=(10, 5), dpi=100)
plt.stackplot(population.index, population.values.T / 1e9)
plt.legend(population.columns, loc='upper left')
plt.ylabel('Population count (B)')
plt.show()
# ## Stacked bar plot with plotly
# region
import plotly.offline as offline
import plotly.graph_objs as go
offline.init_notebook_mode()
# endregion
data = [go.Scatter(x=population.index, y=population[zone], name=zone, stackgroup='World')
for zone in zones]
fig = go.Figure(data=data,
layout=go.Layout(title='World population'))
offline.iplot(fig)
================================================
FILE: demo/World population.md
================================================
---
jupyter:
jupytext:
cell_markers: region,endregion
formats: ipynb,.pct.py:percent,.lgt.py:light,.spx.py:sphinx,md,Rmd,.pandoc.md:pandoc
text_representation:
extension: .md
format_name: markdown
format_version: '1.1'
jupytext_version: 1.1.0
kernelspec:
display_name: Python 3
language: python
name: python3
---
# A quick insight at world population
## Collecting population data
In the below we retrieve population data from the
[World Bank](http://www.worldbank.org/)
using the [wbdata](https://github.com/OliverSherouse/wbdata) python package
```python
import pandas as pd
import wbdata as wb
pd.options.display.max_rows = 6
pd.options.display.max_columns = 20
```
Corresponding indicator is found using search method - or, directly,
the World Bank site.
```python
wb.search_indicators('Population, total') # SP.POP.TOTL
# wb.search_indicators('area')
# => https://data.worldbank.org/indicator is easier to use
```
Now we download the population data
```python
indicators = {'SP.POP.TOTL': 'Population, total',
'AG.SRF.TOTL.K2': 'Surface area (sq. km)',
'AG.LND.TOTL.K2': 'Land area (sq. km)',
'AG.LND.ARBL.ZS': 'Arable land (% of land area)'}
data = wb.get_dataframe(indicators, convert_date=True).sort_index()
data
```
World is one of the countries
```python
data.loc['World']
```
Can we classify over continents?
```python
data.loc[(slice(None), '2017-01-01'), :]['Population, total'].dropna(
).sort_values().tail(60).index.get_level_values('country')
```
Extract zones manually (in order of increasing population)
```python
zones = ['North America', 'Middle East & North Africa',
'Latin America & Caribbean', 'Europe & Central Asia',
'Sub-Saharan Africa', 'South Asia',
'East Asia & Pacific'][::-1]
```
And extract population information (and check total is right)
```python
population = data.loc[zones]['Population, total'].swaplevel().unstack()
population = population[zones]
assert all(data.loc['World']['Population, total'] == population.sum(axis=1))
```
## Stacked area plot with matplotlib
```python
import matplotlib.pyplot as plt
```
```python
plt.clf()
plt.figure(figsize=(10, 5), dpi=100)
plt.stackplot(population.index, population.values.T / 1e9)
plt.legend(population.columns, loc='upper left')
plt.ylabel('Population count (B)')
plt.show()
```
## Stacked bar plot with plotly
```python
import plotly.offline as offline
import plotly.graph_objs as go
offline.init_notebook_mode()
```
```python
data = [go.Scatter(x=population.index, y=population[zone], name=zone, stackgroup='World')
for zone in zones]
fig = go.Figure(data=data,
layout=go.Layout(title='World population'))
offline.iplot(fig)
```
================================================
FILE: demo/World population.myst.md
================================================
---
jupytext:
formats: ipynb,.pct.py:percent,.lgt.py:light,.spx.py:sphinx,md,Rmd,.pandoc.md:pandoc,.myst.md:myst
text_representation:
extension: '.md'
format_name: myst
format_version: '0.7'
jupytext_version: 1.4.0+dev
kernelspec:
display_name: Python 3
language: python
name: python3
---
# A quick insight at world population
## Collecting population data
In the below we retrieve population data from the
[World Bank](http://www.worldbank.org/)
using the [wbdata](https://github.com/OliverSherouse/wbdata) python package
```{code-cell} ipython3
import pandas as pd
import wbdata as wb
pd.options.display.max_rows = 6
pd.options.display.max_columns = 20
```
Corresponding indicator is found using search method - or, directly,
the World Bank site.
```{code-cell} ipython3
wb.search_indicators('Population, total') # SP.POP.TOTL
# wb.search_indicators('area')
# => https://data.worldbank.org/indicator is easier to use
```
Now we download the population data
```{code-cell} ipython3
indicators = {'SP.POP.TOTL': 'Population, total',
'AG.SRF.TOTL.K2': 'Surface area (sq. km)',
'AG.LND.TOTL.K2': 'Land area (sq. km)',
'AG.LND.ARBL.ZS': 'Arable land (% of land area)'}
data = wb.get_dataframe(indicators, convert_date=True).sort_index()
data
```
World is one of the countries
```{code-cell} ipython3
data.loc['World']
```
Can we classify over continents?
```{code-cell} ipython3
data.loc[(slice(None), '2017-01-01'), :]['Population, total'].dropna(
).sort_values().tail(60).index.get_level_values('country')
```
Extract zones manually (in order of increasing population)
```{code-cell} ipython3
zones = ['North America', 'Middle East & North Africa',
'Latin America & Caribbean', 'Europe & Central Asia',
'Sub-Saharan Africa', 'South Asia',
'East Asia & Pacific'][::-1]
```
And extract population information (and check total is right)
```{code-cell} ipython3
population = data.loc[zones]['Population, total'].swaplevel().unstack()
population = population[zones]
assert all(data.loc['World']['Population, total'] == population.sum(axis=1))
```
## Stacked area plot with matplotlib
```{code-cell} ipython3
import matplotlib.pyplot as plt
```
```{code-cell} ipython3
plt.clf()
plt.figure(figsize=(10, 5), dpi=100)
plt.stackplot(population.index, population.values.T / 1e9)
plt.legend(population.columns, loc='upper left')
plt.ylabel('Population count (B)')
plt.show()
```
## Stacked bar plot with plotly
+++
Stacked area plots (with cumulated values computed depending on
selected legends) are
[on their way](https://github.com/plotly/plotly.js/pull/2960) at Plotly. For
now we just do a stacked bar plot.
```{code-cell} ipython3
import plotly.offline as offline
import plotly.graph_objs as go
offline.init_notebook_mode()
```
```{code-cell} ipython3
bars = [go.Bar(x=population.index, y=population[zone], name=zone)
for zone in zones]
fig = go.Figure(data=bars,
layout=go.Layout(title='World population',
barmode='stack'))
offline.iplot(fig)
```
================================================
FILE: demo/World population.pandoc.md
================================================
---
jupyter:
jupytext:
cell_markers: 'region,endregion'
formats: 'ipynb,.pct.py:percent,.lgt.py:light,.spx.py:sphinx,md,Rmd,.pandoc.md:pandoc'
text_representation:
extension: '.md'
format_name: pandoc
format_version: '2.7.2'
jupytext_version: '1.1.0'
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .markdown}
# A quick insight at world population
## Collecting population data
In the below we retrieve population data from the
[World Bank](http://www.worldbank.org/)
using the [wbdata](https://github.com/OliverSherouse/wbdata) python package
:::
::: {.cell .code}
``` {.python}
import pandas as pd
import wbdata as wb
pd.options.display.max_rows = 6
pd.options.display.max_columns = 20
```
:::
::: {.cell .markdown}
Corresponding indicator is found using search method - or, directly,
the World Bank site.
:::
::: {.cell .code}
``` {.python}
wb.search_indicators('Population, total') # SP.POP.TOTL
# wb.search_indicators('area')
# => https://data.worldbank.org/indicator is easier to use
```
:::
::: {.cell .markdown}
Now we download the population data
:::
::: {.cell .code}
``` {.python}
indicators = {'SP.POP.TOTL': 'Population, total',
'AG.SRF.TOTL.K2': 'Surface area (sq. km)',
'AG.LND.TOTL.K2': 'Land area (sq. km)',
'AG.LND.ARBL.ZS': 'Arable land (% of land area)'}
data = wb.get_dataframe(indicators, convert_date=True).sort_index()
data
```
:::
::: {.cell .markdown}
World is one of the countries
:::
::: {.cell .code}
``` {.python}
data.loc['World']
```
:::
::: {.cell .markdown}
Can we classify over continents?
:::
::: {.cell .code}
``` {.python}
data.loc[(slice(None), '2017-01-01'), :]['Population, total'].dropna(
).sort_values().tail(60).index.get_level_values('country')
```
:::
::: {.cell .markdown}
Extract zones manually (in order of increasing population)
:::
::: {.cell .code}
``` {.python}
zones = ['North America', 'Middle East & North Africa',
'Latin America & Caribbean', 'Europe & Central Asia',
'Sub-Saharan Africa', 'South Asia',
'East Asia & Pacific'][::-1]
```
:::
::: {.cell .markdown}
And extract population information (and check total is right)
:::
::: {.cell .code}
``` {.python}
population = data.loc[zones]['Population, total'].swaplevel().unstack()
population = population[zones]
assert all(data.loc['World']['Population, total'] == population.sum(axis=1))
```
:::
::: {.cell .markdown}
## Stacked area plot with matplotlib
:::
::: {.cell .code}
``` {.python}
import matplotlib.pyplot as plt
```
:::
::: {.cell .code}
``` {.python}
plt.clf()
plt.figure(figsize=(10, 5), dpi=100)
plt.stackplot(population.index, population.values.T / 1e9)
plt.legend(population.columns, loc='upper left')
plt.ylabel('Population count (B)')
plt.show()
```
:::
::: {.cell .markdown}
## Stacked bar plot with plotly
:::
::: {.cell .code}
``` {.python}
import plotly.offline as offline
import plotly.graph_objs as go
offline.init_notebook_mode()
```
:::
::: {.cell .code}
``` {.python}
data = [go.Scatter(x=population.index, y=population[zone], name=zone, stackgroup='World')
for zone in zones]
fig = go.Figure(data=data,
layout=go.Layout(title='World population'))
offline.iplot(fig)
```
:::
================================================
FILE: demo/World population.pct.py
================================================
# ---
# jupyter:
# jupytext:
# cell_markers: region,endregion
# formats: ipynb,.pct.py:percent,.lgt.py:light,.spx.py:sphinx,md,Rmd,.pandoc.md:pandoc
# text_representation:
# extension: .py
# format_name: percent
# format_version: '1.2'
# jupytext_version: 1.1.0
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# # A quick insight at world population
#
# ## Collecting population data
#
# In the below we retrieve population data from the
# [World Bank](http://www.worldbank.org/)
# using the [wbdata](https://github.com/OliverSherouse/wbdata) python package
# %%
import pandas as pd
import wbdata as wb
pd.options.display.max_rows = 6
pd.options.display.max_columns = 20
# %% [markdown]
# Corresponding indicator is found using search method - or, directly,
# the World Bank site.
# %%
wb.search_indicators('Population, total') # SP.POP.TOTL
# wb.search_indicators('area')
# => https://data.worldbank.org/indicator is easier to use
# %% [markdown]
# Now we download the population data
# %%
indicators = {'SP.POP.TOTL': 'Population, total',
'AG.SRF.TOTL.K2': 'Surface area (sq. km)',
'AG.LND.TOTL.K2': 'Land area (sq. km)',
'AG.LND.ARBL.ZS': 'Arable land (% of land area)'}
data = wb.get_dataframe(indicators, convert_date=True).sort_index()
data
# %% [markdown]
# World is one of the countries
# %%
data.loc['World']
# %% [markdown]
# Can we classify over continents?
# %%
data.loc[(slice(None), '2017-01-01'), :]['Population, total'].dropna(
).sort_values().tail(60).index.get_level_values('country')
# %% [markdown]
# Extract zones manually (in order of increasing population)
# %%
zones = ['North America', 'Middle East & North Africa',
'Latin America & Caribbean', 'Europe & Central Asia',
'Sub-Saharan Africa', 'South Asia',
'East Asia & Pacific'][::-1]
# %% [markdown]
# And extract population information (and check total is right)
# %%
population = data.loc[zones]['Population, total'].swaplevel().unstack()
population = population[zones]
assert all(data.loc['World']['Population, total'] == population.sum(axis=1))
# %% [markdown]
# ## Stacked area plot with matplotlib
# %%
import matplotlib.pyplot as plt
# %%
plt.clf()
plt.figure(figsize=(10, 5), dpi=100)
plt.stackplot(population.index, population.values.T / 1e9)
plt.legend(population.columns, loc='upper left')
plt.ylabel('Population count (B)')
plt.show()
# %% [markdown]
# ## Stacked bar plot with plotly
# %%
import plotly.offline as offline
import plotly.graph_objs as go
offline.init_notebook_mode()
# %%
data = [go.Scatter(x=population.index, y=population[zone], name=zone, stackgroup='World')
for zone in zones]
fig = go.Figure(data=data,
layout=go.Layout(title='World population'))
offline.iplot(fig)
================================================
FILE: demo/World population.spx.py
================================================
# ---
# jupyter:
# jupytext:
# cell_markers: region,endregion
# formats: ipynb,.pct.py:percent,.lgt.py:light,.spx.py:sphinx,md,Rmd,.pandoc.md:pandoc
# text_representation:
# extension: .py
# format_name: sphinx
# format_version: '1.1'
# jupytext_version: 1.1.0
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
"""
# A quick insight at world population
## Collecting population data
In the below we retrieve population data from the
[World Bank](http://www.worldbank.org/)
using the [wbdata](https://github.com/OliverSherouse/wbdata) python package
"""
import pandas as pd
import wbdata as wb
pd.options.display.max_rows = 6
pd.options.display.max_columns = 20
###############################################################################
# Corresponding indicator is found using search method - or, directly,
# the World Bank site.
wb.search_indicators('Population, total') # SP.POP.TOTL
# wb.search_indicators('area')
# => https://data.worldbank.org/indicator is easier to use
###############################################################################
# Now we download the population data
indicators = {'SP.POP.TOTL': 'Population, total',
'AG.SRF.TOTL.K2': 'Surface area (sq. km)',
'AG.LND.TOTL.K2': 'Land area (sq. km)',
'AG.LND.ARBL.ZS': 'Arable land (% of land area)'}
data = wb.get_dataframe(indicators, convert_date=True).sort_index()
data
###############################################################################
# World is one of the countries
data.loc['World']
###############################################################################
# Can we classify over continents?
data.loc[(slice(None), '2017-01-01'), :]['Population, total'].dropna(
).sort_values().tail(60).index.get_level_values('country')
###############################################################################
# Extract zones manually (in order of increasing population)
zones = ['North America', 'Middle East & North Africa',
'Latin America & Caribbean', 'Europe & Central Asia',
'Sub-Saharan Africa', 'South Asia',
'East Asia & Pacific'][::-1]
###############################################################################
# And extract population information (and check total is right)
population = data.loc[zones]['Population, total'].swaplevel().unstack()
population = population[zones]
assert all(data.loc['World']['Population, total'] == population.sum(axis=1))
###############################################################################
# ## Stacked area plot with matplotlib
import matplotlib.pyplot as plt
""
plt.clf()
plt.figure(figsize=(10, 5), dpi=100)
plt.stackplot(population.index, population.values.T / 1e9)
plt.legend(population.columns, loc='upper left')
plt.ylabel('Population count (B)')
plt.show()
###############################################################################
# ## Stacked bar plot with plotly
import plotly.offline as offline
import plotly.graph_objs as go
offline.init_notebook_mode()
""
data = [go.Scatter(x=population.index, y=population[zone], name=zone, stackgroup='World')
for zone in zones]
fig = go.Figure(data=data,
layout=go.Layout(title='World population'))
offline.iplot(fig)
================================================
FILE: demo/get_started.md
================================================
---
jupyter:
jupytext:
formats: ipynb,md
text_representation:
extension: .md
format_name: markdown
format_version: '1.1'
jupytext_version: 1.1.6
kernelspec:
display_name: Python 3
language: python
name: python3
---
# Getting started with Jupytext
This small notebook shows you how to activate Jupytext in the JupyterLab
environment. We'll show you a few things that you can do with Jupytext and
a bit of what happens under the hood.
**Note: to run this notebook locally, you need to first follow the Jupytext
installation instructions and activate the JupyterLab plugin. If you're on
Binder, it should already work.**
## Enabling Jupytext in a new notebook
This notebook is brand new - it hasn't had any special extra metadata added
to it.
If we want Jupytext to save files in multiple formats automatically,
we can use the JupyterLab **command palette** to do so.
* In the _View_ menu, click on _Activate Command Palette_
* Then type **`Jupytext`**. You should see a number of commands come up. Each
one tells Jupytext to save the notebook in a different
file format automatically.
* Select **Pair notebook with MyST Markdown**
That's it! If you have Jupytext installed, it will now save your notebook in
markdown format automatically when you save this `.ipynb` file
**in addition to** saving the `.ipynb` file itself.
After you've done this, save the notebook. You should now see a new file called
**`get_started.md`** in the same directory as this notebook.
## How does Jupytext know to do this?
Jupytext uses notebook-level metadata to keep track of what formats are paired
with a notebook. Below we'll print the metadata of this notebook so you can see
what the Jupytext metadata looks like.
```python
import nbformat as nbf
from IPython.display import JSON
notebook = nbf.read('./get_started.ipynb', nbf.NO_CONVERT)
JSON(notebook['metadata'])
```
As you select different formats from the command palette (following the instructions
above) and save the notebook, you'll see this metadata change.
## That's it!
Play around with different kinds of code and outputs to see how each is
converted into its corresponding text format. Here's a little Python code
to get you started:
```python
import numpy as np
import matplotlib.pyplot as plt
plt.scatter(*np.random.randn(2, 100), c=np.random.randn(100), s=np.random.rand(100)*100)
```
# Experiment with the demo notebook!
In the *`demo/`* folder for `jupytext` there is a notebook called **`World population.ipynb`**.
By default, saving the demo notebook will also create *many* possible Jupytext
outputs so you can see what each looks like and which you prefer.
================================================
FILE: demo/vscode/notebook.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"id": "fba07815",
"metadata": {},
"source": [
"This paired notebook can be edited either as\n",
"a Python script or as a Jupyter notebook in\n",
"VS Code. Thanks to the Jupytext Sync\n",
"extension, changes are automatically synced to\n",
"the other paired file(s) when you save.\n",
"\n",
"💡 Tip: don't forget to hit \"Save\" before\n",
"switching to the other editor. If you don't save\n",
"your changes, you will run into conflicting edits\n",
"as VS Code does not autoreload files that have\n",
"unsaved edits."
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "1e480a09",
"metadata": {},
"outputs": [],
"source": [
"import plotly.express as px"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "80da494e-465e-472b-b94b-cea9d4e49451",
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.plotly.v1+json": {
"config": {
"plotlyServerURL": "https://plot.ly"
},
"data": [
{
"hovertemplate": "species=setosa
sepal_width=%{x}
sepal_length=%{y}
sepal_width=%{x}
sepal_length=%{y}
sepal_width=%{x}
sepal_length=%{y} {
const model = notebookTracker.currentWidget.context.model;
const jupytext: IJupytextSection = (model as any).getMetadata('jupytext');
if (!jupytext) {
return [];
}
const formats: Array = jupytext.formats
? jupytext.formats.split(',')
: [];
return formats.filter((format) => {
return format !== '';
});
}
/**
* Get file extension of current notebook widget
*/
function getNotebookFileExtension(notebookTracker: INotebookTracker): string {
let notebookFileExtension: string | undefined =
notebookTracker.currentWidget.context.path.split('.').pop();
if (!notebookFileExtension) {
return '';
}
notebookFileExtension = LANGUAGE_INDEPENDENT_NOTEBOOK_EXTENSIONS.includes(
notebookFileExtension,
)
? notebookFileExtension
: 'auto';
return notebookFileExtension;
}
/**
* Get a list of all selected formats
*/
function getSelectedFormats(notebookTracker: INotebookTracker): Array {
if (!notebookTracker.currentWidget) {
return [];
}
let formats = getWidgetJupytextFormats(notebookTracker);
const model = notebookTracker.currentWidget.context.model;
const languageInfo = (model as any).getMetadata(
'language_info',
) as nbformat.ILanguageInfoMetadata;
if (languageInfo && languageInfo.file_extension) {
const scriptExt = languageInfo.file_extension.substring(1);
formats = formats.map((format) => {
// By default use percent format
if (format === scriptExt) {
return 'auto:percent';
}
// Replace language specific extension with auto
return format.replace(`${scriptExt}:`, 'auto:');
});
}
const notebookFileExtension = getNotebookFileExtension(notebookTracker);
if (!notebookFileExtension) {
return formats;
}
// Remove variant after : in format
const formatExtensions = formats.map((format) => {
return format.split(':')[0];
});
// If current notebook file extension in formats, return
if (formatExtensions.includes(notebookFileExtension)) {
return formats;
}
// When notebook loads for the first time, ipynb extension would not be
// in the formats. Here we add it and return formats
if (
LANGUAGE_INDEPENDENT_NOTEBOOK_EXTENSIONS.includes(notebookFileExtension)
) {
formats.push(notebookFileExtension);
} else {
const model = notebookTracker.currentWidget.context.model;
const jupytext: IJupytextSection = (model as any).getMetadata(
'jupytext',
) as IJupytextSection;
const formatName = jupytext
? jupytext?.text_representation?.formatName || 'percent'
: 'percent';
formats.push(`auto:${formatName}`);
}
return formats;
}
/**
* Toggle pair command
*/
export function isPairCommandToggled(
format: string,
notebookTracker: INotebookTracker,
): boolean {
if (!notebookTracker.currentWidget) {
return false;
}
// Get selected formats on current widget
const selectedFormats = getSelectedFormats(notebookTracker);
if (format === 'custom') {
for (const selectedFormat of selectedFormats) {
if (!JUPYTEXT_FORMATS.includes(selectedFormat)) {
return true;
}
}
return false;
}
return selectedFormats.includes(format);
}
/**
* Enable pair command
*/
export function isPairCommandEnabled(
format: string,
notebookTracker: INotebookTracker,
): boolean {
if (!notebookTracker.currentWidget) {
return false;
}
const notebookFileExtension: string | undefined =
notebookTracker.currentWidget.context.path.split('.').pop();
if (format === notebookFileExtension) {
return false;
}
// Get selected formats on current widget
const selectedFormats = getSelectedFormats(notebookTracker);
if (format === 'none') {
return selectedFormats.length > 1;
}
return true;
}
/**
* Execute pair command
*/
export function executePairCommand(
command: string,
format: string,
notebookTracker: INotebookTracker,
trans: TranslationBundle,
): void {
if (!notebookTracker.currentWidget) {
return;
}
const model = notebookTracker.currentWidget.context.model;
let jupytext: IJupytextSection = (model as any).getMetadata('jupytext') as
| IJupytextSection
| undefined;
// Get selected formats on current widget
let selectedFormats = getSelectedFormats(notebookTracker);
// Toggle the selected format
console.debug('Jupytext: executing command=' + command);
if (format === 'custom') {
showErrorMessage(
trans.__('Error'),
trans.__(
'Please edit the notebook metadata directly if you wish a custom configuration.',
),
);
return;
}
// Get current notebook widget extension
const notebookFileExtension = getNotebookFileExtension(notebookTracker);
// Toggle the selected format
const index = selectedFormats.indexOf(format);
if (format === 'none') {
// Only keep one format - one that matches the current extension
for (const selectedFormat of selectedFormats) {
if (selectedFormat.split(':')[0] === notebookFileExtension) {
selectedFormats = [selectedFormat];
break;
}
}
} else if (index !== -1) {
selectedFormats.splice(index, 1);
// The current file extension can't be unpaired
let extFound = false;
for (const selectedFormat of selectedFormats) {
if (selectedFormat.split(':')[0] === notebookFileExtension) {
extFound = true;
break;
}
}
if (!extFound) {
return;
}
} else {
// We can't have the same extension multiple times
const newFormats = [];
for (const selectedFormat of selectedFormats) {
if (selectedFormat.split(':')[0] !== format.split(':')[0]) {
newFormats.push(selectedFormat);
}
}
selectedFormats = newFormats;
selectedFormats.push(format);
}
if (selectedFormats.length === 1) {
if (notebookFileExtension !== 'auto') {
selectedFormats = [];
} else if (jupytext?.text_representation) {
jupytext.text_representation.formatName =
selectedFormats[0].split(':')[1];
selectedFormats = [];
}
}
if (selectedFormats.length === 0) {
// an older version was re-fetching the jupytext metadata here
// but this is not necessary, as the metadata is already available
if (!jupytext) {
return;
}
if (jupytext.formats) {
delete jupytext.formats;
}
if (Object.keys(jupytext).length === 0) {
(model as any).deleteMetadata('jupytext');
}
(model as any).setMetadata('jupytext', jupytext);
return;
}
// set the desired format
if (jupytext) {
jupytext.formats = selectedFormats.join();
} else {
jupytext = { formats: selectedFormats.join() };
}
(model as any).setMetadata('jupytext', jupytext);
}
/**
* Toggle metadata command
*/
export function isMetadataCommandToggled(
notebookTracker: INotebookTracker,
): boolean {
if (!notebookTracker.currentWidget) {
return false;
}
const model = notebookTracker.currentWidget.context.model;
const jupytextMetadata = (model as any).getMetadata('jupytext');
if (!jupytextMetadata) {
return false;
}
const jupytext: IJupytextSection =
jupytextMetadata as unknown as IJupytextSection;
if (jupytext.notebook_metadata_filter === '-all') {
return false;
}
return true;
}
/**
* Enable metadata command
*/
export function isMetadataCommandEnabled(
notebookTracker: INotebookTracker,
): boolean {
if (!notebookTracker.currentWidget) {
return false;
}
const model = notebookTracker.currentWidget.context.model;
const jupytextMetadata = (model as any).getMetadata('jupytext');
if (!jupytextMetadata) {
return false;
}
const jupytext: IJupytextSection =
jupytextMetadata as unknown as IJupytextSection;
if (jupytext.notebook_metadata_filter === undefined) {
return true;
}
if (jupytext.notebook_metadata_filter === '-all') {
return true;
}
return false;
}
/**
* Execute metadata command
*/
export function executeMetadataCommand(
notebookTracker: INotebookTracker,
): void {
console.debug('Jupytext: toggling YAML header');
if (!notebookTracker.currentWidget) {
return;
}
const model = notebookTracker.currentWidget.context.model;
const jupytextMetadata = (model as any).getMetadata('jupytext');
if (!jupytextMetadata) {
return;
}
const jupytext = ((jupytextMetadata as unknown) ?? {}) as IJupytextSection;
if (jupytext.notebook_metadata_filter) {
delete jupytext.notebook_metadata_filter;
if (jupytext.notebook_metadata_filter === '-all') {
delete jupytext.notebook_metadata_filter;
}
} else {
jupytext.notebook_metadata_filter = '-all';
if (jupytext.notebook_metadata_filter === undefined) {
jupytext.notebook_metadata_filter = '-all';
}
}
(model as any).setMetadata('jupytext', jupytext);
}
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/src/factory.ts
================================================
import {
IToolbarWidgetRegistry,
createToolbarFactory,
} from '@jupyterlab/apputils';
import {
INotebookTracker,
NotebookPanel,
NotebookWidgetFactory,
} from '@jupyterlab/notebook';
import { ISettingRegistry } from '@jupyterlab/settingregistry';
import { DocumentRegistry } from '@jupyterlab/docregistry';
import { IRenderMimeRegistry } from '@jupyterlab/rendermime';
import { IEditorServices } from '@jupyterlab/codeeditor';
import { ITranslator, TranslationBundle } from '@jupyterlab/translation';
import { IDisposable } from '@lumino/disposable';
import { IRisePreviewFactory } from 'jupyterlab-rise';
import { FACTORY, FILE_TYPES } from './tokens';
export function createFactory(
kernelFileTypeNames: string[],
toolbarRegistry: IToolbarWidgetRegistry,
settingRegistry: ISettingRegistry,
docRegistry: DocumentRegistry,
notebookTracker: INotebookTracker,
notebookFactory: NotebookWidgetFactory.IFactory,
contentFactory: NotebookPanel.IContentFactory,
editorServices: IEditorServices,
rendermime: IRenderMimeRegistry,
translator: ITranslator,
trans: TranslationBundle,
riseFactory: IRisePreviewFactory | null,
) {
const allFileTypes = FILE_TYPES.concat(kernelFileTypeNames);
// primarily this block is copied/pasted from jlab4 code and specifically
// jupyterlab/packages/notebook-extension/src/index.ts
// inside the function `activateWidgetFactory` at line 1150 as of this writing
//
const toolbarFactory = createToolbarFactory(
toolbarRegistry,
settingRegistry,
'Notebook',
'@jupyterlab/notebook-extension:panel',
translator,
);
// Duplicate notebook factory to apply it on Jupytext notebooks
// Mirror: https://github.com/jupyterlab/jupyterlab/blob/8a8c3752564f37493d4eb6b4c59008027fa83880/packages/notebook-extension/src/index.ts#L860
const factory = new NotebookWidgetFactory({
name: FACTORY,
label: trans.__(FACTORY),
fileTypes: allFileTypes,
modelName: notebookFactory.modelName ?? 'notebook',
preferKernel: notebookFactory.preferKernel ?? true,
canStartKernel: notebookFactory.canStartKernel ?? true,
rendermime,
contentFactory,
editorConfig: notebookFactory.editorConfig,
notebookConfig: notebookFactory.notebookConfig,
mimeTypeService: editorServices.mimeTypeService,
toolbarFactory: toolbarFactory,
translator,
});
docRegistry.addWidgetFactory(factory);
// The list of extensions in the Jupytext Notebook factory.
const factoryExtensions: IDisposable[] = [];
const updateWidgetExtensions = () => {
// Dispose of all existing extensions.
factoryExtensions.forEach((extension) => extension.dispose());
// Add all the widgets extensions in the Notebook factory.
for (const extension of docRegistry.widgetExtensions('Notebook')) {
docRegistry.addWidgetExtension(FACTORY, extension);
}
};
// Listen for changes in Notebook factory extensions.
docRegistry.changed.connect((_, change) => {
if (change.type === 'widgetExtension' && change.name === 'Notebook') {
updateWidgetExtensions();
}
});
updateWidgetExtensions();
// Register widget created with the new factory in the notebook tracker
// This is required to activate notebook commands (and therefore shortcuts)
let id = 0; // The ID counter for notebook panels.
const ft = docRegistry.getFileType('notebook');
factory.widgetCreated.connect((sender, widget) => {
// If the notebook panel does not have an ID, assign it one.
widget.id = widget.id || `notebook-jupytext-${++id}`;
// Set up the title icon
widget.title.icon = ft?.icon;
widget.title.iconClass = ft?.iconClass ?? '';
widget.title.iconLabel = ft?.iconLabel ?? '';
// Notify the widget tracker if restore data needs to update.
widget.context.pathChanged.connect(() => {
// @ts-expect-error Trick using private API
void notebookTracker.save(widget);
});
// Add the notebook panel to the tracker.
// @ts-expect-error Trick using private API
void notebookTracker.add(widget);
});
// Add support for RISE slides
if (riseFactory) {
for (const fileType of allFileTypes) {
riseFactory.addFileType(fileType);
}
}
}
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/src/index.ts
================================================
import {
JupyterFrontEnd,
JupyterFrontEndPlugin,
} from '@jupyterlab/application';
import {
ICommandPalette,
IToolbarWidgetRegistry,
showErrorMessage,
} from '@jupyterlab/apputils';
import { IDocumentManager } from '@jupyterlab/docmanager';
import { IEditorLanguageRegistry } from '@jupyterlab/codemirror';
import { Contents } from '@jupyterlab/services';
import { ILauncher } from '@jupyterlab/launcher';
import { ISettingRegistry } from '@jupyterlab/settingregistry';
import { IEditorServices } from '@jupyterlab/codeeditor';
import {
INotebookTracker,
INotebookWidgetFactory,
NotebookPanel,
NotebookWidgetFactory,
} from '@jupyterlab/notebook';
import { IRenderMimeRegistry } from '@jupyterlab/rendermime';
import { IDefaultFileBrowser } from '@jupyterlab/filebrowser';
import { IMainMenu } from '@jupyterlab/mainmenu';
import { ITranslator, nullTranslator } from '@jupyterlab/translation';
import { LabIcon } from '@jupyterlab/ui-components';
import { DisposableSet } from '@lumino/disposable';
import { Menu } from '@lumino/widgets';
import { JSONExt, ReadonlyJSONValue } from '@lumino/coreutils';
import { IRisePreviewFactory } from 'jupyterlab-rise';
import {
JUPYTEXT_EXTENSION_ID,
JUPYTEXT_PAIR_COMMANDS_FILETYPE_DATA,
JUPYTEXT_FORMATS,
TEXT_NOTEBOOKS_LAUNCHER_ICONS,
CommandIDs,
IFileTypeData,
JupytextIcon,
AUTO_LANGUAGE_FILETYPE_DATA,
} from './tokens';
import {
isPairCommandToggled,
isPairCommandEnabled,
executePairCommand,
isMetadataCommandToggled,
isMetadataCommandEnabled,
executeMetadataCommand,
} from './commands';
import { registerFileTypes } from './registry';
import { createFactory } from './factory';
import {
getAvailableKernelLanguages,
getAvailableCreateTextNotebookCommands,
createNewTextNotebook,
} from './utils';
/**
* Initialization data for the jupyterlab-jupytext extension.
*/
const extension: JupyterFrontEndPlugin = {
id: JUPYTEXT_EXTENSION_ID,
autoStart: true,
optional: [
ILauncher,
IMainMenu,
IDefaultFileBrowser,
ITranslator,
ICommandPalette,
IRisePreviewFactory,
],
requires: [
NotebookPanel.IContentFactory,
IEditorServices,
IDocumentManager,
IEditorLanguageRegistry,
IRenderMimeRegistry,
INotebookWidgetFactory,
INotebookTracker,
ISettingRegistry,
IToolbarWidgetRegistry,
],
activate: async (
app: JupyterFrontEnd,
contentFactory: NotebookPanel.IContentFactory,
editorServices: IEditorServices,
docManager: IDocumentManager,
languages: IEditorLanguageRegistry,
rendermime: IRenderMimeRegistry,
notebookFactory: NotebookWidgetFactory.IFactory,
notebookTracker: INotebookTracker,
settingRegistry: ISettingRegistry,
toolbarRegistry: IToolbarWidgetRegistry,
launcher: ILauncher | null,
mainmenu: IMainMenu | null,
defaultBrowser: IDefaultFileBrowser | null,
translator: ITranslator | null,
palette: ICommandPalette | null,
riseFactory: IRisePreviewFactory | null,
) => {
console.log('JupyterLab extension jupytext is activating...');
const trans = (translator ?? nullTranslator).load('jupytext');
// Load settings
const includeFormats = TEXT_NOTEBOOKS_LAUNCHER_ICONS;
if (settingRegistry) {
const settings = await settingRegistry.load(extension.id);
for (const format of JUPYTEXT_FORMATS) {
const addFormat = settings.get(format).composite as boolean;
if (addFormat && !includeFormats.includes(format)) {
includeFormats.push(format);
} else if (!addFormat && includeFormats.includes(format)) {
includeFormats.splice(includeFormats.indexOf(format), 1);
}
}
}
// Unpack necessary components
const { commands, serviceManager, docRegistry } = app;
// Initialise Jupytext create notebook submenu and add it to File menu
const jupytextCreateMenu = new Menu({ commands: app.commands });
jupytextCreateMenu.id = 'jp-mainmenu-jupytext-new-menu';
jupytextCreateMenu.title.label = trans.__('New Text Notebook');
mainmenu.fileMenu.addItem({
rank: 0.97,
type: 'submenu',
submenu: jupytextCreateMenu,
});
// Add create text notebook submenu to context menu
// Rank 53 as 52 is used for classic notebook
// https://github.com/jupyterlab/jupyterlab/blob/4d34bbbea2afc7385169d92bf7bc0c9e0face3a9/packages/notebook-extension/schema/tracker.json#L363-L369
app.contextMenu.addItem({
submenu: jupytextCreateMenu,
type: 'submenu',
selector: '.jp-DirListing-content',
rank: 53,
});
// Initialise Jupytext menu and add it to main menu
const jupytextMenu = new Menu({ commands: app.commands });
mainmenu.fileMenu.addItem({
rank: 0.98,
type: 'submenu',
submenu: jupytextMenu,
});
jupytextMenu.id = 'jp-mainmenu-jupytext-menu';
jupytextMenu.title.label = trans.__('Jupytext');
// Get all Jupytext formats
let rank = 0;
const separatorIndex: number[] = [];
JUPYTEXT_PAIR_COMMANDS_FILETYPE_DATA.forEach(
(value: IFileTypeData[], key: string) => {
value.map((fileType: IFileTypeData) => {
const format = key;
const command = `jupytext:pair-nb-with-${format}`;
commands.addCommand(command, {
label: (args) => {
if (args.isPalette) {
return (
(fileType.paletteLabel as string) ?? trans.__('Pair notebook')
);
}
return (fileType.caption as string) ?? trans.__('Pair notebook');
},
caption: trans.__(fileType.caption),
icon: (args) => {
if (args.isPalette) {
return undefined;
} else {
return fileType.iconName
? LabIcon.resolve({
icon: fileType.iconName as string,
})
: undefined;
}
},
isToggled: () => {
return isPairCommandToggled(format, notebookTracker);
},
isEnabled: () => {
return isPairCommandEnabled(format, notebookTracker);
},
execute: () => {
return executePairCommand(
command,
format,
notebookTracker,
trans,
);
},
});
console.debug(
'Registering pairing command=' + command + ' with rank=' + rank,
);
palette?.addItem({
command,
args: { isPalette: true },
rank: rank + 1,
category: 'Jupytext',
});
// Add to jupytext pair menu
jupytextMenu.addItem({
command: command,
});
if (fileType.separator) {
separatorIndex.push(rank);
}
rank += 1;
});
},
);
// Add separators in jupytext pair menu
separatorIndex.map((index, idx) => {
jupytextMenu.insertItem(index + idx + 1, {
type: 'separator',
});
});
// Metadata in text representation
commands.addCommand(CommandIDs.metadata, {
label: trans.__('Include Metadata'),
icon: (args) => {
if (args.isPalette) {
return undefined;
} else {
return JupytextIcon;
}
},
isToggled: () => {
return isMetadataCommandToggled(notebookTracker);
},
isEnabled: () => {
return isMetadataCommandEnabled(notebookTracker);
},
execute: () => {
return executeMetadataCommand(notebookTracker);
},
});
palette?.addItem({
command: CommandIDs.metadata,
args: { isPalette: true },
rank: 98,
category: 'Jupytext',
});
jupytextMenu.addItem({
type: 'separator',
});
jupytextMenu.addItem({
command: CommandIDs.metadata,
});
jupytextMenu.addItem({
type: 'separator',
});
// Register Jupytext FAQ command
commands.addCommand(CommandIDs.faq, {
label: trans.__('Jupytext FAQ'),
icon: (args) => {
if (args.isPalette) {
return undefined;
} else {
return JupytextIcon;
}
},
execute: () => {
window.open('https://jupytext.readthedocs.io/en/latest/faq.html');
},
});
palette?.addItem({
command: CommandIDs.faq,
args: { isPalette: true },
rank: 99,
category: 'Jupytext',
});
jupytextMenu.addItem({
command: CommandIDs.faq,
});
// Register Jupytext Reference
commands.addCommand(CommandIDs.reference, {
label: trans.__('Jupytext Reference'),
icon: (args) => {
if (args.isPalette) {
return undefined;
} else {
return JupytextIcon;
}
},
execute: () => {
window.open('https://jupytext.readthedocs.io/en/latest/');
},
});
palette?.addItem({
command: CommandIDs.reference,
args: { isPalette: true },
rank: 100,
category: 'Jupytext',
});
jupytextMenu.addItem({
command: CommandIDs.reference,
});
// Register a new command to create untitled file. This snippet is taken
// from docManager package https://github.com/jupyterlab/jupyterlab/blob/c106f0a19110efad7c5e1b136144985819e21100/packages/docmanager-extension/src/index.tsx#L679-L680
// We are "duplicating" it as base command adds extension to the options
// only if it is of type file. But we are interested in creating notebook type
// files with different Jupytext supported extensions. So we create a dedicated
// create new text notebook command here and make sure we pass extension in options
commands.addCommand(CommandIDs.newUntitled, {
execute: async (args) => {
const errorTitle = (args['error'] as string) || trans.__('Error');
const path =
typeof args['path'] === 'undefined' ? '' : (args['path'] as string);
const options: Partial = {
type: args['type'] as Contents.ContentType,
path,
};
// Ensure we pass extension to command always
options.ext = (args['ext'] as string) || '.txt';
return docManager.services.contents
.newUntitled(options)
.catch((error) => showErrorMessage(errorTitle, error));
},
label: (args) =>
(args['label'] as string) || `New ${args['type'] as string}`,
});
// We dont need to add this command to palettte as it is a utility one
// which does not have direct usage
// palette?.addItem({
// command: CommandIDs.newUntitled,
// rank: 50,
// category: 'Jupytext',
// });
// Get a map of available kernel languages in current widget
const availableKernelLanguages = await getAvailableKernelLanguages(
languages,
docRegistry,
serviceManager,
);
// Get a map of all create text notebook commands
const createTextNotebookCommands =
await getAvailableCreateTextNotebookCommands(
includeFormats,
availableKernelLanguages,
);
// Register Jupytext text notebooks file types
registerFileTypes(
availableKernelLanguages,
[
...[...JUPYTEXT_PAIR_COMMANDS_FILETYPE_DATA.values()].flat(),
...[...AUTO_LANGUAGE_FILETYPE_DATA.values()].flat(),
],
docRegistry,
trans,
);
// Get all kernel file types to add to Jupytext factory
const kernelLanguageNames: string[] = [];
for (const kernelLanguage of availableKernelLanguages.keys()) {
kernelLanguageNames.push(kernelLanguage);
}
// Create a factory for Jupytext
createFactory(
kernelLanguageNames,
toolbarRegistry,
settingRegistry,
docRegistry,
notebookTracker,
notebookFactory,
contentFactory,
editorServices,
rendermime,
translator,
trans,
riseFactory,
);
// Register all the commands that create text notebooks with different formats
// Nicked from notebook-extension package in JupyterLab
// https://github.com/jupyterlab/jupyterlab/blob/c106f0a19110efad7c5e1b136144985819e21100/packages/notebook-extension/src/index.ts#L1902-L1965
createTextNotebookCommands.forEach((fileTypes: IFileTypeData[], _) => {
fileTypes.map((fileType: IFileTypeData) => {
const format = fileType.fileExt;
const command = `jupytext:create-new-text-notebook-${format}`;
const iconName = fileType.iconName;
const kernelIcon = fileType.kernelIcon;
commands.addCommand(command, {
label: (args) => {
if (args['isLauncher']) {
return trans.__(fileType.launcherLabel);
}
return trans.__(fileType.paletteLabel);
},
caption: trans.__(fileType.caption),
icon: (args) => {
if (args.isPalette) {
return undefined;
} else {
if (iconName) {
return LabIcon.resolve({
icon: iconName as string,
});
}
if (kernelIcon) {
return kernelIcon;
}
return LabIcon.resolve({
icon: 'ui-components:kernel',
});
}
},
execute: (args) => {
const cwd =
(args['cwd'] as string) || (defaultBrowser?.model.path ?? '');
const kernelId = (args['kernelId'] as string) || '';
const kernelName = (args['kernelName'] as string) || '';
return createNewTextNotebook(
cwd,
kernelId,
kernelName,
format,
commands,
);
},
});
console.debug(
'Registering create new text notebook command=' +
command +
' with rank=' +
rank,
);
palette?.addItem({
command,
args: { isPalette: true },
rank: rank,
category: 'Jupytext',
});
if (includeFormats.includes(format)) {
jupytextCreateMenu.addItem({
command: command,
args: { isMainMenu: true },
});
// Add separator after each kernel type
if (fileType.separator) {
jupytextCreateMenu.addItem({
type: 'separator',
});
}
}
// Add a launcher item if the launcher is available.
if (launcher && includeFormats.includes(format)) {
void serviceManager.ready.then(() => {
let disposables: DisposableSet | null = null;
const onSpecsChanged = () => {
if (disposables) {
disposables.dispose();
disposables = null;
}
const specs = serviceManager.kernelspecs.specs;
if (!specs) {
return;
}
disposables = new DisposableSet();
const kernelIconUrl =
specs.kernelspecs[fileType.kernelName]?.resources['logo-svg'] ||
specs.kernelspecs[fileType.kernelName]?.resources['logo-64x64'];
disposables.add(
launcher.add({
command: command,
args: { isLauncher: true, kernelName: fileType.kernelName },
category: trans.__('Jupytext'),
rank: rank++,
kernelIconUrl,
metadata: {
kernel: JSONExt.deepCopy(
specs.kernelspecs[fileType.kernelName]?.metadata || {},
) as ReadonlyJSONValue,
},
}),
);
};
onSpecsChanged();
serviceManager.kernelspecs.specsChanged.connect(onSpecsChanged);
});
}
// Increment rank
rank += 1;
});
});
},
};
export default extension;
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/src/registry.ts
================================================
import { DocumentRegistry } from '@jupyterlab/docregistry';
import { TranslationBundle } from '@jupyterlab/translation';
import { markdownIcon, LabIcon, fileIcon } from '@jupyterlab/ui-components';
import { IFileTypeData } from './tokens';
export function registerFileTypes(
availableKernelLanguages: Map,
jupytextFormatsWithFileTypeData: IFileTypeData[],
docRegistry: DocumentRegistry,
trans: TranslationBundle,
) {
const mystExtensions = ['myst', 'mystnb', 'mnb'];
const rmdExtensions = ['Rmd'];
const quartoExtensions = ['qmd'];
const extensionsWithFactory = [
...mystExtensions,
...rmdExtensions,
...quartoExtensions,
];
// Add a catch-all file type to overrride icon which by default is derive from model type.
// Because jupytext changes the type of all files it can handle to Notebook, we need to
// override it. We exclude file types which have dedicated icons (handled later).
const excludedExtensions = [
'ipynb',
...jupytextFormatsWithFileTypeData.map((f) => f.fileExt),
...extensionsWithFactory,
].join('|');
docRegistry.addFileType({
name: 'jupytext-notebook-file',
contentType: 'notebook',
pattern: `^(?!.*\\.(${excludedExtensions})$).*$`,
icon: fileIcon,
});
// Handle file types with dedicated icons
for (const format of jupytextFormatsWithFileTypeData) {
if (!extensionsWithFactory.includes(format.fileExt)) {
docRegistry.addFileType({
name: `${format.fileExt}-jupytext-notebook`,
contentType: 'notebook',
// `pattern` field gives it precedence over other file type information when resolving the icon
pattern: `\\.${format.fileExt}$`,
extensions: [`.${format.fileExt}`],
icon: format.iconName
? LabIcon.resolve({ icon: format.iconName })
: format.kernelIcon,
});
}
}
// Add kernel file types to registry
availableKernelLanguages.forEach(
(kernelFileTypes: IFileTypeData[], kernelLanguage: string) => {
kernelFileTypes.map((kernelFileType) => {
docRegistry.addFileType({
name: kernelLanguage,
contentType: 'notebook',
pattern: `\\.${kernelFileType.fileExt}$`,
displayName: trans.__(
kernelFileType.paletteLabel.split('New')[1].trim(),
),
extensions: [`.${kernelFileType.fileExt}`],
icon: kernelFileType.iconName
? LabIcon.resolve({ icon: kernelFileType.iconName })
: kernelFileType.kernelIcon,
});
});
},
);
const markdownNotebookIcon = markdownIcon.bindprops({
boxSizing: 'border-box',
border: '2px solid var(--jp-notebook-icon-color)',
borderRadius: '2px',
});
// Add markdown file types to registry - these will be open with Notebook by default
docRegistry.addFileType(
{
name: 'myst',
contentType: 'notebook',
displayName: trans.__('MyST Markdown Notebook'),
extensions: mystExtensions.map((ext) => '.' + ext),
icon: markdownNotebookIcon,
},
['Notebook'],
);
docRegistry.addFileType(
{
name: 'r-markdown',
contentType: 'notebook',
displayName: trans.__('R Markdown Notebook'),
// Extension file are transformed to lower case...
extensions: rmdExtensions.map((ext) => '.' + ext),
icon: markdownNotebookIcon,
},
['Notebook'],
);
docRegistry.addFileType(
{
name: 'quarto',
contentType: 'notebook',
displayName: trans.__('Quarto Notebook'),
extensions: quartoExtensions.map((ext) => '.' + ext),
pattern: '\\.qmd$',
icon: markdownNotebookIcon,
},
['Notebook'],
);
}
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/src/svg.d.ts
================================================
declare module '*.svg' {
const image: string;
export default image;
}
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/src/tokens.ts
================================================
import { ServerConnection } from '@jupyterlab/services';
import { LabIcon } from '@jupyterlab/ui-components';
import jupytextSvgstr from '../style/icons/logo.svg';
/**
* Jupytext extension ID
*/
export const JUPYTEXT_EXTENSION_ID = 'jupyterlab-jupytext:plugin';
/**
* Jupytext widget factory
*/
export const FACTORY = 'Jupytext Notebook';
/**
* Supported file formats.
*/
export const LANGUAGE_INDEPENDENT_NOTEBOOK_EXTENSIONS = [
'ipynb',
'md',
'Rmd',
'qmd',
];
/**
* Supported file types names.
*/
export const FILE_TYPES = [
'markdown',
'myst',
'r-markdown',
'quarto',
'julia',
'python',
'r',
];
/**
* The short namespace for commands, etc.
*/
export const NS = 'jupytext';
/**
* Command IDs of Jupytext
*/
export namespace CommandIDs {
export const metadata = `${NS}:metadata`;
export const reference = `${NS}:reference`;
export const faq = `${NS}:faq`;
export const newUntitled = `${NS}:new-untitled-text-notebook`;
}
/**
* Jupytext logo icon
*/
export const JupytextIcon = new LabIcon({
name: `${NS}:icon:logo`,
svgstr: jupytextSvgstr,
});
/**
* Current Jupyter server settings
*/
export const SERVER_SETTINGS = ServerConnection.makeSettings();
/**
* Supported Jupytext pairings along with metadata.
*/
export const JUPYTEXT_PAIR_COMMANDS_FILETYPE_DATA = new Map<
string,
IFileTypeData[]
>([
[
'ipynb',
[
{
fileExt: 'ipynb',
paletteLabel: 'Pair with ipynb',
caption: 'Pair Notebook with ipynb document',
iconName: 'ui-components:notebook',
separator: true,
},
],
],
[
'auto:percent',
[
{
fileExt: 'auto:percent',
paletteLabel: 'Pair with percent script',
caption: 'Pair Notebook with Percent Format',
iconName: 'ui-components:text-editor',
},
],
],
[
'auto:light',
[
{
fileExt: 'auto:light',
paletteLabel: 'Pair with light script',
caption: 'Pair Notebook with Light Format',
iconName: 'ui-components:text-editor',
},
],
],
[
'auto:nomarker',
[
{
fileExt: 'auto:nomarker',
paletteLabel: 'Pair with nomarker script',
caption: 'Pair Notebook with Nomarker Format',
iconName: 'ui-components:text-editor',
separator: true,
},
],
],
[
'py:marimo',
[
{
fileExt: 'py:marimo',
paletteLabel: 'Pair with Marimo Python script',
caption: 'Pair Notebook with Marimo Python script',
iconName: 'ui-components:text-editor',
separator: true,
},
],
],
[
'md',
[
{
fileExt: 'md',
paletteLabel: 'Pair with md',
caption: 'Pair Notebook with Markdown',
iconName: 'ui-components:markdown',
},
],
],
[
'md:myst',
[
{
fileExt: 'md:myst',
paletteLabel: 'Pair with myst md',
caption: 'Pair Notebook with MyST Markdown',
iconName: 'ui-components:markdown',
separator: true,
},
],
],
[
'Rmd',
[
{
fileExt: 'Rmd',
paletteLabel: 'Pair with Rmd',
caption: 'Pair Notebook with R Markdown',
iconName: 'ui-components:markdown',
},
],
],
[
'qmd',
[
{
fileExt: 'qmd',
paletteLabel: 'Pair with qmd',
caption: 'Pair Notebook with Quarto (qmd)',
iconName: 'ui-components:markdown',
separator: true,
},
],
],
[
'custom',
[
{
fileExt: 'custom',
paletteLabel: 'Custom pair',
caption: 'Custom Pairing',
iconName: 'ui-components:text-editor',
},
],
],
[
'none',
[
{
fileExt: 'none',
paletteLabel: 'Unpair',
caption: 'Unpair Current Notebook',
},
],
],
]);
/**
* Supported kernels file types metadata
*/
export const AUTO_LANGUAGE_FILETYPE_DATA = new Map([
[
'python',
[
{
fileExt: 'py',
paletteLabel: 'New Python Text Notebook',
caption: 'Create a new Python Text Notebook',
iconName: 'ui-components:python',
launcherLabel: 'Python',
kernelName: 'python3',
},
],
],
[
'julia',
[
{
fileExt: 'jl',
paletteLabel: 'New Julia Text Notebook',
caption: 'Create a new Julia Text Notebook',
iconName: 'ui-components:julia',
launcherLabel: 'Julia',
kernelName: 'julia',
},
],
],
[
'R',
[
{
fileExt: 'R',
paletteLabel: 'New R Text Notebook',
caption: 'Create a new R Text Notebook',
iconName: 'ui-components:r-kernel',
launcherLabel: 'R',
kernelName: 'ir',
},
],
],
]);
/**
* Supported Jupytext create new text notebooks file types
*/
export const JUPYTEXT_CREATE_TEXT_NOTEBOOK_FILETYPE_DATA = new Map<
string,
IFileTypeData[]
>([
[
'auto:percent',
[
{
fileExt: 'auto:percent',
paletteLabel: 'Percent Format',
caption: 'Percent Format',
launcherLabel: 'Percent Format',
},
],
],
[
'auto:light',
[
{
fileExt: 'auto:light',
paletteLabel: 'Light Format',
caption: 'Light Format',
launcherLabel: 'Light Format',
},
],
],
[
'auto:nomarker',
[
{
fileExt: 'auto:nomarker',
paletteLabel: 'Nomarker Format',
caption: 'Nomarker Format',
launcherLabel: 'Nomarker Format',
},
],
],
[
'py:marimo',
[
{
fileExt: 'py:marimo',
paletteLabel: 'Marimo Format',
caption: 'Marimo Format',
launcherLabel: 'Marimo Format',
},
],
],
[
'md',
[
{
fileExt: 'md',
paletteLabel: 'New Markdown Text Notebook',
caption: 'Create a new Markdown Text Notebook',
iconName: 'ui-components:markdown',
launcherLabel: 'Markdown',
},
],
],
[
'md:myst',
[
{
fileExt: 'md:myst',
paletteLabel: 'New MyST Markdown Text Notebook',
caption: 'Create a new MyST Markdown Text Notebook',
iconName: 'ui-components:markdown',
launcherLabel: 'MyST Markdown',
},
],
],
[
'Rmd',
[
{
fileExt: 'Rmd',
paletteLabel: 'New R Markdown Text Notebook',
caption: 'Create a new R Markdown Text Notebook',
iconName: 'ui-components:markdown',
launcherLabel: 'R Markdown',
},
],
],
[
'qmd',
[
{
fileExt: 'qmd',
paletteLabel: 'New Quarto Markdown Text Notebook',
caption: 'Create a new Quarto Markdown Text Notebook',
iconName: 'ui-components:markdown',
launcherLabel: 'Quarto Markdown',
},
],
],
]);
/**
* Supported Jupytext format extensions bar custom and none
*/
export const JUPYTEXT_FORMATS = Array.from(
JUPYTEXT_PAIR_COMMANDS_FILETYPE_DATA.keys(),
)
.map((format) => {
return format;
})
.filter((format) => {
return !['custom', 'none'].includes(format);
});
/**
* List of formats that would be added to launcher icons
*/
export const TEXT_NOTEBOOKS_LAUNCHER_ICONS = JUPYTEXT_FORMATS.filter(
(format) => {
return !['ipynb', 'auto:nomarker', 'qmd', 'custom', 'none'].includes(
format,
);
},
);
/**
* An interface for file type metadata
*/
export interface IFileTypeData {
fileExt: string;
paletteLabel: string;
caption: string;
iconName?: string;
kernelIcon?: LabIcon;
launcherLabel?: string;
kernelName?: string;
separator?: boolean;
}
/**
* An interface for Jupytext representation
*/
export interface IJupytextRepresentation {
formatName: string;
extension: string;
}
/**
* An interface for Jupytext metadata
*/
export interface IJupytextSection {
formats?: string;
notebook_metadata_filter?: string;
cell_metadata_filer?: string;
text_representation?: IJupytextRepresentation;
}
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/src/utils.ts
================================================
import { IEditorLanguageRegistry } from '@jupyterlab/codemirror';
import {
ServiceManager,
ServerConnection,
KernelSpec,
} from '@jupyterlab/services';
import { LabIcon } from '@jupyterlab/ui-components';
import { URLExt } from '@jupyterlab/coreutils';
import { DocumentRegistry, IDocumentWidget } from '@jupyterlab/docregistry';
import { CommandRegistry } from '@lumino/commands';
import { Buffer } from 'buffer';
import {
NS,
SERVER_SETTINGS,
AUTO_LANGUAGE_FILETYPE_DATA,
JUPYTEXT_CREATE_TEXT_NOTEBOOK_FILETYPE_DATA,
FACTORY,
CommandIDs,
IFileTypeData,
} from './tokens';
/**
* Get kernel icon SVG string
*/
async function getKernelIconBase64String(
kernelIconUrl: string,
): Promise {
// Seems like URL prefix is already included in kernelIconUrl. We need to strip
// it off as baseUrl will already has url prefix.
kernelIconUrl = `/kernelspecs${kernelIconUrl.split('kernelspecs')[1]}`;
const url = URLExt.join(SERVER_SETTINGS.baseUrl, kernelIconUrl);
const response = await ServerConnection.makeRequest(url, {}, SERVER_SETTINGS);
const blob = await response.arrayBuffer();
const contentType = response.headers.get('content-type');
return `data:${contentType};base64,${Buffer.from(blob).toString('base64')}`;
}
/**
* Make a SVG string from base64 image
*/
function base64ToSvgStr(width: number, imageBase64: string): string {
return ``.replace(/\n/g, ' ');
}
/**
* Get kernel Icon
*/
async function getKernelIcon(
specModel: KernelSpec.ISpecModel,
fileType: DocumentRegistry.IFileType | undefined,
): Promise {
// First check for logo-svg
if (specModel.resources['logo-svg']) {
const svgStr = await getKernelIconBase64String(
specModel.resources['logo-svg'],
);
return new LabIcon({
name: `${NS}:icon:${specModel.name}`,
svgstr: svgStr,
});
}
// Else check if 64x64 kernel icon is available
if (specModel.resources['logo-64x64']) {
const iconBase64String = await getKernelIconBase64String(
specModel.resources['logo-64x64'],
);
return new LabIcon({
name: `${NS}:icon:${specModel.name}`,
svgstr: base64ToSvgStr(64, iconBase64String),
});
}
// Finally check for 32x32 kernel icon
if (specModel.resources['logo-32x32']) {
const iconBase64String = await getKernelIconBase64String(
specModel.resources['logo-32x32'],
);
return new LabIcon({
name: `${NS}:icon:${specModel.name}`,
svgstr: base64ToSvgStr(32, iconBase64String),
});
}
if (fileType && fileType.icon) {
return fileType.icon;
}
// If not found, make a generic kernel icon
return LabIcon.resolve({
icon: 'ui-components:kernel',
});
}
/**
* Get all available kernel languages so that we replace auto format
* with these language file extensions
*/
export async function getAvailableKernelLanguages(
languages: IEditorLanguageRegistry,
docRegistry: DocumentRegistry,
serviceManager: ServiceManager.IManager,
): Promise> {
const specsManager = serviceManager.kernelspecs;
await specsManager.ready;
const fileTypes = new Map();
const specs = specsManager.specs?.kernelspecs ?? {};
for (const [spec, specModel] of Object.entries(specs)) {
if (specModel) {
// First check if kernel is one of the pre-defined types (Python, R, Julia)
const exts = AUTO_LANGUAGE_FILETYPE_DATA.get(specModel.language);
if (exts !== undefined) {
fileTypes.set(specModel.language, exts);
} else {
// If not, try to get languageInfo from codemirror languages
const languageInfo = languages.findByName(specModel.language);
// If we managed to find the language, construct the FileTypeData
// Here we make an assumption that first extension in
// languageInfo.extensions is the most common one.
const fileExt = languageInfo.extensions[0];
const fileType = docRegistry.getFileTypesForPath(`test.${fileExt}`)[0];
if (languageInfo) {
// We attempt to get kernelIcon here for specModel.resources
// If none provided, we return generic kernel icon
const kernelIcon = await getKernelIcon(specModel, fileType);
const displayName =
languageInfo.displayName || specModel.display_name;
const exts: IFileTypeData[] = [
{
fileExt,
paletteLabel: `New ${displayName} Text Notebook`,
caption: `Create a new ${displayName} Text Notebook`,
kernelIcon: kernelIcon,
launcherLabel: displayName,
kernelName: spec,
},
];
fileTypes.set(specModel.language, exts);
}
}
}
}
return fileTypes;
}
/**
* Get all available 'Create New Text Notebook' commands based on configured
* formats and available kernels
*/
export async function getAvailableCreateTextNotebookCommands(
includeFormats: string[],
availableKernelLanguages: Map,
): Promise> {
const numKernels = availableKernelLanguages.size;
// Initialise a map of 'Create New Text Notebook' command filetypes
const createTextNotebookCommands = new Map();
// Iterate through all JUPYTEXT_CREATE_TEXT_NOTEBOOK_FILETYPE_DATA file types.
JUPYTEXT_CREATE_TEXT_NOTEBOOK_FILETYPE_DATA.forEach(
(fileTypes: IFileTypeData[], format: string) => {
fileTypes.map((fileType: IFileTypeData) => {
// If format is auto, we need to add all currently available kernels
// For instance if there are Python and R kernels available, format
// auto:percent will be replaced by py:percent and R:percent
if (format.startsWith('auto')) {
const formatType = format.split(':')[1];
let mapIndex = 0;
availableKernelLanguages.forEach(
(kernelLanguages: IFileTypeData[], kernelKey: string) => {
const updatedKernelKey = `${kernelKey}:${formatType}`;
createTextNotebookCommands.set(updatedKernelKey, []);
mapIndex += 1;
kernelLanguages.map((kernelLanguageFileType) => {
// Merge fileType object from kernel and Jupytext format and push
// it to createTextNotebookCommands
const updatedKernelLanguageFileType = {
...kernelLanguageFileType,
};
updatedKernelLanguageFileType.fileExt = `${updatedKernelLanguageFileType.fileExt}:${formatType}`;
updatedKernelLanguageFileType.paletteLabel = `${updatedKernelLanguageFileType.paletteLabel} with ${fileType.paletteLabel}`;
updatedKernelLanguageFileType.caption = `${updatedKernelLanguageFileType.caption} with ${fileType.caption}`;
updatedKernelLanguageFileType.launcherLabel = `${updatedKernelLanguageFileType.launcherLabel} - ${fileType.launcherLabel}`;
if (numKernels === mapIndex) {
updatedKernelLanguageFileType.separator = true;
}
createTextNotebookCommands
.get(updatedKernelKey)
.push(updatedKernelLanguageFileType);
// Update includeFormats with the language specific formats
// Effectiviely we will add formats like py:light, js:light here
if (includeFormats.includes(format)) {
includeFormats.push(updatedKernelLanguageFileType.fileExt);
}
});
},
);
} else {
if (createTextNotebookCommands.get(format) === undefined) {
createTextNotebookCommands.set(format, []);
}
createTextNotebookCommands.get(format).push(fileType);
}
});
},
);
return createTextNotebookCommands;
}
/**
* Create New Text Notebook file
*/
export const createNewTextNotebook = async (
cwd: string,
kernelId: string,
kernelName: string,
format: string,
commands: CommandRegistry,
) => {
const model = await commands.execute(CommandIDs.newUntitled, {
path: cwd,
type: 'notebook',
// We should not have auto in format at this point. If somehow we end up having
// it, ensure we replace by py as Python kernel exists always
ext: format.replace('auto', 'py'),
});
if (model !== undefined) {
const widget = (await commands.execute('docmanager:open', {
path: model.path,
factory: FACTORY,
kernel: { id: kernelId, name: kernelName },
})) as unknown as IDocumentWidget;
widget.isUntitled = true;
return widget;
}
};
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/style/base.css
================================================
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/style/index.css
================================================
@import url('base.css');
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/style/index.js
================================================
import './base.css';
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/tsconfig.json
================================================
{
"compilerOptions": {
"declaration": true,
"lib": ["es2018", "dom"],
"module": "commonjs",
"moduleResolution": "node",
"noEmitOnError": true,
"noUnusedLocals": true,
"outDir": "lib",
"rootDir": "src",
"strict": true,
"strictNullChecks": false,
"target": "es2018",
"types": ["node"],
"esModuleInterop": true,
"skipLibCheck": true
},
"include": ["src/*"]
}
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/ui-tests/README.md
================================================
# Integration Testing
This folder contains the integration tests of the extension.
They are defined using [Playwright](https://playwright.dev/docs/intro) test runner
and [Galata](https://github.com/jupyterlab/jupyterlab/tree/main/galata) helper.
The Playwright configuration is defined in [playwright.config.js](./playwright.config.js).
The JupyterLab server configuration to use for the integration test is defined
in [jupyter_server_test_config.py](./jupyter_server_test_config.py).
The default configuration will produce video for failing tests and an HTML report.
> There is a new experimental UI mode that you may fall in love with; see [that video](https://www.youtube.com/watch?v=jF0yA-JLQW0).
## Run the tests
> All commands are assumed to be executed from the _jupyterlab-jupytext-extension_ directory
To run the tests, you need to:
1. Compile the extension:
```sh
jlpm install
jlpm build:prod
```
> Check the extension is installed in JupyterLab.
2. Install test dependencies (needed only once):
```sh
cd ./ui-tests
jlpm install
jlpm playwright install
cd ..
```
3. Execute the [Playwright](https://playwright.dev/docs/intro) tests:
```sh
cd ./ui-tests
jlpm playwright test
```
Test results will be shown in the terminal. In case of any test failures, the test report
will be opened in your browser at the end of the tests execution; see
[Playwright documentation](https://playwright.dev/docs/test-reporters#html-reporter)
for configuring that behavior.
## Update the tests snapshots
> All commands are assumed to be executed from the _main-menu_ directory
If you are comparing snapshots to validate your tests, you may need to update
the reference snapshots stored in the repository. To do that, you need to:
1. Compile the extension:
```sh
jlpm install
jlpm build:prod
```
> Check the extension is installed in JupyterLab.
2. Install test dependencies (needed only once):
```sh
cd ./ui-tests
jlpm install
jlpm playwright install
cd ..
```
3. Execute the [Playwright](https://playwright.dev/docs/intro) command:
```sh
cd ./ui-tests
jlpm playwright test -u
```
> Some discrepancy may occurs between the snapshots generated on your computer and
> the one generated on the CI. To ease updating the snapshots on a PR, you can
> type `please update playwright snapshots` to trigger the update by a bot on the CI.
> Once the bot has computed new snapshots, it will commit them to the PR branch.
## Create tests
> All commands are assumed to be executed from the _main-menu_ directory
To create tests, the easiest way is to use the code generator tool of playwright:
1. Compile the extension:
```sh
jlpm install
jlpm build:prod
```
> Check the extension is installed in JupyterLab.
2. Install test dependencies (needed only once):
```sh
cd ./ui-tests
jlpm install
jlpm playwright install
cd ..
```
3. Start the server:
```sh
cd ./ui-tests
jlpm start
```
4. Execute the [Playwright code generator](https://playwright.dev/docs/codegen) in **another terminal**:
```sh
cd ./ui-tests
jlpm playwright codegen localhost:8888
```
## Debug tests
> All commands are assumed to be executed from the _main-menu_ directory
To debug tests, a good way is to use the inspector tool of playwright:
1. Compile the extension:
```sh
jlpm install
jlpm build:prod
```
> Check the extension is installed in JupyterLab.
2. Install test dependencies (needed only once):
```sh
cd ./ui-tests
jlpm install
jlpm playwright install
cd ..
```
3. Execute the Playwright tests in [debug mode](https://playwright.dev/docs/debug):
```sh
cd ./ui-tests
jlpm playwright test --debug
```
## Upgrade Playwright and the browsers
To update the web browser versions, you must update the package `@playwright/test`:
```sh
cd ./ui-tests
jlpm up "@playwright/test"
jlpm playwright install
```
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/ui-tests/jupyter_server_test_config.py
================================================
"""Server configuration for integration tests.
!! Never use this configuration in production because it
opens the server to the world and provide access to JupyterLab
JavaScript objects through the global window variable.
"""
from jupyterlab.galata import configure_jupyter_server
configure_jupyter_server(c) # noqa: F821
# Uncomment to set server log level to debug level
# c.ServerApp.log_level = "DEBUG"
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/ui-tests/package.json
================================================
{
"name": "jupyterlab-jupytext-ui-tests",
"version": "1.4.1",
"description": "Basic Integration Tests",
"private": true,
"scripts": {
"start": "python -m bash_kernel.install && jupyter lab --allow-root --config jupyter_server_test_config.py",
"test": "jlpm playwright test",
"test:update": "jlpm playwright test --update-snapshots"
},
"devDependencies": {
"@jupyterlab/galata": "^5.5.2",
"@playwright/test": "^1.55.1"
}
}
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/ui-tests/playwright.config.js
================================================
/**
* Configuration for Playwright using default from @jupyterlab/galata
*/
const baseConfig = require('@jupyterlab/galata/lib/playwright-config');
module.exports = {
...baseConfig,
projects: [
{
name: 'jupytext',
testMatch: 'tests/*.ts',
testIgnore: '**/.ipynb_checkpoints/**',
timeout: 60000,
// use: {
// launchOptions: {
// // Force slow motion
// slowMo: 1000,
// },
// },
},
],
// Visual comparison of screenshots can be flaky. Use a tolerance
expect: {
toMatchSnapshot: {
maxDiffPixelRatio: 0.02,
},
},
webServer: {
command: 'jlpm start',
url: 'http://localhost:8888/lab',
timeout: 120 * 1000,
reuseExistingServer: !process.env.CI,
},
// Switch to 'always' to keep raw assets for all tests
preserveOutput: 'failures-only', // Breaks HTML report if use.video == 'on'
// Try 3 retries as some tests are flaky
retries: process.env.CI ? 3 : 0,
};
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/ui-tests/tests/jupytext-launcher.spec.ts
================================================
import { expect, test } from '@jupyterlab/galata';
test.describe('Jupytext Launcher Category', () => {
test.use({ autoGoto: false, viewport: { height: 1020, width: 1280 } });
test('should have Jupytext category in launcher', async ({ page }) => {
await page.goto();
await page.waitForSelector('.jp-LauncherCard-label');
const imageName = 'launcher-category.png';
expect(await page.screenshot()).toMatchSnapshot(imageName.toLowerCase());
});
});
test.describe('Jupytext Context Menu', () => {
test.use({ autoGoto: false, viewport: { height: 1020, width: 1280 } });
test('should have New Text Notebook in Context Menu', async ({ page }) => {
await page.goto();
await page.waitForSelector('.jp-FileBrowser');
// Right click within file browser
await page.locator('.jp-FileBrowser').click({ button: 'right' });
// Wait for a moment to observe the context menu
await page.waitForTimeout(5000);
const imageName = 'context-menu.png';
expect(await page.screenshot()).toMatchSnapshot(imageName.toLowerCase());
});
});
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/ui-tests/tests/jupytext-menu.spec.ts
================================================
import { expect, test } from '@jupyterlab/galata';
// Main Jupytext menu
const jupytextMenu = ['File>New Text Notebook', 'File>Jupytext'];
test.describe('Jupytext Menu Tests', () => {
test.use({ autoGoto: false });
jupytextMenu.forEach((menuPath) => {
test(`Open menu item ${menuPath}`, async ({ page }) => {
await page.goto();
await page.menu.open(menuPath);
expect(await page.menu.isOpen(menuPath)).toBeTruthy();
const imageName = `opened-jupytext-menu-${menuPath.replace(
/>/g,
'-',
)}.png`;
// const menu = await page.menu.getOpenMenu();
expect(await page!.screenshot()).toMatchSnapshot(imageName.toLowerCase());
});
});
});
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/ui-tests/tests/jupytext-notebook.spec.ts
================================================
import { expect, test } from '@jupyterlab/galata';
// Currently we are enabling only percent and MyST formats in Jupytext menu
// So test for only these cases.
// If we update our test env with more external kernels, we can include them
// here in the formats
const createTests = [
{
label: 'New Python Text Notebook with Percent Format',
extension: '.py',
},
{
label: 'New Shell Text Notebook with Percent Format',
extension: '.sh',
},
{
label: 'New MyST Markdown Text Notebook',
extension: '.md',
},
];
const pairTests = [
{
label: 'Percent Format',
extension: '.py',
},
{
label: 'Light Format',
extension: '.py',
},
{
label: 'MyST Markdown',
extension: '.md',
},
];
// Get all possible menuPaths
const createNewMenuPaths = createTests.map((format) => {
return {
menuPath: `File>New Text Notebook>${format.label}`,
extension: format.extension,
};
});
const pairMenuPaths = pairTests.map((format) => {
return {
menuPath: `File>Jupytext>Pair Notebook>Pair Notebook with ${format.label}`,
extension: format.extension,
};
});
// Toggle metadata
const toggleMetadataPath = 'File>Jupytext>Include Metadata';
// Name of notebook file
const fileName = 'notebook.ipynb';
/**
* Helper function to populate notebook cells and run them
*/
async function populateNotebook(extension, page) {
await page.notebook.setCell(0, 'raw', 'Just a raw cell');
await page.notebook.addCell(
'markdown',
'## This is **bold** and *italic* [link to jupyter.org!](http://jupyter.org)',
);
await page.notebook.runCell(1, true);
// For bash, use shell code
if (extension === '.sh') {
await page.notebook.addCell('code', 'echo "This is Bash Kernel"');
} else {
await page.notebook.addCell('code', '2 ** 3');
}
await page.notebook.runCell(2, true);
}
test.describe('Jupytext Create Text Notebooks from Menu Tests', () => {
createNewMenuPaths.forEach((paths) => {
test(`Open menu item ${paths.menuPath}`, async ({ page }) => {
// await page.goto();
// Create new text notebook by clicking menupath item
await page.menu.clickMenuItem(paths.menuPath);
// Wait for the kernel dialog and accept it
await page.waitForSelector('.jp-Dialog');
const select = await page.$('.jp-Dialog-body >> select');
// Select appropriate kernel
let option: any;
if (paths.extension === '.sh') {
option = await select!.$('option:has-text("Bash")');
} else {
option = await select!.$('option:has-text("Python")');
}
await select!.selectOption(option);
await page.click('.jp-Dialog .jp-mod-accept');
const firstCell = await page.notebook.getCellLocator(0);
await firstCell?.hover();
await expect(firstCell!.locator('.jp-cell-toolbar')).toHaveCount(1);
// Populate page
await populateNotebook(paths.extension, page);
// Toggle Include Metadata. It is enabled by default.
// It is to avoid having Jupytext version in metadata in snapshot
// If we include it, for every version bump we need to update snapshots as
// version changes which will fail UI tests. Just do not include metadata
// which will ensure smooth version bumping
await page.menu.clickMenuItem(toggleMetadataPath);
// Save notebook
await page.notebook.save();
// Try to open saved text notebook with Editor factory
await page.filebrowser.open(`Untitled${paths.extension}`, 'Editor');
// Compare text notebook contents
const imageName = `opened-${paths.menuPath.replace(/>/g, '-')}-text.png`;
expect(await page.screenshot()).toMatchSnapshot(imageName.toLowerCase());
});
});
});
test.describe('Jupytext Pair Python Notebooks from Menu Tests', () => {
// Before each test start a new notebook and add some cell data
test.beforeEach(async ({ page }) => {
await page.notebook.createNew(fileName, { kernel: 'python3' });
await populateNotebook('.py', page);
});
pairMenuPaths.forEach((paths) => {
test(`Open menu item ${paths.menuPath}`, async ({ page }) => {
// Click pairing command
await page.menu.clickMenuItem(paths.menuPath);
// Toggle Include Metadata. It is enabled by default.
// It is to avoid having Jupytext version in metadata in snapshot
// If we include it, for every version bump we need to update snapshots as
// version changes which will fail UI tests. Just do not include metadata
// which will ensure smooth version bumping
await page.menu.clickMenuItem(toggleMetadataPath);
// Wait until we save notebook. Once we save it, paired file appears
await page.notebook.save();
// Try to open paired file
await page.filebrowser.open(fileName.replace('.ipynb', paths.extension));
const imageName = `paired-jupytext-${paths.menuPath.replace(
/>/g,
'-',
)}.png`;
expect(await page.screenshot()).toMatchSnapshot(imageName.toLowerCase());
});
});
});
================================================
FILE: jupyterlab/packages/jupyterlab-jupytext-extension/ui-tests/tests/jupytext-settings.spec.ts
================================================
import { expect, test } from '@jupyterlab/galata';
test('Open the settings editor with a Jupytext query', async ({ page }) => {
await page.evaluate(async () => {
await window.jupyterapp.commands.execute('settingeditor:open', {
query: 'Jupytext',
});
});
// Seems like this test is very flaky. Moreover it does not add a lot of value
// expect(
// await page.locator('.jp-PluginList .jp-FilterBox input').inputValue()
// ).toEqual('Jupytext');
await expect(page.locator('.jp-SettingsForm')).toHaveCount(1);
const pluginList = page.locator('.jp-PluginList');
expect(await pluginList.screenshot()).toMatchSnapshot(
'jupytext-settings-plugin-list.png',
);
const settingsPanel = page.locator('.jp-SettingsPanel');
expect(await settingsPanel.screenshot()).toMatchSnapshot(
'jupytext-settings-panel.png',
);
});
================================================
FILE: jupyterlab/scripts/install_extension.py
================================================
# This script does the "same" job as `jupyter labextension develop --overwrite .`
#
# Seems like we cannot use the upstream script on our repo organization.
# If we want to use the upstream script we need to have a setup.py or pyproject.toml
# in jupyterlab/jupyterlab-jupytext folder with the name of the package.
#
# We are only interested in making a symlink to the
# sys.prefix/share/jupyter/labextensions folder for development. We should be able
# to do it in simple script
#
import os
import jupyterlab_jupytext
from jupyterlab.federated_labextensions import build_labextension, develop_labextension
def main():
"""Create symlink in sys.prefix based on name of extension"""
labexts = jupyterlab_jupytext._jupyter_labextension_paths()
base_path = os.path.join(
os.path.dirname(os.path.dirname(os.path.abspath(__file__))),
"jupyterlab_jupytext",
)
for labext in labexts:
src = os.path.join(base_path, labext["src"])
dest = labext["dest"]
print(f"Installing {src} -> {dest}")
if not os.path.exists(src):
build_labextension(base_path)
full_dest = develop_labextension(
src,
overwrite=True,
symlink=True,
user=False,
sys_prefix=True,
labextensions_dir="",
destination=dest,
)
print(f"Creating symlink at {full_dest}")
if __name__ == "__main__":
main()
================================================
FILE: jupyterlab/tsconfig.eslint.json
================================================
{
"compilerOptions": {
"declaration": true,
"lib": ["es2018", "dom"],
"module": "commonjs",
"moduleResolution": "node",
"noEmitOnError": true,
"noUnusedLocals": true,
"outDir": "lib",
"rootDir": "src",
"strict": true,
"strictNullChecks": false,
"target": "es2018",
"types": [],
"esModuleInterop": true
},
"extends": "../../tsconfig.eslint.json",
"include": ["**/src/*"]
}
================================================
FILE: pyproject.toml
================================================
[build-system]
requires = ["hatchling>=1.5.0", "hatch-jupyter-builder>=0.5", "jupyterlab>=4"]
build-backend = "hatchling.build"
[project]
name = "jupytext"
description = "Jupyter notebooks as Markdown documents, Julia, Python or R scripts"
license = { file = "LICENSE" }
authors = [
{ name = "Marc Wouts", email = "marc.wouts@gmail.com" },
]
readme = "build/README_with_absolute_links.md"
requires-python = ">=3.9"
classifiers = [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Environment :: Console",
"Framework :: Jupyter",
"Framework :: Jupyter :: JupyterLab :: 4",
"Framework :: Jupyter :: JupyterLab :: Extensions",
"Framework :: Jupyter :: JupyterLab :: Extensions :: Prebuilt",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Topic :: Text Processing :: Markup",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
]
dependencies = [
"nbformat",
"mdit-py-plugins",
"markdown-it-py>=1.0",
"packaging",
"pyyaml",
"tomli;python_version<\"3.11\"",
]
dynamic = ["version"]
[project.urls]
Homepage = "https://github.com/mwouts/jupytext"
"Source Code" = "https://github.com/mwouts/jupytext"
Documentation = "https://jupytext.readthedocs.io"
[project.optional-dependencies]
# Test related dependencies
test = [
"pytest",
"pytest-asyncio",
"pytest-xdist",
"pytest-randomly"
]
test-functional = [
"jupytext[test]",
"black",
]
test-integration = [
"jupytext[test-functional]",
"jupyter-server!=2.11", # issue 1165
# jupytext --execute
"nbconvert",
"ipykernel",
]
test-external = [
"jupytext[test-integration]",
# jupytext --pipe and --check
"autopep8",
"isort",
"flake8",
# Sphinx gallery
"sphinx",
"sphinx-gallery>=0.8",
# Pre-commit tests
"gitpython",
"pre-commit",
# Marimo notebooks
"marimo>=0.17.6,<=0.19.4", #1485
# Interaction with other contents managers
"jupyter-fs[fs]>=1.0" # 1398
]
# Coverage requirements
test-cov = [
"jupytext[test-integration]",
"pytest-cov>=2.6.1",
]
# Galata test env
# Install a non python kernel to ensure extension is working as expected
# Kernel spec is installed before running UI tests
test-ui = [
"bash_kernel",
]
dev = [
"jupytext[test-cov,test-external]",
]
# Documentation dependencies
docs = [
"sphinx",
"sphinx-copybutton",
"sphinx-rtd-theme",
"myst-parser",
]
[project.scripts]
"jupytext" = "jupytext.cli:jupytext"
"jupytext-config" = "jupytext_config.__main__:main"
[tool.hatch.metadata.hooks.custom]
path = "tools/absolute_links_in_readme.py"
[tool.hatch.version]
# Read version string from version.py and use it for the package
path = "src/jupytext/version.py"
# Hatch first build sdist and then builds a wheel out of that sdist
# By using the below config, we remove path prefixes in sdist meaning
# that sdist will not have a src in root but directly jupytext and other
# modules.
#
# So when it attempts to build wheel out of the sdist there is no more
# src folder and hence it complains about not finding src/jupytext/version.py
# file. So, we **should not** use hatch.build.sources here which removes
# path prefixes
# [tool.hatch.build]
# sources = ["src", "jupyterlab"]
# Following config is related to JupyterLab extension
[tool.hatch.build.targets.sdist]
artifacts = ["jupyterlab/jupyterlab_jupytext/labextension"]
[tool.hatch.build.targets.wheel]
packages = ["src/jupytext", "src/jupytext_config", "jupyterlab/jupyterlab_jupytext"]
[tool.hatch.build.targets.wheel.shared-data]
"jupyterlab/jupyter-config" = "etc/jupyter"
"jupyterlab/jupyterlab_jupytext/labextension" = "share/jupyter/labextensions/jupyterlab-jupytext"
[tool.hatch.build.hooks.jupyter-builder]
enable-by-default = false
# We enable this hook by setting env var HATCH_BUILD_HOOKS_ENABLE=true
# So `pip install .` will **not** build JupyterLab related
# extension. To install the extension, it is required to run
# `HATCH_BUILD_HOOKS_ENABLE=true pip install .`
# Runtime dependency for this build hook
# We need jupyterlab as build time depdendency to get jlpm (wrapper around yarn)
# UPDATE 20260118: Based on https://github.com/jupyterlab/hatch-jupyter-builder/issues/146
# we moved all the dependencies to build system dependencies
# We use npm_builder to build the jupyterlab extension
build-function = "hatch_jupyter_builder.npm_builder"
# Hatch will mark this hook as success upon creation of following files
# in the build_dir
ensured-targets = [
"jupyterlab/jupyterlab_jupytext/labextension/static/style.js",
"jupyterlab/jupyterlab_jupytext/labextension/package.json",
]
# If these files already exists in build_dir (after first build),
# hatch will skip build step. If there are changes in src/ of
# the extension, build will be triggered even if the build assets exist
skip-if-exists = ["jupyterlab/jupyterlab_jupytext/labextension/static/style.js"]
[tool.hatch.build.hooks.jupyter-builder.build-kwargs]
# Root directory where build should be done
path = "jupyterlab"
# Build command that is defined in package.json
build_cmd = "build:prod"
# We use jlpm, which is wrapper around yarn to build transpiled assets
npm = ["jlpm"]
[tool.hatch.build.hooks.jupyter-builder.editable-build-kwargs]
path = "jupyterlab"
build_cmd = "build"
npm = ["jlpm"]
# hatch-jupyter-builder hook will check the mtime of source_dir and
# compare it with build_dir to decide if build is necessary or not
source_dir = "jupyterlab/packages"
build_dir = "jupyterlab/jupyterlab_jupytext/labextension"
[tool.check-wheel-contents]
ignore = ["W002"]
# flake8 config has been moved to ruff and a pre-commit config has been
# added
[tool.ruff]
line-length = 127
exclude = [
"tests/data/notebooks/*",
]
# Seems like W503 is not implemented in ruff
# ref: https://github.com/astral-sh/ruff/issues/4125
lint.ignore = [
"E203", "E231",
]
[tool.pytest.ini_options]
markers = [
"requires_black",
"requires_isort",
"requires_flake8",
"requires_autopep8",
"requires_nbconvert",
"requires_myst",
"requires_no_myst",
"requires_quarto",
"requires_marimo",
"requires_pandoc",
"requires_no_pandoc",
"requires_sphinx_gallery",
"requires_user_kernel_python3",
"requires_ir_kernel",
"skip_on_windows",
"pre_commit",
"asyncio"
]
filterwarnings = [
# Uncomment this "error" to turn all unfiltered warnings into errors
# "error",
# Our cwd_tmpdir fixture
"ignore:pathlib.Path.__enter__\\(\\) is deprecated and scheduled for removal in Python 3.13:DeprecationWarning",
# Pre-commit
"ignore:read_text is deprecated. Use files\\(\\) instead:DeprecationWarning",
"ignore:open_text is deprecated. Use files\\(\\) instead:DeprecationWarning",
# Jupyter
"ignore:Jupyter is migrating its paths to use standard platformdirs:DeprecationWarning",
# Jupyter notebook
"ignore:Support for bleach <5 will be removed in a future version of nbconvert:DeprecationWarning",
# jupyterfs
"ignore:run_pre_save_hook is deprecated, use run_pre_save_hooks instead:DeprecationWarning",
"ignore:run_post_save_hook is deprecated, use run_post_save_hooks instead:DeprecationWarning",
"ignore:Deprecated call to `pkg_resources.declare_namespace:DeprecationWarning",
"ignore:pkg_resources is deprecated as an API:DeprecationWarning",
# use single quote to denote raw strings in toml
# (10 warnings)
'ignore:Passing unrecognized arguments to super\(KernelSpec\).__init__:DeprecationWarning',
# Not seen any more with latest Python + libs
"ignore:Passing a schema to Validator.iter_errors is deprecated and will be removed in a future release:DeprecationWarning",
# in test_utf8_out_331 and two others
# Not seen any more with latest Python + libs
'ignore:Exception ignored in. (fmt, formats) where
# fmt is the current format, and formats the paired formats.
self.paired_notebooks = dict()
# Configuration cache, useful when notebooks are listed in a given directory
self.cached_config = namedtuple("cached_config", "path config_file config")
self.super = super()
self.super.__init__(*args, **kwargs)
def all_nb_extensions(self, config):
"""All extensions that should be classified as notebooks"""
return [ext if ext.startswith(".") else "." + ext for ext in config.notebook_extensions]
def drop_paired_notebook(self, path):
"""Remove the current notebook from the list of paired notebooks"""
if path not in self.paired_notebooks:
return
fmt, formats = self.paired_notebooks.pop(path)
prev_paired_paths = paired_paths(path, fmt, formats)
for alt_path, _ in prev_paired_paths:
if alt_path in self.paired_notebooks:
self.drop_paired_notebook(alt_path)
def update_paired_notebooks(self, path, formats):
"""Update the list of paired notebooks to include/update the current pair"""
if not formats:
self.drop_paired_notebook(path)
return
formats = long_form_multiple_formats(formats)
_, fmt = find_base_path_and_format(path, formats)
new_paired_paths = paired_paths(path, fmt, formats)
for alt_path, _ in new_paired_paths:
self.drop_paired_notebook(alt_path)
if len(formats) == 1 and set(formats[0]) <= {"extension"}:
return
short_formats = short_form_multiple_formats(formats)
for alt_path, alt_fmt in new_paired_paths:
self.paired_notebooks[alt_path] = (
short_form_one_format(alt_fmt),
short_formats,
)
async def create_prefix_dir(self, path, fmt):
"""Create the prefix dir, if missing"""
if "prefix" in fmt and "/" in path:
parent_dir = self.get_parent_dir(path)
if not await self.dir_exists(parent_dir):
await self.create_prefix_dir(parent_dir, fmt)
self.log.info("Creating directory %s", parent_dir)
await self.super.save(dict(type="directory"), parent_dir)
async def save(self, model, path=""):
"""Save the file model and return the model with no content."""
if model["type"] != "notebook":
return await self.super.save(model, path)
path = path.strip("/")
nbk = model["content"]
try:
config = await self.get_config(path)
jupytext_formats = notebook_formats(nbk, config, path)
_, jupytext_formats = self._drop_formats_if_they_dont_match_path(path, None, jupytext_formats)
self.update_paired_notebooks(path, jupytext_formats)
async def save_one_file(path, fmt):
if "format_name" in fmt and fmt["extension"] not in [
".md",
".markdown",
".Rmd",
]:
self.log.info(
"Saving %s in format %s:%s",
os.path.basename(path),
fmt["extension"][1:],
fmt["format_name"],
)
else:
self.log.info("Saving %s", os.path.basename(path))
await self.create_prefix_dir(path, fmt)
if fmt["extension"] == ".ipynb":
return await self.super.save(
dict(
type="notebook",
content=drop_text_representation_metadata(model["content"]),
),
path,
)
if model["content"]["metadata"].get("jupytext", {}).get("notebook_metadata_filter") == "-all":
self.log.warning(
"Stripping metadata from {} as 'Include Metadata' is off "
"(toggle 'Include Metadata' in the Jupytext Menu or Commands if desired)".format(path)
)
text_model = dict(
type="file",
format="text",
content=writes(nbformat.from_dict(model["content"]), fmt=fmt, config=config),
)
return await self.super.save(text_model, path)
return await write_pair(path, jupytext_formats, save_one_file)
except Exception as e:
self.log.error("Error while saving file: %s %s", path, e, exc_info=True)
raise HTTPError(500, f"Unexpected error while saving file: {path} {e}")
async def _get_with_no_require_hash_argument(
self,
path,
content=True,
type=None,
format=None,
load_alternative_format=True,
):
return await self._get_with_require_hash_argument(
path,
content=content,
type=type,
format=format,
require_hash=False,
load_alternative_format=load_alternative_format,
)
async def _get_with_require_hash_argument(
self,
path,
content=True,
type=None,
format=None,
require_hash=False,
load_alternative_format=True,
):
"""Takes a path for an entity and returns its model"""
path = path.strip("/")
ext = os.path.splitext(path)[1]
super_kwargs = {"content": content, "type": type, "format": format}
if require_hash:
super_kwargs["require_hash"] = require_hash
# Not a notebook?
if not await self.file_exists(path) or await self.dir_exists(path) or (type is not None and type != "notebook"):
return await self.super.get(path, **super_kwargs)
config = await self.get_config(path, use_cache=content is False)
if ext not in self.all_nb_extensions(config):
return await self.super.get(path, **super_kwargs)
fmt = preferred_format(ext, config.preferred_jupytext_formats_read)
if ext == ".ipynb":
super_kwargs["type"] = "notebook"
model = await self.super.get(path, **super_kwargs)
else:
super_kwargs["type"] = "file"
super_kwargs["format"] = "text"
model = await self.super.get(path, **super_kwargs)
model["type"] = "notebook"
if content:
# We may need to update these keys, inherited from text files formats
# Cf. https://github.com/mwouts/jupytext/issues/659
model["format"] = "json"
model["mimetype"] = None
try:
model["content"] = reads(model["content"], fmt=fmt, config=config)
# mark all code cells from text notebooks as 'trusted'
# as they don't have any outputs, cf. #941
for cell in model["content"].cells:
if cell.cell_type == "code":
cell["metadata"]["trusted"] = True
except Exception as err:
self.log.error("Error while reading file: %s %s", path, err, exc_info=True)
raise HTTPError(500, str(err))
if not load_alternative_format:
return model
# We will now read a second file if this is a paired notebooks.
if content:
nbk = model["content"]
formats = nbk.metadata.get("jupytext", {}).get("formats") or config.default_formats(path)
formats = long_form_multiple_formats(formats, nbk.metadata, auto_ext_requires_language_info=False)
else:
if path not in self.paired_notebooks:
return model
_, formats = self.paired_notebooks.get(path)
formats = long_form_multiple_formats(formats)
# Compute paired notebooks from formats
alt_paths = [(path, fmt)]
fmt, formats = self._drop_formats_if_they_dont_match_path(path, fmt, formats)
if formats:
try:
_, fmt = find_base_path_and_format(path, formats)
alt_paths = paired_paths(path, fmt, formats)
self.update_paired_notebooks(path, formats)
except InconsistentPath as err:
self.log.error(
"Unable to read paired notebook: %s %s",
path,
err,
exc_info=True,
)
raise HTTPError(500, f"Unable to read paired notebook: {path} {err}")
else:
if path in self.paired_notebooks:
fmt, formats = self.paired_notebooks.get(path)
alt_paths = paired_paths(path, fmt, formats)
formats = long_form_multiple_formats(formats)
if content and len(alt_paths) > 1 and ext == ".ipynb":
# Apply default options (like saving and reloading would do)
jupytext_metadata = model["content"]["metadata"].get("jupytext", {})
config.set_default_format_options(jupytext_metadata, read=True)
if jupytext_metadata:
model["content"]["metadata"]["jupytext"] = jupytext_metadata
async def get_timestamp(alt_path):
# self.exists is not async for AsyncLargeManager,
# but MetaManager from fs_manager has an async version
exists = self.exists(alt_path)
if inspect.isawaitable(exists):
exists = await exists
if not exists:
return None
if alt_path == path:
return model["last_modified"]
return (await self.super.get(alt_path, content=False))["last_modified"]
async def read_one_file(alt_path, alt_fmt):
if alt_path == path:
return model["content"]
if alt_path.endswith(".ipynb"):
self.log.info(f"Reading OUTPUTS from {alt_path}")
return (await self.super.get(alt_path, content=True, type="notebook", format=format))["content"]
self.log.info(f"Reading SOURCE from {alt_path}")
text = (
await self.super.get(
alt_path,
content=True,
type="file",
# Don't use the parent format, see https://github.com/mwouts/jupytext/issues/1124
format=None,
)
)["content"]
return reads(text, fmt=alt_fmt, config=config)
timestamps = {alt_path: await get_timestamp(alt_path) for alt_path, alt_fmt in paired_paths(path, fmt, formats)}
inputs, outputs = latest_inputs_and_outputs(
path,
fmt,
formats,
lambda alt_path: timestamps[alt_path],
contents_manager_mode=True,
)
# Modification time of a paired notebook is the timestamp of inputs #118 #978
model["last_modified"] = inputs.timestamp
if require_hash:
if inputs.path is not None and outputs.path is not None and inputs.path != outputs.path:
model_other = await self.super.get(
inputs.path if path == outputs.path else outputs.path,
content=False,
require_hash=True,
)
# The hash of a paired file is the concatenation of
# the hashes of the input and output files
if path == outputs.path:
model["hash"] = model_other["hash"] + model["hash"]
else:
model["hash"] = model["hash"] + model_other["hash"]
if not content:
return model
# Before we combine the two files, we make sure we're not overwriting ipynb cells
# with an outdated text file
content = None
try:
if outputs.timestamp and outputs.timestamp > inputs.timestamp + timedelta(
seconds=config.outdated_text_notebook_margin
):
ts_mismatch = (
"{out} (last modified {out_last}) is more recent than {src} (last modified {src_last})".format(
src=inputs.path,
src_last=inputs.timestamp,
out=outputs.path,
out_last=outputs.timestamp,
)
)
self.log.warning(ts_mismatch)
try:
content = await read_pair(inputs, outputs, read_one_file, must_match=True)
self.log.warning(
"The inputs in {src} and {out} are identical, so the mismatch in timestamps was ignored".format(
src=inputs.path, out=outputs.path
)
)
except HTTPError:
raise
except PairedFilesDiffer as diff:
raise HTTPError(
400,
"""{ts_mismatch}
Differences (jupytext --diff {src} {out}) are:
{diff}
Please either:
- open {src} in a text editor, make sure it is up to date, and save it,
- or delete {src} if not up to date,
- or increase check margin by adding, say,
outdated_text_notebook_margin = 5 # default is 1 (second)
to your jupytext.toml file
""".format(
ts_mismatch=ts_mismatch,
src=inputs.path,
out=outputs.path,
diff=diff,
),
)
except OverflowError:
pass
if content is not None:
model["content"] = content
else:
try:
model["content"] = await read_pair(inputs, outputs, read_one_file)
except HTTPError:
raise
except Exception as err:
self.log.error("Error while reading file: %s %s", path, err, exc_info=True)
raise HTTPError(500, str(err))
if not outputs.timestamp:
set_kernelspec_from_language(model["content"])
return model
async def new_untitled(self, path="", type="", ext=""):
"""Create a new untitled file or directory in path
We override the base function because that one does not take the 'ext' argument
into account when type=="notebook". See https://github.com/mwouts/jupytext/issues/443
"""
if type != "notebook" and ext != ".ipynb":
return await self.super.new_untitled(path, type, ext)
ext = ext or ".ipynb"
if ":" in ext:
ext, format_name = ext.split(":", 1)
else:
format_name = ""
path = path.strip("/")
if not await self.dir_exists(path):
raise HTTPError(404, "No such directory: %s" % path)
untitled = self.untitled_notebook
config = await self.get_config(path)
name = self.increment_notebook_filename(config, untitled + ext, path)
path = f"{path}/{name}"
model = {"type": "notebook"}
if format_name:
model["format"] = "json"
model["content"] = nbformat.v4.nbbase.new_notebook(metadata={"jupytext": {"formats": ext + ":" + format_name}})
return await self.new(model, path)
def increment_notebook_filename(self, config, filename, path=""):
"""Increment a notebook filename until it is unique, regardless of extension"""
# Extract the full suffix from the filename (e.g. .tar.gz)
path = path.strip("/")
basename, dot, ext = filename.partition(".")
ext = dot + ext
for i in itertools.count():
if i:
insert_i = f"{i}"
else:
insert_i = ""
basename_i = basename + insert_i
name = basename_i + ext
if not any(self.exists(f"{path}/{basename_i}{nb_ext}") for nb_ext in config.notebook_extensions):
break
return name
async def trust_notebook(self, path):
"""Trust the current notebook"""
if path.endswith(".ipynb") or path not in self.paired_notebooks:
await self.super.trust_notebook(path)
return
fmt, formats = self.paired_notebooks[path]
for alt_path, alt_fmt in paired_paths(path, fmt, formats):
if alt_fmt["extension"] == ".ipynb":
await self.super.trust_notebook(alt_path)
async def rename_file(self, old_path, new_path):
"""
Rename the current file. If the file is a notebook,
we rename the paired files as well
"""
# If the file is not a notebook, we call the parent rename_file method
ext = os.path.splitext(old_path)[1]
config = await self.get_config(old_path, use_cache=True)
if ext not in self.all_nb_extensions(config):
await self.super.rename_file(old_path, new_path)
return
if old_path not in self.paired_notebooks:
try:
# we do not know yet if this is a paired notebook (#190)
# -> to get this information we open the notebook
self.log.info("Opening %s to check if it is a paired notebook", old_path)
await self.get(old_path, content=True)
except Exception:
pass
if old_path not in self.paired_notebooks:
await self.super.rename_file(old_path, new_path)
return
fmt, formats = self.paired_notebooks.get(old_path)
fmt, formats = self._drop_formats_if_they_dont_match_path(new_path, fmt, formats)
old_alt_paths = paired_paths(old_path, fmt, formats)
# Is the new file name consistent with suffix?
try:
new_base = base_path(new_path, fmt)
except HTTPError:
raise
except Exception as err:
self.log.error(
"Error while renaming file from %s to %s: %s",
old_path,
new_path,
err,
exc_info=True,
)
raise HTTPError(500, str(err))
for old_alt_path, alt_fmt in old_alt_paths:
new_alt_path = full_path(new_base, alt_fmt)
if self.exists(old_alt_path):
await self.create_prefix_dir(new_alt_path, alt_fmt)
await self.super.rename_file(old_alt_path, new_alt_path)
self.drop_paired_notebook(old_path)
self.update_paired_notebooks(new_path, formats)
def get_parent_dir(self, path):
"""The parent directory"""
if "/" in path:
return path.rsplit("/", 1)[0]
# jupyter-fs
if ":" in path and hasattr(self, "_managers"):
if path.endswith(":"):
return ""
return path.rsplit(":", 1)[0] + ":"
return ""
async def get_config_file(self, directory):
"""Return the jupytext configuration file, if any"""
for jupytext_config_file in JUPYTEXT_CONFIG_FILES:
path = directory + "/" + jupytext_config_file
if await self.file_exists(path):
if not self.allow_hidden and jupytext_config_file.startswith("."):
self.log.warning(f"Ignoring config file {path} (see Jupytext issue #964)")
continue
return path
pyproject_path = directory + "/" + PYPROJECT_FILE
if await self.file_exists(pyproject_path):
model = await self.get(pyproject_path, type="file")
try:
doc = tomllib.loads(model["content"])
except tomllib.TOMLDecodeError as e:
self.log.warning(f"Cannot load {pyproject_path}: {e}")
else:
if doc.get("tool", {}).get("jupytext") is not None:
return pyproject_path
if not directory:
return None
parent_dir = self.get_parent_dir(directory)
return await self.get_config_file(parent_dir)
async def load_config_file(self, config_file, *, prev_config_file, prev_config, is_os_path=False):
"""Load the configuration file"""
if config_file is None:
return None
if config_file.endswith(".py") and not is_os_path:
config_file = self._get_os_path(config_file)
is_os_path = True
config_content = None
if not is_os_path:
try:
model = await self.super.get(config_file, content=True, type="file")
config_content = model["content"]
except HTTPError:
pass
config = load_jupytext_configuration_file(config_file, config_content)
if config is None:
return config
log_level = config.cm_config_log_level
if log_level == "info_if_changed":
if config_file != prev_config_file or config != prev_config:
log_level = "info"
else:
log_level = "none"
if log_level != "none":
getattr(self.log, log_level)("Loaded Jupytext configuration file at %s", config_file)
return config
async def get_config(self, path, use_cache=False):
"""Return the Jupytext configuration for the given path"""
parent_dir = self.get_parent_dir(path)
# When listing the notebooks for the tree view, we use a cache for the configuration file
# The cache will be refreshed when a notebook is opened or saved, or when we go
# to a different directory.
if not use_cache or parent_dir != self.cached_config.path:
try:
config_file = await self.get_config_file(parent_dir)
if config_file:
self.cached_config.config = await self.load_config_file(
config_file,
prev_config_file=self.cached_config.config_file,
prev_config=self.cached_config.config,
)
else:
config_file = find_global_jupytext_configuration_file()
self.cached_config.config = await self.load_config_file(
config_file,
prev_config_file=self.cached_config.config_file,
prev_config=self.cached_config.config,
is_os_path=True,
)
self.cached_config.config_file = config_file
self.cached_config.path = parent_dir
except JupytextConfigurationError as err:
self.log.error(
"Error while reading config file: %s %s",
config_file,
err,
exc_info=True,
)
raise HTTPError(500, f"{err}")
if self.cached_config.config is not None:
return self.cached_config.config
if isinstance(self.notebook_extensions, str):
self.notebook_extensions = self.notebook_extensions.split(",")
return self
def _drop_formats_if_they_dont_match_path(self, path, fmt, formats):
if formats is None:
return fmt, formats
list_of_formats = long_form_multiple_formats(formats)
try:
_, _ = find_base_path_and_format(path, list_of_formats)
except InconsistentPath:
for fmt in list_of_formats:
try:
_, adjusted_format = base_path_and_adjusted_fmt(path, fmt)
except InconsistentPath:
continue
else:
self.log.warning(
"Notebook %s matches none of the expected formats. "
'Ignoring formats="%s" and using formats="%s" instead.',
path,
short_form_multiple_formats(formats),
short_form_one_format(adjusted_format),
)
new_formats = [adjusted_format]
if isinstance(formats, list):
return adjusted_format, new_formats
return short_form_one_format(adjusted_format), short_form_multiple_formats(new_formats)
return fmt, formats
if "require_hash" in inspect.signature(base_contents_manager_class.get).parameters:
AsyncJupytextContentsManager.get = AsyncJupytextContentsManager._get_with_require_hash_argument
else:
AsyncJupytextContentsManager.get = AsyncJupytextContentsManager._get_with_no_require_hash_argument
return AsyncJupytextContentsManager
try:
# The AsyncLargeFileManager is taken by default from jupyter_server if available
from jupyter_server.services.contents.largefilemanager import AsyncLargeFileManager
AsyncTextFileContentsManager = build_async_jupytext_contents_manager_class(AsyncLargeFileManager)
except ImportError:
# If we can't find jupyter_server then we take the file manager from notebook
# import notebook.transutils needs to happen before notebook.services.contents.filemanager, see #75
try:
import notebook.transutils # noqa
except ImportError:
pass
try:
from notebook.services.contents.largefilemanager import AsyncLargeFileManager
AsyncTextFileContentsManager = build_async_jupytext_contents_manager_class(AsyncLargeFileManager)
except ImportError:
# Older versions of notebook do not have the LargeFileManager #217
from notebook.services.contents.filemanager import FileContentsManager
AsyncTextFileContentsManager = build_async_jupytext_contents_manager_class(FileContentsManager)
================================================
FILE: src/jupytext/async_pairs.py
================================================
import jupytext
from .combine import combine_inputs_with_outputs
from .compare import compare
from .formats import check_file_version, long_form_multiple_formats
from .paired_paths import find_base_path_and_format, full_path
from .pairs import PairedFilesDiffer
async def read_pair(inputs, outputs, read_one_file, must_match=False):
"""Read a notebook given its inputs and outputs path and formats"""
if not outputs.path or outputs.path == inputs.path:
return await read_one_file(inputs.path, inputs.fmt)
notebook = await read_one_file(inputs.path, inputs.fmt)
check_file_version(notebook, inputs.path, outputs.path)
notebook_with_outputs = await read_one_file(outputs.path, outputs.fmt)
if must_match:
in_text = jupytext.writes(notebook, inputs.fmt)
out_text = jupytext.writes(notebook_with_outputs, inputs.fmt)
diff = compare(out_text, in_text, outputs.path, inputs.path, return_diff=True)
if diff:
raise PairedFilesDiffer(diff)
notebook = combine_inputs_with_outputs(notebook, notebook_with_outputs, fmt=inputs.fmt)
return notebook
async def write_pair(path, formats, write_one_file):
"""
Call the function 'write_one_file' on each of the paired path/formats
"""
formats = long_form_multiple_formats(formats)
base, _ = find_base_path_and_format(path, formats)
# Save as ipynb first
return_value = None
value = None
ipynb_changed = False
for fmt in formats[::-1]:
if fmt["extension"] != ".ipynb":
continue
alt_path = full_path(base, fmt)
value = await write_one_file(alt_path, fmt)
ipynb_changed = ipynb_changed or value.get("modified", False)
if alt_path == path:
return_value = value
# And then to the other formats, in reverse order so that
# the first format is the most recent
for fmt in formats[::-1]:
if fmt["extension"] == ".ipynb":
continue
alt_path = full_path(base, fmt)
if ipynb_changed:
value = await write_one_file(alt_path, fmt, force_update_timestamp=True)
else:
# in the contents manager the write_one_file always writes anyway
value = await write_one_file(alt_path, fmt)
if alt_path == path:
return_value = value
# Update modified timestamp to match that of the pair #207
if isinstance(return_value, dict) and "last_modified" in return_value:
return_value["last_modified"] = value["last_modified"]
return return_value
================================================
FILE: src/jupytext/cell_metadata.py
================================================
"""
Convert between text notebook metadata and jupyter cell metadata.
Standard cell metadata are documented here:
See also https://ipython.org/ipython-doc/3/notebook/nbformat.html#cell-metadata
"""
import ast
import re
from json import dumps, loads
try:
from json import JSONDecodeError
except ImportError:
JSONDecodeError = ValueError
from .languages import _JUPYTER_LANGUAGES
# Map R Markdown's "echo", "results" and "include" to "hide_input" and "hide_output", that are understood by the
# `runtools` extension for Jupyter notebook, and by nbconvert (use the `hide_input_output.tpl` template).
# See http://jupyter-contrib-nbextensions.readthedocs.io/en/latest/nbextensions/runtools/readme.html
_RMARKDOWN_TO_RUNTOOLS_OPTION_MAP = [
(("include", "FALSE"), [("hide_input", True), ("hide_output", True)]),
(("echo", "FALSE"), [("hide_input", True)]),
(("results", "'hide'"), [("hide_output", True)]),
(("results", '"hide"'), [("hide_output", True)]),
]
# Alternatively, Jupytext can also map the Jupyter Book options to R Markdown
_RMARKDOWN_TO_JUPYTER_BOOK_MAP = [
(("include", "FALSE"), "remove_cell"),
(("echo", "FALSE"), "remove_input"),
(("results", "'hide'"), "remove_output"),
(("results", '"hide"'), "remove_output"),
]
_JUPYTEXT_CELL_METADATA = [
# Pre-jupytext metadata
"skipline",
"noskipline",
# Jupytext metadata
"cell_marker",
"lines_to_next_cell",
"lines_to_end_of_cell_marker",
]
_IGNORE_CELL_METADATA = ",".join(
f"-{name}"
for name in [
# Frequent cell metadata that should not enter the text representation
# (these metadata are preserved in the paired Jupyter notebook).
"autoscroll",
"collapsed",
"scrolled",
"trusted",
"execution",
"ExecuteTime",
]
+ _JUPYTEXT_CELL_METADATA
)
# In R Markdown we might have options without a value
_IS_IDENTIFIER = re.compile(r"^[a-zA-Z_\.]+[a-zA-Z0-9_\.]*$")
_IS_VALID_METADATA_KEY = re.compile(r"^[a-zA-Z0-9_\.@/-]+$")
class RLogicalValueError(Exception):
"""Incorrect value for R boolean"""
class RMarkdownOptionParsingError(Exception):
"""Error when parsing Rmd cell options"""
def _py_logical_values(rbool):
if rbool in ["TRUE", "T"]:
return True
if rbool in ["FALSE", "F"]:
return False
raise RLogicalValueError
def metadata_to_rmd_options(language, metadata, use_runtools=False):
"""Convert language and metadata information to their rmd representation"""
options = (language or "R").lower()
if "name" in metadata:
options += " " + metadata["name"] + ","
del metadata["name"]
if use_runtools:
for rmd_option, jupyter_options in _RMARKDOWN_TO_RUNTOOLS_OPTION_MAP:
if all([metadata.get(opt_name) == opt_value for opt_name, opt_value in jupyter_options]):
options += " {}={},".format(rmd_option[0], "FALSE" if rmd_option[1] is False else rmd_option[1])
for opt_name, _ in jupyter_options:
metadata.pop(opt_name)
else:
for rmd_option, tag in _RMARKDOWN_TO_JUPYTER_BOOK_MAP:
if tag in metadata.get("tags", []):
options += " {}={},".format(rmd_option[0], "FALSE" if rmd_option[1] is False else rmd_option[1])
metadata["tags"] = [i for i in metadata["tags"] if i != tag]
if not metadata["tags"]:
metadata.pop("tags")
for opt_name in metadata:
opt_value = metadata[opt_name]
opt_name = opt_name.strip()
if opt_name == "active":
options += f' {opt_name}="{str(opt_value)}",'
elif isinstance(opt_value, bool):
options += " {}={},".format(opt_name, "TRUE" if opt_value else "FALSE")
elif isinstance(opt_value, list):
options += " {}={},".format(
opt_name,
"c({})".format(", ".join([f'"{str(v)}"' for v in opt_value])),
)
elif isinstance(opt_value, str):
if opt_value.startswith("#R_CODE#"):
options += f" {opt_name}={opt_value[8:]},"
elif '"' not in opt_value:
options += f' {opt_name}="{opt_value}",'
else:
options += f" {opt_name}='{opt_value}',"
else:
options += f" {opt_name}={str(opt_value)},"
if not language:
options = options[2:]
return options.strip(",").strip()
def update_metadata_from_rmd_options(name, value, metadata, use_runtools=False):
"""Map the R Markdown cell visibility options to the Jupyter ones"""
if use_runtools:
for rmd_option, jupyter_options in _RMARKDOWN_TO_RUNTOOLS_OPTION_MAP:
if name == rmd_option[0] and value == rmd_option[1]:
for opt_name, opt_value in jupyter_options:
metadata[opt_name] = opt_value
return True
else:
for rmd_option, tag in _RMARKDOWN_TO_JUPYTER_BOOK_MAP:
if name == rmd_option[0] and value == rmd_option[1]:
metadata.setdefault("tags", []).append(tag)
return True
return False
class ParsingContext:
"""
Class for determining where to split rmd options
"""
parenthesis_count = 0
curly_bracket_count = 0
square_bracket_count = 0
in_single_quote = False
in_double_quote = False
def __init__(self, line):
self.line = line
def in_global_expression(self):
"""Currently inside an expression"""
return (
self.parenthesis_count == 0
and self.curly_bracket_count == 0
and self.square_bracket_count == 0
and not self.in_single_quote
and not self.in_double_quote
)
def count_special_chars(self, char, prev_char):
"""Update parenthesis counters"""
if char == "(":
self.parenthesis_count += 1
elif char == ")":
self.parenthesis_count -= 1
if self.parenthesis_count < 0:
raise RMarkdownOptionParsingError(f'Option line "{self.line}" has too many closing parentheses')
elif char == "{":
self.curly_bracket_count += 1
elif char == "}":
self.curly_bracket_count -= 1
if self.curly_bracket_count < 0:
raise RMarkdownOptionParsingError(f'Option line "{self.line}" has too many closing curly brackets')
elif char == "[":
self.square_bracket_count += 1
elif char == "]":
self.square_bracket_count -= 1
if self.square_bracket_count < 0:
raise RMarkdownOptionParsingError(f'Option line "{self.line}" has too many closing square brackets')
elif char == "'" and prev_char != "\\" and not self.in_double_quote:
self.in_single_quote = not self.in_single_quote
elif char == '"' and prev_char != "\\" and not self.in_single_quote:
self.in_double_quote = not self.in_double_quote
def parse_rmd_options(line):
"""
Given a R markdown option line, returns a list of pairs name,value
:param line:
:return:
"""
parsing_context = ParsingContext(line)
result = []
prev_char = ""
name = ""
value = ""
for char in "," + line + ",":
if parsing_context.in_global_expression():
if char == ",":
if name != "" or value != "":
if result and name == "":
raise RMarkdownOptionParsingError(f'Option line "{line}" has no name for option value {value}')
result.append((name.strip(), value.strip()))
name = ""
value = ""
elif char == "=":
if name == "":
name = value
value = ""
else:
value += char
else:
parsing_context.count_special_chars(char, prev_char)
value += char
else:
parsing_context.count_special_chars(char, prev_char)
value += char
prev_char = char
if not parsing_context.in_global_expression():
raise RMarkdownOptionParsingError(f'Option line "{line}" is not properly terminated')
return result
def rmd_options_to_metadata(options, use_runtools=False):
"""Parse rmd options and return a metadata dictionary"""
options = re.split(r"\s|,", options, maxsplit=1)
# Special case Wolfram Language, which sadly has a space in the language
# name.
if options[0:2] == ["wolfram", "language"]:
options[0:2] = ["wolfram language"]
if len(options) == 1:
language = options[0]
chunk_options = []
else:
language, others = options
language = language.rstrip(" ,")
others = others.lstrip(" ,")
chunk_options = parse_rmd_options(others)
language = "R" if language == "r" else language
metadata = {}
for i, opt in enumerate(chunk_options):
name, value = opt
if i == 0 and name == "":
metadata["name"] = value
continue
if update_metadata_from_rmd_options(name, value, metadata, use_runtools=use_runtools):
continue
try:
metadata[name] = _py_logical_values(value)
continue
except RLogicalValueError:
metadata[name] = value
for name in metadata:
try_eval_metadata(metadata, name)
if "eval" in metadata and not is_active(".Rmd", metadata):
del metadata["eval"]
return metadata.get("language") or language, metadata
def try_eval_metadata(metadata, name):
"""Evaluate the metadata to a python object, if possible"""
value = metadata[name]
if not isinstance(value, str):
return
if (value.startswith('"') and value.endswith('"')) or (value.startswith("'") and value.endswith("'")):
metadata[name] = value[1:-1]
return
if value.startswith("c(") and value.endswith(")"):
value = "[" + value[2:-1] + "]"
elif value.startswith("list(") and value.endswith(")"):
value = "[" + value[5:-1] + "]"
try:
metadata[name] = ast.literal_eval(value)
except (SyntaxError, ValueError):
if name != "name":
metadata[name] = "#R_CODE#" + value
return
def is_active(ext, metadata, default=True):
"""Is the cell active for the given file extension?"""
if metadata.get("run_control", {}).get("frozen") is True:
return ext == ".ipynb"
for tag in metadata.get("tags", []):
if tag.startswith("active-"):
return ext.replace(".", "") in tag.split("-")
if "active" not in metadata:
return default
return ext.replace(".", "") in re.split(r"\.|,", metadata["active"])
def metadata_to_double_percent_options(metadata, plain_json):
"""Metadata to double percent lines"""
text = []
if "title" in metadata:
text.append(metadata.pop("title"))
if "cell_depth" in metadata:
text.insert(0, "%" * metadata.pop("cell_depth"))
if "cell_type" in metadata:
text.append("[{}]".format(metadata.pop("region_name", metadata.pop("cell_type"))))
return metadata_to_text(" ".join(text), metadata, plain_json=plain_json)
def incorrectly_encoded_metadata(text):
"""Encode a text that Jupytext cannot parse as a cell metadata"""
return {"incorrectly_encoded_metadata": text}
def is_identifier(text):
return bool(_IS_IDENTIFIER.match(text))
def is_valid_metadata_key(text):
"""Can this text be a proper key?"""
return bool(_IS_VALID_METADATA_KEY.match(text))
def is_jupyter_language(language):
"""Is this a jupyter language?"""
for lang in _JUPYTER_LANGUAGES:
if language.lower() == lang.lower():
return True
return False
def parse_key_equal_value(text):
"""Parse a string of the form 'key1=value1 key2=value2'"""
# Empty metadata?
text = text.strip()
if not text:
return {}
last_space_pos = text.rfind(" ")
# Just an identifier?
if not text.startswith("--") and is_identifier(text[last_space_pos + 1 :]):
key = text[last_space_pos + 1 :]
value = None
result = {key: value}
if last_space_pos > 0:
result.update(parse_key_equal_value(text[:last_space_pos]))
return result
# Iterate on the '=' signs, starting from the right
equal_sign_pos = None
while True:
equal_sign_pos = text.rfind("=", None, equal_sign_pos)
if equal_sign_pos < 0:
return incorrectly_encoded_metadata(text)
# Do we have an identifier on the left of the equal sign?
prev_whitespace = text[:equal_sign_pos].rstrip().rfind(" ")
key = text[prev_whitespace + 1 : equal_sign_pos].strip()
if not is_valid_metadata_key(key):
continue
try:
value = relax_json_loads(text[equal_sign_pos + 1 :])
except (ValueError, SyntaxError):
# try with a longer expression
continue
# Combine with remaining metadata
metadata = parse_key_equal_value(text[:prev_whitespace]) if prev_whitespace > 0 else {}
# Append our value
metadata[key] = value
# And return
return metadata
def relax_json_loads(text, catch=False):
"""Parse a JSON string or similar"""
text = text.strip()
try:
return loads(text)
except JSONDecodeError:
pass
if not catch:
return ast.literal_eval(text)
try:
return ast.literal_eval(text)
except (ValueError, SyntaxError):
pass
return incorrectly_encoded_metadata(text)
def is_json_metadata(text):
"""Is this a JSON metadata?"""
first_curly_bracket = text.find("{")
if first_curly_bracket < 0:
return False
first_equal_sign = text.find("=")
if first_equal_sign < 0:
return True
return first_curly_bracket < first_equal_sign
def text_to_metadata(text, allow_title=False):
"""Parse the language/cell title and associated metadata"""
# Parse the language or cell title = everything before the last blank space before { or =
text = text.strip()
first_curly_bracket = text.find("{")
first_equal_sign = text.find("=")
if first_curly_bracket < 0 or (0 <= first_equal_sign < first_curly_bracket):
# this is a key=value metadata line
# case one = the options may be preceded with a language
if not allow_title:
if is_jupyter_language(text):
return text, {}
if " " not in text:
return "", parse_key_equal_value(text)
language, options = text.split(" ", 1)
if is_jupyter_language(language):
return language, parse_key_equal_value(options)
return "", parse_key_equal_value(text)
# case two = a title may be before the options
# we split the title into words
if first_equal_sign >= 0:
words = text[:first_equal_sign].split(" ")
# last word is the key before the equal sign!
while words and not words[-1]:
words.pop()
if words:
words.pop()
else:
words = text.split(" ")
# and we remove words on the right that are attributes (they start with '.')
while words and (not words[-1].strip() or words[-1].startswith(".")):
words.pop()
title = " ".join(words)
return title, parse_key_equal_value(text[len(title) :])
# json metadata line
return (
text[:first_curly_bracket].strip(),
relax_json_loads(text[first_curly_bracket:], catch=True),
)
def metadata_to_text(language_or_title, metadata=None, plain_json=False):
"""Write the cell metadata in the format key=value"""
# Was metadata the first argument?
if metadata is None:
metadata, language_or_title = language_or_title, metadata
metadata = {key: metadata[key] for key in metadata if key not in _JUPYTEXT_CELL_METADATA}
text = [language_or_title] if language_or_title else []
if language_or_title is None:
if "title" in metadata and "{" not in metadata["title"] and "=" not in metadata["title"]:
text.append(metadata.pop("title"))
if plain_json:
if metadata:
text.append(dumps(metadata))
else:
for key in metadata:
if key == "incorrectly_encoded_metadata":
text.append(metadata[key])
elif metadata[key] is None:
text.append(key)
else:
text.append(f"{key}={dumps(metadata[key])}")
return " ".join(text)
================================================
FILE: src/jupytext/cell_reader.py
================================================
"""Read notebook cells from their text representation"""
import re
from collections import defaultdict
from copy import copy
from itertools import count
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_raw_cell
from .doxygen import doxygen_to_markdown
from .languages import _SCRIPT_EXTENSIONS
# Sphinx Gallery is an optional dependency. And we intercept the SyntaxError for #301
try:
from sphinx_gallery.notebook import rst2md
except (ImportError, SyntaxError): # pragma: no cover
rst2md = None
from .cell_metadata import (
is_active,
is_json_metadata,
rmd_options_to_metadata,
text_to_metadata,
)
from .languages import _JUPYTER_LANGUAGES_LOWER_AND_UPPER
from .magics import is_magic, need_explicit_marker, uncomment_magic, unescape_code_start
from .pep8 import pep8_lines_between_cells
from .stringparser import StringParser
_BLANK_LINE = re.compile(r"^\s*$")
_PY_INDENTED = re.compile(r"^\s")
def uncomment(lines, prefix="#", suffix=""):
"""Remove prefix and space, or only prefix, when possible"""
if prefix:
prefix_and_space = prefix + " "
length_prefix = len(prefix)
length_prefix_and_space = len(prefix_and_space)
lines = [
(
line[length_prefix_and_space:]
if line.startswith(prefix_and_space)
else (line[length_prefix:] if line.startswith(prefix) else line)
)
for line in lines
]
if suffix:
space_and_suffix = " " + suffix
length_suffix = len(suffix)
length_space_and_suffix = len(space_and_suffix)
lines = [
(
line[:-length_space_and_suffix]
if line.endswith(space_and_suffix)
else (line[:-length_suffix] if line.endswith(suffix) else line)
)
for line in lines
]
return lines
def paragraph_is_fully_commented(lines, comment, main_language):
"""Is the paragraph fully commented?"""
for i, line in enumerate(lines):
if line.startswith(comment):
if line[len(comment) :].lstrip().startswith(comment):
continue
if is_magic(line, main_language):
return False
continue
return i > 0 and _BLANK_LINE.match(line)
return True
def next_code_is_indented(lines):
"""Is the next unescaped line indented?"""
for line in lines:
if _BLANK_LINE.match(line):
continue
return _PY_INDENTED.match(line)
return False
def count_lines_to_next_cell(cell_end_marker, next_cell_start, total, explicit_eoc):
"""How many blank lines between end of cell marker and next cell?"""
if cell_end_marker < total:
lines_to_next_cell = next_cell_start - cell_end_marker
if explicit_eoc:
lines_to_next_cell -= 1
if next_cell_start >= total:
lines_to_next_cell += 1
return lines_to_next_cell
return 1
def last_two_lines_blank(source):
"""Are the two last lines blank, and not the third last one?"""
if len(source) < 3:
return False
return not _BLANK_LINE.match(source[-3]) and _BLANK_LINE.match(source[-2]) and _BLANK_LINE.match(source[-1])
class BaseCellReader:
"""A class that can read notebook cells from their text representation"""
default_comment_magics = None
lines_to_next_cell = 1
start_code_re = None
simple_start_code_re = None
end_code_re = None
# How to make code inactive
comment = ""
# Any specific prefix for lines in markdown cells (like in R spin format?)
markdown_prefix = None
def __init__(self, fmt=None, default_language=None):
"""Create a cell reader with empty content"""
if not fmt:
fmt = {}
self.ext = fmt.get("extension")
self.default_language = default_language or _SCRIPT_EXTENSIONS.get(self.ext, {}).get("language", "python")
self.comment_magics = fmt.get("comment_magics", self.default_comment_magics)
self.use_runtools = fmt.get("use_runtools", False)
self.format_version = fmt.get("format_version")
self.metadata = None
self.org_content = []
self.content = []
self.explicit_soc = None
self.explicit_eoc = None
self.cell_type = None
self.language = None
self.cell_metadata_json = fmt.get("cell_metadata_json", False)
self.doxygen_equation_markers = fmt.get("doxygen_equation_markers", False)
def read(self, lines):
"""Read one cell from the given lines, and return the cell,
plus the position of the next cell
"""
# Do we have an explicit code marker on the first line?
self.metadata_and_language_from_option_line(lines[0])
if self.metadata and "language" in self.metadata:
self.language = self.metadata.pop("language")
# Parse cell till its end and set content, lines_to_next_cell
pos_next_cell = self.find_cell_content(lines)
if self.cell_type == "code":
new_cell = new_code_cell
elif self.cell_type == "markdown":
new_cell = new_markdown_cell
else:
new_cell = new_raw_cell
if not self.metadata:
self.metadata = {}
if self.ext == ".py":
expected_blank_lines = pep8_lines_between_cells(self.org_content or [""], lines[pos_next_cell:], self.ext)
else:
expected_blank_lines = 1
if self.lines_to_next_cell != expected_blank_lines:
self.metadata["lines_to_next_cell"] = self.lines_to_next_cell
if self.language:
self.metadata["language"] = self.language
return (
new_cell(source="\n".join(self.content), metadata=self.metadata),
pos_next_cell,
)
def metadata_and_language_from_option_line(self, line):
"""Parse code options on the given line. When a start of a code cell
is found, self.metadata is set to a dictionary."""
if self.start_code_re.match(line):
self.language, self.metadata = self.options_to_metadata(self.start_code_re.findall(line)[0])
def options_to_metadata(self, options):
"""Return language (str) and metadata (dict) from the option line"""
raise NotImplementedError("Option parsing must be implemented in a sub class")
def find_cell_end(self, lines):
"""Return position of end of cell marker, and position
of first line after cell"""
raise NotImplementedError("This method must be implemented in a sub class")
def find_cell_content(self, lines):
"""Parse cell till its end and set content, lines_to_next_cell.
Return the position of next cell start"""
cell_end_marker, next_cell_start, self.explicit_eoc = self.find_cell_end(lines)
# Metadata to dict
if self.metadata is None:
cell_start = 0
self.metadata = {}
else:
cell_start = 1
# Cell content
source = lines[cell_start:cell_end_marker]
self.org_content = copy(source)
# Exactly two empty lines at the end of cell (caused by PEP8)?
if self.ext == ".py" and self.explicit_eoc:
if last_two_lines_blank(source):
source = source[:-2]
lines_to_end_of_cell_marker = 2
else:
lines_to_end_of_cell_marker = 0
pep8_lines = pep8_lines_between_cells(source, lines[cell_end_marker:], self.ext)
if lines_to_end_of_cell_marker != (0 if pep8_lines == 1 else 2):
self.metadata["lines_to_end_of_cell_marker"] = lines_to_end_of_cell_marker
# Uncomment content
self.explicit_soc = cell_start > 0
self.content = self.extract_content(source)
# Is this an inactive cell?
if self.cell_type == "code":
if not is_active(".ipynb", self.metadata):
if self.metadata.get("active") == "":
del self.metadata["active"]
self.cell_type = "raw"
elif self.ext in [".md", ".markdown"] and not self.language:
# Markdown files in version >= 1.3 represent code chunks with no language as Markdown cells
if self.format_version not in ["1.0", "1.1"]:
self.cell_type = "markdown"
self.explicit_eoc = False
cell_end_marker += 1
self.content = lines[:cell_end_marker]
# Previous versions mapped those to raw cells
else:
self.cell_type = "raw"
# Explicit end of cell marker?
if (
next_cell_start + 1 < len(lines)
and _BLANK_LINE.match(lines[next_cell_start])
and not _BLANK_LINE.match(lines[next_cell_start + 1])
):
next_cell_start += 1
elif (
self.explicit_eoc
and next_cell_start + 2 < len(lines)
and _BLANK_LINE.match(lines[next_cell_start])
and _BLANK_LINE.match(lines[next_cell_start + 1])
and not _BLANK_LINE.match(lines[next_cell_start + 2])
):
next_cell_start += 2
self.lines_to_next_cell = count_lines_to_next_cell(cell_end_marker, next_cell_start, len(lines), self.explicit_eoc)
return next_cell_start
def uncomment_code_and_magics(self, lines):
"""Uncomment code and possibly commented magic commands"""
raise NotImplementedError("This method must be implemented in a sub class")
def extract_content(self, lines):
# Code cells with just a multiline string become Markdown cells
if self.ext == ".py" and not is_active(self.ext, self.metadata, self.cell_type == "code"):
content = "\n".join(lines).strip()
for prefix in [""] if self.ext != ".py" else ["", "r", "R"]:
for triple_quote in ['"""', "'''"]:
left = prefix + triple_quote
right = triple_quote
if content.startswith(left) and content.endswith(right) and len(content) >= len(left + right):
content = content[len(left) : -len(right)]
# Trim first/last line return
if content.startswith("\n"):
content = content[1:]
left = left + "\n"
if content.endswith("\n"):
content = content[:-1]
right = "\n" + right
if not prefix:
if len(left) == len(right) == 4:
self.metadata["cell_marker"] = left[:3]
elif len(left[1:]) == len(right) == 4:
self.metadata["cell_marker"] = left[:4]
else:
self.metadata["cell_marker"] = left + "," + right
return content.splitlines()
if not is_active(self.ext, self.metadata) or (
"active" not in self.metadata and self.language and self.language != self.default_language
):
return uncomment(lines, self.comment if self.ext not in [".r", ".R"] else "#")
return self.uncomment_code_and_magics(lines)
class MarkdownCellReader(BaseCellReader):
"""Read notebook cells from Markdown documents"""
comment = ""
start_code_re = re.compile(
r"^```(`*)(\s*)({})($|\s.*$)".format("|".join(_JUPYTER_LANGUAGES_LOWER_AND_UPPER).replace("+", "\\+"))
)
non_jupyter_code_re = re.compile(r"^```")
end_code_re = re.compile(r"^```\s*$")
start_region_re = re.compile(r"^\s*$")
end_region_re = None
default_comment_magics = False
def __init__(self, fmt=None, default_language=None):
super().__init__(fmt, default_language)
self.split_at_heading = (fmt or {}).get("split_at_heading", False)
self.in_region = False
self.in_raw = False
if self.format_version in ["1.0", "1.1"] and self.ext != ".Rmd":
# Restore the pattern used in Markdown <= 1.1
self.start_code_re = re.compile(r"^```(.*)")
self.non_jupyter_code_re = re.compile(r"^```\{")
def metadata_and_language_from_option_line(self, line):
match_region = self.start_region_re.match(line)
if match_region:
self.in_region = True
groups = match_region.groups()
region_name = groups[0]
self.end_region_re = re.compile(rf"^\s*$")
self.cell_metadata_json = self.cell_metadata_json or is_json_metadata(groups[1])
title, self.metadata = text_to_metadata(groups[1], allow_title=True)
if region_name == "raw":
self.cell_type = "raw"
else:
self.cell_type = "markdown"
if title:
self.metadata["title"] = title
if region_name in ["markdown", "md"]:
self.metadata["region_name"] = region_name
elif self.start_code_re.match(line):
self.language, self.metadata = self.options_to_metadata(self.start_code_re.findall(line)[0])
# Cells with a .noeval attribute are markdown cells #347
if self.metadata.get(".noeval", "") is None:
self.cell_type = "markdown"
self.metadata = {}
self.language = None
def options_to_metadata(self, options):
if isinstance(options, tuple):
self.end_code_re = re.compile("```" + options[0])
options = " ".join(options[1:])
else:
self.end_code_re = re.compile(r"^```\s*$")
self.cell_metadata_json = self.cell_metadata_json or is_json_metadata(options)
return text_to_metadata(options)
def find_cell_end(self, lines):
"""Return position of end of cell marker, and position
of first line after cell"""
if self.in_region:
for i, line in enumerate(lines):
if self.end_region_re.match(line):
return i, i + 1, True
elif self.metadata is None:
# default markdown: (last) two consecutive blank lines, except when in code blocks
self.cell_type = "markdown"
prev_blank = 0
in_explicit_code_block = False
in_indented_code_block = False
for i, line in enumerate(lines):
if in_explicit_code_block and self.end_code_re.match(line):
in_explicit_code_block = False
continue
if prev_blank and line.startswith(" ") and not _BLANK_LINE.match(line):
in_indented_code_block = True
prev_blank = 0
continue
if in_indented_code_block and not _BLANK_LINE.match(line) and not line.startswith(" "):
in_indented_code_block = False
if in_indented_code_block or in_explicit_code_block:
continue
if self.start_region_re.match(line):
if i > 1 and prev_blank:
return i - 1, i, False
return i, i, False
if self.start_code_re.match(line):
language, metadata = self.options_to_metadata(self.start_code_re.findall(line)[0])
# Cells with a .noeval attribute are markdown cells #347
# R Markdown notebooks can have bibliography and index blocks, cf #1161 and #1429
if language not in _JUPYTER_LANGUAGES_LOWER_AND_UPPER or metadata.get(".noeval", "") is None:
in_explicit_code_block = True
prev_blank = 0
continue
if i > 1 and prev_blank:
return i - 1, i, False
return i, i, False
elif line.startswith("```{"):
# These are non-code blocks but we still need to look for their end
in_explicit_code_block = True
prev_blank = 0
continue
if self.non_jupyter_code_re.match(line):
if prev_blank >= 2:
return i - 2, i, True
in_explicit_code_block = True
prev_blank = 0
continue
if self.split_at_heading and line.startswith("#") and prev_blank >= 1:
return i - 1, i, False
if _BLANK_LINE.match(lines[i]):
prev_blank += 1
elif prev_blank >= 2:
return i - 2, i, True
else:
prev_blank = 0
else:
self.cell_type = "code"
# At some point we could remove the below, in which we make sure not to break language strings
# into multiple cells (#419). Indeed, now that the markdown cell uses one extra backtick (#712)
# we should not have the issue any more
parser = StringParser(self.language or self.default_language)
for i, line in enumerate(lines):
# skip cell header
if i == 0:
continue
if parser.is_quoted():
parser.read_line(line)
continue
parser.read_line(line)
if self.end_code_re.match(line):
return i, i + 1, True
# End not found
return len(lines), len(lines), False
def uncomment_code_and_magics(self, lines):
if self.cell_type == "code" and self.comment_magics:
lines = uncomment_magic(lines, self.language)
if self.cell_type == "markdown" and self.doxygen_equation_markers:
lines = doxygen_to_markdown("\n".join(lines)).splitlines()
return lines
class RMarkdownCellReader(MarkdownCellReader):
"""Read notebook cells from R Markdown notebooks"""
comment = ""
start_code_re = re.compile(r"^```{(.*)}\s*$")
non_jupyter_code_re = re.compile(r"^```([^\{]|\s*$)")
default_language = "R"
default_comment_magics = True
def options_to_metadata(self, options):
return rmd_options_to_metadata(options, self.use_runtools)
def uncomment_code_and_magics(self, lines):
if self.cell_type == "code" and self.comment_magics and is_active(self.ext, self.metadata):
uncomment_magic(lines, self.language or self.default_language)
return lines
class ScriptCellReader(BaseCellReader): # pylint: disable=W0223
"""Read notebook cells from scripts
(common base for R and Python scripts)"""
def uncomment_code_and_magics(self, lines):
if self.cell_type == "code" or self.comment != "#'":
if self.comment_magics:
if is_active(self.ext, self.metadata):
uncomment_magic(
lines,
self.language or self.default_language,
explicitly_code=self.explicit_soc,
)
if (
self.cell_type == "code"
and not self.explicit_soc
and need_explicit_marker(lines, self.language or self.default_language)
):
self.metadata["comment_questions"] = False
else:
lines = uncomment(lines)
if self.default_language == "go" and self.language is None:
lines = [re.sub(r"^((//\s*)*)(//\s*gonb:%%)", r"\1%%", line) for line in lines]
if self.cell_type == "code":
return unescape_code_start(lines, self.ext, self.language or self.default_language)
return uncomment(lines, self.markdown_prefix or self.comment, self.comment_suffix)
class RScriptCellReader(ScriptCellReader):
"""Read notebook cells from R scripts written according
to the knitr-spin syntax"""
comment = "#'"
comment_suffix = ""
markdown_prefix = "#'"
default_language = "R"
start_code_re = re.compile(r"^#\+(.*)\s*$")
default_comment_magics = True
def options_to_metadata(self, options):
return rmd_options_to_metadata("r " + options, self.use_runtools)
def find_cell_end(self, lines):
"""Return position of end of cell marker, and position
of first line after cell"""
if self.metadata is None and lines[0].startswith("#'"):
self.cell_type = "markdown"
for i, line in enumerate(lines):
if not line.startswith("#'"):
if _BLANK_LINE.match(line):
return i, i + 1, False
return i, i, False
return len(lines), len(lines), False
if self.metadata and "cell_type" in self.metadata:
self.cell_type = self.metadata.pop("cell_type")
else:
self.cell_type = "code"
parser = StringParser(self.language or self.default_language)
for i, line in enumerate(lines):
# skip cell header
if self.metadata is not None and i == 0:
continue
if parser.is_quoted():
parser.read_line(line)
continue
parser.read_line(line)
if self.start_code_re.match(line) or (self.markdown_prefix and line.startswith(self.markdown_prefix)):
if i > 0 and _BLANK_LINE.match(lines[i - 1]):
if i > 1 and _BLANK_LINE.match(lines[i - 2]):
return i - 2, i, False
return i - 1, i, False
return i, i, False
if _BLANK_LINE.match(line):
if not next_code_is_indented(lines[i:]):
if i > 0:
return i, i + 1, False
if len(lines) > 1 and not _BLANK_LINE.match(lines[1]):
return 1, 1, False
return 1, 2, False
return len(lines), len(lines), False
class LightScriptCellReader(ScriptCellReader):
"""Read notebook cells from plain Python or Julia files. Cells
are identified by line breaks, unless they start with an
explicit marker '# +'"""
default_comment_magics = True
cell_marker_start = None
cell_marker_end = None
def __init__(self, fmt=None, default_language=None):
super().__init__(fmt, default_language)
self.ext = self.ext or ".py"
script = _SCRIPT_EXTENSIONS[self.ext]
self.default_language = default_language or script["language"]
self.comment = script["comment"]
self.comment_suffix = script.get("comment_suffix", "")
self.ignore_end_marker = True
self.explicit_end_marker_required = False
if fmt and fmt.get("format_name", "light") == "light" and "cell_markers" in fmt and fmt["cell_markers"] != "+,-":
self.cell_marker_start, self.cell_marker_end = fmt["cell_markers"].split(",", 1)
self.start_code_re = re.compile("^" + re.escape(self.comment) + r"\s*" + self.cell_marker_start + r"(.*)$")
self.end_code_re = re.compile("^" + re.escape(self.comment) + r"\s*" + self.cell_marker_end + r"\s*$")
else:
self.start_code_re = re.compile("^" + re.escape(self.comment) + r"\s*\+(.*)$")
def metadata_and_language_from_option_line(self, line):
if self.start_code_re.match(line):
# Remove the OCAML suffix
if self.comment_suffix:
if line.endswith(" " + self.comment_suffix):
line = line[: -len(" " + self.comment_suffix)]
elif line.endswith(self.comment_suffix):
line = line[: -len(self.comment_suffix)]
# We want to parse inner most regions as cells.
# Thus, if we find another region start before the end for this region,
# we will have ignore the metadata that we found here, and move on to the next cell.
groups = self.start_code_re.match(line).groups()
self.language, self.metadata = self.options_to_metadata(groups[0])
self.ignore_end_marker = False
if self.cell_marker_start:
self.explicit_end_marker_required = True
elif self.simple_start_code_re and self.simple_start_code_re.match(line):
self.metadata = {}
self.ignore_end_marker = False
elif self.cell_marker_end and self.end_code_re.match(line):
self.metadata = None
self.cell_type = "code"
def options_to_metadata(self, options):
self.cell_metadata_json = self.cell_metadata_json or is_json_metadata(options)
title, metadata = text_to_metadata(options, allow_title=True)
# Cell type
for cell_type in ["markdown", "raw", "md"]:
code = f"[{cell_type}]"
if code in title:
title = title.replace(code, "").strip()
metadata["cell_type"] = cell_type
if cell_type == "md":
metadata["region_name"] = cell_type
metadata["cell_type"] = "markdown"
break
# Spyder has sub cells
cell_depth = 0
while title.startswith("%"):
cell_depth += 1
title = title[1:]
if cell_depth:
metadata["cell_depth"] = cell_depth
title = title.strip()
if title:
metadata["title"] = title
return None, metadata
def find_cell_end(self, lines):
"""Return position of end of cell marker, and position of first line after cell"""
if (
self.metadata is None
and not (self.cell_marker_end and self.end_code_re.match(lines[0]))
and paragraph_is_fully_commented(lines, self.comment, self.default_language)
):
self.cell_type = "markdown"
for i, line in enumerate(lines):
if _BLANK_LINE.match(line):
return i, i + 1, False
return len(lines), len(lines), False
if self.metadata is None:
self.end_code_re = None
elif not self.cell_marker_end:
end_of_cell = self.metadata.get("endofcell", "-")
self.end_code_re = re.compile("^" + re.escape(self.comment) + " " + end_of_cell + r"\s*$")
return self.find_region_end(lines)
def find_region_end(self, lines):
"""Find the end of the region started with start and end markers"""
if self.metadata and "cell_type" in self.metadata:
self.cell_type = self.metadata.pop("cell_type")
else:
self.cell_type = "code"
parser = StringParser(self.language or self.default_language)
for i, line in enumerate(lines):
# skip cell header
if self.metadata is not None and i == 0:
continue
if parser.is_quoted():
parser.read_line(line)
continue
parser.read_line(line)
# New code region
# Simple code pattern in LightScripts must be preceded with a blank line
if self.start_code_re.match(line) or (
self.simple_start_code_re
and self.simple_start_code_re.match(line)
and (self.cell_marker_start or i == 0 or _BLANK_LINE.match(lines[i - 1]))
):
if self.explicit_end_marker_required:
# Metadata here was conditioned on finding an explicit end marker
# before the next start marker. So we dismiss it.
self.metadata = None
self.language = None
if i > 0 and _BLANK_LINE.match(lines[i - 1]):
if i > 1 and _BLANK_LINE.match(lines[i - 2]):
return i - 2, i, False
return i - 1, i, False
return i, i, False
if not self.ignore_end_marker and self.end_code_re:
if self.end_code_re.match(line):
return i, i + 1, True
elif _BLANK_LINE.match(line):
if not next_code_is_indented(lines[i:]):
if i > 0:
return i, i + 1, False
if len(lines) > 1 and not _BLANK_LINE.match(lines[1]):
return 1, 1, False
return 1, 2, False
return len(lines), len(lines), False
class DoublePercentScriptCellReader(LightScriptCellReader):
"""Read notebook cells from Spyder/VScode scripts (#59)"""
default_comment_magics = True
def __init__(self, fmt, default_language=None):
LightScriptCellReader.__init__(self, fmt, default_language)
script = _SCRIPT_EXTENSIONS[self.ext]
self.default_language = default_language or script["language"]
self.comment = script["comment"]
self.comment_suffix = script.get("comment_suffix", "")
self.start_code_re = re.compile(rf"^\s*{re.escape(self.comment)}\s*%%(%*)\s(.*)$")
self.alternative_start_code_re = re.compile(rf"^\s*{re.escape(self.comment)}\s*(%%||In\[[0-9 ]*\]:?)\s*$")
self.explicit_soc = True
def metadata_and_language_from_option_line(self, line):
"""Parse code options on the given line. When a start of a code cell
is found, self.metadata is set to a dictionary."""
if self.start_code_re.match(line):
line = uncomment([line], self.comment, self.comment_suffix)[0]
self.language, self.metadata = self.options_to_metadata(line[line.find("%%") + 2 :])
else:
self.metadata = {}
def find_cell_content(self, lines):
"""Parse cell till its end and set content, lines_to_next_cell.
Return the position of next cell start"""
cell_end_marker, next_cell_start, explicit_eoc = self.find_cell_end(lines)
# Metadata to dict
if self.start_code_re.match(lines[0]) or self.alternative_start_code_re.match(lines[0]):
cell_start = 1
else:
cell_start = 0
# Cell content
source = lines[cell_start:cell_end_marker]
self.org_content = copy(source)
self.content = self.extract_content(source)
self.lines_to_next_cell = count_lines_to_next_cell(cell_end_marker, next_cell_start, len(lines), explicit_eoc)
return next_cell_start
def find_cell_end(self, lines):
"""Return position of end of cell marker, and position
of first line after cell"""
if self.metadata and "cell_type" in self.metadata:
self.cell_type = self.metadata.pop("cell_type")
elif not is_active(".ipynb", self.metadata):
if self.metadata.get("active") == "":
del self.metadata["active"]
self.cell_type = "raw"
if is_active(self.ext, self.metadata):
self.comment = ""
else:
self.cell_type = "code"
next_cell = len(lines)
parser = StringParser(self.language or self.default_language)
for i, line in enumerate(lines):
if parser.is_quoted():
parser.read_line(line)
continue
parser.read_line(line)
if i > 0 and (self.start_code_re.match(line) or self.alternative_start_code_re.match(line)):
next_cell = i
break
if last_two_lines_blank(lines[:next_cell]):
return next_cell - 2, next_cell, False
if next_cell > 0 and _BLANK_LINE.match(lines[next_cell - 1]):
return next_cell - 1, next_cell, False
return next_cell, next_cell, False
class HydrogenCellReader(DoublePercentScriptCellReader):
"""Read notebook cells from Hydrogen scripts (#59)"""
default_comment_magics = False
class SphinxGalleryScriptCellReader(ScriptCellReader): # pylint: disable=W0223
"""Read notebook cells from Sphinx Gallery scripts (#80)"""
comment = "#"
default_language = "python"
default_comment_magics = True
twenty_hash = re.compile(r"^#( |)#{19,}\s*$")
default_markdown_cell_marker = "#" * 79
markdown_marker = None
def __init__(self, fmt=None, default_language="python"):
super().__init__(fmt, default_language)
self.ext = ".py"
self.rst2md = (fmt or {}).get("rst2md", False)
def start_of_new_markdown_cell(self, line):
"""Does this line starts a new markdown cell?
Then, return the cell marker"""
for empty_markdown_cell in ['""', "''"]:
if line == empty_markdown_cell:
return empty_markdown_cell
for triple_quote in ['"""', "'''"]:
if line.startswith(triple_quote):
return triple_quote
if self.twenty_hash.match(line):
return line
return None
def metadata_and_language_from_option_line(self, line):
self.markdown_marker = self.start_of_new_markdown_cell(line)
if self.markdown_marker:
self.cell_type = "markdown"
if self.markdown_marker != self.default_markdown_cell_marker:
self.metadata = {"cell_marker": self.markdown_marker}
else:
self.cell_type = "code"
def find_cell_end(self, lines):
"""Return position of end of cell, and position
of first line after cell, and whether there was an
explicit end of cell marker"""
if self.cell_type == "markdown":
# Empty cell "" or ''
if len(self.markdown_marker) <= 2:
if len(lines) == 1 or _BLANK_LINE.match(lines[1]):
return 0, 2, True
return 0, 1, True
# Multi-line comment with triple quote
if len(self.markdown_marker) == 3:
for i, line in enumerate(lines):
if (i > 0 or line.strip() != self.markdown_marker) and line.rstrip().endswith(self.markdown_marker):
explicit_end_of_cell_marker = line.strip() == self.markdown_marker
if explicit_end_of_cell_marker:
end_of_cell = i
else:
end_of_cell = i + 1
if len(lines) <= i + 1 or _BLANK_LINE.match(lines[i + 1]):
return end_of_cell, i + 2, explicit_end_of_cell_marker
return end_of_cell, i + 1, explicit_end_of_cell_marker
else:
# 20 # or more
for i, line in enumerate(lines[1:], 1):
if not line.startswith(self.comment):
if _BLANK_LINE.match(line):
return i, i + 1, False
return i, i, False
elif self.cell_type == "code":
parser = StringParser("python")
for i, line in enumerate(lines):
if parser.is_quoted():
parser.read_line(line)
continue
if self.start_of_new_markdown_cell(line):
if i > 0 and _BLANK_LINE.match(lines[i - 1]):
return i - 1, i, False
return i, i, False
parser.read_line(line)
return len(lines), len(lines), False
def find_cell_content(self, lines):
"""Parse cell till its end and set content, lines_to_next_cell.
Return the position of next cell start"""
cell_end_marker, next_cell_start, explicit_eoc = self.find_cell_end(lines)
# Metadata to dict
cell_start = 0
if self.cell_type == "markdown":
if self.markdown_marker in ['"""', "'''"]:
# Remove the triple quotes
if lines[0].strip() == self.markdown_marker:
cell_start = 1
else:
lines[0] = lines[0][3:]
if not explicit_eoc:
last = lines[cell_end_marker - 1]
lines[cell_end_marker - 1] = last[: last.rfind(self.markdown_marker)]
if self.twenty_hash.match(self.markdown_marker):
cell_start = 1
else:
self.metadata = {}
# Cell content
source = lines[cell_start:cell_end_marker]
self.org_content = copy(source)
if self.cell_type == "code" and self.comment_magics:
uncomment_magic(source, self.language or self.default_language)
if self.cell_type == "markdown" and source:
if self.markdown_marker.startswith(self.comment):
source = uncomment(source, self.comment)
if self.rst2md:
if rst2md:
gallery_conf = {"notebook_images": False}
heading_level_counter = count(start=1)
heading_levels = defaultdict(lambda: next(heading_level_counter))
source = rst2md("\n".join(source), gallery_conf, "", heading_levels).splitlines()
else:
raise ImportError("Could not import rst2md from sphinx_gallery.notebook") # pragma: no cover
self.content = source
self.lines_to_next_cell = count_lines_to_next_cell(cell_end_marker, next_cell_start, len(lines), explicit_eoc)
return next_cell_start
================================================
FILE: src/jupytext/cell_to_text.py
================================================
"""Export notebook cells as text"""
import re
import warnings
from copy import copy
from .cell_metadata import (
_IGNORE_CELL_METADATA,
is_active,
metadata_to_double_percent_options,
metadata_to_rmd_options,
metadata_to_text,
)
from .cell_reader import LightScriptCellReader, MarkdownCellReader, RMarkdownCellReader
from .doxygen import markdown_to_doxygen
from .languages import _SCRIPT_EXTENSIONS, cell_language, comment_lines, same_language
from .magics import comment_magic, escape_code_start, need_explicit_marker
from .metadata_filter import filter_metadata
from .pep8 import pep8_lines_between_cells
def cell_source(cell):
"""Return the source of the current cell, as an array of lines"""
source = cell.source
if source == "":
return [""]
if source.endswith("\n"):
return source.splitlines() + [""]
return source.splitlines()
def three_backticks_or_more(lines):
"""Return a string with enough backticks to encapsulate the given code cell in Markdown
cf. https://github.com/mwouts/jupytext/issues/712"""
code_cell_delimiter = "```"
for line in lines:
if not line.startswith(code_cell_delimiter):
continue
for char in line[len(code_cell_delimiter) :]:
if char != "`":
break
code_cell_delimiter += "`"
code_cell_delimiter += "`"
return code_cell_delimiter
class BaseCellExporter:
"""A class that represent a notebook cell as text"""
default_comment_magics = None
parse_cell_language = True
def __init__(self, cell, default_language, fmt=None, unsupported_keys=None):
self.fmt = fmt or {}
self.ext = self.fmt.get("extension")
self.cell_type = cell.cell_type
self.source = cell_source(cell)
self.unfiltered_metadata = cell.metadata
self.metadata = filter_metadata(
cell.metadata,
self.fmt.get("cell_metadata_filter"),
_IGNORE_CELL_METADATA,
unsupported_keys=unsupported_keys,
)
if self.parse_cell_language:
custom_cell_magics = self.fmt.get("custom_cell_magics", "").split(",")
self.language, magic_args = cell_language(self.source, default_language, custom_cell_magics)
if magic_args:
self.metadata["magic_args"] = magic_args
else:
self.language = None
if self.language and not self.ext.endswith(".Rmd"):
self.metadata["language"] = self.language
self.language = self.language or cell.metadata.get("language", default_language)
self.default_language = default_language
self.comment = _SCRIPT_EXTENSIONS.get(self.ext, {}).get("comment", "#")
self.comment_suffix = _SCRIPT_EXTENSIONS.get(self.ext, {}).get("comment_suffix", "")
self.comment_magics = self.fmt.get("comment_magics", self.default_comment_magics)
self.cell_metadata_json = self.fmt.get("cell_metadata_json", False)
self.use_runtools = self.fmt.get("use_runtools", False)
self.doxygen_equation_markers = self.fmt.get("doxygen_equation_markers", False)
# how many blank lines before next cell
self.lines_to_next_cell = cell.metadata.get("lines_to_next_cell")
self.lines_to_end_of_cell_marker = cell.metadata.get("lines_to_end_of_cell_marker")
if (
cell.cell_type == "raw"
and "active" not in self.metadata
and not any(tag.startswith("active-") for tag in self.metadata.get("tags", []))
):
self.metadata["active"] = ""
def is_code(self):
"""Is this cell a code cell?"""
if self.cell_type == "code":
return True
if (
self.cell_type == "raw"
and "active" in self.metadata
or any(tag.startswith("active-") for tag in self.metadata.get("tags", []))
):
return True
return False
def use_triple_quotes(self):
"""Should this markdown cell use triple quote?"""
if "cell_marker" not in self.unfiltered_metadata:
return False
cell_marker = self.unfiltered_metadata["cell_marker"]
if cell_marker in ['"""', "'''"]:
return True
if "," not in cell_marker:
return False
left, right = cell_marker.split(",")
return left[:3] == right[-3:] and left[:3] in ['"""', "'''"]
def cell_to_text(self):
"""Return the text representation for the cell"""
# Trigger cell marker in case we are using multiline quotes
if self.cell_type != "code" and not self.metadata and self.use_triple_quotes():
self.metadata["cell_type"] = self.cell_type
# Go notebooks have '%%' or '%% -' magic commands that need to be escaped
if self.default_language == "go" and self.language == "go":
self.source = [re.sub(r"^(//\s*)*(%%\s*$|%%\s+-.*$)", r"\1//gonb:\2", line) for line in self.source]
if self.is_code():
return self.code_to_text()
source = copy(self.source)
if not self.comment:
escape_code_start(source, self.ext, None)
return self.markdown_to_text(source)
def markdown_to_text(self, source):
"""Escape the given source, for a markdown cell"""
cell_markers = self.unfiltered_metadata.get("cell_marker", self.fmt.get("cell_markers"))
if cell_markers:
if "," in cell_markers:
left, right = cell_markers.split(",", 1)
else:
left = cell_markers + "\n"
if cell_markers.startswith(("r", "R")):
cell_markers = cell_markers[1:]
right = "\n" + cell_markers
if (left[:3] == right[-3:] or (left[:1] in ["r", "R"] and left[1:4] == right[-3:])) and right[-3:] in [
'"""',
"'''",
]:
# Markdown cells that contain a backslash should be encoded as raw strings
if left[:1] not in ["r", "R"] and "\\" in "\n".join(source) and self.fmt.get("format_name") == "percent":
left = "r" + left
source = copy(source)
source[0] = left + source[0]
source[-1] = source[-1] + right
return source
if (
self.comment
and self.comment != "#'"
and is_active(self.ext, self.metadata)
and self.fmt.get("format_name") not in ["percent", "hydrogen"]
):
source = copy(source)
comment_magic(
source,
self.language,
self.comment_magics,
explicitly_code=self.cell_type == "code",
)
return comment_lines(source, self.comment, self.comment_suffix)
def code_to_text(self):
"""Return the text representation of this cell as a code cell"""
raise NotImplementedError("This method must be implemented in a sub-class")
def remove_eoc_marker(self, text, next_text):
"""Remove end-of-cell marker when possible"""
# pylint: disable=W0613,R0201
return text
class MarkdownCellExporter(BaseCellExporter):
"""A class that represent a notebook cell as Markdown"""
default_comment_magics = False
cell_reader = MarkdownCellReader
def __init__(self, *args, **kwargs):
BaseCellExporter.__init__(self, *args, **kwargs)
self.comment = ""
def html_comment(self, metadata, code="region"):
"""Protect a Markdown or Raw cell with HTML comments"""
if metadata:
region_start = [
"",
]
region_start = " ".join(region_start)
else:
region_start = f""
return [region_start] + self.source + [f""]
def cell_to_text(self):
"""Return the text representation of a cell"""
if self.cell_type == "markdown":
if self.doxygen_equation_markers and self.cell_type == "markdown":
self.source = markdown_to_doxygen("\n".join(self.source)).splitlines()
# Is an explicit region required?
if self.metadata:
protect = True
else:
# Would the text be parsed to a shorter cell/a cell with a different type?
cell, pos = self.cell_reader(self.fmt).read(self.source)
protect = pos < len(self.source) or cell.cell_type != self.cell_type
if protect:
return self.html_comment(self.metadata, self.metadata.pop("region_name", "region"))
return self.source
return self.code_to_text()
def code_to_text(self):
"""Return the text representation of a code cell"""
source = copy(self.source)
comment_magic(source, self.language, self.comment_magics)
if self.metadata.get("active") == "":
self.metadata.pop("active")
self.language = self.metadata.pop("language", self.language)
if self.cell_type == "raw" and not is_active(self.ext, self.metadata, False):
return self.html_comment(self.metadata, "raw")
options = metadata_to_text(self.language, self.metadata)
code_cell_delimiter = three_backticks_or_more(self.source)
return [code_cell_delimiter + options] + source + [code_cell_delimiter]
class RMarkdownCellExporter(MarkdownCellExporter):
"""A class that represent a notebook cell as R Markdown"""
default_comment_magics = True
cell_reader = RMarkdownCellReader
def __init__(self, *args, **kwargs):
MarkdownCellExporter.__init__(self, *args, **kwargs)
self.ext = ".Rmd"
self.comment = ""
def code_to_text(self):
"""Return the text representation of a code cell"""
active = is_active(self.ext, self.metadata)
source = copy(self.source)
if active:
comment_magic(source, self.language, self.comment_magics)
lines = []
if not is_active(self.ext, self.metadata):
self.metadata["eval"] = False
options = metadata_to_rmd_options(self.language, self.metadata, self.use_runtools)
lines.append(f"```{{{options}}}")
lines.extend(source)
lines.append("```")
return lines
def endofcell_marker(source, comment):
"""Issues #31 #38: does the cell contain a blank line? In that case
we add an end-of-cell marker"""
endofcell = "-"
while True:
endofcell_re = re.compile(rf"^{re.escape(comment)}( )" + endofcell + r"\s*$")
if list(filter(endofcell_re.match, source)):
endofcell = endofcell + "-"
else:
return endofcell
class LightScriptCellExporter(BaseCellExporter):
"""A class that represent a notebook cell as a Python or Julia script"""
default_comment_magics = True
use_cell_markers = True
cell_marker_start = None
cell_marker_end = None
def __init__(self, *args, **kwargs):
BaseCellExporter.__init__(self, *args, **kwargs)
if "cell_markers" in self.fmt:
if "," not in self.fmt["cell_markers"]:
warnings.warn(
"Ignored cell markers '{}' as it does not match the expected 'start,end' pattern".format(
self.fmt.pop("cell_markers")
)
)
elif self.fmt["cell_markers"] != "+,-":
self.cell_marker_start, self.cell_marker_end = self.fmt["cell_markers"].split(",", 1)
for key in ["endofcell"]:
if key in self.unfiltered_metadata:
self.metadata[key] = self.unfiltered_metadata[key]
def is_code(self):
# Treat markdown cells with metadata as code cells (#66)
if (self.cell_type == "markdown" and self.metadata) or self.use_triple_quotes():
if is_active(self.ext, self.metadata):
self.metadata["cell_type"] = self.cell_type
self.source = self.markdown_to_text(self.source)
self.cell_type = "code"
self.unfiltered_metadata = copy(self.unfiltered_metadata)
self.unfiltered_metadata.pop("cell_marker", "")
return True
return super().is_code()
def code_to_text(self):
"""Return the text representation of a code cell"""
active = is_active(self.ext, self.metadata, same_language(self.language, self.default_language))
source = copy(self.source)
escape_code_start(source, self.ext, self.language)
comment_questions = self.metadata.pop("comment_questions", True)
if active:
comment_magic(source, self.language, self.comment_magics, comment_questions)
else:
source = self.markdown_to_text(source)
if (
active and comment_questions and need_explicit_marker(self.source, self.language, self.comment_magics)
) or self.explicit_start_marker(source):
self.metadata["endofcell"] = self.cell_marker_end or endofcell_marker(source, self.comment)
if not self.metadata or not self.use_cell_markers:
return source
lines = []
endofcell = self.metadata["endofcell"]
if endofcell == "-" or self.cell_marker_end:
del self.metadata["endofcell"]
cell_start = [self.comment, self.cell_marker_start or "+"]
options = metadata_to_double_percent_options(self.metadata, self.cell_metadata_json)
if options:
cell_start.append(options)
lines.append(" ".join(cell_start))
lines.extend(source)
lines.append(self.comment + f" {endofcell}")
return lines
def explicit_start_marker(self, source):
"""Does the python representation of this cell requires an explicit
start of cell marker?"""
if not self.use_cell_markers:
return False
if self.metadata:
return True
if self.cell_marker_start:
start_code_re = re.compile("^" + self.comment + r"\s*" + self.cell_marker_start + r"\s*(.*)$")
end_code_re = re.compile("^" + self.comment + r"\s*" + self.cell_marker_end + r"\s*$")
if start_code_re.match(source[0]) or end_code_re.match(source[0]):
return False
if all([line.startswith(self.comment) for line in self.source]):
return True
if LightScriptCellReader(self.fmt).read(source)[1] < len(source):
return True
return False
def remove_eoc_marker(self, text, next_text):
"""Remove end of cell marker when next cell has an explicit start marker"""
if self.cell_marker_start:
return text
if self.is_code() and text[-1] == self.comment + " -":
# remove end of cell marker when redundant with next explicit marker
if not next_text or next_text[0].startswith(self.comment + " +"):
text = text[:-1]
# When we do not need the end of cell marker, number of blank lines is the max
# between that required at the end of the cell, and that required before the next cell.
if self.lines_to_end_of_cell_marker and (
self.lines_to_next_cell is None or self.lines_to_end_of_cell_marker > self.lines_to_next_cell
):
self.lines_to_next_cell = self.lines_to_end_of_cell_marker
else:
# Insert blank lines at the end of the cell
blank_lines = self.lines_to_end_of_cell_marker
if blank_lines is None:
# two blank lines when required by pep8
blank_lines = pep8_lines_between_cells(text[:-1], next_text, self.ext)
blank_lines = 0 if blank_lines < 2 else 2
text = text[:-1] + [""] * blank_lines + text[-1:]
return text
class BareScriptCellExporter(LightScriptCellExporter):
"""A class that writes notebook cells as scripts with no cell markers"""
use_cell_markers = False
class RScriptCellExporter(BaseCellExporter):
"""A class that can represent a notebook cell as a R script"""
default_comment_magics = True
def __init__(self, *args, **kwargs):
BaseCellExporter.__init__(self, *args, **kwargs)
self.comment = "#'"
def code_to_text(self):
"""Return the text representation of a code cell"""
active = is_active(self.ext, self.metadata)
source = copy(self.source)
escape_code_start(source, self.ext, self.language)
if active:
comment_magic(source, self.language, self.comment_magics)
if not active:
source = ["# " + line if line else "#" for line in source]
lines = []
if not is_active(self.ext, self.metadata):
self.metadata["eval"] = False
options = metadata_to_rmd_options(None, self.metadata, self.use_runtools)
if options:
lines.append(f"#+ {options}")
lines.extend(source)
return lines
class DoublePercentCellExporter(BaseCellExporter): # pylint: disable=W0223
"""A class that can represent a notebook cell as a Spyder/VScode script (#59)"""
default_comment_magics = True
parse_cell_language = True
def __init__(self, *args, **kwargs):
BaseCellExporter.__init__(self, *args, **kwargs)
self.cell_markers = self.fmt.get("cell_markers")
def cell_to_text(self):
"""Return the text representation for the cell"""
# Go notebooks have '%%' or '%% -' magic commands that need to be escaped
if self.default_language == "go" and self.language == "go":
self.source = [re.sub(r"^(//\s*)*(%%\s*$|%%\s+-.*$)", r"\1//gonb:\2", line) for line in self.source]
active = is_active(self.ext, self.metadata, same_language(self.language, self.default_language))
if self.cell_type == "raw" and "active" in self.metadata and self.metadata["active"] == "":
del self.metadata["active"]
if not self.is_code():
self.metadata["cell_type"] = self.cell_type
options = metadata_to_double_percent_options(self.metadata, self.cell_metadata_json)
indent = ""
if self.is_code() and active and self.source:
first_line = self.source[0]
if first_line.strip():
left_space = re.compile(r"^(\s*)").match(first_line)
if left_space:
indent = left_space.groups()[0]
if options.startswith("%") or not options:
lines = comment_lines(["%%" + options], indent + self.comment, self.comment_suffix)
else:
lines = comment_lines(["%% " + options], indent + self.comment, self.comment_suffix)
if self.is_code() and active:
source = copy(self.source)
comment_magic(source, self.language, self.comment_magics)
if source == [""]:
return lines
return lines + source
return lines + self.markdown_to_text(self.source)
class HydrogenCellExporter(DoublePercentCellExporter): # pylint: disable=W0223
"""A class that can represent a notebook cell as a Hydrogen script (#59)"""
default_comment_magics = False
parse_cell_language = False
class SphinxGalleryCellExporter(BaseCellExporter): # pylint: disable=W0223
"""A class that can represent a notebook cell as a
Sphinx Gallery script (#80)"""
default_cell_marker = "#" * 79
default_comment_magics = True
def __init__(self, *args, **kwargs):
BaseCellExporter.__init__(self, *args, **kwargs)
self.comment = "#"
for key in ["cell_marker"]:
if key in self.unfiltered_metadata:
self.metadata[key] = self.unfiltered_metadata[key]
if self.fmt.get("rst2md"):
raise ValueError(
"The 'rst2md' option is a read only option. The reverse conversion is not "
"implemented. Please either deactivate the option, or save to another format."
) # pragma: no cover
def cell_to_text(self):
"""Return the text representation for the cell"""
if self.cell_type == "code":
source = copy(self.source)
return comment_magic(source, self.language, self.comment_magics)
if "cell_marker" in self.metadata:
cell_marker = self.metadata.pop("cell_marker")
else:
cell_marker = self.default_cell_marker
if self.source == [""]:
return [cell_marker] if cell_marker in ['""', "''"] else ['""']
if cell_marker in ['"""', "'''"]:
return [cell_marker] + self.source + [cell_marker]
return [(cell_marker if cell_marker.startswith("#" * 20) else self.default_cell_marker)] + comment_lines(
self.source, self.comment, self.comment_suffix
)
================================================
FILE: src/jupytext/cli.py
================================================
"""`jupytext` as a command line tool"""
import argparse
import glob
import json
import os
import re
import shlex
import subprocess
import sys
import warnings
from copy import copy
from tempfile import NamedTemporaryFile
from typing import Optional
from .combine import combine_inputs_with_outputs
from .compare import NotebookDifference, compare, test_round_trip_conversion
from .config import load_jupytext_config, notebook_formats
from .formats import (
_BINARY_FORMAT_OPTIONS,
_VALID_FORMAT_OPTIONS,
JUPYTEXT_FORMATS,
NOTEBOOK_EXTENSIONS,
check_auto_ext,
check_file_version,
long_form_multiple_formats,
long_form_one_format,
short_form_one_format,
)
from .header import recursive_update
from .jupytext import (
create_prefix_dir,
get_formats_from_notebook_path,
read,
reads,
write,
writes,
)
from .kernels import find_kernel_specs, get_kernel_spec, kernelspec_from_language
from .languages import _SCRIPT_EXTENSIONS
from .paired_paths import (
InconsistentPath,
base_path,
find_base_path_and_format,
full_path,
paired_paths,
)
from .pairs import latest_inputs_and_outputs
from .sync_pairs import read_pair, write_pair
from .version import __version__
def system(*args, **kwargs):
"""Execute the given bash command"""
kwargs.setdefault("stdout", subprocess.PIPE)
proc = subprocess.Popen(args, **kwargs)
out, _ = proc.communicate()
if proc.returncode:
raise SystemExit(proc.returncode)
return out.decode("utf-8")
def tool_version(tool):
try:
args = tool.split(" ")
args.append("--version")
return system(*args)
except (OSError, SystemExit): # pragma: no cover
return None
def str2bool(value):
"""Parse Yes/No/Default string
https://stackoverflow.com/questions/15008758/parsing-boolean-values-with-argparse"""
if value.lower() in ("yes", "true", "t", "y", "1"):
return True
if value.lower() in ("no", "false", "f", "n", "0"):
return False
if value.lower() in ("d", "default", ""):
return None
raise argparse.ArgumentTypeError("Expected: (Y)es/(T)rue/(N)o/(F)alse/(D)efault")
def parse_jupytext_args(args=None):
"""Command line parser for jupytext"""
parser = argparse.ArgumentParser(
description="Jupyter Notebooks as Markdown Documents, Julia, Python or R Scripts",
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
)
# Input
parser.add_argument(
"notebooks",
help="One or more notebook(s). Notebook is read from stdin when this argument is empty.",
nargs="*",
)
parser.add_argument(
"--from",
dest="input_format",
help="Jupytext format for the input(s). Inferred from the file extension and content when missing.",
)
# Destination format & act on metadata
selected_file_extensions = ["md", "Rmd", "jl", "py", "R"]
parser.add_argument(
"--to",
dest="output_format",
help=(
"The destination format: 'ipynb', 'markdown' or 'script', or a file extension: "
"'{}', ... or 'auto' (script extension matching the notebook language), "
"or a combination of an extension and a format name, e.g. {} ".format(
"', '".join(selected_file_extensions),
", ".join({f"md:{fmt.format_name}" for fmt in JUPYTEXT_FORMATS if fmt.extension == ".md"}),
)
+ " or {}. ".format(", ".join({f"py:{fmt.format_name}" for fmt in JUPYTEXT_FORMATS if fmt.extension == ".py"}))
+ "The default format for scripts is the 'percent' format, "
"which uses '# %%%%' as cell markers and is compatible with VS Code and PyCharm. "
"Alternatively, you can also use the 'light' format, which uses fewer cell markers. "
"The main formats (MyST Markdown, Markdown, percent, light) preserve "
"notebooks and text documents in a roundtrip. Use the "
"--test and and --test-strict commands to test the roundtrip on your files. "
"Read more about the available formats at "
"https://jupytext.readthedocs.io/en/latest/formats.html. "
"NB: in addition to the extensions listed above, you can also use these: '{}'".format(
"', '".join(
sorted(
{ext.removeprefix(".") for ext in NOTEBOOK_EXTENSIONS}
- set(selected_file_extensions + ["auto", "ipynb"])
)
)
)
),
)
# Destination file
parser.add_argument(
"-o",
"--output",
help="Destination file. Defaults to the original file, "
"with prefix/suffix/extension changed according to "
"the destination format. "
"Use '-' to print the notebook on stdout.",
)
parser.add_argument(
"--update",
action="store_true",
help="Preserve the output cells when the destination notebook is an .ipynb file that already exists",
)
parser.add_argument(
"--set-formats",
type=str,
help="Turn the notebook or text document to one or more alternative representations "
"with e.g. '--set-formats ipynb,py:light'. "
"The --set-formats option also triggers the creation/update of all paired files",
)
# Action: convert(default)/version/list paired paths/sync/apply/test
action = parser.add_mutually_exclusive_group()
action.add_argument(
"--sync",
"-s",
help="Synchronize the content of the paired representations of "
"the given notebook. Input cells are taken from the file that "
"was last modified, and outputs are read from the ipynb file, "
"if present.",
action="store_true",
)
action.add_argument(
"--paired-paths",
"-p",
help="List the locations of the alternative representations for this notebook.",
action="store_true",
)
parser.add_argument(
"--format-options",
"--opt",
action="append",
help="Set format options with e.g. '--opt comment_magics=true' or '--opt notebook_metadata_filter=-kernelspec'.",
)
parser.add_argument(
"--update-metadata",
default={},
type=json.loads,
help="Update the notebook metadata with the desired dictionary. "
"Argument must be given in JSON format. For instance, if you "
"want to activate a pairing in the generated file, use e.g. "
"""--update-metadata '{"jupytext":{"formats":"ipynb,py:light"}}' """
"See also the --opt and --set-formats options for other ways "
"to operate on the Jupytext metadata.",
)
parser.add_argument(
"--use-source-timestamp",
help="Set the modification timestamp of the output file(s) equal"
"to that of the source file, and keep the source file and "
"its timestamp unchanged.",
action="store_true",
)
parser.add_argument(
"--check-source-is-newer",
help="Check that the file given as argument is the most recent of all paired files, and "
"if applicable, checks that it is newer than the destination file.",
action="store_true",
)
parser.add_argument(
"--warn-only",
"-w",
action="store_true",
help="Only issue a warning and continue processing other notebooks when the conversion of a given notebook fails",
)
action.add_argument(
"--test",
action="store_true",
help="Test that the notebook is stable under a round trip conversion, up to the expected changes",
)
action.add_argument(
"--test-strict",
action="store_true",
help="Test that the notebook is strictly stable under a round trip conversion",
)
parser.add_argument(
"--stop",
"-x",
dest="stop_on_first_error",
action="store_true",
help="In --test mode, stop on first round trip conversion error, and report stack traceback",
)
# Pipe notebook inputs into other commands
parser.add_argument(
"--pipe",
action="append",
help="Pipe the text representation (in format --pipe-fmt) of the notebook into "
"another program, and read the notebook back. For instance, reformat "
"your notebook with: "
"'jupytext notebook.ipynb --pipe black' "
"If you want to reformat it and sync the paired representation, execute: "
"'jupytext notebook.ipynb --sync --pipe black' "
"In case the program that you want to execute does not accept pipes, use {} "
"as a placeholder for a temporary file name into which jupytext will "
"write the text representation of the notebook, e.g.: "
"jupytext notebook.ipynb --pipe 'black {}'",
)
parser.add_argument(
"--diff",
"-d",
action="store_true",
help="Show the differences between (the inputs) of two notebooks",
)
parser.add_argument(
"--diff-format",
help="The text format used to show differences in --diff",
)
parser.add_argument(
"--check",
action="append",
help="Pipe the text representation (in format --pipe-fmt) of the notebook into "
"another program, and test that the returned value is non zero. For "
"instance, test that your notebook is pep8 compliant with: "
"'jupytext notebook.ipynb --check flake8' "
"or run pytest on your notebook with: "
"'jupytext notebook.ipynb --check pytest' "
"In case the program that you want to execute does not accept pipes, use {} "
"as a placeholder for a temporary file name into which jupytext will "
"write the text representation of the notebook, e.g.: "
"jupytext notebook.ipynb --check 'pytest {}'",
)
parser.add_argument(
"--pipe-fmt",
default="auto:percent",
help="The format in which the notebook should be piped to other programs, "
"when using the --pipe and/or --check commands.",
)
# Execute the notebook
parser.add_argument(
"--set-kernel",
"-k",
type=str,
help="Set the kernel with the given name on the notebook. "
"Use '--set-kernel -' to set a kernel matching the current "
"environment on Python notebooks, and matching the notebook "
"language otherwise (get the list of available kernels with "
"'jupyter kernelspec list')",
)
parser.add_argument(
"--execute",
action="store_true",
help="Execute the notebook with the given kernel. In the "
"--pre-commit-mode, the notebook is executed only if a code "
"cell changed, or if some execution outputs are missing "
"or not ordered.",
)
parser.add_argument(
"--run-path",
type=str,
help="Execute the notebook at the given path (defaults to the notebook parent directory)",
)
parser.add_argument(
"--quiet",
"-q",
action="store_true",
help="Quiet mode: do not comment about files being updated or created",
)
parser.add_argument(
"--show-changes",
action="store_true",
help="Display the diff for each output file",
)
action.add_argument(
"--version",
"-v",
action="store_true",
help="Show jupytext's version number and exit",
)
parser.add_argument(
"--pre-commit",
action="store_true",
help="Ignore the notebook argument, and instead apply Jupytext "
"on the notebooks found in the git index, which have an "
"extension that matches the (optional) --from argument.",
)
parser.add_argument(
"--pre-commit-mode",
action="store_true",
help="This is a mode that is compatible with the pre-commit framework. "
"In this mode, --sync won't use timestamp but instead will "
"determines the source notebook as the element of the pair "
"that is added to the git index. An alert is raised if multiple inconsistent representations are "
"in the index. It also raises an alert after updating the paired files or outputs if those "
"files need to be added to the index. Finally, filepaths that aren't in the source format "
"you are trying to convert from are ignored.",
)
return parser.parse_args(args)
def jupytext(args=None):
"""Entry point for the jupytext script"""
args = parse_jupytext_args(args)
def log(text):
if not args.quiet:
sys.stdout.write(text + "\n")
if args.version:
log(__version__)
return 0
if args.pre_commit:
warnings.warn(
"The --pre-commit argument is deprecated. "
"Please consider switching to the pre-commit.com framework "
"(let us know at https://github.com/mwouts/jupytext/issues "
"if that is an issue for you)",
DeprecationWarning,
)
if args.notebooks:
raise ValueError("--pre-commit takes notebooks from the git index. Do not pass any notebook here.")
args.notebooks = notebooks_in_git_index(args.input_format)
log("[jupytext] Notebooks in git index are:")
for nb_file in args.notebooks:
log(nb_file)
# Read notebook from stdin
if not args.notebooks:
if not args.pre_commit:
args.notebooks = ["-"]
if args.set_formats is not None:
# Replace empty string with None
args.update_metadata = recursive_update(args.update_metadata, {"jupytext": {"formats": args.set_formats or None}})
args.sync = True
if args.paired_paths:
if len(args.notebooks) != 1:
raise ValueError("--paired-paths applies to a single notebook")
print_paired_paths(args.notebooks[0], args.input_format)
return 1
if args.run_path:
args.execute = True
if (args.test or args.test_strict) and not args.output_format and not args.output and not args.sync:
raise ValueError("Please provide one of --to, --output or --sync")
if (
not args.output_format
and not args.output
and not args.sync
and not args.pipe
and not args.diff
and not args.check
and not args.update_metadata
and not args.format_options
and not args.set_kernel
and not args.execute
):
raise ValueError(
"Please provide one of --to, --output, --set-formats, --sync, --pipe, --diff, "
"--check, --update-metadata, --format-options, --set-kernel or --execute"
)
if args.diff:
if (
len(args.notebooks) != 2
or args.output_format
or args.output
or args.sync
or args.pipe
or args.check
or args.update_metadata
or args.format_options
or args.set_kernel
or args.execute
):
raise ValueError(
"Please provide two notebooks after 'jupytext --diff'.\n"
"NB: Use --show-changes if you wish to see the changes in "
"a notebook being updated by Jupytext."
)
nb_file1, nb_file2 = args.notebooks
nb1 = read(nb_file1)
nb2 = read(nb_file2)
def fmt_if_not_ipynb(nb):
fmt = nb.metadata["jupytext"]["text_representation"]
if fmt["extension"] == ".ipynb":
return None
return short_form_one_format(fmt)
diff_fmt = args.diff_format or fmt_if_not_ipynb(nb1) or fmt_if_not_ipynb(nb2) or "md"
diff = compare(
writes(nb2, diff_fmt),
writes(nb1, diff_fmt),
nb_file2,
nb_file1,
return_diff=True,
)
sys.stdout.write(diff)
return
if args.output and len(args.notebooks) != 1:
raise ValueError("Please input a single notebook when using --output")
# Warn if '--to' is used in place of '--output'
if (
not args.output
and args.output_format
and "." in args.output_format
# a suffix is expected to start with one of these characters #901
and not args.output_format.startswith((".", "-", "_"))
and "//" not in args.output_format
):
def single_line(msg, *args, **kwargs):
return f"[warning] {msg}\n"
warnings.formatwarning = single_line
warnings.warn(
"You might have passed a file name to the '--to' option, "
"when a format description was expected. Maybe you want to use the '-o' option instead?"
)
if args.input_format:
args.input_format = long_form_one_format(args.input_format)
if args.output_format:
args.output_format = long_form_one_format(args.output_format)
set_format_options(args.output_format, args.format_options)
# Wildcard extension on Windows #202
notebooks = []
for pattern in args.notebooks:
if "*" in pattern or "?" in pattern:
# Exclude the .jupytext.py configuration file
notebooks.extend(glob.glob(pattern, recursive=True))
else:
notebooks.append(pattern)
# Count how many files have round-trip issues when testing
exit_code = 0
for nb_file in notebooks:
if not args.warn_only:
exit_code += jupytext_single_file(nb_file, args, log)
else:
try:
exit_code += jupytext_single_file(nb_file, args, log)
except Exception as err:
sys.stderr.write(f"[jupytext] Error: {str(err)}\n")
return exit_code
def jupytext_single_file(nb_file, args, log):
"""Apply the jupytext command, with given arguments, to a single file"""
if nb_file == "-" and args.sync:
msg = "Missing notebook path."
if args.set_formats is not None and os.path.isfile(args.set_formats):
msg += f" Did you mean 'jupytext --sync {args.set_formats}' ?"
raise ValueError(msg)
nb_dest = None
if args.output:
nb_dest = args.output
elif nb_file == "-":
nb_dest = "-"
else:
try:
bp = base_path(nb_file, args.input_format)
except InconsistentPath:
if args.pre_commit_mode:
log(
"[jupytext] Ignoring unmatched input path {}{}".format(
nb_file,
f" for format {args.input_format}" if args.input_format else "",
)
)
return 0
raise
if args.output_format:
nb_dest = full_path(bp, args.output_format)
config = load_jupytext_config(os.path.abspath(nb_file))
# Just acting on metadata / pipe => save in place
save_in_place = not nb_dest and not args.sync
if save_in_place:
nb_dest = nb_file
if nb_dest == "-":
args.quiet = True
# I. ### Read the notebook ###
fmt = copy(args.input_format) or {}
if not fmt:
ext = os.path.splitext(nb_file)[1]
if ext:
fmt = {"extension": ext}
if fmt:
set_format_options(fmt, args.format_options)
log(
"[jupytext] Reading {}{}".format(
nb_file if nb_file != "-" else "stdin",
f" in format {short_form_one_format(fmt)}" if "extension" in fmt else "",
)
)
timestamp_checker = TimestampChecker(pre_commit_mode=args.pre_commit_mode)
timestamp_checker.get_and_check_timestamp(nb_file)
notebook = read(nb_file, fmt=fmt, config=config)
if "extension" in fmt and "format_name" not in fmt:
text_representation = notebook.metadata.get("jupytext", {}).get("text_representation", {})
if text_representation.get("extension") == fmt["extension"]:
fmt["format_name"] = text_representation["format_name"]
# Compute actual extension when using script/auto, and update nb_dest if necessary
dest_fmt = args.output_format
if dest_fmt and dest_fmt["extension"] == ".auto":
dest_fmt = check_auto_ext(dest_fmt, notebook.metadata, "--to")
if not args.output and nb_file != "-":
nb_dest = full_path(base_path(nb_file, args.input_format), dest_fmt)
# Set the kernel
set_kernel = args.set_kernel
if (not set_kernel) and args.execute and notebook.metadata.get("kernelspec", {}).get("name") is None:
set_kernel = "-"
if set_kernel:
if set_kernel == "-":
language = (
notebook.metadata.get("jupytext", {}).get("main_language") or notebook.metadata["kernelspec"]["language"]
)
if not language:
raise ValueError("Cannot infer a kernel as notebook language is not defined")
kernelspec = kernelspec_from_language(language)
else:
try:
kernelspec = get_kernel_spec(set_kernel)
except KeyError as err:
raise KeyError(f"Please choose a kernel name among {find_kernel_specs().keys()}") from err
kernelspec = {
"name": args.set_kernel,
"language": kernelspec.language,
"display_name": kernelspec.display_name,
}
log("[jupytext] Setting kernel {}".format(kernelspec.get("name")))
args.update_metadata["kernelspec"] = kernelspec
# Read paired notebooks
nb_files = [nb_file, nb_dest]
if args.sync:
# If we are also setting the formats, we take the information
# from the --set-formats option
if args.set_formats is not None:
formats = long_form_multiple_formats(args.set_formats)
else:
formats = notebook_formats(notebook, config, nb_file, fallback_on_current_fmt=False)
set_prefix_and_suffix(fmt, formats, nb_file)
try:
notebook, inputs_nb_file, outputs_nb_file = load_paired_notebook(
notebook, fmt, config, formats, nb_file, log, args.pre_commit_mode, timestamp_checker
)
nb_files = [inputs_nb_file, outputs_nb_file]
except NotAPairedNotebook as err:
sys.stderr.write("[jupytext] Warning: " + str(err) + "\n")
return 0
except InconsistentVersions as err:
sys.stderr.write("[jupytext] Error: " + str(err) + "\n")
return 1
# Are we updating a text file that has a metadata filter? #212
if args.update_metadata or args.format_options:
if notebook.metadata.get("jupytext", {}).get("notebook_metadata_filter") == "-all":
notebook.metadata.get("jupytext", {}).pop("notebook_metadata_filter")
# Update the metadata
if args.update_metadata:
log(f"[jupytext] Updating notebook metadata with '{json.dumps(args.update_metadata)}'")
if "kernelspec" in args.update_metadata and "main_language" in notebook.metadata.get("jupytext", {}):
notebook.metadata["jupytext"].pop("main_language")
recursive_update(notebook.metadata, args.update_metadata)
# II. ### Apply commands onto the notebook ###
# Pipe the notebook into the desired commands
if nb_file == "-":
prefix = None
directory = None
else:
prefix = os.path.splitext(os.path.basename(nb_file))[0]
directory = os.path.dirname(nb_file)
for cmd in args.pipe or []:
notebook = pipe_notebook(
notebook,
cmd,
args.pipe_fmt,
quiet=args.quiet,
prefix=prefix,
directory=directory,
warn_only=args.warn_only,
)
# and/or test the desired commands onto the notebook
for cmd in args.check or []:
pipe_notebook(
notebook,
cmd,
args.pipe_fmt,
update=False,
quiet=args.quiet,
prefix=prefix,
directory=directory,
warn_only=args.warn_only,
)
if (
args.execute
and args.pre_commit_mode
and execution_counts_are_in_order(notebook)
and not code_cells_have_changed(notebook, nb_files)
):
log(f"[jupytext] Execution of {shlex.quote(nb_file)} skipped as code cells have not changed and outputs are present.")
args.execute = False
# Execute the notebook
if args.execute:
kernel_name = notebook.metadata.get("kernelspec", {}).get("name")
log(f"[jupytext] Executing notebook with kernel {kernel_name}")
if nb_dest is not None and nb_dest != "-":
nb_path = os.path.dirname(nb_dest)
elif nb_file != "-":
nb_path = os.path.dirname(nb_file)
else:
nb_path = None
run_path = args.run_path or nb_path
if args.run_path and not os.path.isdir(run_path):
# is this a relative directory?
for base_dir in [nb_path, os.getcwd()]:
try_path = os.path.join(base_dir, run_path)
if os.path.isdir(try_path):
run_path = try_path
break
if not os.path.isdir(run_path):
raise ValueError(f"--run-path={args.run_path} is not a valid path")
if run_path:
resources = {"metadata": {"path": run_path}}
else:
resources = {}
try:
from nbconvert.preprocessors import ExecutePreprocessor
exec_proc = ExecutePreprocessor(timeout=None, kernel_name=kernel_name)
exec_proc.preprocess(notebook, resources=resources)
except (ImportError, RuntimeError) as err:
if args.pre_commit_mode:
raise RuntimeError(
"An error occurred while executing the notebook. Please "
"make sure that you have listed 'nbconvert' and 'ipykernel' "
"under 'additional_dependencies' in the jupytext hook."
) from err
raise RuntimeError(
"An error occurred while executing the notebook. Please "
"make sure that 'nbconvert' and 'ipykernel' are installed."
) from err
# III. ### Possible actions ###
# a. Test round trip conversion
if args.test or args.test_strict:
try:
# Round trip from an ipynb document
if fmt["extension"] == ".ipynb":
test_round_trip_conversion(
notebook,
dest_fmt,
update=args.update,
allow_expected_differences=not args.test_strict,
stop_on_first_error=args.stop_on_first_error,
)
# Round trip from a text file
else:
# We read the original text from disk a second time
with open(nb_file, encoding="utf-8") as fp:
org_text = fp.read()
# We also make sure that the text file
# has not changed since we first read it!
timestamp_checker.check_timestamp(nb_file)
# If the destination is not ipynb, we convert to/back that format
if dest_fmt["extension"] != ".ipynb":
dest_text = writes(notebook, fmt=dest_fmt)
notebook = reads(dest_text, fmt=dest_fmt)
text = writes(notebook, fmt=fmt, config=config)
if args.test_strict:
compare(text, org_text)
else:
# we ignore the YAML header in the comparison #414
comment = _SCRIPT_EXTENSIONS.get(fmt["extension"], {}).get("comment", "")
# white spaces between the comment char and the YAML delimiters are allowed
if comment:
comment = comment + r"\s*"
yaml_header = re.compile(
r"^{comment}---\s*\n.*\n{comment}---\s*\n".format(comment=comment),
re.MULTILINE | re.DOTALL,
)
compare(re.sub(yaml_header, "", text), re.sub(yaml_header, "", org_text))
except (NotebookDifference, AssertionError) as err:
sys.stdout.write(f"{nb_file}: {str(err)}")
return 1
return 0
# b. Output to the desired file or format
untracked_files = 0
def lazy_write(
path,
fmt=None,
action=None,
update_timestamp_only=False,
force_update_timestamp=False,
):
"""Write the notebook only if it has changed"""
# Used in tests only
if _callback_on_lazy_write is not None:
_callback_on_lazy_write(path)
if path == "-":
timestamp_checker.check_all_timestamps()
write(notebook, "-", fmt=fmt)
return
nonlocal untracked_files
if update_timestamp_only:
modified = False
else:
_, ext = os.path.splitext(path)
fmt = copy(fmt or {})
fmt = long_form_one_format(fmt, update={"extension": ext})
new_content = writes(notebook, fmt=fmt, config=config)
diff = None
if not new_content.endswith("\n"):
new_content += "\n"
if not os.path.isfile(path):
modified = True
diff = "(file did not exist)"
else:
# We load the current file from disk
# NB: in the --to mode, it might be the first
# time we actually read this file
timestamp_checker.get_and_check_timestamp(path)
with open(path, encoding="utf-8") as fp:
current_content = fp.read()
timestamp_checker.check_timestamp(path)
modified = new_content != current_content
if modified and args.show_changes:
diff = compare(
new_content,
current_content,
"",
"",
return_diff=True,
)
tmp_path = path
if modified:
# The text representation of the notebook has changed, we write it on disk
create_prefix_dir(path, fmt)
# Create a temporary file in the same directory as path. Later on we will move
# that temporary file back to path (os.replace is atomic on most OS)
name, ext = os.path.splitext(path)
tmp_path = name + f"_tmp_jupytext_{os.getpid()}" + ext
with open(tmp_path, "w", encoding="utf-8") as fp:
fp.write(new_content)
# We check that none of the input files changed while we were
# doing our processing. If they did, we abort as we would
# otherwise overwrite the modifications.
try:
timestamp_checker.check_all_timestamps()
except SynchronousModificationError:
if modified:
os.remove(tmp_path)
raise
# When the content is unchanged, we still need to update the timestamp of
# the text file to make sure they remain more recent than the ipynb file, for compatibility with the
# Jupytext contents manager for Jupyter
if args.use_source_timestamp:
if tmp_path != nb_file:
log(f"[jupytext] Setting the timestamp of {shlex.quote(path)} equal to that of {shlex.quote(nb_file)}")
os.utime(tmp_path, (os.stat(nb_file).st_atime, os.stat(nb_file).st_mtime))
elif not modified:
if path.endswith(".ipynb"):
# No need to update the timestamp of ipynb files
log(f"[jupytext] Unchanged {shlex.quote(path)}")
elif args.sync and not force_update_timestamp:
# if the content is unchanged (and matches ipynb), we don't need
# to update the timestamp as the contents manager will not throw in
# that case (see the try/catch on read_pair(... must_match=True))
log(f"[jupytext] Unchanged {shlex.quote(path)}")
else:
log(f"[jupytext] Updating the timestamp of {shlex.quote(path)}")
os.utime(path, None)
if modified:
if action is None:
message = f"[jupytext] Updating {shlex.quote(path)}"
else:
message = "[jupytext] Writing {path}{format}{action}".format(
path=shlex.quote(path),
format=(" in format " + short_form_one_format(fmt) if fmt and "format_name" in fmt else ""),
action=action,
)
if args.show_changes:
message += " with this change:\n" + diff
log(message)
os.replace(tmp_path, path)
# If we changed the file timestamp, we update our checker accordingly
if modified or args.use_source_timestamp or force_update_timestamp:
timestamp_checker.update_timestamp(path)
if args.pre_commit:
system("git", "add", path)
if args.pre_commit_mode and is_untracked(path):
log(
f"[jupytext] Error: the git index is outdated.\n"
f"Please add the paired notebook with:\n"
f" git add {shlex.quote(path)}"
)
untracked_files += 1
return {"modified": modified}
if nb_dest:
if args.check_source_is_newer:
ts_src = timestamp_checker.check_file_is_newest(nb_file)
ts_dest = timestamp_checker.get_and_check_timestamp(nb_dest)
if ts_dest is not None and ts_dest > ts_src:
raise ValueError(f"Source {nb_file} is older than destination {nb_dest}")
if nb_dest == nb_file and not dest_fmt:
dest_fmt = fmt
# Test consistency between dest name and output format
if dest_fmt and nb_dest != "-":
base_path(nb_dest, dest_fmt)
# Describe what jupytext is doing
if save_in_place:
action = ""
elif os.path.isfile(nb_dest) and args.update:
if not nb_dest.endswith(".ipynb"):
raise ValueError("--update is only for ipynb files")
action = " (destination file updated)"
check_file_version(notebook, nb_file, nb_dest)
notebook = combine_inputs_with_outputs(notebook, read(nb_dest), fmt=fmt)
elif os.path.isfile(nb_dest):
suggest_update = " [use --update to preserve cell outputs and ids]" if nb_dest.endswith(".ipynb") else ""
action = f" (destination file replaced{suggest_update})"
else:
action = ""
formats = notebook.metadata.get("jupytext", {}).get("formats")
formats = long_form_multiple_formats(formats)
if formats:
try:
base_path_out, _ = find_base_path_and_format(nb_dest, formats)
except InconsistentPath:
# Drop 'formats' if the destination is not part of the paired notebooks
formats = {}
notebook.metadata.get("jupytext", {}).pop("formats")
lazy_write(nb_dest, fmt=dest_fmt, action=action)
nb_dest_in_pair = formats and any(
os.path.exists(alt_path) and os.path.samefile(nb_dest, alt_path)
for alt_path, _ in paired_paths(nb_file, fmt, formats)
)
if (
nb_dest_in_pair
and os.path.isfile(nb_file)
and not nb_file.endswith(".ipynb")
and os.path.isfile(nb_dest)
and nb_dest.endswith(".ipynb")
):
# If the destination is an ipynb file and is in the pair, then we
# update the original text file timestamp, as required by our Content Manager
# Otherwise Jupyter will refuse to open the paired notebook #335
# NB: An alternative is --use-source-timestamp
lazy_write(nb_file, update_timestamp_only=True)
# c. Synchronize paired notebooks
elif args.sync:
if args.check_source_is_newer:
timestamp_checker.check_file_is_newest(nb_file)
write_pair(nb_file, formats, lazy_write)
return untracked_files
def notebooks_in_git_index(fmt):
"""Return the list of modified and deleted ipynb files in the git index that match the given format"""
git_status = system("git", "status", "--porcelain")
re_modified = re.compile(r"^[AM]+\s+(?P.*)", re.MULTILINE)
modified_files_in_git_index = re_modified.findall(git_status)
files = []
for nb_file in modified_files_in_git_index:
if nb_file.startswith('"') and nb_file.endswith('"'):
nb_file = nb_file[1:-1]
try:
base_path(nb_file, fmt)
files.append(nb_file)
except InconsistentPath:
continue
return files
def is_untracked(filepath):
"""Check whether a file was created or modified and needs to be added to the git index"""
if not filepath:
return False
output = system("git", "ls-files", filepath).strip()
if output == "":
return True
output = system("git", "diff", filepath).strip()
if output != "":
return True
return False
def print_paired_paths(nb_file, fmt):
"""Display the paired paths for this notebook"""
formats = get_formats_from_notebook_path(nb_file, fmt)
if formats:
for path, _ in paired_paths(nb_file, fmt, formats):
if path != nb_file:
sys.stdout.write(path + "\n")
def set_format_options(fmt, format_options):
"""Apply the desired format options to the format description fmt"""
if not format_options:
return
for opt in format_options:
try:
key, value = opt.split("=")
except ValueError as err:
raise ValueError(f"Format options are expected to be of the form key=value, not '{opt}'") from err
if key not in _VALID_FORMAT_OPTIONS:
raise ValueError(
"'{}' is not a valid format option. Expected one of '{}'".format(key, "', '".join(_VALID_FORMAT_OPTIONS))
)
if key in _BINARY_FORMAT_OPTIONS:
value = str2bool(value)
fmt[key] = value
def set_prefix_and_suffix(fmt, formats, nb_file):
"""Add prefix and suffix information from jupytext.formats if format and path matches"""
for alt_fmt in long_form_multiple_formats(formats):
if alt_fmt["extension"] == fmt["extension"] and fmt.get("format_name") == alt_fmt.get("format_name"):
try:
base_path(nb_file, alt_fmt)
fmt.update(alt_fmt)
return
except InconsistentPath:
continue
class NotAPairedNotebook(ValueError):
"""An error raised when a notebook is not a paired notebook"""
class InconsistentVersions(ValueError):
"""An error raised when two paired files in the git index contain inconsistent representations"""
def file_in_git_index(path):
if not os.path.isfile(path):
return False
return system("git", "status", "--porcelain", path).strip().startswith(("M", "A"))
def git_timestamp(path):
if not os.path.isfile(path):
return None
# Files that are in the git index are considered most recent
if file_in_git_index(path):
return float("inf")
# Return the commit timestamp
try:
git_ts_str = system("git", "log", "-1", "--pretty=%ct", "--no-show-signature", path).strip()
except SystemExit as err:
if err.code == 128:
# git not initialized
git_ts_str = ""
else:
raise
if git_ts_str:
return float(git_ts_str)
# The file is not in the git index
return get_timestamp(path)
def get_timestamp(path: str) -> Optional[float]:
if not os.path.isfile(path):
return None
return os.stat(path).st_mtime
class SynchronousModificationError(OSError):
"""An error raised when a file was modified while Jupytext was running"""
class TimestampChecker:
"""
This class keeps track of the timestamps of files that have been used by Jupytext
when loading a paired notebook. Either the timestamp of each file was consulted to
identify the most recent input file, or its content was read.
"""
def __init__(self, pre_commit_mode: bool = False):
self.pre_commit_mode = pre_commit_mode
self._timestamps: dict[str, Optional[float]] = {}
def get_and_check_timestamp(self, path: str) -> Optional[float]:
if path in self._timestamps:
ts = self.check_timestamp(path)
else:
ts = get_timestamp(path)
self._timestamps[path] = ts
if self.pre_commit_mode:
return git_timestamp(path)
return ts
def check_timestamp(self, path: str) -> Optional[float]:
if path not in self._timestamps:
raise ValueError(
f"The timestamp of {shlex.quote(path)} was not previously recorded. So far Jupytext has only recorded timestamps for {', '.join(shlex.quote(p) for p in self._timestamps)}"
)
ts = get_timestamp(path)
old_ts = self._timestamps[path]
if old_ts is None and ts is not None:
raise SynchronousModificationError(f"The file {shlex.quote(path)} was created while Jupytext was running")
if old_ts is not None and ts is None:
raise SynchronousModificationError(f"The file {shlex.quote(path)} was deleted while Jupytext was running")
if ts != old_ts:
raise SynchronousModificationError(f"The file {shlex.quote(path)} was modified while Jupytext was running")
return ts
def update_timestamp(self, path: str):
ts = get_timestamp(path)
if ts is None:
raise FileNotFoundError(f"The file {shlex.quote(path)} does not exist")
self._timestamps[path] = ts
def check_all_timestamps(self):
for path in self._timestamps:
self.check_timestamp(path)
def check_file_is_newest(self, path: str) -> Optional[float]:
"""Check that the given file is the most recent among all files whose timestamp
was recorded by this TimestampChecker. Return its timestamp."""
ts = self._timestamps[path]
assert ts is not None, f"The timestamp of {shlex.quote(path)} was not previously recorded"
for p, p_ts in self._timestamps.items():
if p == path or p_ts is None:
continue
if p_ts > ts:
raise ValueError(f"Source {shlex.quote(path)} is older than paired file {shlex.quote(p)}")
return ts
# If not none, this function is called with the path of each file
# that Jupytext CLI considers to write back (to be used in tests)
_callback_on_lazy_write = None
def load_paired_notebook(
notebook, fmt, config, formats, nb_file, log, pre_commit_mode: bool, timestamp_checker: TimestampChecker
):
"""Update the notebook with the inputs and outputs of the most recent paired files"""
if not formats:
raise NotAPairedNotebook(f"{shlex.quote(nb_file)} is not a paired notebook")
formats = long_form_multiple_formats(formats)
_, fmt_with_prefix_suffix = find_base_path_and_format(nb_file, formats)
fmt.update(fmt_with_prefix_suffix)
def read_one_file(path, fmt):
if path == nb_file:
return notebook
log(f"[jupytext] Loading {shlex.quote(path)}")
timestamp_checker.get_and_check_timestamp(path)
return read(path, fmt=fmt, config=config)
if pre_commit_mode and file_in_git_index(nb_file):
# We raise an error if two representations of this notebook in the git index are inconsistent
nb_files_in_git_index = sorted(
((alt_path, alt_fmt) for alt_path, alt_fmt in paired_paths(nb_file, fmt, formats) if file_in_git_index(alt_path)),
key=lambda x: 0 if x[1]["extension"] != ".ipynb" else 1,
)
if len(nb_files_in_git_index) > 1:
path0, fmt0 = nb_files_in_git_index[0]
timestamp_checker.get_and_check_timestamp(path0)
with open(path0, encoding="utf-8") as fp:
text0 = fp.read()
for alt_path, alt_fmt in nb_files_in_git_index[1:]:
timestamp_checker.get_and_check_timestamp(alt_path)
nb = read(alt_path, fmt=alt_fmt, config=config)
alt_text = writes(nb, fmt=fmt0, config=config)
if alt_text != text0:
diff = compare(alt_text, text0, alt_path, path0, return_diff=True)
raise InconsistentVersions(
f"{shlex.quote(alt_path)} and {shlex.quote(path0)} are inconsistent.\n"
+ diff
+ f"\nPlease revert JUST ONE of the files with EITHER\n"
f" git reset {shlex.quote(alt_path)} && git checkout -- {shlex.quote(alt_path)}\nOR\n"
f" git reset {shlex.quote(path0)} && git checkout -- {shlex.quote(path0)}\n"
)
inputs, outputs = latest_inputs_and_outputs(nb_file, fmt, formats, timestamp_checker.get_and_check_timestamp)
notebook = read_pair(inputs, outputs, read_one_file)
return notebook, inputs.path, outputs.path
def exec_command(command, input=None, capture=False, warn_only=False, quiet=False):
"""Execute the desired command, and pipe the given input into it"""
assert isinstance(command, list)
if not quiet:
sys.stdout.write("[jupytext] Executing {}\n".format(" ".join(command)))
process = subprocess.Popen(
command,
**(dict(stdout=subprocess.PIPE, stdin=subprocess.PIPE) if input is not None else {}),
)
out, err = process.communicate(input=input)
if out and not capture and not quiet:
sys.stdout.write(out.decode("utf-8"))
if err:
sys.stderr.write(err.decode("utf-8"))
if process.returncode:
msg = f"The command '{' '.join(command)}' exited with code {process.returncode}"
hint = "" if warn_only else " (use --warn-only to turn this error into a warning)"
sys.stderr.write(f"[jupytext] {'Warning' if warn_only else 'Error'}: {msg}{hint}\n")
if not warn_only:
raise SystemExit(process.returncode)
return out
def pipe_notebook(
notebook,
command,
fmt="py:percent",
update=True,
quiet=False,
prefix=None,
directory=None,
warn_only=False,
):
"""Pipe the notebook, in the desired representation, to the given command. Update the notebook
with the returned content if desired."""
if command in ["black", "flake8", "autopep8"]:
command = command + " -"
elif command in ["pytest", "unittest"]:
command = command + " {}"
fmt = long_form_one_format(fmt, notebook.metadata, auto_ext_requires_language_info=False)
fmt = check_auto_ext(fmt, notebook.metadata, "--pipe-fmt")
text = writes(notebook, fmt)
command = shlex.split(command)
if "{}" in command:
if prefix is not None:
prefix = prefix + "-"
tmp_file_args = dict(
mode="w+",
encoding="utf8",
prefix=prefix,
suffix=fmt["extension"],
dir=directory,
delete=False,
)
try:
tmp = NamedTemporaryFile(**tmp_file_args)
except TypeError:
# NamedTemporaryFile does not have an 'encoding' argument on pypy
tmp_file_args.pop("encoding")
tmp = NamedTemporaryFile(**tmp_file_args)
try:
tmp.write(text)
tmp.close()
exec_command(
[cmd if cmd != "{}" else tmp.name for cmd in command],
capture=update,
quiet=quiet,
warn_only=warn_only,
)
if not update:
return notebook
piped_notebook = read(tmp.name, fmt=fmt)
finally:
os.remove(tmp.name)
else:
cmd_output = exec_command(
command,
text.encode("utf-8"),
capture=update,
warn_only=warn_only,
quiet=quiet,
)
if not update:
return notebook
if not cmd_output:
sys.stderr.write(
"[jupytext] The command '{}' had no output. As a result, the notebook is empty. "
"Is this expected? If not, use --check rather than --pipe for this command.".format(command)
)
piped_notebook = reads(cmd_output.decode("utf-8"), fmt)
if fmt["extension"] != ".ipynb":
piped_notebook = combine_inputs_with_outputs(piped_notebook, notebook, fmt)
# Remove jupytext / text_representation entry
if "jupytext" in notebook.metadata:
piped_notebook.metadata["jupytext"] = notebook.metadata["jupytext"]
else:
piped_notebook.metadata.pop("jupytext", None)
return piped_notebook
def execution_counts_are_in_order(notebook):
"""Returns True if all the code cells have an execution count, ordered from 1 to N with no missing number"""
expected_execution_count = 1
for cell in notebook.cells:
if cell.cell_type == "code":
if cell.execution_count != expected_execution_count:
return False
expected_execution_count += 1
return True
def code_cells_have_changed(notebook, nb_files):
"""The source for the code cells has not changed"""
for nb_file in nb_files:
if not os.path.exists(nb_file):
return True
nb_ref = read(nb_file)
# Are the new code cells equals to those in the file?
ref = [cell.source for cell in nb_ref.cells if cell.cell_type == "code"]
new = [cell.source for cell in notebook.cells if cell.cell_type == "code"]
if ref != new:
return True
return False
================================================
FILE: src/jupytext/combine.py
================================================
"""Combine source and outputs from two notebooks"""
import re
from copy import copy
from nbformat import NotebookNode
from .cell_metadata import _IGNORE_CELL_METADATA
from .formats import long_form_one_format
from .header import _DEFAULT_NOTEBOOK_METADATA
from .metadata_filter import restore_filtered_metadata
_BLANK_LINE = re.compile(r"^\s*$")
def black_invariant(text, chars=None):
"""Remove characters that may be changed when reformatting the text with black"""
if chars is None:
chars = [" ", "\t", "\n", ",", "'", '"', "(", ")", "\\"]
for char in chars:
text = text.replace(char, "")
return text
def same_content(ref, test, endswith=False):
"""Is the content of two cells the same, up to reformatting by black"""
ref = black_invariant(ref)
test = black_invariant(test)
if endswith and test:
return ref.endswith(test)
return ref == test
def combine_inputs_with_outputs(nb_source, nb_outputs, fmt=None):
"""Return a notebook that combines the text and metadata from the first notebook,
with the outputs and metadata of the second notebook."""
# nbformat version number taken from the notebook with outputs
assert nb_outputs.nbformat == nb_source.nbformat, (
"The notebook with outputs is in format {}.{}, please upgrade it to {}.x".format(
nb_outputs.nbformat, nb_outputs.nbformat_minor, nb_source.nbformat
)
)
nb_source.nbformat_minor = nb_outputs.nbformat_minor
fmt = long_form_one_format(fmt)
text_repr = nb_source.metadata.get("jupytext", {}).get("text_representation", {})
ext = fmt.get("extension") or text_repr.get("extension")
format_name = fmt.get("format_name") or text_repr.get("format_name")
notebook_metadata_filter = nb_source.metadata.get("jupytext", {}).get("notebook_metadata_filter")
if notebook_metadata_filter == "-all":
nb_metadata = nb_outputs.metadata
else:
nb_metadata = restore_filtered_metadata(
nb_source.metadata,
nb_outputs.metadata,
notebook_metadata_filter,
_DEFAULT_NOTEBOOK_METADATA,
)
source_is_md_version_one = ext in [".md", ".markdown", ".Rmd"] and text_repr.get("format_version") == "1.0"
if nb_metadata.get("jupytext", {}).get("formats") or ext in [
".md",
".markdown",
".Rmd",
]:
nb_metadata.get("jupytext", {}).pop("text_representation", None)
if not nb_metadata.get("jupytext", {}):
nb_metadata.pop("jupytext", {})
if format_name in ["nomarker", "sphinx", "marimo"] or source_is_md_version_one:
cell_metadata_filter = "-all"
else:
cell_metadata_filter = nb_metadata.get("jupytext", {}).get("cell_metadata_filter")
outputs_map = map_outputs_to_inputs(nb_source.cells, nb_outputs.cells)
cells = []
for source_cell, j in zip(nb_source.cells, outputs_map):
if j is None:
cells.append(source_cell)
continue
output_cell = nb_outputs.cells[j]
# Outputs and optional attributes are taken from the notebook with outputs
cell = copy(output_cell)
# Cell text is taken from the source notebook
cell.source = source_cell.source
# We also restore the cell metadata that has been filtered
cell.metadata = restore_filtered_metadata(
source_cell.metadata,
output_cell.metadata,
# The 'spin' format does not allow metadata on non-code cells
("-all" if format_name == "spin" and source_cell.cell_type != "code" else cell_metadata_filter),
_IGNORE_CELL_METADATA,
)
cells.append(cell)
# We call NotebookNode rather than new_notebook as we don't want to validate
# the notebook (some of the notebook in the collection of test notebooks
# do have some invalid properties - probably inherited from an older version
# of the notebook format).
return NotebookNode(
cells=cells,
metadata=nb_metadata,
nbformat=nb_outputs.nbformat,
nbformat_minor=nb_outputs.nbformat_minor,
)
def map_outputs_to_inputs(cells_inputs, cells_outputs):
"""Returns a map i->(j or None) that maps the cells with outputs to the input cells"""
n_in = len(cells_inputs)
n_out = len(cells_outputs)
outputs_map = [None] * n_in
# First rule: match based on cell type, content, in increasing order, for each cell type
first_unmatched_output_per_cell_type = {}
for i in range(n_in):
cell_input = cells_inputs[i]
for j in range(first_unmatched_output_per_cell_type.get(cell_input.cell_type, 0), n_out):
cell_output = cells_outputs[j]
if cell_input.cell_type == cell_output.cell_type and same_content(cell_input.source, cell_output.source):
outputs_map[i] = j
first_unmatched_output_per_cell_type[cell_input.cell_type] = j + 1
break
# Second rule: match unused outputs based on cell type and content
# Third rule: is the new cell the final part of a previous cell with outputs?
unused_ouputs = set(range(n_out)).difference(outputs_map)
for endswith in [False, True]:
if not unused_ouputs:
return outputs_map
for i in range(n_in):
if outputs_map[i] is not None:
continue
cell_input = cells_inputs[i]
for j in unused_ouputs:
cell_output = cells_outputs[j]
if cell_input.cell_type == cell_output.cell_type and same_content(
cell_output.source, cell_input.source, endswith
):
outputs_map[i] = j
unused_ouputs.remove(j)
break
# Fourth rule: match based on increasing index (and cell type) for non-empty cells
if not unused_ouputs:
return outputs_map
prev_j = -1
for i in range(n_in):
if outputs_map[i] is not None:
prev_j = outputs_map[i]
continue
j = prev_j + 1
if j not in unused_ouputs:
continue
cell_input = cells_inputs[i]
cell_output = cells_outputs[j]
if cell_input.cell_type == cell_output.cell_type and cell_input.source.strip() != "":
outputs_map[i] = j
unused_ouputs.remove(j)
prev_j = j
return outputs_map
================================================
FILE: src/jupytext/compare.py
================================================
"""Compare two Jupyter notebooks"""
import difflib
import json
import os
import re
from jupytext.marimo import marimo_version
from jupytext.paired_paths import full_path
from .cell_metadata import _IGNORE_CELL_METADATA
from .combine import combine_inputs_with_outputs
from .formats import check_auto_ext, long_form_one_format
from .header import _DEFAULT_NOTEBOOK_METADATA
from .jupytext import read, reads, write, writes
from .metadata_filter import filter_metadata
_BLANK_LINE = re.compile(r"^\s*$")
def _multilines(obj):
try:
lines = obj.splitlines()
return lines + [""] if obj.endswith("\n") else lines
except AttributeError:
# Remove the final blank space on Python 2.7
# return json.dumps(obj, indent=True, sort_keys=True).splitlines()
return [line.rstrip() for line in json.dumps(obj, indent=True, sort_keys=True).splitlines()]
def compare(actual, expected, actual_name="actual", expected_name="expected", return_diff=False):
"""Compare two strings, lists or dict-like objects"""
if actual != expected:
diff = difflib.unified_diff(
_multilines(expected),
_multilines(actual),
expected_name,
actual_name,
lineterm="",
)
if expected_name == "" and actual_name == "":
diff = list(diff)[2:]
diff = "\n".join(diff)
if return_diff:
return diff
raise AssertionError("\n" + diff)
return "" if return_diff else None
def filtered_cell(cell, preserve_outputs, cell_metadata_filter):
"""Cell type, metadata and source from given cell"""
filtered = {
"cell_type": cell.cell_type,
"source": cell.source,
"metadata": filter_metadata(cell.metadata, cell_metadata_filter, _IGNORE_CELL_METADATA),
}
if preserve_outputs:
for key in ["execution_count", "outputs"]:
if key in cell:
filtered[key] = cell[key]
return filtered
def filtered_notebook_metadata(notebook, ignore_kernelspec=False):
"""Notebook metadata, filtered for metadata added by Jupytext itself"""
metadata = filter_metadata(
notebook.metadata,
notebook.metadata.get("jupytext", {}).get("notebook_metadata_filter"),
_DEFAULT_NOTEBOOK_METADATA,
)
# Quarto round-trips may change the kernelspec
if ignore_kernelspec:
metadata.pop("kernelspec", None)
if "jupytext" in metadata:
del metadata["jupytext"]
return metadata
class NotebookDifference(Exception):
"""Report notebook differences"""
def same_content(ref_source, test_source, allow_removed_final_blank_line):
"""Is the content of two cells the same, except for an optional final blank line?"""
if ref_source == test_source:
return True
if not allow_removed_final_blank_line:
return False
# Is ref identical to test, plus one blank line?
ref_source = ref_source.splitlines()
test_source = test_source.splitlines()
if not ref_source:
return False
if ref_source[:-1] != test_source:
return False
return _BLANK_LINE.match(ref_source[-1])
def compare_notebooks(
notebook_actual,
notebook_expected,
fmt=None,
allow_expected_differences=True,
raise_on_first_difference=True,
compare_outputs=False,
compare_ids=None,
):
"""Compare the two notebooks, and raise with a meaningful message
that explains the differences, if any"""
fmt = long_form_one_format(fmt)
format_name = fmt.get("format_name")
if format_name == "sphinx" and notebook_actual.cells and notebook_actual.cells[0].source == "%matplotlib inline":
notebook_actual.cells = notebook_actual.cells[1:]
if compare_ids is None:
compare_ids = compare_outputs
modified_cells, modified_cell_metadata = compare_cells(
notebook_actual.cells,
notebook_expected.cells,
raise_on_first_difference,
compare_outputs=compare_outputs,
compare_ids=compare_ids,
cell_metadata_filter="-all"
if format_name == "marimo"
else notebook_actual.get("jupytext", {}).get("cell_metadata_filter"),
allow_missing_code_cell_metadata=(allow_expected_differences and format_name in ["sphinx", "marimo"]),
allow_missing_markdown_cell_metadata=(allow_expected_differences and format_name in ["sphinx", "spin", "marimo"]),
allow_filtered_cell_metadata=allow_expected_differences,
allow_removed_final_blank_line=allow_expected_differences,
)
# Compare notebook metadata
modified_metadata = False
if fmt.get("format_name") != "marimo":
try:
ignore_kernelspec = fmt.get("extension") == ".qmd" and allow_expected_differences
compare(
filtered_notebook_metadata(notebook_actual, ignore_kernelspec),
filtered_notebook_metadata(notebook_expected, ignore_kernelspec),
)
except AssertionError as error:
if raise_on_first_difference:
raise NotebookDifference(f"Notebook metadata differ: {str(error)}")
modified_metadata = True
error = []
if modified_cells:
error.append(
"Cells {} differ ({}/{})".format(
",".join([str(i) for i in modified_cells]),
len(modified_cells),
len(notebook_expected.cells),
)
)
if modified_cell_metadata:
error.append("Cell metadata '{}' differ".format("', '".join([str(i) for i in modified_cell_metadata])))
if modified_metadata:
error.append("Notebook metadata differ")
if error:
raise NotebookDifference(" | ".join(error))
def compare_cells(
actual_cells,
expected_cells,
raise_on_first_difference=True,
compare_outputs=True,
compare_ids=True,
cell_metadata_filter=None,
allow_missing_code_cell_metadata=False,
allow_missing_markdown_cell_metadata=False,
allow_filtered_cell_metadata=False,
allow_removed_final_blank_line=False,
):
"""Compare two collection of notebook cells"""
test_cell_iter = iter(actual_cells)
modified_cells = set()
modified_cell_metadata = set()
for i, ref_cell in enumerate(expected_cells, 1):
try:
test_cell = next(test_cell_iter)
except StopIteration:
if raise_on_first_difference:
raise NotebookDifference(f"No cell corresponding to {ref_cell.cell_type} cell #{i}:\n{ref_cell.source}")
modified_cells.update(range(i, len(expected_cells) + 1))
break
ref_lines = [line for line in ref_cell.source.splitlines() if not _BLANK_LINE.match(line)]
test_lines = []
# 1. test cell type
if ref_cell.cell_type != test_cell.cell_type:
if raise_on_first_difference:
raise NotebookDifference(
f"When comparing cell #{i}: "
f"expecting a {ref_cell.cell_type} cell, but got a {test_cell.cell_type} cell.\n"
f"Expected content:\n{ref_cell.source}\nActual content:\n{test_cell.source}"
)
modified_cells.add(i)
# Compare cell ids (introduced in nbformat 5.1.0)
if compare_ids and test_cell.get("id") != ref_cell.get("id"):
if raise_on_first_difference:
raise NotebookDifference(
f"Cell ids differ on {test_cell['cell_type']} cell #{i}: '{test_cell.get('id')}' != '{ref_cell.get('id')}'"
)
modified_cells.add(i)
# 2. test cell metadata
if (ref_cell.cell_type == "code" and not allow_missing_code_cell_metadata) or (
ref_cell.cell_type != "code" and not allow_missing_markdown_cell_metadata
):
ref_metadata = ref_cell.metadata
test_metadata = test_cell.metadata
if allow_filtered_cell_metadata:
ref_metadata = {key: ref_metadata[key] for key in ref_metadata if key not in _IGNORE_CELL_METADATA}
test_metadata = {key: test_metadata[key] for key in test_metadata if key not in _IGNORE_CELL_METADATA}
if ref_metadata != test_metadata:
if raise_on_first_difference:
try:
compare(test_metadata, ref_metadata)
except AssertionError as error:
raise NotebookDifference(
"Metadata differ on {} cell #{}: {}\nCell content:\n{}".format(
test_cell.cell_type, i, str(error), ref_cell.source
)
)
else:
modified_cell_metadata.update(set(test_metadata).difference(ref_metadata))
modified_cell_metadata.update(set(ref_metadata).difference(test_metadata))
for key in set(ref_metadata).intersection(test_metadata):
if ref_metadata[key] != test_metadata[key]:
modified_cell_metadata.add(key)
test_lines.extend([line for line in test_cell.source.splitlines() if not _BLANK_LINE.match(line)])
# 3. test cell content
if ref_lines != test_lines:
if raise_on_first_difference:
try:
compare("\n".join(test_lines), "\n".join(ref_lines))
except AssertionError as error:
raise NotebookDifference(f"Cell content differ on {test_cell.cell_type} cell #{i}: {str(error)}")
else:
modified_cells.add(i)
# 3. bis test entire cell content
if not same_content(ref_cell.source, test_cell.source, allow_removed_final_blank_line):
if ref_cell.source != test_cell.source:
if raise_on_first_difference:
diff = compare(test_cell.source, ref_cell.source, return_diff=True)
raise NotebookDifference(f"Cell content differ on {test_cell.cell_type} cell #{i}: {diff}")
modified_cells.add(i)
if not compare_outputs:
continue
if ref_cell.cell_type != "code":
continue
ref_cell = filtered_cell(
ref_cell,
preserve_outputs=compare_outputs,
cell_metadata_filter=cell_metadata_filter,
)
test_cell = filtered_cell(
test_cell,
preserve_outputs=compare_outputs,
cell_metadata_filter=cell_metadata_filter,
)
try:
compare(test_cell, ref_cell)
except AssertionError as error:
if raise_on_first_difference:
raise NotebookDifference(
"Cell outputs differ on {} cell #{}: {}".format(test_cell["cell_type"], i, str(error))
)
modified_cells.add(i)
# More cells in the actual notebook?
remaining_cell_count = 0
while True:
try:
test_cell = next(test_cell_iter)
if raise_on_first_difference:
raise NotebookDifference(f"Additional {test_cell.cell_type} cell: {test_cell.source}")
remaining_cell_count += 1
except StopIteration:
break
if remaining_cell_count and not raise_on_first_difference:
modified_cells.update(
range(
len(expected_cells) + 1,
len(expected_cells) + 1 + remaining_cell_count,
)
)
return modified_cells, modified_cell_metadata
def test_round_trip_conversion(notebook, fmt, update, allow_expected_differences=True, stop_on_first_error=True):
"""Test round trip conversion for a Jupyter notebook"""
text = writes(notebook, fmt)
round_trip = reads(text, fmt)
if update:
round_trip = combine_inputs_with_outputs(round_trip, notebook, fmt)
compare_notebooks(
round_trip,
notebook,
fmt,
allow_expected_differences,
raise_on_first_difference=stop_on_first_error,
)
# The functions below are used in the Jupytext text collection
def create_mirror_file_if_missing(mirror_file, notebook, fmt):
if not os.path.isfile(mirror_file):
write(notebook, mirror_file, fmt=fmt)
def assert_conversion_same_as_mirror(nb_file, fmt, mirror_name, compare_notebook=False):
"""This function is used in the tests"""
dirname, basename = os.path.split(nb_file)
file_name, org_ext = os.path.splitext(basename)
fmt = long_form_one_format(fmt)
notebook = read(nb_file, fmt=fmt)
fmt = check_auto_ext(fmt, notebook.metadata, "")
ext = fmt["extension"]
mirror_file = os.path.join(dirname, "..", "..", "outputs", mirror_name, full_path(file_name, fmt))
# it's better not to have Jupytext metadata in test notebooks:
if fmt == "ipynb" and "jupytext" in notebook.metadata: # pragma: no cover
notebook.metadata.pop("jupytext")
write(nb_file, fmt=fmt)
create_mirror_file_if_missing(mirror_file, notebook, fmt)
# Compare the text representation of the two notebooks
if compare_notebook:
# Read and convert the mirror file to the latest nbformat version if necessary
nb_mirror = read(mirror_file, as_version=notebook.nbformat)
nb_mirror.nbformat_minor = notebook.nbformat_minor
compare_notebooks(nb_mirror, notebook)
return
elif ext == ".ipynb":
notebook = read(mirror_file)
fmt.update({"extension": org_ext})
actual = writes(notebook, fmt)
with open(nb_file, encoding="utf-8") as fp:
expected = fp.read()
else:
actual = writes(notebook, fmt)
with open(mirror_file, encoding="utf-8") as fp:
expected = fp.read()
if not actual.endswith("\n"):
actual = actual + "\n"
if fmt.get("format_name") == "marimo":
lines = expected.splitlines()
lines = [
# mirror files were generated with marimo 0.17.8
f'__generated_with = "{marimo_version()}"' if line == '__generated_with = "0.17.8"' else line
for line in lines
]
expected = "\n".join(lines) + "\n"
compare(actual, expected)
# Compare the two notebooks
if ext != ".ipynb":
notebook = read(nb_file)
nb_mirror = read(mirror_file, fmt=fmt)
if fmt.get("format_name") == "sphinx":
nb_mirror.cells = nb_mirror.cells[1:]
for cell in notebook.cells:
cell.metadata = {}
for cell in nb_mirror.cells:
cell.metadata = {}
compare_notebooks(nb_mirror, notebook, fmt)
nb_mirror = combine_inputs_with_outputs(nb_mirror, notebook)
compare_notebooks(nb_mirror, notebook, fmt, compare_outputs=True)
def notebook_model(nb):
"""Return a notebook model, with content a
dictionary rather than a notebook object.
To be used in tests only."""
return dict(type="notebook", content=json.loads(json.dumps(nb)))
================================================
FILE: src/jupytext/config.py
================================================
"""Find and read Jupytext configuration files"""
import json
import os
from pathlib import Path
try:
import tomllib
except ImportError:
import tomli as tomllib
import warnings
import yaml
from traitlets import Bool, Dict, Enum, Float, List, Unicode, Union
from traitlets.config import Configurable
from traitlets.config.loader import PyFileConfigLoader
from traitlets.traitlets import TraitError
import typing
from .formats import (
NOTEBOOK_EXTENSIONS,
get_formats_from_notebook_metadata,
long_form_multiple_formats,
long_form_one_format,
short_form_multiple_formats,
)
class JupytextConfigurationError(ValueError):
"""Error in the specification of the format for the text notebook"""
JUPYTEXT_CONFIG_FILES = [
"jupytext",
"jupytext.toml",
"jupytext.yml",
"jupytext.yaml",
"jupytext.json",
]
JUPYTEXT_CONFIG_FILES.extend(["." + filename for filename in JUPYTEXT_CONFIG_FILES] + [".jupytext.py"])
PYPROJECT_FILE = "pyproject.toml"
JUPYTEXT_CEILING_DIRECTORIES = [path for path in os.environ.get("JUPYTEXT_CEILING_DIRECTORIES", "").split(":") if path]
class JupytextConfiguration(Configurable):
"""Jupytext Configuration's options"""
formats = Union(
[Unicode(), List(Unicode()), List(Dict(Unicode())), Dict(Unicode())],
help="Save notebooks to these file extensions. "
"Can be any of ipynb,Rmd,md,jl,py,R,nb.jl,nb.py,nb.R "
"comma separated. If you want another format than the "
"default one, append the format name to the extension, "
"e.g. ipynb,py:percent to save the notebook to "
"hydrogen/spyder/vscode compatible scripts. "
"Can also be a list of format dictionaries for first-match pairing.",
config=True,
)
default_jupytext_formats = Unicode(help="Deprecated. Use 'formats' instead", config=True)
preferred_jupytext_formats_save = Unicode(
help="Preferred format when saving notebooks as text, per extension. "
'Use "jl:percent,py:percent,R:percent" if you want to save '
"Julia, Python and R scripts in the double percent format and "
'only write "jupytext_formats": "py" in the notebook metadata.',
config=True,
)
preferred_jupytext_formats_read = Unicode(
help="Preferred format when reading notebooks from text, per "
'extension. Use "py:sphinx" if you want to read all python '
"scripts as Sphinx gallery scripts.",
config=True,
)
notebook_metadata_filter = Unicode(
help="Notebook metadata that should be save in the text representations. "
"Examples: 'all', '-all', 'widgets,nteract', 'kernelspec,jupytext-all'",
config=True,
)
default_notebook_metadata_filter = Unicode("", help="Deprecated. Use 'notebook_metadata_filter' instead", config=True)
hide_notebook_metadata = Enum(
values=[True, False],
allow_none=True,
help="Should the notebook metadata be wrapped into an HTML comment in the Markdown format?",
config=True,
)
root_level_metadata_as_raw_cell = Bool(
True,
help="Should the root level metadata of text documents (like the fields 'title' or 'author' in "
"R Markdown document) appear as a raw cell in the notebook (True), or go to the notebook"
"metadata?",
config=True,
)
root_level_metadata_filter = Unicode(
help="Notebook metadata that should be promoted to the root level in the text representations. "
"Examples: 'all', '-all', 'kernelspec,jupytext'",
config=True,
)
cell_metadata_filter = Unicode(
help="Cell metadata that should be saved in the text representations. Examples: 'all', 'hide_input,hide_output'",
config=True,
)
default_cell_metadata_filter = Unicode("", help="Deprecated. Use 'cell_metadata_filter' instead", config=True)
comment_magics = Enum(
values=[True, False],
allow_none=True,
help="Should Jupyter magic commands be commented out in the text representation?",
config=True,
)
split_at_heading = Bool(
False,
help="Split markdown cells on headings (Markdown and R Markdown formats only)",
config=True,
)
sphinx_convert_rst2md = Bool(
False,
help="When opening a Sphinx Gallery script, convert the reStructuredText to markdown",
config=True,
)
doxygen_equation_markers = Bool(
False,
help="Should equation markers use the DOxygen format? (see https://github.com/mwouts/jupytext/issues/517)",
config=True,
)
outdated_text_notebook_margin = Float(
1.0,
help="Refuse to overwrite inputs of a ipynb notebooks with those of a "
"text notebook when the text notebook plus margin is older than "
"the ipynb notebook (NB: This option is ignored by Jupytext CLI)",
config=True,
)
cm_config_log_level = Enum(
values=["warning", "info", "info_if_changed", "debug", "none"],
default_value="info_if_changed",
help="The log level for config file logs in the Jupytext contents manager",
config=True,
)
cell_markers = Unicode(
help='Start and end cell markers for the light format, comma separated. Use "{{{,}}}" to mark cells'
'as foldable regions in Vim, and "region,endregion" to mark cells as Vscode/PyCharm regions',
config=True,
)
default_cell_markers = Unicode(help="Deprecated. Use 'cell_markers' instead", config=True)
notebook_extensions = Union(
[List(Unicode(), NOTEBOOK_EXTENSIONS), Unicode()],
help="A list of notebook extensions",
config=True,
)
custom_cell_magics = Unicode(
help='A comma separated list of cell magics. Use e.g. custom_cell_magics = "configure,local" '
'if you want code cells starting with the Spark magic cell commands "configure" and "local" '
"to be commented out when converted to scripts.",
config=True,
)
def set_default_format_options(self, format_options, read=False):
"""Set default format option"""
if self.default_notebook_metadata_filter:
warnings.warn(
"The option 'default_notebook_metadata_filter' is deprecated. Please use 'notebook_metadata_filter' instead.",
FutureWarning,
)
format_options.setdefault("notebook_metadata_filter", self.default_notebook_metadata_filter)
if self.notebook_metadata_filter:
format_options.setdefault("notebook_metadata_filter", self.notebook_metadata_filter)
if self.default_cell_metadata_filter:
warnings.warn(
"The option 'default_cell_metadata_filter' is deprecated. Please use 'cell_metadata_filter' instead.",
FutureWarning,
)
format_options.setdefault("cell_metadata_filter", self.default_cell_metadata_filter)
if self.root_level_metadata_filter:
format_options.setdefault("root_level_metadata_filter", self.root_level_metadata_filter)
if self.cell_metadata_filter:
format_options.setdefault("cell_metadata_filter", self.cell_metadata_filter)
if self.hide_notebook_metadata is not None:
format_options.setdefault("hide_notebook_metadata", self.hide_notebook_metadata)
if self.root_level_metadata_as_raw_cell is False:
format_options.setdefault("root_level_metadata_as_raw_cell", self.root_level_metadata_as_raw_cell)
if self.comment_magics is not None:
format_options.setdefault("comment_magics", self.comment_magics)
if self.split_at_heading:
format_options.setdefault("split_at_heading", self.split_at_heading)
if self.doxygen_equation_markers:
format_options.setdefault("doxygen_equation_markers", self.doxygen_equation_markers)
if not read:
if self.default_cell_markers:
warnings.warn(
"The option 'default_cell_markers' is deprecated. Please use 'cell_markers' instead.",
FutureWarning,
)
format_options.setdefault("cell_markers", self.default_cell_markers)
if self.cell_markers:
format_options.setdefault("cell_markers", self.cell_markers)
if read and self.sphinx_convert_rst2md:
format_options.setdefault("rst2md", self.sphinx_convert_rst2md)
if self.custom_cell_magics:
format_options.setdefault("custom_cell_magics", self.custom_cell_magics)
def default_formats(self, path):
"""Return the default formats, if they apply to the current path #157"""
from .paired_paths import InconsistentPath, base_path
if self.default_jupytext_formats:
warnings.warn(
"The option 'default_jupytext_formats' is deprecated. Please use 'formats' instead.",
FutureWarning,
)
# formats is a list of paired formats - find the first match
for paired_formats in normalize_formats(self.formats or self.default_jupytext_formats):
# Check if one of the paired format matches the current path
for fmt in long_form_multiple_formats(paired_formats):
try:
base_path(path, fmt)
return paired_formats
except InconsistentPath:
continue
return None
def __eq__(self, other):
for key in self.class_trait_names():
if getattr(self, key) != getattr(other, key):
return False
return True
def preferred_format(incomplete_format, preferred_formats):
"""Return the preferred format for the given extension"""
incomplete_format = long_form_one_format(incomplete_format)
if "format_name" in incomplete_format:
return incomplete_format
for fmt in long_form_multiple_formats(preferred_formats):
if (
(
incomplete_format["extension"] == fmt["extension"]
or (
fmt["extension"] == ".auto"
and incomplete_format["extension"] not in [".md", ".markdown", ".Rmd", ".ipynb"]
)
)
and incomplete_format.get("suffix") == fmt.get("suffix", incomplete_format.get("suffix"))
and incomplete_format.get("prefix") == fmt.get("prefix", incomplete_format.get("prefix"))
):
fmt.update(incomplete_format)
return fmt
return incomplete_format
def global_jupytext_configuration_directories():
"""Return the directories in which Jupytext will search for a configuration file"""
config_dirs = []
if "XDG_CONFIG_HOME" in os.environ:
config_dirs.extend(os.environ["XDG_CONFIG_HOME"].split(":"))
elif "USERPROFILE" in os.environ:
config_dirs.append(os.environ["USERPROFILE"])
elif "HOME" in os.environ:
config_dirs.append(os.path.join(os.environ["HOME"], ".config"))
config_dirs.append(os.environ["HOME"])
if "XDG_CONFIG_DIRS" in os.environ:
config_dirs.extend(os.environ["XDG_CONFIG_DIRS"].split(":"))
elif "ALLUSERSPROFILE" in os.environ:
config_dirs.append(os.environ["ALLUSERSPROFILE"])
else:
config_dirs.extend(["/usr/local/share/", "/usr/share/"])
for config_dir in config_dirs:
yield from [
os.path.join(config_dir, "jupytext"),
config_dir,
]
def find_global_jupytext_configuration_file():
"""Return the global Jupytext configuration file, if any"""
for config_dir in global_jupytext_configuration_directories():
config_file = find_jupytext_configuration_file(config_dir, False)
if config_file:
return config_file
return None
def find_jupytext_configuration_file(path: typing.Union[str, Path], search_parent_dirs=True) -> str:
"""Return the first jupytext configuration file in the current directory, or any parent directory"""
path = Path(path).absolute()
if path.is_dir():
for filename in JUPYTEXT_CONFIG_FILES:
full_path = path / filename
if full_path.is_file():
return str(full_path)
pyproject_path = path / PYPROJECT_FILE
if pyproject_path.is_file():
with pyproject_path.open() as stream:
doc = tomllib.loads(stream.read())
if doc.get("tool", {}).get("jupytext") is not None:
return str(pyproject_path)
if not search_parent_dirs:
return None
if JUPYTEXT_CEILING_DIRECTORIES and path.is_dir():
for ceiling_dir in JUPYTEXT_CEILING_DIRECTORIES:
if Path(ceiling_dir).is_dir() and path.absolute() == Path(ceiling_dir).absolute():
return None
parent_dir = path.parent
if parent_dir == path:
return find_global_jupytext_configuration_file()
return find_jupytext_configuration_file(parent_dir, True)
def parse_jupytext_configuration_file(jupytext_config_file, stream=None):
"""Read a Jupytext config file, and return a dict"""
if not jupytext_config_file.endswith(".py") and stream is None:
with open(jupytext_config_file, encoding="utf-8") as stream:
return parse_jupytext_configuration_file(jupytext_config_file, stream.read())
try:
if jupytext_config_file.endswith((".toml", "jupytext")):
doc = tomllib.loads(stream)
if jupytext_config_file.endswith(PYPROJECT_FILE):
return doc["tool"]["jupytext"]
else:
return doc
if jupytext_config_file.endswith((".yml", ".yaml")):
return yaml.safe_load(stream)
if jupytext_config_file.endswith(".json"):
return json.loads(stream)
return PyFileConfigLoader(jupytext_config_file).load_config()
except (ValueError, NameError) as err:
raise JupytextConfigurationError(f"The Jupytext configuration file {jupytext_config_file} is incorrect: {err}")
def normalize_formats(formats) -> list[str]:
"""Normalize the formats option into a list of string-encoded paired formats"""
# Process formats - can be string, dict, or list
if isinstance(formats, str):
# Split on semicolon for multiple format groups
formats = formats.split(";")
elif isinstance(formats, dict):
# Single dict - wrap in list for uniform processing
formats = [formats]
elif formats is None:
formats = []
elif not isinstance(formats, list):
raise JupytextConfigurationError(
f"Invalid type for 'formats': {type(formats).__name__}. Expected str, dict, list of str or dict."
)
# Each group of paired formats can be a string or a dict
string_encoded_pairing_formats = []
for paired_formats in formats:
if isinstance(paired_formats, str):
string_encoded_pairing_formats.append(paired_formats)
elif isinstance(paired_formats, dict):
# Convert dict to format string
paired_formats = [
(f if not prefix else (prefix[:-1] if prefix.endswith("/") else prefix) + "///" + f)
for prefix, f in paired_formats.items()
]
string_encoded_pairing_formats.append(short_form_multiple_formats(paired_formats))
else:
raise JupytextConfigurationError(
f"Invalid paired formats: {paired_formats}. Expected str or dict, got {type(paired_formats).__name__}."
)
return string_encoded_pairing_formats
def load_jupytext_configuration_file(config_file, stream=None):
"""Read and validate a Jupytext configuration file, and return a JupytextConfiguration object"""
config_dict = parse_jupytext_configuration_file(config_file, stream)
config = validate_jupytext_configuration_file(config_file, config_dict)
config.formats = normalize_formats(config.formats or config.default_jupytext_formats)
if isinstance(config.notebook_extensions, str):
config.notebook_extensions = config.notebook_extensions.split(",")
return config
def load_jupytext_config(nb_file):
"""Return the jupytext configuration file in the same folder, or in a parent folder, of the current file, if any"""
config_file = find_jupytext_configuration_file(nb_file)
if config_file is None:
return None
if os.path.isfile(nb_file) and os.path.samefile(config_file, nb_file):
return None
config_file = find_jupytext_configuration_file(nb_file)
return load_jupytext_configuration_file(config_file)
def validate_jupytext_configuration_file(config_file, config_dict):
"""Turn a dict-like config into a JupytextConfiguration object"""
if config_dict is None:
return None
try:
config = JupytextConfiguration(**config_dict)
except TraitError as err:
raise JupytextConfigurationError(f"The Jupytext configuration file {config_file} is incorrect: {err}")
invalid_options = set(config_dict).difference(dir(JupytextConfiguration()))
if any(invalid_options):
raise JupytextConfigurationError(
"The Jupytext configuration file {} is incorrect: options {} are not supported".format(
config_file, ",".join(invalid_options)
)
)
return config
def notebook_formats(nbk, config, path, fallback_on_current_fmt=True):
"""Return the list of formats for the current notebook"""
metadata = nbk.get("metadata")
jupytext_metadata = metadata.get("jupytext", {})
formats = jupytext_metadata.get("formats") or metadata.get("jupytext_formats")
if formats:
formats = long_form_multiple_formats(formats, metadata, auto_ext_requires_language_info=False)
elif config:
current_format = jupytext_metadata.get("text_representation", {"extension": os.path.splitext(path)[1]})
default_formats = long_form_multiple_formats(
config.default_formats(path),
metadata,
auto_ext_requires_language_info=False,
)
if any(
current_format.get("extension") == fmt["extension"]
and (
"format_name" not in fmt
or "format_name" not in current_format
or current_format["format_name"] == fmt.get("format_name")
)
for fmt in default_formats
):
formats = default_formats
if not formats:
if not fallback_on_current_fmt:
return None
text_repr = jupytext_metadata.get("text_representation", {})
ext = os.path.splitext(path)[1]
fmt = {"extension": ext}
if ext == text_repr.get("extension") and text_repr.get("format_name"):
fmt["format_name"] = text_repr.get("format_name")
formats = [fmt]
# Set preferred formats if no format name has been given yet
if config:
formats = [preferred_format(f, config.preferred_jupytext_formats_save) for f in formats]
return formats
def get_formats_from_notebook_and_config(notebook, config, nb_file):
"""
Get the notebook formats from notebook metadata or config.
Notebook metadata takes precedence over config. If the notebook metadata contains pairing information,
it is used; otherwise, the configuration is used as a fallback.
Parameters
----------
notebook : dict
The notebook object (as a dictionary).
config : JupytextConfiguration or None
The Jupytext configuration object.
nb_file : str
The path to the notebook file.
Returns
-------
list
A list of format dictionaries describing the notebook's paired formats.
"""
formats = get_formats_from_notebook_metadata(notebook)
if formats:
return long_form_multiple_formats(formats)
else:
return notebook_formats(notebook, config, nb_file)
================================================
FILE: src/jupytext/doxygen.py
================================================
"""Convert Markdown equations to doxygen equations and back
See https://github.com/mwouts/jupytext/issues/517"""
import re
def markdown_to_doxygen(string):
"""Markdown to Doxygen equations"""
long_equations = re.sub(r"(?\\f]", string, flags=re.DOTALL)
inline_equations = re.sub(r"(?$$", string, flags=re.DOTALL)
inline_equations = re.sub(r"\\f\$", "$", long_equations)
return inline_equations
================================================
FILE: src/jupytext/formats.py
================================================
"""
In this file the various text notebooks formats are defined. Please contribute
new formats here!
"""
import os
import re
import warnings
import nbformat
import yaml
from .cell_reader import (
DoublePercentScriptCellReader,
HydrogenCellReader,
LightScriptCellReader,
MarkdownCellReader,
RMarkdownCellReader,
RScriptCellReader,
SphinxGalleryScriptCellReader,
)
from .cell_to_text import (
BareScriptCellExporter,
DoublePercentCellExporter,
HydrogenCellExporter,
LightScriptCellExporter,
MarkdownCellExporter,
RMarkdownCellExporter,
RScriptCellExporter,
SphinxGalleryCellExporter,
)
from .header import header_to_metadata_and_cell, insert_or_test_version_number
from .languages import _COMMENT_CHARS, _SCRIPT_EXTENSIONS, same_language
from .magics import is_magic
from .metadata_filter import metadata_filter_as_string
from .myst import (
MYST_FORMAT_NAME,
is_myst_available,
matches_mystnb,
myst_extensions,
myst_version,
)
from .pandoc import is_pandoc_available, pandoc_version
from .stringparser import StringParser
from .version import __version__
class JupytextFormatError(ValueError):
"""Error in the specification of the format for the text notebook"""
class NotebookFormatDescription:
"""Description of a notebook format"""
def __init__(
self,
format_name,
extension,
header_prefix,
cell_reader_class,
cell_exporter_class,
current_version_number,
header_suffix="",
min_readable_version_number=None,
):
self.format_name = format_name
self.extension = extension
self.header_prefix = header_prefix
self.header_suffix = header_suffix
self.cell_reader_class = cell_reader_class
self.cell_exporter_class = cell_exporter_class
self.current_version_number = current_version_number
self.min_readable_version_number = min_readable_version_number
JUPYTEXT_FORMATS = (
[
NotebookFormatDescription(
format_name="markdown",
extension=".md",
header_prefix="",
cell_reader_class=MarkdownCellReader,
cell_exporter_class=MarkdownCellExporter,
# Version 1.0 on 2018-08-31 - jupytext v0.6.0 : Initial version
# Version 1.1 on 2019-03-24 - jupytext v1.1.0 : Markdown regions and cell metadata
# Version 1.2 on 2019-09-21 - jupytext v1.3.0 : Raw regions are now encoded with HTML comments (#321)
# and by default, cell metadata use the key=value representation (#347)
# Version 1.3 on 2021-01-24 - jupytext v1.10.0 : Code cells may start with more than three backticks (#712)
current_version_number="1.3",
min_readable_version_number="1.0",
),
NotebookFormatDescription(
format_name="markdown",
extension=".markdown",
header_prefix="",
cell_reader_class=MarkdownCellReader,
cell_exporter_class=MarkdownCellExporter,
current_version_number="1.2",
min_readable_version_number="1.0",
),
NotebookFormatDescription(
format_name="rmarkdown",
extension=".Rmd",
header_prefix="",
cell_reader_class=RMarkdownCellReader,
cell_exporter_class=RMarkdownCellExporter,
# Version 1.0 on 2018-08-22 - jupytext v0.5.2 : Initial version
# Version 1.1 on 2019-03-24 - jupytext v1.1.0 : Markdown regions and cell metadata
# Version 1.2 on 2019-09-21 - jupytext v1.3.0 : Raw regions are now encoded with HTML comments (#321)
# and by default, cell metadata use the key=value representation in raw and markdown cells (#347)
current_version_number="1.2",
min_readable_version_number="1.0",
),
]
+ [
NotebookFormatDescription(
format_name="light",
extension=ext,
header_prefix=_SCRIPT_EXTENSIONS[ext]["comment"],
header_suffix=_SCRIPT_EXTENSIONS[ext].get("comment_suffix", ""),
cell_reader_class=LightScriptCellReader,
cell_exporter_class=LightScriptCellExporter,
# Version 1.5 on 2019-10-19 - jupytext v1.3.0 - Cell metadata represented as key=value by default
# Version 1.4 on 2019-03-30 - jupytext v1.1.0 - custom cell markers allowed
# Version 1.3 on 2018-09-22 - jupytext v0.7.0rc0 : Metadata are
# allowed for all cell types (and then include 'cell_type')
# Version 1.2 on 2018-09-05 - jupytext v0.6.3 : Metadata bracket
# can be omitted when empty, if previous line is empty #57
# Version 1.1 on 2018-08-25 - jupytext v0.6.0 : Cells separated
# with one blank line #38
# Version 1.0 on 2018-08-22 - jupytext v0.5.2 : Initial version
current_version_number="1.5",
min_readable_version_number="1.1",
)
for ext in _SCRIPT_EXTENSIONS
]
+ [
NotebookFormatDescription(
format_name="nomarker",
extension=ext,
header_prefix=_SCRIPT_EXTENSIONS[ext]["comment"],
header_suffix=_SCRIPT_EXTENSIONS[ext].get("comment_suffix", ""),
cell_reader_class=LightScriptCellReader,
cell_exporter_class=BareScriptCellExporter,
current_version_number="1.0",
min_readable_version_number="1.0",
)
for ext in _SCRIPT_EXTENSIONS
]
+ [
NotebookFormatDescription(
format_name="percent",
extension=ext,
header_prefix=_SCRIPT_EXTENSIONS[ext]["comment"],
header_suffix=_SCRIPT_EXTENSIONS[ext].get("comment_suffix", ""),
cell_reader_class=DoublePercentScriptCellReader,
cell_exporter_class=DoublePercentCellExporter,
# Version 1.3 on 2019-09-21 - jupytext v1.3.0: Markdown cells can be quoted using triple quotes #305
# and cell metadata are represented as key=value by default
# Version 1.2 on 2018-11-18 - jupytext v0.8.6: Jupyter magics are commented by default #126, #132
# Version 1.1 on 2018-09-23 - jupytext v0.7.0rc1 : [markdown] and
# [raw] for markdown and raw cells.
# Version 1.0 on 2018-09-22 - jupytext v0.7.0rc0 : Initial version
current_version_number="1.3",
min_readable_version_number="1.1",
)
for ext in _SCRIPT_EXTENSIONS
]
+ [
NotebookFormatDescription(
format_name="hydrogen",
extension=ext,
header_prefix=_SCRIPT_EXTENSIONS[ext]["comment"],
header_suffix=_SCRIPT_EXTENSIONS[ext].get("comment_suffix", ""),
cell_reader_class=HydrogenCellReader,
cell_exporter_class=HydrogenCellExporter,
# Version 1.2 on 2018-12-14 - jupytext v0.9.0: same as percent - only magics are not commented by default
current_version_number="1.3",
min_readable_version_number="1.1",
)
for ext in _SCRIPT_EXTENSIONS
]
+ [
NotebookFormatDescription(
format_name="spin",
extension=ext,
header_prefix="#'",
cell_reader_class=RScriptCellReader,
cell_exporter_class=RScriptCellExporter,
# Version 1.0 on 2018-08-22 - jupytext v0.5.2 : Initial version
current_version_number="1.0",
)
for ext in [".r", ".R"]
]
+ [
NotebookFormatDescription(
format_name="sphinx",
extension=".py",
header_prefix="#",
cell_reader_class=SphinxGalleryScriptCellReader,
cell_exporter_class=SphinxGalleryCellExporter,
# Version 1.0 on 2018-09-22 - jupytext v0.7.0rc0 : Initial version
current_version_number="1.1",
),
NotebookFormatDescription(
format_name="pandoc",
extension=".md",
header_prefix="",
cell_reader_class=None,
cell_exporter_class=None,
current_version_number=pandoc_version(),
),
NotebookFormatDescription(
format_name="quarto",
extension=".qmd",
header_prefix="",
cell_reader_class=None,
cell_exporter_class=None,
# Version 1.0 on 2021-09-07 = quarto --version >= 0.2.134,
# cf. https://github.com/mwouts/jupytext/issues/837
current_version_number="1.0",
),
NotebookFormatDescription(
format_name="marimo",
extension=".py",
header_prefix="",
cell_reader_class=None,
cell_exporter_class=None,
# Version 1.0 on 2025-09-07
current_version_number="1.0",
),
]
+ [
NotebookFormatDescription(
format_name=MYST_FORMAT_NAME,
extension=ext,
header_prefix="",
cell_reader_class=None,
cell_exporter_class=None,
current_version_number=myst_version(),
)
for ext in myst_extensions()
]
)
NOTEBOOK_EXTENSIONS = list(dict.fromkeys([".ipynb"] + [fmt.extension for fmt in JUPYTEXT_FORMATS]))
EXTENSION_PREFIXES = [".lgt", ".spx", ".pct", ".hyd", ".nb"]
FORMATS_WITH_NO_CELL_METADATA = {"sphinx", "nomarker", "spin", "quarto", "marimo"}
def get_format_implementation(ext, format_name=None):
"""Return the implementation for the desired format"""
# remove pre-extension if any
ext = "." + ext.split(".")[-1]
formats_for_extension = []
for fmt in JUPYTEXT_FORMATS:
if fmt.extension == ext:
if fmt.format_name == format_name or not format_name:
return fmt
formats_for_extension.append(fmt.format_name)
if formats_for_extension:
raise JupytextFormatError(
"Format '{}' is not associated to extension '{}'. Please choose one of: {}.".format(
format_name, ext, ", ".join(formats_for_extension)
)
)
raise JupytextFormatError(f"No format associated to extension '{ext}'")
def read_metadata(text, ext):
"""Return the header metadata"""
ext = "." + ext.split(".")[-1]
lines = text.splitlines()
if ext in [".md", ".markdown", ".Rmd"]:
comment = comment_suffix = ""
else:
comment = _SCRIPT_EXTENSIONS.get(ext, {}).get("comment", "#")
comment_suffix = _SCRIPT_EXTENSIONS.get(ext, {}).get("comment_suffix", "")
metadata, _, _, _ = header_to_metadata_and_cell(lines, comment, comment_suffix, ext)
if ext in [".r", ".R"] and not metadata:
metadata, _, _, _ = header_to_metadata_and_cell(lines, "#'", "", ext)
# metadata in MyST format may be at root level (i.e. not caught above)
if not metadata and ext in myst_extensions() and text.startswith("---"):
for header in yaml.safe_load_all(text):
if not isinstance(header, dict):
continue
if header.get("jupytext", {}).get("text_representation", {}).get("format_name") == MYST_FORMAT_NAME:
return header
return metadata
return metadata
def read_format_from_metadata(text, ext):
"""Return the format of the file, when that information is available from the metadata"""
metadata = read_metadata(text, ext)
rearrange_jupytext_metadata(metadata)
return format_name_for_ext(metadata, ext, explicit_default=False)
def guess_format(text, ext):
"""Guess the format and format options of the file, given its extension and content"""
metadata = read_metadata(text, ext)
if "text_representation" in metadata.get("jupytext", {}):
return format_name_for_ext(metadata, ext), {}
if is_myst_available() and ext in myst_extensions() and matches_mystnb(text, ext, requires_meta=False):
return MYST_FORMAT_NAME, {}
lines = text.splitlines()
# Is this a Hydrogen-like script?
# Or a Sphinx-gallery script?
if ext in _SCRIPT_EXTENSIONS:
unescaped_comment = _SCRIPT_EXTENSIONS[ext]["comment"]
comment = re.escape(unescaped_comment)
language = _SCRIPT_EXTENSIONS[ext]["language"]
twenty_hash_re = re.compile(r"^#( |)#{19,}\s*$")
double_percent_re = re.compile(rf"^{comment}( %%|%%)$")
double_percent_and_space_re = re.compile(rf"^{comment}( %%|%%)\s")
nbconvert_script_re = re.compile(rf"^{comment}( | In\[[0-9 ]*\]:?)")
vim_folding_markers_re = re.compile(rf"^{comment}\s*" + "{{{")
vscode_folding_markers_re = re.compile(rf"^{comment}\s*region")
marimo_cell_re = re.compile(r"^@app.cell.*")
twenty_hash_count = 0
double_percent_count = 0
magic_command_count = 0
rspin_comment_count = 0
vim_folding_markers_count = 0
vscode_folding_markers_count = 0
marimo_app_count = 0
parser = StringParser(language="R" if ext in [".r", ".R"] else "python")
for line in lines:
parser.read_line(line)
if parser.is_quoted():
continue
# Don't count escaped Jupyter magics (no space between %% and command) as cells
if double_percent_re.match(line) or double_percent_and_space_re.match(line) or nbconvert_script_re.match(line):
double_percent_count += 1
if not line.startswith(unescaped_comment) and is_magic(line, language):
magic_command_count += 1
if twenty_hash_re.match(line) and ext == ".py":
twenty_hash_count += 1
if line.startswith("#'") and ext in [".R", ".r"]:
rspin_comment_count += 1
if vim_folding_markers_re.match(line):
vim_folding_markers_count += 1
if vscode_folding_markers_re.match(line):
vscode_folding_markers_count += 1
if ext == ".py" and (line in {"import marimo", "app = marimo.App()"} or marimo_cell_re.match(line)):
marimo_app_count += 1
if double_percent_count >= 1:
if magic_command_count:
return "hydrogen", {}
return "percent", {}
if marimo_app_count >= 2:
return "marimo", {}
if vim_folding_markers_count:
return "light", {"cell_markers": "{{{,}}}"}
if vscode_folding_markers_count:
return "light", {"cell_markers": "region,endregion"}
if twenty_hash_count >= 2:
return "sphinx", {}
if rspin_comment_count >= 1:
return "spin", {}
if ext in [".md", ".markdown"]:
for line in lines:
if line.startswith(":::"): # Pandoc div
return "pandoc", {}
# Default format
return get_format_implementation(ext).format_name, {}
def divine_format(text):
"""Guess the format of the notebook, based on its content #148"""
try:
nbformat.reads(text, as_version=4)
return "ipynb"
except nbformat.reader.NotJSONError:
pass
lines = text.splitlines()
for comment in ["", "#"] + _COMMENT_CHARS:
metadata, _, _, _ = header_to_metadata_and_cell(lines, comment, "")
ext = metadata.get("jupytext", {}).get("text_representation", {}).get("extension")
if ext:
return ext[1:] + ":" + guess_format(text, ext)[0]
# No metadata, but ``` on at least one line => markdown
for line in lines:
if line == "```":
return "md"
return "py:" + guess_format(text, ".py")[0]
def check_file_version(notebook, source_path, outputs_path):
"""Raise if file version in source file would override outputs"""
if not insert_or_test_version_number():
return
if source_path == "-":
# https://github.com/mwouts/jupytext/issues/1282
ext = notebook.metadata["jupytext"]["text_representation"]["extension"]
else:
_, ext = os.path.splitext(source_path)
assert not ext.endswith(".ipynb"), f"source_path={source_path} should be a text file"
version = notebook.metadata.get("jupytext", {}).get("text_representation", {}).get("format_version")
format_name = format_name_for_ext(notebook.metadata, ext)
fmt = get_format_implementation(ext, format_name)
current = fmt.current_version_number
# Missing version, still generated by jupytext?
if notebook.metadata and not version:
version = current
# Same version? OK
if version == fmt.current_version_number:
return
# Version larger than minimum readable version
if (fmt.min_readable_version_number or current) <= version <= current:
return
jupytext_version_in_file = (
notebook.metadata.get("jupytext", {}).get("text_representation", {}).get("jupytext_version", "N/A")
)
raise JupytextFormatError(
"The file {source_path} was generated with jupytext version {jupytext_version_in_file} "
"but you have {jupytext_version} installed. Please upgrade jupytext to version "
"{jupytext_version_in_file}, or remove either {source_path} or {output_path}. "
"This error occurs because {source_path} is in the {format_name} format in version {format_version}, "
"while jupytext version {jupytext_version} installed at {jupytext_path} can only read the "
"{format_name} format in versions {min_format_version} to {current_format_version}.".format(
source_path=os.path.basename(source_path),
output_path=os.path.basename(outputs_path),
format_name=format_name,
format_version=version,
jupytext_version_in_file=jupytext_version_in_file,
jupytext_version=__version__,
jupytext_path=os.path.dirname(os.path.dirname(__file__)),
min_format_version=fmt.min_readable_version_number or current,
current_format_version=current,
)
)
def format_name_for_ext(metadata, ext, cm_default_formats=None, explicit_default=True):
"""Return the format name for that extension"""
# Is the format information available in the text representation?
text_repr = metadata.get("jupytext", {}).get("text_representation", {})
if text_repr.get("extension", "").endswith(ext) and text_repr.get("format_name"):
return text_repr.get("format_name")
# Format from jupytext.formats
formats = metadata.get("jupytext", {}).get("formats", "") or cm_default_formats
formats = long_form_multiple_formats(formats)
for fmt in formats:
if fmt["extension"] == ext:
if (not explicit_default) or fmt.get("format_name"):
return fmt.get("format_name")
if (not explicit_default) or ext in [".md", ".markdown", ".Rmd"]:
return None
return get_format_implementation(ext).format_name
def identical_format_path(fmt1, fmt2):
"""Do the two (long representation) of formats target the same file?"""
for key in ["extension", "prefix", "suffix"]:
if fmt1.get(key) != fmt2.get(key):
return False
return True
def update_jupytext_formats_metadata(metadata, new_format):
"""Update the jupytext_format metadata in the Jupyter notebook"""
new_format = long_form_one_format(new_format)
formats = long_form_multiple_formats(metadata.get("jupytext", {}).get("formats", ""))
if not formats:
return
for fmt in formats:
if identical_format_path(fmt, new_format):
fmt["format_name"] = new_format.get("format_name")
break
metadata.setdefault("jupytext", {})["formats"] = short_form_multiple_formats(formats)
def rearrange_jupytext_metadata(metadata):
"""Convert the jupytext_formats metadata entry to jupytext/formats, etc. See #91"""
# Backward compatibility with nbrmd
for key in ["nbrmd_formats", "nbrmd_format_version"]:
if key in metadata:
metadata[key.replace("nbrmd", "jupytext")] = metadata.pop(key)
jupytext_metadata = metadata.get("jupytext", {})
if "jupytext_formats" in metadata:
jupytext_metadata["formats"] = metadata.pop("jupytext_formats")
if "jupytext_format_version" in metadata:
jupytext_metadata["text_representation"] = {"format_version": metadata.pop("jupytext_format_version")}
if "main_language" in metadata:
jupytext_metadata["main_language"] = metadata.pop("main_language")
for entry in ["encoding", "executable"]:
if entry in metadata:
jupytext_metadata[entry] = metadata.pop(entry)
filters = jupytext_metadata.pop("metadata_filter", {})
if "notebook" in filters:
jupytext_metadata["notebook_metadata_filter"] = filters["notebook"]
if "cells" in filters:
jupytext_metadata["cell_metadata_filter"] = filters["cells"]
for filter_level in ["notebook_metadata_filter", "cell_metadata_filter"]:
if filter_level in jupytext_metadata:
jupytext_metadata[filter_level] = metadata_filter_as_string(jupytext_metadata[filter_level])
if jupytext_metadata.get("text_representation", {}).get("jupytext_version", "").startswith("0."):
formats = jupytext_metadata.get("formats")
if formats:
jupytext_metadata["formats"] = ",".join(["." + fmt if fmt.rfind(".") > 0 else fmt for fmt in formats.split(",")])
# auto to actual extension
formats = jupytext_metadata.get("formats")
if formats:
jupytext_metadata["formats"] = short_form_multiple_formats(long_form_multiple_formats(formats, metadata))
if jupytext_metadata:
metadata["jupytext"] = jupytext_metadata
def long_form_one_format(jupytext_format, metadata=None, update=None, auto_ext_requires_language_info=True):
"""Parse 'sfx.py:percent' into {'suffix':'sfx', 'extension':'py', 'format_name':'percent'}"""
if isinstance(jupytext_format, dict):
if update:
jupytext_format.update(update)
return validate_one_format(jupytext_format)
if not jupytext_format:
return {}
common_name_to_ext = {
"notebook": "ipynb",
"rmarkdown": "Rmd",
"quarto": "qmd",
"marimo": "py",
"markdown": "md",
"script": "auto",
"c++": "cpp",
"myst": "md:myst",
"pandoc": "md:pandoc",
}
if jupytext_format.lower() in common_name_to_ext:
jupytext_format = common_name_to_ext[jupytext_format.lower()]
fmt = {}
if jupytext_format.rfind("/") > 0:
fmt["prefix"], jupytext_format = jupytext_format.rsplit("/", 1)
if jupytext_format.rfind(":") >= 0:
ext, fmt["format_name"] = jupytext_format.rsplit(":", 1)
if fmt["format_name"] == "bare":
warnings.warn(
"The `bare` format has been renamed to `nomarker` - (see https://github.com/mwouts/jupytext/issues/397)",
DeprecationWarning,
)
fmt["format_name"] = "nomarker"
elif not jupytext_format or "." in jupytext_format or ("." + jupytext_format) in NOTEBOOK_EXTENSIONS + [".auto"]:
ext = jupytext_format
elif jupytext_format in _VALID_FORMAT_NAMES:
fmt["format_name"] = jupytext_format
ext = ""
else:
raise JupytextFormatError(
"'{}' is not a notebook extension (one of {}), nor a notebook format (one of {})".format(
jupytext_format,
", ".join(NOTEBOOK_EXTENSIONS),
", ".join(_VALID_FORMAT_NAMES),
)
)
if ext.rfind(".") > 0:
fmt["suffix"], ext = os.path.splitext(ext)
if not ext.startswith("."):
ext = "." + ext
if ext == ".auto":
ext = auto_ext_from_metadata(metadata) if metadata is not None else ".auto"
if not ext:
if auto_ext_requires_language_info:
raise JupytextFormatError(
"No language information in this notebook. Please replace 'auto' with an actual script extension."
)
ext = ".auto"
fmt["extension"] = ext
if update:
fmt.update(update)
return validate_one_format(fmt)
def long_form_multiple_formats(
jupytext_formats: str, metadata=None, auto_ext_requires_language_info=True
) -> list[dict[str, str]]:
"""Convert a concise encoding of jupytext.formats to a list of formats, encoded as dictionaries"""
if not jupytext_formats:
return []
if not isinstance(jupytext_formats, list):
jupytext_formats = [fmt for fmt in jupytext_formats.split(",") if fmt]
jupytext_formats = [
long_form_one_format(
fmt,
metadata,
auto_ext_requires_language_info=auto_ext_requires_language_info,
)
for fmt in jupytext_formats
]
if not auto_ext_requires_language_info:
jupytext_formats = [fmt for fmt in jupytext_formats if fmt["extension"] != ".auto"]
return jupytext_formats
def short_form_one_format(jupytext_format: dict[str, str]) -> str:
"""Represent one jupytext format as a string"""
if not isinstance(jupytext_format, dict):
return jupytext_format
fmt = jupytext_format["extension"]
if "suffix" in jupytext_format:
fmt = jupytext_format["suffix"] + fmt
elif fmt.startswith("."):
fmt = fmt[1:]
if "prefix" in jupytext_format:
fmt = jupytext_format["prefix"] + "/" + fmt
if jupytext_format.get("format_name"):
if jupytext_format["extension"] not in [
".md",
".markdown",
".Rmd",
] or jupytext_format["format_name"] in ["pandoc", MYST_FORMAT_NAME]:
fmt = fmt + ":" + jupytext_format["format_name"]
return fmt
def short_form_multiple_formats(jupytext_formats: list[dict[str, str]]) -> str:
"""Convert jupytext formats, represented as a list of dictionaries, to a comma separated list"""
if not isinstance(jupytext_formats, list):
return jupytext_formats
jupytext_formats = [short_form_one_format(fmt) for fmt in jupytext_formats]
return ",".join(jupytext_formats)
_VALID_FORMAT_INFO = ["extension", "format_name", "suffix", "prefix"]
_BINARY_FORMAT_OPTIONS = [
"comment_magics",
"hide_notebook_metadata",
"root_level_metadata_as_raw_cell",
"split_at_heading",
"rst2md",
"cell_metadata_json",
"use_runtools",
"doxygen_equation_markers",
]
_VALID_FORMAT_OPTIONS = _BINARY_FORMAT_OPTIONS + [
"notebook_metadata_filter",
"root_level_metadata_filter",
"cell_metadata_filter",
"cell_markers",
"custom_cell_magics",
]
_VALID_FORMAT_NAMES = {fmt.format_name for fmt in JUPYTEXT_FORMATS}
def validate_one_format(jupytext_format: dict[str, str]) -> dict[str, str]:
"""Validate extension and options for the given format"""
if not isinstance(jupytext_format, dict):
raise JupytextFormatError("Jupytext format should be a dictionary")
if "format_name" in jupytext_format and jupytext_format["format_name"] not in _VALID_FORMAT_NAMES:
raise JupytextFormatError(
"{} is not a valid format name. Please choose one of {}".format(
jupytext_format.get("format_name"), ", ".join(_VALID_FORMAT_NAMES)
)
)
for key in jupytext_format:
if key not in _VALID_FORMAT_INFO + _VALID_FORMAT_OPTIONS:
raise JupytextFormatError(
"Unknown format option '{}' - should be one of '{}'".format(key, "', '".join(_VALID_FORMAT_OPTIONS))
)
value = jupytext_format[key]
if key in _BINARY_FORMAT_OPTIONS:
if not isinstance(value, bool):
raise JupytextFormatError(f"Format option '{key}' should be a bool, not '{str(value)}'")
if "extension" not in jupytext_format:
raise JupytextFormatError("Missing format extension")
ext = jupytext_format["extension"]
if ext not in NOTEBOOK_EXTENSIONS + [".auto"]:
raise JupytextFormatError(
"Extension '{}' is not a notebook extension. Please use one of '{}'.".format(
ext, "', '".join(NOTEBOOK_EXTENSIONS + [".auto"])
)
)
return jupytext_format
def auto_ext_from_metadata(metadata):
"""Script extension from notebook metadata"""
auto_ext = metadata.get("language_info", {}).get("file_extension")
# Sage notebooks have ".py" as the associated extension in "language_info",
# so we change it to ".sage" in that case, see #727
if auto_ext == ".py" and metadata.get("kernelspec", {}).get("language") == "sage":
auto_ext = ".sage"
if auto_ext is None:
language = metadata.get("kernelspec", {}).get("language") or metadata.get("jupytext", {}).get("main_language")
if language:
for ext in _SCRIPT_EXTENSIONS:
if same_language(language, _SCRIPT_EXTENSIONS[ext]["language"]):
auto_ext = ext
break
if auto_ext == ".r":
return ".R"
if auto_ext == ".fs":
return ".fsx"
if auto_ext == ".resource":
return ".robot"
# Handle ROOT C++ notebooks
# https://tinyurl.com/root-cpp-notebook-doc
if auto_ext == ".C":
return ".cpp"
return auto_ext
def check_auto_ext(fmt, metadata, option):
"""Replace the auto extension with the actual file extension, and raise a ValueError if it cannot be determined"""
if fmt["extension"] != ".auto":
return fmt
auto_ext = auto_ext_from_metadata(metadata)
if auto_ext:
fmt = fmt.copy()
fmt["extension"] = auto_ext
return fmt
raise ValueError(
"The notebook does not have a 'language_info' metadata. "
"Please replace 'auto' with the actual language extension in the {} option (currently {}).".format(
option, short_form_one_format(fmt)
)
)
def formats_with_support_for_cell_metadata():
for fmt in JUPYTEXT_FORMATS:
if fmt.format_name == "myst" and not is_myst_available():
continue
if fmt.format_name == "pandoc" and not is_pandoc_available():
continue
if fmt.format_name in FORMATS_WITH_NO_CELL_METADATA:
continue
yield f"{fmt.extension[1:]}:{fmt.format_name}"
def get_formats_from_notebook_metadata(notebook):
"""
Get the pairing information from the notebook metadata.
Parameters
----------
notebook : nbformat.NotebookNode
The notebook object whose metadata will be inspected.
Returns
-------
formats : None or str
The value of the 'formats' field in the 'jupytext' metadata, which can be None or a string.
"""
return notebook.metadata.get("jupytext", {}).get("formats")
================================================
FILE: src/jupytext/header.py
================================================
"""Parse header of text notebooks"""
import logging
import re
import nbformat
import yaml
from nbformat.v4.nbbase import new_raw_cell
from yaml.representer import SafeRepresenter
from .languages import (
_SCRIPT_EXTENSIONS,
comment_lines,
default_language_from_metadata_and_ext,
)
from .metadata_filter import (
_DEFAULT_NOTEBOOK_METADATA,
_DEFAULT_ROOT_LEVEL_METADATA,
_JUPYTER_METADATA_NAMESPACE,
filter_metadata,
)
from .myst import MYST_FORMAT_NAME
from .pep8 import pep8_lines_between_cells
from .version import __version__
SafeRepresenter.add_representer(nbformat.NotebookNode, SafeRepresenter.represent_dict)
_HEADER_RE = re.compile(r"^---\s*$")
_BLANK_RE = re.compile(r"^\s*$")
_JUPYTER_RE = re.compile(r"^jupyter\s*:\s*$")
_LEFTSPACE_RE = re.compile(r"^\s")
_UTF8_HEADER = " -*- coding: utf-8 -*-"
# Change this to False in tests
INSERT_AND_CHECK_VERSION_NUMBER = True
def insert_or_test_version_number():
"""Should the format name and version number be inserted in text
representations (not in tests!)"""
return INSERT_AND_CHECK_VERSION_NUMBER
def uncomment_line(line, prefix, suffix=""):
"""Remove prefix (and space) from line"""
if prefix:
if line.startswith(prefix + " "):
line = line[len(prefix) + 1 :]
elif line.startswith(prefix):
line = line[len(prefix) :]
if suffix:
if line.endswith(suffix + " "):
line = line[: -(1 + len(suffix))]
elif line.endswith(suffix):
line = line[: -len(suffix)]
return line
def encoding_and_executable(notebook, metadata, ext):
"""Return encoding and executable lines for a notebook, if applicable"""
lines = []
comment = _SCRIPT_EXTENSIONS.get(ext, {}).get("comment")
jupytext_metadata = metadata.get("jupytext", {})
if comment is not None and "executable" in jupytext_metadata:
lines.append("#!" + jupytext_metadata.pop("executable"))
if comment is not None:
if "encoding" in jupytext_metadata:
lines.append(jupytext_metadata.pop("encoding"))
elif default_language_from_metadata_and_ext(metadata, ext) != "python":
for cell in notebook.cells:
try:
cell.source.encode("ascii")
except (UnicodeEncodeError, UnicodeDecodeError):
lines.append(comment + _UTF8_HEADER)
break
return lines
def insert_jupytext_info_and_filter_metadata(metadata, fmt, text_format, unsupported_keys):
"""Update the notebook metadata to include Jupytext information, and filter
the notebook metadata according to the default or user filter"""
if insert_or_test_version_number():
metadata.setdefault("jupytext", {})["text_representation"] = {
"extension": fmt["extension"],
"format_name": text_format.format_name,
"format_version": text_format.current_version_number,
"jupytext_version": __version__,
}
if "jupytext" in metadata and not metadata["jupytext"]:
del metadata["jupytext"]
notebook_metadata_filter = fmt.get("notebook_metadata_filter")
return filter_metadata(
metadata,
notebook_metadata_filter,
_DEFAULT_NOTEBOOK_METADATA,
unsupported_keys=unsupported_keys,
)
def metadata_and_cell_to_header(notebook, metadata, text_format, fmt, unsupported_keys=None):
"""
Return the text header corresponding to a notebook, and remove the
first cell of the notebook if it contained the header
"""
header = []
lines_to_next_cell = None
root_level_metadata = {}
root_level_metadata_as_raw_cell = fmt.get("root_level_metadata_as_raw_cell", True)
if not root_level_metadata_as_raw_cell:
root_level_metadata = metadata.get("jupytext", {}).pop("root_level_metadata", {})
elif notebook.cells:
cell = notebook.cells[0]
if cell.cell_type == "raw":
lines = cell.source.strip("\n\t ").splitlines()
if len(lines) >= 2 and _HEADER_RE.match(lines[0]) and _HEADER_RE.match(lines[-1]):
header = lines[1:-1]
lines_to_next_cell = cell.metadata.get("lines_to_next_cell")
notebook.cells = notebook.cells[1:]
metadata = insert_jupytext_info_and_filter_metadata(metadata, fmt, text_format, unsupported_keys)
if metadata:
root_level_metadata["jupyter"] = metadata
if root_level_metadata:
header.extend(yaml.safe_dump(root_level_metadata, default_flow_style=False).splitlines())
if header:
header = ["---"] + header + ["---"]
if fmt.get("hide_notebook_metadata", False) and text_format.format_name == "markdown":
header = [""]
return (
comment_lines(header, text_format.header_prefix, text_format.header_suffix),
lines_to_next_cell,
)
def recursive_update(target, update, overwrite=True):
"""Update recursively a (nested) dictionary with the content of another.
Inspired from https://stackoverflow.com/questions/3232943/update-value-of-a-nested-dictionary-of-varying-depth
"""
for key in update:
value = update[key]
if value is None:
del target[key]
elif isinstance(value, dict):
target[key] = recursive_update(
target.get(key, {}),
value,
overwrite=overwrite,
)
elif overwrite:
target[key] = value
else:
target.setdefault(key, value)
return target
def header_to_metadata_and_cell(lines, header_prefix, header_suffix, ext=None, root_level_metadata_as_raw_cell=True):
"""
Return the metadata, a boolean to indicate if a jupyter section was found,
the first cell of notebook if some metadata is found outside
the jupyter section, and next loc in text
"""
header = []
jupyter = []
in_jupyter = False
in_html_div = False
start = 0
started = False
ended = False
metadata = {}
i = -1
comment = "#" if header_prefix == "#'" else header_prefix
encoding_re = re.compile(rf"^[ \t\f]*{re.escape(comment)}.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)")
for i, line in enumerate(lines):
if i == 0 and line.startswith("#!"):
metadata.setdefault("jupytext", {})["executable"] = line[2:]
start = i + 1
continue
if i == 0 or (i == 1 and not encoding_re.match(lines[0])):
encoding = encoding_re.match(line)
if encoding:
if encoding.group(1) != "utf-8":
raise ValueError("Encodings other than utf-8 are not supported")
metadata.setdefault("jupytext", {})["encoding"] = line
start = i + 1
continue
if not line.startswith(header_prefix):
break
if not comment:
if line.strip().startswith("" in line:
break
if not started and not line.strip():
continue
line = uncomment_line(line, header_prefix, header_suffix)
if _HEADER_RE.match(line):
if not started:
started = True
continue
ended = True
if in_html_div:
continue
break
# Stop if there is something else than a YAML header
if not started and line.strip():
break
if _JUPYTER_RE.match(line):
in_jupyter = True
elif line and not _LEFTSPACE_RE.match(line):
in_jupyter = False
if in_jupyter:
jupyter.append(line)
else:
header.append(line)
if ended:
if jupyter:
extra_metadata = metadata
metadata = yaml.safe_load("\n".join(jupyter))["jupyter"]
recursive_update(metadata, extra_metadata)
lines_to_next_cell = 1
if len(lines) > i + 1:
line = uncomment_line(lines[i + 1], header_prefix)
if not _BLANK_RE.match(line):
lines_to_next_cell = 0
else:
i = i + 1
else:
lines_to_next_cell = 0
if header:
if root_level_metadata_as_raw_cell:
cell = new_raw_cell(
source="\n".join(["---"] + header + ["---"]),
metadata=(
{}
if lines_to_next_cell == pep8_lines_between_cells(["---"], lines[i + 1 :], ext)
else {"lines_to_next_cell": lines_to_next_cell}
),
)
else:
cell = None
root_level_metadata = yaml.safe_load("\n".join(header))
metadata.setdefault("jupytext", {})["root_level_metadata"] = root_level_metadata
else:
cell = None
return metadata, jupyter, cell, i + 1
return metadata, False, None, start
def default_root_level_metadata_filter(fmt):
"""Return defaults for settings that promote or demote root level metadata."""
if fmt and fmt.get("format_name") == MYST_FORMAT_NAME:
from .myst import _DEFAULT_ROOT_LEVEL_METADATA as default_filter
else:
default_filter = _DEFAULT_ROOT_LEVEL_METADATA
return default_filter
def metadata_to_metadata_and_cell(nb, metadata, fmt, unsupported_keys=None):
# stash notebook metadata, including keys promoted to the root level
metadata = recursive_update(
metadata,
filter_metadata(
nb.metadata,
fmt.get("root_level_metadata_filter", ""),
default_root_level_metadata_filter(fmt),
unsupported_keys=unsupported_keys,
remove=True,
),
)
# move remaining metadata (i.e. frontmatter) to the first notebook cell
if nb.metadata and fmt.get("root_level_metadata_as_raw_cell", True):
frontmatter = yaml.safe_dump(nb.metadata, sort_keys=False)
nb.cells.insert(0, new_raw_cell("---\n" + frontmatter + "---"))
# attach the stashed metadata to notebook
nb.metadata = metadata
return nb
def metadata_and_cell_to_metadata(nb, fmt, unsupported_keys=None):
# new metadata from filtered nb.metadata
metadata = filter_metadata(
nb.metadata,
fmt.get("root_level_metadata_filter", ""),
default_root_level_metadata_filter(fmt),
unsupported_keys=unsupported_keys,
remove=True,
)
# remaining nb.metadata moved under namespace key for jupyter metadata
if nb.metadata:
metadata[_JUPYTER_METADATA_NAMESPACE] = nb.metadata
# move first cell frontmatter to the root level of nb.metadata (overwrites)
if nb.cells and fmt.get("root_level_metadata_as_raw_cell", True):
cell = nb.cells[0]
if cell.cell_type == "raw":
lines = cell.source.strip("\n\t ").splitlines()
if len(lines) >= 2 and _HEADER_RE.match(lines[0]) and _HEADER_RE.match(lines[-1]):
try:
frontmatter = next(yaml.safe_load_all(cell.source))
except (yaml.parser.ParserError, yaml.scanner.ScannerError):
logging.warning("[jupytext] failed to parse YAML in raw cell")
else:
if not isinstance(frontmatter, dict):
logging.warning("[jupytext] YAML header in raw cell is not a dictionary")
else:
nb.cells = nb.cells[1:]
if "root_level_metadata_filter" not in fmt and default_root_level_metadata_filter(fmt) == "all":
metadata.setdefault("jupytext", {})["root_level_metadata_filter"] = "-" + ",-".join(frontmatter)
metadata = recursive_update(frontmatter, metadata, overwrite=False)
nb.metadata = metadata
return nb
================================================
FILE: src/jupytext/jupytext.py
================================================
"""Read and write Jupyter notebooks as text files"""
import logging
import os
import sys
import warnings
from copy import copy, deepcopy
import nbformat
from nbformat.v4.nbbase import NotebookNode, new_code_cell, new_notebook
from nbformat.v4.rwbase import NotebookReader, NotebookWriter
from .cell_metadata import _IGNORE_CELL_METADATA
from .config import get_formats_from_notebook_and_config, load_jupytext_config
from .formats import (
_VALID_FORMAT_OPTIONS,
divine_format,
format_name_for_ext,
get_format_implementation,
guess_format,
long_form_one_format,
read_format_from_metadata,
rearrange_jupytext_metadata,
update_jupytext_formats_metadata,
)
from .header import (
_JUPYTER_METADATA_NAMESPACE,
encoding_and_executable,
header_to_metadata_and_cell,
insert_jupytext_info_and_filter_metadata,
insert_or_test_version_number,
metadata_and_cell_to_header,
metadata_and_cell_to_metadata,
metadata_to_metadata_and_cell,
)
from .languages import (
_SCRIPT_EXTENSIONS,
default_language_from_metadata_and_ext,
set_main_and_cell_language,
)
from .metadata_filter import filter_metadata, update_metadata_filters
from .myst import MYST_FORMAT_NAME, myst_extensions, myst_to_notebook, notebook_to_myst
from .pandoc import md_to_notebook, notebook_to_md
from .pep8 import pep8_lines_between_cells
from .quarto import notebook_to_qmd, qmd_to_notebook
from .marimo import notebook_to_marimo_py, marimo_py_to_notebook
from .version import __version__
class NotSupportedNBFormatVersion(NotImplementedError):
"""An error issued when the current notebook format is not supported by this version of Jupytext"""
class TextNotebookConverter(NotebookReader, NotebookWriter):
"""A class that can read or write a Jupyter notebook as text"""
def __init__(self, fmt, config):
self.fmt = copy(long_form_one_format(fmt))
self.config = config
self.ext = self.fmt["extension"]
self.implementation = get_format_implementation(self.ext, self.fmt.get("format_name"))
def update_fmt_with_notebook_options(self, metadata, read=False):
"""Update format options with the values in the notebook metadata, and record those
options in the notebook metadata"""
# The settings in the Jupytext configuration file have precedence over the metadata in the notebook
# when the notebook is saved. This is because the metadata in the notebook might not be visible
# in the text representation when e.g. notebook_metadata_filter="-all", which makes them hard to edit.
if not read and self.config is not None:
self.config.set_default_format_options(self.fmt, read)
# Use format options from the notebook if not already set by the config
for opt in _VALID_FORMAT_OPTIONS:
if opt in metadata.get("jupytext", {}):
self.fmt.setdefault(opt, metadata["jupytext"][opt])
# When we read the notebook we use the values of the config as defaults, as again the text representation
# of the notebook might not store the format options when notebook_metadata_filter="-all"
if read and self.config is not None:
self.config.set_default_format_options(self.fmt, read=read)
# We save the format options in the notebook metadata
for opt in _VALID_FORMAT_OPTIONS:
if opt in self.fmt:
metadata.setdefault("jupytext", {})[opt] = self.fmt[opt]
# Is this format the same as that documented in the YAML header? If so, we want to know the format version
file_fmt = metadata.get("jupytext", {}).get("text_representation", {})
if self.fmt.get("extension") == file_fmt.get("extension") and self.fmt.get("format_name") == file_fmt.get(
"format_name"
):
self.fmt.update(file_fmt)
# rST to md conversion should happen only once
if metadata.get("jupytext", {}).get("rst2md") is True:
metadata["jupytext"]["rst2md"] = False
def reads(self, s, **_):
"""Read a notebook represented as text"""
if self.fmt.get("format_name") == "pandoc":
return md_to_notebook(s)
if self.fmt.get("format_name") == "quarto":
return qmd_to_notebook(s)
if self.fmt.get("format_name") == "marimo":
return marimo_py_to_notebook(s)
if self.fmt.get("format_name") == MYST_FORMAT_NAME:
nb = myst_to_notebook(s)
return self.split_frontmatter(nb)
lines = s.splitlines()
cells = []
metadata, jupyter_md, header_cell, pos = header_to_metadata_and_cell(
lines,
self.implementation.header_prefix,
self.implementation.header_suffix,
self.implementation.extension,
self.fmt.get(
"root_level_metadata_as_raw_cell",
(self.config.root_level_metadata_as_raw_cell if self.config is not None else True),
),
)
default_language = default_language_from_metadata_and_ext(metadata, self.implementation.extension)
self.update_fmt_with_notebook_options(metadata, read=True)
if header_cell:
cells.append(header_cell)
lines = lines[pos:]
if self.implementation.format_name and self.implementation.format_name.startswith("sphinx"):
cells.append(new_code_cell(source="%matplotlib inline"))
cell_metadata_json = False
while lines:
reader = self.implementation.cell_reader_class(self.fmt, default_language)
cell, pos = reader.read(lines)
cells.append(cell)
cell_metadata_json = cell_metadata_json or reader.cell_metadata_json
if pos <= 0:
raise Exception("Blocked at lines " + "\n".join(lines[:6])) # pragma: no cover
lines = lines[pos:]
custom_cell_magics = self.fmt.get("custom_cell_magics", "").split(",")
set_main_and_cell_language(metadata, cells, self.implementation.extension, custom_cell_magics)
cell_metadata = set()
for cell in cells:
cell_metadata.update(cell.metadata.keys())
update_metadata_filters(metadata, jupyter_md, cell_metadata)
if cell_metadata_json:
metadata.setdefault("jupytext", {}).setdefault("cell_metadata_json", True)
if self.implementation.format_name and self.implementation.format_name.startswith("sphinx"):
filtered_cells = []
for i, cell in enumerate(cells):
if (
cell.source == ""
and i > 0
and i + 1 < len(cells)
and cells[i - 1].cell_type != "markdown"
and cells[i + 1].cell_type != "markdown"
):
continue
filtered_cells.append(cell)
cells = filtered_cells
return new_notebook(cells=cells, metadata=metadata)
def filter_notebook(self, nb, metadata, preserve_cell_ids=True):
self.update_fmt_with_notebook_options(nb.metadata)
unsupported_keys = set()
metadata = insert_jupytext_info_and_filter_metadata(
metadata, self.fmt, self.implementation, unsupported_keys=unsupported_keys
)
# We sort the notebook metadata for consistency with v1.16
metadata = dict(sorted(metadata.items()))
cells = []
for cell in nb.cells:
cell_kwargs = dict(cell)
cell_kwargs["metadata"] = filter_metadata(
cell.metadata,
self.fmt.get("cell_metadata_filter"),
_IGNORE_CELL_METADATA,
unsupported_keys=unsupported_keys,
)
if not preserve_cell_ids:
cell_kwargs.pop("id", None)
elif hasattr(cell, "id"):
cell_kwargs["id"] = cell.id
if cell.cell_type == "code":
# Drop outputs and execution count
cell_kwargs["outputs"] = []
cell_kwargs["execution_count"] = None
cells.append(NotebookNode(**cell_kwargs))
_warn_on_unsupported_keys(unsupported_keys)
return NotebookNode(
nbformat=nb.nbformat,
nbformat_minor=nb.nbformat_minor,
metadata=metadata,
cells=cells,
)
def writes(self, nb, metadata=None, **kwargs):
"""Return the text representation of the notebook"""
if self.fmt.get("format_name") == "pandoc":
return notebook_to_md(self.filter_notebook(nb, metadata))
if self.fmt.get("format_name") == "quarto" or self.ext == ".qmd":
return notebook_to_qmd(self.filter_notebook(nb, metadata))
if self.fmt.get("format_name") == "marimo":
return notebook_to_marimo_py(self.filter_notebook(nb, metadata))
if self.fmt.get("format_name") == MYST_FORMAT_NAME or self.ext in myst_extensions(no_md=True):
default_lexer_from_language_info = metadata.get("language_info", {}).get("pygments_lexer", None)
default_lexer_from_jupytext_metadata = metadata.get("jupytext", {}).pop("default_lexer", None)
default_lexer = default_lexer_from_language_info or default_lexer_from_jupytext_metadata
nb = self.filter_notebook(nb, metadata)
nb = self.merge_frontmatter(nb)
return notebook_to_myst(nb, default_lexer=default_lexer)
# Copy the notebook, in order to be sure we do not modify the original notebook
nb = NotebookNode(
nbformat=nb.nbformat,
nbformat_minor=nb.nbformat_minor,
metadata=deepcopy(metadata or nb.metadata),
cells=nb.cells,
)
metadata = nb.metadata
default_language = default_language_from_metadata_and_ext(metadata, self.implementation.extension, True) or "python"
self.update_fmt_with_notebook_options(nb.metadata)
if "use_runtools" not in self.fmt:
for cell in nb.cells:
if cell.metadata.get("hide_input", False) or cell.metadata.get("hide_output", False):
self.fmt["use_runtools"] = True
break
header = encoding_and_executable(nb, metadata, self.ext)
unsupported_keys = set()
header_content, header_lines_to_next_cell = metadata_and_cell_to_header(
nb,
metadata,
self.implementation,
self.fmt,
unsupported_keys=unsupported_keys,
)
header.extend(header_content)
cell_exporters = []
looking_for_first_markdown_cell = self.implementation.format_name and self.implementation.format_name.startswith(
"sphinx"
)
split_at_heading = self.fmt.get("split_at_heading", False)
for cell in nb.cells:
if looking_for_first_markdown_cell and cell.cell_type == "markdown":
cell.metadata.setdefault("cell_marker", '"""')
looking_for_first_markdown_cell = False
cell_exporters.append(
self.implementation.cell_exporter_class(cell, default_language, self.fmt, unsupported_keys=unsupported_keys)
)
_warn_on_unsupported_keys(unsupported_keys)
texts = [cell.cell_to_text() for cell in cell_exporters]
lines = []
# concatenate cells in reverse order to determine how many blank lines (pep8)
for i, cell in reversed(list(enumerate(cell_exporters))):
text = cell.remove_eoc_marker(texts[i], lines)
if (
i == 0
and self.implementation.format_name
and self.implementation.format_name.startswith("sphinx")
and (text in [["%matplotlib inline"], ["# %matplotlib inline"]])
):
continue
lines_to_next_cell = cell.lines_to_next_cell
if lines_to_next_cell is None:
lines_to_next_cell = pep8_lines_between_cells(text, lines, self.implementation.extension)
text.extend([""] * lines_to_next_cell)
# two blank lines between markdown cells in Rmd when those do not have explicit region markers
if self.ext in [".md", ".markdown", ".Rmd"] and not cell.is_code():
if (
i + 1 < len(cell_exporters)
and not cell_exporters[i + 1].is_code()
and not texts[i][0].startswith(" 1\u001b[1;33m \u001b[0mundefined_variable\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[1;31mNameError\u001b[0m: name 'undefined_variable' is not defined"
]
}
],
"source": [
"undefined_variable"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.4"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_q/kalman_filter_and_visualization.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 32,
"metadata": {},
"outputs": [],
"source": [
"plt: .p.import`matplotlib.pyplot"
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {},
"outputs": [],
"source": [
"filter: {\n",
" t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);\n",
" (first t), iterate[R; R]\\[first t; 1 _ t] \n",
" }\n",
"\n",
"iterate: {[Q; R; x; y]\n",
" x[`p]+: Q;\n",
" k: x[`p] % R + x[`p];\n",
" `x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])\n",
" }"
]
},
{
"cell_type": "code",
"execution_count": 36,
"metadata": {},
"outputs": [],
"source": [
"price: 100 + sums 0.5 - (n:50)?1."
]
},
{
"cell_type": "code",
"execution_count": 37,
"metadata": {},
"outputs": [],
"source": [
"output:filter price"
]
},
{
"cell_type": "code",
"execution_count": 38,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAZoAAAEnCAYAAACQUoXIAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMi4yLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvhp/UCwAAIABJREFUeJzs3Xd81dX9+PHXuTd73ITsxUgIZEDCJjJEERFU3Lu21lpHXdVua61aa63f6q+tdjlqnXVUcCHIlL0JI4MQMiF7733vPb8/zg0JkDCybsZ5Ph48Qj753M99X8Z938857/M+QkqJpmmapvUXg70D0DRN04Y3nWg0TdO0fqUTjaZpmtavdKLRNE3T+pVONJqmaVq/0olG0zRN61c60Wiapmn9SicaTdM0rV/pRKNpmqb1Kwd7B3Ah/Pz85Lhx4+wdhqZpmgYkJiaWSyn9z3XekEo048aNY//+/fYOQ9M0TQOEEMfP5zw9dKZpmqb1K51oNE3TtH6lE42maZrWr4bUHI2maVpfaGtrIz8/n+bmZnuHMiS4uLgQFhaGo6Njjx6vE42maSNOfn4+np6ejBs3DiGEvcMZ1KSUVFRUkJ+fT3h4eI+uoYfONE0bcZqbm/H19dVJ5jwIIfD19e3V3Z9ONJqmjUg6yZy/3v5Z6USjaZqm9SudaDRN0waxp59+mg0bNtg7jF7RxQCaNswdr2jgl8uT8HRx4N/fn2XvcLQLYLFYeO655+wdRq/pRKNpw5SUkk8T8/ndV6k0tFoAyKtsZLSPm50jG1x+tzKVI4W1fXrN2BATz1wz6azn5ObmsnTpUhISEjh48CATJ07kvffeIzY2lnvuuYd169bxyCOPsGbNGpYtW8bNN9/Mvn37eOyxx2hoaMDZ2ZmNGzfi5ubGE088webNm2lpaeHhhx/mgQce6NPX01t66EzThqGqhlYe/OAAv1yeRFyYFx/ddxEAa1KK7RyZ1ll6ejr3338/SUlJmEwm/vnPfwJq3cr27du5/fbbT57b2trKbbfdxiuvvMLhw4fZsGEDrq6uvPXWW3h5ebFv3z727dvHm2++SU5Ojr1eUpfOeUcjhPgPsAwolVJOth3zAT4BxgG5wK1SyiqhShNeAa4CGoG7pZQHurjmZiAYaLIdukJKWdrbF6NpGmw9VsbPPz1MVWMrT14Vzb3zIzAYBJNCTKxKLuK+BRH2DnFQOdedR38aPXo08+bNA+C73/0ur776KgC33XbbGeemp6cTHBzMrFlq+NNkMgGwbt06kpKSWL58OQA1NTVkZGT0eM1LfzifobN3gL8D73U69gSwUUr5ohDiCdv3vwKuBCbYfiUA/7J97cqdUkrdilnT+ojZYuX5VWm8szOXCQEevP2DWUwK8Tr586vignlpbToF1U2EervaMVKt3ellw+3fu7u7n3GulLLLMmMpJX/7299YsmRJ/wTZB845dCal3ApUnnb4OuBd2+/fBa7vdPw9qewGvIUQwX0VrKZp3VuVXMQ7O3P5/pyxrHx0/ilJBuDqOPVf8ZvkInuEp3XhxIkT7Nq1C4CPPvqI+fPnd3tudHQ0hYWF7Nu3D4C6ujrMZjNLlizhX//6F21tbQAcO3aMhoaG/g/+AvR0jiZQSlkEYPsaYDseCuR1Oi/fdqwrbwshDgkhfiv0yilN67UdmeV4uTryzDWTcHE0nvHzcX7uxAabWK0TzaARExPDu+++S3x8PJWVlTz44IPdnuvk5MQnn3zCo48+ypQpU1i8eDHNzc3ce++9xMbGMn36dCZPnswDDzyA2WwewFdxbn1dddZVwpBdHLtTSlkghPAEVgDf49ShuY4LCnE/cD/AmDFj+ipOTRtWpJTsyKxgToQvBkMX/w0PfwxVuVw1+UZeXp9BYXUTIXr4zO4MBgOvvfbaKcdyc3NP+f6dd945+ftZs2axe/fuM67zwgsv8MILL/RHiH2ip3c0Je1DYrav7RP5+cDoTueFAYWnP1hKWWD7Wgd8CMzu7omklG9IKWdKKWf6+59zx1BNG5HyKpsoqG5ibqTvmT+sKYCVj8PmP/KdthWArj7TBlZPE81XwPdtv/8+8GWn43cJ5SKgpn2IrZ0QwkEI4Wf7vSOqoi2lh3FomgbszCoHYO74LhLNxudAWmHCEnx2v8gPfZL18NkgMG7cOFJSRsZb3zkTjRDiI2AXECWEyBdC/BB4EVgshMgAFtu+B1gNZAOZwJvAQ52uc8j2W2dgrRAiCTgEFNjO1TSth3ZmVRDg6cx4f49Tf1BwAJI+hjkPwa3vQdgsnmj+C00nDlBco/di0QbGOedopJR3dPOjRV2cK4GHu7nOVNvXBmDGBcSoadpZSCnZmVXB/MjT2t5LCWt/A25+MP+n4OgCt38Ir13KW5aX2bJ/Frct6m71weD35aECSmqbuX/BeHuHop2D7gygaUNcRmk95fUtzB3vd+oP0lbCiZ1w2W/ARS3uwyMAx+/+D5NoZuauh6G1ceAD7gNWq+RPa9L58/pjtJgt9g5HOwedaDRtiNuZqeZn5nSenzG3wPrfgn8MTLvr1AcETWZDzB8Ib8uk+dP7wWodwGj7xsG8Kgqqm2hus3LgeLW9w9HOQScaTRvidmZVMNrH9dRmmXvfgKpcWPIHMJ45Qh5z6a28YP4OLhkrYfPgLYvtzsrDRTg5GDAaBDtsiXaoefXVV4mJieHOO++0dygcOnSI1atX99v1daLRtCHMYpXszq5gXudhs4YK2PISRC6GyDOmUgGYEOjJFp9b+dZ1CWx9CY6tHaCIe89ilXydVMSi6ACmhHmxfYgmmn/+85+sXr2a//73v+c8t78XYPZ3otHbBGjaEHaksJbaZvOpw2ZbXoTWerji+bM+9qr4EH707Z2k+SZj3P82TBy8vbI625NdQXl9C8viQ0gvruXvmzKpaWrDy9WxZxf85gkoTu7bIIPi4MoXu/3xj370I7Kzs7n22mu5++672bZtG9nZ2bi5ufHGG28QHx/Ps88+S2FhIbm5ufj5+fH+++93ux3An/70J95//30MBgNXXnklL774Im+++SZvvPEGra2tREZG8v777+Pm5sann37K7373O4xGI15eXmzYsIGnn36apqYmtm/fzq9//esum3r2hr6j0bQhrH39zMlEU3YM9r0FM+6GgOizPvaquGBapQPHfC+DrI3QXNPP0faNlUlFuDkZuSw6gHmRflilSj5DyWuvvUZISAibNm0iNzeXadOmkZSUxAsvvMBdd3XMqSUmJvLll1/y4YcfdrsdwDfffMMXX3zBnj17OHz4ML/85S8BuPHGG9m3bx+HDx8mJiaGt956C4DnnnuOtWvXcvjwYb766iucnJx47rnnuO222zh06FCfJxnQdzSaNqTtyKpgQoAHAZ4u6sC6p8DJHRY+ec7HTgz0YLy/Ox81TOc5yweQvgam9P2bTF9qs1j5JqWIxbGBuDoZmTZmFK6ORnZklnPFpKCeXfQsdx4DYfv27axYoTo2XHbZZVRUVFBTo5L+tddei6urahXU3XYAGzZs4Ac/+AFubmqOzsfHB4CUlBSeeuopqqurqa+vP9nded68edx9993ceuut3HjjjQPyGvUdjaYNUa1mK/tyKju6AZzYAxlrYcHPwd3v7A9GtaS/Oi6Y/xYEYPEIhiNf9HPEvbc9s5zqxjauiQ8BwMnBQEKEz5CdpwG1Dup0XW0X0L4dwKFDhzh06BA5OTlcccUV3W4fcPfdd/P3v/+d5ORknnnmGZqb1QLd1157jeeff568vDymTp1KRUX/3w3qRKNpQ9Th/Gqa2izMaS8ESPsKjE4w84fnfY0r44KxSAOZfosgcyM09+2Wxn1t5eFCPF0cuHiiHyT9Dzb/H/PG+5FV1kBRTdO5LzAILViw4GRBwObNm/Hz8zu5qVln3W0HcMUVV/Cf//yHxka1JqqyUu3qUldXR3BwMG1tbacUHGRlZZGQkMBzzz2Hn58feXl5eHp6UldX12+vUScaTRuidmZWIATMibDd0WRugDFzwNnj7A/sJDrIk0CTM6stCWBpgWNr+ina3mtus7AutYSlk4JwtjTCqp/D5hdYalDdjHdkDq15mnbPPvss+/fvJz4+nieeeIJ33323y/O62w5g6dKlXHvttcycOZOpU6fy8ssvA/D73/+ehIQEFi9eTHR0x3zdL37xC+Li4pg8eTILFixgypQpLFy4kCNHjjB16lQ++eSTPn+NoqvbtsFq5syZcv9+vSmnpgHc9vouGlstrHx0PlTnwV8nq0qzuY9e0HUe/egg+7PL2enyY0TINLjjw36KuHfWpBTzow8See+e2Syo+B+sfRK8xyBbG1jc/CfioyL5821Tz+taaWlpxMTE9HPEw0tXf2ZCiEQp5cxzPVbf0WjaENTUauHgieqO+ZnM9epr5OILvtbscB+K6lqpj7hS3RUN0uGzr5MK8XF3Yu44E+z6J4ydB3d8gmip4yW399ieWd7lfIdmfzrRaNoQtP94Ja0Wa0dZc+ZG8BoN/lEXfK2EcFWltM/9Etvw2eBbvNnYamZjWilXxQXhcPQrqM2HuT+GwFi49Amm1W9hVsMWMkvr7R2q1gWdaDRtCNqZVYGDQTBrnA+YWyF7M0ReDj3YFT3S34NRbo6sqR4DnoOz+mxDWilNbRaWxQXDzlfALwomXKF+OPcxWgKn8pzj2+w/cuy8r6nvfs5fb/+sdKLRtCFoZ1YF08Z44+7sAHm7VSeACRc+bAZgsCWsPcerIeZayFgPLf1XgdQTKw8XEmhyZpZMVqv45z4CBtvbl9EB55tex1M0MWHfM2p7hHNwcXGhoqJCJ5vzIKWkoqICFxeXHl9DL9jUtCGmtrmN5PxqHrlsgjqQsR4MjhC+oMfXnB3uw7ojJVSOuwqfva+r4bO4m/so4t6paWpjS3oZ371oLMZdvwGPQIg/bWFpQDTfBv2QpcWvY0legTH+7LGHhYWRn59PWVlZP0Y+fLi4uBAWFtbjx+tEo2lDzJ7sSqyy07bNmRtg7Bxw9uzxNWfb5ml2tEZyjUcQpH4+aBLN+iMltFqs3DK6GhK/hUVPg4PzGefJOY9yaMUGJq/6OUQsAI+Abq/p6OhIeHh4f4atdaKHzjRtiNmZVY6zg4FpY7yhJh9Kj/So2qyz2GAT7k5G9uZWQ+y1Knm1DI6J9ZWHCwkb5Up09jvg6A4z7+nyvIsiA/m5+UfQ2gBf/+S8htC0gaETjaYNMTszK5g1zgdnB6NKCKAKAXrBwWhgxjgf9uZUQuz1YG62y+LNVrOV4ppmUgtr2JZRxmcH8tmeWc4dUUZEygqYfhe4jurysaPcnXAJjuFjj+/B0a/VDqPaoKCHzjRtCMktbyC9pI6bZ9jGyzPWgykUAnq/+DAh3IeX1qZT5XsZozwCVfXZAAyfSSm5//1EdmdVUNdy5r4rDgbBHXKVukOZ89BZrzUv0o/fb7+M7/h/i2HPa+ruTLM7nWg0bQhZlVwEwFXxwbay5i0w+cYelTWfrn2eZt+JGq6IuRYOvq+Gzy6gpU1PZJbWs/5ICYuiA5g62hsfDyd83Z0Y5eaEr4cTAU6tmP55P0y6AbzHnPVa8yP9eH1LNjljb2L84ZehPAP8JvRr/Nq56aEzTRtCvk4qYvoYb0K9XSFvD7TW9bis+XTxYV44ORjU8Nkk2/BZRv8v3lyTUgzACzfG8eiiCdyZMJalk4NJiPAlMsATU+oH6nWeR2udWeN8cHIwsFIsBIMDJL7Tz9Fr52PEJJpDm1eQsu1Le4ehaT2WVVZPWlEty2wt8sncoN5Mwy/pk+s7OxiZNtqbvbmVqjmnewCk9v/izbVHipk+xptAUxfrNMytsPs1Vbodcu4+Zi6ORmaOHcXa4xKiroLDH4G5pR+i1i7EiEk0pm3PYdj+Z3uHoWk9tiqpCCHUzphAR7dmlzNbyvdUQrgPKQU11LdJNb+Rsb5fd97Mq2wkpaCWpZO72LRMSljzK6grhHmPnfc150X6kVZUS03sd6CxQhUGaHY1YhLNca8EIltSoLXR3qFoWo98nVTIrLE+BHm5QG0hlKT0utrsdLPDfbFKSDxeBdO+B+Ym2P92nz5HZ2tT1bDZktN3x5QSvvkl7P8PzP8JjF903tecF6n259lsngxeYyCx67b72sAZMYmmefQCnDBTd2yLvUPRtAt2rKSOYyX1LJvS6W4G+mx+pt20Md4YDYK9ORVqqCpiIez+J7Q19+nztFuXWkJ0kCdjfTt2kkRKWPsb2PsGzHkEFj1zQcUOcaFe+Lg78W16uSqHztkCldn9EL12vkZMojFFL6BFOlKXss7eoWjaBfs6qQiDoGOIKWM9eIZAQGyfPo+7swOTQ73Yl1OlDsz/CdSXqLmOPlZW18K+45WnDptJCeufht3/gIQH1f46F1hRZzQIFkUH8G1aKa1xd4AwwoH3+jh67UKMmEQzMSyQfdaJuORttXcomnZBpJR8nVRIQrgvAZ4uYGlT3Zon9Kxb87kkhPtwKK+a5jaLbRJ+Oux8FayWPn2e9UdKkLJT8pQSvv29eq5Z98LSP/b49S2ZFERdi5mdZU4wcQkc/K/6c9PsYsQkGn9PZw46TsOnIRPqiu0djqadt7SiOrLLGjqGzfL2Qkttr9vOdGf2OB9aLVYO51WrN/r5j6uhp7Sv+vR51qQWM87XjahAW4+2zS/Ctv8H078PV77UqyQ6f4Ifbk5G1qaWwIy7oaEU0r/pm8C1C3bORCOE+I8QolQIkdLpmI8QYr0QIsP2dZTtuBBCvCqEyBRCJAkhpndzzRlCiGTbea8K0Q8fy7pQ4j9X/SZr00A8nab1iVXJhRgNgqXtE+aZ61VZc8Sl/fJ8s8b5IARqPQ1A9DLwjYTtf+mz/mE1TW3syipnyaQghBCw7c+w5UWY+l1Y9teOLQB6yMXRyMKoANYfKcESsUh1T9BrauzmfP423wGWnnbsCWCjlHICsNH2PcCVwATbr/uBf3VzzX/Zft5+7unX7xeuo6dQIU1Ys74diKfTtF5Tw2ZFzB3vi6+HrWNxxgYYfVGfljV35uXmSFSgp1pPA2AwqvLiosOQ3Tcf0jYdLaXNIlkyOQjqSmDTHyD2Orj21V4nmXZXTAqkvL6Fg/m1qoIu61uoOt4n19YuzDn/RqWUW4HK0w5fB7TXDL4LXN/p+HtS2Q14CyGCOz/Q9r1JSrlLql2H3uv0+H4VHezNDuskrFmbdWdXbUhIKajleEUjy+Jt/40qsqAkGaL697NZQrgPiceraLNY1YH429Tum9v/0ifXX5NSTKDJmalh3nDov2A1w2W/VUmtjyyMDsDRKFQJ9bTvqoMH3++z62vnr6cfHQKllEUAtq/tGz+EAnmdzsu3Hess1Hb8bOecJIS4XwixXwixv7ebFEUHe7LNGodDY6lqra5pg9zXyYU4GETHOpPUz9XXSTf06/PODvelsdVCamGtOuDgDBc9BDlboSCxV9duarWw+VgpSyYFYUCqirCx8/q8J5nJxZG54/1Ym1qC9ApTpeAHPwDLmY07tf7V18UAXc21nH7rcD7ndPxAyjeklDOllDP9/f17FVxkgAe7ZLz6Rg+faYOclJJVSUXMn+CHt5uTOpj6uRo28+r5bofnY1a4asW/N6ei4+CMu8HFC7b/tVfX3ppRRnObVSXP3G1QlaMKAPrBkklBnKhs5GhxnXqOuiLI0EscBlpPE01J+5CY7Wup7Xg+MLrTeWFA4WmPzbcdP9s5/cLZwYi7/1gKHcfoggBt0DuUV01+VVNHb7OydNUNYPKN/f7cAZ4uhPu5dxQEgJoTmnWv2uelPKPH116bUoy3m6PqFn3gXZW8+qmd/+LYQISwdSCYuERtA31AdwoYaD1NNF8B7R9Bvg982en4Xbbqs4uAmvYhtna27+uEEBfZqs3u6vT4fhcd7Ml2axwc39lvq501rS+sSirCyWhgcWygOpDyGSDUpPkAmG3bCM1i7TTgkPAjNYy245UeXbPNYmVDWgmXxwTi2FKtklb87eDo2kdRn8rf05kZY0apMmejI0y9U93R1JX0y/NpXTuf8uaPgF1AlBAiXwjxQ+BFYLEQIgNYbPseYDWQDWQCbwIPdbrOoU6XfRD4t+28LGDACtyjg0ysaYpRPZzydg/U02raBbFaJauSi1gw0Q8vV0dVvJL6GYybD55dNKDsB4tiAqhtNvPfPZ0qtTwC1MT64Y9Vv7ULtDu7gtpmsyrVPvwxWFphRv8Mm7VbMimItKJa8iob1d2gtA7I9gdah/OpOrtDShkspXSUUoZJKd+SUlZIKRdJKSfYvlbazpVSyoellOOllHFSyv2drjO10+/3Sykn2857xFZ9NiCigz3ZY43BKhz08Jk2aB04UUVRTXPHsFlJCpQfG5Bhs3aLYwO5eIIff1qTTkltp7v/OY+AtMDu7lYvdG9NSjFuTkbmR/qqIazQmRA4qQ+jPlN7IcXa1GIInAxeoyF94LepHslGTGeAdjFBJhpwpcwrvs/WBGhaX/s6qQgnBwOXdx42E0aIGZhhMwAhBM9fP5k2i5XfrUzt+IFPuNrrJemTC2pLY7FK1qaWsDAqAJfiRCg7qppe9rMxvm7EBJvUBmtCwMSlqhioranfn1tTRlyiCTQ5M8rNkcPO06EoCRrK7R2Spp3CYhs2WxQdgIezQ8ewWcSl4O47oLGM9XXnx4smsDq5mI1pneY1Jt+kmm0e33He1zp4oory+ha1SPPAu+Dkoa4zAJZMCiTxRBVldS0QdaUaOs/WndwHyohLNEIIooNMrG+JBaRqTqhpg8ie7ArK6lq4Zopt2KzwAFTlDuiwWWf3XRzBhAAPnv4ylcZW2xqUiUvA0c1WoHB+1qeV4GgULBzrrB43+SZw9uinqE+1ZFKQagx9pETNczl5wjHd+2ygjLhEA2qeZnVFMNLFSw+faYPOyqRC3J1Ury5AvSkbHCH6arvE4+Rg4IUb4yiobuKvG2xlzU7uKtmkfXXeCyD351YRH+aNZ8bn6o6in4sAOosO8mSMj5uap3FwhsjL1DyN1TpgMYxkIzLRxASZaGiTNIbOB92ORhtEWs1WvkkpZnFsIK5ORvVGmPq52knTdZTd4po1zoc7Zo/mre05pBbatnaedKPaKjn33FtvNLdZSM6vYebYUWrHy8A4tf3AABFCsGRSIDuzyqltblNzTPXFUHRwwGIYyUZkookOVm3Jc0yzoDa/V4vPNK0v7cgsp7qxrWPYLH8v1BbYbdiss18tjWaUmyNPfpas1tZMWKzmWc5j+Cy1sIZWi5VLTQVQnKTuZgamaftJSyYF0WaRbDpaChOuAGHQ1WcDZEQmmomBnhgE7DFMUQf08Jk2SKw8XIiXqyMXT7C1W0r5DBxc1AS2nXm7OfHbZbEczq/hg93H1SLLqKvUoktz61kfuz9X7dg5texLcHCFuFsGIuRTTB8zCj8PZ9alloCbj2rlo/eoGRAjMtG4OBoJ93NnT5UJRoXr9TTaoNDcZmHdkRKunByEk4NBlQ4f+UJ9+nb2tHd4AFw7JYSLJ/jx0tp0imua1Z1Wc/U5i2oSj1cR42vENe1zmHQ9uHoPTMCdGAyCxbGBbEovVbuHRl2pOmFXnxjwWEaaEZloAKKDTarR3viFqrGf3uZVs7NNR0upbzF3DJsd36FKiAfBsFm7zmtrXl6XDuMvA2cvVX7dDSkliceruNuUCK11/dZA83xcHhNAY6uFA8er1N0YwDHdJaC/jdhEExPkyYnKRprGLIDWesjfZ++QtBFuZVIhfh7OXBRhWyuT8hk4usOEJfYN7DRjfd25dkoI61KLMQtHiFkGR1d12zvweEUjbQ1VXFP5NgRPgTEXDXDEHRIifDEaBDuyysEvUu0cmr7abvGMFCM20UQHqd0J011snXEuYOGZpvW1+hYzG9NKuTouCKNBqDvsI1+qDc6c3Owd3hkWRqs+aAfzqlX1WUstZG3s8tz9x6v4pcPHuLZWwDWvDHgRQGcezg5MG+3N9kzb9gdRV0LONmiutVtMI8HITTS2yrOUSgP4x8DxXXaOSBvJNhwpocVs7Rg2y9kCTZUDtnL+Qs2f4IeDQfDt0VKIuARcfbqtPis/spnvOmyEhAchZNoAR3qmuZF+JOdXU9PYBhOvBGub3p+qn43YRBPq7YqniwNHi2th7BzI23tBfZs0rS+tPFxIiJcL08fY1sqkfAbOJhi/yL6BdcPk4sjMcaNUqbDREWKuURVcrY2nnmhu4cqcFyk3BiIWPmmfYE8zP9IPq4Rd2RUwOkGtT9LVZ/1qxCYaIQQxQSaOFtXBmLlqkrIkxd5haSNQdWMrWzPKuGZKCAaDAHOLKhmOXgaOLvYOr1sLowI4WlxHUU2TKlhoazhj98rmTf+PsdY8dsY8OWDtZs5l6mhv3JyM7MwqB6ODmgPLWKe3eO5HIzbRgBo+O1pchxyToA7o4TPNDtakFNNmkR3DZhnr1ZxH3OAcNmu3MFq1yNl0tAzGzgc3P9XFoF1ZOk67/syXlrn4TVtmpyjP5ORgICHch+2Ztoa6UUvVMGX+XvsGNoyN7EQTZKK+xUy+1U/tUXFCJxpt4K1MKiTcz51JIapAhZQV4OYL4ZfYN7BzmBDgQai3K5vSS9WdQex1qlS4pV61zln5OC3ClT9YvsfU0QO/buZs5kX6kV3WQGF1kxqeNDjq6rN+NLITja0g4GhxHYyZoxKN7numDaDSumZ2ZVVwTXwwQgj1Jp3+DcRer+Y+BjEhBAuj/dmRWU6L2aKGz8xNcGwNHHwPTuzkPc97CQweg5uTg73DPcW8SD9AtfzBxQThF+t2NP1oRCeaqEBPhIC0olpV219fApXZ9g5LG0G+SS7GKukYNju2Rr1ZD9Jqs9MtjFILIPfmVKoPax5BsO8tWPc01rHz+WvFbGaMtV8z0O5EBXri5+HEzixbmfPEK6EiY0j2PdxyrIz73tuvkv0gNaITjbuzA2N93GyVZ3PVQT18pg2glYcLiQ7yZEKgrcVMygrwDFFv2kPA3PF+ODkY1DyNwajay5zYCeZmMmY/T1ObdVAmGoNBMHe8H9szy5FSqnkaGHLVZykFNTz4QSLrj5Rw6ES1vcPp1ohONKDmaY4W1YFflCpz1IlGGyCF1U3sP17VcTc7a0MfAAAgAElEQVTTVKUKASbfCIah8V/T1cnInAhfNqeXqgPtzTIv+QU7q9W8zMxxgy/RgCpzLqtrIaO0HrzHQMAkyNxg77DOW0F1Ez94Zx9ero4IAXtyKu0dUreGxr/mfhQd7ElORQNNZqm6uerKM22AbLBtjbx0cpA6kPa1Wjw4RIbN2i2M8ie7vIHc8gYImwkP7oL5PyPxeBWh3q4Ee7naO8QuzY1UrX62Z9iqz8ZcBAUHhsR6utrmNn7w9l6a2yy8e89sooNM7MmpsHdY3dKJJsiElJBeUqcWblZmQV3JuR+oab20Ia2UcD93xvvb1pekLFfdxAfB6vkLcbLMuf2uJjAWDAYSj1cxfRAOm7ULG+XGOF83VRAAEDZLracrP2bfwM6h1WzlwQ8SyS5r4PXvzmBioCcJ4T4kHq+i1Tw4dwwd8YmmvaQ0tbBGLdwEyNttx4i0kaC+xczurAoW2d6kqS+FnK3qbsaOvcB6YqyvOxH+7mxKLzt5rKC6iaKaZrWj5iA2L9KPPTmVtFms6m4MIH+/fYM6CyklT36ezI7MCl68KZ65tuq5iyJ8aG6zklwwOOdpRnyiCRvlirebI8n5NaqzrIOrHj7T+t32jDJaLVYWxQSqA6lfgLRC3M32DayHFkYFsDu7gsZWtbo+8bja6GwwFgJ0Nj/Sj/oWM0n51eAzHly8BnUn91c3ZrI8MZ/HL5/AzTPC1MHcHSxM+TWuNLM7e3DO04z4RCOEIC7Ui6T8GnBwUp9qTuy0d1jaMLchrRSTi0PHRHnKCgiIhYAY+wbWQwujAmg1W9lp64qcmFuJm5OR6KDBsWFbd+aM90UI2J5RoQowQmdCQaK9w+rSisR8/rLhGDdND+OxRRPUwaYqWPFDnI9+zs+8twzagoARn2gApoR5c6ykTu26N2YOFCdDS529w9KGKYtV7Vt/aVQAjkYDVOep4dohVgTQ2azwUbg7GU/O0ySeqGLqaG8cjIP7LcbbzYnJIV6d5mlmQukRtXB2ECmobuLXnyUzd7wvf7wxTi3uBVj9C2gog6A4vtP2OUdz8zFbBt88zeD+VzBA4sK8MFslR9oXbkqr6uasaf3gUF41FQ2tLIqxzc+07045iHbSvFDODkbmRfqxOb2MhhYzaUV1g35+pt28SD8O5lXR0GJWBQHSCoUH7R3WKf61OROJ5OVbpqhtvkENtyZ/Cgt+Cde8ipulltssq0gpHHx76+hEA8SHeQGoeZrRs0EY9Hoard9sTCvBaBBcOtGWaJKXQ+gM8Imwb2C9tDA6gILqJv63Pw+LVQ7qirPO5kf60WaR7M2tVH8PMKjmaYpqmvjfvnxumTmaEG9bqXh9KXz9E1WhePFPIXQ6LeOXcp/Dag6m59g34C70KtEIIR4TQqQIIVKFEI/bjk0RQuwSQiQLIVYKIUzdPDbXds4hIYRdyzyCTC74eTireRpnTwiK1wUBWr/ZmFbKrHGj8HJzVC1PipOG9LBZu0uj/AH4x6YshIBpY4ZGopk5bhRODgZ2ZJSDm48qChhE8zSvb8nGKiUPXjJeHZASVj4GrQ1ww+sne+I5L34Kk2jEL/lNO0bbtR4nGiHEZOA+YDYwBVgmhJgA/Bt4QkoZB3wO/OIsl1kopZwqpZzZ0zj6ghCC+DCvjtLAMXOgYD+YW+0ZljYM5VU2kl5Sx+Xt1WYpKwABk26wa1x9IdjLlZhgE+X1LUwM8MTLdXA3BW3n4mhk5thRHdsGhM1UdzSDoMFuaW0zH+49wU3TwxjtY9vS+9CHqtP0oqfBP6rj5KA4kr0u5bLqFVjqy896XatV8u9t2ZTXt/Rj9B16c0cTA+yWUjZKKc3AFuAGIArYajtnPTAkPqrFh3mRWVqvxmnHzgFzMxQdsndY2jCz0dYNYFFMoHojS1kBY+eBKcTOkfWNhba7mhmDtO1Md+ZF+nG0uE698YbNUg12a/LtHRavb83GYpU8tNB2N1OdB2ueUP9mLnrojPPLZvwEV1qoXPfSWa+78Wgpz69K6yiC6Ge9STQpwAIhhK8Qwg24ChhtO36t7ZxbbMe6IoF1QohEIcT93T2JEOJ+IcR+IcT+srKy7k7rtfgwL6wSUgtrOxoaHtdlzlrf2ni0lAh/d8L93FV1Y/mxIV0EcLr2dUEJ4T52juTCzLctfNyZVTFo5mnK6lr4757jXD81lLG+7mqPny8fUsUK1/+zy354sVMu4ivrHLxT3lHzON14Y2sW4V4Gro4L7sdX0KHHiUZKmQb8H+quZQ1wGDAD9wAPCyESAU+gu/GneVLK6cCVtvMXdPM8b0gpZ0opZ/r7+/c03HOaHKoKApLyq8EjQI3TntAdArS+U9fcxu7sik7DZsvB4KD2nhkmZowdxYoH57IsfmjdoU0O9cLk4qDmaQIng9HZ7vM0/96WTavZysPtdzP7/q26Ryz5A4wa1+Vjgrxc+NTjTozWVtj+ly7POXC8krATX7FaPoTDiR39FP2pelUMIKV8S0o5XUq5AKgEMqSUR6WUV0gpZwAfAVndPLbQ9rUUNZczuzex9FaApwvBXi4kF9SoA2NtG6FZB19NujY0bcsop80iVdsZqxVSPoOIheDua+/Q+tSMsaMwGoZWGx2jQTB97CgO51erhdshU+16R1NR38J7u45zzZQQIvw9oK4YNjwDkYth+vfP+tiQiDhWsgC57y2oLTz1h6VpeHx0HX9x+hdOfuGqY/0A6G3VWYDt6xjgRuCjTscMwFPAa108zl0I4dn+e+AK1JCbXcWH2ToEgOp71lwNZUcv+DqF1U19HJk2HGxIK8HL1VG1ZcnfBzV5Q7blzHAUE2wis7RebSAWOhOKDtutIOit7Tk0my08sjBSHdj+FzC3wFUvnbMXXkKELy+1XA/SAtv+nzrYUg/rn0a+Np+ApizWhP8a470bIGhyP78SpbfraFYIIY4AK4GHpZRVwB1CiGPAUaAQeBtACBEihGjflDsQ2C6EOAzsBVZJKe2+j2p8mDc55Q3UNLWphZtwwetpViUVMe//viWjRHcW0DpYrJLN6WUsjPJXq+VTloODC0Rfbe/QNJuYYBNmqySztF5VnpmboWTgP/9WN7by7s5crooLVhvi1RTA/rdh2p3gE37OxyeE+5AvAzgWch0kvgv7/wP/SIAdr3DAeylLzH9h+g2PD+ieR70dOrtYShkrpZwipdxoO/aKlHKi7dcTUqoaQSlloZTyKtvvs22PmSKlnCSl/EPvX0rvxdnmaVILatTiOY/AC040H+87gZSw39ZUUNMADp6oorKhVU2WW8yQ+jlMXKLWbWmDQmywWvKXVlTX0cnZDvM0/9meQ0OrhUcva7+b+bMqALj45+f1+NE+boR6u/Kewy3q7ufrn4CLF7V3fM2dZd/lkmnRBJhc+vEVnEl3BuikPdEkFdSov6Axc9TkW2vjeT2+uKb5ZC1+Uv7gbNet2ceGtFIcDIJLovwhd6vqTzUMFmkOJ+F+7rg4GkgrqgWv0eqD5gDP09Q0tfH2zlyWTgoiOsikypkT34Xp34NRY8/7OgnhPqzNd0Be+ze46mV4YCtv5wXR3GblvosHvgOFTjSdjHJ3YoyPW0eSmPVDVU+/8Xfn9fjPDxYgJUT4uXM4r6YfI9WGmo1pJcwO98Hk4gjJK8DJEyZcYe+wtE6MBkFUoKdKNEKoeZoB3pvmvZ251DWbeXSR7W5m28sqlot/dkHXSYjwoby+lazgq2H2fTRbBe/tyuWy6AA1HDfAdKI5TVzngoDwBTD7AdjzGmRvOevjpJSsOJDPlWGtPO/1JcdLKlQ3aG3EO1HRSEZpvRo2M7dA2kqIWQaOg3OL45EsJthEWlEtUko1fFaZBY0D03rfYpV8uPcEF0/wY1KIF1TlwsEPVJWZV9gFXSshXFUytu9Ps+JAPhUNrdy/wD799HSiOU18qBf5VU1UNtiqTS5/Fnwj4cuHobn7u5TkghoqSwv5U+PTzC34D8vEdtUNWhvxNh5V3QAujwmAjPXQUgOTdbXZYBQTbKKqsY3i2uYBn6fZkVlOUU0zt82yrXHf+hIIo2qaeYHG+roRaHJmT04lFqvk39tymBLmZbeFtDrRnCauvZNz+3oaJze4/jWoLYA1T3b7uK/2ZvCO80t4tJZi8QjhNuMm1Q1aG9GklHyTXExkgIda3Z2yHNx8IeISe4emdSHmZEFAreqMLAxnnafZm1PJn9cf65Pn/jQxHy9XR7WgtzIbDn0EM+/pUXsiIQQJ4b7sya5g/ZEScsobuG9BRMc+NgNMJ5rTnCwIyOs0mT96Fsz/CRz6ANK/OeMxrS0tXJL0CyaLHMTNb2OY+xDTDZkUZ+leaSPdt0dL2Ztbye2zRqu1DOlrVCcA49BoODnSRAer+Yu0ojpVEegfc9Z5mn9vy+bVjRlUN/ZuvU1NYxtrU4u5bmoILo5G2PISGJ3U+04PJUT4UFrXwgur0xjt48rSSUG9irE3dKI5jaeLIxH+7qryrLNLnoDAOPjqx9BQ0XFcSko/+hEXc5Bjs56D6KsQU+7AjAPj8z4b2OC1QaXVbOX3Xx8hwt+du+aMUx9SzE16keYgZnJxZLSPa8ewd9gM1cm9iw4hVqttDxs6jYD00MqkQlrNVm6ZMRrKMyHpY1WM5BnY42u2z9OcqGzk3vkRdt3tVCeaLsSHep057OXgBDe8pvbo/vrxjhbi3z5PWO5nvCFuJXLpw+qYux85vgtY2PIt9Y3nVxqtDT9v78ght6KR3y6LVbsipiwHUyiMvsjeoWlnEROkCgIA1cm5uUYVBZzmWGkds5p3cb9xZUcBUQ99mphPdJAnk0NNsOX/1GLeeY/16prj/d3x83DG282RW2ZeWDFBX9OJpgtxYd4U1zZTWtt86g+CJsPCJyHtK7WF6r5/w7aX+dh6GaXTHz/lE0PjpO/gK+oo3KPvakai0rpm/vZtJpdFB7AwKkBVLmVuVPvODOCKbO3CxQSbyC1voKnV1ooGzpynaWuGVT/nTac/86TjR5RmH+7x82WU1HE4r5qbZ4Qhyo+p95bZ96nmvr0ghOC3y2J48cZ43JwcenWt3tL/4rvQvrVzl59S5j0GYbPVattVP+eE/6X8pvUH3DTz1N0QQmdeTaH0wSXlw4EIWRtkXlqTTovZwm+XxaoDaV+BtU0Pmw0BMcEmrBLSS+rUxmJOnqfO01RkwVuLic77hM+NS7BiIKLw6x4/36eJ+TgYBNdPC4XNfwQnd5jbu7uZdtdNDWXpZPvNzbTTiaYLk0JMGARnztMAGIxqCE1KCJvFz6yPEhU86mS1Sjs/kxvrHBYRVrFL9SrSRozDedV8mpjPPfPC1b4zAMnL1dYTwVPtG5x2Tu2taI4U1qr/76HT1DwNqL/H1y9B1uTxE8MTbJv4JAW+F3G5eQtltRfeTLfNYuWzAwUsjA7Ar/aIak100YPDrqO3TjRdcHNyYEKAJ8ndtZHxHQ+PJpJ59UfsK2jhxumhXZ6WGXodBqxq61VtRJBS8uzKVPw8nHmkvVdVbRHkbld3M3YqL9XOX9goVzycHU6dpylOgS8fgRU/hMBYjt+8ls8b40mI8KEl9jZCRQV5B9dd8HNtPVZGeX0Lt8wIgw3PgqsPzP1x376gQUAnmm7EhXmRXFCD7G7fcFMwyw+VYzQIrpvadaIJiYhhh2USlgPv631tRogvDhVw8EQ1v1wahaeLrYQ59XNA6kWaQ4TBIIgJ9uxINKEzVcv9g+/DvMfh7lVsL1NNKRPCfQlOuJE66Ypz6qcX/Fyf7s/Hz8OJy5yOQPZmWPBzcDGd83FDjU403YgP86K8vpWimuYuf26xSr44WMClE/3x93Tu+hqh3nxiuRRjzXHVSFEb1hpazLz4zVHiw7y4ebqtykdKVaoaFAf+E+0boHbeYoJNHC2uw2qVqhVV3K1w53JY/DswOrInp5JAkzNjfd1w9zCxw2ku48s2nHcDXoDKhlY2Hi3h+ikhOGx6TjXynPnDfnxV9qMTTTfiw7yB7rsw78wqp7i2mRund182GBfmxVrrLJodPOHA+/0SpzZ4/HNzJiW1LTxzzSQM7TtM5mxVG2jNvMe+wWkXJCbYRH2LmfyqJnD2gJvehAmLATU8uju7goRw35Mr7bNDrsFFNiGPrjrv5/jiYAFtFskPfJKg8CBc+mtwHNj2/QNFJ5puRAd54mAQXVaelde38MHu45hcHFgU030JoperIyF+o9jldplqpNik96gZrk5UNPLmthxumBaqdtBst+MVcA+AKd+xX3DaBWsv7umqX2FOeQNldS0kRHT0DXOfeAkF0peWA+c/H/tpYj7TQt0JTXxJdSCYcnvvAx+k7FtcPYi5OBqJCvJkR2Y5H+w+zrGSOtuv+pMNN38wb5xqF3EWcaFevJN9MQstX0LSp5Bw/0CErw2wD/eewGqV/GppdMfBoiTI2giLnh62n1SHq6hATwxCJZrTy4P35KhuAO0r7wHiRo/iC8s8Hsr9GupKzrmiP6WghrSiWj6angZHsuD2j1SF2zCl72jOYtoYbw7n1/DUFyl8dqCAFrOVxTGBPHV1DO/dM5vfXBVzzmvEh3mxpS6EtoA4OPjeAESt2cOmo6XMGudDkFenhLLjFXDyGLbj7sOZq5ORcX7uHQUBnezJrsDPw5nx/u4nj8UGm/jKugCBVXWAOIflifmYjG0kHH8DRidA1JV9Gv9go+9ozuIXV0SzdFIwEf7uBHu59KjzaftcT3bYDUQdeA4KD0GIXksxnBRUN5FeUseTV3W6m6nK7VgT4eptt9i0nosNNnEo79Q5Wikle3IqSQj3OeX9wMXRiDEwmuz6iUQc/hjmPNztdVvNVr48VMBzwdsxlJfAre8M+7J3fUdzFl5ujsyf4EeIt2uP22u3L/7c6HgJGJ1ViaQ2rGw6WgrAZdGd5ut2/UO1mD/LG442uMUEm8ivaqK2ue3ksbzKJopqmk+Zn2kXH+bFp+Z5UJwEJUe6ve63R0uwNFZxdc0nMGEJjJ3bL/EPJjrR9DN3ZwciAzzYV2xVe8Qf/EDtA64NG5uOljLax5Xx/h7qQEO5qjKMv61He4log0N7h4CjRXUnj+3OUZ3bO8/PtIsP8+Z/TbORwqhK2ruxPLGAn7utxqGtTs3fjQA60QyA+DBvtfhz4a/VgQ3P2jUere80t1nYkVXOZVEBHXe9e99U2wHMG34rvEeSUzZBs9mTXckoN0cmBHiccX58mBcVeFEaeDEk/Q+sZ27lXlHfQtmx3dwhv0HE36oa9Y4AOtEMgPbFn4X4q/YSKcvhxB57h6X1gV3ZFTS3WVnYPmzW2gB7X4eoq1RDRm3ICjQ5M8rN8dREk1PB7HCfjnVSnUwM9MTJaGCn++VQV6TWUHXWUk/R/37KZw5PIVy94LKn+vslDBo60QyAk4s/86pV92fPYFjzhG5LMwxsOlqKq6ORiyJsQykH3lfrpeY9bt/AtF4TQhATbDq5lqaguon8qqYuh80AnBwMxAR78lljHDh7QdInHT88uhr+kcDkEx+w1uVKHB7dB95jBuJlDAo60QyAk4s/C2rUKuPLn4XCA6f+Q9SGHCkl3x4tZV6kr1pPZWmDXX+HMXNgTIK9w9P6QEywifTiOswWK3uybfMzXRQCtIsP8+ZgYQsy9jo48hWUZ8DHd8LHd9Di4MGNLc9SsuCFEVeJqBPNAHBxNBId7NnRzibuVgidARt/p/aR14akrLJ68quauDTKNmyW+jnU5PV6Z0Rt8IgNNtFitpJb0cCe7EpMLg5EB3Xf9DIuzIv6FjOF466Dtgb4x2y14d3lv+MvEf8mSURx7ZSRVyCiE80AiQv1Jinf1g3aYIClL6px3B1/tXdoWg99aytrXhgdoJpn7ngF/KNVyao2LHS0oqmzzc/4YuxifqZd+6aJey0T1Z3thCvg4d2Y5/yYFYdLWBgdgK9H1014hzOdaAbIlDAv6prN5FbYuruOnq3axu/8G1SfsG9wWo98e7SU6CBPQr1dVauZkhR1N6O3ah42IgM8cDQKNh8tJbeikYvOMmwGEOnvgYujgaSCOrhnDXznExg1ju2Z5ZTVtXBTN3tXDXe9+h8hhHhMCJEihEgVQjxuOzZFCLFLCJEshFgphOjyPlMIsVQIkS6EyBRCPNGbOIaCLrtBL/4dIGD9M/YJSuux2uY29udWdVSbHfwvuPnqPWeGGScHA+P9Pfg6qQjoev1MZw5GA5NDvEg+rRnvigMFeLs5dvx7GWF6nGiEEJOB+4DZwBRgmRBiAvBv4AkpZRzwOfCLLh5rBP4BXAnEAncIIWJ7GstQMCHQA2cHw6ndoL3C1FqL1M/gxG77BaddsG3HyjFbpeoG0FIP6d9A7PXg4GTv0LQ+FhtsotVixdPZgdiQc29KFhfmRWphLWaLqiqtbW5jXWox104Jwdlh+DbOPJve3NHEALullI1SSjOwBbgBiALaC8jXAzd18djZQKaUMltK2Qp8DFzXi1gGPUejgUkhJrZnlNNm6VTWPO8x8AyBb36ly52HkG+PluLl6si00d6Qvlot0Iy7xd5haf2gfZ5m5rhRZ52faRcf5kVTm4XMMlXoszqpiBaz9ax7Vw13vUk0KcACIYSvEMINuAoYbTt+re2cW2zHThcKdO7Dkm87dgYhxP1CiP1CiP1lZWW9CNf+fjAvnPSSOn7/dac+SE7uqty56BB8fAccW9flimJt8LBaJVuOlbJgoj8ORgMkLwdTmOrCqw077XcxCRFnHzZr1zFMrkYvVhzIZ7y/O1NshQIjUY8TjZQyDfg/1F3LGuAwYAbuAR4WQiQCnkBrFw/v6mOB7OZ53pBSzpRSzvT39+9puIPCNVNCeGBBBO/tOs5HezsVAMTdApf8CvL3w4e3wF8mw8bfQ2WO/YLVupVcUEN5fSuXRftDY6UqBIi7SRcBDFMzx43innnh3HieE/nhvu54ODuQnF/D8YoG9uVWcdOMsB435h0OevU/Q0r5lpRyupRyAVAJZEgpj0opr5BSzgA+ArK6eGg+p97phAGFvYllqPjl0mgumejP01+msD9XbaCEwQALn4SfpsGt76v+R9v/DK9OhXevgSNf2jdo7RTfHi1FCLhkYgAc+QKsZl0EMIw5Oxh5+ppYAjzPb/M6g0EwOdREUn41nx0oQAi4YdrIrDZr19uqswDb1zHAjcBHnY4ZgKeA17p46D5gghAiXAjhBNwOfNWbWIYKo0Hw6u3TCBvlxo8+OEBhdVPHDx2cIPZauPNTeDwFFj4FVcfhf3epyjTZ5U2fNsA2pZcybbQ3Pu5OatjMLwqC4uwdljaIxId5k1ZUx/LEfOaN9yPYy9XeIdlVb+/1VwghjgArgYellFWoCrJjwFHUXcrbAEKIECHEagBb8cAjwFogDfiflDK1l7EMGV5ujrx510xa2iw88H4izW1dzMl4hVI18zH+NvlTtnpdqxZ2rvqpLhiws9K6ZpLya1S1WU0+HN8BcTcP+42rtAsTH+ZFq8VKQXUTN80Y2Xcz0MsdNqWUF3dx7BXglS6OF6IKBtq/Xw2s7s3zD2WRAR789fap3Pvefn61Iom/3jb15BhubnkDb23P4dPEPJrbrAhxG68FurFk/3+gpQ6u/xcYHe38CkamzemqIGVhdACkvKsOTu6qsFIbyeJDVUGAu5ORJZOC7ByN/emtnO1oUUwgP78iipfWphMbbGLmuFG8sTWbdUdKcDQYuH5aCPdeHMGW9DIeWC34JNafhOS/qVb0N78Njuc3Zqz1nU1HSwk0OatNsb76FEKmg+94e4elDTKjfVwJ9nLh0qgA3Jz026z+E7Czhy4dT1pRLX/85igAXq6OPHxpJHfNHXty8nFCgAcH86r4Tupc1s/3I2LvM/Dfm+GOj8DZ057hjyitZivbMspZFh+MKM9QW/Yu+aO9w9IGISEEKx+dj4ezfosFnWjsTgjBn26Ox9PWFfaWmWFnfAJS50whvXg7tx6YxIal/8B77Y/hvetV4YDb2fsvaX1jT04F9S1mNT+T8h9AwKQb7B2WNkj5jcDmmd3Rhf+DgJuTA3+8MZ7vzx3X7W22h7MDr39vBk2tFu45EE7bze+qT9SrfjbA0Y5c61JLcHU0smCCn6o2C78YTMH2DkvTBj2daIaQyABP/nTzFA6cqOb5zHCYcrva68Jitndow56UkvVHSlgw0Q+XsiSozNItZzTtPOlEM8RcHR/MfReH8+6u4+w1TIGWGig8aO+whr3kghqKa5u5IjYIUlaAwRFirrF3WJo2JOhEMwT9amk0s8N9+PEeTyQCsjfbO6Rhb11qCUaD4LKJvirRTLgCXEfZOyxNGxJ0ohmCHIwG/v6daZidfTjhFAnZm+wd0rC37kgxs8aNYlT5frUzapxeO6Np50snmiEqwNOFiyf4s9U8CfL2qj1RhjGzxcr7u4/T0DLw81G55Q0cK6lXw2bJn4KjO0y8csDj0LShSieaISw6yJO1zTFgbYMTu+wdTr9ak1rMb79I4dP9eec+uY+tP1ICwBUTTarBafTV4OQ24HFo2lClE80QFhNsYp81CqvBCbKG9/DZ8sR8ALZmlA/4c687UkxssImwrI+huRpmfH/AY9C0oUwnmiEsJthEC04UeU8b1gUBJbXNbD1WhqujkZ1Z5V03Ie0n5fUt7D9exZVRJtj+FwhfAOPmD9jza9pwoBPNEObv6YyfhzOHHKZCaSrUldg7pH7x2YECrBJ+sSSK5jYr+9r38RkAG9NKkBJuta6GhjK1dYOmaRdEJ5ohLibYk3UtMeqbnC32DaYfSClZnpjHzLGjuH32aJwcDGxJH7gtvdcfKWGClyQg+XWIvBzG6O2aNe1C6UQzxMUEm1hbEYB0HTUsh88O5VWTVdbAzTNUD7iEcB+2HBuYRNPQYmZrRjlP+m5GNFWpXVA1TbtgOtEMcTHBnjSboT5knioIGGa7cC5PzMfF0cBV8aqn2CUT/ckoraeg886k/WRbRhku5lTxmQwAABvKSURBVFouLvsYoq6C0Bn9/pyaNhzpRDPExQSbAMjynAl1hVCeYeeI+k5zm4WvDheydFIQJhe10dulUf4AAzJ8ti61hEdc1uLQVqfvZjStF3SiGeLG+3vgaBTsklPUgWHUJWD9kRLqms3cMnP0yWPj/T0I9XZly7HSfn1us8VKYlomdxlWQ+x1EBTXr8+nacOZTjRDnKPRQGSAJ7urPGDUuGE1T7M8MZ8QLxfmRPiePCaEYMFEf3ZkVtBmsfbbc+/NreQO8xc4W5vh0l/32/No2kigE80wEBPsSVpRLUQshJxtw2LbgOKaZrZllHHTjDAMBnHKzy6N8qe+xcyB41U9vn5NYxtrUoqpaWzr8uc7DqVxl3Edlkk3QUBMj59H0zSdaIaF2GATpXUt1IXMh9Y6KEi0d0i99tnBfKwSbpoepg601MM3T0BZOnPH++JgEGzuQfVZm8XKOztyuOTlTfzog0Qu+uNGfvN5MpmldSfPkVIy5sjruIg2HBbquxlN6y29lfMw0F4QcMRlCgnt2wYM4fUeau1MPrPGjWKcn7s6mPoZ7PkXHPkSzx+uZcbYUWxJL+NXS6PP+5ob0kr54+o0sssbWBzhzKNjSkgsbOGbxHTu3etOVMQ4bp03iVCHWq43r+H46GsJ94vsx1eqaSODTjTDQHSQJwDJlUYSQqaqgoBLf2XnqHruYF412WUNPLAgouNg8nLwDIbWBnj/BpZEvcZz31ZSWttMgMnlrNdLKajh+VVH2J1dyRQ/yaYZuxiX+R6isJZ44AcOqP8JBWD5RNCMEwaseC/9TX++TE0bMXSiGQZ8PZwJ8HTmSFEtRFwKO/8GLXXg7Gnv0Hrk5NqZOLV2hroSyN0GF/8Mxi+C96/njoyf8v94jK0Z5dw8I6zL61itkme+SuWDPccZ69rCV7G7iCv4CJFaB9HLYO6jYHSCxkporMDy/9u78+io7ivB49+rHQntEiAkQAKxiFUxILyCAbcX7MZLPBnbyRl6TmynM06O7UniTtLTzkn69GLH6STjSWfaY6eTPrGdOMbOJLFDQkhM7MEICbNJFmLRwiaQoIQkBEhIdeeP3xMSINaqUklV93OOTql+9V69q9+huPV+v/t+r/MYexsbadi3H1/GLB4qmDaEf7UxkcsSTYQoyUujpqkDFix1iz82boBpd4Q7rKt2+kwvv952iBWz80j1rp3h41+C+mH2gzBmBnzqP0h6/WF+POp7vFrzwkUTzb/9uY5fb6zix5M2sLh1NVJ3AkpWwpK/gXGzL9g+Fph2I1h6MSa4LNFEiJK8NDbsraN7/K0kxCW5VQJGYKL5XfVhOk73nJs8drwJY2a5JAMw7Q7kvn9l4dufo23Ps/T2vEts3IB/yqpUfbiGMet+wKZRm4g/0o3MvBeWPANjZw3tH2SMsUQTKUryUjnTq9Qd72HGxBtG7PU0b310kPyMUVzfd+1MayMc2ATLnz13w3kPUb2njtt2PMfRN75AzsM/dKsrb3udnsqfMLt1L4WxyUjpw8gNf20lysaEkZU3R4i+yrOapnaYshRaaqDjcJijujpdPb1srDvG7bPG9l87U7XaPc7+5AXb59/1Zf61ZyU5u16H/7MM/qUE1j7L7hNJfNX/32h6dBvx937fkowxYRZQohGRJ0WkSkSqReQpr61URDaKyFYRqRSRsovs2+tts1VEfhVIHAYm56SQEBfj5mmKlrjG+vfDG9RV2n6gja4ef//ZDEDVW1Cw0K16cJ6M5AT+kPc53km6B9oPwvWf56W5P+eujr+l7L4nmFowZuiCN8Zc1DUnGhGZDTwGlAHzgHtEZCrwPPBNVS0FnvWeD+aUqpZ6PyuvNQ7jxMXGMG3saHdGM3Y2xKe4IacRpLzuGABlhVmuoaUWjuwY9Gymz5LpY/lC2yP4Pl/F2oIv8o+benlk0UQeuG7wAgFjzNAL5IymBNioqidVtQdYD9wPKJDmbZMOHAosRHOlZozzKs9i46BgPuwvD3dIV6W83seMcalkpiS4hh1vgsTArPsvus+S6bmowmvljXzpja3Mzk/j2XtmDlHExpgrEUiiqQIWi0i2iCQDK4AJwFPAt0VkP/ACcLE1PJK8obWNInJfAHEYT0leGkdPdNHS0QUFZXC4yl3gOAKc6fWzubGVRUXe2Yyqm58pvBlSx110v7n56WSlJPDC73cB8MNPzycpPnYoQjbGXKFrTjSqWgM8B6wF1gDbgB7g88DTqjoBeBp45SJvMVFVFwCPAN8TkSmDbSQij3sJqbKlZehu4TsSleS5CzRrmtphwiLQXjj4UZijujI7DrZxsruXRX3zM01bwbfXXTtzCTExwi1TcwD4zqdKmZCVHOpQjTFXKaBiAFV9RVWvU9XFgA/YDawC3vI2+QVuDmewfQ95j3XAe8AnLrLdS6q6QFUX5ObmBhJuxCsZN6DyrGCBaxwh8zQb++Zn+s5odrwJMfFQ8peX3fcrd0zn3/9qIX8xc2woQzTGXKNAq87GeI8TgQeA13FzMl7ZE8twyef8/TJFJNH7PQe4Cfg4kFgMZKYkMC4tiZ2HOyA5C7Knwv6KcId1RcrrfBSPGU3O6ETw+6H6bShe7v6OyyjITGbpDKswM2a4CvSCzdUikg2cAZ5Q1VYReQz4vojEAaeBxwFEZAHw16r6KK6Q4N9ExI9Ldv+sqpZoguDsvWnADZ/t+q2b7xC59I5h1NPrp7LBx32fyHcN+ze6cuXbvhnewIwxQRFQolHVWwZp+wCYP0h7JfCo9/sGwO6NGwIleWm8v/soXT29JE5YCFt/Cr46yB50CmxYqD7UTufA+Zkdb0LcKJh+V3gDM8YEha0MEGFK8tLo8St7mk+4yjMY9mXO5fVufub6oizoPeMW0Zx+JySODnNkxphgsEQTYfoqz3Y2dUDuDEhMg/3DuyCgvM7H5JwUd1+Z+vVw8thlq82MMSOHJZoIU5idQmJcjJuniYlx1WcHhm9BQK9f2dTgY9Hkvmqz1ZCYDlP/IryBGWOCxhJNhImLjWH6uFRqDg8oCDhSDafbwxvYRdQ0tdNxuodFRdlu2Kz2HZixAuISwx2aMSZILNFEoBJvKRpVdQtSonBwc7jDGlTf9TOLJme5m7WdboMZd4c5KmNMMFmiiUAz8lLxdXbT3NHlXbgpw3b4rLzex8SsZPLSR0HtuxCXBFOWhTssY0wQWaKJQH33pvm4qR2S0t39WIZh5Znfr1Q0+Nz6Zqqw812YfCskpIQ7NGNMEFmiiUCzxrtEU3WgzTUULHRnNH5/GKO6UO2RDo6fPOOunzlSBW37YPqKcIdljAkySzQRKDUpnsm5KWw/6CWaCWVu7uPorvAGdp6++88sKspyZzOIXaRpTASyRBOh5uans6PvjGbCIvc4zBbYLK/3kZ8xyq24XPuOO/MabWuWGRNpLNFEqDkFGRxuP01z+2nILoZRmcPqwk1Vpbzeu36m7QA0bXNlzcaYiGOJJkLNLUgH3H1eEHHL0QyjRLO7+QS+zm6uL8qG2t+6xulW1mxMJLJEE6FmjU8jRmDb2eGzhXC0Fk61hjcwT/nA62dq33VnXbnTwhyVMSYULNFEqOSEOKaOSWXHgeOuoW+BzQOV4QtqgI31PsalJTEx+QzUv29FAMZEMEs0EWxOQTo7Dra5FQLy54PEDIvhM1WlvM7Nz8jedeA/Y8NmxkQwSzQRbG5BOkdPdNPUdtotuT921rCoPKs72snRE11ufbOd70JyjivBNsZEJEs0EWxOvisI2H72ws0yN3Tm7w1jVPDu9iYAFk1Khd1rYdqdEBMb1piMMaFjiSaCleSlERcjbO+bp5mwCLpPQHNN2GL6aF8r31+3m9tnjmVy51boarOyZmMinCWaCJYUH8v0camuxBlc5RmEbfjs+MluvvjaFsalJ/HtB+chte+6WzZPXhqWeIwxQ8MSTYSbW5DO9gNeQUBmEaTkhqUgQFX58i+20dxxmv/1yHWkj4pz8zNTlkJC8pDHY4wZOpZoItyc/AzaTp1hv+9U/4Wb+zYOeRwvv1/PH2qa+dpdJZROyIDD26H9gC2iaUwUsEQT4fpWCNh+0JunKV4GrfVuyZchsrmxlefW7OSOWWP5rzcVusba3wLiCgGMMRHNEk2EmzY2lYTYmP4FNmd/EmITYMurQ3L81s5uvvjaR+RlJPH8g/MQEffCzndcccLo3CGJwxgTPpZoIlxCXAwleals66s8G5XpbpW84w3o6Qrpsf1+5Uu/2EbLiS5+8Mh1pI+Kdy8c3++GzqzazJioYIkmCswtyKDqYDt+v7qG0s+4Nc92rQnpcV/+oI4/7mzmb1eUMLcgo/+Fqjfdo83PGBMVLNFEgTkF6Zzo6qH+WKdrmLIUUseHdPistbOb59fUcuescay6sbD/ha4O2PCiK2nOmRqy4xtjhg9LNFHg7C0D+uZpYmJh3kOwZy10HA7JMSsafPT4lc/eUtQ/LwOw8X/DyWOw7O9CclxjzPBjiSYKFOeOJik+pn8pGoDST4P6YdvPQnLMigYfCXExZ5Mc4IbrNrzoFtAsmB+S4xpjhh9LNFEgLjaGWePT+5eiAcgpdlVfW18F1aAfc1O9j9KCDBLjBqxhtuFF6GqHpV8P+vGMMcNXQIlGRJ4UkSoRqRaRp7y2UhHZKCJbRaRSRAZdlldEVonIbu9nVSBxmMubW5BO9aF2enr9/Y2ln4aju+Dg5qAeq7Orh6pD7SwsyuxvPNHihs1mPwDjZgf1eMaY4e2aE42IzAYeA8qAecA9IjIVeB74pqqWAs96z8/fNwv4BrDI2/8bIpJ5/nYmeOYWpHPqTC97Wzr7G2fd79Ya2/LToB5ry77j9PqVhYVZ/Y0ffBd6TsGtXwvqsYwxw18gZzQlwEZVPamqPcB64H5AgTRvm3Tg0CD73gGsVVWfqrYCawG7RDyE5uS78uJzhs+S0mDmvVD1Fpw5FbRjbWrwESMwf5L33aHtIFS8DPMesUozY6JQIImmClgsItkikgysACYATwHfFpH9wAvAYF9h84H9A54f8NouICKPe0NwlS0tLQGEG90m56SQkhDbv5Jzn9JH3FL9Nb8J2rEq6n3MHJ9GapJ3geb7L7jCgyXPBO0YxpiR45oTjarWAM/hzkbWANuAHuDzwNOqOgF4GnhlkN1lkLZBZ6RV9SVVXaCqC3JzbbmSaxUTI8zOTz+38gyg8BbImOiKAoKgu8fPlv2t/cNmvnr46D9g/irInBSUYxhjRpaAigFU9RVVvU5VFwM+YDewCnjL2+QXuDmY8x3Anf30KWDwITYTRHML0vm4qZ3ungEFATExbkir7j23NEyAdhxs4/QZP2V9iWb98xATB7d8OeD3NsaMTIFWnY3xHicCDwCv4xLGEm+TZbjkc77fAbeLSKZXBHC712ZCaG5BBt09fnYd6Tj3hdKHAQ3KNTUVDT4AFhRmQUstbP8ZLHwU0vICfm9jzMgU6HU0q0XkY+DXwBPexP5jwHdEZBvwj8DjACKyQEReBlBVH/D3QIX38y2vzYTQ2RUCzp+nySx0Q2hBuKamot7H5JwUclMT4b1/gvhkuPnpgN7TGDOyBTp0douqzlTVeaq6zmv7QFXne22LVHWz116pqo8O2PdHqlrs/fx7YH+GuRITs5JJS4q7cJ4G3DU1rfXQuOGa39/vVyobvfmZ1kaofhsWfQ5ScgKI2hgz0tnKAFFERJhbkHFuiXOfmSshYXT/ysrXYFdzB22nzlBWlAXV3jTddf/lmt/PGBMZLNFEmRumZFN9qJ0Pdh8994WEFChaAnv+cM3DZxX1bvSzrCgLqlZD/gI3LGeMiWqWaKLMZ28uYnJOCl99azudXT3nvli8HI7vg2N7rum9y+t9jEtLoqB3Pxze4e7maYyJepZookxSfCzPPziXg8dP8e3f1Z77YvFy97hn3VW/r6pS0eBjYVEWUv02IG6JG2NM1LNEE4UWFGax6oZCfryhgU31A4r9Mgshuxj2Xn2i2e87xZH2LsomZbhhs8KbraTZGANYoolaz9w5nQlZo3jmzW2c6u7tf2HKcqh/H86cvqr32+RdP3Nz2hG3IvTsB4IZrjFmBLNEE6WSE+J47oG5NBw7yXf/sKv/heLlbpXlfR9e1ftV1PtIHxVPYdMakFgouTfIERtjRipLNFHsxuIcHlk0kZffr2PLvlbXWHgzxCa46rOrUNHgY+GkDKR6NUxZCinZIYjYGDMSWaKJcl+7awZj05L4ypvb6erpdWXOE2+AvX+84vdo7jhN3dFO7s465KrWrNrMGDOAJZool5oUzz89MIc9zSd4cZ1X1lx8GzR/7O4jcwUqG9zZ0I1d693Z0Iy7QxWuMWYEskRjuHX6GB6cX8AP1++l6mBbf5nzFZ7VbKr3kRwPYxrfham3Q1J6CKM1xow0lmgMAH9390xGJ8bxo/9XD2NmQmreFZc5VzT4eGjMAeTEYRs2M8ZcwBKNASA9OZ4bJme7Zf5FXJnz3j+Bv/eS+3WcPkNNUzv3xW2E+BSYdscQRWyMGSks0Zizyoqy2O87RVPbKSheBqePw8GPLrnP5sZWYrSHkuN/gul3uWICY4wZwBKNOausyN0Vc1O9DyYvBYm5bJnzpnofi2Orie9qtWEzY8ygLNGYs0ry0hidGOeGz5KzYPx1l52n+bDuGJ8ZvRkS0/uLCIwxZgBLNOas2Bhh/qTM/vXPipfDwc1wcvCbnx4/2U3N/mZu6vkQSv4S4hKHMFpjzEhhicaco6woi11HTtDa2e2up1E/1L036LYf7DnKYtlGYm+nrW1mjLkoSzTmHH3zNBUNPjd0lpR+0eGzyupdPJXwSzQ5x900zRhjBmGJxpxjbkE6CXExLtHExrmigD3rLrjrph7ewedqP0uxHEJW/k+3rTHGDMISjTlHYlwspQUZbPKWlaF4OXQ0QXNN/0a1v8X/yh2I9rL+xp/YkjPGmEuyRGMuUFaURdXBNner5yl9y9F4ZzUbXoTXH8aXNJF7u/6eOWVLwxusMWbYs0RjLrCwKItev7Jl33FIz4fcEqhdA7/6Avz+f8DMlXxl9D+TMXYS49KTwh2uMWaYs0RjLjB/UiYxApvqj7mG4uXQ+AFs+Sks+Rs6V77Mhn2nWDI9N7yBGmNGBEs05gKjE+OYNT797O2ZmfMgpBXAJ1+BpV9nY30r3b1+lkyzRGOMuTwrFTKDWliYxavljXT19JI4/hPw36vPvrZ+Vwuj4mNZUJgZxgiNMSOFndGYQZUVZdHV43f3pznP+l0t3DAlm8S42DBEZowZaSzRmEEt9M5WNtW3ntPecLSTxmMnbdjMGHPFAko0IvKkiFSJSLWIPOW1/VxEtno/DSKy9SL7NojIDm+7ykDiMMGXPTqR4jGj+wsCPH/e3QJgicYYc8WueY5GRGYDjwFlQDewRkTeUdX/PGCb7wAXjr30W6qqR681BhNaCwuz+M32Q/T6ldgYAWB9bQsTs5IpzLH7zhhjrkwgZzQlwEZVPamqPcB64P6+F0VEgE8BrwcWogmXsqJMOk73sPNwOwBdPb18WHfMzmaMMVclkERTBSwWkWwRSQZWABMGvH4LcERVd19kfwV+LyKbReTxix1ERB4XkUoRqWxpaQkgXHO1yoqyAajwbhuwuaGVk929lmiMMVflmhONqtYAzwFrgTXANqBnwCYPc+mzmZtU9TrgLuAJEVl8keO8pKoLVHVBbq79BzeU8jNGkZ8xigpv3bP1u1qIjxVumJId5siMMSNJQMUAqvqKql6nqosBH7AbQETigAeAn19i30PeYzPwNm6uxwwzZUVZlNf7UFXW72phwaQsUhLt8itjzJULtOpsjPc4EZdY+s5gbgN2quqBi+yXIiKpfb8Dt+OG4swws7Awi6Mnuiiv97HzcIctO2OMuWqBfjVdLSLZwBngCVXtu+jiIc4bNhOR8cDLqroCGAu87eoFiANeU9U1AcZiQqCsyF1P88LvagFYPNUSjTHm6gSUaFT1lou0/9UgbYdwBQOoah0wL5Bjm6ExJXc0WSkJVDa2kpuaSElearhDMsaMMLYygLkkETm7SsCSabl4Z6HGGHPFLNGYy+orc15sZc3GmGtg5UPmslbOG0/jsU5uKxkT7lCMMSOQJRpzWbmpiXzr3tnhDsMYM0LZ0JkxxpiQskRjjDEmpCzRGGOMCSlLNMYYY0LKEo0xxpiQskRjjDEmpCzRGGOMCSlLNMYYY0LKEo0xxpiQskRjjDEmpERVwx3DFRORFqAxgLfIAY4GKZyRzPrBsX7oZ33hWD84V9oPk1T1sqvtjqhEEygRqVTVBeGOI9ysHxzrh37WF471gxPsfrChM2OMMSFlicYYY0xIRVuieSncAQwT1g+O9UM/6wvH+sEJaj9E1RyNMcaYoRdtZzTGGGOGmCUaY4wxIRUViUZE7hSRWhHZIyJfDXc8Q0lEfiQizSJSNaAtS0TWishu7zEznDEOBRGZICJ/EpEaEakWkSe99qjqCxFJEpFNIrLN64dveu1FIlLu9cPPRSQh3LEOBRGJFZEtIvIb73m09kODiOwQka0iUum1Be2zEfGJRkRigR8AdwEzgYdFZGZ4oxpSPwbuPK/tq8A6VZ0KrPOeR7oe4EuqWgJcDzzh/TuItr7oApap6jygFLhTRK4HngO+6/VDK/DZMMY4lJ4EagY8j9Z+AFiqqqUDrp8J2mcj4hMNUAbsUdU6Ve0GfgbcG+aYhoyq/hnwndd8L/AT7/efAPcNaVBhoKpNqvqR93sH7j+XfKKsL9Q54T2N934UWAa86bVHfD8AiEgBcDfwsvdciMJ+uISgfTaiIdHkA/sHPD/gtUWzsaraBO4/YGBMmOMZUiJSCHwCKCcK+8IbLtoKNANrgb3AcVXt8TaJls/I94BnAL/3PJvo7AdwXzZ+LyKbReRxry1on424IAQ43MkgbVbTHaVEZDSwGnhKVdvdl9jooqq9QKmIZABvAyWDbTa0UQ0tEbkHaFbVzSJya1/zIJtGdD8McJOqHhKRMcBaEdkZzDePhjOaA8CEAc8LgENhimW4OCIieQDeY3OY4xkSIhKPSzKvqupbXnNU9gWAqh4H3sPNWWWISN8Xz2j4jNwErBSRBtxw+jLcGU609QMAqnrIe2zGffkoI4ifjWhINBXAVK+aJAF4CPhVmGMKt18Bq7zfVwH/N4yxDAlv/P0VoEZV/2XAS1HVFyKS653JICKjgNtw81V/Ah70Nov4flDVr6lqgaoW4v5P+KOqfpoo6wcAEUkRkdS+34HbgSqC+NmIipUBRGQF7ttKLPAjVf2HMIc0ZETkdeBW3LLfR4BvAL8E3gAmAvuA/6Sq5xcMRBQRuRl4H9hB/5j813HzNFHTFyIyFzexG4v7ovmGqn5LRCbjvtlnAVuAz6hqV/giHTre0NmXVfWeaOwH729+23saB7ymqv8gItkE6bMRFYnGGGNM+ETD0JkxxpgwskRjjDEmpCzRGGOMCSlLNMYYY0LKEo0xxpiQskRjjDEmpCzRGGOMCan/D3v1ZaBZTunwAAAAAElFTkSuQmCC",
"text/plain": [
"
sepal_width=%{x}
sepal_length=%{y}
sepal_width=%{x}
sepal_length=%{y}
sepal_width=%{x}
sepal_length=%{y}
"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"plt[`:plot][til n; output`x; `label pykw \"price\"];\n",
"plt[`:plot][til n; output`xh;`label pykw \"forecast\"];\n",
"plt[`:legend][];\n",
"plt[`:show][];"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Q 3.5",
"language": "q",
"name": "qpk"
},
"language_info": {
"file_extension": ".q",
"mimetype": "text/x-q",
"name": "q",
"version": "3.6.0"
},
"toc": {
"base_numbering": 1,
"nav_menu": {},
"number_sections": true,
"sideBar": true,
"skip_h1_title": false,
"title_cell": "Table of Contents",
"title_sidebar": "Contents",
"toc_cell": false,
"toc_position": {},
"toc_section_display": true,
"toc_window_display": false
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_robot/simple_robot_notebook.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"*** Settings ***\n",
"\n",
"Library Collections"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"*** Keywords ***\n",
"\n",
"Head\n",
" [Arguments] ${list}\n",
" ${value}= Get from list ${list} 0\n",
" [Return] ${value}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"lines_to_next_cell": 0
},
"outputs": [],
"source": [
"*** Tasks ***\n",
"\n",
"Get head\n",
" ${array}= Create list 1 2 3 4 5\n",
" ${head}= Head ${array}\n",
" Should be equal ${head} 1"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Robot Framework",
"language": "robotframework",
"name": "robotkernel"
},
"language_info": {
"codemirror_mode": "robotframework",
"file_extension": ".robot",
"mimetype": "text/plain",
"name": "robotframework",
"pygments_lexer": "robotframework"
},
"pycharm": {
"stem_cell": {
"cell_type": "raw",
"metadata": {
"collapsed": false
},
"source": []
}
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_rust/evcxr_jupyter_tour.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Tour of the EvCxR Jupyter Kernel\n",
"For those not already familiar with Jupyter notebook, it lets you write code into \"cells\" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.\n",
"\n",
"## Printing to outputs and evaluating expressions\n",
"Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"Hello error\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Hello world\n"
]
},
{
"data": {
"text/plain": [
"\"Hello world\""
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"println!(\"Hello world\");\n",
"eprintln!(\"Hello error\");\n",
"format!(\"Hello {}\", \"world\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Assigning and making use of variables\n",
"We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted."
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"let mut message = \"Hello \".to_owned();"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [],
"source": [
"message.push_str(\"world!\");"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"\"Hello world!\""
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"message"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Defining and redefining functions\n",
"Next we'll define a function"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"pub fn fib(x: i32) -> i32 {\n",
" if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"(1..13).map(fib).collect::>()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Hmm, that doesn't look right. Lets redefine the function. In practice, we'd go back and edit the function above and reevaluate it, but here, lets redefine it in a separate cell."
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"pub fn fib(x: i32) -> i32 {\n",
" if x <= 2 {2} else {fib(x - 2) + fib(x - 1)}\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[2, 2, 4, 6, 10, 16, 26, 42, 68, 110, 178, 288]"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"let values = (1..13).map(fib).collect::>();\n",
"values"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Spawning a separate thread and communicating with it\n",
"We can spawn a thread to do stuff in the background, then continue executing code in other cells."
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [],
"source": [
"use std::sync::{Mutex, Arc};\n",
"let counter = Arc::new(Mutex::new(0i32));\n",
"std::thread::spawn({\n",
" let counter = Arc::clone(&counter);\n",
" move || {\n",
" for i in 1..300 {\n",
" *counter.lock().unwrap() += 1;\n",
" std::thread::sleep(std::time::Duration::from_millis(100));\n",
" }\n",
"}});"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"17"
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"*counter.lock().unwrap()"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"29"
]
},
"execution_count": 12,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"*counter.lock().unwrap()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Loading external crates\n",
"We can load external crates. This one takes a while to compile, but once it's compiled, subsequent cells shouldn't need to recompile it, so it should be much quicker."
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"\"AQIDBA==\""
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
":dep base64 = \"0.10.1\"\n",
"base64::encode(&vec![1, 2, 3, 4])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Customizing how types are displayed\n",
"We can also customize how our types are displayed, including presenting them as HTML. Here's an example where we define a custom display function for a type `Matrix`."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"use std::fmt::Debug;\n",
"pub struct Matrix {pub values: Vec, pub row_size: usize}\n",
"impl Matrix {\n",
" pub fn evcxr_display(&self) {\n",
" let mut html = String::new();\n",
" html.push_str(\"\");\n",
" for r in 0..(self.values.len() / self.row_size) {\n",
" html.push_str(\"
\");\n",
" println!(\"EVCXR_BEGIN_CONTENT text/html\\n{}\\nEVCXR_END_CONTENT\", html);\n",
" }\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"
"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"let m = Matrix {values: vec![1,2,3,4,5,6,7,8,9], row_size: 3};\n",
"m"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can also return images, we just need to base64 encode them. First, we set up code for displaying RGB and grayscale images."
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [],
"source": [
"extern crate image;\n",
"extern crate base64;\n",
"pub trait EvcxrResult {fn evcxr_display(&self);}\n",
"impl EvcxrResult for image::RgbImage {\n",
" fn evcxr_display(&self) {\n",
" let mut buffer = Vec::new();\n",
" image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),\n",
" image::ColorType::RGB(8)).unwrap();\n",
" let img = base64::encode(&buffer);\n",
" println!(\"EVCXR_BEGIN_CONTENT image/png\\n{}\\nEVCXR_END_CONTENT\", img); \n",
" }\n",
"}\n",
"impl EvcxrResult for image::GrayImage {\n",
" fn evcxr_display(&self) {\n",
" let mut buffer = Vec::new();\n",
" image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),\n",
" image::ColorType::Gray(8)).unwrap();\n",
" let img = base64::encode(&buffer);\n",
" println!(\"EVCXR_BEGIN_CONTENT image/png\\n{}\\nEVCXR_END_CONTENT\", img); \n",
" }\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAQAAAAEACAIAAADTED8xAAAGBklEQVR4nO3TCVIcRxBAUfn+h7aRRUgIhpleasnlvQiHBczSVZn/nx8//v3x7u3f0Mvb0v8O4M3bj9DI28Z/DODN22+gi1/rrgGa+r3rGqCjj4uuAdr5tOUaoJevK64BGnm43xqgi++WWwO08GSzNUB9z9daAxT3cqc1QGVHFloDlHVwmzVATcdXWQMUdGqPNUA1Z5dYA5RyYYM1QB3X1lcDFHF5dzVABXcWVwOkd3NrNUBu91dWAyQ2ZF81QFajllUDpDRwUzVAPmPXVAMkM3xHNUAmMxZUA6QxaTs1QA7zVlMDJDB1LzVAdLOXUgOEtmAjNUBca9ZRAwS1bBc1QEQrF1EDhLN4CzVALOtXUAMEsmX/NEAUu5ZPA4SwcfM0wH57104DbLZ95zTAThEWTgNsE2TbNMAecVZNA2wQas80wGrRlkwDLBVwwzTAOjHXSwMsEna3NMAKkRdLA0wXfKs0wFzxV0oDTJRinzTALFmWSQNMkWiTNMB4udZIAwyWboc0wEgZF0gDDJN0ezTAGHlXRwMMkHpvNMBd2ZdGA9xSYGM0wHU11kUDXFRmVzTAFZUWRQOcVmxLNMA59VZEA5xQcj80wFFVl0MDHFJ4MzTAa7XXQgO8UH4nNMAzHRZCA3yryTZogMf6rIIGeKDVHmiAz7otgQb4S8MN0AB/9By/BnjXdvYa4KfOg9cA3aeuge6MXAOtmfcbDfRl2L9ooCmT/k0DHRnzRxpox4w/0UAvBvyVBhox3Yc00IXRfkcDLZjrExqoz1Cf00BxJvqSBiozziM0UJZZHqSBmgzyOA0UZIqnaKAaIzxLA6WY3wUaqMPwrtFAESZ3mQYqMLY7NJCemd2kgdwM7D4NJGZaQ2ggK6MaRQMpmdNAGsjHkMbSQDImNJwGMjGeGTSQhtlMooEcDGYeDSRgKlNpIDojmU0DoZnHAhqIyzDW0EBQJrGMBiIyhpU0EI4ZLKaBWAxgPQ0E4va30EAUrn4XDYTg3jfSwH4ufS8NbObGt9PATq47Ag1s466D0MAeLjoODWzglkPRwGquOBoNLOV+A9LAOi43Jg0s4mbD0sAKrjUyDUznToPTwFwuND4NTOQ2U9DALK4yCw1M4R4T0cB4LjEXDQzmBtPRwEiuLyMNDOPuktLAGC4uLw0M4NZS08Bdriw7DdzivgrQwHUuqwYNXOSmytDAFa6pEg2c5o6K0cA5LqgeDZzgdkrSwFGupioNHOJeCtPAay6lNg284EbK08AzrqMDDXzLXTShgcdcRB8aeMAttKKBz1xBNxr4S/fzt6SBP1ofvjENvOt78vY08FPTY/M/DbQ8Mx90b6DdgfmidQO9Tss3+jbQ6Kg81bSBLufkgI4NtDgkh7VroP4JOalXA8WPxyWNGqh8Nm7o0kDZg3FbiwZqnopB6jdQ8EgMVbyBaudhgsoNlDoM05RtoM5JmKxmA0WOwRIFG6hwBhaq1kD6A7BcqQZyPz2b1Gkg8aOzVZEGsj43AVRoIOVDE0b6BvI9McHkbiDZ4xJS4gYyPSuBZW0gzYMSXsoGcjwlSeRrIMEjkkqyBqI/HwllaiD0w5FWmgbiPhnJ5Wgg6GNRQoIGIj4ThURvINwDUU7oBmI9DUXFbSDQo1Ba0AaiPAcNRGwgxEPQRrgG9j8BzcRqYPPX01KgBnZ+N41FaWDbF9NeiAb2fCv8b38DG74SPtjcwOrvgy92NrD0y+Ab2xpY903w1J4GFn0NHLChgRXfAYetbmD6F8BJSxuY++lwyboGJn403LCogVmfC7etaGDKh8Ig0xsY/4kw1NwGBn8cTDCxgZGfBdPMamDYB8FkUxoY8ymwxPgGBnwELDS4gbvvh+VGNnDrzbDJsAauvxO2GtPAxbdBAAMauPIeCONuA6ffAMHcauDcqyGk6w2ceCkEdrGBo6+D8K40cOhFkMTpBl6/AlI518CLP0NCJxp49jdI62gD3/4BkjvUwOPfQgmvG3jwKyjkRQOff4ZynjXw1w9Q1LcN/PkXlPa4gff/QQMPGvj5H7TxuQEB0M1fDQiAhv40IAB6em/gP4B1AQ2EIi+6AAAAAElFTkSuQmCC"
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"image::ImageBuffer::from_fn(256, 256, |x, y| {\n",
" if (x as i32 - y as i32).abs() < 3 {\n",
" image::Rgb([0, 0, 255])\n",
" } else {\n",
" image::Rgb([0, 0, 0])\n",
" }\n",
"})"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Display of compilation errors\n",
"Here's how compilation errors are presented. Here we forgot an & and passed a String instead of an &str."
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"ename": "Error",
"evalue": "mismatched types",
"output_type": "error",
"traceback": [
"s.push_str(format!(\"foo {}\", 42));",
"\u001b[91m ^^^^^^^^^^^^^^^^^^^^^\u001b[0m \u001b[94mexpected &str, found struct `std::string::String`\u001b[0m",
"mismatched types"
]
}
],
"source": [
"let mut s = String::new();\n",
"s.push_str(format!(\"foo {}\", 42));"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Seeing what variables have been defined\n",
"We can print a table of defined variables and their types with the :vars command."
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"
"
],
"text/plain": [
"counter: std::sync::Arc>\n",
"message: String\n",
"m: user_code_13::Matrix\n",
"values: std::vec::Vec\n"
]
},
"execution_count": 19,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
":vars"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Other built-in commands can be found via :help"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
":vars List bound variables and their types\n",
":opt [level] Toggle/set optimization level\n",
":explain Print explanation of last error\n",
":clear Clear all state, keeping compilation cache\n",
":dep Add dependency. e.g. :dep regex = \"1.0\"\n",
":version Print Evcxr version\n",
":preserve_vars_on_panic [0|1] Try to keep vars on panic\n",
"\n",
"Mostly for development / debugging purposes:\n",
":last_compile_dir Print the directory in which we last compiled\n",
":timing Toggle printing of how long evaluations take\n",
":last_error_json Print the last compilation error as JSON (for debugging)\n",
":time_passes Toggle printing of rustc pass times (requires nightly)\n",
":internal_debug Toggle various internal debugging code\n"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
":help"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Rust",
"language": "rust",
"name": "rust"
},
"language_info": {
"codemirror_mode": "rust",
"file_extension": ".rs",
"mimetype": "text/rust",
"name": "Rust",
"pygment_lexer": "rust",
"version": ""
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_sage/sage_print_hello.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(\"Hello world\")"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "SageMath 9.2",
"language": "sage",
"name": "sagemath"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.1"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_sas/sas.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"id": "14a71cf0-4339-4ae6-982d-7dda15f3810e",
"metadata": {},
"source": [
"# SAS Notebooks with jupytext"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "47346888-e79f-4205-82fd-3a5fdfde9b4d",
"metadata": {},
"outputs": [],
"source": [
"proc sql;\n",
" select *\n",
" from sashelp.cars (obs=10)\n",
" ;\n",
"quit; "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c96b0faf-26fe-4245-a1d9-78dee30b19c3",
"metadata": {},
"outputs": [],
"source": [
"%let name = \"Jupytext\";"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "56cafffb-e397-4c3b-97ab-c6970149b6bc",
"metadata": {},
"outputs": [],
"source": [
"%put &name;"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "bbc273c9-8690-450d-bd9b-2d075d512437",
"metadata": {},
"outputs": [],
"source": [
"/* Note when defining macros \"%macro\" cannot be the first line of text in the cell */\n",
"%macro test;\n",
" data temp;\n",
" set sashelp.cars;\n",
" name = \"testx\";\n",
" run; \n",
" proc print data = temp (obs=10);\n",
" run; \n",
"%mend test;\n",
"\n",
"%test"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "SAS",
"language": "sas",
"name": "sas"
},
"language_info": {
"codemirror_mode": "sas",
"file_extension": ".sas",
"mimetype": "text/x-sas",
"name": "sas"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_scala/simple_scala_notebook.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"defined object SampleObject\n",
"result = 3\n"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/plain": [
"3"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"// This is just a simple scala notebook\n",
"\n",
"object SampleObject {\n",
" def calculation(x: Int, y: Int): Int = x + y\n",
"}\n",
"\n",
"val result = SampleObject.calculation(1, 2)"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"30\n"
]
}
],
"source": [
"println(result * 10)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Apache Toree - Scala",
"language": "scala",
"name": "apache_toree_scala"
},
"language_info": {
"codemirror_mode": "text/x-scala",
"file_extension": ".scala",
"mimetype": "text/x-scala",
"name": "scala",
"pygments_lexer": "scala",
"version": "2.11.12"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_scheme/Reference Guide for Calysto Scheme.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
" \n",
"
\n",
" \n",
"\n",
"It has breakpoints (click in left margin). You must press Stop to exit the debugger."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"```scheme\n",
"%%debug\n",
"\n",
"(begin\n",
" (define x 1)\n",
" (set! x 2)\n",
")\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Python Integration\n",
"\n",
"You can import and use any Python library in Calysto Scheme.\n",
"\n",
"In addition, if you wish, you can execute expressions and statements in a Python environment:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(python-eval \"1 + 2\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(python-exec \n",
"\"\n",
"def mypyfunc(a, b):\n",
" return a * b\n",
"\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This is a shared environment with Scheme:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(mypyfunc 4 5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define! mypyfunc2 (func (lambda (n) n)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(python-eval \"mypyfunc2(34)\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Differences Between Languages\n",
"\n",
"## Major differences between Scheme and Python\n",
"\n",
"1. In Scheme, double quotes are used for strings and may contain newlines\n",
"1. In Scheme, a single quote is short for (quote ...) and means \"literal\"\n",
"1. In Scheme, everything is an expression and has a return value\n",
"1. Python does not support macros (e.g., extending syntax)\n",
"1. In Python, \"if X\" is false if X is None, False, [], (,) or 0. In Scheme, \"if X\" is only false if X is #f or 0\n",
"1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)\n",
"1. Scheme procedures are not Python functions, but there are means to use one as the other.\n",
"\n",
"## Major Differences Between Calysto Scheme and other Schemes\n",
"\n",
"1. define-syntax works slightly differently\n",
"1. In Calysto Scheme, #(...) is short for '#(...)\n",
"1. Calysto Scheme is missing many standard functions (see list at bottom)\n",
"1. Calysto Scheme has a built-in amb operator called `choose`\n",
"1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)\n",
"\n",
"### Stack Trace\n",
"\n",
"Calysto Scheme acts as if it has a call stack, for easier debugging. For example:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define fact\n",
" (lambda (n)\n",
" (if (= n 1)\n",
" q\n",
" (* n (fact (- n 1))))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(fact 5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To turn off the stack trace on error:\n",
"\n",
"```scheme\n",
"(use-stack-trace #f)\n",
"```\n",
"That will allow infinite recursive loops without keeping track of the \"stack\"."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Calysto Scheme Variables\n",
"\n",
"## SCHEMEPATH\n",
"SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"SCHEMEPATH"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(set-cdr! (cdr SCHEMEPATH) (list \"/var/modules\"))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"SCHEMEPATH"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Getting Started\n",
"\n",
"Note that you can use the word `lambda` or \\lambda and then press [TAB]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define factorial\n",
" (λ (n)\n",
" (cond\n",
" ((zero? n) 1)\n",
" (else (* n (factorial (- n 1)))))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(factorial 5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## define-syntax\n",
"(define-syntax NAME RULES): a method for creating macros"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define-syntax time \n",
" [(time ?exp) (let ((start (current-time)))\n",
" ?exp\n",
" (- (current-time) start))])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(time (car '(1 2 3 4)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
";;---------------------------------------------------------------------\n",
";; collect is like list comprehension in Python\n",
"\n",
"(define-syntax collect\n",
" [(collect ?exp for ?var in ?list)\n",
" (filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]\n",
" [(collect ?exp for ?var in ?list if ?condition)\n",
" (filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])\n",
"\n",
"(define filter-map\n",
" (lambda (f pred? values)\n",
" (if (null? values)\n",
" '()\n",
" (if (pred? (car values))\n",
" (cons (f (car values)) (filter-map f pred? (cdr values)))\n",
" (filter-map f pred? (cdr values))))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(collect (* n n) for n in (range 10))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(collect (* n n) for n in (range 5 20 3))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(collect (* n n) for n in (range 10) if (> n 5))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
";;---------------------------------------------------------------------\n",
";; for loops\n",
"\n",
"(define-syntax for\n",
" [(for ?exp times do . ?bodies)\n",
" (for-repeat ?exp (lambda () . ?bodies))]\n",
" [(for ?var in ?exp do . ?bodies)\n",
" (for-iterate1 ?exp (lambda (?var) . ?bodies))]\n",
" [(for ?var at (?i) in ?exp do . ?bodies)\n",
" (for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]\n",
" [(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)\n",
" (for ?var at (?i) in ?exp do\n",
" (for ?var at (?j . ?rest) in ?var do . ?bodies))])\n",
"\n",
"(define for-repeat\n",
" (lambda (n f)\n",
" (if (< n 1)\n",
" 'done\n",
" (begin\n",
" (f)\n",
" (for-repeat (- n 1) f)))))\n",
"\n",
"(define for-iterate1\n",
" (lambda (values f)\n",
" (if (null? values)\n",
" 'done\n",
" (begin\n",
" (f (car values))\n",
" (for-iterate1 (cdr values) f)))))\n",
"\n",
"(define for-iterate2\n",
" (lambda (i values f)\n",
" (if (null? values)\n",
" 'done\n",
" (begin\n",
" (f (car values) i)\n",
" (for-iterate2 (+ i 1) (cdr values) f)))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define matrix2d\n",
" '((10 20)\n",
" (30 40)\n",
" (50 60)\n",
" (70 80)))\n",
"\n",
"(define matrix3d\n",
" '(((10 20 30) (40 50 60))\n",
" ((70 80 90) (100 110 120))\n",
" ((130 140 150) (160 170 180))\n",
" ((190 200 210) (220 230 240))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(begin \n",
" (define hello 0)\n",
" (for 5 times do (set! hello (+ hello 1)))\n",
" hello\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for n in (range 10 20 2) do (print n))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for n at (i j) in matrix2d do (print (list n 'coords: i j)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define-syntax scons\n",
" [(scons ?x ?y) (cons ?x (lambda () ?y))])\n",
"\n",
"(define scar car)\n",
"\n",
"(define scdr\n",
" (lambda (s)\n",
" (let ((result ((cdr s))))\n",
" (set-cdr! s (lambda () result))\n",
" result)))\n",
"\n",
"(define first\n",
" (lambda (n s)\n",
" (if (= n 0)\n",
" '()\n",
" (cons (scar s) (first (- n 1) (scdr s))))))\n",
"\n",
"(define nth\n",
" (lambda (n s)\n",
" (if (= n 0)\n",
" (scar s)\n",
" (nth (- n 1) (scdr s)))))\n",
"\n",
"(define smap\n",
" (lambda (f s)\n",
" (scons (f (scar s)) (smap f (scdr s)))))\n",
"\n",
"(define ones (scons 1 ones))\n",
"\n",
"(define nats (scons 0 (combine nats + ones)))\n",
"\n",
"(define combine\n",
" (lambda (s1 op s2)\n",
" (scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))\n",
"\n",
"(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))\n",
"\n",
"(define facts (scons 1 (combine facts * (scdr nats))))\n",
"\n",
"(define ! (lambda (n) (nth n facts)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(! 5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(nth 10 facts)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(nth 20 fibs)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(first 30 fibs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## for-each\n",
"(for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for-each (lambda (n) (print n)) '(3 4 5))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## format\n",
"(format STRING ITEM ...): format the string with ITEMS as arguments"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(format \"This uses formatting ~a ~s ~%\" 'apple 'apple)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## func\n",
"\n",
"Turns a lambda into a Python function.\n",
"\n",
"(func (lambda ...))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(func (lambda (n) n))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## There's more!\n",
"\n",
"Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Calysto Scheme (Python)",
"language": "scheme",
"name": "calysto_scheme"
},
"language_info": {
"codemirror_mode": {
"name": "scheme"
},
"mimetype": "text/x-scheme",
"name": "scheme",
"pygments_lexer": "scheme"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_sos/jupytext_replication.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "SoS"
},
"source": [
"# Text SOS-kernel with Jupytext\n",
"\n",
"## What is SOS kernel\n",
"\n",
"SoS consists of a ployglot notebook that allows the use of multiple kernels in one Jupyter notebook, and a workflow system that is designed for daily computational research. Basically,\n",
"\n",
"- SoS Polyglot Notebook is a Jupyter Notebook with a SoS kernel.\n",
"- SoS Notebook serves as a super kernel to all other Jupyter kernels and allows the use of multiple kernels in one Jupyter notebook.\n",
"- SoS Workflow System is a Python based workflow system that is designed to be readable, shareable, and suitable for daily data analysis.\n",
"- SoS Workflow System can be used from command line or use SoS Notebook as its IDE.\n",
"\n",
"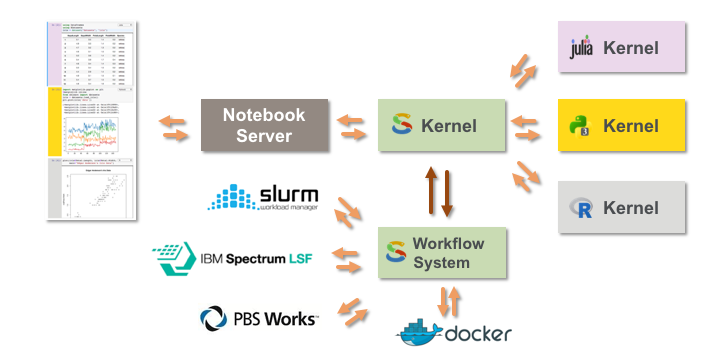\n",
"\n",
"### How to install SOS-kernel\n",
"\n",
"Please follow this [link](https://vatlab.github.io/sos-docs/running.html#Conda-installation) to setup SOS\n",
"\n",
"I run some issue with the latest version of R on my Mac, so I had to install an earlier version of R\n",
"\n",
"```\n",
"conda install -c r r=3.5.1\n",
"conda install sos-notebook jupyterlab-sos sos-papermill -c conda-forge\n",
"```\n",
"\n",
"## Related issue with Jupytext\n",
"\n",
"Jupytext works fine with Python/R kernel but converts code cells into markdown cells when using the SOS kernel.\n",
"\n",
"cf the image below. It is a code cell. After saving the notebook and restart it, it converted the code cell into markdown\n",
"\n",
"
\n",
"\n",
"It has breakpoints (click in left margin). You must press Stop to exit the debugger."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"```scheme\n",
"%%debug\n",
"\n",
"(begin\n",
" (define x 1)\n",
" (set! x 2)\n",
")\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Python Integration\n",
"\n",
"You can import and use any Python library in Calysto Scheme.\n",
"\n",
"In addition, if you wish, you can execute expressions and statements in a Python environment:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(python-eval \"1 + 2\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(python-exec \n",
"\"\n",
"def mypyfunc(a, b):\n",
" return a * b\n",
"\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This is a shared environment with Scheme:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(mypyfunc 4 5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define! mypyfunc2 (func (lambda (n) n)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(python-eval \"mypyfunc2(34)\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Differences Between Languages\n",
"\n",
"## Major differences between Scheme and Python\n",
"\n",
"1. In Scheme, double quotes are used for strings and may contain newlines\n",
"1. In Scheme, a single quote is short for (quote ...) and means \"literal\"\n",
"1. In Scheme, everything is an expression and has a return value\n",
"1. Python does not support macros (e.g., extending syntax)\n",
"1. In Python, \"if X\" is false if X is None, False, [], (,) or 0. In Scheme, \"if X\" is only false if X is #f or 0\n",
"1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)\n",
"1. Scheme procedures are not Python functions, but there are means to use one as the other.\n",
"\n",
"## Major Differences Between Calysto Scheme and other Schemes\n",
"\n",
"1. define-syntax works slightly differently\n",
"1. In Calysto Scheme, #(...) is short for '#(...)\n",
"1. Calysto Scheme is missing many standard functions (see list at bottom)\n",
"1. Calysto Scheme has a built-in amb operator called `choose`\n",
"1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)\n",
"\n",
"### Stack Trace\n",
"\n",
"Calysto Scheme acts as if it has a call stack, for easier debugging. For example:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define fact\n",
" (lambda (n)\n",
" (if (= n 1)\n",
" q\n",
" (* n (fact (- n 1))))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(fact 5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To turn off the stack trace on error:\n",
"\n",
"```scheme\n",
"(use-stack-trace #f)\n",
"```\n",
"That will allow infinite recursive loops without keeping track of the \"stack\"."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Calysto Scheme Variables\n",
"\n",
"## SCHEMEPATH\n",
"SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"SCHEMEPATH"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(set-cdr! (cdr SCHEMEPATH) (list \"/var/modules\"))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"SCHEMEPATH"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Getting Started\n",
"\n",
"Note that you can use the word `lambda` or \\lambda and then press [TAB]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define factorial\n",
" (λ (n)\n",
" (cond\n",
" ((zero? n) 1)\n",
" (else (* n (factorial (- n 1)))))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(factorial 5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## define-syntax\n",
"(define-syntax NAME RULES): a method for creating macros"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define-syntax time \n",
" [(time ?exp) (let ((start (current-time)))\n",
" ?exp\n",
" (- (current-time) start))])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(time (car '(1 2 3 4)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
";;---------------------------------------------------------------------\n",
";; collect is like list comprehension in Python\n",
"\n",
"(define-syntax collect\n",
" [(collect ?exp for ?var in ?list)\n",
" (filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]\n",
" [(collect ?exp for ?var in ?list if ?condition)\n",
" (filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])\n",
"\n",
"(define filter-map\n",
" (lambda (f pred? values)\n",
" (if (null? values)\n",
" '()\n",
" (if (pred? (car values))\n",
" (cons (f (car values)) (filter-map f pred? (cdr values)))\n",
" (filter-map f pred? (cdr values))))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(collect (* n n) for n in (range 10))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(collect (* n n) for n in (range 5 20 3))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(collect (* n n) for n in (range 10) if (> n 5))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
";;---------------------------------------------------------------------\n",
";; for loops\n",
"\n",
"(define-syntax for\n",
" [(for ?exp times do . ?bodies)\n",
" (for-repeat ?exp (lambda () . ?bodies))]\n",
" [(for ?var in ?exp do . ?bodies)\n",
" (for-iterate1 ?exp (lambda (?var) . ?bodies))]\n",
" [(for ?var at (?i) in ?exp do . ?bodies)\n",
" (for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]\n",
" [(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)\n",
" (for ?var at (?i) in ?exp do\n",
" (for ?var at (?j . ?rest) in ?var do . ?bodies))])\n",
"\n",
"(define for-repeat\n",
" (lambda (n f)\n",
" (if (< n 1)\n",
" 'done\n",
" (begin\n",
" (f)\n",
" (for-repeat (- n 1) f)))))\n",
"\n",
"(define for-iterate1\n",
" (lambda (values f)\n",
" (if (null? values)\n",
" 'done\n",
" (begin\n",
" (f (car values))\n",
" (for-iterate1 (cdr values) f)))))\n",
"\n",
"(define for-iterate2\n",
" (lambda (i values f)\n",
" (if (null? values)\n",
" 'done\n",
" (begin\n",
" (f (car values) i)\n",
" (for-iterate2 (+ i 1) (cdr values) f)))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define matrix2d\n",
" '((10 20)\n",
" (30 40)\n",
" (50 60)\n",
" (70 80)))\n",
"\n",
"(define matrix3d\n",
" '(((10 20 30) (40 50 60))\n",
" ((70 80 90) (100 110 120))\n",
" ((130 140 150) (160 170 180))\n",
" ((190 200 210) (220 230 240))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(begin \n",
" (define hello 0)\n",
" (for 5 times do (set! hello (+ hello 1)))\n",
" hello\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for n in (range 10 20 2) do (print n))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for n at (i j) in matrix2d do (print (list n 'coords: i j)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define-syntax scons\n",
" [(scons ?x ?y) (cons ?x (lambda () ?y))])\n",
"\n",
"(define scar car)\n",
"\n",
"(define scdr\n",
" (lambda (s)\n",
" (let ((result ((cdr s))))\n",
" (set-cdr! s (lambda () result))\n",
" result)))\n",
"\n",
"(define first\n",
" (lambda (n s)\n",
" (if (= n 0)\n",
" '()\n",
" (cons (scar s) (first (- n 1) (scdr s))))))\n",
"\n",
"(define nth\n",
" (lambda (n s)\n",
" (if (= n 0)\n",
" (scar s)\n",
" (nth (- n 1) (scdr s)))))\n",
"\n",
"(define smap\n",
" (lambda (f s)\n",
" (scons (f (scar s)) (smap f (scdr s)))))\n",
"\n",
"(define ones (scons 1 ones))\n",
"\n",
"(define nats (scons 0 (combine nats + ones)))\n",
"\n",
"(define combine\n",
" (lambda (s1 op s2)\n",
" (scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))\n",
"\n",
"(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))\n",
"\n",
"(define facts (scons 1 (combine facts * (scdr nats))))\n",
"\n",
"(define ! (lambda (n) (nth n facts)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(! 5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(nth 10 facts)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(nth 20 fibs)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(first 30 fibs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## for-each\n",
"(for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for-each (lambda (n) (print n)) '(3 4 5))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## format\n",
"(format STRING ITEM ...): format the string with ITEMS as arguments"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(format \"This uses formatting ~a ~s ~%\" 'apple 'apple)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## func\n",
"\n",
"Turns a lambda into a Python function.\n",
"\n",
"(func (lambda ...))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(func (lambda (n) n))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## There's more!\n",
"\n",
"Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Calysto Scheme (Python)",
"language": "scheme",
"name": "calysto_scheme"
},
"language_info": {
"codemirror_mode": {
"name": "scheme"
},
"mimetype": "text/x-scheme",
"name": "scheme",
"pygments_lexer": "scheme"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_sos/jupytext_replication.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "SoS"
},
"source": [
"# Text SOS-kernel with Jupytext\n",
"\n",
"## What is SOS kernel\n",
"\n",
"SoS consists of a ployglot notebook that allows the use of multiple kernels in one Jupyter notebook, and a workflow system that is designed for daily computational research. Basically,\n",
"\n",
"- SoS Polyglot Notebook is a Jupyter Notebook with a SoS kernel.\n",
"- SoS Notebook serves as a super kernel to all other Jupyter kernels and allows the use of multiple kernels in one Jupyter notebook.\n",
"- SoS Workflow System is a Python based workflow system that is designed to be readable, shareable, and suitable for daily data analysis.\n",
"- SoS Workflow System can be used from command line or use SoS Notebook as its IDE.\n",
"\n",
"\n",
"\n",
"### How to install SOS-kernel\n",
"\n",
"Please follow this [link](https://vatlab.github.io/sos-docs/running.html#Conda-installation) to setup SOS\n",
"\n",
"I run some issue with the latest version of R on my Mac, so I had to install an earlier version of R\n",
"\n",
"```\n",
"conda install -c r r=3.5.1\n",
"conda install sos-notebook jupyterlab-sos sos-papermill -c conda-forge\n",
"```\n",
"\n",
"## Related issue with Jupytext\n",
"\n",
"Jupytext works fine with Python/R kernel but converts code cells into markdown cells when using the SOS kernel.\n",
"\n",
"cf the image below. It is a code cell. After saving the notebook and restart it, it converted the code cell into markdown\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "SoS"
},
"source": [
"## Step 1\n",
"\n",
"Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"Collapsed": "false",
"kernel": "SoS"
},
"outputs": [],
"source": [
"import pandas as pd \n",
"import numpy as np\n",
"\n",
"pd.DataFrame({\n",
" 'x': np.random.random(10),\n",
" 'y': np.random.random(10),\n",
"})"
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "python3"
},
"source": [
"## Step 2\n",
"\n",
"Now, pair it with Jupytex\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "python3"
},
"source": [
"### Step 3\n",
"\n",
"Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen"
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "python3"
},
"source": [
"### Step 4\n",
"\n",
"Reopen the notebook. Here is the outcome\n",
"\n",
"\n",
"\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "SoS",
"language": "sos",
"name": "sos"
},
"language_info": {
"codemirror_mode": "sos",
"file_extension": ".sos",
"mimetype": "text/x-sos",
"name": "sos",
"nbconvert_exporter": "sos_notebook.converter.SoS_Exporter",
"pygments_lexer": "sos"
},
"sos": {
"kernels": [
[
"python3",
"python3",
"python3",
"",
""
]
],
"version": "0.20.6"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_stata/stata_notebook.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"id": "a4033377",
"metadata": {},
"outputs": [],
"source": [
"// This notebook uses the stata_kernel: https://github.com/kylebarron/stata_kernel"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "5f4a41aa-92fb-4344-accf-fca4df13d0b1",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(1978 Automobile Data)\n"
]
}
],
"source": [
"use http://www.stata-press.com/data/r13/auto"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "3f8bc0a3-2e04-4025-97b6-fe07b341d359",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
" Variable | Obs Mean Std. dev. Min Max\n",
"-------------+---------------------------------------------------------\n",
" make | 0\n",
" price | 74 6165.257 2949.496 3291 15906\n",
" mpg | 74 21.2973 5.785503 12 41\n",
" rep78 | 69 3.405797 .9899323 1 5\n",
" headroom | 74 2.993243 .8459948 1.5 5\n",
"-------------+---------------------------------------------------------\n",
" trunk | 74 13.75676 4.277404 5 23\n",
" weight | 74 3019.459 777.1936 1760 4840\n",
" length | 74 187.9324 22.26634 142 233\n",
" turn | 74 39.64865 4.399354 31 51\n",
"displacement | 74 197.2973 91.83722 79 425\n",
"-------------+---------------------------------------------------------\n",
" gear_ratio | 74 3.014865 .4562871 2.19 3.89\n",
" foreign | 74 .2972973 .4601885 0 1\n"
]
}
],
"source": [
"summarize"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "ce932414-a959-40e7-ab27-b59f9dc2a5af",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"This front-end cannot display the desired image type."
]
},
"metadata": {
"image/svg+xml": {
"height": 436,
"width": 600
},
"text/html": {
"height": 436,
"width": 600
}
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
" format\n"
]
},
{
"data": {
"text/plain": [
"This front-end cannot display the desired image type."
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
" format\n"
]
}
],
"source": [
"scatter weight length"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Stata",
"language": "stata",
"name": "stata"
},
"language_info": {
"codemirror_mode": "stata",
"file_extension": ".do",
"mimetype": "text/x-stata",
"name": "stata",
"version": "15.1"
},
"widgets": {
"application/vnd.jupyter.widget-state+json": {
"state": {},
"version_major": 2,
"version_minor": 0
}
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_tcl/tcl_test.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Assign Values"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"a = 1\n"
]
}
],
"source": [
"set a 1\n",
"puts \"a = $a\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Loop"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"I inside first loop: 0\n",
"I inside first loop: 1\n",
"I inside first loop: 2\n",
"I inside first loop: 3\n",
"I inside first loop: 4\n",
"I inside first loop: 5\n",
"I inside first loop: 6\n",
"I inside first loop: 7\n",
"I inside first loop: 8\n",
"I inside first loop: 9\n"
]
}
],
"source": [
"for {set i 0} {$i < 10} {incr i} {\n",
" puts \"I inside first loop: $i\"\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Tcl",
"language": "tcl",
"name": "tcljupyter"
},
"language_info": {
"file_extension": ".tcl",
"mimetype": "txt/x-tcl",
"name": "tcl",
"version": "8.6.11"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_ts/itypescript.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"hi\n"
]
},
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 1,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"let x: number = 5;\n",
"const y: number = 6;\n",
"var z: string = \"hi\";\n",
"console.log(z);\n",
"x + y;"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"function add(num1: number, num2: number): number {\n",
" return num1 + num2\n",
"}\n",
"add(x, y);"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"const arrowAdd = (num1: number, num2: number) => num1 + num2;\n",
"arrowAdd(x, y);"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"\"Hello, I'm John\""
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"class User {\n",
" constructor(private name: string) {\n",
" this.name = name;\n",
" }\n",
" sayHello(): string {\n",
" return \"Hello, I'm \" + this.name;\n",
" }\n",
"}\n",
"let John: User;\n",
"John = new User(\"John\");\n",
"John.sayHello();"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Typescript 3.5",
"language": "typescript",
"name": "typescript"
},
"language_info": {
"file_extension": ".ts",
"mimetype": "application/x-typescript",
"name": "typescript",
"version": "3.5.1"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_wolfram/wolfram.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"id": "f48fe6fa",
"metadata": {},
"source": [
"**Note:** The `language_info` `file_extension` in this notebook should be `.m`, but it was deliberately changed to `.wolfram` to avoid conflicts with Matlab which is using the same extension."
]
},
{
"cell_type": "markdown",
"id": "19ffc137",
"metadata": {},
"source": [
"We start with..."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "17c5b20c",
"metadata": {},
"outputs": [],
"source": [
"Print[\"Hello, World!\"];"
]
},
{
"cell_type": "markdown",
"id": "2b9e8c46",
"metadata": {},
"source": [
"Then we draw the first example plot from the [ListPlot](https://reference.wolfram.com/language/ref/ListPlot.html) reference:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "7c4dfdc2",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "SoS"
},
"source": [
"## Step 1\n",
"\n",
"Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"Collapsed": "false",
"kernel": "SoS"
},
"outputs": [],
"source": [
"import pandas as pd \n",
"import numpy as np\n",
"\n",
"pd.DataFrame({\n",
" 'x': np.random.random(10),\n",
" 'y': np.random.random(10),\n",
"})"
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "python3"
},
"source": [
"## Step 2\n",
"\n",
"Now, pair it with Jupytex\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "python3"
},
"source": [
"### Step 3\n",
"\n",
"Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen"
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "python3"
},
"source": [
"### Step 4\n",
"\n",
"Reopen the notebook. Here is the outcome\n",
"\n",
"\n",
"\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "SoS",
"language": "sos",
"name": "sos"
},
"language_info": {
"codemirror_mode": "sos",
"file_extension": ".sos",
"mimetype": "text/x-sos",
"name": "sos",
"nbconvert_exporter": "sos_notebook.converter.SoS_Exporter",
"pygments_lexer": "sos"
},
"sos": {
"kernels": [
[
"python3",
"python3",
"python3",
"",
""
]
],
"version": "0.20.6"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_stata/stata_notebook.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"id": "a4033377",
"metadata": {},
"outputs": [],
"source": [
"// This notebook uses the stata_kernel: https://github.com/kylebarron/stata_kernel"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "5f4a41aa-92fb-4344-accf-fca4df13d0b1",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(1978 Automobile Data)\n"
]
}
],
"source": [
"use http://www.stata-press.com/data/r13/auto"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "3f8bc0a3-2e04-4025-97b6-fe07b341d359",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
" Variable | Obs Mean Std. dev. Min Max\n",
"-------------+---------------------------------------------------------\n",
" make | 0\n",
" price | 74 6165.257 2949.496 3291 15906\n",
" mpg | 74 21.2973 5.785503 12 41\n",
" rep78 | 69 3.405797 .9899323 1 5\n",
" headroom | 74 2.993243 .8459948 1.5 5\n",
"-------------+---------------------------------------------------------\n",
" trunk | 74 13.75676 4.277404 5 23\n",
" weight | 74 3019.459 777.1936 1760 4840\n",
" length | 74 187.9324 22.26634 142 233\n",
" turn | 74 39.64865 4.399354 31 51\n",
"displacement | 74 197.2973 91.83722 79 425\n",
"-------------+---------------------------------------------------------\n",
" gear_ratio | 74 3.014865 .4562871 2.19 3.89\n",
" foreign | 74 .2972973 .4601885 0 1\n"
]
}
],
"source": [
"summarize"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "ce932414-a959-40e7-ab27-b59f9dc2a5af",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"This front-end cannot display the desired image type."
]
},
"metadata": {
"image/svg+xml": {
"height": 436,
"width": 600
},
"text/html": {
"height": 436,
"width": 600
}
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
" format\n"
]
},
{
"data": {
"text/plain": [
"This front-end cannot display the desired image type."
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
" format\n"
]
}
],
"source": [
"scatter weight length"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Stata",
"language": "stata",
"name": "stata"
},
"language_info": {
"codemirror_mode": "stata",
"file_extension": ".do",
"mimetype": "text/x-stata",
"name": "stata",
"version": "15.1"
},
"widgets": {
"application/vnd.jupyter.widget-state+json": {
"state": {},
"version_major": 2,
"version_minor": 0
}
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_tcl/tcl_test.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Assign Values"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"a = 1\n"
]
}
],
"source": [
"set a 1\n",
"puts \"a = $a\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Loop"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"I inside first loop: 0\n",
"I inside first loop: 1\n",
"I inside first loop: 2\n",
"I inside first loop: 3\n",
"I inside first loop: 4\n",
"I inside first loop: 5\n",
"I inside first loop: 6\n",
"I inside first loop: 7\n",
"I inside first loop: 8\n",
"I inside first loop: 9\n"
]
}
],
"source": [
"for {set i 0} {$i < 10} {incr i} {\n",
" puts \"I inside first loop: $i\"\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Tcl",
"language": "tcl",
"name": "tcljupyter"
},
"language_info": {
"file_extension": ".tcl",
"mimetype": "txt/x-tcl",
"name": "tcl",
"version": "8.6.11"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_ts/itypescript.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"hi\n"
]
},
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 1,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"let x: number = 5;\n",
"const y: number = 6;\n",
"var z: string = \"hi\";\n",
"console.log(z);\n",
"x + y;"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"function add(num1: number, num2: number): number {\n",
" return num1 + num2\n",
"}\n",
"add(x, y);"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"const arrowAdd = (num1: number, num2: number) => num1 + num2;\n",
"arrowAdd(x, y);"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"\"Hello, I'm John\""
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"class User {\n",
" constructor(private name: string) {\n",
" this.name = name;\n",
" }\n",
" sayHello(): string {\n",
" return \"Hello, I'm \" + this.name;\n",
" }\n",
"}\n",
"let John: User;\n",
"John = new User(\"John\");\n",
"John.sayHello();"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Typescript 3.5",
"language": "typescript",
"name": "typescript"
},
"language_info": {
"file_extension": ".ts",
"mimetype": "application/x-typescript",
"name": "typescript",
"version": "3.5.1"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_wolfram/wolfram.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"id": "f48fe6fa",
"metadata": {},
"source": [
"**Note:** The `language_info` `file_extension` in this notebook should be `.m`, but it was deliberately changed to `.wolfram` to avoid conflicts with Matlab which is using the same extension."
]
},
{
"cell_type": "markdown",
"id": "19ffc137",
"metadata": {},
"source": [
"We start with..."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "17c5b20c",
"metadata": {},
"outputs": [],
"source": [
"Print[\"Hello, World!\"];"
]
},
{
"cell_type": "markdown",
"id": "2b9e8c46",
"metadata": {},
"source": [
"Then we draw the first example plot from the [ListPlot](https://reference.wolfram.com/language/ref/ListPlot.html) reference:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "7c4dfdc2",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
" "
],
"text/plain": [
"-Graphics-"
]
},
"execution_count": 2,
"metadata": {
"text/html": [],
"text/plain": []
},
"output_type": "execute_result"
}
],
"source": [
"ListPlot[Prime[Range[25]]]"
]
},
{
"cell_type": "markdown",
"id": "0e549b21",
"metadata": {},
"source": [
"We also test the math outputs as in the [Simplify](https://reference.wolfram.com/language/ref/Simplify.html) example:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "5c2010aa",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"
"
],
"text/plain": [
"-Graphics-"
]
},
"execution_count": 2,
"metadata": {
"text/html": [],
"text/plain": []
},
"output_type": "execute_result"
}
],
"source": [
"ListPlot[Prime[Range[25]]]"
]
},
{
"cell_type": "markdown",
"id": "0e549b21",
"metadata": {},
"source": [
"We also test the math outputs as in the [Simplify](https://reference.wolfram.com/language/ref/Simplify.html) example:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "5c2010aa",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
" "
],
"text/plain": [
" 1 -1 + 2 x 2\n",
"--------- - -------------- + -------------------\n",
"3 (1 + x) 2 2\n",
" 6 (1 - x + x ) (-1 + 2 x)\n",
" 3 (1 + -----------)\n",
" 3"
]
},
"execution_count": 3,
"metadata": {
"text/html": [],
"text/plain": []
},
"output_type": "execute_result"
}
],
"source": [
"D[Integrate[1/(x^3 + 1), x], x]"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Wolfram Language 13.1",
"language": "Wolfram Language",
"name": "wolframlanguage13.1"
},
"language_info": {
"codemirror_mode": "mathematica",
"file_extension": ".wolfram",
"mimetype": "application/vnd.wolfram.m",
"name": "Wolfram Language",
"pygments_lexer": "mathematica",
"version": "12.0"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_xonsh/xonsh_example.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"35196\n"
]
}
],
"source": [
"len($(curl -L https://xon.sh))"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"xonsh_example.ipynb\n",
"\n"
]
}
],
"source": [
"for filename in `.*`:\n",
" print(filename)\n",
" du -sh @(filename)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Xonsh",
"language": "xonsh",
"name": "xonsh"
},
"language_info": {
"codemirror_mode": "shell",
"file_extension": ".xsh",
"mimetype": "text/x-sh",
"name": "xonsh",
"pygments_lexer": "xonsh",
"version": "0.14.4"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/julia/julia_sample_script.jl
================================================
# -*- coding: utf-8 -*-
# From https://juliabyexample.helpmanual.io/
# function to calculate the volume of a sphere
function sphere_vol(r)
# julia allows Unicode names (in UTF-8 encoding)
# so either "pi" or the symbol π can be used
return 4/3*pi*r^3
end
# functions can also be defined more succinctly
quadratic(a, sqr_term, b) = (-b + sqr_term) / 2a
# calculates x for 0 = a*x^2+b*x+c, arguments types can be defined in function definitions
function quadratic2(a::Float64, b::Float64, c::Float64)
# unlike other languages 2a is equivalent to 2*a
# a^2 is used instead of a**2 or pow(a,2)
sqr_term = sqrt(b^2-4a*c)
r1 = quadratic(a, sqr_term, b)
r2 = quadratic(a, -sqr_term, b)
# multiple values can be returned from a function using tuples
# if the return keyword is omitted, the last term is returned
r1, r2
end
vol = sphere_vol(3)
# @printf allows number formatting but does not automatically append the \n to statements, see below
@printf "volume = %0.3f\n" vol
#> volume = 113.097
quad1, quad2 = quadratic2(2.0, -2.0, -12.0)
println("result 1: ", quad1)
#> result 1: 3.0
println("result 2: ", quad2)
#> result 2: -2.0
================================================
FILE: tests/data/notebooks/inputs/marimo/basic_marimo_example.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
This is a simple marimo notebook
""")
return
@app.cell
def _():
x = 1
return (x,)
@app.cell
def _(x):
y = x+1
y
return
@app.cell
def _():
import marimo as mo
return (mo,)
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/inputs/md/jupytext_markdown.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
# Markdown, code and raw cells
## Markdown cells
This is a Markdown cell. Markdown cells end with either a code cell, or two consecutive blank lines in the text.
If you prefer that Markdown headings define new cells, have a look at the `split_at_heading` option.
Indented code is accepted, and consecutive blank lines there do not break Markdown cells:
def f(x):
return 1
def h(x):
return f(x)+2
## Code cells
```python
"""This code cell starts with ` ```python`"""
1 + 1
```
## Raw cells
Raw cells are delimited with `` and , like here:
this is a raw cell
# Protected Markdown cells
If you want to include code blocks (or two consecutive blank lines) in a Markdown cell, use explicit Markdown cell delimiters `` and ``.
This Markdown cell has two consecutive blank lines
And then a code block which is not a Jupyter code cell:
```python
2 + 2
```
# Metadata
Metadata are supported for all cell types.
## Markdown cells
A cell with a title and additional metadata.
## Code cells
```python tags=["parameters"]
a = 2
```
================================================
FILE: tests/data/notebooks/inputs/md/plain_markdown.md
================================================
---
title: A sample document
---
This document is a plain Markdown document that was not created from a notebook.
We use this document to test that inputing a Markdown file into Jupytext, and then converting the
resulting notebook to a Markdown file using nbconvert, is the identity
Another paragraph
# A header
Indented code
def f(x):
return 1
def h(x):
return f(x)+2
A Python code snippet
```python
"""This code cell starts with ` ```python`"""
1 + 1
```
Code snippet without an explicit language
```
echo 'Hello world'
```
Markdown comments
VS Code region markers
This Markdown cell has two consecutive blank lines
And continues here
================================================
FILE: tests/data/notebooks/inputs/myst/fenced_code_vs_code_cells.md
================================================
# Fenced code
## No language
```
# a generic code instruction
1 + 1
```
## Python
```python
1 + 1
```
## Bash
```python
echo Hi
```
# Code cells
```{code-cell} ipython3
# This code gets executed in notebooks
1 + 1
```
================================================
FILE: tests/data/notebooks/inputs/myst/reference_link.md
================================================
This documents contains a code cell to make sure it is recognized as a MyST document.
```{code-cell} ipython3
1 + 1
```
This is a [reference-link to the issue][].
:::{note}
This note is key... not sure why.
:::
[reference-link to the issue]:
"
],
"text/plain": [
" 1 -1 + 2 x 2\n",
"--------- - -------------- + -------------------\n",
"3 (1 + x) 2 2\n",
" 6 (1 - x + x ) (-1 + 2 x)\n",
" 3 (1 + -----------)\n",
" 3"
]
},
"execution_count": 3,
"metadata": {
"text/html": [],
"text/plain": []
},
"output_type": "execute_result"
}
],
"source": [
"D[Integrate[1/(x^3 + 1), x], x]"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Wolfram Language 13.1",
"language": "Wolfram Language",
"name": "wolframlanguage13.1"
},
"language_info": {
"codemirror_mode": "mathematica",
"file_extension": ".wolfram",
"mimetype": "application/vnd.wolfram.m",
"name": "Wolfram Language",
"pygments_lexer": "mathematica",
"version": "12.0"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_xonsh/xonsh_example.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"35196\n"
]
}
],
"source": [
"len($(curl -L https://xon.sh))"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"xonsh_example.ipynb\n",
"\n"
]
}
],
"source": [
"for filename in `.*`:\n",
" print(filename)\n",
" du -sh @(filename)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Xonsh",
"language": "xonsh",
"name": "xonsh"
},
"language_info": {
"codemirror_mode": "shell",
"file_extension": ".xsh",
"mimetype": "text/x-sh",
"name": "xonsh",
"pygments_lexer": "xonsh",
"version": "0.14.4"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/julia/julia_sample_script.jl
================================================
# -*- coding: utf-8 -*-
# From https://juliabyexample.helpmanual.io/
# function to calculate the volume of a sphere
function sphere_vol(r)
# julia allows Unicode names (in UTF-8 encoding)
# so either "pi" or the symbol π can be used
return 4/3*pi*r^3
end
# functions can also be defined more succinctly
quadratic(a, sqr_term, b) = (-b + sqr_term) / 2a
# calculates x for 0 = a*x^2+b*x+c, arguments types can be defined in function definitions
function quadratic2(a::Float64, b::Float64, c::Float64)
# unlike other languages 2a is equivalent to 2*a
# a^2 is used instead of a**2 or pow(a,2)
sqr_term = sqrt(b^2-4a*c)
r1 = quadratic(a, sqr_term, b)
r2 = quadratic(a, -sqr_term, b)
# multiple values can be returned from a function using tuples
# if the return keyword is omitted, the last term is returned
r1, r2
end
vol = sphere_vol(3)
# @printf allows number formatting but does not automatically append the \n to statements, see below
@printf "volume = %0.3f\n" vol
#> volume = 113.097
quad1, quad2 = quadratic2(2.0, -2.0, -12.0)
println("result 1: ", quad1)
#> result 1: 3.0
println("result 2: ", quad2)
#> result 2: -2.0
================================================
FILE: tests/data/notebooks/inputs/marimo/basic_marimo_example.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
This is a simple marimo notebook
""")
return
@app.cell
def _():
x = 1
return (x,)
@app.cell
def _(x):
y = x+1
y
return
@app.cell
def _():
import marimo as mo
return (mo,)
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/inputs/md/jupytext_markdown.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
# Markdown, code and raw cells
## Markdown cells
This is a Markdown cell. Markdown cells end with either a code cell, or two consecutive blank lines in the text.
If you prefer that Markdown headings define new cells, have a look at the `split_at_heading` option.
Indented code is accepted, and consecutive blank lines there do not break Markdown cells:
def f(x):
return 1
def h(x):
return f(x)+2
## Code cells
```python
"""This code cell starts with ` ```python`"""
1 + 1
```
## Raw cells
Raw cells are delimited with `` and , like here:
this is a raw cell
# Protected Markdown cells
If you want to include code blocks (or two consecutive blank lines) in a Markdown cell, use explicit Markdown cell delimiters `` and ``.
This Markdown cell has two consecutive blank lines
And then a code block which is not a Jupyter code cell:
```python
2 + 2
```
# Metadata
Metadata are supported for all cell types.
## Markdown cells
A cell with a title and additional metadata.
## Code cells
```python tags=["parameters"]
a = 2
```
================================================
FILE: tests/data/notebooks/inputs/md/plain_markdown.md
================================================
---
title: A sample document
---
This document is a plain Markdown document that was not created from a notebook.
We use this document to test that inputing a Markdown file into Jupytext, and then converting the
resulting notebook to a Markdown file using nbconvert, is the identity
Another paragraph
# A header
Indented code
def f(x):
return 1
def h(x):
return f(x)+2
A Python code snippet
```python
"""This code cell starts with ` ```python`"""
1 + 1
```
Code snippet without an explicit language
```
echo 'Hello world'
```
Markdown comments
VS Code region markers
This Markdown cell has two consecutive blank lines
And continues here
================================================
FILE: tests/data/notebooks/inputs/myst/fenced_code_vs_code_cells.md
================================================
# Fenced code
## No language
```
# a generic code instruction
1 + 1
```
## Python
```python
1 + 1
```
## Bash
```python
echo Hi
```
# Code cells
```{code-cell} ipython3
# This code gets executed in notebooks
1 + 1
```
================================================
FILE: tests/data/notebooks/inputs/myst/reference_link.md
================================================
This documents contains a code cell to make sure it is recognized as a MyST document.
```{code-cell} ipython3
1 + 1
```
This is a [reference-link to the issue][].
:::{note}
This note is key... not sure why.
:::
[reference-link to the issue]:
================================================
FILE: tests/data/notebooks/inputs/percent/hydrogen.py
================================================
# %%
import pandas as pd
# %% Display a data frame
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
# %% Pandas plot {"tags": ["parameters"]}
df.plot(kind='bar')
================================================
FILE: tests/data/notebooks/inputs/ps1/build.ps1
================================================
# This file originates from
# https://github.com/MicrosoftDocs/PowerShell-Docs/blob/staging/build.ps1
param(
[switch]$SkipCabs,
[switch]$ShowProgress
)
# Turning off the progress display, by default
$global:ProgressPreference = 'SilentlyContinue'
if ($ShowProgress) { $ProgressPreference = 'Continue' }
[Net.ServicePointManager]::SecurityProtocol = [Net.ServicePointManager]::SecurityProtocol -bor [Net.SecurityProtocolType]::Tls12
$tempDir = [System.IO.Path]::GetTempPath()
# Pandoc source URL
$panDocVersion = "2.7.3"
$pandocSourceURL = "https://github.com/jgm/pandoc/releases/download/$panDocVersion/pandoc-$panDocVersion-windows-x86_64.zip"
$pandocDestinationPath = New-Item (Join-Path $tempDir "pandoc") -ItemType Directory -Force
$pandocZipPath = Join-Path $pandocDestinationPath "pandoc-$panDocVersion-windows-x86_64.zip"
Invoke-WebRequest -Uri $pandocSourceURL -OutFile $pandocZipPath
Expand-Archive -Path $pandocZipPath -DestinationPath $pandocDestinationPath -Force
$pandocExePath = Join-Path (Join-Path $pandocDestinationPath "pandoc-$panDocVersion-windows-x86_64") "pandoc.exe"
# Install ThreadJob if not available
$threadJob = Get-Module ThreadJob -ListAvailable
if ($null -eq $threadjob) {
Install-Module ThreadJob -RequiredVersion 1.1.2 -Scope CurrentUser -Force
}
# Find the reference folder path w.r.t the script
$ReferenceDocset = Join-Path $PSScriptRoot 'reference'
# Go through all the directories in the reference folder
$jobs = [System.Collections.Generic.List[object]]::new()
$excludeList = 'module', 'media', 'docs-conceptual', 'mapping', 'bread', '7'
Get-ChildItem $ReferenceDocset -Directory -Exclude $excludeList | ForEach-Object -Process {
$job = Start-ThreadJob -Name $_.Name -ArgumentList @($SkipCabs,$pandocExePath,$PSScriptRoot,$_) -ScriptBlock {
param($SkipCabs, $pandocExePath, $WorkingDirectory, $DocSet)
$tempDir = [System.IO.Path]::GetTempPath()
$workingDir = Join-Path $tempDir $DocSet.Name
$workingDir = New-Item -ItemType Directory -Path $workingDir -Force
Set-Location $WorkingDir
function Get-ContentWithoutHeader {
param(
$path
)
$doc = Get-Content $path -Encoding UTF8
$start = $end = -1
# search the first 30 lines for the Yaml header
# no yaml header in our docset will ever be that long
for ($x = 0; $x -lt 30; $x++) {
if ($doc[$x] -eq '---') {
if ($start -eq -1) {
$start = $x
}
else {
if ($end -eq -1) {
$end = $x + 1
break
}
}
}
}
if ($end -gt $start) {
Write-Output ($doc[$end..$($doc.count)] -join "`r`n")
}
else {
Write-Output ($doc -join "`r`n")
}
}
$Version = $DocSet.Name
Write-Verbose -Verbose "Version = $Version"
$VersionFolder = $DocSet.FullName
Write-Verbose -Verbose "VersionFolder = $VersionFolder"
# For each of the directories, go through each module folder
Get-ChildItem $VersionFolder -Directory | ForEach-Object -Process {
$ModuleName = $_.Name
Write-Verbose -Verbose "ModuleName = $ModuleName"
$ModulePath = Join-Path $VersionFolder $ModuleName
Write-Verbose -Verbose "ModulePath = $ModulePath"
$LandingPage = Join-Path $ModulePath "$ModuleName.md"
Write-Verbose -Verbose "LandingPage = $LandingPage"
$MamlOutputFolder = Join-Path "$WorkingDirectory\maml" "$Version\$ModuleName"
Write-Verbose -Verbose "MamlOutputFolder = $MamlOutputFolder"
$CabOutputFolder = Join-Path "$WorkingDirectory\updatablehelp" "$Version\$ModuleName"
Write-Verbose -Verbose "CabOutputFolder = $CabOutputFolder"
if (-not (Test-Path $MamlOutputFolder)) {
New-Item $MamlOutputFolder -ItemType Directory -Force > $null
}
# Process the about topics if any
$AboutFolder = Join-Path $ModulePath "About"
if (Test-Path $AboutFolder) {
Write-Verbose -Verbose "AboutFolder = $AboutFolder"
Get-ChildItem "$aboutfolder/about_*.md" | ForEach-Object {
$aboutFileFullName = $_.FullName
$aboutFileOutputName = "$($_.BaseName).help.txt"
$aboutFileOutputFullName = Join-Path $MamlOutputFolder $aboutFileOutputName
$pandocArgs = @(
"--from=gfm",
"--to=plain+multiline_tables",
"--columns=75",
"--output=$aboutFileOutputFullName",
"--quiet"
)
Get-ContentWithoutHeader $aboutFileFullName | & $pandocExePath $pandocArgs
}
}
try {
# For each module, create a single maml help file
# Adding warningaction=stop to throw errors for all warnings, erroraction=stop to make them terminating errors
New-ExternalHelp -Path $ModulePath -OutputPath $MamlOutputFolder -Force -WarningAction Stop -ErrorAction Stop
# For each module, create update-help help files (cab and helpinfo.xml files)
if (-not $SkipCabs) {
$cabInfo = New-ExternalHelpCab -CabFilesFolder $MamlOutputFolder -LandingPagePath $LandingPage -OutputFolder $CabOutputFolder
# Only output the cab fileinfo object
if ($cabInfo.Count -eq 8) { $cabInfo[-1].FullName }
}
}
catch {
Write-Error -Message "PlatyPS failure: $ModuleName -- $Version" -Exception $_
}
}
Remove-Item $workingDir -Force -ErrorAction SilentlyContinue
}
Write-Verbose -Verbose "Started job for $($_.Name)"
$jobs += $job
}
$null = $jobs | Wait-Job
# Variable to collect any errors in during processing
$allErrors = [System.Collections.Generic.List[string]]::new()
foreach ($job in $jobs) {
Write-Verbose -Verbose "$($job.Name) output:"
if ($job.Verbose.Count -gt 0) {
foreach ($verboseMessage in $job.Verbose) {
Write-Verbose -Verbose $verboseMessage
}
}
if ($job.State -eq "Failed") {
$allErrors += "$($job.Name) failed due to unhandled exception"
}
if ($job.Error.Count -gt 0) {
$allErrors += "$($job.Name) failed with errors:"
$allErrors += $job.Error.ReadAll()
}
}
# If the above block, produced any errors, throw and fail the job
if ($allErrors.Count -gt 0) {
$allErrors
throw "There are errors during platyPS run!`nPlease fix your markdown to comply with the schema: https://github.com/PowerShell/platyPS/blob/master/platyPS.schema.md"
}
================================================
FILE: tests/data/notebooks/inputs/python/light_sample.py
================================================
# ---
# jupyter:
# jupytext:
# formats: ipynb,py:light
# ---
# # Sample notebook
a = 1
b = 2
a + b
================================================
FILE: tests/data/notebooks/inputs/python/python_notebook_sample.py
================================================
# # Specifications for Jupyter notebooks as python scripts
# ## Markdown cells
# Markdown cells are escaped with a single quote. Two consecutive
# cells are separated with a blank line.
# ## Code cells
# Python code and adjacent comments are mapped to cell codes.
# For instance, this is a code cell that starts with a
# code comment, where we define a variable
a = 1
# A cell with another variable
b = 2
# In this cell we define a function
def f(x):
return x + 1
# Now simple function calls
c = f(b)
a * b + c
# Line breaks in code cells are supported but then the cell need to have
# metadata and an end-of-cell marker. Metadata information in json format,
# escaped with '#+' or '# +'
# +
def g(x):
return x + 2
d = 4
# -
# One more cell
a * b + g(c) + d
# ## Raw cells, and cells active in py or ipynb only
# Raw cells are commented code cells with metadata "active": "".
# + {"active": ""}
# This is a raw cell
# -
# Actually, using the "active" key you can have cells active in Jupyter
# and inactive in python scripts
# + {"active": "py"}
1 + 1 # done only in py script, inactive (raw) in ipynb
# + {"active": "ipynb"}
# 2 + 2 # active in ipynb only
================================================
FILE: tests/data/notebooks/inputs/sphinx/plot_notebook.py
================================================
# -*- coding: utf-8 -*-
"""
Notebook styled examples
========================
The gallery is capable of transforming Python files into reStructuredText files
with a notebook structure. For this to be used you need to respect some syntax
rules.
It makes a lot of sense to contrast this output rst file with the
:download:`original Python script ` to get better feeling of
the necessary file structure.
Anything before the Python script docstring is ignored by sphinx-gallery and
will not appear in the rst file, nor will it be executed.
This Python docstring requires an reStructuredText title to name the file and
correctly build the reference links.
Once you close the docstring you would be writing Python code. This code gets
executed by sphinx gallery shows the plots and attaches the generating code.
Nevertheless you can break your code into blocks and give the rendered file
a notebook style. In this case you have to include a code comment breaker
a line of at least 20 hashes and then every comment start with the a new hash.
As in this example we start by first writing this module
style docstring, then for the first code block we write the example file author
and script license continued by the import modules instructions.
Original script from:
https://sphinx-gallery.readthedocs.io/en/latest/tutorials/plot_notebook.html
"""
# Code source: Óscar Nájera
# License: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
##############################################################################
# This code block is executed, although it produces no output. Lines starting
# with a simple hash are code comment and get treated as part of the code
# block. To include this new comment string we started the new block with a
# long line of hashes.
#
# The sphinx-gallery parser will assume everything after this splitter and that
# continues to start with a **comment hash and space** (respecting code style)
# is text that has to be rendered in
# html format. Keep in mind to always keep your comments always together by
# comment hashes. That means to break a paragraph you still need to comment
# that line break.
#
# In this example the next block of code produces some plotable data. Code is
# executed, figure is saved and then code is presented next, followed by the
# inlined figure.
x = np.linspace(-np.pi, np.pi, 300)
xx, yy = np.meshgrid(x, x)
z = np.cos(xx) + np.cos(yy)
plt.figure()
plt.imshow(z)
plt.colorbar()
plt.xlabel('$x$')
plt.ylabel('$y$')
###########################################################################
# Again it is possible to continue the discussion with a new Python string. This
# time to introduce the next code block generates 2 separate figures.
plt.figure()
plt.imshow(z, cmap=plt.cm.get_cmap('hot'))
plt.figure()
plt.imshow(z, cmap=plt.cm.get_cmap('Spectral'), interpolation='none')
##########################################################################
# There's some subtle differences between rendered html rendered comment
# strings and code comment strings which I'll demonstrate below. (Some of this
# only makes sense if you look at the
# :download:`raw Python script `)
#
# Comments in comment blocks remain nested in the text.
def dummy():
"""Dummy function to make sure docstrings don't get rendered as text"""
pass
# Code comments not preceded by the hash splitter are left in code blocks.
string = """
Triple-quoted string which tries to break parser but doesn't.
"""
############################################################################
# Output of the script is captured:
print('Some output from Python')
############################################################################
# Finally, I'll call ``show`` at the end just so someone running the Python
# code directly will see the plots; this is not necessary for creating the docs
plt.show()
############################################################################
# You can also include :math:`math` inline, or as separate equations:
#
# .. math::
#
# \exp(j\pi) = -1
#
# You can also insert images:
#
# .. image:: http://www.sphinx-doc.org/en/stable/_static/sphinxheader.png
# :alt: Sphinx header
#
================================================
FILE: tests/data/notebooks/outputs/Rmd_to_ipynb/R_sample.ipynb
================================================
{
"cells": [
{
"cell_type": "raw",
"metadata": {},
"source": [
"---\n",
"title: \"R Notebook\"\n",
"output: html_notebook\n",
"---"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This is an [R Markdown](http://rmarkdown.rstudio.com) Notebook. When you execute code within the notebook, the results appear beneath the code. \n",
"\n",
"Try executing this chunk by clicking the *Run* button within the chunk or by placing your cursor inside it and pressing *Ctrl+Shift+Enter*. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"plot(cars)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Add a new chunk by clicking the *Insert Chunk* button on the toolbar or by pressing *Ctrl+Alt+I*.\n",
"\n",
"When you save the notebook, an HTML file containing the code and output will be saved alongside it (click the *Preview* button or press *Ctrl+Shift+K* to preview the HTML file).\n",
"\n",
"The preview shows you a rendered HTML copy of the contents of the editor. Consequently, unlike *Knit*, *Preview* does not run any R code chunks. Instead, the output of the chunk when it was last run in the editor is displayed."
]
}
],
"metadata": {
"jupytext": {
"cell_metadata_filter": "-all",
"main_language": "R",
"notebook_metadata_filter": "-all"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/outputs/Rmd_to_ipynb/chunk_options.ipynb
================================================
{
"cells": [
{
"cell_type": "raw",
"metadata": {},
"source": [
"---\n",
"title: \"Test chunk options in Rmd/Jupyter conversion\"\n",
"author: \"Marc Wouts\"\n",
"date: \"June 16, 2018\"\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"lines_to_next_cell": 2,
"name": "knitr_setup",
"tags": [
"remove_cell"
]
},
"outputs": [],
"source": [
"%%R\n",
"knitr::opts_chunk$set(echo = FALSE, fig.width = 10, fig.height = 5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"echo": true
},
"outputs": [],
"source": [
"import pandas as pd\n",
"x = pd.Series({'A':1, 'B':3, 'C':2})"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"fig.height": 5,
"fig.width": 8,
"lines_to_next_cell": 0,
"name": "bar_plot",
"tags": [
"remove_input"
]
},
"outputs": [],
"source": [
"x.plot(kind='bar', title='Sample plot')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/outputs/Rmd_to_ipynb/ioslides.ipynb
================================================
{
"cells": [
{
"cell_type": "raw",
"metadata": {},
"source": [
"---\n",
"title: \"Quick ioslides\"\n",
"subtitle: \"Slides generated using R, python and ioslides\"\n",
"author: \"Marc Wouts\"\n",
"date: \"June 15, 2018\"\n",
"output:\n",
" ioslides_presentation:\n",
" widescreen: true\n",
" smaller: true\n",
"editor_options:\n",
" chunk_output_type: console\n",
"---"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## What is ioslides?\n",
"\n",
"This is the default format in rstudio for building interactive HTML presentations.\n",
"\n",
"Enjoy the [manual](https://rmarkdown.rstudio.com/ioslides_presentation_format.html)!\n",
"\n",
"These slides can be turned to a single HTML file with either a click on 'knitr' in rstudio, or, command line:\n",
"```bash\n",
"R -e 'rmarkdown::render(\"ioslides.Rmd\")'\n",
"```\n",
"\n",
"## A sample plot\n",
"\n",
"
| \");\n", " html.push_str(&format!(\"{:?}\", self.values[r * self.row_size + c]));\n", " html.push_str(\" | \");\n", " }\n", " html.push_str(\"
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
| Variable | Type |
|---|---|
| counter | std::sync::Arc<std::sync::Mutex<i32>> |
| message | String |
| m | user_code_13::Matrix<i32> |
| values | std::vec::Vec<i32> |
Reference Guide for Calysto Scheme
\n", "\n", "[Calysto Scheme](https://github.com/Calysto/calysto_scheme) is a real Scheme programming language, with full support for continuations, including call/cc. It can also use all Python libraries. Also has some extensions that make it more useful (stepper-debugger, choose/fail, stack traces), or make it better integrated with Python.\n", "\n", "In Jupyter notebooks, because Calysto Scheme uses [MetaKernel](https://github.com/Calysto/metakernel/blob/master/README.rst), it has a fully-supported set of \"magics\"---meta-commands for additional functionality. This includes running Scheme in parallel. See all of the [MetaKernel Magics](https://github.com/Calysto/metakernel/blob/master/metakernel/magics/README.md).\n", "\n", "Calysto Scheme is written in Scheme, and then translated into Python (and other backends). The entire functionality lies in a single Python file: https://github.com/Calysto/calysto_scheme/blob/master/calysto_scheme/scheme.py However, you can easily install it (see below).\n", "\n", "Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.\n", "\n", "## Installation\n", "\n", "You can install Calysto Scheme with Python3:\n", "\n", "```\n", "pip3 install --upgrade calysto-scheme --user -U\n", "python3 -m calysto_kernel install --user\n", "```\n", "\n", "or in the system kernel folder with:\n", "\n", "```\n", "sudo pip3 install --upgrade calysto-scheme -U\n", "sudo python3 -m calysto_kernel install\n", "```\n", "\n", "Change pip3/python3 to use a different pip or Python. The version of Python used will determine how Calysto Scheme is run.\n", "\n", "Use it in the console, qtconsole, or notebook with IPython 3:\n", "\n", "```\n", "ipython console --kernel calysto_scheme\n", "ipython qtconsole --kernel calysto_scheme\n", "ipython notebook --kernel calysto_scheme\n", "```\n", "\n", "In addition to all of the following items, Calysto Scheme also has access to all of Python's builtin functions, and all of Python's libraries. For example, you can use `(complex 3 2)` to create a complex number by calling Python's complex function.\n", "\n", "## Jupyter Enhancements\n", "\n", "When you run Calysto Scheme in Jupyter (console, notebook, qtconsole, etc.) you get:\n", "\n", "* TAB completions of Scheme functions and variable names\n", "* display of rich media\n", "* stepper/debugger\n", "* magics (% macros)\n", "* shell commands (! command)\n", "* LaTeX equations\n", "* LaTeX-style variables\n", "* Python integration" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### LaTeX-style variables\n", "\n", "Calysto Scheme allows you to use LaTeX-style variables in code. For example, if you type:\n", "\n", "```\n", "\\beta\n", "```\n", "\n", "with the cursor right after the 'a' in beta, and then press TAB, it will turn into the unicode character:\n", "\n", "```\n", "β\n", "```\n", "\n", "There are nearly 1300 different symbols defined (thanks to the Julia language) and documented here:\n", "\n", "http://docs.julialang.org/en/release-0.4/manual/unicode-input/#man-unicode-input\n", "\n", "Calysto Scheme may not implement all of those. Some useful and suggestive ones:\n", "\n", "* \\pi - π\n", "* \\Pi - Π\n", "* \\Sigma - Σ\n", "* \\_i - subscript i, such as vectorᵢ" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "(define α 67)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "α" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "(define i 2)\n", "(define vectorᵢ (vector-ref (vector 0 6 3 2) i))\n", "vectorᵢ" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Rich media" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "(import \"calysto.display\")" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "(calysto.display.HTML \"This is bold, italics, underlined.\")" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "(import \"calysto.graphics\")" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "(define canvas (calysto.graphics.Canvas))" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "(define ball (calysto.graphics.Circle '(150 150) 100))" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "(ball.draw canvas)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Shell commands" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "! ls /tmp" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Stepper/Debugger\n", "\n", "Here is what the debugger looks like:\n", "\n", "\n",
"\n",
"It has breakpoints (click in left margin). You must press Stop to exit the debugger."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"```scheme\n",
"%%debug\n",
"\n",
"(begin\n",
" (define x 1)\n",
" (set! x 2)\n",
")\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Python Integration\n",
"\n",
"You can import and use any Python library in Calysto Scheme.\n",
"\n",
"In addition, if you wish, you can execute expressions and statements in a Python environment:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(python-eval \"1 + 2\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(python-exec \n",
"\"\n",
"def mypyfunc(a, b):\n",
" return a * b\n",
"\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This is a shared environment with Scheme:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(mypyfunc 4 5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define! mypyfunc2 (func (lambda (n) n)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(python-eval \"mypyfunc2(34)\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Differences Between Languages\n",
"\n",
"## Major differences between Scheme and Python\n",
"\n",
"1. In Scheme, double quotes are used for strings and may contain newlines\n",
"1. In Scheme, a single quote is short for (quote ...) and means \"literal\"\n",
"1. In Scheme, everything is an expression and has a return value\n",
"1. Python does not support macros (e.g., extending syntax)\n",
"1. In Python, \"if X\" is false if X is None, False, [], (,) or 0. In Scheme, \"if X\" is only false if X is #f or 0\n",
"1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)\n",
"1. Scheme procedures are not Python functions, but there are means to use one as the other.\n",
"\n",
"## Major Differences Between Calysto Scheme and other Schemes\n",
"\n",
"1. define-syntax works slightly differently\n",
"1. In Calysto Scheme, #(...) is short for '#(...)\n",
"1. Calysto Scheme is missing many standard functions (see list at bottom)\n",
"1. Calysto Scheme has a built-in amb operator called `choose`\n",
"1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)\n",
"\n",
"### Stack Trace\n",
"\n",
"Calysto Scheme acts as if it has a call stack, for easier debugging. For example:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define fact\n",
" (lambda (n)\n",
" (if (= n 1)\n",
" q\n",
" (* n (fact (- n 1))))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(fact 5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To turn off the stack trace on error:\n",
"\n",
"```scheme\n",
"(use-stack-trace #f)\n",
"```\n",
"That will allow infinite recursive loops without keeping track of the \"stack\"."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Calysto Scheme Variables\n",
"\n",
"## SCHEMEPATH\n",
"SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"SCHEMEPATH"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(set-cdr! (cdr SCHEMEPATH) (list \"/var/modules\"))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"SCHEMEPATH"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Getting Started\n",
"\n",
"Note that you can use the word `lambda` or \\lambda and then press [TAB]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define factorial\n",
" (λ (n)\n",
" (cond\n",
" ((zero? n) 1)\n",
" (else (* n (factorial (- n 1)))))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(factorial 5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## define-syntax\n",
"(define-syntax NAME RULES): a method for creating macros"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define-syntax time \n",
" [(time ?exp) (let ((start (current-time)))\n",
" ?exp\n",
" (- (current-time) start))])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(time (car '(1 2 3 4)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
";;---------------------------------------------------------------------\n",
";; collect is like list comprehension in Python\n",
"\n",
"(define-syntax collect\n",
" [(collect ?exp for ?var in ?list)\n",
" (filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]\n",
" [(collect ?exp for ?var in ?list if ?condition)\n",
" (filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])\n",
"\n",
"(define filter-map\n",
" (lambda (f pred? values)\n",
" (if (null? values)\n",
" '()\n",
" (if (pred? (car values))\n",
" (cons (f (car values)) (filter-map f pred? (cdr values)))\n",
" (filter-map f pred? (cdr values))))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(collect (* n n) for n in (range 10))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(collect (* n n) for n in (range 5 20 3))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(collect (* n n) for n in (range 10) if (> n 5))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
";;---------------------------------------------------------------------\n",
";; for loops\n",
"\n",
"(define-syntax for\n",
" [(for ?exp times do . ?bodies)\n",
" (for-repeat ?exp (lambda () . ?bodies))]\n",
" [(for ?var in ?exp do . ?bodies)\n",
" (for-iterate1 ?exp (lambda (?var) . ?bodies))]\n",
" [(for ?var at (?i) in ?exp do . ?bodies)\n",
" (for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]\n",
" [(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)\n",
" (for ?var at (?i) in ?exp do\n",
" (for ?var at (?j . ?rest) in ?var do . ?bodies))])\n",
"\n",
"(define for-repeat\n",
" (lambda (n f)\n",
" (if (< n 1)\n",
" 'done\n",
" (begin\n",
" (f)\n",
" (for-repeat (- n 1) f)))))\n",
"\n",
"(define for-iterate1\n",
" (lambda (values f)\n",
" (if (null? values)\n",
" 'done\n",
" (begin\n",
" (f (car values))\n",
" (for-iterate1 (cdr values) f)))))\n",
"\n",
"(define for-iterate2\n",
" (lambda (i values f)\n",
" (if (null? values)\n",
" 'done\n",
" (begin\n",
" (f (car values) i)\n",
" (for-iterate2 (+ i 1) (cdr values) f)))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define matrix2d\n",
" '((10 20)\n",
" (30 40)\n",
" (50 60)\n",
" (70 80)))\n",
"\n",
"(define matrix3d\n",
" '(((10 20 30) (40 50 60))\n",
" ((70 80 90) (100 110 120))\n",
" ((130 140 150) (160 170 180))\n",
" ((190 200 210) (220 230 240))))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(begin \n",
" (define hello 0)\n",
" (for 5 times do (set! hello (+ hello 1)))\n",
" hello\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for n in (range 10 20 2) do (print n))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for n at (i j) in matrix2d do (print (list n 'coords: i j)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(define-syntax scons\n",
" [(scons ?x ?y) (cons ?x (lambda () ?y))])\n",
"\n",
"(define scar car)\n",
"\n",
"(define scdr\n",
" (lambda (s)\n",
" (let ((result ((cdr s))))\n",
" (set-cdr! s (lambda () result))\n",
" result)))\n",
"\n",
"(define first\n",
" (lambda (n s)\n",
" (if (= n 0)\n",
" '()\n",
" (cons (scar s) (first (- n 1) (scdr s))))))\n",
"\n",
"(define nth\n",
" (lambda (n s)\n",
" (if (= n 0)\n",
" (scar s)\n",
" (nth (- n 1) (scdr s)))))\n",
"\n",
"(define smap\n",
" (lambda (f s)\n",
" (scons (f (scar s)) (smap f (scdr s)))))\n",
"\n",
"(define ones (scons 1 ones))\n",
"\n",
"(define nats (scons 0 (combine nats + ones)))\n",
"\n",
"(define combine\n",
" (lambda (s1 op s2)\n",
" (scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))\n",
"\n",
"(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))\n",
"\n",
"(define facts (scons 1 (combine facts * (scdr nats))))\n",
"\n",
"(define ! (lambda (n) (nth n facts)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(! 5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(nth 10 facts)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(nth 20 fibs)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(first 30 fibs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## for-each\n",
"(for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(for-each (lambda (n) (print n)) '(3 4 5))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## format\n",
"(format STRING ITEM ...): format the string with ITEMS as arguments"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(format \"This uses formatting ~a ~s ~%\" 'apple 'apple)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## func\n",
"\n",
"Turns a lambda into a Python function.\n",
"\n",
"(func (lambda ...))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"(func (lambda (n) n))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## There's more!\n",
"\n",
"Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Calysto Scheme (Python)",
"language": "scheme",
"name": "calysto_scheme"
},
"language_info": {
"codemirror_mode": {
"name": "scheme"
},
"mimetype": "text/x-scheme",
"name": "scheme",
"pygments_lexer": "scheme"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_sos/jupytext_replication.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "SoS"
},
"source": [
"# Text SOS-kernel with Jupytext\n",
"\n",
"## What is SOS kernel\n",
"\n",
"SoS consists of a ployglot notebook that allows the use of multiple kernels in one Jupyter notebook, and a workflow system that is designed for daily computational research. Basically,\n",
"\n",
"- SoS Polyglot Notebook is a Jupyter Notebook with a SoS kernel.\n",
"- SoS Notebook serves as a super kernel to all other Jupyter kernels and allows the use of multiple kernels in one Jupyter notebook.\n",
"- SoS Workflow System is a Python based workflow system that is designed to be readable, shareable, and suitable for daily data analysis.\n",
"- SoS Workflow System can be used from command line or use SoS Notebook as its IDE.\n",
"\n",
"\n",
"\n",
"### How to install SOS-kernel\n",
"\n",
"Please follow this [link](https://vatlab.github.io/sos-docs/running.html#Conda-installation) to setup SOS\n",
"\n",
"I run some issue with the latest version of R on my Mac, so I had to install an earlier version of R\n",
"\n",
"```\n",
"conda install -c r r=3.5.1\n",
"conda install sos-notebook jupyterlab-sos sos-papermill -c conda-forge\n",
"```\n",
"\n",
"## Related issue with Jupytext\n",
"\n",
"Jupytext works fine with Python/R kernel but converts code cells into markdown cells when using the SOS kernel.\n",
"\n",
"cf the image below. It is a code cell. After saving the notebook and restart it, it converted the code cell into markdown\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "SoS"
},
"source": [
"## Step 1\n",
"\n",
"Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"Collapsed": "false",
"kernel": "SoS"
},
"outputs": [],
"source": [
"import pandas as pd \n",
"import numpy as np\n",
"\n",
"pd.DataFrame({\n",
" 'x': np.random.random(10),\n",
" 'y': np.random.random(10),\n",
"})"
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "python3"
},
"source": [
"## Step 2\n",
"\n",
"Now, pair it with Jupytex\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "python3"
},
"source": [
"### Step 3\n",
"\n",
"Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen"
]
},
{
"cell_type": "markdown",
"metadata": {
"Collapsed": "false",
"kernel": "python3"
},
"source": [
"### Step 4\n",
"\n",
"Reopen the notebook. Here is the outcome\n",
"\n",
"\n",
"\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "SoS",
"language": "sos",
"name": "sos"
},
"language_info": {
"codemirror_mode": "sos",
"file_extension": ".sos",
"mimetype": "text/x-sos",
"name": "sos",
"nbconvert_exporter": "sos_notebook.converter.SoS_Exporter",
"pygments_lexer": "sos"
},
"sos": {
"kernels": [
[
"python3",
"python3",
"python3",
"",
""
]
],
"version": "0.20.6"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_stata/stata_notebook.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"id": "a4033377",
"metadata": {},
"outputs": [],
"source": [
"// This notebook uses the stata_kernel: https://github.com/kylebarron/stata_kernel"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "5f4a41aa-92fb-4344-accf-fca4df13d0b1",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(1978 Automobile Data)\n"
]
}
],
"source": [
"use http://www.stata-press.com/data/r13/auto"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "3f8bc0a3-2e04-4025-97b6-fe07b341d359",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
" Variable | Obs Mean Std. dev. Min Max\n",
"-------------+---------------------------------------------------------\n",
" make | 0\n",
" price | 74 6165.257 2949.496 3291 15906\n",
" mpg | 74 21.2973 5.785503 12 41\n",
" rep78 | 69 3.405797 .9899323 1 5\n",
" headroom | 74 2.993243 .8459948 1.5 5\n",
"-------------+---------------------------------------------------------\n",
" trunk | 74 13.75676 4.277404 5 23\n",
" weight | 74 3019.459 777.1936 1760 4840\n",
" length | 74 187.9324 22.26634 142 233\n",
" turn | 74 39.64865 4.399354 31 51\n",
"displacement | 74 197.2973 91.83722 79 425\n",
"-------------+---------------------------------------------------------\n",
" gear_ratio | 74 3.014865 .4562871 2.19 3.89\n",
" foreign | 74 .2972973 .4601885 0 1\n"
]
}
],
"source": [
"summarize"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "ce932414-a959-40e7-ab27-b59f9dc2a5af",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"This front-end cannot display the desired image type."
]
},
"metadata": {
"image/svg+xml": {
"height": 436,
"width": 600
},
"text/html": {
"height": 436,
"width": 600
}
},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
" format\n"
]
},
{
"data": {
"text/plain": [
"This front-end cannot display the desired image type."
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
" format\n"
]
}
],
"source": [
"scatter weight length"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Stata",
"language": "stata",
"name": "stata"
},
"language_info": {
"codemirror_mode": "stata",
"file_extension": ".do",
"mimetype": "text/x-stata",
"name": "stata",
"version": "15.1"
},
"widgets": {
"application/vnd.jupyter.widget-state+json": {
"state": {},
"version_major": 2,
"version_minor": 0
}
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_tcl/tcl_test.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Assign Values"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"a = 1\n"
]
}
],
"source": [
"set a 1\n",
"puts \"a = $a\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Loop"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"I inside first loop: 0\n",
"I inside first loop: 1\n",
"I inside first loop: 2\n",
"I inside first loop: 3\n",
"I inside first loop: 4\n",
"I inside first loop: 5\n",
"I inside first loop: 6\n",
"I inside first loop: 7\n",
"I inside first loop: 8\n",
"I inside first loop: 9\n"
]
}
],
"source": [
"for {set i 0} {$i < 10} {incr i} {\n",
" puts \"I inside first loop: $i\"\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Tcl",
"language": "tcl",
"name": "tcljupyter"
},
"language_info": {
"file_extension": ".tcl",
"mimetype": "txt/x-tcl",
"name": "tcl",
"version": "8.6.11"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_ts/itypescript.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"hi\n"
]
},
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 1,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"let x: number = 5;\n",
"const y: number = 6;\n",
"var z: string = \"hi\";\n",
"console.log(z);\n",
"x + y;"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"function add(num1: number, num2: number): number {\n",
" return num1 + num2\n",
"}\n",
"add(x, y);"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"const arrowAdd = (num1: number, num2: number) => num1 + num2;\n",
"arrowAdd(x, y);"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"\"Hello, I'm John\""
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"class User {\n",
" constructor(private name: string) {\n",
" this.name = name;\n",
" }\n",
" sayHello(): string {\n",
" return \"Hello, I'm \" + this.name;\n",
" }\n",
"}\n",
"let John: User;\n",
"John = new User(\"John\");\n",
"John.sayHello();"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Typescript 3.5",
"language": "typescript",
"name": "typescript"
},
"language_info": {
"file_extension": ".ts",
"mimetype": "application/x-typescript",
"name": "typescript",
"version": "3.5.1"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/inputs/ipynb_wolfram/wolfram.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"id": "f48fe6fa",
"metadata": {},
"source": [
"**Note:** The `language_info` `file_extension` in this notebook should be `.m`, but it was deliberately changed to `.wolfram` to avoid conflicts with Matlab which is using the same extension."
]
},
{
"cell_type": "markdown",
"id": "19ffc137",
"metadata": {},
"source": [
"We start with..."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "17c5b20c",
"metadata": {},
"outputs": [],
"source": [
"Print[\"Hello, World!\"];"
]
},
{
"cell_type": "markdown",
"id": "2b9e8c46",
"metadata": {},
"source": [
"Then we draw the first example plot from the [ListPlot](https://reference.wolfram.com/language/ref/ListPlot.html) reference:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "7c4dfdc2",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"Here we create a sample data set for plotting."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"echo": true
},
"outputs": [],
"source": [
"import pandas as pd\n",
"x = pd.Series({'A':1, 'B':3, 'C':2})"
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 0
},
"source": [
"Then, in another column we plot. The R notebook code chunks have many [options](https://yihui.name/knitr/options/).\n",
"For this plot I chose not to display the source code.\n",
"
\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"fig.height": 5,
"fig.width": 8,
"lines_to_next_cell": 0,
"tags": [
"remove_input"
]
},
"outputs": [],
"source": [
"x.plot(kind='bar', title='Sample plot')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
"
]
}
],
"metadata": {
"jupytext": {
"cell_metadata_filter": "echo,tags,fig.width,fig.height,-all",
"main_language": "python",
"notebook_metadata_filter": "-all"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/outputs/Rmd_to_ipynb/knitr-spin.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The below derives from\n",
"https://github.com/yihui/knitr/blob/master/inst/examples/knitr-spin.R\n",
"\n",
"This is a special R script which can be used to generate a report. You can\n",
"write normal text in roxygen comments.\n",
"\n",
"First we set up some options (you do not have to do this):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"name": "setup",
"tags": [
"remove_cell"
]
},
"outputs": [],
"source": [
"library(knitr)\n",
"opts_chunk$set(fig.path = 'figure/silk-')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The report begins here."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cache": false,
"name": "test-a"
},
"outputs": [],
"source": [
"# boring examples as usual\n",
"set.seed(123)\n",
"x = rnorm(5)\n",
"mean(x)"
]
},
{
"cell_type": "markdown",
"metadata": {
"lines_to_next_cell": 0
},
"source": [
"You can not use here the special syntax {{code}} to embed inline expressions, e.g."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"lines_to_next_cell": 0
},
"outputs": [],
"source": [
"{{mean(x) + 2}}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"is the mean of x plus 2.\n",
"The code itself may contain braces, but these are not checked. Thus,\n",
"perfectly valid (though very strange) R code such as `{{2 + 3}} - {{4 - 5}}`\n",
"can lead to errors because `2 + 3}} - {{4 - 5` will be treated as inline code.\n",
"\n",
"Now we continue writing the report. We can draw plots as well."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"fig.height": 5,
"fig.width": 5,
"name": "test-b"
},
"outputs": [],
"source": [
"par(mar = c(4, 4, .1, .1)); plot(x)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Actually you do not have to write chunk options, in which case knitr will use\n",
"default options. For example, the code below has no options attached:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"var(x)\n",
"quantile(x)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And you can also write two chunks successively like this:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"lines_to_next_cell": 0,
"name": "test-chisq5"
},
"outputs": [],
"source": [
"sum(x^2) # chi-square distribution with df 5"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"name": "test-chisq4"
},
"outputs": [],
"source": [
"sum((x - mean(x))^2) # df is 4 now"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Done. Call spin('knitr-spin.R') to make silk from sow's ear now and knit a\n",
"lovely purse."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# /* you can write comments between /* and */ like C comments (the preceding #\n",
"# is optional)\n",
"Sys.sleep(60)\n",
"# */"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# /* there is no inline comment; you have to write block comments */"
]
}
],
"metadata": {
"jupytext": {
"cell_metadata_filter": "tags,name,fig.width,cache,fig.height,-all",
"main_language": "R",
"notebook_metadata_filter": "-all"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/outputs/Rmd_to_ipynb/markdown.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# This is a plain markdown file\n",
"\n",
"```python\n",
"1+1\n",
"```\n",
"\n",
"And more comments\n",
"\n",
"Another comment separated by one line"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This is another cell, separated by two or more lines from the previous one."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And a last markdown cell, followed by a code cell\n",
"```python\n",
"1+1\n",
"```"
]
}
],
"metadata": {
"jupytext": {
"cell_metadata_filter": "-all",
"main_language": "python",
"notebook_metadata_filter": "-all"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/Line_breaks_in_LateX_305.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
This cell uses no particular cell marker
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
This cell uses no particular cell marker, and a single slash in the $\LaTeX$ equation
$$
\begin{align}
\dot{x} & = \sigma(y-x) \
\dot{y} & = \rho x - y - xz \
\dot{z} & = -\beta z + xy
\end{align}
$$
This cell uses the triple quote cell markers introduced at https://github.com/mwouts/jupytext/issues/305
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/Notebook with function and cell metadata 164.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
1 + 1
```
A markdown cell
And below, the cell for function f has non trivial cell metadata. And the next cell as well.
```{python attributes={'classes': [], 'id': '', 'n': '10'}}
def f(x):
return x
```
```{python attributes={'classes': [], 'id': '', 'n': '10'}}
f(5)
```
More text
```{python}
2 + 2
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/Notebook with html and latex cells.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{html}

 It has breakpoints (click in left margin). You must press Stop to exit the debugger.
```scheme
%%debug
(begin
(define x 1)
(set! x 2)
)
```
### Python Integration
You can import and use any Python library in Calysto Scheme.
In addition, if you wish, you can execute expressions and statements in a Python environment:
```{scheme}
(python-eval "1 + 2")
```
```{scheme}
(python-exec
"
def mypyfunc(a, b):
return a * b
")
```
This is a shared environment with Scheme:
```{scheme}
(mypyfunc 4 5)
```
You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
```{scheme}
(define! mypyfunc2 (func (lambda (n) n)))
```
```{scheme}
(python-eval "mypyfunc2(34)")
```
# Differences Between Languages
## Major differences between Scheme and Python
1. In Scheme, double quotes are used for strings and may contain newlines
1. In Scheme, a single quote is short for (quote ...) and means "literal"
1. In Scheme, everything is an expression and has a return value
1. Python does not support macros (e.g., extending syntax)
1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
1. Scheme procedures are not Python functions, but there are means to use one as the other.
## Major Differences Between Calysto Scheme and other Schemes
1. define-syntax works slightly differently
1. In Calysto Scheme, #(...) is short for '#(...)
1. Calysto Scheme is missing many standard functions (see list at bottom)
1. Calysto Scheme has a built-in amb operator called `choose`
1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
### Stack Trace
Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
```{scheme}
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
```
```{scheme}
(fact 5)
```
To turn off the stack trace on error:
```scheme
(use-stack-trace #f)
```
That will allow infinite recursive loops without keeping track of the "stack".
# Calysto Scheme Variables
## SCHEMEPATH
SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
```{scheme}
SCHEMEPATH
```
```{scheme}
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
```
```{scheme}
SCHEMEPATH
```
## Getting Started
Note that you can use the word `lambda` or \lambda and then press [TAB]
```{scheme}
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
```
```{scheme}
(factorial 5)
```
## define-syntax
(define-syntax NAME RULES): a method for creating macros
```{scheme}
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
```
```{scheme}
(time (car '(1 2 3 4)))
```
```{scheme}
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
```
```{scheme}
(collect (* n n) for n in (range 10))
```
```{scheme}
(collect (* n n) for n in (range 5 20 3))
```
```{scheme}
(collect (* n n) for n in (range 10) if (> n 5))
```
```{scheme}
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
```
```{scheme}
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
```
```{scheme}
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
```
```{scheme}
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
```
```{scheme}
(for n in (range 10 20 2) do (print n))
```
```{scheme}
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
```
```{scheme}
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
```
```{scheme}
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
```
```{scheme}
(! 5)
```
```{scheme}
(nth 10 facts)
```
```{scheme}
(nth 20 fibs)
```
```{scheme}
(first 30 fibs)
```
## for-each
(for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
```{scheme}
(for-each (lambda (n) (print n)) '(3 4 5))
```
## format
(format STRING ITEM ...): format the string with ITEMS as arguments
```{scheme}
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
```
## func
Turns a lambda into a Python function.
(func (lambda ...))
```{scheme}
(func (lambda (n) n))
```
## There's more!
Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/The flavors of raw cells.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python raw_mimetype="text/latex", active="", eval=FALSE}
$1+1$
```
```{python raw_mimetype="text/restructuredtext", active="", eval=FALSE}
:math:`1+1`
```
```{python raw_mimetype="text/html", active="", eval=FALSE}
Bold text
```
```{python raw_mimetype="text/markdown", active="", eval=FALSE}
**Bold text**
```
```{python raw_mimetype="text/x-python", active="", eval=FALSE}
1 + 1
```
```{python active="", eval=FALSE}
Not formatted
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/cat_variable.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
cat = 42
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/coconut_homepage_demo.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Coconut
language: coconut
name: coconut
---
Taken from [coconut-lang.org](coconut-lang.org)
pipeline-style programming
```{coconut}
"hello, world!" |> print
```
prettier lambdas
```{coconut}
x -> x ** 2
```
partial application
```{coconut}
range(10) |> map$(pow$(?, 2)) |> list
```
pattern-matching
```{coconut}
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
```
destructuring assignment
```{coconut}
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
```
infix notation
```{coconut}
# 5 `mod` 3 == 2
```
operator functions
```{coconut}
product = reduce$(*)
```
function composition
```{coconut}
# (f..g..h)(x, y, z)
```
lazy lists
```{coconut}
# (| first_elem() |) :: rest_elems()
```
parallel programming
```{coconut}
range(100) |> parallel_map$(pow$(2)) |> list
```
tail call optimization
```{coconut}
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
```
algebraic data types
```{coconut}
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
```
and much more!
Like what you see? Don't forget to star Coconut on GitHub!
```{coconut}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/convert_to_py_then_test_with_update83.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
# %%time
print('asdf')
```
Thanks for jupytext!
```{python}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/csharp.Rmd
================================================
---
jupyter:
kernelspec:
display_name: .NET (C#)
language: C#
name: .net-csharp
---
We start with...
```{csharp}
Console.WriteLine("Hello World!");
```
Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
```{csharp}
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
```
We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
```{csharp}
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
```
```{csharp}
(MathString)@"e^{i \pi} = -1"
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/demo_gdl_fbp.Rmd
================================================
---
jupyter:
kernelspec:
display_name: IDL [conda env:gdl] *
language: IDL
name: conda-env-gdl-idl
---
## GDL demo notebook
Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
```{idl}
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
```
```{idl}
;; Enable inline plotting
!inline=1
```
```{idl}
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
```
Now we define simple forward and backprojection functions:
```{idl}
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
```
```{idl}
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
```
This allows us to create a sinogram:
```{idl}
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
```
On this we can apply a simple FBP reconstruction:
```{idl}
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
```
```{idl}
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
```
### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/evcxr_jupyter_tour.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Rust
language: rust
name: rust
---
# Tour of the EvCxR Jupyter Kernel
For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
## Printing to outputs and evaluating expressions
Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
```{rust}
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
```
## Assigning and making use of variables
We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
```{rust}
let mut message = "Hello ".to_owned();
```
```{rust}
message.push_str("world!");
```
```{rust}
message
```
## Defining and redefining functions
Next we'll define a function
```{rust}
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
```
```{rust}
(1..13).map(fib).collect::
It has breakpoints (click in left margin). You must press Stop to exit the debugger.
```scheme
%%debug
(begin
(define x 1)
(set! x 2)
)
```
### Python Integration
You can import and use any Python library in Calysto Scheme.
In addition, if you wish, you can execute expressions and statements in a Python environment:
```{scheme}
(python-eval "1 + 2")
```
```{scheme}
(python-exec
"
def mypyfunc(a, b):
return a * b
")
```
This is a shared environment with Scheme:
```{scheme}
(mypyfunc 4 5)
```
You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
```{scheme}
(define! mypyfunc2 (func (lambda (n) n)))
```
```{scheme}
(python-eval "mypyfunc2(34)")
```
# Differences Between Languages
## Major differences between Scheme and Python
1. In Scheme, double quotes are used for strings and may contain newlines
1. In Scheme, a single quote is short for (quote ...) and means "literal"
1. In Scheme, everything is an expression and has a return value
1. Python does not support macros (e.g., extending syntax)
1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
1. Scheme procedures are not Python functions, but there are means to use one as the other.
## Major Differences Between Calysto Scheme and other Schemes
1. define-syntax works slightly differently
1. In Calysto Scheme, #(...) is short for '#(...)
1. Calysto Scheme is missing many standard functions (see list at bottom)
1. Calysto Scheme has a built-in amb operator called `choose`
1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
### Stack Trace
Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
```{scheme}
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
```
```{scheme}
(fact 5)
```
To turn off the stack trace on error:
```scheme
(use-stack-trace #f)
```
That will allow infinite recursive loops without keeping track of the "stack".
# Calysto Scheme Variables
## SCHEMEPATH
SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
```{scheme}
SCHEMEPATH
```
```{scheme}
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
```
```{scheme}
SCHEMEPATH
```
## Getting Started
Note that you can use the word `lambda` or \lambda and then press [TAB]
```{scheme}
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
```
```{scheme}
(factorial 5)
```
## define-syntax
(define-syntax NAME RULES): a method for creating macros
```{scheme}
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
```
```{scheme}
(time (car '(1 2 3 4)))
```
```{scheme}
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
```
```{scheme}
(collect (* n n) for n in (range 10))
```
```{scheme}
(collect (* n n) for n in (range 5 20 3))
```
```{scheme}
(collect (* n n) for n in (range 10) if (> n 5))
```
```{scheme}
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
```
```{scheme}
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
```
```{scheme}
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
```
```{scheme}
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
```
```{scheme}
(for n in (range 10 20 2) do (print n))
```
```{scheme}
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
```
```{scheme}
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
```
```{scheme}
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
```
```{scheme}
(! 5)
```
```{scheme}
(nth 10 facts)
```
```{scheme}
(nth 20 fibs)
```
```{scheme}
(first 30 fibs)
```
## for-each
(for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
```{scheme}
(for-each (lambda (n) (print n)) '(3 4 5))
```
## format
(format STRING ITEM ...): format the string with ITEMS as arguments
```{scheme}
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
```
## func
Turns a lambda into a Python function.
(func (lambda ...))
```{scheme}
(func (lambda (n) n))
```
## There's more!
Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/The flavors of raw cells.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python raw_mimetype="text/latex", active="", eval=FALSE}
$1+1$
```
```{python raw_mimetype="text/restructuredtext", active="", eval=FALSE}
:math:`1+1`
```
```{python raw_mimetype="text/html", active="", eval=FALSE}
Bold text
```
```{python raw_mimetype="text/markdown", active="", eval=FALSE}
**Bold text**
```
```{python raw_mimetype="text/x-python", active="", eval=FALSE}
1 + 1
```
```{python active="", eval=FALSE}
Not formatted
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/cat_variable.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
cat = 42
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/coconut_homepage_demo.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Coconut
language: coconut
name: coconut
---
Taken from [coconut-lang.org](coconut-lang.org)
pipeline-style programming
```{coconut}
"hello, world!" |> print
```
prettier lambdas
```{coconut}
x -> x ** 2
```
partial application
```{coconut}
range(10) |> map$(pow$(?, 2)) |> list
```
pattern-matching
```{coconut}
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
```
destructuring assignment
```{coconut}
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
```
infix notation
```{coconut}
# 5 `mod` 3 == 2
```
operator functions
```{coconut}
product = reduce$(*)
```
function composition
```{coconut}
# (f..g..h)(x, y, z)
```
lazy lists
```{coconut}
# (| first_elem() |) :: rest_elems()
```
parallel programming
```{coconut}
range(100) |> parallel_map$(pow$(2)) |> list
```
tail call optimization
```{coconut}
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
```
algebraic data types
```{coconut}
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
```
and much more!
Like what you see? Don't forget to star Coconut on GitHub!
```{coconut}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/convert_to_py_then_test_with_update83.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
# %%time
print('asdf')
```
Thanks for jupytext!
```{python}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/csharp.Rmd
================================================
---
jupyter:
kernelspec:
display_name: .NET (C#)
language: C#
name: .net-csharp
---
We start with...
```{csharp}
Console.WriteLine("Hello World!");
```
Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
```{csharp}
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
```
We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
```{csharp}
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
```
```{csharp}
(MathString)@"e^{i \pi} = -1"
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/demo_gdl_fbp.Rmd
================================================
---
jupyter:
kernelspec:
display_name: IDL [conda env:gdl] *
language: IDL
name: conda-env-gdl-idl
---
## GDL demo notebook
Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
```{idl}
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
```
```{idl}
;; Enable inline plotting
!inline=1
```
```{idl}
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
```
Now we define simple forward and backprojection functions:
```{idl}
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
```
```{idl}
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
```
This allows us to create a sinogram:
```{idl}
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
```
On this we can apply a simple FBP reconstruction:
```{idl}
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
```
```{idl}
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
```
### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/evcxr_jupyter_tour.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Rust
language: rust
name: rust
---
# Tour of the EvCxR Jupyter Kernel
For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
## Printing to outputs and evaluating expressions
Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
```{rust}
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
```
## Assigning and making use of variables
We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
```{rust}
let mut message = "Hello ".to_owned();
```
```{rust}
message.push_str("world!");
```
```{rust}
message
```
## Defining and redefining functions
Next we'll define a function
```{rust}
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
```
```{rust}
(1..13).map(fib).collect::>()
```
Hmm, that doesn't look right. Lets redefine the function. In practice, we'd go back and edit the function above and reevaluate it, but here, lets redefine it in a separate cell.
```{rust}
pub fn fib(x: i32) -> i32 {
if x <= 2 {2} else {fib(x - 2) + fib(x - 1)}
}
```
```{rust}
let values = (1..13).map(fib).collect::>();
values
```
## Spawning a separate thread and communicating with it
We can spawn a thread to do stuff in the background, then continue executing code in other cells.
```{rust}
use std::sync::{Mutex, Arc};
let counter = Arc::new(Mutex::new(0i32));
std::thread::spawn({
let counter = Arc::clone(&counter);
move || {
for i in 1..300 {
*counter.lock().unwrap() += 1;
std::thread::sleep(std::time::Duration::from_millis(100));
}
}});
```
```{rust}
*counter.lock().unwrap()
```
```{rust}
*counter.lock().unwrap()
```
## Loading external crates
We can load external crates. This one takes a while to compile, but once it's compiled, subsequent cells shouldn't need to recompile it, so it should be much quicker.
```{rust}
// :dep base64 = "0.10.1"
base64::encode(&vec![1, 2, 3, 4])
```
## Customizing how types are displayed
We can also customize how our types are displayed, including presenting them as HTML. Here's an example where we define a custom display function for a type `Matrix`.
```{rust}
use std::fmt::Debug;
pub struct Matrix {pub values: Vec, pub row_size: usize}
impl Matrix {
pub fn evcxr_display(&self) {
let mut html = String::new();
html.push_str("");
for r in 0..(self.values.len() / self.row_size) {
html.push_str("
");
println!("EVCXR_BEGIN_CONTENT text/html\n{}\nEVCXR_END_CONTENT", html);
}
}
```
```{rust}
let m = Matrix {values: vec![1,2,3,4,5,6,7,8,9], row_size: 3};
m
```
We can also return images, we just need to base64 encode them. First, we set up code for displaying RGB and grayscale images.
```{rust}
extern crate image;
extern crate base64;
pub trait EvcxrResult {fn evcxr_display(&self);}
impl EvcxrResult for image::RgbImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::RGB(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
impl EvcxrResult for image::GrayImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::Gray(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
```
```{rust}
image::ImageBuffer::from_fn(256, 256, |x, y| {
if (x as i32 - y as i32).abs() < 3 {
image::Rgb([0, 0, 255])
} else {
image::Rgb([0, 0, 0])
}
})
```
## Display of compilation errors
Here's how compilation errors are presented. Here we forgot an & and passed a String instead of an &str.
```{rust}
let mut s = String::new();
s.push_str(format!("foo {}", 42));
```
## Seeing what variables have been defined
We can print a table of defined variables and their types with the :vars command.
```{rust}
// :vars
```
Other built-in commands can be found via :help
```{rust}
// :help
```
```{rust}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/frozen_cell.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
# This is an unfrozen cell. Works as usual.
print("I'm a regular cell so I run and print!")
```
```{python deletable=FALSE, editable=FALSE, run_control={'frozen': True}, eval=FALSE}
# This is an frozen cell
print("I'm frozen so Im not executed :(")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/fsharp.Rmd
================================================
---
jupyter:
kernelspec:
display_name: .NET (F#)
language: F#
name: .net-fsharp
---
This notebook was inspired by [Plottting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/fsharp/Docs/Plotting%20with%20Xplot.ipynb).
```{fsharp}
open XPlot.Plotly
```
```{fsharp}
let bar =
Bar(
name = "Bar 1",
x = ["A"; "B"; "C"],
y = [1; 3; 2])
[bar]
|> Chart.Plot
|> Chart.WithTitle "A sample bar plot"
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/gnuplot_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: gnuplot
language: gnuplot
name: gnuplot
---
# Sample gnuplot notebook
## Simple plotting
```{gnuplot}
# Plot sin and cos with different linetypes
f(x) = sin(x)
g(x) = cos(x)
set xrange[0:2*pi]
set xtics(0, "{/Symbol p}" pi , "2{/Symbol p}" 2*pi)
set ytics 1
plot f(x) linewidth 2 title "sin(x)", \
g(x) linewidth 2 dashtype "--" title "cos(x)"
```
## Example of line magic
```{gnuplot}
# %gnuplot inline pngcairo enhanced background rgb "#EEEEEE" size 600, 600
# Parametric plot without border
reset
set parametric
set size ratio -1
unset border
unset tics
plot f(t), g(t) linewidth 2 notitle
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/haskell_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Haskell
language: haskell
name: haskell
---
# Example Haskell Notebook
Define a function to add two numbers.
```{haskell}
f :: Num a => a -> a -> a
f x y = x + y
```
Try to use the function
```{haskell}
f 1 2
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/hello_world_gonb.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Go (gonb)
language: go
name: gonb
---
A notebook that use [GoNB](https://github.com/janpfeifer/gonb)
the code below comes from [tutorial.ipynb](https://github.com/janpfeifer/gonb/blob/main/examples/tutorial.ipynb)
```{go}
func main() {
fmt.Printf("Hello World!")
}
```
```{go}
%%
fmt.Printf("Hello World!")
```
%% --who=world can pass flags to main func
```{go}
import (
"flag"
"fmt"
)
var flagWho = flag.String("who", "", "Your name!")
%% --who=world
fmt.Printf("Hello %s!\n", *flagWho)
```
%args also can pass flags
```{go}
// %args --who=Wally
func main() {
flag.Parse()
fmt.Printf("Where is %s?", *flagWho)
}
```
```{go}
import "github.com/janpfeifer/gonb/gonbui"
%%
gonbui.DisplayHtml(`I 🧡 GoNB!`)
```
```{go}
%%
gonbui.DisplayMarkdown("#### Objective\n\n1. Have fun coding **Go**;\n1. Profit...\n"+
`$$f(x) = \int_{-\infty}^{\infty} e^{-x^2} dx$$`)
```
```{go}
func init_a() {
fmt.Println("init_a")
}
%%
fmt.Println("main")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/html-demo.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Clojure
language: clojure
name: clojure
---
# Clojupyter Demo
This example notebook is from the [Clojupyter](https://github.com/clojupyter/clojupyter/blob/1637f6b2557f01db1e35bae5389bc38522eefe9a/examples/html-demo.ipynb) project.
This notebook demonstrates some of the more advanced features of Clojupyter.
## Displaying HTML
To display HTML, you'll need to require a clojupyter helper function to change the cell output
```{clojure}
(require '[clojupyter.misc.display :as display])
```
```{clojure}
(println ">> should print some text")
;; displaying html
(display/hiccup-html
[:ul
[:li "a " [:i "emphatic"] " idea"]
[:li "a " [:b "bold"] " idea"]
[:li "an " [:span {:style "text-decoration: underline;"} "important"] " idea"]])
```
We can also use this to render SVG:
```{clojure}
(display/hiccup-html
[:svg {:height 100 :width 100 :xmlns "http://www.w3.org/2000/svg"}
[:circle {:cx 50 :cy 40 :r 40 :fill "red"}]])
```
## Adding External Clojure Dependencies
You can fetch external Clojure dependencies using the `clojupyter.misc.helper` namespace.
```{clojure}
(require '[clojupyter.misc.helper :as helper])
```
```{clojure}
(helper/add-dependencies '[org.clojure/data.json "0.2.6"])
(require '[clojure.data.json :as json])
```
```{clojure}
(json/write-str {:a 1 :b [2, 3] :c "c"})
```
## Adding External Javascript Dependency
Since you can render arbitrary HTML using `display/hiccup-html`, it's pretty easy to use external Javascript libraries to do things like generate charts. Here's an example using [Highcharts](https://www.highcharts.com/).
First, we use a cell to add javascript to the running notebook:
```{clojure}
(helper/add-javascript "https://code.highcharts.com/highcharts.js")
```
Now we define a function which takes Clojure data and returns hiccup HTML to display:
```{clojure}
(defn plot-highchart [highchart-json]
(let [id (str (java.util.UUID/randomUUID))
code (format "Highcharts.chart('%s', %s );" id, (json/write-str highchart-json))]
(display/hiccup-html
[:div [:div {:id id :style {:background-color "red"}}]
[:script code]])))
```
Now we can make generate interactive plots (try hovering over plot):
```{clojure}
(def raw-data (map #(+ (* 22 (+ % (Math/random)) 78)) (range)))
(def data-1 (take 500 raw-data))
(def data-2 (take 500 (drop 500 raw-data)))
(plot-highchart {:chart {:type "line"}
:title {:text "Plot of random data"}
:series [{:data data-1} {:data data-2}]})
```
```{clojure}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/ijavascript.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Javascript (Node.js)
language: javascript
name: javascript
---
## A notebook that uses IJavascript kernel
```{javascript}
let x = 5;
const y = 6;
var z = 10;
```
```{javascript}
x + y;
```
```{javascript}
function add(num1, num2) {
return num1 + num2
}
```
```{javascript}
add(x, y);
```
```{javascript}
const arrowAdd = (num1, num2) => num1 + num2;
```
```{javascript}
arrowAdd(x, y);
```
```{javascript}
const myCar = {
color: "blue",
weight: 850,
model: "fiat",
start: () => "car started!",
doors: [1,2,3,4]
}
```
```{javascript}
console.log("color:", myCar.color);
```
```{javascript}
console.log("start:", myCar.start());
```
```{javascript}
for (let door of myCar.doors) {
console.log("I'm door", door)
}
```
```{javascript}
myCar;
```
```{javascript}
class User {
constructor(name){
this.name = name;
}
sayHello(){
return "Hello, I'm " + this.name;
}
}
```
```{javascript}
let John = new User("John");
John.sayHello();
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/ir_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: R
language: R
name: ir
---
This is a jupyter notebook that uses the IR kernel.
```{r}
sum(1:10)
```
```{r}
plot(cars)
```
```{r}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/itypescript.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Typescript 3.5
language: typescript
name: typescript
---
```{typescript}
let x: number = 5;
const y: number = 6;
var z: string = "hi";
console.log(z);
x + y;
```
```{typescript}
function add(num1: number, num2: number): number {
return num1 + num2
}
add(x, y);
```
```{typescript}
const arrowAdd = (num1: number, num2: number) => num1 + num2;
arrowAdd(x, y);
```
```{typescript}
class User {
constructor(private name: string) {
this.name = name;
}
sayHello(): string {
return "Hello, I'm " + this.name;
}
}
let John: User;
John = new User("John");
John.sayHello();
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/julia_benchmark_plotly_barchart.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Julia 1.1.1
language: julia
name: julia-1.1
---
```{julia}
# IJulia rocks! So does Plotly. Check it out
using Plotly
api_key = "" # visit https://plot.ly/api to generate an API username and password
username = ""
Plotly.signin(username, api_key)
```
```{julia}
# Following data taken from http://julialang.org/ frontpage
benchmarks = ["fib", "parse_int", "quicksort3", "mandel", "pi_sum", "rand_mat_stat", "rand_mat_mul"]
platforms = ["Fortran", "Julia", "Python", "R", "Matlab", "Mathematica", "Javascript", "Go"]
data = {
platforms[1] => [0.26, 5.03, 1.11, 0.86, 0.80, 0.64, 0.96],
platforms[2] => [0.91, 1.60, 1.14, 0.85, 1.00, 1.66, 1.01],
platforms[3] => [30.37, 13.95, 31.98, 14.19, 16.33, 13.52, 3.41 ],
platforms[4] => [411.36, 59.40, 524.29, 106.97, 15.42, 10.84, 3.98 ],
platforms[5] => [1992.00, 1463.16, 101.84, 64.58, 1.29, 6.61, 1.10 ],
platforms[6] => [64.46, 29.54, 35.74, 6.07, 1.32, 4.52, 1.16 ],
platforms[7] => [2.18, 2.43, 3.51, 3.49, 0.84, 3.28, 14.60],
platforms[8] => [1.03, 4.79, 1.25, 2.36, 1.41, 8.12, 8.51]
}
pdata = [ {"x"=>benchmarks,"y"=>data[k],"bardir"=>"h","type"=>"bar","name"=>k} for k = platforms ]
layout = {
"title"=> "Julia benchmark comparison (smaller is better, C performance = 1.0)",
"barmode"=> "group",
"autosize"=> false,
"width"=> 900,
"height"=> 900,
"titlefont"=>
{
"family"=> "Open Sans",
"size"=> 18,
"color"=> "rgb(84, 39, 143)"
},
"margin"=> {"l"=>160, "pad"=>0},
"xaxis"=> {
"title"=> "Benchmark log-time",
"type"=> "log"
},
"yaxis"=> {"title"=> "Benchmark Name"}
}
response = Plotly.plot(pdata,["layout"=>layout])
# Embed in an iframe within IJulia
s = string("")
display("text/html", s)
```
```{julia}
# checkout https://plot.ly/api/ for more Julia examples!
# But to show off some other Plotly features:
x = 1:1500
y1 = sin(2*pi*x/1500.) + rand(1500)-0.5
y2 = sin(2*pi*x/1500.)
fish = {"x"=>x,"y"=> y1,
"type"=>"scatter","mode"=>"markers",
"marker"=>{"color"=>"rgb(0, 0, 255)","opacity"=>0.5 } }
fit = {"x"=> x,"y"=> y2,
"type"=>"scatter", "mode"=>"markers", "opacity"=>0.8,
"marker"=>{"color"=>"rgb(255, 0, 0)"} }
layout = {"autosize"=> false,
"width"=> 650, "height"=> 550,
"title"=>"Fish School",
"xaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[0,1500] },
"yaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[-2.2,2.2] },
"plot_bgcolor"=> "rgb(245,245,247)",
"showlegend"=> false,
"hovermode"=> "closest"}
response = Plotly.plot([fish, fit],["layout"=>layout])
s = string("")
display("text/html", s)
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/julia_functional_geometry.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Julia 1.1.1
language: julia
name: julia-1.1
---
```{julia}
# This notebook is a semi top-down explanation. This cell needs to be
# executed first so that the operators and helper functions are defined
# All of this is explained in the later half of the notebook
using Compose, Interact
Compose.set_default_graphic_size(2inch, 2inch)
points_f = [
(.1, .1),
(.9, .1),
(.9, .2),
(.2, .2),
(.2, .4),
(.6, .4),
(.6, .5),
(.2, .5),
(.2, .9),
(.1, .9),
(.1, .1)
]
f = compose(context(), stroke("black"), line(points_f))
rot(pic) = compose(context(rotation=Rotation(-deg2rad(90))), pic)
flip(pic) = compose(context(mirror=Mirror(deg2rad(90), 0.5w, 0.5h)), pic)
above(m, n, p, q) =
compose(context(),
(context(0, 0, 1, m/(m+n)), p),
(context(0, m/(m+n), 1, n/(m+n)), q))
above(p, q) = above(1, 1, p, q)
beside(m, n, p, q) =
compose(context(),
(context(0, 0, m/(m+n), 1), p),
(context(m/(m+n), 0, n/(m+n), 1), q))
beside(p, q) = beside(1, 1, p, q)
over(p, q) = compose(context(),
(context(), p), (context(), q))
rot45(pic) =
compose(context(0, 0, 1/sqrt(2), 1/sqrt(2),
rotation=Rotation(-deg2rad(45), 0w, 0h)), pic)
# Utility function to zoom out and look at the context
zoomout(pic) = compose(context(),
(context(0.2, 0.2, 0.6, 0.6), pic),
(context(0.2, 0.2, 0.6, 0.6), fill(nothing), stroke("black"), strokedash([0.5mm, 0.5mm]),
polygon([(0, 0), (1, 0), (1, 1), (0, 1)])))
function read_path(p_str)
tokens = [try parsefloat(x) catch symbol(x) end for x in split(p_str, r"[\s,]+")]
path(tokens)
end
fish = compose(context(units=UnitBox(260, 260)), stroke("black"),
read_path(strip(readall("fish.path"))))
rotatable(pic) = @manipulate for θ=0:0.001:2π
compose(context(rotation=Rotation(θ)), pic)
end
blank = compose(context())
fliprot45(pic) = rot45(compose(context(mirror=Mirror(deg2rad(-45))),pic))
# Hide this cell.
display(MIME("text/html"), """""")
```
# Functional Geometry
*Functional Geometry* is a paper by Peter Henderson ([original (1982)](users.ecs.soton.ac.uk/peter/funcgeo.pdf), [revisited (2002)](https://cs.au.dk/~hosc/local/HOSC-15-4-pp349-365.pdf)) which deconstructs the MC Escher woodcut *Square Limit*

> A picture is an example of a complex object that can be described in terms of its parts.
Yet a picture needs to be rendered on a printer or a screen by a device that expects to
be given a sequence of commands. Programming that sequence of commands directly is
much harder than having an application generate the commands automatically from the
simpler, denotational description.
A `picture` is a *denotation* of something to draw.
e.g. The value of f here denotes the picture of the letter F
Original at http://nbviewer.jupyter.org/github/shashi/ijulia-notebooks/blob/master/funcgeo/Functional%20Geometry.ipynb
## In conclusion
We described Escher's *Square Limit* from the description of its smaller parts, which in turn were described in terms of their smaller parts.
This seemed simple because we chose to talk in terms of an *algebra* to describe pictures. The primitives `rot`, `flip`, `fliprot45`, `above`, `beside` and `over` fit the job perfectly.
We were able to describe these primitives in terms of `compose` `contexts`, which the Compose library knows how to render.
Denotation can be an easy way to describe a system as well as a practical implementation method.
[Abstraction barriers](https://mitpress.mit.edu/sicp/full-text/sicp/book/node29.html) are useful tools that can reduce the cognitive overhead on the programmer. It entails creating layers consisting of functions which only use functions in the same layer or layers below in their own implementation. The layers in our language were:
------------------[ squarelimit ]------------------
-------------[ quartet, cycle, nonet ]-------------
---[ rot, flip, fliprot45, above, beside, over ]---
-------[ compose, context, line, path,... ]--------
Drawing this diagram out is a useful way to begin building any library.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/jupyter.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
# Jupyter notebook
This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition:
```{python}
a = 1
b = 2
a + b
```
Now we return a few tuples
```{python}
a, b
```
```{python}
a, b, a+b
```
And this is already the end of the notebook
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/jupyter_again.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
c = '''
title: "Quick test"
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type console
'''
```
```{python}
import yaml
print(yaml.dump(yaml.load(c)))
```
```{python}
# ?next
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/jupyter_with_raw_cell_in_body.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
1+2+3
```
```{python active="", eval=FALSE}
This is a raw cell
```
This is a markdown cell
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/jupyter_with_raw_cell_on_top.Rmd
================================================
---
title: Quick test
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type: console
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
1+2+3
```
```{python}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/jupyter_with_raw_cell_with_invalid_yaml.Rmd
================================================
---
title: Exception: Test
jupyter:
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
---
```{python}
1 + 2 + 3
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/jupyterlab-slideshow_1441.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
---
> **Note**
>
> `slide` layer with a `top` of `30%`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/jupytext_replication.Rmd
================================================
---
jupyter:
kernelspec:
display_name: SoS
language: sos
name: sos
---
# Text SOS-kernel with Jupytext
## What is SOS kernel
SoS consists of a ployglot notebook that allows the use of multiple kernels in one Jupyter notebook, and a workflow system that is designed for daily computational research. Basically,
- SoS Polyglot Notebook is a Jupyter Notebook with a SoS kernel.
- SoS Notebook serves as a super kernel to all other Jupyter kernels and allows the use of multiple kernels in one Jupyter notebook.
- SoS Workflow System is a Python based workflow system that is designed to be readable, shareable, and suitable for daily data analysis.
- SoS Workflow System can be used from command line or use SoS Notebook as its IDE.

### How to install SOS-kernel
Please follow this [link](https://vatlab.github.io/sos-docs/running.html#Conda-installation) to setup SOS
I run some issue with the latest version of R on my Mac, so I had to install an earlier version of R
```
conda install -c r r=3.5.1
conda install sos-notebook jupyterlab-sos sos-papermill -c conda-forge
```
## Related issue with Jupytext
Jupytext works fine with Python/R kernel but converts code cells into markdown cells when using the SOS kernel.
cf the image below. It is a code cell. After saving the notebook and restart it, it converted the code cell into markdown
 ## Step 1
Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.

```{sos Collapsed="false", kernel="SoS"}
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
```
## Step 2
Now, pair it with Jupytex

### Step 3
Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
### Step 4
Reopen the notebook. Here is the outcome

================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/kalman_filter_and_visualization.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Q 3.5
language: q
name: qpk
---
```{q}
plt: .p.import`matplotlib.pyplot
```
```{q}
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
```
```{q}
price: 100 + sums 0.5 - (n:50)?1.
```
```{q}
output:filter price
```
```{q}
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
```
```{q}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/logtalk_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Logtalk
language: logtalk
name: logtalk_kernel
---
# An implementation of the Ackermann function
```{logtalk vscode={'languageId': 'logtalk'}}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
```
## Sample query
```{logtalk vscode={'languageId': 'logtalk'}}
ack::ack(2, 4, V).
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/lua_example.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Lua
language: lua
name: lua
---
Source: https://www.lua.org/pil/19.3.html
# Sort
Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
```{lua}
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
```
Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
```{lua}
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
```
Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
```{lua}
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
```
With this function, it is easy to print those function names in alphabetical order. The loop
```{lua}
for name, line in pairsByKeys(lines) do
print(name, line)
end
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/maxima_example.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Maxima
language: maxima
name: maxima
---
## maxima misc
```{maxima}
kill(all)$
```
```{maxima}
f(x) := 1/(x^2+l^2)^(3/2);
```
```{maxima}
integrate(f(x), x);
```
```{maxima}
tex(%)$
```
```{maxima}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/notebook_with_complex_metadata.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/nteract_with_parameter.Rmd
================================================
---
jupyter:
kernel_info:
name: python3
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python inputHidden=FALSE, outputHidden=FALSE, tags=c("parameters")}
param = 4
```
```{python inputHidden=FALSE, outputHidden=FALSE}
import pandas as pd
```
```{python inputHidden=FALSE, outputHidden=FALSE}
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
```
```{python inputHidden=FALSE, outputHidden=FALSE}
# %matplotlib inline
df.plot(kind='bar')
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/ocaml_notebook.Rmd
================================================
---
jupyter:
jupytext:
formats: ipynb:markdown,md
kernelspec:
display_name: OCaml default
language: OCaml
name: ocaml-jupyter
---
# Example of an OCaml notebook
```{ocaml}
let sum x y = x + y
```
Let's try our function:
```{ocaml}
sum 3 4 = 7 + 0
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/octave_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Octave
language: octave
name: octave
---
A markdown cell
```{octave}
1 + 1
```
```{octave}
% a code cell with comments
2 + 2
```
```{octave}
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
```
```{octave}
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
```
And to finish with, a Python cell
```{python}
a = 1
```
```{python}
a + 1
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/plotly_graphs.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
This notebook contains complex outputs, including plotly javascript graphs.
# Interactive plots
We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
```{python}
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
```
```{python}
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/powershell.Rmd
================================================
---
jupyter:
kernelspec:
display_name: PowerShell
language: PowerShell
name: powershell
---
This is an extract from
https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
```{powershell}
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/raw_cell_with_complex_yaml_like_content.Rmd
================================================
---
This is a complex paragraph
that is split over multiple lines.
It also includes blank lines.
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/raw_cell_with_non_dict_yaml_content.Rmd
================================================
---
Content.
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/root_cpp.Rmd
================================================
---
jupyter:
kernelspec:
display_name: ROOT C++
language: c++
name: root
---
```{c++}
#include
## Step 1
Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.

```{sos Collapsed="false", kernel="SoS"}
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
```
## Step 2
Now, pair it with Jupytex

### Step 3
Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
### Step 4
Reopen the notebook. Here is the outcome

================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/kalman_filter_and_visualization.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Q 3.5
language: q
name: qpk
---
```{q}
plt: .p.import`matplotlib.pyplot
```
```{q}
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
```
```{q}
price: 100 + sums 0.5 - (n:50)?1.
```
```{q}
output:filter price
```
```{q}
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
```
```{q}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/logtalk_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Logtalk
language: logtalk
name: logtalk_kernel
---
# An implementation of the Ackermann function
```{logtalk vscode={'languageId': 'logtalk'}}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
```
## Sample query
```{logtalk vscode={'languageId': 'logtalk'}}
ack::ack(2, 4, V).
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/lua_example.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Lua
language: lua
name: lua
---
Source: https://www.lua.org/pil/19.3.html
# Sort
Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
```{lua}
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
```
Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
```{lua}
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
```
Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
```{lua}
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
```
With this function, it is easy to print those function names in alphabetical order. The loop
```{lua}
for name, line in pairsByKeys(lines) do
print(name, line)
end
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/maxima_example.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Maxima
language: maxima
name: maxima
---
## maxima misc
```{maxima}
kill(all)$
```
```{maxima}
f(x) := 1/(x^2+l^2)^(3/2);
```
```{maxima}
integrate(f(x), x);
```
```{maxima}
tex(%)$
```
```{maxima}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/notebook_with_complex_metadata.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/nteract_with_parameter.Rmd
================================================
---
jupyter:
kernel_info:
name: python3
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python inputHidden=FALSE, outputHidden=FALSE, tags=c("parameters")}
param = 4
```
```{python inputHidden=FALSE, outputHidden=FALSE}
import pandas as pd
```
```{python inputHidden=FALSE, outputHidden=FALSE}
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
```
```{python inputHidden=FALSE, outputHidden=FALSE}
# %matplotlib inline
df.plot(kind='bar')
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/ocaml_notebook.Rmd
================================================
---
jupyter:
jupytext:
formats: ipynb:markdown,md
kernelspec:
display_name: OCaml default
language: OCaml
name: ocaml-jupyter
---
# Example of an OCaml notebook
```{ocaml}
let sum x y = x + y
```
Let's try our function:
```{ocaml}
sum 3 4 = 7 + 0
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/octave_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Octave
language: octave
name: octave
---
A markdown cell
```{octave}
1 + 1
```
```{octave}
% a code cell with comments
2 + 2
```
```{octave}
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
```
```{octave}
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
```
And to finish with, a Python cell
```{python}
a = 1
```
```{python}
a + 1
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/plotly_graphs.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
This notebook contains complex outputs, including plotly javascript graphs.
# Interactive plots
We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
```{python}
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
```
```{python}
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/powershell.Rmd
================================================
---
jupyter:
kernelspec:
display_name: PowerShell
language: PowerShell
name: powershell
---
This is an extract from
https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
```{powershell}
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/raw_cell_with_complex_yaml_like_content.Rmd
================================================
---
This is a complex paragraph
that is split over multiple lines.
It also includes blank lines.
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/raw_cell_with_non_dict_yaml_content.Rmd
================================================
---
Content.
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/root_cpp.Rmd
================================================
---
jupyter:
kernelspec:
display_name: ROOT C++
language: c++
name: root
---
```{c++}
#include
#include
```
```{c++}
int k = 4;
std::string foo = "This string says \"foo\"";
```
```{c++}
std::cout << "k = " << k << '\n' << foo << '\n';
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/sage_print_hello.Rmd
================================================
---
jupyter:
kernelspec:
display_name: SageMath 9.2
language: sage
name: sagemath
---
```{sage}
print("Hello world")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/sample_bash_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Bash
language: bash
name: bash
---
```{bash}
ls
```
```{bash}
# https://coderwall.com/p/euwpig/a-better-git-log
git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"
```
```{bash}
git lg
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/sample_rise_notebook_66.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
A markdown cell
```{python slideshow={'slide_type': ''}}
1+1
```
Markdown cell two
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/sas.Rmd
================================================
---
jupyter:
kernelspec:
display_name: SAS
language: sas
name: sas
---
# SAS Notebooks with jupytext
```{sas}
proc sql;
select *
from sashelp.cars (obs=10)
;
quit;
```
```{sas}
%let name = "Jupytext";
```
```{sas}
%put &name;
```
```{sas}
/* Note when defining macros "%macro" cannot be the first line of text in the cell */
%macro test;
data temp;
set sashelp.cars;
name = "testx";
run;
proc print data = temp (obs=10);
run;
%mend test;
%test
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/simple-helloworld.Rmd
================================================
---
jupyter:
jupytext:
encoding: '// -*- coding: utf-8 -*-'
formats: ipynb,java:light
kernelspec:
display_name: Java
language: java
name: java
---
Let's define some class.
```{java}
class A {
public void hello() {
System.out.println("Hello World");
}
}
```
And now we call its method.
```{java}
new A().hello();
```
You can run it e.g. with `jshell`
* from command line, as `jshell simple-helloworld.java`
* from jshell's shell with `/open simple-helloworld.java`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/simple_robot_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Robot Framework
language: robotframework
name: robotkernel
---
```{robotframework}
*** Settings ***
Library Collections
```
```{robotframework}
*** Keywords ***
Head
[Arguments] ${list}
${value}= Get from list ${list} 0
[Return] ${value}
```
```{robotframework}
*** Tasks ***
Get head
${array}= Create list 1 2 3 4 5
${head}= Head ${array}
Should be equal ${head} 1
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/simple_scala_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Apache Toree - Scala
language: scala
name: apache_toree_scala
---
```{scala}
// This is just a simple scala notebook
object SampleObject {
def calculation(x: Int, y: Int): Int = x + y
}
val result = SampleObject.calculation(1, 2)
```
```{scala}
println(result * 10)
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/stata_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Stata
language: stata
name: stata
---
```{stata}
// This notebook uses the stata_kernel: https://github.com/kylebarron/stata_kernel
```
```{stata}
use http://www.stata-press.com/data/r13/auto
```
```{stata}
summarize
```
```{stata}
scatter weight length
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/tailrecursive-factorial.Rmd
================================================
---
jupyter:
jupytext:
encoding: '// -*- coding: utf-8 -*-'
formats: ipynb,groovy:light
kernelspec:
display_name: Groovy
language: groovy
name: groovy
---
# TailRecursive annotation
Let's check what is the effect of `@TailRecursive` annotation on the simple recursive definition of factorial function.
```{groovy}
import groovy.transform.CompileStatic
import groovy.transform.TailRecursive
import groovy.transform.TypeChecked
@CompileStatic
@TypeChecked
class X {
static final BigInteger factorial0(int n) {
(n <= 1) ? 1G : factorial0(n-1).multiply(BigInteger.valueOf(n))
}
static final BigInteger factorial1(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial1(n-1, acc.multiply(BigInteger.valueOf(n)))
}
@TailRecursive
static final BigInteger factorial2(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial2(n-1, acc.multiply(BigInteger.valueOf(n)))
}
}
x = new X()
```
Although we can time the execution of the calls, it is not very accurate; such micro benchmarks should be performed in more controlled environment, such us under [JMH](https://openjdk.java.net/projects/code-tools/jmh/).
For example, see [blog posts of Szymon Stępniak](https://e.printstacktrace.blog/tail-recursive-methods-in-groovy/).
```{groovy}
// %%timeit
x.factorial0(19_000).toString().length()
```
```{groovy}
// %%timeit
x.factorial1(19_000).toString().length()
```
```{groovy}
// %%timeit
x.factorial2(19_000).toString().length()
```
The real difference is the use of stack. Non-tail recursive calls exhaust the stack space at some point, whereas tail recursive calls don't add frames to the stack.
```{groovy}
factSize = { n, cl ->
println "Factorial of ${n} has ${cl(n).toString().length()} digits"
}
factSize 2_000, x.&factorial0
factSize 2_000, x.&factorial1
factSize 2_000, x.&factorial2
factSize 100_000, x.&factorial2
```
```{groovy}
try {
factSize 100_000, x.&factorial1
} catch (Throwable e) {
assert e instanceof StackOverflowError
println e
}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/tcl_test.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Tcl
language: tcl
name: tcljupyter
---
# Assign Values
```{tcl}
set a 1
puts "a = $a"
```
# Loop
```{tcl}
for {set i 0} {$i < 10} {incr i} {
puts "I inside first loop: $i"
}
```
```{tcl}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/text_outputs_and_images.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
This notebook contains outputs of many different types: text, HTML, plots and errors.
# Text outputs
Using `print`, `sys.stdout` and `sys.stderr`
```{python}
import sys
print('using print')
sys.stdout.write('using sys.stdout.write')
sys.stderr.write('using sys.stderr.write')
```
```{python}
import logging
logging.debug('Debug')
logging.info('Info')
logging.warning('Warning')
logging.error('Error')
```
# HTML outputs
Using `pandas`. Here we find two representations: both text and HTML.
```{python}
import pandas as pd
pd.DataFrame([4])
```
```{python}
from IPython.display import display
display(pd.DataFrame([5]))
display(pd.DataFrame([6]))
```
# Images
```{python}
# %matplotlib inline
```
```{python}
# First plot
from matplotlib import pyplot as plt
import numpy as np
w, h = 3, 3
data = np.zeros((h, w, 3), dtype=np.uint8)
data[0,:] = [0,255,0]
data[1,:] = [0,0,255]
data[2,:] = [0,255,0]
data[1:3,1:3] = [255, 0, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# Second plot
data[1:3,1:3] = [255, 255, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
```
# Errors
```{python}
undefined_variable
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/wolfram.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Wolfram Language 13.1
language: Wolfram Language
name: wolframlanguage13.1
---
**Note:** The `language_info` `file_extension` in this notebook should be `.m`, but it was deliberately changed to `.wolfram` to avoid conflicts with Matlab which is using the same extension.
We start with...
```{wolfram language}
Print["Hello, World!"];
```
Then we draw the first example plot from the [ListPlot](https://reference.wolfram.com/language/ref/ListPlot.html) reference:
```{wolfram language}
ListPlot[Prime[Range[25]]]
```
We also test the math outputs as in the [Simplify](https://reference.wolfram.com/language/ref/Simplify.html) example:
```{wolfram language}
D[Integrate[1/(x^3 + 1), x], x]
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/xcpp_by_quantstack.Rmd
================================================
---
jupyter:
kernelspec:
display_name: C++14
language: C++14
name: xeus-cling-cpp14
---
[](https://github.com/QuantStack/xeus-cling/)
A Jupyter kernel for C++ based on the `cling` C++ interpreter and the `xeus` native implementation of the Jupyter protocol, xeus.
- GitHub repository: https://github.com/QuantStack/xeus-cling/
- Online documentation: https://xeus-cling.readthedocs.io/
## Usage
## Output and error streams
`std::cout` and `std::cerr` are redirected to the notebook frontend.
```{c++}
#include
std::cout << "some output" << std::endl;
```
```{c++}
std::cerr << "some error" << std::endl;
```
```{c++}
#include
```
```{c++}
throw std::runtime_error("Unknown exception");
```
Omitting the `;` in the last statement of a cell results in an output being printed
```{c++}
int j = 5;
```
```{c++}
j
```
# Interpreting the C++ programming language
`cling` has a broad support of the features of C++. You can define functions, classes, templates, etc ...
## Functions
```{c++}
double sqr(double a)
{
return a * a;
}
```
```{c++}
double a = 2.5;
double asqr = sqr(a);
asqr
```
## Classes
```{c++}
class Foo
{
public:
virtual ~Foo() {}
virtual void print(double value) const
{
std::cout << "Foo value = " << value << std::endl;
}
};
```
```{c++}
Foo bar;
bar.print(1.2);
```
## Polymorphism
```{c++}
class Bar : public Foo
{
public:
virtual ~Bar() {}
virtual void print(double value) const
{
std::cout << "Bar value = " << 2 * value << std::endl;
}
};
```
```{c++}
Foo* bar2 = new Bar;
bar2->print(1.2);
delete bar2;
```
## Templates
```{c++}
#include
template
class FooT
{
public:
explicit FooT(const T& t) : m_t(t) {}
void print() const
{
std::cout << typeid(T).name() << " m_t = " << m_t << std::endl;
}
private:
T m_t;
};
template <>
class FooT
{
public:
explicit FooT(const int& t) : m_t(t) {}
void print() const
{
std::cout << "m_t = " << m_t << std::endl;
}
private:
int m_t;
};
```
```{c++}
FooT foot1(1.2);
foot1.print();
```
```{c++}
FooT foot2(4);
foot2.print();
```
## C++11 / C++14 support
```{c++}
class Foo11
{
public:
Foo11() { std::cout << "Foo11 default constructor" << std::endl; }
Foo11(const Foo11&) { std::cout << "Foo11 copy constructor" << std::endl; }
Foo11(Foo11&&) { std::cout << "Foo11 move constructor" << std::endl; }
};
```
```{c++}
Foo11 f1;
Foo11 f2(f1);
Foo11 f3(std::move(f1));
```
```{c++}
#include
std::vector v = { 1, 2, 3};
auto iter = ++v.begin();
v
```
```{c++}
*iter
```
... and also lambda, universal references, `decltype`, etc ...
## Documentation and completion
- Documentation for types of the standard library is retrieved on cppreference.com.
- The quick-help feature can also be enabled for user-defined types and third-party libraries. More documentation on this feature is available at https://xeus-cling.readthedocs.io/en/latest/inline_help.html.
```{c++}
?std::vector
```
## Using the `display_data` mechanism
For a user-defined type `T`, the rich rendering in the notebook and JupyterLab can be enabled by by implementing the function `xeus::xjson mime_bundle_repr(const T& im)`, which returns the JSON mime bundle for that type.
More documentation on the rich display system of Jupyter and Xeus-cling is available at https://xeus-cling.readthedocs.io/en/latest/rich_display.html
### Image example
```{c++}
#include
#include
#include "xtl/xbase64.hpp"
#include "xeus/xjson.hpp"
namespace im
{
struct image
{
inline image(const std::string& filename)
{
std::ifstream fin(filename, std::ios::binary);
m_buffer << fin.rdbuf();
}
std::stringstream m_buffer;
};
xeus::xjson mime_bundle_repr(const image& i)
{
auto bundle = xeus::xjson::object();
bundle["image/png"] = xtl::base64encode(i.m_buffer.str());
return bundle;
}
}
```
```{c++}
im::image marie("images/marie.png");
marie
```
### Audio example
```{c++}
#include
#include
#include "xtl/xbase64.hpp"
#include "xeus/xjson.hpp"
namespace au
{
struct audio
{
inline audio(const std::string& filename)
{
std::ifstream fin(filename, std::ios::binary);
m_buffer << fin.rdbuf();
}
std::stringstream m_buffer;
};
xeus::xjson mime_bundle_repr(const audio& a)
{
auto bundle = xeus::xjson::object();
bundle["text/html"] =
std::string("";
return bundle;
}
}
```
```{c++}
au::audio drums("audio/audio.wav");
drums
```
### Display
```{c++}
#include "xcpp/xdisplay.hpp"
```
```{c++}
xcpp::display(drums);
```
### Update-display
```{c++}
#include
#include "xcpp/xdisplay.hpp"
namespace ht
{
struct html
{
inline html(const std::string& content)
{
m_content = content;
}
std::string m_content;
};
xeus::xjson mime_bundle_repr(const html& a)
{
auto bundle = xeus::xjson::object();
bundle["text/html"] = a.m_content;
return bundle;
}
}
// A red rectangle
ht::html rect(R"(
#include
```
```{c++}
std::vector to_shuffle = {1, 2, 3, 4};
```
```{c++}
// %timeit std::random_shuffle(to_shuffle.begin(), to_shuffle.end());
```
[](https://github.com/QuantStack/xtensor/)
- GitHub repository: https://github.com/QuantStack/xtensor/
- Online documentation: https://xtensor.readthedocs.io/
- NumPy to xtensor cheat sheet: http://xtensor.readthedocs.io/en/latest/numpy.html
`xtensor` is a C++ library for manipulating N-D arrays with an API very similar to that of numpy.
```{c++}
#include
#include "xtensor/xarray.hpp"
#include "xtensor/xio.hpp"
#include "xtensor/xview.hpp"
xt::xarray arr1
{{1.0, 2.0, 3.0},
{2.0, 5.0, 7.0},
{2.0, 5.0, 7.0}};
xt::xarray arr2
{5.0, 6.0, 7.0};
xt::view(arr1, 1) + arr2
```
Together with the C++ Jupyter kernel, `xtensor` offers a similar experience as `NumPy` in the Python Jupyter kernel, including broadcasting and universal functions.
```{c++}
#include
#include "xtensor/xarray.hpp"
#include "xtensor/xio.hpp"
```
```{c++}
xt::xarray arr
{1, 2, 3, 4, 5, 6, 7, 8, 9};
arr.reshape({3, 3});
std::cout << arr;
```
```{c++}
#include "xtensor-blas/xlinalg.hpp"
```
```{c++}
xt::xtensor m = {{1.5, 0.5}, {0.7, 1.0}};
std::cout << "Matrix rank: " << std::endl << xt::linalg::matrix_rank(m) << std::endl;
std::cout << "Matrix inverse: " << std::endl << xt::linalg::inv(m) << std::endl;
std::cout << "Eigen values: " << std::endl << xt::linalg::eigvals(m) << std::endl;
```
```{c++}
xt::xarray arg1 = xt::arange(9);
xt::xarray arg2 = xt::arange(18);
arg1.reshape({3, 3});
arg2.reshape({2, 3, 3});
std::cout << xt::linalg::dot(arg1, arg2) << std::endl;
```
```{c++}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/xonsh_example.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Xonsh
language: xonsh
name: xonsh
---
```{xonsh}
len($(curl -L https://xon.sh))
```
```{xonsh}
for filename in `.*`:
print(filename)
du -sh @(filename)
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/Line_breaks_in_LateX_305.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# This cell uses no particular cell marker
#
# $$
# \begin{align}
# \dot{x} & = \sigma(y-x)\\
# \dot{y} & = \rho x - y - xz \\
# \dot{z} & = -\beta z + xy
# \end{align}
# $$
# %% [markdown]
# This cell uses no particular cell marker, and a single slash in the $\LaTeX$ equation
#
# $$
# \begin{align}
# \dot{x} & = \sigma(y-x) \
# \dot{y} & = \rho x - y - xz \
# \dot{z} & = -\beta z + xy
# \end{align}
# $$
# %% [markdown]
'''
This cell uses the triple quote cell markers introduced at https://github.com/mwouts/jupytext/issues/305
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
'''
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/Notebook with function and cell metadata 164.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
1 + 1
# %% [markdown]
# A markdown cell
# And below, the cell for function f has non trivial cell metadata. And the next cell as well.
# %% attributes={"classes": [], "id": "", "n": "10"}
def f(x):
return x
# %% attributes={"classes": [], "id": "", "n": "10"}
f(5)
# %% [markdown]
# More text
# %%
2 + 2
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/Notebook with html and latex cells.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
%%html
;;
;;
;; It has breakpoints (click in left margin). You must press Stop to exit the debugger.
;; %% [markdown]
;; ```scheme
;; %%debug
;;
;; (begin
;; (define x 1)
;; (set! x 2)
;; )
;; ```
;; %% [markdown]
;; ### Python Integration
;;
;; You can import and use any Python library in Calysto Scheme.
;;
;; In addition, if you wish, you can execute expressions and statements in a Python environment:
;; %%
(python-eval "1 + 2")
;; %%
(python-exec
"
def mypyfunc(a, b):
return a * b
")
;; %% [markdown]
;; This is a shared environment with Scheme:
;; %%
(mypyfunc 4 5)
;; %% [markdown]
;; You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
;; %%
(define! mypyfunc2 (func (lambda (n) n)))
;; %%
(python-eval "mypyfunc2(34)")
;; %% [markdown]
;; # Differences Between Languages
;;
;; ## Major differences between Scheme and Python
;;
;; 1. In Scheme, double quotes are used for strings and may contain newlines
;; 1. In Scheme, a single quote is short for (quote ...) and means "literal"
;; 1. In Scheme, everything is an expression and has a return value
;; 1. Python does not support macros (e.g., extending syntax)
;; 1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
;; 1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
;; 1. Scheme procedures are not Python functions, but there are means to use one as the other.
;;
;; ## Major Differences Between Calysto Scheme and other Schemes
;;
;; 1. define-syntax works slightly differently
;; 1. In Calysto Scheme, #(...) is short for '#(...)
;; 1. Calysto Scheme is missing many standard functions (see list at bottom)
;; 1. Calysto Scheme has a built-in amb operator called `choose`
;; 1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
;;
;; ### Stack Trace
;;
;; Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
;; %%
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
;; %%
(fact 5)
;; %% [markdown]
;; To turn off the stack trace on error:
;;
;; ```scheme
;; (use-stack-trace #f)
;; ```
;; That will allow infinite recursive loops without keeping track of the "stack".
;; %% [markdown]
;; # Calysto Scheme Variables
;;
;; ## SCHEMEPATH
;; SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
;; %%
SCHEMEPATH
;; %%
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
;; %%
SCHEMEPATH
;; %% [markdown]
;; ## Getting Started
;;
;; Note that you can use the word `lambda` or \lambda and then press [TAB]
;; %%
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
;; %%
(factorial 5)
;; %% [markdown]
;; ## define-syntax
;; (define-syntax NAME RULES): a method for creating macros
;; %%
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
;; %%
(time (car '(1 2 3 4)))
;; %%
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
;; %%
(collect (* n n) for n in (range 10))
;; %%
(collect (* n n) for n in (range 5 20 3))
;; %%
(collect (* n n) for n in (range 10) if (> n 5))
;; %%
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
;; %%
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
;; %%
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
;; %%
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
;; %%
(for n in (range 10 20 2) do (print n))
;; %%
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
;; %%
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
;; %%
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
;; %%
(! 5)
;; %%
(nth 10 facts)
;; %%
(nth 20 fibs)
;; %%
(first 30 fibs)
;; %% [markdown]
;; ## for-each
;; (for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
;; %%
(for-each (lambda (n) (print n)) '(3 4 5))
;; %% [markdown]
;; ## format
;; (format STRING ITEM ...): format the string with ITEMS as arguments
;; %%
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
;; %% [markdown]
;; ## func
;;
;; Turns a lambda into a Python function.
;;
;; (func (lambda ...))
;; %%
(func (lambda (n) n))
;; %% [markdown]
;; ## There's more!
;;
;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/The flavors of raw cells.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [raw] raw_mimetype="text/latex"
# $1+1$
# %% [raw] raw_mimetype="text/restructuredtext"
# :math:`1+1`
# %% [raw] raw_mimetype="text/html"
# Bold text
# %% [raw] raw_mimetype="text/markdown"
# **Bold text**
# %% [raw] raw_mimetype="text/x-python"
# 1 + 1
# %% [raw]
# Not formatted
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/cat_variable.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
cat = 42
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/coconut_homepage_demo.coco
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Coconut
# language: coconut
# name: coconut
# ---
# %% [markdown]
# Taken from [coconut-lang.org](coconut-lang.org)
# %% [markdown]
# pipeline-style programming
# %%
"hello, world!" |> print
# %% [markdown]
# prettier lambdas
# %%
x -> x ** 2
# %% [markdown]
# partial application
# %%
range(10) |> map$(pow$(?, 2)) |> list
# %% [markdown]
# pattern-matching
# %%
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
# %% [markdown]
# destructuring assignment
# %%
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
# %% [markdown]
# infix notation
# %%
# 5 `mod` 3 == 2
# %% [markdown]
# operator functions
# %%
product = reduce$(*)
# %% [markdown]
# function composition
# %%
# (f..g..h)(x, y, z)
# %% [markdown]
# lazy lists
# %%
# (| first_elem() |) :: rest_elems()
# %% [markdown]
# parallel programming
# %%
range(100) |> parallel_map$(pow$(2)) |> list
# %% [markdown]
# tail call optimization
# %%
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
# %% [markdown]
# algebraic data types
# %%
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
# %% [markdown]
# and much more!
#
# Like what you see? Don't forget to star Coconut on GitHub!
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/convert_to_py_then_test_with_update83.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
%%time
print('asdf')
# %% [markdown]
# Thanks for jupytext!
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/csharp.cs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: .NET (C#)
// language: C#
// name: .net-csharp
// ---
// %% [markdown]
// We start with...
// %%
Console.WriteLine("Hello World!");
// %% [markdown]
// Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
// %%
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
// %% [markdown]
// We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
// %%
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
// %%
(MathString)@"e^{i \pi} = -1"
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/demo_gdl_fbp.pro
================================================
; -*- coding: utf-8 -*-
; ---
; jupyter:
; kernelspec:
; display_name: IDL [conda env:gdl] *
; language: IDL
; name: conda-env-gdl-idl
; ---
; %% [markdown]
; ## GDL demo notebook
; %% [markdown]
; Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
;
; This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
; %%
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
; %%
;; Enable inline plotting
!inline=1
; %%
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
; %% [markdown]
; Now we define simple forward and backprojection functions:
; %%
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
; %%
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
; %% [markdown]
; This allows us to create a sinogram:
; %%
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
; %% [markdown]
; On this we can apply a simple FBP reconstruction:
; %%
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
; %%
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
; %% [markdown]
; ### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/evcxr_jupyter_tour.rs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Rust
// language: rust
// name: rust
// ---
// %% [markdown]
// # Tour of the EvCxR Jupyter Kernel
// For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
//
// ## Printing to outputs and evaluating expressions
// Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
// %%
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
// %% [markdown]
// ## Assigning and making use of variables
// We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
// %%
let mut message = "Hello ".to_owned();
// %%
message.push_str("world!");
// %%
message
// %% [markdown]
// ## Defining and redefining functions
// Next we'll define a function
// %%
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
// %%
(1..13).map(fib).collect::>()
// %% [markdown]
// Hmm, that doesn't look right. Lets redefine the function. In practice, we'd go back and edit the function above and reevaluate it, but here, lets redefine it in a separate cell.
// %%
pub fn fib(x: i32) -> i32 {
if x <= 2 {2} else {fib(x - 2) + fib(x - 1)}
}
// %%
let values = (1..13).map(fib).collect::>();
values
// %% [markdown]
// ## Spawning a separate thread and communicating with it
// We can spawn a thread to do stuff in the background, then continue executing code in other cells.
// %%
use std::sync::{Mutex, Arc};
let counter = Arc::new(Mutex::new(0i32));
std::thread::spawn({
let counter = Arc::clone(&counter);
move || {
for i in 1..300 {
*counter.lock().unwrap() += 1;
std::thread::sleep(std::time::Duration::from_millis(100));
}
}});
// %%
*counter.lock().unwrap()
// %%
*counter.lock().unwrap()
// %% [markdown]
// ## Loading external crates
// We can load external crates. This one takes a while to compile, but once it's compiled, subsequent cells shouldn't need to recompile it, so it should be much quicker.
// %%
:dep base64 = "0.10.1"
base64::encode(&vec![1, 2, 3, 4])
// %% [markdown]
// ## Customizing how types are displayed
// We can also customize how our types are displayed, including presenting them as HTML. Here's an example where we define a custom display function for a type `Matrix`.
// %%
use std::fmt::Debug;
pub struct Matrix {pub values: Vec, pub row_size: usize}
impl Matrix {
pub fn evcxr_display(&self) {
let mut html = String::new();
html.push_str("");
for r in 0..(self.values.len() / self.row_size) {
html.push_str("
");
println!("EVCXR_BEGIN_CONTENT text/html\n{}\nEVCXR_END_CONTENT", html);
}
}
// %%
let m = Matrix {values: vec![1,2,3,4,5,6,7,8,9], row_size: 3};
m
// %% [markdown]
// We can also return images, we just need to base64 encode them. First, we set up code for displaying RGB and grayscale images.
// %%
extern crate image;
extern crate base64;
pub trait EvcxrResult {fn evcxr_display(&self);}
impl EvcxrResult for image::RgbImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::RGB(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
impl EvcxrResult for image::GrayImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::Gray(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
// %%
image::ImageBuffer::from_fn(256, 256, |x, y| {
if (x as i32 - y as i32).abs() < 3 {
image::Rgb([0, 0, 255])
} else {
image::Rgb([0, 0, 0])
}
})
// %% [markdown]
// ## Display of compilation errors
// Here's how compilation errors are presented. Here we forgot an & and passed a String instead of an &str.
// %%
let mut s = String::new();
s.push_str(format!("foo {}", 42));
// %% [markdown]
// ## Seeing what variables have been defined
// We can print a table of defined variables and their types with the :vars command.
// %%
:vars
// %% [markdown]
// Other built-in commands can be found via :help
// %%
:help
// %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/frozen_cell.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
# This is an unfrozen cell. Works as usual.
print("I'm a regular cell so I run and print!")
# %% deletable=false editable=false run_control={"frozen": true}
# # This is an frozen cell
# print("I'm frozen so Im not executed :(")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/fsharp.fsx
================================================
// ---
// jupyter:
// kernelspec:
// display_name: .NET (F#)
// language: F#
// name: .net-fsharp
// ---
// %% [markdown]
// This notebook was inspired by [Plottting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/fsharp/Docs/Plotting%20with%20Xplot.ipynb).
// %%
open XPlot.Plotly
// %%
let bar =
Bar(
name = "Bar 1",
x = ["A"; "B"; "C"],
y = [1; 3; 2])
[bar]
|> Chart.Plot
|> Chart.WithTitle "A sample bar plot"
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/gnuplot_notebook.gp
================================================
# ---
# jupyter:
# kernelspec:
# display_name: gnuplot
# language: gnuplot
# name: gnuplot
# ---
# %% [markdown]
# # Sample gnuplot notebook
# %% [markdown]
# ## Simple plotting
# %%
# Plot sin and cos with different linetypes
f(x) = sin(x)
g(x) = cos(x)
set xrange[0:2*pi]
set xtics(0, "{/Symbol p}" pi , "2{/Symbol p}" 2*pi)
set ytics 1
plot f(x) linewidth 2 title "sin(x)", \
g(x) linewidth 2 dashtype "--" title "cos(x)"
# %% [markdown]
# ## Example of line magic
# %%
%gnuplot inline pngcairo enhanced background rgb "#EEEEEE" size 600, 600
# Parametric plot without border
reset
set parametric
set size ratio -1
unset border
unset tics
plot f(t), g(t) linewidth 2 notitle
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/haskell_notebook.hs
================================================
-- ---
-- jupyter:
-- kernelspec:
-- display_name: Haskell
-- language: haskell
-- name: haskell
-- ---
-- %% [markdown]
-- # Example Haskell Notebook
-- %% [markdown]
-- Define a function to add two numbers.
-- %%
f :: Num a => a -> a -> a
f x y = x + y
-- %% [markdown]
-- Try to use the function
-- %%
f 1 2
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/hello_world_gonb.go
================================================
// -*- coding: utf-8 -*-
// ---
// jupyter:
// kernelspec:
// display_name: Go (gonb)
// language: go
// name: gonb
// ---
// %% [markdown]
// A notebook that use [GoNB](https://github.com/janpfeifer/gonb)
// %% [markdown]
// the code below comes from [tutorial.ipynb](https://github.com/janpfeifer/gonb/blob/main/examples/tutorial.ipynb)
// %%
func main() {
fmt.Printf("Hello World!")
}
// %%
//gonb:%%
fmt.Printf("Hello World!")
// %% [markdown]
// //gonb:%% --who=world can pass flags to main func
// %%
import (
"flag"
"fmt"
)
var flagWho = flag.String("who", "", "Your name!")
//gonb:%% --who=world
fmt.Printf("Hello %s!\n", *flagWho)
// %% [markdown]
// %args also can pass flags
// %%
%args --who=Wally
func main() {
flag.Parse()
fmt.Printf("Where is %s?", *flagWho)
}
// %%
import "github.com/janpfeifer/gonb/gonbui"
//gonb:%%
gonbui.DisplayHtml(`I 🧡 GoNB!`)
// %%
//gonb:%%
gonbui.DisplayMarkdown("#### Objective\n\n1. Have fun coding **Go**;\n1. Profit...\n"+
`$$f(x) = \int_{-\infty}^{\infty} e^{-x^2} dx$$`)
// %%
func init_a() {
fmt.Println("init_a")
}
//gonb:%%
fmt.Println("main")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/html-demo.clj
================================================
;; ---
;; jupyter:
;; kernelspec:
;; display_name: Clojure
;; language: clojure
;; name: clojure
;; ---
;; %% [markdown]
;; # Clojupyter Demo
;;
;; This example notebook is from the [Clojupyter](https://github.com/clojupyter/clojupyter/blob/1637f6b2557f01db1e35bae5389bc38522eefe9a/examples/html-demo.ipynb) project.
;; This notebook demonstrates some of the more advanced features of Clojupyter.
;; %% [markdown]
;; ## Displaying HTML
;;
;; To display HTML, you'll need to require a clojupyter helper function to change the cell output
;; %%
(require '[clojupyter.misc.display :as display])
;; %%
(println ">> should print some text")
;; displaying html
(display/hiccup-html
[:ul
[:li "a " [:i "emphatic"] " idea"]
[:li "a " [:b "bold"] " idea"]
[:li "an " [:span {:style "text-decoration: underline;"} "important"] " idea"]])
;; %% [markdown]
;; We can also use this to render SVG:
;; %%
(display/hiccup-html
[:svg {:height 100 :width 100 :xmlns "http://www.w3.org/2000/svg"}
[:circle {:cx 50 :cy 40 :r 40 :fill "red"}]])
;; %% [markdown]
;; ## Adding External Clojure Dependencies
;;
;; You can fetch external Clojure dependencies using the `clojupyter.misc.helper` namespace.
;; %%
(require '[clojupyter.misc.helper :as helper])
;; %%
(helper/add-dependencies '[org.clojure/data.json "0.2.6"])
(require '[clojure.data.json :as json])
;; %%
(json/write-str {:a 1 :b [2, 3] :c "c"})
;; %% [markdown]
;; ## Adding External Javascript Dependency
;;
;; Since you can render arbitrary HTML using `display/hiccup-html`, it's pretty easy to use external Javascript libraries to do things like generate charts. Here's an example using [Highcharts](https://www.highcharts.com/).
;;
;; First, we use a cell to add javascript to the running notebook:
;; %%
(helper/add-javascript "https://code.highcharts.com/highcharts.js")
;; %% [markdown]
;; Now we define a function which takes Clojure data and returns hiccup HTML to display:
;; %%
(defn plot-highchart [highchart-json]
(let [id (str (java.util.UUID/randomUUID))
code (format "Highcharts.chart('%s', %s );" id, (json/write-str highchart-json))]
(display/hiccup-html
[:div [:div {:id id :style {:background-color "red"}}]
[:script code]])))
;; %% [markdown]
;; Now we can make generate interactive plots (try hovering over plot):
;; %%
(def raw-data (map #(+ (* 22 (+ % (Math/random)) 78)) (range)))
(def data-1 (take 500 raw-data))
(def data-2 (take 500 (drop 500 raw-data)))
(plot-highchart {:chart {:type "line"}
:title {:text "Plot of random data"}
:series [{:data data-1} {:data data-2}]})
;; %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/ijavascript.js
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Javascript (Node.js)
// language: javascript
// name: javascript
// ---
// %% [markdown]
// ## A notebook that uses IJavascript kernel
// %%
let x = 5;
const y = 6;
var z = 10;
// %%
x + y;
// %%
function add(num1, num2) {
return num1 + num2
}
// %%
add(x, y);
// %%
const arrowAdd = (num1, num2) => num1 + num2;
// %%
arrowAdd(x, y);
// %%
const myCar = {
color: "blue",
weight: 850,
model: "fiat",
start: () => "car started!",
doors: [1,2,3,4]
}
// %%
console.log("color:", myCar.color);
// %%
console.log("start:", myCar.start());
// %%
for (let door of myCar.doors) {
console.log("I'm door", door)
}
// %%
myCar;
// %%
class User {
constructor(name){
this.name = name;
}
sayHello(){
return "Hello, I'm " + this.name;
}
}
// %%
let John = new User("John");
John.sayHello();
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/ir_notebook.R
================================================
# ---
# jupyter:
# kernelspec:
# display_name: R
# language: R
# name: ir
# ---
# %% [markdown]
# This is a jupyter notebook that uses the IR kernel.
# %%
sum(1:10)
# %%
plot(cars)
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/itypescript.ts
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Typescript 3.5
// language: typescript
// name: typescript
// ---
// %%
let x: number = 5;
const y: number = 6;
var z: string = "hi";
console.log(z);
x + y;
// %%
function add(num1: number, num2: number): number {
return num1 + num2
}
add(x, y);
// %%
const arrowAdd = (num1: number, num2: number) => num1 + num2;
arrowAdd(x, y);
// %%
class User {
constructor(private name: string) {
this.name = name;
}
sayHello(): string {
return "Hello, I'm " + this.name;
}
}
let John: User;
John = new User("John");
John.sayHello();
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/julia_benchmark_plotly_barchart.jl
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Julia 1.1.1
# language: julia
# name: julia-1.1
# ---
# %%
# IJulia rocks! So does Plotly. Check it out
using Plotly
api_key = "" # visit https://plot.ly/api to generate an API username and password
username = ""
Plotly.signin(username, api_key)
# %%
# Following data taken from http://julialang.org/ frontpage
benchmarks = ["fib", "parse_int", "quicksort3", "mandel", "pi_sum", "rand_mat_stat", "rand_mat_mul"]
platforms = ["Fortran", "Julia", "Python", "R", "Matlab", "Mathematica", "Javascript", "Go"]
data = {
platforms[1] => [0.26, 5.03, 1.11, 0.86, 0.80, 0.64, 0.96],
platforms[2] => [0.91, 1.60, 1.14, 0.85, 1.00, 1.66, 1.01],
platforms[3] => [30.37, 13.95, 31.98, 14.19, 16.33, 13.52, 3.41 ],
platforms[4] => [411.36, 59.40, 524.29, 106.97, 15.42, 10.84, 3.98 ],
platforms[5] => [1992.00, 1463.16, 101.84, 64.58, 1.29, 6.61, 1.10 ],
platforms[6] => [64.46, 29.54, 35.74, 6.07, 1.32, 4.52, 1.16 ],
platforms[7] => [2.18, 2.43, 3.51, 3.49, 0.84, 3.28, 14.60],
platforms[8] => [1.03, 4.79, 1.25, 2.36, 1.41, 8.12, 8.51]
}
pdata = [ {"x"=>benchmarks,"y"=>data[k],"bardir"=>"h","type"=>"bar","name"=>k} for k = platforms ]
layout = {
"title"=> "Julia benchmark comparison (smaller is better, C performance = 1.0)",
"barmode"=> "group",
"autosize"=> false,
"width"=> 900,
"height"=> 900,
"titlefont"=>
{
"family"=> "Open Sans",
"size"=> 18,
"color"=> "rgb(84, 39, 143)"
},
"margin"=> {"l"=>160, "pad"=>0},
"xaxis"=> {
"title"=> "Benchmark log-time",
"type"=> "log"
},
"yaxis"=> {"title"=> "Benchmark Name"}
}
response = Plotly.plot(pdata,["layout"=>layout])
# Embed in an iframe within IJulia
s = string("")
display("text/html", s)
# %%
# checkout https://plot.ly/api/ for more Julia examples!
# But to show off some other Plotly features:
x = 1:1500
y1 = sin(2*pi*x/1500.) + rand(1500)-0.5
y2 = sin(2*pi*x/1500.)
fish = {"x"=>x,"y"=> y1,
"type"=>"scatter","mode"=>"markers",
"marker"=>{"color"=>"rgb(0, 0, 255)","opacity"=>0.5 } }
fit = {"x"=> x,"y"=> y2,
"type"=>"scatter", "mode"=>"markers", "opacity"=>0.8,
"marker"=>{"color"=>"rgb(255, 0, 0)"} }
layout = {"autosize"=> false,
"width"=> 650, "height"=> 550,
"title"=>"Fish School",
"xaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[0,1500] },
"yaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[-2.2,2.2] },
"plot_bgcolor"=> "rgb(245,245,247)",
"showlegend"=> false,
"hovermode"=> "closest"}
response = Plotly.plot([fish, fit],["layout"=>layout])
s = string("")
display("text/html", s)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/julia_functional_geometry.jl
================================================
# -*- coding: utf-8 -*-
# ---
# jupyter:
# kernelspec:
# display_name: Julia 1.1.1
# language: julia
# name: julia-1.1
# ---
# %%
# This notebook is a semi top-down explanation. This cell needs to be
# executed first so that the operators and helper functions are defined
# All of this is explained in the later half of the notebook
using Compose, Interact
Compose.set_default_graphic_size(2inch, 2inch)
points_f = [
(.1, .1),
(.9, .1),
(.9, .2),
(.2, .2),
(.2, .4),
(.6, .4),
(.6, .5),
(.2, .5),
(.2, .9),
(.1, .9),
(.1, .1)
]
f = compose(context(), stroke("black"), line(points_f))
rot(pic) = compose(context(rotation=Rotation(-deg2rad(90))), pic)
flip(pic) = compose(context(mirror=Mirror(deg2rad(90), 0.5w, 0.5h)), pic)
above(m, n, p, q) =
compose(context(),
(context(0, 0, 1, m/(m+n)), p),
(context(0, m/(m+n), 1, n/(m+n)), q))
above(p, q) = above(1, 1, p, q)
beside(m, n, p, q) =
compose(context(),
(context(0, 0, m/(m+n), 1), p),
(context(m/(m+n), 0, n/(m+n), 1), q))
beside(p, q) = beside(1, 1, p, q)
over(p, q) = compose(context(),
(context(), p), (context(), q))
rot45(pic) =
compose(context(0, 0, 1/sqrt(2), 1/sqrt(2),
rotation=Rotation(-deg2rad(45), 0w, 0h)), pic)
# Utility function to zoom out and look at the context
zoomout(pic) = compose(context(),
(context(0.2, 0.2, 0.6, 0.6), pic),
(context(0.2, 0.2, 0.6, 0.6), fill(nothing), stroke("black"), strokedash([0.5mm, 0.5mm]),
polygon([(0, 0), (1, 0), (1, 1), (0, 1)])))
function read_path(p_str)
tokens = [try parsefloat(x) catch symbol(x) end for x in split(p_str, r"[\s,]+")]
path(tokens)
end
fish = compose(context(units=UnitBox(260, 260)), stroke("black"),
read_path(strip(readall("fish.path"))))
rotatable(pic) = @manipulate for θ=0:0.001:2π
compose(context(rotation=Rotation(θ)), pic)
end
blank = compose(context())
fliprot45(pic) = rot45(compose(context(mirror=Mirror(deg2rad(-45))),pic))
# Hide this cell.
display(MIME("text/html"), """""")
# %% [markdown]
# # Functional Geometry
# *Functional Geometry* is a paper by Peter Henderson ([original (1982)](users.ecs.soton.ac.uk/peter/funcgeo.pdf), [revisited (2002)](https://cs.au.dk/~hosc/local/HOSC-15-4-pp349-365.pdf)) which deconstructs the MC Escher woodcut *Square Limit*
#
# 
# %% [markdown]
# > A picture is an example of a complex object that can be described in terms of its parts.
# Yet a picture needs to be rendered on a printer or a screen by a device that expects to
# be given a sequence of commands. Programming that sequence of commands directly is
# much harder than having an application generate the commands automatically from the
# simpler, denotational description.
# %% [markdown]
# A `picture` is a *denotation* of something to draw.
#
# e.g. The value of f here denotes the picture of the letter F
# %% [markdown]
# Original at http://nbviewer.jupyter.org/github/shashi/ijulia-notebooks/blob/master/funcgeo/Functional%20Geometry.ipynb
# %% [markdown]
# ## In conclusion
#
# We described Escher's *Square Limit* from the description of its smaller parts, which in turn were described in terms of their smaller parts.
#
# This seemed simple because we chose to talk in terms of an *algebra* to describe pictures. The primitives `rot`, `flip`, `fliprot45`, `above`, `beside` and `over` fit the job perfectly.
#
# We were able to describe these primitives in terms of `compose` `contexts`, which the Compose library knows how to render.
#
# Denotation can be an easy way to describe a system as well as a practical implementation method.
#
# [Abstraction barriers](https://mitpress.mit.edu/sicp/full-text/sicp/book/node29.html) are useful tools that can reduce the cognitive overhead on the programmer. It entails creating layers consisting of functions which only use functions in the same layer or layers below in their own implementation. The layers in our language were:
#
# ------------------[ squarelimit ]------------------
# -------------[ quartet, cycle, nonet ]-------------
# ---[ rot, flip, fliprot45, above, beside, over ]---
# -------[ compose, context, line, path,... ]--------
#
# Drawing this diagram out is a useful way to begin building any library.
#
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/jupyter.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# # Jupyter notebook
#
# This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition:
# %%
a = 1
b = 2
a + b
# %% [markdown]
# Now we return a few tuples
# %%
a, b
# %%
a, b, a+b
# %% [markdown]
# And this is already the end of the notebook
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/jupyter_again.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
c = '''
title: "Quick test"
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type console
'''
# %%
import yaml
print(yaml.dump(yaml.load(c)))
# %%
?next
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/jupyter_with_raw_cell_in_body.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
1+2+3
# %% [raw]
# This is a raw cell
# %% [markdown]
# This is a markdown cell
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/jupyter_with_raw_cell_on_top.py
================================================
# ---
# title: Quick test
# output:
# ioslides_presentation:
# widescreen: true
# smaller: true
# editor_options:
# chunk_output_type: console
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
1+2+3
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/jupyter_with_raw_cell_with_invalid_yaml.py
================================================
# ---
# title: Exception: Test
# jupyter:
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# %%
1 + 2 + 3
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/jupyterlab-slideshow_1441.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# %% [markdown] @deathbeds/jupyterlab-fonts={"styles": {"": {"body[data-jp-deck-mode='presenting'] &": {"right": "0", "top": "30%", "width": "25%", "z-index": 1}}}} jupyterlab-slideshow={"layer": "slide"}
# > **Note**
# >
# > `slide` layer with a `top` of `30%`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/jupytext_replication.sos
================================================
# ---
# jupyter:
# kernelspec:
# display_name: SoS
# language: sos
# name: sos
# ---
# %% [markdown] Collapsed="false" kernel="SoS"
# # Text SOS-kernel with Jupytext
#
# ## What is SOS kernel
#
# SoS consists of a ployglot notebook that allows the use of multiple kernels in one Jupyter notebook, and a workflow system that is designed for daily computational research. Basically,
#
# - SoS Polyglot Notebook is a Jupyter Notebook with a SoS kernel.
# - SoS Notebook serves as a super kernel to all other Jupyter kernels and allows the use of multiple kernels in one Jupyter notebook.
# - SoS Workflow System is a Python based workflow system that is designed to be readable, shareable, and suitable for daily data analysis.
# - SoS Workflow System can be used from command line or use SoS Notebook as its IDE.
#
# 
#
# ### How to install SOS-kernel
#
# Please follow this [link](https://vatlab.github.io/sos-docs/running.html#Conda-installation) to setup SOS
#
# I run some issue with the latest version of R on my Mac, so I had to install an earlier version of R
#
# ```
# conda install -c r r=3.5.1
# conda install sos-notebook jupyterlab-sos sos-papermill -c conda-forge
# ```
#
# ## Related issue with Jupytext
#
# Jupytext works fine with Python/R kernel but converts code cells into markdown cells when using the SOS kernel.
#
# cf the image below. It is a code cell. After saving the notebook and restart it, it converted the code cell into markdown
#
#
# %% [markdown] Collapsed="false" kernel="SoS"
# ## Step 1
#
# Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.
#
# 
# %% Collapsed="false" kernel="SoS"
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
# %% [markdown] Collapsed="false" kernel="python3"
# ## Step 2
#
# Now, pair it with Jupytex
#
# 
# %% [markdown] Collapsed="false" kernel="python3"
# ### Step 3
#
# Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
# %% [markdown] Collapsed="false" kernel="python3"
# ### Step 4
#
# Reopen the notebook. Here is the outcome
#
# 
#
#
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/kalman_filter_and_visualization.q
================================================
/ ---
/ jupyter:
/ kernelspec:
/ display_name: Q 3.5
/ language: q
/ name: qpk
/ ---
/ %%
plt: .p.import`matplotlib.pyplot
/ %%
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
/ %%
price: 100 + sums 0.5 - (n:50)?1.
/ %%
output:filter price
/ %%
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
/ %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/logtalk_notebook.lgt
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Logtalk
% language: logtalk
% name: logtalk_kernel
% ---
% %% [markdown]
% # An implementation of the Ackermann function
% %% vscode={"languageId": "logtalk"}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
% %% [markdown]
% ## Sample query
% %% vscode={"languageId": "logtalk"}
ack::ack(2, 4, V).
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/lua_example.lua
================================================
-- -*- coding: utf-8 -*-
-- ---
-- jupyter:
-- kernelspec:
-- display_name: Lua
-- language: lua
-- name: lua
-- ---
-- %% [markdown]
-- Source: https://www.lua.org/pil/19.3.html
-- %% [markdown]
-- # Sort
-- %% [markdown]
-- Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
-- %% [markdown]
-- A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
-- %%
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
-- %% [markdown]
-- Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
-- %%
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
-- %% [markdown]
-- Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
-- %% [markdown]
-- As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
-- %%
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
-- %% [markdown]
-- With this function, it is easy to print those function names in alphabetical order. The loop
-- %%
for name, line in pairsByKeys(lines) do
print(name, line)
end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/maxima_example.mac
================================================
/* --- */
/* jupyter: */
/* kernelspec: */
/* display_name: Maxima */
/* language: maxima */
/* name: maxima */
/* --- */
/* %% [markdown] */
/* ## maxima misc */
/* %% */
kill(all)$
/* %% */
f(x) := 1/(x^2+l^2)^(3/2);
/* %% */
integrate(f(x), x);
/* %% */
tex(%)$
/* %% */
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/notebook_with_complex_metadata.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/nteract_with_parameter.py
================================================
# ---
# jupyter:
# kernel_info:
# name: python3
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% inputHidden=false outputHidden=false tags=["parameters"]
param = 4
# %% inputHidden=false outputHidden=false
import pandas as pd
# %% inputHidden=false outputHidden=false
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
# %% inputHidden=false outputHidden=false
%matplotlib inline
df.plot(kind='bar')
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/ocaml_notebook.ml
================================================
(* --- *)
(* jupyter: *)
(* jupytext: *)
(* formats: ipynb:markdown,md *)
(* kernelspec: *)
(* display_name: OCaml default *)
(* language: OCaml *)
(* name: ocaml-jupyter *)
(* --- *)
(* %% [markdown] *)
(* # Example of an OCaml notebook *)
(* %% *)
let sum x y = x + y
(* %% [markdown] *)
(* Let's try our function: *)
(* %% *)
sum 3 4 = 7 + 0
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/octave_notebook.m
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Octave
% language: octave
% name: octave
% ---
% %% [markdown]
% A markdown cell
% %%
1 + 1
% %%
% a code cell with comments
2 + 2
% %%
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
% %%
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
% %% [markdown]
% And to finish with, a Python cell
% %%
%%python
a = 1
% %%
%%python
a + 1
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/plotly_graphs.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# This notebook contains complex outputs, including plotly javascript graphs.
# %% [markdown]
# # Interactive plots
# %% [markdown]
# We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
# %%
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
# %%
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/powershell.ps1
================================================
# ---
# jupyter:
# kernelspec:
# display_name: PowerShell
# language: PowerShell
# name: powershell
# ---
# %% [markdown]
# This is an extract from
# https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
# %%
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/raw_cell_with_complex_yaml_like_content.py
================================================
# ---
#
# This is a complex paragraph
# that is split over multiple lines.
#
# It also includes blank lines.
#
#
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/raw_cell_with_non_dict_yaml_content.py
================================================
# ---
# Content.
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/root_cpp.cpp
================================================
// ---
// jupyter:
// kernelspec:
// display_name: ROOT C++
// language: c++
// name: root
// ---
// %%
#include
#include
// %%
int k = 4;
std::string foo = "This string says \"foo\"";
// %%
std::cout << "k = " << k << '\n' << foo << '\n';
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/sage_print_hello.sage
================================================
# ---
# jupyter:
# kernelspec:
# display_name: SageMath 9.2
# language: sage
# name: sagemath
# ---
# %%
print("Hello world")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/sample_bash_notebook.sh
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Bash
# language: bash
# name: bash
# ---
# %%
ls
# %%
# https://coderwall.com/p/euwpig/a-better-git-log
git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"
# %%
git lg
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/sample_rise_notebook_66.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown] slideshow={"slide_type": "slide"}
# A markdown cell
# %% slideshow={"slide_type": ""}
1+1
# %% [markdown] cell_style="center" slideshow={"slide_type": "fragment"}
# Markdown cell two
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/sas.sas
================================================
/* --- */
/* jupyter: */
/* kernelspec: */
/* display_name: SAS */
/* language: sas */
/* name: sas */
/* --- */
/* %% [markdown] */
/* # SAS Notebooks with jupytext */
/* %% */
proc sql;
select *
from sashelp.cars (obs=10)
;
quit;
/* %% */
%let name = "Jupytext";
/* %% */
%put &name;
/* %% */
/* Note when defining macros "%macro" cannot be the first line of text in the cell */
%macro test;
data temp;
set sashelp.cars;
name = "testx";
run;
proc print data = temp (obs=10);
run;
%mend test;
%test
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/simple-helloworld.java
================================================
// -*- coding: utf-8 -*-
// ---
// jupyter:
// jupytext:
// formats: ipynb,java:hydrogen
// kernelspec:
// display_name: Java
// language: java
// name: java
// ---
// %% [markdown]
// Let's define some class.
// %%
class A {
public void hello() {
System.out.println("Hello World");
}
}
// %% [markdown]
// And now we call its method.
// %%
new A().hello();
// %% [markdown]
// You can run it e.g. with `jshell`
//
// * from command line, as `jshell simple-helloworld.java`
// * from jshell's shell with `/open simple-helloworld.java`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/simple_robot_notebook.robot
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Robot Framework
# language: robotframework
# name: robotkernel
# ---
# %%
*** Settings ***
Library Collections
# %%
*** Keywords ***
Head
[Arguments] ${list}
${value}= Get from list ${list} 0
[Return] ${value}
# %%
*** Tasks ***
Get head
${array}= Create list 1 2 3 4 5
${head}= Head ${array}
Should be equal ${head} 1
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/simple_scala_notebook.scala
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Apache Toree - Scala
// language: scala
// name: apache_toree_scala
// ---
// %%
// This is just a simple scala notebook
object SampleObject {
def calculation(x: Int, y: Int): Int = x + y
}
val result = SampleObject.calculation(1, 2)
// %%
println(result * 10)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/stata_notebook.do
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Stata
// language: stata
// name: stata
// ---
// %%
// This notebook uses the stata_kernel: https://github.com/kylebarron/stata_kernel
// %%
use http://www.stata-press.com/data/r13/auto
// %%
summarize
// %%
scatter weight length
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/tailrecursive-factorial.groovy
================================================
// -*- coding: utf-8 -*-
// ---
// jupyter:
// jupytext:
// formats: ipynb,groovy:hydrogen
// kernelspec:
// display_name: Groovy
// language: groovy
// name: groovy
// ---
// %% [markdown]
// # TailRecursive annotation
//
// Let's check what is the effect of `@TailRecursive` annotation on the simple recursive definition of factorial function.
// %%
import groovy.transform.CompileStatic
import groovy.transform.TailRecursive
import groovy.transform.TypeChecked
@CompileStatic
@TypeChecked
class X {
static final BigInteger factorial0(int n) {
(n <= 1) ? 1G : factorial0(n-1).multiply(BigInteger.valueOf(n))
}
static final BigInteger factorial1(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial1(n-1, acc.multiply(BigInteger.valueOf(n)))
}
@TailRecursive
static final BigInteger factorial2(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial2(n-1, acc.multiply(BigInteger.valueOf(n)))
}
}
x = new X()
// %% [markdown]
// Although we can time the execution of the calls, it is not very accurate; such micro benchmarks should be performed in more controlled environment, such us under [JMH](https://openjdk.java.net/projects/code-tools/jmh/).
//
// For example, see [blog posts of Szymon Stępniak](https://e.printstacktrace.blog/tail-recursive-methods-in-groovy/).
// %%
%%timeit
x.factorial0(19_000).toString().length()
// %%
%%timeit
x.factorial1(19_000).toString().length()
// %%
%%timeit
x.factorial2(19_000).toString().length()
// %% [markdown]
// The real difference is the use of stack. Non-tail recursive calls exhaust the stack space at some point, whereas tail recursive calls don't add frames to the stack.
// %%
factSize = { n, cl ->
println "Factorial of ${n} has ${cl(n).toString().length()} digits"
}
factSize 2_000, x.&factorial0
factSize 2_000, x.&factorial1
factSize 2_000, x.&factorial2
factSize 100_000, x.&factorial2
// %%
try {
factSize 100_000, x.&factorial1
} catch (Throwable e) {
assert e instanceof StackOverflowError
println e
}
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/tcl_test.tcl
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Tcl
# language: tcl
# name: tcljupyter
# ---
# %% [markdown]
# # Assign Values
# %%
set a 1
puts "a = $a"
# %% [markdown]
# # Loop
# %%
for {set i 0} {$i < 10} {incr i} {
puts "I inside first loop: $i"
}
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/text_outputs_and_images.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# This notebook contains outputs of many different types: text, HTML, plots and errors.
# %% [markdown]
# # Text outputs
#
# Using `print`, `sys.stdout` and `sys.stderr`
# %%
import sys
print('using print')
sys.stdout.write('using sys.stdout.write')
sys.stderr.write('using sys.stderr.write')
# %%
import logging
logging.debug('Debug')
logging.info('Info')
logging.warning('Warning')
logging.error('Error')
# %% [markdown]
# # HTML outputs
#
# Using `pandas`. Here we find two representations: both text and HTML.
# %%
import pandas as pd
pd.DataFrame([4])
# %%
from IPython.display import display
display(pd.DataFrame([5]))
display(pd.DataFrame([6]))
# %% [markdown]
# # Images
# %%
%matplotlib inline
# %%
# First plot
from matplotlib import pyplot as plt
import numpy as np
w, h = 3, 3
data = np.zeros((h, w, 3), dtype=np.uint8)
data[0,:] = [0,255,0]
data[1,:] = [0,0,255]
data[2,:] = [0,255,0]
data[1:3,1:3] = [255, 0, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# Second plot
data[1:3,1:3] = [255, 255, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# %% [markdown]
# # Errors
# %%
undefined_variable
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/wolfram.wolfram
================================================
(* --- *)
(* jupyter: *)
(* kernelspec: *)
(* display_name: Wolfram Language 13.1 *)
(* language: Wolfram Language *)
(* name: wolframlanguage13.1 *)
(* --- *)
(* %% [markdown] *)
(* **Note:** The `language_info` `file_extension` in this notebook should be `.m`, but it was deliberately changed to `.wolfram` to avoid conflicts with Matlab which is using the same extension. *)
(* %% [markdown] *)
(* We start with... *)
(* %% *)
Print["Hello, World!"];
(* %% [markdown] *)
(* Then we draw the first example plot from the [ListPlot](https://reference.wolfram.com/language/ref/ListPlot.html) reference: *)
(* %% *)
ListPlot[Prime[Range[25]]]
(* %% [markdown] *)
(* We also test the math outputs as in the [Simplify](https://reference.wolfram.com/language/ref/Simplify.html) example: *)
(* %% *)
D[Integrate[1/(x^3 + 1), x], x]
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/xcpp_by_quantstack.cpp
================================================
// ---
// jupyter:
// kernelspec:
// display_name: C++14
// language: C++14
// name: xeus-cling-cpp14
// ---
// %% [markdown]
// [](https://github.com/QuantStack/xeus-cling/)
//
// A Jupyter kernel for C++ based on the `cling` C++ interpreter and the `xeus` native implementation of the Jupyter protocol, xeus.
//
// - GitHub repository: https://github.com/QuantStack/xeus-cling/
// - Online documentation: https://xeus-cling.readthedocs.io/
// %% [markdown]
// ## Usage
//
//
std::cout << "some output" << std::endl;
// %%
std::cerr << "some error" << std::endl;
// %%
#include
// %%
throw std::runtime_error("Unknown exception");
// %% [markdown]
// Omitting the `;` in the last statement of a cell results in an output being printed
// %%
int j = 5;
// %%
j
// %% [markdown]
// # Interpreting the C++ programming language
//
// `cling` has a broad support of the features of C++. You can define functions, classes, templates, etc ...
// %% [markdown]
// ## Functions
// %%
double sqr(double a)
{
return a * a;
}
// %%
double a = 2.5;
double asqr = sqr(a);
asqr
// %% [markdown]
// ## Classes
// %%
class Foo
{
public:
virtual ~Foo() {}
virtual void print(double value) const
{
std::cout << "Foo value = " << value << std::endl;
}
};
// %%
Foo bar;
bar.print(1.2);
// %% [markdown]
// ## Polymorphism
// %%
class Bar : public Foo
{
public:
virtual ~Bar() {}
virtual void print(double value) const
{
std::cout << "Bar value = " << 2 * value << std::endl;
}
};
// %%
Foo* bar2 = new Bar;
bar2->print(1.2);
delete bar2;
// %% [markdown]
// ## Templates
// %%
#include
template
class FooT
{
public:
explicit FooT(const T& t) : m_t(t) {}
void print() const
{
std::cout << typeid(T).name() << " m_t = " << m_t << std::endl;
}
private:
T m_t;
};
template <>
class FooT
{
public:
explicit FooT(const int& t) : m_t(t) {}
void print() const
{
std::cout << "m_t = " << m_t << std::endl;
}
private:
int m_t;
};
// %%
FooT foot1(1.2);
foot1.print();
// %%
FooT foot2(4);
foot2.print();
// %% [markdown]
// ## C++11 / C++14 support
// %%
class Foo11
{
public:
Foo11() { std::cout << "Foo11 default constructor" << std::endl; }
Foo11(const Foo11&) { std::cout << "Foo11 copy constructor" << std::endl; }
Foo11(Foo11&&) { std::cout << "Foo11 move constructor" << std::endl; }
};
// %%
Foo11 f1;
Foo11 f2(f1);
Foo11 f3(std::move(f1));
// %%
#include
std::vector v = { 1, 2, 3};
auto iter = ++v.begin();
v
// %%
*iter
// %% [markdown]
// ... and also lambda, universal references, `decltype`, etc ...
// %% [markdown]
// ## Documentation and completion
//
// - Documentation for types of the standard library is retrieved on cppreference.com.
// - The quick-help feature can also be enabled for user-defined types and third-party libraries. More documentation on this feature is available at https://xeus-cling.readthedocs.io/en/latest/inline_help.html.
//
// %%
?std::vector
// %% [markdown]
// ## Using the `display_data` mechanism
// %% [markdown]
// For a user-defined type `T`, the rich rendering in the notebook and JupyterLab can be enabled by by implementing the function `xeus::xjson mime_bundle_repr(const T& im)`, which returns the JSON mime bundle for that type.
//
// More documentation on the rich display system of Jupyter and Xeus-cling is available at https://xeus-cling.readthedocs.io/en/latest/rich_display.html
// %% [markdown]
// ### Image example
// %%
#include
#include
#include "xtl/xbase64.hpp"
#include "xeus/xjson.hpp"
namespace im
{
struct image
{
inline image(const std::string& filename)
{
std::ifstream fin(filename, std::ios::binary);
m_buffer << fin.rdbuf();
}
std::stringstream m_buffer;
};
xeus::xjson mime_bundle_repr(const image& i)
{
auto bundle = xeus::xjson::object();
bundle["image/png"] = xtl::base64encode(i.m_buffer.str());
return bundle;
}
}
// %%
im::image marie("images/marie.png");
marie
// %% [markdown]
// ### Audio example
// %%
#include
#include
#include "xtl/xbase64.hpp"
#include "xeus/xjson.hpp"
namespace au
{
struct audio
{
inline audio(const std::string& filename)
{
std::ifstream fin(filename, std::ios::binary);
m_buffer << fin.rdbuf();
}
std::stringstream m_buffer;
};
xeus::xjson mime_bundle_repr(const audio& a)
{
auto bundle = xeus::xjson::object();
bundle["text/html"] =
std::string("";
return bundle;
}
}
// %%
au::audio drums("audio/audio.wav");
drums
// %% [markdown]
// ### Display
// %%
#include "xcpp/xdisplay.hpp"
// %%
xcpp::display(drums);
// %% [markdown]
// ### Update-display
// %%
#include
#include "xcpp/xdisplay.hpp"
namespace ht
{
struct html
{
inline html(const std::string& content)
{
m_content = content;
}
std::string m_content;
};
xeus::xjson mime_bundle_repr(const html& a)
{
auto bundle = xeus::xjson::object();
bundle["text/html"] = a.m_content;
return bundle;
}
}
// A red rectangle
ht::html rect(R"(
#include
// %%
std::vector to_shuffle = {1, 2, 3, 4};
// %%
%timeit std::random_shuffle(to_shuffle.begin(), to_shuffle.end());
// %% [markdown]
// [](https://github.com/QuantStack/xtensor/)
//
// - GitHub repository: https://github.com/QuantStack/xtensor/
// - Online documentation: https://xtensor.readthedocs.io/
// - NumPy to xtensor cheat sheet: http://xtensor.readthedocs.io/en/latest/numpy.html
//
// `xtensor` is a C++ library for manipulating N-D arrays with an API very similar to that of numpy.
// %%
#include
#include "xtensor/xarray.hpp"
#include "xtensor/xio.hpp"
#include "xtensor/xview.hpp"
xt::xarray arr1
{{1.0, 2.0, 3.0},
{2.0, 5.0, 7.0},
{2.0, 5.0, 7.0}};
xt::xarray arr2
{5.0, 6.0, 7.0};
xt::view(arr1, 1) + arr2
// %% [markdown]
// Together with the C++ Jupyter kernel, `xtensor` offers a similar experience as `NumPy` in the Python Jupyter kernel, including broadcasting and universal functions.
// %%
#include
#include "xtensor/xarray.hpp"
#include "xtensor/xio.hpp"
// %%
xt::xarray arr
{1, 2, 3, 4, 5, 6, 7, 8, 9};
arr.reshape({3, 3});
std::cout << arr;
// %%
#include "xtensor-blas/xlinalg.hpp"
// %%
xt::xtensor m = {{1.5, 0.5}, {0.7, 1.0}};
std::cout << "Matrix rank: " << std::endl << xt::linalg::matrix_rank(m) << std::endl;
std::cout << "Matrix inverse: " << std::endl << xt::linalg::inv(m) << std::endl;
std::cout << "Eigen values: " << std::endl << xt::linalg::eigvals(m) << std::endl;
// %%
xt::xarray arg1 = xt::arange(9);
xt::xarray arg2 = xt::arange(18);
arg1.reshape({3, 3});
arg2.reshape({2, 3, 3});
std::cout << xt::linalg::dot(arg1, arg2) << std::endl;
// %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/xonsh_example.xsh
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Xonsh
# language: xonsh
# name: xonsh
# ---
# %%
len($(curl -L https://xon.sh))
# %%
for filename in `.*`:
print(filename)
du -sh @(filename)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_marimo/Line_breaks_in_LateX_305.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
This cell uses no particular cell marker
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
""")
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
This cell uses no particular cell marker, and a single slash in the $\LaTeX$ equation
$$
\begin{align}
\dot{x} & = \sigma(y-x) \
\dot{y} & = \rho x - y - xz \
\dot{z} & = -\beta z + xy
\end{align}
$$
""")
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
This cell uses the triple quote cell markers introduced at https://github.com/mwouts/jupytext/issues/305
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
""")
return
@app.cell
def _():
import marimo as mo
return (mo,)
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_marimo/Notebook with function and cell metadata 164.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell
def _():
1 + 1
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
A markdown cell
And below, the cell for function f has non trivial cell metadata. And the next cell as well.
""")
return
@app.function
def f(x):
return x
@app.cell
def _():
f(5)
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
More text
""")
return
@app.cell
def _():
2 + 2
return
@app.cell
def _():
import marimo as mo
return (mo,)
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_marimo/Notebook with many hash signs.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
##################################################################
This is a notebook that contains many hash signs.
Hopefully its python representation is not recognized as a Sphinx Gallery script...
##################################################################
""")
return
@app.cell
def _():
some = 1
code = 2
some+code
##################################################################
# A comment
##################################################################
# Another comment
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
##################################################################
This is a notebook that contains many hash signs.
Hopefully its python representation is not recognized as a Sphinx Gallery script...
##################################################################
""")
return
@app.cell
def _():
import marimo as mo
return (mo,)
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_marimo/cat_variable.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell
def _():
cat = 42
return
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_marimo/frozen_cell.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell
def _():
# This is an unfrozen cell. Works as usual.
print("I'm a regular cell so I run and print!")
return
@app.cell
def _():
# This is an frozen cell
print("I'm frozen so Im not executed :(")
return
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_marimo/jupyter.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
# Jupyter notebook
This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition:
""")
return
@app.cell
def _():
a = 1
b = 2
a + b
return a, b
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
Now we return a few tuples
""")
return
@app.cell
def _(a, b):
a, b
return
@app.cell
def _(a, b):
a, b, a+b
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
And this is already the end of the notebook
""")
return
@app.cell
def _():
import marimo as mo
return (mo,)
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_marimo/notebook_with_complex_metadata.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell
def _():
return
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_marimo/plotly_graphs.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
This notebook contains complex outputs, including plotly javascript graphs.
""")
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
# Interactive plots
""")
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
""")
return
@app.cell
def _():
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
return
@app.cell
def _():
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
return
@app.cell
def _():
import marimo as mo
return (mo,)
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_marimo/sample_rise_notebook_66.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
A markdown cell
""")
return
@app.cell
def _():
1+1
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
Markdown cell two
""")
return
@app.cell
def _():
import marimo as mo
return (mo,)
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_marimo/text_outputs_and_images.py
================================================
import marimo
__generated_with = "0.17.8"
app = marimo.App()
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
This notebook contains outputs of many different types: text, HTML, plots and errors.
""")
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
# Text outputs
Using `print`, `sys.stdout` and `sys.stderr`
""")
return
@app.cell
def _():
import sys
print('using print')
sys.stdout.write('using sys.stdout.write')
sys.stderr.write('using sys.stderr.write')
return
@app.cell
def _():
import logging
logging.debug('Debug')
logging.info('Info')
logging.warning('Warning')
logging.error('Error')
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
# HTML outputs
Using `pandas`. Here we find two representations: both text and HTML.
""")
return
@app.cell
def _():
import pandas as pd
pd.DataFrame([4])
return (pd,)
@app.cell
def _(pd):
from IPython.display import display
display(pd.DataFrame([5]))
display(pd.DataFrame([6]))
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
# Images
""")
return
@app.cell
def _():
# '%matplotlib inline' command supported automatically in marimo
return
@app.cell
def _():
# First plot
from matplotlib import pyplot as plt
import numpy as np
w, h = 3, 3
data = np.zeros((h, w, 3), dtype=np.uint8)
data[0,:] = [0,255,0]
data[1,:] = [0,0,255]
data[2,:] = [0,255,0]
data[1:3,1:3] = [255, 0, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# Second plot
data[1:3,1:3] = [255, 255, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
return
@app.cell(hide_code=True)
def _(mo):
mo.md(r"""
# Errors
""")
return
@app.cell
def _(undefined_variable):
undefined_variable
return
@app.cell
def _():
import marimo as mo
return (mo,)
if __name__ == "__main__":
app.run()
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/Line_breaks_in_LateX_305.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
This cell uses no particular cell marker
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
This cell uses no particular cell marker, and a single slash in the $\LaTeX$ equation
$$
\begin{align}
\dot{x} & = \sigma(y-x) \
\dot{y} & = \rho x - y - xz \
\dot{z} & = -\beta z + xy
\end{align}
$$
This cell uses the triple quote cell markers introduced at https://github.com/mwouts/jupytext/issues/305
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/Notebook with function and cell metadata 164.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
1 + 1
```
A markdown cell
And below, the cell for function f has non trivial cell metadata. And the next cell as well.
```python attributes={"classes": [], "id": "", "n": "10"}
def f(x):
return x
```
```python attributes={"classes": [], "id": "", "n": "10"}
f(5)
```
More text
```python
2 + 2
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/Notebook with html and latex cells.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```html
It has breakpoints (click in left margin). You must press Stop to exit the debugger.
```scheme
%%debug
(begin
(define x 1)
(set! x 2)
)
```
### Python Integration
You can import and use any Python library in Calysto Scheme.
In addition, if you wish, you can execute expressions and statements in a Python environment:
```scheme
(python-eval "1 + 2")
```
```scheme
(python-exec
"
def mypyfunc(a, b):
return a * b
")
```
This is a shared environment with Scheme:
```scheme
(mypyfunc 4 5)
```
You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
```scheme
(define! mypyfunc2 (func (lambda (n) n)))
```
```scheme
(python-eval "mypyfunc2(34)")
```
# Differences Between Languages
## Major differences between Scheme and Python
1. In Scheme, double quotes are used for strings and may contain newlines
1. In Scheme, a single quote is short for (quote ...) and means "literal"
1. In Scheme, everything is an expression and has a return value
1. Python does not support macros (e.g., extending syntax)
1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
1. Scheme procedures are not Python functions, but there are means to use one as the other.
## Major Differences Between Calysto Scheme and other Schemes
1. define-syntax works slightly differently
1. In Calysto Scheme, #(...) is short for '#(...)
1. Calysto Scheme is missing many standard functions (see list at bottom)
1. Calysto Scheme has a built-in amb operator called `choose`
1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
### Stack Trace
Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
```scheme
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
```
```scheme
(fact 5)
```
To turn off the stack trace on error:
```scheme
(use-stack-trace #f)
```
That will allow infinite recursive loops without keeping track of the "stack".
# Calysto Scheme Variables
## SCHEMEPATH
SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
```scheme
SCHEMEPATH
```
```scheme
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
```
```scheme
SCHEMEPATH
```
## Getting Started
Note that you can use the word `lambda` or \lambda and then press [TAB]
```scheme
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
```
```scheme
(factorial 5)
```
## define-syntax
(define-syntax NAME RULES): a method for creating macros
```scheme
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
```
```scheme
(time (car '(1 2 3 4)))
```
```scheme
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
```
```scheme
(collect (* n n) for n in (range 10))
```
```scheme
(collect (* n n) for n in (range 5 20 3))
```
```scheme
(collect (* n n) for n in (range 10) if (> n 5))
```
```scheme
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
```
```scheme
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
```
```scheme
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
```
```scheme
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
```
```scheme
(for n in (range 10 20 2) do (print n))
```
```scheme
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
```
```scheme
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
```
```scheme
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
```
```scheme
(! 5)
```
```scheme
(nth 10 facts)
```
```scheme
(nth 20 fibs)
```
```scheme
(first 30 fibs)
```
## for-each
(for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
```scheme
(for-each (lambda (n) (print n)) '(3 4 5))
```
## format
(format STRING ITEM ...): format the string with ITEMS as arguments
```scheme
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
```
## func
Turns a lambda into a Python function.
(func (lambda ...))
```scheme
(func (lambda (n) n))
```
## There's more!
Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/The flavors of raw cells.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
$1+1$
:math:`1+1`
Bold text
**Bold text**
1 + 1
Not formatted
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/cat_variable.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
cat = 42
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/coconut_homepage_demo.md
================================================
---
jupyter:
kernelspec:
display_name: Coconut
language: coconut
name: coconut
---
Taken from [coconut-lang.org](coconut-lang.org)
pipeline-style programming
```coconut
"hello, world!" |> print
```
prettier lambdas
```coconut
x -> x ** 2
```
partial application
```coconut
range(10) |> map$(pow$(?, 2)) |> list
```
pattern-matching
```coconut
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
```
destructuring assignment
```coconut
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
```
infix notation
```coconut
# 5 `mod` 3 == 2
```
operator functions
```coconut
product = reduce$(*)
```
function composition
```coconut
# (f..g..h)(x, y, z)
```
lazy lists
```coconut
# (| first_elem() |) :: rest_elems()
```
parallel programming
```coconut
range(100) |> parallel_map$(pow$(2)) |> list
```
tail call optimization
```coconut
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
```
algebraic data types
```coconut
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
```
and much more!
Like what you see? Don't forget to star Coconut on GitHub!
```coconut
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/convert_to_py_then_test_with_update83.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
%%time
print('asdf')
```
Thanks for jupytext!
```python
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/csharp.md
================================================
---
jupyter:
kernelspec:
display_name: .NET (C#)
language: C#
name: .net-csharp
---
We start with...
```csharp
Console.WriteLine("Hello World!");
```
Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
```csharp
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
```
We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
```csharp
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
```
```csharp
(MathString)@"e^{i \pi} = -1"
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/demo_gdl_fbp.md
================================================
---
jupyter:
kernelspec:
display_name: IDL [conda env:gdl] *
language: IDL
name: conda-env-gdl-idl
---
## GDL demo notebook
Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
```idl
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
```
```idl
;; Enable inline plotting
!inline=1
```
```idl
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
```
Now we define simple forward and backprojection functions:
```idl
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
```
```idl
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
```
This allows us to create a sinogram:
```idl
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
```
On this we can apply a simple FBP reconstruction:
```idl
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
```
```idl
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
```
### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/evcxr_jupyter_tour.md
================================================
---
jupyter:
kernelspec:
display_name: Rust
language: rust
name: rust
---
# Tour of the EvCxR Jupyter Kernel
For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
## Printing to outputs and evaluating expressions
Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
```rust
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
```
## Assigning and making use of variables
We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
```rust
let mut message = "Hello ".to_owned();
```
```rust
message.push_str("world!");
```
```rust
message
```
## Defining and redefining functions
Next we'll define a function
```rust
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
```
```rust
(1..13).map(fib).collect::>()
```
Hmm, that doesn't look right. Lets redefine the function. In practice, we'd go back and edit the function above and reevaluate it, but here, lets redefine it in a separate cell.
```rust
pub fn fib(x: i32) -> i32 {
if x <= 2 {2} else {fib(x - 2) + fib(x - 1)}
}
```
```rust
let values = (1..13).map(fib).collect::>();
values
```
## Spawning a separate thread and communicating with it
We can spawn a thread to do stuff in the background, then continue executing code in other cells.
```rust
use std::sync::{Mutex, Arc};
let counter = Arc::new(Mutex::new(0i32));
std::thread::spawn({
let counter = Arc::clone(&counter);
move || {
for i in 1..300 {
*counter.lock().unwrap() += 1;
std::thread::sleep(std::time::Duration::from_millis(100));
}
}});
```
```rust
*counter.lock().unwrap()
```
```rust
*counter.lock().unwrap()
```
## Loading external crates
We can load external crates. This one takes a while to compile, but once it's compiled, subsequent cells shouldn't need to recompile it, so it should be much quicker.
```rust
:dep base64 = "0.10.1"
base64::encode(&vec![1, 2, 3, 4])
```
## Customizing how types are displayed
We can also customize how our types are displayed, including presenting them as HTML. Here's an example where we define a custom display function for a type `Matrix`.
```rust
use std::fmt::Debug;
pub struct Matrix {pub values: Vec, pub row_size: usize}
impl Matrix {
pub fn evcxr_display(&self) {
let mut html = String::new();
html.push_str("");
for r in 0..(self.values.len() / self.row_size) {
html.push_str("
");
println!("EVCXR_BEGIN_CONTENT text/html\n{}\nEVCXR_END_CONTENT", html);
}
}
```
```rust
let m = Matrix {values: vec![1,2,3,4,5,6,7,8,9], row_size: 3};
m
```
We can also return images, we just need to base64 encode them. First, we set up code for displaying RGB and grayscale images.
```rust
extern crate image;
extern crate base64;
pub trait EvcxrResult {fn evcxr_display(&self);}
impl EvcxrResult for image::RgbImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::RGB(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
impl EvcxrResult for image::GrayImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::Gray(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
```
```rust
image::ImageBuffer::from_fn(256, 256, |x, y| {
if (x as i32 - y as i32).abs() < 3 {
image::Rgb([0, 0, 255])
} else {
image::Rgb([0, 0, 0])
}
})
```
## Display of compilation errors
Here's how compilation errors are presented. Here we forgot an & and passed a String instead of an &str.
```rust
let mut s = String::new();
s.push_str(format!("foo {}", 42));
```
## Seeing what variables have been defined
We can print a table of defined variables and their types with the :vars command.
```rust
:vars
```
Other built-in commands can be found via :help
```rust
:help
```
```rust
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/frozen_cell.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
# This is an unfrozen cell. Works as usual.
print("I'm a regular cell so I run and print!")
```
```python deletable=false editable=false run_control={"frozen": true}
# This is an frozen cell
print("I'm frozen so Im not executed :(")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/fsharp.md
================================================
---
jupyter:
kernelspec:
display_name: .NET (F#)
language: F#
name: .net-fsharp
---
This notebook was inspired by [Plottting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/fsharp/Docs/Plotting%20with%20Xplot.ipynb).
```fsharp
open XPlot.Plotly
```
```fsharp
let bar =
Bar(
name = "Bar 1",
x = ["A"; "B"; "C"],
y = [1; 3; 2])
[bar]
|> Chart.Plot
|> Chart.WithTitle "A sample bar plot"
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/gnuplot_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: gnuplot
language: gnuplot
name: gnuplot
---
# Sample gnuplot notebook
## Simple plotting
```gnuplot
# Plot sin and cos with different linetypes
f(x) = sin(x)
g(x) = cos(x)
set xrange[0:2*pi]
set xtics(0, "{/Symbol p}" pi , "2{/Symbol p}" 2*pi)
set ytics 1
plot f(x) linewidth 2 title "sin(x)", \
g(x) linewidth 2 dashtype "--" title "cos(x)"
```
## Example of line magic
```gnuplot
%gnuplot inline pngcairo enhanced background rgb "#EEEEEE" size 600, 600
# Parametric plot without border
reset
set parametric
set size ratio -1
unset border
unset tics
plot f(t), g(t) linewidth 2 notitle
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/haskell_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: Haskell
language: haskell
name: haskell
---
# Example Haskell Notebook
Define a function to add two numbers.
```haskell
f :: Num a => a -> a -> a
f x y = x + y
```
Try to use the function
```haskell
f 1 2
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/hello_world_gonb.md
================================================
---
jupyter:
kernelspec:
display_name: Go (gonb)
language: go
name: gonb
---
A notebook that use [GoNB](https://github.com/janpfeifer/gonb)
the code below comes from [tutorial.ipynb](https://github.com/janpfeifer/gonb/blob/main/examples/tutorial.ipynb)
```go
func main() {
fmt.Printf("Hello World!")
}
```
```go
%%
fmt.Printf("Hello World!")
```
%% --who=world can pass flags to main func
```go
import (
"flag"
"fmt"
)
var flagWho = flag.String("who", "", "Your name!")
%% --who=world
fmt.Printf("Hello %s!\n", *flagWho)
```
%args also can pass flags
```go
%args --who=Wally
func main() {
flag.Parse()
fmt.Printf("Where is %s?", *flagWho)
}
```
```go
import "github.com/janpfeifer/gonb/gonbui"
%%
gonbui.DisplayHtml(`I 🧡 GoNB!`)
```
```go
%%
gonbui.DisplayMarkdown("#### Objective\n\n1. Have fun coding **Go**;\n1. Profit...\n"+
`$$f(x) = \int_{-\infty}^{\infty} e^{-x^2} dx$$`)
```
```go
func init_a() {
fmt.Println("init_a")
}
%%
fmt.Println("main")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/html-demo.md
================================================
---
jupyter:
kernelspec:
display_name: Clojure
language: clojure
name: clojure
---
# Clojupyter Demo
This example notebook is from the [Clojupyter](https://github.com/clojupyter/clojupyter/blob/1637f6b2557f01db1e35bae5389bc38522eefe9a/examples/html-demo.ipynb) project.
This notebook demonstrates some of the more advanced features of Clojupyter.
## Displaying HTML
To display HTML, you'll need to require a clojupyter helper function to change the cell output
```clojure
(require '[clojupyter.misc.display :as display])
```
```clojure
(println ">> should print some text")
;; displaying html
(display/hiccup-html
[:ul
[:li "a " [:i "emphatic"] " idea"]
[:li "a " [:b "bold"] " idea"]
[:li "an " [:span {:style "text-decoration: underline;"} "important"] " idea"]])
```
We can also use this to render SVG:
```clojure
(display/hiccup-html
[:svg {:height 100 :width 100 :xmlns "http://www.w3.org/2000/svg"}
[:circle {:cx 50 :cy 40 :r 40 :fill "red"}]])
```
## Adding External Clojure Dependencies
You can fetch external Clojure dependencies using the `clojupyter.misc.helper` namespace.
```clojure
(require '[clojupyter.misc.helper :as helper])
```
```clojure
(helper/add-dependencies '[org.clojure/data.json "0.2.6"])
(require '[clojure.data.json :as json])
```
```clojure
(json/write-str {:a 1 :b [2, 3] :c "c"})
```
## Adding External Javascript Dependency
Since you can render arbitrary HTML using `display/hiccup-html`, it's pretty easy to use external Javascript libraries to do things like generate charts. Here's an example using [Highcharts](https://www.highcharts.com/).
First, we use a cell to add javascript to the running notebook:
```clojure
(helper/add-javascript "https://code.highcharts.com/highcharts.js")
```
Now we define a function which takes Clojure data and returns hiccup HTML to display:
```clojure
(defn plot-highchart [highchart-json]
(let [id (str (java.util.UUID/randomUUID))
code (format "Highcharts.chart('%s', %s );" id, (json/write-str highchart-json))]
(display/hiccup-html
[:div [:div {:id id :style {:background-color "red"}}]
[:script code]])))
```
Now we can make generate interactive plots (try hovering over plot):
```clojure
(def raw-data (map #(+ (* 22 (+ % (Math/random)) 78)) (range)))
(def data-1 (take 500 raw-data))
(def data-2 (take 500 (drop 500 raw-data)))
(plot-highchart {:chart {:type "line"}
:title {:text "Plot of random data"}
:series [{:data data-1} {:data data-2}]})
```
```clojure
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/ijavascript.md
================================================
---
jupyter:
kernelspec:
display_name: Javascript (Node.js)
language: javascript
name: javascript
---
## A notebook that uses IJavascript kernel
```javascript
let x = 5;
const y = 6;
var z = 10;
```
```javascript
x + y;
```
```javascript
function add(num1, num2) {
return num1 + num2
}
```
```javascript
add(x, y);
```
```javascript
const arrowAdd = (num1, num2) => num1 + num2;
```
```javascript
arrowAdd(x, y);
```
```javascript
const myCar = {
color: "blue",
weight: 850,
model: "fiat",
start: () => "car started!",
doors: [1,2,3,4]
}
```
```javascript
console.log("color:", myCar.color);
```
```javascript
console.log("start:", myCar.start());
```
```javascript
for (let door of myCar.doors) {
console.log("I'm door", door)
}
```
```javascript
myCar;
```
```javascript
class User {
constructor(name){
this.name = name;
}
sayHello(){
return "Hello, I'm " + this.name;
}
}
```
```javascript
let John = new User("John");
John.sayHello();
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/ir_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: R
language: R
name: ir
---
This is a jupyter notebook that uses the IR kernel.
```R
sum(1:10)
```
```R
plot(cars)
```
```R
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/itypescript.md
================================================
---
jupyter:
kernelspec:
display_name: Typescript 3.5
language: typescript
name: typescript
---
```typescript
let x: number = 5;
const y: number = 6;
var z: string = "hi";
console.log(z);
x + y;
```
```typescript
function add(num1: number, num2: number): number {
return num1 + num2
}
add(x, y);
```
```typescript
const arrowAdd = (num1: number, num2: number) => num1 + num2;
arrowAdd(x, y);
```
```typescript
class User {
constructor(private name: string) {
this.name = name;
}
sayHello(): string {
return "Hello, I'm " + this.name;
}
}
let John: User;
John = new User("John");
John.sayHello();
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/julia_benchmark_plotly_barchart.md
================================================
---
jupyter:
kernelspec:
display_name: Julia 1.1.1
language: julia
name: julia-1.1
---
```julia
# IJulia rocks! So does Plotly. Check it out
using Plotly
api_key = "" # visit https://plot.ly/api to generate an API username and password
username = ""
Plotly.signin(username, api_key)
```
```julia
# Following data taken from http://julialang.org/ frontpage
benchmarks = ["fib", "parse_int", "quicksort3", "mandel", "pi_sum", "rand_mat_stat", "rand_mat_mul"]
platforms = ["Fortran", "Julia", "Python", "R", "Matlab", "Mathematica", "Javascript", "Go"]
data = {
platforms[1] => [0.26, 5.03, 1.11, 0.86, 0.80, 0.64, 0.96],
platforms[2] => [0.91, 1.60, 1.14, 0.85, 1.00, 1.66, 1.01],
platforms[3] => [30.37, 13.95, 31.98, 14.19, 16.33, 13.52, 3.41 ],
platforms[4] => [411.36, 59.40, 524.29, 106.97, 15.42, 10.84, 3.98 ],
platforms[5] => [1992.00, 1463.16, 101.84, 64.58, 1.29, 6.61, 1.10 ],
platforms[6] => [64.46, 29.54, 35.74, 6.07, 1.32, 4.52, 1.16 ],
platforms[7] => [2.18, 2.43, 3.51, 3.49, 0.84, 3.28, 14.60],
platforms[8] => [1.03, 4.79, 1.25, 2.36, 1.41, 8.12, 8.51]
}
pdata = [ {"x"=>benchmarks,"y"=>data[k],"bardir"=>"h","type"=>"bar","name"=>k} for k = platforms ]
layout = {
"title"=> "Julia benchmark comparison (smaller is better, C performance = 1.0)",
"barmode"=> "group",
"autosize"=> false,
"width"=> 900,
"height"=> 900,
"titlefont"=>
{
"family"=> "Open Sans",
"size"=> 18,
"color"=> "rgb(84, 39, 143)"
},
"margin"=> {"l"=>160, "pad"=>0},
"xaxis"=> {
"title"=> "Benchmark log-time",
"type"=> "log"
},
"yaxis"=> {"title"=> "Benchmark Name"}
}
response = Plotly.plot(pdata,["layout"=>layout])
# Embed in an iframe within IJulia
s = string("")
display("text/html", s)
```
```julia
# checkout https://plot.ly/api/ for more Julia examples!
# But to show off some other Plotly features:
x = 1:1500
y1 = sin(2*pi*x/1500.) + rand(1500)-0.5
y2 = sin(2*pi*x/1500.)
fish = {"x"=>x,"y"=> y1,
"type"=>"scatter","mode"=>"markers",
"marker"=>{"color"=>"rgb(0, 0, 255)","opacity"=>0.5 } }
fit = {"x"=> x,"y"=> y2,
"type"=>"scatter", "mode"=>"markers", "opacity"=>0.8,
"marker"=>{"color"=>"rgb(255, 0, 0)"} }
layout = {"autosize"=> false,
"width"=> 650, "height"=> 550,
"title"=>"Fish School",
"xaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[0,1500] },
"yaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[-2.2,2.2] },
"plot_bgcolor"=> "rgb(245,245,247)",
"showlegend"=> false,
"hovermode"=> "closest"}
response = Plotly.plot([fish, fit],["layout"=>layout])
s = string("")
display("text/html", s)
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/julia_functional_geometry.md
================================================
---
jupyter:
kernelspec:
display_name: Julia 1.1.1
language: julia
name: julia-1.1
---
```julia
# This notebook is a semi top-down explanation. This cell needs to be
# executed first so that the operators and helper functions are defined
# All of this is explained in the later half of the notebook
using Compose, Interact
Compose.set_default_graphic_size(2inch, 2inch)
points_f = [
(.1, .1),
(.9, .1),
(.9, .2),
(.2, .2),
(.2, .4),
(.6, .4),
(.6, .5),
(.2, .5),
(.2, .9),
(.1, .9),
(.1, .1)
]
f = compose(context(), stroke("black"), line(points_f))
rot(pic) = compose(context(rotation=Rotation(-deg2rad(90))), pic)
flip(pic) = compose(context(mirror=Mirror(deg2rad(90), 0.5w, 0.5h)), pic)
above(m, n, p, q) =
compose(context(),
(context(0, 0, 1, m/(m+n)), p),
(context(0, m/(m+n), 1, n/(m+n)), q))
above(p, q) = above(1, 1, p, q)
beside(m, n, p, q) =
compose(context(),
(context(0, 0, m/(m+n), 1), p),
(context(m/(m+n), 0, n/(m+n), 1), q))
beside(p, q) = beside(1, 1, p, q)
over(p, q) = compose(context(),
(context(), p), (context(), q))
rot45(pic) =
compose(context(0, 0, 1/sqrt(2), 1/sqrt(2),
rotation=Rotation(-deg2rad(45), 0w, 0h)), pic)
# Utility function to zoom out and look at the context
zoomout(pic) = compose(context(),
(context(0.2, 0.2, 0.6, 0.6), pic),
(context(0.2, 0.2, 0.6, 0.6), fill(nothing), stroke("black"), strokedash([0.5mm, 0.5mm]),
polygon([(0, 0), (1, 0), (1, 1), (0, 1)])))
function read_path(p_str)
tokens = [try parsefloat(x) catch symbol(x) end for x in split(p_str, r"[\s,]+")]
path(tokens)
end
fish = compose(context(units=UnitBox(260, 260)), stroke("black"),
read_path(strip(readall("fish.path"))))
rotatable(pic) = @manipulate for θ=0:0.001:2π
compose(context(rotation=Rotation(θ)), pic)
end
blank = compose(context())
fliprot45(pic) = rot45(compose(context(mirror=Mirror(deg2rad(-45))),pic))
# Hide this cell.
display(MIME("text/html"), """""")
```
# Functional Geometry
*Functional Geometry* is a paper by Peter Henderson ([original (1982)](users.ecs.soton.ac.uk/peter/funcgeo.pdf), [revisited (2002)](https://cs.au.dk/~hosc/local/HOSC-15-4-pp349-365.pdf)) which deconstructs the MC Escher woodcut *Square Limit*

> A picture is an example of a complex object that can be described in terms of its parts.
Yet a picture needs to be rendered on a printer or a screen by a device that expects to
be given a sequence of commands. Programming that sequence of commands directly is
much harder than having an application generate the commands automatically from the
simpler, denotational description.
A `picture` is a *denotation* of something to draw.
e.g. The value of f here denotes the picture of the letter F
Original at http://nbviewer.jupyter.org/github/shashi/ijulia-notebooks/blob/master/funcgeo/Functional%20Geometry.ipynb
## In conclusion
We described Escher's *Square Limit* from the description of its smaller parts, which in turn were described in terms of their smaller parts.
This seemed simple because we chose to talk in terms of an *algebra* to describe pictures. The primitives `rot`, `flip`, `fliprot45`, `above`, `beside` and `over` fit the job perfectly.
We were able to describe these primitives in terms of `compose` `contexts`, which the Compose library knows how to render.
Denotation can be an easy way to describe a system as well as a practical implementation method.
[Abstraction barriers](https://mitpress.mit.edu/sicp/full-text/sicp/book/node29.html) are useful tools that can reduce the cognitive overhead on the programmer. It entails creating layers consisting of functions which only use functions in the same layer or layers below in their own implementation. The layers in our language were:
------------------[ squarelimit ]------------------
-------------[ quartet, cycle, nonet ]-------------
---[ rot, flip, fliprot45, above, beside, over ]---
-------[ compose, context, line, path,... ]--------
Drawing this diagram out is a useful way to begin building any library.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/jupyter.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
# Jupyter notebook
This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition:
```python
a = 1
b = 2
a + b
```
Now we return a few tuples
```python
a, b
```
```python
a, b, a+b
```
And this is already the end of the notebook
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/jupyter_again.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
c = '''
title: "Quick test"
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type console
'''
```
```python
import yaml
print(yaml.dump(yaml.load(c)))
```
```python
?next
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/jupyter_with_raw_cell_in_body.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
1+2+3
```
This is a raw cell
This is a markdown cell
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/jupyter_with_raw_cell_on_top.md
================================================
---
title: Quick test
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type: console
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
1+2+3
```
```python
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/jupyter_with_raw_cell_with_invalid_yaml.md
================================================
---
title: Exception: Test
jupyter:
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
---
```python
1 + 2 + 3
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/jupyterlab-slideshow_1441.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
---
> **Note**
>
> `slide` layer with a `top` of `30%`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/jupytext_replication.md
================================================
---
jupyter:
kernelspec:
display_name: SoS
language: sos
name: sos
---
# Text SOS-kernel with Jupytext
## What is SOS kernel
SoS consists of a ployglot notebook that allows the use of multiple kernels in one Jupyter notebook, and a workflow system that is designed for daily computational research. Basically,
- SoS Polyglot Notebook is a Jupyter Notebook with a SoS kernel.
- SoS Notebook serves as a super kernel to all other Jupyter kernels and allows the use of multiple kernels in one Jupyter notebook.
- SoS Workflow System is a Python based workflow system that is designed to be readable, shareable, and suitable for daily data analysis.
- SoS Workflow System can be used from command line or use SoS Notebook as its IDE.

### How to install SOS-kernel
Please follow this [link](https://vatlab.github.io/sos-docs/running.html#Conda-installation) to setup SOS
I run some issue with the latest version of R on my Mac, so I had to install an earlier version of R
```
conda install -c r r=3.5.1
conda install sos-notebook jupyterlab-sos sos-papermill -c conda-forge
```
## Related issue with Jupytext
Jupytext works fine with Python/R kernel but converts code cells into markdown cells when using the SOS kernel.
cf the image below. It is a code cell. After saving the notebook and restart it, it converted the code cell into markdown
## Step 1
Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.

```sos Collapsed="false" kernel="SoS"
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
```
## Step 2
Now, pair it with Jupytex

### Step 3
Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
### Step 4
Reopen the notebook. Here is the outcome

================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/kalman_filter_and_visualization.md
================================================
---
jupyter:
kernelspec:
display_name: Q 3.5
language: q
name: qpk
---
```q
plt: .p.import`matplotlib.pyplot
```
```q
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
```
```q
price: 100 + sums 0.5 - (n:50)?1.
```
```q
output:filter price
```
```q
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
```
```q
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/logtalk_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: Logtalk
language: logtalk
name: logtalk_kernel
---
# An implementation of the Ackermann function
```logtalk vscode={"languageId": "logtalk"}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
```
## Sample query
```logtalk vscode={"languageId": "logtalk"}
ack::ack(2, 4, V).
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/lua_example.md
================================================
---
jupyter:
kernelspec:
display_name: Lua
language: lua
name: lua
---
Source: https://www.lua.org/pil/19.3.html
# Sort
Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
```lua
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
```
Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
```lua
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
```
Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
```lua
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
```
With this function, it is easy to print those function names in alphabetical order. The loop
```lua
for name, line in pairsByKeys(lines) do
print(name, line)
end
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/maxima_example.md
================================================
---
jupyter:
kernelspec:
display_name: Maxima
language: maxima
name: maxima
---
## maxima misc
```maxima
kill(all)$
```
```maxima
f(x) := 1/(x^2+l^2)^(3/2);
```
```maxima
integrate(f(x), x);
```
```maxima
tex(%)$
```
```maxima
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/notebook_with_complex_metadata.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/nteract_with_parameter.md
================================================
---
jupyter:
kernel_info:
name: python3
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python inputHidden=false outputHidden=false tags=["parameters"]
param = 4
```
```python inputHidden=false outputHidden=false
import pandas as pd
```
```python inputHidden=false outputHidden=false
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
```
```python inputHidden=false outputHidden=false
%matplotlib inline
df.plot(kind='bar')
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/ocaml_notebook.md
================================================
---
jupyter:
jupytext:
formats: ipynb:markdown,md
kernelspec:
display_name: OCaml default
language: OCaml
name: ocaml-jupyter
---
# Example of an OCaml notebook
```ocaml
let sum x y = x + y
```
Let's try our function:
```ocaml
sum 3 4 = 7 + 0
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/octave_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: Octave
language: octave
name: octave
---
A markdown cell
```octave
1 + 1
```
```octave
% a code cell with comments
2 + 2
```
```octave
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
```
```octave
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
```
And to finish with, a Python cell
```python
a = 1
```
```python
a + 1
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/plotly_graphs.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
This notebook contains complex outputs, including plotly javascript graphs.
# Interactive plots
We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
```python
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
```
```python
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/powershell.md
================================================
---
jupyter:
kernelspec:
display_name: PowerShell
language: PowerShell
name: powershell
---
This is an extract from
https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
```powershell
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/raw_cell_with_complex_yaml_like_content.md
================================================
---
This is a complex paragraph
that is split over multiple lines.
It also includes blank lines.
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/raw_cell_with_non_dict_yaml_content.md
================================================
---
Content.
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/root_cpp.md
================================================
---
jupyter:
kernelspec:
display_name: ROOT C++
language: c++
name: root
---
```c++
#include
#include
```
```c++
int k = 4;
std::string foo = "This string says \"foo\"";
```
```c++
std::cout << "k = " << k << '\n' << foo << '\n';
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/sage_print_hello.md
================================================
---
jupyter:
kernelspec:
display_name: SageMath 9.2
language: sage
name: sagemath
---
```sage
print("Hello world")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/sample_bash_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: Bash
language: bash
name: bash
---
```bash
ls
```
```bash
# https://coderwall.com/p/euwpig/a-better-git-log
git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"
```
```bash
git lg
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/sample_rise_notebook_66.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
A markdown cell
```python slideshow={"slide_type": ""}
1+1
```
Markdown cell two
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/sas.md
================================================
---
jupyter:
kernelspec:
display_name: SAS
language: sas
name: sas
---
# SAS Notebooks with jupytext
```sas
proc sql;
select *
from sashelp.cars (obs=10)
;
quit;
```
```sas
%let name = "Jupytext";
```
```sas
%put &name;
```
```sas
/* Note when defining macros "%macro" cannot be the first line of text in the cell */
%macro test;
data temp;
set sashelp.cars;
name = "testx";
run;
proc print data = temp (obs=10);
run;
%mend test;
%test
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/simple-helloworld.md
================================================
---
jupyter:
jupytext:
encoding: '// -*- coding: utf-8 -*-'
formats: ipynb,java:light
kernelspec:
display_name: Java
language: java
name: java
---
Let's define some class.
```java
class A {
public void hello() {
System.out.println("Hello World");
}
}
```
And now we call its method.
```java
new A().hello();
```
You can run it e.g. with `jshell`
* from command line, as `jshell simple-helloworld.java`
* from jshell's shell with `/open simple-helloworld.java`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/simple_robot_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: Robot Framework
language: robotframework
name: robotkernel
---
```robotframework
*** Settings ***
Library Collections
```
```robotframework
*** Keywords ***
Head
[Arguments] ${list}
${value}= Get from list ${list} 0
[Return] ${value}
```
```robotframework
*** Tasks ***
Get head
${array}= Create list 1 2 3 4 5
${head}= Head ${array}
Should be equal ${head} 1
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/simple_scala_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: Apache Toree - Scala
language: scala
name: apache_toree_scala
---
```scala
// This is just a simple scala notebook
object SampleObject {
def calculation(x: Int, y: Int): Int = x + y
}
val result = SampleObject.calculation(1, 2)
```
```scala
println(result * 10)
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/stata_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: Stata
language: stata
name: stata
---
```stata
// This notebook uses the stata_kernel: https://github.com/kylebarron/stata_kernel
```
```stata
use http://www.stata-press.com/data/r13/auto
```
```stata
summarize
```
```stata
scatter weight length
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/tailrecursive-factorial.md
================================================
---
jupyter:
jupytext:
encoding: '// -*- coding: utf-8 -*-'
formats: ipynb,groovy:light
kernelspec:
display_name: Groovy
language: groovy
name: groovy
---
# TailRecursive annotation
Let's check what is the effect of `@TailRecursive` annotation on the simple recursive definition of factorial function.
```groovy
import groovy.transform.CompileStatic
import groovy.transform.TailRecursive
import groovy.transform.TypeChecked
@CompileStatic
@TypeChecked
class X {
static final BigInteger factorial0(int n) {
(n <= 1) ? 1G : factorial0(n-1).multiply(BigInteger.valueOf(n))
}
static final BigInteger factorial1(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial1(n-1, acc.multiply(BigInteger.valueOf(n)))
}
@TailRecursive
static final BigInteger factorial2(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial2(n-1, acc.multiply(BigInteger.valueOf(n)))
}
}
x = new X()
```
Although we can time the execution of the calls, it is not very accurate; such micro benchmarks should be performed in more controlled environment, such us under [JMH](https://openjdk.java.net/projects/code-tools/jmh/).
For example, see [blog posts of Szymon Stępniak](https://e.printstacktrace.blog/tail-recursive-methods-in-groovy/).
```groovy
%%timeit
x.factorial0(19_000).toString().length()
```
```groovy
%%timeit
x.factorial1(19_000).toString().length()
```
```groovy
%%timeit
x.factorial2(19_000).toString().length()
```
The real difference is the use of stack. Non-tail recursive calls exhaust the stack space at some point, whereas tail recursive calls don't add frames to the stack.
```groovy
factSize = { n, cl ->
println "Factorial of ${n} has ${cl(n).toString().length()} digits"
}
factSize 2_000, x.&factorial0
factSize 2_000, x.&factorial1
factSize 2_000, x.&factorial2
factSize 100_000, x.&factorial2
```
```groovy
try {
factSize 100_000, x.&factorial1
} catch (Throwable e) {
assert e instanceof StackOverflowError
println e
}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/tcl_test.md
================================================
---
jupyter:
kernelspec:
display_name: Tcl
language: tcl
name: tcljupyter
---
# Assign Values
```tcl
set a 1
puts "a = $a"
```
# Loop
```tcl
for {set i 0} {$i < 10} {incr i} {
puts "I inside first loop: $i"
}
```
```tcl
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/text_outputs_and_images.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
This notebook contains outputs of many different types: text, HTML, plots and errors.
# Text outputs
Using `print`, `sys.stdout` and `sys.stderr`
```python
import sys
print('using print')
sys.stdout.write('using sys.stdout.write')
sys.stderr.write('using sys.stderr.write')
```
```python
import logging
logging.debug('Debug')
logging.info('Info')
logging.warning('Warning')
logging.error('Error')
```
# HTML outputs
Using `pandas`. Here we find two representations: both text and HTML.
```python
import pandas as pd
pd.DataFrame([4])
```
```python
from IPython.display import display
display(pd.DataFrame([5]))
display(pd.DataFrame([6]))
```
# Images
```python
%matplotlib inline
```
```python
# First plot
from matplotlib import pyplot as plt
import numpy as np
w, h = 3, 3
data = np.zeros((h, w, 3), dtype=np.uint8)
data[0,:] = [0,255,0]
data[1,:] = [0,0,255]
data[2,:] = [0,255,0]
data[1:3,1:3] = [255, 0, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# Second plot
data[1:3,1:3] = [255, 255, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
```
# Errors
```python
undefined_variable
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/wolfram.md
================================================
---
jupyter:
kernelspec:
display_name: Wolfram Language 13.1
language: Wolfram Language
name: wolframlanguage13.1
---
**Note:** The `language_info` `file_extension` in this notebook should be `.m`, but it was deliberately changed to `.wolfram` to avoid conflicts with Matlab which is using the same extension.
We start with...
```wolfram language
Print["Hello, World!"];
```
Then we draw the first example plot from the [ListPlot](https://reference.wolfram.com/language/ref/ListPlot.html) reference:
```wolfram language
ListPlot[Prime[Range[25]]]
```
We also test the math outputs as in the [Simplify](https://reference.wolfram.com/language/ref/Simplify.html) example:
```wolfram language
D[Integrate[1/(x^3 + 1), x], x]
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/xcpp_by_quantstack.md
================================================
---
jupyter:
kernelspec:
display_name: C++14
language: C++14
name: xeus-cling-cpp14
---
[](https://github.com/QuantStack/xeus-cling/)
A Jupyter kernel for C++ based on the `cling` C++ interpreter and the `xeus` native implementation of the Jupyter protocol, xeus.
- GitHub repository: https://github.com/QuantStack/xeus-cling/
- Online documentation: https://xeus-cling.readthedocs.io/
## Usage
## Output and error streams
`std::cout` and `std::cerr` are redirected to the notebook frontend.
```c++
#include
std::cout << "some output" << std::endl;
```
```c++
std::cerr << "some error" << std::endl;
```
```c++
#include
```
```c++
throw std::runtime_error("Unknown exception");
```
Omitting the `;` in the last statement of a cell results in an output being printed
```c++
int j = 5;
```
```c++
j
```
# Interpreting the C++ programming language
`cling` has a broad support of the features of C++. You can define functions, classes, templates, etc ...
## Functions
```c++
double sqr(double a)
{
return a * a;
}
```
```c++
double a = 2.5;
double asqr = sqr(a);
asqr
```
## Classes
```c++
class Foo
{
public:
virtual ~Foo() {}
virtual void print(double value) const
{
std::cout << "Foo value = " << value << std::endl;
}
};
```
```c++
Foo bar;
bar.print(1.2);
```
## Polymorphism
```c++
class Bar : public Foo
{
public:
virtual ~Bar() {}
virtual void print(double value) const
{
std::cout << "Bar value = " << 2 * value << std::endl;
}
};
```
```c++
Foo* bar2 = new Bar;
bar2->print(1.2);
delete bar2;
```
## Templates
```c++
#include
template
class FooT
{
public:
explicit FooT(const T& t) : m_t(t) {}
void print() const
{
std::cout << typeid(T).name() << " m_t = " << m_t << std::endl;
}
private:
T m_t;
};
template <>
class FooT
{
public:
explicit FooT(const int& t) : m_t(t) {}
void print() const
{
std::cout << "m_t = " << m_t << std::endl;
}
private:
int m_t;
};
```
```c++
FooT foot1(1.2);
foot1.print();
```
```c++
FooT foot2(4);
foot2.print();
```
## C++11 / C++14 support
```c++
class Foo11
{
public:
Foo11() { std::cout << "Foo11 default constructor" << std::endl; }
Foo11(const Foo11&) { std::cout << "Foo11 copy constructor" << std::endl; }
Foo11(Foo11&&) { std::cout << "Foo11 move constructor" << std::endl; }
};
```
```c++
Foo11 f1;
Foo11 f2(f1);
Foo11 f3(std::move(f1));
```
```c++
#include
std::vector v = { 1, 2, 3};
auto iter = ++v.begin();
v
```
```c++
*iter
```
... and also lambda, universal references, `decltype`, etc ...
## Documentation and completion
- Documentation for types of the standard library is retrieved on cppreference.com.
- The quick-help feature can also be enabled for user-defined types and third-party libraries. More documentation on this feature is available at https://xeus-cling.readthedocs.io/en/latest/inline_help.html.
```c++
?std::vector
```
## Using the `display_data` mechanism
For a user-defined type `T`, the rich rendering in the notebook and JupyterLab can be enabled by by implementing the function `xeus::xjson mime_bundle_repr(const T& im)`, which returns the JSON mime bundle for that type.
More documentation on the rich display system of Jupyter and Xeus-cling is available at https://xeus-cling.readthedocs.io/en/latest/rich_display.html
### Image example
```c++
#include
#include
#include "xtl/xbase64.hpp"
#include "xeus/xjson.hpp"
namespace im
{
struct image
{
inline image(const std::string& filename)
{
std::ifstream fin(filename, std::ios::binary);
m_buffer << fin.rdbuf();
}
std::stringstream m_buffer;
};
xeus::xjson mime_bundle_repr(const image& i)
{
auto bundle = xeus::xjson::object();
bundle["image/png"] = xtl::base64encode(i.m_buffer.str());
return bundle;
}
}
```
```c++
im::image marie("images/marie.png");
marie
```
### Audio example
```c++
#include
#include
#include "xtl/xbase64.hpp"
#include "xeus/xjson.hpp"
namespace au
{
struct audio
{
inline audio(const std::string& filename)
{
std::ifstream fin(filename, std::ios::binary);
m_buffer << fin.rdbuf();
}
std::stringstream m_buffer;
};
xeus::xjson mime_bundle_repr(const audio& a)
{
auto bundle = xeus::xjson::object();
bundle["text/html"] =
std::string("";
return bundle;
}
}
```
```c++
au::audio drums("audio/audio.wav");
drums
```
### Display
```c++
#include "xcpp/xdisplay.hpp"
```
```c++
xcpp::display(drums);
```
### Update-display
```c++
#include
#include "xcpp/xdisplay.hpp"
namespace ht
{
struct html
{
inline html(const std::string& content)
{
m_content = content;
}
std::string m_content;
};
xeus::xjson mime_bundle_repr(const html& a)
{
auto bundle = xeus::xjson::object();
bundle["text/html"] = a.m_content;
return bundle;
}
}
// A red rectangle
ht::html rect(R"(
#include
```
```c++
std::vector to_shuffle = {1, 2, 3, 4};
```
```c++
%timeit std::random_shuffle(to_shuffle.begin(), to_shuffle.end());
```
[](https://github.com/QuantStack/xtensor/)
- GitHub repository: https://github.com/QuantStack/xtensor/
- Online documentation: https://xtensor.readthedocs.io/
- NumPy to xtensor cheat sheet: http://xtensor.readthedocs.io/en/latest/numpy.html
`xtensor` is a C++ library for manipulating N-D arrays with an API very similar to that of numpy.
```c++
#include
#include "xtensor/xarray.hpp"
#include "xtensor/xio.hpp"
#include "xtensor/xview.hpp"
xt::xarray arr1
{{1.0, 2.0, 3.0},
{2.0, 5.0, 7.0},
{2.0, 5.0, 7.0}};
xt::xarray arr2
{5.0, 6.0, 7.0};
xt::view(arr1, 1) + arr2
```
Together with the C++ Jupyter kernel, `xtensor` offers a similar experience as `NumPy` in the Python Jupyter kernel, including broadcasting and universal functions.
```c++
#include
#include "xtensor/xarray.hpp"
#include "xtensor/xio.hpp"
```
```c++
xt::xarray arr
{1, 2, 3, 4, 5, 6, 7, 8, 9};
arr.reshape({3, 3});
std::cout << arr;
```
```c++
#include "xtensor-blas/xlinalg.hpp"
```
```c++
xt::xtensor m = {{1.5, 0.5}, {0.7, 1.0}};
std::cout << "Matrix rank: " << std::endl << xt::linalg::matrix_rank(m) << std::endl;
std::cout << "Matrix inverse: " << std::endl << xt::linalg::inv(m) << std::endl;
std::cout << "Eigen values: " << std::endl << xt::linalg::eigvals(m) << std::endl;
```
```c++
xt::xarray arg1 = xt::arange(9);
xt::xarray arg2 = xt::arange(18);
arg1.reshape({3, 3});
arg2.reshape({2, 3, 3});
std::cout << xt::linalg::dot(arg1, arg2) << std::endl;
```
```c++
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/xonsh_example.md
================================================
---
jupyter:
kernelspec:
display_name: Xonsh
language: xonsh
name: xonsh
---
```xonsh
len($(curl -L https://xon.sh))
```
```xonsh
for filename in `.*`:
print(filename)
du -sh @(filename)
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/Line_breaks_in_LateX_305.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
This cell uses no particular cell marker
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
+++
This cell uses no particular cell marker, and a single slash in the $\LaTeX$ equation
$$
\begin{align}
\dot{x} & = \sigma(y-x) \
\dot{y} & = \rho x - y - xz \
\dot{z} & = -\beta z + xy
\end{align}
$$
+++
This cell uses the triple quote cell markers introduced at https://github.com/mwouts/jupytext/issues/305
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/Notebook with function and cell metadata 164.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
1 + 1
```
A markdown cell
And below, the cell for function f has non trivial cell metadata. And the next cell as well.
```{code-cell} ipython3
---
attributes:
classes: []
id: ''
n: '10'
---
def f(x):
return x
```
```{code-cell} ipython3
---
attributes:
classes: []
id: ''
n: '10'
---
f(5)
```
More text
```{code-cell} ipython3
2 + 2
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/Notebook with html and latex cells.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
%%html
It has breakpoints (click in left margin). You must press Stop to exit the debugger.
+++
```scheme
%%debug
(begin
(define x 1)
(set! x 2)
)
```
+++
### Python Integration
You can import and use any Python library in Calysto Scheme.
In addition, if you wish, you can execute expressions and statements in a Python environment:
```{code-cell} scheme
(python-eval "1 + 2")
```
```{code-cell} scheme
(python-exec
"
def mypyfunc(a, b):
return a * b
")
```
This is a shared environment with Scheme:
```{code-cell} scheme
(mypyfunc 4 5)
```
You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
```{code-cell} scheme
(define! mypyfunc2 (func (lambda (n) n)))
```
```{code-cell} scheme
(python-eval "mypyfunc2(34)")
```
# Differences Between Languages
## Major differences between Scheme and Python
1. In Scheme, double quotes are used for strings and may contain newlines
1. In Scheme, a single quote is short for (quote ...) and means "literal"
1. In Scheme, everything is an expression and has a return value
1. Python does not support macros (e.g., extending syntax)
1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
1. Scheme procedures are not Python functions, but there are means to use one as the other.
## Major Differences Between Calysto Scheme and other Schemes
1. define-syntax works slightly differently
1. In Calysto Scheme, #(...) is short for '#(...)
1. Calysto Scheme is missing many standard functions (see list at bottom)
1. Calysto Scheme has a built-in amb operator called `choose`
1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
### Stack Trace
Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
```{code-cell} scheme
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
```
```{code-cell} scheme
(fact 5)
```
To turn off the stack trace on error:
```scheme
(use-stack-trace #f)
```
That will allow infinite recursive loops without keeping track of the "stack".
+++
# Calysto Scheme Variables
## SCHEMEPATH
SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
```{code-cell} scheme
SCHEMEPATH
```
```{code-cell} scheme
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
```
```{code-cell} scheme
SCHEMEPATH
```
## Getting Started
Note that you can use the word `lambda` or \lambda and then press [TAB]
```{code-cell} scheme
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
```
```{code-cell} scheme
(factorial 5)
```
## define-syntax
(define-syntax NAME RULES): a method for creating macros
```{code-cell} scheme
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
```
```{code-cell} scheme
(time (car '(1 2 3 4)))
```
```{code-cell} scheme
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
```
```{code-cell} scheme
(collect (* n n) for n in (range 10))
```
```{code-cell} scheme
(collect (* n n) for n in (range 5 20 3))
```
```{code-cell} scheme
(collect (* n n) for n in (range 10) if (> n 5))
```
```{code-cell} scheme
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
```
```{code-cell} scheme
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
```
```{code-cell} scheme
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
```
```{code-cell} scheme
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
```
```{code-cell} scheme
(for n in (range 10 20 2) do (print n))
```
```{code-cell} scheme
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
```
```{code-cell} scheme
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
```
```{code-cell} scheme
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
```
```{code-cell} scheme
(! 5)
```
```{code-cell} scheme
(nth 10 facts)
```
```{code-cell} scheme
(nth 20 fibs)
```
```{code-cell} scheme
(first 30 fibs)
```
## for-each
(for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
```{code-cell} scheme
(for-each (lambda (n) (print n)) '(3 4 5))
```
## format
(format STRING ITEM ...): format the string with ITEMS as arguments
```{code-cell} scheme
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
```
## func
Turns a lambda into a Python function.
(func (lambda ...))
```{code-cell} scheme
(func (lambda (n) n))
```
## There's more!
Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/The flavors of raw cells.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{raw-cell}
:raw_mimetype: text/latex
$1+1$
```
```{raw-cell}
:raw_mimetype: text/restructuredtext
:math:`1+1`
```
```{raw-cell}
:raw_mimetype: text/html
Bold text
```
```{raw-cell}
:raw_mimetype: text/markdown
**Bold text**
```
```{raw-cell}
:raw_mimetype: text/x-python
1 + 1
```
```{raw-cell}
Not formatted
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/cat_variable.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
cat = 42
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/coconut_homepage_demo.md
================================================
---
kernelspec:
display_name: Coconut
language: coconut
name: coconut
---
Taken from [coconut-lang.org](coconut-lang.org)
+++
pipeline-style programming
```{code-cell} coconut
"hello, world!" |> print
```
prettier lambdas
```{code-cell} coconut
x -> x ** 2
```
partial application
```{code-cell} coconut
range(10) |> map$(pow$(?, 2)) |> list
```
pattern-matching
```{code-cell} coconut
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
```
destructuring assignment
```{code-cell} coconut
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
```
infix notation
```{code-cell} coconut
# 5 `mod` 3 == 2
```
operator functions
```{code-cell} coconut
product = reduce$(*)
```
function composition
```{code-cell} coconut
# (f..g..h)(x, y, z)
```
lazy lists
```{code-cell} coconut
# (| first_elem() |) :: rest_elems()
```
parallel programming
```{code-cell} coconut
range(100) |> parallel_map$(pow$(2)) |> list
```
tail call optimization
```{code-cell} coconut
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
```
algebraic data types
```{code-cell} coconut
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
```
and much more!
Like what you see? Don't forget to star Coconut on GitHub!
```{code-cell} coconut
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/convert_to_py_then_test_with_update83.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
%%time
print('asdf')
```
Thanks for jupytext!
```{code-cell} ipython3
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/csharp.md
================================================
---
kernelspec:
display_name: .NET (C#)
language: C#
name: .net-csharp
---
We start with...
```{code-cell} csharp
Console.WriteLine("Hello World!");
```
Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
```{code-cell} csharp
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
```
We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
```{code-cell} csharp
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
```
```{code-cell} csharp
(MathString)@"e^{i \pi} = -1"
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/demo_gdl_fbp.md
================================================
---
kernelspec:
display_name: IDL [conda env:gdl] *
language: IDL
name: conda-env-gdl-idl
---
## GDL demo notebook
+++
Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
```{code-cell}
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
```
```{code-cell}
;; Enable inline plotting
!inline=1
```
```{code-cell}
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
```
Now we define simple forward and backprojection functions:
```{code-cell}
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
```
```{code-cell}
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
```
This allows us to create a sinogram:
```{code-cell}
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
```
On this we can apply a simple FBP reconstruction:
```{code-cell}
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
```
```{code-cell}
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
```
### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/evcxr_jupyter_tour.md
================================================
---
kernelspec:
display_name: Rust
language: rust
name: rust
---
# Tour of the EvCxR Jupyter Kernel
For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
## Printing to outputs and evaluating expressions
Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
```{code-cell}
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
```
## Assigning and making use of variables
We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
```{code-cell}
let mut message = "Hello ".to_owned();
```
```{code-cell}
message.push_str("world!");
```
```{code-cell}
message
```
## Defining and redefining functions
Next we'll define a function
```{code-cell}
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
```
```{code-cell}
(1..13).map(fib).collect::>()
```
Hmm, that doesn't look right. Lets redefine the function. In practice, we'd go back and edit the function above and reevaluate it, but here, lets redefine it in a separate cell.
```{code-cell}
pub fn fib(x: i32) -> i32 {
if x <= 2 {2} else {fib(x - 2) + fib(x - 1)}
}
```
```{code-cell}
let values = (1..13).map(fib).collect::>();
values
```
## Spawning a separate thread and communicating with it
We can spawn a thread to do stuff in the background, then continue executing code in other cells.
```{code-cell}
use std::sync::{Mutex, Arc};
let counter = Arc::new(Mutex::new(0i32));
std::thread::spawn({
let counter = Arc::clone(&counter);
move || {
for i in 1..300 {
*counter.lock().unwrap() += 1;
std::thread::sleep(std::time::Duration::from_millis(100));
}
}});
```
```{code-cell}
*counter.lock().unwrap()
```
```{code-cell}
*counter.lock().unwrap()
```
## Loading external crates
We can load external crates. This one takes a while to compile, but once it's compiled, subsequent cells shouldn't need to recompile it, so it should be much quicker.
```{code-cell}
:dep base64 = "0.10.1"
base64::encode(&vec![1, 2, 3, 4])
```
## Customizing how types are displayed
We can also customize how our types are displayed, including presenting them as HTML. Here's an example where we define a custom display function for a type `Matrix`.
```{code-cell}
use std::fmt::Debug;
pub struct Matrix {pub values: Vec, pub row_size: usize}
impl Matrix {
pub fn evcxr_display(&self) {
let mut html = String::new();
html.push_str("");
for r in 0..(self.values.len() / self.row_size) {
html.push_str("
");
println!("EVCXR_BEGIN_CONTENT text/html\n{}\nEVCXR_END_CONTENT", html);
}
}
```
```{code-cell}
let m = Matrix {values: vec![1,2,3,4,5,6,7,8,9], row_size: 3};
m
```
We can also return images, we just need to base64 encode them. First, we set up code for displaying RGB and grayscale images.
```{code-cell}
extern crate image;
extern crate base64;
pub trait EvcxrResult {fn evcxr_display(&self);}
impl EvcxrResult for image::RgbImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::RGB(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
impl EvcxrResult for image::GrayImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::Gray(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
```
```{code-cell}
image::ImageBuffer::from_fn(256, 256, |x, y| {
if (x as i32 - y as i32).abs() < 3 {
image::Rgb([0, 0, 255])
} else {
image::Rgb([0, 0, 0])
}
})
```
## Display of compilation errors
Here's how compilation errors are presented. Here we forgot an & and passed a String instead of an &str.
```{code-cell}
let mut s = String::new();
s.push_str(format!("foo {}", 42));
```
## Seeing what variables have been defined
We can print a table of defined variables and their types with the :vars command.
```{code-cell}
:vars
```
Other built-in commands can be found via :help
```{code-cell}
:help
```
```{code-cell}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/frozen_cell.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
# This is an unfrozen cell. Works as usual.
print("I'm a regular cell so I run and print!")
```
```{code-cell} ipython3
---
deletable: false
editable: false
run_control:
frozen: true
---
# This is an frozen cell
print("I'm frozen so Im not executed :(")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/fsharp.md
================================================
---
kernelspec:
display_name: .NET (F#)
language: F#
name: .net-fsharp
---
This notebook was inspired by [Plottting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/fsharp/Docs/Plotting%20with%20Xplot.ipynb).
```{code-cell} fsharp
open XPlot.Plotly
```
```{code-cell} fsharp
let bar =
Bar(
name = "Bar 1",
x = ["A"; "B"; "C"],
y = [1; 3; 2])
[bar]
|> Chart.Plot
|> Chart.WithTitle "A sample bar plot"
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/gnuplot_notebook.md
================================================
---
kernelspec:
display_name: gnuplot
language: gnuplot
name: gnuplot
---
# Sample gnuplot notebook
+++
## Simple plotting
```{code-cell}
# Plot sin and cos with different linetypes
f(x) = sin(x)
g(x) = cos(x)
set xrange[0:2*pi]
set xtics(0, "{/Symbol p}" pi , "2{/Symbol p}" 2*pi)
set ytics 1
plot f(x) linewidth 2 title "sin(x)", \
g(x) linewidth 2 dashtype "--" title "cos(x)"
```
## Example of line magic
```{code-cell}
%gnuplot inline pngcairo enhanced background rgb "#EEEEEE" size 600, 600
# Parametric plot without border
reset
set parametric
set size ratio -1
unset border
unset tics
plot f(t), g(t) linewidth 2 notitle
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/haskell_notebook.md
================================================
---
kernelspec:
display_name: Haskell
language: haskell
name: haskell
---
# Example Haskell Notebook
+++
Define a function to add two numbers.
```{code-cell} Haskell
f :: Num a => a -> a -> a
f x y = x + y
```
Try to use the function
```{code-cell} Haskell
f 1 2
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/hello_world_gonb.md
================================================
---
kernelspec:
display_name: Go (gonb)
language: go
name: gonb
---
A notebook that use [GoNB](https://github.com/janpfeifer/gonb)
+++
the code below comes from [tutorial.ipynb](https://github.com/janpfeifer/gonb/blob/main/examples/tutorial.ipynb)
```{code-cell}
func main() {
fmt.Printf("Hello World!")
}
```
```{code-cell}
%%
fmt.Printf("Hello World!")
```
%% --who=world can pass flags to main func
```{code-cell}
import (
"flag"
"fmt"
)
var flagWho = flag.String("who", "", "Your name!")
%% --who=world
fmt.Printf("Hello %s!\n", *flagWho)
```
%args also can pass flags
```{code-cell}
%args --who=Wally
func main() {
flag.Parse()
fmt.Printf("Where is %s?", *flagWho)
}
```
```{code-cell}
import "github.com/janpfeifer/gonb/gonbui"
%%
gonbui.DisplayHtml(`I 🧡 GoNB!`)
```
```{code-cell}
%%
gonbui.DisplayMarkdown("#### Objective\n\n1. Have fun coding **Go**;\n1. Profit...\n"+
`$$f(x) = \int_{-\infty}^{\infty} e^{-x^2} dx$$`)
```
```{code-cell}
func init_a() {
fmt.Println("init_a")
}
%%
fmt.Println("main")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/ijavascript.md
================================================
---
kernelspec:
display_name: Javascript (Node.js)
language: javascript
name: javascript
---
## A notebook that uses IJavascript kernel
```{code-cell}
let x = 5;
const y = 6;
var z = 10;
```
```{code-cell}
x + y;
```
```{code-cell}
function add(num1, num2) {
return num1 + num2
}
```
```{code-cell}
add(x, y);
```
```{code-cell}
const arrowAdd = (num1, num2) => num1 + num2;
```
```{code-cell}
arrowAdd(x, y);
```
```{code-cell}
const myCar = {
color: "blue",
weight: 850,
model: "fiat",
start: () => "car started!",
doors: [1,2,3,4]
}
```
```{code-cell}
console.log("color:", myCar.color);
```
```{code-cell}
console.log("start:", myCar.start());
```
```{code-cell}
for (let door of myCar.doors) {
console.log("I'm door", door)
}
```
```{code-cell}
myCar;
```
```{code-cell}
class User {
constructor(name){
this.name = name;
}
sayHello(){
return "Hello, I'm " + this.name;
}
}
```
```{code-cell}
let John = new User("John");
John.sayHello();
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/ir_notebook.md
================================================
---
kernelspec:
display_name: R
language: R
name: ir
---
This is a jupyter notebook that uses the IR kernel.
```{code-cell} r
sum(1:10)
```
```{code-cell} r
plot(cars)
```
```{code-cell} r
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/itypescript.md
================================================
---
kernelspec:
display_name: Typescript 3.5
language: typescript
name: typescript
---
```{code-cell}
let x: number = 5;
const y: number = 6;
var z: string = "hi";
console.log(z);
x + y;
```
```{code-cell}
function add(num1: number, num2: number): number {
return num1 + num2
}
add(x, y);
```
```{code-cell}
const arrowAdd = (num1: number, num2: number) => num1 + num2;
arrowAdd(x, y);
```
```{code-cell}
class User {
constructor(private name: string) {
this.name = name;
}
sayHello(): string {
return "Hello, I'm " + this.name;
}
}
let John: User;
John = new User("John");
John.sayHello();
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/julia_benchmark_plotly_barchart.md
================================================
---
kernelspec:
display_name: Julia 1.1.1
language: julia
name: julia-1.1
---
```{code-cell}
# IJulia rocks! So does Plotly. Check it out
using Plotly
api_key = "" # visit https://plot.ly/api to generate an API username and password
username = ""
Plotly.signin(username, api_key)
```
```{code-cell}
# Following data taken from http://julialang.org/ frontpage
benchmarks = ["fib", "parse_int", "quicksort3", "mandel", "pi_sum", "rand_mat_stat", "rand_mat_mul"]
platforms = ["Fortran", "Julia", "Python", "R", "Matlab", "Mathematica", "Javascript", "Go"]
data = {
platforms[1] => [0.26, 5.03, 1.11, 0.86, 0.80, 0.64, 0.96],
platforms[2] => [0.91, 1.60, 1.14, 0.85, 1.00, 1.66, 1.01],
platforms[3] => [30.37, 13.95, 31.98, 14.19, 16.33, 13.52, 3.41 ],
platforms[4] => [411.36, 59.40, 524.29, 106.97, 15.42, 10.84, 3.98 ],
platforms[5] => [1992.00, 1463.16, 101.84, 64.58, 1.29, 6.61, 1.10 ],
platforms[6] => [64.46, 29.54, 35.74, 6.07, 1.32, 4.52, 1.16 ],
platforms[7] => [2.18, 2.43, 3.51, 3.49, 0.84, 3.28, 14.60],
platforms[8] => [1.03, 4.79, 1.25, 2.36, 1.41, 8.12, 8.51]
}
pdata = [ {"x"=>benchmarks,"y"=>data[k],"bardir"=>"h","type"=>"bar","name"=>k} for k = platforms ]
layout = {
"title"=> "Julia benchmark comparison (smaller is better, C performance = 1.0)",
"barmode"=> "group",
"autosize"=> false,
"width"=> 900,
"height"=> 900,
"titlefont"=>
{
"family"=> "Open Sans",
"size"=> 18,
"color"=> "rgb(84, 39, 143)"
},
"margin"=> {"l"=>160, "pad"=>0},
"xaxis"=> {
"title"=> "Benchmark log-time",
"type"=> "log"
},
"yaxis"=> {"title"=> "Benchmark Name"}
}
response = Plotly.plot(pdata,["layout"=>layout])
# Embed in an iframe within IJulia
s = string("")
display("text/html", s)
```
```{code-cell}
# checkout https://plot.ly/api/ for more Julia examples!
# But to show off some other Plotly features:
x = 1:1500
y1 = sin(2*pi*x/1500.) + rand(1500)-0.5
y2 = sin(2*pi*x/1500.)
fish = {"x"=>x,"y"=> y1,
"type"=>"scatter","mode"=>"markers",
"marker"=>{"color"=>"rgb(0, 0, 255)","opacity"=>0.5 } }
fit = {"x"=> x,"y"=> y2,
"type"=>"scatter", "mode"=>"markers", "opacity"=>0.8,
"marker"=>{"color"=>"rgb(255, 0, 0)"} }
layout = {"autosize"=> false,
"width"=> 650, "height"=> 550,
"title"=>"Fish School",
"xaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[0,1500] },
"yaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[-2.2,2.2] },
"plot_bgcolor"=> "rgb(245,245,247)",
"showlegend"=> false,
"hovermode"=> "closest"}
response = Plotly.plot([fish, fit],["layout"=>layout])
s = string("")
display("text/html", s)
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/jupyter.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
# Jupyter notebook
This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition:
```{code-cell} ipython3
a = 1
b = 2
a + b
```
Now we return a few tuples
```{code-cell} ipython3
a, b
```
```{code-cell} ipython3
a, b, a+b
```
And this is already the end of the notebook
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/jupyter_again.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
c = '''
title: "Quick test"
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type console
'''
```
```{code-cell} ipython3
import yaml
print(yaml.dump(yaml.load(c)))
```
```{code-cell} ipython3
?next
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/jupyter_with_raw_cell_in_body.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
1+2+3
```
```{raw-cell}
This is a raw cell
```
This is a markdown cell
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/jupyter_with_raw_cell_on_top.md
================================================
---
title: Quick test
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type: console
kernelspec:
display_name: Python 3
language: python
name: python3
jupytext:
root_level_metadata_filter: -title,-output,-editor_options
---
```{code-cell} ipython3
1+2+3
```
```{code-cell} ipython3
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/jupyter_with_raw_cell_with_invalid_yaml.md
================================================
---
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
---
```{raw-cell}
---
title: Exception: Test
---
```
```{code-cell} ipython3
1 + 2 + 3
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/jupyterlab-slideshow_1441.md
================================================
---
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
---
+++ {"@deathbeds/jupyterlab-fonts": {"styles": {"": {"body[data-jp-deck-mode='presenting'] &": {"right": "0", "top": "30%", "width": "25%", "z-index": 1}}}}, "jupyterlab-slideshow": {"layer": "slide"}}
> **Note**
>
> `slide` layer with a `top` of `30%`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/jupytext_replication.md
================================================
---
kernelspec:
display_name: SoS
language: sos
name: sos
---
+++ {"Collapsed": "false", "kernel": "SoS"}
# Text SOS-kernel with Jupytext
## What is SOS kernel
SoS consists of a ployglot notebook that allows the use of multiple kernels in one Jupyter notebook, and a workflow system that is designed for daily computational research. Basically,
- SoS Polyglot Notebook is a Jupyter Notebook with a SoS kernel.
- SoS Notebook serves as a super kernel to all other Jupyter kernels and allows the use of multiple kernels in one Jupyter notebook.
- SoS Workflow System is a Python based workflow system that is designed to be readable, shareable, and suitable for daily data analysis.
- SoS Workflow System can be used from command line or use SoS Notebook as its IDE.

### How to install SOS-kernel
Please follow this [link](https://vatlab.github.io/sos-docs/running.html#Conda-installation) to setup SOS
I run some issue with the latest version of R on my Mac, so I had to install an earlier version of R
```
conda install -c r r=3.5.1
conda install sos-notebook jupyterlab-sos sos-papermill -c conda-forge
```
## Related issue with Jupytext
Jupytext works fine with Python/R kernel but converts code cells into markdown cells when using the SOS kernel.
cf the image below. It is a code cell. After saving the notebook and restart it, it converted the code cell into markdown
+++ {"Collapsed": "false", "kernel": "SoS"}
## Step 1
Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.

```{code-cell} sos
:Collapsed: 'false'
:kernel: SoS
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
```
+++ {"Collapsed": "false", "kernel": "python3"}
## Step 2
Now, pair it with Jupytex

+++ {"Collapsed": "false", "kernel": "python3"}
### Step 3
Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
+++ {"Collapsed": "false", "kernel": "python3"}
### Step 4
Reopen the notebook. Here is the outcome

================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/kalman_filter_and_visualization.md
================================================
---
kernelspec:
display_name: Q 3.5
language: q
name: qpk
---
```{code-cell}
plt: .p.import`matplotlib.pyplot
```
```{code-cell}
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
```
```{code-cell}
price: 100 + sums 0.5 - (n:50)?1.
```
```{code-cell}
output:filter price
```
```{code-cell}
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
```
```{code-cell}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/logtalk_notebook.md
================================================
---
kernelspec:
display_name: Logtalk
language: logtalk
name: logtalk_kernel
---
# An implementation of the Ackermann function
```{code-cell}
---
vscode:
languageId: logtalk
---
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
```
## Sample query
```{code-cell}
---
vscode:
languageId: logtalk
---
ack::ack(2, 4, V).
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/lua_example.md
================================================
---
kernelspec:
display_name: Lua
language: lua
name: lua
---
Source: https://www.lua.org/pil/19.3.html
+++
# Sort
+++
Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
+++
A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
```{code-cell}
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
```
Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
```{code-cell}
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
```
Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
+++
As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
```{code-cell}
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
```
With this function, it is easy to print those function names in alphabetical order. The loop
```{code-cell}
for name, line in pairsByKeys(lines) do
print(name, line)
end
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/maxima_example.md
================================================
---
kernelspec:
display_name: Maxima
language: maxima
name: maxima
---
## maxima misc
```{code-cell} maxima
kill(all)$
```
```{code-cell} maxima
f(x) := 1/(x^2+l^2)^(3/2);
```
```{code-cell} maxima
integrate(f(x), x);
```
```{code-cell} maxima
tex(%)$
```
```{code-cell} maxima
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/notebook_with_complex_metadata.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/nteract_with_parameter.md
================================================
---
kernel_info:
name: python3
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
:inputHidden: false
:outputHidden: false
:tags: [parameters]
param = 4
```
```{code-cell} ipython3
:inputHidden: false
:outputHidden: false
import pandas as pd
```
```{code-cell} ipython3
:inputHidden: false
:outputHidden: false
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
```
```{code-cell} ipython3
:inputHidden: false
:outputHidden: false
%matplotlib inline
df.plot(kind='bar')
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/ocaml_notebook.md
================================================
---
jupytext:
formats: ipynb:markdown,md:myst
kernelspec:
display_name: OCaml default
language: OCaml
name: ocaml-jupyter
---
# Example of an OCaml notebook
```{code-cell} OCaml
let sum x y = x + y
```
Let's try our function:
```{code-cell} OCaml
sum 3 4 = 7 + 0
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/octave_notebook.md
================================================
---
kernelspec:
display_name: Octave
language: octave
name: octave
---
A markdown cell
```{code-cell}
1 + 1
```
```{code-cell}
% a code cell with comments
2 + 2
```
```{code-cell}
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
```
```{code-cell}
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
```
And to finish with, a Python cell
```{code-cell}
%%python
a = 1
```
```{code-cell}
%%python
a + 1
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/plotly_graphs.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
This notebook contains complex outputs, including plotly javascript graphs.
+++
# Interactive plots
+++
We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
```{code-cell} ipython3
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
```
```{code-cell} ipython3
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/powershell.md
================================================
---
kernelspec:
display_name: PowerShell
language: PowerShell
name: powershell
---
This is an extract from
https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
```{code-cell} powershell
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/raw_cell_with_complex_yaml_like_content.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{raw-cell}
---
This is a complex paragraph
that is split over multiple lines.
It also includes blank lines.
---
```
```{code-cell}
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/raw_cell_with_non_dict_yaml_content.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{raw-cell}
---
Content.
---
```
```{code-cell}
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/root_cpp.md
================================================
---
kernelspec:
display_name: ROOT C++
language: c++
name: root
---
```{code-cell}
#include
#include
```
```{code-cell}
int k = 4;
std::string foo = "This string says \"foo\"";
```
```{code-cell}
std::cout << "k = " << k << '\n' << foo << '\n';
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/sage_print_hello.md
================================================
---
kernelspec:
display_name: SageMath 9.2
language: sage
name: sagemath
---
```{code-cell} ipython3
print("Hello world")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/sample_bash_notebook.md
================================================
---
kernelspec:
display_name: Bash
language: bash
name: bash
---
```{code-cell}
ls
```
```{code-cell}
# https://coderwall.com/p/euwpig/a-better-git-log
git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"
```
```{code-cell}
git lg
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/sample_rise_notebook_66.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
+++ {"slideshow": {"slide_type": "slide"}}
A markdown cell
```{code-cell} ipython3
---
slideshow:
slide_type: ''
---
1+1
```
+++ {"cell_style": "center", "slideshow": {"slide_type": "fragment"}}
Markdown cell two
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/sas.md
================================================
---
kernelspec:
display_name: SAS
language: sas
name: sas
---
# SAS Notebooks with jupytext
```{code-cell}
proc sql;
select *
from sashelp.cars (obs=10)
;
quit;
```
```{code-cell}
%let name = "Jupytext";
```
```{code-cell}
%put &name;
```
```{code-cell}
/* Note when defining macros "%macro" cannot be the first line of text in the cell */
%macro test;
data temp;
set sashelp.cars;
name = "testx";
run;
proc print data = temp (obs=10);
run;
%mend test;
%test
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/simple-helloworld.md
================================================
---
jupytext:
encoding: '// -*- coding: utf-8 -*-'
formats: ipynb,java:light
kernelspec:
display_name: Java
language: java
name: java
---
Let's define some class.
```{code-cell}
class A {
public void hello() {
System.out.println("Hello World");
}
}
```
And now we call its method.
```{code-cell}
new A().hello();
```
You can run it e.g. with `jshell`
* from command line, as `jshell simple-helloworld.java`
* from jshell's shell with `/open simple-helloworld.java`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/simple_robot_notebook.md
================================================
---
kernelspec:
display_name: Robot Framework
language: robotframework
name: robotkernel
---
```{code-cell} robotframework
*** Settings ***
Library Collections
```
```{code-cell} robotframework
*** Keywords ***
Head
[Arguments] ${list}
${value}= Get from list ${list} 0
[Return] ${value}
```
```{code-cell} robotframework
*** Tasks ***
Get head
${array}= Create list 1 2 3 4 5
${head}= Head ${array}
Should be equal ${head} 1
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/simple_scala_notebook.md
================================================
---
kernelspec:
display_name: Apache Toree - Scala
language: scala
name: apache_toree_scala
---
```{code-cell} scala
// This is just a simple scala notebook
object SampleObject {
def calculation(x: Int, y: Int): Int = x + y
}
val result = SampleObject.calculation(1, 2)
```
```{code-cell} scala
println(result * 10)
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/stata_notebook.md
================================================
---
kernelspec:
display_name: Stata
language: stata
name: stata
---
```{code-cell}
// This notebook uses the stata_kernel: https://github.com/kylebarron/stata_kernel
```
```{code-cell}
use http://www.stata-press.com/data/r13/auto
```
```{code-cell}
summarize
```
```{code-cell}
scatter weight length
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/tailrecursive-factorial.md
================================================
---
jupytext:
encoding: '// -*- coding: utf-8 -*-'
formats: ipynb,groovy:light
kernelspec:
display_name: Groovy
language: groovy
name: groovy
---
# TailRecursive annotation
Let's check what is the effect of `@TailRecursive` annotation on the simple recursive definition of factorial function.
```{code-cell}
import groovy.transform.CompileStatic
import groovy.transform.TailRecursive
import groovy.transform.TypeChecked
@CompileStatic
@TypeChecked
class X {
static final BigInteger factorial0(int n) {
(n <= 1) ? 1G : factorial0(n-1).multiply(BigInteger.valueOf(n))
}
static final BigInteger factorial1(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial1(n-1, acc.multiply(BigInteger.valueOf(n)))
}
@TailRecursive
static final BigInteger factorial2(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial2(n-1, acc.multiply(BigInteger.valueOf(n)))
}
}
x = new X()
```
Although we can time the execution of the calls, it is not very accurate; such micro benchmarks should be performed in more controlled environment, such us under [JMH](https://openjdk.java.net/projects/code-tools/jmh/).
For example, see [blog posts of Szymon Stępniak](https://e.printstacktrace.blog/tail-recursive-methods-in-groovy/).
```{code-cell}
%%timeit
x.factorial0(19_000).toString().length()
```
```{code-cell}
%%timeit
x.factorial1(19_000).toString().length()
```
```{code-cell}
%%timeit
x.factorial2(19_000).toString().length()
```
The real difference is the use of stack. Non-tail recursive calls exhaust the stack space at some point, whereas tail recursive calls don't add frames to the stack.
```{code-cell}
factSize = { n, cl ->
println "Factorial of ${n} has ${cl(n).toString().length()} digits"
}
factSize 2_000, x.&factorial0
factSize 2_000, x.&factorial1
factSize 2_000, x.&factorial2
factSize 100_000, x.&factorial2
```
```{code-cell}
try {
factSize 100_000, x.&factorial1
} catch (Throwable e) {
assert e instanceof StackOverflowError
println e
}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/tcl_test.md
================================================
---
kernelspec:
display_name: Tcl
language: tcl
name: tcljupyter
---
# Assign Values
```{code-cell}
set a 1
puts "a = $a"
```
# Loop
```{code-cell}
for {set i 0} {$i < 10} {incr i} {
puts "I inside first loop: $i"
}
```
```{code-cell}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/text_outputs_and_images.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
This notebook contains outputs of many different types: text, HTML, plots and errors.
+++
# Text outputs
Using `print`, `sys.stdout` and `sys.stderr`
```{code-cell} ipython3
import sys
print('using print')
sys.stdout.write('using sys.stdout.write')
sys.stderr.write('using sys.stderr.write')
```
```{code-cell} ipython3
import logging
logging.debug('Debug')
logging.info('Info')
logging.warning('Warning')
logging.error('Error')
```
# HTML outputs
Using `pandas`. Here we find two representations: both text and HTML.
```{code-cell} ipython3
import pandas as pd
pd.DataFrame([4])
```
```{code-cell} ipython3
from IPython.display import display
display(pd.DataFrame([5]))
display(pd.DataFrame([6]))
```
# Images
```{code-cell} ipython3
%matplotlib inline
```
```{code-cell} ipython3
# First plot
from matplotlib import pyplot as plt
import numpy as np
w, h = 3, 3
data = np.zeros((h, w, 3), dtype=np.uint8)
data[0,:] = [0,255,0]
data[1,:] = [0,0,255]
data[2,:] = [0,255,0]
data[1:3,1:3] = [255, 0, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# Second plot
data[1:3,1:3] = [255, 255, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
```
# Errors
```{code-cell} ipython3
undefined_variable
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/wolfram.md
================================================
---
kernelspec:
display_name: Wolfram Language 13.1
language: Wolfram Language
name: wolframlanguage13.1
---
**Note:** The `language_info` `file_extension` in this notebook should be `.m`, but it was deliberately changed to `.wolfram` to avoid conflicts with Matlab which is using the same extension.
+++
We start with...
```{code-cell} mathematica
Print["Hello, World!"];
```
Then we draw the first example plot from the [ListPlot](https://reference.wolfram.com/language/ref/ListPlot.html) reference:
```{code-cell} mathematica
ListPlot[Prime[Range[25]]]
```
We also test the math outputs as in the [Simplify](https://reference.wolfram.com/language/ref/Simplify.html) example:
```{code-cell} mathematica
D[Integrate[1/(x^3 + 1), x], x]
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/xonsh_example.md
================================================
---
kernelspec:
display_name: Xonsh
language: xonsh
name: xonsh
---
```{code-cell} xonsh
len($(curl -L https://xon.sh))
```
```{code-cell} xonsh
for filename in `.*`:
print(filename)
du -sh @(filename)
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/Notebook_with_R_magic.md
================================================
---
jupyter:
kernelspec:
display_name: Python 2
language: python
name: python2
nbformat: 4
nbformat_minor: 2
---
::: {.cell .markdown}
# A notebook with R cells
This notebook shows the use of R cells to generate plots
:::
::: {.cell .code}
``` python
%load_ext rpy2.ipython
```
:::
::: {.cell .code}
``` python
%%R
suppressMessages(require(tidyverse))
```
:::
::: {.cell .code}
``` python
%%R
ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point()
```
:::
::: {.cell .markdown}
The default plot dimensions are not good for us, so we use the -w and -h parameters in %%R magic to set the plot size
:::
::: {.cell .code}
``` python
%%R -w 400 -h 240
ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point()
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/Notebook_with_more_R_magic_111.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .code}
``` python
%load_ext rpy2.ipython
import pandas as pd
df = pd.DataFrame(
{
"Letter": ["a", "a", "a", "b", "b", "b", "c", "c", "c"],
"X": [4, 3, 5, 2, 1, 7, 7, 5, 9],
"Y": [0, 4, 3, 6, 7, 10, 11, 9, 13],
"Z": [1, 2, 3, 1, 2, 3, 1, 2, 3],
}
)
```
:::
::: {.cell .code}
``` python
%%R -i df
library("ggplot2")
ggplot(data = df) + geom_point(aes(x = X, y = Y, color = Letter, size = Z))
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/cat_variable.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .code}
``` python
cat = 42
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/convert_to_py_then_test_with_update83.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .code}
``` python
%%time
print('asdf')
```
:::
::: {.cell .markdown}
Thanks for jupytext!
:::
::: {.cell .code}
``` python
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/frozen_cell.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .code}
``` python
# This is an unfrozen cell. Works as usual.
print("I'm a regular cell so I run and print!")
```
:::
::: {.cell .code deletable="false" editable="false" run_control="{\"frozen\":true}"}
``` python
# This is an frozen cell
print("I'm frozen so Im not executed :(")
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/ir_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: R
language: R
name: ir
nbformat: 4
nbformat_minor: 2
---
::: {.cell .markdown}
This is a jupyter notebook that uses the IR kernel.
:::
::: {.cell .code}
``` R
sum(1:10)
```
:::
::: {.cell .code}
``` R
plot(cars)
```
:::
::: {.cell .code}
``` R
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/julia_benchmark_plotly_barchart.md
================================================
---
jupyter:
kernelspec:
display_name: Julia 1.1.1
language: julia
name: julia-1.1
nbformat: 4
nbformat_minor: 1
---
::: {.cell .code}
``` julia
# IJulia rocks! So does Plotly. Check it out
using Plotly
api_key = "" # visit https://plot.ly/api to generate an API username and password
username = ""
Plotly.signin(username, api_key)
```
:::
::: {.cell .code}
``` julia
# Following data taken from http://julialang.org/ frontpage
benchmarks = ["fib", "parse_int", "quicksort3", "mandel", "pi_sum", "rand_mat_stat", "rand_mat_mul"]
platforms = ["Fortran", "Julia", "Python", "R", "Matlab", "Mathematica", "Javascript", "Go"]
data = {
platforms[1] => [0.26, 5.03, 1.11, 0.86, 0.80, 0.64, 0.96],
platforms[2] => [0.91, 1.60, 1.14, 0.85, 1.00, 1.66, 1.01],
platforms[3] => [30.37, 13.95, 31.98, 14.19, 16.33, 13.52, 3.41 ],
platforms[4] => [411.36, 59.40, 524.29, 106.97, 15.42, 10.84, 3.98 ],
platforms[5] => [1992.00, 1463.16, 101.84, 64.58, 1.29, 6.61, 1.10 ],
platforms[6] => [64.46, 29.54, 35.74, 6.07, 1.32, 4.52, 1.16 ],
platforms[7] => [2.18, 2.43, 3.51, 3.49, 0.84, 3.28, 14.60],
platforms[8] => [1.03, 4.79, 1.25, 2.36, 1.41, 8.12, 8.51]
}
pdata = [ {"x"=>benchmarks,"y"=>data[k],"bardir"=>"h","type"=>"bar","name"=>k} for k = platforms ]
layout = {
"title"=> "Julia benchmark comparison (smaller is better, C performance = 1.0)",
"barmode"=> "group",
"autosize"=> false,
"width"=> 900,
"height"=> 900,
"titlefont"=>
{
"family"=> "Open Sans",
"size"=> 18,
"color"=> "rgb(84, 39, 143)"
},
"margin"=> {"l"=>160, "pad"=>0},
"xaxis"=> {
"title"=> "Benchmark log-time",
"type"=> "log"
},
"yaxis"=> {"title"=> "Benchmark Name"}
}
response = Plotly.plot(pdata,["layout"=>layout])
# Embed in an iframe within IJulia
s = string("")
display("text/html", s)
```
:::
::: {.cell .code}
``` julia
# checkout https://plot.ly/api/ for more Julia examples!
# But to show off some other Plotly features:
x = 1:1500
y1 = sin(2*pi*x/1500.) + rand(1500)-0.5
y2 = sin(2*pi*x/1500.)
fish = {"x"=>x,"y"=> y1,
"type"=>"scatter","mode"=>"markers",
"marker"=>{"color"=>"rgb(0, 0, 255)","opacity"=>0.5 } }
fit = {"x"=> x,"y"=> y2,
"type"=>"scatter", "mode"=>"markers", "opacity"=>0.8,
"marker"=>{"color"=>"rgb(255, 0, 0)"} }
layout = {"autosize"=> false,
"width"=> 650, "height"=> 550,
"title"=>"Fish School",
"xaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[0,1500] },
"yaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[-2.2,2.2] },
"plot_bgcolor"=> "rgb(245,245,247)",
"showlegend"=> false,
"hovermode"=> "closest"}
response = Plotly.plot([fish, fit],["layout"=>layout])
s = string("")
display("text/html", s)
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/jupyter.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .markdown}
# Jupyter notebook
This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition:
:::
::: {.cell .code}
``` python
a = 1
b = 2
a + b
```
:::
::: {.cell .markdown}
Now we return a few tuples
:::
::: {.cell .code}
``` python
a, b
```
:::
::: {.cell .code}
``` python
a, b, a+b
```
:::
::: {.cell .markdown}
And this is already the end of the notebook
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/jupyter_again.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .code}
``` python
c = '''
title: "Quick test"
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type console
'''
```
:::
::: {.cell .code}
``` python
import yaml
print(yaml.dump(yaml.load(c)))
```
:::
::: {.cell .code}
``` python
?next
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/jupyter_with_raw_cell_in_body.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .code}
``` python
1+2+3
```
:::
::: {.cell .raw}
```{=ipynb}
This is a raw cell
```
:::
::: {.cell .markdown}
This is a markdown cell
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/jupyter_with_raw_cell_on_top.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .raw}
```{=ipynb}
---
title: Quick test
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type: console
---
```
:::
::: {.cell .code}
``` python
1+2+3
```
:::
::: {.cell .code}
``` python
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/notebook_with_complex_metadata.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .code}
``` python
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/nteract_with_parameter.md
================================================
---
jupyter:
kernel_info:
name: python3
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .code inputHidden="false" outputHidden="false" tags="[\"parameters\"]"}
``` python
param = 4
```
:::
::: {.cell .code inputHidden="false" outputHidden="false"}
``` python
import pandas as pd
```
:::
::: {.cell .code inputHidden="false" outputHidden="false"}
``` python
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
```
:::
::: {.cell .code inputHidden="false" outputHidden="false"}
``` python
%matplotlib inline
df.plot(kind='bar')
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/plotly_graphs.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .markdown}
This notebook contains complex outputs, including plotly javascript graphs.
:::
::: {.cell .markdown}
# Interactive plots
:::
::: {.cell .markdown}
We use Plotly\'s connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
:::
::: {.cell .code}
``` python
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
```
:::
::: {.cell .code}
``` python
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/raw_cell_with_complex_yaml_like_content.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 5
---
::: {#b32297a4 .cell .raw}
```{=ipynb}
---
This is a complex paragraph
that is split over multiple lines.
It also includes blank lines.
---
```
:::
::: {#0b3bde0a .cell .code}
``` python
print("Hello, World!")
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/raw_cell_with_non_dict_yaml_content.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 5
---
::: {#b32297a4 .cell .raw}
```{=ipynb}
---
Content.
---
```
:::
::: {#0b3bde0a .cell .code}
``` python
print("Hello, World!")
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/sample_rise_notebook_66.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .markdown slideshow="{\"slide_type\":\"slide\"}"}
A markdown cell
:::
::: {.cell .code slideshow="{\"slide_type\":\"\"}"}
``` python
1+1
```
:::
::: {.cell .markdown cell_style="center" slideshow="{\"slide_type\":\"fragment\"}"}
Markdown cell two
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_pandoc/text_outputs_and_images.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
nbformat: 4
nbformat_minor: 2
---
::: {.cell .markdown}
This notebook contains outputs of many different types: text, HTML, plots and errors.
:::
::: {.cell .markdown}
# Text outputs
Using `print`, `sys.stdout` and `sys.stderr`
:::
::: {.cell .code}
``` python
import sys
print('using print')
sys.stdout.write('using sys.stdout.write')
sys.stderr.write('using sys.stderr.write')
```
:::
::: {.cell .code}
``` python
import logging
logging.debug('Debug')
logging.info('Info')
logging.warning('Warning')
logging.error('Error')
```
:::
::: {.cell .markdown}
# HTML outputs
Using `pandas`. Here we find two representations: both text and HTML.
:::
::: {.cell .code}
``` python
import pandas as pd
pd.DataFrame([4])
```
:::
::: {.cell .code}
``` python
from IPython.display import display
display(pd.DataFrame([5]))
display(pd.DataFrame([6]))
```
:::
::: {.cell .markdown}
# Images
:::
::: {.cell .code}
``` python
%matplotlib inline
```
:::
::: {.cell .code}
``` python
# First plot
from matplotlib import pyplot as plt
import numpy as np
w, h = 3, 3
data = np.zeros((h, w, 3), dtype=np.uint8)
data[0,:] = [0,255,0]
data[1,:] = [0,0,255]
data[2,:] = [0,255,0]
data[1:3,1:3] = [255, 0, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# Second plot
data[1:3,1:3] = [255, 255, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
```
:::
::: {.cell .markdown}
# Errors
:::
::: {.cell .code}
``` python
undefined_variable
```
:::
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/Line_breaks_in_LateX_305.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# This cell uses no particular cell marker
#
# $$
# \begin{align}
# \dot{x} & = \sigma(y-x)\\
# \dot{y} & = \rho x - y - xz \\
# \dot{z} & = -\beta z + xy
# \end{align}
# $$
# %% [markdown]
# This cell uses no particular cell marker, and a single slash in the $\LaTeX$ equation
#
# $$
# \begin{align}
# \dot{x} & = \sigma(y-x) \
# \dot{y} & = \rho x - y - xz \
# \dot{z} & = -\beta z + xy
# \end{align}
# $$
# %% [markdown]
r'''
This cell uses the triple quote cell markers introduced at https://github.com/mwouts/jupytext/issues/305
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
'''
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/Notebook with function and cell metadata 164.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
1 + 1
# %% [markdown]
# A markdown cell
# And below, the cell for function f has non trivial cell metadata. And the next cell as well.
# %% attributes={"classes": [], "id": "", "n": "10"}
def f(x):
return x
# %% attributes={"classes": [], "id": "", "n": "10"}
f(5)
# %% [markdown]
# More text
# %%
2 + 2
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/Notebook with html and latex cells.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% language="html"
#
;;
;;
;; It has breakpoints (click in left margin). You must press Stop to exit the debugger.
;; %% [markdown]
;; ```scheme
;; %%debug
;;
;; (begin
;; (define x 1)
;; (set! x 2)
;; )
;; ```
;; %% [markdown]
;; ### Python Integration
;;
;; You can import and use any Python library in Calysto Scheme.
;;
;; In addition, if you wish, you can execute expressions and statements in a Python environment:
;; %%
(python-eval "1 + 2")
;; %%
(python-exec
"
def mypyfunc(a, b):
return a * b
")
;; %% [markdown]
;; This is a shared environment with Scheme:
;; %%
(mypyfunc 4 5)
;; %% [markdown]
;; You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
;; %%
(define! mypyfunc2 (func (lambda (n) n)))
;; %%
(python-eval "mypyfunc2(34)")
;; %% [markdown]
;; # Differences Between Languages
;;
;; ## Major differences between Scheme and Python
;;
;; 1. In Scheme, double quotes are used for strings and may contain newlines
;; 1. In Scheme, a single quote is short for (quote ...) and means "literal"
;; 1. In Scheme, everything is an expression and has a return value
;; 1. Python does not support macros (e.g., extending syntax)
;; 1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
;; 1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
;; 1. Scheme procedures are not Python functions, but there are means to use one as the other.
;;
;; ## Major Differences Between Calysto Scheme and other Schemes
;;
;; 1. define-syntax works slightly differently
;; 1. In Calysto Scheme, #(...) is short for '#(...)
;; 1. Calysto Scheme is missing many standard functions (see list at bottom)
;; 1. Calysto Scheme has a built-in amb operator called `choose`
;; 1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
;;
;; ### Stack Trace
;;
;; Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
;; %%
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
;; %%
(fact 5)
;; %% [markdown]
;; To turn off the stack trace on error:
;;
;; ```scheme
;; (use-stack-trace #f)
;; ```
;; That will allow infinite recursive loops without keeping track of the "stack".
;; %% [markdown]
;; # Calysto Scheme Variables
;;
;; ## SCHEMEPATH
;; SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
;; %%
SCHEMEPATH
;; %%
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
;; %%
SCHEMEPATH
;; %% [markdown]
;; ## Getting Started
;;
;; Note that you can use the word `lambda` or \lambda and then press [TAB]
;; %%
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
;; %%
(factorial 5)
;; %% [markdown]
;; ## define-syntax
;; (define-syntax NAME RULES): a method for creating macros
;; %%
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
;; %%
(time (car '(1 2 3 4)))
;; %%
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
;; %%
(collect (* n n) for n in (range 10))
;; %%
(collect (* n n) for n in (range 5 20 3))
;; %%
(collect (* n n) for n in (range 10) if (> n 5))
;; %%
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
;; %%
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
;; %%
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
;; %%
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
;; %%
(for n in (range 10 20 2) do (print n))
;; %%
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
;; %%
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
;; %%
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
;; %%
(! 5)
;; %%
(nth 10 facts)
;; %%
(nth 20 fibs)
;; %%
(first 30 fibs)
;; %% [markdown]
;; ## for-each
;; (for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
;; %%
(for-each (lambda (n) (print n)) '(3 4 5))
;; %% [markdown]
;; ## format
;; (format STRING ITEM ...): format the string with ITEMS as arguments
;; %%
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
;; %% [markdown]
;; ## func
;;
;; Turns a lambda into a Python function.
;;
;; (func (lambda ...))
;; %%
(func (lambda (n) n))
;; %% [markdown]
;; ## There's more!
;;
;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/Reference Guide for Calysto Scheme.ss
================================================
;; -*- coding: utf-8 -*-
;; ---
;; jupyter:
;; kernelspec:
;; display_name: Calysto Scheme (Python)
;; language: scheme
;; name: calysto_scheme
;; ---
;; %% [markdown]
;;
;;
;;
;; It has breakpoints (click in left margin). You must press Stop to exit the debugger.
;; %% [markdown]
;; ```scheme
;; %%debug
;;
;; (begin
;; (define x 1)
;; (set! x 2)
;; )
;; ```
;; %% [markdown]
;; ### Python Integration
;;
;; You can import and use any Python library in Calysto Scheme.
;;
;; In addition, if you wish, you can execute expressions and statements in a Python environment:
;; %%
(python-eval "1 + 2")
;; %%
(python-exec
"
def mypyfunc(a, b):
return a * b
")
;; %% [markdown]
;; This is a shared environment with Scheme:
;; %%
(mypyfunc 4 5)
;; %% [markdown]
;; You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
;; %%
(define! mypyfunc2 (func (lambda (n) n)))
;; %%
(python-eval "mypyfunc2(34)")
;; %% [markdown]
;; # Differences Between Languages
;;
;; ## Major differences between Scheme and Python
;;
;; 1. In Scheme, double quotes are used for strings and may contain newlines
;; 1. In Scheme, a single quote is short for (quote ...) and means "literal"
;; 1. In Scheme, everything is an expression and has a return value
;; 1. Python does not support macros (e.g., extending syntax)
;; 1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
;; 1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
;; 1. Scheme procedures are not Python functions, but there are means to use one as the other.
;;
;; ## Major Differences Between Calysto Scheme and other Schemes
;;
;; 1. define-syntax works slightly differently
;; 1. In Calysto Scheme, #(...) is short for '#(...)
;; 1. Calysto Scheme is missing many standard functions (see list at bottom)
;; 1. Calysto Scheme has a built-in amb operator called `choose`
;; 1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
;;
;; ### Stack Trace
;;
;; Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
;; %%
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
;; %%
(fact 5)
;; %% [markdown]
;; To turn off the stack trace on error:
;;
;; ```scheme
;; (use-stack-trace #f)
;; ```
;; That will allow infinite recursive loops without keeping track of the "stack".
;; %% [markdown]
;; # Calysto Scheme Variables
;;
;; ## SCHEMEPATH
;; SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
;; %%
SCHEMEPATH
;; %%
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
;; %%
SCHEMEPATH
;; %% [markdown]
;; ## Getting Started
;;
;; Note that you can use the word `lambda` or \lambda and then press [TAB]
;; %%
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
;; %%
(factorial 5)
;; %% [markdown]
;; ## define-syntax
;; (define-syntax NAME RULES): a method for creating macros
;; %%
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
;; %%
(time (car '(1 2 3 4)))
;; %%
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
;; %%
(collect (* n n) for n in (range 10))
;; %%
(collect (* n n) for n in (range 5 20 3))
;; %%
(collect (* n n) for n in (range 10) if (> n 5))
;; %%
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
;; %%
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
;; %%
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
;; %%
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
;; %%
(for n in (range 10 20 2) do (print n))
;; %%
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
;; %%
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
;; %%
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
;; %%
(! 5)
;; %%
(nth 10 facts)
;; %%
(nth 20 fibs)
;; %%
(first 30 fibs)
;; %% [markdown]
;; ## for-each
;; (for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
;; %%
(for-each (lambda (n) (print n)) '(3 4 5))
;; %% [markdown]
;; ## format
;; (format STRING ITEM ...): format the string with ITEMS as arguments
;; %%
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
;; %% [markdown]
;; ## func
;;
;; Turns a lambda into a Python function.
;;
;; (func (lambda ...))
;; %%
(func (lambda (n) n))
;; %% [markdown]
;; ## There's more!
;;
;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/The flavors of raw cells.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [raw] raw_mimetype="text/latex"
# $1+1$
# %% [raw] raw_mimetype="text/restructuredtext"
# :math:`1+1`
# %% [raw] raw_mimetype="text/html"
# Bold text
# %% [raw] raw_mimetype="text/markdown"
# **Bold text**
# %% [raw] raw_mimetype="text/x-python"
# 1 + 1
# %% [raw]
# Not formatted
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/cat_variable.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
cat = 42
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/coconut_homepage_demo.coco
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Coconut
# language: coconut
# name: coconut
# ---
# %% [markdown]
# Taken from [coconut-lang.org](coconut-lang.org)
# %% [markdown]
# pipeline-style programming
# %%
"hello, world!" |> print
# %% [markdown]
# prettier lambdas
# %%
x -> x ** 2
# %% [markdown]
# partial application
# %%
range(10) |> map$(pow$(?, 2)) |> list
# %% [markdown]
# pattern-matching
# %%
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
# %% [markdown]
# destructuring assignment
# %%
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
# %% [markdown]
# infix notation
# %%
# 5 `mod` 3 == 2
# %% [markdown]
# operator functions
# %%
product = reduce$(*)
# %% [markdown]
# function composition
# %%
# (f..g..h)(x, y, z)
# %% [markdown]
# lazy lists
# %%
# (| first_elem() |) :: rest_elems()
# %% [markdown]
# parallel programming
# %%
range(100) |> parallel_map$(pow$(2)) |> list
# %% [markdown]
# tail call optimization
# %%
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
# %% [markdown]
# algebraic data types
# %%
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
# %% [markdown]
# and much more!
#
# Like what you see? Don't forget to star Coconut on GitHub!
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/convert_to_py_then_test_with_update83.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
# %%time
print('asdf')
# %% [markdown]
# Thanks for jupytext!
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/csharp.cs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: .NET (C#)
// language: C#
// name: .net-csharp
// ---
// %% [markdown]
// We start with...
// %%
Console.WriteLine("Hello World!");
// %% [markdown]
// Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
// %%
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
// %% [markdown]
// We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
// %%
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
// %%
(MathString)@"e^{i \pi} = -1"
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/demo_gdl_fbp.pro
================================================
; -*- coding: utf-8 -*-
; ---
; jupyter:
; kernelspec:
; display_name: IDL [conda env:gdl] *
; language: IDL
; name: conda-env-gdl-idl
; ---
; %% [markdown]
; ## GDL demo notebook
; %% [markdown]
; Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
;
; This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
; %%
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
; %%
;; Enable inline plotting
!inline=1
; %%
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
; %% [markdown]
; Now we define simple forward and backprojection functions:
; %%
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
; %%
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
; %% [markdown]
; This allows us to create a sinogram:
; %%
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
; %% [markdown]
; On this we can apply a simple FBP reconstruction:
; %%
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
; %%
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
; %% [markdown]
; ### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/evcxr_jupyter_tour.rs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Rust
// language: rust
// name: rust
// ---
// %% [markdown]
// # Tour of the EvCxR Jupyter Kernel
// For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
//
// ## Printing to outputs and evaluating expressions
// Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
// %%
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
// %% [markdown]
// ## Assigning and making use of variables
// We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
// %%
let mut message = "Hello ".to_owned();
// %%
message.push_str("world!");
// %%
message
// %% [markdown]
// ## Defining and redefining functions
// Next we'll define a function
// %%
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
// %%
(1..13).map(fib).collect::>()
// %% [markdown]
// Hmm, that doesn't look right. Lets redefine the function. In practice, we'd go back and edit the function above and reevaluate it, but here, lets redefine it in a separate cell.
// %%
pub fn fib(x: i32) -> i32 {
if x <= 2 {2} else {fib(x - 2) + fib(x - 1)}
}
// %%
let values = (1..13).map(fib).collect::>();
values
// %% [markdown]
// ## Spawning a separate thread and communicating with it
// We can spawn a thread to do stuff in the background, then continue executing code in other cells.
// %%
use std::sync::{Mutex, Arc};
let counter = Arc::new(Mutex::new(0i32));
std::thread::spawn({
let counter = Arc::clone(&counter);
move || {
for i in 1..300 {
*counter.lock().unwrap() += 1;
std::thread::sleep(std::time::Duration::from_millis(100));
}
}});
// %%
*counter.lock().unwrap()
// %%
*counter.lock().unwrap()
// %% [markdown]
// ## Loading external crates
// We can load external crates. This one takes a while to compile, but once it's compiled, subsequent cells shouldn't need to recompile it, so it should be much quicker.
// %%
// :dep base64 = "0.10.1"
base64::encode(&vec![1, 2, 3, 4])
// %% [markdown]
// ## Customizing how types are displayed
// We can also customize how our types are displayed, including presenting them as HTML. Here's an example where we define a custom display function for a type `Matrix`.
// %%
use std::fmt::Debug;
pub struct Matrix {pub values: Vec, pub row_size: usize}
impl Matrix {
pub fn evcxr_display(&self) {
let mut html = String::new();
html.push_str("");
for r in 0..(self.values.len() / self.row_size) {
html.push_str("
");
println!("EVCXR_BEGIN_CONTENT text/html\n{}\nEVCXR_END_CONTENT", html);
}
}
// %%
let m = Matrix {values: vec![1,2,3,4,5,6,7,8,9], row_size: 3};
m
// %% [markdown]
// We can also return images, we just need to base64 encode them. First, we set up code for displaying RGB and grayscale images.
// %%
extern crate image;
extern crate base64;
pub trait EvcxrResult {fn evcxr_display(&self);}
impl EvcxrResult for image::RgbImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::RGB(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
impl EvcxrResult for image::GrayImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::Gray(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
// %%
image::ImageBuffer::from_fn(256, 256, |x, y| {
if (x as i32 - y as i32).abs() < 3 {
image::Rgb([0, 0, 255])
} else {
image::Rgb([0, 0, 0])
}
})
// %% [markdown]
// ## Display of compilation errors
// Here's how compilation errors are presented. Here we forgot an & and passed a String instead of an &str.
// %%
let mut s = String::new();
s.push_str(format!("foo {}", 42));
// %% [markdown]
// ## Seeing what variables have been defined
// We can print a table of defined variables and their types with the :vars command.
// %%
// :vars
// %% [markdown]
// Other built-in commands can be found via :help
// %%
// :help
// %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/frozen_cell.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
# This is an unfrozen cell. Works as usual.
print("I'm a regular cell so I run and print!")
# %% deletable=false editable=false run_control={"frozen": true}
# # This is an frozen cell
# print("I'm frozen so Im not executed :(")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/fsharp.fsx
================================================
// ---
// jupyter:
// kernelspec:
// display_name: .NET (F#)
// language: F#
// name: .net-fsharp
// ---
// %% [markdown]
// This notebook was inspired by [Plottting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/fsharp/Docs/Plotting%20with%20Xplot.ipynb).
// %%
open XPlot.Plotly
// %%
let bar =
Bar(
name = "Bar 1",
x = ["A"; "B"; "C"],
y = [1; 3; 2])
[bar]
|> Chart.Plot
|> Chart.WithTitle "A sample bar plot"
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/gnuplot_notebook.gp
================================================
# ---
# jupyter:
# kernelspec:
# display_name: gnuplot
# language: gnuplot
# name: gnuplot
# ---
# %% [markdown]
# # Sample gnuplot notebook
# %% [markdown]
# ## Simple plotting
# %%
# Plot sin and cos with different linetypes
f(x) = sin(x)
g(x) = cos(x)
set xrange[0:2*pi]
set xtics(0, "{/Symbol p}" pi , "2{/Symbol p}" 2*pi)
set ytics 1
plot f(x) linewidth 2 title "sin(x)", \
g(x) linewidth 2 dashtype "--" title "cos(x)"
# %% [markdown]
# ## Example of line magic
# %%
# %gnuplot inline pngcairo enhanced background rgb "#EEEEEE" size 600, 600
# Parametric plot without border
reset
set parametric
set size ratio -1
unset border
unset tics
plot f(t), g(t) linewidth 2 notitle
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/haskell_notebook.hs
================================================
-- ---
-- jupyter:
-- kernelspec:
-- display_name: Haskell
-- language: haskell
-- name: haskell
-- ---
-- %% [markdown]
-- # Example Haskell Notebook
-- %% [markdown]
-- Define a function to add two numbers.
-- %%
f :: Num a => a -> a -> a
f x y = x + y
-- %% [markdown]
-- Try to use the function
-- %%
f 1 2
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/hello_world_gonb.go
================================================
// -*- coding: utf-8 -*-
// ---
// jupyter:
// kernelspec:
// display_name: Go (gonb)
// language: go
// name: gonb
// ---
// %% [markdown]
// A notebook that use [GoNB](https://github.com/janpfeifer/gonb)
// %% [markdown]
// the code below comes from [tutorial.ipynb](https://github.com/janpfeifer/gonb/blob/main/examples/tutorial.ipynb)
// %%
func main() {
fmt.Printf("Hello World!")
}
// %%
//gonb:%%
fmt.Printf("Hello World!")
// %% [markdown]
// //gonb:%% --who=world can pass flags to main func
// %%
import (
"flag"
"fmt"
)
var flagWho = flag.String("who", "", "Your name!")
//gonb:%% --who=world
fmt.Printf("Hello %s!\n", *flagWho)
// %% [markdown]
// %args also can pass flags
// %%
// %args --who=Wally
func main() {
flag.Parse()
fmt.Printf("Where is %s?", *flagWho)
}
// %%
import "github.com/janpfeifer/gonb/gonbui"
//gonb:%%
gonbui.DisplayHtml(`I 🧡 GoNB!`)
// %%
//gonb:%%
gonbui.DisplayMarkdown("#### Objective\n\n1. Have fun coding **Go**;\n1. Profit...\n"+
`$$f(x) = \int_{-\infty}^{\infty} e^{-x^2} dx$$`)
// %%
func init_a() {
fmt.Println("init_a")
}
//gonb:%%
fmt.Println("main")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/html-demo.clj
================================================
;; ---
;; jupyter:
;; kernelspec:
;; display_name: Clojure
;; language: clojure
;; name: clojure
;; ---
;; %% [markdown]
;; # Clojupyter Demo
;;
;; This example notebook is from the [Clojupyter](https://github.com/clojupyter/clojupyter/blob/1637f6b2557f01db1e35bae5389bc38522eefe9a/examples/html-demo.ipynb) project.
;; This notebook demonstrates some of the more advanced features of Clojupyter.
;; %% [markdown]
;; ## Displaying HTML
;;
;; To display HTML, you'll need to require a clojupyter helper function to change the cell output
;; %%
(require '[clojupyter.misc.display :as display])
;; %%
(println ">> should print some text")
;; displaying html
(display/hiccup-html
[:ul
[:li "a " [:i "emphatic"] " idea"]
[:li "a " [:b "bold"] " idea"]
[:li "an " [:span {:style "text-decoration: underline;"} "important"] " idea"]])
;; %% [markdown]
;; We can also use this to render SVG:
;; %%
(display/hiccup-html
[:svg {:height 100 :width 100 :xmlns "http://www.w3.org/2000/svg"}
[:circle {:cx 50 :cy 40 :r 40 :fill "red"}]])
;; %% [markdown]
;; ## Adding External Clojure Dependencies
;;
;; You can fetch external Clojure dependencies using the `clojupyter.misc.helper` namespace.
;; %%
(require '[clojupyter.misc.helper :as helper])
;; %%
(helper/add-dependencies '[org.clojure/data.json "0.2.6"])
(require '[clojure.data.json :as json])
;; %%
(json/write-str {:a 1 :b [2, 3] :c "c"})
;; %% [markdown]
;; ## Adding External Javascript Dependency
;;
;; Since you can render arbitrary HTML using `display/hiccup-html`, it's pretty easy to use external Javascript libraries to do things like generate charts. Here's an example using [Highcharts](https://www.highcharts.com/).
;;
;; First, we use a cell to add javascript to the running notebook:
;; %%
(helper/add-javascript "https://code.highcharts.com/highcharts.js")
;; %% [markdown]
;; Now we define a function which takes Clojure data and returns hiccup HTML to display:
;; %%
(defn plot-highchart [highchart-json]
(let [id (str (java.util.UUID/randomUUID))
code (format "Highcharts.chart('%s', %s );" id, (json/write-str highchart-json))]
(display/hiccup-html
[:div [:div {:id id :style {:background-color "red"}}]
[:script code]])))
;; %% [markdown]
;; Now we can make generate interactive plots (try hovering over plot):
;; %%
(def raw-data (map #(+ (* 22 (+ % (Math/random)) 78)) (range)))
(def data-1 (take 500 raw-data))
(def data-2 (take 500 (drop 500 raw-data)))
(plot-highchart {:chart {:type "line"}
:title {:text "Plot of random data"}
:series [{:data data-1} {:data data-2}]})
;; %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/ijavascript.js
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Javascript (Node.js)
// language: javascript
// name: javascript
// ---
// %% [markdown]
// ## A notebook that uses IJavascript kernel
// %%
let x = 5;
const y = 6;
var z = 10;
// %%
x + y;
// %%
function add(num1, num2) {
return num1 + num2
}
// %%
add(x, y);
// %%
const arrowAdd = (num1, num2) => num1 + num2;
// %%
arrowAdd(x, y);
// %%
const myCar = {
color: "blue",
weight: 850,
model: "fiat",
start: () => "car started!",
doors: [1,2,3,4]
}
// %%
console.log("color:", myCar.color);
// %%
console.log("start:", myCar.start());
// %%
for (let door of myCar.doors) {
console.log("I'm door", door)
}
// %%
myCar;
// %%
class User {
constructor(name){
this.name = name;
}
sayHello(){
return "Hello, I'm " + this.name;
}
}
// %%
let John = new User("John");
John.sayHello();
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/ir_notebook.R
================================================
# ---
# jupyter:
# kernelspec:
# display_name: R
# language: R
# name: ir
# ---
# %% [markdown]
# This is a jupyter notebook that uses the IR kernel.
# %%
sum(1:10)
# %%
plot(cars)
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/ir_notebook.low.r
================================================
# ---
# jupyter:
# kernelspec:
# display_name: R
# language: R
# name: ir
# ---
# %% [markdown]
# This is a jupyter notebook that uses the IR kernel.
# %%
sum(1:10)
# %%
plot(cars)
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/itypescript.ts
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Typescript 3.5
// language: typescript
// name: typescript
// ---
// %%
let x: number = 5;
const y: number = 6;
var z: string = "hi";
console.log(z);
x + y;
// %%
function add(num1: number, num2: number): number {
return num1 + num2
}
add(x, y);
// %%
const arrowAdd = (num1: number, num2: number) => num1 + num2;
arrowAdd(x, y);
// %%
class User {
constructor(private name: string) {
this.name = name;
}
sayHello(): string {
return "Hello, I'm " + this.name;
}
}
let John: User;
John = new User("John");
John.sayHello();
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/julia_benchmark_plotly_barchart.jl
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Julia 1.1.1
# language: julia
# name: julia-1.1
# ---
# %%
# IJulia rocks! So does Plotly. Check it out
using Plotly
api_key = "" # visit https://plot.ly/api to generate an API username and password
username = ""
Plotly.signin(username, api_key)
# %%
# Following data taken from http://julialang.org/ frontpage
benchmarks = ["fib", "parse_int", "quicksort3", "mandel", "pi_sum", "rand_mat_stat", "rand_mat_mul"]
platforms = ["Fortran", "Julia", "Python", "R", "Matlab", "Mathematica", "Javascript", "Go"]
data = {
platforms[1] => [0.26, 5.03, 1.11, 0.86, 0.80, 0.64, 0.96],
platforms[2] => [0.91, 1.60, 1.14, 0.85, 1.00, 1.66, 1.01],
platforms[3] => [30.37, 13.95, 31.98, 14.19, 16.33, 13.52, 3.41 ],
platforms[4] => [411.36, 59.40, 524.29, 106.97, 15.42, 10.84, 3.98 ],
platforms[5] => [1992.00, 1463.16, 101.84, 64.58, 1.29, 6.61, 1.10 ],
platforms[6] => [64.46, 29.54, 35.74, 6.07, 1.32, 4.52, 1.16 ],
platforms[7] => [2.18, 2.43, 3.51, 3.49, 0.84, 3.28, 14.60],
platforms[8] => [1.03, 4.79, 1.25, 2.36, 1.41, 8.12, 8.51]
}
pdata = [ {"x"=>benchmarks,"y"=>data[k],"bardir"=>"h","type"=>"bar","name"=>k} for k = platforms ]
layout = {
"title"=> "Julia benchmark comparison (smaller is better, C performance = 1.0)",
"barmode"=> "group",
"autosize"=> false,
"width"=> 900,
"height"=> 900,
"titlefont"=>
{
"family"=> "Open Sans",
"size"=> 18,
"color"=> "rgb(84, 39, 143)"
},
"margin"=> {"l"=>160, "pad"=>0},
"xaxis"=> {
"title"=> "Benchmark log-time",
"type"=> "log"
},
"yaxis"=> {"title"=> "Benchmark Name"}
}
response = Plotly.plot(pdata,["layout"=>layout])
# Embed in an iframe within IJulia
s = string("")
display("text/html", s)
# %%
# checkout https://plot.ly/api/ for more Julia examples!
# But to show off some other Plotly features:
x = 1:1500
y1 = sin(2*pi*x/1500.) + rand(1500)-0.5
y2 = sin(2*pi*x/1500.)
fish = {"x"=>x,"y"=> y1,
"type"=>"scatter","mode"=>"markers",
"marker"=>{"color"=>"rgb(0, 0, 255)","opacity"=>0.5 } }
fit = {"x"=> x,"y"=> y2,
"type"=>"scatter", "mode"=>"markers", "opacity"=>0.8,
"marker"=>{"color"=>"rgb(255, 0, 0)"} }
layout = {"autosize"=> false,
"width"=> 650, "height"=> 550,
"title"=>"Fish School",
"xaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[0,1500] },
"yaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[-2.2,2.2] },
"plot_bgcolor"=> "rgb(245,245,247)",
"showlegend"=> false,
"hovermode"=> "closest"}
response = Plotly.plot([fish, fit],["layout"=>layout])
s = string("")
display("text/html", s)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/julia_functional_geometry.jl
================================================
# -*- coding: utf-8 -*-
# ---
# jupyter:
# kernelspec:
# display_name: Julia 1.1.1
# language: julia
# name: julia-1.1
# ---
# %%
# This notebook is a semi top-down explanation. This cell needs to be
# executed first so that the operators and helper functions are defined
# All of this is explained in the later half of the notebook
using Compose, Interact
Compose.set_default_graphic_size(2inch, 2inch)
points_f = [
(.1, .1),
(.9, .1),
(.9, .2),
(.2, .2),
(.2, .4),
(.6, .4),
(.6, .5),
(.2, .5),
(.2, .9),
(.1, .9),
(.1, .1)
]
f = compose(context(), stroke("black"), line(points_f))
rot(pic) = compose(context(rotation=Rotation(-deg2rad(90))), pic)
flip(pic) = compose(context(mirror=Mirror(deg2rad(90), 0.5w, 0.5h)), pic)
above(m, n, p, q) =
compose(context(),
(context(0, 0, 1, m/(m+n)), p),
(context(0, m/(m+n), 1, n/(m+n)), q))
above(p, q) = above(1, 1, p, q)
beside(m, n, p, q) =
compose(context(),
(context(0, 0, m/(m+n), 1), p),
(context(m/(m+n), 0, n/(m+n), 1), q))
beside(p, q) = beside(1, 1, p, q)
over(p, q) = compose(context(),
(context(), p), (context(), q))
rot45(pic) =
compose(context(0, 0, 1/sqrt(2), 1/sqrt(2),
rotation=Rotation(-deg2rad(45), 0w, 0h)), pic)
# Utility function to zoom out and look at the context
zoomout(pic) = compose(context(),
(context(0.2, 0.2, 0.6, 0.6), pic),
(context(0.2, 0.2, 0.6, 0.6), fill(nothing), stroke("black"), strokedash([0.5mm, 0.5mm]),
polygon([(0, 0), (1, 0), (1, 1), (0, 1)])))
function read_path(p_str)
tokens = [try parsefloat(x) catch symbol(x) end for x in split(p_str, r"[\s,]+")]
path(tokens)
end
fish = compose(context(units=UnitBox(260, 260)), stroke("black"),
read_path(strip(readall("fish.path"))))
rotatable(pic) = @manipulate for θ=0:0.001:2π
compose(context(rotation=Rotation(θ)), pic)
end
blank = compose(context())
fliprot45(pic) = rot45(compose(context(mirror=Mirror(deg2rad(-45))),pic))
# Hide this cell.
display(MIME("text/html"), """""")
# %% [markdown]
# # Functional Geometry
# *Functional Geometry* is a paper by Peter Henderson ([original (1982)](users.ecs.soton.ac.uk/peter/funcgeo.pdf), [revisited (2002)](https://cs.au.dk/~hosc/local/HOSC-15-4-pp349-365.pdf)) which deconstructs the MC Escher woodcut *Square Limit*
#
# 
# %% [markdown]
# > A picture is an example of a complex object that can be described in terms of its parts.
# Yet a picture needs to be rendered on a printer or a screen by a device that expects to
# be given a sequence of commands. Programming that sequence of commands directly is
# much harder than having an application generate the commands automatically from the
# simpler, denotational description.
# %% [markdown]
# A `picture` is a *denotation* of something to draw.
#
# e.g. The value of f here denotes the picture of the letter F
# %% [markdown]
# Original at http://nbviewer.jupyter.org/github/shashi/ijulia-notebooks/blob/master/funcgeo/Functional%20Geometry.ipynb
# %% [markdown]
# ## In conclusion
#
# We described Escher's *Square Limit* from the description of its smaller parts, which in turn were described in terms of their smaller parts.
#
# This seemed simple because we chose to talk in terms of an *algebra* to describe pictures. The primitives `rot`, `flip`, `fliprot45`, `above`, `beside` and `over` fit the job perfectly.
#
# We were able to describe these primitives in terms of `compose` `contexts`, which the Compose library knows how to render.
#
# Denotation can be an easy way to describe a system as well as a practical implementation method.
#
# [Abstraction barriers](https://mitpress.mit.edu/sicp/full-text/sicp/book/node29.html) are useful tools that can reduce the cognitive overhead on the programmer. It entails creating layers consisting of functions which only use functions in the same layer or layers below in their own implementation. The layers in our language were:
#
# ------------------[ squarelimit ]------------------
# -------------[ quartet, cycle, nonet ]-------------
# ---[ rot, flip, fliprot45, above, beside, over ]---
# -------[ compose, context, line, path,... ]--------
#
# Drawing this diagram out is a useful way to begin building any library.
#
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/jupyter.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# # Jupyter notebook
#
# This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition:
# %%
a = 1
b = 2
a + b
# %% [markdown]
# Now we return a few tuples
# %%
a, b
# %%
a, b, a+b
# %% [markdown]
# And this is already the end of the notebook
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/jupyter_again.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
c = '''
title: "Quick test"
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type console
'''
# %%
import yaml
print(yaml.dump(yaml.load(c)))
# %%
# ?next
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/jupyter_with_raw_cell_in_body.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
1+2+3
# %% [raw]
# This is a raw cell
# %% [markdown]
# This is a markdown cell
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/jupyter_with_raw_cell_on_top.py
================================================
# ---
# title: Quick test
# output:
# ioslides_presentation:
# widescreen: true
# smaller: true
# editor_options:
# chunk_output_type: console
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
1+2+3
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/jupyter_with_raw_cell_with_invalid_yaml.py
================================================
# ---
# title: Exception: Test
# jupyter:
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# %%
1 + 2 + 3
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/jupyterlab-slideshow_1441.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# %% [markdown] @deathbeds/jupyterlab-fonts={"styles": {"": {"body[data-jp-deck-mode='presenting'] &": {"right": "0", "top": "30%", "width": "25%", "z-index": 1}}}} jupyterlab-slideshow={"layer": "slide"}
# > **Note**
# >
# > `slide` layer with a `top` of `30%`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/jupytext_replication.sos
================================================
# ---
# jupyter:
# kernelspec:
# display_name: SoS
# language: sos
# name: sos
# ---
# %% [markdown] Collapsed="false" kernel="SoS"
# # Text SOS-kernel with Jupytext
#
# ## What is SOS kernel
#
# SoS consists of a ployglot notebook that allows the use of multiple kernels in one Jupyter notebook, and a workflow system that is designed for daily computational research. Basically,
#
# - SoS Polyglot Notebook is a Jupyter Notebook with a SoS kernel.
# - SoS Notebook serves as a super kernel to all other Jupyter kernels and allows the use of multiple kernels in one Jupyter notebook.
# - SoS Workflow System is a Python based workflow system that is designed to be readable, shareable, and suitable for daily data analysis.
# - SoS Workflow System can be used from command line or use SoS Notebook as its IDE.
#
# 
#
# ### How to install SOS-kernel
#
# Please follow this [link](https://vatlab.github.io/sos-docs/running.html#Conda-installation) to setup SOS
#
# I run some issue with the latest version of R on my Mac, so I had to install an earlier version of R
#
# ```
# conda install -c r r=3.5.1
# conda install sos-notebook jupyterlab-sos sos-papermill -c conda-forge
# ```
#
# ## Related issue with Jupytext
#
# Jupytext works fine with Python/R kernel but converts code cells into markdown cells when using the SOS kernel.
#
# cf the image below. It is a code cell. After saving the notebook and restart it, it converted the code cell into markdown
#
#
# %% [markdown] Collapsed="false" kernel="SoS"
# ## Step 1
#
# Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.
#
# 
# %% Collapsed="false" kernel="SoS"
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
# %% [markdown] Collapsed="false" kernel="python3"
# ## Step 2
#
# Now, pair it with Jupytex
#
# 
# %% [markdown] Collapsed="false" kernel="python3"
# ### Step 3
#
# Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
# %% [markdown] Collapsed="false" kernel="python3"
# ### Step 4
#
# Reopen the notebook. Here is the outcome
#
# 
#
#
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/kalman_filter_and_visualization.q
================================================
/ ---
/ jupyter:
/ kernelspec:
/ display_name: Q 3.5
/ language: q
/ name: qpk
/ ---
/ %%
plt: .p.import`matplotlib.pyplot
/ %%
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
/ %%
price: 100 + sums 0.5 - (n:50)?1.
/ %%
output:filter price
/ %%
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
/ %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/logtalk_notebook.lgt
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Logtalk
% language: logtalk
% name: logtalk_kernel
% ---
% %% [markdown]
% # An implementation of the Ackermann function
% %% vscode={"languageId": "logtalk"}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
% %% [markdown]
% ## Sample query
% %% vscode={"languageId": "logtalk"}
ack::ack(2, 4, V).
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/lua_example.lua
================================================
-- -*- coding: utf-8 -*-
-- ---
-- jupyter:
-- kernelspec:
-- display_name: Lua
-- language: lua
-- name: lua
-- ---
-- %% [markdown]
-- Source: https://www.lua.org/pil/19.3.html
-- %% [markdown]
-- # Sort
-- %% [markdown]
-- Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
-- %% [markdown]
-- A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
-- %%
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
-- %% [markdown]
-- Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
-- %%
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
-- %% [markdown]
-- Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
-- %% [markdown]
-- As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
-- %%
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
-- %% [markdown]
-- With this function, it is easy to print those function names in alphabetical order. The loop
-- %%
for name, line in pairsByKeys(lines) do
print(name, line)
end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/maxima_example.mac
================================================
/* --- */
/* jupyter: */
/* kernelspec: */
/* display_name: Maxima */
/* language: maxima */
/* name: maxima */
/* --- */
/* %% [markdown] */
/* ## maxima misc */
/* %% */
kill(all)$
/* %% */
f(x) := 1/(x^2+l^2)^(3/2);
/* %% */
integrate(f(x), x);
/* %% */
tex(%)$
/* %% */
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/notebook_with_complex_metadata.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/nteract_with_parameter.py
================================================
# ---
# jupyter:
# kernel_info:
# name: python3
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% inputHidden=false outputHidden=false tags=["parameters"]
param = 4
# %% inputHidden=false outputHidden=false
import pandas as pd
# %% inputHidden=false outputHidden=false
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
# %% inputHidden=false outputHidden=false
# %matplotlib inline
df.plot(kind='bar')
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/ocaml_notebook.ml
================================================
(* --- *)
(* jupyter: *)
(* jupytext: *)
(* formats: ipynb:markdown,md *)
(* kernelspec: *)
(* display_name: OCaml default *)
(* language: OCaml *)
(* name: ocaml-jupyter *)
(* --- *)
(* %% [markdown] *)
(* # Example of an OCaml notebook *)
(* %% *)
let sum x y = x + y
(* %% [markdown] *)
(* Let's try our function: *)
(* %% *)
sum 3 4 = 7 + 0
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/octave_notebook.m
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Octave
% language: octave
% name: octave
% ---
% %% [markdown]
% A markdown cell
% %%
1 + 1
% %%
% a code cell with comments
2 + 2
% %%
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
% %%
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
% %% [markdown]
% And to finish with, a Python cell
% %% language="python"
% a = 1
% %% language="python"
% a + 1
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/plotly_graphs.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# This notebook contains complex outputs, including plotly javascript graphs.
# %% [markdown]
# # Interactive plots
# %% [markdown]
# We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
# %%
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
# %%
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/powershell.ps1
================================================
# ---
# jupyter:
# kernelspec:
# display_name: PowerShell
# language: PowerShell
# name: powershell
# ---
# %% [markdown]
# This is an extract from
# https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
# %%
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/raw_cell_with_complex_yaml_like_content.py
================================================
# ---
#
# This is a complex paragraph
# that is split over multiple lines.
#
# It also includes blank lines.
#
#
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/raw_cell_with_non_dict_yaml_content.py
================================================
# ---
# Content.
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/root_cpp.cpp
================================================
// ---
// jupyter:
// kernelspec:
// display_name: ROOT C++
// language: c++
// name: root
// ---
// %%
#include
#include
// %%
int k = 4;
std::string foo = "This string says \"foo\"";
// %%
std::cout << "k = " << k << '\n' << foo << '\n';
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/sage_print_hello.sage
================================================
# ---
# jupyter:
# kernelspec:
# display_name: SageMath 9.2
# language: sage
# name: sagemath
# ---
# %%
print("Hello world")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/sample_bash_notebook.sh
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Bash
# language: bash
# name: bash
# ---
# %%
ls
# %%
# https://coderwall.com/p/euwpig/a-better-git-log
git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"
# %%
git lg
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/sample_rise_notebook_66.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown] slideshow={"slide_type": "slide"}
# A markdown cell
# %% slideshow={"slide_type": ""}
1+1
# %% [markdown] cell_style="center" slideshow={"slide_type": "fragment"}
# Markdown cell two
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/sas.sas
================================================
/* --- */
/* jupyter: */
/* kernelspec: */
/* display_name: SAS */
/* language: sas */
/* name: sas */
/* --- */
/* %% [markdown] */
/* # SAS Notebooks with jupytext */
/* %% */
proc sql;
select *
from sashelp.cars (obs=10)
;
quit;
/* %% */
%let name = "Jupytext";
/* %% */
%put &name;
/* %% */
/* Note when defining macros "%macro" cannot be the first line of text in the cell */
%macro test;
data temp;
set sashelp.cars;
name = "testx";
run;
proc print data = temp (obs=10);
run;
%mend test;
%test
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/simple-helloworld.java
================================================
// -*- coding: utf-8 -*-
// ---
// jupyter:
// jupytext:
// formats: ipynb,java:percent
// kernelspec:
// display_name: Java
// language: java
// name: java
// ---
// %% [markdown]
// Let's define some class.
// %%
class A {
public void hello() {
System.out.println("Hello World");
}
}
// %% [markdown]
// And now we call its method.
// %%
new A().hello();
// %% [markdown]
// You can run it e.g. with `jshell`
//
// * from command line, as `jshell simple-helloworld.java`
// * from jshell's shell with `/open simple-helloworld.java`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/simple_robot_notebook.robot
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Robot Framework
# language: robotframework
# name: robotkernel
# ---
# %%
*** Settings ***
Library Collections
# %%
*** Keywords ***
Head
[Arguments] ${list}
${value}= Get from list ${list} 0
[Return] ${value}
# %%
*** Tasks ***
Get head
${array}= Create list 1 2 3 4 5
${head}= Head ${array}
Should be equal ${head} 1
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/simple_scala_notebook.scala
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Apache Toree - Scala
// language: scala
// name: apache_toree_scala
// ---
// %%
// This is just a simple scala notebook
object SampleObject {
def calculation(x: Int, y: Int): Int = x + y
}
val result = SampleObject.calculation(1, 2)
// %%
println(result * 10)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/stata_notebook.do
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Stata
// language: stata
// name: stata
// ---
// %%
// This notebook uses the stata_kernel: https://github.com/kylebarron/stata_kernel
// %%
use http://www.stata-press.com/data/r13/auto
// %%
summarize
// %%
scatter weight length
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/tailrecursive-factorial.groovy
================================================
// -*- coding: utf-8 -*-
// ---
// jupyter:
// jupytext:
// formats: ipynb,groovy:percent
// kernelspec:
// display_name: Groovy
// language: groovy
// name: groovy
// ---
// %% [markdown]
// # TailRecursive annotation
//
// Let's check what is the effect of `@TailRecursive` annotation on the simple recursive definition of factorial function.
// %%
import groovy.transform.CompileStatic
import groovy.transform.TailRecursive
import groovy.transform.TypeChecked
@CompileStatic
@TypeChecked
class X {
static final BigInteger factorial0(int n) {
(n <= 1) ? 1G : factorial0(n-1).multiply(BigInteger.valueOf(n))
}
static final BigInteger factorial1(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial1(n-1, acc.multiply(BigInteger.valueOf(n)))
}
@TailRecursive
static final BigInteger factorial2(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial2(n-1, acc.multiply(BigInteger.valueOf(n)))
}
}
x = new X()
// %% [markdown]
// Although we can time the execution of the calls, it is not very accurate; such micro benchmarks should be performed in more controlled environment, such us under [JMH](https://openjdk.java.net/projects/code-tools/jmh/).
//
// For example, see [blog posts of Szymon Stępniak](https://e.printstacktrace.blog/tail-recursive-methods-in-groovy/).
// %%
// %%timeit
x.factorial0(19_000).toString().length()
// %%
// %%timeit
x.factorial1(19_000).toString().length()
// %%
// %%timeit
x.factorial2(19_000).toString().length()
// %% [markdown]
// The real difference is the use of stack. Non-tail recursive calls exhaust the stack space at some point, whereas tail recursive calls don't add frames to the stack.
// %%
factSize = { n, cl ->
println "Factorial of ${n} has ${cl(n).toString().length()} digits"
}
factSize 2_000, x.&factorial0
factSize 2_000, x.&factorial1
factSize 2_000, x.&factorial2
factSize 100_000, x.&factorial2
// %%
try {
factSize 100_000, x.&factorial1
} catch (Throwable e) {
assert e instanceof StackOverflowError
println e
}
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/tcl_test.tcl
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Tcl
# language: tcl
# name: tcljupyter
# ---
# %% [markdown]
# # Assign Values
# %%
set a 1
puts "a = $a"
# %% [markdown]
# # Loop
# %%
for {set i 0} {$i < 10} {incr i} {
puts "I inside first loop: $i"
}
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/text_outputs_and_images.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# This notebook contains outputs of many different types: text, HTML, plots and errors.
# %% [markdown]
# # Text outputs
#
# Using `print`, `sys.stdout` and `sys.stderr`
# %%
import sys
print('using print')
sys.stdout.write('using sys.stdout.write')
sys.stderr.write('using sys.stderr.write')
# %%
import logging
logging.debug('Debug')
logging.info('Info')
logging.warning('Warning')
logging.error('Error')
# %% [markdown]
# # HTML outputs
#
# Using `pandas`. Here we find two representations: both text and HTML.
# %%
import pandas as pd
pd.DataFrame([4])
# %%
from IPython.display import display
display(pd.DataFrame([5]))
display(pd.DataFrame([6]))
# %% [markdown]
# # Images
# %%
# %matplotlib inline
# %%
# First plot
from matplotlib import pyplot as plt
import numpy as np
w, h = 3, 3
data = np.zeros((h, w, 3), dtype=np.uint8)
data[0,:] = [0,255,0]
data[1,:] = [0,0,255]
data[2,:] = [0,255,0]
data[1:3,1:3] = [255, 0, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# Second plot
data[1:3,1:3] = [255, 255, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# %% [markdown]
# # Errors
# %%
undefined_variable
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/wolfram.wolfram
================================================
(* --- *)
(* jupyter: *)
(* kernelspec: *)
(* display_name: Wolfram Language 13.1 *)
(* language: Wolfram Language *)
(* name: wolframlanguage13.1 *)
(* --- *)
(* %% [markdown] *)
(* **Note:** The `language_info` `file_extension` in this notebook should be `.m`, but it was deliberately changed to `.wolfram` to avoid conflicts with Matlab which is using the same extension. *)
(* %% [markdown] *)
(* We start with... *)
(* %% *)
Print["Hello, World!"];
(* %% [markdown] *)
(* Then we draw the first example plot from the [ListPlot](https://reference.wolfram.com/language/ref/ListPlot.html) reference: *)
(* %% *)
ListPlot[Prime[Range[25]]]
(* %% [markdown] *)
(* We also test the math outputs as in the [Simplify](https://reference.wolfram.com/language/ref/Simplify.html) example: *)
(* %% *)
D[Integrate[1/(x^3 + 1), x], x]
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/xcpp_by_quantstack.cpp
================================================
// ---
// jupyter:
// kernelspec:
// display_name: C++14
// language: C++14
// name: xeus-cling-cpp14
// ---
// %% [markdown]
// [](https://github.com/QuantStack/xeus-cling/)
//
// A Jupyter kernel for C++ based on the `cling` C++ interpreter and the `xeus` native implementation of the Jupyter protocol, xeus.
//
// - GitHub repository: https://github.com/QuantStack/xeus-cling/
// - Online documentation: https://xeus-cling.readthedocs.io/
// %% [markdown]
// ## Usage
//
//
std::cout << "some output" << std::endl;
// %%
std::cerr << "some error" << std::endl;
// %%
#include
// %%
throw std::runtime_error("Unknown exception");
// %% [markdown]
// Omitting the `;` in the last statement of a cell results in an output being printed
// %%
int j = 5;
// %%
j
// %% [markdown]
// # Interpreting the C++ programming language
//
// `cling` has a broad support of the features of C++. You can define functions, classes, templates, etc ...
// %% [markdown]
// ## Functions
// %%
double sqr(double a)
{
return a * a;
}
// %%
double a = 2.5;
double asqr = sqr(a);
asqr
// %% [markdown]
// ## Classes
// %%
class Foo
{
public:
virtual ~Foo() {}
virtual void print(double value) const
{
std::cout << "Foo value = " << value << std::endl;
}
};
// %%
Foo bar;
bar.print(1.2);
// %% [markdown]
// ## Polymorphism
// %%
class Bar : public Foo
{
public:
virtual ~Bar() {}
virtual void print(double value) const
{
std::cout << "Bar value = " << 2 * value << std::endl;
}
};
// %%
Foo* bar2 = new Bar;
bar2->print(1.2);
delete bar2;
// %% [markdown]
// ## Templates
// %%
#include
template
class FooT
{
public:
explicit FooT(const T& t) : m_t(t) {}
void print() const
{
std::cout << typeid(T).name() << " m_t = " << m_t << std::endl;
}
private:
T m_t;
};
template <>
class FooT
{
public:
explicit FooT(const int& t) : m_t(t) {}
void print() const
{
std::cout << "m_t = " << m_t << std::endl;
}
private:
int m_t;
};
// %%
FooT foot1(1.2);
foot1.print();
// %%
FooT foot2(4);
foot2.print();
// %% [markdown]
// ## C++11 / C++14 support
// %%
class Foo11
{
public:
Foo11() { std::cout << "Foo11 default constructor" << std::endl; }
Foo11(const Foo11&) { std::cout << "Foo11 copy constructor" << std::endl; }
Foo11(Foo11&&) { std::cout << "Foo11 move constructor" << std::endl; }
};
// %%
Foo11 f1;
Foo11 f2(f1);
Foo11 f3(std::move(f1));
// %%
#include
std::vector v = { 1, 2, 3};
auto iter = ++v.begin();
v
// %%
*iter
// %% [markdown]
// ... and also lambda, universal references, `decltype`, etc ...
// %% [markdown]
// ## Documentation and completion
//
// - Documentation for types of the standard library is retrieved on cppreference.com.
// - The quick-help feature can also be enabled for user-defined types and third-party libraries. More documentation on this feature is available at https://xeus-cling.readthedocs.io/en/latest/inline_help.html.
//
// %%
?std::vector
// %% [markdown]
// ## Using the `display_data` mechanism
// %% [markdown]
// For a user-defined type `T`, the rich rendering in the notebook and JupyterLab can be enabled by by implementing the function `xeus::xjson mime_bundle_repr(const T& im)`, which returns the JSON mime bundle for that type.
//
// More documentation on the rich display system of Jupyter and Xeus-cling is available at https://xeus-cling.readthedocs.io/en/latest/rich_display.html
// %% [markdown]
// ### Image example
// %%
#include
#include
#include "xtl/xbase64.hpp"
#include "xeus/xjson.hpp"
namespace im
{
struct image
{
inline image(const std::string& filename)
{
std::ifstream fin(filename, std::ios::binary);
m_buffer << fin.rdbuf();
}
std::stringstream m_buffer;
};
xeus::xjson mime_bundle_repr(const image& i)
{
auto bundle = xeus::xjson::object();
bundle["image/png"] = xtl::base64encode(i.m_buffer.str());
return bundle;
}
}
// %%
im::image marie("images/marie.png");
marie
// %% [markdown]
// ### Audio example
// %%
#include
#include
#include "xtl/xbase64.hpp"
#include "xeus/xjson.hpp"
namespace au
{
struct audio
{
inline audio(const std::string& filename)
{
std::ifstream fin(filename, std::ios::binary);
m_buffer << fin.rdbuf();
}
std::stringstream m_buffer;
};
xeus::xjson mime_bundle_repr(const audio& a)
{
auto bundle = xeus::xjson::object();
bundle["text/html"] =
std::string("";
return bundle;
}
}
// %%
au::audio drums("audio/audio.wav");
drums
// %% [markdown]
// ### Display
// %%
#include "xcpp/xdisplay.hpp"
// %%
xcpp::display(drums);
// %% [markdown]
// ### Update-display
// %%
#include
#include "xcpp/xdisplay.hpp"
namespace ht
{
struct html
{
inline html(const std::string& content)
{
m_content = content;
}
std::string m_content;
};
xeus::xjson mime_bundle_repr(const html& a)
{
auto bundle = xeus::xjson::object();
bundle["text/html"] = a.m_content;
return bundle;
}
}
// A red rectangle
ht::html rect(R"(
#include
// %%
std::vector to_shuffle = {1, 2, 3, 4};
// %%
// %timeit std::random_shuffle(to_shuffle.begin(), to_shuffle.end());
// %% [markdown]
// [](https://github.com/QuantStack/xtensor/)
//
// - GitHub repository: https://github.com/QuantStack/xtensor/
// - Online documentation: https://xtensor.readthedocs.io/
// - NumPy to xtensor cheat sheet: http://xtensor.readthedocs.io/en/latest/numpy.html
//
// `xtensor` is a C++ library for manipulating N-D arrays with an API very similar to that of numpy.
// %%
#include
#include "xtensor/xarray.hpp"
#include "xtensor/xio.hpp"
#include "xtensor/xview.hpp"
xt::xarray arr1
{{1.0, 2.0, 3.0},
{2.0, 5.0, 7.0},
{2.0, 5.0, 7.0}};
xt::xarray arr2
{5.0, 6.0, 7.0};
xt::view(arr1, 1) + arr2
// %% [markdown]
// Together with the C++ Jupyter kernel, `xtensor` offers a similar experience as `NumPy` in the Python Jupyter kernel, including broadcasting and universal functions.
// %%
#include
#include "xtensor/xarray.hpp"
#include "xtensor/xio.hpp"
// %%
xt::xarray arr
{1, 2, 3, 4, 5, 6, 7, 8, 9};
arr.reshape({3, 3});
std::cout << arr;
// %%
#include "xtensor-blas/xlinalg.hpp"
// %%
xt::xtensor m = {{1.5, 0.5}, {0.7, 1.0}};
std::cout << "Matrix rank: " << std::endl << xt::linalg::matrix_rank(m) << std::endl;
std::cout << "Matrix inverse: " << std::endl << xt::linalg::inv(m) << std::endl;
std::cout << "Eigen values: " << std::endl << xt::linalg::eigvals(m) << std::endl;
// %%
xt::xarray arg1 = xt::arange(9);
xt::xarray arg2 = xt::arange(18);
arg1.reshape({3, 3});
arg2.reshape({2, 3, 3});
std::cout << xt::linalg::dot(arg1, arg2) << std::endl;
// %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/xonsh_example.xsh
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Xonsh
# language: xonsh
# name: xonsh
# ---
# %%
len($(curl -L https://xon.sh))
# %%
for filename in `.*`:
print(filename)
du -sh @(filename)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_quarto/Notebook_with_more_R_magic_111.qmd
================================================
---
jupyter: python3
---
```{python}
%load_ext rpy2.ipython
import pandas as pd
df = pd.DataFrame(
{
"Letter": ["a", "a", "a", "b", "b", "b", "c", "c", "c"],
"X": [4, 3, 5, 2, 1, 7, 7, 5, 9],
"Y": [0, 4, 3, 6, 7, 10, 11, 9, 13],
"Z": [1, 2, 3, 1, 2, 3, 1, 2, 3],
}
)
```
```{python}
%%R -i df
library("ggplot2")
ggplot(data = df) + geom_point(aes(x = X, y = Y, color = Letter, size = Z))
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_quarto/cat_variable.qmd
================================================
---
jupyter: python3
---
```{python}
cat = 42
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_quarto/frozen_cell.qmd
================================================
---
jupyter: python3
---
```{python}
# This is an unfrozen cell. Works as usual.
print("I'm a regular cell so I run and print!")
```
```{python}
#| deletable: false
#| editable: false
#| run_control: {frozen: true}
# This is an frozen cell
print("I'm frozen so Im not executed :(")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_quarto/julia_benchmark_plotly_barchart.qmd
================================================
---
jupyter:
kernelspec:
display_name: Julia 1.1.1
language: julia
name: julia-1.1
---
```{julia}
# IJulia rocks! So does Plotly. Check it out
using Plotly
api_key = "" # visit https://plot.ly/api to generate an API username and password
username = ""
Plotly.signin(username, api_key)
```
```{julia}
# Following data taken from http://julialang.org/ frontpage
benchmarks = ["fib", "parse_int", "quicksort3", "mandel", "pi_sum", "rand_mat_stat", "rand_mat_mul"]
platforms = ["Fortran", "Julia", "Python", "R", "Matlab", "Mathematica", "Javascript", "Go"]
data = {
platforms[1] => [0.26, 5.03, 1.11, 0.86, 0.80, 0.64, 0.96],
platforms[2] => [0.91, 1.60, 1.14, 0.85, 1.00, 1.66, 1.01],
platforms[3] => [30.37, 13.95, 31.98, 14.19, 16.33, 13.52, 3.41 ],
platforms[4] => [411.36, 59.40, 524.29, 106.97, 15.42, 10.84, 3.98 ],
platforms[5] => [1992.00, 1463.16, 101.84, 64.58, 1.29, 6.61, 1.10 ],
platforms[6] => [64.46, 29.54, 35.74, 6.07, 1.32, 4.52, 1.16 ],
platforms[7] => [2.18, 2.43, 3.51, 3.49, 0.84, 3.28, 14.60],
platforms[8] => [1.03, 4.79, 1.25, 2.36, 1.41, 8.12, 8.51]
}
pdata = [ {"x"=>benchmarks,"y"=>data[k],"bardir"=>"h","type"=>"bar","name"=>k} for k = platforms ]
layout = {
"title"=> "Julia benchmark comparison (smaller is better, C performance = 1.0)",
"barmode"=> "group",
"autosize"=> false,
"width"=> 900,
"height"=> 900,
"titlefont"=>
{
"family"=> "Open Sans",
"size"=> 18,
"color"=> "rgb(84, 39, 143)"
},
"margin"=> {"l"=>160, "pad"=>0},
"xaxis"=> {
"title"=> "Benchmark log-time",
"type"=> "log"
},
"yaxis"=> {"title"=> "Benchmark Name"}
}
response = Plotly.plot(pdata,["layout"=>layout])
# Embed in an iframe within IJulia
s = string("")
display("text/html", s)
```
```{julia}
# checkout https://plot.ly/api/ for more Julia examples!
# But to show off some other Plotly features:
x = 1:1500
y1 = sin(2*pi*x/1500.) + rand(1500)-0.5
y2 = sin(2*pi*x/1500.)
fish = {"x"=>x,"y"=> y1,
"type"=>"scatter","mode"=>"markers",
"marker"=>{"color"=>"rgb(0, 0, 255)","opacity"=>0.5 } }
fit = {"x"=> x,"y"=> y2,
"type"=>"scatter", "mode"=>"markers", "opacity"=>0.8,
"marker"=>{"color"=>"rgb(255, 0, 0)"} }
layout = {"autosize"=> false,
"width"=> 650, "height"=> 550,
"title"=>"Fish School",
"xaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[0,1500] },
"yaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[-2.2,2.2] },
"plot_bgcolor"=> "rgb(245,245,247)",
"showlegend"=> false,
"hovermode"=> "closest"}
response = Plotly.plot([fish, fit],["layout"=>layout])
s = string("")
display("text/html", s)
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/Line_breaks_in_LateX_305.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# This cell uses no particular cell marker
#
# $$
# \begin{align}
# \dot{x} & = \sigma(y-x)\\
# \dot{y} & = \rho x - y - xz \\
# \dot{z} & = -\beta z + xy
# \end{align}
# $$
# This cell uses no particular cell marker, and a single slash in the $\LaTeX$ equation
#
# $$
# \begin{align}
# \dot{x} & = \sigma(y-x) \
# \dot{y} & = \rho x - y - xz \
# \dot{z} & = -\beta z + xy
# \end{align}
# $$
# + [markdown]
'''
This cell uses the triple quote cell markers introduced at https://github.com/mwouts/jupytext/issues/305
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
'''
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/Notebook with function and cell metadata 164.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
1 + 1
# A markdown cell
# And below, the cell for function f has non trivial cell metadata. And the next cell as well.
# + attributes={"classes": [], "id": "", "n": "10"}
def f(x):
return x
# + attributes={"classes": [], "id": "", "n": "10"}
f(5)
# -
# More text
2 + 2
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/Notebook with html and latex cells.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + language="html"
#
;;
;;
;; It has breakpoints (click in left margin). You must press Stop to exit the debugger.
;; ```scheme
;; ;; %%debug
;;
;; (begin
;; (define x 1)
;; (set! x 2)
;; )
;; ```
;; ### Python Integration
;;
;; You can import and use any Python library in Calysto Scheme.
;;
;; In addition, if you wish, you can execute expressions and statements in a Python environment:
(python-eval "1 + 2")
(python-exec
"
def mypyfunc(a, b):
return a * b
")
;; This is a shared environment with Scheme:
(mypyfunc 4 5)
;; You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
(define! mypyfunc2 (func (lambda (n) n)))
(python-eval "mypyfunc2(34)")
;; # Differences Between Languages
;;
;; ## Major differences between Scheme and Python
;;
;; 1. In Scheme, double quotes are used for strings and may contain newlines
;; 1. In Scheme, a single quote is short for (quote ...) and means "literal"
;; 1. In Scheme, everything is an expression and has a return value
;; 1. Python does not support macros (e.g., extending syntax)
;; 1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
;; 1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
;; 1. Scheme procedures are not Python functions, but there are means to use one as the other.
;;
;; ## Major Differences Between Calysto Scheme and other Schemes
;;
;; 1. define-syntax works slightly differently
;; 1. In Calysto Scheme, #(...) is short for '#(...)
;; 1. Calysto Scheme is missing many standard functions (see list at bottom)
;; 1. Calysto Scheme has a built-in amb operator called `choose`
;; 1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
;;
;; ### Stack Trace
;;
;; Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
(fact 5)
;; To turn off the stack trace on error:
;;
;; ```scheme
;; (use-stack-trace #f)
;; ```
;; That will allow infinite recursive loops without keeping track of the "stack".
;; # Calysto Scheme Variables
;;
;; ## SCHEMEPATH
;; SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
SCHEMEPATH
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
SCHEMEPATH
;; ## Getting Started
;;
;; Note that you can use the word `lambda` or \lambda and then press [TAB]
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
(factorial 5)
;; ## define-syntax
;; (define-syntax NAME RULES): a method for creating macros
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
(time (car '(1 2 3 4)))
;; +
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
;; -
(collect (* n n) for n in (range 10))
(collect (* n n) for n in (range 5 20 3))
(collect (* n n) for n in (range 10) if (> n 5))
;; +
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
;; +
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
;; -
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
(for n in (range 10 20 2) do (print n))
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
;; +
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
;; -
(! 5)
(nth 10 facts)
(nth 20 fibs)
(first 30 fibs)
;; ## for-each
;; (for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
(for-each (lambda (n) (print n)) '(3 4 5))
;; ## format
;; (format STRING ITEM ...): format the string with ITEMS as arguments
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
;; ## func
;;
;; Turns a lambda into a Python function.
;;
;; (func (lambda ...))
(func (lambda (n) n))
;; ## There's more!
;;
;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/Reference Guide for Calysto Scheme.ss
================================================
;; -*- coding: utf-8 -*-
;; ---
;; jupyter:
;; kernelspec:
;; display_name: Calysto Scheme (Python)
;; language: scheme
;; name: calysto_scheme
;; ---
;;
;;
;;
;; It has breakpoints (click in left margin). You must press Stop to exit the debugger.
;; ```scheme
;; ;; %%debug
;;
;; (begin
;; (define x 1)
;; (set! x 2)
;; )
;; ```
;; ### Python Integration
;;
;; You can import and use any Python library in Calysto Scheme.
;;
;; In addition, if you wish, you can execute expressions and statements in a Python environment:
(python-eval "1 + 2")
(python-exec
"
def mypyfunc(a, b):
return a * b
")
;; This is a shared environment with Scheme:
(mypyfunc 4 5)
;; You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
(define! mypyfunc2 (func (lambda (n) n)))
(python-eval "mypyfunc2(34)")
;; # Differences Between Languages
;;
;; ## Major differences between Scheme and Python
;;
;; 1. In Scheme, double quotes are used for strings and may contain newlines
;; 1. In Scheme, a single quote is short for (quote ...) and means "literal"
;; 1. In Scheme, everything is an expression and has a return value
;; 1. Python does not support macros (e.g., extending syntax)
;; 1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
;; 1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
;; 1. Scheme procedures are not Python functions, but there are means to use one as the other.
;;
;; ## Major Differences Between Calysto Scheme and other Schemes
;;
;; 1. define-syntax works slightly differently
;; 1. In Calysto Scheme, #(...) is short for '#(...)
;; 1. Calysto Scheme is missing many standard functions (see list at bottom)
;; 1. Calysto Scheme has a built-in amb operator called `choose`
;; 1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
;;
;; ### Stack Trace
;;
;; Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
(fact 5)
;; To turn off the stack trace on error:
;;
;; ```scheme
;; (use-stack-trace #f)
;; ```
;; That will allow infinite recursive loops without keeping track of the "stack".
;; # Calysto Scheme Variables
;;
;; ## SCHEMEPATH
;; SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
SCHEMEPATH
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
SCHEMEPATH
;; ## Getting Started
;;
;; Note that you can use the word `lambda` or \lambda and then press [TAB]
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
(factorial 5)
;; ## define-syntax
;; (define-syntax NAME RULES): a method for creating macros
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
(time (car '(1 2 3 4)))
;; +
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
;; -
(collect (* n n) for n in (range 10))
(collect (* n n) for n in (range 5 20 3))
(collect (* n n) for n in (range 10) if (> n 5))
;; +
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
;; +
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
;; -
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
(for n in (range 10 20 2) do (print n))
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
;; +
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
;; -
(! 5)
(nth 10 facts)
(nth 20 fibs)
(first 30 fibs)
;; ## for-each
;; (for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
(for-each (lambda (n) (print n)) '(3 4 5))
;; ## format
;; (format STRING ITEM ...): format the string with ITEMS as arguments
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
;; ## func
;;
;; Turns a lambda into a Python function.
;;
;; (func (lambda ...))
(func (lambda (n) n))
;; ## There's more!
;;
;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/The flavors of raw cells.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + raw_mimetype="text/latex" active=""
# $1+1$
# + raw_mimetype="text/restructuredtext" active=""
# :math:`1+1`
# + raw_mimetype="text/html" active=""
# Bold text
# + raw_mimetype="text/markdown" active=""
# **Bold text**
# + raw_mimetype="text/x-python" active=""
# 1 + 1
# + active=""
# Not formatted
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/cat_variable.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
cat = 42
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/coconut_homepage_demo.coco
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Coconut
# language: coconut
# name: coconut
# ---
# Taken from [coconut-lang.org](coconut-lang.org)
# pipeline-style programming
"hello, world!" |> print
# prettier lambdas
x -> x ** 2
# partial application
range(10) |> map$(pow$(?, 2)) |> list
# pattern-matching
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
# destructuring assignment
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
# infix notation
# +
# 5 `mod` 3 == 2
# -
# operator functions
product = reduce$(*)
# function composition
# +
# (f..g..h)(x, y, z)
# -
# lazy lists
# +
# (| first_elem() |) :: rest_elems()
# -
# parallel programming
range(100) |> parallel_map$(pow$(2)) |> list
# tail call optimization
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
# algebraic data types
# +
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
# -
# and much more!
#
# Like what you see? Don't forget to star Coconut on GitHub!
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/convert_to_py_then_test_with_update83.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
# %%time
print('asdf')
# -
# Thanks for jupytext!
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/csharp.cs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: .NET (C#)
// language: C#
// name: .net-csharp
// ---
// We start with...
Console.WriteLine("Hello World!");
// Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
// +
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
// -
// We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
(MathString)@"e^{i \pi} = -1"
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/demo_gdl_fbp.pro
================================================
; -*- coding: utf-8 -*-
; ---
; jupyter:
; kernelspec:
; display_name: IDL [conda env:gdl] *
; language: IDL
; name: conda-env-gdl-idl
; ---
; ## GDL demo notebook
; Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
;
; This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
; +
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
; -
;; Enable inline plotting
!inline=1
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
; Now we define simple forward and backprojection functions:
; +
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
; +
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
; -
; This allows us to create a sinogram:
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
; On this we can apply a simple FBP reconstruction:
; +
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
; +
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
; -
; ### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/evcxr_jupyter_tour.rs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Rust
// language: rust
// name: rust
// ---
// # Tour of the EvCxR Jupyter Kernel
// For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
//
// ## Printing to outputs and evaluating expressions
// Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
// ## Assigning and making use of variables
// We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
let mut message = "Hello ".to_owned();
message.push_str("world!");
message
// ## Defining and redefining functions
// Next we'll define a function
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
(1..13).map(fib).collect::>()
// Hmm, that doesn't look right. Lets redefine the function. In practice, we'd go back and edit the function above and reevaluate it, but here, lets redefine it in a separate cell.
pub fn fib(x: i32) -> i32 {
if x <= 2 {2} else {fib(x - 2) + fib(x - 1)}
}
let values = (1..13).map(fib).collect::>();
values
// ## Spawning a separate thread and communicating with it
// We can spawn a thread to do stuff in the background, then continue executing code in other cells.
use std::sync::{Mutex, Arc};
let counter = Arc::new(Mutex::new(0i32));
std::thread::spawn({
let counter = Arc::clone(&counter);
move || {
for i in 1..300 {
*counter.lock().unwrap() += 1;
std::thread::sleep(std::time::Duration::from_millis(100));
}
}});
*counter.lock().unwrap()
*counter.lock().unwrap()
// ## Loading external crates
// We can load external crates. This one takes a while to compile, but once it's compiled, subsequent cells shouldn't need to recompile it, so it should be much quicker.
// :dep base64 = "0.10.1"
base64::encode(&vec![1, 2, 3, 4])
// ## Customizing how types are displayed
// We can also customize how our types are displayed, including presenting them as HTML. Here's an example where we define a custom display function for a type `Matrix`.
use std::fmt::Debug;
pub struct Matrix {pub values: Vec, pub row_size: usize}
impl Matrix {
pub fn evcxr_display(&self) {
let mut html = String::new();
html.push_str("");
for r in 0..(self.values.len() / self.row_size) {
html.push_str("
");
println!("EVCXR_BEGIN_CONTENT text/html\n{}\nEVCXR_END_CONTENT", html);
}
}
let m = Matrix {values: vec![1,2,3,4,5,6,7,8,9], row_size: 3};
m
// We can also return images, we just need to base64 encode them. First, we set up code for displaying RGB and grayscale images.
extern crate image;
extern crate base64;
pub trait EvcxrResult {fn evcxr_display(&self);}
impl EvcxrResult for image::RgbImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::RGB(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
impl EvcxrResult for image::GrayImage {
fn evcxr_display(&self) {
let mut buffer = Vec::new();
image::png::PNGEncoder::new(&mut buffer).encode(&**self, self.width(), self.height(),
image::ColorType::Gray(8)).unwrap();
let img = base64::encode(&buffer);
println!("EVCXR_BEGIN_CONTENT image/png\n{}\nEVCXR_END_CONTENT", img);
}
}
image::ImageBuffer::from_fn(256, 256, |x, y| {
if (x as i32 - y as i32).abs() < 3 {
image::Rgb([0, 0, 255])
} else {
image::Rgb([0, 0, 0])
}
})
// ## Display of compilation errors
// Here's how compilation errors are presented. Here we forgot an & and passed a String instead of an &str.
let mut s = String::new();
s.push_str(format!("foo {}", 42));
// ## Seeing what variables have been defined
// We can print a table of defined variables and their types with the :vars command.
// :vars
// Other built-in commands can be found via :help
// :help
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/frozen_cell.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# This is an unfrozen cell. Works as usual.
print("I'm a regular cell so I run and print!")
# + deletable=false editable=false run_control={"frozen": true}
# # This is an frozen cell
# print("I'm frozen so Im not executed :(")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/fsharp.fsx
================================================
// ---
// jupyter:
// kernelspec:
// display_name: .NET (F#)
// language: F#
// name: .net-fsharp
// ---
// This notebook was inspired by [Plottting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/fsharp/Docs/Plotting%20with%20Xplot.ipynb).
open XPlot.Plotly
// +
let bar =
Bar(
name = "Bar 1",
x = ["A"; "B"; "C"],
y = [1; 3; 2])
[bar]
|> Chart.Plot
|> Chart.WithTitle "A sample bar plot"
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/gnuplot_notebook.gp
================================================
# ---
# jupyter:
# kernelspec:
# display_name: gnuplot
# language: gnuplot
# name: gnuplot
# ---
# # Sample gnuplot notebook
# ## Simple plotting
# +
# Plot sin and cos with different linetypes
f(x) = sin(x)
g(x) = cos(x)
set xrange[0:2*pi]
set xtics(0, "{/Symbol p}" pi , "2{/Symbol p}" 2*pi)
set ytics 1
plot f(x) linewidth 2 title "sin(x)", \
g(x) linewidth 2 dashtype "--" title "cos(x)"
# -
# ## Example of line magic
# +
# %gnuplot inline pngcairo enhanced background rgb "#EEEEEE" size 600, 600
# Parametric plot without border
reset
set parametric
set size ratio -1
unset border
unset tics
plot f(t), g(t) linewidth 2 notitle
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/haskell_notebook.hs
================================================
-- ---
-- jupyter:
-- kernelspec:
-- display_name: Haskell
-- language: haskell
-- name: haskell
-- ---
-- # Example Haskell Notebook
-- Define a function to add two numbers.
f :: Num a => a -> a -> a
f x y = x + y
-- Try to use the function
f 1 2
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/hello_world_gonb.go
================================================
// -*- coding: utf-8 -*-
// ---
// jupyter:
// kernelspec:
// display_name: Go (gonb)
// language: go
// name: gonb
// ---
// A notebook that use [GoNB](https://github.com/janpfeifer/gonb)
// the code below comes from [tutorial.ipynb](https://github.com/janpfeifer/gonb/blob/main/examples/tutorial.ipynb)
func main() {
fmt.Printf("Hello World!")
}
//gonb:%%
fmt.Printf("Hello World!")
// //gonb:%% --who=world can pass flags to main func
// +
import (
"flag"
"fmt"
)
var flagWho = flag.String("who", "", "Your name!")
//gonb:%% --who=world
fmt.Printf("Hello %s!\n", *flagWho)
// -
// // %args also can pass flags
// +
// %args --who=Wally
func main() {
flag.Parse()
fmt.Printf("Where is %s?", *flagWho)
}
// +
import "github.com/janpfeifer/gonb/gonbui"
//gonb:%%
gonbui.DisplayHtml(`I 🧡 GoNB!`)
// -
//gonb:%%
gonbui.DisplayMarkdown("#### Objective\n\n1. Have fun coding **Go**;\n1. Profit...\n"+
`$$f(x) = \int_{-\infty}^{\infty} e^{-x^2} dx$$`)
func init_a() {
fmt.Println("init_a")
}
//gonb:%%
fmt.Println("main")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/html-demo.clj
================================================
;; ---
;; jupyter:
;; kernelspec:
;; display_name: Clojure
;; language: clojure
;; name: clojure
;; ---
;; # Clojupyter Demo
;;
;; This example notebook is from the [Clojupyter](https://github.com/clojupyter/clojupyter/blob/1637f6b2557f01db1e35bae5389bc38522eefe9a/examples/html-demo.ipynb) project.
;; This notebook demonstrates some of the more advanced features of Clojupyter.
;; ## Displaying HTML
;;
;; To display HTML, you'll need to require a clojupyter helper function to change the cell output
(require '[clojupyter.misc.display :as display])
(println ">> should print some text")
;; displaying html
(display/hiccup-html
[:ul
[:li "a " [:i "emphatic"] " idea"]
[:li "a " [:b "bold"] " idea"]
[:li "an " [:span {:style "text-decoration: underline;"} "important"] " idea"]])
;; We can also use this to render SVG:
(display/hiccup-html
[:svg {:height 100 :width 100 :xmlns "http://www.w3.org/2000/svg"}
[:circle {:cx 50 :cy 40 :r 40 :fill "red"}]])
;; ## Adding External Clojure Dependencies
;;
;; You can fetch external Clojure dependencies using the `clojupyter.misc.helper` namespace.
(require '[clojupyter.misc.helper :as helper])
(helper/add-dependencies '[org.clojure/data.json "0.2.6"])
(require '[clojure.data.json :as json])
(json/write-str {:a 1 :b [2, 3] :c "c"})
;; ## Adding External Javascript Dependency
;;
;; Since you can render arbitrary HTML using `display/hiccup-html`, it's pretty easy to use external Javascript libraries to do things like generate charts. Here's an example using [Highcharts](https://www.highcharts.com/).
;;
;; First, we use a cell to add javascript to the running notebook:
(helper/add-javascript "https://code.highcharts.com/highcharts.js")
;; Now we define a function which takes Clojure data and returns hiccup HTML to display:
(defn plot-highchart [highchart-json]
(let [id (str (java.util.UUID/randomUUID))
code (format "Highcharts.chart('%s', %s );" id, (json/write-str highchart-json))]
(display/hiccup-html
[:div [:div {:id id :style {:background-color "red"}}]
[:script code]])))
;; Now we can make generate interactive plots (try hovering over plot):
;; +
(def raw-data (map #(+ (* 22 (+ % (Math/random)) 78)) (range)))
(def data-1 (take 500 raw-data))
(def data-2 (take 500 (drop 500 raw-data)))
(plot-highchart {:chart {:type "line"}
:title {:text "Plot of random data"}
:series [{:data data-1} {:data data-2}]})
;; -
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/ijavascript.js
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Javascript (Node.js)
// language: javascript
// name: javascript
// ---
// ## A notebook that uses IJavascript kernel
let x = 5;
const y = 6;
var z = 10;
x + y;
function add(num1, num2) {
return num1 + num2
}
add(x, y);
const arrowAdd = (num1, num2) => num1 + num2;
arrowAdd(x, y);
const myCar = {
color: "blue",
weight: 850,
model: "fiat",
start: () => "car started!",
doors: [1,2,3,4]
}
console.log("color:", myCar.color);
console.log("start:", myCar.start());
for (let door of myCar.doors) {
console.log("I'm door", door)
}
myCar;
class User {
constructor(name){
this.name = name;
}
sayHello(){
return "Hello, I'm " + this.name;
}
}
let John = new User("John");
John.sayHello();
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/ir_notebook.R
================================================
# ---
# jupyter:
# kernelspec:
# display_name: R
# language: R
# name: ir
# ---
# This is a jupyter notebook that uses the IR kernel.
sum(1:10)
plot(cars)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/ir_notebook.low.r
================================================
# ---
# jupyter:
# kernelspec:
# display_name: R
# language: R
# name: ir
# ---
# This is a jupyter notebook that uses the IR kernel.
sum(1:10)
plot(cars)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/itypescript.ts
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Typescript 3.5
// language: typescript
// name: typescript
// ---
let x: number = 5;
const y: number = 6;
var z: string = "hi";
console.log(z);
x + y;
function add(num1: number, num2: number): number {
return num1 + num2
}
add(x, y);
const arrowAdd = (num1: number, num2: number) => num1 + num2;
arrowAdd(x, y);
class User {
constructor(private name: string) {
this.name = name;
}
sayHello(): string {
return "Hello, I'm " + this.name;
}
}
let John: User;
John = new User("John");
John.sayHello();
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/julia_benchmark_plotly_barchart.jl
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Julia 1.1.1
# language: julia
# name: julia-1.1
# ---
# +
# IJulia rocks! So does Plotly. Check it out
using Plotly
api_key = "" # visit https://plot.ly/api to generate an API username and password
username = ""
Plotly.signin(username, api_key)
# +
# Following data taken from http://julialang.org/ frontpage
benchmarks = ["fib", "parse_int", "quicksort3", "mandel", "pi_sum", "rand_mat_stat", "rand_mat_mul"]
platforms = ["Fortran", "Julia", "Python", "R", "Matlab", "Mathematica", "Javascript", "Go"]
data = {
platforms[1] => [0.26, 5.03, 1.11, 0.86, 0.80, 0.64, 0.96],
platforms[2] => [0.91, 1.60, 1.14, 0.85, 1.00, 1.66, 1.01],
platforms[3] => [30.37, 13.95, 31.98, 14.19, 16.33, 13.52, 3.41 ],
platforms[4] => [411.36, 59.40, 524.29, 106.97, 15.42, 10.84, 3.98 ],
platforms[5] => [1992.00, 1463.16, 101.84, 64.58, 1.29, 6.61, 1.10 ],
platforms[6] => [64.46, 29.54, 35.74, 6.07, 1.32, 4.52, 1.16 ],
platforms[7] => [2.18, 2.43, 3.51, 3.49, 0.84, 3.28, 14.60],
platforms[8] => [1.03, 4.79, 1.25, 2.36, 1.41, 8.12, 8.51]
}
pdata = [ {"x"=>benchmarks,"y"=>data[k],"bardir"=>"h","type"=>"bar","name"=>k} for k = platforms ]
layout = {
"title"=> "Julia benchmark comparison (smaller is better, C performance = 1.0)",
"barmode"=> "group",
"autosize"=> false,
"width"=> 900,
"height"=> 900,
"titlefont"=>
{
"family"=> "Open Sans",
"size"=> 18,
"color"=> "rgb(84, 39, 143)"
},
"margin"=> {"l"=>160, "pad"=>0},
"xaxis"=> {
"title"=> "Benchmark log-time",
"type"=> "log"
},
"yaxis"=> {"title"=> "Benchmark Name"}
}
response = Plotly.plot(pdata,["layout"=>layout])
# Embed in an iframe within IJulia
s = string("")
display("text/html", s)
# +
# checkout https://plot.ly/api/ for more Julia examples!
# But to show off some other Plotly features:
x = 1:1500
y1 = sin(2*pi*x/1500.) + rand(1500)-0.5
y2 = sin(2*pi*x/1500.)
fish = {"x"=>x,"y"=> y1,
"type"=>"scatter","mode"=>"markers",
"marker"=>{"color"=>"rgb(0, 0, 255)","opacity"=>0.5 } }
fit = {"x"=> x,"y"=> y2,
"type"=>"scatter", "mode"=>"markers", "opacity"=>0.8,
"marker"=>{"color"=>"rgb(255, 0, 0)"} }
layout = {"autosize"=> false,
"width"=> 650, "height"=> 550,
"title"=>"Fish School",
"xaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[0,1500] },
"yaxis"=>{ "ticks"=> "",
"gridcolor"=> "white",
"zerolinecolor"=> "white",
"linecolor"=> "white",
"autorange"=> false,
"range"=>[-2.2,2.2] },
"plot_bgcolor"=> "rgb(245,245,247)",
"showlegend"=> false,
"hovermode"=> "closest"}
response = Plotly.plot([fish, fit],["layout"=>layout])
s = string("")
display("text/html", s)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/julia_functional_geometry.jl
================================================
# -*- coding: utf-8 -*-
# ---
# jupyter:
# kernelspec:
# display_name: Julia 1.1.1
# language: julia
# name: julia-1.1
# ---
# +
# This notebook is a semi top-down explanation. This cell needs to be
# executed first so that the operators and helper functions are defined
# All of this is explained in the later half of the notebook
using Compose, Interact
Compose.set_default_graphic_size(2inch, 2inch)
points_f = [
(.1, .1),
(.9, .1),
(.9, .2),
(.2, .2),
(.2, .4),
(.6, .4),
(.6, .5),
(.2, .5),
(.2, .9),
(.1, .9),
(.1, .1)
]
f = compose(context(), stroke("black"), line(points_f))
rot(pic) = compose(context(rotation=Rotation(-deg2rad(90))), pic)
flip(pic) = compose(context(mirror=Mirror(deg2rad(90), 0.5w, 0.5h)), pic)
above(m, n, p, q) =
compose(context(),
(context(0, 0, 1, m/(m+n)), p),
(context(0, m/(m+n), 1, n/(m+n)), q))
above(p, q) = above(1, 1, p, q)
beside(m, n, p, q) =
compose(context(),
(context(0, 0, m/(m+n), 1), p),
(context(m/(m+n), 0, n/(m+n), 1), q))
beside(p, q) = beside(1, 1, p, q)
over(p, q) = compose(context(),
(context(), p), (context(), q))
rot45(pic) =
compose(context(0, 0, 1/sqrt(2), 1/sqrt(2),
rotation=Rotation(-deg2rad(45), 0w, 0h)), pic)
# Utility function to zoom out and look at the context
zoomout(pic) = compose(context(),
(context(0.2, 0.2, 0.6, 0.6), pic),
(context(0.2, 0.2, 0.6, 0.6), fill(nothing), stroke("black"), strokedash([0.5mm, 0.5mm]),
polygon([(0, 0), (1, 0), (1, 1), (0, 1)])))
function read_path(p_str)
tokens = [try parsefloat(x) catch symbol(x) end for x in split(p_str, r"[\s,]+")]
path(tokens)
end
fish = compose(context(units=UnitBox(260, 260)), stroke("black"),
read_path(strip(readall("fish.path"))))
rotatable(pic) = @manipulate for θ=0:0.001:2π
compose(context(rotation=Rotation(θ)), pic)
end
blank = compose(context())
fliprot45(pic) = rot45(compose(context(mirror=Mirror(deg2rad(-45))),pic))
# Hide this cell.
display(MIME("text/html"), """""")
# -
# # Functional Geometry
# *Functional Geometry* is a paper by Peter Henderson ([original (1982)](users.ecs.soton.ac.uk/peter/funcgeo.pdf), [revisited (2002)](https://cs.au.dk/~hosc/local/HOSC-15-4-pp349-365.pdf)) which deconstructs the MC Escher woodcut *Square Limit*
#
# 
# > A picture is an example of a complex object that can be described in terms of its parts.
# Yet a picture needs to be rendered on a printer or a screen by a device that expects to
# be given a sequence of commands. Programming that sequence of commands directly is
# much harder than having an application generate the commands automatically from the
# simpler, denotational description.
# A `picture` is a *denotation* of something to draw.
#
# e.g. The value of f here denotes the picture of the letter F
# Original at http://nbviewer.jupyter.org/github/shashi/ijulia-notebooks/blob/master/funcgeo/Functional%20Geometry.ipynb
# ## In conclusion
#
# We described Escher's *Square Limit* from the description of its smaller parts, which in turn were described in terms of their smaller parts.
#
# This seemed simple because we chose to talk in terms of an *algebra* to describe pictures. The primitives `rot`, `flip`, `fliprot45`, `above`, `beside` and `over` fit the job perfectly.
#
# We were able to describe these primitives in terms of `compose` `contexts`, which the Compose library knows how to render.
#
# Denotation can be an easy way to describe a system as well as a practical implementation method.
#
# [Abstraction barriers](https://mitpress.mit.edu/sicp/full-text/sicp/book/node29.html) are useful tools that can reduce the cognitive overhead on the programmer. It entails creating layers consisting of functions which only use functions in the same layer or layers below in their own implementation. The layers in our language were:
#
# ------------------[ squarelimit ]------------------
# -------------[ quartet, cycle, nonet ]-------------
# ---[ rot, flip, fliprot45, above, beside, over ]---
# -------[ compose, context, line, path,... ]--------
#
# Drawing this diagram out is a useful way to begin building any library.
#
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/jupyter.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Jupyter notebook
#
# This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition:
a = 1
b = 2
a + b
# Now we return a few tuples
a, b
a, b, a+b
# And this is already the end of the notebook
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/jupyter_again.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
c = '''
title: "Quick test"
output:
ioslides_presentation:
widescreen: true
smaller: true
editor_options:
chunk_output_type console
'''
import yaml
print(yaml.dump(yaml.load(c)))
# ?next
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/jupyter_with_raw_cell_in_body.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
1+2+3
# + active=""
# This is a raw cell
# -
# This is a markdown cell
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/jupyter_with_raw_cell_on_top.py
================================================
# ---
# title: Quick test
# output:
# ioslides_presentation:
# widescreen: true
# smaller: true
# editor_options:
# chunk_output_type: console
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
1+2+3
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/jupyter_with_raw_cell_with_invalid_yaml.py
================================================
# ---
# title: Exception: Test
# jupyter:
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
1 + 2 + 3
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/jupyterlab-slideshow_1441.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# + [markdown] @deathbeds/jupyterlab-fonts={"styles": {"": {"body[data-jp-deck-mode='presenting'] &": {"right": "0", "top": "30%", "width": "25%", "z-index": 1}}}} jupyterlab-slideshow={"layer": "slide"}
# > **Note**
# >
# > `slide` layer with a `top` of `30%`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/jupytext_replication.sos
================================================
# ---
# jupyter:
# kernelspec:
# display_name: SoS
# language: sos
# name: sos
# ---
# + [markdown] Collapsed="false" kernel="SoS"
# # Text SOS-kernel with Jupytext
#
# ## What is SOS kernel
#
# SoS consists of a ployglot notebook that allows the use of multiple kernels in one Jupyter notebook, and a workflow system that is designed for daily computational research. Basically,
#
# - SoS Polyglot Notebook is a Jupyter Notebook with a SoS kernel.
# - SoS Notebook serves as a super kernel to all other Jupyter kernels and allows the use of multiple kernels in one Jupyter notebook.
# - SoS Workflow System is a Python based workflow system that is designed to be readable, shareable, and suitable for daily data analysis.
# - SoS Workflow System can be used from command line or use SoS Notebook as its IDE.
#
# 
#
# ### How to install SOS-kernel
#
# Please follow this [link](https://vatlab.github.io/sos-docs/running.html#Conda-installation) to setup SOS
#
# I run some issue with the latest version of R on my Mac, so I had to install an earlier version of R
#
# ```
# conda install -c r r=3.5.1
# conda install sos-notebook jupyterlab-sos sos-papermill -c conda-forge
# ```
#
# ## Related issue with Jupytext
#
# Jupytext works fine with Python/R kernel but converts code cells into markdown cells when using the SOS kernel.
#
# cf the image below. It is a code cell. After saving the notebook and restart it, it converted the code cell into markdown
#
#
# + [markdown] Collapsed="false" kernel="SoS"
# ## Step 1
#
# Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.
#
# 
# + Collapsed="false" kernel="SoS"
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
# + [markdown] Collapsed="false" kernel="python3"
# ## Step 2
#
# Now, pair it with Jupytex
#
# 
# + [markdown] Collapsed="false" kernel="python3"
# ### Step 3
#
# Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
# + [markdown] Collapsed="false" kernel="python3"
# ### Step 4
#
# Reopen the notebook. Here is the outcome
#
# 
#
#
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/kalman_filter_and_visualization.q
================================================
/ ---
/ jupyter:
/ kernelspec:
/ display_name: Q 3.5
/ language: q
/ name: qpk
/ ---
plt: .p.import`matplotlib.pyplot
/ +
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
/ -
price: 100 + sums 0.5 - (n:50)?1.
output:filter price
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/logtalk_notebook.lgt
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Logtalk
% language: logtalk
% name: logtalk_kernel
% ---
% # An implementation of the Ackermann function
% + vscode={"languageId": "logtalk"}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
% -
% ## Sample query
% + vscode={"languageId": "logtalk"}
ack::ack(2, 4, V).
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/lua_example.lua
================================================
-- -*- coding: utf-8 -*-
-- ---
-- jupyter:
-- kernelspec:
-- display_name: Lua
-- language: lua
-- name: lua
-- ---
-- Source: https://www.lua.org/pil/19.3.html
-- # Sort
-- Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
-- A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
-- Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
-- Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
-- As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
-- With this function, it is easy to print those function names in alphabetical order. The loop
for name, line in pairsByKeys(lines) do
print(name, line)
end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/maxima_example.mac
================================================
/* --- */
/* jupyter: */
/* kernelspec: */
/* display_name: Maxima */
/* language: maxima */
/* name: maxima */
/* --- */
/* ## maxima misc */
kill(all)$
f(x) := 1/(x^2+l^2)^(3/2);
integrate(f(x), x);
tex(%)$
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/notebook_with_complex_metadata.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/nteract_with_parameter.py
================================================
# ---
# jupyter:
# kernel_info:
# name: python3
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + inputHidden=false outputHidden=false tags=["parameters"]
param = 4
# + inputHidden=false outputHidden=false
import pandas as pd
# + inputHidden=false outputHidden=false
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
# + inputHidden=false outputHidden=false
# %matplotlib inline
df.plot(kind='bar')
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/ocaml_notebook.ml
================================================
(* --- *)
(* jupyter: *)
(* jupytext: *)
(* formats: ipynb:markdown,md *)
(* kernelspec: *)
(* display_name: OCaml default *)
(* language: OCaml *)
(* name: ocaml-jupyter *)
(* --- *)
(* # Example of an OCaml notebook *)
let sum x y = x + y
(* Let's try our function: *)
sum 3 4 = 7 + 0
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/octave_notebook.m
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Octave
% language: octave
% name: octave
% ---
% A markdown cell
1 + 1
% a code cell with comments
2 + 2
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
% And to finish with, a Python cell
% + language="python"
% a = 1
% + language="python"
% a + 1
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/plotly_graphs.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# This notebook contains complex outputs, including plotly javascript graphs.
# # Interactive plots
# We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/powershell.ps1
================================================
# ---
# jupyter:
# kernelspec:
# display_name: PowerShell
# language: PowerShell
# name: powershell
# ---
# This is an extract from
# https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
# +
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/raw_cell_with_complex_yaml_like_content.py
================================================
# ---
#
# This is a complex paragraph
# that is split over multiple lines.
#
# It also includes blank lines.
#
#
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/raw_cell_with_non_dict_yaml_content.py
================================================
# ---
# Content.
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/root_cpp.cpp
================================================
// ---
// jupyter:
// kernelspec:
// display_name: ROOT C++
// language: c++
// name: root
// ---
#include
#include
int k = 4;
std::string foo = "This string says \"foo\"";
std::cout << "k = " << k << '\n' << foo << '\n';
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/sage_print_hello.sage
================================================
# ---
# jupyter:
# kernelspec:
# display_name: SageMath 9.2
# language: sage
# name: sagemath
# ---
print("Hello world")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/sample_bash_notebook.sh
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Bash
# language: bash
# name: bash
# ---
ls
# https://coderwall.com/p/euwpig/a-better-git-log
git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"
git lg
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/sample_rise_notebook_66.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] slideshow={"slide_type": "slide"}
# A markdown cell
# + slideshow={"slide_type": ""}
1+1
# + [markdown] cell_style="center" slideshow={"slide_type": "fragment"}
# Markdown cell two
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/sas.sas
================================================
/* --- */
/* jupyter: */
/* kernelspec: */
/* display_name: SAS */
/* language: sas */
/* name: sas */
/* --- */
/* # SAS Notebooks with jupytext */
proc sql;
select *
from sashelp.cars (obs=10)
;
quit;
%let name = "Jupytext";
%put &name;
/* +
/* Note when defining macros "%macro" cannot be the first line of text in the cell */
%macro test;
data temp;
set sashelp.cars;
name = "testx";
run;
proc print data = temp (obs=10);
run;
%mend test;
%test
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/simple-helloworld.java
================================================
// -*- coding: utf-8 -*-
// ---
// jupyter:
// jupytext:
// formats: ipynb,java:light
// kernelspec:
// display_name: Java
// language: java
// name: java
// ---
// Let's define some class.
class A {
public void hello() {
System.out.println("Hello World");
}
}
// And now we call its method.
new A().hello();
// You can run it e.g. with `jshell`
//
// * from command line, as `jshell simple-helloworld.java`
// * from jshell's shell with `/open simple-helloworld.java`
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/simple_robot_notebook.robot
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Robot Framework
# language: robotframework
# name: robotkernel
# ---
# +
*** Settings ***
Library Collections
# +
*** Keywords ***
Head
[Arguments] ${list}
${value}= Get from list ${list} 0
[Return] ${value}
# +
*** Tasks ***
Get head
${array}= Create list 1 2 3 4 5
${head}= Head ${array}
Should be equal ${head} 1
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/simple_scala_notebook.scala
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Apache Toree - Scala
// language: scala
// name: apache_toree_scala
// ---
// +
// This is just a simple scala notebook
object SampleObject {
def calculation(x: Int, y: Int): Int = x + y
}
val result = SampleObject.calculation(1, 2)
// -
println(result * 10)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/stata_notebook.do
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Stata
// language: stata
// name: stata
// ---
// +
// This notebook uses the stata_kernel: https://github.com/kylebarron/stata_kernel
// -
use http://www.stata-press.com/data/r13/auto
summarize
scatter weight length
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/tailrecursive-factorial.groovy
================================================
// -*- coding: utf-8 -*-
// ---
// jupyter:
// jupytext:
// formats: ipynb,groovy:light
// kernelspec:
// display_name: Groovy
// language: groovy
// name: groovy
// ---
// # TailRecursive annotation
//
// Let's check what is the effect of `@TailRecursive` annotation on the simple recursive definition of factorial function.
// +
import groovy.transform.CompileStatic
import groovy.transform.TailRecursive
import groovy.transform.TypeChecked
@CompileStatic
@TypeChecked
class X {
static final BigInteger factorial0(int n) {
(n <= 1) ? 1G : factorial0(n-1).multiply(BigInteger.valueOf(n))
}
static final BigInteger factorial1(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial1(n-1, acc.multiply(BigInteger.valueOf(n)))
}
@TailRecursive
static final BigInteger factorial2(int n, BigInteger acc = 1G) {
(n <= 1) ? acc : factorial2(n-1, acc.multiply(BigInteger.valueOf(n)))
}
}
x = new X()
// -
// Although we can time the execution of the calls, it is not very accurate; such micro benchmarks should be performed in more controlled environment, such us under [JMH](https://openjdk.java.net/projects/code-tools/jmh/).
//
// For example, see [blog posts of Szymon Stępniak](https://e.printstacktrace.blog/tail-recursive-methods-in-groovy/).
// +
// %%timeit
x.factorial0(19_000).toString().length()
// +
// %%timeit
x.factorial1(19_000).toString().length()
// +
// %%timeit
x.factorial2(19_000).toString().length()
// -
// The real difference is the use of stack. Non-tail recursive calls exhaust the stack space at some point, whereas tail recursive calls don't add frames to the stack.
// +
factSize = { n, cl ->
println "Factorial of ${n} has ${cl(n).toString().length()} digits"
}
factSize 2_000, x.&factorial0
factSize 2_000, x.&factorial1
factSize 2_000, x.&factorial2
factSize 100_000, x.&factorial2
// -
try {
factSize 100_000, x.&factorial1
} catch (Throwable e) {
assert e instanceof StackOverflowError
println e
}
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/tcl_test.tcl
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Tcl
# language: tcl
# name: tcljupyter
# ---
# # Assign Values
set a 1
puts "a = $a"
# # Loop
for {set i 0} {$i < 10} {incr i} {
puts "I inside first loop: $i"
}
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/text_outputs_and_images.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# This notebook contains outputs of many different types: text, HTML, plots and errors.
# # Text outputs
#
# Using `print`, `sys.stdout` and `sys.stderr`
import sys
print('using print')
sys.stdout.write('using sys.stdout.write')
sys.stderr.write('using sys.stderr.write')
import logging
logging.debug('Debug')
logging.info('Info')
logging.warning('Warning')
logging.error('Error')
# # HTML outputs
#
# Using `pandas`. Here we find two representations: both text and HTML.
import pandas as pd
pd.DataFrame([4])
from IPython.display import display
display(pd.DataFrame([5]))
display(pd.DataFrame([6]))
# # Images
# %matplotlib inline
# First plot
from matplotlib import pyplot as plt
import numpy as np
w, h = 3, 3
data = np.zeros((h, w, 3), dtype=np.uint8)
data[0,:] = [0,255,0]
data[1,:] = [0,0,255]
data[2,:] = [0,255,0]
data[1:3,1:3] = [255, 0, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# Second plot
data[1:3,1:3] = [255, 255, 0]
plt.imshow(data)
plt.axis('off')
plt.show()
# # Errors
undefined_variable
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/wolfram.wolfram
================================================
(* --- *)
(* jupyter: *)
(* kernelspec: *)
(* display_name: Wolfram Language 13.1 *)
(* language: Wolfram Language *)
(* name: wolframlanguage13.1 *)
(* --- *)
(* **Note:** The `language_info` `file_extension` in this notebook should be `.m`, but it was deliberately changed to `.wolfram` to avoid conflicts with Matlab which is using the same extension. *)
(* We start with... *)
Print["Hello, World!"];
(* Then we draw the first example plot from the [ListPlot](https://reference.wolfram.com/language/ref/ListPlot.html) reference: *)
ListPlot[Prime[Range[25]]]
(* We also test the math outputs as in the [Simplify](https://reference.wolfram.com/language/ref/Simplify.html) example: *)
D[Integrate[1/(x^3 + 1), x], x]
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/xcpp_by_quantstack.cpp
================================================
// ---
// jupyter:
// kernelspec:
// display_name: C++14
// language: C++14
// name: xeus-cling-cpp14
// ---
// [](https://github.com/QuantStack/xeus-cling/)
//
// A Jupyter kernel for C++ based on the `cling` C++ interpreter and the `xeus` native implementation of the Jupyter protocol, xeus.
//
// - GitHub repository: https://github.com/QuantStack/xeus-cling/
// - Online documentation: https://xeus-cling.readthedocs.io/
// ## Usage
//
//
std::cout << "some output" << std::endl;
// -
std::cerr << "some error" << std::endl;
#include
throw std::runtime_error("Unknown exception");
// Omitting the `;` in the last statement of a cell results in an output being printed
int j = 5;
j
// # Interpreting the C++ programming language
//
// `cling` has a broad support of the features of C++. You can define functions, classes, templates, etc ...
// ## Functions
double sqr(double a)
{
return a * a;
}
double a = 2.5;
double asqr = sqr(a);
asqr
// ## Classes
class Foo
{
public:
virtual ~Foo() {}
virtual void print(double value) const
{
std::cout << "Foo value = " << value << std::endl;
}
};
Foo bar;
bar.print(1.2);
// ## Polymorphism
class Bar : public Foo
{
public:
virtual ~Bar() {}
virtual void print(double value) const
{
std::cout << "Bar value = " << 2 * value << std::endl;
}
};
Foo* bar2 = new Bar;
bar2->print(1.2);
delete bar2;
// ## Templates
// +
#include
template
class FooT
{
public:
explicit FooT(const T& t) : m_t(t) {}
void print() const
{
std::cout << typeid(T).name() << " m_t = " << m_t << std::endl;
}
private:
T m_t;
};
template <>
class FooT
{
public:
explicit FooT(const int& t) : m_t(t) {}
void print() const
{
std::cout << "m_t = " << m_t << std::endl;
}
private:
int m_t;
};
// -
FooT foot1(1.2);
foot1.print();
FooT foot2(4);
foot2.print();
// ## C++11 / C++14 support
class Foo11
{
public:
Foo11() { std::cout << "Foo11 default constructor" << std::endl; }
Foo11(const Foo11&) { std::cout << "Foo11 copy constructor" << std::endl; }
Foo11(Foo11&&) { std::cout << "Foo11 move constructor" << std::endl; }
};
Foo11 f1;
Foo11 f2(f1);
Foo11 f3(std::move(f1));
// +
#include
std::vector v = { 1, 2, 3};
auto iter = ++v.begin();
v
// -
*iter
// ... and also lambda, universal references, `decltype`, etc ...
// ## Documentation and completion
//
// - Documentation for types of the standard library is retrieved on cppreference.com.
// - The quick-help feature can also be enabled for user-defined types and third-party libraries. More documentation on this feature is available at https://xeus-cling.readthedocs.io/en/latest/inline_help.html.
//
?std::vector
// ## Using the `display_data` mechanism
// For a user-defined type `T`, the rich rendering in the notebook and JupyterLab can be enabled by by implementing the function `xeus::xjson mime_bundle_repr(const T& im)`, which returns the JSON mime bundle for that type.
//
// More documentation on the rich display system of Jupyter and Xeus-cling is available at https://xeus-cling.readthedocs.io/en/latest/rich_display.html
// ### Image example
// +
#include
#include
#include "xtl/xbase64.hpp"
#include "xeus/xjson.hpp"
namespace im
{
struct image
{
inline image(const std::string& filename)
{
std::ifstream fin(filename, std::ios::binary);
m_buffer << fin.rdbuf();
}
std::stringstream m_buffer;
};
xeus::xjson mime_bundle_repr(const image& i)
{
auto bundle = xeus::xjson::object();
bundle["image/png"] = xtl::base64encode(i.m_buffer.str());
return bundle;
}
}
// -
im::image marie("images/marie.png");
marie
// ### Audio example
// +
#include
#include
#include "xtl/xbase64.hpp"
#include "xeus/xjson.hpp"
namespace au
{
struct audio
{
inline audio(const std::string& filename)
{
std::ifstream fin(filename, std::ios::binary);
m_buffer << fin.rdbuf();
}
std::stringstream m_buffer;
};
xeus::xjson mime_bundle_repr(const audio& a)
{
auto bundle = xeus::xjson::object();
bundle["text/html"] =
std::string("";
return bundle;
}
}
// -
au::audio drums("audio/audio.wav");
drums
// ### Display
#include "xcpp/xdisplay.hpp"
xcpp::display(drums);
// ### Update-display
// +
#include
#include "xcpp/xdisplay.hpp"
namespace ht
{
struct html
{
inline html(const std::string& content)
{
m_content = content;
}
std::string m_content;
};
xeus::xjson mime_bundle_repr(const html& a)
{
auto bundle = xeus::xjson::object();
bundle["text/html"] = a.m_content;
return bundle;
}
}
// A red rectangle
ht::html rect(R"(
#include
std::vector to_shuffle = {1, 2, 3, 4};
// %timeit std::random_shuffle(to_shuffle.begin(), to_shuffle.end());
// [](https://github.com/QuantStack/xtensor/)
//
// - GitHub repository: https://github.com/QuantStack/xtensor/
// - Online documentation: https://xtensor.readthedocs.io/
// - NumPy to xtensor cheat sheet: http://xtensor.readthedocs.io/en/latest/numpy.html
//
// `xtensor` is a C++ library for manipulating N-D arrays with an API very similar to that of numpy.
// +
#include
#include "xtensor/xarray.hpp"
#include "xtensor/xio.hpp"
#include "xtensor/xview.hpp"
xt::xarray arr1
{{1.0, 2.0, 3.0},
{2.0, 5.0, 7.0},
{2.0, 5.0, 7.0}};
xt::xarray arr2
{5.0, 6.0, 7.0};
xt::view(arr1, 1) + arr2
// -
// Together with the C++ Jupyter kernel, `xtensor` offers a similar experience as `NumPy` in the Python Jupyter kernel, including broadcasting and universal functions.
#include
#include "xtensor/xarray.hpp"
#include "xtensor/xio.hpp"
// +
xt::xarray arr
{1, 2, 3, 4, 5, 6, 7, 8, 9};
arr.reshape({3, 3});
std::cout << arr;
// -
#include "xtensor-blas/xlinalg.hpp"
xt::xtensor m = {{1.5, 0.5}, {0.7, 1.0}};
std::cout << "Matrix rank: " << std::endl << xt::linalg::matrix_rank(m) << std::endl;
std::cout << "Matrix inverse: " << std::endl << xt::linalg::inv(m) << std::endl;
std::cout << "Eigen values: " << std::endl << xt::linalg::eigvals(m) << std::endl;
// +
xt::xarray arg1 = xt::arange(9);
xt::xarray arg2 = xt::arange(18);
arg1.reshape({3, 3});
arg2.reshape({2, 3, 3});
std::cout << xt::linalg::dot(arg1, arg2) << std::endl;
// -
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/xonsh_example.xsh
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Xonsh
# language: xonsh
# name: xonsh
# ---
len($(curl -L https://xon.sh))
for filename in `.*`:
print(filename)
du -sh @(filename)
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/Line_breaks_in_LateX_305.py
================================================
# ---
# jupyter:
# jupytext:
# cell_markers: '{{{,}}}'
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# This cell uses no particular cell marker
#
# $$
# \begin{align}
# \dot{x} & = \sigma(y-x)\\
# \dot{y} & = \rho x - y - xz \\
# \dot{z} & = -\beta z + xy
# \end{align}
# $$
# This cell uses no particular cell marker, and a single slash in the $\LaTeX$ equation
#
# $$
# \begin{align}
# \dot{x} & = \sigma(y-x) \
# \dot{y} & = \rho x - y - xz \
# \dot{z} & = -\beta z + xy
# \end{align}
# $$
# {{{ [markdown]
'''
This cell uses the triple quote cell markers introduced at https://github.com/mwouts/jupytext/issues/305
$$
\begin{align}
\dot{x} & = \sigma(y-x)\\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
'''
# }}}
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/Notebook with function and cell metadata 164.py
================================================
# ---
# jupyter:
# jupytext:
# cell_markers: '{{{,}}}'
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
1 + 1
# A markdown cell
# And below, the cell for function f has non trivial cell metadata. And the next cell as well.
# {{{ attributes={"classes": [], "id": "", "n": "10"}
def f(x):
return x
# }}}
# {{{ attributes={"classes": [], "id": "", "n": "10"}
f(5)
# }}}
# More text
2 + 2
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/Notebook with html and latex cells.py
================================================
# ---
# jupyter:
# jupytext:
# cell_markers: '{{{,}}}'
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# {{{ language="html"
# "
]
}
],
"metadata": {
"jupytext": {
"default_lexer": "ipython3",
"notebook_metadata_filter": "-all"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: tests/data/notebooks/outputs/script_to_ipynb/basic_marimo_example.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"id": "Hbol",
"metadata": {
"marimo": {
"config": {
"hide_code": true
}
}
},
"source": [
"This is a simple marimo notebook"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "MJUe",
"metadata": {},
"outputs": [],
"source": [
"x = 1"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "vblA",
"metadata": {},
"outputs": [],
"source": [
"y = x+1\n",
"y"
]
}
],
"metadata": {},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: tests/data/notebooks/outputs/script_to_ipynb/build.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This file originates from\n",
"https://github.com/MicrosoftDocs/PowerShell-Docs/blob/staging/build.ps1"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"param(\n",
" [switch]$SkipCabs,\n",
" [switch]$ShowProgress\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Turning off the progress display, by default\n",
"$global:ProgressPreference = 'SilentlyContinue'\n",
"if ($ShowProgress) { $ProgressPreference = 'Continue' }"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"[Net.ServicePointManager]::SecurityProtocol = [Net.ServicePointManager]::SecurityProtocol -bor [Net.SecurityProtocolType]::Tls12\n",
"$tempDir = [System.IO.Path]::GetTempPath()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Pandoc source URL\n",
"$panDocVersion = \"2.7.3\"\n",
"$pandocSourceURL = \"https://github.com/jgm/pandoc/releases/download/$panDocVersion/pandoc-$panDocVersion-windows-x86_64.zip\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"$pandocDestinationPath = New-Item (Join-Path $tempDir \"pandoc\") -ItemType Directory -Force\n",
"$pandocZipPath = Join-Path $pandocDestinationPath \"pandoc-$panDocVersion-windows-x86_64.zip\"\n",
"Invoke-WebRequest -Uri $pandocSourceURL -OutFile $pandocZipPath"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"Expand-Archive -Path $pandocZipPath -DestinationPath $pandocDestinationPath -Force\n",
"$pandocExePath = Join-Path (Join-Path $pandocDestinationPath \"pandoc-$panDocVersion-windows-x86_64\") \"pandoc.exe\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Install ThreadJob if not available\n",
"$threadJob = Get-Module ThreadJob -ListAvailable\n",
"if ($null -eq $threadjob) {\n",
" Install-Module ThreadJob -RequiredVersion 1.1.2 -Scope CurrentUser -Force\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Find the reference folder path w.r.t the script\n",
"$ReferenceDocset = Join-Path $PSScriptRoot 'reference'"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Go through all the directories in the reference folder\n",
"$jobs = [System.Collections.Generic.List[object]]::new()\n",
"$excludeList = 'module', 'media', 'docs-conceptual', 'mapping', 'bread', '7'\n",
"Get-ChildItem $ReferenceDocset -Directory -Exclude $excludeList | ForEach-Object -Process {\n",
" $job = Start-ThreadJob -Name $_.Name -ArgumentList @($SkipCabs,$pandocExePath,$PSScriptRoot,$_) -ScriptBlock {\n",
" param($SkipCabs, $pandocExePath, $WorkingDirectory, $DocSet)\n",
"\n",
" $tempDir = [System.IO.Path]::GetTempPath()\n",
" $workingDir = Join-Path $tempDir $DocSet.Name\n",
" $workingDir = New-Item -ItemType Directory -Path $workingDir -Force\n",
" Set-Location $WorkingDir\n",
"\n",
" function Get-ContentWithoutHeader {\n",
" param(\n",
" $path\n",
" )\n",
"\n",
" $doc = Get-Content $path -Encoding UTF8\n",
" $start = $end = -1\n",
"\n",
" # search the first 30 lines for the Yaml header\n",
" # no yaml header in our docset will ever be that long\n",
"\n",
" for ($x = 0; $x -lt 30; $x++) {\n",
" if ($doc[$x] -eq '---') {\n",
" if ($start -eq -1) {\n",
" $start = $x\n",
" }\n",
" else {\n",
" if ($end -eq -1) {\n",
" $end = $x + 1\n",
" break\n",
" }\n",
" }\n",
" }\n",
" }\n",
" if ($end -gt $start) {\n",
" Write-Output ($doc[$end..$($doc.count)] -join \"`r`n\")\n",
" }\n",
" else {\n",
" Write-Output ($doc -join \"`r`n\")\n",
" }\n",
" }\n",
"\n",
" $Version = $DocSet.Name\n",
" Write-Verbose -Verbose \"Version = $Version\"\n",
"\n",
" $VersionFolder = $DocSet.FullName\n",
" Write-Verbose -Verbose \"VersionFolder = $VersionFolder\"\n",
"\n",
" # For each of the directories, go through each module folder\n",
" Get-ChildItem $VersionFolder -Directory | ForEach-Object -Process {\n",
" $ModuleName = $_.Name\n",
" Write-Verbose -Verbose \"ModuleName = $ModuleName\"\n",
"\n",
" $ModulePath = Join-Path $VersionFolder $ModuleName\n",
" Write-Verbose -Verbose \"ModulePath = $ModulePath\"\n",
"\n",
" $LandingPage = Join-Path $ModulePath \"$ModuleName.md\"\n",
" Write-Verbose -Verbose \"LandingPage = $LandingPage\"\n",
"\n",
" $MamlOutputFolder = Join-Path \"$WorkingDirectory\\maml\" \"$Version\\$ModuleName\"\n",
" Write-Verbose -Verbose \"MamlOutputFolder = $MamlOutputFolder\"\n",
"\n",
" $CabOutputFolder = Join-Path \"$WorkingDirectory\\updatablehelp\" \"$Version\\$ModuleName\"\n",
" Write-Verbose -Verbose \"CabOutputFolder = $CabOutputFolder\"\n",
"\n",
" if (-not (Test-Path $MamlOutputFolder)) {\n",
" New-Item $MamlOutputFolder -ItemType Directory -Force > $null\n",
" }\n",
"\n",
" # Process the about topics if any\n",
" $AboutFolder = Join-Path $ModulePath \"About\"\n",
"\n",
" if (Test-Path $AboutFolder) {\n",
" Write-Verbose -Verbose \"AboutFolder = $AboutFolder\"\n",
" Get-ChildItem \"$aboutfolder/about_*.md\" | ForEach-Object {\n",
" $aboutFileFullName = $_.FullName\n",
" $aboutFileOutputName = \"$($_.BaseName).help.txt\"\n",
" $aboutFileOutputFullName = Join-Path $MamlOutputFolder $aboutFileOutputName\n",
"\n",
" $pandocArgs = @(\n",
" \"--from=gfm\",\n",
" \"--to=plain+multiline_tables\",\n",
" \"--columns=75\",\n",
" \"--output=$aboutFileOutputFullName\",\n",
" \"--quiet\"\n",
" )\n",
"\n",
" Get-ContentWithoutHeader $aboutFileFullName | & $pandocExePath $pandocArgs\n",
" }\n",
" }\n",
"\n",
" try {\n",
" # For each module, create a single maml help file\n",
" # Adding warningaction=stop to throw errors for all warnings, erroraction=stop to make them terminating errors\n",
" New-ExternalHelp -Path $ModulePath -OutputPath $MamlOutputFolder -Force -WarningAction Stop -ErrorAction Stop\n",
"\n",
" # For each module, create update-help help files (cab and helpinfo.xml files)\n",
" if (-not $SkipCabs) {\n",
" $cabInfo = New-ExternalHelpCab -CabFilesFolder $MamlOutputFolder -LandingPagePath $LandingPage -OutputFolder $CabOutputFolder\n",
"\n",
" # Only output the cab fileinfo object\n",
" if ($cabInfo.Count -eq 8) { $cabInfo[-1].FullName }\n",
" }\n",
" }\n",
" catch {\n",
" Write-Error -Message \"PlatyPS failure: $ModuleName -- $Version\" -Exception $_\n",
" }\n",
" }\n",
"\n",
" Remove-Item $workingDir -Force -ErrorAction SilentlyContinue\n",
" }\n",
" Write-Verbose -Verbose \"Started job for $($_.Name)\"\n",
" $jobs += $job\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"$null = $jobs | Wait-Job"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Variable to collect any errors in during processing\n",
"$allErrors = [System.Collections.Generic.List[string]]::new()\n",
"foreach ($job in $jobs) {\n",
" Write-Verbose -Verbose \"$($job.Name) output:\"\n",
" if ($job.Verbose.Count -gt 0) {\n",
" foreach ($verboseMessage in $job.Verbose) {\n",
" Write-Verbose -Verbose $verboseMessage\n",
" }\n",
" }\n",
"\n",
" if ($job.State -eq \"Failed\") {\n",
" $allErrors += \"$($job.Name) failed due to unhandled exception\"\n",
" }\n",
"\n",
" if ($job.Error.Count -gt 0) {\n",
" $allErrors += \"$($job.Name) failed with errors:\"\n",
" $allErrors += $job.Error.ReadAll()\n",
" }\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# If the above block, produced any errors, throw and fail the job\n",
"if ($allErrors.Count -gt 0) {\n",
" $allErrors\n",
" throw \"There are errors during platyPS run!`nPlease fix your markdown to comply with the schema: https://github.com/PowerShell/platyPS/blob/master/platyPS.schema.md\"\n",
"}"
]
}
],
"metadata": {
"jupytext": {
"cell_metadata_filter": "-all",
"main_language": "powershell",
"notebook_metadata_filter": "-all"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/outputs/script_to_ipynb/hydrogen.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"title": "Display a data frame"
},
"outputs": [],
"source": [
"df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]},\n",
" index=pd.Index(['x0', 'x1'], name='x'))\n",
"df"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": [
"parameters"
],
"title": "Pandas plot"
},
"outputs": [],
"source": [
"df.plot(kind='bar')"
]
}
],
"metadata": {
"jupytext": {
"cell_metadata_filter": "title,tags,-all",
"cell_metadata_json": true,
"main_language": "python",
"notebook_metadata_filter": "-all"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/outputs/script_to_ipynb/hydrogen_latex_html_R_magics.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"1 + 1"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"pd.Series({'A':5, 'B':2}).plot()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%matplotlib inline\n",
"pd.Series({'A':5, 'B':2}).plot(figsize=(3,2))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%html\n",
"` to get better feeling of\n",
"the necessary file structure.\n",
"\n",
"Anything before the Python script docstring is ignored by sphinx-gallery and\n",
"will not appear in the rst file, nor will it be executed.\n",
"This Python docstring requires an reStructuredText title to name the file and\n",
"correctly build the reference links.\n",
"\n",
"Once you close the docstring you would be writing Python code. This code gets\n",
"executed by sphinx gallery shows the plots and attaches the generating code.\n",
"Nevertheless you can break your code into blocks and give the rendered file\n",
"a notebook style. In this case you have to include a code comment breaker\n",
"a line of at least 20 hashes and then every comment start with the a new hash.\n",
"\n",
"As in this example we start by first writing this module\n",
"style docstring, then for the first code block we write the example file author\n",
"and script license continued by the import modules instructions.\n",
"\n",
"Original script from:\n",
"https://sphinx-gallery.readthedocs.io/en/latest/tutorials/plot_notebook.html"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Code source: Óscar Nájera\n",
"# License: BSD 3 clause\n",
"\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "##############################################################################"
},
"source": [
"This code block is executed, although it produces no output. Lines starting\n",
"with a simple hash are code comment and get treated as part of the code\n",
"block. To include this new comment string we started the new block with a\n",
"long line of hashes.\n",
"\n",
"The sphinx-gallery parser will assume everything after this splitter and that\n",
"continues to start with a **comment hash and space** (respecting code style)\n",
"is text that has to be rendered in\n",
"html format. Keep in mind to always keep your comments always together by\n",
"comment hashes. That means to break a paragraph you still need to comment\n",
"that line break.\n",
"\n",
"In this example the next block of code produces some plotable data. Code is\n",
"executed, figure is saved and then code is presented next, followed by the\n",
"inlined figure."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"x = np.linspace(-np.pi, np.pi, 300)\n",
"xx, yy = np.meshgrid(x, x)\n",
"z = np.cos(xx) + np.cos(yy)\n",
"\n",
"plt.figure()\n",
"plt.imshow(z)\n",
"plt.colorbar()\n",
"plt.xlabel('$x$')\n",
"plt.ylabel('$y$')"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "###########################################################################"
},
"source": [
"Again it is possible to continue the discussion with a new Python string. This\n",
"time to introduce the next code block generates 2 separate figures."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"plt.figure()\n",
"plt.imshow(z, cmap=plt.cm.get_cmap('hot'))\n",
"plt.figure()\n",
"plt.imshow(z, cmap=plt.cm.get_cmap('Spectral'), interpolation='none')"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "##########################################################################"
},
"source": [
"There's some subtle differences between rendered html rendered comment\n",
"strings and code comment strings which I'll demonstrate below. (Some of this\n",
"only makes sense if you look at the\n",
":download:`raw Python script `)\n",
"\n",
"Comments in comment blocks remain nested in the text."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"def dummy():\n",
" \"\"\"Dummy function to make sure docstrings don't get rendered as text\"\"\"\n",
" pass\n",
"\n",
"# Code comments not preceded by the hash splitter are left in code blocks.\n",
"\n",
"string = \"\"\"\n",
"Triple-quoted string which tries to break parser but doesn't.\n",
"\"\"\""
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "############################################################################"
},
"source": [
"Output of the script is captured:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print('Some output from Python')"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "############################################################################"
},
"source": [
"Finally, I'll call ``show`` at the end just so someone running the Python\n",
"code directly will see the plots; this is not necessary for creating the docs"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "############################################################################"
},
"source": [
"You can also include $math$ inline, or as separate equations:\n",
"\n",
"\\begin{align}\\exp(j\\pi) = -1\\end{align}\n",
"\n",
"You can also insert images:\n",
"\n",
" "
]
}
],
"metadata": {
"jupytext": {
"cell_metadata_filter": "-all",
"encoding": "# -*- coding: utf-8 -*-",
"main_language": "python",
"notebook_metadata_filter": "-all",
"rst2md": false
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/outputs/sphinx_to_ipynb/plot_notebook.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%matplotlib inline"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "\"\"\""
},
"source": [
"Notebook styled examples\n",
"========================\n",
"\n",
"The gallery is capable of transforming Python files into reStructuredText files\n",
"with a notebook structure. For this to be used you need to respect some syntax\n",
"rules.\n",
"\n",
"It makes a lot of sense to contrast this output rst file with the\n",
":download:`original Python script
"
]
}
],
"metadata": {
"jupytext": {
"cell_metadata_filter": "-all",
"encoding": "# -*- coding: utf-8 -*-",
"main_language": "python",
"notebook_metadata_filter": "-all",
"rst2md": false
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/outputs/sphinx_to_ipynb/plot_notebook.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%matplotlib inline"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "\"\"\""
},
"source": [
"Notebook styled examples\n",
"========================\n",
"\n",
"The gallery is capable of transforming Python files into reStructuredText files\n",
"with a notebook structure. For this to be used you need to respect some syntax\n",
"rules.\n",
"\n",
"It makes a lot of sense to contrast this output rst file with the\n",
":download:`original Python script ` to get better feeling of\n",
"the necessary file structure.\n",
"\n",
"Anything before the Python script docstring is ignored by sphinx-gallery and\n",
"will not appear in the rst file, nor will it be executed.\n",
"This Python docstring requires an reStructuredText title to name the file and\n",
"correctly build the reference links.\n",
"\n",
"Once you close the docstring you would be writing Python code. This code gets\n",
"executed by sphinx gallery shows the plots and attaches the generating code.\n",
"Nevertheless you can break your code into blocks and give the rendered file\n",
"a notebook style. In this case you have to include a code comment breaker\n",
"a line of at least 20 hashes and then every comment start with the a new hash.\n",
"\n",
"As in this example we start by first writing this module\n",
"style docstring, then for the first code block we write the example file author\n",
"and script license continued by the import modules instructions.\n",
"\n",
"Original script from:\n",
"https://sphinx-gallery.readthedocs.io/en/latest/tutorials/plot_notebook.html"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Code source: Óscar Nájera\n",
"# License: BSD 3 clause\n",
"\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "##############################################################################"
},
"source": [
"This code block is executed, although it produces no output. Lines starting\n",
"with a simple hash are code comment and get treated as part of the code\n",
"block. To include this new comment string we started the new block with a\n",
"long line of hashes.\n",
"\n",
"The sphinx-gallery parser will assume everything after this splitter and that\n",
"continues to start with a **comment hash and space** (respecting code style)\n",
"is text that has to be rendered in\n",
"html format. Keep in mind to always keep your comments always together by\n",
"comment hashes. That means to break a paragraph you still need to comment\n",
"that line break.\n",
"\n",
"In this example the next block of code produces some plotable data. Code is\n",
"executed, figure is saved and then code is presented next, followed by the\n",
"inlined figure."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"x = np.linspace(-np.pi, np.pi, 300)\n",
"xx, yy = np.meshgrid(x, x)\n",
"z = np.cos(xx) + np.cos(yy)\n",
"\n",
"plt.figure()\n",
"plt.imshow(z)\n",
"plt.colorbar()\n",
"plt.xlabel('$x$')\n",
"plt.ylabel('$y$')"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "###########################################################################"
},
"source": [
"Again it is possible to continue the discussion with a new Python string. This\n",
"time to introduce the next code block generates 2 separate figures."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"plt.figure()\n",
"plt.imshow(z, cmap=plt.cm.get_cmap('hot'))\n",
"plt.figure()\n",
"plt.imshow(z, cmap=plt.cm.get_cmap('Spectral'), interpolation='none')"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "##########################################################################"
},
"source": [
"There's some subtle differences between rendered html rendered comment\n",
"strings and code comment strings which I'll demonstrate below. (Some of this\n",
"only makes sense if you look at the\n",
":download:`raw Python script `)\n",
"\n",
"Comments in comment blocks remain nested in the text."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"def dummy():\n",
" \"\"\"Dummy function to make sure docstrings don't get rendered as text\"\"\"\n",
" pass\n",
"\n",
"# Code comments not preceded by the hash splitter are left in code blocks.\n",
"\n",
"string = \"\"\"\n",
"Triple-quoted string which tries to break parser but doesn't.\n",
"\"\"\""
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "############################################################################"
},
"source": [
"Output of the script is captured:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print('Some output from Python')"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "############################################################################"
},
"source": [
"Finally, I'll call ``show`` at the end just so someone running the Python\n",
"code directly will see the plots; this is not necessary for creating the docs"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "############################################################################"
},
"source": [
"You can also include :math:`math` inline, or as separate equations:\n",
"\n",
".. math::\n",
"\n",
" \\exp(j\\pi) = -1\n",
"\n",
"You can also insert images:\n",
"\n",
".. image:: http://www.sphinx-doc.org/en/stable/_static/sphinxheader.png\n",
" :alt: Sphinx header\n"
]
}
],
"metadata": {
"jupytext": {
"cell_metadata_filter": "-all",
"encoding": "# -*- coding: utf-8 -*-",
"main_language": "python",
"notebook_metadata_filter": "-all"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/external/cli/test_black.py
================================================
import os
from copy import deepcopy
from shutil import copyfile
import pytest
from nbformat.v4.nbbase import new_code_cell, new_notebook
from jupytext import read, write
from jupytext.cli import jupytext, pipe_notebook, system
from jupytext.combine import black_invariant
from jupytext.compare import compare, compare_cells, compare_notebooks
from jupytext.header import _DEFAULT_NOTEBOOK_METADATA
@pytest.mark.requires_black
def test_apply_black_on_python_notebooks(tmpdir, cwd_tmpdir, ipynb_py_file):
if "cell metadata" in ipynb_py_file:
pytest.skip()
copyfile(ipynb_py_file, "notebook.ipynb")
jupytext(args=["notebook.ipynb", "--to", "py:percent"])
system("black", "notebook.py")
jupytext(args=["notebook.py", "--to", "ipynb", "--update"])
nb1 = read(ipynb_py_file)
nb2 = read("notebook.ipynb")
nb3 = read("notebook.py")
assert len(nb1.cells) == len(nb2.cells)
assert len(nb1.cells) == len(nb3.cells)
for c1, c2 in zip(nb1.cells, nb2.cells):
# same content (almost)
assert black_invariant(c1.source) == black_invariant(c2.source)
# python representation is pep8
assert "lines_to_next_cell" not in c2.metadata
# outputs are preserved
assert c1.cell_type == c2.cell_type
if c1.cell_type == "code":
compare(c1.outputs, c2.outputs)
compare(nb1.metadata, nb2.metadata)
def test_black_invariant():
text_org = """long_string = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" \\
"bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb"
"""
text_black = """long_string = (
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"
"bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb"
)
"""
assert black_invariant(text_org) == black_invariant(text_black)
@pytest.mark.requires_black
def test_pipe_into_black():
nb_org = new_notebook(cells=[new_code_cell("1 +1", id="cell-id")])
nb_dest = new_notebook(cells=[new_code_cell("1 + 1", id="cell-id")])
nb_pipe = pipe_notebook(nb_org, "black")
compare_notebooks(nb_pipe, nb_dest, allow_expected_differences=False, compare_ids=True)
@pytest.mark.requires_autopep8
def test_pipe_into_autopep8():
nb_org = new_notebook(cells=[new_code_cell("1 +1", id="cell-id")])
nb_dest = new_notebook(cells=[new_code_cell("1 + 1", id="cell-id")])
nb_pipe = pipe_notebook(nb_org, "autopep8 -")
compare_notebooks(nb_pipe, nb_dest, allow_expected_differences=False, compare_ids=True)
@pytest.mark.requires_flake8
def test_pipe_into_flake8():
# Notebook OK
nb = new_notebook(cells=[new_code_cell("# correct code\n1 + 1")])
pipe_notebook(nb, "flake8", update=False)
# Notebook not OK
nb = new_notebook(cells=[new_code_cell("incorrect code")])
with pytest.raises(SystemExit):
pipe_notebook(nb, "flake8", update=False)
@pytest.mark.requires_black
@pytest.mark.requires_flake8
def test_apply_black_through_jupytext(tmpdir, python_notebook):
# Load real notebook metadata to get the 'auto' extension in --pipe-fmt to work
metadata = python_notebook.metadata
nb_org = new_notebook(cells=[new_code_cell("1 +1", id="cell-id")], metadata=metadata)
nb_black = new_notebook(cells=[new_code_cell("1 + 1", id="cell-id")], metadata=metadata)
tmp_ipynb = str(tmpdir.mkdir("notebook_folder").join("notebook.ipynb"))
tmp_py = str(tmpdir.mkdir("script_folder").join("notebook.py"))
# Black in place
write(nb_org, tmp_ipynb)
jupytext([tmp_ipynb, "--pipe", "black"])
nb_now = read(tmp_ipynb)
compare_notebooks(nb_now, nb_black, compare_ids=True)
# Write to another folder using dots
write(nb_org, tmp_ipynb)
jupytext([tmp_ipynb, "--to", "../script_folder//py:percent", "--pipe", "black"])
assert os.path.isfile(tmp_py)
nb_now = read(tmp_py)
nb_now.metadata = metadata
compare_notebooks(nb_now, nb_black)
os.remove(tmp_py)
# Map to another folder based on file name
write(nb_org, tmp_ipynb)
jupytext(
[
tmp_ipynb,
"--from",
"notebook_folder//ipynb",
"--to",
"script_folder//py:percent",
"--pipe",
"black",
"--check",
"flake8",
]
)
assert os.path.isfile(tmp_py)
nb_now = read(tmp_py)
nb_now.metadata = metadata
compare_notebooks(nb_now, nb_black)
@pytest.mark.requires_black
def test_apply_black_and_sync_on_paired_notebook(tmpdir, cwd_tmpdir, python_notebook):
# Load real notebook metadata to get the 'auto' extension in --pipe-fmt to work
metadata = python_notebook.metadata
metadata["jupytext"] = {"formats": "ipynb,py"}
assert "language_info" in metadata
nb_org = new_notebook(cells=[new_code_cell("1 +1", id="cell-id")], metadata=metadata)
nb_black = new_notebook(cells=[new_code_cell("1 + 1", id="cell-id")], metadata=metadata)
# Black in place
write(nb_org, "notebook.ipynb")
jupytext(["notebook.ipynb", "--pipe", "black", "--sync"])
nb_now = read("notebook.ipynb")
compare_notebooks(nb_now, nb_black, compare_ids=True)
assert "language_info" in nb_now.metadata
nb_now = read("notebook.py")
nb_now.metadata["jupytext"].pop("text_representation")
nb_black.metadata = {
key: nb_black.metadata[key] for key in nb_black.metadata if key in _DEFAULT_NOTEBOOK_METADATA.split(",")
}
compare_notebooks(nb_now, nb_black)
@pytest.mark.requires_black
def test_apply_black_on_markdown_notebook(tmpdir):
text = """---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
language_info:
codemirror_mode:
name: ipython
version: 3
file_extension: .py
mimetype: text/x-python
name: python
nbconvert_exporter: python
pygments_lexer: ipython3
version: 3.7.4
---
```python
1 + \
2+3\
+4
```
"""
tmp_md = str(tmpdir.join("test.md"))
with open(tmp_md, "w") as fp:
fp.write(text)
jupytext([tmp_md, "--pipe", "black"])
nb = read(tmp_md)
compare_cells(nb.cells, [new_code_cell("1 + 2 + 3 + 4")], compare_ids=False)
@pytest.mark.requires_black
def test_black_through_tempfile(
tmpdir,
text="""```python
1 + 2 \
+ 3
```
""",
black="""```python
1 + 2 + 3
```
""",
):
tmp_md = str(tmpdir.join("notebook.md"))
with open(tmp_md, "w") as fp:
fp.write(text)
jupytext([tmp_md, "--pipe", "black {}"])
with open(tmp_md) as fp:
compare(fp.read(), black)
@pytest.mark.requires_black
def test_pipe_black_removes_lines_to_next_cell_metadata(
tmpdir,
cwd_tmpdir,
text="""# %%
def func():
return 42
# %%
func()""",
):
tmpdir.join("notebook.py").write(text)
jupytext(["--set-formats", "ipynb,py:percent", "notebook.py"])
nb = read(tmpdir.join("notebook.ipynb"))
assert nb.cells[0].metadata["lines_to_next_cell"] == 0
jupytext(["--sync", "notebook.py", "--pipe", "black"])
nb = read(tmpdir.join("notebook.ipynb"))
assert "lines_to_next_cell" not in nb.cells[0].metadata
new_text = tmpdir.join("notebook.py").read()
assert "\n\n# %%\nfunc()" in new_text
@pytest.mark.requires_black
@pytest.mark.parametrize(
"code,black_should_fail",
[("myvar = %dont_format_me", False), ("incomplete_instruction = (...", True)],
)
def test_pipe_black_uses_warn_only_781(tmpdir, cwd_tmpdir, code, black_should_fail, python_notebook, capsys):
nb = python_notebook
nb.cells.append(new_code_cell(code))
write(nb, "notebook.ipynb")
if not black_should_fail:
jupytext(["--pipe", "black", "notebook.ipynb"])
return
with pytest.raises(SystemExit):
jupytext(["--pipe", "black", "notebook.ipynb"])
out, err = capsys.readouterr()
assert "Error: The command 'black -' exited with code" in err
assert "--warn-only" in err
# With warn-only we just get a warning
jupytext(["--pipe", "black", "notebook.ipynb", "--warn-only"])
out, err = capsys.readouterr()
assert "Warning: The command 'black -' exited with code" in err
# If black fails the notebook should be left unchanged
actual = read("notebook.ipynb")
compare_notebooks(actual, nb)
@pytest.mark.requires_black
def test_pipe_black_preserve_outputs(notebook_with_outputs, tmpdir, cwd_tmpdir, capsys):
write(notebook_with_outputs, "test.ipynb")
jupytext(["--pipe", "black", "test.ipynb"])
# Outputs are preserved
nb = read("test.ipynb")
expected = deepcopy(notebook_with_outputs)
expected.cells[0].source = "1 + 1"
compare_notebooks(nb, expected)
# No mention of --update
out, err = capsys.readouterr()
assert not err
assert "replaced" not in out
assert "--update" not in out
================================================
FILE: tests/external/cli/test_cli_check.py
================================================
import pytest
from nbformat.v4.nbbase import new_code_cell, new_notebook
from jupytext import write
from jupytext.cli import jupytext
@pytest.fixture
def non_black_notebook(python_notebook):
return new_notebook(metadata=python_notebook.metadata, cells=[new_code_cell("1+1")])
@pytest.mark.requires_black
def test_check_notebooks_left_or_right_black(python_notebook, tmpdir, cwd_tmpdir):
write(python_notebook, str(tmpdir / "nb1.ipynb"))
write(python_notebook, str(tmpdir / "nb2.ipynb"))
jupytext(["*.ipynb", "--check", "black --check {}"])
jupytext(["--check", "black --check {}", "*.ipynb"])
@pytest.mark.requires_black
def test_check_notebooks_left_or_right_not_black(non_black_notebook, tmpdir, cwd_tmpdir):
write(non_black_notebook, str(tmpdir / "nb1.ipynb"))
write(non_black_notebook, str(tmpdir / "nb2.ipynb"))
with pytest.raises(SystemExit):
jupytext(["*.ipynb", "--check", "black --check {}"])
with pytest.raises(SystemExit):
jupytext(["--check", "black --check {}", "*.ipynb"])
================================================
FILE: tests/external/cli/test_isort.py
================================================
import pytest
from jupytext import reads, writes
from jupytext.cli import pipe_notebook
from jupytext.compare import compare
@pytest.mark.requires_isort
def test_pipe_into_isort():
text_org = """# %%
import numpy as np
np.array([1,2,3])
# %%
import pandas as pd
pd.Series([1,2,3])
# %%
# This is a comment on the second import
import pandas as pd
pd.Series([4,5,6])
"""
text_target = """# %%
import numpy as np
# This is a comment on the second import
import pandas as pd
np.array([1,2,3])
# %%
pd.Series([1,2,3])
# %%
pd.Series([4,5,6])
"""
nb_org = reads(text_org, fmt="py:percent")
nb_pipe = pipe_notebook(nb_org, 'isort - --treat-comment-as-code "# %%" --float-to-top')
text_actual = writes(nb_pipe, "py:percent")
compare(text_actual, text_target)
================================================
FILE: tests/external/conftest.py
================================================
import pytest
from git import Repo
@pytest.fixture
def tmp_repo(tmpdir):
repo = Repo.init(str(tmpdir))
return repo
================================================
FILE: tests/external/contents_manager/test_contentsmanager_external.py
================================================
import re
import pytest
from jupyter_server.utils import ensure_async
import jupytext
from jupytext.compare import compare_notebooks, notebook_model
pytestmark = pytest.mark.asyncio
@pytest.mark.requires_pandoc
async def test_save_load_paired_md_pandoc_notebook(ipynb_py_R_jl_file, tmpdir, cm):
if re.match(r".*(functional|Notebook with|flavors|invalid|305|jupyterlab-slideshow).*", ipynb_py_R_jl_file):
pytest.skip()
tmp_ipynb = "notebook.ipynb"
tmp_md = "notebook.md"
cm.root_dir = str(tmpdir)
# open ipynb, save with cm, reopen
nb = jupytext.read(ipynb_py_R_jl_file)
nb.metadata["jupytext"] = {"formats": "ipynb,md:pandoc"}
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
nb_md = await ensure_async(cm.get(tmp_md))
compare_notebooks(nb_md["content"], nb, "md:pandoc")
assert nb_md["content"].metadata["jupytext"]["formats"] == "ipynb,md:pandoc"
@pytest.mark.requires_quarto
async def test_save_load_paired_qmd_notebook(ipynb_py_R_jl_file, tmpdir, cm):
if re.match(
r".*(functional|Notebook with|plotly_graphs|flavors|complex_metadata|"
"update83|raw_cell|_66|nteract|LaTeX|invalid|305|text_outputs|ir_notebook|jupyter|with_R_magic).*",
ipynb_py_R_jl_file,
):
pytest.skip()
tmp_ipynb = "notebook.ipynb"
tmp_qmd = "notebook.qmd"
cm.root_dir = str(tmpdir)
# open ipynb, save with cm, reopen
nb = jupytext.read(ipynb_py_R_jl_file)
nb.metadata["jupytext"] = {"formats": "ipynb,qmd"}
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
nb_md = await ensure_async(cm.get(tmp_qmd))
compare_notebooks(nb_md["content"], nb, "qmd")
assert nb_md["content"].metadata["jupytext"]["formats"] == "ipynb,qmd"
================================================
FILE: tests/external/docs/test_using_cli.py
================================================
import os
import shlex
import pytest
from nbformat.v4.nbbase import new_code_cell, new_notebook
import jupytext
from jupytext.cli import jupytext as jupytext_cli
doc_path = os.path.join(os.path.dirname(__file__), "..", "..", "..", "docs")
@pytest.mark.requires_user_kernel_python3
@pytest.mark.requires_black
@pytest.mark.requires_myst
@pytest.mark.skipif(not os.path.isdir(doc_path), reason="Documentation folder is missing")
def test_jupytext_commands_in_the_documentation_work(tmpdir):
# Read the documentation as a bash notebook
using_cli = os.path.join(doc_path, "using-cli.md")
assert os.path.isfile(using_cli)
using_cli_nb = jupytext.read(using_cli)
# Run the commands in tmpdir on a sample notebook
jupytext.write(new_notebook(cells=[new_code_cell("1+1")]), str(tmpdir.join("notebook.ipynb")))
os.chdir(str(tmpdir))
cmd_tested = 0
for cell in using_cli_nb.cells:
if cell.cell_type != "code":
continue
if not cell.source.startswith("jupytext"):
continue
for cmd in cell.source.splitlines():
if not cmd.startswith("jupytext"):
continue
# Do not test commands that involve reading a notebook from stdin
if "read ipynb from stdin" in cmd:
continue
# We can't run pytest inside pytest
if "pytest {}" in cmd:
continue
# We need to remove the comments that may follow the jupytext command
if "#" in cmd:
left, comment = cmd.rsplit("#", 1)
if '"' not in comment:
cmd = left
print(f"Testing: {cmd}")
args = shlex.split(cmd)[1:]
assert not jupytext_cli(args), cmd
cmd_tested += 1
assert cmd_tested >= 10
================================================
FILE: tests/external/jupyter_fs/test_jupyter_fs.py
================================================
import logging
import pytest
from jupyter_server.utils import ensure_async
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
import jupytext
from jupytext.compare import compare_cells, notebook_model
@pytest.fixture(params=["sync", "async"])
def cm_from_fs_meta_manager(tmpdir, request):
try:
from jupyterfs.metamanager import MetaManager, SyncMetaManager
except ImportError:
pytest.skip("jupyterfs is not available")
if request.param == "sync":
cm_class = jupytext.build_sync_jupytext_contents_manager_class(SyncMetaManager)
else:
cm_class = jupytext.build_async_jupytext_contents_manager_class(MetaManager)
logger = logging.getLogger("jupyter-fs")
cm = cm_class(parent=None, log=logger)
cm.initResource(
{
"url": f"osfs://{tmpdir}",
}
)
return cm
@pytest.mark.asyncio
async def test_jupytext_jupyter_fs_metamanager(cm_from_fs_meta_manager):
"""Test the basic get/save functions of Jupytext with a fs manager
https://github.com/mwouts/jupytext/issues/618"""
cm = cm_from_fs_meta_manager
# the hash that corresponds to the osfs
osfs = [h for h in cm._managers if h != ""][0]
# save a few files
text = "some text\n"
await ensure_async(cm.save(dict(type="file", content=text, format="text"), path=osfs + ":text.md"))
nb = new_notebook(cells=[new_markdown_cell("A markdown cell"), new_code_cell("1 + 1")])
await ensure_async(cm.save(notebook_model(nb), osfs + ":notebook.ipynb"))
await ensure_async(cm.save(notebook_model(nb), osfs + ":text_notebook.md"))
# list the directory
directory = await ensure_async(cm.get(osfs + ":/"))
assert {file["name"] for file in directory["content"]} == {
"text.md",
"text_notebook.md",
"notebook.ipynb",
}
# get the files
model = await ensure_async(cm.get(osfs + ":/text.md", type="file"))
assert model["type"] == "file"
assert model["content"] == text
model = await ensure_async(cm.get(osfs + ":text.md", type="notebook"))
assert model["type"] == "notebook"
# We only compare the cells, as kernelspecs are added to the notebook metadata
compare_cells(model["content"].cells, [new_markdown_cell(text.strip())], compare_ids=False)
for nb_file in ["notebook.ipynb", "text_notebook.md"]:
model = await ensure_async(cm.get(osfs + ":" + nb_file))
assert model["type"] == "notebook"
actual_cells = model["content"].cells
# saving adds 'trusted=True' to the code cell metadata
for cell in actual_cells:
cell.metadata = {}
compare_cells(actual_cells, nb.cells, compare_ids=False)
@pytest.mark.asyncio
async def test_config_jupytext_jupyter_fs_meta_manager(tmpdir, cm_from_fs_meta_manager):
"""Test the configuration of Jupytext with a fs manager"""
tmpdir.join("jupytext.toml").write('formats = "ipynb,py"')
cm = cm_from_fs_meta_manager
# the hash that corresponds to the osfs
osfs = [h for h in cm._managers if h != ""][0]
# save a few files
nb = new_notebook()
await ensure_async(cm.save(dict(type="file", content="text", format="text"), path=osfs + ":text.md"))
await ensure_async(cm.save(notebook_model(nb), osfs + ":script.py"))
await ensure_async(cm.save(notebook_model(nb), osfs + ":text_notebook.md"))
await ensure_async(cm.save(notebook_model(nb), osfs + ":notebook.ipynb"))
# list the directory
directory = await ensure_async(cm.get(osfs + ":/"))
assert {file["name"] for file in directory["content"]} == {
"jupytext.toml",
"text.md",
"text_notebook.md",
"notebook.ipynb",
"notebook.py",
"script.py",
"script.ipynb",
}
================================================
FILE: tests/external/pre_commit/test_pre_commit_0_ipynb_to_py.py
================================================
import pytest
from git.exc import HookExecutionError
from nbformat.v4.nbbase import new_markdown_cell, new_notebook
from pre_commit.main import main as pre_commit
from jupytext import read, write
from jupytext.cli import jupytext
from jupytext.compare import compare_cells
def test_pre_commit_hook_ipynb_to_py(tmpdir, cwd_tmpdir, tmp_repo, jupytext_repo_root, jupytext_repo_rev):
"""Here we document and test the expected behavior of the pre-commit hook in the
directional (--to) mode. Note that here, the ipynb file is always the source for
updates - i.e. changes on the .py file will not trigger the hook.
"""
# set up the tmpdir repo with pre-commit
pre_commit_config_yaml = f"""
repos:
- repo: {jupytext_repo_root}
rev: {jupytext_repo_rev}
hooks:
- id: jupytext
args: [--from, ipynb, --to, "py:percent"]
"""
tmpdir.join(".pre-commit-config.yaml").write(pre_commit_config_yaml)
tmp_repo.git.add(".pre-commit-config.yaml")
pre_commit(["install", "--install-hooks"])
# write test notebook and output file
nb = new_notebook(cells=[new_markdown_cell("A short notebook")])
write(nb, "test.ipynb")
jupytext(["--from", "ipynb", "--to", "py:percent", "test.ipynb"])
tmp_repo.git.add(".")
tmp_repo.index.commit("test")
# make a change to the notebook
nb = new_notebook(cells=[new_markdown_cell("Some other text")])
write(nb, "test.ipynb")
tmp_repo.git.add("test.ipynb")
# now a commit will fail, and keep failing until we add the new
# changes made to the existing output to the index ourselves
with pytest.raises(HookExecutionError, match="files were modified by this hook"):
tmp_repo.index.commit("fails")
with pytest.raises(HookExecutionError, match="git add test.py"):
tmp_repo.index.commit("fails again")
# once we add the changes, it will pass
tmp_repo.git.add("test.py")
tmp_repo.index.commit("succeeds")
assert "test.ipynb" in tmp_repo.tree()
assert "test.py" in tmp_repo.tree()
# Updating the .py file is possible
nb = new_notebook(cells=[new_markdown_cell("Some updated text")])
write(nb, "test.py", fmt="py:percent")
tmp_repo.index.commit("update py version")
# But it won't change the ipynb file (if you want that, use the --sync mode)
nb = read("test.ipynb")
compare_cells(nb.cells, [new_markdown_cell("Some other text")], compare_ids=False)
================================================
FILE: tests/external/pre_commit/test_pre_commit_1_sync.py
================================================
import shutil
import pytest
from git.exc import HookExecutionError
from nbformat.v4.nbbase import new_markdown_cell
from pre_commit.main import main as pre_commit
from jupytext import read, write
from jupytext.cli import jupytext
def test_pre_commit_hook_sync(
tmpdir,
cwd_tmpdir,
tmp_repo,
jupytext_repo_root,
jupytext_repo_rev,
python_notebook,
):
pre_commit_config_yaml = f"""
repos:
- repo: {jupytext_repo_root}
rev: {jupytext_repo_rev}
hooks:
- id: jupytext
args: [--sync]
"""
tmpdir.join(".pre-commit-config.yaml").write(pre_commit_config_yaml)
tmp_repo.git.add(".pre-commit-config.yaml")
pre_commit(["install", "--install-hooks", "-f"])
# write a test notebook and sync it to py:percent
nb = python_notebook
write(nb, "test.ipynb")
jupytext(["--set-formats", "ipynb,py:percent", "test.ipynb"])
# try to commit it, should fail because the py version hasn't been added
tmp_repo.git.add("test.ipynb")
with pytest.raises(
HookExecutionError,
match="git add test.py",
):
tmp_repo.index.commit("failing")
# add the py file, now the commit will succeed
tmp_repo.git.add("test.py")
tmp_repo.index.commit("passing")
assert "test.ipynb" in tmp_repo.tree()
assert "test.py" in tmp_repo.tree()
# modify the ipynb file
nb = read("test.ipynb")
nb.cells.append(new_markdown_cell("A new cell"))
write(nb, "test.ipynb")
tmp_repo.git.add("test.ipynb")
# We try to commit one more time, this updates the py file
with pytest.raises(
HookExecutionError,
match="files were modified by this hook",
):
tmp_repo.index.commit("failing")
# the text file has been updated
assert "A new cell" in tmpdir.join("test.py").read()
# trying to commit should fail again because we forgot to add the .py version
with pytest.raises(HookExecutionError, match="git add test.py"):
tmp_repo.index.commit("still failing")
nb = read("test.ipynb")
assert len(nb.cells) == 2
# add the text file, now the commit will succeed
tmp_repo.git.add("test.py")
tmp_repo.index.commit("passing")
# modify the .py file
nb.cells.append(new_markdown_cell("A third cell"))
write(nb, "test.py", fmt="py:percent")
tmp_repo.git.add("test.py")
# the pre-commit hook will update the .ipynb file
with pytest.raises(HookExecutionError, match="git add test.ipynb"):
tmp_repo.index.commit("failing")
tmp_repo.git.add("test.ipynb")
tmp_repo.index.commit("passing")
nb = read("test.ipynb")
assert len(nb.cells) == 3
# finally we move the paired notebook to a subfolder
tmpdir.mkdir("subfolder")
shutil.move("test.py", "subfolder")
shutil.move("test.ipynb", "subfolder")
# adding both files works on the first commit as notebooks are in sync
tmp_repo.git.add("subfolder/test.ipynb")
tmp_repo.git.add("subfolder/test.py")
tmp_repo.index.commit("passing")
# and we don't get any error or message when we run 'pre-commit run --all'
status = pre_commit(["run", "--all"])
assert status == 0
================================================
FILE: tests/external/pre_commit/test_pre_commit_1_sync_with_config.py
================================================
import pytest
from git.exc import HookExecutionError
from nbformat.v4.nbbase import new_markdown_cell
from pre_commit.main import main as pre_commit
from jupytext import TextFileContentsManager, read
def test_pre_commit_hook_sync_with_config(
tmpdir,
cwd_tmpdir,
tmp_repo,
jupytext_repo_root,
jupytext_repo_rev,
python_notebook,
):
pre_commit_config_yaml = f"""
repos:
- repo: {jupytext_repo_root}
rev: {jupytext_repo_rev}
hooks:
- id: jupytext
args: [--sync]
"""
tmpdir.join(".pre-commit-config.yaml").write(pre_commit_config_yaml)
tmp_repo.git.add(".pre-commit-config.yaml")
pre_commit(["install", "--install-hooks", "-f"])
tmpdir.join("jupytext.toml").write('formats = "ipynb,py:percent"\n')
# create a test notebook and save it in Jupyter
nb = python_notebook
cm = TextFileContentsManager()
cm.root_dir = str(tmpdir)
cm.save(dict(type="notebook", content=nb), "test.ipynb")
# Assert that "text_representation" is in the Jupytext metadata #900
assert "text_representation" in tmpdir.join("test.py").read()
# But not in the ipynb notebook
assert "text_representation" not in tmpdir.join("test.ipynb").read()
# try to commit it, should fail as the py version hasn't been added
tmp_repo.git.add("test.ipynb")
with pytest.raises(
HookExecutionError,
match="git add test.py",
):
tmp_repo.index.commit("failing")
# add the py file, now the commit will succeed
tmp_repo.git.add("test.py")
tmp_repo.index.commit("passing")
assert "test.ipynb" in tmp_repo.tree()
assert "test.py" in tmp_repo.tree()
# The text representation metadata is still in the py file
assert "text_representation" in tmpdir.join("test.py").read()
# But not in the ipynb notebook
assert "text_representation" not in tmpdir.join("test.ipynb").read()
# modify the ipynb file in Jupyter
# Reload the notebook
nb = cm.get("test.ipynb")["content"]
nb.cells.append(new_markdown_cell("A new cell"))
cm.save(dict(type="notebook", content=nb), "test.ipynb")
# The text representation metadata is in the py file
assert "text_representation" in tmpdir.join("test.py").read()
# But not in the ipynb notebook
assert "text_representation" not in tmpdir.join("test.ipynb").read()
# the text file has been updated (and the ipynb file as well)
assert "A new cell" in tmpdir.join("test.py").read()
nb = read("test.ipynb")
assert len(nb.cells) == 2
# add both files, the commit will succeed
tmp_repo.git.add("test.ipynb")
tmp_repo.git.add("test.py")
tmp_repo.index.commit("passing")
================================================
FILE: tests/external/pre_commit/test_pre_commit_1_sync_with_no_config.py
================================================
from copy import deepcopy
import pytest
from git.exc import HookExecutionError
from nbformat.v4.nbbase import new_markdown_cell
from pre_commit.main import main as pre_commit
import jupytext
from jupytext import TextFileContentsManager
from jupytext.compare import compare_notebooks
def test_pre_commit_hook_sync_with_no_config(
tmpdir,
cwd_tmpdir,
tmp_repo,
jupytext_repo_root,
jupytext_repo_rev,
notebook_with_outputs,
):
"""In this test we reproduce the setting from https://github.com/mwouts/jupytext/issues/967"""
pre_commit_config_yaml = f"""
repos:
- repo: {jupytext_repo_root}
rev: {jupytext_repo_rev}
hooks:
- id: jupytext
args: [
'--sync',
'--set-formats',
'ipynb,py:percent',
'--show-changes',
'--'
]
"""
# Save a sample notebook with outputs in Jupyter
nb = deepcopy(notebook_with_outputs)
(tmpdir / "notebooks").mkdir()
cm = TextFileContentsManager()
cm.root_dir = str(tmpdir)
cm.save(dict(type="notebook", content=nb), "nb.ipynb")
# Add it to git
tmp_repo.git.add("nb.ipynb")
tmp_repo.index.commit("Notebook with outputs")
# Configure the pre-commit hook
tmpdir.join(".pre-commit-config.yaml").write(pre_commit_config_yaml)
tmp_repo.git.add(".pre-commit-config.yaml")
pre_commit(["install", "--install-hooks", "-f"])
# Modify and save the notebook
nb.cells.append(new_markdown_cell("New markdown cell"))
cm.save(dict(type="notebook", content=nb), "nb.ipynb")
# No .py file at the moment
assert not (tmpdir / "nb.py").exists()
# try to commit it, should fail as the py version hasn't been added
tmp_repo.git.add("nb.ipynb")
with pytest.raises(
HookExecutionError,
match="git add nb.py",
):
tmp_repo.index.commit("failing")
# Now the .py file is present
assert "New markdown cell" in tmpdir.join("nb.py").read()
# add the ipynb and the py file, now the commit will succeed
tmp_repo.git.add("nb.ipynb")
tmp_repo.git.add("nb.py")
tmp_repo.index.commit("passing")
assert "nb.ipynb" in tmp_repo.tree()
assert "nb.py" in tmp_repo.tree()
# The notebook on disk is the same as the original, except for the new cell added
nb = jupytext.read(tmpdir / "nb.ipynb")
extra_cell = nb.cells.pop()
assert extra_cell.cell_type == "markdown"
assert extra_cell.source == "New markdown cell"
compare_notebooks(
nb,
notebook_with_outputs,
compare_ids=True,
compare_outputs=True,
)
================================================
FILE: tests/external/pre_commit/test_pre_commit_2_sync_nbstripout.py
================================================
import pytest
from git.exc import HookExecutionError
from pre_commit.main import main as pre_commit
from jupytext import read, write
from jupytext.cli import jupytext
def test_pre_commit_hook_sync_nbstripout(
tmpdir,
cwd_tmpdir,
tmp_repo,
jupytext_repo_root,
jupytext_repo_rev,
notebook_with_outputs,
):
"""Here we sync the ipynb notebook with a Markdown file and also apply nbstripout."""
pre_commit_config_yaml = f"""
repos:
- repo: {jupytext_repo_root}
rev: {jupytext_repo_rev}
hooks:
- id: jupytext
args: [--sync]
- repo: https://github.com/kynan/nbstripout
rev: 0.5.0
hooks:
- id: nbstripout
"""
tmpdir.join(".pre-commit-config.yaml").write(pre_commit_config_yaml)
tmp_repo.git.add(".pre-commit-config.yaml")
pre_commit(["install", "--install-hooks", "-f"])
# write a test notebook
write(notebook_with_outputs, "test.ipynb")
# We pair the notebook to a md file
jupytext(["--set-formats", "ipynb,md", "test.ipynb"])
# try to commit it, should fail because
# 1. the md version hasn't been added
# 2. the notebook has outputs
tmp_repo.git.add("test.ipynb")
with pytest.raises(
HookExecutionError,
match="files were modified by this hook",
):
tmp_repo.index.commit("failing")
# Add the two files
tmp_repo.git.add("test.ipynb")
tmp_repo.git.add("test.md")
# now the commit will succeed
tmp_repo.index.commit("passing")
assert "test.ipynb" in tmp_repo.tree()
assert "test.md" in tmp_repo.tree()
# the ipynb file has no outputs on disk
nb = read("test.ipynb")
assert not nb.cells[0].outputs
================================================
FILE: tests/external/pre_commit/test_pre_commit_3_sync_black_nbstripout.py
================================================
import pytest
from git.exc import HookExecutionError
from pre_commit.main import main as pre_commit
from jupytext import read, write
import sys
@pytest.mark.skipif(sys.version_info >= (3, 14), reason="this test fails on Python 3.14")
def test_pre_commit_hook_sync_black_nbstripout(
tmpdir,
cwd_tmpdir,
tmp_repo,
jupytext_repo_root,
jupytext_repo_rev,
notebook_with_outputs,
):
"""Here we sync the ipynb notebook with a py:percent file and also apply black and nbstripout."""
pre_commit_config_yaml = f"""
repos:
- repo: {jupytext_repo_root}
rev: {jupytext_repo_rev}
hooks:
- id: jupytext
args: [--sync, --pipe, black]
additional_dependencies:
- black==22.3.0 # Matches hook
- repo: https://github.com/psf/black
rev: 22.3.0
hooks:
- id: black
- repo: https://github.com/kynan/nbstripout
rev: 0.5.0
hooks:
- id: nbstripout
"""
tmpdir.join(".pre-commit-config.yaml").write(pre_commit_config_yaml)
tmp_repo.git.add(".pre-commit-config.yaml")
pre_commit(["install", "--install-hooks", "-f"])
tmpdir.join("jupytext.toml").write('formats = "ipynb,py:percent"')
tmp_repo.git.add("jupytext.toml")
tmp_repo.index.commit("pair notebooks")
# write a test notebook
write(notebook_with_outputs, "test.ipynb")
# try to commit it, should fail because
# 1. the py version hasn't been added
# 2. the first cell is '1+1' which is not black compliant
# 3. the notebook has outputs
tmp_repo.git.add("test.ipynb")
with pytest.raises(
HookExecutionError,
match="files were modified by this hook",
):
tmp_repo.index.commit("failing")
# Add the two files
tmp_repo.git.add("test.ipynb")
tmp_repo.git.add("test.py")
# now the commit will succeed
tmp_repo.index.commit("passing")
assert "test.ipynb" in tmp_repo.tree()
assert "test.py" in tmp_repo.tree()
# the first cell was reformatted
nb = read("test.ipynb")
assert nb.cells[0].source == "1 + 1"
# the ipynb file has no outputs
assert not nb.cells[0].outputs
================================================
FILE: tests/external/pre_commit/test_pre_commit_4_sync_execute.py
================================================
import pytest
from git.exc import HookExecutionError
from nbformat.v4.nbbase import new_code_cell
from pre_commit.main import main as pre_commit
from jupytext import read, write
@pytest.mark.requires_user_kernel_python3
def test_pre_commit_hook_sync_execute(
tmpdir,
cwd_tmpdir,
tmp_repo,
jupytext_repo_root,
jupytext_repo_rev,
notebook_with_outputs,
):
"""Here we sync the ipynb notebook with a py:percent file and execute it (this is probably not a very
recommendable hook!)"""
pre_commit_config_yaml = f"""
repos:
- repo: {jupytext_repo_root}
rev: {jupytext_repo_rev}
hooks:
- id: jupytext
args: [--sync, --execute, --show-changes]
additional_dependencies:
- nbconvert
"""
tmpdir.join(".pre-commit-config.yaml").write(pre_commit_config_yaml)
tmp_repo.git.add(".pre-commit-config.yaml")
pre_commit(["install", "--install-hooks", "-f"])
# simple notebook with kernel 'user_kernel_python3'
nb = notebook_with_outputs
nb.cells = [new_code_cell("3+4")]
# pair it to a py file and write it to disk
nb.metadata["jupytext"] = {"formats": "ipynb,py:percent"}
write(nb, "test.ipynb")
# try to commit it, should fail because
# 1. the py version hasn't been added
# 2. the outputs are missing
tmp_repo.git.add("test.ipynb")
with pytest.raises(
HookExecutionError,
match="files were modified by this hook",
):
tmp_repo.index.commit("failing")
# Add the two files
tmp_repo.git.add("test.ipynb")
tmp_repo.git.add("test.py")
# now the commit will succeed
tmp_repo.index.commit("passing")
assert "test.ipynb" in tmp_repo.tree()
assert "test.py" in tmp_repo.tree()
# the first cell has the expected output
nb = read("test.ipynb")
assert nb.cells[0].outputs[0]["data"]["text/plain"] == "7"
================================================
FILE: tests/external/pre_commit/test_pre_commit_5_reformat_markdown.py
================================================
import pytest
from git.exc import HookExecutionError
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
from pre_commit.main import main as pre_commit
from jupytext import read, write
@pytest.mark.requires_pandoc
def test_pre_commit_hook_sync_reformat_code_and_markdown(
tmpdir,
cwd_tmpdir,
tmp_repo,
jupytext_repo_root,
jupytext_repo_rev,
notebook_with_outputs,
):
"""Here we sync the ipynb notebook with a py:percent file and also apply black and pandoc to reformat both
code and markdown cells.
"""
pre_commit_config_yaml = f"""
repos:
- repo: {jupytext_repo_root}
rev: {jupytext_repo_rev}
hooks:
- id: jupytext
args: [--sync, --pipe-fmt, ipynb, --pipe, 'pandoc --from ipynb --to ipynb --markdown-headings=atx', --show-changes]
- id: jupytext
args: [--sync, --pipe, black, --show-changes]
additional_dependencies:
- black==22.3.0 # Matches black hook below
- repo: https://github.com/psf/black
rev: 22.3.0
hooks:
- id: black
"""
tmpdir.join(".pre-commit-config.yaml").write(pre_commit_config_yaml)
tmp_repo.git.add(".pre-commit-config.yaml")
pre_commit(["install", "--install-hooks", "-f"])
tmpdir.join("jupytext.toml").write('formats = "ipynb,py:percent"')
tmp_repo.git.add("jupytext.toml")
tmp_repo.index.commit("pair notebooks")
# write a test notebook
notebook = new_notebook(
cells=[
new_code_cell("1+1"),
new_markdown_cell(
"""This is a complex markdown cell
# With a h1 header
## And a h2 header
| And | A | Table |
| --------- | ---| ----- |
| 0 | 1 | 2 |
!!!WARNING!!! This hook does not seem compatible with
explicit paragraph breaks (two spaces at the end of a line).
And a VERY long line.
""".replace("VERY ", "very " * 51)
),
],
metadata=notebook_with_outputs.metadata,
)
write(notebook, "test.ipynb")
# try to commit it, should fail because
# 1. the py version hasn't been added
# 2. the first cell is '1+1' which is not black compliant
# 3. the second cell needs to be wrapped
tmp_repo.git.add("test.ipynb")
with pytest.raises(
HookExecutionError,
match="files were modified by this hook",
):
tmp_repo.index.commit("failing")
# Add the two files
tmp_repo.git.add("test.ipynb")
tmp_repo.git.add("test.py")
# now the commit will succeed
tmp_repo.index.commit("passing")
assert "test.ipynb" in tmp_repo.tree()
assert "test.py" in tmp_repo.tree()
# both the code and the markdown cells were reformatted
nb = read("test.ipynb")
assert nb.cells[0].source == "1 + 1"
print(nb.cells[1].source)
assert (
nb.cells[1].source
== """This is a complex markdown cell
# With a h1 header
## And a h2 header
| And | A | Table |
|-----|-----|-------|
| 0 | 1 | 2 |
!!!WARNING!!! This hook does not seem compatible with explicit paragraph
breaks (two spaces at the end of a line).
And a very very very very very very very very very very very very very
very very very very very very very very very very very very very very
very very very very very very very very very very very very very very
very very very very very very very very very very long line."""
)
================================================
FILE: tests/external/pre_commit/test_pre_commit_mode.py
================================================
import os
import time
import pytest
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
from jupytext import read, write
from jupytext.cli import get_timestamp, git_timestamp, is_untracked, jupytext
def test_is_untracked(tmpdir, cwd_tmpdir, tmp_repo):
# make a test file
file = "test.txt"
tmpdir.join(file).write("test file\n")
# untracked
assert is_untracked(file)
# added, not committed
tmp_repo.git.add(file)
assert not is_untracked(file)
# committed
tmp_repo.index.commit("test")
assert not is_untracked(file)
# changed
tmpdir.join(file).write("modified file\n")
assert is_untracked(file)
# added, not committed
tmp_repo.git.add(file)
assert not is_untracked(file)
def test_ignore_unmatched_ignores(tmpdir, cwd_tmpdir):
# Unmatched file
file = "test.txt"
tmpdir.join(file).write("Hello\n")
# Run jupytext
status = jupytext(["--from", "ipynb", "--to", "py:percent", "--pre-commit-mode", file])
assert status == 0
assert not tmpdir.join("test.py").exists()
def test_alert_untracked_alerts(tmpdir, cwd_tmpdir, tmp_repo, capsys):
file = "test.py"
tmpdir.join(file).write("print('hello')\n")
# Run jupytext
status = jupytext(["--from", ".py", "--to", "ipynb", "--pre-commit-mode", file])
assert status != 0
assert tmpdir.join("test.ipynb").exists()
out = capsys.readouterr()
assert "git add test.ipynb" in out.out
def test_alert_untracked_alerts_when_using_sync(tmpdir, cwd_tmpdir, tmp_repo, capsys):
tmpdir.join("test.py").write("print('hello')\n")
tmp_repo.git.add("test.py")
tmpdir.join("jupytext.toml").write('formats = "ipynb,py"')
# Run jupytext
status = jupytext(["--sync", "--pre-commit-mode", "test.py"])
assert status != 0
assert tmpdir.join("test.ipynb").exists()
out = capsys.readouterr()
assert "git add test.ipynb" in out.out
def test_alert_untracked_alerts_for_modified(tmpdir, cwd_tmpdir, tmp_repo, capsys):
# write test notebook
nb = new_notebook(cells=[new_markdown_cell("A short notebook")])
write(nb, "test.ipynb")
# write existing output
tmpdir.join("test.py").write("# Hello")
# track output file
tmp_repo.git.add("test.py")
# Run jupytext
status = jupytext(["--from", "ipynb", "--to", "py:percent", "--pre-commit-mode", "test.ipynb"])
assert status == 1
out = capsys.readouterr()
assert "git add test.py" in out.out
def test_alert_inconsistent_versions(tmpdir, cwd_tmpdir, tmp_repo, capsys):
"""Jupytext refuses to sync two inconsistent notebooks"""
write(new_notebook(cells=[new_markdown_cell("A short py notebook")]), "test.py")
write(
new_notebook(
cells=[new_markdown_cell("Another ipynb notebook")],
metadata={"jupytext": {"formats": "ipynb,py"}},
),
"test.ipynb",
)
# Add them both
tmp_repo.git.add("test.py")
tmp_repo.git.add("test.ipynb")
# Run jupytext
status = jupytext(["--sync", "--pre-commit-mode", "test.ipynb"])
# The diff should be visible
assert status == 1
out = capsys.readouterr()
assert (
"""--- test.py
+++ test.ipynb"""
in out.err
)
assert """-# A short py notebook
+# Another ipynb notebook
"""
assert "Error: test.ipynb and test.py are inconsistent" in out.err
assert "git reset test.py && git checkout -- test.py" in out.err
assert "git reset test.ipynb && git checkout -- test.ipynb" in out.err
def test_pre_commit_local_config(tmpdir, cwd_tmpdir, tmp_repo, python_notebook, capsys):
tmpdir.join("jupytext.toml").write_text(
"""notebook_metadata_filter = "-all"
cell_metadata_filter = "-all"
formats = "ipynb,py:percent"
""",
encoding="utf-8",
)
write(python_notebook, str(tmpdir.join("test.ipynb")))
# create the paired file
jupytext(["--sync", "test.ipynb"])
print("--------- test.ipynb ---------")
print(tmpdir.join("test.ipynb").read_text("utf-8"))
print("--------- test.py ---------")
print(tmpdir.join("test.py").read_text("utf-8"))
tmp_repo.git.add(".")
capsys.readouterr()
exit_code = jupytext(["--pre-commit-mode", "--sync", "test.ipynb", "--show-changes"])
out, err = capsys.readouterr()
assert not err, err
assert "updating test" not in out.lower(), out
assert exit_code == 0, out
def test_git_timestamp(tmpdir, cwd_tmpdir, tmp_repo):
# No commit yet => return the file timestamp
tmpdir.join("file_1").write("")
assert git_timestamp("file_1") == get_timestamp("file_1")
# Staged files are always considered more recent than committed files, i.e timestamp==inf
time.sleep(0.1)
tmpdir.join("file_2").write("")
tmp_repo.git.add(".")
assert get_timestamp("file_1") < get_timestamp("file_2")
assert git_timestamp("file_1") == git_timestamp("file_2") == float("inf")
tmp_repo.index.commit("Add file_1 and file_2")
assert get_timestamp("file_1") < get_timestamp("file_2")
assert git_timestamp("file_1") == git_timestamp("file_2") < float("inf")
assert git_timestamp("file_1") < get_timestamp("file_1") + 1 < git_timestamp("file_1") + 2
# Git timestamps have a resolution of 1 sec, so if we want to see
# different git timestamps between file_1 and file_2 we need this:
time.sleep(1.2)
# Here we just touch the file (content unchanged). The git timestamp is not modified
tmpdir.join("file_1").write("")
assert get_timestamp("file_1") > get_timestamp("file_2")
assert git_timestamp("file_1") == git_timestamp("file_2") < float("inf")
# When we modify the file then its "git_timestamp" becomes inf again
tmpdir.join("file_1").write("modified")
assert get_timestamp("file_1") > get_timestamp("file_2")
assert float("inf") == git_timestamp("file_1") > git_timestamp("file_2")
tmp_repo.git.add(".")
assert float("inf") == git_timestamp("file_1") > git_timestamp("file_2")
# When the file is committed its timestamp is the commit timestamp
tmp_repo.index.commit("Update file_1")
assert float("inf") > git_timestamp("file_1") > git_timestamp("file_2")
# If a file is not in the git repo then we return its timestamp
tmpdir.join("file_3").write("")
assert git_timestamp("file_3") == get_timestamp("file_3")
@pytest.mark.parametrize("commit_order", [["test.py", "test.ipynb"], ["test.ipynb", "test.py"]])
@pytest.mark.parametrize("sync_file", ["test.py", "test.ipynb"])
def test_sync_pre_commit_mode_respects_commit_order_780(
tmpdir,
cwd_tmpdir,
tmp_repo,
python_notebook,
commit_order,
sync_file,
):
file_1, file_2 = commit_order
nb = python_notebook
nb.metadata["jupytext"] = {"formats": "ipynb,py:percent"}
nb.cells = [new_code_cell("1 + 1")]
write(nb, file_1)
tmp_repo.git.add(file_1)
tmp_repo.index.commit(file_1)
# This needs to >1 sec because commit timestamps have a one-second resolution
time.sleep(1.2)
nb.cells = [new_code_cell("2 + 2")]
write(nb, file_2)
tmp_repo.git.add(file_2)
tmp_repo.index.commit(file_2)
# Invert file timestamps
ts_1 = os.stat(file_1).st_mtime
ts_2 = os.stat(file_2).st_mtime
os.utime(file_1, (ts_2, ts_2))
os.utime(file_2, (ts_1, ts_1))
jupytext(["--sync", "--pre-commit-mode", sync_file])
for file in commit_order:
nb = read(file)
assert nb.cells[0].source == "2 + 2", file
@pytest.mark.requires_user_kernel_python3
def test_skip_execution(tmpdir, cwd_tmpdir, tmp_repo, python_notebook, capsys):
write(
new_notebook(cells=[new_code_cell("1 + 1")], metadata=python_notebook.metadata),
"test.ipynb",
)
tmp_repo.index.add("test.ipynb")
jupytext(["--execute", "--pre-commit-mode", "test.ipynb"])
captured = capsys.readouterr()
assert "Executing notebook" in captured.out
nb = read("test.ipynb")
assert nb.cells[0].execution_count == 1
jupytext(["--execute", "--pre-commit-mode", "test.ipynb"])
captured = capsys.readouterr()
assert "skipped" in captured.out
================================================
FILE: tests/external/pre_commit/test_pre_commit_scripts.py
================================================
import os
import stat
import unittest.mock as mock
import pytest
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
from jupytext import read, write
from jupytext.cli import jupytext, system
from jupytext.compare import compare_cells, compare_notebooks
def git_in_tmpdir(tmpdir):
"""Return a function that will execute git instruction in the desired directory"""
def git(*args):
out = system("git", *args, cwd=str(tmpdir))
print(out)
return out
git("init", "--initial-branch", "main")
git("status")
git("config", "user.name", "jupytext-test-cli")
git("config", "user.email", "jupytext@tests.com")
return git
def system_in_tmpdir(tmpdir):
"""Return a function that will execute system commands in the desired directory"""
def system_(*args):
return system(*args, cwd=str(tmpdir))
return system_
def test_pre_commit_hook(tmpdir):
tmp_ipynb = str(tmpdir.join("nb with spaces.ipynb"))
tmp_py = str(tmpdir.join("nb with spaces.py"))
nb = new_notebook(cells=[])
git = git_in_tmpdir(tmpdir)
hook = str(tmpdir.join(".git/hooks/pre-commit"))
with open(hook, "w") as fp:
fp.write("#!/bin/sh\njupytext --to py:percent --pre-commit\n")
st = os.stat(hook)
os.chmod(hook, st.st_mode | stat.S_IEXEC)
write(nb, tmp_ipynb)
assert os.path.isfile(tmp_ipynb)
assert not os.path.isfile(tmp_py)
git("add", "nb with spaces.ipynb")
git("status")
git("commit", "-m", "created")
git("status")
assert "nb with spaces.py" in git("ls-tree", "-r", "main", "--name-only")
assert os.path.isfile(tmp_py)
def test_sync_with_pre_commit_hook(tmpdir):
# Init git and create a pre-commit hook
git = git_in_tmpdir(tmpdir)
hook = str(tmpdir.join(".git/hooks/pre-commit"))
with open(hook, "w") as fp:
fp.write("#!/bin/sh\njupytext --sync --pre-commit\n")
st = os.stat(hook)
os.chmod(hook, st.st_mode | stat.S_IEXEC)
# Create a notebook that is not paired
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_md = str(tmpdir.join("notebook.md"))
nb = new_notebook(cells=[new_markdown_cell("A short notebook")])
write(nb, tmp_ipynb)
assert os.path.isfile(tmp_ipynb)
assert not os.path.isfile(tmp_md)
git("add", "notebook.ipynb")
git("status")
git("commit", "-m", "created")
git("status")
assert "notebook.ipynb" in git("ls-tree", "-r", "main", "--name-only")
assert "notebook.md" not in git("ls-tree", "-r", "main", "--name-only")
assert os.path.isfile(tmp_ipynb)
assert not os.path.exists(tmp_md)
# Pair the notebook
jupytext(["--set-formats", "ipynb,md", tmp_ipynb])
# Remove the md file (it will be regenerated by the pre-commit hook)
os.remove(tmp_md)
# Commit the ipynb file
git("add", "notebook.ipynb")
git("status")
git("commit", "-m", "paired")
git("status")
# The pre-commit script should have created and committed the md file
assert "notebook.ipynb" in git("ls-tree", "-r", "main", "--name-only")
assert "notebook.md" in git("ls-tree", "-r", "main", "--name-only")
assert os.path.isfile(tmp_md)
nb_md = read(tmp_md)
compare_notebooks(nb_md, nb)
# Edit the md file
with open(tmp_md) as fp:
md_text = fp.read()
with open(tmp_md, "w") as fp:
fp.write(md_text.replace("A short notebook", "Notebook was edited"))
# commit the md file
git("add", "notebook.md")
git("status")
git("commit", "-m", "edited md")
git("status")
# The pre-commit script should have sync and committed the ipynb file
assert "notebook.ipynb" in git("ls-tree", "-r", "main", "--name-only")
assert "notebook.md" in git("ls-tree", "-r", "main", "--name-only")
nb = read(tmp_ipynb)
compare_cells(nb.cells, [new_markdown_cell("Notebook was edited")], compare_ids=False)
# create and commit a jpg file
tmp_jpg = str(tmpdir.join("image.jpg"))
with open(tmp_jpg, "wb") as fp:
fp.write(b"")
git("add", "image.jpg")
git("commit", "-m", "added image")
def test_pre_commit_hook_in_subfolder(tmpdir):
tmp_ipynb = str(tmpdir.join("nb with spaces.ipynb"))
tmp_py = str(tmpdir.join("python", "nb with spaces.py"))
nb = new_notebook(cells=[])
git = git_in_tmpdir(tmpdir)
hook = str(tmpdir.join(".git/hooks/pre-commit"))
with open(hook, "w") as fp:
fp.write("#!/bin/sh\njupytext --from ipynb --to python//py:percent --pre-commit\n")
st = os.stat(hook)
os.chmod(hook, st.st_mode | stat.S_IEXEC)
write(nb, tmp_ipynb)
assert os.path.isfile(tmp_ipynb)
assert not os.path.isfile(tmp_py)
git("add", "nb with spaces.ipynb")
git("status")
git("commit", "-m", "created")
git("status")
assert "nb with spaces.py" in git("ls-tree", "-r", "main", "--name-only")
assert os.path.isfile(tmp_py)
def test_pre_commit_hook_py_to_ipynb_and_md(tmpdir):
tmp_ipynb = str(tmpdir.join("nb with spaces.ipynb"))
tmp_py = str(tmpdir.join("nb with spaces.py"))
tmp_md = str(tmpdir.join("nb with spaces.md"))
nb = new_notebook(cells=[])
git = git_in_tmpdir(tmpdir)
hook = str(tmpdir.join(".git/hooks/pre-commit"))
with open(hook, "w") as fp:
fp.write(
"#!/bin/sh\njupytext --from py:percent --to ipynb --pre-commit\njupytext --from py:percent --to md --pre-commit\n"
)
st = os.stat(hook)
os.chmod(hook, st.st_mode | stat.S_IEXEC)
write(nb, tmp_py)
assert os.path.isfile(tmp_py)
assert not os.path.isfile(tmp_ipynb)
assert not os.path.isfile(tmp_md)
git("add", "nb with spaces.py")
git("status")
git("commit", "-m", "created")
git("status")
assert "nb with spaces.ipynb" in git("ls-tree", "-r", "main", "--name-only")
assert "nb with spaces.md" in git("ls-tree", "-r", "main", "--name-only")
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_md)
@pytest.mark.requires_black
@pytest.mark.requires_flake8
def test_pre_commit_hook_sync_black_flake8(tmpdir, python_notebook):
# Load real notebook metadata to get the 'auto' extension in --pipe-fmt to work
metadata = python_notebook.metadata
git = git_in_tmpdir(tmpdir)
hook = str(tmpdir.join(".git/hooks/pre-commit"))
with open(hook, "w") as fp:
fp.write(
"#!/bin/sh\n"
"# Pair ipynb notebooks to a python file, reformat content with black, and run flake8\n"
"# Note: this hook only acts on ipynb files. When pulling, run 'jupytext --sync' to "
"update the ipynb file.\n"
"jupytext --pre-commit --from ipynb --set-formats ipynb,py --pipe black --check flake8\n"
)
st = os.stat(hook)
os.chmod(hook, st.st_mode | stat.S_IEXEC)
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_py = str(tmpdir.join("notebook.py"))
nb = new_notebook(cells=[new_code_cell(source="1+ 1")], metadata=metadata)
write(nb, tmp_ipynb)
git("add", "notebook.ipynb")
git("status")
git("commit", "-m", "created")
git("status")
assert os.path.isfile(tmp_py)
assert os.path.isfile(tmp_ipynb)
with open(tmp_py) as fp:
assert fp.read().splitlines()[-1] == "1 + 1"
nb = new_notebook(
cells=[new_code_cell(source='"""trailing \nwhitespace""" ')],
metadata=metadata,
)
write(nb, tmp_ipynb)
git("add", "notebook.ipynb")
git("status")
with open(tmp_py) as fp:
assert fp.read().splitlines()[-1] == "1 + 1"
@pytest.mark.requires_flake8
def test_pre_commit_hook_sync_flake8(tmpdir, python_notebook):
"""This test was extracted from test_pre_commit_hook_sync_black_flake8 to make sure that the
pre-commit stops the commit when flake8 fails"""
metadata = python_notebook.metadata
git = git_in_tmpdir(tmpdir)
hook = str(tmpdir.join(".git/hooks/pre-commit"))
with open(hook, "w") as fp:
fp.write(
"#!/bin/sh\n"
"# Pair ipynb notebooks to a python file, and run flake8\n"
"# Note: this hook only acts on ipynb files. When pulling, run 'jupytext --sync' to "
"update the ipynb file.\n"
"jupytext --pre-commit --from ipynb --set-formats ipynb,py --check flake8\n"
)
st = os.stat(hook)
os.chmod(hook, st.st_mode | stat.S_IEXEC)
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
nb = new_notebook(
cells=[new_code_cell(source='"""trailing \nwhitespace""" ')],
metadata=metadata,
)
write(nb, tmp_ipynb)
git("add", "notebook.ipynb")
git("status")
with pytest.raises(SystemExit): # not flake8
git("commit", "-m", "created")
@pytest.mark.filterwarnings("ignore:The --pre-commit argument is deprecated")
def test_manual_call_of_pre_commit_hook(tmpdir):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_py = str(tmpdir.join("notebook.py"))
nb = new_notebook(cells=[])
os.chdir(str(tmpdir))
git = git_in_tmpdir(tmpdir)
def hook():
with mock.patch("jupytext.cli.system", system_in_tmpdir(tmpdir)):
jupytext(["--to", "py", "--pre-commit"])
write(nb, tmp_ipynb)
assert os.path.isfile(tmp_ipynb)
assert not os.path.isfile(tmp_py)
git("add", "notebook.ipynb")
git("status")
hook()
git("commit", "-m", "created")
git("status")
assert "notebook.py" in git("ls-tree", "-r", "main", "--name-only")
assert os.path.isfile(tmp_py)
def test_pre_commit_hook_with_subfolders_issue_506(tmpdir):
"""I have the following directory structure, where the nb/test.ipynb is paired with the py/test.py.
├── nb
│ └── test.ipynb
└── py
└── test.py
"""
nb_file = tmpdir.mkdir("nb").join("test.ipynb")
py_file = tmpdir.mkdir("py").join("test.py")
"""The notebook and Python file are paired with "jupytext": {"formats": "py//py,nb//ipynb"}.
(using jupytext --set-formats py//py,nb//ipynb nb/test.ipynb)"""
write(
new_notebook(
cells=[new_markdown_cell("A Markdown cell")],
metadata={"jupytext": {"formats": "py//py,nb//ipynb"}},
),
str(py_file),
)
"""This works fine when syncing with jupytext --sync nb/test.ipynb
but when syncing with jupytext --sync --pre-commit I get the following exception: (...)"""
git = git_in_tmpdir(tmpdir)
hook = str(tmpdir.join(".git/hooks/pre-commit"))
with open(hook, "w") as fp:
fp.write("#!/bin/sh\njupytext --sync --pre-commit\n")
st = os.stat(hook)
os.chmod(hook, st.st_mode | stat.S_IEXEC)
assert not os.path.isfile(str(nb_file))
git("add", "py/test.py")
git("status")
git("commit", "-m", "notebook created")
git("status")
assert os.path.isfile(str(nb_file))
assert read(str(nb_file)).cells[0].source == "A Markdown cell"
@pytest.mark.requires_pandoc
def test_wrap_markdown_cell(tmpdir):
"""Use a pre-commit hook to sync a notebook to a script paired in a tree, and reformat
the markdown cells using pandoc"""
tmpdir.join("jupytext.toml").write(
"""# By default, the notebooks in this repository are in the notebooks subfolder
# and they are paired to scripts in the script subfolder.
formats = "notebooks///ipynb,scripts///py:percent"
"""
)
git = git_in_tmpdir(tmpdir)
hook = str(tmpdir.join(".git/hooks/pre-commit"))
with open(hook, "w") as fp:
fp.write(
"#!/bin/sh\n"
"jupytext --pre-commit --sync --pipe-fmt ipynb --pipe \\\n"
" 'pandoc --from ipynb --to ipynb --markdown-headings=atx'\n"
)
st = os.stat(hook)
os.chmod(hook, st.st_mode | stat.S_IEXEC)
nb_file = tmpdir.mkdir("notebooks").mkdir("subfolder").join("wrap_markdown.ipynb")
long_text = "This is a " + ("very " * 24) + "long sentence."
nb = new_notebook(cells=[new_markdown_cell(long_text)])
write(nb, str(nb_file))
nb = read(str(nb_file))
assert nb.cells[0].source == long_text
git("add", str(nb_file))
git("commit", "-m", "'notebook with long cells'")
py_text = tmpdir.join("scripts").join("subfolder").join("wrap_markdown.py").read()
assert "This is a very very" in py_text
for line in py_text.splitlines():
assert len(line) <= 79
nb = read(nb_file, as_version=4)
text = nb.cells[0].source
assert len(text.splitlines()) >= 2
assert text != long_text
================================================
FILE: tests/external/round_trip/test_mirror_external.py
================================================
import pytest
from jupytext.compare import assert_conversion_same_as_mirror
"""---------------------------------------------------------------------------------
Part I: ipynb -> fmt -> ipynb
---------------------------------------------------------------------------------"""
@pytest.mark.requires_pandoc
def test_ipynb_to_pandoc(ipynb_to_pandoc, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_to_pandoc, "md:pandoc", "ipynb_to_pandoc")
@pytest.mark.requires_quarto
def test_ipynb_to_quarto(
ipynb_to_quarto,
no_jupytext_version_number,
):
assert_conversion_same_as_mirror(ipynb_to_quarto, "qmd", "ipynb_to_quarto")
@pytest.mark.requires_sphinx_gallery
def test_ipynb_to_python_sphinx(ipynb_to_sphinx, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_to_sphinx, "py:sphinx", "ipynb_to_sphinx")
"""---------------------------------------------------------------------------------
Part II: text -> ipynb -> text
---------------------------------------------------------------------------------"""
def test_Rmd_to_ipynb(rmd_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(rmd_file, "ipynb", "Rmd_to_ipynb")
@pytest.mark.requires_sphinx_gallery
def test_sphinx_to_ipynb(sphinx_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(sphinx_file, "ipynb:sphinx", "sphinx_to_ipynb")
@pytest.mark.requires_sphinx_gallery
def test_sphinx_md_to_ipynb(sphinx_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(
sphinx_file,
{"extension": ".ipynb", "format_name": "sphinx", "rst2md": True},
"sphinx-rst2md_to_ipynb",
compare_notebook=True,
)
================================================
FILE: tests/external/rst2md/test_rst2md.py
================================================
import os
import pytest
from nbformat.v4.nbbase import new_markdown_cell, new_notebook
from jupytext import TextFileContentsManager, read, write
from jupytext.cli import jupytext
@pytest.mark.requires_sphinx_gallery
def test_rst2md(tmpdir, cwd_tmpdir):
tmp_py = "notebook.py"
tmp_ipynb = "notebook.ipynb"
# Write notebook in sphinx format
nb = new_notebook(
cells=[
new_markdown_cell("A short sphinx notebook"),
new_markdown_cell(":math:`1+1`"),
]
)
write(nb, tmp_py, fmt="py:sphinx")
jupytext(
[
tmp_py,
"--from",
"py:sphinx",
"--to",
"ipynb",
"--opt",
"rst2md=True",
"--opt",
"cell_metadata_filter=-all",
]
)
assert os.path.isfile(tmp_ipynb)
nb = read(tmp_ipynb)
assert nb.metadata["jupytext"]["cell_metadata_filter"] == "-all"
assert nb.metadata["jupytext"]["rst2md"] is False
# Was rst to md conversion effective?
assert nb.cells[2].source == "$1+1$"
@pytest.mark.requires_sphinx_gallery
def test_rst2md_option(tmpdir):
tmp_py = str(tmpdir.join("notebook.py"))
# Write notebook in sphinx format
nb = new_notebook(
cells=[
new_markdown_cell("A short sphinx notebook"),
new_markdown_cell(":math:`1+1`"),
]
)
write(nb, tmp_py, fmt="py:sphinx")
cm = TextFileContentsManager()
cm.sphinx_convert_rst2md = True
cm.root_dir = str(tmpdir)
nb2 = cm.get("notebook.py")["content"]
# Was rst to md conversion effective?
assert nb2.cells[2].source == "$1+1$"
assert nb2.metadata["jupytext"]["rst2md"] is False
================================================
FILE: tests/external/simple_external_notebooks/test_read_simple_pandoc.py
================================================
import pytest
from nbformat.v4.nbbase import new_markdown_cell, new_notebook
import jupytext
from jupytext.cli import jupytext as jupytext_cli
from jupytext.compare import compare, compare_notebooks
from jupytext.pandoc import PandocError
@pytest.mark.requires_pandoc
def test_pandoc_implicit(
cell_id,
markdown="""# Lorem ipsum
**Lorem ipsum** dolor sit amet, consectetur adipiscing elit. Nunc luctus
bibendum felis dictum sodales.
``` code
print("hello")
```
""",
):
nb = jupytext.reads(markdown, "md:pandoc")
markdown2 = jupytext.writes(nb, "md")
nb2 = jupytext.reads(markdown2, "md")
compare_notebooks(nb2, nb)
markdown3 = jupytext.writes(nb2, "md")
compare(markdown3, markdown2)
@pytest.mark.requires_pandoc
def test_pandoc_explicit(
markdown="""::: {#cell_id .cell .markdown}
# Lorem
**Lorem ipsum** dolor sit amet, consectetur adipiscing elit. Nunc luctus
bibendum felis dictum sodales.
:::""",
):
nb = jupytext.reads(markdown, "md")
markdown2 = jupytext.writes(nb, "md")
compare("\n".join(markdown2.splitlines()[12:]), markdown)
@pytest.mark.requires_pandoc
def test_pandoc_utf8_in_md(
markdown="""::: {#cell_id .cell .markdown}
# Utf-8 support
This is the greek letter $\\pi$: π
:::""",
):
nb = jupytext.reads(markdown, "md")
markdown2 = jupytext.writes(nb, "md")
compare("\n".join(markdown2.splitlines()[12:]), markdown)
@pytest.mark.requires_pandoc
def test_pandoc_utf8_in_nb(
nb=new_notebook(
cells=[
new_markdown_cell(
"""# Utf-8 support
This is the greek letter $\\pi$: π"""
)
]
),
):
markdown = jupytext.writes(nb, "md:pandoc")
nb2 = jupytext.reads(markdown, "md:pandoc")
nb2.metadata.pop("jupytext")
compare_notebooks(nb, nb2, "md:pandoc")
@pytest.mark.requires_no_pandoc
def test_meaningfull_error_when_pandoc_is_missing(tmpdir):
nb_file = tmpdir.join("notebook.ipynb")
jupytext.write(new_notebook(), str(nb_file))
with pytest.raises(PandocError, match="The Pandoc Markdown format requires 'pandoc>=2.7.2'"):
jupytext_cli([str(nb_file), "--to", "md:pandoc"])
================================================
FILE: tests/external/simple_external_notebooks/test_read_simple_quarto.py
================================================
import pytest
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
import jupytext
from jupytext.compare import compare, compare_notebooks
@pytest.mark.requires_quarto
def test_qmd_to_ipynb(
qmd="""Some text
```{python}
1 + 1
```
""",
nb=new_notebook(
cells=[
new_markdown_cell("Some text"),
new_code_cell("1 + 1"),
],
metadata={
"kernelspec": {
"display_name": "python_kernel",
"language": "python",
"name": "python_kernel",
}
},
),
):
nb2 = jupytext.reads(qmd, "qmd")
compare_notebooks(nb2, nb, fmt="qmd")
# after a round trip we do get a yaml header.
# here we remove it to make the comparison
qmd2 = jupytext.writes(nb, "qmd")
qmd2_without_header = qmd2.rsplit("---\n\n", 1)[1]
compare(qmd2_without_header, qmd)
================================================
FILE: tests/external/test_marimo.py
================================================
from jupytext.marimo import marimo_py_to_notebook, notebook_to_marimo_py, marimo_version
import pytest
from nbformat.v4.nbbase import new_notebook, new_code_cell
from jupytext.compare import compare, compare_notebooks
from jupytext.formats import guess_format
@pytest.fixture
def py_marimo() -> str:
return f"""import marimo
__generated_with = "{marimo_version()}"
app = marimo.App()
@app.cell
def _():
x = 1
return
if __name__ == "__main__":
app.run()"""
@pytest.fixture
def notebook():
return new_notebook(cells=[new_code_cell("x = 1")])
def test_guess_format(py_marimo):
assert guess_format(py_marimo, ".py") == ("marimo", {})
@pytest.mark.requires_marimo
def test_notebook_to_py_marimo(py_marimo, notebook):
actual = notebook_to_marimo_py(notebook)
compare(actual, py_marimo)
@pytest.mark.requires_marimo
def test_marimo_py_to_notebook(py_marimo, notebook):
actual = marimo_py_to_notebook(py_marimo)
compare_notebooks(actual, notebook)
================================================
FILE: tests/functional/cli/test_cli.py
================================================
import os
import sys
import time
import unittest.mock as mock
import warnings
from argparse import ArgumentTypeError
from io import StringIO
from shutil import copyfile
from subprocess import check_call
import nbformat
import pytest
from jupyter_client.kernelspec import find_kernel_specs, get_kernel_spec
from jupyter_server.utils import ensure_async
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
from jupytext import __version__, read, reads, write, writes
from jupytext.cli import jupytext, parse_jupytext_args, str2bool, system
from jupytext.compare import compare, compare_notebooks
from jupytext.formats import JupytextFormatError, long_form_one_format
from jupytext.myst import is_myst_available
from jupytext.paired_paths import InconsistentPath, paired_paths
from jupytext.pandoc import is_pandoc_available
def test_str2bool():
assert str2bool("d") is None
assert str2bool("TRUE") is True
assert str2bool("0") is False
with pytest.raises(ArgumentTypeError):
str2bool("UNEXPECTED")
def test_cli_single_file(ipynb_py_R_jl_file):
assert parse_jupytext_args([ipynb_py_R_jl_file] + ["--to", "py"]).notebooks == [ipynb_py_R_jl_file]
def test_cli_multiple_files(ipynb_py_R_jl_files):
assert parse_jupytext_args(ipynb_py_R_jl_files + ["--to", "py"]).notebooks == ipynb_py_R_jl_files
def test_convert_single_file_in_place(ipynb_py_file, tmpdir):
nb_org = str(tmpdir.join(os.path.basename(ipynb_py_file)))
copyfile(ipynb_py_file, nb_org)
base, ext = os.path.splitext(nb_org)
nb_other = base + ".py"
jupytext([nb_org, "--to", "py"])
nb1 = read(nb_org)
nb2 = read(nb_other)
compare_notebooks(nb2, nb1)
def test_convert_single_file_in_place_m(ipynb_py_file, tmpdir):
nb_org = str(tmpdir.join(os.path.basename(ipynb_py_file)))
copyfile(ipynb_py_file, nb_org)
base, ext = os.path.splitext(nb_org)
for fmt_ext in ("py", "Rmd"):
nb_other = base + "." + fmt_ext
check_call([sys.executable, "-m", "jupytext", nb_org, "--to", fmt_ext])
nb1 = read(nb_org)
nb2 = read(nb_other)
compare_notebooks(nb2, nb1)
def test_convert_single_file(ipynb_or_rmd_file, tmpdir, capsys):
nb_org = str(tmpdir.join(os.path.basename(ipynb_or_rmd_file)))
copyfile(ipynb_or_rmd_file, nb_org)
nb1 = read(ipynb_or_rmd_file)
pynb = writes(nb1, "py")
jupytext([nb_org, "--to", "py", "-o", "-"])
out, err = capsys.readouterr()
assert err == ""
compare(out, pynb)
def test_jupytext_version(capsys):
jupytext(["--version"])
out, err = capsys.readouterr()
assert err == ""
compare(out, __version__ + "\n")
def test_wildcard(tmpdir):
nb1_ipynb = str(tmpdir.join("nb1.ipynb"))
nb2_ipynb = str(tmpdir.join("nb2.ipynb"))
nb1_py = str(tmpdir.join("nb1.py"))
nb2_py = str(tmpdir.join("nb2.py"))
write(new_notebook(metadata={"notebook": 1}), nb1_ipynb)
write(new_notebook(metadata={"notebook": 2}), nb2_ipynb)
os.chdir(str(tmpdir))
jupytext(["nb*.ipynb", "--to", "py"])
assert os.path.isfile(nb1_py)
assert os.path.isfile(nb2_py)
with pytest.raises(IOError):
jupytext(["nb3.ipynb", "--to", "py"])
def test_to_cpluplus(ipynb_cpp_file, tmpdir, capsys):
nb_org = str(tmpdir.join(os.path.basename(ipynb_cpp_file)))
copyfile(ipynb_cpp_file, nb_org)
nb1 = read(nb_org)
text_cpp = writes(nb1, "cpp")
jupytext([nb_org, "--to", "c++", "--output", "-"])
out, err = capsys.readouterr()
assert err == ""
compare(out, text_cpp)
def test_convert_multiple_file(ipynb_py_files, tmpdir):
nb_orgs = []
nb_others = []
for nb_file in ipynb_py_files:
nb_org = str(tmpdir.join(os.path.basename(nb_file)))
base, ext = os.path.splitext(nb_org)
nb_other = base + ".py"
copyfile(nb_file, nb_org)
nb_orgs.append(nb_org)
nb_others.append(nb_other)
jupytext(nb_orgs + ["--to", "py"])
for nb_org, nb_other in zip(nb_orgs, nb_others):
nb1 = read(nb_org)
nb2 = read(nb_other)
compare_notebooks(nb2, nb1)
def test_error_not_notebook_ext_input(tmpdir, capsys):
tmp_file = str(tmpdir.join("notebook.ext"))
with open(tmp_file, "w") as fp:
fp.write("\n")
with pytest.raises(InconsistentPath, match="is not a notebook. Supported extensions are"):
jupytext([tmp_file, "--to", "py"])
@pytest.fixture
def tmp_ipynb(tmpdir):
tmp_file = str(tmpdir.join("notebook.ipynb"))
write(new_notebook(), tmp_file)
return tmp_file
@pytest.fixture
def tmp_py(tmpdir):
tmp_file = str(tmpdir.join("notebook.py"))
with open(tmp_file, "w") as fp:
fp.write("\n")
return tmp_file
def test_error_not_notebook_ext_to(tmp_ipynb):
with pytest.raises(JupytextFormatError, match="'ext' is not a notebook extension"):
jupytext([tmp_ipynb, "--to", "ext"])
def test_error_not_notebook_ext_output(tmp_ipynb, tmpdir):
with pytest.raises(
JupytextFormatError,
match="Extension '.ext' is not a notebook extension. Please use one of",
):
jupytext([tmp_ipynb, "-o", str(tmpdir.join("not.ext"))])
def test_error_not_same_ext(tmp_ipynb, tmpdir):
with pytest.raises(InconsistentPath):
jupytext([tmp_ipynb, "--to", "py", "-o", str(tmpdir.join("not.md"))])
def test_error_no_action(tmp_ipynb):
with pytest.raises(ValueError, match="Please provide one of"):
jupytext([tmp_ipynb])
def test_error_update_not_ipynb(tmp_py):
with pytest.raises(ValueError, match="--update is only for ipynb files"):
jupytext([tmp_py, "--to", "py", "--update"])
def test_error_multiple_input(tmp_ipynb):
with pytest.raises(ValueError, match="Please input a single notebook when using --output"):
jupytext([tmp_ipynb, tmp_ipynb, "--to", "py", "-o", "notebook.py"])
def test_error_opt_missing_equal(tmp_ipynb):
with pytest.raises(ValueError, match="key=value"):
jupytext([tmp_ipynb, "--to", "py", "--opt", "missing_equal"])
def test_error_unknown_opt(tmp_ipynb):
with pytest.raises(ValueError, match="is not a valid format option"):
jupytext([tmp_ipynb, "--to", "py", "--opt", "unknown=true"])
def test_combine_same_version_ok(tmpdir):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_nbpy = str(tmpdir.join("notebook.py"))
tmp_rmd = str(tmpdir.join("notebook.Rmd"))
with open(tmp_nbpy, "w") as fp:
fp.write(
"""# ---
# jupyter:
# jupytext_formats: ipynb,py
# jupytext_format_version: '1.2'
# ---
# New cell
"""
)
nb = new_notebook(metadata={"jupytext_formats": "ipynb,py"})
write(nb, tmp_ipynb)
# to jupyter notebook
jupytext([tmp_nbpy, "--to", "ipynb", "--update"])
# test round trip
jupytext([tmp_nbpy, "--to", "notebook", "--test"])
# test ipynb to rmd
jupytext([tmp_ipynb, "--to", "rmarkdown"])
nb = read(tmp_ipynb)
cells = nb["cells"]
assert len(cells) == 1
assert cells[0].cell_type == "markdown"
assert cells[0].source == "New cell"
nb = read(tmp_rmd)
cells = nb["cells"]
assert len(cells) == 1
assert cells[0].cell_type == "markdown"
assert cells[0].source == "New cell"
def test_combine_lower_version_raises(tmpdir):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_nbpy = str(tmpdir.join("notebook.py"))
with open(tmp_nbpy, "w") as fp:
fp.write(
"""# ---
# jupyter:
# jupytext:
# formats: ipynb,py:light
# text_representation:
# extension: .py
# format_name: light
# format_version: '55.4'
# jupytext_version: 42.1.1
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# New cell
"""
)
nb = new_notebook(metadata={"jupytext_formats": "ipynb,py"})
write(nb, tmp_ipynb)
with pytest.raises(
ValueError,
match="The file notebook.py was generated with jupytext version 42.1.1 but you have .* installed. "
"Please upgrade jupytext to version 42.1.1, or remove either notebook.py or notebook.ipynb. "
"This error occurs because notebook.py is in the light format in version 55.4, "
"while jupytext version .* installed at .* can only read the light format in versions .*",
):
jupytext([tmp_nbpy, "--to", "ipynb", "--update"])
def test_ipynb_to_py_then_update_test(ipynb_py_file, tmpdir):
"""Reproduce https://github.com/mwouts/jupytext/issues/83"""
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_nbpy = str(tmpdir.join("notebook.py"))
copyfile(ipynb_py_file, tmp_ipynb)
jupytext(["--to", "py", tmp_ipynb])
jupytext(["--test", "--update", "--to", "ipynb", tmp_nbpy])
def test_test_to_ipynb_ignore_version_number_414(
tmpdir,
text="""# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.4'
# jupytext_version: 1.1.0
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# A short markdown cell
# Followed by a code cell
2 + 2
""",
):
tmp_py = str(tmpdir.join("script.py"))
with open(tmp_py, "w") as fp:
fp.write(text)
assert jupytext(["--test", "--to", "ipynb", tmp_py]) == 0
def test_convert_to_percent_format(ipynb_py_file, tmpdir):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_nbpy = str(tmpdir.join("notebook.py"))
copyfile(ipynb_py_file, tmp_ipynb)
jupytext(["--to", "py:percent", tmp_ipynb])
with open(tmp_nbpy) as stream:
py_script = stream.read()
assert "format_name: percent" in py_script
nb1 = read(tmp_ipynb)
nb2 = read(tmp_nbpy)
compare_notebooks(nb2, nb1)
def test_convert_to_percent_format_and_keep_magics(ipynb_py_file, tmpdir):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_nbpy = str(tmpdir.join("notebook.py"))
copyfile(ipynb_py_file, tmp_ipynb)
jupytext(["--to", "py:percent", "--opt", "comment_magics=False", tmp_ipynb])
with open(tmp_nbpy) as stream:
py_script = stream.read()
assert "format_name: percent" in py_script
assert "comment_magics: false" in py_script
assert "# %%time" not in py_script
nb1 = read(tmp_ipynb)
nb2 = read(tmp_nbpy)
compare_notebooks(nb2, nb1)
def test_set_formats(python_file, tmpdir):
tmp_py = str(tmpdir.join("notebook.py"))
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
copyfile(python_file, tmp_py)
jupytext([tmp_py, "--set-formats", "ipynb,py:light"])
nb = read(tmp_ipynb)
assert nb.metadata["jupytext"]["formats"] == "ipynb,py:light"
def test_update_metadata(python_file, tmpdir, capsys):
tmp_py = str(tmpdir.join("notebook.py"))
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
copyfile(python_file, tmp_py)
jupytext(
[
"--to",
"ipynb",
tmp_py,
"--update-metadata",
'{"jupytext":{"formats":"ipynb,py:light"}}',
]
)
nb = read(tmp_ipynb)
assert nb.metadata["jupytext"]["formats"] == "ipynb,py:light"
jupytext(["--to", "py", tmp_ipynb, "--update-metadata", '{"jupytext":{"formats":null}}'])
nb = read(tmp_py)
assert "formats" not in nb.metadata["jupytext"]
with pytest.raises(SystemExit):
jupytext(["--to", "ipynb", tmp_py, "--update-metadata", '{"incorrect": "JSON"'])
out, err = capsys.readouterr()
assert "invalid" in err
@pytest.mark.requires_user_kernel_python3
def test_set_kernel_inplace(python_file, tmpdir):
tmp_py = str(tmpdir.join("notebook.py"))
copyfile(python_file, tmp_py)
jupytext([tmp_py, "--set-kernel", "-"])
nb = read(tmp_py)
kernel_name = nb.metadata["kernelspec"]["name"]
cmd = get_kernel_spec(kernel_name).argv[0]
assert cmd == "python" or os.path.samefile(cmd, sys.executable)
@pytest.mark.requires_user_kernel_python3
def test_set_kernel_auto(python_file, tmpdir):
tmp_py = str(tmpdir.join("notebook.py"))
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
copyfile(python_file, tmp_py)
jupytext(["--to", "ipynb", tmp_py, "--set-kernel", "-"])
nb = read(tmp_ipynb)
kernel_name = nb.metadata["kernelspec"]["name"]
cmd = get_kernel_spec(kernel_name).argv[0]
assert cmd == "python" or os.path.samefile(cmd, sys.executable)
@pytest.mark.requires_user_kernel_python3
def test_set_kernel_with_name(python_file, tmpdir):
tmp_py = str(tmpdir.join("notebook.py"))
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
copyfile(python_file, tmp_py)
for kernel in find_kernel_specs():
jupytext(["--to", "ipynb", tmp_py, "--set-kernel", kernel])
nb = read(tmp_ipynb)
assert nb.metadata["kernelspec"]["name"] == kernel
with pytest.raises(KeyError):
jupytext(["--to", "ipynb", tmp_py, "--set-kernel", "non_existing_env"])
def test_paired_paths(ipynb_py_file, tmpdir, capsys):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
nb = read(ipynb_py_file)
nb.metadata.setdefault("jupytext", {})["formats"] = "ipynb,_light.py,_percent.py:percent"
write(nb, tmp_ipynb)
jupytext(["--paired-paths", tmp_ipynb])
out, err = capsys.readouterr()
assert not err
formats = nb.metadata.get("jupytext", {}).get("formats")
assert set(out.splitlines()).union([tmp_ipynb]) == {path for path, _ in paired_paths(tmp_ipynb, "ipynb", formats)}
def test_sync(ipynb_py_file, tmpdir, cwd_tmpdir, capsys):
tmp_ipynb = "notebook.ipynb"
tmp_py = "notebook.py"
tmp_rmd = "notebook.Rmd"
nb = read(ipynb_py_file)
write(nb, tmp_ipynb)
# Test that sync issues a warning when the notebook is not paired
jupytext(["--sync", tmp_ipynb])
_, err = capsys.readouterr()
assert "is not a paired notebook" in err
# Now with a pairing information
nb.metadata.setdefault("jupytext", {})["formats"] = "py,Rmd,ipynb"
write(nb, tmp_ipynb)
# Test that missing files are created
jupytext(["--sync", tmp_ipynb])
assert os.path.isfile(tmp_py)
compare_notebooks(read(tmp_py), nb)
assert os.path.isfile(tmp_rmd)
compare_notebooks(read(tmp_rmd), nb, "Rmd")
write(nb, tmp_rmd, fmt="Rmd")
jupytext(["--sync", tmp_ipynb])
nb2 = read(tmp_ipynb)
compare_notebooks(nb2, nb, "Rmd", compare_outputs=True)
write(nb, tmp_py, fmt="py")
jupytext(["--sync", tmp_ipynb])
nb2 = read(tmp_ipynb)
compare_notebooks(nb2, nb, compare_outputs=True)
# Finally we recreate the ipynb
os.remove(tmp_ipynb)
time.sleep(0.1)
jupytext(["--sync", tmp_py])
nb2 = read(tmp_ipynb)
compare_notebooks(nb2, nb)
# ipynb must be older than py file, otherwise our Contents Manager will complain
assert os.path.getmtime(tmp_ipynb) <= os.path.getmtime(tmp_py)
@pytest.mark.requires_pandoc
def test_sync_pandoc(ipynb_to_pandoc, tmpdir, cwd_tmpdir, capsys):
tmp_ipynb = "notebook.ipynb"
tmp_md = "notebook.md"
nb = read(ipynb_to_pandoc)
write(nb, tmp_ipynb)
# Test that sync issues a warning when the notebook is not paired
jupytext(["--sync", tmp_ipynb])
_, err = capsys.readouterr()
assert "is not a paired notebook" in err
# Now with a pairing information
nb.metadata.setdefault("jupytext", {})["formats"] = "ipynb,md:pandoc"
write(nb, tmp_ipynb)
# Test that missing files are created
jupytext(["--sync", tmp_ipynb])
assert os.path.isfile(tmp_md)
compare_notebooks(read(tmp_md), nb, "md:pandoc")
with open(tmp_md) as fp:
assert "pandoc" in fp.read()
def test_cli_can_infer_jupytext_format(ipynb_py_R_jl_file, ipynb_py_R_jl_ext, tmpdir, cwd_tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_text = "notebook" + ipynb_py_R_jl_ext
nb = read(ipynb_py_R_jl_file)
# Light format to Jupyter notebook
write(nb, tmp_text)
jupytext(["--to", "notebook", tmp_text])
nb2 = read(tmp_ipynb)
compare_notebooks(nb2, nb)
# Percent format to Jupyter notebook
write(nb, tmp_text, fmt=ipynb_py_R_jl_ext + ":percent")
jupytext(["--to", "notebook", tmp_text])
nb2 = read(tmp_ipynb)
compare_notebooks(nb2, nb)
def test_cli_to_script(ipynb_py_R_jl_file, ipynb_py_R_jl_ext, tmpdir, cwd_tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_text = "notebook" + ipynb_py_R_jl_ext
nb = read(ipynb_py_R_jl_file)
write(nb, tmp_ipynb)
jupytext(["--to", "script", tmp_ipynb])
nb2 = read(tmp_text)
compare_notebooks(nb2, nb)
def test_cli_to_auto(ipynb_py_R_jl_file, ipynb_py_R_jl_ext, tmpdir, cwd_tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_text = "notebook" + ipynb_py_R_jl_ext
nb = read(ipynb_py_R_jl_file)
write(nb, tmp_ipynb)
jupytext(["--to", "auto", tmp_ipynb])
nb2 = read(tmp_text)
compare_notebooks(nb2, nb)
def test_cli_can_infer_jupytext_format_from_stdin(ipynb_py_file, tmpdir, cwd_tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_py = "notebook.py"
tmp_rmd = "notebook.Rmd"
nb = read(ipynb_py_file)
# read ipynb notebook on stdin, write to python
with open(ipynb_py_file) as fp, mock.patch("sys.stdin", fp):
jupytext(["--to", "py:percent", "-o", tmp_py])
nb2 = read(tmp_py)
compare_notebooks(nb2, nb)
# read python notebook on stdin, write to ipynb
with open(tmp_py) as fp, mock.patch("sys.stdin", fp):
jupytext(["-o", tmp_ipynb])
nb2 = read(tmp_ipynb)
compare_notebooks(nb2, nb)
# read ipynb notebook on stdin, write to R markdown
with open(ipynb_py_file) as fp, mock.patch("sys.stdin", fp):
jupytext(["-o", tmp_rmd])
nb2 = read(tmp_rmd)
compare_notebooks(nb2, nb, "Rmd")
# read markdown notebook on stdin, write to ipynb
with open(tmp_rmd) as fp, mock.patch("sys.stdin", fp):
jupytext(["-o", tmp_ipynb])
nb2 = read(tmp_ipynb)
compare_notebooks(nb2, nb, "Rmd")
@pytest.mark.requires_user_kernel_python3
def test_set_kernel_works_with_pipes_326(capsys):
md = """```python
1 + 1
```"""
with mock.patch("sys.stdin", StringIO(md)):
jupytext(["--to", "ipynb", "--set-kernel", "-", "-"])
out, err = capsys.readouterr()
assert err == ""
nb = reads(out, "ipynb")
assert "kernelspec" in nb.metadata
@pytest.mark.filterwarnings("ignore:The --pre-commit argument is deprecated")
def test_cli_expect_errors(tmp_ipynb):
with pytest.raises(ValueError):
jupytext([])
with pytest.raises(ValueError):
jupytext(["--sync"])
with pytest.raises(ValueError):
jupytext([tmp_ipynb, tmp_ipynb, "--paired-paths"])
with pytest.raises(ValueError):
jupytext(["--pre-commit", "notebook.ipynb"])
with pytest.raises(ValueError):
jupytext(["notebook.ipynb", "--from", "py:percent", "--to", "md"])
with pytest.raises(ValueError):
jupytext([])
with pytest.raises((SystemExit, TypeError)): # SystemExit on Windows, TypeError on Linux
system("jupytext", ["notebook.ipynb", "--from", "py:percent", "--to", "md"])
@pytest.mark.filterwarnings(
"error",
"ignore:You might have passed a file name to the '--to' option, "
"when a format description was expected. "
"Maybe you want to use the '-o' option instead?",
)
def test_format_prefix_suffix(tmpdir, cwd_tmpdir):
os.makedirs("notebooks")
tmp_ipynb = "notebooks/notebook_name.ipynb"
tmp_py = "scripts/notebook_name.py"
write(new_notebook(), tmp_ipynb)
jupytext([tmp_ipynb, "--to", "../scripts//py"])
assert os.path.isfile(tmp_py)
os.remove(tmp_py)
jupytext([tmp_ipynb, "--to", "scripts//py", "--from", "notebooks//ipynb"])
assert os.path.isfile(tmp_py)
os.remove(tmp_py)
tmp_ipynb = "notebooks/nb_prefix_notebook_name.ipynb"
tmp_py = "scripts/script_prefix_notebook_name.py"
write(new_notebook(), tmp_ipynb)
jupytext(
[
tmp_ipynb,
"--to",
"scripts/script_prefix_/py",
"--from",
"notebooks/nb_prefix_/ipynb",
]
)
assert os.path.isfile(tmp_py)
os.remove(tmp_py)
tmp_ipynb = "notebooks/nb_prefix_notebook_name_nb_suffix.ipynb"
tmp_py = "scripts/script_prefix_notebook_name_script_suffix.py"
write(new_notebook(), tmp_ipynb)
jupytext(
[
tmp_ipynb,
"--to",
"scripts/script_prefix_/_script_suffix.py",
"--from",
"notebooks/nb_prefix_/_nb_suffix.ipynb",
]
)
assert os.path.isfile(tmp_py)
os.remove(tmp_py)
def test_cli_sync_file_with_suffix(tmpdir, cwd_tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_pct_py = "notebook.pct.py"
tmp_lgt_py = "notebook.lgt.py"
tmp_rmd = "notebook.Rmd"
nb = new_notebook(
cells=[new_code_cell(source="1+1")],
metadata={"jupytext": {"formats": "ipynb,.pct.py:percent,.lgt.py:light,Rmd"}},
)
write(nb, tmp_pct_py, fmt=".pct.py:percent")
jupytext(["--sync", tmp_pct_py])
assert os.path.isfile(tmp_lgt_py)
assert os.path.isfile(tmp_rmd)
assert os.path.isfile(tmp_ipynb)
jupytext(["--sync", tmp_lgt_py])
jupytext(["--sync", tmp_ipynb])
with open(tmp_lgt_py) as fp:
assert fp.read().splitlines()[-2:] == ["", "1+1"]
with open(tmp_pct_py) as fp:
fp.read().splitlines()[-3:] == ["", "# %%", "1+1"]
with open(tmp_rmd) as fp:
fp.read().splitlines()[-4:] == ["", "```{python}", "1+1", "```"]
def test_cli_sync_file_with_prefix_974(tmp_path, python_notebook):
"""Only the files that are in the example directory and that start with 'example' should be paired"""
(tmp_path / "pyproject.toml").write_text(
"""[tool.jupytext]
formats = "examples//example/ipynb,examples//example/py:percent"
"""
)
write(python_notebook, tmp_path / "example_notebook.ipynb")
(tmp_path / "examples" / "folder1").mkdir(parents=True)
write(python_notebook, tmp_path / "examples/folder1/utils.py")
write(python_notebook, tmp_path / "examples/folder1/example_paired.ipynb")
jupytext(
[
"--sync",
str(tmp_path / "example_notebook.ipynb"),
str(tmp_path / "examples/folder1/utils.py"),
str(tmp_path / "examples/folder1/example_paired.ipynb"),
]
)
assert not (tmp_path / "example_notebook.py").exists(), "Not in the 'examples' directory"
assert not (tmp_path / "examples/folder1/utils_not_paired.ipynb").exists(), "Not with the 'example' prefix"
assert (tmp_path / "examples/folder1/example_paired.py").exists(), "Paired"
def test_remove_jupytext_metadata(tmpdir, cwd_tmpdir):
tmp_ipynb = "notebook.ipynb"
nb = new_notebook(
metadata={
"jupytext": {
"main_language": "python",
"text_representation": {
"extension": ".md",
"format_name": "markdown",
"format_version": "1.0",
"jupytext_version": "0.8.6",
},
}
}
)
nbformat.write(nb, tmp_ipynb, version=nbformat.NO_CONVERT)
# Jupytext removes the 'text_representation' information from the notebook
jupytext([tmp_ipynb, "--update-metadata", '{"jupytext":{"main_language":null}}'])
nb2 = read(tmp_ipynb)
assert not nb2.metadata
nbformat.write(nb, tmp_ipynb, version=nbformat.NO_CONVERT)
jupytext([tmp_ipynb, "--set-formats", "ipynb,py:light"])
nb2 = read(tmp_ipynb)
assert nb2.metadata == {"jupytext": {"formats": "ipynb,py:light", "main_language": "python"}}
@pytest.mark.parametrize("fmt", ["py:light", "py:percent", "md"])
def test_convert_and_update_preserves_notebook(ipynb_py_file, fmt, tmpdir, cwd_tmpdir):
# cannot encode magic parameters in markdown yet
if ("magic" in ipynb_py_file or "LateX" in ipynb_py_file) and fmt == "md":
return
tmp_ipynb = "notebook.ipynb"
copyfile(ipynb_py_file, tmp_ipynb)
ext = long_form_one_format(fmt)["extension"]
tmp_text = "notebook" + ext
jupytext(["--to", fmt, tmp_ipynb])
jupytext(["--to", "ipynb", "--update", tmp_text])
nb_org = read(ipynb_py_file)
nb_now = read(tmp_ipynb)
# The cell marker changes from """ to r""" on the LateX notebook #836
if "LateX" in ipynb_py_file and fmt == "py:percent":
last_cell = nb_now.cells[-1]
last_cell.metadata["cell_marker"] = last_cell.metadata["cell_marker"][1:]
compare(nb_now, nb_org)
def test_incorrect_notebook_causes_early_exit(tmpdir, cwd_tmpdir):
incorrect_ipynb = "incorrect.ipynb"
incorrect_md = "incorrect.md"
with open(incorrect_ipynb, "w") as fp:
fp.write('{"nbformat": 4, "nbformat_minor": 2, "metadata": {INCORRECT}, "cells": []}')
correct_ipynb = "correct.ipynb"
correct_md = "correct.md"
with open(correct_ipynb, "w") as fp:
fp.write('{"nbformat": 4, "nbformat_minor": 2, "metadata": {}, "cells": []}')
with pytest.raises(nbformat.reader.NotJSONError, match="Notebook does not appear to be JSON"):
jupytext([incorrect_ipynb, correct_ipynb, "--to", "md"])
assert not os.path.exists(incorrect_md)
assert not os.path.exists(correct_md)
def test_warn_only_skips_incorrect_notebook(tmpdir, cwd_tmpdir, capsys):
incorrect_ipynb = "incorrect.ipynb"
incorrect_md = "incorrect.md"
with open(incorrect_ipynb, "w") as fp:
fp.write('{"nbformat": 4, "nbformat_minor": 2, "metadata": {INCORRECT}, "cells": []}')
correct_ipynb = "correct.ipynb"
correct_md = "correct.md"
with open(correct_ipynb, "w") as fp:
fp.write('{"nbformat": 4, "nbformat_minor": 2, "metadata": {}, "cells": []}')
jupytext([incorrect_ipynb, correct_ipynb, "--to", "md", "--warn-only"])
_, err = capsys.readouterr()
assert "Notebook does not appear to be JSON" in str(err)
assert not os.path.exists(incorrect_md)
assert os.path.exists(correct_md)
@pytest.mark.parametrize("fmt", ["md", "Rmd", "py", "py:percent", "py:hydrogen"])
def test_339_ipynb(tmpdir, cwd_tmpdir, fmt):
tmp_ipynb = "test.ipynb"
nb = new_notebook(cells=[new_code_cell("cat = 42")])
nbformat.write(nb, tmp_ipynb)
assert jupytext([tmp_ipynb, "--to", fmt, "--test-strict"]) == 0
def test_339_py(tmpdir, cwd_tmpdir):
"""Test that an incorrect round trip conversion on the text file is detected"""
tmp_py = "test.py"
with open(tmp_py, "w") as fp:
fp.write(
"""# %%
cat = 42
"""
)
def erroneous_is_magic(line, language, comment_magics, explicitly_code):
return "cat" in line
with mock.patch("jupytext.magics.is_magic", erroneous_is_magic):
assert jupytext([tmp_py, "--to", "ipynb", "--test-strict"]) != 0
def test_339_require_to(tmpdir, cwd_tmpdir):
"""Test that the `--to` argument is asked for when a `--test` command is provided"""
with pytest.raises(ValueError, match="--to"):
jupytext(["test.py", "--test-strict"])
def test_399_to_script_then_set_formats(tmpdir, cwd_tmpdir):
nb = new_notebook(cells=[new_code_cell("1 + 1")])
tmp_py = "notebook_first.py"
tmp_ipynb = "notebook_first.ipynb"
nbformat.write(nb, tmp_ipynb)
jupytext(["--to", "py:percent", tmp_ipynb])
assert os.path.isfile(tmp_py)
jupytext(["--set-formats", "ipynb,py:percent", tmp_ipynb])
def test_set_format_with_subfolder(tmpdir, cwd_tmpdir):
"""Here we reproduce issue #450"""
py = """# %% [markdown]
# A short notebook
"""
tmpdir.mkdir("python_scripts").join("01_tabular_data_exploration.py").write(py)
jupytext(
[
"--set-formats",
"python_scripts//py:percent,notebooks//ipynb",
"python_scripts/01_tabular_data_exploration.py",
]
)
def skip_if_format_missing(format_name):
"""Check whether MyST or Pandoc are available and skip if not"""
if format_name == "md:myst" and not is_myst_available():
pytest.skip("MyST markdown is not available")
elif format_name == "md:pandoc" and not is_pandoc_available():
pytest.skip("Pandoc is not available")
@pytest.mark.parametrize("format_name", ["md", "md:myst", "md:pandoc"])
def test_create_header_with_set_formats(format_name, cwd_tmpdir, tmpdir):
"""Test jupytext --set-formats #485"""
skip_if_format_missing(format_name)
tmpdir.join("notebook.md").write("\n")
jupytext(["--set-formats", format_name, "notebook.md"])
nb = read("notebook.md")
assert nb["metadata"]["jupytext"]["formats"] == format_name
@pytest.mark.requires_user_kernel_python3
@pytest.mark.parametrize("format_name", ["md", "md:myst", "md:pandoc", "py:light", "py:percent"])
def test_create_header_with_set_formats_and_set_kernel(format_name, tmpdir, cwd_tmpdir):
"""Test jupytext --set-formats --set-kernel - #485"""
skip_if_format_missing(format_name)
ext = format_name.split(":")[0]
tmp_nb = "notebook." + ext
tmpdir.join(tmp_nb).write("\n")
jupytext(["--set-formats", format_name, "--set-kernel", "-", tmp_nb])
nb = read(tmp_nb)
assert nb["metadata"]["jupytext"]["formats"] == format_name
assert "kernelspec" in nb["metadata"]
def test_set_option_split_at_heading(tmpdir, cwd_tmpdir):
tmp_rmd = tmpdir.join("notebook.Rmd")
tmp_rmd.write(
"""A paragraph
# H1 Header
"""
)
jupytext(["notebook.Rmd", "--opt", "split_at_heading=true"])
assert "split_at_heading: true" in tmp_rmd.read()
nb = read("notebook.Rmd")
nb_expected = new_notebook(cells=[new_markdown_cell("A paragraph"), new_markdown_cell("# H1 Header")])
compare_notebooks(nb, nb_expected)
def test_pair_in_tree(tmpdir):
nb_file = tmpdir.mkdir("notebooks").mkdir("subfolder").join("example.ipynb")
py_file = tmpdir.mkdir("scripts").mkdir("subfolder").join("example.py")
write(new_notebook(cells=[new_markdown_cell("A markdown cell")]), str(nb_file))
jupytext(["--set-formats", "notebooks///ipynb,scripts///py:percent", str(nb_file)])
assert py_file.exists()
assert "A markdown cell" in py_file.read()
def test_pair_in_tree_and_parent(tmpdir):
nb_file = tmpdir.mkdir("notebooks").mkdir("subfolder").mkdir("a").mkdir("b").join("example.ipynb")
py_file = tmpdir.mkdir("scripts").mkdir("subfolder").mkdir("c").join("example.py")
write(new_notebook(cells=[new_markdown_cell("A markdown cell")]), str(nb_file))
jupytext(["--set-formats", "notebooks//a/b//ipynb,scripts//c//py:percent", str(nb_file)])
assert py_file.exists()
assert "A markdown cell" in py_file.read()
@pytest.mark.requires_pandoc
def test_sync_pipe_config(tmpdir):
"""Sync a notebook to a script paired in a tree, and reformat the markdown cells using pandoc"""
tmpdir.join("jupytext.toml").write(
"""# By default, the notebooks in this repository are in the notebooks subfolder
# and they are paired to scripts in the script subfolder.
formats = "notebooks///ipynb,scripts///py:percent"
"""
)
nb_file = tmpdir.mkdir("notebooks").join("wrap_markdown.ipynb")
long_text = "This is a " + ("very " * 24) + "long sentence."
assert len(long_text) > 100
nb = new_notebook(cells=[new_markdown_cell(long_text)])
write(nb, str(nb_file))
jupytext(
[
"--sync",
"--pipe-fmt",
"ipynb",
"--pipe",
"pandoc --from ipynb --to ipynb --markdown-headings=atx",
str(nb_file),
]
)
py_text = tmpdir.join("scripts").join("wrap_markdown.py").read()
assert "This is a very very" in py_text
for line in py_text.splitlines():
assert len(line) <= 79
nb = read(nb_file, as_version=4)
text = nb.cells[0].source
assert len(text.splitlines()) == 3
assert text != long_text
def test_sync_script_dotdot_folder_564(tmpdir):
"""Reproduce the setting of issue #564"""
nb_file = tmpdir.mkdir("colabs").mkdir("colabs").join("rigid_object_tutorial.ipynb")
py_file = tmpdir.join("colabs").mkdir("nb_python").join("rigid_object_tutorial.py")
py_file.write("1 + 1\n")
jupytext(["--set-formats", "../nb_python//py:percent,../colabs//ipynb", str(py_file)])
assert nb_file.exists()
jupytext(["--sync", str(py_file)])
jupytext(["--sync", str(nb_file)])
def test_jupytext_to_file_emits_a_warning(tmpdir):
"""The user may type
jupytext notebook.ipynb --to script.py
meaning
jupytext notebook.ipynb -o script.py
"""
os.chdir(str(tmpdir))
nb_file = tmpdir.join("notebook.ipynb")
write(new_notebook(), str(nb_file))
with warnings.catch_warnings():
warnings.simplefilter("error")
jupytext(["notebook.ipynb", "-o", "script.py"])
with pytest.warns(UserWarning, match="Maybe you want to use the '-o' option"):
jupytext(["notebook.ipynb", "--to", "script.py"])
def test_jupytext_set_formats_file_gives_an_informative_error(tmpdir, cwd_tmpdir):
"""The user may type
jupytext --set-formats notebook.md
meaning
jupytext --sync notebook.md
"""
cfg_file = tmpdir.join("jupytext.toml")
cfg_file.write('formats = "md,ipynb,py:percent"')
md_file = tmpdir.join("notebook.md")
py_file = tmpdir.join("notebook.py")
nb_file = tmpdir.join("notebook.ipynb")
md_file.write("Some text")
with warnings.catch_warnings():
warnings.simplefilter("error")
jupytext(["--sync", "notebook.md"])
assert py_file.exists()
assert nb_file.exists()
with pytest.raises(ValueError, match="jupytext --sync notebook.md"):
jupytext(["--set-formats", "notebook.md"])
# Remove the config file, otherwise test_jupytext_jupyter_fs_metamanager fails later on!
cfg_file.remove()
def test_diff(tmpdir, cwd_tmpdir, capsys):
write(new_notebook(cells=[new_code_cell("1 + 1")]), "test.ipynb")
write(new_notebook(cells=[new_code_cell("2 + 2")]), "test.py", fmt="py:percent")
jupytext(["--diff", "test.py", "test.ipynb"])
captured = capsys.readouterr()
assert "-2 + 2\n+1 + 1" in captured.out
def test_show_changes(tmpdir, cwd_tmpdir, capsys):
write(new_notebook(cells=[new_code_cell("1 + 1")]), "test.ipynb")
write(new_notebook(cells=[new_code_cell("2 + 2")]), "test.py", fmt="py:percent")
jupytext(["--to", "py:percent", "test.ipynb", "--show-changes"])
captured = capsys.readouterr()
assert "-2 + 2\n+1 + 1" in captured.out
def test_glob_recursive(tmpdir, cwd_tmpdir):
tmpdir.mkdir("subfolder").join("test.py").write("1 + 1\n")
tmpdir.join("test.py").write("2 + 2\n")
jupytext(["--to", "ipynb", "**/*.py"])
assert tmpdir.join("test.ipynb").isfile()
assert tmpdir.join("subfolder").join("test.ipynb").isfile()
def test_jupytext_sync_preserves_cell_ids(tmpdir, cwd_tmpdir, notebook_with_outputs):
write(notebook_with_outputs, "test.ipynb")
# Sync with a py file, this should not change the cell id
jupytext(["--set-formats", "ipynb,py:percent", "test.ipynb"])
nb = read("test.ipynb")
assert nb.cells[0].source == "1+1"
assert nb.cells[0].id == notebook_with_outputs.cells[0].id
# Change the py file and sync. This should not change the cell id neither
py_nb = tmpdir.join("test.py")
py = py_nb.read()
py_nb.write(py.replace("1+1", "2+2"))
jupytext(["--sync", "test.ipynb"])
nb = read("test.ipynb")
assert nb.cells[0].source == "2+2"
assert nb.cells[0].id == notebook_with_outputs.cells[0].id
def test_jupytext_update_preserves_cell_ids(tmpdir, cwd_tmpdir, notebook_with_outputs):
write(notebook_with_outputs, "test.ipynb")
# Sync with a py file, this should not change the cell id
jupytext(["--to", "py:percent", "test.ipynb"])
nb = read("test.ipynb")
assert nb.cells[0].source == "1+1"
assert nb.cells[0].id == notebook_with_outputs.cells[0].id
# Change the py file and update the ipynb file.
# This should not change the cell id neither
py_nb = tmpdir.join("test.py")
py = py_nb.read()
py_nb.write(py.replace("1+1", "2+2"))
jupytext(["--to", "notebook", "--update", "test.py"])
nb = read("test.ipynb")
assert nb.cells[0].source == "2+2"
assert nb.cells[0].id == notebook_with_outputs.cells[0].id
def test_jupytext_to_ipynb_suggests_update(tmpdir, cwd_tmpdir, capsys):
tmpdir.join("test.py").write("1 + 1\n")
jupytext(["--to", "ipynb", "test.py"])
capture = capsys.readouterr()
assert "update" not in capture.out
jupytext(["--to", "ipynb", "test.py"])
capture = capsys.readouterr()
assert "update" in capture.out
@pytest.mark.parametrize("formats", ["", "py:percent", "py", "py:percent,ipynb"])
def test_jupytext_to_ipynb_does_not_update_timestamp_if_output_not_in_pair(
tmpdir, cwd_tmpdir, python_notebook, capsys, formats
):
# Write a text notebook
nb = python_notebook
if formats:
nb.metadata["jupytext"] = {"formats": formats}
test_py = tmpdir.join("test.py")
write(nb, str(test_py))
# make it read-only
test_py.chmod(0o444)
# py -> ipynb
if "ipynb" not in formats:
jupytext(["--to", "ipynb", "test.py"])
else:
jupytext(["--to", "ipynb", "test.py", "-o", "another.ipynb"])
capture = capsys.readouterr()
assert "Updating the timestamp" not in capture.out
@pytest.mark.parametrize("formats", ["py:percent", "py", None])
def test_jupytext_to_ipynb_does_not_update_timestamp_if_not_paired(tmpdir, cwd_tmpdir, python_notebook, capsys, formats):
# Write a text notebook
nb = python_notebook
if formats:
nb.metadata["jupytext"] = {"formats": formats}
test_py = tmpdir.join("test.py")
write(nb, str(test_py))
# make it read-only
test_py.chmod(0o444)
# py -> ipynb
jupytext(["--to", "ipynb", "test.py"])
capture = capsys.readouterr()
assert "Updating the timestamp" not in capture.out
@pytest.mark.asyncio
@pytest.mark.parametrize("formats", ["ipynb,py", "py:percent", "py:light", None])
async def test_use_source_timestamp(tmpdir, cwd_tmpdir, python_notebook, capsys, formats, cm):
# Write a text notebook
nb = python_notebook
if formats:
nb.metadata["jupytext"] = {"formats": formats}
test_py = tmpdir.join("test.py")
test_ipynb = tmpdir.join("test.ipynb")
write(nb, str(test_py))
src_timestamp = test_py.stat().mtime
# Wait...
time.sleep(0.1)
# py -> ipynb
jupytext(["--to", "ipynb", "test.py", "--use-source-timestamp"])
capture = capsys.readouterr()
assert "Updating the timestamp" not in capture.out
dest_timestamp = test_ipynb.stat().mtime
# on Mac OS the dest_timestamp is truncated at the microsecond (#790)
assert src_timestamp - 1e-6 <= dest_timestamp <= src_timestamp
# Make sure that we can open the file in Jupyter
cm.outdated_text_notebook_margin = 0.001
cm.root_dir = str(tmpdir)
# No error here
await ensure_async(cm.get("test.ipynb"))
# But now if we don't use --use-source-timestamp
jupytext(["--to", "ipynb", "test.py"])
os.utime(test_py, (src_timestamp, src_timestamp))
# Then we can't open paired notebooks
if formats == "ipynb,py:percent":
from tornado.web import HTTPError
with pytest.raises(HTTPError, match="is more recent than test.py"):
await ensure_async(cm.get("test.ipynb"))
else:
await ensure_async(cm.get("test.ipynb"))
def test_round_trip_with_null_metadata_792(tmpdir, cwd_tmpdir, python_notebook):
nb = python_notebook
nb.metadata.kernelspec = {
"argv": ["python", "-m", "ipykernel_launcher", "-f", "{connection_file}"],
"display_name": "Python 3",
"env": None,
"interrupt_mode": "signal",
"language": "python",
"metadata": None,
"name": "python3",
}
write(nb, "test.ipynb")
jupytext(["--to", "py:percent", "test.ipynb"])
jupytext(["--to", "ipynb", "test.py"])
nb = read("test.ipynb")
assert nb.metadata.kernelspec.env is None
def test_set_shebang_with_update_metadata(tmp_path, python_notebook):
tmp_py = tmp_path / "nb.py"
write(python_notebook, tmp_py, fmt="py:percent")
jupytext(
[
str(tmp_py),
"--update-metadata",
'{"jupytext":{"executable":"/usr/bin/python"}}',
]
)
assert tmp_py.read_text().startswith("#!/usr/bin/python")
@pytest.mark.parametrize("compare_ids", [False, True])
@pytest.mark.parametrize("compare_outputs", [False, True])
def test_set_formats_does_not_override_existing_ipynb(tmp_path, notebook_with_outputs, compare_ids, compare_outputs):
tmp_py = tmp_path / "nb.py"
tmp_ipynb = tmp_path / "nb.ipynb"
write(notebook_with_outputs, tmp_ipynb)
jupytext([str(tmp_ipynb), "--set-formats", "ipynb,py:percent"])
jupytext([str(tmp_py), "--set-formats", "ipynb,py:percent"])
nb = read(tmp_ipynb)
compare_notebooks(
nb,
notebook_with_outputs,
compare_ids=compare_ids,
compare_outputs=compare_outputs,
)
@pytest.mark.requires_myst
@pytest.mark.parametrize(
"header",
[
"",
"""---
jupytext:
text_representation:
extension: .md
format_name: myst
kernelspec:
display_name: ipython3
language: python
name: ipython3
---
""",
],
)
def test_lexer_is_preserved_in_round_trips(
tmp_path,
no_jupytext_version_number,
header,
text="""```{code-cell} ipython3
1 + 1
```
""",
):
text = header + text
tmp_md = tmp_path / "notebook.md"
tmp_md.write_text(text)
jupytext(["--to", "myst", str(tmp_md)])
assert tmp_md.read_text() == text
@pytest.mark.requires_black
def test_pipe_with_quiet_does_not_print(tmp_path, capsys):
tmp_py = tmp_path / "nb.py"
tmp_py.write_text("# %%\n1+1\n")
jupytext(["--quiet", "--pipe", "black", str(tmp_py)])
captured = capsys.readouterr()
assert captured.out == ""
assert captured.err == ""
assert tmp_py.read_text() == "# %%\n1 + 1\n"
def test_update_formats_1386(python_notebook, tmp_path, capsys):
"""
Test that we can change the formats in an already paired notebook
"""
tmp_py = tmp_path / "notebook.py"
tmp_md = tmp_path / "notebook.md"
tmp_ipynb = tmp_path / "notebook.ipynb"
write(python_notebook, tmp_py, fmt="py:percent")
formats = "py:percent,md"
jupytext([str(tmp_py), "--set-formats", formats])
# We need to update all the files, not only their timestamps
capture = capsys.readouterr()
assert "Updating the timestamp" not in capture.out
# Each paired file should have the new formats
assert read(tmp_py)["metadata"]["jupytext"]["formats"] == formats
assert read(tmp_md)["metadata"]["jupytext"]["formats"] == formats
# The issue occurred when the py file was older than the md file
current_time = time.time()
os.utime(tmp_py, (current_time - 1, current_time - 1))
os.utime(tmp_md, (current_time, current_time))
formats = "ipynb,py:percent,md"
jupytext([str(tmp_py), "--set-formats", formats])
# We need to update all the files, not only their timestamps
capture = capsys.readouterr()
assert "Updating the timestamp" not in capture.out
# And each paired file should have the new formats
assert read(tmp_py)["metadata"]["jupytext"]["formats"] == formats
assert read(tmp_md)["metadata"]["jupytext"]["formats"] == formats
assert read(tmp_ipynb)["metadata"]["jupytext"]["formats"] == formats
def test_paired_paths_from_notebook_metadata(tmp_path, python_notebook, capsys):
ipynb_notebook_path = tmp_path / "notebook.ipynb"
python_notebook.metadata["jupytext"] = {"formats": "ipynb,py:percent,md"}
write(python_notebook, ipynb_notebook_path)
jupytext([str(ipynb_notebook_path), "--paired-paths"])
capture = capsys.readouterr()
paired_paths = capture.out.strip().split("\n")
assert paired_paths == [
str(tmp_path / "notebook.py"),
str(tmp_path / "notebook.md"),
], paired_paths
def test_paired_paths_from_config(tmp_path, python_notebook, capsys):
ipynb_notebook_path = tmp_path / "notebook.ipynb"
write(python_notebook, ipynb_notebook_path)
(tmp_path / "jupytext.toml").write_text('''formats="ipynb,py:percent,md"''')
jupytext([str(ipynb_notebook_path), "--paired-paths"])
capture = capsys.readouterr()
paired_paths = capture.out.strip().split("\n")
assert paired_paths == [
str(tmp_path / "notebook.py"),
str(tmp_path / "notebook.md"),
], paired_paths
@pytest.mark.parametrize("with_config", [False, True])
def test_sync_keeps_simple_python_file_unchanged(tmp_path, with_config: bool):
"""Test that jupytext --sync on a simple Python file leaves it unchanged,
even if a Jupytext configuration has formats=ipynb,py:percent
"""
# Create a simple Python file without jupytext metadata
if with_config:
config_file = tmp_path / "jupytext.toml"
config_file.write_text('formats = "ipynb,py:percent"')
py_file = tmp_path / "simple.py"
py_content = '''#!/usr/bin/env python3
"""A simple Python script"""
def hello():
print("Hello, world!")
if __name__ == "__main__":
hello()
'''
py_file.write_text(py_content)
# Record original timestamp and content
original_mtime = py_file.stat().st_mtime
original_content = py_file.read_text()
# Wait a bit to ensure timestamp would change if file was modified
time.sleep(0.1)
# Run jupytext --sync on the file
jupytext(["--sync", str(py_file)])
# Verify file is unchanged
final_mtime = py_file.stat().st_mtime
final_content = py_file.read_text()
assert final_mtime == original_mtime, "File timestamp should be unchanged"
assert final_content == original_content, "File content should be unchanged"
# Verify no additional files were created
files_in_dir = list(tmp_path.iterdir())
if with_config:
assert len(files_in_dir) == 2, f"Expected only 2 files, found: {[f.name for f in files_in_dir]}"
assert set(files_in_dir) == {py_file, config_file}
else:
assert len(files_in_dir) == 1, f"Expected only 1 file, found: {[f.name for f in files_in_dir]}"
assert files_in_dir[0] == py_file
def test_set_formats_pairing_in_subfolders(tmp_path, python_notebook):
"""Test that jupytext --set-formats works with subfolders, including on Windows (#1028)"""
ipynb_notebook_dir = tmp_path / "notebooks" / "subfolder"
ipynb_notebook_dir.mkdir(parents=True)
ipynb_notebook_path = ipynb_notebook_dir / "notebook.ipynb"
write(python_notebook, ipynb_notebook_path)
jupytext([str(ipynb_notebook_path), "--set-formats", "notebooks///ipynb,scripts///py:percent"])
assert (tmp_path / "scripts" / "subfolder" / "notebook.py").exists()
def test_sync_in_subfolders(tmp_path, python_notebook):
"""Test that jupytext --sync works with subfolders, including on Windows (#1028)"""
ipynb_notebook_dir = tmp_path / "notebooks" / "subfolder"
ipynb_notebook_dir.mkdir(parents=True)
ipynb_notebook_path = ipynb_notebook_dir / "notebook.ipynb"
write(python_notebook, ipynb_notebook_path)
(tmp_path / "jupytext.toml").write_text("""[formats]
"notebooks/" = "ipynb"
"scripts/" = "py:percent"
""")
jupytext([str(ipynb_notebook_path), "--sync"])
assert (tmp_path / "scripts" / "subfolder" / "notebook.py").exists()
================================================
FILE: tests/functional/cli/test_cli_config.py
================================================
import nbformat
import pytest
from nbformat.v4.nbbase import new_code_cell, new_notebook
from jupytext.cli import jupytext
from jupytext.compare import compare
from jupytext.header import header_to_metadata_and_cell
from jupytext.jupytext import read, write
def test_pairing_through_config_leaves_ipynb_unmodified(tmpdir):
cfg_file = tmpdir.join(".jupytext.yml")
nb_file = tmpdir.join("notebook.ipynb")
py_file = tmpdir.join("notebook.py")
cfg_file.write("formats: 'ipynb,py'\n")
nbformat.write(new_notebook(), str(nb_file))
jupytext([str(nb_file), "--sync"])
assert nb_file.isfile()
assert py_file.isfile()
nb = nbformat.read(nb_file, as_version=4)
assert "jupytext" not in nb.metadata
def test_formats(tmpdir):
tmpdir.join(".jupytext").write(
'''# Default pairing
formats = "ipynb,py"'''
)
test = tmpdir.join("test.py")
test.write("1 + 1\n")
jupytext([str(test), "--sync"])
assert tmpdir.join("test.ipynb").isfile()
def test_formats_with_suffix(tmpdir):
tmpdir.join(".jupytext").write('formats = "ipynb,.nb.py"')
test = tmpdir.join("test.py")
test.write("1 + 1\n")
test_nb = tmpdir.join("test.nb.py")
test_nb.write("1 + 1\n")
jupytext([str(test), "--sync"])
assert not tmpdir.join("test.ipynb").isfile()
jupytext([str(test_nb), "--sync"])
assert tmpdir.join("test.ipynb").isfile()
def test_formats_does_not_apply_to_config_file(tmpdir):
config = tmpdir.join(".jupytext.py")
config.write('c.formats = "ipynb,py"')
test = tmpdir.join("test.py")
test.write("1 + 1\n")
jupytext([str(test), str(config), "--sync"])
assert tmpdir.join("test.ipynb").isfile()
assert not tmpdir.join(".jupytext.ipynb").isfile()
def test_preferred_jupytext_formats_save(tmpdir):
tmpdir.join(".jupytext.yml").write("preferred_jupytext_formats_save: jl:percent")
tmp_ipynb = tmpdir.join("notebook.ipynb")
tmp_jl = tmpdir.join("notebook.jl")
nb = new_notebook(cells=[new_code_cell("1 + 1")], metadata={"jupytext": {"formats": "ipynb,jl"}})
write(nb, str(tmp_ipynb))
jupytext([str(tmp_ipynb), "--sync"])
with open(str(tmp_jl)) as stream:
text_jl = stream.read()
# Parse the YAML header
metadata, _, _, _ = header_to_metadata_and_cell(text_jl.splitlines(), "#", "")
assert metadata["jupytext"]["formats"] == "ipynb,jl:percent"
@pytest.mark.parametrize(
"config",
[
# Way 1: preferred_jupytext_formats_save + formats
"""preferred_jupytext_formats_save: "python//py:percent"
formats: "ipynb,python//py"
""",
# Way 2: formats
"formats: ipynb,python//py:percent",
],
)
def test_save_using_preferred_and_default_format(config, tmpdir):
tmpdir.join(".jupytext.yml").write(config)
tmp_ipynb = tmpdir.join("notebook.ipynb")
tmp_py = tmpdir.join("python").join("notebook.py")
nb = new_notebook(cells=[new_code_cell("1 + 1")])
write(nb, str(tmp_ipynb))
jupytext([str(tmp_ipynb), "--sync"])
# read py file
nb_py = read(str(tmp_py))
assert nb_py.metadata["jupytext"]["text_representation"]["format_name"] == "percent"
def test_hide_notebook_metadata(tmpdir, no_jupytext_version_number):
tmpdir.join(".jupytext").write("hide_notebook_metadata = true")
tmp_ipynb = tmpdir.join("notebook.ipynb")
tmp_md = tmpdir.join("notebook.md")
nb = new_notebook(cells=[new_code_cell("1 + 1")], metadata={"jupytext": {"formats": "ipynb,md"}})
write(nb, str(tmp_ipynb))
jupytext([str(tmp_ipynb), "--sync"])
with open(str(tmp_md)) as stream:
text_md = stream.read()
compare(
text_md,
"""
```python
1 + 1
```
""",
)
def test_cli_config_on_windows_issue_629(tmpdir):
cfg_file = tmpdir.join("jupytext.yml")
cfg_file.write(
"""formats: "notebooks///ipynb,scripts///py:percent"
notebook_metadata_filter: "jupytext"
"""
)
tmpdir.mkdir("scripts").join("test.py").write("# %%\n 1+1\n")
jupytext(["--sync", str(tmpdir.join("scripts").join("*.py"))])
assert tmpdir.join("notebooks").join("test.ipynb").exists()
def test_sync_config_does_not_create_formats_metadata(tmpdir, cwd_tmpdir, python_notebook):
tmpdir.join("jupytext.yml").write(
"""formats: "ipynb,py:percent"
"""
)
write(python_notebook, "test.ipynb")
jupytext(["--sync", "test.ipynb"])
nb = read("test.py")
assert "formats" not in nb.metadata["jupytext"]
def test_multiple_formats_771(tmpdir, cwd_tmpdir, python_notebook):
tmpdir.join("jupytext.toml").write(
"""formats = "notebooks///ipynb,notebooks///py,scripts///py:percent"
"""
)
notebooks_dir = tmpdir.mkdir("notebooks")
scripts_dir = tmpdir.join("scripts")
write(python_notebook, str(notebooks_dir.join("notebook.ipynb")))
jupytext(["--sync", "notebooks/notebook.ipynb"])
assert notebooks_dir.join("notebook.py").isfile()
assert scripts_dir.join("notebook.py").isfile()
notebooks_dir.join("module.py").write("1 + 1\n")
jupytext(["--sync", "notebooks/module.py"])
assert notebooks_dir.join("module.ipynb").isfile()
assert scripts_dir.join("module.py").isfile()
================================================
FILE: tests/functional/cli/test_source_is_newer.py
================================================
"""
Here we test the --check-source-is-newer option of the jupytext CLI
"""
import os
from jupytext import cli
from jupytext import write
import pytest
def test_check_source_is_newer_when_using_jupytext_to(tmp_path, python_notebook):
tmp_ipynb = tmp_path / "notebook.ipynb"
tmp_py = tmp_path / "notebook.py"
write(python_notebook, tmp_ipynb, fmt="ipynb")
# First, we convert the .ipynb to .py
cli.jupytext([str(tmp_ipynb), "--to", "py", "--check-source-is-newer"])
assert tmp_py.exists()
# Now, we modify the .py file so that it is more recent than the .ipynb file
text = tmp_py.read_text() + "\n# A new comment"
tmp_py.write_text(text)
# We can convert the .py to .ipynb because the .py is more recent than the .ipynb
cli.jupytext([str(tmp_py), "--to", "ipynb", "--check-source-is-newer"])
# We modify the .ipynb file so that it is more recent than the .py file
text = tmp_ipynb.read_text().replace("A new comment", "Another new comment")
tmp_ipynb.write_text(text)
# Now, trying to convert the .py to .ipynb raises an error because the .py is older than the .ipynb
with pytest.raises(ValueError, match=r"Source .*notebook\.py.* is older than destination .*notebook\.ipynb.*"):
cli.jupytext([str(tmp_py), "--to", "ipynb", "--check-source-is-newer"])
def test_check_source_is_newer_when_using_jupytext_sync(tmp_path, python_notebook):
tmp_ipynb = tmp_path / "notebook.ipynb"
tmp_py = tmp_path / "notebook.py"
write(python_notebook, tmp_ipynb, fmt="ipynb")
# First, we turn the notebook into a paired notebook
cli.jupytext([str(tmp_ipynb), "--set-formats", "ipynb,py", "--check-source-is-newer"])
assert tmp_py.exists()
# Running sync on the .py file works as .py is always more recent after a --sync operation
cli.jupytext([str(tmp_py), "--sync", "--check-source-is-newer"])
# Make .ipynb slightly older again to ensure .py is newer
stat = os.stat(tmp_ipynb)
os.utime(tmp_ipynb, (stat.st_atime, stat.st_mtime - 1))
# Now, trying to sync the .ipynb to .py raises an error because .ipynb is older than .py
with pytest.raises(ValueError, match=r"Source .*notebook\.ipynb.* is older than paired file .*notebook\.py.*"):
cli.jupytext([str(tmp_ipynb), "--sync", "--check-source-is-newer"])
# We modify the .ipynb file so that it is more recent than the .py file
text = tmp_ipynb.read_text().replace("A short notebook", "A short notebook with a modification")
tmp_ipynb.write_text(text)
# Make .py slightly older to ensure .ipynb is newer
stat = os.stat(tmp_py)
os.utime(tmp_py, (stat.st_atime, stat.st_mtime - 1))
# Now, trying to sync the .py to .ipynb raises an error because the .py is older than the .ipynb
with pytest.raises(ValueError, match=r"Source .*notebook\.py.* is older than paired file .*notebook\.ipynb.*"):
cli.jupytext([str(tmp_py), "--sync", "--check-source-is-newer"])
# Running sync on the .ipynb file works as .ipynb is now more recent than .py
cli.jupytext([str(tmp_ipynb), "--sync", "--check-source-is-newer"])
================================================
FILE: tests/functional/cli/test_synchronous_changes.py
================================================
"""
These tests ensure that Jupytext raises an error when a file loaded by Jupytext
changes while Jupytext is running.
To make the simultaneous change occur in the tests, we monkey-patch the function `create_prefix_dir`
which is called just before writing the file back to disk.
"""
from jupytext import cli
from jupytext import write
import pytest
def test_jupytext_sync_raises_on_synchronous_edits(tmp_path, python_notebook, monkeypatch):
(tmp_path / "jupytext.toml").write_text("""formats = "ipynb,py" """)
tmp_py = tmp_path / "notebook.py"
tmp_ipynb = tmp_path / "notebook.ipynb"
write(python_notebook, tmp_py, fmt="py:percent")
def edit_py_file(path):
text = tmp_py.read_text() + "\n# A new comment"
tmp_py.write_text(text)
# The print statements help to see which Jupytext actions correspond to which test
print("Testing a synchronous edit on a .py file that does not have a .ipynb counterpart")
monkeypatch.setattr(cli, "_callback_on_lazy_write", edit_py_file)
with pytest.raises(
cli.SynchronousModificationError, match=r"The file .*notebook\.py.* was modified while Jupytext was running"
):
cli.jupytext([str(tmp_py), "--sync"])
assert not tmp_ipynb.exists()
print("Testing the normal sync command that creates the .ipynb file")
monkeypatch.setattr(cli, "_callback_on_lazy_write", None)
cli.jupytext([str(tmp_py), "--sync"])
assert tmp_ipynb.exists()
print("Testing a synchronous edit on a .py file that does have a .ipynb counterpart")
monkeypatch.setattr(cli, "_callback_on_lazy_write", edit_py_file)
with pytest.raises(
cli.SynchronousModificationError, match=r"The file .*notebook\.py.* was modified while Jupytext was running"
):
cli.jupytext([str(tmp_py), "--sync"])
print("Testing a synchronous deletion of the .ipynb file")
def rm_ipynb_file(path):
tmp_ipynb.unlink()
monkeypatch.setattr(cli, "_callback_on_lazy_write", rm_ipynb_file)
with pytest.raises(
cli.SynchronousModificationError, match=r"The file .*notebook\.ipynb.* was deleted while Jupytext was running"
):
cli.jupytext([str(tmp_py), "--sync"])
assert not tmp_ipynb.exists()
print("Testing a synchronous creation of the .ipynb file")
def create_ipynb_file(path):
tmp_ipynb.write_text("{}")
monkeypatch.setattr(cli, "_callback_on_lazy_write", create_ipynb_file)
with pytest.raises(
cli.SynchronousModificationError, match=r"The file .*notebook\.ipynb.* was created while Jupytext was running"
):
cli.jupytext([str(tmp_py), "--sync"])
def test_jupytext_to_raises_on_synchronous_edits(tmp_path, python_notebook, monkeypatch):
tmp_py = tmp_path / "notebook.py"
tmp_ipynb = tmp_path / "notebook.ipynb"
write(python_notebook, tmp_py, fmt="py:percent")
def edit_py_file(path):
text = tmp_py.read_text() + "\n# A new comment"
tmp_py.write_text(text)
# The print statements help to see which Jupytext actions correspond to which test
print("Testing a synchronous edit on a .py file")
monkeypatch.setattr(cli, "_callback_on_lazy_write", edit_py_file)
with pytest.raises(
cli.SynchronousModificationError, match=r"The file .*notebook\.py.* was modified while Jupytext was running"
):
cli.jupytext([str(tmp_py), "--to", "ipynb"])
assert not tmp_ipynb.exists()
print("Testing the normal to command that creates the .ipynb file")
monkeypatch.setattr(cli, "_callback_on_lazy_write", None)
cli.jupytext([str(tmp_py), "--to", "ipynb"])
assert tmp_ipynb.exists()
print("Testing a synchronous edit on a .py file that is not paired to a .ipynb file")
monkeypatch.setattr(cli, "_callback_on_lazy_write", edit_py_file)
# This one works as the .py file is not paired, so it is not read
cli.jupytext([str(tmp_ipynb), "--to", "py"])
print("Turning the .py file into a paired notebook")
monkeypatch.setattr(cli, "_callback_on_lazy_write", None)
cli.jupytext([str(tmp_ipynb), "--set-formats", "ipynb,py"])
print("Testing a synchronous edit on a paired .py file")
monkeypatch.setattr(cli, "_callback_on_lazy_write", edit_py_file)
with pytest.raises(
cli.SynchronousModificationError, match=r"The file .*notebook\.py.* was modified while Jupytext was running"
):
cli.jupytext([str(tmp_py), "--to", "ipynb"])
================================================
FILE: tests/functional/config/test_config.py
================================================
import os
from pathlib import Path
from contextlib import contextmanager
import pytest
from jupytext.config import (
find_jupytext_configuration_file,
load_jupytext_configuration_file,
notebook_formats,
)
from jupytext.jupytext import load_jupytext_config, read
@contextmanager
def change_dir(path):
"""Context manager to temporarily change directory."""
old_cwd = os.getcwd()
try:
os.chdir(path)
yield
finally:
os.chdir(old_cwd)
@pytest.fixture
def temp_folder_tree(tmp_path):
"""
Fixture that creates a temporary folder tree.
tmp_path is a pytest built-in fixture that auto-cleans up.
"""
# Create folder structure
(tmp_path / "subdir").mkdir()
# Create some files
(tmp_path / "jupytext.toml").write_text("")
(tmp_path / "subdir" / "notebook.ipynb").write_text("")
return tmp_path
def test_issue_1440(temp_folder_tree):
"""Test that jupytext finds the config file even in parent of cwd"""
notebook = Path("notebook.ipynb")
notebook_str = str(notebook)
expected_toml = str(temp_folder_tree / "jupytext.toml")
with change_dir(temp_folder_tree / "subdir"):
assert notebook.exists()
config_file_from_path = find_jupytext_configuration_file(notebook)
assert config_file_from_path == expected_toml
config_file_from_str = find_jupytext_configuration_file(notebook_str)
assert config_file_from_str == expected_toml
def test_find_jupytext_configuration_file(tmpdir):
nested = tmpdir.mkdir("nested")
# Start with no configuration
assert find_jupytext_configuration_file(str(nested)) is None
# Configuration file in the parent directory
root_config = tmpdir.join("jupytext.yml")
root_config.write("\n")
assert os.path.samefile(find_jupytext_configuration_file(str(tmpdir)), str(root_config))
assert os.path.samefile(find_jupytext_configuration_file(str(nested)), str(root_config))
# Local pyproject file
pyproject_config = nested.join("pyproject.toml")
pyproject_config.write("[tool.jupytext]\n")
assert os.path.samefile(find_jupytext_configuration_file(str(tmpdir)), str(root_config))
assert os.path.samefile(find_jupytext_configuration_file(str(nested)), str(pyproject_config))
# Local configuration file
local_config = nested.join(".jupytext")
local_config.write("\n")
assert os.path.samefile(find_jupytext_configuration_file(str(tmpdir)), str(root_config))
assert os.path.samefile(find_jupytext_configuration_file(str(nested)), str(local_config))
def test_jupytext_py_is_not_a_configuration_file(tmpdir):
jupytext_py = tmpdir.join("jupytext.py")
jupytext_py.write("# Not a config file!")
assert find_jupytext_configuration_file(str(tmpdir)) is None
dot_jupytext_py = tmpdir.join(".jupytext.py")
dot_jupytext_py.write("# This is a config file!")
assert find_jupytext_configuration_file(str(tmpdir)) == str(dot_jupytext_py)
@pytest.mark.parametrize(
"config_file",
[
"pyproject.toml",
"jupytext",
"jupytext.toml",
"jupytext.yml",
"jupytext.json",
"jupytext.py",
],
)
def test_load_jupytext_configuration_file(tmpdir, config_file):
full_config_path = tmpdir.join(config_file)
if config_file == "pyproject.toml":
full_config_path.write(
"""[tool.jupytext]
formats = "ipynb,py:percent"
notebook_metadata_filter = "all"
cell_metadata_filter = "all"
"""
)
elif config_file.endswith(("jupytext", ".toml")):
full_config_path.write(
"""formats = "ipynb,py:percent"
notebook_metadata_filter = "all"
cell_metadata_filter = "all"
"""
)
elif config_file.endswith(".yml"):
full_config_path.write(
"""formats: ipynb,py:percent
notebook_metadata_filter: all
cell_metadata_filter: all
"""
)
elif config_file.endswith(".json"):
full_config_path.write(
"""{"formats": "ipynb,py:percent",
"notebook_metadata_filter": "all",
"cell_metadata_filter": "all"
}
"""
)
elif config_file.endswith(".py"):
full_config_path.write(
"""c.formats = "ipynb,py:percent"
c.notebook_metadata_filter = "all"
c.cell_metadata_filter = "all"
"""
)
config = load_jupytext_configuration_file(str(full_config_path))
assert config.formats == ["ipynb,py:percent"]
assert config.notebook_metadata_filter == "all"
assert config.cell_metadata_filter == "all"
@pytest.mark.parametrize(
"content_toml,formats_short_form",
[
(
"""# always pair ipynb notebooks to py:percent files
formats = "ipynb,py:percent"
""",
"ipynb,py:percent",
),
(
"""# always pair ipynb notebooks to py:percent files
formats = "ipynb,py:percent"
""",
"ipynb,py:percent",
),
(
"""# Pair notebooks in subfolders of 'notebooks' to scripts in subfolders of 'scripts'
[formats]
"notebooks/" = "ipynb"
"scripts/" = "py:percent"
""",
"notebooks///ipynb,scripts///py:percent",
),
(
"""# Pair notebooks in subfolders of 'notebooks' to scripts in subfolders of 'scripts'
[formats]
"notebooks" = "ipynb"
"scripts" = "py:percent"
""",
"notebooks///ipynb,scripts///py:percent",
),
(
"""# Pair local notebooks to scripts in 'notebooks_py' and md files in 'notebooks_md'
[formats]
"" = "ipynb"
"notebooks_py" = "py:percent"
"notebooks_md" = "md:myst"
""",
"ipynb,notebooks_py///py:percent,notebooks_md///md:myst",
),
],
)
def test_jupytext_formats(tmpdir, content_toml, formats_short_form):
jupytext_toml = tmpdir.join("jupytext.toml")
jupytext_toml.write(content_toml)
config = load_jupytext_configuration_file(str(jupytext_toml))
assert config.formats == [formats_short_form]
def test_deprecated_formats_cause_warning(tmpdir, content_toml="default_jupytext_formats = 'ipynb,md'"):
jupytext_toml = tmpdir.join("jupytext.toml")
jupytext_toml.write(content_toml)
config = load_jupytext_configuration_file(str(jupytext_toml))
with pytest.warns(FutureWarning, match="use 'formats'"):
assert config.default_formats(str(tmpdir.join("test.md"))) == "ipynb,md"
@pytest.mark.parametrize(
"option_name",
["notebook_metadata_filter", "cell_metadata_filter", "cell_markers"],
)
def test_deprecated_options_cause_warning(tmpdir, option_name):
jupytext_toml = tmpdir.join("jupytext.toml")
jupytext_toml.write(f"default_{option_name} = 'value'")
config = load_jupytext_configuration_file(str(jupytext_toml))
fmt = {}
with pytest.warns(FutureWarning, match=f"use '{option_name}'"):
config.set_default_format_options(fmt)
assert fmt[option_name] == "value"
def test_simple_py_file_is_not_paired(tmp_path):
py_file = tmp_path / "simple.py"
py_file.write_text('print("Hello, world!")')
config_file = tmp_path / "jupytext.toml"
config_file.write_text('formats = "ipynb,py:percent"')
notebook = read(str(py_file))
config_file = load_jupytext_config(str(config_file))
formats = notebook_formats(notebook, config_file, str(py_file))
assert formats == [{"extension": ".py", "format_name": "light"}], formats
def test_pairing_groups(tmp_path):
"""Test list-based formats for subset-specific pairing"""
jupytext_toml = tmp_path / "jupytext.toml"
jupytext_toml.write_text("""
[[formats]]
"notebooks/tutorials/" = "ipynb"
"docs/tutorials/" = "md"
"scripts/tutorials/" = "py:percent"
[[formats]]
"notebooks/" = "ipynb"
"scripts/" = "py:percent"
""")
config = load_jupytext_configuration_file(str(jupytext_toml))
# Formats should be a list of str
assert isinstance(config.formats, list)
assert len(config.formats) == 2
assert all(isinstance(f, str) for f in config.formats)
# Test that default_formats returns the correct formats based on path
# Tutorial notebook should match first format (tutorials)
tutorial_notebook = str(tmp_path / "notebooks" / "tutorials" / "getting_started.ipynb")
assert (
config.default_formats(tutorial_notebook)
== "notebooks/tutorials///ipynb,docs/tutorials///md,scripts/tutorials///py:percent"
)
# Regular notebook should match second format (main)
regular_notebook = str(tmp_path / "notebooks" / "hello.ipynb")
assert config.default_formats(regular_notebook) == "notebooks///ipynb,scripts///py:percent"
def test_pairing_groups_multiple_groups(tmp_path):
"""Test multiple format sets with list-based formats"""
jupytext_toml = tmp_path / "jupytext.toml"
jupytext_toml.write_text("""
[[formats]]
"notebooks/tutorials/" = "ipynb"
"docs/tutorials/" = "md"
[[formats]]
"notebooks/examples/" = "ipynb"
"docs/examples/" = "md:myst"
[[formats]]
"notebooks/" = "ipynb"
"scripts/" = "py:percent"
""")
config = load_jupytext_configuration_file(str(jupytext_toml))
# Check formats is a list of dicts
assert isinstance(config.formats, list)
assert len(config.formats) == 3
# Test that the correct format is selected based on path (first match wins)
tutorial_notebook = str(tmp_path / "notebooks" / "tutorials" / "intro.ipynb")
assert config.default_formats(tutorial_notebook) == "notebooks/tutorials///ipynb,docs/tutorials///md"
example_notebook = str(tmp_path / "notebooks" / "examples" / "demo.ipynb")
assert config.default_formats(example_notebook) == "notebooks/examples///ipynb,docs/examples///md:myst"
# Regular notebook should use the last (default) format
regular_notebook = str(tmp_path / "notebooks" / "regular.ipynb")
assert config.default_formats(regular_notebook) == "notebooks///ipynb,scripts///py:percent"
def test_formats_list_without_default(tmp_path):
"""Test list-based formats without a default catchall"""
jupytext_toml = tmp_path / "jupytext.toml"
jupytext_toml.write_text("""
[[formats]]
"notebooks/tutorials/" = "ipynb"
"docs/tutorials/" = "md"
""")
config = load_jupytext_configuration_file(str(jupytext_toml))
# Formats should be a list
assert isinstance(config.formats, list)
assert len(config.formats) == 1
# Matching notebook should work
tutorial_notebook = str(tmp_path / "notebooks" / "tutorials" / "getting_started.ipynb")
assert config.default_formats(tutorial_notebook) == "notebooks/tutorials///ipynb,docs/tutorials///md"
# Non-matching notebook should return None
other_notebook = str(tmp_path / "notebooks" / "other.ipynb")
assert config.default_formats(other_notebook) is None
def test_formats_list_yaml(tmp_path):
"""Test list-based formats with YAML config"""
jupytext_yml = tmp_path / "jupytext.yml"
jupytext_yml.write_text("""
formats:
- notebooks/tutorials/: ipynb
docs/tutorials/: md
- notebooks/: ipynb
scripts/: py:percent
""")
config = load_jupytext_configuration_file(str(jupytext_yml))
# Formats should be a list
assert isinstance(config.formats, list)
assert len(config.formats) == 2
def test_formats_list_json(tmp_path):
"""Test list-based formats with JSON config"""
jupytext_json = tmp_path / "jupytext.json"
jupytext_json.write_text("""{
"formats": [
{
"notebooks/tutorials/": "ipynb",
"docs/tutorials/": "md"
},
{
"notebooks/": "ipynb",
"scripts/": "py:percent"
}
]
}
""")
config = load_jupytext_configuration_file(str(jupytext_json))
# Formats should be a list
assert isinstance(config.formats, list)
assert len(config.formats) == 2
def test_formats_semicolon_separated(tmp_path):
"""Test semicolon-separated format strings"""
jupytext_toml = tmp_path / "jupytext.toml"
jupytext_toml.write_text("""
formats = "notebooks///ipynb,scripts///py:percent;ipynb,py:percent"
""")
config = load_jupytext_configuration_file(str(jupytext_toml))
# Formats should be split into a list
assert isinstance(config.formats, list)
assert len(config.formats) == 2
assert config.formats[0] == "notebooks///ipynb,scripts///py:percent"
assert config.formats[1] == "ipynb,py:percent"
# Test that the correct format is selected based on path
notebook_in_notebooks = str(tmp_path / "notebooks" / "test.ipynb")
assert config.default_formats(notebook_in_notebooks) == "notebooks///ipynb,scripts///py:percent"
notebook_elsewhere = str(tmp_path / "test.ipynb")
assert config.default_formats(notebook_elsewhere) == "ipynb,py:percent"
def test_formats_toml_list_of_strings(tmp_path):
"""Test TOML list with string format specifications"""
jupytext_toml = tmp_path / "jupytext.toml"
jupytext_toml.write_text("""
formats = [
"notebooks///ipynb,scripts///py:percent",
"ipynb,py:percent"
]
""")
config = load_jupytext_configuration_file(str(jupytext_toml))
# Formats should be a list
assert isinstance(config.formats, list)
assert len(config.formats) == 2
assert config.formats[0] == "notebooks///ipynb,scripts///py:percent"
assert config.formats[1] == "ipynb,py:percent"
# Test that the correct format is selected based on path
notebook_in_notebooks = str(tmp_path / "notebooks" / "test.ipynb")
assert config.default_formats(notebook_in_notebooks) == "notebooks///ipynb,scripts///py:percent"
notebook_elsewhere = str(tmp_path / "test.ipynb")
assert config.default_formats(notebook_elsewhere) == "ipynb,py:percent"
================================================
FILE: tests/functional/contents_manager/test_async_and_sync_contents_manager_are_in_sync.py
================================================
from pathlib import Path
import pytest
from black import FileMode, format_str
from jupytext.async_contentsmanager import __file__ as async_contentsmanager_file
from jupytext.async_pairs import __file__ as async_pairs_file
from jupytext.sync_contentsmanager import __file__ as sync_contentsmanager_file
from jupytext.sync_pairs import __file__ as sync_pairs_file
def generate_sync_code_from_async_code(async_code: str) -> str:
# No async methods
sync_code = async_code.replace("async def", "def")
# Don't await
sync_code = sync_code.replace("await ", "")
# Rename the contents manager
sync_code = sync_code.replace("AsyncLargeFileManager", "LargeFileManager")
sync_code = sync_code.replace("AsyncJupytextContentsManager", "SyncJupytextContentsManager")
sync_code = sync_code.replace("AsyncTextFileContentsManager", "TextFileContentsManager")
sync_code = sync_code.replace("asynchronous", "synchronous")
sync_code = sync_code.replace("async_", "sync_")
# Add a header
sync_code = f'''"""
This file is automatically generated by
tests/functional/contents_manager/test_async_and_sync_contents_manager_are_in_sync.py
Do not edit this file manually.
"""
{sync_code}'''
sync_code = format_str(sync_code, mode=FileMode())
return sync_code
@pytest.mark.parametrize(
"async_file, sync_file",
[
(async_contentsmanager_file, sync_contentsmanager_file),
(async_pairs_file, sync_pairs_file),
],
)
def test_async_and_sync_files_are_in_sync(async_file, sync_file):
async_code = Path(async_file).read_text()
sync_code = generate_sync_code_from_async_code(async_code)
actual_sync_code = Path(sync_file).read_text()
try:
assert actual_sync_code == sync_code
except AssertionError:
Path(sync_file).write_text(sync_code)
raise
================================================
FILE: tests/functional/docs/test_changelog.py
================================================
import re
import sys
from pathlib import Path
import pytest
from jupytext.version import __version__
def replace_issue_number_with_links(text):
return re.sub(
r"([^\[-])#([0-9]+)",
r"\1[#\2](https://github.com/mwouts/jupytext/issues/\2)",
text,
)
@pytest.mark.parametrize(
"input,output",
[
(
"Issue #535",
"Issue [#535](https://github.com/mwouts/jupytext/issues/535)",
),
(
"Multiline\ntext (#123)",
"Multiline\ntext ([#123](https://github.com/mwouts/jupytext/issues/123))",
),
(
"(#123) and [Another-project-#535](https://custom_url)",
"([#123](https://github.com/mwouts/jupytext/issues/123)) and [Another-project-#535](https://custom_url)",
),
],
)
def test_replace_issue_numbers_with_links(input, output):
assert replace_issue_number_with_links(input) == output
@pytest.mark.skipif(sys.version_info < (3, 5), reason="'PosixPath' object has no attribute 'read_text'")
def test_update_changelog():
changelog_file = Path(__file__).parent.parent.parent.parent / "CHANGELOG.md"
cur_text = changelog_file.read_text()
new_text = replace_issue_number_with_links(cur_text)
if cur_text != new_text:
changelog_file.write_text(new_text) # pragma: no cover
def test_version_matches_changelog():
root_path = Path(__file__).parent.parent.parent.parent
changelog_file = root_path / "CHANGELOG.md"
# Read version from version.py
current_version = __version__
# Read first version from CHANGELOG.md
changelog_text = changelog_file.read_text()
prev_line = ""
for line in changelog_text.splitlines():
if not line.startswith("--------"):
prev_line = line
continue
changelog_version = prev_line.split("(")[0].strip()
assert current_version == changelog_version, (
f"Version mismatch: version.py has {current_version}, but CHANGELOG.md has {changelog_version}"
)
return
raise ValueError("No version found in CHANGELOG.md")
def test_version_pep440_compliance():
pep440_regex = r"^(?:(?:0|[1-9]\d*)\.){2}(?:0|[1-9]\d*)(?:[abc]|rc)?(?:\d+)?(?:\.post\d+)?(?:\.dev\d+)?$"
assert re.match(pep440_regex, __version__), f"Version {__version__} is not PEP 440 compliant"
================================================
FILE: tests/functional/docs/test_doc_files_are_notebooks.py
================================================
from pathlib import Path
import pytest
from jupytext import read
def documentation_files():
for path in (Path(__file__).parent / "../../../docs").iterdir():
if path.suffix == ".md":
yield path
@pytest.mark.parametrize(
"doc_file",
documentation_files(),
ids=[doc_file.stem for doc_file in documentation_files()],
)
def test_doc_files_are_notebooks(doc_file):
nb = read(doc_file)
# count how many cell types
counts = {"markdown": 0, "raw": 0, "code": 0}
for cell in nb.cells:
counts[cell.cell_type] += 1
assert counts["raw"] <= 1
================================================
FILE: tests/functional/metadata/test_metadata_filter.py
================================================
from copy import deepcopy
import pytest
from nbformat.v4.nbbase import new_code_cell, new_notebook
from jupytext import reads, writes
from jupytext.cli import jupytext as jupytext_cli
from jupytext.compare import compare, compare_notebooks
from jupytext.metadata_filter import filter_metadata, metadata_filter_as_dict
def to_dict(keys):
return {key: None for key in keys}
@pytest.mark.parametrize(
"metadata_filter_string,metadata_filter_dict",
[
(
"all, -widgets,-varInspector",
{"additional": "all", "excluded": ["widgets", "varInspector"]},
),
("toc", {"additional": ["toc"]}),
("+ toc", {"additional": ["toc"]}),
("preserve,-all", {"additional": ["preserve"], "excluded": "all"}),
(
"ExecuteTime, autoscroll, -hide_output",
{"additional": ["ExecuteTime", "autoscroll"], "excluded": ["hide_output"]},
),
],
)
def test_string_to_dict_conversion(metadata_filter_string, metadata_filter_dict):
assert metadata_filter_as_dict(metadata_filter_string) == metadata_filter_dict
def test_metadata_filter_as_dict():
assert metadata_filter_as_dict(True) == metadata_filter_as_dict("all")
assert metadata_filter_as_dict(False) == metadata_filter_as_dict("-all")
assert metadata_filter_as_dict({"excluded": "all"}) == metadata_filter_as_dict("-all")
def test_metadata_filter_default():
assert filter_metadata(to_dict(["technical", "user", "preserve"]), None, "-technical") == to_dict(["user", "preserve"])
assert filter_metadata(to_dict(["technical", "user", "preserve"]), None, "preserve,-all") == to_dict(["preserve"])
def test_metadata_filter_user_plus_default():
assert filter_metadata(to_dict(["technical", "user", "preserve"]), "-user", "-technical") == to_dict(["preserve"])
assert filter_metadata(to_dict(["technical", "user", "preserve"]), "all,-user", "-technical") == to_dict(
["preserve", "technical"]
)
assert filter_metadata(to_dict(["technical", "user", "preserve"]), "user", "preserve,-all") == to_dict(
["user", "preserve"]
)
def test_metadata_filter_user_overrides_default():
assert filter_metadata(to_dict(["technical", "user", "preserve"]), "all,-user", "-technical") == to_dict(
["technical", "preserve"]
)
assert filter_metadata(to_dict(["technical", "user", "preserve"]), "user,-all", "preserve") == to_dict(["user"])
def test_negative_cell_metadata_filter():
assert filter_metadata(to_dict(["exectime"]), "-linesto", "-exectime") == to_dict([])
def test_cell_metadata_filter_is_updated():
text = """---
jupyter:
jupytext:
cell_metadata_filter: -all
---
```{r cache=FALSE}
1+1
```
"""
nb = reads(text, "Rmd")
assert nb.metadata["jupytext"]["cell_metadata_filter"] == "cache,-all"
text2 = writes(nb, "Rmd")
assert text.splitlines()[-3:] == text2.splitlines()[-3:]
def test_notebook_metadata_all():
nb = new_notebook(
metadata={
"user_metadata": [1, 2, 3],
"jupytext": {"notebook_metadata_filter": "all"},
}
)
text = writes(nb, "md")
assert "user_metadata" in text
def test_notebook_metadata_none():
nb = new_notebook(metadata={"jupytext": {"notebook_metadata_filter": "-all"}})
text = writes(nb, "md")
assert "---" not in text
def test_filter_nested_metadata():
metadata = {"I": {"1": {"a": 1, "b": 2}}}
assert filter_metadata(metadata, "I", "-all") == {"I": {"1": {"a": 1, "b": 2}}}
assert filter_metadata(metadata, "-I") == {}
assert filter_metadata(metadata, "I.1.a", "-all") == {"I": {"1": {"a": 1}}}
assert filter_metadata(metadata, "-I.1.b") == {"I": {"1": {"a": 1}}}
assert filter_metadata(metadata, "-I.1.b", "I") == {"I": {"1": {"a": 1}}}
# That one is not supported yet
# assert filter_metadata(metadata, 'I.1.a', '-I') == {'I': {'1': {'a': 1}}}
def test_filter_out_execution_metadata():
nb = new_notebook(
cells=[
new_code_cell(
"1 + 1",
metadata={
"execution": {
"iopub.execute_input": "2020-10-12T19:13:45.306603Z",
"iopub.status.busy": "2020-10-12T19:13:45.306233Z",
"iopub.status.idle": "2020-10-12T19:13:45.316103Z",
"shell.execute_reply": "2020-10-12T19:13:45.315429Z",
"shell.execute_reply.started": "2020-10-12T19:13:45.306577Z",
}
},
)
]
)
text = writes(nb, fmt="py:percent")
assert "execution" not in text
def test_default_config_has_priority_over_current_metadata(
tmpdir,
text="""# %% some_metadata_key=5
1 + 1
""",
):
py_file = tmpdir.join("notebook.py")
py_file.write(text)
cfg_file = tmpdir.join("jupytext.toml")
cfg_file.write(
"""cell_metadata_filter = "-some_metadata_key"
"""
)
jupytext_cli([str(py_file), "--to", "py"])
assert (
py_file.read()
== """# %%
1 + 1
"""
)
@pytest.mark.requires_myst
def test_metadata_filter_in_notebook_757():
md = """---
jupytext:
cell_metadata_filter: all,-hidden,-heading_collapsed
notebook_metadata_filter: all,-language_info,-toc,-jupytext.text_representation.jupytext_version,-jupytext.text_representation.format_version
text_representation:
extension: .md
format_name: myst
kernelspec:
display_name: Python 3
language: python
name: python3
nbhosting:
title: 'Exercice: Taylor'
---
```python
1 + 1
```
""" # noqa
nb = reads(md, fmt="md:myst")
assert nb.metadata["jupytext"]["notebook_metadata_filter"] == ",".join(
[
"all",
"-language_info",
"-toc",
"-jupytext.text_representation.jupytext_version",
"-jupytext.text_representation.format_version",
]
)
md2 = writes(nb, fmt="md:myst")
compare(md2, md)
for fmt in ["py:light", "py:percent", "md"]:
text = writes(nb, fmt=fmt)
nb2 = reads(text, fmt=fmt)
compare_notebooks(nb2, nb, fmt=fmt)
ref_metadata = deepcopy(nb.metadata)
del ref_metadata["jupytext"]["text_representation"]
del nb2.metadata["jupytext"]["text_representation"]
compare(nb2.metadata, ref_metadata)
================================================
FILE: tests/functional/metadata/test_metadata_filters_from_config.py
================================================
import nbformat
import pytest
import yaml
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
from jupytext.cli import jupytext as jupytext_cli
from jupytext.compare import compare, compare_notebooks
from jupytext.header import _JUPYTER_METADATA_NAMESPACE
def test_metadata_filters_from_config(tmpdir):
cfg_file = tmpdir.join("jupytext.toml")
nb_file = tmpdir.join("notebook.ipynb")
md_file = tmpdir.join("notebook.md")
cfg_file.write(
"""notebook_metadata_filter = "-all"
cell_metadata_filter = "-all"
"""
)
nb = new_notebook(
cells=[new_markdown_cell("A markdown cell")],
metadata={
"kernelspec": {
"display_name": "Python [conda env:.conda-week1]",
"language": "python",
"name": "conda-env-.conda-week1-py",
},
"language_info": {
"codemirror_mode": {"name": "ipython", "version": 3},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.3",
},
"nbsphinx": {"execute": "never"},
},
)
nbformat.write(nb, str(nb_file))
jupytext_cli([str(nb_file), "--to", "md"])
md = md_file.read()
compare(md, "A markdown cell\n")
jupytext_cli([str(md_file), "--to", "notebook", "--update"])
nb2 = nbformat.read(str(nb_file), as_version=4)
compare_notebooks(nb2, nb)
@pytest.mark.requires_myst
def test_root_level_metadata_filters_from_config(tmpdir):
cfg_file = tmpdir.join("jupytext.toml")
nb_file = tmpdir.join("notebook.ipynb")
md_file = tmpdir.join("notebook.md")
cfg_file.write(
"""root_level_metadata_filter = "-all"
"""
)
nb = new_notebook(
cells=[new_code_cell("1 + 1")],
metadata={
"language_info": {
"name": "python",
"pygments_lexer": "ipython3",
},
},
)
nbformat.write(nb, str(nb_file))
jupytext_cli([str(nb_file), "--to", "md:myst"])
header = next(yaml.safe_load_all(md_file.read()))
assert list(header) == [_JUPYTER_METADATA_NAMESPACE]
jupytext_cli([str(md_file), "--to", "notebook", "--update"])
nb2 = nbformat.read(str(nb_file), as_version=4)
compare_notebooks(nb2, nb)
================================================
FILE: tests/functional/others/invalid_file_896.md
================================================
---
jupytext:
formats: ipynb,md:myst
text_representation:
extension: .md
format_name: myst
format_version: 0.13
jupytext_version: 1.11.5
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
---
Et voil!
================================================
FILE: tests/functional/others/test_active_cells.py
================================================
import pytest
from nbformat import NotebookNode
import jupytext
from jupytext.compare import compare, compare_cells
HEADER = {
".py": """# ---
# jupyter:
# jupytext:
# main_language: python
# ---
""",
".R": """# ---
# jupyter:
# jupytext:
# main_language: python
# ---
""",
".md": """---
jupyter:
jupytext:
main_language: python
---
""",
".Rmd": """---
jupyter:
jupytext:
main_language: python
---
""",
}
ACTIVE_ALL = {
".py": """# %% active="ipynb,py,R,Rmd"
# This cell is active in all extensions
""",
".Rmd": """```{python active="ipynb,py,R,Rmd"}
# This cell is active in all extensions
```
""",
".md": """```python active="ipynb,py,R,Rmd"
# This cell is active in all extensions
```
""",
".R": """# %% active="ipynb,py,R,Rmd"
# This cell is active in all extensions
""",
".ipynb": {
"cell_type": "code",
"source": "# This cell is active in all extensions",
"metadata": {"active": "ipynb,py,R,Rmd"},
"execution_count": None,
"outputs": [],
},
}
def check_active_cell(ext, active_dict):
text = ("" if ext == ".py" else HEADER[ext]) + active_dict[ext]
nb = jupytext.reads(text, ext)
assert len(nb.cells) == 1
compare(jupytext.writes(nb, ext), text)
cell = NotebookNode(active_dict[".ipynb"])
compare_cells(nb.cells, [cell], compare_ids=False)
@pytest.mark.parametrize("ext", [".Rmd", ".md", ".py", ".R"])
def test_active_all(ext, no_jupytext_version_number):
check_active_cell(ext, ACTIVE_ALL)
ACTIVE_IPYNB = {
".py": """# %% active="ipynb"
# # This cell is active only in ipynb
# %matplotlib inline
""",
".Rmd": """```{python active="ipynb", eval=FALSE}
# This cell is active only in ipynb
%matplotlib inline
```
""",
".md": """```python active="ipynb"
# This cell is active only in ipynb
%matplotlib inline
```
""",
".R": """# %% active="ipynb"
# # This cell is active only in ipynb
# %matplotlib inline
""",
".ipynb": {
"cell_type": "code",
"source": "# This cell is active only in ipynb\n%matplotlib inline",
"metadata": {"active": "ipynb"},
"execution_count": None,
"outputs": [],
},
}
@pytest.mark.parametrize("ext", [".Rmd", ".md", ".py", ".R"])
def test_active_ipynb(ext, no_jupytext_version_number):
check_active_cell(ext, ACTIVE_IPYNB)
ACTIVE_IPYNB_RMD_USING_TAG = {
".py": """# %% tags=["active-ipynb-Rmd"]
# # This cell is active only in ipynb and Rmd
# %matplotlib inline
""",
".Rmd": """```{python tags=c("active-ipynb-Rmd")}
# This cell is active only in ipynb and Rmd
# %matplotlib inline
```
""",
".md": """```python tags=["active-ipynb-Rmd"]
# This cell is active only in ipynb and Rmd
%matplotlib inline
```
""",
".R": """# %% tags=["active-ipynb-Rmd"]
# # This cell is active only in ipynb and Rmd
# %matplotlib inline
""",
".ipynb": {
"cell_type": "code",
"source": "# This cell is active only in ipynb and Rmd\n%matplotlib inline",
"metadata": {"tags": ["active-ipynb-Rmd"]},
"execution_count": None,
"outputs": [],
},
}
@pytest.mark.parametrize("ext", [".Rmd", ".md", ".py", ".R"])
def test_active_ipynb_rmd_using_tags(ext, no_jupytext_version_number):
check_active_cell(ext, ACTIVE_IPYNB_RMD_USING_TAG)
ACTIVE_IPYNB_RSPIN = {
".R": """#+ active="ipynb", eval=FALSE
# # This cell is active only in ipynb
# 1 + 1
""",
".ipynb": {
"cell_type": "code",
"source": "# This cell is active only in ipynb\n1 + 1",
"metadata": {"active": "ipynb"},
"execution_count": None,
"outputs": [],
},
}
def test_active_ipynb_rspin(no_jupytext_version_number):
nb = jupytext.reads(ACTIVE_IPYNB_RSPIN[".R"], "R:spin")
assert len(nb.cells) == 1
compare(jupytext.writes(nb, "R:spin"), ACTIVE_IPYNB_RSPIN[".R"])
cell = NotebookNode(ACTIVE_IPYNB_RSPIN[".ipynb"])
compare_cells(nb.cells, [cell], compare_ids=False)
ACTIVE_PY_IPYNB = {
".py": """# %% active="ipynb,py"
# This cell is active in py and ipynb extensions
""",
".Rmd": """```{python active="ipynb,py", eval=FALSE}
# This cell is active in py and ipynb extensions
```
""",
".md": """```python active="ipynb,py"
# This cell is active in py and ipynb extensions
```
""",
".R": """# %% active="ipynb,py"
# # This cell is active in py and ipynb extensions
""",
".ipynb": {
"cell_type": "code",
"source": "# This cell is active in py and ipynb extensions",
"metadata": {"active": "ipynb,py"},
"execution_count": None,
"outputs": [],
},
}
@pytest.mark.parametrize("ext", [".Rmd", ".md", ".py", ".R"])
def test_active_py_ipynb(ext, no_jupytext_version_number):
check_active_cell(ext, ACTIVE_PY_IPYNB)
ACTIVE_PY_R_IPYNB = {
".py": """# %% active="ipynb,py,R"
# This cell is active in py, R and ipynb extensions
""",
".Rmd": """```{python active="ipynb,py,R", eval=FALSE}
# This cell is active in py, R and ipynb extensions
```
""",
".R": """# %% active="ipynb,py,R"
# This cell is active in py, R and ipynb extensions
""",
".ipynb": {
"cell_type": "code",
"source": "# This cell is active in py, R and ipynb extensions",
"metadata": {"active": "ipynb,py,R"},
"execution_count": None,
"outputs": [],
},
}
@pytest.mark.parametrize("ext", [".Rmd", ".py", ".R"])
def test_active_py_r_ipynb(ext, no_jupytext_version_number):
check_active_cell(ext, ACTIVE_PY_R_IPYNB)
ACTIVE_RMD = {
".py": """# %% active="Rmd"
# # This cell is active in Rmd only
""",
".Rmd": """```{python active="Rmd"}
# This cell is active in Rmd only
```
""",
".R": """# %% active="Rmd"
# # This cell is active in Rmd only
""",
".ipynb": {
"cell_type": "raw",
"source": "# This cell is active in Rmd only",
"metadata": {"active": "Rmd"},
},
}
@pytest.mark.parametrize("ext", [".Rmd", ".py", ".R"])
def test_active_rmd(ext, no_jupytext_version_number):
check_active_cell(ext, ACTIVE_RMD)
ACTIVE_NOT_INCLUDE_RMD = {
".py": """# %% tags=["remove_cell"] active="Rmd"
# # This cell is active in Rmd only
""",
".Rmd": """```{python include=FALSE, active="Rmd"}
# This cell is active in Rmd only
```
""",
".R": """# %% tags=["remove_cell"] active="Rmd"
# # This cell is active in Rmd only
""",
".ipynb": {
"cell_type": "raw",
"source": "# This cell is active in Rmd only",
"metadata": {"active": "Rmd", "tags": ["remove_cell"]},
},
}
@pytest.mark.parametrize("ext", [".Rmd", ".py", ".R"])
def test_active_not_include_rmd(ext, no_jupytext_version_number):
check_active_cell(ext, ACTIVE_NOT_INCLUDE_RMD)
def test_active_cells_from_py_percent(
text="""# %% active="py"
print('should only be displayed in py file')
# %% tags=["active-py"]
print('should only be displayed in py file')
# %% active="ipynb"
# print('only in jupyter')
""",
):
"""Example taken from https://github.com/mwouts/jupytext/issues/477"""
nb = jupytext.reads(text, "py:percent")
assert nb.cells[0].cell_type == "raw"
assert nb.cells[1].cell_type == "raw"
assert nb.cells[2].cell_type == "code"
assert nb.cells[2].source == "print('only in jupyter')"
text2 = jupytext.writes(nb, "py:percent")
compare(text2, text)
def test_comments_work_in_active_cells_from_py_percent_1131(
text="""# %% tags=["active-py"]
# this is a comment
""",
):
nb = jupytext.reads(text, "py:percent")
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "# this is a comment"
text2 = jupytext.writes(nb, "py:percent")
compare(text2, text)
def test_comments_work_in_active_cells_from_py_light_1131(
text="""# + tags=["active-py"]
# this is a comment
""",
):
nb = jupytext.reads(text, "py:light")
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "# this is a comment"
text2 = jupytext.writes(nb, "py:light")
compare(text2, text)
def test_comments_plus_code_work_in_active_cells_from_py_percent_1131(
text="""# %% tags=["active-py"]
# this is a comment
1 + 1
""",
):
nb = jupytext.reads(text, "py:percent")
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "# this is a comment\n1 + 1"
text2 = jupytext.writes(nb, "py:percent")
compare(text2, text)
def test_comments_plus_code_work_in_active_cells_from_py_light_1131(
text="""# + tags=["active-py"]
# this is a comment
1 + 1
""",
):
nb = jupytext.reads(text, "py:light")
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "# this is a comment\n1 + 1"
text2 = jupytext.writes(nb, "py:light")
compare(text2, text)
def test_active_cells_from_py_light(
text="""# + active="py"
print('should only be displayed in py file')
# + tags=["active-py"]
print('should only be displayed in py file')
# + active="ipynb"
# print('only in jupyter')
""",
):
"""Example adapted from https://github.com/mwouts/jupytext/issues/477"""
nb = jupytext.reads(text, "py:light")
assert nb.cells[0].cell_type == "raw"
assert nb.cells[1].cell_type == "raw"
assert nb.cells[2].cell_type == "code"
assert nb.cells[2].source == "print('only in jupyter')"
text2 = jupytext.writes(nb, "py")
compare(text2, text)
================================================
FILE: tests/functional/others/test_auto_ext.py
================================================
import pytest
from jupytext import read, reads, writes
from jupytext.formats import JupytextFormatError, auto_ext_from_metadata
def test_auto_in_fmt(ipynb_py_R_file):
nb = read(ipynb_py_R_file)
auto_ext = auto_ext_from_metadata(nb.metadata)
fmt = auto_ext[1:] + ":percent"
text = writes(nb, "auto:percent")
assert "auto" not in text
nb2 = reads(text, fmt)
assert nb2.metadata["jupytext"]["text_representation"]["extension"]
assert nb2.metadata["jupytext"]["text_representation"]["format_name"] == "percent"
del nb.metadata["language_info"]
del nb.metadata["kernelspec"]
with pytest.raises(JupytextFormatError):
writes(nb, "auto:percent")
def test_auto_from_kernelspecs_works(ipynb_file):
nb = read(ipynb_file)
language_info = nb.metadata.pop("language_info")
expected_ext = language_info.get("file_extension")
if not expected_ext:
pytest.skip("No file_extension in language_info")
if expected_ext == ".r":
expected_ext = ".R"
elif expected_ext == ".fs":
expected_ext = ".fsx"
elif expected_ext == ".C":
# ROOT-flavored C++ notebooks have a .C extension in the language_info, see PR #1384
expected_ext = ".cpp"
auto_ext = auto_ext_from_metadata(nb.metadata)
if auto_ext == ".sage":
pytest.skip("Sage notebooks have Python in their language_info metadata, see #727")
assert auto_ext == expected_ext
def test_auto_in_formats(ipynb_py_R_jl_file):
if any(pattern in ipynb_py_R_jl_file for pattern in ["plotly", "julia"]):
pytest.skip()
nb = read(ipynb_py_R_jl_file)
nb.metadata["jupytext"] = {"formats": "ipynb,auto:percent"}
fmt = auto_ext_from_metadata(nb.metadata)[1:] + ":percent"
expected_formats = "ipynb," + fmt
text = writes(nb, "ipynb")
assert "auto" not in text
nb2 = reads(text, "ipynb")
assert nb2.metadata["jupytext"]["formats"] == expected_formats
text = writes(nb, "auto:percent")
assert "auto" not in text
nb2 = reads(text, fmt)
assert nb2.metadata["jupytext"]["formats"] == expected_formats
del nb.metadata["language_info"]
del nb.metadata["kernelspec"]
with pytest.raises(JupytextFormatError):
writes(nb, "ipynb")
with pytest.raises(JupytextFormatError):
writes(nb, "auto:percent")
================================================
FILE: tests/functional/others/test_cell_markers.py
================================================
from nbformat.v4.nbbase import new_raw_cell
from jupytext import reads, writes
from jupytext.cli import jupytext
def test_set_cell_markers_cli(tmpdir, cwd_tmpdir):
tmpdir.join("test.py").write("# %% [markdown]\n# A Markdown cell\n")
jupytext(["--format-options", 'cell_markers="""', "test.py"])
py = tmpdir.join("test.py").read()
assert py.endswith('# %% [markdown]\n"""\nA Markdown cell\n"""\n')
def test_add_cell_to_script_with_cell_markers(
no_jupytext_version_number,
py='''# ---
# jupyter:
# jupytext:
# formats: py:percent
# cell_markers: '"""'
# ---
''',
):
nb = reads(py, fmt="py:percent")
nb.cells = [new_raw_cell("A raw cell")]
py2 = writes(nb, fmt="py:percent")
assert py2.endswith(
'''# %% [raw]
"""
A raw cell
"""
'''
)
================================================
FILE: tests/functional/others/test_cell_metadata.py
================================================
import pytest
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell
import jupytext
from jupytext.cell_metadata import (
_IGNORE_CELL_METADATA,
RMarkdownOptionParsingError,
is_valid_metadata_key,
metadata_to_rmd_options,
metadata_to_text,
parse_key_equal_value,
parse_rmd_options,
rmd_options_to_metadata,
text_to_metadata,
try_eval_metadata,
)
from jupytext.combine import combine_inputs_with_outputs
from jupytext.compare import compare, compare_notebooks
from jupytext.metadata_filter import filter_metadata
def r_options_language_metadata():
yield from [
("r", "R", {}),
(
'r plot_1, dpi=72, fig.path="fig_path/"',
"R",
{"name": "plot_1", "dpi": 72, "fig.path": "fig_path/"},
),
(
'r plot_1, bool=TRUE, fig.path="fig_path/"',
"R",
{"name": "plot_1", "bool": True, "fig.path": "fig_path/"},
),
("r echo=FALSE", "R", {"tags": ["remove_input"]}),
("r plot_1, echo=TRUE", "R", {"name": "plot_1", "echo": True}),
(
"python echo=if a==5 then TRUE else FALSE",
"python",
{"echo": "#R_CODE#if a==5 then TRUE else FALSE"},
),
(
'python noname, tags=c("a", "b", "c"), echo={sum(a+c(1,2))>1}',
"python",
{
"name": "noname",
"tags": ["a", "b", "c"],
"echo": "#R_CODE#{sum(a+c(1,2))>1}",
},
),
('python active="ipynb,py"', "python", {"active": "ipynb,py"}),
(
'python include=FALSE, active="Rmd"',
"python",
{"active": "Rmd", "tags": ["remove_cell"]},
),
(
'r chunk_name, include=FALSE, active="Rmd"',
"R",
{"name": "chunk_name", "active": "Rmd", "tags": ["remove_cell"]},
),
('python tags=c("parameters")', "python", {"tags": ["parameters"]}),
]
@pytest.mark.parametrize("options,language, metadata", r_options_language_metadata())
def test_parse_rmd_options(options, language, metadata):
compare(rmd_options_to_metadata(options), (language, metadata))
@pytest.mark.parametrize("options,language, metadata", r_options_language_metadata())
def test_build_options(options, language, metadata):
compare(metadata_to_rmd_options(*(language, metadata)), options)
@pytest.mark.parametrize("options,language, metadata", r_options_language_metadata())
def test_build_options_random_order(options, language, metadata):
# Older python has no respect for order...
# assert to_chunk_options(metadata) == options
def split_and_strip(opt):
{o.strip() for o in opt.split(",")}
assert split_and_strip(metadata_to_rmd_options(*(language, metadata))) == split_and_strip(options)
@pytest.mark.parametrize("options", ["a={)", "name, name2", "a=}", "b=]", "c=["])
def test_parsing_error(options):
with pytest.raises(RMarkdownOptionParsingError):
parse_rmd_options(options)
def test_ignore_metadata():
metadata = {"trusted": True, "tags": ["remove_input"]}
metadata = filter_metadata(metadata, None, _IGNORE_CELL_METADATA)
assert metadata_to_rmd_options("R", metadata) == "r echo=FALSE"
def test_filter_metadata():
assert filter_metadata({"scrolled": True}, None, _IGNORE_CELL_METADATA) == {}
def test_try_eval_metadata():
metadata = {"list": 'list("a",5)', "c": "c(1,2,3)"}
try_eval_metadata(metadata, "list")
try_eval_metadata(metadata, "c")
assert metadata == {"list": ["a", 5], "c": [1, 2, 3]}
def test_language_no_metadata(text="python", value=("python", {})):
compare(text_to_metadata(text), value)
assert metadata_to_text(*value) == text.strip()
def test_only_metadata(text='key="value"', value=("", {"key": "value"})):
compare(text_to_metadata(text), value)
assert metadata_to_text(*value) == text
def test_only_metadata_2(text='key="value"', value=("", {"key": "value"})):
compare(text_to_metadata(text, allow_title=True), value)
assert metadata_to_text(*value) == text
def test_no_language(text=".class", value=("", {".class": None})):
compare(text_to_metadata(text), value)
assert metadata_to_text(*value) == text
def test_language_metadata_no_space(text='python{"a":1}', value=("python", {"a": 1})):
compare(text_to_metadata(text), value)
assert metadata_to_text(*value) == "python a=1"
def test_title_no_metadata(text="title", value=("title", {})):
compare(text_to_metadata(text, allow_title=True), value)
assert metadata_to_text(*value) == text.strip()
def test_simple_metadata(
text='python string="value" number=1.0 array=["a", "b"]',
value=("python", {"string": "value", "number": 1.0, "array": ["a", "b"]}),
):
compare(text_to_metadata(text), value)
assert metadata_to_text(*value) == text
def test_simple_metadata_with_spaces(
text='python string = "value" number = 1.0 array = ["a", "b"]',
value=("python", {"string": "value", "number": 1.0, "array": ["a", "b"]}),
):
compare(text_to_metadata(text), value)
assert metadata_to_text(*value) == 'python string="value" number=1.0 array=["a", "b"]'
def test_title_and_relax_json(
text="cell title string='value' number=1.0 array=['a', \"b\"]",
value=("cell title", {"string": "value", "number": 1.0, "array": ["a", "b"]}),
):
compare(text_to_metadata(text, allow_title=True), value)
assert metadata_to_text(*value) == 'cell title string="value" number=1.0 array=["a", "b"]'
def test_title_and_json_dict(
text='cell title {"string": "value", "number": 1.0, "array": ["a", "b"]}',
value=("cell title", {"string": "value", "number": 1.0, "array": ["a", "b"]}),
):
compare(text_to_metadata(text, allow_title=True), value)
assert metadata_to_text(*value) == 'cell title string="value" number=1.0 array=["a", "b"]'
@pytest.mark.parametrize("allow_title", [True, False])
def test_attribute(allow_title):
text = ".class"
value = ("", {".class": None})
compare(text_to_metadata(text, allow_title), value)
assert metadata_to_text(*value) == text
def test_language_and_attribute(text="python .class", value=("python", {".class": None})):
compare(text_to_metadata(text), value)
assert metadata_to_text(*value) == text
def test_title_and_attribute(text="This is my title. .class", value=("This is my title.", {".class": None})):
compare(text_to_metadata(text, allow_title=True), value)
assert metadata_to_text(*value) == text
def test_values_with_equal_signs_inside(text='python string="value=5"', value=("python", {"string": "value=5"})):
compare(text_to_metadata(text), value)
assert metadata_to_text(*value) == text
def test_incorrectly_encoded(text="this is an incorrect expression d={{4 b=3"):
value = text_to_metadata(text, allow_title=True)
assert metadata_to_text(*value) == text
def test_incorrectly_encoded_json(text='this is an incorrect expression {"d": "}'):
value = text_to_metadata(text, allow_title=True)
assert metadata_to_text(*value) == text
def test_parse_key_value():
assert parse_key_equal_value("key='value' key2=5.0") == {
"key": "value",
"key2": 5.0,
}
def test_parse_key_value_key():
assert parse_key_equal_value("key='value' key2") == {
"key": "value",
"key2": None,
}
@pytest.mark.parametrize("key", ["ok", "also.ok", "all_right_55", "not,ok", "unexpected,key"])
def test_is_valid_metadata_key(key):
assert is_valid_metadata_key(key) == ("," not in key)
@pytest.fixture()
def notebook_with_unsupported_key_in_metadata(python_notebook):
nb = python_notebook
nb.cells.append(new_markdown_cell("text", metadata={"unexpected,key": True}))
return nb
def test_unsupported_key_in_metadata(notebook_with_unsupported_key_in_metadata, fmt_with_cell_metadata):
"""Notebook metadata that can't be parsed in text notebook cannot go to the text file,
but it should still remain available in the ipynb file for paired notebooks."""
with pytest.warns(
UserWarning,
match="The following metadata cannot be exported to the text notebook",
):
text = jupytext.writes(notebook_with_unsupported_key_in_metadata, fmt_with_cell_metadata)
assert "unexpected" not in text
nb_text = jupytext.reads(text, fmt=fmt_with_cell_metadata)
nb = combine_inputs_with_outputs(nb_text, notebook_with_unsupported_key_in_metadata, fmt=fmt_with_cell_metadata)
assert nb.cells[-1].metadata == {"unexpected,key": True}
@pytest.fixture()
def notebook_with_collapsed_cell(python_notebook):
nb = python_notebook
nb.cells.append(new_markdown_cell("## Data", metadata={"jp-MarkdownHeadingCollapsed": True}))
return nb
def test_notebook_with_collapsed_cell(notebook_with_collapsed_cell, fmt_with_cell_metadata):
text = jupytext.writes(notebook_with_collapsed_cell, fmt_with_cell_metadata)
assert "MarkdownHeadingCollapsed" in text
nb = jupytext.reads(text, fmt=fmt_with_cell_metadata)
compare_notebooks(nb, notebook_with_collapsed_cell, fmt=fmt_with_cell_metadata)
def test_empty_tags_are_not_saved_in_text_notebooks(no_jupytext_version_number, python_notebook, fmt="py:percent"):
nb = python_notebook
nb.cells.append(new_code_cell(metadata={"tags": []}))
text = jupytext.writes(nb, fmt=fmt)
assert "tags" not in text
nb_text = jupytext.reads(text, fmt=fmt)
nb2 = combine_inputs_with_outputs(nb_text, nb, fmt=fmt)
assert nb2.cells[-1].metadata["tags"] == []
================================================
FILE: tests/functional/others/test_cell_tags_are_preserved.py
================================================
import pytest
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell
from jupytext import reads, writes
from jupytext.formats import formats_with_support_for_cell_metadata, is_myst_available
@pytest.fixture()
def notebook_with_tags(python_notebook):
nb = python_notebook
nb.cells = [
new_code_cell("1 + 1", metadata={"tags": ["tag1"]}),
new_markdown_cell("some text", metadata={"tags": ["tag2"]}),
]
return nb
@pytest.mark.parametrize("fmt", ["py:percent", "py:light", "md:markdown", "md:myst", "Rmd:rmarkdown"])
def test_main_formats_support_cell_metadata(fmt):
if fmt == "md:myst" and not is_myst_available():
pytest.skip("myst is not available")
assert fmt in set(formats_with_support_for_cell_metadata())
def test_tags_are_preserved(notebook_with_tags, fmt_with_cell_metadata):
text = writes(notebook_with_tags, fmt_with_cell_metadata)
nb = reads(text, fmt_with_cell_metadata)
assert nb.cells[0]["metadata"]["tags"] == ["tag1"]
assert nb.cells[1]["metadata"]["tags"] == ["tag2"]
================================================
FILE: tests/functional/others/test_cells.py
================================================
import pytest
from nbformat.v4.nbbase import new_markdown_cell
from jupytext.cell_reader import (
LightScriptCellReader,
RMarkdownCellReader,
paragraph_is_fully_commented,
uncomment,
)
from jupytext.cell_to_text import RMarkdownCellExporter
@pytest.mark.parametrize(
"lines",
[
"# text",
"""# # %%R
# # comment
# 1 + 1
# 2 + 2
""",
],
)
def test_paragraph_is_fully_commented(lines):
assert paragraph_is_fully_commented(lines.splitlines(), comment="#", main_language="python")
def test_paragraph_is_not_fully_commented(lines="# text\nnot fully commented out"):
assert not paragraph_is_fully_commented(lines.splitlines(), comment="#", main_language="python")
def test_uncomment():
assert uncomment(["# line one", "#line two", "line three"], "#") == [
"line one",
"line two",
"line three",
]
assert uncomment(["# line one", "#line two", "line three"], "") == [
"# line one",
"#line two",
"line three",
]
def test_text_to_code_cell():
text = """```{python}
1+2+3
```
"""
lines = text.splitlines()
cell, pos = RMarkdownCellReader().read(lines)
assert cell.cell_type == "code"
assert cell.source == "1+2+3"
assert cell.metadata == {"language": "python"}
assert lines[pos:] == []
def test_text_to_code_cell_empty_code():
text = """```{python}
```
"""
lines = text.splitlines()
cell, pos = RMarkdownCellReader().read(lines)
assert cell.cell_type == "code"
assert cell.source == ""
assert cell.metadata == {"language": "python"}
assert lines[pos:] == []
def test_text_to_code_cell_empty_code_no_blank_line():
text = """```{python}
```
"""
lines = text.splitlines()
cell, pos = RMarkdownCellReader().read(lines)
assert cell.cell_type == "code"
assert cell.source == ""
assert cell.metadata == {"language": "python"}
assert lines[pos:] == []
def test_text_to_markdown_cell():
text = """This is
a markdown cell
```{python}
1+2+3
```
"""
lines = text.splitlines()
cell, pos = RMarkdownCellReader().read(lines)
assert cell.cell_type == "markdown"
assert cell.source == "This is\na markdown cell"
assert cell.metadata == {}
assert pos == 3
def test_text_to_markdown_no_blank_line():
text = """This is
a markdown cell
```{python}
1+2+3
```
"""
lines = text.splitlines()
cell, pos = RMarkdownCellReader().read(lines)
assert cell.cell_type == "markdown"
assert cell.source == "This is\na markdown cell"
assert cell.metadata == {"lines_to_next_cell": 0}
assert pos == 2
def test_text_to_markdown_two_blank_line():
text = """
```{python}
1+2+3
```
"""
lines = text.splitlines()
cell, pos = RMarkdownCellReader().read(lines)
assert cell.cell_type == "markdown"
assert cell.source == ""
assert cell.metadata == {}
assert pos == 2
def test_text_to_markdown_one_blank_line():
text = """
```{python}
1+2+3
```
"""
lines = text.splitlines()
cell, pos = RMarkdownCellReader().read(lines)
assert cell.cell_type == "markdown"
assert cell.source == ""
assert cell.metadata == {"lines_to_next_cell": 0}
assert pos == 1
def test_empty_markdown_to_text():
cell = new_markdown_cell(source="")
text = RMarkdownCellExporter(cell, "python").cell_to_text()
assert text == [""]
def test_text_to_cell_py():
text = "1+1\n"
lines = text.splitlines()
cell, pos = LightScriptCellReader().read(lines)
assert cell.cell_type == "code"
assert cell.source == "1+1"
assert cell.metadata == {}
assert pos == 1
def test_text_to_cell_py2():
text = """def f(x):
return x+1"""
lines = text.splitlines()
cell, pos = LightScriptCellReader().read(lines)
assert cell.cell_type == "code"
assert cell.source == """def f(x):\n return x+1"""
assert cell.metadata == {}
assert pos == 2
def test_code_to_cell():
text = """def f(x):
return x+1"""
lines = text.splitlines()
cell, pos = LightScriptCellReader().read(lines)
assert cell.cell_type == "code"
assert cell.source == """def f(x):\n return x+1"""
assert cell.metadata == {}
assert pos == 2
def test_uncomment_ocaml():
assert uncomment(["(* ## *)"], "(*", "*)") == ["##"]
assert uncomment(["(*##*)"], "(*", "*)") == ["##"]
================================================
FILE: tests/functional/others/test_combine.py
================================================
from copy import deepcopy
import pytest
from jupyter_server.utils import ensure_async
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
import jupytext
from jupytext.combine import combine_inputs_with_outputs
from jupytext.compare import compare, compare_notebooks
def test_combine():
nb_source = new_notebook(
cells=[
new_markdown_cell("Markdown text"),
new_code_cell("a=3"),
new_code_cell("a+1"),
new_code_cell("a+1"),
new_markdown_cell("Markdown text"),
new_code_cell("a+2"),
]
)
nb_outputs = new_notebook(
cells=[
new_markdown_cell("Markdown text"),
new_code_cell("a=3"),
new_code_cell("a+1"),
new_code_cell("a+2"),
new_markdown_cell("Markdown text"),
]
)
nb_outputs.cells[2].outputs = ["4"]
nb_outputs.cells[3].outputs = ["5"]
nb_source = combine_inputs_with_outputs(nb_source, nb_outputs)
assert nb_source.cells[2].outputs == ["4"]
assert nb_source.cells[3].outputs == []
assert nb_source.cells[5].outputs == ["5"]
@pytest.mark.asyncio
async def test_read_text_and_combine_with_outputs(tmpdir, cm):
tmp_ipynb = "notebook.ipynb"
tmp_script = "notebook.py"
with open(str(tmpdir.join(tmp_script)), "w") as fp:
fp.write(
"""# ---
# jupyter:
# jupytext_formats: ipynb,py:light
# ---
1+1
2+2
3+3
"""
)
with open(str(tmpdir.join(tmp_ipynb)), "w") as fp:
fp.write(
"""{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"2"
]
},
"execution_count": 1,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"1+1"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"6"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"3+3"
]
}
],
"metadata": {},
"nbformat": 4,
"nbformat_minor": 2
}
"""
)
# create contents manager
cm.root_dir = str(tmpdir)
# load notebook from script
model = await ensure_async(cm.get(tmp_script))
nb = model["content"]
assert nb.cells[0]["source"] == "1+1"
assert nb.cells[1]["source"] == "2+2"
assert nb.cells[2]["source"] == "3+3"
# No output for the second cell, which is not in the ipynb
assert nb.cells[0]["outputs"]
assert not nb.cells[1]["outputs"]
assert nb.cells[2]["outputs"]
assert len(nb.cells) == 3
def test_combine_stable(ipynb_file):
nb_org = jupytext.read(ipynb_file)
nb_source = deepcopy(nb_org)
nb_outputs = deepcopy(nb_org)
for cell in nb_source.cells:
cell.outputs = []
nb_source = combine_inputs_with_outputs(nb_source, nb_outputs)
compare_notebooks(nb_source, nb_org)
def test_combine_reorder():
nb_source = new_notebook(
cells=[
new_markdown_cell("Markdown text"),
new_code_cell("1+1"),
new_code_cell("2+2"),
new_code_cell("3+3"),
new_markdown_cell("Markdown text"),
new_code_cell("4+4"),
]
)
nb_outputs = new_notebook(
cells=[
new_markdown_cell("Markdown text"),
new_code_cell("2+2"),
new_code_cell("4+4"),
new_code_cell("1+1"),
new_code_cell("3+3"),
new_markdown_cell("Markdown text"),
]
)
nb_outputs.cells[1].outputs = ["4"]
nb_outputs.cells[2].outputs = ["8"]
nb_outputs.cells[3].outputs = ["2"]
nb_outputs.cells[4].outputs = ["6"]
nb_source = combine_inputs_with_outputs(nb_source, nb_outputs)
assert nb_source.cells[1].outputs == ["2"]
assert nb_source.cells[2].outputs == ["4"]
assert nb_source.cells[3].outputs == ["6"]
assert nb_source.cells[5].outputs == ["8"]
def test_combine_split():
nb_source = new_notebook(cells=[new_code_cell("1+1"), new_code_cell("2+2")])
nb_outputs = new_notebook(cells=[new_code_cell("1+1\n2+2")])
nb_outputs.cells[0].outputs = ["4"]
nb_source = combine_inputs_with_outputs(nb_source, nb_outputs)
assert nb_source.cells[0].outputs == []
assert nb_source.cells[1].outputs == ["4"]
def test_combine_refactor():
nb_source = new_notebook(cells=[new_code_cell("a=1"), new_code_cell("a+1"), new_code_cell("a+2")])
nb_outputs = new_notebook(cells=[new_code_cell("b=1"), new_code_cell("b+1"), new_code_cell("b+2")])
nb_outputs.cells[1].outputs = ["2"]
nb_outputs.cells[2].outputs = ["3"]
nb_source = combine_inputs_with_outputs(nb_source, nb_outputs)
assert nb_source.cells[0].outputs == []
assert nb_source.cells[1].outputs == ["2"]
assert nb_source.cells[2].outputs == ["3"]
def test_combine_attachments():
nb_source = new_notebook(cells=[new_markdown_cell("")])
nb_outputs = new_notebook(
cells=[
new_markdown_cell(
"",
attachments={"image.png": {"image/png": "SOME_LONG_IMAGE_CODE...=="}},
)
]
)
nb_source = combine_inputs_with_outputs(nb_source, nb_outputs)
compare(nb_source, nb_outputs)
================================================
FILE: tests/functional/others/test_custom_cell_magics.py
================================================
import nbformat
from nbformat.v4.nbbase import new_code_cell, new_notebook
from jupytext.cli import jupytext as jupytext_cli
from jupytext.compare import compare_notebooks
from jupytext.languages import _JUPYTER_LANGUAGES_LOWER_AND_UPPER
def test_custom_cell_magics(
tmpdir,
nb=new_notebook(
cells=[
new_code_cell("%%sql -o tables -q\n SHOW TABLES"),
new_code_cell(
"""%%configure -f
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}"""
),
new_code_cell("%%local\na=1"),
]
),
):
cfg_file = tmpdir.join("jupytext.toml")
nb_file = tmpdir.join("notebook.ipynb")
py_file = tmpdir.join("notebook.py")
cfg_file.write('custom_cell_magics = "configure,local"')
assert "configure" not in _JUPYTER_LANGUAGES_LOWER_AND_UPPER
assert "logs" not in _JUPYTER_LANGUAGES_LOWER_AND_UPPER
nbformat.write(nb, str(nb_file))
jupytext_cli([str(nb_file), "--to", "py"])
py = py_file.read()
for line in py.splitlines():
if line:
assert line.startswith("# "), line
jupytext_cli([str(py_file), "--to", "notebook"])
nb2 = nbformat.read(str(nb_file), as_version=4)
compare_notebooks(nb2, nb)
================================================
FILE: tests/functional/others/test_doxygen.py
================================================
import nbformat
import pytest
import jupytext
from jupytext.cli import jupytext as jupytext_cli
from jupytext.compare import compare, compare_notebooks
from jupytext.doxygen import doxygen_to_markdown, markdown_to_doxygen
SAMPLE_MARKDOWN = """A latex formula $$1+1$$, another one $$2+2
$$
An inline formula $3+3$
"""
SAMPLE_DOXYGEN = """A latex formula \\f[1+1\\f], another one \\f[2+2
\\f]
An inline formula \\f$3+3\\f$
"""
def test_markdown_to_doxygen():
compare(markdown_to_doxygen(SAMPLE_MARKDOWN), SAMPLE_DOXYGEN)
def test_doxygen_to_markdown():
compare(doxygen_to_markdown(SAMPLE_DOXYGEN), SAMPLE_MARKDOWN)
@pytest.mark.parametrize(
"latex,doxygen",
[
("$$", "$$"),
("$1+1$", "\\f$1+1\\f$"),
("$1\\$ $", "\\f$1\\$ \\f$"),
("$$2+2$$", "\\f[2+2\\f]"),
("$$2+2$$ then $$3+3$$", "\\f[2+2\\f] then \\f[3+3\\f]"),
("$$2+2\n$$", "\\f[2+2\n\\f]"),
("$$1\\$+2\\$=3\\$$$", "\\f[1\\$+2\\$=3\\$\\f]"),
],
)
def test_simple_equations_to_doxygen_and_back(latex, doxygen):
assert markdown_to_doxygen(latex) == doxygen
assert doxygen_to_markdown(doxygen) == latex
def test_doxygen_equation_markers(tmpdir):
cfg_file = tmpdir.join("jupytext.toml")
nb_file = tmpdir.join("notebook.ipynb")
md_file = tmpdir.join("notebook.md")
cfg_file.write("hide_notebook_metadata = true\ndoxygen_equation_markers = true")
nb = jupytext.reads(SAMPLE_MARKDOWN, "md")
del nb.metadata["jupytext"]
nbformat.write(nb, str(nb_file))
jupytext_cli([str(nb_file), "--to", "md"])
md = md_file.read()
# Doxygen equation markers
assert "$$" not in md
assert "\\f[" in md
assert "\\f]" in md
assert "\\f$" in md
assert "\\f$" in md
# Metadata hidden
assert md.startswith("", ""]]
# language is not inserted by nbconvert
md_expected = ["```" if line.startswith("```") else line for line in md_expected]
# nbconvert inserts no empty line after the YAML header (which is in a Raw cell)
md_expected = "\n".join(md_expected).replace("---\n\n", "---\n") + "\n"
# an extra blank line is inserted before code cells
md_nbconvert = md_nbconvert.replace("\n\n```", "\n```")
jupytext.compare.compare(md_nbconvert, md_expected)
@pytest.mark.requires_nbconvert
def test_jupytext_markdown_similar_to_nbconvert(ipynb_py_R_jl_file):
"""Test that the nbconvert export for a notebook matches Jupytext's one"""
if "magic" in ipynb_py_R_jl_file or "html" in ipynb_py_R_jl_file:
pytest.skip()
nb = jupytext.read(ipynb_py_R_jl_file)
# Remove cell outputs and metadata
for cell in nb.cells:
if "outputs" in cell:
cell.outputs = []
if "metadata" in cell:
cell.metadata = {}
md_jupytext = jupytext.writes(nb, fmt="md")
import nbconvert
md_nbconvert, _ = nbconvert.export(nbconvert.MarkdownExporter, nb)
# our expectations
# nbconvert file has no YAML header
md_jupytext_lines = md_jupytext.splitlines()
_, _, raw_cell, pos = header_to_metadata_and_cell(md_jupytext_lines, "", "")
md_jupytext = "\n".join(md_jupytext_lines[pos:]) + "\n"
if raw_cell is not None:
md_jupytext = raw_cell.source + "\n\n" + md_jupytext
# region comments are not in nbconvert
md_jupytext = md_jupytext.replace("\n", "").replace("\n", "")
# Jupytext uses HTML comments to keep track of raw cells
md_jupytext = (
md_jupytext.replace("\n\n", "").replace("\n", "").replace("\n\n", "")
)
# nbconvert file may start with an empty line
md_jupytext = md_jupytext.lstrip("\n")
md_nbconvert = md_nbconvert.lstrip("\n")
# Jupytext may not always have two blank lines between cells like Jupyter nbconvert
md_jupytext = md_jupytext.replace("\n\n\n", "\n\n")
md_nbconvert = md_nbconvert.replace("\n\n\n", "\n\n")
jupytext.compare.compare(md_nbconvert, md_jupytext)
================================================
FILE: tests/functional/round_trip/test_mirror.py
================================================
"""Here we generate mirror representation of py, Rmd and ipynb files
as py or ipynb, and make sure that these representations minimally
change on new releases.
"""
import os
import re
import pytest
from nbformat.v4.nbbase import new_notebook
import jupytext
from jupytext.compare import (
assert_conversion_same_as_mirror,
compare_notebooks,
create_mirror_file_if_missing,
)
from jupytext.formats import auto_ext_from_metadata
from jupytext.languages import _SCRIPT_EXTENSIONS
def test_create_mirror_file_if_missing(tmpdir, no_jupytext_version_number):
py_file = str(tmpdir.join("notebook.py"))
assert not os.path.isfile(py_file)
create_mirror_file_if_missing(py_file, new_notebook(), "py")
assert os.path.isfile(py_file)
"""---------------------------------------------------------------------------------
Part I: ipynb -> fmt -> ipynb
---------------------------------------------------------------------------------"""
def test_ipynb_to_percent(ipynb_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_file, "auto:percent", "ipynb_to_percent")
def test_ipynb_to_hydrogen(ipynb_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_file, "auto:hydrogen", "ipynb_to_hydrogen")
def test_ipynb_to_light(ipynb_to_light, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_to_light, "auto:light", "ipynb_to_script")
@pytest.mark.requires_marimo
def test_ipynb_to_marimo(marimo_compatible_ipynb, no_jupytext_version_number):
assert_conversion_same_as_mirror(
marimo_compatible_ipynb,
"auto:marimo",
"ipynb_to_marimo",
)
def test_ipynb_to_md(ipynb_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_file, "md", "ipynb_to_md")
def test_ipynb_to_Rmd(ipynb_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_file, "Rmd", "ipynb_to_Rmd")
@pytest.mark.requires_myst
def test_ipynb_to_myst(ipynb_file, no_jupytext_version_number):
if re.match(r".*(html-demo|julia_functional_geometry|xcpp_by_quantstack).*", ipynb_file):
pytest.skip()
assert_conversion_same_as_mirror(ipynb_file, "md:myst", "ipynb_to_myst")
"""---------------------------------------------------------------------------------
Part II: text -> ipynb -> text
---------------------------------------------------------------------------------"""
def test_script_to_ipynb(script_to_ipynb, no_jupytext_version_number):
assert_conversion_same_as_mirror(script_to_ipynb, "ipynb:light", "script_to_ipynb")
def test_percent_to_ipynb(percent_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(percent_file, "ipynb:percent", "script_to_ipynb")
def test_hydrogen_to_ipynb(hydrogen_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(hydrogen_file, "ipynb:hydrogen", "script_to_ipynb")
def test_spin_to_ipynb(r_spin_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(r_spin_file, "ipynb:spin", "script_to_ipynb")
@pytest.mark.requires_marimo
def test_marimo_to_ipynb(marimo_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(marimo_file, "ipynb:marimo", "script_to_ipynb")
def test_md_to_ipynb(md_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(md_file, "ipynb", "md_to_ipynb")
@pytest.mark.requires_myst
def test_myst_file_has_myst_format(myst_file):
with open(myst_file) as f:
text = f.read()
fmt = jupytext.guess_format(text, ".md")
assert fmt == ("myst", {})
@pytest.mark.requires_myst
def test_myst_to_ipynb(myst_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(myst_file, "ipynb:myst", "myst_to_ipynb")
"""---------------------------------------------------------------------------------
Part III: More specific round trip tests
---------------------------------------------------------------------------------"""
def test_ipynb_to_percent_to_light(ipynb_file):
nb = jupytext.read(ipynb_file)
pct = jupytext.writes(nb, "auto:percent")
auto_ext = auto_ext_from_metadata(nb.metadata)
comment = _SCRIPT_EXTENSIONS[auto_ext]["comment"]
lgt = (
pct.replace(comment + " %%\n", comment + " +\n")
.replace(comment + " %% ", comment + " + ")
.replace(
comment + " format_name: percent",
comment + " format_name: light",
)
)
nb2 = jupytext.reads(lgt, auto_ext)
compare_notebooks(nb2, nb)
def test_ipynb_to_python_vim(ipynb_py_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(
ipynb_py_file,
{"extension": ".py", "cell_markers": "{{{,}}}"},
"ipynb_to_script_vim_folding_markers",
)
def test_ipynb_to_python_vscode(ipynb_py_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(
ipynb_py_file,
{"extension": ".py", "cell_markers": "region,endregion"},
"ipynb_to_script_vscode_folding_markers",
)
def test_ipynb_to_r_light(ipynb_R_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_R_file, ".low.r:light", "ipynb_to_script")
def test_ipynb_to_r_percent(ipynb_R_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_R_file, ".low.r:percent", "ipynb_to_percent")
def test_ipynb_to_R_spin(ipynb_R_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_R_file, "R:spin", "ipynb_to_spin")
def test_ipynb_to_r_spin(ipynb_R_file, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_R_file, ".low.r:spin", "ipynb_to_spin")
@pytest.mark.parametrize("extension", ("ss", "scm"))
def test_ipynb_to_scheme_light(ipynb_scheme_file, extension, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_scheme_file, f"{extension}:light", "ipynb_to_script")
@pytest.mark.parametrize("extension", ("ss", "scm"))
def test_ipynb_to_scheme_percent(ipynb_scheme_file, extension, no_jupytext_version_number):
assert_conversion_same_as_mirror(ipynb_scheme_file, f"{extension}:percent", "ipynb_to_percent")
================================================
FILE: tests/functional/round_trip/test_myst_header.py
================================================
import pytest
from nbformat.v4.nbbase import new_notebook, new_raw_cell
from jupytext import reads, writes
from jupytext.compare import compare, compare_notebooks
from jupytext.config import load_jupytext_configuration_file
from jupytext.header import _JUPYTER_METADATA_NAMESPACE
from jupytext.myst import dump_yaml_blocks
@pytest.mark.requires_myst
def test_myst_header_is_stable_1247_using_inline_filter(
md="""---
jupytext:
formats: md:myst
notebook_metadata_filter: -jupytext.text_representation.jupytext_version,settings,mystnb
text_representation:
extension: .md
format_name: myst
format_version: 0.13
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
mystnb:
execution_mode: 'off'
settings:
output_matplotlib_strings: remove
---
""",
):
nb = reads(md, fmt="md")
md2 = writes(nb, fmt="md")
compare(md2, md)
@pytest.mark.requires_myst
def test_myst_header_is_stable_1247_using_config(
jupytext_toml_content="""notebook_metadata_filter = "-jupytext.text_representation.jupytext_version,settings,mystnb"
""",
md="""---
jupytext:
formats: md:myst
text_representation:
extension: .md
format_name: myst
format_version: 0.13
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
mystnb:
execution_mode: 'off'
settings:
output_matplotlib_strings: remove
---
""",
):
config = load_jupytext_configuration_file("jupytext.toml", jupytext_toml_content)
nb = reads(md, fmt="md", config=config)
md2 = writes(nb, fmt="md", config=config)
compare(md2, md)
@pytest.mark.requires_myst
def test_myst_frontmatter_metadata_combo(no_jupytext_version_number):
# ---
# foo: bar
# jupyter: <- subkeys become notebook metadata
# lorem: ipsum
# ---
frontmatter = {"foo": "bar"}
metadata = {"lorem": "ipsum"}
md = dump_yaml_blocks(
{**frontmatter, _JUPYTER_METADATA_NAMESPACE: metadata},
compact=False,
)
config = load_jupytext_configuration_file(
"jupytext.toml",
"\n".join(
(
'notebook_metadata_filter = "all,-jupytext"',
'root_level_metadata_filter = "-all"',
)
),
)
actual_nb = reads(md, fmt="md:myst", config=config)
expected_nb = new_notebook(
metadata=metadata,
cells=[
new_raw_cell(dump_yaml_blocks(frontmatter, compact=False).strip()),
],
)
compare_notebooks(actual_nb, expected_nb)
# {
# "cells": [
# {
# "cell_type": "raw",
# "source": "---\nfoo: bar\n---", <- merge with metadata in frontmatter
# ...
# }
# ],
# "metadata": {"foo": "baz"},
# ...
# }
actual_md = writes(actual_nb, fmt="md:myst", config=config)
expected_md = md
compare(actual_md, expected_md)
================================================
FILE: tests/functional/round_trip/test_read_all_py.py
================================================
import jupytext
from jupytext.compare import compare
def test_identity_source_write_read(py_file):
with open(py_file) as fp:
py = fp.read()
nb = jupytext.reads(py, "py")
py2 = jupytext.writes(nb, "py")
compare(py2, py)
================================================
FILE: tests/functional/round_trip/test_rmd_to_ipynb.py
================================================
import jupytext
from jupytext.compare import compare
def test_identity_write_read(rmd_file, no_jupytext_version_number):
"""Test that writing the notebook with ipynb, and read again, yields identity"""
with open(rmd_file) as fp:
rmd = fp.read()
nb = jupytext.reads(rmd, "Rmd")
rmd2 = jupytext.writes(nb, "Rmd")
compare(rmd2, rmd)
def test_two_blank_lines_as_cell_separator():
rmd = """Some markdown
text
And a new cell
"""
nb = jupytext.reads(rmd, "Rmd")
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[0].source == "Some markdown\ntext"
assert nb.cells[1].source == "And a new cell"
================================================
FILE: tests/functional/simple_notebooks/test_ipynb_to_R.py
================================================
import nbformat
import pytest
import jupytext
from jupytext.compare import compare_notebooks
@pytest.mark.parametrize("ext", [".r", ".R"])
def test_identity_source_write_read(ipynb_R_file, ext):
"""
Test that writing the notebook with R, and read again,
is the same as removing outputs
"""
with open(ipynb_R_file) as fp:
nb1 = nbformat.read(fp, as_version=4)
R = jupytext.writes(nb1, ext)
nb2 = jupytext.reads(R, ext)
compare_notebooks(nb2, nb1)
================================================
FILE: tests/functional/simple_notebooks/test_ipynb_to_myst.py
================================================
import json
import unittest.mock as mock
from textwrap import dedent
import pytest
from jupyter_server.utils import ensure_async
from nbformat.v4.nbbase import new_notebook
from tornado.web import HTTPError
import jupytext
from jupytext.cli import jupytext as jupytext_cli
from jupytext.compare import compare
from jupytext.formats import (
JupytextFormatError,
get_format_implementation,
guess_format,
)
from jupytext.myst import (
CODE_DIRECTIVE,
MystMetadataParsingError,
matches_mystnb,
myst_extensions,
myst_to_notebook,
)
@pytest.mark.requires_myst
def test_bad_notebook_metadata():
"""Test exception raised if notebook metadata cannot be parsed."""
with pytest.raises(MystMetadataParsingError):
myst_to_notebook(
dedent(
"""\
---
{{a
---
"""
)
)
@pytest.mark.requires_myst
def test_bad_code_metadata():
"""Test exception raised if cell metadata cannot be parsed."""
with pytest.raises(MystMetadataParsingError):
myst_to_notebook(
dedent(
"""\
```{0}
---
{{a
---
```
"""
).format(CODE_DIRECTIVE)
)
@pytest.mark.requires_myst
def test_bad_markdown_metadata():
"""Test exception raised if markdown metadata cannot be parsed."""
with pytest.raises(MystMetadataParsingError):
myst_to_notebook(
dedent(
"""\
+++ {{a
"""
)
)
@pytest.mark.requires_myst
def test_bad_markdown_metadata2():
"""Test exception raised if markdown metadata is not a dict."""
with pytest.raises(MystMetadataParsingError):
myst_to_notebook(
dedent(
"""\
+++ [1, 2]
"""
)
)
@pytest.mark.requires_myst
def test_matches_mystnb():
assert matches_mystnb("") is False
assert matches_mystnb("```{code-cell}\n```") is False
assert matches_mystnb("---\njupytext: true\n---") is False
for ext in myst_extensions(no_md=True):
assert matches_mystnb("", ext=ext) is True
text = dedent(
"""\
---
{{a
---
```{code-cell}
:b: {{c
```
"""
)
assert matches_mystnb(text) is True
text = dedent(
"""\
---
jupyter:
jupytext:
text_representation:
format_name: myst
extension: .md
---
"""
)
assert matches_mystnb(text) is True
text = dedent(
"""\
---
jupytext:
text_representation:
format_name: myst
extension: .md
---
"""
)
assert matches_mystnb(text) is True
text = dedent(
"""\
---
a: 1
---
> ```{code-cell}
```
"""
)
assert matches_mystnb(text) is True
assert guess_format(text, ".md") == ("myst", {})
def test_not_installed():
with mock.patch("jupytext.formats.JUPYTEXT_FORMATS", return_value=[]):
with pytest.raises(JupytextFormatError):
get_format_implementation(".myst")
@pytest.mark.requires_myst
def test_add_source_map():
notebook = myst_to_notebook(
dedent(
"""\
---
a: 1
---
abc
+++
def
```{0}
---
b: 2
---
c = 3
```
xyz
"""
).format(CODE_DIRECTIVE),
add_source_map=True,
)
assert notebook.metadata.source_map == [3, 5, 7, 12]
PLEASE_INSTALL_MYST = "The MyST Markdown format requires .*"
@pytest.mark.requires_no_myst
def test_meaningfull_error_write_myst_missing(tmpdir):
nb_file = tmpdir.join("notebook.ipynb")
jupytext.write(new_notebook(), str(nb_file))
with pytest.raises(ImportError, match=PLEASE_INSTALL_MYST):
jupytext_cli([str(nb_file), "--to", "md:myst"])
@pytest.mark.asyncio
@pytest.mark.requires_no_myst
async def test_meaningfull_error_open_myst_missing(tmpdir, cm):
md_file = tmpdir.join("notebook.md")
md_file.write(
"""---
jupytext:
text_representation:
extension: '.md'
format_name: myst
kernelspec:
display_name: Python 3
language: python
name: python3
---
1 + 1
"""
)
with pytest.raises(ImportError, match=PLEASE_INSTALL_MYST):
jupytext_cli([str(md_file), "--to", "ipynb"])
cm.root_dir = str(tmpdir)
with pytest.raises(HTTPError, match=PLEASE_INSTALL_MYST):
await ensure_async(cm.get("notebook.md"))
@pytest.mark.asyncio
@pytest.mark.requires_myst
@pytest.mark.parametrize("language_info", ["none", "std", "no_pygments_lexer"])
async def test_myst_representation_same_cli_or_contents_manager(tmpdir, cwd_tmpdir, cm, notebook_with_outputs, language_info):
"""This test gives some information on #759. As of Jupytext 1.11.1, in the MyST Markdown format,
the code cells have an ipython3 lexer when the notebook "language_info" metadata has "ipython3"
as the pygments_lexer. This information comes from the kernel and ATM it is not clear how the user
can choose to include it or not in the md file."""
nb = notebook_with_outputs
if language_info != "none":
nb["metadata"]["language_info"] = {
"codemirror_mode": {"name": "ipython", "version": 3},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.3",
}
if language_info == "no_pygments_lexer":
del nb["metadata"]["language_info"]["pygments_lexer"]
# Writing the notebook with the Python API
text_api = jupytext.writes(nb, fmt="md:myst")
# How do code cells look like?
code_cells = {line for line in text_api.splitlines() if line.startswith("```{code-cell")}
if language_info == "std":
assert code_cells == {"```{code-cell} ipython3"}
else:
assert code_cells == {"```{code-cell}"}
# We get the same file with the command line jupytext
tmpdir.mkdir("cli").join("notebook.ipynb").write(json.dumps(nb))
jupytext_cli(["--to", "md:myst", "cli/notebook.ipynb"])
text_cli = tmpdir.join("cli").join("notebook.md").read()
compare(text_cli, text_api)
# Or with the contents manager
cm.formats = "ipynb,md:myst"
cm.root_dir = str(tmpdir.mkdir("contents_manager"))
await ensure_async(cm.save(model=dict(content=nb, type="notebook"), path="notebook.ipynb"))
text_cm = tmpdir.join("contents_manager").join("notebook.md").read()
compare(text_cm, text_api)
================================================
FILE: tests/functional/simple_notebooks/test_ipynb_to_py.py
================================================
import nbformat
import jupytext
from jupytext.compare import compare_notebooks
def test_identity_source_write_read(ipynb_py_file):
"""Test that writing the notebook with jupytext, and read again,
is the same as removing outputs"""
with open(ipynb_py_file) as fp:
nb1 = nbformat.read(fp, as_version=4)
py = jupytext.writes(nb1, "py")
nb2 = jupytext.reads(py, "py")
compare_notebooks(nb2, nb1)
================================================
FILE: tests/functional/simple_notebooks/test_ipynb_to_rmd.py
================================================
import nbformat
import jupytext
from jupytext.compare import compare_notebooks
def test_identity_source_write_read(ipynb_py_R_jl_file):
"""Test that writing the notebook with rmd, and read again,
is the same as removing outputs"""
with open(ipynb_py_R_jl_file) as fp:
nb1 = nbformat.read(fp, as_version=4)
rmd = jupytext.writes(nb1, "Rmd")
nb2 = jupytext.reads(rmd, "Rmd")
compare_notebooks(nb2, nb1, "Rmd")
================================================
FILE: tests/functional/simple_notebooks/test_knitr_spin.py
================================================
import jupytext
def test_jupytext_same_as_knitr_spin(r_spin_file, tmpdir):
nb = jupytext.read(r_spin_file)
rmd_jupytext = jupytext.writes(nb, "Rmd")
# Rmd file generated with spin(hair='R/spin.R', knit=FALSE)
rmd_file = r_spin_file.replace("R_spin", "Rmd").replace(".R", ".Rmd")
with open(rmd_file) as fp:
rmd_spin = fp.read()
assert rmd_spin == rmd_jupytext
================================================
FILE: tests/functional/simple_notebooks/test_read_dotnet_try_markdown.py
================================================
import jupytext
from jupytext.cell_metadata import parse_key_equal_value
from jupytext.compare import compare
def test_parse_metadata():
assert parse_key_equal_value("--key value --key-2 .\\a\\b.cs") == {
"incorrectly_encoded_metadata": "--key value --key-2 .\\a\\b.cs"
}
def test_parse_double_hyphen_metadata():
assert parse_key_equal_value("--key1 value1 --key2 value2") == {
"incorrectly_encoded_metadata": "--key1 value1 --key2 value2"
}
def test_read_dotnet_try_markdown(
md="""This is a dotnet/try Markdown file, inspired
from this [post](https://devblogs.microsoft.com/dotnet/creating-interactive-net-documentation/)
``` cs --region methods --source-file .\\myapp\\Program.cs --project .\\myapp\\myapp.csproj
var name ="Rain";
Console.WriteLine($"Hello {name.ToUpper()}!");
```
""",
):
# Read the notebook
nb = jupytext.reads(md, fmt=".md")
assert nb.metadata["jupytext"]["main_language"] == "csharp"
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[1].cell_type == "code"
assert (
nb.cells[1].source
== """var name ="Rain";
Console.WriteLine($"Hello {name.ToUpper()}!");"""
)
compare(
nb.cells[1].metadata,
{
"language": "cs",
"incorrectly_encoded_metadata": "--region methods --source-file .\\myapp\\Program.cs --project .\\myapp\\myapp.csproj", # noqa: E501
},
)
# Round trip to Markdown
md2 = jupytext.writes(nb, "md")
compare(md2, md.replace("``` cs", "```cs"))
================================================
FILE: tests/functional/simple_notebooks/test_read_empty_text_notebook.py
================================================
import pytest
from nbformat.notebooknode import NotebookNode
import jupytext
from jupytext.formats import NOTEBOOK_EXTENSIONS
from jupytext.myst import is_myst_available, myst_extensions
from jupytext.quarto import is_quarto_available
@pytest.mark.parametrize("ext", sorted(set(NOTEBOOK_EXTENSIONS) - {".ipynb"}))
def test_read_empty_text_notebook(ext, tmp_path):
if ext == ".qmd" and not is_quarto_available(min_version="0.2.0"):
pytest.skip("quarto is not available")
if ext in myst_extensions(no_md=True) and not is_myst_available():
pytest.skip("MyST is not available")
empty_nb = (tmp_path / "notebook").with_suffix(ext)
empty_nb.touch()
nb = jupytext.read(empty_nb)
assert isinstance(nb, NotebookNode)
assert not nb.cells
================================================
FILE: tests/functional/simple_notebooks/test_read_folding_markers.py
================================================
import jupytext
from jupytext.compare import compare
# region Folding markers as cell boundaries
# region Sub-region with metadata {"key": "value"}
def test_mark_cell_with_vim_folding_markers(
script="""# This is a markdown cell
# {{{ And this is a foldable code region with metadata {"key": "value"}
a = 1
b = 2
c = 3
# }}}
""",
):
nb = jupytext.reads(script, "py")
assert nb.metadata["jupytext"]["cell_markers"] == "{{{,}}}"
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "This is a markdown cell"
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "a = 1\n\nb = 2\n\nc = 3"
assert nb.cells[1].metadata == {
"title": "And this is a foldable code region with metadata",
"key": "value",
}
script2 = jupytext.writes(nb, "py")
compare(script2, script)
# endregion
def test_mark_cell_with_vscode_pycharm_folding_markers(
script="""# This is a markdown cell
# region And this is a foldable code region with metadata {"key": "value"}
a = 1
b = 2
c = 3
# endregion
""",
):
nb = jupytext.reads(script, "py")
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "This is a markdown cell"
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "a = 1\n\nb = 2\n\nc = 3"
assert nb.cells[1].metadata == {
"title": "And this is a foldable code region with metadata",
"key": "value",
}
script2 = jupytext.writes(nb, "py")
compare(script2, script)
def test_mark_cell_with_no_title_and_inner_region(
script="""# This is a markdown cell
# region {"key": "value"}
a = 1
# region An inner region
b = 2
# endregion
def f(x):
return x + 1
# endregion
d = 4
""",
):
nb = jupytext.reads(script, "py")
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "This is a markdown cell"
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == '# region {"key": "value"}\na = 1'
assert nb.cells[2].cell_type == "code"
assert nb.cells[2].metadata["title"] == "An inner region"
assert nb.cells[2].source == "b = 2"
assert nb.cells[3].cell_type == "code"
assert nb.cells[3].source == "def f(x):\n return x + 1"
assert nb.cells[4].cell_type == "code"
assert nb.cells[4].source == "# endregion"
assert nb.cells[5].cell_type == "code"
assert nb.cells[5].source == "d = 4"
assert len(nb.cells) == 6
script2 = jupytext.writes(nb, "py")
compare(script2, script)
# endregion
def test_adjacent_regions(
script="""# region global
# region innermost
a = 1
b = 2
# endregion
# endregion
""",
):
nb = jupytext.reads(script, "py")
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "code"
assert nb.cells[0].source == "# region global"
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "a = 1\n\nb = 2"
assert nb.cells[2].cell_type == "code"
assert nb.cells[2].source == "# endregion"
script2 = jupytext.writes(nb, "py")
compare(script2, script)
def test_indented_markers_are_ignored(
script="""# region global
# region indented
a = 1
b = 2
# endregion
# endregion
""",
):
nb = jupytext.reads(script, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "code"
script2 = jupytext.writes(nb, "py")
compare(script2, script)
================================================
FILE: tests/functional/simple_notebooks/test_read_incomplete_rmd.py
================================================
import jupytext
def test_incomplete_header(
rmd="""---
title: Incomplete header
```{python}
1+1
```
""",
):
nb = jupytext.reads(rmd, "Rmd")
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "---\ntitle: Incomplete header"
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "1+1"
def test_code_in_markdown_block(
rmd="""```{python}
a = 1
b = 2
a + b
```
```python
'''Code here goes to a Markdown cell'''
'''even if we have two blank lines above'''
```
```{bash}
ls -l
```
""",
):
nb = jupytext.reads(rmd, "Rmd")
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "code"
assert nb.cells[0].source == "a = 1\nb = 2\na + b"
assert nb.cells[1].cell_type == "markdown"
assert (
nb.cells[1].source
== """```python
'''Code here goes to a Markdown cell'''
'''even if we have two blank lines above'''
```"""
)
assert nb.cells[2].cell_type == "code"
assert nb.cells[2].source == "%%bash\nls -l"
def test_unterminated_header(
rmd="""---
title: Unterminated header
```{python}
1+3
```
some text
```{r}
1+4
```
```{python not_terminated}
1+5
""",
):
nb = jupytext.reads(rmd, "Rmd")
assert len(nb.cells) == 5
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "---\ntitle: Unterminated header"
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "1+3"
assert nb.cells[2].cell_type == "markdown"
assert nb.cells[2].source == "some text"
assert nb.cells[3].cell_type == "code"
assert nb.cells[3].source == "%%R\n1+4"
assert nb.cells[4].cell_type == "code"
assert nb.cells[4].metadata == {"name": "not_terminated"}
assert nb.cells[4].source == "1+5"
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_R.py
================================================
import pytest
import jupytext
from jupytext.compare import compare
@pytest.mark.parametrize("ext", [".r", ".R"])
def test_read_simple_file(
ext,
rnb="""#' ---
#' title: Simple file
#' ---
#' Here we have some text
#' And below we have some R code
f <- function(x) {
x + 1
}
h <- function(y)
y + 1
""",
):
nb = jupytext.reads(rnb, ext)
assert len(nb.cells) == 4
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: Simple file\n---"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "Here we have some text\nAnd below we have some R code"
assert nb.cells[2].cell_type == "code"
compare(
nb.cells[2].source,
"""f <- function(x) {
x + 1
}""",
)
assert nb.cells[3].cell_type == "code"
compare(
nb.cells[3].source,
"""h <- function(y)
y + 1""",
)
rnb2 = jupytext.writes(nb, ext)
compare(rnb2, rnb)
@pytest.mark.parametrize("ext", [".r", ".R"])
def test_read_less_simple_file(
ext,
rnb="""#' ---
#' title: Less simple file
#' ---
#' Here we have some text
#' And below we have some R code
# This is a comment about function f
f <- function(x) {
return(x+1)}
# And a comment on h
h <- function(y) {
return(y-1)
}
""",
):
nb = jupytext.reads(rnb, ext)
assert len(nb.cells) == 4
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: Less simple file\n---"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "Here we have some text\nAnd below we have some R code"
assert nb.cells[2].cell_type == "code"
compare(
nb.cells[2].source,
"""# This is a comment about function f
f <- function(x) {
return(x+1)}""",
)
assert nb.cells[3].cell_type == "code"
compare(
nb.cells[3].source,
"""# And a comment on h
h <- function(y) {
return(y-1)
}""",
)
rnb2 = jupytext.writes(nb, ext)
compare(rnb2, rnb)
@pytest.mark.parametrize("ext", [".r", ".R"])
def test_no_space_after_code(
ext,
rnb="""# -*- coding: utf-8 -*-
#' Markdown cell
f <- function(x)
{
return(x+1)
}
#' And a new cell, and non ascii contênt
""",
):
nb = jupytext.reads(rnb, ext)
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "Markdown cell"
assert nb.cells[1].cell_type == "code"
assert (
nb.cells[1].source
== """f <- function(x)
{
return(x+1)
}"""
)
assert nb.cells[2].cell_type == "markdown"
assert nb.cells[2].source == "And a new cell, and non ascii contênt"
rnb2 = jupytext.writes(nb, ext)
compare(rnb2, rnb)
@pytest.mark.parametrize("ext", [".r", ".R"])
def test_read_write_script(
ext,
rnb="""#!/usr/bin/env Rscript
# coding=utf-8
print('Hello world')
""",
):
nb = jupytext.reads(rnb, ext)
rnb2 = jupytext.writes(nb, ext)
compare(rnb2, rnb)
@pytest.mark.parametrize("ext", [".r", ".R"])
def test_escape_start_pattern(
ext,
rnb="""#' The code start pattern '#+' can
#' appear in code and markdown cells.
#' In markdown cells it is escaped like here:
#' #+ fig.width=12
# In code cells like this one, it is also escaped
# #+ cell_name language="python"
1 + 1
""",
):
nb = jupytext.reads(rnb, ext)
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[2].cell_type == "code"
assert (
nb.cells[1].source
== """In markdown cells it is escaped like here:
#+ fig.width=12"""
)
assert (
nb.cells[2].source
== """# In code cells like this one, it is also escaped
#+ cell_name language="python"
1 + 1"""
)
rnb2 = jupytext.writes(nb, ext)
compare(rnb2, rnb)
@pytest.mark.parametrize("ext", [".r", ".R"])
def test_read_simple_r(
ext,
text="""# This is a very simple R file
# I expect to get three cells here.
#
# The first one is markdown. The two others
# are code cells
cars
plot(cars)
""",
):
nb = jupytext.reads(text, ext)
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[1].cell_type == "code"
assert nb.cells[2].cell_type == "code"
assert nb.cells[1].source == "cars"
assert nb.cells[2].source == "plot(cars)"
text2 = jupytext.writes(nb, ext)
compare(text2, text)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_clojure.py
================================================
import jupytext
from jupytext.compare import compare
def test_read_simple_file(
script=""";; ---
;; title: Simple file
;; ---
;; Here we have some text
;; And below we have some code
((fn
[]
(println "Hello World")))
""",
):
nb = jupytext.reads(script, "clj")
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: Simple file\n---"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "Here we have some text\nAnd below we have some code"
assert nb.cells[2].cell_type == "code"
compare(
nb.cells[2].source,
"""((fn
[]
(println "Hello World")))""",
)
script2 = jupytext.writes(nb, "clj")
compare(script2, script)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_csharp.py
================================================
import pytest
import jupytext
from jupytext.compare import compare
@pytest.mark.parametrize("lang", ["cs", "c#", "csharp"])
def test_simple_cs(lang):
source = """// A Hello World! program in C#.
Console.WriteLine("Hello World!");
"""
md = """```{lang}
{source}
```
""".format(lang=lang, source=source)
nb = jupytext.reads(md, "md")
assert nb.metadata["jupytext"]["main_language"] == "csharp"
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "code"
cs = jupytext.writes(nb, "cs")
assert source in cs
if lang != "csharp":
assert cs.startswith(f'// %% language="{lang}"')
md2 = jupytext.writes(nb, "md")
compare(md2, md)
@pytest.mark.parametrize("lang", ["cs", "c#", "csharp"])
def test_csharp_magics(no_jupytext_version_number, lang):
md = """```{lang}
#!html
Hello!
```
""".format(lang=lang)
nb = jupytext.reads(md, "md")
nb.metadata["jupytext"].pop("notebook_metadata_filter")
nb.metadata["jupytext"].pop("cell_metadata_filter")
assert nb.metadata["jupytext"]["main_language"] == "csharp"
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "code"
cs = jupytext.writes(nb, "cs")
assert all(line.startswith("//") for line in cs.splitlines()), cs
md2 = jupytext.writes(nb, "md")
md_expected = """---
jupyter:
jupytext:
main_language: csharp
---
```html
Hello!
```
"""
compare(md2, md_expected)
def test_read_html_cell_from_md(no_jupytext_version_number):
md = """---
jupyter:
jupytext:
main_language: csharp
---
```html
Hello!
```
"""
nb = jupytext.reads(md, "md")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "code"
compare(nb.cells[0].source, "#!html\nHello!")
md2 = jupytext.writes(nb, "md")
compare(md2, md)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_go.py
================================================
import jupytext
from jupytext.compare import compare
def test_read_simple_file(
go="""// -*- coding: utf-8 -*-
// ---
// jupyter:
// kernelspec:
// display_name: Go (gonb)
// language: go
// name: gonb
// ---
// A notebook that use [GoNB](https://github.com/janpfeifer/gonb)
// the code below comes from [tutorial.ipynb](https://github.com/janpfeifer/gonb/blob/main/examples/tutorial.ipynb)
func main() {
fmt.Printf("Hello World!")
}
""",
):
nb = jupytext.reads(go, "go:light")
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[2].cell_type == "code"
def test_read_go_notebook_with_percent_percent_and_arguments(
go="""// %% [markdown]
// # Square Function
//
// Defines a function $f(x) = x^2$
// %%
func Square(x float64) float64 {
return x*x
}
// %% [markdown]
// # Examples
//
// ## Example A: $x = 3$
// %%
var x = flag.Float64("x", 0.0, "value of x to feed f(x)")
//gonb:%% -x=3
fmt.Printf("Square(%g)=%g\n", *x, Square(*x))
// %% [markdown]
// ## Example B: $x = 4$
// %%
//gonb:%% -x=4
fmt.Printf("Square(%g)=%g\n", *x, Square(*x))
""",
):
nb = jupytext.reads(go, "go")
for cell in nb.cells:
assert "gonb" not in cell.source, cell.source
go2 = jupytext.writes(nb, "go")
compare(go2, go)
def test_read_go_notebook_with_magic_main(
go="""// %%
package square
// %% [markdown]
// # Defining a $x^2$ function
// It returns x*x.
// %%
func Square(x float64) float64 {
return x * x
}
// %% [markdown]
// # Examples
//
// ## Example A: $x = 3$
// %%
var x = flag.Float64("x", 0.0, "Value of x")
func example() {
fmt.Printf("Square(%g)=%g\n", *x, Square(*x))
}
// %main example -x=3
// %% [markdown]
// ## Example B: $x = 4$
// %%
// %main example -x=4
""",
):
nb = jupytext.reads(go, "go")
for cell in nb.cells:
assert "gonb" not in cell.source, cell.source
go2 = jupytext.writes(nb, "go")
compare(go2, go)
def test_commented_magic(
go="""// %%
// This is a commented magic
// //gonb:%%
// %% [markdown]
// This is a commented magic in a markdown cell
// // //gonb:%%
""",
):
nb = jupytext.reads(go, "go")
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "code"
assert (
nb.cells[0].source
== """// This is a commented magic
// %%"""
)
assert nb.cells[1].cell_type == "markdown"
assert (
nb.cells[1].source
== """This is a commented magic in a markdown cell
// %%"""
)
go2 = jupytext.writes(nb, "go")
compare(go2, go)
def test_magic_commands_are_commented(
go="""// %%
// !*rm -f go.work && go work init && go work use . ${HOME}/Projects/gopjrt
// %goworkfix
// %env LD_LIBRARY_PATH=/usr/local/lib
""",
):
nb = jupytext.reads(go, "go:percent")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "code"
assert (
nb.cells[0].source
== """!*rm -f go.work && go work init && go work use . ${HOME}/Projects/gopjrt
%goworkfix
%env LD_LIBRARY_PATH=/usr/local/lib"""
)
go2 = jupytext.writes(nb, "go")
compare(go2, go)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_groovy.py
================================================
import jupytext
from jupytext.compare import compare
def test_read_simple_file(
script="""// ---
// title: Simple file
// ---
// Here we have some text
// And below we have some code
println("Hello World")
""",
):
nb = jupytext.reads(script, "groovy")
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: Simple file\n---"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "Here we have some text\nAnd below we have some code"
assert nb.cells[2].cell_type == "code"
assert nb.cells[2].source == """println("Hello World")"""
script2 = jupytext.writes(nb, "groovy")
compare(script2, script)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_hydrogen.py
================================================
import jupytext
from jupytext.compare import compare
def test_read_simple_file(
script="""# ---
# title: Simple file
# ---
# %% [markdown]
# This is a markdown cell
# %% [raw]
# This is a raw cell
# %%% sub-cell title
# This is a sub-cell
# %%%% sub-sub-cell title
# This is a sub-sub-cell
# %% And now a code cell
1 + 2 + 3 + 4
5
6
%%pylab inline
7
""",
):
nb = jupytext.reads(script, "py:hydrogen")
assert len(nb.cells) == 6
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: Simple file\n---"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "This is a markdown cell"
assert nb.cells[2].cell_type == "raw"
assert nb.cells[2].source == "This is a raw cell"
assert nb.cells[3].cell_type == "code"
assert nb.cells[3].source == "# This is a sub-cell"
assert nb.cells[3].metadata["title"] == "sub-cell title"
assert nb.cells[4].cell_type == "code"
assert nb.cells[4].source == "# This is a sub-sub-cell"
assert nb.cells[4].metadata["title"] == "sub-sub-cell title"
assert nb.cells[5].cell_type == "code"
compare(
nb.cells[5].source,
"""1 + 2 + 3 + 4
5
6
%%pylab inline
7""",
)
assert nb.cells[5].metadata == {"title": "And now a code cell"}
script2 = jupytext.writes(nb, "py:hydrogen")
compare(script2, script)
def test_read_cell_with_metadata(
script="""# %% a code cell with parameters {"tags": ["parameters"]}
a = 3
""",
):
nb = jupytext.reads(script, "py:hydrogen")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "code"
assert nb.cells[0].source == "a = 3"
assert nb.cells[0].metadata == {
"title": "a code cell with parameters",
"tags": ["parameters"],
}
script2 = jupytext.writes(nb, "py:hydrogen")
compare(script2, script)
def test_read_nbconvert_script(
script="""
# coding: utf-8
# A markdown cell
# In[1]:
%pylab inline
import pandas as pd
pd.options.display.max_rows = 6
pd.options.display.max_columns = 20
# Another markdown cell
# In[2]:
1 + 1
# Again, a markdown cell
# In[33]:
2 + 2
#
3 + 3
""",
):
assert jupytext.formats.guess_format(script, ".py")[0] == "hydrogen"
nb = jupytext.reads(script, ".py")
assert len(nb.cells) == 5
def test_read_remove_blank_lines(
script="""# %%
import pandas as pd
# %% Display a data frame
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
# %% Pandas plot {"tags": ["parameters"]}
df.plot(kind='bar')
# %% sample class
class MyClass:
pass
# %% a function
def f(x):
return 42 * x
""",
):
nb = jupytext.reads(script, "py")
assert len(nb.cells) == 5
for i in range(5):
assert nb.cells[i].cell_type == "code"
assert not nb.cells[i].source.startswith("\n")
assert not nb.cells[i].source.endswith("\n")
script2 = jupytext.writes(nb, "py:hydrogen")
compare(script2, script)
def test_no_crash_on_square_bracket(
script="""# %% In [2]
print('Hello')
""",
):
nb = jupytext.reads(script, "py")
script2 = jupytext.writes(nb, "py:hydrogen")
compare(script2, script)
def test_nbconvert_cell(
script="""# In[2]:
print('Hello')
""",
):
nb = jupytext.reads(script, "py")
script2 = jupytext.writes(nb, "py:hydrogen")
expected = """# %%
print('Hello')
"""
compare(script2, expected)
def test_nbformat_v3_nbpy_cell(
script="""#
print('Hello')
""",
):
nb = jupytext.reads(script, "py")
script2 = jupytext.writes(nb, "py:hydrogen")
expected = """# %%
print('Hello')
"""
compare(script2, expected)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_ipynb.py
================================================
import nbformat
from nbformat.v4.nbbase import new_notebook
import jupytext
from jupytext.compare import compare
def test_save_ipynb_with_jupytext_has_final_newline(tmpdir):
nb = new_notebook()
file_jupytext = str(tmpdir.join("jupytext.ipynb"))
file_nbformat = str(tmpdir.join("nbformat.ipynb"))
jupytext.write(nb, file_jupytext)
with open(file_nbformat, "w") as fp:
nbformat.write(nb, fp)
with open(file_jupytext) as fp:
text_jupytext = fp.read()
with open(file_nbformat) as fp:
text_nbformat = fp.read()
compare(text_jupytext, text_nbformat)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_java.py
================================================
import jupytext
from jupytext.compare import compare
def test_read_simple_file(
script="""// ---
// title: Simple file
// ---
// Here we have some text
// And below we have some code
System.out.println("Hello World");
""",
):
nb = jupytext.reads(script, "java")
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: Simple file\n---"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "Here we have some text\nAnd below we have some code"
assert nb.cells[2].cell_type == "code"
assert nb.cells[2].source == """System.out.println("Hello World");"""
script2 = jupytext.writes(nb, "java")
compare(script2, script)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_julia.py
================================================
import jupytext
from jupytext.compare import compare
def test_read_simple_file(
julia='''"""
cube(x)
Compute the cube of `x`, ``x^3``.
# Examples
```jldoctest
julia> cube(2)
8
```
"""
function cube(x)
x^3
end
cube(x)
# And a markdown comment
''',
):
nb = jupytext.reads(julia, "jl")
assert nb.metadata["jupytext"]["main_language"] == "julia"
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "code"
assert (
nb.cells[0].source
== '''"""
cube(x)
Compute the cube of `x`, ``x^3``.
# Examples
```jldoctest
julia> cube(2)
8
```
"""
function cube(x)
x^3
end'''
)
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "cube(x)"
assert nb.cells[2].cell_type == "markdown"
compare(nb.cells[2].source, "And a markdown comment")
julia2 = jupytext.writes(nb, "jl")
compare(julia2, julia)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_markdown.py
================================================
from nbformat.v4.nbbase import (
new_code_cell,
new_markdown_cell,
new_notebook,
new_raw_cell,
)
import jupytext
from jupytext.combine import combine_inputs_with_outputs
from jupytext.compare import compare, compare_cells, compare_notebooks
def test_read_mostly_py_markdown_file(
markdown="""---
title: Simple file
---
```python
import numpy as np
x = np.arange(0, 2*math.pi, eps)
```
```python
x = np.arange(0,1,eps)
y = np.abs(x)-.5
```
This is
a Markdown cell
```
# followed by a code cell with no language info
```
```
# another code cell
# with two blank lines
```
And the same markdown cell continues
this is a raw cell
```R
ls()
```
```R
cat(stringi::stri_rand_lipsum(3), sep='\n\n')
```
""",
):
nb = jupytext.reads(markdown, "md")
assert nb.metadata["jupytext"]["main_language"] == "python"
compare_cells(
nb.cells,
[
new_raw_cell("---\ntitle: Simple file\n---"),
new_code_cell("import numpy as np\nx = np.arange(0, 2*math.pi, eps)"),
new_code_cell("x = np.arange(0,1,eps)\ny = np.abs(x)-.5"),
new_markdown_cell(
"""This is
a Markdown cell
```
# followed by a code cell with no language info
```
```
# another code cell
# with two blank lines
```
And the same markdown cell continues"""
),
new_raw_cell("this is a raw cell"),
new_code_cell("%%R\nls()"),
new_code_cell("%%R\ncat(stringi::stri_rand_lipsum(3), sep='\n\n')"),
],
compare_ids=False,
)
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_read_md_and_markdown_regions(
markdown="""Some text
A
long
cell
Another
long
cell
""",
):
nb = jupytext.reads(markdown, "md")
assert nb.metadata["jupytext"]["main_language"] == "python"
compare_cells(
nb.cells,
[
new_markdown_cell("Some text"),
new_markdown_cell(
"""A
long
cell""",
metadata={"region_name": "md"},
),
new_markdown_cell(
"""Another
long
cell""",
metadata={"region_name": "markdown"},
),
],
compare_ids=False,
)
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_read_mostly_R_markdown_file(
markdown="""```R
ls()
```
```R
cat(stringi::stri_rand_lipsum(3), sep='\n\n')
```
""",
):
nb = jupytext.reads(markdown, "md")
assert nb.metadata["jupytext"]["main_language"] == "R"
compare_cells(
nb.cells,
[
new_code_cell("ls()"),
new_code_cell("cat(stringi::stri_rand_lipsum(3), sep='\n\n')"),
],
compare_ids=False,
)
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_read_markdown_file_no_language(
markdown="""```
ls
```
```
echo 'Hello World'
```
""",
):
nb = jupytext.reads(markdown, "md")
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_read_julia_notebook(
markdown="""```julia
1 + 1
```
""",
):
nb = jupytext.reads(markdown, "md")
assert nb.metadata["jupytext"]["main_language"] == "julia"
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "code"
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_split_on_header(
markdown="""A paragraph
# H1 Header
## H2 Header
Another paragraph
""",
):
fmt = {"extension": ".md", "split_at_heading": True}
nb = jupytext.reads(markdown, fmt)
assert nb.cells[0].source == "A paragraph"
assert nb.cells[1].source == "# H1 Header"
assert nb.cells[2].source == "## H2 Header\n\nAnother paragraph"
assert len(nb.cells) == 3
markdown2 = jupytext.writes(nb, fmt)
compare(markdown2, markdown)
def test_split_on_header_after_two_blank_lines(
markdown="""A paragraph
# H1 Header
""",
):
fmt = {"extension": ".Rmd", "split_at_heading": True}
nb = jupytext.reads(markdown, fmt)
markdown2 = jupytext.writes(nb, fmt)
compare(markdown2, markdown)
def test_split_at_heading_in_metadata(
markdown="""---
jupyter:
jupytext:
split_at_heading: true
---
A paragraph
# H1 Header
""",
nb_expected=new_notebook(cells=[new_markdown_cell("A paragraph"), new_markdown_cell("# H1 Header")]),
):
nb = jupytext.reads(markdown, ".md")
compare_notebooks(nb, nb_expected)
def test_code_cell_with_metadata(
markdown="""```python tags=["parameters"]
a = 1
b = 2
```
""",
):
nb = jupytext.reads(markdown, "md")
compare_cells(
nb.cells,
[new_code_cell(source="a = 1\nb = 2", metadata={"tags": ["parameters"]})],
compare_ids=False,
)
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_raw_cell_with_metadata_json(
markdown="""
raw content
""",
):
nb = jupytext.reads(markdown, "md")
compare_cells(
nb.cells,
[new_raw_cell(source="raw content", metadata={"key": "value"})],
compare_ids=False,
)
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_raw_cell_with_metadata(
markdown="""
raw content
""",
):
nb = jupytext.reads(markdown, "md")
compare_cells(
nb.cells,
[new_raw_cell(source="raw content", metadata={"key": "value"})],
compare_ids=False,
)
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_read_raw_cell_markdown_version_1_1(
markdown="""---
jupyter:
jupytext:
text_representation:
extension: .md
format_name: markdown
format_version: '1.1'
jupytext_version: 1.1.0
---
```key="value"
raw content
```
""",
):
nb = jupytext.reads(markdown, "md")
compare_cells(
nb.cells,
[new_raw_cell(source="raw content", metadata={"key": "value"})],
compare_ids=False,
)
md2 = jupytext.writes(nb, "md")
assert "format_version: '1.1'" not in md2
def test_read_raw_cell_markdown_version_1_1_with_mimetype(
header="""---
jupyter:
jupytext:
text_representation:
extension: .md
format_name: markdown
format_version: '1.1'
jupytext_version: 1.1.0-rc0
kernelspec:
display_name: Python 3
language: python
name: python3
---
""",
markdown_11="""```raw_mimetype="text/restructuredtext"
.. meta::
:description: Topic: Integrated Development Environments, Difficulty: Easy, Category: Tools
:keywords: python, introduction, IDE, PyCharm, VSCode, Jupyter, recommendation, tools
```
""",
markdown_12="""
.. meta::
:description: Topic: Integrated Development Environments, Difficulty: Easy, Category: Tools
:keywords: python, introduction, IDE, PyCharm, VSCode, Jupyter, recommendation, tools
""",
):
nb = jupytext.reads(header + "\n" + markdown_11, "md")
compare_cells(
nb.cells,
[
new_raw_cell(
source=""".. meta::
:description: Topic: Integrated Development Environments, Difficulty: Easy, Category: Tools
:keywords: python, introduction, IDE, PyCharm, VSCode, Jupyter, recommendation, tools""",
metadata={"raw_mimetype": "text/restructuredtext"},
)
],
compare_ids=False,
)
md2 = jupytext.writes(nb, "md")
assert "format_version: '1.1'" not in md2
nb.metadata["jupytext"]["notebook_metadata_filter"] = "-all"
md2 = jupytext.writes(nb, "md")
compare(md2, markdown_12)
def test_markdown_cell_with_metadata_json(
markdown="""
A long
markdown cell
""",
):
nb = jupytext.reads(markdown, "md")
compare_cells(
nb.cells,
[new_markdown_cell(source="A long\n\n\nmarkdown cell", metadata={"key": "value"})],
compare_ids=False,
)
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_markdown_cell_with_metadata(
markdown="""
A long
markdown cell
""",
):
nb = jupytext.reads(markdown, "md")
compare_cells(
nb.cells,
[new_markdown_cell(source="A long\n\n\nmarkdown cell", metadata={"key": "value"})],
compare_ids=False,
)
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_two_markdown_cells(
markdown="""# A header
A long
markdown cell
""",
):
nb = jupytext.reads(markdown, "md")
compare_cells(
nb.cells,
[
new_markdown_cell(source="# A header"),
new_markdown_cell(source="A long\n\n\nmarkdown cell"),
],
compare_ids=False,
)
markdown2 = jupytext.writes(nb, "md")
compare(markdown2, markdown)
def test_combine_md_version_one():
markdown = """---
jupyter:
jupytext:
text_representation:
extension: .md
format_name: markdown
format_version: '1.0'
jupytext_version: 1.0.0
kernelspec:
display_name: Python 3
language: python
name: python3
---
A short markdown cell
```
a raw cell
```
```python
1 + 1
```
"""
# notebook read from markdown file in version 1.0
nb_source = jupytext.reads(markdown, "md")
# actual notebook has metadata
nb_meta = jupytext.reads(markdown, "md")
for cell in nb_meta.cells:
cell.metadata = {"key": "value"}
nb_source = combine_inputs_with_outputs(nb_source, nb_meta)
for cell in nb_source.cells:
assert cell.metadata == {"key": "value"}, cell.source
def test_jupyter_cell_is_not_split():
text = """Here we have a markdown
file with a jupyter code cell
```python
1 + 1
2 + 2
```
the code cell should become a Jupyter cell.
"""
nb = jupytext.reads(text, "md")
assert nb.cells[0].cell_type == "markdown"
compare(
nb.cells[0].source,
"""Here we have a markdown
file with a jupyter code cell""",
)
assert nb.cells[1].cell_type == "code"
compare(
nb.cells[1].source,
"""1 + 1
2 + 2""",
)
assert nb.cells[2].cell_type == "markdown"
compare(nb.cells[2].source, "the code cell should become a Jupyter cell.")
assert len(nb.cells) == 3
def test_indented_code_is_not_split():
text = """Here we have a markdown
file with an indented code cell
1 + 1
2 + 2
the code cell should not become a Jupyter cell,
nor be split into two pieces."""
nb = jupytext.reads(text, "md")
compare(nb.cells[0].source, text)
assert nb.cells[0].cell_type == "markdown"
assert len(nb.cells) == 1
def test_non_jupyter_code_is_not_split():
text = """Here we have a markdown
file with a non-jupyter code cell
```{.python}
1 + 1
2 + 2
```
the code cell should not become a Jupyter cell,
nor be split into two pieces."""
nb = jupytext.reads(text, "md")
compare(nb.cells[0].source, text)
assert nb.cells[0].cell_type == "markdown"
assert len(nb.cells) == 1
def test_read_markdown_idl(
no_jupytext_version_number,
text="""---
jupyter:
kernelspec:
display_name: IDL [conda env:gdl] *
language: IDL
name: conda-env-gdl-idl
---
# A sample IDL Markdown notebook
```idl
a = 1
```
""",
):
nb = jupytext.reads(text, "md")
assert len(nb.cells) == 2
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "a = 1"
text2 = jupytext.writes(nb, "md")
compare(text2, text)
def test_read_markdown_IDL(
no_jupytext_version_number,
text="""---
jupyter:
kernelspec:
display_name: IDL [conda env:gdl] *
language: IDL
name: conda-env-gdl-idl
---
# A sample IDL Markdown notebook
```IDL
a = 1
```
""",
):
nb = jupytext.reads(text, "md")
assert len(nb.cells) == 2
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "a = 1"
text2 = jupytext.writes(nb, "md")
compare(text2, text)
def test_inactive_cell(
text="""```python active="md"
# This becomes a raw cell in Jupyter
```
""",
expected=new_notebook(cells=[new_raw_cell("# This becomes a raw cell in Jupyter", metadata={"active": "md"})]),
):
nb = jupytext.reads(text, "md")
compare_notebooks(nb, expected)
text2 = jupytext.writes(nb, "md")
compare(text2, text)
def test_inactive_cell_using_tag(
text="""```python tags=["active-md"]
# This becomes a raw cell in Jupyter
```
""",
expected=new_notebook(cells=[new_raw_cell("# This becomes a raw cell in Jupyter", metadata={"tags": ["active-md"]})]),
):
nb = jupytext.reads(text, "md")
compare_notebooks(nb, expected)
text2 = jupytext.writes(nb, "md")
compare(text2, text)
def test_inactive_cell_using_noeval(
text="""This is text
```python .noeval
# This is python code.
# It should not become a code cell
```
""",
):
expected = new_notebook(cells=[new_markdown_cell(text[:-1])])
nb = jupytext.reads(text, "md")
compare_notebooks(nb, expected)
text2 = jupytext.writes(nb, "md")
compare(text2, text)
def test_noeval_followed_by_code_works(
text="""```python .noeval
# Not a code cell in Jupyter
```
```python
1 + 1
```
""",
expected=new_notebook(
cells=[
new_markdown_cell(
"""```python .noeval
# Not a code cell in Jupyter
```"""
),
new_code_cell("1 + 1"),
]
),
):
nb = jupytext.reads(text, "md")
compare_notebooks(nb, expected)
text2 = jupytext.writes(nb, "md")
compare(text2, text)
def test_markdown_cell_with_code_works(
nb=new_notebook(
cells=[
new_markdown_cell(
"""```python
1 + 1
```"""
)
]
),
):
text = jupytext.writes(nb, "md")
nb2 = jupytext.reads(text, "md")
compare_notebooks(nb2, nb)
def test_markdown_cell_with_noeval_code_works(
nb=new_notebook(
cells=[
new_markdown_cell(
"""```python .noeval
1 + 1
```"""
)
]
),
):
text = jupytext.writes(nb, "md")
nb2 = jupytext.reads(text, "md")
compare_notebooks(nb2, nb)
def test_two_markdown_cell_with_code_works(
nb=new_notebook(
cells=[
new_markdown_cell(
"""```python
1 + 1
```"""
),
new_markdown_cell(
"""```python
2 + 2
```"""
),
]
),
):
text = jupytext.writes(nb, "md")
nb2 = jupytext.reads(text, "md")
compare_notebooks(nb2, nb)
def test_two_markdown_cell_with_no_language_code_works(
nb=new_notebook(
cells=[
new_markdown_cell(
"""```
1 + 1
```"""
),
new_markdown_cell(
"""```
2 + 2
```"""
),
]
),
):
text = jupytext.writes(nb, "md")
nb2 = jupytext.reads(text, "md")
compare_notebooks(nb2, nb)
def test_markdown_cell_with_code_inside_multiline_string_419(
text='''```python
readme = """
above
```python
x = 2
```
below
"""
```
''',
):
"""A code cell containing triple backticks is converted to a code cell encapsulated with four backticks"""
nb = jupytext.reads(text, "md")
compare(jupytext.writes(nb, "md"), "`" + text[:-1] + "`\n")
assert len(nb.cells) == 1
def test_notebook_with_python3_magic(
no_jupytext_version_number,
nb=new_notebook(
metadata={
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3",
}
},
cells=[
new_code_cell("%%python2\na = 1\nprint a"),
new_code_cell("%%python3\nb = 2\nprint(b)"),
],
),
text="""---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python2
a = 1
print a
```
```python3
b = 2
print(b)
```
""",
):
md = jupytext.writes(nb, "md")
compare(md, text)
nb2 = jupytext.reads(md, "md")
compare_notebooks(nb2, nb)
def test_update_metadata_filter(
no_jupytext_version_number,
org="""---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
extra:
key: value
---
""",
target="""---
jupyter:
extra:
key: value
jupytext:
notebook_metadata_filter: extra
kernelspec:
display_name: Python 3
language: python
name: python3
---
""",
):
nb = jupytext.reads(org, "md")
text = jupytext.writes(nb, "md")
compare(text, target)
def test_update_metadata_filter_2(
no_jupytext_version_number,
org="""---
jupyter:
jupytext:
notebook_metadata_filter: -extra
kernelspec:
display_name: Python 3
language: python
name: python3
extra:
key: value
---
""",
target="""---
jupyter:
jupytext:
notebook_metadata_filter: -extra
kernelspec:
display_name: Python 3
language: python
name: python3
---
""",
):
nb = jupytext.reads(org, "md")
text = jupytext.writes(nb, "md")
compare(text, target)
def test_custom_metadata(
no_jupytext_version_number,
nb=new_notebook(
metadata={
"author": "John Doe",
"title": "Some serious math",
"jupytext": {"notebook_metadata_filter": "title,author"},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3",
},
}
),
md="""---
jupyter:
author: John Doe
jupytext:
notebook_metadata_filter: title,author
kernelspec:
display_name: Python 3
language: python
name: python3
title: Some serious math
---
""",
):
"""Here we test the addition of custom metadata, cf. https://github.com/mwouts/jupytext/issues/469"""
md2 = jupytext.writes(nb, "md")
compare(md2, md)
nb2 = jupytext.reads(md, "md")
compare_notebooks(nb2, nb)
def test_hide_notebook_metadata(
no_jupytext_version_number,
nb=new_notebook(
metadata={
"jupytext": {"hide_notebook_metadata": True},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3",
},
}
),
md="""
""",
):
"""Test the hide_notebook_metadata option"""
md2 = jupytext.writes(nb, "md")
compare(md2, md)
nb2 = jupytext.reads(md, "md")
compare_notebooks(nb2, nb)
def test_notebook_with_empty_header_1070(
md="""---
---
This file has empty frontmatter.
""",
):
nb = jupytext.reads(md, fmt="md:markdown")
md2 = jupytext.writes(nb, "md")
compare(md2, md)
nb2 = jupytext.reads(md, "md")
compare_notebooks(nb2, nb)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_matlab.py
================================================
from nbformat.v4.nbbase import new_code_cell, new_notebook
import jupytext
from jupytext.compare import compare, compare_notebooks
def test_hide_code_tag(
no_jupytext_version_number,
nb=new_notebook(
metadata={"jupytext": {"main_language": "matlab"}},
cells=[new_code_cell("1 + 1", metadata={"tags": ["hide_code"]})],
),
text="""% %% tags=["hide_code"]
1 + 1
""",
):
text2 = jupytext.writes(nb, "m")
compare(text2, text)
nb2 = jupytext.reads(text, "m")
compare_notebooks(nb2, nb)
def test_hide_code_tag_percent_format(
no_jupytext_version_number,
nb=new_notebook(
metadata={"jupytext": {"main_language": "matlab"}},
cells=[new_code_cell("1 + 1", metadata={"tags": ["hide_code"]})],
),
text="""% %% tags=["hide_code"]
1 + 1
""",
):
text2 = jupytext.writes(nb, "m:percent")
compare(text2, text)
nb2 = jupytext.reads(text, "m:percent")
compare_notebooks(nb2, nb)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_nomarker.py
================================================
import os
import pytest
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
from jupytext import reads, write, writes
from jupytext.cli import jupytext as jupytext_cli
from jupytext.combine import combine_inputs_with_outputs
from jupytext.compare import compare
def test_write_reload_simple_notebook():
nb1 = new_notebook(
cells=[
new_markdown_cell("A markdown cell", metadata={"md": "value"}),
new_code_cell("1 + 1"),
new_markdown_cell("A markdown cell", metadata={"md": "value"}),
new_code_cell(
"""def f(x):
return x""",
metadata={"md": "value"},
),
new_markdown_cell("A markdown cell", metadata={"md": "value"}),
new_code_cell(
"""def g(x):
return x
def h(x):
return x
""",
metadata={"md": "value"},
),
]
)
text = writes(nb1, "py:nomarker")
nb2 = reads(text, "py:nomarker")
nb2 = combine_inputs_with_outputs(nb2, nb1, "py:nomarker")
nb2.metadata.pop("jupytext")
assert len(nb2.cells) == 7
nb1.cells = nb1.cells[:5]
nb2.cells = nb2.cells[:5]
compare(nb2, nb1)
with pytest.warns(DeprecationWarning, match="nomarker"):
text = writes(nb2, "py:bare")
with pytest.warns(DeprecationWarning, match="nomarker"):
nb3 = reads(text, "py:bare")
with pytest.warns(DeprecationWarning, match="nomarker"):
nb3 = combine_inputs_with_outputs(nb3, nb2, "py:bare")
nb3.metadata.pop("jupytext")
compare(nb3, nb2)
def test_jupytext_cli_bare(tmpdir):
tmp_py = str(tmpdir.join("test.py"))
tmp_ipynb = str(tmpdir.join("test.ipynb"))
write(new_notebook(cells=[new_code_cell("1 + 1")]), tmp_ipynb)
with pytest.warns(DeprecationWarning, match="nomarker"):
jupytext_cli([tmp_ipynb, "--to", "py:bare"])
assert os.path.isfile(tmp_py)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_ocaml.py
================================================
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
import jupytext
from jupytext.compare import compare, compare_notebooks
def test_read_simple_code(
no_jupytext_version_number,
ml="""(* %% *)
let sum x y = x + y
""",
nb=new_notebook(
cells=[
new_code_cell("""let sum x y = x + y"""),
]
),
):
nb2 = jupytext.reads(ml, "ml:percent")
compare_notebooks(nb2, nb)
ml2 = jupytext.writes(nb, "ml:percent")
compare(ml2, ml)
def test_read_simple_markdown(
no_jupytext_version_number,
ml="""(* %% [markdown] *)
(* # Example of an OCaml notebook *)
""",
nb=new_notebook(
cells=[
new_markdown_cell("# Example of an OCaml notebook"),
]
),
):
nb2 = jupytext.reads(ml, "ml:percent")
compare_notebooks(nb2, nb)
ml2 = jupytext.writes(nb, "ml:percent")
compare(ml2, ml)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_percent.py
================================================
import os
import pytest
from jupyter_server.utils import ensure_async
from nbformat.v4.nbbase import (
new_code_cell,
new_markdown_cell,
new_notebook,
new_raw_cell,
)
import jupytext
from jupytext.compare import compare, compare_notebooks, notebook_model
def test_read_simple_file(
script="""# ---
# title: Simple file
# ---
# %% [markdown]
# This is a markdown cell
# %% [md]
# This is also a markdown cell
# %% [raw]
# This is a raw cell
# %%% sub-cell title
# This is a sub-cell
# %%%% sub-sub-cell title
# This is a sub-sub-cell
# %% And now a code cell
1 + 2 + 3 + 4
5
6
# %%magic # this is a commented magic, not a cell
7
""",
):
nb = jupytext.reads(script, "py:percent")
compare_notebooks(
new_notebook(
cells=[
new_raw_cell("---\ntitle: Simple file\n---"),
new_markdown_cell("This is a markdown cell"),
new_markdown_cell("This is also a markdown cell", metadata={"region_name": "md"}),
new_raw_cell("This is a raw cell"),
new_code_cell(
"# This is a sub-cell",
metadata={"title": "sub-cell title", "cell_depth": 1},
),
new_code_cell(
"# This is a sub-sub-cell",
metadata={"title": "sub-sub-cell title", "cell_depth": 2},
),
new_code_cell(
"""1 + 2 + 3 + 4
5
6
%%magic # this is a commented magic, not a cell
7""",
metadata={"title": "And now a code cell"},
),
]
),
nb,
)
script2 = jupytext.writes(nb, "py:percent")
compare(script2, script)
def test_read_cell_with_metadata(
script="""# %% a code cell with parameters {"tags": ["parameters"]}
a = 3
""",
):
nb = jupytext.reads(script, "py:percent")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "code"
assert nb.cells[0].source == "a = 3"
assert nb.cells[0].metadata == {
"title": "a code cell with parameters",
"tags": ["parameters"],
}
script2 = jupytext.writes(nb, "py:percent")
compare(script2, script)
def test_read_nbconvert_script(
script="""
# coding: utf-8
# A markdown cell
# In[1]:
import pandas as pd
pd.options.display.max_rows = 6
pd.options.display.max_columns = 20
# Another markdown cell
# In[2]:
1 + 1
# Again, a markdown cell
# In[33]:
2 + 2
#
3 + 3
""",
):
assert jupytext.formats.guess_format(script, ".py")[0] == "percent"
nb = jupytext.reads(script, ".py")
assert len(nb.cells) == 5
def test_read_remove_blank_lines(
script="""# %%
import pandas as pd
# %% Display a data frame
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
# %% Pandas plot {"tags": ["parameters"]}
df.plot(kind='bar')
# %% sample class
class MyClass:
pass
# %% a function
def f(x):
return 42 * x
""",
):
nb = jupytext.reads(script, "py")
assert len(nb.cells) == 5
for i in range(5):
assert nb.cells[i].cell_type == "code"
assert not nb.cells[i].source.startswith("\n")
assert not nb.cells[i].source.endswith("\n")
script2 = jupytext.writes(nb, "py:percent")
compare(script2, script)
def test_no_crash_on_square_bracket(
script="""# %% In [2]
print('Hello')
""",
):
nb = jupytext.reads(script, "py")
script2 = jupytext.writes(nb, "py:percent")
compare(script2, script)
def test_nbconvert_cell(
script="""# In[2]:
print('Hello')
""",
):
nb = jupytext.reads(script, "py")
script2 = jupytext.writes(nb, "py:percent")
expected = """# %%
print('Hello')
"""
compare(script2, expected)
def test_nbformat_v3_nbpy_cell(
script="""#
print('Hello')
""",
):
nb = jupytext.reads(script, "py")
script2 = jupytext.writes(nb, "py:percent")
expected = """# %%
print('Hello')
"""
compare(script2, expected)
def test_multiple_empty_cells():
nb = new_notebook(
cells=[new_code_cell(), new_code_cell(), new_code_cell()],
metadata={"jupytext": {"notebook_metadata_filter": "-all"}},
)
text = jupytext.writes(nb, "py:percent")
expected = """# %%
# %%
# %%
"""
compare(text, expected)
nb2 = jupytext.reads(text, "py:percent")
nb2.metadata = nb.metadata
compare_notebooks(nb2, nb)
def test_first_cell_markdown_191():
text = """# %% [markdown]
# Docstring
# %%
from math import pi
# %% [markdown]
# Another markdown cell
"""
nb = jupytext.reads(text, "py")
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[1].cell_type == "code"
assert nb.cells[2].cell_type == "markdown"
def test_multiline_comments_in_markdown_1():
text = """# %% [markdown]
'''
a
long
cell
'''
"""
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "a\nlong\ncell"
py = jupytext.writes(nb, "py")
compare(py, text)
def test_multiline_comments_in_markdown_2():
text = '''# %% [markdown]
"""
a
long
cell
"""
'''
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "a\nlong\ncell"
py = jupytext.writes(nb, "py")
compare(py, text)
def test_multiline_comments_format_option():
text = '''# %% [markdown]
"""
a
long
cell
"""
'''
nb = new_notebook(
cells=[new_markdown_cell("a\nlong\ncell")],
metadata={"jupytext": {"cell_markers": '"""', "notebook_metadata_filter": "-all"}},
)
py = jupytext.writes(nb, "py:percent")
compare(py, text)
def test_multiline_comments_in_raw_cell():
text = '''# %% [raw]
"""
some
text
"""
'''
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "some\ntext"
py = jupytext.writes(nb, "py")
compare(py, text)
def test_multiline_comments_in_markdown_cell_no_line_return():
text = '''# %% [markdown]
"""a
long
cell"""
'''
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "a\nlong\ncell"
def test_multiline_comments_in_markdown_cell_is_robust_to_additional_cell_marker():
text = '''# %% [markdown]
"""
some text, and a fake cell marker
# %% [raw]
"""
'''
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "some text, and a fake cell marker\n# %% [raw]"
py = jupytext.writes(nb, "py")
compare(py, text)
@pytest.mark.asyncio
async def test_cell_markers_option_in_contents_manager(tmpdir, cm):
tmp_ipynb = tmpdir / "notebook.ipynb"
tmp_py = tmpdir / "notebook.py"
cm.root_dir = str(tmpdir)
nb = new_notebook(
cells=[new_code_cell("1 + 1"), new_markdown_cell("a\nlong\ncell")],
metadata={
"jupytext": {
"formats": "ipynb,py:percent",
"notebook_metadata_filter": "-all",
"cell_markers": "'''",
}
},
)
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.ipynb"))
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_py)
with open(tmp_py) as fp:
text = fp.read()
compare(
text,
"""# %%
1 + 1
# %% [markdown]
'''
a
long
cell
'''
""",
)
nb2 = jupytext.read(tmp_py)
compare_notebooks(nb, nb2)
@pytest.mark.asyncio
async def test_cell_markers_in_config(tmpdir, python_notebook, cm):
(tmpdir / "jupytext.toml").write('''cell_markers = '"""'\n''')
cm.root_dir = str(tmpdir)
nb = python_notebook
nb.metadata["jupytext"] = {"formats": "ipynb,py:percent"}
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.ipynb"))
text = (tmpdir / "notebook.py").read()
assert (
'''# %% [markdown]
"""
A short notebook
"""
'''
in text
)
nb2 = jupytext.read(tmpdir / "notebook.py")
compare_notebooks(nb, nb2)
@pytest.mark.asyncio
async def test_cell_markers_in_contents_manager(tmpdir, cm):
tmp_ipynb = tmpdir / "notebook.ipynb"
tmp_py = tmpdir / "notebook.py"
cm.root_dir = str(tmpdir)
cm.cell_markers = "'''"
nb = new_notebook(
cells=[new_code_cell("1 + 1"), new_markdown_cell("a\nlong\ncell")],
metadata={
"jupytext": {
"formats": "ipynb,py:percent",
"notebook_metadata_filter": "-all",
}
},
)
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.ipynb"))
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_py)
with open(tmp_py) as fp:
text = fp.read()
compare(
text,
"""# %%
1 + 1
# %% [markdown]
'''
a
long
cell
'''
""",
)
nb2 = jupytext.read(tmp_py)
compare_notebooks(nb, nb2)
@pytest.mark.asyncio
async def test_cell_markers_in_contents_manager_does_not_impact_light_format(tmpdir, cm):
tmp_ipynb = tmpdir / "notebook.ipynb"
tmp_py = tmpdir / "notebook.py"
cm.root_dir = str(tmpdir)
cm.cell_markers = "'''"
nb = new_notebook(
cells=[new_code_cell("1 + 1"), new_markdown_cell("a\nlong\ncell")],
metadata={
"jupytext": {
"formats": "ipynb,py:light",
"notebook_metadata_filter": "-all",
}
},
)
with pytest.warns(UserWarning, match="Ignored cell markers"):
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.ipynb"))
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_py)
with open(tmp_py) as fp:
text = fp.read()
compare(
text,
"""1 + 1
# a
# long
# cell
""",
)
nb2 = jupytext.read(tmp_py)
compare_notebooks(nb, nb2)
def test_single_triple_quote_works(
no_jupytext_version_number,
text='''# ---
# jupyter:
# jupytext:
# cell_markers: '"""'
# formats: ipynb,py:percent
# text_representation:
# extension: .py
# format_name: percent
# ---
# %%
print("hello")
''',
notebook=new_notebook(cells=[new_code_cell('print("hello")')]),
):
compare_notebooks(jupytext.reads(text, "py"), notebook)
def test_docstring_with_quadruple_quote(
nb=new_notebook(
cells=[
new_code_cell(
'''def fun_1(df):
""""
docstring starting with 4 double quotes and ending with 3
"""
return df'''
),
new_code_cell(
'''def fun_2(df):
"""
docstring
"""
return df'''
),
]
),
):
"""Reproduces https://github.com/mwouts/jupytext/issues/460"""
py = jupytext.writes(nb, "py:percent")
nb2 = jupytext.reads(py, "py")
compare_notebooks(nb2, nb)
def test_cell_marker_has_same_indentation_as_code(
text="""# %%
if __name__ == '__main__':
print(1)
# %%
# INDENTED COMMENT
print(2)
""",
nb_expected=new_notebook(
cells=[
new_code_cell(
"""if __name__ == '__main__':
print(1)"""
),
new_code_cell(
""" # INDENTED COMMENT
print(2)"""
),
]
),
):
"""The cell marker should have the same indentation as the first code line. See issue #562"""
nb_actual = jupytext.reads(text, fmt="py:percent")
compare_notebooks(nb_actual, nb_expected)
text_actual = jupytext.writes(nb_actual, fmt="py:percent")
compare(text_actual, text)
@pytest.mark.parametrize("space_in_gonb", [False, True])
def test_read_simple_gonb_cell_with_double_percent(
space_in_gonb,
go_percent="""// ---
// jupyter:
// kernelspec:
// display_name: Go (gonb)
// language: go
// name: gonb
// ---
// %%
//gonb:%%
fmt.Printf("Hello World!")
""",
):
"""The cell marker should have the same indentation as the first code line. See issue #562"""
if space_in_gonb:
go_percent = go_percent.replace("//gonb:%%", "// gonb:%%")
nb = jupytext.reads(go_percent, fmt="go:percent")
assert len(nb.cells) == 1
(cell,) = nb.cells
assert cell.cell_type == "code", cell.cell_type
assert (
cell.source
== """%%
fmt.Printf("Hello World!")"""
)
def test_write_simple_gonb_cell_with_double_percent(
no_jupytext_version_number,
go_percent="""// ---
// jupyter:
// kernelspec:
// display_name: Go (gonb)
// language: go
// name: gonb
// ---
// %%
//gonb:%%
fmt.Printf("Hello World!")
""",
):
"""The cell marker should have the same indentation as the first code line. See issue #562"""
nb = jupytext.reads(go_percent, fmt="go:percent")
go = jupytext.writes(nb, fmt="go:percent")
compare(go, go_percent)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_python.py
================================================
import pytest
from nbformat.v4.nbbase import (
new_code_cell,
new_markdown_cell,
new_notebook,
new_raw_cell,
)
import jupytext
from jupytext.compare import compare, compare_notebooks
def test_read_simple_file(
pynb="""# ---
# title: Simple file
# ---
# Here we have some text
# And below we have some python code
def f(x):
return x+1
def h(y):
return y-1
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 4
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: Simple file\n---"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "Here we have some text\nAnd below we have some python code"
assert nb.cells[2].cell_type == "code"
compare(
nb.cells[2].source,
"""def f(x):
return x+1""",
)
assert nb.cells[3].cell_type == "code"
compare(
nb.cells[3].source,
"""def h(y):
return y-1""",
)
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_read_less_simple_file(
pynb="""# ---
# title: Less simple file
# ---
# Here we have some text
# And below we have some python code
# This is a comment about function f
def f(x):
return x+1
# And a comment on h
def h(y):
return y-1
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 4
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: Less simple file\n---"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "Here we have some text\nAnd below we have some python code"
assert nb.cells[2].cell_type == "code"
compare(
nb.cells[2].source,
"# This is a comment about function f\ndef f(x):\n return x+1",
)
assert nb.cells[3].cell_type == "code"
compare(nb.cells[3].source, """# And a comment on h\ndef h(y):\n return y-1""")
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_indented_comment(
text="""def f():
return 1
# f returns 1
def g():
return 2
# h returns 3
def h():
return 3
""",
ref=new_notebook(
cells=[
new_code_cell(
"""def f():
return 1
# f returns 1"""
),
new_code_cell("def g():\n return 2"),
new_code_cell("# h returns 3\ndef h():\n return 3"),
]
),
):
nb = jupytext.reads(text, "py")
compare_notebooks(nb, ref)
py = jupytext.writes(nb, "py")
compare(py, text)
def test_non_pep8(
text="""def f():
return 1
def g():
return 2
def h():
return 3
""",
ref=new_notebook(
cells=[
new_code_cell(
"def f():\n return 1\ndef g():\n return 2",
metadata={"lines_to_next_cell": 1},
),
new_code_cell("def h():\n return 3"),
]
),
):
nb = jupytext.reads(text, "py")
compare_notebooks(nb, ref)
py = jupytext.writes(nb, "py")
compare(py, text)
def test_read_non_pep8_file(
pynb="""# ---
# title: Non-pep8 file
# ---
# This file is non-pep8 as the function below has
# two consecutive blank lines in its body
def f(x):
return x+1
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: Non-pep8 file\n---"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "This file is non-pep8 as the function below has\ntwo consecutive blank lines in its body"
assert nb.cells[2].cell_type == "code"
compare(nb.cells[2].source, "def f(x):\n\n\n return x+1")
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_read_cell_two_blank_lines(
pynb="""# ---
# title: cell with two consecutive blank lines
# ---
# +
a = 1
a + 2
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: cell with two consecutive blank lines\n---"
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "a = 1\n\n\na + 2"
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_read_cell_explicit_start(
pynb="""
import pandas as pd
# +
def data():
return pd.DataFrame({'A': [0, 1]})
data()
""",
):
nb = jupytext.reads(pynb, "py")
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_read_complex_cells(
pynb="""import pandas as pd
# +
def data():
return pd.DataFrame({'A': [0, 1]})
data()
# +
def data2():
return pd.DataFrame({'B': [0, 1]})
data2()
# +
# Finally we have a cell with only comments
# This cell should remain a code cell and not get converted
# to markdown
# + {"endofcell": "--"}
# This cell has an enumeration in it that should not
# match the endofcell marker!
# - item 1
# - item 2
# -
# --
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 5
assert nb.cells[0].cell_type == "code"
assert nb.cells[1].cell_type == "code"
assert nb.cells[2].cell_type == "code"
assert nb.cells[3].cell_type == "code"
assert nb.cells[4].cell_type == "code"
assert (
nb.cells[3].source
== """# Finally we have a cell with only comments
# This cell should remain a code cell and not get converted
# to markdown"""
)
assert (
nb.cells[4].source
== """# This cell has an enumeration in it that should not
# match the endofcell marker!
# - item 1
# - item 2
# -"""
)
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_read_prev_function(
pynb="""def test_read_cell_explicit_start_end(pynb='''
import pandas as pd
# +
def data():
return pd.DataFrame({'A': [0, 1]})
data()
'''):
nb = jupytext.reads(pynb, 'py')
pynb2 = jupytext.writes(nb, 'py')
compare(pynb2, pynb)
""",
):
nb = jupytext.reads(pynb, "py")
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_read_cell_with_one_blank_line_end(
pynb="""import pandas
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 1
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_read_code_cell_fully_commented(
pynb="""# +
# This is a code cell that
# only contains comments
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "code"
assert (
nb.cells[0].source
== """# This is a code cell that
# only contains comments"""
)
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_file_with_two_blank_line_end(
pynb="""import pandas
""",
):
nb = jupytext.reads(pynb, "py")
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_one_blank_lines_after_endofcell(
pynb="""# +
# This is a code cell with explicit end of cell
1 + 1
2 + 2
# -
# This cell is a cell with implicit start
1 + 1
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "code"
assert (
nb.cells[0].source
== """# This is a code cell with explicit end of cell
1 + 1
2 + 2"""
)
assert nb.cells[1].cell_type == "code"
assert (
nb.cells[1].source
== """# This cell is a cell with implicit start
1 + 1"""
)
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_two_cells_with_explicit_start(
pynb="""# +
# Cell one
1 + 1
1 + 1
# +
# Cell two
2 + 2
2 + 2
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "code"
assert (
nb.cells[0].source
== """# Cell one
1 + 1
1 + 1"""
)
assert nb.cells[1].cell_type == "code"
assert (
nb.cells[1].source
== """# Cell two
2 + 2
2 + 2"""
)
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_escape_start_pattern(
pynb="""# The code start pattern '# +' can
# appear in code and markdown cells.
# In markdown cells it is escaped like here:
# # + {"sample_metadata": "value"}
# In code cells like this one, it is also escaped
# # + {"sample_metadata": "value"}
1 + 1
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[2].cell_type == "code"
assert (
nb.cells[1].source
== """In markdown cells it is escaped like here:
# + {"sample_metadata": "value"}"""
)
assert (
nb.cells[2].source
== """# In code cells like this one, it is also escaped
# + {"sample_metadata": "value"}
1 + 1"""
)
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_dictionary_with_blank_lines_not_broken(
pynb="""# This is a markdown cell, and below
# we have a long dictionary with blank lines
# inside it
dictionary = {
'a': 'A',
'b': 'B',
# and the end
'z': 'Z'}
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[1].cell_type == "code"
assert (
nb.cells[0].source
== """This is a markdown cell, and below
we have a long dictionary with blank lines
inside it"""
)
assert (
nb.cells[1].source
== """dictionary = {
'a': 'A',
'b': 'B',
# and the end
'z': 'Z'}"""
)
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_isolated_cell_with_magic(
pynb="""# ---
# title: cell with isolated jupyter magic
# ---
# A magic command included in a markdown
# paragraph is code
#
# %matplotlib inline
# a code block may start with
# a magic command, like this one:
# %matplotlib inline
# or that one
# %matplotlib inline
1 + 1
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 6
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: cell with isolated jupyter magic\n---"
assert nb.cells[1].cell_type == "code"
assert nb.cells[2].cell_type == "markdown"
assert nb.cells[3].cell_type == "code"
assert nb.cells[3].source == "%matplotlib inline"
assert nb.cells[4].cell_type == "markdown"
assert nb.cells[5].cell_type == "code"
assert nb.cells[5].source == "%matplotlib inline\n1 + 1"
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_ipython_help_are_commented_297(
text="""# This is a markdown cell
# that ends with a question: float?
# The next cell is also a markdown cell,
# because it has no code marker:
# float?
# +
# float?
# +
# float??
# +
# Finally a question in a code
# # cell?
""",
nb=new_notebook(
cells=[
new_markdown_cell("This is a markdown cell\nthat ends with a question: float?"),
new_markdown_cell("The next cell is also a markdown cell,\nbecause it has no code marker:"),
new_markdown_cell("float?"),
new_code_cell("float?"),
new_code_cell("float??"),
new_code_cell("# Finally a question in a code\n# cell?"),
]
),
):
nb2 = jupytext.reads(text, "py")
compare_notebooks(nb2, nb)
text2 = jupytext.writes(nb2, "py")
compare(text2, text)
def test_questions_in_unmarked_cells_are_not_uncommented_297(
text="""# This cell has no explicit marker
# question?
1 + 2
""",
nb=new_notebook(
cells=[
new_code_cell(
"# This cell has no explicit marker\n# question?\n1 + 2",
metadata={"comment_questions": False},
)
]
),
):
nb2 = jupytext.reads(text, "py")
compare_notebooks(nb2, nb)
text2 = jupytext.writes(nb2, "py")
compare(text2, text)
def test_read_multiline_comment(
pynb="""'''This is a multiline
comment with "quotes", 'single quotes'
# and comments
and line breaks
and it ends here'''
1 + 1
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 2
assert nb.cells[0].cell_type == "code"
assert (
nb.cells[0].source
== """'''This is a multiline
comment with "quotes", 'single quotes'
# and comments
and line breaks
and it ends here'''"""
)
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "1 + 1"
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_no_space_after_code(
pynb="""# -*- coding: utf-8 -*-
# Markdown cell
def f(x):
return x+1
# And a new cell, and non ascii contênt
""",
):
nb = jupytext.reads(pynb, "py")
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "Markdown cell"
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "def f(x):\n return x+1"
assert nb.cells[2].cell_type == "markdown"
assert nb.cells[2].source == "And a new cell, and non ascii contênt"
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_read_write_script(
pynb="""#!/usr/bin/env python
# coding=utf-8
print('Hello world')
""",
):
nb = jupytext.reads(pynb, "py")
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_read_write_script_with_metadata_241(
no_jupytext_version_number,
pynb="""#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
a = 2
a + 1
""",
):
nb = jupytext.reads(pynb, "py")
assert "executable" in nb.metadata["jupytext"]
assert "encoding" in nb.metadata["jupytext"]
pynb2 = jupytext.writes(nb, "py")
compare(pynb2, pynb)
def test_notebook_blank_lines(
script="""# +
# This is a comment
# followed by two variables
a = 3
b = 4
# -
# New cell is a variable
c = 5
# +
# Now we have two functions
def f(x):
return x + x
def g(x):
return x + x + x
# -
# A commented block that is two lines away
# from previous cell
# A function again
def h(x):
return x + 1
# variable
d = 6
""",
):
notebook = jupytext.reads(script, "py")
assert len(notebook.cells) >= 6
for cell in notebook.cells:
lines = cell.source.splitlines()
if len(lines) != 1:
assert lines[0], cell.source
assert lines[-1], cell.source
script2 = jupytext.writes(notebook, "py")
compare(script2, script)
def test_notebook_two_blank_lines_before_next_cell(
script="""# +
# This is cell with a function
def f(x):
return 4
# +
# Another cell
c = 5
def g(x):
return 6
# +
# Final cell
1 + 1
""",
):
notebook = jupytext.reads(script, "py")
assert len(notebook.cells) == 3
for cell in notebook.cells:
lines = cell.source.splitlines()
if len(lines) != 1:
assert lines[0]
assert lines[-1]
script2 = jupytext.writes(notebook, "py")
compare(script2, script)
def test_notebook_one_blank_line_between_cells(
script="""# +
1 + 1
2 + 2
# +
3 + 3
4 + 4
# +
5 + 5
def g(x):
return 6
# +
7 + 7
def h(x):
return 8
# +
def i(x):
return 9
10 + 10
# +
def j(x):
return 11
12 + 12
""",
):
notebook = jupytext.reads(script, "py")
for cell in notebook.cells:
lines = cell.source.splitlines()
assert lines[0]
assert lines[-1]
assert not cell.metadata, cell.source
script2 = jupytext.writes(notebook, "py")
compare(script2, script)
def test_notebook_with_magic_and_bash_cells(
script="""# This is a test for issue #181
# %load_ext line_profiler
# !head -4 data/president_heights.csv
""",
):
notebook = jupytext.reads(script, "py")
for cell in notebook.cells:
lines = cell.source.splitlines()
assert lines[0]
assert lines[-1]
assert not cell.metadata, cell.source
script2 = jupytext.writes(notebook, "py")
compare(script2, script)
def test_notebook_no_line_to_next_cell(
nb=new_notebook(
cells=[
new_markdown_cell("Markdown cell #1"),
new_code_cell("%load_ext line_profiler"),
new_markdown_cell("Markdown cell #2"),
new_code_cell("%lprun -f ..."),
new_markdown_cell("Markdown cell #3"),
new_code_cell("# And a function!\ndef f(x):\n return 5"),
]
),
):
script = jupytext.writes(nb, "py")
nb2 = jupytext.reads(script, "py")
nb2.metadata.pop("jupytext")
compare_notebooks(nb2, nb)
def test_notebook_one_blank_line_before_first_markdown_cell(
script="""
# This is a markdown cell
1 + 1
""",
):
notebook = jupytext.reads(script, "py")
script2 = jupytext.writes(notebook, "py")
compare(script2, script)
assert len(notebook.cells) == 3
for cell in notebook.cells:
lines = cell.source.splitlines()
if len(lines):
assert lines[0]
assert lines[-1]
def test_read_markdown_cell_with_triple_quote_307(
script="""# This script test that commented triple quotes '''
# do not impede the correct identification of Markdown cells
# Here is Markdown cell number 2 '''
""",
):
notebook = jupytext.reads(script, "py")
assert len(notebook.cells) == 2
assert notebook.cells[0].cell_type == "markdown"
assert (
notebook.cells[0].source
== """This script test that commented triple quotes '''
do not impede the correct identification of Markdown cells"""
)
assert notebook.cells[1].cell_type == "markdown"
assert notebook.cells[1].source == "Here is Markdown cell number 2 '''"
script2 = jupytext.writes(notebook, "py")
compare(script2, script)
def test_read_explicit_markdown_cell_with_triple_quote_307(
script="""# {{{ [md] {"special": "metadata"}
# some text '''
# }}}
print('hello world')
# {{{ [md] {"special": "metadata"}
# more text '''
# }}}
""",
):
notebook = jupytext.reads(script, "py")
assert len(notebook.cells) == 3
assert notebook.cells[0].cell_type == "markdown"
assert notebook.cells[0].source == "some text '''"
assert notebook.cells[1].cell_type == "code"
assert notebook.cells[1].source == "print('hello world')"
assert notebook.cells[2].cell_type == "markdown"
assert notebook.cells[2].source == "more text '''"
script2 = jupytext.writes(notebook, "py")
compare(script2, script)
def test_round_trip_markdown_cell_with_magic():
notebook = new_notebook(
cells=[new_markdown_cell("IPython has magic commands like\n%quickref")],
metadata={"jupytext": {"main_language": "python"}},
)
text = jupytext.writes(notebook, "py")
notebook2 = jupytext.reads(text, "py")
compare_notebooks(notebook2, notebook)
def test_round_trip_python_with_js_cell():
notebook = new_notebook(
cells=[
new_code_cell(
"""import notebook.nbextensions
notebook.nbextensions.install_nbextension('index.js', user=True)"""
),
new_code_cell(
"""%%javascript
Jupyter.utils.load_extensions('jupytext')"""
),
]
)
text = jupytext.writes(notebook, "py")
notebook2 = jupytext.reads(text, "py")
compare_notebooks(notebook2, notebook)
def test_round_trip_python_with_js_cell_no_cell_metadata():
notebook = new_notebook(
cells=[
new_code_cell(
"""import notebook.nbextensions
notebook.nbextensions.install_nbextension('index.js', user=True)"""
),
new_code_cell(
"""%%javascript
Jupyter.utils.load_extensions('jupytext')"""
),
],
metadata={
"jupytext": {
"notebook_metadata_filter": "-all",
"cell_metadata_filter": "-all",
}
},
)
text = jupytext.writes(notebook, "py")
notebook2 = jupytext.reads(text, "py")
compare_notebooks(notebook2, notebook)
def test_raw_with_metadata(
text="""# + key="value" active=""
# Raw cell
# # Commented line
""",
notebook=new_notebook(cells=[new_raw_cell("Raw cell\n# Commented line", metadata={"key": "value"})]),
):
nb2 = jupytext.reads(text, "py")
compare_notebooks(nb2, notebook)
text2 = jupytext.writes(nb2, "py")
compare(text2, text)
def test_raw_with_metadata_2(
no_jupytext_version_number,
text="""# + [raw] key="value"
# Raw cell
# # Commented line
""",
notebook=new_notebook(cells=[new_raw_cell("Raw cell\n# Commented line", metadata={"key": "value"})]),
):
nb2 = jupytext.reads(text, "py")
compare_notebooks(nb2, notebook)
def test_markdown_with_metadata(
text="""# + [markdown] key="value"
# Markdown cell
""",
notebook=new_notebook(cells=[new_markdown_cell("Markdown cell", metadata={"key": "value"})]),
):
nb2 = jupytext.reads(text, "py")
compare_notebooks(nb2, notebook)
text2 = jupytext.writes(nb2, "py")
compare(text2, text)
def test_multiline_comments_in_markdown_1():
text = """# + [markdown]
'''
a
long
cell
'''
"""
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "a\nlong\ncell"
py = jupytext.writes(nb, "py")
compare(py, text)
def test_multiline_comments_in_markdown_2():
text = '''# + [markdown]
"""
a
long
cell
"""
'''
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "a\nlong\ncell"
py = jupytext.writes(nb, "py")
compare(py, text)
def test_multiline_comments_in_raw_cell():
text = '''# + active=""
"""
some
text
"""
'''
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "some\ntext"
py = jupytext.writes(nb, "py")
compare(py, text)
def test_multiline_comments_in_markdown_cell_no_line_return():
text = '''# + [md]
"""a
long
cell"""
'''
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "a\nlong\ncell"
def test_multiline_comments_in_markdown_cell_is_robust_to_additional_cell_marker():
text = '''# + [md]
"""
some text, and a fake cell marker
# + [raw]
"""
'''
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[0].source == "some text, and a fake cell marker\n# + [raw]"
py = jupytext.writes(nb, "py")
compare(py, text)
def test_active_tag(
text="""# + tags=["active-py"]
interpreter = 'python'
# + tags=["active-ipynb"]
# interpreter = 'ipython'
""",
ref=new_notebook(
cells=[
new_raw_cell("interpreter = 'python'", metadata={"tags": ["active-py"]}),
new_code_cell("interpreter = 'ipython'", metadata={"tags": ["active-ipynb"]}),
]
),
):
nb = jupytext.reads(text, "py")
compare_notebooks(nb, ref)
py = jupytext.writes(nb, "py")
compare(py, text)
def test_indented_bash_command(
no_jupytext_version_number,
nb=new_notebook(
cells=[
new_code_cell(
"""try:
!echo jo
pass
except:
pass"""
)
]
),
text="""try:
# !echo jo
pass
except:
pass
""",
):
"""Reproduces https://github.com/mwouts/jupytext/issues/437"""
py = jupytext.writes(nb, "py:light")
compare(py, text)
nb2 = jupytext.reads(py, "py")
compare_notebooks(nb2, nb)
def test_two_raw_cells_are_preserved(nb=new_notebook(cells=[new_raw_cell("---\nX\n---"), new_raw_cell("Y")])):
"""Test the pattern described at https://github.com/mwouts/jupytext/issues/466"""
py = jupytext.writes(nb, "py")
nb2 = jupytext.reads(py, "py")
compare_notebooks(nb2, nb)
def test_no_metadata_on_multiline_decorator(
text="""import pytest
@pytest.mark.parametrize(
"arg",
[
'a',
'b',
'c'
],
)
def test_arg(arg):
assert isinstance(arg, str)
""",
):
"""Applying black on the code of jupytext 1.4.2 turns some pytest parameters into multi-lines ones, and
causes a few failures in test_pep8.py:test_no_metadata_when_py_is_pep8"""
nb = jupytext.reads(text, "py")
assert len(nb.cells) == 2
for cell in nb.cells:
assert cell.cell_type == "code"
assert nb.cells[0].source == "import pytest"
assert nb.cells[0].metadata == {}
@pytest.mark.parametrize(
"script,cell",
[
(
"""if True:
# # !rm file 1
# !rm file 2
""",
"""if True:
# !rm file 1
!rm file 2""",
),
(
"""# +
if True:
# help?
# ?help
# # ?help
# # help?
""",
"""if True:
help?
?help
# ?help
# help?""",
),
],
)
def test_indented_magic_commands(script, cell):
nb = jupytext.reads(script, "py")
assert len(nb.cells) == 1
assert nb.cells[0].cell_type == "code"
compare(nb.cells[0].source, cell)
assert nb.cells[0].metadata == {}
compare(jupytext.writes(nb, "py"), script)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_rmd.py
================================================
import re
from time import sleep
import nbformat
import pytest
from nbformat.v4.nbbase import (
new_code_cell,
new_markdown_cell,
new_notebook,
new_raw_cell,
)
import jupytext
from jupytext.cli import jupytext as jupytext_cli
from jupytext.compare import compare, compare_cells, compare_notebooks
def test_read_mostly_py_rmd_file(
rmd="""---
title: Simple file
---
```{python, echo=TRUE}
import numpy as np
x = np.arange(0, 2*math.pi, eps)
```
```{python, echo=TRUE}
x = np.arange(0,1,eps)
y = np.abs(x)-.5
```
```{r}
ls()
```
```{r, results="asis", magic_args="-i x"}
cat(stringi::stri_rand_lipsum(3), sep='\n\n')
```
""",
):
nb = jupytext.reads(rmd, "Rmd")
compare_cells(
nb.cells,
[
new_raw_cell("---\ntitle: Simple file\n---"),
new_code_cell(
"import numpy as np\nx = np.arange(0, 2*math.pi, eps)",
metadata={"echo": True},
),
new_code_cell("x = np.arange(0,1,eps)\ny = np.abs(x)-.5", metadata={"echo": True}),
new_code_cell("%%R\nls()"),
new_code_cell(
"%%R -i x\ncat(stringi::stri_rand_lipsum(3), sep='\n\n')",
metadata={"results": "asis"},
),
],
compare_ids=False,
)
rmd2 = jupytext.writes(nb, "Rmd")
rmd2 = re.sub(r"```{r ", "```{r, ", rmd2)
rmd2 = re.sub(r"```{python ", "```{python, ", rmd2)
compare(rmd2, rmd)
def test_markdown_cell_with_code_works(
nb=new_notebook(
cells=[
new_markdown_cell(
"""```python
1 + 1
```"""
)
]
),
):
text = jupytext.writes(nb, "Rmd")
nb2 = jupytext.reads(text, "Rmd")
compare_notebooks(nb2, nb)
def test_two_markdown_cell_with_code_works(
nb=new_notebook(
cells=[
new_markdown_cell(
"""```python
1 + 1
```"""
),
new_markdown_cell(
"""```python
2 + 2
```"""
),
]
),
):
text = jupytext.writes(nb, "Rmd")
nb2 = jupytext.reads(text, "Rmd")
compare_notebooks(nb2, nb)
def test_tags_in_rmd(
rmd="""---
jupyter:
jupytext:
text_representation:
extension: .Rmd
format_name: rmarkdown
format_version: '1.1'
jupytext_version: 1.2.3
---
```{python tags=c("parameters")}
p = 1
```
""",
nb=new_notebook(cells=[new_code_cell("p = 1", metadata={"tags": ["parameters"]})]),
):
nb2 = jupytext.reads(rmd, "Rmd")
compare_notebooks(nb2, nb)
def round_trip_cell_metadata(cell_metadata):
nb = new_notebook(
metadata={"jupytext": {"main_language": "python"}},
cells=[new_code_cell("1 + 1", metadata=cell_metadata)],
)
text = jupytext.writes(nb, "Rmd")
nb2 = jupytext.reads(text, "Rmd")
compare_notebooks(nb2, nb)
def test_comma_in_metadata(cell_metadata={"a": "b, c"}):
round_trip_cell_metadata(cell_metadata)
def test_dict_in_metadata(cell_metadata={"a": {"b": "c"}}):
round_trip_cell_metadata(cell_metadata)
def test_list_in_metadata(cell_metadata={"d": ["e"]}):
round_trip_cell_metadata(cell_metadata)
@pytest.mark.parametrize("root_level_metadata_as_raw_cell", [True, False])
def test_root_level_metadata_as_raw_cell(
tmpdir,
root_level_metadata_as_raw_cell,
rmd="""---
author: R Markdown document author
title: R Markdown notebook title
---
```{r}
1 + 1
```
""",
):
nb_file = tmpdir.join("notebook.ipynb")
rmd_file = tmpdir.join("notebook.Rmd")
cfg_file = tmpdir.join("jupytext.toml")
cfg_file.write("root_level_metadata_as_raw_cell = {}".format("true" if root_level_metadata_as_raw_cell else "false"))
rmd_file.write(rmd)
jupytext_cli([str(rmd_file), "--to", "ipynb"])
nb = nbformat.read(str(nb_file), as_version=4)
if root_level_metadata_as_raw_cell:
compare_cells(
nb.cells,
[
new_raw_cell(
"""---
author: R Markdown document author
title: R Markdown notebook title
---"""
),
new_code_cell("1 + 1"),
],
compare_ids=False,
)
else:
compare_cells(nb.cells, [new_code_cell("1 + 1")], compare_ids=False)
assert nb.metadata["jupytext"]["root_level_metadata"] == {
"title": "R Markdown notebook title",
"author": "R Markdown document author",
}
# Writing back to Rmd should preserve the original document
jupytext_cli([str(nb_file), "--to", "Rmd"])
compare(rmd_file.read(), rmd)
def test_pair_rmd_file_with_cell_tags_and_options(tmpdir, cwd_tmpdir, no_jupytext_version_number):
rmd = """```{r plot_1, dpi=72}
plot(3:30)
```
"""
rmd_file = tmpdir.join("test.Rmd")
rmd_file.write(rmd)
# Pair Rmd with ipynb
jupytext_cli(["--set-formats", "ipynb,Rmd", "test.Rmd"])
# Wait so that ipynb will be more recent
sleep(0.2)
# Modify the ipynb file
nb_file = tmpdir.join("test.ipynb")
nb = nbformat.read(nb_file, as_version=4)
nb.cells[0].source = "plot(4:40)"
nb_file.write(nbformat.writes(nb))
# Sync the two files
jupytext_cli(["--sync", "test.Rmd"])
# Remove the header
rmd2 = rmd_file.read()
rmd2 = rmd2.rsplit("---\n\n")[1]
# The new code chunk has the new code, and options are still there
compare(rmd2, rmd.replace("3", "4"))
def test_apostrophe_in_parameter_1079(
rmd="""```{python some-name, param="Problem's"}
a = 1
```
""",
):
nb = jupytext.reads(rmd, fmt="Rmd")
rmd2 = jupytext.writes(nb, fmt="Rmd")
compare(rmd2, rmd)
nb2 = jupytext.reads(rmd, fmt="Rmd")
compare_notebooks(nb2, nb)
@pytest.mark.parametrize("line", [" #'''", "a = 2 #'''"])
def test_commented_triple_quote_1060(line):
rmd = f"""```{{python}}
{line}
```
```{{python}}
# Another cell
```
"""
nb = jupytext.reads(rmd, fmt="Rmd")
assert nb.cells[0].source == line
rmd2 = jupytext.writes(nb, fmt="Rmd")
compare(rmd2, rmd)
nb2 = jupytext.reads(rmd, fmt="Rmd")
compare_notebooks(nb2, nb)
def test_bibliography_in_rmd(
rmd="""Issue #1161
The bibliography section below should not
become a code cell
```{bibliography}
```
```{r}
6
```
""",
):
nb = jupytext.reads(rmd, fmt="Rmd")
assert len(nb.cells) == 2, nb.cells
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "6"
rmd2 = jupytext.writes(nb, fmt="Rmd")
compare(rmd2, rmd)
def test_non_language_code_fence():
"""
This test reproduces the example from issue #1429
"""
rmd = """# A title
```{index} equations
```
Some text.
```{python}
a = 10
```
"""
nb = jupytext.reads(rmd, fmt="Rmd")
assert len(nb.cells) == 2, nb.cells
assert nb.cells[0].cell_type == "markdown"
assert nb.cells[1].cell_type == "code"
assert nb.cells[1].source == "a = 10"
rmd2 = jupytext.writes(nb, fmt="Rmd")
compare(rmd2, rmd)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_rust.py
================================================
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
import jupytext
from jupytext.compare import compare, compare_notebooks
def test_read_magics(text="// :vars\n"):
nb = jupytext.reads(text, "rs")
compare_notebooks(nb, new_notebook(cells=[new_code_cell(":vars")]))
compare(jupytext.writes(nb, "rs"), text)
def test_read_simple_file(
text="""println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
// A Function
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
// This is a
// Markdown cell
// This is a magic instruction
// :vars
// This is a rust identifier
::std::mem::drop
""",
):
nb = jupytext.reads(text, "rs")
compare_notebooks(
nb,
new_notebook(
cells=[
new_code_cell(
"""println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")"""
),
new_code_cell(
"""// A Function
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}"""
),
new_markdown_cell("This is a\nMarkdown cell"),
new_code_cell(
"""// This is a magic instruction
:vars"""
),
new_code_cell(
"""// This is a rust identifier
::std::mem::drop"""
),
]
),
)
compare(jupytext.writes(nb, "rs"), text)
def test_read_write_script_with_metadata_241(
no_jupytext_version_number,
rsnb="""#!/usr/bin/env scriptisto
// ---
// jupyter:
// jupytext:
// text_representation:
// extension: .rs
// format_name: light
// kernelspec:
// display_name: Rust
// language: rust
// name: rust
// ---
let mut a: i32 = 2;
a += 1;
""",
):
nb = jupytext.reads(rsnb, "rs")
assert "executable" in nb.metadata["jupytext"]
rsnb2 = jupytext.writes(nb, "rs")
compare(rsnb, rsnb2)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_scheme.py
================================================
import jupytext
from jupytext.compare import compare
def test_read_simple_file(
script=""";; ---
;; title: Simple file
;; ---
;; Here we have some text
;; And below we have some code
(define a 35)
""",
):
for file_extension in ("ss", "scm"):
nb = jupytext.reads(script, file_extension)
assert len(nb.cells) == 3
assert nb.cells[0].cell_type == "raw"
assert nb.cells[0].source == "---\ntitle: Simple file\n---"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "Here we have some text\nAnd below we have some code"
assert nb.cells[2].cell_type == "code"
compare(nb.cells[2].source, "(define a 35)")
script2 = jupytext.writes(nb, file_extension)
compare(script2, script)
================================================
FILE: tests/functional/simple_notebooks/test_read_simple_sphinx.py
================================================
import jupytext
from jupytext.compare import compare
def test_read_simple_file(
script='''# -*- coding: utf-8 -*-
"""
This is a markdown cell
"""
1 + 2 + 3 + 4
5
6
""
7
#################################
# Another markdown cell
def f(x):
"""Sample docstring"""
return 4
''',
):
nb = jupytext.reads(script, "py:sphinx")
assert nb.cells[0].cell_type == "code"
assert nb.cells[0].source == "%matplotlib inline"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "This is a markdown cell"
assert nb.cells[2].cell_type == "code"
compare(
nb.cells[2].source,
"""1 + 2 + 3 + 4
5
6""",
)
assert nb.cells[3].cell_type == "code"
assert nb.cells[3].source == "7"
assert nb.cells[4].cell_type == "markdown"
assert nb.cells[4].source == "Another markdown cell"
assert nb.cells[5].cell_type == "code"
assert (
nb.cells[5].source
== '''def f(x):
"""Sample docstring"""
return 4'''
)
assert len(nb.cells) == 6
script2 = jupytext.writes(nb, "py:sphinx")
compare(script2, script)
def test_read_more_complex_file(
script="""'''This is a markdown cell'''
1 + 2 + 3 + 4
5
6
'''
Another markdown cell'''
#################################
# A third one
'''
Another markdown cell'''
1 + 2 + 3 + 4
# ################################
# A fifth one
'''And a last one
'''
""",
):
nb = jupytext.reads(script, "py:sphinx")
assert nb.cells[0].cell_type == "code"
assert nb.cells[0].source == "%matplotlib inline"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "This is a markdown cell"
assert nb.cells[2].cell_type == "code"
compare(
nb.cells[2].source,
"""1 + 2 + 3 + 4
5
6""",
)
assert nb.cells[3].cell_type == "markdown"
assert nb.cells[3].source == "Another markdown cell"
assert nb.cells[4].cell_type == "markdown"
assert nb.cells[4].source == "A third one"
assert nb.cells[5].cell_type == "markdown"
assert nb.cells[5].source == "Another markdown cell"
assert nb.cells[6].cell_type == "code"
assert nb.cells[6].source == "1 + 2 + 3 + 4"
assert nb.cells[7].cell_type == "markdown"
assert nb.cells[7].source == "A fifth one"
assert nb.cells[8].cell_type == "markdown"
assert nb.cells[8].source == "And a last one"
assert len(nb.cells) == 9
def test_read_empty_code_cell(
script='''"""
Markdown cell
"""
''',
):
nb = jupytext.reads(script, "py:sphinx")
assert nb.cells[0].cell_type == "code"
assert nb.cells[0].source == "%matplotlib inline"
assert nb.cells[1].cell_type == "markdown"
assert nb.cells[1].source == "Markdown cell"
assert nb.cells[2].cell_type == "code"
assert nb.cells[2].source == ""
assert len(nb.cells) == 3
assert jupytext.writes(nb, "py:sphinx") == script
================================================
FILE: tests/integration/cli/test_cli_pipe.py
================================================
import pytest
from jupytext.cli import jupytext
@pytest.mark.requires_myst
@pytest.mark.requires_black
def test_cli_black_myst(
tmp_path,
no_jupytext_version_number,
text="""---
jupytext:
formats: md:myst
text_representation:
extension: .md
format_name: myst
format_version: 0.13
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
---
# Quantum yield efficiency of photosynthesis
```{code-cell} python
# I'm some code
x = 1
```
""",
):
tmp_md = tmp_path / "notebook.md"
tmp_md.write_text(text)
jupytext(["--pipe", "black", str(tmp_md)])
assert tmp_md.read_text() == text
================================================
FILE: tests/integration/cli/test_execute.py
================================================
import shutil
from io import StringIO
from unittest import mock
import pytest
from jupytext import read, reads
from jupytext.cli import jupytext
from jupytext.version import __version__
@pytest.mark.requires_user_kernel_python3
@pytest.mark.requires_nbconvert
@pytest.mark.skip_on_windows
def test_pipe_nbconvert_execute(tmpdir):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_py = str(tmpdir.join("notebook.py"))
with open(tmp_py, "w") as fp:
fp.write(
"""1 + 2
"""
)
jupytext(
args=[
tmp_py,
"--to",
"ipynb",
"--pipe-fmt",
"ipynb",
"--pipe",
"jupyter nbconvert --stdin --stdout --to notebook --execute",
]
)
nb = read(tmp_ipynb)
assert len(nb.cells) == 1
assert nb.cells[0].outputs[0]["data"] == {"text/plain": "3"}
@pytest.mark.requires_user_kernel_python3
@pytest.mark.requires_nbconvert
@pytest.mark.skip_on_windows
def test_pipe_nbconvert_execute_sync(tmpdir):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_py = str(tmpdir.join("notebook.py"))
with open(tmp_py, "w") as fp:
fp.write(
"""1 + 2
"""
)
jupytext(
args=[
tmp_py,
"--set-formats",
"py,ipynb",
"--sync",
"--pipe-fmt",
"ipynb",
"--pipe",
"jupyter nbconvert --stdin --stdout --to notebook --execute",
]
)
nb = read(tmp_ipynb)
assert len(nb.cells) == 1
assert nb.cells[0].outputs[0]["data"] == {"text/plain": "3"}
@pytest.mark.requires_user_kernel_python3
@pytest.mark.requires_nbconvert
@pytest.mark.skip_on_windows
def test_execute(tmpdir, caplog, capsys):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_py = str(tmpdir.join("notebook.py"))
with open(tmp_py, "w") as fp:
fp.write(
"""1 + 2
"""
)
jupytext(args=[tmp_py, "--to", "ipynb", "--execute"])
nb = read(tmp_ipynb)
assert len(nb.cells) == 1
assert nb.cells[0].outputs[0]["data"] == {"text/plain": "3"}
@pytest.mark.requires_user_kernel_python3
@pytest.mark.requires_nbconvert
def test_execute_readme_ok(tmpdir):
tmp_md = str(tmpdir.join("notebook.md"))
with open(tmp_md, "w") as fp:
fp.write(
"""
A readme with correct instructions
```python
1 + 2
```
"""
)
jupytext(args=[tmp_md, "--execute"])
@pytest.mark.requires_user_kernel_python3
@pytest.mark.requires_nbconvert
@pytest.mark.skip_on_windows
def test_execute_readme_not_ok(tmpdir):
tmp_md = str(tmpdir.join("notebook.md"))
with open(tmp_md, "w") as fp:
fp.write(
"""
A readme with incorrect instructions (a is not defined)
```python
a + 1
```
"""
)
import nbconvert
with pytest.raises(nbconvert.preprocessors.execute.CellExecutionError, match="is not defined"):
jupytext(args=[tmp_md, "--execute"])
@pytest.mark.requires_user_kernel_python3
@pytest.mark.requires_nbconvert
@pytest.mark.skip_on_windows
def test_execute_sync(tmpdir, caplog, capsys):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_py = str(tmpdir.join("notebook.py"))
with open(tmp_py, "w") as fp:
fp.write(
"""1 + 2
"""
)
jupytext(args=[tmp_py, "--set-formats", "py,ipynb", "--sync", "--execute"])
nb = read(tmp_ipynb)
assert len(nb.cells) == 1
assert nb.cells[0].outputs[0]["data"] == {"text/plain": "3"}
@pytest.mark.requires_nbconvert
@pytest.mark.requires_ir_kernel
@pytest.mark.skip_on_windows
def test_execute_r(tmpdir, caplog, capsys): # pragma: no cover
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_md = str(tmpdir.join("notebook.md"))
with open(tmp_md, "w") as fp:
fp.write(
"""```r
1 + 2 + 3
```
"""
)
jupytext(args=[tmp_md, "--to", "ipynb", "--execute"])
nb = read(tmp_ipynb)
assert len(nb.cells) == 1
assert nb.cells[0].outputs[0]["data"]["text/markdown"] == "6"
@pytest.mark.requires_user_kernel_python3
@pytest.mark.requires_nbconvert
@pytest.mark.skip_on_windows
def test_execute_in_subfolder(tmpdir, caplog, capsys):
subfolder = tmpdir.mkdir("subfolder")
tmp_csv = str(subfolder.join("inputs.csv"))
tmp_py = str(subfolder.join("notebook.py"))
tmp_ipynb = str(subfolder.join("notebook.ipynb"))
with open(tmp_csv, "w") as fp:
fp.write("1\n2\n")
with open(tmp_py, "w") as fp:
fp.write(
"""import ast
with open('inputs.csv') as fp:
text = fp.read()
sum(ast.literal_eval(line) for line in text.splitlines())
"""
)
jupytext(args=[tmp_py, "--to", "ipynb", "--execute"])
nb = read(tmp_ipynb)
assert len(nb.cells) == 3
assert nb.cells[2].outputs[0]["data"] == {"text/plain": "3"}
tmp2_py = str(tmpdir.mkdir("another_folder").join("notebook.py"))
tmp2_ipynb = str(tmpdir.join("another_folder", "notebook.ipynb"))
shutil.copy(tmp_py, tmp2_py)
# Executing without run-path fails
import nbconvert
with pytest.raises(
nbconvert.preprocessors.execute.CellExecutionError,
match="No such file or directory: 'inputs.csv'",
):
jupytext(args=[tmp2_py, "--to", "ipynb", "--execute"])
# Raise if folder does not exists
with pytest.raises(ValueError, match="is not a valid path"):
jupytext(args=[tmp2_py, "--to", "ipynb", "--run-path", "wrong_path"])
# Execute in full path
jupytext(args=[tmp2_py, "--to", "ipynb", "--run-path", str(subfolder)])
nb = read(tmp2_ipynb)
assert len(nb.cells) == 3
assert nb.cells[2].outputs[0]["data"] == {"text/plain": "3"}
# Execute in path relative to notebook dir
jupytext(args=[tmp2_py, "--to", "ipynb", "--run-path", "../subfolder"])
nb = read(tmp2_ipynb)
assert len(nb.cells) == 3
assert nb.cells[2].outputs[0]["data"] == {"text/plain": "3"}
@pytest.fixture()
def sample_md_notebook():
"""This is a sample md notebook with an outdated version of Jupytext
and no kernel information, to test #908"""
return """---
jupyter:
jupytext:
text_representation:
extension: .md
format_name: markdown
format_version: '1.1'
jupytext_version: 1.1.0
---
```python
1 + 1
```
"""
@pytest.mark.requires_user_kernel_python3
def test_execute_text_file_does_update_the_metadata(sample_md_notebook, tmp_path):
md_file = tmp_path / "nb.md"
md_file.write_text(sample_md_notebook)
jupytext([str(md_file), "--execute"])
new_md_text = md_file.read_text()
assert __version__ in new_md_text
assert "kernelspec" in new_md_text
@pytest.mark.requires_user_kernel_python3
def test_cat_execute_does_not_update_the_metadata(sample_md_notebook, tmp_path):
md_file = tmp_path / "nb.md"
md_file.write_text(sample_md_notebook)
# read md notebook on stdin - this does the same as
# cat notebook.md | jupytext --execute
with open(md_file) as fp, mock.patch("sys.stdin", fp):
jupytext(["--execute"])
new_md_text = md_file.read_text()
assert __version__ not in new_md_text
assert "kernelspec" not in new_md_text
@pytest.mark.requires_user_kernel_python3
@pytest.mark.skip_on_windows
@pytest.mark.filterwarnings("ignore")
def test_utf8_out_331(capsys, caplog):
py = "from IPython.core.display import HTML; HTML(u'\xd7')"
with mock.patch("sys.stdin", StringIO(py)):
jupytext(["--to", "ipynb", "--execute", "-"])
out, err = capsys.readouterr()
assert err == ""
nb = reads(out, "ipynb")
assert len(nb.cells) == 1
print(nb.cells[0].outputs)
assert nb.cells[0].outputs[0]["data"]["text/html"] == "\xd7"
================================================
FILE: tests/integration/contents_manager/test_cm_config.py
================================================
import logging
import os
import sys
import unittest.mock as mock
import pytest
from jupyter_server.utils import ensure_async
from nbformat import read
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
from tornado.web import HTTPError
import jupytext
from jupytext.compare import compare_cells, notebook_model
SAMPLE_NOTEBOOK = new_notebook(cells=[new_markdown_cell("A Markdown cell"), new_code_cell("# A code cell\n1 + 1")])
pytestmark = pytest.mark.asyncio
async def test_local_config_overrides_cm_config(tmpdir, cm):
cm.root_dir = str(tmpdir)
cm.formats = "ipynb,py"
nested = tmpdir.mkdir("nested")
with open(str(nested.join("jupytext.yml")), "w") as fp:
fp.write("formats: ''\n")
await ensure_async(cm.save(notebook_model(SAMPLE_NOTEBOOK), "notebook.ipynb"))
assert os.path.isfile(str(tmpdir.join("notebook.ipynb")))
assert os.path.isfile(str(tmpdir.join("notebook.py")))
await ensure_async(cm.save(notebook_model(SAMPLE_NOTEBOOK), "nested/notebook.ipynb"))
assert os.path.isfile(str(nested.join("notebook.ipynb")))
assert not os.path.isfile(str(nested.join("notebook.py")))
async def test_config_file_is_called_just_once(tmpdir, cm, n=2):
cm.root_dir = str(tmpdir)
tmpdir.join("jupytext.toml").write("")
nb_files = [str(tmpdir.join(f"notebook{i}.ipynb")) for i in range(n)]
for nb_file in nb_files:
jupytext.write(SAMPLE_NOTEBOOK, nb_file)
mock_config = mock.MagicMock(return_value=None)
with mock.patch("jupytext.sync_contentsmanager.load_jupytext_configuration_file", mock_config):
with mock.patch(
"jupytext.async_contentsmanager.load_jupytext_configuration_file",
mock_config,
):
for i in range(n):
await ensure_async(cm.get(f"notebook{i}.ipynb", content=False))
# Listing the contents should not call the config more than once
assert mock_config.call_count == 1
async def test_pairing_through_config_leaves_ipynb_unmodified(tmpdir, cm):
cm.root_dir = str(tmpdir)
cfg_file = tmpdir.join("jupytext.yml")
nb_file = tmpdir.join("notebook.ipynb")
py_file = tmpdir.join("notebook.py")
cfg_file.write("formats: 'ipynb,py'\n")
await ensure_async(cm.save(notebook_model(SAMPLE_NOTEBOOK), "notebook.ipynb"))
assert nb_file.isfile()
assert py_file.isfile()
nb = read(nb_file, as_version=4)
assert "jupytext" not in nb.metadata
@pytest.mark.parametrize(
"cfg_file,cfg_text",
[
# Should be false, not False
("jupytext.toml", "hide_notebook_metadata = False"),
("jupytext.toml", 'hide_notebook_metadata = "False"'),
("jupytext.toml", "not_a_jupytext_option = true"),
("pyproject.toml", "[tool.jupytext]\nnot_a_jupytext_option = true"),
("jupytext.json", '{"notebook_metadata_filter":"-all",}'),
],
)
@pytest.mark.filterwarnings(
r"ignore:Passing (unrecognized|unrecoginized) arguments "
r"to super\(JupytextConfiguration\).__init__"
)
async def test_incorrect_config_message(tmpdir, cfg_file, cfg_text, cm):
cm.root_dir = str(tmpdir)
tmpdir.join(cfg_file).write(cfg_text)
tmpdir.join("empty.ipynb").write("{}")
expected_message = f"The Jupytext configuration file .*{cfg_file} is incorrect"
with pytest.raises(HTTPError, match=expected_message):
await ensure_async(cm.get("empty.ipynb", type="notebook", content=False))
with pytest.raises(HTTPError, match=expected_message):
await ensure_async(cm.save(notebook_model(SAMPLE_NOTEBOOK), "notebook.ipynb"))
async def test_global_config_file(tmpdir, cm):
cm_dir = tmpdir.join("cm_dir").mkdir()
cm.root_dir = str(cm_dir)
tmpdir.join("jupytext.toml").write('formats = "ipynb,Rmd"')
def fake_global_config_directory():
return [str(tmpdir)]
with mock.patch(
"jupytext.config.global_jupytext_configuration_directories",
fake_global_config_directory,
):
nb = new_notebook(cells=[new_code_cell("1+1")])
model = notebook_model(nb)
await ensure_async(cm.save(model, "notebook.ipynb"))
assert {model["path"] for model in (await ensure_async(cm.get("/", content=True)))["content"]} == {
"notebook.ipynb",
"notebook.Rmd",
}
@pytest.mark.skipif(
sys.platform.startswith("win"),
reason="AttributeError: 'LocalPath' object has no attribute 'mksymlinkto'",
)
async def test_paired_files_and_symbolic_links(tmpdir, cm):
"""We test that we don't get issues when pairing files into folders
that are symbolic links"""
actual = tmpdir.mkdir("actual_files")
actual_notebooks = actual.mkdir("notebooks")
actual_scripts = actual.mkdir("scripts")
# Open the contents manager in another dir
jupyter_dir = tmpdir.mkdir("jupyter_dir")
cm.root_dir = str(jupyter_dir)
# Create sym links to the notebook/script folders
jupyter_dir.join("link_to_notebooks").mksymlinkto(actual_notebooks)
jupyter_dir.join("link_to_scripts").mksymlinkto(actual_scripts)
# Pair the notebooks in the linked folders
jupyter_dir.join("jupytext.toml").write('formats = "link_to_notebooks///ipynb,link_to_scripts///py:percent"')
# Save a notebook
await ensure_async(cm.save(notebook_model(SAMPLE_NOTEBOOK), "link_to_notebooks/notebook.ipynb"))
# This creates two files in the destinations folders
assert actual_notebooks.join("notebook.ipynb").isfile()
assert actual_scripts.join("notebook.py").isfile()
# Re-open the notebook (here, the text version)
await ensure_async(cm.get("link_to_scripts/notebook.py"))
# Update the text version
jupyter_dir.join("link_to_scripts").join("notebook.py").write_text("# %%\n3 + 3\n", encoding="utf-8")
# Reload and make sure that we get the updated notebook
model = await ensure_async(cm.get("link_to_notebooks/notebook.ipynb"))
nb = model["content"]
compare_cells(nb.cells, [new_code_cell("3 + 3")], compare_ids=False)
async def test_metadata_filter_from_config_has_precedence_over_notebook_metadata(tmpdir, cwd_tmpdir, cm, python_notebook):
python_notebook.metadata["jupytext"] = {"notebook_metadata_filter": "-all"}
tmpdir.join("jupytext.toml").write('notebook_metadata_filter = "all"')
cm.root_dir = str(tmpdir)
await ensure_async(cm.save(notebook_model(python_notebook), "test.py"))
py = tmpdir.join("test.py").read()
assert "notebook_metadata_filter: all" in py
async def test_test_no_text_representation_metadata_in_ipynb_900(tmpdir, python_notebook, cm):
tmpdir.join("jupytext.toml").write('formats = "ipynb,py:percent"\n')
# create a test notebook and save it in Jupyter
nb = python_notebook
cm.root_dir = str(tmpdir)
await ensure_async(cm.save(dict(type="notebook", content=nb), "test.ipynb"))
# Assert that "text_representation" is in the Jupytext metadata #900
assert "text_representation" in tmpdir.join("test.py").read()
# But not in the ipynb notebook
assert "text_representation" not in tmpdir.join("test.ipynb").read()
# modify the ipynb file in Jupyter
# Reload the notebook
nb = (await ensure_async(cm.get("test.ipynb")))["content"]
nb.cells.append(new_markdown_cell("A new cell"))
await ensure_async(cm.save(dict(type="notebook", content=nb), "test.ipynb"))
# The text representation metadata is in the py file
assert "text_representation" in tmpdir.join("test.py").read()
# But not in the ipynb notebook
assert "text_representation" not in tmpdir.join("test.ipynb").read()
async def test_cm_config_no_log(cwd_tmp_path, tmp_path, caplog, cm):
cm.root_dir = str(tmp_path)
config = 'cm_config_log_level="none"'
(tmp_path / "jupytext.toml").write_text(config)
(tmp_path / "nb1.py").write_text("# %%")
(tmp_path / "subfolder").mkdir()
(tmp_path / "subfolder" / "jupytext.toml").write_text(config)
(tmp_path / "subfolder" / "nb2.py").write_text("# %%")
caplog.set_level(logging.DEBUG)
await ensure_async(cm.get("nb1.py", type="notebook", content=False))
await ensure_async(cm.get("nb1.py", type="notebook", content=True))
await ensure_async(cm.get("subfolder/nb2.py", type="notebook", content=False))
await ensure_async(cm.get("subfolder/nb2.py", type="notebook", content=True))
assert "Jupytext configuration file" not in caplog.text
async def test_cm_config_log_only_if_changed(cwd_tmp_path, tmp_path, caplog, cm):
cm.root_dir = str(tmp_path)
config = ""
(tmp_path / "jupytext.toml").write_text(config)
(tmp_path / "nb1.py").write_text("# %%")
(tmp_path / "subfolder").mkdir()
(tmp_path / "subfolder" / "jupytext.toml").write_text(config)
(tmp_path / "subfolder" / "nb2.py").write_text("# %%")
caplog.set_level(logging.INFO)
await ensure_async(cm.get("nb1.py", type="notebook", content=False))
assert "Jupytext configuration file" in caplog.text
caplog.clear()
# Same notebook, same config => no log
await ensure_async(cm.get("nb1.py", type="notebook", content=True))
assert "Jupytext configuration file" not in caplog.text
# Same notebook, config changed => log
(tmp_path / "jupytext.toml").write_text('formats="ipynb,py:percent"')
await ensure_async(cm.get("nb1.py", type="notebook", content=True))
assert "Jupytext configuration file" in caplog.text
caplog.clear()
# Different folder, different config
await ensure_async(cm.get("subfolder/nb2.py", type="notebook", content=False))
assert "Jupytext configuration file" in caplog.text
caplog.clear()
# Same config as previously => no log
await ensure_async(cm.get("subfolder/nb2.py", type="notebook", content=False))
assert "Jupytext configuration file" not in caplog.text
================================================
FILE: tests/integration/contents_manager/test_contentsmanager.py
================================================
import inspect
import os
import re
import shutil
import time
import pytest
from jupyter_server.utils import ensure_async
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_notebook
from tornado.web import HTTPError
import jupytext
from jupytext.cli import jupytext as jupytext_cli
from jupytext.compare import compare, compare_notebooks, notebook_model
from jupytext.formats import auto_ext_from_metadata, read_format_from_metadata
from jupytext.header import header_to_metadata_and_cell
from jupytext.jupytext import read, write, writes
from jupytext.kernels import kernelspec_from_language
pytestmark = pytest.mark.asyncio
async def test_rename(tmpdir, cm):
org_file = str(tmpdir.join("notebook.ipynb"))
new_file = str(tmpdir.join("new.ipynb"))
jupytext.write(new_notebook(), org_file)
cm.root_dir = str(tmpdir)
await ensure_async(cm.rename_file("notebook.ipynb", "new.ipynb"))
assert os.path.isfile(new_file)
assert not os.path.isfile(org_file)
async def test_rename_inconsistent_path(tmpdir, cm):
org_file = str(tmpdir.join("notebook_suffix.ipynb"))
new_file = str(tmpdir.join("new.ipynb"))
jupytext.write(new_notebook(metadata={"jupytext": {"formats": "_suffix.ipynb"}}), org_file)
cm.root_dir = str(tmpdir)
# Read notebook, and learn about its format
model = await ensure_async(cm.get("notebook_suffix.ipynb"))
assert model["content"]["metadata"]["jupytext"]["formats"] == "_suffix.ipynb"
# Since #1414 the notebook can be moved
await ensure_async(cm.rename_file("notebook_suffix.ipynb", "new.ipynb"))
assert os.path.isfile(new_file)
assert not os.path.isfile(org_file)
# The new notebook is unchanged
new_model = await ensure_async(cm.get("new.ipynb"))
compare_notebooks(new_model["content"], model["content"])
async def test_pair_unpair_notebook(tmpdir, cm):
tmp_ipynb = "notebook.ipynb"
tmp_md = "notebook.md"
nb = new_notebook(
metadata={
"kernelspec": {
"display_name": "Python3",
"language": "python",
"name": "python3",
}
},
cells=[
new_code_cell(
"1 + 1",
outputs=[
{
"data": {"text/plain": ["2"]},
"execution_count": 1,
"metadata": {},
"output_type": "execute_result",
}
],
)
],
)
cm.root_dir = str(tmpdir)
# save notebook
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
assert not os.path.isfile(str(tmpdir.join(tmp_md)))
# pair notebook
nb["metadata"]["jupytext"] = {"formats": "ipynb,md"}
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
assert os.path.isfile(str(tmpdir.join(tmp_md)))
# reload and get outputs
nb2 = (await ensure_async(cm.get(tmp_md)))["content"]
compare_notebooks(nb, nb2)
# unpair and save as md
del nb["metadata"]["jupytext"]
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_md))
nb2 = (await ensure_async(cm.get(tmp_md)))["content"]
# we get no outputs here
compare_notebooks(nb, nb2, compare_outputs=False)
assert len(nb2.cells[0]["outputs"]) == 0
async def test_load_save_rename(ipynb_py_R_jl_file, cm, tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_rmd = "notebook.Rmd"
cm.formats = "ipynb,Rmd"
cm.root_dir = str(tmpdir)
cm.delete_to_trash = False
# open ipynb, save Rmd, reopen
nb = jupytext.read(ipynb_py_R_jl_file)
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_rmd))
nb_rmd = await ensure_async(cm.get(tmp_rmd))
compare_notebooks(nb_rmd["content"], nb, "Rmd")
# save ipynb
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# rename_file ipynb
await ensure_async(cm.rename_file(tmp_ipynb, "new.ipynb"))
assert not os.path.isfile(str(tmpdir.join(tmp_ipynb)))
assert not os.path.isfile(str(tmpdir.join(tmp_rmd)))
assert os.path.isfile(str(tmpdir.join("new.ipynb")))
assert os.path.isfile(str(tmpdir.join("new.Rmd")))
# delete one file, test that we can still read and rename_file it
await ensure_async(cm.delete("new.Rmd"))
assert not os.path.isfile(str(tmpdir.join("new.Rmd")))
model = await ensure_async(cm.get("new.ipynb", content=False))
assert "last_modified" in model
await ensure_async(cm.save(model=notebook_model(nb), path="new.ipynb"))
assert os.path.isfile(str(tmpdir.join("new.Rmd")))
await ensure_async(cm.delete("new.Rmd"))
await ensure_async(cm.rename_file("new.ipynb", tmp_ipynb))
assert os.path.isfile(str(tmpdir.join(tmp_ipynb)))
assert not os.path.isfile(str(tmpdir.join(tmp_rmd)))
assert not os.path.isfile(str(tmpdir.join("new.ipynb")))
assert not os.path.isfile(str(tmpdir.join("new.Rmd")))
async def test_save_load_paired_md_notebook(ipynb_py_R_jl_file, cm, tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_md = "notebook.md"
cm.root_dir = str(tmpdir)
# open ipynb, save with cm, reopen
nb = jupytext.read(ipynb_py_R_jl_file)
nb.metadata["jupytext"] = {"formats": "ipynb,md"}
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
nb_md = await ensure_async(cm.get(tmp_md))
compare_notebooks(nb_md["content"], nb, "md")
assert nb_md["content"].metadata["jupytext"]["formats"] == "ipynb,md"
async def test_pair_plain_script(percent_file, cm, tmpdir, caplog):
tmp_py = "notebook.py"
tmp_ipynb = "notebook.ipynb"
cm.root_dir = str(tmpdir)
# open py file, pair, save with cm
nb = jupytext.read(percent_file)
nb.metadata["jupytext"]["formats"] = "ipynb,py:hydrogen"
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_py))
# assert "'Include Metadata' is off" in caplog.text
assert os.path.isfile(str(tmpdir.join(tmp_py)))
assert os.path.isfile(str(tmpdir.join(tmp_ipynb)))
# Make sure we've not changed the script
with open(percent_file) as fp:
script = fp.read()
with open(str(tmpdir.join(tmp_py))) as fp:
script2 = fp.read()
compare(script2, script)
# reopen py file with the cm
nb2 = (await ensure_async(cm.get(tmp_py)))["content"]
compare_notebooks(nb2, nb)
assert nb2.metadata["jupytext"]["formats"] == "ipynb,py:hydrogen"
# remove the pairing and save
del nb.metadata["jupytext"]["formats"]
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_py))
# reopen py file with the cm
nb2 = (await ensure_async(cm.get(tmp_py)))["content"]
compare_notebooks(nb2, nb)
assert "formats" not in nb2.metadata["jupytext"]
async def test_load_save_rename_nbpy(ipynb_py_file, cm, tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_nbpy = "notebook.nb.py"
cm.formats = "ipynb,.nb.py"
cm.root_dir = str(tmpdir)
# open ipynb, save nb.py, reopen
nb = jupytext.read(ipynb_py_file)
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_nbpy))
nbpy = await ensure_async(cm.get(tmp_nbpy))
compare_notebooks(nbpy["content"], nb)
# save ipynb
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# rename_file nbpy
await ensure_async(cm.rename_file(tmp_nbpy, "new.nb.py"))
assert not os.path.isfile(str(tmpdir.join(tmp_ipynb)))
assert not os.path.isfile(str(tmpdir.join(tmp_nbpy)))
assert os.path.isfile(str(tmpdir.join("new.ipynb")))
assert os.path.isfile(str(tmpdir.join("new.nb.py")))
# rename_file to a non-matching pattern
with pytest.raises(HTTPError):
await ensure_async(cm.rename_file(tmp_nbpy, "suffix_missing.py"))
async def test_load_save_py_freeze_metadata(python_file, cm, tmpdir):
if "light" in python_file:
pytest.skip()
tmp_nbpy = "notebook.py"
cm.root_dir = str(tmpdir)
# read original file
with open(python_file) as fp:
text_py = fp.read()
# write to tmp_nbpy
with open(str(tmpdir.join(tmp_nbpy)), "w") as fp:
fp.write(text_py)
# open and save notebook
nb = (await ensure_async(cm.get(tmp_nbpy)))["content"]
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_nbpy))
with open(str(tmpdir.join(tmp_nbpy))) as fp:
text_py2 = fp.read()
compare(text_py2, text_py)
async def test_load_text_notebook(tmpdir, cm):
cm.root_dir = str(tmpdir)
nbpy = "text.py"
with open(str(tmpdir.join(nbpy)), "w") as fp:
fp.write("# %%\n1 + 1\n")
py_model = await ensure_async(cm.get(nbpy, content=False))
assert py_model["type"] == "notebook"
assert py_model["content"] is None
py_model = await ensure_async(cm.get(nbpy, content=True))
assert py_model["type"] == "notebook"
assert "cells" in py_model["content"]
# The model returned by the CM should match that of a classical ipynb notebook
nb_model = dict(type="notebook", content=new_notebook(cells=[new_markdown_cell("A cell")]))
await ensure_async(cm.save(nb_model, "notebook.ipynb"))
nb_model = await ensure_async(cm.get("notebook.ipynb", content=True))
for key in ["format", "mimetype", "type"]:
assert nb_model[key] == py_model[key], key
async def test_load_save_rename_notebook_with_dot(ipynb_py_file, cm, tmpdir):
tmp_ipynb = "1.notebook.ipynb"
tmp_nbpy = "1.notebook.py"
cm.formats = "ipynb,py"
cm.root_dir = str(tmpdir)
# open ipynb, save nb.py, reopen
nb = jupytext.read(ipynb_py_file)
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_nbpy))
nbpy = await ensure_async(cm.get(tmp_nbpy))
compare_notebooks(nbpy["content"], nb)
# save ipynb
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# rename_file py
await ensure_async(cm.rename_file(tmp_nbpy, "2.new_notebook.py"))
assert not os.path.isfile(str(tmpdir.join(tmp_ipynb)))
assert not os.path.isfile(str(tmpdir.join(tmp_nbpy)))
assert os.path.isfile(str(tmpdir.join("2.new_notebook.ipynb")))
assert os.path.isfile(str(tmpdir.join("2.new_notebook.py")))
async def test_load_save_rename_nbpy_default_config(ipynb_py_file, cm, tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_nbpy = "notebook.nb.py"
cm.formats = "ipynb,.nb.py"
cm.root_dir = str(tmpdir)
# open ipynb, save nb.py, reopen
nb = jupytext.read(ipynb_py_file)
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_nbpy))
nbpy = await ensure_async(cm.get(tmp_nbpy))
compare_notebooks(nbpy["content"], nb)
# open ipynb
nbipynb = await ensure_async(cm.get(tmp_ipynb))
compare_notebooks(nbipynb["content"], nb)
# save ipynb
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# rename_file notebook.nb.py to new.nb.py
await ensure_async(cm.rename_file(tmp_nbpy, "new.nb.py"))
assert not os.path.isfile(str(tmpdir.join(tmp_ipynb)))
assert not os.path.isfile(str(tmpdir.join(tmp_nbpy)))
assert os.path.isfile(str(tmpdir.join("new.ipynb")))
assert os.path.isfile(str(tmpdir.join("new.nb.py")))
# rename_file new.ipynb to notebook.ipynb
await ensure_async(cm.rename_file("new.ipynb", tmp_ipynb))
assert os.path.isfile(str(tmpdir.join(tmp_ipynb)))
assert os.path.isfile(str(tmpdir.join(tmp_nbpy)))
assert not os.path.isfile(str(tmpdir.join("new.ipynb")))
assert not os.path.isfile(str(tmpdir.join("new.nb.py")))
async def test_load_save_rename_non_ascii_path(ipynb_py_file, cm, tmpdir):
tmp_ipynb = "notebôk.ipynb"
tmp_nbpy = "notebôk.nb.py"
cm.formats = "ipynb,.nb.py"
tmpdir = "" + str(tmpdir)
cm.root_dir = tmpdir
# open ipynb, save nb.py, reopen
nb = jupytext.read(ipynb_py_file)
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_nbpy))
nbpy = await ensure_async(cm.get(tmp_nbpy))
compare_notebooks(nbpy["content"], nb)
# open ipynb
nbipynb = await ensure_async(cm.get(tmp_ipynb))
compare_notebooks(nbipynb["content"], nb)
# save ipynb
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# rename_file notebôk.nb.py to nêw.nb.py
await ensure_async(cm.rename_file(tmp_nbpy, "nêw.nb.py"))
assert not os.path.isfile(os.path.join(tmpdir, tmp_ipynb))
assert not os.path.isfile(os.path.join(tmpdir, tmp_nbpy))
assert os.path.isfile(os.path.join(tmpdir, "nêw.ipynb"))
assert os.path.isfile(os.path.join(tmpdir, "nêw.nb.py"))
# rename_file nêw.ipynb to notebôk.ipynb
await ensure_async(cm.rename_file("nêw.ipynb", tmp_ipynb))
assert os.path.isfile(os.path.join(tmpdir, tmp_ipynb))
assert os.path.isfile(os.path.join(tmpdir, tmp_nbpy))
assert not os.path.isfile(os.path.join(tmpdir, "nêw.ipynb"))
assert not os.path.isfile(os.path.join(tmpdir, "nêw.nb.py"))
async def test_outdated_text_notebook(python_notebook, cm, tmpdir):
# 1. write py ipynb
cm.formats = "py,ipynb"
cm.outdated_text_notebook_margin = 0
cm.root_dir = str(tmpdir)
# open ipynb, save py, reopen
nb = python_notebook
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.py"))
model_py = await ensure_async(cm.get("notebook.py", load_alternative_format=False))
model_ipynb = await ensure_async(cm.get("notebook.ipynb", load_alternative_format=False))
# 2. check that time of ipynb <= py
assert model_ipynb["last_modified"] <= model_py["last_modified"]
# 3. wait some time
time.sleep(0.5)
# 4. modify ipynb
nb.cells.append(new_markdown_cell("New cell"))
write(nb, str(tmpdir.join("notebook.ipynb")))
# 5. test error
with pytest.raises(HTTPError):
await ensure_async(cm.get("notebook.py"))
# 6. test OK with
cm.outdated_text_notebook_margin = 5.0
await ensure_async(cm.get("notebook.py"))
# 7. test OK with
cm.outdated_text_notebook_margin = float("inf")
await ensure_async(cm.get("notebook.py"))
async def test_outdated_text_notebook_no_diff_ok(tmpdir, cm, python_notebook):
# 1. write py ipynb
cm.formats = "py,ipynb"
cm.outdated_text_notebook_margin = 0
cm.root_dir = str(tmpdir)
# open ipynb, save py, reopen
nb = python_notebook
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.py"))
model_py = await ensure_async(cm.get("notebook.py", load_alternative_format=False))
model_ipynb = await ensure_async(cm.get("notebook.ipynb", load_alternative_format=False))
# 2. check that time of ipynb <= py
assert model_ipynb["last_modified"] <= model_py["last_modified"]
# 3. wait some time
time.sleep(0.5)
# 4. touch ipynb
with open(tmpdir / "notebook.ipynb", "a"):
os.utime(tmpdir / "notebook.ipynb", None)
# 5. No error since both files correspond to the same notebook #799
await ensure_async(cm.get("notebook.py"))
async def test_outdated_text_notebook_diff_is_shown(tmpdir, cm, python_notebook):
# 1. write py ipynb
cm.formats = "py,ipynb"
cm.outdated_text_notebook_margin = 0
cm.root_dir = str(tmpdir)
# open ipynb, save py, reopen
nb = python_notebook
nb.cells = [new_markdown_cell("Text version 1.0")]
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.py"))
model_py = await ensure_async(cm.get("notebook.py", load_alternative_format=False))
model_ipynb = await ensure_async(cm.get("notebook.ipynb", load_alternative_format=False))
# 2. check that time of ipynb <= py
assert model_ipynb["last_modified"] <= model_py["last_modified"]
# 3. wait some time
time.sleep(0.5)
# 4. modify ipynb
nb.cells = [new_markdown_cell("Text version 2.0")]
jupytext.write(nb, str(tmpdir / "notebook.ipynb"))
# 5. The diff is shown in the error
with pytest.raises(HTTPError) as excinfo:
await ensure_async(cm.get("notebook.py"))
diff = excinfo.value.log_message
diff = diff[diff.find("Differences") : diff.rfind("Please")]
compare(
# In the reference below, lines with a single space
# have been stripped by the pre-commit hook
diff.replace("\n \n", "\n\n"),
"""Differences (jupytext --diff notebook.py notebook.ipynb) are:
--- notebook.py
+++ notebook.ipynb
@@ -13,5 +13,5 @@
# ---
# %%%% [markdown]
-# Text version 1.0
+# Text version 2.0
""",
)
async def test_reload_notebook_after_jupytext_cli(python_notebook, cm, tmpdir):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_nbpy = str(tmpdir.join("notebook.py"))
cm.outdated_text_notebook_margin = 0
cm.root_dir = str(tmpdir)
# write the paired notebook
nb = python_notebook
nb.metadata.setdefault("jupytext", {})["formats"] = "py,ipynb"
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.py"))
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_nbpy)
# run jupytext CLI
jupytext_cli([tmp_nbpy, "--to", "ipynb", "--update"])
# test reload
nb1 = (await ensure_async(cm.get("notebook.py")))["content"]
nb2 = (await ensure_async(cm.get("notebook.ipynb")))["content"]
compare_notebooks(nb, nb1)
compare_notebooks(nb, nb2)
async def test_load_save_percent_format(percent_file, cm, tmpdir):
tmp_py = "notebook.py"
with open(percent_file) as stream:
text_py = stream.read()
with open(str(tmpdir.join(tmp_py)), "w") as stream:
stream.write(text_py)
cm.root_dir = str(tmpdir)
# open python, save
nb = (await ensure_async(cm.get(tmp_py)))["content"]
del nb.metadata["jupytext"]["notebook_metadata_filter"]
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_py))
# compare the new file with original one
with open(str(tmpdir.join(tmp_py))) as stream:
text_py2 = stream.read()
# do we find 'percent' in the header?
header = text_py2[: -len(text_py)]
assert any(["percent" in line for line in header.splitlines()])
# Remove the YAML header
text_py2 = text_py2[-len(text_py) :]
compare(text_py2, text_py)
async def test_save_to_percent_format(ipynb_julia_file, cm, tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_jl = "notebook.jl"
cm.root_dir = str(tmpdir)
cm.preferred_jupytext_formats_save = "jl:percent"
nb = jupytext.read(ipynb_julia_file)
nb["metadata"]["jupytext"] = {"formats": "ipynb,jl"}
# save to ipynb and jl
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# read jl file
with open(str(tmpdir.join(tmp_jl))) as stream:
text_jl = stream.read()
# Parse the YAML header
metadata, _, _, _ = header_to_metadata_and_cell(text_jl.splitlines(), "#", "")
assert metadata["jupytext"]["formats"] == "ipynb,jl:percent"
async def test_save_using_preferred_and_default_format_170(ipynb_py_file, cm, tmpdir):
nb = read(ipynb_py_file)
# Way 0: preferred_jupytext_formats_save, no prefix + formats
tmp_py = str(tmpdir.join("python/notebook.py"))
cm.root_dir = str(tmpdir)
cm.preferred_jupytext_formats_save = "py:percent"
cm.formats = "ipynb,python//py"
# save to ipynb and py
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.ipynb"))
# read py file
nb_py = read(tmp_py)
assert nb_py.metadata["jupytext"]["text_representation"]["format_name"] == "percent"
# Way 1: preferred_jupytext_formats_save + formats
tmp_py = str(tmpdir.join("python/notebook.py"))
cm.root_dir = str(tmpdir)
cm.preferred_jupytext_formats_save = "python//py:percent"
cm.formats = "ipynb,python//py"
# save to ipynb and py
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.ipynb"))
# read py file
nb_py = read(tmp_py)
assert nb_py.metadata["jupytext"]["text_representation"]["format_name"] == "percent"
# Way 2: formats
tmp_py = str(tmpdir.join("python/notebook.py"))
cm.root_dir = str(tmpdir)
cm.formats = "ipynb,python//py:percent"
# save to ipynb and py
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.ipynb"))
# read py file
nb_py = read(tmp_py)
assert nb_py.metadata["jupytext"]["text_representation"]["format_name"] == "percent"
async def test_open_using_preferred_and_default_format_174(ipynb_py_file, cm, tmpdir):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_py = str(tmpdir.join("python/notebook.py"))
tmp_py2 = str(tmpdir.join("other/notebook.py"))
os.makedirs(str(tmpdir.join("other")))
shutil.copyfile(ipynb_py_file, tmp_ipynb)
cm.root_dir = str(tmpdir)
cm.formats = "ipynb,python//py:percent"
cm.notebook_metadata_filter = "all"
cm.cell_metadata_filter = "all"
# load notebook
model = await ensure_async(cm.get("notebook.ipynb"))
# save to ipynb and py
await ensure_async(cm.save(model=model, path="notebook.ipynb"))
assert os.path.isfile(tmp_py)
os.remove(tmp_ipynb)
# read py file
model2 = await ensure_async(cm.get("python/notebook.py"))
compare_notebooks(model2["content"], model["content"])
# move py file to the another folder
shutil.move(tmp_py, tmp_py2)
model2 = await ensure_async(cm.get("other/notebook.py"))
compare_notebooks(model2["content"], model["content"])
await ensure_async(cm.save(model=model, path="other/notebook.py"))
assert not os.path.isfile(tmp_ipynb)
assert not os.path.isfile(str(tmpdir.join("other/notebook.ipynb")))
async def test_kernelspec_are_preserved(ipynb_py_file, cm, tmpdir):
if "many hash" in ipynb_py_file:
pytest.skip()
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_py = str(tmpdir.join("notebook.py"))
shutil.copyfile(ipynb_py_file, tmp_ipynb)
cm.root_dir = str(tmpdir)
cm.formats = "ipynb,py"
cm.notebook_metadata_filter = "-all"
# load notebook
model = await ensure_async(cm.get("notebook.ipynb"))
model["content"].metadata["kernelspec"] = {
"display_name": "Kernel name",
"language": "python",
"name": "custom",
}
# save to ipynb and py
await ensure_async(cm.save(model=model, path="notebook.ipynb"))
assert os.path.isfile(tmp_py)
# read ipynb
model2 = await ensure_async(cm.get("notebook.ipynb"))
compare_notebooks(model2["content"], model["content"])
async def test_save_to_light_percent_sphinx_format(ipynb_py_file, cm, tmpdir):
tmp_ipynb = "notebook.ipynb"
tmp_lgt_py = "notebook.lgt.py"
tmp_pct_py = "notebook.pct.py"
tmp_spx_py = "notebook.spx.py"
cm.root_dir = str(tmpdir)
nb = jupytext.read(ipynb_py_file)
nb["metadata"]["jupytext"] = {"formats": "ipynb,.pct.py:percent,.lgt.py:light,.spx.py:sphinx"}
# save to ipynb and three python flavors
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# read files
with open(str(tmpdir.join(tmp_pct_py))) as stream:
assert read_format_from_metadata(stream.read(), ".py") == "percent"
with open(str(tmpdir.join(tmp_lgt_py))) as stream:
assert read_format_from_metadata(stream.read(), ".py") == "light"
with open(str(tmpdir.join(tmp_spx_py))) as stream:
assert read_format_from_metadata(stream.read(), ".py") == "sphinx"
model = await ensure_async(cm.get(path=tmp_pct_py))
compare_notebooks(model["content"], nb)
model = await ensure_async(cm.get(path=tmp_lgt_py))
compare_notebooks(model["content"], nb)
model = await ensure_async(cm.get(path=tmp_spx_py))
# (notebooks not equal as we insert %matplotlib inline in sphinx)
model = await ensure_async(cm.get(path=tmp_ipynb))
compare_notebooks(model["content"], nb)
async def test_pair_notebook_with_dot(ipynb_py_file, cm, tmpdir):
# Reproduce issue #138
tmp_py = "file.5.1.py"
tmp_ipynb = "file.5.1.ipynb"
cm.root_dir = str(tmpdir)
nb = jupytext.read(ipynb_py_file)
nb["metadata"]["jupytext"] = {"formats": "ipynb,py:percent"}
# save to ipynb and three python flavors
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
assert os.path.isfile(str(tmpdir.join(tmp_ipynb)))
# read files
with open(str(tmpdir.join(tmp_py))) as stream:
assert read_format_from_metadata(stream.read(), ".py") == "percent"
model = await ensure_async(cm.get(path=tmp_py))
assert model["name"] == "file.5.1.py"
compare_notebooks(model["content"], nb)
model = await ensure_async(cm.get(path=tmp_ipynb))
assert model["name"] == "file.5.1.ipynb"
compare_notebooks(model["content"], nb)
async def test_preferred_format_allows_to_read_others_format(python_notebook, cm, tmpdir):
# 1. write py ipynb
tmp_ipynb = "notebook.ipynb"
tmp_nbpy = "notebook.py"
cm.preferred_jupytext_formats_save = "py:light"
cm.root_dir = str(tmpdir)
# load notebook and save it using the cm
nb = python_notebook
nb["metadata"]["jupytext"] = {"formats": "ipynb,py"}
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# Saving does not update the metadata, as 'save' makes a copy of the notebook
# assert nb['metadata']['jupytext']['formats'] == 'ipynb,py:light'
# Set preferred format for reading
cm.preferred_jupytext_formats_read = "py:percent"
# Read notebook
model = await ensure_async(cm.get(tmp_nbpy))
# Check that format is explicit
assert model["content"]["metadata"]["jupytext"]["formats"] == "ipynb,py:light"
# Check contents
compare_notebooks(model["content"], nb)
# Change save format and save
model["content"]["metadata"]["jupytext"]["formats"] == "ipynb,py"
cm.preferred_jupytext_formats_save = "py:percent"
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# Read notebook
model = await ensure_async(cm.get(tmp_nbpy))
compare_notebooks(model["content"], nb)
# Check that format is explicit
assert model["content"]["metadata"]["jupytext"]["formats"] == "ipynb,py:percent"
async def test_preferred_formats_read_auto(tmpdir, cm):
tmp_py = "notebook.py"
with open(str(tmpdir.join(tmp_py)), "w") as script:
script.write(
"""# cell one
1 + 1
"""
)
# create contents manager with default load format as percent
cm.preferred_jupytext_formats_read = "auto:percent"
cm.root_dir = str(tmpdir)
# load notebook
model = await ensure_async(cm.get(tmp_py))
# check that script is opened as percent
assert "percent" == model["content"]["metadata"]["jupytext"]["text_representation"]["format_name"]
async def test_save_in_auto_extension_global(ipynb_py_R_jl_file, cm, tmpdir):
# load notebook
nb = jupytext.read(ipynb_py_R_jl_file)
auto_ext = auto_ext_from_metadata(nb.metadata)
tmp_ipynb = "notebook.ipynb"
tmp_script = "notebook" + auto_ext
# create contents manager with default load format as percent
cm.formats = "ipynb,auto"
cm.preferred_jupytext_formats_save = "auto:percent"
cm.root_dir = str(tmpdir)
# save notebook
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# check that text representation exists, and is in percent format
with open(str(tmpdir.join(tmp_script))) as stream:
assert read_format_from_metadata(stream.read(), auto_ext) == "percent"
# reload and compare with original notebook
model = await ensure_async(cm.get(path=tmp_script))
# saving should not create a format entry #95
assert "formats" not in model["content"].metadata.get("jupytext", {})
compare_notebooks(model["content"], nb)
async def test_global_auto_pairing_works_with_empty_notebook(tmpdir, cm):
nb = new_notebook()
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_py = str(tmpdir.join("notebook.py"))
tmp_auto = str(tmpdir.join("notebook.auto"))
# create contents manager with default load format as percent
cm.formats = "ipynb,auto"
cm.preferred_jupytext_formats_save = "auto:percent"
cm.root_dir = str(tmpdir)
# save notebook
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.ipynb"))
# check that only the ipynb representation exists
assert os.path.isfile(tmp_ipynb)
assert not os.path.isfile(tmp_py)
assert not os.path.isfile(tmp_auto)
assert "notebook.ipynb" not in cm.paired_notebooks
model = await ensure_async(cm.get(path="notebook.ipynb"))
compare_notebooks(model["content"], nb)
# add language information to the notebook
nb.metadata["language_info"] = {
"codemirror_mode": {"name": "ipython", "version": 3},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.3",
}
# save again
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.ipynb"))
# check that ipynb + py representations exists
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_py)
assert not os.path.isfile(tmp_auto)
assert len(cm.paired_notebooks["notebook.ipynb"]) == 2
# add a cell in the py file
with open(tmp_py, "a") as fp:
fp.write("# %%\n2+2\n")
nb2 = (await ensure_async(cm.get(path="notebook.ipynb")))["content"]
assert len(nb2.cells) == 1
assert nb2.cells[0].source == "2+2"
async def test_save_in_auto_extension_global_with_format(ipynb_py_R_jl_file, cm, tmpdir):
# load notebook
nb = jupytext.read(ipynb_py_R_jl_file)
auto_ext = auto_ext_from_metadata(nb.metadata)
tmp_ipynb = "notebook.ipynb"
tmp_script = "notebook" + auto_ext
# create contents manager with default load format as percent
cm.formats = "ipynb,auto:percent"
cm.root_dir = str(tmpdir)
# save notebook
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# check that text representation exists, and is in percent format
with open(str(tmpdir.join(tmp_script))) as stream:
assert read_format_from_metadata(stream.read(), auto_ext) == "percent"
# reload and compare with original notebook
model = await ensure_async(cm.get(path=tmp_script))
# saving should not create a format entry #95
assert "formats" not in model["content"].metadata.get("jupytext", {})
compare_notebooks(model["content"], nb)
async def test_save_in_auto_extension_local(ipynb_py_R_jl_file, cm, tmpdir):
# load notebook
nb = jupytext.read(ipynb_py_R_jl_file)
nb.metadata.setdefault("jupytext", {})["formats"] = "ipynb,auto:percent"
auto_ext = auto_ext_from_metadata(nb.metadata)
tmp_ipynb = "notebook.ipynb"
tmp_script = "notebook" + auto_ext
# create contents manager with default load format as percent
cm.root_dir = str(tmpdir)
# save notebook
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# check that text representation exists, and is in percent format
with open(str(tmpdir.join(tmp_script))) as stream:
assert read_format_from_metadata(stream.read(), auto_ext) == "percent"
# reload and compare with original notebook
model = await ensure_async(cm.get(path=tmp_script))
compare_notebooks(model["content"], nb)
async def test_save_in_pct_and_lgt_auto_extensions(ipynb_py_R_jl_file, cm, tmpdir):
# load notebook
nb = jupytext.read(ipynb_py_R_jl_file)
auto_ext = auto_ext_from_metadata(nb.metadata)
tmp_ipynb = "notebook.ipynb"
tmp_pct_script = "notebook.pct" + auto_ext
tmp_lgt_script = "notebook.lgt" + auto_ext
# create contents manager with default load format as percent
cm.formats = "ipynb,.pct.auto,.lgt.auto"
cm.preferred_jupytext_formats_save = ".pct.auto:percent,.lgt.auto:light"
cm.root_dir = str(tmpdir)
# save notebook
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# check that text representation exists in percent format
with open(str(tmpdir.join(tmp_pct_script))) as stream:
assert read_format_from_metadata(stream.read(), auto_ext) == "percent"
# check that text representation exists in light format
with open(str(tmpdir.join(tmp_lgt_script))) as stream:
assert read_format_from_metadata(stream.read(), auto_ext) == "light"
async def test_metadata_filter_is_effective(ipynb_py_R_jl_file, cm, tmpdir):
if re.match(r".*(magic|305).*", ipynb_py_R_jl_file):
pytest.skip()
nb = jupytext.read(ipynb_py_R_jl_file)
tmp_ipynb = "notebook.ipynb"
tmp_script = "notebook.py"
# create contents manager
cm.root_dir = str(tmpdir)
# save notebook to tmpdir
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# set config
cm.formats = "ipynb,py"
cm.notebook_metadata_filter = "jupytext,-all"
cm.cell_metadata_filter = "-all"
# load notebook
nb = (await ensure_async(cm.get(tmp_ipynb)))["content"]
assert nb.metadata["jupytext"]["cell_metadata_filter"] == "-all"
assert nb.metadata["jupytext"]["notebook_metadata_filter"] == "jupytext,-all"
# save notebook again
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_ipynb))
# read text version
nb2 = jupytext.read(str(tmpdir.join(tmp_script)))
# test no metadata
assert set(nb2.metadata.keys()) <= {"jupytext", "kernelspec"}
for cell in nb2.cells:
assert not cell.metadata
# read paired notebook
nb3 = (await ensure_async(cm.get(tmp_script)))["content"]
compare_notebooks(nb3, nb)
async def test_no_metadata_added_to_scripts_139(tmpdir, cm):
tmp_script = str(tmpdir.join("script.py"))
text = """import os
print('hello1')
print('hello2')
"""
with open(tmp_script, "w") as fp:
fp.write(text)
# create contents manager
cm.root_dir = str(tmpdir)
# Andre's config #139
cm.freeze_metadata = True
cm.notebook_metadata_filter = "-all"
cm.cell_metadata_filter = "-lines_to_next_cell"
# load notebook
model = await ensure_async(cm.get("script.py"))
# add cell metadata
for cell in model["content"].cells:
cell.metadata.update(
{
"ExecuteTime": {
"start_time": "2019-02-06T11:53:21.208644Z",
"end_time": "2019-02-06T11:53:21.213071Z",
}
}
)
# save notebook
await ensure_async(cm.save(model=model, path="script.py"))
with open(tmp_script) as fp:
compare(fp.read(), text)
@pytest.mark.parametrize("ext", [".py", ".ipynb"])
async def test_local_format_can_deactivate_pairing(ipynb_py_file, cm, ext, tmpdir):
"""This is a test for #157: local format can be used to deactivate the global pairing"""
nb = jupytext.read(ipynb_py_file)
nb.metadata["jupytext_formats"] = ext[1:] # py or ipynb
# create contents manager with default pairing
cm.formats = "ipynb,py"
cm.root_dir = str(tmpdir)
# save notebook
await ensure_async(cm.save(model=notebook_model(nb), path="notebook" + ext))
# check that only the text representation exists
assert os.path.isfile(str(tmpdir.join("notebook.py"))) == (ext == ".py")
assert os.path.isfile(str(tmpdir.join("notebook.ipynb"))) == (ext == ".ipynb")
nb2 = (await ensure_async(cm.get("notebook" + ext)))["content"]
compare_notebooks(nb2, nb)
# resave, check again
await ensure_async(cm.save(model=notebook_model(nb2), path="notebook" + ext))
assert os.path.isfile(str(tmpdir.join("notebook.py"))) == (ext == ".py")
assert os.path.isfile(str(tmpdir.join("notebook.ipynb"))) == (ext == ".ipynb")
nb3 = (await ensure_async(cm.get("notebook" + ext)))["content"]
compare_notebooks(nb3, nb)
async def test_global_pairing_allows_to_save_other_file_types(rmd_file, cm, tmpdir):
"""This is a another test for #157: local format can be used to deactivate the global pairing"""
nb = jupytext.read(rmd_file)
# create contents manager with default pairing
cm.formats = "ipynb,py"
cm.root_dir = str(tmpdir)
# save notebook
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.Rmd"))
# check that only the original file is saved
assert os.path.isfile(str(tmpdir.join("notebook.Rmd")))
assert not os.path.isfile(str(tmpdir.join("notebook.py")))
assert not os.path.isfile(str(tmpdir.join("notebook.ipynb")))
nb2 = (await ensure_async(cm.get("notebook.Rmd")))["content"]
compare_notebooks(nb2, nb)
@pytest.mark.requires_user_kernel_python3
async def test_python_kernel_preserves_R_files(r_file, cm, tmpdir):
"""Opening a R file with a Jupyter server that has no R kernel should not modify the file"""
tmp_r_file = str(tmpdir.join("script.R"))
with open(r_file) as fp:
script = fp.read()
with open(tmp_r_file, "w") as fp:
fp.write(script)
# create contents manager
cm.root_dir = str(tmpdir)
# open notebook, set Python kernel and save
model = await ensure_async(cm.get("script.R"))
model["content"].metadata["kernelspec"] = kernelspec_from_language("python")
await ensure_async(cm.save(model=model, path="script.R"))
with open(tmp_r_file) as fp:
script2 = fp.read()
compare(script2, script)
async def test_pair_notebook_in_another_folder(tmpdir, cm):
cm.root_dir = str(tmpdir)
os.makedirs(str(tmpdir.join("notebooks")))
tmp_ipynb = str(tmpdir.join("notebooks/notebook_name.ipynb"))
tmp_py = str(tmpdir.join("scripts/notebook_name.py"))
await ensure_async(
cm.save(
model=notebook_model(
new_notebook(metadata={"jupytext": {"formats": "notebooks//ipynb,scripts//py"}}),
),
path="notebooks/notebook_name.ipynb",
)
)
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_py)
await ensure_async(cm.get("notebooks/notebook_name.ipynb"))
await ensure_async(cm.get("scripts/notebook_name.py"))
async def test_pair_notebook_in_dotdot_folder(tmpdir, cm):
cm.root_dir = str(tmpdir)
os.makedirs(str(tmpdir.join("notebooks")))
tmp_ipynb = str(tmpdir.join("notebooks/notebook_name.ipynb"))
tmp_py = str(tmpdir.join("scripts/notebook_name.py"))
await ensure_async(
cm.save(
model=notebook_model(new_notebook(metadata={"jupytext": {"formats": "ipynb,../scripts//py"}})),
path="notebooks/notebook_name.ipynb",
)
)
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_py)
await ensure_async(cm.get("notebooks/notebook_name.ipynb"))
await ensure_async(cm.get("scripts/notebook_name.py"))
async def test_split_at_heading_option(tmpdir, cm):
text = """Markdown text
# Header one
## Header two
"""
tmp_md = str(tmpdir.join("notebook.md"))
with open(tmp_md, "w") as fp:
fp.write(text)
cm.root_dir = str(tmpdir)
cm.split_at_heading = True
nb = (await ensure_async(cm.get("notebook.md")))["content"]
# Was rst to md conversion effective?
assert nb.cells[0].source == "Markdown text"
assert nb.cells[1].source == "# Header one"
assert nb.cells[2].source == "## Header two"
nb.metadata["jupytext"]["notebook_metadata_filter"] = "-all"
text2 = writes(nb, "md")
compare(text2, text)
async def test_load_then_change_formats(tmpdir, cm):
tmp_ipynb = str(tmpdir.join("nb.ipynb"))
tmp_py = str(tmpdir.join("nb.py"))
nb = new_notebook(metadata={"jupytext": {"formats": "ipynb,py:light"}})
write(nb, tmp_ipynb)
cm.root_dir = str(tmpdir)
model = await ensure_async(cm.get("nb.ipynb"))
assert model["content"].metadata["jupytext"]["formats"] == "ipynb,py:light"
await ensure_async(cm.save(model, path="nb.ipynb"))
assert os.path.isfile(tmp_py)
assert read(tmp_py).metadata["jupytext"]["formats"] == "ipynb,py:light"
time.sleep(0.5)
del model["content"].metadata["jupytext"]["formats"]
await ensure_async(cm.save(model, path="nb.ipynb"))
# test that we have not kept the 'ipynb/py' pairing info, and that we can read the ipynb
await ensure_async(cm.get("nb.ipynb"))
os.remove(tmp_py)
model["content"].metadata.setdefault("jupytext", {})["formats"] = "ipynb,py:percent"
await ensure_async(cm.save(model, path="nb.ipynb"))
assert os.path.isfile(tmp_py)
assert read(tmp_py).metadata["jupytext"]["formats"] == "ipynb,py:percent"
os.remove(tmp_py)
del model["content"].metadata["jupytext"]["formats"]
await ensure_async(cm.save(model, path="nb.ipynb"))
assert not os.path.isfile(tmp_py)
async def test_set_then_change_formats(tmpdir, cm):
tmp_py = str(tmpdir.join("nb.py"))
nb = new_notebook(metadata={"jupytext": {"formats": "ipynb,py:light"}})
cm.root_dir = str(tmpdir)
await ensure_async(cm.save(model=notebook_model(nb), path="nb.ipynb"))
assert os.path.isfile(tmp_py)
assert read(tmp_py).metadata["jupytext"]["formats"] == "ipynb,py:light"
os.remove(tmp_py)
nb.metadata["jupytext"]["formats"] = "ipynb,py:percent"
await ensure_async(cm.save(model=notebook_model(nb), path="nb.ipynb"))
assert os.path.isfile(tmp_py)
assert read(tmp_py).metadata["jupytext"]["formats"] == "ipynb,py:percent"
os.remove(tmp_py)
del nb.metadata["jupytext"]["formats"]
await ensure_async(cm.save(model=notebook_model(nb), path="nb.ipynb"))
assert not os.path.isfile(tmp_py)
async def test_set_then_change_auto_formats(tmpdir, cm, python_notebook):
tmp_ipynb = str(tmpdir.join("nb.ipynb"))
tmp_py = str(tmpdir.join("nb.py"))
tmp_rmd = str(tmpdir.join("nb.Rmd"))
nb = new_notebook(metadata=python_notebook.metadata)
cm.root_dir = str(tmpdir)
# Pair ipynb/py and save
nb.metadata["jupytext"] = {"formats": "ipynb,auto:light"}
await ensure_async(cm.save(model=notebook_model(nb), path="nb.ipynb"))
assert "nb.py" in cm.paired_notebooks
assert "nb.auto" not in cm.paired_notebooks
assert os.path.isfile(tmp_py)
assert read(tmp_ipynb).metadata["jupytext"]["formats"] == "ipynb,py:light"
# Pair ipynb/Rmd and save
time.sleep(0.5)
nb.metadata["jupytext"] = {"formats": "ipynb,Rmd"}
await ensure_async(cm.save(model=notebook_model(nb), path="nb.ipynb"))
assert "nb.Rmd" in cm.paired_notebooks
assert "nb.py" not in cm.paired_notebooks
assert "nb.auto" not in cm.paired_notebooks
assert os.path.isfile(tmp_rmd)
assert read(tmp_ipynb).metadata["jupytext"]["formats"] == "ipynb,Rmd"
await ensure_async(cm.get("nb.ipynb"))
# Unpair and save
time.sleep(0.5)
del nb.metadata["jupytext"]
await ensure_async(cm.save(model=notebook_model(nb), path="nb.ipynb"))
assert "nb.Rmd" not in cm.paired_notebooks
assert "nb.py" not in cm.paired_notebooks
assert "nb.auto" not in cm.paired_notebooks
await ensure_async(cm.get("nb.ipynb"))
async def test_share_py_recreate_ipynb(tmpdir, cm, ipynb_py_R_jl_file):
tmp_ipynb = str(tmpdir.join("nb.ipynb"))
tmp_py = str(tmpdir.join("nb.py"))
cm.root_dir = str(tmpdir)
# set default py format
cm.preferred_jupytext_formats_save = "py:percent"
# every new file is paired
cm.formats = "ipynb,py"
# the text files don't need a YAML header
cm.notebook_metadata_filter = "-all"
cm.cell_metadata_filter = "-all"
nb = read(ipynb_py_R_jl_file)
model_ipynb = await ensure_async(cm.save(model=notebook_model(nb), path="nb.ipynb"))
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_py)
os.remove(tmp_ipynb)
# reopen and save nb.py
model = await ensure_async(cm.get("nb.py"))
await ensure_async(cm.save(model=model, path="nb.py"))
# ipynb is re-created
assert os.path.isfile(tmp_ipynb)
# save time of ipynb is that of py file
assert model_ipynb["last_modified"] == model["last_modified"]
async def test_vim_folding_markers(tmpdir, cm):
tmp_ipynb = str(tmpdir.join("nb.ipynb"))
tmp_py = str(tmpdir.join("nb.py"))
cm.root_dir = str(tmpdir)
# Default Vim folding markers
cm.cell_markers = "{{{,}}}"
cm.formats = "ipynb,py:light"
nb = new_notebook(
cells=[
new_code_cell(
"""# region
'''Sample cell with region markers'''
'''End of the cell'''
# end region"""
),
new_code_cell("a = 1\n\n\nb = 1"),
]
)
await ensure_async(cm.save(model=notebook_model(nb), path="nb.ipynb"))
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_py)
nb2 = (await ensure_async(cm.get("nb.ipynb")))["content"]
compare_notebooks(nb2, nb)
nb3 = read(tmp_py)
assert nb3.metadata["jupytext"]["cell_markers"] == "{{{,}}}"
with open(tmp_py) as fp:
text = fp.read()
# Remove YAML header
text = re.sub(re.compile(r"# ---.*# ---\n\n", re.DOTALL), "", text)
compare(
text,
"""# region
'''Sample cell with region markers'''
'''End of the cell'''
# end region
# {{{
a = 1
b = 1
# }}}
""",
)
async def test_vscode_pycharm_folding_markers(tmpdir, cm):
tmp_ipynb = str(tmpdir.join("nb.ipynb"))
tmp_py = str(tmpdir.join("nb.py"))
cm.root_dir = str(tmpdir)
# Default VScode/PyCharm folding markers
cm.cell_markers = "region,endregion"
cm.formats = "ipynb,py:light"
nb = new_notebook(
cells=[
new_code_cell(
"""# {{{
'''Sample cell with region markers'''
'''End of the cell'''
# }}}"""
),
new_code_cell("a = 1\n\n\nb = 1"),
]
)
await ensure_async(cm.save(model=notebook_model(nb), path="nb.ipynb"))
assert os.path.isfile(tmp_ipynb)
assert os.path.isfile(tmp_py)
nb2 = (await ensure_async(cm.get("nb.ipynb")))["content"]
compare_notebooks(nb2, nb)
nb3 = read(tmp_py)
assert nb3.metadata["jupytext"]["cell_markers"] == "region,endregion"
with open(tmp_py) as fp:
text = fp.read()
# Remove YAML header
text = re.sub(re.compile(r"# ---.*# ---\n\n", re.DOTALL), "", text)
compare(
text,
"""# {{{
'''Sample cell with region markers'''
'''End of the cell'''
# }}}
# region
a = 1
b = 1
# endregion
""",
)
async def test_open_file_with_cell_markers(tmpdir, cm):
tmp_py = str(tmpdir.join("nb.py"))
cm.root_dir = str(tmpdir)
# Default VScode/PyCharm folding markers
cm.cell_markers = "region,endregion"
text = """# +
# this is a unique code cell
1 + 1
2 + 2
"""
with open(tmp_py, "w") as fp:
fp.write(text)
nb = (await ensure_async(cm.get("nb.py")))["content"]
assert len(nb.cells) == 1
await ensure_async(cm.save(model=notebook_model(nb), path="nb.py"))
with open(tmp_py) as fp:
text2 = fp.read()
expected = """# region
# this is a unique code cell
1 + 1
2 + 2
# endregion
"""
compare(text2, expected)
async def test_save_file_with_cell_markers(tmpdir, cm):
tmp_py = str(tmpdir.join("nb.py"))
cm.root_dir = str(tmpdir)
# Default VScode/PyCharm folding markers
cm.cell_markers = "region,endregion"
text = """# +
# this is a unique code cell
1 + 1
2 + 2
"""
with open(tmp_py, "w") as fp:
fp.write(text)
nb = (await ensure_async(cm.get("nb.py")))["content"]
assert len(nb.cells) == 1
await ensure_async(cm.save(model=notebook_model(nb), path="nb.py"))
with open(tmp_py) as fp:
text2 = fp.read()
compare(
text2,
"""# region
# this is a unique code cell
1 + 1
2 + 2
# endregion
""",
)
nb2 = (await ensure_async(cm.get("nb.py")))["content"]
compare_notebooks(nb2, nb)
assert nb2.metadata["jupytext"]["cell_markers"] == "region,endregion"
async def test_notebook_extensions(tmpdir, cm, cwd_tmpdir):
nb = new_notebook()
write(nb, "script.py")
write(nb, "notebook.Rmd")
write(nb, "notebook.ipynb")
cm.root_dir = str(tmpdir)
cm.notebook_extensions = "ipynb,Rmd"
model = await ensure_async(cm.get("notebook.ipynb"))
assert model["type"] == "notebook"
model = await ensure_async(cm.get("notebook.Rmd"))
assert model["type"] == "notebook"
model = await ensure_async(cm.get("script.py"))
assert model["type"] == "file"
async def test_notebook_extensions_in_config(tmpdir, cm, cwd_tmpdir):
nb = new_notebook()
write(nb, "script.py")
write(nb, "notebook.Rmd")
write(nb, "notebook.ipynb")
tmpdir.join("jupytext.toml").write("""notebook_extensions = ["ipynb", "Rmd"]""")
cm.root_dir = str(tmpdir)
model = await ensure_async(cm.get("notebook.ipynb"))
assert model["type"] == "notebook"
model = await ensure_async(cm.get("notebook.Rmd"))
assert model["type"] == "notebook"
model = await ensure_async(cm.get("script.py"))
assert model["type"] == "file"
async def test_invalid_config_in_cm(tmpdir, cm, cwd_tmpdir):
nb = new_notebook()
write(nb, "notebook.ipynb")
tmpdir.join("pyproject.toml").write(
"""[tool.jupysql.SqlMagic]
autopandas = False
displaylimit = 1"""
)
cm.root_dir = str(tmpdir)
# list directory
await ensure_async(cm.get(""))
model = await ensure_async(cm.get("notebook.ipynb"))
assert model["type"] == "notebook"
async def test_download_file_318(tmpdir, cm):
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_py = str(tmpdir.join("notebook.py"))
nb = new_notebook()
nb.metadata["jupytext"] = {"formats": "ipynb,py"}
write(nb, tmp_ipynb)
write(nb, tmp_py)
cm.root_dir = str(tmpdir)
cm.notebook_extensions = "ipynb"
model = await ensure_async(cm.get("notebook.ipynb", content=True, type=None, format=None))
assert model["type"] == "notebook"
async def test_markdown_and_r_extensions(tmpdir, cm):
tmp_r = str(tmpdir.join("script.r"))
tmp_markdown = str(tmpdir.join("notebook.markdown"))
nb = new_notebook()
write(nb, tmp_r)
write(nb, tmp_markdown)
cm.root_dir = str(tmpdir)
model = await ensure_async(cm.get("script.r"))
assert model["type"] == "notebook"
model = await ensure_async(cm.get("notebook.markdown"))
assert model["type"] == "notebook"
async def test_server_extension_issubclass(cm):
class SubClassTextFileContentsManager(jupytext.TextFileContentsManager):
pass
assert not isinstance(SubClassTextFileContentsManager, jupytext.TextFileContentsManager)
assert issubclass(SubClassTextFileContentsManager, jupytext.TextFileContentsManager)
async def test_multiple_pairing(tmpdir, cm):
"""Test that multiple pairing works. Input cells are loaded from the most recent text representation among
the paired ones"""
tmp_ipynb = str(tmpdir.join("notebook.ipynb"))
tmp_md = str(tmpdir.join("notebook.md"))
tmp_py = str(tmpdir.join("notebook.py"))
def nb(text):
return new_notebook(
cells=[new_markdown_cell(text)],
metadata={"jupytext": {"formats": "ipynb,md,py"}},
)
cm.root_dir = str(tmpdir)
await ensure_async(cm.save(model=notebook_model(nb("saved from cm")), path="notebook.ipynb"))
compare_notebooks(jupytext.read(tmp_ipynb), nb("saved from cm"))
compare_notebooks(jupytext.read(tmp_md), nb("saved from cm"))
compare_notebooks(jupytext.read(tmp_py), nb("saved from cm"))
jupytext.write(nb("md edited"), tmp_md)
model = await ensure_async(cm.get("notebook.ipynb"))
compare_notebooks(model["content"], nb("md edited"))
await ensure_async(cm.save(model=model, path="notebook.ipynb"))
compare_notebooks(jupytext.read(tmp_ipynb), nb("md edited"))
compare_notebooks(jupytext.read(tmp_md), nb("md edited"))
compare_notebooks(jupytext.read(tmp_py), nb("md edited"))
jupytext.write(nb("py edited"), tmp_py)
# Loading the md file give the content of that file
model = await ensure_async(cm.get("notebook.md"))
compare_notebooks(model["content"], nb("md edited"))
# Loading the ipynb files gives the content of the most recent text file
model = await ensure_async(cm.get("notebook.ipynb"))
compare_notebooks(model["content"], nb("py edited"))
await ensure_async(cm.save(model=model, path="notebook.ipynb"))
compare_notebooks(jupytext.read(tmp_ipynb), nb("py edited"))
compare_notebooks(jupytext.read(tmp_md), nb("py edited"))
compare_notebooks(jupytext.read(tmp_py), nb("py edited"))
model_ipynb = await ensure_async(cm.get("notebook.ipynb", content=False, load_alternative_format=False))
model_md = await ensure_async(cm.get("notebook.md", content=False, load_alternative_format=False))
model_py = await ensure_async(cm.get("notebook.py", content=False, load_alternative_format=False))
# ipynb is the oldest one, then py, then md
# so that we read cell inputs from the py file
assert model_ipynb["last_modified"] <= model_py["last_modified"]
assert model_py["last_modified"] <= model_md["last_modified"]
async def test_filter_jupytext_version_information_416(python_notebook, cm, tmpdir, cwd_tmpdir):
cm.root_dir = str(tmpdir)
cm.notebook_metadata_filter = "-jupytext.text_representation.jupytext_version"
# load notebook
notebook = python_notebook
notebook.metadata["jupytext_formats"] = "ipynb,py"
model = notebook_model(notebook)
# save to ipynb and py
await ensure_async(cm.save(model=model, path="notebook.ipynb"))
assert os.path.isfile("notebook.py")
# read py file
with open("notebook.py") as fp:
text = fp.read()
assert "---" in text
assert "jupytext:" in text
assert "kernelspec:" in text
assert "jupytext_version:" not in text
@pytest.mark.requires_myst
async def test_new_untitled(tmpdir, cm):
cm.root_dir = str(tmpdir)
# untitled is "Untitled" only when the locale is English #636
untitled, ext = (await ensure_async(cm.new_untitled(type="notebook")))["path"].split(".")
assert untitled
assert ext == "ipynb"
# Jupytext related files
assert (await ensure_async(cm.new_untitled(type="notebook", ext=".md")))["path"] == untitled + "1.md"
assert (await ensure_async(cm.new_untitled(type="notebook", ext=".py")))["path"] == untitled + "2.py"
assert (await ensure_async(cm.new_untitled(type="notebook", ext=".md:myst")))["path"] == untitled + "3.md"
assert (await ensure_async(cm.new_untitled(type="notebook", ext=".py:percent")))["path"] == untitled + "4.py"
assert (await ensure_async(cm.new_untitled(type="notebook", ext=".Rmd")))["path"] == untitled + "5.Rmd"
# Test native formats that should not be changed by Jupytext and model should
# not contain any Jupytext metadata neither file name should start with Uppercase
for ext in [".py", ".md"]:
model = await ensure_async(cm.new_untitled(type="file", ext=ext))
assert model["content"] is None
assert model["path"] == f"untitled{ext}"
assert (await ensure_async(cm.new_untitled(type="directory")))["path"] == "Untitled Folder"
async def test_nested_prefix(tmpdir, cm):
cm.root_dir = str(tmpdir)
# save to ipynb and py
nb = new_notebook(
cells=[new_code_cell("1+1"), new_markdown_cell("Some text")],
metadata={"jupytext": {"formats": "ipynb,nested/prefix//.py"}},
)
await ensure_async(cm.save(model=notebook_model(nb), path="notebook.ipynb"))
assert tmpdir.join("nested").join("prefix").join("notebook.py").isfile()
async def test_timestamp_is_correct_after_reload_978(tmp_path, cm, python_notebook):
"""Here we reproduce the conditions in Issue #978 and make sure no
warning is generated"""
nb = python_notebook
nb.metadata["jupytext"] = {"formats": "ipynb,py:percent"}
cm.root_dir = str(tmp_path)
ipynb_py_R_jl_file = tmp_path / "nb.ipynb"
py_file = tmp_path / "nb.py"
# 1. Save the paired notebook
await ensure_async(cm.save(notebook_model(nb), path="nb.ipynb"))
assert ipynb_py_R_jl_file.exists()
assert py_file.exists()
# and reload to get the original timestamp
org_model = await ensure_async(cm.get("nb.ipynb"))
# 2. Edit the py file
time.sleep(0.5)
text = py_file.read_text()
text = (
text
+ """
# %%
# A new cell
2 + 2
"""
)
py_file.write_text(text)
# 3. Reload the paired notebook and make sure it has the modified content
model = await ensure_async(cm.get("nb.ipynb"))
nb = model["content"]
assert "A new cell" in nb.cells[-1].source
assert model["last_modified"] > org_model["last_modified"]
async def test_move_paired_notebook_to_subdir_1059(tmp_path, cm, python_notebook):
(tmp_path / "jupytext.toml").write_text('formats = "notebooks///ipynb,scripts///py:percent"\n')
cm.root_dir = str(tmp_path)
# create paired notebook
(tmp_path / "notebooks").mkdir()
await ensure_async(cm.save(notebook_model(python_notebook), path="notebooks/my_notebook.ipynb"))
assert (tmp_path / "notebooks" / "my_notebook.ipynb").exists()
assert (tmp_path / "scripts" / "my_notebook.py").exists()
# move notebook
(tmp_path / "notebooks" / "subdir").mkdir()
await ensure_async(cm.rename_file("notebooks/my_notebook.ipynb", "notebooks/subdir/my_notebook.ipynb"))
assert (tmp_path / "notebooks" / "subdir" / "my_notebook.ipynb").exists()
assert (tmp_path / "scripts" / "subdir" / "my_notebook.py").exists()
assert not (tmp_path / "notebooks" / "my_notebook.ipynb").exists()
assert not (tmp_path / "scripts" / "my_notebook.py").exists()
# check notebook content
model = await ensure_async(cm.get("scripts/subdir/my_notebook.py"))
nb = model["content"]
compare_notebooks(nb, python_notebook, fmt="py:percent")
def list_folder_contents(tmp_path):
return [
str(file_path.relative_to(tmp_path))
for file_path in (tmp_path).rglob("*")
if file_path.is_file() and ".ipynb_checkpoints" not in file_path.parts
]
@pytest.mark.parametrize("copy", [False, True])
@pytest.mark.parametrize("config_file", [False, True])
async def test_move_paired_notebook_outside_of_notebook_dir_1414(tmp_path, cm, python_notebook, copy: bool, config_file: bool):
cm.root_dir = str(tmp_path)
nb = python_notebook
if config_file:
(tmp_path / "jupytext.toml").write_text('formats = "notebooks///ipynb,scripts///py:percent"\n')
else:
nb.metadata["jupytext"] = {"formats": ["notebooks///ipynb", "scripts///py:percent"]}
# create paired notebook
(tmp_path / "notebooks").mkdir()
await ensure_async(cm.save(notebook_model(python_notebook), path="notebooks/my_notebook.ipynb"))
assert (tmp_path / "notebooks" / "my_notebook.ipynb").exists()
assert (tmp_path / "scripts" / "my_notebook.py").exists()
folder_contents = list_folder_contents(tmp_path)
assert len(folder_contents) == 2 + config_file, folder_contents
# move notebook still within the config reach, but outside the notebooks folder
if copy:
await ensure_async(cm.copy("notebooks/my_notebook.ipynb", "my_notebook.ipynb"))
else:
await ensure_async(cm.rename_file("notebooks/my_notebook.ipynb", "my_notebook.ipynb"))
assert (tmp_path / "notebooks" / "my_notebook.ipynb").exists() == copy
assert (tmp_path / "scripts" / "my_notebook.py").exists()
assert (tmp_path / "my_notebook.ipynb").exists()
folder_contents = list_folder_contents(tmp_path)
assert len(folder_contents) == 2 + copy + config_file, folder_contents
# Open and save the notebook - this should create no additional file
model = await ensure_async(cm.get("my_notebook.ipynb"))
await ensure_async(cm.save(model=model, path="my_notebook.ipynb"))
folder_contents = list_folder_contents(tmp_path)
assert len(folder_contents) == 2 + copy + config_file, folder_contents
async def test_move_paired_notebook_outside_of_pairing_config_1414(tmp_path, cm, python_notebook):
(tmp_path / "within_config").mkdir()
(tmp_path / "within_config" / "jupytext.toml").write_text('formats = "notebooks///ipynb,scripts///py:percent"\n')
cm.root_dir = str(tmp_path)
# create paired notebook
(tmp_path / "within_config" / "notebooks").mkdir()
await ensure_async(
cm.save(
notebook_model(python_notebook),
path="within_config/notebooks/my_notebook.ipynb",
)
)
assert (tmp_path / "within_config" / "notebooks" / "my_notebook.ipynb").exists()
assert (tmp_path / "within_config" / "scripts" / "my_notebook.py").exists()
folder_contents = list_folder_contents(tmp_path)
assert len(folder_contents) == 3, folder_contents
# move notebook still within the config reach, but outside the notebooks folder
(tmp_path / "other").mkdir()
await ensure_async(cm.rename_file("within_config/notebooks/my_notebook.ipynb", "other/my_notebook.ipynb"))
assert not (tmp_path / "within_config" / "notebooks" / "my_notebook.ipynb").exists()
assert (tmp_path / "other" / "my_notebook.ipynb").exists()
assert (tmp_path / "within_config" / "scripts" / "my_notebook.py").exists()
folder_contents = list_folder_contents(tmp_path)
assert len(folder_contents) == 3, folder_contents
# Open and save the notebook - this should create no additional file
model = await ensure_async(cm.get("other/my_notebook.ipynb"))
await ensure_async(cm.save(model=model, path="other/my_notebook.ipynb"))
assert not (tmp_path / "within_config" / "notebooks" / "my_notebook.ipynb").exists()
assert (tmp_path / "other" / "my_notebook.ipynb").exists()
assert (tmp_path / "within_config" / "scripts" / "my_notebook.py").exists()
folder_contents = list_folder_contents(tmp_path)
assert len(folder_contents) == 3, folder_contents
async def test_hash_changes_if_paired_file_is_edited(tmp_path, cm, python_notebook):
# 1. write py ipynb
if "require_hash" not in inspect.signature(cm.get).parameters:
pytest.skip(reason="This JupytextContentsManager does not have a 'require_hash' parameter in cm.get")
cm.formats = "ipynb,py:percent"
cm.root_dir = str(tmp_path)
# save ipynb
nb = python_notebook
nb_name = "notebook.ipynb"
await ensure_async(cm.save(model=notebook_model(nb), path=nb_name))
org_model = await ensure_async(cm.get(nb_name, require_hash=True))
py_file = tmp_path / "notebook.py"
text = py_file.read_text()
assert "# %% [markdown]" in text.splitlines(), text
# modify the timestamp of the paired file
time.sleep(0.5)
py_file.write_text(text)
model = await ensure_async(cm.get(nb_name, require_hash=True))
# not sure why the hash changes on Windows?
assert (model["hash"] == org_model["hash"]) or (os.name == "nt")
# modify the paired file
py_file.write_text(text + "\n# %%\n1 + 1\n")
new_model = await ensure_async(cm.get(nb_name, require_hash=True))
assert new_model["hash"] != org_model["hash"]
# the hash is for the pair (inputs first)
model_from_py_file = await ensure_async(cm.get("notebook.py", require_hash=True))
assert model_from_py_file["hash"] == new_model["hash"]
@pytest.mark.requires_myst
async def test_metadata_stays_in_order_1368(
tmp_path,
cm,
md="""---
jupytext:
formats: md:myst
notebook_metadata_filter: -jupytext.text_representation.jupytext_version
text_representation:
extension: .md
format_name: myst
format_version: 0.13
kernelspec:
display_name: itables
language: python
name: itables
---
A markdown cell
""",
):
cm.root_dir = str(tmp_path)
(tmp_path / "nb.md").write_text(md)
model = await ensure_async(cm.get(path="nb.md"))
assert list(model["content"]["metadata"].keys()) == [
"jupytext",
"kernelspec",
], "order must be preserved"
await ensure_async(cm.save(model=model, path="nb.md"))
compare((tmp_path / "nb.md").read_text(), md)
@pytest.mark.requires_myst
async def test_jupytext_orders_root_metadata(
tmp_path,
cm,
md="""---
title: Quick test
jupytext:
formats: md:myst
notebook_metadata_filter: -jupytext.text_representation.jupytext_version
root_level_metadata_filter: -title
text_representation:
extension: .md
format_name: myst
format_version: 0.13
kernelspec:
display_name: itables
language: python
name: itables
---
A markdown cell
""",
):
cm.root_dir = str(tmp_path)
(tmp_path / "nb.md").write_text(md)
model = await ensure_async(cm.get(path="nb.md"))
assert list(model["content"]["metadata"].keys()) == [
"jupytext",
"kernelspec",
], "order must be preserved"
# simulate jupyter changing the order of the metadata
model["content"]["metadata"]["jupytext"] = model["content"]["metadata"].pop("jupytext")
assert list(model["content"]["metadata"].keys()) == ["kernelspec", "jupytext"]
await ensure_async(cm.save(model=model, path="nb.md"))
compare((tmp_path / "nb.md").read_text(), md)
@pytest.mark.parametrize("with_config", [False, True])
async def test_load_save_keeps_simple_python_file_unchanged(tmp_path, cm, with_config: bool):
"""Test that jupytext --sync on a simple Python file leaves it unchanged,
even if a Jupytext configuration has formats=ipynb,py:percent
"""
cm.root_dir = str(tmp_path)
if with_config:
config_file = tmp_path / "jupytext.toml"
config_file.write_text('formats = "ipynb,py:percent"')
# Create a simple Python file without jupytext metadata
py_file = tmp_path / "simple.py"
py_content = '''#!/usr/bin/env python3
"""A simple Python script"""
def hello():
print("Hello, world!")
if __name__ == "__main__":
hello()
'''
py_file.write_text(py_content)
# Record original content
original_content = py_file.read_text()
# Open and save the file using our contents manager
model = await ensure_async(cm.get(path="simple.py"))
await ensure_async(cm.save(model=model, path="simple.py"))
# Verify file is unchanged
final_content = py_file.read_text()
assert final_content == original_content, "File content should be unchanged"
# Verify no additional files were created
files_in_dir = list(tmp_path.iterdir())
if with_config:
assert len(files_in_dir) == 2, f"Expected only 2 files, found: {[f.name for f in files_in_dir]}"
assert set(files_in_dir) == {py_file, config_file}
else:
assert len(files_in_dir) == 1, f"Expected only 1 file, found: {[f.name for f in files_in_dir]}"
assert files_in_dir[0] == py_file
async def test_pairing_groups_in_contents_manager(tmp_path, cm, python_notebook):
cm.root_dir = str(tmp_path)
# With config file using list-based formats
(tmp_path / "jupytext.toml").write_text(
"""
# Tutorial notebooks get paired to markdown docs
[[formats]]
"notebooks/tutorials/" = "ipynb"
"docs/" = "md"
# Main pairing: all other notebooks are paired with Python scripts
[[formats]]
"" = "ipynb,py:percent"
"""
)
cm = jupytext.TextFileContentsManager()
cm.root_dir = str(tmp_path)
(tmp_path / "notebooks").mkdir()
await ensure_async(cm.save(model=notebook_model(python_notebook), path="notebooks/notebook.ipynb"))
assert (tmp_path / "notebooks" / "notebook.ipynb").exists()
assert (tmp_path / "notebooks" / "notebook.py").exists()
assert not (tmp_path / "docs" / "notebook.md").exists()
# A notebook under 'tutorials' is paired to md in the docs folder
(tmp_path / "notebooks" / "tutorials").mkdir()
await ensure_async(cm.save(model=notebook_model(python_notebook), path="notebooks/tutorials/notebook.ipynb"))
assert (tmp_path / "notebooks" / "tutorials" / "notebook.ipynb").exists()
assert not (tmp_path / "notebooks" / "tutorials" / "notebook.py").exists()
assert (tmp_path / "docs" / "notebook.md").exists()
================================================
FILE: tests/integration/contents_manager/test_load_multiple.py
================================================
import pytest
from jupyter_server.utils import ensure_async
from nbformat.v4.nbbase import new_notebook
from tornado.web import HTTPError
import jupytext
@pytest.mark.asyncio
async def test_combine_same_version_ok(tmpdir, cm):
tmp_ipynb = "notebook.ipynb"
tmp_nbpy = "notebook.py"
with open(str(tmpdir.join(tmp_nbpy)), "w") as fp:
fp.write(
"""# ---
# jupyter:
# jupytext_formats: ipynb,py
# jupytext_format_version: '1.2'
# ---
# New cell
"""
)
nb = new_notebook(metadata={"jupytext_formats": "ipynb,py"})
jupytext.write(nb, str(tmpdir.join(tmp_ipynb)))
cm.formats = "ipynb,py"
cm.root_dir = str(tmpdir)
nb = await ensure_async(cm.get(tmp_ipynb))
cells = nb["content"]["cells"]
assert len(cells) == 1
assert cells[0].cell_type == "markdown"
assert cells[0].source == "New cell"
@pytest.mark.asyncio
async def test_combine_lower_version_raises(tmpdir, cm):
tmp_ipynb = "notebook.ipynb"
tmp_nbpy = "notebook.py"
with open(str(tmpdir.join(tmp_nbpy)), "w") as fp:
fp.write(
"""# ---
# jupyter:
# jupytext_formats: ipynb,py
# jupytext_format_version: '0.0'
# ---
# New cell
"""
)
nb = new_notebook(metadata={"jupytext_formats": "ipynb,py"})
jupytext.write(nb, str(tmpdir.join(tmp_ipynb)))
cm.formats = "ipynb,py"
cm.root_dir = str(tmpdir)
with pytest.raises(HTTPError):
await ensure_async(cm.get(tmp_ipynb))
================================================
FILE: tests/integration/jupytext_config/test_jupytext_config.py
================================================
from jupytext.cli import system
def test_jupytext_config_cli(tmp_path):
settings_file = tmp_path / "default_setting_overrides.json"
system("jupytext-config", "-h")
system(
"jupytext-config",
"--settings-file",
str(settings_file),
"set-default-viewer",
"python",
"markdown",
)
assert "python" in (settings_file).read_text()
assert "markdown" in system("jupytext-config", "--settings-file", settings_file, "list-default-viewer")
system(
"jupytext-config",
"--settings-file",
str(settings_file),
"unset-default-viewer",
"markdown",
)
list_viewers = system("jupytext-config", "--settings-file", settings_file, "list-default-viewer")
assert "python" in list_viewers
assert "markdown" not in list_viewers
================================================
FILE: tests/unit/test_cell_id.py
================================================
from nbformat.v4.nbbase import new_code_cell, new_markdown_cell, new_raw_cell
def test_cell_id_is_not_random():
assert new_code_cell().id == "cell-1"
assert new_code_cell().id == "cell-2"
assert new_markdown_cell().id == "cell-3"
assert new_raw_cell().id == "cell-4"
================================================
FILE: tests/unit/test_compare.py
================================================
import pytest
from nbformat.v4.nbbase import (
new_code_cell,
new_markdown_cell,
new_notebook,
new_raw_cell,
)
from jupytext.compare import (
NotebookDifference,
compare,
compare_cells,
compare_notebooks,
)
from jupytext.compare import test_round_trip_conversion as round_trip_conversion
def notebook_metadata():
return {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3",
},
"language_info": {
"codemirror_mode": {"name": "ipython", "version": 3},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.3",
},
"toc": {
"base_numbering": 1,
"nav_menu": {},
"number_sections": True,
"sideBar": True,
"skip_h1_title": False,
"title_cell": "Table of Contents",
"title_sidebar": "Contents",
"toc_cell": False,
"toc_position": {},
"toc_section_display": True,
"toc_window_display": False,
},
}
@pytest.fixture()
def notebook_expected():
return new_notebook(
metadata=notebook_metadata(),
cells=[
new_markdown_cell("First markdown cell", id="markdown-cell-one"),
new_code_cell("1 + 1", id="code-cell-one"),
new_markdown_cell("Second markdown cell", id="markdown-cell-two"),
],
)
@pytest.fixture()
def notebook_actual():
metadata = notebook_metadata()
metadata["language_info"]["version"] = "3.6.8"
return new_notebook(
metadata=metadata,
cells=[
new_markdown_cell("First markdown cell", id="markdown-cell-one"),
new_code_cell("1 + 1", id="code-cell-one"),
new_markdown_cell("Modified markdown cell", id="markdown-cell-two"),
],
)
def test_compare_on_notebooks(notebook_actual, notebook_expected):
with pytest.raises(AssertionError) as err:
compare(notebook_actual, notebook_expected)
assert (
str(err.value)
== """
--- expected
+++ actual
@@ -18,7 +18,7 @@
"cell_type": "markdown",
"id": "markdown-cell-two",
"metadata": {},
- "source": "Second markdown cell"
+ "source": "Modified markdown cell"
}
],
"metadata": {
@@ -37,7 +37,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.7.3"
+ "version": "3.6.8"
},
"toc": {
"base_numbering": 1,"""
)
def test_raise_on_different_metadata():
ref = new_notebook(
metadata={
"kernelspec": {
"language": "python",
"name": "python",
"display_name": "Python",
}
},
cells=[new_markdown_cell("Cell one")],
)
test = new_notebook(
metadata={"kernelspec": {"language": "R", "name": "R", "display_name": "R"}},
cells=[new_markdown_cell("Cell one")],
)
with pytest.raises(NotebookDifference):
compare_notebooks(test, ref, "md")
@pytest.mark.parametrize("raise_on_first_difference", [True, False])
def test_raise_on_different_cell_type(raise_on_first_difference):
ref = new_notebook(cells=[new_markdown_cell("Cell one"), new_code_cell("Cell two")])
test = new_notebook(cells=[new_markdown_cell("Cell one"), new_raw_cell("Cell two")])
with pytest.raises(NotebookDifference):
compare_notebooks(test, ref, "md", raise_on_first_difference=raise_on_first_difference)
@pytest.mark.parametrize("raise_on_first_difference", [True, False])
def test_raise_on_different_cell_content(raise_on_first_difference):
ref = new_notebook(cells=[new_markdown_cell("Cell one"), new_code_cell("Cell two")])
test = new_notebook(cells=[new_markdown_cell("Cell one"), new_code_cell("Modified cell two")])
with pytest.raises(NotebookDifference):
compare_notebooks(test, ref, "md", raise_on_first_difference=raise_on_first_difference)
def test_raise_on_incomplete_markdown_cell():
ref = new_notebook(cells=[new_markdown_cell("Cell one\n\n\nsecond line")])
test = new_notebook(cells=[new_markdown_cell("Cell one")])
with pytest.raises(NotebookDifference):
compare_notebooks(test, ref, "md")
def test_does_raise_on_split_markdown_cell():
ref = new_notebook(cells=[new_markdown_cell("Cell one\n\n\nsecond line")])
test = new_notebook(cells=[new_markdown_cell("Cell one"), new_markdown_cell("second line")])
with pytest.raises(NotebookDifference):
compare_notebooks(test, ref, "md")
def test_raise_on_different_cell_metadata():
ref = new_notebook(cells=[new_code_cell("1+1")])
test = new_notebook(cells=[new_code_cell("1+1", metadata={"metakey": "value"})])
with pytest.raises(NotebookDifference):
compare_notebooks(test, ref, "py:light")
@pytest.mark.parametrize("raise_on_first_difference", [True, False])
def test_raise_on_different_cell_count(raise_on_first_difference):
ref = new_notebook(cells=[new_code_cell("1")])
test = new_notebook(cells=[new_code_cell("1"), new_code_cell("2")])
with pytest.raises(NotebookDifference):
compare_notebooks(test, ref, "py:light", raise_on_first_difference=raise_on_first_difference)
with pytest.raises(NotebookDifference):
compare_notebooks(ref, test, "py:light", raise_on_first_difference=raise_on_first_difference)
def test_does_not_raise_on_blank_line_removed():
ref = new_notebook(cells=[new_code_cell("1+1\n ")])
test = new_notebook(cells=[new_code_cell("1+1")])
compare_notebooks(test, ref, "py:light")
def test_strict_raise_on_blank_line_removed():
ref = new_notebook(cells=[new_code_cell("1+1\n")])
test = new_notebook(cells=[new_code_cell("1+1")])
with pytest.raises(NotebookDifference):
compare_notebooks(test, ref, "py:light", allow_expected_differences=False)
def test_dont_raise_on_different_outputs():
ref = new_notebook(cells=[new_code_cell("1+1")])
test = new_notebook(
cells=[
new_code_cell(
"1+1",
outputs=[
{
"data": {"text/plain": ["2"]},
"execution_count": 1,
"metadata": {},
"output_type": "execute_result",
}
],
)
]
)
compare_notebooks(test, ref, "md")
@pytest.mark.parametrize("raise_on_first_difference", [True, False])
def test_raise_on_different_outputs(raise_on_first_difference):
ref = new_notebook(cells=[new_code_cell("1+1")])
test = new_notebook(
cells=[
new_code_cell(
"1+1",
outputs=[
{
"data": {"text/plain": ["2"]},
"execution_count": 1,
"metadata": {},
"output_type": "execute_result",
}
],
)
]
)
with pytest.raises(NotebookDifference):
compare_notebooks(
test,
ref,
"md",
raise_on_first_difference=raise_on_first_difference,
compare_outputs=True,
)
def test_test_round_trip_conversion():
notebook = new_notebook(
cells=[
new_code_cell(
"1+1",
outputs=[
{
"data": {"text/plain": ["2"]},
"execution_count": 1,
"metadata": {},
"output_type": "execute_result",
}
],
)
],
metadata={"main_language": "python"},
)
round_trip_conversion(notebook, {"extension": ".py"}, update=True)
def test_mutiple_cells_differ():
nb1 = new_notebook(cells=[new_code_cell(""), new_code_cell("2")])
nb2 = new_notebook(cells=[new_code_cell("1+1"), new_code_cell("2\n2")])
with pytest.raises(NotebookDifference) as exception_info:
compare_notebooks(nb2, nb1, raise_on_first_difference=False)
assert "Cells 1,2 differ" in exception_info.value.args[0]
def test_cell_metadata_differ():
nb1 = new_notebook(
cells=[
new_code_cell("1"),
new_code_cell("2", metadata={"additional": "metadata1"}),
]
)
nb2 = new_notebook(
cells=[
new_code_cell("1"),
new_code_cell("2", metadata={"additional": "metadata2"}),
]
)
with pytest.raises(NotebookDifference) as exception_info:
compare_notebooks(nb2, nb1, raise_on_first_difference=False)
assert "Cell metadata 'additional' differ" in exception_info.value.args[0]
def test_notebook_metadata_differ():
nb1 = new_notebook(cells=[new_code_cell("1"), new_code_cell("2")])
nb2 = new_notebook(
cells=[new_code_cell("1"), new_code_cell("2")],
metadata={
"kernelspec": {
"language": "python",
"name": "python",
"display_name": "Python",
}
},
)
with pytest.raises(NotebookDifference) as exception_info:
compare_notebooks(nb2, nb1, raise_on_first_difference=False)
assert "Notebook metadata differ" in exception_info.value.args[0]
def test_cell_ids_differ():
with pytest.raises(NotebookDifference, match="'id-one' != 'id-two'"):
compare_cells([new_code_cell("1", id="id-one")], [new_code_cell("1", id="id-two")])
================================================
FILE: tests/unit/test_escape_magics.py
================================================
import pytest
from jupyter_server.utils import ensure_async
from nbformat.v4.nbbase import new_code_cell, new_notebook
import jupytext
from jupytext.compare import compare, compare_notebooks, notebook_model
from jupytext.magics import (
_PYTHON_MAGIC_ASSIGN,
comment_magic,
is_magic,
uncomment_magic,
unesc,
)
def test_unesc():
assert unesc("# comment", "python") == "comment"
assert unesc("#comment", "python") == "comment"
assert unesc("comment", "python") == "comment"
@pytest.mark.parametrize(
"line",
[
"%matplotlib inline",
"#%matplotlib inline",
"##%matplotlib inline",
"%%HTML",
"%autoreload",
"%store",
],
)
def test_escape(line):
assert comment_magic([line]) == ["# " + line]
assert uncomment_magic(comment_magic([line])) == [line]
@pytest.mark.parametrize("line", ["@pytest.fixture"])
def test_escape_magic_only(line):
assert comment_magic([line]) == [line]
@pytest.mark.parametrize("line", ["%matplotlib inline #noescape"])
def test_force_noescape(line):
assert comment_magic([line]) == [line]
@pytest.mark.parametrize("line", ["%matplotlib inline #noescape"])
def test_force_noescape_with_gbl_esc_flag(line):
assert comment_magic([line], global_escape_flag=True) == [line]
@pytest.mark.parametrize("line", ["%matplotlib inline #escape"])
def test_force_escape_with_gbl_esc_flag(line):
assert comment_magic([line], global_escape_flag=False) == ["# " + line]
@pytest.mark.parametrize(
"fmt,commented",
zip(
[
"md",
"Rmd",
"py:light",
"py:percent",
"py:sphinx",
"R",
"ss:light",
"ss:percent",
],
[False, True, True, True, True, True, True, True],
),
)
def test_magics_commented_default(fmt, commented):
nb = new_notebook(cells=[new_code_cell("%pylab inline")])
text = jupytext.writes(nb, fmt)
assert ("%pylab inline" in text.splitlines()) != commented
nb2 = jupytext.reads(text, fmt)
if "sphinx" in fmt:
nb2.cells = nb2.cells[1:]
compare_notebooks(nb2, nb)
@pytest.mark.parametrize(
"fmt",
["md", "Rmd", "py:light", "py:percent", "py:sphinx", "R", "ss:light", "ss:percent"],
)
def test_magics_are_commented(fmt):
nb = new_notebook(
cells=[new_code_cell("%pylab inline")],
metadata={
"jupytext": {
"comment_magics": True,
"main_language": ("R" if fmt == "R" else "scheme" if fmt.startswith("ss") else "python"),
}
},
)
text = jupytext.writes(nb, fmt)
assert "%pylab inline" not in text.splitlines()
nb2 = jupytext.reads(text, fmt)
if "sphinx" in fmt:
nb2.cells = nb2.cells[1:]
compare_notebooks(nb2, nb)
@pytest.mark.parametrize(
"fmt",
["md", "Rmd", "py:light", "py:percent", "py:sphinx", "R", "ss:light", "ss:percent"],
)
def test_magics_are_not_commented(fmt):
nb = new_notebook(
cells=[new_code_cell("%pylab inline")],
metadata={
"jupytext": {
"comment_magics": False,
"main_language": ("R" if fmt == "R" else "scheme" if fmt.startswith("ss") else "python"),
}
},
)
text = jupytext.writes(nb, fmt)
assert "%pylab inline" in text.splitlines()
nb2 = jupytext.reads(text, fmt)
if "sphinx" in fmt:
nb2.cells = nb2.cells[1:]
compare_notebooks(nb2, nb)
@pytest.mark.asyncio
async def test_force_comment_using_contents_manager(tmpdir, cm):
tmp_py = "notebook.py"
cm.preferred_jupytext_formats_save = "py:percent"
cm.root_dir = str(tmpdir)
nb = new_notebook(cells=[new_code_cell("%pylab inline")])
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_py))
with open(str(tmpdir.join(tmp_py))) as stream:
assert "# %pylab inline" in stream.read().splitlines()
cm.comment_magics = False
await ensure_async(cm.save(model=notebook_model(nb), path=tmp_py))
with open(str(tmpdir.join(tmp_py))) as stream:
assert "%pylab inline" in stream.read().splitlines()
@pytest.mark.parametrize(
"magic_cmd",
[
"ls",
"!ls",
"ls -al",
"!whoami",
"# ls",
"# mv a b",
"! mkdir tmp",
"!./script",
"! ./script",
"!./script args",
"!./script.sh args",
"! ./script.sh args",
"!~/script.sh args",
"! ~/script.sh args",
"!../script.sh $ENV $USER",
"! ../script.sh $ENV $USER",
"!$HOME/script.sh $ENV $USER",
"!/bin/sh $ENV $USER",
"! /bin/sh $ENV $USER",
r"! \bin\sh $ENV $USER",
r"!\bin\sh $ENV $USER",
"cat",
"cat ",
"cat hello.txt",
"cat --option=value hello.txt",
"!{x}",
],
)
def test_comment_bash_commands_in_python(magic_cmd):
assert comment_magic([magic_cmd]) == ["# " + magic_cmd]
assert uncomment_magic(["# " + magic_cmd]) == [magic_cmd]
@pytest.mark.parametrize(
"not_magic_cmd",
["copy(a)", "copy.deepcopy", "cat = 3", "cat=5", "cat, other = 5,3", "cat(5)"],
)
def test_do_not_comment_python_cmds(not_magic_cmd):
assert comment_magic([not_magic_cmd]) == [not_magic_cmd]
assert uncomment_magic([not_magic_cmd]) == [not_magic_cmd]
@pytest.mark.parametrize("magic_cmd", ["ls", "!ls", "ls -al", "!whoami", "# ls", "# mv a b"])
def test_do_not_comment_bash_commands_in_R(magic_cmd):
assert comment_magic([magic_cmd], language="R") == [magic_cmd]
assert uncomment_magic([magic_cmd], language="R") == [magic_cmd]
def test_markdown_image_is_not_magic():
assert is_magic("# !cmd", "python")
assert not is_magic("# 
def test_question_is_not_magic():
assert is_magic("float?", "python", explicitly_code=True)
assert is_magic("# float?", "python", explicitly_code=True)
assert not is_magic("# question: float?", "python", explicitly_code=True)
def test_multiline_python_magic(no_jupytext_version_number):
nb = new_notebook(
cells=[
new_code_cell(
"""%load_ext watermark
%watermark -u -n -t -z \\
-p jupytext -v
def g(x):
return x+1"""
)
]
)
text = jupytext.writes(nb, "py:light")
compare(
text,
"""# +
# %load_ext watermark
# %watermark -u -n -t -z \\
# -p jupytext -v
def g(x):
return x+1
""",
)
compare_notebooks(jupytext.reads(text, "py"), nb)
def test_configure_magic(no_jupytext_version_number):
nb = new_notebook(
cells=[
new_code_cell(
"""%%configure -f \\
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}"""
)
]
)
text = jupytext.writes(nb, "py:light")
compare(
text,
"""# %%configure -f \\
# {"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
""",
)
compare_notebooks(jupytext.reads(text, "py"), nb)
def test_indented_magic():
assert is_magic(" !rm file", "python")
assert is_magic(" # !rm file", "python")
assert is_magic(" %cd", "python")
assert comment_magic([" !rm file"]) == [" # !rm file"]
assert uncomment_magic([" # !rm file"]) == [" !rm file"]
assert comment_magic([" %cd"]) == [" # %cd"]
assert uncomment_magic([" # %cd"]) == [" %cd"]
def test_magic_assign_781():
assert _PYTHON_MAGIC_ASSIGN.match("name = %magic")
assert _PYTHON_MAGIC_ASSIGN.match("# name = %magic")
assert not _PYTHON_MAGIC_ASSIGN.match("# not a name = %magic")
assert not _PYTHON_MAGIC_ASSIGN.match("# 0name = %magic")
assert is_magic("result = %sql SELECT * FROM quickdemo WHERE value > 25", "python")
def test_magic_assign_816():
assert _PYTHON_MAGIC_ASSIGN.match("flake8_version = !flake8 --version")
assert _PYTHON_MAGIC_ASSIGN.match("# flake8_version = !flake8 --version")
assert _PYTHON_MAGIC_ASSIGN.match("name = %time 2+2")
assert _PYTHON_MAGIC_ASSIGN.match("# name = %time 2+2")
================================================
FILE: tests/unit/test_formats.py
================================================
import pytest
from jupyter_server.utils import ensure_async
from nbformat.v4.nbbase import new_notebook
import jupytext
from jupytext.compare import compare
from jupytext.formats import (
JupytextFormatError,
divine_format,
get_format_implementation,
guess_format,
long_form_multiple_formats,
read_format_from_metadata,
rearrange_jupytext_metadata,
short_form_multiple_formats,
update_jupytext_formats_metadata,
validate_one_format,
)
def test_guess_format_light(python_file):
with open(python_file) as stream:
assert guess_format(stream.read(), ext=".py")[0] == "light"
def test_guess_format_percent(percent_file):
with open(percent_file) as stream:
assert guess_format(stream.read(), ext=".py")[0] == "percent"
def test_guess_format_simple_percent(
nb="""# %%
print("hello world!")
""",
):
assert guess_format(nb, ext=".py")[0] == "percent"
def test_guess_format_simple_percent_with_magic(
nb="""# %%
# %time
print("hello world!")
""",
):
assert guess_format(nb, ext=".py")[0] == "percent"
def test_guess_format_simple_hydrogen_with_magic(
nb="""# %%
%time
print("hello world!")
""",
):
assert guess_format(nb, ext=".py")[0] == "hydrogen"
def test_guess_format_sphinx(sphinx_file):
with open(sphinx_file) as stream:
assert guess_format(stream.read(), ext=".py")[0] == "sphinx"
def test_guess_format_hydrogen():
text = """# %%
cat hello.txt
"""
assert guess_format(text, ext=".py")[0] == "hydrogen"
def test_divine_format():
assert divine_format('{"cells":[]}') == "ipynb"
assert (
divine_format(
"""def f(x):
x + 1"""
)
== "py:light"
)
assert (
divine_format(
"""# %%
def f(x):
x + 1
# %%
def g(x):
x + 2
"""
)
== "py:percent"
)
assert (
divine_format(
"""This is a markdown file
with one code block
```
1 + 1
```
"""
)
== "md"
)
assert (
divine_format(
""";; ---
;; jupyter:
;; jupytext:
;; text_representation:
;; extension: .ss
;; format_name: percent
;; ---"""
)
== "ss:percent"
)
def test_get_format_implementation():
assert get_format_implementation(".py").format_name == "light"
assert get_format_implementation(".py", "percent").format_name == "percent"
with pytest.raises(JupytextFormatError):
get_format_implementation(".py", "wrong_format")
def test_script_with_magics_not_percent(
script="""# %%time
1 + 2""",
):
assert guess_format(script, ".py")[0] == "light"
def test_script_with_spyder_cell_is_percent(
script="""#%%
1 + 2""",
):
assert guess_format(script, ".py")[0] == "percent"
def test_script_with_percent_cell_and_magic_is_hydrogen(
script="""#%%
%matplotlib inline
""",
):
assert guess_format(script, ".py")[0] == "hydrogen"
def test_script_with_percent_cell_and_kernelspec(
script="""# ---
# jupyter:
# kernelspec:
# display_name: Python3
# language: python
# name: python3
# ---
# %%
a = 1
""",
):
assert guess_format(script, ".py")[0] == "percent"
def test_script_with_spyder_cell_with_name_is_percent(
script="""#%% cell name
1 + 2""",
):
assert guess_format(script, ".py")[0] == "percent"
def test_read_format_from_metadata(
script="""---
jupyter:
jupytext:
formats: ipynb,pct.py:percent,lgt.py:light,spx.py:sphinx,md,Rmd
text_representation:
extension: .pct.py
format_name: percent
format_version: '1.1'
jupytext_version: 0.8.0
---""",
):
assert read_format_from_metadata(script, ".Rmd") is None
def test_update_jupytext_formats_metadata():
nb = new_notebook(metadata={"jupytext": {"formats": "py"}})
update_jupytext_formats_metadata(nb.metadata, "py:light")
assert nb.metadata["jupytext"]["formats"] == "py:light"
nb = new_notebook(metadata={"jupytext": {"formats": "ipynb,py"}})
update_jupytext_formats_metadata(nb.metadata, "py:light")
assert nb.metadata["jupytext"]["formats"] == "ipynb,py:light"
def test_decompress_formats():
assert long_form_multiple_formats("ipynb") == [{"extension": ".ipynb"}]
assert long_form_multiple_formats("ipynb,md") == [
{"extension": ".ipynb"},
{"extension": ".md"},
]
assert long_form_multiple_formats("ipynb,py:light") == [
{"extension": ".ipynb"},
{"extension": ".py", "format_name": "light"},
]
assert long_form_multiple_formats(["ipynb", ".py:light"]) == [
{"extension": ".ipynb"},
{"extension": ".py", "format_name": "light"},
]
assert long_form_multiple_formats(".pct.py:percent") == [{"extension": ".py", "suffix": ".pct", "format_name": "percent"}]
def test_compress_formats():
assert short_form_multiple_formats([{"extension": ".ipynb"}]) == "ipynb"
assert short_form_multiple_formats("ipynb") == "ipynb"
assert short_form_multiple_formats([{"extension": ".ipynb"}, {"extension": ".md"}]) == "ipynb,md"
assert (
short_form_multiple_formats([{"extension": ".ipynb"}, {"extension": ".py", "format_name": "light"}])
== "ipynb,py:light"
)
assert (
short_form_multiple_formats(
[
{"extension": ".ipynb"},
{"extension": ".py", "format_name": "light"},
{"extension": ".md", "comment_magics": True},
]
)
== "ipynb,py:light,md"
)
assert short_form_multiple_formats([{"extension": ".py", "suffix": ".pct", "format_name": "percent"}]) == ".pct.py:percent"
def test_rearrange_jupytext_metadata():
metadata = {"nbrmd_formats": "ipynb,py"}
rearrange_jupytext_metadata(metadata)
compare(metadata, {"jupytext": {"formats": "ipynb,py"}})
metadata = {"jupytext_formats": "ipynb,py"}
rearrange_jupytext_metadata(metadata)
compare(metadata, {"jupytext": {"formats": "ipynb,py"}})
metadata = {"executable": "#!/bin/bash"}
rearrange_jupytext_metadata(metadata)
compare(metadata, {"jupytext": {"executable": "#!/bin/bash"}})
def test_rearrange_jupytext_metadata_metadata_filter():
metadata = {
"jupytext": {
"metadata_filter": {
"notebook": {"additional": ["one", "two"], "excluded": "all"},
"cells": {"additional": "all", "excluded": ["three", "four"]},
}
}
}
rearrange_jupytext_metadata(metadata)
compare(
metadata,
{
"jupytext": {
"notebook_metadata_filter": "one,two,-all",
"cell_metadata_filter": "all,-three,-four",
}
},
)
def test_rearrange_jupytext_metadata_add_dot_in_suffix():
metadata = {
"jupytext": {
"text_representation": {"jupytext_version": "0.8.6"},
"formats": "ipynb,pct.py,lgt.py",
}
}
rearrange_jupytext_metadata(metadata)
compare(
metadata,
{
"jupytext": {
"text_representation": {"jupytext_version": "0.8.6"},
"formats": "ipynb,.pct.py,.lgt.py",
}
},
)
def test_fix_139():
text = """# ---
# jupyter:
# jupytext:
# metadata_filter:
# cells:
# additional:
# - "lines_to_next_cell"
# excluded:
# - "all"
# ---
# + {"lines_to_next_cell": 2}
1 + 1
# -
1 + 1
"""
nb = jupytext.reads(text, "py:light")
text2 = jupytext.writes(nb, "py:light")
assert "cell_metadata_filter: -all" in text2
assert "lines_to_next_cell" not in text2
def test_validate_one_format():
with pytest.raises(JupytextFormatError):
validate_one_format("py:percent")
with pytest.raises(JupytextFormatError):
validate_one_format({"extension": "py", "format_name": "invalid"})
with pytest.raises(JupytextFormatError):
validate_one_format({})
with pytest.raises(JupytextFormatError):
validate_one_format({"extension": ".py", "unknown_option": True})
with pytest.raises(JupytextFormatError):
validate_one_format({"extension": ".py", "comment_magics": "TRUE"})
def test_set_auto_ext():
with pytest.raises(ValueError):
long_form_multiple_formats("ipynb,auto:percent", {})
@pytest.mark.requires_pandoc
def test_pandoc_format_is_preserved():
formats_org = "ipynb,md,.pandoc.md:pandoc,py:light"
long = long_form_multiple_formats(formats_org)
formats_new = short_form_multiple_formats(long)
compare(formats_new, formats_org)
@pytest.mark.requires_myst
def test_write_as_myst(tmpdir):
"""Inspired by https://github.com/mwouts/jupytext/issues/462"""
nb = new_notebook()
tmp_md = str(tmpdir.join("notebook.md"))
jupytext.write(nb, tmp_md, fmt="myst")
with open(tmp_md) as fp:
md = fp.read()
assert "myst" in md
def test_write_raises_when_fmt_does_not_exists(tmpdir):
"""Inspired by https://github.com/mwouts/jupytext/issues/462"""
nb = new_notebook()
tmp_md = str(tmpdir.join("notebook.md"))
with pytest.raises(JupytextFormatError):
jupytext.write(nb, tmp_md, fmt="unknown_format")
@pytest.mark.asyncio
@pytest.mark.parametrize(
"config_file,config_contents",
[
(
"jupytext.toml",
"""# Always pair ipynb notebooks to md files
formats = "ipynb,md"
""",
),
(
"jupytext.toml",
"""# Always pair ipynb notebooks to py:percent files
formats = "ipynb,py:percent"
""",
),
(
"pyproject.toml",
"""[tool.jupytext]
formats = "ipynb,py:percent"
""",
),
(
"jupytext.toml",
"""# Pair notebooks in subfolders of 'notebooks' to scripts in subfolders of 'scripts'
formats = "notebooks///ipynb,scripts///py:percent"
""",
),
(
"jupytext.toml",
"""[formats]
"notebooks/" = "ipynb"
"scripts/" = "py:percent"
""",
),
],
)
async def test_configuration_examples_from_documentation(config_file, config_contents, python_notebook, tmp_path, cm):
"""Here we make sure that the config examples from
https://jupytext.readthedocs.io/en/latest/config.html#configuring-paired-notebooks-globally
just work
"""
(tmp_path / config_file).write_text(config_contents)
cm.root_dir = str(tmp_path)
# Save the notebook
(tmp_path / "notebooks").mkdir()
await ensure_async(cm.save(dict(type="notebook", content=python_notebook), "notebooks/nb.ipynb"))
# Make sure that ipynb and text version are created
assert (tmp_path / "notebooks" / "nb.ipynb").is_file()
assert (
(tmp_path / "notebooks" / "nb.py").is_file()
or (tmp_path / "notebooks" / "nb.md").is_file()
or (tmp_path / "scripts" / "nb.py").is_file()
)
================================================
FILE: tests/unit/test_header.py
================================================
from nbformat.v4.nbbase import new_markdown_cell, new_notebook, new_raw_cell
import jupytext
from jupytext.compare import compare
from jupytext.formats import get_format_implementation
from jupytext.header import (
header_to_metadata_and_cell,
metadata_and_cell_to_header,
recursive_update,
uncomment_line,
)
def test_uncomment():
assert uncomment_line("# line one", "#") == "line one"
assert uncomment_line("#line two", "#") == "line two"
assert uncomment_line("#line two", "") == "#line two"
def test_header_to_metadata_and_cell_blank_line():
text = """---
title: Sample header
---
Header is followed by a blank line
"""
lines = text.splitlines()
metadata, _, cell, pos = header_to_metadata_and_cell(lines, "", "")
assert metadata == {}
assert cell.cell_type == "raw"
assert (
cell.source
== """---
title: Sample header
---"""
)
assert cell.metadata == {}
assert lines[pos].startswith("Header is")
def test_header_to_metadata_and_cell_no_blank_line():
text = """---
title: Sample header
---
Header is not followed by a blank line
"""
lines = text.splitlines()
metadata, _, cell, pos = header_to_metadata_and_cell(lines, "", "")
assert metadata == {}
assert cell.cell_type == "raw"
assert (
cell.source
== """---
title: Sample header
---"""
)
assert cell.metadata == {"lines_to_next_cell": 0}
assert lines[pos].startswith("Header is")
def test_header_to_metadata_and_cell_metadata():
text = """---
title: Sample header
jupyter:
mainlanguage: python
---
"""
lines = text.splitlines()
metadata, _, cell, pos = header_to_metadata_and_cell(lines, "", "")
assert metadata == {"mainlanguage": "python"}
assert cell.cell_type == "raw"
assert (
cell.source
== """---
title: Sample header
---"""
)
assert cell.metadata == {"lines_to_next_cell": 0}
assert pos == len(lines)
def test_metadata_and_cell_to_header(no_jupytext_version_number):
metadata = {"jupytext": {"mainlanguage": "python"}}
nb = new_notebook(metadata=metadata, cells=[new_raw_cell(source="---\ntitle: Sample header\n---")])
header, lines_to_next_cell = metadata_and_cell_to_header(
nb, metadata, get_format_implementation(".md"), {"extension": ".md"}
)
assert (
"\n".join(header)
== """---
title: Sample header
jupyter:
jupytext:
mainlanguage: python
---"""
)
assert nb.cells == []
assert lines_to_next_cell is None
def test_metadata_and_cell_to_header2(no_jupytext_version_number):
nb = new_notebook(cells=[new_markdown_cell(source="Some markdown\ntext")])
header, lines_to_next_cell = metadata_and_cell_to_header(nb, {}, get_format_implementation(".md"), {"extension": ".md"})
assert header == []
assert len(nb.cells) == 1
assert lines_to_next_cell is None
def test_notebook_from_plain_script_has_metadata_filter(
script="""print('Hello world")
""",
):
nb = jupytext.reads(script, ".py")
assert nb.metadata.get("jupytext", {}).get("notebook_metadata_filter") == "-all"
assert nb.metadata.get("jupytext", {}).get("cell_metadata_filter") == "-all"
script2 = jupytext.writes(nb, ".py")
compare(script2, script)
def test_multiline_metadata(
no_jupytext_version_number,
notebook=new_notebook(
metadata={
"multiline": """A multiline string
with a blank line""",
"jupytext": {
"notebook_metadata_filter": "all",
"text_representation": {"extension": ".md", "format_name": "markdown"},
},
}
),
markdown="""---
jupyter:
jupytext:
notebook_metadata_filter: all
text_representation:
extension: .md
format_name: markdown
multiline: 'A multiline string
with a blank line'
---
""",
):
actual = jupytext.writes(notebook, ".md")
compare(actual, markdown)
nb2 = jupytext.reads(markdown, ".md")
compare(nb2, notebook)
def test_header_in_html_comment():
text = """
"""
lines = text.splitlines()
metadata, _, cell, _ = header_to_metadata_and_cell(lines, "", "")
assert metadata == {"title": "Sample header"}
assert cell is None
def test_header_to_html_comment(no_jupytext_version_number):
metadata = {"jupytext": {"mainlanguage": "python"}}
nb = new_notebook(metadata=metadata, cells=[])
header, lines_to_next_cell = metadata_and_cell_to_header(
nb,
metadata,
get_format_implementation(".md"),
{"extension": ".md", "hide_notebook_metadata": True},
)
compare(
"\n".join(header),
"""""",
)
def test_recusive_update():
assert recursive_update({0: {1: 2}}, {0: {1: 3}, 4: 5}) == {0: {1: 3}, 4: 5}
assert recursive_update({0: {1: 2}}, {0: {1: 3}, 4: 5}, overwrite=False) == {
0: {1: 2},
4: 5,
}
# the value of `None`` is a special case
assert recursive_update({0: 1}, {0: None}) == {}
assert recursive_update({0: 1}, {0: None}, overwrite=False) == {}
================================================
FILE: tests/unit/test_labconfig.py
================================================
import json
import pytest
from jupytext_config.labconfig import LabConfig
@pytest.fixture()
def sample_viewer_config():
return {
"@jupyterlab/docmanager-extension:plugin": {
"defaultViewers": {
"markdown": "Jupytext Notebook",
"myst": "Jupytext Notebook",
"r-markdown": "Jupytext Notebook",
"quarto": "Jupytext Notebook",
"julia": "Jupytext Notebook",
"python": "Jupytext Notebook",
"r": "Jupytext Notebook",
}
}
}
@pytest.fixture()
def sample_empty_viewer_config():
return {"@jupyterlab/docmanager-extension:plugin": {"defaultViewers": {}}}
@pytest.fixture()
def settings_file(tmp_path):
return tmp_path / "default_setting_overrides.json"
def test_read_config(settings_file, sample_viewer_config):
(settings_file).write_text(json.dumps(sample_viewer_config))
labconfig = LabConfig(settings_file=settings_file).read()
assert labconfig.config == sample_viewer_config
def test_set_unset_default_viewers(settings_file, sample_viewer_config, sample_empty_viewer_config):
labconfig = LabConfig(settings_file=settings_file)
labconfig.set_default_viewers()
assert labconfig.config == sample_viewer_config
labconfig.unset_default_viewers()
assert labconfig.config == sample_empty_viewer_config
def test_write_config(settings_file, sample_viewer_config):
labconfig = LabConfig(settings_file=settings_file)
labconfig.set_default_viewers()
labconfig.write()
assert json.loads(settings_file.read_text()) == sample_viewer_config
================================================
FILE: tests/unit/test_markdown_in_code_cells.py
================================================
"""Issue #712"""
import pytest
from nbformat.v4.nbbase import new_code_cell, new_notebook
from jupytext import reads, writes
from jupytext.cell_to_text import three_backticks_or_more
from jupytext.compare import compare, compare_notebooks
def test_three_backticks_or_more():
assert three_backticks_or_more([""]) == "```"
assert three_backticks_or_more(["``"]) == "```"
assert three_backticks_or_more(["```python"]) == "````"
assert three_backticks_or_more(["```"]) == "````"
assert three_backticks_or_more(["`````python"]) == "``````"
assert three_backticks_or_more(["`````"]) == "``````"
def test_triple_backticks_in_code_cell(
no_jupytext_version_number,
nb=new_notebook(
metadata={"main_language": "python"},
cells=[
new_code_cell(
'''a = """
```
foo
```
"""'''
)
],
),
text='''---
jupyter:
jupytext:
main_language: python
---
````python
a = """
```
foo
```
"""
````
''',
):
actual_text = writes(nb, fmt="md")
compare(actual_text, text)
actual_nb = reads(text, fmt="md")
compare_notebooks(actual_nb, nb)
@pytest.mark.requires_myst
def test_triple_backticks_in_code_cell_myst(
no_jupytext_version_number,
nb=new_notebook(
metadata={"jupytext": {"default_lexer": "ipython3"}},
cells=[
new_code_cell(
'''a = """
```
foo
```
"""'''
)
],
),
text='''````{code-cell} ipython3
a = """
```
foo
```
"""
````
''',
):
actual_text = writes(nb, fmt="md:myst")
compare(actual_text, text)
actual_nb = reads(text, fmt="md:myst")
compare_notebooks(actual_nb, nb)
def test_alternate_tree_four_five_backticks(
no_jupytext_version_number,
nb=new_notebook(
metadata={"main_language": "python"},
cells=[
new_code_cell('a = """\n```\n"""'),
new_code_cell("b = 2"),
new_code_cell('c = """\n````\n"""'),
],
),
text='''---
jupyter:
jupytext:
main_language: python
---
````python
a = """
```
"""
````
```python
b = 2
```
`````python
c = """
````
"""
`````
''',
):
actual_text = writes(nb, fmt="md")
compare(actual_text, text)
actual_nb = reads(text, fmt="md")
compare_notebooks(actual_nb, nb)
================================================
FILE: tests/unit/test_paired_paths.py
================================================
import os
import unittest.mock as mock
import pytest
import jupytext
from jupytext.cli import jupytext as jupytext_cli
from jupytext.compare import compare
from jupytext.formats import (
long_form_multiple_formats,
long_form_one_format,
short_form_multiple_formats,
)
from jupytext.paired_paths import (
InconsistentPath,
base_path,
base_path_and_adjusted_fmt,
full_path,
paired_paths,
)
def test_simple_pair():
formats = long_form_multiple_formats("ipynb,py")
expected_paths = ["notebook.ipynb", "notebook.py"]
compare(
paired_paths("notebook.ipynb", "ipynb", formats),
list(zip(expected_paths, formats)),
)
compare(paired_paths("notebook.py", "py", formats), list(zip(expected_paths, formats)))
def test_base_path():
fmt = long_form_one_format("dir/prefix_/ipynb")
assert base_path("dir/prefix_NAME.ipynb", fmt) == "NAME"
with pytest.raises(InconsistentPath):
base_path("dir/incorrect_prefix_NAME.ipynb", fmt)
def test_base_path_dotdot():
fmt = long_form_one_format("../scripts//py")
assert base_path("scripts/test.py", fmt=fmt) == "scripts/test"
def test_full_path_dotdot():
fmt = long_form_one_format("../scripts//py")
assert full_path("scripts/test", fmt=fmt) == "scripts/test.py"
def test_base_path_in_tree_from_root():
fmt = long_form_one_format("scripts///py")
assert base_path("scripts/subfolder/test.py", fmt=fmt) == "//subfolder/test"
assert base_path("/scripts/subfolder/test.py", fmt=fmt) == "///subfolder/test"
def test_base_path_in_tree_from_non_root():
fmt = long_form_one_format("scripts///py")
assert base_path("/parent_folder/scripts/subfolder/test.py", fmt=fmt) == "/parent_folder///subfolder/test"
def test_base_path_in_tree_from_non_root_no_subfolder():
nb_file = "/parent/notebooks/wrap_markdown.ipynb"
formats = "notebooks///ipynb,scripts///py:percent"
fmt = "notebooks///ipynb"
assert base_path(nb_file, fmt) == "/parent///wrap_markdown"
paired_paths(nb_file, fmt, formats)
def test_full_path_in_tree_from_root():
fmt = long_form_one_format("notebooks///ipynb")
assert full_path("//subfolder/test", fmt=fmt) == "notebooks/subfolder/test.ipynb"
assert full_path("///subfolder/test", fmt=fmt) == "/notebooks/subfolder/test.ipynb"
def test_full_path_in_tree_from_root_no_subfolder():
fmt = long_form_one_format("notebooks///ipynb")
assert full_path("//test", fmt=fmt) == "notebooks/test.ipynb"
assert full_path("///test", fmt=fmt) == "/notebooks/test.ipynb"
def test_full_path_in_tree_from_non_root():
fmt = long_form_one_format("notebooks///ipynb")
assert full_path("/parent_folder///subfolder/test", fmt=fmt) == "/parent_folder/notebooks/subfolder/test.ipynb"
def test_paired_paths_windows():
nb_file = "C:\\Users\\notebooks\\notebooks\\subfolder\\nb.ipynb"
formats = "notebooks///ipynb,scripts///py"
with mock.patch("os.path.sep", "\\"):
assert base_path(nb_file, "notebooks///ipynb") == "C:\\Users\\notebooks\\//subfolder\\nb"
paired_paths(nb_file, "notebooks///ipynb", formats)
def test_paired_paths_windows_no_subfolder():
nb_file = "C:\\Users\\notebooks\\notebooks\\nb.ipynb"
formats = "notebooks///ipynb,scripts///py"
with mock.patch("os.path.sep", "\\"):
assert base_path(nb_file, "notebooks///ipynb") == "C:\\Users\\notebooks\\//nb"
paired_paths(nb_file, "notebooks///ipynb", formats)
def test_paired_paths_windows_relative():
"""Test Windows pairing with relative paths and backslash as path separator, issue #1028"""
nb_file = "C:\\notebooks\\example.ipynb"
formats = "notebooks///ipynb,scripts///py:percent"
with mock.patch("os.path.sep", "\\"):
# Should not raise InconsistentPath
paths = paired_paths(nb_file, "notebooks///ipynb", formats)
# Verify the notebook path is in the paired paths
path_list = [p[0] for p in paths]
assert nb_file in path_list, f"Expected {nb_file} to be in paired paths {path_list}"
# Verify both paths use backslashes on Windows
assert paths[0][0] == "C:\\notebooks\\example.ipynb"
assert paths[1][0] == "C:\\scripts\\example.py"
@pytest.mark.parametrize("os_path_sep", ["\\", "/"])
def test_paired_path_dotdot_564(os_path_sep):
main_path = os_path_sep.join(["examples", "tutorials", "colabs", "rigid_object_tutorial.ipynb"])
formats = "../nb_python//py:percent,../colabs//ipynb"
with mock.patch("os.path.sep", os_path_sep):
assert base_path(main_path, None, long_form_multiple_formats(formats)) == os_path_sep.join(
["examples", "tutorials", "colabs", "rigid_object_tutorial"]
)
paired_paths(main_path, "ipynb", formats)
def test_path_in_tree_limited_to_config_dir(tmpdir):
root_nb_dir = tmpdir.mkdir("notebooks")
nb_dir = root_nb_dir.mkdir("notebooks")
src_dir = root_nb_dir.mkdir("scripts")
other_dir = root_nb_dir.mkdir("other")
formats = "notebooks///ipynb,scripts///py"
fmt = long_form_multiple_formats(formats)[0]
# Notebook in nested 'notebook' dir is paired
notebook_in_nb_dir = nb_dir.join("subfolder").join("nb.ipynb")
assert {path for (path, _) in paired_paths(str(notebook_in_nb_dir), fmt, formats)} == {
str(notebook_in_nb_dir),
str(src_dir.join("subfolder").join("nb.py")),
}
# Notebook in base 'notebook' dir is paired if no config file is found
notebook_in_other_dir = other_dir.mkdir("subfolder").join("nb.ipynb")
assert {path for (path, _) in paired_paths(str(notebook_in_other_dir), fmt, formats)} == {
str(notebook_in_other_dir),
str(tmpdir.join("scripts").join("other").join("subfolder").join("nb.py")),
}
# When a config file exists
root_nb_dir.join("jupytext.toml").write("\n")
# Notebook in nested 'notebook' dir is still paired
assert {path for (path, _) in paired_paths(str(notebook_in_nb_dir), fmt, formats)} == {
str(notebook_in_nb_dir),
str(src_dir.join("subfolder").join("nb.py")),
}
# But the notebook in base 'notebook' dir is not paired any more
alert = (
"Notebook directory '/other/subfolder' does not match prefix root 'notebooks'"
if os.path.sep == "/"
# we escape twice the backslash because pytest.raises matches it as a regular expression
else "Notebook directory '\\\\other\\\\subfolder' does not match prefix root 'notebooks'"
)
with pytest.raises(InconsistentPath, match=alert):
paired_paths(str(notebook_in_other_dir), fmt, formats)
def test_many_and_suffix():
formats = long_form_multiple_formats("ipynb,.pct.py,_lgt.py")
expected_paths = ["notebook.ipynb", "notebook.pct.py", "notebook_lgt.py"]
for fmt, path in zip(formats, expected_paths):
compare(paired_paths(path, fmt, formats), list(zip(expected_paths, formats)))
with pytest.raises(InconsistentPath):
paired_paths("wrong_suffix.py", "py", formats)
def test_prefix_and_suffix():
short_formats = (
"notebook_folder/notebook_prefix_/_notebook_suffix.ipynb,"
"script_folder//_in_percent_format.py:percent,"
"script_folder//_in_light_format.py"
)
formats = long_form_multiple_formats(short_formats)
assert short_form_multiple_formats(formats) == short_formats
expected_paths = [
"parent/notebook_folder/notebook_prefix_NOTEBOOK_NAME_notebook_suffix.ipynb",
"parent/script_folder/NOTEBOOK_NAME_in_percent_format.py",
"parent/script_folder/NOTEBOOK_NAME_in_light_format.py",
]
for fmt, path in zip(formats, expected_paths):
compare(paired_paths(path, fmt, formats), list(zip(expected_paths, formats)))
# without the parent folder
expected_paths = [path[7:] for path in expected_paths]
for fmt, path in zip(formats, expected_paths):
compare(paired_paths(path, fmt, formats), list(zip(expected_paths, formats)))
# Not the expected parent folder
with pytest.raises(InconsistentPath):
paired_paths(
"script_folder_incorrect/NOTEBOOK_NAME_in_percent_format.py",
formats[1],
formats,
)
# Not the expected suffix
with pytest.raises(InconsistentPath):
paired_paths("parent/script_folder/NOTEBOOK_NAME_in_LIGHT_format.py", formats[2], formats)
# Not the expected extension
with pytest.raises(InconsistentPath):
paired_paths(
"notebook_folder/notebook_prefix_NOTEBOOK_NAME_notebook_suffix.py",
formats[0],
formats,
)
def test_prefix_on_root_174():
short_formats = "ipynb,python//py:percent"
formats = long_form_multiple_formats(short_formats)
assert short_form_multiple_formats(formats) == short_formats
expected_paths = ["Untitled.ipynb", "python/Untitled.py"]
for fmt, path in zip(formats, expected_paths):
compare(paired_paths(path, fmt, formats), list(zip(expected_paths, formats)))
def test_duplicated_paths():
formats = long_form_multiple_formats("ipynb,py:percent,py:light")
with pytest.raises(InconsistentPath):
paired_paths("notebook.ipynb", "ipynb", formats)
@pytest.mark.asyncio
async def test_cm_paired_paths(cm):
cm.paired_notebooks = dict()
three = "ipynb,py,md"
cm.update_paired_notebooks("nb.ipynb", three)
assert cm.paired_notebooks == {"nb." + fmt: (fmt, three) for fmt in three.split(",")}
two = "ipynb,Rmd"
cm.update_paired_notebooks("nb.ipynb", two)
assert cm.paired_notebooks == {"nb." + fmt: (fmt, two) for fmt in two.split(",")}
one = "ipynb"
cm.update_paired_notebooks("nb.ipynb", one)
assert cm.paired_notebooks == {}
zero = ""
cm.update_paired_notebooks("nb.ipynb", zero)
assert cm.paired_notebooks == {}
def test_paired_path_with_prefix(
nb_file="scripts/test.py",
fmt={"extension": ".py", "format_name": "percent"},
formats=[
{"extension": ".ipynb"},
{"prefix": "scripts/", "format_name": "percent", "extension": ".py"},
],
):
assert paired_paths(nb_file, fmt, formats) == [
("test.ipynb", {"extension": ".ipynb"}),
(
"scripts/test.py",
{"prefix": "scripts/", "format_name": "percent", "extension": ".py"},
),
]
def test_paired_notebook_ipynb_root_scripts_in_folder_806(tmpdir, cwd_tmpdir, python_notebook):
"""In this test we pair a notebook with a script in a subfolder, and then do some
natural operations like delete/recreate one of the paired files"""
# Save sample notebook
test_ipynb = tmpdir / "test.ipynb"
jupytext.write(python_notebook, str(test_ipynb))
# Pair the notebook to a script in a subfolder
jupytext_cli(["--set-formats", "ipynb,scripts//py:percent", "test.ipynb"])
assert (tmpdir / "scripts" / "test.py").exists()
# Delete and then recreate the ipynb notebook using --to notebook
test_ipynb.remove()
jupytext_cli(
[
"--to",
"notebook",
"--output",
"test.ipynb",
"scripts/test.py",
]
)
assert test_ipynb.exists()
# Delete and then recreate the ipynb notebook using --sync
test_ipynb.remove()
jupytext_cli(
[
"--sync",
"scripts/test.py",
]
)
assert test_ipynb.exists()
@pytest.mark.parametrize(
"path, input_fmt, adjusted_fmt",
[
(
"scripts/test.py",
{"extension": ".py", "format_name": "percent", "prefix": "scripts//"},
{"extension": ".py", "format_name": "percent", "prefix": "scripts//"},
),
(
"test.py",
{"extension": ".py", "format_name": "percent", "prefix": "scripts//"},
{
"extension": ".py",
"format_name": "percent",
},
),
(
"test.py",
{"extension": ".py", "format_name": "percent", "prefix": "prefix_"},
{"extension": ".py", "format_name": "percent"},
),
],
)
def test_paired_paths_and_adjusted_fmt(path, input_fmt, adjusted_fmt):
base_path, actual_adjusted_fmt = base_path_and_adjusted_fmt(path, input_fmt)
assert actual_adjusted_fmt == adjusted_fmt
@pytest.mark.parametrize("os_sep", ["\\", "/"])
def test_base_path_os_sep(os_sep):
fmt = "notebooks/tutorials///ipynb"
root = ("" if os_sep == "/" else "C:") + os_sep
path = root + os_sep.join(["notebooks", "tutorials", "subfolder", "notebook.ipynb"])
with mock.patch("os.path.sep", os_sep):
assert base_path(path, fmt) == root + os_sep.join(["//subfolder", "notebook"])
================================================
FILE: tests/unit/test_pep8.py
================================================
from nbformat.v4.nbbase import new_code_cell, new_notebook
from jupytext import read, reads, writes
from jupytext.compare import compare
from jupytext.pep8 import (
cell_ends_with_code,
cell_ends_with_function_or_class,
cell_has_code,
next_instruction_is_function_or_class,
pep8_lines_between_cells,
)
def test_next_instruction_is_function_or_class():
text = """@pytest.mark.parametrize('py_file',
[py_file for py_file in list_notebooks('../src/jupytext') + list_notebooks('.') if
py_file.endswith('.py')])
def test_no_metadata_when_py_is_pep8(py_file):
pass
"""
assert next_instruction_is_function_or_class(text.splitlines())
def test_cell_ends_with_code():
assert not cell_ends_with_code([])
def test_cell_ends_with_function_or_class():
text = """class A:
__init__():
'''A docstring
with two lines or more'''
self.a = 0
"""
assert cell_ends_with_function_or_class(text.splitlines())
lines = ["#", "#"]
assert not cell_ends_with_function_or_class(lines)
text = """# two blank line after this class
class A:
pass
# so we do not need to insert two blank lines below this cell
"""
assert not cell_ends_with_function_or_class(text.splitlines())
text = """# All lines
# are commented"""
assert not cell_ends_with_function_or_class(text.splitlines())
text = """# Two blank lines after function
def f(x):
return x
# And a comment here"""
assert not cell_ends_with_function_or_class(text.splitlines())
assert not cell_ends_with_function_or_class(["", "#"])
def test_pep8_lines_between_cells():
prev_lines = """a = a_long_instruction(
over_two_lines=True)""".splitlines()
next_lines = """def f(x):
return x""".splitlines()
assert cell_ends_with_code(prev_lines)
assert next_instruction_is_function_or_class(next_lines)
assert pep8_lines_between_cells(prev_lines, next_lines, ".py") == 2
def test_pep8_lines_between_cells_bis():
prev_lines = """def f(x):
return x""".splitlines()
next_lines = """# A markdown cell
# An instruction
a = 5
""".splitlines()
assert cell_ends_with_function_or_class(prev_lines)
assert cell_has_code(next_lines)
assert pep8_lines_between_cells(prev_lines, next_lines, ".py") == 2
next_lines = """# A markdown cell
# Only markdown here
# And here
""".splitlines()
assert cell_ends_with_function_or_class(prev_lines)
assert not cell_has_code(next_lines)
assert pep8_lines_between_cells(prev_lines, next_lines, ".py") == 1
def test_pep8_lines_between_cells_ter():
prev_lines = ["from jupytext.cell_to_text import RMarkdownCellExporter"]
next_lines = '''@pytest.mark.parametrize(
"lines",
[
"# text",
"""# # %%R
# # comment
# 1 + 1
# 2 + 2
""",
],
)
def test_paragraph_is_fully_commented(lines):
assert paragraph_is_fully_commented(
lines.splitlines(), comment="#", main_language="python"
)'''.splitlines()
assert cell_ends_with_code(prev_lines)
assert next_instruction_is_function_or_class(next_lines)
assert pep8_lines_between_cells(prev_lines, next_lines, ".py") == 2
def test_pep8():
text = """import os
path = os.path
# code cell #1, with a comment on f
def f(x):
return x + 1
# markdown cell #1
# code cell #2 - an instruction
a = 4
# markdown cell #2
# code cell #3 with a comment on g
def g(x):
return x + 1
# markdown cell #3
# the two lines are:
# - right below the function/class
# - below the last python paragraph (i.e. NOT ABOVE g)
# code cell #4
x = 4
"""
nb = reads(text, "py")
for cell in nb.cells:
assert not cell.metadata
text2 = writes(nb, "py")
compare(text2, text)
def test_pep8_bis():
text = """# This is a markdown cell
# a code cell
def f(x):
return x + 1
# And another markdown cell
# Separated from f by just one line
# As there is no code here
"""
nb = reads(text, "py")
for cell in nb.cells:
assert not cell.metadata
text2 = writes(nb, "py")
compare(text2, text)
def test_no_metadata_when_py_is_pep8(py_file):
"""This test assumes that all Python files in the jupytext folder follow PEP8 rules"""
nb = read(py_file)
for i, cell in enumerate(nb.cells):
if "title" in cell.metadata:
cell.metadata.pop("title") # pragma: no cover
if i == 0 and not cell.source:
assert cell.metadata == {"lines_to_next_cell": 0}, py_file # pragma: no cover
else:
assert not cell.metadata, (py_file, cell.source)
def test_notebook_ends_with_exactly_one_empty_line_682():
"""(Issue #682)
Steps to reproduce:
Have a notebook that ends in a python code cell (with no empty lines at the end of the cell).
run jupytext --to py:percent notebookWithCodeCell.ipynb.
See that the generated python code file has two empty lines at the end.
I would expect there to just be one new line."""
nb = new_notebook(cells=[new_code_cell("1+1")], metadata={"jupytext": {"main_language": "python"}})
py = writes(nb, "py:percent")
assert py.endswith("1+1\n")
================================================
FILE: tests/unit/test_stringparser.py
================================================
from jupytext.stringparser import StringParser
def test_long_string(
text="""'''This is a multiline
comment with "quotes", 'single quotes'
# and comments
and line breaks
and it ends here'''
1 + 1
""",
):
quoted = []
sp = StringParser("python")
for i, line in enumerate(text.splitlines()):
if sp.is_quoted():
quoted.append(i)
sp.read_line(line)
assert quoted == [1, 2, 3, 4, 5, 6]
def test_single_chars(
text="""'This is a single line comment'''
'and another one'
# and comments
"and line breaks"
"and it ends here'''"
1 + 1
""",
):
sp = StringParser("python")
for line in text.splitlines():
assert not sp.is_quoted()
sp.read_line(line)
def test_long_string_with_four_quotes(
text="""''''This is a multiline
comment that starts with four quotes
'''
1 + 1
""",
):
quoted = []
sp = StringParser("python")
for i, line in enumerate(text.splitlines()):
if sp.is_quoted():
quoted.append(i)
sp.read_line(line)
assert quoted == [1, 2]
def test_long_string_ends_with_four_quotes(
text="""'''This is a multiline
comment that ends with four quotes
''''
1 + 1
""",
):
quoted = []
sp = StringParser("python")
for i, line in enumerate(text.splitlines()):
if sp.is_quoted():
quoted.append(i)
sp.read_line(line)
assert quoted == [1, 2]
================================================
FILE: tools/absolute_links_in_readme.py
================================================
import re
from pathlib import Path
from hatchling.metadata.plugin.interface import MetadataHookInterface
class AbsoluteLinksInReadme(MetadataHookInterface):
"""Hook that processes README.md to make relative links absolute."""
def update(self, metadata):
"""Process README.md when metadata is being prepared."""
readme_src_path = Path("README.md")
readme_output_path = Path("build/README_with_absolute_links.md")
base_url = "https://github.com/mwouts/jupytext/blob/main/"
# Ensure the dist directory exists
readme_output_path.parent.mkdir(exist_ok=True)
self.convert_links(readme_src_path, readme_output_path, base_url)
return metadata
def convert_links(self, src_path, output_path, base_url):
"""Convert relative links in README.md to absolute links."""
print(f"Processing {src_path} to generate {output_path} with absolute links")
content = src_path.read_text(encoding="utf-8")
# Find markdown links that don't start with http:// or https://
pattern = re.compile(r"\[([^\]]+)\]\((?!http)([^)]+)\)")
def replace_link(match):
text, url = match.groups()
if not url.startswith(("http://", "https://", "#")):
url = base_url + url
return f"[{text}]({url})"
new_content = pattern.sub(replace_link, content)
# Write the processed content to the output file
output_path.parent.mkdir(exist_ok=True)
output_path.write_text(new_content, encoding="utf-8")
print(f"Generated {output_path} with absolute links")
Jupytext on GitHub
``` ```{latex} $\frac{\pi}{2}$ ``` ```{python} # %load_ext rpy2.ipython ``` ```{r} library(ggplot2) ggplot(data=data.frame(x=c('A', 'B'), y=c(5, 2)), aes(x,weight=y)) + geom_bar() ``` ```{python} # %matplotlib inline import pandas as pd pd.Series({'A':5, 'B':2}).plot(figsize=(3,2), kind='bar') ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/Notebook with many hash signs.Rmd ================================================ --- jupyter: kernelspec: display_name: Python 3 language: python name: python3 --- ################################################################## This is a notebook that contains many hash signs. Hopefully its python representation is not recognized as a Sphinx Gallery script... ################################################################## ```{python} some = 1 code = 2 some+code ################################################################## # A comment ################################################################## # Another comment ``` ################################################################## This is a notebook that contains many hash signs. Hopefully its python representation is not recognized as a Sphinx Gallery script... ################################################################## ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/Notebook with metadata and long cells.Rmd ================================================ --- jupyter: kernelspec: display_name: Python 3 language: python name: python3 --- # Part one - various cells Here we have a markdown cell with two blank lines Now we have a markdown cell with a code block inside it ```python 1 + 1 ``` After that cell we'll have a code cell ```{python} 2 + 2 3 + 3 ``` Followed by a raw cell ```{python active="", eval=FALSE} This is the content of the raw cell ``` # Part two - cell metadata This is a markdown cell with cell metadata `{"key": "value"}` ```{python .class=None, tags=c("parameters")} """This is a code cell with metadata `{"tags":["parameters"], ".class":null}`""" ``` ```{python key="value", active="", eval=FALSE} This is a raw cell with cell metadata `{"key": "value"}` ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/Notebook_with_R_magic.Rmd ================================================ --- jupyter: kernelspec: display_name: Python 2 language: python name: python2 --- # A notebook with R cells This notebook shows the use of R cells to generate plots ```{python} # %load_ext rpy2.ipython ``` ```{r} suppressMessages(require(tidyverse)) ``` ```{r} ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() ``` The default plot dimensions are not good for us, so we use the -w and -h parameters in %%R magic to set the plot size ```{r magic_args="-w 400 -h 240"} ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/Notebook_with_more_R_magic_111.Rmd ================================================ --- jupyter: kernelspec: display_name: Python 3 language: python name: python3 --- ```{python} # %load_ext rpy2.ipython import pandas as pd df = pd.DataFrame( { "Letter": ["a", "a", "a", "b", "b", "b", "c", "c", "c"], "X": [4, 3, 5, 2, 1, 7, 7, 5, 9], "Y": [0, 4, 3, 6, 7, 10, 11, 9, 13], "Z": [1, 2, 3, 1, 2, 3, 1, 2, 3], } ) ``` ```{r magic_args="-i df"} library("ggplot2") ggplot(data = df) + geom_point(aes(x = X, y = Y, color = Letter, size = Z)) ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/R notebook with invalid cell keys.Rmd ================================================ --- jupyter: kernelspec: display_name: R language: R name: ir --- This notebook was created with IRKernel 0.8.12, and is not completely valid, as the code cell below contains an unexpected 'source' entry. This did cause https://github.com/mwouts/jupytext/issues/234. Note that the problem is solved when one upgrades to IRKernel 1.0.0. ```{r} library("ggplot2") ggplot(mtcars, aes(mpg)) + stat_ecdf() ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/Reference Guide for Calysto Scheme.Rmd ================================================ --- jupyter: kernelspec: display_name: Calysto Scheme (Python) language: scheme name: calysto_scheme ---Reference Guide for Calysto Scheme
[Calysto Scheme](https://github.com/Calysto/calysto_scheme) is a real Scheme programming language, with full support for continuations, including call/cc. It can also use all Python libraries. Also has some extensions that make it more useful (stepper-debugger, choose/fail, stack traces), or make it better integrated with Python. In Jupyter notebooks, because Calysto Scheme uses [MetaKernel](https://github.com/Calysto/metakernel/blob/master/README.rst), it has a fully-supported set of "magics"---meta-commands for additional functionality. This includes running Scheme in parallel. See all of the [MetaKernel Magics](https://github.com/Calysto/metakernel/blob/master/metakernel/magics/README.md). Calysto Scheme is written in Scheme, and then translated into Python (and other backends). The entire functionality lies in a single Python file: https://github.com/Calysto/calysto_scheme/blob/master/calysto_scheme/scheme.py However, you can easily install it (see below). Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language. ## Installation You can install Calysto Scheme with Python3: ``` pip3 install --upgrade calysto-scheme --user -U python3 -m calysto_kernel install --user ``` or in the system kernel folder with: ``` sudo pip3 install --upgrade calysto-scheme -U sudo python3 -m calysto_kernel install ``` Change pip3/python3 to use a different pip or Python. The version of Python used will determine how Calysto Scheme is run. Use it in the console, qtconsole, or notebook with IPython 3: ``` ipython console --kernel calysto_scheme ipython qtconsole --kernel calysto_scheme ipython notebook --kernel calysto_scheme ``` In addition to all of the following items, Calysto Scheme also has access to all of Python's builtin functions, and all of Python's libraries. For example, you can use `(complex 3 2)` to create a complex number by calling Python's complex function. ## Jupyter Enhancements When you run Calysto Scheme in Jupyter (console, notebook, qtconsole, etc.) you get: * TAB completions of Scheme functions and variable names * display of rich media * stepper/debugger * magics (% macros) * shell commands (! command) * LaTeX equations * LaTeX-style variables * Python integration ### LaTeX-style variables Calysto Scheme allows you to use LaTeX-style variables in code. For example, if you type: ``` \beta ``` with the cursor right after the 'a' in beta, and then press TAB, it will turn into the unicode character: ``` β ``` There are nearly 1300 different symbols defined (thanks to the Julia language) and documented here: http://docs.julialang.org/en/release-0.4/manual/unicode-input/#man-unicode-input Calysto Scheme may not implement all of those. Some useful and suggestive ones: * \pi - π * \Pi - Π * \Sigma - Σ * \_i - subscript i, such as vectorᵢ ```{scheme} (define α 67) ``` ```{scheme} α ``` ```{scheme} (define i 2) (define vectorᵢ (vector-ref (vector 0 6 3 2) i)) vectorᵢ ``` ### Rich media ```{scheme} (import "calysto.display") ``` ```{scheme} (calysto.display.HTML "This is bold, italics, underlined.") ``` ```{scheme} (import "calysto.graphics") ``` ```{scheme} (define canvas (calysto.graphics.Canvas)) ``` ```{scheme} (define ball (calysto.graphics.Circle '(150 150) 100)) ``` ```{scheme} (ball.draw canvas) ``` ### Shell commands ```{scheme} ! ls /tmp ``` ### Stepper/Debugger Here is what the debugger looks like:
It has breakpoints (click in left margin). You must press Stop to exit the debugger.
```scheme
%%debug
(begin
(define x 1)
(set! x 2)
)
```
### Python Integration
You can import and use any Python library in Calysto Scheme.
In addition, if you wish, you can execute expressions and statements in a Python environment:
```{scheme}
(python-eval "1 + 2")
```
```{scheme}
(python-exec
"
def mypyfunc(a, b):
return a * b
")
```
This is a shared environment with Scheme:
```{scheme}
(mypyfunc 4 5)
```
You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
```{scheme}
(define! mypyfunc2 (func (lambda (n) n)))
```
```{scheme}
(python-eval "mypyfunc2(34)")
```
# Differences Between Languages
## Major differences between Scheme and Python
1. In Scheme, double quotes are used for strings and may contain newlines
1. In Scheme, a single quote is short for (quote ...) and means "literal"
1. In Scheme, everything is an expression and has a return value
1. Python does not support macros (e.g., extending syntax)
1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
1. Scheme procedures are not Python functions, but there are means to use one as the other.
## Major Differences Between Calysto Scheme and other Schemes
1. define-syntax works slightly differently
1. In Calysto Scheme, #(...) is short for '#(...)
1. Calysto Scheme is missing many standard functions (see list at bottom)
1. Calysto Scheme has a built-in amb operator called `choose`
1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
### Stack Trace
Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
```{scheme}
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
```
```{scheme}
(fact 5)
```
To turn off the stack trace on error:
```scheme
(use-stack-trace #f)
```
That will allow infinite recursive loops without keeping track of the "stack".
# Calysto Scheme Variables
## SCHEMEPATH
SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
```{scheme}
SCHEMEPATH
```
```{scheme}
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
```
```{scheme}
SCHEMEPATH
```
## Getting Started
Note that you can use the word `lambda` or \lambda and then press [TAB]
```{scheme}
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
```
```{scheme}
(factorial 5)
```
## define-syntax
(define-syntax NAME RULES): a method for creating macros
```{scheme}
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
```
```{scheme}
(time (car '(1 2 3 4)))
```
```{scheme}
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
```
```{scheme}
(collect (* n n) for n in (range 10))
```
```{scheme}
(collect (* n n) for n in (range 5 20 3))
```
```{scheme}
(collect (* n n) for n in (range 10) if (> n 5))
```
```{scheme}
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
```
```{scheme}
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
```
```{scheme}
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
```
```{scheme}
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
```
```{scheme}
(for n in (range 10 20 2) do (print n))
```
```{scheme}
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
```
```{scheme}
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
```
```{scheme}
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
```
```{scheme}
(! 5)
```
```{scheme}
(nth 10 facts)
```
```{scheme}
(nth 20 fibs)
```
```{scheme}
(first 30 fibs)
```
## for-each
(for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
```{scheme}
(for-each (lambda (n) (print n)) '(3 4 5))
```
## format
(format STRING ITEM ...): format the string with ITEMS as arguments
```{scheme}
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
```
## func
Turns a lambda into a Python function.
(func (lambda ...))
```{scheme}
(func (lambda (n) n))
```
## There's more!
Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/The flavors of raw cells.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python raw_mimetype="text/latex", active="", eval=FALSE}
$1+1$
```
```{python raw_mimetype="text/restructuredtext", active="", eval=FALSE}
:math:`1+1`
```
```{python raw_mimetype="text/html", active="", eval=FALSE}
Bold text
```
```{python raw_mimetype="text/markdown", active="", eval=FALSE}
**Bold text**
```
```{python raw_mimetype="text/x-python", active="", eval=FALSE}
1 + 1
```
```{python active="", eval=FALSE}
Not formatted
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/cat_variable.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
cat = 42
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/coconut_homepage_demo.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Coconut
language: coconut
name: coconut
---
Taken from [coconut-lang.org](coconut-lang.org)
pipeline-style programming
```{coconut}
"hello, world!" |> print
```
prettier lambdas
```{coconut}
x -> x ** 2
```
partial application
```{coconut}
range(10) |> map$(pow$(?, 2)) |> list
```
pattern-matching
```{coconut}
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
```
destructuring assignment
```{coconut}
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
```
infix notation
```{coconut}
# 5 `mod` 3 == 2
```
operator functions
```{coconut}
product = reduce$(*)
```
function composition
```{coconut}
# (f..g..h)(x, y, z)
```
lazy lists
```{coconut}
# (| first_elem() |) :: rest_elems()
```
parallel programming
```{coconut}
range(100) |> parallel_map$(pow$(2)) |> list
```
tail call optimization
```{coconut}
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
```
algebraic data types
```{coconut}
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
```
and much more!
Like what you see? Don't forget to star Coconut on GitHub!
```{coconut}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/convert_to_py_then_test_with_update83.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
# %%time
print('asdf')
```
Thanks for jupytext!
```{python}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/csharp.Rmd
================================================
---
jupyter:
kernelspec:
display_name: .NET (C#)
language: C#
name: .net-csharp
---
We start with...
```{csharp}
Console.WriteLine("Hello World!");
```
Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
```{csharp}
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
```
We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
```{csharp}
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
```
```{csharp}
(MathString)@"e^{i \pi} = -1"
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/demo_gdl_fbp.Rmd
================================================
---
jupyter:
kernelspec:
display_name: IDL [conda env:gdl] *
language: IDL
name: conda-env-gdl-idl
---
## GDL demo notebook
Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
```{idl}
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
```
```{idl}
;; Enable inline plotting
!inline=1
```
```{idl}
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
```
Now we define simple forward and backprojection functions:
```{idl}
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
```
```{idl}
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
```
This allows us to create a sinogram:
```{idl}
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
```
On this we can apply a simple FBP reconstruction:
```{idl}
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
```
```{idl}
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
```
### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/evcxr_jupyter_tour.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Rust
language: rust
name: rust
---
# Tour of the EvCxR Jupyter Kernel
For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
## Printing to outputs and evaluating expressions
Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
```{rust}
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
```
## Assigning and making use of variables
We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
```{rust}
let mut message = "Hello ".to_owned();
```
```{rust}
message.push_str("world!");
```
```{rust}
message
```
## Defining and redefining functions
Next we'll define a function
```{rust}
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
```
```{rust}
(1..13).map(fib).collect::| "); html.push_str(&format!("{:?}", self.values[r * self.row_size + c])); html.push_str(" | "); } html.push_str("
## Step 1
Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.

```{sos Collapsed="false", kernel="SoS"}
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
```
## Step 2
Now, pair it with Jupytex

### Step 3
Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
### Step 4
Reopen the notebook. Here is the outcome

================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/kalman_filter_and_visualization.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Q 3.5
language: q
name: qpk
---
```{q}
plt: .p.import`matplotlib.pyplot
```
```{q}
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
```
```{q}
price: 100 + sums 0.5 - (n:50)?1.
```
```{q}
output:filter price
```
```{q}
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
```
```{q}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/logtalk_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Logtalk
language: logtalk
name: logtalk_kernel
---
# An implementation of the Ackermann function
```{logtalk vscode={'languageId': 'logtalk'}}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
```
## Sample query
```{logtalk vscode={'languageId': 'logtalk'}}
ack::ack(2, 4, V).
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/lua_example.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Lua
language: lua
name: lua
---
Source: https://www.lua.org/pil/19.3.html
# Sort
Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
```{lua}
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
```
Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
```{lua}
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
```
Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
```{lua}
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
```
With this function, it is easy to print those function names in alphabetical order. The loop
```{lua}
for name, line in pairsByKeys(lines) do
print(name, line)
end
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/maxima_example.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Maxima
language: maxima
name: maxima
---
## maxima misc
```{maxima}
kill(all)$
```
```{maxima}
f(x) := 1/(x^2+l^2)^(3/2);
```
```{maxima}
integrate(f(x), x);
```
```{maxima}
tex(%)$
```
```{maxima}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/notebook_with_complex_metadata.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/nteract_with_parameter.Rmd
================================================
---
jupyter:
kernel_info:
name: python3
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python inputHidden=FALSE, outputHidden=FALSE, tags=c("parameters")}
param = 4
```
```{python inputHidden=FALSE, outputHidden=FALSE}
import pandas as pd
```
```{python inputHidden=FALSE, outputHidden=FALSE}
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
```
```{python inputHidden=FALSE, outputHidden=FALSE}
# %matplotlib inline
df.plot(kind='bar')
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/ocaml_notebook.Rmd
================================================
---
jupyter:
jupytext:
formats: ipynb:markdown,md
kernelspec:
display_name: OCaml default
language: OCaml
name: ocaml-jupyter
---
# Example of an OCaml notebook
```{ocaml}
let sum x y = x + y
```
Let's try our function:
```{ocaml}
sum 3 4 = 7 + 0
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/octave_notebook.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Octave
language: octave
name: octave
---
A markdown cell
```{octave}
1 + 1
```
```{octave}
% a code cell with comments
2 + 2
```
```{octave}
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
```
```{octave}
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
```
And to finish with, a Python cell
```{python}
a = 1
```
```{python}
a + 1
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/plotly_graphs.Rmd
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
This notebook contains complex outputs, including plotly javascript graphs.
# Interactive plots
We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
```{python}
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
```
```{python}
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/powershell.Rmd
================================================
---
jupyter:
kernelspec:
display_name: PowerShell
language: PowerShell
name: powershell
---
This is an extract from
https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
```{powershell}
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/raw_cell_with_complex_yaml_like_content.Rmd
================================================
---
This is a complex paragraph
that is split over multiple lines.
It also includes blank lines.
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/raw_cell_with_non_dict_yaml_content.Rmd
================================================
---
Content.
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{python}
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_Rmd/root_cpp.Rmd
================================================
---
jupyter:
kernelspec:
display_name: ROOT C++
language: c++
name: root
---
```{c++}
#include
To run the selected code cell, hit
Shift + Enter
Original
)");
```
```{c++}
xcpp::display(rect, "some_display_id");
```
```{c++}
// Update the rectangle to be blue
rect.m_content = R"(
Updated
)";
xcpp::display(rect, "some_display_id", true);
```
## Magics
Magics are special commands for the kernel that are not part of the C++ language.
They are defined with the symbol `%` for a line magic and `%%` for a cell magic.
More documentation for magics is available at https://xeus-cling.readthedocs.io/en/latest/magics.html.
```{c++}
#include Jupytext on GitHub
# %% %%latex $\frac{\pi}{2}$ # %% %load_ext rpy2.ipython # %% %%R library(ggplot2) ggplot(data=data.frame(x=c('A', 'B'), y=c(5, 2)), aes(x,weight=y)) + geom_bar() # %% %matplotlib inline import pandas as pd pd.Series({'A':5, 'B':2}).plot(figsize=(3,2), kind='bar') ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/Notebook with many hash signs.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # %% [markdown] # ################################################################## # This is a notebook that contains many hash signs. # Hopefully its python representation is not recognized as a Sphinx Gallery script... # ################################################################## # %% some = 1 code = 2 some+code ################################################################## # A comment ################################################################## # Another comment # %% [markdown] # ################################################################## # This is a notebook that contains many hash signs. # Hopefully its python representation is not recognized as a Sphinx Gallery script... # ################################################################## ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/Notebook with metadata and long cells.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # %% [markdown] # # Part one - various cells # %% [markdown] # Here we have a markdown cell # # # with two blank lines # %% [markdown] # Now we have a markdown cell # with a code block inside it # # ```python # 1 + 1 # ``` # # After that cell we'll have a code cell # %% 2 + 2 3 + 3 # %% [markdown] # Followed by a raw cell # %% [raw] # This is # the content # of the raw cell # %% [markdown] # # Part two - cell metadata # %% [markdown] key="value" # This is a markdown cell with cell metadata `{"key": "value"}` # %% .class tags=["parameters"] """This is a code cell with metadata `{"tags":["parameters"], ".class":null}`""" # %% [raw] key="value" # This is a raw cell with cell metadata `{"key": "value"}` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/Notebook_with_R_magic.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 2 # language: python # name: python2 # --- # %% [markdown] # # A notebook with R cells # # This notebook shows the use of R cells to generate plots # %% %load_ext rpy2.ipython # %% %%R suppressMessages(require(tidyverse)) # %% %%R ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() # %% [markdown] # The default plot dimensions are not good for us, so we use the -w and -h parameters in %%R magic to set the plot size # %% %%R -w 400 -h 240 ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/Notebook_with_more_R_magic_111.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # %% %load_ext rpy2.ipython import pandas as pd df = pd.DataFrame( { "Letter": ["a", "a", "a", "b", "b", "b", "c", "c", "c"], "X": [4, 3, 5, 2, 1, 7, 7, 5, 9], "Y": [0, 4, 3, 6, 7, 10, 11, 9, 13], "Z": [1, 2, 3, 1, 2, 3, 1, 2, 3], } ) # %% %%R -i df library("ggplot2") ggplot(data = df) + geom_point(aes(x = X, y = Y, color = Letter, size = Z)) ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/R notebook with invalid cell keys.R ================================================ # --- # jupyter: # kernelspec: # display_name: R # language: R # name: ir # --- # %% [markdown] # This notebook was created with IRKernel 0.8.12, and is not completely valid, as the code cell below contains an unexpected 'source' entry. This did cause https://github.com/mwouts/jupytext/issues/234. Note that the problem is solved when one upgrades to IRKernel 1.0.0. # %% library("ggplot2") ggplot(mtcars, aes(mpg)) + stat_ecdf() ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/Reference Guide for Calysto Scheme.ss ================================================ ;; -*- coding: utf-8 -*- ;; --- ;; jupyter: ;; kernelspec: ;; display_name: Calysto Scheme (Python) ;; language: scheme ;; name: calysto_scheme ;; --- ;; %% [markdown] ;;Reference Guide for Calysto Scheme
;; ;; [Calysto Scheme](https://github.com/Calysto/calysto_scheme) is a real Scheme programming language, with full support for continuations, including call/cc. It can also use all Python libraries. Also has some extensions that make it more useful (stepper-debugger, choose/fail, stack traces), or make it better integrated with Python. ;; ;; In Jupyter notebooks, because Calysto Scheme uses [MetaKernel](https://github.com/Calysto/metakernel/blob/master/README.rst), it has a fully-supported set of "magics"---meta-commands for additional functionality. This includes running Scheme in parallel. See all of the [MetaKernel Magics](https://github.com/Calysto/metakernel/blob/master/metakernel/magics/README.md). ;; ;; Calysto Scheme is written in Scheme, and then translated into Python (and other backends). The entire functionality lies in a single Python file: https://github.com/Calysto/calysto_scheme/blob/master/calysto_scheme/scheme.py However, you can easily install it (see below). ;; ;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language. ;; ;; ## Installation ;; ;; You can install Calysto Scheme with Python3: ;; ;; ``` ;; pip3 install --upgrade calysto-scheme --user -U ;; python3 -m calysto_kernel install --user ;; ``` ;; ;; or in the system kernel folder with: ;; ;; ``` ;; sudo pip3 install --upgrade calysto-scheme -U ;; sudo python3 -m calysto_kernel install ;; ``` ;; ;; Change pip3/python3 to use a different pip or Python. The version of Python used will determine how Calysto Scheme is run. ;; ;; Use it in the console, qtconsole, or notebook with IPython 3: ;; ;; ``` ;; ipython console --kernel calysto_scheme ;; ipython qtconsole --kernel calysto_scheme ;; ipython notebook --kernel calysto_scheme ;; ``` ;; ;; In addition to all of the following items, Calysto Scheme also has access to all of Python's builtin functions, and all of Python's libraries. For example, you can use `(complex 3 2)` to create a complex number by calling Python's complex function. ;; ;; ## Jupyter Enhancements ;; ;; When you run Calysto Scheme in Jupyter (console, notebook, qtconsole, etc.) you get: ;; ;; * TAB completions of Scheme functions and variable names ;; * display of rich media ;; * stepper/debugger ;; * magics (% macros) ;; * shell commands (! command) ;; * LaTeX equations ;; * LaTeX-style variables ;; * Python integration ;; %% [markdown] ;; ### LaTeX-style variables ;; ;; Calysto Scheme allows you to use LaTeX-style variables in code. For example, if you type: ;; ;; ``` ;; \beta ;; ``` ;; ;; with the cursor right after the 'a' in beta, and then press TAB, it will turn into the unicode character: ;; ;; ``` ;; β ;; ``` ;; ;; There are nearly 1300 different symbols defined (thanks to the Julia language) and documented here: ;; ;; http://docs.julialang.org/en/release-0.4/manual/unicode-input/#man-unicode-input ;; ;; Calysto Scheme may not implement all of those. Some useful and suggestive ones: ;; ;; * \pi - π ;; * \Pi - Π ;; * \Sigma - Σ ;; * \_i - subscript i, such as vectorᵢ ;; %% (define α 67) ;; %% α ;; %% (define i 2) (define vectorᵢ (vector-ref (vector 0 6 3 2) i)) vectorᵢ ;; %% [markdown] ;; ### Rich media ;; %% (import "calysto.display") ;; %% (calysto.display.HTML "This is bold, italics, underlined.") ;; %% (import "calysto.graphics") ;; %% (define canvas (calysto.graphics.Canvas)) ;; %% (define ball (calysto.graphics.Circle '(150 150) 100)) ;; %% (ball.draw canvas) ;; %% [markdown] ;; ### Shell commands ;; %% ! ls /tmp ;; %% [markdown] ;; ### Stepper/Debugger ;; ;; Here is what the debugger looks like: ;; ;;
;;
;; It has breakpoints (click in left margin). You must press Stop to exit the debugger.
;; %% [markdown]
;; ```scheme
;; %%debug
;;
;; (begin
;; (define x 1)
;; (set! x 2)
;; )
;; ```
;; %% [markdown]
;; ### Python Integration
;;
;; You can import and use any Python library in Calysto Scheme.
;;
;; In addition, if you wish, you can execute expressions and statements in a Python environment:
;; %%
(python-eval "1 + 2")
;; %%
(python-exec
"
def mypyfunc(a, b):
return a * b
")
;; %% [markdown]
;; This is a shared environment with Scheme:
;; %%
(mypyfunc 4 5)
;; %% [markdown]
;; You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
;; %%
(define! mypyfunc2 (func (lambda (n) n)))
;; %%
(python-eval "mypyfunc2(34)")
;; %% [markdown]
;; # Differences Between Languages
;;
;; ## Major differences between Scheme and Python
;;
;; 1. In Scheme, double quotes are used for strings and may contain newlines
;; 1. In Scheme, a single quote is short for (quote ...) and means "literal"
;; 1. In Scheme, everything is an expression and has a return value
;; 1. Python does not support macros (e.g., extending syntax)
;; 1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
;; 1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
;; 1. Scheme procedures are not Python functions, but there are means to use one as the other.
;;
;; ## Major Differences Between Calysto Scheme and other Schemes
;;
;; 1. define-syntax works slightly differently
;; 1. In Calysto Scheme, #(...) is short for '#(...)
;; 1. Calysto Scheme is missing many standard functions (see list at bottom)
;; 1. Calysto Scheme has a built-in amb operator called `choose`
;; 1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
;;
;; ### Stack Trace
;;
;; Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
;; %%
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
;; %%
(fact 5)
;; %% [markdown]
;; To turn off the stack trace on error:
;;
;; ```scheme
;; (use-stack-trace #f)
;; ```
;; That will allow infinite recursive loops without keeping track of the "stack".
;; %% [markdown]
;; # Calysto Scheme Variables
;;
;; ## SCHEMEPATH
;; SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
;; %%
SCHEMEPATH
;; %%
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
;; %%
SCHEMEPATH
;; %% [markdown]
;; ## Getting Started
;;
;; Note that you can use the word `lambda` or \lambda and then press [TAB]
;; %%
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
;; %%
(factorial 5)
;; %% [markdown]
;; ## define-syntax
;; (define-syntax NAME RULES): a method for creating macros
;; %%
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
;; %%
(time (car '(1 2 3 4)))
;; %%
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
;; %%
(collect (* n n) for n in (range 10))
;; %%
(collect (* n n) for n in (range 5 20 3))
;; %%
(collect (* n n) for n in (range 10) if (> n 5))
;; %%
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
;; %%
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
;; %%
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
;; %%
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
;; %%
(for n in (range 10 20 2) do (print n))
;; %%
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
;; %%
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
;; %%
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
;; %%
(! 5)
;; %%
(nth 10 facts)
;; %%
(nth 20 fibs)
;; %%
(first 30 fibs)
;; %% [markdown]
;; ## for-each
;; (for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
;; %%
(for-each (lambda (n) (print n)) '(3 4 5))
;; %% [markdown]
;; ## format
;; (format STRING ITEM ...): format the string with ITEMS as arguments
;; %%
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
;; %% [markdown]
;; ## func
;;
;; Turns a lambda into a Python function.
;;
;; (func (lambda ...))
;; %%
(func (lambda (n) n))
;; %% [markdown]
;; ## There's more!
;;
;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/The flavors of raw cells.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [raw] raw_mimetype="text/latex"
# $1+1$
# %% [raw] raw_mimetype="text/restructuredtext"
# :math:`1+1`
# %% [raw] raw_mimetype="text/html"
# Bold text
# %% [raw] raw_mimetype="text/markdown"
# **Bold text**
# %% [raw] raw_mimetype="text/x-python"
# 1 + 1
# %% [raw]
# Not formatted
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/cat_variable.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
cat = 42
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/coconut_homepage_demo.coco
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Coconut
# language: coconut
# name: coconut
# ---
# %% [markdown]
# Taken from [coconut-lang.org](coconut-lang.org)
# %% [markdown]
# pipeline-style programming
# %%
"hello, world!" |> print
# %% [markdown]
# prettier lambdas
# %%
x -> x ** 2
# %% [markdown]
# partial application
# %%
range(10) |> map$(pow$(?, 2)) |> list
# %% [markdown]
# pattern-matching
# %%
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
# %% [markdown]
# destructuring assignment
# %%
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
# %% [markdown]
# infix notation
# %%
# 5 `mod` 3 == 2
# %% [markdown]
# operator functions
# %%
product = reduce$(*)
# %% [markdown]
# function composition
# %%
# (f..g..h)(x, y, z)
# %% [markdown]
# lazy lists
# %%
# (| first_elem() |) :: rest_elems()
# %% [markdown]
# parallel programming
# %%
range(100) |> parallel_map$(pow$(2)) |> list
# %% [markdown]
# tail call optimization
# %%
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
# %% [markdown]
# algebraic data types
# %%
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
# %% [markdown]
# and much more!
#
# Like what you see? Don't forget to star Coconut on GitHub!
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/convert_to_py_then_test_with_update83.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
%%time
print('asdf')
# %% [markdown]
# Thanks for jupytext!
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/csharp.cs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: .NET (C#)
// language: C#
// name: .net-csharp
// ---
// %% [markdown]
// We start with...
// %%
Console.WriteLine("Hello World!");
// %% [markdown]
// Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
// %%
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
// %% [markdown]
// We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
// %%
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
// %%
(MathString)@"e^{i \pi} = -1"
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/demo_gdl_fbp.pro
================================================
; -*- coding: utf-8 -*-
; ---
; jupyter:
; kernelspec:
; display_name: IDL [conda env:gdl] *
; language: IDL
; name: conda-env-gdl-idl
; ---
; %% [markdown]
; ## GDL demo notebook
; %% [markdown]
; Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
;
; This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
; %%
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
; %%
;; Enable inline plotting
!inline=1
; %%
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
; %% [markdown]
; Now we define simple forward and backprojection functions:
; %%
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
; %%
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
; %% [markdown]
; This allows us to create a sinogram:
; %%
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
; %% [markdown]
; On this we can apply a simple FBP reconstruction:
; %%
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
; %%
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
; %% [markdown]
; ### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/evcxr_jupyter_tour.rs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Rust
// language: rust
// name: rust
// ---
// %% [markdown]
// # Tour of the EvCxR Jupyter Kernel
// For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
//
// ## Printing to outputs and evaluating expressions
// Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
// %%
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
// %% [markdown]
// ## Assigning and making use of variables
// We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
// %%
let mut message = "Hello ".to_owned();
// %%
message.push_str("world!");
// %%
message
// %% [markdown]
// ## Defining and redefining functions
// Next we'll define a function
// %%
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
// %%
(1..13).map(fib).collect::| "); html.push_str(&format!("{:?}", self.values[r * self.row_size + c])); html.push_str(" | "); } html.push_str("
# %% [markdown] Collapsed="false" kernel="SoS"
# ## Step 1
#
# Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.
#
# 
# %% Collapsed="false" kernel="SoS"
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
# %% [markdown] Collapsed="false" kernel="python3"
# ## Step 2
#
# Now, pair it with Jupytex
#
# 
# %% [markdown] Collapsed="false" kernel="python3"
# ### Step 3
#
# Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
# %% [markdown] Collapsed="false" kernel="python3"
# ### Step 4
#
# Reopen the notebook. Here is the outcome
#
# 
#
#
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/kalman_filter_and_visualization.q
================================================
/ ---
/ jupyter:
/ kernelspec:
/ display_name: Q 3.5
/ language: q
/ name: qpk
/ ---
/ %%
plt: .p.import`matplotlib.pyplot
/ %%
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
/ %%
price: 100 + sums 0.5 - (n:50)?1.
/ %%
output:filter price
/ %%
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
/ %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/logtalk_notebook.lgt
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Logtalk
% language: logtalk
% name: logtalk_kernel
% ---
% %% [markdown]
% # An implementation of the Ackermann function
% %% vscode={"languageId": "logtalk"}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
% %% [markdown]
% ## Sample query
% %% vscode={"languageId": "logtalk"}
ack::ack(2, 4, V).
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/lua_example.lua
================================================
-- -*- coding: utf-8 -*-
-- ---
-- jupyter:
-- kernelspec:
-- display_name: Lua
-- language: lua
-- name: lua
-- ---
-- %% [markdown]
-- Source: https://www.lua.org/pil/19.3.html
-- %% [markdown]
-- # Sort
-- %% [markdown]
-- Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
-- %% [markdown]
-- A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
-- %%
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
-- %% [markdown]
-- Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
-- %%
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
-- %% [markdown]
-- Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
-- %% [markdown]
-- As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
-- %%
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
-- %% [markdown]
-- With this function, it is easy to print those function names in alphabetical order. The loop
-- %%
for name, line in pairsByKeys(lines) do
print(name, line)
end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/maxima_example.mac
================================================
/* --- */
/* jupyter: */
/* kernelspec: */
/* display_name: Maxima */
/* language: maxima */
/* name: maxima */
/* --- */
/* %% [markdown] */
/* ## maxima misc */
/* %% */
kill(all)$
/* %% */
f(x) := 1/(x^2+l^2)^(3/2);
/* %% */
integrate(f(x), x);
/* %% */
tex(%)$
/* %% */
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/notebook_with_complex_metadata.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/nteract_with_parameter.py
================================================
# ---
# jupyter:
# kernel_info:
# name: python3
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% inputHidden=false outputHidden=false tags=["parameters"]
param = 4
# %% inputHidden=false outputHidden=false
import pandas as pd
# %% inputHidden=false outputHidden=false
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
# %% inputHidden=false outputHidden=false
%matplotlib inline
df.plot(kind='bar')
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/ocaml_notebook.ml
================================================
(* --- *)
(* jupyter: *)
(* jupytext: *)
(* formats: ipynb:markdown,md *)
(* kernelspec: *)
(* display_name: OCaml default *)
(* language: OCaml *)
(* name: ocaml-jupyter *)
(* --- *)
(* %% [markdown] *)
(* # Example of an OCaml notebook *)
(* %% *)
let sum x y = x + y
(* %% [markdown] *)
(* Let's try our function: *)
(* %% *)
sum 3 4 = 7 + 0
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/octave_notebook.m
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Octave
% language: octave
% name: octave
% ---
% %% [markdown]
% A markdown cell
% %%
1 + 1
% %%
% a code cell with comments
2 + 2
% %%
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
% %%
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
% %% [markdown]
% And to finish with, a Python cell
% %%
%%python
a = 1
% %%
%%python
a + 1
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/plotly_graphs.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# This notebook contains complex outputs, including plotly javascript graphs.
# %% [markdown]
# # Interactive plots
# %% [markdown]
# We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
# %%
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
# %%
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/powershell.ps1
================================================
# ---
# jupyter:
# kernelspec:
# display_name: PowerShell
# language: PowerShell
# name: powershell
# ---
# %% [markdown]
# This is an extract from
# https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
# %%
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/raw_cell_with_complex_yaml_like_content.py
================================================
# ---
#
# This is a complex paragraph
# that is split over multiple lines.
#
# It also includes blank lines.
#
#
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/raw_cell_with_non_dict_yaml_content.py
================================================
# ---
# Content.
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_hydrogen/root_cpp.cpp
================================================
// ---
// jupyter:
// kernelspec:
// display_name: ROOT C++
// language: c++
// name: root
// ---
// %%
#include
//
//
//
// %% [markdown]
// ## Output and error streams
//
// `std::cout` and `std::cerr` are redirected to the notebook frontend.
// %%
#include
// To run the selected code cell, hit
// Shift + Enter//
Original
)");
// %%
xcpp::display(rect, "some_display_id");
// %%
// Update the rectangle to be blue
rect.m_content = R"(
Updated
)";
xcpp::display(rect, "some_display_id", true);
// %% [markdown]
// ## Magics
//
// Magics are special commands for the kernel that are not part of the C++ language.
//
// They are defined with the symbol `%` for a line magic and `%%` for a cell magic.
//
// More documentation for magics is available at https://xeus-cling.readthedocs.io/en/latest/magics.html.
// %%
#include Jupytext on GitHub
``` ```latex $\frac{\pi}{2}$ ``` ```python %load_ext rpy2.ipython ``` ```R library(ggplot2) ggplot(data=data.frame(x=c('A', 'B'), y=c(5, 2)), aes(x,weight=y)) + geom_bar() ``` ```python %matplotlib inline import pandas as pd pd.Series({'A':5, 'B':2}).plot(figsize=(3,2), kind='bar') ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_md/Notebook with many hash signs.md ================================================ --- jupyter: kernelspec: display_name: Python 3 language: python name: python3 --- ################################################################## This is a notebook that contains many hash signs. Hopefully its python representation is not recognized as a Sphinx Gallery script... ################################################################## ```python some = 1 code = 2 some+code ################################################################## # A comment ################################################################## # Another comment ``` ################################################################## This is a notebook that contains many hash signs. Hopefully its python representation is not recognized as a Sphinx Gallery script... ################################################################## ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_md/Notebook with metadata and long cells.md ================================================ --- jupyter: kernelspec: display_name: Python 3 language: python name: python3 --- # Part one - various cells Here we have a markdown cell with two blank lines Now we have a markdown cell with a code block inside it ```python 1 + 1 ``` After that cell we'll have a code cell ```python 2 + 2 3 + 3 ``` Followed by a raw cell This is the content of the raw cell # Part two - cell metadata This is a markdown cell with cell metadata `{"key": "value"}` ```python .class tags=["parameters"] """This is a code cell with metadata `{"tags":["parameters"], ".class":null}`""" ``` This is a raw cell with cell metadata `{"key": "value"}` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_md/Notebook_with_R_magic.md ================================================ --- jupyter: kernelspec: display_name: Python 2 language: python name: python2 --- # A notebook with R cells This notebook shows the use of R cells to generate plots ```python %load_ext rpy2.ipython ``` ```R suppressMessages(require(tidyverse)) ``` ```R ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() ``` The default plot dimensions are not good for us, so we use the -w and -h parameters in %%R magic to set the plot size ```R magic_args="-w 400 -h 240" ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_md/Notebook_with_more_R_magic_111.md ================================================ --- jupyter: kernelspec: display_name: Python 3 language: python name: python3 --- ```python %load_ext rpy2.ipython import pandas as pd df = pd.DataFrame( { "Letter": ["a", "a", "a", "b", "b", "b", "c", "c", "c"], "X": [4, 3, 5, 2, 1, 7, 7, 5, 9], "Y": [0, 4, 3, 6, 7, 10, 11, 9, 13], "Z": [1, 2, 3, 1, 2, 3, 1, 2, 3], } ) ``` ```R magic_args="-i df" library("ggplot2") ggplot(data = df) + geom_point(aes(x = X, y = Y, color = Letter, size = Z)) ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_md/R notebook with invalid cell keys.md ================================================ --- jupyter: kernelspec: display_name: R language: R name: ir --- This notebook was created with IRKernel 0.8.12, and is not completely valid, as the code cell below contains an unexpected 'source' entry. This did cause https://github.com/mwouts/jupytext/issues/234. Note that the problem is solved when one upgrades to IRKernel 1.0.0. ```R library("ggplot2") ggplot(mtcars, aes(mpg)) + stat_ecdf() ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_md/Reference Guide for Calysto Scheme.md ================================================ --- jupyter: kernelspec: display_name: Calysto Scheme (Python) language: scheme name: calysto_scheme ---Reference Guide for Calysto Scheme
[Calysto Scheme](https://github.com/Calysto/calysto_scheme) is a real Scheme programming language, with full support for continuations, including call/cc. It can also use all Python libraries. Also has some extensions that make it more useful (stepper-debugger, choose/fail, stack traces), or make it better integrated with Python. In Jupyter notebooks, because Calysto Scheme uses [MetaKernel](https://github.com/Calysto/metakernel/blob/master/README.rst), it has a fully-supported set of "magics"---meta-commands for additional functionality. This includes running Scheme in parallel. See all of the [MetaKernel Magics](https://github.com/Calysto/metakernel/blob/master/metakernel/magics/README.md). Calysto Scheme is written in Scheme, and then translated into Python (and other backends). The entire functionality lies in a single Python file: https://github.com/Calysto/calysto_scheme/blob/master/calysto_scheme/scheme.py However, you can easily install it (see below). Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language. ## Installation You can install Calysto Scheme with Python3: ``` pip3 install --upgrade calysto-scheme --user -U python3 -m calysto_kernel install --user ``` or in the system kernel folder with: ``` sudo pip3 install --upgrade calysto-scheme -U sudo python3 -m calysto_kernel install ``` Change pip3/python3 to use a different pip or Python. The version of Python used will determine how Calysto Scheme is run. Use it in the console, qtconsole, or notebook with IPython 3: ``` ipython console --kernel calysto_scheme ipython qtconsole --kernel calysto_scheme ipython notebook --kernel calysto_scheme ``` In addition to all of the following items, Calysto Scheme also has access to all of Python's builtin functions, and all of Python's libraries. For example, you can use `(complex 3 2)` to create a complex number by calling Python's complex function. ## Jupyter Enhancements When you run Calysto Scheme in Jupyter (console, notebook, qtconsole, etc.) you get: * TAB completions of Scheme functions and variable names * display of rich media * stepper/debugger * magics (% macros) * shell commands (! command) * LaTeX equations * LaTeX-style variables * Python integration ### LaTeX-style variables Calysto Scheme allows you to use LaTeX-style variables in code. For example, if you type: ``` \beta ``` with the cursor right after the 'a' in beta, and then press TAB, it will turn into the unicode character: ``` β ``` There are nearly 1300 different symbols defined (thanks to the Julia language) and documented here: http://docs.julialang.org/en/release-0.4/manual/unicode-input/#man-unicode-input Calysto Scheme may not implement all of those. Some useful and suggestive ones: * \pi - π * \Pi - Π * \Sigma - Σ * \_i - subscript i, such as vectorᵢ ```scheme (define α 67) ``` ```scheme α ``` ```scheme (define i 2) (define vectorᵢ (vector-ref (vector 0 6 3 2) i)) vectorᵢ ``` ### Rich media ```scheme (import "calysto.display") ``` ```scheme (calysto.display.HTML "This is bold, italics, underlined.") ``` ```scheme (import "calysto.graphics") ``` ```scheme (define canvas (calysto.graphics.Canvas)) ``` ```scheme (define ball (calysto.graphics.Circle '(150 150) 100)) ``` ```scheme (ball.draw canvas) ``` ### Shell commands ```scheme ! ls /tmp ``` ### Stepper/Debugger Here is what the debugger looks like:
It has breakpoints (click in left margin). You must press Stop to exit the debugger.
```scheme
%%debug
(begin
(define x 1)
(set! x 2)
)
```
### Python Integration
You can import and use any Python library in Calysto Scheme.
In addition, if you wish, you can execute expressions and statements in a Python environment:
```scheme
(python-eval "1 + 2")
```
```scheme
(python-exec
"
def mypyfunc(a, b):
return a * b
")
```
This is a shared environment with Scheme:
```scheme
(mypyfunc 4 5)
```
You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
```scheme
(define! mypyfunc2 (func (lambda (n) n)))
```
```scheme
(python-eval "mypyfunc2(34)")
```
# Differences Between Languages
## Major differences between Scheme and Python
1. In Scheme, double quotes are used for strings and may contain newlines
1. In Scheme, a single quote is short for (quote ...) and means "literal"
1. In Scheme, everything is an expression and has a return value
1. Python does not support macros (e.g., extending syntax)
1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
1. Scheme procedures are not Python functions, but there are means to use one as the other.
## Major Differences Between Calysto Scheme and other Schemes
1. define-syntax works slightly differently
1. In Calysto Scheme, #(...) is short for '#(...)
1. Calysto Scheme is missing many standard functions (see list at bottom)
1. Calysto Scheme has a built-in amb operator called `choose`
1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
### Stack Trace
Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
```scheme
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
```
```scheme
(fact 5)
```
To turn off the stack trace on error:
```scheme
(use-stack-trace #f)
```
That will allow infinite recursive loops without keeping track of the "stack".
# Calysto Scheme Variables
## SCHEMEPATH
SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
```scheme
SCHEMEPATH
```
```scheme
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
```
```scheme
SCHEMEPATH
```
## Getting Started
Note that you can use the word `lambda` or \lambda and then press [TAB]
```scheme
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
```
```scheme
(factorial 5)
```
## define-syntax
(define-syntax NAME RULES): a method for creating macros
```scheme
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
```
```scheme
(time (car '(1 2 3 4)))
```
```scheme
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
```
```scheme
(collect (* n n) for n in (range 10))
```
```scheme
(collect (* n n) for n in (range 5 20 3))
```
```scheme
(collect (* n n) for n in (range 10) if (> n 5))
```
```scheme
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
```
```scheme
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
```
```scheme
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
```
```scheme
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
```
```scheme
(for n in (range 10 20 2) do (print n))
```
```scheme
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
```
```scheme
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
```
```scheme
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
```
```scheme
(! 5)
```
```scheme
(nth 10 facts)
```
```scheme
(nth 20 fibs)
```
```scheme
(first 30 fibs)
```
## for-each
(for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
```scheme
(for-each (lambda (n) (print n)) '(3 4 5))
```
## format
(format STRING ITEM ...): format the string with ITEMS as arguments
```scheme
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
```
## func
Turns a lambda into a Python function.
(func (lambda ...))
```scheme
(func (lambda (n) n))
```
## There's more!
Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/The flavors of raw cells.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
$1+1$
:math:`1+1`
Bold text
**Bold text**
1 + 1
Not formatted
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/cat_variable.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
cat = 42
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/coconut_homepage_demo.md
================================================
---
jupyter:
kernelspec:
display_name: Coconut
language: coconut
name: coconut
---
Taken from [coconut-lang.org](coconut-lang.org)
pipeline-style programming
```coconut
"hello, world!" |> print
```
prettier lambdas
```coconut
x -> x ** 2
```
partial application
```coconut
range(10) |> map$(pow$(?, 2)) |> list
```
pattern-matching
```coconut
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
```
destructuring assignment
```coconut
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
```
infix notation
```coconut
# 5 `mod` 3 == 2
```
operator functions
```coconut
product = reduce$(*)
```
function composition
```coconut
# (f..g..h)(x, y, z)
```
lazy lists
```coconut
# (| first_elem() |) :: rest_elems()
```
parallel programming
```coconut
range(100) |> parallel_map$(pow$(2)) |> list
```
tail call optimization
```coconut
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
```
algebraic data types
```coconut
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
```
and much more!
Like what you see? Don't forget to star Coconut on GitHub!
```coconut
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/convert_to_py_then_test_with_update83.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
%%time
print('asdf')
```
Thanks for jupytext!
```python
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/csharp.md
================================================
---
jupyter:
kernelspec:
display_name: .NET (C#)
language: C#
name: .net-csharp
---
We start with...
```csharp
Console.WriteLine("Hello World!");
```
Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
```csharp
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
```
We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
```csharp
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
```
```csharp
(MathString)@"e^{i \pi} = -1"
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/demo_gdl_fbp.md
================================================
---
jupyter:
kernelspec:
display_name: IDL [conda env:gdl] *
language: IDL
name: conda-env-gdl-idl
---
## GDL demo notebook
Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
```idl
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
```
```idl
;; Enable inline plotting
!inline=1
```
```idl
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
```
Now we define simple forward and backprojection functions:
```idl
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
```
```idl
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
```
This allows us to create a sinogram:
```idl
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
```
On this we can apply a simple FBP reconstruction:
```idl
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
```
```idl
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
```
### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/evcxr_jupyter_tour.md
================================================
---
jupyter:
kernelspec:
display_name: Rust
language: rust
name: rust
---
# Tour of the EvCxR Jupyter Kernel
For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
## Printing to outputs and evaluating expressions
Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
```rust
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
```
## Assigning and making use of variables
We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
```rust
let mut message = "Hello ".to_owned();
```
```rust
message.push_str("world!");
```
```rust
message
```
## Defining and redefining functions
Next we'll define a function
```rust
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
```
```rust
(1..13).map(fib).collect::| "); html.push_str(&format!("{:?}", self.values[r * self.row_size + c])); html.push_str(" | "); } html.push_str("
## Step 1
Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.

```sos Collapsed="false" kernel="SoS"
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
```
## Step 2
Now, pair it with Jupytex

### Step 3
Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
### Step 4
Reopen the notebook. Here is the outcome

================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/kalman_filter_and_visualization.md
================================================
---
jupyter:
kernelspec:
display_name: Q 3.5
language: q
name: qpk
---
```q
plt: .p.import`matplotlib.pyplot
```
```q
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
```
```q
price: 100 + sums 0.5 - (n:50)?1.
```
```q
output:filter price
```
```q
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
```
```q
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/logtalk_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: Logtalk
language: logtalk
name: logtalk_kernel
---
# An implementation of the Ackermann function
```logtalk vscode={"languageId": "logtalk"}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
```
## Sample query
```logtalk vscode={"languageId": "logtalk"}
ack::ack(2, 4, V).
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/lua_example.md
================================================
---
jupyter:
kernelspec:
display_name: Lua
language: lua
name: lua
---
Source: https://www.lua.org/pil/19.3.html
# Sort
Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
```lua
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
```
Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
```lua
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
```
Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
```lua
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
```
With this function, it is easy to print those function names in alphabetical order. The loop
```lua
for name, line in pairsByKeys(lines) do
print(name, line)
end
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/maxima_example.md
================================================
---
jupyter:
kernelspec:
display_name: Maxima
language: maxima
name: maxima
---
## maxima misc
```maxima
kill(all)$
```
```maxima
f(x) := 1/(x^2+l^2)^(3/2);
```
```maxima
integrate(f(x), x);
```
```maxima
tex(%)$
```
```maxima
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/notebook_with_complex_metadata.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/nteract_with_parameter.md
================================================
---
jupyter:
kernel_info:
name: python3
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python inputHidden=false outputHidden=false tags=["parameters"]
param = 4
```
```python inputHidden=false outputHidden=false
import pandas as pd
```
```python inputHidden=false outputHidden=false
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
```
```python inputHidden=false outputHidden=false
%matplotlib inline
df.plot(kind='bar')
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/ocaml_notebook.md
================================================
---
jupyter:
jupytext:
formats: ipynb:markdown,md
kernelspec:
display_name: OCaml default
language: OCaml
name: ocaml-jupyter
---
# Example of an OCaml notebook
```ocaml
let sum x y = x + y
```
Let's try our function:
```ocaml
sum 3 4 = 7 + 0
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/octave_notebook.md
================================================
---
jupyter:
kernelspec:
display_name: Octave
language: octave
name: octave
---
A markdown cell
```octave
1 + 1
```
```octave
% a code cell with comments
2 + 2
```
```octave
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
```
```octave
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
```
And to finish with, a Python cell
```python
a = 1
```
```python
a + 1
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/plotly_graphs.md
================================================
---
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
This notebook contains complex outputs, including plotly javascript graphs.
# Interactive plots
We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
```python
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
```
```python
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/powershell.md
================================================
---
jupyter:
kernelspec:
display_name: PowerShell
language: PowerShell
name: powershell
---
This is an extract from
https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
```powershell
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/raw_cell_with_complex_yaml_like_content.md
================================================
---
This is a complex paragraph
that is split over multiple lines.
It also includes blank lines.
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/raw_cell_with_non_dict_yaml_content.md
================================================
---
Content.
jupyter:
kernelspec:
display_name: Python 3
language: python
name: python3
---
```python
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_md/root_cpp.md
================================================
---
jupyter:
kernelspec:
display_name: ROOT C++
language: c++
name: root
---
```c++
#include
To run the selected code cell, hit
Shift + Enter
Original
)");
```
```c++
xcpp::display(rect, "some_display_id");
```
```c++
// Update the rectangle to be blue
rect.m_content = R"(
Updated
)";
xcpp::display(rect, "some_display_id", true);
```
## Magics
Magics are special commands for the kernel that are not part of the C++ language.
They are defined with the symbol `%` for a line magic and `%%` for a cell magic.
More documentation for magics is available at https://xeus-cling.readthedocs.io/en/latest/magics.html.
```c++
#include Jupytext on GitHub
``` ```{code-cell} ipython3 %%latex $\frac{\pi}{2}$ ``` ```{code-cell} ipython3 %load_ext rpy2.ipython ``` ```{code-cell} ipython3 %%R library(ggplot2) ggplot(data=data.frame(x=c('A', 'B'), y=c(5, 2)), aes(x,weight=y)) + geom_bar() ``` ```{code-cell} ipython3 %matplotlib inline import pandas as pd pd.Series({'A':5, 'B':2}).plot(figsize=(3,2), kind='bar') ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_myst/Notebook with many hash signs.md ================================================ --- kernelspec: display_name: Python 3 language: python name: python3 --- ################################################################## This is a notebook that contains many hash signs. Hopefully its python representation is not recognized as a Sphinx Gallery script... ################################################################## ```{code-cell} ipython3 some = 1 code = 2 some+code ################################################################## # A comment ################################################################## # Another comment ``` ################################################################## This is a notebook that contains many hash signs. Hopefully its python representation is not recognized as a Sphinx Gallery script... ################################################################## ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_myst/Notebook with metadata and long cells.md ================================================ --- kernelspec: display_name: Python 3 language: python name: python3 --- # Part one - various cells +++ Here we have a markdown cell with two blank lines +++ Now we have a markdown cell with a code block inside it ```python 1 + 1 ``` After that cell we'll have a code cell ```{code-cell} ipython3 2 + 2 3 + 3 ``` Followed by a raw cell ```{raw-cell} This is the content of the raw cell ``` # Part two - cell metadata +++ {"key": "value"} This is a markdown cell with cell metadata `{"key": "value"}` ```{code-cell} ipython3 --- .class: null tags: [parameters] --- """This is a code cell with metadata `{"tags":["parameters"], ".class":null}`""" ``` ```{raw-cell} :key: value This is a raw cell with cell metadata `{"key": "value"}` ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_myst/Notebook_with_R_magic.md ================================================ --- kernelspec: display_name: Python 2 language: python name: python2 --- # A notebook with R cells This notebook shows the use of R cells to generate plots ```{code-cell} ipython2 %load_ext rpy2.ipython ``` ```{code-cell} ipython2 %%R suppressMessages(require(tidyverse)) ``` ```{code-cell} ipython2 %%R ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() ``` The default plot dimensions are not good for us, so we use the -w and -h parameters in %%R magic to set the plot size ```{code-cell} ipython2 %%R -w 400 -h 240 ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_myst/Notebook_with_more_R_magic_111.md ================================================ --- kernelspec: display_name: Python 3 language: python name: python3 --- ```{code-cell} ipython3 %load_ext rpy2.ipython import pandas as pd df = pd.DataFrame( { "Letter": ["a", "a", "a", "b", "b", "b", "c", "c", "c"], "X": [4, 3, 5, 2, 1, 7, 7, 5, 9], "Y": [0, 4, 3, 6, 7, 10, 11, 9, 13], "Z": [1, 2, 3, 1, 2, 3, 1, 2, 3], } ) ``` ```{code-cell} ipython3 %%R -i df library("ggplot2") ggplot(data = df) + geom_point(aes(x = X, y = Y, color = Letter, size = Z)) ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_myst/R notebook with invalid cell keys.md ================================================ --- kernelspec: display_name: R language: R name: ir --- This notebook was created with IRKernel 0.8.12, and is not completely valid, as the code cell below contains an unexpected 'source' entry. This did cause https://github.com/mwouts/jupytext/issues/234. Note that the problem is solved when one upgrades to IRKernel 1.0.0. ```{code-cell} r library("ggplot2") ggplot(mtcars, aes(mpg)) + stat_ecdf() ``` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_myst/Reference Guide for Calysto Scheme.md ================================================ --- kernelspec: display_name: Calysto Scheme (Python) language: scheme name: calysto_scheme ---Reference Guide for Calysto Scheme
[Calysto Scheme](https://github.com/Calysto/calysto_scheme) is a real Scheme programming language, with full support for continuations, including call/cc. It can also use all Python libraries. Also has some extensions that make it more useful (stepper-debugger, choose/fail, stack traces), or make it better integrated with Python. In Jupyter notebooks, because Calysto Scheme uses [MetaKernel](https://github.com/Calysto/metakernel/blob/master/README.rst), it has a fully-supported set of "magics"---meta-commands for additional functionality. This includes running Scheme in parallel. See all of the [MetaKernel Magics](https://github.com/Calysto/metakernel/blob/master/metakernel/magics/README.md). Calysto Scheme is written in Scheme, and then translated into Python (and other backends). The entire functionality lies in a single Python file: https://github.com/Calysto/calysto_scheme/blob/master/calysto_scheme/scheme.py However, you can easily install it (see below). Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language. ## Installation You can install Calysto Scheme with Python3: ``` pip3 install --upgrade calysto-scheme --user -U python3 -m calysto_kernel install --user ``` or in the system kernel folder with: ``` sudo pip3 install --upgrade calysto-scheme -U sudo python3 -m calysto_kernel install ``` Change pip3/python3 to use a different pip or Python. The version of Python used will determine how Calysto Scheme is run. Use it in the console, qtconsole, or notebook with IPython 3: ``` ipython console --kernel calysto_scheme ipython qtconsole --kernel calysto_scheme ipython notebook --kernel calysto_scheme ``` In addition to all of the following items, Calysto Scheme also has access to all of Python's builtin functions, and all of Python's libraries. For example, you can use `(complex 3 2)` to create a complex number by calling Python's complex function. ## Jupyter Enhancements When you run Calysto Scheme in Jupyter (console, notebook, qtconsole, etc.) you get: * TAB completions of Scheme functions and variable names * display of rich media * stepper/debugger * magics (% macros) * shell commands (! command) * LaTeX equations * LaTeX-style variables * Python integration +++ ### LaTeX-style variables Calysto Scheme allows you to use LaTeX-style variables in code. For example, if you type: ``` \beta ``` with the cursor right after the 'a' in beta, and then press TAB, it will turn into the unicode character: ``` β ``` There are nearly 1300 different symbols defined (thanks to the Julia language) and documented here: http://docs.julialang.org/en/release-0.4/manual/unicode-input/#man-unicode-input Calysto Scheme may not implement all of those. Some useful and suggestive ones: * \pi - π * \Pi - Π * \Sigma - Σ * \_i - subscript i, such as vectorᵢ ```{code-cell} scheme (define α 67) ``` ```{code-cell} scheme α ``` ```{code-cell} scheme (define i 2) (define vectorᵢ (vector-ref (vector 0 6 3 2) i)) vectorᵢ ``` ### Rich media ```{code-cell} scheme (import "calysto.display") ``` ```{code-cell} scheme (calysto.display.HTML "This is bold, italics, underlined.") ``` ```{code-cell} scheme (import "calysto.graphics") ``` ```{code-cell} scheme (define canvas (calysto.graphics.Canvas)) ``` ```{code-cell} scheme (define ball (calysto.graphics.Circle '(150 150) 100)) ``` ```{code-cell} scheme (ball.draw canvas) ``` ### Shell commands ```{code-cell} scheme ! ls /tmp ``` ### Stepper/Debugger Here is what the debugger looks like:
It has breakpoints (click in left margin). You must press Stop to exit the debugger.
+++
```scheme
%%debug
(begin
(define x 1)
(set! x 2)
)
```
+++
### Python Integration
You can import and use any Python library in Calysto Scheme.
In addition, if you wish, you can execute expressions and statements in a Python environment:
```{code-cell} scheme
(python-eval "1 + 2")
```
```{code-cell} scheme
(python-exec
"
def mypyfunc(a, b):
return a * b
")
```
This is a shared environment with Scheme:
```{code-cell} scheme
(mypyfunc 4 5)
```
You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
```{code-cell} scheme
(define! mypyfunc2 (func (lambda (n) n)))
```
```{code-cell} scheme
(python-eval "mypyfunc2(34)")
```
# Differences Between Languages
## Major differences between Scheme and Python
1. In Scheme, double quotes are used for strings and may contain newlines
1. In Scheme, a single quote is short for (quote ...) and means "literal"
1. In Scheme, everything is an expression and has a return value
1. Python does not support macros (e.g., extending syntax)
1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
1. Scheme procedures are not Python functions, but there are means to use one as the other.
## Major Differences Between Calysto Scheme and other Schemes
1. define-syntax works slightly differently
1. In Calysto Scheme, #(...) is short for '#(...)
1. Calysto Scheme is missing many standard functions (see list at bottom)
1. Calysto Scheme has a built-in amb operator called `choose`
1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
### Stack Trace
Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
```{code-cell} scheme
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
```
```{code-cell} scheme
(fact 5)
```
To turn off the stack trace on error:
```scheme
(use-stack-trace #f)
```
That will allow infinite recursive loops without keeping track of the "stack".
+++
# Calysto Scheme Variables
## SCHEMEPATH
SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
```{code-cell} scheme
SCHEMEPATH
```
```{code-cell} scheme
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
```
```{code-cell} scheme
SCHEMEPATH
```
## Getting Started
Note that you can use the word `lambda` or \lambda and then press [TAB]
```{code-cell} scheme
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
```
```{code-cell} scheme
(factorial 5)
```
## define-syntax
(define-syntax NAME RULES): a method for creating macros
```{code-cell} scheme
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
```
```{code-cell} scheme
(time (car '(1 2 3 4)))
```
```{code-cell} scheme
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
```
```{code-cell} scheme
(collect (* n n) for n in (range 10))
```
```{code-cell} scheme
(collect (* n n) for n in (range 5 20 3))
```
```{code-cell} scheme
(collect (* n n) for n in (range 10) if (> n 5))
```
```{code-cell} scheme
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
```
```{code-cell} scheme
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
```
```{code-cell} scheme
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
```
```{code-cell} scheme
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
```
```{code-cell} scheme
(for n in (range 10 20 2) do (print n))
```
```{code-cell} scheme
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
```
```{code-cell} scheme
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
```
```{code-cell} scheme
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
```
```{code-cell} scheme
(! 5)
```
```{code-cell} scheme
(nth 10 facts)
```
```{code-cell} scheme
(nth 20 fibs)
```
```{code-cell} scheme
(first 30 fibs)
```
## for-each
(for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
```{code-cell} scheme
(for-each (lambda (n) (print n)) '(3 4 5))
```
## format
(format STRING ITEM ...): format the string with ITEMS as arguments
```{code-cell} scheme
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
```
## func
Turns a lambda into a Python function.
(func (lambda ...))
```{code-cell} scheme
(func (lambda (n) n))
```
## There's more!
Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/The flavors of raw cells.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{raw-cell}
:raw_mimetype: text/latex
$1+1$
```
```{raw-cell}
:raw_mimetype: text/restructuredtext
:math:`1+1`
```
```{raw-cell}
:raw_mimetype: text/html
Bold text
```
```{raw-cell}
:raw_mimetype: text/markdown
**Bold text**
```
```{raw-cell}
:raw_mimetype: text/x-python
1 + 1
```
```{raw-cell}
Not formatted
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/cat_variable.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
cat = 42
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/coconut_homepage_demo.md
================================================
---
kernelspec:
display_name: Coconut
language: coconut
name: coconut
---
Taken from [coconut-lang.org](coconut-lang.org)
+++
pipeline-style programming
```{code-cell} coconut
"hello, world!" |> print
```
prettier lambdas
```{code-cell} coconut
x -> x ** 2
```
partial application
```{code-cell} coconut
range(10) |> map$(pow$(?, 2)) |> list
```
pattern-matching
```{code-cell} coconut
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
```
destructuring assignment
```{code-cell} coconut
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
```
infix notation
```{code-cell} coconut
# 5 `mod` 3 == 2
```
operator functions
```{code-cell} coconut
product = reduce$(*)
```
function composition
```{code-cell} coconut
# (f..g..h)(x, y, z)
```
lazy lists
```{code-cell} coconut
# (| first_elem() |) :: rest_elems()
```
parallel programming
```{code-cell} coconut
range(100) |> parallel_map$(pow$(2)) |> list
```
tail call optimization
```{code-cell} coconut
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
```
algebraic data types
```{code-cell} coconut
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
```
and much more!
Like what you see? Don't forget to star Coconut on GitHub!
```{code-cell} coconut
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/convert_to_py_then_test_with_update83.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
%%time
print('asdf')
```
Thanks for jupytext!
```{code-cell} ipython3
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/csharp.md
================================================
---
kernelspec:
display_name: .NET (C#)
language: C#
name: .net-csharp
---
We start with...
```{code-cell} csharp
Console.WriteLine("Hello World!");
```
Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
```{code-cell} csharp
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
```
We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
```{code-cell} csharp
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
```
```{code-cell} csharp
(MathString)@"e^{i \pi} = -1"
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/demo_gdl_fbp.md
================================================
---
kernelspec:
display_name: IDL [conda env:gdl] *
language: IDL
name: conda-env-gdl-idl
---
## GDL demo notebook
+++
Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
```{code-cell}
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
```
```{code-cell}
;; Enable inline plotting
!inline=1
```
```{code-cell}
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
```
Now we define simple forward and backprojection functions:
```{code-cell}
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
```
```{code-cell}
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
```
This allows us to create a sinogram:
```{code-cell}
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
```
On this we can apply a simple FBP reconstruction:
```{code-cell}
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
```
```{code-cell}
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
```
### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/evcxr_jupyter_tour.md
================================================
---
kernelspec:
display_name: Rust
language: rust
name: rust
---
# Tour of the EvCxR Jupyter Kernel
For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
## Printing to outputs and evaluating expressions
Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
```{code-cell}
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
```
## Assigning and making use of variables
We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
```{code-cell}
let mut message = "Hello ".to_owned();
```
```{code-cell}
message.push_str("world!");
```
```{code-cell}
message
```
## Defining and redefining functions
Next we'll define a function
```{code-cell}
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
```
```{code-cell}
(1..13).map(fib).collect::| "); html.push_str(&format!("{:?}", self.values[r * self.row_size + c])); html.push_str(" | "); } html.push_str("
+++ {"Collapsed": "false", "kernel": "SoS"}
## Step 1
Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.

```{code-cell} sos
:Collapsed: 'false'
:kernel: SoS
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
```
+++ {"Collapsed": "false", "kernel": "python3"}
## Step 2
Now, pair it with Jupytex

+++ {"Collapsed": "false", "kernel": "python3"}
### Step 3
Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
+++ {"Collapsed": "false", "kernel": "python3"}
### Step 4
Reopen the notebook. Here is the outcome

================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/kalman_filter_and_visualization.md
================================================
---
kernelspec:
display_name: Q 3.5
language: q
name: qpk
---
```{code-cell}
plt: .p.import`matplotlib.pyplot
```
```{code-cell}
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
```
```{code-cell}
price: 100 + sums 0.5 - (n:50)?1.
```
```{code-cell}
output:filter price
```
```{code-cell}
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
```
```{code-cell}
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/logtalk_notebook.md
================================================
---
kernelspec:
display_name: Logtalk
language: logtalk
name: logtalk_kernel
---
# An implementation of the Ackermann function
```{code-cell}
---
vscode:
languageId: logtalk
---
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
```
## Sample query
```{code-cell}
---
vscode:
languageId: logtalk
---
ack::ack(2, 4, V).
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/lua_example.md
================================================
---
kernelspec:
display_name: Lua
language: lua
name: lua
---
Source: https://www.lua.org/pil/19.3.html
+++
# Sort
+++
Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
+++
A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
```{code-cell}
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
```
Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
```{code-cell}
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
```
Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
+++
As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
```{code-cell}
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
```
With this function, it is easy to print those function names in alphabetical order. The loop
```{code-cell}
for name, line in pairsByKeys(lines) do
print(name, line)
end
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/maxima_example.md
================================================
---
kernelspec:
display_name: Maxima
language: maxima
name: maxima
---
## maxima misc
```{code-cell} maxima
kill(all)$
```
```{code-cell} maxima
f(x) := 1/(x^2+l^2)^(3/2);
```
```{code-cell} maxima
integrate(f(x), x);
```
```{code-cell} maxima
tex(%)$
```
```{code-cell} maxima
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/notebook_with_complex_metadata.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/nteract_with_parameter.md
================================================
---
kernel_info:
name: python3
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{code-cell} ipython3
:inputHidden: false
:outputHidden: false
:tags: [parameters]
param = 4
```
```{code-cell} ipython3
:inputHidden: false
:outputHidden: false
import pandas as pd
```
```{code-cell} ipython3
:inputHidden: false
:outputHidden: false
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
```
```{code-cell} ipython3
:inputHidden: false
:outputHidden: false
%matplotlib inline
df.plot(kind='bar')
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/ocaml_notebook.md
================================================
---
jupytext:
formats: ipynb:markdown,md:myst
kernelspec:
display_name: OCaml default
language: OCaml
name: ocaml-jupyter
---
# Example of an OCaml notebook
```{code-cell} OCaml
let sum x y = x + y
```
Let's try our function:
```{code-cell} OCaml
sum 3 4 = 7 + 0
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/octave_notebook.md
================================================
---
kernelspec:
display_name: Octave
language: octave
name: octave
---
A markdown cell
```{code-cell}
1 + 1
```
```{code-cell}
% a code cell with comments
2 + 2
```
```{code-cell}
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
```
```{code-cell}
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
```
And to finish with, a Python cell
```{code-cell}
%%python
a = 1
```
```{code-cell}
%%python
a + 1
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/plotly_graphs.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
This notebook contains complex outputs, including plotly javascript graphs.
+++
# Interactive plots
+++
We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
```{code-cell} ipython3
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
```
```{code-cell} ipython3
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/powershell.md
================================================
---
kernelspec:
display_name: PowerShell
language: PowerShell
name: powershell
---
This is an extract from
https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
```{code-cell} powershell
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/raw_cell_with_complex_yaml_like_content.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{raw-cell}
---
This is a complex paragraph
that is split over multiple lines.
It also includes blank lines.
---
```
```{code-cell}
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/raw_cell_with_non_dict_yaml_content.md
================================================
---
kernelspec:
display_name: Python 3
language: python
name: python3
---
```{raw-cell}
---
Content.
---
```
```{code-cell}
print("Hello, World!")
```
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_myst/root_cpp.md
================================================
---
kernelspec:
display_name: ROOT C++
language: c++
name: root
---
```{code-cell}
#include Jupytext on GitHub
# %% language="latex" # $\frac{\pi}{2}$ # %% # %load_ext rpy2.ipython # %% language="R" # library(ggplot2) # ggplot(data=data.frame(x=c('A', 'B'), y=c(5, 2)), aes(x,weight=y)) + geom_bar() # %% # %matplotlib inline import pandas as pd pd.Series({'A':5, 'B':2}).plot(figsize=(3,2), kind='bar') ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_percent/Notebook with many hash signs.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # %% [markdown] # ################################################################## # This is a notebook that contains many hash signs. # Hopefully its python representation is not recognized as a Sphinx Gallery script... # ################################################################## # %% some = 1 code = 2 some+code ################################################################## # A comment ################################################################## # Another comment # %% [markdown] # ################################################################## # This is a notebook that contains many hash signs. # Hopefully its python representation is not recognized as a Sphinx Gallery script... # ################################################################## ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_percent/Notebook with metadata and long cells.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # %% [markdown] # # Part one - various cells # %% [markdown] # Here we have a markdown cell # # # with two blank lines # %% [markdown] # Now we have a markdown cell # with a code block inside it # # ```python # 1 + 1 # ``` # # After that cell we'll have a code cell # %% 2 + 2 3 + 3 # %% [markdown] # Followed by a raw cell # %% [raw] # This is # the content # of the raw cell # %% [markdown] # # Part two - cell metadata # %% [markdown] key="value" # This is a markdown cell with cell metadata `{"key": "value"}` # %% .class tags=["parameters"] """This is a code cell with metadata `{"tags":["parameters"], ".class":null}`""" # %% [raw] key="value" # This is a raw cell with cell metadata `{"key": "value"}` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_percent/Notebook_with_R_magic.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 2 # language: python # name: python2 # --- # %% [markdown] # # A notebook with R cells # # This notebook shows the use of R cells to generate plots # %% # %load_ext rpy2.ipython # %% language="R" # suppressMessages(require(tidyverse)) # %% language="R" # ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() # %% [markdown] # The default plot dimensions are not good for us, so we use the -w and -h parameters in %%R magic to set the plot size # %% magic_args="-w 400 -h 240" language="R" # ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_percent/Notebook_with_more_R_magic_111.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # %% # %load_ext rpy2.ipython import pandas as pd df = pd.DataFrame( { "Letter": ["a", "a", "a", "b", "b", "b", "c", "c", "c"], "X": [4, 3, 5, 2, 1, 7, 7, 5, 9], "Y": [0, 4, 3, 6, 7, 10, 11, 9, 13], "Z": [1, 2, 3, 1, 2, 3, 1, 2, 3], } ) # %% magic_args="-i df" language="R" # library("ggplot2") # ggplot(data = df) + geom_point(aes(x = X, y = Y, color = Letter, size = Z)) ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_percent/R notebook with invalid cell keys.R ================================================ # --- # jupyter: # kernelspec: # display_name: R # language: R # name: ir # --- # %% [markdown] # This notebook was created with IRKernel 0.8.12, and is not completely valid, as the code cell below contains an unexpected 'source' entry. This did cause https://github.com/mwouts/jupytext/issues/234. Note that the problem is solved when one upgrades to IRKernel 1.0.0. # %% library("ggplot2") ggplot(mtcars, aes(mpg)) + stat_ecdf() ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_percent/R notebook with invalid cell keys.low.r ================================================ # --- # jupyter: # kernelspec: # display_name: R # language: R # name: ir # --- # %% [markdown] # This notebook was created with IRKernel 0.8.12, and is not completely valid, as the code cell below contains an unexpected 'source' entry. This did cause https://github.com/mwouts/jupytext/issues/234. Note that the problem is solved when one upgrades to IRKernel 1.0.0. # %% library("ggplot2") ggplot(mtcars, aes(mpg)) + stat_ecdf() ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_percent/Reference Guide for Calysto Scheme.scm ================================================ ;; -*- coding: utf-8 -*- ;; --- ;; jupyter: ;; kernelspec: ;; display_name: Calysto Scheme (Python) ;; language: scheme ;; name: calysto_scheme ;; --- ;; %% [markdown] ;;Reference Guide for Calysto Scheme
;; ;; [Calysto Scheme](https://github.com/Calysto/calysto_scheme) is a real Scheme programming language, with full support for continuations, including call/cc. It can also use all Python libraries. Also has some extensions that make it more useful (stepper-debugger, choose/fail, stack traces), or make it better integrated with Python. ;; ;; In Jupyter notebooks, because Calysto Scheme uses [MetaKernel](https://github.com/Calysto/metakernel/blob/master/README.rst), it has a fully-supported set of "magics"---meta-commands for additional functionality. This includes running Scheme in parallel. See all of the [MetaKernel Magics](https://github.com/Calysto/metakernel/blob/master/metakernel/magics/README.md). ;; ;; Calysto Scheme is written in Scheme, and then translated into Python (and other backends). The entire functionality lies in a single Python file: https://github.com/Calysto/calysto_scheme/blob/master/calysto_scheme/scheme.py However, you can easily install it (see below). ;; ;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language. ;; ;; ## Installation ;; ;; You can install Calysto Scheme with Python3: ;; ;; ``` ;; pip3 install --upgrade calysto-scheme --user -U ;; python3 -m calysto_kernel install --user ;; ``` ;; ;; or in the system kernel folder with: ;; ;; ``` ;; sudo pip3 install --upgrade calysto-scheme -U ;; sudo python3 -m calysto_kernel install ;; ``` ;; ;; Change pip3/python3 to use a different pip or Python. The version of Python used will determine how Calysto Scheme is run. ;; ;; Use it in the console, qtconsole, or notebook with IPython 3: ;; ;; ``` ;; ipython console --kernel calysto_scheme ;; ipython qtconsole --kernel calysto_scheme ;; ipython notebook --kernel calysto_scheme ;; ``` ;; ;; In addition to all of the following items, Calysto Scheme also has access to all of Python's builtin functions, and all of Python's libraries. For example, you can use `(complex 3 2)` to create a complex number by calling Python's complex function. ;; ;; ## Jupyter Enhancements ;; ;; When you run Calysto Scheme in Jupyter (console, notebook, qtconsole, etc.) you get: ;; ;; * TAB completions of Scheme functions and variable names ;; * display of rich media ;; * stepper/debugger ;; * magics (% macros) ;; * shell commands (! command) ;; * LaTeX equations ;; * LaTeX-style variables ;; * Python integration ;; %% [markdown] ;; ### LaTeX-style variables ;; ;; Calysto Scheme allows you to use LaTeX-style variables in code. For example, if you type: ;; ;; ``` ;; \beta ;; ``` ;; ;; with the cursor right after the 'a' in beta, and then press TAB, it will turn into the unicode character: ;; ;; ``` ;; β ;; ``` ;; ;; There are nearly 1300 different symbols defined (thanks to the Julia language) and documented here: ;; ;; http://docs.julialang.org/en/release-0.4/manual/unicode-input/#man-unicode-input ;; ;; Calysto Scheme may not implement all of those. Some useful and suggestive ones: ;; ;; * \pi - π ;; * \Pi - Π ;; * \Sigma - Σ ;; * \_i - subscript i, such as vectorᵢ ;; %% (define α 67) ;; %% α ;; %% (define i 2) (define vectorᵢ (vector-ref (vector 0 6 3 2) i)) vectorᵢ ;; %% [markdown] ;; ### Rich media ;; %% (import "calysto.display") ;; %% (calysto.display.HTML "This is bold, italics, underlined.") ;; %% (import "calysto.graphics") ;; %% (define canvas (calysto.graphics.Canvas)) ;; %% (define ball (calysto.graphics.Circle '(150 150) 100)) ;; %% (ball.draw canvas) ;; %% [markdown] ;; ### Shell commands ;; %% ! ls /tmp ;; %% [markdown] ;; ### Stepper/Debugger ;; ;; Here is what the debugger looks like: ;; ;;
;;
;; It has breakpoints (click in left margin). You must press Stop to exit the debugger.
;; %% [markdown]
;; ```scheme
;; %%debug
;;
;; (begin
;; (define x 1)
;; (set! x 2)
;; )
;; ```
;; %% [markdown]
;; ### Python Integration
;;
;; You can import and use any Python library in Calysto Scheme.
;;
;; In addition, if you wish, you can execute expressions and statements in a Python environment:
;; %%
(python-eval "1 + 2")
;; %%
(python-exec
"
def mypyfunc(a, b):
return a * b
")
;; %% [markdown]
;; This is a shared environment with Scheme:
;; %%
(mypyfunc 4 5)
;; %% [markdown]
;; You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
;; %%
(define! mypyfunc2 (func (lambda (n) n)))
;; %%
(python-eval "mypyfunc2(34)")
;; %% [markdown]
;; # Differences Between Languages
;;
;; ## Major differences between Scheme and Python
;;
;; 1. In Scheme, double quotes are used for strings and may contain newlines
;; 1. In Scheme, a single quote is short for (quote ...) and means "literal"
;; 1. In Scheme, everything is an expression and has a return value
;; 1. Python does not support macros (e.g., extending syntax)
;; 1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
;; 1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
;; 1. Scheme procedures are not Python functions, but there are means to use one as the other.
;;
;; ## Major Differences Between Calysto Scheme and other Schemes
;;
;; 1. define-syntax works slightly differently
;; 1. In Calysto Scheme, #(...) is short for '#(...)
;; 1. Calysto Scheme is missing many standard functions (see list at bottom)
;; 1. Calysto Scheme has a built-in amb operator called `choose`
;; 1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
;;
;; ### Stack Trace
;;
;; Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
;; %%
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
;; %%
(fact 5)
;; %% [markdown]
;; To turn off the stack trace on error:
;;
;; ```scheme
;; (use-stack-trace #f)
;; ```
;; That will allow infinite recursive loops without keeping track of the "stack".
;; %% [markdown]
;; # Calysto Scheme Variables
;;
;; ## SCHEMEPATH
;; SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
;; %%
SCHEMEPATH
;; %%
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
;; %%
SCHEMEPATH
;; %% [markdown]
;; ## Getting Started
;;
;; Note that you can use the word `lambda` or \lambda and then press [TAB]
;; %%
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
;; %%
(factorial 5)
;; %% [markdown]
;; ## define-syntax
;; (define-syntax NAME RULES): a method for creating macros
;; %%
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
;; %%
(time (car '(1 2 3 4)))
;; %%
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
;; %%
(collect (* n n) for n in (range 10))
;; %%
(collect (* n n) for n in (range 5 20 3))
;; %%
(collect (* n n) for n in (range 10) if (> n 5))
;; %%
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
;; %%
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
;; %%
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
;; %%
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
;; %%
(for n in (range 10 20 2) do (print n))
;; %%
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
;; %%
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
;; %%
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
;; %%
(! 5)
;; %%
(nth 10 facts)
;; %%
(nth 20 fibs)
;; %%
(first 30 fibs)
;; %% [markdown]
;; ## for-each
;; (for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
;; %%
(for-each (lambda (n) (print n)) '(3 4 5))
;; %% [markdown]
;; ## format
;; (format STRING ITEM ...): format the string with ITEMS as arguments
;; %%
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
;; %% [markdown]
;; ## func
;;
;; Turns a lambda into a Python function.
;;
;; (func (lambda ...))
;; %%
(func (lambda (n) n))
;; %% [markdown]
;; ## There's more!
;;
;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/Reference Guide for Calysto Scheme.ss
================================================
;; -*- coding: utf-8 -*-
;; ---
;; jupyter:
;; kernelspec:
;; display_name: Calysto Scheme (Python)
;; language: scheme
;; name: calysto_scheme
;; ---
;; %% [markdown]
;; Reference Guide for Calysto Scheme
;; ;; [Calysto Scheme](https://github.com/Calysto/calysto_scheme) is a real Scheme programming language, with full support for continuations, including call/cc. It can also use all Python libraries. Also has some extensions that make it more useful (stepper-debugger, choose/fail, stack traces), or make it better integrated with Python. ;; ;; In Jupyter notebooks, because Calysto Scheme uses [MetaKernel](https://github.com/Calysto/metakernel/blob/master/README.rst), it has a fully-supported set of "magics"---meta-commands for additional functionality. This includes running Scheme in parallel. See all of the [MetaKernel Magics](https://github.com/Calysto/metakernel/blob/master/metakernel/magics/README.md). ;; ;; Calysto Scheme is written in Scheme, and then translated into Python (and other backends). The entire functionality lies in a single Python file: https://github.com/Calysto/calysto_scheme/blob/master/calysto_scheme/scheme.py However, you can easily install it (see below). ;; ;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language. ;; ;; ## Installation ;; ;; You can install Calysto Scheme with Python3: ;; ;; ``` ;; pip3 install --upgrade calysto-scheme --user -U ;; python3 -m calysto_kernel install --user ;; ``` ;; ;; or in the system kernel folder with: ;; ;; ``` ;; sudo pip3 install --upgrade calysto-scheme -U ;; sudo python3 -m calysto_kernel install ;; ``` ;; ;; Change pip3/python3 to use a different pip or Python. The version of Python used will determine how Calysto Scheme is run. ;; ;; Use it in the console, qtconsole, or notebook with IPython 3: ;; ;; ``` ;; ipython console --kernel calysto_scheme ;; ipython qtconsole --kernel calysto_scheme ;; ipython notebook --kernel calysto_scheme ;; ``` ;; ;; In addition to all of the following items, Calysto Scheme also has access to all of Python's builtin functions, and all of Python's libraries. For example, you can use `(complex 3 2)` to create a complex number by calling Python's complex function. ;; ;; ## Jupyter Enhancements ;; ;; When you run Calysto Scheme in Jupyter (console, notebook, qtconsole, etc.) you get: ;; ;; * TAB completions of Scheme functions and variable names ;; * display of rich media ;; * stepper/debugger ;; * magics (% macros) ;; * shell commands (! command) ;; * LaTeX equations ;; * LaTeX-style variables ;; * Python integration ;; %% [markdown] ;; ### LaTeX-style variables ;; ;; Calysto Scheme allows you to use LaTeX-style variables in code. For example, if you type: ;; ;; ``` ;; \beta ;; ``` ;; ;; with the cursor right after the 'a' in beta, and then press TAB, it will turn into the unicode character: ;; ;; ``` ;; β ;; ``` ;; ;; There are nearly 1300 different symbols defined (thanks to the Julia language) and documented here: ;; ;; http://docs.julialang.org/en/release-0.4/manual/unicode-input/#man-unicode-input ;; ;; Calysto Scheme may not implement all of those. Some useful and suggestive ones: ;; ;; * \pi - π ;; * \Pi - Π ;; * \Sigma - Σ ;; * \_i - subscript i, such as vectorᵢ ;; %% (define α 67) ;; %% α ;; %% (define i 2) (define vectorᵢ (vector-ref (vector 0 6 3 2) i)) vectorᵢ ;; %% [markdown] ;; ### Rich media ;; %% (import "calysto.display") ;; %% (calysto.display.HTML "This is bold, italics, underlined.") ;; %% (import "calysto.graphics") ;; %% (define canvas (calysto.graphics.Canvas)) ;; %% (define ball (calysto.graphics.Circle '(150 150) 100)) ;; %% (ball.draw canvas) ;; %% [markdown] ;; ### Shell commands ;; %% ! ls /tmp ;; %% [markdown] ;; ### Stepper/Debugger ;; ;; Here is what the debugger looks like: ;; ;;
;;
;; It has breakpoints (click in left margin). You must press Stop to exit the debugger.
;; %% [markdown]
;; ```scheme
;; %%debug
;;
;; (begin
;; (define x 1)
;; (set! x 2)
;; )
;; ```
;; %% [markdown]
;; ### Python Integration
;;
;; You can import and use any Python library in Calysto Scheme.
;;
;; In addition, if you wish, you can execute expressions and statements in a Python environment:
;; %%
(python-eval "1 + 2")
;; %%
(python-exec
"
def mypyfunc(a, b):
return a * b
")
;; %% [markdown]
;; This is a shared environment with Scheme:
;; %%
(mypyfunc 4 5)
;; %% [markdown]
;; You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
;; %%
(define! mypyfunc2 (func (lambda (n) n)))
;; %%
(python-eval "mypyfunc2(34)")
;; %% [markdown]
;; # Differences Between Languages
;;
;; ## Major differences between Scheme and Python
;;
;; 1. In Scheme, double quotes are used for strings and may contain newlines
;; 1. In Scheme, a single quote is short for (quote ...) and means "literal"
;; 1. In Scheme, everything is an expression and has a return value
;; 1. Python does not support macros (e.g., extending syntax)
;; 1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
;; 1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
;; 1. Scheme procedures are not Python functions, but there are means to use one as the other.
;;
;; ## Major Differences Between Calysto Scheme and other Schemes
;;
;; 1. define-syntax works slightly differently
;; 1. In Calysto Scheme, #(...) is short for '#(...)
;; 1. Calysto Scheme is missing many standard functions (see list at bottom)
;; 1. Calysto Scheme has a built-in amb operator called `choose`
;; 1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
;;
;; ### Stack Trace
;;
;; Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
;; %%
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
;; %%
(fact 5)
;; %% [markdown]
;; To turn off the stack trace on error:
;;
;; ```scheme
;; (use-stack-trace #f)
;; ```
;; That will allow infinite recursive loops without keeping track of the "stack".
;; %% [markdown]
;; # Calysto Scheme Variables
;;
;; ## SCHEMEPATH
;; SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
;; %%
SCHEMEPATH
;; %%
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
;; %%
SCHEMEPATH
;; %% [markdown]
;; ## Getting Started
;;
;; Note that you can use the word `lambda` or \lambda and then press [TAB]
;; %%
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
;; %%
(factorial 5)
;; %% [markdown]
;; ## define-syntax
;; (define-syntax NAME RULES): a method for creating macros
;; %%
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
;; %%
(time (car '(1 2 3 4)))
;; %%
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
;; %%
(collect (* n n) for n in (range 10))
;; %%
(collect (* n n) for n in (range 5 20 3))
;; %%
(collect (* n n) for n in (range 10) if (> n 5))
;; %%
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
;; %%
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
;; %%
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
;; %%
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
;; %%
(for n in (range 10 20 2) do (print n))
;; %%
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
;; %%
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
;; %%
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
;; %%
(! 5)
;; %%
(nth 10 facts)
;; %%
(nth 20 fibs)
;; %%
(first 30 fibs)
;; %% [markdown]
;; ## for-each
;; (for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
;; %%
(for-each (lambda (n) (print n)) '(3 4 5))
;; %% [markdown]
;; ## format
;; (format STRING ITEM ...): format the string with ITEMS as arguments
;; %%
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
;; %% [markdown]
;; ## func
;;
;; Turns a lambda into a Python function.
;;
;; (func (lambda ...))
;; %%
(func (lambda (n) n))
;; %% [markdown]
;; ## There's more!
;;
;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/The flavors of raw cells.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [raw] raw_mimetype="text/latex"
# $1+1$
# %% [raw] raw_mimetype="text/restructuredtext"
# :math:`1+1`
# %% [raw] raw_mimetype="text/html"
# Bold text
# %% [raw] raw_mimetype="text/markdown"
# **Bold text**
# %% [raw] raw_mimetype="text/x-python"
# 1 + 1
# %% [raw]
# Not formatted
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/cat_variable.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
cat = 42
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/coconut_homepage_demo.coco
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Coconut
# language: coconut
# name: coconut
# ---
# %% [markdown]
# Taken from [coconut-lang.org](coconut-lang.org)
# %% [markdown]
# pipeline-style programming
# %%
"hello, world!" |> print
# %% [markdown]
# prettier lambdas
# %%
x -> x ** 2
# %% [markdown]
# partial application
# %%
range(10) |> map$(pow$(?, 2)) |> list
# %% [markdown]
# pattern-matching
# %%
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
# %% [markdown]
# destructuring assignment
# %%
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
# %% [markdown]
# infix notation
# %%
# 5 `mod` 3 == 2
# %% [markdown]
# operator functions
# %%
product = reduce$(*)
# %% [markdown]
# function composition
# %%
# (f..g..h)(x, y, z)
# %% [markdown]
# lazy lists
# %%
# (| first_elem() |) :: rest_elems()
# %% [markdown]
# parallel programming
# %%
range(100) |> parallel_map$(pow$(2)) |> list
# %% [markdown]
# tail call optimization
# %%
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
# %% [markdown]
# algebraic data types
# %%
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
# %% [markdown]
# and much more!
#
# Like what you see? Don't forget to star Coconut on GitHub!
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/convert_to_py_then_test_with_update83.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
# %%time
print('asdf')
# %% [markdown]
# Thanks for jupytext!
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/csharp.cs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: .NET (C#)
// language: C#
// name: .net-csharp
// ---
// %% [markdown]
// We start with...
// %%
Console.WriteLine("Hello World!");
// %% [markdown]
// Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
// %%
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
// %% [markdown]
// We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
// %%
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
// %%
(MathString)@"e^{i \pi} = -1"
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/demo_gdl_fbp.pro
================================================
; -*- coding: utf-8 -*-
; ---
; jupyter:
; kernelspec:
; display_name: IDL [conda env:gdl] *
; language: IDL
; name: conda-env-gdl-idl
; ---
; %% [markdown]
; ## GDL demo notebook
; %% [markdown]
; Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
;
; This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
; %%
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
; %%
;; Enable inline plotting
!inline=1
; %%
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
; %% [markdown]
; Now we define simple forward and backprojection functions:
; %%
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
; %%
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
; %% [markdown]
; This allows us to create a sinogram:
; %%
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
; %% [markdown]
; On this we can apply a simple FBP reconstruction:
; %%
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
; %%
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
; %% [markdown]
; ### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/evcxr_jupyter_tour.rs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Rust
// language: rust
// name: rust
// ---
// %% [markdown]
// # Tour of the EvCxR Jupyter Kernel
// For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
//
// ## Printing to outputs and evaluating expressions
// Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
// %%
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
// %% [markdown]
// ## Assigning and making use of variables
// We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
// %%
let mut message = "Hello ".to_owned();
// %%
message.push_str("world!");
// %%
message
// %% [markdown]
// ## Defining and redefining functions
// Next we'll define a function
// %%
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
// %%
(1..13).map(fib).collect::| "); html.push_str(&format!("{:?}", self.values[r * self.row_size + c])); html.push_str(" | "); } html.push_str("
# %% [markdown] Collapsed="false" kernel="SoS"
# ## Step 1
#
# Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.
#
# 
# %% Collapsed="false" kernel="SoS"
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
# %% [markdown] Collapsed="false" kernel="python3"
# ## Step 2
#
# Now, pair it with Jupytex
#
# 
# %% [markdown] Collapsed="false" kernel="python3"
# ### Step 3
#
# Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
# %% [markdown] Collapsed="false" kernel="python3"
# ### Step 4
#
# Reopen the notebook. Here is the outcome
#
# 
#
#
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/kalman_filter_and_visualization.q
================================================
/ ---
/ jupyter:
/ kernelspec:
/ display_name: Q 3.5
/ language: q
/ name: qpk
/ ---
/ %%
plt: .p.import`matplotlib.pyplot
/ %%
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
/ %%
price: 100 + sums 0.5 - (n:50)?1.
/ %%
output:filter price
/ %%
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
/ %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/logtalk_notebook.lgt
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Logtalk
% language: logtalk
% name: logtalk_kernel
% ---
% %% [markdown]
% # An implementation of the Ackermann function
% %% vscode={"languageId": "logtalk"}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
% %% [markdown]
% ## Sample query
% %% vscode={"languageId": "logtalk"}
ack::ack(2, 4, V).
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/lua_example.lua
================================================
-- -*- coding: utf-8 -*-
-- ---
-- jupyter:
-- kernelspec:
-- display_name: Lua
-- language: lua
-- name: lua
-- ---
-- %% [markdown]
-- Source: https://www.lua.org/pil/19.3.html
-- %% [markdown]
-- # Sort
-- %% [markdown]
-- Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
-- %% [markdown]
-- A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
-- %%
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
-- %% [markdown]
-- Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
-- %%
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
-- %% [markdown]
-- Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
-- %% [markdown]
-- As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
-- %%
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
-- %% [markdown]
-- With this function, it is easy to print those function names in alphabetical order. The loop
-- %%
for name, line in pairsByKeys(lines) do
print(name, line)
end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/maxima_example.mac
================================================
/* --- */
/* jupyter: */
/* kernelspec: */
/* display_name: Maxima */
/* language: maxima */
/* name: maxima */
/* --- */
/* %% [markdown] */
/* ## maxima misc */
/* %% */
kill(all)$
/* %% */
f(x) := 1/(x^2+l^2)^(3/2);
/* %% */
integrate(f(x), x);
/* %% */
tex(%)$
/* %% */
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/notebook_with_complex_metadata.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/nteract_with_parameter.py
================================================
# ---
# jupyter:
# kernel_info:
# name: python3
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% inputHidden=false outputHidden=false tags=["parameters"]
param = 4
# %% inputHidden=false outputHidden=false
import pandas as pd
# %% inputHidden=false outputHidden=false
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
# %% inputHidden=false outputHidden=false
# %matplotlib inline
df.plot(kind='bar')
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/ocaml_notebook.ml
================================================
(* --- *)
(* jupyter: *)
(* jupytext: *)
(* formats: ipynb:markdown,md *)
(* kernelspec: *)
(* display_name: OCaml default *)
(* language: OCaml *)
(* name: ocaml-jupyter *)
(* --- *)
(* %% [markdown] *)
(* # Example of an OCaml notebook *)
(* %% *)
let sum x y = x + y
(* %% [markdown] *)
(* Let's try our function: *)
(* %% *)
sum 3 4 = 7 + 0
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/octave_notebook.m
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Octave
% language: octave
% name: octave
% ---
% %% [markdown]
% A markdown cell
% %%
1 + 1
% %%
% a code cell with comments
2 + 2
% %%
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
% %%
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
% %% [markdown]
% And to finish with, a Python cell
% %% language="python"
% a = 1
% %% language="python"
% a + 1
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/plotly_graphs.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %% [markdown]
# This notebook contains complex outputs, including plotly javascript graphs.
# %% [markdown]
# # Interactive plots
# %% [markdown]
# We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
# %%
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
# %%
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/powershell.ps1
================================================
# ---
# jupyter:
# kernelspec:
# display_name: PowerShell
# language: PowerShell
# name: powershell
# ---
# %% [markdown]
# This is an extract from
# https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
# %%
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/raw_cell_with_complex_yaml_like_content.py
================================================
# ---
#
# This is a complex paragraph
# that is split over multiple lines.
#
# It also includes blank lines.
#
#
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/raw_cell_with_non_dict_yaml_content.py
================================================
# ---
# Content.
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %%
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_percent/root_cpp.cpp
================================================
// ---
// jupyter:
// kernelspec:
// display_name: ROOT C++
// language: c++
// name: root
// ---
// %%
#include
//
//
//
// %% [markdown]
// ## Output and error streams
//
// `std::cout` and `std::cerr` are redirected to the notebook frontend.
// %%
#include
// To run the selected code cell, hit
// Shift + Enter//
Original
)");
// %%
xcpp::display(rect, "some_display_id");
// %%
// Update the rectangle to be blue
rect.m_content = R"(
Updated
)";
xcpp::display(rect, "some_display_id", true);
// %% [markdown]
// ## Magics
//
// Magics are special commands for the kernel that are not part of the C++ language.
//
// They are defined with the symbol `%` for a line magic and `%%` for a cell magic.
//
// More documentation for magics is available at https://xeus-cling.readthedocs.io/en/latest/magics.html.
// %%
#include Jupytext on GitHub
# + language="latex" # $\frac{\pi}{2}$ # - # %load_ext rpy2.ipython # + language="R" # library(ggplot2) # ggplot(data=data.frame(x=c('A', 'B'), y=c(5, 2)), aes(x,weight=y)) + geom_bar() # - # %matplotlib inline import pandas as pd pd.Series({'A':5, 'B':2}).plot(figsize=(3,2), kind='bar') ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script/Notebook with metadata and long cells.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # # Part one - various cells # Here we have a markdown cell # # # with two blank lines # Now we have a markdown cell # with a code block inside it # # ```python # 1 + 1 # ``` # # After that cell we'll have a code cell # + 2 + 2 3 + 3 # - # Followed by a raw cell # + active="" # This is # the content # of the raw cell # - # # Part two - cell metadata # + [markdown] key="value" # This is a markdown cell with cell metadata `{"key": "value"}` # + .class tags=["parameters"] """This is a code cell with metadata `{"tags":["parameters"], ".class":null}`""" # + key="value" active="" # This is a raw cell with cell metadata `{"key": "value"}` ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script/Notebook_with_R_magic.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 2 # language: python # name: python2 # --- # # A notebook with R cells # # This notebook shows the use of R cells to generate plots # %load_ext rpy2.ipython # + language="R" # suppressMessages(require(tidyverse)) # + language="R" # ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() # - # The default plot dimensions are not good for us, so we use the -w and -h parameters in %%R magic to set the plot size # + magic_args="-w 400 -h 240" language="R" # ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script/Notebook_with_more_R_magic_111.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # + # %load_ext rpy2.ipython import pandas as pd df = pd.DataFrame( { "Letter": ["a", "a", "a", "b", "b", "b", "c", "c", "c"], "X": [4, 3, 5, 2, 1, 7, 7, 5, 9], "Y": [0, 4, 3, 6, 7, 10, 11, 9, 13], "Z": [1, 2, 3, 1, 2, 3, 1, 2, 3], } ) # + magic_args="-i df" language="R" # library("ggplot2") # ggplot(data = df) + geom_point(aes(x = X, y = Y, color = Letter, size = Z)) ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script/R notebook with invalid cell keys.R ================================================ # --- # jupyter: # kernelspec: # display_name: R # language: R # name: ir # --- # This notebook was created with IRKernel 0.8.12, and is not completely valid, as the code cell below contains an unexpected 'source' entry. This did cause https://github.com/mwouts/jupytext/issues/234. Note that the problem is solved when one upgrades to IRKernel 1.0.0. library("ggplot2") ggplot(mtcars, aes(mpg)) + stat_ecdf() ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script/R notebook with invalid cell keys.low.r ================================================ # --- # jupyter: # kernelspec: # display_name: R # language: R # name: ir # --- # This notebook was created with IRKernel 0.8.12, and is not completely valid, as the code cell below contains an unexpected 'source' entry. This did cause https://github.com/mwouts/jupytext/issues/234. Note that the problem is solved when one upgrades to IRKernel 1.0.0. library("ggplot2") ggplot(mtcars, aes(mpg)) + stat_ecdf() ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script/Reference Guide for Calysto Scheme.scm ================================================ ;; -*- coding: utf-8 -*- ;; --- ;; jupyter: ;; kernelspec: ;; display_name: Calysto Scheme (Python) ;; language: scheme ;; name: calysto_scheme ;; --- ;;Reference Guide for Calysto Scheme
;; ;; [Calysto Scheme](https://github.com/Calysto/calysto_scheme) is a real Scheme programming language, with full support for continuations, including call/cc. It can also use all Python libraries. Also has some extensions that make it more useful (stepper-debugger, choose/fail, stack traces), or make it better integrated with Python. ;; ;; In Jupyter notebooks, because Calysto Scheme uses [MetaKernel](https://github.com/Calysto/metakernel/blob/master/README.rst), it has a fully-supported set of "magics"---meta-commands for additional functionality. This includes running Scheme in parallel. See all of the [MetaKernel Magics](https://github.com/Calysto/metakernel/blob/master/metakernel/magics/README.md). ;; ;; Calysto Scheme is written in Scheme, and then translated into Python (and other backends). The entire functionality lies in a single Python file: https://github.com/Calysto/calysto_scheme/blob/master/calysto_scheme/scheme.py However, you can easily install it (see below). ;; ;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language. ;; ;; ## Installation ;; ;; You can install Calysto Scheme with Python3: ;; ;; ``` ;; pip3 install --upgrade calysto-scheme --user -U ;; python3 -m calysto_kernel install --user ;; ``` ;; ;; or in the system kernel folder with: ;; ;; ``` ;; sudo pip3 install --upgrade calysto-scheme -U ;; sudo python3 -m calysto_kernel install ;; ``` ;; ;; Change pip3/python3 to use a different pip or Python. The version of Python used will determine how Calysto Scheme is run. ;; ;; Use it in the console, qtconsole, or notebook with IPython 3: ;; ;; ``` ;; ipython console --kernel calysto_scheme ;; ipython qtconsole --kernel calysto_scheme ;; ipython notebook --kernel calysto_scheme ;; ``` ;; ;; In addition to all of the following items, Calysto Scheme also has access to all of Python's builtin functions, and all of Python's libraries. For example, you can use `(complex 3 2)` to create a complex number by calling Python's complex function. ;; ;; ## Jupyter Enhancements ;; ;; When you run Calysto Scheme in Jupyter (console, notebook, qtconsole, etc.) you get: ;; ;; * TAB completions of Scheme functions and variable names ;; * display of rich media ;; * stepper/debugger ;; * magics (% macros) ;; * shell commands (! command) ;; * LaTeX equations ;; * LaTeX-style variables ;; * Python integration ;; ### LaTeX-style variables ;; ;; Calysto Scheme allows you to use LaTeX-style variables in code. For example, if you type: ;; ;; ``` ;; \beta ;; ``` ;; ;; with the cursor right after the 'a' in beta, and then press TAB, it will turn into the unicode character: ;; ;; ``` ;; β ;; ``` ;; ;; There are nearly 1300 different symbols defined (thanks to the Julia language) and documented here: ;; ;; http://docs.julialang.org/en/release-0.4/manual/unicode-input/#man-unicode-input ;; ;; Calysto Scheme may not implement all of those. Some useful and suggestive ones: ;; ;; * \pi - π ;; * \Pi - Π ;; * \Sigma - Σ ;; * \_i - subscript i, such as vectorᵢ (define α 67) α (define i 2) (define vectorᵢ (vector-ref (vector 0 6 3 2) i)) vectorᵢ ;; ### Rich media (import "calysto.display") (calysto.display.HTML "This is bold, italics, underlined.") (import "calysto.graphics") (define canvas (calysto.graphics.Canvas)) (define ball (calysto.graphics.Circle '(150 150) 100)) (ball.draw canvas) ;; ### Shell commands ! ls /tmp ;; ### Stepper/Debugger ;; ;; Here is what the debugger looks like: ;; ;;
;;
;; It has breakpoints (click in left margin). You must press Stop to exit the debugger.
;; ```scheme
;; ;; %%debug
;;
;; (begin
;; (define x 1)
;; (set! x 2)
;; )
;; ```
;; ### Python Integration
;;
;; You can import and use any Python library in Calysto Scheme.
;;
;; In addition, if you wish, you can execute expressions and statements in a Python environment:
(python-eval "1 + 2")
(python-exec
"
def mypyfunc(a, b):
return a * b
")
;; This is a shared environment with Scheme:
(mypyfunc 4 5)
;; You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
(define! mypyfunc2 (func (lambda (n) n)))
(python-eval "mypyfunc2(34)")
;; # Differences Between Languages
;;
;; ## Major differences between Scheme and Python
;;
;; 1. In Scheme, double quotes are used for strings and may contain newlines
;; 1. In Scheme, a single quote is short for (quote ...) and means "literal"
;; 1. In Scheme, everything is an expression and has a return value
;; 1. Python does not support macros (e.g., extending syntax)
;; 1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
;; 1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
;; 1. Scheme procedures are not Python functions, but there are means to use one as the other.
;;
;; ## Major Differences Between Calysto Scheme and other Schemes
;;
;; 1. define-syntax works slightly differently
;; 1. In Calysto Scheme, #(...) is short for '#(...)
;; 1. Calysto Scheme is missing many standard functions (see list at bottom)
;; 1. Calysto Scheme has a built-in amb operator called `choose`
;; 1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
;;
;; ### Stack Trace
;;
;; Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
(fact 5)
;; To turn off the stack trace on error:
;;
;; ```scheme
;; (use-stack-trace #f)
;; ```
;; That will allow infinite recursive loops without keeping track of the "stack".
;; # Calysto Scheme Variables
;;
;; ## SCHEMEPATH
;; SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
SCHEMEPATH
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
SCHEMEPATH
;; ## Getting Started
;;
;; Note that you can use the word `lambda` or \lambda and then press [TAB]
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
(factorial 5)
;; ## define-syntax
;; (define-syntax NAME RULES): a method for creating macros
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
(time (car '(1 2 3 4)))
;; +
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
;; -
(collect (* n n) for n in (range 10))
(collect (* n n) for n in (range 5 20 3))
(collect (* n n) for n in (range 10) if (> n 5))
;; +
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
;; +
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
;; -
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
(for n in (range 10 20 2) do (print n))
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
;; +
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
;; -
(! 5)
(nth 10 facts)
(nth 20 fibs)
(first 30 fibs)
;; ## for-each
;; (for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
(for-each (lambda (n) (print n)) '(3 4 5))
;; ## format
;; (format STRING ITEM ...): format the string with ITEMS as arguments
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
;; ## func
;;
;; Turns a lambda into a Python function.
;;
;; (func (lambda ...))
(func (lambda (n) n))
;; ## There's more!
;;
;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/Reference Guide for Calysto Scheme.ss
================================================
;; -*- coding: utf-8 -*-
;; ---
;; jupyter:
;; kernelspec:
;; display_name: Calysto Scheme (Python)
;; language: scheme
;; name: calysto_scheme
;; ---
;; Reference Guide for Calysto Scheme
;; ;; [Calysto Scheme](https://github.com/Calysto/calysto_scheme) is a real Scheme programming language, with full support for continuations, including call/cc. It can also use all Python libraries. Also has some extensions that make it more useful (stepper-debugger, choose/fail, stack traces), or make it better integrated with Python. ;; ;; In Jupyter notebooks, because Calysto Scheme uses [MetaKernel](https://github.com/Calysto/metakernel/blob/master/README.rst), it has a fully-supported set of "magics"---meta-commands for additional functionality. This includes running Scheme in parallel. See all of the [MetaKernel Magics](https://github.com/Calysto/metakernel/blob/master/metakernel/magics/README.md). ;; ;; Calysto Scheme is written in Scheme, and then translated into Python (and other backends). The entire functionality lies in a single Python file: https://github.com/Calysto/calysto_scheme/blob/master/calysto_scheme/scheme.py However, you can easily install it (see below). ;; ;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language. ;; ;; ## Installation ;; ;; You can install Calysto Scheme with Python3: ;; ;; ``` ;; pip3 install --upgrade calysto-scheme --user -U ;; python3 -m calysto_kernel install --user ;; ``` ;; ;; or in the system kernel folder with: ;; ;; ``` ;; sudo pip3 install --upgrade calysto-scheme -U ;; sudo python3 -m calysto_kernel install ;; ``` ;; ;; Change pip3/python3 to use a different pip or Python. The version of Python used will determine how Calysto Scheme is run. ;; ;; Use it in the console, qtconsole, or notebook with IPython 3: ;; ;; ``` ;; ipython console --kernel calysto_scheme ;; ipython qtconsole --kernel calysto_scheme ;; ipython notebook --kernel calysto_scheme ;; ``` ;; ;; In addition to all of the following items, Calysto Scheme also has access to all of Python's builtin functions, and all of Python's libraries. For example, you can use `(complex 3 2)` to create a complex number by calling Python's complex function. ;; ;; ## Jupyter Enhancements ;; ;; When you run Calysto Scheme in Jupyter (console, notebook, qtconsole, etc.) you get: ;; ;; * TAB completions of Scheme functions and variable names ;; * display of rich media ;; * stepper/debugger ;; * magics (% macros) ;; * shell commands (! command) ;; * LaTeX equations ;; * LaTeX-style variables ;; * Python integration ;; ### LaTeX-style variables ;; ;; Calysto Scheme allows you to use LaTeX-style variables in code. For example, if you type: ;; ;; ``` ;; \beta ;; ``` ;; ;; with the cursor right after the 'a' in beta, and then press TAB, it will turn into the unicode character: ;; ;; ``` ;; β ;; ``` ;; ;; There are nearly 1300 different symbols defined (thanks to the Julia language) and documented here: ;; ;; http://docs.julialang.org/en/release-0.4/manual/unicode-input/#man-unicode-input ;; ;; Calysto Scheme may not implement all of those. Some useful and suggestive ones: ;; ;; * \pi - π ;; * \Pi - Π ;; * \Sigma - Σ ;; * \_i - subscript i, such as vectorᵢ (define α 67) α (define i 2) (define vectorᵢ (vector-ref (vector 0 6 3 2) i)) vectorᵢ ;; ### Rich media (import "calysto.display") (calysto.display.HTML "This is bold, italics, underlined.") (import "calysto.graphics") (define canvas (calysto.graphics.Canvas)) (define ball (calysto.graphics.Circle '(150 150) 100)) (ball.draw canvas) ;; ### Shell commands ! ls /tmp ;; ### Stepper/Debugger ;; ;; Here is what the debugger looks like: ;; ;;
;;
;; It has breakpoints (click in left margin). You must press Stop to exit the debugger.
;; ```scheme
;; ;; %%debug
;;
;; (begin
;; (define x 1)
;; (set! x 2)
;; )
;; ```
;; ### Python Integration
;;
;; You can import and use any Python library in Calysto Scheme.
;;
;; In addition, if you wish, you can execute expressions and statements in a Python environment:
(python-eval "1 + 2")
(python-exec
"
def mypyfunc(a, b):
return a * b
")
;; This is a shared environment with Scheme:
(mypyfunc 4 5)
;; You can use `func` to turn a Scheme procedure into a Python function, and `define!` to put it into the shared environment with Python:
(define! mypyfunc2 (func (lambda (n) n)))
(python-eval "mypyfunc2(34)")
;; # Differences Between Languages
;;
;; ## Major differences between Scheme and Python
;;
;; 1. In Scheme, double quotes are used for strings and may contain newlines
;; 1. In Scheme, a single quote is short for (quote ...) and means "literal"
;; 1. In Scheme, everything is an expression and has a return value
;; 1. Python does not support macros (e.g., extending syntax)
;; 1. In Python, "if X" is false if X is None, False, [], (,) or 0. In Scheme, "if X" is only false if X is #f or 0
;; 1. Calysto Scheme uses continuations, not the call stack. However, for debugging there is a pseudo-stack when an error is raised. You can turn that off with (use-stack-trace #f)
;; 1. Scheme procedures are not Python functions, but there are means to use one as the other.
;;
;; ## Major Differences Between Calysto Scheme and other Schemes
;;
;; 1. define-syntax works slightly differently
;; 1. In Calysto Scheme, #(...) is short for '#(...)
;; 1. Calysto Scheme is missing many standard functions (see list at bottom)
;; 1. Calysto Scheme has a built-in amb operator called `choose`
;; 1. For debugging there is a pseudo-stack when errors are raised in Calysto Scheme. You can turn that off with (use-stack-trace #f)
;;
;; ### Stack Trace
;;
;; Calysto Scheme acts as if it has a call stack, for easier debugging. For example:
(define fact
(lambda (n)
(if (= n 1)
q
(* n (fact (- n 1))))))
(fact 5)
;; To turn off the stack trace on error:
;;
;; ```scheme
;; (use-stack-trace #f)
;; ```
;; That will allow infinite recursive loops without keeping track of the "stack".
;; # Calysto Scheme Variables
;;
;; ## SCHEMEPATH
;; SCHEMEPATH is a list of search directories used with (load NAME). This is a reference, so you should append to it rather than attempting to redefine it.
SCHEMEPATH
(set-cdr! (cdr SCHEMEPATH) (list "/var/modules"))
SCHEMEPATH
;; ## Getting Started
;;
;; Note that you can use the word `lambda` or \lambda and then press [TAB]
(define factorial
(λ (n)
(cond
((zero? n) 1)
(else (* n (factorial (- n 1)))))))
(factorial 5)
;; ## define-syntax
;; (define-syntax NAME RULES): a method for creating macros
(define-syntax time
[(time ?exp) (let ((start (current-time)))
?exp
(- (current-time) start))])
(time (car '(1 2 3 4)))
;; +
;;---------------------------------------------------------------------
;; collect is like list comprehension in Python
(define-syntax collect
[(collect ?exp for ?var in ?list)
(filter-map (lambda (?var) ?exp) (lambda (?var) #t) ?list)]
[(collect ?exp for ?var in ?list if ?condition)
(filter-map (lambda (?var) ?exp) (lambda (?var) ?condition) ?list)])
(define filter-map
(lambda (f pred? values)
(if (null? values)
'()
(if (pred? (car values))
(cons (f (car values)) (filter-map f pred? (cdr values)))
(filter-map f pred? (cdr values))))))
;; -
(collect (* n n) for n in (range 10))
(collect (* n n) for n in (range 5 20 3))
(collect (* n n) for n in (range 10) if (> n 5))
;; +
;;---------------------------------------------------------------------
;; for loops
(define-syntax for
[(for ?exp times do . ?bodies)
(for-repeat ?exp (lambda () . ?bodies))]
[(for ?var in ?exp do . ?bodies)
(for-iterate1 ?exp (lambda (?var) . ?bodies))]
[(for ?var at (?i) in ?exp do . ?bodies)
(for-iterate2 0 ?exp (lambda (?var ?i) . ?bodies))]
[(for ?var at (?i ?j . ?rest) in ?exp do . ?bodies)
(for ?var at (?i) in ?exp do
(for ?var at (?j . ?rest) in ?var do . ?bodies))])
(define for-repeat
(lambda (n f)
(if (< n 1)
'done
(begin
(f)
(for-repeat (- n 1) f)))))
(define for-iterate1
(lambda (values f)
(if (null? values)
'done
(begin
(f (car values))
(for-iterate1 (cdr values) f)))))
(define for-iterate2
(lambda (i values f)
(if (null? values)
'done
(begin
(f (car values) i)
(for-iterate2 (+ i 1) (cdr values) f)))))
;; +
(define matrix2d
'((10 20)
(30 40)
(50 60)
(70 80)))
(define matrix3d
'(((10 20 30) (40 50 60))
((70 80 90) (100 110 120))
((130 140 150) (160 170 180))
((190 200 210) (220 230 240))))
;; -
(begin
(define hello 0)
(for 5 times do (set! hello (+ hello 1)))
hello
)
(for sym in '(a b c d) do (define x 1) (set! x sym) (print x))
(for n in (range 10 20 2) do (print n))
(for n at (i j) in matrix2d do (print (list n 'coords: i j)))
(for n at (i j k) in matrix3d do (print (list n 'coords: i j k)))
;; +
(define-syntax scons
[(scons ?x ?y) (cons ?x (lambda () ?y))])
(define scar car)
(define scdr
(lambda (s)
(let ((result ((cdr s))))
(set-cdr! s (lambda () result))
result)))
(define first
(lambda (n s)
(if (= n 0)
'()
(cons (scar s) (first (- n 1) (scdr s))))))
(define nth
(lambda (n s)
(if (= n 0)
(scar s)
(nth (- n 1) (scdr s)))))
(define smap
(lambda (f s)
(scons (f (scar s)) (smap f (scdr s)))))
(define ones (scons 1 ones))
(define nats (scons 0 (combine nats + ones)))
(define combine
(lambda (s1 op s2)
(scons (op (scar s1) (scar s2)) (combine (scdr s1) op (scdr s2)))))
(define fibs (scons 1 (scons 1 (combine fibs + (scdr fibs)))))
(define facts (scons 1 (combine facts * (scdr nats))))
(define ! (lambda (n) (nth n facts)))
;; -
(! 5)
(nth 10 facts)
(nth 20 fibs)
(first 30 fibs)
;; ## for-each
;; (for-each PROCEDURE LIST): apply PROCEDURE to each item in LIST; like `map` but don't return results
(for-each (lambda (n) (print n)) '(3 4 5))
;; ## format
;; (format STRING ITEM ...): format the string with ITEMS as arguments
(format "This uses formatting ~a ~s ~%" 'apple 'apple)
;; ## func
;;
;; Turns a lambda into a Python function.
;;
;; (func (lambda ...))
(func (lambda (n) n))
;; ## There's more!
;;
;; Please see [Calysto Scheme Language](Calysto%20Scheme%20Language.ipynb) for more details on the Calysto Scheme language.
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/The flavors of raw cells.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + raw_mimetype="text/latex" active=""
# $1+1$
# + raw_mimetype="text/restructuredtext" active=""
# :math:`1+1`
# + raw_mimetype="text/html" active=""
# Bold text
# + raw_mimetype="text/markdown" active=""
# **Bold text**
# + raw_mimetype="text/x-python" active=""
# 1 + 1
# + active=""
# Not formatted
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/cat_variable.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
cat = 42
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/coconut_homepage_demo.coco
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Coconut
# language: coconut
# name: coconut
# ---
# Taken from [coconut-lang.org](coconut-lang.org)
# pipeline-style programming
"hello, world!" |> print
# prettier lambdas
x -> x ** 2
# partial application
range(10) |> map$(pow$(?, 2)) |> list
# pattern-matching
match [head] + tail in [0, 1, 2, 3]:
print(head, tail)
# destructuring assignment
{"list": [0] + rest} = {"list": [0, 1, 2, 3]}
# infix notation
# +
# 5 `mod` 3 == 2
# -
# operator functions
product = reduce$(*)
# function composition
# +
# (f..g..h)(x, y, z)
# -
# lazy lists
# +
# (| first_elem() |) :: rest_elems()
# -
# parallel programming
range(100) |> parallel_map$(pow$(2)) |> list
# tail call optimization
def factorial(n, acc=1):
case n:
match 0:
return acc
match _ is int if n > 0:
return factorial(n-1, acc*n)
# algebraic data types
# +
data Empty()
data Leaf(n)
data Node(l, r)
def size(Empty()) = 0
addpattern def size(Leaf(n)) = 1
addpattern def size(Node(l, r)) = size(l) + size(r)
# -
# and much more!
#
# Like what you see? Don't forget to star Coconut on GitHub!
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/convert_to_py_then_test_with_update83.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
# %%time
print('asdf')
# -
# Thanks for jupytext!
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/csharp.cs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: .NET (C#)
// language: C#
// name: .net-csharp
// ---
// We start with...
Console.WriteLine("Hello World!");
// Then we do a plot with Plotly, following the [Plotting with XPlot](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Plotting%20with%20Xplot.ipynb) example from `dotnet/interactive`:
// +
using XPlot.Plotly;
var bar = new Graph.Bar
{
name = "Bar",
x = new[] {'A', 'B', 'C'},
y = new[] {1, 3, 2}
};
var chart = Chart.Plot(new[] {bar});
chart.WithTitle("A bar plot");
display(chart);
// -
// We also test the math outputs as in the [Math and Latex](https://github.com/dotnet/interactive/blob/master/NotebookExamples/csharp/Docs/Math%20and%20LaTeX.ipynb) example:
(LaTeXString)@"\begin{align} e^{i \pi} = -1\end{align}"
(MathString)@"e^{i \pi} = -1"
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/demo_gdl_fbp.pro
================================================
; -*- coding: utf-8 -*-
; ---
; jupyter:
; kernelspec:
; display_name: IDL [conda env:gdl] *
; language: IDL
; name: conda-env-gdl-idl
; ---
; ## GDL demo notebook
; Demonstration of GDL [(gnudatalanguage)](https://github.com/gnudatalanguage/gdl)
;
; This notebook creates a Shepp-Logan phantom, projects it and then performs an FBP reconstruction.
; +
;; L.A. Shepp and B.F. Logan, “The Fourier reconstruction of a head section,”
;; IEEE Trans. Nucl. Sci. 21(3), 21–43 (1974).
function shepplogan, size = size
if NOT keyword_set(size) then size = 256
phantom = fltarr(size,size)
tmp = (findgen(size)-((size-1)/2.0)) / (size/2.0)
xcor = rebin(tmp,size,size)
ycor = rebin(transpose(tmp),size,size)
tmp = fltarr(size,size)
aa={cx: 0.0, cy: 0.0, maj:0.69, min:0.92, theta: 0.0, val: 2.0 }
bb={cx: 0.0, cy:-0.0184, maj:0.6624, min:0.874, theta: 0.0, val:-0.98}
cc={cx: 0.22, cy: 0.0, maj:0.11, min:0.31, theta:-18.0, val:-0.02}
dd={cx:-0.22, cy: 0.0, maj:0.16, min:0.41, theta: 18.0, val:-0.02}
ee={cx: 0.0, cy: 0.35, maj:0.21, min:0.25, theta: 0.0, val:-0.01}
ff={cx: 0.0, cy: 0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
gg={cx: 0.0, cy:-0.1, maj:0.046, min:0.046, theta: 0.0, val:-0.01}
hh={cx:-0.08, cy:-0.605, maj:0.046, min:0.023, theta: 0.0, val:-0.01}
ii={cx: 0.0, cy:-0.605, maj:0.023, min:0.023, theta: 0.0, val:-0.01}
jj={cx: 0.06, cy:-0.605, maj:0.023, min:0.046, theta: 0.0, val:-0.01}
list = [aa,bb,cc,dd,ee,ff,gg,hh,ii,jj]
for n = 0, n_elements(list)-1 do begin
tmp = ((xcor-list[n].cx) / list[n].maj)^2 $
+ ((ycor-list[n].cy) / list[n].min)^2
if list[n].theta NE 0 then begin
nx = (size-1) * (list[n].cx + 1) / 2
ny = (size-1) * (list[n].cy + 1) / 2
tmp = rot(tmp, -list[n].theta, 1, nx, ny, /interp, /pivot)
endif
phantom[where(tmp LE 1.0)] += list[n].val
endfor
return, phantom < 1.1
end
; -
;; Enable inline plotting
!inline=1
phantom = shepplogan()
window, 0, xsize=256, ysize=256
tvscl, phantom > 0.95
; Now we define simple forward and backprojection functions:
; +
function proj, image, angle
sino_size_x = max(size(image,/dim))
sino_size_y = n_elements(angle)
sino = fltarr(sino_size_x, sino_size_y)
for aa=0, n_elements(angle)-1 do begin
sino[*,aa] = total(rot(image, angle[aa], /interp), 2)
endfor
return, sino
end
; +
function back, sino, angle
image_size = n_elements(sino[*,0])
image = fltarr(image_size,image_size)
for aa=0, n_elements(angle)-1 do begin
image += rot(rebin(sino[*,aa],[image_size,image_size]), -angle[aa], /interp)
endfor
return, image / n_elements(angle)
end
; -
; This allows us to create a sinogram:
angles = findgen(360)
sino = proj(phantom, angles)
window, 0, xsize=256, ysize=360
tvscl, sino
; On this we can apply a simple FBP reconstruction:
; +
;; G.L. Zeng, “Revisit of the Ramp Filter,”
;; IEEE Trans. Nucl. Sci. 62(1), 131–136 (2015).
function fbp, sino, angles
ntot = n_elements(sino[*,0])
nang = n_elements(sino[0,*])
npos = ntot / 2 + 1 ; integer division needed !
nneg = ntot - npos
freq = findgen(ntot)
freq[npos:ntot-1] = REVERSE(freq[1:nneg])
freq[0] = 1
filter = -1 / (!pi * freq)^2
filter[where(freq mod 2 EQ 0)] *= -0.0
filter[0] = 0.25
filter = abs(fft(filter)) * ntot
filter[ntot/4:ntot/4+ntot/2-1] *= 0.0
filter = rebin(filter,ntot,nang)
;; apply filter to the sinogram
fsino = fft(sino, dim=1)
fsino *= filter
fsino = fft(fsino, dim=1, /overwrite, /inverse)
fsino = !pi * real_part(fsino)
;; backproject the filtered sinogram
return, back(fsino, angles)
end
; +
reconstruction = fbp(sino, angles)
window, 0, xsize=512, ysize=256
tvscl, [phantom, reconstruction] > 0.8
; -
; ### The end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/evcxr_jupyter_tour.rs
================================================
// ---
// jupyter:
// kernelspec:
// display_name: Rust
// language: rust
// name: rust
// ---
// # Tour of the EvCxR Jupyter Kernel
// For those not already familiar with Jupyter notebook, it lets you write code into "cells" like the box below. Cells can alternatively contain markdown, like this text here. Each code cell is compiled and executed separately, but variables, defined functions etc persist between cells.
//
// ## Printing to outputs and evaluating expressions
// Lets print something to stdout and stderr then return a final expression to see how that's presented. Note that stdout and stderr are separate streams, so may not appear in the same order is their respective print statements.
println!("Hello world");
eprintln!("Hello error");
format!("Hello {}", "world")
// ## Assigning and making use of variables
// We define a variable `message`, then in the subsequent cell, modify the string and finally print it out. We could also do all this in the one cell if we wanted.
let mut message = "Hello ".to_owned();
message.push_str("world!");
message
// ## Defining and redefining functions
// Next we'll define a function
pub fn fib(x: i32) -> i32 {
if x <= 2 {0} else {fib(x - 2) + fib(x - 1)}
}
(1..13).map(fib).collect::| "); html.push_str(&format!("{:?}", self.values[r * self.row_size + c])); html.push_str(" | "); } html.push_str("
# + [markdown] Collapsed="false" kernel="SoS"
# ## Step 1
#
# Please, choose SOS Kernel and then, in the cell code, choose SOS (or any other kernel available), the outcome is the same.
#
# 
# + Collapsed="false" kernel="SoS"
import pandas as pd
import numpy as np
pd.DataFrame({
'x': np.random.random(10),
'y': np.random.random(10),
})
# + [markdown] Collapsed="false" kernel="python3"
# ## Step 2
#
# Now, pair it with Jupytex
#
# 
# + [markdown] Collapsed="false" kernel="python3"
# ### Step 3
#
# Save the notebook, restart and clear all, **save**, then Shut down kernel. Close the notebook and reopen
# + [markdown] Collapsed="false" kernel="python3"
# ### Step 4
#
# Reopen the notebook. Here is the outcome
#
# 
#
#
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/kalman_filter_and_visualization.q
================================================
/ ---
/ jupyter:
/ kernelspec:
/ display_name: Q 3.5
/ language: q
/ name: qpk
/ ---
plt: .p.import`matplotlib.pyplot
/ +
filter: {
t: ([] x: `float $ x; xh: `float $ x; p: (count x) # R: var x);
(first t), iterate[R; R]\[first t; 1 _ t]
}
iterate: {[Q; R; x; y]
x[`p]+: Q;
k: x[`p] % R + x[`p];
`x`xh`p ! (y[`x]; x[`xh] + k * y[`x] - x[`xh]; (1 - k) * x[`p])
}
/ -
price: 100 + sums 0.5 - (n:50)?1.
output:filter price
plt[`:plot][til n; output`x; `label pykw "price"];
plt[`:plot][til n; output`xh;`label pykw "forecast"];
plt[`:legend][];
plt[`:show][];
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/logtalk_notebook.lgt
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Logtalk
% language: logtalk
% name: logtalk_kernel
% ---
% # An implementation of the Ackermann function
% + vscode={"languageId": "logtalk"}
%%load ack.lgt
:- object(ack).
:- info([
version is 1:0:0,
author is 'Paulo Moura',
date is 2008-3-31,
comment is 'Ackermann function (general recursive function).'
]).
:- public(ack/3).
:- mode(ack(+integer, +integer, -integer), one).
:- info(ack/3, [
comment is 'Ackermann function.',
argnames is ['M', 'N', 'V']
]).
ack(0, N, V) :-
!,
V is N + 1.
ack(M, 0, V) :-
!,
M2 is M - 1,
ack(M2, 1, V).
ack(M, N, V) :-
M2 is M - 1,
N2 is N - 1,
ack(M, N2, V2),
ack(M2, V2, V).
:- end_object.
% -
% ## Sample query
% + vscode={"languageId": "logtalk"}
ack::ack(2, 4, V).
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/lua_example.lua
================================================
-- -*- coding: utf-8 -*-
-- ---
-- jupyter:
-- kernelspec:
-- display_name: Lua
-- language: lua
-- name: lua
-- ---
-- Source: https://www.lua.org/pil/19.3.html
-- # Sort
-- Another useful function on arrays is table.sort, which we have seen before. It receives the array to be sorted, plus an optional order function. This order function receives two arguments and must return true if the first argument should come first in the sorted array. If this function is not provided, sort uses the default less-than operation (corresponding to the `<´ operator).
-- A common mistake is to try to order the indices of a table. In a table, the indices form a set, and have no order whatsoever. If you want to order them, you have to copy them to an array and then sort the array. Let us see an example. Suppose that you read a source file and build a table that gives, for each function name, the line where that function is defined; something like this:
lines = {
luaH_set = 10,
luaH_get = 24,
luaH_present = 48,
}
-- Now you want to print these function names in alphabetical order. If you traverse this table with pairs, the names appear in an arbitrary order. However, you cannot sort them directly, because these names are keys of the table. However, when you put these names into an array, then you can sort them. First, you must create an array with those names, then sort it, and finally print the result:
a = {}
for n in pairs(lines) do table.insert(a, n) end
table.sort(a)
for i,n in ipairs(a) do print(n) end
-- Note that, for Lua, arrays also have no order. But we know how to count, so we get ordered values as long as we access the array with ordered indices. That is why you should always traverse arrays with ipairs, rather than pairs. The first imposes the key order 1, 2, ..., whereas the latter uses the natural arbitrary order of the table.
-- As a more advanced solution, we can write an iterator that traverses a table following the order of its keys. An optional parameter f allows the specification of an alternative order. It first sorts the keys into an array, and then iterates on the array. At each step, it returns the key and value from the original table:
function pairsByKeys (t, f)
local a = {}
for n in pairs(t) do table.insert(a, n) end
table.sort(a, f)
local i = 0 -- iterator variable
local iter = function () -- iterator function
i = i + 1
if a[i] == nil then return nil
else return a[i], t[a[i]]
end
end
return iter
end
-- With this function, it is easy to print those function names in alphabetical order. The loop
for name, line in pairsByKeys(lines) do
print(name, line)
end
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/maxima_example.mac
================================================
/* --- */
/* jupyter: */
/* kernelspec: */
/* display_name: Maxima */
/* language: maxima */
/* name: maxima */
/* --- */
/* ## maxima misc */
kill(all)$
f(x) := 1/(x^2+l^2)^(3/2);
integrate(f(x), x);
tex(%)$
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/notebook_with_complex_metadata.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/nteract_with_parameter.py
================================================
# ---
# jupyter:
# kernel_info:
# name: python3
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + inputHidden=false outputHidden=false tags=["parameters"]
param = 4
# + inputHidden=false outputHidden=false
import pandas as pd
# + inputHidden=false outputHidden=false
df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]},
index=pd.Index(['x0', 'x1'], name='x'))
df
# + inputHidden=false outputHidden=false
# %matplotlib inline
df.plot(kind='bar')
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/ocaml_notebook.ml
================================================
(* --- *)
(* jupyter: *)
(* jupytext: *)
(* formats: ipynb:markdown,md *)
(* kernelspec: *)
(* display_name: OCaml default *)
(* language: OCaml *)
(* name: ocaml-jupyter *)
(* --- *)
(* # Example of an OCaml notebook *)
let sum x y = x + y
(* Let's try our function: *)
sum 3 4 = 7 + 0
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/octave_notebook.m
================================================
% ---
% jupyter:
% kernelspec:
% display_name: Octave
% language: octave
% name: octave
% ---
% A markdown cell
1 + 1
% a code cell with comments
2 + 2
% a simple plot
x = -10:0.1:10;
plot (x, sin (x));
%plot -w 800
% a simple plot with a magic instruction
x = -10:0.1:10;
plot (x, sin (x));
% And to finish with, a Python cell
% + language="python"
% a = 1
% + language="python"
% a + 1
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/plotly_graphs.py
================================================
# ---
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# This notebook contains complex outputs, including plotly javascript graphs.
# # Interactive plots
# We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web.
import plotly.offline as offline
offline.init_notebook_mode(connected=True)
import plotly.graph_objects as go
fig = go.Figure(
data=[go.Bar(y=[2, 3, 1])],
layout=go.Layout(title="bar plot"))
fig.show()
fig.data[0].marker = dict(color='purple')
fig
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/powershell.ps1
================================================
# ---
# jupyter:
# kernelspec:
# display_name: PowerShell
# language: PowerShell
# name: powershell
# ---
# This is an extract from
# https://github.com/Jaykul/Jupyter-PowerShell/blob/master/LiterateDevOps.ipynb
# +
$imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/2/2f/PowerShell_5.0_icon.png'
$ImageData = @{ "png" = (Invoke-WebRequest $imageUrl -UseBasicParsing).RawContentStream.GetBuffer() }
# $ImageData
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 32 } }
Write-Jupyter -InputObject $ImageData -Metadata @{ "image/png" = @{ 'width' = 64 } }
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/raw_cell_with_complex_yaml_like_content.py
================================================
# ---
#
# This is a complex paragraph
# that is split over multiple lines.
#
# It also includes blank lines.
#
#
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/raw_cell_with_non_dict_yaml_content.py
================================================
# ---
# Content.
# jupyter:
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
print("Hello, World!")
================================================
FILE: tests/data/notebooks/outputs/ipynb_to_script/root_cpp.cpp
================================================
// ---
// jupyter:
// kernelspec:
// display_name: ROOT C++
// language: c++
// name: root
// ---
#include
//
//
//
// ## Output and error streams
//
// `std::cout` and `std::cerr` are redirected to the notebook frontend.
// +
#include
// To run the selected code cell, hit
// Shift + Enter//
Original
)");
// -
xcpp::display(rect, "some_display_id");
// +
// Update the rectangle to be blue
rect.m_content = R"(
Updated
)";
xcpp::display(rect, "some_display_id", true);
// -
// ## Magics
//
// Magics are special commands for the kernel that are not part of the C++ language.
//
// They are defined with the symbol `%` for a line magic and `%%` for a cell magic.
//
// More documentation for magics is available at https://xeus-cling.readthedocs.io/en/latest/magics.html.
#include Jupytext on GitHub
# }}} # {{{ language="latex" # $\frac{\pi}{2}$ # }}} # %load_ext rpy2.ipython # {{{ language="R" # library(ggplot2) # ggplot(data=data.frame(x=c('A', 'B'), y=c(5, 2)), aes(x,weight=y)) + geom_bar() # }}} # %matplotlib inline import pandas as pd pd.Series({'A':5, 'B':2}).plot(figsize=(3,2), kind='bar') ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/Notebook with many hash signs.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # ################################################################## # This is a notebook that contains many hash signs. # Hopefully its python representation is not recognized as a Sphinx Gallery script... # ################################################################## # {{{ some = 1 code = 2 some+code ################################################################## # A comment ################################################################## # Another comment # }}} # ################################################################## # This is a notebook that contains many hash signs. # Hopefully its python representation is not recognized as a Sphinx Gallery script... # ################################################################## ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/Notebook with metadata and long cells.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # # Part one - various cells # Here we have a markdown cell # # # with two blank lines # Now we have a markdown cell # with a code block inside it # # ```python # 1 + 1 # ``` # # After that cell we'll have a code cell # {{{ 2 + 2 3 + 3 # }}} # Followed by a raw cell # {{{ active="" # This is # the content # of the raw cell # }}} # # Part two - cell metadata # {{{ [markdown] key="value" # This is a markdown cell with cell metadata `{"key": "value"}` # }}} # {{{ .class tags=["parameters"] """This is a code cell with metadata `{"tags":["parameters"], ".class":null}`""" # }}} # {{{ key="value" active="" # This is a raw cell with cell metadata `{"key": "value"}` # }}} ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/Notebook_with_R_magic.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 2 # language: python # name: python2 # --- # # A notebook with R cells # # This notebook shows the use of R cells to generate plots # %load_ext rpy2.ipython # {{{ language="R" # suppressMessages(require(tidyverse)) # }}} # {{{ language="R" # ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() # }}} # The default plot dimensions are not good for us, so we use the -w and -h parameters in %%R magic to set the plot size # {{{ magic_args="-w 400 -h 240" language="R" # ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() # }}} ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/Notebook_with_more_R_magic_111.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # {{{ # %load_ext rpy2.ipython import pandas as pd df = pd.DataFrame( { "Letter": ["a", "a", "a", "b", "b", "b", "c", "c", "c"], "X": [4, 3, 5, 2, 1, 7, 7, 5, 9], "Y": [0, 4, 3, 6, 7, 10, 11, 9, 13], "Z": [1, 2, 3, 1, 2, 3, 1, 2, 3], } ) # }}} # {{{ magic_args="-i df" language="R" # library("ggplot2") # ggplot(data = df) + geom_point(aes(x = X, y = Y, color = Letter, size = Z)) # }}} ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/The flavors of raw cells.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # {{{ raw_mimetype="text/latex" active="" # $1+1$ # }}} # {{{ raw_mimetype="text/restructuredtext" active="" # :math:`1+1` # }}} # {{{ raw_mimetype="text/html" active="" # Bold text # }}} # {{{ raw_mimetype="text/markdown" active="" # **Bold text** # }}} # {{{ raw_mimetype="text/x-python" active="" # 1 + 1 # }}} # {{{ active="" # Not formatted # }}} ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/cat_variable.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- cat = 42 ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/convert_to_py_then_test_with_update83.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # {{{ # %%time print('asdf') # }}} # Thanks for jupytext! ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/frozen_cell.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # This is an unfrozen cell. Works as usual. print("I'm a regular cell so I run and print!") # {{{ deletable=false editable=false run_control={"frozen": true} # # This is an frozen cell # print("I'm frozen so Im not executed :(") # }}} ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/jupyter.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # # Jupyter notebook # # This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition: a = 1 b = 2 a + b # Now we return a few tuples a, b a, b, a+b # And this is already the end of the notebook ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/jupyter_again.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- c = ''' title: "Quick test" output: ioslides_presentation: widescreen: true smaller: true editor_options: chunk_output_type console ''' import yaml print(yaml.dump(yaml.load(c))) # ?next ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/jupyter_with_raw_cell_in_body.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- 1+2+3 # {{{ active="" # This is a raw cell # }}} # This is a markdown cell ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/jupyter_with_raw_cell_on_top.py ================================================ # --- # title: Quick test # output: # ioslides_presentation: # widescreen: true # smaller: true # editor_options: # chunk_output_type: console # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- 1+2+3 ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/jupyter_with_raw_cell_with_invalid_yaml.py ================================================ # --- # title: Exception: Test # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 (ipykernel) # language: python # name: python3 # --- 1 + 2 + 3 ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/jupyterlab-slideshow_1441.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 (ipykernel) # language: python # name: python3 # --- # {{{ [markdown] @deathbeds/jupyterlab-fonts={"styles": {"": {"body[data-jp-deck-mode='presenting'] &": {"right": "0", "top": "30%", "width": "25%", "z-index": 1}}}} jupyterlab-slideshow={"layer": "slide"} # > **Note** # > # > `slide` layer with a `top` of `30%` # }}} ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/notebook_with_complex_metadata.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/nteract_with_parameter.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernel_info: # name: python3 # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # {{{ inputHidden=false outputHidden=false tags=["parameters"] param = 4 # }}} # {{{ inputHidden=false outputHidden=false import pandas as pd # }}} # {{{ inputHidden=false outputHidden=false df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]}, index=pd.Index(['x0', 'x1'], name='x')) df # }}} # {{{ inputHidden=false outputHidden=false # %matplotlib inline df.plot(kind='bar') # }}} ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/plotly_graphs.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # This notebook contains complex outputs, including plotly javascript graphs. # # Interactive plots # We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web. import plotly.offline as offline offline.init_notebook_mode(connected=True) import plotly.graph_objects as go fig = go.Figure( data=[go.Bar(y=[2, 3, 1])], layout=go.Layout(title="bar plot")) fig.show() fig.data[0].marker = dict(color='purple') fig ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/raw_cell_with_complex_yaml_like_content.py ================================================ # --- # # This is a complex paragraph # that is split over multiple lines. # # It also includes blank lines. # # # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- print("Hello, World!") ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/raw_cell_with_non_dict_yaml_content.py ================================================ # --- # Content. # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- print("Hello, World!") ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/sample_rise_notebook_66.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # {{{ [markdown] slideshow={"slide_type": "slide"} # A markdown cell # }}} # {{{ slideshow={"slide_type": ""} 1+1 # }}} # {{{ [markdown] cell_style="center" slideshow={"slide_type": "fragment"} # Markdown cell two # }}} ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vim_folding_markers/text_outputs_and_images.py ================================================ # --- # jupyter: # jupytext: # cell_markers: '{{{,}}}' # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # This notebook contains outputs of many different types: text, HTML, plots and errors. # # Text outputs # # Using `print`, `sys.stdout` and `sys.stderr` import sys print('using print') sys.stdout.write('using sys.stdout.write') sys.stderr.write('using sys.stderr.write') import logging logging.debug('Debug') logging.info('Info') logging.warning('Warning') logging.error('Error') # # HTML outputs # # Using `pandas`. Here we find two representations: both text and HTML. import pandas as pd pd.DataFrame([4]) from IPython.display import display display(pd.DataFrame([5])) display(pd.DataFrame([6])) # # Images # %matplotlib inline # First plot from matplotlib import pyplot as plt import numpy as np w, h = 3, 3 data = np.zeros((h, w, 3), dtype=np.uint8) data[0,:] = [0,255,0] data[1,:] = [0,0,255] data[2,:] = [0,255,0] data[1:3,1:3] = [255, 0, 0] plt.imshow(data) plt.axis('off') plt.show() # Second plot data[1:3,1:3] = [255, 255, 0] plt.imshow(data) plt.axis('off') plt.show() # # Errors undefined_variable ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/Line_breaks_in_LateX_305.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # This cell uses no particular cell marker # # $$ # \begin{align} # \dot{x} & = \sigma(y-x)\\ # \dot{y} & = \rho x - y - xz \\ # \dot{z} & = -\beta z + xy # \end{align} # $$ # This cell uses no particular cell marker, and a single slash in the $\LaTeX$ equation # # $$ # \begin{align} # \dot{x} & = \sigma(y-x) \ # \dot{y} & = \rho x - y - xz \ # \dot{z} & = -\beta z + xy # \end{align} # $$ # region [markdown] ''' This cell uses the triple quote cell markers introduced at https://github.com/mwouts/jupytext/issues/305 $$ \begin{align} \dot{x} & = \sigma(y-x)\\ \dot{y} & = \rho x - y - xz \\ \dot{z} & = -\beta z + xy \end{align} $$ ''' # endregion ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/Notebook with function and cell metadata 164.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- 1 + 1 # A markdown cell # And below, the cell for function f has non trivial cell metadata. And the next cell as well. # region attributes={"classes": [], "id": "", "n": "10"} def f(x): return x # endregion # region attributes={"classes": [], "id": "", "n": "10"} f(5) # endregion # More text 2 + 2 ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/Notebook with html and latex cells.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # region language="html" #Jupytext on GitHub
# endregion # region language="latex" # $\frac{\pi}{2}$ # endregion # %load_ext rpy2.ipython # region language="R" # library(ggplot2) # ggplot(data=data.frame(x=c('A', 'B'), y=c(5, 2)), aes(x,weight=y)) + geom_bar() # endregion # %matplotlib inline import pandas as pd pd.Series({'A':5, 'B':2}).plot(figsize=(3,2), kind='bar') ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/Notebook with many hash signs.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # ################################################################## # This is a notebook that contains many hash signs. # Hopefully its python representation is not recognized as a Sphinx Gallery script... # ################################################################## # region some = 1 code = 2 some+code ################################################################## # A comment ################################################################## # Another comment # endregion # ################################################################## # This is a notebook that contains many hash signs. # Hopefully its python representation is not recognized as a Sphinx Gallery script... # ################################################################## ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/Notebook with metadata and long cells.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # # Part one - various cells # Here we have a markdown cell # # # with two blank lines # Now we have a markdown cell # with a code block inside it # # ```python # 1 + 1 # ``` # # After that cell we'll have a code cell # region 2 + 2 3 + 3 # endregion # Followed by a raw cell # region active="" # This is # the content # of the raw cell # endregion # # Part two - cell metadata # region [markdown] key="value" # This is a markdown cell with cell metadata `{"key": "value"}` # endregion # region .class tags=["parameters"] """This is a code cell with metadata `{"tags":["parameters"], ".class":null}`""" # endregion # region key="value" active="" # This is a raw cell with cell metadata `{"key": "value"}` # endregion ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/Notebook_with_R_magic.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 2 # language: python # name: python2 # --- # # A notebook with R cells # # This notebook shows the use of R cells to generate plots # %load_ext rpy2.ipython # region language="R" # suppressMessages(require(tidyverse)) # endregion # region language="R" # ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() # endregion # The default plot dimensions are not good for us, so we use the -w and -h parameters in %%R magic to set the plot size # region magic_args="-w 400 -h 240" language="R" # ggplot(iris, aes(x = Sepal.Length, y = Petal.Length, color=Species)) + geom_point() # endregion ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/Notebook_with_more_R_magic_111.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # region # %load_ext rpy2.ipython import pandas as pd df = pd.DataFrame( { "Letter": ["a", "a", "a", "b", "b", "b", "c", "c", "c"], "X": [4, 3, 5, 2, 1, 7, 7, 5, 9], "Y": [0, 4, 3, 6, 7, 10, 11, 9, 13], "Z": [1, 2, 3, 1, 2, 3, 1, 2, 3], } ) # endregion # region magic_args="-i df" language="R" # library("ggplot2") # ggplot(data = df) + geom_point(aes(x = X, y = Y, color = Letter, size = Z)) # endregion ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/The flavors of raw cells.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # region raw_mimetype="text/latex" active="" # $1+1$ # endregion # region raw_mimetype="text/restructuredtext" active="" # :math:`1+1` # endregion # region raw_mimetype="text/html" active="" # Bold text # endregion # region raw_mimetype="text/markdown" active="" # **Bold text** # endregion # region raw_mimetype="text/x-python" active="" # 1 + 1 # endregion # region active="" # Not formatted # endregion ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/cat_variable.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- cat = 42 ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/convert_to_py_then_test_with_update83.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # region # %%time print('asdf') # endregion # Thanks for jupytext! ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/frozen_cell.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # This is an unfrozen cell. Works as usual. print("I'm a regular cell so I run and print!") # region deletable=false editable=false run_control={"frozen": true} # # This is an frozen cell # print("I'm frozen so Im not executed :(") # endregion ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/jupyter.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # # Jupyter notebook # # This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition: a = 1 b = 2 a + b # Now we return a few tuples a, b a, b, a+b # And this is already the end of the notebook ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/jupyter_again.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- c = ''' title: "Quick test" output: ioslides_presentation: widescreen: true smaller: true editor_options: chunk_output_type console ''' import yaml print(yaml.dump(yaml.load(c))) # ?next ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/jupyter_with_raw_cell_in_body.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- 1+2+3 # region active="" # This is a raw cell # endregion # This is a markdown cell ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/jupyter_with_raw_cell_on_top.py ================================================ # --- # title: Quick test # output: # ioslides_presentation: # widescreen: true # smaller: true # editor_options: # chunk_output_type: console # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- 1+2+3 ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/jupyter_with_raw_cell_with_invalid_yaml.py ================================================ # --- # title: Exception: Test # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 (ipykernel) # language: python # name: python3 # --- 1 + 2 + 3 ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/jupyterlab-slideshow_1441.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 (ipykernel) # language: python # name: python3 # --- # region [markdown] @deathbeds/jupyterlab-fonts={"styles": {"": {"body[data-jp-deck-mode='presenting'] &": {"right": "0", "top": "30%", "width": "25%", "z-index": 1}}}} jupyterlab-slideshow={"layer": "slide"} # > **Note** # > # > `slide` layer with a `top` of `30%` # endregion ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/notebook_with_complex_metadata.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/nteract_with_parameter.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernel_info: # name: python3 # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # region inputHidden=false outputHidden=false tags=["parameters"] param = 4 # endregion # region inputHidden=false outputHidden=false import pandas as pd # endregion # region inputHidden=false outputHidden=false df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]}, index=pd.Index(['x0', 'x1'], name='x')) df # endregion # region inputHidden=false outputHidden=false # %matplotlib inline df.plot(kind='bar') # endregion ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/plotly_graphs.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # This notebook contains complex outputs, including plotly javascript graphs. # # Interactive plots # We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web. import plotly.offline as offline offline.init_notebook_mode(connected=True) import plotly.graph_objects as go fig = go.Figure( data=[go.Bar(y=[2, 3, 1])], layout=go.Layout(title="bar plot")) fig.show() fig.data[0].marker = dict(color='purple') fig ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/raw_cell_with_complex_yaml_like_content.py ================================================ # --- # # This is a complex paragraph # that is split over multiple lines. # # It also includes blank lines. # # # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- print("Hello, World!") ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/raw_cell_with_non_dict_yaml_content.py ================================================ # --- # Content. # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- print("Hello, World!") ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/sample_rise_notebook_66.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # region [markdown] slideshow={"slide_type": "slide"} # A markdown cell # endregion # region slideshow={"slide_type": ""} 1+1 # endregion # region [markdown] cell_style="center" slideshow={"slide_type": "fragment"} # Markdown cell two # endregion ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_script_vscode_folding_markers/text_outputs_and_images.py ================================================ # --- # jupyter: # jupytext: # cell_markers: region,endregion # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # This notebook contains outputs of many different types: text, HTML, plots and errors. # # Text outputs # # Using `print`, `sys.stdout` and `sys.stderr` import sys print('using print') sys.stdout.write('using sys.stdout.write') sys.stderr.write('using sys.stderr.write') import logging logging.debug('Debug') logging.info('Info') logging.warning('Warning') logging.error('Error') # # HTML outputs # # Using `pandas`. Here we find two representations: both text and HTML. import pandas as pd pd.DataFrame([4]) from IPython.display import display display(pd.DataFrame([5])) display(pd.DataFrame([6])) # # Images # %matplotlib inline # First plot from matplotlib import pyplot as plt import numpy as np w, h = 3, 3 data = np.zeros((h, w, 3), dtype=np.uint8) data[0,:] = [0,255,0] data[1,:] = [0,0,255] data[2,:] = [0,255,0] data[1:3,1:3] = [255, 0, 0] plt.imshow(data) plt.axis('off') plt.show() # Second plot data[1:3,1:3] = [255, 255, 0] plt.imshow(data) plt.axis('off') plt.show() # # Errors undefined_variable ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/Line_breaks_in_LateX_305.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- """ This cell uses no particular cell marker $$ \begin{align} \dot{x} & = \sigma(y-x)\\ \dot{y} & = \rho x - y - xz \\ \dot{z} & = -\beta z + xy \end{align} $$ """ ############################################################################### # This cell uses no particular cell marker, and a single slash in the $\LaTeX$ equation # # $$ # \begin{align} # \dot{x} & = \sigma(y-x) \ # \dot{y} & = \rho x - y - xz \ # \dot{z} & = -\beta z + xy # \end{align} # $$ ''' This cell uses the triple quote cell markers introduced at https://github.com/mwouts/jupytext/issues/305 $$ \begin{align} \dot{x} & = \sigma(y-x)\\ \dot{y} & = \rho x - y - xz \\ \dot{z} & = -\beta z + xy \end{align} $$ ''' ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/cat_variable.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- cat = 42 ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/convert_to_py_then_test_with_update83.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- # %%time print('asdf') """ Thanks for jupytext! """ ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/jupyter.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- """ # Jupyter notebook This notebook is a simple jupyter notebook. It only has markdown and code cells. And it does not contain consecutive markdown cells. We start with an addition: """ a = 1 b = 2 a + b ############################################################################### # Now we return a few tuples a, b "" a, b, a+b ############################################################################### # And this is already the end of the notebook ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/jupyter_again.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- c = ''' title: "Quick test" output: ioslides_presentation: widescreen: true smaller: true editor_options: chunk_output_type console ''' "" import yaml print(yaml.dump(yaml.load(c))) "" # ?next ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/jupyterlab-slideshow_1441.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 (ipykernel) # language: python # name: python3 # --- """ > **Note** > > `slide` layer with a `top` of `30%` """ ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/notebook_with_complex_metadata.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/nteract_with_parameter.py ================================================ # --- # jupyter: # kernel_info: # name: python3 # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- param = 4 "" import pandas as pd "" df = pd.DataFrame({'A': [1, 2], 'B': [3 + param, 4]}, index=pd.Index(['x0', 'x1'], name='x')) df "" # %matplotlib inline df.plot(kind='bar') ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/plotly_graphs.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- """ This notebook contains complex outputs, including plotly javascript graphs. """ ############################################################################### # # Interactive plots ############################################################################### # We use Plotly's connected mode to make the notebook lighter - when connected, the notebook downloads the `plotly.js` library from the web. import plotly.offline as offline offline.init_notebook_mode(connected=True) "" import plotly.graph_objects as go fig = go.Figure( data=[go.Bar(y=[2, 3, 1])], layout=go.Layout(title="bar plot")) fig.show() fig.data[0].marker = dict(color='purple') fig ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/sample_rise_notebook_66.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- """ A markdown cell """ 1+1 ############################################################################### # Markdown cell two ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_sphinx/text_outputs_and_images.py ================================================ # --- # jupyter: # kernelspec: # display_name: Python 3 # language: python # name: python3 # --- """ This notebook contains outputs of many different types: text, HTML, plots and errors. """ ############################################################################### # # Text outputs # # Using `print`, `sys.stdout` and `sys.stderr` import sys print('using print') sys.stdout.write('using sys.stdout.write') sys.stderr.write('using sys.stderr.write') "" import logging logging.debug('Debug') logging.info('Info') logging.warning('Warning') logging.error('Error') ############################################################################### # # HTML outputs # # Using `pandas`. Here we find two representations: both text and HTML. import pandas as pd pd.DataFrame([4]) "" from IPython.display import display display(pd.DataFrame([5])) display(pd.DataFrame([6])) ############################################################################### # # Images # %matplotlib inline "" # First plot from matplotlib import pyplot as plt import numpy as np w, h = 3, 3 data = np.zeros((h, w, 3), dtype=np.uint8) data[0,:] = [0,255,0] data[1,:] = [0,0,255] data[2,:] = [0,255,0] data[1:3,1:3] = [255, 0, 0] plt.imshow(data) plt.axis('off') plt.show() # Second plot data[1:3,1:3] = [255, 255, 0] plt.imshow(data) plt.axis('off') plt.show() ############################################################################### # # Errors undefined_variable ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_spin/R notebook with invalid cell keys.R ================================================ #' --- #' jupyter: #' kernelspec: #' display_name: R #' language: R #' name: ir #' --- #' This notebook was created with IRKernel 0.8.12, and is not completely valid, as the code cell below contains an unexpected 'source' entry. This did cause https://github.com/mwouts/jupytext/issues/234. Note that the problem is solved when one upgrades to IRKernel 1.0.0. library("ggplot2") ggplot(mtcars, aes(mpg)) + stat_ecdf() ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_spin/R notebook with invalid cell keys.low.r ================================================ #' --- #' jupyter: #' kernelspec: #' display_name: R #' language: R #' name: ir #' --- #' This notebook was created with IRKernel 0.8.12, and is not completely valid, as the code cell below contains an unexpected 'source' entry. This did cause https://github.com/mwouts/jupytext/issues/234. Note that the problem is solved when one upgrades to IRKernel 1.0.0. library("ggplot2") ggplot(mtcars, aes(mpg)) + stat_ecdf() ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_spin/ir_notebook.R ================================================ #' --- #' jupyter: #' kernelspec: #' display_name: R #' language: R #' name: ir #' --- #' This is a jupyter notebook that uses the IR kernel. sum(1:10) plot(cars) ================================================ FILE: tests/data/notebooks/outputs/ipynb_to_spin/ir_notebook.low.r ================================================ #' --- #' jupyter: #' kernelspec: #' display_name: R #' language: R #' name: ir #' --- #' This is a jupyter notebook that uses the IR kernel. sum(1:10) plot(cars) ================================================ FILE: tests/data/notebooks/outputs/md_to_ipynb/jupytext_markdown.ipynb ================================================ { "cells": [ { "cell_type": "markdown", "metadata": {}, "source": [ "# Markdown, code and raw cells\n", "\n", "## Markdown cells\n", "\n", "This is a Markdown cell. Markdown cells end with either a code cell, or two consecutive blank lines in the text.\n", "\n", "If you prefer that Markdown headings define new cells, have a look at the `split_at_heading` option.\n", "\n", "Indented code is accepted, and consecutive blank lines there do not break Markdown cells:\n", "\n", " def f(x):\n", " return 1\n", "\n", "\n", " def h(x):\n", " return f(x)+2\n", "\n", "\n", "## Code cells" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "\"\"\"This code cell starts with ` ```python`\"\"\"\n", "1 + 1" ] }, { "cell_type": "markdown", "metadata": { "lines_to_next_cell": 0 }, "source": [ "## Raw cells\n", "\n", "Raw cells are delimited with `` and , like here:" ] }, { "cell_type": "raw", "metadata": {}, "source": [ "this is a raw cell" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "# Protected Markdown cells\n", "\n", "If you want to include code blocks (or two consecutive blank lines) in a Markdown cell, use explicit Markdown cell delimiters `` and ``." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "This Markdown cell has two consecutive blank lines\n", "\n", "\n", "And then a code block which is not a Jupyter code cell:\n", "```python\n", "2 + 2\n", "```" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "# Metadata\n", "\n", "Metadata are supported for all cell types.\n", "\n", "## Markdown cells" ] }, { "cell_type": "markdown", "metadata": { "key": "value", "title": "Region title" }, "source": [ "A cell with a title and additional metadata." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Code cells" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "tags": [ "parameters" ] }, "outputs": [], "source": [ "a = 2" ] } ], "metadata": { "kernelspec": { "display_name": "Python 3", "language": "python", "name": "python3" } }, "nbformat": 4, "nbformat_minor": 2 } ================================================ FILE: tests/data/notebooks/outputs/md_to_ipynb/plain_markdown.ipynb ================================================ { "cells": [ { "cell_type": "raw", "metadata": {}, "source": [ "---\n", "title: A sample document\n", "---" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "This document is a plain Markdown document that was not created from a notebook.\n", "We use this document to test that inputing a Markdown file into Jupytext, and then converting the\n", "resulting notebook to a Markdown file using nbconvert, is the identity\n", "\n", "Another paragraph\n", "\n", "# A header\n", "\n", "Indented code\n", "\n", " def f(x):\n", " return 1\n", "\n", "\n", " def h(x):\n", " return f(x)+2\n", "\n", "\n", "A Python code snippet" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "\"\"\"This code cell starts with ` ```python`\"\"\"\n", "1 + 1" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Code snippet without an explicit language\n", "```\n", "echo 'Hello world'\n", "```\n", "\n", "Markdown comments\n", "\n", "\n", "VS Code region markers" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "This Markdown cell has two consecutive blank lines\n", "\n", "\n", "And continues here" ] } ], "metadata": { "jupytext": { "cell_metadata_filter": "-all", "main_language": "python", "notebook_metadata_filter": "-all" } }, "nbformat": 4, "nbformat_minor": 2 } ================================================ FILE: tests/data/notebooks/outputs/myst_to_ipynb/fenced_code_vs_code_cells.ipynb ================================================ { "cells": [ { "cell_type": "markdown", "id": "cell-1", "metadata": {}, "source": [ "# Fenced code\n", "\n", "## No language\n", "\n", "```\n", "# a generic code instruction\n", "1 + 1\n", "```\n", "\n", "## Python\n", "\n", "```python\n", "1 + 1\n", "```\n", "\n", "## Bash\n", "\n", "```python\n", "echo Hi\n", "```\n", "\n", "# Code cells" ] }, { "cell_type": "code", "execution_count": null, "id": "cell-2", "metadata": {}, "outputs": [], "source": [ "# This code gets executed in notebooks\n", "1 + 1" ] } ], "metadata": { "jupytext": { "default_lexer": "ipython3", "notebook_metadata_filter": "-all" } }, "nbformat": 4, "nbformat_minor": 5 } ================================================ FILE: tests/data/notebooks/outputs/myst_to_ipynb/reference_link.ipynb ================================================ { "cells": [ { "cell_type": "markdown", "id": "cell-1", "metadata": {}, "source": [ "This documents contains a code cell to make sure it is recognized as a MyST document." ] }, { "cell_type": "code", "execution_count": null, "id": "cell-2", "metadata": {}, "outputs": [], "source": [ "1 + 1" ] }, { "cell_type": "markdown", "id": "cell-3", "metadata": {}, "source": [ "This is a [reference-link to the issue][].\n", "\n", ":::{note}\n", "This note is key... not sure why.\n", ":::\n", "\n", "[reference-link to the issue]:Jupytext on GitHub
" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "%load_ext rpy2.ipython" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "%%R -w 400 -h 200\n", "library(ggplot2)\n", "ggplot(data=data.frame(x=c('A', 'B'), y=c(5, 2)), aes(x,weight=y)) + geom_bar()" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "%%latex\n", "$\\frac{\\pi}{2}$" ] } ], "metadata": { "jupytext": { "cell_metadata_filter": "-all", "main_language": "python", "notebook_metadata_filter": "-all" } }, "nbformat": 4, "nbformat_minor": 2 } ================================================ FILE: tests/data/notebooks/outputs/script_to_ipynb/julia_sample_script.ipynb ================================================ { "cells": [ { "cell_type": "markdown", "metadata": {}, "source": [ "From https://juliabyexample.helpmanual.io/" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# function to calculate the volume of a sphere\n", "function sphere_vol(r)\n", " # julia allows Unicode names (in UTF-8 encoding)\n", " # so either \"pi\" or the symbol π can be used\n", " return 4/3*pi*r^3\n", "end" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# functions can also be defined more succinctly\n", "quadratic(a, sqr_term, b) = (-b + sqr_term) / 2a" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# calculates x for 0 = a*x^2+b*x+c, arguments types can be defined in function definitions\n", "function quadratic2(a::Float64, b::Float64, c::Float64)\n", " # unlike other languages 2a is equivalent to 2*a\n", " # a^2 is used instead of a**2 or pow(a,2)\n", " sqr_term = sqrt(b^2-4a*c)\n", " r1 = quadratic(a, sqr_term, b)\n", " r2 = quadratic(a, -sqr_term, b)\n", " # multiple values can be returned from a function using tuples\n", " # if the return keyword is omitted, the last term is returned\n", " r1, r2\n", "end" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "vol = sphere_vol(3)\n", "# @printf allows number formatting but does not automatically append the \\n to statements, see below\n", "@printf \"volume = %0.3f\\n\" vol\n", "#> volume = 113.097" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "quad1, quad2 = quadratic2(2.0, -2.0, -12.0)\n", "println(\"result 1: \", quad1)\n", "#> result 1: 3.0\n", "println(\"result 2: \", quad2)\n", "#> result 2: -2.0" ] } ], "metadata": { "jupytext": { "cell_metadata_filter": "-all", "encoding": "# -*- coding: utf-8 -*-", "main_language": "julia", "notebook_metadata_filter": "-all" } }, "nbformat": 4, "nbformat_minor": 2 } ================================================ FILE: tests/data/notebooks/outputs/script_to_ipynb/knitr-spin.ipynb ================================================ { "cells": [ { "cell_type": "markdown", "metadata": {}, "source": [ "The below derives from\n", "https://github.com/yihui/knitr/blob/master/inst/examples/knitr-spin.R\n", "\n", "This is a special R script which can be used to generate a report. You can\n", "write normal text in roxygen comments.\n", "\n", "First we set up some options (you do not have to do this):" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "hide_input": true, "hide_output": true, "name": "setup" }, "outputs": [], "source": [ "library(knitr)\n", "opts_chunk$set(fig.path = 'figure/silk-')" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "The report begins here." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "cache": false, "name": "test-a" }, "outputs": [], "source": [ "# boring examples as usual\n", "set.seed(123)\n", "x = rnorm(5)\n", "mean(x)" ] }, { "cell_type": "markdown", "metadata": { "lines_to_next_cell": 0 }, "source": [ "You can not use here the special syntax {{code}} to embed inline expressions, e.g." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "lines_to_next_cell": 0 }, "outputs": [], "source": [ "{{mean(x) + 2}}" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "is the mean of x plus 2.\n", "The code itself may contain braces, but these are not checked. Thus,\n", "perfectly valid (though very strange) R code such as `{{2 + 3}} - {{4 - 5}}`\n", "can lead to errors because `2 + 3}} - {{4 - 5` will be treated as inline code.\n", "\n", "Now we continue writing the report. We can draw plots as well." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "fig.height": 5, "fig.width": 5, "name": "test-b" }, "outputs": [], "source": [ "par(mar = c(4, 4, .1, .1)); plot(x)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Actually you do not have to write chunk options, in which case knitr will use\n", "default options. For example, the code below has no options attached:" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "var(x)\n", "quantile(x)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "And you can also write two chunks successively like this:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "lines_to_next_cell": 0, "name": "test-chisq5" }, "outputs": [], "source": [ "sum(x^2) # chi-square distribution with df 5" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "name": "test-chisq4" }, "outputs": [], "source": [ "sum((x - mean(x))^2) # df is 4 now" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Done. Call spin('knitr-spin.R') to make silk from sow's ear now and knit a\n", "lovely purse." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# /* you can write comments between /* and */ like C comments (the preceding #\n", "# is optional)\n", "Sys.sleep(60)\n", "# */" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# /* there is no inline comment; you have to write block comments */" ] } ], "metadata": { "jupytext": { "cell_metadata_filter": "name,hide_input,fig.width,fig.height,cache,hide_output,-all", "main_language": "R", "notebook_metadata_filter": "-all" } }, "nbformat": 4, "nbformat_minor": 2 } ================================================ FILE: tests/data/notebooks/outputs/script_to_ipynb/light_sample.ipynb ================================================ { "cells": [ { "cell_type": "markdown", "metadata": {}, "source": [ "# Sample notebook" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "a = 1\n", "b = 2\n", "a + b" ] } ], "metadata": { "jupytext": { "formats": "ipynb,py:light", "main_language": "python" } }, "nbformat": 4, "nbformat_minor": 2 } ================================================ FILE: tests/data/notebooks/outputs/script_to_ipynb/python_notebook_sample.ipynb ================================================ { "cells": [ { "cell_type": "markdown", "metadata": {}, "source": [ "# Specifications for Jupyter notebooks as python scripts" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Markdown cells" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Markdown cells are escaped with a single quote. Two consecutive\n", "cells are separated with a blank line." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Code cells" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Python code and adjacent comments are mapped to cell codes." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# For instance, this is a code cell that starts with a\n", "# code comment, where we define a variable\n", "a = 1" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# A cell with another variable\n", "b = 2" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# In this cell we define a function\n", "def f(x):\n", " return x + 1" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Now simple function calls\n", "c = f(b)\n", "a * b + c" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Line breaks in code cells are supported but then the cell need to have\n", "metadata and an end-of-cell marker. Metadata information in json format,\n", "escaped with '#+' or '# +'" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "def g(x):\n", " return x + 2\n", "\n", "\n", "d = 4" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# One more cell\n", "a * b + g(c) + d" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Raw cells, and cells active in py or ipynb only" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Raw cells are commented code cells with metadata \"active\": \"\"." ] }, { "cell_type": "raw", "metadata": {}, "source": [ "This is a raw cell" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Actually, using the \"active\" key you can have cells active in Jupyter\n", "and inactive in python scripts" ] }, { "cell_type": "raw", "metadata": { "active": "py" }, "source": [ "1 + 1 # done only in py script, inactive (raw) in ipynb" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "active": "ipynb" }, "outputs": [], "source": [ "2 + 2 # active in ipynb only" ] } ], "metadata": { "jupytext": { "cell_metadata_filter": "active,-all", "cell_metadata_json": true, "main_language": "python", "notebook_metadata_filter": "-all" } }, "nbformat": 4, "nbformat_minor": 2 } ================================================ FILE: tests/data/notebooks/outputs/script_to_ipynb/simple_r_script.ipynb ================================================ { "cells": [ { "cell_type": "markdown", "metadata": {}, "source": [ "This is a comment" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "cars" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "plot(cars)" ] } ], "metadata": { "jupytext": { "cell_metadata_filter": "-all", "main_language": "R", "notebook_metadata_filter": "-all" } }, "nbformat": 4, "nbformat_minor": 2 } ================================================ FILE: tests/data/notebooks/outputs/sphinx-rst2md_to_ipynb/plot_notebook.ipynb ================================================ { "cells": [ { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "%matplotlib inline" ] }, { "cell_type": "markdown", "metadata": { "cell_marker": "\"\"\"" }, "source": [ "# Notebook styled examples\n", "\n", "The gallery is capable of transforming Python files into reStructuredText files\n", "with a notebook structure. For this to be used you need to respect some syntax\n", "rules.\n", "\n", "It makes a lot of sense to contrast this output rst file with the\n", ":download:`original Python script"
]
}
],
"metadata": {
"jupytext": {
"cell_metadata_filter": "-all",
"encoding": "# -*- coding: utf-8 -*-",
"main_language": "python",
"notebook_metadata_filter": "-all",
"rst2md": false
}
},
"nbformat": 4,
"nbformat_minor": 2
}
================================================
FILE: tests/data/notebooks/outputs/sphinx_to_ipynb/plot_notebook.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%matplotlib inline"
]
},
{
"cell_type": "markdown",
"metadata": {
"cell_marker": "\"\"\""
},
"source": [
"Notebook styled examples\n",
"========================\n",
"\n",
"The gallery is capable of transforming Python files into reStructuredText files\n",
"with a notebook structure. For this to be used you need to respect some syntax\n",
"rules.\n",
"\n",
"It makes a lot of sense to contrast this output rst file with the\n",
":download:`original Python script