\n
\n \n
\n \n \n \n``` \n以上代码主要测试js与java相互调用,而由于按键这种系统事件被webview截获掉,有如下两种方式进行处理\n\n1、把方向键的流程改成:先传给webcore,假如没处理,再在webview里面处理,这个需要修改webview.java代码\n2、直接应用搞定,java捕获按键,然后调js函数,上面代码就是使用这种方法。\n\n测试结果如下: 点击buttons按钮:\nI/A ( 4990): Callfunction\nI/A ( 4990): getSize\nI/A ( 4990): getObject\nI/A ( 4990): GetList:test\nI/A ( 4990): getObject\nI/A ( 4990): GetList:test\nI/A ( 4990): getObject\nI/A ( 4990): GetList:test\nI/A ( 4990): getObject\nI/A ( 4990): GetList:test\nI/A ( 4990): getObject\nI/A ( 4990): GetList:test\n\nyou press KEY_RIGHT\nI/AA ( 4990): keyCode=22\nI/A ( 4990): GetList:22\n\nyou press KEY_UP\nI/AA ( 4990): keyCode=19\nI/A ( 4990): GetList:19\n\nyou press KEY_DOWN\nI/AA ( 4990): keyCode=20\nI/A ( 4990): GetList:20\n\nyou press KEY_LEFT\nI/AA ( 4990): keyCode=21\nI/A ( 4990): GetList:21\n\n这里为何使用这种方式,是因为对于上下左右及确定这种功能键被webview截取掉了,无法传递到webcore中,而只能重载OnKeyDown/OnKeyUp方法,再由js调用java方法来获取得。\n对于数字键的处理可以直接在js中进行处理:\nlogcat中会有明显的打印,对于这些键没有截掉,所以可以直接获取得到:\nD/webcore ( 4990): proc key: code=12\nD/webcore ( 4990): proc key: nativeKey return false\nD/webcore ( 4990): proc key: nativeKey return true\njs代码可以如此编写:\n\n```\n \n``` \n39.Service和Activity在同一个线程吗\n\n默认情况同一线程 main主线程 ui线程40.ViewStub的应用\n\n 在开发应用程序的时候,经常会遇到这样的情况,会在运行时动态根据条件来决定显示哪个View或某个布局。那么最通常的想法就是把可能用到的View都写在上面,先把它们的可见性都设为View.GONE,然后在代码中动态的更改它的可见性。这样的做法的优点是逻辑简单而且控制起来比较灵活。但是它的缺点就是,耗费资源。虽然把View的初始可见View.GONE但是在Inflate布局的时候View仍然会被Inflate,也就是说仍然会创建对象,会被实例化,会被设置属性。也就是说,会耗费内存等资源。\n 推荐的做法是使用android.view.ViewStub,ViewStub是一个轻量级的View,它一个看不见的,不占布局位置,占用资源非常小的控件。可以为ViewStub指定一个布局,在Inflate布局的时候,只有ViewStub会被初始化,然后当ViewStub被设置为可见的时候,或是调用了ViewStub.inflate()的时候,ViewStub所向的布局就会被Inflate和实例化,然后ViewStub的布局属性都会传给它所指向的布局。这样,就可以使用ViewStub来方便的在运行时,要还是不要显示某个布局。\n 但ViewStub也不是万能的,下面总结下ViewStub能做的事儿和什么时候该用ViewStub,什么时候该用可见性的控制。\n 首先来说说ViewStub的一些特点:\n 1. ViewStub只能Inflate一次,之后ViewStub对象会被置为空。按句话说,某个被ViewStub指定的布局被Inflate后,就不会够再通过ViewStub来控制它了。\n 2. ViewStub只能用来Inflate一个布局文件,而不是某个具体的View,当然也可以把View写在某个布局文件中。\n 基于以上的特点,那么可以考虑使用ViewStub的情况有:\n 1. 在程序的运行期间,某个布局在Inflate后,就不会有变化,除非重新启动。\n 因为ViewStub只能Inflate一次,之后会被置空,所以无法指望后面接着使用ViewStub来控制布局。所以当需要在运行时不止一次的显示和隐藏某个布局,那么ViewStub是做不到的。这时就只能使用View的可见性来控制了。\n 2. 想要控制显示与隐藏的是一个布局文件,而非某个View。\n 因为设置给ViewStub的只能是某个布局文件的Id,所以无法让它来控制某个View。\n 所以,如果想要控制某个View(如Button或TextView)的显示与隐藏,或者想要在运行时不断的显示与隐藏某个布局或View,只能使用View的可见性来控制。\n下面来看一个实例\n在这个例子中,要显示二种不同的布局,一个是用TextView显示一段文字,另一个则是用ImageView显示一个图片。这二个是在onCreate()时决定是显示哪一个,这里就是应用ViewStub的最佳地点。\n先来看看布局,一个是主布局,里面只定义二个ViewStub,一个用来控制TextView一个用来控制ImageView,另外就是一个是为显示文字的做的TextView布局,一个是为ImageView而做的布局:\n\n```xml\n \n \n \n \n \n```\n为TextView的布局:\n\n\n```xml\n \n \n \n \n``` \n为ImageView的布局:\n\n\n```\n \n \n \n \n``` \n下面来看代码,决定来显示哪一个,只需要找到相应的ViewStub然后调用其infalte()就可以获得相应想要的布局:\n\n\n```java\npackage com.effective; \n \nimport android.app.Activity; \nimport android.os.Bundle; \nimport android.view.ViewStub; \nimport android.widget.ImageView; \nimport android.widget.TextView; \n \npublic class ViewStubDemoActivity extends Activity { \n @Override \n public void onCreate(Bundle savedInstanceState) { \n super.onCreate(savedInstanceState); \n setContentView(R.layout.viewstub_demo_activity); \n if ((((int) (Math.random() * 100)) & 0x01) == 0) { \n // to show text \n // all you have to do is inflate the ViewStub for textview \n ViewStub stub = (ViewStub) findViewById(R.id.viewstub_demo_text); \n stub.inflate(); \n TextView text = (TextView) findViewById(R.id.viewstub_demo_textview); \n text.setText(\"The tree of liberty must be refreshed from time to time\" + \n \" with the blood of patroits and tyrants! Freedom is nothing but \" + \n \"a chance to be better!\"); \n } else { \n // to show image \n // all you have to do is inflate the ViewStub for imageview \n ViewStub stub = (ViewStub) findViewById(R.id.viewstub_demo_image); \n stub.inflate(); \n ImageView image = (ImageView) findViewById(R.id.viewstub_demo_imageview); \n image.setImageResource(R.drawable.happy_running_dog); \n } \n } \n} \n```\n运行结果:\n\n\n使用的时候的注意事项:\n1. 某些布局属性要加在ViewStub而不是实际的布局上面,才会起作用,比如上面用的android:layout_margin*系列属性,如果加在TextView上面,则不会起作用,需要放在它的ViewStub上面才会起作用。而ViewStub的属性在inflate()后会都传给相应的布局。\n41.android开发中怎么去调试bug\n\n逻辑错误 \n1.断点 debug \n2. logcat ,\n界面布局,显示 hierarchyviewer.bat42.书写出android工程的目录结构以及相关作用\n\n下面是HelloAndroid项目在eclipse中的目录层次结构:\n\n由上图可以看出项目的根目录下共有九个文件(夹),下面就这九个文件(夹)进行详解:\n1.1src文件夹和assets文件夹:\n每个Android程序都包含资源目录(src)和资产目录(assets),资源和资产听起来感觉没有多大差别,但在存储外部内容时用资源(src)比较多,其中它们的区别在于存放在资源(src)下的内容可以通过应用程序的R类进行访问,而存放在资产(assets)下的内容会保持原始文件的格式,如果需要访问,则必须使用AssetManager以字节流的方式来读取,用起来非常的不方便。为了方便使用,通常文件和数据都会保存在资源(src)目录下\n1.2res(Resource)目录:资源目录\n可以存放一些图标,界面文件和应用中用到的文字信息,下图为res目录截图:\n1.2.1 drawable-*dpi文件夹:将图标按分辨率的高低放入不同的目录,其中draeable-hdpi用来存放高分辨率的图标,drawable-mdpi用来存放中等分辨率的图标,drawable-ldpi用来存放低分辨率的图标\n1.2.2 values文件夹:用来存放文字的信息\n(1)strings.xml:用来定义字符串和数值\n\n\n \n Hello World, Hello 3G \n Android1.1 \n 哥想你了 \n 按钮1 \n 按钮1 \n \n每个string标签生命了一个字符串,name属性指定它的引用值\n(2)为什么要把这些出现的文字单独放在strings.xml文件中?\n答案:一是为了国际化,如果需要将文件中的文字换成别的国家的语言,就可以只需要替换掉一个strings.xml文件就可以了\n二是为了减少应用的体积,例如,我们要在应用中使用“哥想你了”这句话1000次,如果我们没有将“哥想你了”定义在strings.xml文件中,而是直接在应用中使用时写上这几个字,那么我们就会在应用中写4000个字。4000个字和4个字占用的内存可是有很大差距的啊,况且手机的内存本来就小,所以应该是能省就省\n(3)另外还有arrays.xml,color.xml等定义数组,颜色的,都最好用单独的一个xml文档\n1.2.3 layout文件:用来存放界面信息\n本例中的布局文件是自动生成的“main.xml”\n\n\n \n \n \n \n元素:线性布局的意思,在该元素下的所有子元素都会根据他的”orientation”属性来决定是按行还是按列或者按逐个显示进行布局的\n元素:是一种显示控件,他的”text”属性指定了在这个元素上显示的内容\n1.3 gen目录:gen目录下只有一个自动生成的“R.java”文件\n\n```java\n/*AUTO-GENERATED FILE. DO NOT MODIFY.\n *\n * This class was automatically generated bythe\n * aapt tool from the resource data itfound. It\n * should not be modified by hand.\n */\n \npackagecn.csdn.android.demo;\n \npublic final class R {\n public static final class attr {\n }\n public static final class drawable {\n public static final int ic_launcher=0x7f020000;\n }\n public static final class id {\n public static final int button1=0x7f050000;\n public static final int radioButton1=0x7f050001;\n public static final int toggleButton1=0x7f050002;\n }\n public static final class layout {\n public static final int main=0x7f030000;\n }\n public static final class string {\n public static final int app_name=0x7f040001;\n public static final int hello=0x7f040000;\n public static final int start=0x7f040004;\n public static final int startButton=0x7f040003;\n public static final int test=0x7f040002;\n }\n}\n```\nR.java文件:默认有attr,drawable,layout,string这四个静态内部类,每个静态内部类对应一中资源,如layout静态内部类对应layout中的界面文件,string静态内部类对应string内部的string标签。如果在layout中在增加一个界面文件或者在string内增加一个string标签,R.java会自动在其对应的内部类增加所增加的内容。\nR.java除了自动标识资源的索引功能外,还有另一个功能,就是当res文件中的某个资源在应用中没有被用到,在这个应用被编译时,系统不会把对应的资源编译到应用中的APR包中。\n1.4 AndroidManifest.xml 功能清单文件\n每个应用程序都会有一个AndroidManifest在它的根目录里面。这个清单为Android系统提供了这个应用的基本信息,系统在运行之前必须知道这些信息,另外,如果我们使用系统自带的服务,如拨号服务,应用安装服务等,都必须在AndroidManifest.xml文件中声明权限\nAndroidManifest.xml的功能:\n命名应用程序的Java应用包,这个包名用来唯一标识应用程序;\n描述应用程序的组件,对实现每个组件和公布其功能的类进行命名,这些声明使得Android系统了解这些组件以及它们在什么条件下可以被启动\n决定哪个组件运行在哪个进程里面\n声明应用程序必须具备的权限,用以访问受保护的API,以及和其他进程的交互\n声明应用程序其他的必备权限,用以组件之间的交互\n列举application所需要链接的库\n以HelloAndroid项目的功能清单为例子进行讲解:\n\n```xml\n\n\n \n \n \n \n \n \n \n \n \n \n```\n\n1.4.1 元素\n\n```xml\n\n```\n元素是AndroidManifest.xml的根元素,”xmlns:android”是指该文件的命名空间,“package”属性是Android应用所在的包,“android:versionCode”指定应用的版本号,如果应用不断升级,则需要修改这个值,”android:versionName”是版本的名称,这个可以根据自己的喜爱改变\n1.4.2 元素\n\n```xml\n\n \n \n \n \n \n \n \n```\n\n元素是一个很重要的元素,开发组件都会在此下定义\n元素的”icon”属性是用来设定应用的图标,其中“@drawable/ic_launcher”的意思是:在R.java文件中的drawable静态内部类下的icon,如下图所示\n元素的“label”属性用来设定应用的名称,其中“@string/app_name”和上述的一样,也是R.java文件中的string静态内部类下的app_name\n1.4.3 元素\n\n```xml\n\n \n \n \n```\n\n元素的作用是注册一个activity信息,当我们在创建“HelloAndroid”这个项目时,指定了“Created Activity”属性为“HelloActivity”,然后ADT在生成项目时帮我们自动创建了一个Activity,就是“HelloActivity.java”;\n元素的“name“属性指定的是Activity的类名,其中“.HelloActivity”中的“.”指的是元素中的“package”属性中指定的当前包,所以“.HelloActivity”就相当于“cn.csdn.android.demo.HelloActivity.java”,如果Activity在应用的包中可以不写“.”,但是为了避免出错,还是写上这个点把\n1.4.4元素\n\n \n如果直接翻译的话是“意图过滤器”,组件通过告诉它们所具备的功能,就是能响应意图类型,在intent中设置action, data, categroy之后在对应的intentfilter中设置相同的属性即可通过过滤被activity调用\n1.5应用要求运行的最低Android版本\n1.6 存放Android自身的jar包 43.ddms 和traceview的区别.\n\n daivilk debug manager system\n1.在应用的主activity的onCreate方法中加入Debug.startMethodTracing(\"要生成的traceview文件的名字\");\n2.同样在主activity的onStop方法中加入Debug.stopMethodTracing();\n3.同时要在AndroidManifest.xml文件中配置权限\n list = new ArrayList(); \n \n public void produceMailSender(int count){ \n for(int i=0; i children = new Vector(); \n \n public TreeNode(String name){ \n this.name = name; \n } \n \n public String getName() { \n return name; \n } \n \n public void setName(String name) { \n this.name = name; \n } \n \n public TreeNode getParent() { \n return parent; \n } \n \n public void setParent(TreeNode parent) { \n this.parent = parent; \n } \n \n //添加孩子节点 \n public void add(TreeNode node){ \n children.add(node); \n } \n \n //删除孩子节点 \n public void remove(TreeNode node){ \n children.remove(node); \n } \n \n //取得孩子节点 \n public Enumeration getChildren(){ \n return children.elements(); \n } \n} \n```\n```java\npublic class Tree { \n \n TreeNode root = null; \n \n public Tree(String name) { \n root = new TreeNode(name); \n } \n \n public static void main(String[] args) { \n Tree tree = new Tree(\"A\"); \n TreeNode nodeB = new TreeNode(\"B\"); \n TreeNode nodeC = new TreeNode(\"C\"); \n \n nodeB.add(nodeC); \n tree.root.add(nodeB); \n System.out.println(\"build the tree finished!\"); \n } \n} \n```\n使用场景:将多个对象组合在一起进行操作,常用于表示树形结构中,例如二叉树,数等。\n12、享元模式(Flyweight)\n享元模式的主要目的是实现对象的共享,即共享池,当系统中对象多的时候可以减少内存的开销,通常与工厂模式一起使用。\n\nFlyWeightFactory负责创建和管理享元单元,当一个客户端请求时,工厂需要检查当前对象池中是否有符合条件的对象,如果有,就返回已经存在的对象,如果没有,则创建一个新对象,FlyWeight是超类。一提到共享池,我们很容易联想到Java里面的JDBC连接池,想想每个连接的特点,我们不难总结出:适用于作共享的一些个对象,他们有一些共有的属性,就拿数据库连接池来说,url、driverClassName、username、password及dbname,这些属性对于每个连接来说都是一样的,所以就适合用享元模式来处理,建一个工厂类,将上述类似属性作为内部数据,其它的作为外部数据,在方法调用时,当做参数传进来,这样就节省了空间,减少了实例的数量。\n看个例子:\n\n看下数据库连接池的代码:\n```java\npublic class ConnectionPool { \n \n private Vector pool; \n \n /*公有属性*/ \n private String url = \"jdbc:mysql://localhost:3306/test\"; \n private String username = \"root\"; \n private String password = \"root\"; \n private String driverClassName = \"com.mysql.jdbc.Driver\"; \n \n private int poolSize = 100; \n private static ConnectionPool instance = null; \n Connection conn = null; \n \n /*构造方法,做一些初始化工作*/ \n private ConnectionPool() { \n pool = new Vector(poolSize); \n \n for (int i = 0; i < poolSize; i++) { \n try { \n Class.forName(driverClassName); \n conn = DriverManager.getConnection(url, username, password); \n pool.add(conn); \n } catch (ClassNotFoundException e) { \n e.printStackTrace(); \n } catch (SQLException e) { \n e.printStackTrace(); \n } \n } \n } \n \n /* 返回连接到连接池 */ \n public synchronized void release() { \n pool.add(conn); \n } \n \n /* 返回连接池中的一个数据库连接 */ \n public synchronized Connection getConnection() { \n if (pool.size() > 0) { \n Connection conn = pool.get(0); \n pool.remove(conn); \n return conn; \n } else { \n return null; \n } \n } \n} \n```\n通过连接池的管理,实现了数据库连接的共享,不需要每一次都重新创建连接,节省了数据库重新创建的开销,提升了系统的性能!本章讲解了7种结构型模式,因为篇幅的问题,剩下的11种行为型模式,\n本章是关于设计模式的最后一讲,会讲到第三种设计模式——行为型模式,共11种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。这段时间一直在写关于设计模式的东西,终于写到一半了,写博文是个很费时间的东西,因为我得为读者负责,不论是图还是代码还是表述,都希望能尽量写清楚,以便读者理解,我想不论是我还是读者,都希望看到高质量的博文出来,从我本人出发,我会一直坚持下去,不断更新,源源动力来自于读者朋友们的不断支持,我会尽自己的努力,写好每一篇文章!希望大家能不断给出意见和建议,共同打造完美的博文!\n \n \n先来张图,看看这11中模式的关系:\n第一类:通过父类与子类的关系进行实现。第二类:两个类之间。第三类:类的状态。第四类:通过中间类\n\n13、策略模式(strategy)\n策略模式定义了一系列算法,并将每个算法封装起来,使他们可以相互替换,且算法的变化不会影响到使用算法的客户。需要设计一个接口,为一系列实现类提供统一的方法,多个实现类实现该接口,设计一个抽象类(可有可无,属于辅助类),提供辅助函数,关系图如下:\n\n图中ICalculator提供同意的方法, AbstractCalculator是辅助类,提供辅助方法,接下来,依次实现下每个类:\n首先统一接口:\n```java\npublic interface ICalculator { \n public int calculate(String exp); \n} \n``` \n辅助类:\n```java\npublic abstract class AbstractCalculator { \n \n public int[] split(String exp,String opt){ \n String array[] = exp.split(opt); \n int arrayInt[] = new int[2]; \n arrayInt[0] = Integer.parseInt(array[0]); \n arrayInt[1] = Integer.parseInt(array[1]); \n return arrayInt; \n } \n} \n``` \n三个实现类:\n```java\npublic class Plus extends AbstractCalculator implements ICalculator { \n \n @Override \n public int calculate(String exp) { \n int arrayInt[] = split(exp,\"\\\\+\"); \n return arrayInt[0]+arrayInt[1]; \n } \n} \n```java\npublic class Minus extends AbstractCalculator implements ICalculator { \n \n @Override \n public int calculate(String exp) { \n int arrayInt[] = split(exp,\"-\"); \n return arrayInt[0]-arrayInt[1]; \n } \n \n} \n```\n```java\npublic class Multiply extends AbstractCalculator implements ICalculator { \n \n @Override \n public int calculate(String exp) { \n int arrayInt[] = split(exp,\"\\\\*\"); \n return arrayInt[0]*arrayInt[1]; \n } \n} \n```\n简单的测试类:\n```java\npublic class StrategyTest { \n \n public static void main(String[] args) { \n String exp = \"2+8\"; \n ICalculator cal = new Plus(); \n int result = cal.calculate(exp); \n System.out.println(result); \n } \n} \n``` \n输出:10\n策略模式的决定权在用户,系统本身提供不同算法的实现,新增或者删除算法,对各种算法做封装。因此,策略模式多用在算法决策系统中,外部用户只需要决定用哪个算法即可。\n14、模板方法模式(Template Method)\n解释一下模板方法模式,就是指:一个抽象类中,有一个主方法,再定义1...n个方法,可以是抽象的,也可以是实际的方法,定义一个类,继承该抽象类,重写抽象方法,通过调用抽象类,实现对子类的调用,先看个关系图:\n\n就是在AbstractCalculator类中定义一个主方法calculate,calculate()调用spilt()等,Plus和Minus分别继承AbstractCalculator类,通过对AbstractCalculator的调用实现对子类的调用,看下面的例子:\n```java\npublic abstract class AbstractCalculator { \n \n /*主方法,实现对本类其它方法的调用*/ \n public final int calculate(String exp,String opt){ \n int array[] = split(exp,opt); \n return calculate(array[0],array[1]); \n } \n \n /*被子类重写的方法*/ \n abstract public int calculate(int num1,int num2); \n \n public int[] split(String exp,String opt){ \n String array[] = exp.split(opt); \n int arrayInt[] = new int[2]; \n arrayInt[0] = Integer.parseInt(array[0]); \n arrayInt[1] = Integer.parseInt(array[1]); \n return arrayInt; \n } \n} \n``` \n```java\npublic class Plus extends AbstractCalculator { \n \n @Override \n public int calculate(int num1,int num2) { \n return num1 + num2; \n } \n} \n``` \n测试类:\n```java\npublic class StrategyTest { \n \n public static void main(String[] args) { \n String exp = \"8+8\"; \n AbstractCalculator cal = new Plus(); \n int result = cal.calculate(exp, \"\\\\+\"); \n System.out.println(result); \n } \n} \n``` \n我跟踪下这个小程序的执行过程:首先将exp和\"\\\\+\"做参数,调用AbstractCalculator类里的calculate(String,String)方法,在calculate(String,String)里调用同类的split(),之后再调用calculate(int ,int)方法,从这个方法进入到子类中,执行完return num1 + num2后,将值返回到AbstractCalculator类,赋给result,打印出来。正好验证了我们开头的思路。\n15、观察者模式(Observer)\n包括这个模式在内的接下来的四个模式,都是类和类之间的关系,不涉及到继承,学的时候应该 记得归纳,记得本文最开始的那个图。观察者模式很好理解,类似于邮件订阅和RSS订阅,当我们浏览一些博客或wiki时,经常会看到RSS图标,就这的意思是,当你订阅了该文章,如果后续有更新,会及时通知你。其实,简单来讲就一句话:当一个对象变化时,其它依赖该对象的对象都会收到通知,并且随着变化!对象之间是一种一对多的关系。先来看看关系图:\n\n我解释下这些类的作用:MySubject类就是我们的主对象,Observer1和Observer2是依赖于MySubject的对象,当MySubject变化时,Observer1和Observer2必然变化。AbstractSubject类中定义着需要监控的对象列表,可以对其进行修改:增加或删除被监控对象,且当MySubject变化时,负责通知在列表内存在的对象。我们看实现代码:\n一个Observer接口:\n```java\npublic interface Observer { \n public void update(); \n} \n```\n两个实现类:\n```java\npublic class Observer1 implements Observer { \n \n @Override \n public void update() { \n System.out.println(\"observer1 has received!\"); \n } \n} \n```\n```java\npublic class Observer2 implements Observer { \n \n @Override \n public void update() { \n System.out.println(\"observer2 has received!\"); \n } \n \n} \n```\nSubject接口及实现类:\n```java\npublic interface Subject { \n \n /*增加观察者*/ \n public void add(Observer observer); \n \n /*删除观察者*/ \n public void del(Observer observer); \n \n /*通知所有的观察者*/ \n public void notifyObservers(); \n \n /*自身的操作*/ \n public void operation(); \n} \n```\n```java\npublic abstract class AbstractSubject implements Subject { \n \n private Vector vector = new Vector(); \n @Override \n public void add(Observer observer) { \n vector.add(observer); \n } \n \n @Override \n public void del(Observer observer) { \n vector.remove(observer); \n } \n \n @Override \n public void notifyObservers() { \n Enumeration enumo = vector.elements(); \n while(enumo.hasMoreElements()){ \n enumo.nextElement().update(); \n } \n } \n} \n``` \n```java\npublic class MySubject extends AbstractSubject { \n \n @Override \n public void operation() { \n System.out.println(\"update self!\"); \n notifyObservers(); \n } \n \n} \n```\n测试类:\n```java\npublic class ObserverTest { \n \n public static void main(String[] args) { \n Subject sub = new MySubject(); \n sub.add(new Observer1()); \n sub.add(new Observer2()); \n \n sub.operation(); \n } \n \n} \n``` \n输出:\nupdate self! observer1 has received! observer2 has received!\n 这些东西,其实不难,只是有些抽象,不太容易整体理解,建议读者:根据关系图,新建项目,自己写代码(或者参考我的代码),按照总体思路走一遍,这样才能体会它的思想,理解起来容易! \n16、迭代子模式(Iterator)\n顾名思义,迭代器模式就是顺序访问聚集中的对象,一般来说,集合中非常常见,如果对集合类比较熟悉的话,理解本模式会十分轻松。这句话包含两层意思:一是需要遍历的对象,即聚集对象,二是迭代器对象,用于对聚集对象进行遍历访问。我们看下关系图:\n \n这个思路和我们常用的一模一样,MyCollection中定义了集合的一些操作,MyIterator中定义了一系列迭代操作,且持有Collection实例,我们来看看实现代码:\n两个接口:\n```java\npublic interface Collection { \n \n public Iterator iterator(); \n \n /*取得集合元素*/ \n public Object get(int i); \n \n /*取得集合大小*/ \n public int size(); \n} \n``` \n```java\npublic interface Iterator { \n //前移 \n public Object previous(); \n \n //后移 \n public Object next(); \n public boolean hasNext(); \n \n //取得第一个元素 \n public Object first(); \n} \n```\n两个实现:\n```java\npublic class MyCollection implements Collection { \n \n public String string[] = {\"A\",\"B\",\"C\",\"D\",\"E\"}; \n @Override \n public Iterator iterator() { \n return new MyIterator(this); \n } \n \n @Override \n public Object get(int i) { \n return string[i]; \n } \n \n @Override \n public int size() { \n return string.length; \n } \n} \n``` \n```java\npublic class MyIterator implements Iterator { \n \n private Collection collection; \n private int pos = -1; \n \n public MyIterator(Collection collection){ \n this.collection = collection; \n } \n \n @Override \n public Object previous() { \n if(pos > 0){ \n pos--; \n } \n return collection.get(pos); \n } \n \n @Override \n public Object next() { \n if(pos2 ) | O(n2 ) | 稳定 | O(1) |\n| 快速排序 | O(n2 ) | O(nlog2 n) | 不稳定 | O(log2 n)~O(n) |\n| 选择排序 | O(n2 ) | O(n2 ) | 稳定 | O(1) |\n| 二叉树排序 | O(n2 ) | O(nlog2n) | 不一顶 | O(n) |\n| 插入排序 | O(n2 ) | O(n2 ) | 稳定 | O(1) |\n| 堆排序 | O(nlog2 n) | O(nlog2 n) | 不稳定 | O(1) |\n| 希尔排序 | O | O | 不稳定 | O(1) |\n\n#### HashMap的实现原理-美团\n\n1.HashMap概述:\n\nHashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。\n\n2.HashMap的数据结构:\n\n在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。\n\n\n\n从上图中可以看出,HashMap底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组。\n\n#### 状态机\n\nhttp://www.jdon.com/designpatterns/designpattern_State.htm\n\n#### int-char-long各占多少字节数\n\n| 类 | 位数 | 字节数 |\n| ------ | :--- | :--- |\n| byte | 8 | 1 |\n| short | 16 | 2 |\n| int | 32 | 4 |\n| long | 64 | 8 |\n| float | 32 | 4 |\n| double | 64 | 8 |\n| char | 16 | 2 |\n\n#### int与integer的区别\n\nhttp://www.cnblogs.com/shenliang123/archive/2011/10/27/2226903.html\n\n#### string-stringbuffer-stringbuilder区别-小米-乐视-百度\n\nString 字符串常量\n\nStringBuffer 字符串变量(线程安全)\n\nStringBuilder 字符串变量(非线程安全)\n\n简要的说, String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,所以经常改变内容的字符串最好不要用String ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后,JVM 的 GC 就会开始工作,那速度是一定会相当慢的。\n\n而如果是使用 StringBuffer 类则结果就不一样了,每次结果都会对 StringBuffer 对象本身进行操作,而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用 StringBuffer ,特别是字符串对象经常改变的情况下。而在某些特别情况下, String 对象的字符串拼接其实是被 JVM 解释成了 StringBuffer 对象的拼接,所以这些时候 String 对象的速度并不会比 StringBuffer 对象慢,而特别是以下的字符串对象生成中, String 效率是远要比 StringBuffer 快的:\n\n```java\nString S1 = \"This is only a\" + \"simple\" + \" test\";\nStringBuffer Sb = new StringBuffer(\"This is only a\").append(\"simple\").append(\"test\");\n```\n\n你会很惊讶的发现,生成 String S1 对象的速度简直太快了,而这个时候 StringBuffer 居然速度上根本一点都不占优势。其实这是 JVM 的一个把戏,在 JVM 眼里,这个\n `String S1 = “This is only a” + “ simple” + “test”;` 其实就是:\n `String S1 = “This is only a simple test”;` 所以当然不需要太多的时间了。但大家这里要注意的是,如果你的字符串是来自另外的 String 对象的话,速度就没那么快了,譬如:\n\n```java\nString S2 = “This is only a”;\nString S3 = “ simple”;\nString S4 = “ test”;\nString S1 = S2 +S3 + S4;\n```\n\n这时候 JVM 会规规矩矩的按照原来的方式去做\n\n在大部分情况下 StringBuffer 快于 String\n\nStringBuffer\n\nJava.lang.StringBuffer线程安全的可变字符序列。一个类似于 String 的字符串缓冲区,但不能修改。虽然在任意时间点上它都包含某种特定的字符序列,但通过某些方法调用可以改变该序列的长度和内容。\n\n可将字符串缓冲区安全地用于多个线程。可以在必要时对这些方法进行同步,因此任意特定实例上的所有操作就好像是以串行顺序发生的,该顺序与所涉及的每个线程进行的方法调用顺序一致。\n\nStringBuffer 上的主要操作是 append 和 insert 方法,可重载这些方法,以接受任意类型的数据。每个方法都能有效地将给定的数据转换成字符串,然后将该字符串的字符追加或插入到字符串缓冲区中。append 方法始终将这些字符添加到缓冲区的末端;而 insert 方法则在指定的点添加字符。\n\n例如,如果 z 引用一个当前内容是“start”的字符串缓冲区对象,则此方法调用 z.append(\"le\") 会使字符串缓冲区包含“startle”,而 z.insert(4, \"le\") 将更改字符串缓冲区,使之包含“starlet”。\n\n在大部分情况下 StringBuilder 快于 StringBuffer\n\njava.lang.StringBuilder\n\njava.lang.StringBuilder一个可变的字符序列是5.0新增的。此类提供一个与 StringBuffer 兼容的 API,但不保证同步。该类被设计用作 StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。如果可能,建议优先采用该类,因为在大多数实现中,它比 StringBuffer 要快。两者的方法基本相同\n\n#### java多态-乐视\n\nJava多态性理解\n\nJava中多态性的实现\n\n什么是多态\n\n面向对象的三大特性:封装、继承、多态。从一定角度来看,封装和继承几乎都是为多态而准备的。这是我们最后一个概念,也是最重要的知识点。\n\n多态的定义:指允许不同类的对象对同一消息做出响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式。(发送消息就是函数调用)\n\n实现多态的技术称为:动态绑定(dynamic binding),是指在执行期间判断所引用对象的实\n际类型,根据其实际的类型调用其相应的方法。\n\n多态的作用:消除类型之间的耦合关系。\n\n现实中,关于多态的例子不胜枚举。比方说按下 F1 键这个动作,如果当前在 Flash 界面下弹出的就是 AS 3 的帮助文档;如果当前在 Word 下弹出的就是 Word 帮助;在 Windows 下弹出的就是 Windows 帮助和支持。同一个事件发生在不同的对象上会产生不同的结果。\n\n下面是多态存在的三个必要条件,要求大家做梦时都能背出来!\n\n多态存在的三个必要条件\n\n- 要有继承\n\n- 要有重写\n\n- 父类引用指向子类对象\n\n多态的好处:\n\n1.可替换性(substitutability)。多态对已存在代码具有可替换性。例如,多态对圆Circle类工作,对其他任何圆形几何体,如圆环,也同样工作。\n\n2.可扩充性(extensibility)。多态对代码具有可扩充性。增加新的子类不影响已存在类的多态性、继承性,以及其他特性的运行和操作。实际上新加子类更容易获得多态功能。例如,在实现了圆锥、半圆锥以及半球体的多态基础上,很容易增添球体类的多态性。\n\n3.接口性(interface-ability)。多态是超类通过方法签名,向子类提供了一个共同接口,由子类来完善或者覆盖它而实现的。如图8.3 所示。图中超类Shape规定了两个实现多态的接口方法,computeArea()以及computeVolume()。子类,如Circle和Sphere为了实现多态,完善或者覆盖这两个接口方法。\n\n4.灵活性(flexibility)。它在应用中体现了灵活多样的操作,提高了使用效率。\n\n5.简化性(simplicity)。多态简化对应用软件的代码编写和修改过程,尤其在处理大量对象的运算和操作时,这个特点尤为突出和重要。\n\nJava中多态的实现方式:接口实现,继承父类进行方法重写,同一个类中进行方法重载。\n\n#### 什么导致线程阻塞-58-美团\n\n线程的阻塞\n\n为了解决对共享存储区的访问冲突,Java 引入了同步机制,现在让我们来考察多个线程对共享资源的访问,显然同步机制已经不够了,因为在任意时刻所要求的资源不一定已经准备好了被访问,反过来,同一时刻准备好了的资源也可能不止一个。为了解决这种情况下的访问控制问题,Java 引入了对阻塞机制的支持\n\n阻塞指的是暂停一个线程的执行以等待某个条件发生(如某资源就绪),学过操作系统的同学对它一定已经很熟悉了。Java 提供了大量方法来支持阻塞,下面让我们逐一分析。\n\n1.sleep() 方法:sleep() 允许 指定以毫秒为单位的一段时间作为参数,它使得线程在指定的时间内进入阻塞状态,不能得到CPU时间,指定的时间一过,线程重新进入可执行状态。\n\n典型地,sleep() 被用在等待某个资源就绪的情形:测试发现条件不满足后,让线程阻塞一段时间后重新测试,直到条件满足为止。\n\n2.suspend() 和 resume() 方法:两个方法配套使用,suspend()使得线程进入阻塞状态,并且不会自动恢复,必须其对应的resume() 被调用,才能使得线程重新进入可执行状态。典型地,suspend() 和 resume() 被用在等待另一个线程产生的结果的情形:测试发现结果还没有产生后,让线程阻塞,另一个线程产生了结果后,调用 resume() 使其恢复。\n\n3.yield() 方法:yield() 使得线程放弃当前分得的 CPU 时间,但是不使线程阻塞,即线程仍处于可执行状态,随时可能再次分得 CPU 时间。调用 yield() 的效果等价于调度程序认为该线程已执行了足够的时间从而转到另一个线程.\n\n4.wait() 和 notify() 方法:两个方法配套使用,wait() 使得线程进入阻塞状态,它有两种形式,一种允许 指定以毫秒为单位的一段时间作为参数,另一种没有参数,前者当对应的 notify() 被调用或者超出指定时间时线程重新进入可执行状态,后者则必须对应的 notify() 被调用.\n\n初看起来它们与 suspend() 和 resume() 方法对没有什么分别,但是事实上它们是截然不同的。区别的核心在于,前面叙述的所有方法,阻塞时都不会释放占用的锁(如果占用了的话),而这一对方法则相反。\n\n上述的核心区别导致了一系列的细节上的区别。\n\n首先,前面叙述的所有方法都隶属于 Thread 类,但是这一对却直接隶属于 Object 类,也就是说,所有对象都拥有这一对方法。初看起来这十分不可思议,但是实际上却是很自然的,因为这一对方法阻塞时要释放占用的锁,而锁是任何对象都具有的,调用任意对象的 wait() 方法导致线程阻塞,并且该对象上的锁被释放。而调用 任意对象的notify()方法则导致因调用该对象的 wait() 方法而阻塞的线程中随机选择的一个解除阻塞(但要等到获得锁后才真正可执行)。\n\n其次,前面叙述的所有方法都可在任何位置调用,但是这一对方法却必须在 synchronized 方法或块中调用,理由也很简单,只有在synchronized 方法或块中当前线程才占有锁,才有锁可以释放。同样的道理,调用这一对方法的对象上的锁必须为当前线程所拥有,这样才有锁可以释放。因此,这一对方法调用必须放置在这样的 synchronized 方法或块中,该方法或块的上锁对象就是调用这一对方法的对象。若不满足这一条件,则程序虽然仍能编译,但在运行时会出现IllegalMonitorStateException 异常。\n\nwait() 和 notify() 方法的上述特性决定了它们经常和synchronized 方法或块一起使用,将它们和操作系统的进程间通信机制作一个比较就会发现它们的相似性:synchronized方法或块提供了类似于操作系统原语的功能,它们的执行不会受到多线程机制的干扰,而这一对方法则相当于 block 和wakeup 原语(这一对方法均声明为 synchronized)。它们的结合使得我们可以实现操作系统上一系列精妙的进程间通信的算法(如信号量算法),并用于解决各种复杂的线程间通信问题。\n\n关于 wait() 和 notify() 方法最后再说明两点:\n\n第一:调用 notify() 方法导致解除阻塞的线程是从因调用该对象的 wait() 方法而阻塞的线程中随机选取的,我们无法预料哪一个线程将会被选择,所以编程时要特别小心,避免因这种不确定性而产生问题。\n\n第二:除了 notify(),还有一个方法 notifyAll() 也可起到类似作用,唯一的区别在于,调用 notifyAll() 方法将把因调用该对象的 wait() 方法而阻塞的所有线程一次性全部解除阻塞。当然,只有获得锁的那一个线程才能进入可执行状态。\n\n谈到阻塞,就不能不谈一谈死锁,略一分析就能发现,suspend() 方法和不指定超时期限的 wait() 方法的调用都可能产生死锁。遗憾的是,Java 并不在语言级别上支持死锁的避免,我们在编程中必须小心地避免死锁。\n\n以上我们对 Java 中实现线程阻塞的各种方法作了一番分析,我们重点分析了 wait() 和 notify() 方法,因为它们的功能最强大,使用也最灵活,但是这也导致了它们的效率较低,较容易出错。实际使用中我们应该灵活使用各种方法,以便更好地达到我们的目的。\n\n#### 抽象类接口区别-360\n\n1.默认的方法实现\n\n抽象类可以有默认的方法实现完全是抽象的。接口根本不存在方法的实现\n\n2.实现\n\n子类使用extends关键字来继承抽象类。如果子类不是抽象类的话,它需要提供抽象类中所有声明的方法的实现。\n\n子类使用关键字implements来实现接口。它需要提供接口中所有声明的方法的实现\n\n3.构造器\n\n抽象类可以有构造器\n\n接口不能有构造器\n\n4.与正常Java类的区别\n\n除了你不能实例化抽象类之外,它和普通Java类没有任何区\n\n接口是完全不同的类型\n\n5.访问修饰符\n\n抽象方法可以有public、protected和default这些修饰符\n\n接口方法默认修饰符是public。你不可以使用其它修饰符。\n\n6.main方法\n\n抽象方法可以有main方法并且我们可以运行它\n\n接口没有main方法,因此我们不能运行它。\n\n7.多继承\n\n抽象类在java语言中所表示的是一种继承关系,一个子类只能存在一个父类,但是可以存在多个接口。\n\n8.速度\n\n它比接口速度要快\n\n接口是稍微有点慢的,因为它需要时间去寻找在类中实现的方法。\n\n9.添加新方法\n\n如果你往抽象类中添加新的方法,你可以给它提供默认的实现。因此你不需要改变你现在的代码。\n\n如果你往接口中添加方法,那么你必须改变实现该接口的类。\n\n#### 容器类之间的区别-乐视-美团\n\nhttp://www.cnblogs.com/yuanermen/archive/2009/08/05/1539917.html\nhttp://alexyyek.github.io/2015/04/06/Collection\nhttp://tianmaying.com/tutorial/java_collection\n\n#### 内部类\n\nhttp://www.cnblogs.com/chenssy/p/3388487.html\n\n#### hashmap和hashtable的区别-乐视-小米\n\nhttp://www.233.com/ncre2/JAVA/jichu/20100717/084230917.html\n\n#### ArrayMap对比HashMap\n\nhttp://lvable.com/?p=217\n\n## Android\n\n#### 如何导入外部数据库\n\n把原数据库包括在项目源码的 res/raw\n\nandroid系统下数据库应该存放在 /data/data/packagename/ 目录下,所以我们需要做的是把已有的数据库传入那个目录下.操作方法是用FileInputStream读取原数据库,再用FileOutputStream把读取到的东西写入到那个目录.\n\n#### 本地广播和全局广播有什么差别\n\n因广播数据在本应用范围内传播,不用担心隐私数据泄露的问题。\n不用担心别的应用伪造广播,造成安全隐患。\n相比在系统内发送全局广播,它更高效。\n\n#### intentService作用是什么,AIDL解决了什么问题-小米\n\n生成一个默认的且与主线程互相独立的工作者线程来执行所有传送至onStartCommand() 方法的Intetnt。\n\n生成一个工作队列来传送Intent对象给你的onHandleIntent()方法,同一时刻只传送一个Intent对象,这样一来,你就不必担心多线程的问题。在所有的请求(Intent)都被执行完以后会自动停止服务,所以,你不需要自己去调用stopSelf()方法来停止。\n\n该服务提供了一个onBind()方法的默认实现,它返回null\n\n提供了一个onStartCommand()方法的默认实现,它将Intent先传送至工作队列,然后从工作队列中每次取出一个传送至onHandleIntent()方法,在该方法中对Intent对相应的处理。\n\nAIDL (Android Interface Definition Language) 是一种IDL 语言,用于生成可以在Android设备上两个进程之间进行进程间通信(interprocess communication, IPC)的代码。如果在一个进程中(例如Activity)要调用另一个进程中(例如Service)对象的操作,就可以使用AIDL生成可序列化的参数。\n\nAIDL IPC机制是面向接口的,像COM或Corba一样,但是更加轻量级。它是使用代理类在客户端和实现端传递数据。\n\n#### Activity/Window/View三者的差别,fragment的特点-360\n\nActivity像一个工匠(控制单元),Window像窗户(承载模型),View像窗花(显示视图)\nLayoutInflater像剪刀,Xml配置像窗花图纸。\n\n1. 在Activity中调用attach,创建了一个Window\n2. 创建的window是其子类PhoneWindow,在attach中创建PhoneWindow\n3. 在Activity中调用setContentView(R.layout.xxx)\n4. 其中实际上是调用的getWindow().setContentView()\n5. 调用PhoneWindow中的setContentView方法\n6. 创建ParentView:作为ViewGroup的子类,实际是创建的DecorView(作为FramLayout的子类)\n7. 将指定的R.layout.xxx进行填充,通过布局填充器进行填充[其中的parent指的就是DecorView]\n8. 调用到ViewGroup\n9. 调用ViewGroup的removeAllView(),先将所有的view移除掉\n10. 添加新的view:addView()\n\nfragment 特点\n\n- Fragment可以作为Activity界面的一部分组成出现\n- 可以在一个Activity中同时出现多个Fragment,并且一个Fragment也可以在多个Activity中使用\n- 在Activity运行过程中,可以添加、移除或者替换Fragment\n- Fragment可以响应自己的输入事件,并且有自己的生命周期,它们的生命周期会受宿主Activity的生命周期影响\n\n#### 描述一次网络请求的流程-新浪\n\n\n\n#### Handler,Thread和HandlerThread的差别-小米\n\nhttp://blog.csdn.net/guolin_blog/article/details/9991569\n\nhttp://droidyue.com/blog/2015/11/08/make-use-of-handlerthread/\n\n从Android中Thread(java.lang.Thread → java.lang.Object)描述可以看出,Android的Thread没有对Java的Thread做任何封装,但是Android提供了一个继承自Thread的类HandlerThread(android.os.HandlerThread → java.lang.Thread),这个类对Java的Thread做了很多便利Android系统的封装。\n\nandroid.os.Handler可以通过Looper对象实例化,并运行于另外的线程中,Android提供了让Handler运行于其它线程的线程实现,也是就HandlerThread。HandlerThread对象start后可以获得其Looper对象,并且使用这个Looper对象实例Handler。\n\n#### 低版本SDK实现高版本api-小米\n\n自己实现或@TargetApi annotation\n\n#### Ubuntu编译安卓系统-百度\n\n1. 进入源码根目录\n2. build/envsetup.sh\n3. lunch\n4. full(编译全部)\n5. userdebug(选择编译版本)\n6. make -j8(开启8个线程编译)\n\n#### LaunchMode应用场景-百度-小米-乐视\n\nstandard,创建一个新的Activity。\n\nsingleTop,栈顶不是该类型的Activity,创建一个新的Activity。否则,onNewIntent。\n\nsingleTask,回退栈中没有该类型的Activity,创建Activity,否则,onNewIntent+ClearTop。\n\n注意:\n\n1. 设置了singleTask启动模式的Activity,它在启动的时候,会先在系统中查找属性值affinity等于它的属性值taskAffinity的Task存在; 如果存在这样的Task,它就会在这个Task中启动,否则就会在新的任务栈中启动。因此, 如果我们想要设置了singleTask启动模式的Activity在新的任务中启动,就要为它设置一个独立的taskAffinity属性值。\n\n2. 如果设置了singleTask启动模式的Activity不是在新的任务中启动时,它会在已有的任务中查看是否已经存在相应的Activity实例, 如果存在,就会把位于这个Activity实例上面的Activity全部结束掉,即最终这个Activity 实例会位于任务的Stack顶端中。\n\n3. 在一个任务栈中只有一个singleTask启动模式的Activity存在。他的上面可以有其他的Activity。这点与singleInstance是有区别的。\n\nsingleInstance,回退栈中,只有这一个Activity,没有其他Activity。\n\nsingleTop适合接收通知启动的内容显示页面。\n\n例如,某个新闻客户端的新闻内容页面,如果收到10个新闻推送,每次都打开一个新闻内容页面是很烦人的。\n\nsingleTask适合作为程序入口点。\n\n例如浏览器的主界面。不管从多少个应用启动浏览器,只会启动主界面一次,其余情况都会走onNewIntent,并且会清空主界面上面的其他页面。\n\nsingleInstance应用场景:\n\n闹铃的响铃界面。 你以前设置了一个闹铃:上午6点。在上午5点58分,你启动了闹铃设置界面,并按 Home 键回桌面;在上午5点59分时,你在微信和朋友聊天;在6点时,闹铃响了,并且弹出了一个对话框形式的 Activity(名为 AlarmAlertActivity) 提示你到6点了(这个 Activity 就是以 SingleInstance 加载模式打开的),你按返回键,回到的是微信的聊天界面,这是因为 AlarmAlertActivity 所在的 Task 的栈只有他一个元素, 因此退出之后这个 Task 的栈空了。如果是以 SingleTask 打开 AlarmAlertActivity,那么当闹铃响了的时候,按返回键应该进入闹铃设置界面。\n\n#### Touch事件传递流程-小米\n\n[Android-三张图搞定Touch事件传递机制](http://hanhailong.com/2015/09/24/Android-三张图搞定Touch事件传递机制/)\n\n#### View绘制流程-百度\n\n[公共技术点之 View 绘制流程](http://www.codekk.com/blogs/detail/54cfab086c4761e5001b253f)\n\n#### 多线程-360\n\n* Activity.runOnUiThread(Runnable)\n* View.post(Runnable),View.postDelay(Runnable,long)\n* Handler\n* AsyncTask\n\n#### 线程同步-百度\n\n[Java基础笔记 – 线程同步问题 解决同步问题的方法 synchronized方法 同步代码块](http://www.itzhai.com/java-based-notebook-thread-synchronization-problem-solving-synchronization-problems-synchronized-block-synchronized-methods.html#read-more)\n\n[Android线程间交互(Java synchronized & Android Handler)](http://www.juwends.com/tech/android/android-inter-thread-comm.html)\n\n单例\n\n```java\npublic class Singleton{\nprivate volatile static Singleton mSingleton;\nprivate Singleton(){\n}\npublic static Singleton getInstance(){\n if(mSingleton == null){\\\\A\n synchronized(Singleton.class){\\\\C\n if(mSingleton == null)\n mSingleton = new Singleton();\\\\B\n }\n }\n return mSingleton;\n }\n}\n```\n\n#### 什么情况导致内存泄漏-美团\n\n1.资源对象没关闭造成的内存泄漏\n\n描述:资源性对象比如(Cursor,File文件等)往往都用了一些缓冲,我们在不使用的时候,应该及时关闭它们,以便它们的缓冲及时回收内存。它们的缓冲不仅存在于 java虚拟机内,还存在于java虚拟机外。如果我们仅仅是把它的引用设置为null,而不关闭它们,往往会造成内存泄漏。因为有些资源性对象,比如 SQLiteCursor(在析构函数finalize(),如果我们没有关闭它,它自己会调close()关闭),如果我们没有关闭它,系统在回收它时也会关闭它,但是这样的效率太低了。因此对于资源性对象在不使用的时候,应该调用它的close()函数,将其关闭掉,然后才置为null.在我们的程序退出时一定要确保我们的资源性对象已经关闭。\n\n程序中经常会进行查询数据库的操作,但是经常会有使用完毕Cursor后没有关闭的情况。如果我们的查询结果集比较小,对内存的消耗不容易被发现,只有在常时间大量操作的情况下才会复现内存问题,这样就会给以后的测试和问题排查带来困难和风险。\n\n2.构造Adapter时,没有使用缓存的convertView\n\n描述:以构造ListView的BaseAdapter为例,在BaseAdapter中提供了方法:\n`public View getView(int position, ViewconvertView, ViewGroup parent)`\n来向ListView提供每一个item所需要的view对象。初始时ListView会从BaseAdapter中根据当前的屏幕布局实例化一定数量的 view对象,同时ListView会将这些view对象缓存起来。当向上滚动ListView时,原先位于最上面的list item的view对象会被回收,然后被用来构造新出现的最下面的list item。这个构造过程就是由getView()方法完成的,getView()的第二个形参View convertView就是被缓存起来的list item的view对象(初始化时缓存中没有view对象则convertView是null)。由此可以看出,如果我们不去使用 convertView,而是每次都在getView()中重新实例化一个View对象的话,即浪费资源也浪费时间,也会使得内存占用越来越大。 ListView回收list item的view对象的过程可以查看:\nandroid.widget.AbsListView.java → voidaddScrapView(View scrap) 方法。\n示例代码:\n\n```java\npublic View getView(int position, ViewconvertView, ViewGroup parent) {\nView view = new Xxx(...); \n...\nreturn view; \n} \n```\n\n修正示例代码:\n\n```java\npublic View getView(int position, ViewconvertView, ViewGroup parent) {\nView view = null; \nif (convertView != null) { \nview = convertView; \npopulate(view, getItem(position)); \n... \n} else { \nview = new Xxx(...); \n... \n} \nreturn view; \n} \n```\n\n3.Bitmap对象不在使用时调用recycle()释放内存\n\n描述:有时我们会手工的操作Bitmap对象,如果一个Bitmap对象比较占内存,当它不在被使用的时候,可以调用Bitmap.recycle()方法回收此对象的像素所占用的内存,但这不是必须的,视情况而定。可以看一下代码中的注释:\n\n```\n/** \n * Free up the memory associated with thisbitmap's pixels, and mark the \n * bitmap as \"dead\", meaning itwill throw an exception if getPixels() or \n * setPixels() is called, and will drawnothing. This operation cannot be \n * reversed, so it should only be called ifyou are sure there are no \n * further uses for the bitmap. This is anadvanced call, and normally need \n * not be called, since the normal GCprocess will free up this memory when \n * there are no more references to thisbitmap. \n */ \n```\n\n4.试着使用关于application的context来替代和activity相关的context\n\n这是一个很隐晦的内存泄漏的情况。有一种简单的方法来避免context相关的内存泄漏。最显著地一个是避免context逃出他自己的范围之外。使用Application context。这个context的生存周期和你的应用的生存周期一样长,而不是取决于activity的生存周期。如果你想保持一个长期生存的对象,并且这个对象需要一个context,记得使用application对象。你可以通过调用 Context.getApplicationContext() or Activity.getApplication()来获得。更多的请看这篇文章如何避免Android内存泄漏。\n\n5.注册没取消造成的内存泄漏\n\n一些Android程序可能引用我们的Anroid程序的对象(比如注册机制)。即使我们的Android程序已经结束了,但是别的引用程序仍然还有对我们的Android程序的某个对象的引用,泄漏的内存依然不能被垃圾回收。调用registerReceiver后未调用unregisterReceiver。\n\n比如:假设我们希望在锁屏界面(LockScreen)中,监听系统中的电话服务以获取一些信息(如信号强度等),则可以在LockScreen中定义一个 PhoneStateListener的对象,同时将它注册到TelephonyManager服务中。对于LockScreen对象,当需要显示锁屏界面的时候就会创建一个LockScreen对象,而当锁屏界面消失的时候LockScreen对象就会被释放掉。\n但是如果在释放 LockScreen对象的时候忘记取消我们之前注册的PhoneStateListener对象,则会导致LockScreen无法被垃圾回收。如果不断的使锁屏界面显示和消失,则最终会由于大量的LockScreen对象没有办法被回收而引起OutOfMemory,使得system_process 进程挂掉。\n\n虽然有些系统程序,它本身好像是可以自动取消注册的(当然不及时),但是我们还是应该在我们的程序中明确的取消注册,程序结束时应该把所有的注册都取消掉。\n\n6.集合中对象没清理造成的内存泄漏\n\n我们通常把一些对象的引用加入到了集合中,当我们不需要该对象时,并没有把它的引用从集合中清理掉,这样这个集合就会越来越大。如果这个集合是static的话,那情况就更严重了。\n\n#### ANR定位和修正\n\n如果开发机器上出现问题,我们可以通过查看/data/anr/traces.txt即可,最新的ANR信息在最开始部分。\n\n* 主线程被IO操作(从4.0之后网络IO不允许在主线程中)阻塞。\n* 主线程中存在耗时的计算\n* 主线程中错误的操作,比如Thread.wait或者Thread.sleep等\n Android系统会监控程序的响应状况,一旦出现下面两种情况,则弹出ANR对话框\n* 应用在5秒内未响应用户的输入事件(如按键或者触摸)\n* BroadcastReceiver未在10秒内完成相关的处理\n* Service在特定的时间内无法处理完成 20秒\n* 使用AsyncTask处理耗时IO操作。\n* 使用Thread或者HandlerThread时,调用`Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND)`设置优先级,否则仍然会降低程序响应,因为默认Thread的优先级和主线程相同。\n* 使用Handler处理工作线程结果,而不是使用Thread.wait()或者Thread.sleep()来阻塞主线程。\n* Activity的onCreate和onResume回调中尽量避免耗时的代码\n* BroadcastReceiver中onReceive代码也要尽量减少耗时,建议使用IntentService处理\n\n#### 什么情况导致oom-乐视-美团\n\n[Android内存优化之OOM](http://www.jcodecraeer.com/a/anzhuokaifa/androidkaifa/2015/0920/3478.html)\n\n- 使用更加轻量的数据结构\n- Android里面使用Enum\n- Bitmap对象的内存占用\n- 更大的图片\n- onDraw方法里面执行对象的创建\n- StringBuilder\n\n#### Service与Activity之间通信的几种方式\n\n- 通过Binder对象\n- 通过broadcast(广播)的形式\n\n#### Android各个版本API的区别\n\nhttp://blog.csdn.net/lijun952048910/article/details/7980562\n\n#### Android代码中实现WAP方式联网-360\n\nhttp://blog.csdn.net/asce1885/article/details/7844159\n\n#### 如何保证service在后台不被Kill\n\n一、onStartCommand方法,返回START_STICKY\n\n1.START_STICKY\n\n在运行onStartCommand后service进程被kill后,那将保留在开始状态,但是不保留那些传入的intent。不久后service就会再次尝试重新创建,因为保留在开始状态,在创建 service后将保证调用onstartCommand。如果没有传递任何开始命令给service,那将获取到null的intent。\n\n2.START_NOT_STICKY\n\n在运行onStartCommand后service进程被kill后,并且没有新的intent传递给它。Service将移出开始状态,并且直到新的明显的方法(startService)调用才重新创建。因为如果没有传递任何未决定的intent那么service是不会启动,也就是期间onstartCommand不会接收到任何null的intent。\n\n3.START_REDELIVER_INTENT\n\n在运行onStartCommand后service进程被kill后,系统将会再次启动service,并传入最后一个intent给onstartCommand。直到调用stopSelf(int)才停止传递intent。如果在被kill后还有未处理好的intent,那被kill后服务还是会自动启动。因此onstartCommand不会接收到任何null的intent。\n\n二、提升service优先级\n\n在AndroidManifest.xml文件中对于intent-filter可以通过`android:priority = \"1000\"`这个属性设置最高优先级,1000是最高值,如果数字越小则优先级越低,同时适用于广播。\n\n三、提升service进程优先级\n\nAndroid中的进程是托管的,当系统进程空间紧张的时候,会依照优先级自动进行进程的回收。Android将进程分为6个等级,它们按优先级顺序由高到低依次是:\n\n1. 前台进程( FOREGROUND_APP)\n2. 可视进程(VISIBLE_APP )\n3. 次要服务进程(SECONDARY_SERVER )\n4. 后台进程 (HIDDEN_APP)\n5. 内容供应节点(CONTENT_PROVIDER)\n6. 空进程(EMPTY_APP)\n\n当service运行在低内存的环境时,将会kill掉一些存在的进程。因此进程的优先级将会很重要,可以使用startForeground 将service放到前台状态。这样在低内存时被kill的几率会低一些。\n\n四、onDestroy方法里重启service\n\nservice +broadcast 方式,就是当service走ondestory的时候,发送一个自定义的广播,当收到广播的时候,重新启动service;\n\n五、Application加上Persistent属性\n\n六、监听系统广播判断Service状态\n\n通过系统的一些广播,比如:手机重启、界面唤醒、应用状态改变等等监听并捕获到,然后判断我们的Service是否还存活,别忘记加权限啊。\n\n#### Requestlayout,onlayout,onDraw,DrawChild区别与联系-猎豹\n\nrequestLayout()方法 :会导致调用measure()过程 和 layout()过程 。\n将会根据标志位判断是否需要ondraw\n\nonLayout()方法(如果该View是ViewGroup对象,需要实现该方法,对每个子视图进行布局)\n\n调用onDraw()方法绘制视图本身 (每个View都需要重载该方法,ViewGroup不需要实现该方法)\n\ndrawChild()去重新回调每个子视图的draw()方法\n\n#### invalidate()和postInvalidate()的区别及使用-百度\n\nhttp://blog.csdn.net/mars2639/article/details/6650876\n\n#### Android动画框架实现原理\n\nAnimation框架定义了透明度,旋转,缩放和位移几种常见的动画,而且控制的是整个View,实现原理是每次绘制视图时View所在的ViewGroup中的drawChild函数获取该View的Animation的Transformation值,然后调用`canvas.concat(transformToApply.getMatrix()),`通过矩阵运算完成动画帧,如果动画没有完成,继续调用invalidate()函数,启动下次绘制来驱动动画,动画过程中的帧之间间隙时间是绘制函数所消耗的时间,可能会导致动画消耗比较多的CPU资源,最重要的是,动画改变的只是显示,并不能相应事件。\n\n#### Android为每个应用程序分配的内存大小是多少-美团\n\nandroid程序内存一般限制在16M,也有的是24M\n\n#### View刷新机制-百度-美团\n\n由ViewRoot对象的performTraversals()方法调用draw()方法发起绘制该View树,值得注意的是每次发起绘图时,并不会重新绘制每个View树的视图,而只会重新绘制那些“需要重绘”的视图,View类内部变量包含了一个标志位DRAWN,当该视图需要重绘时,就会为该View添加该标志位。\n\n调用流程 :\n\nmView.draw()开始绘制,draw()方法实现的功能如下:\n\n1. 绘制该View的背景\n2. 为显示渐变框做一些准备操作(见5,大多数情况下,不需要改渐变框) \n3. 调用onDraw()方法绘制视图本身 (每个View都需要重载该方法,ViewGroup不需要实现该方法)\n4. 调用dispatchDraw ()方法绘制子视图(如果该View类型不为ViewGroup,即不包含子视图,不需要重载该方法)值得说明的是,ViewGroup类已经为我们重写了dispatchDraw ()的功能实现,应用程序一般不需要重写该方法,但可以重载父类函数实现具体的功能。\n\n#### LinearLayout和RelativeLayout性能对比-百度\n\n1. RelativeLayout会让子View调用2次onMeasure,LinearLayout 在有weight时,也会调用子View2次onMeasure\n2. RelativeLayout的子View如果高度和RelativeLayout不同,则会引发效率问题,当子View很复杂时,这个问题会更加严重。如果可以,尽量使用padding代替margin。\n3. 在不影响层级深度的情况下,使用LinearLayout和FrameLayout而不是RelativeLayout。\n\n最后再思考一下文章开头那个矛盾的问题,为什么Google给开发者默认新建了个RelativeLayout,而自己却在DecorView中用了个LinearLayout。因为DecorView的层级深度是已知而且固定的,上面一个标题栏,下面一个内容栏。采用RelativeLayout并不会降低层级深度,所以此时在根节点上用LinearLayout是效率最高的。而之所以给开发者默认新建了个RelativeLayout是希望开发者能采用尽量少的View层级来表达布局以实现性能最优,因为复杂的View嵌套对性能的影响会更大一些。\n\n#### 优化自定义view百度-乐视-小米\n\n为了加速你的view,对于频繁调用的方法,需要尽量减少不必要的代码。先从onDraw开始,需要特别注意不应该在这里做内存分配的事情,因为它会导致GC,从而导致卡顿。在初始化或者动画间隙期间做分配内存的动作。不要在动画正在执行的时候做内存分配的事情。\n\n你还需要尽可能的减少onDraw被调用的次数,大多数时候导致onDraw都是因为调用了invalidate().因此请尽量减少调用invaildate()的次数。如果可能的话,尽量调用含有4个参数的invalidate()方法而不是没有参数的invalidate()。没有参数的invalidate会强制重绘整个view。\n\n另外一个非常耗时的操作是请求layout。任何时候执行requestLayout(),会使得Android UI系统去遍历整个View的层级来计算出每一个view的大小。如果找到有冲突的值,它会需要重新计算好几次。另外需要尽量保持View的层级是扁平化的,这样对提高效率很有帮助。\n\n如果你有一个复杂的UI,你应该考虑写一个自定义的ViewGroup来执行他的layout操作。与内置的view不同,自定义的view可以使得程序仅仅测量这一部分,这避免了遍历整个view的层级结构来计算大小。这个PieChart 例子展示了如何继承ViewGroup作为自定义view的一部分。PieChart 有子views,但是它从来不测量它们。而是根据他自身的layout法则,直接设置它们的大小。\n\n#### ContentProvider-乐视\n\nhttp://blog.csdn.net/coder_pig/article/details/47858489\n\n#### Fragment生命周期\n\n \n\n#### volley解析-美团-乐视\n\nhttp://a.codekk.com/detail/Android/grumoon/Volley%20%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90\n\n#### Glide源码解析\n\nhttp://www.lightskystreet.com/2015/10/12/glide_source_analysis/\nhttp://frodoking.github.io/2015/10/10/android-glide/\n\n#### Android设计模式\n\nhttp://blog.csdn.net/bboyfeiyu/article/details/44563871\n\n#### 架构设计-搜狐\n\n\n\nhttp://www.tianmaying.com/tutorial/AndroidMVC\n\n#### Android属性动画特性-乐视-小米\n\n如果你的需求中只需要对View进行移动、缩放、旋转和淡入淡出操作,那么补间动画确实已经足够健全了。但是很显然,这些功能是不足以覆盖所有的场景的,一旦我们的需求超出了移动、缩放、旋转和淡入淡出这四种对View的操作,那么补间动画就不能再帮我们忙了,也就是说它在功能和可扩展方面都有相当大的局限性,那么下面我们就来看看补间动画所不能胜任的场景。\n\n注意上面我在介绍补间动画的时候都有使用“对View进行操作”这样的描述,没错,补间动画是只能够作用在View上的。也就是说,我们可以对一个Button、TextView、甚至是LinearLayout、或者其它任何继承自View的组件进行动画操作,但是如果我们想要对一个非View的对象进行动画操作,抱歉,补间动画就帮不上忙了。可能有的朋友会感到不能理解,我怎么会需要对一个非View的对象进行动画操作呢?这里我举一个简单的例子,比如说我们有一个自定义的View,在这个View当中有一个Point对象用于管理坐标,然后在onDraw()方法当中就是根据这个Point对象的坐标值来进行绘制的。也就是说,如果我们可以对Point对象进行动画操作,那么整个自定义View的动画效果就有了。显然,补间动画是不具备这个功能的,这是它的第一个缺陷。\n\n然后补间动画还有一个缺陷,就是它只能够实现移动、缩放、旋转和淡入淡出这四种动画操作,那如果我们希望可以对View的背景色进行动态地改变呢?很遗憾,我们只能靠自己去实现了。说白了,之前的补间动画机制就是使用硬编码的方式来完成的,功能限定死就是这些,基本上没有任何扩展性可言。\n\n最后,补间动画还有一个致命的缺陷,就是它只是改变了View的显示效果而已,而不会真正去改变View的属性。什么意思呢?比如说,现在屏幕的左上角有一个按钮,然后我们通过补间动画将它移动到了屏幕的右下角,现在你可以去尝试点击一下这个按钮,点击事件是绝对不会触发的,因为实际上这个按钮还是停留在屏幕的左上角,只不过补间动画将这个按钮绘制到了屏幕的右下角而已。\n\n### 专题\n\n### 性能优化\n\n#### [Android性能优化典范 - 第1季](http://hukai.me/android-performance-patterns/)\n\n1. **Render Performance** Android系统每隔16ms发出VSYNC信号,触发对UI进行渲染,如果每次渲染都成功,这样就能够达到流畅的画面所需要的60fps,为了能够实现60fps,这意味着程序的大多数操作都必须在16ms内完成。我们可以通过一些工具来定位问题,比如可以使用HierarchyViewer来查找Activity中的布局是否过于复杂,也可以使用手机设置里面的开发者选项,打开Show GPU Overdraw等选项进行观察。你还可以使用TraceView来观察CPU的执行情况,更加快捷的找到性能瓶颈。\n\n2. **Understanding Overdraw** Overdraw(过度绘制)描述的是屏幕上的某个像素在同一帧的时间内被绘制了多次。在多层次的UI结构里面,如果不可见的UI也在做绘制的操作,这就会导致某些像素区域被绘制了多次。这就浪费大量的CPU以及GPU资源。Overdraw有时候是因为你的UI布局存在大量重叠的部分,还有的时候是因为非必须的重叠背景。例如某个Activity有一个背景,然后里面的Layout又有自己的背景,同时子View又分别有自己的背景。仅仅是通过移除非必须的背景图片,这就能够减少大量的红色Overdraw区域,增加蓝色区域的占比。这一措施能够显著提升程序性能。\n\n3. **Understanding VSYNC** Refresh Rate:代表了屏幕在一秒内刷新屏幕的次数,这取决于硬件的固定参数,例如60Hz。Frame Rate:代表了GPU在一秒内绘制操作的帧数,例如30fps,60fps。通常来说,帧率超过刷新频率只是一种理想的状况,在超过60fps的情况下,GPU所产生的帧数据会因为等待VSYNC的刷新信息而被Hold住,这样能够保持每次刷新都有实际的新的数据可以显示。但是我们遇到更多的情况是帧率小于刷新频率。\n\n4. **Tool:Profile GPU Rendering** 性能问题如此的麻烦,幸好我们可以有工具来进行调试。打开手机里面的开发者选项,选择Profile GPU Rendering,选中On screen as bars的选项。\n\n5. **Why 60fps?** 我们通常都会提到60fps与16ms,可是知道为何会是以程序是否达到60fps来作为App性能的衡量标准吗?这是因为人眼与大脑之间的协作无法感知超过60fps的画面更新。开发app的性能目标就是保持60fps,这意味着每一帧你只有16ms=1000/60的时间来处理所有的任务。\n\n6. **Android, UI and the GPU** 在Android里面那些由主题所提供的资源,例如Bitmaps,Drawables都是一起打包到统一的Texture纹理当中,然后再传递到GPU里面,这意味着每次你需要使用这些资源的时候,都是直接从纹理里面进行获取渲染的。当然随着UI组件的越来越丰富,有了更多演变的形态。例如显示图片的时候,需要先经过CPU的计算加载到内存中,然后传递给GPU进行渲染。文字的显示更加复杂,需要先经过CPU换算成纹理,然后再交给GPU进行渲染,回到CPU绘制单个字符的时候,再重新引用经过GPU渲染的内容。动画则是一个更加复杂的操作流程。为了能够使得App流畅,我们需要在每一帧16ms以内处理完所有的CPU与GPU计算,绘制,渲染等等操作。\n\n7. **Invalidations, Layouts, and Performance** 任何时候View中的绘制内容发生变化时,都会重新执行创建DisplayList,渲染DisplayList,更新到屏幕上等一系列操作。这个流程的表现性能取决于你的View的复杂程度,View的状态变化以及渲染管道的执行性能。举个例子,假设某个Button的大小需要增大到目前的两倍,在增大Button大小之前,需要通过父View重新计算并摆放其他子View的位置。修改View的大小会触发整个HierarcyView的重新计算大小的操作。如果是修改View的位置则会触发HierarchView重新计算其他View的位置。如果布局很复杂,这就会很容易导致严重的性能问题。我们需要尽量减少Overdraw。\n\n8. **Overdraw, Cliprect, QuickReject** 我们可以通过canvas.clipRect()来帮助系统识别那些可见的区域。这个方法可以指定一块矩形区域,只有在这个区域内才会被绘制,其他的区域会被忽视。这个API可以很好的帮助那些有多组重叠组件的自定义View来控制显示的区域。同时clipRect方法还可以帮助节约CPU与GPU资源,在clipRect区域之外的绘制指令都不会被执行,那些部分内容在矩形区域内的组件,仍然会得到绘制。\n\n9. **Memory Churn and performance** 执行GC操作的时候,所有线程的任何操作都会需要暂停,等待GC操作完成之后,其他操作才能够继续运行。Memory Churn内存抖动,内存抖动是因为大量的对象被创建又在短时间内马上被释放。瞬间产生大量的对象会严重占用Young Generation的内存区域,当达到阀值,剩余空间不够的时候,也会触发GC。即使每次分配的对象占用了很少的内存,但是他们叠加在一起会增加Heap的压力,从而触发更多其他类型的GC。这个操作有可能会影响到帧率,并使得用户感知到性能问题。\n\n10. **Garbage Collection in Android** 原始JVM中的GC机制在Android中得到了很大程度上的优化。Android里面是一个三级Generation的内存模型,最近分配的对象会存放在Young Generation区域,当这个对象在这个区域停留的时间达到一定程度,它会被移动到Old Generation,最后到Permanent Generation区域。如果不小心在最小的for循环单元里面执行了创建对象的操作,这将很容易引起GC并导致性能问题。通过Memory Monitor我们可以查看到内存的占用情况,每一次瞬间的内存降低都是因为此时发生了GC操作,如果在短时间内发生大量的内存上涨与降低的事件,这说明很有可能这里有性能问题。我们还可以通过Heap and Allocation Tracker工具来查看此时内存中分配的到底有哪些对象。\n\n11. **Performance Cost of Memory Leaks** 内存泄漏指的是那些程序不再使用的对象无法被GC识别,这样就导致这个对象一直留在内存当中,占用了宝贵的内存空间。显然,这还使得每级Generation的内存区域可用空间变小,GC就会更容易被触发,从而引起性能问题。\n\n12. **Memory Performance** 通常来说,Android对GC做了大量的优化操作,虽然执行GC操作的时候会暂停其他任务,可是大多数情况下,GC操作还是相对很安静并且高效的。但是如果我们对内存的使用不恰当,导致GC频繁执行,这样就会引起不小的性能问题。\n\n13. **Tool - Memory Monitor** Android Studio中的Memory Monitor可以很好的帮助我们查看程序的内存使用情况。\n\n14. **Battery Performance** 我们应该尽量减少唤醒屏幕的次数与持续的时间,使用WakeLock来处理唤醒的问题,能够正确执行唤醒操作并根据设定及时关闭操作进入睡眠状态。某些非必须马上执行的操作,例如上传歌曲,图片处理等,可以等到设备处于充电状态或者电量充足的时候才进行。触发网络请求的操作,每次都会保持无线信号持续一段时间,我们可以把零散的网络请求打包进行一次操作,避免过多的无线信号引起的电量消耗。关于网络请求引起无线信号的电量消耗\n\n15. **Understanding Battery Drain on Android** 使用WakeLock或者JobScheduler唤醒设备处理定时的任务之后,一定要及时让设备回到初始状态。每次唤醒无线信号进行数据传递,都会消耗很多电量,它比WiFi等操作更加的耗电\n\n16. **Battery Drain and WakeLocks** 这正是JobScheduler API所做的事情。它会根据当前的情况与任务,组合出理想的唤醒时间,例如等到正在充电或者连接到WiFi的时候,或者集中任务一起执行。我们可以通过这个API实现很多免费的调度算法。\n\n#### [Android性能优化典范 - 第2季](http://hukai.me/android-performance-patterns-season-2/)\n\n1. **Battery Drain and Networking** 我们可以有针对性的把请求行为捆绑起来,延迟到某个时刻统一发起请求。这部分主要会涉及到Prefetch(预取)与Compressed(压缩)这两个技术。对于Prefetch的使用,我们需要预先判断用户在此次操作之后,后续零散的请求是否很有可能会马上被触发,可以把后面5分钟有可能会使用到的零散请求都一次集中执行完毕。对于Compressed的使用,在上传与下载数据之前,使用CPU对数据进行压缩与解压,可以很大程度上减少网络传输的时间。\n\n2. **Wear & Sensors** 首先我们需要尽量使用Android平台提供的既有运动数据,而不是自己去实现监听采集数据,因为大多数Android Watch自身记录Sensor数据的行为是有经过做电量优化的。其次在Activity不需要监听某些Sensor数据的时候需要尽快释放监听注册。还有我们需要尽量控制更新的频率,仅仅在需要刷新显示数据的时候才触发获取最新数据的操作。另外我们可以针对Sensor的数据做批量处理,待数据累积一定次数或者某个程度的时候才更新到UI上。最后当Watch与Phone连接起来的时候,可以把某些复杂操作的事情交给Phone来执行,Watch只需要等待返回的结果。\n\n3. **Smooth Android Wear Animation** 在Android里面一个相对操作比较繁重的事情是对Bitmap进行旋转,缩放,裁剪等等。例如在一个圆形的钟表图上,我们把时钟的指针抠出来当做单独的图片进行旋转会比旋转一张完整的圆形图的所形成的帧率要高56%。\n\n4. **Android Wear Data Batching** 仅仅在真正需要刷新界面的时候才发出请求,尽量把计算复杂操作的任务交给Phone来处理,Phone仅仅在数据发生变化的时候才通知到Wear,把零碎的数据请求捆绑一起再进行操作。\n\n5. **Object Pools** 使用对象池技术有很多好处,它可以避免内存抖动,提升性能,但是在使用的时候有一些内容是需要特别注意的。通常情况下,初始化的对象池里面都是空白的,当使用某个对象的时候先去对象池查询是否存在,如果不存在则创建这个对象然后加入对象池,但是我们也可以在程序刚启动的时候就事先为对象池填充一些即将要使用到的数据,这样可以在需要使用到这些对象的时候提供更快的首次加载速度,这种行为就叫做预分配。使用对象池也有不好的一面,程序员需要手动管理这些对象的分配与释放,所以我们需要慎重地使用这项技术,避免发生对象的内存泄漏。为了确保所有的对象能够正确被释放,我们需要保证加入对象池的对象和其他外部对象没有互相引用的关系。\n\n6. **To Index or Iterate?** for index的方式有更好的效率,但是因为不同平台编译器优化各有差异,我们最好还是针对实际的方法做一下简单的测量比较好,拿到数据之后,再选择效率最高的那个方式。\n\n7. **The Magic of LRU Cache** 使用LRU Cache能够显著提升应用的性能,可是也需要注意LRU Cache中被淘汰对象的回收,否者会引起严重的内存泄露。\n\n8. **Using LINT for Performance Tips** Lint已经集成到Android Studio中了,我们可以手动去触发这个工具,点击工具栏的Analysis → Inspect Code,触发之后,Lint会开始工作,并把结果输出到底部的工具栏,我们可以逐个查看原因并根据指示做相应的优化修改。\n\n9. **Hidden Cost of Transparency** 通常来说,对于不透明的View,显示它只需要渲染一次即可,可是如果这个View设置了alpha值,会至少需要渲染两次。\n\n10. **Avoiding Allocations in onDraw()** 首先onDraw()方法是执行在UI线程的,在UI线程尽量避免做任何可能影响到性能的操作。虽然分配内存的操作并不需要花费太多系统资源,但是这并不意味着是免费无代价的。设备有一定的刷新频率,导致View的onDraw方法会被频繁的调用,如果onDraw方法效率低下,在频繁刷新累积的效应下,效率低的问题会被扩大,然后会对性能有严重的影响。\n\n11. **Tool: Strict Mode** Android提供了一个叫做Strict Mode的工具,我们可以通过手机设置里面的开发者选项,打开Strict Mode选项,如果程序存在潜在的隐患,屏幕就会闪现红色。我们也可以通过StrictMode API在代码层面做细化的跟踪,可以设置StrictMode监听那些潜在问题,出现问题时如何提醒开发者,可以对屏幕闪红色,也可以输出错误日志。\n\n12. **Custom Views and Performance** Useless calls to onDraw():我们知道调用View.invalidate()会触发View的重绘,有两个原则需要遵守,第1个是仅仅在View的内容发生改变的时候才去触发invalidate方法,第2个是尽量使用ClipRect等方法来提高绘制的性能。Useless pixels:减少绘制时不必要的绘制元素,对于那些不可见的元素,我们需要尽量避免重绘。Wasted CPU cycles:对于不在屏幕上的元素,可以使用Canvas.quickReject把他们给剔除,避免浪费CPU资源。另外尽量使用GPU来进行UI的渲染,这样能够极大的提高程序的整体表现性能。\n\n13. **Batching Background Work Until Later**\n1.AlarmManager 使用AlarmManager设置定时任务,可以选择精确的间隔时间,也可以选择非精确时间作为参数。除非程序有很强烈的需要使用精确的定时唤醒,否者一定要避免使用他,我们应该尽量使用非精确的方式。2.SyncAdapter 我们可以使用SyncAdapter为应用添加设置账户,这样在手机设置的账户列表里面可以找到我们的应用。这种方式功能更多,但是实现起来比较复杂。我们可以从这里看到官方的培训课程:http://developer.android.com/training/sync-adapters/index.html 3.JobSchedulor 这是最简单高效的方法,我们可以设置任务延迟的间隔,执行条件,还可以增加重试机制。\n\n14. **Smaller Pixel Formats** Android的Heap空间是不会自动做兼容压缩的,意思就是如果Heap空间中的图片被收回之后,这块区域并不会和其他已经回收过的区域做重新排序合并处理,那么当一个更大的图片需要放到heap之前,很可能找不到那么大的连续空闲区域,那么就会触发GC,使得heap腾出一块足以放下这张图片的空闲区域,如果无法腾出,就会发生OOM。\n\n15. **Smaller PNG Files** 尽量减少PNG图片的大小是Android里面很重要的一条规范。相比起JPEG,PNG能够提供更加清晰无损的图片,但是PNG格式的图片会更大,占用更多的磁盘空间。到底是使用PNG还是JPEG,需要设计师仔细衡量,对于那些使用JPEG就可以达到视觉效果的,可以考虑采用JPEG即可。\n\n16. **Pre-scaling Bitmaps** 对bitmap做缩放,这也是Android里面最遇到的问题。对bitmap做缩放的意义很明显,提示显示性能,避免分配不必要的内存。Android提供了现成的bitmap缩放的API,叫做createScaledBitmap()\n\n17. **Re-using Bitmaps** 使用inBitmap属性可以告知Bitmap解码器去尝试使用已经存在的内存区域,新解码的bitmap会尝试去使用之前那张bitmap在heap中所占据的pixel data内存区域,而不是去问内存重新申请一块区域来存放bitmap。利用这种特性,即使是上千张的图片,也只会仅仅只需要占用屏幕所能够显示的图片数量的内存大小。\n\n18. **The Performance Lifecycle** Gather:收集数据,Insight:分析数据,Action:解决问题\n\n#### [Android性能优化典范 - 第3季](http://hukai.me/android-performance-patterns-season-3/)\n\n1. **Fun with ArrayMaps** 为了解决HashMap更占内存的弊端,Android提供了内存效率更高的ArrayMap。它内部使用两个数组进行工作,其中一个数组记录key hash过后的顺序列表,另外一个数组按key的顺序记录Key-Value值\n\n2. **Beware Autoboxing** 有时候性能问题也可能是因为那些不起眼的小细节引起的,例如在代码中不经意的“自动装箱”。我们知道基础数据类型的大小:boolean(8 bits), int(32 bits), float(32 bits),long(64 bits),为了能够让这些基础数据类型在大多数Java容器中运作,会需要做一个autoboxing的操作,转换成Boolean,Integer,Float等对象\n\n3. **SparseArray Family Ties** 为了避免HashMap的autoboxing行为,Android系统提供了SparseBoolMap,SparseIntMap,SparseLongMap,LongSparseMap等容器。\n\n4. **The price of ENUMs** Android官方强烈建议不要在Android程序里面使用到enum。\n\n5. **Trimming and Sharing Memory** Android系统提供了一些回调来通知应用的内存使用情况,通常来说,当所有的background应用都被kill掉的时候,forground应用会收到onLowMemory()的回调。在这种情况下,需要尽快释放当前应用的非必须内存资源,从而确保系统能够稳定继续运行。Android系统还提供了onTrimMemory()的回调,当系统内存达到某些条件的时候,所有正在运行的应用都会收到这个回调\n\n6. **DO NOT LEAK VIEWS** 避免使用异步回调,避免使用Static对象,避免把View添加到没有清除机制的容器里面\n\n7. **Location & Battery Drain** 其中存在的一个优化点是,我们可以通过判断返回的位置信息是否相同,从而决定设置下次的更新间隔是否增加一倍,通过这种方式可以减少电量的消耗\n\n8. **Double Layout Taxation** 布局中的任何一个View一旦发生一些属性变化,都可能引起很大的连锁反应。例如某个button的大小突然增加一倍,有可能会导致兄弟视图的位置变化,也有可能导致父视图的大小发生改变。当大量的layout()操作被频繁调用执行的时候,就很可能引起丢帧的现象。\n\n9. **Network Performance 101** 减少移动网络被激活的时间与次数,压缩传输数据\n\n10. **Effective Network Batching** 发起网络请求与接收返回数据都是比较耗电的,在网络硬件模块被激活之后,会继续保持几十秒的电量消耗,直到没有新的网络操作行为之后,才会进入休眠状态。前面一个段落介绍了使用Batching的技术来捆绑网络请求,从而达到减少网络请求的频率。那么如何实现Batching技术呢?通常来说,我们可以会把那些发出的网络请求,先暂存到一个PendingQueue里面,等到条件合适的时候再触发Queue里面的网络请求。\n\n11. **Optimizing Network Request Frequencies** 前面的段落已经提到了应该减少网络请求的频率,这是为了减少电量的消耗。我们可以使用Batching,Prefetching的技术来避免频繁的网络请求。Google提供了GCMNetworkManager来帮助开发者实现那些功能,通过提供的API,我们可以选择在接入WiFi,开始充电,等待移动网络被激活等条件下再次激活网络请求。\n\n12. **Effective Prefetching** 类似上面的情况会频繁触发网络请求,但是如果我们能够预先请求后续可能会使用到网络资源,避免频繁的触发网络请求,这样就能够显著的减少电量的消耗。可是预先获取多少数据量是很值得考量的,因为如果预取数据量偏少,就起不到减少频繁请求的作用,可是如果预取数据过多,就会造成资源的浪费。\n\n#### [Android性能优化典范 - 第4季](http://hukai.me/android-performance-patterns-season-4/)\n\n1. **Cachematters for networking** 想要使得Android系统上的网络访问操作更加的高效就必须做好网络数据的缓存。这是提高网络访问性能最基础的步骤之一。从手机的缓存中直接读取数据肯定比从网络上获取数据要更加的便捷高效,特别是对于那些会被频繁访问到的数据,需要把这些数据缓存到设备上,以便更加快速的进行访问。\n\n2. **Optimizing Network Request Frequencies** 首先我们要对网络行为进行分类,区分需要立即更新数据的行为和其他可以进行延迟的更新行为,为不同的场景进行差异化处理。其次要避免客户端对服务器的轮询操作,这样会浪费很多的电量与带宽流量。解决这个问题,我们可以使用Google Cloud Message来对更新的数据进行推送。然后在某些必须做同步的场景下,需要避免使用固定的间隔频率来进行更新操作,我们应该在返回的数据无更新的时候,使用双倍的间隔时间来进行下一次同步。最后更进一步,我们还可以通过判断当前设备的状态来决定同步的频率,例如判断设备处于休眠,运动等不同的状态设计各自不同时间间隔的同步频率。\n\n3. **Effective Prefetching** 到底预取多少才比较合适呢?一个比较普适的规则是,在3G网络下可以预取1-5Mb的数据量,或者是按照提前预期后续1-2分钟的数据作为基线标准。在实际的操作当中,我们还需要考虑当前的网络速度来决定预取的数据量,例如在同样的时间下,4G网络可以获取到12张图片的数据,而2G网络则只能拿到3张图片的数据。所以,我们还需要把当前的网络环境情况添加到设计预取数据量的策略当中去。判断当前设备的状态与网络情况,可以使用前面提到过的GCMNetworkManager。\n\n4. **Adapting to Latency** 一个典型的网络操作行为,通常包含以下几个步骤:首先手机端发起网络请求,到达网络服务运营商的基站,再转移到服务提供者的服务器上,经过解码之后,接着访问本地的存储数据库,获取到数据之后,进行编码,最后按照原来传递的路径逐层返回。常来说,我们可以把网络请求延迟划分为三档:例如把网络延迟小于60ms的划分为GOOD,大于220ms的划分为BAD,介于两者之间的划分为OK(这里的60ms,220ms会需要根据不同的场景提前进行预算推测)。\n\n5. **Minimizing Asset Payload** 为了能够减小网络传输的数据量,我们需要对传输的数据做压缩的处理,这样能够提高网络操作的性能。首先需要做的是减少图片的大小,其次需要做的是减少序列化数据的大小。\n\n6. **Service Performance Patterns** Service是Android程序里面最常用的基础组件之一,但是使用Service很容易引起电量的过度消耗以及系统资源的未及时释放。避免错误的使用Service,例如我们不应该使用Service来监听某些事件的变化,不应该搞一个Service在后台对服务器不断的进行轮询(应该使用Google Cloud Messaging)。如果已经事先知道Service里面的任务应该执行在后台线程(非默认的主线程)的时候,我们应该使用IntentService或者结合HanderThread,AsycnTask Loader实现的Service。\n\n7. **Removing unused code** Android为我们提供了Proguard的工具来帮助应用程序对代码进行瘦身,优化,混淆的处理。它会帮助移除那些没有使用到的代码,还可以对类名,方法名进行混淆处理以避免程序被反编译。\n\n8. **Removing unused resources** 所幸的是,我们可以使用Gradle来帮助我们分析代码,分析引用的资源,对于那些没有被引用到的资源,会在编译阶段被排除在APK安装包之外,要实现这个功能,对我们来说仅仅只需要在build.gradle文件中配置shrinkResource为true就好了\n\n9. **Perf Theory: Caching** 当我们讨论性能优化的时候,缓存是最常见最有效的策略之一。无论是为了提高CPU的计算速度还是提高数据的访问速度,在绝大多数的场景下,我们都会使用到缓存。\n\n10. **Perf Theory: Approximation(近似法)** 例如使用一张比较接近实际大小的图片来替代原图,换取更快的加载速度。所以对于那些对计算结果要求不需要十分精确的场景,我们可以使用近似法则来提高程序的性能。\n\n11. **Perf Theory: Culling(遴选,挑选)** 一个提高性能的方法是逐步对数据进行过滤筛选,减小搜索的数据集,以此提高程序的执行性能。例如我们需要搜索到居住在某个地方,年龄是多少,符合某些特定条件的候选人,就可以通过逐层过滤筛选的方式来提高后续搜索的执行效率。\n\n12. **Perf Theory: Threading** 使用多线程并发处理任务,从某种程度上可以快速提高程序的执行性能。对于Android程序来说,主线程通常也成为UI线程,需要处理UI的渲染,响应用户的操作等等。\n\n13. **Perf Theory: Batching** 网络请求的批量执行是另外一个比较适合说明batching使用场景的例子,因为每次发起网络请求都相对来说比较耗时耗电,如果能够做到批量一起执行,可以大大的减少电量的消耗。\n\n14. **Serialization performance** 数据序列化的行为可能发生在数据传递过程中的任何阶段,例如网络传输,不同进程间数据传递,不同类之间的参数传递,把数据存储到磁盘上等等。通常情况下,我们会把那些需要序列化的类实现Serializable接口(如下图所示),但是这种传统的做法效率不高,实施的过程会消耗更多的内存。但是我们如果使用GSON库来处理这个序列化的问题,不仅仅执行速度更快,内存的使用效率也更高。Android的XML布局文件会在编译的阶段被转换成更加复杂的格式,具备更加高效的执行性能与更高的内存使用效率。\n\n15. **Smaller Serialized Data** 数据呈现的顺序以及结构会对序列化之后的空间产生不小的影响。\n\n16. **Caching UI data** 缓存UI界面上的数据,可以采用方案有存储到文件系统,Preference,SQLite等等,做了缓存之后,这样就可以在请求数据返回结果之前,呈现给用户旧的数据,而不是使用正在加载的方式让用户什么数据都看不到,当然在请求网络最新数据的过程中,需要有正在刷新的提示。至于到底选择哪个方案来对数据进行缓存,就需要根据具体情况来做选择了。\n\n17. **CPU Frequency Scaling** 调节CPU的频率会执行的性能产生较大的影响,为了最大化的延长设备的续航时间,系统会动态调整CPU的频率,频率越高执行代码的速度自然就越快。我们可以使用Systrace工具来导出CPU的执行情况,以便帮助定位性能问题。\n\n#### [Android性能优化典范 - 第5季](http://hukai.me/android-performance-patterns-season-5/)\n\n1. **Threading Performance** AsyncTask: 为UI线程与工作线程之间进行快速的切换提供一种简单便捷的机制。适用于当下立即需要启动,但是异步执行的生命周期短暂的使用场景。HandlerThread: 为某些回调方法或者等待某些任务的执行设置一个专属的线程,并提供线程任务的调度机制。ThreadPool: 把任务分解成不同的单元,分发到各个不同的线程上,进行同时并发处理。IntentService: 适合于执行由UI触发的后台Service任务,并可以把后台任务执行的情况通过一定的机制反馈给UI。\n\n2. **Understanding Android Threading** 通常来说,一个线程需要经历三个生命阶段:开始,执行,结束。线程会在任务执行完毕之后结束,那么为了确保线程的存活,我们会在执行阶段给线程赋予不同的任务,然后在里面添加退出的条件从而确保任务能够执行完毕后退出。\n\n3. **Memory & Threading** 不要在任何非UI线程里面去持有UI对象的引用。系统为了确保所有的UI对象都只会被UI线程所进行创建,更新,销毁的操作,特地设计了对应的工作机制(当Activity被销毁的时候,由该Activity所触发的非UI线程都将无法对UI对象进行操作,否者就会抛出程序执行异常的错误)来防止UI对象被错误的使用。\n\n4. **Good AsyncTask Hunting** AsyncTask虽然提供了一种简单便捷的异步机制,但是我们还是很有必要特别关注到他的缺点,避免出现因为使用错误而导致的严重系统性能问题。\n\n5. **Getting a HandlerThread** HandlerThread比较合适处理那些在工作线程执行,需要花费时间偏长的任务。我们只需要把任务发送给HandlerThread,然后就只需要等待任务执行结束的时候通知返回到主线程就好了。另外很重要的一点是,一旦我们使用了HandlerThread,需要特别注意给HandlerThread设置不同的线程优先级,CPU会根据设置的不同线程优先级对所有的线程进行调度优化。\n\n6. **Swimming in Threadpools** 线程池适合用在把任务进行分解,并发进行执行的场景。通常来说,系统里面会针对不同的任务设置一个单独的守护线程用来专门处理这项任务。\n\n7. **The Zen of IntentService** 默认的Service是执行在主线程的,可是通常情况下,这很容易影响到程序的绘制性能(抢占了主线程的资源)。除了前面介绍过的AsyncTask与HandlerThread,我们还可以选择使用IntentService来实现异步操作。IntentService继承自普通Service同时又在内部创建了一个HandlerThread,在onHandlerIntent()的回调里面处理扔到IntentService的任务。所以IntentService就不仅仅具备了异步线程的特性,还同时保留了Service不受主页面生命周期影响的特点。\n\n8. **Threading and Loaders** 当启动工作线程的Activity被销毁的时候,我们应该做点什么呢?为了方便的控制工作线程的启动与结束,Android为我们引入了Loader来解决这个问题。我们知道Activity有可能因为用户的主动切换而频繁的被创建与销毁,也有可能是因为类似屏幕发生旋转等被动原因而销毁再重建。在Activity不停的创建与销毁的过程当中,很有可能因为工作线程持有Activity的View而导致内存泄漏(因为工作线程很可能持有View的强引用,另外工作线程的生命周期还无法保证和Activity的生命周期一致,这样就容易发生内存泄漏了)。除了可能引起内存泄漏之外,在Activity被销毁之后,工作线程还继续更新视图是没有意义的,因为此时视图已经不在界面上显示了。\n\n9. **The Importance of Thread Priority** 在Android系统里面,我们可以通过android.os.Process.setThreadPriority(int)设置线程的优先级,参数范围从-20到24,数值越小优先级越高。Android系统还为我们提供了以下的一些预设值,我们可以通过给不同的工作线程设置不同数值的优先级来达到更细粒度的控制。\n\n10. **Profile GPU Rendering : M Update** 从Android M系统开始,系统更新了GPU Profiling的工具来帮助我们定位UI的渲染性能问题。早期的CPU Profiling工具只能粗略的显示出Process,Execute,Update三大步骤的时间耗费情况。\n\n#### [官方性能优化系列教程](https://www.youtube.com/playlist?list=PLWz5rJ2EKKc9CBxr3BVjPTPoDPLdPIFCE)\n\n### 架构分析\n\n[MVVM](http://tech.meituan.com/android_mvvm.html)\n\n[MVP](https://code.tutsplus.com/series/how-to-adopt-model-view-presenter-on-android--cms-1012)\n\n### 阿里面试题\n\n#### 进程间通信方式\n\n1. 通过Intent在Activity、Service或BroadcastReceiver间进行进程间通信,可通过Intent传递数据\n2. AIDL方式\n3. Messenger方式\n4. 利用ContentProvider\n5. Socket方式\n6. 基于文件共享的方式\n\n#### 什么是协程\n\n我们知道多个线程相对独立,有自己的上下文,切换受系统控制;而协程也相对独立,有自己的上下文,但是其切换由自己控制,由当前协程切换到其他协程由当前协程来控制。\n\n#### 内存泄露是怎么回事\n\n由忘记释放分配的内存导致的\n\n#### 程序计数器,引到了逻辑地址(虚地址)和物理地址及其映射关系\n\n虚拟机中的程序计数器是Java运行时数据区中的一小块内存区域,但是它的功能和通常的程序计数器是类似的,它指向虚拟机正在执行字节码指令的地址。具体点儿说,当虚拟机执行的方法不是native的时,程序计数器指向虚拟机正在执行字节码指令的地址;当虚拟机执行的方法是native的时,程序计数器中的值是未定义的。另外,程序计数器是线程私有的,也就是说,每一个线程都拥有仅属于自己的程序计数器。\n\n#### 数组和链表的区别\n\n数组是将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。但是如果要在数组中增加一个元素,需要移动大量元素,在内存中空出一个元素的空间,然后将要增加的元素放在其中。同样的道理,如果想删除一个元素,同样需要移动大量元素去填掉被移动的元素。如果应用需要快速访问数据,很少或不插入和删除元素,就应该用数组。\n\n链表恰好相反,链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起。比如:上一个元素有个指针指到下一个元素,以此类推,直到最后一个元素。如果要访问链表中一个元素,需要从第一个元素开始,一直找到需要的元素位置。但是增加和删除一个元素对于链表数据结构就非常简单了,只要修改元素中的指针就可以了。如果应用需要经常插入和删除元素你就需要用链表数据结构了。\n\n#### 二叉树的深度优先遍历和广度优先遍历的具体实现\n\nhttp://www.i3geek.com/archives/794\n\n#### 堆的结构\n\n年轻代(Young Generation)、年老代(Old Generation)和持久代(Permanent \nGeneration)。其中持久代主要存放的是Java类的类信息,与垃圾收集要收集的Java对象关系\n不大。年轻代和年老代的划分是对垃 圾收集影响比较大的。\n\n#### bitmap对象的理解\nhttp://blog.csdn.net/angel1hao/article/details/51890938\n\n#### 什么是深拷贝和浅拷\n\n浅拷贝:使用一个已知实例对新创建实例的成员变量逐个赋值,这个方式被称为浅拷贝。\n深拷贝:当一个类的拷贝构造方法,不仅要复制对象的所有非引用成员变量值,还要为引用类型的成员变量创建新的实例,并且初始化为形式参数实例值。这个方式称为深拷贝\n\n#### 对象锁和类锁是否会互相影响\n\n对象锁:Java的所有对象都含有1个互斥锁,这个锁由JVM自动获取和释放。线程进入synchronized方法的时候获取该对象的锁,当然如果已经有线程获取了这个对象的锁,那么当前线程会等待;synchronized方法正常返回或者抛异常而终止,JVM会自动释放对象锁。这里也体现了用synchronized来加锁的1个好处,方法抛异常的时候,锁仍然可以由JVM来自动释放。\n\n类锁: 对象锁是用来控制实例方法之间的同步,类锁是用来控制静态方法(或静态变量互斥体)之间的同步。其实类锁只是一个概念上的东西,并不是真实存在的,它只是用来帮助我们理解锁定实例方法和静态方法的区别的。我们都知道,java类可能会有很多个对象,但是只有1个Class对象,也就是说类的不同实例之间共享该类的Class对象。Class对象其实也仅仅是1个java对象,只不过有点特殊而已。由于每个java对象都有1个互斥锁,而类的静态方法是需要Class对象。所以所谓的类锁,不过是Class对象的锁而已。获取类的Class对象有好几种,最简单的就是MyClass.class的方式。\n\n类锁和对象锁不是同1个东西,一个是类的Class对象的锁,一个是类的实例的锁。也就是说:1个线程访问静态synchronized的时候,允许另一个线程访问对象的实例synchronized方法。反过来也是成立的,因为他们需要的锁是不同的。\n\n#### looper架构\nhttp://wangkuiwu.github.io/2014/08/26/MessageQueue/\n\n#### 自定义控件原理\nhttp://www.jianshu.com/p/988326f9c8a3\n\n#### binder工作原理\nBinder是客户端和服务端进行通讯的媒介\n\n#### ActivityThread,Ams,Wms的工作原理\nActivityThread: 运行在应用进程的主线程上,响应 ActivityManangerService 启动、暂停Activity,广播接收等消息。\n\nams:统一调度各应用程序的Activity、内存管理、进程管理\n\n#### Java中final,finally,finalize的区别\n\n- final 用于声明属性,方法和类, 分别表示属性不可变, 方法不可覆盖, 类不可继承\n- finally 是异常处理语句结构的一部分,表示总是执行\n- finalize 是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等. JVM不保证此方法总被调用\n\n#### 一个文件中有100万个整数,由空格分开,在程序中判断用户输入的整数是否在此文件中。说出最优的方法\n\n#### 两个进程同时要求写或者读,能不能实现?如何防止进程的同步?\n\n#### volatile 的意义?\n\n防止CPU指令重排序\n\n#### 单例\n\n```java\npublic class Singleton{\nprivate volatile static Singleton mSingleton;\nprivate Singleton(){\n}\npublic static Singleton getInstance(){\n if(mSingleton == null){\\\\A\n synchronized(Singleton.class){\\\\C\n if(mSingleton == null)\n mSingleton = new Singleton();\\\\B\n }\n }\n return mSingleton;\n }\n}\n```\n\n#### Given a string, determine if it is a palindrome(回文,如果不清楚,按字面意思脑补下), considering only alphanumeric characters and ignoring cases. \n\nFor example, \"A man, a plan, a canal: Panama\" is a palindrome. \"race a car\" is not a palindrome. \n\nNote: Have you consider that the string might be empty? This is a good question to ask during an interview. For the purpose of this problem, we define empty string as valid palindrome.\n\n```java\npublic boolean isPalindrome(String palindrome){\n\t\tchar[] palindromes = palidrome.toCharArray();\n \t\tif(palindromes.lengh == 0){\n\t \t\treturn true\n \t\t}\n \t\tArraylist temp = new Arraylist();\n \t\tfor(int i=0;i'a' && palindromes[i]<'z')||palindromes[i]>'A' && palindromes[i]<'Z')){\n \t\ttemp.add(palindromes[i].toLowerCase());\n \t\t}\n\t\t}\n \t\tfor(int i=0;i 来源:微信公众号「LJ 说」,id:「LjNotes」。\n\n“你居然要从腾讯离职了!?”\n\n这是身边朋友得知我要离开后的反应,似乎大家都难以理解这样的决定。\n\n从行业环境来看,中国互联网正处于一派繁荣之境;从公司形势来看,也正要准备大刀阔斧地干一番大事业;从个人发展来看,自己在公司也会担任越来越重要的角色。\n\n所有的环境都是好的,更加显得离职的决策不理智。\n\nHR 系统弹窗给出最后的挽留:你确定要提交离职申请吗?\n\n经过各种综合考虑后,我还是点了“确定”按钮,正式从工作了三年的腾讯离职。\n\n一直有朋友问,在腾讯的工作感觉怎么样?\n\n关于这个问题,从来没有好好思考过,觉得当局者迷,尽量做好手上工作就是了。\n\n现在终于有时间梳理一番。\n\n回想起这几年的经历,既有取得成就的喜悦,也有遭受挫折的失落,个中唏嘘,在离开之际,希望与你分享一二。\n\n## 大公司之病\n\n\n\n3 年前,我面试完,从腾讯出来,融入了深南大道熙熙攘攘的下班人群中。\n\n在过天桥的时候,我特意拍了一张腾大的夜景,留作纪念,表示我终于要到腾讯上班了。\n\n虽然还没正式通知,不过凭着面试反馈,我知道自己终究还是要进入这家梦寐已久的公司了。\n\n3 年后,同样是腾讯大厦,我站的位置已经发生改变。\n\n从外面的仰望变成了里面的远眺,心情体会也随之改变。\n\n只要在大型企业工作过的人,都会被大公司病深深困扰着。\n\n### 你厉害还是平台厉害\n\nBAT 的光环是非常牛逼的,它意味着你进入国内任何一家互联网公司都畅通无阻,它意味着你可以对外分享自己的经验和心得,享受着他人崇拜的目光。\n\n然而,在一家几万人的巨头企业,几乎每个人都是一个普通员工,毫无存在感可言,其中滋味就如人饮水,冷暖自知。\n\n看《权利的游戏》,我在想,龙妈拥有三条喷火巨龙,为什么还要四处斡旋、拉帮结派,直接骑着三条龙到处喷火,不早就征服七大王国了吗。\n\n直到有一幕场景,大龙“Drogo”在斗兽场,被很多小兵拿着矛乱刺,身受重伤,我才反应过来,不管龙妈和她的三条龙再厉害,始终赢不了训练有素的军队。\n\n这就是大企业的一个缩影。\n\n公司征战,并不需要一个能斗天斗地的英雄,而是需要一支能打仗的队伍。\n\n尽管在招聘的时候,大公司往往会筛选出最厉害的一批人,但这并不代表着每个人都举足轻重。\n\n事实上,不管你是清北名校毕业光环加持,还是二三本拼搏多年进入大平台,公司想要的结果其实都一样。\n\n公司希望每个一线的员工坚守着自己一亩三分地,不需要你把控全局,不需要你战略思考,只要努力地当好螺丝钉。\n\n每个人手上分到一小块工作,然后在未来的很长一段时间内,不断地重复着这个工作,成为这个小模块的“专家”。\n\n负责个性化皮肤的,可能几年内都在钻研怎么把更多皮肤卖出去;写文案的,长年累月地追着微博热点写文章;做渠道运营的,风雨无阻地盯着各个渠道把自己的广告上线……\n\n并不是说公司不重视个人创造力,恰恰相反,公司希望的是大家发挥创造力,把自己变成更可靠的螺丝钉,成为一个更靠谱的零部件。\n\n全公司上下形成一股合力,用军队的方式赢得战争。\n\n赢的方式,不是靠武艺高超的英雄,而是让所有人在统一指挥下,移动、格挡、举矛、刺杀,每个动作都如此简单,但千军万马在一起,就能击破对手。\n\n这也就意味着铁打的营盘流水的兵,在大平台工作,一件事情成功之后,很容易让人觉得是因为自己牛逼,其实真正的原因是平台的力量。\n\n同一件事情,放张三能做成,放李四也 OK。\n\n在这里,你不是英雄,你是一个日夜训练着重复动作的小兵。更可悲的是,对于绝大部分人而言,公司压根没计划让你成为一个英雄或将军。\n\n你只是千军万马中的一员,平台缺少了你,马上能找到一个人填补上去,而你一旦离开了平台,就会发现很难再复制以往的成功。\n\n### 无尽的流程和制度\n\n把大象放进冰箱一共要三步:打开冰箱门、放进大象、关上冰箱门。\n\n但是在大公司,这个流程就远不止三步了。\n\n你要给个报告写清楚把大象放到冰箱的意义和重要性,搞清楚哪种冰箱放哪种大象,把开门动作、放大象的路线描绘清楚,把关门的力度写出来,拿着完整的方案找项目经理去排期,直到有人力来把大象放进冰箱。\n\n一个产品或功能,从无到有需要经历漫长的流程。一个大企业的员工,每天为制度所困。\n\n某些产品一两年内都没有可感知的外观变化,例如微信,有人就会问这么多工作人员都在忙些什么呢。\n\n其实工作人员都很忙,忙在了“流程”和“制度”上。\n\n当你们是一个三五人的创业团队,大家就坐在一起,有事情吼一声就可以。比如说想要做一个功能改变,可能就是抬起头跟对面的开发说要怎么怎么改,半天之后就能在产品上看到了。线上反馈好,就保留,反馈不好就改回来,不过是几个小时的事情。\n\n然而,对于一个巨型产品来说,所有人的 80% 精力并不是在做“正经的工作”。\n\n每个产品经理电脑上都躺着十几份写好的需求文档,在等候着漫长的项目排期。等排期终于到了的时候,有的需求已经不再适用了,或者写它的产品经理已经走了,要是需求和人都还在的话,那就要谢天谢地,守得云开见明月,终于要上线了。\n\n每个开发脑子里都存放着许多改进方案,很多可能就是改一行代码的事情,但是不能擅自改动,所有的改动都应该以产品需求为主,否则出了问题那就闯大祸了。\n\n遇到跨团队、跨部门沟通,更加是考验人的忍耐力,找一个接口人要花上大半天。对方要么不回复,要么回一句“这不是我负责的”。好不容易对接上了,好家伙,群里面出现四五个接口人,每个人都得交待一遍来龙去脉。\n\n除此之外,每个人身上还背负着各种会议、分享、周报月报,PPT 模板成了最受欢迎的文件。\n\n能够安心写代码、写需求的时间,算下来也许还真的没有20%。但工作还是要完成的,于是就只好加班加班,成为了互联网行业的一大特色。\n\n流程制度是一个好东西,也是一个坏东西。\n\n好的地方在于保证企业这条大船高效率地运转,坏的地方在于牺牲了个人效率来满足集体的效率。\n\n### 逃不过的修罗场\n\n对于大企业工作的朋友,是万万不能问什么时候升职的。就像不能问魏忠贤魏公公什么时候生个小孩,这是要杀头的大罪。\n\n越是受过高等教育的人,越是想着要改变世界。当初怀着远大的志向进入大公司,想要施展拳脚做一件不凡的事情。\n\n但几年后,大多数人的志气早已被磨消。修身齐家治国平天下,他们连修身都做不好。\n\n眼看着身边的朋友在中小公司鹤立鸡群,一路扶摇直上,成为有决策权的管理者,而自己只是数年如一日地坐在小隔间,每周想着如何跟老板汇报工作。\n\n也许离 CEO 的办公室只有十米不到的距离,也许每天还能跟几个高管寒暄一下,似乎离他们好近,但是心里明白这种阶层的差距是一道无法逾越的鸿沟。\n\nHR 在设计个人发展体系的时候,给每个人都提供了两种路径,一个是专业能力晋级,一个是管理职能晋升。\n\n所有人都能在专业能力通道上一步步地打怪升级,最终成为高级产品经理、高级工程师,甚至专家 xx。\n\n但是在管理通道上,坑位就那么几个,而且大企业内具有管理头衔的人流动性远远低于普通员工,于是国企中“一个萝卜一个坑”的现象在创新的互联网企业同样存在。\n\n不少人已经工作十多年,但仍然是一线普通员工。\n\n至于谁能晋升,这个话题,不说也罢。\n\n要是运气不好,赶上了“宫廷大戏”,轻则工作上举步维艰,重则随着失败一方的领导一起离开。\n\n这里就是一个几万人的修罗场,陷于其中的人,个个都身不由己。\n\n## 外面的世界很精彩?\n\n\n\n前面说了那么多,你可能会以为我在痛陈大公司的弊端,但这并非我本意。\n\n我并没有在真正意义上的创业团队工作过,但也有过小团队的经历,加上平时和不少创业团队的朋友交流,对小公司的辛酸也是略知一二。总结起来,不过是几个字:人少事杂、管理混乱、野蛮生长。\n\n### 人少事杂\n\n在小团队,可能出现最多的头衔是“全栈 xx”,这并不是说明他有多厉害,而是在一个人手不足的团队中,每个人可能都身兼数职。\n\n写前端页面的,可能没人把写好的接口交给你,而是需要自己写服务器脚本、自己调优数据库,还得自己盯着运维数据,宕机了得马上修复。\n\n做产品的,不是只打开 word 来写需求文档,用户调研、交互图得自己做,上线后的运营还得自己跟。\n\n做运营的,更加是无所不包,大到策划一个线上活动,小到做客服回答用户的咨询。\n\n每个人也很忙,似乎什么都能做。\n\n这也是小团队吸引人的噱头,能对付过来的人,就成为一个真正的“全栈”,疲于奔命的人,就什么都做什么都学不精。\n\n### 管理混乱\n\n小团队是否意味着效率高呢,其实也可能存在更加胡乱的管理。\n\n曾听朋友讲过他的经历。一个普通员工,需要同时向两个领导汇报,而两个领导还经常互掐,于是该朋友就一脸懵逼了,经常接收到两个完全相反的指令。\n\n还有可能,前一周刚刚跟另外一个团队开完会,达成决定做个方案,下周再找他们就发现整个团队被老板裁撤了。\n\n又或者,团队在短时间内爆发性增长,为了融资,为了数字,找来了一批新人,大家都面面相觑,不知道谁该做什么,本来公司也并不是因为业务需要而招新人,所以干脆大家都逛淘宝、刷微博。\n\n如果说大公司内部的身不由己还有章可循,小公司的变化就是充满着惊喜。\n\n### 野蛮生长\n\n大公司令人艳羡的地方就是有很多现成的基础服务,而在小团队干活的人都会非常痛苦,大多时候都需要自己造轮子。\n\nCDN 网络需要自己搭建,大数据平台需要自己开发,账号体系需要自己建设,支付系统需要从零开始……\n\n一个最简单的例子,大公司有成熟的数据体系,每个可以看各种各样的报表,以便调整运营策略,但是小团队可能看个数据就需要提导数据的需求,等到一两周之后才能看到。\n\n从一片荒芜中把业务从零开始做起来,是一件很锻炼人的事情,但其实背后更多的是资源浪费。\n\n## 都是围城\n\n\n\n万物皆有裂痕,要看到裂痕中照进来的光,而不是裂痕本身。\n\n一位长者曾说过,一个人的命运啊,当然要靠自我奋斗,但也要考虑到历史进程。\n\n历史的进程和外部的环境,都是我们所不能控制的,但是说到自我奋斗的话,大公司却提供了温暖的襁褓。\n\n### 在正规化中成长\n\n流程制度的反面就是“正规化”。\n\n当有人问我要不要去大公司的时候,我都会回答,如果有合适的机会就去吧。不为别的,就为了体验这种正规化的流程制度。\n\n管理两三个人的时候可以靠命令,管理二三十个人的时候可以凭个人魅力,管理几百人、上万人就只能依赖于流程制度了。\n\n前面说过流程是牺牲个人效率满足集体效率,从个人成长而言,依然能从中学习到受益终身的东西。\n\n你可以知道一个业务从零到一是怎么搭建团队的,各个团队通过什么样的流程进行配合,各司其职代表着每个环节都能产出精品,于是你就知道一个优秀的作品应该是怎么样的,以后碰到类似的场景就有经验了。\n\n总而言之,身处在“正规军”当中,虽然自己只是其中的普通一员,但是也可以耳濡目染地学习到最顶尖的产品是如何打造出来的。\n\n当然,前提是你有心去了解和学习。\n\n### 站在巨人肩膀上\n\n大公司汇聚了最优秀的资源,包括人才、技术、资金、经验等。\n\n在平时,如果你想了解或钻研某一事物,往往能在内网上找到独家优质的经验分享。\n\n更进一步,可以直接联系这个领域的高手咨询请教。内部使用的软件,上至 CEO 下至电脑维修小哥,都静静地躺在好友列表里,等着你联系。\n\n在大公司工作的人,是真正的能做到聚焦于业务逻辑本身,而不用被琐碎的杂事打扰。\n\n行政上,公司配备了饭堂、班车、体检、节假日福利、家人福利等等,让你能安心地工作。\n\n业务上,有专门的基础服务部门,IT设备、开发组件、大数据平台、安全防御、用户数据等等,都可以拿来马上用。\n\n个人成长上,虽然不是每个人都能平步青云,但是完善的薪酬福利让每个人都能获得相对合理的回报,各种培训让大家都能适当跳出舒适区获得成长。\n\n这些基础服务都是十多年无数人的心血积累,可想而知,站在这样一个巨人的肩膀上,新人可以获得更高速的成长。\n\n### 围城里外的人\n\n前段时间见到一位大学好友,在外闯荡多年,辗转了几个公司,现在已经是带着小团队的“总监”。\n\n我说,这几年间你升职加薪,走上人生巅峰,让人好生羡慕啊。最重要的是可以根据自己想法去实施一些方案,而不会被束手束脚,跟随着高速成长的公司也能让自己的思维和能力快速成长。\n\n而他谈到小公司的经历,眼中难掩失落,反而羡慕大公司内提供的坚实后盾。更让我惊讶的是他其实已经在找BAT的机会,准备年后就进入巨头企业了,即使放弃管理者的头衔做一个普通员工。\n\n所以你看啊,大公司就是一座围城,外面的人想进去,里面的人想出来。\n\n而他们想进去或想出来的原因,其实都是一样的东西。"
},
{
"path": "docs/android/Android-Interview/经验分享/我为什么离开锤子科技?.md",
"content": "我在2015年3月入职锤子科技,最近几天离职,现在特别想把这不到两年的时间里的经历和我对这家公司的想法写下来。最近一段时间公司发生了大面积的裁员,但是我并不属于这一次陆陆续续的裁员的范围,而是自己提出离职的,最后发生了一些不愉快的事情,后面也会提到。\n\n我2012年本科毕业的时候对自己要去什么样的公司完全没有概念,我的专业是软件工程,但是当时不想去任何一家IT 公司,于是我选择了出国留学。锤子科技是2012年5月份创立的,我在大学期间是一名典型的罗粉,但就是这样我还是没有太关心这家由老罗创立的公司,心里甚至觉得老罗有玩票的嫌疑,而且那个时候出国的手续基本办完了,所以也有点行色匆匆的意思,就没有特别关注这家公司。\n\n锤子科技的第一个ROM是在2013年3月份发布的,当时人在国外,全程看了发布会的回放,我第一时间刷了这个ROM,虽然问题多多,但是非常喜欢这个系统的很多细节。我第一次动念头想要去锤子科技上班是T1 发布会之后,当时T1 发布之后我也是属于第一批预定的用户。因为我是南方人,回国后找工作简历直接先投了锤子科技,因为如果不行,我是不太可能来北京工作的。当然从面试到最后入职都很顺利,我入职的时候差不多是T2 这个项目刚开始的时候。说到当时入职锤子科技我还是比较感激公司的,因为这是我的第一份工作,之前没有任何Android 相关的开发经验。入职之后知道公司在当时项目非常紧张,需要来了就能干活的人·。想到公司愿意招我这个新人,我心里是有几分侥幸和感谢的。\n\n锤子科技在科技圈的公司里可能算名气比较大的企业了,对于它的各种说法和想法都很多,这两年时间确实和公司一起经历了很多。但是在这个时候我最想提的一个点是公司的一次营销活动,就是让大家参与进来以“天生骄傲”为题写一些自己天生骄傲的经历。我觉得这个可能是这个公司最吸引我的点,也是我作为一个罗粉,老罗最吸引我的点,就是有一种永远要做正确的事情的骄傲。\n\n我还记得的一个“天生骄傲”的故事是老罗转发的一则,一个人因为工作原因用车很多,他开的是自己的车但是公司会给他报油费,他每次会特别留心记下哪些是因为工作原因用车,哪些不是,每次向公司报销的时候,会去掉平时非工作用车的里程数。·我记得原作者的表达要更让我震撼一些,我自己转述的有点啰嗦,反正意思是差不多的。刚到公司那一会我的确相信这是一家天生骄傲的公司,并且可能是由内而外的,并不简单是公司的营销策略。\n\n因为就我当时的观察,来锤子科技入职的同事,有一部分是和我一样的罗粉,他们可能是被相同的价值观吸引来的。还有一部分在入职之前并不知道老罗是谁,但是加入公司之后对这种价值观是很认同的,当然这肯定不包括所有的同事,但我想在我入职那会儿应该包括了大部分同事。但是现在是不是这样,甚至是否公司还能相信自己天生骄傲,我都是不敢确信的。\n\n我一直觉得,我的性格是那种,如果在有选择自由的情况下,还愿意做自己不喜欢做的事情,那肯定是有一种我认为正确的价值观或者理想之类的东西在激励我,我相信这也是很多人的情况。我在锤子科技工作的第一年,有一段时间项目特别紧,几乎每天都要工作到9 到10 点钟。我是很不喜欢加班的,工作做完都是想尽早回家做自己的事情,毕竟工作这么忙了,难得有时间干自己喜欢干的事情,说白了我理解的工作就是自己生活的保障,并没有什么特别大的野心要在并不是自己兴趣的工作上有什么作为。虽然这样,只要是觉得有必要在当天做完的工作,不管到多晚我都会做完的,当时让我有这种决心的,可能就是那种对公司的认同感。\n\n我入职的时候,面试我的软件副总裁是跟我说过公司的工作时间制度的,锤子科技是采用那种弹性工作制,虽然有一个规定的早十点到晚七点的工作时间,但是只要能保证工作做完,并不强制一定要十点到,七点走,但是如果规定时间内工作做不完,就得自觉加班。这是当时面试我的软件这一块的副总裁原话跟我说的。\n\n说实话,我当时对这种工作制度的想法是很理想化的,非常认同,并且也是这么做的。刚入职那会安排我的工作是先理解代码,看文档,刚开始的一周我基本晚上都是7 点准时走,说实话一天时间里有些代码我翻来覆去能看两三遍,基本也都能看懂,而且我也不觉得再多看一两个小时效果会好,毕竟按我学习东西的节奏我不想一天时间看太多东西。但是第二周我们20几个人的组的经理马上找我谈话了,我立刻就意识到有些事情可能并不是我想象的那样,不过他最后给出的理由我也算勉强接受了,他给的理由是要和组里的同事保持步调一致,不然可能有时候找不到你。当然在之后差不多两年的工作时间里,我慢慢对弹性工作制的认识从理想化的状态变成了公司不愿意给加班费,因为所谓的弹性工作制就是一种可以让你每天加班到10点但是不用付薪水的制度。\n\n关于工作时间,甚至做到了你没事情做也得在公司待着的地步,感觉就是如果7 点准时走会有人不爽,而这个不爽的人就是我们软件部门实际的负责人,这个人后来升到了软件副总裁的位置,在他升上去之前有些东西还处于含含糊糊的地带,等到他升上去了之后这些都变成了实质的制度。顺便一说,我在公司的两年多时间,弹性工作制从来都是从7 点往后弹的,这倒不是说我们真的有多忙,只是如果你每天的工作时间恰好只有9 个小时,那就会有人找你谈话,不管你的工作做没做完,做得好不好。\n\n当然我还是愿意相信公司的很多同事是从理想化的角度来理解弹性工作制的,包括当时面试我的前副总裁,他是一位很和蔼的中年大叔,大概好像几个月前退休了。可是为什么在我眼里公司慢慢变得不那么骄傲了呢?甚至我现在确信公司已经不再有脸面在自己内部员工面前说我们是一家天生骄傲的公司了,为什么会变呢?这可能得好好说一说我们这个组的经理,从他可能能侧面说明这个问题的原因。\n\n我们的这位经理是在原来他的经理升上去之后被提拔的,可能就是所谓的自己人吧,但是这个人到底能力怎么样,我觉得可能公司并没有明确考核过,或者甚至本身就没有考核这一步吧,毕竟我对公司管理不是很清楚。我们的软件组里其实并没有明确区分技术和管理的Leader,可以理解为我们的经理需要兼顾这两个方面的工作。\n\n我们组大概维护手机软件部分的大大小小几个模块,锤子的软件部分可以说是很出彩的,但是说我们公司软件的技术多么牛逼,我真不敢说,因为我们的工作主要在于实现产品提出的需求,所以只要能实现了产品功能和性能上的需求,并没有人在意你是怎么实现的,至少我们组完全没有所谓软件架构,如果你负责的某一个小模块需要实现一个新需求,那么从设计方案到软件架构到coding很有可能都是你一个人完成的,公司很有可能没有第二个人知道你是怎么实现的。\n\n这里说一下在我眼里我们组的经理每天的工作似乎就是满足于不挨他上级的骂,所以像整个组的bug 数量和新需求是否超期这些敏感数据是他最关心的。经常遇到的情况是,有一些bug 比较不好分析,或者需要仔细分析前因后果再做合理修改,但是他会在你分析bug 期间催你,经常用到的句式是:“某某,你那个bug 优先级比较高,快点看一下”,好像我们没有在看一样。而且有时候为了降低bug 数量,他还要经常帮我们解bug,有时候他不好意思让我们来加班,自己周六跑到公司解bug,然后我们周一来了发现他解得不对还要帮他擦屁股。倒不是说他技术有多差,只是组里那么多模块的代码他并不都熟悉。只要当天bug 数量降低了,他就满意了。不过话又说回来帮组里同事解bug 也算是他完成他技术Leader的工作吧。\n\n另外虽然他是大组经理,但是其实下面按模块还是分了几个小组的,一般小组内的工作都是我们组长分的。我们小组组长的方式我是很认同的,有的时候他并不会主动给我们分bug,我们会自己从他那里取,这种方法看似放任,但其实我们组长是基于对我们的了解以及建立在这种了解之上的信任才这么做的,这种方式和公司的弹性工作制本质上是类似的,我觉得我们小组内这样合作的方式是很合适并且效率很高的。然而我们这位经理经常越过我们组长给我们分bug,有的时候他不太了解我们组内工作的分配,这样分bug反而会给组内同事造成困扰和压力。在工作的这几年时间内,我们的经理似乎对我们完全没有什么具体的了解,只是象征性的组织过几次团建,吃过几次饭而已。\n\n我想这对他做管理方面的工作是很致命的,因为他要做的不只是每天催我们尽快解bug 而已。也有很多同事为他解释,说他是工程师出生,人又内向,所以有时候表达不到位,但是我想说的是,既然这样,他为什么能做20 几个人团队的经理?他似乎只是作为一个单向的通道存在,项目催的紧了,他就也来催我们一下。其实问题可能很简单,因为他是自己人,有的时候看到他被骂心里其实也很难受,但是这样能力的人当上经理,可能也是从侧面反映了,为什么我越来越感到公司不那么天生骄傲了。\n\n我写这些的目的是很明确的,字里行间都能看出我是带着对公司管理层的怨恨的,因为他们可能就是锤子科技变成今天这样的罪魁祸首。这里说一下我离职的原因,今年公司软件团建的时候采取了很幼稚的形式(发小学的时候用的那种大红奖状,完了竟然没有奖金)奖励了一些加班时间最多,解bug数量最多的同事,我对这样的价值取向是很不认同的,因为这对不用加班就可以把工作做完甚至做得更好的同事是不公平的。\n\n借着酒劲,我在公司群里说了很难听的话,顺便在当晚老罗和我们互动的微信群里问了过年红包还会不会发,结果是直接被退群。当然我后来很后悔,本来年后我也打算离职回老家了,还是忍一忍的好,毕竟后面经历的事情都非常荒诞。我再到公司的时候发现我的办公电脑被收走了,据说公司邮箱也被封了,据说是经理怕我再做出可怕的事情说出可怕的话。但是公司HR对我说公司的正常裁员已经结束了,也不会开我,这里我真想说难道让我把电脑搬回来继续干吗?我实在没有心力和公司耗下去,就自己提了离职。\n\n我在职期间有一次经理找我聊天问我为什么最近工作不积极对公司有什么不满,我主要对他说了两点,一是公司取消本来就屈指可数的中秋节红包福利为什么不在公司层面通知一下(我和同事等了一天发红包,虽然锤科福利不多,但是逢年过节是直接给现金红包的,每次领红包都很开心),二是公司裁员为什么采取遮遮掩掩的态度,因为即使你不说外面的人一样知道,反而如果你对内部员工都不开诚布公,却会造成我们的恐慌和懈怠。\n\n经理的答复是,这个不可能按你想象得那么理想化的,其他公司都是这样的。其实从他这番话也大概能了解为什么公司在做出这些决定的时候是这样的态度,因为公司的管理层似乎都被他这样的人占领了,他这句话在我看来好像就是锤子科技变得不再特殊的宣言吧。这里想告诉那些还想来锤子科技入职的朋友,了解一家公司不能光看公司自己的官博。\n\n其实最后我还想说一句,锤子科技没有做错任何事情,因为站在公司角度来看,简直可以用为了盈利把所有问题都说通,但是这家公司已经不能再公开宣称自己天生骄傲了。也许正是被天生骄傲的价值观吸引来的,在离开的时候看清公司的现状才不会有任何遗憾。"
},
{
"path": "docs/android/Android-Interview/经验分享/我为什么要离开华为?.md",
"content": "> 原文链接:微信公众号[小李成长笔记]\n\n到 9 月中旬,我在华为工作就满 6 年了。\n\n同事听说我要离职,都很诧异。干的好好的啊,怎么突然说要走?\n\n是啊,在现在的部门这么久了,人和事都很熟了,偶然有些小摩擦,都可以理解和接受。那为什么要走?\n\n华为的 34,胶片文化,强绩效主义,部门墙,研发的低效等等这些,大家说过很多,就不再重复了。在我看来,这些都是微不足道的外因,我完全不认同,但可以理解。\n\n真正推动我下定决心离开的还是内因:我那颗躁动不安的心。\n\n在华为 3 年后,工作真的变成了工作。我常常想不起来昨天都做了些什么,只是模糊记得接了几个电话,帮助客户解决了几个问题,接入了几个莫名其妙的会议,回复了几个邮件。就这样一周过去了,一个月过去了,一年也过去了...\n\n职级在升,工资在涨,年终奖也一年比一年多。可我却越来越心虚,越来越焦虑。\n\n有 2 个我一直在争辩。一个我:现实点,这就是份工作,出卖时间,换取工资而已。干嘛期望那么多?另一个我:还这么年轻,就认命了吗。想想这些年你都干了些啥。每天处理些 stupid 问题,一年年重复自己,你还想像这样过多少年?\n\n2 个我不停的争吵,日子在争吵中慢慢过去。\n\n我知道不能再这样下去了,我要行动起来。我要做准备,离开这个安逸,不再成长的环境。\n\n## 学习 Andoid 开发,重拾开发乐趣\n\n16 年 Android 很火。我想学 Android 开发,买了《第一行代码》,边看书边搭环境,敲代码。买 vpn,用 google 搜索问题答案。关注了张哥的公众号「stormzhang」,知道了 stackoverflow 网站,github 网站。知道了开源软件。慢慢摸索,年底时也能做个还能用的 app 了。上传到应用商店,看到后台统计数据,每天有上百人下载,也有一些用户评论说不错,很喜欢。感觉很充实,很有成就感。\n\n## 走出去,接触外面的世界\n\n在华为的日子,每天按部就班工作,大家都很勤奋,专注。只需要埋头干活就可以了。慢慢的,好像和外面的世界隔离了。\n\n当我第一次参加一个武汉产品经理交流活动,看到不大的会议室里坐满了上百名自发参加的朋友,被大家渴望知识和交流的态度感动,原来,我们身边还有这样一群人。\n\n也参加过几次程序员自发组织的编程活动,大家一起结对编程,分享各自的工作流,推荐好用的工具和软件。能感受到他们对自己工作的热爱,让我羡慕感动。大周末的,放弃陪老婆孩子的休息时间,穿越大半个城市,和一群素未谋面的伙伴编程,绝对的真爱。当然,我们也成了网上的好朋友,虽然平时不咋联系,但大家知道,我们都是一类人。\n\n## 关注互联网大 V,了解另一个世界\n\n这期间关注了好多互联网行业大v的公众号。有耿直风趣的冯大辉,温和幽默的 MacTalk,黑白灰道都熟的 Caoz,硅谷 Airbnb 美女程序员 angena,Android 开发者帅比 stormzhang...每天看他们的文章,看他们写自己的从业感悟,写互联网行业的灰与黑,写曾经的迷茫和奋斗...真实有力,催人奋发。牛人都在奋斗,我还在温室里等死。\n\n## 偶遇付费社群,见识网赚套路开眼界\n\n转眼到了 17 年,好像一夜之间,知识付费就火了起来。\n\n机缘巧合之下,加入了网友亦仁的生财有道小密圈,亲身经历了圈主 30 天收百万入圈费,见识圈主高超的运营手法,圈友大牛们分享的各种生财,吸粉套路。彻底改变了我对广告,对一些互联网业务的认知。\n\n以往的我,对各种广告很不屑,认为都是骗人的。ppt 教程,excel 教程,这么 low 的东西,我可是 it 专家,哪看的上这些...\n\n选择性无视,不看,不听,不想。\n\n现在我会去想为什么会有这个,有多大市场,针对哪些人群,它们有哪些套路,有哪些值得学习的地方?这个事情有哪些门槛,如果我去做,可以吗。\n\n脑袋瓜被慢慢的打开,不再是以前那个非黑即白,只有 0 和 1 的工科男死脑筋了。\n\n还加入了刘大猫的财富移动城堡。了解到刘大猫,是看了他写的自传文,一个从高中开始就做网站,做淘宝客,做流量变现,27 岁就积累千万财富的大牛人。听他分享各种总结,经验和看法,思路清晰,态度诚恳。不满足现状,完全放弃还很赚钱的淘宝客生意,坚决转型公司和个人发展方向。让我汗颜,想到自己畏惧风险,待在舒适圈里不愿出来,无地自容。\n\n还有好多社群,这些社群让我有了“近距离”观察和交流大牛的机会。他们就像存在你身边,就是你的一个学长或者朋友,你好像看着他们一步步成长为大牛,有时候会想,或许有一天,我也会牛起来。\n\n## 开发微信小程序,体验流量的威力\n\n网上和群友交流,不能光说不练,你总得有些拿的出手的东西。听再多的套路,经验不如亲自去实践下。\n\n趁着小程序这股东风,自学开发了一个文字转语音的小工具。从 app 名的选择,简介,到搜索关键词,app 界面,功能都做了一些思考。开发上线后,收集用户反馈,和用户交流使用场景,慢慢的每天用户竟然有近 300 了,排名也一直上升到第一名。\n\n有天看后台数据,访问量突然增加了 10 倍,当天新增用户 3.5 k。吓坏了,以为后台出统计故障了。原来是知晓程序公众号当天的文章推荐了。那天好多用户联系我,夸工具好用,确实帮他们解决了一些问题。好开心,体验了一把网红的感觉。\n\n## 以后咋发展\n\n写到这里,可能很多朋友会问,你写了这么多瞎折腾的经历,和你离职到底有啥关系呢,是要转行搞互联网产品开发吗?老实说,我也不肯定。\n\n我只知道这些经历潜移默化改变了我,让我不再封闭,不再纠结。我庆幸这些经历让现在的我经过华为近 6 年的“摧残”后,心还火热,对未来还留有希望。\n\n工作咋办呢,32 岁“高龄”了,还要去做程序员吗,还有公司要吗?没事,我觉得自己还年轻,如何做产品,还有很多可以学,我也相信,华为 6 年的经历,磨练,纠结,折腾,这些都是我未来宝贵的财富。\n\n终于,我做了选择,不再纠结,重新出发。"
},
{
"path": "docs/android/Android-Interview/经验分享/扫清Android面试障碍.md",
"content": "## [扫清Android面试障碍](http://chaojimiaomiao.github.io/2016/05/08/%E6%89%AB%E6%B8%85Android%E9%9D%A2%E8%AF%95%E9%9A%9C%E7%A2%8D.html)\n\n怎样快速突破初级瓶颈,变身高级开发?怎样在短时间内提高自我身价,月薪提高50%?你是否是个代码高手,面试中却发挥不出来,想进阶却摸不着头脑。博主在互联网行业摸爬滚打,百面成钢。特来总结与分享自己面试的心路历程和经验。\n\n本系列将分为四大部分切入,包括**第一部分面试前的准备**:从长期来看要做点什么来提高自己的身价,短期内怎样迅速进入面试状态,以及如何准备简历才能吸引HR的眼球。**第二部分是安卓初级中级高级面试题**,大概会有几十个问题,基本覆盖了小白到大牛进阶的所有会被问到的问题。**第三部分是除了安卓经验**,你还会被问到哪些问题。**第四部分是关于 offer的选择**,以及一起探讨未来的职业规划。从这四部分看来,已经涵盖了一个程序员的方方面面。我一直觉得面试也是一种考试,只要是考试就有套路,有套路就能被总结,能被总结就能被练习,就好比高考模拟卷或者培训班,能教你的也就是反复练习。 \n\n先交代一下背景:博主本科毕业于国内某985大学,10年大二开始接触Android开发,参加了两届谷歌举办的全国大学生安卓应用竞赛并获奖。实习和工作都在上海的互联网公司做app开发。曾误入 iOS深处,沉醉不知归路。后来惊醒还是转投回安卓的世界中去。目前工作三年。本文的目的在于总结回顾上一波的面试,给未来的自己看看当时的努力与心情,更重要的是希望对业内还在迷茫中想要提高自己的开发们指点迷津。\n\n前两个月,我面试了上海多家互联网公司,按规模上至阿里携程新美大,中至爱奇艺安居客B站平安科技,下至格瓦拉触宝科技蜻蜓fm,偏至招行信用卡微鲸科技等。并非有意要面那么多,只是一开始行动力太旺盛不小心简历投多了。秉承“自己投的简历,跪着也要面完”;以及想一窥上海互联网公司发展情况等多种心理下,横扫了各大Android面试题。经验积累了不少,从简历准备到技术准备再到扯淡环节,甚至于怎样针对不同的公司不同的面试官提出不一样的问题等等。\n\n这整个过程不是一帆风顺的,就像给程序做优化一样,一点点完善、一点点让自己的表现趋近完美。我当时甚至会在家对着镜子针对可能被问到的问题,练习说话的语速和表情。请理解一个心机 girl 总会想太多,比如有的问题面试官或许会觉得这道题是他的杀手锏,那你就不要表现出一副做了充分准备、分分钟秒杀他的气势。毕竟咱面的是普通开发,最后还得在人手底下做事呢~ 这种情况下最好的办法是面露一点点思考与回忆交加的表情,一点点说出对方希望你说出来的答案;而不是一股脑全说完了。当然了,不同的面试官有不同的套路,比如我最欣赏携程的一个初面面试官,能感觉到那是一个智商超群的人。和聪明人讲话,你就不用再拐弯抹角了。Anyway,假如这个面试官最后露出了满意的笑容,那就恭喜你成功了\n\n面试真的是个体力活,有两次我都想放弃了懒得再面了,让我继续坚持下去的除了有始有终的信念以外,还有照云兄一句“ 所谓自由就是随时拥有说’不’的权利。” 我理解就是给自己多一种选择。这一波面试下来,最遗憾的还是阿里几个想让我去的部门都在杭州,但我是上海人还要在交大在职读研。另外,上海的BAT Android岗位实在是太少了,腾讯基本就不在上海招。曾有冲动为了工作收起行囊就那么离家去杭州,但理智最终制止了我。阿里现在有点像软件界的华为,基本打来的电话都在晚上八点,有种血汗工厂的感觉。总体来说,上海的互联网公司规模都没成气候,还是中小企业居多。看了好几年上海互联网的起起落落,唯有”恨其不争“能形容这种感受了。PS:我最后选择了一份”钱多事少离家近“的工作:请不必问我现在何处,因为我一定会对公司和薪资守口如瓶。\n\n话不多扯,上文的各种体会是为了下文抛砖引玉。这个系列的文章除了全面,更重要的补全除技术以外的短板。比如,当一个面试官问你:**你的职业规划是什么**。相信每个面试者都被问过。\n\n大部分人的内心OS想必是:\nwhat,职业规划是什么? \nwhat,这个问题究竟有什么意义?\nwhat,我该怎么回答他?\n\n如果技术面过了,栽在这种问题上岂不吃亏?相反假如你答得好,却会为你的薪资增加筹码。其实这个问题究竟该怎么回答,要具体情况具体分析。首先要看这家公司处于它这个行业的什么位置,它未来的公司战略规划是什么,它想招进来一个怎样的人,它希望你发挥的是什么作用,坐在你对面的是app leader还是CTO 抑或是HR?都会有不同的最佳回答。因为每个人想听到的是不一样的“实话”,实话打引号表示经过包装以后的答案。\n\n关键就是你得理解这话背后的意思,面试官为什么要问这个问题呢,他想知道的无非是:\n\n1. 你会在这家公司呆多久?\n2. 你未来可能处于公司什么样的角色中。\n3. 你能否适应公司现有文化?\n4. 你能为公司发挥多少价值。\n5. 面试官还有自己的小算盘。\n\n如果坐在你对面的是app leader,你说你以后想做到这里的技术leader,那你一定是撞枪口上了,除非他就是要离职前招个leader进来。请注意这种情况是很有可能发生的。大多数面试官进来不会介绍他的职位,面试level 也未必和面试顺序正相关。这就好像在一个暗箱中博弈,通过察言观色和判断得到的信息是有限的,知己知彼你才能不出错,然后才是怎样最大化说出对方想听到的接近答案。\n\n## 面试前的准备\n\n- [长期准备:](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section)\n - [1. 订阅几个高质量的公众号](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-1)\n - [2. 加入一个本地android组织](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#android)\n - [3. 看几本必看的进阶书](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-2)\n - [4. 收藏几个博客,紧跟几个专家](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-3)\n - [5. 写自己的独立技术博客](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-4)\n - [6. 看源码](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-5)\n - [7. 提交自己的开源代码](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-6)\n- [短期准备:](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-7)\n - [1. 去NewCoder刷题](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#newcoder)\n - [2. 去极客学院阅读几本微书](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-8)\n - [3. 看几篇分析源码的文章](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-9)\n - [4. 梳理一下知识体系,找出薄弱环节](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-10)\n- [简历的准备:](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-11)[有几点](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-12)[千万别…](http://www.bingjie.me/2016/05/12/%E6%89%AB%E6%B8%85%E9%9D%A2%E8%AF%95%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87.html#section-13)\n\n有的时候我们在职场上会碰到各种各样的坑…… 不管是创业公司倒闭啦,新同事合不来啦,氛围太差受不了啦。如果说女人的安全感来自于独立,那么程序员的安全感就是手中有技术,心中有源码。想飞得更高,有哪些是你平时可以做的呢?\n\n本篇接上一篇 [扫清面试障碍](http://www.bingjie.me/2016/05/08/%E6%89%AB%E6%B8%85Android%E9%9D%A2%E8%AF%95%E9%9A%9C%E7%A2%8D.html)。上篇主要抛砖引玉,提到了许多技术和非技术相关的面试技巧等。本篇讲述面试前的准备,这不仅是技术实力的积累,还有相当一部分软实力的积累。即使是暂时没有跳槽想法的技术人,也应当生于忧患之中。行业的发展非常迅速,逆水行舟不进则退。危机意识很重要,厚积薄发才能更上一层楼。\n\n友情刺激大家: [《高二Android大牛是这样炼成的》](http://chuansong.me/n/329510551337)\n\n面试前的准备可分为长期准备,和短期准备。首先声明,文中提到的书籍以及公众号,博客等,都是我自己觉得特别优秀的,绝没收任何广告费\n\n### 长期准备:\n\n#### 1. 订阅几个高质量的公众号\n\n很多大厂都有自己的微信订阅号,很多人的阅读时间非常琐碎,那么你就可以在地铁上、在等公交车的间隙去刷刷最新技术的发展。订阅号贵精不贵多,某个订阅号里的文章一天也最多一篇,不然就容易粗制滥造。这里推荐几个高质量的android公众号: \n\n腾讯Bugly: weixinBugly。\n\n\n\n是[腾讯bugly](http://www.bingjie.me/2016/05/12/bugly.qq.com),专门做性能监控的平台,里面的文章也都是总结bugly bbs上企鹅工程师文章的精华。发送频率很低,质量都不错。后期面试中很多关于内存泄漏的答案都来自于此。\n\n移动开发前线:bornmobile。info主编徐川个人的微信公众号,里面的文章有原创也有很多精华集锦。关键是都比较严肃,不像某些个人公众号发展到后期变个人的独白段子手,干货也多,由于大都是搬很多个人博客和采访,所以质量还不错。\n\nAndroid程序员:androidtrending。公众号所有者应该是汤涛。虽然Android技术公众号不少,个人感觉这个公众号是比较能紧跟潮流的。也没有什么废话而是纯技术。\n\n程序媛:programgirl。一个程序媛发声的平台,更新不定期,`欢迎所有女程序员都来投稿,投稿地址:chaojimiaomiao@qq.com`. 比如本期android面试就会连载在里面。\n\n#### 2. 加入一个本地android组织\n\n大学时期我开始沉迷于android技术,但当时不善社交自命清高,往往是孤军奋战。回过头看,一个人的力量是有限的,只有交流才能进步,闭关锁国是没前途的。结识一批有同样追求的同行,甚至有很多比自己厉害许多的专家人才,你才能看到你未来努力的方向。人外有人,天外有天,千万别做井底之蛙。信息时代信息的交换是有价值的,小伙伴们一起努力也会将你带入一个好的氛围。\n\n但是要谨慎地选择伙伴。我知道男生聚在一起最容易犯的错误是互相影响,比如大家一起去打一盘游戏啦,各种吹牛或恭维啦,,这些都是不可取的。低调而务实的小伙伴们聚在一起才有创造力,你们共同完成一个梦想一件事。\n\n这里举个例子,https://github.com/LittleFriendsGroup/ 里的AndroidSdkSourceAnalysis。 他们发起了一个开源项目:18天认领android源码解析。这就是共同进步共同成长的典型呐~ 朋友应当是志同道合的,而非没目标的乌合之众。\n\n#### 3. 看几本必看的进阶书\n\n市面上入门书籍泛滥,而适合中高级的主流技术书实在太少。一方面是能写这种书的大牛懒得写,据我所知每卖出一本技术书,作者才拿到4块钱稿费。而中高级的受众面毕竟窄,即使热卖,卖出一万本,那么所拿稿费也不过是4万。然而有这种水平的开发者根本不缺这几万块钱。写书是一件特别耗费精力的事,除了内容还要排版,吃力不讨好。更何况还会面临盗版横行的情况,就更不值了。写书仅剩的吸引人的价值,恐怕是成书后带来的名声与成就感。由于这种客观情况的存在,市面上粗制滥造的书实在太多,我在此帮大家剔除糟粕,列举几本我觉得值得的书。\n\n**推荐书单:**\n\n**《Android开发艺术探索》任玉刚**\n\n业界良心!里面的很多东西面试都被问到了!\n\n\n\n**《App研发录》包建强**\n\n[App研发录](https://read.douban.com/ebook/16178944/):架构设计、Crash分析和竞品技术分析。这是一本非常务实的书,书里提到的内容都可以直接拿来用在项目上。这个作者原先是搞.net的,工作十多年经验非常丰富。\n\n摘录一段读后感:\n\n> “落地”,是阅读此书的最大感受,大到技术架构、竞品分析、发布流程,小到每个Crash、员工座位安排、开展技术分享、简历筛选,作者总在寻求落地的解决方案,细细阅读,你不觉得这种方案有多么高大上,不觉得背后有多么华丽的理论支撑,但是你会觉得,一切都是踏踏实实、真真切切可落地实践的,为工作带来不少的实践指导。\n\n**《Android内核设计思想》**\n\n这本书写得很深,基本是这三本书里最接近底层的书了,读起来也比较晦涩。需要有一定的理解能力。\n全书从操作系统的基础知识入手,全面剖析进程/线程、内存管理、Binder机制、GUI显示系统、多媒体管理、输入系统等核心技术在Android中的实现原理。书中讲述的知识点大部分来源于工程项目研发,因而具有较强的实用性,希望可以让读者“知其然,更知其所以然”。全书分为编译篇、系统原理篇、应用原理篇、系统工具篇共4篇22章,基本涵盖了参与Android开发所需具备的知识。\n\n#### 4. 收藏几个博客,紧跟几个专家\n\n有一阵我很迷茫,不知道继续进步的方向,也不知道我能达到什么样的程度。我甚至因为找不到安卓上进步的空间而横向求索,玩了一年的iOS开发。就在这时,我的偶像来了。偶然间一次搜索,翻到了 hukai.me。(当然发现作者长得帅也是一个激动的原因)\n\n原来安卓还可以这么玩~!可以像胡凯一样紧跟谷歌的最新视频教程并翻译它们。 也可以像 [代码家](http://www.bingjie.me/2016/05/12/daimajia.com) 那样写控件造轮子。代码家甚至因为轮子造得好而被谷歌发现,发出了工作邀请。\n\n具体你可以关注哪些安卓的优秀博客可以见 [这个链接](https://github.com/chaojimiaomiao/androidBlogCN):\n\n博客地址 \n\n- [柳志超博客](http://liuzhichao.com/) \n- [代码家](http://blog.daimajia.com/) \n- [胡凯](http://hukai.me/) \n- [禅](http://www.bingjie.me/) \n- [Trinea](http://www.trinea.cn/) \n- [方杰](http://blog.fangjie.info/) \n- [技术小黑屋](http://droidyue.com/) \n- [程序亦非猿](http://yifeiyuan.me/) \n- [脉脉不得语](http://www.inferjay.com/) \n- [陈启超的博客](http://chenqichao.me/)\n\n#### 5. 写自己的独立技术博客\n\n见贤思齐焉。\n\n有了那么几个专家榜样,我的视野突然变开阔了,也想变成像他们一样厉害的人。这个时候你已经阅读了几本书,也有了一定的积累,自然而然也会想发表自己的看法和见解。\n\n总之,克服瓶颈期的最好的办法就是六个字——总结、归纳、演绎。把你的收获都写到自己的博客上吧。最好是独立的博客,一方面你会收获到折腾独立博客的乐趣,另一方面它也是你的个人品牌,假如你能长期积累、坚持的话。独立博客唯一的缺点是导流。当然,你对自己的技术总结,目标是为了精益求精,为了自己的进步成长,至于读者多不多,倒是其次的。这个后期在面试中也大有裨益。别人刚认识你的时候对你不了解,你扔出一个博客地址,胜过你的千言万语。\n\n没事的时候就去写写博客吧,记住__不要写很多生活琐事__,而是__记录进步__。别人不是为了看你的个人秀而来到你的空间,而是搜索到你对技术新的见解,觉得对他可能会有帮助才过来的。牢骚什么的,写到你的社交网站上去。\n\n有的人很勤奋,博客天天更新。有量而没有质,感觉很空虚。我主张坚持精品博文才是正道,,毕竟信息已经那么泛滥了,不要再为互联网制造过剩的垃圾辣。。。(真的不是教你懒) 想要写一个优秀的博客,不仅要有实际的项目积累和广泛的阅读积累以外,uml类图,流程图,顺序图等,也是你必不可少的好助手。假如再加上__思维导图__,不仅使你的思路更清晰,读者也能一目了然,有一个全局观。现在就开始试试这些工具吧,会让你的博客更严谨更正式,更熠熠生辉。\n\n#### 6. 看源码\n\n这里列举几个你必须要看的源码:\n\n- Binder\n- LruCache\n- Handler\n- AsyncTask\n- EventBus\n\n不要怀疑,这些在面试中一定会被问到的。前期你看过源码也会淡忘的,先有一个大致的印象就行。\n\n#### 7. 提交自己的开源代码\n\n写什么样的开源代码,有这么几个方向。\n\n一是你博客中的例子。一个好的技术博客不仅有图有文字,假如有例子,更胜过苍白的自然语言。百闻不如一见,说得再多也不如实际一个例子。\n\n二是自定义的控件基础库。这个主要集中在酷炫的动画,还有交互更简洁的自定义控件上。这方面的大牛比如很多国外的库,还有国内代码家博客上提到的开源库~\n\n三是有关测试方面的工具。像leakCannary, blockCannary等,能让开发者更好地测试内存卡顿泄漏等。\n\n四是一些反编译的工具。\n\n五是一个完整的上架作品。\n\n### 短期准备:\n\n#### 1. 去NewCoder刷题\n\n这个网站主要包括了几套公司真题,比如有 [Android的](https://www.nowcoder.com/contestRoom?mutiTagIds=642),[算法讲解](http://www.nowcoder.com/live/2),[数据结构](http://www.nowcoder.com/review#3)。\n\n有时间的可以去上面刷刷题,题量较大\n\n#### 2. 去极客学院阅读几本微书\n\n没时间阅读厚重的大部头怎么办?有一些不出版的非纸质微书也是极好的选择。极客学院有[几个系列](http://wiki.jikexueyuan.com/list/android/) 写得不错,比如《深入理解 Android 卷》系列,《Java 集合学习指南》等。\n\n做工程的开发者容易陷入埋头写代码的怪圈,实际上多看一些技术书,吸收别人的思想精华进步会更快。\n\n#### 3. 看几篇分析源码的文章\n\n在长期准备中,你已经接触过一些源码了;当然你可能跳槽时间比较紧,那不如关注一下这个开源项目吧,里面包括了大量的 android源码分析。\n\nANDROID SDK 源码解析:[AndroidSdkSourceAnalysis](https://github.com/LittleFriendsGroup/AndroidSdkSourceAnalysis)\n\n如果你有时间,你也可以参与到这个项目中去。\n\n#### 4. 梳理一下知识体系,找出薄弱环节\n\n总结、总结,再总结。\n\n总结是一个人非常重要的品质,在总结中思考自己的不足,完善自我。不仅适用于面试,也适用于职场,日常生活等等。常思考,才可能变成一个智慧的人。\n\n具体有哪些可能的薄弱环节,可以看下一篇整理的30个发散性问题。\n\n### 简历的准备:\n\n写好简历也是一个重要的环节。程序员最好常备一份简历,以备不时之需。另一方面,更新简历的过程中也会明白,哪些经历是无用功,哪些是加分项。\n\n#### 有几点\n\n1、尽量避免主观表述,少一点语义模糊的形容词,除非是大公司大牛,已经有成果撑腰,否则慎用「熟悉…」、「使用过…」\n\n2、多一点表意清楚,语气肯定的数量词、名词、成果描述。一定要将自己的优势和期望明晰地表达出来,便于招聘方能对候选人有更准确的定位:\n\n- 介绍技术:最近几份工作经历中所参与过的产品、项目、角色\n\n- 在工作中做的项目的技术细节\n\n- 克服过的技术难点与细节\n\n- 感兴趣的技术\n\n- 在程序马拉松上参加的项目或者是业余的个人项目(+link)\n\n- 如果领导过技术团队,写下带的团队的规模与管理风格\n\n- 介绍自己:过往有特点经历、擅长的方向、对互联网的理解、职业发展规划\n\n3、突出重点。重要的放前面,不重要的经历往后排。尽量注明每段经历的时间,不然技术官或hr会一头雾水。比如你面试 Android开发,iOS的经历就放后面一笔带过,另外时间越远的优先级也越低。对了,记得把联系方式写在开头,不然对方联系不到你,可就把你忘了。\n\n3、试试用markdown语法,注意下排版,预览再提交,版面整洁、干净,也是加分项。\n\n4、HR/技术负责人更喜欢看到一份显示「职业上升趋势」的简历。比如你做开发五年,跳过两三次槽。那么你的职位,你所做的技术难度应当是越来越具挑战,而不是依然罗列各种琐碎的需求实现。\n\n5、牛人讲结果,普通人讲过程。话虽如此,你只要不太啰嗦,该列出的事情还是要列出来的。不仅如此,你在该项目中发挥了什么作用,有什么反思,也可以写出来。记住,你出卖的不仅是技术,还有能力。\n\n#### 千万别…\n\n1、真实的反映你的工作,别浮夸。\n因为你的面试官之后一定会问起浮夸的事情,假如你不能自圆其说,会留下非常不好的印象。\n\n2、记得最好不要出现“**精通**”等词汇。\n很少有人能精通JAVA,精通数据库,这样的字眼基本等于自杀。好的办法是阐述事实。比如用JAVA开发过什么系统,在什么项目中深入接触数据库等等。\n\n3、简历上的所有技术,你必须谙熟于心。\n甚至你应当练习几遍,找出可能发散出去的所有问题。只有你非常熟悉,并且在面试中足够自信,你才有能力引导面试官问到你想要的坑中。\n\n4、简历长度不要超过三页。最好是两页这样一目了然,当然如果从业经历比较长,也可以多写点。\n\n5、别撒谎。天下没有不透风的墙。假如你不想让人知道什么,你可以不写;假如你在原公司的锻炼机会太少,那么你可以将经历写到自己的开源项目中去。\n\n## 三十道android开放题\n\n为姗姗来迟的安卓面试题表示抱歉。\n大家可以先思考一下这些问题,答案会过一阵在后文放出。\n\n### 基础题\n\n- Activity生命周期和启动模式,以及使用场景\n\n- Service的生命周期,如何启用/停用Service\n\n- 可能导致OOM内存溢出的情况有哪些,怎么解决\n\n- Android中的动画有哪几类,它们的特点和区别是什么\n\n- 注册广播几种方式\n\n- 如何自定义View\n\n- 程序crash的所有可能原因\n\n- android动画\n\n- Android操作系统分层\n\n### 中级题\n\n- Android事件处理机制\n\n- 内存泄露的案例\n\n- 图片加载库的使用及比较,内在逻辑分析\n\n- 网络库的使用和比较\n\n- android线程间通信\n\n- android进程间通信。Binder源码与Looper关系等\n\n- 设计模式在android中的应用,手写几个典型模式\n\n- annotation 以及java反射机制\n\n- Java虚拟机\n\n- Java几种线程池\n\n### 高级题\n\n- 热修复技术,原理及其应用\n\n- react native\n\n- 几种架构模式\n\n- 新建一个工程,需要加入哪些库和模块,该怎么设计\n\n有关测试: \n\n- DDMS + MAT\n- monkey test和logcat命令的常用过滤参数 \n- android作优化有哪些可以考虑的方向?\n\n### 开放题\n\n- 当我在浏览器中输入一个url,世界发生了什么。\n\n- http和https的区别\n\n- 几种加密方式区别,对称与非对称。\n\n- 你还了解什么其他的语言?和Java对比一下。\n\n> 原文链接:冰洁的技术博客,http://www.bingjie.me/"
},
{
"path": "docs/android/Android-Interview/经验分享/技术硬碰硬—阳哥带你玩转上海Android招聘市场.md",
"content": "# 1. 挑战公司No.1:上海创梯信息科技有限公司\n\n公司地址:上海杨浦区昆明路1209号尚凯大厦副楼504室\n\n面试时间:5月12日 10:00 AM.\n面试结果:顺利砍下Android技术总监,15K offer\n面试过程:\n10:00 到公司,前台MM给了张面试人员登记表,10分钟搞定表格。\n10:30 由于公司BOSS正在面试其他人,因此,又等了几分钟。\n10:40 在BOSS办公室与BOSS斗智斗勇,聊了有接近1个小时。\n\n疯狂的笔试+面试记录(前方内容“高能”:funk:,请准备高度精神集中前行):\n\n## 1. 笔试\n\n由于BOSS正在打造公司新业务,刚刚开始组建公司技术团队,公司没有人懂IT技术,故本次面试没有笔试题,额\n\n## 2. 面试过程问答精选:\n\n旁白:进入办公室后,我淡定等待,约莫几分钟后,一位35岁左右,看起来非常老道的BOSS走了进来。几句寒暄之后,问了我一些关于我的学校、专业、工作经验、接触的Android项目等普通流水线式的没有营养问题,轻松搞定!接着,BOSS终于切入到了重点:\n\nBOSS问:其实我们想做一个快递业务的APP,类似于滴滴打车。用户如果想要寄快递,只需要打开APP,查找附近都有哪些快递员,然后直接跟附近的快递员联系。如此,既能方便用户,又能提高快递员的收入。\n\n我(阳哥)答:我有一个问题想要问一下,咱们公司(注意,一定要说“咱们”,让别人感觉你已经融入他们的公司团队了)不像顺丰,不是典型的物流公司,为什么我们要做快递类的APP呢(主动沟通交流,有问题就问,这样面试官才能跟你聊起来!)?\n\nBOSS答:你知道的那些物流公司现在都是各自为政。例如,你用顺丰快递,你可以下载个顺丰的APP。但是,你以后可能还要用中通、申通、圆通等等这些物流公司,难道你要下载十几个APP吗?而我们要做通用的快递类APP!\n\nBOSS问:你知道一个APP重要的是什么吗?\n\n我(阳哥)答:用户体验!\n\nBOSS说:不对,是流量,也就是用户数量(好吧,阳哥作为技术屌丝,关注多的就是APP用户体验,所以,不敢去反驳他,先顺着他的意思来)。\n\nBOSS问:如果让你去做一个类似于滴滴打车的APP,你认为自己做的出来吗?\n\n我(阳哥)答:像滴滴打车这样的APP,不仅仅只是客户端的问题。它不是由几个简单的客户端程序员就能做出来的,实际上,它应该是由一个技术团队完成的大型项目。您目前能够看得见的仅仅是用户客户端,看不见的是庞大的后台系统。说详细点就是:滴滴打车这样的项目应该分3部分:服务器端,用户客户端,出租车司机客户端。服务部端考虑的是数据的存储,业务的调度处理,以及与各个客户端的数据交互。而用户客户端我个人理解主要是一个UI的显示和与用户数据交互的功能。比如,用户将自己的当前坐标发送到服务器端(当前坐标可以通过百度地图、高德地图获取),服务器根据用户的坐标查找附近的所有空闲状态的出租车,然后将用户的用车需求推送到出租车司机客户端端。出租车司机接收到信息后,如果愿意接这笔单子,就向服务器发送同意信息。服务器就是作为一个中介将用户与出租车司机联系起来。大概逻辑就是这样一个过程,中间的技术细节比较多。总之,一个人做滴滴打车是不太现实的(大家可以看出来,这一段,阳哥是傻瓜式教学,没有说的太复杂,好让BOSS能够听明白。不然,技术说的太深,BOSS就不知道说什么了,还怎么聊的开心。面试的最终目的就是让对方觉得看你很顺眼,这是关键!)。\n\n(顺便啰嗦一下,黑马的Android课程中有部分JavaWEB课程。我们做为APP开发人员,不管是服务器端还是移动端都应该有所了解。如果仅仅会移动端开发技术而不懂服务端知识,长久看来,确实会很影响Android程序员向更高层次发展。)\n\nBOSS问:那么,如果我让你负责客户端的开发呢?\n\n我(阳哥)答:客户端Android开发并不难,比如支付宝是一个很强大的金融系统。但是,你让我做它的Android端开发,我感觉我没问题。毕竟,Android客户端重点是信息的展示和与用户的交互。所以一个人做客户端是没有问题的。但是,目前市场上的企业很少有一个人做一个客户端项目的。市场竞争如此激烈,一个人做耗时太长,可能你还没有做出来,产品已经被淘汰了。因此,应该多招几个Android程序员,这样团队就算有人员流失也不会影响整个公司的发展(展示自己对于项目组人数把控的个人看法)。\n\n旁白:几轮PK下来,BOSS基本上对我已经很信服了。\n\nBOSS说:其实,在面试你之前,我已经招聘到了两个移动开发的程序员,一个是Android程序员(6K),一个是iOS程序员(8K),你可以看一下他们两个的面试登记信息和他们的简历。\n\n我(阳哥)问:根据这两份简历可以看出来,这两个人的技术有些一般(不是装逼,他们的简历写的确实有点LOW)。\n\nBOSS问:是的,我看的出来,你的经验要比他们丰富地多。所以,我准备让你出任我们公司的技术总监,带着他们两个做客户端开发,你认为你有信心做好吗?\n\n我(阳哥)答:这个职位我以前没有做过,所以心里没有多大的底(阳哥认为这样的问题确实比较考验人,你直接回答“可以,没问题”,就会显得你浮夸、不谨慎、办事不牢靠。如果你直接回答“不能”,又显得你不敢担当,没有上进和挑战的精神。因此回答这样的问题必须两者兼顾,既要谦虚谨慎又要表现出富有挑战精神)。\n\nBOSS说:我知道你没有做过,但是,一个人挑战任何一样新工作之前都是没有做过的。你有没有想过一旦你能够胜任我们的公司的技术总监,你以后的身价将和现在完全不同,所以,对自己要有一些信心(BOSS故意画大饼,就说明你有戏了!)。当然,这是一个管理岗位,需要什么样的技术人员你可以招。\n\n我(阳哥)说:好吧,其实我希望挑战一下,但是我不一定能够达到您对我那么高的期望(始终保持谦虚的态度很重要!你的态度决定别人对待你的态度!)。\nBOSS问:你尽力就好,请问你的期望月薪是多少?\n\n我(阳哥)答:15k(第一次面试,我心里也不太清楚上海的市场,15k一般是黑马班里的大神级同学要的薪资,所以,试水一下)。\n\nBOSS说:好的,没问题(竟然没有砍价:L,额,土豪公司)。\n\n旁白:随后,阳哥又和BOSS聊了一些其他内容,由于BOSS马上要开会,就告诉阳哥如果你同接受我们的邀请,那么我希望我们明天下午可以好好聊聊。。。。之后,一堆寒暄,不列出来了。虽然,第一家面试就这样结束了,没有技术上太多的PK。但是,却使阳哥在精神上却得到了巨大的鼓励,面试第二家上海公司有了更大的信心!\n\n## 面试吐槽\n\n阳哥的上海处女面就这样丢掉了!遗憾的是BOSS不太懂技术,没有碰撞出技术的火花。但是,让人幸运的是他提供给我了一个技术总监的岗位。整个过程可以看到,面试的时候,面试官一方面会明中考察我们的技术。另一方面,在暗中实际上也在考察我们的沟通能力、思维逻辑能力、管理能力等这些软实力。所以,黑马的每一位达人,在黑马拼命码代码的同事,别忘了多和你的小伙伴分享技术,不要忘记中午的时候抓住每一次的公开演讲机会。有时候,一个人综合实力远大于单纯的技术竞争力!加油吧,骚年们!\n\n# 2. 挑战公司No.2:上海复深蓝信息技术有限公司\n\n公司地址:上海市徐汇区漕河泾开发区虹梅路2007号1号楼\n\n面试时间:5月12日 14:00 PM.\n面试结果:顺利砍下Android工程师,17K offer+1K补助 = 18K 月薪:victory:\n面试过程:\n\n14:00 到公司,前台MM给了一张面试登记表和一张Android笔试试题,然后一位和蔼的大叔(技术大拿)将我带公司接待处,让我开始笔试。\n\n14:20 笔试完成,笔试很简单,做完后把试题交给前台,前台帮我联系面试官。\n14:25 跟一个年龄大概在25~30岁之间的年轻技术官进行了接近1个小时的面试(通过交谈阳哥感觉面试官应该是项目经理或者开发组组长)。\n\n15:20 人事面试,人事面试后提前跟我说CTO会对我进行一个电话复试。\n\n第二天晚上大概19:00,公司CTO对我进行了技术复试,总共持续了31分钟。电话复试题要比初试难的多了,姜还是老的辣。我把复试的对话录音保存下来了,作为以后上海黑马就业指导课程的案例讲解(内容何止“高能”,简直就是高达!)。\n\n疯狂的笔试+面试记录(前方内容“残酷”:funk:,请准备受虐心态前行):\n\n## 1. 笔试\n\n笔试时出现了一个小插曲,和大家分享一下。阳哥笔试所在的接待区是一个半开放式的区域,共有3张桌子,每张桌子上都有一支签字笔。我先用第一张桌子,发现笔是坏的(郁闷),然后换到第二张桌子,发现笔还是坏的(心想:尼玛,这么霉,顺便汗一下),最后只能换到第三张桌子,你猜怎么滴,对,笔还是坏的(想要骂娘了,FUCK!)。没辙了,翻遍我的背包,自己也没带笔。难道企业是用这种方式考察一个应聘者的吗?这怎么办?\n\n我想去前台借吧,前台肯定有(不要去人事那里借,前台毕竟只是前台,不会管你太多的细节,人事可就不一样了,他们会认为一个面试者来比试不带笔是极不严肃的表现)。热心的前台MM很乐意地把自己的笔借给了我(心里一阵暖啊!这家必须拿下!)。\n\n为了方便大家更清晰的看到笔试题目,阳哥手录笔试题和答案,看你能做对多少?!\nQ:Android的四大组件有哪些?\nA:Activity、Service、ContentProvider、BroadcastReceiver。\n\nQ:请描述下Activity的生命周期?\nA:onCreate、onStart、onResume、onPause、onStop、onDestroy、onRestart。\n\nQ:如何将一个Activity设置成窗口模式?\nA:将Activity的样式设置成:android:theme=\"@android:style/Theme.Dialog\n\nQ:如何退出Activity?如何安全退出已调用多个Activity的Application?\nA:调用Activity的finish方法可以退出当前Activity。可以自定义一个Application,在Application中声明一个成员变量ArrayList用于存放打开的Activity,当退出时遍历ArrayList,依次调用Activity的finish方法。\n\nQ:请介绍下Android的五种布局。\nA:LinearLayout、RelativeLayout、FrameLayout、RelativeLayout、TableLagout\n\nQ:请介绍下Android的数据存储方式。\nA:SharedPreference、XML、SQLite、文件系统\n\nQ:DDMS和TraceView的区别。\nA:DDMS 的全称是Dalvik Debug Monitor Service,是 Android 开发环境中的Dalvik虚拟机调试监控服务。TraceView是程序性能分析器\n\nQ:说说Activity、Intent、Service以及他们之间的关系。\nA:Activity负责界面的显示和用户的交互,Intent封装了数据,可以实现Activity之间以及Activity和Service之间数据的传递。Service运行在后台进程,一般我们会让给其运行一些后台任务,Activity通过StartService(Intent)或者BindService(Intent)可以启动Service。\n\nQ:请介绍一下ContentProvider是如何实现数据共享的。\nA:我们可以定义一个类继承ContentProvider,然后覆写该类的insert、delete、update等方法,在这些方法里访问数据库等资源。同时将我们ContentProvider注册在AndroidManifest文件中,其他应用需要使用的时候只需获取ContentResolver,然后通过ContentResolver访问即可。\n\n## 2. ROUND 1:PK项目经理技术面试问答精选\n\n项目经理问:Activity都有哪些生命周期?\n我(阳哥)答:这个问题其实在笔试题中我已经给出答案了(此时,阳哥表示非常疑惑~)。\n项目经理说:我知道,你再说一遍。\n\n旁白:当时阳哥我真没搞明白,为何笔试上的题目他还是问我一遍,而且笔试上的好几道题他都重复问了一遍。现在想想应该是他怀疑我笔试的时候作弊了,比如我可以百度什么的。好吧,我不就是笔试的时候出去跟前台妹子借了一支笔,然后又把笔试题给拍了个照片而已嘛。而且,我那3G的联通定制机安装的移动4G的卡,只能享受2G的网速,我打开个百度都得几分钟。算了,不能和面试官较劲!我忍!\n\n我(阳哥)答:Activity有以下生命周期回调方法,比如常用的有onCreate、onStart、onResume、onPause、onStop、onDestroy、onRestart。默认情况下,如果我们不给Activity设置横竖屏配置信息的话,在横竖屏切换时会将一个Activity销毁掉然后重新创建。\n项目经理问:Fragment你用过吗?\n\n我(阳哥)答:这个当然用过呀。现在的应用中基本都有Fragment的应用,Fragment比较小巧灵活。\n\n项目经理问:那Fragment跟Activity之间是如何实现值传递的?\n\n旁白:其实项目经理在问我会不会Fragment的时候,我已经预料到接下来会问我Fragment跟Activity直接的值传递问题。对于前面的问题,如果我说不会,就不会有下面的问题,但是如果说不会的话,那么项目经理很可能因为这一个问题而把我PASS掉,因为Fragment是Android中一个非常重要的知识,这个是必须会的(黑马的Android基础课程中有一天就是讲Fragment的)。如果连这个都不会,那么再好的面试技巧也挽救不了同学们的!\n\n我(阳哥)答:Activity可以先获取FragmentSupportManager或者FragmentManager,前者是v4包下的,向下兼容因此用的比较多。然后这些Manager通过Fragment的tag或者id调用findFragmentByTag(\"tag\"),findFragmentById(\"id\")找到我们需要的Fragment对象,然后通过调用Fragment对象的方法来进行值的传递。\n\n项目经理问:Android中都有哪些组件需要在清单文件中注册?\n\n旁白:四大组件是学习Android的必会知识点,也是黑马Android基础中的重点内容,因此这个问题同学们其实应该是很好回答的!\n\n我(阳哥)答:一般来说四大组件都需要在AndroidManifest.xml中进行注册,不过其中Activity、Service、ContentResolver是必须注册的,而BroadCastReceiver可以在清单文件中注册,也可以不注册,这也分别叫做静态注册和动态注册。\n\n旁白:在Android中一般通过XML文件注册的组件,我们叫静态注册,而通过代码注册或者创建的组件我们叫做动态注册。动态注册和静态注册这两个名称听起来很高大山,其实理解起来so easy滴!\n\n项目经理问:你自己有做过自定义控件吗?\n\n我(阳哥)答:自定义控件做过,比如我们项目中的SlideMenu,LazyViewPager,Pull2RefreshListView,VerticalSeekbar,RandomLayout等都是自定义控件。\n项目经理问:那你说说View的绘制过程?\n\n我(阳哥)答:View绘制是从根节点(Activity是DecorView)开始,他是一个自上而下的过程。View的绘制经历三个过程:Measure、Layout、Draw。\n\n旁白:黑马的老版本课程体系中有2天的自定义控件,在这两天课程中同学们能够学会SlideMenu,Pull2RefreshListView,优酷菜单等自定义控件,目前的黑马课程又对自定义控制进行了加强,添加了多种QQ5.0新特性内容,当然难度其实也不小。\n\n项目经理问:ListView你们应该有用过吧?\n\n我(阳哥)答:这个在我们的项目中应用的很多,其实在如今所有流行的App中,ListView都有一个大量的应用,说ListView是一个使用率高的控件都不为过。\n\n项目经理问:ListView的优化你们是怎么做的?\n\n我(阳哥)答:ListView的优化有多种多样的策略。在我们的项目中主要做了如下优化。1、重用ConvertView,2、给ConvertView绑定ViewHolder,3、分页加载数据,4、使用缓存。前两个是通用的解决方案,后两个是针对我们业务的个性化解决方案。我们的数据来自服务端,如果服务端有1000条数据的话,我们客户端不可能傻瓜式的一次性用ListView把这些数据全部加载进来,因此我们就用分页加载数据,每次加载20页,当用户请求更多的时候再获取更多数据,网络的访问就算网速再快也多多少少会有一定的延迟,因此我们的网络请求是异步处理的,同时从网络加载来的数据使用了2级缓存来处理,第一级是内存级别的缓存,第二级是本地文件的缓存。当ListView加载数据的时候首先从内存中找,如果找不到再去本地文件中找,只有都找不到的情况下才去请求网络。\n\n旁白:ListView的优化是黑马课程一个重要的知识点,因此大家上课的时候这个必须得学会,不然在以后的面试中肯定会栽跟头的。\n\n## 3. ROUND 2:第二轮PK CTO(非人类)技术面试问答精选\n\n旁白:第二轮技术复试是在第二天晚上7点时开始的,当时,阳哥我刚从外面面试完回到家中。跟我聊的是他们公司的CTO,通过聊天也能感受到他的技术非同寻常,前几个问题问我时感觉多方有种咄咄逼人的气势(貌似面试的人太多了,对于被面试人员都是不屑的口气)。不过几轮技术PK后,发现原来CTO对人类也可以这么温柔和气的(尼玛,技术好才能被人看得起啊!心底话!)。\n\nCTO问:说说你对泛型的了解?\n\n我(阳哥)答:泛型是jdk5.0版本出来的新特性,他的引入主要有两个好处,一是提高了数据类型的安全性,可以将运行时异常提高到编译时期,比如ArrayList类就是一个支持泛型的类,这样我们给ArrayList声明成什么泛型,那么他只能添加什么类型的数据。第二,也是我个人认为意义远远大于第一个的就是他实现了我们代码的抽取,大大简化了代码的抽取,提高了开发效率。比如我们对数据的操作,如果我们有Person、Department、Device三个实体,每个实体都对应数据库中的一张表,每个实体都有增删改查方法,这些方法基本都是通用的,因此我们可以抽取出一个BaseDao,里面提供CRUD方法,这样我们操作谁只需要将我之前提到的三个类作为泛型值传递进去就OK了。而数据的安全性,其实程序员本身通过主观意识是完全可以避免的,何况某些情况下,我们还真的想在ArrayList中既添加String类型的数据又添加Integer类型的数据。\n\nCTO问:你知道Java的继承机制吗?\n\n我(阳哥)答:知道呀,这个问题很简单呀!java是单继承多实现呀。\n\nCTO问:那你知道java为何这样设计吗?\n\n旁白:从上面的问题也可以看出越是资历老的程序猿越喜欢刨根问底,因此如果同学们面试的时候遇到一个年龄稍微大点的程序员,那么一定要提前做好思想准备了,他可能先问你一个看似很简单的问题,然后再追问一个很深的思想或者原理。\n\n我(阳哥)答:为何Java这样设计,其实这也是我一直的一个小疑惑。不过我是这样理解的。我只能用反证法,如果一个类继承了类A和类B,A和B都有一个C方法,那么当我们用这个子类对象调用C方法的时候,jvm就晕了,因为他不能确定你到底是调用A类的C方法还是调用了B类的C方法。而多实现就不会出现这样的问题,假设A和B都是接口,都有C方法,那么问题就能解决了,因为接口里的方法仅仅是个方法的声明,并没有实现,子类实现了A和B接口只需要实现一个C方法就OK了,这样调用子类的C方法时,Java不至于神志不清。从另外一个方面考虑的话应该就是Java是严格的面向对象思想的语言,一个孩子只能有一个亲爸爸。\n\nCTO问:Java的异常体系你知道吗?\n\n我(阳哥)答:知道呀,顶层是Throwable接口,往下分了两大类,一个RunntimeException另一个是普通的Exception。\n\nCTO问:那你知道这两类异常的区别吗?\n\n我(阳哥)答:当然知道,java的命名是见名知意的。从名字上我们也知道RunntimeException就是运行时异常,在运行的时候才能被jvm发现导致程序的终止,而普通Exception必须进行try、catch处理,或者在方法上用throws声明。\n\nCTO问:那你的期望薪资是多少?\n\n我(阳哥)答:我期望的薪资已经给贵公司人事说过了,是17k。\n\nCTO问:你这么年轻,就想要到17k呀!\n\n我(阳哥)问:对的,我是还年轻,高中同样是学习3年,有的考上了重点大学,有的却只考上了个大专院校,甚至落榜,不同的人学习能力是完全不一样的,甚至可以用天壤之别来形容,因此如果只简单的用时间来衡量一个人的价值显然就是不太合理的,比尔盖茨跟我这样大年龄的时候已经是亿万富翁了,而我还在找17、18k薪水的工作(前面的问题已经回答的这么漂亮了,谈薪水的时候一定要表现出绝对的自信!)。\n\nCTO问:你说的对,不过我还得问你几个问题,你说你们项目中有用到图片吗?\n\n我(阳哥)答:这个当然有呀,我们新闻客户端基本上每条新闻都有图片,只有图文并茂的新闻才会有人看。\n\nCTO问:那你说你们遇到OOM异常吗?\n\n我(阳哥)说:这个前期的时候我们的APP确实遇到过这样的问题,不过现在新的版本早就吧这些问题给解决了。\n\nCTO问:那你们是怎么解决的?\n\n我(阳哥)答:OOM异常是Android中经常遇到的一个问题,程序员稍微不注意可能就导致其产生。因为Android的每一个应用都是一个Davlik虚拟机,该虚拟机的默认堆内存只有16M,远远无法跟我们的PC机比较,因此和容易导致OOM(Out Of Memory)异常的产生。导致这样的异常主要有以下原因:1、加载大图片或数量过多的图片,因为图片是超级耗内存的,2、操作数据库的时候Cursor忘记关闭,3、资源未释放,比如io流,file等,4、内存泄露。我们用用的OOM主要是加载图片导致的。因为后面的三种原因都是可以通过约束程序员的编码规范来进行预防,或者使用性能分析工具来检查。\n\nCTO问:好的,那你们的图片是怎么处理的?\n\n旁白:随后这就是CTO面试应聘者的一个习惯,他会追着一个知识点往死里问,直到问到系统的底层,或者他能理解的底。\n\n我(阳哥)答:图片的处理主要用两种方式。我们的应用中有两处用到了图片,一个是ListView中展示的图片缩略图,这种情况的特点是数量大,但是单个图片内存小,只有几kb,另外一种是大图片,就是用户通过手机拍摄的图片,然后通过http的post提交的方式提交到服务器上。然后在客户端将这个大图片也展示出来。对于第一种情形,我们是通过三种技术手段来解决问题的,一是图片的缓存策略,二是ListView的优化,其实在上面我已经讲过,三是WeakRefrence(弱引用)的使用。对于第二种情形,我们主要是首先通过BitmapFactory.Options参数获取图片的宽和高,然后再根据我们ImageView的宽高对图片进行一个很大比例压缩。\n\nCTO问:那你说说弱引用是怎么使用的?\n\n我(阳哥)答:WeakRefrence是一个类,在ArrayList中我们把这个类作为对象传递进去,把我们的图片放在WeakRefrence里面,这样当davlik虚拟机内存不够用的时候,就会把WeakRefrence对象回收掉,这样我们在WeakRefrence里面保存的数据也被回收了。\n\n## 面试吐槽\n\n阳哥在上海的第二面终于遇到懂技术的人,把笔试、技术一面、人事、技术二面一气呵成的通了个关,不拖泥带水,最终人事给了基本薪资17k+1k多补助的offer,这种感觉也许只有你经历过了才能体会吧!相信黑马学子经过四个月的刻苦磨练也能远远超过我的水平。加油吧,骚年们!\n\n这家公司所在楼有两层是高德地图的!\n\n阳哥冒死偷拍的笔试题!\n\n阳哥录用通知邮件!\n\n\n# 3. 挑战公司No.3:中阜投融资产管理股份有限公司---中投融\n\n公司地址:上海市静安区威海路228号招商局广场南楼21楼\n\n面试时间:5月12日 16:30 PM.\n面试结果:顺利拿下Android工程师,15K offer+1k住房补贴=16k:victory:\n面试过程:\n\n16:30 到公司,因为这一天安排了3家面试,这家本来是安排的16:00的,但是迟到了半个小时,不过企业招人都比较急,这个可以理解。\n16:30~16:40 填写面试登记表,这家没有笔试题,填完后坐在公司前台附件的沙发上等了几分钟,桌子上放了一盘水果糖,诱人,也不敢吃,哈哈。\n16:40~17:15 跟一位Android程序员进行第一轮PK。\n17:20~17:50 跟项目经理进行第二轮PK。\n17:50~18:00 跟人事谈薪资。\n\n疯狂的笔试+面试记录(前方内容“高能”:funk:,请准备高度精神集中前行):\n\n## 1. 笔试\n\n这一家没有笔试题,其实阳哥发现一个规律,一般Android开发团队刚刚组建的,或者Android开发人员不多的企业基本都没有笔试这一环节,这可能是他们公司的Android开发团队各方面还没有形成一套标准的流程原因吧。\n\n## 2. 第一轮技术面试过程问答精选\n\n旁白:面试我的哥们儿比较腼腆,也许是他也刚进公司没多久的缘故,好像才4个月的样子。他主要问了我都做过哪些Android项目,怎么学习的Android,都做过哪些Android控件,然后他又问了一个他们公司目前正在做的项目遇到的一个难题,问我怎么解决。\n\nPS:最后这个问题,阳哥感觉他并不是在考察我的技术,而是以请教我问题的态度在向我咨询了。面试能面到这种程度,基本已经有戏了。\n\n面试官问:介绍下你都做过哪些Android项目?\n\n我(阳哥)答:这自己主要做过3个项目,新闻类的,应用平台类的,手机管理类的,其中自己参与多也做的成熟的是新闻类的一款App。\n\n旁白:上面的三种类型的项目,都是黑马Android课程体系中的教案,因此介绍项目基本没压力。\n\n面试官问:那你在项目的开发中担任一个什么角色?\n\n旁白:这样的问题其实很多面试官都问我了,感觉被问到的概率有80%,此种问题显然是想考察我们的担当能力,技术担当和责任担当。在上海黑马66期的开班典礼上,我是这样给大家说的,我们66期有70多位同学,我们班分成10个小组,每个小组选出一名组长,组长负责全组的学习,组长不是固定不变的,每周考试一次,每次考试成绩高者为组长。每次考试如果这个组的平均分在班排名低的,组长得无条件接受惩罚。在黑马,没有个人排名,只有团队排名,我们更注重团队的协同能力,而不注重个人的表现。\n\n我(阳哥)答:我在这个项目中属于主要参与者之一吧,或者说是主要负责人,我们Android项目不像是javaweb项目那样需要大量的程序员,像我们的项目,总共2到3个程序员3个月功夫就能搞定,因此我们几个人也没有绝对的说谁领导谁。不过这样的项目,让我们任何一个人去开发都是很OK的,只是时间问题。\n\n面试官问:你们用什么代码管理软件?\n\n我(阳哥)答:SVN。\n\n旁白:在黑马有专门的一节课是讲SVN和Git的,并且后面的项目也是用SVN跟大家进行代码共享的。\n\n面试官问:你学习Android的途径都有哪些?\n\n我(阳哥)答:现在是互联网时代了,不像我们大学时代主要通过书本学习。在大学的时候选修的Java课程,那时候还是诺基亚时代,图书馆的移动开发书架基本是被诺基亚的塞班占据的。自己大学毕业的时候Android已经开始风靡全国了,那时候自己从网络上看到的Android开发的各种视频,然后开始学习的Android。自己在Android的开发中遇到的各种问题一般都是靠百度解决的,说度娘是好老师真不为过,其实也用过Google,不过被屏蔽了,也懒得翻墙,百度现在做的也不差,百度出来的Android技术主要来自如下专业网站,比如:CSDN、51CTO、ITEye、AndroidBus、EOEAndroid等,对了还有一个国外的没有被屏蔽的网站是Github,我们项目中的很多控件其实都是从Github上学习过来的。\n\n面试官问:那你从Github上都用到过什么控件?\n\n我(阳哥)答:Github上的开源项目非常的多,基本上你想用的东西都有,比如xUtils、HelloCharts、Clander、SlideMenu、SeatTable、LDrawer、SmoothProgress、Touch Gallery、ViewPagerIndicator。\n\n面试官问:你自己有做过自定义控件吗?\n\n我(阳哥)答:自定义控件做过,比如我们项目中的SlideMenu,LazyViewPager,Pull2RefreshListView,VerticalSeekbar,RandomLayout等都是自定义控件。哦,对了,最近我刚给我女朋友还做了一个HideSlideBar控件,我可以让你看一看。里面主要由VerticalSeekBar+ProgressBar+NineOldAnimation完成的。\n\n旁白:我把我自己做的自定义控件给他演示了一遍,这个是我女朋友项目中需要用的一个需求,她不会做,我帮她写了一个Demo,没想到正好用上了。\n\n面试官问:哦,不错,你这个动画用的是属性动画吧?\n\n我(阳哥)答:对的,这个属性动画,用了JakeWharton大神的开源框架。不过这个属性动画其实自己写也可以,内部原理比较简单,就是给控件设置一个开始位置,一个结束位置,设置一个延时时间,然后不停的更改控件的layout位置即可。\n\n旁白:这个东西在黑马的项目中都有讲解,回答不难,在Android应用中我们会用到很多第三发的框架,我们不仅仅要会用别人的东西还必须知道别人写这个东西的内部原理。\n面试官问:那好,现在我们有个项目遇到一个问题,你看如果让你做你应该怎么去解决?\n旁白:这时候,阳哥已经感觉到自己已经PK成功了。不过面试官性格也不错,遇到问题善于寻求外界的任何帮助。\n\n我(阳哥)答:可以的,什么需求您讲吧,我听听。\n\n面试官问:我们的项目中有多个Fragment,Fragment A跳转到Fragment B,Fragment B跳转到FragmentC,那么这时候我多次按返回键,如何能让Fragment跟Activity的任务栈一样,依次从FragmentC跳转到FragmentB,再跳转到FragmentA?\n\n旁白:这个确实是需要比较棘手的问题。其实面试官也知道你没有做过类似需求的开发,事实也是这样。这就比较考验临场发挥能力了。这种问题可以从模仿Activity任务栈考虑解决。任务栈是一种数据结构,我们可以自定义这种数据结构,然后管理这个数据结构,但是每个Fragment都是独立的,如何把这些独立的Fragment关联起来,这都是需要考虑的问题。\n\n我(阳哥)答:这个需求应该很好实现。我们可以这样,首先定义一个BaseFragment,让FragmentA、FragmentB、FragmentC都继承BaseFragment,第二在BaseFragment中定义一个ArrayList,每打开一个Fragment,把这个Fragment对象添加到ArrayList中,这样这个ArrayList就可以当做一个栈结构,第三我们需要设置返回键监听,当监听到返回键的时候,查看当前ArrayList中倒数第二个Fragment有没有Fragment,如果有则取出该Fragment并把ArrayList中末尾Fragment删除,然后用FragmentManager的Replace方法,将当前Fragment替换成最新Fragment即可,如果ArrayList中只有一个Fragment,且监听到了返回键,那就不对Fragment做处理,同时也不拦截该事件,这样也不会影响其他Activity之间的切换。\n旁白:回答了上面的问题后,面试官说他回去试试,然后就去叫他们的领导了。\n\n## 3. 第二轮技术复试过程问答精选:\n\n旁白:第二轮面试我的是个技术大拿,主要负责公司整个软件架构的设计,这家公司之前只有web端,全都是他干的,现在公司向移动端发展,因此最近一直在招Android和iOS开发人员,他不太懂Android,不然估计他一个人就能把一个Android项目搞定了。他问了我一些关于http、数据安全的知识,然后就开始跟我谈人生了,一直到他们快下班,他才把人事叫来跟我谈了谈薪资。\n\n经理问:你做的Android的项目跟服务器交互都有哪些接口?\n\n旁白:大家不要被接口这个词给迷惑了。这里的接口不是java中的接口类,也不是很高大上的东西,其实换成大白话就是你们的客户端跟服务端是如何实现数据的交互的。\n\n我(阳哥)答:我们的接口有多种形式,第一种是http的形式,客户端跟服务器通过http协议传输数据,比如我们的新闻列表的请求都是给服务器发送的get请求,然后服务器把数据发给我们,我们上传给服务的图片是通过http的post请求方式完成的。第二种是socket完成的,服务端开启ServerSocket,客户端开启socket,然后客户端跟服务端建立长连接,这样实现了客户端跟服务端数据的即时通信,通信的协议是我们公司按照xmpp开放协议的基础上修改的,其实xmpp协议就是一个xml格式的数据。第三种是集成了第三方接口,比如分享功能用的是ShareSDK,消息推送用的是JPush,内置广告用的是万普世纪。\n\n经理问:你们http传输数据的时候安全是怎么保证的?\n\n我(阳哥)答:我们的数据有些是需要安全设置的有些不需要,我们的新闻类数据不需要特殊的添加安全设置,而用户注册,用户登录以及用户隐私数据保存是考虑安全性的。用户的密码等信息肯定不能进行明文传输的,我们将用户的密码在本地进行了MD5算法的加密,然后再传输。同时保存在本地的时候也是加密后的数据。还有需要安全性更高的数据需要通过我们自定义协议通过Socket传输。\n\n经理问:那你知道MD5的原理吗?\n\n旁白:老程序员就是喜欢刨根问底,如果技术功底不雄厚的话确实这个问题很难应付,因为对于大多数人只需要用一个技术就行了,不会去关注他的内部原理。\n\n我(阳哥)答:MD5算以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了复杂处理后,输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。这个过程是不可逆的,我们也把他叫做数据指纹,但是我们依然对用户的输入进行安全校验,如果是纯数字类型密码,是不允许注册的,因此就算你MD5加密了,黑客也可以通过彩虹碰撞的形式进行暴力破解。\n\n旁白:接下来,经理问了我几个问题可能能难住我,关键是他也不懂Android,只能问我javaSE和思想上的一些东西,之后就开始跟我聊人生了,说他们公司是国企背景,自己在公司发展多么好,公司未来要做一个什么什么样的产品,公司弹性工作制,每年至少14薪,又问我女朋友在哪,什么时候考虑结婚,在哪买房,老家是哪的,爸妈是干什么工作的,你是如何规划未来的等等。。。。。\n\n## 4. 人事面试:\n\n这家的人事面试与其说是人事面试还不如说成人事咨询,人事跟我介绍了公司背景,跟我谈了薪资,跟我谈了入职安排,又谈公司发展,公司的福利待遇等等。人事的最后一个问题都是出奇的相似,\n\n人事:我该问你的问题都问完了,你还有什么要问我的吗?\n\nPS:这些问题千万不要一个都不问,这样人事会认为你这个应聘者对我们公司不感兴趣。如果有其他人也去面试,那么你就可以能被PASS了。其实我们真的想去这家公司的话,肯定会有一大堆问题的,但是也不要问的太多,问的太多显得你很啰嗦,人事的耐心也是有限的,同时也不要问太低级的问题。对于我们程序员来说,应该最关注如下两大类问题,一是自己将要加入的开发团队的情况,二是公司的薪资待遇以及员工培训发展情况。第一类问题显得我们技术专业,技术屌丝的特性被发挥的淋淋尽致,第二类问题很现实,我们不仅要眼前的工资还要考虑未来的发展。\n\n我(阳哥)答:咱们公司的技术团队目前有多少人,都做哪些项目?\n\n人事:公司目前技术团队还在不停的扩建,目前总共有十几名,不过服务端人比较多。现在主要做p2p理财类产品,这也是很火的一个趋势。\n\n我(阳哥)答:咱们公司给开发人员有定期的培训吗?\n\n人事:有的,公司每年都有拓展培训,拓展培训是针对全体员工的,技术团队的话每周或者每个月可能有技术分享活动,每周一名技术人员进行分享,同时可以获100元/次的奖励。\n\n## 面试吐槽:\n\n阳哥在上海第一天竟然面试了3家,上海这么大,每个公司都在不同的区,回到家已经晚上7点多了,我的感受只有一个字儿累,躺在床上就起不来了,不过还好今天本来是抱着被面试官“虐”的心态去的,结果没有被“虐”,而且还能旗开得胜。这给了我很多自信,不仅仅是对自己技术的自信,更是对黑马Android课程的自信。\n\n最后送大家一句话:没有企业给不了的薪资,只有自己掌握不了的技术。没有自己掌握不了的技术,只有不够努力的自己。\n\n录用Offer!\n\n# 4. 挑战公司No.4:上海游竞网络科技有限公司---PLU\n\n公司地址:上海市闸北区广中西路777弄99号江裕大厦10层\n\n面试时间:5月13日 14:00 PM.\n面试结果:Android工程师,16K offer+500元住房补贴+490元交通和饭补+200元全勤奖=17.1k:victory:\n面试过程:\n\n16:00到公司,这家公司在闸北区,比较远,不过办公楼很高大上。\n16:00~16:30 填写面试登记表和笔试题。\n16:30~17:15 跟面试官进行技术PK(这家面试流程比较简洁,技术只考察一轮就让人事谈薪资了)。\n17:20~17:40 跟人事谈人生谈薪资。\n\n疯狂的笔试+面试记录(前方内容“高能”:funk:,请准备高度精神集中前行):\n\n1. 笔试\n\nPS:笔试是在公司前台旁白的桌子上做的。阳哥本来胆子就小,这一下搞的偷拍都没自信了,导致对焦不成功,拍出来的照片很模糊,大家凑合着看吧,我把图片上的试题以文本的形式列出来,如下。\n\nQ:Activity的生命周期?\nPS:我晕,跟复深蓝的笔试题如此的雷同,难道他们两家公司技术人员互相抄袭的吗?忍住,不笑!\nA:onCreate、onStart、onResume、onPause、onStop、onDestroy、onRestart。\n\nQ:Activity销毁前,如何保存Activity的状态?\nA:可以使用onSaveInstanceState(Bundle)方法将Activity中需要的数据保存起来,当下次重新启动Activity的时候在onCreate(Bundle)中获取Bundle数据。\n\nQ:请介绍下Android中常用的5种布局?\nA:LinearLayout、RelativeLayout、FrameLayout、RelativeLayout、TableLagout。\n\nQ:请介绍下Android的数据存储方式?\nA:SharedPreference、XML、SQLite、文件系统、内存(如果算的话)。\n\nQ:AIDL的全称是什么?如何工作?能处理哪些类型的数据?\nA:\n\n- Android Interface Definition Language\n\n- AIDL一般用于远程服务,也就是进程间通信。我们可以分服务端和客户端,服务端声明AIDL文件,该文件命名为xxx.aidl,ADT会自动将xxx.aidl生成代码文件,代码文件提供了aidl中接口的实现。客户端如果要使用服务端提供的服务需要将xxx.aidl文件放到客户端源代码目录下,然后生成xxx.java类,客户端通过bindService的形参ServiceConnection的onServiceConnected获取到Service对象,这个对象通过Stub.asInterface(service)返回aidl的实现类。之后我们就可用调用这个aidl的实现类。\n\n- 基本数据类型都可以,复杂对象也可以,只不过需要实现Parcelable接口。\n\nQ:请介绍一下handler机制?\nA:Android中handler多用于主线程和子线程之间的通信,比如在Android中子线程是不允许修改UI的,如果修改只能让子线程给主线程通过handler发送message,然后主线程进行修改。Handler整个机制的实现,还依赖Looper、Message两个核心内容。在主线程中Android默认给我们创建了Looper\n\nQ:java如何调用c、c++语言?\nA:java通过JNI调用C/C++代码,在使用的时候首先通过System.loadLibrary(\"xxx\")将xxx.so文件加载到jvm中,同时在类中必须对so文件中的方法进行生命,格式:public native void test();\n\nQ:Android分几层,分别是什么?\nA:四层。Linux Core、Libraries(Android Runtime)、Application Framework、Applications。\n\nQ:final、finally、finalize的区别?\nA:第一个是关键字最终,用final修饰的类为最终类,不能被继承,修饰的方法不能被覆写,修饰的变量不能被改变。finally是异常体系中的关键字,当系统遇到异常是,在进行trycatch的时候,finally代码块里的代码是必须被执行的。finalize是Object类中的方法,当GC回收对象时回调的方法。\n\nQ:heap和stack的区别?\nA:堆和栈。栈存放对象的引用,堆存放对象实体。堆中的对象是有jvm的垃圾回收器负责回收。\n\n## 2. 第一轮技术面试过程问答精选:\n\n旁白:面试我的是85年出生的Android组组长(这是后来他们公司人事给我打电话让我入职的时候,跟我说的)。他们公司是做游戏视频直播平台的,因此对app的性能要求比较高,他用手机让我看了一段代码。代码(记得不是很清楚了)大概如下:\n\n```java\npublic class MainActivity extends Activity {\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n new Thread(new Runnable() {\n @Override\n public void run() {\n while (true) {\n SystemClock.sleep(1000);\n }\n }\n }).start();\n }\n}\n```\n面试官问:上面的代码有问题吗?\n\n我(阳哥)答:当然有问题呀,这个Activity在启动的时候开启了一个子线程,但是当Activity退出的时候该子线程还在运行,并没有停止。子线程运行在进程中的,Activity退出的时候进程并没有退出,而由前台进程变为后台进程。\n\n面试官问:那应该怎么解决?\n\n我(阳哥)答:我们可以这样,把while(true)改成while(flag),flag是一个boolean类型的变量,通过改变flag的true或者false来终止子线程的运行,当Activity退出时会调用onDestroy方法,因此在该方法中我们可以把flag设置为false。\n\n旁白:面试官听了我的答案,从他的表情上来看好像他不是很满意。但是他也没说我说的对不对,而是给我说了他心中的答案,不过他给的答案我当时是虚心接受了,不过到现在我还没明白他说的道理在哪,我写了测试代码也没测试出来啥。\n\n面试官问:这个代码有问题就出在这个Thread是一个匿名的,而且没有声明为静态成员变量?\n\n我(阳哥)答:哦,这样子呀,这个我真不知道。\n\n旁白:其实我内心是很想问他为什么呢?但是如果他答不上来就会让他很难堪,如果回答上来了倒没啥问题。从他也不自信的言语中我感觉还是不问他比较好?\n\n面试官问:你对RTSP流媒体协议有了解吗?有没有做过手机播放器的应用?\n\n我(阳哥)答:这个知道,自己做过流媒体播放器。我使用过开源的Vitamio开源库。\n旁白:黑马课程中有一个项目是手机影音。因此这个东西自己是知道的。不懂的人可能以为RSTP、ffmpeg这些专业名词都多么的高大上,其实在黑马手机影音中,我们会做一个视频播放器,视频播放器分两种,一种是Android自带解码,第二种是万能播放器,所谓万能播放器就是绝大多数流媒体格式都支持。\n\n面试官问:那你知道代码测试怎么测?\n\n旁白:关于测试,阳哥真心不太懂,怎么办??尽量回答一些自己知道的,同时把测试方面的话题给关闭掉,省得面试官追问我。\n\n我(阳哥)答:您说的是Monkey Test吗?。\n\n面试官问:恩。。。也算吧?还有其他吗?\n\n我(阳哥)答:我们程序员在写代码的时候都是有规范的,优良的代码规范是规避bug重要的一步,同时我们公司每周都有一个代码走读会议,所谓的代码走读,就是开发人员互相看对方的代码,检查代码是否规范以及是否存在bug。当然也有测试,不过我们的测试都是黑盒测试。\n\n面试官问:哦,代码测试,就是可以通过测试一段代码来分析这段代码有没有问题,性能是否可靠。\n\n我(阳哥)答:对的,Android自带了AndroidTest功能,可以对一个类一个方法进行测试。\n面试官问:那好,图片你有处理过吧?\n\n我(阳哥)答:这个肯定有呀,哪个Android应用没有图片。比如图片缓存呀,图片缩放呀,图片缓存呀。\n\n旁白:其实自己对图片处理这块儿,还是比较了解的,可惜他也没怎么深问我,没有给我很大的发挥机会。\n\n面试官问:我们现在要做一个视频在线播放的app,播放的都是游戏直播或者录像视频,iOS已经做好了的,Android还没有做好,你要是进来的话你就是做视频直播这一块儿。\n我(阳哥)答:这个已经做好的能让我看一下吗?\n\n旁白:面试官拿来水果机让我看了一下,主界面就是一个ListView,每个ListView的一行都有大概4个视频预览图,点击之后可以播放。\n\n我(阳哥)问:这个切图,设计啥的都做好了吧,剩下的就是编码了其实?\n面试官答:是的,后期我们Android团队还会不停的夸大,我们的发展重心已经偏向移动端。\n旁白:接下来就是跟面试官侃大山了,从天文到地理,从BAT到初创型公司,阳哥也不能甘拜下风。\n\n我(阳哥)答:恩,现在是移动互联网时代了,移动端肯定得做好,不管什么样的公司都特别重视移动端。咱们公司现在才开始研发移动端,其实已经稍微有点儿晚了,就得赶紧拼命追赶了。\n\n## 3. 人事面试:\n\n跟面试官聊完后,技术官对我的评价是,我挺喜欢你,你跟人事好好聊聊吧,哈哈,我肯定会跟人事MM好好聊天的。人事问的问题太老套路了,感觉全上海人事问的问题都一样,难道他们都是从一个地方培训出来的?人事也有培训吗?其实应付人事的问题不难,难的是如何回答人事的问题。答题的方式直接决定了我们在人事那里的印象。我把人事问的几个问题大概列一下。\n\n人事:你为什么离职来上海?\n\nPS:人事问这个问题的主要目的就是看你的动机纯不纯,有没有不良倾向。\n\n我(阳哥)答:主要是两个方面吧,第一个是我的女朋友在这边工作,我年龄也不小了,也到了谈婚论嫁的时候了,我不着急,家里父母亲着急呀,来上海工作的话离女朋友比较近,结婚就比较好办,第二个主要还是。。怎么说呢。。。高大上的说就是为了自己事业更高的发展吧,说的直接点就是上海毕竟国际化都市,发展机会很多,自己也想来上海工作个3~5年挣钱买个房子首付啥的,如果在上海的这几年发展的好可以考虑再公司附近买房,如果自己发展的不好,在上海周边买个房也行。\n\n人事:你女朋友一直在上海,还是刚回来上海?。\n\n我(阳哥)答:她上一年来的这边,之前是我大学同学,主要是她家有亲戚帮她找了一份设计院的工作,而我只能靠自己找工作。\n\n人事:你以后打算长期留在上海了吗?\n\n旁白:上面的问题其实是人事在考察你的稳定性,公司可不想招到一个人刚培养出来就走掉了。但是如果你直接肯定的回答:我会一直留在上海,又显得很假。“装”的高境界就是让对方感觉你很不会“装”。\n\n我(阳哥)答:这个有想过,自己其实蛮喜欢上海的,可是计划赶不上变化,来上海的前一年我也从来没想到我会来,因此不能说一辈子都在上海,不过目前这几年是打算在上海好好发展一下。上海的房价、户口政策都是问题,现在不是我选不选择上海,而是上海选择不选择我的问题,呵呵,其实谁都不傻,都想来好地方,关键就看自己有没有本事扎根于此了。\n\n人事:你能承受加班吗?\n\n旁白:其实互联网企业加班是很常见的现象,尤其是像上海这种生活节奏比较快的城市,加班肯定是避免不了的,但是我们也有我们的底线,不能无条件无休止的为公司加班,但是也不能一点儿班都不能加,毕竟有时候公司忙的话,比如新产品上线,新bug的解决都是需要加班的,这个时候我们还真的义不容辞的为公司付出,毕竟我们的薪水是公司给的。在公司工作一方面是我们为公司付出,另一方面我也要知道感恩公司。\n\n我(阳哥)答:加班很正常,自己之前的公司也经常加班。不过公司加班一般都不会让员工平白无辜的加班的,我们加班的时候公司会发晚餐补助,打车补助等,如果加班超过半天会计入到我们的存休中,等活不忙的时候我们可以申请休息。因此只要不是高频度的天天加班到凌晨应该没啥问题的。\n\n人事:你的五年规划是啥?\n\n我(阳哥)答:自己还是想往技术方向发展,自己也比较喜欢代码,愿意去研究技术。人往高处走水往低处流,经过自己几年的积累后自己想当一名技术总监或者项目经理类的技术管理类岗位。不过这些都得靠自己的努力以及对机遇的把握情况了。\n\n面试吐槽:\n\n这家企业各个方面的条件真心不错,想拒绝都很难找到合适的理由!我要了15k的薪资,人家给了16k,还有各种诱人的福利。感觉还是游戏类的公司土豪。你以为你要15k,人家给你16k已经很高了吗?请让我把话说完,告诉你啥叫游戏公司。该入职的时候,当然我没有去入职(入职是上午10:00),上午10:20的公司人事给我打电话,问我迟到了还是怎么会儿事儿,我说对不起,感谢贵公司对我的认可,自己已经有了新的选择。把他们给拒绝了。下午1点多的时候,我正在吃饭,结果这家公司的技术官又给我打电话来了,在电话里跟我聊了很久,他说如果再给你多几k你会考虑过来上班呢?我哑巴了,自己从来就没有享受过这么好的待遇,受宠若惊的阳哥无言以对!自己的内心像打翻了五味瓶一样,这种感觉估计也没有几个人理解。后来还是被我给拒绝了,内心在流泪!\n\n这篇文章阳哥已经写到尾声了,但是想给大家说的话却依然很多很多。\n\n亲爱的黑马同学们:如果你还在撸着代码,看着视频,再苦再难,请你一定要坚持,今天你付出的一点一滴都将会在明天变成千千万万倍的回报。加油&坚持!\n\n# 5. 挑战公司No.5:一号店旗下壹药网\n\n公司地址:上海市浦东新区碧波路572弄115号10幢\n\n\n(偷拍前台妹子~天热,穿的少其实是正常的,可惜桌子挡住了该看的,哦,不该看的:lol)\n\n面试时间:5月14日 10:00 AM.\n面试结果:Android工程师,15K offer&14个月薪资:victory:\n面试过程:\n10:10到公司,这就是传说中的一号店!,公司总共三栋独栋楼,两个在装修,一个在用,因此工位紧张,导致我面试都是在前台所在的大厅里进行的。\n10:20~10:50 填写面试登记表和技术官面试。\n10:50~11:10 跟研发部Leader面试。\n11:10~11:30 跟人事谈薪资以及入职事宜。\n\n疯狂的笔试+面试记录(前方内容“高能”:funk:,请准备高度精神集中前行):\nPS:笔试跟面试是一起的,一个技术官拿着一张正反面都写满题的A4纸,从第一题到最后一题,他指一题我回答一题,我回答一题,他指下一题。配合的天意无缝,哈哈~~~\n\n## 1. 笔试\n\n### java基础部分\n\nQ:Java面向对象有哪些特征?\nA:封装、继承、多态。\n\nQ:`short s1=1;s1=s1+1`有什么错?`short s1=1;s1+=1;`有什么错?\n\nA:第一个是有错的,short在内存中占2个字节,而整数1默认为int型占4个字节,s1+1其实这个时候就向上转型为int类型了,因此第一行代码必须强转才行。第二个之所以可以是以为这句话翻译过来就是s1++,也就是short类型的数据自身加增1,因此不会有问题。\n\nQ:静态成员类、非静态成员类有什么区别?什么是匿名内部类?\nA:静态成员类相当于外部类的静态成员,是外部类在加载的时候进行初始化,非静态成员类相当于外部类的普通成员,当外部类创建对象的时候才会初始化。匿名内部一般都是在方法里面直接通过`new ClassName(){};`形式的类。比如我们`new Thread(new Runnable(){}).start();`就用到了匿名内部类。\n\nQ:abstract class 和 interface有什么区别?\nA:前者是抽象类,可以有抽象方法,也可以没有。后者是接口,只能有抽象方法。他们都不能创建对象,需要被继承。\n\nQ:ArrayList是不是线程安全的?如果不是,如何是ArrayList成为线程安全的?\nA:不安全的。可以使用Collections.synchronizedList(list)将list变为线程安全的。\n\nQ:是否可以继承String类?\nA:不可以,因为String类是final类。为啥不解释了吧。\n\nQ:以下两条语句返回值为true的有:\n A:`\"yiyaowang\"==\"yiyaowang\";`\n B: `\"yiyaowang\".equals(new String(\"yiyaowang\"));`\nA:第一个返回true,都是字符串常量,存储在字符串常量池中,且只有一份。第二个返回true,用equals比较的是字符串内容。\n\nQ:当一个对象被当做参数传递到一个方法后,此方法可以改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?\nA:java中只有值传递,没有引用传递。这里的引用本身就是值,传递的是引用这个值。\n\nQ:定义类A和类B如下:\n\n```java\nclass A{\n int a =1;\n double d = 2.0;\n void show(){\n System.out.println(\"Class A:a=\"+a+\"\\td=\"+d);\n }\n}\nclass B extends A{\n float a = 3.0f;\n String d = \"Hello World!\";\n void show(){\n super.show();\n System.out.println(\"Class B:a=\"+a+\"\\td=\"+d);\n }\n}\n```\n(1)若在应用程序的main方法中有以下语句:\n```java\nA a = new A();\na.show();\n```\n则输出结果是?\n\n(2)若在应用程序的main方法中定义类B的对象b:\n```java\nA b = new B();\nb.show();\n```\n则输出结果是?\n\nA:第一个是ClassA :a=1 d=2.0\n 第二个是ClassA :a =1 d=2.0 \nClassB : a=3.0 d=Hello World!\n\nQ:heap和stack有什么区别?\nA:堆和栈。栈存放对象的引用,堆存放对象实体。堆中的对象是有jvm的垃圾回收器负责回收。\n\nQ:请描述下JVM加载class文件的原理机制。\nA:JVM加载class是动态性的,也就是当“需要”的时候才会加载,这是也是为节约JVM内存来考虑的。同时JVM的类加载是父类委托机制,这个机制简单来讲,就是“类装载器有载入类的需求时,会先请示其Parent使用其搜索路径帮忙载入,如果Parent 找不到,那么才由自己依照自己的搜索路径搜索类”。\n\n### Android基础部分\n\nQ:如何适配不同屏幕分辨率的机型?\nA:屏幕适配方式就多了去了。Android系统本身提供了很多适配方法,比如存放图片资源的drawable目录根据不同分辨率的手机提供了drawable-hdpi、drawable-ldpi、drawable-mdpi、drawable-xhdpi等多中目录。我们只需把适应不同分辨率的多套图片分别放到对应的目录中即可。Android的layout、values目录也提供了类似drawable的适配功能。但是在开发中,不可能针对不同的手机分辨率提供多种图片资源,这太耗费资源了。我们一般在写控件宽高的时候都会用dp单位取代pix单位。因为dp是一个相对单位,pix是绝对单位,使用dp替代pix也可以解决很多适配问题。dp跟pix之间可以通过公式进行转换。\n\nQ:View和ViewGroup的关系是什么?View的绘制过程(主要方法)有哪些?\nA:ViewGroup继承了View。onMesure、onLayout、onDraw。\n\nQ:Activity和Task的区别及启动模式有哪些?\nA:Activity运行Task中。Activity有四种启动模式。standard、singleTop、singleTask、singleInstance。standard:默认的启动模式,多个Activity位于同一Task中。singleTop,顾名知义就是Task栈顶只能有一个相同的Activity,singleTask就是一个Task中只有一个Activity,singleInstance就是一个Activity独享一个Task。\nPS:关于Activity的四种启动模式其实还有更详细的说法,我在上面就简单介绍一下了,如果面试官需要问的更详细再往深处介绍就行了。\n\nQ:如何注册BroadCastReceiver和Service?Service有什么特征,哪些情况会用到Service?\nA:都可以通过AndroidManifest.xml进行静态注册。不过BroadCastReceiver可以在代码中通过registReceiver方法来注册。Service运行在后天进程中,一般需要在后台一直运行的任务会让Service来完成。比如我们的telephoneService、locationService等等。\n\nQ:Android有哪些安全机制?\nA:权限机制。我们的应用只要涉及到了用户的隐私、网络都需要在AndroidManifest.xml中进行声明,这样用户在安装的时候可以根据你申请的权限进行判断是否允许应用的某些行为。\n\nQ:Handler机制的原理,内部是如何实现的?\nA:Android中handler多用于主线程和子线程之间的通信,比如在Android中子线程是不允许修改UI的,如果修改只能让子线程给主线程通过handler发送message,然后主线程进行修改。Handler整个机制的实现,还依赖Looper、Message两个核心内容。在主线程中Android默认给我们创建了Looper,当我们通过handler.sendMessage()后,该消息被添加到MessageQueue中,Looper.looper中有个while(true)的循环不停的从消息队列中取消息。取消息的过程是线程阻塞的,这样不至于在没有消息的时候过多的耗费CPU资源。\n\nQ:Thread和AsyncTask的区别是什么?\nA:AsyncTask是封装好的线程池,比起Thread+Handler的方式,AsyncTask在操作UI线程上更方便,因为onPreExecute()、onPostExecute()及更新UI方法onProgressUpdate()均运行在主线程中,这样就不用Handler发消息处理了;\n\nQ:说说MVC模式的原理,在Android中的运用。\nA:MVC是Model、View、Controller三部分组成的。其中View主要由xml布局文件,或者用代码编写动态布局来体现。Model是数据模型,其实类似javabean,不过这些JavaBean封装了对数据库、网络等的操作。Controller一般由Activity负责,它根据用户的输入,控制用户界面数据的显示及更新model对象的状态,它通过控制View和Model跟用户进行交互。\n\nQ:如何加载ndk库?如何在jni中注册native函数,有几种注册方式?\nA:通过System.loadLibrary(\"xxx\")进行加载。其实native有几种注册方式,自己当时并不知道,自己只知道一种注册方法,就是首先根据native 方法名,生成Java_com_xxx_MethodName(xxx,xxx);当然这个c/c++源码文件中需要引入jni.h,然后把这个c/c++源码编译成so文件。\n\n自己后来百度了一下,网上有人数还有一种注册方式是动态注册,我就把关于动态注册的东西直接拷贝过来:\nJNI 允许你提供一个函数映射表,注册给Jave虚拟机,这样Jvm就可以用函数映射表来调用相应的函数,就可以不必通过函数名来查找需要调用的函数了。Java与JNI通过JNINativeMethod的结构来建立联系,它在jni.h中被定义,其结构内容如下:\n\n```c\ntypedef struct {\n const char* name; //Java中函数的名字\n const char* signature; //用字符串描述的函数的参数和返回值\n void* fnPtr; //指向C函数的函数指针\n} JNINativeMethod;\n```\n\n第一个变量name是Java中函数的名字。\n第二个变量signature,用字符串是描述了函数的参数和返回值\n第三个变量fnPtr是函数指针,指向C函数。\n当java通过System.loadLibrary加载完JNI动态库后,紧接着会查找一个JNI_OnLoad的函数,如果有,就调用它,\n而动态注册的工作就是在这里完成的。\n\n1)JNI_OnLoad()函数\n\nJNI_OnLoad()函数在VM执行System.loadLibrary(xxx)函数时被调用,它有两个重要的作用:\n指定JNI版本:告诉VM该组件使用那一个JNI版本(若未提供JNI_OnLoad()函数,VM会默认该使用最老的JNI 1.1版),如果要使用新版本的JNI,\n例如JNI 1.4版,则必须由JNI_OnLoad()函数返回常量JNI_VERSION_1_4(该常量定义在jni.h中) 来告知VM。\n初始化设定,当VM执行到System.loadLibrary()函数时,会立即先呼叫JNI_OnLoad()方法,因此在该方法中进行各种资源的初始化操作很恰当,\n\n2)RegisterNatives\n\nRegisterNatives在AndroidRunTime里定义\nsyntax:\njint RegisterNatives(jclass clazz, const JNINativeMethod* methods,jint nMethods)\nQ:App在什么情况下会出现内存泄露?如何避免这些情况?\nA:造成内存泄露的可能性有很多,我说几种吧,1)资源未及时释放,比如引用的io流资源、网络资源、数据库游标Cursor等没有释放2)注册的监听器、广播等未及时取消3)集合对象没有及时清理4)不良代码\n\n避免上述问题,主要还看程序员知识掌握的程度和编码经验的多少,但是从技术角度考虑我们需要注意一些细节,比如,重复使用的资源可以考虑使用缓存技术、池技术。使用的任何资源都记得关闭或者异常处理,保证在恶劣的情况下也能使资源得到释放。对于图片的操作要注意缓存的使用,同时要记住对图片对象进行及时的回收。使用ListView的时候,尽量让ConvertView得到复用。\n\n3)逻辑思考\n\nQ:你让工人为你工作7天,给你工人的回报是一根金条,金条评分成7段,你必须在每天结束时给他们一段金条,如果只许你两次把金条弄断,如何给你的工人付费?\nPS:因为上面的问题自己回答的都比较溜,所有这个逻辑思考题,面试官直接说我想着你也会就不做吧。哈哈~面试官已经放弃继续考察我了,嗨皮。然后他去找老大去了,趁机我赶紧把笔试题给偷拍了下来(是不是阳哥胆子越来越大呀?!),这样才能大家看到真实的笔试题是什么样子滴。\n\n哦,对了,上面的逻辑思考题我面试的时候是免试的,亲爱的黑马童鞋们你们知道答案吗?\n\n## 2. 第二轮面试过程问答精选:\n\n旁白:面试我的应该是开发组部门的老大。胖胖的,黑黑的,矮矮的,从开始面试到结束,一直面带微笑。因为之前那个技术官已经面试过我的技术了,因此他也没问我技术,就是跟我瞎聊了一些关于Android方面的东西。因此详细内容这里就省略了,请大家直接进入下一关~duang~\n\n## 3. 人事面试:\n\n人事面试的问题,其实我在V4版本中也说过,基本所有的人事问的问题都大同小异,跟这个人事聊的唯一有趣的就是,由于公司正在装修,找不到面试我的办公地点,然后她竟然把我带到公司旁边的凉亭子下面,我们两个并排坐着,就聊起来了,知道的知道我们是在面试,不知道的估计还以为我们在谈恋爱呢\n\n面试吐槽:\n\n在前台我填写面试登记表的时候写的期望薪资是15k,他们也没有压低我工资,我知道我要少了。不过,没办法,谁让阳哥不懂行情,在投递简历的时候都是写着期望15k呢!想写个16、17、18都不好意思了,因此大家以后找工作可别学阳哥这么傻,能多要一定多要。\n\n跟大家分享一个励志语句以结束本篇文章吧:相信梦想是价值的源泉,相信眼光决定未来的一切,相信成功的信念比成功本身更重要,相信人生有挫折没有失败,相信生命的质量来自决不妥协的信念。\n\n录用Offer!\n\n笔试题(在前台眼皮底下偷拍~)\n\n# 6. 挑战公司No.6:聚信租赁\n公司地址:上海市徐汇区漕溪北路398号汇智大厦28楼\n\n面试时间:5月14日 14:00 PM.\n面试结果:Android工程师,16K +入职送iPhone 6+每年出国旅游一次+补充住房公积金+至少14薪:victory:\n面试过程:\n14:00到公司前台,领了一大堆资料,然后让我在一间办公室做题。\n14:00~14:30 填写面试登记表和性格测试。\n14:30~15:20 两个技术官坐在我对面,同时面试我。\n15:20~15:30 人事妹子跟我单聊公司薪资福利以及入职事宜。\n\n疯狂的笔试+面试记录(前方内容“高能”:funk:,请准备高度精神集中前行):\n\n## 1. 笔试\n\n这家比较奇怪,是给了6页的笔试题,打开一看全是性格测试题。性格测试题只拍了一张图片,在该篇文章的结果。估计大多数童鞋都想遇到阳哥这样的狗屎运吧;P~阳哥的性格绝对没问题的,这个我可以保证哈~:P\n\n## 2. 技术面试\n\n竟然同时来了两个技术官面我,一大一小,一高一矮,并排坐在一起,一对二,好吧,阳哥还是首次遇到1:2的阵容,这下可有好戏看了。PS:阳哥是个没有见过世面的人,面试的时候上个31层高的楼都兴奋的不得了,上去以后,发现上错楼了~糗事说多了都是泪:#,要不是阳哥有着过五关斩六将身经百战的成功经验,估计要吓尿:loveliness:。好吧开始吧,阳哥命中注定必有次劫,看来是躲不过了。\n\nQ:你做一个自我介绍吧?\n旁白:其实遇到好几家面试官都让我做自我介绍了,该如何自我介绍阳哥估计都会背了,好玩(恶心)的是在万达信息面试,面试了3个技术官,每个人都分别让我做了自我介绍,尼玛,他们3个就不会沟通一下要问我啥吗,一个问题至于问我3遍吗~:funk:阳哥是敢怒不敢言,毕竟在人家的地盘。\n\nPS:自我介绍的内容就不说了,每个人都是独特的,我就跟大家说一下应该如何自我介绍吧。\n\n一个优良的自我介绍会给面试官留下深刻的印象,大部分情况下,所谓的面试好坏其实看的就是你给面试官留下的印象怎么样了,我们用俗语叫感觉。\n\n自我介绍应该分以下几个部分,按照一定的逻辑连贯起来。如果连贯不起来,或者不够熟练一定在台下多背几遍,多讲几遍,但是面试的时候不要说的跟背过似的,高境界就是让面试官感觉你是临场发挥的,却又比背的都好。\n\n- 个人基本信息(姓名、年龄、老家、居住地等)\n\n- 自己来自哪里(工作地点),是干什么的(给自己一个清晰的定位,比如:我是一名Android开发工程师),担任过什么职务、做过什么样的项目\n\n- 自己为何来贵公司面试\n\n- 最后祝愿(希望能得到贵公司的认可等等,不用太多,一两句话就ok)\n\nQ:介绍一下你做过的项目吧?\nPS:黑马那么多项目,随便准备3个就ok了。\n 介绍项目大概的思路如下:\n 1)这个项目是干什么的(比如是一个类似网易新闻的地方新闻客户端,或者类似美团的o2o,或者类似豌豆荚的一个应用市场,或者类似淘宝的购物平台)?解释就是拿一个市场上耳熟能详的应用跟自己的应用做类比,省的面试官听的云里雾里的。\n 2)自己负责了哪些模块(功能)的职责(比如负责系统的架构,核心代码的编写,xx功能模块的开发等等)\n 3)自己在这个项目中担当的责任(比如,这个项目是自己独立开发的,这个项目是和另外一个同事一起架构一起开发的,这个项目是自己负责了几个核心模块)\n 4)项目中都用到了哪些技术\n 5)从项目中学到了哪些东西(可以从技术方向和业务两个方向入手)\n\n旁白:面试官问的很多技术性问题跟之前问的都大同小异,因此这里只给出有特色且技术含量高的。阳哥正在写面试宝典,该宝典核心内容针对的还是技术问题,阳哥会从javase基础到javase高级,从Android基础到Android高级以及到Android项目依次展开分析,其次也会写一些常见的非技术性问题,敬请期待~\n\nQ:①在Listview的优化中,我们为何使用ConvertView?②为何使用ViewHolder?③你认为哪个更能解决问题?④你认为view.inflate和view.findviewById哪个更耗时,为什么?⑤如果这两个AP让你重新写,你怎么写?\n\nPS:上面的问题,阳哥认为是面试以来遇到很难的一个,也是很有技术含量的一道题。前一半问题还好回答,最后一个问题真的需要发挥想象了。\n\nA:①使用ConvertView可以实现对view的复用,这样大大节约了每次创建对象的时间,提升了ListView的显示效率。②使用ViewHolder作为内部类,可以将view的子控件封装在ViewHolder类中,然后通过View.setTag(ViewHolder)将view和ViewHolder进行绑定,这样我们就不用每次都调用view的findViewById(id)方法来查找控件。③使用ConvertView解决了一大部分问题,使用ViewHolder实现了控件换时间的问题,因为给View对象设置一个Tag本身就是占用内存的,因此ViewHolder的使用还是需要区分不同的应用场景的, 没有绝对的好与不好。如果内存足够需要高效则ViewHolder建议使用,否则不建议使用。④当然是view.inflate耗时,这个函数完成的功能是把xml布局文件通过pullParser的形式给解析到内存中,需要io,需要递归子节点。⑤我其实还不太相信我写出来的代码比Google官方写的好,如果让我写的话我可能会这样考虑,当用户在使用view.inflate的时候将多个id作为数组添加到形参中,这样在初始化view的使用我就可以给这个view直接调用setTag方法绑定需要的子控件。不过这个原生方法其实也应该保留共不同的需求使用。\n\nPS:技术面试时间并不长,我回答了几个之后,他们两个大眼瞪小眼,A看看B问:你还有什么问的吗?B说我没有,你还有吗?A说我也没了。那行,接下来,他们就让我等人事了。\n\n## 3. 人事面试:\n\n人事问的问题都差不多,我在上一篇也说过,这里就不说人事的问题了。唯一要给大家爆料的就是人事给我讲的他们公司的福利待遇,可以用土豪不差钱形容:)\n\n人事说:入职后转正即送iPhone 6一部。\n\n我(阳哥)说:我是做Android开发的,给我iPhone 6干嘛\n\n旁白:你认为阳哥真不想要iPhone 6吗?为了显示咱的高度敬业精神,毕竟咱是做Android开发的,更需要的是Android手机,决不能像iPhone低腰(ni dao shi gei wo ya)!\n人事说:我们Android开发人员也会额外配Android机的,iPhone6可以生活用。\n\n旁白:我去~这就是没见过世面的阳哥,当时的表情。\n\n人事说:转正满一年,每年都有一次出国旅游。\n\n我(阳哥)说:哦,咱们公司还挺不错的嘛!\n\n旁白:不知说啥好了,只能用表情来形容了,阳哥至今没出过国,国外啥个样子嘛,\n人事说:我们一般一年更少发14薪,都是介于14~16薪之间,具体发多少要看个人平时的一个KPI考核了。\n\n我(阳哥)说:哦,这样呀,还行吧。\n\n## 面试吐槽:\n\n在家公司的人事跟我算了基本工资16k+各种补助1k=17k+。每年出国旅游,入职送iPhone,补充住房公积金,好吧,阳哥受宠若惊了。自己回来会百度了一下,终于搞明白这家公司为何这么奢侈!不多说,看图吧。\n\n跟人事面试的时候,人事说他们在上海总部目前有大概100多名员工,阳哥不懂经济,不知道100多人的公司能融资13个亿是个什么样的概念?这再次验证了阳哥的那句千古流传的话语,只要技术好,公司不差钱!"
},
{
"path": "docs/android/Android-Interview/经验分享/杭州找 Android 工作的点点滴滴.md",
"content": "## 写在前面的话\n\n我从 14 年毕业到现在一直待一个三线城市,就用 C 市 代替吧。地方很小,适合居住,但不适合 it 开发,城市很小、圈子很小,it 不发达,想要在 it 上面有出路的还是得去北上广深大城市。我在这个城市呆了三年左右由于自己的一些私事所以趁机就出来想找个大城市呆呆,原本打算去其他城市的,后来稀里糊涂的来到了杭州,在朋友这呆了半个月,直到找到工作。我是 17 年 3 月 25 号就辞职了,递交了辞职申请之后然后就跑去云南玩了一圈之后才想到要找工作的,然后就来杭州了,以上就是大概背景,接下来就写写关于在杭州找一份关于 Android 开发的工作中所遇到的人和事,不看不知道,原来世界真的很大各种人都有,果真印证了一句话:林子大了,什么鸟都有。\n\n## 简历\n\n面试之前,当然得准备一份简历啦,我的简历是当年刚毕业的时候写的一份简历,这里面用到的模板是 [乔布简历]() http://cv.qiaobutang.com/ 里面的简历模板不错(哈哈,这不是给它打广告的,我一直用这个,感觉不错就推荐了)。简历模板找到了,下面就是内容了,俗话说,要想找到好工作,一个好的简历必不可少的。因为公司越大的话,投递的人肯定越多,HR 筛选的时间就少了,所以简历有亮点就能打动HR,这样才能有面试资格,有了这个面试资格后才有可能得到这个工作机会,有的人写了简历投给公司后,就像石沉大海一样,毫无音讯,所以,如果有小伙伴,投了简历但是没有回应,不妨修改一下简历,但这里修改简历不是要你去造假,这里面有个梗,待会说~,写完了简历,接下来就是投简历了,有几个渠道可以找工作:\n\n- 内推,内推的质量是最高的,但也是最难的。\n- 第三方招聘网站,如 拉钩,51Job,智联招聘,猎聘同道等。\n\n就以我而言,使用上面四种方式进行对比,拉勾网上面公司质量还是不错的,但是HR筛选简历这关有点问题,里面给出的筛选不通过理由都是一样的。51job 和智联招聘两者类似,都差不多,我就是在智联招聘上面找到工作的。猎聘同道里面猎头比较多,我第一次面试就是上面的猎头进行联系的。总的而言,前三个多投投简历,重点放在智联招聘和拉勾网上面,其他也可以稍微投投~\n\n## 面试\n\n经过上面简历这个步骤,相信我们能够接到一些公司的面试邀请的,在接受公司面试邀请之前,我们得复习面试中所遇到的一些基本知识,主要有 Java 和 Android 这两方面的面试知识。\n\n- Java 基础知识,主要有面向对象三大特性及理解,接口与抽象类、泛型、线程池、集合框架、设计模式、常用算法等知识点。\n- Android 知识,主要就是一些常用的知识,待会儿给出一些链接。\n\n以上是专业知识准备,还得准备一些其他人文方面的知识,譬如自我介绍啊、兴趣爱好啊之类的。\n\n有了上面的知识基础,我们就可以上面进行面对面接触啦,我总共大概用了 10 天左右时间,面试了大概 15 家公司,其中有三家是明确拒绝我的,还有四家是我明确拒绝他的,还有几家我对比了一下,然后选择了一个性价比比较高的公司的。在这些公司里面,花样百出,有的公司不知道怎么想的,想花一年工作经验的工资找一个三年工作经验的人,这是典型的想得美。还有的公司忽悠你,就是变相的让你加班,我问他工资能给多少,他说看你能力而定,能力多大,工资多高,我说具体个数,如果我面试通过了,你能不能给我准确的数,他就不说话了,而且是早上 10 点上班,晚上 9 点下班,呵呵,不评价,忽悠应届生呢吧~\n\n印象最深的一家公司,地址是 https://www.lagou.com/gongsi/191783.html 没错,里面的评论就是我评论的,刚进去,给人的感觉,公司环境还不错,宽敞明亮的,然后 HR 给了我 A4 纸,正反面,填写个人的信息,详细程度令人咋舌。好不容易花了几分钟填完之后又给我整整三张面试题,没错,是整整三张,题目很多很多,让我做,哎,我也好忽悠,第一次碰到这种情况,所以就按部就班老老实实的做完了,花了 20 分钟,做之前还把我的手机给收了,娘的,当成学校考试呢啊???更奇葩的还在后面,做完面试题目之后,就开始了面试,那个面试官好像是子公司分责人吧,类似于总经理吧,看着我的简历,竟然问我有没有造假???WTF!!!还跟我说,他要想查的话很快就能查到了,我就无语了,我的简历竟然能让他怀疑我造假了,我的简历是有多雷人啊!!!接着就开始问我各种知识点,回答出来 95 以上吧,有几个平时没接触过,所以不知道怎么回答,最后面试结束了,没什么问题就开始讨论工资的问题,他看了我的期望薪水,问我,为什么翻了一倍?我跟他说,我以前呆的城市,非常小,基本连三线都不到,房价只有几千块,跟杭州能比吗???然后他就无语了,我就问他,为什么杭州房价比 C 房价高出 4~5 倍,你还想工资都差不多???面试简章上面的薪水范围跟实际给出的范围严重不符,我估计这家公司就是想把人先忽悠过去,然后开始各种压价,这太他么的可耻了,最后果断被我给拒绝了,而且是当面拒绝,没有留有情面,给再多也不会去的,这是情怀问题,感觉对程序员不尊重!!!以后大伙找公司,注意这家公司,过来人的经验~\n\n上面就是我遇到的印象比较深刻的一家公司。接下来我们就来总结一下面试过程中提出的各种问题,如果有需要的小伙伴可以参考一下。\n\n## 面试问题\n\n### 关于人文方面的问题\n\n- 先介绍一下你自己?\n- 你有什么兴趣爱好?\n- 你平常空闲时间会干什么,看哪些书,有什么心得体会?\n- 你为什么要从上家公司离职?\n- 如果面试过了的话,就会问你的期望薪资,然后就开始各种压榨你。\n\n### 关于 Java 方面的问到的知识点\n\n- 面向对象的三大特性,如何理解其中的多态?\n- JVM 的内存模型?\n- String、StringBuilder、StringBuffer 的区别,StringBuffer 是如何实现线程安全的?\n- 了解过 HTTP 吗?说说它的特点,它里面有哪些方法,有了解过吗?知道 HTTPS 吗?这两者有什么区别?\n- 你平常是怎么进行加密的?MD5 加密是可逆的吗?\n- 接口与抽象类的区别?static 方法可以被覆盖吗?为什么?\n- 创建线程的方式,他们有什么区别?知道线程池吗?说说对线程池的理解?\n- 你了解过 Java 的四种引用吗?分别代表什么含义,他们有什么区别?\n- Java 中关于 equals 和 hashcode 的理解?\n- 关于 Java 中深拷贝和浅拷贝的区别?\n- 简单的说下 Java 的垃圾回收?\n- 了解过 Java 的集合吗?说说 HashMap 的底层实现原理?ArrayList 和 LinkedList 的区别?Java 集合中哪些是线程安全的?\n- 如何实现对象的排序?\n- 知道 ThreadLocal 吗?说说对它的理解?\n- 在你写代码的过程中有使用过设计模式吗?你知道哪些?为什么要这样用,能解决什么问题?\n- 了解注解吗?了解反射吗?为什么要使用反射?\n- 数据结构中常用排序算法?\n\n以上就是关于 Java 所问道的知识点,记得不是太清楚了,待补充。。。\n\n### 关于 Android 方面的问到的知识点\n\n- Activity 的生命周期是什么? onPause 和 onStop 有什么区别?\n- Android 五种布局的性能对比?\n- Android 四大组件是什么?分别说说对它们的理解?\n- 关于 Service 的理解?它的启动方式有什么区别?\n- 了解 fragment 吗?说说你对它的理解?\n- 自定义过 view 吗?它的步骤是什么?说说你自定义 view 过程中出现的问题,以及是如何解决的?\n- 刷新 view 的几种方式,他们有什么区别?\n- Android 实现数据存储的几种方式?\n- 如何实现 Android 中的缓存的,通过使用第三方库和自定义来分别说明一下缓存技术的实现?\n- 如何实现 Activity 与 fragment 的通信?\n- Android 5.0、6.0、7.0 新特性?\n- Android 中的动画分类?\n- 你以前是如何进行屏幕适配的?\n- 说说 Activity 创建过程?\n- Android 中如何与 JS 交互的?\n- 了解 APP 的启动流程?\n- 你知道哪些图片加载库?他们有什么区别?ImageLoader 的内部缓存机制是什么?是如何实现的?\n- Android 中是如何实现异步通信的?\n- 说说 Handler 内部实现原理?\n- 使用过 AsyncTask 吗?说说它的内部实现原理?它有什么缺陷?如何改进?\n- 知道 JNI、Binder 吗?说说你对它们的理解?\n- 如何实现进程间的通信?\n- 说说 Android view 和 viewGroup 的事件分发机制?\n- 你开发过程中使用到了哪些第三方库?了解过他们的源码吗?\n- 你了解广播吗?它与 EventBus 有什么区别?能互相实现吗?\n- 你们网络请求是如何实现的?知道 Volley 吗?内部实现流程是什么?它与 OKHttp 有什么区别?\n- 你了解哪些第三方功能?知道推送吗?它的原理是什么?\n- 接触过 MVP 模式吗?说说看对它的认识?\n- 知道 Android 中的多渠道打包吗?\n- Android 签名机制的原理?反编译解压后的文件夹所包含的内容有哪些?\n- 你了解过模块化、组件化开发吗?\n- 开始开发 APP 如何进行架构?\n- APP 工程模块是如何划分的?你是如何进行封装的?\n- APP 是如何进行优化的?知道 OOM 吗?如何解决内存泄漏?\n\n以上就是我这次面试过程中涉及到的一些关于 Android 方面的知识点,有点模糊了,全凭记忆,待补充....\n\n经过上面的几个阶段,历时半个月,最终我找到了一家比较心仪的公司,整体的性价比个人感觉比较高,符合我的期望。以上便是我这次来杭州面试的点点滴滴,希望对有需求的小伙伴一些帮助~\n\n请记住一点,薪水并不是唯一所要关注的重点,关键还得看看公司环境、领导、同事相处愉快不愉快?要不然给你再多的薪水,每天干的不爽,那不是很悲哀?\n\n最后我会提供一些我面试准备阶段复习所用到的一些基础知识点链接,面试必问的一些基础原理一定得知道,不能含糊,要不然面试过程中必定会露马脚。有需要的小伙伴可以参考一下。\n\n## 相关链接\n\n- [Java面试题集](http://blog.csdn.net/dd864140130/article/details/55833087) \n- [Android 名企面试题及涉及知识点整理](https://github.com/Mr-YangCheng/ForAndroidInterview)\n- [40个 Android 面试题](http://www.devstore.cn/essay/essayInfo/7195.html) "
},
{
"path": "docs/android/Android-Interview/经验分享/给培训班出来的一点不成熟的小建议.md",
"content": "## 那些IT培训出来的Android工程师,希望你面试时涨点记性\n\n这几天,公司在前程无忧上发布了招聘 Andriod 工程师广告。不到 3 个小时, hr 就抱怨说投递 Andriod 工程师的简历已经多达 300 份了。不得已将 Andriod 工程师招聘就下架,然后就去筛选简历了。\n\n我也顺便看了看公司的要求,写的很简单,主要有:\n\n> 经验:1 年以上。\n>\n> 有开发过蓝牙相关项目经验优先。\n>\n> 学历:大专及以上。\n\n不知道 hr 和部门经理花费了多少时间挑选了 10 个人出来了。然后就预约了他们过来面试。\n\n很荣幸,经理让我出一点面试题,还特意嘱咐,毕竟我们是软硬件的方案公司,已经有成熟的架构了。app 的难度不大,只要后面肯学是一样。就把第一轮面试的任务交给我。这里我并不是歧视培训机构出来的 Andriod 工程师,而是这几天面试下来,让我觉得很不可思议。如果有的人再用心一点,或许 offer 就是你的了。也希望不论你是正常毕业出来找工作,还是培训出来,自学的,或者中途转行的,都涨一点记性。\n\n### 先说说笔试部分\n\n有两道题基本上回答的很令人无语。\n\n**1、写一写自定义 view 的思路。**\n\n有几个人直接写了一个 onMeasure() 方法放那里了,就写了这几个单词,难道就不用多写一点解释。\n\n我一看简历的工作经验,不是 2 年,就是 2 年半,还有 3 年的,怎么一个自定义 view 都没有遇到过?真的是让我怀疑你的工作经验是怎么来的。\n\n重点是:有一个面试者就直接向我坦诚了自己是培训出来的。我瞬间就恍然了很多。我也是个打工的,没必要去指责他,只是给他讲了讲自定义 view,简历应该如何如何。这哥们居然临走时感谢我,要了我的微信。\n\n**2、有没有访问过公司官网?如果有,谈谈你的意见。(这一题是 hr 要求加上去的。)**\n\n结果很失望,只有 3 个人说访问过。\n\n你去别人家公司面试,就不去访问别人一下官网,更何况,你投简历的时候,你就不用看公司简介,上上别人家公司官网。就算你是群投,收到面试通知后,都不用好好准备一下吗?去官网看看公司文化,团队,产品,特别是产品,大概就知道会用到哪些技术。\n\n### 再说说口头问的部分\n\n**1、搞清楚自己的开发工具**\n\n1) 请问你现在开发使用的什么工具?\n\n面试者:Android Studio\n\n2) 那你现在主要使用哪个版本开发?\n\n面试者:2.4\n\n一瞬间,我直接懵了。Google 才放出正式的 2.3 版本。你就用起 2.4 呢? 后面还补充告诉我,自己去官网下载的,一直在使用\n\n**2、不要刻意去讨好公司,技术的知识点不确定就不要随便回答。**\n\n1) 你在简历上说自己做过蓝牙相关的项目,那你告诉我,一般使用蓝牙需要哪几个权限?\n\n面试者:好像两个,两三个吧?\n\n2) 那你能不能说一下?\n\n面试者:我都是直接复制粘贴的\n\n唉,你让我说什么好。你要是做过蓝牙相关开发,哪怕是你忘记了权限,你也可以说一下蓝牙连接的流程。就算以前没做过,招聘的岗位都告诉你了,有做过蓝牙项目 app 的优先,你就可以去补充一下 Andriod 关于蓝牙的知识点啊?\n\n**3、别把别人上架的 app 当成自己的。**\n\n1) 你有没有 app 上架过?\n\n面试者:有\n\n等他在应用市场找给我的时候,我一看就傻眼了,下载量破 500 万了,一看开发者就不是你。唉,我当时就想,兄弟啊,你没有可以告诉我,就算找一个别人的,能不能不要这么多下载量的?更何况,国内 Andriod 应用市场这么多,想自己的 app 上架都不是什么难事。\n\n更可况,面试要求你,也没有说非要你上架 app。毕竟我们公司的 app 的难度还好。\n\n**4、Andoid 6.0 权限的处理。**\n\n1)在实际开发中,你说如何处理 6.0 以上手机权限问题的。\n\n面试者:我们开发的 app 不需要适配 6.0 啊。\n\n2)要是客户的手机是 6.0 的,客户要求你的 app 项目适配 6.0 的呢?\n\n面试者:不会吧,都不用适配 6.0 的\n\n你不是都有两三年开发经验了? 6.0 以上权限适配属于最基本的知识。随便说个思路,先申明权限,到用的时候,对高版本手机进行判断撒的……都是可以的,实际开发项目时,又不是不让你上网去学习研究。\n\n唉……不知道该怎么说好了!\n\n拒绝做面试题的!\n\n有两个过来面试的,直接告诉我:\n\n我写不好,能不能直接说啊!\n\n我也只好同意了,毕竟从那么多简历里面,把你们筛选出来是多么地不容易。结果,好是令人失望。\n\n如果你没有过硬的技术,请不要随便拒绝面试题。\n\n## 后记\n\n那个坦诚告诉我是培训出来的人,晚上发信息告诉我一些信息。\n\n他们说 Andriod 面试,不用做题的?\n\n现在企业喜欢经验多的,我们都是被要求写几年经验。这样才有面试机会。\n\n你们招聘公司职位要求的技术不是随便写的吗?\n\n大家都不容易,但是做技术这一行,还是需要硬实力。再怎么包装你有几年经验,拿到面试通知时,为什么不去好好准备面试,去背诵知识点。你连最起码的别人公司的官网都不上,你又有什么话语权?\n\n哪怕你没有 app 上过架,确实是刚毕业,转行,或者刚培训出来的,如果临时抱佛脚,复习了公司要求的知识,这个 offer 就属于你的了。毕竟还有 3 个月试用期。\n\n不论什么原因让你的简历如何完美,但是还请你的技术能够跟上。我所知道的,同事,朋友做 IT 的,有的是跨专业,有的是高中,有的是培训出来的,既然他们都行,请你也行!"
},
{
"path": "docs/android/Android-Interview/经验分享/腾讯公司程序员面试题及答案详解.md",
"content": "今天给大家带来的是腾讯的面试题,觉得有用的亲,赏个脸,轻点上面蓝色黑马程序员几个字关注我吧!\n\n**1、腾讯笔试题:const的含义及实现机制const的含义及实现机制,比如:const int i,是怎么做到i只可读的?**\n\nconst用来说明所定义的变量是只读的。\n\n这些在编译期间完成,编译器可能使用常数直接替换掉对此变量的引用。\n\n**2、腾讯笔试题:买200返100优惠券,实际上折扣是多少?**\n\n到商店里买200的商品返还100优惠券(可以在本商店代替现金)。请问实际上折扣是多少?\n\n由于优惠券可以代替现金,所以可以使用200元优惠券买东西,然后还可以获得100元的优惠券。\n\n假设开始时花了x元,那么可以买到 x + x/2 + x/4 + ...的东西。所以实际上折扣是50%.(当然,大部分时候很难一直兑换下去,所以50%是折扣的上限) 如果使用优惠券买东西不能获得新的优惠券,那么总过花去了200元,可以买到200+100元的商品,所以实际折扣为 200/300 = 67%.\n\n**3、腾讯笔试题:tcp三次握手的过程,accept发生在三次握手哪个阶段?**\n\naccept发生在三次握手之后。\n\n第一次握手:客户端发送syn包(syn=j)到服务器。\n\n第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个ASK包(ask=k)。\n\n第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1)。\n\n三次握手完成后,客户端和服务器就建立了tcp连接。这时可以调用accept函数获得此连接。\n\n**4、腾讯笔试题:用UDP协议通讯时怎样得知目标机是否获得了数据包用UDP协议通讯时怎样得知目标机是否获得了数据包?**\n\n可以在每个数据包中插入一个唯一的ID,比如timestamp或者递增的int。\n\n发送方在发送数据时将此ID和发送时间记录在本地。\n\n接收方在收到数据后将ID再发给发送方作为回应。\n\n发送方如果收到回应,则知道接收方已经收到相应的数据包;如果在指定时间内没有收到回应,则数据包可能丢失,需要重复上面的过程重新发送一次,直到确定对方收到。\n\n**5、腾讯笔试题:统计论坛在线人数分布 求一个论坛的在线人数,假设有一个论坛,其注册ID有两亿个,每个ID从登陆到退出会向一个日志文件中记下登陆时间和退出时间,要求写一个算法统计一天中论坛的用户在线分布,取样粒度为秒。**\n\n一天总共有 360024 = 86400秒。\n\n定义一个长度为86400的整数数组int delta[86400],每个整数对应这一秒的人数变化值,可能为正也可能为负。开始时将数组元素都初始化为0。\n\n然后依次读入每个用户的登录时间和退出时间,将与登录时间对应的整数值加1,将与退出时间对应的整数值减1。\n\n这样处理一遍后数组中存储了每秒中的人数变化情况。\n\n定义另外一个长度为86400的整数数组int online_num[86400],每个整数对应这一秒的论坛在线人数。\n\n假设一天开始时论坛在线人数为0,则第1秒的人数online_num[0] = delta[0]。第n+1秒的人数online_num[n] = online_num[n-1] + delta[n]。\n\n这样我们就获得了一天中任意时间的在线人数。\n\n**6、腾讯笔试题:从10G个数中找到中数 在一个文件中有 10G 个整数,乱序排列,要求找出中位数。内存限制为 2G。**\n\n不妨假设10G个整数是64bit的。\n\n2G内存可以存放256M个64bit整数。\n\n我们可以将64bit的整数空间平均分成256M个取值范围,用2G的内存对每个取值范围内出现整数个数进行统计。这样遍历一边10G整数后,我们便知道中数在那个范围内出现,以及这个范围内总共出现了多少个整数。\n\n如果中数所在范围出现的整数比较少,我们就可以对这个范围内的整数进行排序,找到中数。如果这个范围内出现的整数比较多,我们还可以采用同样的方法将此范围再次分成多个更小的范围(256M=2^28,所以最多需要3次就可以将此范围缩小到1,也就找到了中数)。\n\n**7、腾讯笔试题:两个整数集合A和B,求其交集两个整数集合A和B,求其交集。**\n\n- 读取整数集合A中的整数,将读到的整数插入到map中,并将对应的值设为1。\n- 读取整数集合B中的整数,如果该整数在map中并且值为1,则将此数加入到交集当中,并将在map中的对应值改为2。\n\n通过更改map中的值,避免了将同样的值输出两次。\n\n**8、腾讯笔试题:找出1到10w中没有出现的两个数字 有1到10w这10w个数,去除2个并打乱次序,如何找出那两个数?**\n\n申请10w个bit的空间,每个bit代表一个数字是否出现过。\n\n开始时将这10w个bit都初始化为0,表示所有数字都没有出现过。\n\n然后依次读入已经打乱循序的数字,并将对应的bit设为1。\n\n当处理完所有数字后,根据为0的bit得出没有出现的数字。\n\n首先计算1到10w的和,平方和。\n\n然后计算给定数字的和,平方和。\n\n两次的到的数字相减,可以得到这两个数字的和,平方和。\n\n所以我们有\n\nx + y = n\n\nx^2 + y^2 = m\n\n解方程可以得到x和y的值。\n\n**9、腾讯笔试题:需要多少只小白鼠才能在24小时内找到毒药有1000瓶水,其中有一瓶有毒,小白鼠只要尝一点带毒的水24小时后就会死亡,至少要多少只小白鼠才能在24小时时鉴别出那瓶水有毒?**\n\n最容易想到的就是用1000只小白鼠,每只喝一瓶。但显然这不是最好答案。\n\n既然每只小白鼠喝一瓶不是最好答案,那就应该每只小白鼠喝多瓶。那每只应该喝多少瓶呢?\n\n首先让我们换种问法,如果有x只小白鼠,那么24小时内可以从多少瓶水中找出那瓶有毒的?\n\n由于每只小白鼠都只有死或者活这两种结果,所以x只小白鼠最大可以表示2^x种结果。如果让每种结果都对应到某瓶水有毒,那么也就可以从2^x瓶水中找到有毒的那瓶水。那如何来实现这种对应关系呢?\n\n第一只小白鼠喝第1到2^(x-1)瓶,第二只小白鼠喝第1到第2^(x-2)和第2^(x-1)+1到第2^(x-1) + 2^(x-2)瓶....以此类推。\n\n回到此题,总过1000瓶水,所以需要最少10只小白鼠。\n\n**10、腾讯笔试题:根据上排的数填写下排的数,并满足要求。**\n\n根据上排给出十个数,在其下排填出对应的十个数, 要求下排每个数都是上排对应位置的数在下排出现的次数。上排的数:0,1,2,3,4,5,6,7,8,9。\n\n**11、腾讯笔试题:判断数字是否出现在40亿个数中?**\n\n给40亿个不重复的unsigned int的整数,没排过序的,然后再给几个数,如何快速判断这几个数是否在那40亿个数当中?\n\n答案:unsigned int 的取值范围是0到2^32-1。我们可以申请连续的2^32/8=512M的内存,用每一个bit对应一个unsigned int数字。首先将512M内存都初始化为0,然后每处理一个数字就将其对应的bit设置为1。当需要查询时,直接找到对应bit,看其值是0还是1即可。"
},
{
"path": "docs/android/Android-Interview/经验分享/阿里+百度+CVTE面经合集.md",
"content": "早上11点,刚刚收到阿里的offer,也算是给自己三个月的春招画上了一个还算圆满的句号。 \n\n先介绍一下本人的基本情况:陕西普通一本非计算机专业大三学生,非985211。主要技能C/C++/Java/数据结构/算法。 \n\n这三个月的经历,首先确实在技术上确实通过不断的面试有了很大的提升,其次在各种面试经验上也有了一些心得。 \n\n眼看春招已经基本结束,所以将这段时间的经历写在牛客上,希望能够帮助大家,在秋招上斩获更满意的offer。 \n\n所以就拿我收到offer的三家重点说说。(按时间排序) \n\n## 一、CVTE:\n\nCVTE的实习生招聘非常早,笔试完了就收到通知,预约了面试时间就早早去了,两轮技术面试一轮HR面试,进行的很顺利,3月26号就已经发了offer。 \n\n一面:面试官非常亲切,其实我当时是第一次参加现场面试,楼主比较怂,其实现场紧张的不要不要的,自我介绍的时候说完了姓名年龄和专业之后,就卡住说不下去了。面试官看在眼里疼在心上,于是很关心的对我说,没事没事不要紧张,这样吧,我们先写两个算法放松一下(Excuse me?)不过好在面试官出的题很简单,第一个是二分查找,我用递归和非递归各写了一遍,重点就在于下标的控制;另一道是在N个数中求前M大个数,其实也很简单,思路就是使用快速排序的思想,每一次当把一个数字放在正确的位置上的时候跟M进行比较,其实在剑指offer上有原题。好在寒假的时候把剑指offer刷了很多遍,所以很快也写出来了。我个人觉得在写代码之前,有很多事情需要跟面试官进行交流,比如函数的参数、返回值、还有一些异常情况的处理,提前跟面试官约定好。比如我在写代码之前,就问面试官:假设参数是`(int *arr, int length, int m)`,在这种情况下,可能会有四种情况会导致程序出现异常情况\n\n- arr ==NULL \n- length <= 0 \n- m > length \n- m <=0\n\n询问他在这四种情况下我们该如何处理?”面试官听完之后一下就有兴趣了,及时跟面试官沟通,一方面是防止思路与面试官预期的差距太大,面试官出的题,因此他有责任让面试者明白他的意思,另一方面表现我们积极思考,向面试官展示我们的思考能力。可能之前的算法写的太顺利,所以给自己建立了蜜汁自信,并且面试官对我的第一印象也好,后面的问题回答的很轻松,有struts2和SpringMVC的区别、Spring中IoC和AOP的理解,不过在数据库方面被难住了,在MySQL中如何定为查询效率较慢的SQL语句,比如慢查询日志、EXPLAIN关键字还有PROFILES等。但是总得来说,一面进行的很顺利。 \n\n二面:CVTE的面试流程是,如果一面的面试官觉得通过了,就会示意现场接待的姐姐,姐姐会安排在场外休息一下,二面大概在十分钟之后进行;而如果觉得不符合要求,姐姐就会亲切地告诉面试者,今天的面试结束了,可以先回去等消息。等了十分钟之后,二面如约而至,二面是一个年纪稍大,但是很有风度的中年人,事后学长说那是他们部门的BOSS,面试官让我设计了一个场景,青蛙爬井,就是画画UML,两个类图,和他们的关系。最后扩展成面向接口的思维,不得不说BOSS确实功力深厚,纠正了我很多问题,最后才勉强满意。然后就是分析项目,挑了一个我比较熟悉的,问了很多问题,比如页面的跳转关系、我所做的功能模块,让我一边画图一边解释,我自认项目准备的还算充分,因为都是自己做的,所以这部分也算顺利。后面就没有什么技术问题,问了一下我什么时候能来实习,还有在校的经历,同学之间是如何评价我的,然后就结束了。 \n\nHR面:晚上回到宿舍就有短信通知,第二天参加终面,当时还在跟女朋友看电影啊,荒原猎人。正看到小李子跟熊搏斗,女朋友吓得不敢看,广州的电话来了,让我预约第二天的终面并且填一个单子。慌慌张张跑回去完成。印象里面那个问卷问的很全面,比如家庭状况、为什么选择去广州、什么情况下会放弃这份工作、小时候印象最深的一件事情、列举出近期让你伤心的事情以及你是如何处理不良情绪的。如果各位到了这一步,一定要谨慎作答,这些问题都会列入到综合评测中。后面的面试就是把这些问题现场问一遍,说是HR面,但我总感觉是高管面,一个高管面三个面试者。 \n\n面试出来之后,等做到地铁上,广州负责的CVTE校招的学长就已经告诉我通过了,效率非常高。3月26号拿到的offer,这是春招的第一个offer,当时的心情还是很激动的。 \n\n## 二、百度\n\n百度是学长内推,技术面是两轮技术面试。 \n\n一面:简单的自我介绍,因为是电话面试,所以流畅了很多(你们懂的)。一个小时满满的技术问题,所以就不用向上面再赘述了,直接上干货 \n\n1.是否了解动态规划\n\n动归,本质上是一种划分子问题的算法,站在任何一个子问题的处理上看,当前子问题的提出都要依据现有的类似结论,而当前问题的结论是后\n面问题求解的铺垫。任何DP都是基于存储的算法,核心是状态转移方程。 \n\n2.JVM调优\n\n其实我没有实际的调优经验,但是我主要介绍了一下JVM的分区、堆的分代以及回收算法还有OOM异常的处理思路 \n\n3.分别介绍一下Struts2和Spring\n\n不用多说,这方面比我答得好的同学肯定大有人在,就不出丑了 \n\n4.职责链模式(设计模式)\n\nGoF经典设计模式的一种 \n\n5.实践中如何优化MySQL\n\n我当时是按以下四条依次回答的,他们四条从效果上第一条影响最大,后面越来越小。 \n\n- SQL语句及索引的优化 \n- 数据库表结构的优化 \n- 系统配置的优化 \n- 硬件的优化 \n\n6.什么情况下设置了索引但无法使用\n\n- 以“%”开头的LIKE语句,模糊匹配 \n- OR语句前后没有同时使用索引 \n- 数据类型出现隐式转化(如varchar不加单引号的话可能会自动转换为int型) \n\n7.SQL语句的优化\n\n- order by要怎么处理\n\n- alter尽量将多次合并为一次\n\n- insert和delete也需要合并\n\n8.索引的底层实现原理和优化\n\nB+树,经过优化的B+树\n\n主要是在所有的叶子结点中增加了指向下一个叶子节点的指针,因此InnoDB建议为大部分表使用默认自增的主键作为主索引。\n\n9.HTTP和HTTPS的主要区别\n\n10.Cookie和Session的区别\n\n11.如何设计一个高并发的系统\n\n- 数据库的优化,包括合理的事务隔离级别、SQL语句优化、索引的优化\n- 使用缓存,尽量减少数据库 IO\n- 分布式数据库、分布式缓存\n- 服务器的负载均衡\n\n12.linux中如何查看进程等命令\n\n13.两条相交的单向链表,如何求他们的第一个公共节点\n\n很简单的链表题目,博客上的做法一搜一大把,我记得当时答在兴头上,又给面试官解释了一下如何求单向局部循环链表的入口,链表中很经典的问题(其实链表也就那几个常用算法,比如逆制、求倒数第K个节点,判断是否有环等)\n\n大概八十分钟吧,最后问面试官有没有对我的意见或者建议,面试官说觉得我今晚的面试表现比简历上写的更出色。。。对面试官的好感度瞬间飙升\n\n二面:可能一面面试官对我的评价还算不错,二面面试官一口气考了我11个设计模式(手动微笑),对,是11个设计模式,有直接提问,也有在场景设计中引导我使用。总共加起来11个,分别是:单例模式、简单工厂模式、工厂模式、抽象工厂模式、策略模式、观察者模式、组合模式、适配器模式、装饰模式、代理模式、外观模式。然后就是设计一个公司下有部门、部门下有经理和员工,经理可以管理经理和员工这样的一个模型,组合模式一套用就行了。后面还问了几个非技术问题,比如和产品、测试发生矛盾了怎么处理,答应的任务发现完成不了该如何处理等,大家如果遇到请随意装逼。 \n\n百度给我最大的印象就是每次新的面试,面试官一定会问什么时候能来实习,能够实习多长时间,答案符合要求了才进行下面的面试。据说百度今年要求6个月的实习时间,回答两三个月的都再无下文。 \n\n机智的我不管哪家公司问都是说从即日起到大四毕业,中间出了期末考试和毕业设计,都能参与实习,近期就能参加实习。不是故意想骗人,只是目前还没有和HR谈条件的筹码,这样说了就算最后去不了,也算是一次面试机会,如果一开始就拒绝的话,连面试机会都没有。等到技术面试结束了,跟一开始比,就有了谈条件的筹码,这个时候大家再根据情况合理要价\n\n三月的CVTE、四月的百度,现在该说五月的阿里了\n\n## 三、阿里巴巴 \n\n阿里巴巴其实同样的简历,在内推阶段直接简历被刷,非常尴尬。但是有幸笔试蜜汁通过,所以收到了参加现场面试的通知。 \n\n一面:一面的面试官长得超级像张家辉,整个面试过程,我满脑子都是《激战》里面的老拳王,当他朝我提问的时候,我就想到激战里面的经典台词“怕输,你就会输一辈子”。不知道面试官老师有没有看出我表情的异样~闲话不多说,上干货。 \n\n## 1. 二叉树的遍历方式,前序、中序、后序和层序\n\n二叉树本身就是一个递归的产物,那前序举例,访问根节点,然后左节点,再右节点,如果左节点是一棵子树,那么就先访问左子树的根节点,再访问左子树的左节点,依次递归;而层序,使用队列进行辅助,实现广度优先搜索 \n\n## 2. volatile关键字\n\n给大家推荐两本书:《Java多线程实战》和《Java并发编程的艺术》,这会儿已经三点了,脑子有点乱书名可能未必无误。对Java实现多线程描述的非常详细。现场跟面试官老师扯了很多,我在这里挑主要的说 \n\nvolatile关键字是Java并发的最轻量级实现,本质上有两个功能,在生成的汇编语句中加入LOCK关键字和内存屏障 \n\n作用就是保证每一次线程load和write两个操作,都会直接从主内存中进行读取和覆盖,而非普通变量从线程内的工作空间(默认各位已经熟悉Java多线程内存模型) \n\n但它有一个很致命的缺点,导致它的使用范围不多,就是他只保证在读取和写入这两个过程是线程安全的。如果我们对一个volatile修饰的变量进行多线程下的自增操作,还是会出现线程安全问题。根本原因在于volatile关键字无法对自增进行安全性修饰,因为自增分为三步,读取-》+1-》写入。中间多个线程同时执行+1操作,还是会出现线程安全性问题。 \n\n## 3. synchronized\n\n- 锁的优化:偏向锁、轻量级锁、自旋锁、重量级锁\n- 锁的膨胀模型,以及锁的优化原理,为什么要这样设计\n- 与Concurrent包下的Lock的区别和联系 \n\nLock能够实现synchronized的所有功能,同时,能够实现长时间请求不到锁时自动放弃、通过构造方法实现公平锁、出现异常时synchronized会由JVM自动释放,而Lock必须手动释放,因此我们需要把unLock()方法放在finally{}语句块中 \n\n## 4. concurrentHashMap\n\n两个hash过程,第一次找到所在的桶,并将桶锁定,第二次执行写操作。 \n\n而读操作不加锁,JDK1.8中ConcurrentHashMap从1600行激增到6000行,中间做了很多细粒度的优化,大家可以查一下。 \n\n## 5. 锁的优化策略\n\n- 读写分离 \n- 分段加锁 \n- 减少锁持有的时间 \n- 多个线程尽量以相同的顺序去获取资源 \n\n等等,这些都不是绝对原则,都要根据情况,比如不能将锁的粒度过于细化,不然可能会出现线程的加锁和释放次数过多,反而效率不如一次加一把大锁。这部分跟面试官谈了很久 \n\n## 6. 操作系统\n\n这部分基本是跪着跟面试官交流的,因为非计算机专业,对这个楼主确实比较欠缺 \n\n不过好在前面的表现还可以,顺利通过了。 \n\n二面:十分钟休息,二面面试官先问了一些无关紧要的问题,比如学校的专业课、平时如何学习新技术等等,然后切入正题,让我选一个熟悉的项目,三分钟画出大体架构图,我在项目部分的准备还算充分,但是面试官真的水平非常高。 \n\n在项目部分,可能是我整个阿里面试过程中最提心吊胆的,缓存的使用,如果现在需要实现一个简单的缓存,供搜索框中的ajax异步请求调用,使用什么结构?我回答ConcurrentHashMap,可是内存中的缓存不能一直存在,用什么算法定期将搜索权重较低的entry去掉?我说先按热度递减放进一个CopyOnWriteArrayList中,保留前多少个然后再存回ConcurrentHashMap中,面试官说效率过低,有没有更高效的算法,我假装冥思苦想(用假装其实是因为,确实想不到方法) \n\n后来面试官说其实这个问题有点难了,换一个,又跟我扯到线程的问题,大体就跟一面面试官问的差不多,就不赘述了。这部分感觉面试官还比较满意,就问题TCP如何保证安全性,我说三次握手、四次回收、超时重传、保序性、奇偶校验、去重、拥塞控制。还讲了滑动窗口模型。 \n\n后面又考了一些红黑树的问题,问到B+数,还有JDK1.8中对HashMap的增强,如果一个桶上的节点数量过多,链表+数组的结构就会转换为红黑树。 \n\n面试官问我项目中使用的单机服务器,如果将它部署成分布式服务器?我当时心里一惊,这个问题确实没有准备过,眼看就要被问死了,临时抖了个机灵,说有一次跟一个师兄尝试这么做的时候,遇到了session共享问题,然后成功地把面试官引向了session共享的问题,跟他讨论了10分钟左右的分布式系统中如何做到session共享。后面面试官可能也觉得我这部分\n\n手写一个线程安全的单例模式,经典的不能再经典,没什么好说的,懒汉饿汉随便选一个。 \n\n还有一些MySQL的常见优化方式、定为慢查询等,回答的七七八八,之前面试总结的问题还有印象,所以感谢自己有面试完及时总结的习惯。 \n\n最后问了问我平时都如何学习、最近都在看什么书,来实习的话学校的考试如何解决等等。 \n\n面试官告诉我他的问题已经问完了,我看没有让我提问的意思,所以我起身跟面试官握了个手(我在参加现场面试的时候有这样的习惯,握手的同时跟面试官强调,“我很珍惜这次面试机会”) \n\n二面出来之后挺紧张的,感觉自己答的还是有很多漏洞,可能面试官虽然发现了,但是觉得我态度不错,虚心学习,所以还是很幸运到了HR面,HR面就不多说了,只要不跟HR乱提要求,比如不考虑某某城市之类的作死要求,再跟HR好好谈谈我们对知识的渴望、希望得到锻炼的决心,我觉得都没什么问题(网易除外,都是泪) \n\n我还重点给HR讲了一下我对项目的反思,哪些地方可以做的更好。又把一次学习新技术时间又很紧的尽力夸大了一下,HR听完之后表示非常羡慕我们这样搞技术的,感觉每天做的事情都很有激情。 \n\n最后就是经过三天的等待,顺利拿到阿里巴巴的实习offer \n\n楼主从三月初到现在,基本能叫的出来的公司都参加了各种面试,很惭愧拿到offer的只有这三家。但是经过大大小小二三十次的面试,我觉得对一个后台程序员来说,重要的不只是语言,还有数据结构算法、网络基础、并发、数据库、设计模式、操作系统、linux等等很多很多技术需要掌握。我就有很强烈的感觉,单论Java,在楼主的周围其实有很多比楼主强得多的人,可是他们有的人面试一直不顺利,原因就在于其他的知识点相对薄弱。这点在阿里巴巴面试中就体现的很深刻。最后HR问我作为非计算机专业学生,什么专业课没有学到最让我遗憾?我回答网络基础、操作系统、计算机组成原理和系统的数据库知识体系。虽然侥幸拿到了阿里巴巴的offer,但这一次的面试让我深深地看到了自己差距。跟二面面试官交流的时候,他考我项目,我就拼命想把他往框架上拉,想解释hibernate和Spring还有mybatis,结果面试官一次也没有上当。每当我说这些的时候,面试官就会打断我,说我不用解释框架,我们就建立在这些东西都双方都清楚的基础上。所以真心劝各位准备面试的朋友们,多重视基础。基础能够决定学习能力和思维方式,而学习能力和思维方式最终决定一个程序员能走多远。\n\n以上是我对春招面试的部分总结,手上还有十份左右的手写面经,都是每次面试完当天晚上自己总结的,有需要的朋友可以私信我。 \n\n最后祝看完这篇文章额所有朋友,找到自己心仪的工作,程序员都不容易。 \n\n最后的最后,牛客在过年到现在这段时间对我的帮助非常大,有我寒假怒刷2000题,也有后面疯狂提交代码(疯狂报错),是金子总会发光,在我的带动下,整个实验室都在刷题,总之祝牛客网越办越好\n"
},
{
"path": "docs/android/Android-Interview/经验分享/面试心得与总结:BAT、网易、蘑菇街 .md",
"content": "之前实习的时候就想着写一篇面经,后来忙就给忘了,现在找完工作了,也是该静下心总结一下走过的路程了,我全盘托出,奉上这篇诚意之作,希望能给未来找工作的人一点指引和总结,也希望能使大家少走点弯路,如果能耐心读完,相信对你会找到你需要的东西。\n\n先说一下LZ的基本情况,LZ是四川某985学校通信专业的研究生(非计算机),大学阶段也就学了C语言,根本没想过最后要成为码农。大四才开始学java,研一下开始学android,所以LZ觉得自己开始就是一个小白,慢慢成长起来的。\n\n## 1. 心态\n\n心态很重要!\n心态很重要!\n心态很重要!\n\n重要的事情说三遍,这一点我觉得是必须放到前面来讲。\n\n找工作之前,有一点你必须清楚,就是找工作是一件看缘分的事情,不是你很牛逼,你就一定能进你想进的公司,都是有一个概率在那。如果你基础好,项目经验足,同时准备充分,那么你拿到offer的概率就会比较高;相反,如果你准备不充分,基础也不好,那么你拿到offer的概率就会比较低,但是你可以多投几家公司,这样拿到offer的几率就要大一点,因为你总有运气好的时候。所以,不要惧怕面试,刚开始失败了没什么的,多投多尝试,面多了你就自然能成面霸了。得失心也不要太重,最后每个人都会有offer的。\n\n还有一个对待工作的心态,有些人可能觉得自己没有动力去找一个好工作。其实你需要明白一件事情,你读了十几二十年的书,为的是什么,最后不就是为了找到一个好工作么。现在到了关键时刻,你为何不努力一把呢,为什么不给自己一个好的未来呢,去一个自己不满意的公司工作,你甘心吗?\n\n想清楚这一点,我相信大多数人都会有一股干劲了,因为LZ刚刚准备开始找实习的时候,BAT这种公司想都不敢想,觉得能进个二线公司就很不错了,后来发现自己不逼自己一把,你真不知道自己有多大能耐,所以请对找工作保持积极与十二分的热情,也请认真对待每一次笔试面试。\n\n## 2. 基础\n\n基础这东西,各个公司都很看重,尤其是BAT这种大公司,他们看中人的潜力,他们舍得花精力去培养,所以基础是重中之重。之前很多人问我,项目经历少怎么办,那就去打牢基础,当你的基础好的发指的时候,你的其他东西都不重要了。\n\n基础无外乎几部分:语言(C/C++或java),操作系统,TCP/IP,数据结构与算法,再加上你所熟悉的领域。这里面其实有很多东西,各大面试宝典都有列举。\n\n在这只列举了Android客户端所需要的和我面试中所遇到的知识点,尽量做到全面,如果你掌握了以下知识点,去面android客户端应该得心应手。\n\n### J2SE基础\n\n1.九种基本数据类型的大小,以及他们的封装类。\n2.Switch能否用string做参数?\n3.equals与==的区别。\n4.Object有哪些公用方法?\n5.Java的四种引用,强弱软虚,用到的场景。\n6.Hashcode的作用。\n7.ArrayList、LinkedList、Vector的区别。\n8.String、StringBuffer与StringBuilder的区别。\n9.Map、Set、List、Queue、Stack的特点与用法。\n10.HashMap和HashTable的区别。\n11.HashMap和ConcurrentHashMap的区别,HashMap的底层源码。\n12.TreeMap、HashMap、LindedHashMap的区别。\n13.Collection包结构,与Collections的区别。\n14.try catch finally,try里有return,finally还执行么?\n15.Excption与Error包结构。OOM你遇到过哪些情况,SOF你遇到过哪些情况。\n16.Java面向对象的三个特征与含义。\n17.Override和Overload的含义去区别。\n18.Interface与abstract类的区别。\n19.Static class 与non static class的区别。\n20.java多态的实现原理。\n21.实现多线程的两种方法:Thread与Runable。\n22.线程同步的方法:sychronized、lock、reentrantLock等。\n23.锁的等级:方法锁、对象锁、类锁。\n24.写出生产者消费者模式。\n25.ThreadLocal的设计理念与作用。\n26.ThreadPool用法与优势。\n27.Concurrent包里的其他东西:ArrayBlockingQueue、CountDownLatch等等。\n28.wait()和sleep()的区别。\n29.foreach与正常for循环效率对比。\n30.Java IO与NIO。\n31.反射的作用于原理。\n32.泛型常用特点,List能否转为List。\n33.解析XML的几种方式的原理与特点:DOM、SAX、PULL。\n34.Java与C++对比。\n35.Java1.7与1.8新特性。\n36.设计模式:单例、工厂、适配器、责任链、观察者等等。\n37.JNI的使用。\n\nJava里有很多很杂的东西,有时候需要你阅读源码,大多数可能书里面讲的不是太清楚,需要你在网上寻找答案。\n\n推荐书籍:《java核心技术卷I》《Thinking in java》《java并发编程》《effictive java》《大话设计模式》\n\n### JVM\n\n1.内存模型以及分区,需要详细到每个区放什么。\n2.堆里面的分区:Eden,survival from to,老年代,各自的特点。\n3.对象创建方法,对象的内存分配,对象的访问定位。\n4.GC的两种判定方法:引用计数与引用链。\n5.GC的三种收集方法:标记清除、标记整理、复制算法的原理与特点,分别用在什么地方,如果让你优化收集方法,有什么思路?\n6.GC收集器有哪些?CMS收集器与G1收集器的特点。\n7.Minor GC与Full GC分别在什么时候发生?\n8.几种常用的内存调试工具:jmap、jstack、jconsole。\n9.类加载的五个过程:加载、验证、准备、解析、初始化。\n10.双亲委派模型:Bootstrap ClassLoader、Extension ClassLoader、ApplicationClassLoader。\n11.分派:静态分派与动态分派。\n\nJVM过去过来就问了这么些问题,没怎么变,内存模型和GC算法这块问得比较多,可以在网上多找几篇博客来看看。\n\n推荐书籍:《深入理解java虚拟机》\n\n### 操作系统\n\n1.进程和线程的区别。\n2.死锁的必要条件,怎么处理死锁。\n3.Window内存管理方式:段存储,页存储,段页存储。\n4.进程的几种状态。\n5.IPC几种通信方式。\n6.什么是虚拟内存。\n7.虚拟地址、逻辑地址、线性地址、物理地址的区别。\n\n因为是做android的这一块问得比较少一点,还有可能上我简历上没有写操作系统的原因。\n\n推荐书籍:《深入理解现代操作系统》\n\n### TCP/IP\n\n1.OSI与TCP/IP各层的结构与功能,都有哪些协议。\n2.TCP与UDP的区别。\n3.TCP报文结构。\n4.TCP的三次握手与四次挥手过程,各个状态名称与含义,TIMEWAIT的作用。\n5.TCP拥塞控制。\n6.TCP滑动窗口与回退N针协议。\n7.Http的报文结构。\n8.Http的状态码含义。\n9.Http request的几种类型。\n10.Http1.1和Http1.0的区别\n11.Http怎么处理长连接。\n12.Cookie与Session的作用于原理。\n13.电脑上访问一个网页,整个过程是怎么样的:DNS、HTTP、TCP、OSPF、IP、ARP。\n14.Ping的整个过程。ICMP报文是什么。\n15.C/S模式下使用socket通信,几个关键函数。\n16.IP地址分类。\n17.路由器与交换机区别。\n\n网络其实大体分为两块,一个TCP协议,一个HTTP协议,只要把这两块以及相关协议搞清楚,一般问题不大。\n\n推荐书籍:《TCP/IP协议族》\n\n### 数据结构与算法\n\n1.链表与数组。\n2.队列和栈,出栈与入栈。\n3.链表的删除、插入、反向。\n4.字符串操作。\n5.Hash表的hash函数,冲突解决方法有哪些。\n6.各种排序:冒泡、选择、插入、希尔、归并、快排、堆排、桶排、基数的原理、平均时间复杂度、最坏时间复杂度、空间复杂度、是否稳定。\n7.快排的partition函数与归并的Merge函数。\n8.对冒泡与快排的改进。\n9.二分查找,与变种二分查找。\n10.二叉树、B+树、AVL树、红黑树、哈夫曼树。\n11.二叉树的前中后续遍历:递归与非递归写法,层序遍历算法。\n12.图的BFS与DFS算法,最小生成树prim算法与最短路径Dijkstra算法。\n13.KMP算法。\n14.排列组合问题。\n15.动态规划、贪心算法、分治算法。(一般不会问到)\n16.大数据处理:类似10亿条数据找出最大的1000个数...等等\n\n算法的话其实是个重点,因为最后都是要你写代码,所以算法还是需要花不少时间准备,这里有太多算法题,写不全,我的建议是没事多在OJ上刷刷题(牛客网、leetcode等),剑指offer上的算法要能理解并自己写出来,编程之美也推荐看一看。\n\n推荐书籍:《大话数据结构》《剑指offer》《编程之美》\n\n### Android\n\n1.Activity与Fragment的生命周期。\n2.Acitivty的四中启动模式与特点。\n3.Activity缓存方法。\n4.Service的生命周期,两种启动方法,有什么区别。\n5.怎么保证service不被杀死。\n6.广播的两种注册方法,有什么区别。\n7.Intent的使用方法,可以传递哪些数据类型。\n8.ContentProvider使用方法。\n9.Thread、AsycTask、IntentService的使用场景与特点。\n10.五种布局:FrameLayout、LinearLayout、AbsoluteLayout、RelativeLayout、TableLayout、GridLayout,各自特点及绘制效率对比。\n11.Android的数据存储形式。\n12.Sqlite的基本操作。\n13.Android中的MVC模式。\n14.Merge、ViewStub的作用。\n15.Json有什么优劣势。\n16.动画有哪两类,各有什么特点?\n17.Handler、Loop消息队列模型,各部分的作用。\n18.怎样退出终止App。\n19.Asset目录与res目录的区别。\n20.Android怎么加速启动Activity。\n21.Android内存优化方法:ListView优化,及时关闭资源,图片缓存等等。\n22.Android中弱引用与软引用的应用场景。\n23.Bitmap的四中属性,与每种属性队形的大小。\n24.View与View Group分类。自定义View过程:onMeasure()、onLayout()、onDraw()。\n25.Touch事件分发机制。\n26.Android长连接,怎么处理心跳机制。\n27.Zygote的启动过程。\n28.Android IPC:Binder原理。\n29.你用过什么框架,是否看过源码,是否知道底层原理。\n30.Android5.0、6.0新特性。\n\nAndroid的话,多是一些项目中的实践,使用多了,自然就知道了,还有就是多逛逛一些名人的博客,书上能讲到的东西不多。另外android底层的东西,有时间的话可以多了解一下,加分项。\n\n推荐书籍:《疯狂android讲义》《深入理解android》\n\n其他综合性的书籍也需要阅读,推荐:《程序员面试笔试宝典》《程序员面试金典》。另外“牛客网www.newcoder.com”是个好地方,里面有各种面试笔试题,也有自己在线的OJ,强烈推荐,还有左程云老师的算法视屏课(已经出书了),反正我看了之后对我帮助很大(这不是植入广告)。\n\n## 3. 项目\n\n关于项目,这部分每个人的所做的项目不同,所以不能具体的讲。项目不再与好与不好,在于你会不会包装,有时候一个很low的项目也能包装成比较高大上的项目,多用一些专业名词,突出关键字,能使面试官能比较容易抓住重点。在聊项目的过程中,其实你的整个介绍应该是有一个大体的逻辑,这个时候是在考验你的表达与叙述能力,所以好好准备很重要。\n\n面试官喜欢问的问题无非就几个点:\n\n1.XXX(某个比较重要的点)是怎么实现的?\n2.你在项目中遇到的最大的困难是什么,怎么解决的?\n3.项目某个部分考虑的不够全面,如果XXXX,你怎么优化?\n4.XXX(一个新功能)需要实现,你有什么思路?\n\n其实你应该能够预料到面试官要问的地方,请提前准备好,如果被问到没有准备到的地方,也不要紧张,一定要说出自己的想法,对不对都不是关键,主要是有自己的想法,另外,你应该对你的项目整体框架和你做的部分足够熟悉。\n\n## 4. 其他\n\n你应该问的问题\n\n面试里,最后面完之后一般面试官都会问你,你有没有什么要问他的。其实这个问题是有考究的,问好了其实是有加分的,一般不要问薪资,主要应该是:关于公司的、技术和自身成长的。\n\n以下是我常问的几个问题,如果需要可以参考:\n\n1.贵公司一向以XXX著称,能不能说明一下公司这方面的特点?\n2.贵公司XXX业务发展很好,这是公司发展的重点么?\n3.对技术和业务怎么看?\n4.贵公司一般的团队是多大,几个人负责一个产品或者业务?\n5.贵公司的开发中是否会使用到一些最新技术?\n6.对新人有没有什么培训,会不会安排导师?\n7.对Full Stack怎么看?\n8.你觉得我有哪些需要提高的地方?\n\n### 知识面\n\n除了基础外,你还应该对其他领域的知识有多少有所涉猎。对于你所熟悉的领域,你需要多了解一点新技术与科技前沿,你才能和面试官谈笑风生。\n\n### 软实力\n\n什么是软实力,就是你的人际交往、灵活应变能力,在面试过程中,良好的礼节、流畅的表达、积极的交流其实都是非常重要的。很多公司可能不光看你的技术水平怎么样,而更看重的是你这个人怎么样的。所以在面试过程中,请保持诚信、积极、乐观、幽默,这样更容易得到公司青睐。\n\n很多时候我们都会遇到一个情况,就是面试官的问题我不会,这时候大多数情况下不要马上说我不会,要懂得牵引,例如面试官问我C++的多态原理,我不懂,但我知道java的,哪我可以向面试官解释说我知道java的,类似的这种可以往相关的地方迁移(但是需要注意的是一定不要不懂装懂,被拆穿了是很尴尬的),意思就是你要尽可能的展示自己,表现出你的主动性,向面试官推销自己。\n\n还有就是遇到智力题的时候,不要什么都不说,面试官其实不是在看你的答案,而是在看你的逻辑思维,你只要说出你自己的见解,有一定的思考过程就行。\n\n## 5. 面经\n\nLZ应聘的职位都是android客户端开发。\n\n面经其实说来话长,包括实习的话面过的公司有:CVTE、腾讯、阿里、百度、网易、蘑菇街、小米。最早得追溯到到今年3月份,那时候刚过完年,然后阿里的实习内推就开始了,我基本都没什么准备,就突如其来的接到了人生中第一个面试电话。\n\n### 阿里实习内推一面\n\n电话面试,\n由于是第一次面试,所以非常紧张,项目都没怎么说清楚。然后面试官就开始问项目细节了,这里我关于一个项目细节和面试官有不同的看法,面试官说我这样做有问题,然后我说我们确实是这样做的,并没有出什么错,差点和面试官吵起来,最后我还是妥协了。然后问了我一个怎么对传输的数据加密,我答的很挫,然后面试官就开始鄙视我:你这个基础不好,那个基础不好,那你说说你还有其他什么优势没?Blabla紧张的说了一些…………只面了30分钟不到,然后妥妥的就挂了。\n\n经过这次面试突然感觉人生的艰辛,几天后我们教研室的其他同学陆续开始了面试,他们都很顺利,其中我的室友(单程车票)很顺利的拿到了offer,他是个大神,然后我就压力无比的大。制定了整套复习计划,从早上9点看书看到晚上10点。\n\n到了3月15号左右有CVTE面试,第一次面试是群面,比较坑,坐了一个小时的车过去群面了5分钟,没什么好说的。\n\n### CVTE实习面\n\n在自我介绍和项目后,面试官开始问一些java基础,object有哪些方法?这个还能说了一些。问hashmap有多大,这个当时一脸茫然,还sb的答了一个65535。然后面试官让我写三分钟内写一个二分查找,当时也是第一次手写代码,并且还计时,完全没经验,最后超时写了出来。中间又问了我一堆基础,都答得不是很完整。最后问我遇到过OOM的情况没有,什么情况下会OOM。这个也没答出来,然后又妥妥的挂了。\n\n这次经历告诉我,我是缺少面试经验,和现场写代码的能力,基础还需要多加强。所以我开始各种准备,在一个月的时间里看了四本面试书(程序员面试宝典、java程序员面试宝典、程序员面试笔试宝典、剑指offer),把所有关于数据结构和算法的东西用代码写了一遍。\n\n然后到了四月初,腾讯来了,我最开始还是非常向往腾讯的,但就当时那个情况,我对自己不报太大希望,觉得能进BAT这样的顶级公司是个奢侈的梦想。\n\n腾讯的面试是在一个5星级酒店里面,逼格高大上,感觉问的东西也比较多,感觉喜欢问智力题,但是我没遇到。 \n\n### 腾讯实习1面\n\n50分钟左右,\n面试的时候还是有些紧张的,但是运气好,遇到了一个学校的师兄,他一直叫我不要紧张。几个比较关键的问题:死锁的必要条件,怎么解决,java和c++比有什么优势,java同步方法,activity生命周期,中间让我设计了个银行排队系统,我说了一堆。然后让我写了一个计算一个int里面二进制有几个1,然后我用最高效的方法(n=n&n-1)写出来之后,面试官有点意外,还说没见过这么写的,让我跟他解释一下。后面就是拉拉家常,问我对工作地点怎么看,让我对比qq和微信,一面出来之后,面试官让我留意通知,心想是过了,其实发挥的不怎么好。\n\n就在会学校的路上,都要到学校了,收到了腾讯二面的通知,下午3点。然后我又跑回去二面。\n\n### 腾讯实习2面\n\n二面是一个很严肃的人,看上去就比较资深那种,一直都不笑,后面才知道是手机管家T4的专家。一开始就问我项目里,心跳包是怎么设计的,我项目里并没有用心跳,然后只能跟他说没做,问我用json传输数据有什么不好(我只知道用哪想过有什么不好)。又问了http和socket的区别,两个协议哪个更高效一点,遇到过java内存泄露没有,用过哪些调试java内存工具,java四种引用。多数都是项目上的东西,基础的东西没问太多,然后感觉自己答的不是很好,很多都不知道,而且还答错了。其实我感觉我应该是过不了的,但是最后我问问题的时候,我让他评价下我的表现,他说不好评价,我自己说了一堆,说在学校里确实见识到的东西比较少,很多东西没考虑全面,然后他表示赞同,和我探讨了一番,我觉得最后这个问题给我加了不少分。二面也面了50分钟左右。\n\n回来后发现我的状态一直没变,而他们二面完了的都到了HR面了,我以为我已经挂定了,后来在一天晚上12点的时候,惊喜的收到了第二天HR面的短信,当晚上几乎高兴得一晚上没睡着觉。\n\n### 腾讯实习3面(HR)\n\n就是hr面,也就面了十几分钟,聊聊天,问问哪的人,未来什么打算的等等,基本不怎么挂人就不详细写了。\n\n就这样拿到了人生中第一个实习offer。\n\n后面找实习的心就放松了,没有复习了。然后到了5月5号,阿里来了。对阿里也只是想去面一面的心态了,因为已经有腾讯的offer了,就没想太多。\n\n### 阿里实习1面\n\n面过腾讯之后发现自己已经比较淡定了,面试得时候能够比较好的交谈了。这一面也遇到一个比较好的面试官,能很轻松的和他交流。主要的问题是android的:activity的生命周期、activity的四种启动模式(当时忘了一些没答全)、线性布局和相对布局、多线程请求,java GC算法与GC方法,内存模型,有一个比较特别的问题是问我微信的朋友圈怎么设计,然后我把思路跟他说了,其他的就是问了项目相关的了。还问了我一个觉得技术深度重要还是技术宽度重要,一面感觉还是比较基础的。\n\n\n### 阿里实习2面\n\n这一面就比较虐心,碰到一个阿里云的CTO,一上去项目看都不看,直接问我写过多少行代码,我说至少3、4万行,然后他让我写了两个题:一个找素数,一个递归求阶层,对我也算手下留情(他后来让我同学写AVL树的插入算法,想想也是醉了)。后面就各种基础了,java的基础挨个问了一遍,比较关键多线程实现,锁的几种等级等,反射的用法,wait()和sleep()(讨论这个的时候他把我说晕了),Java还好,多数能应付,然后他就开始问c++的了。虽然是基础,但是lz忘了差不多了,什么指针数组和数组指针,虚函数,多态实现(这个我扯到java上了)等等,问了很多,很多都没答上来,然后他说我基础不太好(我想说我简历上写的了解C++,为什么要追着我问TT)。\n\n\n就这样出来了,本来以为挂了,后面被通知过了。同学都只有2面技术面,我居然多了一面,叫交叉面试,心想这下肯定完了。\n\n### 阿里实习3面\n\n这一面遇到了后面我去实习时候的部门boss,人非常好,来的时候走的时候都要和我握手,非常的平易近人。这一面还是问项目上的一些东西居多,基础就问了个java多线程,各个排序的时间复杂度、思想。技术问了半个小时,后面半个小时就开始各种聊人生了(@_@),我家是哪的,父母干嘛的,中学怎么样,大学怎么样,等等,完全就不像是技术面嘛(后来才知道,我一个同学一开始来就和他聊人生,还聊过了。再次感叹找工作是看缘分呐)。\n\n### 阿里实习4面(HR)\n\n阿里hr比腾讯hr面专业,面了一个小时,把我的生活经历趴了一遍,(问了类似你的优缺点,最让你高兴的一件事,最让你伤心的一件事,你的职业规划,你的理想等等,这种,现在想不起来了)也没什么特别好说的。\n\n面完后第二天去圆桌签offer,就这样又拿到了阿里的实习offer。\n\nLZ后面衡量了杭州阿里B2B和广州腾讯MIG,最后选择去了阿里,因为在总部,感觉大boss人比较好,发展前途可能不错,而且留下来的几率比较大,而腾讯是一个分部门,感觉可能不是很有前景(但是后来了解到其实广州腾讯MIG发展前景非常好,环境也非常和谐,我同学去实习的都留下来了。哎,只能感叹选择是个大问题)。在阿里实习的两个月时间也挺愉快的,学到了不少东西,也认识了很好的师兄和主管,只因最后被拥抱了变化没有拿到正式offer。\n\n实习面经就已经写完了,后面是正式找工作的经历,主要是内推比较多:腾讯、网易、蘑菇街、小米,校招就面了家百度。\n\n在阿里实习的时候,面了网易和蘑菇街。\n\n网易面试是我面了这么多中,问得最专业的了。\n\n### 网易内推1面\n\n电话面,一天在里中午休息的时候面的。这一面我面得很烂,由于在阿里实习,面试官恰好也在阿里呆过,问了我在阿里学到了哪些东西,看过哪些框架,看过源码没有,我支支吾吾说了一些,面试官不太满意(我表示我都说不全啊,在阿里就来了不久,哪那么多时间看源码)。项目各种细节问一通之后,开始问基础,Http报文结构,Handler、Looper模型,ThreadLocal(这个LZ当时没答上来),怎么使service不被杀死,android内存优化,自己实现线程队列模型,问我怎么设计(这个当时被前面的问题问蒙了,直接说不知道了),面了20+分钟,感觉答得都不怎么好,然后面试官问我说还有没有什么比较擅长的他没有问道的,我就把android Framework里zygote的启动和Binder通信说了一遍(这里强行装了一次逼)。\n\n面完之后本以为挂定了,然后师姐跟我说居然过了,也是够神奇,我觉得是我后面补充的内容救了我。\n\n### 网易内推2面\n\n二面是现场面,就在阿滨江区的隔壁。时间是一天中午,吃了饭就到了隔壁。面试官是个比较年轻人,可能大不了我几岁,也是非常好说话,开始也是聊项目,我把在阿里做的app和自己写的小框架拿出来,他就指着上面各种问,这里怎么实现,会有什么问题,你怎么解决,然后他描述了一个场景说,两个activity,前面的是个dialog activity,怎么在dialog activity存在的情况下改变后面的activity(lz答的用广播)。android怎么解决缓存,要是内存超了怎么办?然后扯到了JVM,GC判定算法与方法,哪个区域用什么GC算法,怎么改进复制算法。然后是基础,也像一面一样问了一些,hashmap和concurrntHashmap的区别、泛型能否强制转换。然后是算法,问了快排和归并的平均时间复杂度与最差时间复杂度,出了个算法题:怎么找到一个随机数组的前50大数、中间50大数,(这个用最小堆和partition函数),复杂度是多少。\n\n面完之后其实感觉还不错,基本都打答上来了,顺利进入三面。\n\n### 网易内推3面(HR)\n\nhr面也是现场,也聊了很多,问我为什么要从阿里来网易,有什么打算,你看中网易的什么(主要是针对我是在阿里实习来问的,我就讲了一堆网易的优势),让来杭州工作愿不愿意。还跟我说了,这次内推是优中选优,有名额限制,如果没有通过,请继续关注网易校招。\n\n后面让师姐查了下状态,状态显示是三面已通过。但是最后没有收到offer,还是有点小失望。\n\n蘑菇街面试感觉比较基础,没有什么技术难度。\n\n### 蘑菇街内推1面\n\n电话面,也是在一个中午面的。18分钟,问了一些项目,主要是问基础、问得非常基础:Arraylist与LinkedList区别,String与StringBuffer用法,HashMap与HashTable区别,Synchronized用法等等等等(非常基础),这不一一列举了,然后很顺利的就过了。\n\n2面是在20天后了,也不知道蘑菇街出了什么岔子。\n\n\n### 蘑菇街内推2面\n\n也是电话面,CTO面试,就整体聊了项目,我在项目中学到了什么,遇到什么困难怎么解决的,在阿里实习学到了哪些东西,有看过源码么,我的优缺点,我为什么选择蘑菇街,我了解蘑菇街哪些东西。最后答完感觉自己答得还行但是也没有过,不知道为什么。\n\n小米是投的内推精英计划,50个名额,解决北京户口。\n\n### 小米内推1面\n\n电话面,大概40分钟,面试的时候那边很吵,不过幸好面试官语速慢,而且我答完一个问题后,面试官会和我交流哪里没有答好。没有问项目,就问了基础,问题也不多:HashMap删除元素的方法,for each和正常for的用在不同数据结构(ArrayList、set、hashmap)上的效率区别(LZ表示没有看过源码,不知道),static class和non-static class的区别,一个大文件几个GB,怎么实现复制(这个也没有答好)。然后问了两个算法:之前一个出现过,另一个是在git里面,如果有n个分支,m次commit怎么找到任意两个节点共同的那个父节点(这个当时我想错了,想到二叉树上去了,没有答好)。然后让两个算法用代码实现,1个小时内写好email给他。\n\n小米面了以后也杳无音信,估计也是要求很高,毕竟解决北京户口。\n\n其实在阿里实习的时候很早就开始投简历了,因为出去实习一段时间后,感觉还是很想留在成都(因为lz是四川人)。腾讯我没有参加校招面试,直接走的内推流程。\n\n### 腾讯1面\n\n电话面,7月20+号,很水,就问了项目,聊了可能有十多分钟,然后面试官说,内推没有什么作用,还是要走校招面试(我觉得他可能是有其他事情,想节省时间),你在实习不能回来,还是要现场面一次才行,然后就留了个电话让我校招联系他,这样就完了。\n\n2面是在我回学校后了。\n\n### 腾讯2面\n\n9月6号我回学校之后,下午3点接到电话,让我晚上7点去腾讯现场面的(我在想为何是在晚上,lz学校到腾讯要2个小时,还让不让人回来了),当时紧张得要死,因为刚从阿里回来不久,都没怎么好好准备基础,在地铁上看了两本基础书,亚历山大。面试是在腾讯里面,微信部门,面试官是个中年人(现在是LZ的主管),看起来还是比较沉稳的那种。也没问基础技术问题,就聊项目细节和一些可优化的地方,然后把lz的简历看了翻了一遍,问了一遍,然后就是问我在阿里学到了什么,为什么当时选择了阿里(这时候肯定要各种跪舔啊)。然后后来他说他是做ios的,我在想难怪不问我基础。\n\n面完了说一周之内通知我结果,也没报太大希望,感觉并不太对口,因为搞不懂为什么是做ios的来面我。\n\n两天之后,在阿里HRG电话通知我拥抱变化之后,几乎同一时间,腾讯电话通知我拿到了成都offer,我只能感叹太巧了(大概这大半辈子的运气都花光了)。\n\n后来校招开始后,只面了百度一家公司,百度确实比较重视基础与算法,看中技术。\n\n### 百度1面\n\n大概1个小时,又是个做ios的师兄面试我,自然就只能聊项目了,我给他展示了我做的app后,也问了些技术问题,缓存怎么做的,内存溢出怎么处理。然后两个算法题:把一个数组中奇数放前面,偶数放后面,这个要求写出来。另一个是3亿条IP中,怎么找到次数出现最多的5000条IP。最后问了是否愿意去北京,对于技术的看法。\n\n### 百度2面\n\n50分钟,写个4个程序题:反转链表、冒泡排序、生产者消费者,这三个都还好写,很快的写出来了,还有一个题是在一组排序数中,给定一个数,返回最接近且不大于这个数的位置,要求时间在O(logn)(这个想了一会,用二分查找,然后特殊处理了一下),最后他看不懂,要我一步一步解释。花了好一整子,最后问了个java反射,就让我走了。百度果然是重视算法。\n\n### 百度3面\n\n这一面应该是个技术高层,笼统的问了我一下项目的问题,然后问了几个基础:java反射机制;android动画有哪些,什么特点?TCP/IP层次架构,每层的作用与协议;TCP拥塞控制;滑动窗口是怎么设计的,有什么好处;android的布局都有哪些。问完这些之后,然后就是有点类似于HR的聊天了:如果这次面试过了你觉得是因为什么原因,没过呢?你觉得百度怎么样?你对技术路线什么打算?有些和前面重复的就不写了。然后他让我问他问题,我就连续问了5、6个问题,最后愉快的走了。\n\n百度这两天给结果。\n\n## 6. 写在最后\n\n\n### 关于选择\n\nLZ当时实习的时候,杭州阿里和广州腾讯选择去了阿里,但是却因为拥抱变化没有留下来,相反这边在腾讯实习的同学却很顺利。但是也是因为没有去广州腾讯,最后我能留在成都腾讯。选择是一件非常重要的事情,它决定着你的未来,但是也有一点你得知道:塞翁失马焉知非福,现在看起来不太好的选择,不一定将来就好,未来有太多未知数。\n\n### 心怀感恩\n\n其实一路走来,我也是在成长,从最初的不自信,到了最后面试一切都比较冷静与沉着。我一直相信,机会是留给有准备的人,所以,请提早准备,越早越好。我很感激能有那么多人帮助我和肯定我,没有最初腾讯的肯定,我肯定不会走的这么顺利,所以我很感恩哪些让我通过的人,也感谢我们实验室的兄弟姐妹,给了我良好的学习成长环境,心怀感恩才能好运常在。\n\n找工作其实就像是一场战役,前面我们经历了高考或者考研,现在是找工作,你不在这个时候搏一搏,怎么对得起你之前的努力。不要担心找不到好工作,你要相信:\n\n天道酬勤!"
},
{
"path": "docs/android/Android-Interview/网络编程/Android客户端和服务端如何使用Token和Session.md",
"content": "对于初学者来说,对Token和Session的使用难免会限于困境,开发过程中知道有这个东西,但却不知道为什么要用他?更不知道其原理,今天我就带大家一起分析分析这东西。\n\n## 我们先解释一下他的含义:\n\n1、Token的引入:Token是在客户端频繁向服务端请求数据,服务端频繁的去数据库查询用户名和密码并进行对比,判断用户名和密码正确与否,并作出相应提示,在这样的背景下,Token便应运而生。\n\n2、Token的定义:Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。\n\n3、使用Token的目的:Token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。\n\n了解了Token的意义后,我们就更明确的知道为什么要用他了。\n\n## 如何使用Token?\n\n这是本文的重点,在这里我就介绍常用的两种方式。\n\n1、用设备号/设备mac地址作为Token(推荐)\n\n客户端:客户端在登录的时候获取设备的设备号/mac地址,并将其作为参数传递到服务端。\n\n服务端:服务端接收到该参数后,便用一个变量来接收同时将其作为Token保存在数据库,并将该Token设置到session中,客户端每次请求的时候都要统一拦截,并将客户端传递的token和服务器端session中的token进行对比,如果相同则放行,不同则拒绝。\n\n分析:此刻客户端和服务器端就统一了一个唯一的标识Token,而且保证了每一个设备拥有了一个唯一的会话。该方法的缺点是客户端需要带设备号/mac地址作为参数传递,而且服务器端还需要保存;优点是客户端不需重新登录,只要登录一次以后一直可以使用,至于超时的问题是有服务器这边来处理,如何处理?若服务器的Token超时后,服务器只需将客户端传递的Token向数据库中查询,同时并赋值给变量Token,如此,Token的超时又重新计时。\n\n2、用session值作为Token\n\n客户端:客户端只需携带用户名和密码登陆即可。\n\n客户端:客户端接收到用户名和密码后并判断,如果正确了就将本地获取sessionID作为Token返回给客户端,客户端以后只需带上请求数据即可。\n\n分析:这种方式使用的好处是方便,不用存储数据,但是缺点就是当session过期后,客户端必须重新登录才能进行访问数据。\n\n## 使用过程中出现的问题以及解决方案?\n\n刚才我们轻松介绍了Token的两种使用方式,但是在使用过程中我们还出现各种问题,Token第一种方法中我们隐藏了一个在网络不好或者并发请求时会导致多次重复提交数据的问题。\n\n该问题的解决方案:将session和Token套用,如此便可解决,如何套用呢?请看这段解释:\n\n\n\n这就是解决重复提交的方案。\n\n总结:以上是个人对开发中使用Token和session的一点总结,如有叙述不当之处请指正,我将及时改正并感谢,我知道还有更多更好的使用方式,我在这里只是抛砖引玉,希望大家将您的使用方式提出来,我们一起讨论,学习,一起进步,同时也为像我一样对这方面理解薄弱的朋友提供点帮助,谢谢。"
},
{
"path": "docs/android/Android-Interview/网络编程/README.md",
"content": "## 网络编程\n\n- [Android客户端和服务端如何使用Token和Session](Android客户端和服务端如何使用Token和Session.md)\n- [推送原理](推送原理.md)\n- [阐述一下对XMPP协议理解以及优缺点?](阐述一下对XMPP协议理解以及优缺点?.md)\n- [简单阐述一下及时推送原理?](简单阐述一下及时推送原理?.md)"
},
{
"path": "docs/android/Android-Interview/网络编程/推送原理.md",
"content": "# 极光推送技术原理:移动无线网络长连接\n\n## 移动互联网应用现状\n\n因为手机平台本身、电量、网络流量的限制,移动互联网应用在设计上跟传统 PC 上的应用很大不一样,需要根据手机本身的特点,尽量的节省电量和流量,同时又要尽可能的保证数据能及时到达客户端。\n\n为了解决数据同步的问题,在手机平台上,常用的方法有2种。一种是定时去服务器上查询数据,也叫Polling,还有一种手机跟服务器之间维护一个 TCP 长连接,当服务器有数据时,实时推送到客户端,也就是我们说的 Push。\n\n从耗费的电量、流量和数据送达的及时性来说,Push 都会有明显的优势,但 Push 的实现和维护成本相对较高。在移动无线网络下维护长连接,相对也有一些技术上的难度。本文试图给大家介绍一下我们[极光推送](http://www.jpush.cn/)在 Android 平台上是如何维护长连接。\n\n## 移动无线网络的特点\n\n因为 IP v4 的 IP 量有限,运营商分配给手机终端的 IP 是运营商内网的 IP,手机要连接 Internet,就需要通过运营商的网关做一个网络地址转换(Network Address Translation,NAT)。简单的说运营商的网关需要维护一个外网 IP、端口到内网 IP、端口的对应关系,以确保内网的手机可以跟 Internet 的服务器通讯。\n\n\n\n图片源自 cisco.com. \n\nNAT 功能由图中的 GGSN 模块实现。\n\n大部分移动无线网络运营商都在链路一段时间没有数据通讯时,会淘汰 NAT 表中的对应项,造成链路中断。\n\n## Android 平台上长连接的实现\n\n为了不让 NAT 表失效,我们需要定时的发心跳,以刷新 NAT 表项,避免被淘汰。\n\nAndroid 上定时运行任务常用的方法有2种,一种方法用 Timer,另一种是AlarmManager。\n\n### Timer\n\nAndroid 的 Timer 类可以用来计划需要循环执行的任务,Timer 的问题是它需要用 WakeLock 让 CPU 保持唤醒状态,这样会大量消耗手机电量,大大减短手机待机时间。这种方式不能满足我们的需求。\n\n### AlarmManager\n\nAlarmManager 是 Android 系统封装的用于管理 RTC 的模块,RTC (Real Time Clock) 是一个独立的硬件时钟,可以在 CPU 休眠时正常运行,在预设的时间到达时,通过中断唤醒 CPU。\n\n这意味着,如果我们用 AlarmManager 来定时执行任务,CPU 可以正常的休眠,只有在需要运行任务时醒来一段很短的时间。极光推送的 Android SDK 就是基于这种技术实现的。\n\n## 服务器设计\n\n当有大量的手机终端需要与服务器维持长连接时,对服务器的设计会是一个很大的挑战。\n\n假设一台服务器维护10万个长连接,当有1000万用户量时,需要有多达100台的服务器来维护这些用户的长连接,这里还不算用于做备份的服务器,这将会是一个巨大的成本问题。那就需要我们尽可能提高单台服务器接入用户的量,也就是业界已经讨论很久了的 C10K 问题。\n\n### C2000K\n\n针对这个问题,我们专门成立了一个项目,命名为C2000K,顾名思义,我们的目标是单机维持200万个长连接。最终我们采用了多消息循环、异步非阻塞的模型,在一台双核、24G内存的服务器上,实现峰值维持超过300万个长连接。\n\n## 后记\n\n稳定维护长连接是推送平台的一个基础,[极光推送团队](http://blog.jpush.cn/)将会在这方面长期投入,以保证用户能有效的节省电量、流量,同时数据能实时送达。\n\n# 即时通信技术-Websocket\n\n以前不管使用HTTP轮询或使用TCP长连接等方式制作在线聊天系统,都有天然缺陷,随着Html5的兴起,其中有一个新的协议WebSocket protocol,可实现浏览器与服务器全双工通信(full-duplex),它可以做到:浏览器和服务器只需要做一个握手的动作,然后,浏览器和服务器之间就形成了一条快速通道。两者之间就直接可以数据互相传送。这个新的协议的特点正好适合这种在线即时通信。"
},
{
"path": "docs/android/Android-Interview/网络编程/简单阐述一下及时推送原理?.md",
"content": "### 源码分析相关面试题\n\n- [Volley源码分析](http://www.jianshu.com/p/ec3dc92df581)\n- [注解框架实现原理](http://www.jianshu.com/p/20da6d6389e1)\n- [okhttp3.0源码分析](http://www.jianshu.com/p/9ed2c2f2a52c)\n- [onSaveInstanceState源码分析](http://www.jianshu.com/p/cbf9c3557d64)\n- [静默安装和源码编译](http://www.jianshu.com/p/2211a5b3c37f)\n\n### Activity相关面试题\n\n- [保存Activity的状态](http://www.jianshu.com/p/cbf9c3557d64)\n\n### 与XMPP相关面试题\n\n- [XMPP协议优缺点](http://www.jianshu.com/p/2c04ac3c526a)\n- [极光消息推送原理](http://www.jianshu.com/p/d88dc66908cf)\n\n### 与性能优化相关面试题\n\n- [内存泄漏和内存溢出区别](http://www.jianshu.com/p/5dd645b05c76)\n- [UI优化和线程池实现原理](http://www.jianshu.com/p/c22398f8587f)\n- [代码优化](http://www.jianshu.com/p/ebd41eab90df)\n- [内存性能分析](http://www.jianshu.com/p/2665c31b9c2f)\n- [内存泄漏检测](http://www.jianshu.com/p/1514c7804a06)\n- [App启动优化](http://www.jianshu.com/p/f0f73fefdd43)\n- [与IPC机制相关面试题](http://www.jianshu.com/p/de4793a4c2d0)\n\n### 与登录相关面试题\n\n- [oauth认证协议原理](http://www.jianshu.com/p/2a6ecbf8d49d)\n- [token产生的意义](http://www.jianshu.com/p/9b7ce2d6c195)\n- [微信扫一扫实现原理](http://www.jianshu.com/p/a9d1f21bd5e0)\n\n### 与开发相关面试题\n\n- [迭代开发的时候如何向前兼容新旧接口](http://www.jianshu.com/p/cbecadec98de)\n- [手把手教你如何解决as jar包冲突](http://www.jianshu.com/p/30fdc391289c)\n- [context的原理分析](http://www.jianshu.com/p/2706c13a1769)\n- [解决ViewPager.setCurrentItem中间很多页面切换方案](http://www.jianshu.com/p/38ab6d856b56)\n\n### 与人事相关面试题\n\n- [人事面试宝典](http://www.jianshu.com/p/d61b553ff8c9)\n\n### 本文配套视频\n\n- [极光推送原理配套视频](https://v.qq.com/x/page/h0394a7zioh.html)\n- [xmpp基本概念配套视频](https://v.qq.com/x/page/s0394k4p10i.html)\n- [配套视频](https://v.qq.com/x/page/h0394s3mc5k.html)\n\n## 4-简单阐述一下及时推送原理?\n\na) 传统获取服务器数据使用的是pull模式,是客户端向服务器请求数据。从客户端发起连接请求,获取到服务器数据后就关闭连接。当连接断开后,服务器就会失去客户端的地址,因此无法主动向客户端发送消息。\n\nb) 推送(push)是服务主动向客户端发送数据。\n\n它的原理是保持一个长连接,当客户端和服务器建立连接后不再断开,这样服务器随时有新消息都可以发送给客户端。\n\n长连接和短连接。所谓长连接,指在一个TCP连接上可以连续发送多个数据包,在TCP连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接。(心跳连接)\n\n```\nwhile(true) {\n request(timeout);\n request(timeout);\n}\n```\n\n短连接是指通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接,即每次TCP连接只完成一对\n\nc) 至于如何获取推送消息。由于服务端传来推送消息的时间是不确定的,这里只能等待推送SDK的回调,比如通过注册监听或者广播接收者。不同的厂商的推送SDK可能会有不同的处理方案,以百度推送SDK来说,是通过广播接收者获取推送数据。\n\n## 5-简要说明一下openfire、smack、spark\n\nopenfire是基于XMPP协议的即时通信的服务器端的一个实现,你不需要编写一行服务端的代码,实现一个简单的点对点通信或是简单的群聊.\n\nsmack 是XMPP传输协议的Java实现,提供了一套API接口,可以连接服务端。一般用于快速开发手机客户端。\n\nspark是基于smack实现的一个XMPP即时通信客户端(PC端的)。\n\n## 6-列出几种常见的解决消息即时获取方案\n\n1. 轮询(Pull)方式:客户端定时向服务器发送询问消息,一旦服务器有变化则立即同步消息。\n2. SMS(短信消息)(Push)方式:通过拦截SMS消息并且解析消息内容来了解服务器的命令,但这种方式一般用户在经济上很难承受。\n3. 持久连接(Push)方式:客户端和服务器之间建立长久连接,这样就可以实现消息的及时行和实时性。\n\n## 7-Timer比AlarmManager实现心跳时更耗电原因\n\n- Timer\n\nAndroid 的 Timer 类可以用来计划需要循环执行的任务。\nTimer 的问题是它需要用 WakeLock 让 CPU 保持唤醒状态,这样会大量消耗手机电量,\n大大减短手机待机时间。这种方式不能满足我们的需求。\n\n- AlarmManager\n\nAlarmManager 是 Android 系统封装的用于管理 RTC 的模块,RTC (Real Time Clock) 是一个独立的硬件时钟,可以在 CPU 休眠时正常运行,在预设的时间到达时,通过中断唤醒 CPU。这意味着,如果我们用 AlarmManager 来定时执行任务,CPU 可以正常的休眠,只有在需要运行任务时醒来一段很短的时间。\n\n- 欢迎关注微信公众号,长期推荐技术文章和技术视频\n\n微信公众号名称:Android干货程序员\n\n"
},
{
"path": "docs/android/Android-Interview/网络编程/阐述一下对XMPP协议理解以及优缺点?.md",
"content": "### 源码分析相关面试题\n\n- [Volley源码分析](http://www.jianshu.com/p/ec3dc92df581)\n- [注解框架实现原理](http://www.jianshu.com/p/20da6d6389e1)\n- [okhttp3.0源码分析](http://www.jianshu.com/p/9ed2c2f2a52c)\n- [onSaveInstanceState源码分析](http://www.jianshu.com/p/cbf9c3557d64)\n- [静默安装和源码编译](http://www.jianshu.com/p/2211a5b3c37f)\n\n### Activity相关面试题\n\n- [保存Activity的状态](http://www.jianshu.com/p/cbf9c3557d64)\n\n### 与XMPP相关面试题\n\n- [XMPP协议优缺点](http://www.jianshu.com/p/2c04ac3c526a)\n- [极光消息推送原理](http://www.jianshu.com/p/d88dc66908cf)\n\n### 与性能优化相关面试题\n\n- [内存泄漏和内存溢出区别](http://www.jianshu.com/p/5dd645b05c76)\n- [UI优化和线程池实现原理](http://www.jianshu.com/p/c22398f8587f)\n- [代码优化](http://www.jianshu.com/p/ebd41eab90df)\n- [内存性能分析](http://www.jianshu.com/p/2665c31b9c2f)\n- [内存泄漏检测](http://www.jianshu.com/p/1514c7804a06)\n- [App启动优化](http://www.jianshu.com/p/f0f73fefdd43)\n- [与IPC机制相关面试题](http://www.jianshu.com/p/de4793a4c2d0)\n\n### 与登录相关面试题\n\n- [oauth认证协议原理](http://www.jianshu.com/p/2a6ecbf8d49d)\n- [token产生的意义](http://www.jianshu.com/p/9b7ce2d6c195)\n- [微信扫一扫实现原理](http://www.jianshu.com/p/a9d1f21bd5e0)\n\n### 与开发相关面试题\n\n- [迭代开发的时候如何向前兼容新旧接口](http://www.jianshu.com/p/cbecadec98de)\n- [手把手教你如何解决as jar包冲突](http://www.jianshu.com/p/30fdc391289c)\n- [context的原理分析](http://www.jianshu.com/p/2706c13a1769)\n- [解决ViewPager.setCurrentItem中间很多页面切换方案](http://www.jianshu.com/p/38ab6d856b56)\n\n### 与人事相关面试题\n\n- [人事面试宝典](http://www.jianshu.com/p/d61b553ff8c9)\n\n### 本文配套视频\n\n- [什么是XMPP配套视频](https://v.qq.com/x/page/t0394w3zhoa.html)\n\n## 3-简单阐述一下对XMPP协议理解以及优缺点?\n\n### 定义:\n\n> XMPP(可扩展消息处理现场协议)的前身是Jabber,由一个开源组织产生的即时通信协议,基于可扩展标记语言(XML)的一种协议,是由IETF(国际互联网小组)通过的网络标准。\n\n- 及时通讯:发送一则消息,对方账号马上即时接收到消息。中间没有出现延时。\n 底层使用 socket实现/java对tcp/ip协议的实现\n\n### 基本网络结构\n\nXMPP中定义了三个角色,客户端,服务器,网关。通信能够在这三者的任意两个之间双向发生。服务器同时承担了客户端信息记录,连接管理和信息的路由功能。网关承担着与异构即时通信系统的互联互通,异构系统可以包括SMS(短信),\nMSN,ICQ等。基本的网络形式是单客户端通过TCP/IP连接到单服务器,然后在之上传输XML。\n\n- 举个例子看看所谓的XML(标准通用标记语言的子集)流是什么样子的?\n\n客户端:\n\n```xml\n\n\n```\n\n服务器:\n\n```xml\n\n\n```\n\n其他通信\n客户端:\n\n```xml\n\n \tArt thou not Romeo, and a Montague?\n\n```\n\n服务器:\n\n```xml\n\n Neither, fair saint, if either thee dislike.\n \n```\n\n客户端:\n\n```xml\n\n```\n\n服务器:\n\n```xml\n\n```\n\n- 以文档的观点来看,客户端或服务器发送的所有XML文本连缀在一起,从<stream>到</stream>构成了一个完整的XML文档。其中的stream标签就是所谓的XML Stream。在<stream>与</stream>中间的那些<message>...</message>这样的XML元素就是所谓的XML Stanza(XML节)。 XMPP核心协议通信的基本模式就是先建立一个stream,然后协商一堆安全之类的东西,中间通信过程就是客户端发送XML Stanza,一个接一个的。服务器根据客户端发送的信息以及程序的逻辑,发送XML Stanza给客户端。但是这个过程并不是一问一答的,\n 任何时候都有可能从一方发信给另外一方。通信的最后阶段是</stream>关闭流,关闭TCP/IP连接。\n\n> XMPP 的消息格式。\n> XMPP 协议的所有消息都是 XML 格式的,在 XMPP 中定义了 3 个顶层消息:\n\n- 2.1 Presence\n\n 用于确定用户的状态。消息结构举例如下(每个 XML 的 node 还会有很多其他 attribute,为了简单起见这里省略,下同):\n\n ```\n \n online \n \n ```\n\n- 2.2 Message\n\n 用于在两个用户之间发送消息。消息结构举例如下:\n\n ```\n \n hello \n \n ```\n\n- 2.3 IQ\n\n 信息/请求,是一个请求-响应机制,管理XMPP服务器上两个用户的转换,允许他们通过相应的XML格式进行查询和响应。\n\n ```\n \n \n ```\n\n\n\n[及时聊天的展示形式](https://v.qq.com/x/page/k0394y5jo6d.html)\n\n\n\n\n\n> 面向连接:三次握手\n\n\n\n- 欢迎关注微信公众号,长期推荐技术文章和技术视频\n\n微信公众号名称:Android干货程序员\n\n"
},
{
"path": "docs/android/Android-Interview/面试技巧/README.md",
"content": "## 面试技巧\n\n- [程序员面试宝典](程序员面试宝典.md)\n- [罗永浩新东方万字求职信](/罗永浩新东方万字求职信.md)\n- [我在面试中最喜欢问开发者的问题,和回答思路](我在面试中最喜欢问开发者的问题,和回答思路.md)"
},
{
"path": "docs/android/Android-Interview/面试技巧/我在面试中最喜欢问开发者的问题,和回答思路.md",
"content": "本文作者是 Zach Mathew,他是 FreshBooks 的经理。\n\n我面试过很多人,大部分是开发者,部分是产品经理,有时候会面试主管或者副总监。但不管是面试什么级别和什么工种的应聘者,我都会在过程中对他们提出一个相同的要求: 现在,请把我当成一个学生,随便教我点什么东西和知识吧。\n\n\n\n什么都行。\n\n可能是什么东西你觉得有意思的,或者你自己在某方面研究比较深的领域。甚至是你最近刚刚学习到的东西,反正是什么都好。你不需要是那方面的专家,但至少能跟我讲明白讲清楚,而且你能够回答我一些基础的问题。\n\n对,现在给你十分钟的时间,把你脑海里想到的东西教给我。\n\n我之所以对面试者提出这个要求,是因为我想知道我能从这个将来的同事身上学习到什么。我也想知道你的团队未来会从你身上学习到什么。\n\n当然,我问这个问题的时候,也想知道你的气质符合不符合我们公司的文化。虽然说 FreshBooks 这个公司并没有具体的规则,但其实每天,无论是实习生或者是管理层,我都会问他们类似问题,而且希望他们能给我满意的回答。\n\n以下是我不久前问自己同事的问题,并从中学习到的事情。\n\n- 我问 Tobi, 他是我团队里的一名开发: 我看到你在代码中正在用 ES6 , 你认为它用起来怎么样?\n- 我问 Marcus, 他是金融公司的一名分析师: 跟我解释下同期群分析是什么意思?我应该在未来使用这个方法吗?\n\n\n\n有的时候,一些初级开发者会问我:我知道的东西,你肯定早就知道了。我没法教你。\n\n不,还是请指点我一下。实际上,当你真正教我的时候,你会吃惊于我多么无知。 而且就算你讲的东西是我早就知道的事情,再听一遍也不是什么大事。\n\n毕竟在那么多次的面试里,肯定会有人告诉我一些我早就知道的东西。那真的无所谓,我真正想从面试里了解到的是:\n\n1. 你是否能和他人进行有效交流?\n2. 你能否在研究一件事情的时候透过表面深入内层?\n3. 你是否具有有条理阐述一件事情的能力,还是说你是对什么都很不耐烦沟通的人?\n\n会学习是一种能力,能把自己学习到的东西表达给别人也是一种能力。\n\n这不仅仅是为了面试,我的意图是考察你其他的技能和潜能。\n\n在公司内部,我们也经常举办这种「教我点什么」的大会。通常是在周五下午,喝点小酒,大家聚在一起,分享彼此之间从本周工作以及最近的项目中得到的灵感。基本上,这就是一个信息的共享大会。不需要准备 ppt 或者演讲稿什么的,只需要张开嘴,放开心扉,告诉别人你的所得。\n\n你也可以反过来,邀请我教你学习点什么。 这当然可以,如果我要求你教我点什么,你也可以对我提出相同要求。面试是一个双方过程,在我评测你的时候,你也可以评价我。\n\n所以拜托,当我要求你教我点什么东西的时候,你也可以对我提出相同的请求。\n\n上文来源:[Medium](https://medium.com/@zachmathew/the-one-question-i-ask-in-every-interview-66561f69c233#.vhvgl44r3)\n\n\n\n我个人感觉,这种「给你十分钟,你随便教我什么东西」的面试思路非常有意思。那身为应聘者,我们该怎么运用这十分钟给面试官留下好印象呢,对爱丽丝来说,其实觉得把这整个场景视为一个小小的自检是否具有有效沟通的过程比较有意思。\n\n我把自己的面试思路分享一下。\n\n首先,你要对面试时间有个预估。对方说给你十分钟,这时间说长不长说短不短。你可以迅速规划一下,比如我先用五分钟的时间讲述我想说东西的具体概念、理论知识和背景感悟。然后,剩下五分钟,可以用来让面试官继续提问或者自己继续补充。切不可自己光说。\n\n其次,你也可以把自己的打算和规划告诉面试官,比如在我最初前几分钟内向你讲述背景知识的时候,请先听我说完,尽量不要打断我的思路。\n\n接着,当你在真正介绍一件事、或传授一个知识的时候,记住一定要有条理,说话慢一些。当回答对方的问题时,多问问对方「我讲清楚没有」,而不是要问对方「你听明白没有」。\n\n最后,面试官都说了他其实并不在乎你讲什么。这是什么意思?这就是说你跟他说怎么烙煎饼和怎么解释引力波,人家根本不在乎。其实主要考察你的交流水平,其实也就是逻辑。\n\n而逻辑简单来说,就是大到小,从浅及深,想清楚影响的因果联系。当对方提出你不懂的问题,可以把他的问题拆解出几个小问题,去解答你懂得的地方。而对于不懂的事情,也不要不懂装懂,反而可以咨询他的意见——相信我,既然他能问出你不懂的问题,就说明他的水平比你高。\n\n让他帮你解释。当面试官比你话多的时候,这绝对是很好的信号。"
},
{
"path": "docs/android/Android-Interview/面试技巧/程序员面试宝典.md",
"content": "行业资深大牛,在实际面试百八十号的程序员工作中,深度总结什么样子的人,比较容易拿到offer!绝对值得一看哦\n\n## 1. 题要做满\n\n一般来说,程序员面试都会先由HR给一张面试题。面试题一般包含:逻辑题、代码规范、数据库理论、简单算法、高级函数应用、服务器基础。大多数公司出的题目,百度上都有。如果面试的岗位是初级开发,大胆去百度吧,只要填满就能获得好感度。如果面试的是中级开发,这些题只需要写重点就行,对做题时间会有要求。如果面试的是高级开发,在中级开发的要求上,把字写得漂亮些。\n\n## 2. 面试问答\n\n第一面,基本是技术主管/经理。可能是因为营造优越感,一定会问高级问题,即使需要的岗位是初级岗位。\n\n提问的第一波是面试题上的细节,确定是百度的还是真的懂的。第二波,会随机提问一些技术问题。\n\nPHP面试最喜欢问的就是常用框架和框架之间的差别。\n\nJava面试最喜欢问关于函数构建、算法加密等问题。\n\n前端面试,基本就拿着其他公司的界面设计问多久可以实现。\n\n会涉及一些数据库,基本都是问增改删查的应用、数据库设计的规范。其他的可能会随机选取一些业务场景,让当场做程序设计。\n\n整体的提问过程,能回答上一半就可以进入下一个面试节点。回答的时候态度一定要好,不知道的就回答“以前工作中没怎么用到”,千万不能胡说八道。知道的,也谦虚一点,回答“我过往是如此运用的”。\n\n## 3. 面试沟通\n\n可能是第二面,也可能是第三面,会有一个看上去和蔼可亲的人来面试。这个人基本上是某个项目负责人,面试的内容是沟通能力。\n\n一开始也会带一点基础技术问题,基本上还是根据面试题扩展的。\n\n然后就会开始问是否可以加班、如果需求发生变更怎么处理、对过往的工作从业务上理解多少、响应Bug会具体怎么做。回答不能啰嗦,要肯定句,比如:可以加班。而不要,模棱两可或者带有场景的回答,比如:不排斥加班,但是无意义的加班不太能接受。\n\n## 4. 面试情怀\n\n一般部门总监会谈这个问题。这部分,每个人都不同,但是未来规划一定要明确。一般程序员就两个发展:管理和技术专家。一般问这个问题,就是看短期内会不会离职,是不是一个有目标的人。\n\n还会问一些兴趣爱好,看未来能不能融入团队氛围。\n\n接下来就问薪资和待遇要求了。这部分,请根据自己的心走。不要觉得不好意思开口,面试是双向选择的过程。如果面试感觉比较好,当然也可以适当的降低一点要求。切记不要说出让自己下不了台的薪资。\n\n## 说几个有意思的对话,在以往面试中遇见过的\n\n注意啊,都是面试失败案例,千万别重蹈覆辙\n\n**程序员李某面试:**\n\n- Q:以前的工作是否用过敏捷开发?\n- A:核心就是以人为本。开发设计功能跟着心走。\n\n结果:回答完,面试就结束了。\n\n**程序员王某面试:**\n\n- Q:你当初做保险行业的,怎么处理用户名、密码、银行卡入库加密这块?\n- A:为什么要加密?明文存就好了啊。\n\n结果:认为明文存是理所当然不假思索的,Pass。\n\n**程序员马某面试:**\n\n- Q:PHP的常用框架了解的有哪些?\n- A:ThinkPHP和Yii。\n- Q:他们的区别是什么?或者说优缺点?\n- A:(沉默了3分钟)其实我没有接触过Yii。\n\n结果:后面的面试也基本是这种一知半解的节奏,Pass。\n\n**程序员刘某面试:**\n\n- Q:如果产品经理安排了一个任务给你,然后当天就需求变更了,你怎么办?\n- A:这种事情绝对不允许发生第二次。\n\n结果:应该会很难融入团队吧,Pass。\n\n## 程序员面试中的5个杀手锏问题\n\n也许你是个JavaScript巨星,为了防止被那些烦人的猎头骚扰,不得不删除你在LinkedIn上的个人资料。又或者,也许你是一个普通、可靠的合作伙伴,一年到头也只会收到2到3次的面试邀请。\n\n不管你去面试的频率如何,下面这五个问题是每个软件工程师都应该问的——将有助于你确定自己在这家公司长期工作是否会合作愉快。\n\n\n\n### 你们的企业文化是什么?\n\n你每天将会有10至12个小时需要与同事的信仰、价值观和行为打交道。企业文化重视技术吗?尊重软件工程师吗?软件工程师在产品开发上有发言权吗?企业有没有提供便利以便于软件工程师将工作做到最好?\n\n为了找到答案,可以问问企业从开发到测试都喜欢什么工具,Luca Bonmassar,Gild公司的联合创始人和首席技术官建议说(Gild是一个用于查找评估和招聘技术人才的SaaS平台)。如果面试官不能回答,Bonmassar说,“这通常是一个坏兆头”,说明该公司对你重视的技术并没有给予足够的重视。\n\n他还建议询问开发流程:“开发人员的投入有多少会进入到产品?项目经理是否决定了进度的每一个细节?需要构建什么,或者工程团队有没有发言权,有多少发言权?“\n\n\n\n询问工程和其他团队之间的关系。Doug Schade,WinterWyman公司软件技术搜索部门的合作伙伴和招聘人员,建议问“在应对项目时,你们公司会给开发人员什么级别的自主性?” Bonmassar说,对软件工程师的反馈缺乏任何机制是一个“危险信号”。\n\n### 如何衡量我?\n\n你的雇主如何定义你的“成功”与给你的工资和津贴等各种福利息息相关。但是,不同公司的评判标准不同,要满足你觉得不舒服的目标会让你的生活苦不堪言。\n\n\n\n有些公司衡量软件工程师看的是他们的努力,比如他们工作了多少小时,提交了多少代码,Ari Weil,Yottaa公司的产品副总裁说(Yottaa是一家自适应的内容分发网络提供商)。也有的用结果来评估软件工程师,如因缺陷而需要召回的代码数量,或在规定时间和预算范围内,小组完成的项目数量。\n\n### 有什么成长计划?\n\nTonyaShtarkman,Riviera Partners的首席技术招聘人员说(Riviera Partners是一家总部位于旧金山的猎头公司),很多软件工程师觉得“他们在当前公司已经不可能有多大发展了。“她建议软件工程师在面试时要询问是否有一个针对软件工程师的成长计划——允许他们继续晋升,并且有机会让他们参加会议和研讨会来建立新的产品和功能,并受到辅导。\n\n许多软件工程师希望雇主会告知他们最新、最好的技术工具,使他们能够保与时俱进。但Bonmassar警告说,“它通常是一个不好的兆头”,当公司坚持某个极其特殊的技能,并要求能迅速改变的时候,可能要不了多久该公司就会开始找人来代替你。如果说需要更匹配的长期合作,他说,那么可能这家公司现在需要的是“聪明,但不必知道工具和技术每一个细节的人”。\n\n他还建议询问一下,多少外部聘请vs公司内部晋升。这答案能说明很多关于随着企业发展你的成长之路会怎么样的趋势。\n\n### 你们的发展计划?\n\n如果你正在考虑去创业公司工作,那么你需要了解他们的发展计划:“加入创业公司,总是涉及着一定程度的风险水平,然而创业公司的工程师往往比大企业的工程师不怕风险, “Shtarkman说。 “不过,将风险控制在一定的稳定范围内是必需的。”\n\n第一个步骤是调查。Shtarkman建议可以问这样的问题,如“你们的资金消耗率(公司的负现金流)是多少?” ,以便于了解公司在没有其他资金和不盈利的情况下能维持多久。Jim Barnett,Glint公司的首席执行官(Glint是一个用于跟踪可以影响保留趋势的网络平台),建议在签署保密协议前可得仔细看清楚。\n\n### 我会喜欢你们的人吗?\n\n聊到目前的团队成员,“我碰到过一些工程师之所以接受创业公司的offer,纯粹是因为他们与团队融合得非常好——有时候甚至是因为某个人的魅力,”Shtarkman说。 “说来说去,公司是由人组成的,如果你不能与你的队友和睦共处,那么当作长期的职业生涯几乎是不可能的。”\n\n试着和公司的内部人士聊天,以便于知道“公司内部管理人员大致的情形,”Barnett说。 “他们好合作吗,他们做事征求意见吗,他们提供反馈吗,他或她投资团队成员并帮助他们成长吗?”\n\n试着和团队中你共事的人进行非正式的交谈。问问他们工作中最让他们沮丧的是什么。比起面试官,他们更可能现实地回答你,Shtarkman说。\n\n底线:挖掘得更深一点以了解今后你每天需要共事的人,和你每天要经历的工作流程,而不要只关注薪水。\n\n## 程序员面试技巧总结\n\n**闲聊**\n\n在深入代码之前,大多数面试官喜欢聊聊你的背景。\n\n\n\n**他们想知道:**\n\n你对编码认知。你是否知道如何编写好代码?\n\n个人能力/领导力。你是否经历过整个工作流程?你是否修复过并不怎么正确的东西,即使你并不需要这么去做?\n\n沟通。和你交流技术问题是有用的还是痛苦的?\n\n**你应该至少说明以下中的一个:**\n\n你曾解决的一个有趣的技术问题\n\n你曾克服的一个人际冲突\n\n显示领导力或个人能力的例子\n\n你曾在以往项目中做出的贡献\n\n最喜欢的语言的一些琐事,对这种语言你做了什么,以及你不喜欢它哪里\n\n有关公司产品/业务的问题\n\n关于该公司的工程策略(测试,Scrum,等等)\n\n热爱技术。表达你对你所做的一切感到骄傲,你对自己的选择充满自信,你对语言和工作流有着自己的看法。\n\n**沟通**\n\n涉及到编码问题的时候,沟通是关键。一个在工作时需要帮助却能和人正确沟通的求职者比那些能轻松解决问题的求职者甚至更好。\n\n**了解这是哪种问题。**\n\n**有两种类型的问题:**\n\n**编码。**面试官希望你能针对问题写出简洁高效的代码。\n\n**闲聊。**面试官希望能和你聊一聊。话题通常是(1)高水平的系统设计(“如何克隆Twitter?”)或(2)琐事(“Javascript中的hoisting是什么意思?”)。有时候这些琐事中也会引入“实际”问题,例如,“如何迅速排序整数列?好的,如果不是整数,是其他类型的呢…… ”。\n\n如果你开始编写代码,并且面试官并不想多说废话,只想尽快过渡到“实际”问题,那么如果你罗哩叭嗦太多的话,她可能会觉得厌烦。不妨直接问,“是不是为这个问题写代码?”\n\n**让人感觉你有团队精神。**面试官想知道和你一起工作是什么感觉,会有什么问题,所以要让他们看到你的团队合作性。使用“我们”来代替“我”,例如,“如果那个时候我们做广度优先搜索的话,就能及时/准时得到解决方案。”如果让你选择在纸上还是在白板上编码的话,选白板。这样,你就可以接近面试官,直接面对他提出的问题(而不是和她在桌子两边遥遥相望)。\n\n**把自己的想法大声说出来。**不是开玩笑,比如说:“我不知道这样做是否有效——但请让我试一试。”如果你不知道怎么办,不知道这个问题该如何解决,那么就说一说你现在的想法。说一说你认为怎么做可能会有效。说一说你认为哪些会有用,以及为什么没用的原因。这同样适用于琐碎的闲聊问题。当面试官要求你解释Javascript闭包的时候,“这与范围有关,不妨把它放到一个函数中”可能会让你得到90%的分数。\n\n**不知为不知。**如果正在谈论的话题(例如,具体的语言事务,具体的琐事,运行时分析)的确是你不曾涉猎的内容,那么不要不懂装懂。相反,你可以直接说:“我不知道,但我猜$thing,因为……”,因为后面可以通过分析排除其他选项,还可以拿其他语言或问题做例子。\n\n**说话不要不经大脑。**不要自信地将答案脱口而出。如果是正确的,那么你还是需要时间来考虑如何解释,如果是错的,那会显得你冲动鲁莽。你不是在和人比速度,而且你这么做更有可能因为打断她的话或者妄下结论而惹恼她。\n\n\n\n**摆脱困境**\n\n**有时候你会陷入僵局。**放松。这并不意味着你已经失败了。请记住,面试官通常更在乎的,是你能否巧妙地从几个不同的角度去揭示问题,而不是一根筋走到底地坚持正确答案。\n\n**画图。**不要浪费时间在脑袋里思考,可以画到板上。画出几个不同的测试输入。画出你如何手动如愿得到所需的输出。然后想想将你的方法转换成代码。\n\n**解决问题的简单版本。**不知道如何找到集合中的第4大条目?那么想想如何找到第1大条目,然后试试能否沿用这种方法。\n\n写一个简洁低效的解决方案,然后对其进行优化。竭尽全力。尽一切可能的方法得到某种答案。\n\n**讲讲自己的思路。**讲一讲你知道什么。讲一讲你认为什么可能工作以及为什么无效的原因。你可能突然会意识到它实际上是可以工作的,或修改版本是有效的。也有可能,你会得到提示。\n\n**等待提示。**不要用期待的眼光盯着面试官,但可以有短暂的“思考”时间——面试官或许已经决定给你个提示也说不定呢,等待她的提示以免打断她。\n\n**考虑空间和运行时的界限。**如果你不知道你是否可以优化解决方案,那么就说出来。\n\n**例如:**\n\n“我必须至少看看所有的条目,我做不到时间复杂度比O(n)还好的了。”\n\n“蛮力方法才能检验所有的可能性。”\n\n“答案将包含n^2数据项,所以我必须至少花费N^2的时间。”\n\n**写下你的思路想法**\n\n**凭空地想很容易自我矛盾。**把你的想法写下来,然后再去考虑细节。\n\n**调用帮助函数,继续前进。**如果你不能或多或少地马上想出如何实现算法,那就跳过它。写一个命名合理的调用函数,例如:“this will do X”,然后继续下一步骤。如果帮助函数非常微不足道,你甚至可以将它忽略。\n\n**不要担心语法。**不妨一笑而过。如果你非要考虑语法,那就还原到英语。只要向面试官说明稍后会回来整理即可。\n\n**预备足够的空间。**你可能后面会想要在代码行之间添加代码或笔记。从白板的顶部开始写,并在每一行之间留一条空白。\n\n**最后写一个重头检查的标志。**不要担心你写的for循环是否应该有“<”或“<=”。在代码的最后画个勾选提醒自己最后再检查一遍。先按自己的思路走。\n\n**使用描述性的变量名。**想名字需要时间,但可以防止你忘记自己写某段代码的目的。使用names_to_phone_nums_map而不是nums。在名称中说明类型。返回布尔值的函数应该以“is_ *”,保存列表的Vars应该以“s”结尾。标准化很有意义。\n\n\n\n**完成之后的整理**\n\n**浏览解决方案,大声地讲,输入一个例子。**当程序运行时记录下变量保存的值——如果你只是记在脑子里,不会让你赢得任何加分。这有助于你发现bug和消除面试官的困惑。\n\n**寻找差一错误。**你的for循环是不是应该使用“<=”来代替“<”?\n\n**测试边缘情况。**措施包括空集合,单项目集合或负数。加分点:提一提单元测试!\n\n**不要惹人厌烦。**有的面试官可能并不在意这些整理步骤。如果你不确定,可以这样说,“我通常会检测一些边缘情况——那么我们接下来是不是做这个呢?“\n\n**实践**\n\n最后,运行实践问题是没有捷径的。\n\n**好记性不如烂笔头。**对自己诚实。用笔写可能一开始会让你觉得别扭。但是如果你现在就能克服这个难题,那么当面试的时候,你就不会觉得笨拙和不顺手了。\n\n本文中的实践问题只是提供了每个面试过程的线索要点,没有真正的金科玉律,在真正面试时还需实际问题实际解决。**最后,祝大家面试成功。**"
},
{
"path": "docs/android/Android-Interview/面试技巧/罗永浩新东方万字求职信.md",
"content": "俞校长您好:\n\n 我先对照一下新东方最新的招聘要求:\n\n 1、有很强的英语水平,英语发音标准\n\n 英语水平还好,发音非常标准,我得承认比王强老师的发音差一点。很多发音恐怖的人(宋昊、陈圣元之流)也可以是新东方的品牌教师,我不知道为什么要要求这一条,尽管我没这方面的问题。\n\n 2、大学本科或以上学历,英语专业者优先\n\n 真不喜欢这么势利的条件,这本来应该是实力、马力之流的学校的要求。\n\n 3、有过考TOEFL、GRE的经验\n\n GRE考过两次。\n\n 4、有教学经验者,尤其是教过以上科目者优先\n\n 教过后来被国家明令禁止的传销课,半年。\n\n 5、口齿伶俐,中文表达能力强,普通话标准\n\n 岂止伶俐,简直凌厉,普通话十分标准,除了对卷舌音不太在意(如果在意,平舌音也会发错,所以两害相衡取其轻)。\n\n 6、具备较强的幽默感,上课能生动活泼\n\n 我会让他们开心。\n\n 7、具备较强的人生和科学知识,上课能旁征博引\n\n 除了陈圣元,我在新东方上过课的老师(张旭、王毅峰、王昆嵩)都和文盲差不多,当然他们还小。说到底,陈圣元的全部知识也只是在于让人看不出他没有知识而已。\n\n 8、具备现代思想和鼓动能力,能引导学员为前途奋斗\n\n 新东方的学员是最合作,最容易被鼓动的,因为他们来上课的最大目的就是接受鼓动,这个没有问题。\n\n 9、年龄在40岁以下\n\n 28岁。\n\n下面是我的简历或是自述:\n\n罗永浩,男,1972年生于吉林省和龙县龙门公社。\n\n 在吉林省延吉市读初中时,因为生性狷介,很早就放弃了一些当时我讨厌的主课,比如代数、化学、英文,后来只好靠走关系才进了当地最好的一所高中,这也是我刚正不阿的三十来年里比较罕见的一个污点。因为我和我国教育制度格格不入又不肯妥协,1989年高中二年级的时候就主动退学了。有时候我想其实我远比那些浑浑噩噩地从小学读到硕士博士的人更渴望高等教育,我们都知道钱钟书进清华的时候数学是零分(后来经证实其实是15分),卢冀野入东南大学的时候也是数学零分,臧克家去山东国立青岛大学的时候也是差不多的情况。今天的大学校长们有这样的胸襟吗?当然,发现自己文章写的不如钱钟书是多年后的事情了,还好终于发现了。\n\n 退学之后基本上我一直都是自我教育(当然我的自我教育远早于退学之前),主要是借助书籍。因为家境还勉勉强强,我得以相对从容地读了几年书,\"独与天地精神往来\"。\n\n 基于\"知识分子要活得有尊严,就得有点钱\"这样的认识(其实主要是因为书价越来越贵),我从1990年至1994年先后筛过沙子,摆过旧书摊,代理过批发市场招商,走私过汽车,做过期货,还以短期旅游身份去韩国销售过中国壮阳药及其他补品。令人难堪的是做过的所有这些都没有让我\"有点钱\",实际上,和共同挣扎过的大部分朋友们比起来,我还要庆幸我至少没有赔钱。\n\n 我渐渐意识到我也许不适合经商,对一个以知识分子自许的人来说,这并不是很难接受的事情,除非这同时意味着我将注定贫穷。\n\n 1994年夏天,我找了个天津中韩合资企业的工作并被派去韩国学习不锈钢金属点焊技术,1995年夏天回国的时候,很不幸我姐姐也转到了这家天津的公司并担任了副总经理,为了避嫌我只好另谋出路。\n\n 1995年8月至1996年初,经一位做传销公司(上海雅婷)的老同学力邀,我讲了半年左右的传销课,深受广大学员爱戴。遗憾的是国家对这种有争议的商业形式采取的不是整顿而是取缔的政策,所以看到形势不对,我们就在强制命令下达之前主动结束了生意。因为那时候我爱上了西方音乐(古典以外的所有形式),大概收有上千张英文唱片,为了听懂他们在唱些什么,我在讲传销课的同时开始学习一度深恶痛绝的英文。我在一个本地的三流私立英语学校上了三个月的基础英语课,后来因为他们巧立名目拒付曾经答应给我的奖金(我去法院起诉过,又被法院硬立名目拒绝受理),我只好又自学了。\n\n 实在不知道困在一个小地方可以做些什么,所以1996年夏天我到天津安顿下来(那时候我很喜欢北京,但是北京房价太丧心病狂了),靠给东北的朋友发些电脑散件以及后来零星翻译一些机械设备的英文技术文章维生,因为生性懒散不觉蹉跎至今。我要感谢那本莫名其妙的预言书\"诸世纪\",尽管我不是一个迷信的人,但是去年五一我看到那段著名的预言\"1999年7月,恐怖的大王将从天而降、、、、、、\"的时候还是有些犹豫,我认真地考虑自己可能即将结束的生命里有什么未了的心愿,结果发现只有减肥。从我有记忆以来我就是个痛苦的胖子,因为胖,我甚至不得不隐藏我性格里比较敏感忧郁的一面,因为胖子通常被大众潜意识里不由分说地认为应该嘻嘻哈哈,应该性情开朗,应该徐小平。他们对一个矫矫不群的胖子的性格能够容忍的上限是严肃,再出格一点就不行了,比如忧郁。虽然他们从来不能如此准确地说出这种想法,但是如果看到一个忧郁的胖子,他们就会直觉哪里不对了,他们的这种直觉的本质是,\"你是个胖子,你凭什么忧郁呢?你还想怎么样?你已经是个胖子了。\"所以很难见到一个肥胖的并且影响广泛的诗人,因为公众不能接受,任凭他的诗歌惨绿无比。当然胖子的痛苦永远不值得同情(除非是因为病理或基因导致),因为他们胖通常是因为缺乏坚强的意志(也许除了丘吉尔)。我就是个典型,我的肥胖完全是因为厌恶运动造成的,我有过十几次失败的减肥经历,我试过节食、锻炼、气功和几乎所有流行过的药物,包括在西方严禁非处方使用的芬弗拉明,我总怀疑我不如小时候开朗是因为误用芬弗拉明造成的,它减肥的药理竟然是通过使人情绪低落从而降低食欲,事实上,它根本就不是研制用来减肥的,它本是用来使轻度狂躁型精神病患者稳定情绪的药。我是中国落后的药检制度的严重受害者。\n\n 过了去年的五一节之后,我制定了严格的计划:每天只吃蔬菜、豆腐、全麦面包、鱼肉、橙汁、脱脂牛奶和善存,每天用一个小时跑10公里,也就是标准跑道的25圈。我不得不骄傲的是,我只用了58天就减掉了48斤体重,去掉休息的星期天,几乎是一天一斤。然后我心情平静地迎接了什么事情都没发生的7月。这件事过后我发现其实我还是很有毅力的一个人。但是我不知道我的毅力应该用来做什么,末日虽然没有来,但是新世纪来了,30岁也快来了,这真是一件让人坐立不安的事情。\n\n 后来我一度想移民加拿大,所以一边找资料看一边到天津大学夜间开办的口语学习班上课,一个班20多个人,一个外国教师(更多的时候是外国留学生)和我们天南地北地胡聊,除了政治。我一共上了四期这样的班,口语就差不多了,当然还是停留在比较普通的交流水平上,至少我看英文电影时还是需要看字幕,尽管在天津的四年间我看过大概600部英文电影。过了元旦,一个小朋友在和我吃饭的时候突然问我,为什么不去新东方教书,你应该很适合去新东方教书。我说我倒是喜欢讲课,但是一个民办教师有什么前途呢?他说如果年薪百万左右的工作不算前途那他就没什么可说的了。我得说我很吃惊。不管怎么样,我仔细地把我能找到的关于新东方的材料都看了一遍,我觉得这个工作很适合我,尤其是看到杨继老师在网页上说\"做一个自由而又敬业的人是我的梦想,新东方是实现它的好地方\"的时候。在我尽管懒散无为却又是勤于思考的三十来年里,好像还是第一次看到一个很适合我并且我也有兴趣去做的工作。杨继还转述席勒的话\"忠于你年轻时的梦想\"。我没看过席勒的东西,光知道有两个能写字儿的席勒,不知道是哪一个说的这话,但是我宁愿把它当成是新东方的精神。我听说教托福和教GRE薪水差不多,但是GRE的学习要苦得多。\n\n 我想了想还是选择了GRE,毕竟托福是专门给非英语国家的学生考的,教书的满足感上逊色很多。\n\n 旧历新年的时候,因为不确定是不是需要大学文凭才行,我试着写了一封应聘信给俞老师,提到我只有高中文凭,结果得到的答复是欢迎来面试,除了感激我还能说什么呢?我是说即便没有文凭不行我还是会来新东方做教师的,但是可能不得不伪造证件,作为一个比大多数人都更有原则、以知识分子自诩的人,如果可能,我还是希望不搞这些虚假的东西,俞校长的开明使得我不必去做大违我的本性和原则的事情,得以保持了人格的完整,这是我时常感念的。\n\n过了春节处理了一些杂事,很快就到了6月份,我买了本\"红宝书\"就上山了。鹫峰山上的学习气氛和恶劣条件我都非常喜欢,应该是因为生活有了明确目标的关系吧。但是我很快发现,讲课教师的水平和他们的报酬以及新东方的声誉比起来还是很不理想的。我看到身边大多数的同学对所有的老师评价都很好,听到那些愚蠢的笑话、对ETS肤浅的分析导致的轻浮谩骂和充满种族歧视、宗教歧视的言论的时候,大多数人都笑得很开心。这最终再次有力地证实了我一直怀有的一个看法:任何一个相对优秀的群体里面都是笨蛋居多。无论台下是300名来听传销的社会闲散人员还是300名来听GRE的大学毕业生,对于一个讲课的人来说并没有多少区别,这也是他们在台上信口开河、吹牛放炮的信心来源。当然这里大多数同学专业都很出色都很勤奋刻苦,积极上进,性格上也远比我更具备成功的素质,我只是说他们缺少情趣,他们聪明(至少他们都敢考GRE的数学,这是我想都不敢想的),但是没有灵气,人品也未必差,只是缺乏独立思考能力。\n\n 我只喜欢陈圣元一个人的课,所以后来也就只去上他一个人的课,其他的时候一个人在宿舍背单词。陈圣元除了胡扯闲聊比较有水准之外,治学态度曾经也让我觉得很好,说起charter这个单词的时候,他说为了找到那个填空句子里面表达的意思查遍了所有的词典都找不到满意的解释,最后花了一千多块钱买了一本巨大沉重的韦氏词典(显然是指MerriamWebsters Third New International Dictionary Unabridged)才终于在该词典所列的关于charter的25条释义中的最后一条里找到了答案。说起市面上粗制滥造的填空参考书的时候他很不以为然,\"我以三年的教学经验也精心编写了一本,那些作者对题目绝对没有我钻研得深,他们就会胡编乱造然后急忙出版抓紧骗钱,我这本可以说是这方面的集大成者,现在正在印刷当中,很快就可以和大家见面\"。由于在山上的时候单词还没怎么背,题目都没做过,所以他这些态度和表现曾经让我很景仰。发现不对头是下山之后开始的,我录了他的全部课堂录音,我听着录音大量做题的时候,才发现他的分析讲解漏洞百出,尽管他批评过去的新东方老师都是拿了正确答案再进行分析讲解,可是他的工作显然也是一样,这样才能解释为什么他总是能用错误的分析推理给你一个正确的答案。另外我发现所有的三流词典,包括英汉词典,都在charter的第一个释义上就解释了他声称在韦氏第三版未删节新国际词典的25条释义的最后一条中找到的答案,\"由君主或立法机关发给城市或大学,规定其特权及宗旨的特许状\",所以我也买了本十多斤重的韦氏第三版回来,发现只有13条释义,而且在第2条里就解释了这个问题。现在他的那本填空教程就在我手边,仅在No、4的52道题中,我就找到了18处错误,如果说翻译的错误对学生不重要,那么解题分析的错误也有10处之多。这也最终使得我改了主意,决定做填空老师,本来我想做词汇老师,那样可以海阔天空地胡扯。\n\n 我以这样的条件敢来新东方应聘,除了脸皮厚这个最显而易见的表面原因之外,主要还是教填空课的自信。第二次考试之后我一直做填空的备课,最消耗时间的是把NO、4到1994年的全部填空题翻译成中文,400多个句子的翻译居然用了我整整一个月的时间,基本上是一个小时翻译三个句子,当然快的时候两分钟一个,慢的时候几个小时翻不好一句。翻译这些句子是我本来的备课计划之外的工作,最终使我不得不做这个工作的原因是钱坤强和陈圣元那两本\"惨不忍睹\"的教材。钱坤强的那本就不必说了,此人中文都有问题,尽管我坚信他的英文要远比我的水平高(也许应该说熟练),但是理论上一个人如果母语都掌握不好(这意味着他对语言本身不敏感),那么他肯定掌握不好任何其他语言,即便他能熟练运用,也不适合做语言方面的工作,比如文字翻译。他那本超级填空教程在新东方地下室卖了两年都没正式出版,一定程度上说明了这本书的水准。至于我非常喜欢的陈圣元,他在那本书的前言中说道:\"翻译时尽量体现原文的结构,以便考生能对照原文体会原文句子结构的特征,从而体会结构与答案选项设计之间的关系......这样做会使得句子略显得欧化而不自然......不会去套用貌似华丽实则似是而非的成语。\"\n\n 作为一个考试学习用的教材,他声称的翻译原则和宗旨是很好的,但是很遗憾,我看到的绝不仅仅是一个欧化或是不自然的问题。首先\"体现原文结构\"应该表现为翻译成中文之后原文中的各个句子成分最大限度地在译文中充当同样的成分,而不是把所有的成分不变动位置地翻译成对应的中文单词,这样的做法和那些《金山快译》之类的拙劣软件的翻译结果有什么区别呢?实际上《金山快译》这一类翻译软件的译文虽然狗屁不通,但是我们即使看不到原文,通过猜测也能大致明白它想说些什么,这就如同没学过日文的中国人看日文电器说明书里面夹杂的汉字也能隐约猜出大意一样。陈圣元的译文本质上就是这样的一种东西,当然程度上有些区别。\n\n 其实欧化并不可怕,尤其是在一本学习用的教材中,即使是在文学中,一些恶性的欧化今天也成了现代白话文的组成部分。陈圣元的译文根本不是欧化的问题,他的译文和钱坤强的一样,最恐怖也让人难以置信的是,作为所谓的译文,如果脱离了原文的对照,没有一个中国人知道这些句子在说什么,我是说这些句子字面上在说什么都没人看得懂,而不是因为句意晦涩难解而使人看不懂它想表达的内涵。\n\n 另外,看得懂的很多句子又翻错了,即便看不懂句子的意思真的不影响正确答案的选择,但是作为一本教学参考书,如果参考译文都翻错了,还怎么让学生信服呢?除非是以一种变态的方式,比如\"陈老师的译文都翻错了,可是他的GRE考分那么高,可见看不懂句子对答题反而有帮助\"这一种。\n\n 我的译文体现了这样几个原则,首先由于不是文学翻译,我注意了最大限度地使用原文的结构,使译文中的句子成分尽量充当原文中的对应成分。为了这种对应,有时候会有些比较不符合中文习惯的句子结构,比如一些在英文中可以置后的定语从句按照中文的语法放到了修饰对象的前面之后,句子显得臃肿不堪,另外还可能导致断句困难。针对这样的问题,我在这类句子中大量地使用了括号和破折号,很多时候,如果只读括号外边的内容,读到的就是这个句子完整的主干,那些使句子结构变得复杂的修饰成分都在括号里边,但是如果假定这些括号不存在把它们连起来读,也是一个通顺完整毫无语病的句子,这样和原文对照阅读时对应的成分和原句的主干结构清晰可辨。\n\n 在解题思路上我修正了陈圣元的书中所有不严谨的地方,难以置信的是这些不严谨的错误在他的书中竟有三成之多。我的草稿还有很多优点,虽然这些优点是我完成的,但是我不想为了向别人解释\"我做的工作牛就牛在、、、、、、\"这样的东西浪费太多的时间,所以不再分析了。如果我们都接受\"不存在完美的东西\"这样一个假设,那么我想说的是,我的这本填空教材是离完美最近的那一个。希望我的坦率不会倒了您的胃口,当然我知道新东方的开明气度才会这样讲话。\n\n 如果新东方出版参考书的惟一标准是书的质量,而不权衡其他方面的因素,那么陈圣元的那本书的寿命不会也不应该超过一年。需要做一个效果未必理想的声明是,我并非有意攻击陈圣元,他在课上说起,新东方的同仁们的一个优点是互相不会拆台,也许私下并无深交但是不会互相诋毁,这对事业或是人生的成功起到了相对积极的作用。这种观点虽然不合我的本性,但是我也知道如果大家都是书生意气,新东方也没有今天。所以我接受了他的这个看法,基于这一点,我也不想对他做更多的攻击,很大程度上我对他的看法现在都坦率地说了出来是因为他已经离开了,不存在和睦相处的问题。何况,他出色的幽默感和极佳的亲和力都是我很佩服的,毕竟他是新东方我见过的最喜欢的老师(如果不是惟一喜欢的)。对于他的工作和治学态度,我更多的是感到遗憾。\n\n 当然我知道会有一些年轻教师不屑地说,教教GRE,算个屁自学?那好吧。\n\n 我想我多半看起来像是个怪物,高中毕业,不敢考数学,居然要来做教师。但是我到新东方应聘不是来做教师的,我是来做优秀教师的,所以不适合以常理判断。即使新东方的声誉和报酬使得它从来都不缺教师,我也知道优秀的教师永远都是不嫌多的,如果新东方从来都不缺优秀教师,那么我也知道更优秀的教师从来都是新东方迫切需要的。\n\n 龚自珍劝天公\"不拘一格降人才\",如果\"不拘一格\"的结果是降下了各方面发展严重失衡的,虽然远不是全面但又是十分优秀的畸形人才,谁来劝新东方\"不拘一格用人才\"呢?想想王强老师的经历,所以我也来试试说服您,我们都知道那个美国老头虽然觉得他很荒唐,但是他还是给了王强老师一个机会去见他,一个机会去说服他,所以我想我需要的也就是这么个机会而已。给我个机会去面试或是试讲吧,我会是新东方最好的老师,最差的情况下也会是\"之一\"。"
},
{
"path": "docs/android/AndroidNote/AdavancedPart/1.热修复实现(一).md",
"content": "\n热修复实现(一)\n===\n\n\n现在的热修复方案已经有很多了,例如`alibaba`的[dexposed](https://github.com/alibaba/dexposed)、[AndFix](https://github.com/alibaba/AndFix)以及`jasonross`的[Nuwa](https://github.com/jasonross/Nuwa)等等。原来没有仔细去分析过也没想写这篇文章,但是之前[InstantRun详解][1]这篇文章中介绍了`Android Studio Instant Run`的\n实现原理,这不就是活生生的一个热修复吗? 随心情久久不能平复,我们何不用这种方式来实现。 \n\n\n方案有很多种,我就只说明下我想到的方式,也就是`Instant Run`的方式: \n分拆到不同的`dex`中,然后通过`classloader`来进行加载。但是在之前[`InstantRun`详解](https://github.com/CharonChui/AndroidNote/blob/master/SourceAnalysis/InstantRun%E8%AF%A6%E8%A7%A3.md)中只说到会通过内部的`server`去判断该类是否有更新,如果有的话就去从新的`dex`中加载该类,否则就从旧的`dex`中加载,但这是如何实现的呢? 怎么去从不同的`dex`中选择最新的那个来进行加载。 \n\n讲到这里需要先介绍一下`ClassLoader`: \n\n< `A class loader is an object that is responsible for loading classes. The class ClassLoader is an abstract class. Given the binary name of a class, a class loader should attempt to locate or generate data that constitutes a definition for the class. A typical strategy is to transform the name into a file name and then read a \"class file\" of that name from a file system.` \n\n\n在一般情况下,应用程序不需要创建`ClassLoader`对象,而是使用当前环境已经存在的`ClassLoader`。因为`Java`的`Runtime`环境在初始化时,其内部会创建一个`ClassLoader`对象用于加载`Runtime`所需的各种`Java`类。 \n每个`ClassLoader`必须有一个父类,在装载`Class`文件时,子`ClassLoader`会先请求父`ClassLoader`加载该`Class`文件,只有当其父`ClassLoader`找不到该`Class`文件时,子`ClassLoader`才会继续装载该类,这是一种安全机制。 \n\n对于`Android`的应用程序,本质上虽然也是用`Java`开发,并且使用标准的`Java`编译器编译出`Class`文件,但最终的`APK`文件中包含的却是`dex`类型的文件。`dex`文件是将所需的所有`Class`文件重新打包,打包的规则不是简单的压缩,而是完全对`Class`文件内部的各种函数表、变量表等进行优化,并产生一个新的文件,这就是`dex`文件。由于`dex`文件是一种经过优化的`Class`文件,因此要加载这样特殊的`Class`文件就需要特殊的类装载器,这就是`DexClassLoader`,`Android SDK`中提供的D`exClassLoader`类就是出于这个目的。\n\n\n总体来说,`Android` 默认主要有三个`ClassLoader`: \n\n- `BootClassLoader`: 系统启动时创建 \n `Provides an explicit representation of the boot class loader. It sits at the\n head of the class loader chain and delegates requests to the VM's internal\n class loading mechanism.`\n- `PathClassLoader`: 可以加载`/data/app`目录下的`apk`,这也意味着,它只能加载已经安装的`apk`;\n- `DexClassLoader`: 可以加载文件系统上的`jar`、`dex`、`apk`;可以从`SD`卡中加载未安装的`apk`\n\n\n通过上面的分析知道,如果用多个`dex`的话肯定会用到`DexClassLoader`类,我们首先来看一下它的源码(这里\n插一嘴,源码可以去[googlesource](https://android.googlesource.com/platform/libcore-snapshot/+/ics-mr1/dalvik/src/main/java/dalvik/system)中找): \n```java\n/**\n * A class loader that loads classes from {@code .jar} and {@code .apk} files\n * containing a {@code classes.dex} entry. This can be used to execute code not\n * installed as part of an application.\n *\n * This class loader requires an application-private, writable directory to\n * cache optimized classes. Use {@code Context.getDir(String, int)} to create\n * such a directory:
{@code\n * File dexOutputDir = context.getDir(\"dex\", 0);\n * } \n *\n * Do not cache optimized classes on external storage. \n * External storage does not provide access controls necessary to protect your\n * application from code injection attacks.\n */\npublic class DexClassLoader extends BaseDexClassLoader {\n /**\n * Creates a {@code DexClassLoader} that finds interpreted and native\n * code. Interpreted classes are found in a set of DEX files contained\n * in Jar or APK files.\n *\n *
The path lists are separated using the character specified by the\n * {@code path.separator} system property, which defaults to {@code :}.\n *\n * @param dexPath the list of jar/apk files containing classes and\n * resources, delimited by {@code File.pathSeparator}, which\n * defaults to {@code \":\"} on Android\n * @param optimizedDirectory directory where optimized dex files\n * should be written; must not be {@code null}\n * @param libraryPath the list of directories containing native\n * libraries, delimited by {@code File.pathSeparator}; may be\n * {@code null}\n * @param parent the parent class loader\n */\n public DexClassLoader(String dexPath, String optimizedDirectory,\n String libraryPath, ClassLoader parent) {\n super(dexPath, new File(optimizedDirectory), libraryPath, parent);\n }\n}\n```\n注释说的太明白了,这里就不翻译了,但是我们并没有找到加载的代码,去它的父类中查找,\n因为家在都是从`loadClass()`方法中,所以我们去`ClassLoader`类中看一下`loadClass()`方法: \n```java\n/**\n * Loads the class with the specified name. Invoking this method is\n * equivalent to calling {@code loadClass(className, false)}.\n *
\n * Note: In the Android reference implementation, the\n * second parameter of {@link #loadClass(String, boolean)} is ignored\n * anyway.\n *
\n *\n * @return the {@code Class} object.\n * @param className\n * the name of the class to look for.\n * @throws ClassNotFoundException\n * if the class can not be found.\n */\n public Class loadClass(String className) throws ClassNotFoundException {\n return loadClass(className, false);\n }\n\n /**\n * Loads the class with the specified name, optionally linking it after\n * loading. The following steps are performed:\n * \n * Call {@link #findLoadedClass(String)} to determine if the requested\n * class has already been loaded. \n * If the class has not yet been loaded: Invoke this method on the\n * parent class loader. \n * If the class has still not been loaded: Call\n * {@link #findClass(String)} to find the class. \n * \n * \n * Note: In the Android reference implementation, the\n * {@code resolve} parameter is ignored; classes are never linked.\n *
\n *\n * @return the {@code Class} object.\n * @param className\n * the name of the class to look for.\n * @param resolve\n * Indicates if the class should be resolved after loading. This\n * parameter is ignored on the Android reference implementation;\n * classes are not resolved.\n * @throws ClassNotFoundException\n * if the class can not be found.\n */\n protected Class loadClass(String className, boolean resolve) throws ClassNotFoundException {\n Class clazz = findLoadedClass(className);\n\n if (clazz == null) {\n ClassNotFoundException suppressed = null;\n try {\n \t// 先检查父ClassLoader是否已经家在过该类\n clazz = parent.loadClass(className, false);\n } catch (ClassNotFoundException e) {\n suppressed = e;\n }\n\n if (clazz == null) {\n try {\n \t// 调用DexClassLoader.findClass()方法。\n clazz = findClass(className);\n } catch (ClassNotFoundException e) {\n e.addSuppressed(suppressed);\n throw e;\n }\n }\n }\n\n return clazz;\n }\n```\n上面会调用`DexClassLoader.findClass()`方法,但是`DexClassLoader`没有实现该方法,所以去它的父类`BaseDexClassLoader`中看,接着看一下`BaseDexClassLoader`的源码: \n```java\n/**\n * Base class for common functionality between various dex-based\n * {@link ClassLoader} implementations.\n */\npublic class BaseDexClassLoader extends ClassLoader {\n /** originally specified path (just used for {@code toString()}) */\n private final String originalPath;\n /** structured lists of path elements */\n private final DexPathList pathList;\n /**\n * Constructs an instance.\n *\n * @param dexPath the list of jar/apk files containing classes and\n * resources, delimited by {@code File.pathSeparator}, which\n * defaults to {@code \":\"} on Android\n * @param optimizedDirectory directory where optimized dex files\n * should be written; may be {@code null}\n * @param libraryPath the list of directories containing native\n * libraries, delimited by {@code File.pathSeparator}; may be\n * {@code null}\n * @param parent the parent class loader\n */\n public BaseDexClassLoader(String dexPath, File optimizedDirectory,\n String libraryPath, ClassLoader parent) {\n super(parent);\n this.originalPath = dexPath;\n this.pathList =\n new DexPathList(this, dexPath, libraryPath, optimizedDirectory);\n }\n @Override\n protected Class findClass(String name) throws ClassNotFoundException {\n // 从DexPathList中找\n Class clazz = pathList.findClass(name);\n if (clazz == null) {\n throw new ClassNotFoundException(name);\n }\n return clazz;\n }\n @Override\n protected URL findResource(String name) {\n return pathList.findResource(name);\n }\n @Override\n protected Enumeration findResources(String name) {\n return pathList.findResources(name);\n }\n @Override\n public String findLibrary(String name) {\n return pathList.findLibrary(name);\n }\n\n```\n在`findClass()`方法中我们看到调用了`DexPathList.findClass()`方法: \n```java\n/**\n * A pair of lists of entries, associated with a {@code ClassLoader}.\n * One of the lists is a dex/resource path — typically referred\n * to as a \"class path\" — list, and the other names directories\n * containing native code libraries. Class path entries may be any of:\n * a {@code .jar} or {@code .zip} file containing an optional\n * top-level {@code classes.dex} file as well as arbitrary resources,\n * or a plain {@code .dex} file (with no possibility of associated\n * resources).\n *\n * This class also contains methods to use these lists to look up\n * classes and resources.
\n */\n/*package*/ final class DexPathList {\n private static final String DEX_SUFFIX = \".dex\";\n private static final String JAR_SUFFIX = \".jar\";\n private static final String ZIP_SUFFIX = \".zip\";\n private static final String APK_SUFFIX = \".apk\";\n /** class definition context */\n private final ClassLoader definingContext;\n /** list of dex/resource (class path) elements */ \n // 把dex封装成一个数组,每个Element代表一个dex\n private final Element[] dexElements;\n /** list of native library directory elements */\n private final File[] nativeLibraryDirectories;\n\n // .....\n\n /**\n * Finds the named class in one of the dex files pointed at by\n * this instance. This will find the one in the earliest listed\n * path element. If the class is found but has not yet been\n * defined, then this method will define it in the defining\n * context that this instance was constructed with.\n *\n * @return the named class or {@code null} if the class is not\n * found in any of the dex files\n */\n public Class findClass(String name) {\n for (Element element : dexElements) {\n DexFile dex = element.dexFile;\n // 遍历数组,拿到第一个就返回\n if (dex != null) {\n Class clazz = dex.loadClassBinaryName(name, definingContext);\n if (clazz != null) {\n return clazz;\n }\n }\n }\n return null;\n }\n}\n```\n从上面的源码中分析,我知道系统会把所有相关的`dex`维护到一个数组中,然后在加载类的时候会从该数组中的第一个元素中取,然后返回。那我们只要保证将我们热修复后的`dex`对应的`Element`放到该数组的第一个位置就可以了,这样系统就会加载我们热修复的`dex`中的类。 \n所以方案出来了,只要把有问题的类修复后,放到一个单独的`dex`,然后把该`Dex`转换成对应的`Element`后再将该`Element`插入到`dexElements`数组的第一个位置就可以了。那该如何去将其插入到`dexElements`数组的第一个位置呢?-- 暴力反射。 \n\n\n\n到这里我感觉初步的思路已经有了: \n\n- 将补丁作为`dex`发布。 \n- 通过反射修改该`dex`所对应的`Element`在数组中的位置。 \n\n但是我也想到肯定还会有类似下面的问题: \n\n- 资源文件的处理\n- 四大组件的处理\n- 清单文件的处理\n\n\n虽然我知道没有这么简单,但是我还是决定抱着不作不死的宗旨继续前行。 \n\n好了,`demo`走起来。 \n\n\n怎么生成`dex`文件呢? 这要讲过两部分: \n\n- `.class`-> `.jar` : `jar -cvf test.jar com/charon/instantfix_sample/MainActivity.class`\n- `.jar`-> `.dex`: `dx --dex --output=target.jar test.jar` `target.jar`就是包含`.dex`的`jar`包\n\n\n生成好`dex`后我们为了模拟先将其放到`asset`目录下(实际开发中肯定要从接口中去下载,当然还会有一些版本号的判断等),然后就是将该`dex`转换成\n \n\n方案中采用的是`MultiDex`,对其进行一部分改造,具体代码: \n\n- 添加`dex`文件,并执行`install`\n\n```java\n/**\n* 添加apk包外的dex文件\n* 自动执行install\n* @param dexFile\n*/\npublic static void addDexFileAutoInstall(Context context, List dexFile,File optimizedDirectory) {\n if (dexFile != null && !dexFile.isEmpty() &&!dexFiles.contains(dexFile)) {\n dexFiles.addAll(dexFile);\n LogUtil.d(TAG, \"add other dexfile\");\n installDexFile(context,optimizedDirectory);\n }\n}\n```\n\n- `installDexFile`直接调用`MultiDex`的`installSecondaryDexes`方法 \n\n```java\n/**\n * 添加apk包外的dex文件,\n * @param context\n */\npublicstatic void installDexFile(Context context, File optimizedDirectory){\n if (checkValidZipFiles(dexFiles)) {\n try {\n installSecondaryDexes(context.getClassLoader(), optimizedDirectory, dexFiles);\n } catch (IllegalAccessExceptione){\n e.printStackTrace();\n } catch (NoSuchFieldExceptione) {\n e.printStackTrace();\n } catch (InvocationTargetExceptione){\n e.printStackTrace();\n } catch (NoSuchMethodExceptione) {\n e.printStackTrace();\n } catch (IOExceptione) {\n e.printStackTrace();\n }\n }\n}\n```\n\n- 将`patch.dex`放在所有`dex`最前面\n\n```java\nprivate static voidexpandFieldArray(Object instance, String fieldName, Object[]extraElements) throws NoSuchFieldException, IllegalArgumentException,\nIllegalAccessException {\n Field jlrField = findField(instance, fieldName);\n Object[]original = (Object[]) jlrField.get(instance);\n Object[]combined = (Object[]) Array.newInstance(original.getClass().getComponentType(),original.length + extraElements.length);\n // 将后来的dex放在前面,主dex放在最后。\n System.arraycopy(extraElements, 0, combined, 0, extraElements.length);\n System.arraycopy(original, 0, combined, extraElements.length,original.length);\n // 原始的dex合并,是将主dex放在前面,其他的dex依次放在后面。\n //System.arraycopy(original, 0, combined, 0, original.length);\n //System.arraycopy(extraElements, 0, combined, original.length,extraElements.length);\n jlrField.set(instance, combined);\n}\n```\n\n到此将`patch.dex`放进了`Element`,接下来的问题就是加载`Class`,当加载`patch.dex`中类的时候,会遇到一个问题,这个问题就是`QQ`空间团队遇到的`Class`的`CLASS_ISPREVERIFIED`。具体原因是`dvmResolveClass`这个方法对`Class`进行了校验。判断这个要`Resolve`的`class`是否和其引用来自一个`dex`。如果不是,就会遇到问题。\n \n当引用这和被引用者不在同一个`dex`中就会抛出异常,导致`Resolve`失败。`QQ`空间团队的方案是阻止所有的`Class`类打上`CLASS_ISPREVERIFIED`来逃过校验,这种方式其实是影响性能。\n我们的方案是和`QQ`团队的类似,但是和`QQ`空间不同的是,我们将`fromUnverifiedConstant`设置为`true`,来逃过校验,达到补丁的路径。具体怎么实现呢?\n要引用`Cydia Hook`技术来`hook Native dalvik`中`dvmResolveClass`这个方法。有关`Cydia Hook`技术请参考: \n\n- [官网地址](http://www.cydiasubstrate.com/)\n- [官方教程](http://www.cydiasubstrate.com/id/38be592b-bda7-4dd2-b049-cec44ef7a73b)\n- [SDK下载地址](http://asdk.cydiasubstrate.com/zips/cydia_substrate-r2.zip)\n\n\n具体代码如下: \n```java\n//指明要hook的lib :\nMSConfig(MSFilterLibrary,\"/system/lib/libdvm.so\")\n \n// 在初始化的时候进行hook\nMSInitialize {\n LOGD(\"Cydia Init\");\n MSImageRef image;\n //载入lib\n image = MSGetImageByName(\"/system/lib/libdvm.so\");\n if (image != NULL) {\n LOGD(\"image is not null\");\n void *dexload=MSFindSymbol(image,\"dvmResolveClass\");\n if(dexload != NULL) {\n LOGD(\"dexloadis not null\");\n MSHookFunction(dexload, (void*)proxyDvmResolveClass, (void**)&dvmResolveClass_Proxy);\n } else{\n LOGD(\"errorfind dvmResolveClass\");\n }\n }\n}\n// 在初始化的时候进行hook//保留原来的地址\nClassObject* (*dvmResolveClass_Proxy)(ClassObject* referrer, u4 classIdx, boolfromUnverifiedConstant);\n// 新方法地址\nstatic ClassObject* proxyDvmResolveClass(ClassObject* referrer, u4 classIdx,bool fromUnverifiedConstant) {\n return dvmResolveClass_Proxy(referrer, classIdx,true);\n}\n```\n\n说到此处,似乎已经是一个完整的方案了,但在实践中,会发现运行加载类的时候报`preverified`错误,原来在`DexPrepare.cpp`,将`dex`转化成`odex`的过程中,会在`DexVerify.cpp`进行校验,\n验证如果直接引用到的类和`clazz`是否在同一个`dex`,如果是,则会打上`CLASS_ISPREVERIFIED`标志。通过在所有类(`Application`除外,当时还没加载自定义类的代码)的构造函数插入一个对在单独的`dex`的类的引用,就可以解决这个问题。空间使用了`javaassist`进行编译时字节码插入。\n\n所以为了实现补丁方案,所以必须从这些方法中入手,防止类被打上`CLASS_ISPREVERIFIED`标志。 最终空间的方案是往所有类的构造函数里面插入了一段代码,代码如下:\n\n```java\nif (ClassVerifier.PREVENT_VERIFY) {\n System.out.println(AntilazyLoad.class);\n}\n```\n\n其中`AntilazyLoad`类会被打包成单独的`antilazy.dex`,这样当安装`apk`的时候,`classes.dex`内的类都会引用一个在不相同`dex`中的`AntilazyLoad`类,这样就防止了类被打上`CLASS_ISPREVERIFIED`的标志了,只要没被打上这个标志的类都可以进行打补丁操作。 然后在应用启动的时候加载进来`AntilazyLoad`类所在的`dex`包必须被先加载进来,不然`AntilazyLoad`类会被标记为不存在,即使后续加载了`hack.dex`包,那么他也是不存在的,这样屏幕就会出现茫茫多的类`AntilazyLoad`找不到的`log`。 所以`Application`作为应用的入口不能插入这段代码。(因为载入`hack.dex`的代码是在`Application`中`onCreate`中执行的,如果在`Application`的构造函数里面插入了这段代码,那么就是在`hack.dex`加载之前就使用该类,该类一次找不到,会被永远的打上找不到的标志)\n\n如何打包补丁包: \n\n1. 空间在正式版本发布的时候,会生成一份缓存文件,里面记录了所有`class`文件的`md5`,还有一份`mapping`混淆文件。\n2. 在后续的版本中使用`-applymapping`选项,应用正式版本的`mapping`文件,然后计算编译完成后的`class`文件的`md5`和正式版本进行比较,把不相同的`class`文件打包成补丁包。\n备注:该方案现在也应用到我们的编译过程当中,编译不需要重新打包`dex`,只需要把修改过的类的`class`文件打包成`patch dex`,然后放到`sdcard`下,那么就会让改变的代码生效。\n\n在`Java`中,只有当两个实例的类名、包名以及加载其的`ClassLoader`都相同,才会被认为是同一种类型。上面分别加载的新类和旧类,虽然包名和类名都完全一样,但是由于加载的`ClassLoader`不同,所以并不是同一种类型,在实际使用中可能会出现类型不符异常。\n同一个`Class`=相同的`ClassName + PackageName + ClassLoader`\n以上问题在采用动态加载功能的开发中容易出现,请注意。\n\n通过上面的分析,我们知道使用`ClassLoader`动态加载一个外部的类是非常容易的事情,所以很容易就能实现动态加载新的可执行代码的功能,但是比起一般的`Java`程序,在`Android`程序中使用动态加载主要有两个麻烦的问题: \n\n- `Android`中许多组件类(如`Activity、Service`等)是需要在`Manifest`文件里面注册后才能工作的(系统会检查该组件有没有注册),所以即使动态加载了一个新的组件类进来,没有注册的话还是无法工作;\n- `Res`资源是`Android`开发中经常用到的,而`Android`是把这些资源用对应的`R.id`注册好,运行时通过这些`ID`从`Resource`实例中获取对应的资源。如果是运行时动态加载进来的新类,那类里面用到`R.id`的地方将会抛出找不到资源或者用错资源的异常,因为新类的资源ID根本和现有的`Resource`实例中保存的资源`ID`对不上;\n\n说到底,抛开虚拟机的差别不说,一个`Android`程序和标准的`Java`程序最大的区别就在于他们的上下文环境`(Context)`不同。`Android`中,这个环境可以给程序提供组件需要用到的功能,也可以提供一些主题、`Res`等资源,其实上面说到的两个问题都可以统一说是这个环境的问题,而现在的各种`Android`动态加载框架中,核心要解决的东西也正是“如何给外部的新类提供上下文环境”的问题。\n\n`DexClassLoader`的使用方法一般有两种: \n\n- 从已安装的`apk`中读取`dex`\n- 从`apk`文件中读取`dex`\n\n假如有两个`APK`,一个是宿主`APK`,叫作`HOST`,一个是插件`APK`,叫作`Plugin`。`Plugin`中有一个类叫`PluginClass`,代码如下: \n```java\npublic class PluginClass {\n public PluginClass() {\n Log.d(\"JG\",\"初始化PluginClass\");\n }\n\n public int function(int a, int b){\n return a+b; \n } \n}\n```\n现在如果想调用插件`APK`中`PluginClass`内的方法,应该怎么办?\n\n#### 从已安装的apk中读取dex\n\n先来看第一种方法,这种方法必须建一个`Activity`,在清单文件中配置`Action`.\n\n```java\n\n \n \n \n \n```\n然后在宿主`APK`中如下使用: \n```java\n/**\n * 这种方式用于从已安装的apk中读取,必须要有一个activity,且需要配置ACTION\n */\nprivate void useDexClassLoader(){\n //创建一个意图,用来找到指定的apk\n Intent intent = new Intent(\"com.maplejaw.plugin\");\n //获得包管理器\n PackageManager pm = getPackageManager();\n List resolveinfoes = pm.queryIntentActivities(intent, 0);\n if(resolveinfoes.size()==0){\n return;\n }\n //获得指定的activity的信息\n ActivityInfo actInfo = resolveinfoes.get(0).activityInfo;\n\n //获得包名\n String packageName = actInfo.packageName;\n //获得apk的目录或者jar的目录\n String apkPath = actInfo.applicationInfo.sourceDir;\n //dex解压后的目录,注意,这个用宿主程序的目录,android中只允许程序读取写自己\n //目录下的文件\n String dexOutputDir = getApplicationInfo().dataDir;\n\n //native代码的目录\n String libPath = actInfo.applicationInfo.nativeLibraryDir;\n\n //创建类加载器,把dex加载到虚拟机中\n DexClassLoader calssLoader = new DexClassLoader(apkPath, dexOutputDir, libPath,\n this.getClass().getClassLoader());\n\n //利用反射调用插件包内的类的方法\n\n try {\n Class clazz = calssLoader.loadClass(packageName+\".PluginClass\");\n\n Object obj = clazz.newInstance();\n Class[] param = new Class[2];\n param[0] = Integer.TYPE;\n param[1] = Integer.TYPE;\n\n Method method = clazz.getMethod(\"function\", param);\n\n Integer ret = (Integer)method.invoke(obj, 12,34);\n\n Log.d(\"JG\", \"返回的调用结果为:\" + ret);\n\n } catch (Exception e) {\n e.printStackTrace();\n } \n }\n```\n我们安装完两个`APK`后,在宿主中就可以直接调用,调用示例如下。\n\n```java\npublic void btnClick(View view){\n useDexClassLoader();\n}\n```\n\n#### 从apk文件中读取dex\n\n这种方法由于并不需要安装,所以不需要通过`Intent`从`activity`中解析信息。换言之,这种方法不需要创建`Activity`。无需配置清单文件。我们只需要打包一个`apk`,然后放到`SD`卡中即可。\n核心代码如下: \n\n```java\n//apk路径\nString path=Environment.getExternalStorageDirectory().getAbsolutePath()+\"/1.apk\";\n\nprivate void useDexClassLoader(String path){\n \n File codeDir=getDir(\"dex\", Context.MODE_PRIVATE);\n\n //创建类加载器,把dex加载到虚拟机中\n DexClassLoader calssLoader = new DexClassLoader(path, codeDir.getAbsolutePath(), null,\n this.getClass().getClassLoader());\n\n //利用反射调用插件包内的类的方法\n\n try {\n Class clazz = calssLoader.loadClass(\"com.maplejaw.plugin.PluginClass\");\n\n Object obj = clazz.newInstance();\n Class[] param = new Class[2];\n param[0] = Integer.TYPE;\n param[1] = Integer.TYPE;\n\n Method method = clazz.getMethod(\"function\", param);\n\n Integer ret = (Integer)method.invoke(obj, 12,21);\n\n Log.d(\"JG\", \"返回的调用结果为: \" + ret);\n\n } catch (Exception e) {\n e.printStackTrace();\n } \n\n```\n\n\n动态加载的几个关键问题: \n\n- 资源访问:无法找到某某`id`所对应的资源\n 因为将`apk`加载到宿主程序中去执行,就无法通过宿主程序的`Context`去取到`apk`中的资源,比如图片、文本等,这是很好理解的,因为`apk`已经不存在上下文了,它执行时所采用的上下文是宿主程序的上下文,\n 用别人的`Context`是无法得到自己的资源的\n \n - 解决方案一:插件中的资源在宿主程序中也预置一份; \n 缺点:增加了宿主`apk`的大小;在这种模式下,每次发布一个插件都需要将资源复制到宿主程序中,这意味着每发布一个插件都要更新一下宿主程序;\n - 解决方案二:将插件中的资源解压出来,然后通过文件流去读取资源; \n 缺点:实际操作起来还是有很大难度的。首先不同资源有不同的文件流格式,比如图片、XML等,其次针对不同设备加载的资源可能是不一样的,如何选择合适的资源也是一个需要解决的问题;\n 实际解决方案: \n `Activity`中有一个叫`mBase`的成员变量,它的类型就是`ContextImpl`。注意到`Context`中有如下两个抽象方法,看起来是和资源有关的,实际上`Context`就是通过它们来获取资源的。这两个抽象方法的真正实现在`ContextImpl`中;\n\n\n```java\n/** Return an AssetManager instance for your application's package. */\n public abstract AssetManager getAssets();\n\n /** Return a Resources instance for your application's package. */\n public abstract Resources getResources();\n```\n具体实现: \n```java\nprotected void loadResources() {\n try {\n AssetManager assetManager = AssetManager.class.newInstance();\n Method addAssetPath = assetManager.getClass().getMethod(\"addAssetPath\", String.class);\n addAssetPath.invoke(assetManager, mDexPath);\n mAssetManager = assetManager;\n } catch (Exception e) {\n e.printStackTrace();\n }\n Resources superRes = super.getResources();\n mResources = new Resources(mAssetManager, superRes.getDisplayMetrics(),\n superRes.getConfiguration());\n mTheme = mResources.newTheme();\n mTheme.setTo(super.getTheme());\n}\n\n```\n\n加载资源的方法是通过反射,通过调用`AssetManager`中的`addAssetPath`方法,我们可以将一个`apk`中的资源加载到`Resources`对象中,由于`addAssetPath`是隐藏`API`我们无法直接调用,所以只能通过反射。\n\n```java\n@hide\n public final int addAssetPath(String path) {\n synchronized (this) {\n int res = addAssetPathNative(path);\n makeStringBlocks(mStringBlocks);\n return res;\n }\n}\n```\n\n`Activity`生命周期的管理:反射方式和接口方式。 \n反射的方式很好理解,首先通过`Java`的反射去获取`Activity`的各种生命周期方法,比如`onCreate`、`onStart`、`onResume`等,然后在代理`Activity`中去调用插件`Activity`对应的生命周期方法即可: \n缺点:一方面是反射代码写起来比较复杂,另一方面是过多使用反射会有一定的性能开销。\n\n反射方式\n```java\n@Override\nprotected void onResume() {\n super.onResume();\n Method onResume = mActivityLifecircleMethods.get(\"onResume\");\n if (onResume != null) {\n try {\n onResume.invoke(mRemoteActivity, new Object[] { });\n } catch (Exception e) {\n e.printStackTrace();\n }\n }\n}\n\n@Override\nprotected void onPause() {\n Method onPause = mActivityLifecircleMethods.get(\"onPause\");\n if (onPause != null) {\n try {\n onPause.invoke(mRemoteActivity, new Object[] { });\n } catch (Exception e) {\n e.printStackTrace();\n }\n }\n super.onPause();\n}\n```\n\n接口方式\n\n```java\npublic interface DLPlugin {\n\n public void onStart();\n\n public void onRestart();\n\n public void onActivityResult(int requestCode, int resultCode, Intent\n\n data);\n\n public void onResume();\n\n public void onPause();\n\n public void onStop();\n\n public void onDestroy();\n\n public void onCreate(Bundle savedInstanceState);\n\n public void setProxy(Activity proxyActivity, String dexPath);\n\n public void onSaveInstanceState(Bundle outState);\n\n public void onNewIntent(Intent intent);\n\n public void onRestoreInstanceState(Bundle savedInstanceState);\n\n public boolean onTouchEvent(MotionEvent event);\n\n public boolean onKeyUp(int keyCode, KeyEvent event);\n\n public void onWindowAttributesChanged(LayoutParams params);\n\n public void onWindowFocusChanged(boolean hasFocus);\n\n public void onBackPressed();\n\n…\n\n}\n```\n代理`Activity`中只需要按如下方式即可调用插件`Activity`的生命周期方法,这就完成了插件`Activity`的生命周期的管理;插件`Activity`需要实现`DLPlugin`接口: \n```java\n@Override\nprotected void onStart() {\n mRemoteActivity.onStart();\n super.onStart();\n}\n\n@Override\nprotected void onRestart() {\n mRemoteActivity.onRestart();\n super.onRestart();\n}\n\n@Override\nprotected void onResume() {\n mRemoteActivity.onResume();\n super.onResume();\n}\n```\n\n\n\n- [Google Instant app](https://developer.android.com/topic/instant-apps/index.html)\n- [微信热补丁实现](https://github.com/WeMobileDev/article/blob/master/%E5%BE%AE%E4%BF%A1Android%E7%83%AD%E8%A1%A5%E4%B8%81%E5%AE%9E%E8%B7%B5%E6%BC%94%E8%BF%9B%E4%B9%8B%E8%B7%AF.md#rd)\n- [多dex分拆](http://my.oschina.net/853294317/blog/308583)\n- [QQ空间热修复方案](https://mp.weixin.qq.com/s?__biz=MzI1MTA1MzM2Nw==&mid=400118620&idx=1&sn=b4fdd5055731290eef12ad0d17f39d4a)\n- [Android dex分包方案](http://my.oschina.net/853294317/blog/308583)\n- [类加载器DexClassLoader](http://www.maplejaw.com/2016/05/24/Android%E6%8F%92%E4%BB%B6%E5%8C%96%E6%8E%A2%E7%B4%A2%EF%BC%88%E4%B8%80%EF%BC%89%E7%B1%BB%E5%8A%A0%E8%BD%BD%E5%99%A8DexClassLoader/)\n- [基于cydia Hook在线热修复补丁方案](http://blog.csdn.net/xwl198937/article/details/49801975)\n- [Android 热补丁动态修复框架小结](http://blog.csdn.net/lmj623565791/article/details/49883661)\n- [美团Android DEX自动拆包及动态加载简介](http://tech.meituan.com/mt-android-auto-split-dex.html)\n- [插件化从放弃到捡起](http://kymjs.com/column/plugin.html)\n- [无需Root也能使用Xposed!](http://weishu.me/)\n- [当你准备开发一个热修复框架的时候,你需要了解的一切](http://www.zjutkz.net/2016/05/23/%E5%BD%93%E4%BD%A0%E5%87%86%E5%A4%87%E5%BC%80%E5%8F%91%E4%B8%80%E4%B8%AA%E7%83%AD%E4%BF%AE%E5%A4%8D%E6%A1%86%E6%9E%B6%E7%9A%84%E6%97%B6%E5%80%99%EF%BC%8C%E4%BD%A0%E9%9C%80%E8%A6%81%E4%BA%86%E8%A7%A3%E7%9A%84%E4%B8%80%E5%88%87/)\t\t\n\n\n[1]: https://github.com/CharonChui/AndroidNote/blob/master/SourceAnalysis/InstantRun%E8%AF%A6%E8%A7%A3.md \"InstantRun详解\"\n\n\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! \n"
},
{
"path": "docs/android/AndroidNote/AdavancedPart/2.热修复实现(二).md",
"content": "\n热修复实现(一)\n===\n\n之前也分析过`InstantRun`的源码,前面也写了一篇热修复实现原理的文章。\n\nBut,最近遇到困难了,所在项目要做插件化,同事在开发过程中遇到了一个在5.0以下手机崩溃的问题,想着一起找找原因修复下。\n但是这个bug已经折腾了我两天了,只找到原因,并没有找出任何解决方案。\n\n深深的感觉到之前的那些都是皮毛,没有真正的去做,真正的去处理一些细节,那些都是没任何意义的。\n\n所以这里系统学习一下,既然学习,就找一个做的最好的来学。 \n\n\n前面的文章也介绍了,目前存在的几个开源框架: \n\n- 手机淘宝基于Xposed进行了改进,产生了针对Android Dalvik虚拟机运行时的Java Method Hook技术-Dexposed。\n但这个方案犹豫底层Dalvik结构过于依赖,最终无法兼容Android 5.0以后的ART虚拟机。 \n\n- 支付宝提出了新的方案Andfix,它同样是一种底层结构替换的方案,也达到了运行时生效即时修复的效果,而且做到了Dalvik和ART全版本的兼容。然而它也\n是由局限性的,且不说其底层固定结构的替换方案稳定性不好,其使用范文也存在着诸多限制,虽然可以通过代码改造来绕过限制达到同样的\n修复目的,但是这种方式即不优雅也不方便。而且更大的问题是Andfix只提供了代码层面的修复,对于资源和so的修复都还未实现。 \n\n- 其他的就是微信Tinker、饿了么的Amigo、美团的Robust,不过他们都各自有各自的局限性,或者不够稳定、或者补丁过大、或者效率低下\n,或者使用起来太繁琐,大部分技术上看起来似乎可行,但是实际体验并不好。\n\n我们学习的就是阿里巴巴的新一代非侵入式Android热修复方案-Sophix。\n它各个方面都比较优秀,使用也比较方便,唯一不支持的就是四大组件的修复。这是因为如果修复四大组件,必须在AndroidManifest里面预先插入代码组件,并且尽可能声明所有权限,这样就会给\n原先的app添加很多臃肿的代码,对app运行流程的侵入性很强。 \n\n\n在Sophix中,唯一需要的就是初始化和请求补丁两行代码,甚至连入口Application类我们都不需要做任何修改。\n\n这样就给了开发者最大的透明度和自由度。我们甚至重新开发了打包工具,使的补丁工具操作图形界面化,这种所见即所得的补丁生成\n方式也是阿里热修复独家的,因此,Sophix的接入成本也是目前市面上所有方案里最低的。 \n\n\n\n\n代码修复\n---\n\n代码修复有两大主要方案: \n\n- 阿里系的底层替换方案:底层替换方案限制颇多,但是时效性最好,加载轻快,立即见效。\n\n\t底层替换方案是在已经加载了的类中直接替换掉原有的方法,是在原来类的基础上进行修改的。因而无法实现对原有类进行方法和字段的增减,因为这样将破坏原有类的结构。 \n\t一旦补丁类中出现了方法的增加和减少,就会导致这个类以及整个dex的方法数的变化,方法数的变化伴随着方法索引的变化,这样在\n\t访问方法时就无法正常的索引到正确的方法了。如果字段发生了增加或减少,和方法变化的情况一样,所有字段的索引都会发生变化。\n\t而新方法中使用到这些老的示例对象时,访问新增字段就会会产生不可预期的结果。 \n\n\t这是该类方案的固有限制,而底层替换方案最为人逅病的地方,在于底层替换的不稳定性。因为Hook方案,都是直接依赖修改虚拟机方法实体的具体字段。因为Art虚拟机和Dalvik虚拟机的不同,每个版本的虚拟机都要适配,而且Android系统是开源的,各个厂商都可以对代码进行改造,如果某个厂商进行了修改,那么这种通用性的替换机制就会出问题。这便是不稳定的根源。 \n\n\n\n- 腾讯系的类加载方案:类加载方案时效性差,需要重新冷启动才能见效,但修复范围广、限制少。 \n\n类加载方案的原理是在app重新启动后让classloader去加载新的类。因为在app运行到一半的时候,所有需要发生变更的类已经被加载过了,在Android上是无法对一个类进行卸载的。如果不重启,原来的类还在虚拟机中,就无法加载新类,因此只有在下次重启的时候,\n在还没走到业务逻辑之前抢先加载补丁中的新类,这样后续访问这个类的时候,就会用新类,从而达到热修复的目的。 \n\n\n为什么sophix更好?\n---\n\n既然底层替换方案和类加载方案各有优点,把他们联合起来就是最好的选择。Sophix就是同时涵盖了这两种方案,可以实现优势互补、完全兼顾的作用,可以灵活的根据实际情况自动切换。 \n\n\n\n\n\n\n但是[Sophix](https://help.aliyun.com/document_detail/57064.html?spm=a2c4g.11186623.6.543.SPhMhO)有一个缺点就是,他不是开源的,而且是收费的。但是确实强大。\n\n\n\n\n- [Google Instant app](https://developer.android.com/topic/instant-apps/index.html)\n- [微信热补丁实现](https://github.com/WeMobileDev/article/blob/master/%E5%BE%AE%E4%BF%A1Android%E7%83%AD%E8%A1%A5%E4%B8%81%E5%AE%9E%E8%B7%B5%E6%BC%94%E8%BF%9B%E4%B9%8B%E8%B7%AF.md#rd)\n- [多dex分拆](http://my.oschina.net/853294317/blog/308583)\n- [QQ空间热修复方案](https://mp.weixin.qq.com/s?__biz=MzI1MTA1MzM2Nw==&mid=400118620&idx=1&sn=b4fdd5055731290eef12ad0d17f39d4a)\n- [Android dex分包方案](http://my.oschina.net/853294317/blog/308583)\n- [类加载器DexClassLoader](http://www.maplejaw.com/2016/05/24/Android%E6%8F%92%E4%BB%B6%E5%8C%96%E6%8E%A2%E7%B4%A2%EF%BC%88%E4%B8%80%EF%BC%89%E7%B1%BB%E5%8A%A0%E8%BD%BD%E5%99%A8DexClassLoader/)\n- [基于cydia Hook在线热修复补丁方案](http://blog.csdn.net/xwl198937/article/details/49801975)\n- [Android 热补丁动态修复框架小结](http://blog.csdn.net/lmj623565791/article/details/49883661)\n- [美团Android DEX自动拆包及动态加载简介](http://tech.meituan.com/mt-android-auto-split-dex.html)\n- [插件化从放弃到捡起](http://kymjs.com/column/plugin.html)\n- [无需Root也能使用Xposed!](http://weishu.me/)\n- [当你准备开发一个热修复框架的时候,你需要了解的一切](http://www.zjutkz.net/2016/05/23/%E5%BD%93%E4%BD%A0%E5%87%86%E5%A4%87%E5%BC%80%E5%8F%91%E4%B8%80%E4%B8%AA%E7%83%AD%E4%BF%AE%E5%A4%8D%E6%A1%86%E6%9E%B6%E7%9A%84%E6%97%B6%E5%80%99%EF%BC%8C%E4%BD%A0%E9%9C%80%E8%A6%81%E4%BA%86%E8%A7%A3%E7%9A%84%E4%B8%80%E5%88%87/)\t\t\n\n\n[1]: https://github.com/CharonChui/AndroidNote/blob/master/SourceAnalysis/InstantRun%E8%AF%A6%E8%A7%A3.md \"InstantRun详解\"\n\n\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! \n"
},
{
"path": "docs/android/AndroidNote/AdavancedPart/3.热修复_addAssetPath不同版本区别原因(三).md",
"content": "在做热修复功能时Java层通过反射调用addAssetPath在Android5.0及以上系统没有问题,在Android 4.x版本找不到资源。 \n\naddAssetPath方法: \n```java\n/**\n * Add an additional set of assets to the asset manager. This can be\n * either a directory or ZIP file. Not for use by applications. Returns\n * the cookie of the added asset, or 0 on failure.\n * {@hide}\n */\npublic final int addAssetPath(String path) {\n int res = addAssetPathNative(path);\n return res;\n}\nprivate native final int addAssetPathNative(String path);\n```\n\naddAssetPath具体的实现方法是native层的。\n\n[AssetManager.cpp源码](https://android.googlesource.com/platform/frameworks/base/+/android-4.4_r1.0.1/libs/androidfw/AssetManager.cpp)\n\n4.4及以前的版本调用addAssetPath方法时,只是把补丁包的路径添加到mAssetPath中,不会去重新解析,真正解析的代码是在app第一次执行AssetManager.getResTable()`方法的时候。\n一旦解析完一次后,mResource对象就不为nil,以后就会直接return掉,不会重新解析。 \n\n```c\nbool AssetManager::addAssetPath(const String8& path, void** cookie)\n{\n AutoMutex _l(mLock);\n asset_path ap;\n String8 realPath(path);\n if (kAppZipName) {\n realPath.appendPath(kAppZipName);\n }\n ap.type = ::getFileType(realPath.string());\n if (ap.type == kFileTypeRegular) {\n ap.path = realPath;\n } else {\n ap.path = path;\n ap.type = ::getFileType(path.string());\n if (ap.type != kFileTypeDirectory && ap.type != kFileTypeRegular) {\n ALOGW(\"Asset path %s is neither a directory nor file (type=%d).\",\n path.string(), (int)ap.type);\n return false;\n }\n }\n // Skip if we have it already.\n for (size_t i=0; i(this)->loadFileNameCacheLocked();\n const size_t N = mAssetPaths.size();\n // 真正解析package的地方\n for (size_t i=0; i(this)->\n mZipSet.getZipResourceTable(ap.path);\n }\n if (sharedRes == NULL) {\n ass = const_cast(this)->\n mZipSet.getZipResourceTableAsset(ap.path);\n if (ass == NULL) {\n ALOGV(\"loading resource table %s\\n\", ap.path.string());\n ass = const_cast(this)->\n openNonAssetInPathLocked(\"resources.arsc\",\n Asset::ACCESS_BUFFER,\n ap);\n if (ass != NULL && ass != kExcludedAsset) {\n ass = const_cast(this)->\n mZipSet.setZipResourceTableAsset(ap.path, ass);\n }\n }\n \n if (i == 0 && ass != NULL) {\n // If this is the first resource table in the asset\n // manager, then we are going to cache it so that we\n // can quickly copy it out for others.\n ALOGV(\"Creating shared resources for %s\", ap.path.string());\n sharedRes = new ResTable();\n sharedRes->add(ass, (void*)(i+1), false, idmap);\n sharedRes = const_cast(this)->\n mZipSet.setZipResourceTable(ap.path, sharedRes);\n }\n }\n } else {\n ALOGV(\"loading resource table %s\\n\", ap.path.string());\n Asset* ass = const_cast(this)->\n openNonAssetInPathLocked(\"resources.arsc\",\n Asset::ACCESS_BUFFER,\n ap);\n shared = false;\n }\n if ((ass != NULL || sharedRes != NULL) && ass != kExcludedAsset) {\n if (rt == NULL) {\n mResources = rt = new ResTable();\n updateResourceParamsLocked();\n }\n ALOGV(\"Installing resource asset %p in to table %p\\n\", ass, mResources);\n if (sharedRes != NULL) {\n ALOGV(\"Copying existing resources for %s\", ap.path.string());\n rt->add(sharedRes);\n } else {\n ALOGV(\"Parsing resources for %s\", ap.path.string());\n rt->add(ass, (void*)(i+1), !shared, idmap);\n }\n if (!shared) {\n delete ass;\n }\n }\n if (idmap != NULL) {\n delete idmap;\n }\n MY_TRACE_END();\n }\n if (required && !rt) ALOGW(\"Unable to find resources file resources.arsc\");\n if (!rt) {\n mResources = rt = new ResTable();\n }\n return rt;\n}\n\n\nconst ResTable& AssetManager::getResources(bool required) const\n{\n const ResTable* rt = getResTable(required);\n return *rt;\n}\n```\n而当我们执行加载补丁的代码的时候,getResTable已经执行过多次了,Android Framework里面的代码会多次调用该方法。所以即使是使用addAssetPath,也只是添加到了mAssetPath,并不会发生解析,所以补丁包里面的资源就是完全不生效的。 \n\n而在android 5.0及以上的代码中: \n\n[Android 5.0 AssetManager.cpp源码](https://android.googlesource.com/platform/frameworks/base/+/android-5.0.0_r7/libs/androidfw/AssetManager.cpp)\n\n```c\nbool AssetManager::addAssetPath(const String8& path, int32_t* cookie)\n{\n AutoMutex _l(mLock);\n asset_path ap;\n String8 realPath(path);\n if (kAppZipName) {\n realPath.appendPath(kAppZipName);\n }\n ap.type = ::getFileType(realPath.string());\n if (ap.type == kFileTypeRegular) {\n ap.path = realPath;\n } else {\n ap.path = path;\n ap.type = ::getFileType(path.string());\n if (ap.type != kFileTypeDirectory && ap.type != kFileTypeRegular) {\n ALOGW(\"Asset path %s is neither a directory nor file (type=%d).\",\n path.string(), (int)ap.type);\n return false;\n }\n }\n // Skip if we have it already.\n for (size_t i=0; i(i+1);\n }\n return true;\n }\n }\n ALOGV(\"In %p Asset %s path: %s\", this,\n ap.type == kFileTypeDirectory ? \"dir\" : \"zip\", ap.path.string());\n // Check that the path has an AndroidManifest.xml\n Asset* manifestAsset = const_cast(this)->openNonAssetInPathLocked(\n kAndroidManifest, Asset::ACCESS_BUFFER, ap);\n if (manifestAsset == NULL) {\n // This asset path does not contain any resources.\n delete manifestAsset;\n return false;\n }\n delete manifestAsset;\n mAssetPaths.add(ap);\n // new paths are always added at the end\n if (cookie) {\n *cookie = static_cast(mAssetPaths.size());\n }\n#ifdef HAVE_ANDROID_OS\n // Load overlays, if any\n asset_path oap;\n for (size_t idx = 0; mZipSet.getOverlay(ap.path, idx, &oap); idx++) {\n mAssetPaths.add(oap);\n }\n#endif\n if (mResources != NULL) {\n // 重新调用该方法去解析package\n appendPathToResTable(ap);\n }\n return true;\n}\n```\n\n```c\nbool AssetManager::appendPathToResTable(const asset_path& ap) const {\n Asset* ass = NULL;\n ResTable* sharedRes = NULL;\n bool shared = true;\n bool onlyEmptyResources = true;\n MY_TRACE_BEGIN(ap.path.string());\n Asset* idmap = openIdmapLocked(ap);\n size_t nextEntryIdx = mResources->getTableCount();\n ALOGV(\"Looking for resource asset in '%s'\\n\", ap.path.string());\n if (ap.type != kFileTypeDirectory) {\n if (nextEntryIdx == 0) {\n // The first item is typically the framework resources,\n // which we want to avoid parsing every time.\n sharedRes = const_cast(this)->\n mZipSet.getZipResourceTable(ap.path);\n if (sharedRes != NULL) {\n // skip ahead the number of system overlay packages preloaded\n nextEntryIdx = sharedRes->getTableCount();\n }\n }\n if (sharedRes == NULL) {\n ass = const_cast(this)->\n mZipSet.getZipResourceTableAsset(ap.path);\n if (ass == NULL) {\n ALOGV(\"loading resource table %s\\n\", ap.path.string());\n ass = const_cast(this)->\n openNonAssetInPathLocked(\"resources.arsc\",\n Asset::ACCESS_BUFFER,\n ap);\n if (ass != NULL && ass != kExcludedAsset) {\n ass = const_cast(this)->\n mZipSet.setZipResourceTableAsset(ap.path, ass);\n }\n }\n \n if (nextEntryIdx == 0 && ass != NULL) {\n // If this is the first resource table in the asset\n // manager, then we are going to cache it so that we\n // can quickly copy it out for others.\n ALOGV(\"Creating shared resources for %s\", ap.path.string());\n sharedRes = new ResTable();\n sharedRes->add(ass, idmap, nextEntryIdx + 1, false);\n#ifdef HAVE_ANDROID_OS\n const char* data = getenv(\"ANDROID_DATA\");\n LOG_ALWAYS_FATAL_IF(data == NULL, \"ANDROID_DATA not set\");\n String8 overlaysListPath(data);\n overlaysListPath.appendPath(kResourceCache);\n overlaysListPath.appendPath(\"overlays.list\");\n addSystemOverlays(overlaysListPath.string(), ap.path, sharedRes, nextEntryIdx);\n#endif\n sharedRes = const_cast(this)->\n mZipSet.setZipResourceTable(ap.path, sharedRes);\n }\n }\n } else {\n ALOGV(\"loading resource table %s\\n\", ap.path.string());\n ass = const_cast(this)->\n openNonAssetInPathLocked(\"resources.arsc\",\n Asset::ACCESS_BUFFER,\n ap);\n shared = false;\n }\n if ((ass != NULL || sharedRes != NULL) && ass != kExcludedAsset) {\n ALOGV(\"Installing resource asset %p in to table %p\\n\", ass, mResources);\n if (sharedRes != NULL) {\n ALOGV(\"Copying existing resources for %s\", ap.path.string());\n mResources->add(sharedRes);\n } else {\n ALOGV(\"Parsing resources for %s\", ap.path.string());\n mResources->add(ass, idmap, nextEntryIdx + 1, !shared);\n }\n onlyEmptyResources = false;\n if (!shared) {\n delete ass;\n }\n } else {\n ALOGV(\"Installing empty resources in to table %p\\n\", mResources);\n mResources->addEmpty(nextEntryIdx + 1);\n }\n if (idmap != NULL) {\n delete idmap;\n }\n MY_TRACE_END();\n return onlyEmptyResources;\n}\nconst ResTable* AssetManager::getResTable(bool required) const\n{\n ResTable* rt = mResources;\n if (rt) {\n return rt;\n }\n // Iterate through all asset packages, collecting resources from each.\n AutoMutex _l(mLock);\n if (mResources != NULL) {\n return mResources;\n }\n if (required) {\n LOG_FATAL_IF(mAssetPaths.size() == 0, \"No assets added to AssetManager\");\n }\n if (mCacheMode != CACHE_OFF && !mCacheValid) {\n const_cast(this)->loadFileNameCacheLocked();\n }\n mResources = new ResTable();\n updateResourceParamsLocked();\n bool onlyEmptyResources = true;\n const size_t N = mAssetPaths.size();\n // 也是调用appendPathToResTable去解析\n for (size_t i=0; i = instance.getStatusById(workRequest.id)\ninstance.cancelWorkById(workRequest.id)\n```\n如果想要顺序的去执行不同的`OneTimeWorker`也是很方便的: \n```kotlin\nWorkContinuation chain1 = WorkManager.getInstance()\n .beginWith(workA)\n .then(workB);\nWorkContinuation chain2 = WorkManager.getInstance()\n .beginWith(workC)\n .then(workD);\nWorkContinuation chain3 = WorkContinuation\n .combine(chain1, chain2)\n .then(workE);\nchain3.enqueue();\n```\n\n上面都是用了`OneTimeWorkRequest`,如果你想定期的去执行某一个`worker`的话,可以使用`PeriodicWorkRequest`: \n```kotlin\nval workRequest = PeriodicWorkRequest.Builder(MineWorker::class.java, 3, TimeUnit.SECONDS)\n .setConstraints(constraints)\n .setInputData(data)\n .build()\n```\n\n但是我使用这个定期任务执行的时候也只是执行了一次,并没有像上面的代码中那样3秒执行一次,什么鬼? \n我们看看`PeriodicWorkRequest`的源码: \n\n```kotlin\n/**\n * A class that represents a request for repeating work.\n */\n\npublic final class PeriodicWorkRequest extends WorkRequest {\n\n /**\n * The minimum interval duration for {@link PeriodicWorkRequest}, in milliseconds.\n * Based on {@see https://android.googlesource.com/platform/frameworks/base/+/master/core/java/android/app/job/JobInfo.java#110}.\n */\n public static final long MIN_PERIODIC_INTERVAL_MILLIS = 15 * 60 * 1000L; // 15 minutes.\n```\n\n上面说的很明白,最小间隔15分钟,- -!\n\n\n总体来说,`WorkManager`并不是要取代线程池`AsyncTask/RxJava`.反而是像`AlarmManager`来做定时任务的意思.即保证你给它的任务能完成, 即使你的应用都没有被打开, 或是设备重启后也能让你的任务被执行.`WorkManager`在设计上设计得比较好.没有把`worker`,任务混为一谈,而是把它们解耦成`Worker`,`WorkRequest`.这样分层就清晰多了, 也好扩展.\n\n\n到了这里突然有了一个大胆的想法。看到没有它能保证任务的执行。\n我们之前写过一篇文章[Android卸载反馈](https://github.com/CharonChui/AndroidNote/blob/master/AdavancedPart/Android%E5%8D%B8%E8%BD%BD%E5%8F%8D%E9%A6%88.md)\n里面用到了`c`中的`fork`来保证存活,达到常驻内存的功能,如果`PeriodicWorkRequest`的最小间隔时间比较短不是15分钟的话,那这里是不是也可以用`WorkManager`来实现? 好了,不说了。\n\n\n\n参考: \n\n- [官方文档](https://developer.android.com/topic/libraries/architecture/workmanager)\n- [Codelabs android-workmanager](https://codelabs.developers.google.com/codelabs/android-workmanager/#0)\n- [示例代码](https://github.com/googlecodelabs/android-workmanager)\n\t\t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/Android6.0权限系统.md",
"content": "Android6.0权限系统\n===\n\n`Android`权限系统是一个非常重要的安全问题,因为它只有在安装时会询问一次。一旦软件本安装之后,应用程序可以在用户毫不知情的情况下使用这些权限来获取所有的内容。 \n\n很多坏蛋会通过这个安全缺陷来收集用户的个人信息并使用它们来做坏事的情况就不足为奇了。 \n\n`Android`团队也意识到了这个问题。在经过了7年后,权限系统终于被重新设置了。从`Anroid 6.0(API Level 23)`开始,应用程序在安装时不会被授予任何权限,取而代之的是在运行时应用回去请求用户授予对应的权限。这样可以让用户能更好的去控制应用功能。例如,一个用户可能会同一个拍照应用使用摄像头的权限,但是不同授权它获取设备位置的权限。用户可以在任何时候通过去应用的设置页面来撤销授权。 \n\n \n\n注意:上面请求权限的对话框不会自动弹出。开发者需要手动的调用。如果开发者调用了一些需要权限的功能,但是用户又拒绝授权的话,应用就会`crash`。 \n\n系统权限被分为两类,`normal`和`dangerous`: \n\n- `Normal Permissions`不需要用户直接授权,如果你的应用在清单文件中声明了`Normal Permissions`,系统会自动授权该权限。 \n- `Dangerous Permissions`可以让应用获取用户的私人数据。如果你的应用在清单文件中申请了`Dangerous Permissions`,那就必须要用户来授权给应用。 \n\n`Normal Permissions`: \n`Normal Permission`是当用户安装或更新应用时,系统将授予应用所请求的权限,又称为`PROTECTION_NORMAL`(安装时授权的一类基本权限)。该类权限只需要在`manifest`文件中声明即可,安装时就授权,不需要每次使用时进行检查,而且用户不能取消以上授权。 \n\n\n- ACCESS_LOCATION_EXTRA_COMMANDS\n- ACCESS_NETWORK_STATE\n- ACCESS_NOTIFICATION_POLICY\n- ACCESS_WIFI_STATE\n- BLUETOOTH\n- BLUETOOTH_ADMIN\n- BROADCAST_STICKY\n- CHANGE_NETWORK_STATE\n- CHANGE_WIFI_MULTICAST_STATE\n- CHANGE_WIFI_STATE\n- DISABLE_KEYGUARD\n- EXPAND_STATUS_BAR\n- GET_PACKAGE_SIZE\n- INSTALL_SHORTCUT\n- INTERNET\n- KILL_BACKGROUND_PROCESSES\n- MODIFY_AUDIO_SETTINGS\n- NFC\n- READ_SYNC_SETTINGS\n- READ_SYNC_STATS\n- RECEIVE_BOOT_COMPLETED\n- REORDER_TASKS\n- REQUEST_IGNORE_BATTERY_OPTIMIZATIONS\n- REQUEST_INSTALL_PACKAGES\n- SET_ALARM\n- SET_TIME_ZONE\n- SET_WALLPAPER\n- SET_WALLPAPER_HINTS\n- TRANSMIT_IR\n- UNINSTALL_SHORTCUT\n- USE_FINGERPRINT\n- VIBRATE\n- WAKE_LOCK\n- WRITE_SYNC_SETTINGS\n\n\n\n下图为`Dangerous permissions and permission groups`: \n\n \n\n\n在所有的`Android`版本中,你的应用都需要在`manifest`文件中声明`normal`和`dangerous`权限。然而声明所影响的效果会因系统版本和你应用的`target SDK lever`有关: \n\n- 如果设备运行的是`Android 5.1`或者之前的系统,或者应用的`targetSdkVersion`是22或者之前版本:如果你在`manifest`中声明了`dangerous permission`,用户需要在安装应用时授权这些权限。如果用户不授权这些权限,系统就不会安装该应用。(我试了下发现即使`targetSdkVersion`是22及以下,在6.0的手机上时,如果你安装时你不同意一些权限,也仍然可以安装的) \n- 如果设备运行的是`Android 6.0`或者更高的系统,并且你应用的`targetSdkVersion`是23或者更高:应用必须在`manifest`文件中申请这些权限,而且必须要在运行时对所需要的`dangerous permission`申请授权。用户可以统一或者拒绝授权,并且及时用户拒绝了授权,应用在无法使用一些功能的情况下也要保证能继续运行。 \n\n也就是说新的运行时权限仅当我们设置`targetSdkVersion`是23及以上时才会起作用。 \n如果你的`targtSdkVersion`低于23,那将被认为该应用没有经过`android 6.0`的测试,当该应用被安装到了6.0的手机上时,仍然会使用之前的旧权限规则,在安装时会提示所有需要的权限(这样做是有道理的,不然对于之前开发的应用,我们都要立马去修改让它适应6.0,来不及的话就导致6.0的手机都无法使用了,显然Android开发团队不会考虑不到这种情况),当然用户可以在安装的界面不允许一些权限,那当程序使用到了这些权限时,会崩溃吗?答案是在`Android 6.0`及以上的手机会直接`crash`,但是在`23`之前的手机上不会`crash`。 \n\n所以如果你的应用没有支持运行时权限的功能,那千万不要讲`targetSdkVersion`设置为23,否则就麻烦了。 \n\n> 注意:从`Android 6.0(API Level 23)`开始,即使应用的`targetSdkVersion`是比较低的版本,但是用户仍然可以在任何时候撤销对应用的授权。所以不管应用的`targetSdkVerison`是什么版本,你都要测试你的应用在不能获取权限时能不能正常运行。 \n\n下面介绍下如何使用`Android Support Library`来检查和请求权限。`Android`框架在`6.0`开始也提供了相同的方法。然而使用`support`包会比较简单,因为这样你就不需要在请求方法时判断当前的系统版本。(后面说的这几个类都是`android.support.v4`中的) \n\n### 检查权限 \n\n如果应用需要使用`dangerous permission`,在任何时候执行需要该权限的操作时你都需要检查是否已经授权。用户可能会经常取消授权,所以即使昨天应用已经使用了摄像头,这也不能保证今天仍然有使用摄像头的权限。 \n\n为了检查是否可以使用该权限,调用`ContextCompat.checkSelfPermission()`。 \n例如: \n```java\n// Assume thisActivity is the current activity\nint permissionCheck = ContextCompat.checkSelfPermission(thisActivity,\n Manifest.permission.WRITE_CALENDAR);\n```\n如果应用有该权限,该方法将返回`PackageManager.PERMISSION_GRANTED`,应用可以进行相关的操作。如果应用不能使用该权限,该方法将返回`PERMISSION_DENIED`,这是应用将必须要向用户申请该权限。 \n\n\n### 申请使用权限\n\n如果应用需要使用清单文件中申明的`dangerous permission`,它必须要向用户申请来授权。`Android`提供了几种申请授权的方法。使用这些方法时将会弹出一个标准的系统对话框,该对话框不能自定义。 \n\n##### 说明为什么应用需要使用这些权限 \n\n在一些情况下,你可能需要帮助用力理解为什么需要该权限。例如,一个用户使用了一个照相的应用,用户不会奇怪为什么应用申请使用摄像头的权限,但是用户可能会不理解为什么应用需要获取位置或者联系人的权限。在请求一个权限之前,你需要该用户一个说明。一定要切记不要通过说明来压倒用户。如果你提供了太多的说明,用户可能会感觉沮丧并且会卸载它。 \n\n一个你需要提供说明的合适时机就是在用户之前已经不同意授权该权限的情况下。如果一个用户继续尝试使用需要权限的功能时,但是之前确禁止了该权限的请求,这就可能是因为用户不理解为什么该功能需要使用该权限。在这种情况下,提供一个说明是非常合适的。 \n\n为了能找到用户可能需要说明的情况,`android`提供了一个工具类方法`ActivityCompat.shouldShowRequestPermissionRationale().`。如果应用之前申请了该权限但是用户拒绝授权后该方法会返回`true`。(在Android 6.0之前调用的时候会直接返回false) \n\n> 注意:如果用户之前拒绝了权限申请并且选择了请求权限对话框中的`Don’t ask again`选项,该方法就会返回`false`。如果设备策略禁止了该应用使用该权限,该方法也会返回`false`。(我测试的时候发现请求权限的对话框中并没有`Don’t asdk again`这一项)\n\n permissionsNeeded = new ArrayList();\n \n final List permissionsList = new ArrayList();\n if (!addPermission(permissionsList, Manifest.permission.ACCESS_FINE_LOCATION))\n permissionsNeeded.add(\"GPS\");\n if (!addPermission(permissionsList, Manifest.permission.READ_CONTACTS))\n permissionsNeeded.add(\"Read Contacts\");\n if (!addPermission(permissionsList, Manifest.permission.WRITE_CONTACTS))\n permissionsNeeded.add(\"Write Contacts\");\n \n if (permissionsList.size() > 0) {\n if (permissionsNeeded.size() > 0) {\n // Need Rationale\n String message = \"You need to grant access to \" + permissionsNeeded.get(0);\n for (int i = 1; i < permissionsNeeded.size(); i++)\n message = message + \", \" + permissionsNeeded.get(i);\n showMessageOKCancel(message,\n new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialog, int which) {\n requestPermissions(permissionsList.toArray(new String[permissionsList.size()]),\n REQUEST_CODE_ASK_MULTIPLE_PERMISSIONS);\n }\n });\n return;\n }\n requestPermissions(permissionsList.toArray(new String[permissionsList.size()]),\n REQUEST_CODE_ASK_MULTIPLE_PERMISSIONS);\n return;\n }\n \n insertDummyContact();\n}\n \nprivate boolean addPermission(List permissionsList, String permission) {\n if (checkSelfPermission(permission) != PackageManager.PERMISSION_GRANTED) {\n permissionsList.add(permission);\n // Check for Rationale Option\n if (!shouldShowRequestPermissionRationale(permission))\n return false;\n }\n return true;\n}\n```\n\n\n上面讲到的都是`Activity`中的使用方法,那`Fragment`中怎么授权呢?\n如果在`Fragment`中使用,用`v13`包中的`FragmentCompat.requestPermissions()`和`FragmentCompat.shouldShowRequestPermissionRationale()`。 \n\n\n\n在`Fragment`中申请权限,不要使用`ActivityCompat.requestPermissions`, 直接使用`Fragment.requestPermissions`方法,\n否则会回调到`Activity`的`onRequestPermissionsResult`。但是虽然你使用`Fragment.requestPermissions`方法,也照样回调不到`Fragment.onRequestPermissionsResult`中。这是`Android`的`Bug`,[详见](https://code.google.com/p/android/issues/detail?can=2&start=0&num=100&q=&colspec=ID%20Status%20Priority%20Owner%20Summary%20Stars%20Reporter%20Opened&groupby=&sort=&id=189121),`Google`已经在`23.3.0`修复了该问题,所以要尽快升级。\n\n所以升级到`23.3.0`及以上就没问题了。如果不升级该怎么处理呢?就是在`Activity.onRequestPermissionsResult`方法中去手动调用每个`Fragment`的方法(当然你要判断下权限个数,不然申请一个权限的情况下会重复调用). \n```java\n@Override\npublic void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions, @NonNull int[] grantResults) {\n super.onRequestPermissionsResult(requestCode, permissions, grantResults);\n List fragments = getSupportFragmentManager().getFragments();\n if (fragments != null) {\n for (Fragment fragment : fragments) {\n fragment.onRequestPermissionsResult(requestCode, permissions, grantResults);\n }\n }\n}\n```\n\n我简单的写了一个工具类: \n\n```java\npublic class PermissionUtil {\n /**\n * 在调用需要权限的功能时使用该方法进行检查。\n *\n * @param activity\n * @param requestCode\n * @param iPermission\n * @param permissions\n */\n public static void checkPermissions(Activity activity, int requestCode, IPermission iPermission, String... permissions) {\n handleRequestPermissions(activity, requestCode, iPermission, permissions);\n }\n\n public static void checkPermissions(Fragment fragment, int requestCode, IPermission iPermission, String... permissions) {\n handleRequestPermissions(fragment, requestCode, iPermission, permissions);\n }\n\n public static void checkPermissions(android.app.Fragment fragment, int requestCode, IPermission iPermission, String... permissions) {\n handleRequestPermissions(fragment, requestCode, iPermission, permissions);\n }\n\n /**\n * 在Actvitiy或者Fragment中重写onRequestPermissionsResult方法后调用该方法。\n *\n * @param activity\n * @param requestCode\n * @param permissions\n * @param grantResults\n * @param iPermission\n */\n public static void onRequestPermissionsResult(Activity activity, int requestCode, String[] permissions,\n int[] grantResults, IPermission iPermission) {\n requestResult(activity, requestCode, permissions, grantResults, iPermission);\n\n }\n\n public static void onRequestPermissionsResult(Fragment fragment, int requestCode, String[] permissions,\n int[] grantResults, IPermission iPermission) {\n requestResult(fragment, requestCode, permissions, grantResults, iPermission);\n }\n\n public static void onRequestPermissionsResult(android.app.Fragment fragment, int requestCode, String[] permissions,\n int[] grantResults, IPermission iPermission) {\n requestResult(fragment, requestCode, permissions, grantResults, iPermission);\n }\n\n public static void requestPermission(T t, int requestCode, String... permission) {\n List permissions = new ArrayList<>();\n for (String s : permission) {\n permissions.add(s);\n }\n requestPermissions(t, requestCode, permissions);\n }\n\n /**\n * 在检查权限后自己处理权限说明的逻辑后调用该方法,直接申请权限。\n *\n * @param t\n * @param requestCode\n * @param permissions\n * @param \n */\n public static void requestPermission(T t, int requestCode, List permissions) {\n if (permissions == null || permissions.size() == 0) {\n return;\n }\n requestPermissions(t, requestCode, permissions);\n }\n\n public static boolean checkSelfPermission(Context context, String permission) {\n if (context == null || TextUtils.isEmpty(permission)) {\n throw new IllegalArgumentException(\"invalidate params: the params is null !\");\n }\n\n context = context.getApplicationContext();\n\n if (android.os.Build.VERSION.SDK_INT >= android.os.Build.VERSION_CODES.M) {\n int result = ContextCompat.checkSelfPermission(context, permission);\n if (PackageManager.PERMISSION_DENIED == result) {\n return false;\n }\n }\n\n return true;\n }\n\n private static void handleRequestPermissions(T t, int requestCode, IPermission iPermission, String... permissions) {\n if (t == null || permissions == null || permissions.length == 0) {\n throw new IllegalArgumentException(\"invalidate params\");\n }\n if (android.os.Build.VERSION.SDK_INT >= android.os.Build.VERSION_CODES.M) {\n Activity activity = getActivity(t);\n List deniedPermissions = getDeniedPermissions(activity, permissions);\n if (deniedPermissions != null && deniedPermissions.size() > 0) {\n\n List rationalPermissions = new ArrayList<>();\n for (String deniedPermission : deniedPermissions) {\n if (ActivityCompat.shouldShowRequestPermissionRationale(activity,\n deniedPermission)) {\n rationalPermissions.add(deniedPermission);\n }\n }\n\n boolean showRational = false;\n if (iPermission != null) {\n showRational = iPermission.showRational(requestCode);\n }\n\n if (rationalPermissions.size() > 0 && showRational) {\n if (iPermission != null) {\n iPermission.onRational(requestCode, deniedPermissions);\n }\n } else {\n requestPermissions(t, requestCode, deniedPermissions);\n }\n } else {\n if (iPermission != null) {\n iPermission.onGranted(requestCode);\n }\n }\n } else {\n if (iPermission != null) {\n iPermission.onGranted(requestCode);\n }\n }\n }\n\n @Nullable\n private static Activity getActivity(T t) {\n Activity activity = null;\n if (t instanceof Activity) {\n activity = (Activity) t;\n } else if (t instanceof Fragment) {\n activity = ((Fragment) t).getActivity();\n } else if (t instanceof android.app.Fragment) {\n activity = ((android.app.Fragment) t).getActivity();\n }\n return activity;\n }\n\n @TargetApi(Build.VERSION_CODES.M)\n private static void requestPermissions(T t, int requestCode, List deniedPermissions) {\n if (deniedPermissions == null || deniedPermissions.size() == 0) {\n return;\n }\n // has denied permissions\n if (t instanceof Activity) {\n ((Activity) t).requestPermissions(deniedPermissions.toArray(new String[deniedPermissions.size()]), requestCode);\n } else if (t instanceof Fragment) {\n ((Fragment) t).requestPermissions(deniedPermissions.toArray(new String[deniedPermissions.size()]), requestCode);\n } else if (t instanceof android.app.Fragment) {\n ((android.app.Fragment) t).requestPermissions(deniedPermissions.toArray(new String[deniedPermissions.size()]), requestCode);\n }\n }\n\n private static List getDeniedPermissions(Context context, String... permissions) {\n if (context == null || permissions == null || permissions.length == 0) {\n return null;\n }\n List denyPermissions = new ArrayList<>();\n for (String permission : permissions) {\n if (!checkSelfPermission(context, permission)) {\n denyPermissions.add(permission);\n }\n }\n return denyPermissions;\n }\n\n\n private static void requestResult(T t, int requestCode, String[] permissions,\n int[] grantResults, IPermission iPermission) {\n List deniedPermissions = new ArrayList<>();\n for (int i = 0; i < grantResults.length; i++) {\n if (grantResults[i] != PackageManager.PERMISSION_GRANTED) {\n deniedPermissions.add(permissions[i]);\n }\n }\n if (deniedPermissions.size() > 0) {\n if (iPermission != null) {\n iPermission.onDenied(requestCode);\n }\n } else {\n if (iPermission != null) {\n iPermission.onGranted(requestCode);\n }\n }\n }\n\n}\n\ninterface IPermission {\n void onGranted(int requestCode);\n\n void onDenied(int requestCode);\n\n void onRational(int requestCode, List permissions);\n\n /**\n * 是否需要提示用户该权限的作用,提示后需要再调用requestPermission()方法来申请。\n *\n * @return true 为提示,false为不提示\n */\n boolean showRational(int requestCode);\n}\n\n```\n\n使用方法: \n```java\npublic class MainFragment extends Fragment implements View.OnClickListener {\n private Button mReqCameraBt;\n private Button mReqContactsBt;\n private Button mReqMoreBt;\n\n @Nullable\n @Override\n public View onCreateView(LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {\n View view = inflater.inflate(R.layout.fragment_main, container, false);\n findView(view);\n initView();\n return view;\n }\n\n private void findView(View view) {\n mReqCameraBt = (Button) view.findViewById(R.id.bt_requestCamera);\n mReqContactsBt = (Button) view.findViewById(R.id.bt_requestContacts);\n mReqMoreBt = (Button) view.findViewById(R.id.bt_requestMore);\n }\n\n private void initView() {\n mReqCameraBt.setOnClickListener(this);\n mReqContactsBt.setOnClickListener(this);\n mReqMoreBt.setOnClickListener(this);\n }\n\n\n public static final int REQUEST_CODE_CAMERA = 0;\n public static final int REQUEST_CODE_CONTACTS = 1;\n public static final int REQUEST_CODE_MORE = 2;\n\n @Override\n public void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions, @NonNull int[] grantResults) {\n super.onRequestPermissionsResult(requestCode, permissions, grantResults);\n PermissionUtil.onRequestPermissionsResult(this, requestCode, permissions, grantResults, mPermission);\n }\n\n public void requestCamera() {\n PermissionUtil.checkPermissions(this, REQUEST_CODE_CAMERA, mPermission, Manifest.permission.CAMERA);\n }\n\n public void requestReadContacts() {\n PermissionUtil.checkPermissions(this, REQUEST_CODE_CONTACTS, mPermission, Manifest.permission.READ_CONTACTS);\n }\n\n public void requestMore() {\n PermissionUtil.checkPermissions(this, REQUEST_CODE_MORE, mPermission, Manifest.permission.READ_CONTACTS, Manifest.permission.READ_CALENDAR, Manifest.permission.CALL_PHONE);\n }\n\n private void showPermissionTipDialog(final int requestCode, final List permissions) {\n AlertDialog.Builder builder = new AlertDialog.Builder(getActivity());\n builder.setMessage(\"I want you permissions\");\n builder.setTitle(\"Hello Permission\");\n builder.setPositiveButton(\"确认\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialog, int which) {\n dialog.dismiss();\n PermissionUtil.requestPermission(MainFragment.this, requestCode, permissions);\n }\n });\n builder.setNegativeButton(\"取消\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialog, int which) {\n dialog.dismiss();\n }\n });\n builder.create().show();\n }\n\n public IPermission mPermission = new IPermission() {\n @Override\n public void onGranted(int requestCode) {\n Toast.makeText(getActivity(), \"onGranted :\" + requestCode, Toast.LENGTH_SHORT).show();\n }\n\n @Override\n public void onDenied(int requestCode) {\n Toast.makeText(getActivity(), \"onDenied :\" + requestCode, Toast.LENGTH_SHORT).show();\n }\n\n @Override\n public void onRational(int requestCode, List permission) {\n showPermissionTipDialog(requestCode, permission);\n }\n\n @Override\n public boolean showRational(int requestCode) {\n switch (requestCode) {\n case REQUEST_CODE_MORE:\n return true;\n\n default:\n break;\n }\n return false;\n }\n };\n\n @Override\n public void onClick(View v) {\n int id = v.getId();\n switch (id) {\n case R.id.bt_requestCamera:\n requestCamera();\n break;\n case R.id.bt_requestContacts:\n requestReadContacts();\n break;\n case R.id.bt_requestMore:\n requestMore();\n break;\n }\n }\n}\n\n```\n\n\t\t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/Android卸载反馈.md",
"content": "Android卸载反馈\n===\n\n最初记得是在360安全卫士中出现的,在手机上卸载他的应用之后浏览器就会弹出一个反馈页面,让用户进行反馈,感觉这种功能对于产品改进特别有帮助。\n但是仔细一想该怎么去实现却犯愁了,最开始想这也简单啊,不就是监听下自身被卸载就可以了,应该系统会有卸载的广播,可惜没有。甚至其他的一些\n方法也是不行的,因为你程序都被卸载了,你的代码怎么会执行呢?皮之不存,毛将焉附。那360是怎样实现的呢?说句真心话360做的产品还是非常有创新\n的,虽然有些时候他会损坏用户的利益,不过但从技术方面,着实让人信服。\n\n既然`Java`实现不了,那就得考虑下其他的了,自然最先想到的就是`JNI`了,可惜`C`的部分不懂,上网搜了很多资料和介绍,找得到可以通过一下方式实现: \n- 通过`c`中的`fork`方法来复制一个子进程。复制出来的子进程在父进程被销毁后,仍然可以存在。\n `pid_t fpid = fork()`被调用前,就一个进程执行该段代码,这条语句执行之后,就会有两个进程执行该代码,两个进程执行没有固定先后顺序,只要看\n\t系统调度策略,`fork()`函数的特别之处在于调用一次会返回两次结果: \n\t - 返回值大于0,当前是父进程。\n\t\t- 返回0,当前是子进程。\n\t\t- 返回小于0的负值。(出错了,可能是内存不足或者是进程数已经达到系统最大值)\n\n- `fork`出子进程后让子进程一直去监听`/data/data/packageName`是否存在,如果不存在了,那就说明程序被卸载了,但是这样一直去轮训判断肯定会浪费\n 系统资源的,当然也会更加费电,对用户来讲肯定是有损害的。所以这种技术最好也不好用,不然大家的手机以后还能了得。万恶的产品。\n\n- 得到程序被卸载之后弹出浏览器打开指定反馈页面。这就要用到`am`命令了,最早知道这个命令是在开发`TV`版的时候,遥控器找不到了,程序安装后无法\n 打开了,用该命令就不怕了,哈哈。但是在`c`中怎么执行`am`命令呢?这就要用到`execlp()`函数,该函数就是`c`中执行系统命令的函数。\n \n\n好了,主要的内容上面都分析完了,下面上代码。\n\n- `Java`层定义`natvie`方法。 \n```java\npublic class MainActivity extends Activity {\n\tprivate static final String TAG = \"@@@\";\n\n\t@Override\n\tprotected void onCreate(Bundle savedInstanceState) {\n\t\tsuper.onCreate(savedInstanceState);\n\t\tsetContentView(R.layout.activity_main);\n\t\tString packageDir = \"/data/data/\" + getPackageName();\n\t\tinitUninstallFeedback(packageDir, Build.VERSION.SDK_INT);\n\t}\n\n\tprivate native void initUninstallFeedback(String packagePath, int sdkVersion);\n\n\tstatic {\n\t\tSystem.loadLibrary(\"uninstall_feedback\");\n\t}\n}\n```\n\n- 创建jni目录,增加`Android.mk`以及`uninstall_feedback.c`文件。\n`Android.mk`的内容:\n\n```c\nLOCAL_PATH := $(call my-dir)\n\ninclude $(CLEAR_VARS)\n\nLOCAL_MODULE := uninstall_feedback\nLOCAL_SRC_FILES := uninstall_feedback.c\n\nLOCAL_C_INCLUDES := $(LOCAL_PATH)/include\nLOCAL_LDLIBS += -L$(SYSROOT)/usr/lib -llog\n\ninclude $(BUILD_SHARED_LIBRARY)\n```\n\n`uninstall_feedback.c`的实现: \n\n```c\n/**\n * 将Java中的String转换成c中的char字符串\n */\nchar* Jstring2CStr(JNIEnv* env, jstring jstr) {\n\tchar* rtn = NULL;\n\tjclass clsstring = (*env)->FindClass(env, \"java/lang/String\"); //String\n\tjstring strencode = (*env)->NewStringUTF(env, \"GB2312\"); // 得到一个java字符串 \"GB2312\"\n\tjmethodID mid = (*env)->GetMethodID(env, clsstring, \"getBytes\",\n\t\t\t\"(Ljava/lang/String;)[B\"); //[ String.getBytes(\"gb2312\");\n\tjbyteArray barr = (jbyteArray)(*env)->CallObjectMethod(env, jstr, mid,\n\t\t\tstrencode); // String .getByte(\"GB2312\");\n\tjsize alen = (*env)->GetArrayLength(env, barr); // byte数组的长度\n\tjbyte* ba = (*env)->GetByteArrayElements(env, barr, JNI_FALSE);\n\tif (alen > 0) {\n\t\trtn = (char*) malloc(alen + 1); //\"\"\n\t\tmemcpy(rtn, ba, alen);\n\t\trtn[alen] = 0;\n\t}\n\t(*env)->ReleaseByteArrayElements(env, barr, ba, 0); //\n\treturn rtn;\n}\n\nvoid Java_com_charon_uninstallfeedback_MainActivity_initUninstallFeedback(\n\t\tJNIEnv* env, jobject thiz, jstring packageDir, jint sdkVersion) {\n\n\tchar * pd = Jstring2CStr(env, packageDir);\n\n\t//fork子进程,以执行轮询任务\n\tpid_t pid = fork();\n\n\tif (pid < 0) {\n\t\t// fork失败了\n\t} else if (pid == 0) {\n\t\t// 可以一直采用一直判断文件是否存在的方式去判断,但是这样效率稍低,下面使用监听的方式,死循环,每个一秒判断一次,这样太浪费资源了。\n\t\tint check = 1;\n\t\twhile (check) {\n\t\t\tFILE* file = fopen(pd, \"rt\");\n\t\t\tif (file == NULL) {\n\t\t\t\tif (sdkVersion >= 17) {\n\t\t\t\t\t// Android4.2系统之后支持多用户操作,所以得指定用户\n\t\t\t\t\texeclp(\"am\", \"am\", \"start\", \"--user\", \"0\", \"-a\",\n\t\t\t\t\t\t\t\"android.intent.action.VIEW\", \"-d\",\n\t\t\t\t\t\t\t\"http://shouji.360.cn/web/uninstall/uninstall.html\",\n\t\t\t\t\t\t\t(char*) NULL);\n\t\t\t\t} else {\n\t\t\t\t\t// Android4.2以前的版本无需指定用户\n\t\t\t\t\texeclp(\"am\", \"am\", \"start\", \"-a\",\n\t\t\t\t\t\t\"android.intent.action.VIEW\", \"-d\",\n\t\t\t\t\t\t\t\"http://shouji.360.cn/web/uninstall/uninstall.html\",\n\t\t\t\t\t\t\t(char*) NULL);\n\t\t\t\t}\n\t\t\t\tcheck = 0;\n\t\t\t} else {\n\t\t\t}\n\t\t\tsleep(1);\n\t\t}\n\t} else {\n\t}\n}\n\n```\n\n- 编译so文件。`Windows`下要用`cygwin`来操作。\n上面的介绍是在`Eclipse`中进行的,用`ndk-build`命令来编译`so`。具体请看之前写的`JNI基础`这篇文章。\n\n有关如何在[Android Stuido中进行ndk开发请看][1]。\n \t\t\n\n[1]: https://github.com/CharonChui/AndroidNote/blob/master/AndroidStudioCourse/AndroidStudio%E4%B8%AD%E8%BF%9B%E8%A1%8Cndk%E5%BC%80%E5%8F%91.md \"Android Stuido中进行ndk开发\"\n\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/Android启动模式详解.md",
"content": "Android启动模式详解\n===\n\n- `standard` \n 默认模式。在该模式下,`Activity`可以拥有多个实例,并且这些实例既可以位于同一个`task`,也可以位于不同的`task`。每次都会新创建。\n- `singleTop` \n 该模式下,在同一个`task`中,如果存在该`Activity`的实例,并且该`Activity`实例位于栈顶则不会创建该`Activity`的示例,而仅仅只是调用`Activity`的`onNewIntent()`。否则的话,则新建该`Activity`的实例,并将其置于栈顶。\n- `singleTask` \n 顾名思义,只容许有一个包含该`Activity`实例的`task`存在!\n 在`android`浏览器`browser`中,`BrowserActivity`的`launcherMode=\"singleTask\"`,因为`browser`不断地启动自己,所以要求这个栈中保持只能有一个自己的实例,`browser`上网的时候,\n\t遇到播放视频的链接,就会通过隐式`intent`方式跳转找`Gallery3D`中的`MovieView`这个类来播放视频,这时候如果你点击`home`键,再点击`browser`,你会发现`MovieView`这个类已经销毁不存在了,\n\t而不会像保存这个`MovieView`的类对象,给客户带来的用户体验特别的不好。就像别人总结的`singleTask`模式的`Activity`不管是位于栈顶还是栈底,再次运行这个`Activity`时,都会`destory`掉它上面的`Activity`来保证整个栈中只有一个自己。 \n 下面是官方文档中的介绍: \n `The system creates a new task and instantiates the activity at the root of the new task. However, if an instance of the activity already exists in a separate task, the system routes the intent to the existing \n\tinstance through a call to its onNewIntent() method, rather than creating a new instance. Only one instance of the activity can exist at a time.`\n 以`singleTask`方式启动的`Activity`,全局只有唯一个实例存在,因此,当我们第一次启动这个`Activity`时,系统便会创建一个新的任务栈,并且初始化一个`Activity`实例,放在新任务栈的底部,如果下次再启动这个`Activity`时,\n\t系统发现已经存在这样的`Activity`实例,就会调用这个`Activity`实例的`onNewIntent`方法,从而把它激活起来。从这句话就可以推断出,以`singleTask`方式启动的`Activity`总是属于一个任务栈的根`Activity`。\n 下面我们看一下示例图: \n 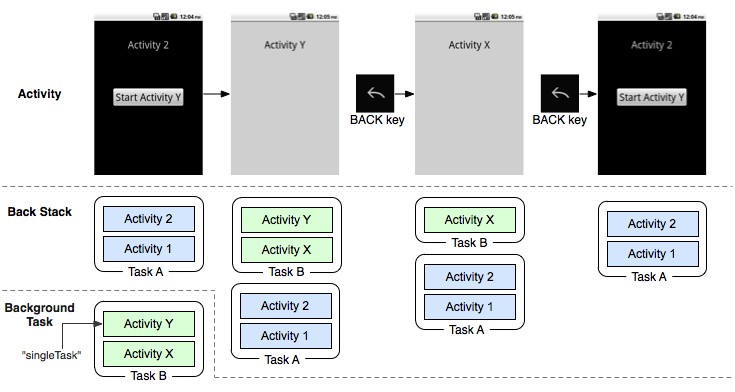 \n 坑爹啊!有木有!前面刚说`singleTask`会在新的任务中运行,并且位于任务堆栈的底部,这里在`Task B`中,一个赤裸裸的带着`singleTask`标签的箭头无情地指向`Task B`堆栈顶端的`Activity Y`,什么鬼? \n这其实是和`taskAffinity`有关,在将要启动时,系统会根据要启动的`Activity`的`taskAffinity`属性值在系统中查找这样的一个`Task`:`Task`的`affinity`属性值与即将要启动的`Activity`的`taskAffinity`属性值一致。如果存在,\n就返回这个`Task`堆栈顶端的`Activity`回去,不重新创建任务栈了,再去启动另外一个`singletask`的`activity`时就会在跟它有相同`taskAffinity`的任务中启动,并且位于这个任务的堆栈顶端,于是,前面那个图中,\n就会出现一个带着`singleTask`标签的箭头指向一个任务堆栈顶端的`Activity Y`了。在上面的`AndroidManifest.xml`文件中,没有配置`MainActivity`和`SubActivity`的`taskAffinity`属性,\n于是它们的`taskAffinity`属性值就默认为父标签`application`的`taskAffinity`属性值,这里,标签`application`的`taskAffinity`也没有配置,于是它们就默认为包名。 \n总的来说:`singleTask`的结论与`android:taskAffinity`相关: \n - 设置了`singleTask`启动模式的`Activity`,它在启动的时候,会先在系统中查找属性值`affinity`等于它的属性值`taskAffinity`的任务栈的存在;如果存在这样的任务栈,它就会在这个任务栈中启动,否则就会在新任务栈中启动。\n\t因此,如果我们想要设置了`singleTask`启动模式的`Activity`在新的任务栈中启动,就要为它设置一个独立的`taskAffinity`属性值。以`A`启动`B`来说当`A`和`B`的`taskAffinity`相同时:第一次创建`B`的实例时,并不会启动新的`task`,\n\t而是直接将`B`添加到`A`所在的`task`;否则,将`B`所在`task`中位于`B`之上的全部`Activity`都删除,然后跳转到`B`中。\n - 如果设置了`singleTask`启动模式的`Activity`不是在新的任务中启动时,它会在已有的任务中查看是否已经存在相应的`Activity`实例,如果存在,就会把位于这个`Activity`实例上面的`Activity`全部结束掉,\n\t即最终这个Activity实例会位于任务的堆栈顶端中。以`A`启动`B`来说,当`A`和`B`的`taskAffinity`不同时:第一次创建`B`的实例时,会启动新的`task`,然后将`B`添加到新建的`task`中;否则,将`B`所在`task`中位于`B`之上的全部`Activity`都删除,然后跳转到`B`中。\n- `singleInstance`\n顾名思义,是单一实例的意思,即任意时刻只允许存在唯一的`Activity`实例,而且该`Activity`所在的`task`不能容纳除该`Activity`之外的其他`Activity`实例! \n它与`singleTask`有相同之处,也有不同之处。 \n相同之处:任意时刻,最多只允许存在一个实例。 \n不同之处:\n - `singleTask`受`android:taskAffinity`属性的影响,而`singleInstance`不受`android:taskAffinity`的影响。 \n - `singleTask`所在的`task`中能有其它的`Activity`,而`singleInstance`的`task`中不能有其他`Activity`。 \n - 当跳转到`singleTask`类型的`Activity`,并且该`Activity`实例已经存在时,会删除该`Activity`所在`task`中位于该`Activity`之上的全部`Activity`实例;而跳转到`singleInstance`类型的`Activity`,并且该`Activity`已经存在时,\n\t不需要删除其他`Activity`,因为它所在的`task`只有该`Activity`唯一一个`Activity`实例。\n\n \n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/Android开发不申请权限来使用对应功能.md",
"content": "Android开发不申请权限来使用对应功能\n===\n\n从用户角度来说很难获取到正确的`android`权限。通常你只需要做一些很基础的事(例如编辑一个联系人)但实际你申请的权限却远远比这更强大(例如可以获取到所有的联系人明细等)。\n\n这样能很容易的理解到用户会怀疑到你的应用。如果你的应用不是开源的,那他们就没有方法来验证你会不会下载所有的联系人数据并上传到服务器。及时你去解释为什么需要这个权限,但是人们不会相信你。原来我会选择不去使用这些敏感的权限来防止用户产生不信任。(当然很多应用他们申请权限只是为了后台获取你的联系人数据上传- -!以及之前被爆的某宝使用摄像头拍照的问题)\n\n这就是说,有一件事在困扰着我,**如何能在做一些操作时不去申请权限。**\n\n打个比方说:`android.permission.CALL_PHONE`这个权限。你需要它来在应用中拨打电话,是吗?这就是你怎么去实现拨号的吗? \n```java\nIntent intent = new Intent(Intent.ACTION_CALL);\nintent.setData(Uri.parse(\"tel:1234567890\"))\nstartActivity(intent);\n```\n错!,你通过这段代码需要该权限的原因是因为你可以在任何时间在不需要用户操作的情况下打电话。也就是说如果我的应用申请了这个权限,我可以在你不知情的情况下每天凌晨三点去拨打骚扰电话。\n\n正确的方式是使用`ACTION_VIEW`或者`ACTION_DIAL`: \n```java\nIntent intent = new Intent(Intent.ACTION_DIAL);\nintent.setData(Uri.parse(\"tel:1234567890\"))\nstartActivity(intent);\n```\n\n这个问题的完美解决方案就是不需要申请权限了。原因就是你不是直接拨号,而是用指定的号码调起拨号器,仍然需要用户点击”拨号”来开始打电话。老实的说,这样让人感觉更好。\n\n简单的说就是如果我想要的操作不是让用户在应用内点击某个按钮就直接开始拨打电话,而是让用户点击在应用内点击某个按钮是我们去调起拨号程序,并且显示指定号码,让用户在拨号器中点击拨号后再开始拨打电话。这样的话我们就完全不用申请拨号权限了。\n\n另一个例子: 我想获取某一个联系人的号码,你可能会想这需要申请获取所有联系人的权限。这是错的!。\n```java\nIntent intent = new Intent(Intent.ACTION_PICK);\nintent.setType(StructuredPostal.CONTENT_TYPE);\nstartActivityForResult(intent, 1);\n```\n我们可以使用上面的代码,来启动联系人管理器,让用户来选择某一个联系人。这样不仅是不需要申请任何权限,也不需要提供任何联系人相关的`UI`。这样也能完全保证你选择联系人时的体验。\n\n\n`Android`系统最酷的部分之一就是`Intent`系统,这意味着我不需要自己来实现所有的东西。应用可以注册处理它所擅长的指定数据,像电话号码、短信或者联系人。如果这些都要自己在一个应用中去实现,那这将会是很大的工作量,也会让应用变得臃肿。\n\n`Android`系统的另一个优势就是你可以使用其他应用申请的权限,而不用自己申请。这样才保证了上面的情况。拨号器需要申请拨打电话的权限,我只需要一个能调起拨号器的`Intent`就好了。用户信任拨号器拨打电话,而不是我们的应用。他们无论如何都宁愿使用系统的拨号器。\n\n写这篇文章的意义是**在你想要申请一个权限的时候,你需要至少看看[Intent的官方文档](https://developer.android.com/reference/android/content/Intent.html)看能否请求另外一个应用来帮我们做这些操作。**如果想要深入的研究,可以学习下[关于权限的详细介绍](https://developer.android.com/guide/topics/security/permissions.html),这里面包含了很多精细的权限。\n\n使用更少的权限可以不但可以让用户更加信任你,而且可以让用户有一个更好的体验,因为他们仍然在使用他们所期望的应用。\n\n1. 遗憾的是,不是一个真实的号码。\n2. 不幸的是,`Intent`系统的属性也建立了[可能会被滥用的漏洞](http://css.csail.mit.edu/6.858/2012/projects/ocderby-dennisw-kcasteel.pdf),但你也不会写一个滥用的应用,是吗?\n\n\n- (译)[感谢Dan Lew](http://blog.danlew.net/2014/11/26/i-dont-need-your-permission/)\n\n\t\t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/Android开发中的MVP模式详解.md",
"content": "Android开发中的MVP模式详解\n===\n\n[MVC、MVP、MVVM介绍][1]\n\n\n\n在`Android`开发中,如果不注重架构的话,`Activity`类就会变得愈发庞大。这是因为在`Android`开发中`View`和其他的线程可以共存于`Activity`内。那最大的问题是什么呢? 其实就是`Activity`中同时存在业务逻辑和`UI`逻辑。这导致增加了单元测试和维护的成本。\n\n\n \n这就是为什么要清晰架构的原因之一。不仅是因为`Activity`类变得臃肿,也是其他的一些问题,例如`Activity`和`Fragment`相结合时的生命周期、数据绑定等等。 \n\n### MVP简介\n\n`MVP(Model,View,Presenter)` \n\n- `View`:负责处理用户时间和视图展现。在`Android`中就可能是`Activity`或者`Fragment`。\n- `Model`: 负责数据访问。数据可以是从接口或者本地数据库中获取。\n- `Presenter`: 负责连接`View`和`Model`。\n\n用一句话来说:`MVP`其实就是面向接口编程,`V`实现接口,`P`使用接口。\n\n清晰的架构: \n\n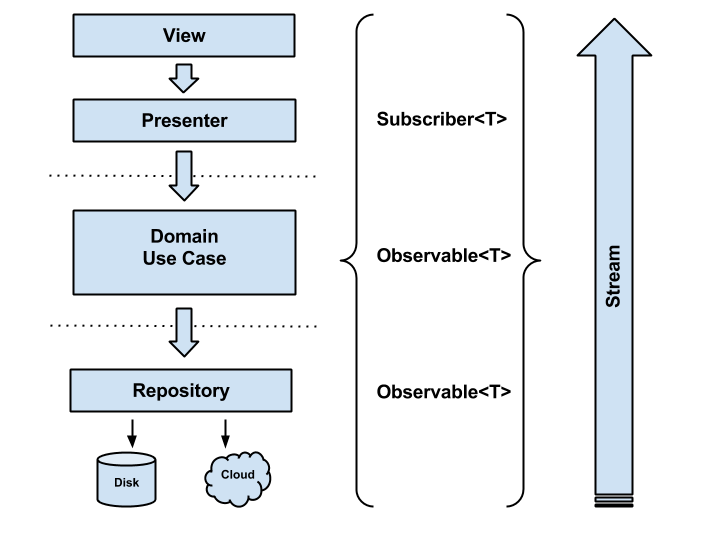\n\n\n举个栗子:\n在`Android Studio`中新建一个`Activity`,系统提供了`LoginActivity`,直接用它是极好的。 \n\n {\n\n void setPresenter(T presenter);\n\n}\n```\n`BaseView`中的`setPresenter()`是将`Presenter`的实例传入到`View`中。 \n`BasePresenter`类: \n```java\npublic interface BasePresenter {\n\n void start();\n\n}\n```\n`BasePresenter`中只有一个`start()`方法,从名字上我们就能看出他的作用。 \n\n接下来继续看一下项目的入口`Activity`,`TaskDetailActivity`的实现: \n```java\npublic class TaskDetailActivity extends AppCompatActivity {\n\n public static final String EXTRA_TASK_ID = \"TASK_ID\";\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n\n setContentView(R.layout.taskdetail_act);\n\n // Set up the toolbar.\n Toolbar toolbar = (Toolbar) findViewById(R.id.toolbar);\n setSupportActionBar(toolbar);\n ActionBar ab = getSupportActionBar();\n ab.setDisplayHomeAsUpEnabled(true);\n ab.setDisplayShowHomeEnabled(true);\n\n // Get the requested task id\n String taskId = getIntent().getStringExtra(EXTRA_TASK_ID);\n \n TaskDetailFragment taskDetailFragment = (TaskDetailFragment) getSupportFragmentManager()\n .findFragmentById(R.id.contentFrame);\n\n if (taskDetailFragment == null) {\n // 创建对应的Fragment\n taskDetailFragment = TaskDetailFragment.newInstance(taskId);\n\n ActivityUtils.addFragmentToActivity(getSupportFragmentManager(),\n taskDetailFragment, R.id.contentFrame);\n }\n\n // Create the presenter,因为Presenter是M和V的连接桥,所以在第二个参数中会传入TasksRepository\n new TaskDetailPresenter(\n taskId,\n Injection.provideTasksRepository(getApplicationContext()),\n taskDetailFragment);\n }\n\n @Override\n public boolean onSupportNavigateUp() {\n onBackPressed();\n return true;\n }\n}\n```\n\n可以看到这里`Activity`相当于一个管理类,里面控制着`MVP`中的`V`和`P`,上面的代码主要做了两部分: \n\n- 创建对应的`Fragment`\n- 创建对应的`Presenter`\n\n这里分别看一下`TaskDetailFragment`和`TaskDetailPresenter`的源码: \n```java\npublic class TaskDetailFragment extends Fragment implements TaskDetailContract.View {\n private TaskDetailContract.Presenter mPresenter;\n\n public static TaskDetailFragment newInstance(@Nullable String taskId) {\n Bundle arguments = new Bundle();\n arguments.putString(ARGUMENT_TASK_ID, taskId);\n TaskDetailFragment fragment = new TaskDetailFragment();\n fragment.setArguments(arguments);\n return fragment;\n }\n\n @Override\n public void onResume() {\n super.onResume();\n // 调用Presenter.start()方法\n mPresenter.start();\n }\n\n @Nullable\n @Override\n public View onCreateView(LayoutInflater inflater, ViewGroup container,\n Bundle savedInstanceState) {\n ....\n }\n\n @Override\n public void setPresenter(@NonNull TaskDetailContract.Presenter presenter) {\n // 将Prsenter传递给V中 \n mPresenter = checkNotNull(presenter);\n }\n\n ....\n}\n```\n及\n```java\npublic class TaskDetailPresenter implements TaskDetailContract.Presenter {\n private final TasksRepository mTasksRepository;\n\n private final TaskDetailContract.View mTaskDetailView;\n\n @Nullable\n private String mTaskId;\n\n // 把M和V传递进来\n public TaskDetailPresenter(@Nullable String taskId,\n @NonNull TasksRepository tasksRepository,\n @NonNull TaskDetailContract.View taskDetailView) {\n mTaskId = taskId;\n mTasksRepository = checkNotNull(tasksRepository, \"tasksRepository cannot be null!\");\n mTaskDetailView = checkNotNull(taskDetailView, \"taskDetailView cannot be null!\");\n // 将该Presenter设置给V\n mTaskDetailView.setPresenter(this);\n }\n\n @Override\n public void start() {\n // 调用获取数据的方法\n openTask();\n }\n ....\n}\n```\n\n可以看到上面分别实现了`TaskDetailContract`类中的`Presenter`和`View`接口,而不是`BasePresenter`和`BaseView`中的接口,那这个`TaskDetailContract`类是什么呢? \n```java\n/**\n * This specifies the contract between the view and the presenter.\n */\npublic interface TaskDetailContract {\n\n interface View extends BaseView {\n\n void setLoadingIndicator(boolean active);\n\n void showMissingTask();\n\n void hideTitle();\n\n void showTitle(String title);\n\n void hideDescription();\n\n void showDescription(String description);\n\n void showCompletionStatus(boolean complete);\n\n void showEditTask(String taskId);\n\n void showTaskDeleted();\n\n void showTaskMarkedComplete();\n\n void showTaskMarkedActive();\n\n boolean isActive();\n }\n\n interface Presenter extends BasePresenter {\n\n void editTask();\n\n void deleteTask();\n\n void completeTask();\n\n void activateTask();\n }\n}\n```\n按照上面描述的介绍可以看出通过这个连接类将`VP`联系到了一起,它统一管理`view`和`presenter`中的所有接口,这样比起分开写会更加清晰。\n\n分析完`VP`之后我们继续看一下`TaskDetailPresenter`类,因为`Presenter`是`MV`的桥梁。\n```java\npublic TaskDetailPresenter(@Nullable String taskId,\n @NonNull TasksRepository tasksRepository,\n @NonNull TaskDetailContract.View taskDetailView) {\n mTaskId = taskId;\n mTasksRepository = checkNotNull(tasksRepository, \"tasksRepository cannot be null!\");\n mTaskDetailView = checkNotNull(taskDetailView, \"taskDetailView cannot be null!\");\n\n mTaskDetailView.setPresenter(this);\n }\n\n @Override\n public void start() {\n openTask();\n }\n\n private void openTask() {\n if (Strings.isNullOrEmpty(mTaskId)) {\n mTaskDetailView.showMissingTask();\n return;\n }\n // 控制V显示UI\n mTaskDetailView.setLoadingIndicator(true);\n // 通过M去获取数据\n mTasksRepository.getTask(mTaskId, new TasksDataSource.GetTaskCallback() {\n @Override\n public void onTaskLoaded(Task task) {\n // The view may not be able to handle UI updates anymore\n if (!mTaskDetailView.isActive()) {\n return;\n }\n mTaskDetailView.setLoadingIndicator(false);\n if (null == task) {\n mTaskDetailView.showMissingTask();\n } else {\n showTask(task);\n }\n }\n\n @Override\n public void onDataNotAvailable() {\n // The view may not be able to handle UI updates anymore\n if (!mTaskDetailView.isActive()) {\n return;\n }\n mTaskDetailView.showMissingTask();\n }\n });\n }\n\n```\n在它的构造函数中传入了一个`TasksRepository`,这个就是`Model`层。而在该`Presenter`中的`start()`方法回去调用获取数据的方法。 \n\n我们继续看一下`M`层`TasksRepository`的实现: \n```java\n/**\n * Concrete implementation to load tasks from the data sources into a cache.\n * \n * For simplicity, this implements a dumb synchronisation between locally persisted data and data\n * obtained from the server, by using the remote data source only if the local database doesn't\n * exist or is empty.\n */\npublic class TasksRepository implements TasksDataSource {\n ....\n}\n```\n\n先看一下`TasksDataSource`接口: \n\n```java\n/**\n * Main entry point for accessing tasks data.\n *
\n * For simplicity, only getTasks() and getTask() have callbacks. Consider adding callbacks to other\n * methods to inform the user of network/database errors or successful operations.\n * For example, when a new task is created, it's synchronously stored in cache but usually every\n * operation on database or network should be executed in a different thread.\n */\npublic interface TasksDataSource {\n\n interface LoadTasksCallback {\n\n void onTasksLoaded(List tasks);\n\n void onDataNotAvailable();\n }\n\n interface GetTaskCallback {\n\n void onTaskLoaded(Task task);\n\n void onDataNotAvailable();\n }\n\n void getTasks(@NonNull LoadTasksCallback callback);\n\n void getTask(@NonNull String taskId, @NonNull GetTaskCallback callback);\n\n void saveTask(@NonNull Task task);\n\n void completeTask(@NonNull Task task);\n\n void completeTask(@NonNull String taskId);\n\n void activateTask(@NonNull Task task);\n\n void activateTask(@NonNull String taskId);\n\n void clearCompletedTasks();\n\n void refreshTasks();\n\n void deleteAllTasks();\n\n void deleteTask(@NonNull String taskId);\n}\n\n```\n\n可以看出`M`层被赋予了数据获取的功能,与之前我们写的`M`层只定义实体对象截然不同,数据的增删改查都是`M`层实现的。`Presenter`只需要调用`M`层的方法即可。这样`model、presenter、view`都只处理各自的任务,此种实现确实是单一职责最好的诠释。\n\n这里我们就以上面用到的`getTasks()`方法为例来介绍一下: \n```java\npublic void getTask(@NonNull final String taskId, @NonNull final GetTaskCallback callback) {\n checkNotNull(taskId);\n checkNotNull(callback);\n // 从缓存中获取数据\n Task cachedTask = getTaskWithId(taskId);\n\n // Respond immediately with cache if available\n if (cachedTask != null) {\n callback.onTaskLoaded(cachedTask);\n return;\n }\n\n // Load from server/persisted if needed.\n\n // Is the task in the local data source? If not, query the network.\n mTasksLocalDataSource.getTask(taskId, new GetTaskCallback() {\n @Override\n public void onTaskLoaded(Task task) {\n // Do in memory cache update to keep the app UI up to date\n if (mCachedTasks == null) {\n mCachedTasks = new LinkedHashMap<>();\n }\n mCachedTasks.put(task.getId(), task);\n callback.onTaskLoaded(task);\n }\n\n @Override\n public void onDataNotAvailable() {\n // 服务器的数据源\n mTasksRemoteDataSource.getTask(taskId, new GetTaskCallback() {\n @Override\n public void onTaskLoaded(Task task) {\n // Do in memory cache update to keep the app UI up to date\n if (mCachedTasks == null) {\n mCachedTasks = new LinkedHashMap<>();\n }\n mCachedTasks.put(task.getId(), task);\n callback.onTaskLoaded(task);\n }\n\n @Override\n public void onDataNotAvailable() {\n callback.onDataNotAvailable();\n }\n });\n }\n });\n }\n```\n\n上面的注释说的非常明白了,这里就不去仔细看了。\n\n\n下面用一张图来总结一下: \n\n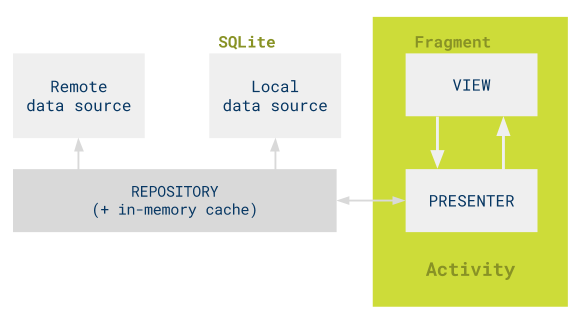\n\n\n由于架构的引入,虽然代码量有了一定的上升,但是功能分离的非常清晰明确,而且每个部分都可以进行单独的测试,对于后期的扩展维护会更加简单容易。\n\n\n\n[1]: https://github.com/CharonChui/AndroidNote/blob/master/JavaKnowledge/MVC%E4%B8%8EMVP%E5%8F%8AMVVM.md \"MVC、MVP、MVVM介绍\"\n\n---\n\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! \n"
},
{
"path": "docs/android/AndroidNote/AdavancedPart/ApplicationId vs PackageName.md",
"content": "ApplicationId vs PackageName\n===\n\n曾几何时,自从转入`Studio`阵营后就发现多了个`applicationId \"com.xx.xxx\"`,虽然知道肯定会有区别,但是我却没有仔细去看,只想着把它和`packageName`设置成相同即可(原谅我的懒惰- -!)。 \n\n直到今天在官网看`Gradle`使用时,终于忍不住要搞明白它俩的区别。 \n\n在`Android`官方文档中有一句是这样描述`applicationId`的:`applicationId : the effective packageName`,真是言简意赅,那既然`applicationId`是有效的包明了,`packageName`算啥? \n\n所有`Android`应用都有一个包名。包名在设备上能唯一的标示一个应用,它在`Google Play`应用商店中也是唯一的。这就意味着一旦你使用一个包名发布应用后,你就永 远不能改变它的包名;如果你改了包名就会导致你的应用被认为是一个新的应用,并且已经使用你之前应用的用户将不会看到作为更新的新应用包。 \n\n之前的`Android Gradle`构建系统中,应用的包名是由你的`manifest`文件中的根元素中的`package`属性定义的: \n \n`AndroidManifest.xml: ` \n\n```\n\n\n```\n然而,这里定义的包也有第二个目的:就是被用来命名你的`R`资源类(以及解析任何与`Activities`相关的类名)的包。在上面的示例中,生成的`R`类就是`com.example.my.app.R`,所以如果你在其他的包中想引用资源,就需要导入`com.example.my.app.R`。 \n \n伴随着新的`Android Gradle`构建系统,你可以很简单的为你的应用构建多个不同的版本;例如,你可以同时为你的应用构建一个免费版本和一个专业版(使用`flavors`),并且他们应该在`Google Play`商店中有不同的包,这样才能让他们可以被单独安装和购买,同时安装两个,等等。同样的你也可能同时为你的应用构建`debug`版、`alpha`版和`beta`版(使用`build types`),这些也可以同样使用不同的包名。 \n \n在这同时,你在代码中导入的`R`类必须一直保持一直;在为应用构建不同的版本时`.java`源文件都不应该发生变化。\n \n因此,我们解耦了`package name`的两种用法: \n\n- 在生成的`.apk`中的`manifest`文件中使用的最终的包名以及在你的设备和`Google Play`商店中用来标示你的包名叫做`application id`的值。\n- 在源代码中指向`R`类的包名以及在解析任何与`activity/service`注册相关的包名继续叫做`package name`。\n\n可以在`gradle`文件中像如下指定`application id`: \n \n`app/build.gradle:` \n\n```\napply plugin: 'com.android.application'\n\nandroid {\n compileSdkVersion 19\n buildToolsVersion \"19.1\"\n\n defaultConfig {\n applicationId \"com.example.my.app\"\n minSdkVersion 15\n targetSdkVersion 19\n versionCode 1\n versionName \"1.0\"\n }\n ...\n```\n\n像之前一样,你需要在`Manifest`文件中指定你在代码中使用的`package name`,像上面`AndroidManifest.xml`的例子。 \n下面进入关键部分了:当你按照上面的方式做完后,这两个包就是相互独立的了。你现在可以很简单的重构你的代码-通过修改`Manifest`中的包名来修改在你的`activitise`和`services`中使用的包和在重构你在代码中的引用声明。这不会影响你应用的最终`id`,也就是在`Gradle`文件中的`applicationId`。 \n\n你可以通过以下`Gradle DSL`方法为应用的`flavors`和`build types`指定不同的`applicationId`: \n\n`app/buid.gradle: ` \n\n```\nproductFlavors {\n pro {\n applicationId = \"com.example.my.pkg.pro\"\n }\n free {\n applicationId = \"com.example.my.pkg.free\"\n }\n}\n\nbuildTypes {\n debug {\n applicationIdSuffix \".debug\"\n }\n}\n....\n```\n(在`Android Studio`中你也可以通过图形化的`Project Structure`的对话框来更改上面所有的配置)\n\n注意:为了兼容性,如果你在`build.gradle`文件中没有定义`applicationId` ,那`applicationId`就是与`AndroidManifest.xml`中配置的包名相同的默认值。在这种情况下,这两者显然脱不了干系,如果你试图重构代码中的包就将会导致同时会改变你应用程序的`id`!在`Android Studio`中新创建的项目都是同时指定他们俩。 \n\n注意2:`package name`必须在默认的`AndroidManifest.xml`文件中指定。如果有多个`manifest`文件(例如对每个`flavor`制定一个`manifest`或者每个`build type`制定一个`manifest`)时,`package name`是可选的,但是如果你指定的话,它必须与主`manifest`中指定的`pakcage`相同。\n\n\t\t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/BroadcastReceiver安全问题.md",
"content": "BroadcastReceiver安全问题\n===\n\n`BroadcastReceiver`设计的初衷是从全局考虑可以方便应用程序和系统、应用程序之间、应用程序内的通信,所以对单个应用程序而言`BroadcastReceiver`是存在安全性问题的(恶意程序脚本不断的去发送你所接收的广播)\n- 保证发送的广播要发送给指定的对象 \n 当应用程序发送某个广播时系统会将发送的`Intent`与系统中所有注册的`BroadcastReceiver`的`IntentFilter`进行匹配,若匹配成功则执行相应的`onReceive`函数。可以通过类似`sendBroadcast(Intent, String)`的接口在发送广播时指定接收者必须具备的`permission`或通过`Intent.setPackage`设置广播仅对某个程序有效。\n\n- 保证我接收到的广播室指定对象发送过来的 \n 当应用程序注册了某个广播时,即便设置了`IntentFilter`还是会接收到来自其他应用程序的广播进行匹配判断。对于动态注册的广播可以通过类似`registerReceiver(BroadcastReceiver, IntentFilter, String, android.os.Handler)`的接口指定发送者必须具备的`permission`,对于静态注册的广播可以通过`android:exported=\"false\"`属性表示接收者对外部应用程序不可用,即不接受来自外部的广播。\n\n`android.support.v4.content.LocalBroadcastManager`工具类,可以实现在自己的进程内进行局部广播发送与注册,使用它比直接通过sendBroadcast(Intent)发送系统全局广播有以下几个好处:\n- 因广播数据在本应用范围内传播,你不用担心隐私数据泄露的问题。\n- 不用担心别的应用伪造广播,造成安全隐患。\n- 相比在系统内发送全局广播,它更高效。\n\n```java\n LocalBroadcastManager mLocalBroadcastManager; \n BroadcastReceiver mReceiver; \n\n@Override\nprotected void onCreate(Bundle savedInstanceState) {\n\tsuper.onCreate(savedInstanceState);\n\t IntentFilter filter = new IntentFilter(); \n\t filter.addAction(\"test\"); \n\n\t mReceiver = new BroadcastReceiver() { \n\t\t@Override \n\t\tpublic void onReceive(Context context, Intent intent) { \n\t\t\tif (intent.getAction().equals(\"test\")) { \n\t\t\t\t//Do Something\n\t\t\t} \n\t\t} \n\t}; \n\tmLocalBroadcastManager = LocalBroadcastManager.getInstance(this);\n\tmLocalBroadcastManager.registerReceiver(mReceiver, filter);\n}\n\n\n@Override\nprotected void onDestroy() {\n mLocalBroadcastManager.unregisterReceiver(mReceiver);\n super.onDestroy();\n} \n```\n\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/ConstraintLaayout简介.md",
"content": "ConstraintLaayout简介\n===\n\n`ConstraintLayout`从发布到现在也得有两年的时间了,但是目前在项目中却很少用到他。今天闲下来记录一下,以后可以用来解决一些布局的嵌套问题。 \n`ConstraintLayout`是`RelativeLayout`的升级版本,但是比`RelativeLayout`更加强调约束,它能让你的布局更加扁平化,一般来说一个界面一层就够了。\n而且它可以直接在布局编辑页面通过拖拖拖的方式就可以把控件摆放好,但是我还是习惯手写。 \n\n在`Android Studio`中可以很方便的将目前的布局直接转换成`ConstraintLayout`,可以在布局的编辑页面上直接右键然后选择就可以了。 \n\n当然项目中要添加它的依赖,目前最新版本: \n```\nimplementation 'com.android.support.constraint:constraint-layout:1.1.0'\n```\n\n\n\t \n\t\t\t\n\t\t \n\t\t\n mOuter;\n\n\t\tpublic MyHandler(MyActivity activity) {\n\t\t\tmOuter = new WeakReference(activity);\n\t\t}\n\n\t\t@Override\n\t\tpublic void handleMessage(Message msg) {\n\t\t\tMyActivity outer = mOuter.get();\n\t\t\tif (outer != null) {\n\t\t\t\t// Do something with outer as your wish.\n\t\t\t}\n\t\t}\n\t}\n}\n```\n\n[1]:(https://github.com/CharonChui/AndroidNote/blob/master/BasicKnowledge/%E5%86%85%E5%AD%98%E6%B3%84%E6%BC%8F.md)\n\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/Library项目中资源id使用case时报错.md",
"content": "Library项目中资源id使用case时报错\n===\n\n在平时开发的过程中对一些常量的判断,都是使用`switch case`语句,因为`switch case`比`if else`的效率稍高。 \n但是也遇到了问题,就是在`library`中使用时会报错: \n```java\npublic void testClick(View view) {\n int id = view.getId();\n switch (id) {\n case R.id.bt_pull:\n\n break;\n case R.id.bt_push:\n\n break;\n }\n}\n```\n我们来看一下错误提示: \n\n\n\n意思就是在`Android Library`的`Module`中的`switch`语句不能使用资源`ID`.这是为什么呢? 我们都知道`R`文件中都是常量啊,`public static final`的,为什么不能用在`switch`语句中,继续看下去: \n```\nResource IDs are non final in th library projects since SDK tools r14, means that the library code cannot treat this IDs as constants.\n```\n说的灰常明白了,也就是说从14开始,library中的资源`id`就不是`final`类型的了,所以不是常量了。 \n\n在一个常规的`Android`项目中,资源`R`文件中的常量都是如下这样声明的: \n`public static final int main=0x7f030004;`\n然后,从`ADT`14开始,在`library`项目中,它们将被这样声明: \n`public static int main=0x7f030004;`\n\n也就是说在`library`项目中这些常量不是`final`的了。为什么这样做的原因也非常简单:当多个`library`项目结合时,这些字段的实际值(必须唯一的值)可能会冲突。在`ADT`14之前,所有的字段都是`final`的,这样就导致了一个结果,就是所有的`libraries`不论何时在被使用时都必须把他们所有的资源和相关的`Java`代码都伴随着主项目一起重新编译。这样做是不合理的,因为它会导致编译非常慢。这也会阻碍一些没有源码的`libraray`项目进行发布,极大的限制了`library`项目的使用范围。 \n\n那些字段不再是`final`的原因就是意味着`library jars`可以被编译一次,然后在其他项目中直接被服用。也就是意味着允许发布二进制版本的`library`项目(r15中开始支持),这让编译变的更快。\n\n然而,这对`library`的源码会有一个影响。类似下面这样的代码就将无法编译: \n```java\npublic void testClick(View view) {\n int id = view.getId();\n switch (id) {\n case R.id.bt_pull:\n\n break;\n case R.id.bt_push:\n\n break;\n }\n}\n```\n这是因为`swtich`语句要求所有`case`后的字段,例如`R.di.bt_pull`在编译的时候都应该是常量(就像可以直接把值拷贝进`.class`文件中)\n\n当然针对这个问题的解决方法也很简单:就是把`switch`语句改成`if-else`语句。幸运的是,在`eclise`中这是非常简单的。只需要在`switch`的关键字上按`Ctrl+1`(`Mac`上是`Cmd+1`)。(`eclipse`都辣么方便了,`Studio`更不用说了啊,直接按修复的快捷键就阔以了)。 \n上面的代码就将变成如下: \n\n```java\npublic void testClick(View view) {\n int id = view.getId();\n if (id == R.id.bt_pull) {\n } else if (id == R.id.bt_push) {\n }\n}\n```\n这在UI代码和性能的影响通常是微不足道的 - -!。\n\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! \n\n"
},
{
"path": "docs/android/AndroidNote/AdavancedPart/Mac下配置adb及Android命令.md",
"content": "Mac下配置adb及Android命令\n===\n\n带着欣喜若狂的心情,买了一个`Mac`本,刚拿到它的时候感觉真的是一件艺术品,哈哈。废话不多说,里面配置`Android`开发环境。\n\n1. 找到`android sdk`的本地路径,\n 我的是:\n - `ADB`\n `/Android/adt-bundle-mac-x86_64-20131030/sdk/platform-tools`\n - `Android`\n `/Android/adt-bundle-mac-x86_64-20131030/sdk/tools`\n\n2. 打开终端输入\n - `touch .bash_profile`创建\n - `open -e .bash_profile`打开\n\n3. 添加路径\n `.bash_profile`打开了,我们在这里添加路径,\n - 如果打开的文档里面已经有内容,我们只要之后添加`:XXXX`**(注意前面一定要用冒号隔开)** \n - 如果是一个空白文档的话,我们就输入一下内容\n `export PATH=${PATH}:XXXX`\n 我的是 \n `export PATH=${PATH}:/Android/adt-bundle-mac-x86_64-20131030/sdk/tools:${PATH}:/Android/adt-bundle-mac-x86_64-20131030/sdk/platform-tools;`\n 保存,关掉这个文档,\n4. 终端输入命令 \n `source .bash_profile`\n5. 大功告成\n\n \n \n ---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/MaterialDesign使用.md",
"content": "MaterialDesign使用\n===\n\n- `Material Design`是`Google`在`2014`年的`I/O`大会上推出的全新设计语言。 \n- `Material Design`是基于`Android 5.0``(API level 21)`的,兼容5.0以下的设备时需要使用版本号`v21.0.0`以上的 \n`support v7`包中的`appcpmpat`,不过遗憾的是`support`包只支持`Material Design`的部分特性。 \n使用`eclipse`或`Android Studio`进行开发时,直接在`Android SDK Manager`中将`Extras->Android Support Library`\n升级至最新版即可。\n\n下面我就简单讲解一下如何通过`support v7`包来使用`Material Design`进行开发。\n\nMaterial Design Theme\n---\n\n`Material`主题: \n\n- @android:style/Theme.Material (dark version) -- Theme.AppCompat \n- @android:style/Theme.Material.Light (light version) -- Theme.AppCompat.Light \n- @android:style/Theme.Material.Light.DarkActionBar -- Theme.AppCompat.Light.DarkActionBar \n\n对应的效果分别如下: \n\n \n\n使用ToolBar\n---\n\n- 禁止Action Bar \n 可以通过使用`Material theme`来让应用使用`Material Design`。想要使用`ToolBar`需要先禁用`ActionBar`。\n 可以通过自定义`theme`继承`Theme.AppCompat.Light.NoActionBar`或者在`theme`中通过以下配置来进行。\n ```xml\n - false
\n - true
\n ```\n \n 下面我通过第二种方式来看一下具体的实现: \n \n 在`style.xml`中自定义`AppTheme`: \n \n ```xml\n \n \n ```\n \n 配置的这几种颜色分别如下图所示: \n 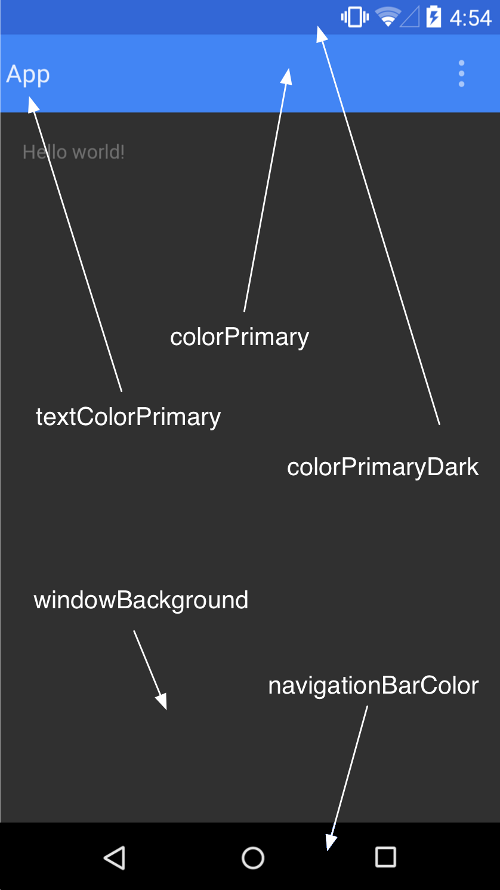\t \n 里面没有`colorAccent`的颜色,这个颜色是设置`Checkbox`等控件选中时的颜色。\n\n 在`values-v21`中的`style.xml`中同样自定义`AppTheme`主题: \n ```xml\n \n ```\n \n- 在`Manifest`文件中设置`AppTheme`主题: \n\n ```xml\n \n \t\n \t
\n ```\n 这里说一下为什么要在`values-v21`中也自定义个主题,这是为了能让在`21`以上的版本能更好的使用`Material Design`,\n在21以上的版本中会有更多的动画、特效等。\n\n- 让Activity继承AppCompatActivity\n\n ```java\n public class MainActivity extends AppCompatActivity {\n \t...\n }\n ```\n\n- 在布局文件中进行声明\n\n 声明`toolbar.xml`,我们把他单独放到一个文件中,方便多布局使用: \n ```xml\n \n \n \t\n \n \n ```\n\n- 在Activity中设置ToolBar\n ```java\n public class MainActivity extends AppCompatActivity{\n private Context mContext;\n private Toolbar mToolbar;\n \n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n mContext = this;\n \t\tmToolbar = (Toolbar) findViewById(R.id.toolbar);\n \t\tmToolbar.setTitle(R.string.app_name);\n \t\t// 将ToolBar设置为ActionBar,这样一设置后他就能像ActionBar一样直接显示menu目录中的菜单资源\n \t\t// 如果不用该方法,那ToolBar就只是一个普通的View,对menu要用inflateMenu去加载布局。\n \t\tsetSupportActionBar(mToolbar);\n \t\tgetSupportActionBar().setDisplayShowHomeEnabled(true);\n }\n }\n ```\n\n到这里运行项目就可以了,就可以看到一个简单的`ToolBar`实现。\n\n接下来我们看一下`ToolBar`中具体有哪些内容: \n\n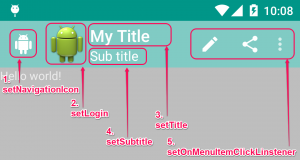\t \n\n我们可以通过对应的方法来修改他们的属性: \n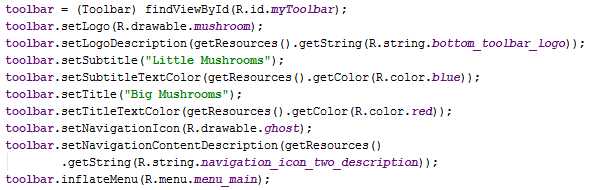\t \n\n对于`ToolBar`中的`Menu`部分我们可以通过一下方法来设置: \n```java\ntoolbar.inflateMenu(R.menu.menu_main);\ntoolbar.setOnMenuItemClickListener();\n```\n或者也可以直接在`Activity`的`onCreateOptionsMenu`及`onOptionsItemSelected`来处理: \n```java\n@Override\npublic boolean onCreateOptionsMenu(Menu menu) {\n\t// Inflate the menu; this adds items to the action bar if it is present.\n\tgetMenuInflater().inflate(R.menu.menu_main, menu);\n\treturn true;\n}\n\n@Override\npublic boolean onOptionsItemSelected(MenuItem item) {\n\t// Handle action bar item clicks here. The action bar will\n\t// automatically handle clicks on the Home/Up button, so long\n\t// as you specify a parent activity in AndroidManifest.xml.\n\tint id = item.getItemId();\n\n\t//noinspection SimplifiableIfStatement\n\tif (id == R.id.action_settings) {\n\t\treturn true;\n\t}\n\tif (id == R.id.action_search) {\n\t\tToast.makeText(getApplicationContext(), \"Search action is selected!\", Toast.LENGTH_SHORT).show();\n\t\treturn true;\n\t}\n\treturn super.onOptionsItemSelected(item);\n}\n```\n`menu`的实现如下: \n```xml\n\n\n \n```\n\n如果想要对`NavigationIcon`添加点击实现: \n```java\ntoolbar.setNavigationOnClickListener(new View.OnClickListener() {\n\t@Override\n\tpublic void onClick(View v) {\n\t\tonBackPressed();\n\t}\n});\n```\n\n运行后发现我们强大的`Activity`切换动画怎么在`5.0`一下系统上实现呢?`support v7`包也帮我们考虑到了。使用`ActivityOptionsCompat`\n及`ActivityCompat.startActivity`,但是悲剧了,他对4.0一下基本都无效,而且就算在4.0上很多动画也不行,具体还是用其他\n大神在`github`写的开源项目吧。\n\n\n- 动态取色Palette \n\n `Palette`这个类中可以提取一下集中颜色: \n \n - Vibrant (有活力)\n - Vibrant dark(有活力 暗色)\n - Vibrant light(有活力 亮色)\n - Muted (柔和)\n - Muted dark(柔和 暗色)\n - Muted light(柔和 亮色)\n \n ```java\n //目标bitmap,代码片段\n Bitmap bm = BitmapFactory.decodeResource(getResources(),\n \t\tR.drawable.kale);\n Palette palette = Palette.generate(bm);\n if (palette.getLightVibrantSwatch() != null) {\n \t//得到不同的样本,设置给imageview进行显示\n \tiv.setBackgroundColor(palette.getLightVibrantSwatch().getRgb());\n \tiv1.setBackgroundColor(palette.getDarkVibrantSwatch().getRgb());\n \tiv2.setBackgroundColor(palette.getLightMutedSwatch().getRgb());\n \tiv3.setBackgroundColor(palette.getDarkMutedSwatch().getRgb());\n }\n ```\n\n使用DrawerLayout\n---\n\n- 布局中的使用\n\n```xml\n\n\n \n \n\n \n\n \n\n \n \n```\n\n使用DrawerLayout后可以实现类似SlidingMenu的效果。但是怎么将DrawerLayout与ToolBar结合起来呢? 还有再结合Navigation Tabs\n以及ViewPager。下面我就直接上代码了。\n\n先看布局: activity_main.xml \n```xml\n\n\n \n \n\n \n\n \n\n \n \n```\n\nMainActivity的代码: \n```java\npublic class MainActivity extends AppCompatActivity {\n\n private Context mContext;\n\n private Toolbar mToolbar;\n private PagerSlidingTabStrip mScrollingTabs;\n private ViewPager mViewPager;\n private MainPagerAdapter mPagerAdapter;\n private ActionBarDrawerToggle mDrawerToggle;\n private DrawerLayout mDrawerLayout;\n\n private List mTitles;\n private List mFragments;\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n mContext = this;\n\n findView();\n setToolBar();\n initView();\n initDrawerFragment();\n }\n\n private void findView() {\n mToolbar = (Toolbar) findViewById(R.id.toolbar);\n mScrollingTabs = (PagerSlidingTabStrip) findViewById(R.id.psts_main);\n mViewPager = (ViewPager) findViewById(R.id.vp_main);\n mDrawerLayout = (DrawerLayout) findViewById(R.id.drawer_layout);\n }\n\n\n private void setToolBar() {\n mToolbar.setTitle(R.string.app_name);\n setSupportActionBar(mToolbar);\n getSupportActionBar().setDisplayShowHomeEnabled(true);\n }\n\n private void initView() {\n mFragments = new ArrayList<>();\n for (int xxx = 0; xxx < 5; xxx++) {\n mFragments.add(new FriendsFragment());\n }\n\n mTitles = new ArrayList<>();\n for (int xxx = 0; xxx < 5; xxx++) {\n mTitles.add(\"Tab : \" + xxx);\n }\n\n mPagerAdapter = new MainPagerAdapter(getSupportFragmentManager(), mFragments, mTitles);\n mViewPager.setAdapter(mPagerAdapter);\n mScrollingTabs.setDividerColor(Color.TRANSPARENT);\n mScrollingTabs.setIndicatorHeight(10);\n mScrollingTabs.setUnderlineHeight(0);\n mScrollingTabs.setTextSize(50);\n mScrollingTabs.setTextColor(Color.BLACK);\n mScrollingTabs.setSelectedTextColor(Color.WHITE);\n mScrollingTabs.setViewPager(mViewPager);\n\n }\n\n private void initDrawerFragment() {\n mDrawerToggle = new ActionBarDrawerToggle(this, mDrawerLayout, mToolbar, R.string.drawer_open, R.string.drawer_close) {\n @Override\n public void onDrawerOpened(View drawerView) {\n super.onDrawerOpened(drawerView);\n MainActivity.this.invalidateOptionsMenu();\n }\n\n @Override\n public void onDrawerClosed(View drawerView) {\n super.onDrawerClosed(drawerView);\n MainActivity.this.invalidateOptionsMenu();\n }\n\n @Override\n public void onDrawerSlide(View drawerView, float slideOffset) {\n super.onDrawerSlide(drawerView, slideOffset);\n mToolbar.setAlpha(1 - slideOffset / 2);\n }\n };\n\n mDrawerLayout.setDrawerListener(mDrawerToggle);\n mDrawerToggle.syncState();\n }\n\n @Override\n public boolean onCreateOptionsMenu(Menu menu) {\n // Inflate the menu; this adds items to the action bar if it is present.\n getMenuInflater().inflate(R.menu.menu_main, menu);\n return true;\n }\n\n @Override\n public boolean onOptionsItemSelected(MenuItem item) {\n // Handle action bar item clicks here. The action bar will\n // automatically handle clicks on the Home/Up button, so long\n // as you specify a parent activity in AndroidManifest.xml.\n int id = item.getItemId();\n\n //noinspection SimplifiableIfStatement\n if (id == R.id.action_settings) {\n return true;\n }\n if (id == R.id.action_search) {\n Toast.makeText(getApplicationContext(), \"Search action is selected!\", Toast.LENGTH_SHORT).show();\n return true;\n }\n return super.onOptionsItemSelected(item);\n }\n\n}\n```\n最后再看一下`DrawerFragment`的代码: \n```java\npublic class DrawerFragment extends Fragment {\n private Context mContext;\n private RecyclerView mRecyclerView;\n private NavigationDrawerAdapter mAdapter;\n private static String[] titles = null;\n\n public DrawerFragment() {\n\n }\n\n public static List getData() {\n List data = new ArrayList<>();\n\n // preparing navigation drawer items\n for (int i = 0; i < titles.length; i++) {\n NavDrawerItem navItem = new NavDrawerItem();\n navItem.setTitle(titles[i]);\n data.add(navItem);\n }\n return data;\n }\n\n @Override\n public void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n mContext = getActivity();\n // drawer labels\n titles = getActivity().getResources().getStringArray(R.array.nav_drawer_labels);\n }\n\n @Override\n public View onCreateView(LayoutInflater inflater, ViewGroup container,\n Bundle savedInstanceState) {\n // Inflating view layout\n View layout = inflater.inflate(R.layout.fragment_navigation_drawer, container, false);\n mRecyclerView = (RecyclerView) layout.findViewById(R.id.drawerList);\n mRecyclerView.setHasFixedSize(true);\n mAdapter = new NavigationDrawerAdapter(getActivity(), getData());\n mRecyclerView.setAdapter(mAdapter);\n mRecyclerView.setLayoutManager(new LinearLayoutManager(getActivity()));\n mAdapter.setOnRecyclerViewListener(new NavigationDrawerAdapter.OnRecyclerViewListener() {\n @Override\n public void onItemClick(int position) {\n Toast.makeText(mContext, getData().get(position).getTitle(), Toast.LENGTH_SHORT).show();\n startActivity(new Intent(getActivity(), FriendsActivity.class));\n }\n\n @Override\n public boolean onItemLongClick(int position) {\n return false;\n }\n });\n return layout;\n }\n\n}\n```\n上面的`PagerSlidingTabStrip`是开源项目,我改了下,添加了一个选中时的文字颜色改变。\n\n[Demo地址](https://github.com/CharonChui/MaterialLibrary)\n\n\nRipple效果\n---\n\n个人非常喜欢的效果。相当于给点击事件加上了动态的赶脚。。。\n\n\n假设现在有一个`Button`的`selector`,我们想给这个`Button`加上`Ripple`效果,肿么办? \n新建一个`xml`文件,用`ripple`包裹`selector`,然后在`Button`的`backgroud`直接引用这个`xml`就好了。\n```xml\n\n\n\n- \n
- \n
\n \n\n```\n但是很遗憾,`ripple`是5.0才有的,而且`support`包中没有实现该功能的扩展。\n`5.0`的这些效果还是无法在低版本上实现,包括一些`TextView`等样式,现在可以用大神的开源项目 \n[MaterialDesignLibrary](https://github.com/navasmdc/MaterialDesignLibrary)\n\n\nRecyclerView\n---\n\n`ListView`的升级版,还有什么理由不去用呢? 同样他也在`support v7`包中。\n```\ncompile 'com.android.support:recyclerview-v7:21.+' \n```\n通过`mRecyclerView.setLayoutManager(new LinearLayoutManager(this)); `设置为`LinearLayoutManager`来实现水平或者竖直\n方向的`ListView`。\n\n\n阴影\n---\n\n通过对`View`设置`backgroud`后再添加`android:elevation=\"2dp\"`来实现背景大小。\n\n\n\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/RecyclerView专题.md",
"content": "RecyclerView专题\n===\n\n### 简介\n\n`RecyclerView`是`Android 5.0`提供的新控件,已经用了很长时间了,但是一直没有时间去仔细的梳理一下。现在项目不太紧,决定来整理下。\n\n官方文档中是这样介绍的: \n`A flexible view for providing a limited window into a large data set.`\n\n`RecyclerView`比`listview`更先进更灵活,对于很多的视图它就是一个容器,可以有效的重用和滚动。当数据动态变化的时候请使用它。\n\n\n\n##### 专业术语:\n\n- `Adapter`: `A subclass of RecyclerView.Adapter responsible for providing views that represent items in a data set.`\n- `Position`: `The position of a data item within an Adapter.`\n- `Index`: `The index of an attached child view as used in a call to getChildAt(int). Contrast with Position.`\n- `Binding`: `The process of preparing a child view to display data corresponding to a position within the adapter.`\n- `Recycle (view)`: `A view previously used to display data for a specific adapter position may be placed in a cache for later reuse to display the same type of data again later. This can drastically improve performance by skipping initial layout inflation or construction.`\n- `Scrap (view)`: `A child view that has entered into a temporarily detached state during layout. Scrap views may be reused without becoming fully detached from the parent RecyclerView, either unmodified if no rebinding is required or modified by the adapter if the view was considered dirty.`\n- `Dirty (view)`: `A child view that must be rebound by the adapter before being displayed.`\n\n##### `RecyclerView`中的位置: \n\n`RecyclerView`在`RecyclerView.Adapter`和`RecyclerView.LayoutManager`中引进了一个抽象的额外中间层来保证在布局计算的过程中能批量的监听到数据变化。这样介绍了`LayoutManager`追踪`adapter`数据变化来计算动画的时间。因为所有的`View`绑定都是在同一时间执行,所以这样也提高了性能和避免了一些非必要的绑定。 \n因为这个原因,在`RecylcerView`中有两种`position`类型相关的方法: \n- `layout position`: 在最近一次`layout`计算是`item`的位置。这是`LayoutManager`角度中的位置。 \n- `adapter position`: `item`在`adapter`中的位置。这是从`Adapter`的角度中的位置。\n \n这两种`position`除了在分发`adapter.notify`事件与之后计算布局更新的这段时间之内外都是相同的。 \n可以通过`getLayoutPosition(),findViewHolderForLayoutPosition(int)`方法来获取最近一次布局计算的`LayoutPosition`。这些`positions`包括从最近一次布局计算的所有改变。你可以根据这些位置来方便的得到用户当前从屏幕上所看到的。例如,如果在屏幕上有一个列表,用户请求的是第五个条目,你可以通过该方法来匹配当前用户正在看的内容。\n \n另一种`AdapterPosition`相关的方法是`getAdapterPosition(),findViewHolderForAdapterPosition(int)`,当及时一些数据可能没有来得及被展现到布局上时便需要获取最新的`adapter`位置可以使用这些相关的方法。例如,如果你想获取一个条目的`ViewHOlder`的`click`事件时,你应该使用`getAdapterPosition()`。需要知道这些方法在`notifyDataSetChange()`方法被调用和新布局还没有被计算之前是不能使用的。鉴于这个原因,你应该小心的去处理这些方法有可能返回`NO_POSITION`或者`null`的情况。\n\n\n\n### 结构\n\n- `RecyclerView.Adapter`: 创建`View`并将数据集合绑定到`View`上\n- `ViewHolder`: 持有所有的用于绑定数据或者需要操作的`View`\n- `LayoutManager`: 布局管理器,负责摆放视图等相关操作\n- `ItemDecoration`: 负责绘制`Item`附近的分割线,通过`RecyclerView.addItemDecoration()`使用\n- `ItemAnimator`: 为`Item`的操作添加动画效果,如,增删条目等,通过`RecyclerView.setItemAnimator(new DefaultItemAnimator());`使用\n\n下图能更直观的了解: \n\n\n##### `RecyclerView`提供这些内置布局管理器: \n\n- `LinearLayoutManager`: 以垂直或水平滚动列表方式显示项目。\n- `GridLayoutManager`: 在网格中显示项目。\n- `StaggeredGridLayoutManager`: 在分散对齐网格中显示项目。\n\n##### `RecyclerView.ItemDecoration`是一个抽象类,可以通过重写以下三个方法,来实现Item之间的偏移量或者装饰效果: \n\n- `public void onDraw(Canvas c, RecyclerView parent)` 装饰的绘制在Item条目绘制之前调用,所以这有可能被Item的内容所遮挡\n- `public void onDrawOver(Canvas c, RecyclerView parent)` 装饰的绘制在Item条目绘制之后调用,因此装饰将浮于Item之上\n- `public void getItemOffsets(Rect outRect, int itemPosition, RecyclerView parent)` 与padding或margin类似,LayoutManager在测量阶段会调用该方法,计算出每一个Item的正确尺寸并设置偏移量。\n\n\n##### `ItemAnimator`触发于以下三种事件: \n\n- 某条数据被插入到数据集合中\n- 从数据集合中移除某条数据\n- 更改数据集合中的某条数据\n\n在之前的版本中,当时据集合发生改变时通过调用`notifyDataSetChanged()`,来刷新列表,因为这样做会触发列表的重绘,所以并不会出现任何动画效果,因此需要调用一些以`notifyItem*()`作为前缀的特殊方法,比如: \n\n- `public final void notifyItemInserted(int position)` 向指定位置插入`Item`\n- `public final void notifyItemRemoved(int position)` 移除指定位置`Item`\n- `public final void notifyItemChanged(int position)` 更新指定位置`Item`\n\n\n\n### 使用介绍: \n\n- 添加依赖库 \n ```\n dependencies {\n compile 'com.android.support:recyclerview-v7:23.4.0'\n }\n ```\n- 示例代码 \n\n ```java\n public class MainActivity extends AppCompatActivity {\n private RecyclerView mRecyclerView;\n private LinearLayoutManager mLayoutManager;\n private RecyclerView.Adapter mAdapter;\n \n private String [] mDatas = {\"Android\",\"ios\",\"jack\",\"tony\",\"window\",\"mac\",\"1234\",\"hehe\",\"495948\", \"89757\", \"66666\"};\n \n \n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n findView();\n initView();\n }\n \n private void findView() {\n mRecyclerView = (RecyclerView) findViewById(R.id.rv);\n }\n \n private void initView() {\n // use this setting to improve performance if you know that changes\n // in content do not change the layout size of the RecyclerView\n mRecyclerView.setHasFixedSize(true);\n \n // use a linear layout manager\n mLayoutManager = new LinearLayoutManager(this);\n mLayoutManager.setOrientation(LinearLayoutManager.VERTICAL);\n mRecyclerView.setLayoutManager(mLayoutManager);\n mAdapter = new MyAdapter(mDatas);\n mRecyclerView.setAdapter(mAdapter);\n }\n \n private class MyAdapter extends RecyclerView.Adapter {\n private String[] mData;\n \n public MyAdapter(String[] data) {\n mData = data;\n }\n \n @Override\n public MyHolder onCreateViewHolder(ViewGroup parent, int viewType) {\n // create a new view\n View v = LayoutInflater.from(parent.getContext()).inflate(\n R.layout.item, parent, false);\n MyHolder holder = new MyHolder(v);\n return holder;\n }\n \n @Override\n public void onBindViewHolder(MyHolder holder, int position) {\n holder.mTitleTv.setText(mData[position]);\n }\n \n @Override\n public int getItemCount() {\n return mData == null ? 0 : mData.length;\n }\n }\n \n static class MyHolder extends RecyclerView.ViewHolder {\n public TextView mTitleTv;\n \n public MyHolder(View itemView) {\n super(itemView);\n mTitleTv = (TextView) itemView;\n }\n }\n }\n ```\n \n `activity_main的内容如下: ` \n ```xml\n \n \n \n ```\n\n\n\n### 点击事件\n\n之前在使用`ListView`的时候,设置点击事件是非常方便的。 \n```java\nmListView.setOnItemClickListener();\nmListView.setOnItemLongClickListener();\n```\n但是`RecylcerView`确没有提供类似的方法。那我们只能是自己去处理。处理的方式也有两种: \n\n\n- 通过`itemView.onClickListener()`以及`onLongClickListener()` \n\n ```java\n public class MainActivity extends AppCompatActivity {\n private RecyclerView mRecyclerView;\n private LinearLayoutManager mLayoutManager;\n private MyAdapter mAdapter;\n \n private String[] mDatas = {\"Android\", \"ios\", \"jack\", \"tony\", \"window\", \"mac\", \"1234\", \"hehe\", \"495948\", \"89757\", \"66666\"};\n \n \n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n findView();\n initView();\n }\n \n private void findView() {\n mRecyclerView = (RecyclerView) findViewById(R.id.rv);\n }\n \n private void initView() {\n // use this setting to improve performance if you know that changes\n // in content do not change the layout size of the RecyclerView\n mRecyclerView.setHasFixedSize(true);\n \n // use a linear layout manager\n mLayoutManager = new LinearLayoutManager(this);\n mLayoutManager.setOrientation(LinearLayoutManager.VERTICAL);\n mRecyclerView.setLayoutManager(mLayoutManager);\n mAdapter = new MyAdapter(mDatas);\n mAdapter.setOnItemClickListener(new OnItemClickListener() {\n @Override\n public void onItemClick(View view, int position) {\n Toast.makeText(MainActivity.this, \"click \" + mDatas[position], Toast.LENGTH_SHORT).show();\n }\n });\n mAdapter.setOnItemLongClickListener(new OnItemLongClickListener() {\n @Override\n public void onItemLongClick(View view, int position) {\n Toast.makeText(MainActivity.this, \"long click \" + mDatas[position], Toast.LENGTH_SHORT).show();\n }\n });\n mRecyclerView.setAdapter(mAdapter);\n }\n \n class MyAdapter extends RecyclerView.Adapter {\n private String[] mData;\n \n public MyAdapter(String[] data) {\n mData = data;\n }\n \n @Override\n public MyHolder onCreateViewHolder(ViewGroup parent, int viewType) {\n // create a new view\n View v = LayoutInflater.from(parent.getContext()).inflate(\n R.layout.item, parent, false);\n MyHolder holder = new MyHolder(v);\n return holder;\n }\n \n @Override\n public void onBindViewHolder(final MyHolder holder, final int position) {\n holder.mTitleTv.setText(mData[position]);\n if (mOnItemClickListener != null) {\n holder.itemView.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View v) {\n mOnItemClickListener.onItemClick(holder.itemView, position);\n }\n });\n }\n if (mOnItemLongClickListener != null) {\n holder.itemView.setOnLongClickListener(new View.OnLongClickListener() {\n @Override\n public boolean onLongClick(View v) {\n mOnItemLongClickListener.onItemLongClick(holder.itemView, position);\n return true;\n }\n });\n }\n }\n \n @Override\n public int getItemCount() {\n return mData == null ? 0 : mData.length;\n }\n \n private OnItemClickListener mOnItemClickListener;\n private OnItemLongClickListener mOnItemLongClickListener;\n \n public void setOnItemClickListener(OnItemClickListener mOnItemClickListener) {\n this.mOnItemClickListener = mOnItemClickListener;\n }\n \n public void setOnItemLongClickListener(OnItemLongClickListener mOnItemLongClickListener) {\n this.mOnItemLongClickListener = mOnItemLongClickListener;\n }\n \n }\n \n static class MyHolder extends RecyclerView.ViewHolder {\n public TextView mTitleTv;\n \n public MyHolder(View itemView) {\n super(itemView);\n mTitleTv = (TextView) itemView;\n }\n }\n \n public interface OnItemClickListener {\n void onItemClick(View view, int position);\n }\n \n public interface OnItemLongClickListener {\n void onItemLongClick(View view, int position);\n }\n \n }\n ```\n- 使用`RecyclerView.OnItemTouchListener` \n\n 虽然没有提供现成的监听器,但是提供了一个内部接口`OnItemTouchListener`。 \n 先来看看它的介绍: \n ```\n /**\n * An OnItemTouchListener allows the application to intercept touch events in progress at the\n * view hierarchy level of the RecyclerView before those touch events are considered for\n * RecyclerView's own scrolling behavior.\n *\n * This can be useful for applications that wish to implement various forms of gestural\n * manipulation of item views within the RecyclerView. OnItemTouchListeners may intercept\n * a touch interaction already in progress even if the RecyclerView is already handling that\n * gesture stream itself for the purposes of scrolling.
\n *\n * @see SimpleOnItemTouchListener\n */\n public static interface OnItemTouchListener {\n ...\n }\n ```\n\n 说的和明白了,而且还让你看`SimpleOnItemTouchListener`,猜也能猜出来是一个默认的实现类。\n 好了直接上代码: \n ```java\n public class MainActivity extends AppCompatActivity {\n private RecyclerView mRecyclerView;\n private LinearLayoutManager mLayoutManager;\n private MyAdapter mAdapter;\n private String[] mDatas = {\"Android\", \"ios\", \"jack\", \"tony\", \"window\", \"mac\", \"1234\", \"hehe\", \"495948\", \"89757\", \"66666\"};\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n findView();\n initView();\n }\n\n private void findView() {\n mRecyclerView = (RecyclerView) findViewById(R.id.rv);\n }\n\n private void initView() {\n // use this setting to improve performance if you know that changes\n // in content do not change the layout size of the RecyclerView\n mRecyclerView.setHasFixedSize(true);\n\n // use a linear layout manager\n mLayoutManager = new LinearLayoutManager(this);\n mLayoutManager.setOrientation(LinearLayoutManager.VERTICAL);\n mRecyclerView.setLayoutManager(mLayoutManager);\n mAdapter = new MyAdapter(mDatas);\n mRecyclerView.setAdapter(mAdapter);\n mRecyclerView.addOnItemTouchListener(new RecyclerViewClickListener(this, mRecyclerView, new OnItemClickListener() {\n @Override\n public void onItemClick(View view, int position) {\n Toast.makeText(MainActivity.this, mDatas[position], Toast.LENGTH_SHORT).show();\n }\n\n @Override\n public void onItemLongClick(View view, int position) {\n Toast.makeText(MainActivity.this, \"Long Click \" + mDatas[position], Toast.LENGTH_SHORT).show();\n }\n }));\n }\n\n class RecyclerViewClickListener extends RecyclerView.SimpleOnItemTouchListener {\n private GestureDetector mGestureDetector;\n private OnItemClickListener mListener;\n\n public RecyclerViewClickListener(Context context, final RecyclerView recyclerView, OnItemClickListener listener) {\n mListener = listener;\n mGestureDetector = new GestureDetector(context,\n new GestureDetector.SimpleOnGestureListener() {\n @Override\n public boolean onSingleTapUp(MotionEvent e) {\n View childView = recyclerView.findChildViewUnder(e.getX(), e.getY());\n if (childView != null && mListener != null) {\n mListener.onItemClick(childView, recyclerView.getChildLayoutPosition(childView));\n return true;\n }\n return false;\n }\n\n @Override\n public void onLongPress(MotionEvent e) {\n View childView = recyclerView.findChildViewUnder(e.getX(), e.getY());\n if (childView != null && mListener != null) {\n mListener.onItemLongClick(childView, recyclerView.getChildLayoutPosition(childView));\n }\n }\n });\n }\n\n @Override\n public boolean onInterceptTouchEvent(RecyclerView rv, MotionEvent e) {\n if (mGestureDetector.onTouchEvent(e)) {\n return true;\n } else\n return super.onInterceptTouchEvent(rv, e);\n }\n\n @Override\n public void onTouchEvent(RecyclerView rv, MotionEvent e) {\n super.onTouchEvent(rv, e);\n }\n\n @Override\n public void onRequestDisallowInterceptTouchEvent(boolean disallowIntercept) {\n super.onRequestDisallowInterceptTouchEvent(disallowIntercept);\n }\n }\n\n interface OnItemClickListener {\n void onItemClick(View view, int position);\n\n void onItemLongClick(View view, int position);\n }\n ```\n 上面的实现稍微有些缺陷,就是如果我手指按住某个条目一直不抬起,他也会执行`Long click`事件,这显然是不合理的,至于怎么解决,就是可以不用`GestureDetector`,自己在`DOWN`和`UP`事件中去判断处理。\n\n### Headerview FooterView\n\n之前在`ListView`中提供了`addHeaderView()`和`addFooterView()`等方法,但是在`RecyclerView`中并没有提供类似的方法,那我们该如何添加呢? 也很简单,就是通过`Adapter`中去添加,利用不同的`itemViewType`,然后根据不同的类型去在`onCreateViewHOlder`中创建不同的视图,通过这种方式来达到`headerview`和`FooterView`的效果。\n\n上一段简单的示例代码: \n```java\n public class HeaderAdapter extends RecyclerView.Adapter {\n private static final int TYPE_HEADER = 0;\n private static final int TYPE_ITEM = 1;\n String[] data;\n\n public HeaderAdapter(String[] data) {\n this.data = data;\n }\n\n @Override\n public RecyclerView.ViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {\n if (viewType == TYPE_ITEM) {\n //inflate your layout and pass it to view holder\n return new VHItem(null);\n } else if (viewType == TYPE_HEADER) {\n //inflate your layout and pass it to view holder\n return new VHHeader(null);\n }\n\n throw new RuntimeException(\"there is no type that matches the type \" + viewType + \" + make sure your using types correctly\");\n }\n\n @Override\n public void onBindViewHolder(RecyclerView.ViewHolder holder, int position) {\n if (holder instanceof VHItem) {\n String dataItem = getItem(position);\n //cast holder to VHItem and set data\n } else if (holder instanceof VHHeader) {\n //cast holder to VHHeader and set data for header.\n }\n }\n\n @Override\n public int getItemCount() {\n return data.length + 1;\n }\n\n @Override\n public int getItemViewType(int position) {\n if (isPositionHeader(position))\n return TYPE_HEADER;\n\n return TYPE_ITEM;\n }\n\n private boolean isPositionHeader(int position) {\n return position == 0;\n }\n\n private String getItem(int position) {\n return data[position - 1];\n }\n\n class VHItem extends RecyclerView.ViewHolder {\n TextView title;\n\n public VHItem(View itemView) {\n super(itemView);\n }\n }\n\n class VHHeader extends RecyclerView.ViewHolder {\n Button button;\n\n public VHHeader(View itemView) {\n super(itemView);\n }\n }\n}\n```\n上面的代码对`LinearLayoutManger`是没问题的,但是使用`GridLayoutManager`呢? 如果是两列,那添加的`HeaderView`并不是占据上第一行,而是`HeaderView`与第二个`ItemView`一起占据第一行。那该怎么处理呢? \n那就是使用`setSpanSizeLookup()`方法。\n比如: \n```java\nrecyclerView.setLayoutManager(new GridLayoutManager(this, 2));\n```\n在上面的基本设置中,我们的`spanCount`为2,每个`item`的`span size`为1,因此一个`header`需要的`span size`则为2。在我尝试着添加`header`之前,我想先看看如何设置`span size`。其实很简单。\n```java\nfinal GridLayoutManager manager = new GridLayoutManager(this, 2);\nrecyclerView.setLayoutManager(manager);\nmanager.setSpanSizeLookup(new GridLayoutManager.SpanSizeLookup() {\n @Override\n public int getSpanSize(int position) {\n return adapter.isHeader(position) ? manager.getSpanCount() : 1;\n }\n});\n```\n\n### 下拉刷新、自动加载\n\n##### 实现下拉刷新 \n实现下拉刷新也很简单了,可以使用`SwipeRefrshLayout`,`SwipeRefrshLayout`是`Google`官方提供的组件,可以实现下拉刷新的功能。已包含到`support.v4`包中。\n\n主要方法有: \n\n- `setOnRefreshListener(OnRefreshListener)`:添加下拉刷新监听器\n- `setRefreshing(boolean)`:显示或者隐藏刷新进度条\n- `isRefreshing()`:检查是否处于刷新状态\n- `setColorSchemeResources()`:设置进度条的颜色主题,最多设置四种。\n\n```xml\n\n \n\n```\n具体实现就不写了。\n\n##### 实现滑动自动加载更多功能\n\n实现方式和`ListView`的实现方式类似,就是通过监听`scroll`时间,然后判断当前显示的`item`。\n\n```java\n//RecyclerView滑动监听\nmRecylcerView.setOnScrollListener(new RecyclerView.OnScrollListener() {\n @Override\n public void onScrollStateChanged(RecyclerView recyclerView, int newState) {\n super.onScrollStateChanged(recyclerView, newState);\n if (newState ==RecyclerView.SCROLL_STATE_IDLE && lastVisibleItem + 1 ==adapter.getItemCount()) {\n new Handler().postDelayed(new Runnable() {\n @Override\n public void run() {\n List newDatas = new ArrayList();\n for (int i = 0; i< 5; i++) {\n int index = i +1;\n newDatas.add(\"more item\" + index);\n }\n adapter.addMoreItem(newDatas);\n }\n },1000);\n }\n }\n @Override\n public void onScrolled(RecyclerView recyclerView, int dx, int dy) {\n super.onScrolled(recyclerView,dx, dy);\n lastVisibleItem =linearLayoutManager.findLastVisibleItemPosition();\n }\n});\n```\n\n然后再通过结合`FooterView`以及增加几种状态就可以实现自动加载更多了。\n\n \t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/如何让Service常驻内存.md",
"content": "如何让Service常驻内存\n===\n\n我非常鄙视这种行文,一个公司应该想到如何把产品做的更完善,而不是用这些技术来损害用户的利益,来获取自己肮脏的所谓的功能。\n\n- `Service`设置成`START_STICKY`,`kill`后会被重启(等待5秒左右),重传`Intent`,保持与重启前一样\n- 通过`startForeground`将进程设置为前台进程,做前台服务,优先级和前台应用一个级别,除非在系统内存非常缺,否则此进程不会被`kill`\n- 双进程`Service`:让2个进程互相保护,其中一个`Service`被清理后,另外没被清理的进程可以立即重启进程\n- `QQ`黑科技:在应用退到后台后,另起一个只有1像素的页面停留在桌面上,让自己保持前台状态,保护自己不被后台清理工具杀死\n- 在已经`root`的设备下,修改相应的权限文件,将`App`伪装成系统级的应用(`Android4.0`系列的一个漏洞,已经确认可行)\n- `Android`系统中当前进程(`Process`)`fork`出来的子进程,被系统认为是两个不同的进程。当父进程被杀死的时候,子进程仍然可以存活,并不受影响。\n 鉴于目前提到的在`Android-Service`层做双守护都会失败,我们可以`fork`出`c`进程,多进程守护。死循环在那检查是否还存在,\n\t具体的思路如下(`Android5.0`以下可行)\n\t- 用`C`编写守护进程(即子进程),守护进程做的事情就是循环检查目标进程是否存在,不存在则启动它。\n\t- 在`NDK`环境中将1中编写的`C`代码编译打包成可执行文件(`BUILD_EXECUTABLE`)。\n\t- 主进程启动时将守护进程放入私有目录下,赋予可执行权限,启动它即可。\n\t\n- 联系厂商,加入白名单\n\n\n\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/屏幕适配之百分比方案详解.md",
"content": "屏幕适配之百分比方案详解\n===\n\n`Android`设备碎片化十分严重,在开发过程中的适配工作也非常很繁琐,有关屏幕适配的介绍请看之前的文章[屏幕适配](https://github.com/CharonChui/AndroidNote/blob/master/BasicKnowledge/%E5%B1%8F%E5%B9%95%E9%80%82%E9%85%8D.md)。\n\n最近看到`DrawerLayout`,`support v4`中提供的类,想到对`google`提供的这些支持库,自己一点都不熟悉,想着看看`Google`提供的支持库都有什么内容。结果看着看着在最后忽然看到了`Percent Support Library`。寻思怎么还百分比呢?仔细一看介绍,我擦,真是太有用了。\n> Percent Support Library\n> The Percent package provides APIs to support adding and managing percentage based dimensions in your app.\n\n> The Percent Support library adds support for the PercentLayoutHelper.PercentLayoutParams interface and various classes, such as PercentFrameLayout and PercentRelativeLayout.\n\n> After you download the Android Support Libraries, this library is located in the /extras/android/support/percent directory. For more information on how to set up your project, follow the instructions in Adding libraries with resources.\n\n> The Gradle build script dependency identifier for this library is as follows:\n> `com.android.support:percent:23.3.0`\n\n看到了吗? 说提供了`PercentFrameLayout`和`PercentRelativeLayout`来支持百分比了。这样不就完美的解决了适配的问题嘛。啥也不说了,立马配置`gradle`来瞧瞧。 \n\n> Subclass of FrameLayout that supports percentage based dimensions and margins. You can specify dimension or a margin of child by using attributes with \"Percent\" suffix. \n\n上代码: \n```xml\n\n \n\n```\n效果如下: \n \n完美. \n\n支持的属性: \n\n- `layout_widthPercent`\n- `layout_heightPercent`\n- `layout_marginPercent`\n- `layout_marginLeftPercent`\n- `layout_marginTopPercent`\n- `layout_marginRightPercent`\n- `layout_marginBottomPercent`\n- `layout_marginStartPercent`\n- `layout_marginEndPercent`\n- `layout_aspectRatio`\n\n> It is not necessary to specify layout_width/height if you specify layout_widthPercent. However, if you want the view to be able to take up more space than what percentage value permits, you can add layout_width/height=\"wrap_content\". In that case if the percentage size is too small for the View's content, it will be resized using wrap_content rule.\n\n如果指定了`layout_widthPercent`就不用指定`layout_width/height`属性了。(`Studio`可能会提示错误,设置忽略就好)。然而,如果你想要该`View`能够占用比设置的百分比值更大的空间时,你可以指定`layout_widht/height=“wrap_content”`。在这种情况下,如果设置的百分比值在显示内容时太小时,将会使用`wrap_content`的值重新计算。\n\n就是这个意思:如果指定的百分比太小怕显示不开的话,也可以给它指定`wrap_content`属性,这样当显示不开的时候就会使用`wrap_content`的值。 \n如下: \n```xml\n\n \n\n```\n\n效果: \n \n\n加入`wrap_content`后一点效果也没有啊,还是显示不全啊,和没加`wrap_content`一样,- -!\n\n\n你也可以通过只设置`width`或者`height`和`layout_aspectRatio`这种比例值的方式来让第另一个值自动计算。例如,如果你想要使用`16:9`的比例,你可以使用: \n```xml\nandroid:layout_width=\"300dp\"\napp:layout_aspectRatio=\"178%\"\n```\n\n这样将会在宽固定为`300dp`的基础上以16:9(1.78:1)来计算高度。\n\n`PercentRelativeLayout`的使用都是一样的,这里就不贴了。 \n\n那它是怎么实现的呢?其实就是内部给通过属性换算,把本布局的宽高和百分比去计算每个`view`的大小和位置。但是还有为什么上面设置的`wrap_content`无效呢?是我理解错了吗?\n\n带着这两个疑问我们来看下源码: \n```java\npublic class PercentFrameLayout extends FrameLayout {\n private final PercentLayoutHelper mHelper = new PercentLayoutHelper(this);\n\n public PercentFrameLayout(Context context) {\n super(context);\n }\n\n public PercentFrameLayout(Context context, AttributeSet attrs) {\n super(context, attrs);\n }\n\n public PercentFrameLayout(Context context, AttributeSet attrs, int defStyleAttr) {\n super(context, attrs, defStyleAttr);\n }\n\n @Override\n protected LayoutParams generateDefaultLayoutParams() {\n return new LayoutParams(LayoutParams.MATCH_PARENT, LayoutParams.MATCH_PARENT);\n }\n\n @Override\n public LayoutParams generateLayoutParams(AttributeSet attrs) {\n return new LayoutParams(getContext(), attrs);\n }\n\n @Override\n protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {\n mHelper.adjustChildren(widthMeasureSpec, heightMeasureSpec);\n super.onMeasure(widthMeasureSpec, heightMeasureSpec);\n // 从名字上就能看出来下面就是处理如果指定百分比过小不足显示内容时,就去使用`wrap_content`的逻辑\n if (mHelper.handleMeasuredStateTooSmall()) {\n super.onMeasure(widthMeasureSpec, heightMeasureSpec);\n }\n }\n\n @Override\n protected void onLayout(boolean changed, int left, int top, int right, int bottom) {\n super.onLayout(changed, left, top, right, bottom);\n mHelper.restoreOriginalParams();\n }\n\n public static class LayoutParams extends FrameLayout.LayoutParams\n implements PercentLayoutHelper.PercentLayoutParams {\n\n private PercentLayoutHelper.PercentLayoutInfo mPercentLayoutInfo;\n\n public LayoutParams(Context c, AttributeSet attrs) {\n super(c, attrs);\n // PercentLayoutInfo中去解析自定义属性的值\n mPercentLayoutInfo = PercentLayoutHelper.getPercentLayoutInfo(c, attrs);\n }\n\n public LayoutParams(int width, int height) {\n super(width, height);\n }\n\n public LayoutParams(int width, int height, int gravity) {\n super(width, height, gravity);\n }\n\n public LayoutParams(ViewGroup.LayoutParams source) {\n super(source);\n }\n\n public LayoutParams(MarginLayoutParams source) {\n super(source);\n }\n\n public LayoutParams(FrameLayout.LayoutParams source) {\n super((MarginLayoutParams) source);\n gravity = source.gravity;\n }\n\n public LayoutParams(LayoutParams source) {\n this((FrameLayout.LayoutParams) source);\n mPercentLayoutInfo = source.mPercentLayoutInfo;\n }\n\n @Override\n public PercentLayoutHelper.PercentLayoutInfo getPercentLayoutInfo() {\n if (mPercentLayoutInfo == null) {\n mPercentLayoutInfo = new PercentLayoutHelper.PercentLayoutInfo();\n }\n\n return mPercentLayoutInfo;\n }\n\n @Override\n protected void setBaseAttributes(TypedArray a, int widthAttr, int heightAttr) {\n PercentLayoutHelper.fetchWidthAndHeight(this, a, widthAttr, heightAttr);\n }\n }\n}\n```\n源码不长,主要是三个部分: \n\n- 重写`onMeasure`,根据百分比转换成对应的尺寸\n- 重写`onLayout`\n- 自定义`LayoutParams`,在`FrameLayout.LayoutParams`的基础上多实现了一个接口。包含了`PercentLayoutHelper.PercentLayoutInfo `属性,而文档中对`PercentLayoutInfo`的介绍是`Container for information about percentage dimensions and margins. It acts as an extension for LayoutParams.`\n\n\n我们也先一步步的来分析,首先看下`mHelper.adjustChildren(widthMeasureSpec, heightMeasureSpec);`: \n```java\n/**\n * Iterates over children and changes their width and height to one calculated from percentage\n * values.\n * @param widthMeasureSpec Width MeasureSpec of the parent ViewGroup.\n * @param heightMeasureSpec Height MeasureSpec of the parent ViewGroup.\n */\npublic void adjustChildren(int widthMeasureSpec, int heightMeasureSpec) {\n if (Log.isLoggable(TAG, Log.DEBUG)) {\n Log.d(TAG, \"adjustChildren: \" + mHost + \" widthMeasureSpec: \"\n + View.MeasureSpec.toString(widthMeasureSpec) + \" heightMeasureSpec: \"\n + View.MeasureSpec.toString(heightMeasureSpec));\n }\n\n int widthHint = View.MeasureSpec.getSize(widthMeasureSpec);\n int heightHint = View.MeasureSpec.getSize(heightMeasureSpec);\n // mHost是由构造函数传递过来的,就是PercentFrameLayout自身。\n for (int i = 0, N = mHost.getChildCount(); i < N; i++) {\n View view = mHost.getChildAt(i);\n ViewGroup.LayoutParams params = view.getLayoutParams();\n if (Log.isLoggable(TAG, Log.DEBUG)) {\n Log.d(TAG, \"should adjust \" + view + \" \" + params);\n }\n if (params instanceof PercentLayoutParams) {\n // 通过PercentLayoutParams. getPercentLayoutInfo()方法得到PercentLayoutInfo,至于PercentLayoutInfo类在上面也说过了。\n PercentLayoutInfo info =\n ((PercentLayoutParams) params).getPercentLayoutInfo();\n if (Log.isLoggable(TAG, Log.DEBUG)) {\n Log.d(TAG, \"using \" + info);\n }\n if (info != null) {\n if (params instanceof ViewGroup.MarginLayoutParams) {\n // PercentFrameLayout.LayoutParams继承自FrameLayout.LayoutParams,而FrameLayout.LayoutParams又继承自ViewGroup.MarginLayoutParams\n info.fillMarginLayoutParams(view, (ViewGroup.MarginLayoutParams) params,\n widthHint, heightHint);\n } else {\n info.fillLayoutParams(params, widthHint, heightHint);\n }\n }\n }\n }\n}\n```\n所以上面代码的意思就是通过对每个子`View`调用`getLayoutParams`方法,然后从该`LayoutParams`中获取到它的`PercentLayoutInfo`属性,然后再调用`PercentLayoutInfo.fillMarginLayoutParams()`方法。\n\n那我们继续看一下`PercentLayoutInfo.fillMarginLayoutParams()`方法的实现,该方法是根据百分比去设置尺寸和margin: \n```java\n/**\n * Fills {@code ViewGroup.MarginLayoutParams} dimensions and margins based on percentage\n * values.\n */\npublic void fillMarginLayoutParams(View view, ViewGroup.MarginLayoutParams params,\n int widthHint, int heightHint) {\n // 根据百分比值设置View的尺寸\n fillLayoutParams(params, widthHint, heightHint);\n\n // 从注释中就能知道,fillLayoutParams是计算尺寸,那下面这部分就是处理margin了\n // mPreservedParams来记录原始的margin值\n // Preserve the original margins, so we can restore them after the measure step.\n mPreservedParams.leftMargin = params.leftMargin;\n mPreservedParams.topMargin = params.topMargin;\n mPreservedParams.rightMargin = params.rightMargin;\n mPreservedParams.bottomMargin = params.bottomMargin;\n MarginLayoutParamsCompat.setMarginStart(mPreservedParams,\n MarginLayoutParamsCompat.getMarginStart(params));\n MarginLayoutParamsCompat.setMarginEnd(mPreservedParams,\n MarginLayoutParamsCompat.getMarginEnd(params));\n\n if (leftMarginPercent >= 0) {\n params.leftMargin = (int) (widthHint * leftMarginPercent);\n }\n if (topMarginPercent >= 0) {\n params.topMargin = (int) (heightHint * topMarginPercent);\n }\n if (rightMarginPercent >= 0) {\n params.rightMargin = (int) (widthHint * rightMarginPercent);\n }\n if (bottomMarginPercent >= 0) {\n params.bottomMargin = (int) (heightHint * bottomMarginPercent);\n }\n boolean shouldResolveLayoutDirection = false;\n if (startMarginPercent >= 0) {\n MarginLayoutParamsCompat.setMarginStart(params,\n (int) (widthHint * startMarginPercent));\n shouldResolveLayoutDirection = true;\n }\n if (endMarginPercent >= 0) {\n MarginLayoutParamsCompat.setMarginEnd(params,\n (int) (widthHint * endMarginPercent));\n shouldResolveLayoutDirection = true;\n }\n if (shouldResolveLayoutDirection && (view != null)) {\n // Force the resolve pass so that start / end margins are propagated to the\n // matching left / right fields\n MarginLayoutParamsCompat.resolveLayoutDirection(params,\n ViewCompat.getLayoutDirection(view));\n }\n if (Log.isLoggable(TAG, Log.DEBUG)) {\n Log.d(TAG, \"after fillMarginLayoutParams: (\" + params.width + \", \" + params.height\n + \")\");\n }\n}\n```\n\n再看一下`PercentLayoutInfo.fillLayoutParams()`的实现,该方法是通过百分比设置`View`的尺寸:\n\n```java\n/**\n * Fills {@code ViewGroup.LayoutParams} dimensions based on percentage values.\n */\npublic void fillLayoutParams(ViewGroup.LayoutParams params, int widthHint,\n int heightHint) {\n // mPreservedParams来记录原始的宽高值\n // Preserve the original layout params, so we can restore them after the measure step.\n mPreservedParams.width = params.width;\n mPreservedParams.height = params.height;\n\n // We assume that width/height set to 0 means that value was unset. This might not\n // necessarily be true, as the user might explicitly set it to 0. However, we use this\n // information only for the aspect ratio. If the user set the aspect ratio attribute,\n // it means they accept or soon discover that it will be disregarded.\n final boolean widthNotSet =\n (mPreservedParams.mIsWidthComputedFromAspectRatio\n || mPreservedParams.width == 0) && (widthPercent < 0);\n final boolean heightNotSet =\n (mPreservedParams.mIsHeightComputedFromAspectRatio\n || mPreservedParams.height == 0) && (heightPercent < 0);\n\n // 如果指定了百分比属性,就用宽高值和百分比去算出具体的宽高\n if (widthPercent >= 0) {\n // 看到了吗?是根据父`View\t`的宽高来乘以百分比,不是根据整个屏幕的宽高,这样可能会有问题,要是ListView这种的高度没法算了\n params.width = (int) (widthHint * widthPercent);\n }\n\n if (heightPercent >= 0) {\n params.height = (int) (heightHint * heightPercent);\n }\n // 如果指定了宽高的比例值,就用比例值去算出宽高,从这里能看出`aspectRatio`的优先级比百分比要高。他可以覆盖百分比之前设置的值。\n if (aspectRatio >= 0) {\n if (widthNotSet) {\n params.width = (int) (params.height * aspectRatio);\n // Keep track that we've filled the width based on the height and aspect ratio.\n mPreservedParams.mIsWidthComputedFromAspectRatio = true;\n }\n if (heightNotSet) {\n params.height = (int) (params.width / aspectRatio);\n // Keep track that we've filled the height based on the width and aspect ratio.\n mPreservedParams.mIsHeightComputedFromAspectRatio = true;\n }\n }\n\n if (Log.isLoggable(TAG, Log.DEBUG)) {\n Log.d(TAG, \"after fillLayoutParams: (\" + params.width + \", \" + params.height + \")\");\n }\n}\n``` \n\n到这里`onMeasure`中通过百分比值设置宽高以及`margin`的部分就看完了,那我们接着看一下关于百分比值过小时对`wrap_content`的处理: \n```java\nif (mHelper.handleMeasuredStateTooSmall()) {\n super.onMeasure(widthMeasureSpec, heightMeasureSpec);\n}\n```\n\n看一下`PercentLayoutHelper.handleMeasuredStateTooSmall()`方法的实现: \n```java\n/**\n * Iterates over children and checks if any of them would like to get more space than it\n * received through the percentage dimension.\n *\n * If you are building a layout that supports percentage dimensions you are encouraged to take\n * advantage of this method. The developer should be able to specify that a child should be\n * remeasured by adding normal dimension attribute with {@code wrap_content} value. For example\n * he might specify child's attributes as {@code app:layout_widthPercent=\"60%p\"} and\n * {@code android:layout_width=\"wrap_content\"}. In this case if the child receives too little\n * space, it will be remeasured with width set to {@code WRAP_CONTENT}.\n *\n * @return True if the measure phase needs to be rerun because one of the children would like\n * to receive more space.\n */\npublic boolean handleMeasuredStateTooSmall() {\n boolean needsSecondMeasure = false;\n for (int i = 0, N = mHost.getChildCount(); i < N; i++) {\n View view = mHost.getChildAt(i);\n ViewGroup.LayoutParams params = view.getLayoutParams();\n if (Log.isLoggable(TAG, Log.DEBUG)) {\n Log.d(TAG, \"should handle measured state too small \" + view + \" \" + params);\n }\n if (params instanceof PercentLayoutParams) {\n PercentLayoutInfo info =\n ((PercentLayoutParams) params).getPercentLayoutInfo();\n if (info != null) {\n // shouldHandleMeasuredWidthTooSmall方法来进行判断\n if (shouldHandleMeasuredWidthTooSmall(view, info)) {\n needsSecondMeasure = true;\n params.width = ViewGroup.LayoutParams.WRAP_CONTENT;\n }\n if (shouldHandleMeasuredHeightTooSmall(view, info)) {\n needsSecondMeasure = true;\n params.height = ViewGroup.LayoutParams.WRAP_CONTENT;\n }\n }\n }\n }\n if (Log.isLoggable(TAG, Log.DEBUG)) {\n Log.d(TAG, \"should trigger second measure pass: \" + needsSecondMeasure);\n }\n return needsSecondMeasure;\n}\n```\n\n那继续看一下`shouldHandleMeasuredWidthTooSmall()`方法: \n```java\nprivate static boolean shouldHandleMeasuredWidthTooSmall(View view, PercentLayoutInfo info) {\n int state = ViewCompat.getMeasuredWidthAndState(view) & ViewCompat.MEASURED_STATE_MASK;\n return state == ViewCompat.MEASURED_STATE_TOO_SMALL && info.widthPercent >= 0 &&\n info.mPreservedParams.width == ViewGroup.LayoutParams.WRAP_CONTENT;\n}\n```\n\n继续看`ViewCompat.getMeasuredWidthAndState()`的源码: \n```java\npublic static int getMeasuredWidthAndState(View view) {\n return IMPL.getMeasuredWidthAndState(view);\n}\n```\n继续往下看,这个`IMPL`是什么呢? \n```java\nstatic final ViewCompatImpl IMPL;\nstatic {\n final int version = android.os.Build.VERSION.SDK_INT;\n if (version >= 23) {\n IMPL = new MarshmallowViewCompatImpl();\n } else if (version >= 21) {\n IMPL = new LollipopViewCompatImpl();\n } else if (version >= 19) {\n IMPL = new KitKatViewCompatImpl();\n } else if (version >= 17) {\n IMPL = new JbMr1ViewCompatImpl();\n } else if (version >= 16) {\n IMPL = new JBViewCompatImpl();\n } else if (version >= 15) {\n IMPL = new ICSMr1ViewCompatImpl();\n } else if (version >= 14) {\n IMPL = new ICSViewCompatImpl();\n } else if (version >= 11) {\n IMPL = new HCViewCompatImpl();\n } else if (version >= 9) {\n IMPL = new GBViewCompatImpl();\n } else if (version >= 7) {\n IMPL = new EclairMr1ViewCompatImpl();\n } else {\n IMPL = new BaseViewCompatImpl();\n }\n}\n```\n继续看,`IMPL.getMeasuredWidthAndState()`,方法其实最终就是使用的`BaseViewCompatImpl.getMeasuredWidthAndState()`方法,接着看它的的源码: \n```java\n@Override\n public int getMeasuredWidthAndState(View view) {\n return view.getMeasuredWidth();\n }\n```\n最后就是调用了`getMeasuredWidth()`方法。 没毛病- -!\n\n\n`onMeasure`的到这里就分析完了。 \n那接着来看一下`onLayout`方法,`onLayout`方法直接调用了`PercentLayoutHelper.restoreOriginalParams`,: \n```java\n/**\n * Iterates over children and restores their original dimensions that were changed for\n * percentage values. Calling this method only makes sense if you previously called\n * {@link PercentLayoutHelper#adjustChildren(int, int)}.\n */\npublic void restoreOriginalParams() {\n for (int i = 0, N = mHost.getChildCount(); i < N; i++) {\n View view = mHost.getChildAt(i);\n ViewGroup.LayoutParams params = view.getLayoutParams();\n if (Log.isLoggable(TAG, Log.DEBUG)) {\n Log.d(TAG, \"should restore \" + view + \" \" + params);\n }\n if (params instanceof PercentLayoutParams) {\n PercentLayoutInfo info =\n ((PercentLayoutParams) params).getPercentLayoutInfo();\n if (Log.isLoggable(TAG, Log.DEBUG)) {\n Log.d(TAG, \"using \" + info);\n }\n if (info != null) {\n if (params instanceof ViewGroup.MarginLayoutParams) {\n info.restoreMarginLayoutParams((ViewGroup.MarginLayoutParams) params);\n } else {\n info.restoreLayoutParams(params);\n }\n }\n }\n }\n}\n```\n\n调用了`PercentLayoutInfo.restoreMarginLayoutParams()`方法,我们看下它的源码: \n```java\n/**\n * Restores original dimensions and margins after they were changed for percentage based\n * values. Calling this method only makes sense if you previously called\n * {@link PercentLayoutHelper.PercentLayoutInfo#fillMarginLayoutParams}.\n */\npublic void restoreMarginLayoutParams(ViewGroup.MarginLayoutParams params) {\n restoreLayoutParams(params);\n // mPreservedParams的值在之前ad\n params.leftMargin = mPreservedParams.leftMargin;\n params.topMargin = mPreservedParams.topMargin;\n params.rightMargin = mPreservedParams.rightMargin;\n params.bottomMargin = mPreservedParams.bottomMargin;\n MarginLayoutParamsCompat.setMarginStart(params,\n MarginLayoutParamsCompat.getMarginStart(mPreservedParams));\n MarginLayoutParamsCompat.setMarginEnd(params,\n MarginLayoutParamsCompat.getMarginEnd(mPreservedParams));\n}\n```\n意思是说,再他们被以百分比为基础的数据更改之后恢复成原始的尺寸和margin。 \n然后继续看一下`restoreLayoutParams()`: \n```java\n/**\n* Restores original dimensions after they were changed for percentage based values. Calling\n* this method only makes sense if you previously called\n* {@link PercentLayoutHelper.PercentLayoutInfo#fillLayoutParams}.\n*/\npublic void restoreLayoutParams(ViewGroup.LayoutParams params) {\n if (!mPreservedParams.mIsWidthComputedFromAspectRatio) {\n // Only restore the width if we didn't compute it based on the height and\n // aspect ratio in the fill pass.\n params.width = mPreservedParams.width;\n }\n if (!mPreservedParams.mIsHeightComputedFromAspectRatio) {\n // Only restore the height if we didn't compute it based on the width and\n // aspect ratio in the fill pass.\n params.height = mPreservedParams.height;\n }\n \n // Reset the tracking flags.\n mPreservedParams.mIsWidthComputedFromAspectRatio = false;\n mPreservedParams.mIsHeightComputedFromAspectRatio = false;\n}\n```\n\n好了到这里也分析完了`onLayout`的方法,大意就是在`onMeasure`之前先将原始的宽高和`margin`都备份一下,然后在`onMeasure`中根据百分比去设置对应的宽高和`margin`,等到设置完之后在`onLayout`方法中再去将这些值恢复到之前备份的起始数据。说实话我没看明白为什么要这样做?\n \n通过上面的代码分析我们知道对布局影响力的优先顺序: `app:layout_aspectRatio > app:layout_heightPercent > android:layout_height`如果我们同时都设置这三个参数值的话,最终会用`app:layout_aspectRatio`的值。\n \n遗留问题: \n\n- 为什么在`onLayout`方法中去恢复数据,这有什么作用?\n- 看代码在处理如果指定的百分比过小但又指定`wrap_content`时,会重新根据`wrap_content`去重新计算的逻辑没有错,但是为什么我在上面测试的时候确没效果?\n- 在上面分析代码时看到`fillLayoutParams`中是根据父`View`的宽高来乘以百分比,不是根据整个屏幕的宽高,这样可能会有问题,要是ListView这种的高度没法算了。\n\n \t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/布局优化.md",
"content": "布局优化\n===\n\n- 去除不必要的嵌套和节点\n 这是最基本的一条,但也是最不好做到的一条,往往不注意的时候难免会一些嵌套等。 \n\t- 首次不需要的节点设置为`GONE`或使用`ViewStud`. \n\t- 使用`Relativelayout`代替`LinearLayout`. \n\t平时写布局的时候要多注意,写完后可以通过`Hierarchy Viewer`或在手机上通过开发者选项中的显示布局边界来查看是否有不必要的嵌套。\n\t\n- 使用`include` \n\t`include`可以用于将布局中一些公共的部分提取出来。在需要的时候使用即可,比喻一些页面统一的`loading`页。 \n\t `include`标签的`layout`属性指定所要包含的布局文件,我们也可以通过`android:id`或者一些其他的属性来覆盖被引入布局的根节点所对应\n 的属性值。 \n\t ```xml\n\t \n\n\t\t \n\t```\n\n- 使用``标签 \n\t`merge`可以有效的解决布局的层级关系。我们通过一个例子来说明一下: \n\t```xml\n\t\n\n\t\t \n\t```\n\n\t我们在一个页面中显示该部分内容,运行后观察`Hierarchy Viewer`。 \n\t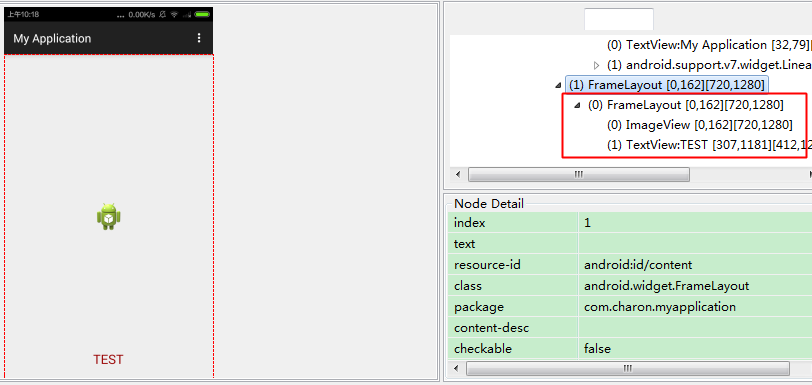 \n\t我们会发现除了我们布局最外层还会有一层`FrameLayout`,这是因为`Activity`内容视图的`parent view`就是一个`FrameLayout`,所以对于我们来说无意中已经多了一层毫无意义的布局。 \n\t接下来`merge`的功能就能发挥了,修改代码如下。 \n\t```xml\n\t\n\n\t\t \n\t```\n\t接下来我们在用`Hierarchy Viewer`观察就会发现完美的去掉了一层`FrameLayout` \n\t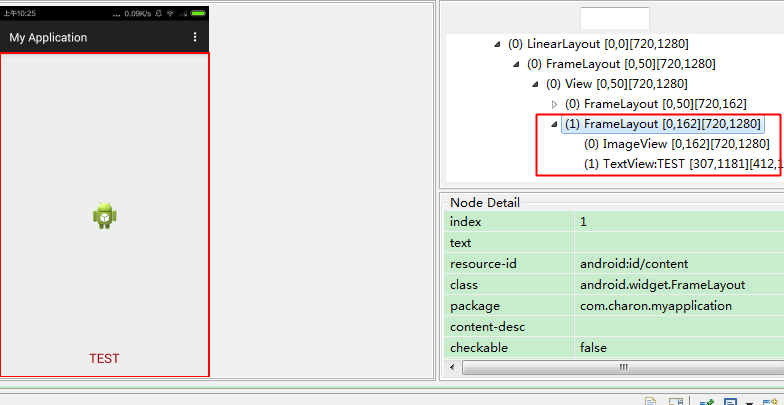 \n\t当然上面我们使用`merge`是因为跟布局正好是`FrameLayout`并且没有`backgroud`和`padding`等这些属性。如果根本局是`LinearLayout`等,就没法直接使用`merge`了。\n\t在`include`的时候很容易造成布局层级嵌套过多,结合`merge`使用能有效解决这个问题。\n\t\n- 使用`ViewStub` \n `ViewStub`标签与`include`一样可以用来引入一个外部布局,但是`Viewstub`引入的布局默认不会解析与显示,宽高为0,`View`也为`null`,这样就会在解析`layout`时节省`cpu`和内存。简单的理解就是`ViewStub`是\n`include`加上`GONE`.`ViewStub`常用来引入那些默认不会显示,只在特殊情况下显示的布局,如进度布局、网络失败显示的刷新布局、信息出错出现的提示布局等.\n ```xml\n\t\n\t\n\n\t\t……\n\t\t \n\t```\n\t在代码中通过`(ViewStub)findViewById(id)`找到`ViewStub`,使用`inflate()`展开`ViewStub`,然后得到子`View`,如下:\n\t```java\n\tprivate View mNetErrorView;\n\n\tprivate void showNetError() {\n\t\tif (mNetErrorView != null) {\n\t\t\tmNetErrorView.setVisibility(View.VISIBLE);\n\t\t\treturn;\n\t\t}\n\n\t\tViewStub stub = (ViewStub)findViewById(R.id.network_unreachble);\n\t\t// 解析并且显示该部分,返回值就是解析后的该`View`\n\t\tmNetErrorView = stub.inflate();\n\t\tButton networkSetting = (Button)mNetErrorView.findViewById(R.id.bt_network);\n\t}\n\n\tprivate void showNormal() {\n\t\tif (mNetErrorView != null) {\n\t\t\tmNetErrorView.setVisibility(View.GONE);\n\t\t}\n\t}\n\t```\n\t或者也可以通过第二种方式:\n\t```java\n\tView viewStub = findViewById(R.id.network_unreachble);\n\t// ViewStub被展开后的布局所替换\n\tviewStub.setVisibility(View.VISIBLE); \n\t// 获取展开后的布局\n\tmNetErrorView = findViewById(R.id.network_unreachble); \n\t```\n\n- 减少不必要的`Inflate` \n 如上一步中`stub.infalte()`后将该`View`进行记录或者是`ListView`中`item inflate`的时候。\n\t\t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/性能优化.md",
"content": "性能优化\n===\n\n代码优化原则: \n---\n\n- 时间换时间:\n\t如禁用电脑的一些开机启动项,通过减少这些没必要的启动项的时间从而节省开机时间\n\t如网站界面上数据的分批获取,`AJAX`技术\n- 时间换空间:\n\t如拷贝文件时new一个字节数组当缓冲器,即`byte[] buffer = new byte[1024]`。\n\t为什么只`new`一个1024个字节的数组呢,`new`一个更大的字节数组不是一下就把文件拷贝完了么?这么做就是为了牺牲时间节省有限的内存空间\n- 空间换时间:\n\t如用`Windows`系统自带的搜索文件的功能搜索文件时会很慢,但是我们牺牲电脑硬盘空间安装一个`everything`软件来搜索文件就特别快\n- 空间换空间:\n\t如虚拟内存\n\t\n`Android`开发中的体现\n---\n\t\n- 采用硬件加速,在清单文件中`application`节点添加`android:hardwareAccelerated=”true”`。不过这个需要在`android 3.0`才可以使用。`android4.0`这个选项是默认开启的。\n- `View`中设置缓存属性`setDrawingCache`为`true`.\n- 优化你的布局.\n- 动态加载`View`. 采用`ViewStub`避免一些不经常的视图长期握住引用.\n- 将`Acitivity`中的`Window`的背景图设置为空。`getWindow().setBackgroundDrawable(null);``android`的默认背景是不是为空。\n- 采用``优化布局层数。 采用``来共享布局。\n- 利用`TraceView`查看跟踪函数调用。有的放矢的优化。\n- `cursor`的使用。不过要注意管理好`cursor`,不要每次打开关闭`cursor`.因为打开关闭`Cursor`非常耗时。 `Cursor.require`用于刷`cursor`.\n- 采用`SurfaceView`在子线程刷新`UI`, 避免手势的处理和绘制在同一`UI`线程(普通`View`都这样做)。\n- 采用`JNI`,将耗时间的处理放到`c/c++`层来处理。\n- 有些能用文件操作的,尽量采用文件操作,文件操作的速度比数据库的操作要快10倍左右。\n- 避免创建不必要的对象\n- 如果方法用不到成员变量,可以把方法申明为`static`,性能会提高到15%到20%\n- 避免使用`getter/setter`存取`field`,可以把`field`申明为`public`,直接访问\n- `static`的变量如果不需要修改,应该使用`static final`修饰符定义为常量\n- 使用增强`for`循环,比普通`for`循环效率高,但是也有缺点就是在遍历 集合过程中,不能对集合本身进行操作\n- 合理利用浮点数,浮点数比整型慢两倍;\n- 针对`ListView`的性能优化\n\t\t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AdavancedPart/注解使用.md",
"content": "注解使用\n===\n\n### 简介\n\n> Annotations, a form of metadata, provide data about a program that is not part of the program itself. Annotations have no direct effect on the operation of the code they annotate.\n\n更通俗的意思是为程序的元素(类、方法、成员变量)加上更直观更明了的说明,这些说明信息是与程序的业务逻辑无关,并且是供指定的工具或框架使用的。\n`Annontation`像一种修饰符一样,应用于包、类型、构造方法、方法、成员变量、参数及本地变量的声明语句中。\n\n`Annotation`其实是一种接口。通过反射来访问`annotation`信息。相关类(框架或工具中的类)根据这些信息来决定如何使用该程序元素或改变它们的行为。\n`Annotation`是不会影响程序代码的执行,无论`annotation`怎么变化,代码都始终如一地执行。\n`Java`语言解释器在工作时会忽略这些`annotation`,因此在`JVM`中这些`annotation`是“不起作用”的,只能通过配套的工具才能对这些`annontaion`类型的信息进行访问和处理。\n\n### 说明\n\n- `Annotation`的声明是通过关键字`@interface`。这个关键字会去继承`Annotation`接口。\n- `Annotation`的方法定义是独特的、受限制的。 \n `Annotation`类型的方法必须声明为无参数、无异常的。这些方法定义了`Annotation`的成员: 方法名代表成员变量名,而方法返回值代表了成员变量的类型。而且方法的返回值类型必须是基本数据类型、`Class`类型、`String类型`、枚举类型、`Annotation`类型或者由前面类型之一作为元素的一维数组。方法的后面可以使用`default`和一个默认的数值来声明成员变量的默认值,`null`不能作为成员变量的默认值,这与我们平时的使用有很大的区别。 \n 注解如果只有一个默认属性,可直接用`value()`函数。一个属性也没有则表示该`Annotation`为`Mark Annotation`。\n 例如:\n \n ```java\n public @interface UnitTest {\n String value();\n }\n ``` \n 在使用时可以直接使用`@UnitTest(\"GCD\")`,`@UnitTest(\"GCD\"`实际上就是是 `@UnitTest(value=\"GCD)`的简单写法。 \n 例如:\n \n ```java\n @Target(ElementType.METHOD)\n @Retention(RetentionPolicy.RUNTIME)\n public @interface UseCase {\n public int id();\n public String description() default \"no description\";\n }\n ```\n\n### 作用\n\n`Annotation`一般作为一种辅助途径,应用在软件框架或者工具中。让这些工具类可以根据不同的`Annotation`注解信息来采取不同的处理过程或者改变相应程的行为。具有“让编译器进行编译检查的作用”。 \n\n具体可分为如下三类: \n\n- 标记,用于告诉编译器一些信息\n- 编译时动态处理,如动态生成代码\n- 运行时动态处理,如得到注解信息\n\n\n### Annotation分类 \n\n\n##### 标准的`Annotaion` \n\n从`jdk 1.5`开始,自带了三种标准的`annotation`类型: \n\n- `Override` \n 它是一种`marker`类型的`Annotation`,用来标注方法,说明被它标注的方法是重载了父类中的方法。如果我们使用了该注解到一个没有覆盖父类方法的方法时,编译器就会提示一个编译错误的警告。 \n\n- `Deprecated` \n 它也是一种`marker`类型的`Annotation`。当方法或者变量使用该注解时,编译器就会提示该方法已经废弃。\n\n- `SuppressWarnings` \n 它不是`marker`类型的`Annotation`。用户告诉编译器不要再对该类、方法或者成员变量进行警告提示。 \n\n\n##### 元`Annotation`\n\n元`Annotation`是指用来定义`Annotation`的`Annotation`。 \n\n- `@Retention` \n 保留时间,可为`RetentionPolicy.SOURCE(源码时)`、`RetentionPolicy.CLASS(编译时)`、`RetentionPolicy.RUNTIME(运行时)`,默认为`CLASS`。如果值为`RetentionPolicy.SOURCE`那大多都是`Mark Annotation`,例如:`Override`、`Deprecated`、`Suppress Warnings`。`SOURCE`表示仅存在于源码中,在`class`文件中不会包含。`CLASS`表示会在`class`文件中存在,但是运行时无法获取。`RUNTIME`表示会在`class`文件中存在,并且在运行时可以通过反射获取。 \n\n- `@Target` \n 用来标记可进行修饰哪些元素,例如`ElementType.TYPE`、`ElementType.METHOD`、`ElementType.CONSTRUCTOR`、`ElementType.FIELD`、`ElementType.PARAMETER`等,如果未指定则默认为可修饰所有。\n- `@Inherited` \n 子类是否可以继承父类中的该注解。它所标注的`Annotation`将具有继承性。 \n 例如: \n\n ```java\n java.lang.annotation.Inherited\n \n @Inherited\n public @interface MyAnnotation {\n \n }\n ```\n \n ```java\n @MyAnnotation\n public class MySuperClass { ... }\n ```\n \n ```java\n public class MySubClass extends MySuperClass { ... }\n ```\n\n 在这个例子中`MySubClass`类继承了`@MyAnnotation`注解,因为`MySubClass`继承了`MySuperClass`类,而`MySuperClass`类使用了`@MyAnnotation`注解。 \n\n- `@Documented` \n 是否会保存到`javadoc`文档中。 \n\n### 自定义`Annotation` \n\n假设现在有个开发团队在每个类的开始都要提供一些信息,例如: \n\n```java\npublic class Generation3List extends Generation2List {\n\n // Author: John Doe\n // Date: 3/17/2002\n // Current revision: 6\n // Last modified: 4/12/2004\n // By: Jane Doe\n // Reviewers: Alice, Bill, Cindy\n\n // class code goes here\n\n}\n```\n\n我们可以声明一个注解来保存这些相同的元数据。如下:\n \n```java\n@interface ClassPreamble {\n String author();\n String date();\n int currentRevision() default 1;\n String lastModified() default \"N/A\";\n String lastModifiedBy() default \"N/A\";\n // Note use of array\n String[] reviewers();\n}\n```\n声明完注解之后我们就可以填写一些参数来使用它,如下:\n \n\n```java\n@ClassPreamble (\n author = \"John Doe\",\n date = \"3/17/2002\",\n currentRevision = 6,\n lastModified = \"4/12/2004\",\n lastModifiedBy = \"Jane Doe\",\n // Note array notation\n reviewers = {\"Alice\", \"Bob\", \"Cindy\"}\n)\npublic class Generation3List extends Generation2List {\n\n// class code goes here\n\n}\n```\n\n### `Annotation`解析 \n\n当`Java`源代码被编译时,编译器的一个插件`annotation`处理器则会处理这些`annotation`。\n处理器可以产生报告信息,或者创建附加的`Java`源文件或资源。\n如果`annotation`本身被加上了`RententionPolicy`的运行时类,\n则`Java`编译器则会将`annotation`的元数据存储到`class`文件中。然后`Java`虚拟机或其他的程序可以查找这些元数据并做相应的处理。\n\n当然除了`annotation`处理器可以处理`annotation`外,我们也可以使用反射自己来处理`annotation`。`Java SE 5`有一个名为`AnnotatedElement`的接口,\n`Java`的反射对象类`Class`,`Constructor`,`Field`,`Method`以及`Package`都实现了这个接口。\n这个接口用来表示当前运行在`Java`虚拟机中的被加上了`annotation`的程序元素。\n通过这个接口可以使用反射读取`annotation`。`AnnotatedElement`接口可以访问被加上`RUNTIME`标记的`annotation`,\n相应的方法有`getAnnotation`,`getAnnotations`,`isAnnotationPresent`。\n由于`Annotation`类型被编译和存储在二进制文件中就像`class`一样,\n所以可以像查询普通的`Java`对象一样查询这些方法返回的`Annotation`。\n\n\n##### 运行时`Annotation`解析\n\n该类是指`@Retention`为`RUNTIME`的`Annotation`。 \n该类型的解析其实本质的使用反射。反射执行的效率是很低的 \n如果不是必要,应当尽量减少反射的使用,因为它会大大拖累你应用的执行效率。\n\n- 类注解\n\n 可以通过`Class`、`Method`、`Field`类来在运行时获取注解。下面是通过`Class`类获取注解的示例: \n \n ```java\n Class aClass = TheClass.class;\n Annotation[] annotations = aClass.getAnnotations();\n \n for(Annotation annotation : annotations){\n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n }\n ```\n 也可以获取一个指定的注解类型: \n \n ```java\n Class aClass = TheClass.class;\n Annotation annotation = aClass.getAnnotation(MyAnnotation.class);\n \n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n ```\n\n `JDK`提供的主要方法有: \n \n ```java\n public A getAnnotation(Class annotationType) {\n ...\n }\n \n public Annotation[] getAnnotations() {\n ...\n }\n \n public boolean isAnnotationPresent(Class annotationType) {\n ...\n }\n ```\n\n- 方法注解\n\n 下面是一个方法使用注解的例子: \n \n ```java\n public class TheClass {\n @MyAnnotation(name=\"someName\", value = \"Hello World\")\n public void doSomething(){}\n }\n ```\n \n 你可以通过如下方式获取方法注解: \n \n ```java\n Method method = ... //obtain method object\n Annotation[] annotations = method.getDeclaredAnnotations();\n \n for(Annotation annotation : annotations){\n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n }\n ```\n 也可以获取一个指定的方法注解,如下: \n \n ```java\n Method method = ... // obtain method object\n Annotation annotation = method.getAnnotation(MyAnnotation.class);\n \n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n ```\n\n- 参数注解\n\n 在方法的参数中声明注解,如下: \n \n ```java\n public class TheClass {\n public static void doSomethingElse(\n @MyAnnotation(name=\"aName\", value=\"aValue\") String parameter){\n }\n }\n ```\n \n 可以通过`Method`对象获取到参数的注解,如下: \n ```java\n Method method = ... //obtain method object\n Annotation[][] parameterAnnotations = method.getParameterAnnotations();\n Class[] parameterTypes = method.getParameterTypes();\n \n int i=0;\n for(Annotation[] annotations : parameterAnnotations){\n Class parameterType = parameterTypes[i++];\n \n for(Annotation annotation : annotations){\n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"param: \" + parameterType.getName());\n System.out.println(\"name : \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n }\n }\n ```\n 注意,`Method.getParameterAnnotations()`方法会返回一个二维的`Annotation`数组,包含每个方法参数的一个注解数组。 \n\n- 变量注解\n\n 下面是一个变量使用注解的例子: \n ```java\n public class TheClass {\n \n @MyAnnotation(name=\"someName\", value = \"Hello World\")\n public String myField = null;\n }\n ``` \n \n 你可以像下面这样获取变量的注解: \n ```java\n Field field = ... //obtain field object\n Annotation[] annotations = field.getDeclaredAnnotations();\n \n for(Annotation annotation : annotations){\n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n }\n ```\n \n 当然也可以获取一个指定的变量注解,如下: \n ```java\n Field field = ... // obtain method object\n Annotation annotation = field.getAnnotation(MyAnnotation.class);\n \n if(annotation instanceof MyAnnotation){\n MyAnnotation myAnnotation = (MyAnnotation) annotation;\n System.out.println(\"name: \" + myAnnotation.name());\n System.out.println(\"value: \" + myAnnotation.value());\n }\n ```\n\n记下来我们来举个栗子,运行时注解示例: \n\n相信很多人都知道`Butter Knife`。它里面就是使用了注解: \n```java\n@BindView(R.id.user) EditText username;\n@BindView(R.id.pass) EditText password;\n\n@BindString(R.string.login_error) String loginErrorMessage;\n\n@OnClick(R.id.submit) void submit() {\n // TODO call server...\n}\n```\n\n那我们就以`onClick`事件为例模仿着他去写一下。 \n\n```java\npublic class InjectorProcessor { \n public void process(final Object object) { \n Class class_=object.getClass(); \n Method[] methods=class_.getDeclaredMethods(); \n for (final Method method : methods) { \n onClick clickMethod=method.getAnnotation(onClick.class); \n if (clickMethod!=null) { \n if (object instanceof Activity) { \n for (int id : clickMethod.value()) { \n View view=((Activity) object).findViewById(id); \n view.setOnClickListener(new View.OnClickListener() { \n @Override \n public void onClick(View v) { \n try { \n method.invoke(object); \n } catch (IllegalAccessException e) { \n e.printStackTrace(); \n } catch (InvocationTargetException e) { \n e.printStackTrace(); \n } \n } \n }); \n } \n } \n } \n } \n }\n}\n```\n\n使用: \n\n```java\npublic class MainActivity extends AppCompatActivity { \n @Override \n protected void onCreate(Bundle savedInstanceState) { \n super.onCreate(savedInstanceState); \n setContentView(R.layout.activity_main); \n InjectorProcessor processor=new InjectorProcessor(); \n processor.process(MainActivity.this); \n } \n\n @onClick({R.id.textview}) \n public void click() { \n Toast.makeText(this, \"HHH\", Toast.LENGTH_SHORT).show(); \n }\n}\n```\n\n很显然大神`JakeWharton`不会这样做的,毕竟反射会影响性能。 \n我们来看一下`ButterKnife`的源码: \n```java\n@Target(METHOD)\n@Retention(CLASS)\n@ListenerClass(\n targetType = \"android.view.View\",\n setter = \"setOnClickListener\",\n type = \"butterknife.internal.DebouncingOnClickListener\",\n method = @ListenerMethod(\n name = \"doClick\",\n parameters = \"android.view.View\"\n )\n)\npublic @interface OnClick {\n /** View IDs to which the method will be bound. */\n @IdRes int[] value() default { View.NO_ID };\n}\n```\n看到了吗?是编译型的注解。这样不会影响性能。\n\n\n\n一张图总结一下: \n\n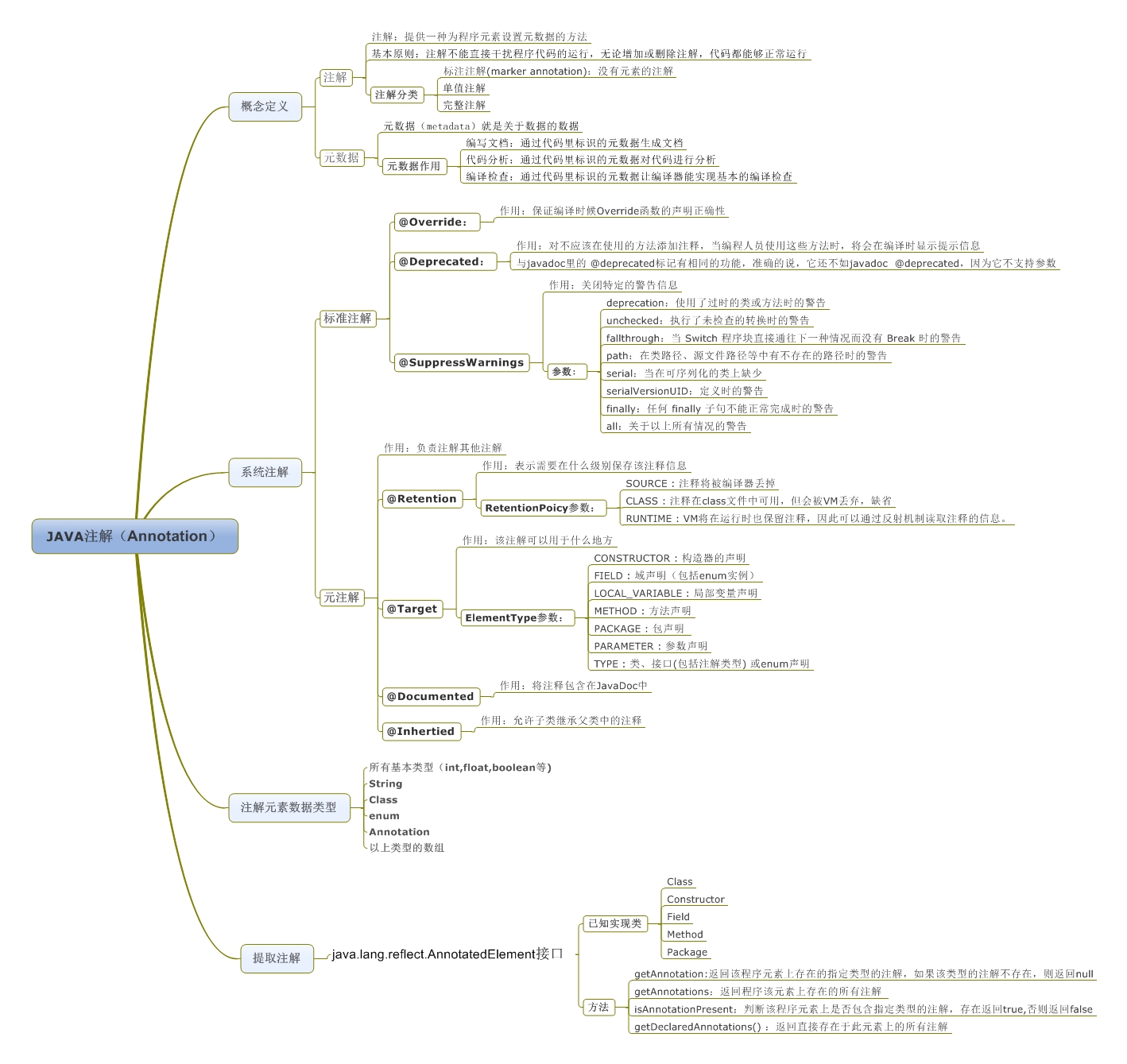\n\n\n\n\n\n##### 编译时`Annotation`解析 \n\n在刚才介绍的运行时注解中,很多人肯定会说使用反射会影响性能,那有没有不影响性能的方式呢?当然有了,那就是编译时注解。在编译时会通过注解标示来动态生成一些类或者`xml`,而在运行时,这里注解是没有的,它会依靠动态生成的类来进行操作。所以它就和直接调用方法一样,当然不会有效率影响了。 \n\n该类型注解值是`@Retention`为`CLASS`的`Annotation`,由`APT(Annotaion Processing Tool)`自动进行解析。是在编译时注入,所以不会像反射一样影响效率问题。 \n\n根据`sun`官方的解释,`APT(annotation processing tool)`是一个命令行工具,\n它对源代码文件进行检测找出其中的`annotation`后,使用`annotation processors`来处理`annotation`。\n而`annotation processors`使用了一套反射`API`并具备对`JSR175`规范的支持。\n\n`annotation processors`处理`annotation`的基本过程如下:\n\n- `APT`运行`annotation processors`根据提供的源文件中的`annotation`生成源代码文件和其它的文件(文件具体内容由`annotation processors`的编写者决定)\n- 接着`APT`将生成的源代码文件和提供的源文件进行编译生成类文件。\n\n\n`APT`在编译时自动查找所有继承自`AbstractProcessor`的类,然后调用他们的`process`方法去处理,这样就拥有了在编译过程中执行代码的能力\n\n\n\n所以我们需要做的是: \n\n- 自定义类继承`AbstractProcessor`\n- 重写`process`方法\n\n那我们就开始写: \n\n```java\npublic class Processor extends AbstractProcessor{\n}\n```\n但是在`Android Studio`死活提示找不到`AbstractProcessor`类,这是因为注解是`javase`中`javax`包里面的,`android.jar`默认是不包含的,所以会编译报错.\n解决方法就是新建一个`Module`,在选择类型时将该`Module`的类型选为`Java Library`。\n然后在该`Module`中创建就好了`Processor`就好了,完美解决。 \n\n\n好,那我们就开始写个编译时处理的`demo` : \n\n- `Android Studio`中创建一个`Android`工程。\n- 新建一个`Module`,然后选择`Java Library`类型(我的名字为`annotations`),并且让`app`依赖该`module`。\n- 在`annotations`的`module`中创建注解类:\n\n ```java\n package com.charon;\n \n import java.lang.annotation.ElementType;\n import java.lang.annotation.Retention;\n import java.lang.annotation.RetentionPolicy;\n import java.lang.annotation.Target;\n \n @Target(ElementType.METHOD)\n @Retention(RetentionPolicy.CLASS)\n public @interface AnnotationTest {\n String value() default \"\";\n }\n ```\n- 然后在`annotations`的`module`自定义`Processor`类\n\n ```java\n package com.charon;\n \n import java.util.Set;\n \n import javax.annotation.processing.AbstractProcessor;\n import javax.annotation.processing.RoundEnvironment;\n import javax.annotation.processing.SupportedAnnotationTypes;\n import javax.annotation.processing.SupportedSourceVersion;\n import javax.lang.model.SourceVersion;\n import javax.lang.model.element.Element;\n import javax.lang.model.element.TypeElement;\n \n @SupportedAnnotationTypes(\"com.charon.AnnotationTest\")\n @SupportedSourceVersion(SourceVersion.RELEASE_7)\n public class TestProcessor extends AbstractProcessor {\n @Override\n public boolean process(Set annotations, RoundEnvironment roundEnv) {\n System.out.println(\"process\");\n for (TypeElement te : annotations) {\n for (Element element : roundEnv.getElementsAnnotatedWith(te)) {\n AnnotationTest annotation = element.getAnnotation(AnnotationTest.class);\n String value = annotation.value();\n System.out.println(\"type : \" + value);\n }\n }\n return true;\n }\n }\n ```\n 注意:`@SupportedAnnotationTypes(\"com.charon.AnnotationTest\")`来指定要处理的注解类。\n `@SupportedSourceVersion(SourceVersion.RELEASE_7)`指定编译的版本。这种通过注解指定编译版本和类型的方式是从`Java 1.7`才有的。\n 对于之前的版本都是通过重写`AbstractProcessor`中的方法来指定的。 \n\n- 注册处理器 \n 我们自定义了`Processor`那如何才能让其生效呢?就是在`annotations`的`java`同级目录新建`resources/META-INF/services/javax.annotation.processing.Processor`文件\n\n ```java\n - java\n - META-INF\n - services\n - javax.annotation.processing.Processor\n ```\n 然后在`javax.annotation.processing.Processor`文件中指定自定义的处理器,如: \n \n ```java\n com.charon.TestProcessor\n ```\n 如果多个话就分行写。 \n\n 然后我们`Build`一下(命令行执行`./gradlew build`),就能看到控制台打印出来如下的信息: \n ```java\n :app:compileReleaseJavaWithJavac\n :app:compileReleaseJavaWithJavac - is not incremental (e.g. outputs have changed, no previous execution, etc.).\n process\n value : haha\n process\n ```\n\n 注意:千万不要去`logcat`中找信息,这是编译时注解。 \n 注意:一定要使用`jdk1.7`,`1.8`对注解的支持有`bug`。\n\n\n上面只是一个简单的例子,如果你想用编译时注解去做一些更高级的事情,例如自动生成一些代码,那你可能就会用到如下几个类库: \n\n- [android-apt](https://bitbucket.org/hvisser/android-apt)\n- [Google Auto](https://github.com/google/auto) \n- [Square javapoet](https://github.com/square/javapoet)\n\n\n这三个库分别的作用为: \n\n- `android-apt` \n `Android Studio`原本是不支持注解处理器的, 但是用`android-apt`这个插件后, 我们就可以使用注解处理器了, \n 这个插件可以自动的帮你为生成的代码创建目录, 让生成的代码编译到`APK`里面去, 而且它还可以让最终编译出来的`APK`里面不包含注解处理器本身的代码,\n 因为这部分代码只是编译的时候需要用来生成代码, 最终运行的时候是不需要的。 \n 也就是说它主要有两个目的: \n \n - 允许配置只在编译时作为注解处理器的依赖,而不添加到最后的`APK`或`library`\n - 设置源路径,使注解处理器生成的代码能被`Android Studio`正确的引用\n\n 那在什么情况下我们会需要使用它呢? \n 当你需要引入`Processor`生成的源代码到你的代码中时。例如当你使用`Dagger 2`或`AndroidAnnotaition`.\n 该插件使得`Android Studio`可以配置生成资源的`build path`,避免`IDE`报错。\n 当使用`apt`添加添加依赖,它将不会被包含到最终的`APK`里。\n\n\n- `Auto` \n\n `Google Auto`的主要作用是注解`Processor`类,并对其生成`META-INF`的配置信息,\n 可以让你不用去写`META-INF`这些配置文件,只要在自定义的`Processor`上面加上`@AutoService(Processor.class)`\n\n- `javapoet` \n `javapoet`:`A Java API for generating .java source files.`可以更方便的生成代码,它可以帮助我们通过类调用的形式来生成代码。 \n\n\n### 自定义编译时注解\n\n在自定义注解时,一般来说可能会建三个`modules`: \n\n- `app module`:写一些使用注解的`android`应用逻辑。\n- `api module`:定义一些可以在`app`中使用的注解。它会被`app`以及`compiler`使用。\n- `compiler module`:定义`Processor`该`module`不会被包含到应用中,它只会在构建过程中被使用。在编译的过程中它会生成一些`java`文件,而这些`java`文件会被打包进`apk`中。\n 我们可以在该`module`中使用`auto`以及`javapoet`。 \n\n\n下面开始配置`android-apt`: \n\n- 配置到`app module`下的`build.gradle`中\n\n ```java\n apply plugin: 'com.android.application'\n // apt\n apply plugin: 'com.neenbedankt.android-apt'\n \n android {\n compileSdkVersion 23\n buildToolsVersion \"23.0.3\"\n \n defaultConfig {\n applicationId \"com.charon.annotationdemo\"\n minSdkVersion 14\n targetSdkVersion 23\n versionCode 1\n versionName \"1.0\"\n }\n buildTypes {\n release {\n minifyEnabled false\n proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'\n }\n }\n compileOptions {\n sourceCompatibility JavaVersion.VERSION_1_7\n targetCompatibility JavaVersion.VERSION_1_7\n }\n }\n \n buildscript {\n repositories {\n jcenter()\n }\n dependencies {\n // 配置apt\n classpath 'com.neenbedankt.gradle.plugins:android-apt:1.8'\n }\n }\n \n dependencies {\n compile fileTree(dir: 'libs', include: ['*.jar'])\n testCompile 'junit:junit:4.12'\n compile 'com.android.support:appcompat-v7:23.4.0'\n compile project(':api')\n apt project(':compiler')\n \n }\n ```\n\n- 接下来在`compiler module`中配置`auto`以及`javapoet`\n\n ```java\n apply plugin: 'java'\n sourceCompatibility = JavaVersion.VERSION_1_7\n targetCompatibility = JavaVersion.VERSION_1_7\n dependencies {\n compile project (':api')\n compile 'com.google.auto.service:auto-service:1.0-rc2'\n compile 'com.squareup:javapoet:1.7.0'\n }\n ```\n- 在`api module`中也加上如下的配置: \n\n ```java\n apply plugin: 'java'\n sourceCompatibility = JavaVersion.VERSION_1_7\n targetCompatibility = JavaVersion.VERSION_1_7\n ```\n\n- 接下来在`api module`中定义一个注解 \n ```java\n package com.charon;\n \n import java.lang.annotation.ElementType;\n import java.lang.annotation.Retention;\n import java.lang.annotation.RetentionPolicy;\n import java.lang.annotation.Target;\n \n @Target(ElementType.METHOD)\n @Retention(RetentionPolicy.CLASS)\n public @interface AnnotationTest {\n String value();\n }\n ```\n- 然后在`compiler module`中自定义一个`Processor` \n\n ```java\n package com.charon;\n \n import com.google.auto.service.AutoService;\n \n import java.util.Set;\n \n import javax.annotation.processing.AbstractProcessor;\n import javax.annotation.processing.ProcessingEnvironment;\n import javax.annotation.processing.Processor;\n import javax.annotation.processing.RoundEnvironment;\n import javax.lang.model.SourceVersion;\n import javax.lang.model.element.TypeElement;\n \n @AutoService(Processor.class)\n public class MyProcessor extends AbstractProcessor {\n /**\n * Initializes the processor with the processing environment by\n * setting the {@code processingEnv} field to the value of the\n * {@code processingEnv} argument. An {@code\n * IllegalStateException} will be thrown if this method is called\n * more than once on the same object.\n *\n * @param processingEnv environment to access facilities the tool framework\n * provides to the processor\n * @throws IllegalStateException if this method is called more than once.\n */\n @Override\n public synchronized void init(ProcessingEnvironment processingEnv) {\n super.init(processingEnv);\n }\n \n /**\n * Processes a set of annotation types on type elements originating from the prior round \n * and returns whether or not these annotations are claimed by this processor. \n * If true is returned, the annotations are claimed and subsequent processors will \n * not be asked to process them; \n * if false is returned, the annotations are unclaimed and subsequent processors may be \n * asked to process them. A processor may always return the same boolean value \n * or may vary the result based on chosen criteria.\n * The input set will be empty if the processor supports \"*\" and the root elements \n * have no annotations. A Processor must gracefully handle an empty set of annotations.\n * @param annotations\n * @param roundEnv\n * @return\n */\n @Override\n public boolean process(Set annotations, RoundEnvironment roundEnv) {\n System.out.println(\"hello processor\");\n return false;\n }\n \n @Override\n public Set getSupportedAnnotationTypes() {\n return super.getSupportedAnnotationTypes();\n }\n \n @Override\n public SourceVersion getSupportedSourceVersion() {\n return SourceVersion.latestSupported();\n }\n \n }\n ```\n \n 这里简单的说一下这几个主要的方法: \n \n - `init()`:初始化操作的方法,`RoundEnvironment`会提供很多有用的工具类`Elements`、`Types`和`Filer`等。\n - `process()`:这相当于每个处理器的主函数`main()`。在该方法中去扫描、评估、处理以及生成`Java`文件。 \n - `getSupportedAnnotationTypes()`:这里你必须指定,该注解器是注册给哪个注解的。\n - `getSupportedSourceVersion()`:用来指定你使用的`java`版本。通常这里会直接放回`SourceVersion.latestSupported()`即可。 \n\n 从`idk 1.7`开始,可以使用如下注解来代替`getSupporedAnnotationTypes()`和`getSupportedSourceVersion()`方法: \n ```java\n @SupportedSourceVersion(SourceVersion.latestSupported())\n @SupportedAnnotationTypes({\n // 合法注解全名的集合\n })\n ```\n\n注解相关`API`: \n\n- `Set getElementsAnnotatedWith(Class a)` \n 返回使用给定注释类型注释的元素。该注释可能直接出现或者被继承。只返回注释处理的此`round`中包括的`package`元素和`type`元素、成员声明、参数或者这些元素中声明的类型参数。\n- `Element` \n 表示一个程序元素,比如包、类或者方法。每个元素都表示一个静态的语言级构造(不表示虚拟机的运行时构造)。\n 元素应该使用`equals(Object)`方法进行比较。不保证总是使用相同的对象表示某个特定的元素。\n 要实现基于`Element`对象类的操作,可以使用`visitor`或者使用`getKind()`方法的结果。使用`instanceof`确定此建模层次结构中某一对象的有效类未必可靠,因为一个实现可以选择让单个对象实现多个`Element`子接口。\n\n- `TypeElement`\n 表示一个类或接口程序元素。提供对有关类型及其成员的信息的访问。注意,枚举类型是一种类,而注释类型是一种接口。\n 而`DeclaredType`表示一个类或接口类型,后者将成为前者的一种使用(或调用)。这种区别对于一般的类型是最明显的,对于这些类型,单个元素可以定义一系列完整的类型。\n 例如,元素`java.util.Set`对应于参数化类型`java.util.Set`和`java.util.Set`(以及其他许多类型),还对应于原始类型`java.util.Set`。\n\n\n\n扯远了,那我们就以上面的目录结构和实现方式,通过一个具体的例子要详细说明,例子真的很难找,我在网上找到了一个大神写的,虽然从这个例子中并不能看出注解的强大之处,但是对于讲解来说还是非常有用的: \n\n我们要解决的问题是我们想要实现一个披萨店,该店会提供两种披萨(`Margherita`和`Calzone`)和一种甜点(`Tiramisu`)。\n\n首先我们在`app module`中创建对应的接口和代码 ,如下: \n\n```java\npublic interface Meal { \n public float getPrice();\n}\n\npublic class MargheritaPizza implements Meal {\n\n @Override public float getPrice() {\n return 6.0f;\n }\n}\n\npublic class CalzonePizza implements Meal {\n\n @Override public float getPrice() {\n return 8.5f;\n }\n}\n\npublic class Tiramisu implements Meal {\n\n @Override public float getPrice() {\n return 4.5f;\n }\n}\n```\n如果消费者想要下单,那么它需要输入对应的物品名字: \n```java\npublic class PizzaStore {\n\n public Meal order(String mealName) {\n\n if (mealName == null) {\n throw new IllegalArgumentException(\"Name of the meal is null!\");\n }\n\n if (\"Margherita\".equals(mealName)) {\n return new MargheritaPizza();\n }\n\n if (\"Calzone\".equals(mealName)) {\n return new CalzonePizza();\n }\n\n if (\"Tiramisu\".equals(mealName)) {\n return new Tiramisu();\n }\n\n throw new IllegalArgumentException(\"Unknown meal '\" + mealName + \"'\");\n }\n\n public static void main(String[] args) throws IOException {\n PizzaStore pizzaStore = new PizzaStore();\n Meal meal = pizzaStore.order(readConsole());\n System.out.println(\"Bill: $\" + meal.getPrice());\n }\n```\n这样的话在`order()`方法中,会有很多`if`语句,并且每当我们添加一种新的披萨,我们都要添加一条新的`if`语句。但是我们可以使用注解和工厂模式,我们就可以让注解来自动生成这些在工厂中的`if`语句。我们期待的代码如下: \n```java\npublic class PizzaStore {\n\n private MealFactory factory = new MealFactory();\n\n public Meal order(String mealName) {\n return factory.create(mealName);\n }\n\n public static void main(String[] args) throws IOException {\n PizzaStore pizzaStore = new PizzaStore();\n Meal meal = pizzaStore.order(readConsole());\n System.out.println(\"Bill: $\" + meal.getPrice());\n }\n}\n\n```\n`MealFactory`的实现应该如下: \n```java\npublic class MealFactory {\n\n public Meal create(String id) {\n if (id == null) {\n throw new IllegalArgumentException(\"id is null!\");\n }\n if (\"Calzone\".equals(id)) {\n return new CalzonePizza();\n }\n\n if (\"Tiramisu\".equals(id)) {\n return new Tiramisu();\n }\n\n if (\"Margherita\".equals(id)) {\n return new MargheritaPizza();\n }\n\n throw new IllegalArgumentException(\"Unknown id = \" + id);\n }\n}\n```\n\n接下来我们要做的就是通过注解来生成`MealFactory`中的代码。\n想法是这样的:我们将使用同样的`type()`注解那些属于同一个工厂的类,并且用注解的`id()`做一个映射,例如从\"Calzone\"映射到\"ClzonePizza\"类。我们使用`@Factory`注解到我们的类中,如下:\n\n```java\n@Factory(\n id = \"Margherita\",\n type = Meal.class\n)\npublic class MargheritaPizza implements Meal {\n\n @Override public float getPrice() {\n return 6f;\n }\n}\n```\n```java\n@Factory(\n id = \"Calzone\",\n type = Meal.class\n)\npublic class CalzonePizza implements Meal {\n\n @Override public float getPrice() {\n return 8.5f;\n }\n}\n```\n```java\n@Factory(\n id = \"Tiramisu\",\n type = Meal.class\n)\npublic class Tiramisu implements Meal {\n\n @Override public float getPrice() {\n return 4.5f;\n }\n}\n```\n\n你可能会问你自己,我们是否可以只把`@Factory`注解应用到`Meal`接口上?答案是注解是不能继承的。一个类`class X`被注解,并不意味着它的子类`class Y extends X`会自动被注解。在我们开始写处理器的代码之前,我们先规定如下一些规则:\n\n- 只有类可以被`@Factory`注解,因为接口或者抽象类并不能用`new`操作实例化;\n- 被`@Factory`注解的类,必须至少提供一个公开的默认构造器(即没有参数的构造函数)。否者我们没法实例化一个对象。\n- 被`@Factory`注解的类必须直接或者间接的继承于`type()`指定的类型;\n- 具有相同的`type`的注解类,将被聚合在一起生成一个工厂类。这个生成的类使用`Factory`后缀,例如`type = Meal.class`,将生成`MealFactory`工厂类;\n- `id`只能是`String`类型,并且在同一个`type`组中必须唯一。\n\n那我们接着看一下在`compiler module`中的自定义的`FactoryProcessor`类: \n```java\n@AutoService(Processor.class)\npublic class FactoryProcessor extends AbstractProcessor {\n\n private Types typeUtils;\n private Elements elementUtils;\n private Filer filer;\n private Messager messager;\n private Map factoryClasses = new LinkedHashMap();\n\n @Override\n public synchronized void init(ProcessingEnvironment processingEnv) {\n super.init(processingEnv);\n typeUtils = processingEnv.getTypeUtils();\n elementUtils = processingEnv.getElementUtils();\n filer = processingEnv.getFiler();\n messager = processingEnv.getMessager();\n }\n\n @Override\n public Set getSupportedAnnotationTypes() {\n Set annotataions = new LinkedHashSet();\n // 指定支持@Factory注解\n annotataions.add(Factory.class.getCanonicalName());\n return annotataions;\n }\n\n @Override\n public SourceVersion getSupportedSourceVersion() {\n return SourceVersion.latestSupported();\n }\n\n @Override\n public boolean process(Set annotations, RoundEnvironment roundEnv) {\n ...\n }\n}\n```\n\n在`init()`方法中,我们初始化了几个变量: \n\n- `Elements`: 处理`Element`的工具类 \n- `Types`: 处理`TypeMirror`的工具类\n- `Filer`: 用来创建你要创建的文件\n- `Messager`:提供给注解处理器一个报告错误、警告以及提示信息的途径。\n\n在注解的处理过程中会扫描所有的`java`源文件。源代码中的每一个部分都是一个特定类型的`Element`。换句话说:`Element`代表程序的元素,例如包、类或者方法等。每个`Element`代表一个构建,例如通过下面的例子我们来说明一下: \n```java\npackage com.example; // PackageElement\n\npublic class Foo { // TypeElement\n\n private int a; // VariableElement\n private Foo other; // VariableElement\n\n public Foo () {} // ExecuteableElement\n\n public void setA ( // ExecuteableElement\n int newA // TypeElement\n ) {}\n}\n```\n所以在注解中我们必须要换一个角度来看待源代码,它只是一个结构化的文本,我们可以像`XML`中的`DOM`一样去解析它。\n例如现在有一个代表`public class Foo`类的`TypeElement`元素,你可以遍历它的子元素,如下: \n```java\nTypeElement fooClass = ... ; \nfor (Element e : fooClass.getEnclosedElements()){ // iterate over children \n Element parent = e.getEnclosingElement(); // parent == fooClass\n}\n```\n正如你所见,`Element`代表的是源代码。`TypeElement`代表的是源代码中的类型元素,例如类。然而`TypeElement`并不包含类本身的信息。你可以从`TypeElement`中获取类的名字,但是你获取不到类的信息,例如它的父类。这种信息需要通过`TypeMirror`获取。你可以通过调用`elements.asType()`获取元素的`TypeMirror`。\n\n接下来我们来继续实现`process()`方法: \n```java\n@AutoService(Processor.class)\npublic class FactoryProcessor extends AbstractProcessor {\n\n private Types typeUtils;\n private Elements elementUtils;\n private Filer filer;\n private Messager messager;\n\n @Override\n public synchronized void init(ProcessingEnvironment processingEnv) {\n super.init(processingEnv);\n typeUtils = processingEnv.getTypeUtils();\n elementUtils = processingEnv.getElementUtils();\n filer = processingEnv.getFiler();\n messager = processingEnv.getMessager();\n }\n\n @Override\n public Set getSupportedAnnotationTypes() {\n Set annotataions = new LinkedHashSet();\n annotataions.add(Factory.class.getCanonicalName());\n return annotataions;\n }\n\n @Override\n public SourceVersion getSupportedSourceVersion() {\n return SourceVersion.latestSupported();\n }\n\n @Override\n public boolean process(Set annotations, RoundEnvironment roundEnv) {\n // roundEnv.getElementsAnnotatedWith(Factory.class))返回所有被注解了@Factory的元素的列表。\n // 你可能已经注意到,我们并没有说“所有被注解了@Factory的类的列表”,因为它真的是返回Element的列表。\n // 请记住:Element可以是类、方法、变量等。所以,接下来,我们必须检查这些Element是否是一个类\n for (Element annotatedElement : roundEnv.getElementsAnnotatedWith(Factory.class)) {\n // Check if a class has been annotated with @Factory\n if (annotatedElement.getKind() != ElementKind.CLASS) {\n return false;\n }\n }\n\n return false;\n }\n}\n```\n\n在继续检查被注解`@Fractory`的类是否满足我们上面说的5条规则之前,我们将介绍一个让我们更方便继续处理的数据结构。有时候,一个问题或者解释器看起来如此简单,以至于程序员倾向于用一个面向过程方式来写整个处理器。但是你知道吗?一个注解处理器仍然是一个`Java`程序,所以我们需要使用面向对象编程、接口、设计模式,以及任何你将在其他普通`Java`程序中使用的技巧。\n\n我们的`FactoryProcessor`非常简单,但是我们仍然想要把一些信息存为对象。在`FactoryAnnotatedClass`中,我们保存被注解类的数据,比如合法的类的名字,以及`@Factory`注解本身的一些信息。也就是说每一个使用了`@Factory`注解的类都对应一个`FactoryAnnotatedClass`类,所以,我们保存`TypeElement`和处理过的`@Factory`注解:\n\n如下: \n```java\npublic class FactoryAnnotatedClass {\n\n private TypeElement annotatedClassElement;\n private String qualifiedSuperClassName;\n private String simpleTypeName;\n private String id;\n\n public FactoryAnnotatedClass(TypeElement classElement) throws IllegalArgumentException {\n this.annotatedClassElement = classElement;\n Factory annotation = classElement.getAnnotation(Factory.class);\n id = annotation.id();\n\n if (StringUtils.isEmpty(id)) {\n throw new IllegalArgumentException(\n String.format(\"id() in @%s for class %s is null or empty! that's not allowed\",\n Factory.class.getSimpleName(), classElement.getQualifiedName().toString()));\n }\n\n // Get the full QualifiedTypeName\n try {\n Class clazz = annotation.type();\n // 返回底层阶级Java语言规范中定义的标准名称。\n qualifiedSuperClassName = clazz.getCanonicalName();\n simpleTypeName = clazz.getSimpleName();\n } catch (MirroredTypeException mte) {\n DeclaredType classTypeMirror = (DeclaredType) mte.getTypeMirror();\n TypeElement classTypeElement = (TypeElement) classTypeMirror.asElement();\n qualifiedSuperClassName = classTypeElement.getQualifiedName().toString();\n simpleTypeName = classTypeElement.getSimpleName().toString();\n }\n }\n\n /**\n * 获取在{@link Factory#id()}中指定的id\n * return the id\n */\n public String getId() {\n return id;\n }\n\n /**\n * 获取在{@link Factory#type()}指定的类型合法全名\n *\n * @return qualified name\n */\n public String getQualifiedFactoryGroupName() {\n return qualifiedSuperClassName;\n }\n\n\n /**\n * 获取在{@link Factory#type()}{@link Factory#type()}指定的类型的简单名字\n *\n * @return qualified name\n */\n public String getSimpleFactoryGroupName() {\n return simpleTypeName;\n }\n\n /**\n * 获取被@Factory注解的原始元素\n */\n public TypeElement getTypeElement() {\n return annotatedClassElement;\n }\n}\n```\n上面我们用到了`Class`,因为这里的类型是一个`java.lang.Class`。这就意味着,他是一个真正的`Class`对象。因为注解处理是在编译`Java`源代码之前。我们需要考虑如下两种情况:\n\n- 这个类已经被编译:这种情况是:如果第三方`.jar`包含已编译的被`@Factory`注解`.class`文件。在这种情况下,可以通过上面的方式在`try`代码块中直接获取。\n- 这个还没有被编译:这种情况是我们尝试编译被`@Fractory`注解的源代码。这种情况下,直接获取`Class`会抛出`MirroredTypeException`异常。幸运的是,`MirroredTypeException`包含一个`TypeMirror`,它表示我们未编译类。因为我们已经知道它必定是一个类类型(我们已经在前面检查过),我们可以直接强制转换为`DeclaredType`,然后读取`TypeElement`来获取合法的名字。\n\n\n好了,我们现在还需要一个数据结构类`FactoryGroupedClasses`,它将简单的组合所有的`FactoryAnnotatedClasses`到一起。\n```java\npublic class FactoryGroupedClasses {\n\n private String qualifiedClassName;\n\n private Map itemsMap =\n new LinkedHashMap();\n\n public FactoryGroupedClasses(String qualifiedClassName) {\n this.qualifiedClassName = qualifiedClassName;\n }\n\n public void add(FactoryAnnotatedClass toInsert) throws IdAlreadyUsedException {\n\n FactoryAnnotatedClass existing = itemsMap.get(toInsert.getId());\n if (existing != null) {\n throw new IdAlreadyUsedException(existing);\n }\n\n itemsMap.put(toInsert.getId(), toInsert);\n }\n\n public void generateCode(Elements elementUtils, Filer filer) throws IOException {\n ...\n }\n}\n```\n\n正如你所见,这是一个基本的`Map`,这个映射表用来映射`@Factory.id()`到`FactoryAnnotatedClass`。我们选择`Map`这个数据类型,是因为我们要确保每个`id`是唯一的,我们可以很容易通过`map`查找实现。`generateCode()`方法将被用来生成工厂类代码(将在后面讨论)。\n\n我们继续实现`process()`方法。接下来我们想要检查被注解的类必须有只要一个公开的构造函数,不是抽象类,继承于特定的类型,以及是一个公开类:\n\n```java\n\n@AutoService(Processor.class)\npublic class FactoryProcessor extends AbstractProcessor {\n\n private Types typeUtils;\n private Elements elementUtils;\n private Filer filer;\n private Messager messager;\n private Map factoryClasses =\n new LinkedHashMap();\n\n @Override\n public synchronized void init(ProcessingEnvironment processingEnv) {\n super.init(processingEnv);\n typeUtils = processingEnv.getTypeUtils();\n elementUtils = processingEnv.getElementUtils();\n filer = processingEnv.getFiler();\n messager = processingEnv.getMessager();\n }\n\n @Override\n public Set getSupportedAnnotationTypes() {\n Set annotataions = new LinkedHashSet();\n annotataions.add(Factory.class.getCanonicalName());\n return annotataions;\n }\n\n @Override\n public SourceVersion getSupportedSourceVersion() {\n return SourceVersion.latestSupported();\n }\n\n @Override\n public boolean process(Set annotations, RoundEnvironment roundEnv) {\n // roundEnv.getElementsAnnotatedWith(Factory.class))返回所有被注解了@Factory的元素的列表。\n // 你可能已经注意到,我们并没有说“所有被注解了@Factory的类的列表”,因为它真的是返回Element的列表。\n // 请记住:Element可以是类、方法、变量等。所以,接下来,我们必须检查这些Element是否是一个类\n for (Element annotatedElement : roundEnv.getElementsAnnotatedWith(Factory.class)) {\n // Check if a class has been annotated with @Factory\n if (annotatedElement.getKind() != ElementKind.CLASS) {\n error(annotatedElement, \"Only classes can be annotated with @%s\",\n Factory.class.getSimpleName());\n return true; // 退出处理\n }\n\n\n // 因为我们已经知道它是ElementKind.CLASS类型,所以可以直接强制转换\n TypeElement typeElement = (TypeElement) annotatedElement;\n\n try {\n FactoryAnnotatedClass annotatedClass =\n new FactoryAnnotatedClass(typeElement); // throws IllegalArgumentException\n\n if (!isValidClass(annotatedClass)) {\n return true; // 已经打印了错误信息,退出处理过程\n }\n\n // 一旦我们检查isValidClass()成功,我们将添加FactoryAnnotatedClass到对应的FactoryGroupedClasses中\n FactoryGroupedClasses factoryClass =\n factoryClasses.get(annotatedClass.getQualifiedFactoryGroupName());\n if (factoryClass == null) {\n String qualifiedGroupName = annotatedClass.getQualifiedFactoryGroupName();\n factoryClass = new FactoryGroupedClasses(qualifiedGroupName);\n factoryClasses.put(qualifiedGroupName, factoryClass);\n }\n\n // 如果和其他的@Factory标注的类的id相同冲突,\n // 抛出IdAlreadyUsedException异常\n factoryClass.add(annotatedClass);\n } catch (IllegalArgumentException e) {\n // @Factory.id()为空 --> 打印错误信息\n error(typeElement, e.getMessage());\n return true;\n } catch (IdAlreadyUsedException e) {\n FactoryAnnotatedClass existing = e.getExisting();\n // 已经存在\n error(annotatedElement,\n \"Conflict: The class %s is annotated with @%s with id ='%s' but %s already uses the same id\",\n typeElement.getQualifiedName().toString(), Factory.class.getSimpleName(),\n existing.getTypeElement().getQualifiedName().toString());\n return true;\n }\n }\n\n // 为每个工厂生成Java文件\n try {\n for (FactoryGroupedClasses factoryClass : factoryClasses.values()) {\n factoryClass.generateCode(elementUtils, filer);\n }\n // TODO ...注意这里会遗留一个问题,我们后面再仔细说。 \n } catch (IOException e) {\n error(null, e.getMessage());\n }\n\n return true;\n }\n\n private void error(Element e, String msg, Object... args) {\n messager.printMessage(\n Diagnostic.Kind.ERROR,\n String.format(msg, args),\n e);\n }\n\n\n private boolean isValidClass(FactoryAnnotatedClass item) {\n\n // 转换为TypeElement, 含有更多特定的方法\n TypeElement classElement = item.getTypeElement();\n\n if (!classElement.getModifiers().contains(Modifier.PUBLIC)) {\n error(classElement, \"The class %s is not public.\",\n classElement.getQualifiedName().toString());\n return false;\n }\n\n // 检查是否是一个抽象类\n if (classElement.getModifiers().contains(Modifier.ABSTRACT)) {\n error(classElement, \"The class %s is abstract. You can't annotate abstract classes with @%\",\n classElement.getQualifiedName().toString(), Factory.class.getSimpleName());\n return false;\n }\n\n // 检查继承关系: 必须是@Factory.type()指定的类型子类\n TypeElement superClassElement =\n elementUtils.getTypeElement(item.getQualifiedFactoryGroupName());\n if (superClassElement.getKind() == ElementKind.INTERFACE) {\n // 检查接口是否实现了\n if(!classElement.getInterfaces().contains(superClassElement.asType())) {\n error(classElement, \"The class %s annotated with @%s must implement the interface %s\",\n classElement.getQualifiedName().toString(), Factory.class.getSimpleName(),\n item.getQualifiedFactoryGroupName());\n return false;\n }\n } else {\n // 检查子类\n TypeElement currentClass = classElement;\n while (true) {\n TypeMirror superClassType = currentClass.getSuperclass();\n\n if (superClassType.getKind() == TypeKind.NONE) {\n // 到达了基本类型(java.lang.Object), 所以退出\n error(classElement, \"The class %s annotated with @%s must inherit from %s\",\n classElement.getQualifiedName().toString(), Factory.class.getSimpleName(),\n item.getQualifiedFactoryGroupName());\n return false;\n }\n\n if (superClassType.toString().equals(item.getQualifiedFactoryGroupName())) {\n // 找到了要求的父类\n break;\n }\n\n // 在继承树上继续向上搜寻\n currentClass = (TypeElement) typeUtils.asElement(superClassType);\n }\n }\n\n // 检查是否提供了默认公开构造函数\n for (Element enclosed : classElement.getEnclosedElements()) {\n if (enclosed.getKind() == ElementKind.CONSTRUCTOR) {\n ExecutableElement constructorElement = (ExecutableElement) enclosed;\n if (constructorElement.getParameters().size() == 0 && constructorElement.getModifiers()\n .contains(Modifier.PUBLIC)) {\n // 找到了默认构造函数\n return true;\n }\n }\n }\n\n // 没有找到默认构造函数\n error(classElement, \"The class %s must provide an public empty default constructor\",\n classElement.getQualifiedName().toString());\n return false;\n }\n\n}\n```\n\n我们这里添加了`isValidClass()`方法,来检查是否我们所有的规则都被满足了:\n\n- 必须是公开类:`classElement.getModifiers().contains(Modifier.PUBLIC)`\n- 必须是非抽象类:`classElement.getModifiers().contains(Modifier.ABSTRACT)`\n- 必须是`@Factoy.type()`指定的类型的子类或者接口的实现:首先我们使用`elementUtils.getTypeElement(item.getQualifiedFactoryGroupName())`创建一个传入的`Class(@Factoy.type())`的元素。是的,你可以仅仅通过已知的合法类名来直接创建`TypeElement`(使用`TypeMirror`)。接下来我们检查它是一个接口还是一个类:`superClassElement.getKind() == ElementKind.INTERFACE`。所以我们这里有两种情况:如果是接口,就判断`classElement.getInterfaces().contains(superClassElement.asType())`;如果是类,我们就必须使用`currentClass.getSuperclass()`扫描继承层级。注意,整个检查也可以使用`typeUtils.isSubtype()`来实现。\n- 类必须有一个公开的默认构造函数:我们遍历所有的闭元素`classElement.getEnclosedElements()`,然后检查`ElementKind.CONSTRUCTOR`、`Modifier.PUBLIC`以及`constructorElement.getParameters().size() == 0`。\n\n\n上面都实现完成后下面就是在`FactoryGroupedClasses.generateCode()`方法中去生成`java`文件了。 \n写`Java`文件,和写其他普通文件没有什么两样。使用`Filer`提供的`Writer`对象,我们可以连接字符串来写我们生成的`Java`代码。但是这样是不是非常麻烦啊?还好良心企业`Square`给我们提供了`Javapoet`,我们可以用它来非常简单的去生成`java`文件。那我们接下来就使用`javapoet`来去生成代码: \n\n```java\npublic class FactoryGroupedClasses {\n\n /**\n * 将被添加到生成的工厂类的名字中\n */\n private static final String SUFFIX = \"Factory\";\n\n private String qualifiedClassName;\n\n private Map itemsMap =\n new LinkedHashMap();\n\n public FactoryGroupedClasses(String qualifiedClassName) {\n this.qualifiedClassName = qualifiedClassName;\n }\n\n public void add(FactoryAnnotatedClass toInsert) throws ProcessingException {\n\n FactoryAnnotatedClass existing = itemsMap.get(toInsert.getId());\n if (existing != null) {\n\n // Alredy existing\n throw new ProcessingException(toInsert.getTypeElement(),\n \"Conflict: The class %s is annotated with @%s with id ='%s' but %s already uses the same id\",\n toInsert.getTypeElement().getQualifiedName().toString(), Factory.class.getSimpleName(),\n toInsert.getId(), existing.getTypeElement().getQualifiedName().toString());\n }\n\n itemsMap.put(toInsert.getId(), toInsert);\n }\n\n public void generateCode(Elements elementUtils, Filer filer) throws IOException {\n TypeElement superClassName = elementUtils.getTypeElement(qualifiedClassName);\n String factoryClassName = superClassName.getSimpleName() + SUFFIX;\n String qualifiedFactoryClassName = qualifiedClassName + SUFFIX;\n PackageElement pkg = elementUtils.getPackageOf(superClassName);\n String packageName = pkg.isUnnamed() ? null : pkg.getQualifiedName().toString();\n\n MethodSpec.Builder method = MethodSpec.methodBuilder(\"create\")\n .addModifiers(Modifier.PUBLIC)\n .addParameter(String.class, \"id\")\n .returns(TypeName.get(superClassName.asType()));\n\n // check if id is null\n method.beginControlFlow(\"if (id == null)\")\n .addStatement(\"throw new IllegalArgumentException($S)\", \"id is null!\")\n .endControlFlow();\n\n // Generate items map\n for (FactoryAnnotatedClass item : itemsMap.values()) {\n method.beginControlFlow(\"if ($S.equals(id))\", item.getId())\n .addStatement(\"return new $L()\", item.getTypeElement().getQualifiedName().toString())\n .endControlFlow();\n }\n\n method.addStatement(\"throw new IllegalArgumentException($S + id)\", \"Unknown id = \");\n\n TypeSpec typeSpec = TypeSpec.classBuilder(factoryClassName).addMethod(method.build()).build();\n\n // Write file\n JavaFile.builder(packageName, typeSpec).build().writeTo(filer);\n }\n}\n```\n\n到这里,我感觉完成了,运行一下,结果发现报错了: \n```java\n:compiler:jar UP-TO-DATE\n:app:compileDebugJavaWithJavac\n错误: Attempt to recreate a file for type com.charon.annotationdemo.inter.MealFactory\n错误: Attempt to recreate a file for type com.charon.annotationdemo.inter.MealFactory\n2 个错误\nError:Execution failed for task ':app:compileDebugJavaWithJavac'.\n> Compilation failed; see the compiler error output for details.\n```\n\n那我们继续来解决这个问题,这个问题是由于循环引起的,我们还要处理一个重要的事情就是循环的问题: \n\n注解处理可能会执行多次,官方文档中是这样介绍的: \n\n> Annotation processing happens in a sequence of rounds. On each round, a processor may be asked to process a subset of the annotations found on the source and class files produced by a prior round. The inputs to the first round of processing are the initial inputs to a run of the tool; these initial inputs can be regarded as the output of a virtual zeroth round of processing.\n\n一个简单的定义:一个处理循环是调用一个注解处理器的`process()`方法。对应到我们的工厂模式的例子中:`FactoryProcessor`被初始化一次(不是每次循环都会新建处理器对象),然而,如果生成了新的源文件`process()`能够被调用多次。听起来有点奇怪不是么?原因是这样的,这些生成的文件中也可能包含`@Factory`注解,它们还将会被`FactoryProcessor`处理。\n\n例如我们的`PizzaStore`的例子中将会经过3次循环处理:\n\n| Round | Input | Output |\n| ------------- |:-------------:| -----:|\n| 1 | CalzonePizza.java Tiramisu.java MargheritaPizza.java Meal.java PizzaStore.java | MealFactory.java |\n| 2 | MealFactory.java | none |\n| 3 | none | none |\n\n会循环三次,但是第一次就会生成代码,所以上面会出现两次重复创建文件的错误。 \n\n解释处理循环还有另外一个原因。如果你看一下我们的`FactoryProcessor`代码你就能注意到,我们收集数据和保存它们在一个私有的域中`Map factoryClasses`。在第一轮中,我们检测到了`MagheritaPizza`, `CalzonePizza`和`Tiramisu`,然后生成了`MealFactory.java`。在第二轮中把`MealFactory`作为输入。因为在`MealFactory`中没有检测到`@Factory`注解,我们预期并没有错误,然而我们得到如下的信息:\n\n```java\n:compiler:jar UP-TO-DATE\n:app:compileDebugJavaWithJavac\n错误: Attempt to recreate a file for type com.charon.annotationdemo.inter.MealFactory\n错误: Attempt to recreate a file for type com.charon.annotationdemo.inter.MealFactory\n2 个错误\nError:Execution failed for task ':app:compileDebugJavaWithJavac'.\n> Compilation failed; see the compiler error output for details.\n```\n\n这个问题是因为我们没有清除`factoryClasses`,这意味着,在第二轮的`process()`中,任然保存着第一轮的数据,并且会尝试生成在第一轮中已经生成的文件,从而导致这个错误的出现。在我们的这个场景中,我们知道只有在第一轮中检查`@Factory`注解的类,所以我们可以简单的修复这个问题,如下:\n```java\n@Override\npublic boolean process(Set annotations, RoundEnvironment roundEnv) { \n try {\n for (FactoryGroupedClasses factoryClass : factoryClasses.values()) {\n factoryClass.generateCode(elementUtils, filer);\n }\n\n // 清除factoryClasses\n factoryClasses.clear();\n\n } catch (IOException e) {\n error(null, e.getMessage());\n }\n ...\n return true;\n}\n```\n\n***我们要记住注解处理过程是需要经过多轮处理的,并且你不能重载或者重新创建已经生成的源代码。***\n\n\n\n好了,到这里就彻底完成了,运行一下,当然成功了,那生成的文件在哪里呢? \n\n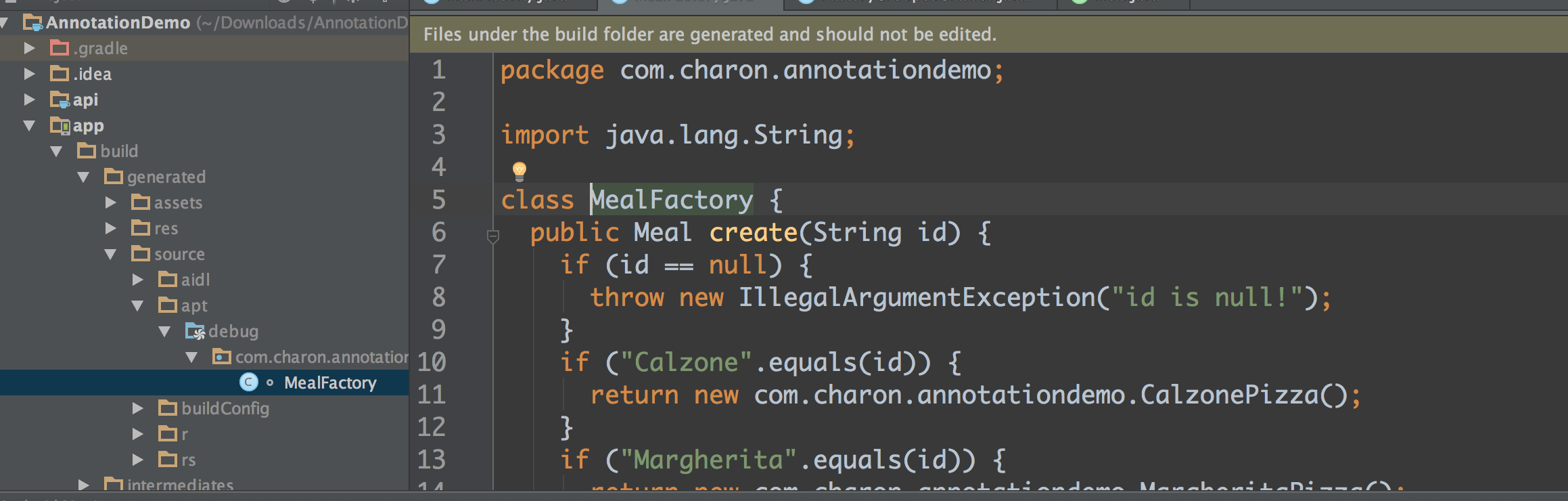 \n\n\n那既然能生成,我们该怎么去调用呢?很简单,像平常一样去用。\n```java\npublic class MainActivity extends AppCompatActivity {\n private View view;\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n view = findViewById(R.id.tv);\n view.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View v) {\n MealFactory factory = new MealFactory();\n factory.create(\"Calzone\");\n }\n });\n }\n}\n```\n\n你可能会发现报错,找不到类,你可以不用管它,直接运行,你会发现一切都`OK`的。当然如果你倒错了包你就当我没说。\n\n作为`Android`开发者,当然应该很熟悉`ButterKnife`。在`ButterKnife`中使用`@InjectView`注解`View`。`ButterKnifeProcessor`生成一个`MyActivity$$ViewInjector`,但是在`ButterKnife`你不需要手动调用`new MyActivity$$ViewInjector()`来实例化一个`ButterKnife`注入的对象,而是使用`Butterknife.inject(activity)`。`ButterKnife`内部使用反射机制来实例化`MyActivity$$ViewInjector()`对象:\n\n```java\ntry { \n Class injector = Class.forName(clsName + \"$$ViewInjector\");\n} catch (ClassNotFoundException e) { ... }\n```\n\n但是反射机制会稍微有些慢,我们使用注解处理来生成本地代码,会不会导致很多的反射性能的问题?的确,反射机制的性能确实是一个问题。然而,它不需要手动去创建对象,确实提高了开发者的开发速度。`ButterKnife`中有一个哈希表`HashMap`来缓存实例化过的对象。所以`MyActivity$$ViewInjector`只是使用反射机制实例化一次,第二次需要`MyActivity$$ViewInjector`的时候,就直接从哈希表中获得。\n\n`FragmentArgs`非常类似于`ButterKnife`。它使用反射机制来创建对象,而不需要开发者手动来做这些。`FragmentArgs`在处理注解的时候生成一个特别的查找表类,它其实就是一种哈希表,所以整个`FragmentArgs`库只是在第一次使用的时候,执行一次反射调用,一旦整个`Class.forName()`的`Fragemnt`的参数对象被创建,后面的都是本地代码运行了。\n\n好了至此例子讲完了。 \n\n最后讲一下按照上面的三层分类:`app`,`api`,`compiler`进行分类的好处。 \n我们这么做是因为想让我们的工厂模式的例子的使用者在他们的工程中只编译注解,而包含处理器模块只是为了编译。有点晕?我们举个例子,如果我们只有一个包。如果另一个开发者想要把我们的工厂模式处理器用于他的项目中,他就必须包含`@Factory`注解和整个`FactoryProcessor`的代码(包括`FactoryAnnotatedClass`和`FactoryGroupedClasses`)到他们项目中。我非常确定的是,他并不需要在他已经编译好的项目中包含处理器相关的代码。如果你是一个`Android`的开发者,你肯定听说过`65536`个方法的限制(即在一个`.dex`文件中,只能寻址65536个方法)。如果你在`FactoryProcessor`中使用`guava`,并且把注解和处理器打包在一个包中,这样的话,`Android APK`安装包中不只是包含`FactoryProcessor`的代码,而也包含了整个`guava`的代码。`Guava`有大约20000个方法。所以分开注解和处理器是非常有意义的。\n\n\n### 使用注解提高代码的检查性 \n\n`Google`提供了`Support-Annotations library`来支持更多的注解功能。 \n可以直接在`build.gradle`中添加如下代码: \n\n```\ndependencies {\n compile 'com.android.support:support-annotations:23.3.0'\n}\n```\n\n`Android`提供了很多注解来支持在方法、参数和返回值上面使用,例如: \n\n- `@Nullable` \n 可以为`null`\n- `@NonNull` \n 不能为`null` \n ```java\n import android.support.annotation.NonNull;\n ...\n \n /** Add support for inflating the tag. */\n @NonNull\n @Override\n public View onCreateView(String name, @NonNull Context context,\n @NonNull AttributeSet attrs) {\n ...\n }\n ...\n ```\n- `@StringRes` \n `R.string`类型的资源。 \n ```java\n import android.support.annotation.StringRes;\n ...\n public abstract void setTitle(@StringRes int resId);\n ...\n \n 遇到那种你写了个`setTitle(int resId)`他确给你传`setTitle(R.drawable.xxx)`的选手,用这种方式能很好的去提示下。 \n ```\n- `@DrawableRes` \n `Drawable`类型的资源。\n- `@ColorRes` \n `Color`类型的资源。\n- `@InterpolatorRes` \n `Interpolatro`类型。\n- `@AnyRes` \n `R.`类型。\n- `@UiThread` \n 从`UI thread`调用。 \n- `@RequiresPermission` \n 来验证该方法的调用者所需要有的权限。检查一个列表中的任何一个权限可以使用`anyOf`属性。想要检查多个权限时,可以使用`allOf`属性。如下: \n ```java\n @RequiresPermission(Manifest.permission.SET_WALLPAPER)\n public abstract void setWallpaper(Bitmap bitmap) throws IOException;\n ```\n 检查多个权限: \n \n ```java\n @RequiresPermission(allOf = {\n Manifest.permission.READ_EXTERNAL_STORAGE,\n Manifest.permission.WRITE_EXTERNAL_STORAGE})\n public static final void copyFile(String dest, String source) {\n ...\n }\n ```\n\n\n示例`Demo`已上传到`Github`:[AnnotationDemo](https://github.com/CharonChui/AnnotationDemo) \n\n文中例子来自`Hannes Dorfmann`大神的`ANNOTATION PROCESSING 101`,我对其重新梳理了下,来让能正常使用,并且上面的示例已经过我实际运行: \n- [Hannes Dorfmann](http://hannesdorfmann.com/annotation-processing/annotationprocessing101)\n \n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! \n\n"
},
{
"path": "docs/android/AndroidNote/AdavancedPart/通过Hardware Layer提高动画性能.md",
"content": "通过Hardware Layer提高动画性能\n===\n\n项目中越来越多的动画,越来越多的效果导致了应用性能越来越低。该如何提升。 \n\n### 简介 \n\n在`View`播放动画的过程中每一帧都需要被重绘。如果使用`view layers`,就不用每帧都去重绘,因为`View`渲染一旦离开屏幕缓冲区就可以被重用。\n\n而且,`hardware layers`会在`GPU`上缓存,这样就会让一些动画过程中的操作变得更快。通过`hardware layers`可以快速的渲染一些简单的转变(位移、选中、缩放、颜色渐变)。由于很多动画都是这些动作的结合,所以`hardware layers`可以显著的提高动画性能。\n\n在`View`当中提供了三种类型的`Layer type`: \n\n- LAYER_TYPE_HARDWARE\n > Indicates that the view has a hardware layer. A hardware layer is backed by a hardware specific texture (generally Frame Buffer Objects or FBO on OpenGL hardware) and causes the view to be rendered using Android's hardware rendering pipeline, but only if hardware acceleration is turned on for the view hierarchy. When hardware acceleration is turned off, hardware layers behave exactly as software layers.\n\n > A hardware layer is useful to apply a specific color filter and/or blending mode and/or translucency to a view and all its children.\n\n > A hardware layer can be used to cache a complex view tree into a texture and reduce the complexity of drawing operations. For instance, when animating a complex view tree with a translation, a hardware layer can be used to render the view tree only once.\n\n > A hardware layer can also be used to increase the rendering quality when rotation transformations are applied on a view. It can also be used to prevent potential clipping issues when applying 3D transforms on a view. \n \n\n- LAYER_TYPE_SOFTWARE\n > Indicates that the view has a software layer. A software layer is backed by a bitmap and causes the view to be rendered using Android's software rendering pipeline, even if hardware acceleration is enabled.\n\n > Software layers have various usages:\n\n > When the application is not using hardware acceleration, a software layer is useful to apply a specific color filter and/or blending mode and/or translucency to a view and all its children.\n\n > When the application is using hardware acceleration, a software layer is useful to render drawing primitives not supported by the hardware accelerated pipeline. It can also be used to cache a complex view tree into a texture and reduce the complexity of drawing operations. For instance, when animating a complex view tree with a translation, a software layer can be used to render the view tree only once.\n\n > Software layers should be avoided when the affected view tree updates often. Every update will require to re-render the software layer, which can potentially be slow (particularly when hardware acceleration is turned on since the layer will have to be uploaded into a hardware texture after every update.)\n\n- LAYER_TYPE_NONE\n > Indicates that the view does not have a layer.\n 默认值。\n\n### 使用\n\n首先使用的前提是在清单文件中开启了硬件加速。否则将无法使用`hardware layer`。这一点在上面的文档中也有说明。\n\n`API`也是非常简单的,直接使用`View.setLayerType()`就好。使用时应该只是暂时的设置`Hardware Layer`,因为它们无法自动释放。 \n基本的使用步骤: \n \n- 对每个想要在动画过程中进行缓存的`view`调用`View.setLayerType(View.LAYER_TYPE_HARDWARE, null)`方法。\n- 执行动画。\n- 在动画执行结束后调用`View.setLayerType(View.LAYER_TYPE_NONE, null)`方法来进行清除。\n\n示例: \n```java\nmView.setLayerType(View.LAYER_TYPE_HARDWARE, null);\n\nanimator.addListener(new AnimatorListenerAdapter() { \n @Override\n public void onAnimationEnd(Animator animation) {\n mView.setLayerType(View.LAYER_TYPE_NONE, null);\n }\n});\n\nanimator.start(); \n\n```\n但是如果在`4.0.x`的版本中使用上面的代码会崩溃,必须要把`setLayerType`放到`Runnable`中。如下: \n```java\nmView.setLayerType(View.LAYER_TYPE_HARDWARE, null);\n\nanimator.addListener(new AnimatorListenerAdapter() { \n @Override\n public void onAnimationEnd(Animator animation) {\n //This will work successfully\n post(new Runnable() {\n @Override\n public void run () {\n setLayerType(LAYER_TYPE_NONE, null);\n }\n }\n }\n});\n\nanimator.start(); \n```\n\n如果你基于`minSdkVersion 16`以上并且使用`ViewPropertyAnimator`时,你可以使用`withLayer()`方法替代如上的操作: \n\n```java\nmView.animate().translationX(150).withLayer().start();\n```\n\n或者在`api 14`以上时使用`ViewCompat.animate().withLayer()`\n这样做,你的动画就会变得更流畅!\n \t\n\n### 注意事项 \n\n你应该知道,事情没那么简单。 \n`Hardware layers`有着惊人的提升动画性能的能力。然而,如果滥用,它的危害更大。**不要盲目的使用`layers`**\n\n- 首先,在有些情况下,`hardware layers`除了`view`渲染外还会执行更多的工作。缓存`layer`将会需要时间,因为首选第一步就需要两个过程: 先将这些`view`渲染到`GPU`的一个`layer`中然后`GPU`再渲染该`layer`到`Window`上。如果要渲染的`View`非常简单(例如一个纯色值),那么这样在初始化的时候就会增加`Hardware Layer`不必要的开销。\n\n- 其次,对所有的缓存来讲,都有一个缓存失效的可能性。任何时候如果在动画过程中调用`view.invalidate()`,那么`layer`就必须要重新渲染。经常的废弃`hardware layers`会比没有`layers`的情况下更糟糕,因为如同上面讲到的`hardware layers`在设置缓存时会有额外的开销。如果你需要经常的重新缓存`layer`,那就会有极大的损害。 \n\n 这个问题也是非常容易出现的,因为动画经常有多个移动的部分。假如现在有一个三个部分移动的动画: \n ```java\n Parent ViewGroup\n —-> Child View1 (往左移动)\n —-> Child View2 (往右移动)\n —-> Child View3 (往上移动)\n ```\n \n 如果你只在父布局`ViewGroup`上设置一个`layer`,那就将经常的缓存失效,因为`ViewGroup`会随着子`View`不断地改变。然而对每个单独的子`Views`而言,他们只是在位移。这种情况下,最好是对每个子`View上`设置`Hardware Layer`(而不是在父布局上)。\n \n ***再次重申,通常是对多个子`View上`适当的设置`Hardware Layer`,这样他们就不会在动画运行时失效。***\n \n 在手机开发者选项中的*显示硬件层更新(Show hardware layers updates)*功能是追踪这个问题的开发利器。当`View`渲染`Hardware Layer`的时候闪烁绿色,它应该在动画开始的时候闪烁一次(也就是`Layer`渲染初始化的时候),然而,如果你的`View`在整个动画期间都是绿色,那就是遇到失效的问题了。\n\n- 最后,`hardware layers`使用`GPU`内存,你当然不想出现内存泄漏的问题。所以你应该在必要的时候再去使用`hardware layers`,就想播放动画时。 \n\n\n这里也没有硬性规则。`Android`渲染系统是非常复杂的。就像所有性能问题一样,测试才是关键。通过使用“显示硬件层更新”开发者选项来确定`layers`是在帮你还是害你。\n\n\n\n\n\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AndroidStudioCourse/Android Studio你可能不知道的操作.md",
"content": "Android Studio你可能不知道的操作\n===\n\n今天看在`Youtube`看视频,看到`Reto Meier`在讲解`Studio`,\n一查才知道他现在是`Studio`的开发人员。\n想起刚开始学`Android`时买的他写的书`Professional Android 4 Application Development`,\n当时很多内容没看懂。不过看了这个视频才发现大神写代码如此之快…\n\n现在天天用着大神开发的工具,没有理由不去好好学习下。\n\n工欲善其事必先利其器,一个好的开发工具可以让你事半功倍。`Android Studio`是一个非常好的开发工具,但是虽然都在用,你可能还是了解的不全面,今天就来说一下一些你可能不知道的功能。\n\n熟练使用快捷键是非常有必要的: \n \n\n\n- 自动导入 \n经常听到同事抱怨,`Studio`怎么没有`Eclipse`那种批量导包啊,那么多类要到,费劲了。其实不用一个个导的。\n使用`Command+Shift+A(Windows或Linux是Ctrl+Shift+A)`快速的查找设置命令。我们输入`auto import`后将`Add unambiguous imports on fly`选项开启就好了,很爽有木有?你的是不是也没开啊? \n \n你可以快速打开一些设置,例如你想在`finder`中查看该文件,直接输入`find`就好了。\n \n\n- 在自动完成代码时使用`Tab`键来替换已存在的方法和参数。 \n经常如我们想要修改一个已经存在的方法时,我们移动到对象的`.`的提示区域,如果使用`Command+Space`来补充代码选择后按`enter`的话,会把之前已经存在的代码往后移动,这样还要再去删除,很不方便。但是如果我们直接使用`Tag`键,那就会直接替换当前已经存在的方法。\n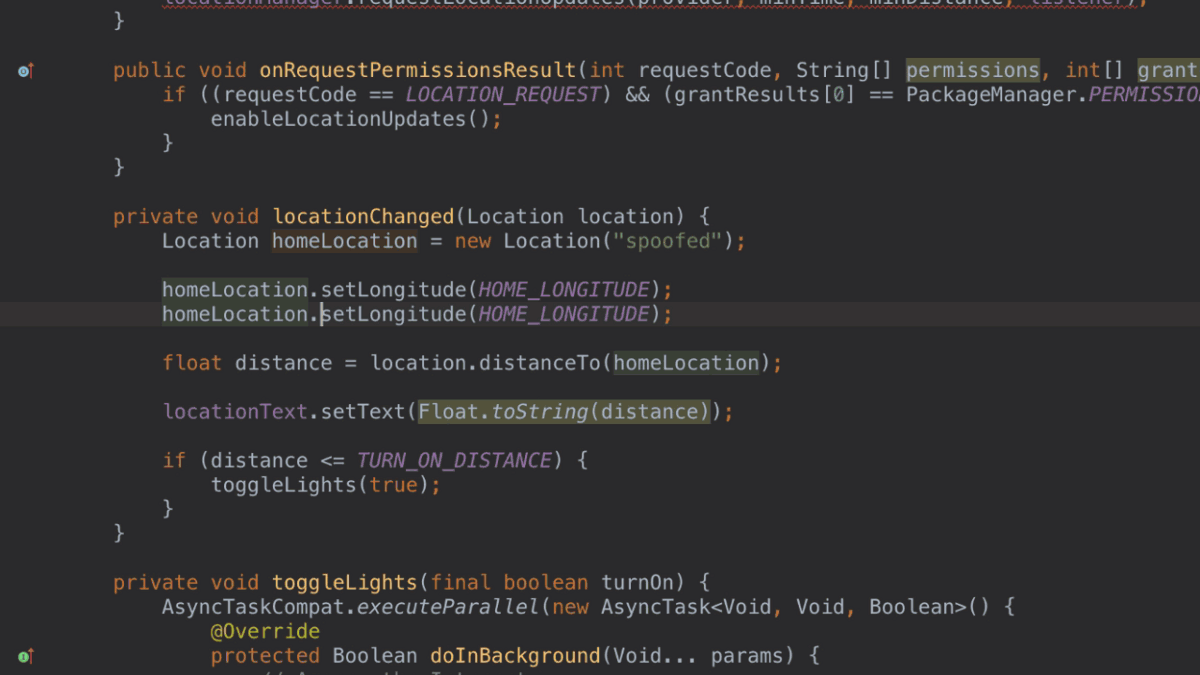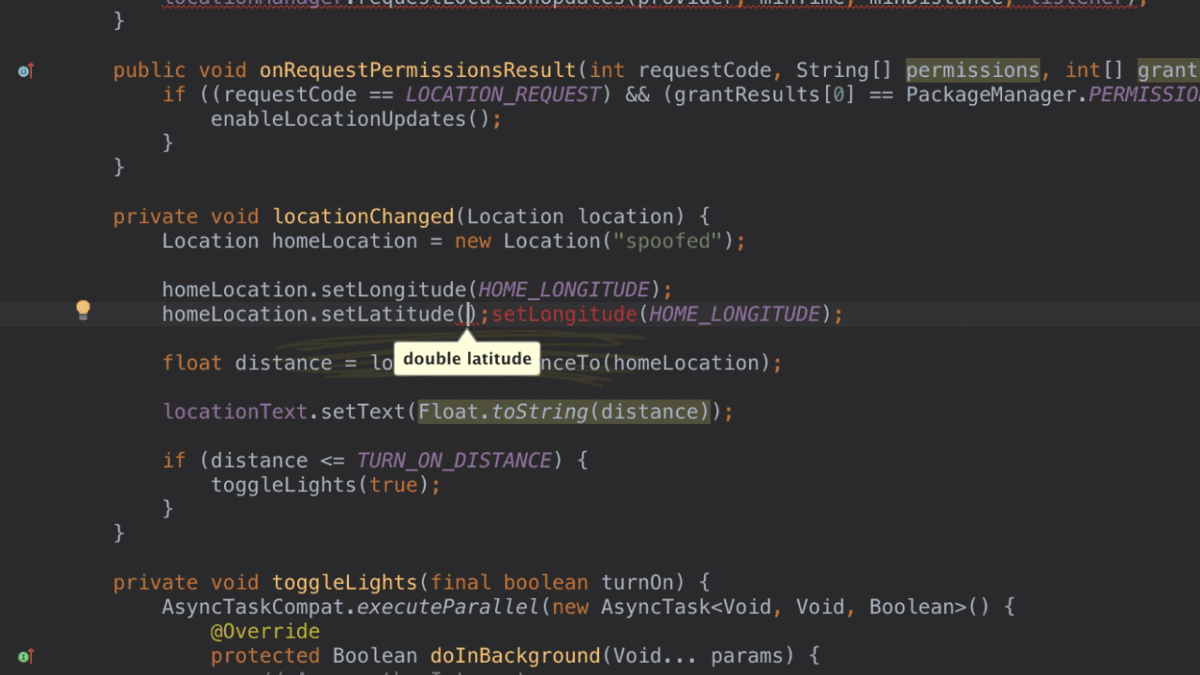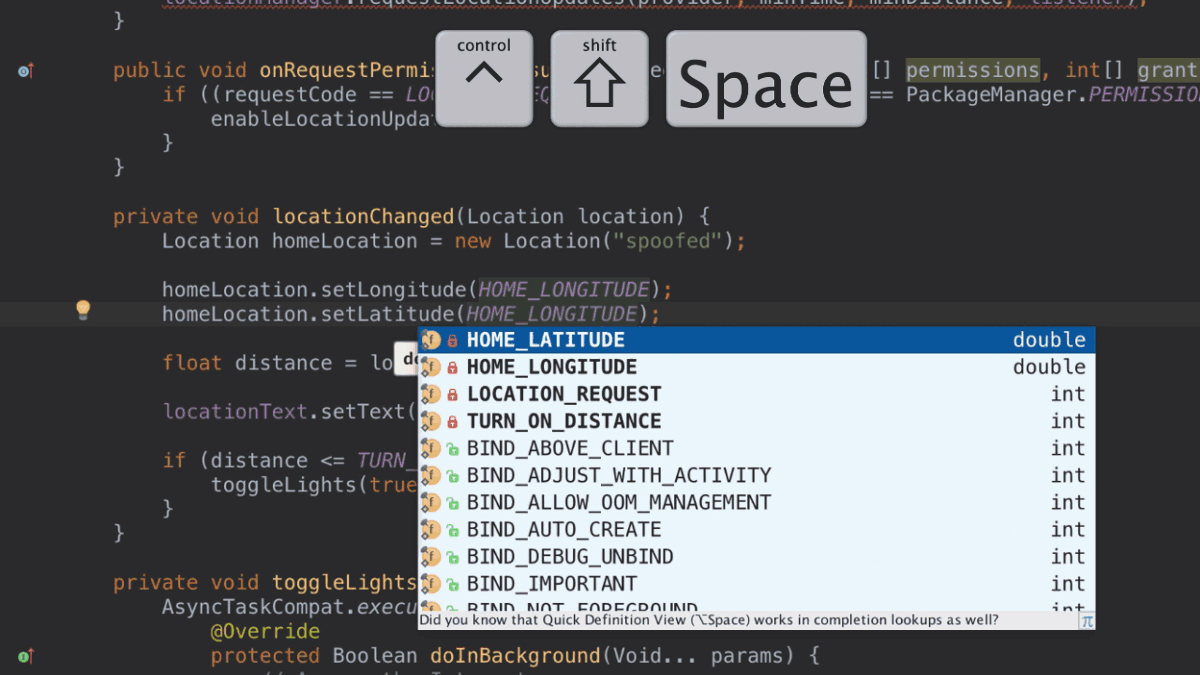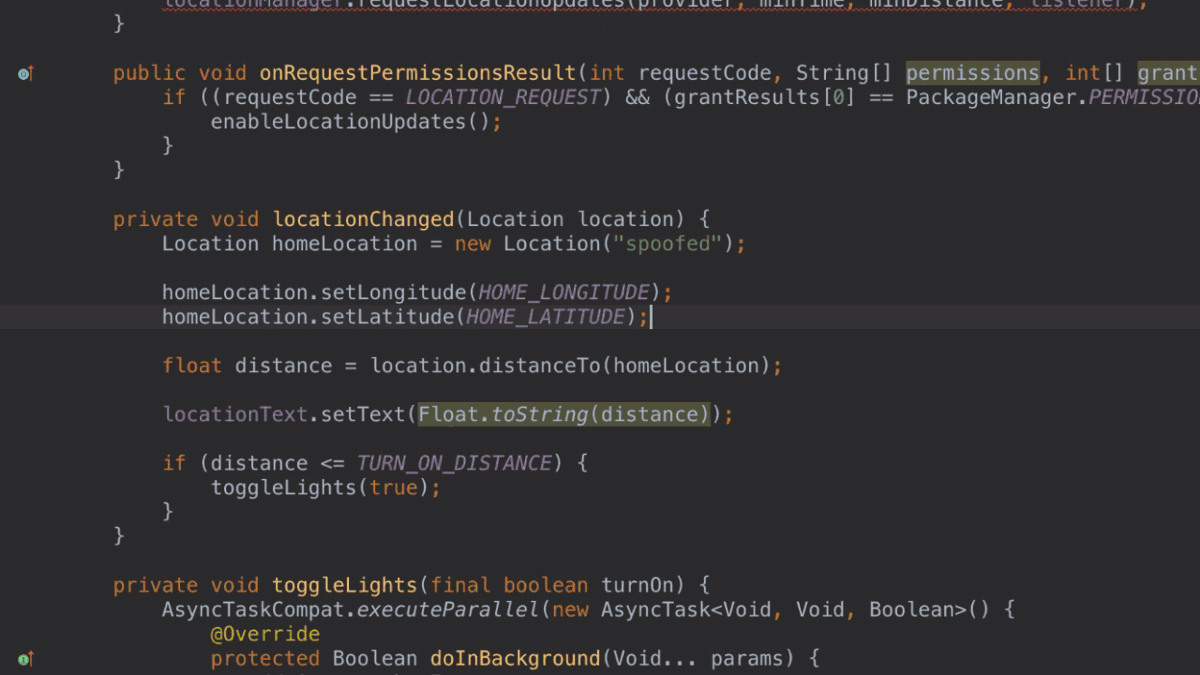 \n\n- 内容选择技巧 \n使用`Control+↑或↓`能在方法间移动。使用`Shift+↑或↓`来选择至上一行或者至下一行代码的代码?那么使用`option++↑或↓(Windows或Linux是alt++↑或↓)`呢?它能选择或者取消选择和你鼠标所在位置的代码区域。同时使用`option+shift++↑或↓(Windows或Linux是alt+shift++↑或↓)可以交换选中代码块与上一行的位置。这样我们就不需要剪切和粘贴了。\n\n- 使用模板补全代码 \n你可以在代码后加用后缀的方式补充代码块,也可以用`Command+J(Windows是Ctrl+J)`来提示。 \n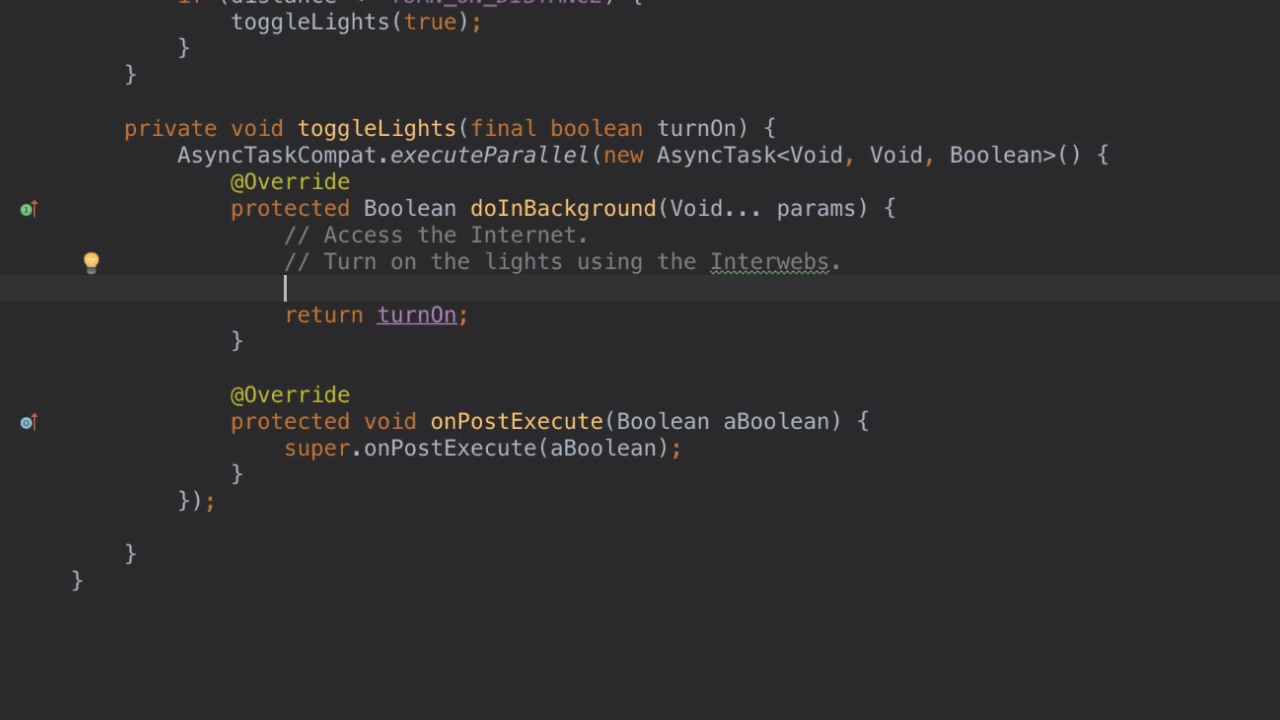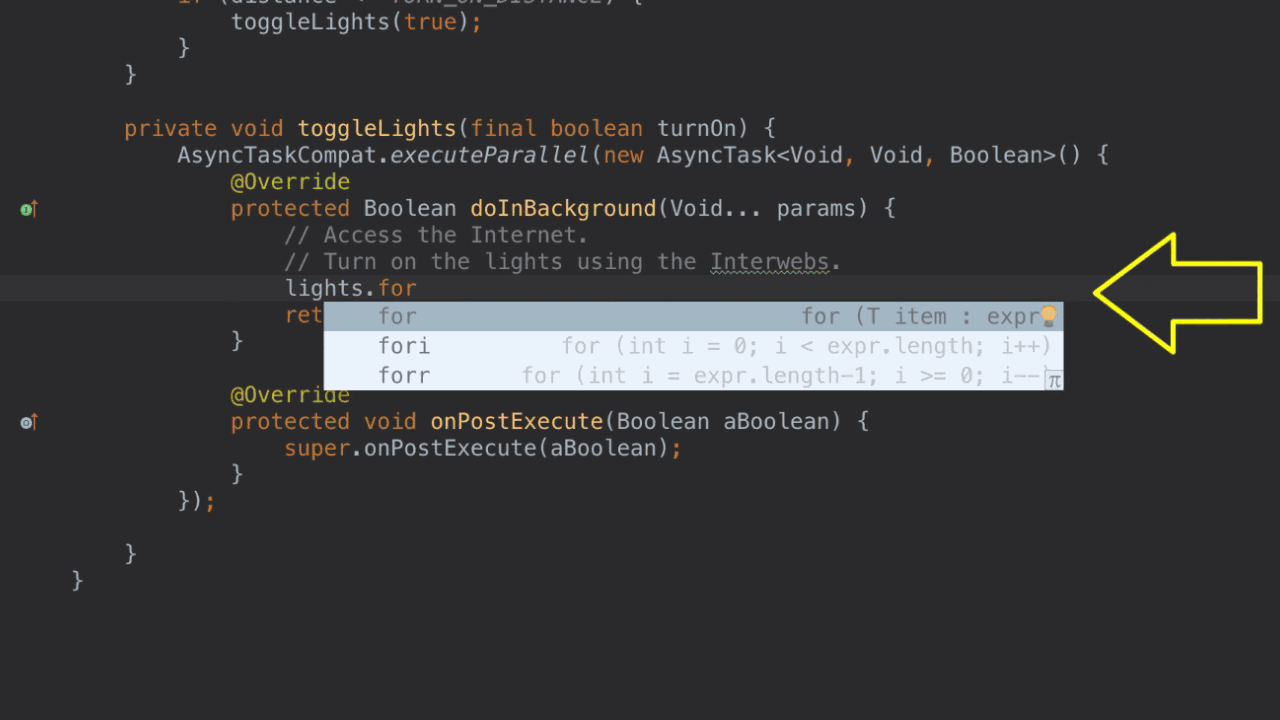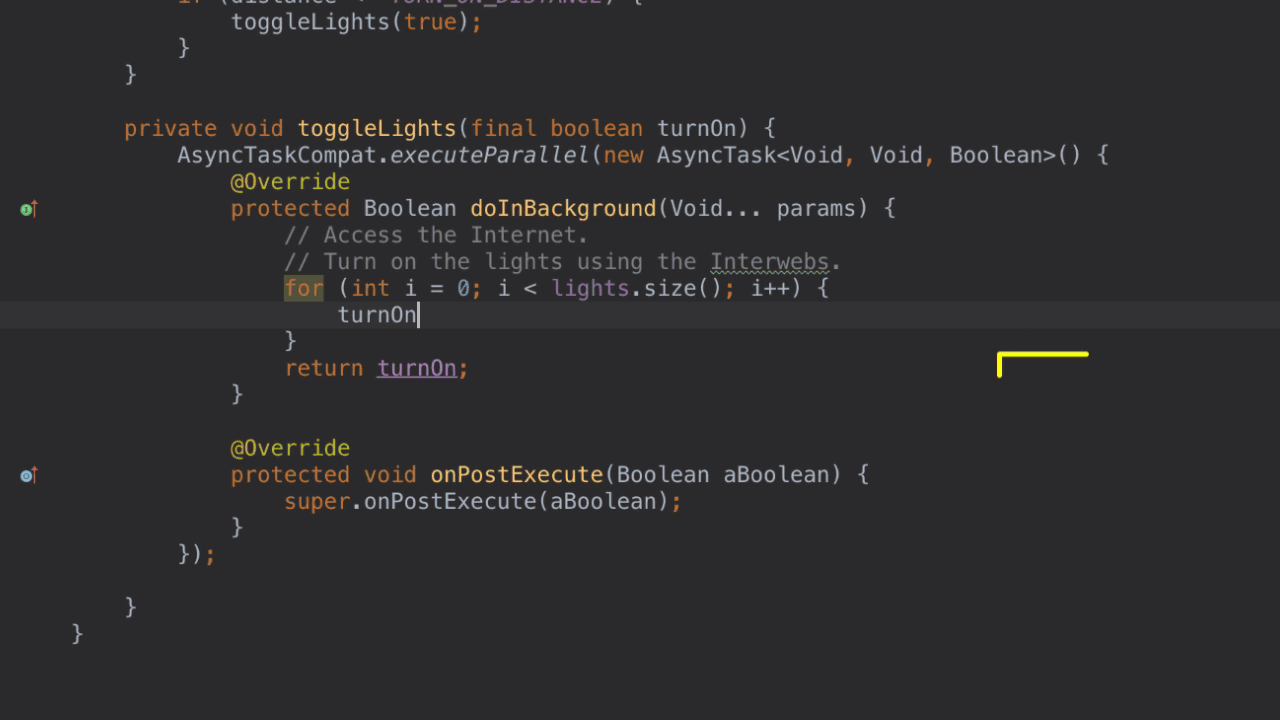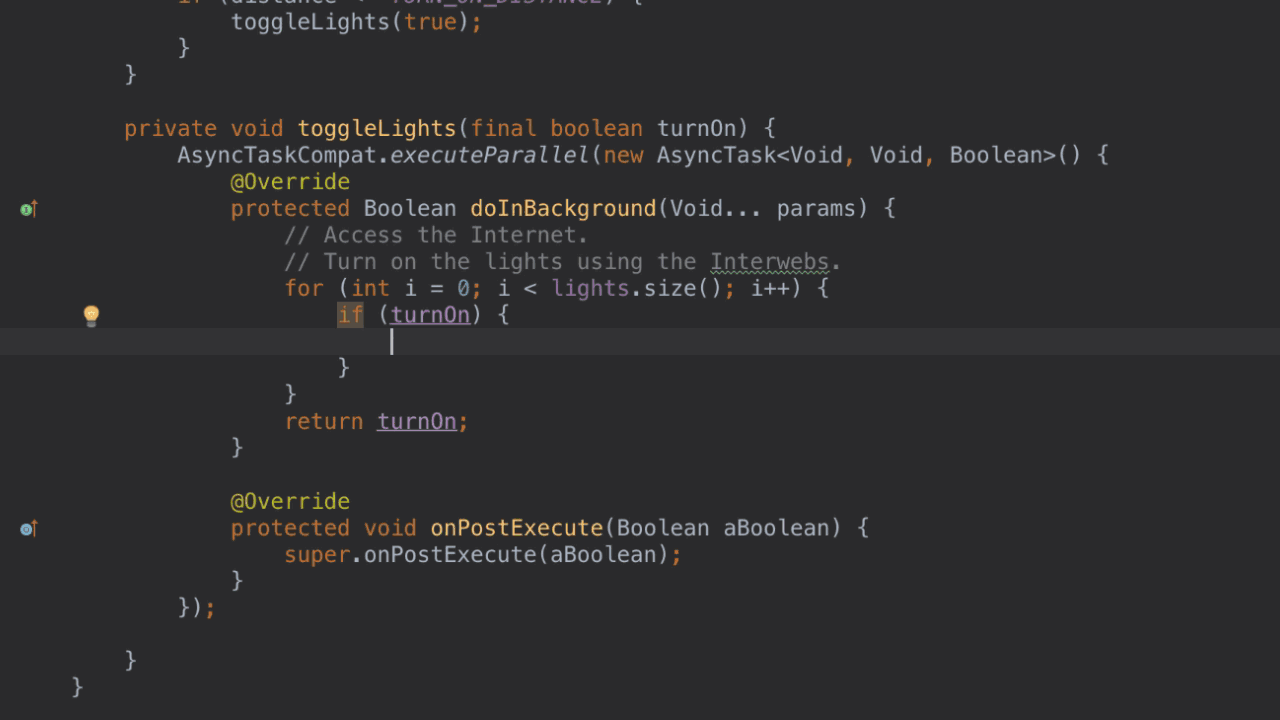 \n对于一些更多的模式,在代码自动完成时也支持生成对应的模板,例如使用`Toast`的快捷键可以很方便的生成一个新的`toast`对象,你只需要指定文字就可以了。 \n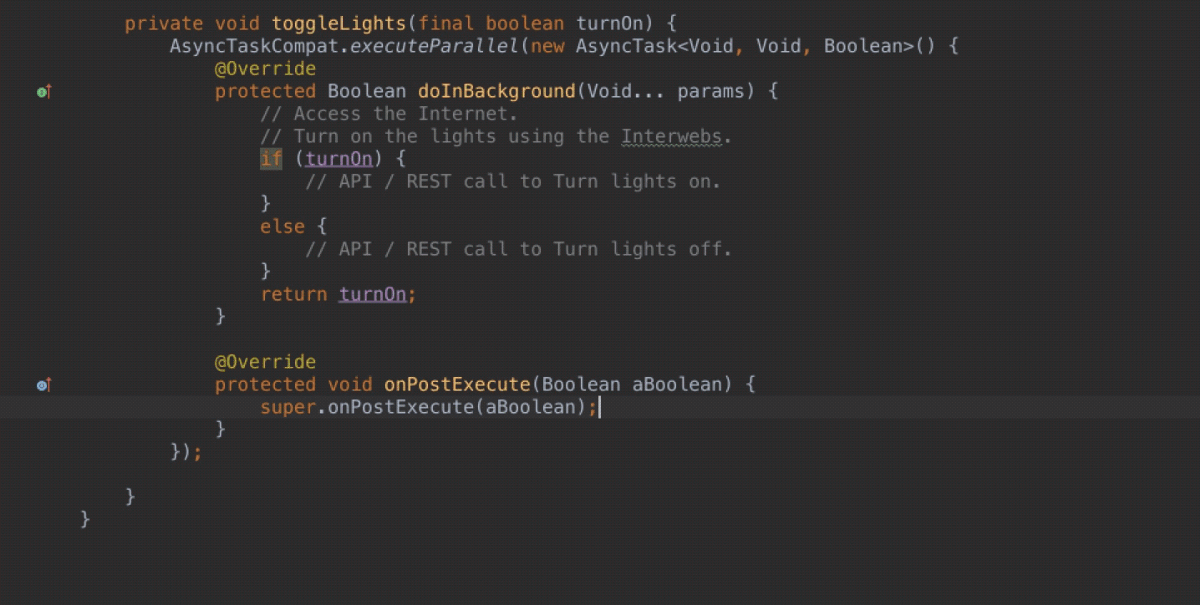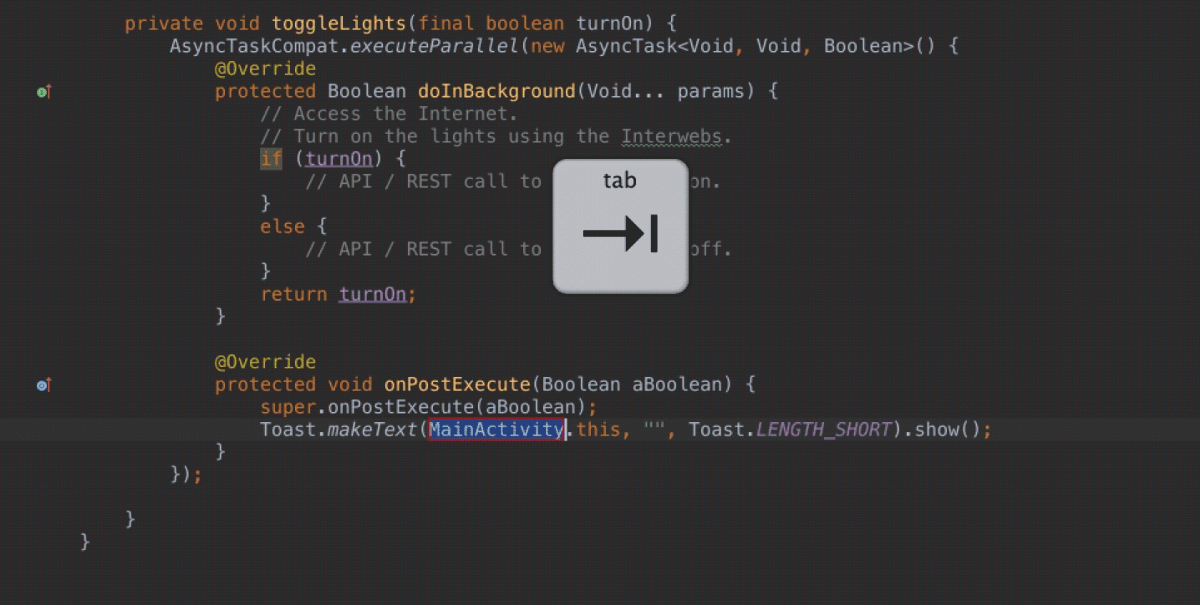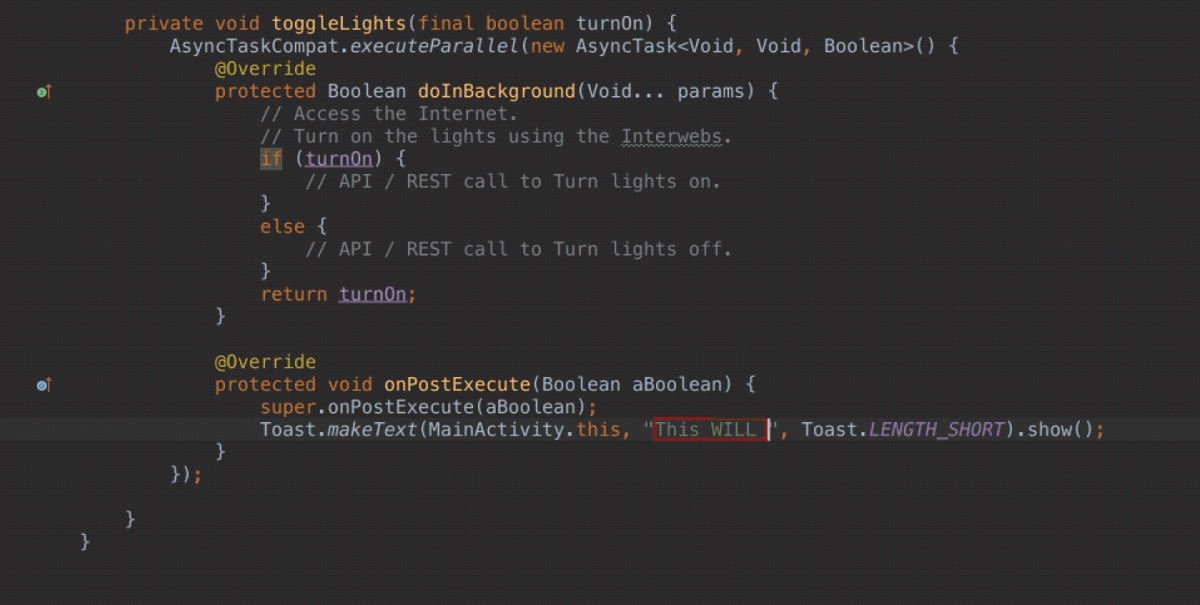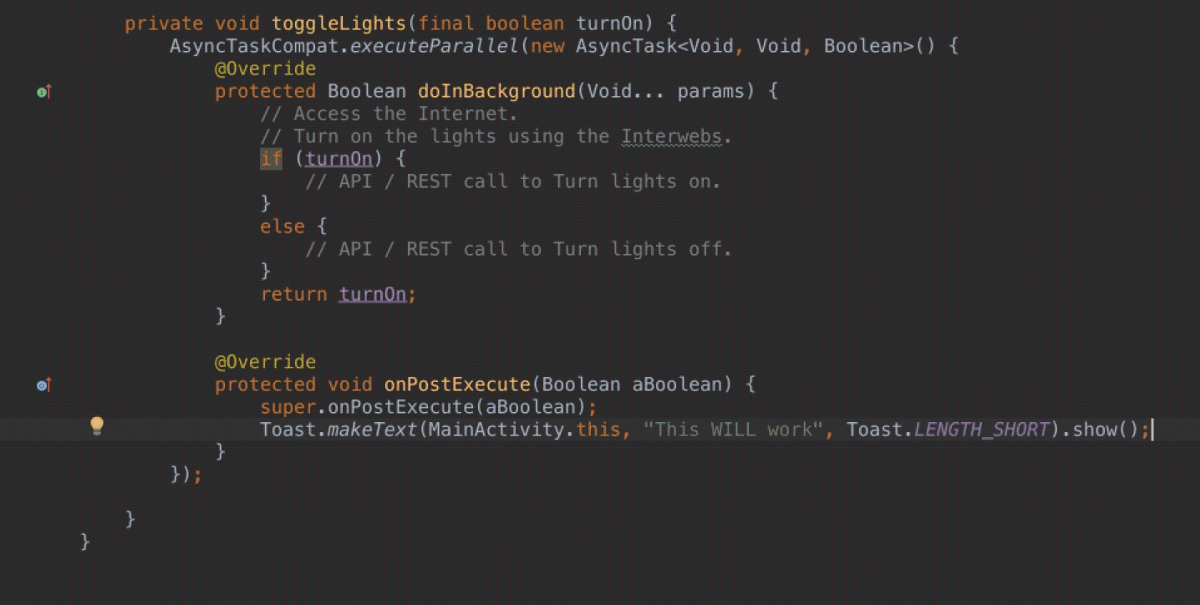 \n用`Command+Shift+A`然后输入`live template`然后打开对应的页面,可以看到目前已经存在的模板。当然你也可以添加新的模板。 \n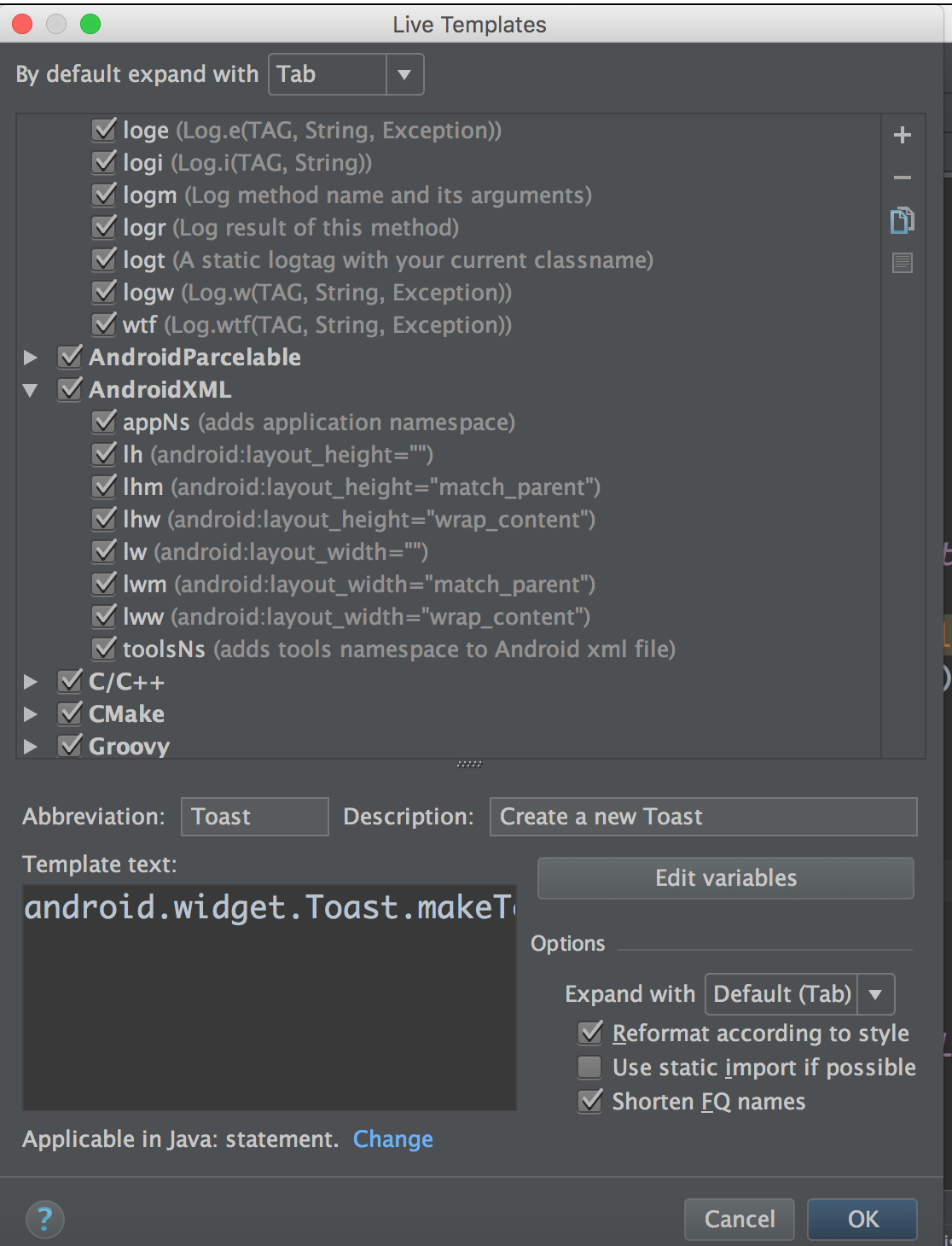 \n\n- 在`Evaluating Expressions`中为`Object`对象指定显示内容 \n如果我们在`debug`的时候查看断点处的变量值或者`evaluating expressions`,你会发现`objects`会显示他们的`toString()`值。如果你的变量是`String`类型或者基础类型那不会有问题,但是大多数其他对象,这样没有什么意义。 \n尤其是在集合对象时,你看的是一个`CallsName:HashValue`的列表。而为了需要看清数据,我们需要知道每个对象的内容。 \n你当然可以去对每个对象类型指定索要显示的内容。在对应的对象上邮件`View as`然后创建你想要显示的内容就可以了。 \n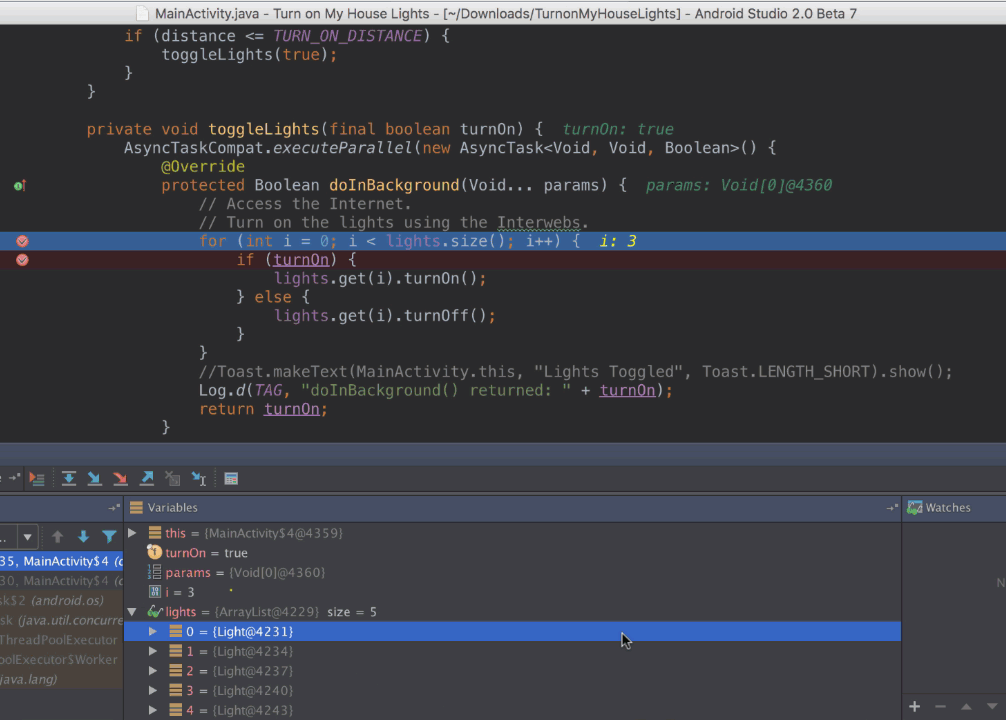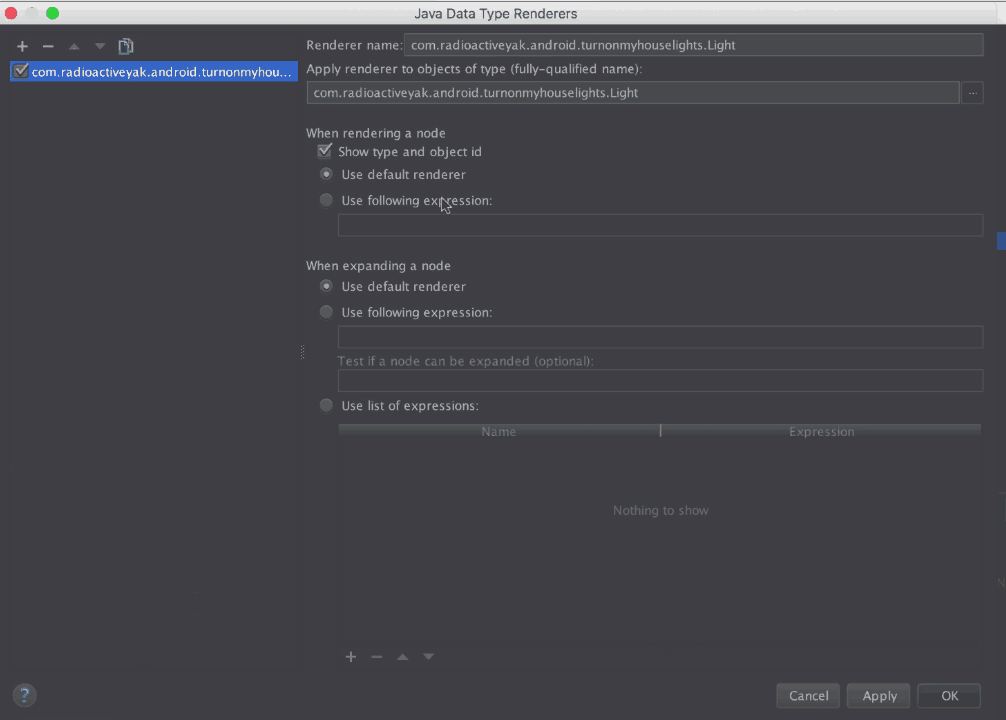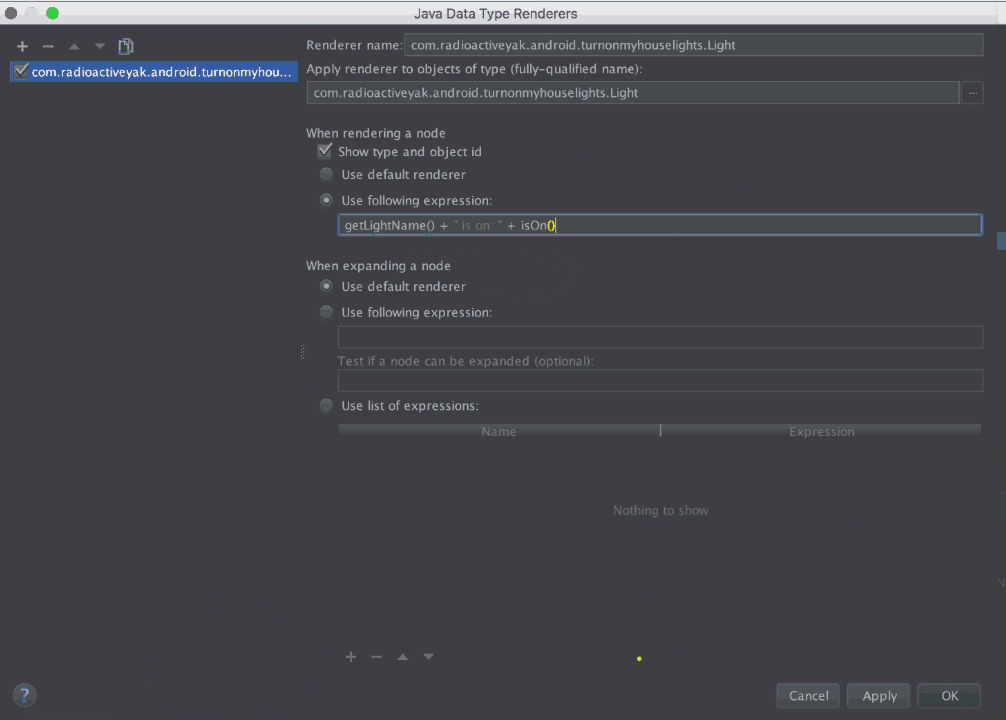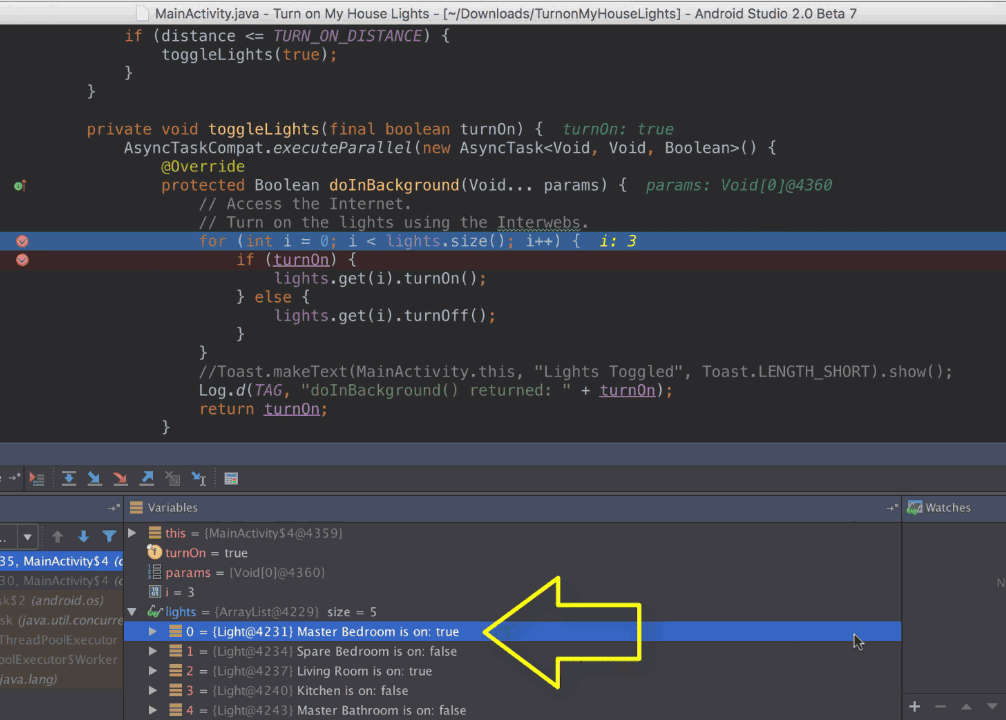 \n\n- 结构性的搜索、替换、和检查 \n`Command+shift+A`然后输入`structural `后选择`search structurally`或者`replace structurally`,然后可以对应的结构性搜索的模板,完成之后所有符合该模板的代码都会提示`warning`。 \n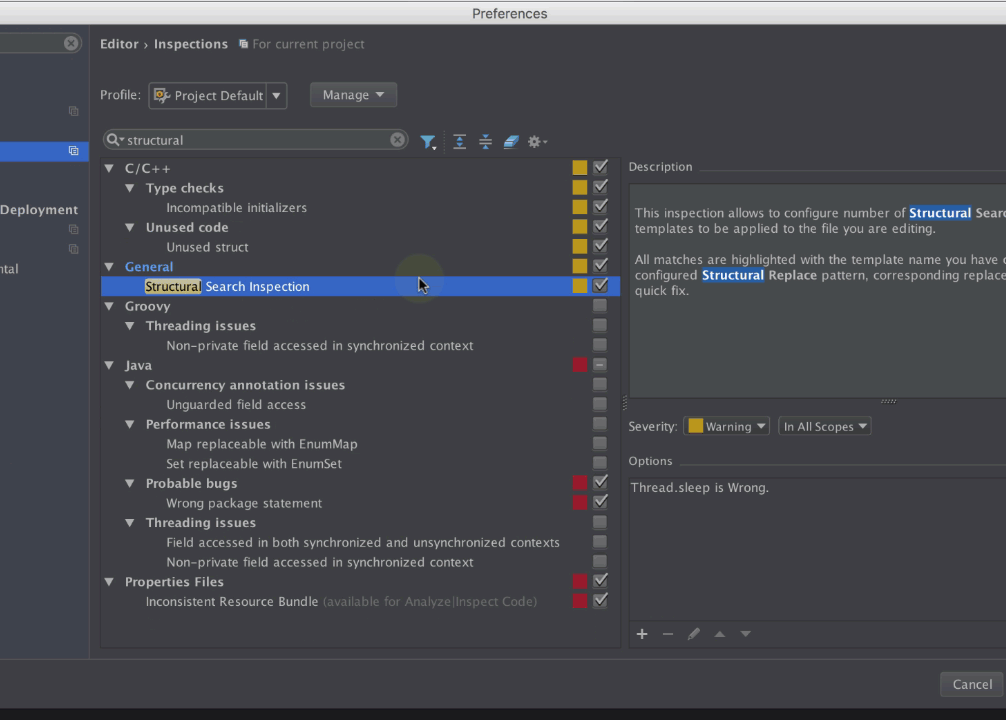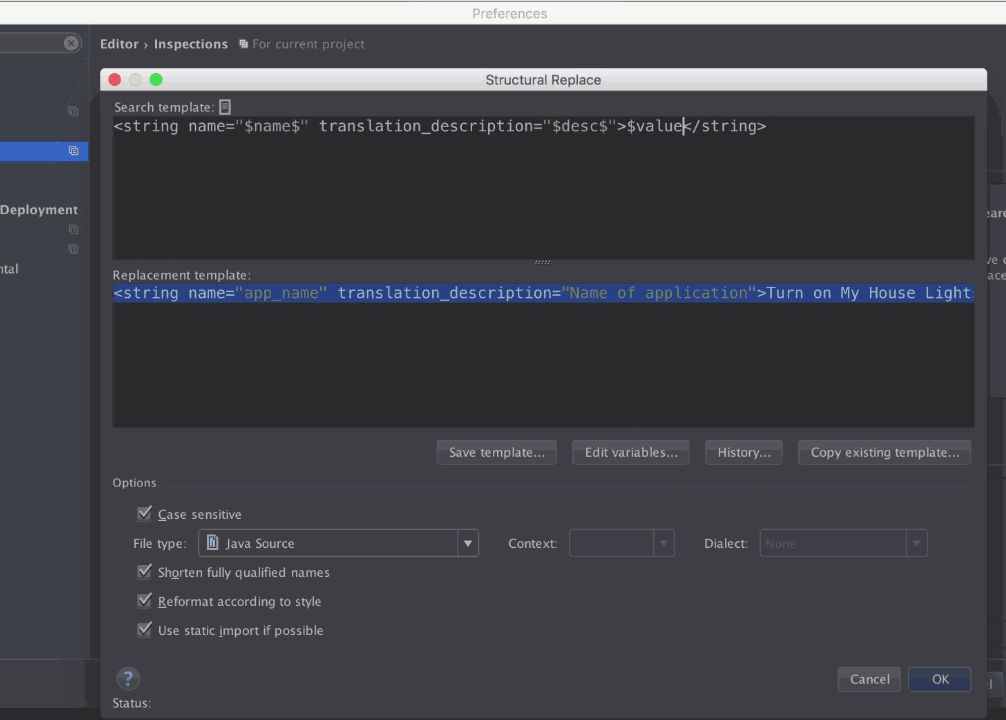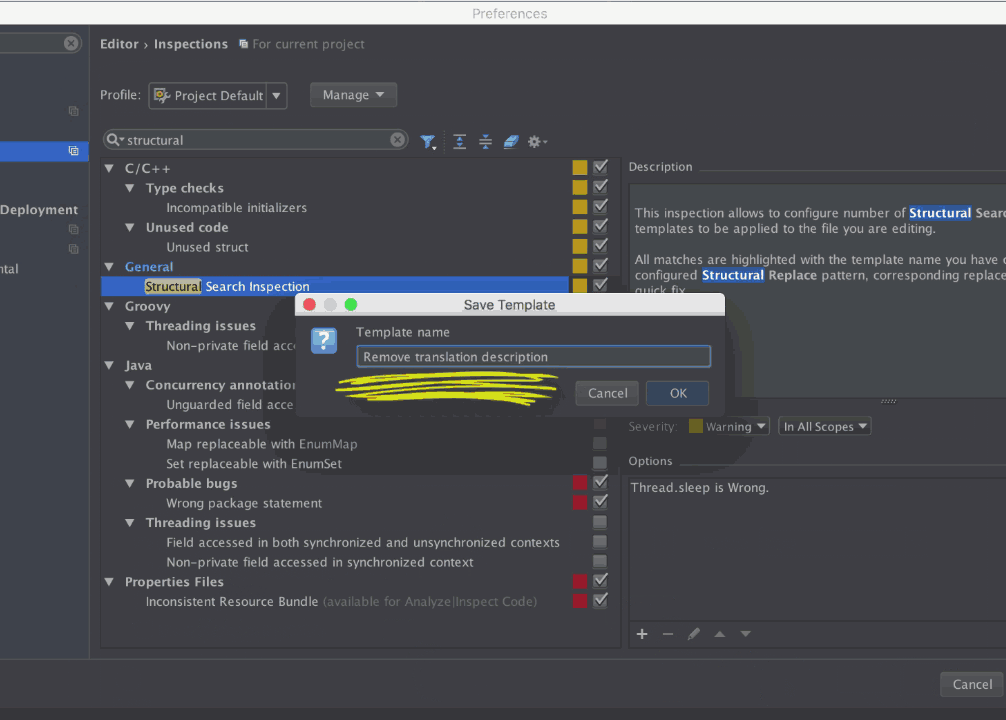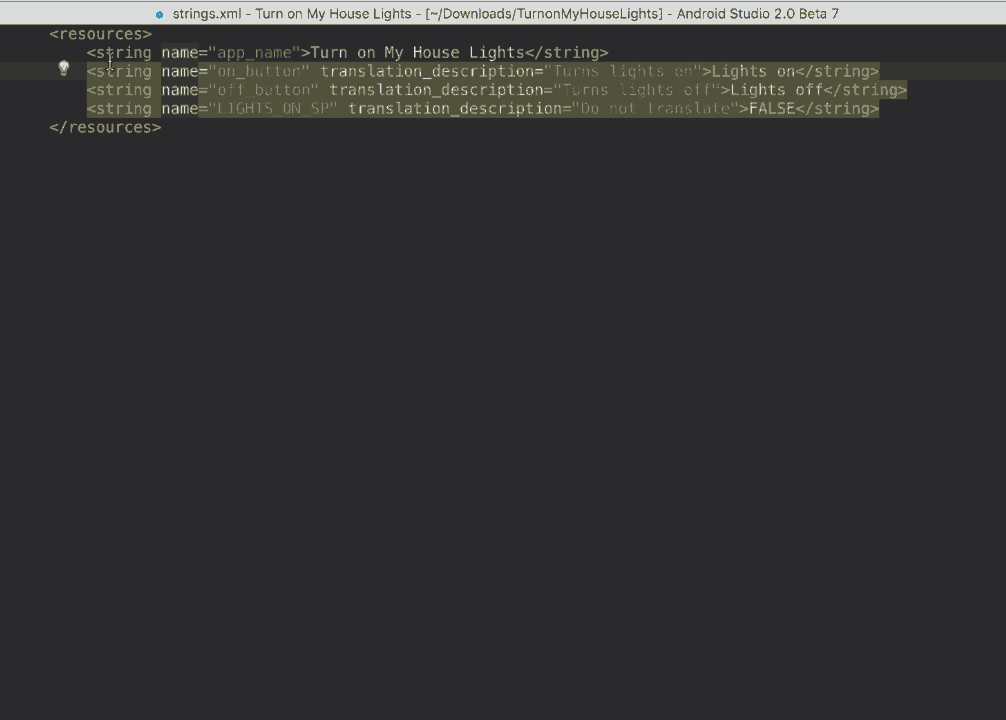 \n更有用的是可以使用快速修复来替换一些代码,例如一些废弃的代码或者你在`review`时发现的其他团队成员提交的一些普遍的错误。\n\n \t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio中进行ndk开发.md",
"content": "AndroidStudio中进行ndk开发\n===\n\n- 创建工程,声明`native`方法。 \n\t```java\n\tprivate native void startDaemon(String serviceName, int sdkVersion);\n\n static {\n System.loadLibrary(\"daemon\");\n }\n\t```\n\t\n\t\n- 生成`class`文件。 \n 执行`Build-Make Project`命令,生成`class`文件。所在目录为`app_path/build/intermediates/classes/debug`\n\n\n- 执行`javah`生成`.h文件` \n\t```\n\tC:\\Users\\Administrator>javah -help\n\t用法:\n\t javah [options] \n\t其中, [options] 包括:\n\t -o 输出文件 (只能使用 -d 或 -o 之一)\n\t -d 输出目录\n\t -v -verbose 启用详细输出\n\t -h --help -? 输出此消息\n\t -version 输出版本信息\n\t -jni 生成 JNI 样式的标头文件 (默认值)\n\t -force 始终写入输出文件\n\t -classpath 从中加载类的路径\n\t -cp 从中加载类的路径\n\t -bootclasspath 从中加载引导类的路径\n\t```\t\n\t在`Studio Terminal`中进入到`src/main`目录下执行`javah`命令: \n\t`javah -d jni -classpath ; `\n\t\n\t`F:\\DaemonService\\app\\src\\main>javah -d jni -classpath C:\\develop\\android-sdk-windows\\platforms\\android-22\\android.jar;..\\..\\build\\intermediates\\classes\\debug com.charonchui.daemonservice.service.DaemonService`\n\t执行完成后就会在`src/main/jni`目录下生成`com_charonchui_daemonservice_service_DaemonService.h`文件。\n\n- 在`module/src/main/jni`目录下创建对应的`.c`文件。\n\n\n\n- 配置`ndk`路径,在项目右键`Moudle Setting`中设置。 \n  \n\t\n- 在`build.gradle`中配置`ndk`选项 \n\n ```java\n\tandroid {\n\t\tcompileSdkVersion 23\n\t\tbuildToolsVersion \"23.0.1\"\n\n\t\tdefaultConfig {\n\t\t\tapplicationId \"com.charonchui.daemonservice\"\n\t\t\tminSdkVersion 8\n\t\t\ttargetSdkVersion 23\n\t\t\tversionCode 1\n\t\t\tversionName \"1.0\"\n\n\t\t\tndk {\n\t\t\t\tmoduleName \"uninstall_feedback\" // 配置so名字\n\t\t\t\tldLibs \"log\"\n\t// abiFilters \"armeabi\", \"x86\" // 默认就是全部的,加了配置才会生成选中的\n\t\t\t}\n\t\t}\n\t\tbuildTypes {\n\t\t\trelease {\n\t\t\t\tminifyEnabled false\n\t\t\t\tproguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'\n\t\t\t}\n\t\t}\n\t}\n\t```\n\t这里可能会出现错误: \n\t- `Error: NDK integration is deprecated in the current plugin. Consider trying the new experimental plugin. For details, see http://tools.android.com/tech-docs/new-build-system/gradle-experimental. Set \"android.useDeprecatedNdk=true\" in gradle.properties to continue using the current NDK integration.`\n\t 解决方法就是在`gradle.properties`文件中添加`android:useDeprecatedNdk=true`就可以了。\n\t- `Error:Execution failed for task ':app:compileDebugNdk'.\n\t\t> com.android.ide.common.process.ProcessException: org.gradle.process.internal.ExecException: Process 'command 'E:\\android-ndk-r10\\ndk-build.cmd'' finished with non-zero exit value 2`\n\t\t解决方法就是在`jni`目录建一个任意名字的`.c`空文件就可以了。\n\t\n- 执行Build \n\t然后就可以在`app/build/intermediates/ndk/debug/obj/local`下看到所有架构的`so`了。\n  \n\t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio使用教程(第一弹).md",
"content": "AndroidStudio使用教程(第一弹)\n===\n\n`Android Studio`是一套面世不久的`IDE`(即集成开发环境),免费向谷歌及`Android`的开发人员发放。`Android Studio`以`IntelliJ IDEA`为基础,\n旨在取代`Eclipse`和`ADT`(`Android`开发者工具)为开发者提供更好的开发工具。 \n运行相应速度、智能提示、布局文件适时多屏预览等都比`Eclipse`要强,但也不能说全部都是有点现在`Studio`中无法在一个窗口管理多个`Project`,\n每个`Project`都要打开一个窗口,或者是`close`当前的后再打开别的。\n\n当但是毕竟是预览版,所以只是暂时试用了下,并没有过多接触,开发中还是使用`Eclipse`。 \n经过一年多的沉淀,如果已到0.8.4版本,最近准备在工作用正式开始使用,所以看了下官网的教程。准备开始了。\n\n- 安装 \n 这个我就不多说了,大家都知道,官网下载安装即可。安装完成后界面和`Eclipse`有些类似,然后就新建一个`Project`,完成之后会发现一直在提示下载,\n\t这是在下载`Gradle`,大约二三十M的大小,由于伟大的防火墙,所以可能需要很长时间,这里就不教大家了,对程序猿来说不是难题,大家都会科学上网。\n\t\n- 区别 \n - 此`Project`非彼`Project`, `Android Studio`的目录结构(`Project`)代表一个`Workspace`,一个`Workspace`里面可以有多个`Module`,\n\t这里`Module`可以理解成`Eclipse`中的一个`Project`.\n\t`Project`代表一个完整的`Android app`,而`modules`则是`app`的一个组件,并且这个组件可以单独`build,test,debug`。`modules`可以分为下面几种: \n\t - Java library modules \n - Android library modules: 包含android相关代码和资源,最后生成AAR(Android ARchive)包 \n - Android application modules \n\t\t\n - 结构发生了变化,在`src`目录下有一个`main`的分组同时包含了`java`和`res`.\n\t 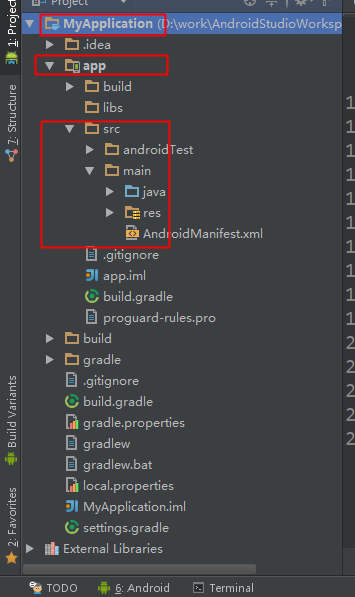 \n\t 如图:`MyApplication`就是`Project`,而`app`就是`Module`.\n\t\n- 设置 \n 进入后你会发现字体或样式等不符合你的习惯。 \n `Windows`下点击左上角`File` -> `Settings`进入设置页面(`Mac`下为 `Android Studio` -> `Preferences`),在搜索框搜`Font`找到`Colors&Font`下的`Font`选项,\n 我们会发现无法修改右侧字体大小。这里修改必须\n 要通过新建`Theme`进行修改的,点击`Save as`输入一个名字后,就可以修改字体了。\n \t\n\n\t这里可能有些人会发现我的主题是黑色的,和`IO`大会演示的一样,但是安装后默认是白色的,有些刺眼。这里可以通过设置页面中修改`Theme`来改变,\n\t默认是`Intellij`, 改为`Darcula`就是黑色的了.\n\t\n\t很酷有木有.\n\t\n- 运行 \n 设置好字体后,当然要走你了。 \n\t运行和`Eclipse`中比较像,点击绿色的箭头。 可以通过箭头左边的下拉菜单选择不同的`Module`,快捷键是`Shift+F10` \n\t\n\n `AndroidStudio`默认安装会启动模拟器,如果想让安装到真机上可以配置一下。在下拉菜单中选择`Edit Configurations`选择提示或者是`USB`设备。\n\t\t\n\t\t\n\t\n- 常用快捷键介绍 \n `AndroidStudio`中可以将快捷键设置成`Eclipse`中的快捷键。具体方法为在设置页面搜索`keymap`然后选择为`Eclipse`就可以了.\n\t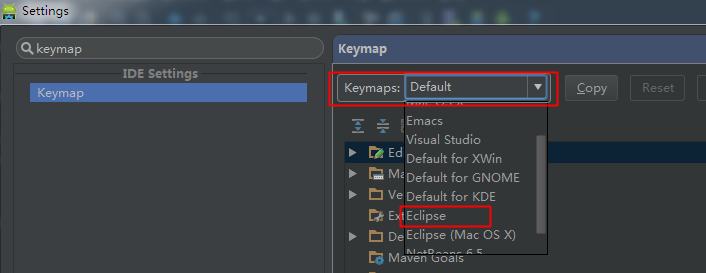\t\n\t\n\t强迫症的人伤不起,非想用默认的快捷键。 \n\t这里我整理下下个人常用的几个快捷键。 每个人的习惯不同,大家各取所需 \n\t`Ctrl+S` 开个玩笑,这个键算是彻底废掉了, 因为`AndroidStudio`与`Eclipse`不同,他是自动保存的,所以我们再也不需要`Ctrl+S`了. \n\n\t| 功能 | Windows | Mac |\n\t| ------------------------------------------------------------ |:-------------------------------------------:| --------------------------------------------:|\n\t| 代码提示 (同`Eclipse`中`Alt+/`) | `Ctrl+空格` | `Ctrl+空格` |\n\t| 查找文件 (同`Eclipse`中`Ctrl+Shift+R`) | `Ctrl+Shjft+N` | `双击Shift` |\n\t| 显示当前文件的结构 (同`Eclipse`中`Ctrl+0`) | `Ctrl+F12` | `Command+F12` |\n\t| 格式化 (同`Eclipse`中`Ctrl+Shift+F`) | `Ctrl+Alt+L` | `Command+Option+L` |\n\t| 优化导入的包 (同`Eclipse`中`Ctrl+Shift+O`) | `Ctrl+Alt+O` | `Ctrl+Option+O` |\n\t| 查看文档 (同`Eclipse`中`F2`) | `Ctrl+Q` | `F1` |\n\t| 查找使用位 (同`Eclipse`中`File Search`) | `Alt+F7` | `Option+F7` |\n\t| 上下移动代码 | `Alt+Shift+Up/Down` | `Option+Shift+Up/Down` |\n\t| 剪切当前行 | `Ctrl+X` | `Command+x` |\n\t| 删除当前行 | `Ctrl+Y` | `Command+Delete` |\t \n\t| 快速重写方法 override | `Ctrl+O` | `Ctrl+O` |\t \n\t| 折叠展开代码块 | `Ctrl+Plus/Minus` | `Command+Plus/Minus` |\t \t \n\t| 折叠展开全部代码块 | `Ctrl+Shift+Plus/Minus` | `Command+Shift+Plus/Minus` |\t \n\t| 大小写转换 | `Ctrl+Shift+U` | `Command+Shift+U` |\t \t\t \n\t| 新建文件或生成代码(`GetSet`) | `Alt+Insert` | `Command+N` |\n\t| 快速修复(同`Eclipse`中`F1`) | `Alt+Enter` | `Option+Enter` |\n\t| 显示方法参数 | `Ctrl+P` | `Command+P` |\t \n\t| 运行项目 | `Shift+F10` | `Ctrl+R` |\t\t\t\t \n\t| 跳转到上次修改的地方 | `Ctrl+Shift+Backspace` | `Command+Shift+Backspace` |\t \n\t| 快捷生成结构体(加try catch等) | `Ctrl+Alt+T` | `Command+Option+T` |\t \n\t| 显示最近编辑列表 | `Ctrl+E` | `Command+E` |\t \n\t| 跳转到大括号开头或结尾 | `Ctrl+{或}` | ..... |\t \n\t| 在方法间移动 | `Alt+↑或↓` | `Ctrl+↑或↓` |\t \n\t| 切换已打开的文件视图 | `Alt+←或→` | `Ctrl+←或→` |\t \n\t| 重命名 | `Shift+F6` | `Shift+F6` |\t \n\t| 直接进入源码 | `F4` | |\t \n\t| 快速打开该类或方法(与F4虽然大部分情况下相同,但他俩不一样) | `Ctrl+B`如在布局文件上点会直接进入布局文件 | `Command+B` |\n\t| 快速定位到文件错误或警告位置 | `F2` | `F2` |\t \n\t| 在当前位置复制当前行 | `Ctrl+D` | `Command+D` |\t \n\t| 选中两个文件或目录后进行比较(活生生一个简单的BeyondCompare) | `Ctrl+D` | `Command+D` |\t \n\t| 开关`Project`视图 | `Alt+1` | `Command+1` |\t \n\t| 关闭当前窗口 | `Ctrl+_F4` | `Command+W` |\t \n\t| 实现接口方法 implement | `Ctrl+I` | `Ctrl+I` |\n\t| 抽象方法查看具体有哪些实现类 | `Ctrl+Alt+B` | `Command+Option+B` |\n\t| 单行注释 | `Ctrl+/` | `Command+/` |\n\t| 多行注释 | `Ctrl+Shit+/` | `Command+Option+/` |\t \n\t| 复制,如果当前行没有选中内容就复制当前行 | `Ctrl+C` | `Command+C` |\t \n\t| 打开该类的关系图,查看该类的继承或实现 | `Ctrl+H` | `Ctrl+H` |\t \t \n\t| 提示代码缩写,如so后点击提示System.out.print等 | `Ctrl+J` | `Command+J` |\t \n\t| 进入父类方法的实现 UP | `Ctrl+U` | `Command+U` |\t \t\t \n\t| 抽取某一个块代码为单独的变量或者方法 | `Ctrl+Alt+V` | `Command+Option+V` 方法是`Command+Option+M` |\t \n\t| 选择最近所有复制过内容的列表 | `Ctrl+Shift+V` | `Command+Shift+V` |\n\t| 通过卡片的方式,直接查看该方法的具体内容或者图片 | `Ctrl+Shift+I` | `Option+Space` |\n\t| 全局搜索 | `Ctrl+Shift+F` | `Command+Shift+F` |\t \n | 上一步、下一步 | `` | `Command+[或]` |\t \n | 高亮所有相同变量 | `Ctrl+Shift+F7` | `Command+Shift+F7` |\n | 方法调用层级弹窗 | `Ctrl+Alt+H` | `Control+Option+H` |\t\n|书签(在当前行打上书签) | `F11` | `F3` | \n|展示书签 | `Shift+F11` | `Command+F3` | \n|整行代码上下移动 | `Alt+Shift++↑或↓` | `Option+Shift+↑或↓` | \n|搜索设置操作命令 | `Ctrl+Shift+A` | `Command+Shift+A` |\n\n\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio使用教程(第七弹).md",
"content": "AndroidStudio使用教程(第七弹)\n===\n\n本文讲解一下`Gradle`的应用,大家都知道`Gradle`使用起来非常方便,那他究竟方便在哪里? \n\n- 很多时候我们在打印`Log`日志的时候都是需要在`Debug`版本中进行打印,而在正式版本中关闭。\n 通常我们都是用一个`Config`文件来配置,不知道大家有没有遇到过正式版中忘记关闭`Log`日志的情况。\n- 多渠道包非常让人头疼。现在国内市场这么多。一个个的打多麻烦,虽然我们会用友盟打包工具等。\n 怎么破?\n \n\n先把项目中的`build.gradle`展现一下,然后慢慢分析。\n```xml\napply plugin: 'com.android.application'\n\nandroid {\n compileSdkVersion 22\n buildToolsVersion \"22.0.1\"\n\n defaultConfig {\n applicationId \"com.charon.*\"\n minSdkVersion 11\n targetSdkVersion 22\n versionCode 1\n versionName \"1.0\"\n\n multiDexEnabled true\n // default umeng channel name\n manifestPlaceholders = [UMENG_CHANNEL_VALUE: \"umeng\"]\n }\n\n signingConfigs {\n debug {\n storeFile file(\"debug.keystore\")\n }\n\n release {\n storeFile file(\"keystore.keystore\")\n storePassword \"android\"\n keyAlias \"androiddebugkey\"\n keyPassword \"android\"\n }\n }\n\n buildTypes {\n debug {\n versionNameSuffix \"-debug\"\n minifyEnabled false\n zipAlignEnabled false\n shrinkResources false\n signingConfig signingConfigs.debug\n }\n\n release {\n zipAlignEnabled true\n // remove unused resources\n shrinkResources true\n minifyEnabled true\n proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'\n signingConfig signingConfigs.release\n }\n }\n\n productFlavors {\n xiaomi {}\n _360 {}\n baidu {}\n qq {}\n }\n\n productFlavors.all {\n // change UMENG_CHANNEL_VALUE to the product channel name\n flavor -> flavor.manifestPlaceholders = [UMENG_CHANNEL_VALUE: name]\n }\n\n lintOptions {\n // if true, stop the gradle build if errors are found\n abortOnError false\n\n // set to true to turn off analysis progress reporting by lint\n // quiet true\n // if true, only report errors\n// ignoreWarnings true\n // if true, emit full/absolute paths to files with errors (true by default)\n //absolutePaths true\n // if true, check all issues, including those that are off by default\n// checkAllWarnings true\n // if true, treat all warnings as errors\n// warningsAsErrors true\n // turn off checking the given issue id's\n// disable 'TypographyFractions','TypographyQuotes'\n // turn on the given issue id's\n// enable 'RtlHardcoded','RtlCompat', 'RtlEnabled'\n // check *only* the given issue id's\n// check 'NewApi', 'InlinedApi'\n // if true, don't include source code lines in the error output\n// noLines true\n // if true, show all locations for an error, do not truncate lists, etc.\n// showAll true\n // Fallback lint configuration (default severities, etc.)\n lintConfig file(\"default-lint.xml\")\n // if true, generate a text report of issues (false by default)\n// textReport true\n // location to write the output; can be a file or 'stdout'\n// textOutput 'stdout'\n // if true, generate an XML report for use by for example Jenkins\n// xmlReport false\n // file to write report to (if not specified, defaults to lint-results.xml)\n// xmlOutput file(\"lint-report.xml\")\n // if true, generate an HTML report (with issue explanations, sourcecode, etc)\n// htmlReport true\n // optional path to report (default will be lint-results.html in the builddir)\n// htmlOutput file(\"lint-report.html\")\n\n // set to true to have all release builds run lint on issues with severity=fatal\n // and abort the build (controlled by abortOnError above) if fatal issues are found\n// checkReleaseBuilds true\n // Set the severity of the given issues to fatal (which means they will be\n // checked during release builds (even if the lint target is not included)\n// fatal 'NewApi', 'InlineApi'\n // Set the severity of the given issues to error\n// error 'Wakelock', 'TextViewEdits'\n // Set the severity of the given issues to warning\n// warning 'ResourceAsColor'\n // Set the severity of the given issues to ignore (same as disabling the check)\n// ignore 'TypographyQuotes'\n }\n\n compileOptions {\n sourceCompatibility JavaVersion.VERSION_1_7\n targetCompatibility JavaVersion.VERSION_1_7\n }\n\n applicationVariants.all { variant ->\n variant.outputs.each { output ->\n def outputFile = output.outputFile\n if (outputFile != null && outputFile.name.endsWith('.apk')) {\n def fileName = outputFile.name.replace(\".apk\", \"-${defaultConfig.versionName}.apk\")\n output.outputFile = new File(outputFile.parent, fileName)\n }\n }\n }\n}\n\ndependencies {\n compile fileTree(dir: 'libs', include: ['*.jar'])\n compile project(':libraries:framework')\n // square leakcanary\n debugCompile 'com.squareup.leakcanary:leakcanary-android:1.3.1'\n releaseCompile 'com.squareup.leakcanary:leakcanary-android-no-op:1.3.1'\n}\n\nrepositories {\n mavenCentral()\n maven{\n url \"[maven reposity path]\"\n }\n}\n\n\n```\n\t \n\n下面来详细讲几个地方:\n\n```xml\napply plugin: 'com.android.application'\n\nandroid {\n ...\n defaultConfig {\n // 支持方法数超过65536后的处理\n multiDexEnabled true\n // 这里就是上面提到的替换友盟统计中channel的值,下面这句话的意思就是默认值为umeng\n manifestPlaceholders = [UMENG_CHANNEL_VALUE: \"umeng\"]\n }\n\n\t// 签名操作\n signingConfigs {\n debug {\n\t\t // debug签名文件配置\n storeFile file(\"debug.keystore\")\n }\n\n release {\n\t\t // 正式版签名文件配置\n storeFile file(\"keystore.keystore\")\n storePassword \"android\"\n keyAlias \"androiddebugkey\"\n keyPassword \"android\"\n }\n }\n\n buildTypes {\n debug {\n\t\t // debug的签名处理\n versionNameSuffix \"-debug\"\n minifyEnabled false\n zipAlignEnabled false\n shrinkResources false\n signingConfig signingConfigs.debug\n }\n\n release {\n\t\t // 正式版签名处理\n zipAlignEnabled true\n // remove unused resources\n shrinkResources true\n\t\t\t// proguard 混淆\n minifyEnabled true\n proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'\n signingConfig signingConfigs.release\n }\n }\n\n\t// 多渠道打包\n productFlavors {\n xiaomi {}\n _360 {}\n baidu {}\n qq {}\n\t\tfree {\n\t\t // 当然这里还可以指定 applicationId 版本等这些内容,比如我们程序有一个收费版一个付费版,他俩的包名不同,这时候就可以通过这种方式来指定。\n\t\t\tapplicationId = 'com.test.test'\n versionName = '1.0'\n versionCode = 1\n\t\t}\n }\n\n productFlavors.all {\n // 统一将manifest中的UMENG_CHANNEL_VALUE值替换为上面productFlavors中对应的渠道名\n flavor -> flavor.manifestPlaceholders = [UMENG_CHANNEL_VALUE: name]\n }\n\n lintOptions {\n // if true, stop the gradle build if errors are found\n abortOnError false\n\n\t\t// 下面是一些其他的选项,一般都用不到\n // set to true to turn off analysis progress reporting by lint\n // quiet true\n // if true, only report errors\n// ignoreWarnings true\n // if true, emit full/absolute paths to files with errors (true by default)\n //absolutePaths true\n // if true, check all issues, including those that are off by default\n// checkAllWarnings true\n // if true, treat all warnings as errors\n// warningsAsErrors true\n // turn off checking the given issue id's\n// disable 'TypographyFractions','TypographyQuotes'\n // turn on the given issue id's\n// enable 'RtlHardcoded','RtlCompat', 'RtlEnabled'\n // check *only* the given issue id's\n// check 'NewApi', 'InlinedApi'\n // if true, don't include source code lines in the error output\n// noLines true\n // if true, show all locations for an error, do not truncate lists, etc.\n// showAll true\n // Fallback lint configuration (default severities, etc.)\n lintConfig file(\"default-lint.xml\")\n // if true, generate a text report of issues (false by default)\n// textReport true\n // location to write the output; can be a file or 'stdout'\n// textOutput 'stdout'\n // if true, generate an XML report for use by for example Jenkins\n// xmlReport false\n // file to write report to (if not specified, defaults to lint-results.xml)\n// xmlOutput file(\"lint-report.xml\")\n // if true, generate an HTML report (with issue explanations, sourcecode, etc)\n// htmlReport true\n // optional path to report (default will be lint-results.html in the builddir)\n// htmlOutput file(\"lint-report.html\")\n\n // set to true to have all release builds run lint on issues with severity=fatal\n // and abort the build (controlled by abortOnError above) if fatal issues are found\n// checkReleaseBuilds true\n // Set the severity of the given issues to fatal (which means they will be\n // checked during release builds (even if the lint target is not included)\n// fatal 'NewApi', 'InlineApi'\n // Set the severity of the given issues to error\n// error 'Wakelock', 'TextViewEdits'\n // Set the severity of the given issues to warning\n// warning 'ResourceAsColor'\n // Set the severity of the given issues to ignore (same as disabling the check)\n// ignore 'TypographyQuotes'\n }\n\n\t// 可以指定用具体哪个JDK版本来进行编译\n compileOptions {\n sourceCompatibility JavaVersion.VERSION_1_7\n targetCompatibility JavaVersion.VERSION_1_7\n }\n\n\t// 更改生成的apk文件名字,方便区分多渠道\n applicationVariants.all { variant ->\n variant.outputs.each { output ->\n def outputFile = output.outputFile\n if (outputFile != null && outputFile.name.endsWith('.apk')) {\n def fileName = outputFile.name.replace(\".apk\", \"-${defaultConfig.versionName}.apk\")\n output.outputFile = new File(outputFile.parent, fileName)\n }\n }\n }\n}\n\ndependencies {\n compile fileTree(dir: 'libs', include: ['*.jar'])\n compile project(':libraries:framework')\n // square leakcanary\n debugCompile 'com.squareup.leakcanary:leakcanary-android:1.3.1'\n releaseCompile 'com.squareup.leakcanary:leakcanary-android-no-op:1.3.1'\n}\n\nrepositories {\n //从中央库里面获取依赖\n mavenCentral()\n //或者使用指定的本地maven 库\n maven{\n url \"file://F:/githubrepo/releases\"\n }\n //或者使用指定的远程maven库\n maven{\n url \"远程库地址\"\n }\n}\n\n上面`build.gradle`中的配置基本就是这些,那么`manifest`中的清单文件该如何对`umeng`渠道进行修改呢? \n```xml\n \n \n \n \n \n\n \n /.gradle/ (Linux)`\n - `/Users//.gradle/ (Mac)`\n - `C:\\Users\\\\.gradle (Windows)`\n\n 文件的内容为: \n ```\n org.gradle.daemon=true\n org.gradle.parallel=true\n ```\n \n 经过上面的这一步修改是对所有工程都有效果的,如果你只想对某一个工程配置的话,那就在该工程目录下的`gralde.properties`中进行配置。\n ```\n # Project-wide Gradle settings.\n \n # IDE (e.g. Android Studio) users:\n # Gradle settings configured through the IDE *will override*\n # any settings specified in this file.\n \n # For more details on how to configure your build environment visit\n # http://www.gradle.org/docs/current/userguide/build_environment.html\n \n # Specifies the JVM arguments used for the daemon process.\n # The setting is particularly useful for tweaking memory settings.\n # Default value: -Xmx10248m -XX:MaxPermSize=256m\n # org.gradle.jvmargs=-Xmx2048m -XX:MaxPermSize=512m -XX:+HeapDumpOnOutOfMemoryError -Dfile.encoding=UTF-8\n \n # When configured, Gradle will run in incubating parallel mode.\n # This option should only be used with decoupled projects. More details, visit\n # http://www.gradle.org/docs/current/userguide/multi_project_builds.html#sec:decoupled_projects\n # org.gradle.parallel=true\n ```\n 打开时默认如上。我们给加添加上面的配置就好。\n \n 当然你也可以通过`Studio`的设置中进行修改。 \n 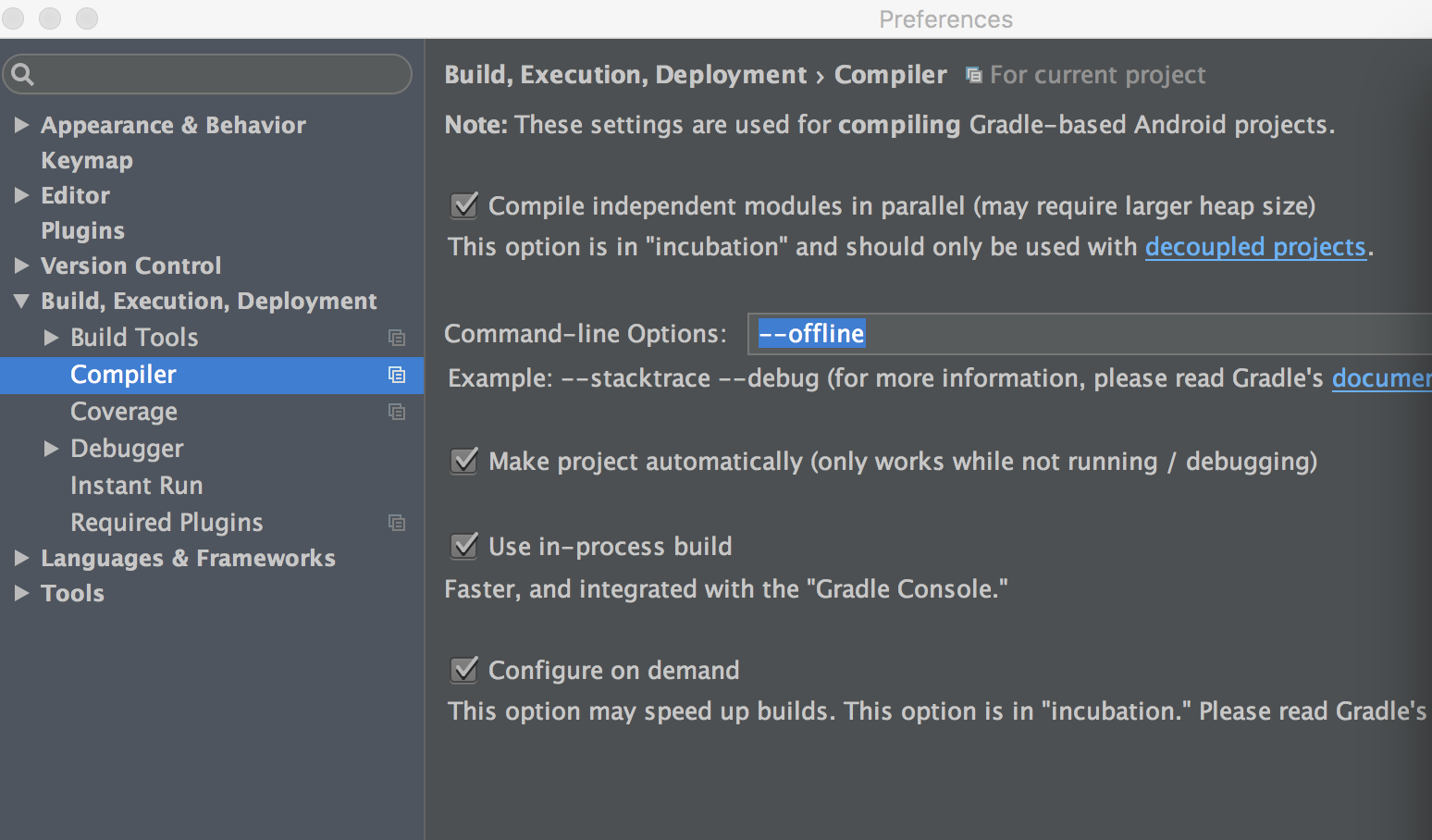\n\n\n- 使用`offline`模式 \n \n 下一步就是开始`offline`模式,因为我们经常会在`gradle`中使用一下依赖库时用`+`这样的话就能保证你的依赖库是最新的版本,但是这样在每次`build`的时候都会去检查是不是最新的版本,所以就会耗时。 \n 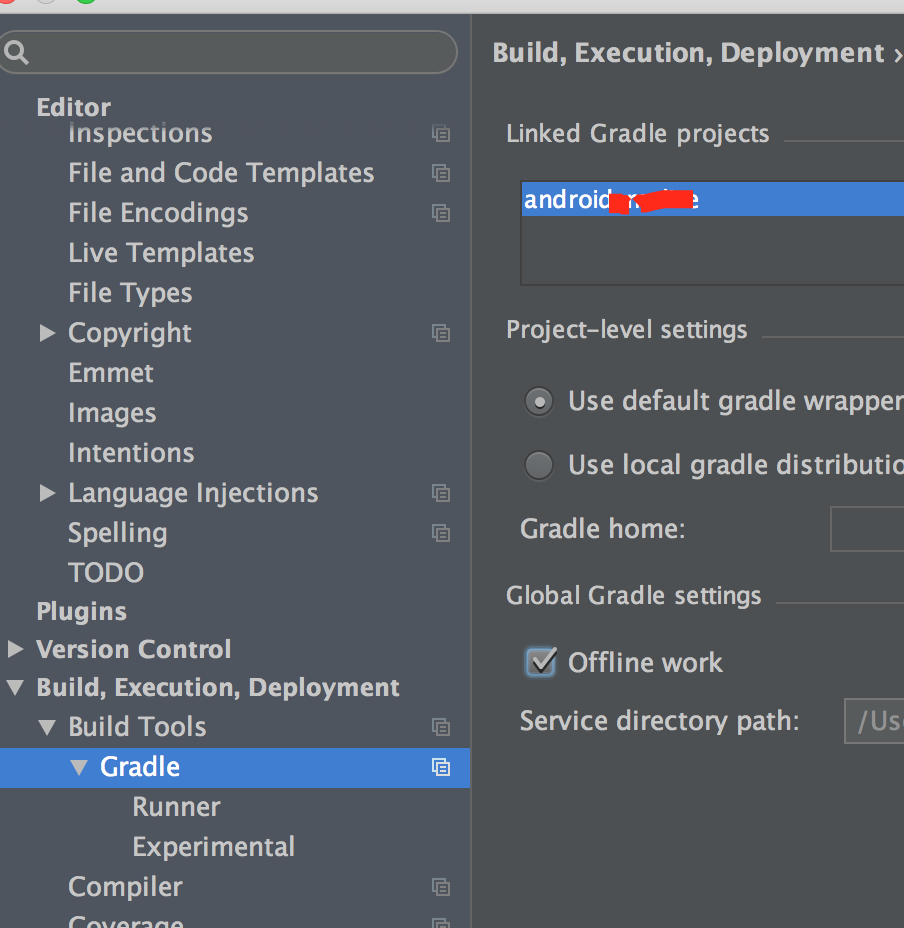\n\n 在开发过程中是不建议使用动态版本的,在`Studio`中使用动态版本的`gradle`中间中使用`ALT+ENTER`键进行修复。\n \n 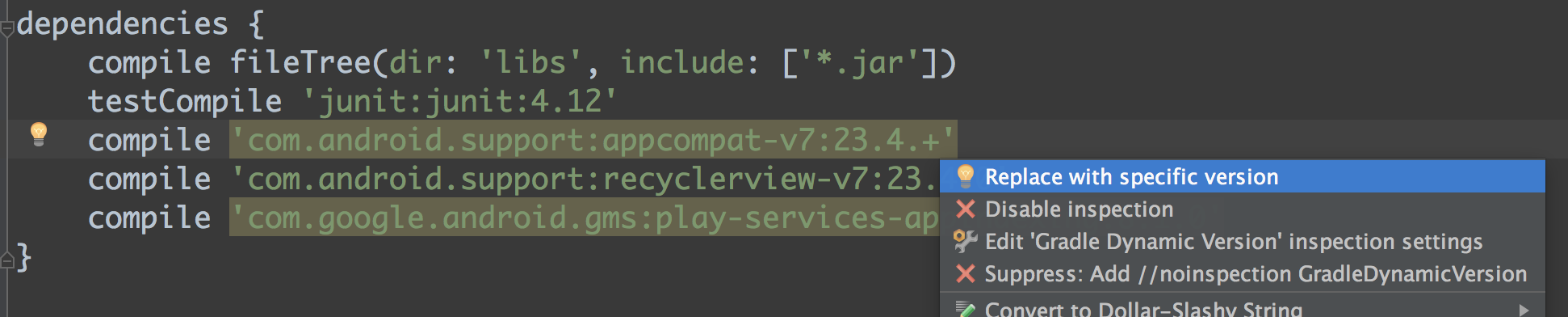\n 详细有关为什么不要使用动态版本的介绍,请参考[Don't use dynamic versions for your dependencies](http://blog.danlew.net/2015/09/09/dont-use-dynamic-versions-for-your-dependencies/)\n\n- 增加内存使用`SSD` \n 首先是增大内存, `Mac`中在`Applications`中找到`Sutio`然后右键显示包内容`Contents/bin/studio.vmoptions`。\n 打开该文件后修改就可以了,我是的是: \n ```\n #\n # *DO NOT* modify this file directly. If there is a value that you would like to override,\n # please add it to your user specific configuration file.\n #\n # See http://tools.android.com/tech-docs/configuration\n #\n -Xms1024m\n -Xmx4096m\n -XX:MaxPermSize=768m\n -XX:ReservedCodeCacheSize=768m\n -XX:+UseCompressedOops\n ```\n 我没看见`DO NOT`的提示- -!\n \n - Xms 是JVN启动起始时的堆内存,堆内存是分配给对象的内容。\n - Xmx 是能使用的最大堆内存。\n\n\n- 使用`Instant Run` \n \n `Instantt Run`放在这里说可能不合适,但是用他确实能大大的减少运行时间。 \n 如果还不了解的话可以参考[Instant Run](http://tools.android.com/tech-docs/instant-run) \n \n\t\t\n---\n\n- 邮箱 :charon.chui@gmail.com \n- Good Luck! "
},
{
"path": "docs/android/AndroidNote/Android基础/Activity详细解析.md",
"content": "# Activity是什么?\n\n我们都知道android中有四大组件(Activity 活动,Service 服务,Content Provider 内容提供者,BroadcastReceiver 广播接收器),Activity是我们用的最多也是最基本的组件,因为应用的所有操作都与用户相关,Activity 提供窗口来和用户进行交互。\n\n官方文档这么说:\n \n\n> An activity is a single, focused thing that the user can do. Almost all activities interact with the user, so the Activity class takes care of creating a window for you in which you can place your UI with setContentView(View). \n> \n> \n> 大概的意思:\n\n>activity是独立平等的,用来处理用户操作。几乎所有的activity都是用来和用户交互的,所以activity类会创建了一个窗口,开发者可以通过setContentView(View)的接口把UI放到给窗口上。\n\n Android中的activity全都归属于task管理 。task 是多个 activity 的集合,这些 activity 按照启动顺序排队存入一个栈(即“back stack”)。android默认会为每个App维持一个task来存放该app的所有activity,task的默认name为该app的packagename。\n\n 当然我们也可以在AndroidMainfest.xml中申明activity的taskAffinity属性来自定义task,但不建议使用,如果其他app也申明相同的task,它就有可能启动到你的activity,带来各种安全问题(比如拿到你的Intent)。\n\n#Activity的内部调用过程\n\n 上面已经说了,系统通过堆栈来管理activity,当一个新的activity开始时,它被放置在堆栈的顶部和成为运行活动,以前的activity始终保持低于它在堆栈,而不会再次到达前台,直到新的活动退出。\n\n 还是上这张官网的activity_lifecycle图:\n  \n\n \n\n - 首先打开一个新的activity实例的时候,系统会依次调用\n\n> onCreate() -> onStart() -> onResume() 然后开始running\n\n running的时候被覆盖了(从它打开了新的activity或是被锁屏,但是它**依然在前台**运行, lost focus but is still visible),系统调用onPause();\n\n \n> 该方法执行activity暂停,通常用于提交未保存的更改到持久化数据,停止动画和其他的东西。但这个activity还是完全活着(它保持所有的状态和成员信息,并保持连接到**窗口管理器**)\n\n接下来它有三条出路\n①用户返回到该activity就调用onResume()方法重新running \n\n②用户回到桌面或是打开其他activity,就会调用onStop()进入停止状态(保留所有的状态和成员信息,**对用户不可见**)\n\n③系统内存不足,拥有更高限权的应用需要内存,那么该activity的进程就可能会被系统回收。(回收onRause()和onStop()状态的activity进程)要想重新打开就必须重新创建一遍。\n\n如果用户返回到onStop()状态的activity(又显示在前台了),系统会调用\n\n> onRestart() -> onStart() -> onResume() 然后重新running\n\n在activity结束(调用finish ())或是被系统杀死之前会调用onDestroy()方法释放所有占用的资源。\n\n\n> activity生命周期中三个嵌套的循环\n\n \n\n - activity的完整生存期会在 onCreate() 调用和 onDestroy() 调用之间发生。 \n \n - activity的可见生存期会在 onStart() 调用和 onStop() 调用之间发生。系统会在activity的整个生存期内多次调用 onStart() 和onStop(), 因为activity可能会在显示和隐藏之间不断地来回切换。 \n \n - activity的前后台切换会在 onResume() 调用和 onPause() 之间发生。\n 因为这个状态可能会经常发生转换,为了避免切换迟缓引起的用户等待,这两个方法中的代码应该相当地轻量化。\n\n## activity被回收的状态和信息保存和恢复过程\n\n```\npublic class MainActivity extends Activity {\n\n\t@Override\n\tprotected void onCreate(Bundle savedInstanceState) {\n\t\tif(savedInstanceState!=null){ //判断是否有以前的保存状态信息\n\t\t\t savedInstanceState.get(\"Key\"); \n\t\t\t }\n\t\tsuper.onCreate(savedInstanceState);\n\t\tsetContentView(R.layout.activity_main);\n\t}\n @Override\nprotected void onSaveInstanceState(Bundle outState) {\n\t// TODO Auto-generated method stub\n\t //可能被回收内存前保存状态和信息,\n\t Bundle data = new Bundle(); \n\t data.putString(\"key\", \"last words before be kill\");\n\t outState.putAll(data);\n\tsuper.onSaveInstanceState(outState);\n}\n @Override\nprotected void onRestoreInstanceState(Bundle savedInstanceState) {\n\t// TODO Auto-generated method stub\n\t if(savedInstanceState!=null){ //判断是否有以前的保存状态信息\n\t\t\t savedInstanceState.get(\"Key\"); \n\t\t\t }\n\tsuper.onRestoreInstanceState(savedInstanceState);\n}\n}\n```\n\n> onSaveInstanceState方法\n\n 在activity 可能被回收之前 调用,用来保存自己的状态和信息,以便回收后重建时恢复数据(在onCreate()或onRestoreInstanceState()中恢复)。旋转屏幕重建activity会调用该方法,但其他情况在onRause()和onStop()状态的activity不一定会调用 ,下面是该方法的文档说明。\n\n\n> One example of when onPause and onStop is called and not this method is when a user navigates back from activity B to activity A: there is no need to call onSaveInstanceState on B because that particular instance will never be restored, so the system avoids calling it. An example when onPause is called and not onSaveInstanceState is when activity B is launched in front of activity A: the system may avoid calling onSaveInstanceState on activity A if it isn't killed during the lifetime of B since the state of the user interface of A will stay intact. \n\n\n也就是说,系统灵活的来决定调不调用该方法,**但是如果要调用就一定发生在onStop方法之前,但并不保证发生在onPause的前面还是后面。**\n\n> onRestoreInstanceState方法\n\n 这个方法在onStart 和 onPostCreate之间调用,在onCreate中也可以状态恢复,但有时候需要所有布局初始化完成后再恢复状态。\n\n onPostCreate:一般不实现这个方法,当程序的代码开始运行时,它调用系统做最后的初始化工作。\n\n# 启动模式\n\n## 启动模式什么?\n \n 简单的说就是定义activity 实例与task 的关联方式。\n \n## 为什么要定义启动模式? \n\n 为了实现一些默认启动(standard)模式之外的需求:\n \n\n - 让某个 activity 启动一个新的 task (而不是被放入当前 task )\n \n - 让 activity 启动时只是调出已有的某个实例(而不是在 back stack 顶创建一个新的实例) \n \n - 或者,你想在用户离开 task 时只保留根 activity,而 back stack 中的其它 activity 都要清空\n\n##怎样定义启动模式?\n\n 定义启动模式的方法有两种:\n\n### 使用 manifest 文件\n\n 在 manifest 文件中activity声明时,利用 activity 元素的 launchMode 属性来设定 activity 与 task 的关系。\n\n \n\n```\n \n .......\n \n```\n\n> 注意: 你用 launchMode 属性为 activity 设置的模式可以被启动 activity 的 intent 标志所覆盖。\n\n####有哪些启动模式?\n\n\n - \"standard\" (默认模式) \n \n 当通过这种模式来启动Activity时, Android总会为目标 Activity创建一个新的实例,并将该Activity添加到当前Task栈中。这种方式不会启动新的Task,只是将新的 Activity添加到原有的Task中。 \n \n - \"singleTop\" \n \n 该模式和standard模式基本一致,但有一点不同:当将要被启动的Activity已经位于Task栈顶时,系统不会重新创建目标Activity实例,而是直接复用Task栈顶的Activity。\n \n - \"singleTask\"\n\n Activity在同一个Task内只有一个实例。\n \n 如果将要启动的Activity不存在,那么系统将会创建该实例,并将其加入Task栈顶; \n\n 如果将要启动的Activity已存在,且存在栈顶,直接复用Task栈顶的Activity。 \n\n 如果Activity存在但是没有位于栈顶,那么此时系统会把位于该Activity上面的所有其他Activity全部移出Task,从而使得该目标Activity位于栈顶。\n\n - \"singleInstance\" \n\n 无论从哪个Task中启动目标Activity,只会创建一个目标Activity实例且会用一个全新的Task栈来装载该Activity实例(全局单例).\n\n 如果将要启动的Activity不存在,那么系统将会先创建一个全新的Task,再创建目标Activity实例并将该Activity实例放入此全新的Task中。\n\n 如果将要启动的Activity已存在,那么无论它位于哪个应用程序,哪个Task中;系统都会把该Activity所在的Task转到前台,从而使该Activity显示出来。\n\n### 使用 Intent 标志\n\n 在要启动 activity 时,你可以在传给 startActivity() 的 intent 中包含相应标志,以修改 activity 与 task 的默认关系。\n\n \n\n```\n Intent i = new Intent(this,NewActivity.class);\n\t\ti.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);\n\t\tstartActivity(i);\n```\n\n#### 可以通过标志修改的默认模式有哪些?\n\n \n\n - FLAG_ACTIVITY_NEW_TASK\n\n 与\"singleTask\"模式相同,在新的 task 中启动 activity。如果要启动的 activity 已经运行于某 task 中,则那个 task 将调入前台。\n\n - FLAG_ACTIVITY_SINGLE_TOP\n\n 与 \"singleTop\"模式相同,如果要启动的 activity位于back stack 顶,系统不会重新创建目标Activity实例,而是直接复用Task栈顶的Activity。\n\n - FLAG_ACTIVITY_CLEAR_TOP\n\n **此种模式在launchMode中没有对应的属性值。**如果要启动的 activity 已经在当前 task 中运行,则不再启动一个新的实例,且所有在其上面的 activity 将被销毁。\n\n#### 关于启动模式的一些建议\n\n 一般不要改变 activity 和 task 默认的工作方式。 如果你确定有必要修改默认方式,请保持谨慎,并确保 activity 在启动和从其它 activity 返回时的可用性,多做测试和安全方面的工作。\n\n\n# Intent Filter\n\n android的3个核心组件——Activity、services、广播接收器——是通过intent传递消息的。intent消息用于在运行时绑定不同的组件。\n 在 Android 的 AndroidManifest.xml 配置文件中可以通过 intent-filter 节点为一个 Activity 指定其 Intent Filter,以便告诉系统该 Activity 可以响应什么类型的 Intent。\n\n## intent-filter 的三大属性\n\n### Action \n\n 一个 Intent Filter 可以包含多个 Action,Action 列表用于标示 Activity 所能接受的“动作”,它是一个用户自定义的字符串。\n\n \n\n```\n \n \n```\n\n在代码中使用以下语句便可以启动该Intent 对象:\n\n```\nIntent i=new Intent(); \ni.setAction(\"com.scu.amazing7Action\");\n```\nAction 列表中包含了“com.scu.amazing7Action”的 Activity 都将会匹配成功\n\n### URL\n\n 在 intent-filter 节点中,通过 data节点匹配外部数据,也就是通过 URI 携带外部数据给目标组件。\n\n \n\n```\n\n```\n注意:只有data的所有的属性都匹配成功时 URI 数据匹配才会成功\n\n### Category \n\n 为组件定义一个 类别列表,当 Intent 中包含这个类别列表的所有项目时才会匹配成功。\n\n```\n\n \n```\n\n## Activity 种 Intent Filter 的匹配过程\n\n ①加载所有的Intent Filter列表\n ②去掉action匹配失败的Intent Filter\n ③去掉url匹配失败的Intent Filter\n ④去掉Category匹配失败的Intent Filter\n ⑤判断剩下的Intent Filter数目是否为0。如果为0查找失败返回异常;如果大于0,就按优先级排序,返回最高优先级的Intent Filter\n\n\n\n# 开发中Activity的一些问题\n\n - \n\n 一般设置Activity为非公开的\n\n \n\n```\n 顺便给大家介绍一款,比较不错的剪裁工具:ucrop\n\n> 链接:https://github.com/Yalantis/uCrop\n\n这款工具,特别的小巧,自定义功能非常强,我在项目中是这样用的:\n\n````\npublic static String startUCrop(Activity activity, String sourceFilePath,\n int requestCode, float aspectRatioX, float aspectRatioY) {\n Uri sourceUri = Uri.fromFile(new File(sourceFilePath));\n File outDir = Environment.getExternalStoragePublicDirectory(Environment.DIRECTORY_PICTURES);\n if (!outDir.exists()) {\n outDir.mkdirs();\n }\n File outFile = new File(outDir, System.currentTimeMillis() + \".jpg\");\n //裁剪后图片的绝对路径\n String cameraScalePath = outFile.getAbsolutePath();\n Uri destinationUri = Uri.fromFile(outFile);\n //初始化,第一个参数:需要裁剪的图片;第二个参数:裁剪后图片\n UCrop uCrop = UCrop.of(sourceUri, destinationUri);\n //初始化UCrop配置\n UCrop.Options options = new UCrop.Options();\n //设置裁剪图片可操作的手势\n options.setAllowedGestures(UCropActivity.SCALE, UCropActivity.ROTATE, UCropActivity.ALL);\n //是否隐藏底部容器,默认显示\n options.setHideBottomControls(true);\n //设置toolbar颜色\n options.setToolbarColor(ActivityCompat.getColor(activity, R.color.colorPrimary));\n //设置状态栏颜色\n options.setStatusBarColor(ActivityCompat.getColor(activity, R.color.colorPrimary));\n //是否能调整裁剪框\n options.setFreeStyleCropEnabled(true);\n //UCrop配置\n uCrop.withOptions(options);\n //设置裁剪图片的宽高比,比如16:9\n uCrop.withAspectRatio(aspectRatioX, aspectRatioY);\n //uCrop.useSourceImageAspectRatio();\n //跳转裁剪页面\n uCrop.start(activity, requestCode);\n return cameraScalePath;\n }\n\n\n````\n\n\n\n\n\n\n看了图片之后,应该不用我说这个库有多强大了吧,通过简单的设置之后,可以轻松的实现图片的旋转啊,图片的缩放啊,和各种实用的操作,特别的实用。\n\n下面展示一下我们调用系统的拍照,和系统的相册的代码:\n\n````\n\n \t/**\n * 启动手机相册\n */\n \n private void fromGallery() {\n Intent intent = new Intent(Intent.ACTION_GET_CONTENT);\n intent.addCategory(Intent.CATEGORY_OPENABLE);\n intent.setType(\"image/*\");\n intent.putExtra(MediaStore.EXTRA_OUTPUT, Uri.fromFile(new File(Environment.getExternalStorageDirectory(), IMAGE_NAME)));\n\n if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) {\n startActivityForResult(intent, GALLERY_KITKAT_REQUEST);\n } else {\n startActivityForResult(intent, GALLERY_REQUEST);\n }\n }\n\n /**\n * 启动手机相机\n */\n private void fromCamera() {\n Intent intent = new Intent(MediaStore.ACTION_IMAGE_CAPTURE);\n if (FileUtil.hasSdcard()) {\n intent.putExtra(MediaStore.EXTRA_OUTPUT, Uri.fromFile(new File(Environment.getExternalStorageDirectory(), IMAGE_NAME)));\n startActivityForResult(intent, CAMERA_REQUEST);\n } else {\n Log.i(\"sys\", \"--lin--> SD not exist\");\n }\n }\n\n````\n\n\n````\n//如果我们采取的是,调用相册中的照片,我们只需要这样便可以获取到图片,并且直接加载到我们的第三方剪裁库里面。\nString url = getPath(ReleaseOrderActivity.this, data.getData());\nLog.i(\"lin\", \"----lin---- url :\" + url);\nstartUCrop(ReleaseOrderActivity.this, url, 1000, 300, 300);\n\n\n````\n\n````\n//如果我们采用的是调用系统的相机的话,采用这种方式便可以获取到照片,并且加载到我们的剪裁的工具里面啦。\nstartUCrop(ReleaseOrderActivity.this, Environment.getExternalStorageDirectory() + \"/\" + IMAGE_NAME, 1000, 300, 300);\n\n\n````\n\n\n当然,上面我们应用到了一个,getPath的方法,当然顾名思义嘛,就是要找到图片的所在位置,但是怕大家懒得自己写,在这里我就给出来:\n\n````\n\n //以下是关键,原本uri返回的是file:///...来着的,android4.4返回的是content:///...\n @SuppressLint(\"NewApi\")\n public static String getPath(final Context context, final Uri uri) {\n final boolean isKitKat = Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT;\n // DocumentProvider\n if (isKitKat && DocumentsContract.isDocumentUri(context, uri)) {\n // ExternalStorageProvider\n if (isExternalStorageDocument(uri)) {\n final String docId = DocumentsContract.getDocumentId(uri);\n final String[] split = docId.split(\":\");\n final String type = split[0];\n if (\"primary\".equalsIgnoreCase(type)) {\n return Environment.getExternalStorageDirectory() + \"/\" + split[1];\n }\n }\n // DownloadsProvider\n else if (isDownloadsDocument(uri)) {\n final String id = DocumentsContract.getDocumentId(uri);\n final Uri contentUri = ContentUris.withAppendedId(Uri.parse(\"content://downloads/public_downloads\"), Long.valueOf(id));\n return getDataColumn(context, contentUri, null, null);\n }\n // MediaProvider\n else if (isMediaDocument(uri)) {\n final String docId = DocumentsContract.getDocumentId(uri);\n final String[] split = docId.split(\":\");\n final String type = split[0];\n\n Uri contentUri = null;\n if (\"image\".equals(type)) {\n contentUri = MediaStore.Images.Media.EXTERNAL_CONTENT_URI;\n } else if (\"video\".equals(type)) {\n contentUri = MediaStore.Video.Media.EXTERNAL_CONTENT_URI;\n } else if (\"audio\".equals(type)) {\n contentUri = MediaStore.Audio.Media.EXTERNAL_CONTENT_URI;\n }\n\n final String selection = \"_id=?\";\n final String[] selectionArgs = new String[]{\n split[1]\n };\n return getDataColumn(context, contentUri, selection, selectionArgs);\n }\n }\n // MediaStore (and general)\n else if (\"content\".equalsIgnoreCase(uri.getScheme())) {\n // Return the remote address\n if (isGooglePhotosUri(uri)) {\n return uri.getLastPathSegment();\n }\n return getDataColumn(context, uri, null, null);\n }\n // File\n else if (\"file\".equalsIgnoreCase(uri.getScheme())) {\n return uri.getPath();\n }\n return null;\n }\n\n public static String getDataColumn(Context context, Uri uri, String selection, String[] selectionArgs) {\n Cursor cursor = null;\n final String column = \"_data\";\n final String[] projection = {column};\n\n try {\n cursor = context.getContentResolver().query(uri, projection, selection, selectionArgs, null);\n if (cursor != null && cursor.moveToFirst()) {\n final int index = cursor.getColumnIndexOrThrow(column);\n return cursor.getString(index);\n }\n } finally {\n if (cursor != null) {\n cursor.close();\n }\n }\n return null;\n }\n\n /**\n * @param uri The Uri to check.\n * @return Whether the Uri authority is ExternalStorageProvider.\n */\n public static boolean isExternalStorageDocument(Uri uri) {\n return \"com.android.externalstorage.documents\".equals(uri.getAuthority());\n }\n\n /**\n * @param uri The Uri to check.\n * @return Whether the Uri authority is DownloadsProvider.\n */\n public static boolean isDownloadsDocument(Uri uri) {\n return \"com.android.providers.downloads.documents\".equals(uri.getAuthority());\n }\n\n /**\n * @param uri The Uri to check.\n * @return Whether the Uri authority is MediaProvider.\n */\n public static boolean isMediaDocument(Uri uri) {\n return \"com.android.providers.media.documents\".equals(uri.getAuthority());\n }\n\n /**\n * @param uri The Uri to check.\n * @return Whether the Uri authority is Google Photos.\n */\n public static boolean isGooglePhotosUri(Uri uri) {\n return \"com.google.android.apps.photos.content\".equals(uri.getAuthority());\n }\n\n````\n\n好了,以上便是我们的解决方案了。\n\n>如果大家感觉总结的还不错,可以给我点个心,或者关注笔者一下~ 有什么问题,也随时欢迎大家留言和我讨论。\n"
},
{
"path": "docs/android/AndroidNote/Android基础/Android异步任务机制之AsycTask.md",
"content": "\n> 在Android中实现异步任务机制有两种方式,**Handler**和**AsyncTask**。 \n> \n> Handler已经在上一篇文章 [异步消息处理机制(Handler 、 Looper 、MessageQueue)源码解析](http://blog.csdn.net/amazing7/article/details/51424038#reply) 说过了。\n> \n> 本篇就说说AsyncTask的异步实现。\n\n\n## 1、什么时候使用 AsnyncTask\n\n 在上一篇文章已经说了,主线程主要负责控制UI页面的显示、更新、交互等。 为了有更好的用户体验,UI线程中的操作要求越短越好。\n\n 我们把耗时的操作(例如网络请求、数据库操作、复杂计算)放到单独的子线程中操作,以避免主线程的阻塞。但是在子线程中不能更新UI界面,这时候需要使用handler。\n\n 但如果耗时的操作太多,那么我们需要开启太多的子线程,这就会给系统带来巨大的负担,随之也会带来性能方面的问题。在这种情况下我们就可以考虑使用类AsyncTask来异步执行任务,不需要子线程和handler,就可以完成异步操作和刷新UI。\n\n\n 不要随意使用AsyncTask,除非你必须要与UI线程交互.默认情况下使用Thread即可,要注意需要将线程优先级调低.AsyncTask适合处理短时间的操作,长时间的操作,比如下载一个很大的视频,这就需要你使用自己的线程来下载,不管是断点下载还是其它的.\n\n## 2、AsnyncTask原理\n\n\n AsyncTask主要有二个部分:一个是与主线程的交互,另一个就是线程的管理调度。虽然可能多个AsyncTask的子类的实例,但是AsyncTask的内部Handler和ThreadPoolExecutor都是进程范围内共享的,其都是static的,也即属于类的,类的属性的作用范围是CLASSPATH,因为一个进程一个VM,所以是AsyncTask控制着进程范围内所有的子类实例。 \n\n AsyncTask内部会创建一个进程作用域的线程池来管理要运行的任务,也就就是说当你调用了AsyncTask的execute()方法后,AsyncTask会把任务交给线程池,由线程池来管理创建Thread和运行Therad。\n\n\n## 3、AsyncTask介绍\n Android的AsyncTask比Handler更轻量级一些(只是代码上轻量一些,而实际上要比handler更耗资源),适用于简单的异步处理。\n \n Android之所以有Handler和AsyncTask,都是为了不阻塞主线程(UI线程),因为UI的更新只能在主线程中完成,因此异步处理是不可避免的。\n\n AsyncTask:对线程间的通讯做了包装,是后台线程和UI线程可以简易通讯:后台线程执行异步任务,将result告知UI线程。\n\n使用AsyncTask分为两步: \n\n① 继承AsyncTask类实现自己的类\n\n```\npublic abstract class AsyncTask {\n```\n\n> Params: 输入参数,对应excute()方法中传递的参数。如果不需要传递参数,则直接设为void即可。\n> \n> Progress:后台任务执行的百分比\n> \n> Result:返回值类型,和doInBackground()方法的返回值类型保持一致。\n\n②复写方法\n\n 最少要重写以下这两个方法:\n\n - doInBackground(Params…) \n\n 在**子线程**(其他方法都在主线程执行)中执行比较耗时的操作,不能更新UI,可以在该方法中调用publishProgress(Progress…)来更新任务的进度。Progress方法是AsycTask中一个final方法只能调用不能重写。\n\n - onPostExecute(Result)\n\n 使用在doInBackground 得到的结果处理操作UI, 在主线程执行,任务执行的结果作为此方法的参数返回。\n \n有时根据需求还要实现以下三个方法:\n\n - onProgressUpdate(Progress…) \n\n 可以使用进度条增加用户体验度。 此方法在主线程执行,用于显示任务执行的进度。\n\n - onPreExecute()\n\n 这里是最终用户调用Excute时的接口,当任务执行之前开始调用此方法,可以在这里显示进度对话框。\n\n - onCancelled() \n\n 用户调用取消时,要做的操作\n\n\n\n## 4、AsyncTask示例\n\n按照上面的步骤定义自己的异步类:\n\n```\npublic class MyTask extends AsyncTask { \n //执行的第一个方法用于在执行后台任务前做一些UI操作 \n @Override \n protected void onPreExecute() { \n \n } \n \n //第二个执行方法,在onPreExecute()后执行,用于后台任务,不可在此方法内修改UI\n @Override \n protected String doInBackground(String... params) { \n //处理耗时操作\n return \"后台任务执行完毕\"; \n } \n \n /*这个函数在doInBackground调用publishProgress(int i)时触发,虽然调用时只有一个参数 \n 但是这里取到的是一个数组,所以要用progesss[0]来取值 \n 第n个参数就用progress[n]来取值 */\n @Override \n protected void onProgressUpdate(Integer... progresses) { \n \t//\"loading...\" + progresses[0] + \"%\"\n super.onProgressUpdate(progress); \n } \n \n /*doInBackground返回时触发,换句话说,就是doInBackground执行完后触发 \n 这里的result就是上面doInBackground执行后的返回值,所以这里是\"后台任务执行完毕\" */\n @Override \n protected void onPostExecute(String result) { \n \t\n } \n \n //onCancelled方法用于在取消执行中的任务时更改UI \n @Override \n protected void onCancelled() { \n \t\n } \n}\n```\n\n在主线程申明该类的对象,调用对象的execute()函数开始执行。\n\n```\nMyTask t= new MyTask();\nt.execute();//这里没有参数\n```\n\n\n## 5、使用AsyncTask需要注意的地方\n\n - AsnycTask内部的Handler需要和主线程交互,所以AsyncTask的实例必须在UI线程中创建\n\n - AsyncTaskResult的doInBackground(mParams)方法执行异步任务运行在子线程中,其他方法运行在主线程中,可以操作UI组件。\n\n - 一个AsyncTask任务只能被执行一次。\n\n - 运行中可以随时调用AsnycTask对象的cancel(boolean)方法取消任务,如果成功,调用isCancelled()会返回true,并且不会执行 onPostExecute() 方法了,而是执行 onCancelled() 方法。\n\n - 对于想要立即开始执行的异步任务,要么直接使用Thread,要么单独创建线程池提供给AsyncTask。默认的AsyncTask不一定会立即执行你的任务,除非你提供给他一个单独的线程池。如果不与主线程交互,直接创建一个Thread就可以了。\n\n \n\n"
},
{
"path": "docs/android/AndroidNote/Android基础/Android数据存储的五种方式.md",
"content": "\n## 1、概述\n \n\n Android提供了5种方式来让用户保存持久化应用程序数据。根据自己的需求来做选择,比如数据是否是应用程序私有的,是否能被其他程序访问,需要多少数据存储空间等,分别是: \n \n\n\n① 使用SharedPreferences存储数据 \n\n② 文件存储数据\n\n③ SQLite数据库存储数据\n\n④ 使用ContentProvider存储数据\n\n⑤ 网络存储数据 \n\nAndroid提供了一种方式来暴露你的数据(甚至是私有数据)给其他应用程序 - ContentProvider。它是一个可选组件,可公开读写你应用程序数据。\n\n\n## 2、SharedPreferences存储\n\n \n\n SharedPreference类提供了一个总体框架,使您可以保存和检索的任何基本数据类型( boolean, float, int, long, string)的持久键-值对(基于XML文件存储的“key-value”键值对数据)。\n\n 通常用来存储程序的一些配置信息。其存储在“data/data/程序包名/shared_prefs目录下。\n\n xml 处理时Dalvik会通过自带底层的本地XML Parser解析,比如XMLpull方式,这样对于内存资源占用比较好。 \n\n**2.1** 我们可以通过以下两种方法获取SharedPreferences对象(通过Context):\n\n> ① getSharedPreferences (String name, int mode)\n\n 当我们有多个SharedPreferences的时候,根据第一个参数name获得相应的SharedPreferences对象。\n\n\n>② getPreferences (int mode)\n\n 如果你的Activity中只需要一个SharedPreferences的时候使用。 \n\n这里的mode有四个选项:\n\n```\nContext.MODE_PRIVATE\n```\n\n 该SharedPreferences数据只能被本应用程序读、写。\n\n```\nContext.MODE_WORLD_READABLE\n```\n\n 该SharedPreferences数据能被其他应用程序读,但不能写。\n\n```\nContext.MODE_WORLD_WRITEABLE\n```\n\n 该SharedPreferences数据能被其他应用程序读和写。\n\n```\nContext.MODE_MULTI_PROCESS\n```\n\n sdk2.3后添加的选项,当多个进程同时读写同一个SharedPreferences时它会检查文件是否修改。 \n\n**2.2** 向Shared Preferences中**写入值**\n \n首先要通过 SharedPreferences.Editor获取到Editor对象;\n\n然后通过Editor的putBoolean() 或 putString()等方法存入值;\n\n最后调用Editor的commit()方法提交;\n\n```\n//Use 0 or MODE_PRIVATE for the default operation \nSharedPreferences settings = getSharedPreferences(\"fanrunqi\", 0);\nSharedPreferences.Editor editor = settings.edit();\neditor.putBoolean(\"isAmazing\", true); \n\n// 提交本次编辑\neditor.commit();\n```\n同时Edit还有两个常用的方法:\n\n> editor.remove(String key) :下一次commit的时候会移除key对应的键值对 \n> \t\n>editor.clear():移除所有键值对\n\n**2.3** 从Shared Preferences中**读取值** \n\n 读取值使用 SharedPreference对象的getBoolean()或getString()等方法就行了(没Editor 啥子事)。\n\n```\nSharedPreferences settings = getSharedPreferences(\"fanrunqi\", 0);\nboolean isAmazing= settings.getBoolean(\"isAmazing\",true);\n```\n\n**2.4** Shared Preferences的优缺点\n\n 可以看出来Preferences是很轻量级的应用,使用起来也很方便,简洁。但存储数据类型比较单一(只有基本数据类型),无法进行条件查询,只能在不复杂的存储需求下使用,比如保存配置信息等。\n\n\n## 3、文件数据存储\n\n \n\n### 3.1 使用内部存储\n\n 当文件被保存在内部存储中时,默认情况下,文件是应用程序私有的,其他应用不能访问。当用户卸载应用程序时这些文件也跟着被删除。\n\n 文件默认存储位置:/data/data/包名/files/文件名。\n\n### 3.1.1 创建和写入一个内部存储的私有文件:\n\n① 调用Context的openFileOutput()函数,填入文件名和操作模式,它会返回一个FileOutputStream对象。\n\n② 通过FileOutputStream对象的write()函数写入数据。\n\n③ FileOutputStream对象的close ()函数关闭流。\n\n例如:\n\n```\n\t\tString FILENAME = \"a.txt\";\n\t\tString string = \"fanrunqi\";\n\n\t\ttry {\n\t\t\tFileOutputStream fos = openFileOutput(FILENAME, Context.MODE_PRIVATE);\n\t\t\tfos.write(string.getBytes());\n\t\t\tfos.close();\n\t\t} catch (Exception e) {\n\t\t\te.printStackTrace();\n\t\t}\n```\n\n在 ``openFileOutput(String name, int mode)``方法中\n \n\n - name参数: 用于指定文件名称,不能包含路径分隔符“/” ,如果文件不存在,Android 会自动创建它。\n \n \n - mode参数:用于指定操作模式,分为四种:\n\n> Context.MODE_PRIVATE = 0\n\n 为默认操作模式,代表该文件是私有数据,只能被应用本身访问,在该模式下,写入的内容会覆盖原文件的内容。\n\n> Context.MODE_APPEND = 32768\n\n 该模式会检查文件是否存在,存在就往文件追加内容,否则就创建新文件。 \n\n> Context.MODE_WORLD_READABLE = 1\n\n 表示当前文件可以被其他应用读取。\n\n> MODE_WORLD_WRITEABLE\n\n 表示当前文件可以被其他应用写入。\n\n### 3.1.2 读取一个内部存储的私有文件:\n\n① 调用openFileInput( ),参数中填入文件名,会返回一个FileInputStream对象。\n\n② 使用流对象的 read()方法读取字节\n\n③ 调用流的close()方法关闭流\n\n例如:\n\n```\n\tString FILENAME = \"a.txt\";\n\t\ttry {\n FileInputStream inStream = openFileInput(FILENAME);\n int len = 0;\n byte[] buf = new byte[1024];\n StringBuilder sb = new StringBuilder();\n while ((len = inStream.read(buf)) != -1) {\n sb.append(new String(buf, 0, len));\n }\n inStream.close();\n } catch (Exception e) {\n e.printStackTrace();\n } \n```\n\n其他一些经常用到的方法:\n\n - getFilesDir(): 得到内存储文件的绝对路径\n\n - getDir(): 在内存储空间中**创建**或**打开一个已经存在**的目录\n\n - deleteFile(): 删除保存在内部存储的文件。 \n - fileList(): 返回当前由应用程序保存的文件的数组(内存储目录下的全部文件)。 \n\n\n\n \n### 3.1.3 保存编译时的静态文件\n\n 如果你想在应用编译时保存静态文件,应该把文件保存在项目的 **res/raw/** 目录下,你可以通过 openRawResource()方法去打开它(传入参数R.raw.filename),这个方法返回一个 InputStream流对象你可以读取文件但是不能修改原始文件。\n\n```\nInputStream is = this.getResources().openRawResource(R.raw.filename);\n```\n\n### 3.1.4 保存内存缓存文件\n\n 有时候我们只想缓存一些数据而不是持久化保存,可以使用getCacheDir()去打开一个文件,文件的存储目录( /data/data/包名/cache )是一个应用专门来保存临时缓存文件的内存目录。\n\n 当设备的内部存储空间比较低的时候,Android可能会删除这些缓存文件来恢复空间,但是你不应该依赖系统来回收,要自己维护这些缓存文件把它们的大小限制在一个合理的范围内,比如1MB.当你卸载应用的时候这些缓存文件也会被移除。\n\n\n## 3.2 使用外部存储(sdcard)\n\n 因为内部存储容量限制,有时候需要存储数据比较大的时候需要用到外部存储,使用外部存储分为以下几个步骤:\n\n### 3.2.1 添加外部存储访问限权\n \n 首先,要在AndroidManifest.xml中加入访问SDCard的权限,如下:\n\n```\n \n \n\n \n \n```\n\n### 3.2.2 检测外部存储的可用性\n\n 在使用外部存储时我们需要检测其状态,它可能被连接到计算机、丢失或者只读等。下面代码将说明如何检查状态:\n\n```\n//获取外存储的状态\nString state = Environment.getExternalStorageState();\nif (Environment.MEDIA_MOUNTED.equals(state)) {\n // 可读可写\n mExternalStorageAvailable = mExternalStorageWriteable = true;\n} else if (Environment.MEDIA_MOUNTED_READ_ONLY.equals(state)) {\n // 可读\n} else {\n // 可能有很多其他的状态,但是我们只需要知道,不能读也不能写 \n}\n```\n\n### 3.2.3 访问外部存储器中的文件\n \n\n**1、如果 API 版本大于或等于8**,使用\n\n> getExternalFilesDir (String type)\n\n 该方法打开一个外存储目录,此方法需要一个类型,指定你想要的子目录,如类型参数DIRECTORY_MUSIC和 DIRECTORY_RINGTONES(传null就是你应用程序的文件目录的根目录)。通过指定目录的类型,确保Android的媒体扫描仪将扫描分类系统中的文件(例如,铃声被确定为铃声)。如果用户卸载应用程序,这个目录及其所有内容将被删除。\n\n例如:\n```\nFile file = new File(getExternalFilesDir(null), \"fanrunqi.jpg\");\n```\n\n**2、如果API 版本小于 8** (7或者更低)\n\n \n\n> getExternalStorageDirectory ()\n\n通过该方法打开外存储的根目录,你应该在以下目录下写入你的应用数据,这样当卸载应用程序时该目录及其所有内容也将被删除。\n\n```\n/Android/data//files/\n```\n\n读写数据:\n\n```\nif(Environment.getExternalStorageState().equals(Environment.MEDIA_MOUNTED)){ \n\t\t File sdCardDir = Environment.getExternalStorageDirectory();//获取SDCard目录 \"/sdcard\" \n\n\t\t File saveFile = new File(sdCardDir,\"a.txt\"); \n\t\t \n\t\t //写数据\n\t\t try {\n\t\t \tFileOutputStream fos= new FileOutputStream(saveFile); \n\t\t \tfos.write(\"fanrunqi\".getBytes()); \n\t\t\t\t\tfos.close();\n\t\t\t\t} catch (Exception e) {\n\t\t\t\t\te.printStackTrace();\n\t\t\t\t} \n\t\t\t\t\n\t\t\t\t//读数据\n\t\t\t\t try {\n\t\t \tFileInputStream fis= new FileInputStream(saveFile); \n\t\t \tint len =0;\n\t\t \tbyte[] buf = new byte[1024];\n\t\t \tStringBuffer sb = new StringBuffer();\n\t\t \twhile((len=fis.read(buf))!=-1){\n\t\t \t\tsb.append(new String(buf, 0, len));\n\t\t \t}\n\t\t \tfis.close();\n\t\t\t\t} catch (Exception e) {\n\t\t\t\t\te.printStackTrace();\n\t\t\t\t} \n\t\t}\n``` \n\n 我们也可以在 /Android/data/package_name/cache/目录下做外部缓存。\n\n部分翻译于:[android-data-storage](http://www.android-doc.com/guide/topics/data/data-storage.html)\n\n# 4、 网络存储数据\n \n## HttpUrlConnection\n\n HttpUrlConnection是Java.net包中提供的API,我们知道Android SDK是基于Java的,所以当然优先考虑HttpUrlConnection这种最原始最基本的API,其实大多数开源的联网框架基本上也是基于JDK的HttpUrlConnection进行的封装罢了,掌握HttpUrlConnection需要以下几个步骤:\n \n1、将访问的路径转换成URL。\n\n> URL url = new URL(path);\n\n2、通过URL获取连接。\n\n \n\n> HttpURLConnection conn = (HttpURLConnection) url.openConnection();\n \n\n3、设置请求方式。\n\n \n\n> conn.setRequestMethod(GET);\n \n\n4、设置连接超时时间。\n\n \n\n>conn.setConnectTimeout(5000);\n\n5、设置请求头的信息。\n\n> conn.setRequestProperty(User-Agent, Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0));\n\n7、针对不同的响应码,做不同的操作(请求码200,表明请求成功,获取返回内容的输入流)\n\n工具类:\n\n```\npublic class StreamTools {\n\t/**\n\t * 将输入流转换成字符串\n\t * \n\t * @param is\n\t * 从网络获取的输入流\n\t * @return\n\t */\n\tpublic static String streamToString(InputStream is) {\n\t\ttry {\n\t\t\tByteArrayOutputStream baos = new ByteArrayOutputStream();\n\t\t\tbyte[] buffer = new byte[1024];\n\t\t\tint len = 0;\n\t\t\twhile ((len = is.read(buffer)) != -1) {\n\t\t\t\tbaos.write(buffer, 0, len);\n\t\t\t}\n\t\t\tbaos.close();\n\t\t\tis.close();\n\t\t\tbyte[] byteArray = baos.toByteArray();\n\t\t\treturn new String(byteArray);\n\t\t} catch (Exception e) {\n\t\t\tLog.e(tag, e.toString());\n\t\t\treturn null;\n\t\t}\n\t}\n}\n```\n\n### HttpUrlConnection发送GET请求\n\n```\npublic static String loginByGet(String username, String password) {\n\t\tString path = http://192.168.0.107:8080/WebTest/LoginServerlet?username= + username + &password= + password;\n\t\ttry {\n\t\t\tURL url = new URL(path);\n\t\t\tHttpURLConnection conn = (HttpURLConnection) url.openConnection();\n\t\t\tconn.setConnectTimeout(5000);\n\t\t\tconn.setRequestMethod(GET);\n\t\t\tint code = conn.getResponseCode();\n\t\t\tif (code == 200) {\n\t\t\t\tInputStream is = conn.getInputStream(); // 字节流转换成字符串\n\t\t\t\treturn StreamTools.streamToString(is);\n\t\t\t} else {\n\t\t\t\treturn 网络访问失败;\n\t\t\t}\n\t\t} catch (Exception e) {\n\t\t\te.printStackTrace();\n\t\t\treturn 网络访问失败;\n\t\t}\n\t}\n```\n\n### HttpUrlConnection发送POST请求\n\n```\npublic static String loginByPost(String username, String password) {\n\t\tString path = http://192.168.0.107:8080/WebTest/LoginServerlet;\n\t\ttry {\n\t\t\tURL url = new URL(path);\n\t\t\tHttpURLConnection conn = (HttpURLConnection) url.openConnection();\n\t\t\tconn.setConnectTimeout(5000);\n\t\t\tconn.setRequestMethod(POST);\n\t\t\tconn.setRequestProperty(Content-Type, application/x-www-form-urlencoded);\n\t\t\tString data = username= + username + &password= + password;\n\t\t\tconn.setRequestProperty(Content-Length, data.length() + );\n\t\t\t// POST方式,其实就是浏览器把数据写给服务器\n\t\t\tconn.setDoOutput(true); // 设置可输出流\n\t\t\tOutputStream os = conn.getOutputStream(); // 获取输出流\n\t\t\tos.write(data.getBytes()); // 将数据写给服务器\n\t\t\tint code = conn.getResponseCode();\n\t\t\tif (code == 200) {\n\t\t\t\tInputStream is = conn.getInputStream();\n\t\t\t\treturn StreamTools.streamToString(is);\n\t\t\t} else {\n\t\t\t\treturn 网络访问失败;\n\t\t\t}\n\t\t} catch (Exception e) {\n\t\t\te.printStackTrace();\n\t\t\treturn 网络访问失败;\n\t\t}\n\t}\n```\n\n## HttpClient\n\n HttpClient是开源组织Apache提供的Java请求网络框架,其最早是为了方便Java服务器开发而诞生的,是对JDK中的HttpUrlConnection各API进行了封装和简化,提高了性能并且降低了调用API的繁琐,Android因此也引进了这个联网框架,我们再不需要导入任何jar或者类库就可以直接使用,值得注意的是Android官方已经宣布不建议使用HttpClient了。\n\n### HttpClient发送GET请求\n\n1、 创建HttpClient对象\n\n2、创建HttpGet对象,指定请求地址(带参数)\n\n3、使用HttpClient的execute(),方法执行HttpGet请求,得到HttpResponse对象\n\n4、调用HttpResponse的getStatusLine().getStatusCode()方法得到响应码\n\n5、调用的HttpResponse的getEntity().getContent()得到输入流,获取服务端写回的数据\n\n```\npublic static String loginByHttpClientGet(String username, String password) {\n\t\tString path = http://192.168.0.107:8080/WebTest/LoginServerlet?username=\n\t\t\t\t+ username + &password= + password;\n\t\tHttpClient client = new DefaultHttpClient(); // 开启网络访问客户端\n\t\tHttpGet httpGet = new HttpGet(path); // 包装一个GET请求\n\t\ttry {\n\t\t\tHttpResponse response = client.execute(httpGet); // 客户端执行请求\n\t\t\tint code = response.getStatusLine().getStatusCode(); // 获取响应码\n\t\t\tif (code == 200) {\n\t\t\t\tInputStream is = response.getEntity().getContent(); // 获取实体内容\n\t\t\t\tString result = StreamTools.streamToString(is); // 字节流转字符串\n\t\t\t\treturn result;\n\t\t\t} else {\n\t\t\t\treturn 网络访问失败;\n\t\t\t}\n\t\t} catch (Exception e) {\n\t\t\te.printStackTrace();\n\t\t\treturn 网络访问失败;\n\t\t}\n\t}\n```\n\n### HttpClient发送POST请求\n\n1,创建HttpClient对象\n\n2,创建HttpPost对象,指定请求地址\n\n3,创建List,用来装载参数\n\n4,调用HttpPost对象的setEntity()方法,装入一个UrlEncodedFormEntity对象,携带之前封装好的参数\n\n5,使用HttpClient的execute()方法执行HttpPost请求,得到HttpResponse对象\n\n6, 调用HttpResponse的getStatusLine().getStatusCode()方法得到响应码\n\n7, 调用的HttpResponse的getEntity().getContent()得到输入流,获取服务端写回的数据\n\n```\npublic static String loginByHttpClientPOST(String username, String password) {\n\t\tString path = http://192.168.0.107:8080/WebTest/LoginServerlet;\n\t\ttry {\n\t\t\tHttpClient client = new DefaultHttpClient(); // 建立一个客户端\n\t\t\tHttpPost httpPost = new HttpPost(path); // 包装POST请求\n\t\t\t// 设置发送的实体参数\n\t\t\tList parameters = new ArrayList();\n\t\t\tparameters.add(new BasicNameValuePair(username, username));\n\t\t\tparameters.add(new BasicNameValuePair(password, password));\n\t\t\thttpPost.setEntity(new UrlEncodedFormEntity(parameters, UTF-8));\n\t\t\tHttpResponse response = client.execute(httpPost); // 执行POST请求\n\t\t\tint code = response.getStatusLine().getStatusCode();\n\t\t\tif (code == 200) {\n\t\t\t\tInputStream is = response.getEntity().getContent();\n\t\t\t\tString result = StreamTools.streamToString(is);\n\t\t\t\treturn result;\n\t\t\t} else {\n\t\t\t\treturn 网络访问失败;\n\t\t\t}\n\t\t} catch (Exception e) {\n\t\t\te.printStackTrace();\n\t\t\treturn 访问网络失败;\n\t\t}\n\t}\n``` \n\n参考:\n\n [Android开发请求网络方式详解](http://www.2cto.com/kf/201501/368943.html)\n## Android提供的其他网络访问框架\n\n HttpClient和HttpUrlConnection的两种网络访问方式编写网络代码,需要自己考虑很多,获取数据或许可以,但是如果要将手机本地数据上传至网络,根据不同的web端接口,需要组织不同的数据内容上传,给手机端造成了很大的工作量。\n \n 目前有几种快捷的网络开发开源框架,给我们提供了非常大的便利。下面是这些项目Github地址,有文档和Api说明。\n \n[android-async-http](https://github.com/loopj/android-async-http) \n\n[http-request](https://github.com/kevinsawicki/http-request)\n\n[okhttp](https://github.com/square/okhttp)\n\n\n# 5、 SQLite数据库存储数据\n\n \n 前面的文章[ SQLite的使用入门](http://blog.csdn.net/amazing7/article/details/51375012)已经做了详细说明,这里就不在多说了。\n\n\n# 6、 使用ContentProvider存储数据\n 同样可以查看 [ContentProvider实例详解](http://blog.csdn.net/amazing7/article/details/51324022)\n\n \n\n"
},
{
"path": "docs/android/AndroidNote/Android基础/Android获取SHA1.md",
"content": "# Android获取SHA1\n\n\n\n1. 在Android Studio中打开Terminal或者进入控制台\n2. cd到jdk的bin目录下\n3. 输入命令 ``keytool -list -keystore /Users/mac/WorkSpace/linGitHub/Daily/key/fuyizhulao.jks``\n4. 上面这个命令,大家需要选择自己的jks文件\n5. 输入密码\n6. 然后就可以看到自己的证书指纹(SHA1)了\n\n\n效果图:\n\n\n"
},
{
"path": "docs/android/AndroidNote/Android基础/Android跟随手指移动的view.md",
"content": "> 实现一个跟随手指移动的view其实是特别容易实现的,不过有的时候还是挺有用的,最近做的视频互动软件就有这样的需求,大概几十行代码就可以搞定,然后记录一下吧。\n\n实现的主要思想,就是利用onTouchListener,然后判断出手指按下的点,同时监听移动的事件,然后稍微计算一下就可以求出来view最终应该呈现的位置了,然后通过改变LayoutParams的值就可以是实现view的跟随手指拖拽的效果了,当然还可以优化,例如通过计算如果移到屏幕边缘就停下来之类的,或者哪里是不能移到地方。\n\n```\npublic class TestActivity extends AppCompatActivity implements View.OnTouchListener {\n\n private ImageView imageView;\n private RelativeLayout relativeLayout;\n\n private int lastX, lastY; //保存手指点下的点的坐标\n final static int IMAGE_SIZE = 150;\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_test);\n\n imageView = (ImageView) findViewById(R.id.image);\n relativeLayout = (RelativeLayout) findViewById(R.id.layout);\n //初始设置一个layoutParams\n RelativeLayout.LayoutParams layoutParams = new RelativeLayout.LayoutParams(IMAGE_SIZE,IMAGE_SIZE);\n imageView.setLayoutParams(layoutParams);\n //设置屏幕触摸事件\n imageView.setOnTouchListener(this);\n }\n\n\n public boolean onTouch(View view, MotionEvent event) {\n switch (event.getAction() & MotionEvent.ACTION_MASK) {\n case MotionEvent.ACTION_DOWN:\n //将点下的点的坐标保存\n lastX = (int) event.getRawX();\n lastY = (int) event.getRawY();\n break;\n\n case MotionEvent.ACTION_MOVE:\n //计算出需要移动的距离\n int dx = (int) event.getRawX() - lastX;\n int dy = (int) event.getRawY() - lastY;\n //将移动距离加上,现在本身距离边框的位置\n int left = view.getLeft() + dx;\n int top = view.getTop() + dy;\n //获取到layoutParams然后改变属性,在设置回去\n RelativeLayout.LayoutParams layoutParams = (RelativeLayout.LayoutParams) view\n .getLayoutParams();\n layoutParams.height = IMAGE_SIZE;\n layoutParams.width = IMAGE_SIZE;\n layoutParams.leftMargin = left;\n layoutParams.topMargin = top;\n view.setLayoutParams(layoutParams);\n //记录最后一次移动的位置\n lastX = (int) event.getRawX();\n lastY = (int) event.getRawY();\n break;\n }\n //刷新界面\n relativeLayout.invalidate();\n return true;\n }\n}\n```\n\n\n\n\n```\n\n\n \n```\n\n----\n\n以上便是这个简单的view啦,思路还是很清晰的,当然能够改造的地方有很多,例如加一个惯性的效果啊,或者弄一个加速度的效果啊,都是可以的\n"
},
{
"path": "docs/android/AndroidNote/Android基础/BroadcastReceiver详细解析.md",
"content": "# BroadcastReceiver的定义\n\n 广播是一种广泛运用的在应用程序之间传输信息的机制,主要用来监听系统或者应用发出的广播信息,然后根据广播信息作为相应的逻辑处理,也可以用来传输少量、频率低的数据。\n\n 在实现开机启动服务和网络状态改变、电量变化、短信和来电时通过接收系统的广播让应用程序作出相应的处理。\n\n BroadcastReceiver 自身并不实现图形用户界面,但是当它收到某个通知后, BroadcastReceiver 可以通过启动 Service 、启动 Activity 或是 NotificationMananger 提醒用户。\n\n# BroadcastReceiver使用注意\n\n 当系统或应用发出广播时,将会扫描系统中的所有广播接收者,通过action匹配将广播发送给相应的接收者,接收者收到广播后将会产生一个广播接收者的实例,执行其中的onReceiver()这个方法;特别需要注意的是这个实例的生命周期只有10秒,如果10秒内没执行结束onReceiver(),系统将会报错。 \n \n 在onReceiver()执行完毕之后,该实例将会被销毁,所以不要在onReceiver()中执行耗时操作,也不要在里面创建子线程处理业务(因为可能子线程没处理完,接收者就被回收了,那么子线程也会跟着被回收掉);正确的处理方法就是通过in调用activity或者service处理业务。\n\n# BroadcastReceiver的注册\n\n BroadcastReceiver的注册方式有且只有两种,一种是静态注册(推荐使用),另外一种是动态注册,广播接收者在注册后就开始监听系统或者应用之间发送的广播消息。\n\n**接收短信广播示例**:\n\n定义自己的BroadcastReceiver 类\n\n```\npublic class MyBroadcastReceiver extends BroadcastReceiver {\n \n// action 名称\nString SMS_RECEIVED = \"android.provider.Telephony.SMS_RECEIVED\" ;\n \n public void onReceive(Context context, Intent intent) {\n \n if (intent.getAction().equals( SMS_RECEIVED )) {\n // 一个receiver可以接收多个action的,即可以有多个intent-filter,需要在onReceive里面对intent.getAction(action name)进行判断。\n }\n }\n}\n```\n\n## 静态方式\n\n 在AndroidManifest.xml的application里面定义receiver并设置要接收的action。\n\n```\n< receiver android:name = \".MyBroadcastReceiver\" > \n\n < intent-filter android:priority = \"777\" > \n \n```\n\n```\n \n```\n\n```\n \n```\n\n 网络是否可用的方法:\n\n```\n public static boolean isNetworkAvailable(Context context) { \n ConnectivityManager mgr = (ConnectivityManager) context.getSystemService(Context.CONNECTIVITY_SERVICE); \n NetworkInfo[] info = mgr.getAllNetworkInfo(); \n if (info != null) { \n for (int i = 0; i < info.length; i++) { \n if (info[i].getState() == NetworkInfo.State.CONNECTED) { \n return true; \n } \n } \n } \n return false; \n } \n```\n\n - 电量变化\n\n```\n \n```\nBroadcastReceiver 的onReceive方法:\n\n```\npublic void onReceive(Context context, Intent intent) { \n int currLevel = intent.getIntExtra(BatteryManager.EXTRA_LEVEL, 0); //当前电量 \n \n int total = intent.getIntExtra(BatteryManager.EXTRA_SCALE, 1); //总电量 \n int percent = currLevel * 100 / total; \n Log.i(TAG, \"battery: \" + percent + \"%\"); \n } \n```\n\n"
},
{
"path": "docs/android/AndroidNote/Android基础/ContentProvider实例详解.md",
"content": "# 1.ContentProvider是什么?\n\n ContentProvider(内容提供者)是Android的四大组件之一,管理android以结构化方式存放的数据,以相对安全的方式封装数据(表)并且提供简易的处理机制和统一的访问接口供**其他程序**调用。 \n \n Android的数据存储方式总共有五种,分别是:Shared Preferences、网络存储、文件存储、外储存储、SQLite。但一般这些存储都只是在单独的一个应用程序之中达到一个数据的共享,有时候我们需要操作其他应用程序的一些数据,就会用到ContentProvider。而且Android为常见的一些数据提供了默认的ContentProvider(包括音频、视频、图片和通讯录等)。\n\n 但注意ContentProvider它也只是一个中间人,真正操作的数据源可能是数据库,也可以是文件、xml或网络等其他存储方式。\n\n# 2.URL\n\n URL(统一资源标识符)代表要操作的数据,可以用来标识每个ContentProvider,这样你就可以通过指定的URI找到想要的ContentProvider,从中获取或修改数据。\n 在Android中URI的格式如下图所示:\n\n \n\n\n \n\n - A\n \n schema,已经由Android所规定为:content://. \n \n - B\n\n 主机名(Authority),是URI的授权部分,是唯一标识符,用来定位ContentProvider。\n\n> C部分和D部分:是每个ContentProvider内部的路径部分\n\n - C\n\n 指向一个对象集合,一般用表的名字,如果没有指定D部分,则返回全部记录。\n\n - D\n\n 指向特定的记录,这里表示操作user表id为7的记录。如果要操作user表中id为7的记录的name字段, D部分变为 **/7/name**即可。\n\n\n> URI模式匹配通配符\n> \n> *:匹配的任意长度的任何有效字符的字符串。 \n> \n> #:匹配的任意长度的数字字符的字符串。 \n> \n> 如:\n> \n> content://com.example.app.provider/*\n> 匹配provider的任何内容url \n> \n> content://com.example.app.provider/table3/# \n> 匹配table3的所有行\n\n \n## 2.1MIME\n\n MIME是指定某个扩展名的文件用一种应用程序来打开,就像你用浏览器查看PDF格式的文件,浏览器会选择合适的应用来打开一样。Android中的工作方式跟HTTP类似,ContentProvider会根据URI来返回MIME类型,ContentProvider会返回一个包含两部分的字符串。MIME类型一般包含两部分,如:\n\n \n\n> text/html\ntext/css\ntext/xml\napplication/pdf\n\n 分为类型和子类型,Android遵循类似的约定来定义MIME类型,每个内容类型的Android MIME类型有两种形式:多条记录(集合)和单条记录。\n\n 集合记录:\n\n```\nvnd.android.cursor.dir/自定义\n```\n\n 单条记录:\n\n```\nvnd.android.cursor.item/自定义\n```\n\n vnd表示这些类型和子类型具有非标准的、供应商特定的形式。Android中类型已经固定好了,不能更改,只能区别是集合还是单条具体记录,子类型可以按照格式自己填写。\n 在使用Intent时,会用到MIME,根据Mimetype打开符合条件的活动。\n\n 下面分别介绍Android系统提供了两个用于操作Uri的工具类:ContentUris和UriMatcher。\n## 2.2 ContentUris\n\n ContetnUris包含一个便利的函数withAppendedId()来向URI追加一个id。\n\n \n\n```\nUri uri = Uri.parse(\"content://cn.scu.myprovider/user\")\nUri resultUri = ContentUris.withAppendedId(uri, 7); \n\n//生成后的Uri为:content://cn.scu.myprovider/user/7\n```\n\n 同时提供parseId(uri)方法用于从URL中获取ID:\n\n```\nUri uri = Uri.parse(\"content://cn.scu.myprovider/user/7\")\nlong personid = ContentUris.parseId(uri);\n//获取的结果为:7\n```\n\n## 2.3UriMatcher\n\n UriMatcher本质上是一个文本过滤器,用在contentProvider中帮助我们过滤,分辨出查询者想要查询哪个数据表。\n\n 举例说明:\n\n - 第一步,初始化:\n\n```\nUriMatcher matcher = new UriMatcher(UriMatcher.NO_MATCH);\n//常量UriMatcher.NO_MATCH表示不匹配任何路径的返回码\n```\n\n - 第二步,注册需要的Uri:\n\n```\n//USER 和 USER_ID是两个int型数据\nmatcher.addURI(\"cn.scu.myprovider\", \"user\", USER);\nmatcher.addURI(\"cn.scu.myprovider\", \"user/#\",USER_ID);\n//如果match()方法匹配content://cn.scu.myprovider/user路径,返回匹配码为USER\n```\n\n - 第三部,与已经注册的Uri进行匹配:\n\n```\n/* \n * 如果操作集合,则必须以vnd.android.cursor.dir开头 \n * 如果操作非集合,则必须以vnd.android.cursor.item开头 \n * */ \n @Override \n public String getType(Uri uri) { \n Uri uri = Uri.parse(\"content://\" + \"cn.scu.myprovider\" + \"/user\"); \n switch(matcher.match(uri)){ \n case USER: \n return \"vnd.android.cursor.dir/user\"; \n case USER_ID: \n return \"vnd.android.cursor.item/user\"; \n } \n } \n``` \n\n# 3.ContentProvider的主要方法\n\n \n\n> public boolean onCreate()\n\n ContentProvider创建后 或 打开系统后其它应用第一次访问该ContentProvider时调用。\n\n> public Uri insert(Uri uri, ContentValues values)\n\n 外部应用向ContentProvider中添加数据。\n\n> public int delete(Uri uri, String selection, String[] selectionArgs)\n\n 外部应用从ContentProvider删除数据。\n\n> public int update(Uri uri, ContentValues values, String selection, String[] selectionArgs):\n\n 外部应用更新ContentProvider中的数据。\n\n> public Cursor query(Uri uri, String[] projection, String selection, String[] selectionArgs, String sortOrder) \n\n 供外部应用从ContentProvider中获取数据。\n \n\n> public String getType(Uri uri)\n\n 该方法用于返回当前Url所代表数据的MIME类型。\n\n# 4.ContentResolver\n\n ContentResolver通过URI来查询ContentProvider中提供的数据。除了URI以 外,还必须知道需要获取的数据段的名称,以及此数据段的数据类型。如果你需要获取一个特定的记录,你就必须知道当前记录的ID,也就是URI中D部分。\n\n ContentResolver 类提供了与ContentProvider类相同签名的四个方法:\n\n \n\n> public Uri insert(Uri uri, ContentValues values) //添加\n\n> public int delete(Uri uri, String selection, String[] selectionArgs) //删除\n> \n> public int update(Uri uri, ContentValues values, String selection, String[] selectionArgs) //更新\n> \n> public Cursor query(Uri uri, String[] projection, String selection, String[] selectionArgs, String sortOrder)//获取\n\n实例代码:\n\n```\nContentResolver resolver = getContentResolver();\nUri uri = Uri.parse(\"content://cn.scu.myprovider/user\");\n\n//添加一条记录\nContentValues values = new ContentValues();\nvalues.put(\"name\", \"fanrunqi\");\nvalues.put(\"age\", 24);\nresolver.insert(uri, values); \n\n//获取user表中所有记录\nCursor cursor = resolver.query(uri, null, null, null, \"userid desc\");\nwhile(cursor.moveToNext()){\n //操作\n}\n\n//把id为1的记录的name字段值更改新为finch\nContentValues updateValues = new ContentValues();\nupdateValues.put(\"name\", \"finch\");\nUri updateIdUri = ContentUris.withAppendedId(uri, 1);\nresolver.update(updateIdUri, updateValues, null, null);\n\n//删除id为2的记录\nUri deleteIdUri = ContentUris.withAppendedId(uri, 2);\nresolver.delete(deleteIdUri, null, null);\n```\n\n# 5.ContentObserver\n\n ContentObserver(内容观察者),目的是观察特定Uri引起的数据库的变化,继而做一些相应的处理,它类似于数据库技术中的触发器(Trigger),当ContentObserver所观察的Uri发生变化时,便会触发它.\n\n 下面是使用内容观察者监听短信的例子:\n\n```\npublic class MainActivity extends Activity {\n \n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n \n//注册观察者Observser \nthis.getContentResolver().registerContentObserver(Uri.parse(\"content://sms\"),true,new SMSObserver(new Handler()));\n \n }\n \n private final class SMSObserver extends ContentObserver {\n \n public SMSObserver(Handler handler) {\n super(handler);\n \n }\n \n \n @Override\n public void onChange(boolean selfChange) {\n \n Cursor cursor = MainActivity.this.getContentResolver().query(\nUri.parse(\"content://sms/inbox\"), null, null, null, null);\n \n while (cursor.moveToNext()) {\n StringBuilder sb = new StringBuilder();\n \n sb.append(\"address=\").append(\n cursor.getString(cursor.getColumnIndex(\"address\")));\n \n sb.append(\";subject=\").append(\n cursor.getString(cursor.getColumnIndex(\"subject\")));\n \n sb.append(\";body=\").append(\n cursor.getString(cursor.getColumnIndex(\"body\")));\n \n sb.append(\";time=\").append(\n cursor.getLong(cursor.getColumnIndex(\"date\")));\n \n System.out.println(\"--------has Receivered SMS::\" + sb.toString());\n \n \n }\n \n }\n \n }\n}\n```\n 同时可以在ContentProvider发生数据变化时调用\ngetContentResolver().notifyChange(uri, null)来通知注册在此URI上的访问者。\n\n \n\n```\npublic class UserContentProvider extends ContentProvider {\n public Uri insert(Uri uri, ContentValues values) {\n db.insert(\"user\", \"userid\", values);\n getContext().getContentResolver().notifyChange(uri, null);\n }\n}\n```\n# 6.实例说明\n\n 数据源是SQLite, 用ContentResolver操作ContentProvider。\n\n\n\nConstant.java(储存一些常量)\n\n```\npublic class Constant { \n \n public static final String TABLE_NAME = \"user\"; \n \n public static final String COLUMN_ID = \"_id\"; \n public static final String COLUMN_NAME = \"name\"; \n \n \n public static final String AUTOHORITY = \"cn.scu.myprovider\"; \n public static final int ITEM = 1; \n public static final int ITEM_ID = 2; \n \n public static final String CONTENT_TYPE = \"vnd.android.cursor.dir/user\"; \n public static final String CONTENT_ITEM_TYPE = \"vnd.android.cursor.item/user\"; \n \n public static final Uri CONTENT_URI = Uri.parse(\"content://\" + AUTOHORITY + \"/user\"); \n} \n```\n\n DBHelper.java(操作数据库)\n\n```\npublic class DBHelper extends SQLiteOpenHelper { \n \n private static final String DATABASE_NAME = \"finch.db\"; \n private static final int DATABASE_VERSION = 1; \n \n public DBHelper(Context context) { \n super(context, DATABASE_NAME, null, DATABASE_VERSION); \n } \n \n @Override \n public void onCreate(SQLiteDatabase db) throws SQLException { \n //创建表格 \n db.execSQL(\"CREATE TABLE IF NOT EXISTS \"+ Constant.TABLE_NAME + \"(\"+ Constant.COLUMN_ID +\" INTEGER PRIMARY KEY AUTOINCREMENT,\" + Constant.COLUMN_NAME +\" VARCHAR NOT NULL);\"); \n } \n \n @Override \n public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) throws SQLException { \n //删除并创建表格 \n db.execSQL(\"DROP TABLE IF EXISTS \"+ Constant.TABLE_NAME+\";\"); \n onCreate(db); \n } \n} \n\n```\n\n MyProvider.java(自定义的ContentProvider) \n\n```\npublic class MyProvider extends ContentProvider { \n \n DBHelper mDbHelper = null; \n SQLiteDatabase db = null; \n \n private static final UriMatcher mMatcher; \n static{ \n mMatcher = new UriMatcher(UriMatcher.NO_MATCH); \n mMatcher.addURI(Constant.AUTOHORITY,Constant.TABLE_NAME, Constant.ITEM); \n mMatcher.addURI(Constant.AUTOHORITY, Constant.TABLE_NAME+\"/#\", Constant.ITEM_ID); \n } \n \n \n @Override \n public String getType(Uri uri) { \n switch (mMatcher.match(uri)) { \n case Constant.ITEM: \n return Constant.CONTENT_TYPE; \n case Constant.ITEM_ID: \n return Constant.CONTENT_ITEM_TYPE; \n default: \n throw new IllegalArgumentException(\"Unknown URI\"+uri); \n } \n } \n \n @Override \n public Uri insert(Uri uri, ContentValues values) { \n // TODO Auto-generated method stub \n long rowId; \n if(mMatcher.match(uri)!=Constant.ITEM){ \n throw new IllegalArgumentException(\"Unknown URI\"+uri); \n } \n rowId = db.insert(Constant.TABLE_NAME,null,values); \n if(rowId>0){ \n Uri noteUri=ContentUris.withAppendedId(Constant.CONTENT_URI, rowId); \n getContext().getContentResolver().notifyChange(noteUri, null); \n return noteUri; \n } \n \n throw new SQLException(\"Failed to insert row into \" + uri); \n } \n \n @Override \n public boolean onCreate() { \n // TODO Auto-generated method stub \n mDbHelper = new DBHelper(getContext()); \n \n db = mDbHelper.getReadableDatabase(); \n \n return true; \n } \n \n @Override \n public Cursor query(Uri uri, String[] projection, String selection, \n String[] selectionArgs, String sortOrder) { \n // TODO Auto-generated method stub \n Cursor c = null; \n switch (mMatcher.match(uri)) { \n case Constant.ITEM: \n c = db.query(Constant.TABLE_NAME, projection, selection, selectionArgs, null, null, sortOrder); \n break; \n case Constant.ITEM_ID: \n c = db.query(Constant.TABLE_NAME, projection,Constant.COLUMN_ID + \"=\"+uri.getLastPathSegment(), selectionArgs, null, null, sortOrder); \n break; \n default: \n throw new IllegalArgumentException(\"Unknown URI\"+uri); \n } \n \n c.setNotificationUri(getContext().getContentResolver(), uri); \n return c; \n } \n \n @Override \n public int update(Uri uri, ContentValues values, String selection, \n String[] selectionArgs) { \n // TODO Auto-generated method stub \n return 0; \n }\n\n\t@Override\n\tpublic int delete(Uri uri, String selection, String[] selectionArgs) {\n\t\t// TODO Auto-generated method stub\n\t\treturn 0;\n\t} \n \n} \n```\nMainActivity.java(ContentResolver操作)\n\n```\npublic class MainActivity extends Activity {\n private ContentResolver mContentResolver = null; \n private Cursor cursor = null; \n @Override\n protected void onCreate(Bundle savedInstanceState) {\n \t// TODO Auto-generated method stub\n \tsuper.onCreate(savedInstanceState);\n \tsetContentView(R.layout.activity_main);\n \t\n \t TextView tv = (TextView) findViewById(R.id.tv);\n\t\t\t\t\n \t\tmContentResolver = getContentResolver(); \n \t\ttv.setText(\"添加初始数据 \");\n for (int i = 0; i < 10; i++) { \n ContentValues values = new ContentValues(); \n values.put(Constant.COLUMN_NAME, \"fanrunqi\"+i); \n mContentResolver.insert(Constant.CONTENT_URI, values); \n } \n \n \ttv.setText(\"查询数据 \");\n cursor = mContentResolver.query(Constant.CONTENT_URI, new String[]{Constant.COLUMN_ID,Constant.COLUMN_NAME}, null, null, null); \n if (cursor.moveToFirst()) {\n \tString s = cursor.getString(cursor.getColumnIndex(Constant.COLUMN_NAME));\n \ttv.setText(\"第一个数据: \"+s);\n }\n }\n \n} \n\n```\n\n最后在manifest申明\n\n```\n\n \n \n \n \n```\n\n最后在Activity中开启服务\n\n```\npublic class MainActivity extends Activity {\n\t@Override\n\tprotected void onCreate(Bundle savedInstanceState) {\n\t\t// TODO Auto-generated method stub\n\t\tsuper.onCreate(savedInstanceState);\n\t\t\n\t\t//同一服务只会开启一个worker thread,在onHandleIntent函数里依次处理intent请求。\n\t\t\n Intent i = new Intent(\"cn.scu.finch\"); \n Bundle bundle = new Bundle(); \n bundle.putString(\"taskName\", \"task1\"); \n i.putExtras(bundle); \n startService(i); \n \n Intent i2 = new Intent(\"cn.scu.finch\"); \n Bundle bundle2 = new Bundle(); \n bundle2.putString(\"taskName\", \"task2\"); \n i2.putExtras(bundle2); \n startService(i2); \n \n startService(i); //多次启动\n\t}\n}\n```\n\n运行结果:\n\n \n\n IntentService在onCreate()函数中通过HandlerThread单独开启一个线程来依次处理所有Intent请求对象所对应的任务。 \n \n 通过onStartCommand()传递给服务intent被**依次**插入到工作队列中。工作队列又把intent逐个发送给onHandleIntent()。\n\n \n\n> 注意:\n> 它只有一个工作线程,名字就是构造函数的那个字符串,也就是“myIntentService”,我们知道多次开启service,只会调用一次onCreate方法(创建一个工作线程),多次onStartCommand方法(用于传入intent通过工作队列再发给onHandleIntent函数做处理)。\n\n"
},
{
"path": "docs/android/AndroidNote/Android基础/RecyclerView的简介.md",
"content": "RecyclerView\n\n一、简介\n\n这个是谷歌官方出的控件,使我们可以非常简单的做出列表装的一个控件,当然recyclerview的功能不止这些,它还可以做出瀑布流的效果,这是一个非常强大的控件,内部自带viewholder可以使我们非常简单的完成许多操作,正在一步一步取代listview这个控件,当然它也有一些小的缺点,那就是谷歌官方并没有直接给我写出它的点击事件的接口,但是这并难不倒我们,我们可以自己写一个回调的接口,实现点击事件,在这里我不仅要为大家介绍recyclerview的item的点击事件,还要为大家介绍,一个item中局部的点击事件,还有添加header、footer,还有添加不同类别的item的布局。可以说彻底的读懂了这篇文章,我们对recyclerview就有了一个新的认识了。\n\n二、涉及到的知识点\n\n \n - item的点击事件\n - item里面内容的点击事件\n - 为recycler view添加header和footer\n - 为item添加不同的布局\n \n三、实现代码\n\n```\n/**\n * Created by linSir on 16/7/24.管理地址界面的适配器\n */\npublic class ManageAddressAdapter extends RecyclerView.Adapter {//在这里我们要继承自官方为我们写好的适配器\n\n public OnTitleClickListener mListener;\n private List mList; //用户列表\n\n public ManageAddressAdapter() {\n mList = new ArrayList<>();\n }\n\n public void setList(List list) {//从外界传入一个list\n mList.clear();\n mList.addAll(list);\n notifyDataSetChanged();\n }\n\n\n @Override\n public RecyclerView.ViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {//重写方法,用上我们下面写好的viewHoler\n return new ManageAddressViewHolder(LayoutInflater.from(parent.getContext()).inflate(R.layout.item_manage_address, parent, false));\n }\n\n @Override public void onBindViewHolder(RecyclerView.ViewHolder holder, int position) {//在这里我们将数据和控件绑定起来\n ManageAddressViewHolder mHolder = (ManageAddressViewHolder) holder;\n mHolder.userName.setText(mList.get(position).getShipName());\n mHolder.userTel.setText(mList.get(position).getPhone());\n\n String address = mList.get(position).getProvince() + \" \" + mList.get(position).getCity()\n + \" \" + mList.get(position).getArea() + \" \" + mList.get(position).getDetail();\n mHolder.address.setText(address);\n\n mHolder._default.setOnClickListener(new ClickListener(String.valueOf(position)));//在这里我们设置了点击事件\n\n }\n\n @Override public int getItemCount() {\n return mList.size();\n }\n\n\n public static class ManageAddressViewHolder extends RecyclerView.ViewHolder {\n\n private TextView userName;\n private TextView userTel;\n private TextView address;\n private TextView _default;\n\n public ManageAddressViewHolder(View itemView) {\n super(itemView);\n userName = (TextView) itemView.findViewById(R.id.manage_userName);\n userTel = (TextView) itemView.findViewById(R.id.manage_userTel);\n address = (TextView) itemView.findViewById(R.id.manage_userAddress);\n _default = (TextView) itemView.findViewById(R.id.manage_default);\n\n\n }\n }\n\n\n public class ClickListener implements View.OnClickListener {//在这里我们重写了点击事件\n private String id;\n\n public ClickListener(String id) {\n this.id = id;\n }\n\n @Override public void onClick(View view) {\n if (mListener != null) {\n mListener.onTitleClick(id);\n }\n }\n }\n\n\n public void setOnTitleClickListener(OnTitleClickListener listener) {//自己写了一个方法,用上我们的接口\n mListener = listener;\n }\n\n\n public interface OnTitleClickListener {//自己写了一个点击事件的接口\n void onTitleClick(String id);\n }\n\n\n}\n```\n\n通过以上的代码,我们已经为recyclerView里面的item里面的textview添加成功了点击事件,我们只需要在调用它的界面实现这个接口,然后重写点击事件的方法,就可以实现这个textview的点击事件了,下面我们一起看一下代码:\n\n```\n/**\n * Created by linSir on 16/7/24.管理地址界面\n */\npublic class ManageAddressActivity extends AppCompatActivity implements ManageAddressAdapter.OnTitleClickListener {//实现上文我们写好的点击事件的接口\n\n private ManageAddressAdapter mAdapter;\n private List list;\n @BindView(R.id.manage_address_recyclerView) RecyclerView mRecyclerView;\n\n @Override protected void onCreate(@Nullable Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_manage);\n ButterKnife.bind(this);\n list = new ArrayList();\n mAdapter = new ManageAddressAdapter();\n LinearLayoutManager linearLayoutManager = new LinearLayoutManager(this);\n mAdapter.setOnTitleClickListener(this);//声明一下\n mRecyclerView.setAdapter(mAdapter);\n mRecyclerView.setLayoutManager(linearLayoutManager);//这里千万不要了为recyclerview设置布局\n\n\n }\n\n @OnClick(R.id.back_manage_address)\n public void back() {\n finish();\n }\n\n @OnClick(R.id.manage_add_address)\n public void add() {\n Intent intent = new Intent(ManageAddressActivity.this, EditAddress.class);\n startActivity(intent);\n }\n\n @Override\n protected void onResume() {\n super.onResume();\n final HttpResultListener> listener;\n\n listener = new HttpResultListener>() {\n @Override\n public void onSuccess(List allAddresses) {\n Toast.makeText(ManageAddressActivity.this, \"获取收货成功\", Toast.LENGTH_SHORT).show();\n mAdapter.setList(allAddresses);\n list = allAddresses;\n\n }\n\n @Override\n public void onError(Throwable e) {\n Log.i(\"lin\", \"----lin----> 获取收货地址失败 \" + e.toString());\n }\n };\n ApiService5.getInstance().allAddress(listener, 1);\n }\n\n @Override public void onTitleClick(String id) {//这里便是我们重写了的点击事件\n Log.i(\"lin\", \"----lin----> onTitleClick 的 id \" + id);\n }\n}\n\n```\n\n以上的代码,我们实现了,为recyclerView的一个item中的textview添加的点击事件,下面我要为大家介绍一下,如何为recyclerView中item添加不同的布局文件,并且如何为item整个添加点击事件:\n\n```\n/**\n * Created by lin_sir on 2016/7/7.部分商品的展示,的适配器\n */\npublic class BuyerRecyclerAdapter extends RecyclerView.Adapter {\n\n public static final int FOOTER_TYPE = 0;//最后一个的类型\n public static final int HAS_IMG_TYPE = 1;//有图片的类型\n\n private List dataList;\n\n private ProgressBar mProgress;\n private TextView mNoMore;\n\n public BuyerRecyclerAdapter() {\n dataList = new ArrayList<>();\n }\n\n public void addData(List list) {\n dataList.addAll(list);\n notifyDataSetChanged();\n }\n\n @Override\n public RecyclerView.ViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {\n if (viewType == FOOTER_TYPE) {\n return new FooterItemViewHolder(LayoutInflater.from(parent.getContext()).inflate(R.layout.item_footer, parent, false));\n } else {\n return new BuyerItemViewHolder(LayoutInflater.from(parent.getContext()).inflate(R.layout.item_buyer, parent, false));\n }\n\n }\n\n @Override\n public void onBindViewHolder(RecyclerView.ViewHolder holder, int position) {\n int type = getItemViewType(position);\n if (type == FOOTER_TYPE) {\n bindFooterView((FooterItemViewHolder) holder);\n } else {\n bindView((BuyerItemViewHolder) holder, dataList.get(position));\n }\n }\n\n @Override\n public int getItemViewType(int position) {\n if (position + 1 == getItemCount()) {\n return FOOTER_TYPE;\n } else {\n FamousPageModel news = dataList.get(position);\n return HAS_IMG_TYPE;\n }\n }\n\n private void bindView(BuyerItemViewHolder holder, FamousPageModel data) {\n\n String productName = data.getProductName();\n String[] products = productName.split(\" \");\n if (products.length != 1) {\n productName = products[1] + \" 等商品\";\n }\n\n String count = data.getNum();\n int sum = 0;\n String[] counts = count.split(\" \");\n if (counts.length == 2) {\n sum = Integer.parseInt(counts[0]) + Integer.parseInt(counts[1]);\n count = String.valueOf(sum);\n }\n\n if (counts.length == 3) {\n sum = Integer.parseInt(counts[0]) + Integer.parseInt(counts[1]) + Integer.parseInt(counts[2]);\n count = String.valueOf(sum);\n }\n\n holder.count.setText(count);\n holder.goods_name.setText(productName);\n holder.price.setText(data.getTotal());\n if (data.getUser() != null) {\n holder.user_name.setText(data.getUser().getName());\n\n }\n\n String imgUrl = data.getPicture();\n\n if (imgUrl != null) {\n ImageUtil.requestImg(BaseApplication.get().getAppContext(), imgUrl, holder.img);\n }\n\n// Picasso.with(BaseApplication.get().getAppContext()).load(data.getPicture()).into(holder.img);\n }\n\n\n @Override\n public int getItemCount() {\n return dataList == null ? 0 : dataList.size() + 1;\n }\n\n public static class BuyerItemViewHolder extends RecyclerView.ViewHolder {\n\n private ImageView img;\n private TextView price;\n private TextView goods_name;\n private TextView count;\n private TextView user_name;\n\n\n public BuyerItemViewHolder(View itemView) {\n\n super(itemView);\n\n img = (ImageView) itemView.findViewById(R.id.iv_user_item_buyer2);\n price = (TextView) itemView.findViewById(R.id.tv_product_price);\n goods_name = (TextView) itemView.findViewById(R.id.tv_product_name);\n count = (TextView) itemView.findViewById(R.id.tv_product_number);\n user_name = (TextView) itemView.findViewById(R.id.tv_user_name);\n\n }\n }\n\n\n /**\n * 刷新列表\n */\n public void refreshList(List list) {\n dataList.clear();\n dataList.addAll(list);\n notifyDataSetChanged();\n }\n\n /**\n * 加载更多\n */\n public void loadMoreList(List list) {\n dataList.addAll(list);\n notifyDataSetChanged();\n }\n\n /**\n * 显示没有更多\n */\n public void showNoMore() {\n if (getItemCount() > 0) {\n if (mProgress != null && mNoMore != null) {\n mNoMore.setVisibility(View.VISIBLE);\n mProgress.setVisibility(View.GONE);\n }\n }\n }\n\n\n /**\n * 显示加载更多\n */\n public void showLoadMore() {\n if (mProgress != null && mNoMore != null) {\n mProgress.setVisibility(View.VISIBLE);\n mNoMore.setVisibility(View.GONE);\n }\n }\n\n private void bindFooterView(FooterItemViewHolder viewHolder) {\n mProgress = viewHolder.mProgress;\n mNoMore = viewHolder.tvNoMore;\n }\n\n\n public static class FooterItemViewHolder extends RecyclerView.ViewHolder {\n\n private ProgressBar mProgress;\n private TextView tvNoMore;\n\n public FooterItemViewHolder(View itemView) {\n super(itemView);\n mProgress = (ProgressBar) itemView.findViewById(R.id.pb_footer_load_more);\n tvNoMore = (TextView) itemView.findViewById(R.id.tv_footer_no_more);\n }\n }\n\n\n /**\n * 获取点击的 item,如果是最后一个,则返回 null\n */\n public FamousPageModel getClickItem(int position) {\n if (position < dataList.size()) {\n return dataList.get(position);\n } else {\n return null;\n }\n }\n\n}\n\n```\n\n在这里我们首先重写了getItemViewType,这里面我目前只写了两种类型,那就是带有图片的类型,和不带有图片的类型,并且我让不带图片的类型出现在了最后面,当然大家可以随意的设置,我们只需要根据它们的特征为他们分好类,然后根据不同的类型加载不同的布局文件即可。\n\n\n```\n/**\n * Created by lin_sir on 2016/7/7. buyer界面\n */\npublic class FragmentBuyer extends Fragment implements SwipeRefreshLayout.OnRefreshListener {\n\n private static int CURRENT_PAGE = 1; //获取需要请求的页号\n private RecyclerView recyclerView; //recyclerView\n private BuyerRecyclerAdapter madapter; //适配器\n private List mlist; //一个装载数据的集合\n private LinearLayoutManager linearLayoutManager; //linearLayoutManger\n private HttpResultListener> listener; //数据请求的回调接口\n private SwipeRefreshLayout refreshLayout; //下拉刷新控件\n private boolean isLoadMore; //是否加载更多\n\n @Nullable\n @Override\n public View onCreateView(LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {\n View view = inflater.inflate(R.layout.fragment_buyer, container, false);\n initviews(view);\n initListener();\n refreshData();\n ButterKnife.bind(this, view);\n return view;\n }\n\n private void initListener() {\n listener = new HttpResultListener>() {\n @Override\n public void onSuccess(List list) {\n Log.i(\"lin\", \"----lin----> refresh success\");\n refreshLayout.setRefreshing(false);\n if (isLoadMore) {\n mlist = list;\n madapter.loadMoreList(mlist);\n madapter.notifyDataSetChanged();\n madapter.showNoMore();\n } else {\n mlist = list;\n madapter.refreshList(list);\n madapter.notifyDataSetChanged();\n }\n }\n\n @Override\n public void onError(Throwable e) {\n Log.i(\"lin\", \"----lin----> refresh error \" + e.toString());\n refreshLayout.setRefreshing(false);\n madapter.showNoMore();\n }\n };\n }\n\n private void initviews(View view) {\n\n mlist = new ArrayList<>();\n\n refreshLayout = (SwipeRefreshLayout) view.findViewById(R.id.refresh_news);\n recyclerView = (RecyclerView) view.findViewById(R.id.rv_buyer);\n\n refreshLayout.setColorSchemeResources(R.color.blue_500, R.color.purple_500, R.color.green_500);\n refreshLayout.setOnRefreshListener(this);\n linearLayoutManager = new LinearLayoutManager(getActivity());\n linearLayoutManager.setOrientation(OrientationHelper.VERTICAL);\n\n madapter = new BuyerRecyclerAdapter();\n madapter.addData(mlist);\n\n recyclerView.setLayoutManager(linearLayoutManager);\n recyclerView.setAdapter(madapter);\n recyclerView.addOnScrollListener(new OnRecyclerScrollListener());\n recyclerView.addOnItemTouchListener(new RecyclerItemClickListener(getActivity(), onItemClickListener));\n }\n\n /**\n * 刷新时,默认请求第一页的数据\n */\n private void refreshData() {\n refreshLayout.setRefreshing(true);\n isLoadMore = false;\n CURRENT_PAGE = 1;\n requestData(1);\n }\n\n /**\n * 加载更多\n */\n private void loadMoreData() {\n refreshLayout.setRefreshing(false);// 加载更多与刷新不能同时存在\n isLoadMore = true;\n requestData(++CURRENT_PAGE);\n }\n\n public class OnRecyclerScrollListener extends RecyclerView.OnScrollListener {\n\n int lastVisibleItem = 0;\n\n @Override\n public void onScrollStateChanged(RecyclerView recyclerView, int newState) {\n super.onScrollStateChanged(recyclerView, newState);\n\n if (madapter != null && newState == RecyclerView.SCROLL_STATE_IDLE && lastVisibleItem + 1 == madapter.getItemCount()) {\n loadMoreData();\n }\n }\n\n @Override\n public void onScrolled(RecyclerView recyclerView, int dx, int dy) {\n super.onScrolled(recyclerView, dx, dy);\n lastVisibleItem = linearLayoutManager.findLastVisibleItemPosition();\n }\n }\n\n /**\n * 请求数据\n */\n private void requestData(int page) {\n madapter.showLoadMore();\n ApiService2.getInstance().famous(listener, page);\n }\n\n @Override\n public void onRefresh() {\n refreshData();\n }\n\n private RecyclerItemClickListener.OnItemClickListener onItemClickListener = new RecyclerItemClickListener.OnItemClickListener() {//这里我们便实现了点击事件\n @Override\n public void onItemClick(View view, int position) {\n Toast.makeText(getActivity(), \"您点击的是: \" + position, Toast.LENGTH_SHORT).show();\n \n }\n };\n\n\n @OnClick(R.id.release_distance_buyer)\n public void release() {\n Intent intent = new Intent(getActivity(), ReleaseOrderActivity.class);\n startActivity(intent);\n\n\n }\n\n @Override public void onDestroy() {\n super.onDestroy();\n }\n\n}\n\n```\n\n以上便是根据我最近做的项目粗略的整理了一下,recyclerview的简单用法,在这里我也用到了,下拉刷新,上拉加载更多,等等等等的方法,写这些也是为了让自己在以后遇到同样的需求的时候,可以很快的写出,如果大家也有这些小问题的可以和我一起交流。\n"
},
{
"path": "docs/android/AndroidNote/Android基础/Service详细解析.md",
"content": "# 什么是服务? \n\n Service是一个应用程序组件,它能够在后台执行一些耗时较长的操作,并且不提供用户界面。服务能被其它应用程序的组件启动,即使用户切换到另外的应用时还能保持后台运行。此外,应用程序组件还能与服务绑定,并与服务进行交互,甚至能进行进程间通信(IPC)。 比如,服务可以处理网络传输、音乐播放、执行文件I/O、或者与content provider进行交互,所有这些都是后台进行的。\n\n\n# Service 与 Thread 的区别\n\n\n 服务仅仅是一个组件,即使用户不再与你的应用程序发生交互,它仍然能在后台运行。因此,应该只在需要时才创建一个服务。\n\n 如果你需要在主线程之外执行一些工作,但仅当用户与你的应用程序交互时才会用到,那你应该创建一个新的线程而不是创建服务。 比如,如果你需要播放一些音乐,但只是当你的activity在运行时才需要播放,你可以在onCreate()中创建一个线程,在onStart()中开始运行,然后在onStop()中终止运行。还可以考虑使用AsyncTask或HandlerThread来取代传统的Thread类。\n\n **由于无法在不同的 Activity 中对同一 Thread 进行控制**,这个时候就要考虑用服务实现。如果你使用了服务,它默认就运行于应用程序的主线程中。因此,如果服务执行密集计算或者阻塞操作,你仍然应该在服务中创建一个新的线程来完成(避免ANR)。\n\n# 服务的分类\n\n## 按运行分类\n\n \n\n - 前台服务\n\n 前台服务是指那些经常会被用户关注的服务,因此内存过低时它不会成为被杀的对象。 前台服务必须提供一个状态栏通知,并会置于“正在进行的”(“Ongoing”)组之下。这意味着只有在服务被终止或从前台移除之后,此通知才能被解除。\n 例如,用服务来播放音乐的播放器就应该运行在前台,因为用户会清楚地知晓它的运行情况。 状态栏通知可能会标明当前播放的歌曲,并允许用户启动一个activity来与播放器进行交互。\n\n 要把你的服务请求为前台运行,可以调用startForeground()方法。此方法有两个参数:唯一标识通知的整数值、状态栏通知Notification对象。例如:\n\n \n\n```\nNotification notification = new Notification(R.drawable.icon, getText(R.string.ticker_text),System.currentTimeMillis());\n\nIntent notificationIntent = new Intent(this,ExampleActivity.class);\n\nPendingIntent pendingIntent = PendingIntent.getActivity(this, 0, notificationIntent, 0);\n\nnotification.setLatestEventInfo(this, getText(R.string.notification_title),\n getText(R.string.notification_message), pendingIntent);\n \nstartForeground(ONGOING_NOTIFICATION, notification);\n```\n\n 要从前台移除服务,请调用stopForeground()方法,这个方法接受个布尔参数,表示是否同时移除状态栏通知。此方法不会终止服务。不过,如果服务在前台运行时被你终止了,那么通知也会同时被移除。\n\n - 后台服务\n\n## 按使用分类 \n\n - 本地服务\n\n 用于应用程序内部,实现一些耗时任务,并不占用应用程序比如Activity所属线程,而是单开线程后台执行。\n 调用Context.startService()启动,调用Context.stopService()结束。在内部可以调用Service.stopSelf() 或 Service.stopSelfResult()来自己停止。\n\n - 远程服务\n\n 用于Android系统内部的应用程序之间,可被其他应用程序复用,比如天气预报服务,其他应用程序不需要再写这样的服务,调用已有的即可。可以定义接口并把接口暴露出来,以便其他应用进行操作。客户端建立到服务对象的连接,并通过那个连接来调用服务。调用Context.bindService()方法建立连接,并启动,以调用 Context.unbindService()关闭连接。多个客户端可以绑定至同一个服务。如果服务此时还没有加载,bindService()会先加载它。\n\n# Service生命周期\n\n \n\nService生命周期方法:\n```\npublic class ExampleService extends Service {\n int mStartMode; // 标识服务被杀死后的处理方式\n IBinder mBinder; // 用于客户端绑定的接口\n boolean mAllowRebind; // 标识是否使用onRebind\n\n @Override\n public void onCreate() {\n // 服务正被创建\n }\n @Override\n public int onStartCommand(Intent intent, int flags, int startId) {\n // 服务正在启动,由startService()调用引发\n return mStartMode;\n }\n @Override\n public IBinder onBind(Intent intent) {\n // 客户端用bindService()绑定服务\n return mBinder;\n }\n @Override\n public boolean onUnbind(Intent intent) {\n // 所有的客户端都用unbindService()解除了绑定\n return mAllowRebind;\n }\n @Override\n public void onRebind(Intent intent) {\n // 某客户端正用bindService()绑定到服务,\n // 而onUnbind()已经被调用过了\n }\n @Override\n public void onDestroy() {\n // 服务用不上了,将被销毁\n }\n}\n```\n\n> 请注意onStartCommand()方法必须返回一个整数。这个整数是描述系统在杀死服务之后应该如何继续运行。onStartCommand()的返回值必须是以下常量之一:\n\n> START_NOT_STICKY \n如果系统在onStartCommand()返回后杀死了服务,则不会重建服务了,除非还存在未发送的intent。 当服务不再是必需的,并且应用程序能够简单地重启那些未完成的工作时,这是避免服务运行的最安全的选项。 \n \n> START_STICKY \n如果系统在onStartCommand()返回后杀死了服务,则将重建服务并调用onStartCommand(),但不会再次送入上一个intent, 而是用null intent来调用onStartCommand() 。除非还有启动服务的intent未发送完,那么这些剩下的intent会继续发送。 这适用于媒体播放器(或类似服务),它们不执行命令,但需要一直运行并随时待命。 \n\n> START_REDELIVER_INTENT \n如果系统在onStartCommand()返回后杀死了服务,则将重建服务并用上一个已送过的intent调用onStartCommand()。任何未发送完的intent也都会依次送入。这适用于那些需要立即恢复工作的活跃服务,比如下载文件。\n\n 服务的生命周期与activity的非常类似。不过,更重要的是你需密切关注服务的创建和销毁环节,因为后台运行的服务是不会引起用户注意的。\n\n 服务的生命周期——从创建到销毁——可以有两种路径:\n\n - 一个started服务\n\n 这类服务由其它组件调用startService()来创建。然后保持运行,且必须通过调用stopSelf()自行终止。其它组件也可通过调用stopService() 终止这类服务。服务终止后,系统会把它销毁。\n\n 如果一个Service被startService 方法多次启动,那么onCreate方法只会调用一次,onStart将会被调用多次(对应调用startService的次数),并且系统只会创建Service的一个实例(因此你应该知道只需要一次stopService调用)。该Service将会一直在后台运行,而不管对应程序的Activity是否在运行,直到被调用stopService,或自身的stopSelf方法。当然如果系统资源不足,android系统也可能结束服务。\n\n \n\n - 一个bound服务\n \n 服务由其它组件(客户端)调用bindService()来创建。然后客户端通过一个IBinder接口与服务进行通信。客户端可以通过调用unbindService()来关闭联接。多个客户端可以绑定到同一个服务上,当所有的客户端都解除绑定后,系统会销毁服务。(服务不需要自行终止。)\n\n 如果一个Service被某个Activity 调用 Context.bindService 方法绑定启动,不管调用 bindService 调用几次,onCreate方法都只会调用一次,同时onStart方法始终不会被调用。当连接建立之后,Service将会一直运行,除非调用Context.unbindService 断开连接或者之前调用bindService 的 Context 不存在了(如Activity被finish的时候),系统将会自动停止Service,对应onDestroy将被调用。\n\n \n\n 这两条路径并不是完全隔离的。也就是说,你可以绑定到一个已经用startService()启动的服务上。例如,一个后台音乐服务可以通过调用startService()来启动,传入一个指明所需播放音乐的 Intent。 之后,用户也许需要用播放器进行一些控制,或者需要查看当前歌曲的信息,这时一个activity可以通过调用bindService()与此服务绑定。在类似这种情况下,stopService()或stopSelf()不会真的终止服务,除非所有的客户端都解除了绑定。\n\n> 当在旋转手机屏幕的时候,当手机屏幕在“横”“竖”变换时,此时如果你的 Activity 如果会自动旋转的话,旋转其实是 Activity 的重新创建,因此旋转之前的使用 bindService 建立的连接便会断开(Context 不存在了)。\n\n# 在manifest中声明服务\n\n 无论是什么类型的服务都必须在manifest中申明,格式如下:\n\n```\n\n ...\n \n \n \n```\n\nService 元素的属性有:\n\n> android:name ------------- 服务类名\n\n>android:label -------------- 服务的名字,如果此项不设置,那么默认显示的服务名则为类名\n\n>android:icon -------------- 服务的图标\n\n>android:permission ------- 申明此服务的权限,这意味着只有提供了该权限的应用才能控制或连接此服务\n\n>android:process ---------- 表示该服务是否运行在另外一个进程,如果设置了此项,那么将会在包名后面加上这段字符串表示另一进程的名字\n\n>android:enabled ---------- 如果此项设置为 true,那么 Service 将会默认被系统启动,不设置默认此项为 false\n\n>android:exported --------- 表示该服务是否能够被其他应用程序所控制或连接,不设置默认此项为 false \n\n android:name是唯一必需的属性——它定义了服务的类名。与activity一样,服务可以定义intent过滤器,使得其它组件能用隐式intent来调用服务。如果你想让服务只能内部使用(其它应用程序无法调用),那么就不必(也不应该)提供任何intent过滤器。\n 此外,如果包含了android:exported属性并且设置为\"false\", 就可以确保该服务是你应用程序的私有服务。即使服务提供了intent过滤器,本属性依然生效。 \n\n# startService 启动服务\n\n 从activity或其它应用程序组件中可以启动一个服务,调用startService()并传入一个Intent(指定所需启动的服务)即可。\n\n```\n\tIntent intent = new Intent(this, MyService.class);\n\tstartService(intent);\n```\n\n服务类:\n\n```\npublic class MyService extends Service {\n\n\t /**\n * onBind 是 Service 的虚方法,因此我们不得不实现它。\n * 返回 null,表示客服端不能建立到此服务的连接。\n */\n\t@Override\n\tpublic IBinder onBind(Intent intent) {\n\t\t// TODO Auto-generated method stub\n\t\treturn null;\n\t}\n \n\t@Override\n public void onCreate() {\n super.onCreate();\n }\n \n @Override\n public int onStartCommand(Intent intent, int flags, int startId) { \t\n //接受传递过来的intent的数据 \n return START_STICKY; \n };\n \n @Override\n public void onDestroy() {\n super.onDestroy();\n }\n\t\n}\n```\n\n 一个started服务必须自行管理生命周期。也就是说,系统不会终止或销毁这类服务,除非必须恢复系统内存并且服务返回后一直维持运行。 因此,服务必须通过调用stopSelf()自行终止,或者其它组件可通过调用stopService()来终止它。\n\n# bindService 启动服务 \n\n 当应用程序中的activity或其它组件需要与服务进行交互,或者应用程序的某些功能需要暴露给其它应用程序时,你应该创建一个bound服务,并通过进程间通信(IPC)来完成。\n\n方法如下:\n\n```\n Intent intent=new Intent(this,BindService.class); \n bindService(intent, ServiceConnection conn, int flags) \n\n```\n\n> 注意bindService是Context中的方法,当没有Context时传入即可。\n\n在进行服务绑定的时,其flags有:\n\n - Context.BIND_AUTO_CREATE \n \n 表示收到绑定请求的时候,如果服务尚未创建,则即刻创建,在系统内存不足需要先摧毁优先级组件来释放内存,且只有驻留该服务的进程成为被摧毁对象时,服务才被摧毁 \n\n - Context.BIND_DEBUG_UNBIND \n \n 通常用于调试场景中判断绑定的服务是否正确,但容易引起内存泄漏,因此非调试目的的时候不建议使用\n\n - Context.BIND_NOT_FOREGROUND \n \n 表示系统将阻止驻留该服务的进程具有前台优先级,仅在后台运行。\n\n服务类:\n\n```\npublic class BindService extends Service {\n\n\t // 实例化MyBinder得到mybinder对象;\n\tprivate final MyBinder binder = new MyBinder();\n\t\n\t /**\n * 返回Binder对象。\n */\n\t@Override\n\tpublic IBinder onBind(Intent intent) {\n\t\t// TODO Auto-generated method stub\n\t\treturn binder;\n\t}\n \n /**\n * 新建内部类MyBinder,继承自Binder(Binder实现IBinder接口),\n * MyBinder提供方法返回BindService实例。\n */\n public class MyBinder extends Binder{\n \n public BindService getService(){\n return BindService.this;\n }\n }\n \n\n\t@Override\n\tpublic boolean onUnbind(Intent intent) {\n\t\t// TODO Auto-generated method stub\n\t\treturn super.onUnbind(intent);\n\t}\n}\n```\n\n启动服务的activity代码:\n\n```\npublic class MainActivity extends Activity {\n\n\t/** 是否绑定 */ \n\tboolean mIsBound = false; \n\tBindService mBoundService;\n\t@Override\n\tprotected void onCreate(Bundle savedInstanceState) {\n\t\tsuper.onCreate(savedInstanceState);\n\t\tsetContentView(R.layout.activity_main);\n\t\tdoBindService();\n\t}\n\t/**\n\t * 实例化ServiceConnection接口的实现类,用于监听服务的状态\n\t */\n\tprivate ServiceConnection conn = new ServiceConnection() { \n\t\t \n\t @Override \n\t public void onServiceConnected(ComponentName name, IBinder service) { \n\t BindService mBoundService = ((BindService.MyBinder) service).getService(); \n\t \n\t } \n\t \n\t @Override \n\t public void onServiceDisconnected(ComponentName name) { \n\t mBoundService = null; \n\t \n\t } \n\t}; \n\t\n\t/** 绑定服务 */ \n\tpublic void doBindService() { \n\t bindService(new Intent(MainActivity.this, BindService.class), conn,Context.BIND_AUTO_CREATE); \n\t mIsBound = true; \n\t} \n\t\n\t/** 解除绑定服务 */ \n\tpublic void doUnbindService() { \n\t if (mIsBound) { \n\t // Detach our existing connection. \n\t unbindService(conn); \n\t mIsBound = false; \n\t } \n\t} \n\t\n\t@Override\n\tprotected void onDestroy() {\n\t\t// TODO Auto-generated method stub\n\t\tsuper.onDestroy();\n\t\t\n\t\tdoUnbindService();\n\t}\n}\n```\n\n> 注意在AndroidMainfest.xml中对Service进行显式声明\n\n\n判断Service是否正在运行:\n\n```\nprivate boolean isServiceRunning() {\n ActivityManager manager = (ActivityManager) getSystemService(ACTIVITY_SERVICE);\n \n {\n if (\"com.example.demo.BindService\".equals(service.service.getClassName())) {\n return true;\n }\n }\n return false;\n}\n```\n\n"
},
{
"path": "docs/android/AndroidNote/Android基础/tablayout记录.md",
"content": "# TabLayout记录\n\n今天用TabLayout的时候发现,TabLayout的setOnPageChangeListener的方法过期了,良好的编程习惯是不在项目中使用过时的方法的,所以要找一个替代的方案:\n\n``addOnPageChangeListener``\n\n- setOnPageChangeListener\n\n```\nmViewPager.setOnPageChangeListener(new ViewPager.OnPageChangeListener() {\n@Override\npublic void onPageScrolled(int position, float positionOffset, int positionOffsetPixels) {\n\n}\n\n@Override\npublic void onPageSelected(int position) {\n\n}\n\n@Override\npublic void onPageScrollStateChanged(int state) {\n\n}\n});\n```\n\n- addOnPageChangeListener\n\n```\nmViewPager.addOnPageChangeListener(new ViewPager.OnPageChangeListener() {\n@Override\npublic void onPageScrolled(int position, float positionOffset, int positionOffsetPixels) {\n\n}\n\n@Override\npublic void onPageSelected(int position) {\n selectedTab(position);\n}\n\n@Override\npublic void onPageScrollStateChanged(int state) {\n\n}\n});\n```\n"
},
{
"path": "docs/android/AndroidNote/Android基础/test.kt",
"content": "\n"
},
{
"path": "docs/android/AndroidNote/Android基础/图片缓存原理.md",
"content": "> 移动开发本质上就是手机和服务器之间进行通信,需要从服务端获取数据。反复通过网络获取数据是比较耗时的,特别是访问比较多的时候,会极大影响了性能,Android中可通过缓存机制来减少频繁的网络操作,减少流量、提升性能。\n\n# 实现原理\n\n 把不需要实时更新的数据缓存下来,通过时间或者其他因素 来判别是读缓存还是网络请求,这样可以缓解服务器压力,一定程度上提高应用响应速度,并且支持离线阅读。\n \n\n# Bitmap的缓存\n\n 在许多的情况下(像 ListView, GridView 或 ViewPager 之类的组件 )我们需要一次性加载大量的图片,在屏幕上显示的图片和所有待显示的图片有可能需要马上就在屏幕上无限制的进行滚动、切换。\n\n 像ListView, GridView 这类组件,它们的子项当不可见时,所占用的内存会被回收以供正在前台显示子项使用。垃圾回收器也会释放你已经加载了的图片占用的内存。如果你想让你的UI运行流畅的话,就不应该每次显示时都去重新加载图片。保持一些内存和文件缓存就变得很有必要了。\n\n## 使用内存缓存\n\n 通过预先消耗应用的一点内存来存储数据,便可快速的为应用中的组件提供数据,是一种典型的以**空间换时间**的策略。\n LruCache 类(Android v4 Support Library 类库中开始提供)非常适合来做图片缓存任务 ,它可以使用一个LinkedHashMap 的强引用来保存最近使用的对象,并且当它保存的对象占用的内存总和超出了为它设计的最大内存时会把**不经常使用**的对象成员踢出以供垃圾回收器回收。\n\n 给LruCache 设置一个合适的内存大小,需考虑如下因素:\n\n - 还剩余多少内存给你的activity或应用使用\n - 屏幕上需要一次性显示多少张图片和多少图片在等待显示\n - 手机的大小和密度是多少(密度越高的设备需要越大的 缓存)\n - 图片的尺寸(决定了所占用的内存大小)\n - 图片的访问频率(频率高的在内存中一直保存)\n - 保存图片的质量(不同像素的在不同情况下显示)\n\n\t\n具体的要根据应用图片使用的具体情况来找到一个合适的解决办法,一个设置 LruCache 例子:\n\n```\nprivate LruCache mMemoryCache;\n\n@Override\nprotected void onCreate(Bundle savedInstanceState) {\n ...\n // 获得虚拟机能提供的最大内存,超过这个大小会抛出OutOfMemory的异常\n final int maxMemory = (int) (Runtime.getRuntime().maxMemory() / 1024);\n\n // 用1/8的内存大小作为内存缓存\n final int cacheSize = maxMemory / 8;\n\n mMemoryCache = new LruCache(cacheSize) {\n @Override\n protected int sizeOf(String key, Bitmap bitmap) {\n // 这里返回的不是item的个数,是cache的size(单位1024个字节)\n return bitmap.getByteCount() / 1024;\n }\n };\n ...\n}\n\npublic void addBitmapToMemoryCache(String key, Bitmap bitmap) {\n if (getBitmapFromMemCache(key) == null) {\n mMemoryCache.put(key, bitmap);\n }\n}\n\npublic Bitmap getBitmapFromMemCache(String key) {\n return mMemoryCache.get(key);\n}\n```\n 当为ImageView加载一张图片时,会先在LruCache 中看看有没有缓存这张图片,如果有的话直接更新到ImageView中,如果没有的话,一个后台线程会被触发来加载这张图片。\n\n```\npublic void loadBitmap(int resId, ImageView imageView) {\n final String imageKey = String.valueOf(resId);\n\n // 查看下内存缓存中是否缓存了这张图片\n final Bitmap bitmap = getBitmapFromMemCache(imageKey);\n if (bitmap != null) {\n mImageView.setImageBitmap(bitmap);\n } else {\n mImageView.setImageResource(R.drawable.image_placeholder);\nBitmapWorkerTask task = new BitmapWorkerTask(mImageView);\n task.execute(resId);\n }\n}\n```\n 在图片加载的Task中,需要把加载好的图片加入到内存缓存中。\n\n```\nclass BitmapWorkerTask extends AsyncTask {\n ...\n // 在后台完成\n @Override\n protected Bitmap doInBackground(Integer... params) {\n final Bitmap bitmap = decodeSampledBitmapFromResource(\n getResources(), params[0], 100, 100));\n addBitmapToMemoryCache(String.valueOf(params[0]), bitmap);\n return bitmap;\n }\n ...\n}\n```\n\n## 使用磁盘缓存\n\n 内存缓存能够快速的获取到最近显示的图片,但不一定就能够获取到。当数据集过大时很容易把内存缓存填满(如GridView )。你的应用也有可能被其它的任务(比如来电)中断进入到后台,后台应用有可能会被杀死,那么相应的内存缓存对象也会被销毁。 当你的应用重新回到前台显示时,你的应用又需要一张一张的去加载图片了。\n\n 磁盘文件缓存能够用来处理这些情况,保存处理好的图片,当内存缓存不可用的时候,直接读取在硬盘中保存好的图片,这样可以有效的减少图片加载的次数。读取磁盘文件要比直接从内存缓存中读取要慢一些,而且需要在一个UI主线程外的线程中进行,因为磁盘的读取速度是不能够保证的,磁盘文件缓存显然也是一种以**空间换时间**的策略。\n\n 如果图片使用非常频繁的话,一个 ContentProvider 可能更适合代替去存储缓存图片,比如图片gallery 应用。\n\n 下面是一个DiskLruCache的部分代码:\n\n```\nprivate DiskLruCache mDiskLruCache;\nprivate final Object mDiskCacheLock = new Object();\nprivate boolean mDiskCacheStarting = true;\nprivate static final int DISK_CACHE_SIZE = 1024 * 1024 * 10; // 10MB\nprivate static final String DISK_CACHE_SUBDIR = \"thumbnails\";\n\n@Override\nprotected void onCreate(Bundle savedInstanceState) {\n ...\n // 初始化内存缓存\n ...\n // 在后台线程中初始化磁盘缓存\n File cacheDir = getDiskCacheDir(this, DISK_CACHE_SUBDIR);\n new InitDiskCacheTask().execute(cacheDir);\n ...\n}\n\nclass InitDiskCacheTask extends AsyncTask {\n @Override\n protected Void doInBackground(File... params) {\n synchronized (mDiskCacheLock) {\n File cacheDir = params[0];\n mDiskLruCache = DiskLruCache.open(cacheDir, DISK_CACHE_SIZE);\n mDiskCacheStarting = false; // 结束初始化\n mDiskCacheLock.notifyAll(); // 唤醒等待线程\n }\n return null;\n }\n}\n\nclass BitmapWorkerTask extends AsyncTask {\n ...\n // 在后台解析图片\n @Override\n protected Bitmap doInBackground(Integer... params) {\n final String imageKey = String.valueOf(params[0]);\n\n // 在后台线程中检测磁盘缓存\n Bitmap bitmap = getBitmapFromDiskCache(imageKey);\n\n if (bitmap == null) { // 没有在磁盘缓存中找到图片\n final Bitmap bitmap = decodeSampledBitmapFromResource(\n getResources(), params[0], 100, 100));\n }\n\n // 把这个final类型的bitmap加到缓存中\n addBitmapToCache(imageKey, bitmap);\n\n return bitmap;\n }\n ...\n}\n\npublic void addBitmapToCache(String key, Bitmap bitmap) {\n // 先加到内存缓存\n if (getBitmapFromMemCache(key) == null) {\n mMemoryCache.put(key, bitmap);\n }\n\n //再加到磁盘缓存\n synchronized (mDiskCacheLock) {\n if (mDiskLruCache != null && mDiskLruCache.get(key) == null) {\n mDiskLruCache.put(key, bitmap);\n }\n }\n}\n\npublic Bitmap getBitmapFromDiskCache(String key) {\n synchronized (mDiskCacheLock) {\n // 等待磁盘缓存从后台线程打开\n while (mDiskCacheStarting) {\n try {\n mDiskCacheLock.wait();\n } catch (InterruptedException e) {}\n }\n if (mDiskLruCache != null) {\n return mDiskLruCache.get(key);\n }\n }\n return null;\n}\n\npublic static File getDiskCacheDir(Context context, String uniqueName) {\n // 优先使用外缓存路径,如果没有挂载外存储,就使用内缓存路径\nfinal String cachePath =\n Environment.MEDIA_MOUNTED.equals(Environment.getExternalStorageState()) ||\n!isExternalStorageRemovable() ?getExternalCacheDir(context).getPath():context.getCacheDir().getPath();\n\n return new File(cachePath + File.separator + uniqueName);\n}\n```\n\n 不能在UI主线程中进行这项操作,因为初始化磁盘缓存也需要对磁盘进行操作。上面的程序片段中,一个锁对象确保了磁盘缓存没有初始化完成之前不能够对磁盘缓存进行访问。\n\n 内存缓存在UI线程中进行检测,磁盘缓存在UI主线程外的线程中进行检测,当图片处理完成之后,分别存储到内存缓存和磁盘缓存中。\n\n## 设备配置参数改变时加载问题\n\n 由于应用在运行的时候设备配置参数可能会发生改变,比如设备朝向改变,会导致Android销毁你的Activity然后按照新的配置重启,这种情况下,我们要避免重新去加载处理所有的图片,让用户能有一个流畅的体验。 \n\n 使用Fragment 能够把内存缓存对象传递到新的activity实例中,调用setRetainInstance(true)) 方法来保留Fragment实例。当activity重新创建好后, 被保留的Fragment依附于activity而存在,通过Fragment就可以获取到已经存在的内存缓存对象了,这样就可以快速的获取到图片,并设置到ImageView上,给用户一个流畅的体验。\n\n下面是一个示例程序片段:\n\n```\nprivate LruCache mMemoryCache;\n\n@Override\nprotected void onCreate(Bundle savedInstanceState) {\n ...\nRetainFragment mRetainFragment = RetainFragment.findOrCreateRetainFragment(getFragmentManager());\n mMemoryCache = RetainFragment.mRetainedCache;\n if (mMemoryCache == null) {\n mMemoryCache = new LruCache(cacheSize) {\n ... //像上面例子中那样初始化缓存\n }\n mRetainFragment.mRetainedCache = mMemoryCache;\n }\n ...\n}\n\nclass RetainFragment extends Fragment {\n private static final String TAG = \"RetainFragment\";\n public LruCache mRetainedCache;\n\n public RetainFragment() {}\n\n public static RetainFragment findOrCreateRetainFragment(FragmentManager fm) {\n RetainFragment fragment = (RetainFragment) fm.findFragmentByTag(TAG);\n if (fragment == null) {\n fragment = new RetainFragment();\n }\n return fragment;\n }\n\n @Override\n public void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n // 使得Fragment在Activity销毁后还能够保留下来\n setRetainInstance(true);\n }\n}\n```\n\n 可以在不适用Fragment(没有界面的服务类Fragment)的情况下旋转设备屏幕。在保留缓存的情况下,你应该能发现填充图片到Activity中几乎是瞬间从内存中取出而没有任何延迟的感觉。任何图片优先从内存缓存获取,没有的话再到硬盘缓存中找,如果都没有,那就以普通方式加载图片。\n \n参考:\n\n[Caching Bitmaps](http://developer.android.com/training/displaying-bitmaps/cache-bitmap.html)\n\n[LruCache](http://developer.android.com/reference/android/util/LruCache.html)\n\n# 使用SQLite进行缓存\n\n 网络请求数据完成后,把文件的相关信息(如url(一般作为唯一标示),下载时间,过期时间)等存放到数据库。下次加载的时候根据url先从数据库中查询,如果查询到并且时间未过期,就根据路径读取本地文件,从而实现缓存的效果。\n\n 注意:缓存的数据库是存放在/data/data//databases/目录下,是占用内存空间的,如果缓存累计,容易浪费内存,需要及时清理缓存。\n\n# 文件缓存\n\n 思路和一般缓存一样,把需要的数据存储在文件中,下次加载时判断文件是否存在和过期(使用File.lastModified()方法得到文件的最后修改时间,与当前时间判断),存在并未过期就加载文件中的数据,否则请求服务器重新下载。\n\n 注意,无网络环境下就默认读取文件缓存中的。\n\n"
},
{
"path": "docs/android/AndroidNote/Android开源框架相关/Android当下最流行的开源框架总结.md",
"content": "# Android中能够简化开发流程的一些框架\n\n> 本文介绍的是一些博主在开发过程中经常用到的Android开源框架,所谓开源框架我的理解就是别人封装好的代码,可以直接拿过来使用,并且源码也全部公开的代码库。\n> 我对于开源框架的使用的态度是,如果完全符合我们项目的需求,或者可定制化的程度非常高的话,那么便可以拿过来直接用,因为开源框架的源码都在那里,如果遇到和项目预期不一样的地方我们也可以把源码拿过来自己改一下,然后重新打个包嘛。\n> 但是,不是很建议刚开始学习安卓的小伙伴们,只会用第三方框架,但是不理解框架内部的实现,在用第三方框架的过程中,我们是可以自己先封装一下简单的框架的,然后再了解一下别人框架内部实现的逻辑什么样的,知其所以然嘛。\n> 同时也非常感谢这些开源框架的作者们,他们的开源精神,真的是非常的伟大啊。\n\n## 网络框架\n- [NoHttp](https://github.com/yanzhenjie/NoHttp)\n- [RxJava](https://github.com/ReactiveX/RxJava) + [retrofit](https://github.com/square/retrofit)\n- [Okhttp](https://github.com/square/okhttp)\n- [okhttp-OkGo](https://github.com/jeasonlzy/okhttp-OkGo)\n\n## Json解析框架\n- [fastJson](https://github.com/alibaba/fastjson)\n- [gson](https://github.com/google/gson)\n\n## 图片加载框架\n- [fresco](https://github.com/facebook/fresco)\n- [Glide](https://github.com/bumptech/glide)\n- [picasso](https://github.com/square/picasso)\n\n## Log类的库\n- [logger](https://github.com/orhanobut/logger)\n- [KLog](https://github.com/ZhaoKaiQiang/KLog)\n- [xLog](https://github.com/elvishew/xLog)\n\n## RecyclerView\n- [UltimateRecyclerView](https://github.com/cymcsg/UltimateRecyclerView)\n- [IndexRecyclerView](https://github.com/jiang111/IndexRecyclerView)\n- [recyclerview-animators](https://github.com/wasabeef/recyclerview-animators)\n\n## Adapter\n- [BaseRecyclerViewAdapterHelper](https://github.com/CymChad/BaseRecyclerViewAdapterHelper)\n- [baseAdapter](https://github.com/hongyangAndroid/baseAdapter)\n- [base-adapter-helper](https://github.com/JoanZapata/base-adapter-helper)\n\n## 数据库\n- [greenDAO](https://github.com/greenrobot/greenDAO)\n- [realm-java](https://github.com/realm/realm-java)\n- [ormlite-android](https://github.com/j256/ormlite-android)\n\n## 注解库\n- [butterknife](https://github.com/JakeWharton/butterknife)\n- [xUtils3](https://github.com/wyouflf/xUtils3)\n- [annotations](http://androidannotations.org/)\n\n## 事件总线\n- [EventBus](https://github.com/greenrobot/EventBus)\n- [RxJava](https://github.com/ReactiveX/RxJava)\n\n## 图片剪裁\n- [uCrop](https://github.com/Yalantis/uCrop)\n- [android-crop](https://github.com/jdamcd/android-crop)\n- [glide-transformations](https://github.com/wasabeef/glide-transformations)\n\n## 性能检测\n- [leakcanary](https://github.com/square/leakcanary)\n\n## 后台任务队列\n- [tape](https://github.com/square/tape)\n\n## UI\n- [Android-Bootstrap](https://github.com/Bearded-Hen/Android-Bootstrap)\n- [material-dialogs](https://github.com/afollestad/material-dialogs)\n- [Android-PickerView](https://github.com/Bigkoo/Android-PickerView)\n- [TastyToast](https://github.com/yadav-rahul/TastyToast)\n- [awesome-android-ui](https://github.com/wasabeef/awesome-android-ui)\n\n\n----\n\n> 感觉这么给大家介绍完了,可能大家会感觉到很抽象,所以打算动手撸一个小的项目,让大家具体感受一下大神们封装的库\n\n[项目源码下载](https://github.com/linsir6/BaseDevelop)\n\n### 项目中用到的库:\n\n* nohttp\n* butterknife\n* glide\n* logger\n* BaseRecyclerViewAdapterHelper\n* eventbus\n* glide-transformations\n* leakcanary\n* Android-Bootstrap\n* TastyToast\n* material-dialogs\n\n\n项目截图:\n\n\n\nnohttp:\n\n```\n//同步请求,结果直接存储在了response\n Request request = NoHttp.createStringRequest(\"自己的url\", RequestMethod.POST);\n Response response = NoHttp.startRequestSync(request);\n String result = response.get();\n //可以直接将结果取出,并且内置了Gson,fastJson,可以直接将结果转换成对应的model\n\n\n\n\n //异步请求,可以构建请求队列,默认同时三个请求一起,参数可调\n RequestQueue requestQueue = NoHttp.newRequestQueue();\n\n OnResponseListener listener = new OnResponseListener() {\n @Override public void onStart(int what) {\n\n }\n\n @Override public void onSucceed(int what, Response response) {\n\n }\n\n @Override public void onFailed(int what, Response response) {\n\n }\n\n @Override public void onFinish(int what) {\n\n }\n };\n\n //请求String\n Request request2 = NoHttp.createStringRequest(\"自己的url\", RequestMethod.GET);\n requestQueue.add(0, request2, listener);\n\n //可以自定义请求类型\n\n/*\n // JsonObject\n Request objRequest = NoHttp.createJsonObjectRequest(\"自己的url\", RequestMethod.POST);\n requestQueue.add(0, objRequest, listener);\n\n // JsonArray\n Request arrayRequest = NoHttp.createJsonArrayRequest(\"自己的url\", RequestMethod.PUT);\n requestQueue.add(0, arrayRequest, listener);\n\n\n Request request = new FastJsonRequest(url, RequestMethod.POST);\n requestQueue.add(0, request, listener);\n\n // 内部使用Gson、FastJson解析成JavaBean\n Request request = new JavaBeanRequest(url, RequestMethod.GET);\n requestQueue.add(0, request, listener);\n\n Request request = new JavaBeanRequest(url, RequestMethod.POST);\n .add(\"name\", \"yoldada\") // String类型\n .add(\"age\", 18) // int类型\n .add(\"sex\", '0') // char类型\n .add(\"time\", 16346468473154) // long类型\n\n // 添加Bitmap\n .add(\"head\", new BitmapBinary(bitmap))\n // 添加File\n .add(\"head\", new FileBinary(file))\n // 添加ByteArray\n .add(\"head\", new ByteArrayBinary(byte[]))\n // 添加InputStream\n .add(\"head\", new InputStreamBinary(inputStream));\n\n*/\n\n\n //nohttp同时有非常完备的缓存的策略,同时对文件上传,请求包体都有非常好的兼容,并且全都是中文文档~\n```\n \n\nbutterknife:\n\n```\n @BindView(R.id.title) TextView title;\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n ButterKnife.bind(this);\n title.setText(\"一些第三方库的测试的demo\");\n\n\n }\n\n @OnClick(R.id.nohttp) public void onNohttpClicked() {\n startActivity(new Intent(MainActivity.this, NoHttpActivity.class));\n }\n\n @OnClick(R.id.glide) public void onGlideClicked() {\n startActivity(new Intent(MainActivity.this,GlideActivity.class));\n }\n\n @OnClick(R.id.baseRecyclerview_adapter_helper) public void onBaseRecyclerviewAdapterHelperClicked() {\n startActivity(new Intent(MainActivity.this,BaseRecyclerViewAdapterActivity.class));\n }\n\n @OnClick(R.id.event_bus) public void onEventBusClicked() {\n startActivity(new Intent(MainActivity.this,EventBusActivity.class));\n }\n\n @OnClick(R.id.glide_transformations) public void onGlideTransformationsClicked() {\n startActivity(new Intent(MainActivity.this,GlideTransFormationActivity.class));\n }\n\n @OnClick(R.id.tasty_toast) public void onTastyToastClicked() {\n startActivity(new Intent(MainActivity.this,TastyToastActivity.class));\n }\n\n @OnClick(R.id.material_dialogs) public void onMaterialDialogsClicked() {\n startActivity(new Intent(MainActivity.this,MaterialDialogActivity.class));\n }\n\n @OnClick(R.id.logger) public void onLoggerClicked() {\n startActivity(new Intent(MainActivity.this,LoggerActivity.class));\n }\n\n\n```\n\nglide:\n\n```\nGlide.with(this).load(\"http://goo.gl/gEgYUd\").into(img1);\n\n\n Glide.with(this)\n .load(\"http://goo.gl/gEgYUd\")\n .fitCenter()\n .centerCrop()\n .into(img2);\n\n\n Glide.with(this)\n .load(\"\")\n .fitCenter()\n .centerCrop()\n .error(R.mipmap.ic_launcher)\n .into(img3);\n\n Glide.with(this)\n .load(\"http://goo.gl/gEgYUd\")\n .diskCacheStrategy(DiskCacheStrategy.ALL)\n .into(img4);\n\n Glide.with(this)\n .load(\"http://goo.gl/gEgYUd\")\n .crossFade()\n .into(img5);\n\n Glide.with(this)\n .load(\"http://goo.gl/gEgYUd\")\n .into(new SimpleTarget() {\n @Override public void onResourceReady(GlideDrawable resource, GlideAnimation glideAnimation) {\n\n img6.setImageDrawable(resource);\n }\n });\n```\n\n\n\n\nlogger:\n\n```\n Logger.d(\"hello\");\n Logger.d(\"hello %s %d\", \"world\", 5); // String.format\n Logger.d(\"hello\");\n Logger.e(\"hello\");\n Logger.w(\"hello\");\n Logger.v(\"hello\");\n Logger.wtf(\"hello\");\n\n// Logger.json(JSON_CONTENT); //打印json\n// Logger.xml(XML_CONTENT);\n// Logger.log(DEBUG, \"tag\", \"message\", throwable);\n// Logger.d(\"hello %s\", \"world\");\n//\n// Logger.d(list); //打印list\n// Logger.d(map);\n// Logger.d(set);\n// Logger.d(new String[]);\n//\n// Logger\n// .init(YOUR_TAG) // default PRETTYLOGGER or use just init()\n// .methodCount(3) // default 2\n// .hideThreadInfo() // default shown\n// .logLevel(LogLevel.NONE) // default LogLevel.FULL\n// .methodOffset(2) // default 0\n// .logAdapter(new AndroidLogAdapter()); //default AndroidLogAdapter\n//\n//\n//\n Logger.log(5000, \"tag\", \"内容\", null);//延时打log\n```\n\n\n\n\n\n\n\nBaseRecyclerViewAdapterHelper:\n\n```\nMultipleItem item1 = new MultipleItem(1, \"aaa\");\n MultipleItem item2 = new MultipleItem(1, \"bbb\");\n MultipleItem item3 = new MultipleItem(1, \"ccc\");\n MultipleItem item4 = new MultipleItem(1, \"ddd\");\n\n MultipleItem item5 = new MultipleItem(2, \"\");\n MultipleItem item6 = new MultipleItem(2, \"\");\n\n\n List list = new ArrayList();\n\n list.add(item1);\n list.add(item2);\n list.add(item5);\n list.add(item3);\n list.add(item4);\n list.add(item6);\n\n\n MultipleItemQuickAdapter adapter = new MultipleItemQuickAdapter(list);\n adapter.setSpanSizeLookup(new BaseQuickAdapter.SpanSizeLookup() {\n @Override public int getSpanSize(GridLayoutManager gridLayoutManager, int position) {\n if (position == 2 || position == 5) {\n return 4;\n } else {\n return 2;\n }\n }\n });\n recyclerView.setLayoutManager(new GridLayoutManager(this, 4));\n recyclerView.setAdapter(adapter);\n\n //轻松实现多种布局,点击事件等\n //添加动画等\n\n\n adapter.setOnItemClickListener(new BaseQuickAdapter.OnItemClickListener() {//item点击事件\n @Override public void onItemClick(BaseQuickAdapter adapter, View view, int position) {\n Toast.makeText(BaseRecyclerViewAdapterActivity.this, \"点击了\" + position, Toast.LENGTH_SHORT).show();\n }\n });\n\n //adapter.addHeaderView();添加headerview\n\n //可以优化Adapter代码\n //添加Item事件\n //添加列表加载动画\n //添加头部、尾部\n //自动加载\n //添加分组\n //自定义不同的item类型\n //设置空布局\n //添加拖拽、滑动删除\n //分组的伸缩栏\n //自定义ViewHolder\n }\n\n public class MultipleItem implements MultiItemEntity {\n public static final int TEXT = 1;\n public static final int IMG = 2;\n public String text;\n private int itemType;\n\n public MultipleItem(int itemType, String text) {\n this.itemType = itemType;\n this.text = text;\n }\n\n @Override\n public int getItemType() {\n return itemType;\n }\n }\n\n public class MultipleItemQuickAdapter extends BaseMultiItemQuickAdapter {\n\n public MultipleItemQuickAdapter(List data) {\n super(data);\n addItemType(MultipleItem.TEXT, R.layout.item_recycler_view);\n addItemType(MultipleItem.IMG, R.layout.item_recycler_view2);\n }\n\n @Override\n protected void convert(BaseViewHolder helper, MultipleItem item) {\n switch (helper.getItemViewType()) {\n case MultipleItem.TEXT:\n helper.setText(R.id.text, item.text);\n break;\n case MultipleItem.IMG:\n //可以在这里面设置图片,现在默认是背景图片\n break;\n }\n }\n\n }\n```\n\n\n\n\neventbus:\n\n```\n//当然,我们目前将,发送与接收放在了一个界面里面,他们可以在不同的界面里面,可以实现app内部的通信\n\n @Override protected void onStart() {\n super.onStart();\n EventBus.getDefault().register(this);\n }\n\n @Override protected void onCreate(@Nullable Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_eventbus);\n ButterKnife.bind(this);\n }\n\n @Subscribe(threadMode = ThreadMode.MAIN)\n public void onMessageEvent(MessageEvent event) {\n Toast.makeText(EventBusActivity.this, \"收到的内容 -> \" + event.event, Toast.LENGTH_SHORT).show();\n }\n\n\n @Override protected void onDestroy() {\n EventBus.getDefault().unregister(this);\n super.onDestroy();\n }\n\n @OnClick(R.id.send) public void onViewClicked() {\n EventBus.getDefault().post(new MessageEvent(\"今天好开心\"));\n }\n\n public class MessageEvent{\n String event;\n\n public MessageEvent(String event){\n this.event = event;\n }\n\n }\n```\n\n\n\n\n\n\nglide-transformations:\n\n```\n//可以修改颜色,加滤镜,剪裁,gpu加速等\n\n Glide.with(this).load(\"https://ws1.sinaimg.cn/large/006tNbRwly1ffs6l68mx3j30ge0gen08.jpg\")\n .bitmapTransform(new BlurTransformation(this, 30), new CropCircleTransformation(this))\n .into((ImageView) findViewById(R.id.img1));\n\n Glide.with(this).load(\"https://ws1.sinaimg.cn/large/006tNbRwly1ffs6l68mx3j30ge0gen08.jpg\")\n .bitmapTransform(new CropCircleTransformation(this))\n .into((ImageView) findViewById(R.id.img2));\n\n Glide.with(this).load(\"https://ws1.sinaimg.cn/large/006tNbRwly1ffs6l68mx3j30ge0gen08.jpg\")\n .bitmapTransform(new CropSquareTransformation(this))\n .into((ImageView) findViewById(R.id.img3));\n\n Glide.with(this).load(\"https://ws1.sinaimg.cn/large/006tNbRwly1ffs6l68mx3j30ge0gen08.jpg\")\n .bitmapTransform(new ColorFilterTransformation(this, 0x80dfdfdf))\n .into((ImageView) findViewById(R.id.img4));\n\n```\n\n\n\n\nleakcanary:\n\n```\n /*\n * LeakCanary用来专注分析系统的进程\n */\n\n if (LeakCanary.isInAnalyzerProcess(this)) {\n return;\n }\n```\n\n\n\n\nAndroid-Bootstrap:\n\n```\n\n\n\n\n  \n
\n \n\n\n
\n\n\n  \n\n\n
\n\n\n  \n\n\n
\n\n\n  \n\n\n
\n\n\n  \n\n\nLicense\n===\n\n MIT License\n \n Copyright (c) 2019 pengMaster\n \n Permission is hereby granted, free of charge, to any person obtaining a copy\n of this software and associated documentation files (the \"Software\"), to deal\n in the Software without restriction, including without limitation the rights\n to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n copies of the Software, and to permit persons to whom the Software is\n furnished to do so, subject to the following conditions:\n \n The above copyright notice and this permission notice shall be included in all\n copies or substantial portions of the Software.\n \n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n SOFTWARE.\n\n\n[1]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/%E8%87%AA%E5%AE%9A%E4%B9%89View%E8%AF%A6%E8%A7%A3.md \"自定义View详解\" \n[2]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Activity%E7%95%8C%E9%9D%A2%E7%BB%98%E5%88%B6%E8%BF%87%E7%A8%8B%E8%AF%A6%E8%A7%A3.md \"Activity界面绘制过程详解\" \n[3]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Activity%E5%90%AF%E5%8A%A8%E8%BF%87%E7%A8%8B.md \"Activity启动过程\"\n[4]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Android%20Touch%E4%BA%8B%E4%BB%B6%E5%88%86%E5%8F%91%E8%AF%A6%E8%A7%A3.md \"Android Touch事件分发详解\"\n[5]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/AsyncTask%E8%AF%A6%E8%A7%A3.md \"AsyncTask详解\"\n[6]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/butterknife%E6%BA%90%E7%A0%81%E8%AF%A6%E8%A7%A3.md \"butterknife源码详解\"\n[7]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/InstantRun%E8%AF%A6%E8%A7%A3.md \"InstantRun详解\"\n[8]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/ListView源码分析.md \"ListView源码分析\"\n[9]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/VideoView%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90.md \"VideoView源码分析\"\n[10]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/View%E7%BB%98%E5%88%B6%E8%BF%87%E7%A8%8B%E8%AF%A6%E8%A7%A3.md \"View绘制过程详解\"\n[11]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//SourceAnalysis/Netowork \"网络部分\"\n[12]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/HttpURLConnection%E8%AF%A6%E8%A7%A3.md \"HttpURLConnection详解\"\n[13]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/HttpURLConnection%E4%B8%8EHttpClient.md \"HttpURLConnection与HttpClient\"\n[14]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/volley-retrofit-okhttp%E4%B9%8B%E6%88%91%E4%BB%AC%E8%AF%A5%E5%A6%82%E4%BD%95%E9%80%89%E6%8B%A9%E7%BD%91%E8%B7%AF%E6%A1%86%E6%9E%B6.md \"volley-retrofit-okhttp之我们该如何选择网路框架\"\n[15]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/Volley%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90.md \"Volley源码分析\"\n[16]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/Retrofit%E8%AF%A6%E8%A7%A3(%E4%B8%8A).md \"Retrofit详解(上)\"\n[17]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/Retrofit%E8%AF%A6%E8%A7%A3(%E4%B8%8B).md \"Retrofit详解(下)\"\n[18]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/%E6%90%AD%E5%BB%BAnginx%2Brtmp%E6%9C%8D%E5%8A%A1%E5%99%A8.md \"搭建nginx+rtmp服务器\"\n[19]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/%E8%A7%86%E9%A2%91%E6%92%AD%E6%94%BE%E7%9B%B8%E5%85%B3%E5%86%85%E5%AE%B9%E6%80%BB%E7%BB%93.md \"视频播放相关内容总结\"\n[20]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/%E8%A7%86%E9%A2%91%E8%A7%A3%E7%A0%81%E4%B9%8B%E8%BD%AF%E8%A7%A3%E4%B8%8E%E7%A1%AC%E8%A7%A3.md \"视频解码之软解与硬解\"\n[21]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/%E9%9F%B3%E8%A7%86%E9%A2%91%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86.md \"音视频基础知识\"\n[22]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/Android%20WebRTC%E7%AE%80%E4%BB%8B.md \"Android WebRTC简介\"\n[23]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/Android%E9%9F%B3%E8%A7%86%E9%A2%91%E5%BC%80%E5%8F%91.md \"Android音视频开发知识\"\n[24]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/DLNA%E7%AE%80%E4%BB%8B.md \"DLNA简介\"\n[25]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/ImageLoaderLibrary/Glide%E7%AE%80%E4%BB%8B(%E4%B8%8A).md \"Glide简介(上)\"\n[26]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/ImageLoaderLibrary/Glide%E7%AE%80%E4%BB%8B(%E4%B8%8B).md \"Glide简介(下)\"\n[27]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/ImageLoaderLibrary/%E5%9B%BE%E7%89%87%E5%8A%A0%E8%BD%BD%E5%BA%93%E6%AF%94%E8%BE%83.md \"图片加载库比较\"\n[28]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/1.RxJava%E8%AF%A6%E8%A7%A3(%E4%B8%80).md \"RxJava详解(一)\"\n[29]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/2.RxJava%E8%AF%A6%E8%A7%A3(%E4%BA%8C).md \"RxJava详解(二)\"\n[30]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/3.RxJava%E8%AF%A6%E8%A7%A3(%E4%B8%89).md \"RxJava详解(三)\"\n[31]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/7.RxJava%E7%B3%BB%E5%88%97%E5%85%A8%E5%AE%B6%E6%A1%B6.md \"RxJava系列全家桶\"\n[32]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/%E7%9B%AE%E5%89%8D%E6%B5%81%E8%A1%8C%E7%9A%84%E5%BC%80%E5%8F%91%E7%BB%84%E5%90%88.md \"目前流行的开发组合\"\n[33]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%E7%9B%B8%E5%85%B3%E5%B7%A5%E5%85%B7.md \"性能优化相关工具\"\n[34]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/Android%E5%BC%80%E5%8F%91%E5%B7%A5%E5%85%B7%E5%8F%8A%E7%B1%BB%E5%BA%93.md \"Android开发工具及类库\"\n[35]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/Github%E4%B8%AA%E4%BA%BA%E4%B8%BB%E9%A1%B5%E7%BB%91%E5%AE%9A%E5%9F%9F%E5%90%8D.md \"Github个人主页绑定域名\"\n[36]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/Markdown%E5%AD%A6%E4%B9%A0%E6%89%8B%E5%86%8C.md \"Markdown学习手册\"\n[37]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/MAT%E5%86%85%E5%AD%98%E5%88%86%E6%9E%90.md \"MAT内存分析\"\n[38]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%B8%80).md \"Kotlin学习教程(一)(未完)\"\n[39]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Gradle%26Maven/Gradle%E4%B8%93%E9%A2%98.md \"Gradle专题\"\n[40]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Gradle%26Maven/%E5%8F%91%E5%B8%83library%E5%88%B0Maven%E4%BB%93%E5%BA%93.md \"发布library到Maven仓库\"\n[41]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AppPublish/Android%E5%BA%94%E7%94%A8%E5%8F%91%E5%B8%83.md \"Android应用发布\"\n[42]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AppPublish/Zipalign%E4%BC%98%E5%8C%96.md \"Zipalign优化\"\n[43]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//SourceAnalysis \"源码解析\"\n[44]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//VideoDevelopment \"音视频开发\"\n[45]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//ImageLoaderLibrary \"图片加载\"\n[46]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//RxJavaPart \"RxJava\"\n[47]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//Tools%26Library \"开发工具\"\n[48]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//KotlinCourse \"Kotlin学习\"\n[49]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//Gradle%26Maven \"Gradle&Maven\"\n[50]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//AppPublish \"应用发布\"\n[51]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//AndroidStudioCourse \"Android Studio使用教程\"\n[52]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//AdavancedPart \"进阶部分\"\n[53]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//JavaKnowledge \"Java基础及算法\"\n[54]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//BasicKnowledge \"基础部分\"\n[55]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E4%B8%80%E5%BC%B9).md \"AndroidStudio使用教程(第一弹)\"\n[56]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E4%BA%8C%E5%BC%B9).md \"AndroidStudio使用教程(第二弹)\"\n[57]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E4%B8%89%E5%BC%B9).md \"AndroidStudio使用教程(第三弹)\"\n[58]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E5%9B%9B%E5%BC%B9).md \"AndroidStudio使用教程(第四弹)\"\n[59]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E4%BA%94%E5%BC%B9).md \"AndroidStudio使用教程(第五弹)\"\n[60]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E5%85%AD%E5%BC%B9).md \"AndroidStudio使用教程(第六弹)\"\n[61]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E4%B8%83%E5%BC%B9).md \"AndroidStudio使用教程(第七弹)\"\n[62]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/Android%20Studio%E4%BD%A0%E5%8F%AF%E8%83%BD%E4%B8%8D%E7%9F%A5%E9%81%93%E7%9A%84%E6%93%8D%E4%BD%9C.md \"Android Studio你可能不知道的操作\"\n[63]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E6%8F%90%E9%AB%98Build%E9%80%9F%E5%BA%A6.md \"AndroidStudio提高Build速度\"\n[64]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%B8%AD%E8%BF%9B%E8%A1%8Cndk%E5%BC%80%E5%8F%91.md \"AndroidStudio中进行ndk开发\"\n[65]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E5%B8%83%E5%B1%80%E4%BC%98%E5%8C%96.md \"布局优化\"\n[66]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E5%B1%8F%E5%B9%95%E9%80%82%E9%85%8D%E4%B9%8B%E7%99%BE%E5%88%86%E6%AF%94%E6%96%B9%E6%A1%88%E8%AF%A6%E8%A7%A3.md \"屏幕适配之百分比方案详解\"\n[67]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E7%83%AD%E4%BF%AE%E5%A4%8D%E5%AE%9E%E7%8E%B0.md \"热修复实现\"\n[68]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E5%A6%82%E4%BD%95%E8%AE%A9Service%E5%B8%B8%E9%A9%BB%E5%86%85%E5%AD%98.md \"如何让Service常驻内存\"\n[69]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E9%80%9A%E8%BF%87Hardware%20Layer%E6%8F%90%E9%AB%98%E5%8A%A8%E7%94%BB%E6%80%A7%E8%83%BD.md \"通过Hardware Layer提高动画性能\"\n[70]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96.md \"性能优化\"\n[71]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E6%B3%A8%E8%A7%A3%E4%BD%BF%E7%94%A8.md \"注解使用\"\n[72]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android6.0%E6%9D%83%E9%99%90%E7%B3%BB%E7%BB%9F.md \"Android6.0权限系统\"\n[73]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android%E5%BC%80%E5%8F%91%E4%B8%8D%E7%94%B3%E8%AF%B7%E6%9D%83%E9%99%90%E6%9D%A5%E4%BD%BF%E7%94%A8%E5%AF%B9%E5%BA%94%E5%8A%9F%E8%83%BD.md \"Android开发不申请权限来使用对应功能\"\n[74]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android%E5%BC%80%E5%8F%91%E4%B8%AD%E7%9A%84MVP%E6%A8%A1%E5%BC%8F%E8%AF%A6%E8%A7%A3.md \"Android开发中的MVP模式详解\"\n[75]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android%E5%90%AF%E5%8A%A8%E6%A8%A1%E5%BC%8F%E8%AF%A6%E8%A7%A3.md \"Android启动模式详解\"\n[76]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android%E5%8D%B8%E8%BD%BD%E5%8F%8D%E9%A6%88.md \"Android卸载反馈\"\n[77]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/ApplicationId%20vs%20PackageName.md \"ApplicationId vs PackageName\"\n[78]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/ART%E4%B8%8EDalvik.md \"ART与Dalvik\"\n[79]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/BroadcastReceiver%E5%AE%89%E5%85%A8%E9%97%AE%E9%A2%98.md \"BroadcastReceiver安全问题\"\n[80]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Handler%E5%AF%BC%E8%87%B4%E5%86%85%E5%AD%98%E6%B3%84%E9%9C%B2%E5%88%86%E6%9E%90.md \"Handler导致内存泄露分析\"\n[81]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Library%E9%A1%B9%E7%9B%AE%E4%B8%AD%E8%B5%84%E6%BA%90id%E4%BD%BF%E7%94%A8case%E6%97%B6%E6%8A%A5%E9%94%99.md \"Library项目中资源id使用case时报错\"\n[82]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Mac%E4%B8%8B%E9%85%8D%E7%BD%AEadb%E5%8F%8AAndroid%E5%91%BD%E4%BB%A4.md \"Mac下配置adb及Android命令\"\n[83]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/MaterialDesign%E4%BD%BF%E7%94%A8.md \"MaterialDesign使用\"\n[84]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/RecyclerView%E4%B8%93%E9%A2%98.md \"RecyclerView专题\"\n[85]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%B8%B8%E7%94%A8%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%A4%A7%E5%85%A8.md \"常用命令行大全\"\n[86]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%8D%95%E4%BE%8B%E7%9A%84%E6%9C%80%E4%BD%B3%E5%AE%9E%E7%8E%B0%E6%96%B9%E5%BC%8F.md \"单例的最佳实现方式\"\n[87]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84.md \"数据结构\"\n[88]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E8%8E%B7%E5%8F%96%E4%BB%8A%E5%90%8E%E5%A4%9A%E5%B0%91%E5%A4%A9%E5%90%8E%E7%9A%84%E6%97%A5%E6%9C%9F.md \"获取今后多少天后的日期\"\n[89]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%89%91%E6%8C%87Offer(%E4%B8%8A).md \"剑指Offer(上)\"\n[90]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/剑指Offer(下).md \"剑指Offer(下)\"\n[91]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%BC%BA%E5%BC%95%E7%94%A8%E3%80%81%E8%BD%AF%E5%BC%95%E7%94%A8%E3%80%81%E5%BC%B1%E5%BC%95%E7%94%A8%E3%80%81%E8%99%9A%E5%BC%95%E7%94%A8.md \"强引用、软引用、弱引用、虚引用\"\n[92]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E7%94%9F%E4%BA%A7%E8%80%85%E6%B6%88%E8%B4%B9%E8%80%85.md \"生产者消费者\"\n[93]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E6%95%B0%E6%8D%AE%E5%8A%A0%E5%AF%86%E5%8F%8A%E8%A7%A3%E5%AF%86.md \"数据加密及解密\"\n[94]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E6%AD%BB%E9%94%81.md \"死锁\"\n[95]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%B8%B8%E8%A7%81%E7%AE%97%E6%B3%95.md \"算法\"\n[96]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E7%BD%91%E7%BB%9C%E8%AF%B7%E6%B1%82%E7%9B%B8%E5%85%B3%E5%86%85%E5%AE%B9%E6%80%BB%E7%BB%93.md \"网络请求相关内容总结\"\n[97]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E7%BA%BF%E7%A8%8B%E6%B1%A0%E7%9A%84%E5%8E%9F%E7%90%86.md \"线程池的原理\"\n[98]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%8E%9F%E5%AD%90%E6%80%A7%E3%80%81%E5%8F%AF%E8%A7%81%E6%80%A7%E4%BB%A5%E5%8F%8A%E6%9C%89%E5%BA%8F%E6%80%A7.md \"原子性、可见性以及有序性\"\n[99]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Base64%E5%8A%A0%E5%AF%86.md \"Base64加密\"\n[100]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Git%E7%AE%80%E4%BB%8B.md \"Git简介\"\n[101]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/hashCode%E4%B8%8Eequals.md \"hashCode与equals\"\n[102]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/HashMap%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86%E5%88%86%E6%9E%90.md \"HashMap实现原理分析\"\n[103]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Java%E5%9F%BA%E7%A1%80%E9%9D%A2%E8%AF%95%E9%A2%98.md \"Java基础面试题\"\n[104]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/JVM%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%E6%9C%BA%E5%88%B6.md \"JVM垃圾回收机制\"\n[105]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/MD5%E5%8A%A0%E5%AF%86.md \"MD5加密\"\n[106]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/MVC%E4%B8%8EMVP%E5%8F%8AMVVM.md \"MVC与MVP及MVVM\"\n[107]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/RMB%E5%A4%A7%E5%B0%8F%E5%86%99%E8%BD%AC%E6%8D%A2.md \"RMB大小写转换\"\n[108]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Vim%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B.md \"Vim使用教程\"\n[109]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/volatile%E5%92%8CSynchronized%E5%8C%BA%E5%88%AB.md \"volatile和Synchronized区别\"\n[110]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%AE%89%E5%85%A8%E9%80%80%E5%87%BA%E5%BA%94%E7%94%A8%E7%A8%8B%E5%BA%8F.md \"安全退出应用程序\"\n[111]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E7%97%85%E6%AF%92.md \"病毒\"\n[112]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%B6%85%E7%BA%A7%E7%AE%A1%E7%90%86%E5%91%98(DevicePoliceManager).md \"超级管理员(DevicePoliceManager)\"\n[113]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E7%A8%8B%E5%BA%8F%E7%9A%84%E5%90%AF%E5%8A%A8%E3%80%81%E5%8D%B8%E8%BD%BD%E5%92%8C%E5%88%86%E4%BA%AB.md \"程序的启动、卸载和分享\"\n[114]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E4%BB%A3%E7%A0%81%E6%B7%B7%E6%B7%86.md \"代码混淆\"\n[115]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%AF%BB%E5%8F%96%E7%94%A8%E6%88%B7logcat%E6%97%A5%E5%BF%97.md \"读取用户logcat日志\"\n[116]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E7%9F%AD%E4%BF%A1%E5%B9%BF%E6%92%AD%E6%8E%A5%E6%94%B6%E8%80%85.md \"短信广播接收者\"\n[117]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%A4%9A%E7%BA%BF%E7%A8%8B%E6%96%AD%E7%82%B9%E4%B8%8B%E8%BD%BD.md \"多线程断点下载\"\n[118]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E9%BB%91%E5%90%8D%E5%8D%95%E6%8C%82%E6%96%AD%E7%94%B5%E8%AF%9D%E5%8F%8A%E5%88%A0%E9%99%A4%E7%94%B5%E8%AF%9D%E8%AE%B0%E5%BD%95.md \"黑名单挂断电话及删除电话记录\"\n[119]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%A8%AA%E5%90%91ListView.md \"横向ListView\"\n[120]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%BB%91%E5%8A%A8%E5%88%87%E6%8D%A2Activity(GestureDetector).md \"滑动切换Activity(GestureDetector)\"\n[121]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%8E%B7%E5%8F%96%E8%81%94%E7%B3%BB%E4%BA%BA.md \"获取联系人\"\n[122]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%8E%B7%E5%8F%96%E6%89%8B%E6%9C%BA%E5%8F%8ASD%E5%8D%A1%E5%8F%AF%E7%94%A8%E5%AD%98%E5%82%A8%E7%A9%BA%E9%97%B4.md \"获取手机及SD卡可用存储空间\"\n[123]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%8E%B7%E5%8F%96%E6%89%8B%E6%9C%BA%E4%B8%AD%E6%89%80%E6%9C%89%E5%AE%89%E8%A3%85%E7%9A%84%E7%A8%8B%E5%BA%8F.md \"获取手机中所有安装的程序\"\n[124]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%8E%B7%E5%8F%96%E4%BD%8D%E7%BD%AE(LocationManager).md \"获取位置(LocationManager)\"\n[125]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%8E%B7%E5%8F%96%E5%BA%94%E7%94%A8%E7%A8%8B%E5%BA%8F%E7%BC%93%E5%AD%98%E5%8F%8A%E4%B8%80%E9%94%AE%E6%B8%85%E7%90%86.md \"获取应用程序缓存及一键清理\"\n[126]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%BC%80%E5%8F%91%E4%B8%AD%E5%BC%82%E5%B8%B8%E7%9A%84%E5%A4%84%E7%90%86.md \"开发中异常的处理\"\n[127]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%BC%80%E5%8F%91%E4%B8%ADLog%E7%9A%84%E7%AE%A1%E7%90%86.md \"开发中Log的管理\"\n[128]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%BF%AB%E6%8D%B7%E6%96%B9%E5%BC%8F%E5%B7%A5%E5%85%B7%E7%B1%BB.md \"快捷方式工具类\"\n[129]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%9D%A5%E7%94%B5%E5%8F%B7%E7%A0%81%E5%BD%92%E5%B1%9E%E5%9C%B0%E6%8F%90%E7%A4%BA%E6%A1%86.md \"来电号码归属地提示框\"\n[130]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%9D%A5%E7%94%B5%E7%9B%91%E5%90%AC%E5%8F%8A%E5%BD%95%E9%9F%B3.md \"来电监听及录音\"\n[131]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E9%9B%B6%E6%9D%83%E9%99%90%E4%B8%8A%E4%BC%A0%E6%95%B0%E6%8D%AE.md \"零权限上传数据\"\n[132]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%86%85%E5%AD%98%E6%B3%84%E6%BC%8F.md \"内存泄漏\"\n[133]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%B1%8F%E5%B9%95%E9%80%82%E9%85%8D.md \"屏幕适配\"\n[134]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E4%BB%BB%E5%8A%A1%E7%AE%A1%E7%90%86%E5%99%A8(ActivityManager).md \"任务管理器(ActivityManager)\"\n[135]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%89%8B%E6%9C%BA%E6%91%87%E6%99%83.md \"手机摇晃\"\n[136]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E7%AB%96%E7%9D%80%E7%9A%84Seekbar.md \"竖着的Seekbar\"\n[137]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%95%B0%E6%8D%AE%E5%AD%98%E5%82%A8.md \"数据存储\"\n[138]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%90%9C%E7%B4%A2%E6%A1%86.md \"搜索框\"\n[139]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E9%94%81%E5%B1%8F%E4%BB%A5%E5%8F%8A%E8%A7%A3%E9%94%81%E7%9B%91%E5%90%AC.md \"锁屏以及解锁监听\"\n[140]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0.md \"文件上传\"\n[141]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E4%B8%8B%E6%8B%89%E5%88%B7%E6%96%B0ListView.md \"下拉刷新ListView\"\n[142]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E4%BF%AE%E6%94%B9%E7%B3%BB%E7%BB%9F%E7%BB%84%E4%BB%B6%E6%A0%B7%E5%BC%8F.md \"修改系统组件样式\"\n[143]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E9%9F%B3%E9%87%8F%E5%8F%8A%E5%B1%8F%E5%B9%95%E4%BA%AE%E5%BA%A6%E8%B0%83%E8%8A%82.md \"音量及屏幕亮度调节\"\n[144]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%BA%94%E7%94%A8%E5%AE%89%E8%A3%85.md \"应用安装\"\n[145]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%BA%94%E7%94%A8%E5%90%8E%E5%8F%B0%E5%94%A4%E9%86%92%E5%90%8E%E6%95%B0%E6%8D%AE%E7%9A%84%E5%88%B7%E6%96%B0.md \"应用后台唤醒后数据的刷新\"\n[146]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E7%9F%A5%E8%AF%86%E5%A4%A7%E6%9D%82%E7%83%A9.md \"知识大杂烩\"\n[147]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%B5%84%E6%BA%90%E6%96%87%E4%BB%B6%E6%8B%B7%E8%B4%9D%E7%9A%84%E4%B8%89%E7%A7%8D%E6%96%B9%E5%BC%8F.md \"资源文件拷贝的三种方式\"\n[148]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%87%AA%E5%AE%9A%E4%B9%89%E8%83%8C%E6%99%AF.md \"自定义背景\"\n[149]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%87%AA%E5%AE%9A%E4%B9%89%E6%8E%A7%E4%BB%B6.md \"自定义控件\"\n[150]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%87%AA%E5%AE%9A%E4%B9%89%E7%8A%B6%E6%80%81%E6%A0%8F%E9%80%9A%E7%9F%A5.md \"自定义状态栏通知\"\n[151]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%87%AA%E5%AE%9A%E4%B9%89Toast.md \"自定义Toast\"\n[152]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/adb%20logcat%E4%BD%BF%E7%94%A8%E7%AE%80%E4%BB%8B.md \"adb logcat使用简介\"\n[153]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E7%BC%96%E7%A0%81%E8%A7%84%E8%8C%83.md \"Android编码规范\"\n[154]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E5%8A%A8%E7%94%BB.md \"Android动画\"\n[155]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E5%9F%BA%E7%A1%80%E9%9D%A2%E8%AF%95%E9%A2%98.md \"Android基础面试题\"\n[156]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E5%85%A5%E9%97%A8%E4%BB%8B%E7%BB%8D.md \"Android入门介绍\"\n[157]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E5%9B%9B%E5%A4%A7%E7%BB%84%E4%BB%B6%E4%B9%8BContentProvider.md \"Android四大组件之ContentProvider\"\n[158]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E5%9B%9B%E5%A4%A7%E7%BB%84%E4%BB%B6%E4%B9%8BService.md \"Android四大组件之Service\"\n[159]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Ant%E6%89%93%E5%8C%85.md \"Ant打包\"\n[160]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Bitmap%E4%BC%98%E5%8C%96.md \"Bitmap优化\"\n[161]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Fragment%E4%B8%93%E9%A2%98.md \"Fragment专题\"\n[162]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Home%E9%94%AE%E7%9B%91%E5%90%AC.md \"Home键监听\"\n[163]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/HttpClient%E6%89%A7%E8%A1%8CGet%E5%92%8CPost%E8%AF%B7%E6%B1%82.md \"HttpClient执行Get和Post请求\"\n[164]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/JNI_C%E8%AF%AD%E8%A8%80%E5%9F%BA%E7%A1%80.md \"JNI_C语言基础\"\n[165]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/JNI%E5%9F%BA%E7%A1%80.md \"JNI基础\"\n[166]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/ListView%E4%B8%93%E9%A2%98.md \"ListView专题\"\n[167]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Parcelable%E5%8F%8ASerializable.md \"Parcelable及Serializable\"\n[168]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/PopupWindow%E7%BB%86%E8%8A%82.md \"PopupWindow细节\"\n[169]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Scroller%E7%AE%80%E4%BB%8B.md \"Scroller简介\"\n[170]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/ScrollingTabs.md \"ScrollingTabs\"\n[171]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/SDK%20Manager%E6%97%A0%E6%B3%95%E6%9B%B4%E6%96%B0%E7%9A%84%E9%97%AE%E9%A2%98.md \"SDK Manager无法更新的问题\"\n[172]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Selector%E4%BD%BF%E7%94%A8.md \"Selector使用\"\n[173]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/SlidingMenu.md \"SlidingMenu\"\n[174]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/String%E6%A0%BC%E5%BC%8F%E5%8C%96.md \"String格式化\"\n[175]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/TextView%E8%B7%91%E9%A9%AC%E7%81%AF%E6%95%88%E6%9E%9C.md \"TextView跑马灯效果\"\n[176]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/WebView%E6%80%BB%E7%BB%93.md \"WebView总结\"\n[177]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Widget(%E7%AA%97%E5%8F%A3%E5%B0%8F%E9%83%A8%E4%BB%B6).md \"Widget(窗口小部件)\"\n[178]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Wifi%E7%8A%B6%E6%80%81%E7%9B%91%E5%90%AC.md \"Wifi状态监听\"\n[179]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/XmlPullParser.md \"XmlPullParser\"\n\n\n[180]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%B8%80).md \"Kotlin学习教程(一)\"\n[181]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%BA%8C).md \"Kotlin学习教程(二)\"\n[182]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%B8%89).md \"Kotlin学习教程(三)\"\n[183]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E5%9B%9B).md \"Kotlin学习教程(四)\"\n[184]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%BA%94).md \"Kotlin学习教程(五)\"\n[185]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E5%85%AD).md \"Kotlin学习教程(六)\"\n[186]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%B8%83).md \"Kotlin学习教程(七)\"\n[187]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E5%85%AB).md \"Kotlin学习教程(八)\"\n[188]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%B9%9D).md \"Kotlin学习教程(九)\"\n[189]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%85%AB%E7%A7%8D%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95.md \"八种排序算法\"\n[190]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E7%BA%BF%E7%A8%8B%E6%B1%A0%E7%AE%80%E4%BB%8B.md \"线程池简介\"\n[191]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F.md \"设计模式\"\n[192]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E7%AE%97%E6%B3%95%E7%9A%84%E5%A4%8D%E6%9D%82%E5%BA%A6.md \"算法复杂度\"\n[193]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%8A%A8%E6%80%81%E4%BB%A3%E7%90%86.md \"动态代理\"\n[194]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/ConstraintLaayout%E7%AE%80%E4%BB%8B.md \"ConstraintLaayout简介\"\n[195]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Http%E4%B8%8EHttps%E7%9A%84%E5%8C%BA%E5%88%AB.md \"Http与Https的区别\"\n[196]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Top-K%E9%97%AE%E9%A2%98.md \"Top-K问题\"\n[197]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E5%8D%81).md \"Kotlin学习教程(十)\"\n[198]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AppPublish/%E4%BD%BF%E7%94%A8Jenkins%E5%AE%9E%E7%8E%B0%E8%87%AA%E5%8A%A8%E5%8C%96%E6%89%93%E5%8C%85.md \"使用Jenkins实现自动化打包\"\n[199]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//Dagger2 \"Dagger2\"\n[200]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/1.Dagger2%E7%AE%80%E4%BB%8B(%E4%B8%80).md \"1.Dagger2简介(一).md\"\n[201]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/2.Dagger2%E5%85%A5%E9%97%A8demo(%E4%BA%8C).md \"2.Dagger2入门demo(二).md\"\n[202]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/3.Dagger2%E5%85%A5%E9%97%A8demo%E6%89%A9%E5%B1%95(%E4%B8%89).md \"3.Dagger2入门demo扩展(三).md\"\n[203]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/4.Dagger2%E5%8D%95%E4%BE%8B(%E5%9B%9B).md \"4.Dagger2单例(四).md\"\n[204]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/5.Dagger2Lay%E5%92%8CProvider(%E4%BA%94).md \"5.Dagger2Lay和Provider(五).md\"\n[205]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/6.Dagger2Android%E7%A4%BA%E4%BE%8B%E4%BB%A3%E7%A0%81(%E5%85%AD).md \"6.Dagger2Android示例代码(六).md\"\n[206]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/7.Dagger2%E4%B9%8Bdagger-android(%E4%B8%83).md \"7.Dagger2之dagger-android(七).md\"\n[207]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/8.Dagger2%E4%B8%8EMVP(%E5%85%AB).md \"8.Dagger2与MVP(八).md\"\n[208]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android%20WorkManager.md \"Android WorkManager.md\"\n\n[209]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/4.RxJava%E8%AF%A6%E8%A7%A3%E4%B9%8B%E6%89%A7%E8%A1%8C%E5%8E%9F%E7%90%86(%E5%9B%9B).md \"4.RxJava详解之执行原理(四)\"\n[210]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/5.RxJava%E8%AF%A6%E8%A7%A3%E4%B9%8B%E6%93%8D%E4%BD%9C%E7%AC%A6%E6%89%A7%E8%A1%8C%E5%8E%9F%E7%90%86(%E4%BA%94).md \"5.RxJava详解之操作符执行原理(五)\"\n[211]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/6.RxJava%E8%AF%A6%E8%A7%A3%E4%B9%8B%E7%BA%BF%E7%A8%8B%E8%B0%83%E5%BA%A6%E5%8E%9F%E7%90%86(%E5%85%AD).md \"6.RxJava详解之线程调度原理(六)\"\n[212]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/9.Dagger2%E5%8E%9F%E7%90%86%E5%88%86%E6%9E%90(%E4%B9%9D).md \"9.Dagger2原理分析(九)\"\n[213]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/%E8%B0%83%E8%AF%95%E5%B9%B3%E5%8F%B0Sonar.md \"调试平台Sonar\"\n"
},
{
"path": "docs/.nojekyll",
"content": ""
},
{
"path": "docs/android/Android-Interview/.gitignore",
"content": "# Node rules:\n## Grunt intermediate storage (http://gruntjs.com/creating-plugins#storing-task-files)\n.grunt\n\n## Dependency directory\n## Commenting this out is preferred by some people, see\n## https://docs.npmjs.com/misc/faq#should-i-check-my-node_modules-folder-into-git\nnode_modules\n\n# Book build output\n_book\n\n# eBook build output\n*.epub\n*.mobi\n*.pdf"
},
{
"path": "docs/android/Android-Interview/Activity/Activity Task和Process.md",
"content": "### 源码分析相关面试题\n\n- [Volley源码分析](http://www.jianshu.com/p/ec3dc92df581)\n- [注解框架实现原理](http://www.jianshu.com/p/20da6d6389e1)\n- [okhttp3.0源码分析](http://www.jianshu.com/p/9ed2c2f2a52c)\n- [onSaveInstanceState源码分析](http://www.jianshu.com/p/cbf9c3557d64)\n- [静默安装和源码编译](http://www.jianshu.com/p/2211a5b3c37f)\n\n### Activity相关面试题\n\n- [保存Activity的状态](http://www.jianshu.com/p/cbf9c3557d64)\n- [深刻剖析activity启动模式(一)](http://www.jianshu.com/p/b33fd8c550bf)\n- [深刻剖析activity启动模式(二)](http://www.jianshu.com/p/e1ea9e542112)\n- [深刻剖析activity启动模式(三)](http://www.jianshu.com/p/d13e3d552d4b)\n- [Activity Task和Process之间的关系](http://www.jianshu.com/p/d13e3d552d4b)\n- [service里面startActivity抛异常?activity不会](http://www.jianshu.com/p/16e880ceb3a4)\n\n### 与XMPP相关面试题\n\n- [XMPP协议优缺点](http://www.jianshu.com/p/2c04ac3c526a)\n- [极光消息推送原理](http://www.jianshu.com/p/d88dc66908cf)\n\n### 与性能优化相关面试题\n\n- [内存泄漏和内存溢出区别](http://www.jianshu.com/p/5dd645b05c76)\n- [UI优化和线程池实现原理](http://www.jianshu.com/p/c22398f8587f)\n- [代码优化](http://www.jianshu.com/p/ebd41eab90df)\n- [内存性能分析](http://www.jianshu.com/p/2665c31b9c2f)\n- [内存泄漏检测](http://www.jianshu.com/p/1514c7804a06)\n- [App启动优化](http://www.jianshu.com/p/f0f73fefdd43)\n- [与IPC机制相关面试题](http://www.jianshu.com/p/de4793a4c2d0)\n\n### 与登录相关面试题\n\n- [oauth认证协议原理](http://www.jianshu.com/p/2a6ecbf8d49d)\n- [token产生的意义](http://www.jianshu.com/p/9b7ce2d6c195)\n- [微信扫一扫实现原理](http://www.jianshu.com/p/a9d1f21bd5e0)\n\n### 与开发相关面试题\n\n- [迭代开发的时候如何向前兼容新旧接口](http://www.jianshu.com/p/cbecadec98de)\n- [手把手教你如何解决as jar包冲突](http://www.jianshu.com/p/30fdc391289c)\n- [context的原理分析](http://www.jianshu.com/p/2706c13a1769)\n- [解决ViewPager.setCurrentItem中间很多页面切换方案](http://www.jianshu.com/p/38ab6d856b56)\n- [字体适配](http://www.jianshu.com/p/33d499170e25)\n- [软键盘顶出去解决方案](http://www.jianshu.com/p/640bac6f58ab)与人事相关面试题\n- [人事面试宝典](http://www.jianshu.com/p/d61b553ff8c9)\n\nAMS提供了一个ArrayList mHistory来管理所有的activity,activity在AMS中的形式是ActivityRecord,task在AMS中的形式为TaskRecord,进程在AMS中的管理形式为ProcessRecord。如下图所示\n\n\n\n从图中我们可以看出如下几点规则:\n\n1) 所有的ActivityRecord会被存储在mHistory管理;\n\n2) 每个ActivityRecord会对应到一个TaskRecord,并且有着相同TaskRecord的ActivityRecord在mHistory中会处在连续的位置;\n\n3) 同一个TaskRecord的Activity可能分别处于不同的进程中,每个Activity所处的进程跟task没有关系;\n\nActivity启动时ActivityManagerService会为其生成对应的ActivityRecord记录,并将其加入到回退栈(back stack)中,另外也会将ActivityRecord记录加入到某个Task中。请记住,ActivityRecord,backstack,Task都是ActivityManagerService的对象,由ActivityManagerService进程负责维护,而不是由应用进程维护。\n\n在回退栈里属于同一个task的ActivityRecord会放在一起,也会形成栈的结构,也就是说后启动的Activity对应的ActivityRecord会放在task的栈顶\n\n执行adb shell dumpsys activity命令,发现有以下输出:\n\n```\nTask id #30\n TaskRecord{7f2f34a #30 A=com.maweiqi.second U=0 sz=2}\n Intent { flg=0x10000000 cmp=com.open.android.task1/.SecondActivity }\n Hist #1: ActivityRecord{a0f9ded u0 com.open.android.task3/.OtherActivity t30}\n Intent { flg=0x10400000 cmp=com.open.android.task3/.OtherActivity }\n ProcessRecord{12090b5 27543:com.open.android.task3/u0a62}\n Hist #0: ActivityRecord{1048af6 u0 com.open.android.task1/.SecondActivity t30}\n Intent { flg=0x10000000 cmp=com.open.android.task1/.SecondActivity }\n ProcessRecord{5bc013e 26035:com.open.android.task1/u0a59}\n\n Task id #31\n TaskRecord{dce52bb #31 A=com.open.android.task3 U=0 sz=1}\n Intent { act=android.intent.action.MAIN cat=[android.intent.category.LAUNCHER] flg=0x10000000 cmp=com.open.android.task3/.MainActivity }\n Hist #0: ActivityRecord{f9e58c5 u0 com.open.android.task3/.MainActivity t31}\n Intent { act=android.intent.action.MAIN cat=[android.intent.category.LAUNCHER] flg=0x10000000 cmp=com.open.android.task3/.MainActivity }\n ProcessRecord{12090b5 27543:com.open.android.task3/u0a62}\n\n Task id #29\n TaskRecord{5b063d8 #29 A=com.open.android.task1 U=0 sz=1}\n Intent { act=android.intent.action.MAIN cat=[android.intent.category.LAUNCHER] flg=0x10000000 cmp=com.open.android.task1/.MainActivity }\n Hist #0: ActivityRecord{689947d u0 com.open.android.task1/.MainActivity t29}\n Intent { act=android.intent.action.MAIN cat=[android.intent.category.LAUNCHER] flg=0x10000000 cmp=com.open.android.task1/.MainActivity }\n ProcessRecord{5bc013e 26035:com.open.android.task1/u0a59}\n\nRunning activities (most recent first):\n TaskRecord{7f2f34a #30 A=com.maweiqi.second U=0 sz=2}\n Run #3: ActivityRecord{a0f9ded u0 com.open.android.task3/.OtherActivity t30}\n TaskRecord{dce52bb #31 A=com.open.android.task3 U=0 sz=1}\n Run #2: ActivityRecord{f9e58c5 u0 com.open.android.task3/.MainActivity t31}\n TaskRecord{7f2f34a #30 A=com.maweiqi.second U=0 sz=2}\n Run #1: ActivityRecord{1048af6 u0 com.open.android.task1/.SecondActivity t30}\n TaskRecord{5b063d8 #29 A=com.open.android.task1 U=0 sz=1}\n Run #0: ActivityRecord{689947d u0 com.open.android.task1/.MainActivity t29}\n\nmResumedActivity: ActivityRecord{a0f9ded u0 com.open.android.task3/.OtherActivity t30}\n```\n\n从图对应文字在对应adb输出,这几个基本概念大家估计就清楚了。\n\n- 欢迎关注微信公众号,长期推荐技术文章和技术视频\n- 微信公众号名称:Android干货程序员\n\n"
},
{
"path": "docs/android/Android-Interview/Activity/App优雅退出.md",
"content": "### **1. RxBus优雅式**\n\n首先,在基类BaseActivity里,注册RxBus监听:\n\n```java\npublic class BaseActivity3 extends AppCompatActivity {\n Subscription mSubscription;\n\n @Override\n public void onCreate(@Nullable Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n initRxBus();\n }\n //接收退出的指令,关闭所有activity\n private void initRxBus() {\n mSubscription = RxBus.getInstance().toObserverable(NormalEvent.class)\n .subscribe(new Action1
\n\n\nLicense\n===\n\n MIT License\n \n Copyright (c) 2019 pengMaster\n \n Permission is hereby granted, free of charge, to any person obtaining a copy\n of this software and associated documentation files (the \"Software\"), to deal\n in the Software without restriction, including without limitation the rights\n to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n copies of the Software, and to permit persons to whom the Software is\n furnished to do so, subject to the following conditions:\n \n The above copyright notice and this permission notice shall be included in all\n copies or substantial portions of the Software.\n \n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n SOFTWARE.\n\n\n[1]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/%E8%87%AA%E5%AE%9A%E4%B9%89View%E8%AF%A6%E8%A7%A3.md \"自定义View详解\" \n[2]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Activity%E7%95%8C%E9%9D%A2%E7%BB%98%E5%88%B6%E8%BF%87%E7%A8%8B%E8%AF%A6%E8%A7%A3.md \"Activity界面绘制过程详解\" \n[3]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Activity%E5%90%AF%E5%8A%A8%E8%BF%87%E7%A8%8B.md \"Activity启动过程\"\n[4]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Android%20Touch%E4%BA%8B%E4%BB%B6%E5%88%86%E5%8F%91%E8%AF%A6%E8%A7%A3.md \"Android Touch事件分发详解\"\n[5]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/AsyncTask%E8%AF%A6%E8%A7%A3.md \"AsyncTask详解\"\n[6]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/butterknife%E6%BA%90%E7%A0%81%E8%AF%A6%E8%A7%A3.md \"butterknife源码详解\"\n[7]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/InstantRun%E8%AF%A6%E8%A7%A3.md \"InstantRun详解\"\n[8]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/ListView源码分析.md \"ListView源码分析\"\n[9]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/VideoView%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90.md \"VideoView源码分析\"\n[10]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/View%E7%BB%98%E5%88%B6%E8%BF%87%E7%A8%8B%E8%AF%A6%E8%A7%A3.md \"View绘制过程详解\"\n[11]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//SourceAnalysis/Netowork \"网络部分\"\n[12]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/HttpURLConnection%E8%AF%A6%E8%A7%A3.md \"HttpURLConnection详解\"\n[13]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/HttpURLConnection%E4%B8%8EHttpClient.md \"HttpURLConnection与HttpClient\"\n[14]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/volley-retrofit-okhttp%E4%B9%8B%E6%88%91%E4%BB%AC%E8%AF%A5%E5%A6%82%E4%BD%95%E9%80%89%E6%8B%A9%E7%BD%91%E8%B7%AF%E6%A1%86%E6%9E%B6.md \"volley-retrofit-okhttp之我们该如何选择网路框架\"\n[15]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/Volley%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90.md \"Volley源码分析\"\n[16]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/Retrofit%E8%AF%A6%E8%A7%A3(%E4%B8%8A).md \"Retrofit详解(上)\"\n[17]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/SourceAnalysis/Netowork/Retrofit%E8%AF%A6%E8%A7%A3(%E4%B8%8B).md \"Retrofit详解(下)\"\n[18]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/%E6%90%AD%E5%BB%BAnginx%2Brtmp%E6%9C%8D%E5%8A%A1%E5%99%A8.md \"搭建nginx+rtmp服务器\"\n[19]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/%E8%A7%86%E9%A2%91%E6%92%AD%E6%94%BE%E7%9B%B8%E5%85%B3%E5%86%85%E5%AE%B9%E6%80%BB%E7%BB%93.md \"视频播放相关内容总结\"\n[20]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/%E8%A7%86%E9%A2%91%E8%A7%A3%E7%A0%81%E4%B9%8B%E8%BD%AF%E8%A7%A3%E4%B8%8E%E7%A1%AC%E8%A7%A3.md \"视频解码之软解与硬解\"\n[21]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/%E9%9F%B3%E8%A7%86%E9%A2%91%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86.md \"音视频基础知识\"\n[22]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/Android%20WebRTC%E7%AE%80%E4%BB%8B.md \"Android WebRTC简介\"\n[23]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/Android%E9%9F%B3%E8%A7%86%E9%A2%91%E5%BC%80%E5%8F%91.md \"Android音视频开发知识\"\n[24]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/VideoDevelopment/DLNA%E7%AE%80%E4%BB%8B.md \"DLNA简介\"\n[25]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/ImageLoaderLibrary/Glide%E7%AE%80%E4%BB%8B(%E4%B8%8A).md \"Glide简介(上)\"\n[26]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/ImageLoaderLibrary/Glide%E7%AE%80%E4%BB%8B(%E4%B8%8B).md \"Glide简介(下)\"\n[27]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/ImageLoaderLibrary/%E5%9B%BE%E7%89%87%E5%8A%A0%E8%BD%BD%E5%BA%93%E6%AF%94%E8%BE%83.md \"图片加载库比较\"\n[28]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/1.RxJava%E8%AF%A6%E8%A7%A3(%E4%B8%80).md \"RxJava详解(一)\"\n[29]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/2.RxJava%E8%AF%A6%E8%A7%A3(%E4%BA%8C).md \"RxJava详解(二)\"\n[30]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/3.RxJava%E8%AF%A6%E8%A7%A3(%E4%B8%89).md \"RxJava详解(三)\"\n[31]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/7.RxJava%E7%B3%BB%E5%88%97%E5%85%A8%E5%AE%B6%E6%A1%B6.md \"RxJava系列全家桶\"\n[32]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/%E7%9B%AE%E5%89%8D%E6%B5%81%E8%A1%8C%E7%9A%84%E5%BC%80%E5%8F%91%E7%BB%84%E5%90%88.md \"目前流行的开发组合\"\n[33]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%E7%9B%B8%E5%85%B3%E5%B7%A5%E5%85%B7.md \"性能优化相关工具\"\n[34]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/Android%E5%BC%80%E5%8F%91%E5%B7%A5%E5%85%B7%E5%8F%8A%E7%B1%BB%E5%BA%93.md \"Android开发工具及类库\"\n[35]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/Github%E4%B8%AA%E4%BA%BA%E4%B8%BB%E9%A1%B5%E7%BB%91%E5%AE%9A%E5%9F%9F%E5%90%8D.md \"Github个人主页绑定域名\"\n[36]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/Markdown%E5%AD%A6%E4%B9%A0%E6%89%8B%E5%86%8C.md \"Markdown学习手册\"\n[37]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/MAT%E5%86%85%E5%AD%98%E5%88%86%E6%9E%90.md \"MAT内存分析\"\n[38]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%B8%80).md \"Kotlin学习教程(一)(未完)\"\n[39]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Gradle%26Maven/Gradle%E4%B8%93%E9%A2%98.md \"Gradle专题\"\n[40]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Gradle%26Maven/%E5%8F%91%E5%B8%83library%E5%88%B0Maven%E4%BB%93%E5%BA%93.md \"发布library到Maven仓库\"\n[41]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AppPublish/Android%E5%BA%94%E7%94%A8%E5%8F%91%E5%B8%83.md \"Android应用发布\"\n[42]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AppPublish/Zipalign%E4%BC%98%E5%8C%96.md \"Zipalign优化\"\n[43]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//SourceAnalysis \"源码解析\"\n[44]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//VideoDevelopment \"音视频开发\"\n[45]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//ImageLoaderLibrary \"图片加载\"\n[46]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//RxJavaPart \"RxJava\"\n[47]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//Tools%26Library \"开发工具\"\n[48]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//KotlinCourse \"Kotlin学习\"\n[49]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//Gradle%26Maven \"Gradle&Maven\"\n[50]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//AppPublish \"应用发布\"\n[51]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//AndroidStudioCourse \"Android Studio使用教程\"\n[52]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//AdavancedPart \"进阶部分\"\n[53]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//JavaKnowledge \"Java基础及算法\"\n[54]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//BasicKnowledge \"基础部分\"\n[55]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E4%B8%80%E5%BC%B9).md \"AndroidStudio使用教程(第一弹)\"\n[56]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E4%BA%8C%E5%BC%B9).md \"AndroidStudio使用教程(第二弹)\"\n[57]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E4%B8%89%E5%BC%B9).md \"AndroidStudio使用教程(第三弹)\"\n[58]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E5%9B%9B%E5%BC%B9).md \"AndroidStudio使用教程(第四弹)\"\n[59]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E4%BA%94%E5%BC%B9).md \"AndroidStudio使用教程(第五弹)\"\n[60]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E5%85%AD%E5%BC%B9).md \"AndroidStudio使用教程(第六弹)\"\n[61]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B(%E7%AC%AC%E4%B8%83%E5%BC%B9).md \"AndroidStudio使用教程(第七弹)\"\n[62]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/Android%20Studio%E4%BD%A0%E5%8F%AF%E8%83%BD%E4%B8%8D%E7%9F%A5%E9%81%93%E7%9A%84%E6%93%8D%E4%BD%9C.md \"Android Studio你可能不知道的操作\"\n[63]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E6%8F%90%E9%AB%98Build%E9%80%9F%E5%BA%A6.md \"AndroidStudio提高Build速度\"\n[64]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AndroidStudioCourse/AndroidStudio%E4%B8%AD%E8%BF%9B%E8%A1%8Cndk%E5%BC%80%E5%8F%91.md \"AndroidStudio中进行ndk开发\"\n[65]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E5%B8%83%E5%B1%80%E4%BC%98%E5%8C%96.md \"布局优化\"\n[66]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E5%B1%8F%E5%B9%95%E9%80%82%E9%85%8D%E4%B9%8B%E7%99%BE%E5%88%86%E6%AF%94%E6%96%B9%E6%A1%88%E8%AF%A6%E8%A7%A3.md \"屏幕适配之百分比方案详解\"\n[67]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E7%83%AD%E4%BF%AE%E5%A4%8D%E5%AE%9E%E7%8E%B0.md \"热修复实现\"\n[68]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E5%A6%82%E4%BD%95%E8%AE%A9Service%E5%B8%B8%E9%A9%BB%E5%86%85%E5%AD%98.md \"如何让Service常驻内存\"\n[69]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E9%80%9A%E8%BF%87Hardware%20Layer%E6%8F%90%E9%AB%98%E5%8A%A8%E7%94%BB%E6%80%A7%E8%83%BD.md \"通过Hardware Layer提高动画性能\"\n[70]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96.md \"性能优化\"\n[71]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/%E6%B3%A8%E8%A7%A3%E4%BD%BF%E7%94%A8.md \"注解使用\"\n[72]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android6.0%E6%9D%83%E9%99%90%E7%B3%BB%E7%BB%9F.md \"Android6.0权限系统\"\n[73]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android%E5%BC%80%E5%8F%91%E4%B8%8D%E7%94%B3%E8%AF%B7%E6%9D%83%E9%99%90%E6%9D%A5%E4%BD%BF%E7%94%A8%E5%AF%B9%E5%BA%94%E5%8A%9F%E8%83%BD.md \"Android开发不申请权限来使用对应功能\"\n[74]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android%E5%BC%80%E5%8F%91%E4%B8%AD%E7%9A%84MVP%E6%A8%A1%E5%BC%8F%E8%AF%A6%E8%A7%A3.md \"Android开发中的MVP模式详解\"\n[75]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android%E5%90%AF%E5%8A%A8%E6%A8%A1%E5%BC%8F%E8%AF%A6%E8%A7%A3.md \"Android启动模式详解\"\n[76]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android%E5%8D%B8%E8%BD%BD%E5%8F%8D%E9%A6%88.md \"Android卸载反馈\"\n[77]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/ApplicationId%20vs%20PackageName.md \"ApplicationId vs PackageName\"\n[78]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/ART%E4%B8%8EDalvik.md \"ART与Dalvik\"\n[79]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/BroadcastReceiver%E5%AE%89%E5%85%A8%E9%97%AE%E9%A2%98.md \"BroadcastReceiver安全问题\"\n[80]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Handler%E5%AF%BC%E8%87%B4%E5%86%85%E5%AD%98%E6%B3%84%E9%9C%B2%E5%88%86%E6%9E%90.md \"Handler导致内存泄露分析\"\n[81]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Library%E9%A1%B9%E7%9B%AE%E4%B8%AD%E8%B5%84%E6%BA%90id%E4%BD%BF%E7%94%A8case%E6%97%B6%E6%8A%A5%E9%94%99.md \"Library项目中资源id使用case时报错\"\n[82]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Mac%E4%B8%8B%E9%85%8D%E7%BD%AEadb%E5%8F%8AAndroid%E5%91%BD%E4%BB%A4.md \"Mac下配置adb及Android命令\"\n[83]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/MaterialDesign%E4%BD%BF%E7%94%A8.md \"MaterialDesign使用\"\n[84]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/RecyclerView%E4%B8%93%E9%A2%98.md \"RecyclerView专题\"\n[85]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%B8%B8%E7%94%A8%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%A4%A7%E5%85%A8.md \"常用命令行大全\"\n[86]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%8D%95%E4%BE%8B%E7%9A%84%E6%9C%80%E4%BD%B3%E5%AE%9E%E7%8E%B0%E6%96%B9%E5%BC%8F.md \"单例的最佳实现方式\"\n[87]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84.md \"数据结构\"\n[88]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E8%8E%B7%E5%8F%96%E4%BB%8A%E5%90%8E%E5%A4%9A%E5%B0%91%E5%A4%A9%E5%90%8E%E7%9A%84%E6%97%A5%E6%9C%9F.md \"获取今后多少天后的日期\"\n[89]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%89%91%E6%8C%87Offer(%E4%B8%8A).md \"剑指Offer(上)\"\n[90]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/剑指Offer(下).md \"剑指Offer(下)\"\n[91]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%BC%BA%E5%BC%95%E7%94%A8%E3%80%81%E8%BD%AF%E5%BC%95%E7%94%A8%E3%80%81%E5%BC%B1%E5%BC%95%E7%94%A8%E3%80%81%E8%99%9A%E5%BC%95%E7%94%A8.md \"强引用、软引用、弱引用、虚引用\"\n[92]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E7%94%9F%E4%BA%A7%E8%80%85%E6%B6%88%E8%B4%B9%E8%80%85.md \"生产者消费者\"\n[93]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E6%95%B0%E6%8D%AE%E5%8A%A0%E5%AF%86%E5%8F%8A%E8%A7%A3%E5%AF%86.md \"数据加密及解密\"\n[94]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E6%AD%BB%E9%94%81.md \"死锁\"\n[95]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%B8%B8%E8%A7%81%E7%AE%97%E6%B3%95.md \"算法\"\n[96]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E7%BD%91%E7%BB%9C%E8%AF%B7%E6%B1%82%E7%9B%B8%E5%85%B3%E5%86%85%E5%AE%B9%E6%80%BB%E7%BB%93.md \"网络请求相关内容总结\"\n[97]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E7%BA%BF%E7%A8%8B%E6%B1%A0%E7%9A%84%E5%8E%9F%E7%90%86.md \"线程池的原理\"\n[98]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%8E%9F%E5%AD%90%E6%80%A7%E3%80%81%E5%8F%AF%E8%A7%81%E6%80%A7%E4%BB%A5%E5%8F%8A%E6%9C%89%E5%BA%8F%E6%80%A7.md \"原子性、可见性以及有序性\"\n[99]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Base64%E5%8A%A0%E5%AF%86.md \"Base64加密\"\n[100]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Git%E7%AE%80%E4%BB%8B.md \"Git简介\"\n[101]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/hashCode%E4%B8%8Eequals.md \"hashCode与equals\"\n[102]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/HashMap%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86%E5%88%86%E6%9E%90.md \"HashMap实现原理分析\"\n[103]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Java%E5%9F%BA%E7%A1%80%E9%9D%A2%E8%AF%95%E9%A2%98.md \"Java基础面试题\"\n[104]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/JVM%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%E6%9C%BA%E5%88%B6.md \"JVM垃圾回收机制\"\n[105]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/MD5%E5%8A%A0%E5%AF%86.md \"MD5加密\"\n[106]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/MVC%E4%B8%8EMVP%E5%8F%8AMVVM.md \"MVC与MVP及MVVM\"\n[107]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/RMB%E5%A4%A7%E5%B0%8F%E5%86%99%E8%BD%AC%E6%8D%A2.md \"RMB大小写转换\"\n[108]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Vim%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B.md \"Vim使用教程\"\n[109]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/volatile%E5%92%8CSynchronized%E5%8C%BA%E5%88%AB.md \"volatile和Synchronized区别\"\n[110]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%AE%89%E5%85%A8%E9%80%80%E5%87%BA%E5%BA%94%E7%94%A8%E7%A8%8B%E5%BA%8F.md \"安全退出应用程序\"\n[111]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E7%97%85%E6%AF%92.md \"病毒\"\n[112]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%B6%85%E7%BA%A7%E7%AE%A1%E7%90%86%E5%91%98(DevicePoliceManager).md \"超级管理员(DevicePoliceManager)\"\n[113]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E7%A8%8B%E5%BA%8F%E7%9A%84%E5%90%AF%E5%8A%A8%E3%80%81%E5%8D%B8%E8%BD%BD%E5%92%8C%E5%88%86%E4%BA%AB.md \"程序的启动、卸载和分享\"\n[114]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E4%BB%A3%E7%A0%81%E6%B7%B7%E6%B7%86.md \"代码混淆\"\n[115]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%AF%BB%E5%8F%96%E7%94%A8%E6%88%B7logcat%E6%97%A5%E5%BF%97.md \"读取用户logcat日志\"\n[116]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E7%9F%AD%E4%BF%A1%E5%B9%BF%E6%92%AD%E6%8E%A5%E6%94%B6%E8%80%85.md \"短信广播接收者\"\n[117]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%A4%9A%E7%BA%BF%E7%A8%8B%E6%96%AD%E7%82%B9%E4%B8%8B%E8%BD%BD.md \"多线程断点下载\"\n[118]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E9%BB%91%E5%90%8D%E5%8D%95%E6%8C%82%E6%96%AD%E7%94%B5%E8%AF%9D%E5%8F%8A%E5%88%A0%E9%99%A4%E7%94%B5%E8%AF%9D%E8%AE%B0%E5%BD%95.md \"黑名单挂断电话及删除电话记录\"\n[119]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%A8%AA%E5%90%91ListView.md \"横向ListView\"\n[120]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%BB%91%E5%8A%A8%E5%88%87%E6%8D%A2Activity(GestureDetector).md \"滑动切换Activity(GestureDetector)\"\n[121]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%8E%B7%E5%8F%96%E8%81%94%E7%B3%BB%E4%BA%BA.md \"获取联系人\"\n[122]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%8E%B7%E5%8F%96%E6%89%8B%E6%9C%BA%E5%8F%8ASD%E5%8D%A1%E5%8F%AF%E7%94%A8%E5%AD%98%E5%82%A8%E7%A9%BA%E9%97%B4.md \"获取手机及SD卡可用存储空间\"\n[123]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%8E%B7%E5%8F%96%E6%89%8B%E6%9C%BA%E4%B8%AD%E6%89%80%E6%9C%89%E5%AE%89%E8%A3%85%E7%9A%84%E7%A8%8B%E5%BA%8F.md \"获取手机中所有安装的程序\"\n[124]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%8E%B7%E5%8F%96%E4%BD%8D%E7%BD%AE(LocationManager).md \"获取位置(LocationManager)\"\n[125]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%8E%B7%E5%8F%96%E5%BA%94%E7%94%A8%E7%A8%8B%E5%BA%8F%E7%BC%93%E5%AD%98%E5%8F%8A%E4%B8%80%E9%94%AE%E6%B8%85%E7%90%86.md \"获取应用程序缓存及一键清理\"\n[126]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%BC%80%E5%8F%91%E4%B8%AD%E5%BC%82%E5%B8%B8%E7%9A%84%E5%A4%84%E7%90%86.md \"开发中异常的处理\"\n[127]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%BC%80%E5%8F%91%E4%B8%ADLog%E7%9A%84%E7%AE%A1%E7%90%86.md \"开发中Log的管理\"\n[128]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%BF%AB%E6%8D%B7%E6%96%B9%E5%BC%8F%E5%B7%A5%E5%85%B7%E7%B1%BB.md \"快捷方式工具类\"\n[129]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%9D%A5%E7%94%B5%E5%8F%B7%E7%A0%81%E5%BD%92%E5%B1%9E%E5%9C%B0%E6%8F%90%E7%A4%BA%E6%A1%86.md \"来电号码归属地提示框\"\n[130]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%9D%A5%E7%94%B5%E7%9B%91%E5%90%AC%E5%8F%8A%E5%BD%95%E9%9F%B3.md \"来电监听及录音\"\n[131]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E9%9B%B6%E6%9D%83%E9%99%90%E4%B8%8A%E4%BC%A0%E6%95%B0%E6%8D%AE.md \"零权限上传数据\"\n[132]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%86%85%E5%AD%98%E6%B3%84%E6%BC%8F.md \"内存泄漏\"\n[133]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%B1%8F%E5%B9%95%E9%80%82%E9%85%8D.md \"屏幕适配\"\n[134]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E4%BB%BB%E5%8A%A1%E7%AE%A1%E7%90%86%E5%99%A8(ActivityManager).md \"任务管理器(ActivityManager)\"\n[135]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%89%8B%E6%9C%BA%E6%91%87%E6%99%83.md \"手机摇晃\"\n[136]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E7%AB%96%E7%9D%80%E7%9A%84Seekbar.md \"竖着的Seekbar\"\n[137]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%95%B0%E6%8D%AE%E5%AD%98%E5%82%A8.md \"数据存储\"\n[138]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%90%9C%E7%B4%A2%E6%A1%86.md \"搜索框\"\n[139]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E9%94%81%E5%B1%8F%E4%BB%A5%E5%8F%8A%E8%A7%A3%E9%94%81%E7%9B%91%E5%90%AC.md \"锁屏以及解锁监听\"\n[140]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0.md \"文件上传\"\n[141]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E4%B8%8B%E6%8B%89%E5%88%B7%E6%96%B0ListView.md \"下拉刷新ListView\"\n[142]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E4%BF%AE%E6%94%B9%E7%B3%BB%E7%BB%9F%E7%BB%84%E4%BB%B6%E6%A0%B7%E5%BC%8F.md \"修改系统组件样式\"\n[143]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E9%9F%B3%E9%87%8F%E5%8F%8A%E5%B1%8F%E5%B9%95%E4%BA%AE%E5%BA%A6%E8%B0%83%E8%8A%82.md \"音量及屏幕亮度调节\"\n[144]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%BA%94%E7%94%A8%E5%AE%89%E8%A3%85.md \"应用安装\"\n[145]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E5%BA%94%E7%94%A8%E5%90%8E%E5%8F%B0%E5%94%A4%E9%86%92%E5%90%8E%E6%95%B0%E6%8D%AE%E7%9A%84%E5%88%B7%E6%96%B0.md \"应用后台唤醒后数据的刷新\"\n[146]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E7%9F%A5%E8%AF%86%E5%A4%A7%E6%9D%82%E7%83%A9.md \"知识大杂烩\"\n[147]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%B5%84%E6%BA%90%E6%96%87%E4%BB%B6%E6%8B%B7%E8%B4%9D%E7%9A%84%E4%B8%89%E7%A7%8D%E6%96%B9%E5%BC%8F.md \"资源文件拷贝的三种方式\"\n[148]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%87%AA%E5%AE%9A%E4%B9%89%E8%83%8C%E6%99%AF.md \"自定义背景\"\n[149]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%87%AA%E5%AE%9A%E4%B9%89%E6%8E%A7%E4%BB%B6.md \"自定义控件\"\n[150]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%87%AA%E5%AE%9A%E4%B9%89%E7%8A%B6%E6%80%81%E6%A0%8F%E9%80%9A%E7%9F%A5.md \"自定义状态栏通知\"\n[151]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/%E8%87%AA%E5%AE%9A%E4%B9%89Toast.md \"自定义Toast\"\n[152]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/adb%20logcat%E4%BD%BF%E7%94%A8%E7%AE%80%E4%BB%8B.md \"adb logcat使用简介\"\n[153]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E7%BC%96%E7%A0%81%E8%A7%84%E8%8C%83.md \"Android编码规范\"\n[154]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E5%8A%A8%E7%94%BB.md \"Android动画\"\n[155]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E5%9F%BA%E7%A1%80%E9%9D%A2%E8%AF%95%E9%A2%98.md \"Android基础面试题\"\n[156]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E5%85%A5%E9%97%A8%E4%BB%8B%E7%BB%8D.md \"Android入门介绍\"\n[157]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E5%9B%9B%E5%A4%A7%E7%BB%84%E4%BB%B6%E4%B9%8BContentProvider.md \"Android四大组件之ContentProvider\"\n[158]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Android%E5%9B%9B%E5%A4%A7%E7%BB%84%E4%BB%B6%E4%B9%8BService.md \"Android四大组件之Service\"\n[159]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Ant%E6%89%93%E5%8C%85.md \"Ant打包\"\n[160]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Bitmap%E4%BC%98%E5%8C%96.md \"Bitmap优化\"\n[161]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Fragment%E4%B8%93%E9%A2%98.md \"Fragment专题\"\n[162]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Home%E9%94%AE%E7%9B%91%E5%90%AC.md \"Home键监听\"\n[163]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/HttpClient%E6%89%A7%E8%A1%8CGet%E5%92%8CPost%E8%AF%B7%E6%B1%82.md \"HttpClient执行Get和Post请求\"\n[164]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/JNI_C%E8%AF%AD%E8%A8%80%E5%9F%BA%E7%A1%80.md \"JNI_C语言基础\"\n[165]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/JNI%E5%9F%BA%E7%A1%80.md \"JNI基础\"\n[166]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/ListView%E4%B8%93%E9%A2%98.md \"ListView专题\"\n[167]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Parcelable%E5%8F%8ASerializable.md \"Parcelable及Serializable\"\n[168]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/PopupWindow%E7%BB%86%E8%8A%82.md \"PopupWindow细节\"\n[169]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Scroller%E7%AE%80%E4%BB%8B.md \"Scroller简介\"\n[170]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/ScrollingTabs.md \"ScrollingTabs\"\n[171]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/SDK%20Manager%E6%97%A0%E6%B3%95%E6%9B%B4%E6%96%B0%E7%9A%84%E9%97%AE%E9%A2%98.md \"SDK Manager无法更新的问题\"\n[172]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Selector%E4%BD%BF%E7%94%A8.md \"Selector使用\"\n[173]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/SlidingMenu.md \"SlidingMenu\"\n[174]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/String%E6%A0%BC%E5%BC%8F%E5%8C%96.md \"String格式化\"\n[175]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/TextView%E8%B7%91%E9%A9%AC%E7%81%AF%E6%95%88%E6%9E%9C.md \"TextView跑马灯效果\"\n[176]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/WebView%E6%80%BB%E7%BB%93.md \"WebView总结\"\n[177]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Widget(%E7%AA%97%E5%8F%A3%E5%B0%8F%E9%83%A8%E4%BB%B6).md \"Widget(窗口小部件)\"\n[178]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/Wifi%E7%8A%B6%E6%80%81%E7%9B%91%E5%90%AC.md \"Wifi状态监听\"\n[179]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/BasicKnowledge/XmlPullParser.md \"XmlPullParser\"\n\n\n[180]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%B8%80).md \"Kotlin学习教程(一)\"\n[181]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%BA%8C).md \"Kotlin学习教程(二)\"\n[182]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%B8%89).md \"Kotlin学习教程(三)\"\n[183]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E5%9B%9B).md \"Kotlin学习教程(四)\"\n[184]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%BA%94).md \"Kotlin学习教程(五)\"\n[185]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E5%85%AD).md \"Kotlin学习教程(六)\"\n[186]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%B8%83).md \"Kotlin学习教程(七)\"\n[187]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E5%85%AB).md \"Kotlin学习教程(八)\"\n[188]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E4%B9%9D).md \"Kotlin学习教程(九)\"\n[189]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%85%AB%E7%A7%8D%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95.md \"八种排序算法\"\n[190]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E7%BA%BF%E7%A8%8B%E6%B1%A0%E7%AE%80%E4%BB%8B.md \"线程池简介\"\n[191]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F.md \"设计模式\"\n[192]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E7%AE%97%E6%B3%95%E7%9A%84%E5%A4%8D%E6%9D%82%E5%BA%A6.md \"算法复杂度\"\n[193]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/%E5%8A%A8%E6%80%81%E4%BB%A3%E7%90%86.md \"动态代理\"\n[194]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/ConstraintLaayout%E7%AE%80%E4%BB%8B.md \"ConstraintLaayout简介\"\n[195]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Http%E4%B8%8EHttps%E7%9A%84%E5%8C%BA%E5%88%AB.md \"Http与Https的区别\"\n[196]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/JavaKnowledge/Top-K%E9%97%AE%E9%A2%98.md \"Top-K问题\"\n[197]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/KotlinCourse/Kotlin%E5%AD%A6%E4%B9%A0%E6%95%99%E7%A8%8B(%E5%8D%81).md \"Kotlin学习教程(十)\"\n[198]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AppPublish/%E4%BD%BF%E7%94%A8Jenkins%E5%AE%9E%E7%8E%B0%E8%87%AA%E5%8A%A8%E5%8C%96%E6%89%93%E5%8C%85.md \"使用Jenkins实现自动化打包\"\n[199]: https://github.com/pengMaster/BestNote/tree/master/docs/android/AndroidNote//Dagger2 \"Dagger2\"\n[200]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/1.Dagger2%E7%AE%80%E4%BB%8B(%E4%B8%80).md \"1.Dagger2简介(一).md\"\n[201]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/2.Dagger2%E5%85%A5%E9%97%A8demo(%E4%BA%8C).md \"2.Dagger2入门demo(二).md\"\n[202]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/3.Dagger2%E5%85%A5%E9%97%A8demo%E6%89%A9%E5%B1%95(%E4%B8%89).md \"3.Dagger2入门demo扩展(三).md\"\n[203]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/4.Dagger2%E5%8D%95%E4%BE%8B(%E5%9B%9B).md \"4.Dagger2单例(四).md\"\n[204]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/5.Dagger2Lay%E5%92%8CProvider(%E4%BA%94).md \"5.Dagger2Lay和Provider(五).md\"\n[205]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/6.Dagger2Android%E7%A4%BA%E4%BE%8B%E4%BB%A3%E7%A0%81(%E5%85%AD).md \"6.Dagger2Android示例代码(六).md\"\n[206]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/7.Dagger2%E4%B9%8Bdagger-android(%E4%B8%83).md \"7.Dagger2之dagger-android(七).md\"\n[207]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/8.Dagger2%E4%B8%8EMVP(%E5%85%AB).md \"8.Dagger2与MVP(八).md\"\n[208]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/AdavancedPart/Android%20WorkManager.md \"Android WorkManager.md\"\n\n[209]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/4.RxJava%E8%AF%A6%E8%A7%A3%E4%B9%8B%E6%89%A7%E8%A1%8C%E5%8E%9F%E7%90%86(%E5%9B%9B).md \"4.RxJava详解之执行原理(四)\"\n[210]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/5.RxJava%E8%AF%A6%E8%A7%A3%E4%B9%8B%E6%93%8D%E4%BD%9C%E7%AC%A6%E6%89%A7%E8%A1%8C%E5%8E%9F%E7%90%86(%E4%BA%94).md \"5.RxJava详解之操作符执行原理(五)\"\n[211]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/RxJavaPart/6.RxJava%E8%AF%A6%E8%A7%A3%E4%B9%8B%E7%BA%BF%E7%A8%8B%E8%B0%83%E5%BA%A6%E5%8E%9F%E7%90%86(%E5%85%AD).md \"6.RxJava详解之线程调度原理(六)\"\n[212]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Dagger2/9.Dagger2%E5%8E%9F%E7%90%86%E5%88%86%E6%9E%90(%E4%B9%9D).md \"9.Dagger2原理分析(九)\"\n[213]: https://github.com/pengMaster/BestNote/blob/master/docs/android/AndroidNote/Tools%26Library/%E8%B0%83%E8%AF%95%E5%B9%B3%E5%8F%B0Sonar.md \"调试平台Sonar\"\n"
},
{
"path": "docs/.nojekyll",
"content": ""
},
{
"path": "docs/android/Android-Interview/.gitignore",
"content": "# Node rules:\n## Grunt intermediate storage (http://gruntjs.com/creating-plugins#storing-task-files)\n.grunt\n\n## Dependency directory\n## Commenting this out is preferred by some people, see\n## https://docs.npmjs.com/misc/faq#should-i-check-my-node_modules-folder-into-git\nnode_modules\n\n# Book build output\n_book\n\n# eBook build output\n*.epub\n*.mobi\n*.pdf"
},
{
"path": "docs/android/Android-Interview/Activity/Activity Task和Process.md",
"content": "### 源码分析相关面试题\n\n- [Volley源码分析](http://www.jianshu.com/p/ec3dc92df581)\n- [注解框架实现原理](http://www.jianshu.com/p/20da6d6389e1)\n- [okhttp3.0源码分析](http://www.jianshu.com/p/9ed2c2f2a52c)\n- [onSaveInstanceState源码分析](http://www.jianshu.com/p/cbf9c3557d64)\n- [静默安装和源码编译](http://www.jianshu.com/p/2211a5b3c37f)\n\n### Activity相关面试题\n\n- [保存Activity的状态](http://www.jianshu.com/p/cbf9c3557d64)\n- [深刻剖析activity启动模式(一)](http://www.jianshu.com/p/b33fd8c550bf)\n- [深刻剖析activity启动模式(二)](http://www.jianshu.com/p/e1ea9e542112)\n- [深刻剖析activity启动模式(三)](http://www.jianshu.com/p/d13e3d552d4b)\n- [Activity Task和Process之间的关系](http://www.jianshu.com/p/d13e3d552d4b)\n- [service里面startActivity抛异常?activity不会](http://www.jianshu.com/p/16e880ceb3a4)\n\n### 与XMPP相关面试题\n\n- [XMPP协议优缺点](http://www.jianshu.com/p/2c04ac3c526a)\n- [极光消息推送原理](http://www.jianshu.com/p/d88dc66908cf)\n\n### 与性能优化相关面试题\n\n- [内存泄漏和内存溢出区别](http://www.jianshu.com/p/5dd645b05c76)\n- [UI优化和线程池实现原理](http://www.jianshu.com/p/c22398f8587f)\n- [代码优化](http://www.jianshu.com/p/ebd41eab90df)\n- [内存性能分析](http://www.jianshu.com/p/2665c31b9c2f)\n- [内存泄漏检测](http://www.jianshu.com/p/1514c7804a06)\n- [App启动优化](http://www.jianshu.com/p/f0f73fefdd43)\n- [与IPC机制相关面试题](http://www.jianshu.com/p/de4793a4c2d0)\n\n### 与登录相关面试题\n\n- [oauth认证协议原理](http://www.jianshu.com/p/2a6ecbf8d49d)\n- [token产生的意义](http://www.jianshu.com/p/9b7ce2d6c195)\n- [微信扫一扫实现原理](http://www.jianshu.com/p/a9d1f21bd5e0)\n\n### 与开发相关面试题\n\n- [迭代开发的时候如何向前兼容新旧接口](http://www.jianshu.com/p/cbecadec98de)\n- [手把手教你如何解决as jar包冲突](http://www.jianshu.com/p/30fdc391289c)\n- [context的原理分析](http://www.jianshu.com/p/2706c13a1769)\n- [解决ViewPager.setCurrentItem中间很多页面切换方案](http://www.jianshu.com/p/38ab6d856b56)\n- [字体适配](http://www.jianshu.com/p/33d499170e25)\n- [软键盘顶出去解决方案](http://www.jianshu.com/p/640bac6f58ab)与人事相关面试题\n- [人事面试宝典](http://www.jianshu.com/p/d61b553ff8c9)\n\nAMS提供了一个ArrayList mHistory来管理所有的activity,activity在AMS中的形式是ActivityRecord,task在AMS中的形式为TaskRecord,进程在AMS中的管理形式为ProcessRecord。如下图所示\n\n\n\n从图中我们可以看出如下几点规则:\n\n1) 所有的ActivityRecord会被存储在mHistory管理;\n\n2) 每个ActivityRecord会对应到一个TaskRecord,并且有着相同TaskRecord的ActivityRecord在mHistory中会处在连续的位置;\n\n3) 同一个TaskRecord的Activity可能分别处于不同的进程中,每个Activity所处的进程跟task没有关系;\n\nActivity启动时ActivityManagerService会为其生成对应的ActivityRecord记录,并将其加入到回退栈(back stack)中,另外也会将ActivityRecord记录加入到某个Task中。请记住,ActivityRecord,backstack,Task都是ActivityManagerService的对象,由ActivityManagerService进程负责维护,而不是由应用进程维护。\n\n在回退栈里属于同一个task的ActivityRecord会放在一起,也会形成栈的结构,也就是说后启动的Activity对应的ActivityRecord会放在task的栈顶\n\n执行adb shell dumpsys activity命令,发现有以下输出:\n\n```\nTask id #30\n TaskRecord{7f2f34a #30 A=com.maweiqi.second U=0 sz=2}\n Intent { flg=0x10000000 cmp=com.open.android.task1/.SecondActivity }\n Hist #1: ActivityRecord{a0f9ded u0 com.open.android.task3/.OtherActivity t30}\n Intent { flg=0x10400000 cmp=com.open.android.task3/.OtherActivity }\n ProcessRecord{12090b5 27543:com.open.android.task3/u0a62}\n Hist #0: ActivityRecord{1048af6 u0 com.open.android.task1/.SecondActivity t30}\n Intent { flg=0x10000000 cmp=com.open.android.task1/.SecondActivity }\n ProcessRecord{5bc013e 26035:com.open.android.task1/u0a59}\n\n Task id #31\n TaskRecord{dce52bb #31 A=com.open.android.task3 U=0 sz=1}\n Intent { act=android.intent.action.MAIN cat=[android.intent.category.LAUNCHER] flg=0x10000000 cmp=com.open.android.task3/.MainActivity }\n Hist #0: ActivityRecord{f9e58c5 u0 com.open.android.task3/.MainActivity t31}\n Intent { act=android.intent.action.MAIN cat=[android.intent.category.LAUNCHER] flg=0x10000000 cmp=com.open.android.task3/.MainActivity }\n ProcessRecord{12090b5 27543:com.open.android.task3/u0a62}\n\n Task id #29\n TaskRecord{5b063d8 #29 A=com.open.android.task1 U=0 sz=1}\n Intent { act=android.intent.action.MAIN cat=[android.intent.category.LAUNCHER] flg=0x10000000 cmp=com.open.android.task1/.MainActivity }\n Hist #0: ActivityRecord{689947d u0 com.open.android.task1/.MainActivity t29}\n Intent { act=android.intent.action.MAIN cat=[android.intent.category.LAUNCHER] flg=0x10000000 cmp=com.open.android.task1/.MainActivity }\n ProcessRecord{5bc013e 26035:com.open.android.task1/u0a59}\n\nRunning activities (most recent first):\n TaskRecord{7f2f34a #30 A=com.maweiqi.second U=0 sz=2}\n Run #3: ActivityRecord{a0f9ded u0 com.open.android.task3/.OtherActivity t30}\n TaskRecord{dce52bb #31 A=com.open.android.task3 U=0 sz=1}\n Run #2: ActivityRecord{f9e58c5 u0 com.open.android.task3/.MainActivity t31}\n TaskRecord{7f2f34a #30 A=com.maweiqi.second U=0 sz=2}\n Run #1: ActivityRecord{1048af6 u0 com.open.android.task1/.SecondActivity t30}\n TaskRecord{5b063d8 #29 A=com.open.android.task1 U=0 sz=1}\n Run #0: ActivityRecord{689947d u0 com.open.android.task1/.MainActivity t29}\n\nmResumedActivity: ActivityRecord{a0f9ded u0 com.open.android.task3/.OtherActivity t30}\n```\n\n从图对应文字在对应adb输出,这几个基本概念大家估计就清楚了。\n\n- 欢迎关注微信公众号,长期推荐技术文章和技术视频\n- 微信公众号名称:Android干货程序员\n\n"
},
{
"path": "docs/android/Android-Interview/Activity/App优雅退出.md",
"content": "### **1. RxBus优雅式**\n\n首先,在基类BaseActivity里,注册RxBus监听:\n\n```java\npublic class BaseActivity3 extends AppCompatActivity {\n Subscription mSubscription;\n\n @Override\n public void onCreate(@Nullable Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n initRxBus();\n }\n //接收退出的指令,关闭所有activity\n private void initRxBus() {\n mSubscription = RxBus.getInstance().toObserverable(NormalEvent.class)\n .subscribe(new Action1