g_native_alloc_sizes;\nstatic CRITICAL_SECTION g_native_alloc_sizes_lock;\n\nstatic void track_native_alloc(void* ptr, size_t size) {\n EnterCriticalSection(&g_native_alloc_sizes_lock);\n g_native_alloc_sizes[ptr] = size;\n LeaveCriticalSection(&g_native_alloc_sizes_lock);\n}\n\nstatic size_t untrack_native_alloc(void* ptr) {\n EnterCriticalSection(&g_native_alloc_sizes_lock);\n auto it = g_native_alloc_sizes.find(ptr);\n size_t size = (it != g_native_alloc_sizes.end()) ? it->second : 0;\n if (it != g_native_alloc_sizes.end()) g_native_alloc_sizes.erase(it);\n LeaveCriticalSection(&g_native_alloc_sizes_lock);\n return size;\n}\n```\n\n### Coordination Between Python and Native Hooks\n\nTo prevent double-counting allocations that go through both Python's allocator AND the native malloc:\n\n1. Python allocator hooks set `g_in_python_allocator = true` when active\n2. Native malloc hooks check this flag and skip if Python allocator is handling it\n3. Each allocation is counted exactly once\n\n```cpp\n// In Python allocator hook:\nstatic void* scalene_malloc(void* ctx, size_t len) {\n g_in_python_allocator = true; // Prevent native hooks\n void* ptr = g_original_mem_allocator.malloc(...);\n // ... tracking code ...\n g_in_python_allocator = false;\n return ptr;\n}\n```\n\n## Fixes Applied\n\n### 1. **ctypes 64-bit Pointer Fix** (Critical)\n- Added `restype` declarations for all Windows API functions that return handles or pointers\n- `MapViewOfFile.restype = ctypes.c_void_p` - returns memory address\n- `OpenFileMappingW.restype = wintypes.HANDLE` - returns handle\n- Also set `argtypes` for functions taking pointers\n\n### 2. Data Format Fix\nChanged malloc/free output from tab-separated 4-field format to comma-separated 9-field format matching Unix:\n```\nM,alloc_time,count,python_fraction,pid,pointer,filename,lineno,bytei\\n\\n\n```\n\n### 3. Removed `thread_local` Variables\nWindows DLLs loaded with `LoadLibrary`/ctypes don't properly support `thread_local` variables. Changed all to static variables:\n- `mallocSampler` and `memcpySampler`\n- `g_pythonCount`, `g_cCount`\n- `g_lastMallocTrigger`, `g_freedLastMallocTrigger`\n- `g_memcpyOps`\n- `inMalloc` (for recursion guard)\n\n### 4. Added Windows Memory Polling\nSince Unix signals (SIGXCPU/SIGXFSZ) don't exist on Windows, added a polling thread in `scalene_signal_manager.py`:\n- `_windows_memory_poll_loop()` - polls every 10ms\n- Triggers `_alloc_sigqueue_processor` and `_memcpy_sigqueue_processor`\n- Started when memory profiling is enabled on Windows\n\n### 5. Safety Checks in Allocator Hooks\nAdded null checks for original allocator function pointers to prevent crashes if allocation hooks are called before initialization.\n\n## Test Results\n\nRunning the profiler now shows memory profiling data being collected:\n```\nmalloc_calls=113807912, samples=595, logged=595\n```\n\nThe profiler correctly tracks:\n- Python vs native time\n- Memory allocations with line attribution\n- Memory timeline/growth rate\n\n## Build Instructions\n\n```bash\n# Configure with CMake (for ARM64 native)\ncmake -B build -A ARM64 -DPython3_ROOT_DIR=\"C:\\Users\\emery\\AppData\\Local\\Programs\\Python\\Python311-arm64\"\n\n# Build the DLL\nMSBuild.exe build/scalene.sln -p:Configuration=Release -p:Platform=ARM64 -t:scalene\n\n# DLL is automatically placed in scalene\\ directory\n\n# Run profiler\npython -m scalene --cli --cpu --memory test\\testme.py\n```\n\n## Key Differences from Unix Implementation\n\n| Aspect | Unix | Windows |\n|--------|------|---------|\n| Native malloc hooking | LD_PRELOAD | **Microsoft Detours** (inline function hooking) |\n| Python allocator | PyMem_SetAllocator | PyMem_SetAllocator (same) |\n| Signals | SIGXCPU/SIGXFSZ | Polling thread |\n| Shared Memory | /tmp files + mmap | Named shared memory |\n| Symbol Lookup | dlsym(RTLD_DEFAULT) | GetProcAddress + accessor functions |\n| Size Tracking | malloc_usable_size | Manual hash map (\\_msize unreliable) |\n| Thread-local | `thread_local` | Static variables (GIL protects) |\n| Pointer handling | Native 64-bit | **Requires explicit ctypes declarations** |\n| Architecture support | All | ARM64, x64, x86 (via Detours) |\n\n## Learnings\n\n### 1. ctypes Default Return Types Are Dangerous on 64-bit Windows\n- **Always** set `restype` for any Windows API function that returns a handle or pointer\n- Default `c_int` (32-bit) silently truncates 64-bit values\n- This causes delayed crashes that are hard to debug (crash happens when truncated pointer is used, not when it's returned)\n- Use `ctypes.c_void_p` for memory addresses, `wintypes.HANDLE` for handles\n\n### 2. Debugging Methodology That Worked\nThe crash was isolated using **systematic component elimination**:\n1. First confirmed DLL was the cause by renaming it (profiler ran without crash)\n2. Tested with allocator hooks disabled - still crashed (ruled out hooks as cause)\n3. Tested with only shared memory initialization - still crashed (narrowed to shared memory)\n4. Examined shared memory code and found the ctypes issue\n\n### 3. Windows DLL Loading Constraints\n- `thread_local` variables don't work reliably in DLLs loaded via `LoadLibrary`/ctypes\n- Static variables work fine since Python's GIL serializes access\n- DLL entry point (`DllMain`) has severe restrictions - avoid complex initialization there\n\n### 4. Build System Considerations\n- CMake generates Visual Studio solutions that work well for cross-platform builds\n- ARM64 native builds require explicit `-A ARM64` and matching Python version\n- MSBuild can be invoked directly for rebuilds without re-running CMake\n\n### 5. Windows vs Unix IPC\n- Named shared memory on Windows uses `Local\\` prefix for per-session namespace\n- Windows Events can replace Unix signals but polling is simpler for this use case\n- Mutexes on Windows are more heavyweight than Unix futexes\n\n### 6. Recursion Guards in malloc Hooks Must Come FIRST\n- **Critical**: Any code in a malloc hook that uses STL containers (std::unordered_map, std::vector, etc.) may internally call malloc\n- The recursion guard (`g_in_native_hook`) MUST be checked and set BEFORE any other operations\n- Failing to do this causes infinite recursion → stack overflow → exit code 127 or crash\n- Pattern: `if (guard) return original(); guard = true; ... ; guard = false; return result;`\n\n### 7. MinHook Does NOT Support ARM64\n- MinHook is a popular inline hooking library but only supports x86 and x64\n- Microsoft Detours supports ARM64, ARM, x86, x64, and IA64\n- Detours is MIT licensed (open source since 2018) and very well tested\n- Use architecture-specific disassemblers: `disolarm64.cpp` for ARM64, `disolx64.cpp` for x64\n\n### 8. _msize() Is Unreliable for Custom Allocators\n- `_msize()` only works for standard CRT heap allocations\n- numpy and other libraries use aligned allocations (`_aligned_malloc`) which `_msize` doesn't handle\n- Solution: Manual size tracking with a hash map, storing size at allocation time\n- This adds ~10% overhead but is necessary for accurate free tracking\n\n### 9. Coordination Between Multiple Hook Layers\n- When hooking at both Python allocator level AND native malloc level, coordination is essential\n- Use a flag (`g_in_python_allocator`) to prevent native hooks from double-counting Python allocations\n- Pattern: Set flag before calling original allocator, clear after\n- This ensures each allocation is tracked exactly once\n\n## Next Steps\n\n### High Priority\n1. **x64 Build and Testing**: Current implementation tested only on ARM64. Need to verify x64 builds work correctly with Detours.\n\n2. **Unicode Console Output**: The `UnicodeEncodeError` for sparkline characters could be handled more gracefully:\n - Detect console encoding and fall back to ASCII sparklines\n - Or auto-set `PYTHONIOENCODING=utf-8` when running on Windows\n\n3. **Performance Optimization**: The polling thread polls every 10ms. Consider:\n - Using Windows Events for more efficient signaling\n - Adaptive polling rate based on allocation frequency\n\n### Medium Priority\n4. **Multi-Process Support**: Test and fix any issues with profiling child processes on Windows (the Unix `redirect_python` mechanism may need Windows adaptation).\n\n5. **GPU Profiling on Windows**: Verify NVIDIA GPU profiling works on Windows (pynvml should work but needs testing).\n\n6. **CI/CD Integration**: Add Windows builds to GitHub Actions workflow:\n - Build DLL for both x64 and ARM64\n - Run tests on Windows\n - Include DLL in wheel packages\n\n### Low Priority\n7. **Windows Event-Based Signaling**: Replace polling with proper Windows Events for lower latency and CPU usage:\n - DLL already creates events (`ScaleneMallocEvent`, etc.)\n - Python side would use `WaitForMultipleObjects` instead of polling\n\n8. **Memory Leak Detection**: The `--memory-leak-detector` feature may need Windows-specific testing.\n\n9. **Web UI Testing**: Verify the web-based GUI works correctly on Windows (browser launching, port binding).\n\n### Completed\n- ~~**Native Library Memory Tracking**: Implement malloc/free hooking for numpy, pandas, etc.~~ ✅ Done (2024-12-17) - Using Microsoft Detours\n\n## Debugging Tips for Future Issues\n\n### Useful Debug Techniques\n```python\n# Add to scalene_mapfile.py to debug shared memory issues\nprint(f\"Handle value: {handle:#x}\", file=sys.stderr)\nprint(f\"View address: {view:#x}\", file=sys.stderr)\n\n# Check if pointer looks valid (should have high bits set on 64-bit)\nif view < 0x100000000:\n print(\"WARNING: Pointer may be truncated!\", file=sys.stderr)\n```\n\n### Building with Debug Output\n```cpp\n// In libscalene_windows.cpp, temporarily add:\nfprintf(stderr, \"DEBUG: ptr=%p, size=%zu\\n\", ptr, size);\n```\n\nThen rebuild with:\n```bash\nMSBuild.exe build/scalene.sln -p:Configuration=Release -p:Platform=ARM64 -t:scalene\n```\n\n### Common Windows Error Codes\n- `0xC0000005` (3221225477) - Access Violation (invalid memory access)\n- `0xC0000008` - Invalid Handle\n- `0xC000001D` - Illegal Instruction (wrong architecture)\n- Error 193 - \"Not a valid Win32 application\" (architecture mismatch)\n\n## References\n\n- Python Memory Allocator API: https://docs.python.org/3/c-api/memory.html\n- Windows Named Shared Memory: https://docs.microsoft.com/en-us/windows/win32/memory/creating-named-shared-memory\n- CMake Windows DLL: https://cmake.org/cmake/help/latest/prop_tgt/WINDOWS_EXPORT_ALL_SYMBOLS.html\n- Windows thread_local issues: https://devblogs.microsoft.com/cppblog/c11-thread-local-storage-and-dll-load-failure/\n- **ctypes 64-bit pointers**: https://docs.python.org/3/library/ctypes.html#return-types\n- **Microsoft Detours**: https://github.com/microsoft/Detours - Official Microsoft library for inline function hooking (MIT license)\n- Detours Wiki: https://github.com/microsoft/Detours/wiki - API documentation and examples\n"
},
{
"path": "benchmarks/bench_torch_memory.py",
"content": "\"\"\"Torch-heavy workload that exposes profiler memory explosion (#991).\n\nRun under Scalene to observe memory behaviour:\n\n scalene run benchmarks/bench_torch_memory.py\n\nOn master (before the fix), the Scalene process RSS grows continuously\nbecause:\n 1. torch.profiler accumulates events with full Python stacks for\n every torch operation for the entire profiling duration.\n 2. cpu_samples_list appends a wallclock timestamp on every CPU sample\n without any bound.\n\nAfter the fix, both are bounded via reservoir sampling / periodic\nprofiler flushing, so RSS stays roughly constant.\n\nUse ``benchmarks/measure_profiler_memory.py`` to automatically measure\nand compare peak RSS.\n\"\"\"\n\nimport sys\nimport time\n\ntry:\n import torch\nexcept ImportError:\n print(\"ERROR: PyTorch is required. pip install torch\", file=sys.stderr)\n sys.exit(1)\n\nDURATION_SECONDS = 60 # wall-clock runtime (longer = more event accumulation)\nMATRIX_SIZE = 256 # small matrices -> many ops per second\n\n\ndef main() -> None:\n print(f\"Running torch workload for ~{DURATION_SECONDS}s \"\n f\"(matrix size {MATRIX_SIZE}) ...\")\n\n ops = 0\n t0 = time.perf_counter()\n deadline = t0 + DURATION_SECONDS\n\n a = torch.randn(MATRIX_SIZE, MATRIX_SIZE)\n b = torch.randn(MATRIX_SIZE, MATRIX_SIZE)\n\n while time.perf_counter() < deadline:\n # Each iteration generates multiple torch profiler events\n c = a @ b\n c = c + a\n c = c.relu()\n a, b = b, c\n ops += 3 # matmul + add + relu\n\n # Re-normalise occasionally to avoid overflow / underflow\n if ops % 3000 == 0:\n a = torch.randn(MATRIX_SIZE, MATRIX_SIZE)\n b = torch.randn(MATRIX_SIZE, MATRIX_SIZE)\n\n elapsed = time.perf_counter() - t0\n print(f\"Completed {ops:,} torch ops in {elapsed:.1f}s \"\n f\"({ops / elapsed:,.0f} ops/s)\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "benchmarks/benchmark.py",
"content": "import os\nimport sys\nimport re\nimport subprocess\nimport traceback\nimport statistics\n\npython = \"python3\"\nprogname = os.path.join(os.path.dirname(__file__), \"julia1_nopil.py\")\nnumber_of_runs = 1 # We take the average of this many runs.\n\n# Output timing string from the benchmark.\nresult_regexp = re.compile(\n \"calculate_z_serial_purepython took ([0-9]*\\.[0-9]+) seconds\"\n)\n\n# Characteristics of the tools.\n\nline_level = {}\ncpu_profiler = {}\nseparate_profiler = {}\nmemory_profiler = {}\nunmodified_code = {}\ntiming = {}\n\nline_level[\"baseline\"] = None\nline_level[\"cProfile\"] = False\nline_level[\"Profile\"] = False\nline_level[\"line_profiler\"] = True\nline_level[\"pyinstrument\"] = False\nline_level[\"yappi_cputime\"] = False\nline_level[\"yappi_wallclock\"] = False\nline_level[\"pprofile_deterministic\"] = True\nline_level[\"pprofile_statistical\"] = True\nline_level[\"py_spy\"] = True\nline_level[\"memory_profiler\"] = True\nline_level[\"scalene_cpu\"] = True\nline_level[\"scalene_cpu_memory\"] = True\n\ncpu_profiler[\"baseline\"] = None\ncpu_profiler[\"cProfile\"] = True\ncpu_profiler[\"Profile\"] = True\ncpu_profiler[\"pyinstrument\"] = True\ncpu_profiler[\"line_profiler\"] = True\ncpu_profiler[\"yappi_cputime\"] = True\ncpu_profiler[\"yappi_wallclock\"] = True\ncpu_profiler[\"pprofile_deterministic\"] = True\ncpu_profiler[\"pprofile_statistical\"] = True\ncpu_profiler[\"py_spy\"] = True\ncpu_profiler[\"memory_profiler\"] = False\ncpu_profiler[\"scalene_cpu\"] = True\ncpu_profiler[\"scalene_cpu_memory\"] = True\n\nseparate_profiler[\"baseline\"] = None\nseparate_profiler[\"cProfile\"] = False\nseparate_profiler[\"Profile\"] = False\nseparate_profiler[\"pyinstrument\"] = False\nseparate_profiler[\"line_profiler\"] = False\nseparate_profiler[\"yappi_cputime\"] = False\nseparate_profiler[\"yappi_wallclock\"] = False\nseparate_profiler[\"pprofile_deterministic\"] = False\nseparate_profiler[\"pprofile_statistical\"] = False\nseparate_profiler[\"py_spy\"] = False\nseparate_profiler[\"memory_profiler\"] = False\nseparate_profiler[\"scalene_cpu\"] = True\nseparate_profiler[\"scalene_cpu_memory\"] = True\n\nmemory_profiler[\"baseline\"] = None\nmemory_profiler[\"cProfile\"] = False\nmemory_profiler[\"Profile\"] = False\nmemory_profiler[\"pyinstrument\"] = False\nmemory_profiler[\"line_profiler\"] = False\nmemory_profiler[\"yappi_cputime\"] = False\nmemory_profiler[\"yappi_wallclock\"] = False\nmemory_profiler[\"pprofile_deterministic\"] = False\nmemory_profiler[\"pprofile_statistical\"] = False\nmemory_profiler[\"py_spy\"] = False\nmemory_profiler[\"memory_profiler\"] = True\nmemory_profiler[\"scalene_cpu\"] = False\nmemory_profiler[\"scalene_cpu_memory\"] = True\n\nunmodified_code[\"baseline\"] = None\nunmodified_code[\"cProfile\"] = True\nunmodified_code[\"Profile\"] = True\nunmodified_code[\"pyinstrument\"] = True\nunmodified_code[\"line_profiler\"] = False\nunmodified_code[\"yappi_cputime\"] = True\nunmodified_code[\"yappi_wallclock\"] = True\nunmodified_code[\"pprofile_deterministic\"] = True\nunmodified_code[\"pprofile_statistical\"] = True\nunmodified_code[\"py_spy\"] = True\nunmodified_code[\"memory_profiler\"] = False\nunmodified_code[\"scalene_cpu\"] = True\nunmodified_code[\"scalene_cpu_memory\"] = True\n\n# how the profilers measure time\n# - wall clock only\n# - virtual (process) time only\n# - either one\nWallClock = 1\nVirtualTime = 2\nEither = 3\n\ntiming[\"baseline\"] = None\ntiming[\"cProfile\"] = WallClock\ntiming[\"Profile\"] = VirtualTime\ntiming[\"pyinstrument\"] = WallClock\ntiming[\"line_profiler\"] = WallClock\ntiming[\"yappi_cputime\"] = Either\ntiming[\"yappi_wallclock\"] = Either\ntiming[\"pprofile_deterministic\"] = WallClock\ntiming[\"pprofile_statistical\"] = WallClock\ntiming[\"py_spy\"] = Either\ntiming[\"memory_profiler\"] = None\ntiming[\"scalene_cpu\"] = Either\ntiming[\"scalene_cpu_memory\"] = Either\n\n\n# Command lines for the various tools.\n\nbaseline = f\"{python} {progname}\"\ncprofile = f\"{python} -m cProfile {progname}\"\nprofile = f\"{python} -m profile {progname}\"\npyinstrument = f\"pyinstrument {progname}\"\nline_profiler = f\"{python} -m kernprof -l -v {progname}\"\npprofile_deterministic = f\"pprofile {progname}\"\npprofile_statistical = f\"pprofile --statistic 0.001 {progname}\" # Same as Scalene\nyappi_cputime = f\"yappi {progname}\"\nyappi_wallclock = f\"yappi -c wall {progname}\"\npy_spy = f\"py-spy record -f raw -o foo.txt -- python3.7 {progname}\"\nscalene_cpu = f\"{python} -m scalene {progname}\"\nscalene_cpu_memory = (\n f\"{python} -m scalene {progname}\" # see below for environment variables\n)\n\nbenchmarks = [\n (baseline, \"baseline\", \"_original program_\"),\n (cprofile, \"cProfile\", \"`cProfile`\"),\n (profile, \"Profile\", \"`Profile`\"),\n (pyinstrument, \"pyinstrument\", \"`pyinstrument`\"),\n (line_profiler, \"line_profiler\", \"`line_profiler`\"),\n (pprofile_deterministic, \"pprofile_deterministic\", \"`pprofile` _(deterministic)_\"),\n (pprofile_statistical, \"pprofile_statistical\", \"`pprofile` _(statistical)_\"),\n (yappi_cputime, \"yappi_cputime\", \"`yappi` _(CPU)_\"),\n (yappi_wallclock, \"yappi_wallclock\", \"`yappi` _(wallclock)_\"),\n (scalene_cpu, \"scalene_cpu\", \"`scalene` _(CPU only)_\"),\n (scalene_cpu_memory, \"scalene_cpu_memory\", \"`scalene` _(CPU + memory)_\"),\n]\n\n# benchmarks = [(baseline, \"baseline\", \"_original program_\"), (pprofile_deterministic, \"`pprofile` _(deterministic)_\")]\n# benchmarks = [(baseline, \"baseline\", \"_original program_\"), (pprofile_statistical, \"pprofile_statistical\", \"`pprofile` _(statistical)_\")]\nbenchmarks = [\n (baseline, \"baseline\", \"_original program_\"),\n (py_spy, \"py_spy\", \"`py-spy`\"),\n (scalene_cpu, \"scalene_cpu\", \"`scalene` _(CPU only)_\"),\n (scalene_cpu_memory, \"scalene_cpu_memory\", \"`scalene` _(CPU + memory)_\"),\n]\n\naverage_time = {}\ncheck = \":heavy_check_mark:\"\n\nprint(\n \"| | Time | Slowdown | Line-level? | CPU? | Python vs. C? | Memory? | Unmodified code? |\"\n)\nprint(\"| :--- | ---: | ---: | :---: | :---: | :---: | :---: | :---: |\")\n\nfor bench in benchmarks:\n print(bench)\n times = []\n for i in range(0, number_of_runs):\n my_env = os.environ.copy()\n if bench[1] == \"scalene_cpu_memory\":\n my_env[\"PYTHONMALLOC\"] = \"malloc\"\n if sys.platform == \"darwin\":\n my_env[\"DYLD_INSERT_LIBRARIES\"] = \"./libscalene.dylib\"\n if sys.platform == \"linux\":\n my_env[\"LD_PRELOAD\"] = \"./libscalene.so\"\n result = subprocess.run(\n bench[0].split(),\n env=my_env,\n stderr=subprocess.STDOUT,\n stdout=subprocess.PIPE,\n )\n output = result.stdout.decode(\"utf-8\")\n print(output)\n match = result_regexp.search(output)\n if match is not None:\n times.append(round(100 * float(match.group(1))) / 100.0)\n else:\n print(\"failed run\")\n average_time[bench[1]] = statistics.mean(times) # sum_time / (number_of_runs * 1.0)\n print(str(average_time[bench[1]]))\n if bench[1] == \"baseline\":\n print(f\"| {bench[2]} | {average_time[bench[1]]}s | 1.0x | | | | | |\")\n print(\"| | | | | |\")\n else:\n try:\n if bench[1].find(\"scalene\") >= 0:\n if bench[1].find(\"scalene_cpu\") >= 0:\n print(\"| | | | | |\")\n print(\n f\"| {bench[2]} | {average_time[bench[1]]}s | **{round(100 * average_time[bench[1]] / average_time['baseline']) / 100}x** | {check if line_level[bench[1]] else 'function-level'} | {check if cpu_profiler[bench[1]] else ''} | {check if separate_profiler[bench[1]] else ''} | {check if memory_profiler[bench[1]] else ''} | {check if unmodified_code[bench[1]] else 'needs `@profile` decorators'} |\"\n )\n else:\n print(\n f\"| {bench[2]} | {average_time[bench[1]]}s | {round(100 * average_time[bench[1]] / average_time['baseline']) / 100}x | {check if line_level[bench[1]] else 'function-level'} | {check if cpu_profiler[bench[1]] else ''} | {check if separate_profiler[bench[1]] else ''} | {check if memory_profiler[bench[1]] else ''} | {check if unmodified_code[bench[1]] else 'needs `@profile` decorators'} |\"\n )\n except Exception as err:\n traceback.print_exc()\n print(\"err = \" + str(err))\n print(\"WOOPS\")\n# print(bench[1] + \" = \" + str(sum_time / 5.0))\n"
},
{
"path": "benchmarks/julia1_nopil.py",
"content": "import sys\n\n# Disable the @profile decorator if none has been declared.\n\ntry:\n # Python 2\n import __builtin__ as builtins\nexcept ImportError:\n # Python 3\n import builtins\n\ntry:\n builtins.profile\nexcept AttributeError:\n # No line profiler, provide a pass-through version\n def profile(func):\n return func\n\n builtins.profile = profile\n\n\n# Pasted from Chapter 2, High Performance Python - O'Reilly Media;\n# minor modifications for Python 3 by Emery Berger\n\n\"\"\"Julia set generator without optional PIL-based image drawing\"\"\"\nimport time\n\n# area of complex space to investigate\nx1, x2, y1, y2 = -1.8, 1.8, -1.8, 1.8\nc_real, c_imag = -0.62772, -0.42193\n\n\n@profile\ndef calculate_z_serial_purepython(maxiter, zs, cs):\n \"\"\"Calculate output list using Julia update rule\"\"\"\n output = [0] * len(zs)\n for i in range(len(zs)):\n n = 0\n z = zs[i]\n c = cs[i]\n while abs(z) < 2 and n < maxiter:\n z = z * z + c\n n += 1\n output[i] = n\n return output\n\n\n@profile\ndef calc_pure_python(desired_width, max_iterations):\n \"\"\"Create a list of complex coordinates (zs) and complex\n parameters (cs), build Julia set, and display\"\"\"\n x_step = float(x2 - x1) / float(desired_width)\n y_step = float(y1 - y2) / float(desired_width)\n x = []\n y = []\n ycoord = y2\n while ycoord > y1:\n y.append(ycoord)\n ycoord += y_step\n xcoord = x1\n while xcoord < x2:\n x.append(xcoord)\n xcoord += x_step\n # Build a list of coordinates and the initial condition for each cell.\n # Note that our initial condition is a constant and could easily be removed;\n # we use it to simulate a real-world scenario with several inputs to\n # our function.\n zs = []\n cs = []\n for ycoord in y:\n for xcoord in x:\n zs.append(complex(xcoord, ycoord))\n cs.append(complex(c_real, c_imag))\n print(\"Length of x:\", len(x))\n print(\"Total elements:\", len(zs))\n start_time = time.process_time()\n output = calculate_z_serial_purepython(max_iterations, zs, cs)\n end_time = time.process_time()\n secs = end_time - start_time\n sys.stdout.flush()\n sys.stderr.flush()\n output_str = \"calculate_z_serial_purepython took \" + str(secs) + \" seconds\"\n print(output_str, file=sys.stderr)\n sys.stderr.flush()\n\n # This sum is expected for a 1000^2 grid with 300 iterations.\n # It catches minor errors we might introduce when we're\n # working on a fixed set of inputs.\n ### assert sum(output) == 33219980\n\n\nif __name__ == \"__main__\":\n # Calculate the Julia set using a pure Python solution with\n # reasonable defaults for a laptop\n calc_pure_python(desired_width=1000, max_iterations=300)\n sys.exit(-1) # To force output from py-spy\n"
},
{
"path": "benchmarks/measure_profiler_memory.py",
"content": "\"\"\"Measure Scalene's peak RSS while profiling a torch-heavy workload.\n\nUsage\n-----\n # On the current branch (should be the fix branch):\n python benchmarks/measure_profiler_memory.py\n\n # Compare against master:\n python benchmarks/measure_profiler_memory.py --compare-master\n\nThe ``--compare-master`` flag will:\n 1. Run the benchmark on the *current* branch and record peak RSS.\n 2. Check out ``master``, run the benchmark again, then restore the\n original branch.\n 3. Print a side-by-side comparison.\n\nWithout the flag it simply profiles and reports peak RSS for the\ncurrent checkout.\n\nRequirements: torch (``pip install torch``).\n\"\"\"\n\nfrom __future__ import annotations\n\nimport argparse\nimport os\nimport platform\nimport resource\nimport shutil\nimport subprocess\nimport sys\nimport tempfile\nimport threading\nimport time\n\nBENCH_SCRIPT = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"bench_torch_memory.py\")\nSAMPLE_INTERVAL = 0.5 # seconds between RSS samples\n\n\n# --- RSS monitoring ----------------------------------------------------------\n\ndef _get_rss_mb(pid: int) -> float | None:\n \"\"\"Return the RSS of *pid* in MiB, or None if unavailable.\"\"\"\n try:\n if platform.system() == \"Darwin\":\n # macOS: use ps (reading /proc is not available)\n out = subprocess.check_output(\n [\"ps\", \"-o\", \"rss=\", \"-p\", str(pid)],\n stderr=subprocess.DEVNULL,\n )\n return int(out.strip()) / 1024 # ps reports KiB on macOS\n else:\n # Linux: read from /proc\n with open(f\"/proc/{pid}/status\") as f:\n for line in f:\n if line.startswith(\"VmRSS:\"):\n return int(line.split()[1]) / 1024 # KiB -> MiB\n except (subprocess.CalledProcessError, FileNotFoundError, ProcessLookupError,\n ValueError, OSError):\n pass\n return None\n\n\nclass RSSMonitor:\n \"\"\"Sample RSS of a subprocess at regular intervals in a background thread.\"\"\"\n\n def __init__(self, pid: int, interval: float = SAMPLE_INTERVAL) -> None:\n self.pid = pid\n self.interval = interval\n self.samples: list[float] = []\n self._stop = threading.Event()\n self._thread = threading.Thread(target=self._run, daemon=True)\n\n def start(self) -> None:\n self._thread.start()\n\n def stop(self) -> None:\n self._stop.set()\n self._thread.join(timeout=5)\n\n def _run(self) -> None:\n while not self._stop.is_set():\n rss = _get_rss_mb(self.pid)\n if rss is not None:\n self.samples.append(rss)\n self._stop.wait(self.interval)\n\n @property\n def peak_mb(self) -> float:\n return max(self.samples) if self.samples else 0.0\n\n @property\n def final_mb(self) -> float:\n return self.samples[-1] if self.samples else 0.0\n\n\n# --- Run benchmark under Scalene --------------------------------------------\n\ndef run_scalene_benchmark(bench_script: str) -> tuple[float, float, float]:\n \"\"\"Profile the workload with Scalene and return (peak_rss_mb, final_rss_mb, elapsed_s).\"\"\"\n # Run in a temp dir so scalene-profile.json doesn't pollute the repo\n work_dir = tempfile.mkdtemp(prefix=\"scalene-bench-\")\n cmd = [\n sys.executable, \"-m\", \"scalene\", \"run\",\n bench_script,\n ]\n print(f\" Command: {' '.join(cmd)}\")\n t0 = time.perf_counter()\n proc = subprocess.Popen(\n cmd,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT,\n cwd=work_dir,\n )\n monitor = RSSMonitor(proc.pid)\n monitor.start()\n stdout, _ = proc.communicate()\n monitor.stop()\n elapsed = time.perf_counter() - t0\n\n # Print the workload output (indented)\n for line in stdout.decode(errors=\"replace\").splitlines():\n print(f\" {line}\")\n\n # Also grab rusage as a cross-check\n rusage = resource.getrusage(resource.RUSAGE_CHILDREN)\n rusage_bytes = rusage.ru_maxrss\n if platform.system() != \"Darwin\":\n # Linux reports KiB; convert to bytes\n rusage_bytes *= 1024\n rusage_mib = rusage_bytes / (1024 * 1024)\n\n print(f\" RSS samples collected: {len(monitor.samples)}\")\n print(f\" Peak RSS (sampled): {monitor.peak_mb:,.1f} MiB\")\n print(f\" Final RSS (sampled): {monitor.final_mb:,.1f} MiB\")\n print(f\" Peak RSS (rusage): {rusage_mib:,.1f} MiB\")\n print(f\" Wall time: {elapsed:.1f}s\")\n\n # Clean up temp dir\n shutil.rmtree(work_dir, ignore_errors=True)\n\n return monitor.peak_mb, monitor.final_mb, elapsed\n\n\n# --- Git helpers for --compare-master ----------------------------------------\n\ndef git(*args: str) -> str:\n return subprocess.check_output(\n [\"git\", *args], stderr=subprocess.STDOUT,\n ).decode().strip()\n\n\ndef compare_master() -> None:\n original_branch = git(\"rev-parse\", \"--abbrev-ref\", \"HEAD\")\n print(f\"Current branch: {original_branch}\\n\")\n\n # Copy the benchmark script to a temp file so it's available on both branches\n tmp_fd, tmp_bench_name = tempfile.mkstemp(prefix=\"bench_torch_memory_\", suffix=\".py\")\n os.close(tmp_fd)\n try:\n shutil.copy2(BENCH_SCRIPT, tmp_bench_name)\n\n # --- Run on current branch -------------------------------------------\n print(f\"=== Benchmarking on {original_branch} ===\")\n fix_peak, fix_final, fix_elapsed = run_scalene_benchmark(tmp_bench_name)\n\n # --- Switch to master ------------------------------------------------\n print()\n print(\"=== Benchmarking on master ===\")\n git(\"checkout\", \"master\")\n try:\n master_peak, master_final, master_elapsed = run_scalene_benchmark(tmp_bench_name)\n finally:\n # Always restore original branch\n print(f\"\\nRestoring branch {original_branch} ...\")\n git(\"checkout\", original_branch)\n finally:\n os.unlink(tmp_bench_name)\n\n # --- Report --------------------------------------------------------------\n print()\n print(\"=\" * 60)\n print(f\"{'':30s} {'master':>12s} {'fix':>12s}\")\n print(\"-\" * 60)\n print(f\"{'Peak RSS (MiB)':30s} {master_peak:12,.1f} {fix_peak:12,.1f}\")\n print(f\"{'Final RSS (MiB)':30s} {master_final:12,.1f} {fix_final:12,.1f}\")\n print(f\"{'Wall time (s)':30s} {master_elapsed:12.1f} {fix_elapsed:12.1f}\")\n if master_peak > 0:\n reduction = (1 - fix_peak / master_peak) * 100\n print(f\"{'Peak RSS reduction':30s} {reduction:11.1f}%\")\n print(\"=\" * 60)\n\n\n# --- Main --------------------------------------------------------------------\n\ndef main() -> None:\n parser = argparse.ArgumentParser(\n description=__doc__,\n formatter_class=argparse.RawDescriptionHelpFormatter,\n )\n parser.add_argument(\n \"--compare-master\", action=\"store_true\",\n help=\"Run on both the current branch and master, then compare.\",\n )\n args = parser.parse_args()\n\n if args.compare_master:\n compare_master()\n else:\n print(\"=== Benchmarking on current checkout ===\")\n run_scalene_benchmark(BENCH_SCRIPT)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "benchmarks/new_benchmark.py",
"content": "import json\nimport subprocess\nimport re\nimport statistics\nfrom glob import glob\nfrom collections import defaultdict\nimport sys\n\ncmds = {\n # \"baseline\": [\"python3\"],\n # \"scalene\": [\"python3\", \"-m\", \"scalene\", \"--json\", \"--outfile\", \"/dev/null\"],\n # \"scalene-cpu\": [\"python3\", \"-m\", \"scalene\", \"--json\", \"--cpu\", \"--outfile\", \"/dev/null\"],\n # \"scalene-cpu-gpu\": [\"python3\", \"-m\", \"scalene\", \"--json\", \"--cpu\", \"--gpu\", \"--outfile\", \"/dev/null\"],\n # \"scalene-5M\": [\"python3\", \"-m\", \"scalene\", \"--json\", \"--outfile\", \"/dev/null\", \"--allocation-sampling-window\", \"5242883\"],\n # \"scalene-10M\": [\"python3\", \"-m\", \"scalene\", \"--json\", \"--outfile\", \"/dev/null\", \"--allocation-sampling-window\", \"10485767\"],\n # \"scalene-20M\": [\"python3\", \"-m\", \"scalene\", \"--json\", \"--outfile\", \"/dev/null\", \"--allocation-sampling-window\",\"20971529\"],\n # \"memray\": [\n # \"python3\",\n # \"-m\",\n # \"memray\",\n # \"run\",\n # \"--trace-python-allocators\",\n # \"-f\",\n # \"-o\",\n # \"/tmp/memray.out\",\n # ],\n # \"fil\": [\"fil-profile\", \"-o\", \"/tmp/abc\", '--no-browser', \"run\"],\n # \"austin_full\": [\"austin\", \"-o\", \"/dev/null\", \"-f\"],\n # \"austin_cpu\": [\"austin\", \"-o\", \"/dev/null\"],\n # 'py-spy': ['py-spy', 'record', '-o', '/tmp/profile.svg', '--', 'python3'],\n # 'cProfile': ['python3', '-m', 'cProfile', '-o', '/dev/null'],\n \"yappi_wall\": [\"python3\", \"-m\", \"yappi\", \"-o\", \"/dev/null\", \"-c\", \"wall\"],\n \"yappi_cpu\": [\"python3\", \"-m\", \"yappi\", \"-o\", \"/dev/null\", \"-c\", \"cpu\"],\n # 'pprofile_det': ['pprofile', '-o', '/dev/null'],\n # 'pprofile_stat': ['pprofile', '-o', '/dev/null', '-s', '0.001'],\n # 'line_profiler': ['kernprof', '-l', '-o', '/dev/null', '-v'],\n # 'profile': ['python3', '-m', 'profile', '-o', '/dev/null']\n}\nresult_regexp = re.compile(r\"Time elapsed:\\s+([0-9]*\\.[0-9]+)\")\n\n\ndef main():\n out = defaultdict(lambda: {})\n\n for progname in [\n # \"./test/expensive_benchmarks/bm_mdp.py\",\n # \"./test/expensive_benchmarks/bm_async_tree_io.py none\",\n # \"./test/expensive_benchmarks/bm_async_tree_io.py io\",\n # \"./test/expensive_benchmarks/bm_async_tree_io.py cpu_io_mixed\",\n # \"./test/expensive_benchmarks/bm_async_tree_io.py memoization\",\n # \"./test/expensive_benchmarks/bm_fannukh.py\",\n # \"./test/expensive_benchmarks/bm_pprint.py\",\n # \"./test/expensive_benchmarks/bm_raytrace.py\",\n # \"./test/expensive_benchmarks/bm_sympy.py\",\n \"./test/expensive_benchmarks/bm_docutils.py\"\n ]:\n for profile_name, profile_cmd in cmds.items():\n times = []\n for i in range(5):\n print(\n f\"Running {profile_name} on {progname} using \\\"{' '.join(profile_cmd + progname.split(' '))}\\\"...\",\n end=\"\",\n flush=True,\n )\n result = subprocess.run(\n profile_cmd + progname.split(\" \"),\n stderr=subprocess.STDOUT,\n stdout=subprocess.PIPE,\n )\n\n output = result.stdout.decode(\"utf-8\")\n # print(output)\n match = result_regexp.search(output)\n if match is not None:\n print(\n f\"... {match.group(1)}\",\n end=(\"\\n\" if profile_name != \"memray\" else \"\"),\n )\n times.append(round(100 * float(match.group(1))) / 100.0)\n if profile_name == \"memray\":\n res2 = subprocess.run(\n [\n \"time\",\n sys.executable,\n \"-m\",\n \"memray\",\n \"flamegraph\",\n \"-f\",\n \"/tmp/memray.out\",\n ],\n capture_output=True,\n env={\"TIME\": \"Time elapsed: %e\"},\n )\n output2 = res2.stderr.decode(\"utf-8\")\n match2 = result_regexp.search(output2)\n if match2 is not None:\n print(f\"... {match2.group(1)}\")\n times[-1] += round(100 * float(match2.group(1))) / 100.0\n else:\n print(\"... RUN FAILED\")\n # exit(1)\n else:\n print(\"RUN FAILED\")\n # exit(1)\n out[profile_name][progname] = times\n with open(\"yappi.json\", \"w+\") as f:\n json.dump(dict(out), f)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "benchmarks/pystone.py",
"content": "#! /usr/bin/env python3\n\n\"\"\"\n\"PYSTONE\" Benchmark Program\n\nVersion: Python/1.1 (corresponds to C/1.1 plus 2 Pystone fixes)\n\nAuthor: Reinhold P. Weicker, CACM Vol 27, No 10, 10/84 pg. 1013.\n\n Translated from ADA to C by Rick Richardson.\n Every method to preserve ADA-likeness has been used,\n at the expense of C-ness.\n\n Translated from C to Python by Guido van Rossum.\n\nVersion History:\n\n Version 1.1 corrects two bugs in version 1.0:\n\n First, it leaked memory: in Proc1(), NextRecord ends\n up having a pointer to itself. I have corrected this\n by zapping NextRecord.PtrComp at the end of Proc1().\n\n Second, Proc3() used the operator != to compare a\n record to None. This is rather inefficient and not\n true to the intention of the original benchmark (where\n a pointer comparison to None is intended; the !=\n operator attempts to find a method __cmp__ to do value\n comparison of the record). Version 1.1 runs 5-10\n percent faster than version 1.0, so benchmark figures\n of different versions can't be compared directly.\n\n\"\"\"\n\nLOOPS = 500000\n\nimport time # from time import clock\n\n__version__ = \"1.1\"\n\n[Ident1, Ident2, Ident3, Ident4, Ident5] = range(1, 6)\n\n\nclass Record:\n\n def __init__(self, PtrComp=None, Discr=0, EnumComp=0, IntComp=0, StringComp=0):\n self.PtrComp = PtrComp\n self.Discr = Discr\n self.EnumComp = EnumComp\n self.IntComp = IntComp\n self.StringComp = StringComp\n\n def copy(self):\n return Record(\n self.PtrComp, self.Discr, self.EnumComp, self.IntComp, self.StringComp\n )\n\n\nTRUE = 1\nFALSE = 0\n\n\ndef main(loops=LOOPS):\n benchtime, stones = pystones(loops)\n print(\"Pystone(%s) time for %d passes = %g\" % (__version__, loops, benchtime))\n print(\"This machine benchmarks at %g pystones/second\" % stones)\n\n\ndef pystones(loops=LOOPS):\n return Proc0(loops)\n\n\nIntGlob = 0\nBoolGlob = FALSE\nChar1Glob = \"\\0\"\nChar2Glob = \"\\0\"\nArray1Glob = [0] * 51\nArray2Glob = [x[:] for x in [Array1Glob] * 51]\nPtrGlb = None\nPtrGlbNext = None\n\n\ndef Proc0(loops=LOOPS):\n global IntGlob\n global BoolGlob\n global Char1Glob\n global Char2Glob\n global Array1Glob\n global Array2Glob\n global PtrGlb\n global PtrGlbNext\n\n starttime = time.perf_counter()\n for i in range(loops):\n pass\n nulltime = time.perf_counter() - starttime\n\n PtrGlbNext = Record()\n PtrGlb = Record()\n PtrGlb.PtrComp = PtrGlbNext\n PtrGlb.Discr = Ident1\n PtrGlb.EnumComp = Ident3\n PtrGlb.IntComp = 40\n PtrGlb.StringComp = \"DHRYSTONE PROGRAM, SOME STRING\"\n String1Loc = \"DHRYSTONE PROGRAM, 1'ST STRING\"\n Array2Glob[8][7] = 10\n\n starttime = time.perf_counter()\n\n for i in range(loops):\n Proc5()\n Proc4()\n IntLoc1 = 2\n IntLoc2 = 3\n String2Loc = \"DHRYSTONE PROGRAM, 2'ND STRING\"\n EnumLoc = Ident2\n BoolGlob = not Func2(String1Loc, String2Loc)\n while IntLoc1 < IntLoc2:\n IntLoc3 = 5 * IntLoc1 - IntLoc2\n IntLoc3 = Proc7(IntLoc1, IntLoc2)\n IntLoc1 = IntLoc1 + 1\n Proc8(Array1Glob, Array2Glob, IntLoc1, IntLoc3)\n PtrGlb = Proc1(PtrGlb)\n CharIndex = \"A\"\n while CharIndex <= Char2Glob:\n if EnumLoc == Func1(CharIndex, \"C\"):\n EnumLoc = Proc6(Ident1)\n CharIndex = chr(ord(CharIndex) + 1)\n IntLoc3 = IntLoc2 * IntLoc1\n IntLoc2 = IntLoc3 / IntLoc1\n IntLoc2 = 7 * (IntLoc3 - IntLoc2) - IntLoc1\n IntLoc1 = Proc2(IntLoc1)\n\n benchtime = time.perf_counter() - starttime - nulltime\n if benchtime == 0.0:\n loopsPerBenchtime = 0.0\n else:\n loopsPerBenchtime = loops / benchtime\n return benchtime, loopsPerBenchtime\n\n\ndef Proc1(PtrParIn):\n PtrParIn.PtrComp = NextRecord = PtrGlb.copy()\n PtrParIn.IntComp = 5\n NextRecord.IntComp = PtrParIn.IntComp\n NextRecord.PtrComp = PtrParIn.PtrComp\n NextRecord.PtrComp = Proc3(NextRecord.PtrComp)\n if NextRecord.Discr == Ident1:\n NextRecord.IntComp = 6\n NextRecord.EnumComp = Proc6(PtrParIn.EnumComp)\n NextRecord.PtrComp = PtrGlb.PtrComp\n NextRecord.IntComp = Proc7(NextRecord.IntComp, 10)\n else:\n PtrParIn = NextRecord.copy()\n NextRecord.PtrComp = None\n return PtrParIn\n\n\ndef Proc2(IntParIO):\n IntLoc = IntParIO + 10\n while 1:\n if Char1Glob == \"A\":\n IntLoc = IntLoc - 1\n IntParIO = IntLoc - IntGlob\n EnumLoc = Ident1\n if EnumLoc == Ident1:\n break\n return IntParIO\n\n\ndef Proc3(PtrParOut):\n global IntGlob\n\n if PtrGlb is not None:\n PtrParOut = PtrGlb.PtrComp\n else:\n IntGlob = 100\n PtrGlb.IntComp = Proc7(10, IntGlob)\n return PtrParOut\n\n\ndef Proc4():\n global Char2Glob\n\n BoolLoc = Char1Glob == \"A\"\n BoolLoc = BoolLoc or BoolGlob\n Char2Glob = \"B\"\n\n\ndef Proc5():\n global Char1Glob\n global BoolGlob\n\n Char1Glob = \"A\"\n BoolGlob = FALSE\n\n\ndef Proc6(EnumParIn):\n EnumParOut = EnumParIn\n if not Func3(EnumParIn):\n EnumParOut = Ident4\n if EnumParIn == Ident1:\n EnumParOut = Ident1\n elif EnumParIn == Ident2:\n if IntGlob > 100:\n EnumParOut = Ident1\n else:\n EnumParOut = Ident4\n elif EnumParIn == Ident3:\n EnumParOut = Ident2\n elif EnumParIn == Ident4:\n pass\n elif EnumParIn == Ident5:\n EnumParOut = Ident3\n return EnumParOut\n\n\ndef Proc7(IntParI1, IntParI2):\n IntLoc = IntParI1 + 2\n IntParOut = IntParI2 + IntLoc\n return IntParOut\n\n\ndef Proc8(Array1Par, Array2Par, IntParI1, IntParI2):\n global IntGlob\n\n IntLoc = IntParI1 + 5\n Array1Par[IntLoc] = IntParI2\n Array1Par[IntLoc + 1] = Array1Par[IntLoc]\n Array1Par[IntLoc + 30] = IntLoc\n for IntIndex in range(IntLoc, IntLoc + 2):\n Array2Par[IntLoc][IntIndex] = IntLoc\n Array2Par[IntLoc][IntLoc - 1] = Array2Par[IntLoc][IntLoc - 1] + 1\n Array2Par[IntLoc + 20][IntLoc] = Array1Par[IntLoc]\n IntGlob = 5\n\n\ndef Func1(CharPar1, CharPar2):\n CharLoc1 = CharPar1\n CharLoc2 = CharLoc1\n if CharLoc2 != CharPar2:\n return Ident1\n else:\n return Ident2\n\n\ndef Func2(StrParI1, StrParI2):\n IntLoc = 1\n while IntLoc <= 1:\n if Func1(StrParI1[IntLoc], StrParI2[IntLoc + 1]) == Ident1:\n CharLoc = \"A\"\n IntLoc = IntLoc + 1\n if CharLoc >= \"W\" and CharLoc <= \"Z\":\n IntLoc = 7\n if CharLoc == \"X\":\n return TRUE\n else:\n if StrParI1 > StrParI2:\n IntLoc = IntLoc + 7\n return TRUE\n else:\n return FALSE\n\n\ndef Func3(EnumParIn):\n EnumLoc = EnumParIn\n if EnumLoc == Ident3:\n return TRUE\n return FALSE\n\n\nif __name__ == \"__main__\":\n import sys\n\n def error(msg):\n print(msg, end=\" \", file=sys.stderr)\n print(\"usage: %s [number_of_loops]\" % sys.argv[0], file=sys.stderr)\n sys.exit(100)\n\n nargs = len(sys.argv) - 1\n if nargs > 1:\n error(\"%d arguments are too many;\" % nargs)\n elif nargs == 1:\n try:\n loops = int(sys.argv[1])\n except ValueError:\n error(\"Invalid argument %r;\" % sys.argv[1])\n else:\n loops = LOOPS\n main(loops)\n"
},
{
"path": "demo_torch_jit.py",
"content": "\"\"\"Test script to verify PyTorch JIT profiling works with Scalene.\"\"\"\n\nimport torch\n\n@torch.jit.script\ndef compute_intensive(x: torch.Tensor) -> torch.Tensor:\n \"\"\"A compute-intensive JIT-compiled function.\"\"\"\n for _ in range(50):\n x = x @ x.T # Line 9: matrix multiplication\n x = torch.relu(x) # Line 10: relu\n x = x / x.max() # Line 11: normalize\n return x\n\n\ndef main():\n print(\"Testing PyTorch JIT profiling with Scalene...\")\n x = torch.randn(500, 500)\n\n print(f\"Running compute_intensive on 500x500 tensor...\")\n for i in range(100):\n result = compute_intensive(x) # Line 21: call site\n\n print(\"Testing torch.jit.save/load...\")\n torch.jit.save(torch.jit.script(compute_intensive), \"/tmp/test_model.pt\")\n loaded = torch.jit.load(\"/tmp/test_model.pt\")\n test_result = loaded(torch.randn(10, 10))\n print(f\"Loaded model output shape: {test_result.shape}\")\n print(\"Done!\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "docs/scalene-demo.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"verbal-arrival\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# An example program to profile\\n\",\n \"\\n\",\n \"import numpy as np\\n\",\n \"\\n\",\n \"def test_me():\\n\",\n \" for i in range(6):\\n\",\n \" x = np.array(range(10**7))\\n\",\n \" y = np.array(np.random.uniform(0, 100, size=(10**8)))\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"lesbian-premium\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"The scalene extension is already loaded. To reload it, use:\\n\",\n \" %reload_ext scalene\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Load Scalene\\n\",\n \"%load_ext scalene\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"listed-keyboard\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/html\": [\n \" [1]: % of time = 100.00% out of 6.02s. \\n\",\n \" ╷ ╷ ╷ ╷ \\n\",\n \" Line │Time │–––––– │–––––– │ \\n\",\n \" │Python │native │system │[1] \\n\",\n \"╺━━━━━━━┿━━━━━━━━┿━━━━━━━┿━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸\\n\",\n \" 1 │ │ │ │# An example program to profile \\n\",\n \" 2 │ │ │ │ \\n\",\n \" 3 │ │ │ │import numpy as np \\n\",\n \" 4 │ │ │ │ \\n\",\n \" 5 │ │ │ │def test_me(): \\n\",\n \" 6 │ │ │ │ for i in range(6): \\n\",\n \" 7 │ 1% │ 35% │ 7% │ x = np.array(range(10**7)) \\n\",\n \" 8 │ 2% │ 55% │ │ y = np.array(np.random.uniform(0, 100, size=(10**8))) \\n\",\n \" │ │ │ │ \\n\",\n \"╶───────┼────────┼───────┼───────┼────────────────────────────────────────────────────────────────────────────────────────────────╴\\n\",\n \" │ │ │ │function summary for <ipython-input-14-3a53cdc5d2d5> \\n\",\n \" 5 │ 3% │ 91% │ 6% │test_me \\n\",\n \" ╵ ╵ ╵ ╵ \\n\",\n \"
\\n\"\n ],\n \"text/plain\": [\n \"\"\n ]\n },\n \"metadata\": {},\n \"output_type\": \"display_data\"\n }\n ],\n \"source\": [\n \"# Profile just one line of code\\n\",\n \"%scrun test_me()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"digital-ratio\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"usage: scalene [-h] [--version] [--outfile OUTFILE] [--html]\\n\",\n \" [--reduced-profile] [--profile-interval PROFILE_INTERVAL]\\n\",\n \" [--cpu-only] [--profile-all] [--profile-only PROFILE_ONLY]\\n\",\n \" [--use-virtual-time]\\n\",\n \" [--cpu-percent-threshold CPU_PERCENT_THRESHOLD]\\n\",\n \" [--cpu-sampling-rate CPU_SAMPLING_RATE]\\n\",\n \" [--malloc-threshold MALLOC_THRESHOLD]\\n\",\n \"\\n\",\n \"Scalene: a high-precision CPU and memory profiler, version 1.3.2\\n\",\n \"https://github.com/plasma-umass/scalene\\n\",\n \"\\n\",\n \"command-line:\\n\",\n \" % scalene [options] yourprogram.py\\n\",\n \"or\\n\",\n \" % python3 -m scalene [options] yourprogram.py\\n\",\n \"\\n\",\n \"in Jupyter, line mode:\\n\",\n \" %scrun [options] statement\\n\",\n \"\\n\",\n \"in Jupyter, cell mode:\\n\",\n \" %%scalene [options]\\n\",\n \" code...\\n\",\n \" code...\\n\",\n \"\\n\",\n \"optional arguments:\\n\",\n \" -h, --help show this help message and exit\\n\",\n \" --version prints the version number for this release of Scalene and exits\\n\",\n \" --outfile OUTFILE file to hold profiler output (default: stdout)\\n\",\n \" --html output as HTML (default: text)\\n\",\n \" --reduced-profile generate a reduced profile, with non-zero lines only (default: False)\\n\",\n \" --profile-interval PROFILE_INTERVAL\\n\",\n \" output profiles every so many seconds (default: inf)\\n\",\n \" --cpu-only only profile CPU time (default: profile CPU, memory, and copying)\\n\",\n \" --profile-all profile all executed code, not just the target program (default: only the target program)\\n\",\n \" --profile-only PROFILE_ONLY\\n\",\n \" profile only code in files matching the given strings, separated by commas (default: no restrictions)\\n\",\n \" --use-virtual-time measure only CPU time, not time spent in I/O or blocking (default: False)\\n\",\n \" --cpu-percent-threshold CPU_PERCENT_THRESHOLD\\n\",\n \" only report profiles with at least this percent of CPU time (default: 1%)\\n\",\n \" --cpu-sampling-rate CPU_SAMPLING_RATE\\n\",\n \" CPU sampling rate (default: every 0.01s)\\n\",\n \" --malloc-threshold MALLOC_THRESHOLD\\n\",\n \" only report profiles with at least this many allocations (default: 100)\\n\",\n \"\\n\",\n \"When running Scalene in the background, you can suspend/resume profiling\\n\",\n \"for the process ID that Scalene reports. For example:\\n\",\n \"\\n\",\n \" % python3 -m scalene [options] yourprogram.py &\\n\",\n \" Scalene now profiling process 12345\\n\",\n \" to suspend profiling: python3 -m scalene.profile --off --pid 12345\\n\",\n \" to resume profiling: python3 -m scalene.profile --on --pid 12345\\n\"\n ]\n }\n ],\n \"source\": [\n \"# A full list of options\\n\",\n \"%scrun --help\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"radio-feelings\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/html\": [\n \" [1]: % of time = 100.00% out of 6.67s. \\n\",\n \" ╷ ╷ ╷ ╷ \\n\",\n \" Line │Time │–––––– │–––––– │ \\n\",\n \" │Python │native │system │[1] \\n\",\n \"╺━━━━━━━┿━━━━━━━━┿━━━━━━━┿━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸\\n\",\n \" ... │ │ │ │ \\n\",\n \" 7 │ │ 34% │ 7% │ x = np.array(range(10**7)) \\n\",\n \" 8 │ 2% │ 49% │ 8% │ y = np.array(np.random.uniform(0, 100, size=(10**8))) \\n\",\n \" │ │ │ │ \\n\",\n \"╶───────┼────────┼───────┼───────┼────────────────────────────────────────────────────────────────────────────────────────────────╴\\n\",\n \" │ │ │ │function summary for <ipython-input-14-3a53cdc5d2d5> \\n\",\n \" 5 │ 2% │ 83% │ 15% │test_me \\n\",\n \" ╵ ╵ ╵ ╵ \\n\",\n \"
\\n\"\n ],\n \"text/plain\": [\n \"\"\n ]\n },\n \"metadata\": {},\n \"output_type\": \"display_data\"\n }\n ],\n \"source\": [\n \"# Generate a reduced profile (only lines with non-zero counts)\\n\",\n \"%scrun --reduced-profile test_me()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"minimal-society\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/html\": [\n \" /var/folders/m7/sln1lr497jqcchb2ddh32rw00000gq/T/scalene_profile_qxy9xnh3.py: % of time = 100.00% out of 0.09s. \\n\",\n \" ╷ ╷ ╷ ╷ \\n\",\n \" Line │Time │–––––– │–––––– │ \\n\",\n \" │Python │native │system │/var/folders/m7/sln1lr497jqcchb2ddh32rw00000gq/T/scalene_profile_qxy9xnh3.py \\n\",\n \"╺━━━━━━━┿━━━━━━━━┿━━━━━━━┿━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸\\n\",\n \" ... │ │ │ │ \\n\",\n \" 4 │ 21% │ │ │ for j in range(1000): \\n\",\n \" 5 │ 59% │ 6% │ 13% │ x += 1 \\n\",\n \" ╵ ╵ ╵ ╵ \\n\",\n \"
\\n\"\n ],\n \"text/plain\": [\n \"\"\n ]\n },\n \"metadata\": {},\n \"output_type\": \"display_data\"\n }\n ],\n \"source\": [\n \"%%scalene --reduced-profile\\n\",\n \"# Profile more than one line of code in a cell\\n\",\n \"x = 0\\n\",\n \"for i in range(1000):\\n\",\n \" for j in range(1000):\\n\",\n \" x += 1\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"id\": \"hungry-yesterday\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": []\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.9.2\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "index.rst",
"content": ".. figure::\n https://github.com/plasma-umass/scalene/raw/master/docs/scalene-icon-white.png\n :alt: scalene\n\n scalene\n\nScalene: a Python CPU+GPU+memory profiler with AI-powered optimization proposals\n================================================================================\n\nby `Emery Berger `__, `Sam\nStern `__, and `Juan Altmayer\nPizzorno `__.\n\n|Scalene community Slack|\\ `Scalene community\nSlack `__\n\n|PyPI Latest Release|\\ |Anaconda-Server Badge| |Downloads|\\ |Anaconda\ndownloads| |image1| |Python versions|\\ |Visual Studio Code Extension\nversion| |License|\n\n.. figure::\n https://github.com/plasma-umass/scalene/raw/master/docs/Ozsvald-tweet.png\n :alt: Ozsvald tweet\n\n Ozsvald tweet\n\n(tweet from Ian Ozsvald, author of `High Performance\nPython `__)\n\n.. figure::\n https://github.com/plasma-umass/scalene/raw/master/docs/semantic-scholar-success.png\n :alt: Semantic Scholar success story\n\n Semantic Scholar success story\n\n**Scalene web-based user interface:**\nhttp://plasma-umass.org/scalene-gui/\n\nAbout Scalene\n-------------\n\nScalene is a high-performance CPU, GPU *and* memory profiler for Python\nthat does a number of things that other Python profilers do not and\ncannot do. It runs orders of magnitude faster than many other profilers\nwhile delivering far more detailed information. It is also the first\nprofiler ever to incorporate AI-powered proposed optimizations.\n\nAI-powered optimization suggestions\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\n **Note**\n\n To enable AI-powered optimization suggestions, you need to enter an\n `OpenAI key `__ in the box under “Advanced\n options”. *Your account will need to have a positive balance for this\n to work* (check your balance at\n https://platform.openai.com/account/usage).\n\nOnce you’ve entered your OpenAI key (see above), click on the lightning\nbolt (⚡) beside any line or the explosion (💥) for an entire region of\ncode to generate a proposed optimization. Click on a proposed\noptimization to copy it to the clipboard.\n\nYou can click as many times as you like on the lightning bolt or\nexplosion, and it will generate different suggested optimizations. Your\nmileage may vary, but in some cases, the suggestions are quite\nimpressive (e.g., order-of-magnitude improvements).\n\nQuick Start\n~~~~~~~~~~~\n\nInstalling Scalene:\n^^^^^^^^^^^^^^^^^^^\n\n.. code:: console\n\n python3 -m pip install -U scalene\n\nor\n\n.. code:: console\n\n conda install -c conda-forge scalene\n\nUsing Scalene:\n^^^^^^^^^^^^^^\n\nAfter installing Scalene, you can use Scalene at the command line, or as\na Visual Studio Code extension.\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nUsing the Scalene VS Code Extension:\n\n.. raw:: html\n\n
\n\nFirst, install the Scalene extension from the VS Code Marketplace or by\nsearching for it within VS Code by typing Command-Shift-X (Mac) or\nCtrl-Shift-X (Windows). Once that’s installed, click Command-Shift-P or\nCtrl-Shift-P to open the Command Palette. Then select “Scalene:\nAI-powered profiling…” (you can start typing Scalene and it will pop up\nif it’s installed). Run that and, assuming your code runs for at least a\nsecond, a Scalene profile will appear in a webview.\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nCommonly used command-line options:\n\n.. raw:: html\n\n
\n\nScalene uses a verb-based command structure with two main commands: ``run`` (to profile) and ``view`` (to display results).\n\n.. code:: console\n\n # Profile a program (saves to scalene-profile.json)\n scalene run your_prog.py\n python3 -m scalene run your_prog.py # equivalent alternative\n\n # View a profile\n scalene view # open profile in browser\n scalene view --cli # view in terminal\n scalene view --html # save to scalene-profile.html\n\n # Common profiling options\n scalene run --cpu-only your_prog.py # only profile CPU (faster)\n scalene run -o results.json your_prog.py # custom output filename\n scalene run -c config.yaml your_prog.py # load options from config file\n\n # Pass arguments to your program (use --- separator)\n scalene run your_prog.py --- --arg1 --arg2\n\n # Get help\n scalene --help # main help\n scalene run --help # profiling options\n scalene run --help-advanced # advanced profiling options\n scalene view --help # viewing options\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nUsing Scalene programmatically in your code:\n\n.. raw:: html\n\n
\n\nInvoke using ``scalene`` as above and then:\n\n.. code:: python\n\n from scalene import scalene_profiler\n\n # Turn profiling on\n scalene_profiler.start()\n\n # your code\n\n # Turn profiling off\n scalene_profiler.stop()\n\n.. code:: python\n\n from scalene.scalene_profiler import enable_profiling\n\n with enable_profiling():\n # do something\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nUsing Scalene to profile only specific functions via @profile:\n\n.. raw:: html\n\n
\n\nJust preface any functions you want to profile with the ``@profile``\ndecorator and run it with Scalene:\n\n.. code:: python\n\n # do not import profile!\n\n @profile\n def slow_function():\n import time\n time.sleep(3)\n\n.. raw:: html\n\n \n\nWeb-based GUI\n^^^^^^^^^^^^^\n\nScalene has both a CLI and a web-based GUI `(demo\nhere) `__.\n\nBy default, once Scalene has profiled your program, it will open a tab\nin a web browser with an interactive user interface (all processing is\ndone locally). Hover over bars to see breakdowns of CPU and memory\nconsumption, and click on underlined column headers to sort the columns.\nThe generated file ``profile.html`` is self-contained and can be saved\nfor later use.\n\n|Scalene web GUI|\n\nScalene Overview\n----------------\n\nScalene talk (PyCon US 2021)\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\n`This talk `__ presented at PyCon 2021\nwalks through Scalene’s advantages and how to use it to debug the\nperformance of an application (and provides some technical details on\nits internals). We highly recommend watching this video!\n\n|Scalene presentation at PyCon 2021|\n\nFast and Accurate\n~~~~~~~~~~~~~~~~~\n\n- Scalene is **fast**. It uses sampling instead of instrumentation or\n relying on Python’s tracing facilities. Its overhead is typically no\n more than 10-20% (and often less).\n\n- Scalene is **accurate**. We tested CPU profiler accuracy and found\n that Scalene is among the most accurate profilers, correctly\n measuring time taken.\n\n.. figure::\n https://github.com/plasma-umass/scalene/raw/master/docs/cpu-accuracy-comparison.png\n :alt: Profiler accuracy\n\n Profiler accuracy\n\n- Scalene performs profiling **at the line level** *and* **per\n function**, pointing to the functions and the specific lines of code\n responsible for the execution time in your program.\n\nCPU profiling\n~~~~~~~~~~~~~\n\n- Scalene **separates out time spent in Python from time in native\n code** (including libraries). Most Python programmers aren’t going to\n optimize the performance of native code (which is usually either in\n the Python implementation or external libraries), so this helps\n developers focus their optimization efforts on the code they can\n actually improve.\n- Scalene **highlights hotspots** (code accounting for significant\n percentages of CPU time or memory allocation) in red, making them\n even easier to spot.\n- Scalene also separates out **system time**, making it easy to find\n I/O bottlenecks.\n\nGPU profiling\n~~~~~~~~~~~~~\n\n- Scalene reports **GPU time** (currently limited to NVIDIA-based\n systems).\n\nMemory profiling\n~~~~~~~~~~~~~~~~\n\n- Scalene **profiles memory usage**. In addition to tracking CPU usage,\n Scalene also points to the specific lines of code responsible for\n memory growth. It accomplishes this via an included specialized\n memory allocator.\n- Scalene separates out the percentage of **memory consumed by Python\n code vs. native code**.\n- Scalene produces **per-line memory profiles**.\n- Scalene **identifies lines with likely memory leaks**.\n- Scalene **profiles copying volume**, making it easy to spot\n inadvertent copying, especially due to crossing Python/library\n boundaries (e.g., accidentally converting ``numpy`` arrays into\n Python arrays, and vice versa).\n\nOther features\n~~~~~~~~~~~~~~\n\n- Scalene can produce **reduced profiles** (via ``--reduced-profile``)\n that only report lines that consume more than 1% of CPU or perform at\n least 100 allocations.\n- Scalene supports ``@profile`` decorators to profile only specific\n functions.\n- When Scalene is profiling a program launched in the background (via\n ``&``), you can **suspend and resume profiling**.\n\nComparison to Other Profilers\n=============================\n\nPerformance and Features\n------------------------\n\nBelow is a table comparing the **performance and features** of various\nprofilers to Scalene.\n\n.. figure::\n https://raw.githubusercontent.com/plasma-umass/scalene/master/docs/images/profiler-comparison.png\n :alt: Performance and feature comparison\n\n Performance and feature comparison\n\n- **Slowdown**: the slowdown when running a benchmark from the\n Pyperformance suite. Green means less than 2x overhead. Scalene’s\n overhead is just a 35% slowdown.\n\nScalene has all of the following features, many of which only Scalene\nsupports:\n\n- **Lines or functions**: does the profiler report information only for\n entire functions, or for every line – Scalene does both.\n- **Unmodified Code**: works on unmodified code.\n- **Threads**: supports Python threads.\n- **Multiprocessing**: supports use of the ``multiprocessing`` library\n – *Scalene only*\n- **Python vs. C time**: breaks out time spent in Python vs. native\n code (e.g., libraries) – *Scalene only*\n- **System time**: breaks out system time (e.g., sleeping or performing\n I/O) – *Scalene only*\n- **Profiles memory**: reports memory consumption per line / function\n- **GPU**: reports time spent on an NVIDIA GPU (if present) – *Scalene\n only*\n- **Memory trends**: reports memory use over time per line / function –\n *Scalene only*\n- **Copy volume**: reports megabytes being copied per second – *Scalene\n only*\n- **Detects leaks**: automatically pinpoints lines responsible for\n likely memory leaks – *Scalene only*\n\nOutput\n------\n\nIf you include the ``--cli`` option, Scalene prints annotated source\ncode for the program being profiled (as text, JSON (``--json``), or HTML\n(``--html``)) and any modules it uses in the same directory or\nsubdirectories (you can optionally have it ``--profile-all`` and only\ninclude files with at least a ``--cpu-percent-threshold`` of time). Here\nis a snippet from ``pystone.py``.\n\n.. figure::\n https://raw.githubusercontent.com/plasma-umass/scalene/master/docs/images/sample-profile-pystone.png\n :alt: Example profile\n\n Example profile\n\n- **Memory usage at the top**: Visualized by “sparklines”, memory\n consumption over the runtime of the profiled code.\n- **“Time Python”**: How much time was spent in Python code.\n- **“native”**: How much time was spent in non-Python code (e.g.,\n libraries written in C/C++).\n- **“system”**: How much time was spent in the system (e.g., I/O).\n- **“GPU”**: (not shown here) How much time spent on the GPU, if your\n system has an NVIDIA GPU installed.\n- **“Memory Python”**: How much of the memory allocation happened on\n the Python side of the code, as opposed to in non-Python code (e.g.,\n libraries written in C/C++).\n- **“net”**: Positive net memory numbers indicate total memory\n allocation in megabytes; negative net memory numbers indicate memory\n reclamation.\n- **“timeline / %”**: Visualized by “sparklines”, memory consumption\n generated by this line over the program runtime, and the percentages\n of total memory activity this line represents.\n- **“Copy (MB/s)”**: The amount of megabytes being copied per second\n (see “About Scalene”).\n\nScalene\n-------\n\nThe following command runs Scalene on a provided example program.\n\n.. code:: console\n\n scalene test/testme.py\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nClick to see all Scalene’s options (available by running with –help)\n\n.. raw:: html\n\n
\n\n.. code:: console\n\n % scalene --help\n Scalene: a high-precision CPU and memory profiler\n https://github.com/plasma-umass/scalene\n\n commands:\n run Profile a Python program (saves to scalene-profile.json)\n view View an existing profile in browser or terminal\n\n examples:\n % scalene run your_program.py # profile, save to scalene-profile.json\n % scalene view # view scalene-profile.json in browser\n % scalene view --cli # view profile in terminal\n\n in Jupyter, line mode:\n %scrun [options] statement\n\n in Jupyter, cell mode:\n %%scalene [options]\n your code here\n\n % scalene run --help\n Profile a Python program with Scalene.\n\n examples:\n % scalene run prog.py # profile, save to scalene-profile.json\n % scalene run -o my.json prog.py # save to custom file\n % scalene run --cpu-only prog.py # profile CPU only (faster)\n % scalene run -c scalene.yaml prog.py # load options from config file\n % scalene run prog.py --- --arg # pass args to program\n % scalene run --help-advanced # show advanced options\n\n options:\n -h, --help show this help message and exit\n -o, --outfile OUTFILE output file (default: scalene-profile.json)\n --cpu-only only profile CPU time (no memory/GPU)\n -c, --config FILE load options from YAML config file\n --help-advanced show advanced options\n\n % scalene run --help-advanced\n Advanced options for scalene run:\n\n background profiling:\n Use --off to start with profiling disabled, then control from another terminal:\n % scalene run --off prog.py # start with profiling off\n % python3 -m scalene.profile --on --pid # resume profiling\n % python3 -m scalene.profile --off --pid # suspend profiling\n\n options:\n --profile-all profile all code, not just the target program\n --profile-only PATH only profile files containing these strings (comma-separated)\n --profile-exclude PATH exclude files containing these strings (comma-separated)\n --profile-system-libraries profile Python stdlib and installed packages (default: skip)\n --gpu profile GPU time and memory\n --memory profile memory usage\n --stacks collect stack traces\n --profile-interval N output profiles every N seconds (default: inf)\n --use-virtual-time measure only CPU time, not I/O or blocking\n --cpu-percent-threshold N only report lines with at least N% CPU (default: 1%)\n --cpu-sampling-rate N CPU sampling rate in seconds (default: 0.01)\n --malloc-threshold N only report lines with at least N allocations (default: 100)\n --memory-leak-detector EXPERIMENTAL: report likely memory leaks\n --on start with profiling on (default)\n --off start with profiling off\n\n % scalene view --help\n View an existing Scalene profile.\n\n examples:\n % scalene view # open in browser\n % scalene view --cli # view in terminal\n % scalene view --html # save to scalene-profile.html\n % scalene view myprofile.json # open specific profile in browser\n\n options:\n -h, --help show this help message and exit\n --cli display profile in the terminal\n --html save to scalene-profile.html (no browser)\n -r, --reduced only show lines with activity (--cli mode)\n\n.. raw:: html\n\n \n\nScalene with Jupyter\n~~~~~~~~~~~~~~~~~~~~\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nInstructions for installing and using Scalene with Jupyter notebooks\n\n.. raw:: html\n\n
\n\n`This\nnotebook `__\nillustrates the use of Scalene in Jupyter.\n\nInstallation:\n\n.. code:: console\n\n !pip install scalene\n %load_ext scalene\n\nLine mode:\n\n.. code:: console\n\n %scrun [options] statement\n\nCell mode:\n\n.. code:: console\n\n %%scalene [options]\n code...\n code...\n\n.. raw:: html\n\n \n\nInstallation\n------------\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nUsing pip (Mac OS X, Linux, Windows, and WSL2)\n\n.. raw:: html\n\n
\n\nScalene is distributed as a ``pip`` package and works on Mac OS X, Linux\n(including Ubuntu in `Windows\nWSL2 `__) and\n(with limitations) Windows platforms.\n\n **Note**\n\n The Windows version currently only supports CPU and GPU profiling,\n but not memory or copy profiling.\n\nYou can install it as follows:\n\n.. code:: console\n\n % pip install -U scalene\n\nor\n\n.. code:: console\n\n % python3 -m pip install -U scalene\n\nYou may need to install some packages first.\n\nSee https://stackoverflow.com/a/19344978/4954434 for full instructions\nfor all Linux flavors.\n\nFor Ubuntu/Debian:\n\n.. code:: console\n\n % sudo apt install git python3-all-dev\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nUsing conda (Mac OS X, Linux, Windows, and WSL2)\n\n.. raw:: html\n\n
\n\n.. code:: console\n\n % conda install -c conda-forge scalene\n\nScalene is distributed as a ``conda`` package and works on Mac OS X,\nLinux (including Ubuntu in `Windows\nWSL2 `__) and\n(with limitations) Windows platforms.\n\n **Note**\n\n The Windows version currently only supports CPU and GPU profiling,\n but not memory or copy profiling.\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nOn ArchLinux\n\n.. raw:: html\n\n
\n\nYou can install Scalene on Arch Linux via the `AUR\npackage `__. Use\nyour favorite AUR helper, or manually download the ``PKGBUILD`` and run\n``makepkg -cirs`` to build. Note that this will place ``libscalene.so``\nin ``/usr/lib``; modify the below usage instructions accordingly.\n\n.. raw:: html\n\n \n\nFrequently Asked Questions\n==========================\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nCan I use Scalene with PyTest?\n\n.. raw:: html\n\n
\n\n**A:** Yes! You can run it as follows (for example):\n\n``scalene run -m pytest your_test.py``\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nIs there any way to get shorter profiles or do more targeted profiling?\n\n.. raw:: html\n\n
\n\n**A:** Yes! There are several options:\n\n1. Use ``--reduced-profile`` to include only lines and files with\n memory/CPU/GPU activity.\n2. Use ``--profile-only`` to include only filenames containing specific\n strings (as in, ``--profile-only foo,bar,baz``).\n3. Decorate functions of interest with ``@profile`` to have Scalene\n report *only* those functions.\n4. Turn profiling on and off programmatically by importing Scalene\n profiler (``from scalene import scalene_profiler``) and then turning\n profiling on and off via ``scalene_profiler.start()`` and\n ``scalene_profiler.stop()``. By default, Scalene runs with profiling\n on, so to delay profiling until desired, use the ``--off``\n command-line option (``scalene run --off yourprogram.py``).\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nHow do I run Scalene in PyCharm?\n\n.. raw:: html\n\n
\n\n**A:** In PyCharm, you can run Scalene at the command line by opening\nthe terminal at the bottom of the IDE and running a Scalene command\n(e.g., ``scalene run ``). Then use ``scalene view --html``\nto generate an HTML file (``scalene-profile.html``) that you can view in the IDE.\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nHow do I use Scalene with Django?\n\n.. raw:: html\n\n
\n\n**A:** Pass in the ``--noreload`` option (see\nhttps://github.com/plasma-umass/scalene/issues/178).\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nDoes Scalene work with gevent/Greenlets?\n\n.. raw:: html\n\n
\n\n**A:** Yes! Put the following code in the beginning of your program, or\nmodify the call to ``monkey.patch_all`` as below:\n\n.. code:: python\n\n from gevent import monkey\n monkey.patch_all(thread=False)\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nHow do I use Scalene with PyTorch on the Mac?\n\n.. raw:: html\n\n
\n\n**A:** Scalene works with PyTorch version 1.5.1 on Mac OS X. There’s a\nbug in newer versions of PyTorch\n(https://github.com/pytorch/pytorch/issues/57185) that interferes with\nScalene (discussion here:\nhttps://github.com/plasma-umass/scalene/issues/110), but only on Macs.\n\n.. raw:: html\n\n \n\nTechnical Information\n=====================\n\nFor details about how Scalene works, please see the following paper,\nwhich won the Jay Lepreau Best Paper Award at `OSDI\n2023 `__:\n`Triangulating Python Performance Issues with\nScalene `__. (Note that this paper\ndoes not include information about the AI-driven proposed\noptimizations.)\n\n.. raw:: html\n\n \n\n.. raw:: html\n\n \n\nTo cite Scalene in an academic paper, please use the following:\n\n.. raw:: html\n\n
\n\n.. code:: latex\n\n @inproceedings{288540,\n author = {Emery D. Berger and Sam Stern and Juan Altmayer Pizzorno},\n title = {Triangulating Python Performance Issues with {S}calene},\n booktitle = {{17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23)}},\n year = {2023},\n isbn = {978-1-939133-34-2},\n address = {Boston, MA},\n pages = {51--64},\n url = {https://www.usenix.org/conference/osdi23/presentation/berger},\n publisher = {USENIX Association},\n month = jul\n }\n\n.. raw:: html\n\n \n\nSuccess Stories\n===============\n\nIf you use Scalene to successfully debug a performance problem, please\n`add a comment to this\nissue `__!\n\nAcknowledgements\n================\n\nLogo created by `Sophia\nBerger `__.\n\nThis material is based upon work supported by the National Science\nFoundation under Grant No. 1955610. Any opinions, findings, and\nconclusions or recommendations expressed in this material are those of\nthe author(s) and do not necessarily reflect the views of the National\nScience Foundation.\n\n.. |Scalene community Slack| image:: https://github.com/plasma-umass/scalene/raw/master/docs/images/slack-logo.png\n :target: https://join.slack.com/t/scaleneprofil-jge3234/shared_invite/zt-110vzrdck-xJh5d4gHnp5vKXIjYD3Uwg\n.. |PyPI Latest Release| image:: https://img.shields.io/pypi/v/scalene.svg\n :target: https://pypi.org/project/scalene/\n.. |Anaconda-Server Badge| image:: https://img.shields.io/conda/v/conda-forge/scalene\n :target: https://anaconda.org/conda-forge/scalene\n.. |Downloads| image:: https://static.pepy.tech/badge/scalene\n :target: https://pepy.tech/project/scalene\n.. |Anaconda downloads| image:: https://img.shields.io/conda/d/conda-forge/scalene?logo=conda\n :target: https://anaconda.org/conda-forge/scalene\n.. |image1| image:: https://static.pepy.tech/badge/scalene/month\n :target: https://pepy.tech/project/scalene\n.. |Python versions| image:: https://img.shields.io/pypi/pyversions/scalene.svg?style=flat-square\n.. |Visual Studio Code Extension version| image:: https://img.shields.io/visual-studio-marketplace/v/emeryberger.scalene?logo=visualstudiocode\n :target: https://marketplace.visualstudio.com/items?itemName=EmeryBerger.scalene\n.. |License| image:: https://img.shields.io/github/license/plasma-umass/scalene\n.. |Scalene web GUI| image:: https://raw.githubusercontent.com/plasma-umass/scalene/master/docs/scalene-gui-example.png\n :target: https://raw.githubusercontent.com/plasma-umass/scalene/master/docs/scalene-gui-example-full.png\n.. |Scalene presentation at PyCon 2021| image:: https://raw.githubusercontent.com/plasma-umass/scalene/master/docs/images/scalene-video-img.png\n :target: https://youtu.be/5iEf-_7mM1k\n"
},
{
"path": "mypy.ini",
"content": "[mypy]\nscripts_are_modules = True\nshow_traceback = True\nplugins = pydantic.mypy\n\n# Options to make the checking stricter.\ncheck_untyped_defs = True\ndisallow_any_unimported = True\ndisallow_untyped_defs = True\ndisallow_any_generics = True\nwarn_no_return = True\nno_implicit_optional = True\nwarn_return_any = True\ndisallow_untyped_calls = True\ndisallow_incomplete_defs = True\nwarn_redundant_casts = True\n\n# Display the codes needed for # type: ignore[code] annotations.\nshow_error_codes = True\n\n# It's useful to try this occasionally, and keep it clean; but when\n# someone fixes a type error we don't want to add a burden for them.\nwarn_unused_ignores = True\n\n# We use a lot of third-party libraries we don't have stubs for, as\n# well as a handful of our own modules that we haven't told mypy how\n# to find. Ignore them. (For some details, see:\n# `git log -p -S ignore_missing_imports mypy.ini`.)\n#\n# This doesn't get in the way of using the stubs we *do* have.\nignore_missing_imports = True\n\n# Warn of unreachable or redundant code.\nwarn_unreachable = False\n# was True\n\nstrict_optional = True\n\n"
},
{
"path": "pyproject.toml",
"content": "[project]\nname = \"scalene\"\ndescription = \"Scalene: A high-resolution, low-overhead CPU, GPU, and memory profiler for Python with AI-powered optimization suggestions\"\nreadme = \"README.md\"\nkeywords = [\"performance\", \"profiler\", \"optimization\", \"CPU\", \"GPU\", \"memory\", \"LLM\"]\nauthors = [\n {name = \"Emery Berger\", email = \"emery@cs.umass.edu\"},\n {name = \"Sam Stern\", email = \"jstern@umass.edu\"},\n {name = \"Juan Altmayer Pizzorno\", email = \"juan@altmayer.com\"},\n]\nrequires-python = \">=3.8,!=3.11.0\"\nclassifiers = [\n \"Development Status :: 5 - Production/Stable\",\n \"Framework :: IPython\",\n \"Framework :: Jupyter\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Science/Research\",\n \"Topic :: Software Development\",\n \"Topic :: Software Development :: Debuggers\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Programming Language :: Python :: 3.12\",\n \"Programming Language :: Python :: 3.13\",\n \"Programming Language :: Python :: 3.14\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: Microsoft :: Windows\"\n]\n# see https://peps.python.org/pep-0508/#environment-markers for conditional syntax\ndependencies = [\n \"rich>=10.7.0\",\n \"cloudpickle>=2.2.1\",\n # \"pynvml>=11.0.0,<=11.5\",\n \"nvidia-ml-py>=12.555.43; platform_system !='Darwin'\",\n \"Jinja2>=3.0.3\",\n \"psutil>=5.9.2\",\n \"numpy>=1.24.0,!=1.27; python_version < '3.14'\",\n \"numpy>=2.3.4; python_version >= '3.14'\",\n \"astunparse>=1.6.3; python_version < '3.9'\",\n \"pydantic>=2.6\",\n \"pyyaml>=6.0\",\n]\n\ndynamic = [\"version\"] # computed by setup.py\n\n[project.optional-dependencies]\ntest = [\n \"pytest>=7.0\",\n \"pytest-asyncio>=0.21\",\n \"hypothesis>=6.0\",\n # TensorFlow for testing library profiler integration\n # TensorFlow doesn't support Python 3.14+ yet\n \"tensorflow>=2.15; python_version < '3.14' and platform_system != 'Windows'\",\n # JAX for testing library profiler integration\n # JAX doesn't support Windows\n \"jax>=0.4.20; python_version < '3.14' and platform_system != 'Windows'\",\n \"jaxlib>=0.4.20; python_version < '3.14' and platform_system != 'Windows'\",\n]\n\n[project.urls]\n\"Homepage\" = \"https://github.com/plasma-umass/scalene\"\n\"Repository\" = \"https://github.com/plasma-umass/scalene\"\n\n[project.scripts]\nscalene = \"scalene.__main__:main\"\n\n[build-system]\nbuild-backend = \"setuptools.build_meta\"\nrequires = [\n \"setuptools>=70.1\",\n \"setuptools_scm>=8\",\n \"cython\",\n]\n"
},
{
"path": "pyrightconfig.json",
"content": "{\n \"include\": [\"scalene\"],\n \"useLibraryCodeForTypes\": true,\n \"reportInvalidStringEscapeSequence\": false,\n \"typeCheckingMode\" : \"basic\"\n}\n"
},
{
"path": "pytest.ini",
"content": "[tool:pytest]\nnorecursedirs = tests/*\n"
},
{
"path": "refactoring_todo.md",
"content": "# Scalene Profiler Refactoring Plan\n\n## Goal\nRefactor `scalene/scalene_profiler.py` into multiple files with clear separation of concerns.\n\n## Status: ✅ COMPLETE\n\nAll verification checks pass:\n- `pytest tests/` - 147 tests passed\n- `mypy scalene` - No issues found\n- `ruff check scalene` - All checks passed\n\n## File Sizes\n\n| File | Lines |\n|------|-------|\n| `scalene_profiler.py` | 1,584 (was 1,885) |\n| `scalene_cpu_profiler.py` | 228 (new) |\n| `scalene_tracing.py` | 225 (new) |\n| `scalene_lifecycle.py` | 198 (new) |\n\n**Net reduction**: ~300 lines from main profiler, with reusable logic extracted\n\n## New Modules Created\n\n### 1. `scalene_cpu_profiler.py` ✅\n- **Class**: `ScaleneCPUProfiler`\n- **Purpose**: CPU profiling sample processing\n- **Key methods**:\n - `process_cpu_sample` - Main CPU sample handler\n - `_update_main_thread_stats` - Main thread statistics\n - `_update_thread_stats` - Other thread statistics\n\n### 2. `scalene_tracing.py` ✅\n- **Class**: `ScaleneTracing`\n- **Purpose**: Tracing decisions and file filtering with `lru_cache`\n- **Key methods**:\n - `should_trace` - Main entry point (cached)\n - `_passes_exclusion_rules` - Library exclusions\n - `_should_trace_by_location` - Path-based filtering\n - `_is_system_library` - System library detection\n\n### 3. `scalene_lifecycle.py` ✅\n- **Class**: `ScaleneLifecycle`\n- **Purpose**: Profiler lifecycle management (prepared for future use)\n\n## Architecture\n\n```\nscalene_profiler.py (Scalene class)\n ├── ScaleneCPUProfiler (CPU sample processing)\n ├── ScaleneTracing (file/function filtering)\n ├── ScaleneMemoryProfiler (already existed)\n └── ScaleneSignalManager (already existed)\n```\n\n## Completed Tasks\n\n- [x] Extracted CPU profiling logic (~150 lines)\n- [x] Extracted tracing/filtering logic (~150 lines)\n- [x] Created lifecycle module for future use\n- [x] Updated type signatures to use `Filename` consistently\n- [x] Applied proper `lru_cache` usage\n- [x] All tests passing (147/147)\n- [x] Type checking passing (mypy)\n- [x] Linting passing (ruff)\n"
},
{
"path": "requirements.txt",
"content": "astunparse>=1.6.3; python_version < '3.9'\ncloudpickle>=2.2.1\nCython>=0.29.28\nipython>=8.10\nJinja2>=3.0.3\nlxml>=5.1.0\npackaging>=24\npsutil>=5.9.2\npyperf>=2.0.0\nrich>=10.7.0\nsetuptools>=65.5.1\nnvidia-ml-py>=12.555.43; platform_system !='Darwin'\nwheel>=0.43.0\n# Per https://github.com/pypa/setuptools/issues/4483#issuecomment-2236528158\nordered-set>=3.1.1\nmore_itertools>=8.8\njaraco.text>=3.7\nimportlib_resources>=5.10.2\nimportlib_metadata>=6\ntomli>=2.0.1\nplatformdirs >= 2.6.2\n"
},
{
"path": "ruff.toml",
"content": "line-length = 88\nindent-width = 4\nexclude = [\"test\", \"tests\", \"node_modules\", \"benchmarks\"]\n\n[lint]\nselect = [\"E\", \"F\", \"B\", \"I\", \"SIM\", \"UP\"]\nignore = [\"E101\", \"E402\", \"E501\", \"E701\", \"E741\", \"F401\", \"F403\", \"F405\", \"B028\"]\n\n"
},
{
"path": "scalene/README.md",
"content": "### Helper functions:\n\n* `adaptive.py`:\n `Adaptive` maintains samples used for memory footprint sparklines.\n \n* `profile.py`:\n used to suspend/resume profiling of Scalene when run in the background (with `&`).\n\n* `replacement_*.py`:\n Scalene needs to interpose on a variety of functions; this functionality is in these files.\n \n* `runningstats.py`:\n `RunningStats` takes input samples and incrementally computes average and other statistics in a fixed amount of space.\n\n* `sparkline.py`:\n Functions to generate sparklines, used to display memory consumption over time.\n\n* `syntaxline.py`:\n A helper function for pretty-printing with the Rich library.\n\n\n### Core Scalene functions:\n\n* `scalene_arguments.py`:\n `ScaleneArguments` holds command-line arguments and their default values.\n\n* `scalene_cpu_profiler.py`:\n `ScaleneCPUProfiler` handles CPU profiling sample processing, including main thread and background thread statistics collection. Extracted from `scalene_profiler.py` for separation of concerns.\n\n* `scalene_gpu.py`:\n `ScaleneGPU` wraps the NVIDIA library to conveniently provide access to GPU statistics required by Scalene.\n\n* `scalene_lifecycle.py`:\n `ScaleneLifecycle` manages profiler lifecycle operations including start, stop, and signal management.\n\n* `scalene_magics.py`:\n Sets up the \"magics\" for using Scalene within Jupyter notebooks (`%scrun` and `%%scalene`).\n\n* `scalene_memory_profiler.py`:\n `ScaleneMemoryProfiler` handles memory profiling sample processing for malloc, free, and memcpy operations.\n\n* `scalene_output.py`:\n `ScaleneOutput` encapsulates functions used for generating Scalene's profiles either as text or HTML.\n\n* `scalene_profiler.py`:\n The core of the Scalene profiler. Coordinates CPU, memory, and GPU profiling by delegating to specialized modules (`ScaleneCPUProfiler`, `ScaleneTracing`, `ScaleneMemoryProfiler`).\n\n* `scalene_signals.py`:\n Defines the Unix signals that Scalene uses (some of which must be kept in sync with `include/sampleheap.hpp`).\n\n* `scalene_statistics.py`:\n Operations for managing the statistics generated by Scalene.\n\n* `scalene_tracing.py`:\n `ScaleneTracing` handles tracing decisions and file filtering. Determines which files and functions should be profiled based on exclusion rules, profile-only patterns, and system library detection. Uses `lru_cache` for performance.\n\n* `scalene_version.py`:\n The version number of Scalene which ultimately is reflected on `pypi` (for `pip` installs, used by `setup.py` in the top level directory).\n \n"
},
{
"path": "scalene/__init__.py",
"content": "# Work around this bug: https://github.com/NVIDIA/cuda-python/issues/29\nimport os\n\nos.environ[\"LC_ALL\"] = \"POSIX\"\n\n# Jupyter support\n\nfrom scalene.scalene_magics import *\n"
},
{
"path": "scalene/__main__.py",
"content": "import sys\nimport traceback\n\n\ndef main() -> None:\n try:\n from scalene import scalene_profiler\n\n scalene_profiler.Scalene.main()\n except SystemExit:\n raise\n except Exception as exc:\n sys.stderr.write(f\"ERROR: Calling Scalene main function failed: {exc}\\n\")\n traceback.print_exc()\n sys.exit(1)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "scalene/adaptive.py",
"content": "from typing import List\n\n\nclass Adaptive:\n \"\"\"Implements sampling to achieve the effect of a uniform random sample.\"\"\"\n\n def __init__(self, size: int) -> None:\n # size must be a power of two\n self.max_samples = size\n self.current_index = 0\n self.sample_array = [0.0] * size\n\n def __add__(self: \"Adaptive\", other: \"Adaptive\") -> \"Adaptive\":\n n = Adaptive(self.max_samples)\n for i in range(0, self.max_samples):\n n.sample_array[i] = self.sample_array[i] + other.sample_array[i]\n n.current_index = max(self.current_index, other.current_index)\n return n\n\n def __iadd__(self: \"Adaptive\", other: \"Adaptive\") -> \"Adaptive\":\n for i in range(0, self.max_samples):\n self.sample_array[i] += other.sample_array[i]\n self.current_index = max(self.current_index, other.current_index)\n return self\n\n def add(self, value: float) -> None:\n if self.current_index >= self.max_samples:\n # Decimate\n new_array = [0.0] * self.max_samples\n for i in range(0, self.max_samples // 3):\n arr = [self.sample_array[i * 3 + j] for j in range(0, 3)]\n arr.sort()\n new_array[i] = arr[1] # Median\n self.current_index = self.max_samples // 3\n self.sample_array = new_array\n self.sample_array[self.current_index] = value\n self.current_index += 1\n\n def get(self) -> List[float]:\n return self.sample_array\n\n def len(self) -> int:\n return self.current_index\n"
},
{
"path": "scalene/find_browser.py",
"content": "import webbrowser\nfrom typing import Optional\n\n\ndef find_browser(browserClass: Optional[str] = None) -> Optional[str]:\n \"\"\"Find the default system browser, excluding text browsers.\n\n If you want a specific browser, pass its class as an argument.\"\"\"\n text_browsers = [\n \"browsh\",\n \"elinks\",\n \"links\",\n \"lynx\",\n \"w3m\",\n ]\n\n try:\n # Get the default browser object\n browser = webbrowser.get(browserClass)\n browser_name = browser.name if browser.name else browser.__class__.__name__\n return browser_name if browser_name not in text_browsers else None\n except AttributeError:\n # https://github.com/plasma-umass/scalene/issues/790\n # https://github.com/python/cpython/issues/105545\n # MacOSXOSAScript._name was deprecated but for pre-Python 3.11,\n # we need to refer to it as such to prevent this error:\n # 'MacOSXOSAScript' object has no attribute 'name'\n browser = webbrowser.get(browserClass)\n return browser._name if browser._name not in text_browsers else None # type: ignore[attr-defined]\n except webbrowser.Error:\n # Return None if there is an error in getting the browser\n return None\n"
},
{
"path": "scalene/get_module_details.py",
"content": "import importlib.util\nimport sys\nfrom importlib.abc import SourceLoader\nfrom importlib.machinery import ModuleSpec\nfrom types import CodeType\nfrom typing import (\n Tuple,\n Type,\n)\n\n\ndef _get_module_details(\n mod_name: str,\n error: Type[Exception] = ImportError,\n) -> Tuple[str, ModuleSpec, CodeType]:\n \"\"\"Copy of `runpy._get_module_details`, but not private.\"\"\"\n if mod_name.startswith(\".\"):\n raise error(\"Relative module names not supported\")\n pkg_name, _, _ = mod_name.rpartition(\".\")\n if pkg_name:\n # Try importing the parent to avoid catching initialization errors\n try:\n __import__(pkg_name)\n except ImportError as e:\n # If the parent or higher ancestor package is missing, let the\n # error be raised by find_spec() below and then be caught. But do\n # not allow other errors to be caught.\n if e.name is None or (\n e.name != pkg_name and not pkg_name.startswith(e.name + \".\")\n ):\n raise\n # Warn if the module has already been imported under its normal name\n existing = sys.modules.get(mod_name)\n if existing is not None and not hasattr(existing, \"__path__\"):\n from warnings import warn\n\n msg = (\n f\"{mod_name!r} found in sys.modules after import of \"\n f\"package {pkg_name!r}, but prior to execution of \"\n f\"{mod_name!r}; this may result in unpredictable \"\n \"behaviour\"\n )\n warn(RuntimeWarning(msg))\n\n try:\n spec = importlib.util.find_spec(mod_name)\n except (ImportError, AttributeError, TypeError, ValueError) as ex:\n # This hack fixes an impedance mismatch between pkgutil and\n # importlib, where the latter raises other errors for cases where\n # pkgutil previously raised ImportError\n msg = \"Error while finding module specification for {!r} ({}: {})\"\n if mod_name.endswith(\".py\"):\n msg += (\n f\". Try using '{mod_name[:-3]}' instead of \"\n f\"'{mod_name}' as the module name.\"\n )\n raise error(msg.format(mod_name, type(ex).__name__, ex)) from ex\n if spec is None:\n raise error(f\"No module named {mod_name}\")\n if spec.submodule_search_locations is not None:\n if mod_name == \"__main__\" or mod_name.endswith(\".__main__\"):\n raise error(\"Cannot use package as __main__ module\")\n try:\n pkg_main_name = mod_name + \".__main__\"\n return _get_module_details(pkg_main_name, error)\n except error as e:\n if mod_name not in sys.modules:\n raise # No module loaded; being a package is irrelevant\n raise error(\n (\"%s; %r is a package and cannot \" + \"be directly executed\")\n % (e, mod_name)\n ) from None\n loader = spec.loader\n # use isinstance instead of `is None` to placate mypy\n if not isinstance(loader, SourceLoader):\n raise error(f\"{mod_name!r} is a namespace package and cannot be executed\")\n try:\n code = loader.get_code(mod_name)\n except ImportError as e:\n raise error(format(e)) from e\n if code is None:\n raise error(f\"No code object available for {mod_name}\")\n return mod_name, spec, code\n"
},
{
"path": "scalene/launchbrowser.py",
"content": "import http.server\nimport os\nimport pathlib\nimport platform\nimport shutil\nimport socket\nimport socketserver\nimport sys\nimport tempfile\nimport threading\nimport time\nimport webbrowser\nfrom typing import Any, NewType\n\nfrom jinja2 import Environment, FileSystemLoader\n\n\ndef launch_browser_insecure(url: str) -> None:\n if platform.system() == \"Windows\":\n chrome_path = \"C:\\\\Program Files (x86)\\\\Google\\\\Chrome\\\\Application\\\\chrome.exe\"\n elif platform.system() == \"Linux\":\n chrome_path = \"/usr/bin/google-chrome\"\n elif platform.system() == \"Darwin\":\n chrome_path = \"/Applications/Google\\\\ Chrome.app/Contents/MacOS/Google\\\\ Chrome\"\n\n # Create a temporary directory\n with tempfile.TemporaryDirectory() as temp_dir:\n # Create a command with the required flags\n chrome_cmd = (\n f'{chrome_path} %s --disable-web-security --user-data-dir=\"{temp_dir}\"'\n )\n\n # Register the new browser type\n webbrowser.register(\n \"chrome_with_flags\",\n None,\n webbrowser.Chrome(chrome_cmd),\n preferred=True,\n )\n\n # Open a URL using the new browser type\n webbrowser.get(chrome_cmd).open(url)\n\n\nHOST = \"localhost\"\nshutdown_requested = False\nlast_heartbeat = time.time()\nserver_running = True\n\n\nclass CustomHandler(http.server.SimpleHTTPRequestHandler):\n def do_GET(self) -> Any:\n global last_heartbeat\n if self.path == \"/heartbeat\":\n last_heartbeat = time.time()\n self.send_response(200)\n self.end_headers()\n return\n else:\n return http.server.SimpleHTTPRequestHandler.do_GET(self)\n\n\ndef monitor_heartbeat() -> None:\n global server_running\n while server_running:\n if time.time() - last_heartbeat > 60: # 60 seconds timeout\n print(\"No heartbeat received, shutting down server...\")\n server_running = False\n os._exit(0)\n time.sleep(1)\n\n\ndef serve_forever(httpd: Any) -> None:\n while server_running:\n httpd.handle_request()\n\n\ndef run_server(host: str, port: int) -> None:\n with socketserver.TCPServer((host, port), CustomHandler) as httpd:\n print(f\"Serving at http://{host}:{port}\")\n serve_forever(httpd)\n\n\ndef is_port_available(port: int) -> bool:\n \"\"\"\n Check if a given TCP port is available to start a server on the local machine.\n\n :param port: Port number as an integer.\n :return: True if the port is available, False otherwise.\n \"\"\"\n with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:\n try:\n s.bind((\"localhost\", port))\n return True\n except OSError:\n return False\n\n\nFilename = NewType(\"Filename\", str)\nLineNumber = NewType(\"LineNumber\", int)\n\n\ndef generate_html(profile_fname: Filename, output_fname: Filename) -> None:\n \"\"\"Apply a template to generate a single HTML payload containing the current profile.\"\"\"\n\n try:\n # Load the profile\n profile_file = pathlib.Path(profile_fname)\n profile = profile_file.read_text()\n except FileNotFoundError:\n assert profile_fname == \"demo\"\n profile = \"{}\"\n # return\n\n scalene_dir = os.path.dirname(__file__)\n\n # Put the profile and everything else into the template.\n environment = Environment(\n loader=FileSystemLoader(os.path.join(scalene_dir, \"scalene-gui\"))\n )\n template = environment.get_template(\"index.html.template\")\n try:\n import scalene_config\n except ModuleNotFoundError:\n import scalene.scalene_config as scalene_config\n rendered_content = template.render(\n profile=profile,\n scalene_version=scalene_config.scalene_version,\n scalene_date=scalene_config.scalene_date,\n api_keys={},\n )\n\n # Write the rendered content to the specified output file.\n try:\n with open(output_fname, \"w\", encoding=\"utf-8\") as f:\n f.write(rendered_content)\n except OSError:\n pass\n\n\ndef start(filename: str, port: int) -> None:\n while not is_port_available(port):\n port += 1\n\n cwd = os.getcwd()\n if filename == \"demo\":\n generate_html(Filename(\"demo\"), Filename(\"demo.html\"))\n filename = \"demo.html\"\n temp_dir = tempfile.gettempdir()\n shutil.copy(filename, os.path.join(temp_dir, \"index.html\"))\n\n # Copy vendored assets for offline support (issue #982)\n scalene_gui_dir = os.path.join(os.path.dirname(__file__), \"scalene-gui\")\n for asset in [\n \"favicon.ico\",\n \"scalene-image.png\",\n \"jquery-3.6.0.slim.min.js\",\n \"bootstrap.min.css\",\n \"bootstrap.bundle.min.js\",\n \"prism.css\",\n \"scalene-gui-bundle.js\",\n ]:\n src = os.path.join(scalene_gui_dir, asset)\n if os.path.exists(src):\n shutil.copy(src, os.path.join(temp_dir, asset))\n\n os.chdir(temp_dir)\n server_thread = threading.Thread(target=run_server, args=[HOST, port])\n server_thread.start()\n threading.Thread(target=monitor_heartbeat).start()\n\n webbrowser.open_new(f\"http://{HOST}:{port}/\")\n server_thread.join()\n\n os.chdir(cwd)\n\n # Optional: a delay to ensure all resources are released\n time.sleep(1)\n os._exit(0) # Forcefully stops the program\n\n\nif __name__ == \"__main__\":\n import sys\n\n if len(sys.argv) > 2:\n filename = sys.argv[1]\n port = int(sys.argv[2])\n start(filename, port)\n else:\n print(\"Need to supply filename and port arguments.\")\n"
},
{
"path": "scalene/merge_scalene_neuron_profiles.py",
"content": "#!/usr/bin/env python3\nimport bisect\nimport json\nimport sys\nfrom pathlib import Path\nfrom typing import List, Optional, Tuple\n\n\ndef parse_debug_file_programmatic(\n debug_file: str, valid_filenames: List[str]\n) -> Tuple[Optional[str], List[Tuple[int, str]]]:\n \"\"\"Parse debug file programmatically to extract execution data\"\"\"\n if not Path(debug_file).exists():\n return None, []\n\n with open(debug_file) as f:\n content = f.read()\n\n # Extract PID\n import re\n\n pid_match = re.search(r\"PID: (\\d+)\", content)\n pid = pid_match.group(1) if pid_match else None\n\n # Extract source locations\n executions = []\n sections = content.split(\"---\")\n\n for section in sections:\n if not section.strip():\n continue\n\n lines = section.strip().split(\"\\n\")\n source_line = None\n kernel_name = None\n\n for line in lines:\n if line.startswith(\"SOURCE: \"):\n source_info = line[8:] # Remove 'SOURCE: '\n if \":\" in source_info:\n # Check if source matches any of the files in scalene profile\n for filename in valid_filenames:\n if filename in source_info:\n source_line = int(source_info.split(\":\")[-1])\n break\n elif line.startswith(\"KERNEL: \"):\n kernel_name = line[8:] # Remove 'KERNEL: '\n\n if source_line:\n executions.append((source_line, kernel_name or \"unknown\"))\n\n return pid, executions\n\n\ndef calculate_cpu_sample_overlap(\n cpu_samples_list: List[float],\n nc_intervals: List[Tuple[float, float]],\n start_time_absolute: float,\n start_time_perf: float,\n) -> Tuple[int, int, float]:\n \"\"\"Calculate overlap between CPU samples and nc_exec_running intervals\n\n Args:\n cpu_samples_list: List of CPU sample timestamps (perf_counter values)\n nc_intervals: List of (start_time, end_time) tuples for nc_exec_running events (in seconds)\n start_time_absolute: Absolute start time (Unix timestamp in seconds)\n start_time_perf: Performance counter start time (in seconds)\n\n Returns:\n tuple: (overlap_count, total_count, overlap_percent)\n \"\"\"\n if not cpu_samples_list or not nc_intervals:\n return 0, len(cpu_samples_list), 0.0\n\n overlap_count = 0\n total_count = len(cpu_samples_list)\n\n # Sort intervals by start time for efficient searching\n sorted_intervals = sorted(nc_intervals, key=lambda x: x[0])\n\n for cpu_sample_perf in cpu_samples_list:\n # Convert CPU sample to absolute time\n cpu_sample_absolute = start_time_absolute + (cpu_sample_perf - start_time_perf)\n\n # Check if CPU sample overlaps with any interval (strict overlap)\n for start, end in sorted_intervals:\n # Check if CPU sample falls within interval exactly\n if start <= cpu_sample_absolute <= end:\n overlap_count += 1\n break\n\n overlap_percent = (overlap_count / total_count * 100) if total_count > 0 else 0.0\n return overlap_count, total_count, overlap_percent\n\n\ndef merge_neuron_into_scalene_programmatic(\n scalene_file: str, neuron_file: str, output_file: str, target_rank: int = 0\n) -> None:\n \"\"\"Merge Neuron timing data into Scalene JSON using programmatic kernel execution data\"\"\"\n\n # Load Scalene data\n try:\n with open(scalene_file) as f:\n content = f.read().strip()\n if \"\" in content:\n json_start = content.find(\"const profile = \") + len(\"const profile = \")\n if json_start > len(\"const profile = \") - 1:\n brace_count = 0\n json_end = json_start\n for i, char in enumerate(content[json_start:]):\n if char == \"{\":\n brace_count += 1\n elif char == \"}\":\n brace_count -= 1\n if brace_count == 0:\n json_end = json_start + i + 1\n break\n content = content[json_start:json_end]\n scalene_data = json.loads(content)\n except json.JSONDecodeError as e:\n print(f\"Error parsing {scalene_file}: {e}\")\n return\n\n # Load Neuron trace data\n with open(neuron_file) as f:\n neuron_data = json.load(f)\n\n # Get timing information from Scalene\n start_time_absolute = scalene_data.get(\"start_time_absolute\", 0)\n start_time_perf = scalene_data.get(\"start_time_perf\", 0)\n\n # Extract valid filenames from Scalene data\n valid_filenames = []\n if \"files\" in scalene_data:\n for filename in scalene_data[\"files\"]:\n # Extract just the basename for matching\n basename = Path(filename).name\n valid_filenames.append(basename)\n\n # Get kernel execution data programmatically\n debug_file = f\"debug_rank_{target_rank}.txt\"\n target_pid, spike_lines = parse_debug_file_programmatic(debug_file, valid_filenames)\n\n if not spike_lines:\n print(f\"No kernel execution data found for rank {target_rank}\")\n return\n\n # Extract events from Neuron trace\n events_list = (\n neuron_data\n if isinstance(neuron_data, list)\n else neuron_data.get(\"trace_event\", [])\n )\n nrt_events = []\n kbl_events = []\n nc_events = []\n nc_intervals = []\n\n for event in events_list:\n event_pid = str(event.get(\"process_id\", \"\"))\n if target_pid is None or event_pid == target_pid:\n if event.get(\"name\") == \"nrt_execute\":\n nrt_events.append(\n {\n \"name\": event.get(\"name\"),\n \"duration_ns\": event.get(\"duration\", 0),\n \"duration_ms\": event.get(\"duration\", 0) / 1000000,\n \"timestamp\": event.get(\"timestamp\", 0),\n \"process_id\": event.get(\"process_id\"),\n \"thread_id\": event.get(\"thread_id\"),\n }\n )\n elif event.get(\"name\") == \"kbl_exec_pre\":\n exec_id = event.get(\"args\", {}).get(\"exec_id\") or event.get(\"exec_id\")\n kbl_events.append(\n {\n \"name\": event.get(\"name\"),\n \"exec_id\": exec_id,\n \"timestamp\": event.get(\"timestamp\", 0),\n \"process_id\": event.get(\"process_id\"),\n \"thread_id\": event.get(\"thread_id\"),\n }\n )\n\n # Collect nc_exec_running events for target PID\n if event.get(\"name\") == \"nc_exec_running\" and (\n target_pid is None or event_pid == target_pid\n ):\n timestamp_ns = event.get(\"timestamp\", 0)\n duration_ns = event.get(\"duration\", 0)\n\n start_time_sec = timestamp_ns / 1e9\n end_time_sec = (timestamp_ns + duration_ns) / 1e9\n\n nc_intervals.append((start_time_sec, end_time_sec))\n\n exec_id = event.get(\"args\", {}).get(\"exec_id\") or event.get(\"exec_id\")\n nc_events.append(\n {\n \"name\": event.get(\"name\"),\n \"duration_ns\": duration_ns,\n \"duration_ms\": duration_ns / 1000000,\n \"timestamp\": timestamp_ns,\n \"exec_id\": exec_id,\n \"process_id\": event.get(\"process_id\"),\n \"thread_id\": event.get(\"thread_id\"),\n }\n )\n\n nrt_events.sort(key=lambda x: x[\"timestamp\"])\n kbl_events.sort(key=lambda x: x[\"timestamp\"])\n nc_events.sort(key=lambda x: x[\"timestamp\"])\n\n # Create exec_id to nrt_execute mapping via kbl_exec_pre\n exec_id_to_nrt_index = {}\n for i, kbl_event in enumerate(kbl_events):\n if i < len(nrt_events) and kbl_event[\"exec_id\"] is not None:\n exec_id_to_nrt_index[kbl_event[\"exec_id\"]] = i\n\n # Map kernel executions to nrt events by timestamp order\n total_neuron_time = sum(event[\"duration_ms\"] for event in nrt_events)\n total_nc_time = sum(event[\"duration_ms\"] for event in nc_events)\n\n # Group spike lines by line number\n from collections import defaultdict\n\n line_to_events = defaultdict(list)\n line_to_nc_events = defaultdict(list)\n\n # Map nrt_execute events to spike lines consecutively\n for i, (spike_line, kernel_name) in enumerate(spike_lines):\n if i < len(nrt_events):\n line_to_events[spike_line].append((nrt_events[i], kernel_name))\n\n # Map nc_exec_running events to spike lines via exec_id\n for nc_event in nc_events:\n exec_id = nc_event.get(\"exec_id\")\n if exec_id in exec_id_to_nrt_index:\n nrt_index = exec_id_to_nrt_index[exec_id]\n if nrt_index < len(spike_lines):\n spike_line, kernel_name = spike_lines[nrt_index]\n line_to_nc_events[spike_line].append((nc_event, kernel_name))\n\n # Process CPU sample overlap for all lines\n total_cpu_samples_with_overlap = 0\n total_cpu_samples = 0\n\n # Add neuron timing to scalene structure\n if \"files\" in scalene_data:\n for filename, file_data in scalene_data[\"files\"].items():\n if \"lines\" in file_data:\n for line_data in file_data[\"lines\"]:\n lineno = line_data.get(\"lineno\")\n cpu_samples_list = line_data.get(\"cpu_samples_list\", [])\n\n # Calculate CPU sample overlap with nc_exec_running for ALL lines with CPU samples\n if cpu_samples_list and nc_intervals:\n overlap_count, total_count, overlap_percent = (\n calculate_cpu_sample_overlap(\n cpu_samples_list,\n nc_intervals,\n start_time_absolute,\n start_time_perf,\n )\n )\n\n line_data[\"cpu_samples_nc_overlap_count\"] = overlap_count\n line_data[\"cpu_samples_total_count\"] = total_count\n line_data[\"cpu_samples_nc_overlap_percent\"] = overlap_percent\n\n total_cpu_samples_with_overlap += overlap_count\n total_cpu_samples += total_count\n else:\n line_data[\"cpu_samples_nc_overlap_count\"] = 0\n line_data[\"cpu_samples_total_count\"] = len(cpu_samples_list)\n line_data[\"cpu_samples_nc_overlap_percent\"] = 0.0\n\n # Check if this line has neuron events\n basename = Path(filename).name\n if basename in valid_filenames and lineno in line_to_events:\n events_for_line = line_to_events[lineno]\n\n # Sum all events for this line\n total_time_ms = sum(\n event[\"duration_ms\"] for event, _ in events_for_line\n )\n all_events = [event for event, _ in events_for_line]\n kernel_name = events_for_line[0][\n 1\n ] # Use first kernel name as reference\n\n # Process nc_exec_running events for this line\n nc_events_for_line = line_to_nc_events.get(lineno, [])\n total_nc_time_ms = sum(\n event[\"duration_ms\"] for event, _ in nc_events_for_line\n )\n all_nc_events = [event for event, _ in nc_events_for_line]\n\n # Add neuron timing fields\n line_data[\"nrt_time_ms\"] = total_time_ms\n line_data[\"nrt_percent\"] = (\n (total_time_ms / total_neuron_time) * 100\n if total_neuron_time > 0\n else 0\n )\n line_data[\"nrt_execute_count\"] = len(all_events)\n line_data[\"nrt_events\"] = all_events\n line_data[\"nrt_source_code\"] = kernel_name\n\n # Add nc_exec_running data\n line_data[\"nc_time_ms\"] = total_nc_time_ms\n line_data[\"nc_percent\"] = (\n (total_nc_time_ms / total_nc_time) * 100\n if total_nc_time > 0\n else 0\n )\n line_data[\"nc_execute_count\"] = len(all_nc_events)\n line_data[\"nc_events\"] = all_nc_events\n\n # Add ratio of nc_exec time to nrt_execute time\n line_data[\"nc_nrt_ratio\"] = (\n total_nc_time_ms / total_time_ms if total_time_ms > 0 else 0\n )\n\n # Keep legacy field for backward compatibility\n line_data[\"neuron_time_ms\"] = total_time_ms\n\n # Add neuron metadata\n if len(nrt_events) > 0:\n scalene_data[\"neuron_total_time_ms\"] = total_neuron_time\n scalene_data[\"neuron_total_nc_time_ms\"] = total_nc_time\n scalene_data[\"neuron_event_count\"] = len(nrt_events)\n scalene_data[\"neuron_nc_event_count\"] = len(nc_events)\n scalene_data[\"cpu_samples_total_with_nc_overlap\"] = (\n total_cpu_samples_with_overlap\n )\n scalene_data[\"cpu_samples_total\"] = total_cpu_samples\n scalene_data[\"cpu_samples_nc_overlap_percent_overall\"] = (\n (total_cpu_samples_with_overlap / total_cpu_samples * 100)\n if total_cpu_samples > 0\n else 0.0\n )\n\n # Write merged data\n with open(output_file, \"w\") as f:\n json.dump(scalene_data, f, indent=2)\n\n print(f\"Merged data written to {output_file}\")\n print(f\"Total neuron time: {total_neuron_time:.2f}ms\")\n print(f\"Total nc_exec time: {total_nc_time:.2f}ms\")\n print(\n f\"Overall CPU sample overlap: {total_cpu_samples_with_overlap}/{total_cpu_samples} ({(total_cpu_samples_with_overlap/total_cpu_samples*100) if total_cpu_samples > 0 else 0:.1f}%)\"\n )\n\n\nif __name__ == \"__main__\":\n if len(sys.argv) != 4:\n print(\n \"Usage: python merge_scalene_neuron_programmatic_with_overlap.py \"\n )\n sys.exit(1)\n\n scalene_file, neuron_file, output_file = sys.argv[1:4]\n merge_neuron_into_scalene_programmatic(scalene_file, neuron_file, output_file)\n"
},
{
"path": "scalene/profile.py",
"content": "import argparse\nimport sys\nfrom textwrap import dedent\n\nusage = dedent(\"\"\"Turn Scalene profiling on or off for a specific process.\"\"\")\n\nparser = argparse.ArgumentParser(\n prog=\"scalene.profile\",\n description=usage,\n formatter_class=argparse.RawTextHelpFormatter,\n allow_abbrev=False,\n)\nparser.add_argument(\"--pid\", dest=\"pid\", type=int, default=0, help=\"process ID\")\ngroup = parser.add_mutually_exclusive_group(required=True)\ngroup.add_argument(\"--on\", action=\"store_true\", help=\"turn profiling on\")\ngroup.add_argument(\"--off\", action=\"store_false\", help=\"turn profiling off\")\n\nargs, left = parser.parse_known_args()\nif len(sys.argv) == 1 or args.pid == 0:\n parser.print_help(sys.stderr)\n sys.exit(-1)\n\ntry:\n from scalene.scalene_signal_manager import ScaleneSignalManager\n\n ScaleneSignalManager.signal_lifecycle_event(args.pid, start=args.on)\n if args.on:\n print(\"Scalene: profiling turned on.\")\n else:\n print(\"Scalene: profiling turned off.\")\n\nexcept ProcessLookupError:\n print(\"Process \" + str(args.pid) + \" not found.\")\n"
},
{
"path": "scalene/redirect_python.py",
"content": "import os\nimport pathlib\nimport stat\nimport sys\n\n\ndef redirect_python(preface: str, cmdline: str, python_alias_dir: pathlib.Path) -> str:\n \"\"\"\n Redirects Python calls to a different command with a preface and cmdline.\n\n Args:\n preface: A string to be prefixed to the Python command.\n cmdline: Additional command line arguments to be appended.\n python_alias_dir: The directory where the alias scripts will be stored.\n \"\"\"\n base_python_extension = \".exe\" if sys.platform == \"win32\" else \"\"\n all_python_names = [\n \"python\" + base_python_extension,\n f\"python{sys.version_info.major}{base_python_extension}\",\n f\"python{sys.version_info.major}.{sys.version_info.minor}{base_python_extension}\",\n ]\n\n shebang = \"@echo off\" if sys.platform == \"win32\" else \"#!/usr/bin/env bash\"\n all_args = \"%*\" if sys.platform == \"win32\" else '\"$@\"'\n\n payload = (\n f\"{shebang}\\n{preface} {sys.executable} -m scalene run {cmdline} {all_args}\\n\"\n )\n\n for name in all_python_names:\n fname = python_alias_dir / name\n if sys.platform == \"win32\":\n fname = fname.with_suffix(\".bat\")\n try:\n with open(fname, \"w\") as file:\n file.write(payload)\n if sys.platform != \"win32\":\n os.chmod(fname, stat.S_IXUSR | stat.S_IRUSR | stat.S_IWUSR)\n except OSError as e:\n print(f\"Error writing to {fname}: {e}\")\n\n sys.path.insert(0, str(python_alias_dir))\n os.environ[\"PATH\"] = f\"{python_alias_dir}{os.pathsep}{os.environ['PATH']}\"\n\n orig_sys_executable = sys.executable\n\n # Compute the new sys executable path\n sys_executable_path = python_alias_dir / all_python_names[0]\n\n # On Windows, adjust the path to use a .bat file instead of .exe\n if sys.platform == \"win32\" and sys_executable_path.suffix == \".exe\":\n sys_executable_path = sys_executable_path.with_suffix(\".bat\")\n\n sys.executable = str(sys_executable_path)\n\n return orig_sys_executable\n"
},
{
"path": "scalene/replacement_asyncio.py",
"content": "\"\"\"Scalene replacement for asyncio event loop instrumentation.\n\nFollows the existing replacement_*.py pattern using @Scalene.shim.\nWhen async profiling is enabled, this module activates the\nScaleneAsync instrumentation (sys.monitoring on 3.12+, polling on older).\n\"\"\"\n\nfrom scalene.scalene_profiler import Scalene\n\n\n@Scalene.shim\ndef replacement_asyncio(scalene: Scalene) -> None:\n \"\"\"Activate async profiling instrumentation when --async is enabled.\n\n This is called during profiler initialization. The actual enable/disable\n is controlled by Scalene.__init__ based on the --async flag.\n ScaleneAsync.enable() installs sys.monitoring callbacks on 3.12+.\n On 3.9-3.11, polling via asyncio.all_tasks() is used instead,\n triggered from the signal queue processor.\n \"\"\"\n # Nothing to do here - activation is handled by the profiler\n # based on the --async flag. This module exists as a placeholder\n # following the replacement_*.py convention, and can be extended\n # with additional event loop wrapping if needed.\n pass\n"
},
{
"path": "scalene/replacement_exec.py",
"content": "\"\"\"Replacement for exec/eval/compile to track dynamically executed code.\n\nThis module intercepts exec(), eval(), and compile() to capture source code\nthat would otherwise be invisible to the profiler. When code is executed via\nexec() or eval() with a string source, Python normally uses '' as the\nfilename, making it impossible to show line-by-line profiling.\n\nBy wrapping these builtins, we:\n1. Generate unique virtual filenames that include the caller's location\n2. Store the source in linecache so it can be retrieved during profiling output\n3. Compile/execute using our virtual filename so profiler samples reference it\n\"\"\"\n\nimport __future__\n\nimport builtins\nimport linecache\nimport os\nimport sys\nfrom types import FrameType\nfrom typing import Any, Dict, Optional\n\nfrom scalene.scalene_profiler import Scalene\n\n# Bitmask covering all __future__ compiler flags. compile() inherits these\n# from the calling frame when dont_inherit=False, but our wrappers break\n# that inheritance chain. We extract them from the real caller's co_flags\n# to propagate them explicitly. This is the same approach CPython's doctest\n# module uses and covers all past and future __future__ features.\n_FUTURE_FLAGS_MASK = 0\nfor _name in __future__.all_feature_names:\n _FUTURE_FLAGS_MASK |= getattr(__future__, _name).compiler_flag\ndel _name\n\n\ndef _caller_future_flags(frame: FrameType) -> int:\n \"\"\"Extract __future__ compiler flags from a frame's code object.\"\"\"\n return frame.f_code.co_flags & _FUTURE_FLAGS_MASK\n\n\ndef _is_synthetic_filename(filename: str) -> bool:\n \"\"\"Check if a filename is a Python synthetic name like ''.\"\"\"\n return filename.startswith(\"<\") and filename.endswith(\">\")\n\n\ndef _register_source_in_linecache(filename: str, source: str) -> None:\n \"\"\"Register source code in linecache for later retrieval.\"\"\"\n lines = source.splitlines(keepends=True)\n # Ensure the last line has a newline\n if lines and not lines[-1].endswith(\"\\n\"):\n lines[-1] += \"\\n\"\n # linecache entry format: (size, mtime, lines, fullname)\n # mtime=None indicates the source won't change\n linecache.cache[filename] = (len(source), None, lines, filename)\n\n\ndef _make_virtual_filename(kind: str, caller_frame: FrameType) -> str:\n \"\"\"Create a virtual filename encoding the caller's location.\n\n Format: or \n \"\"\"\n caller_filename = caller_frame.f_code.co_filename\n caller_lineno = caller_frame.f_lineno\n # Use basename to keep the filename short\n basename = os.path.basename(caller_filename)\n return f\"<{kind}@{basename}:{caller_lineno}>\"\n\n\n@Scalene.shim\ndef replacement_exec(scalene: Scalene) -> None: # noqa: ARG001\n \"\"\"Replace exec(), eval(), and compile() to track dynamic code execution.\"\"\"\n orig_exec = builtins.exec\n orig_eval = builtins.eval\n orig_compile = builtins.compile\n\n def exec_replacement(\n __source: Any,\n /,\n globals: Optional[Dict[str, Any]] = None,\n locals: Optional[Dict[str, Any]] = None,\n **kwargs: Any,\n ) -> None:\n \"\"\"Replacement for exec() that tracks source code.\n\n When given a string, we compile it with a unique virtual filename\n and register the source in linecache for profiling.\n\n Note: In Python 3.14+, exec() accepts globals/locals as keyword arguments,\n plus a keyword-only 'closure' parameter. We use 'globals' and 'locals'\n as parameter names (shadowing builtins) to match the built-in signature.\n \"\"\"\n # Get caller frame - needed both for virtual filename and for\n # getting globals/locals when not provided\n caller_frame = sys._getframe(1)\n\n if isinstance(__source, str):\n virtual_filename = _make_virtual_filename(\"exec\", caller_frame)\n _register_source_in_linecache(virtual_filename, __source)\n # Propagate the caller's __future__ flags (e.g. annotations)\n # so that code compiled here behaves the same as if exec()\n # compiled it directly in the caller's context.\n flags = _caller_future_flags(caller_frame)\n code_obj = orig_compile(\n __source,\n virtual_filename,\n \"exec\",\n flags=flags,\n dont_inherit=True,\n )\n __source = code_obj\n\n # When globals/locals are not specified, exec() uses the caller's frame.\n # Since we're wrapping exec, we need to explicitly get the caller's frame.\n if globals is None:\n globals = caller_frame.f_globals\n if locals is None:\n locals = caller_frame.f_locals\n\n if locals is None:\n orig_exec(__source, globals, **kwargs)\n else:\n orig_exec(__source, globals, locals, **kwargs)\n\n def eval_replacement(\n __source: Any,\n /,\n globals: Optional[Dict[str, Any]] = None,\n locals: Optional[Dict[str, Any]] = None,\n ) -> Any:\n \"\"\"Replacement for eval() that tracks source code.\n\n When given a string, we compile it with a unique virtual filename\n and register the source in linecache for profiling.\n\n Note: In Python 3.14+, eval() accepts globals/locals as keyword arguments.\n We use 'globals' and 'locals' as parameter names (shadowing builtins)\n to match the built-in signature exactly.\n \"\"\"\n # Get caller frame - needed both for virtual filename and for\n # getting globals/locals when not provided\n caller_frame = sys._getframe(1)\n\n if isinstance(__source, str):\n virtual_filename = _make_virtual_filename(\"eval\", caller_frame)\n _register_source_in_linecache(virtual_filename, __source)\n flags = _caller_future_flags(caller_frame)\n code_obj = orig_compile(\n __source,\n virtual_filename,\n \"eval\",\n flags=flags,\n dont_inherit=True,\n )\n __source = code_obj\n\n # When globals/locals are not specified, eval() uses the caller's frame.\n # Since we're wrapping eval, we need to explicitly get the caller's frame.\n if globals is None:\n globals = caller_frame.f_globals\n if locals is None:\n locals = caller_frame.f_locals\n\n if locals is None:\n return orig_eval(__source, globals)\n else:\n return orig_eval(__source, globals, locals)\n\n def compile_replacement(\n source: Any,\n filename: str,\n mode: str,\n flags: int = 0,\n dont_inherit: bool = False,\n optimize: int = -1,\n **kwargs: Any,\n ) -> Any:\n \"\"\"Replacement for compile() that tracks source code.\n\n When the filename is a synthetic name like '' and we have\n a string source, we register it in linecache with the given filename.\n This handles cases where users call compile() directly.\n \"\"\"\n if isinstance(source, str) and _is_synthetic_filename(filename):\n _register_source_in_linecache(filename, source)\n\n if not dont_inherit:\n # The real compile() would inherit __future__ flags from its\n # caller's frame. Since our wrapper is now the immediate caller,\n # we must manually propagate flags from the real caller.\n caller_frame = sys._getframe(1)\n flags |= _caller_future_flags(caller_frame)\n dont_inherit = True\n\n return orig_compile(\n source, filename, mode, flags, dont_inherit, optimize, **kwargs\n )\n\n builtins.exec = exec_replacement # type: ignore[assignment]\n builtins.eval = eval_replacement # type: ignore[assignment]\n builtins.compile = compile_replacement # type: ignore[assignment]\n"
},
{
"path": "scalene/replacement_exit.py",
"content": "import os\nimport sys\n\nfrom scalene.scalene_profiler import Scalene\n\n\n@Scalene.shim\ndef replacement_exit(scalene: Scalene) -> None:\n \"\"\"\n Shims out the unconditional exit with\n the \"neat exit\" (which raises the SystemExit error and\n allows Scalene to exit neatly)\n \"\"\"\n # Note: MyPy doesn't like this, but it works because passing an int\n # to sys.exit does the right thing\n os._exit = sys.exit # type: ignore\n"
},
{
"path": "scalene/replacement_fork.py",
"content": "import os\n\nfrom scalene.scalene_profiler import Scalene\n\n\n@Scalene.shim\ndef replacement_fork(scalene: Scalene) -> None:\n \"\"\"\n Executes Scalene fork() handling.\n Works just like os.register_at_fork(), but unlike that also provides the child PID.\n \"\"\"\n orig_fork = os.fork\n\n def fork_replacement() -> int:\n scalene.before_fork()\n\n child_pid = orig_fork()\n if child_pid == 0:\n scalene.after_fork_in_child()\n else:\n scalene.after_fork_in_parent(child_pid)\n\n return child_pid\n\n os.fork = fork_replacement\n"
},
{
"path": "scalene/replacement_get_context.py",
"content": "import multiprocessing\nfrom typing import Any\n\nfrom scalene.scalene_profiler import Scalene\n\n\n@Scalene.shim\ndef replacement_mp_get_context(scalene: Scalene) -> None:\n old_get_context = multiprocessing.get_context\n\n def replacement_get_context(method: Any = None) -> Any:\n # Respect the user's requested method instead of forcing fork\n return old_get_context(method)\n\n multiprocessing.get_context = replacement_get_context\n"
},
{
"path": "scalene/replacement_lock.py",
"content": "import contextlib\nimport sys\nimport threading\nimport time\nfrom typing import Any\n\nfrom scalene.scalene_profiler import Scalene\n\n\n@Scalene.shim\ndef replacement_lock(scalene: Scalene) -> None:\n class ReplacementLock:\n \"\"\"Replace lock with a version that periodically yields and updates sleeping status.\"\"\"\n\n def __init__(self) -> None:\n # Cache the original lock (which we replace)\n # print(\"INITIALIZING LOCK\")\n self.__lock: threading.Lock = scalene.get_original_lock()\n\n def acquire(self, blocking: bool = True, timeout: float = -1) -> bool:\n tident = threading.get_ident()\n if blocking == 0:\n blocking = False\n start_time = time.perf_counter()\n if blocking:\n if timeout < 0:\n interval = sys.getswitchinterval()\n else:\n interval = min(timeout, sys.getswitchinterval())\n else:\n interval = -1\n while True:\n scalene.set_thread_sleeping(tident)\n acquired_lock = self.__lock.acquire(blocking, interval)\n scalene.reset_thread_sleeping(tident)\n if acquired_lock:\n return True\n if not blocking:\n return False\n # If a timeout was specified, check to see if it's expired.\n if timeout != -1:\n end_time = time.perf_counter()\n if end_time - start_time >= timeout:\n return False\n\n def release(self) -> None:\n self.__lock.release()\n\n def locked(self) -> bool:\n return self.__lock.locked()\n\n def _at_fork_reinit(self) -> None:\n with contextlib.suppress(AttributeError):\n self.__lock._at_fork_reinit() # type: ignore\n\n def __enter__(self) -> None:\n self.acquire()\n\n def __exit__(self, type: str, value: str, traceback: Any) -> None:\n self.release()\n\n threading.Lock = ReplacementLock # type: ignore\n"
},
{
"path": "scalene/replacement_mp_lock.py",
"content": "import multiprocessing.synchronize\n\n# import _multiprocessing\n# The _multiprocessing module is entirely undocumented-- the header of the\n# acquire function is\n# static PyObject * _multiprocessing_SemLock_acquire_impl(SemLockObject *self, int blocking, PyObject *timeout_obj)\n#\n# timeout_obj is parsed as a double\nfrom scalene.replacement_sem_lock import ReplacementSemLock\nfrom scalene.scalene_profiler import Scalene\n\n\n@Scalene.shim\ndef replacement_mp_semlock(scalene: Scalene) -> None:\n ReplacementSemLock.__qualname__ = \"replacement_semlock.ReplacementSemLock\"\n multiprocessing.synchronize.Lock = ReplacementSemLock # type: ignore\n"
},
{
"path": "scalene/replacement_pjoin.py",
"content": "import multiprocessing\nimport os\nimport sys\nimport threading\nimport time\n\nfrom scalene.scalene_profiler import Scalene\n\nminor_version = sys.version_info.minor\n\n\n@Scalene.shim\ndef replacement_pjoin(scalene: Scalene) -> None:\n def replacement_process_join(self, timeout: float = -1) -> None: # type: ignore\n \"\"\"\n A drop-in replacement for multiprocessing.Process.join\n that periodically yields to handle signals\n \"\"\"\n # print(multiprocessing.process.active_children())\n if minor_version >= 7:\n self._check_closed()\n assert self._parent_pid == os.getpid(), \"can only join a child process\"\n assert self._popen is not None, \"can only join a started process\"\n tident = threading.get_ident()\n if timeout < 0:\n interval = sys.getswitchinterval()\n else:\n interval = min(timeout, sys.getswitchinterval())\n start_time = time.perf_counter()\n while True:\n scalene.set_thread_sleeping(tident)\n res = self._popen.wait(interval)\n if res is not None:\n from multiprocessing.process import _children # type: ignore\n\n scalene.remove_child_pid(self.pid)\n _children.discard(self)\n return\n scalene.reset_thread_sleeping(tident)\n # I think that this should be timeout--\n # Interval is the sleep time per-tic,\n # but timeout determines whether it returns\n if timeout != -1:\n end_time = time.perf_counter()\n if end_time - start_time >= timeout:\n from multiprocessing.process import ( # type: ignore\n _children,\n )\n\n _children.discard(self)\n return\n\n multiprocessing.Process.join = replacement_process_join # type: ignore\n"
},
{
"path": "scalene/replacement_poll_selector.py",
"content": "import selectors\nimport sys\nimport threading\nimport time\nfrom typing import List, Optional, Tuple\n\nfrom scalene.scalene_profiler import Scalene\n\n\n@Scalene.shim\ndef replacement_poll_selector(scalene: Scalene) -> None:\n \"\"\"\n A replacement for selectors.PollSelector that\n periodically wakes up to accept signals\n \"\"\"\n\n class ReplacementPollSelector(selectors.PollSelector):\n def select(\n self, timeout: Optional[float] = -1\n ) -> List[Tuple[selectors.SelectorKey, int]]:\n tident = threading.get_ident()\n start_time = time.perf_counter()\n if not timeout or timeout < 0:\n interval = sys.getswitchinterval()\n else:\n interval = min(timeout, sys.getswitchinterval())\n while True:\n scalene.set_thread_sleeping(tident)\n selected = super().select(interval)\n scalene.reset_thread_sleeping(tident)\n if selected or timeout == 0:\n return selected\n end_time = time.perf_counter()\n if timeout and timeout != -1 and end_time - start_time >= timeout:\n return [] # None\n\n ReplacementPollSelector.__qualname__ = (\n \"replacement_poll_selector.ReplacementPollSelector\"\n )\n selectors.PollSelector = ReplacementPollSelector # type: ignore\n"
},
{
"path": "scalene/replacement_sem_lock.py",
"content": "import multiprocessing.context\nimport multiprocessing.synchronize\nimport random\nimport sys\nimport threading\nfrom typing import Any, Callable, Optional, Tuple, Union\n\nfrom scalene.scalene_profiler import Scalene\n\n\ndef _make_replacement_semlock(method: Optional[str] = None) -> \"ReplacementSemLock\":\n # Create lock using the specified context method for spawn-safety\n ctx = multiprocessing.get_context(method)\n return ReplacementSemLock(ctx=ctx)\n\n\nclass ReplacementSemLock(multiprocessing.synchronize.Lock):\n def __init__(\n self,\n ctx: Optional[\n Union[\n multiprocessing.context.DefaultContext,\n multiprocessing.context.BaseContext,\n ]\n ] = None,\n ) -> None:\n # Ensure to use the appropriate context while initializing\n if ctx is None:\n ctx = multiprocessing.get_context()\n # Store the context method for pickling (spawn-safety)\n self._ctx_method: Optional[str] = getattr(ctx, \"_name\", None)\n super().__init__(ctx=ctx)\n\n def __enter__(self) -> bool:\n switch_interval = sys.getswitchinterval()\n max_timeout = switch_interval\n tident = threading.get_ident()\n while True:\n timeout = random.random() * max_timeout\n Scalene.set_thread_sleeping(tident)\n acquired = self._semlock.acquire(timeout=timeout) # type: ignore\n Scalene.reset_thread_sleeping(tident)\n if acquired:\n return True\n else:\n max_timeout *= 2 # Exponential backoff\n # Cap timeout at 1 second\n if max_timeout >= 1.0:\n max_timeout = 1.0\n\n def __exit__(self, *args: Any) -> None:\n super().__exit__(*args)\n\n def __reduce__(self) -> Tuple[Callable[..., Any], Tuple[Any, ...]]:\n # Pass the context method to preserve it across spawn\n return (_make_replacement_semlock, (self._ctx_method,))\n\n\n# important: force the class to live in the module name that workers will import\nReplacementSemLock.__module__ = \"scalene.replacement_sem_lock\"\n"
},
{
"path": "scalene/replacement_signal_fns.py",
"content": "import os\nimport signal\nimport sys\nfrom typing import Any, Dict, Optional, Set, Tuple\n\nfrom scalene.scalene_profiler import Scalene\n\n\n@Scalene.shim\ndef replacement_signal_fns(scalene: Scalene) -> None:\n scalene_signals = scalene.get_signals()\n expected_handlers_map = {\n scalene_signals.malloc_signal: scalene.malloc_signal_handler,\n scalene_signals.free_signal: scalene.free_signal_handler,\n scalene_signals.memcpy_signal: scalene.memcpy_signal_handler,\n signal.SIGTERM: scalene.term_signal_handler,\n scalene_signals.cpu_signal: scalene.cpu_signal_handler,\n }\n old_signal = signal.signal\n old_raise_signal = signal.raise_signal\n\n old_kill = os.kill\n\n if sys.platform != \"win32\":\n new_cpu_signal = signal.SIGUSR1\n else:\n new_cpu_signal = signal.SIGFPE\n\n # Track which warnings we've already printed to avoid spam\n _warned_signals: Set[int] = set()\n\n # On Linux, we can use real-time signals (SIGRTMIN+n) for cleaner signal redirection.\n # Real-time signals are guaranteed to be delivered and queued, and are rarely used by libraries.\n # On other platforms (macOS, Windows), we fall back to signal handler chaining.\n _use_rt_signals = sys.platform == \"linux\" and hasattr(signal, \"SIGRTMIN\")\n\n # Map original signals to their alternate (redirected) signals\n # On Linux: use real-time signals; on other platforms: None (use chaining)\n _signal_redirects: Dict[int, int] = {}\n if _use_rt_signals:\n # Allocate real-time signals for each Scalene signal that might conflict\n # SIGRTMIN+0 is often used by threading libraries, so start from SIGRTMIN+1\n rt_base = getattr(signal, \"SIGRTMIN\") + 1 # noqa: B009\n start_signal, stop_signal = scalene.get_lifecycle_signals()\n # Map lifecycle and memory signals to real-time signals\n rt_offset = 0\n for sig in [\n start_signal,\n stop_signal,\n scalene_signals.memcpy_signal,\n scalene_signals.malloc_signal,\n scalene_signals.free_signal,\n ]:\n if sig is not None:\n _signal_redirects[sig] = rt_base + rt_offset\n rt_offset += 1\n\n # Store chained handlers for platforms without real-time signal support\n # Maps signal number -> user's handler\n _chained_handlers: Dict[int, Any] = {}\n\n def _make_chained_handler(scalene_handler: Any, user_handler: Any) -> Any:\n \"\"\"Create a handler that calls both Scalene's handler and the user's handler.\"\"\"\n import contextlib\n from types import FrameType\n from typing import Optional\n\n def chained_handler(sig: int, frame: Optional[FrameType]) -> None:\n # Call Scalene's handler first (don't let errors break user code)\n with contextlib.suppress(Exception):\n scalene_handler(sig, frame)\n # Then call the user's handler (don't let errors propagate)\n if callable(user_handler):\n with contextlib.suppress(Exception):\n user_handler(sig, frame)\n\n return chained_handler\n\n def replacement_signal(signum: int, handler: Any) -> Any:\n all_signals = scalene.get_all_signals_set()\n timer_signal, cpu_signal = scalene.get_timer_signals()\n timer_signal_str = signal.strsignal(signum)\n start_signal, stop_signal = scalene.get_lifecycle_signals()\n\n # Handle CPU profiling signal - redirect to an alternate signal\n # This allows both Scalene and user code to use timer-based profiling\n if signum == cpu_signal:\n if signum not in _warned_signals:\n print(\n f\"WARNING: Scalene uses {timer_signal_str} to profile.\\n\"\n f\"If your code raises {timer_signal_str} from non-Python code, use SIGUSR1.\\n\"\n \"Code that raises signals from within Python code will be rerouted.\"\n )\n _warned_signals.add(signum)\n return old_signal(new_cpu_signal, handler)\n\n # Handle lifecycle signals (SIGILL, SIGBUS) - allow co-existence with user code\n if start_signal is not None and signum == start_signal:\n return _handle_signal_coexistence(signum, handler, timer_signal_str)\n\n if stop_signal is not None and signum == stop_signal:\n return _handle_signal_coexistence(signum, handler, timer_signal_str)\n\n # Fallthrough condition-- if we haven't dealt with the signal at this point in the call and the handler is\n # a NOP-like, then we can ignore it. It can't have been set already, and the expected return value is the\n # previous handler, so this behavior is reasonable\n if signum in all_signals and (\n handler is signal.SIG_IGN or handler is signal.SIG_DFL\n ):\n return handler\n # If trying to \"reset\" to a handler that we already set it to, ignore\n if (\n signal.Signals(signum) in expected_handlers_map\n and expected_handlers_map[signal.Signals(signum)] is handler\n ):\n return signal.SIG_IGN\n\n # Handle memory profiling signals (SIGPROF, SIGXCPU, SIGXFSZ) - allow co-existence\n if signum in all_signals:\n return _handle_signal_coexistence(signum, handler, timer_signal_str)\n\n return old_signal(signum, handler)\n\n def _handle_signal_coexistence(\n signum: int, handler: Any, signal_name: \"Optional[str]\"\n ) -> Any:\n \"\"\"Handle a signal that both Scalene and user code want to use.\n\n On Linux: Redirect user's handler to a real-time signal for clean separation.\n On other platforms: Chain handlers so both get called.\n \"\"\"\n if signum not in _warned_signals:\n sig_str = signal_name or f\"signal {signum}\"\n if _use_rt_signals and signum in _signal_redirects:\n print(\n f\"WARNING: {sig_str} is also used by Scalene.\\n\"\n \"Your code's handler will be redirected to an alternate signal.\"\n )\n else:\n print(\n f\"WARNING: {sig_str} is also used by Scalene.\\n\"\n \"Both Scalene and your code will handle this signal.\"\n )\n _warned_signals.add(signum)\n\n # On Linux with real-time signals: redirect to alternate signal\n if _use_rt_signals and signum in _signal_redirects:\n return old_signal(_signal_redirects[signum], handler)\n\n # On other platforms: chain handlers\n if handler in (signal.SIG_IGN, signal.SIG_DFL):\n return old_signal(signum, handler)\n\n scalene_handler = expected_handlers_map.get(signal.Signals(signum))\n if scalene_handler:\n old_user_handler = _chained_handlers.get(signum)\n _chained_handlers[signum] = handler\n chained = _make_chained_handler(scalene_handler, handler)\n old_signal(signum, chained)\n return old_user_handler if old_user_handler else signal.SIG_DFL\n return old_signal(signum, handler)\n\n def replacement_raise_signal(signum: int) -> None:\n _, cpu_signal = scalene.get_timer_signals()\n if signum == cpu_signal:\n old_raise_signal(new_cpu_signal)\n return\n # On Linux, redirect to real-time signal if applicable\n if _use_rt_signals and signum in _signal_redirects:\n old_raise_signal(_signal_redirects[signum])\n return\n old_raise_signal(signum)\n\n def replacement_kill(pid: int, signum: int) -> None:\n _, cpu_signal = scalene.get_timer_signals()\n is_self_or_child = pid == os.getpid() or pid in scalene.child_pids\n if is_self_or_child and signum == cpu_signal:\n return old_kill(pid, new_cpu_signal)\n # On Linux, redirect to real-time signal if applicable\n if is_self_or_child and _use_rt_signals and signum in _signal_redirects:\n return old_kill(pid, _signal_redirects[signum])\n old_kill(pid, signum)\n\n if sys.platform != \"win32\":\n old_setitimer = signal.setitimer\n old_siginterrupt = signal.siginterrupt\n\n def replacement_siginterrupt(signum: int, flag: bool) -> None:\n _, cpu_signal = scalene.get_timer_signals()\n if signum == cpu_signal:\n return old_siginterrupt(new_cpu_signal, flag)\n # On Linux, redirect to real-time signal if applicable\n if _use_rt_signals and signum in _signal_redirects:\n return old_siginterrupt(_signal_redirects[signum], flag)\n return old_siginterrupt(signum, flag)\n\n def replacement_setitimer(\n which: int, seconds: float, interval: float = 0.0\n ) -> Tuple[float, float]:\n timer_signal, cpu_signal = scalene.get_timer_signals()\n if which == timer_signal:\n old = scalene.client_timer.get_itimer()\n if seconds == 0:\n scalene.client_timer.reset()\n else:\n scalene.client_timer.set_itimer(seconds, interval)\n return old\n return old_setitimer(which, seconds, interval)\n\n signal.setitimer = replacement_setitimer\n signal.siginterrupt = replacement_siginterrupt\n\n signal.signal = replacement_signal # type: ignore[unused-ignore,assignment]\n signal.raise_signal = replacement_raise_signal\n os.kill = replacement_kill\n"
},
{
"path": "scalene/replacement_thread_join.py",
"content": "import sys\nimport threading\nimport time\nfrom typing import Optional\n\nfrom scalene.scalene_profiler import Scalene\n\n\n@Scalene.shim\ndef replacement_thread_join(scalene: Scalene) -> None:\n orig_thread_join = threading.Thread.join\n\n def thread_join_replacement(\n self: threading.Thread, timeout: Optional[float] = None\n ) -> None:\n \"\"\"We replace threading.Thread.join with this method which always\n periodically yields.\"\"\"\n start_time = time.perf_counter()\n interval = sys.getswitchinterval()\n while self.is_alive():\n scalene.set_thread_sleeping(threading.get_ident())\n orig_thread_join(self, interval)\n scalene.reset_thread_sleeping(threading.get_ident())\n # If a timeout was specified, check to see if it's expired.\n if timeout is not None:\n end_time = time.perf_counter()\n if end_time - start_time >= timeout:\n return None\n return None\n\n threading.Thread.join = thread_join_replacement # type: ignore\n"
},
{
"path": "scalene/runningstats.py",
"content": "# Simplified running statistics - only computes mean and peak\n# (variance/skewness/kurtosis removed as they were unused)\n\n\nclass RunningStats:\n \"\"\"Incrementally compute mean and peak statistics using Welford's algorithm.\"\"\"\n\n __slots__ = (\"_n\", \"_m1\", \"_peak\")\n\n def __init__(self) -> None:\n self._n: int = 0\n self._m1: float = 0.0\n self._peak: float = 0.0\n\n def __add__(self: \"RunningStats\", other: \"RunningStats\") -> \"RunningStats\":\n s = RunningStats()\n if other._n > 0:\n total_n = self._n + other._n\n s._m1 = (self._m1 * self._n + other._m1 * other._n) / total_n\n s._n = total_n\n s._peak = max(self._peak, other._peak)\n else:\n s._n = self._n\n s._m1 = self._m1\n s._peak = self._peak\n return s\n\n def clear(self) -> None:\n \"\"\"Reset for new samples.\"\"\"\n self._n = 0\n self._m1 = 0.0\n self._peak = 0.0\n\n def push(self, x: float) -> None:\n \"\"\"Add a sample using Welford's online algorithm for mean.\"\"\"\n if x > self._peak:\n self._peak = x\n self._n += 1\n # Welford's algorithm: mean += (x - mean) / n\n self._m1 += (x - self._m1) / self._n\n\n def peak(self) -> float:\n \"\"\"The maximum sample seen.\"\"\"\n return self._peak\n\n def size(self) -> int:\n \"\"\"The number of samples.\"\"\"\n return self._n\n\n def mean(self) -> float:\n \"\"\"Arithmetic mean (average).\"\"\"\n return self._m1\n"
},
{
"path": "scalene/scalene-gui/README.md",
"content": "This repository holds the [Scalene](https://github.com/plasma-umass/scalene) GUI.\n\n[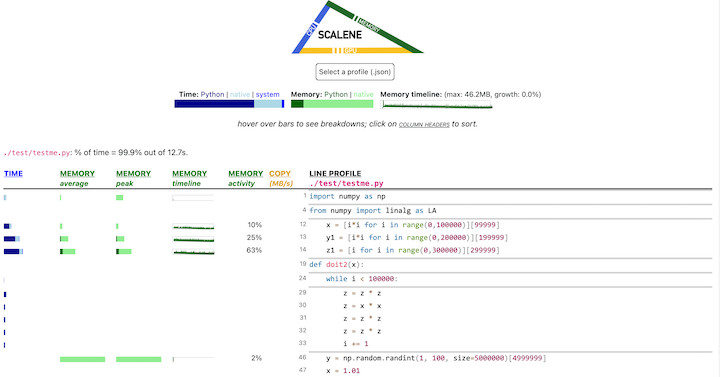](https://raw.githubusercontent.com/plasma-umass/scalene/master/docs/scalene-gui-example-full.png)\n\nTo use the interactive demo, go to the [Scalene GUI](https://plasma-umass.org/scalene-gui/) site.\n\n# Acknowledgements\n\nScalene's web GUI makes use of the following wonderful systems. Many thanks to their authors.\n\n- [Vega-Lite](https://vega.github.io/vega-lite/) for rendering graphs\n- [Prism](https://prismjs.com/) for code highlighting\n- [tablesort](https://github.com/tristen/tablesort) for sorting tables by columns\n\nThis material is based upon work supported by the National Science\nFoundation under Grant No. 1955610. Any opinions, findings, and\nconclusions or recommendations expressed in this material are those of\nthe author(s) and do not necessarily reflect the views of the National\nScience Foundation.\n"
},
{
"path": "scalene/scalene-gui/TODO-TypeScript.md",
"content": "# TypeScript Conversion Plan for Scalene GUI\n\n## Overview\n\nConverting the Scalene GUI JavaScript files to TypeScript for improved type safety, better IDE support, and easier maintenance.\n\n## Build Configuration\n\n- **Bundler**: esbuild (fast, simple, no webpack overhead)\n- **Type Checker**: TypeScript compiler (tsc --noEmit)\n- **Target**: ES2020\n- **Module System**: ESNext with bundler resolution\n\n### package.json Scripts\n\n```json\n{\n \"scripts\": {\n \"build\": \"esbuild scalene-gui.ts --bundle --minify --sourcemap --target=es2020 --outfile=scalene-gui-bundle.js\",\n \"build:dev\": \"esbuild scalene-gui.ts --bundle --sourcemap --target=es2020 --outfile=scalene-gui-bundle.js\",\n \"watch\": \"esbuild scalene-gui.ts --bundle --sourcemap --target=es2020 --outfile=scalene-gui-bundle.js --watch\",\n \"typecheck\": \"tsc --noEmit\"\n }\n}\n```\n\n## Conversion Status\n\n### Completed\n\n- [x] `utils.ts` - Utility functions (escapeHTML, extractCode, makeTextRecursivelySelectable)\n- [x] `openai.ts` - OpenAI API integration with proper interfaces\n- [x] `ollama.ts` - Ollama local LLM integration\n- [x] `amazon.ts` - AWS Bedrock integration (Anthropic and OpenAI-style responses)\n- [x] `azure.ts` - Azure OpenAI integration\n- [x] `persistence.ts` - LocalStorage state persistence\n- [x] `gui-elements.ts` - Vega-Lite chart builders with LineProfile/FileProfile interfaces\n- [x] `optimizations.ts` - AI optimization request handling\n- [x] `scalene-gui.ts` - Main entry point (largest file, imports all others)\n- [x] `scalene-demo.ts` - Demo functionality\n- [x] `scalene-fetch.ts` - Profile fetching utilities\n- [x] `prism.d.ts` - Type declarations for Prism.js\n- [x] `tablesort.d.ts` - Type declarations for Tablesort.js\n\n### External Libraries (Kept as JS with type declarations)\n\n- `prism.js` - Syntax highlighting (external library, with prism.d.ts declarations)\n- `tablesort.js` - Table sorting (external library, with tablesort.d.ts declarations)\n\n## Type Definitions Added\n\n### Interfaces\n\n- `OpenAIChoice`, `OpenAIResponse` - OpenAI API responses\n- `OllamaModel`, `OllamaTagsResponse`, `OllamaMessage`, `OllamaResponse` - Ollama API\n- `AnthropicResponse`, `OpenAIStyleResponse` - Amazon Bedrock responses\n- `AzureOpenAIChoice`, `AzureOpenAIResponse` - Azure API responses\n- `LineProfile`, `FileProfile`, `ChartParams` - Profile data structures for Vega-Lite charts\n- `LineData`, `FunctionData`, `FileData`, `Profile` - Main profile data types\n- `Column`, `TableParams`, `OptimizationParams` - GUI-specific types\n\n### DOM Element Types\n\nAll DOM element access uses proper type assertions:\n```typescript\nconst element = document.getElementById(\"my-id\") as HTMLInputElement | null;\n```\n\n## Dependencies\n\n```json\n{\n \"devDependencies\": {\n \"@types/node\": \"^20.10.0\",\n \"@types/prismjs\": \"^1.26.0\",\n \"esbuild\": \"^0.24.0\",\n \"typescript\": \"^5.3.3\"\n },\n \"dependencies\": {\n \"@aws-sdk/client-bedrock-runtime\": \"^3.729.0\",\n \"buffer\": \"^6.0.3\",\n \"vega\": \"^5.30.0\",\n \"vega-embed\": \"^6.28.0\",\n \"vega-lite\": \"^5.21.0\"\n }\n}\n```\n\n## Build Steps\n\n1. Install dependencies: `npm install`\n2. Type check: `npm run typecheck`\n3. Build bundle: `npm run build`\n4. Development build (unminified): `npm run build:dev`\n5. Watch mode: `npm run watch`\n\n## Notes\n\n- Using `strictNullChecks: true` for better null safety\n- All external API responses have explicit interface definitions\n- DOM element access uses null-safe patterns with optional chaining\n- External JS libraries (`prism.js`, `tablesort.js`) kept as-is with `.d.ts` declaration files\n- Window functions exposed globally for HTML onclick handlers\n- Build produces ~1.1MB minified bundle with source maps\n\n## Migration Complete\n\nAll JavaScript files have been successfully converted to TypeScript. The original `.js` files can be removed once the TypeScript version is verified in production.\n"
},
{
"path": "scalene/scalene-gui/amazon.ts",
"content": "import {\n BedrockRuntimeClient,\n InvokeModelCommand,\n} from \"@aws-sdk/client-bedrock-runtime\";\n\ninterface AnthropicResponse {\n content: Array<{ text: string }>;\n}\n\ninterface OpenAIStyleResponse {\n choices: Array<{\n message: {\n content: string;\n };\n }>;\n}\n\nexport async function sendPromptToAmazon(prompt: string): Promise {\n const accessKeyIdElement = document.getElementById(\"aws-access-key\") as HTMLInputElement | null;\n const secretAccessKeyElement = document.getElementById(\"aws-secret-key\") as HTMLInputElement | null;\n const regionElement = document.getElementById(\"aws-region\") as HTMLInputElement | null;\n\n const accessKeyId =\n accessKeyIdElement?.value ||\n localStorage.getItem(\"aws-access-key\") ||\n \"\";\n const secretAccessKey =\n secretAccessKeyElement?.value ||\n localStorage.getItem(\"aws-secret-key\") ||\n \"\";\n const region =\n regionElement?.value ||\n localStorage.getItem(\"aws-region\") ||\n \"us-east-1\";\n\n // Configure AWS Credentials\n const credentials = {\n accessKeyId: accessKeyId,\n secretAccessKey: secretAccessKey,\n };\n\n // Initialize the Bedrock Runtime Client\n const client = new BedrockRuntimeClient({\n region: region,\n credentials: credentials,\n });\n\n let body: Record = {};\n const max_tokens = 65536; // arbitrary large number\n\n const modelElement = document.getElementById(\"language-model-amazon\") as HTMLSelectElement | null;\n const modelId = modelElement?.value ?? \"\";\n\n if (modelId.startsWith(\"us.anthropic\")) {\n body = {\n anthropic_version: \"bedrock-2023-05-31\",\n max_tokens: max_tokens,\n messages: [\n {\n role: \"user\",\n content: [\n {\n type: \"text\",\n text: prompt,\n },\n ],\n },\n ],\n };\n } else {\n body = {\n max_completion_tokens: max_tokens,\n messages: [\n {\n role: \"user\",\n content: [\n {\n type: \"text\",\n text: prompt,\n },\n ],\n },\n ],\n };\n }\n\n const params = {\n modelId: modelId,\n body: JSON.stringify(body),\n };\n\n try {\n const command = new InvokeModelCommand(params);\n const response = await client.send(command);\n\n // Convert the response body to text\n const responseBlob = new Blob([response.body as BlobPart]);\n const responseText = await responseBlob.text();\n const parsedResponse = JSON.parse(responseText);\n console.log(\"parsedResponse = \" + responseText);\n\n if (modelId.startsWith(\"us.anthropic\")) {\n const anthropicResponse = parsedResponse as AnthropicResponse;\n const responseContents = anthropicResponse.content[0].text;\n return responseContents.trim();\n } else {\n const openaiResponse = parsedResponse as OpenAIStyleResponse;\n const responseContents = openaiResponse.choices[0].message.content.replace(\n /[\\s\\S]*?<\\/reasoning>/g,\n \"\"\n );\n return responseContents.trim();\n }\n } catch (err) {\n const error = err as Error;\n console.error(err);\n return `# Error: ${error.message}`;\n }\n}\n"
},
{
"path": "scalene/scalene-gui/anthropic.ts",
"content": "interface AnthropicErrorResponse {\n error?: {\n type?: string;\n message?: string;\n };\n}\n\ninterface AnthropicContentBlock {\n type: string;\n text: string;\n}\n\ninterface AnthropicResponse extends AnthropicErrorResponse {\n content?: AnthropicContentBlock[];\n}\n\nexport async function sendPromptToAnthropic(\n prompt: string,\n apiKey: string\n): Promise {\n // Check for custom URL override (for Anthropic-compatible servers)\n const customUrlElement = document.getElementById(\"anthropic-custom-url\") as HTMLInputElement | null;\n const customUrl = customUrlElement?.value?.trim() || \"\";\n const endpoint = customUrl || \"https://api.anthropic.com/v1/messages\";\n\n // Check for custom model override\n const customModelElement = document.getElementById(\"anthropic-custom-model\") as HTMLInputElement | null;\n const customModel = customModelElement?.value?.trim() || \"\";\n const modelElement = document.getElementById(\"language-model-anthropic\") as HTMLSelectElement | null;\n const model = customModel || modelElement?.value || \"claude-sonnet-4-5-20250929\";\n\n const body = JSON.stringify({\n model: model,\n max_tokens: 4096,\n messages: [\n {\n role: \"user\",\n content: prompt,\n },\n ],\n system:\n \"You are a Python programming assistant who ONLY responds with blocks of commented, optimized code. You never respond with text. Just code, starting with ``` and ending with ```.\",\n });\n\n console.log(body);\n\n const response = await fetch(endpoint, {\n method: \"POST\",\n headers: {\n \"Content-Type\": \"application/json\",\n \"x-api-key\": apiKey,\n \"anthropic-version\": \"2023-06-01\",\n \"anthropic-dangerous-direct-browser-access\": \"true\",\n },\n body: body,\n });\n\n const data: AnthropicResponse = await response.json();\n if (data.error) {\n console.error(\"Anthropic API error:\", data.error);\n if (data.error.type === \"authentication_error\") {\n alert(\"Invalid Anthropic API key. Please check your API key and try again.\");\n } else if (data.error.type === \"rate_limit_error\") {\n alert(\"Rate limit exceeded. Please wait a moment and try again.\");\n } else {\n alert(`Anthropic API error: ${data.error.message || \"Unknown error\"}`);\n }\n return \"\";\n }\n\n try {\n if (data.content && data.content[0]) {\n console.log(\n `Debugging info: Retrieved ${JSON.stringify(data.content[0], null, 4)}`\n );\n return data.content[0].text.replace(/^\\s*[\\r\\n]/gm, \"\");\n }\n return \"# Query failed. See JavaScript console (in Chrome: View > Developer > JavaScript Console) for more info.\\n\";\n } catch {\n return \"# Query failed. See JavaScript console (in Chrome: View > Developer > JavaScript Console) for more info.\\n\";\n }\n}\n"
},
{
"path": "scalene/scalene-gui/azure.ts",
"content": "interface AzureOpenAIChoice {\n message: {\n content: string;\n };\n}\n\ninterface AzureOpenAIResponse {\n error?: {\n code?: string;\n };\n choices?: AzureOpenAIChoice[];\n}\n\nexport async function sendPromptToAzureOpenAI(\n prompt: string,\n apiKey: string,\n apiUrl: string,\n aiModel: string\n): Promise {\n const apiVersionElement = document.getElementById(\"azure-api-version\") as HTMLInputElement | null;\n const apiVersion = apiVersionElement?.value ?? \"2024-02-15-preview\";\n const endpoint = `${apiUrl}/openai/deployments/${aiModel}/chat/completions?api-version=${apiVersion}`;\n\n const body = JSON.stringify({\n messages: [\n {\n role: \"system\",\n content:\n \"You are a Python programming assistant who ONLY responds with blocks of commented, optimized code. You never respond with text. Just code, starting with ``` and ending with ```.\",\n },\n {\n role: \"user\",\n content: prompt,\n },\n ],\n user: \"scalene-user\",\n });\n\n console.log(body);\n\n const response = await fetch(endpoint, {\n method: \"POST\",\n headers: {\n \"Content-Type\": \"application/json\",\n \"api-key\": apiKey,\n },\n body: body,\n });\n\n const data: AzureOpenAIResponse = await response.json();\n if (data.error) {\n if (\n data.error.code &&\n data.error.code in {\n invalid_request_error: true,\n model_not_found: true,\n insufficient_quota: true,\n }\n ) {\n return \"\";\n }\n }\n try {\n if (data.choices && data.choices[0]) {\n console.log(\n `Debugging info: Retrieved ${JSON.stringify(data.choices[0], null, 4)}`\n );\n }\n } catch {\n console.log(\n `Debugging info: Failed to retrieve data.choices from the server. data = ${JSON.stringify(data)}`\n );\n }\n\n try {\n if (data.choices && data.choices[0]) {\n return data.choices[0].message.content.replace(/^\\s*[\\r\\n]/gm, \"\");\n }\n return \"# Query failed. See JavaScript console (in Chrome: View > Developer > JavaScript Console) for more info.\\n\";\n } catch {\n return \"# Query failed. See JavaScript console (in Chrome: View > Developer > JavaScript Console) for more info.\\n\";\n }\n}\n"
},
{
"path": "scalene/scalene-gui/example-profile.js",
"content": "const example_profile = {\n elapsed_time_sec: 12.696948051452637,\n memory: true,\n files: {\n \"./test/testme.py\": {\n imports: [],\n functions: [\n {\n line: \"doit1\",\n lineno: 8,\n memory_samples: [\n [428532500, 9.570051193237305],\n [445064208, 11.226824760437012],\n [467929458, 9.749224662780762],\n [467933333, 7.894305229187012],\n [651147208, 9.467050552368164],\n [661861583, 11.117934226989746],\n [668149041, 9.640334129333496],\n [668150333, 7.785323143005371],\n [810188791, 9.357297897338867],\n [819091291, 11.008158683776855],\n [827225333, 9.530558586120605],\n [827227250, 7.6755781173706055],\n [964097833, 9.248224258422852],\n [973085041, 10.89908504486084],\n [981253250, 9.42148494720459],\n [981254500, 7.56650447845459],\n [1113670791, 9.138654708862305],\n [1126232208, 10.789484977722168],\n [1140849791, 9.311884880065918],\n [1140851041, 7.456873893737793],\n [1267816125, 9.028757095336914],\n [1278337458, 10.679617881774902],\n [1294287916, 9.202017784118652],\n [1294289166, 7.347006797790527],\n [1424228291, 8.919004440307617],\n [1433313750, 10.569865226745605],\n [1441482708, 9.092265129089355],\n [1441483875, 7.2372541427612305],\n [1576166708, 8.809465408325195],\n [1586517375, 10.460295677185059],\n [1594678416, 8.982695579528809],\n [1594679583, 7.127715110778809],\n [1730114333, 8.699773788452148],\n [1739212375, 10.350634574890137],\n [1747344291, 8.873034477233887],\n [1747345666, 7.018054008483887],\n [1883137000, 8.589975357055664],\n [1898345333, 10.240836143493652],\n [1898347625, 8.763236045837402],\n [1898349000, 6.908255577087402],\n [2042904500, 8.480405807495117],\n [2042907958, 10.037023544311523],\n [2053159625, 8.653666496276855],\n [2053160916, 6.7986555099487305],\n [2196880416, 8.370790481567383],\n [2196883625, 9.927408218383789],\n [2204029583, 8.544051170349121],\n [2204030875, 6.689040184020996],\n [2338301750, 8.261251449584961],\n [2352917083, 9.912020683288574],\n [2359497791, 8.434420585632324],\n [2359499000, 6.579440116882324],\n [2501090625, 8.151735305786133],\n [2510295291, 9.802596092224121],\n [2519173666, 8.324995994567871],\n [2519174875, 6.470015525817871],\n [2651119791, 8.042112350463867],\n [2663691041, 9.69294261932373],\n [2672632583, 8.21534252166748],\n [2672633833, 6.3603315353393555],\n [2808274125, 7.932390213012695],\n [2817241083, 9.583250999450684],\n [2825362500, 8.105650901794434],\n [2825363708, 6.250670433044434],\n [2967276500, 7.823369979858398],\n [2967280416, 9.379987716674805],\n [2976146916, 7.996630668640137],\n [2976148208, 6.141619682312012],\n [3109490458, 7.713602066040039],\n [3122068833, 9.364432334899902],\n [3130361916, 7.886832237243652],\n [3130363083, 6.031821250915527],\n [3265027166, 7.603918075561523],\n [3271320291, 9.254679679870605],\n [3282568291, 7.7770795822143555],\n [3282569458, 5.9220991134643555],\n [3422217791, 7.494386672973633],\n [3437609416, 9.145247459411621],\n [3437611583, 7.667647361755371],\n [3437613041, 5.812666893005371],\n [3575513458, 7.384756088256836],\n [3584540708, 9.035616874694824],\n [3592703166, 7.558016777038574],\n [3592704333, 5.703036308288574],\n [3723742875, 7.275102615356445],\n [3734449208, 8.925963401794434],\n [3745659166, 7.448363304138184],\n [3745660250, 5.593352317810059],\n [3881893166, 7.165685653686523],\n [3897173333, 8.816546440124512],\n [3897175416, 7.338946342468262],\n [3897176666, 5.483965873718262],\n [4034441041, 7.056039810180664],\n [4050005958, 8.706870079040527],\n [4050007583, 7.229269981384277],\n [4050008958, 5.374289512634277],\n [4184483375, 6.946355819702148],\n [4197052708, 8.59711742401123],\n [4205576916, 7.1195173263549805],\n [4205578166, 5.2645063400268555],\n [4347725000, 6.836626052856445],\n [4347728041, 8.393243789672852],\n [4358553500, 7.009886741638184],\n [4358554583, 5.154875755310059],\n [4492837750, 6.727071762084961],\n [4502908041, 8.377902030944824],\n [4511011375, 6.900301933288574],\n [4511012541, 5.045321464538574],\n [4646531000, 6.617380142211914],\n [4661992208, 8.268240928649902],\n [4661994166, 6.790640830993652],\n [4661995500, 4.935660362243652],\n [4805872333, 6.50782585144043],\n [4805875458, 8.064443588256836],\n [4816663458, 6.681086540222168],\n [4816664916, 4.826075553894043],\n [4954285750, 6.398340225219727],\n [4963335000, 8.049201011657715],\n [4971800083, 6.571600914001465],\n [4971801291, 4.716620445251465],\n [5108196500, 6.288686752319336],\n [5123296458, 7.939547538757324],\n [5123298416, 6.461947441101074],\n [5123299708, 4.606966972351074],\n [5261455875, 6.179033279418945],\n [5270583000, 7.829894065856934],\n [5278670500, 6.352293968200684],\n [5278671833, 4.497313499450684],\n [5413466541, 6.069440841674805],\n [5423099541, 7.720301628112793],\n [5430323333, 6.242701530456543],\n [5430324625, 4.387721061706543],\n [5565807583, 5.959833145141602],\n [5575698250, 7.61063289642334],\n [5582189041, 6.13303279876709],\n [5582190291, 4.27805233001709],\n [5713625000, 5.850225448608398],\n [5726142000, 7.501086235046387],\n [5732466750, 6.023486137390137],\n [5732468041, 4.168475151062012],\n [5872050708, 5.741365432739258],\n [5881280666, 7.392195701599121],\n [5889371000, 5.914595603942871],\n [5889372208, 4.059615135192871],\n [6023858541, 5.631811141967773],\n [6033953416, 7.282641410827637],\n [6042215291, 5.805041313171387],\n [6042216500, 3.9500608444213867],\n [6176588416, 5.522188186645508],\n [6182908666, 7.173018455505371],\n [6201797875, 5.695418357849121],\n [6201799041, 3.840407371520996],\n [6331915791, 5.412542343139648],\n [6348609666, 7.063403129577637],\n [6348611833, 5.585803031921387],\n [6348613125, 3.7308225631713867],\n [6484444250, 5.302881240844727],\n [6496964458, 6.953742027282715],\n [6506744041, 5.476141929626465],\n [6506745250, 3.62113094329834],\n [6638721125, 5.193334579467773],\n [6651084000, 6.844195365905762],\n [6659817208, 5.366595268249512],\n [6659818375, 3.5115842819213867],\n [6788692208, 5.083703994750977],\n [6803875291, 6.73453426361084],\n [6811955708, 5.25693416595459],\n [6811956916, 3.401923179626465],\n [6942827708, 4.974020004272461],\n [6953656666, 6.624880790710449],\n [6959926041, 5.147280693054199],\n [6959927375, 3.292269706726074],\n [7096960208, 4.864442825317383],\n [7109526708, 6.515303611755371],\n [7124614083, 5.037703514099121],\n [7124615250, 3.182692527770996],\n [7254360708, 4.754880905151367],\n [7263431791, 6.4057416915893555],\n [7271670041, 4.9281415939331055],\n [7271671208, 3.0731611251831055],\n [7408255583, 4.645288467407227],\n [7417207291, 6.296149253845215],\n [7425292250, 4.818549156188965],\n [7425293541, 2.963568687438965],\n [7557260708, 4.535665512084961],\n [7569857958, 6.186495780944824],\n [7585415291, 4.708895683288574],\n [7585416416, 2.853884696960449],\n [7714997916, 4.42607307434082],\n [7730199916, 6.076933860778809],\n [7730201708, 4.599333763122559],\n [7730202916, 2.7443532943725586],\n [7866120000, 4.316427230834961],\n [7875908250, 5.967257499694824],\n [7890269833, 4.489657402038574],\n [7890271041, 2.634676933288574],\n [8013597291, 4.206743240356445],\n [8026055708, 5.857604026794434],\n [8032387416, 4.380003929138184],\n [8032388666, 2.5249929428100586],\n [8170270500, 4.097265243530273],\n [8180642250, 5.748095512390137],\n [8188875500, 4.270495414733887],\n [8188876625, 2.4155149459838867],\n [8320641916, 3.9876651763916016],\n [8332800958, 5.63852596282959],\n [8342211291, 4.16092586517334],\n [8342212500, 2.305914878845215],\n [8473975291, 3.8780956268310547],\n [8484424833, 5.528956413269043],\n [8495070500, 4.051356315612793],\n [8495071750, 2.196345329284668],\n [8626539708, 3.7685108184814453],\n [8636981708, 5.419371604919434],\n [8643245333, 3.9417715072631836],\n [8643246500, 2.0867605209350586],\n [8783219791, 3.6589794158935547],\n [8792149541, 5.309840202331543],\n [8800236916, 3.832240104675293],\n [8800238125, 1.977259635925293],\n [8935519958, 3.5494556427001953],\n [8950778666, 5.200316429138184],\n [8950780791, 3.7227163314819336],\n [8950782333, 1.8677358627319336],\n [9087624208, 3.439970016479492],\n [9096657916, 5.0908308029174805],\n [9104695375, 3.6132307052612305],\n [9104696583, 1.7588300704956055],\n [9238711333, 3.331697463989258],\n [9249853541, 4.982527732849121],\n [9258138375, 3.504927635192871],\n [9258139541, 1.649947166442871],\n [9393347833, 3.2223033905029297],\n [9409346291, 4.873133659362793],\n [9409348208, 3.395533561706543],\n [9409349583, 1.540553092956543],\n [9542842958, 3.1133060455322266],\n [9556594875, 4.76413631439209],\n [9564736583, 3.28653621673584],\n [9564737708, 1.4315252304077148],\n [9700385875, 3.0036983489990234],\n [9709378000, 4.654559135437012],\n [9717558041, 3.1769590377807617],\n [9717559333, 1.3219785690307617],\n [9849538500, 2.894113540649414],\n [9860017000, 4.544974327087402],\n [9877549916, 3.0673742294311523],\n [9877551125, 1.2123632431030273],\n [10003729750, 2.784605026245117],\n [10015718125, 4.4354658126831055],\n [10022006791, 2.9578657150268555],\n [10022007916, 1.1028547286987305],\n [10166653041, 2.675233840942383],\n [10166656458, 4.231851577758789],\n [10176171416, 2.848494529724121],\n [10176172583, 0.9934835433959961],\n [10309492333, 2.5655269622802734],\n [10322073083, 4.216357231140137],\n [10343426708, 2.7387571334838867],\n [10343427916, 0.8837461471557617],\n [10463716625, 2.455934524536133],\n [10475263291, 4.106764793395996],\n [10483376500, 2.629164695739746],\n [10483377708, 0.7741842269897461],\n [10613975750, 2.346220016479492],\n [10627739125, 3.9970502853393555],\n [10635846250, 2.5194501876831055],\n [10635847375, 0.6644392013549805],\n [10767835750, 2.236543655395508],\n [10779923500, 3.887373924255371],\n [10788059083, 2.409773826599121],\n [10788060250, 0.5547933578491211],\n [10926140750, 2.1269893646240234],\n [10935088083, 3.7778501510620117],\n [10943147250, 2.3002500534057617],\n [10943148708, 0.4452695846557617],\n [11075597208, 2.017404556274414],\n [11088158916, 3.6682348251342773],\n [11096836916, 2.1906347274780273],\n [11096838208, 0.33562374114990234],\n [11232944875, 1.9078807830810547],\n [11242620916, 3.558711051940918],\n [11257050708, 2.081110954284668],\n [11257052000, 0.22613048553466797],\n [11384783666, 1.7982349395751953],\n [11391132458, 3.4490652084350586],\n [11397366583, 1.9714651107788086],\n [11397367833, 0.1164541244506836],\n [11573774375, 1.6887569427490234],\n [11582847833, 3.3396177291870117],\n [11591304416, 1.8620176315307617],\n [11591305625, 0.007037162780761719],\n [11737134291, 1.6248445510864258],\n [11737137708, 3.181462287902832],\n [11747075916, 1.798105239868164],\n [11747077208, -0.05690574645996094],\n [11882963625, 1.6248445510864258],\n [11893308541, 3.275705337524414],\n [11907866833, 1.798105239868164],\n [11907868125, -0.05690574645996094],\n [12037364666, 1.6248979568481445],\n [12046407333, 3.275758743286133],\n [12054504875, 1.7981586456298828],\n [12054505958, -0.05682182312011719],\n [12184473750, 1.6248140335083008],\n [12196997083, 3.275674819946289],\n [12203330375, 1.798074722290039],\n [12203331625, -0.05693626403808594],\n [12343375875, 1.6248292922973633],\n [12353697041, 3.2756900787353516],\n [12366382375, 1.7980899810791016],\n [12366383625, -0.05689048767089844],\n [12501165625, 1.6248598098754883],\n [12519042541, 3.2756900787353516],\n [12519044416, 1.7980899810791016],\n [12519045666, -0.05689048767089844],\n [12651156250, 1.6247835159301758],\n [12663171666, 3.275644302368164],\n [12669437708, 1.798044204711914],\n [12669438958, -0.05696678161621094],\n [12815936958, 1.6249208450317383],\n [12815939958, 3.1815385818481445],\n [12826641666, 1.7981815338134766],\n [12826643083, -0.05682945251464844],\n [467950083, 9.424517631530762],\n [480011041, 11.200347900390625],\n [501608208, 13.148506164550781],\n [534547000, 15.418411254882812],\n [555500041, 13.940811157226562],\n [555501500, 12.463211059570312],\n [555502500, 10.985610961914062],\n [555503458, 9.508010864257812],\n [555504583, 7.8679351806640625],\n [668153375, 9.315535545349121],\n [682672875, 11.09133529663086],\n [693283000, 13.03952407836914],\n [705307875, 15.309368133544922],\n [716903083, 13.831768035888672],\n [716904500, 12.354167938232422],\n [716905416, 10.876567840576172],\n [716906291, 9.398967742919922],\n [716907375, 7.758892059326172],\n [827231583, 9.205790519714355],\n [834454208, 10.982154846191406],\n [846991333, 12.930343627929688],\n [859534666, 15.200157165527344],\n [870443625, 13.722557067871094],\n [870444791, 12.244956970214844],\n [870445708, 10.767356872558594],\n [870446708, 9.289756774902344],\n [870447666, 7.649681091308594],\n [981257666, 9.09671688079834],\n [988426000, 10.872547149658203],\n [998615708, 12.820735931396484],\n [1013968958, 15.09054946899414],\n [1025432666, 13.61294937133789],\n [1025433833, 12.13534927368164],\n [1025434833, 10.65774917602539],\n [1025435791, 9.18014907836914],\n [1025436791, 7.540073394775391],\n [1140854333, 8.987086296081543],\n [1140856500, 10.668673515319824],\n [1154928250, 12.711074829101562],\n [1167686333, 14.980918884277344],\n [1184549000, 13.503318786621094],\n [1184550416, 12.025718688964844],\n [1184551458, 10.548118591308594],\n [1184552458, 9.070518493652344],\n [1184553458, 7.430442810058594],\n [1294292791, 8.877219200134277],\n [1294294875, 10.558806419372559],\n [1315191416, 12.601146697998047],\n [1315193375, 14.870990753173828],\n [1326181208, 13.393390655517578],\n [1326182500, 11.915790557861328],\n [1326183625, 10.438190460205078],\n [1326184458, 8.960590362548828],\n [1326185583, 7.320484161376953],\n [1441486833, 8.76746654510498],\n [1451792333, 10.543296813964844],\n [1462320958, 12.491485595703125],\n [1474265541, 14.761329650878906],\n [1485631291, 13.283729553222656],\n [1485632291, 11.806129455566406],\n [1485633291, 10.328529357910156],\n [1485634291, 8.850929260253906],\n [1485635291, 7.210853576660156],\n [1594682500, 8.657927513122559],\n [1604963750, 10.433757781982422],\n [1615432250, 12.381877899169922],\n [1621695125, 14.651721954345703],\n [1634493000, 13.174121856689453],\n [1634494125, 11.696521759033203],\n [1634495083, 10.218921661376953],\n [1634496041, 8.741321563720703],\n [1634497041, 7.101245880126953],\n [1747348541, 8.548266410827637],\n [1755371166, 10.324043273925781],\n [1767914291, 12.272201538085938],\n [1780037375, 14.542015075683594],\n [1791382833, 13.064414978027344],\n [1791385000, 11.586814880371094],\n [1791385958, 10.109214782714844],\n [1791386875, 8.631614685058594],\n [1791387875, 6.991539001464844],\n [1898352000, 8.438437461853027],\n [1906989791, 10.21426773071289],\n [1921336458, 12.162425994873047],\n [1930364750, 14.432270050048828],\n [1945026333, 12.954669952392578],\n [1945027666, 11.477069854736328],\n [1945028583, 9.999469757080078],\n [1945029458, 8.521869659423828],\n [1945030375, 6.881763458251953],\n [2053164416, 8.32886791229248],\n [2064736083, 10.104667663574219],\n [2074923416, 12.0528564453125],\n [2081200625, 14.322647094726562],\n [2098845208, 12.845046997070312],\n [2098846416, 11.367446899414062],\n [2098847500, 9.889846801757812],\n [2098848500, 8.412246704101562],\n [2098849500, 6.7721710205078125],\n [2204033833, 8.219252586364746],\n [2215335958, 9.99508285522461],\n [2226162458, 11.94327163696289],\n [2238716250, 14.213115692138672],\n [2252120250, 12.735515594482422],\n [2252121333, 11.257915496826172],\n [2252122291, 9.780315399169922],\n [2252123208, 8.302715301513672],\n [2252124166, 6.662609100341797],\n [2359502083, 8.109652519226074],\n [2370129750, 9.885482788085938],\n [2376411791, 11.833641052246094],\n [2392833625, 14.103485107421875],\n [2405350166, 12.625885009765625],\n [2405351250, 11.148284912109375],\n [2405352208, 9.670684814453125],\n [2405353125, 8.193084716796875],\n [2405354125, 6.552978515625],\n [2519178875, 8.000227928161621],\n [2529543875, 9.776058197021484],\n [2540148041, 11.724246978759766],\n [2558420583, 13.994091033935547],\n [2558422291, 12.516490936279297],\n [2558423416, 11.038890838623047],\n [2558424500, 9.561290740966797],\n [2558425541, 8.083690643310547],\n [2558426625, 6.443614959716797],\n [2672636833, 7.8905439376831055],\n [2682918583, 9.666374206542969],\n [2693627750, 11.61456298828125],\n [2701119666, 13.884407043457031],\n [2716928416, 12.406806945800781],\n [2716929583, 10.929206848144531],\n [2716930500, 9.451606750488281],\n [2716931375, 7.974006652832031],\n [2716932291, 6.333900451660156],\n [2825367125, 7.780882835388184],\n [2832063750, 9.556713104248047],\n [2843282958, 11.504901885986328],\n [2858265166, 13.774715423583984],\n [2867822500, 12.297115325927734],\n [2867823750, 10.819515228271484],\n [2867824666, 9.341915130615234],\n [2867825583, 7.864315032958984],\n [2867826500, 6.224239349365234],\n [2976151416, 7.671832084655762],\n [2982453250, 9.4476318359375],\n [3005093375, 11.395790100097656],\n [3005095291, 13.665634155273438],\n [3034657708, 12.188034057617188],\n [3034659416, 10.710433959960938],\n [3034660333, 9.232833862304688],\n [3034661208, 7.7552337646484375],\n [3034662125, 6.1151275634765625],\n [3130366000, 7.562033653259277],\n [3147039333, 9.33786392211914],\n [3147041500, 11.286052703857422],\n [3157046125, 13.555866241455078],\n [3174617541, 12.078266143798828],\n [3174618583, 10.600666046142578],\n [3174619583, 9.123065948486328],\n [3174620458, 7.645465850830078],\n [3174621416, 6.005390167236328],\n [3282572791, 7.4523115158081055],\n [3293275416, 9.228141784667969],\n [3299548708, 11.176300048828125],\n [3315505500, 13.446144104003906],\n [3328157916, 11.968544006347656],\n [3328159291, 10.490943908691406],\n [3328160333, 9.013343811035156],\n [3328161333, 7.535743713378906],\n [3328162333, 5.895637512207031],\n [3437616291, 7.342848777770996],\n [3449239000, 9.11867904663086],\n [3459936166, 11.06686782836914],\n [3471865958, 13.336711883544922],\n [3483698333, 11.859111785888672],\n [3483699416, 10.381511688232422],\n [3483700375, 8.903911590576172],\n [3483701250, 7.426311492919922],\n [3483702208, 5.786205291748047],\n [3592707750, 7.233248710632324],\n [3599236458, 9.009078979492188],\n [3613642500, 10.957237243652344],\n [3620071666, 13.227081298828125],\n [3636928458, 11.749481201171875],\n [3636929625, 10.271881103515625],\n [3636930541, 8.794281005859375],\n [3636931416, 7.316680908203125],\n [3636932333, 5.67657470703125],\n [3745664583, 7.123595237731934],\n [3756017250, 8.899394989013672],\n [3766550750, 10.847583770751953],\n [3778435291, 13.117427825927734],\n [3790088583, 11.639827728271484],\n [3790089625, 10.162227630615234],\n [3790090583, 8.684627532958984],\n [3790091541, 7.207027435302734],\n [3790092458, 5.566951751708984],\n [3897179625, 7.014147758483887],\n [3915726791, 8.789947509765625],\n [3915728708, 10.738136291503906],\n [3931954708, 13.007949829101562],\n [3943414666, 11.530349731445312],\n [3943415833, 10.052749633789062],\n [3943416833, 8.575149536132812],\n [3943417791, 7.0975494384765625],\n [3943418750, 5.4574737548828125],\n [4050012166, 6.904471397399902],\n [4059490750, 8.680301666259766],\n [4072037458, 10.628459930419922],\n [4084401375, 12.898273468017578],\n [4095851958, 11.420673370361328],\n [4095853166, 9.943073272705078],\n [4095854125, 8.465473175048828],\n [4095855041, 6.987873077392578],\n [4095856000, 5.347797393798828],\n [4205582125, 6.7947187423706055],\n [4222331833, 8.570549011230469],\n [4222333833, 10.51873779296875],\n [4234443333, 12.788551330566406],\n [4244777291, 11.310951232910156],\n [4244778500, 9.833351135253906],\n [4244779416, 8.355751037597656],\n [4244780375, 6.878150939941406],\n [4244781333, 5.238075256347656],\n [4358557708, 6.685088157653809],\n [4365447958, 8.460918426513672],\n [4379415666, 10.409076690673828],\n [4388705500, 12.678852081298828],\n [4402726291, 11.201251983642578],\n [4402727541, 9.723651885986328],\n [4402728583, 8.246051788330078],\n [4402729500, 6.768451690673828],\n [4402731458, 5.128345489501953],\n [4511016083, 6.575533866882324],\n [4517762000, 8.351364135742188],\n [4531949708, 10.299522399902344],\n [4540447250, 12.569366455078125],\n [4555231333, 11.091766357421875],\n [4555232375, 9.614166259765625],\n [4555233291, 8.136566162109375],\n [4555234166, 6.658966064453125],\n [4555235083, 5.01885986328125],\n [4661999000, 6.465842247009277],\n [4672057916, 8.24167251586914],\n [4684632291, 10.189830780029297],\n [4702990625, 12.459644317626953],\n [4702992583, 10.982044219970703],\n [4702994083, 9.504444122314453],\n [4702995291, 8.026844024658203],\n [4702996500, 6.549243927001953],\n [4702997708, 4.909168243408203],\n [4816668083, 6.356287956237793],\n [4823797375, 8.132118225097656],\n [4836394625, 10.080276489257812],\n [4846976125, 12.350120544433594],\n [4860942375, 10.872520446777344],\n [4860943625, 9.394920349121094],\n [4860944625, 7.917320251464844],\n [4860945625, 6.439720153808594],\n [4860946625, 4.799613952636719],\n [4971805333, 6.246832847595215],\n [4980344583, 8.022663116455078],\n [4992514291, 9.97085189819336],\n [5005164791, 12.24069595336914],\n [5023308708, 10.76309585571289],\n [5023310750, 9.28549575805664],\n [5023312208, 7.807895660400391],\n [5023313541, 6.330295562744141],\n [5023314875, 4.690189361572266],\n [5123303583, 6.137148857116699],\n [5134428958, 7.9129791259765625],\n [5146181666, 9.861167907714844],\n [5157165708, 12.131011962890625],\n [5167807208, 10.653411865234375],\n [5167808375, 9.175811767578125],\n [5167809291, 7.698211669921875],\n [5167810166, 6.220611572265625],\n [5167811083, 4.580535888671875],\n [5278674916, 6.027525901794434],\n [5288734833, 7.803356170654297],\n [5299486333, 9.751514434814453],\n [5311409083, 12.021358489990234],\n [5322814041, 10.543758392333984],\n [5322815333, 9.066158294677734],\n [5322816250, 7.588558197021484],\n [5322817208, 6.110958099365234],\n [5322818250, 4.470882415771484],\n [5430328083, 5.917933464050293],\n [5441573958, 7.693733215332031],\n [5452078208, 9.641921997070312],\n [5470314583, 11.911766052246094],\n [5470316416, 10.434165954589844],\n [5470317708, 8.956565856933594],\n [5470318833, 7.478965759277344],\n [5470319958, 6.001365661621094],\n [5470321125, 4.361289978027344],\n [5582194000, 5.80826473236084],\n [5592824666, 7.584095001220703],\n [5604736458, 9.53225326538086],\n [5616646666, 11.80209732055664],\n [5628024000, 10.32449722290039],\n [5628025125, 8.84689712524414],\n [5628026208, 7.369297027587891],\n [5628027291, 5.891696929931641],\n [5628028375, 4.251621246337891],\n [5732471291, 5.698687553405762],\n [5746847625, 7.474540710449219],\n [5757285625, 9.4227294921875],\n [5763546125, 11.692573547363281],\n [5776178166, 10.214973449707031],\n [5776179291, 8.737373352050781],\n [5776180291, 7.259773254394531],\n [5776181208, 5.782173156738281],\n [5776182166, 4.142097473144531],\n [5889375500, 5.589827537536621],\n [5896965125, 7.365657806396484],\n [5909528000, 9.31381607055664],\n [5920176500, 11.583660125732422],\n [5932745458, 10.106060028076172],\n [5932746541, 8.628459930419922],\n [5932747583, 7.150859832763672],\n [5932748541, 5.673259735107422],\n [5932749541, 4.033153533935547],\n [6042220375, 5.480273246765137],\n [6052706708, 7.256103515625],\n [6059516583, 9.204292297363281],\n [6070229500, 11.474136352539062],\n [6082723750, 9.996536254882812],\n [6082724916, 8.518936157226562],\n [6082725916, 7.0413360595703125],\n [6082726791, 5.5637359619140625],\n [6082727708, 3.9236602783203125],\n [6201802458, 5.370619773864746],\n [6201804333, 7.052206993103027],\n [6216203875, 9.094608306884766],\n [6234602791, 11.364452362060547],\n [6234604625, 9.886852264404297],\n [6234605875, 8.409252166748047],\n [6234607041, 6.931652069091797],\n [6234608166, 5.454051971435547],\n [6234609375, 3.813976287841797],\n [6348616125, 5.261004447937012],\n [6366779208, 7.036834716796875],\n [6366781333, 8.985023498535156],\n [6390473000, 11.254837036132812],\n [6390474875, 9.777236938476562],\n [6390476041, 8.299636840820312],\n [6390477041, 6.8220367431640625],\n [6390478083, 5.3444366455078125],\n [6390479208, 3.7043609619140625],\n [6506749583, 5.15134334564209],\n [6517145583, 6.927173614501953],\n [6527678208, 8.875362396240234],\n [6539907833, 11.145206451416016],\n [6551332375, 9.667606353759766],\n [6551333750, 8.190006256103516],\n [6551334708, 6.712406158447266],\n [6551335583, 5.234806060791016],\n [6551336583, 3.5947303771972656],\n [6659821750, 5.041796684265137],\n [6670074916, 6.817626953125],\n [6680510333, 8.765815734863281],\n [6688715083, 11.035659790039062],\n [6703736250, 9.558059692382812],\n [6703737291, 8.080459594726562],\n [6703738250, 6.6028594970703125],\n [6703739125, 5.1252593994140625],\n [6703740041, 3.4851531982421875],\n [6811960416, 4.932135581970215],\n [6822391916, 6.707965850830078],\n [6832958583, 8.65615463256836],\n [6851142875, 10.92599868774414],\n [6851144583, 9.44839859008789],\n [6851145875, 7.970798492431641],\n [6851147041, 6.493198394775391],\n [6851148208, 5.015598297119141],\n [6851149375, 3.3755226135253906],\n [6959931750, 4.822482109069824],\n [6981281541, 6.598335266113281],\n [6981283541, 8.546524047851562],\n [7003760208, 10.816337585449219],\n [7003762250, 9.338737487792969],\n [7003763541, 7.861137390136719],\n [7003764750, 6.383537292480469],\n [7003765875, 4.905937194824219],\n [7003767041, 3.2658615112304688],\n [7124618791, 4.712904930114746],\n [7124620708, 6.394492149353027],\n [7139070708, 8.436893463134766],\n [7151226625, 10.706737518310547],\n [7168924875, 9.229137420654297],\n [7168926000, 7.751537322998047],\n [7168926916, 6.273937225341797],\n [7168927833, 4.796337127685547],\n [7168928750, 3.156261444091797],\n [7271675208, 4.6033735275268555],\n [7280306708, 6.379203796386719],\n [7286626166, 8.327362060546875],\n [7303586708, 10.597206115722656],\n [7309867416, 9.119606018066406],\n [7309870541, 7.642005920410156],\n [7309871375, 6.164405822753906],\n [7309872166, 4.686805725097656],\n [7309873000, 3.0466995239257812],\n [7425296791, 4.493781089782715],\n [7432751708, 6.269611358642578],\n [7445323166, 8.217769622802734],\n [7453590500, 10.487613677978516],\n [7466128208, 9.010013580322266],\n [7466129333, 7.532413482666016],\n [7466130250, 6.054813385009766],\n [7466131125, 4.577213287353516],\n [7466132083, 2.9371376037597656],\n [7585419750, 4.384127616882324],\n [7585421583, 6.0656843185424805],\n [7600045291, 8.108085632324219],\n [7618278500, 10.3779296875],\n [7618280291, 8.90032958984375],\n [7618281541, 7.4227294921875],\n [7618282708, 5.94512939453125],\n [7618283833, 4.467529296875],\n [7618285000, 2.82745361328125],\n [7730206083, 4.274535179138184],\n [7739121833, 6.050365447998047],\n [7751067958, 7.998554229736328],\n [7763611625, 10.268367767333984],\n [7773978041, 8.790767669677734],\n [7773979083, 7.313167572021484],\n [7773980000, 5.835567474365234],\n [7773980916, 4.357967376708984],\n [7773981875, 2.7178916931152344],\n [7890274416, 4.164889335632324],\n [7890276458, 5.8464765548706055],\n [7899436500, 7.888877868652344],\n [7922984291, 10.15869140625],\n [7922986000, 8.68109130859375],\n [7922987125, 7.2034912109375],\n [7922988208, 5.72589111328125],\n [7922989333, 4.248291015625],\n [7922990458, 2.60821533203125],\n [8032392083, 4.055205345153809],\n [8052683250, 5.831058502197266],\n [8052685166, 7.779247283935547],\n [8075218333, 10.049060821533203],\n [8075220166, 8.571460723876953],\n [8075221458, 7.093860626220703],\n [8075222666, 5.616260528564453],\n [8075223791, 4.138660430908203],\n [8075224958, 2.498584747314453],\n [8188880083, 3.9457273483276367],\n [8199114875, 5.7215576171875],\n [8206809333, 7.669746398925781],\n [8221570375, 9.939559936523438],\n [8228816583, 8.461959838867188],\n [8228817708, 6.9843597412109375],\n [8228818750, 5.5067596435546875],\n [8228821125, 4.0291595458984375],\n [8228822125, 2.3890838623046875],\n [8342216583, 3.83615779876709],\n [8352695375, 5.611957550048828],\n [8363300708, 7.560146331787109],\n [8375225958, 9.82999038696289],\n [8392941833, 8.35239028930664],\n [8392943000, 6.874790191650391],\n [8392944166, 5.397190093994141],\n [8392945125, 3.9195899963378906],\n [8392946125, 2.2795143127441406],\n [8495075250, 3.726557731628418],\n [8505475458, 5.502388000488281],\n [8516066666, 7.4505767822265625],\n [8527981166, 9.720420837402344],\n [8539415500, 8.242820739746094],\n [8539416916, 6.765220642089844],\n [8539417916, 5.287620544433594],\n [8539418875, 3.8100204467773438],\n [8539419833, 2.1699447631835938],\n [8649702166, 3.7112159729003906],\n [8658581833, 5.392803192138672],\n [8669098541, 7.340991973876953],\n [8681025250, 9.610836029052734],\n [8692400875, 8.133235931396484],\n [8692402208, 6.655635833740234],\n [8692403208, 5.178035736083984],\n [8692404125, 3.7004356384277344],\n [8692405291, 2.0603599548339844],\n [8800241791, 3.507472038269043],\n [8809383500, 5.283302307128906],\n [8815657666, 7.2314605712890625],\n [8839327000, 9.501304626464844],\n [8839328875, 8.023704528808594],\n [8839329958, 6.546104431152344],\n [8839331000, 5.068504333496094],\n [8839332041, 3.5909042358398438],\n [8839333125, 1.9508285522460938],\n [8950785458, 3.3979177474975586],\n [8959493416, 5.173748016357422],\n [8973360375, 7.121906280517578],\n [8980815625, 9.39175033569336],\n [8996633041, 7.914150238037109],\n [8996634291, 6.436550140380859],\n [8996635333, 4.958950042724609],\n [8996636291, 3.4813499450683594],\n [8996637333, 1.8412437438964844],\n [9104700125, 3.2890424728393555],\n [9113232875, 5.065467834472656],\n [9119527750, 7.0136260986328125],\n [9134379083, 9.283470153808594],\n [9144595250, 7.805870056152344],\n [9144596541, 6.328269958496094],\n [9144597541, 4.850669860839844],\n [9144598541, 3.3730697631835938],\n [9144599583, 1.7329940795898438],\n [9258142833, 3.180159568786621],\n [9268505250, 4.955989837646484],\n [9276182666, 6.904178619384766],\n [9291074458, 9.173992156982422],\n [9302424541, 7.696392059326172],\n [9302425875, 6.218791961669922],\n [9302426833, 4.741191864013672],\n [9302427750, 3.263591766357422],\n [9302429291, 1.6234855651855469],\n [9409353000, 3.070734977722168],\n [9416169750, 4.847198486328125],\n [9432215166, 6.795356750488281],\n [9444124708, 9.065200805664062],\n [9455917708, 7.5876007080078125],\n [9455918833, 6.1100006103515625],\n [9455919791, 4.6324005126953125],\n [9455920708, 3.1548004150390625],\n [9455921666, 1.5147247314453125],\n [9564740958, 2.96176815032959],\n [9575088750, 4.737567901611328],\n [9585687458, 6.685756683349609],\n [9597607791, 8.95560073852539],\n [9609052458, 7.478000640869141],\n [9609053708, 6.000400543212891],\n [9609054833, 4.522800445556641],\n [9609055833, 3.0452003479003906],\n [9609056833, 1.4051246643066406],\n [9717562416, 2.8521909713745117],\n [9726166083, 4.628021240234375],\n [9732440250, 6.576179504394531],\n [9749529833, 8.846023559570312],\n [9755954916, 7.3684234619140625],\n [9755956166, 5.8908233642578125],\n [9755957083, 4.4132232666015625],\n [9755957916, 2.9356231689453125],\n [9755958833, 1.2955169677734375],\n [9877554291, 2.7426061630249023],\n [9877556125, 4.424162864685059],\n [9898585458, 6.466564178466797],\n [9898587625, 8.736408233642578],\n [9909523750, 7.258808135986328],\n [9909524916, 5.781208038330078],\n [9909525791, 4.303607940673828],\n [9909526541, 2.826007843017578],\n [9909527375, 1.1859016418457031],\n [10022011125, 2.6330671310424805],\n [10034561666, 4.408866882324219],\n [10051395250, 6.3570556640625],\n [10051397250, 8.626899719238281],\n [10068887916, 7.149299621582031],\n [10068889166, 5.671699523925781],\n [10068890208, 4.194099426269531],\n [10068891166, 2.7164993286132812],\n [10068892166, 1.0763931274414062],\n [10176176125, 2.523695945739746],\n [10187819000, 4.299495697021484],\n [10204757041, 6.247684478759766],\n [10204759166, 8.517528533935547],\n [10228388958, 7.039928436279297],\n [10228390458, 5.562328338623047],\n [10228391416, 4.084728240966797],\n [10228392333, 2.607128143310547],\n [10228393333, 0.9670219421386719],\n [10343431333, 2.4139585494995117],\n [10343433166, 4.095545768737793],\n [10351890000, 6.137947082519531],\n [10363845958, 8.407791137695312],\n [10375247083, 6.9301910400390625],\n [10375248166, 5.4525909423828125],\n [10375249291, 3.9749908447265625],\n [10375250166, 2.4973907470703125],\n [10375251208, 0.8573150634765625],\n [10483380708, 2.304396629333496],\n [10493674791, 4.080226898193359],\n [10501163750, 6.028415679931641],\n [10516118083, 8.298229217529297],\n [10527505583, 6.820629119873047],\n [10527506625, 5.343029022216797],\n [10527507541, 3.865428924560547],\n [10527508416, 2.387828826904297],\n [10527510541, 0.7477226257324219],\n [10635850375, 2.1946516036987305],\n [10646199125, 3.9704818725585938],\n [10656751875, 5.918670654296875],\n [10663705250, 8.188514709472656],\n [10679894000, 6.710914611816406],\n [10679895250, 5.233314514160156],\n [10679896333, 3.7557144165039062],\n [10679897291, 2.2781143188476562],\n [10679898291, 0.6380081176757812],\n [10788063583, 2.085005760192871],\n [10804907041, 3.8608360290527344],\n [10804909041, 5.809024810791016],\n [10816468125, 8.078838348388672],\n [10840273875, 6.601238250732422],\n [10840275083, 5.123638153076172],\n [10840276041, 3.646038055419922],\n [10840276958, 2.168437957763672],\n [10840277916, 0.5283622741699219],\n [10943152208, 1.9754819869995117],\n [10949585416, 3.751312255859375],\n [10961035541, 5.699501037597656],\n [10976165333, 7.9693145751953125],\n [10982958166, 6.4917144775390625],\n [10982959416, 5.0141143798828125],\n [10982960333, 3.5365142822265625],\n [10982961250, 2.0589141845703125],\n [10982962166, 0.4188385009765625],\n [11096841500, 1.8658361434936523],\n [11107369708, 3.6416664123535156],\n [11118517000, 5.589855194091797],\n [11130516500, 7.859699249267578],\n [11142093625, 6.382099151611328],\n [11142094750, 4.904499053955078],\n [11142095875, 3.426898956298828],\n [11142096875, 1.9492988586425781],\n [11142097833, 0.3092231750488281],\n [11257055291, 1.756342887878418],\n [11257057291, 3.437930107116699],\n [11266261333, 5.4803314208984375],\n [11283573625, 7.750144958496094],\n [11290272291, 6.272544860839844],\n [11290273625, 4.794944763183594],\n [11290274625, 3.3173446655273438],\n [11290275541, 1.8397445678710938],\n [11290276500, 0.19966888427734375],\n [11403672750, 1.7409095764160156],\n [11409931750, 3.422496795654297],\n [11425560125, 5.370685577392578],\n [11438276833, 7.640529632568359],\n [11459236583, 6.162929534912109],\n [11459240375, 4.685329437255859],\n [11459243583, 3.2077293395996094],\n [11459246625, 1.7301292419433594],\n [11459249958, 0.09005355834960938],\n [11591309458, 1.5372495651245117],\n [11602022208, 3.313079833984375],\n [11608272125, 5.261268615722656],\n [11622100375, 7.5311126708984375],\n [11637136625, 6.0535125732421875],\n [11637137916, 4.5759124755859375],\n [11637138875, 3.0983123779296875],\n [11637139750, 1.6207122802734375],\n [11637140708, -0.0193939208984375],\n [11747080875, 1.473306655883789],\n [11758417666, 3.3060121536254883],\n [11769115541, 5.2542009353637695],\n [11781375500, 7.524044990539551],\n [11793056791, 6.046444892883301],\n [11793058000, 4.568844795227051],\n [11793058958, 3.091244697570801],\n [11793059875, 1.6136445999145508],\n [11793060791, -0.02643108367919922],\n [11907871750, 1.473306655883789],\n [11907873708, 3.1548938751220703],\n [11916298041, 5.2542009353637695],\n [11934474833, 7.524044990539551],\n [11945984916, 6.046444892883301],\n [11945986041, 4.568844795227051],\n [11945987000, 3.091244697570801],\n [11945990166, 1.6136445999145508],\n [11945991125, -0.02643108367919922],\n [12054509666, 1.4733905792236328],\n [12063261375, 3.3060426712036133],\n [12074139125, 5.2542314529418945],\n [12084480875, 7.524075508117676],\n [12094924791, 6.046475410461426],\n [12094925958, 4.568875312805176],\n [12094926916, 3.091275215148926],\n [12094927791, 1.6136751174926758],\n [12094928708, -0.02640056610107422],\n [12203334708, 1.473276138305664],\n [12217599291, 3.306065559387207],\n [12229401583, 5.254254341125488],\n [12249113875, 7.5240983963012695],\n [12249115833, 6.0464982986450195],\n [12249116958, 4.5688982009887695],\n [12249117916, 3.0912981033325195],\n [12249118833, 1.6136980056762695],\n [12249119791, -0.02637767791748047],\n [12366387916, 1.4733219146728516],\n [12376687958, 3.3060426712036133],\n [12383011625, 5.2542009353637695],\n [12399670166, 7.524044990539551],\n [12412263083, 6.046444892883301],\n [12412264250, 4.568844795227051],\n [12412265250, 3.091244697570801],\n [12412266166, 1.6136445999145508],\n [12412267125, -0.02646160125732422],\n [12519048833, 1.4732913970947266],\n [12531295541, 3.3060121536254883],\n [12541782958, 5.2542009353637695],\n [12553649041, 7.524044990539551],\n [12565102500, 6.046444892883301],\n [12565103708, 4.568844795227051],\n [12565104750, 3.091244697570801],\n [12565105791, 1.6136445999145508],\n [12565106833, -0.02643108367919922],\n [12669442125, 1.473245620727539],\n [12683720416, 3.306065559387207],\n [12694433583, 5.254254341125488],\n [12712894375, 7.5240983963012695],\n [12712897125, 6.0464982986450195],\n [12712898291, 4.5688982009887695],\n [12712899375, 3.0912981033325195],\n [12712900416, 1.6136980056762695],\n [12712901541, -0.02637767791748047],\n [12826646458, 1.4733829498291016],\n [12833011458, 3.3060426712036133],\n [12843311041, 5.2542314529418945],\n [12859614458, 7.524044990539551],\n [12866377916, 6.046444892883301],\n [12866379125, 4.568844795227051],\n [12866380125, 3.091244697570801],\n [12866381125, 1.6136445999145508],\n [12866382208, -0.02643108367919922],\n [555511875, 9.390792846679688],\n [565001708, 11.16716480255127],\n [575258416, 13.11535358428955],\n [586841333, 15.385197639465332],\n [597092625, 17.341931343078613],\n [597095916, 15.779431343078613],\n [597098041, 18.5227632522583],\n [597099375, 16.7727632522583],\n [605396958, 19.86289691925049],\n [605398791, 17.89414691925049],\n [618511291, 21.3744478225708],\n [618513333, 19.1556978225708],\n [618514583, 17.678105354309082],\n [618515833, 16.200505256652832],\n [618516958, 14.722905158996582],\n [618518083, 13.245305061340332],\n [618519250, 11.767704963684082],\n [618520750, 7.842289924621582],\n [716911291, 9.281749725341797],\n [725632333, 11.057496070861816],\n [734916625, 13.005684852600098],\n [751884791, 15.27541446685791],\n [751886958, 17.23214817047119],\n [751888625, 15.669648170471191],\n [761087791, 18.412949562072754],\n [761089500, 16.662949562072754],\n [767328041, 19.753045082092285],\n [767329375, 17.784295082092285],\n [775905583, 21.264504432678223],\n [775907250, 19.045754432678223],\n [775908375, 17.568161964416504],\n [775909333, 16.090561866760254],\n [775915375, 14.612961769104004],\n [775916750, 13.135361671447754],\n [775917708, 11.657761573791504],\n [775918666, 7.732377052307129],\n [870451875, 9.172538757324219],\n [880999041, 10.948307991027832],\n [890439291, 12.896496772766113],\n [907388625, 15.166340827941895],\n [907390625, 17.123074531555176],\n [907392791, 15.560574531555176],\n [916867125, 18.30387592315674],\n [916868541, 16.55387592315674],\n [916870375, 19.643986701965332],\n [916871500, 17.675236701965332],\n [929537916, 21.15550708770752],\n [929540000, 18.93675708770752],\n [929541083, 17.4591646194458],\n [929542083, 15.98156452178955],\n [929543041, 14.5039644241333],\n [929544000, 13.02636432647705],\n [929544916, 11.5487642288208],\n [929546125, 7.623379707336426],\n [1025440625, 9.062931060791016],\n [1031966083, 10.838730812072754],\n [1043298000, 12.786919593811035],\n [1049550791, 15.056733131408691],\n [1064023458, 17.013436317443848],\n [1064026791, 15.450936317443848],\n [1064028833, 18.19429874420166],\n [1064030083, 16.44429874420166],\n [1076172333, 19.534432411193848],\n [1076173916, 17.565682411193848],\n [1083924625, 21.045952796936035],\n [1083927666, 18.827202796936035],\n [1083928625, 17.349610328674316],\n [1083929500, 15.872010231018066],\n [1083930416, 14.394410133361816],\n [1083931333, 12.916810035705566],\n [1083932250, 11.439209938049316],\n [1083933166, 7.513794898986816],\n [1184557500, 8.953300476074219],\n [1184559666, 10.634857177734375],\n [1195587500, 12.677258491516113],\n [1201858833, 14.94701099395752],\n [1217549500, 16.903592109680176],\n [1217552375, 15.341092109680176],\n [1217554541, 18.08445453643799],\n [1217555750, 16.33445453643799],\n [1236180458, 19.42455768585205],\n [1236182500, 17.45580768585205],\n [1236184333, 20.936108589172363],\n [1236185500, 18.717358589172363],\n [1236186500, 17.239766120910645],\n [1236187500, 15.762166023254395],\n [1236188583, 14.284565925598145],\n [1236189583, 12.806965827941895],\n [1236190583, 11.329365730285645],\n [1236191541, 7.4039201736450195],\n [1338627083, 8.93758487701416],\n [1338629291, 10.619111061096191],\n [1348636625, 12.567269325256348],\n [1361178541, 14.837082862854004],\n [1383309833, 16.79378604888916],\n [1383312250, 15.23128604888916],\n [1383314291, 17.974648475646973],\n [1383315458, 16.224648475646973],\n [1383317333, 19.31483554840088],\n [1383318458, 17.34608554840088],\n [1389642333, 20.826355934143066],\n [1389644583, 18.607605934143066],\n [1389645625, 17.130013465881348],\n [1389646583, 15.652413368225098],\n [1389647541, 14.174813270568848],\n [1389648500, 12.697213172912598],\n [1389649416, 11.219613075256348],\n [1389650458, 7.294228553771973],\n [1485638875, 8.733711242675781],\n [1500745250, 10.50951099395752],\n [1500747416, 12.4576997756958],\n [1509511291, 14.727513313293457],\n [1520752041, 16.68424701690674],\n [1520754125, 15.121747016906738],\n [1529887458, 17.865017890930176],\n [1529889000, 16.115017890930176],\n [1536118583, 19.20518207550049],\n [1536120000, 17.23643207550049],\n [1542874458, 20.7167329788208],\n [1542876333, 18.4979829788208],\n [1542877458, 17.020390510559082],\n [1542878458, 15.542790412902832],\n [1542879375, 14.065190315246582],\n [1542880333, 12.587590217590332],\n [1542881250, 11.109990119934082],\n [1542882250, 7.184575080871582],\n [1634500833, 8.624103546142578],\n [1647016583, 10.399903297424316],\n [1656918250, 12.348061561584473],\n [1667544250, 14.617905616760254],\n [1677042708, 16.574639320373535],\n [1677044458, 15.012139320373535],\n [1677046500, 17.755501747131348],\n [1677047708, 16.005501747131348],\n [1695595291, 19.09560489654541],\n [1695597000, 17.12685489654541],\n [1695598708, 20.607155799865723],\n [1695599708, 18.388405799865723],\n [1695600666, 16.910813331604004],\n [1695601583, 15.433213233947754],\n [1695602458, 13.955613136291504],\n [1695603375, 12.478013038635254],\n [1695604291, 11.000412940979004],\n [1695605250, 7.074967384338379],\n [1791391791, 8.514427185058594],\n [1806471458, 10.290196418762207],\n [1806473416, 12.238385200500488],\n [1815312500, 14.508198738098145],\n [1829626958, 16.4649019241333],\n [1829629166, 14.9024019241333],\n [1829631000, 17.64573383331299],\n [1829632208, 15.895733833312988],\n [1838273250, 18.985806465148926],\n [1838274750, 17.017056465148926],\n [1848706625, 20.49729633331299],\n [1848708666, 18.27854633331299],\n [1848709750, 16.80095386505127],\n [1848710666, 15.32335376739502],\n [1848711541, 13.84575366973877],\n [1848712500, 12.36815357208252],\n [1848713416, 10.89055347442627],\n [1848714375, 6.9651384353637695],\n [1945034541, 8.404621124267578],\n [1954097250, 10.180390357971191],\n [1963537916, 12.128579139709473],\n [1974254208, 14.398423194885254],\n [1983813833, 16.355156898498535],\n [1983816333, 14.792656898498535],\n [1983818375, 17.535988807678223],\n [1983819583, 15.785988807678223],\n [1992820583, 18.876229286193848],\n [1992821875, 16.907479286193848],\n [2003450958, 20.387749671936035],\n [2003453458, 18.168999671936035],\n [2003454708, 16.691407203674316],\n [2003455708, 15.213807106018066],\n [2003456666, 13.736207008361816],\n [2003457583, 12.258606910705566],\n [2003458500, 10.781006813049316],\n [2003459458, 6.855622291564941],\n [2098853583, 8.295028686523438],\n [2107703000, 10.070828437805176],\n [2117127875, 12.019017219543457],\n [2123391375, 14.288861274719238],\n [2137372666, 16.245564460754395],\n [2137374458, 14.683064460754395],\n [2137376375, 17.426396369934082],\n [2137377666, 15.676396369934082],\n [2144789750, 18.76653003692627],\n [2144791208, 16.79778003692627],\n [2156970875, 20.278050422668457],\n [2156972875, 18.059300422668457],\n [2156973958, 16.58170795440674],\n [2156974958, 15.104107856750488],\n [2156975875, 13.626507759094238],\n [2156976791, 12.148907661437988],\n [2156977750, 10.671307563781738],\n [2156978750, 6.745923042297363],\n [2252128250, 8.185497283935547],\n [2261111000, 9.96126651763916],\n [2270495416, 11.909455299377441],\n [2281010250, 14.179299354553223],\n [2288727875, 16.136033058166504],\n [2288729791, 14.573533058166504],\n [2296531666, 17.31686496734619],\n [2296533291, 15.566864967346191],\n [2296535458, 18.657029151916504],\n [2296536625, 16.688279151916504],\n [2316518875, 20.16854953765869],\n [2316520583, 17.94979953765869],\n [2316521625, 16.472207069396973],\n [2316522541, 14.994606971740723],\n [2316523458, 13.517006874084473],\n [2316524375, 12.039406776428223],\n [2316525291, 10.561806678771973],\n [2316526291, 6.636391639709473],\n [2405358041, 8.07586669921875],\n [2414186750, 9.851635932922363],\n [2423603500, 11.799824714660645],\n [2434183083, 14.069668769836426],\n [2443616916, 16.026402473449707],\n [2443619041, 14.463902473449707],\n [2443621208, 17.207234382629395],\n [2443622375, 15.457234382629395],\n [2451122625, 18.54747486114502],\n [2451123916, 16.57872486114502],\n [2463408833, 20.058995246887207],\n [2463411958, 17.840245246887207],\n [2463413041, 16.36265277862549],\n [2463414083, 14.885052680969238],\n [2463415083, 13.407452583312988],\n [2463416083, 11.929852485656738],\n [2463417083, 10.452252388000488],\n [2463420666, 6.526867866516113],\n [2558430208, 7.966442108154297],\n [2567834833, 9.742241859436035],\n [2581782250, 11.690400123596191],\n [2590380458, 13.960183143615723],\n [2596683583, 15.916886329650879],\n [2596686166, 14.354386329650879],\n [2608509958, 17.097771644592285],\n [2608511958, 15.347771644592285],\n [2608513916, 18.437935829162598],\n [2608515083, 16.469185829162598],\n [2628441916, 19.949456214904785],\n [2628443791, 17.730706214904785],\n [2628444875, 16.253113746643066],\n [2628445791, 14.775513648986816],\n [2628446708, 13.297913551330566],\n [2628447625, 11.820313453674316],\n [2628448500, 10.342713356018066],\n [2628449416, 6.417298316955566],\n [2716936291, 7.856758117675781],\n [2723704333, 9.63249683380127],\n [2729981750, 11.580655097961426],\n [2745614583, 13.850468635559082],\n [2761433333, 15.807202339172363],\n [2761437375, 14.244702339172363],\n [2761439458, 16.988064765930176],\n [2761440833, 15.238064765930176],\n [2761442791, 18.32816791534424],\n [2761443958, 16.35941791534424],\n [2773086416, 19.83971881866455],\n [2773088083, 17.62096881866455],\n [2773089208, 16.143376350402832],\n [2773090333, 14.665776252746582],\n [2773091416, 13.188176155090332],\n [2773092583, 11.710576057434082],\n [2773093666, 10.232975959777832],\n [2773095541, 6.307560920715332],\n [2867830583, 7.747097015380859],\n [2884560958, 9.522866249084473],\n [2884563083, 11.471055030822754],\n [2892822375, 13.74086856842041],\n [2907884000, 15.698105812072754],\n [2907886125, 14.135605812072754],\n [2907888000, 16.87893772125244],\n [2907889250, 15.128937721252441],\n [2915387791, 18.21907138824463],\n [2915389375, 16.25032138824463],\n [2926667500, 19.73062229156494],\n [2926669625, 17.51187229156494],\n [2926670625, 16.034279823303223],\n [2926671583, 14.556679725646973],\n [2926672625, 13.079079627990723],\n [2926673625, 11.601479530334473],\n [2926674583, 10.123879432678223],\n [2926675625, 6.198464393615723],\n [3034666125, 7.6379852294921875],\n [3034668041, 9.319541931152344],\n [3034669750, 11.2677001953125],\n [3046989583, 13.631756782531738],\n [3060246125, 15.588459968566895],\n [3060247916, 14.025959968566895],\n [3060249750, 16.769291877746582],\n [3060250916, 15.019291877746582],\n [3072037500, 18.10942554473877],\n [3072039166, 16.14067554473877],\n [3086011833, 19.620945930480957],\n [3086013958, 17.402195930480957],\n [3086015083, 15.924603462219238],\n [3086016083, 14.447003364562988],\n [3086017166, 12.969403266906738],\n [3086018125, 11.491803169250488],\n [3086019041, 10.014203071594238],\n [3086020000, 6.088788032531738],\n [3174625125, 7.528247833251953],\n [3183568041, 9.304047584533691],\n [3192818916, 11.252236366271973],\n [3199073833, 13.522049903869629],\n [3219456666, 15.478753089904785],\n [3219458958, 13.916253089904785],\n [3219460916, 16.659615516662598],\n [3219462000, 14.909615516662598],\n [3219463708, 17.99971866607666],\n [3219464750, 16.03096866607666],\n [3232053958, 19.511269569396973],\n [3232056041, 17.292519569396973],\n [3232057125, 15.814927101135254],\n [3232058041, 14.337327003479004],\n [3232059000, 12.859726905822754],\n [3232059916, 11.382126808166504],\n [3232060833, 9.904526710510254],\n [3232061791, 5.979111671447754],\n [3328167291, 7.418495178222656],\n [3337774666, 9.19426441192627],\n [3347573000, 11.14245319366455],\n [3358798833, 13.412297248840332],\n [3375074833, 15.369030952453613],\n [3375077125, 13.806530952453613],\n [3375079000, 16.549893379211426],\n [3375080166, 14.799893379211426],\n [3375081916, 17.890103340148926],\n [3375083000, 15.921353340148926],\n [3382591416, 19.40165424346924],\n [3382593625, 17.18290424346924],\n [3393229458, 15.70531177520752],\n [3393230708, 14.22771167755127],\n [3393231500, 12.75011157989502],\n [3393232291, 11.27251148223877],\n [3393233125, 9.79491138458252],\n [3393233916, 5.8694963455200195],\n [3483706583, 7.309093475341797],\n [3498923166, 9.08486270904541],\n [3498925250, 11.033051490783691],\n [3507070083, 13.302865028381348],\n [3517781541, 15.259598731994629],\n [3517784083, 13.697098731994629],\n [3534458125, 16.440430641174316],\n [3534459625, 14.690430641174316],\n [3534461375, 17.78059482574463],\n [3534462583, 15.811844825744629],\n [3540753750, 19.292115211486816],\n [3540760500, 17.073365211486816],\n [3540761583, 15.595772743225098],\n [3540762500, 14.118172645568848],\n [3540763458, 12.640572547912598],\n [3540764375, 11.162972450256348],\n [3540765291, 9.685372352600098],\n [3540766208, 5.759957313537598],\n [3636936250, 7.199432373046875],\n [3643253833, 8.975232124328613],\n [3649555708, 10.92339038848877],\n [3665517083, 13.193203926086426],\n [3681314625, 15.149937629699707],\n [3681316833, 13.587437629699707],\n [3681318833, 16.33080005645752],\n [3681320000, 14.58080005645752],\n [3681321708, 17.670903205871582],\n [3681322791, 15.702153205871582],\n [3694533125, 19.182454109191895],\n [3694535208, 16.963704109191895],\n [3694536291, 15.486111640930176],\n [3694537250, 14.008511543273926],\n [3694538125, 12.530911445617676],\n [3694539083, 11.053311347961426],\n [3694539958, 9.575711250305176],\n [3694540916, 5.650296211242676],\n [3790098791, 7.089809417724609],\n [3798911541, 8.865555763244629],\n [3808257708, 10.81374454498291],\n [3815910166, 13.083588600158691],\n [3822191208, 15.040291786193848],\n [3822193208, 13.477791786193848],\n [3828487166, 16.221177101135254],\n [3828488500, 14.471177101135254],\n [3840441541, 17.561440467834473],\n [3840442958, 15.592690467834473],\n [3846821041, 19.07296085357666],\n [3846822958, 16.85421085357666],\n [3846823958, 15.376618385314941],\n [3846824875, 13.899018287658691],\n [3846825791, 12.421418190002441],\n [3846826708, 10.943818092346191],\n [3846827583, 9.466217994689941],\n [3846828625, 5.540833473205566],\n [3943422500, 6.9803619384765625],\n [3958368375, 8.756131172180176],\n [3958370500, 10.704319953918457],\n [3966165833, 12.974133491516113],\n [3981619916, 14.93083667755127],\n [3981623875, 13.36833667755127],\n [3981625791, 16.111668586730957],\n [3981626958, 14.361668586730957],\n [3989149166, 17.451802253723145],\n [3989150791, 15.483052253723145],\n [4000965208, 18.963269233703613],\n [4000967375, 16.744519233703613],\n [4000968458, 15.266926765441895],\n [4000969375, 13.789326667785645],\n [4000970291, 12.311726570129395],\n [4000971208, 10.834126472473145],\n [4000972125, 9.356526374816895],\n [4000973041, 5.4311418533325195],\n [4095860250, 6.870655059814453],\n [4105109375, 8.646454811096191],\n [4114606291, 10.594643592834473],\n [4122073833, 12.864487648010254],\n [4134668416, 14.82119083404541],\n [4134670708, 13.25869083404541],\n [4134672666, 16.002022743225098],\n [4134673833, 14.252022743225098],\n [4147024291, 17.34212589263916],\n [4147025625, 15.37337589263916],\n [4153339500, 18.853676795959473],\n [4153341291, 16.634926795959473],\n [4153342333, 15.157334327697754],\n [4153343291, 13.679734230041504],\n [4153344250, 12.202134132385254],\n [4153345208, 10.724534034729004],\n [4153346166, 9.246933937072754],\n [4153347125, 5.321518898010254],\n [4244786125, 6.760932922363281],\n [4257113208, 8.53673267364502],\n [4263442208, 10.484890937805176],\n [4278888958, 12.754704475402832],\n [4294709791, 14.711438179016113],\n [4294712000, 13.148938179016113],\n [4294713875, 15.892300605773926],\n [4294714958, 14.142300605773926],\n [4294716666, 17.23240375518799],\n [4294717750, 15.263653755187988],\n [4306235625, 18.7439546585083],\n [4306237708, 16.5252046585083],\n [4306238916, 15.047612190246582],\n [4306240041, 13.570012092590332],\n [4306241166, 12.092411994934082],\n [4306242375, 10.614811897277832],\n [4306243500, 9.137211799621582],\n [4306244625, 5.211796760559082],\n [4402735458, 6.651203155517578],\n [4411437708, 8.426972389221191],\n [4420925333, 10.375161170959473],\n [4431466500, 12.645005226135254],\n [4438017708, 14.601738929748535],\n [4438019375, 13.039238929748535],\n [4453015833, 15.782624244689941],\n [4453019166, 14.032624244689941],\n [4453021166, 17.122788429260254],\n [4453022375, 15.154038429260254],\n [4459552083, 18.63430881500244],\n [4459553666, 16.41555881500244],\n [4459554750, 14.937966346740723],\n [4459555750, 13.460366249084473],\n [4459556708, 11.982766151428223],\n [4459557708, 10.505166053771973],\n [4459558625, 9.027565956115723],\n [4459559625, 5.102150917053223],\n [4555238708, 6.541717529296875],\n [4563668750, 8.317517280578613],\n [4569932541, 10.26567554473877],\n [4590304041, 12.535489082336426],\n [4590306291, 14.492222785949707],\n [4590308416, 12.929722785949707],\n [4599289375, 15.67302417755127],\n [4599290958, 13.92302417755127],\n [4599293041, 17.013188362121582],\n [4599294333, 15.044438362121582],\n [4611807916, 18.524739265441895],\n [4611809708, 16.305989265441895],\n [4611810750, 14.828396797180176],\n [4611811708, 13.350796699523926],\n [4611812708, 11.873196601867676],\n [4611813666, 10.395596504211426],\n [4611814708, 8.917996406555176],\n [4611815791, 4.992581367492676],\n [4703001166, 6.431995391845703],\n [4717039083, 8.207795143127441],\n [4726370083, 10.155983924865723],\n [4734432875, 12.425827980041504],\n [4740758083, 14.38253116607666],\n [4740759958, 12.82003116607666],\n [4752320625, 15.563416481018066],\n [4752322250, 13.813416481018066],\n [4752324041, 16.90358066558838],\n [4752325208, 14.934830665588379],\n [4765011333, 18.415101051330566],\n [4765013416, 16.196351051330566],\n [4765014458, 14.718758583068848],\n [4765015416, 13.241158485412598],\n [4765016375, 11.763558387756348],\n [4765017291, 10.285958290100098],\n [4765018208, 8.808358192443848],\n [4765019166, 4.882973670959473],\n [4860951041, 6.322502136230469],\n [4869187791, 8.098271369934082],\n [4879627916, 10.046460151672363],\n [4890477166, 12.316304206848145],\n [4897023333, 14.273037910461426],\n [4897025583, 12.710537910461426],\n [4906051166, 15.453923225402832],\n [4906053708, 13.703923225402832],\n [4912887500, 16.794087409973145],\n [4912889458, 14.825337409973145],\n [4919814125, 18.305577278137207],\n [4919816208, 16.086827278137207],\n [4919817250, 14.609234809875488],\n [4919818166, 13.131634712219238],\n [4919819125, 11.654034614562988],\n [4919820083, 10.176434516906738],\n [4919821000, 8.698834419250488],\n [4919823833, 4.773419380187988],\n [5023320041, 6.213077545166016],\n [5023323125, 7.894603729248047],\n [5029641916, 9.937005043029785],\n [5044781916, 12.206818580627441],\n [5050837250, 14.163552284240723],\n [5050839333, 12.601052284240723],\n [5057138833, 15.34438419342041],\n [5057140166, 13.59438419342041],\n [5063449041, 16.684517860412598],\n [5063450291, 14.715767860412598],\n [5069771416, 18.195984840393066],\n [5069772708, 15.977234840393066],\n [5078160250, 14.499642372131348],\n [5078161416, 13.022042274475098],\n [5078162333, 11.544442176818848],\n [5078163166, 10.066842079162598],\n [5078163958, 8.589241981506348],\n [5078164916, 4.663826942443848],\n [5167815333, 6.1033935546875],\n [5177588416, 7.879162788391113],\n [5194539583, 9.827351570129395],\n [5194541625, 12.097195625305176],\n [5202341125, 14.053898811340332],\n [5202343416, 12.491398811340332],\n [5220412083, 15.23473072052002],\n [5220413625, 13.48473072052002],\n [5220415500, 16.574894905090332],\n [5220416750, 14.606144905090332],\n [5226693833, 18.08641529083252],\n [5226695916, 15.86766529083252],\n [5226696958, 14.3900728225708],\n [5226697875, 12.91247272491455],\n [5226698833, 11.4348726272583],\n [5226699708, 9.95727252960205],\n [5226700625, 8.4796724319458],\n [5226701625, 4.554257392883301],\n [5322822500, 5.993740081787109],\n [5331672708, 7.769539833068848],\n [5338285250, 9.717728614807129],\n [5350854458, 11.987542152404785],\n [5359496833, 13.944275856018066],\n [5359498666, 12.381775856018066],\n [5365814000, 15.125107765197754],\n [5365815583, 13.375107765197754],\n [5372042791, 16.46524143218994],\n [5372044416, 14.496491432189941],\n [5380466375, 17.97676181793213],\n [5380488791, 15.758011817932129],\n [5380490083, 14.28041934967041],\n [5380491041, 12.80281925201416],\n [5380491958, 11.32521915435791],\n [5380492916, 9.84761905670166],\n [5380493875, 8.37001895904541],\n [5380494875, 4.44460391998291],\n [5470324958, 5.884117126464844],\n [5478485041, 7.659916877746582],\n [5493524500, 9.608075141906738],\n [5501088708, 11.87791919708252],\n [5507374875, 13.834622383117676],\n [5507376791, 12.272122383117676],\n [5525673541, 15.015507698059082],\n [5525675125, 13.265507698059082],\n [5525676916, 16.355671882629395],\n [5525678041, 14.386921882629395],\n [5532040750, 17.867161750793457],\n [5532042333, 15.648411750793457],\n [5532043375, 14.170819282531738],\n [5532044291, 12.693219184875488],\n [5532045208, 11.215619087219238],\n [5532046125, 9.738018989562988],\n [5532047083, 8.260418891906738],\n [5532052375, 4.335034370422363],\n [5628032083, 5.774478912353516],\n [5636955125, 7.550278663635254],\n [5646291708, 9.498467445373535],\n [5655363166, 11.768311500549316],\n [5661695375, 13.725014686584473],\n [5661697125, 12.162514686584473],\n [5672175625, 14.905900001525879],\n [5672177000, 13.155900001525879],\n [5672178875, 16.246033668518066],\n [5672180083, 14.277283668518066],\n [5684715750, 17.75752353668213],\n [5684717625, 15.538773536682129],\n [5684718625, 14.06118106842041],\n [5684719583, 12.58358097076416],\n [5684720500, 11.10598087310791],\n [5684721458, 9.62838077545166],\n [5684722375, 8.15078067779541],\n [5684723333, 4.22536563873291],\n [5776186333, 5.664955139160156],\n [5788316833, 7.4407548904418945],\n [5798866875, 9.38891315460205],\n [5809500166, 11.658757209777832],\n [5825329666, 13.615490913391113],\n [5825332875, 12.052990913391113],\n [5825334833, 14.796353340148926],\n [5825336000, 13.046353340148926],\n [5825337791, 16.13645648956299],\n [5825338916, 14.167706489562988],\n [5834431250, 17.648655891418457],\n [5834432875, 15.429905891418457],\n [5843298875, 13.952313423156738],\n [5843299958, 12.474713325500488],\n [5843300833, 10.997113227844238],\n [5843301583, 9.519513130187988],\n [5843302416, 8.041913032531738],\n [5843303250, 4.116497993469238],\n [5932753666, 5.556041717529297],\n [5942303625, 7.33181095123291],\n [5951736208, 9.279999732971191],\n [5968644000, 11.549843788146973],\n [5968646000, 13.506577491760254],\n [5968647791, 11.944077491760254],\n [5983957208, 14.687378883361816],\n [5983958916, 12.937378883361816],\n [5983961000, 16.02754306793213],\n [5983962291, 14.058793067932129],\n [5996582875, 17.539063453674316],\n [5996584625, 15.320313453674316],\n [5996585666, 13.842720985412598],\n [5996586625, 12.365120887756348],\n [5996587583, 10.887520790100098],\n [5996588583, 9.409920692443848],\n [5996589541, 7.932320594787598],\n [5996590541, 4.006905555725098],\n [6082731250, 5.4465179443359375],\n [6093244166, 7.222317695617676],\n [6099501750, 9.170475959777832],\n [6115769500, 11.440289497375488],\n [6125370500, 13.39702320098877],\n [6125372500, 11.83452320098877],\n [6125374500, 14.577885627746582],\n [6125375750, 12.827885627746582],\n [6137464916, 15.917988777160645],\n [6137466583, 13.949238777160645],\n [6143755000, 17.429539680480957],\n [6143756958, 15.210789680480957],\n [6143758041, 13.733197212219238],\n [6143759000, 12.255597114562988],\n [6143759916, 10.777997016906738],\n [6143760833, 9.300396919250488],\n [6143761833, 7.822796821594238],\n [6143762833, 3.8973817825317383],\n [6234613208, 5.336803436279297],\n [6243245916, 7.112603187561035],\n [6257785875, 9.060761451721191],\n [6266030708, 11.330605506896973],\n [6272334625, 13.287308692932129],\n [6272336875, 11.724808692932129],\n [6289988291, 14.468194007873535],\n [6289994583, 12.718194007873535],\n [6289996458, 15.808358192443848],\n [6289997750, 13.839608192443848],\n [6302588958, 17.31984806060791],\n [6302591208, 15.10109806060791],\n [6302592250, 13.623505592346191],\n [6302593333, 12.145905494689941],\n [6302594291, 10.668305397033691],\n [6302595291, 9.190705299377441],\n [6302596333, 7.713105201721191],\n [6302597333, 3.7877206802368164],\n [6390482541, 5.2271881103515625],\n [6401091625, 7.002987861633301],\n [6412865208, 8.951176643371582],\n [6419126333, 11.220990180969238],\n [6434483208, 13.177693367004395],\n [6434485125, 11.615193367004395],\n [6434487250, 14.358555793762207],\n [6434488500, 12.608555793762207],\n [6446846666, 15.69871997833252],\n [6446848666, 13.72996997833252],\n [6455603458, 17.210240364074707],\n [6455605541, 14.991490364074707],\n [6455606666, 13.513897895812988],\n [6455607708, 12.036297798156738],\n [6455608666, 10.558697700500488],\n [6455609625, 9.081097602844238],\n [6455610625, 7.603497505187988],\n [6455611625, 3.6780824661254883],\n [6551340166, 5.117588043212891],\n [6566544208, 6.893387794494629],\n [6566546333, 8.84157657623291],\n [6578061333, 11.111390113830566],\n [6602241708, 13.068093299865723],\n [6602243916, 11.505593299865723],\n [6602245750, 14.248955726623535],\n [6602246958, 12.498955726623535],\n [6602248666, 15.589142799377441],\n [6602249833, 13.620392799377441],\n [6608597291, 17.10066318511963],\n [6608599250, 14.881913185119629],\n [6608600333, 13.40432071685791],\n [6608601250, 11.92672061920166],\n [6608602208, 10.44912052154541],\n [6608603125, 8.97152042388916],\n [6608604041, 7.49392032623291],\n [6608605041, 3.56850528717041],\n [6703743750, 5.0080108642578125],\n [6718685916, 6.783780097961426],\n [6718688166, 8.731968879699707],\n [6726152166, 11.001782417297363],\n [6741937000, 12.95848560333252],\n [6741946500, 11.39598560333252],\n [6741948416, 14.139317512512207],\n [6741949708, 12.389317512512207],\n [6751076666, 15.479451179504395],\n [6751077958, 13.510701179504395],\n [6757386000, 16.990971565246582],\n [6757387416, 14.772221565246582],\n [6763727125, 13.294629096984863],\n [6763728416, 11.817028999328613],\n [6763729250, 10.339428901672363],\n [6763730125, 8.861828804016113],\n [6763730958, 7.384228706359863],\n [6763731875, 3.4588136672973633],\n [6851153291, 4.898349761962891],\n [6859499458, 6.674149513244629],\n [6874403375, 8.622307777404785],\n [6882233666, 10.892151832580566],\n [6888538750, 12.848855018615723],\n [6888540833, 11.286355018615723],\n [6894837291, 14.029740333557129],\n [6894838625, 12.279740333557129],\n [6906424583, 15.369874000549316],\n [6906425833, 13.401124000549316],\n [6912790333, 16.881394386291504],\n [6912792208, 14.662644386291504],\n [6912793375, 13.185051918029785],\n [6912794375, 11.707451820373535],\n [6912795333, 10.229851722717285],\n [6912796250, 8.752251625061035],\n [6912797166, 7.274651527404785],\n [6912798166, 3.349236488342285],\n [7003770375, 4.788688659667969],\n [7011609083, 6.564488410949707],\n [7027232541, 8.512646675109863],\n [7033464583, 10.782490730285645],\n [7046696541, 12.739224433898926],\n [7046700125, 11.176724433898926],\n [7053895583, 13.920056343078613],\n [7053897583, 12.170056343078613],\n [7053899583, 15.260220527648926],\n [7053901000, 13.291470527648926],\n [7067522875, 16.771740913391113],\n [7067525125, 14.552990913391113],\n [7067526250, 13.075398445129395],\n [7067527208, 11.597798347473145],\n [7067528166, 10.120198249816895],\n [7067529125, 8.642598152160645],\n [7067530041, 7.1649980545043945],\n [7067531041, 3.2395830154418945],\n [7168933125, 4.679119110107422],\n [7168935083, 6.360675811767578],\n [7176566708, 8.403077125549316],\n [7191593416, 10.672890663146973],\n [7199429333, 12.629624366760254],\n [7199431958, 11.067124366760254],\n [7206961291, 13.810456275939941],\n [7206963041, 12.060456275939941],\n [7206965041, 15.150620460510254],\n [7206966333, 13.181870460510254],\n [7220339958, 16.662171363830566],\n [7220342125, 14.443421363830566],\n [7220343125, 12.965828895568848],\n [7220344083, 11.488228797912598],\n [7220345125, 10.010628700256348],\n [7220346041, 8.533028602600098],\n [7220347000, 7.055428504943848],\n [7220348000, 3.1300134658813477],\n [7316084791, 4.663830757141113],\n [7325138333, 6.3453874588012695],\n [7334582041, 8.29357624053955],\n [7351638375, 10.563420295715332],\n [7351640291, 12.520153999328613],\n [7351642375, 10.957653999328613],\n [7359897666, 13.7009859085083],\n [7359899291, 11.9509859085083],\n [7367202916, 15.041119575500488],\n [7367204333, 13.072369575500488],\n [7373492125, 16.5526704788208],\n [7373494375, 14.3339204788208],\n [7373495500, 12.856328010559082],\n [7373496541, 11.378727912902832],\n [7373497541, 9.901127815246582],\n [7373498500, 8.423527717590332],\n [7373499500, 6.945927619934082],\n [7373500541, 3.020512580871582],\n [7466136083, 4.459995269775391],\n [7476558250, 6.235795021057129],\n [7482890041, 8.183953285217285],\n [7499235125, 10.453766822814941],\n [7508872833, 12.410500526428223],\n [7508875125, 10.848000526428223],\n [7508877125, 13.591362953186035],\n [7508878250, 11.841362953186035],\n [7520261125, 14.931496620178223],\n [7520262458, 12.962746620178223],\n [7528224041, 16.44301700592041],\n [7528226333, 14.22426700592041],\n [7528227375, 12.746674537658691],\n [7528228333, 11.269074440002441],\n [7528229250, 9.791474342346191],\n [7528230166, 8.313874244689941],\n [7528231125, 6.836274147033691],\n [7528232125, 2.9108591079711914],\n [7618288291, 4.35028076171875],\n [7626573083, 6.126080513000488],\n [7641592166, 8.074238777160645],\n [7649427041, 10.344082832336426],\n [7655708291, 12.300786018371582],\n [7655710500, 10.738286018371582],\n [7667459041, 13.481671333312988],\n [7667460708, 11.731671333312988],\n [7667462625, 14.8218355178833],\n [7667463875, 12.8530855178833],\n [7679976541, 16.33335590362549],\n [7679978458, 14.114605903625488],\n [7679979416, 12.63701343536377],\n [7679980375, 11.15941333770752],\n [7679981333, 9.68181324005127],\n [7679982291, 8.20421314239502],\n [7679983208, 6.7266130447387695],\n [7679984166, 2.8012285232543945],\n [7773985541, 4.240749359130859],\n [7784402958, 6.016549110412598],\n [7790662125, 7.964707374572754],\n [7810971500, 10.23452091217041],\n [7810973708, 12.191254615783691],\n [7810975291, 10.628754615783691],\n [7817748541, 13.372086524963379],\n [7817750250, 11.622086524963379],\n [7832559291, 14.712220191955566],\n [7832561166, 12.743470191955566],\n [7832563041, 16.22377109527588],\n [7832564083, 14.005021095275879],\n [7832565083, 12.52742862701416],\n [7832566041, 11.04982852935791],\n [7832567000, 9.57222843170166],\n [7832570208, 8.09462833404541],\n [7832571208, 6.61702823638916],\n [7832572333, 2.691582679748535],\n [7922994083, 4.13104248046875],\n [7932775750, 5.906842231750488],\n [7945337000, 7.8550004959106445],\n [7953611083, 10.124844551086426],\n [7959889083, 12.081547737121582],\n [7959891041, 10.519047737121582],\n [7966055125, 13.262433052062988],\n [7966056500, 11.512433052062988],\n [7977993166, 14.602566719055176],\n [7977994625, 12.633816719055176],\n [7984344791, 16.114087104797363],\n [7984346625, 13.895337104797363],\n [7984347666, 12.417744636535645],\n [7984348583, 10.940144538879395],\n [7984349500, 9.462544441223145],\n [7984350458, 7.9849443435668945],\n [7984351375, 6.5073442459106445],\n [7984352333, 2.5819292068481445],\n [8075228541, 4.021411895751953],\n [8082781916, 5.797211647033691],\n [8098281875, 7.745369911193848],\n [8108783458, 10.015213966369629],\n [8116131166, 11.97194766998291],\n [8116133375, 10.40944766998291],\n [8124245541, 13.152779579162598],\n [8124247208, 11.402779579162598],\n [8124249166, 14.49294376373291],\n [8124250375, 12.52419376373291],\n [8137013625, 16.004494667053223],\n [8137015791, 13.785744667053223],\n [8137016875, 12.308152198791504],\n [8137017791, 10.830552101135254],\n [8137018750, 9.352952003479004],\n [8137019666, 7.875351905822754],\n [8137020583, 6.397751808166504],\n [8137021583, 2.472336769104004],\n [8228826375, 3.9119415283203125],\n [8240680541, 5.687741279602051],\n [8251054875, 7.635930061340332],\n [8257330708, 9.905743598937988],\n [8271154500, 11.862446784973145],\n [8271156750, 10.299946784973145],\n [8271158666, 13.043309211730957],\n [8271159875, 11.293309211730957],\n [8282650583, 14.38341236114502],\n [8282652833, 12.41466236114502],\n [8291123875, 15.894963264465332],\n [8291125708, 13.676213264465332],\n [8291126750, 12.198620796203613],\n [8291127666, 10.721020698547363],\n [8291128583, 9.243420600891113],\n [8291129541, 7.765820503234863],\n [8291130458, 6.288220405578613],\n [8291131416, 2.3628053665161133],\n [8392950541, 3.8023719787597656],\n [8392952708, 5.483928680419922],\n [8403638000, 7.52632999420166],\n [8409890708, 9.796143531799316],\n [8431111916, 11.752846717834473],\n [8431113791, 10.190346717834473],\n [8431115750, 12.933709144592285],\n [8431116958, 11.183709144592285],\n [8431118750, 14.273812294006348],\n [8431119833, 12.305062294006348],\n [8439101375, 15.78536319732666],\n [8439102541, 13.56661319732666],\n [8449067541, 12.089020729064941],\n [8449068750, 10.611420631408691],\n [8449069541, 9.133820533752441],\n [8449070333, 7.656220436096191],\n [8449071166, 6.178620338439941],\n [8449072083, 2.2532052993774414],\n [8539423791, 3.6928024291992188],\n [8548272541, 5.468602180480957],\n [8555782416, 7.416790962219238],\n [8562089875, 9.686604499816895],\n [8583991625, 11.64330768585205],\n [8583993625, 10.08080768585205],\n [8583995500, 12.824170112609863],\n [8583996666, 11.074170112609863],\n [8583998375, 14.164273262023926],\n [8583999458, 12.195523262023926],\n [8597094666, 15.675824165344238],\n [8597096583, 13.457074165344238],\n [8597097625, 11.97948169708252],\n [8597098583, 10.50188159942627],\n [8597099541, 9.02428150177002],\n [8597100458, 7.5466814041137695],\n [8597101416, 6.0690813064575195],\n [8597102416, 2.1436662673950195],\n [8692409625, 3.5832481384277344],\n [8707328333, 5.359017372131348],\n [8707330291, 7.307206153869629],\n [8717721958, 9.577019691467285],\n [8728510041, 11.533753395080566],\n [8728512041, 9.971253395080566],\n [8742288750, 12.714585304260254],\n [8742290625, 10.964585304260254],\n [8742292916, 14.054749488830566],\n [8742294125, 12.085999488830566],\n [8754893791, 15.566239356994629],\n [8754895666, 13.347489356994629],\n [8754896625, 11.86989688873291],\n [8754897541, 10.39229679107666],\n [8754898458, 8.91469669342041],\n [8754899416, 7.43709659576416],\n [8754900333, 5.95949649810791],\n [8754901291, 2.034111976623535],\n [8839336416, 3.4736557006835938],\n [8853248750, 5.249455451965332],\n [8862653041, 7.197644233703613],\n [8870236500, 9.467488288879395],\n [8876539583, 11.42419147491455],\n [8876541750, 9.86169147491455],\n [8882642625, 12.605076789855957],\n [8882643916, 10.855076789855957],\n [8894576833, 13.945210456848145],\n [8894578125, 11.976460456848145],\n [8907180958, 15.456730842590332],\n [8907183041, 13.237980842590332],\n [8907184083, 11.760388374328613],\n [8907185041, 10.282788276672363],\n [8907185958, 8.805188179016113],\n [8907186875, 7.327588081359863],\n [8907187833, 5.849987983703613],\n [8907188791, 1.9246034622192383],\n [8996641041, 3.3641014099121094],\n [9005356000, 5.139870643615723],\n [9014702125, 7.088059425354004],\n [9025219750, 9.357903480529785],\n [9034624208, 11.314637184143066],\n [9034626166, 9.752137184143066],\n [9034628250, 12.495469093322754],\n [9034629458, 10.745469093322754],\n [9042829750, 13.835709571838379],\n [9042831291, 11.866959571838379],\n [9053968125, 15.347229957580566],\n [9053969875, 13.128479957580566],\n [9053970958, 11.650887489318848],\n [9053971916, 10.173287391662598],\n [9053972875, 8.695687294006348],\n [9053973833, 7.218087196350098],\n [9053974791, 5.740487098693848],\n [9053975791, 1.8151025772094727],\n [9144603041, 3.2558517456054688],\n [9157169791, 5.031651496887207],\n [9167324958, 6.979809761047363],\n [9178110416, 9.249653816223145],\n [9194000708, 11.206387519836426],\n [9194002458, 9.643887519836426],\n [9194004291, 12.387249946594238],\n [9194005416, 10.637249946594238],\n [9194007125, 13.7273530960083],\n [9194008208, 11.7586030960083],\n [9201048625, 15.238903999328613],\n [9201049833, 13.020153999328613],\n [9207340750, 11.542561531066895],\n [9207341625, 10.064961433410645],\n [9207342375, 8.587361335754395],\n [9207343166, 7.1097612380981445],\n [9207343958, 5.6321611404418945],\n [9207344791, 1.7067461013793945],\n [9302433750, 3.146373748779297],\n [9311151791, 4.92214298248291],\n [9320643791, 6.870331764221191],\n [9331272208, 9.140175819396973],\n [9338275625, 11.096909523010254],\n [9338277291, 9.534409523010254],\n [9352660958, 12.27779483795166],\n [9352662416, 10.52779483795166],\n [9352664291, 13.617959022521973],\n [9352665458, 11.649209022521973],\n [9360059083, 15.129448890686035],\n [9360060875, 12.910698890686035],\n [9360061916, 11.433106422424316],\n [9360063125, 9.955506324768066],\n [9360064083, 8.477906227111816],\n [9360065041, 7.000306129455566],\n [9360065958, 5.522706031799316],\n [9360066916, 1.5973520278930664],\n [9455925750, 3.0375823974609375],\n [9464776750, 4.813382148742676],\n [9472791583, 6.761570930480957],\n [9479088208, 9.031384468078613],\n [9500772333, 10.98808765411377],\n [9500774375, 9.42558765411377],\n [9500776333, 12.168950080871582],\n [9500777416, 10.418950080871582],\n [9500779125, 13.509053230285645],\n [9500780208, 11.540303230285645],\n [9513728916, 15.020604133605957],\n [9513731041, 12.801854133605957],\n [9513732125, 11.324261665344238],\n [9513733208, 9.846661567687988],\n [9513734166, 8.369061470031738],\n [9513735083, 6.891461372375488],\n [9513736041, 5.413861274719238],\n [9513737083, 1.4884462356567383],\n [9609060666, 2.9279823303222656],\n [9624226000, 4.703782081604004],\n [9624228041, 6.651970863342285],\n [9634511583, 8.921784400939941],\n [9647057208, 10.878487586975098],\n [9647059416, 9.315987586975098],\n [9647061458, 12.059319496154785],\n [9647062708, 10.309319496154785],\n [9657363791, 13.399453163146973],\n [9657365166, 11.430703163146973],\n [9666877791, 14.91097354888916],\n [9666879625, 12.69222354888916],\n [9666880708, 11.214631080627441],\n [9666881666, 9.737030982971191],\n [9666882625, 8.259430885314941],\n [9666883500, 6.781830787658691],\n [9666884416, 5.304230690002441],\n [9666885416, 1.3788461685180664],\n [9761919625, 2.9126176834106445],\n [9770368416, 4.594204902648926],\n [9776645458, 6.542363166809082],\n [9791089083, 8.812176704406738],\n [9806952625, 10.76891040802002],\n [9806954875, 9.20641040802002],\n [9806956875, 11.949772834777832],\n [9806958083, 10.199772834777832],\n [9806959875, 13.289875984191895],\n [9806961041, 11.321125984191895],\n [9816194125, 14.801426887512207],\n [9816195458, 12.582676887512207],\n [9831393958, 11.105084419250488],\n [9831395125, 9.627484321594238],\n [9831395958, 8.149884223937988],\n [9831396708, 6.672284126281738],\n [9831397500, 5.194684028625488],\n [9831398333, 1.2692689895629883],\n [9916727750, 2.80300235748291],\n [9924698208, 4.484589576721191],\n [9932873000, 6.432778358459473],\n [9939152791, 8.702591896057129],\n [9960544500, 10.659295082092285],\n [9960546541, 9.096795082092285],\n [9960548458, 11.840157508850098],\n [9960549666, 10.090157508850098],\n [9960551375, 13.18026065826416],\n [9960552500, 11.21151065826416],\n [9967836458, 14.691811561584473],\n [9967837666, 12.473061561584473],\n [9974138583, 10.995469093322754],\n [9974139666, 9.517868995666504],\n [9974140500, 8.040268898010254],\n [9974141291, 6.562668800354004],\n [9974142041, 5.085068702697754],\n [9974142875, 1.159653663635254],\n [10068896125, 2.5992507934570312],\n [10077671875, 4.3750505447387695],\n [10087134041, 6.323239326477051],\n [10097715125, 8.593083381652832],\n [10107291041, 10.549817085266113],\n [10107293375, 8.987317085266113],\n [10107295166, 11.7306489944458],\n [10107296333, 9.9806489944458],\n [10116215208, 13.070889472961426],\n [10116216458, 11.102139472961426],\n [10126709250, 14.582409858703613],\n [10126711791, 12.363659858703613],\n [10126712833, 10.886067390441895],\n [10126713750, 9.408467292785645],\n [10126714750, 7.9308671951293945],\n [10126715708, 6.4532670974731445],\n [10126716625, 4.9756669998168945],\n [10126717625, 1.0502824783325195],\n [10228397541, 2.489879608154297],\n [10228399541, 4.171436309814453],\n [10240194875, 6.213837623596191],\n [10247062833, 8.483681678771973],\n [10259656541, 10.440384864807129],\n [10259658625, 8.877884864807129],\n [10272069166, 11.621216773986816],\n [10272070916, 9.871216773986816],\n [10272072958, 12.961380958557129],\n [10272074166, 10.992630958557129],\n [10280290916, 14.472870826721191],\n [10280293083, 12.254120826721191],\n [10280294166, 10.776528358459473],\n [10280295125, 9.298928260803223],\n [10280296041, 7.821328163146973],\n [10280296958, 6.343728065490723],\n [10280297875, 4.866127967834473],\n [10280298875, 0.9407129287719727],\n [10375254875, 2.3801727294921875],\n [10383933791, 4.155972480773926],\n [10390739291, 6.104161262512207],\n [10403268541, 8.373974800109863],\n [10413509375, 10.33067798614502],\n [10413511125, 8.76817798614502],\n [10413513208, 11.511540412902832],\n [10413514416, 9.761540412902832],\n [10425547875, 12.851696968078613],\n [10425549375, 10.882946968078613],\n [10431817458, 14.363247871398926],\n [10431819250, 12.144497871398926],\n [10431820208, 10.666905403137207],\n [10431821125, 9.189305305480957],\n [10431822041, 7.711705207824707],\n [10431822958, 6.234105110168457],\n [10431823875, 4.756505012512207],\n [10431824833, 0.831089973449707],\n [10527514375, 2.270610809326172],\n [10542503250, 4.046380043029785],\n [10542505083, 5.994568824768066],\n [10551167791, 8.264382362365723],\n [10565694458, 10.221085548400879],\n [10565696666, 8.658585548400879],\n [10565698583, 11.401917457580566],\n [10565699875, 9.651917457580566],\n [10576167333, 12.742051124572754],\n [10576169000, 10.773301124572754],\n [10585158208, 14.253571510314941],\n [10585160333, 12.034821510314941],\n [10585161375, 10.557229042053223],\n [10585162291, 9.079628944396973],\n [10585163208, 7.602028846740723],\n [10585164083, 6.124428749084473],\n [10585165000, 4.646828651428223],\n [10585165916, 0.7214136123657227],\n [10679902333, 2.1608657836914062],\n [10694787208, 3.9366350173950195],\n [10694789208, 5.884823799133301],\n [10707466291, 8.154637336730957],\n [10718130458, 10.111371040344238],\n [10718132125, 8.548871040344238],\n [10718133958, 11.292202949523926],\n [10718135125, 9.542202949523926],\n [10736509375, 12.632336616516113],\n [10736511500, 10.663586616516113],\n [10736513500, 14.143887519836426],\n [10736514541, 11.925137519836426],\n [10736515666, 10.447545051574707],\n [10736516666, 8.969944953918457],\n [10736517708, 7.492344856262207],\n [10736518666, 6.014744758605957],\n [10736519625, 4.537144660949707],\n [10736520625, 0.611699104309082],\n [10840282375, 2.051219940185547],\n [10840284458, 3.732776641845703],\n [10849612583, 5.775177955627441],\n [10860022125, 8.045022010803223],\n [10872596250, 10.001725196838379],\n [10872598458, 8.439225196838379],\n [10872600333, 11.182557106018066],\n [10872601541, 9.432557106018066],\n [10882916125, 12.522690773010254],\n [10882917333, 10.553940773010254],\n [10905076250, 14.034211158752441],\n [10905078166, 11.815461158752441],\n [10905079208, 10.337868690490723],\n [10905080208, 8.860268592834473],\n [10905081250, 7.382668495178223],\n [10905082166, 5.905068397521973],\n [10905083125, 4.427468299865723],\n [10905084125, 0.5020837783813477],\n [10982966416, 1.9416961669921875],\n [10993338083, 3.717495918273926],\n [11003769375, 5.665684700012207],\n [11016296041, 7.935528755187988],\n [11026691291, 9.892231941223145],\n [11026693333, 8.329731941223145],\n [11026695250, 11.073094367980957],\n [11026696416, 9.323094367980957],\n [11037193791, 12.413228034973145],\n [11037195125, 10.444478034973145],\n [11046151666, 13.924748420715332],\n [11046154625, 11.705998420715332],\n [11046155666, 10.228405952453613],\n [11046156583, 8.750805854797363],\n [11046157500, 7.273205757141113],\n [11046158416, 5.795605659484863],\n [11046159375, 4.318005561828613],\n [11046160375, 0.3925905227661133],\n [11142101958, 1.8320808410644531],\n [11157123166, 3.6078805923461914],\n [11157125416, 5.556069374084473],\n [11166258041, 7.825882911682129],\n [11176659583, 9.78261661529541],\n [11176662166, 8.22011661529541],\n [11192579791, 10.963448524475098],\n [11192581791, 9.213448524475098],\n [11192583791, 12.30361270904541],\n [11192585083, 10.33486270904541],\n [11199880333, 13.815102577209473],\n [11199882166, 11.596352577209473],\n [11199883250, 10.118760108947754],\n [11199884208, 8.641160011291504],\n [11199885125, 7.163559913635254],\n [11199886041, 5.685959815979004],\n [11199886958, 4.208359718322754],\n [11199887916, 0.2829751968383789],\n [11290280500, 1.7225265502929688],\n [11301166458, 3.498326301574707],\n [11307445291, 5.446484565734863],\n [11323843791, 7.7162981033325195],\n [11339677500, 9.6730318069458],\n [11339679375, 8.1105318069458],\n [11339681416, 10.853894233703613],\n [11339682666, 9.103894233703613],\n [11339684583, 12.193997383117676],\n [11339685750, 10.225247383117676],\n [11351282291, 13.705548286437988],\n [11351284291, 11.486798286437988],\n [11351285416, 10.00920581817627],\n [11351286500, 8.53160572052002],\n [11351287708, 7.0540056228637695],\n [11351288791, 5.5764055252075195],\n [11351289875, 4.0988054275512695],\n [11351291125, 0.17339038848876953],\n [11459265375, 1.6129112243652344],\n [11459271833, 3.2944679260253906],\n [11479420041, 5.336899757385254],\n [11497722458, 7.60671329498291],\n [11514445583, 9.563446998596191],\n [11514448333, 8.000946998596191],\n [11525430250, 10.744309425354004],\n [11525432083, 8.994309425354004],\n [11531662291, 12.084473609924316],\n [11531664625, 10.115723609924316],\n [11545973750, 13.595993995666504],\n [11545976125, 11.377243995666504],\n [11545977125, 9.899651527404785],\n [11545978041, 8.422051429748535],\n [11545978958, 6.944451332092285],\n [11545979875, 5.466851234436035],\n [11545980833, 3.989251136779785],\n [11545981833, 0.06386661529541016],\n [11637145541, 1.5034637451171875],\n [11646080291, 3.2986268997192383],\n [11655690333, 5.2468156814575195],\n [11666421916, 7.516659736633301],\n [11676161250, 9.474095344543457],\n [11676163416, 7.911595344543457],\n [11676165416, 10.654927253723145],\n [11676166750, 8.904927253723145],\n [11684479916, 11.99516773223877],\n [11684481708, 10.02641773223877],\n [11694955791, 13.506688117980957],\n [11694958083, 11.287938117980957],\n [11694959291, 9.810345649719238],\n [11694960416, 8.332745552062988],\n [11694961500, 6.855145454406738],\n [11694962625, 5.377545356750488],\n [11694963750, 3.8999452590942383],\n [11694964916, -0.02543926239013672],\n [11793064583, 1.4964265823364258],\n [11801811458, 3.2986574172973633],\n [11809493291, 5.2468461990356445],\n [11815791500, 7.516659736633301],\n [11837618083, 9.473362922668457],\n [11837620291, 7.910862922668457],\n [11837622083, 10.65422534942627],\n [11837623208, 8.90422534942627],\n [11837624875, 11.994328498840332],\n [11837625916, 10.025578498840332],\n [11849392958, 13.505879402160645],\n [11849395000, 11.287129402160645],\n [11849396166, 9.809536933898926],\n [11849397291, 8.331936836242676],\n [11849398333, 6.854336738586426],\n [11849399375, 5.376736640930176],\n [11849400458, 3.899136543273926],\n [11849401500, -0.02627849578857422],\n [11945996375, 1.4964265823364258],\n [11954879916, 3.2986574172973633],\n [11964169833, 5.2468461990356445],\n [11971820291, 7.516690254211426],\n [11984360375, 9.473393440246582],\n [11984362416, 7.910893440246582],\n [11984364666, 10.65422534942627],\n [11984365875, 8.90422534942627],\n [11993308500, 11.994359016418457],\n [11993309791, 10.025609016418457],\n [11999589625, 13.505879402160645],\n [11999590958, 11.287129402160645],\n [12005909375, 9.809536933898926],\n [12005910416, 8.331936836242676],\n [12005911166, 6.854336738586426],\n [12005911916, 5.376736640930176],\n [12005912708, 3.899136543273926],\n [12005913541, -0.02627849578857422],\n [12094932958, 1.4964570999145508],\n [12107397875, 3.2986268997192383],\n [12123030833, 5.2468156814575195],\n [12123032791, 7.516659736633301],\n [12142997375, 9.473362922668457],\n [12142999750, 7.910862922668457],\n [12143001625, 10.65422534942627],\n [12143002833, 8.90422534942627],\n [12143004583, 11.994328498840332],\n [12143005666, 10.025578498840332],\n [12156182250, 13.505879402160645],\n [12156184208, 11.287129402160645],\n [12156185375, 9.809536933898926],\n [12156186333, 8.331936836242676],\n [12156187250, 6.854336738586426],\n [12156188166, 5.376736640930176],\n [12156189083, 3.899136543273926],\n [12156190125, -0.02627849578857422],\n [12255301583, 1.617100715637207],\n [12263787541, 3.2986574172973633],\n [12273490541, 5.247906684875488],\n [12284254541, 7.517926216125488],\n [12294010708, 9.47465991973877],\n [12294013166, 7.9121599197387695],\n [12294015166, 10.655491828918457],\n [12294016375, 8.905491828918457],\n [12306510041, 11.995732307434082],\n [12306512166, 10.026982307434082],\n [12312797208, 13.507283210754395],\n [12312800041, 11.288533210754395],\n [12312801083, 9.810940742492676],\n [12312802000, 8.333340644836426],\n [12312802916, 6.855740547180176],\n [12312803833, 5.378140449523926],\n [12312804750, 3.900540351867676],\n [12312805750, -0.02487468719482422],\n [12412272458, 1.4963960647583008],\n [12420502333, 3.2986574172973633],\n [12430569500, 5.2468156814575195],\n [12441200041, 7.516659736633301],\n [12456973208, 9.473393440246582],\n [12456975541, 7.910893440246582],\n [12456977458, 10.654255867004395],\n [12456978666, 8.904255867004395],\n [12456980458, 11.994412422180176],\n [12456981583, 10.025662422180176],\n [12468596125, 13.505963325500488],\n [12468597708, 11.287213325500488],\n [12468598875, 9.80962085723877],\n [12468600000, 8.33202075958252],\n [12468601041, 6.8544206619262695],\n [12468602125, 5.3768205642700195],\n [12468603416, 3.8992204666137695],\n [12468604541, -0.02619457244873047],\n [12565110458, 1.4964265823364258],\n [12573889833, 3.2986574172973633],\n [12583136625, 5.2468461990356445],\n [12589988083, 7.516690254211426],\n [12602705666, 9.473393440246582],\n [12602707625, 7.910893440246582],\n [12602709541, 10.65422534942627],\n [12602710791, 8.90422534942627],\n [12615077666, 11.994389533996582],\n [12615079041, 10.025639533996582],\n [12622640541, 13.50590991973877],\n [12622642583, 11.28715991973877],\n [12622643666, 9.80956745147705],\n [12622644625, 8.3319673538208],\n [12622645541, 6.854367256164551],\n [12622646458, 5.376767158508301],\n [12622647375, 3.899167060852051],\n [12622648375, -0.02624797821044922],\n [12712905333, 1.4964799880981445],\n [12726887083, 3.2986268997192383],\n [12736326000, 5.2468156814575195],\n [12742815458, 7.516659736633301],\n [12755360666, 9.473362922668457],\n [12755362750, 7.910862922668457],\n [12761633791, 10.654194831848145],\n [12761635208, 8.904194831848145],\n [12767878583, 11.994359016418457],\n [12767879833, 10.025609016418457],\n [12788602125, 13.505879402160645],\n [12788604041, 11.287129402160645],\n [12788605000, 9.809536933898926],\n [12788605916, 8.331936836242676],\n [12788606833, 6.854336738586426],\n [12788607750, 5.376736640930176],\n [12788608708, 3.899136543273926],\n [12788609708, -0.02624797821044922],\n [12866386083, 1.4964265823364258],\n [12877738166, 3.2986574172973633],\n [12884012291, 5.2468156814575195],\n [12899734875, 7.516629219055176],\n [12915539666, 9.473362922668457],\n [12915541833, 7.910862922668457],\n [12915543916, 10.65422534942627],\n [12915545166, 8.90422534942627],\n [12915546958, 11.994328498840332],\n [12915548083, 10.025578498840332],\n [12924181166, 13.505879402160645],\n [12924182375, 11.287129402160645],\n [12939781208, 9.809536933898926],\n [12939782416, 8.331936836242676],\n [12939783375, 6.854336738586426],\n [12939784208, 5.376736640930176],\n [12939785000, 3.899136543273926],\n [12939785833, -0.02627849578857422],\n ],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 15.85280501325518,\n n_cpu_percent_python: 58.95372800766973,\n n_gpu_percent: 0,\n n_growth_mb: 13.413040161132812,\n n_malloc_mb: 2366.0141983032227,\n n_mallocs: 243,\n n_peak_mb: 13.413040161132812,\n n_python_fraction: 0.37192399803769643,\n n_sys_percent: 1.7721340966865076,\n n_usage_fraction: 0.9809516071621144,\n },\n {\n line: \"doit2\",\n lineno: 19,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 2.566693282322446,\n n_cpu_percent_python: 12.965426382708367,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 0,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.42433226093041604,\n n_usage_fraction: 0.0,\n },\n {\n line: \"stuff\",\n lineno: 45,\n memory_samples: [\n [376561916, 46.03816890716553],\n [419515541, 7.945382118225098],\n ],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 2.1150691718295715,\n n_cpu_percent_python: 0.06865792500233953,\n n_gpu_percent: 0,\n n_growth_mb: 38.45994186401367,\n n_malloc_mb: 38.45994186401367,\n n_mallocs: 1,\n n_peak_mb: 38.45994186401367,\n n_python_fraction: 0.0003818475199016959,\n n_sys_percent: 0.0,\n n_usage_fraction: 0.015945526366630304,\n },\n ],\n lines: [\n {\n line: \"import numpy as np\\n\",\n lineno: 1,\n memory_samples: [\n [255127500, 1.4791831970214844],\n [292883416, 3.0510921478271484],\n [319242208, 4.622952461242676],\n [334186250, 6.100545883178711],\n [364484250, 7.5782270431518555],\n ],\n n_avg_mb: 1.4791831970214844,\n n_copy_mb_s: 0.17320883014245084,\n n_cpu_percent_c: 4.010810602239169,\n n_cpu_percent_python: 0.5492634000187162,\n n_gpu_percent: 0,\n n_growth_mb: 6.004800796508789,\n n_malloc_mb: 7.483983993530273,\n n_mallocs: 1,\n n_peak_mb: 6.004800796508789,\n n_python_fraction: 0.0017520807864979666,\n n_sys_percent: 0.0,\n n_usage_fraction: 0.003102866471255301,\n },\n {\n line: \"from numpy import linalg as LA\\n\",\n lineno: 4,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.0,\n n_cpu_percent_python: 0.0,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 1,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.0,\n n_usage_fraction: 0.0,\n },\n {\n line: \" x = [i*i for i in range(0,100000)][99999]\\n\",\n lineno: 12,\n memory_samples: [\n [428532500, 9.570051193237305],\n [445064208, 11.226824760437012],\n [467929458, 9.749224662780762],\n [467933333, 7.894305229187012],\n [651147208, 9.467050552368164],\n [661861583, 11.117934226989746],\n [668149041, 9.640334129333496],\n [668150333, 7.785323143005371],\n [810188791, 9.357297897338867],\n [819091291, 11.008158683776855],\n [827225333, 9.530558586120605],\n [827227250, 7.6755781173706055],\n [964097833, 9.248224258422852],\n [973085041, 10.89908504486084],\n [981253250, 9.42148494720459],\n [981254500, 7.56650447845459],\n [1113670791, 9.138654708862305],\n [1126232208, 10.789484977722168],\n [1140849791, 9.311884880065918],\n [1140851041, 7.456873893737793],\n [1267816125, 9.028757095336914],\n [1278337458, 10.679617881774902],\n [1294287916, 9.202017784118652],\n [1294289166, 7.347006797790527],\n [1424228291, 8.919004440307617],\n [1433313750, 10.569865226745605],\n [1441482708, 9.092265129089355],\n [1441483875, 7.2372541427612305],\n [1576166708, 8.809465408325195],\n [1586517375, 10.460295677185059],\n [1594678416, 8.982695579528809],\n [1594679583, 7.127715110778809],\n [1730114333, 8.699773788452148],\n [1739212375, 10.350634574890137],\n [1747344291, 8.873034477233887],\n [1747345666, 7.018054008483887],\n [1883137000, 8.589975357055664],\n [1898345333, 10.240836143493652],\n [1898347625, 8.763236045837402],\n [1898349000, 6.908255577087402],\n [2042904500, 8.480405807495117],\n [2042907958, 10.037023544311523],\n [2053159625, 8.653666496276855],\n [2053160916, 6.7986555099487305],\n [2196880416, 8.370790481567383],\n [2196883625, 9.927408218383789],\n [2204029583, 8.544051170349121],\n [2204030875, 6.689040184020996],\n [2338301750, 8.261251449584961],\n [2352917083, 9.912020683288574],\n [2359497791, 8.434420585632324],\n [2359499000, 6.579440116882324],\n [2501090625, 8.151735305786133],\n [2510295291, 9.802596092224121],\n [2519173666, 8.324995994567871],\n [2519174875, 6.470015525817871],\n [2651119791, 8.042112350463867],\n [2663691041, 9.69294261932373],\n [2672632583, 8.21534252166748],\n [2672633833, 6.3603315353393555],\n [2808274125, 7.932390213012695],\n [2817241083, 9.583250999450684],\n [2825362500, 8.105650901794434],\n [2825363708, 6.250670433044434],\n [2967276500, 7.823369979858398],\n [2967280416, 9.379987716674805],\n [2976146916, 7.996630668640137],\n [2976148208, 6.141619682312012],\n [3109490458, 7.713602066040039],\n [3122068833, 9.364432334899902],\n [3130361916, 7.886832237243652],\n [3130363083, 6.031821250915527],\n [3265027166, 7.603918075561523],\n [3271320291, 9.254679679870605],\n [3282568291, 7.7770795822143555],\n [3282569458, 5.9220991134643555],\n [3422217791, 7.494386672973633],\n [3437609416, 9.145247459411621],\n [3437611583, 7.667647361755371],\n [3437613041, 5.812666893005371],\n [3575513458, 7.384756088256836],\n [3584540708, 9.035616874694824],\n [3592703166, 7.558016777038574],\n [3592704333, 5.703036308288574],\n [3723742875, 7.275102615356445],\n [3734449208, 8.925963401794434],\n [3745659166, 7.448363304138184],\n [3745660250, 5.593352317810059],\n [3881893166, 7.165685653686523],\n [3897173333, 8.816546440124512],\n [3897175416, 7.338946342468262],\n [3897176666, 5.483965873718262],\n [4034441041, 7.056039810180664],\n [4050005958, 8.706870079040527],\n [4050007583, 7.229269981384277],\n [4050008958, 5.374289512634277],\n [4184483375, 6.946355819702148],\n [4197052708, 8.59711742401123],\n [4205576916, 7.1195173263549805],\n [4205578166, 5.2645063400268555],\n [4347725000, 6.836626052856445],\n [4347728041, 8.393243789672852],\n [4358553500, 7.009886741638184],\n [4358554583, 5.154875755310059],\n [4492837750, 6.727071762084961],\n [4502908041, 8.377902030944824],\n [4511011375, 6.900301933288574],\n [4511012541, 5.045321464538574],\n [4646531000, 6.617380142211914],\n [4661992208, 8.268240928649902],\n [4661994166, 6.790640830993652],\n [4661995500, 4.935660362243652],\n [4805872333, 6.50782585144043],\n [4805875458, 8.064443588256836],\n [4816663458, 6.681086540222168],\n [4816664916, 4.826075553894043],\n [4954285750, 6.398340225219727],\n [4963335000, 8.049201011657715],\n [4971800083, 6.571600914001465],\n [4971801291, 4.716620445251465],\n [5108196500, 6.288686752319336],\n [5123296458, 7.939547538757324],\n [5123298416, 6.461947441101074],\n [5123299708, 4.606966972351074],\n [5261455875, 6.179033279418945],\n [5270583000, 7.829894065856934],\n [5278670500, 6.352293968200684],\n [5278671833, 4.497313499450684],\n [5413466541, 6.069440841674805],\n [5423099541, 7.720301628112793],\n [5430323333, 6.242701530456543],\n [5430324625, 4.387721061706543],\n [5565807583, 5.959833145141602],\n [5575698250, 7.61063289642334],\n [5582189041, 6.13303279876709],\n [5582190291, 4.27805233001709],\n [5713625000, 5.850225448608398],\n [5726142000, 7.501086235046387],\n [5732466750, 6.023486137390137],\n [5732468041, 4.168475151062012],\n [5872050708, 5.741365432739258],\n [5881280666, 7.392195701599121],\n [5889371000, 5.914595603942871],\n [5889372208, 4.059615135192871],\n [6023858541, 5.631811141967773],\n [6033953416, 7.282641410827637],\n [6042215291, 5.805041313171387],\n [6042216500, 3.9500608444213867],\n [6176588416, 5.522188186645508],\n [6182908666, 7.173018455505371],\n [6201797875, 5.695418357849121],\n [6201799041, 3.840407371520996],\n [6331915791, 5.412542343139648],\n [6348609666, 7.063403129577637],\n [6348611833, 5.585803031921387],\n [6348613125, 3.7308225631713867],\n [6484444250, 5.302881240844727],\n [6496964458, 6.953742027282715],\n [6506744041, 5.476141929626465],\n [6506745250, 3.62113094329834],\n [6638721125, 5.193334579467773],\n [6651084000, 6.844195365905762],\n [6659817208, 5.366595268249512],\n [6659818375, 3.5115842819213867],\n [6788692208, 5.083703994750977],\n [6803875291, 6.73453426361084],\n [6811955708, 5.25693416595459],\n [6811956916, 3.401923179626465],\n [6942827708, 4.974020004272461],\n [6953656666, 6.624880790710449],\n [6959926041, 5.147280693054199],\n [6959927375, 3.292269706726074],\n [7096960208, 4.864442825317383],\n [7109526708, 6.515303611755371],\n [7124614083, 5.037703514099121],\n [7124615250, 3.182692527770996],\n [7254360708, 4.754880905151367],\n [7263431791, 6.4057416915893555],\n [7271670041, 4.9281415939331055],\n [7271671208, 3.0731611251831055],\n [7408255583, 4.645288467407227],\n [7417207291, 6.296149253845215],\n [7425292250, 4.818549156188965],\n [7425293541, 2.963568687438965],\n [7557260708, 4.535665512084961],\n [7569857958, 6.186495780944824],\n [7585415291, 4.708895683288574],\n [7585416416, 2.853884696960449],\n [7714997916, 4.42607307434082],\n [7730199916, 6.076933860778809],\n [7730201708, 4.599333763122559],\n [7730202916, 2.7443532943725586],\n [7866120000, 4.316427230834961],\n [7875908250, 5.967257499694824],\n [7890269833, 4.489657402038574],\n [7890271041, 2.634676933288574],\n [8013597291, 4.206743240356445],\n [8026055708, 5.857604026794434],\n [8032387416, 4.380003929138184],\n [8032388666, 2.5249929428100586],\n [8170270500, 4.097265243530273],\n [8180642250, 5.748095512390137],\n [8188875500, 4.270495414733887],\n [8188876625, 2.4155149459838867],\n [8320641916, 3.9876651763916016],\n [8332800958, 5.63852596282959],\n [8342211291, 4.16092586517334],\n [8342212500, 2.305914878845215],\n [8473975291, 3.8780956268310547],\n [8484424833, 5.528956413269043],\n [8495070500, 4.051356315612793],\n [8495071750, 2.196345329284668],\n [8626539708, 3.7685108184814453],\n [8636981708, 5.419371604919434],\n [8643245333, 3.9417715072631836],\n [8643246500, 2.0867605209350586],\n [8783219791, 3.6589794158935547],\n [8792149541, 5.309840202331543],\n [8800236916, 3.832240104675293],\n [8800238125, 1.977259635925293],\n [8935519958, 3.5494556427001953],\n [8950778666, 5.200316429138184],\n [8950780791, 3.7227163314819336],\n [8950782333, 1.8677358627319336],\n [9087624208, 3.439970016479492],\n [9096657916, 5.0908308029174805],\n [9104695375, 3.6132307052612305],\n [9104696583, 1.7588300704956055],\n [9238711333, 3.331697463989258],\n [9249853541, 4.982527732849121],\n [9258138375, 3.504927635192871],\n [9258139541, 1.649947166442871],\n [9393347833, 3.2223033905029297],\n [9409346291, 4.873133659362793],\n [9409348208, 3.395533561706543],\n [9409349583, 1.540553092956543],\n [9542842958, 3.1133060455322266],\n [9556594875, 4.76413631439209],\n [9564736583, 3.28653621673584],\n [9564737708, 1.4315252304077148],\n [9700385875, 3.0036983489990234],\n [9709378000, 4.654559135437012],\n [9717558041, 3.1769590377807617],\n [9717559333, 1.3219785690307617],\n [9849538500, 2.894113540649414],\n [9860017000, 4.544974327087402],\n [9877549916, 3.0673742294311523],\n [9877551125, 1.2123632431030273],\n [10003729750, 2.784605026245117],\n [10015718125, 4.4354658126831055],\n [10022006791, 2.9578657150268555],\n [10022007916, 1.1028547286987305],\n [10166653041, 2.675233840942383],\n [10166656458, 4.231851577758789],\n [10176171416, 2.848494529724121],\n [10176172583, 0.9934835433959961],\n [10309492333, 2.5655269622802734],\n [10322073083, 4.216357231140137],\n [10343426708, 2.7387571334838867],\n [10343427916, 0.8837461471557617],\n [10463716625, 2.455934524536133],\n [10475263291, 4.106764793395996],\n [10483376500, 2.629164695739746],\n [10483377708, 0.7741842269897461],\n [10613975750, 2.346220016479492],\n [10627739125, 3.9970502853393555],\n [10635846250, 2.5194501876831055],\n [10635847375, 0.6644392013549805],\n [10767835750, 2.236543655395508],\n [10779923500, 3.887373924255371],\n [10788059083, 2.409773826599121],\n [10788060250, 0.5547933578491211],\n [10926140750, 2.1269893646240234],\n [10935088083, 3.7778501510620117],\n [10943147250, 2.3002500534057617],\n [10943148708, 0.4452695846557617],\n [11075597208, 2.017404556274414],\n [11088158916, 3.6682348251342773],\n [11096836916, 2.1906347274780273],\n [11096838208, 0.33562374114990234],\n [11232944875, 1.9078807830810547],\n [11242620916, 3.558711051940918],\n [11257050708, 2.081110954284668],\n [11257052000, 0.22613048553466797],\n [11384783666, 1.7982349395751953],\n [11391132458, 3.4490652084350586],\n [11397366583, 1.9714651107788086],\n [11397367833, 0.1164541244506836],\n [11573774375, 1.6887569427490234],\n [11582847833, 3.3396177291870117],\n [11591304416, 1.8620176315307617],\n [11591305625, 0.007037162780761719],\n [11737134291, 1.6248445510864258],\n [11737137708, 3.181462287902832],\n [11747075916, 1.798105239868164],\n [11747077208, -0.05690574645996094],\n [11882963625, 1.6248445510864258],\n [11893308541, 3.275705337524414],\n [11907866833, 1.798105239868164],\n [11907868125, -0.05690574645996094],\n [12037364666, 1.6248979568481445],\n [12046407333, 3.275758743286133],\n [12054504875, 1.7981586456298828],\n [12054505958, -0.05682182312011719],\n [12184473750, 1.6248140335083008],\n [12196997083, 3.275674819946289],\n [12203330375, 1.798074722290039],\n [12203331625, -0.05693626403808594],\n [12343375875, 1.6248292922973633],\n [12353697041, 3.2756900787353516],\n [12366382375, 1.7980899810791016],\n [12366383625, -0.05689048767089844],\n [12501165625, 1.6248598098754883],\n [12519042541, 3.2756900787353516],\n [12519044416, 1.7980899810791016],\n [12519045666, -0.05689048767089844],\n [12651156250, 1.6247835159301758],\n [12663171666, 3.275644302368164],\n [12669437708, 1.798044204711914],\n [12669438958, -0.05696678161621094],\n [12815936958, 1.6249208450317383],\n [12815939958, 3.1815385818481445],\n [12826641666, 1.7981815338134766],\n [12826643083, -0.05682945251464844],\n ],\n n_avg_mb: 1.5563542872299383,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 3.2513205077474945,\n n_cpu_percent_python: 10.134091287434035,\n n_gpu_percent: 0,\n n_growth_mb: 1.562530517578125,\n n_malloc_mb: 250.06993865966797,\n n_mallocs: 81,\n n_peak_mb: 1.562530517578125,\n n_python_fraction: 0.0704750565601485,\n n_sys_percent: 0.21740526694453302,\n n_usage_fraction: 0.10367922069404875,\n },\n {\n line: \" y1 = [i*i for i in range(0,200000)][199999]\\n\",\n lineno: 13,\n memory_samples: [\n [467950083, 9.424517631530762],\n [480011041, 11.200347900390625],\n [501608208, 13.148506164550781],\n [534547000, 15.418411254882812],\n [555500041, 13.940811157226562],\n [555501500, 12.463211059570312],\n [555502500, 10.985610961914062],\n [555503458, 9.508010864257812],\n [555504583, 7.8679351806640625],\n [668153375, 9.315535545349121],\n [682672875, 11.09133529663086],\n [693283000, 13.03952407836914],\n [705307875, 15.309368133544922],\n [716903083, 13.831768035888672],\n [716904500, 12.354167938232422],\n [716905416, 10.876567840576172],\n [716906291, 9.398967742919922],\n [716907375, 7.758892059326172],\n [827231583, 9.205790519714355],\n [834454208, 10.982154846191406],\n [846991333, 12.930343627929688],\n [859534666, 15.200157165527344],\n [870443625, 13.722557067871094],\n [870444791, 12.244956970214844],\n [870445708, 10.767356872558594],\n [870446708, 9.289756774902344],\n [870447666, 7.649681091308594],\n [981257666, 9.09671688079834],\n [988426000, 10.872547149658203],\n [998615708, 12.820735931396484],\n [1013968958, 15.09054946899414],\n [1025432666, 13.61294937133789],\n [1025433833, 12.13534927368164],\n [1025434833, 10.65774917602539],\n [1025435791, 9.18014907836914],\n [1025436791, 7.540073394775391],\n [1140854333, 8.987086296081543],\n [1140856500, 10.668673515319824],\n [1154928250, 12.711074829101562],\n [1167686333, 14.980918884277344],\n [1184549000, 13.503318786621094],\n [1184550416, 12.025718688964844],\n [1184551458, 10.548118591308594],\n [1184552458, 9.070518493652344],\n [1184553458, 7.430442810058594],\n [1294292791, 8.877219200134277],\n [1294294875, 10.558806419372559],\n [1315191416, 12.601146697998047],\n [1315193375, 14.870990753173828],\n [1326181208, 13.393390655517578],\n [1326182500, 11.915790557861328],\n [1326183625, 10.438190460205078],\n [1326184458, 8.960590362548828],\n [1326185583, 7.320484161376953],\n [1441486833, 8.76746654510498],\n [1451792333, 10.543296813964844],\n [1462320958, 12.491485595703125],\n [1474265541, 14.761329650878906],\n [1485631291, 13.283729553222656],\n [1485632291, 11.806129455566406],\n [1485633291, 10.328529357910156],\n [1485634291, 8.850929260253906],\n [1485635291, 7.210853576660156],\n [1594682500, 8.657927513122559],\n [1604963750, 10.433757781982422],\n [1615432250, 12.381877899169922],\n [1621695125, 14.651721954345703],\n [1634493000, 13.174121856689453],\n [1634494125, 11.696521759033203],\n [1634495083, 10.218921661376953],\n [1634496041, 8.741321563720703],\n [1634497041, 7.101245880126953],\n [1747348541, 8.548266410827637],\n [1755371166, 10.324043273925781],\n [1767914291, 12.272201538085938],\n [1780037375, 14.542015075683594],\n [1791382833, 13.064414978027344],\n [1791385000, 11.586814880371094],\n [1791385958, 10.109214782714844],\n [1791386875, 8.631614685058594],\n [1791387875, 6.991539001464844],\n [1898352000, 8.438437461853027],\n [1906989791, 10.21426773071289],\n [1921336458, 12.162425994873047],\n [1930364750, 14.432270050048828],\n [1945026333, 12.954669952392578],\n [1945027666, 11.477069854736328],\n [1945028583, 9.999469757080078],\n [1945029458, 8.521869659423828],\n [1945030375, 6.881763458251953],\n [2053164416, 8.32886791229248],\n [2064736083, 10.104667663574219],\n [2074923416, 12.0528564453125],\n [2081200625, 14.322647094726562],\n [2098845208, 12.845046997070312],\n [2098846416, 11.367446899414062],\n [2098847500, 9.889846801757812],\n [2098848500, 8.412246704101562],\n [2098849500, 6.7721710205078125],\n [2204033833, 8.219252586364746],\n [2215335958, 9.99508285522461],\n [2226162458, 11.94327163696289],\n [2238716250, 14.213115692138672],\n [2252120250, 12.735515594482422],\n [2252121333, 11.257915496826172],\n [2252122291, 9.780315399169922],\n [2252123208, 8.302715301513672],\n [2252124166, 6.662609100341797],\n [2359502083, 8.109652519226074],\n [2370129750, 9.885482788085938],\n [2376411791, 11.833641052246094],\n [2392833625, 14.103485107421875],\n [2405350166, 12.625885009765625],\n [2405351250, 11.148284912109375],\n [2405352208, 9.670684814453125],\n [2405353125, 8.193084716796875],\n [2405354125, 6.552978515625],\n [2519178875, 8.000227928161621],\n [2529543875, 9.776058197021484],\n [2540148041, 11.724246978759766],\n [2558420583, 13.994091033935547],\n [2558422291, 12.516490936279297],\n [2558423416, 11.038890838623047],\n [2558424500, 9.561290740966797],\n [2558425541, 8.083690643310547],\n [2558426625, 6.443614959716797],\n [2672636833, 7.8905439376831055],\n [2682918583, 9.666374206542969],\n [2693627750, 11.61456298828125],\n [2701119666, 13.884407043457031],\n [2716928416, 12.406806945800781],\n [2716929583, 10.929206848144531],\n [2716930500, 9.451606750488281],\n [2716931375, 7.974006652832031],\n [2716932291, 6.333900451660156],\n [2825367125, 7.780882835388184],\n [2832063750, 9.556713104248047],\n [2843282958, 11.504901885986328],\n [2858265166, 13.774715423583984],\n [2867822500, 12.297115325927734],\n [2867823750, 10.819515228271484],\n [2867824666, 9.341915130615234],\n [2867825583, 7.864315032958984],\n [2867826500, 6.224239349365234],\n [2976151416, 7.671832084655762],\n [2982453250, 9.4476318359375],\n [3005093375, 11.395790100097656],\n [3005095291, 13.665634155273438],\n [3034657708, 12.188034057617188],\n [3034659416, 10.710433959960938],\n [3034660333, 9.232833862304688],\n [3034661208, 7.7552337646484375],\n [3034662125, 6.1151275634765625],\n [3130366000, 7.562033653259277],\n [3147039333, 9.33786392211914],\n [3147041500, 11.286052703857422],\n [3157046125, 13.555866241455078],\n [3174617541, 12.078266143798828],\n [3174618583, 10.600666046142578],\n [3174619583, 9.123065948486328],\n [3174620458, 7.645465850830078],\n [3174621416, 6.005390167236328],\n [3282572791, 7.4523115158081055],\n [3293275416, 9.228141784667969],\n [3299548708, 11.176300048828125],\n [3315505500, 13.446144104003906],\n [3328157916, 11.968544006347656],\n [3328159291, 10.490943908691406],\n [3328160333, 9.013343811035156],\n [3328161333, 7.535743713378906],\n [3328162333, 5.895637512207031],\n [3437616291, 7.342848777770996],\n [3449239000, 9.11867904663086],\n [3459936166, 11.06686782836914],\n [3471865958, 13.336711883544922],\n [3483698333, 11.859111785888672],\n [3483699416, 10.381511688232422],\n [3483700375, 8.903911590576172],\n [3483701250, 7.426311492919922],\n [3483702208, 5.786205291748047],\n [3592707750, 7.233248710632324],\n [3599236458, 9.009078979492188],\n [3613642500, 10.957237243652344],\n [3620071666, 13.227081298828125],\n [3636928458, 11.749481201171875],\n [3636929625, 10.271881103515625],\n [3636930541, 8.794281005859375],\n [3636931416, 7.316680908203125],\n [3636932333, 5.67657470703125],\n [3745664583, 7.123595237731934],\n [3756017250, 8.899394989013672],\n [3766550750, 10.847583770751953],\n [3778435291, 13.117427825927734],\n [3790088583, 11.639827728271484],\n [3790089625, 10.162227630615234],\n [3790090583, 8.684627532958984],\n [3790091541, 7.207027435302734],\n [3790092458, 5.566951751708984],\n [3897179625, 7.014147758483887],\n [3915726791, 8.789947509765625],\n [3915728708, 10.738136291503906],\n [3931954708, 13.007949829101562],\n [3943414666, 11.530349731445312],\n [3943415833, 10.052749633789062],\n [3943416833, 8.575149536132812],\n [3943417791, 7.0975494384765625],\n [3943418750, 5.4574737548828125],\n [4050012166, 6.904471397399902],\n [4059490750, 8.680301666259766],\n [4072037458, 10.628459930419922],\n [4084401375, 12.898273468017578],\n [4095851958, 11.420673370361328],\n [4095853166, 9.943073272705078],\n [4095854125, 8.465473175048828],\n [4095855041, 6.987873077392578],\n [4095856000, 5.347797393798828],\n [4205582125, 6.7947187423706055],\n [4222331833, 8.570549011230469],\n [4222333833, 10.51873779296875],\n [4234443333, 12.788551330566406],\n [4244777291, 11.310951232910156],\n [4244778500, 9.833351135253906],\n [4244779416, 8.355751037597656],\n [4244780375, 6.878150939941406],\n [4244781333, 5.238075256347656],\n [4358557708, 6.685088157653809],\n [4365447958, 8.460918426513672],\n [4379415666, 10.409076690673828],\n [4388705500, 12.678852081298828],\n [4402726291, 11.201251983642578],\n [4402727541, 9.723651885986328],\n [4402728583, 8.246051788330078],\n [4402729500, 6.768451690673828],\n [4402731458, 5.128345489501953],\n [4511016083, 6.575533866882324],\n [4517762000, 8.351364135742188],\n [4531949708, 10.299522399902344],\n [4540447250, 12.569366455078125],\n [4555231333, 11.091766357421875],\n [4555232375, 9.614166259765625],\n [4555233291, 8.136566162109375],\n [4555234166, 6.658966064453125],\n [4555235083, 5.01885986328125],\n [4661999000, 6.465842247009277],\n [4672057916, 8.24167251586914],\n [4684632291, 10.189830780029297],\n [4702990625, 12.459644317626953],\n [4702992583, 10.982044219970703],\n [4702994083, 9.504444122314453],\n [4702995291, 8.026844024658203],\n [4702996500, 6.549243927001953],\n [4702997708, 4.909168243408203],\n [4816668083, 6.356287956237793],\n [4823797375, 8.132118225097656],\n [4836394625, 10.080276489257812],\n [4846976125, 12.350120544433594],\n [4860942375, 10.872520446777344],\n [4860943625, 9.394920349121094],\n [4860944625, 7.917320251464844],\n [4860945625, 6.439720153808594],\n [4860946625, 4.799613952636719],\n [4971805333, 6.246832847595215],\n [4980344583, 8.022663116455078],\n [4992514291, 9.97085189819336],\n [5005164791, 12.24069595336914],\n [5023308708, 10.76309585571289],\n [5023310750, 9.28549575805664],\n [5023312208, 7.807895660400391],\n [5023313541, 6.330295562744141],\n [5023314875, 4.690189361572266],\n [5123303583, 6.137148857116699],\n [5134428958, 7.9129791259765625],\n [5146181666, 9.861167907714844],\n [5157165708, 12.131011962890625],\n [5167807208, 10.653411865234375],\n [5167808375, 9.175811767578125],\n [5167809291, 7.698211669921875],\n [5167810166, 6.220611572265625],\n [5167811083, 4.580535888671875],\n [5278674916, 6.027525901794434],\n [5288734833, 7.803356170654297],\n [5299486333, 9.751514434814453],\n [5311409083, 12.021358489990234],\n [5322814041, 10.543758392333984],\n [5322815333, 9.066158294677734],\n [5322816250, 7.588558197021484],\n [5322817208, 6.110958099365234],\n [5322818250, 4.470882415771484],\n [5430328083, 5.917933464050293],\n [5441573958, 7.693733215332031],\n [5452078208, 9.641921997070312],\n [5470314583, 11.911766052246094],\n [5470316416, 10.434165954589844],\n [5470317708, 8.956565856933594],\n [5470318833, 7.478965759277344],\n [5470319958, 6.001365661621094],\n [5470321125, 4.361289978027344],\n [5582194000, 5.80826473236084],\n [5592824666, 7.584095001220703],\n [5604736458, 9.53225326538086],\n [5616646666, 11.80209732055664],\n [5628024000, 10.32449722290039],\n [5628025125, 8.84689712524414],\n [5628026208, 7.369297027587891],\n [5628027291, 5.891696929931641],\n [5628028375, 4.251621246337891],\n [5732471291, 5.698687553405762],\n [5746847625, 7.474540710449219],\n [5757285625, 9.4227294921875],\n [5763546125, 11.692573547363281],\n [5776178166, 10.214973449707031],\n [5776179291, 8.737373352050781],\n [5776180291, 7.259773254394531],\n [5776181208, 5.782173156738281],\n [5776182166, 4.142097473144531],\n [5889375500, 5.589827537536621],\n [5896965125, 7.365657806396484],\n [5909528000, 9.31381607055664],\n [5920176500, 11.583660125732422],\n [5932745458, 10.106060028076172],\n [5932746541, 8.628459930419922],\n [5932747583, 7.150859832763672],\n [5932748541, 5.673259735107422],\n [5932749541, 4.033153533935547],\n [6042220375, 5.480273246765137],\n [6052706708, 7.256103515625],\n [6059516583, 9.204292297363281],\n [6070229500, 11.474136352539062],\n [6082723750, 9.996536254882812],\n [6082724916, 8.518936157226562],\n [6082725916, 7.0413360595703125],\n [6082726791, 5.5637359619140625],\n [6082727708, 3.9236602783203125],\n [6201802458, 5.370619773864746],\n [6201804333, 7.052206993103027],\n [6216203875, 9.094608306884766],\n [6234602791, 11.364452362060547],\n [6234604625, 9.886852264404297],\n [6234605875, 8.409252166748047],\n [6234607041, 6.931652069091797],\n [6234608166, 5.454051971435547],\n [6234609375, 3.813976287841797],\n [6348616125, 5.261004447937012],\n [6366779208, 7.036834716796875],\n [6366781333, 8.985023498535156],\n [6390473000, 11.254837036132812],\n [6390474875, 9.777236938476562],\n [6390476041, 8.299636840820312],\n [6390477041, 6.8220367431640625],\n [6390478083, 5.3444366455078125],\n [6390479208, 3.7043609619140625],\n [6506749583, 5.15134334564209],\n [6517145583, 6.927173614501953],\n [6527678208, 8.875362396240234],\n [6539907833, 11.145206451416016],\n [6551332375, 9.667606353759766],\n [6551333750, 8.190006256103516],\n [6551334708, 6.712406158447266],\n [6551335583, 5.234806060791016],\n [6551336583, 3.5947303771972656],\n [6659821750, 5.041796684265137],\n [6670074916, 6.817626953125],\n [6680510333, 8.765815734863281],\n [6688715083, 11.035659790039062],\n [6703736250, 9.558059692382812],\n [6703737291, 8.080459594726562],\n [6703738250, 6.6028594970703125],\n [6703739125, 5.1252593994140625],\n [6703740041, 3.4851531982421875],\n [6811960416, 4.932135581970215],\n [6822391916, 6.707965850830078],\n [6832958583, 8.65615463256836],\n [6851142875, 10.92599868774414],\n [6851144583, 9.44839859008789],\n [6851145875, 7.970798492431641],\n [6851147041, 6.493198394775391],\n [6851148208, 5.015598297119141],\n [6851149375, 3.3755226135253906],\n [6959931750, 4.822482109069824],\n [6981281541, 6.598335266113281],\n [6981283541, 8.546524047851562],\n [7003760208, 10.816337585449219],\n [7003762250, 9.338737487792969],\n [7003763541, 7.861137390136719],\n [7003764750, 6.383537292480469],\n [7003765875, 4.905937194824219],\n [7003767041, 3.2658615112304688],\n [7124618791, 4.712904930114746],\n [7124620708, 6.394492149353027],\n [7139070708, 8.436893463134766],\n [7151226625, 10.706737518310547],\n [7168924875, 9.229137420654297],\n [7168926000, 7.751537322998047],\n [7168926916, 6.273937225341797],\n [7168927833, 4.796337127685547],\n [7168928750, 3.156261444091797],\n [7271675208, 4.6033735275268555],\n [7280306708, 6.379203796386719],\n [7286626166, 8.327362060546875],\n [7303586708, 10.597206115722656],\n [7309867416, 9.119606018066406],\n [7309870541, 7.642005920410156],\n [7309871375, 6.164405822753906],\n [7309872166, 4.686805725097656],\n [7309873000, 3.0466995239257812],\n [7425296791, 4.493781089782715],\n [7432751708, 6.269611358642578],\n [7445323166, 8.217769622802734],\n [7453590500, 10.487613677978516],\n [7466128208, 9.010013580322266],\n [7466129333, 7.532413482666016],\n [7466130250, 6.054813385009766],\n [7466131125, 4.577213287353516],\n [7466132083, 2.9371376037597656],\n [7585419750, 4.384127616882324],\n [7585421583, 6.0656843185424805],\n [7600045291, 8.108085632324219],\n [7618278500, 10.3779296875],\n [7618280291, 8.90032958984375],\n [7618281541, 7.4227294921875],\n [7618282708, 5.94512939453125],\n [7618283833, 4.467529296875],\n [7618285000, 2.82745361328125],\n [7730206083, 4.274535179138184],\n [7739121833, 6.050365447998047],\n [7751067958, 7.998554229736328],\n [7763611625, 10.268367767333984],\n [7773978041, 8.790767669677734],\n [7773979083, 7.313167572021484],\n [7773980000, 5.835567474365234],\n [7773980916, 4.357967376708984],\n [7773981875, 2.7178916931152344],\n [7890274416, 4.164889335632324],\n [7890276458, 5.8464765548706055],\n [7899436500, 7.888877868652344],\n [7922984291, 10.15869140625],\n [7922986000, 8.68109130859375],\n [7922987125, 7.2034912109375],\n [7922988208, 5.72589111328125],\n [7922989333, 4.248291015625],\n [7922990458, 2.60821533203125],\n [8032392083, 4.055205345153809],\n [8052683250, 5.831058502197266],\n [8052685166, 7.779247283935547],\n [8075218333, 10.049060821533203],\n [8075220166, 8.571460723876953],\n [8075221458, 7.093860626220703],\n [8075222666, 5.616260528564453],\n [8075223791, 4.138660430908203],\n [8075224958, 2.498584747314453],\n [8188880083, 3.9457273483276367],\n [8199114875, 5.7215576171875],\n [8206809333, 7.669746398925781],\n [8221570375, 9.939559936523438],\n [8228816583, 8.461959838867188],\n [8228817708, 6.9843597412109375],\n [8228818750, 5.5067596435546875],\n [8228821125, 4.0291595458984375],\n [8228822125, 2.3890838623046875],\n [8342216583, 3.83615779876709],\n [8352695375, 5.611957550048828],\n [8363300708, 7.560146331787109],\n [8375225958, 9.82999038696289],\n [8392941833, 8.35239028930664],\n [8392943000, 6.874790191650391],\n [8392944166, 5.397190093994141],\n [8392945125, 3.9195899963378906],\n [8392946125, 2.2795143127441406],\n [8495075250, 3.726557731628418],\n [8505475458, 5.502388000488281],\n [8516066666, 7.4505767822265625],\n [8527981166, 9.720420837402344],\n [8539415500, 8.242820739746094],\n [8539416916, 6.765220642089844],\n [8539417916, 5.287620544433594],\n [8539418875, 3.8100204467773438],\n [8539419833, 2.1699447631835938],\n [8649702166, 3.7112159729003906],\n [8658581833, 5.392803192138672],\n [8669098541, 7.340991973876953],\n [8681025250, 9.610836029052734],\n [8692400875, 8.133235931396484],\n [8692402208, 6.655635833740234],\n [8692403208, 5.178035736083984],\n [8692404125, 3.7004356384277344],\n [8692405291, 2.0603599548339844],\n [8800241791, 3.507472038269043],\n [8809383500, 5.283302307128906],\n [8815657666, 7.2314605712890625],\n [8839327000, 9.501304626464844],\n [8839328875, 8.023704528808594],\n [8839329958, 6.546104431152344],\n [8839331000, 5.068504333496094],\n [8839332041, 3.5909042358398438],\n [8839333125, 1.9508285522460938],\n [8950785458, 3.3979177474975586],\n [8959493416, 5.173748016357422],\n [8973360375, 7.121906280517578],\n [8980815625, 9.39175033569336],\n [8996633041, 7.914150238037109],\n [8996634291, 6.436550140380859],\n [8996635333, 4.958950042724609],\n [8996636291, 3.4813499450683594],\n [8996637333, 1.8412437438964844],\n [9104700125, 3.2890424728393555],\n [9113232875, 5.065467834472656],\n [9119527750, 7.0136260986328125],\n [9134379083, 9.283470153808594],\n [9144595250, 7.805870056152344],\n [9144596541, 6.328269958496094],\n [9144597541, 4.850669860839844],\n [9144598541, 3.3730697631835938],\n [9144599583, 1.7329940795898438],\n [9258142833, 3.180159568786621],\n [9268505250, 4.955989837646484],\n [9276182666, 6.904178619384766],\n [9291074458, 9.173992156982422],\n [9302424541, 7.696392059326172],\n [9302425875, 6.218791961669922],\n [9302426833, 4.741191864013672],\n [9302427750, 3.263591766357422],\n [9302429291, 1.6234855651855469],\n [9409353000, 3.070734977722168],\n [9416169750, 4.847198486328125],\n [9432215166, 6.795356750488281],\n [9444124708, 9.065200805664062],\n [9455917708, 7.5876007080078125],\n [9455918833, 6.1100006103515625],\n [9455919791, 4.6324005126953125],\n [9455920708, 3.1548004150390625],\n [9455921666, 1.5147247314453125],\n [9564740958, 2.96176815032959],\n [9575088750, 4.737567901611328],\n [9585687458, 6.685756683349609],\n [9597607791, 8.95560073852539],\n [9609052458, 7.478000640869141],\n [9609053708, 6.000400543212891],\n [9609054833, 4.522800445556641],\n [9609055833, 3.0452003479003906],\n [9609056833, 1.4051246643066406],\n [9717562416, 2.8521909713745117],\n [9726166083, 4.628021240234375],\n [9732440250, 6.576179504394531],\n [9749529833, 8.846023559570312],\n [9755954916, 7.3684234619140625],\n [9755956166, 5.8908233642578125],\n [9755957083, 4.4132232666015625],\n [9755957916, 2.9356231689453125],\n [9755958833, 1.2955169677734375],\n [9877554291, 2.7426061630249023],\n [9877556125, 4.424162864685059],\n [9898585458, 6.466564178466797],\n [9898587625, 8.736408233642578],\n [9909523750, 7.258808135986328],\n [9909524916, 5.781208038330078],\n [9909525791, 4.303607940673828],\n [9909526541, 2.826007843017578],\n [9909527375, 1.1859016418457031],\n [10022011125, 2.6330671310424805],\n [10034561666, 4.408866882324219],\n [10051395250, 6.3570556640625],\n [10051397250, 8.626899719238281],\n [10068887916, 7.149299621582031],\n [10068889166, 5.671699523925781],\n [10068890208, 4.194099426269531],\n [10068891166, 2.7164993286132812],\n [10068892166, 1.0763931274414062],\n [10176176125, 2.523695945739746],\n [10187819000, 4.299495697021484],\n [10204757041, 6.247684478759766],\n [10204759166, 8.517528533935547],\n [10228388958, 7.039928436279297],\n [10228390458, 5.562328338623047],\n [10228391416, 4.084728240966797],\n [10228392333, 2.607128143310547],\n [10228393333, 0.9670219421386719],\n [10343431333, 2.4139585494995117],\n [10343433166, 4.095545768737793],\n [10351890000, 6.137947082519531],\n [10363845958, 8.407791137695312],\n [10375247083, 6.9301910400390625],\n [10375248166, 5.4525909423828125],\n [10375249291, 3.9749908447265625],\n [10375250166, 2.4973907470703125],\n [10375251208, 0.8573150634765625],\n [10483380708, 2.304396629333496],\n [10493674791, 4.080226898193359],\n [10501163750, 6.028415679931641],\n [10516118083, 8.298229217529297],\n [10527505583, 6.820629119873047],\n [10527506625, 5.343029022216797],\n [10527507541, 3.865428924560547],\n [10527508416, 2.387828826904297],\n [10527510541, 0.7477226257324219],\n [10635850375, 2.1946516036987305],\n [10646199125, 3.9704818725585938],\n [10656751875, 5.918670654296875],\n [10663705250, 8.188514709472656],\n [10679894000, 6.710914611816406],\n [10679895250, 5.233314514160156],\n [10679896333, 3.7557144165039062],\n [10679897291, 2.2781143188476562],\n [10679898291, 0.6380081176757812],\n [10788063583, 2.085005760192871],\n [10804907041, 3.8608360290527344],\n [10804909041, 5.809024810791016],\n [10816468125, 8.078838348388672],\n [10840273875, 6.601238250732422],\n [10840275083, 5.123638153076172],\n [10840276041, 3.646038055419922],\n [10840276958, 2.168437957763672],\n [10840277916, 0.5283622741699219],\n [10943152208, 1.9754819869995117],\n [10949585416, 3.751312255859375],\n [10961035541, 5.699501037597656],\n [10976165333, 7.9693145751953125],\n [10982958166, 6.4917144775390625],\n [10982959416, 5.0141143798828125],\n [10982960333, 3.5365142822265625],\n [10982961250, 2.0589141845703125],\n [10982962166, 0.4188385009765625],\n [11096841500, 1.8658361434936523],\n [11107369708, 3.6416664123535156],\n [11118517000, 5.589855194091797],\n [11130516500, 7.859699249267578],\n [11142093625, 6.382099151611328],\n [11142094750, 4.904499053955078],\n [11142095875, 3.426898956298828],\n [11142096875, 1.9492988586425781],\n [11142097833, 0.3092231750488281],\n [11257055291, 1.756342887878418],\n [11257057291, 3.437930107116699],\n [11266261333, 5.4803314208984375],\n [11283573625, 7.750144958496094],\n [11290272291, 6.272544860839844],\n [11290273625, 4.794944763183594],\n [11290274625, 3.3173446655273438],\n [11290275541, 1.8397445678710938],\n [11290276500, 0.19966888427734375],\n [11403672750, 1.7409095764160156],\n [11409931750, 3.422496795654297],\n [11425560125, 5.370685577392578],\n [11438276833, 7.640529632568359],\n [11459236583, 6.162929534912109],\n [11459240375, 4.685329437255859],\n [11459243583, 3.2077293395996094],\n [11459246625, 1.7301292419433594],\n [11459249958, 0.09005355834960938],\n [11591309458, 1.5372495651245117],\n [11602022208, 3.313079833984375],\n [11608272125, 5.261268615722656],\n [11622100375, 7.5311126708984375],\n [11637136625, 6.0535125732421875],\n [11637137916, 4.5759124755859375],\n [11637138875, 3.0983123779296875],\n [11637139750, 1.6207122802734375],\n [11637140708, -0.0193939208984375],\n [11747080875, 1.473306655883789],\n [11758417666, 3.3060121536254883],\n [11769115541, 5.2542009353637695],\n [11781375500, 7.524044990539551],\n [11793056791, 6.046444892883301],\n [11793058000, 4.568844795227051],\n [11793058958, 3.091244697570801],\n [11793059875, 1.6136445999145508],\n [11793060791, -0.02643108367919922],\n [11907871750, 1.473306655883789],\n [11907873708, 3.1548938751220703],\n [11916298041, 5.2542009353637695],\n [11934474833, 7.524044990539551],\n [11945984916, 6.046444892883301],\n [11945986041, 4.568844795227051],\n [11945987000, 3.091244697570801],\n [11945990166, 1.6136445999145508],\n [11945991125, -0.02643108367919922],\n [12054509666, 1.4733905792236328],\n [12063261375, 3.3060426712036133],\n [12074139125, 5.2542314529418945],\n [12084480875, 7.524075508117676],\n [12094924791, 6.046475410461426],\n [12094925958, 4.568875312805176],\n [12094926916, 3.091275215148926],\n [12094927791, 1.6136751174926758],\n [12094928708, -0.02640056610107422],\n [12203334708, 1.473276138305664],\n [12217599291, 3.306065559387207],\n [12229401583, 5.254254341125488],\n [12249113875, 7.5240983963012695],\n [12249115833, 6.0464982986450195],\n [12249116958, 4.5688982009887695],\n [12249117916, 3.0912981033325195],\n [12249118833, 1.6136980056762695],\n [12249119791, -0.02637767791748047],\n [12366387916, 1.4733219146728516],\n [12376687958, 3.3060426712036133],\n [12383011625, 5.2542009353637695],\n [12399670166, 7.524044990539551],\n [12412263083, 6.046444892883301],\n [12412264250, 4.568844795227051],\n [12412265250, 3.091244697570801],\n [12412266166, 1.6136445999145508],\n [12412267125, -0.02646160125732422],\n [12519048833, 1.4732913970947266],\n [12531295541, 3.3060121536254883],\n [12541782958, 5.2542009353637695],\n [12553649041, 7.524044990539551],\n [12565102500, 6.046444892883301],\n [12565103708, 4.568844795227051],\n [12565104750, 3.091244697570801],\n [12565105791, 1.6136445999145508],\n [12565106833, -0.02643108367919922],\n [12669442125, 1.473245620727539],\n [12683720416, 3.306065559387207],\n [12694433583, 5.254254341125488],\n [12712894375, 7.5240983963012695],\n [12712897125, 6.0464982986450195],\n [12712898291, 4.5688982009887695],\n [12712899375, 3.0912981033325195],\n [12712900416, 1.6136980056762695],\n [12712901541, -0.02637767791748047],\n [12826646458, 1.4733829498291016],\n [12833011458, 3.3060426712036133],\n [12843311041, 5.2542314529418945],\n [12859614458, 7.524044990539551],\n [12866377916, 6.046444892883301],\n [12866379125, 4.568844795227051],\n [12866380125, 3.091244697570801],\n [12866381125, 1.6136445999145508],\n [12866382208, -0.02643108367919922],\n ],\n n_avg_mb: 7.3380991617838545,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 7.174404078555208,\n n_cpu_percent_python: 20.677884165844787,\n n_gpu_percent: 0,\n n_growth_mb: 7.4304046630859375,\n n_malloc_mb: 601.8158340454102,\n n_mallocs: 81,\n n_peak_mb: 7.4304046630859375,\n n_python_fraction: 0.11390462197583993,\n n_sys_percent: 0.5389171972072154,\n n_usage_fraction: 0.24951338417403499,\n },\n {\n line: \" z1 = [i for i in range(0,300000)][299999]\\n\",\n lineno: 14,\n memory_samples: [\n [555511875, 9.390792846679688],\n [565001708, 11.16716480255127],\n [575258416, 13.11535358428955],\n [586841333, 15.385197639465332],\n [597092625, 17.341931343078613],\n [597095916, 15.779431343078613],\n [597098041, 18.5227632522583],\n [597099375, 16.7727632522583],\n [605396958, 19.86289691925049],\n [605398791, 17.89414691925049],\n [618511291, 21.3744478225708],\n [618513333, 19.1556978225708],\n [618514583, 17.678105354309082],\n [618515833, 16.200505256652832],\n [618516958, 14.722905158996582],\n [618518083, 13.245305061340332],\n [618519250, 11.767704963684082],\n [618520750, 7.842289924621582],\n [716911291, 9.281749725341797],\n [725632333, 11.057496070861816],\n [734916625, 13.005684852600098],\n [751884791, 15.27541446685791],\n [751886958, 17.23214817047119],\n [751888625, 15.669648170471191],\n [761087791, 18.412949562072754],\n [761089500, 16.662949562072754],\n [767328041, 19.753045082092285],\n [767329375, 17.784295082092285],\n [775905583, 21.264504432678223],\n [775907250, 19.045754432678223],\n [775908375, 17.568161964416504],\n [775909333, 16.090561866760254],\n [775915375, 14.612961769104004],\n [775916750, 13.135361671447754],\n [775917708, 11.657761573791504],\n [775918666, 7.732377052307129],\n [870451875, 9.172538757324219],\n [880999041, 10.948307991027832],\n [890439291, 12.896496772766113],\n [907388625, 15.166340827941895],\n [907390625, 17.123074531555176],\n [907392791, 15.560574531555176],\n [916867125, 18.30387592315674],\n [916868541, 16.55387592315674],\n [916870375, 19.643986701965332],\n [916871500, 17.675236701965332],\n [929537916, 21.15550708770752],\n [929540000, 18.93675708770752],\n [929541083, 17.4591646194458],\n [929542083, 15.98156452178955],\n [929543041, 14.5039644241333],\n [929544000, 13.02636432647705],\n [929544916, 11.5487642288208],\n [929546125, 7.623379707336426],\n [1025440625, 9.062931060791016],\n [1031966083, 10.838730812072754],\n [1043298000, 12.786919593811035],\n [1049550791, 15.056733131408691],\n [1064023458, 17.013436317443848],\n [1064026791, 15.450936317443848],\n [1064028833, 18.19429874420166],\n [1064030083, 16.44429874420166],\n [1076172333, 19.534432411193848],\n [1076173916, 17.565682411193848],\n [1083924625, 21.045952796936035],\n [1083927666, 18.827202796936035],\n [1083928625, 17.349610328674316],\n [1083929500, 15.872010231018066],\n [1083930416, 14.394410133361816],\n [1083931333, 12.916810035705566],\n [1083932250, 11.439209938049316],\n [1083933166, 7.513794898986816],\n [1184557500, 8.953300476074219],\n [1184559666, 10.634857177734375],\n [1195587500, 12.677258491516113],\n [1201858833, 14.94701099395752],\n [1217549500, 16.903592109680176],\n [1217552375, 15.341092109680176],\n [1217554541, 18.08445453643799],\n [1217555750, 16.33445453643799],\n [1236180458, 19.42455768585205],\n [1236182500, 17.45580768585205],\n [1236184333, 20.936108589172363],\n [1236185500, 18.717358589172363],\n [1236186500, 17.239766120910645],\n [1236187500, 15.762166023254395],\n [1236188583, 14.284565925598145],\n [1236189583, 12.806965827941895],\n [1236190583, 11.329365730285645],\n [1236191541, 7.4039201736450195],\n [1338627083, 8.93758487701416],\n [1338629291, 10.619111061096191],\n [1348636625, 12.567269325256348],\n [1361178541, 14.837082862854004],\n [1383309833, 16.79378604888916],\n [1383312250, 15.23128604888916],\n [1383314291, 17.974648475646973],\n [1383315458, 16.224648475646973],\n [1383317333, 19.31483554840088],\n [1383318458, 17.34608554840088],\n [1389642333, 20.826355934143066],\n [1389644583, 18.607605934143066],\n [1389645625, 17.130013465881348],\n [1389646583, 15.652413368225098],\n [1389647541, 14.174813270568848],\n [1389648500, 12.697213172912598],\n [1389649416, 11.219613075256348],\n [1389650458, 7.294228553771973],\n [1485638875, 8.733711242675781],\n [1500745250, 10.50951099395752],\n [1500747416, 12.4576997756958],\n [1509511291, 14.727513313293457],\n [1520752041, 16.68424701690674],\n [1520754125, 15.121747016906738],\n [1529887458, 17.865017890930176],\n [1529889000, 16.115017890930176],\n [1536118583, 19.20518207550049],\n [1536120000, 17.23643207550049],\n [1542874458, 20.7167329788208],\n [1542876333, 18.4979829788208],\n [1542877458, 17.020390510559082],\n [1542878458, 15.542790412902832],\n [1542879375, 14.065190315246582],\n [1542880333, 12.587590217590332],\n [1542881250, 11.109990119934082],\n [1542882250, 7.184575080871582],\n [1634500833, 8.624103546142578],\n [1647016583, 10.399903297424316],\n [1656918250, 12.348061561584473],\n [1667544250, 14.617905616760254],\n [1677042708, 16.574639320373535],\n [1677044458, 15.012139320373535],\n [1677046500, 17.755501747131348],\n [1677047708, 16.005501747131348],\n [1695595291, 19.09560489654541],\n [1695597000, 17.12685489654541],\n [1695598708, 20.607155799865723],\n [1695599708, 18.388405799865723],\n [1695600666, 16.910813331604004],\n [1695601583, 15.433213233947754],\n [1695602458, 13.955613136291504],\n [1695603375, 12.478013038635254],\n [1695604291, 11.000412940979004],\n [1695605250, 7.074967384338379],\n [1791391791, 8.514427185058594],\n [1806471458, 10.290196418762207],\n [1806473416, 12.238385200500488],\n [1815312500, 14.508198738098145],\n [1829626958, 16.4649019241333],\n [1829629166, 14.9024019241333],\n [1829631000, 17.64573383331299],\n [1829632208, 15.895733833312988],\n [1838273250, 18.985806465148926],\n [1838274750, 17.017056465148926],\n [1848706625, 20.49729633331299],\n [1848708666, 18.27854633331299],\n [1848709750, 16.80095386505127],\n [1848710666, 15.32335376739502],\n [1848711541, 13.84575366973877],\n [1848712500, 12.36815357208252],\n [1848713416, 10.89055347442627],\n [1848714375, 6.9651384353637695],\n [1945034541, 8.404621124267578],\n [1954097250, 10.180390357971191],\n [1963537916, 12.128579139709473],\n [1974254208, 14.398423194885254],\n [1983813833, 16.355156898498535],\n [1983816333, 14.792656898498535],\n [1983818375, 17.535988807678223],\n [1983819583, 15.785988807678223],\n [1992820583, 18.876229286193848],\n [1992821875, 16.907479286193848],\n [2003450958, 20.387749671936035],\n [2003453458, 18.168999671936035],\n [2003454708, 16.691407203674316],\n [2003455708, 15.213807106018066],\n [2003456666, 13.736207008361816],\n [2003457583, 12.258606910705566],\n [2003458500, 10.781006813049316],\n [2003459458, 6.855622291564941],\n [2098853583, 8.295028686523438],\n [2107703000, 10.070828437805176],\n [2117127875, 12.019017219543457],\n [2123391375, 14.288861274719238],\n [2137372666, 16.245564460754395],\n [2137374458, 14.683064460754395],\n [2137376375, 17.426396369934082],\n [2137377666, 15.676396369934082],\n [2144789750, 18.76653003692627],\n [2144791208, 16.79778003692627],\n [2156970875, 20.278050422668457],\n [2156972875, 18.059300422668457],\n [2156973958, 16.58170795440674],\n [2156974958, 15.104107856750488],\n [2156975875, 13.626507759094238],\n [2156976791, 12.148907661437988],\n [2156977750, 10.671307563781738],\n [2156978750, 6.745923042297363],\n [2252128250, 8.185497283935547],\n [2261111000, 9.96126651763916],\n [2270495416, 11.909455299377441],\n [2281010250, 14.179299354553223],\n [2288727875, 16.136033058166504],\n [2288729791, 14.573533058166504],\n [2296531666, 17.31686496734619],\n [2296533291, 15.566864967346191],\n [2296535458, 18.657029151916504],\n [2296536625, 16.688279151916504],\n [2316518875, 20.16854953765869],\n [2316520583, 17.94979953765869],\n [2316521625, 16.472207069396973],\n [2316522541, 14.994606971740723],\n [2316523458, 13.517006874084473],\n [2316524375, 12.039406776428223],\n [2316525291, 10.561806678771973],\n [2316526291, 6.636391639709473],\n [2405358041, 8.07586669921875],\n [2414186750, 9.851635932922363],\n [2423603500, 11.799824714660645],\n [2434183083, 14.069668769836426],\n [2443616916, 16.026402473449707],\n [2443619041, 14.463902473449707],\n [2443621208, 17.207234382629395],\n [2443622375, 15.457234382629395],\n [2451122625, 18.54747486114502],\n [2451123916, 16.57872486114502],\n [2463408833, 20.058995246887207],\n [2463411958, 17.840245246887207],\n [2463413041, 16.36265277862549],\n [2463414083, 14.885052680969238],\n [2463415083, 13.407452583312988],\n [2463416083, 11.929852485656738],\n [2463417083, 10.452252388000488],\n [2463420666, 6.526867866516113],\n [2558430208, 7.966442108154297],\n [2567834833, 9.742241859436035],\n [2581782250, 11.690400123596191],\n [2590380458, 13.960183143615723],\n [2596683583, 15.916886329650879],\n [2596686166, 14.354386329650879],\n [2608509958, 17.097771644592285],\n [2608511958, 15.347771644592285],\n [2608513916, 18.437935829162598],\n [2608515083, 16.469185829162598],\n [2628441916, 19.949456214904785],\n [2628443791, 17.730706214904785],\n [2628444875, 16.253113746643066],\n [2628445791, 14.775513648986816],\n [2628446708, 13.297913551330566],\n [2628447625, 11.820313453674316],\n [2628448500, 10.342713356018066],\n [2628449416, 6.417298316955566],\n [2716936291, 7.856758117675781],\n [2723704333, 9.63249683380127],\n [2729981750, 11.580655097961426],\n [2745614583, 13.850468635559082],\n [2761433333, 15.807202339172363],\n [2761437375, 14.244702339172363],\n [2761439458, 16.988064765930176],\n [2761440833, 15.238064765930176],\n [2761442791, 18.32816791534424],\n [2761443958, 16.35941791534424],\n [2773086416, 19.83971881866455],\n [2773088083, 17.62096881866455],\n [2773089208, 16.143376350402832],\n [2773090333, 14.665776252746582],\n [2773091416, 13.188176155090332],\n [2773092583, 11.710576057434082],\n [2773093666, 10.232975959777832],\n [2773095541, 6.307560920715332],\n [2867830583, 7.747097015380859],\n [2884560958, 9.522866249084473],\n [2884563083, 11.471055030822754],\n [2892822375, 13.74086856842041],\n [2907884000, 15.698105812072754],\n [2907886125, 14.135605812072754],\n [2907888000, 16.87893772125244],\n [2907889250, 15.128937721252441],\n [2915387791, 18.21907138824463],\n [2915389375, 16.25032138824463],\n [2926667500, 19.73062229156494],\n [2926669625, 17.51187229156494],\n [2926670625, 16.034279823303223],\n [2926671583, 14.556679725646973],\n [2926672625, 13.079079627990723],\n [2926673625, 11.601479530334473],\n [2926674583, 10.123879432678223],\n [2926675625, 6.198464393615723],\n [3034666125, 7.6379852294921875],\n [3034668041, 9.319541931152344],\n [3034669750, 11.2677001953125],\n [3046989583, 13.631756782531738],\n [3060246125, 15.588459968566895],\n [3060247916, 14.025959968566895],\n [3060249750, 16.769291877746582],\n [3060250916, 15.019291877746582],\n [3072037500, 18.10942554473877],\n [3072039166, 16.14067554473877],\n [3086011833, 19.620945930480957],\n [3086013958, 17.402195930480957],\n [3086015083, 15.924603462219238],\n [3086016083, 14.447003364562988],\n [3086017166, 12.969403266906738],\n [3086018125, 11.491803169250488],\n [3086019041, 10.014203071594238],\n [3086020000, 6.088788032531738],\n [3174625125, 7.528247833251953],\n [3183568041, 9.304047584533691],\n [3192818916, 11.252236366271973],\n [3199073833, 13.522049903869629],\n [3219456666, 15.478753089904785],\n [3219458958, 13.916253089904785],\n [3219460916, 16.659615516662598],\n [3219462000, 14.909615516662598],\n [3219463708, 17.99971866607666],\n [3219464750, 16.03096866607666],\n [3232053958, 19.511269569396973],\n [3232056041, 17.292519569396973],\n [3232057125, 15.814927101135254],\n [3232058041, 14.337327003479004],\n [3232059000, 12.859726905822754],\n [3232059916, 11.382126808166504],\n [3232060833, 9.904526710510254],\n [3232061791, 5.979111671447754],\n [3328167291, 7.418495178222656],\n [3337774666, 9.19426441192627],\n [3347573000, 11.14245319366455],\n [3358798833, 13.412297248840332],\n [3375074833, 15.369030952453613],\n [3375077125, 13.806530952453613],\n [3375079000, 16.549893379211426],\n [3375080166, 14.799893379211426],\n [3375081916, 17.890103340148926],\n [3375083000, 15.921353340148926],\n [3382591416, 19.40165424346924],\n [3382593625, 17.18290424346924],\n [3393229458, 15.70531177520752],\n [3393230708, 14.22771167755127],\n [3393231500, 12.75011157989502],\n [3393232291, 11.27251148223877],\n [3393233125, 9.79491138458252],\n [3393233916, 5.8694963455200195],\n [3483706583, 7.309093475341797],\n [3498923166, 9.08486270904541],\n [3498925250, 11.033051490783691],\n [3507070083, 13.302865028381348],\n [3517781541, 15.259598731994629],\n [3517784083, 13.697098731994629],\n [3534458125, 16.440430641174316],\n [3534459625, 14.690430641174316],\n [3534461375, 17.78059482574463],\n [3534462583, 15.811844825744629],\n [3540753750, 19.292115211486816],\n [3540760500, 17.073365211486816],\n [3540761583, 15.595772743225098],\n [3540762500, 14.118172645568848],\n [3540763458, 12.640572547912598],\n [3540764375, 11.162972450256348],\n [3540765291, 9.685372352600098],\n [3540766208, 5.759957313537598],\n [3636936250, 7.199432373046875],\n [3643253833, 8.975232124328613],\n [3649555708, 10.92339038848877],\n [3665517083, 13.193203926086426],\n [3681314625, 15.149937629699707],\n [3681316833, 13.587437629699707],\n [3681318833, 16.33080005645752],\n [3681320000, 14.58080005645752],\n [3681321708, 17.670903205871582],\n [3681322791, 15.702153205871582],\n [3694533125, 19.182454109191895],\n [3694535208, 16.963704109191895],\n [3694536291, 15.486111640930176],\n [3694537250, 14.008511543273926],\n [3694538125, 12.530911445617676],\n [3694539083, 11.053311347961426],\n [3694539958, 9.575711250305176],\n [3694540916, 5.650296211242676],\n [3790098791, 7.089809417724609],\n [3798911541, 8.865555763244629],\n [3808257708, 10.81374454498291],\n [3815910166, 13.083588600158691],\n [3822191208, 15.040291786193848],\n [3822193208, 13.477791786193848],\n [3828487166, 16.221177101135254],\n [3828488500, 14.471177101135254],\n [3840441541, 17.561440467834473],\n [3840442958, 15.592690467834473],\n [3846821041, 19.07296085357666],\n [3846822958, 16.85421085357666],\n [3846823958, 15.376618385314941],\n [3846824875, 13.899018287658691],\n [3846825791, 12.421418190002441],\n [3846826708, 10.943818092346191],\n [3846827583, 9.466217994689941],\n [3846828625, 5.540833473205566],\n [3943422500, 6.9803619384765625],\n [3958368375, 8.756131172180176],\n [3958370500, 10.704319953918457],\n [3966165833, 12.974133491516113],\n [3981619916, 14.93083667755127],\n [3981623875, 13.36833667755127],\n [3981625791, 16.111668586730957],\n [3981626958, 14.361668586730957],\n [3989149166, 17.451802253723145],\n [3989150791, 15.483052253723145],\n [4000965208, 18.963269233703613],\n [4000967375, 16.744519233703613],\n [4000968458, 15.266926765441895],\n [4000969375, 13.789326667785645],\n [4000970291, 12.311726570129395],\n [4000971208, 10.834126472473145],\n [4000972125, 9.356526374816895],\n [4000973041, 5.4311418533325195],\n [4095860250, 6.870655059814453],\n [4105109375, 8.646454811096191],\n [4114606291, 10.594643592834473],\n [4122073833, 12.864487648010254],\n [4134668416, 14.82119083404541],\n [4134670708, 13.25869083404541],\n [4134672666, 16.002022743225098],\n [4134673833, 14.252022743225098],\n [4147024291, 17.34212589263916],\n [4147025625, 15.37337589263916],\n [4153339500, 18.853676795959473],\n [4153341291, 16.634926795959473],\n [4153342333, 15.157334327697754],\n [4153343291, 13.679734230041504],\n [4153344250, 12.202134132385254],\n [4153345208, 10.724534034729004],\n [4153346166, 9.246933937072754],\n [4153347125, 5.321518898010254],\n [4244786125, 6.760932922363281],\n [4257113208, 8.53673267364502],\n [4263442208, 10.484890937805176],\n [4278888958, 12.754704475402832],\n [4294709791, 14.711438179016113],\n [4294712000, 13.148938179016113],\n [4294713875, 15.892300605773926],\n [4294714958, 14.142300605773926],\n [4294716666, 17.23240375518799],\n [4294717750, 15.263653755187988],\n [4306235625, 18.7439546585083],\n [4306237708, 16.5252046585083],\n [4306238916, 15.047612190246582],\n [4306240041, 13.570012092590332],\n [4306241166, 12.092411994934082],\n [4306242375, 10.614811897277832],\n [4306243500, 9.137211799621582],\n [4306244625, 5.211796760559082],\n [4402735458, 6.651203155517578],\n [4411437708, 8.426972389221191],\n [4420925333, 10.375161170959473],\n [4431466500, 12.645005226135254],\n [4438017708, 14.601738929748535],\n [4438019375, 13.039238929748535],\n [4453015833, 15.782624244689941],\n [4453019166, 14.032624244689941],\n [4453021166, 17.122788429260254],\n [4453022375, 15.154038429260254],\n [4459552083, 18.63430881500244],\n [4459553666, 16.41555881500244],\n [4459554750, 14.937966346740723],\n [4459555750, 13.460366249084473],\n [4459556708, 11.982766151428223],\n [4459557708, 10.505166053771973],\n [4459558625, 9.027565956115723],\n [4459559625, 5.102150917053223],\n [4555238708, 6.541717529296875],\n [4563668750, 8.317517280578613],\n [4569932541, 10.26567554473877],\n [4590304041, 12.535489082336426],\n [4590306291, 14.492222785949707],\n [4590308416, 12.929722785949707],\n [4599289375, 15.67302417755127],\n [4599290958, 13.92302417755127],\n [4599293041, 17.013188362121582],\n [4599294333, 15.044438362121582],\n [4611807916, 18.524739265441895],\n [4611809708, 16.305989265441895],\n [4611810750, 14.828396797180176],\n [4611811708, 13.350796699523926],\n [4611812708, 11.873196601867676],\n [4611813666, 10.395596504211426],\n [4611814708, 8.917996406555176],\n [4611815791, 4.992581367492676],\n [4703001166, 6.431995391845703],\n [4717039083, 8.207795143127441],\n [4726370083, 10.155983924865723],\n [4734432875, 12.425827980041504],\n [4740758083, 14.38253116607666],\n [4740759958, 12.82003116607666],\n [4752320625, 15.563416481018066],\n [4752322250, 13.813416481018066],\n [4752324041, 16.90358066558838],\n [4752325208, 14.934830665588379],\n [4765011333, 18.415101051330566],\n [4765013416, 16.196351051330566],\n [4765014458, 14.718758583068848],\n [4765015416, 13.241158485412598],\n [4765016375, 11.763558387756348],\n [4765017291, 10.285958290100098],\n [4765018208, 8.808358192443848],\n [4765019166, 4.882973670959473],\n [4860951041, 6.322502136230469],\n [4869187791, 8.098271369934082],\n [4879627916, 10.046460151672363],\n [4890477166, 12.316304206848145],\n [4897023333, 14.273037910461426],\n [4897025583, 12.710537910461426],\n [4906051166, 15.453923225402832],\n [4906053708, 13.703923225402832],\n [4912887500, 16.794087409973145],\n [4912889458, 14.825337409973145],\n [4919814125, 18.305577278137207],\n [4919816208, 16.086827278137207],\n [4919817250, 14.609234809875488],\n [4919818166, 13.131634712219238],\n [4919819125, 11.654034614562988],\n [4919820083, 10.176434516906738],\n [4919821000, 8.698834419250488],\n [4919823833, 4.773419380187988],\n [5023320041, 6.213077545166016],\n [5023323125, 7.894603729248047],\n [5029641916, 9.937005043029785],\n [5044781916, 12.206818580627441],\n [5050837250, 14.163552284240723],\n [5050839333, 12.601052284240723],\n [5057138833, 15.34438419342041],\n [5057140166, 13.59438419342041],\n [5063449041, 16.684517860412598],\n [5063450291, 14.715767860412598],\n [5069771416, 18.195984840393066],\n [5069772708, 15.977234840393066],\n [5078160250, 14.499642372131348],\n [5078161416, 13.022042274475098],\n [5078162333, 11.544442176818848],\n [5078163166, 10.066842079162598],\n [5078163958, 8.589241981506348],\n [5078164916, 4.663826942443848],\n [5167815333, 6.1033935546875],\n [5177588416, 7.879162788391113],\n [5194539583, 9.827351570129395],\n [5194541625, 12.097195625305176],\n [5202341125, 14.053898811340332],\n [5202343416, 12.491398811340332],\n [5220412083, 15.23473072052002],\n [5220413625, 13.48473072052002],\n [5220415500, 16.574894905090332],\n [5220416750, 14.606144905090332],\n [5226693833, 18.08641529083252],\n [5226695916, 15.86766529083252],\n [5226696958, 14.3900728225708],\n [5226697875, 12.91247272491455],\n [5226698833, 11.4348726272583],\n [5226699708, 9.95727252960205],\n [5226700625, 8.4796724319458],\n [5226701625, 4.554257392883301],\n [5322822500, 5.993740081787109],\n [5331672708, 7.769539833068848],\n [5338285250, 9.717728614807129],\n [5350854458, 11.987542152404785],\n [5359496833, 13.944275856018066],\n [5359498666, 12.381775856018066],\n [5365814000, 15.125107765197754],\n [5365815583, 13.375107765197754],\n [5372042791, 16.46524143218994],\n [5372044416, 14.496491432189941],\n [5380466375, 17.97676181793213],\n [5380488791, 15.758011817932129],\n [5380490083, 14.28041934967041],\n [5380491041, 12.80281925201416],\n [5380491958, 11.32521915435791],\n [5380492916, 9.84761905670166],\n [5380493875, 8.37001895904541],\n [5380494875, 4.44460391998291],\n [5470324958, 5.884117126464844],\n [5478485041, 7.659916877746582],\n [5493524500, 9.608075141906738],\n [5501088708, 11.87791919708252],\n [5507374875, 13.834622383117676],\n [5507376791, 12.272122383117676],\n [5525673541, 15.015507698059082],\n [5525675125, 13.265507698059082],\n [5525676916, 16.355671882629395],\n [5525678041, 14.386921882629395],\n [5532040750, 17.867161750793457],\n [5532042333, 15.648411750793457],\n [5532043375, 14.170819282531738],\n [5532044291, 12.693219184875488],\n [5532045208, 11.215619087219238],\n [5532046125, 9.738018989562988],\n [5532047083, 8.260418891906738],\n [5532052375, 4.335034370422363],\n [5628032083, 5.774478912353516],\n [5636955125, 7.550278663635254],\n [5646291708, 9.498467445373535],\n [5655363166, 11.768311500549316],\n [5661695375, 13.725014686584473],\n [5661697125, 12.162514686584473],\n [5672175625, 14.905900001525879],\n [5672177000, 13.155900001525879],\n [5672178875, 16.246033668518066],\n [5672180083, 14.277283668518066],\n [5684715750, 17.75752353668213],\n [5684717625, 15.538773536682129],\n [5684718625, 14.06118106842041],\n [5684719583, 12.58358097076416],\n [5684720500, 11.10598087310791],\n [5684721458, 9.62838077545166],\n [5684722375, 8.15078067779541],\n [5684723333, 4.22536563873291],\n [5776186333, 5.664955139160156],\n [5788316833, 7.4407548904418945],\n [5798866875, 9.38891315460205],\n [5809500166, 11.658757209777832],\n [5825329666, 13.615490913391113],\n [5825332875, 12.052990913391113],\n [5825334833, 14.796353340148926],\n [5825336000, 13.046353340148926],\n [5825337791, 16.13645648956299],\n [5825338916, 14.167706489562988],\n [5834431250, 17.648655891418457],\n [5834432875, 15.429905891418457],\n [5843298875, 13.952313423156738],\n [5843299958, 12.474713325500488],\n [5843300833, 10.997113227844238],\n [5843301583, 9.519513130187988],\n [5843302416, 8.041913032531738],\n [5843303250, 4.116497993469238],\n [5932753666, 5.556041717529297],\n [5942303625, 7.33181095123291],\n [5951736208, 9.279999732971191],\n [5968644000, 11.549843788146973],\n [5968646000, 13.506577491760254],\n [5968647791, 11.944077491760254],\n [5983957208, 14.687378883361816],\n [5983958916, 12.937378883361816],\n [5983961000, 16.02754306793213],\n [5983962291, 14.058793067932129],\n [5996582875, 17.539063453674316],\n [5996584625, 15.320313453674316],\n [5996585666, 13.842720985412598],\n [5996586625, 12.365120887756348],\n [5996587583, 10.887520790100098],\n [5996588583, 9.409920692443848],\n [5996589541, 7.932320594787598],\n [5996590541, 4.006905555725098],\n [6082731250, 5.4465179443359375],\n [6093244166, 7.222317695617676],\n [6099501750, 9.170475959777832],\n [6115769500, 11.440289497375488],\n [6125370500, 13.39702320098877],\n [6125372500, 11.83452320098877],\n [6125374500, 14.577885627746582],\n [6125375750, 12.827885627746582],\n [6137464916, 15.917988777160645],\n [6137466583, 13.949238777160645],\n [6143755000, 17.429539680480957],\n [6143756958, 15.210789680480957],\n [6143758041, 13.733197212219238],\n [6143759000, 12.255597114562988],\n [6143759916, 10.777997016906738],\n [6143760833, 9.300396919250488],\n [6143761833, 7.822796821594238],\n [6143762833, 3.8973817825317383],\n [6234613208, 5.336803436279297],\n [6243245916, 7.112603187561035],\n [6257785875, 9.060761451721191],\n [6266030708, 11.330605506896973],\n [6272334625, 13.287308692932129],\n [6272336875, 11.724808692932129],\n [6289988291, 14.468194007873535],\n [6289994583, 12.718194007873535],\n [6289996458, 15.808358192443848],\n [6289997750, 13.839608192443848],\n [6302588958, 17.31984806060791],\n [6302591208, 15.10109806060791],\n [6302592250, 13.623505592346191],\n [6302593333, 12.145905494689941],\n [6302594291, 10.668305397033691],\n [6302595291, 9.190705299377441],\n [6302596333, 7.713105201721191],\n [6302597333, 3.7877206802368164],\n [6390482541, 5.2271881103515625],\n [6401091625, 7.002987861633301],\n [6412865208, 8.951176643371582],\n [6419126333, 11.220990180969238],\n [6434483208, 13.177693367004395],\n [6434485125, 11.615193367004395],\n [6434487250, 14.358555793762207],\n [6434488500, 12.608555793762207],\n [6446846666, 15.69871997833252],\n [6446848666, 13.72996997833252],\n [6455603458, 17.210240364074707],\n [6455605541, 14.991490364074707],\n [6455606666, 13.513897895812988],\n [6455607708, 12.036297798156738],\n [6455608666, 10.558697700500488],\n [6455609625, 9.081097602844238],\n [6455610625, 7.603497505187988],\n [6455611625, 3.6780824661254883],\n [6551340166, 5.117588043212891],\n [6566544208, 6.893387794494629],\n [6566546333, 8.84157657623291],\n [6578061333, 11.111390113830566],\n [6602241708, 13.068093299865723],\n [6602243916, 11.505593299865723],\n [6602245750, 14.248955726623535],\n [6602246958, 12.498955726623535],\n [6602248666, 15.589142799377441],\n [6602249833, 13.620392799377441],\n [6608597291, 17.10066318511963],\n [6608599250, 14.881913185119629],\n [6608600333, 13.40432071685791],\n [6608601250, 11.92672061920166],\n [6608602208, 10.44912052154541],\n [6608603125, 8.97152042388916],\n [6608604041, 7.49392032623291],\n [6608605041, 3.56850528717041],\n [6703743750, 5.0080108642578125],\n [6718685916, 6.783780097961426],\n [6718688166, 8.731968879699707],\n [6726152166, 11.001782417297363],\n [6741937000, 12.95848560333252],\n [6741946500, 11.39598560333252],\n [6741948416, 14.139317512512207],\n [6741949708, 12.389317512512207],\n [6751076666, 15.479451179504395],\n [6751077958, 13.510701179504395],\n [6757386000, 16.990971565246582],\n [6757387416, 14.772221565246582],\n [6763727125, 13.294629096984863],\n [6763728416, 11.817028999328613],\n [6763729250, 10.339428901672363],\n [6763730125, 8.861828804016113],\n [6763730958, 7.384228706359863],\n [6763731875, 3.4588136672973633],\n [6851153291, 4.898349761962891],\n [6859499458, 6.674149513244629],\n [6874403375, 8.622307777404785],\n [6882233666, 10.892151832580566],\n [6888538750, 12.848855018615723],\n [6888540833, 11.286355018615723],\n [6894837291, 14.029740333557129],\n [6894838625, 12.279740333557129],\n [6906424583, 15.369874000549316],\n [6906425833, 13.401124000549316],\n [6912790333, 16.881394386291504],\n [6912792208, 14.662644386291504],\n [6912793375, 13.185051918029785],\n [6912794375, 11.707451820373535],\n [6912795333, 10.229851722717285],\n [6912796250, 8.752251625061035],\n [6912797166, 7.274651527404785],\n [6912798166, 3.349236488342285],\n [7003770375, 4.788688659667969],\n [7011609083, 6.564488410949707],\n [7027232541, 8.512646675109863],\n [7033464583, 10.782490730285645],\n [7046696541, 12.739224433898926],\n [7046700125, 11.176724433898926],\n [7053895583, 13.920056343078613],\n [7053897583, 12.170056343078613],\n [7053899583, 15.260220527648926],\n [7053901000, 13.291470527648926],\n [7067522875, 16.771740913391113],\n [7067525125, 14.552990913391113],\n [7067526250, 13.075398445129395],\n [7067527208, 11.597798347473145],\n [7067528166, 10.120198249816895],\n [7067529125, 8.642598152160645],\n [7067530041, 7.1649980545043945],\n [7067531041, 3.2395830154418945],\n [7168933125, 4.679119110107422],\n [7168935083, 6.360675811767578],\n [7176566708, 8.403077125549316],\n [7191593416, 10.672890663146973],\n [7199429333, 12.629624366760254],\n [7199431958, 11.067124366760254],\n [7206961291, 13.810456275939941],\n [7206963041, 12.060456275939941],\n [7206965041, 15.150620460510254],\n [7206966333, 13.181870460510254],\n [7220339958, 16.662171363830566],\n [7220342125, 14.443421363830566],\n [7220343125, 12.965828895568848],\n [7220344083, 11.488228797912598],\n [7220345125, 10.010628700256348],\n [7220346041, 8.533028602600098],\n [7220347000, 7.055428504943848],\n [7220348000, 3.1300134658813477],\n [7316084791, 4.663830757141113],\n [7325138333, 6.3453874588012695],\n [7334582041, 8.29357624053955],\n [7351638375, 10.563420295715332],\n [7351640291, 12.520153999328613],\n [7351642375, 10.957653999328613],\n [7359897666, 13.7009859085083],\n [7359899291, 11.9509859085083],\n [7367202916, 15.041119575500488],\n [7367204333, 13.072369575500488],\n [7373492125, 16.5526704788208],\n [7373494375, 14.3339204788208],\n [7373495500, 12.856328010559082],\n [7373496541, 11.378727912902832],\n [7373497541, 9.901127815246582],\n [7373498500, 8.423527717590332],\n [7373499500, 6.945927619934082],\n [7373500541, 3.020512580871582],\n [7466136083, 4.459995269775391],\n [7476558250, 6.235795021057129],\n [7482890041, 8.183953285217285],\n [7499235125, 10.453766822814941],\n [7508872833, 12.410500526428223],\n [7508875125, 10.848000526428223],\n [7508877125, 13.591362953186035],\n [7508878250, 11.841362953186035],\n [7520261125, 14.931496620178223],\n [7520262458, 12.962746620178223],\n [7528224041, 16.44301700592041],\n [7528226333, 14.22426700592041],\n [7528227375, 12.746674537658691],\n [7528228333, 11.269074440002441],\n [7528229250, 9.791474342346191],\n [7528230166, 8.313874244689941],\n [7528231125, 6.836274147033691],\n [7528232125, 2.9108591079711914],\n [7618288291, 4.35028076171875],\n [7626573083, 6.126080513000488],\n [7641592166, 8.074238777160645],\n [7649427041, 10.344082832336426],\n [7655708291, 12.300786018371582],\n [7655710500, 10.738286018371582],\n [7667459041, 13.481671333312988],\n [7667460708, 11.731671333312988],\n [7667462625, 14.8218355178833],\n [7667463875, 12.8530855178833],\n [7679976541, 16.33335590362549],\n [7679978458, 14.114605903625488],\n [7679979416, 12.63701343536377],\n [7679980375, 11.15941333770752],\n [7679981333, 9.68181324005127],\n [7679982291, 8.20421314239502],\n [7679983208, 6.7266130447387695],\n [7679984166, 2.8012285232543945],\n [7773985541, 4.240749359130859],\n [7784402958, 6.016549110412598],\n [7790662125, 7.964707374572754],\n [7810971500, 10.23452091217041],\n [7810973708, 12.191254615783691],\n [7810975291, 10.628754615783691],\n [7817748541, 13.372086524963379],\n [7817750250, 11.622086524963379],\n [7832559291, 14.712220191955566],\n [7832561166, 12.743470191955566],\n [7832563041, 16.22377109527588],\n [7832564083, 14.005021095275879],\n [7832565083, 12.52742862701416],\n [7832566041, 11.04982852935791],\n [7832567000, 9.57222843170166],\n [7832570208, 8.09462833404541],\n [7832571208, 6.61702823638916],\n [7832572333, 2.691582679748535],\n [7922994083, 4.13104248046875],\n [7932775750, 5.906842231750488],\n [7945337000, 7.8550004959106445],\n [7953611083, 10.124844551086426],\n [7959889083, 12.081547737121582],\n [7959891041, 10.519047737121582],\n [7966055125, 13.262433052062988],\n [7966056500, 11.512433052062988],\n [7977993166, 14.602566719055176],\n [7977994625, 12.633816719055176],\n [7984344791, 16.114087104797363],\n [7984346625, 13.895337104797363],\n [7984347666, 12.417744636535645],\n [7984348583, 10.940144538879395],\n [7984349500, 9.462544441223145],\n [7984350458, 7.9849443435668945],\n [7984351375, 6.5073442459106445],\n [7984352333, 2.5819292068481445],\n [8075228541, 4.021411895751953],\n [8082781916, 5.797211647033691],\n [8098281875, 7.745369911193848],\n [8108783458, 10.015213966369629],\n [8116131166, 11.97194766998291],\n [8116133375, 10.40944766998291],\n [8124245541, 13.152779579162598],\n [8124247208, 11.402779579162598],\n [8124249166, 14.49294376373291],\n [8124250375, 12.52419376373291],\n [8137013625, 16.004494667053223],\n [8137015791, 13.785744667053223],\n [8137016875, 12.308152198791504],\n [8137017791, 10.830552101135254],\n [8137018750, 9.352952003479004],\n [8137019666, 7.875351905822754],\n [8137020583, 6.397751808166504],\n [8137021583, 2.472336769104004],\n [8228826375, 3.9119415283203125],\n [8240680541, 5.687741279602051],\n [8251054875, 7.635930061340332],\n [8257330708, 9.905743598937988],\n [8271154500, 11.862446784973145],\n [8271156750, 10.299946784973145],\n [8271158666, 13.043309211730957],\n [8271159875, 11.293309211730957],\n [8282650583, 14.38341236114502],\n [8282652833, 12.41466236114502],\n [8291123875, 15.894963264465332],\n [8291125708, 13.676213264465332],\n [8291126750, 12.198620796203613],\n [8291127666, 10.721020698547363],\n [8291128583, 9.243420600891113],\n [8291129541, 7.765820503234863],\n [8291130458, 6.288220405578613],\n [8291131416, 2.3628053665161133],\n [8392950541, 3.8023719787597656],\n [8392952708, 5.483928680419922],\n [8403638000, 7.52632999420166],\n [8409890708, 9.796143531799316],\n [8431111916, 11.752846717834473],\n [8431113791, 10.190346717834473],\n [8431115750, 12.933709144592285],\n [8431116958, 11.183709144592285],\n [8431118750, 14.273812294006348],\n [8431119833, 12.305062294006348],\n [8439101375, 15.78536319732666],\n [8439102541, 13.56661319732666],\n [8449067541, 12.089020729064941],\n [8449068750, 10.611420631408691],\n [8449069541, 9.133820533752441],\n [8449070333, 7.656220436096191],\n [8449071166, 6.178620338439941],\n [8449072083, 2.2532052993774414],\n [8539423791, 3.6928024291992188],\n [8548272541, 5.468602180480957],\n [8555782416, 7.416790962219238],\n [8562089875, 9.686604499816895],\n [8583991625, 11.64330768585205],\n [8583993625, 10.08080768585205],\n [8583995500, 12.824170112609863],\n [8583996666, 11.074170112609863],\n [8583998375, 14.164273262023926],\n [8583999458, 12.195523262023926],\n [8597094666, 15.675824165344238],\n [8597096583, 13.457074165344238],\n [8597097625, 11.97948169708252],\n [8597098583, 10.50188159942627],\n [8597099541, 9.02428150177002],\n [8597100458, 7.5466814041137695],\n [8597101416, 6.0690813064575195],\n [8597102416, 2.1436662673950195],\n [8692409625, 3.5832481384277344],\n [8707328333, 5.359017372131348],\n [8707330291, 7.307206153869629],\n [8717721958, 9.577019691467285],\n [8728510041, 11.533753395080566],\n [8728512041, 9.971253395080566],\n [8742288750, 12.714585304260254],\n [8742290625, 10.964585304260254],\n [8742292916, 14.054749488830566],\n [8742294125, 12.085999488830566],\n [8754893791, 15.566239356994629],\n [8754895666, 13.347489356994629],\n [8754896625, 11.86989688873291],\n [8754897541, 10.39229679107666],\n [8754898458, 8.91469669342041],\n [8754899416, 7.43709659576416],\n [8754900333, 5.95949649810791],\n [8754901291, 2.034111976623535],\n [8839336416, 3.4736557006835938],\n [8853248750, 5.249455451965332],\n [8862653041, 7.197644233703613],\n [8870236500, 9.467488288879395],\n [8876539583, 11.42419147491455],\n [8876541750, 9.86169147491455],\n [8882642625, 12.605076789855957],\n [8882643916, 10.855076789855957],\n [8894576833, 13.945210456848145],\n [8894578125, 11.976460456848145],\n [8907180958, 15.456730842590332],\n [8907183041, 13.237980842590332],\n [8907184083, 11.760388374328613],\n [8907185041, 10.282788276672363],\n [8907185958, 8.805188179016113],\n [8907186875, 7.327588081359863],\n [8907187833, 5.849987983703613],\n [8907188791, 1.9246034622192383],\n [8996641041, 3.3641014099121094],\n [9005356000, 5.139870643615723],\n [9014702125, 7.088059425354004],\n [9025219750, 9.357903480529785],\n [9034624208, 11.314637184143066],\n [9034626166, 9.752137184143066],\n [9034628250, 12.495469093322754],\n [9034629458, 10.745469093322754],\n [9042829750, 13.835709571838379],\n [9042831291, 11.866959571838379],\n [9053968125, 15.347229957580566],\n [9053969875, 13.128479957580566],\n [9053970958, 11.650887489318848],\n [9053971916, 10.173287391662598],\n [9053972875, 8.695687294006348],\n [9053973833, 7.218087196350098],\n [9053974791, 5.740487098693848],\n [9053975791, 1.8151025772094727],\n [9144603041, 3.2558517456054688],\n [9157169791, 5.031651496887207],\n [9167324958, 6.979809761047363],\n [9178110416, 9.249653816223145],\n [9194000708, 11.206387519836426],\n [9194002458, 9.643887519836426],\n [9194004291, 12.387249946594238],\n [9194005416, 10.637249946594238],\n [9194007125, 13.7273530960083],\n [9194008208, 11.7586030960083],\n [9201048625, 15.238903999328613],\n [9201049833, 13.020153999328613],\n [9207340750, 11.542561531066895],\n [9207341625, 10.064961433410645],\n [9207342375, 8.587361335754395],\n [9207343166, 7.1097612380981445],\n [9207343958, 5.6321611404418945],\n [9207344791, 1.7067461013793945],\n [9302433750, 3.146373748779297],\n [9311151791, 4.92214298248291],\n [9320643791, 6.870331764221191],\n [9331272208, 9.140175819396973],\n [9338275625, 11.096909523010254],\n [9338277291, 9.534409523010254],\n [9352660958, 12.27779483795166],\n [9352662416, 10.52779483795166],\n [9352664291, 13.617959022521973],\n [9352665458, 11.649209022521973],\n [9360059083, 15.129448890686035],\n [9360060875, 12.910698890686035],\n [9360061916, 11.433106422424316],\n [9360063125, 9.955506324768066],\n [9360064083, 8.477906227111816],\n [9360065041, 7.000306129455566],\n [9360065958, 5.522706031799316],\n [9360066916, 1.5973520278930664],\n [9455925750, 3.0375823974609375],\n [9464776750, 4.813382148742676],\n [9472791583, 6.761570930480957],\n [9479088208, 9.031384468078613],\n [9500772333, 10.98808765411377],\n [9500774375, 9.42558765411377],\n [9500776333, 12.168950080871582],\n [9500777416, 10.418950080871582],\n [9500779125, 13.509053230285645],\n [9500780208, 11.540303230285645],\n [9513728916, 15.020604133605957],\n [9513731041, 12.801854133605957],\n [9513732125, 11.324261665344238],\n [9513733208, 9.846661567687988],\n [9513734166, 8.369061470031738],\n [9513735083, 6.891461372375488],\n [9513736041, 5.413861274719238],\n [9513737083, 1.4884462356567383],\n [9609060666, 2.9279823303222656],\n [9624226000, 4.703782081604004],\n [9624228041, 6.651970863342285],\n [9634511583, 8.921784400939941],\n [9647057208, 10.878487586975098],\n [9647059416, 9.315987586975098],\n [9647061458, 12.059319496154785],\n [9647062708, 10.309319496154785],\n [9657363791, 13.399453163146973],\n [9657365166, 11.430703163146973],\n [9666877791, 14.91097354888916],\n [9666879625, 12.69222354888916],\n [9666880708, 11.214631080627441],\n [9666881666, 9.737030982971191],\n [9666882625, 8.259430885314941],\n [9666883500, 6.781830787658691],\n [9666884416, 5.304230690002441],\n [9666885416, 1.3788461685180664],\n [9761919625, 2.9126176834106445],\n [9770368416, 4.594204902648926],\n [9776645458, 6.542363166809082],\n [9791089083, 8.812176704406738],\n [9806952625, 10.76891040802002],\n [9806954875, 9.20641040802002],\n [9806956875, 11.949772834777832],\n [9806958083, 10.199772834777832],\n [9806959875, 13.289875984191895],\n [9806961041, 11.321125984191895],\n [9816194125, 14.801426887512207],\n [9816195458, 12.582676887512207],\n [9831393958, 11.105084419250488],\n [9831395125, 9.627484321594238],\n [9831395958, 8.149884223937988],\n [9831396708, 6.672284126281738],\n [9831397500, 5.194684028625488],\n [9831398333, 1.2692689895629883],\n [9916727750, 2.80300235748291],\n [9924698208, 4.484589576721191],\n [9932873000, 6.432778358459473],\n [9939152791, 8.702591896057129],\n [9960544500, 10.659295082092285],\n [9960546541, 9.096795082092285],\n [9960548458, 11.840157508850098],\n [9960549666, 10.090157508850098],\n [9960551375, 13.18026065826416],\n [9960552500, 11.21151065826416],\n [9967836458, 14.691811561584473],\n [9967837666, 12.473061561584473],\n [9974138583, 10.995469093322754],\n [9974139666, 9.517868995666504],\n [9974140500, 8.040268898010254],\n [9974141291, 6.562668800354004],\n [9974142041, 5.085068702697754],\n [9974142875, 1.159653663635254],\n [10068896125, 2.5992507934570312],\n [10077671875, 4.3750505447387695],\n [10087134041, 6.323239326477051],\n [10097715125, 8.593083381652832],\n [10107291041, 10.549817085266113],\n [10107293375, 8.987317085266113],\n [10107295166, 11.7306489944458],\n [10107296333, 9.9806489944458],\n [10116215208, 13.070889472961426],\n [10116216458, 11.102139472961426],\n [10126709250, 14.582409858703613],\n [10126711791, 12.363659858703613],\n [10126712833, 10.886067390441895],\n [10126713750, 9.408467292785645],\n [10126714750, 7.9308671951293945],\n [10126715708, 6.4532670974731445],\n [10126716625, 4.9756669998168945],\n [10126717625, 1.0502824783325195],\n [10228397541, 2.489879608154297],\n [10228399541, 4.171436309814453],\n [10240194875, 6.213837623596191],\n [10247062833, 8.483681678771973],\n [10259656541, 10.440384864807129],\n [10259658625, 8.877884864807129],\n [10272069166, 11.621216773986816],\n [10272070916, 9.871216773986816],\n [10272072958, 12.961380958557129],\n [10272074166, 10.992630958557129],\n [10280290916, 14.472870826721191],\n [10280293083, 12.254120826721191],\n [10280294166, 10.776528358459473],\n [10280295125, 9.298928260803223],\n [10280296041, 7.821328163146973],\n [10280296958, 6.343728065490723],\n [10280297875, 4.866127967834473],\n [10280298875, 0.9407129287719727],\n [10375254875, 2.3801727294921875],\n [10383933791, 4.155972480773926],\n [10390739291, 6.104161262512207],\n [10403268541, 8.373974800109863],\n [10413509375, 10.33067798614502],\n [10413511125, 8.76817798614502],\n [10413513208, 11.511540412902832],\n [10413514416, 9.761540412902832],\n [10425547875, 12.851696968078613],\n [10425549375, 10.882946968078613],\n [10431817458, 14.363247871398926],\n [10431819250, 12.144497871398926],\n [10431820208, 10.666905403137207],\n [10431821125, 9.189305305480957],\n [10431822041, 7.711705207824707],\n [10431822958, 6.234105110168457],\n [10431823875, 4.756505012512207],\n [10431824833, 0.831089973449707],\n [10527514375, 2.270610809326172],\n [10542503250, 4.046380043029785],\n [10542505083, 5.994568824768066],\n [10551167791, 8.264382362365723],\n [10565694458, 10.221085548400879],\n [10565696666, 8.658585548400879],\n [10565698583, 11.401917457580566],\n [10565699875, 9.651917457580566],\n [10576167333, 12.742051124572754],\n [10576169000, 10.773301124572754],\n [10585158208, 14.253571510314941],\n [10585160333, 12.034821510314941],\n [10585161375, 10.557229042053223],\n [10585162291, 9.079628944396973],\n [10585163208, 7.602028846740723],\n [10585164083, 6.124428749084473],\n [10585165000, 4.646828651428223],\n [10585165916, 0.7214136123657227],\n [10679902333, 2.1608657836914062],\n [10694787208, 3.9366350173950195],\n [10694789208, 5.884823799133301],\n [10707466291, 8.154637336730957],\n [10718130458, 10.111371040344238],\n [10718132125, 8.548871040344238],\n [10718133958, 11.292202949523926],\n [10718135125, 9.542202949523926],\n [10736509375, 12.632336616516113],\n [10736511500, 10.663586616516113],\n [10736513500, 14.143887519836426],\n [10736514541, 11.925137519836426],\n [10736515666, 10.447545051574707],\n [10736516666, 8.969944953918457],\n [10736517708, 7.492344856262207],\n [10736518666, 6.014744758605957],\n [10736519625, 4.537144660949707],\n [10736520625, 0.611699104309082],\n [10840282375, 2.051219940185547],\n [10840284458, 3.732776641845703],\n [10849612583, 5.775177955627441],\n [10860022125, 8.045022010803223],\n [10872596250, 10.001725196838379],\n [10872598458, 8.439225196838379],\n [10872600333, 11.182557106018066],\n [10872601541, 9.432557106018066],\n [10882916125, 12.522690773010254],\n [10882917333, 10.553940773010254],\n [10905076250, 14.034211158752441],\n [10905078166, 11.815461158752441],\n [10905079208, 10.337868690490723],\n [10905080208, 8.860268592834473],\n [10905081250, 7.382668495178223],\n [10905082166, 5.905068397521973],\n [10905083125, 4.427468299865723],\n [10905084125, 0.5020837783813477],\n [10982966416, 1.9416961669921875],\n [10993338083, 3.717495918273926],\n [11003769375, 5.665684700012207],\n [11016296041, 7.935528755187988],\n [11026691291, 9.892231941223145],\n [11026693333, 8.329731941223145],\n [11026695250, 11.073094367980957],\n [11026696416, 9.323094367980957],\n [11037193791, 12.413228034973145],\n [11037195125, 10.444478034973145],\n [11046151666, 13.924748420715332],\n [11046154625, 11.705998420715332],\n [11046155666, 10.228405952453613],\n [11046156583, 8.750805854797363],\n [11046157500, 7.273205757141113],\n [11046158416, 5.795605659484863],\n [11046159375, 4.318005561828613],\n [11046160375, 0.3925905227661133],\n [11142101958, 1.8320808410644531],\n [11157123166, 3.6078805923461914],\n [11157125416, 5.556069374084473],\n [11166258041, 7.825882911682129],\n [11176659583, 9.78261661529541],\n [11176662166, 8.22011661529541],\n [11192579791, 10.963448524475098],\n [11192581791, 9.213448524475098],\n [11192583791, 12.30361270904541],\n [11192585083, 10.33486270904541],\n [11199880333, 13.815102577209473],\n [11199882166, 11.596352577209473],\n [11199883250, 10.118760108947754],\n [11199884208, 8.641160011291504],\n [11199885125, 7.163559913635254],\n [11199886041, 5.685959815979004],\n [11199886958, 4.208359718322754],\n [11199887916, 0.2829751968383789],\n [11290280500, 1.7225265502929688],\n [11301166458, 3.498326301574707],\n [11307445291, 5.446484565734863],\n [11323843791, 7.7162981033325195],\n [11339677500, 9.6730318069458],\n [11339679375, 8.1105318069458],\n [11339681416, 10.853894233703613],\n [11339682666, 9.103894233703613],\n [11339684583, 12.193997383117676],\n [11339685750, 10.225247383117676],\n [11351282291, 13.705548286437988],\n [11351284291, 11.486798286437988],\n [11351285416, 10.00920581817627],\n [11351286500, 8.53160572052002],\n [11351287708, 7.0540056228637695],\n [11351288791, 5.5764055252075195],\n [11351289875, 4.0988054275512695],\n [11351291125, 0.17339038848876953],\n [11459265375, 1.6129112243652344],\n [11459271833, 3.2944679260253906],\n [11479420041, 5.336899757385254],\n [11497722458, 7.60671329498291],\n [11514445583, 9.563446998596191],\n [11514448333, 8.000946998596191],\n [11525430250, 10.744309425354004],\n [11525432083, 8.994309425354004],\n [11531662291, 12.084473609924316],\n [11531664625, 10.115723609924316],\n [11545973750, 13.595993995666504],\n [11545976125, 11.377243995666504],\n [11545977125, 9.899651527404785],\n [11545978041, 8.422051429748535],\n [11545978958, 6.944451332092285],\n [11545979875, 5.466851234436035],\n [11545980833, 3.989251136779785],\n [11545981833, 0.06386661529541016],\n [11637145541, 1.5034637451171875],\n [11646080291, 3.2986268997192383],\n [11655690333, 5.2468156814575195],\n [11666421916, 7.516659736633301],\n [11676161250, 9.474095344543457],\n [11676163416, 7.911595344543457],\n [11676165416, 10.654927253723145],\n [11676166750, 8.904927253723145],\n [11684479916, 11.99516773223877],\n [11684481708, 10.02641773223877],\n [11694955791, 13.506688117980957],\n [11694958083, 11.287938117980957],\n [11694959291, 9.810345649719238],\n [11694960416, 8.332745552062988],\n [11694961500, 6.855145454406738],\n [11694962625, 5.377545356750488],\n [11694963750, 3.8999452590942383],\n [11694964916, -0.02543926239013672],\n [11793064583, 1.4964265823364258],\n [11801811458, 3.2986574172973633],\n [11809493291, 5.2468461990356445],\n [11815791500, 7.516659736633301],\n [11837618083, 9.473362922668457],\n [11837620291, 7.910862922668457],\n [11837622083, 10.65422534942627],\n [11837623208, 8.90422534942627],\n [11837624875, 11.994328498840332],\n [11837625916, 10.025578498840332],\n [11849392958, 13.505879402160645],\n [11849395000, 11.287129402160645],\n [11849396166, 9.809536933898926],\n [11849397291, 8.331936836242676],\n [11849398333, 6.854336738586426],\n [11849399375, 5.376736640930176],\n [11849400458, 3.899136543273926],\n [11849401500, -0.02627849578857422],\n [11945996375, 1.4964265823364258],\n [11954879916, 3.2986574172973633],\n [11964169833, 5.2468461990356445],\n [11971820291, 7.516690254211426],\n [11984360375, 9.473393440246582],\n [11984362416, 7.910893440246582],\n [11984364666, 10.65422534942627],\n [11984365875, 8.90422534942627],\n [11993308500, 11.994359016418457],\n [11993309791, 10.025609016418457],\n [11999589625, 13.505879402160645],\n [11999590958, 11.287129402160645],\n [12005909375, 9.809536933898926],\n [12005910416, 8.331936836242676],\n [12005911166, 6.854336738586426],\n [12005911916, 5.376736640930176],\n [12005912708, 3.899136543273926],\n [12005913541, -0.02627849578857422],\n [12094932958, 1.4964570999145508],\n [12107397875, 3.2986268997192383],\n [12123030833, 5.2468156814575195],\n [12123032791, 7.516659736633301],\n [12142997375, 9.473362922668457],\n [12142999750, 7.910862922668457],\n [12143001625, 10.65422534942627],\n [12143002833, 8.90422534942627],\n [12143004583, 11.994328498840332],\n [12143005666, 10.025578498840332],\n [12156182250, 13.505879402160645],\n [12156184208, 11.287129402160645],\n [12156185375, 9.809536933898926],\n [12156186333, 8.331936836242676],\n [12156187250, 6.854336738586426],\n [12156188166, 5.376736640930176],\n [12156189083, 3.899136543273926],\n [12156190125, -0.02627849578857422],\n [12255301583, 1.617100715637207],\n [12263787541, 3.2986574172973633],\n [12273490541, 5.247906684875488],\n [12284254541, 7.517926216125488],\n [12294010708, 9.47465991973877],\n [12294013166, 7.9121599197387695],\n [12294015166, 10.655491828918457],\n [12294016375, 8.905491828918457],\n [12306510041, 11.995732307434082],\n [12306512166, 10.026982307434082],\n [12312797208, 13.507283210754395],\n [12312800041, 11.288533210754395],\n [12312801083, 9.810940742492676],\n [12312802000, 8.333340644836426],\n [12312802916, 6.855740547180176],\n [12312803833, 5.378140449523926],\n [12312804750, 3.900540351867676],\n [12312805750, -0.02487468719482422],\n [12412272458, 1.4963960647583008],\n [12420502333, 3.2986574172973633],\n [12430569500, 5.2468156814575195],\n [12441200041, 7.516659736633301],\n [12456973208, 9.473393440246582],\n [12456975541, 7.910893440246582],\n [12456977458, 10.654255867004395],\n [12456978666, 8.904255867004395],\n [12456980458, 11.994412422180176],\n [12456981583, 10.025662422180176],\n [12468596125, 13.505963325500488],\n [12468597708, 11.287213325500488],\n [12468598875, 9.80962085723877],\n [12468600000, 8.33202075958252],\n [12468601041, 6.8544206619262695],\n [12468602125, 5.3768205642700195],\n [12468603416, 3.8992204666137695],\n [12468604541, -0.02619457244873047],\n [12565110458, 1.4964265823364258],\n [12573889833, 3.2986574172973633],\n [12583136625, 5.2468461990356445],\n [12589988083, 7.516690254211426],\n [12602705666, 9.473393440246582],\n [12602707625, 7.910893440246582],\n [12602709541, 10.65422534942627],\n [12602710791, 8.90422534942627],\n [12615077666, 11.994389533996582],\n [12615079041, 10.025639533996582],\n [12622640541, 13.50590991973877],\n [12622642583, 11.28715991973877],\n [12622643666, 9.80956745147705],\n [12622644625, 8.3319673538208],\n [12622645541, 6.854367256164551],\n [12622646458, 5.376767158508301],\n [12622647375, 3.899167060852051],\n [12622648375, -0.02624797821044922],\n [12712905333, 1.4964799880981445],\n [12726887083, 3.2986268997192383],\n [12736326000, 5.2468156814575195],\n [12742815458, 7.516659736633301],\n [12755360666, 9.473362922668457],\n [12755362750, 7.910862922668457],\n [12761633791, 10.654194831848145],\n [12761635208, 8.904194831848145],\n [12767878583, 11.994359016418457],\n [12767879833, 10.025609016418457],\n [12788602125, 13.505879402160645],\n [12788604041, 11.287129402160645],\n [12788605000, 9.809536933898926],\n [12788605916, 8.331936836242676],\n [12788606833, 6.854336738586426],\n [12788607750, 5.376736640930176],\n [12788608708, 3.899136543273926],\n [12788609708, -0.02624797821044922],\n [12866386083, 1.4964265823364258],\n [12877738166, 3.2986574172973633],\n [12884012291, 5.2468156814575195],\n [12899734875, 7.516629219055176],\n [12915539666, 9.473362922668457],\n [12915541833, 7.910862922668457],\n [12915543916, 10.65422534942627],\n [12915545166, 8.90422534942627],\n [12915546958, 11.994328498840332],\n [12915548083, 10.025578498840332],\n [12924181166, 13.505879402160645],\n [12924182375, 11.287129402160645],\n [12939781208, 9.809536933898926],\n [12939782416, 8.331936836242676],\n [12939783375, 6.854336738586426],\n [12939784208, 5.376736640930176],\n [12939785000, 3.899136543273926],\n [12939785833, -0.02627849578857422],\n ],\n n_avg_mb: 13.246117768464265,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 5.449897122642313,\n n_cpu_percent_python: 28.1417525543909,\n n_gpu_percent: 0,\n n_growth_mb: 13.413040161132812,\n n_malloc_mb: 1514.1284255981445,\n n_mallocs: 81,\n n_peak_mb: 13.413040161132812,\n n_python_fraction: 0.18754431950170797,\n n_sys_percent: 0.9929949368449258,\n n_usage_fraction: 0.6277590022940307,\n },\n {\n line: \"def doit2(x):\\n\",\n lineno: 19,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.0,\n n_cpu_percent_python: 0.0,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 81,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.0,\n n_usage_fraction: 0.0,\n },\n {\n line: \" while i < 100000:\\n\",\n lineno: 24,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.20224910523405576,\n n_cpu_percent_python: 0.40196582576581585,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 0,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.015004028803713564,\n n_usage_fraction: 0.0,\n },\n {\n line: \" z = z * z\\n\",\n lineno: 29,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.6919713187718092,\n n_cpu_percent_python: 4.130177787133885,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 0,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.14782644020114388,\n n_usage_fraction: 0.0,\n },\n {\n line: \" z = x * x\\n\",\n lineno: 30,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.3736870036889326,\n n_cpu_percent_python: 2.0118100119639823,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 0,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.05683015570030471,\n n_usage_fraction: 0.0,\n },\n {\n line: \" z = z * z\\n\",\n lineno: 31,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.5930309068593924,\n n_cpu_percent_python: 2.332668210842781,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 0,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.08824647405051865,\n n_usage_fraction: 0.0,\n },\n {\n line: \" z = z * z\\n\",\n lineno: 32,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.41799293599671067,\n n_cpu_percent_python: 2.214194405491557,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 0,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.061242458976033795,\n n_usage_fraction: 0.0,\n },\n {\n line: \" i += 1\\n\",\n lineno: 33,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.2877928269391876,\n n_cpu_percent_python: 1.87461014151035,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 0,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.055151888031057916,\n n_usage_fraction: 0.0,\n },\n {\n line: \" y = np.random.randint(1, 100, size=5000000)[4999999]\\n\",\n lineno: 46,\n memory_samples: [\n [376561916, 46.03816890716553],\n [419515541, 7.945382118225098],\n ],\n n_avg_mb: 38.45994186401367,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.0,\n n_cpu_percent_python: 0.0,\n n_gpu_percent: 0,\n n_growth_mb: 38.45994186401367,\n n_malloc_mb: 38.45994186401367,\n n_mallocs: 1,\n n_peak_mb: 38.45994186401367,\n n_python_fraction: 0.0003818475199016959,\n n_sys_percent: 0.0,\n n_usage_fraction: 0.015945526366630304,\n },\n {\n line: \" x = 1.01\\n\",\n lineno: 47,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.0,\n n_cpu_percent_python: 0.0,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 1,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.0,\n n_usage_fraction: 0.0,\n },\n {\n line: \" print(i)\\n\",\n lineno: 49,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 2.1150691718295715,\n n_cpu_percent_python: 0.06865792500233953,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 0,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.0,\n n_usage_fraction: 0.0,\n },\n {\n line: 'print(\"TESTME\")\\n',\n lineno: 58,\n memory_samples: [],\n n_avg_mb: 0.0,\n n_copy_mb_s: 0.0,\n n_cpu_percent_c: 0.56700460783932,\n n_cpu_percent_python: 0.06865792500233953,\n n_gpu_percent: 0,\n n_growth_mb: 0.0,\n n_malloc_mb: 0.0,\n n_mallocs: 0,\n n_peak_mb: 0.0,\n n_python_fraction: 0,\n n_sys_percent: 0.0,\n n_usage_fraction: 0.0,\n },\n ],\n percent_cpu_time: 99.91458267550459,\n },\n },\n gpu: false,\n growth_rate: 0.003907325283865515,\n max_footprint_mb: 46.22665500640869,\n samples: [\n [255111708, 1.4791831970214844],\n [255112958, 1.5734262466430664],\n [292870041, 3.0510921478271484],\n [319227875, 4.622952461242676],\n [334173583, 6.100545883178711],\n [364468750, 7.5782270431518555],\n [376535708, 7.6724700927734375],\n [376537750, 46.13241195678711],\n [376539291, 46.22665500640869],\n [419496125, 7.945382118225098],\n [419498000, 8.03962516784668],\n [428523041, 9.570051193237305],\n [428523916, 9.664294242858887],\n [445050833, 11.226824760437012],\n [467909583, 9.749224662780762],\n [467911958, 7.894305229187012],\n [467914208, 7.988548278808594],\n [467916458, 9.518760681152344],\n [479993166, 11.200347900390625],\n [501593000, 13.148506164550781],\n [534540791, 15.418411254882812],\n [555492541, 13.940811157226562],\n [555493375, 12.463211059570312],\n [555493875, 10.985610961914062],\n [555494375, 9.508010864257812],\n [555495000, 7.8679351806640625],\n [555495583, 7.9621782302856445],\n [555496041, 9.48503589630127],\n [564997333, 11.16716480255127],\n [575255208, 13.11535358428955],\n [586837916, 15.385197639465332],\n [597083708, 17.341931343078613],\n [597084708, 15.779431343078613],\n [597085458, 18.5227632522583],\n [597086125, 16.7727632522583],\n [605392791, 19.86289691925049],\n [605393875, 17.89414691925049],\n [618500208, 21.3744478225708],\n [618501833, 19.1556978225708],\n [618502458, 17.678105354309082],\n [618503041, 16.200505256652832],\n [618504166, 14.722905158996582],\n [618504666, 13.245305061340332],\n [618505208, 11.767704963684082],\n [618505875, 7.842289924621582],\n [629845625, 7.936532974243164],\n [651142333, 9.467050552368164],\n [651143041, 9.561293601989746],\n [661857958, 11.117934226989746],\n [668143500, 9.640334129333496],\n [668144250, 7.785323143005371],\n [668144916, 7.879566192626953],\n [668145458, 9.409778594970703],\n [682669583, 11.09133529663086],\n [693279916, 13.03952407836914],\n [705305375, 15.309368133544922],\n [716897250, 13.831768035888672],\n [716897916, 12.354167938232422],\n [716898458, 10.876567840576172],\n [716898875, 9.398967742919922],\n [716899375, 7.758892059326172],\n [716899916, 7.853135108947754],\n [716900458, 9.375992774963379],\n [725629333, 11.057496070861816],\n [734912916, 13.005684852600098],\n [751879625, 15.27541446685791],\n [751880208, 17.23214817047119],\n [751881708, 15.669648170471191],\n [761084833, 18.412949562072754],\n [761085500, 16.662949562072754],\n [767325000, 19.753045082092285],\n [767325541, 17.784295082092285],\n [775891666, 21.264504432678223],\n [775893000, 19.045754432678223],\n [775893583, 17.568161964416504],\n [775894041, 16.090561866760254],\n [775894541, 14.612961769104004],\n [775898708, 13.135361671447754],\n [775899166, 11.657761573791504],\n [775899875, 7.732377052307129],\n [775900416, 7.826620101928711],\n [810184791, 9.357297897338867],\n [810185416, 9.45154094696045],\n [819088458, 11.008158683776855],\n [827216458, 9.530558586120605],\n [827217208, 7.6755781173706055],\n [827218000, 7.7698211669921875],\n [827218458, 9.300033569335938],\n [834450750, 10.982154846191406],\n [846987041, 12.930343627929688],\n [859531333, 15.200157165527344],\n [870435083, 13.722557067871094],\n [870435875, 12.244956970214844],\n [870437583, 10.767356872558594],\n [870438125, 9.289756774902344],\n [870438625, 7.649681091308594],\n [870439333, 7.743924140930176],\n [870439791, 9.2667818069458],\n [880995750, 10.948307991027832],\n [890436375, 12.896496772766113],\n [907383666, 15.166340827941895],\n [907384250, 17.123074531555176],\n [907385166, 15.560574531555176],\n [916862583, 18.30387592315674],\n [916863250, 16.55387592315674],\n [916863750, 19.643986701965332],\n [916864250, 17.675236701965332],\n [929525166, 21.15550708770752],\n [929526291, 18.93675708770752],\n [929530458, 17.4591646194458],\n [929530875, 15.98156452178955],\n [929531333, 14.5039644241333],\n [929531750, 13.02636432647705],\n [929532166, 11.5487642288208],\n [929532833, 7.623379707336426],\n [929533333, 7.717622756958008],\n [964094250, 9.248224258422852],\n [964094833, 9.342467308044434],\n [973082125, 10.89908504486084],\n [981249500, 9.42148494720459],\n [981250166, 7.56650447845459],\n [981250666, 7.660747528076172],\n [981251125, 9.190959930419922],\n [988422541, 10.872547149658203],\n [998613000, 12.820735931396484],\n [1013966083, 15.09054946899414],\n [1025426416, 13.61294937133789],\n [1025427041, 12.13534927368164],\n [1025427541, 10.65774917602539],\n [1025428333, 9.18014907836914],\n [1025428791, 7.540073394775391],\n [1025429333, 7.634316444396973],\n [1025429750, 9.157174110412598],\n [1031962916, 10.838730812072754],\n [1043294666, 12.786919593811035],\n [1049547916, 15.056733131408691],\n [1064018666, 17.013436317443848],\n [1064019583, 15.450936317443848],\n [1064020083, 18.19429874420166],\n [1064020583, 16.44429874420166],\n [1076168208, 19.534432411193848],\n [1076169166, 17.565682411193848],\n [1083915041, 21.045952796936035],\n [1083916000, 18.827202796936035],\n [1083916458, 17.349610328674316],\n [1083916875, 15.872010231018066],\n [1083917291, 14.394410133361816],\n [1083917708, 12.916810035705566],\n [1083918125, 11.439209938049316],\n [1083919291, 7.513794898986816],\n [1083919791, 7.608037948608398],\n [1113666458, 9.138654708862305],\n [1113667125, 9.232897758483887],\n [1126228375, 10.789484977722168],\n [1140844916, 9.311884880065918],\n [1140845666, 7.456873893737793],\n [1140846250, 7.551116943359375],\n [1140846708, 9.081329345703125],\n [1140847166, 10.762916564941406],\n [1154924791, 12.711074829101562],\n [1167683458, 14.980918884277344],\n [1184540791, 13.503318786621094],\n [1184541541, 12.025718688964844],\n [1184542083, 10.548118591308594],\n [1184542583, 9.070518493652344],\n [1184543125, 7.430442810058594],\n [1184543750, 7.524685859680176],\n [1184544208, 9.0475435256958],\n [1184544750, 10.729100227355957],\n [1195584708, 12.677258491516113],\n [1201856541, 14.94701099395752],\n [1217542958, 16.903592109680176],\n [1217543791, 15.341092109680176],\n [1217545666, 18.08445453643799],\n [1217546166, 16.33445453643799],\n [1236168958, 19.42455768585205],\n [1236170000, 17.45580768585205],\n [1236170541, 20.936108589172363],\n [1236171083, 18.717358589172363],\n [1236171583, 17.239766120910645],\n [1236172083, 15.762166023254395],\n [1236172666, 14.284565925598145],\n [1236173125, 12.806965827941895],\n [1236173583, 11.329365730285645],\n [1236174458, 7.4039201736450195],\n [1236174875, 7.498163223266602],\n [1267811916, 9.028757095336914],\n [1267812541, 9.123000144958496],\n [1278334625, 10.679617881774902],\n [1294282916, 9.202017784118652],\n [1294283666, 7.347006797790527],\n [1294284208, 7.441249847412109],\n [1294284666, 8.97146224975586],\n [1294285083, 10.65304946899414],\n [1315187041, 12.601146697998047],\n [1315187625, 14.870990753173828],\n [1326173958, 13.393390655517578],\n [1326174958, 11.915790557861328],\n [1326175583, 10.438190460205078],\n [1326176083, 8.960590362548828],\n [1326176500, 7.320484161376953],\n [1326177416, 7.414727210998535],\n [1338623000, 8.93758487701416],\n [1338623583, 10.619111061096191],\n [1348634125, 12.567269325256348],\n [1361175166, 14.837082862854004],\n [1383303375, 16.79378604888916],\n [1383304250, 15.23128604888916],\n [1383304750, 17.974648475646973],\n [1383305291, 16.224648475646973],\n [1383305833, 19.31483554840088],\n [1383306375, 17.34608554840088],\n [1389632416, 20.826355934143066],\n [1389633458, 18.607605934143066],\n [1389634000, 17.130013465881348],\n [1389634458, 15.652413368225098],\n [1389634875, 14.174813270568848],\n [1389635333, 12.697213172912598],\n [1389635833, 11.219613075256348],\n [1389636583, 7.294228553771973],\n [1389637041, 7.388471603393555],\n [1424223625, 8.919004440307617],\n [1424224250, 9.0132474899292],\n [1433310041, 10.569865226745605],\n [1441478583, 9.092265129089355],\n [1441479416, 7.2372541427612305],\n [1441479958, 7.3314971923828125],\n [1441480333, 8.861709594726562],\n [1451789791, 10.543296813964844],\n [1462318083, 12.491485595703125],\n [1474262916, 14.761329650878906],\n [1485623958, 13.283729553222656],\n [1485624666, 11.806129455566406],\n [1485625875, 10.328529357910156],\n [1485626375, 8.850929260253906],\n [1485626958, 7.210853576660156],\n [1485627541, 7.305096626281738],\n [1485628000, 8.827954292297363],\n [1500741375, 10.50951099395752],\n [1500741958, 12.4576997756958],\n [1509507666, 14.727513313293457],\n [1520748625, 16.68424701690674],\n [1520749416, 15.121747016906738],\n [1529883750, 17.865017890930176],\n [1529884583, 16.115017890930176],\n [1536115583, 19.20518207550049],\n [1536116208, 17.23643207550049],\n [1542864250, 20.7167329788208],\n [1542865583, 18.4979829788208],\n [1542866125, 17.020390510559082],\n [1542866541, 15.542790412902832],\n [1542867000, 14.065190315246582],\n [1542867458, 12.587590217590332],\n [1542867875, 11.109990119934082],\n [1542868625, 7.184575080871582],\n [1542869125, 7.278818130493164],\n [1576162250, 8.809465408325195],\n [1576162833, 8.903708457946777],\n [1586513833, 10.460295677185059],\n [1594674500, 8.982695579528809],\n [1594675208, 7.127715110778809],\n [1594675750, 7.221958160400391],\n [1594676166, 8.75217056274414],\n [1604961083, 10.433757781982422],\n [1615429833, 12.381877899169922],\n [1621692833, 14.651721954345703],\n [1634485791, 13.174121856689453],\n [1634486625, 11.696521759033203],\n [1634487333, 10.218921661376953],\n [1634488041, 8.741321563720703],\n [1634488625, 7.101245880126953],\n [1634489250, 7.195488929748535],\n [1634489750, 8.71834659576416],\n [1647013666, 10.399903297424316],\n [1656915416, 12.348061561584473],\n [1667541541, 14.617905616760254],\n [1677038291, 16.574639320373535],\n [1677039125, 15.012139320373535],\n [1677039583, 17.755501747131348],\n [1677040166, 16.005501747131348],\n [1695585750, 19.09560489654541],\n [1695586708, 17.12685489654541],\n [1695587208, 20.607155799865723],\n [1695587708, 18.388405799865723],\n [1695588125, 16.910813331604004],\n [1695588583, 15.433213233947754],\n [1695589041, 13.955613136291504],\n [1695589458, 12.478013038635254],\n [1695589875, 11.000412940979004],\n [1695590458, 7.074967384338379],\n [1695590916, 7.169210433959961],\n [1730109875, 8.699773788452148],\n [1730110458, 8.79401683807373],\n [1739209333, 10.350634574890137],\n [1747339916, 8.873034477233887],\n [1747340625, 7.018054008483887],\n [1747341208, 7.112297058105469],\n [1747341750, 8.642509460449219],\n [1755368333, 10.324043273925781],\n [1767911458, 12.272201538085938],\n [1780034666, 14.542015075683594],\n [1791376541, 13.064414978027344],\n [1791377250, 11.586814880371094],\n [1791377750, 10.109214782714844],\n [1791378208, 8.631614685058594],\n [1791378750, 6.991539001464844],\n [1791379250, 7.085782051086426],\n [1791379708, 8.608670234680176],\n [1806466750, 10.290196418762207],\n [1806468583, 12.238385200500488],\n [1815309083, 14.508198738098145],\n [1829621916, 16.4649019241333],\n [1829622791, 14.9024019241333],\n [1829623333, 17.64573383331299],\n [1829623916, 15.895733833312988],\n [1838269916, 18.985806465148926],\n [1838270500, 17.017056465148926],\n [1848696583, 20.49729633331299],\n [1848697875, 18.27854633331299],\n [1848698375, 16.80095386505127],\n [1848698833, 15.32335376739502],\n [1848699250, 13.84575366973877],\n [1848699666, 12.36815357208252],\n [1848700083, 10.89055347442627],\n [1848700833, 6.9651384353637695],\n [1848701291, 7.059381484985352],\n [1883132041, 8.589975357055664],\n [1883132708, 8.684218406677246],\n [1898338791, 10.240836143493652],\n [1898340125, 8.763236045837402],\n [1898340750, 6.908255577087402],\n [1898341208, 7.002498626708984],\n [1898341625, 8.53268051147461],\n [1906986166, 10.21426773071289],\n [1921332083, 12.162425994873047],\n [1930356541, 14.432270050048828],\n [1945018250, 12.954669952392578],\n [1945018958, 11.477069854736328],\n [1945019458, 9.999469757080078],\n [1945019875, 8.521869659423828],\n [1945020416, 6.881763458251953],\n [1945021041, 6.976006507873535],\n [1945021458, 8.49886417388916],\n [1954093791, 10.180390357971191],\n [1963534833, 12.128579139709473],\n [1974251458, 14.398423194885254],\n [1983809208, 16.355156898498535],\n [1983810041, 14.792656898498535],\n [1983810541, 17.535988807678223],\n [1983811041, 15.785988807678223],\n [1992817333, 18.876229286193848],\n [1992817958, 16.907479286193848],\n [2003438666, 20.387749671936035],\n [2003442416, 18.168999671936035],\n [2003442958, 16.691407203674316],\n [2003443416, 15.213807106018066],\n [2003443875, 13.736207008361816],\n [2003444333, 12.258606910705566],\n [2003444791, 10.781006813049316],\n [2003445375, 6.855622291564941],\n [2003445916, 6.949865341186523],\n [2042892708, 8.480405807495117],\n [2042893333, 8.5746488571167],\n [2042893791, 10.131266593933105],\n [2053155250, 8.653666496276855],\n [2053156083, 6.7986555099487305],\n [2053156625, 6.8928985595703125],\n [2053157083, 8.423110961914062],\n [2064732625, 10.104667663574219],\n [2074920541, 12.0528564453125],\n [2081198125, 14.322647094726562],\n [2098838916, 12.845046997070312],\n [2098839625, 11.367446899414062],\n [2098840250, 9.889846801757812],\n [2098840750, 8.412246704101562],\n [2098841250, 6.7721710205078125],\n [2098841791, 6.8664140701293945],\n [2098842250, 8.38927173614502],\n [2107699791, 10.070828437805176],\n [2117125208, 12.019017219543457],\n [2123386291, 14.288861274719238],\n [2137367458, 16.245564460754395],\n [2137368291, 14.683064460754395],\n [2137368833, 17.426396369934082],\n [2137369375, 15.676396369934082],\n [2144786625, 18.76653003692627],\n [2144787208, 16.79778003692627],\n [2156960416, 20.278050422668457],\n [2156961708, 18.059300422668457],\n [2156962333, 16.58170795440674],\n [2156962833, 15.104107856750488],\n [2156963250, 13.626507759094238],\n [2156963708, 12.148907661437988],\n [2156964166, 10.671307563781738],\n [2156964916, 6.745923042297363],\n [2156965500, 6.840166091918945],\n [2196875708, 8.370790481567383],\n [2196876291, 8.465033531188965],\n [2196876708, 10.021651268005371],\n [2204024500, 8.544051170349121],\n [2204025208, 6.689040184020996],\n [2204026625, 6.783283233642578],\n [2204027125, 8.313495635986328],\n [2215333041, 9.99508285522461],\n [2226158750, 11.94327163696289],\n [2238712791, 14.213115692138672],\n [2252113916, 12.735515594482422],\n [2252114541, 11.257915496826172],\n [2252115041, 9.780315399169922],\n [2252115541, 8.302715301513672],\n [2252116041, 6.662609100341797],\n [2252116541, 6.756852149963379],\n [2252117000, 8.279740333557129],\n [2261108125, 9.96126651763916],\n [2270492166, 11.909455299377441],\n [2281007625, 14.179299354553223],\n [2288724250, 16.136033058166504],\n [2288725125, 14.573533058166504],\n [2296526291, 17.31686496734619],\n [2296527250, 15.566864967346191],\n [2296527791, 18.657029151916504],\n [2296528416, 16.688279151916504],\n [2316508916, 20.16854953765869],\n [2316510000, 17.94979953765869],\n [2316510500, 16.472207069396973],\n [2316510958, 14.994606971740723],\n [2316511375, 13.517006874084473],\n [2316511875, 12.039406776428223],\n [2316512375, 10.561806678771973],\n [2316513041, 6.636391639709473],\n [2316513500, 6.730634689331055],\n [2338297750, 8.261251449584961],\n [2338298333, 8.355494499206543],\n [2352914000, 9.912020683288574],\n [2359494083, 8.434420585632324],\n [2359494750, 6.579440116882324],\n [2359495291, 6.673683166503906],\n [2359495750, 8.203895568847656],\n [2370126416, 9.885482788085938],\n [2376408666, 11.833641052246094],\n [2392830208, 14.103485107421875],\n [2405343958, 12.625885009765625],\n [2405344666, 11.148284912109375],\n [2405345166, 9.670684814453125],\n [2405345666, 8.193084716796875],\n [2405346125, 6.552978515625],\n [2405346666, 6.647221565246582],\n [2405347125, 8.170109748840332],\n [2414183791, 9.851635932922363],\n [2423600625, 11.799824714660645],\n [2434180166, 14.069668769836426],\n [2443612208, 16.026402473449707],\n [2443613041, 14.463902473449707],\n [2443613625, 17.207234382629395],\n [2443614125, 15.457234382629395],\n [2451117208, 18.54747486114502],\n [2451117875, 16.57872486114502],\n [2463395416, 20.058995246887207],\n [2463396666, 17.840245246887207],\n [2463397208, 16.36265277862549],\n [2463397666, 14.885052680969238],\n [2463398166, 13.407452583312988],\n [2463398666, 11.929852485656738],\n [2463399125, 10.452252388000488],\n [2463399916, 6.526867866516113],\n [2463400416, 6.621110916137695],\n [2501084375, 8.151735305786133],\n [2501085166, 8.245978355407715],\n [2510289458, 9.802596092224121],\n [2519167958, 8.324995994567871],\n [2519168916, 6.470015525817871],\n [2519169541, 6.564258575439453],\n [2519169958, 8.094470977783203],\n [2529540916, 9.776058197021484],\n [2540144458, 11.724246978759766],\n [2558413000, 13.994091033935547],\n [2558413875, 12.516490936279297],\n [2558414416, 11.038890838623047],\n [2558414875, 9.561290740966797],\n [2558415333, 8.083690643310547],\n [2558415791, 6.443614959716797],\n [2558416250, 6.537858009338379],\n [2558416666, 8.060685157775879],\n [2567831041, 9.742241859436035],\n [2581776333, 11.690400123596191],\n [2590376958, 13.960183143615723],\n [2596678750, 15.916886329650879],\n [2596679875, 14.354386329650879],\n [2608502916, 17.097771644592285],\n [2608504083, 15.347771644592285],\n [2608504583, 18.437935829162598],\n [2608505125, 16.469185829162598],\n [2628432625, 19.949456214904785],\n [2628433750, 17.730706214904785],\n [2628434250, 16.253113746643066],\n [2628434666, 14.775513648986816],\n [2628435125, 13.297913551330566],\n [2628435500, 11.820313453674316],\n [2628435916, 10.342713356018066],\n [2628436500, 6.417298316955566],\n [2628437000, 6.511541366577148],\n [2651115750, 8.042112350463867],\n [2651116416, 8.13635540008545],\n [2663687958, 9.69294261932373],\n [2672628958, 8.21534252166748],\n [2672629666, 6.3603315353393555],\n [2672630250, 6.4545745849609375],\n [2672630666, 7.9847869873046875],\n [2682914458, 9.666374206542969],\n [2693624916, 11.61456298828125],\n [2701116750, 13.884407043457031],\n [2716921916, 12.406806945800781],\n [2716922583, 10.929206848144531],\n [2716923166, 9.451606750488281],\n [2716923666, 7.974006652832031],\n [2716924166, 6.333900451660156],\n [2716924750, 6.428143501281738],\n [2716925250, 7.951001167297363],\n [2723700625, 9.63249683380127],\n [2729979166, 11.580655097961426],\n [2745605125, 13.850468635559082],\n [2761422500, 15.807202339172363],\n [2761423458, 14.244702339172363],\n [2761424000, 16.988064765930176],\n [2761424541, 15.238064765930176],\n [2761425041, 18.32816791534424],\n [2761425666, 16.35941791534424],\n [2773077916, 19.83971881866455],\n [2773078666, 17.62096881866455],\n [2773079250, 16.143376350402832],\n [2773079833, 14.665776252746582],\n [2773080375, 13.188176155090332],\n [2773080916, 11.710576057434082],\n [2773081458, 10.232975959777832],\n [2773082250, 6.307560920715332],\n [2785779083, 6.401803970336914],\n [2808270541, 7.932390213012695],\n [2808271083, 8.026633262634277],\n [2817238083, 9.583250999450684],\n [2825357708, 8.105650901794434],\n [2825358416, 6.250670433044434],\n [2825359000, 6.344913482666016],\n [2825359416, 7.875125885009766],\n [2832060208, 9.556713104248047],\n [2843280041, 11.504901885986328],\n [2858262166, 13.774715423583984],\n [2867815125, 12.297115325927734],\n [2867815958, 10.819515228271484],\n [2867816500, 9.341915130615234],\n [2867816958, 7.864315032958984],\n [2867817458, 6.224239349365234],\n [2867818208, 6.318482398986816],\n [2867818708, 7.841340065002441],\n [2884557000, 9.522866249084473],\n [2884557708, 11.471055030822754],\n [2892819166, 13.74086856842041],\n [2907878791, 15.698105812072754],\n [2907879500, 14.135605812072754],\n [2907880166, 16.87893772125244],\n [2907880708, 15.128937721252441],\n [2915383916, 18.21907138824463],\n [2915384708, 16.25032138824463],\n [2926657333, 19.73062229156494],\n [2926658583, 17.51187229156494],\n [2926659083, 16.034279823303223],\n [2926659500, 14.556679725646973],\n [2926659958, 13.079079627990723],\n [2926660375, 11.601479530334473],\n [2926660791, 10.123879432678223],\n [2926661583, 6.198464393615723],\n [2926662041, 6.292707443237305],\n [2967271708, 7.823369979858398],\n [2967272291, 7.9176130294799805],\n [2967272708, 9.474230766296387],\n [2976143083, 7.996630668640137],\n [2976143750, 6.141619682312012],\n [2976144291, 6.235862731933594],\n [2976144750, 7.766075134277344],\n [2982450583, 9.4476318359375],\n [3005089666, 11.395790100097656],\n [3005090166, 13.665634155273438],\n [3034649458, 12.188034057617188],\n [3034650416, 10.710433959960938],\n [3034650875, 9.232833862304688],\n [3034651333, 7.7552337646484375],\n [3034651833, 6.1151275634765625],\n [3034652333, 6.2093706130981445],\n [3034652750, 7.7322282791137695],\n [3034653166, 9.413784980773926],\n [3034653541, 11.361943244934082],\n [3046986333, 13.631756782531738],\n [3060237208, 15.588459968566895],\n [3060237833, 14.025959968566895],\n [3060242791, 16.769291877746582],\n [3060243500, 15.019291877746582],\n [3072034000, 18.10942554473877],\n [3072034791, 16.14067554473877],\n [3086001625, 19.620945930480957],\n [3086002791, 17.402195930480957],\n [3086003500, 15.924603462219238],\n [3086004000, 14.447003364562988],\n [3086004458, 12.969403266906738],\n [3086004916, 11.491803169250488],\n [3086005500, 10.014203071594238],\n [3086006125, 6.088788032531738],\n [3086006708, 6.18303108215332],\n [3109486416, 7.713602066040039],\n [3109487083, 7.807845115661621],\n [3122066000, 9.364432334899902],\n [3130358250, 7.886832237243652],\n [3130358916, 6.031821250915527],\n [3130359458, 6.126064300537109],\n [3130359916, 7.656276702880859],\n [3147035875, 9.33786392211914],\n [3147036416, 11.286052703857422],\n [3157043666, 13.555866241455078],\n [3174609375, 12.078266143798828],\n [3174610083, 10.600666046142578],\n [3174610625, 9.123065948486328],\n [3174611083, 7.645465850830078],\n [3174611541, 6.005390167236328],\n [3174612041, 6.09963321685791],\n [3174612500, 7.622490882873535],\n [3183564708, 9.304047584533691],\n [3192816000, 11.252236366271973],\n [3199070708, 13.522049903869629],\n [3219448875, 15.478753089904785],\n [3219449791, 13.916253089904785],\n [3219450333, 16.659615516662598],\n [3219450833, 14.909615516662598],\n [3219451250, 17.99971866607666],\n [3219451791, 16.03096866607666],\n [3232043625, 19.511269569396973],\n [3232044708, 17.292519569396973],\n [3232045208, 15.814927101135254],\n [3232045625, 14.337327003479004],\n [3232046125, 12.859726905822754],\n [3232046541, 11.382126808166504],\n [3232046958, 9.904526710510254],\n [3232047541, 5.979111671447754],\n [3232048083, 6.073354721069336],\n [3265022458, 7.603918075561523],\n [3265023083, 7.6981611251831055],\n [3271316583, 9.254679679870605],\n [3282563750, 7.7770795822143555],\n [3282564458, 5.9220991134643555],\n [3282565000, 6.0163421630859375],\n [3282565458, 7.5465545654296875],\n [3293271708, 9.228141784667969],\n [3299543541, 11.176300048828125],\n [3315502083, 13.446144104003906],\n [3328144541, 11.968544006347656],\n [3328145333, 10.490943908691406],\n [3328145916, 9.013343811035156],\n [3328146375, 7.535743713378906],\n [3328146958, 5.895637512207031],\n [3328147791, 5.989880561828613],\n [3328148250, 7.512738227844238],\n [3337771291, 9.19426441192627],\n [3347566083, 11.14245319366455],\n [3358794416, 13.412297248840332],\n [3375066916, 15.369030952453613],\n [3375067958, 13.806530952453613],\n [3375068458, 16.549893379211426],\n [3375069000, 14.799893379211426],\n [3375069458, 17.890103340148926],\n [3375069916, 15.921353340148926],\n [3382583958, 19.40165424346924],\n [3382585500, 17.18290424346924],\n [3393219166, 15.70531177520752],\n [3393220125, 14.22771167755127],\n [3393220750, 12.75011157989502],\n [3393221208, 11.27251148223877],\n [3393224000, 9.79491138458252],\n [3393224791, 5.8694963455200195],\n [3393225458, 5.963739395141602],\n [3422212166, 7.494386672973633],\n [3422213000, 7.588629722595215],\n [3437602000, 9.145247459411621],\n [3437603291, 7.667647361755371],\n [3437604000, 5.812666893005371],\n [3437604500, 5.906909942626953],\n [3437604916, 7.437091827392578],\n [3449235125, 9.11867904663086],\n [3459932500, 11.06686782836914],\n [3471862208, 13.336711883544922],\n [3483691291, 11.859111785888672],\n [3483692208, 10.381511688232422],\n [3483692708, 8.903911590576172],\n [3483693166, 7.426311492919922],\n [3483693625, 5.786205291748047],\n [3483694208, 5.880448341369629],\n [3483694666, 7.403336524963379],\n [3498917333, 9.08486270904541],\n [3498918041, 11.033051490783691],\n [3507067000, 13.302865028381348],\n [3517777750, 15.259598731994629],\n [3517778666, 13.697098731994629],\n [3534453375, 16.440430641174316],\n [3534454166, 14.690430641174316],\n [3534454666, 17.78059482574463],\n [3534455125, 15.811844825744629],\n [3540744125, 19.292115211486816],\n [3540745250, 17.073365211486816],\n [3540745750, 15.595772743225098],\n [3540746250, 14.118172645568848],\n [3540746708, 12.640572547912598],\n [3540747083, 11.162972450256348],\n [3540747541, 9.685372352600098],\n [3540748166, 5.759957313537598],\n [3540748666, 5.85420036315918],\n [3575509666, 7.384756088256836],\n [3575510208, 7.478999137878418],\n [3584537583, 9.035616874694824],\n [3592698750, 7.558016777038574],\n [3592699458, 5.703036308288574],\n [3592700000, 5.797279357910156],\n [3592700458, 7.327491760253906],\n [3599233166, 9.009078979492188],\n [3613639166, 10.957237243652344],\n [3620069125, 13.227081298828125],\n [3636921708, 11.749481201171875],\n [3636922500, 10.271881103515625],\n [3636923000, 8.794281005859375],\n [3636923458, 7.316680908203125],\n [3636924000, 5.67657470703125],\n [3636924583, 5.770817756652832],\n [3636925000, 7.293675422668457],\n [3643251250, 8.975232124328613],\n [3649553250, 10.92339038848877],\n [3665513958, 13.193203926086426],\n [3681309083, 15.149937629699707],\n [3681309958, 13.587437629699707],\n [3681310416, 16.33080005645752],\n [3681310916, 14.58080005645752],\n [3681311375, 17.670903205871582],\n [3681311958, 15.702153205871582],\n [3694522291, 19.182454109191895],\n [3694523541, 16.963704109191895],\n [3694524083, 15.486111640930176],\n [3694524500, 14.008511543273926],\n [3694525000, 12.530911445617676],\n [3694525416, 11.053311347961426],\n [3694525833, 9.575711250305176],\n [3694526583, 5.650296211242676],\n [3694527166, 5.744539260864258],\n [3723738708, 7.275102615356445],\n [3723739291, 7.369345664978027],\n [3734446291, 8.925963401794434],\n [3745654458, 7.448363304138184],\n [3745655458, 5.593352317810059],\n [3745655958, 5.687595367431641],\n [3745656375, 7.217838287353516],\n [3756014416, 8.899394989013672],\n [3766548375, 10.847583770751953],\n [3778433041, 13.117427825927734],\n [3790074625, 11.639827728271484],\n [3790075708, 10.162227630615234],\n [3790076250, 8.684627532958984],\n [3790076708, 7.207027435302734],\n [3790077291, 5.566951751708984],\n [3790080833, 5.661194801330566],\n [3790081416, 7.184052467346191],\n [3798908250, 8.865555763244629],\n [3808254916, 10.81374454498291],\n [3815907375, 13.083588600158691],\n [3822187458, 15.040291786193848],\n [3822188583, 13.477791786193848],\n [3828484250, 16.221177101135254],\n [3828484916, 14.471177101135254],\n [3840434916, 17.561440467834473],\n [3840438208, 15.592690467834473],\n [3846811333, 19.07296085357666],\n [3846812083, 16.85421085357666],\n [3846812583, 15.376618385314941],\n [3846812958, 13.899018287658691],\n [3846813458, 12.421418190002441],\n [3846813916, 10.943818092346191],\n [3846814333, 9.466217994689941],\n [3846814875, 5.540833473205566],\n [3846815375, 5.635076522827148],\n [3881888500, 7.165685653686523],\n [3881889083, 7.2599287033081055],\n [3897167041, 8.816546440124512],\n [3897168041, 7.338946342468262],\n [3897168583, 5.483965873718262],\n [3897169000, 5.578208923339844],\n [3897169500, 7.108390808105469],\n [3915722958, 8.789947509765625],\n [3915723458, 10.738136291503906],\n [3931951333, 13.007949829101562],\n [3943408541, 11.530349731445312],\n [3943409375, 10.052749633789062],\n [3943409916, 8.575149536132812],\n [3943410416, 7.0975494384765625],\n [3943410916, 5.4574737548828125],\n [3943411458, 5.5517168045043945],\n [3943411916, 7.0746049880981445],\n [3958364916, 8.756131172180176],\n [3958365416, 10.704319953918457],\n [3966163166, 12.974133491516113],\n [3981614583, 14.93083667755127],\n [3981615500, 13.36833667755127],\n [3981616041, 16.111668586730957],\n [3981616541, 14.361668586730957],\n [3989145666, 17.451802253723145],\n [3989146375, 15.483052253723145],\n [4000956083, 18.963269233703613],\n [4000957166, 16.744519233703613],\n [4000957666, 15.266926765441895],\n [4000958125, 13.789326667785645],\n [4000958541, 12.311726570129395],\n [4000958958, 10.834126472473145],\n [4000959375, 9.356526374816895],\n [4000960125, 5.4311418533325195],\n [4000960625, 5.525384902954102],\n [4034436833, 7.056039810180664],\n [4034437416, 7.150282859802246],\n [4050000166, 8.706870079040527],\n [4050001166, 7.229269981384277],\n [4050001791, 5.374289512634277],\n [4050002291, 5.468532562255859],\n [4050002875, 6.998714447021484],\n [4059487416, 8.680301666259766],\n [4072034541, 10.628459930419922],\n [4084398625, 12.898273468017578],\n [4095844458, 11.420673370361328],\n [4095845291, 9.943073272705078],\n [4095845833, 8.465473175048828],\n [4095846375, 6.987873077392578],\n [4095846833, 5.347797393798828],\n [4095847541, 5.44204044342041],\n [4095848000, 6.964898109436035],\n [4105105916, 8.646454811096191],\n [4114601541, 10.594643592834473],\n [4122070375, 12.864487648010254],\n [4134662791, 14.82119083404541],\n [4134663958, 13.25869083404541],\n [4134664625, 16.002022743225098],\n [4134665166, 14.252022743225098],\n [4147021041, 17.34212589263916],\n [4147021708, 15.37337589263916],\n [4153329541, 18.853676795959473],\n [4153330708, 16.634926795959473],\n [4153331250, 15.157334327697754],\n [4153331708, 13.679734230041504],\n [4153332208, 12.202134132385254],\n [4153332625, 10.724534034729004],\n [4153333041, 9.246933937072754],\n [4153333750, 5.321518898010254],\n [4153334250, 5.415761947631836],\n [4184476000, 6.946355819702148],\n [4184476666, 7.0405988693237305],\n [4197048916, 8.59711742401123],\n [4205570375, 7.1195173263549805],\n [4205571333, 5.2645063400268555],\n [4205571958, 5.3587493896484375],\n [4205572458, 6.8889617919921875],\n [4222327541, 8.570549011230469],\n [4222328125, 10.51873779296875],\n [4234438750, 12.788551330566406],\n [4244769625, 11.310951232910156],\n [4244770541, 9.833351135253906],\n [4244771041, 8.355751037597656],\n [4244771583, 6.878150939941406],\n [4244772041, 5.238075256347656],\n [4244772791, 5.332318305969238],\n [4244773208, 6.855175971984863],\n [4257109833, 8.53673267364502],\n [4263438958, 10.484890937805176],\n [4278885750, 12.754704475402832],\n [4294703250, 14.711438179016113],\n [4294704333, 13.148938179016113],\n [4294704875, 15.892300605773926],\n [4294705416, 14.142300605773926],\n [4294705916, 17.23240375518799],\n [4294706458, 15.263653755187988],\n [4306226541, 18.7439546585083],\n [4306227583, 16.5252046585083],\n [4306228250, 15.047612190246582],\n [4306228791, 13.570012092590332],\n [4306229375, 12.092411994934082],\n [4306229875, 10.614811897277832],\n [4306230500, 9.137211799621582],\n [4306231291, 5.211796760559082],\n [4312647583, 5.306039810180664],\n [4347720458, 6.836626052856445],\n [4347721000, 6.930869102478027],\n [4347721458, 8.487486839294434],\n [4358549291, 7.009886741638184],\n [4358550125, 5.154875755310059],\n [4358550708, 5.249118804931641],\n [4358551166, 6.779331207275391],\n [4365445208, 8.460918426513672],\n [4379412625, 10.409076690673828],\n [4388702625, 12.678852081298828],\n [4402719833, 11.201251983642578],\n [4402720625, 9.723651885986328],\n [4402721166, 8.246051788330078],\n [4402721625, 6.768451690673828],\n [4402722166, 5.128345489501953],\n [4402722791, 5.222588539123535],\n [4402723250, 6.74544620513916],\n [4411434708, 8.426972389221191],\n [4420922583, 10.375161170959473],\n [4431463916, 12.645005226135254],\n [4438014583, 14.601738929748535],\n [4438015250, 13.039238929748535],\n [4453011666, 15.782624244689941],\n [4453012333, 14.032624244689941],\n [4453012791, 17.122788429260254],\n [4453013291, 15.154038429260254],\n [4459542375, 18.63430881500244],\n [4459543500, 16.41555881500244],\n [4459544041, 14.937966346740723],\n [4459544458, 13.460366249084473],\n [4459544875, 11.982766151428223],\n [4459545291, 10.505166053771973],\n [4459545750, 9.027565956115723],\n [4459546416, 5.102150917053223],\n [4459546875, 5.196393966674805],\n [4492833291, 6.727071762084961],\n [4492833916, 6.821314811706543],\n [4502904958, 8.377902030944824],\n [4511007333, 6.900301933288574],\n [4511007916, 5.045321464538574],\n [4511008416, 5.139564514160156],\n [4511008875, 6.669776916503906],\n [4517759375, 8.351364135742188],\n [4531946583, 10.299522399902344],\n [4540444291, 12.569366455078125],\n [4555224875, 11.091766357421875],\n [4555225541, 9.614166259765625],\n [4555226250, 8.136566162109375],\n [4555226750, 6.658966064453125],\n [4555227291, 5.01885986328125],\n [4555227833, 5.113102912902832],\n [4555228291, 6.635960578918457],\n [4563665291, 8.317517280578613],\n [4569929666, 10.26567554473877],\n [4590299750, 12.535489082336426],\n [4590300291, 14.492222785949707],\n [4590301166, 12.929722785949707],\n [4599284458, 15.67302417755127],\n [4599285291, 13.92302417755127],\n [4599285750, 17.013188362121582],\n [4599286250, 15.044438362121582],\n [4611797791, 18.524739265441895],\n [4611798666, 16.305989265441895],\n [4611799166, 14.828396797180176],\n [4611799625, 13.350796699523926],\n [4611800041, 11.873196601867676],\n [4611800541, 10.395596504211426],\n [4611800958, 8.917996406555176],\n [4611801791, 4.992581367492676],\n [4611802333, 5.086824417114258],\n [4646526333, 6.617380142211914],\n [4646527000, 6.711623191833496],\n [4661985708, 8.268240928649902],\n [4661986791, 6.790640830993652],\n [4661987541, 4.935660362243652],\n [4661988041, 5.029903411865234],\n [4661988458, 6.560085296630859],\n [4672054708, 8.24167251586914],\n [4684627791, 10.189830780029297],\n [4702979458, 12.459644317626953],\n [4702980791, 10.982044219970703],\n [4702981458, 9.504444122314453],\n [4702982000, 8.026844024658203],\n [4702982458, 6.549243927001953],\n [4702982958, 4.909168243408203],\n [4702983500, 5.003411293029785],\n [4702984041, 6.526238441467285],\n [4717036125, 8.207795143127441],\n [4726367583, 10.155983924865723],\n [4734430041, 12.425827980041504],\n [4740754500, 14.38253116607666],\n [4740755458, 12.82003116607666],\n [4752316000, 15.563416481018066],\n [4752316791, 13.813416481018066],\n [4752317291, 16.90358066558838],\n [4752317833, 14.934830665588379],\n [4765001458, 18.415101051330566],\n [4765002458, 16.196351051330566],\n [4765003000, 14.718758583068848],\n [4765003458, 13.241158485412598],\n [4765003958, 11.763558387756348],\n [4765004416, 10.285958290100098],\n [4765004875, 8.808358192443848],\n [4765005625, 4.882973670959473],\n [4765006166, 4.977216720581055],\n [4805867833, 6.50782585144043],\n [4805868416, 6.602068901062012],\n [4805868875, 8.158686637878418],\n [4816659583, 6.681086540222168],\n [4816660166, 4.826075553894043],\n [4816660708, 4.920318603515625],\n [4816661125, 6.450531005859375],\n [4823793916, 8.132118225097656],\n [4836392083, 10.080276489257812],\n [4846973833, 12.350120544433594],\n [4860935375, 10.872520446777344],\n [4860936208, 9.394920349121094],\n [4860936708, 7.917320251464844],\n [4860937208, 6.439720153808594],\n [4860937666, 4.799613952636719],\n [4860938291, 4.893857002258301],\n [4860938791, 6.416745185852051],\n [4869182625, 8.098271369934082],\n [4879623000, 10.046460151672363],\n [4890473166, 12.316304206848145],\n [4897018916, 14.273037910461426],\n [4897020083, 12.710537910461426],\n [4906043916, 15.453923225402832],\n [4906045250, 13.703923225402832],\n [4912880875, 16.794087409973145],\n [4912882250, 14.825337409973145],\n [4919803625, 18.305577278137207],\n [4919804833, 16.086827278137207],\n [4919805375, 14.609234809875488],\n [4919805791, 13.131634712219238],\n [4919806208, 11.654034614562988],\n [4919806666, 10.176434516906738],\n [4919807083, 8.698834419250488],\n [4919807750, 4.773419380187988],\n [4919808250, 4.86766242980957],\n [4954279791, 6.398340225219727],\n [4954280625, 6.492583274841309],\n [4963331000, 8.049201011657715],\n [4971794833, 6.571600914001465],\n [4971795666, 4.716620445251465],\n [4971796291, 4.810863494873047],\n [4971796708, 6.341075897216797],\n [4980337708, 8.022663116455078],\n [4992509125, 9.97085189819336],\n [5005161583, 12.24069595336914],\n [5023299958, 10.76309585571289],\n [5023300875, 9.28549575805664],\n [5023301416, 7.807895660400391],\n [5023301958, 6.330295562744141],\n [5023302458, 4.690189361572266],\n [5023303125, 4.784432411193848],\n [5023303666, 6.307320594787598],\n [5023304208, 7.988846778869629],\n [5029638416, 9.937005043029785],\n [5044778666, 12.206818580627441],\n [5050833625, 14.163552284240723],\n [5050834750, 12.601052284240723],\n [5057135791, 15.34438419342041],\n [5057136416, 13.59438419342041],\n [5063445708, 16.684517860412598],\n [5063446375, 14.715767860412598],\n [5069768250, 18.195984840393066],\n [5069768875, 15.977234840393066],\n [5078150875, 14.499642372131348],\n [5078151791, 13.022042274475098],\n [5078152333, 11.544442176818848],\n [5078152750, 10.066842079162598],\n [5078153166, 8.589241981506348],\n [5078154083, 4.663826942443848],\n [5078154708, 4.75806999206543],\n [5108192000, 6.288686752319336],\n [5108192625, 6.382929801940918],\n [5123289625, 7.939547538757324],\n [5123290666, 6.461947441101074],\n [5123291375, 4.606966972351074],\n [5123291833, 4.701210021972656],\n [5123292333, 6.231391906738281],\n [5134424666, 7.9129791259765625],\n [5146178375, 9.861167907714844],\n [5157161166, 12.131011962890625],\n [5167799333, 10.653411865234375],\n [5167800083, 9.175811767578125],\n [5167800708, 7.698211669921875],\n [5167801250, 6.220611572265625],\n [5167801750, 4.580535888671875],\n [5167802416, 4.674778938293457],\n [5167802875, 6.197636604309082],\n [5177584333, 7.879162788391113],\n [5194535541, 9.827351570129395],\n [5194536083, 12.097195625305176],\n [5202336500, 14.053898811340332],\n [5202337416, 12.491398811340332],\n [5220407416, 15.23473072052002],\n [5220408291, 13.48473072052002],\n [5220408791, 16.574894905090332],\n [5220409250, 14.606144905090332],\n [5226684250, 18.08641529083252],\n [5226685166, 15.86766529083252],\n [5226685666, 14.3900728225708],\n [5226686125, 12.91247272491455],\n [5226686541, 11.4348726272583],\n [5226686958, 9.95727252960205],\n [5226687375, 8.4796724319458],\n [5226688083, 4.554257392883301],\n [5226688583, 4.648500442504883],\n [5261451875, 6.179033279418945],\n [5261452458, 6.273276329040527],\n [5270580041, 7.829894065856934],\n [5278665625, 6.352293968200684],\n [5278666291, 4.497313499450684],\n [5278667791, 4.591556549072266],\n [5278668208, 6.121768951416016],\n [5288731833, 7.803356170654297],\n [5299483500, 9.751514434814453],\n [5311406375, 12.021358489990234],\n [5322807416, 10.543758392333984],\n [5322808125, 9.066158294677734],\n [5322808666, 7.588558197021484],\n [5322809125, 6.110958099365234],\n [5322809666, 4.470882415771484],\n [5322810208, 4.565125465393066],\n [5322810666, 6.087983131408691],\n [5331669666, 7.769539833068848],\n [5338282458, 9.717728614807129],\n [5350851458, 11.987542152404785],\n [5359493541, 13.944275856018066],\n [5359494333, 12.381775856018066],\n [5365810500, 15.125107765197754],\n [5365811333, 13.375107765197754],\n [5372039583, 16.46524143218994],\n [5372040250, 14.496491432189941],\n [5380457666, 17.97676181793213],\n [5380458625, 15.758011817932129],\n [5380459083, 14.28041934967041],\n [5380459500, 12.80281925201416],\n [5380459916, 11.32521915435791],\n [5380460333, 9.84761905670166],\n [5380460750, 8.37001895904541],\n [5380461375, 4.44460391998291],\n [5380461833, 4.538846969604492],\n [5413462666, 6.069440841674805],\n [5413463250, 6.163683891296387],\n [5423096291, 7.720301628112793],\n [5430319250, 6.242701530456543],\n [5430319916, 4.387721061706543],\n [5430320500, 4.481964111328125],\n [5430320958, 6.012176513671875],\n [5441570375, 7.693733215332031],\n [5452075333, 9.641921997070312],\n [5470306958, 11.911766052246094],\n [5470308000, 10.434165954589844],\n [5470308583, 8.956565856933594],\n [5470309083, 7.478965759277344],\n [5470309625, 6.001365661621094],\n [5470310125, 4.361289978027344],\n [5470310583, 4.455533027648926],\n [5470311041, 5.978360176086426],\n [5478482166, 7.659916877746582],\n [5493521333, 9.608075141906738],\n [5501086166, 11.87791919708252],\n [5507371750, 13.834622383117676],\n [5507372541, 12.272122383117676],\n [5525668541, 15.015507698059082],\n [5525669541, 13.265507698059082],\n [5525670083, 16.355671882629395],\n [5525670583, 14.386921882629395],\n [5532032458, 17.867161750793457],\n [5532033208, 15.648411750793457],\n [5532033666, 14.170819282531738],\n [5532034125, 12.693219184875488],\n [5532034541, 11.215619087219238],\n [5532034916, 9.738018989562988],\n [5532035375, 8.260418891906738],\n [5532036041, 4.335034370422363],\n [5532036500, 4.429277420043945],\n [5565803583, 5.959833145141602],\n [5565804208, 6.054076194763184],\n [5575695708, 7.61063289642334],\n [5582184583, 6.13303279876709],\n [5582185333, 4.27805233001709],\n [5582185916, 4.372295379638672],\n [5582186416, 5.902507781982422],\n [5592821958, 7.584095001220703],\n [5604733833, 9.53225326538086],\n [5616643958, 11.80209732055664],\n [5628017333, 10.32449722290039],\n [5628018083, 8.84689712524414],\n [5628018625, 7.369297027587891],\n [5628019125, 5.891696929931641],\n [5628019708, 4.251621246337891],\n [5628020291, 4.345864295959473],\n [5628020791, 5.868721961975098],\n [5636952291, 7.550278663635254],\n [5646289375, 9.498467445373535],\n [5655360583, 11.768311500549316],\n [5661691916, 13.725014686584473],\n [5661692750, 12.162514686584473],\n [5672171208, 14.905900001525879],\n [5672171916, 13.155900001525879],\n [5672172375, 16.246033668518066],\n [5672172916, 14.277283668518066],\n [5684706583, 17.75752353668213],\n [5684707500, 15.538773536682129],\n [5684708000, 14.06118106842041],\n [5684708500, 12.58358097076416],\n [5684709000, 11.10598087310791],\n [5684709500, 9.62838077545166],\n [5684709916, 8.15078067779541],\n [5684710500, 4.22536563873291],\n [5684710958, 4.319608688354492],\n [5713620750, 5.850225448608398],\n [5713621375, 5.9444684982299805],\n [5726138625, 7.501086235046387],\n [5732462250, 6.023486137390137],\n [5732462958, 4.168475151062012],\n [5732463583, 4.262718200683594],\n [5732464041, 5.792930603027344],\n [5746844625, 7.474540710449219],\n [5757283083, 9.4227294921875],\n [5763543916, 11.692573547363281],\n [5776172041, 10.214973449707031],\n [5776172791, 8.737373352050781],\n [5776173375, 7.259773254394531],\n [5776173916, 5.782173156738281],\n [5776174458, 4.142097473144531],\n [5776175000, 4.236340522766113],\n [5776175458, 5.759198188781738],\n [5788313791, 7.4407548904418945],\n [5798864166, 9.38891315460205],\n [5809497375, 11.658757209777832],\n [5825323291, 13.615490913391113],\n [5825324333, 12.052990913391113],\n [5825324791, 14.796353340148926],\n [5825325291, 13.046353340148926],\n [5825325750, 16.13645648956299],\n [5825326250, 14.167706489562988],\n [5834424541, 17.648655891418457],\n [5834428125, 15.429905891418457],\n [5843290541, 13.952313423156738],\n [5843291500, 12.474713325500488],\n [5843292041, 10.997113227844238],\n [5843292458, 9.519513130187988],\n [5843292875, 8.041913032531738],\n [5843293708, 4.116497993469238],\n [5843294375, 4.21074104309082],\n [5872046083, 5.741365432739258],\n [5872046708, 5.83560848236084],\n [5881277583, 7.392195701599121],\n [5889366666, 5.914595603942871],\n [5889367333, 4.059615135192871],\n [5889367875, 4.153858184814453],\n [5889368458, 5.684070587158203],\n [5896962250, 7.365657806396484],\n [5909522041, 9.31381607055664],\n [5920174208, 11.583660125732422],\n [5932738083, 10.106060028076172],\n [5932738750, 8.628459930419922],\n [5932739333, 7.150859832763672],\n [5932739875, 5.673259735107422],\n [5932740333, 4.033153533935547],\n [5932740958, 4.127396583557129],\n [5932741416, 5.650284767150879],\n [5942300625, 7.33181095123291],\n [5951733416, 9.279999732971191],\n [5968639708, 11.549843788146973],\n [5968640291, 13.506577491760254],\n [5968641250, 11.944077491760254],\n [5983952791, 14.687378883361816],\n [5983953458, 12.937378883361816],\n [5983953916, 16.02754306793213],\n [5983954416, 14.058793067932129],\n [5996574333, 17.539063453674316],\n [5996575333, 15.320313453674316],\n [5996575791, 13.842720985412598],\n [5996576250, 12.365120887756348],\n [5996576666, 10.887520790100098],\n [5996577125, 9.409920692443848],\n [5996577541, 7.932320594787598],\n [5996578083, 4.006905555725098],\n [5996578541, 4.10114860534668],\n [6023854250, 5.631811141967773],\n [6023854875, 5.7260541915893555],\n [6033950166, 7.282641410827637],\n [6042210333, 5.805041313171387],\n [6042211041, 3.9500608444213867],\n [6042211625, 4.044303894042969],\n [6042212125, 5.574516296386719],\n [6052701375, 7.256103515625],\n [6059513083, 9.204292297363281],\n [6070225541, 11.474136352539062],\n [6082716166, 9.996536254882812],\n [6082716750, 8.518936157226562],\n [6082717250, 7.0413360595703125],\n [6082717750, 5.5637359619140625],\n [6082718208, 3.9236602783203125],\n [6082718791, 4.0179033279418945],\n [6082719208, 5.5407609939575195],\n [6093240458, 7.222317695617676],\n [6099498041, 9.170475959777832],\n [6115766666, 11.440289497375488],\n [6125366416, 13.39702320098877],\n [6125367125, 11.83452320098877],\n [6125367625, 14.577885627746582],\n [6125368125, 12.827885627746582],\n [6137461166, 15.917988777160645],\n [6137462125, 13.949238777160645],\n [6143745375, 17.429539680480957],\n [6143746291, 15.210789680480957],\n [6143746791, 13.733197212219238],\n [6143747208, 12.255597114562988],\n [6143747666, 10.777997016906738],\n [6143748083, 9.300396919250488],\n [6143748500, 7.822796821594238],\n [6143749208, 3.8973817825317383],\n [6143749708, 3.9916248321533203],\n [6176584125, 5.522188186645508],\n [6176584708, 5.61643123626709],\n [6182905625, 7.173018455505371],\n [6201793041, 5.695418357849121],\n [6201793583, 3.840407371520996],\n [6201794083, 3.934650421142578],\n [6201794500, 5.464862823486328],\n [6201794916, 7.146450042724609],\n [6216200666, 9.094608306884766],\n [6234594666, 11.364452362060547],\n [6234595708, 9.886852264404297],\n [6234596291, 8.409252166748047],\n [6234596916, 6.931652069091797],\n [6234597416, 5.454051971435547],\n [6234597916, 3.813976287841797],\n [6234598416, 3.908219337463379],\n [6234598875, 5.431046485900879],\n [6243242791, 7.112603187561035],\n [6257783000, 9.060761451721191],\n [6266028333, 11.330605506896973],\n [6272331416, 13.287308692932129],\n [6272332166, 11.724808692932129],\n [6289983500, 14.468194007873535],\n [6289984208, 12.718194007873535],\n [6289984666, 15.808358192443848],\n [6289985166, 13.839608192443848],\n [6302579416, 17.31984806060791],\n [6302580541, 15.10109806060791],\n [6302581041, 13.623505592346191],\n [6302581416, 12.145905494689941],\n [6302581833, 10.668305397033691],\n [6302582291, 9.190705299377441],\n [6302582708, 7.713105201721191],\n [6302583458, 3.7877206802368164],\n [6302583916, 3.8819637298583984],\n [6331909375, 5.412542343139648],\n [6331910166, 5.5067853927612305],\n [6348601083, 7.063403129577637],\n [6348602458, 5.585803031921387],\n [6348603083, 3.7308225631713867],\n [6348603666, 3.8250656127929688],\n [6348604083, 5.355247497558594],\n [6366771875, 7.036834716796875],\n [6366772916, 8.985023498535156],\n [6390463166, 11.254837036132812],\n [6390464500, 9.777236938476562],\n [6390465083, 8.299636840820312],\n [6390465541, 6.8220367431640625],\n [6390466041, 5.3444366455078125],\n [6390466500, 3.7043609619140625],\n [6390466958, 3.7986040115356445],\n [6390467416, 5.3214311599731445],\n [6401087000, 7.002987861633301],\n [6412862208, 8.951176643371582],\n [6419122541, 11.220990180969238],\n [6434475458, 13.177693367004395],\n [6434476625, 11.615193367004395],\n [6434477125, 14.358555793762207],\n [6434477625, 12.608555793762207],\n [6446840500, 15.69871997833252],\n [6446841375, 13.72996997833252],\n [6455593916, 17.210240364074707],\n [6455595250, 14.991490364074707],\n [6455595750, 13.513897895812988],\n [6455596166, 12.036297798156738],\n [6455596625, 10.558697700500488],\n [6455597041, 9.081097602844238],\n [6455597416, 7.603497505187988],\n [6455598125, 3.6780824661254883],\n [6455598583, 3.7723255157470703],\n [6484438208, 5.302881240844727],\n [6484439166, 5.397124290466309],\n [6496959250, 6.953742027282715],\n [6506738750, 5.476141929626465],\n [6506739541, 3.62113094329834],\n [6506740166, 3.715373992919922],\n [6506740583, 5.245586395263672],\n [6517142458, 6.927173614501953],\n [6527674708, 8.875362396240234],\n [6539903791, 11.145206451416016],\n [6551325041, 9.667606353759766],\n [6551325875, 8.190006256103516],\n [6551326375, 6.712406158447266],\n [6551326833, 5.234806060791016],\n [6551327500, 3.5947303771972656],\n [6551328083, 3.6889734268188477],\n [6551328541, 5.211831092834473],\n [6566540416, 6.893387794494629],\n [6566540958, 8.84157657623291],\n [6578056666, 11.111390113830566],\n [6602234916, 13.068093299865723],\n [6602236041, 11.505593299865723],\n [6602236541, 14.248955726623535],\n [6602237041, 12.498955726623535],\n [6602237458, 15.589142799377441],\n [6602237958, 13.620392799377441],\n [6608582875, 17.10066318511963],\n [6608584041, 14.881913185119629],\n [6608584500, 13.40432071685791],\n [6608590208, 11.92672061920166],\n [6608590583, 10.44912052154541],\n [6608591125, 8.97152042388916],\n [6608591583, 7.49392032623291],\n [6608592375, 3.56850528717041],\n [6608592875, 3.662748336791992],\n [6638717125, 5.193334579467773],\n [6638717750, 5.2875776290893555],\n [6651080916, 6.844195365905762],\n [6659813291, 5.366595268249512],\n [6659814000, 3.5115842819213867],\n [6659814583, 3.6058273315429688],\n [6659814958, 5.136039733886719],\n [6670072250, 6.817626953125],\n [6680508166, 8.765815734863281],\n [6688712875, 11.035659790039062],\n [6703730208, 9.558059692382812],\n [6703730958, 8.080459594726562],\n [6703731416, 6.6028594970703125],\n [6703731875, 5.1252593994140625],\n [6703732416, 3.4851531982421875],\n [6703733000, 3.5793962478637695],\n [6703733458, 5.1022539138793945],\n [6718681791, 6.783780097961426],\n [6718682375, 8.731968879699707],\n [6726149291, 11.001782417297363],\n [6741932083, 12.95848560333252],\n [6741932833, 11.39598560333252],\n [6741933291, 14.139317512512207],\n [6741933791, 12.389317512512207],\n [6751073416, 15.479451179504395],\n [6751074041, 13.510701179504395],\n [6757382916, 16.990971565246582],\n [6757383583, 14.772221565246582],\n [6763719458, 13.294629096984863],\n [6763720166, 11.817028999328613],\n [6763720708, 10.339428901672363],\n [6763721208, 8.861828804016113],\n [6763721708, 7.384228706359863],\n [6763722541, 3.4588136672973633],\n [6763723125, 3.5530567169189453],\n [6788687791, 5.083703994750977],\n [6788688458, 5.177947044372559],\n [6803872166, 6.73453426361084],\n [6811951625, 5.25693416595459],\n [6811952375, 3.401923179626465],\n [6811952916, 3.496166229248047],\n [6811953333, 5.026378631591797],\n [6822389166, 6.707965850830078],\n [6832955666, 8.65615463256836],\n [6851135125, 10.92599868774414],\n [6851136333, 9.44839859008789],\n [6851137000, 7.970798492431641],\n [6851137541, 6.493198394775391],\n [6851138041, 5.015598297119141],\n [6851138541, 3.3755226135253906],\n [6851139041, 3.4697656631469727],\n [6851139500, 4.992592811584473],\n [6859496416, 6.674149513244629],\n [6874400958, 8.622307777404785],\n [6882231416, 10.892151832580566],\n [6888535625, 12.848855018615723],\n [6888536291, 11.286355018615723],\n [6894834416, 14.029740333557129],\n [6894835000, 12.279740333557129],\n [6906421750, 15.369874000549316],\n [6906422333, 13.401124000549316],\n [6912780916, 16.881394386291504],\n [6912782125, 14.662644386291504],\n [6912782666, 13.185051918029785],\n [6912783125, 11.707451820373535],\n [6912783541, 10.229851722717285],\n [6912784000, 8.752251625061035],\n [6912784416, 7.274651527404785],\n [6912785000, 3.349236488342285],\n [6912785500, 3.443479537963867],\n [6942823791, 4.974020004272461],\n [6942824416, 5.068263053894043],\n [6953653208, 6.624880790710449],\n [6959921000, 5.147280693054199],\n [6959921916, 3.292269706726074],\n [6959922666, 3.3865127563476562],\n [6959923125, 4.916725158691406],\n [6981277875, 6.598335266113281],\n [6981278458, 8.546524047851562],\n [7003751416, 10.816337585449219],\n [7003752541, 9.338737487792969],\n [7003753166, 7.861137390136719],\n [7003753666, 6.383537292480469],\n [7003754125, 4.905937194824219],\n [7003754708, 3.2658615112304688],\n [7003755250, 3.360104560852051],\n [7003755750, 4.882931709289551],\n [7011606291, 6.564488410949707],\n [7027225458, 8.512646675109863],\n [7033460416, 10.782490730285645],\n [7046692791, 12.739224433898926],\n [7046693791, 11.176724433898926],\n [7053889041, 13.920056343078613],\n [7053890041, 12.170056343078613],\n [7053890583, 15.260220527648926],\n [7053891125, 13.291470527648926],\n [7067512791, 16.771740913391113],\n [7067514000, 14.552990913391113],\n [7067514458, 13.075398445129395],\n [7067514875, 11.597798347473145],\n [7067515375, 10.120198249816895],\n [7067515791, 8.642598152160645],\n [7067516208, 7.1649980545043945],\n [7067517000, 3.2395830154418945],\n [7067517458, 3.3338260650634766],\n [7096955541, 4.864442825317383],\n [7096956208, 4.958685874938965],\n [7109522708, 6.515303611755371],\n [7124609541, 5.037703514099121],\n [7124610250, 3.182692527770996],\n [7124610708, 3.276935577392578],\n [7124611125, 4.807147979736328],\n [7124611541, 6.488735198974609],\n [7139067416, 8.436893463134766],\n [7151224291, 10.706737518310547],\n [7168917250, 9.229137420654297],\n [7168918166, 7.751537322998047],\n [7168918666, 6.273937225341797],\n [7168919125, 4.796337127685547],\n [7168919666, 3.156261444091797],\n [7168920291, 3.250504493713379],\n [7168920708, 4.773362159729004],\n [7168921125, 6.45491886138916],\n [7176563333, 8.403077125549316],\n [7191589875, 10.672890663146973],\n [7199425083, 12.629624366760254],\n [7199426083, 11.067124366760254],\n [7206955625, 13.810456275939941],\n [7206956500, 12.060456275939941],\n [7206957041, 15.150620460510254],\n [7206957500, 13.181870460510254],\n [7220330166, 16.662171363830566],\n [7220331291, 14.443421363830566],\n [7220331791, 12.965828895568848],\n [7220332250, 11.488228797912598],\n [7220332708, 10.010628700256348],\n [7220333125, 8.533028602600098],\n [7220333500, 7.055428504943848],\n [7220334250, 3.1300134658813477],\n [7220334750, 3.2242565155029297],\n [7254355666, 4.754880905151367],\n [7254356375, 4.849123954772949],\n [7263428583, 6.4057416915893555],\n [7271664875, 4.9281415939331055],\n [7271665625, 3.0731611251831055],\n [7271666125, 3.1674041748046875],\n [7271666583, 4.6976165771484375],\n [7280303958, 6.379203796386719],\n [7286623666, 8.327362060546875],\n [7303583583, 10.597206115722656],\n [7309860166, 9.119606018066406],\n [7309861125, 7.642005920410156],\n [7309861625, 6.164405822753906],\n [7309862083, 4.686805725097656],\n [7309862541, 3.0466995239257812],\n [7309863333, 3.1409425735473633],\n [7316081000, 4.663830757141113],\n [7325135625, 6.3453874588012695],\n [7334578291, 8.29357624053955],\n [7351633000, 10.563420295715332],\n [7351633541, 12.520153999328613],\n [7351634416, 10.957653999328613],\n [7359893500, 13.7009859085083],\n [7359894416, 11.9509859085083],\n [7367199541, 15.041119575500488],\n [7367200291, 13.072369575500488],\n [7373479125, 16.5526704788208],\n [7373480333, 14.3339204788208],\n [7373480875, 12.856328010559082],\n [7373481333, 11.378727912902832],\n [7373481750, 9.901127815246582],\n [7373482208, 8.423527717590332],\n [7373482666, 6.945927619934082],\n [7373483291, 3.020512580871582],\n [7373486458, 3.114755630493164],\n [7408251375, 4.645288467407227],\n [7408252041, 4.739531517028809],\n [7417204625, 6.296149253845215],\n [7425287583, 4.818549156188965],\n [7425288375, 2.963568687438965],\n [7425288916, 3.057811737060547],\n [7425289333, 4.588024139404297],\n [7432749125, 6.269611358642578],\n [7445316375, 8.217769622802734],\n [7453587708, 10.487613677978516],\n [7466119875, 9.010013580322266],\n [7466120833, 7.532413482666016],\n [7466121375, 6.054813385009766],\n [7466122000, 4.577213287353516],\n [7466122458, 2.9371376037597656],\n [7466123208, 3.0313806533813477],\n [7466123708, 4.554238319396973],\n [7476554458, 6.235795021057129],\n [7482886250, 8.183953285217285],\n [7499232083, 10.453766822814941],\n [7508868208, 12.410500526428223],\n [7508869083, 10.848000526428223],\n [7508869625, 13.591362953186035],\n [7508870166, 11.841362953186035],\n [7520257708, 14.931496620178223],\n [7520258333, 12.962746620178223],\n [7528214708, 16.44301700592041],\n [7528215708, 14.22426700592041],\n [7528216166, 12.746674537658691],\n [7528216625, 11.269074440002441],\n [7528217208, 9.791474342346191],\n [7528217625, 8.313874244689941],\n [7528218041, 6.836274147033691],\n [7528218666, 2.9108591079711914],\n [7528219166, 3.0051021575927734],\n [7557256625, 4.535665512084961],\n [7557257291, 4.629908561706543],\n [7569854541, 6.186495780944824],\n [7585410291, 4.708895683288574],\n [7585411083, 2.853884696960449],\n [7585411583, 2.9481277465820312],\n [7585412041, 4.478370666503906],\n [7585412458, 6.1599273681640625],\n [7600042583, 8.108085632324219],\n [7618270875, 10.3779296875],\n [7618271833, 8.90032958984375],\n [7618272375, 7.4227294921875],\n [7618272875, 5.94512939453125],\n [7618273375, 4.467529296875],\n [7618273875, 2.82745361328125],\n [7618274333, 2.921696662902832],\n [7618274791, 4.444523811340332],\n [7626569541, 6.126080513000488],\n [7641589250, 8.074238777160645],\n [7649424750, 10.344082832336426],\n [7655704916, 12.300786018371582],\n [7655705916, 10.738286018371582],\n [7667454208, 13.481671333312988],\n [7667455083, 11.731671333312988],\n [7667455583, 14.8218355178833],\n [7667456083, 12.8530855178833],\n [7679967791, 16.33335590362549],\n [7679968791, 14.114605903625488],\n [7679969250, 12.63701343536377],\n [7679969666, 11.15941333770752],\n [7679970083, 9.68181324005127],\n [7679970500, 8.20421314239502],\n [7679970916, 6.7266130447387695],\n [7679971500, 2.8012285232543945],\n [7679971916, 2.8954715728759766],\n [7714993416, 4.42607307434082],\n [7714994083, 4.520316123962402],\n [7730193458, 6.076933860778809],\n [7730194583, 4.599333763122559],\n [7730195250, 2.7443532943725586],\n [7730195666, 2.8385963439941406],\n [7730196125, 4.368778228759766],\n [7739118125, 6.050365447998047],\n [7751065083, 7.998554229736328],\n [7763608625, 10.268367767333984],\n [7773971166, 8.790767669677734],\n [7773972000, 7.313167572021484],\n [7773972541, 5.835567474365234],\n [7773973000, 4.357967376708984],\n [7773973458, 2.7178916931152344],\n [7773974208, 2.8121347427368164],\n [7773974666, 4.334992408752441],\n [7784399875, 6.016549110412598],\n [7790657833, 7.964707374572754],\n [7810966833, 10.23452091217041],\n [7810967333, 12.191254615783691],\n [7810968000, 10.628754615783691],\n [7817743833, 13.372086524963379],\n [7817744833, 11.622086524963379],\n [7832548958, 14.712220191955566],\n [7832549875, 12.743470191955566],\n [7832550375, 16.22377109527588],\n [7832550833, 14.005021095275879],\n [7832551291, 12.52742862701416],\n [7832551750, 11.04982852935791],\n [7832552208, 9.57222843170166],\n [7832552666, 8.09462833404541],\n [7832553083, 6.61702823638916],\n [7832553791, 2.691582679748535],\n [7832554250, 2.785825729370117],\n [7866115583, 4.316427230834961],\n [7866116208, 4.410670280456543],\n [7875905500, 5.967257499694824],\n [7890265208, 4.489657402038574],\n [7890265916, 2.634676933288574],\n [7890266458, 2.7289199829101562],\n [7890266875, 4.259132385253906],\n [7890267333, 5.9407196044921875],\n [7899434041, 7.888877868652344],\n [7922976500, 10.15869140625],\n [7922977458, 8.68109130859375],\n [7922978041, 7.2034912109375],\n [7922978500, 5.72589111328125],\n [7922978958, 4.248291015625],\n [7922979375, 2.60821533203125],\n [7922979875, 2.702458381652832],\n [7922980291, 4.225285530090332],\n [7932772000, 5.906842231750488],\n [7945333500, 7.8550004959106445],\n [7953608625, 10.124844551086426],\n [7959885458, 12.081547737121582],\n [7959886500, 10.519047737121582],\n [7966052083, 13.262433052062988],\n [7966052666, 11.512433052062988],\n [7977989166, 14.602566719055176],\n [7977990000, 12.633816719055176],\n [7984335666, 16.114087104797363],\n [7984336541, 13.895337104797363],\n [7984337000, 12.417744636535645],\n [7984337458, 10.940144538879395],\n [7984338041, 9.462544441223145],\n [7984338458, 7.9849443435668945],\n [7984338875, 6.5073442459106445],\n [7984339458, 2.5819292068481445],\n [7984339916, 2.6761722564697266],\n [8013593708, 4.206743240356445],\n [8013594250, 4.300986289978027],\n [8026052416, 5.857604026794434],\n [8032382916, 4.380003929138184],\n [8032383583, 2.5249929428100586],\n [8032384208, 2.6192359924316406],\n [8032384666, 4.149448394775391],\n [8052679500, 5.831058502197266],\n [8052680000, 7.779247283935547],\n [8075210583, 10.049060821533203],\n [8075211583, 8.571460723876953],\n [8075212125, 7.093860626220703],\n [8075212625, 5.616260528564453],\n [8075213083, 4.138660430908203],\n [8075213583, 2.498584747314453],\n [8075214041, 2.592827796936035],\n [8075214500, 4.115654945373535],\n [8082779208, 5.797211647033691],\n [8098278708, 7.745369911193848],\n [8108780750, 10.015213966369629],\n [8116126958, 11.97194766998291],\n [8116127875, 10.40944766998291],\n [8124240625, 13.152779579162598],\n [8124241458, 11.402779579162598],\n [8124241958, 14.49294376373291],\n [8124242458, 12.52419376373291],\n [8137002916, 16.004494667053223],\n [8137004208, 13.785744667053223],\n [8137004750, 12.308152198791504],\n [8137005166, 10.830552101135254],\n [8137005583, 9.352952003479004],\n [8137006000, 7.875351905822754],\n [8137006416, 6.397751808166504],\n [8137007208, 2.472336769104004],\n [8137007708, 2.566579818725586],\n [8170265375, 4.097265243530273],\n [8170266000, 4.1915082931518555],\n [8180639458, 5.748095512390137],\n [8188870583, 4.270495414733887],\n [8188871250, 2.4155149459838867],\n [8188871750, 2.5097579956054688],\n [8188872166, 4.039970397949219],\n [8199111625, 5.7215576171875],\n [8206806750, 7.669746398925781],\n [8221567500, 9.939559936523438],\n [8228809208, 8.461959838867188],\n [8228810041, 6.9843597412109375],\n [8228810541, 5.5067596435546875],\n [8228811041, 4.0291595458984375],\n [8228811500, 2.3890838623046875],\n [8228812208, 2.4833269119262695],\n [8228812750, 4.0061845779418945],\n [8240676958, 5.687741279602051],\n [8251052250, 7.635930061340332],\n [8257328458, 9.905743598937988],\n [8271149000, 11.862446784973145],\n [8271150041, 10.299946784973145],\n [8271150583, 13.043309211730957],\n [8271151125, 11.293309211730957],\n [8282643750, 14.38341236114502],\n [8282645083, 12.41466236114502],\n [8291112416, 15.894963264465332],\n [8291113541, 13.676213264465332],\n [8291116375, 12.198620796203613],\n [8291116791, 10.721020698547363],\n [8291117166, 9.243420600891113],\n [8291117583, 7.765820503234863],\n [8291118000, 6.288220405578613],\n [8291118666, 2.3628053665161133],\n [8291119166, 2.4570484161376953],\n [8320635791, 3.9876651763916016],\n [8320636583, 4.081908226013184],\n [8332796666, 5.63852596282959],\n [8342206250, 4.16092586517334],\n [8342207083, 2.305914878845215],\n [8342207708, 2.400157928466797],\n [8342208166, 3.930400848388672],\n [8352692166, 5.611957550048828],\n [8363297458, 7.560146331787109],\n [8375223166, 9.82999038696289],\n [8392933833, 8.35239028930664],\n [8392934500, 6.874790191650391],\n [8392935083, 5.397190093994141],\n [8392935625, 3.9195899963378906],\n [8392936083, 2.2795143127441406],\n [8392936750, 2.3737573623657227],\n [8392937208, 3.8966150283813477],\n [8392937625, 5.578171730041504],\n [8403634708, 7.52632999420166],\n [8409887791, 9.796143531799316],\n [8431105291, 11.752846717834473],\n [8431106125, 10.190346717834473],\n [8431106708, 12.933709144592285],\n [8431107291, 11.183709144592285],\n [8431107750, 14.273812294006348],\n [8431108291, 12.305062294006348],\n [8439098333, 15.78536319732666],\n [8439098958, 13.56661319732666],\n [8449059083, 12.089020729064941],\n [8449060000, 10.611420631408691],\n [8449060500, 9.133820533752441],\n [8449061000, 7.656220436096191],\n [8449061458, 6.178620338439941],\n [8449062208, 2.2532052993774414],\n [8449062833, 2.3474483489990234],\n [8473971125, 3.8780956268310547],\n [8473971750, 3.9723386764526367],\n [8484420500, 5.528956413269043],\n [8495065791, 4.051356315612793],\n [8495066541, 2.196345329284668],\n [8495067000, 2.29058837890625],\n [8495067416, 3.82080078125],\n [8505472250, 5.502388000488281],\n [8516063666, 7.4505767822265625],\n [8527978250, 9.720420837402344],\n [8539408208, 8.242820739746094],\n [8539409041, 6.765220642089844],\n [8539409583, 5.287620544433594],\n [8539410083, 3.8100204467773438],\n [8539410625, 2.1699447631835938],\n [8539411208, 2.264187812805176],\n [8539411625, 3.787045478820801],\n [8548269791, 5.468602180480957],\n [8555779666, 7.416790962219238],\n [8562087166, 9.686604499816895],\n [8583985791, 11.64330768585205],\n [8583986625, 10.08080768585205],\n [8583987083, 12.824170112609863],\n [8583987583, 11.074170112609863],\n [8583988000, 14.164273262023926],\n [8583988458, 12.195523262023926],\n [8597085125, 15.675824165344238],\n [8597086125, 13.457074165344238],\n [8597086583, 11.97948169708252],\n [8597087000, 10.50188159942627],\n [8597087458, 9.02428150177002],\n [8597087875, 7.5466814041137695],\n [8597088333, 6.0690813064575195],\n [8597089125, 2.1436662673950195],\n [8597089666, 2.2379093170166016],\n [8626535916, 3.7685108184814453],\n [8626536458, 3.8627538681030273],\n [8636977875, 5.419371604919434],\n [8643240916, 3.9417715072631836],\n [8643241708, 2.0867605209350586],\n [8643242458, 2.1810035705566406],\n [8649698583, 3.7112159729003906],\n [8658579208, 5.392803192138672],\n [8669096083, 7.340991973876953],\n [8681022458, 9.610836029052734],\n [8692394583, 8.133235931396484],\n [8692395333, 6.655635833740234],\n [8692395791, 5.178035736083984],\n [8692396250, 3.7004356384277344],\n [8692396750, 2.0603599548339844],\n [8692397291, 2.1546030044555664],\n [8692397708, 3.6774911880493164],\n [8707324791, 5.359017372131348],\n [8707325291, 7.307206153869629],\n [8717719541, 9.577019691467285],\n [8728505791, 11.533753395080566],\n [8728506750, 9.971253395080566],\n [8742284333, 12.714585304260254],\n [8742285083, 10.964585304260254],\n [8742285583, 14.054749488830566],\n [8742286166, 12.085999488830566],\n [8754885625, 15.566239356994629],\n [8754886458, 13.347489356994629],\n [8754886916, 11.86989688873291],\n [8754887333, 10.39229679107666],\n [8754887750, 8.91469669342041],\n [8754888166, 7.43709659576416],\n [8754888541, 5.95949649810791],\n [8754889083, 2.034111976623535],\n [8754889500, 2.128355026245117],\n [8783215291, 3.6589794158935547],\n [8783215875, 3.7532224655151367],\n [8792146791, 5.309840202331543],\n [8800233500, 3.832240104675293],\n [8800234041, 1.977259635925293],\n [8800234541, 2.071502685546875],\n [8800234916, 3.601715087890625],\n [8809380250, 5.283302307128906],\n [8815653791, 7.2314605712890625],\n [8839318250, 9.501304626464844],\n [8839319500, 8.023704528808594],\n [8839320083, 6.546104431152344],\n [8839320583, 5.068504333496094],\n [8839321208, 3.5909042358398438],\n [8839321708, 1.9508285522460938],\n [8839322166, 2.045071601867676],\n [8839322625, 3.567898750305176],\n [8853244791, 5.249455451965332],\n [8862650375, 7.197644233703613],\n [8870233708, 9.467488288879395],\n [8876535750, 11.42419147491455],\n [8876536875, 9.86169147491455],\n [8882639625, 12.605076789855957],\n [8882640291, 10.855076789855957],\n [8894574000, 13.945210456848145],\n [8894574583, 11.976460456848145],\n [8907172041, 15.456730842590332],\n [8907173208, 13.237980842590332],\n [8907173666, 11.760388374328613],\n [8907174083, 10.282788276672363],\n [8907174458, 8.805188179016113],\n [8907174833, 7.327588081359863],\n [8907175250, 5.849987983703613],\n [8907175916, 1.9246034622192383],\n [8907176375, 2.0188465118408203],\n [8935515833, 3.5494556427001953],\n [8935516416, 3.6436986923217773],\n [8950772666, 5.200316429138184],\n [8950773625, 3.7227163314819336],\n [8950774333, 1.8677358627319336],\n [8950774916, 1.9619789123535156],\n [8950775375, 3.4921607971191406],\n [8959490166, 5.173748016357422],\n [8973357541, 7.121906280517578],\n [8980812833, 9.39175033569336],\n [8996627125, 7.914150238037109],\n [8996627750, 6.436550140380859],\n [8996628208, 4.958950042724609],\n [8996628708, 3.4813499450683594],\n [8996629208, 1.8412437438964844],\n [8996629791, 1.9354867935180664],\n [8996630250, 3.4583444595336914],\n [9005353416, 5.139870643615723],\n [9014699500, 7.088059425354004],\n [9025217125, 9.357903480529785],\n [9034620000, 11.314637184143066],\n [9034620833, 9.752137184143066],\n [9034621291, 12.495469093322754],\n [9034621791, 10.745469093322754],\n [9042825583, 13.835709571838379],\n [9042826416, 11.866959571838379],\n [9053959333, 15.347229957580566],\n [9053960041, 13.128479957580566],\n [9053960500, 11.650887489318848],\n [9053960916, 10.173287391662598],\n [9053961333, 8.695687294006348],\n [9053961750, 7.218087196350098],\n [9053962166, 5.740487098693848],\n [9053962708, 1.8151025772094727],\n [9053963208, 1.9093456268310547],\n [9087620625, 3.439970016479492],\n [9087621125, 3.534213066101074],\n [9096655208, 5.0908308029174805],\n [9104690916, 3.6132307052612305],\n [9104691625, 1.7588300704956055],\n [9104692250, 1.8530731201171875],\n [9104692750, 3.3832855224609375],\n [9113229750, 5.065467834472656],\n [9119525291, 7.0136260986328125],\n [9134376208, 9.283470153808594],\n [9144588000, 7.805870056152344],\n [9144588666, 6.328269958496094],\n [9144589208, 4.850669860839844],\n [9144589666, 3.3730697631835938],\n [9144590166, 1.7329940795898438],\n [9144591041, 1.8272371292114258],\n [9144591583, 3.350094795227051],\n [9157166875, 5.031651496887207],\n [9167322000, 6.979809761047363],\n [9178107666, 9.249653816223145],\n [9193995375, 11.206387519836426],\n [9193996250, 9.643887519836426],\n [9193996750, 12.387249946594238],\n [9193997208, 10.637249946594238],\n [9193997625, 13.7273530960083],\n [9193998125, 11.7586030960083],\n [9201045833, 15.238903999328613],\n [9201046416, 13.020153999328613],\n [9207333916, 11.542561531066895],\n [9207334500, 10.064961433410645],\n [9207334916, 8.587361335754395],\n [9207335333, 7.1097612380981445],\n [9207335750, 5.6321611404418945],\n [9207336291, 1.7067461013793945],\n [9207336791, 1.8009891510009766],\n [9238707208, 3.331697463989258],\n [9238707750, 3.42594051361084],\n [9249850375, 4.982527732849121],\n [9258133916, 3.504927635192871],\n [9258134750, 1.649947166442871],\n [9258135333, 1.7441902160644531],\n [9258135791, 3.274402618408203],\n [9268503083, 4.955989837646484],\n [9276179833, 6.904178619384766],\n [9291071750, 9.173992156982422],\n [9302416208, 7.696392059326172],\n [9302418125, 6.218791961669922],\n [9302418625, 4.741191864013672],\n [9302419083, 3.263591766357422],\n [9302419541, 1.6234855651855469],\n [9302420083, 1.717728614807129],\n [9302420541, 3.240616798400879],\n [9311149375, 4.92214298248291],\n [9320641333, 6.870331764221191],\n [9331269291, 9.140175819396973],\n [9338272375, 11.096909523010254],\n [9338273166, 9.534409523010254],\n [9352655916, 12.27779483795166],\n [9352656666, 10.52779483795166],\n [9352657125, 13.617959022521973],\n [9352657791, 11.649209022521973],\n [9360048583, 15.129448890686035],\n [9360049708, 12.910698890686035],\n [9360050166, 11.433106422424316],\n [9360050583, 9.955506324768066],\n [9360051000, 8.477906227111816],\n [9360051416, 7.000306129455566],\n [9360051875, 5.522706031799316],\n [9360052541, 1.5973520278930664],\n [9360053000, 1.6915950775146484],\n [9393342583, 3.2223033905029297],\n [9393343250, 3.3165464401245117],\n [9409339541, 4.873133659362793],\n [9409340791, 3.395533561706543],\n [9409341416, 1.540553092956543],\n [9409341875, 1.634796142578125],\n [9409342375, 3.16497802734375],\n [9416166583, 4.847198486328125],\n [9432210791, 6.795356750488281],\n [9444122125, 9.065200805664062],\n [9455910083, 7.5876007080078125],\n [9455910916, 6.1100006103515625],\n [9455911416, 4.6324005126953125],\n [9455911875, 3.1548004150390625],\n [9455912416, 1.5147247314453125],\n [9455913041, 1.6089677810668945],\n [9455913541, 3.1318254470825195],\n [9464773416, 4.813382148742676],\n [9472788916, 6.761570930480957],\n [9479085458, 9.031384468078613],\n [9500765833, 10.98808765411377],\n [9500766791, 9.42558765411377],\n [9500767375, 12.168950080871582],\n [9500768000, 10.418950080871582],\n [9500768458, 13.509053230285645],\n [9500769041, 11.540303230285645],\n [9513719333, 15.020604133605957],\n [9513720541, 12.801854133605957],\n [9513721083, 11.324261665344238],\n [9513721500, 9.846661567687988],\n [9513721916, 8.369061470031738],\n [9513722333, 6.891461372375488],\n [9513722791, 5.413861274719238],\n [9513723416, 1.4884462356567383],\n [9513723875, 1.5826892852783203],\n [9542839416, 3.1133060455322266],\n [9542839958, 3.2075490951538086],\n [9556591166, 4.76413631439209],\n [9564732750, 3.28653621673584],\n [9564733333, 1.4315252304077148],\n [9564733916, 1.5257682800292969],\n [9564734375, 3.056011199951172],\n [9575086208, 4.737567901611328],\n [9585684958, 6.685756683349609],\n [9597604875, 8.95560073852539],\n [9609045333, 7.478000640869141],\n [9609046000, 6.000400543212891],\n [9609046500, 4.522800445556641],\n [9609046958, 3.0452003479003906],\n [9609047458, 1.4051246643066406],\n [9609048125, 1.4993677139282227],\n [9609048583, 3.0222253799438477],\n [9624223125, 4.703782081604004],\n [9624223583, 6.651970863342285],\n [9634509041, 8.921784400939941],\n [9647052875, 10.878487586975098],\n [9647053666, 9.315987586975098],\n [9647054125, 12.059319496154785],\n [9647054625, 10.309319496154785],\n [9657360666, 13.399453163146973],\n [9657361250, 11.430703163146973],\n [9666868541, 14.91097354888916],\n [9666869416, 12.69222354888916],\n [9666869958, 11.214631080627441],\n [9666870375, 9.737030982971191],\n [9666870833, 8.259430885314941],\n [9666871291, 6.781830787658691],\n [9666871708, 5.304230690002441],\n [9666872375, 1.3788461685180664],\n [9666872875, 1.4730892181396484],\n [9700382000, 3.0036983489990234],\n [9700382708, 3.0979413986206055],\n [9709375041, 4.654559135437012],\n [9717553291, 3.1769590377807617],\n [9717554083, 1.3219785690307617],\n [9717554583, 1.4162216186523438],\n [9717555041, 2.9464340209960938],\n [9726163458, 4.628021240234375],\n [9732437708, 6.576179504394531],\n [9749526583, 8.846023559570312],\n [9755947583, 7.3684234619140625],\n [9755948458, 5.8908233642578125],\n [9755949000, 4.4132232666015625],\n [9755949458, 2.9356231689453125],\n [9755949916, 1.2955169677734375],\n [9755950500, 1.3897600173950195],\n [9761915666, 2.9126176834106445],\n [9770365000, 4.594204902648926],\n [9776642458, 6.542363166809082],\n [9791085541, 8.812176704406738],\n [9806946000, 10.76891040802002],\n [9806946958, 9.20641040802002],\n [9806947500, 11.949772834777832],\n [9806948041, 10.199772834777832],\n [9806948541, 13.289875984191895],\n [9806949125, 11.321125984191895],\n [9816190458, 14.801426887512207],\n [9816191208, 12.582676887512207],\n [9831386791, 11.105084419250488],\n [9831387625, 9.627484321594238],\n [9831388041, 8.149884223937988],\n [9831388416, 6.672284126281738],\n [9831388875, 5.194684028625488],\n [9831389416, 1.2692689895629883],\n [9831390000, 1.3635120391845703],\n [9849533083, 2.894113540649414],\n [9849533750, 2.988356590270996],\n [9860013000, 4.544974327087402],\n [9877544833, 3.0673742294311523],\n [9877545541, 1.2123632431030273],\n [9877546083, 1.3066062927246094],\n [9877546541, 2.8368492126464844],\n [9877547000, 4.518405914306641],\n [9898580875, 6.466564178466797],\n [9898581458, 8.736408233642578],\n [9909517291, 7.258808135986328],\n [9909518208, 5.781208038330078],\n [9909518791, 4.303607940673828],\n [9909519291, 2.826007843017578],\n [9909519791, 1.1859016418457031],\n [9909520333, 1.2801446914672852],\n [9916724375, 2.80300235748291],\n [9924695875, 4.484589576721191],\n [9932870000, 6.432778358459473],\n [9939150125, 8.702591896057129],\n [9960538166, 10.659295082092285],\n [9960539250, 9.096795082092285],\n [9960539750, 11.840157508850098],\n [9960540291, 10.090157508850098],\n [9960540708, 13.18026065826416],\n [9960541250, 11.21151065826416],\n [9967833500, 14.691811561584473],\n [9967834083, 12.473061561584473],\n [9974130791, 10.995469093322754],\n [9974131666, 9.517868995666504],\n [9974132125, 8.040268898010254],\n [9974132666, 6.562668800354004],\n [9974133250, 5.085068702697754],\n [9974134291, 1.159653663635254],\n [9974134833, 1.253896713256836],\n [10003724916, 2.784605026245117],\n [10003725541, 2.878848075866699],\n [10015714541, 4.4354658126831055],\n [10022002000, 2.9578657150268555],\n [10022002791, 1.1028547286987305],\n [10022003500, 1.1970977783203125],\n [10022003916, 2.7273101806640625],\n [10034558833, 4.408866882324219],\n [10051390166, 6.3570556640625],\n [10051390833, 8.626899719238281],\n [10068880875, 7.149299621582031],\n [10068881583, 5.671699523925781],\n [10068882083, 4.194099426269531],\n [10068882541, 2.7164993286132812],\n [10068883000, 1.0763931274414062],\n [10068883541, 1.1706361770629883],\n [10068884000, 2.6934938430786133],\n [10077669166, 4.3750505447387695],\n [10087131250, 6.323239326477051],\n [10097712458, 8.593083381652832],\n [10107286333, 10.549817085266113],\n [10107287333, 8.987317085266113],\n [10107287833, 11.7306489944458],\n [10107288333, 9.9806489944458],\n [10116212041, 13.070889472961426],\n [10116212666, 11.102139472961426],\n [10126699875, 14.582409858703613],\n [10126700791, 12.363659858703613],\n [10126701208, 10.886067390441895],\n [10126701666, 9.408467292785645],\n [10126702125, 7.9308671951293945],\n [10126702541, 6.4532670974731445],\n [10126702958, 4.9756669998168945],\n [10126703708, 1.0502824783325195],\n [10126704125, 1.1445255279541016],\n [10166647541, 2.675233840942383],\n [10166648208, 2.769476890563965],\n [10166648666, 4.326094627380371],\n [10176167000, 2.848494529724121],\n [10176167666, 0.9934835433959961],\n [10176168208, 1.0877265930175781],\n [10176168625, 2.617938995361328],\n [10187814625, 4.299495697021484],\n [10204751625, 6.247684478759766],\n [10204752416, 8.517528533935547],\n [10228380750, 7.039928436279297],\n [10228381458, 5.562328338623047],\n [10228381958, 4.084728240966797],\n [10228382416, 2.607128143310547],\n [10228382875, 0.9670219421386719],\n [10228383583, 1.061264991760254],\n [10228384166, 2.584122657775879],\n [10228384625, 4.265679359436035],\n [10240192208, 6.213837623596191],\n [10247060500, 8.483681678771973],\n [10259651416, 10.440384864807129],\n [10259652416, 8.877884864807129],\n [10272064375, 11.621216773986816],\n [10272065166, 9.871216773986816],\n [10272065708, 12.961380958557129],\n [10272066208, 10.992630958557129],\n [10280281166, 14.472870826721191],\n [10280282375, 12.254120826721191],\n [10280283000, 10.776528358459473],\n [10280283458, 9.298928260803223],\n [10280283958, 7.821328163146973],\n [10280284500, 6.343728065490723],\n [10280284958, 4.866127967834473],\n [10280285750, 0.9407129287719727],\n [10280286250, 1.0349559783935547],\n [10309488333, 2.5655269622802734],\n [10309489000, 2.6597700119018555],\n [10322070125, 4.216357231140137],\n [10343421625, 2.7387571334838867],\n [10343422291, 0.8837461471557617],\n [10343422833, 0.9779891967773438],\n [10343423291, 2.5082015991210938],\n [10343423666, 4.189788818359375],\n [10351887750, 6.137947082519531],\n [10363843500, 8.407791137695312],\n [10375241208, 6.9301910400390625],\n [10375241833, 5.4525909423828125],\n [10375242291, 3.9749908447265625],\n [10375242750, 2.4973907470703125],\n [10375243208, 0.8573150634765625],\n [10375243791, 0.9515581130981445],\n [10375244250, 2.4744157791137695],\n [10383930875, 4.155972480773926],\n [10390735458, 6.104161262512207],\n [10403265458, 8.373974800109863],\n [10413502875, 10.33067798614502],\n [10413503708, 8.76817798614502],\n [10413506291, 11.511540412902832],\n [10413506916, 9.761540412902832],\n [10425544375, 12.851696968078613],\n [10425545166, 10.882946968078613],\n [10431808500, 14.363247871398926],\n [10431809333, 12.144497871398926],\n [10431809833, 10.666905403137207],\n [10431810250, 9.189305305480957],\n [10431810708, 7.711705207824707],\n [10431811125, 6.234105110168457],\n [10431811541, 4.756505012512207],\n [10431812291, 0.831089973449707],\n [10431812750, 0.9253330230712891],\n [10463712625, 2.455934524536133],\n [10463713166, 2.550177574157715],\n [10475260291, 4.106764793395996],\n [10483372833, 2.629164695739746],\n [10483373458, 0.7741842269897461],\n [10483373916, 0.8684272766113281],\n [10483374333, 2.398639678955078],\n [10493672416, 4.080226898193359],\n [10501161541, 6.028415679931641],\n [10516115541, 8.298229217529297],\n [10527499666, 6.820629119873047],\n [10527500291, 5.343029022216797],\n [10527500791, 3.865428924560547],\n [10527501250, 2.387828826904297],\n [10527501708, 0.7477226257324219],\n [10527502208, 0.8419656753540039],\n [10527502625, 2.364853858947754],\n [10542499958, 4.046380043029785],\n [10542500416, 5.994568824768066],\n [10551164666, 8.264382362365723],\n [10565689666, 10.221085548400879],\n [10565690375, 8.658585548400879],\n [10565690875, 11.401917457580566],\n [10565691375, 9.651917457580566],\n [10576163750, 12.742051124572754],\n [10576164541, 10.773301124572754],\n [10585149041, 14.253571510314941],\n [10585150291, 12.034821510314941],\n [10585150833, 10.557229042053223],\n [10585151250, 9.079628944396973],\n [10585151625, 7.602028846740723],\n [10585152083, 6.124428749084473],\n [10585152458, 4.646828651428223],\n [10585153125, 0.7214136123657227],\n [10585153583, 0.8156566619873047],\n [10613971583, 2.346220016479492],\n [10613972125, 2.440463066101074],\n [10627735958, 3.9970502853393555],\n [10635842500, 2.5194501876831055],\n [10635843208, 0.6644392013549805],\n [10635843750, 0.7586822509765625],\n [10635844166, 2.2888946533203125],\n [10646196250, 3.9704818725585938],\n [10656749583, 5.918670654296875],\n [10663702916, 8.188514709472656],\n [10679887958, 6.710914611816406],\n [10679888708, 5.233314514160156],\n [10679889208, 3.7557144165039062],\n [10679889708, 2.2781143188476562],\n [10679890250, 0.6380081176757812],\n [10679890791, 0.7322511672973633],\n [10679891250, 2.2551088333129883],\n [10694783708, 3.9366350173950195],\n [10694784333, 5.884823799133301],\n [10707463208, 8.154637336730957],\n [10718126000, 10.111371040344238],\n [10718126708, 8.548871040344238],\n [10718127208, 11.292202949523926],\n [10718127750, 9.542202949523926],\n [10736498291, 12.632336616516113],\n [10736499250, 10.663586616516113],\n [10736499750, 14.143887519836426],\n [10736500208, 11.925137519836426],\n [10736500666, 10.447545051574707],\n [10736501083, 8.969944953918457],\n [10736501541, 7.492344856262207],\n [10736502000, 6.014744758605957],\n [10736502458, 4.537144660949707],\n [10736503291, 0.611699104309082],\n [10736503750, 0.7059421539306641],\n [10767831666, 2.236543655395508],\n [10767832250, 2.33078670501709],\n [10779920500, 3.887373924255371],\n [10788054500, 2.409773826599121],\n [10788055250, 0.5547933578491211],\n [10788055875, 0.6490364074707031],\n [10788056250, 2.179248809814453],\n [10804901166, 3.8608360290527344],\n [10804901833, 5.809024810791016],\n [10816462125, 8.078838348388672],\n [10840265666, 6.601238250732422],\n [10840266583, 5.123638153076172],\n [10840267125, 3.646038055419922],\n [10840267541, 2.168437957763672],\n [10840268000, 0.5283622741699219],\n [10840268708, 0.6226053237915039],\n [10840269166, 2.145462989807129],\n [10840269583, 3.827019691467285],\n [10849606833, 5.775177955627441],\n [10860018500, 8.045022010803223],\n [10872590291, 10.001725196838379],\n [10872591375, 8.439225196838379],\n [10872592041, 11.182557106018066],\n [10872592625, 9.432557106018066],\n [10882912958, 12.522690773010254],\n [10882913541, 10.553940773010254],\n [10905067375, 14.034211158752441],\n [10905068541, 11.815461158752441],\n [10905069000, 10.337868690490723],\n [10905069375, 8.860268592834473],\n [10905069791, 7.382668495178223],\n [10905070166, 5.905068397521973],\n [10905070666, 4.427468299865723],\n [10905071208, 0.5020837783813477],\n [10905071708, 0.5963268280029297],\n [10926136041, 2.1269893646240234],\n [10926136833, 2.2212324142456055],\n [10935084916, 3.7778501510620117],\n [10943143166, 2.3002500534057617],\n [10943143833, 0.4452695846557617],\n [10943144416, 0.5395126342773438],\n [10943144916, 2.0697250366210938],\n [10949582291, 3.751312255859375],\n [10961032250, 5.699501037597656],\n [10976159166, 7.9693145751953125],\n [10982949875, 6.4917144775390625],\n [10982951041, 5.0141143798828125],\n [10982951625, 3.5365142822265625],\n [10982952083, 2.0589141845703125],\n [10982952541, 0.4188385009765625],\n [10982953416, 0.5130815505981445],\n [10982953916, 2.0359392166137695],\n [10993334500, 3.717495918273926],\n [11003763708, 5.665684700012207],\n [11016290958, 7.935528755187988],\n [11026686333, 9.892231941223145],\n [11026687208, 8.329731941223145],\n [11026687708, 11.073094367980957],\n [11026688250, 9.323094367980957],\n [11037190458, 12.413228034973145],\n [11037191125, 10.444478034973145],\n [11046139541, 13.924748420715332],\n [11046141041, 11.705998420715332],\n [11046141541, 10.228405952453613],\n [11046141958, 8.750805854797363],\n [11046142458, 7.273205757141113],\n [11046142875, 5.795605659484863],\n [11046143291, 4.318005561828613],\n [11046144000, 0.3925905227661133],\n [11046144541, 0.4868335723876953],\n [11075593125, 2.017404556274414],\n [11075593875, 2.111647605895996],\n [11088155583, 3.6682348251342773],\n [11096832666, 2.1906347274780273],\n [11096833291, 0.33562374114990234],\n [11096833791, 0.4298667907714844],\n [11096834208, 1.9600791931152344],\n [11107363458, 3.6416664123535156],\n [11118512041, 5.589855194091797],\n [11130513458, 7.859699249267578],\n [11142087416, 6.382099151611328],\n [11142088083, 4.904499053955078],\n [11142088583, 3.426898956298828],\n [11142089000, 1.9492988586425781],\n [11142089500, 0.3092231750488281],\n [11142090083, 0.40346622467041016],\n [11142090500, 1.9263238906860352],\n [11157117583, 3.6078805923461914],\n [11157118291, 5.556069374084473],\n [11166255375, 7.825882911682129],\n [11176655125, 9.78261661529541],\n [11176656083, 8.22011661529541],\n [11192574375, 10.963448524475098],\n [11192575166, 9.213448524475098],\n [11192575666, 12.30361270904541],\n [11192576166, 10.33486270904541],\n [11199870500, 13.815102577209473],\n [11199871625, 11.596352577209473],\n [11199872208, 10.118760108947754],\n [11199872708, 8.641160011291504],\n [11199873166, 7.163559913635254],\n [11199873666, 5.685959815979004],\n [11199874125, 4.208359718322754],\n [11199874791, 0.2829751968383789],\n [11199875250, 0.37721824645996094],\n [11232939625, 1.9078807830810547],\n [11232940375, 2.0021238327026367],\n [11242617708, 3.558711051940918],\n [11257045333, 2.081110954284668],\n [11257046333, 0.22613048553466797],\n [11257046875, 0.32037353515625],\n [11257047333, 1.8505859375],\n [11257047750, 3.5321731567382812],\n [11266258666, 5.4803314208984375],\n [11283567833, 7.750144958496094],\n [11290265000, 6.272544860839844],\n [11290265708, 4.794944763183594],\n [11290266208, 3.3173446655273438],\n [11290266708, 1.8397445678710938],\n [11290267125, 0.19966888427734375],\n [11290267791, 0.2939119338989258],\n [11290268208, 1.8167695999145508],\n [11301162875, 3.498326301574707],\n [11307442333, 5.446484565734863],\n [11323840250, 7.7162981033325195],\n [11339670916, 9.6730318069458],\n [11339671875, 8.1105318069458],\n [11339672458, 10.853894233703613],\n [11339673000, 9.103894233703613],\n [11339673541, 12.193997383117676],\n [11339674041, 10.225247383117676],\n [11351273708, 13.705548286437988],\n [11351274500, 11.486798286437988],\n [11351275125, 10.00920581817627],\n [11351275666, 8.53160572052002],\n [11351276166, 7.0540056228637695],\n [11351276708, 5.5764055252075195],\n [11351277208, 4.0988054275512695],\n [11351278041, 0.17339038848876953],\n [11363950708, 0.26763343811035156],\n [11384779166, 1.7982349395751953],\n [11384779750, 1.8924779891967773],\n [11391129166, 3.4490652084350586],\n [11397362208, 1.9714651107788086],\n [11397362958, 0.1164541244506836],\n [11397363541, 0.21069717407226562],\n [11403666916, 1.7409095764160156],\n [11409927125, 3.422496795654297],\n [11425555583, 5.370685577392578],\n [11438270208, 7.640529632568359],\n [11459207791, 6.162929534912109],\n [11459210500, 4.685329437255859],\n [11459212250, 3.2077293395996094],\n [11459213750, 1.7301292419433594],\n [11459215458, 0.09005355834960938],\n [11459217500, 0.1842966079711914],\n [11459219166, 1.7071542739868164],\n [11459220750, 3.3887109756469727],\n [11479406541, 5.336899757385254],\n [11497716500, 7.60671329498291],\n [11514436791, 9.563446998596191],\n [11514438333, 8.000946998596191],\n [11525424250, 10.744309425354004],\n [11525425333, 8.994309425354004],\n [11531655458, 12.084473609924316],\n [11531656458, 10.115723609924316],\n [11545962583, 13.595993995666504],\n [11545963708, 11.377243995666504],\n [11545964166, 9.899651527404785],\n [11545964583, 8.422051429748535],\n [11545965000, 6.944451332092285],\n [11545965333, 5.466851234436035],\n [11545965750, 3.989251136779785],\n [11545966375, 0.06386661529541016],\n [11545966791, 0.1581096649169922],\n [11573768708, 1.6887569427490234],\n [11573769541, 1.7829999923706055],\n [11582842250, 3.3396177291870117],\n [11591298958, 1.8620176315307617],\n [11591299833, 0.007037162780761719],\n [11591300500, 0.10128021240234375],\n [11591300916, 1.6314926147460938],\n [11602014083, 3.313079833984375],\n [11608265208, 5.261268615722656],\n [11622095125, 7.5311126708984375],\n [11637128125, 6.0535125732421875],\n [11637128958, 4.5759124755859375],\n [11637129458, 3.0983123779296875],\n [11637129916, 1.6207122802734375],\n [11637130583, 0],\n [11637131416, 0.09424304962158203],\n [11637131916, 1.617100715637207],\n [11646075875, 3.2986268997192383],\n [11655687208, 5.2468156814575195],\n [11666417000, 7.516659736633301],\n [11676156041, 9.474095344543457],\n [11676157083, 7.911595344543457],\n [11676157750, 10.654927253723145],\n [11676158333, 8.904927253723145],\n [11684474833, 11.99516773223877],\n [11684475750, 10.02641773223877],\n [11694942500, 13.506688117980957],\n [11694943833, 11.287938117980957],\n [11694944375, 9.810345649719238],\n [11694944833, 8.332745552062988],\n [11694948625, 6.855145454406738],\n [11694949083, 5.377545356750488],\n [11694949583, 3.8999452590942383],\n [11694950375, 0],\n [11701325291, 0.09424304962158203],\n [11737127416, 1.6248445510864258],\n [11737128166, 1.7190876007080078],\n [11737128583, 3.275705337524414],\n [11747069458, 1.798105239868164],\n [11747070708, 0],\n [11747071541, 0.09424304962158203],\n [11747072041, 1.624455451965332],\n [11758414458, 3.3060121536254883],\n [11769110875, 5.2542009353637695],\n [11781372000, 7.524044990539551],\n [11793048791, 6.046444892883301],\n [11793049541, 4.568844795227051],\n [11793050083, 3.091244697570801],\n [11793050541, 1.6136445999145508],\n [11793051208, 0],\n [11793051916, 0.09424304962158203],\n [11793052416, 1.617100715637207],\n [11801807541, 3.2986574172973633],\n [11809489958, 5.2468461990356445],\n [11815788833, 7.516659736633301],\n [11837611875, 9.473362922668457],\n [11837612958, 7.910862922668457],\n [11837613500, 10.65422534942627],\n [11837614000, 8.90422534942627],\n [11837614458, 11.994328498840332],\n [11837614916, 10.025578498840332],\n [11849383583, 13.505879402160645],\n [11849384833, 11.287129402160645],\n [11849385375, 9.809536933898926],\n [11849385833, 8.331936836242676],\n [11849386333, 6.854336738586426],\n [11849386791, 5.376736640930176],\n [11849387250, 3.899136543273926],\n [11849388000, 0],\n [11855799125, 0.09424304962158203],\n [11882959291, 1.6248445510864258],\n [11882960000, 1.7190876007080078],\n [11893305375, 3.275705337524414],\n [11907861000, 1.798105239868164],\n [11907861958, 0],\n [11907862625, 0.09424304962158203],\n [11907863166, 1.624455451965332],\n [11907863583, 3.3060426712036133],\n [11916294791, 5.2542009353637695],\n [11934470500, 7.524044990539551],\n [11945975291, 6.046444892883301],\n [11945976041, 4.568844795227051],\n [11945976541, 3.091244697570801],\n [11945976958, 1.6136445999145508],\n [11945977666, 0],\n [11945978375, 0.09424304962158203],\n [11945978833, 1.617100715637207],\n [11954876958, 3.2986574172973633],\n [11964166958, 5.2468461990356445],\n [11971817958, 7.516690254211426],\n [11984355791, 9.473393440246582],\n [11984356541, 7.910893440246582],\n [11984357000, 10.65422534942627],\n [11984357541, 8.90422534942627],\n [11993305291, 11.994359016418457],\n [11993305916, 10.025609016418457],\n [11999586541, 13.505879402160645],\n [11999587166, 11.287129402160645],\n [12005901000, 9.809536933898926],\n [12005901791, 8.331936836242676],\n [12005902250, 6.854336738586426],\n [12005902666, 5.376736640930176],\n [12005903083, 3.899136543273926],\n [12005903958, 0],\n [12005904583, 0.09424304962158203],\n [12037360208, 1.6248979568481445],\n [12037360791, 1.7191410064697266],\n [12046404541, 3.275758743286133],\n [12054500041, 1.7981586456298828],\n [12054500750, 0],\n [12054501291, 0.09424304962158203],\n [12054501708, 1.624455451965332],\n [12063257541, 3.3060426712036133],\n [12074136000, 5.2542314529418945],\n [12084477416, 7.524075508117676],\n [12094917541, 6.046475410461426],\n [12094918250, 4.568875312805176],\n [12094918791, 3.091275215148926],\n [12094919333, 1.6136751174926758],\n [12094919875, 0],\n [12094920583, 0.09424304962158203],\n [12094921041, 1.617100715637207],\n [12107394583, 3.2986268997192383],\n [12123027083, 5.2468156814575195],\n [12123027625, 7.516659736633301],\n [12142991583, 9.473362922668457],\n [12142992458, 7.910862922668457],\n [12142993041, 10.65422534942627],\n [12142993583, 8.90422534942627],\n [12142994041, 11.994328498840332],\n [12142994583, 10.025578498840332],\n [12156171708, 13.505879402160645],\n [12156172916, 11.287129402160645],\n [12156173500, 9.809536933898926],\n [12156173958, 8.331936836242676],\n [12156174500, 6.854336738586426],\n [12156174958, 5.376736640930176],\n [12156175500, 3.899136543273926],\n [12156176458, 0],\n [12156176958, 0.09424304962158203],\n [12184469083, 1.6248140335083008],\n [12184469708, 1.7190570831298828],\n [12196993625, 3.275674819946289],\n [12203325958, 1.798074722290039],\n [12203326666, 0],\n [12203327250, 0.09424304962158203],\n [12203327708, 1.624455451965332],\n [12217593833, 3.306065559387207],\n [12229393375, 5.254254341125488],\n [12249104583, 7.5240983963012695],\n [12249106208, 6.0464982986450195],\n [12249106791, 4.5688982009887695],\n [12249107208, 3.0912981033325195],\n [12249107583, 1.6136980056762695],\n [12249108041, 0],\n [12249108541, 0.09424304962158203],\n [12255297458, 1.617100715637207],\n [12263781750, 3.2986574172973633],\n [12273487416, 5.247906684875488],\n [12284248750, 7.517926216125488],\n [12294003791, 9.47465991973877],\n [12294004916, 7.9121599197387695],\n [12294005458, 10.655491828918457],\n [12294006000, 8.905491828918457],\n [12306503666, 11.995732307434082],\n [12306504750, 10.026982307434082],\n [12312782416, 13.507283210754395],\n [12312783750, 11.288533210754395],\n [12312784291, 9.810940742492676],\n [12312784708, 8.333340644836426],\n [12312785125, 6.855740547180176],\n [12312785583, 5.378140449523926],\n [12312786000, 3.900540351867676],\n [12312786791, 0],\n [12312787541, 0.09424304962158203],\n [12343368750, 1.6248292922973633],\n [12343369666, 1.7190723419189453],\n [12353690125, 3.2756900787353516],\n [12366374458, 1.7980899810791016],\n [12366375750, 0],\n [12366376583, 0.09424304962158203],\n [12366377083, 1.624455451965332],\n [12376683750, 3.3060426712036133],\n [12383007958, 5.2542009353637695],\n [12399666166, 7.524044990539551],\n [12412253000, 6.046444892883301],\n [12412253750, 4.568844795227051],\n [12412254250, 3.091244697570801],\n [12412255041, 1.6136445999145508],\n [12412255583, 0],\n [12412256125, 0.09424304962158203],\n [12412256625, 1.617100715637207],\n [12420498041, 3.2986574172973633],\n [12430566583, 5.2468156814575195],\n [12441197375, 7.516659736633301],\n [12456966166, 9.473393440246582],\n [12456967041, 7.910893440246582],\n [12456967625, 10.654255867004395],\n [12456968208, 8.904255867004395],\n [12456968708, 11.994412422180176],\n [12456969291, 10.025662422180176],\n [12468587666, 13.505963325500488],\n [12468588375, 11.287213325500488],\n [12468588916, 9.80962085723877],\n [12468589375, 8.33202075958252],\n [12468589916, 6.8544206619262695],\n [12468590416, 5.3768205642700195],\n [12468590958, 3.8992204666137695],\n [12468591833, 0],\n [12475001916, 0.09424304962158203],\n [12501159916, 1.6248598098754883],\n [12501160791, 1.7191028594970703],\n [12519035875, 3.2756900787353516],\n [12519037125, 1.7980899810791016],\n [12519037750, 0],\n [12519038375, 0.09424304962158203],\n [12519038791, 1.624424934387207],\n [12531292833, 3.3060121536254883],\n [12541779750, 5.2542009353637695],\n [12553646125, 7.524044990539551],\n [12565095625, 6.046444892883301],\n [12565096333, 4.568844795227051],\n [12565096833, 3.091244697570801],\n [12565097250, 1.6136445999145508],\n [12565097791, 0],\n [12565098375, 0.09424304962158203],\n [12565098833, 1.617100715637207],\n [12573886875, 3.2986574172973633],\n [12583134375, 5.2468461990356445],\n [12589985583, 7.516690254211426],\n [12602700791, 9.473393440246582],\n [12602701750, 7.910893440246582],\n [12602702208, 10.65422534942627],\n [12602702708, 8.90422534942627],\n [12615074500, 11.994389533996582],\n [12615075125, 10.025639533996582],\n [12622630583, 13.50590991973877],\n [12622631750, 11.28715991973877],\n [12622632333, 9.80956745147705],\n [12622632750, 8.3319673538208],\n [12622633208, 6.854367256164551],\n [12622633625, 5.376767158508301],\n [12622634041, 3.899167060852051],\n [12622634958, 0],\n [12622635541, 0.09424304962158203],\n [12651152333, 1.6247835159301758],\n [12651152958, 1.7190265655517578],\n [12663168166, 3.275644302368164],\n [12669433291, 1.798044204711914],\n [12669434083, 0],\n [12669434708, 0.09424304962158203],\n [12669435208, 1.624455451965332],\n [12683717458, 3.306065559387207],\n [12694430708, 5.254254341125488],\n [12712884958, 7.5240983963012695],\n [12712886125, 6.0464982986450195],\n [12712886666, 4.5688982009887695],\n [12712887166, 3.0912981033325195],\n [12712887583, 1.6136980056762695],\n [12712888083, 0],\n [12712888583, 0.09424304962158203],\n [12712889000, 1.617100715637207],\n [12726883916, 3.2986268997192383],\n [12736323583, 5.2468156814575195],\n [12742813041, 7.516659736633301],\n [12755357125, 9.473362922668457],\n [12755357875, 7.910862922668457],\n [12761630541, 10.654194831848145],\n [12761631375, 8.904194831848145],\n [12767874833, 11.994359016418457],\n [12767875500, 10.025609016418457],\n [12788592583, 13.505879402160645],\n [12788593666, 11.287129402160645],\n [12788594125, 9.809536933898926],\n [12788594583, 8.331936836242676],\n [12788595000, 6.854336738586426],\n [12788595375, 5.376736640930176],\n [12788595791, 3.899136543273926],\n [12788596458, 0],\n [12788596958, 0.09424304962158203],\n [12815932416, 1.6249208450317383],\n [12815933000, 1.7191638946533203],\n [12815933416, 3.2757816314697266],\n [12826637333, 1.7981815338134766],\n [12826638083, 0],\n [12826638750, 0.09424304962158203],\n [12826639250, 1.624455451965332],\n [12833008041, 3.3060426712036133],\n [12843308250, 5.2542314529418945],\n [12859610541, 7.524044990539551],\n [12866371083, 6.046444892883301],\n [12866371750, 4.568844795227051],\n [12866372291, 3.091244697570801],\n [12866372791, 1.6136445999145508],\n [12866373333, 0],\n [12866374083, 0.09424304962158203],\n [12866374583, 1.617100715637207],\n [12877735375, 3.2986574172973633],\n [12884009875, 5.2468156814575195],\n [12899731625, 7.516629219055176],\n [12915533458, 9.473362922668457],\n [12915534416, 7.910862922668457],\n [12915534916, 10.65422534942627],\n [12915535458, 8.90422534942627],\n [12915535916, 11.994328498840332],\n [12915536458, 10.025578498840332],\n [12924178041, 13.505879402160645],\n [12924178708, 11.287129402160645],\n [12939773083, 9.809536933898926],\n [12939773958, 8.331936836242676],\n [12939774416, 6.854336738586426],\n [12939774833, 5.376736640930176],\n [12939775250, 3.899136543273926],\n [12939776083, 0],\n [12939776750, 0.09424304962158203],\n ],\n};\n"
},
{
"path": "scalene/scalene-gui/gemini.ts",
"content": "interface GeminiErrorResponse {\n error?: {\n code?: number;\n message?: string;\n status?: string;\n };\n}\n\ninterface GeminiContentPart {\n text: string;\n}\n\ninterface GeminiContent {\n parts: GeminiContentPart[];\n role: string;\n}\n\ninterface GeminiCandidate {\n content: GeminiContent;\n}\n\ninterface GeminiResponse extends GeminiErrorResponse {\n candidates?: GeminiCandidate[];\n}\n\ninterface GeminiModelInfo {\n name: string;\n displayName: string;\n supportedGenerationMethods: string[];\n}\n\ninterface GeminiModelsResponse extends GeminiErrorResponse {\n models?: GeminiModelInfo[];\n}\n\nexport async function sendPromptToGemini(\n prompt: string,\n apiKey: string\n): Promise {\n // Check for custom URL override (for Gemini-compatible servers)\n const customUrlElement = document.getElementById(\"gemini-custom-url\") as HTMLInputElement | null;\n const customUrl = customUrlElement?.value?.trim() || \"\";\n\n // Check for custom model override\n const customModelElement = document.getElementById(\"gemini-custom-model\") as HTMLInputElement | null;\n const customModel = customModelElement?.value?.trim() || \"\";\n const modelElement = document.getElementById(\"language-model-gemini\") as HTMLSelectElement | null;\n const model = customModel || modelElement?.value || \"gemini-2.0-flash\";\n\n // Construct endpoint URL\n const baseUrl = customUrl || \"https://generativelanguage.googleapis.com/v1beta\";\n const endpoint = `${baseUrl}/models/${model}:generateContent?key=${apiKey}`;\n\n const body = JSON.stringify({\n contents: [\n {\n parts: [\n {\n text: prompt,\n },\n ],\n },\n ],\n systemInstruction: {\n parts: [\n {\n text: \"You are a Python programming assistant who ONLY responds with blocks of commented, optimized code. You never respond with text. Just code, starting with ``` and ending with ```.\",\n },\n ],\n },\n generationConfig: {\n temperature: 0.3,\n maxOutputTokens: 4096,\n },\n });\n\n console.log(body);\n\n const response = await fetch(endpoint, {\n method: \"POST\",\n headers: {\n \"Content-Type\": \"application/json\",\n },\n body: body,\n });\n\n const data: GeminiResponse = await response.json();\n if (data.error) {\n console.error(\"Gemini API error:\", data.error);\n if (data.error.status === \"INVALID_ARGUMENT\" || data.error.code === 400) {\n alert(`Gemini API error: ${data.error.message || \"Invalid request\"}`);\n } else if (data.error.status === \"UNAUTHENTICATED\" || data.error.code === 401) {\n alert(\"Invalid Gemini API key. Please check your API key and try again.\");\n } else if (data.error.status === \"RESOURCE_EXHAUSTED\" || data.error.code === 429) {\n alert(\"Rate limit exceeded. Please wait a moment and try again.\");\n } else {\n alert(`Gemini API error: ${data.error.message || \"Unknown error\"}`);\n }\n return \"\";\n }\n\n try {\n if (data.candidates && data.candidates[0] && data.candidates[0].content) {\n const text = data.candidates[0].content.parts\n .map((part) => part.text)\n .join(\"\");\n console.log(\n `Debugging info: Retrieved ${JSON.stringify(data.candidates[0], null, 4)}`\n );\n return text.replace(/^\\s*[\\r\\n]/gm, \"\");\n }\n return \"# Query failed. See JavaScript console (in Chrome: View > Developer > JavaScript Console) for more info.\\n\";\n } catch {\n return \"# Query failed. See JavaScript console (in Chrome: View > Developer > JavaScript Console) for more info.\\n\";\n }\n}\n\n// Fetch available models from Gemini API\nexport async function fetchGeminiModels(apiKey: string): Promise {\n if (!apiKey) return [];\n\n // Check for custom URL\n const customUrlElement = document.getElementById(\"gemini-custom-url\") as HTMLInputElement | null;\n const customUrl = customUrlElement?.value?.trim() || \"\";\n const baseUrl = customUrl || \"https://generativelanguage.googleapis.com/v1beta\";\n const endpoint = `${baseUrl}/models?key=${apiKey}`;\n\n try {\n const response = await fetch(endpoint, {\n method: \"GET\",\n headers: {\n \"Content-Type\": \"application/json\",\n },\n });\n\n const data: GeminiModelsResponse = await response.json();\n if (data.error || !data.models) {\n console.error(\"Failed to fetch Gemini models:\", data.error);\n return [];\n }\n\n // Filter for models that support generateContent and extract model ID\n const chatModels = data.models\n .filter((m) => m.supportedGenerationMethods?.includes(\"generateContent\"))\n .map((m) => m.name.replace(\"models/\", \"\"))\n .filter((id) => id.includes(\"gemini\"))\n .sort();\n\n return chatModels;\n } catch (error) {\n console.error(\"Error fetching Gemini models:\", error);\n return [];\n }\n}\n"
},
{
"path": "scalene/scalene-gui/gui-elements.ts",
"content": "import { memory_consumed_str, time_consumed_str } from \"./utils\";\n\nexport const Lightning = \"⚡\"; // lightning bolt (for optimizing a line)\nexport const Explosion = \"💥\"; // explosion (for optimizing a region)\nexport const WhiteLightning = `${Lightning}`; // invisible but same width as lightning bolt\nexport const WhiteExplosion = `${Explosion}`; // invisible but same width as explosion\nexport const RightTriangle = \"►\"; // right-facing triangle symbol (collapsed view)\nexport const DownTriangle = \"▼\"; // downward-facing triangle symbol (expanded view)\n\n// Type for chart parameters\nexport interface ChartParams {\n width: number;\n height: number;\n}\n\n// Type for profile data - extending globalThis\ndeclare global {\n interface Window {\n profile?: {\n elapsed_time_sec: number;\n [key: string]: unknown;\n };\n }\n // eslint-disable-next-line no-var\n var profile: {\n elapsed_time_sec: number;\n max_footprint_mb: number;\n growth_rate: number;\n gpu: boolean;\n gpu_device: string;\n memory: boolean;\n samples: Array<[number, number]>;\n files: Record;\n program?: string;\n stacks?: unknown;\n };\n}\n\nexport interface LineProfile {\n lineno: number;\n line: string;\n n_cpu_percent_python: number;\n n_cpu_percent_c: number;\n n_sys_percent: number;\n n_gpu_percent: number;\n n_gpu_peak_memory_mb: number;\n n_peak_mb: number;\n n_avg_mb: number;\n n_python_fraction: number;\n n_usage_fraction: number;\n n_copy_mb_s: number;\n n_copy_mb: number;\n n_malloc_mb: number;\n n_core_utilization: number;\n memory_samples: Array<[number, number]>;\n start_region_line: number;\n end_region_line: number;\n nrt_time_ms?: number;\n nrt_percent?: number;\n nc_time_ms?: number;\n cpu_samples_nc_overlap_percent?: number;\n}\n\nexport interface FileProfile {\n lines: LineProfile[];\n functions: LineProfile[];\n imports: string[];\n percent_cpu_time: number;\n leaks?: Record;\n}\n\nfunction makeTooltip(title: string, value: number): string {\n // Tooltip for time bars, below\n const secs = (value / 100) * globalThis.profile.elapsed_time_sec;\n return (\n `(${title}) ` +\n value.toFixed(1) +\n \"%\" +\n \" [\" +\n time_consumed_str(secs * 1e3) +\n \"]\"\n );\n}\n\nexport function makeBar(\n python: number,\n native: number,\n system: number,\n params: ChartParams\n): object {\n // Make a time bar\n const widthThreshold1 = 20;\n const widthThreshold2 = 10;\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n config: {\n view: {\n stroke: \"transparent\",\n },\n },\n autosize: {\n contains: \"padding\",\n },\n width: params.width,\n height: params.height,\n padding: 0,\n data: {\n values: [\n {\n x: 0,\n y: python.toFixed(1),\n c: makeTooltip(\"Python\", python),\n d:\n python >= widthThreshold1\n ? python.toFixed(0) + \"%\"\n : python >= widthThreshold2\n ? python.toFixed(0)\n : \"\",\n q: python / 2,\n },\n {\n x: 0,\n y: native.toFixed(1),\n c: makeTooltip(\"native\", native),\n d:\n native >= widthThreshold1\n ? native.toFixed(0) + \"%\"\n : native >= widthThreshold2\n ? native.toFixed(0)\n : \"\",\n q: python + native / 2,\n },\n {\n x: 0,\n y: system.toFixed(1),\n c: makeTooltip(\"system\", system),\n d:\n system >= widthThreshold1\n ? system.toFixed(0) + \"%\"\n : system >= widthThreshold2\n ? system.toFixed(0)\n : \"\",\n q: python + native + system / 2,\n },\n ],\n },\n layer: [\n {\n mark: { type: \"bar\" },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"y\",\n axis: false,\n stack: \"zero\",\n scale: { domain: [0, 100] },\n },\n color: {\n field: \"c\",\n type: \"nominal\",\n legend: false,\n scale: { range: [\"darkblue\", \"#6495ED\", \"blue\"] },\n },\n tooltip: [{ field: \"c\", type: \"nominal\", title: \"time\" }],\n },\n },\n {\n mark: {\n type: \"text\",\n align: \"center\",\n baseline: \"middle\",\n dx: 0,\n },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"q\",\n axis: false,\n },\n text: { field: \"d\" },\n color: { value: \"white\" },\n tooltip: [{ field: \"c\", type: \"nominal\", title: \"time\" }],\n },\n },\n ],\n };\n}\n\nexport function makeAwaitPie(\n await_pct: number,\n params: ChartParams,\n startAngle: number = 0\n): object {\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n config: {\n view: {\n stroke: \"transparent\",\n },\n },\n autosize: {\n contains: \"padding\",\n },\n width: params.width,\n height: params.height,\n padding: 0,\n data: {\n values: [\n {\n category: \"await\",\n value: await_pct.toFixed(1),\n c: \"await: \" + await_pct.toFixed(1) + \"%\",\n },\n {\n category: \"other\",\n value: (100 - await_pct).toFixed(1),\n c: \"\",\n },\n ],\n },\n mark: \"arc\",\n encoding: {\n theta: {\n field: \"value\",\n type: \"quantitative\",\n scale: {\n range: [startAngle, startAngle + 2 * Math.PI],\n },\n },\n color: {\n field: \"category\",\n type: \"nominal\",\n legend: false,\n scale: {\n domain: [\"await\", \"other\"],\n range: [\"darkcyan\", \"#e0f2f1\"],\n },\n },\n tooltip: [{ field: \"c\", type: \"nominal\", title: \"await\" }],\n },\n };\n}\n\nexport function makeGPUPie(\n util: number,\n gpu_device: string,\n params: ChartParams,\n startAngle: number = 0\n): object {\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n config: {\n view: {\n stroke: \"transparent\",\n },\n },\n autosize: {\n contains: \"padding\",\n },\n width: params.width,\n height: params.height,\n padding: 0,\n data: {\n values: [\n {\n category: \"in use\",\n value: util.toFixed(1),\n c: \"in use: \" + util.toFixed(1) + \"%\",\n },\n {\n category: \"idle\",\n value: (100 - util).toFixed(1),\n c: \"\",\n },\n ],\n },\n mark: \"arc\",\n encoding: {\n theta: {\n field: \"value\",\n type: \"quantitative\",\n scale: {\n range: [startAngle, startAngle + 2 * Math.PI],\n },\n },\n color: {\n field: \"category\",\n type: \"nominal\",\n legend: false,\n scale: {\n domain: [\"in use\", \"idle\"],\n range: [\"goldenrod\", \"#f4e6c2\"],\n },\n },\n tooltip: [{ field: \"c\", type: \"nominal\", title: gpu_device }],\n },\n };\n}\n\nexport function makeGPUBar(\n util: number,\n gpu_device: string,\n params: ChartParams\n): object {\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n config: {\n view: {\n stroke: \"transparent\",\n },\n },\n autosize: {\n contains: \"padding\",\n },\n width: params.width,\n height: params.height,\n padding: 0,\n data: {\n values: [\n {\n x: 0,\n y: util.toFixed(0),\n q: (util / 2).toFixed(0),\n d: util >= 20 ? util.toFixed(0) + \"%\" : \"\",\n dd: \"in use: \" + util.toFixed(0) + \"%\",\n },\n ],\n },\n layer: [\n {\n mark: { type: \"bar\" },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"y\",\n axis: false,\n scale: { domain: [0, 100] },\n },\n color: {\n field: \"dd\",\n type: \"nominal\",\n legend: false,\n scale: { range: [\"goldenrod\", \"#f4e6c2\"] },\n },\n tooltip: [{ field: \"dd\", type: \"nominal\", title: gpu_device + \":\" }],\n },\n },\n {\n mark: {\n type: \"text\",\n align: \"center\",\n baseline: \"middle\",\n dx: 0,\n },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"q\",\n axis: false,\n },\n text: { field: \"d\" },\n color: { value: \"white\" },\n tooltip: [{ field: \"dd\", type: \"nominal\", title: gpu_device + \":\" }],\n },\n },\n ],\n };\n}\n\nexport function makeMemoryPie(\n native_mem: number,\n python_mem: number,\n params: { width: number }\n): object {\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n width: params.width,\n height: 20,\n padding: 0,\n data: {\n values: [\n {\n category: 1,\n value: native_mem.toFixed(1),\n c: \"native: \" + native_mem.toFixed(1) + \"%\",\n },\n {\n category: 2,\n value: python_mem.toFixed(1),\n c: \"Python: \" + python_mem.toFixed(1) + \"%\",\n },\n ],\n },\n mark: \"arc\",\n encoding: {\n theta: {\n field: \"value\",\n type: \"quantitative\",\n scale: { domain: [0, 100] },\n },\n color: {\n field: \"c\",\n type: \"nominal\",\n legend: false,\n scale: { range: [\"darkgreen\", \"#50C878\"] },\n },\n tooltip: [{ field: \"c\", type: \"nominal\", title: \"memory\" }],\n },\n };\n}\n\nexport function makeMemoryBar(\n memory: number | string,\n _title: string,\n python_percent: number,\n total: number | string,\n color: string,\n params: ChartParams\n): object {\n const memoryNum = typeof memory === \"string\" ? parseFloat(memory) : memory;\n const totalNum = typeof total === \"string\" ? parseFloat(total) : total;\n\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n config: {\n view: {\n stroke: \"transparent\",\n },\n },\n autosize: {\n contains: \"padding\",\n },\n width: params.width,\n height: params.height,\n padding: 0,\n data: {\n values: [\n {\n x: 0,\n y: python_percent * memoryNum,\n c: \"(Python) \" + memory_consumed_str(python_percent * memoryNum),\n d:\n python_percent * memoryNum > totalNum * 0.2\n ? memory_consumed_str(python_percent * memoryNum)\n : \"\",\n q: (python_percent * memoryNum) / 2,\n },\n {\n x: 0,\n y: (1.0 - python_percent) * memoryNum,\n c: \"(native) \" + memory_consumed_str((1.0 - python_percent) * memoryNum),\n d:\n (1.0 - python_percent) * memoryNum > totalNum * 0.2\n ? memory_consumed_str((1.0 - python_percent) * memoryNum)\n : \"\",\n q: python_percent * memoryNum + ((1.0 - python_percent) * memoryNum) / 2,\n },\n ],\n },\n layer: [\n {\n mark: { type: \"bar\" },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"y\",\n axis: false,\n scale: { domain: [0, totalNum] },\n },\n color: {\n field: \"c\",\n type: \"nominal\",\n legend: false,\n scale: { range: [color, \"#50C878\", \"green\"] },\n },\n },\n },\n {\n mark: {\n type: \"text\",\n align: \"center\",\n baseline: \"middle\",\n dx: 0,\n },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"q\",\n axis: false,\n },\n text: { field: \"d\" },\n color: { value: \"white\" },\n },\n },\n ],\n };\n}\n\nexport function makeSparkline(\n samples: Array<[number, number]>,\n max_x: number,\n max_y: number,\n leak_velocity: number = 0,\n params: ChartParams\n): object {\n const values = samples.map((v) => {\n let leak_str = \"\";\n if (leak_velocity != 0) {\n leak_str = `; possible leak (${memory_consumed_str(leak_velocity)}/s)`;\n }\n return {\n x: v[0],\n y: v[1],\n y_text:\n memory_consumed_str(v[1]) +\n \" (@ \" +\n time_consumed_str(v[0] / 1e6) +\n \")\" +\n leak_str,\n };\n });\n let leak_info = \"\";\n let height = params.height;\n if (leak_velocity != 0) {\n leak_info = \"possible leak\";\n height -= 10; // FIXME should be actual height of font\n }\n\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n data: { values: values },\n width: params.width,\n height: height,\n padding: 0,\n title: {\n text: leak_info,\n baseline: \"line-bottom\",\n color: \"red\",\n offset: 0,\n lineHeight: 10,\n orient: \"bottom\",\n fontStyle: \"italic\",\n },\n encoding: {\n x: {\n field: \"x\",\n type: \"quantitative\",\n title: \"\",\n axis: {\n tickCount: 10,\n tickSize: 0,\n labelExpr: \"\",\n },\n scale: {\n domain: [0, max_x],\n },\n },\n },\n layer: [\n {\n encoding: {\n y: {\n field: \"y\",\n type: \"quantitative\",\n axis: null,\n scale: {\n domain: [0, max_y],\n },\n },\n color: {\n field: \"c\",\n type: \"nominal\",\n legend: null,\n scale: {\n range: [\"darkgreen\"],\n },\n },\n },\n layer: [\n { mark: \"line\" },\n {\n transform: [{ filter: { param: \"hover\", empty: false } }],\n mark: \"point\",\n },\n ],\n },\n {\n mark: \"rule\",\n encoding: {\n opacity: {\n condition: { value: 0.3, param: \"hover\", empty: false },\n value: 0,\n },\n tooltip: [{ field: \"y_text\", type: \"nominal\", title: \"memory\" }],\n },\n params: [\n {\n name: \"hover\",\n select: {\n type: \"point\",\n fields: [\"y\"],\n nearest: true,\n on: \"mousemove\",\n },\n },\n ],\n },\n ],\n };\n}\n\nexport function makeNRTBar(\n nrt_time_ms: number,\n elapsed_time_sec: number,\n params: ChartParams\n): object {\n const widthThreshold1 = 15;\n const widthThreshold2 = 8;\n\n const elapsed_time_ms = elapsed_time_sec * 1000;\n const nrt_percent =\n elapsed_time_ms > 0 ? (nrt_time_ms / elapsed_time_ms) * 100 : 0;\n\n const tooltipText =\n \"NRT: \" +\n nrt_percent.toFixed(1) +\n \"% of elapsed time [\" +\n time_consumed_str(nrt_time_ms) +\n \"]\";\n\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n config: {\n view: {\n stroke: \"transparent\",\n },\n },\n autosize: {\n contains: \"padding\",\n },\n width: params.width,\n height: params.height,\n padding: 0,\n data: {\n values: [\n {\n x: 0,\n y: nrt_percent.toFixed(1),\n c: tooltipText,\n d:\n nrt_percent >= widthThreshold1\n ? nrt_percent.toFixed(0) + \"%\"\n : nrt_percent >= widthThreshold2\n ? nrt_percent.toFixed(0)\n : \"\",\n q: nrt_percent / 2,\n },\n ],\n },\n layer: [\n {\n mark: { type: \"bar\" },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"y\",\n axis: false,\n stack: \"zero\",\n scale: { domain: [0, 100] },\n },\n color: {\n field: \"c\",\n type: \"nominal\",\n legend: false,\n scale: { range: [\"purple\"] },\n },\n tooltip: [{ field: \"c\", type: \"nominal\", title: \"NRT time\" }],\n },\n },\n {\n mark: {\n type: \"text\",\n align: \"center\",\n baseline: \"middle\",\n dx: 0,\n },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"q\",\n axis: false,\n },\n text: { field: \"d\" },\n color: { value: \"white\" },\n tooltip: [{ field: \"c\", type: \"nominal\", title: \"NRT time\" }],\n },\n },\n ],\n };\n}\n\nexport function makeNCNRTPie(\n nc_time_ms: number,\n nrt_time_ms: number,\n params: ChartParams\n): object {\n const total_time = nc_time_ms + nrt_time_ms;\n const nc_proportion = (nc_time_ms / total_time) * 100;\n const nrt_proportion = (nrt_time_ms / total_time) * 100;\n\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n config: {\n view: {\n stroke: \"transparent\",\n },\n },\n autosize: {\n contains: \"padding\",\n },\n width: params.width,\n height: params.height,\n padding: 0,\n data: {\n values: [\n {\n category: \"NC\",\n value: nc_time_ms,\n c:\n \"NC: \" +\n time_consumed_str(nc_time_ms) +\n \" (\" +\n nc_proportion.toFixed(1) +\n \"%)\",\n },\n {\n category: \"NRT\",\n value: nrt_time_ms,\n c:\n \"NRT: \" +\n time_consumed_str(nrt_time_ms) +\n \" (\" +\n nrt_proportion.toFixed(1) +\n \"%)\",\n },\n ],\n },\n mark: \"arc\",\n encoding: {\n theta: {\n field: \"value\",\n type: \"quantitative\",\n },\n color: {\n field: \"category\",\n type: \"nominal\",\n legend: false,\n scale: {\n domain: [\"NC\", \"NRT\"],\n range: [\"darkorange\", \"white\"],\n },\n },\n tooltip: [{ field: \"c\", type: \"nominal\", title: \"NC vs NRT time\" }],\n },\n };\n}\n\nexport function makeNCTimeBar(\n nc_time_ms: number,\n elapsed_time_sec: number,\n params: ChartParams\n): object {\n const widthThreshold1 = 15;\n const widthThreshold2 = 8;\n\n const elapsed_time_ms = elapsed_time_sec * 1000;\n const nc_percent =\n elapsed_time_ms > 0 ? (nc_time_ms / elapsed_time_ms) * 100 : 0;\n\n const tooltipText =\n \"NC: \" +\n nc_percent.toFixed(1) +\n \"% of elapsed time [\" +\n time_consumed_str(nc_time_ms) +\n \"]\";\n\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n config: {\n view: {\n stroke: \"transparent\",\n },\n },\n autosize: {\n contains: \"padding\",\n },\n width: params.width,\n height: params.height,\n padding: 0,\n data: {\n values: [\n {\n x: 0,\n y: nc_percent.toFixed(1),\n c: tooltipText,\n d:\n nc_percent >= widthThreshold1\n ? nc_percent.toFixed(0) + \"%\"\n : nc_percent >= widthThreshold2\n ? nc_percent.toFixed(0)\n : \"\",\n q: nc_percent / 2,\n },\n ],\n },\n layer: [\n {\n mark: { type: \"bar\" },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"y\",\n axis: false,\n stack: \"zero\",\n scale: { domain: [0, 100] },\n },\n color: {\n field: \"c\",\n type: \"nominal\",\n legend: false,\n scale: { range: [\"darkorange\"] },\n },\n tooltip: [{ field: \"c\", type: \"nominal\", title: \"NC time\" }],\n },\n },\n {\n mark: {\n type: \"text\",\n align: \"center\",\n baseline: \"middle\",\n dx: 0,\n },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"q\",\n axis: false,\n },\n text: { field: \"d\" },\n color: { value: \"white\" },\n tooltip: [{ field: \"c\", type: \"nominal\", title: \"NC time\" }],\n },\n },\n ],\n };\n}\n\nexport function makeTotalNeuronBar(\n total_time_ms: number,\n elapsed_time_sec: number,\n label: string,\n color: string,\n params: ChartParams\n): object {\n const widthThreshold1 = 15;\n const widthThreshold2 = 8;\n\n const elapsed_time_ms = elapsed_time_sec * 1000;\n const time_percent =\n elapsed_time_ms > 0 ? (total_time_ms / elapsed_time_ms) * 100 : 0;\n\n const tooltipText = `${label}: ${time_percent.toFixed(1)}% of elapsed time [${time_consumed_str(total_time_ms)}]`;\n\n return {\n $schema: \"https://vega.github.io/schema/vega-lite/v5.json\",\n config: {\n view: {\n stroke: \"transparent\",\n },\n },\n autosize: {\n contains: \"padding\",\n },\n width: params.width,\n height: params.height,\n padding: 0,\n data: {\n values: [\n {\n x: 0,\n y: time_percent.toFixed(1),\n c: tooltipText,\n d:\n time_percent >= widthThreshold1\n ? time_percent.toFixed(0) + \"%\"\n : time_percent >= widthThreshold2\n ? time_percent.toFixed(0)\n : \"\",\n q: time_percent / 2,\n },\n ],\n },\n layer: [\n {\n mark: { type: \"bar\" },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"y\",\n axis: false,\n stack: \"zero\",\n scale: { domain: [0, 100] },\n },\n color: {\n field: \"c\",\n type: \"nominal\",\n legend: false,\n scale: { range: [color] },\n },\n tooltip: [{ field: \"c\", type: \"nominal\", title: label + \" time\" }],\n },\n },\n {\n mark: {\n type: \"text\",\n align: \"center\",\n baseline: \"middle\",\n dx: 0,\n },\n encoding: {\n x: {\n aggregate: \"sum\",\n field: \"q\",\n axis: false,\n },\n text: { field: \"d\" },\n color: { value: \"white\" },\n tooltip: [{ field: \"c\", type: \"nominal\", title: label + \" time\" }],\n },\n },\n ],\n };\n}\n"
},
{
"path": "scalene/scalene-gui/index.html",
"content": "\n \n Scalene\n \n \n \n \n \n \n \n \n \n \n \n\n \n \n \n \n \n \n \n \n \n \n\t \n
\n
\n \n \n \n\t\n \n
\n\tProfile your Python code\n\twith Scalene,\n\tthen select the generated\n\tfile profile.json.\n
\n
Click demo to explore an\n\texample Scalene profile.\n
\n
\n
\n
\n AI optimization options
\n\n \n \n \n \n
\n\n
\n\n \n \n
\n
\n \n \n \n
\n
▶ Advanced options
\n
\n
\n
\n
\n \n \n
\n
▶ Advanced options
\n
\n
\n
\n
\n \n \n \n
\n
▶ Advanced options
\n
\n
\n
\n \n \n
\n
\n
\n \n \n
\n
\n \n \n
\n
\n
\n
\n \n \n
\n
\n \n \n
\n
▶ Advanced options
\n
\n
\n
\n Run AI locally with
Ollama.\n
\n
\n \n \n :\n \n
\n
\n Server not found. Run: ollama pull codellama\n
\n
\n
\n Click 💥 for region optimizations or ⚡ for line optimizations.
\n Note: AI-generated suggestions may not always be correct.\n
\n\n \n
\n
\n {% if standalone %}\n \n {% else %}\n \n {% endif %}\n \n \n \n\n"
},
{
"path": "scalene/scalene-gui/list-amazon-models.py",
"content": "import boto3\n\nclient = boto3.client(\"bedrock\")\nresponse = client.list_foundation_models()\nfor model_summary in response[\"modelSummaries\"]:\n print(\n f\"Model ID: {model_summary['modelId']}, Provider: {model_summary['providerName']}\"\n )\n"
},
{
"path": "scalene/scalene-gui/ollama.ts",
"content": "interface OllamaModel {\n name: string;\n}\n\ninterface OllamaTagsResponse {\n models: OllamaModel[];\n}\n\ninterface OllamaMessage {\n content?: string;\n}\n\ninterface OllamaResponse {\n message?: OllamaMessage;\n done?: boolean;\n}\n\nexport async function fetchModelNames(\n local_ip: string,\n local_port: string,\n revealInstallMessage: () => void\n): Promise {\n try {\n const response = await fetch(`http://${local_ip}:${local_port}/api/tags`);\n if (!response.ok) {\n throw new Error(`HTTP error! status: ${response.status}`);\n }\n const data: OllamaTagsResponse = await response.json();\n\n // Extracting the model names\n const modelNames = data.models.map((model) => model.name);\n if (modelNames.length === 0) {\n revealInstallMessage();\n }\n return modelNames;\n } catch (error) {\n console.error(\"Error fetching model names:\", error);\n revealInstallMessage();\n return [];\n }\n}\n\nexport async function sendPromptToOllama(\n prompt: string,\n model: string,\n ipAddr: string,\n portNum: string\n): Promise {\n const url = `http://${ipAddr}:${portNum}/api/chat`;\n const headers = { \"Content-Type\": \"application/json\" };\n const body = JSON.stringify({\n model: model,\n messages: [\n {\n role: \"system\",\n content:\n \"You are an expert code assistant who only responds in Python code.\",\n },\n {\n role: \"user\",\n content: prompt,\n },\n ],\n stream: false,\n temperature: 0.3,\n frequency_penalty: 0,\n presence_penalty: 0,\n user: \"scalene-user\",\n });\n\n console.log(body);\n\n let done = false;\n let responseAggregated = \"\";\n let retried = 0;\n const retries = 3;\n\n while (!done) {\n if (retried >= retries) {\n return \"\";\n }\n\n try {\n const response = await fetch(url, {\n method: \"POST\",\n headers: headers,\n body: body,\n });\n\n if (!response.ok) {\n throw new Error(`HTTP error! status: ${response.status}`);\n }\n\n const text = await response.text();\n const responses = text.split(\"\\n\");\n for (const resp of responses) {\n if (!resp.trim()) continue;\n const responseJson: OllamaResponse = JSON.parse(resp);\n if (responseJson.message && responseJson.message.content) {\n responseAggregated += responseJson.message.content;\n }\n\n if (responseJson.done) {\n done = true;\n break;\n }\n }\n } catch (error) {\n console.log(`Error: ${error}`);\n retried++;\n }\n }\n\n console.log(responseAggregated);\n try {\n return responseAggregated;\n } catch {\n return \"# Query failed. See JavaScript console (in Chrome: View > Developer > JavaScript Console) for more info.\\n\";\n }\n}\n"
},
{
"path": "scalene/scalene-gui/openai.ts",
"content": "interface OpenAIErrorResponse {\n error?: {\n code?: string;\n message?: string;\n };\n}\n\ninterface OpenAIChoice {\n message: {\n content: string;\n };\n}\n\ninterface OpenAIResponse extends OpenAIErrorResponse {\n choices?: OpenAIChoice[];\n}\n\ninterface OpenAIModel {\n id: string;\n owned_by: string;\n}\n\ninterface OpenAIModelsResponse extends OpenAIErrorResponse {\n data?: OpenAIModel[];\n}\n\nasync function tryApi(apiKey: string): Promise {\n const response = await fetch(\"https://api.openai.com/v1/completions\", {\n method: \"GET\",\n headers: {\n \"Content-Type\": \"application/json\",\n Authorization: `Bearer ${apiKey}`,\n },\n });\n return response;\n}\n\nexport async function isValidApiKey(apiKey: string): Promise {\n const response = await tryApi(apiKey);\n const data: OpenAIErrorResponse = await response.json();\n if (\n data.error &&\n data.error.code &&\n data.error.code in {\n invalid_api_key: true,\n invalid_request_error: true,\n model_not_found: true,\n insufficient_quota: true,\n }\n ) {\n return false;\n } else {\n return true;\n }\n}\n\n// Fetch available models from OpenAI API\nexport async function fetchOpenAIModels(apiKey: string): Promise {\n if (!apiKey) return [];\n\n // Check for custom URL\n const customUrlElement = document.getElementById(\"openai-custom-url\") as HTMLInputElement | null;\n const customUrl = customUrlElement?.value?.trim() || \"\";\n const baseUrl = customUrl || \"https://api.openai.com/v1\";\n const endpoint = `${baseUrl}/models`;\n\n try {\n const response = await fetch(endpoint, {\n method: \"GET\",\n headers: {\n Authorization: `Bearer ${apiKey}`,\n },\n });\n\n const data: OpenAIModelsResponse = await response.json();\n if (data.error || !data.data) {\n console.error(\"Failed to fetch OpenAI models:\", data.error);\n return [];\n }\n\n // Filter for chat models and sort alphabetically\n const chatModels = data.data\n .map((m) => m.id)\n .filter((id) =>\n id.includes(\"gpt\") ||\n id.includes(\"o1\") ||\n id.includes(\"o3\") ||\n id.includes(\"o4\")\n )\n .filter((id) => !id.includes(\"instruct\") && !id.includes(\"realtime\") && !id.includes(\"audio\"))\n .sort();\n\n return chatModels;\n } catch (error) {\n console.error(\"Error fetching OpenAI models:\", error);\n return [];\n }\n}\n\nexport function checkApiKey(apiKey: string): void {\n (async () => {\n try {\n window.localStorage.setItem(\"scalene-api-key\", apiKey);\n } catch {\n // Do nothing if key not found\n }\n // If the API key is empty, clear the status indicator.\n if (apiKey.length === 0) {\n const validKeyElement = document.getElementById(\"valid-api-key\");\n if (validKeyElement) {\n validKeyElement.innerHTML = \"\";\n }\n return;\n }\n // Skip validation if using a custom URL (OpenAI-compatible servers may not have the same validation endpoint)\n const customUrlElement = document.getElementById(\"openai-custom-url\") as HTMLInputElement | null;\n const customUrl = customUrlElement?.value?.trim() || \"\";\n if (customUrl) {\n const validKeyElement = document.getElementById(\"valid-api-key\");\n if (validKeyElement) {\n validKeyElement.innerHTML = \"\"; // Don't show validation for custom endpoints\n }\n return;\n }\n const isValid = await isValidApiKey(apiKey);\n const validKeyElement = document.getElementById(\"valid-api-key\");\n if (validKeyElement) {\n if (!isValid) {\n validKeyElement.innerHTML = \"✕\";\n } else {\n validKeyElement.innerHTML = \"✓\";\n }\n }\n })();\n}\n\nexport async function sendPromptToOpenAI(\n prompt: string,\n apiKey: string\n): Promise {\n // Check for custom URL override (for OpenAI-compatible servers like vLLM, Cohere)\n const customUrlElement = document.getElementById(\"openai-custom-url\") as HTMLInputElement | null;\n const customUrl = customUrlElement?.value?.trim() || \"\";\n const endpoint = customUrl || \"https://api.openai.com/v1/chat/completions\";\n\n // Check for custom model override\n const customModelElement = document.getElementById(\"openai-custom-model\") as HTMLInputElement | null;\n const customModel = customModelElement?.value?.trim() || \"\";\n const modelElement = document.getElementById(\"language-model-openai\") as HTMLSelectElement | null;\n const model = customModel || modelElement?.value || \"gpt-4\";\n\n const body = JSON.stringify({\n model: model,\n messages: [\n {\n role: \"system\",\n content:\n \"You are a Python programming assistant who ONLY responds with blocks of commented, optimized code. You never respond with text. Just code, starting with ``` and ending with ```.\",\n },\n {\n role: \"user\",\n content: prompt,\n },\n ],\n user: \"scalene-user\",\n });\n\n console.log(body);\n\n const response = await fetch(endpoint, {\n method: \"POST\",\n headers: {\n \"Content-Type\": \"application/json\",\n Authorization: `Bearer ${apiKey}`,\n },\n body: body,\n });\n\n const data: OpenAIResponse = await response.json();\n if (data.error) {\n if (\n data.error.code &&\n data.error.code in {\n invalid_request_error: true,\n model_not_found: true,\n insufficient_quota: true,\n }\n ) {\n if (data.error.code === \"model_not_found\" && model === \"gpt-4\") {\n // Technically, model_not_found applies only for GPT-4.0\n // if an account has not been funded with at least $1.\n alert(\n \"You either need to add funds to your OpenAI account to use this feature, or you need to switch to GPT-3.5 if you are using free credits.\"\n );\n } else {\n alert(\n \"You need to add funds to your OpenAI account to use this feature.\"\n );\n }\n return \"\";\n }\n }\n try {\n if (data.choices && data.choices[0]) {\n console.log(\n `Debugging info: Retrieved ${JSON.stringify(data.choices[0], null, 4)}`\n );\n }\n } catch {\n console.log(\n `Debugging info: Failed to retrieve data.choices from the server. data = ${JSON.stringify(data)}`\n );\n }\n\n try {\n if (data.choices && data.choices[0]) {\n return data.choices[0].message.content.replace(/^\\s*[\\r\\n]/gm, \"\");\n }\n return \"# Query failed. See JavaScript console (in Chrome: View > Developer > JavaScript Console) for more info.\\n\";\n } catch {\n return \"# Query failed. See JavaScript console (in Chrome: View > Developer > JavaScript Console) for more info.\\n\";\n }\n}\n"
},
{
"path": "scalene/scalene-gui/optimizations.ts",
"content": "import { sendPromptToOpenAI, isValidApiKey } from \"./openai\";\nimport { sendPromptToAnthropic } from \"./anthropic\";\nimport { sendPromptToGemini } from \"./gemini\";\nimport { sendPromptToOllama } from \"./ollama\";\nimport { sendPromptToAmazon } from \"./amazon\";\nimport { sendPromptToAzureOpenAI } from \"./azure\";\nimport { countSpaces } from \"./utils\";\nimport { WhiteLightning, WhiteExplosion } from \"./gui-elements\";\n\ndeclare const Prism: {\n highlight: (code: string, grammar: unknown, language: string) => string;\n languages: { python: unknown };\n};\n\ndeclare const globalThis: {\n profile: {\n gpu: boolean;\n files: Record;\n };\n};\n\ninterface LineData {\n lineno: number;\n line: string;\n n_cpu_percent_python: number;\n n_cpu_percent_c: number;\n n_sys_percent: number;\n n_core_utilization: number;\n n_peak_mb: number;\n n_python_fraction: number;\n n_copy_mb_s: number;\n n_copy_mb: number;\n n_gpu_percent: number;\n start_region_line: number;\n end_region_line: number;\n}\n\ninterface OptimizationParams {\n regions: boolean;\n}\n\nasync function copyOnClick(event: Event, message: string): Promise {\n event.preventDefault();\n event.stopPropagation();\n await navigator.clipboard.writeText(message);\n}\n\nfunction extractCode(text: string): string {\n /**\n * Extracts code block from the given completion text.\n *\n * @param {string} text - A string containing text and other data.\n * @returns {string} Extracted code block from the completion object.\n */\n if (!text) {\n return text;\n }\n const lines = text.split(\"\\n\");\n let i = 0;\n while (i < lines.length && lines[i].trim() === \"\") {\n i++;\n }\n const first_line = lines[i].trim();\n let code_block: string;\n if (first_line === \"```\") {\n code_block = text.slice(3);\n } else if (first_line.startsWith(\"```\")) {\n const word = first_line.slice(3).trim();\n if (word.length > 0 && !word.includes(\" \")) {\n code_block = text.slice(first_line.length);\n } else {\n code_block = text;\n }\n } else {\n code_block = text;\n }\n const end_index = code_block.indexOf(\"```\");\n if (end_index !== -1) {\n code_block = code_block.slice(0, end_index);\n }\n return code_block;\n}\n\nfunction generateScaleneOptimizedCodeRequest(\n context: string,\n sourceCode: string,\n line: LineData,\n recommendedLibraries: string[] = [],\n includeGpuOptimizations = false,\n GPUdeviceName = \"GPU\"\n): string {\n // Default high-performance libraries known for their efficiency\n const defaultLibraries = [\n \"NumPy\",\n \"Scikit-learn\",\n \"Pandas\",\n \"TensorFlow\",\n \"PyTorch\",\n ];\n const highPerformanceLibraries = [\n ...new Set([...defaultLibraries, ...recommendedLibraries]),\n ];\n\n const promptParts: string[] = [\n \"Optimize the following Python code to make it more efficient WITHOUT CHANGING ITS RESULTS.\\n\\n\",\n context.trim(),\n \"\\n# Start of code\\n\",\n sourceCode.trim(),\n \"\\n# End of code\\n\\n\",\n \"Rewrite the above Python code from 'Start of code' to 'End of code', aiming for clear and simple optimizations. \",\n \"Your output should consist only of valid Python code, with brief explanatory comments prefaced with #. \",\n \"Include a detailed explanatory comment before the code, starting with '# Proposed optimization:'. \",\n `Leverage high-performance native libraries, especially those utilizing ${GPUdeviceName}, for significant performance improvements. `,\n \"Consider using the following other libraries, if appropriate:\\n\",\n highPerformanceLibraries.map((e) => \" import \" + e).join(\"\\n\") + \"\\n\",\n \"Eliminate as many for loops, while loops, and list or dict comprehensions as possible, replacing them with vectorized equivalents. \",\n \"Quantify the expected speedup in terms of orders of magnitude if possible. \",\n \"Fix any errors in the optimized code. \",\n ];\n\n // Conditional inclusion of GPU optimizations\n if (includeGpuOptimizations) {\n promptParts.push(\n `Use ${GPUdeviceName}-accelerated libraries whenever it would substantially increase performance. `\n );\n }\n\n // Performance Insights\n promptParts.push(\n \"Consider the following insights gathered from the Scalene profiler for optimization:\\n\"\n );\n const total_cpu_percent =\n line.n_cpu_percent_python + line.n_cpu_percent_c + line.n_sys_percent;\n\n promptParts.push(\n `- CPU time: percent spent in the Python interpreter: ${((100 * line.n_cpu_percent_python) / total_cpu_percent).toFixed(2)}%\\n`\n );\n promptParts.push(\n `- CPU time: percent spent executing native code: ${((100 * line.n_cpu_percent_c) / total_cpu_percent).toFixed(2)}%\\n`\n );\n promptParts.push(\n `- CPU time: percent of system time: ${((100 * line.n_sys_percent) / total_cpu_percent).toFixed(2)}%\\n`\n );\n promptParts.push(\n `- Core utilization: ${((100 * line.n_core_utilization) / total_cpu_percent).toFixed(2)}%\\n`\n );\n promptParts.push(\n `- Peak memory usage: ${line.n_peak_mb.toFixed(0)}MB (${(100 * line.n_python_fraction).toFixed(2)}% Python memory)\\n`\n );\n if (line.n_copy_mb_s > 1) {\n promptParts.push(\n `- Megabytes copied per second by memcpy/strcpy: ${line.n_copy_mb_s.toFixed(2)}\\n`\n );\n }\n if (includeGpuOptimizations) {\n promptParts.push(\n `- GPU percent utilization: ${(100 * line.n_gpu_percent).toFixed(2)}%\\n`\n );\n }\n promptParts.push(`Optimized code:`);\n return promptParts.join(\"\");\n}\n\nfunction extractPythonCodeBlock(markdown: string): string {\n // Pattern to match code blocks optionally tagged with \"python\"\n const pattern = /```python\\s*([\\s\\S]*?)```|```([\\s\\S]*?)```/g;\n\n let match: RegExpExecArray | null;\n let extractedCode = \"\";\n // Use a loop to find all matches\n while ((match = pattern.exec(markdown)) !== null) {\n // Check which group matched. Group 1 is for explicitly tagged Python code, group 2 for any code block\n const codeBlock = match[1] ? match[1] : match[2];\n // Concatenate the extracted code blocks, separated by new lines if there's more than one block\n if (extractedCode && codeBlock) extractedCode += \"\\n\\n\";\n extractedCode += codeBlock;\n }\n\n return extractedCode;\n}\n\nexport async function optimizeCode(\n imports: string,\n code: string,\n line: LineData,\n context: string\n): Promise {\n // Tailor prompt to request GPU optimizations or not.\n const useGPUCheckbox = document.getElementById(\"use-gpu-checkbox\") as HTMLInputElement | null;\n const useGPUs = useGPUCheckbox?.checked ?? false;\n\n const recommendedLibraries: string[] = [\"sklearn\"];\n if (useGPUs) {\n // Suggest cupy if we are using the GPU.\n recommendedLibraries.push(\"cupy\");\n } else {\n // Suggest numpy otherwise.\n recommendedLibraries.push(\"numpy\");\n }\n\n const acceleratorNameElement = document.getElementById(\"accelerator-name\");\n const GPUdeviceName = acceleratorNameElement?.innerHTML || \"GPU\";\n\n const bigPrompt = generateScaleneOptimizedCodeRequest(\n context,\n code,\n line,\n recommendedLibraries,\n useGPUs,\n GPUdeviceName\n );\n\n const useGPUstring = useGPUs ? ` or ${GPUdeviceName}-optimizations ` : \" \";\n\n // Check for a valid API key.\n let apiKey = \"\";\n const serviceSelect = document.getElementById(\"service-select\") as HTMLSelectElement | null;\n const aiService = serviceSelect?.value ?? \"\";\n\n if (aiService === \"openai\") {\n const apiKeyElement = document.getElementById(\"api-key\") as HTMLInputElement | null;\n apiKey = apiKeyElement?.value ?? \"\";\n } else if (aiService === \"anthropic\") {\n const anthropicApiKeyElement = document.getElementById(\"anthropic-api-key\") as HTMLInputElement | null;\n apiKey = anthropicApiKeyElement?.value ?? \"\";\n } else if (aiService === \"gemini\") {\n const geminiApiKeyElement = document.getElementById(\"gemini-api-key\") as HTMLInputElement | null;\n apiKey = geminiApiKeyElement?.value ?? \"\";\n } else if (aiService === \"azure-openai\") {\n const azureApiKeyElement = document.getElementById(\"azure-api-key\") as HTMLInputElement | null;\n apiKey = azureApiKeyElement?.value ?? \"\";\n }\n\n if ((aiService === \"openai\" || aiService === \"azure-openai\") && !apiKey) {\n alert(\n \"To activate proposed optimizations, enter an OpenAI API key in AI optimization options.\"\n );\n const aiOptOptions = document.getElementById(\"ai-optimization-options\") as HTMLDetailsElement | null;\n if (aiOptOptions) {\n aiOptOptions.open = true;\n }\n return \"\";\n }\n\n if (aiService === \"anthropic\" && !apiKey) {\n alert(\n \"To activate proposed optimizations, enter an Anthropic API key in AI optimization options.\"\n );\n const aiOptOptions = document.getElementById(\"ai-optimization-options\") as HTMLDetailsElement | null;\n if (aiOptOptions) {\n aiOptOptions.open = true;\n }\n return \"\";\n }\n\n if (aiService === \"gemini\" && !apiKey) {\n alert(\n \"To activate proposed optimizations, enter a Google Gemini API key in AI optimization options.\"\n );\n const aiOptOptions = document.getElementById(\"ai-optimization-options\") as HTMLDetailsElement | null;\n if (aiOptOptions) {\n aiOptOptions.open = true;\n }\n return \"\";\n }\n\n // If the code to be optimized is just one line of code, say so.\n let lineOf = \" \";\n if (code.split(\"\\n\").length <= 2) {\n lineOf = \" line of \";\n }\n\n let libraries = \"import sklearn\";\n if (useGPUs) {\n // Suggest cupy if we are using the GPU.\n libraries += \"\\nimport cupy\";\n } else {\n // Suggest numpy otherwise.\n libraries += \"\\nimport numpy as np\";\n }\n\n // Construct the prompt.\n const optimizePerformancePrompt = `Optimize the following${lineOf}Python code:\\n\\n${context}\\n\\n# Start of code\\n\\n${code}\\n\\n# End of code\\n\\nRewrite the above Python code only from \"Start of code\" to \"End of code\", to make it more efficient WITHOUT CHANGING ITS RESULTS. Assume the code has already executed all these imports; do NOT include them in the optimized code:\\n\\n${imports}\\n\\nUse native libraries if that would make it faster than pure Python. Consider using the following other libraries, if appropriate:\\n\\n${libraries}\\n\\nYour output should only consist of valid Python code. Output the resulting Python with brief explanations only included as comments prefaced with #. Include a detailed explanatory comment before the code, starting with the text \"# Proposed optimization:\". Make the code as clear and simple as possible, while also making it as fast and memory-efficient as possible. Use vectorized operations${useGPUstring}whenever it would substantially increase performance, and quantify the speedup in terms of orders of magnitude. Eliminate as many for loops, while loops, and list or dict comprehensions as possible, replacing them with vectorized equivalents. If the performance is not likely to increase, leave the code unchanged. Fix any errors in the optimized code. Optimized${lineOf}code:`;\n\n const memoryEfficiencyPrompt = `Optimize the following${lineOf} Python code:\\n\\n${context}\\n\\n# Start of code\\n\\n${code}\\n\\n\\n# End of code\\n\\nRewrite the above Python code only from \"Start of code\" to \"End of code\", to make it more memory-efficient WITHOUT CHANGING ITS RESULTS. Assume the code has already executed all these imports; do NOT include them in the optimized code:\\n\\n${imports}\\n\\nUse native libraries if that would make it more space efficient than pure Python. Consider using the following other libraries, if appropriate:\\n\\n${libraries}\\n\\nYour output should only consist of valid Python code. Output the resulting Python with brief explanations only included as comments prefaced with #. Include a detailed explanatory comment before the code, starting with the text \"# Proposed optimization:\". Make the code as clear and simple as possible, while also making it as fast and memory-efficient as possible. Use native libraries whenever possible to reduce memory consumption; invoke del on variables and array elements as soon as it is safe to do so. If the memory consumption is not likely to be reduced, leave the code unchanged. Fix any errors in the optimized code. Optimized${lineOf}code:`;\n\n const optimizePerfCheckbox = document.getElementById(\"optimize-performance\") as HTMLInputElement | null;\n const optimizePerf = optimizePerfCheckbox?.checked ?? true;\n\n let prompt: string;\n if (optimizePerf) {\n prompt = optimizePerformancePrompt;\n } else {\n prompt = memoryEfficiencyPrompt;\n }\n\n // Just use big prompt maybe FIXME\n prompt = bigPrompt;\n\n switch (aiService) {\n case \"openai\": {\n console.log(prompt);\n const result = await sendPromptToOpenAI(prompt, apiKey);\n return extractCode(result);\n }\n case \"anthropic\": {\n console.log(\"Running \" + aiService);\n console.log(prompt);\n const result = await sendPromptToAnthropic(prompt, apiKey);\n return extractCode(result);\n }\n case \"gemini\": {\n console.log(\"Running \" + aiService);\n console.log(prompt);\n const result = await sendPromptToGemini(prompt, apiKey);\n return extractCode(result);\n }\n case \"local\": {\n console.log(\"Running \" + aiService);\n console.log(prompt);\n const modelElement = document.getElementById(\"language-model-local\") as HTMLSelectElement | null;\n const ipElement = document.getElementById(\"local-ip\") as HTMLInputElement | null;\n const portElement = document.getElementById(\"local-port\") as HTMLInputElement | null;\n\n const result = await sendPromptToOllama(\n prompt,\n modelElement?.value ?? \"\",\n ipElement?.value ?? \"\",\n portElement?.value ?? \"\"\n );\n if (result.includes(\"```\")) {\n return extractPythonCodeBlock(result);\n } else {\n return result;\n }\n }\n case \"amazon\": {\n console.log(\"Running \" + aiService);\n console.log(prompt);\n const result = await sendPromptToAmazon(prompt);\n return extractCode(result);\n }\n case \"azure-openai\": {\n console.log(\"Running \" + aiService);\n console.log(prompt);\n const azureUrlElement = document.getElementById(\"azure-api-url\") as HTMLInputElement | null;\n const azureCustomModelElement = document.getElementById(\"azure-custom-model\") as HTMLInputElement | null;\n const azureModelSelectElement = document.getElementById(\"language-model-azure\") as HTMLSelectElement | null;\n\n const azureOpenAiEndpoint = azureUrlElement?.value ?? \"\";\n const azureCustomModel = azureCustomModelElement?.value?.trim() || \"\";\n const azureOpenAiModel = azureCustomModel || azureModelSelectElement?.value || \"gpt-5.2\";\n const result = await sendPromptToAzureOpenAI(\n prompt,\n apiKey,\n azureOpenAiEndpoint,\n azureOpenAiModel\n );\n return extractCode(result);\n }\n default:\n return \"\";\n }\n}\n\nexport function proposeOptimization(\n filename: string,\n file_number: number,\n line: LineData,\n params: OptimizationParams\n): void {\n filename = unescape(filename);\n const useRegion = params[\"regions\"];\n const prof = globalThis.profile;\n const this_file = prof.files[filename].lines;\n const imports = prof.files[filename].imports.join(\"\\n\");\n const start_region_line = this_file[line.lineno - 1][\"start_region_line\"];\n const end_region_line = this_file[line.lineno - 1][\"end_region_line\"];\n let context: string;\n const code_line = this_file[line.lineno - 1][\"line\"];\n let code_region: string;\n\n if (useRegion) {\n code_region = this_file\n .slice(start_region_line - 1, end_region_line)\n .map((e: LineData) => e[\"line\"])\n .join(\"\");\n context = this_file\n .slice(\n Math.max(0, start_region_line - 10),\n Math.min(start_region_line - 1, this_file.length)\n )\n .map((e: LineData) => e[\"line\"])\n .join(\"\");\n } else {\n code_region = code_line;\n context = this_file\n .slice(\n Math.max(0, line.lineno - 10),\n Math.min(line.lineno - 1, this_file.length)\n )\n .map((e: LineData) => e[\"line\"])\n .join(\"\");\n }\n\n // Count the number of leading spaces to match indentation level on output\n const leadingSpaceCount = countSpaces(code_line) + 3; // including the lightning bolt and explosion\n const indent =\n WhiteLightning + WhiteExplosion + \" \".repeat(leadingSpaceCount - 1);\n const elt = document.getElementById(`code-${file_number}-${line.lineno}`);\n\n (async () => {\n // TODO: check Amazon credentials\n const serviceSelect = document.getElementById(\"service-select\") as HTMLSelectElement | null;\n const service = serviceSelect?.value ?? \"\";\n\n if (service === \"openai\") {\n const apiKeyElement = document.getElementById(\"api-key\") as HTMLInputElement | null;\n const isValid = await isValidApiKey(apiKeyElement?.value ?? \"\");\n if (!isValid) {\n alert(\n \"You must enter a valid OpenAI API key to activate proposed optimizations.\"\n );\n const aiOptOptions = document.getElementById(\"ai-optimization-options\") as HTMLDetailsElement | null;\n if (aiOptOptions) {\n aiOptOptions.open = true;\n }\n return;\n }\n }\n if (service === \"anthropic\") {\n const apiKeyElement = document.getElementById(\"anthropic-api-key\") as HTMLInputElement | null;\n if (!apiKeyElement?.value) {\n alert(\n \"You must enter an Anthropic API key to activate proposed optimizations.\"\n );\n const aiOptOptions = document.getElementById(\"ai-optimization-options\") as HTMLDetailsElement | null;\n if (aiOptOptions) {\n aiOptOptions.open = true;\n }\n return;\n }\n }\n if (service === \"gemini\") {\n const apiKeyElement = document.getElementById(\"gemini-api-key\") as HTMLInputElement | null;\n if (!apiKeyElement?.value) {\n alert(\n \"You must enter a Google Gemini API key to activate proposed optimizations.\"\n );\n const aiOptOptions = document.getElementById(\"ai-optimization-options\") as HTMLDetailsElement | null;\n if (aiOptOptions) {\n aiOptOptions.open = true;\n }\n return;\n }\n }\n if (service === \"local\") {\n const localModelsList = document.getElementById(\"local-models-list\");\n if (localModelsList?.style.display === \"none\") {\n // No service was found.\n alert(\n \"You must be connected to a running Ollama server to activate proposed optimizations.\"\n );\n const aiOptOptions = document.getElementById(\"ai-optimization-options\") as HTMLDetailsElement | null;\n if (aiOptOptions) {\n aiOptOptions.open = true;\n }\n return;\n }\n }\n\n if (elt) {\n elt.innerHTML = `${indent}working...`;\n }\n\n let message = await optimizeCode(imports, code_region, line, context);\n if (!message) {\n if (elt) {\n elt.innerHTML = \"\";\n }\n return;\n }\n\n // Canonicalize newlines\n message = message.replace(/\\r?\\n/g, \"\\n\");\n\n // Indent every line and format it\n const formattedCode = message\n .split(\"\\n\")\n .map(\n (line) =>\n indent + Prism.highlight(line, Prism.languages.python, \"python\")\n )\n .join(\"
\");\n\n // Display the proposed optimization, with click-to-copy functionality.\n if (elt) {\n elt.innerHTML = `
${formattedCode}`;\n }\n\n const thisElt = document.getElementById(\n `opt-${file_number}-${line.lineno}`\n );\n\n if (thisElt) {\n thisElt.addEventListener(\"click\", async (e) => {\n await copyOnClick(e, message);\n // After copying, briefly change the cursor back to the default to provide some visual feedback..\n (thisElt as HTMLElement).style.cursor = \"auto\";\n await new Promise((resolve) => setTimeout(resolve, 125));\n (thisElt as HTMLElement).style.cursor = \"copy\";\n });\n }\n })();\n}\n"
},
{
"path": "scalene/scalene-gui/package.json",
"content": "{\n \"dependencies\": {\n \"@aws-sdk/client-bedrock\": \"^3.687.0\",\n \"buffer\": \"^6.0.3\",\n \"@aws-sdk/client-bedrock-runtime\": \"^3.687.0\",\n \"@aws-sdk/credential-provider-cognito-identity\": \"^3.687.0\",\n \"@aws-sdk/credential-provider-web-identity\": \"^3.686.0\",\n \"@aws-sdk/protocol-http\": \"^3.374.0\",\n \"@aws-sdk/signature-v4\": \"^3.374.0\",\n \"vega\": \"^5.30.0\",\n \"vega-embed\": \"^6.28.0\",\n \"vega-lite\": \"^5.21.0\"\n },\n \"devDependencies\": {\n \"@types/node\": \"^20.10.0\",\n \"@types/prismjs\": \"^1.26.0\",\n \"esbuild\": \"^0.24.0\",\n \"typescript\": \"^5.3.3\"\n },\n \"scripts\": {\n \"build\": \"esbuild scalene-gui.ts --bundle --minify --sourcemap --target=es2020 --outfile=scalene-gui-bundle.js --define:process.env.LANG='\\\"en_US.UTF-8\\\"'\",\n \"build:dev\": \"esbuild scalene-gui.ts --bundle --sourcemap --target=es2020 --outfile=scalene-gui-bundle.js --define:process.env.LANG='\\\"en_US.UTF-8\\\"'\",\n \"watch\": \"esbuild scalene-gui.ts --bundle --sourcemap --target=es2020 --outfile=scalene-gui-bundle.js --define:process.env.LANG='\\\"en_US.UTF-8\\\"' --watch\",\n \"typecheck\": \"tsc --noEmit\"\n }\n}\n"
},
{
"path": "scalene/scalene-gui/persistence.ts",
"content": "// Declare envApiKeys as a global variable that may be injected by the template\ndeclare const envApiKeys: {\n openai?: string;\n anthropic?: string;\n gemini?: string;\n azure?: string;\n azureUrl?: string;\n awsAccessKey?: string;\n awsSecretKey?: string;\n awsRegion?: string;\n} | undefined;\n\n// Map element IDs to their corresponding environment variable keys\nconst envKeyMap: Record> = {\n \"api-key\": \"openai\",\n \"anthropic-api-key\": \"anthropic\",\n \"gemini-api-key\": \"gemini\",\n \"azure-api-key\": \"azure\",\n \"azure-api-url\": \"azureUrl\",\n \"aws-access-key\": \"awsAccessKey\",\n \"aws-secret-key\": \"awsSecretKey\",\n \"aws-region\": \"awsRegion\",\n};\n\nfunction restoreState(el: HTMLInputElement): void {\n const savedValue = localStorage.getItem(el.id);\n\n if (savedValue !== null) {\n switch (el.type) {\n case \"checkbox\":\n case \"radio\":\n el.checked = savedValue === \"true\";\n break;\n default:\n el.value = savedValue;\n break;\n }\n } else {\n // If no localStorage value, check for environment variable fallback\n const envKey = envKeyMap[el.id];\n if (envKey && typeof envApiKeys !== \"undefined\" && envApiKeys[envKey]) {\n el.value = envApiKeys[envKey] as string;\n }\n }\n}\n\nfunction saveState(el: HTMLInputElement): void {\n el.addEventListener(\"change\", () => {\n switch (el.type) {\n case \"checkbox\":\n case \"radio\":\n localStorage.setItem(el.id, String(el.checked));\n break;\n default:\n localStorage.setItem(el.id, el.value);\n break;\n }\n });\n}\n\n// Process all DOM elements in the class 'persistent', which saves their state in localStorage and restores them on load.\nexport function processPersistentElements(): void {\n const persistentElements = document.querySelectorAll(\".persistent\");\n\n // Restore state\n persistentElements.forEach((el) => {\n restoreState(el);\n });\n\n // Save state\n persistentElements.forEach((el) => {\n saveState(el);\n });\n}\n\n// Handle updating persistence when the DOM is updated.\nexport const observeDOM = (): void => {\n const observer = new MutationObserver((mutations) => {\n mutations.forEach((mutation) => {\n if (mutation.addedNodes) {\n mutation.addedNodes.forEach((node) => {\n if (node.nodeType === 1) {\n const element = node as Element;\n if (element.matches && element.matches(\".persistent\")) {\n const inputElement = element as HTMLInputElement;\n restoreState(inputElement);\n inputElement.addEventListener(\"change\", () => saveState(inputElement));\n }\n }\n });\n }\n });\n });\n\n observer.observe(document.body, {\n childList: true,\n subtree: true,\n });\n};\n"
},
{
"path": "scalene/scalene-gui/prism.css",
"content": "/* PrismJS 1.26.0\nhttps://prismjs.com/download.html#themes=prism&languages=markup+css+clike+javascript+python&plugins=normalize-whitespace */\n/**\n * prism.js default theme for JavaScript, CSS and HTML\n * Based on dabblet (http://dabblet.com)\n * @author Lea Verou\n */\n\ncode[class*=\"language-\"],\npre[class*=\"language-\"] {\n\tcolor: black;\n\tbackground: none;\n\ttext-shadow: 0 1px white;\n\tfont-family: Consolas, Monaco, 'Andale Mono', 'Ubuntu Mono', monospace;\n\tfont-size: 1em;\n\ttext-align: left;\n\twhite-space: pre;\n\tword-spacing: normal;\n\tword-break: normal;\n\tword-wrap: normal;\n\tline-height: 1.5;\n\n\t-moz-tab-size: 4;\n\t-o-tab-size: 4;\n\ttab-size: 4;\n\n\t-webkit-hyphens: none;\n\t-moz-hyphens: none;\n\t-ms-hyphens: none;\n\thyphens: none;\n}\n\npre[class*=\"language-\"]::-moz-selection, pre[class*=\"language-\"] ::-moz-selection,\ncode[class*=\"language-\"]::-moz-selection, code[class*=\"language-\"] ::-moz-selection {\n\ttext-shadow: none;\n\tbackground: #b3d4fc;\n}\n\npre[class*=\"language-\"]::selection, pre[class*=\"language-\"] ::selection,\ncode[class*=\"language-\"]::selection, code[class*=\"language-\"] ::selection {\n\ttext-shadow: none;\n\tbackground: #b3d4fc;\n}\n\n@media print {\n\tcode[class*=\"language-\"],\n\tpre[class*=\"language-\"] {\n\t\ttext-shadow: none;\n\t}\n}\n\n/* Code blocks */\npre[class*=\"language-\"] {\n\tpadding: 1em;\n\tmargin: .5em 0;\n\toverflow: auto;\n}\n\n:not(pre) > code[class*=\"language-\"],\npre[class*=\"language-\"] {\n\tbackground: #f5f2f0;\n}\n\n/* Inline code */\n:not(pre) > code[class*=\"language-\"] {\n\tpadding: .1em;\n\tborder-radius: .3em;\n\twhite-space: normal;\n}\n\n.token.comment,\n.token.prolog,\n.token.doctype,\n.token.cdata {\n\tcolor: slategray;\n}\n\n.token.punctuation {\n\tcolor: #999;\n}\n\n.token.namespace {\n\topacity: .7;\n}\n\n.token.property,\n.token.tag,\n.token.boolean,\n.token.number,\n.token.constant,\n.token.symbol,\n.token.deleted {\n\tcolor: #905;\n}\n\n.token.selector,\n.token.attr-name,\n.token.string,\n.token.char,\n.token.builtin,\n.token.inserted {\n\tcolor: #690;\n}\n\n.token.operator,\n.token.entity,\n.token.url,\n.language-css .token.string,\n.style .token.string {\n\tcolor: #9a6e3a;\n\t/* This background color was intended by the author of this theme. */\n\tbackground: hsla(0, 0%, 100%, .5);\n}\n\n.token.atrule,\n.token.attr-value,\n.token.keyword {\n\tcolor: #07a;\n}\n\n.token.function,\n.token.class-name {\n\tcolor: #DD4A68;\n}\n\n.token.regex,\n.token.important,\n.token.variable {\n\tcolor: #e90;\n}\n\n.token.important,\n.token.bold {\n\tfont-weight: bold;\n}\n.token.italic {\n\tfont-style: italic;\n}\n\n.token.entity {\n\tcursor: help;\n}\n\n"
},
{
"path": "scalene/scalene-gui/prism.d.ts",
"content": "// Type declarations for prism.js\nexport const Prism: {\n highlight: (code: string, grammar: unknown, language: string) => string;\n languages: {\n python: unknown;\n [key: string]: unknown;\n };\n};\n\nexport default Prism;\n"
},
{
"path": "scalene/scalene-gui/prism.js",
"content": "/* PrismJS 1.26.0\nhttps://prismjs.com/download.html#themes=prism&languages=markup+css+clike+javascript+python&plugins=normalize-whitespace */\n/// \n\nvar _self =\n typeof window !== \"undefined\"\n ? window // if in browser\n : typeof WorkerGlobalScope !== \"undefined\" &&\n self instanceof WorkerGlobalScope\n ? self // if in worker\n : {}; // if in node js\n\n/**\n * Prism: Lightweight, robust, elegant syntax highlighting\n *\n * @license MIT \n * @author Lea Verou \n * @namespace\n * @public\n */\nexport var Prism = (function (_self) {\n // Private helper vars\n var lang = /(?:^|\\s)lang(?:uage)?-([\\w-]+)(?=\\s|$)/i;\n var uniqueId = 0;\n\n // The grammar object for plaintext\n var plainTextGrammar = {};\n\n var _ = {\n /**\n * By default, Prism will attempt to highlight all code elements (by calling {@link Prism.highlightAll}) on the\n * current page after the page finished loading. This might be a problem if e.g. you wanted to asynchronously load\n * additional languages or plugins yourself.\n *\n * By setting this value to `true`, Prism will not automatically highlight all code elements on the page.\n *\n * You obviously have to change this value before the automatic highlighting started. To do this, you can add an\n * empty Prism object into the global scope before loading the Prism script like this:\n *\n * ```js\n * window.Prism = window.Prism || {};\n * Prism.manual = true;\n * // add a new \n \n \n \n \n \n \n \n \n\n \n \n \n \n \n \n \n \n \n \n \n\t\n
\n \n \n \n
\n \n \n \n \n\nYou can click as many times as you like on the lightning bolt or explosion, and it will generate different suggested optimizations. Your mileage may vary, but in some cases, the suggestions are quite impressive (e.g., order-of-magnitude improvements). \n \n### Quick Start\n\n#### Installing Scalene:\n\n```console\npython3 -m pip install -U scalene\n```\n\nor\n\n```console\nconda install -c conda-forge scalene\n```\n\n#### Using Scalene:\n\nAfter installing Scalene, you can use Scalene at the command line, or as a Visual Studio Code extension.\n\n
\n\nYou can click as many times as you like on the lightning bolt or explosion, and it will generate different suggested optimizations. Your mileage may vary, but in some cases, the suggestions are quite impressive (e.g., order-of-magnitude improvements). \n \n### Quick Start\n\n#### Installing Scalene:\n\n```console\npython3 -m pip install -U scalene\n```\n\nor\n\n```console\nconda install -c conda-forge scalene\n```\n\n#### Using Scalene:\n\nAfter installing Scalene, you can use Scalene at the command line, or as a Visual Studio Code extension.\n\n \n\n
\n\n