Basic Examples |

|

|

|
python -m newton.examples basic_pendulum
|
python -m newton.examples basic_urdf
|
python -m newton.examples basic_viewer
|

|

|

|
python -m newton.examples basic_shapes
|
python -m newton.examples basic_joints
|
python -m newton.examples basic_conveyor
|

|

|
|
python -m newton.examples basic_heightfield
|
python -m newton.examples recording
|
python -m newton.examples replay_viewer
|
|
|
|
python -m newton.examples basic_plotting
|
|
|
Robot Examples |

|

|

|
python -m newton.examples robot_cartpole
|
python -m newton.examples robot_g1
|
python -m newton.examples robot_h1
|

|

|
|
python -m newton.examples robot_anymal_d
|
python -m newton.examples robot_anymal_c_walk
|

|

|

|
python -m newton.examples robot_policy
|
python -m newton.examples robot_ur10
|
python -m newton.examples robot_panda_hydro
|

|
|
|
python -m newton.examples robot_allegro_hand
|
|
|
Cable Examples |

|

|

|
python -m newton.examples cable_twist
|
python -m newton.examples cable_y_junction
|
python -m newton.examples cable_bundle_hysteresis
|

|
|
|
python -m newton.examples cable_pile
|
|
|
Cloth Examples |

|

|

|
python -m newton.examples cloth_bending
|
python -m newton.examples cloth_hanging
|
python -m newton.examples cloth_style3d
|

|

|

|
python -m newton.examples cloth_h1
|
python -m newton.examples cloth_twist
|
python -m newton.examples cloth_franka
|

|

|
|
python -m newton.examples cloth_rollers
|
python -m newton.examples cloth_poker_cards
|
|
Inverse Kinematics Examples |
|
|
|
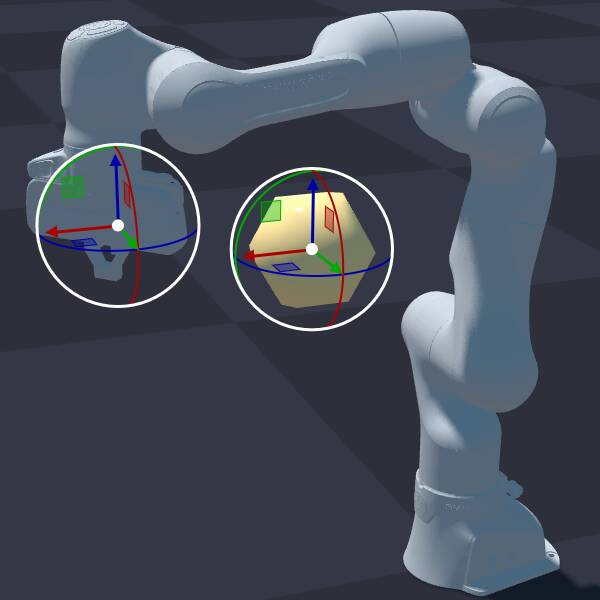
python -m newton.examples ik_franka
|
python -m newton.examples ik_h1
|
python -m newton.examples ik_custom
|

|
|
|
python -m newton.examples ik_cube_stacking
|
|
|
MPM Examples |

|

|

|
python -m newton.examples mpm_granular
|
python -m newton.examples mpm_anymal
|
python -m newton.examples mpm_twoway_coupling
|

|

|

|
python -m newton.examples mpm_grain_rendering
|
python -m newton.examples mpm_multi_material
|
python -m newton.examples mpm_viscous
|

|

|
|
python -m newton.examples mpm_beam_twist
|
python -m newton.examples mpm_snow_ball
|
|
Sensor Examples |

|

|

|
python -m newton.examples sensor_contact
|
python -m newton.examples sensor_tiled_camera
|
python -m newton.examples sensor_imu
|
Selection Examples |

|

|

|
python -m newton.examples selection_cartpole
|
python -m newton.examples selection_materials
|
python -m newton.examples selection_articulations
|

|
|
|
python -m newton.examples selection_multiple
|
|
|
DiffSim Examples |

|
|
|
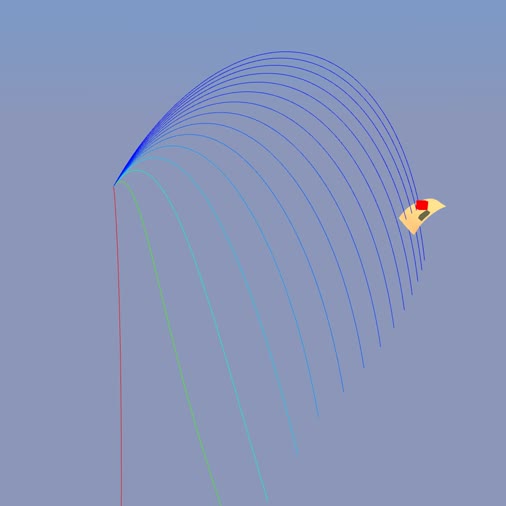
python -m newton.examples diffsim_ball
|
python -m newton.examples diffsim_cloth
|
python -m newton.examples diffsim_drone
|
|

|

|
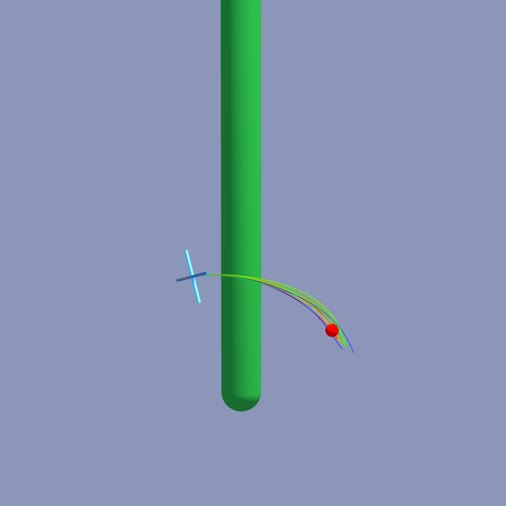
python -m newton.examples diffsim_spring_cage
|
python -m newton.examples diffsim_soft_body
|
python -m newton.examples diffsim_bear
|
Multi-Physics Examples |

|

|
|
python -m newton.examples softbody_gift
|
python -m newton.examples softbody_dropping_to_cloth
|
|
Contacts Examples |

|

|

|
python -m newton.examples nut_bolt_hydro
|
python -m newton.examples nut_bolt_sdf
|
python -m newton.examples brick_stacking
|

|

|
|
python -m newton.examples pyramid
|
python -m newton.examples contacts_rj45_plug
|
|
Softbody Examples |

|

|
|
python -m newton.examples softbody_hanging
|
python -m newton.examples softbody_franka
|
|
### Example Options
The examples support the following command-line arguments:
| Argument | Description | Default |
| --------------- | --------------------------------------------------------------------------------------------------- | ---------------------------- |
| `--viewer` | Viewer type: `gl` (OpenGL window), `usd` (USD file output), `rerun` (ReRun), or `null` (no viewer). | `gl` |
| `--device` | Compute device to use, e.g., `cpu`, `cuda:0`, etc. | `None` (default Warp device) |
| `--num-frames` | Number of frames to simulate (for USD output). | `100` |
| `--output-path` | Output path for USD files (required if `--viewer usd` is used). | `None` |
Some examples may add additional arguments (see their respective source files for details).
### Example Usage
```bash
# List available examples
python -m newton.examples
# Run with the USD viewer and save to my_output.usd
python -m newton.examples basic_viewer --viewer usd --output-path my_output.usd
# Run on a selected device
python -m newton.examples basic_urdf --device cuda:0
# Combine options
python -m newton.examples basic_viewer --viewer gl --num-frames 500 --device cpu
```
## Contributing and Development
See the [contribution guidelines](https://github.com/newton-physics/newton-governance/blob/main/CONTRIBUTING.md) and the [development guide](https://newton-physics.github.io/newton/latest/guide/development.html) for instructions on how to contribute to Newton.
## Support and Community Discussion
For questions, please consult the [Newton documentation](https://newton-physics.github.io/newton/latest/guide/overview.html) first before creating [a discussion in the main repository](https://github.com/newton-physics/newton/discussions).
## Code of Conduct
By participating in this community, you agree to abide by the Linux Foundation [Code of Conduct](https://lfprojects.org/policies/code-of-conduct/).
## Project Governance, Legal, and Members
Please see the [newton-governance repository](https://github.com/newton-physics/newton-governance) for more information about project governance.
================================================
FILE: SECURITY.md
================================================
Please refer to the [SECURITY.md](https://github.com/newton-physics/newton-governance/blob/main/SECURITY.md) in the newton-governance repository.
================================================
FILE: asv/benchmarks/__init__.py
================================================
================================================
FILE: asv/benchmarks/benchmark_ik.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2026 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
###########################################################################
# Used for benchmarking the Newton IK solver.
#
# This module provides shared logic for IK benchmarks on the
# Franka Emika Panda robot.
###########################################################################
from __future__ import annotations
import numpy as np
import warp as wp
import newton
import newton.ik as ik
import newton.utils
def create_franka_model() -> newton.Model:
builder = newton.ModelBuilder()
builder.num_rigid_contacts_per_world = 0
builder.default_shape_cfg.density = 100.0
asset_path = newton.utils.download_asset("franka_emika_panda") / "urdf/fr3.urdf"
builder.add_urdf(asset_path, floating=False, scale=1.0)
return builder.finalize(requires_grad=False)
def random_solutions(model: newton.Model, n: int, rng: np.random.Generator) -> np.ndarray:
n_coords = model.joint_coord_count
lower = model.joint_limit_lower.numpy()[:n_coords]
upper = model.joint_limit_upper.numpy()[:n_coords]
span = upper - lower
mask = np.abs(span) > 1e5
span[mask] = 0.0
q = rng.random((n, n_coords)) * span + lower
q[:, mask] = 0.0
return q.astype(np.float32)
def build_ik_solver(model: newton.Model, n_problems: int, ee_links: tuple[int, ...]):
zero_pos = [wp.zeros(n_problems, dtype=wp.vec3) for _ in ee_links]
zero_rot = [wp.zeros(n_problems, dtype=wp.vec4) for _ in ee_links]
objectives = []
for ee, link in enumerate(ee_links):
objectives.append(ik.IKObjectivePosition(link, wp.vec3(), zero_pos[ee]))
for ee, link in enumerate(ee_links):
objectives.append(
ik.IKObjectiveRotation(
link,
wp.quat_identity(),
zero_rot[ee],
canonicalize_quat_err=False,
)
)
objectives.append(
ik.IKObjectiveJointLimit(
model.joint_limit_lower,
model.joint_limit_upper,
weight=1.0,
)
)
solver = ik.IKSolver(
model,
n_problems,
objectives,
sampler=ik.IKSampler.ROBERTS,
n_seeds=64,
lambda_factor=4.0,
jacobian_mode=ik.IKJacobianType.ANALYTIC,
)
return (
solver,
objectives[: len(ee_links)],
objectives[len(ee_links) : 2 * len(ee_links)],
)
def fk_targets(solver, model: newton.Model, q_batch: np.ndarray, ee_links: tuple[int, ...]):
batch_size = q_batch.shape[0]
solver._fk_two_pass(
model,
wp.array(q_batch, dtype=wp.float32),
solver.body_q,
solver.X_local,
batch_size,
)
wp.synchronize_device()
bq = solver.body_q.numpy()[:batch_size]
ee = np.asarray(ee_links)
return bq[:, ee, :3].copy(), bq[:, ee, 3:7].copy()
def eval_success(solver, model, q_best, tgt_pos, tgt_rot, ee_links, pos_thresh_m, ori_thresh_rad):
batch_size = q_best.shape[0]
solver._fk_two_pass(
model,
wp.array(q_best, dtype=wp.float32),
solver.body_q,
solver.X_local,
batch_size,
)
wp.synchronize_device()
bq = solver.body_q.numpy()[:batch_size]
ee = np.asarray(ee_links)
pos_err = np.linalg.norm(bq[:, ee, :3] - tgt_pos, axis=-1).max(axis=-1)
def _qmul(a, b):
# Quaternions stored as (x, y, z, w) — scalar-last, matching Warp convention.
x1, y1, z1, w1 = np.moveaxis(a, -1, 0)
x2, y2, z2, w2 = np.moveaxis(b, -1, 0)
return np.stack(
(
w1 * x2 + x1 * w2 + y1 * z2 - z1 * y2,
w1 * y2 - x1 * z2 + y1 * w2 + z1 * x2,
w1 * z2 + x1 * y2 - y1 * x2 + z1 * w2,
w1 * w2 - x1 * x2 - y1 * y2 - z1 * z2,
),
axis=-1,
)
tgt_conj = np.concatenate([-tgt_rot[..., :3], tgt_rot[..., 3:]], axis=-1)
rel = _qmul(tgt_conj, bq[:, ee, 3:7])
rot_err = (2 * np.arctan2(np.linalg.norm(rel[..., :3], axis=-1), np.abs(rel[..., 3]))).max(axis=-1)
success = (pos_err < pos_thresh_m) & (rot_err < ori_thresh_rad)
return success
================================================
FILE: asv/benchmarks/benchmark_mujoco.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
###########################################################################
# Used for benchmarking MjWarp.
#
# This script allows us to choose between several predefined robots and
# provides a large range of customizable options.
#
###########################################################################
import time
import numpy as np
import warp as wp
wp.config.enable_backward = False
import newton
import newton.examples
import newton.utils
from newton.sensors import SensorContact
from newton.utils import EventTracer
ROBOT_CONFIGS = {
"humanoid": {
"solver": "newton",
"integrator": "implicitfast",
"njmax": 80,
"nconmax": 25,
"ls_parallel": False,
"cone": "pyramidal",
"sensing_bodies": ["*thigh*", "*shin*", "*foot*", "*arm*"],
},
"g1": {
"solver": "newton",
"integrator": "implicitfast",
"njmax": 210,
"nconmax": 35,
"ls_parallel": False,
"cone": "pyramidal",
},
"h1": {
"solver": "newton",
"integrator": "implicitfast",
"njmax": 65,
"nconmax": 15,
"ls_parallel": False,
"cone": "pyramidal",
},
"cartpole": {
"solver": "newton",
"integrator": "implicitfast",
"njmax": 5,
"nconmax": 0,
"ls_parallel": False,
"cone": "pyramidal",
},
"ant": {
"solver": "newton",
"integrator": "implicitfast",
"njmax": 38,
"nconmax": 15,
"ls_parallel": False,
"cone": "pyramidal",
},
"quadruped": {
"solver": "newton",
"integrator": "implicitfast",
"njmax": 75,
"nconmax": 50,
"ls_parallel": False,
"cone": "pyramidal",
},
"allegro": {
"solver": "newton",
"integrator": "implicitfast",
"njmax": 60,
"nconmax": 40,
"ls_parallel": False,
"cone": "elliptic",
},
"kitchen": {
"setup_builder": lambda x: _setup_kitchen(x),
"njmax": 3800,
"nconmax": 900,
},
"tabletop": {
"setup_builder": lambda x: _setup_tabletop(x),
"njmax": 100,
"nconmax": 20,
},
}
def _setup_humanoid(articulation_builder):
articulation_builder.add_mjcf(
newton.examples.get_asset("nv_humanoid.xml"),
ignore_names=["floor", "ground"],
up_axis="Z",
parse_sites=False, # AD: remove once asset is fixed
enable_self_collisions=False, # Keep False for consistent benchmark performance
)
# Setting root pose
root_dofs = 7
articulation_builder.joint_q[:3] = [0.0, 0.0, 1.5]
return root_dofs
def _setup_g1(articulation_builder):
articulation_builder.default_joint_cfg = newton.ModelBuilder.JointDofConfig(
limit_ke=1.0e3, limit_kd=1.0e1, friction=1e-5
)
articulation_builder.default_shape_cfg.ke = 5.0e4
articulation_builder.default_shape_cfg.kd = 5.0e2
articulation_builder.default_shape_cfg.kf = 1.0e3
articulation_builder.default_shape_cfg.mu = 0.75
asset_path = newton.utils.download_asset("unitree_g1")
articulation_builder.add_usd(
str(asset_path / "usd" / "g1_isaac.usd"),
xform=wp.transform(wp.vec3(0, 0, 0.8)),
collapse_fixed_joints=True,
enable_self_collisions=False,
hide_collision_shapes=True,
)
for i in range(6, articulation_builder.joint_dof_count):
articulation_builder.joint_target_ke[i] = 1000.0
articulation_builder.joint_target_kd[i] = 5.0
# approximate meshes for faster collision detection
articulation_builder.approximate_meshes("bounding_box")
root_dofs = 7
return root_dofs
def _setup_h1(articulation_builder):
articulation_builder.default_joint_cfg = newton.ModelBuilder.JointDofConfig(
limit_ke=1.0e3, limit_kd=1.0e1, friction=1e-5
)
articulation_builder.default_shape_cfg.ke = 5.0e4
articulation_builder.default_shape_cfg.kd = 5.0e2
articulation_builder.default_shape_cfg.kf = 1.0e3
articulation_builder.default_shape_cfg.mu = 0.75
asset_path = newton.utils.download_asset("unitree_h1")
asset_file = str(asset_path / "usd" / "h1_minimal.usda")
articulation_builder.add_usd(
asset_file,
ignore_paths=["/GroundPlane"],
collapse_fixed_joints=False,
enable_self_collisions=False,
hide_collision_shapes=True,
)
# approximate meshes for faster collision detection
articulation_builder.approximate_meshes("bounding_box")
for i in range(articulation_builder.joint_dof_count):
articulation_builder.joint_target_ke[i] = 150
articulation_builder.joint_target_kd[i] = 5
root_dofs = 7
return root_dofs
def _setup_cartpole(articulation_builder):
articulation_builder.default_shape_cfg.density = 100.0
articulation_builder.default_joint_cfg.armature = 0.1
articulation_builder.add_usd(
newton.examples.get_asset("cartpole_single_pendulum.usda"),
enable_self_collisions=False,
collapse_fixed_joints=True,
)
armature_inertia = wp.mat33(np.eye(3, dtype=np.float32)) * 0.1
for i in range(articulation_builder.body_count):
articulation_builder.body_inertia[i] = articulation_builder.body_inertia[i] + armature_inertia
# set initial joint positions (cartpole has 2 joints: prismatic slider + revolute pole)
# joint_q[0] = slider position, joint_q[1] = pole angle
articulation_builder.joint_q[0] = 0.0 # slider at origin
articulation_builder.joint_q[1] = 0.3 # pole tilted
# Setting root pose
root_dofs = 1
return root_dofs
def _setup_ant(articulation_builder):
articulation_builder.add_usd(
newton.examples.get_asset("ant.usda"),
collapse_fixed_joints=True,
)
# Setting root pose
root_dofs = 7
articulation_builder.joint_q[:3] = [0.0, 0.0, 1.5]
return root_dofs
def _setup_quadruped(articulation_builder):
articulation_builder.default_joint_cfg.armature = 0.01
articulation_builder.default_shape_cfg.ke = 1.0e4
articulation_builder.default_shape_cfg.kd = 1.0e2
articulation_builder.default_shape_cfg.kf = 1.0e2
articulation_builder.default_shape_cfg.mu = 1.0
articulation_builder.add_urdf(
newton.examples.get_asset("quadruped.urdf"),
xform=wp.transform([0.0, 0.0, 0.7], wp.quat_identity()),
floating=True,
enable_self_collisions=False,
)
armature_inertia = wp.mat33(np.eye(3, dtype=np.float32)) * 0.01
for i in range(articulation_builder.body_count):
articulation_builder.body_inertia[i] = articulation_builder.body_inertia[i] + armature_inertia
root_dofs = 7
return root_dofs
def _setup_allegro(articulation_builder):
asset_path = newton.utils.download_asset("wonik_allegro")
asset_file = str(asset_path / "usd" / "allegro_left_hand_with_cube.usda")
articulation_builder.add_usd(
asset_file,
xform=wp.transform(wp.vec3(0, 0, 0.5)),
enable_self_collisions=True,
ignore_paths=[".*Dummy", ".*CollisionPlane", ".*goal", ".*DexCube/visuals"],
)
# set joint targets and joint drive gains
for i in range(articulation_builder.joint_dof_count):
articulation_builder.joint_target_ke[i] = 150
articulation_builder.joint_target_kd[i] = 5
articulation_builder.joint_target_pos[i] = 0.0
root_dofs = 1
return root_dofs
def _setup_kitchen(articulation_builder):
asset_path = newton.utils.download_asset("kitchen")
asset_file = str(asset_path / "mjcf" / "kitchen.xml")
articulation_builder.add_mjcf(
asset_file,
collapse_fixed_joints=True,
enable_self_collisions=False, # Keep False for consistent benchmark performance
)
# Change pose of the robot to minimize overlap
articulation_builder.joint_q[:2] = [1.5, -1.5]
def _setup_tabletop(articulation_builder):
articulation_builder.add_mjcf(
newton.examples.get_asset("tabletop.xml"),
collapse_fixed_joints=True,
)
class Example:
def __init__(
self,
robot="humanoid",
environment="None",
stage_path=None,
world_count=1,
use_cuda_graph=True,
use_mujoco_cpu=False,
randomize=False,
headless=False,
actuation="None",
solver=None,
integrator=None,
solver_iteration=None,
ls_iteration=None,
njmax=None,
nconmax=None,
builder=None,
ls_parallel=None,
cone=None,
):
fps = 600
self.sim_time = 0.0
self.benchmark_time = 0.0
self.frame_dt = 1.0 / fps
self.sim_substeps = 10
self.contacts = None
self.sim_dt = self.frame_dt / self.sim_substeps
self.world_count = world_count
self.use_cuda_graph = use_cuda_graph
self.use_mujoco_cpu = use_mujoco_cpu
self.actuation = actuation
# set numpy random seed
self.seed = 123
self.rng = np.random.default_rng(self.seed)
if not stage_path:
stage_path = "example_" + robot + ".usd"
if builder is None:
builder = Example.create_model_builder(robot, world_count, environment, randomize, self.seed)
# finalize model
self.model = builder.finalize()
self.solver = Example.create_solver(
self.model,
robot,
use_mujoco_cpu=use_mujoco_cpu,
environment=environment,
solver=solver,
integrator=integrator,
solver_iteration=solver_iteration,
ls_iteration=ls_iteration,
njmax=njmax,
nconmax=nconmax,
ls_parallel=ls_parallel,
cone=cone,
)
if stage_path and not headless:
self.renderer = newton.viewer.ViewerGL()
self.renderer.set_model(self.model)
self.renderer.set_world_offsets((4.0, 4.0, 0.0))
else:
self.renderer = None
self.control = self.model.control()
self.state_0, self.state_1 = self.model.state(), self.model.state()
newton.eval_fk(self.model, self.model.joint_q, self.model.joint_qd, self.state_0)
self.sensor_contact = None
sensing_bodies = ROBOT_CONFIGS.get(robot, {}).get("sensing_bodies", None)
if sensing_bodies is not None:
self.sensor_contact = SensorContact(self.model, sensing_obj_bodies=sensing_bodies, counterpart_bodies="*")
self.contacts = newton.Contacts(
self.solver.get_max_contact_count(),
0,
device=self.model.device,
requested_attributes=self.model.get_requested_contact_attributes(),
)
self.graph = None
if self.use_cuda_graph:
# simulate() allocates memory via a clone, so we can't use graph capture if the device does not support mempools
cuda_graph_comp = wp.get_device().is_cuda and wp.is_mempool_enabled(wp.get_device())
if not cuda_graph_comp:
print("Cannot use graph capture. Graph capture is disabled.")
else:
with wp.ScopedCapture() as capture:
self.simulate()
self.graph = capture.graph
def simulate(self):
for _ in range(self.sim_substeps):
self.state_0.clear_forces()
self.solver.step(self.state_0, self.state_1, self.control, self.contacts, self.sim_dt)
self.state_0, self.state_1 = self.state_1, self.state_0
if self.sensor_contact is not None:
self.solver.update_contacts(self.contacts, self.state_0)
self.sensor_contact.update(self.state_0, self.contacts)
def step(self):
if self.actuation == "random":
joint_target = wp.array(self.rng.uniform(-1.0, 1.0, size=self.model.joint_dof_count), dtype=wp.float32)
wp.copy(self.control.joint_target_pos, joint_target)
wp.synchronize_device()
start_time = time.time()
if self.use_cuda_graph:
wp.capture_launch(self.graph)
else:
self.simulate()
wp.synchronize_device()
end_time = time.time()
self.benchmark_time += end_time - start_time
self.sim_time += self.frame_dt
def render(self):
if self.renderer is None:
return
self.renderer.begin_frame(self.sim_time)
self.renderer.log_state(self.state_0)
self.renderer.end_frame()
@staticmethod
def create_model_builder(robot, world_count, environment="None", randomize=False, seed=123) -> newton.ModelBuilder:
rng = np.random.default_rng(seed)
articulation_builder = newton.ModelBuilder()
articulation_builder.default_shape_cfg.ke = 1.0e3
articulation_builder.default_shape_cfg.kd = 1.0e2
newton.solvers.SolverMuJoCo.register_custom_attributes(articulation_builder)
if robot == "humanoid":
root_dofs = _setup_humanoid(articulation_builder)
elif robot == "g1":
root_dofs = _setup_g1(articulation_builder)
elif robot == "h1":
root_dofs = _setup_h1(articulation_builder)
elif robot == "cartpole":
root_dofs = _setup_cartpole(articulation_builder)
elif robot == "ant":
root_dofs = _setup_ant(articulation_builder)
elif robot == "quadruped":
root_dofs = _setup_quadruped(articulation_builder)
elif robot == "allegro":
root_dofs = _setup_allegro(articulation_builder)
else:
raise ValueError(f"Name of the provided robot not recognized: {robot}")
custom_setup_fn = ROBOT_CONFIGS.get(environment, {}).get("setup_builder", None)
if custom_setup_fn is not None:
custom_setup_fn(articulation_builder)
builder = newton.ModelBuilder()
builder.replicate(articulation_builder, world_count)
if randomize:
njoint = len(articulation_builder.joint_q)
for i in range(world_count):
istart = i * njoint
builder.joint_q[istart + root_dofs : istart + njoint] = rng.uniform(
-1.0, 1.0, size=(njoint - root_dofs)
).tolist()
builder.default_shape_cfg.ke = 1.0e3
builder.default_shape_cfg.kd = 1.0e2
if robot != "cartpole":
# Disable all collisions for the cartpole benchmark
builder.add_ground_plane()
return builder
@staticmethod
def create_solver(
model,
robot,
*,
use_mujoco_cpu=False,
environment="None",
solver=None,
integrator=None,
solver_iteration=None,
ls_iteration=None,
njmax=None,
nconmax=None,
ls_parallel=None,
cone=None,
):
solver_iteration = solver_iteration if solver_iteration is not None else 100
ls_iteration = ls_iteration if ls_iteration is not None else 50
solver = solver if solver is not None else ROBOT_CONFIGS[robot]["solver"]
integrator = integrator if integrator is not None else ROBOT_CONFIGS[robot]["integrator"]
njmax = njmax if njmax is not None else ROBOT_CONFIGS[robot]["njmax"]
nconmax = nconmax if nconmax is not None else ROBOT_CONFIGS[robot]["nconmax"]
ls_parallel = ls_parallel if ls_parallel is not None else ROBOT_CONFIGS[robot]["ls_parallel"]
cone = cone if cone is not None else ROBOT_CONFIGS[robot]["cone"]
njmax += ROBOT_CONFIGS.get(environment, {}).get("njmax", 0)
nconmax += ROBOT_CONFIGS.get(environment, {}).get("nconmax", 0)
return newton.solvers.SolverMuJoCo(
model,
use_mujoco_cpu=use_mujoco_cpu,
solver=solver,
integrator=integrator,
iterations=solver_iteration,
ls_iterations=ls_iteration,
njmax=njmax,
nconmax=nconmax,
ls_parallel=ls_parallel,
cone=cone,
)
def print_trace(trace, indent, steps):
if indent == 0:
print("================= Profiling =================")
for k, v in trace.items():
times, sub_trace = v
print(" " * indent + f"{k}: {times / steps:.4f}")
print_trace(sub_trace, indent + 1, steps)
if indent == 0:
step_time = trace["step"][0]
step_trace = trace["step"][1]
mujoco_warp_step_time = step_trace["_mujoco_warp_step"][0]
overhead = 100.0 * (step_time - mujoco_warp_step_time) / step_time
print("---------------------------------------------")
print(f"Newton overhead:\t{overhead:.2f} %")
print("=============================================")
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--robot", type=str, default="humanoid", help="Name of the robot to simulate.")
parser.add_argument("--env", type=str, default="None", help="Name of the environment where the robot is located.")
parser.add_argument(
"--event-trace", default=False, action=argparse.BooleanOptionalAction, help="Print profiling information."
)
parser.add_argument("--device", type=str, default=None, help="Override the default Warp device.")
parser.add_argument(
"--stage-path",
type=lambda x: None if x == "None" else str(x),
default=None,
help="Path to the output USD file.",
)
parser.add_argument("--num-frames", type=int, default=12000, help="Total number of frames.")
parser.add_argument("--world-count", type=int, default=1, help="Total number of simulated worlds.")
parser.add_argument("--use-cuda-graph", default=True, action=argparse.BooleanOptionalAction)
parser.add_argument(
"--use-mujoco-cpu",
default=False,
action=argparse.BooleanOptionalAction,
help="Use Mujoco-C CPU (Not yet supported).",
)
parser.add_argument(
"--headless", default=False, action=argparse.BooleanOptionalAction, help="Run the simulation in headless mode."
)
parser.add_argument(
"--random-init", default=False, action=argparse.BooleanOptionalAction, help="Randomize initial pose."
)
parser.add_argument(
"--actuation",
type=str,
default="None",
choices=["None", "random"],
help="Type of action to apply at each step.",
)
parser.add_argument(
"--solver", type=str, default=None, choices=["cg", "newton"], help="Mujoco model constraint solver used."
)
parser.add_argument(
"--integrator", type=str, default=None, choices=["euler", "rk4", "implicit"], help="Mujoco integrator used."
)
parser.add_argument("--solver-iteration", type=int, default=None, help="Number of solver iterations.")
parser.add_argument("--ls-iteration", type=int, default=None, help="Number of linesearch iterations.")
parser.add_argument("--njmax", type=int, default=None, help="Maximum number of constraints per world.")
parser.add_argument("--nconmax", type=int, default=None, help="Maximum number of collision per world.")
parser.add_argument(
"--ls-parallel", default=None, action=argparse.BooleanOptionalAction, help="Use parallel line search."
)
parser.add_argument("--cone", type=str, default=None, choices=["pyramidal", "elliptic"], help="Friction cone type.")
args = parser.parse_known_args()[0]
if args.use_mujoco_cpu:
args.use_mujoco_cpu = False
print("The option ``use-mujoco-cpu`` is not yet supported. Disabling it.")
trace = {}
with EventTracer(enabled=args.event_trace) as tracer:
with wp.ScopedDevice(args.device):
example = Example(
robot=args.robot,
environment=args.env,
stage_path=args.stage_path,
world_count=args.world_count,
use_cuda_graph=args.use_cuda_graph,
use_mujoco_cpu=args.use_mujoco_cpu,
randomize=args.random_init,
headless=args.headless,
actuation=args.actuation,
solver=args.solver,
integrator=args.integrator,
solver_iteration=args.solver_iteration,
ls_iteration=args.ls_iteration,
njmax=args.njmax,
nconmax=args.nconmax,
ls_parallel=args.ls_parallel,
cone=args.cone,
)
# Print simulation configuration summary
LABEL_WIDTH = 25
TOTAL_WIDTH = 45
title = " Simulation Configuration "
print(f"\n{title.center(TOTAL_WIDTH, '=')}")
print(f"{'Simulation Steps':<{LABEL_WIDTH}}: {args.num_frames * example.sim_substeps}")
print(f"{'World Count':<{LABEL_WIDTH}}: {args.world_count}")
print(f"{'Robot Type':<{LABEL_WIDTH}}: {args.robot}")
print(f"{'Timestep (dt)':<{LABEL_WIDTH}}: {example.sim_dt:.6f}s")
print(f"{'Randomize Initial Pose':<{LABEL_WIDTH}}: {args.random_init!s}")
print("-" * TOTAL_WIDTH)
# Map MuJoCo solver enum back to string
solver_value = example.solver.mj_model.opt.solver
solver_map = {0: "PGS", 1: "CG", 2: "Newton"} # mjSOL_PGS = 0, mjSOL_CG = 1, mjSOL_NEWTON = 2
actual_solver = solver_map.get(solver_value, f"unknown({solver_value})")
# Map MuJoCo integrator enum back to string
integrator_map = {
0: "Euler",
1: "RK4",
2: "Implicit",
3: "Implicitfast",
} # mjINT_EULER = 0, mjINT_RK4 = 1, mjINT_IMPLICIT = 2, mjINT_IMPLICITFAST = 3
actual_integrator = integrator_map.get(example.solver.mj_model.opt.integrator, "unknown")
# Map MuJoCo cone enum back to string
cone_value = example.solver.mj_model.opt.cone
cone_map = {0: "pyramidal", 1: "elliptic"} # mjCONE_PYRAMIDAL = 0, mjCONE_ELLIPTIC = 1
actual_cone = cone_map.get(cone_value, f"unknown({cone_value})")
# Get actual max constraints and contacts from MuJoCo Warp data
actual_njmax = example.solver.mjw_data.njmax
actual_nconmax = (
example.solver.mjw_data.naconmax // args.world_count
if args.world_count > 0
else example.solver.mjw_data.naconmax
)
print(f"{'Solver':<{LABEL_WIDTH}}: {actual_solver}")
print(f"{'Integrator':<{LABEL_WIDTH}}: {actual_integrator}")
# print(f"{'Parallel Line Search':<{LABEL_WIDTH}}: {example.solver.mj_model.opt.ls_parallel}")
print(f"{'Cone':<{LABEL_WIDTH}}: {actual_cone}")
print(f"{'Solver Iterations':<{LABEL_WIDTH}}: {example.solver.mj_model.opt.iterations}")
print(f"{'Line Search Iterations':<{LABEL_WIDTH}}: {example.solver.mj_model.opt.ls_iterations}")
print(f"{'Max Constraints / world':<{LABEL_WIDTH}}: {actual_njmax}")
print(f"{'Max Contacts / world':<{LABEL_WIDTH}}: {actual_nconmax}")
print(f"{'Joint DOFs':<{LABEL_WIDTH}}: {example.model.joint_dof_count}")
print(f"{'Body Count':<{LABEL_WIDTH}}: {example.model.body_count}")
print("-" * TOTAL_WIDTH)
print(f"{'Execution Device':<{LABEL_WIDTH}}: {wp.get_device()}")
print(f"{'Use CUDA Graph':<{LABEL_WIDTH}}: {example.use_cuda_graph!s}")
print("=" * TOTAL_WIDTH + "\n")
for _ in range(args.num_frames):
example.step()
example.render()
if args.event_trace:
trace = tracer.add_trace(trace, tracer.trace())
if args.event_trace:
print_trace(trace, 0, args.num_frames * example.sim_substeps)
================================================
FILE: asv/benchmarks/compilation/__init__.py
================================================
================================================
FILE: asv/benchmarks/compilation/bench_example_load.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import subprocess
import sys
import warp as wp
wp.config.enable_backward = False
wp.config.quiet = True
from asv_runner.benchmarks.mark import skip_benchmark_if
class SlowExampleRobotAnymal:
warmup_time = 0
repeat = 2
number = 1
timeout = 600
def setup(self):
wp.build.clear_lto_cache()
wp.build.clear_kernel_cache()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_load(self):
"""Time the amount of time it takes to load and run one frame of the example."""
command = [
sys.executable,
"-m",
"newton.examples.robot.example_robot_anymal_c_walk",
"--num-frames",
"1",
"--viewer",
"null",
]
# Run the script as a subprocess
subprocess.run(command, capture_output=True, text=True, check=True)
class SlowExampleRobotCartpole:
warmup_time = 0
repeat = 2
number = 1
timeout = 600
def setup(self):
wp.build.clear_lto_cache()
wp.build.clear_kernel_cache()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_load(self):
"""Time the amount of time it takes to load and run one frame of the example."""
command = [
sys.executable,
"-m",
"newton.examples.robot.example_robot_cartpole",
"--num-frames",
"1",
"--viewer",
"null",
]
# Run the script as a subprocess
subprocess.run(command, capture_output=True, text=True, check=True)
class SlowExampleClothFranka:
warmup_time = 0
repeat = 2
number = 1
def setup(self):
wp.build.clear_lto_cache()
wp.build.clear_kernel_cache()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_load(self):
"""Time the amount of time it takes to load and run one frame of the example."""
command = [
sys.executable,
"-m",
"newton.examples.cloth.example_cloth_franka",
"--num-frames",
"1",
"--viewer",
"null",
]
# Run the script as a subprocess
subprocess.run(command, capture_output=True, text=True, check=True)
class SlowExampleClothTwist:
warmup_time = 0
repeat = 2
number = 1
def setup(self):
wp.build.clear_lto_cache()
wp.build.clear_kernel_cache()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_load(self):
"""Time the amount of time it takes to load and run one frame of the example."""
command = [
sys.executable,
"-m",
"newton.examples.cloth.example_cloth_twist",
"--num-frames",
"1",
"--viewer",
"null",
]
# Run the script as a subprocess
subprocess.run(command, capture_output=True, text=True, check=True)
class SlowExampleBasicUrdf:
warmup_time = 0
repeat = 2
number = 1
timeout = 600
def setup(self):
wp.build.clear_lto_cache()
wp.build.clear_kernel_cache()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_load(self):
"""Time the amount of time it takes to load and run one frame of the example."""
command = [
sys.executable,
"-m",
"newton.examples.basic.example_basic_urdf",
"--num-frames",
"1",
"--viewer",
"null",
]
# Run the script as a subprocess
subprocess.run(command, capture_output=True, text=True, check=True)
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"SlowExampleBasicUrdf": SlowExampleBasicUrdf,
"SlowExampleRobotAnymal": SlowExampleRobotAnymal,
"SlowExampleRobotCartpole": SlowExampleRobotCartpole,
"SlowExampleClothFranka": SlowExampleClothFranka,
"SlowExampleClothTwist": SlowExampleClothTwist,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/setup/__init__.py
================================================
================================================
FILE: asv/benchmarks/setup/bench_model.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import gc
import os
import sys
# Force headless mode for CI environments before any pyglet imports
os.environ["PYGLET_HEADLESS"] = "1"
import warp as wp
wp.config.enable_backward = False
wp.config.quiet = True
from asv_runner.benchmarks.mark import skip_benchmark_if
parent_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
sys.path.append(parent_dir)
from benchmark_mujoco import Example
from newton.viewer import ViewerGL
class KpiInitializeModel:
params = (["humanoid", "g1", "cartpole"], [8192])
param_names = ["robot", "world_count"]
rounds = 1
repeat = 3
number = 1
min_run_count = 1
timeout = 3600
def setup(self, robot, world_count):
wp.init()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_initialize_model(self, robot, world_count):
builder = Example.create_model_builder(robot, world_count, randomize=True, seed=123)
# finalize model
_model = builder.finalize()
wp.synchronize_device()
class KpiInitializeSolver:
params = (["humanoid", "g1", "cartpole", "ant"], [8192])
param_names = ["robot", "world_count"]
rounds = 1
repeat = 3
number = 1
min_run_count = 1
timeout = 3600
def setup(self, robot, world_count):
wp.init()
builder = Example.create_model_builder(robot, world_count, randomize=True, seed=123)
# finalize model
self._model = builder.finalize()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_initialize_solver(self, robot, world_count):
self._solver = Example.create_solver(self._model, robot, use_mujoco_cpu=False)
wp.synchronize_device()
def teardown(self, robot, world_count):
del self._solver
del self._model
class KpiInitializeViewerGL:
params = (["g1"], [8192])
param_names = ["robot", "world_count"]
rounds = 1
repeat = 3
number = 1
min_run_count = 1
def setup(self, robot, world_count):
wp.init()
builder = Example.create_model_builder(robot, world_count, randomize=True, seed=123)
# finalize model
self._model = builder.finalize()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_initialize_renderer(self, robot, world_count):
# Setting up the renderer
self.renderer = ViewerGL(headless=True)
self.renderer.set_model(self._model)
wp.synchronize_device()
self.renderer.close()
def teardown(self, robot, world_count):
del self._model
class FastInitializeModel:
params = (["humanoid", "g1", "cartpole"], [256])
param_names = ["robot", "world_count"]
rounds = 1
repeat = 3
number = 1
min_run_count = 1
def setup_cache(self):
# Load a small model to cache the kernels
for robot in self.params[0]:
builder = Example.create_model_builder(robot, 1, randomize=False, seed=123)
model = builder.finalize(device="cpu")
del model
del builder
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_initialize_model(self, robot, world_count):
builder = Example.create_model_builder(robot, world_count, randomize=True, seed=123)
# finalize model
_model = builder.finalize()
wp.synchronize_device()
def peakmem_initialize_model_cpu(self, robot, world_count):
gc.collect()
with wp.ScopedDevice("cpu"):
builder = Example.create_model_builder(robot, world_count, randomize=True, seed=123)
# finalize model
model = builder.finalize()
del model
class FastInitializeSolver:
params = (["humanoid", "g1", "cartpole"], [256])
param_names = ["robot", "world_count"]
rounds = 1
repeat = 3
number = 1
min_run_count = 1
def setup(self, robot, world_count):
wp.init()
builder = Example.create_model_builder(robot, world_count, randomize=True, seed=123)
# finalize model
self._model = builder.finalize()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_initialize_solver(self, robot, world_count):
self._solver = Example.create_solver(self._model, robot, use_mujoco_cpu=False)
wp.synchronize_device()
def teardown(self, robot, world_count):
del self._solver
del self._model
class FastInitializeViewerGL:
params = (["g1"], [256])
param_names = ["robot", "world_count"]
rounds = 1
repeat = 3
number = 1
min_run_count = 1
def setup(self, robot, world_count):
wp.init()
builder = Example.create_model_builder(robot, world_count, randomize=True, seed=123)
# finalize model
self._model = builder.finalize()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_initialize_renderer(self, robot, world_count):
# Setting up the renderer
self.renderer = ViewerGL(headless=True)
self.renderer.set_model(self._model)
wp.synchronize_device()
self.renderer.close()
def teardown(self, robot, world_count):
del self._model
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"KpiInitializeModel": KpiInitializeModel,
"FastInitializeModel": FastInitializeModel,
"KpiInitializeSolver": KpiInitializeSolver,
"FastInitializeSolver": FastInitializeSolver,
"KpiInitializeViewerGL": KpiInitializeViewerGL,
"FastInitializeViewerGL": FastInitializeViewerGL,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/simulation/__init__.py
================================================
================================================
FILE: asv/benchmarks/simulation/bench_anymal.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import warp as wp
from asv_runner.benchmarks.mark import skip_benchmark_if
wp.config.enable_backward = False
wp.config.quiet = True
import newton
import newton.examples
from newton.examples.robot.example_robot_anymal_c_walk import Example
class FastExampleAnymalPretrained:
repeat = 3
number = 1
def setup(self):
self.num_frames = 50
if hasattr(newton.examples, "default_args"):
args = newton.examples.default_args()
else:
args = None
self.example = Example(newton.viewer.ViewerNull(num_frames=self.num_frames), args)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_simulate(self):
for _ in range(self.num_frames):
self.example.step()
wp.synchronize_device()
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"FastExampleAnymalPretrained": FastExampleAnymalPretrained,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/simulation/bench_cable.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2026 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import warp as wp
from asv_runner.benchmarks.mark import skip_benchmark_if
wp.config.enable_backward = False
wp.config.quiet = True
import newton.examples
from newton.examples.cable.example_cable_pile import Example as ExampleCablePile
from newton.viewer import ViewerNull
class FastExampleCablePile:
number = 1
rounds = 2
repeat = 2
def setup(self):
self.num_frames = 30
if hasattr(newton.examples, "default_args"):
args = newton.examples.default_args()
else:
args = None
self.example = ExampleCablePile(ViewerNull(num_frames=self.num_frames), args)
wp.synchronize_device()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_simulate(self):
newton.examples.run(self.example, args=None)
wp.synchronize_device()
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"FastExampleCablePile": FastExampleCablePile,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/simulation/bench_cloth.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import warp as wp
from asv_runner.benchmarks.mark import skip_benchmark_if
wp.config.quiet = True
import newton.examples
from newton.examples.cloth.example_cloth_franka import Example as ExampleClothManipulation
from newton.examples.cloth.example_cloth_twist import Example as ExampleClothTwist
from newton.viewer import ViewerNull
class FastExampleClothManipulation:
timeout = 300
repeat = 3
number = 1
def setup(self):
self.num_frames = 30
if hasattr(newton.examples, "default_args"):
args = newton.examples.default_args()
else:
args = None
self.example = ExampleClothManipulation(ViewerNull(num_frames=self.num_frames), args)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_simulate(self):
newton.examples.run(self.example, args=None)
wp.synchronize_device()
class FastExampleClothTwist:
repeat = 5
number = 1
def setup(self):
self.num_frames = 100
if hasattr(newton.examples, "default_args"):
args = newton.examples.default_args()
else:
args = None
self.example = ExampleClothTwist(ViewerNull(num_frames=self.num_frames), args)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_simulate(self):
newton.examples.run(self.example, None)
wp.synchronize_device()
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"FastExampleClothManipulation": FastExampleClothManipulation,
"FastExampleClothTwist": FastExampleClothTwist,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/simulation/bench_contacts.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2026 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import warp as wp
from asv_runner.benchmarks.mark import SkipNotImplemented, skip_benchmark_if
wp.config.enable_backward = False
wp.config.quiet = True
import importlib
import newton.examples
from newton.viewer import ViewerNull
ISAACGYM_ENVS_REPO_URL = "https://github.com/isaac-sim/IsaacGymEnvs.git"
ISAACGYM_NUT_BOLT_FOLDER = "assets/factory/mesh/factory_nut_bolt"
try:
from newton.examples import download_external_git_folder as _download_external_git_folder
except ImportError:
from newton._src.utils.download_assets import download_git_folder as _download_external_git_folder
def _import_example_class(module_names: list[str]):
"""Import and return the ``Example`` class from candidate modules.
Args:
module_names: Ordered module names to try importing.
Returns:
The first successfully imported module's ``Example`` class.
Raises:
SkipNotImplemented: If none of the module names can be imported.
"""
for module_name in module_names:
try:
module = importlib.import_module(module_name)
except ModuleNotFoundError:
continue
return module.Example
raise SkipNotImplemented
class FastExampleContactSdfDefaults:
"""Benchmark the SDF nut-bolt example default configuration."""
repeat = 2
number = 1
def setup_cache(self):
_download_external_git_folder(ISAACGYM_ENVS_REPO_URL, ISAACGYM_NUT_BOLT_FOLDER)
def setup(self):
example_cls = _import_example_class(
[
"newton.examples.contacts.example_nut_bolt_sdf",
]
)
self.num_frames = 20
if hasattr(newton.examples, "default_args") and hasattr(example_cls, "create_parser"):
args = newton.examples.default_args(example_cls.create_parser())
self.example = example_cls(ViewerNull(num_frames=self.num_frames), args)
else:
self.example = example_cls(
viewer=ViewerNull(num_frames=self.num_frames),
world_count=100,
num_per_world=1,
scene="nut_bolt",
solver="mujoco",
test_mode=False,
)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_simulate(self):
for _ in range(self.num_frames):
self.example.step()
wp.synchronize_device()
class FastExampleContactHydroWorkingDefaults:
"""Benchmark the hydroelastic nut-bolt example default configuration."""
repeat = 2
number = 1
def setup_cache(self):
_download_external_git_folder(ISAACGYM_ENVS_REPO_URL, ISAACGYM_NUT_BOLT_FOLDER)
def setup(self):
example_cls = _import_example_class(
[
"newton.examples.contacts.example_nut_bolt_hydro",
]
)
self.num_frames = 20
if hasattr(newton.examples, "default_args") and hasattr(example_cls, "create_parser"):
args = newton.examples.default_args(example_cls.create_parser())
self.example = example_cls(ViewerNull(num_frames=self.num_frames), args)
else:
self.example = example_cls(
viewer=ViewerNull(num_frames=self.num_frames),
world_count=20,
num_per_world=1,
scene="nut_bolt",
solver="mujoco",
test_mode=False,
)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_simulate(self):
for _ in range(self.num_frames):
self.example.step()
wp.synchronize_device()
class FastExampleContactPyramidDefaults:
"""Benchmark the box pyramid example with default configuration."""
repeat = 2
number = 1
def setup(self):
example_cls = _import_example_class(
[
"newton.examples.contacts.example_pyramid",
]
)
self.num_frames = 20
if hasattr(newton.examples, "default_args") and hasattr(example_cls, "create_parser"):
args = newton.examples.default_args(example_cls.create_parser())
self.example = example_cls(ViewerNull(num_frames=self.num_frames), args)
else:
self.example = example_cls(
viewer=ViewerNull(num_frames=self.num_frames),
solver="xpbd",
test_mode=False,
)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_simulate(self):
for _ in range(self.num_frames):
self.example.step()
wp.synchronize_device()
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"FastExampleContactSdfDefaults": FastExampleContactSdfDefaults,
"FastExampleContactHydroWorkingDefaults": FastExampleContactHydroWorkingDefaults,
"FastExampleContactPyramidDefaults": FastExampleContactPyramidDefaults,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/simulation/bench_heightfield.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2026 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import warp as wp
from asv_runner.benchmarks.mark import SkipNotImplemented, skip_benchmark_if
wp.config.enable_backward = False
wp.config.quiet = True
import numpy as np
import newton
def _build_heightfield_scene(num_bodies=200, nrow=100, ncol=100):
"""Build a scene with many spheres dropped onto a large heightfield."""
builder = newton.ModelBuilder()
hx, hy = 20.0, 20.0
x = np.linspace(-hx, hx, ncol)
y = np.linspace(-hy, hy, nrow)
xx, yy = np.meshgrid(x, y)
elevation = np.sin(xx * 0.5) * np.cos(yy * 0.5) * 1.0
hfield = newton.Heightfield(data=elevation, nrow=nrow, ncol=ncol, hx=hx, hy=hy)
builder.add_shape_heightfield(heightfield=hfield)
# Grid of spheres above the terrain
grid_size = int(np.ceil(np.sqrt(num_bodies)))
spacing = 2.0 * hx / (grid_size + 1)
count = 0
for i in range(grid_size):
for j in range(grid_size):
if count >= num_bodies:
break
x_pos = -hx + spacing * (i + 1)
y_pos = -hy + spacing * (j + 1)
body = builder.add_body(
xform=wp.transform(p=wp.vec3(x_pos, y_pos, 3.0), q=wp.quat_identity()),
)
builder.add_shape_sphere(body=body, radius=0.3)
count += 1
model = builder.finalize()
model.rigid_contact_max = num_bodies * 20
return model
class HeightfieldCollision:
"""Benchmark heightfield collision with many spheres on a 100x100 grid."""
repeat = 8
number = 1
def setup(self):
cuda_graph_comp = wp.get_device().is_cuda and wp.is_mempool_enabled(wp.get_device())
if not cuda_graph_comp:
raise SkipNotImplemented
self.num_frames = 50
self.model = _build_heightfield_scene(num_bodies=200, nrow=100, ncol=100)
self.solver = newton.solvers.SolverXPBD(self.model, iterations=10)
self.contacts = self.model.contacts()
self.state_0 = self.model.state()
self.state_1 = self.model.state()
self.control = self.model.control()
self.sim_substeps = 10
self.sim_dt = (1.0 / 100.0) / self.sim_substeps
wp.synchronize_device()
with wp.ScopedCapture() as capture:
for _sub in range(self.sim_substeps):
self.state_0.clear_forces()
self.model.collide(self.state_0, self.contacts)
self.solver.step(self.state_0, self.state_1, self.control, self.contacts, self.sim_dt)
self.state_0, self.state_1 = self.state_1, self.state_0
self.graph = capture.graph
wp.synchronize_device()
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_simulate(self):
for _frame in range(self.num_frames):
wp.capture_launch(self.graph)
wp.synchronize_device()
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"HeightfieldCollision": HeightfieldCollision,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/simulation/bench_ik.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2026 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
from __future__ import annotations
import os
import sys
import numpy as np
import warp as wp
from asv_runner.benchmarks.mark import SkipNotImplemented, skip_benchmark_if
wp.config.quiet = True
wp.config.enable_backward = False
parent_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
sys.path.append(parent_dir)
from benchmark_ik import build_ik_solver, create_franka_model, eval_success, fk_targets, random_solutions
class _IKBenchmark:
"""Utility base class for IK benchmarks."""
params = None
param_names = ["batch_size"]
repeat = None
number = 1
rounds = 2
EE_LINKS = (9,)
ITERATIONS = 16
STEP_SIZE = 1.0
POS_THRESH_M = 5e-3
ORI_THRESH_RAD = 0.05
SEED = 123
NUM_SOLVES = 50
def setup(self, batch_size):
if not (wp.get_device().is_cuda and wp.is_mempool_enabled(wp.get_device())):
raise SkipNotImplemented
self.model = create_franka_model()
self.solver, self.pos_obj, self.rot_obj = build_ik_solver(self.model, batch_size, self.EE_LINKS)
self.n_coords = self.model.joint_coord_count
rng = np.random.default_rng(self.SEED)
q_gt = random_solutions(self.model, batch_size, rng)
self.tgt_p, self.tgt_r = fk_targets(self.solver, self.model, q_gt, self.EE_LINKS)
self.winners_d = wp.zeros((batch_size, self.n_coords), dtype=wp.float32)
self.seeds_d = wp.zeros((batch_size, self.n_coords), dtype=wp.float32)
# Set targets
for ee in range(len(self.EE_LINKS)):
self.pos_obj[ee].set_target_positions(
wp.array(self.tgt_p[:, ee].astype(np.float32, copy=False), dtype=wp.vec3)
)
self.rot_obj[ee].set_target_rotations(
wp.array(self.tgt_r[:, ee].astype(np.float32, copy=False), dtype=wp.vec4)
)
with wp.ScopedCapture() as cap:
self.solver.step(self.seeds_d, self.winners_d, iterations=self.ITERATIONS, step_size=self.STEP_SIZE)
self.solve_graph = cap.graph
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_solve(self, batch_size):
for _ in range(self.NUM_SOLVES):
wp.capture_launch(self.solve_graph)
wp.synchronize_device()
def teardown(self, batch_size):
q_best = self.winners_d.numpy()
success = eval_success(
self.solver,
self.model,
q_best,
self.tgt_p,
self.tgt_r,
self.EE_LINKS,
self.POS_THRESH_M,
self.ORI_THRESH_RAD,
)
if not success.all():
n_failed = int((~success).sum())
raise RuntimeError(f"IK failed for {n_failed}/{batch_size} problems")
class FastIKSolve(_IKBenchmark):
params = ([512],)
repeat = 6
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"FastSolve": FastIKSolve,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/simulation/bench_mujoco.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import os
import sys
import warp as wp
wp.config.enable_backward = False
wp.config.quiet = True
from asv_runner.benchmarks.mark import SkipNotImplemented, skip_benchmark_if
parent_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
sys.path.append(parent_dir)
from benchmark_mujoco import Example
from newton.utils import EventTracer
@wp.kernel
def apply_random_control(state: wp.uint32, joint_target: wp.array[float]):
tid = wp.tid()
joint_target[tid] = wp.randf(state) * 2.0 - 1.0
class _FastBenchmark:
"""Utility base class for fast benchmarks."""
num_frames = None
robot = None
number = 1
rounds = 2
repeat = None
world_count = None
random_init = None
environment = "None"
def setup(self):
if not hasattr(self, "builder") or self.builder is None:
self.builder = Example.create_model_builder(
self.robot, self.world_count, randomize=self.random_init, seed=123
)
self.example = Example(
stage_path=None,
robot=self.robot,
randomize=self.random_init,
headless=True,
actuation="None",
use_cuda_graph=True,
builder=self.builder,
environment=self.environment,
)
wp.synchronize_device()
# Recapture the graph with control application included
cuda_graph_comp = wp.get_device().is_cuda and wp.is_mempool_enabled(wp.get_device())
if not cuda_graph_comp:
raise SkipNotImplemented
else:
state = wp.rand_init(self.example.seed)
with wp.ScopedCapture() as capture:
wp.launch(
apply_random_control,
dim=(self.example.model.joint_dof_count,),
inputs=[state],
outputs=[self.example.control.joint_target_pos],
)
self.example.simulate()
self.graph = capture.graph
wp.synchronize_device()
def time_simulate(self):
for _ in range(self.num_frames):
wp.capture_launch(self.graph)
wp.synchronize_device()
class _KpiBenchmark:
"""Utility base class for KPI benchmarks."""
param_names = ["world_count"]
num_frames = None
params = None
robot = None
samples = None
ls_iteration = None
random_init = None
environment = "None"
def setup(self, world_count):
if not hasattr(self, "builder") or self.builder is None:
self.builder = {}
if world_count not in self.builder:
self.builder[world_count] = Example.create_model_builder(
self.robot, world_count, randomize=self.random_init, seed=123
)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def track_simulate(self, world_count):
total_time = 0.0
for _iter in range(self.samples):
example = Example(
stage_path=None,
robot=self.robot,
randomize=self.random_init,
headless=True,
actuation="random",
use_cuda_graph=True,
builder=self.builder[world_count],
ls_iteration=self.ls_iteration,
environment=self.environment,
)
wp.synchronize_device()
for _ in range(self.num_frames):
example.step()
wp.synchronize_device()
total_time += example.benchmark_time
return total_time * 1000 / (self.num_frames * example.sim_substeps * world_count * self.samples)
track_simulate.unit = "ms/world-step"
class _NewtonOverheadBenchmark:
"""Utility base class for measuring Newton overhead."""
param_names = ["world_count"]
num_frames = None
params = None
robot = None
samples = None
ls_iteration = None
random_init = None
def setup(self, world_count):
if not hasattr(self, "builder") or self.builder is None:
self.builder = {}
if world_count not in self.builder:
self.builder[world_count] = Example.create_model_builder(
self.robot, world_count, randomize=self.random_init, seed=123
)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def track_simulate(self, world_count):
trace = {}
with EventTracer(enabled=True) as tracer:
for _iter in range(self.samples):
example = Example(
stage_path=None,
robot=self.robot,
randomize=self.random_init,
headless=True,
actuation="random",
world_count=world_count,
use_cuda_graph=True,
builder=self.builder[world_count],
ls_iteration=self.ls_iteration,
)
for _ in range(self.num_frames):
example.step()
trace = tracer.add_trace(trace, tracer.trace())
step_time = trace["step"][0]
step_trace = trace["step"][1]
mujoco_warp_step_time = step_trace["_mujoco_warp_step"][0]
overhead = 100.0 * (step_time - mujoco_warp_step_time) / step_time
return overhead
track_simulate.unit = "%"
class FastCartpole(_FastBenchmark):
num_frames = 50
robot = "cartpole"
repeat = 8
world_count = 256
random_init = True
environment = "None"
class KpiCartpole(_KpiBenchmark):
params = [[8192]]
num_frames = 50
robot = "cartpole"
samples = 4
ls_iteration = 3
random_init = True
environment = "None"
class FastG1(_FastBenchmark):
num_frames = 25
robot = "g1"
repeat = 2
world_count = 256
random_init = True
environment = "None"
class KpiG1(_KpiBenchmark):
params = [[8192]]
num_frames = 50
robot = "g1"
timeout = 900
samples = 2
ls_iteration = 10
random_init = True
environment = "None"
class FastNewtonOverheadG1(_NewtonOverheadBenchmark):
params = [[256]]
num_frames = 25
robot = "g1"
repeat = 2
samples = 1
random_init = True
class KpiNewtonOverheadG1(_NewtonOverheadBenchmark):
params = [[8192]]
num_frames = 50
robot = "g1"
timeout = 900
samples = 2
ls_iteration = 10
random_init = True
class FastHumanoid(_FastBenchmark):
num_frames = 50
robot = "humanoid"
repeat = 8
world_count = 256
random_init = True
environment = "None"
class KpiHumanoid(_KpiBenchmark):
params = [[8192]]
num_frames = 100
robot = "humanoid"
samples = 4
ls_iteration = 15
random_init = True
environment = "None"
class FastNewtonOverheadHumanoid(_NewtonOverheadBenchmark):
params = [[256]]
num_frames = 50
robot = "humanoid"
repeat = 8
samples = 1
random_init = True
class KpiNewtonOverheadHumanoid(_NewtonOverheadBenchmark):
params = [[8192]]
num_frames = 100
robot = "humanoid"
samples = 4
ls_iteration = 15
random_init = True
class FastAllegro(_FastBenchmark):
num_frames = 100
robot = "allegro"
repeat = 2
world_count = 256
random_init = False
environment = "None"
class KpiAllegro(_KpiBenchmark):
params = [[8192]]
num_frames = 300
robot = "allegro"
samples = 2
ls_iteration = 10
random_init = False
environment = "None"
class FastKitchenG1(_FastBenchmark):
num_frames = 25
robot = "g1"
repeat = 2
world_count = 32
random_init = True
environment = "kitchen"
class KpiKitchenG1(_KpiBenchmark):
params = [[512]]
num_frames = 50
robot = "g1"
timeout = 900
samples = 2
ls_iteration = 10
random_init = True
environment = "kitchen"
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"FastCartpole": FastCartpole,
"FastG1": FastG1,
"FastHumanoid": FastHumanoid,
"FastAllegro": FastAllegro,
"FastKitchenG1": FastKitchenG1,
"FastNewtonOverheadG1": FastNewtonOverheadG1,
"FastNewtonOverheadHumanoid": FastNewtonOverheadHumanoid,
"KpiCartpole": KpiCartpole,
"KpiG1": KpiG1,
"KpiHumanoid": KpiHumanoid,
"KpiAllegro": KpiAllegro,
"KpiKitchenG1": KpiKitchenG1,
"KpiNewtonOverheadG1": KpiNewtonOverheadG1,
"KpiNewtonOverheadHumanoid": KpiNewtonOverheadHumanoid,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/simulation/bench_quadruped_xpbd.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import warp as wp
from asv_runner.benchmarks.mark import skip_benchmark_if
wp.config.enable_backward = False
wp.config.quiet = True
import newton
import newton.examples
from newton.examples.basic.example_basic_urdf import Example
class FastExampleQuadrupedXPBD:
repeat = 10
number = 1
def setup(self):
self.num_frames = 1000
if hasattr(newton.examples, "default_args") and hasattr(Example, "create_parser"):
args = newton.examples.default_args(Example.create_parser())
args.world_count = 200
self.example = Example(newton.viewer.ViewerNull(num_frames=self.num_frames), args)
else:
self.example = Example(newton.viewer.ViewerNull(num_frames=self.num_frames), 200)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_simulate(self):
for _ in range(self.num_frames):
self.example.step()
wp.synchronize_device()
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"FastExampleQuadrupedXPBD": FastExampleQuadrupedXPBD,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/simulation/bench_selection.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import warp as wp
from asv_runner.benchmarks.mark import skip_benchmark_if
wp.config.enable_backward = False
wp.config.quiet = True
import newton
import newton.examples
from newton.examples.selection.example_selection_cartpole import Example
class FastExampleSelectionCartpoleMuJoCo:
repeat = 10
number = 1
def setup(self):
self.num_frames = 200
if hasattr(newton.examples, "default_args") and hasattr(Example, "create_parser"):
args = newton.examples.default_args(Example.create_parser())
self.example = Example(newton.viewer.ViewerNull(num_frames=self.num_frames), args)
else:
self.example = Example(
viewer=newton.viewer.ViewerNull(num_frames=self.num_frames), world_count=16, verbose=False
)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_simulate(self):
for _ in range(self.num_frames):
self.example.step()
wp.synchronize_device()
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"FastExampleSelectionCartpoleMuJoCo": FastExampleSelectionCartpoleMuJoCo,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv/benchmarks/simulation/bench_sensor_tiled_camera.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import warp as wp
from asv_runner.benchmarks.mark import skip_benchmark_if
wp.config.enable_backward = False
wp.config.quiet = True
import math
import newton
from newton.sensors import SensorTiledCamera
NICE_NAMES = {}
def nice_name(value):
def decorator(func):
func._nice_name = value
return func
return decorator
def nice_name_collector():
def decorator(instance):
for name, attr in instance.__dict__.items():
if nice_name := getattr(attr, "_nice_name", None):
NICE_NAMES[name] = nice_name
return instance
return decorator
@nice_name_collector()
class SensorTiledCameraBenchmark:
param_names = ["resolution", "world_count", "iterations"]
params = ([64], [4096], [50])
def setup(self, resolution: int, world_count: int, iterations: int):
self.device = wp.get_preferred_device()
franka = newton.ModelBuilder()
franka.add_urdf(
newton.utils.download_asset("franka_emika_panda") / "urdf/fr3_franka_hand.urdf",
floating=False,
)
scene = newton.ModelBuilder()
scene.replicate(franka, world_count)
scene.add_ground_plane()
self.model = scene.finalize()
self.state = self.model.state()
newton.eval_fk(self.model, self.model.joint_q, self.model.joint_qd, self.state)
self.camera_transforms = wp.array(
[
[
wp.transformf(
wp.vec3f(2.4, 0.0, 0.8),
wp.quatf(0.4187639653682709, 0.4224344491958618, 0.5708873867988586, 0.5659270882606506),
)
]
* world_count
],
dtype=wp.transformf,
)
self.tiled_camera_sensor = SensorTiledCamera(model=self.model)
self.tiled_camera_sensor.utils.create_default_light(enable_shadows=False)
self.tiled_camera_sensor.utils.assign_checkerboard_material_to_all_shapes()
self.camera_rays = self.tiled_camera_sensor.utils.compute_pinhole_camera_rays(
resolution, resolution, math.radians(45.0)
)
self.color_image = self.tiled_camera_sensor.utils.create_color_image_output(resolution, resolution)
self.depth_image = self.tiled_camera_sensor.utils.create_depth_image_output(resolution, resolution)
self.tiled_camera_sensor.sync_transforms(self.state)
# Warmup Kernels
self.tiled_camera_sensor.render_config.render_order = SensorTiledCamera.RenderOrder.TILED
self.tiled_camera_sensor.render_config.tile_width = 8
self.tiled_camera_sensor.render_config.tile_height = 8
for out_color, out_depth in [(True, True), (True, False), (False, True)]:
for _ in range(iterations):
self.tiled_camera_sensor.update(
None,
self.camera_transforms,
self.camera_rays,
color_image=self.color_image if out_color else None,
depth_image=self.depth_image if out_depth else None,
)
self.tiled_camera_sensor.render_config.render_order = SensorTiledCamera.RenderOrder.PIXEL_PRIORITY
for out_color, out_depth in [(True, True), (True, False), (False, True)]:
for _ in range(iterations):
self.tiled_camera_sensor.update(
None,
self.camera_transforms,
self.camera_rays,
color_image=self.color_image if out_color else None,
depth_image=self.depth_image if out_depth else None,
)
@nice_name("Rendering (Pixel)")
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_rendering_pixel_priority_color_depth(self, resolution: int, world_count: int, iterations: int):
self.tiled_camera_sensor.render_config.render_order = SensorTiledCamera.RenderOrder.PIXEL_PRIORITY
for _ in range(iterations):
self.tiled_camera_sensor.update(
None,
self.camera_transforms,
self.camera_rays,
color_image=self.color_image,
depth_image=self.depth_image,
refit_bvh=False,
)
wp.synchronize()
@nice_name("Rendering (Pixel) (Color Only)")
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_rendering_pixel_priority_color_only(self, resolution: int, world_count: int, iterations: int):
self.tiled_camera_sensor.render_config.render_order = SensorTiledCamera.RenderOrder.PIXEL_PRIORITY
for _ in range(iterations):
self.tiled_camera_sensor.update(
None,
self.camera_transforms,
self.camera_rays,
color_image=self.color_image,
refit_bvh=False,
)
wp.synchronize()
@nice_name("Rendering (Pixel) (Depth Only)")
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_rendering_pixel_priority_depth_only(self, resolution: int, world_count: int, iterations: int):
self.tiled_camera_sensor.render_config.render_order = SensorTiledCamera.RenderOrder.PIXEL_PRIORITY
for _ in range(iterations):
self.tiled_camera_sensor.update(
None,
self.camera_transforms,
self.camera_rays,
depth_image=self.depth_image,
refit_bvh=False,
)
wp.synchronize()
@nice_name("Rendering (Tiled)")
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_rendering_tiled_color_depth(self, resolution: int, world_count: int, iterations: int):
self.tiled_camera_sensor.render_config.render_order = SensorTiledCamera.RenderOrder.TILED
self.tiled_camera_sensor.render_config.tile_width = 8
self.tiled_camera_sensor.render_config.tile_height = 8
for _ in range(iterations):
self.tiled_camera_sensor.update(
None,
self.camera_transforms,
self.camera_rays,
color_image=self.color_image,
depth_image=self.depth_image,
refit_bvh=False,
)
wp.synchronize()
@nice_name("Rendering (Tiled) (Color Only)")
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_rendering_tiled_color_only(self, resolution: int, world_count: int, iterations: int):
self.tiled_camera_sensor.render_config.render_order = SensorTiledCamera.RenderOrder.TILED
self.tiled_camera_sensor.render_config.tile_width = 8
self.tiled_camera_sensor.render_config.tile_height = 8
for _ in range(iterations):
self.tiled_camera_sensor.update(
None,
self.camera_transforms,
self.camera_rays,
color_image=self.color_image,
refit_bvh=False,
)
wp.synchronize()
@nice_name("Rendering (Tiled) (Depth Only)")
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_rendering_tiled_depth_only(self, resolution: int, world_count: int, iterations: int):
self.tiled_camera_sensor.render_config.render_order = SensorTiledCamera.RenderOrder.TILED
self.tiled_camera_sensor.render_config.tile_width = 8
self.tiled_camera_sensor.render_config.tile_height = 8
for _ in range(iterations):
self.tiled_camera_sensor.update(
None,
self.camera_transforms,
self.camera_rays,
depth_image=self.depth_image,
refit_bvh=False,
)
wp.synchronize()
def print_fps(name: str, duration: float, resolution: int, world_count: int, iterations: int):
camera_count = 1
title = f"{name}"
if iterations > 1:
title += " average"
average = f"{duration * 1000.0 / iterations:.2f} ms"
fps = f"({(1.0 / (duration / iterations) * (world_count * camera_count)):,.2f} fps)"
print(f"{title} {'.' * (50 - len(title) - len(average))} {average} {fps if iterations > 1 else ''}")
def print_fps_results(results: dict[tuple[str, tuple[int, int, int]], float]):
print("")
print("=== Benchmark Results (FPS) ===")
for (method_name, params), avg in results.items():
print_fps(NICE_NAMES.get(method_name, method_name), avg, *params)
print("")
if __name__ == "__main__":
from newton.utils import run_benchmark
results = run_benchmark(SensorTiledCameraBenchmark)
print_fps_results(results)
================================================
FILE: asv/benchmarks/simulation/bench_viewer.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
import os
import sys
# Force headless mode for CI environments before any pyglet imports
os.environ["PYGLET_HEADLESS"] = "1"
import warp as wp
wp.config.enable_backward = False
wp.config.quiet = True
from asv_runner.benchmarks.mark import skip_benchmark_if
parent_dir = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
sys.path.append(parent_dir)
from benchmark_mujoco import Example
from newton.viewer import ViewerGL
class KpiViewerGL:
params = (["g1"], [8192])
param_names = ["robot", "world_count"]
rounds = 1
repeat = 3
number = 1
min_run_count = 1
def setup(self, robot, world_count):
wp.init()
builder = Example.create_model_builder(robot, world_count, randomize=True, seed=123)
# finalize model
self._model = builder.finalize()
self._state = self._model.state()
# Setting up the renderer
self.renderer = ViewerGL(headless=True)
self.renderer.set_model(self._model)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_rendering_frame(self, robot, world_count):
# Rendering one frame
self.renderer.begin_frame(0.0)
self.renderer.log_state(self._state)
self.renderer.end_frame()
wp.synchronize_device()
def teardown(self, robot, world_count):
self.renderer.close()
del self.renderer
del self._model
del self._state
class FastViewerGL:
params = (["g1"], [256])
param_names = ["robot", "world_count"]
rounds = 1
repeat = 3
number = 1
min_run_count = 1
def setup(self, robot, world_count):
wp.init()
builder = Example.create_model_builder(robot, world_count, randomize=True, seed=123)
# finalize model
self._model = builder.finalize()
self._state = self._model.state()
# Setting up the renderer
self.renderer = ViewerGL(headless=True)
self.renderer.set_model(self._model)
@skip_benchmark_if(wp.get_cuda_device_count() == 0)
def time_rendering_frame(self, robot, world_count):
# Rendering one frame
self.renderer.begin_frame(0.0)
self.renderer.log_state(self._state)
self.renderer.end_frame()
wp.synchronize_device()
def teardown(self, robot, world_count):
self.renderer.close()
del self.renderer
del self._model
del self._state
if __name__ == "__main__":
import argparse
from newton.utils import run_benchmark
benchmark_list = {
"KpiViewerGL": KpiViewerGL,
"FastViewerGL": FastViewerGL,
}
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
"-b", "--bench", default=None, action="append", choices=benchmark_list.keys(), help="Run a single benchmark."
)
args = parser.parse_known_args()[0]
if args.bench is None:
benchmarks = benchmark_list.keys()
else:
benchmarks = args.bench
for key in benchmarks:
benchmark = benchmark_list[key]
run_benchmark(benchmark)
================================================
FILE: asv.conf.json
================================================
{
"version": 1,
"project": "newton",
"project_url": "https://github.com/newton-physics/newton",
"repo": ".",
"branches": ["main"],
"dvcs": "git",
"environment_type": "virtualenv",
"show_commit_url": "https://github.com/newton-physics/newton/commit/",
"benchmark_dir": "asv/benchmarks",
"env_dir": "asv/env",
"results_dir": "asv/results",
"html_dir": "asv/html",
"build_cache_size": 20,
"default_benchmark_timeout": 600,
"build_command": ["python -m build --wheel -o {build_cache_dir} {build_dir}"],
"install_command": [
"python -m pip install -U numpy",
"python -m pip install -U warp-lang==1.12.0 --index-url=https://pypi.nvidia.com/",
"python -m pip install -U mujoco==3.6.0",
"python -m pip install -U mujoco-warp==3.6.0",
"python -m pip install -U torch==2.10.0+cu130 --index-url https://download.pytorch.org/whl/cu130",
"in-dir={env_dir} python -m pip install {wheel_file}[dev]"
]
}
================================================
FILE: docs/Makefile
================================================
# Minimal makefile for Sphinx documentation
#
# You can set these variables from the command line, and also
# from the environment for the first two.
SPHINXOPTS ?= -j auto
SPHINXBUILD ?= sphinx-build
SOURCEDIR = .
BUILDDIR = _build
# Put it first so that "make" without argument is like "make help".
help:
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
.PHONY: help Makefile
# Catch-all target: route all unknown targets to Sphinx using the new
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
%: Makefile
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
================================================
FILE: docs/_ext/autodoc_filter.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
from __future__ import annotations
import sys
from typing import Any
# NOTE: This file is *imported by Sphinx* when building the docs.
# It must therefore avoid heavy third-party imports that might not be
# available in the documentation environment.
# ---------------------------------------------------------------------------
# Skip handler implementation
def _should_skip_member(
app: Any, # Sphinx application (unused)
what: str,
name: str,
obj: Any,
skip: bool,
options: Any, # autodoc options (unused)
) -> bool | None:
"""Determine whether *obj* should be skipped by autodoc.
We apply two simple rules that make API pages cleaner:
1. Private helpers (names that start with an underscore but are not
special dunder methods) are hidden unless they are explicitly
marked as public via a ``:meta public:`` field.
2. Public members that have **no** docstring are hidden. This keeps the
generated documentation focused on the public, documented API.
Returning ``True`` tells Sphinx to skip the member, ``False`` to include
it, and ``None`` to fall back to Sphinx's default behaviour.
"""
# Respect decisions made by other handlers first.
if skip:
return True
# Keep dunder methods that are explicitly requested elsewhere.
if name.startswith("__") and name.endswith("__"):
return None # keep default behaviour
# Skip private helpers (single underscore) that are not explicitly public.
if name.startswith("_"):
# Let users override via :meta public:
doc = getattr(obj, "__doc__", "") or ""
if ":meta public:" not in doc:
return True
return None
# If the member is public but undocumented, decide based on its nature.
doc = getattr(obj, "__doc__", None)
if not doc:
# Keep an undocumented callable **only** if it overrides a documented
# attribute from a base-class. This covers cases like ``step`` in
# solver subclasses while still hiding brand-new helpers that have no
# documentation.
is_callable = callable(obj) or isinstance(
obj,
property | staticmethod | classmethod,
)
if is_callable and what == "class":
# Try to determine the parent class from the qualified name.
qualname = getattr(obj, "__qualname__", "")
parts = qualname.split(".")
if len(parts) >= 2:
cls_name = parts[-2]
module = sys.modules.get(obj.__module__)
parent_cls = getattr(module, cls_name, None)
if isinstance(parent_cls, type):
for base in parent_cls.__mro__[1:]:
if hasattr(base, name):
return None # overrides something -> keep it
# Otherwise hide the undocumented member to keep the page concise.
return True
# Default: do not override Sphinx's decision.
return None
def setup(app): # type: ignore[override]
"""Hook into the Sphinx build."""
app.connect("autodoc-skip-member", _should_skip_member)
# Tell Sphinx our extension is parallel-safe.
return {
"parallel_read_safe": True,
"parallel_write_safe": True,
}
================================================
FILE: docs/_ext/autodoc_wpfunc.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2025 The Newton Developers
# SPDX-License-Identifier: Apache-2.0
"""Sphinx extension to document Warp `@wp.func` functions.
This extension registers a custom *autodoc* documenter that recognises
`warp.types.Function` objects (created by the :pyfunc:`warp.func` decorator),
unwraps them to their original Python function (stored in the ``.func``
attribute) and then delegates all further processing to the standard
:class:`sphinx.ext.autodoc.FunctionDocumenter`.
With this in place, *autosummary* and *autodoc* treat Warp kernels exactly like
regular Python functions: the original signature and docstring are used and
`__all__` filtering works as expected.
"""
from __future__ import annotations
import inspect
from typing import Any
from sphinx.ext.autodoc import FunctionDocumenter
# NOTE: We do **not** import warp at module import time. Doing so would require
# CUDA and other heavy deps during the Sphinx build. Instead, detection of a
# Warp function is performed purely via *duck typing* (checking attributes and
# class name) so the extension is safe even when Warp cannot be imported.
class WarpFunctionDocumenter(FunctionDocumenter):
"""Autodoc documenter that unwraps :pyclass:`warp.types.Function`."""
objtype = "warpfunc"
directivetype = "function"
# Ensure we run *before* the builtin FunctionDocumenter (higher priority)
priority = FunctionDocumenter.priority + 10
# ---------------------------------------------------------------------
# Helper methods
# ---------------------------------------------------------------------
@staticmethod
def _looks_like_warp_function(obj: Any) -> bool:
"""Return *True* if *obj* appears to be a `warp.types.Function`."""
cls = obj.__class__
return getattr(cls, "__name__", "") == "Function" and hasattr(obj, "func")
@classmethod
def can_document_member(
cls,
member: Any,
member_name: str,
isattr: bool,
parent,
) -> bool:
"""Return *True* when *member* is a Warp function we can handle."""
return cls._looks_like_warp_function(member)
# ------------------------------------------------------------------
# Autodoc overrides - we proxy to the underlying Python function.
# ------------------------------------------------------------------
def _unwrap(self):
"""Return the original Python function or *self.object* as fallback."""
orig = getattr(self.object, "func", None)
if orig and inspect.isfunction(orig):
return orig
return self.object
# Each of these hooks replaces *self.object* with the unwrapped function
# *before* delegating to the base implementation.
def format_args(self):
self.object = self._unwrap()
return super().format_args()
def get_doc(self, *args: Any, **kwargs: Any) -> list[list[str]]:
self.object = self._unwrap()
return super().get_doc(*args, **kwargs)
def add_directive_header(self, sig: str) -> None:
self.object = self._unwrap()
super().add_directive_header(sig)
# ----------------------------------------------------------------------------
# Sphinx extension entry point
# ----------------------------------------------------------------------------
def setup(app): # type: ignore[override]
"""Register the :class:`WarpFunctionDocumenter` with *app*."""
app.add_autodocumenter(WarpFunctionDocumenter, override=True)
# Declare the extension safe for parallel reading/writing
return {
"parallel_read_safe": True,
"parallel_write_safe": True,
}
================================================
FILE: docs/_static/custom.css
================================================
/* Reduce spacing between class members */
.py-attribute, .py-method, .py-property, .py-class {
margin-top: 0.5em !important;
margin-bottom: 0.5em !important;
}
/* Reduce spacing in docstring sections */
.section > dl > dt {
margin-top: 0.2em !important;
margin-bottom: 0.2em !important;
}
/* Reduce padding in parameter lists */
.field-list .field {
margin-bottom: 0.2em !important;
padding-bottom: 0.2em !important;
}
/* Reduce spacing between headings and content */
h2, h3, h4, h5, h6 {
margin-top: 1em !important;
margin-bottom: 0.5em !important;
}
/* Reduce spacing in enum documentation */
.py.class .py.attribute {
margin-bottom: 0.5em !important;
}
/* Reduce spacing between enum values */
dl.py.attribute {
margin-bottom: 0.3em !important;
}
================================================
FILE: docs/_static/gh-pages-404.html
================================================