 \n\n
\n\n \n\n\n
\n\n\n \n\n\n
\n\n\n \n\n\n \n\n\n## Companion Book / Sequel\n\n[*Build A Reasoning Model (From Scratch)*](https://mng.bz/lZ5B), while a standalone book, can be considered as a sequel to *Build A Large Language Model (From Scratch)*.\n\nIt starts with a pretrained model and implements different reasoning approaches, including inference-time scaling, reinforcement learning, and distillation, to improve the model's reasoning capabilities.\n\nSimilar to *Build A Large Language Model (From Scratch)*, [*Build A Reasoning Model (From Scratch)*](https://mng.bz/lZ5B) takes a hands-on approach implementing these methods from scratch.\n\n
\n\n\n \n\n\n## Companion Book / Sequel\n\n[*Build A Reasoning Model (From Scratch)*](https://mng.bz/lZ5B), while a standalone book, can be considered as a sequel to *Build A Large Language Model (From Scratch)*.\n\nIt starts with a pretrained model and implements different reasoning approaches, including inference-time scaling, reinforcement learning, and distillation, to improve the model's reasoning capabilities.\n\nSimilar to *Build A Large Language Model (From Scratch)*, [*Build A Reasoning Model (From Scratch)*](https://mng.bz/lZ5B) takes a hands-on approach implementing these methods from scratch.\n\n \n\n- Amazon link (TBD)\n- [Manning link](https://mng.bz/lZ5B)\n- [GitHub repository](https://github.com/rasbt/reasoning-from-scratch)\n\n
\n\n- Amazon link (TBD)\n- [Manning link](https://mng.bz/lZ5B)\n- [GitHub repository](https://github.com/rasbt/reasoning-from-scratch)\n\n \n\n \n## Bonus Material\n\nSeveral folders contain optional materials as a bonus for interested readers:\n- **Setup**\n - [Python Setup Tips](setup/01_optional-python-setup-preferences)\n - [Installing Python Packages and Libraries Used in This Book](setup/02_installing-python-libraries)\n - [Docker Environment Setup Guide](setup/03_optional-docker-environment)\n\n- **Chapter 2: Working With Text Data**\n - [Byte Pair Encoding (BPE) Tokenizer From Scratch](ch02/05_bpe-from-scratch/bpe-from-scratch-simple.ipynb)\n - [Comparing Various Byte Pair Encoding (BPE) Implementations](ch02/02_bonus_bytepair-encoder)\n - [Understanding the Difference Between Embedding Layers and Linear Layers](ch02/03_bonus_embedding-vs-matmul)\n - [Dataloader Intuition With Simple Numbers](ch02/04_bonus_dataloader-intuition)\n\n- **Chapter 3: Coding Attention Mechanisms**\n - [Comparing Efficient Multi-Head Attention Implementations](ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb)\n - [Understanding PyTorch Buffers](ch03/03_understanding-buffers/understanding-buffers.ipynb)\n\n- **Chapter 4: Implementing a GPT Model From Scratch**\n - [FLOPs Analysis](ch04/02_performance-analysis/flops-analysis.ipynb)\n - [KV Cache](ch04/03_kv-cache)\n - [Attention Alternatives](ch04/#attention-alternatives)\n - [Grouped-Query Attention](ch04/04_gqa)\n - [Multi-Head Latent Attention](ch04/05_mla)\n - [Sliding Window Attention](ch04/06_swa)\n - [Gated DeltaNet](ch04/08_deltanet)\n - [Mixture-of-Experts (MoE)](ch04/07_moe)\n\n- **Chapter 5: Pretraining on Unlabeled Data**\n - [Alternative Weight Loading Methods](ch05/02_alternative_weight_loading/)\n - [Pretraining GPT on the Project Gutenberg Dataset](ch05/03_bonus_pretraining_on_gutenberg)\n - [Adding Bells and Whistles to the Training Loop](ch05/04_learning_rate_schedulers)\n - [Optimizing Hyperparameters for Pretraining](ch05/05_bonus_hparam_tuning)\n - [Building a User Interface to Interact With the Pretrained LLM](ch05/06_user_interface)\n - [Converting GPT to Llama](ch05/07_gpt_to_llama)\n - [Memory-efficient Model Weight Loading](ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb)\n - [Extending the Tiktoken BPE Tokenizer with New Tokens](ch05/09_extending-tokenizers/extend-tiktoken.ipynb)\n - [PyTorch Performance Tips for Faster LLM Training](ch05/10_llm-training-speed)\n - [LLM Architectures](ch05/#llm-architectures-from-scratch)\n - [Llama 3.2 From Scratch](ch05/07_gpt_to_llama/standalone-llama32.ipynb)\n - [Qwen3 Dense and Mixture-of-Experts (MoE) From Scratch](ch05/11_qwen3/)\n - [Gemma 3 From Scratch](ch05/12_gemma3/)\n - [Olmo 3 From Scratch](ch05/13_olmo3/)\n - [Tiny Aya From Scratch](ch05/15_tiny-aya/)\n - [Qwen3.5 From Scratch](ch05/16_qwen3.5/)\n - [Chapter 5 with other LLMs as Drop-In Replacement (e.g., Llama 3, Qwen 3)](ch05/14_ch05_with_other_llms/)\n- **Chapter 6: Finetuning for classification**\n - [Additional Experiments Finetuning Different Layers and Using Larger Models](ch06/02_bonus_additional-experiments)\n - [Finetuning Different Models on the 50k IMDb Movie Review Dataset](ch06/03_bonus_imdb-classification)\n - [Building a User Interface to Interact With the GPT-based Spam Classifier](ch06/04_user_interface)\n- **Chapter 7: Finetuning to follow instructions**\n - [Dataset Utilities for Finding Near Duplicates and Creating Passive Voice Entries](ch07/02_dataset-utilities)\n - [Evaluating Instruction Responses Using the OpenAI API and Ollama](ch07/03_model-evaluation)\n - [Generating a Dataset for Instruction Finetuning](ch07/05_dataset-generation/llama3-ollama.ipynb)\n - [Improving a Dataset for Instruction Finetuning](ch07/05_dataset-generation/reflection-gpt4.ipynb)\n - [Generating a Preference Dataset With Llama 3.1 70B and Ollama](ch07/04_preference-tuning-with-dpo/create-preference-data-ollama.ipynb)\n - [Direct Preference Optimization (DPO) for LLM Alignment](ch07/04_preference-tuning-with-dpo/dpo-from-scratch.ipynb)\n - [Building a User Interface to Interact With the Instruction-Finetuned GPT Model](ch07/06_user_interface)\n\nMore bonus material from the [Reasoning From Scratch](https://github.com/rasbt/reasoning-from-scratch) repository:\n\n- **Qwen3 (From Scratch) Basics**\n - [Qwen3 Source Code Walkthrough](https://github.com/rasbt/reasoning-from-scratch/blob/main/chC/01_main-chapter-code/chC_main.ipynb)\n - [Optimized Qwen3](https://github.com/rasbt/reasoning-from-scratch/tree/main/ch02/03_optimized-LLM)\n\n- **Evaluation**\n - [Verifier-Based Evaluation (MATH-500)](https://github.com/rasbt/reasoning-from-scratch/tree/main/ch03)\n - [Multiple-Choice Evaluation (MMLU)](https://github.com/rasbt/reasoning-from-scratch/blob/main/chF/02_mmlu)\n - [LLM Leaderboard Evaluation](https://github.com/rasbt/reasoning-from-scratch/blob/main/chF/03_leaderboards)\n - [LLM-as-a-Judge Evaluation](https://github.com/rasbt/reasoning-from-scratch/blob/main/chF/04_llm-judge)\n- **Inference Scaling**\n - [Self-Consistency](https://github.com/rasbt/reasoning-from-scratch/blob/main/ch04/01_main-chapter-code/ch04_main.ipynb)\n - [Self-Refinement](https://github.com/rasbt/reasoning-from-scratch/blob/main/ch05/01_main-chapter-code/ch05_main.ipynb)\n\n- **Reinforcement Learning** (RL)\n - [RLVR with GRPO From Scratch](https://github.com/rasbt/reasoning-from-scratch/blob/main/ch06/01_main-chapter-code/ch06_main.ipynb)\n\n\n
\n\n \n## Bonus Material\n\nSeveral folders contain optional materials as a bonus for interested readers:\n- **Setup**\n - [Python Setup Tips](setup/01_optional-python-setup-preferences)\n - [Installing Python Packages and Libraries Used in This Book](setup/02_installing-python-libraries)\n - [Docker Environment Setup Guide](setup/03_optional-docker-environment)\n\n- **Chapter 2: Working With Text Data**\n - [Byte Pair Encoding (BPE) Tokenizer From Scratch](ch02/05_bpe-from-scratch/bpe-from-scratch-simple.ipynb)\n - [Comparing Various Byte Pair Encoding (BPE) Implementations](ch02/02_bonus_bytepair-encoder)\n - [Understanding the Difference Between Embedding Layers and Linear Layers](ch02/03_bonus_embedding-vs-matmul)\n - [Dataloader Intuition With Simple Numbers](ch02/04_bonus_dataloader-intuition)\n\n- **Chapter 3: Coding Attention Mechanisms**\n - [Comparing Efficient Multi-Head Attention Implementations](ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb)\n - [Understanding PyTorch Buffers](ch03/03_understanding-buffers/understanding-buffers.ipynb)\n\n- **Chapter 4: Implementing a GPT Model From Scratch**\n - [FLOPs Analysis](ch04/02_performance-analysis/flops-analysis.ipynb)\n - [KV Cache](ch04/03_kv-cache)\n - [Attention Alternatives](ch04/#attention-alternatives)\n - [Grouped-Query Attention](ch04/04_gqa)\n - [Multi-Head Latent Attention](ch04/05_mla)\n - [Sliding Window Attention](ch04/06_swa)\n - [Gated DeltaNet](ch04/08_deltanet)\n - [Mixture-of-Experts (MoE)](ch04/07_moe)\n\n- **Chapter 5: Pretraining on Unlabeled Data**\n - [Alternative Weight Loading Methods](ch05/02_alternative_weight_loading/)\n - [Pretraining GPT on the Project Gutenberg Dataset](ch05/03_bonus_pretraining_on_gutenberg)\n - [Adding Bells and Whistles to the Training Loop](ch05/04_learning_rate_schedulers)\n - [Optimizing Hyperparameters for Pretraining](ch05/05_bonus_hparam_tuning)\n - [Building a User Interface to Interact With the Pretrained LLM](ch05/06_user_interface)\n - [Converting GPT to Llama](ch05/07_gpt_to_llama)\n - [Memory-efficient Model Weight Loading](ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb)\n - [Extending the Tiktoken BPE Tokenizer with New Tokens](ch05/09_extending-tokenizers/extend-tiktoken.ipynb)\n - [PyTorch Performance Tips for Faster LLM Training](ch05/10_llm-training-speed)\n - [LLM Architectures](ch05/#llm-architectures-from-scratch)\n - [Llama 3.2 From Scratch](ch05/07_gpt_to_llama/standalone-llama32.ipynb)\n - [Qwen3 Dense and Mixture-of-Experts (MoE) From Scratch](ch05/11_qwen3/)\n - [Gemma 3 From Scratch](ch05/12_gemma3/)\n - [Olmo 3 From Scratch](ch05/13_olmo3/)\n - [Tiny Aya From Scratch](ch05/15_tiny-aya/)\n - [Qwen3.5 From Scratch](ch05/16_qwen3.5/)\n - [Chapter 5 with other LLMs as Drop-In Replacement (e.g., Llama 3, Qwen 3)](ch05/14_ch05_with_other_llms/)\n- **Chapter 6: Finetuning for classification**\n - [Additional Experiments Finetuning Different Layers and Using Larger Models](ch06/02_bonus_additional-experiments)\n - [Finetuning Different Models on the 50k IMDb Movie Review Dataset](ch06/03_bonus_imdb-classification)\n - [Building a User Interface to Interact With the GPT-based Spam Classifier](ch06/04_user_interface)\n- **Chapter 7: Finetuning to follow instructions**\n - [Dataset Utilities for Finding Near Duplicates and Creating Passive Voice Entries](ch07/02_dataset-utilities)\n - [Evaluating Instruction Responses Using the OpenAI API and Ollama](ch07/03_model-evaluation)\n - [Generating a Dataset for Instruction Finetuning](ch07/05_dataset-generation/llama3-ollama.ipynb)\n - [Improving a Dataset for Instruction Finetuning](ch07/05_dataset-generation/reflection-gpt4.ipynb)\n - [Generating a Preference Dataset With Llama 3.1 70B and Ollama](ch07/04_preference-tuning-with-dpo/create-preference-data-ollama.ipynb)\n - [Direct Preference Optimization (DPO) for LLM Alignment](ch07/04_preference-tuning-with-dpo/dpo-from-scratch.ipynb)\n - [Building a User Interface to Interact With the Instruction-Finetuned GPT Model](ch07/06_user_interface)\n\nMore bonus material from the [Reasoning From Scratch](https://github.com/rasbt/reasoning-from-scratch) repository:\n\n- **Qwen3 (From Scratch) Basics**\n - [Qwen3 Source Code Walkthrough](https://github.com/rasbt/reasoning-from-scratch/blob/main/chC/01_main-chapter-code/chC_main.ipynb)\n - [Optimized Qwen3](https://github.com/rasbt/reasoning-from-scratch/tree/main/ch02/03_optimized-LLM)\n\n- **Evaluation**\n - [Verifier-Based Evaluation (MATH-500)](https://github.com/rasbt/reasoning-from-scratch/tree/main/ch03)\n - [Multiple-Choice Evaluation (MMLU)](https://github.com/rasbt/reasoning-from-scratch/blob/main/chF/02_mmlu)\n - [LLM Leaderboard Evaluation](https://github.com/rasbt/reasoning-from-scratch/blob/main/chF/03_leaderboards)\n - [LLM-as-a-Judge Evaluation](https://github.com/rasbt/reasoning-from-scratch/blob/main/chF/04_llm-judge)\n- **Inference Scaling**\n - [Self-Consistency](https://github.com/rasbt/reasoning-from-scratch/blob/main/ch04/01_main-chapter-code/ch04_main.ipynb)\n - [Self-Refinement](https://github.com/rasbt/reasoning-from-scratch/blob/main/ch05/01_main-chapter-code/ch05_main.ipynb)\n\n- **Reinforcement Learning** (RL)\n - [RLVR with GRPO From Scratch](https://github.com/rasbt/reasoning-from-scratch/blob/main/ch06/01_main-chapter-code/ch06_main.ipynb)\n\n\n| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \" \\n\",\n \" \\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1e3c0555-88f6-4515-8c99-aa56b0769d54\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1e3c0555-88f6-4515-8c99-aa56b0769d54\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2100cf2e-7459-4ab3-92a8-43e86ab35a9b\",\n \"metadata\": {},\n \"source\": [\n \"## A.2 Understanding tensors\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3c484e87-bfc9-4105-b0a7-1e23b2a72a30\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2100cf2e-7459-4ab3-92a8-43e86ab35a9b\",\n \"metadata\": {},\n \"source\": [\n \"## A.2 Understanding tensors\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3c484e87-bfc9-4105-b0a7-1e23b2a72a30\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"26d7f785-e048-42bc-9182-a556af6bb7f4\",\n \"metadata\": {},\n \"source\": [\n \"### A.2.1 Scalars, vectors, matrices, and tensors\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"a3a464d6-cec8-4363-87bd-ea4f900baced\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import numpy as np\\n\",\n \"\\n\",\n \"# create a 0D tensor (scalar) from a Python integer\\n\",\n \"tensor0d = torch.tensor(1)\\n\",\n \"\\n\",\n \"# create a 1D tensor (vector) from a Python list\\n\",\n \"tensor1d = torch.tensor([1, 2, 3])\\n\",\n \"\\n\",\n \"# create a 2D tensor from a nested Python list\\n\",\n \"tensor2d = torch.tensor([[1, 2], \\n\",\n \" [3, 4]])\\n\",\n \"\\n\",\n \"# create a 3D tensor from a nested Python list\\n\",\n \"tensor3d_1 = torch.tensor([[[1, 2], [3, 4]], \\n\",\n \" [[5, 6], [7, 8]]])\\n\",\n \"\\n\",\n \"# create a 3D tensor from NumPy array\\n\",\n \"ary3d = np.array([[[1, 2], [3, 4]], \\n\",\n \" [[5, 6], [7, 8]]])\\n\",\n \"tensor3d_2 = torch.tensor(ary3d) # Copies NumPy array\\n\",\n \"tensor3d_3 = torch.from_numpy(ary3d) # Shares memory with NumPy array\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"dbe14c47-499a-4d48-b354-a0e6fd957872\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[1, 2],\\n\",\n \" [3, 4]],\\n\",\n \"\\n\",\n \" [[5, 6],\\n\",\n \" [7, 8]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"ary3d[0, 0, 0] = 999\\n\",\n \"print(tensor3d_2) # remains unchanged\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"e3e4c23a-cdba-46f5-a2dc-5fb32bf9117b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[999, 2],\\n\",\n \" [ 3, 4]],\\n\",\n \"\\n\",\n \" [[ 5, 6],\\n\",\n \" [ 7, 8]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(tensor3d_3) # changes because of memory sharing\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"63dec48d-2b60-41a2-ac06-fef7e718605a\",\n \"metadata\": {},\n \"source\": [\n \"### A.2.2 Tensor data types\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"3f48c014-e1a2-4a53-b5c5-125812d4034c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.int64\\n\"\n ]\n }\n ],\n \"source\": [\n \"tensor1d = torch.tensor([1, 2, 3])\\n\",\n \"print(tensor1d.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"5429a086-9de2-4ac7-9f14-d087a7507394\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.float32\\n\"\n ]\n }\n ],\n \"source\": [\n \"floatvec = torch.tensor([1.0, 2.0, 3.0])\\n\",\n \"print(floatvec.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"a9a438d1-49bb-481c-8442-7cc2bb3dd4af\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.float32\\n\"\n ]\n }\n ],\n \"source\": [\n \"floatvec = tensor1d.to(torch.float32)\\n\",\n \"print(floatvec.dtype)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2020deb5-aa02-4524-b311-c010f4ad27ff\",\n \"metadata\": {},\n \"source\": [\n \"### A.2.3 Common PyTorch tensor operations\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"c02095f2-8a48-4953-b3c9-5313d4362ce7\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[1, 2, 3],\\n\",\n \" [4, 5, 6]])\"\n ]\n },\n \"execution_count\": 9,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d = torch.tensor([[1, 2, 3], \\n\",\n \" [4, 5, 6]])\\n\",\n \"tensor2d\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"f33e1d45-5b2c-4afe-b4b2-66ac4099fd1a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"torch.Size([2, 3])\"\n ]\n },\n \"execution_count\": 10,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d.shape\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"f3a4129d-f870-4e03-9c32-cd8521cb83fe\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[1, 2],\\n\",\n \" [3, 4],\\n\",\n \" [5, 6]])\"\n ]\n },\n \"execution_count\": 11,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d.reshape(3, 2)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"589ac0a7-adc7-41f3-b721-155f580e9369\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[1, 2],\\n\",\n \" [3, 4],\\n\",\n \" [5, 6]])\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d.view(3, 2)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"344e307f-ba5d-4f9a-a791-2c75a3d1417e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[1, 4],\\n\",\n \" [2, 5],\\n\",\n \" [3, 6]])\"\n ]\n },\n \"execution_count\": 13,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d.T\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"19a75030-6a41-4ca8-9aae-c507ae79225c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[14, 32],\\n\",\n \" [32, 77]])\"\n ]\n },\n \"execution_count\": 14,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d.matmul(tensor2d.T)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"e7c950bc-d640-4203-b210-3ac8932fe4d4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[14, 32],\\n\",\n \" [32, 77]])\"\n ]\n },\n \"execution_count\": 15,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d @ tensor2d.T\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4c15bdeb-78e2-4870-8a4f-a9f591666f38\",\n \"metadata\": {},\n \"source\": [\n \"## A.3 Seeing models as computation graphs\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0f3e16c3-07df-44b6-9106-a42fb24452a9\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"26d7f785-e048-42bc-9182-a556af6bb7f4\",\n \"metadata\": {},\n \"source\": [\n \"### A.2.1 Scalars, vectors, matrices, and tensors\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"a3a464d6-cec8-4363-87bd-ea4f900baced\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import numpy as np\\n\",\n \"\\n\",\n \"# create a 0D tensor (scalar) from a Python integer\\n\",\n \"tensor0d = torch.tensor(1)\\n\",\n \"\\n\",\n \"# create a 1D tensor (vector) from a Python list\\n\",\n \"tensor1d = torch.tensor([1, 2, 3])\\n\",\n \"\\n\",\n \"# create a 2D tensor from a nested Python list\\n\",\n \"tensor2d = torch.tensor([[1, 2], \\n\",\n \" [3, 4]])\\n\",\n \"\\n\",\n \"# create a 3D tensor from a nested Python list\\n\",\n \"tensor3d_1 = torch.tensor([[[1, 2], [3, 4]], \\n\",\n \" [[5, 6], [7, 8]]])\\n\",\n \"\\n\",\n \"# create a 3D tensor from NumPy array\\n\",\n \"ary3d = np.array([[[1, 2], [3, 4]], \\n\",\n \" [[5, 6], [7, 8]]])\\n\",\n \"tensor3d_2 = torch.tensor(ary3d) # Copies NumPy array\\n\",\n \"tensor3d_3 = torch.from_numpy(ary3d) # Shares memory with NumPy array\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"dbe14c47-499a-4d48-b354-a0e6fd957872\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[1, 2],\\n\",\n \" [3, 4]],\\n\",\n \"\\n\",\n \" [[5, 6],\\n\",\n \" [7, 8]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"ary3d[0, 0, 0] = 999\\n\",\n \"print(tensor3d_2) # remains unchanged\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"e3e4c23a-cdba-46f5-a2dc-5fb32bf9117b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[999, 2],\\n\",\n \" [ 3, 4]],\\n\",\n \"\\n\",\n \" [[ 5, 6],\\n\",\n \" [ 7, 8]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(tensor3d_3) # changes because of memory sharing\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"63dec48d-2b60-41a2-ac06-fef7e718605a\",\n \"metadata\": {},\n \"source\": [\n \"### A.2.2 Tensor data types\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"3f48c014-e1a2-4a53-b5c5-125812d4034c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.int64\\n\"\n ]\n }\n ],\n \"source\": [\n \"tensor1d = torch.tensor([1, 2, 3])\\n\",\n \"print(tensor1d.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"5429a086-9de2-4ac7-9f14-d087a7507394\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.float32\\n\"\n ]\n }\n ],\n \"source\": [\n \"floatvec = torch.tensor([1.0, 2.0, 3.0])\\n\",\n \"print(floatvec.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"a9a438d1-49bb-481c-8442-7cc2bb3dd4af\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.float32\\n\"\n ]\n }\n ],\n \"source\": [\n \"floatvec = tensor1d.to(torch.float32)\\n\",\n \"print(floatvec.dtype)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2020deb5-aa02-4524-b311-c010f4ad27ff\",\n \"metadata\": {},\n \"source\": [\n \"### A.2.3 Common PyTorch tensor operations\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"c02095f2-8a48-4953-b3c9-5313d4362ce7\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[1, 2, 3],\\n\",\n \" [4, 5, 6]])\"\n ]\n },\n \"execution_count\": 9,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d = torch.tensor([[1, 2, 3], \\n\",\n \" [4, 5, 6]])\\n\",\n \"tensor2d\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"f33e1d45-5b2c-4afe-b4b2-66ac4099fd1a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"torch.Size([2, 3])\"\n ]\n },\n \"execution_count\": 10,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d.shape\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"f3a4129d-f870-4e03-9c32-cd8521cb83fe\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[1, 2],\\n\",\n \" [3, 4],\\n\",\n \" [5, 6]])\"\n ]\n },\n \"execution_count\": 11,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d.reshape(3, 2)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"589ac0a7-adc7-41f3-b721-155f580e9369\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[1, 2],\\n\",\n \" [3, 4],\\n\",\n \" [5, 6]])\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d.view(3, 2)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"344e307f-ba5d-4f9a-a791-2c75a3d1417e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[1, 4],\\n\",\n \" [2, 5],\\n\",\n \" [3, 6]])\"\n ]\n },\n \"execution_count\": 13,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d.T\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"19a75030-6a41-4ca8-9aae-c507ae79225c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[14, 32],\\n\",\n \" [32, 77]])\"\n ]\n },\n \"execution_count\": 14,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d.matmul(tensor2d.T)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"e7c950bc-d640-4203-b210-3ac8932fe4d4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[14, 32],\\n\",\n \" [32, 77]])\"\n ]\n },\n \"execution_count\": 15,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tensor2d @ tensor2d.T\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4c15bdeb-78e2-4870-8a4f-a9f591666f38\",\n \"metadata\": {},\n \"source\": [\n \"## A.3 Seeing models as computation graphs\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0f3e16c3-07df-44b6-9106-a42fb24452a9\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"22af61e9-0443-4705-94d7-24c21add09c7\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(0.0852)\\n\"\n ]\n }\n ],\n \"source\": [\n \"import torch.nn.functional as F\\n\",\n \"\\n\",\n \"y = torch.tensor([1.0]) # true label\\n\",\n \"x1 = torch.tensor([1.1]) # input feature\\n\",\n \"w1 = torch.tensor([2.2]) # weight parameter\\n\",\n \"b = torch.tensor([0.0]) # bias unit\\n\",\n \"\\n\",\n \"z = x1 * w1 + b # net input\\n\",\n \"a = torch.sigmoid(z) # activation & output\\n\",\n \"\\n\",\n \"loss = F.binary_cross_entropy(a, y)\\n\",\n \"print(loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f9424f26-2bac-47e7-b834-92ece802247c\",\n \"metadata\": {},\n \"source\": [\n \"## A.4 Automatic differentiation made easy\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"33aa2ee4-6f1d-448d-8707-67cd5278233c\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"22af61e9-0443-4705-94d7-24c21add09c7\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(0.0852)\\n\"\n ]\n }\n ],\n \"source\": [\n \"import torch.nn.functional as F\\n\",\n \"\\n\",\n \"y = torch.tensor([1.0]) # true label\\n\",\n \"x1 = torch.tensor([1.1]) # input feature\\n\",\n \"w1 = torch.tensor([2.2]) # weight parameter\\n\",\n \"b = torch.tensor([0.0]) # bias unit\\n\",\n \"\\n\",\n \"z = x1 * w1 + b # net input\\n\",\n \"a = torch.sigmoid(z) # activation & output\\n\",\n \"\\n\",\n \"loss = F.binary_cross_entropy(a, y)\\n\",\n \"print(loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f9424f26-2bac-47e7-b834-92ece802247c\",\n \"metadata\": {},\n \"source\": [\n \"## A.4 Automatic differentiation made easy\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"33aa2ee4-6f1d-448d-8707-67cd5278233c\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"ebf5cef7-48d6-4d2a-8ab0-0fb10bdd7d1a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"(tensor([-0.0898]),)\\n\",\n \"(tensor([-0.0817]),)\\n\"\n ]\n }\n ],\n \"source\": [\n \"import torch.nn.functional as F\\n\",\n \"from torch.autograd import grad\\n\",\n \"\\n\",\n \"y = torch.tensor([1.0])\\n\",\n \"x1 = torch.tensor([1.1])\\n\",\n \"w1 = torch.tensor([2.2], requires_grad=True)\\n\",\n \"b = torch.tensor([0.0], requires_grad=True)\\n\",\n \"\\n\",\n \"z = x1 * w1 + b \\n\",\n \"a = torch.sigmoid(z)\\n\",\n \"\\n\",\n \"loss = F.binary_cross_entropy(a, y)\\n\",\n \"\\n\",\n \"grad_L_w1 = grad(loss, w1, retain_graph=True)\\n\",\n \"grad_L_b = grad(loss, b, retain_graph=True)\\n\",\n \"\\n\",\n \"print(grad_L_w1)\\n\",\n \"print(grad_L_b)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"93c5875d-f6b2-492c-b5ef-7e132f93a4e0\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([-0.0898])\\n\",\n \"tensor([-0.0817])\\n\"\n ]\n }\n ],\n \"source\": [\n \"loss.backward()\\n\",\n \"\\n\",\n \"print(w1.grad)\\n\",\n \"print(b.grad)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f53bdd7d-44e6-40ab-8a5a-4eef74ef35dc\",\n \"metadata\": {},\n \"source\": [\n \"## A.5 Implementing multilayer neural networks\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d6cb9787-2bc8-4379-9e8c-a3401ac63c51\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"ebf5cef7-48d6-4d2a-8ab0-0fb10bdd7d1a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"(tensor([-0.0898]),)\\n\",\n \"(tensor([-0.0817]),)\\n\"\n ]\n }\n ],\n \"source\": [\n \"import torch.nn.functional as F\\n\",\n \"from torch.autograd import grad\\n\",\n \"\\n\",\n \"y = torch.tensor([1.0])\\n\",\n \"x1 = torch.tensor([1.1])\\n\",\n \"w1 = torch.tensor([2.2], requires_grad=True)\\n\",\n \"b = torch.tensor([0.0], requires_grad=True)\\n\",\n \"\\n\",\n \"z = x1 * w1 + b \\n\",\n \"a = torch.sigmoid(z)\\n\",\n \"\\n\",\n \"loss = F.binary_cross_entropy(a, y)\\n\",\n \"\\n\",\n \"grad_L_w1 = grad(loss, w1, retain_graph=True)\\n\",\n \"grad_L_b = grad(loss, b, retain_graph=True)\\n\",\n \"\\n\",\n \"print(grad_L_w1)\\n\",\n \"print(grad_L_b)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"93c5875d-f6b2-492c-b5ef-7e132f93a4e0\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([-0.0898])\\n\",\n \"tensor([-0.0817])\\n\"\n ]\n }\n ],\n \"source\": [\n \"loss.backward()\\n\",\n \"\\n\",\n \"print(w1.grad)\\n\",\n \"print(b.grad)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f53bdd7d-44e6-40ab-8a5a-4eef74ef35dc\",\n \"metadata\": {},\n \"source\": [\n \"## A.5 Implementing multilayer neural networks\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d6cb9787-2bc8-4379-9e8c-a3401ac63c51\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"84b749e1-7768-4cfe-94d6-a08c7feff4a1\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class NeuralNetwork(torch.nn.Module):\\n\",\n \" def __init__(self, num_inputs, num_outputs):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" self.layers = torch.nn.Sequential(\\n\",\n \" \\n\",\n \" # 1st hidden layer\\n\",\n \" torch.nn.Linear(num_inputs, 30),\\n\",\n \" torch.nn.ReLU(),\\n\",\n \"\\n\",\n \" # 2nd hidden layer\\n\",\n \" torch.nn.Linear(30, 20),\\n\",\n \" torch.nn.ReLU(),\\n\",\n \"\\n\",\n \" # output layer\\n\",\n \" torch.nn.Linear(20, num_outputs),\\n\",\n \" )\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" logits = self.layers(x)\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"c5b59e2e-1930-456d-93b9-f69263e3adbe\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"model = NeuralNetwork(50, 3)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"39d02a21-33e7-4879-8fd2-d6309faf2f8d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"NeuralNetwork(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=50, out_features=30, bias=True)\\n\",\n \" (1): ReLU()\\n\",\n \" (2): Linear(in_features=30, out_features=20, bias=True)\\n\",\n \" (3): ReLU()\\n\",\n \" (4): Linear(in_features=20, out_features=3, bias=True)\\n\",\n \" )\\n\",\n \")\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(model)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"94535738-de02-4c2a-9b44-1cd186fa990a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of trainable model parameters: 2213\\n\"\n ]\n }\n ],\n \"source\": [\n \"num_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(\\\"Total number of trainable model parameters:\\\", num_params)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"2c394106-ad71-4ccb-a3c9-9b60af3fa748\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Parameter containing:\\n\",\n \"tensor([[ 0.0979, 0.0412, 0.1005, ..., -0.0544, -0.0804, 0.0842],\\n\",\n \" [-0.0115, 0.0382, -0.0261, ..., 0.0573, 0.1094, 0.1364],\\n\",\n \" [ 0.0162, -0.0050, 0.0752, ..., 0.1298, 0.1250, -0.0117],\\n\",\n \" ...,\\n\",\n \" [-0.0312, 0.1319, -0.0954, ..., -0.1066, -0.0970, -0.0373],\\n\",\n \" [ 0.0563, -0.1373, -0.1226, ..., 0.0154, -0.0969, 0.0113],\\n\",\n \" [-0.0872, -0.0098, 0.0322, ..., -0.0108, 0.1091, -0.1043]],\\n\",\n \" requires_grad=True)\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(model.layers[0].weight)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"b201882b-9285-4db9-bb63-43afe6a2ff9e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Parameter containing:\\n\",\n \"tensor([[-0.0577, 0.0047, -0.0702, ..., 0.0222, 0.1260, 0.0865],\\n\",\n \" [ 0.0502, 0.0307, 0.0333, ..., 0.0951, 0.1134, -0.0297],\\n\",\n \" [ 0.1077, -0.1108, 0.0122, ..., 0.0108, -0.1049, -0.1063],\\n\",\n \" ...,\\n\",\n \" [-0.0787, 0.1259, 0.0803, ..., 0.1218, 0.1303, -0.1351],\\n\",\n \" [ 0.1359, 0.0175, -0.0673, ..., 0.0674, 0.0676, 0.1058],\\n\",\n \" [ 0.0790, 0.1343, -0.0293, ..., 0.0344, -0.0971, -0.0509]],\\n\",\n \" requires_grad=True)\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"model = NeuralNetwork(50, 3)\\n\",\n \"print(model.layers[0].weight)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"1da9a35e-44f3-460c-90fe-304519736fd6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([30, 50])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(model.layers[0].weight.shape)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"57eadbae-90fe-43a3-a33f-c23a095ba42a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[-0.1262, 0.1080, -0.1792]], grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"84b749e1-7768-4cfe-94d6-a08c7feff4a1\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class NeuralNetwork(torch.nn.Module):\\n\",\n \" def __init__(self, num_inputs, num_outputs):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" self.layers = torch.nn.Sequential(\\n\",\n \" \\n\",\n \" # 1st hidden layer\\n\",\n \" torch.nn.Linear(num_inputs, 30),\\n\",\n \" torch.nn.ReLU(),\\n\",\n \"\\n\",\n \" # 2nd hidden layer\\n\",\n \" torch.nn.Linear(30, 20),\\n\",\n \" torch.nn.ReLU(),\\n\",\n \"\\n\",\n \" # output layer\\n\",\n \" torch.nn.Linear(20, num_outputs),\\n\",\n \" )\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" logits = self.layers(x)\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"c5b59e2e-1930-456d-93b9-f69263e3adbe\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"model = NeuralNetwork(50, 3)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"39d02a21-33e7-4879-8fd2-d6309faf2f8d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"NeuralNetwork(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=50, out_features=30, bias=True)\\n\",\n \" (1): ReLU()\\n\",\n \" (2): Linear(in_features=30, out_features=20, bias=True)\\n\",\n \" (3): ReLU()\\n\",\n \" (4): Linear(in_features=20, out_features=3, bias=True)\\n\",\n \" )\\n\",\n \")\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(model)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"94535738-de02-4c2a-9b44-1cd186fa990a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of trainable model parameters: 2213\\n\"\n ]\n }\n ],\n \"source\": [\n \"num_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(\\\"Total number of trainable model parameters:\\\", num_params)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"2c394106-ad71-4ccb-a3c9-9b60af3fa748\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Parameter containing:\\n\",\n \"tensor([[ 0.0979, 0.0412, 0.1005, ..., -0.0544, -0.0804, 0.0842],\\n\",\n \" [-0.0115, 0.0382, -0.0261, ..., 0.0573, 0.1094, 0.1364],\\n\",\n \" [ 0.0162, -0.0050, 0.0752, ..., 0.1298, 0.1250, -0.0117],\\n\",\n \" ...,\\n\",\n \" [-0.0312, 0.1319, -0.0954, ..., -0.1066, -0.0970, -0.0373],\\n\",\n \" [ 0.0563, -0.1373, -0.1226, ..., 0.0154, -0.0969, 0.0113],\\n\",\n \" [-0.0872, -0.0098, 0.0322, ..., -0.0108, 0.1091, -0.1043]],\\n\",\n \" requires_grad=True)\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(model.layers[0].weight)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"b201882b-9285-4db9-bb63-43afe6a2ff9e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Parameter containing:\\n\",\n \"tensor([[-0.0577, 0.0047, -0.0702, ..., 0.0222, 0.1260, 0.0865],\\n\",\n \" [ 0.0502, 0.0307, 0.0333, ..., 0.0951, 0.1134, -0.0297],\\n\",\n \" [ 0.1077, -0.1108, 0.0122, ..., 0.0108, -0.1049, -0.1063],\\n\",\n \" ...,\\n\",\n \" [-0.0787, 0.1259, 0.0803, ..., 0.1218, 0.1303, -0.1351],\\n\",\n \" [ 0.1359, 0.0175, -0.0673, ..., 0.0674, 0.0676, 0.1058],\\n\",\n \" [ 0.0790, 0.1343, -0.0293, ..., 0.0344, -0.0971, -0.0509]],\\n\",\n \" requires_grad=True)\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"model = NeuralNetwork(50, 3)\\n\",\n \"print(model.layers[0].weight)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"1da9a35e-44f3-460c-90fe-304519736fd6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([30, 50])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(model.layers[0].weight.shape)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"57eadbae-90fe-43a3-a33f-c23a095ba42a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[-0.1262, 0.1080, -0.1792]], grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"b9dc2745-8be8-4344-80ef-325f02cda7b7\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"X_train = torch.tensor([\\n\",\n \" [-1.2, 3.1],\\n\",\n \" [-0.9, 2.9],\\n\",\n \" [-0.5, 2.6],\\n\",\n \" [2.3, -1.1],\\n\",\n \" [2.7, -1.5]\\n\",\n \"])\\n\",\n \"\\n\",\n \"y_train = torch.tensor([0, 0, 0, 1, 1])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"88283948-5fca-461a-98a1-788b6be191d5\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"X_test = torch.tensor([\\n\",\n \" [-0.8, 2.8],\\n\",\n \" [2.6, -1.6],\\n\",\n \"])\\n\",\n \"\\n\",\n \"y_test = torch.tensor([0, 1])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"edf323e2-1789-41a0-8e44-f3cab16e5f5d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import Dataset\\n\",\n \"\\n\",\n \"\\n\",\n \"class ToyDataset(Dataset):\\n\",\n \" def __init__(self, X, y):\\n\",\n \" self.features = X\\n\",\n \" self.labels = y\\n\",\n \"\\n\",\n \" def __getitem__(self, index):\\n\",\n \" one_x = self.features[index]\\n\",\n \" one_y = self.labels[index] \\n\",\n \" return one_x, one_y\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return self.labels.shape[0]\\n\",\n \"\\n\",\n \"train_ds = ToyDataset(X_train, y_train)\\n\",\n \"test_ds = ToyDataset(X_test, y_test)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"b7014705-1fdc-4f72-b892-d8db8bebc331\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"5\"\n ]\n },\n \"execution_count\": 32,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"len(train_ds)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"3ec6627a-4c3f-481a-b794-d2131be95eaf\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_loader = DataLoader(\\n\",\n \" dataset=train_ds,\\n\",\n \" batch_size=2,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=0\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"8c9446de-5e4b-44fa-bf9a-a63e2661027e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"test_ds = ToyDataset(X_test, y_test)\\n\",\n \"\\n\",\n \"test_loader = DataLoader(\\n\",\n \" dataset=test_ds,\\n\",\n \" batch_size=2,\\n\",\n \" shuffle=False,\\n\",\n \" num_workers=0\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"99d4404c-9884-419f-979c-f659742d86ef\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Batch 1: tensor([[ 2.3000, -1.1000],\\n\",\n \" [-0.9000, 2.9000]]) tensor([1, 0])\\n\",\n \"Batch 2: tensor([[-1.2000, 3.1000],\\n\",\n \" [-0.5000, 2.6000]]) tensor([0, 0])\\n\",\n \"Batch 3: tensor([[ 2.7000, -1.5000]]) tensor([1])\\n\"\n ]\n }\n ],\n \"source\": [\n \"for idx, (x, y) in enumerate(train_loader):\\n\",\n \" print(f\\\"Batch {idx+1}:\\\", x, y)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"9d003f7e-7a80-40bf-a7fb-7a0d7dbba9db\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"train_loader = DataLoader(\\n\",\n \" dataset=train_ds,\\n\",\n \" batch_size=2,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=0,\\n\",\n \" drop_last=True\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"4db4d7f4-82da-44a4-b94e-ee04665d9c3c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Batch 1: tensor([[-1.2000, 3.1000],\\n\",\n \" [-0.5000, 2.6000]]) tensor([0, 0])\\n\",\n \"Batch 2: tensor([[ 2.3000, -1.1000],\\n\",\n \" [-0.9000, 2.9000]]) tensor([1, 0])\\n\"\n ]\n }\n ],\n \"source\": [\n \"for idx, (x, y) in enumerate(train_loader):\\n\",\n \" print(f\\\"Batch {idx+1}:\\\", x, y)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"eb03ed57-df38-4ee0-a553-0863450df39b\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"b9dc2745-8be8-4344-80ef-325f02cda7b7\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"X_train = torch.tensor([\\n\",\n \" [-1.2, 3.1],\\n\",\n \" [-0.9, 2.9],\\n\",\n \" [-0.5, 2.6],\\n\",\n \" [2.3, -1.1],\\n\",\n \" [2.7, -1.5]\\n\",\n \"])\\n\",\n \"\\n\",\n \"y_train = torch.tensor([0, 0, 0, 1, 1])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"88283948-5fca-461a-98a1-788b6be191d5\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"X_test = torch.tensor([\\n\",\n \" [-0.8, 2.8],\\n\",\n \" [2.6, -1.6],\\n\",\n \"])\\n\",\n \"\\n\",\n \"y_test = torch.tensor([0, 1])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"edf323e2-1789-41a0-8e44-f3cab16e5f5d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import Dataset\\n\",\n \"\\n\",\n \"\\n\",\n \"class ToyDataset(Dataset):\\n\",\n \" def __init__(self, X, y):\\n\",\n \" self.features = X\\n\",\n \" self.labels = y\\n\",\n \"\\n\",\n \" def __getitem__(self, index):\\n\",\n \" one_x = self.features[index]\\n\",\n \" one_y = self.labels[index] \\n\",\n \" return one_x, one_y\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return self.labels.shape[0]\\n\",\n \"\\n\",\n \"train_ds = ToyDataset(X_train, y_train)\\n\",\n \"test_ds = ToyDataset(X_test, y_test)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"b7014705-1fdc-4f72-b892-d8db8bebc331\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"5\"\n ]\n },\n \"execution_count\": 32,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"len(train_ds)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"3ec6627a-4c3f-481a-b794-d2131be95eaf\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_loader = DataLoader(\\n\",\n \" dataset=train_ds,\\n\",\n \" batch_size=2,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=0\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"8c9446de-5e4b-44fa-bf9a-a63e2661027e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"test_ds = ToyDataset(X_test, y_test)\\n\",\n \"\\n\",\n \"test_loader = DataLoader(\\n\",\n \" dataset=test_ds,\\n\",\n \" batch_size=2,\\n\",\n \" shuffle=False,\\n\",\n \" num_workers=0\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"99d4404c-9884-419f-979c-f659742d86ef\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Batch 1: tensor([[ 2.3000, -1.1000],\\n\",\n \" [-0.9000, 2.9000]]) tensor([1, 0])\\n\",\n \"Batch 2: tensor([[-1.2000, 3.1000],\\n\",\n \" [-0.5000, 2.6000]]) tensor([0, 0])\\n\",\n \"Batch 3: tensor([[ 2.7000, -1.5000]]) tensor([1])\\n\"\n ]\n }\n ],\n \"source\": [\n \"for idx, (x, y) in enumerate(train_loader):\\n\",\n \" print(f\\\"Batch {idx+1}:\\\", x, y)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"9d003f7e-7a80-40bf-a7fb-7a0d7dbba9db\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"train_loader = DataLoader(\\n\",\n \" dataset=train_ds,\\n\",\n \" batch_size=2,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=0,\\n\",\n \" drop_last=True\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"4db4d7f4-82da-44a4-b94e-ee04665d9c3c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Batch 1: tensor([[-1.2000, 3.1000],\\n\",\n \" [-0.5000, 2.6000]]) tensor([0, 0])\\n\",\n \"Batch 2: tensor([[ 2.3000, -1.1000],\\n\",\n \" [-0.9000, 2.9000]]) tensor([1, 0])\\n\"\n ]\n }\n ],\n \"source\": [\n \"for idx, (x, y) in enumerate(train_loader):\\n\",\n \" print(f\\\"Batch {idx+1}:\\\", x, y)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"eb03ed57-df38-4ee0-a553-0863450df39b\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d904ca82-e50f-4f3d-a3ac-fc6ca53dd00e\",\n \"metadata\": {},\n \"source\": [\n \"## A.7 A typical training loop\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"93f1791a-d887-4fc5-a307-5e5bde9e06f6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Epoch: 001/003 | Batch 001/002 | Train/Val Loss: 0.75\\n\",\n \"Epoch: 001/003 | Batch 002/002 | Train/Val Loss: 0.65\\n\",\n \"Epoch: 002/003 | Batch 001/002 | Train/Val Loss: 0.44\\n\",\n \"Epoch: 002/003 | Batch 002/002 | Train/Val Loss: 0.13\\n\",\n \"Epoch: 003/003 | Batch 001/002 | Train/Val Loss: 0.03\\n\",\n \"Epoch: 003/003 | Batch 002/002 | Train/Val Loss: 0.00\\n\"\n ]\n }\n ],\n \"source\": [\n \"import torch.nn.functional as F\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model = NeuralNetwork(num_inputs=2, num_outputs=2)\\n\",\n \"optimizer = torch.optim.SGD(model.parameters(), lr=0.5)\\n\",\n \"\\n\",\n \"num_epochs = 3\\n\",\n \"\\n\",\n \"for epoch in range(num_epochs):\\n\",\n \" \\n\",\n \" model.train()\\n\",\n \" for batch_idx, (features, labels) in enumerate(train_loader):\\n\",\n \"\\n\",\n \" logits = model(features)\\n\",\n \" \\n\",\n \" loss = F.cross_entropy(logits, labels) # Loss function\\n\",\n \" \\n\",\n \" optimizer.zero_grad()\\n\",\n \" loss.backward()\\n\",\n \" optimizer.step()\\n\",\n \" \\n\",\n \" ### LOGGING\\n\",\n \" print(f\\\"Epoch: {epoch+1:03d}/{num_epochs:03d}\\\"\\n\",\n \" f\\\" | Batch {batch_idx+1:03d}/{len(train_loader):03d}\\\"\\n\",\n \" f\\\" | Train/Val Loss: {loss:.2f}\\\")\\n\",\n \"\\n\",\n \" model.eval()\\n\",\n \" # Optional model evaluation\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"00dcf57f-6a7e-4af7-aa5a-df2cb0866fa5\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[ 2.8569, -4.1618],\\n\",\n \" [ 2.5382, -3.7548],\\n\",\n \" [ 2.0944, -3.1820],\\n\",\n \" [-1.4814, 1.4816],\\n\",\n \" [-1.7176, 1.7342]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"model.eval()\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" outputs = model(X_train)\\n\",\n \"\\n\",\n \"print(outputs)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 40,\n \"id\": \"19be7390-18b8-43f9-9841-d7fb1919f6fd\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.9991, 0.0009],\\n\",\n \" [0.9982, 0.0018],\\n\",\n \" [0.9949, 0.0051],\\n\",\n \" [0.0491, 0.9509],\\n\",\n \" [0.0307, 0.9693]])\\n\",\n \"tensor([0, 0, 0, 1, 1])\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.set_printoptions(sci_mode=False)\\n\",\n \"probas = torch.softmax(outputs, dim=1)\\n\",\n \"print(probas)\\n\",\n \"\\n\",\n \"predictions = torch.argmax(probas, dim=1)\\n\",\n \"print(predictions)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 41,\n \"id\": \"07e7e530-f8d3-429c-9f5e-cf8078078c0e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0, 0, 0, 1, 1])\\n\"\n ]\n }\n ],\n \"source\": [\n \"predictions = torch.argmax(outputs, dim=1)\\n\",\n \"print(predictions)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"5f756f0d-63c8-41b5-a5d8-01baa847e026\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([True, True, True, True, True])\"\n ]\n },\n \"execution_count\": 42,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"predictions == y_train\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"da274bb0-f11c-4c81-a880-7a031fbf2943\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor(5)\"\n ]\n },\n \"execution_count\": 43,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"torch.sum(predictions == y_train)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"16d62314-8dee-45b0-8f55-9e5aae2b24f4\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def compute_accuracy(model, dataloader):\\n\",\n \"\\n\",\n \" model.eval()\\n\",\n \" correct = 0.0\\n\",\n \" total_examples = 0\\n\",\n \" \\n\",\n \" for idx, (features, labels) in enumerate(dataloader):\\n\",\n \" \\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(features)\\n\",\n \" \\n\",\n \" predictions = torch.argmax(logits, dim=1)\\n\",\n \" compare = labels == predictions\\n\",\n \" correct += torch.sum(compare)\\n\",\n \" total_examples += len(compare)\\n\",\n \"\\n\",\n \" return (correct / total_examples).item()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"4f6c9c17-2a5f-46c0-804b-873f169b729a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"1.0\"\n ]\n },\n \"execution_count\": 45,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"compute_accuracy(model, train_loader)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 46,\n \"id\": \"311ed864-e21e-4aac-97c7-c6086caef27a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"1.0\"\n ]\n },\n \"execution_count\": 46,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"compute_accuracy(model, test_loader)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4d5cd469-3a45-4394-944b-3ce543f41dac\",\n \"metadata\": {},\n \"source\": [\n \"## A.8 Saving and loading models\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 47,\n \"id\": \"b013127d-a2c3-4b04-9fb3-a6a7c88d83c5\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"torch.save(model.state_dict(), \\\"model.pth\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 48,\n \"id\": \"b2b428c2-3a44-4d91-97c4-8298cf2b51eb\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d904ca82-e50f-4f3d-a3ac-fc6ca53dd00e\",\n \"metadata\": {},\n \"source\": [\n \"## A.7 A typical training loop\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"93f1791a-d887-4fc5-a307-5e5bde9e06f6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Epoch: 001/003 | Batch 001/002 | Train/Val Loss: 0.75\\n\",\n \"Epoch: 001/003 | Batch 002/002 | Train/Val Loss: 0.65\\n\",\n \"Epoch: 002/003 | Batch 001/002 | Train/Val Loss: 0.44\\n\",\n \"Epoch: 002/003 | Batch 002/002 | Train/Val Loss: 0.13\\n\",\n \"Epoch: 003/003 | Batch 001/002 | Train/Val Loss: 0.03\\n\",\n \"Epoch: 003/003 | Batch 002/002 | Train/Val Loss: 0.00\\n\"\n ]\n }\n ],\n \"source\": [\n \"import torch.nn.functional as F\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model = NeuralNetwork(num_inputs=2, num_outputs=2)\\n\",\n \"optimizer = torch.optim.SGD(model.parameters(), lr=0.5)\\n\",\n \"\\n\",\n \"num_epochs = 3\\n\",\n \"\\n\",\n \"for epoch in range(num_epochs):\\n\",\n \" \\n\",\n \" model.train()\\n\",\n \" for batch_idx, (features, labels) in enumerate(train_loader):\\n\",\n \"\\n\",\n \" logits = model(features)\\n\",\n \" \\n\",\n \" loss = F.cross_entropy(logits, labels) # Loss function\\n\",\n \" \\n\",\n \" optimizer.zero_grad()\\n\",\n \" loss.backward()\\n\",\n \" optimizer.step()\\n\",\n \" \\n\",\n \" ### LOGGING\\n\",\n \" print(f\\\"Epoch: {epoch+1:03d}/{num_epochs:03d}\\\"\\n\",\n \" f\\\" | Batch {batch_idx+1:03d}/{len(train_loader):03d}\\\"\\n\",\n \" f\\\" | Train/Val Loss: {loss:.2f}\\\")\\n\",\n \"\\n\",\n \" model.eval()\\n\",\n \" # Optional model evaluation\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"00dcf57f-6a7e-4af7-aa5a-df2cb0866fa5\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[ 2.8569, -4.1618],\\n\",\n \" [ 2.5382, -3.7548],\\n\",\n \" [ 2.0944, -3.1820],\\n\",\n \" [-1.4814, 1.4816],\\n\",\n \" [-1.7176, 1.7342]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"model.eval()\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" outputs = model(X_train)\\n\",\n \"\\n\",\n \"print(outputs)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 40,\n \"id\": \"19be7390-18b8-43f9-9841-d7fb1919f6fd\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.9991, 0.0009],\\n\",\n \" [0.9982, 0.0018],\\n\",\n \" [0.9949, 0.0051],\\n\",\n \" [0.0491, 0.9509],\\n\",\n \" [0.0307, 0.9693]])\\n\",\n \"tensor([0, 0, 0, 1, 1])\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.set_printoptions(sci_mode=False)\\n\",\n \"probas = torch.softmax(outputs, dim=1)\\n\",\n \"print(probas)\\n\",\n \"\\n\",\n \"predictions = torch.argmax(probas, dim=1)\\n\",\n \"print(predictions)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 41,\n \"id\": \"07e7e530-f8d3-429c-9f5e-cf8078078c0e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0, 0, 0, 1, 1])\\n\"\n ]\n }\n ],\n \"source\": [\n \"predictions = torch.argmax(outputs, dim=1)\\n\",\n \"print(predictions)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"5f756f0d-63c8-41b5-a5d8-01baa847e026\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([True, True, True, True, True])\"\n ]\n },\n \"execution_count\": 42,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"predictions == y_train\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"da274bb0-f11c-4c81-a880-7a031fbf2943\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor(5)\"\n ]\n },\n \"execution_count\": 43,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"torch.sum(predictions == y_train)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"16d62314-8dee-45b0-8f55-9e5aae2b24f4\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def compute_accuracy(model, dataloader):\\n\",\n \"\\n\",\n \" model.eval()\\n\",\n \" correct = 0.0\\n\",\n \" total_examples = 0\\n\",\n \" \\n\",\n \" for idx, (features, labels) in enumerate(dataloader):\\n\",\n \" \\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(features)\\n\",\n \" \\n\",\n \" predictions = torch.argmax(logits, dim=1)\\n\",\n \" compare = labels == predictions\\n\",\n \" correct += torch.sum(compare)\\n\",\n \" total_examples += len(compare)\\n\",\n \"\\n\",\n \" return (correct / total_examples).item()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"4f6c9c17-2a5f-46c0-804b-873f169b729a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"1.0\"\n ]\n },\n \"execution_count\": 45,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"compute_accuracy(model, train_loader)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 46,\n \"id\": \"311ed864-e21e-4aac-97c7-c6086caef27a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"1.0\"\n ]\n },\n \"execution_count\": 46,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"compute_accuracy(model, test_loader)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4d5cd469-3a45-4394-944b-3ce543f41dac\",\n \"metadata\": {},\n \"source\": [\n \"## A.8 Saving and loading models\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 47,\n \"id\": \"b013127d-a2c3-4b04-9fb3-a6a7c88d83c5\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"torch.save(model.state_dict(), \\\"model.pth\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 48,\n \"id\": \"b2b428c2-3a44-4d91-97c4-8298cf2b51eb\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \\n\",\n \"
\\n\",\n \" \"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"T4\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.11.11\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 4\n}\n"
},
{
"path": "appendix-A/01_main-chapter-code/exercise-solutions.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"T4\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.11.11\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 4\n}\n"
},
{
"path": "appendix-A/01_main-chapter-code/exercise-solutions.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4edd43c9-8ec5-48e6-b3fc-5fb3c16037cc\",\n \"metadata\": {\n \"id\": \"4edd43c9-8ec5-48e6-b3fc-5fb3c16037cc\"\n },\n \"source\": [\n \"- If you paid close attention, the full finetuning and LoRA depictions in the figure above look slightly different from the formulas I have shown earlier\\n\",\n \"- That's due to the distributive law of matrix multiplication: we don't have to add the weights with the updated weights but can keep them separate\\n\",\n \"- For instance, if $x$ is the input data, then we can write the following for regular finetuning:\\n\",\n \"\\n\",\n \"$$x (W+\\\\Delta W) = x W + x \\\\Delta W$$\\n\",\n \"\\n\",\n \"- Similarly, we can write the following for LoRA:\\n\",\n \"\\n\",\n \"$$x (W+A B) = x W + x A B$$\\n\",\n \"\\n\",\n \"- The fact that we can keep the LoRA weight matrices separate makes LoRA especially attractive\\n\",\n \"- In practice, this means that we don't have to modify the weights of the pretrained model at all, as we can apply the LoRA matrices on the fly\\n\",\n \"- After setting up the dataset and loading the model, we will implement LoRA in the code to make these concepts less abstract\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c7017a2-32aa-4002-a2f3-12aac293ccdf\",\n \"metadata\": {\n \"id\": \"8c7017a2-32aa-4002-a2f3-12aac293ccdf\"\n },\n \"source\": [\n \"## E.2 Preparing the dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"669c64df-4431-4d27-834d-2bb38a01fc02\",\n \"metadata\": {\n \"id\": \"669c64df-4431-4d27-834d-2bb38a01fc02\"\n },\n \"source\": [\n \"- This section repeats the code from chapter 6 to load and prepare the dataset\\n\",\n \"- Instead of repeating this code, one could open and run the chapter 6 notebook and then insert the LoRA code from section E.4 there\\n\",\n \"- (The LoRA code was originally the last section of chapter 6 but was moved to the appendix due to the length of chapter 6)\\n\",\n \"- In a similar fashion, we could also apply LoRA to the models in chapter 7 for instruction finetuning\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"def7c09b-af9c-4216-90ce-5e67aed1065c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"def7c09b-af9c-4216-90ce-5e67aed1065c\",\n \"outputId\": \"a67a7afe-b401-4463-c731-87025d20f72d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"sms_spam_collection/SMSSpamCollection.tsv already exists. Skipping download and extraction.\\n\"\n ]\n }\n ],\n \"source\": [\n \"# import urllib\\n\",\n \"import requests\\n\",\n \"from pathlib import Path\\n\",\n \"import pandas as pd\\n\",\n \"from previous_chapters import (\\n\",\n \" download_and_unzip_spam_data,\\n\",\n \" create_balanced_dataset,\\n\",\n \" random_split\\n\",\n \")\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch06 import (\\n\",\n \"# download_and_unzip_spam_data,\\n\",\n \"# create_balanced_dataset,\\n\",\n \"# random_split\\n\",\n \"# )\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"url = \\\"https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip\\\"\\n\",\n \"zip_path = \\\"sms_spam_collection.zip\\\"\\n\",\n \"extracted_path = \\\"sms_spam_collection\\\"\\n\",\n \"data_file_path = Path(extracted_path) / \\\"SMSSpamCollection.tsv\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"try:\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"except (requests.exceptions.RequestException, TimeoutError) as e:\\n\",\n \" print(f\\\"Primary URL failed: {e}. Trying backup URL...\\\")\\n\",\n \" url = \\\"https://f001.backblazeb2.com/file/LLMs-from-scratch/sms%2Bspam%2Bcollection.zip\\\"\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"\\n\",\n \"# The book originally used\\n\",\n \"# except (urllib.error.HTTPError, urllib.error.URLError, TimeoutError) as e:\\n\",\n \"# in the code above.\\n\",\n \"# However, some VPN users reported issues with `urllib`, so the code was updated\\n\",\n \"# to use `requests` instead\\n\",\n \"\\n\",\n \"df = pd.read_csv(data_file_path, sep=\\\"\\\\t\\\", header=None, names=[\\\"Label\\\", \\\"Text\\\"])\\n\",\n \"balanced_df = create_balanced_dataset(df)\\n\",\n \"balanced_df[\\\"Label\\\"] = balanced_df[\\\"Label\\\"].map({\\\"ham\\\": 0, \\\"spam\\\": 1})\\n\",\n \"\\n\",\n \"train_df, validation_df, test_df = random_split(balanced_df, 0.7, 0.1)\\n\",\n \"train_df.to_csv(\\\"train.csv\\\", index=None)\\n\",\n \"validation_df.to_csv(\\\"validation.csv\\\", index=None)\\n\",\n \"test_df.to_csv(\\\"test.csv\\\", index=None)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"74c3c463-8763-4cc0-9320-41c7eaad8ab7\",\n \"metadata\": {\n \"id\": \"74c3c463-8763-4cc0-9320-41c7eaad8ab7\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import tiktoken\\n\",\n \"from previous_chapters import SpamDataset\\n\",\n \"\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"train_dataset = SpamDataset(\\\"train.csv\\\", max_length=None, tokenizer=tokenizer)\\n\",\n \"val_dataset = SpamDataset(\\\"validation.csv\\\", max_length=train_dataset.max_length, tokenizer=tokenizer)\\n\",\n \"test_dataset = SpamDataset(\\\"test.csv\\\", max_length=train_dataset.max_length, tokenizer=tokenizer)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"8681adc0-6f02-4e75-b01a-a6ab75d05542\",\n \"metadata\": {\n \"id\": \"8681adc0-6f02-4e75-b01a-a6ab75d05542\"\n },\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"num_workers = 0\\n\",\n \"batch_size = 8\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_loader = DataLoader(\\n\",\n \" dataset=train_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=True,\\n\",\n \")\\n\",\n \"\\n\",\n \"val_loader = DataLoader(\\n\",\n \" dataset=val_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=False,\\n\",\n \")\\n\",\n \"\\n\",\n \"test_loader = DataLoader(\\n\",\n \" dataset=test_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=False,\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ab7335db-e0bb-4e27-80c5-eea11e593a57\",\n \"metadata\": {\n \"id\": \"ab7335db-e0bb-4e27-80c5-eea11e593a57\"\n },\n \"source\": [\n \"- As a verification step, we iterate through the data loaders and check that the batches contain 8 training examples each, where each training example consists of 120 tokens\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"4dee6882-4c3a-4964-af15-fa31f86ad047\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"4dee6882-4c3a-4964-af15-fa31f86ad047\",\n \"outputId\": \"2ae34de1-dd01-4f99-d2c8-ba4dca400754\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"Input batch dimensions: torch.Size([8, 120])\\n\",\n \"Label batch dimensions torch.Size([8])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for input_batch, target_batch in train_loader:\\n\",\n \" pass\\n\",\n \"\\n\",\n \"print(\\\"Input batch dimensions:\\\", input_batch.shape)\\n\",\n \"print(\\\"Label batch dimensions\\\", target_batch.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5cdd7947-7039-49bf-8a5e-c0a2f4281ca1\",\n \"metadata\": {\n \"id\": \"5cdd7947-7039-49bf-8a5e-c0a2f4281ca1\"\n },\n \"source\": [\n \"- Lastly, let's print the total number of batches in each dataset\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"IZfw-TYD2zTj\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"IZfw-TYD2zTj\",\n \"outputId\": \"4d19ed61-cf7a-4ec4-b822-c847dd1c5d77\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"130 training batches\\n\",\n \"19 validation batches\\n\",\n \"38 test batches\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(f\\\"{len(train_loader)} training batches\\\")\\n\",\n \"print(f\\\"{len(val_loader)} validation batches\\\")\\n\",\n \"print(f\\\"{len(test_loader)} test batches\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dec9aa4a-ffd2-4d9f-a835-cce1059fe604\",\n \"metadata\": {\n \"id\": \"dec9aa4a-ffd2-4d9f-a835-cce1059fe604\"\n },\n \"source\": [\n \"## E.3 Initializing the model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f36ebdaf-810e-46a2-9ad9-e017a04051b1\",\n \"metadata\": {\n \"id\": \"f36ebdaf-810e-46a2-9ad9-e017a04051b1\"\n },\n \"source\": [\n \"- This section repeats the code from chapter 6 to load and prepare the model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"02b3a506-3879-4258-82b5-93a5b6bafa74\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"02b3a506-3879-4258-82b5-93a5b6bafa74\",\n \"outputId\": \"b8c9b125-bb52-45d3-8071-fa5054dbf5a9\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"File already exists and is up-to-date: gpt2/124M/checkpoint\\n\",\n \"File already exists and is up-to-date: gpt2/124M/encoder.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/hparams.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.data-00000-of-00001\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.index\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.meta\\n\",\n \"File already exists and is up-to-date: gpt2/124M/vocab.bpe\\n\"\n ]\n }\n ],\n \"source\": [\n \"from gpt_download import download_and_load_gpt2\\n\",\n \"from previous_chapters import GPTModel, load_weights_into_gpt\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"# from llms_from_scratch.ch05 import load_weights_into_gpt\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"CHOOSE_MODEL = \\\"gpt2-small (124M)\\\"\\n\",\n \"INPUT_PROMPT = \\\"Every effort moves\\\"\\n\",\n \"\\n\",\n \"BASE_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"drop_rate\\\": 0.0, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": True # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\\n\",\n \"\\n\",\n \"model_size = CHOOSE_MODEL.split(\\\" \\\")[-1].lstrip(\\\"(\\\").rstrip(\\\")\\\")\\n\",\n \"settings, params = download_and_load_gpt2(model_size=model_size, models_dir=\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"load_weights_into_gpt(model, params)\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"252614cd-7ce6-4908-83e6-3761f519904e\",\n \"metadata\": {\n \"id\": \"252614cd-7ce6-4908-83e6-3761f519904e\"\n },\n \"source\": [\n \"- To ensure that the model was loaded corrected, let's double-check that it generates coherent text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"8b6ce20c-0700-4783-8be0-4cf17c200a7f\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"8b6ce20c-0700-4783-8be0-4cf17c200a7f\",\n \"outputId\": \"28ccbca5-8de9-41a0-c093-da00fcbaa91c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Every effort moves you forward.\\n\",\n \"\\n\",\n \"The first step is to understand the importance of your work\\n\"\n ]\n }\n ],\n \"source\": [\n \"from previous_chapters import (\\n\",\n \" generate_text_simple,\\n\",\n \" text_to_token_ids,\\n\",\n \" token_ids_to_text\\n\",\n \")\\n\",\n \"\\n\",\n \"\\n\",\n \"text_1 = \\\"Every effort moves you\\\"\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(text_1, tokenizer),\\n\",\n \" max_new_tokens=15,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8174b31b-1ab5-4115-b01c-245369da5af3\",\n \"metadata\": {\n \"id\": \"8174b31b-1ab5-4115-b01c-245369da5af3\"\n },\n \"source\": [\n \"- Then, we prepare the model for classification finetuning similar to chapter 6, where we replace the output layer\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e255ce91-d73a-4854-90a4-95804928eb16\",\n \"metadata\": {\n \"id\": \"e255ce91-d73a-4854-90a4-95804928eb16\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"num_classes = 2\\n\",\n \"model.out_head = torch.nn.Linear(in_features=768, out_features=num_classes)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"02e6f057-1383-4ece-8444-0a88e71ac75d\",\n \"metadata\": {\n \"id\": \"02e6f057-1383-4ece-8444-0a88e71ac75d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Device: mps\\n\"\n ]\n }\n ],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"print(\\\"Device:\\\", device)\\n\",\n \"\\n\",\n \"model.to(device); # no assignment model = model.to(device) necessary for nn.Module classes\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8e951cd6-5e42-44d2-b21f-895cb61004fe\",\n \"metadata\": {\n \"id\": \"8e951cd6-5e42-44d2-b21f-895cb61004fe\"\n },\n \"source\": [\n \"- Lastly, let's calculate the initial classification accuracy of the non-finetuned model (we expect this to be around 50%, which means that the model is not able to distinguish between spam and non-spam messages yet reliably)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"fc7dd72c-73a2-4881-ade0-0a9605f1ab8c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"fc7dd72c-73a2-4881-ade0-0a9605f1ab8c\",\n \"outputId\": \"74848515-5a49-4125-fecb-9f4bac23f812\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training accuracy: 46.25%\\n\",\n \"Validation accuracy: 45.00%\\n\",\n \"Test accuracy: 48.75%\\n\"\n ]\n }\n ],\n \"source\": [\n \"from previous_chapters import calc_accuracy_loader\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch06 import calc_accuracy_loader\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=10)\\n\",\n \"val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=10)\\n\",\n \"test_accuracy = calc_accuracy_loader(test_loader, model, device, num_batches=10)\\n\",\n \"\\n\",\n \"print(f\\\"Training accuracy: {train_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Validation accuracy: {val_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Test accuracy: {test_accuracy*100:.2f}%\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"398a1ec9-e2a1-43d6-bf9f-12ee54b46a7b\",\n \"metadata\": {\n \"id\": \"398a1ec9-e2a1-43d6-bf9f-12ee54b46a7b\"\n },\n \"source\": [\n \"## E.4 Parameter-efficient finetuning with LoRA\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"652a4a82-61ef-4d0a-9858-8988e844f12c\",\n \"metadata\": {\n \"id\": \"652a4a82-61ef-4d0a-9858-8988e844f12c\"\n },\n \"source\": [\n \"- We begin by initializing a LoRALayer that creates the matrices $A$ and $B$, along with the `alpha` scaling hyperparameter and the `rank` ($r$) hyperparameters\\n\",\n \"- This layer can accept an input and compute the corresponding output, as illustrated in the figure below\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4edd43c9-8ec5-48e6-b3fc-5fb3c16037cc\",\n \"metadata\": {\n \"id\": \"4edd43c9-8ec5-48e6-b3fc-5fb3c16037cc\"\n },\n \"source\": [\n \"- If you paid close attention, the full finetuning and LoRA depictions in the figure above look slightly different from the formulas I have shown earlier\\n\",\n \"- That's due to the distributive law of matrix multiplication: we don't have to add the weights with the updated weights but can keep them separate\\n\",\n \"- For instance, if $x$ is the input data, then we can write the following for regular finetuning:\\n\",\n \"\\n\",\n \"$$x (W+\\\\Delta W) = x W + x \\\\Delta W$$\\n\",\n \"\\n\",\n \"- Similarly, we can write the following for LoRA:\\n\",\n \"\\n\",\n \"$$x (W+A B) = x W + x A B$$\\n\",\n \"\\n\",\n \"- The fact that we can keep the LoRA weight matrices separate makes LoRA especially attractive\\n\",\n \"- In practice, this means that we don't have to modify the weights of the pretrained model at all, as we can apply the LoRA matrices on the fly\\n\",\n \"- After setting up the dataset and loading the model, we will implement LoRA in the code to make these concepts less abstract\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c7017a2-32aa-4002-a2f3-12aac293ccdf\",\n \"metadata\": {\n \"id\": \"8c7017a2-32aa-4002-a2f3-12aac293ccdf\"\n },\n \"source\": [\n \"## E.2 Preparing the dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"669c64df-4431-4d27-834d-2bb38a01fc02\",\n \"metadata\": {\n \"id\": \"669c64df-4431-4d27-834d-2bb38a01fc02\"\n },\n \"source\": [\n \"- This section repeats the code from chapter 6 to load and prepare the dataset\\n\",\n \"- Instead of repeating this code, one could open and run the chapter 6 notebook and then insert the LoRA code from section E.4 there\\n\",\n \"- (The LoRA code was originally the last section of chapter 6 but was moved to the appendix due to the length of chapter 6)\\n\",\n \"- In a similar fashion, we could also apply LoRA to the models in chapter 7 for instruction finetuning\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"def7c09b-af9c-4216-90ce-5e67aed1065c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"def7c09b-af9c-4216-90ce-5e67aed1065c\",\n \"outputId\": \"a67a7afe-b401-4463-c731-87025d20f72d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"sms_spam_collection/SMSSpamCollection.tsv already exists. Skipping download and extraction.\\n\"\n ]\n }\n ],\n \"source\": [\n \"# import urllib\\n\",\n \"import requests\\n\",\n \"from pathlib import Path\\n\",\n \"import pandas as pd\\n\",\n \"from previous_chapters import (\\n\",\n \" download_and_unzip_spam_data,\\n\",\n \" create_balanced_dataset,\\n\",\n \" random_split\\n\",\n \")\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch06 import (\\n\",\n \"# download_and_unzip_spam_data,\\n\",\n \"# create_balanced_dataset,\\n\",\n \"# random_split\\n\",\n \"# )\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"url = \\\"https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip\\\"\\n\",\n \"zip_path = \\\"sms_spam_collection.zip\\\"\\n\",\n \"extracted_path = \\\"sms_spam_collection\\\"\\n\",\n \"data_file_path = Path(extracted_path) / \\\"SMSSpamCollection.tsv\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"try:\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"except (requests.exceptions.RequestException, TimeoutError) as e:\\n\",\n \" print(f\\\"Primary URL failed: {e}. Trying backup URL...\\\")\\n\",\n \" url = \\\"https://f001.backblazeb2.com/file/LLMs-from-scratch/sms%2Bspam%2Bcollection.zip\\\"\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"\\n\",\n \"# The book originally used\\n\",\n \"# except (urllib.error.HTTPError, urllib.error.URLError, TimeoutError) as e:\\n\",\n \"# in the code above.\\n\",\n \"# However, some VPN users reported issues with `urllib`, so the code was updated\\n\",\n \"# to use `requests` instead\\n\",\n \"\\n\",\n \"df = pd.read_csv(data_file_path, sep=\\\"\\\\t\\\", header=None, names=[\\\"Label\\\", \\\"Text\\\"])\\n\",\n \"balanced_df = create_balanced_dataset(df)\\n\",\n \"balanced_df[\\\"Label\\\"] = balanced_df[\\\"Label\\\"].map({\\\"ham\\\": 0, \\\"spam\\\": 1})\\n\",\n \"\\n\",\n \"train_df, validation_df, test_df = random_split(balanced_df, 0.7, 0.1)\\n\",\n \"train_df.to_csv(\\\"train.csv\\\", index=None)\\n\",\n \"validation_df.to_csv(\\\"validation.csv\\\", index=None)\\n\",\n \"test_df.to_csv(\\\"test.csv\\\", index=None)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"74c3c463-8763-4cc0-9320-41c7eaad8ab7\",\n \"metadata\": {\n \"id\": \"74c3c463-8763-4cc0-9320-41c7eaad8ab7\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import tiktoken\\n\",\n \"from previous_chapters import SpamDataset\\n\",\n \"\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"train_dataset = SpamDataset(\\\"train.csv\\\", max_length=None, tokenizer=tokenizer)\\n\",\n \"val_dataset = SpamDataset(\\\"validation.csv\\\", max_length=train_dataset.max_length, tokenizer=tokenizer)\\n\",\n \"test_dataset = SpamDataset(\\\"test.csv\\\", max_length=train_dataset.max_length, tokenizer=tokenizer)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"8681adc0-6f02-4e75-b01a-a6ab75d05542\",\n \"metadata\": {\n \"id\": \"8681adc0-6f02-4e75-b01a-a6ab75d05542\"\n },\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"num_workers = 0\\n\",\n \"batch_size = 8\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_loader = DataLoader(\\n\",\n \" dataset=train_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=True,\\n\",\n \")\\n\",\n \"\\n\",\n \"val_loader = DataLoader(\\n\",\n \" dataset=val_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=False,\\n\",\n \")\\n\",\n \"\\n\",\n \"test_loader = DataLoader(\\n\",\n \" dataset=test_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=False,\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ab7335db-e0bb-4e27-80c5-eea11e593a57\",\n \"metadata\": {\n \"id\": \"ab7335db-e0bb-4e27-80c5-eea11e593a57\"\n },\n \"source\": [\n \"- As a verification step, we iterate through the data loaders and check that the batches contain 8 training examples each, where each training example consists of 120 tokens\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"4dee6882-4c3a-4964-af15-fa31f86ad047\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"4dee6882-4c3a-4964-af15-fa31f86ad047\",\n \"outputId\": \"2ae34de1-dd01-4f99-d2c8-ba4dca400754\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"Input batch dimensions: torch.Size([8, 120])\\n\",\n \"Label batch dimensions torch.Size([8])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for input_batch, target_batch in train_loader:\\n\",\n \" pass\\n\",\n \"\\n\",\n \"print(\\\"Input batch dimensions:\\\", input_batch.shape)\\n\",\n \"print(\\\"Label batch dimensions\\\", target_batch.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5cdd7947-7039-49bf-8a5e-c0a2f4281ca1\",\n \"metadata\": {\n \"id\": \"5cdd7947-7039-49bf-8a5e-c0a2f4281ca1\"\n },\n \"source\": [\n \"- Lastly, let's print the total number of batches in each dataset\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"IZfw-TYD2zTj\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"IZfw-TYD2zTj\",\n \"outputId\": \"4d19ed61-cf7a-4ec4-b822-c847dd1c5d77\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"130 training batches\\n\",\n \"19 validation batches\\n\",\n \"38 test batches\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(f\\\"{len(train_loader)} training batches\\\")\\n\",\n \"print(f\\\"{len(val_loader)} validation batches\\\")\\n\",\n \"print(f\\\"{len(test_loader)} test batches\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dec9aa4a-ffd2-4d9f-a835-cce1059fe604\",\n \"metadata\": {\n \"id\": \"dec9aa4a-ffd2-4d9f-a835-cce1059fe604\"\n },\n \"source\": [\n \"## E.3 Initializing the model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f36ebdaf-810e-46a2-9ad9-e017a04051b1\",\n \"metadata\": {\n \"id\": \"f36ebdaf-810e-46a2-9ad9-e017a04051b1\"\n },\n \"source\": [\n \"- This section repeats the code from chapter 6 to load and prepare the model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"02b3a506-3879-4258-82b5-93a5b6bafa74\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"02b3a506-3879-4258-82b5-93a5b6bafa74\",\n \"outputId\": \"b8c9b125-bb52-45d3-8071-fa5054dbf5a9\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"File already exists and is up-to-date: gpt2/124M/checkpoint\\n\",\n \"File already exists and is up-to-date: gpt2/124M/encoder.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/hparams.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.data-00000-of-00001\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.index\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.meta\\n\",\n \"File already exists and is up-to-date: gpt2/124M/vocab.bpe\\n\"\n ]\n }\n ],\n \"source\": [\n \"from gpt_download import download_and_load_gpt2\\n\",\n \"from previous_chapters import GPTModel, load_weights_into_gpt\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"# from llms_from_scratch.ch05 import load_weights_into_gpt\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"CHOOSE_MODEL = \\\"gpt2-small (124M)\\\"\\n\",\n \"INPUT_PROMPT = \\\"Every effort moves\\\"\\n\",\n \"\\n\",\n \"BASE_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"drop_rate\\\": 0.0, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": True # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\\n\",\n \"\\n\",\n \"model_size = CHOOSE_MODEL.split(\\\" \\\")[-1].lstrip(\\\"(\\\").rstrip(\\\")\\\")\\n\",\n \"settings, params = download_and_load_gpt2(model_size=model_size, models_dir=\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"load_weights_into_gpt(model, params)\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"252614cd-7ce6-4908-83e6-3761f519904e\",\n \"metadata\": {\n \"id\": \"252614cd-7ce6-4908-83e6-3761f519904e\"\n },\n \"source\": [\n \"- To ensure that the model was loaded corrected, let's double-check that it generates coherent text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"8b6ce20c-0700-4783-8be0-4cf17c200a7f\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"8b6ce20c-0700-4783-8be0-4cf17c200a7f\",\n \"outputId\": \"28ccbca5-8de9-41a0-c093-da00fcbaa91c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Every effort moves you forward.\\n\",\n \"\\n\",\n \"The first step is to understand the importance of your work\\n\"\n ]\n }\n ],\n \"source\": [\n \"from previous_chapters import (\\n\",\n \" generate_text_simple,\\n\",\n \" text_to_token_ids,\\n\",\n \" token_ids_to_text\\n\",\n \")\\n\",\n \"\\n\",\n \"\\n\",\n \"text_1 = \\\"Every effort moves you\\\"\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(text_1, tokenizer),\\n\",\n \" max_new_tokens=15,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8174b31b-1ab5-4115-b01c-245369da5af3\",\n \"metadata\": {\n \"id\": \"8174b31b-1ab5-4115-b01c-245369da5af3\"\n },\n \"source\": [\n \"- Then, we prepare the model for classification finetuning similar to chapter 6, where we replace the output layer\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e255ce91-d73a-4854-90a4-95804928eb16\",\n \"metadata\": {\n \"id\": \"e255ce91-d73a-4854-90a4-95804928eb16\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"num_classes = 2\\n\",\n \"model.out_head = torch.nn.Linear(in_features=768, out_features=num_classes)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"02e6f057-1383-4ece-8444-0a88e71ac75d\",\n \"metadata\": {\n \"id\": \"02e6f057-1383-4ece-8444-0a88e71ac75d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Device: mps\\n\"\n ]\n }\n ],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"print(\\\"Device:\\\", device)\\n\",\n \"\\n\",\n \"model.to(device); # no assignment model = model.to(device) necessary for nn.Module classes\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8e951cd6-5e42-44d2-b21f-895cb61004fe\",\n \"metadata\": {\n \"id\": \"8e951cd6-5e42-44d2-b21f-895cb61004fe\"\n },\n \"source\": [\n \"- Lastly, let's calculate the initial classification accuracy of the non-finetuned model (we expect this to be around 50%, which means that the model is not able to distinguish between spam and non-spam messages yet reliably)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"fc7dd72c-73a2-4881-ade0-0a9605f1ab8c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"fc7dd72c-73a2-4881-ade0-0a9605f1ab8c\",\n \"outputId\": \"74848515-5a49-4125-fecb-9f4bac23f812\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training accuracy: 46.25%\\n\",\n \"Validation accuracy: 45.00%\\n\",\n \"Test accuracy: 48.75%\\n\"\n ]\n }\n ],\n \"source\": [\n \"from previous_chapters import calc_accuracy_loader\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch06 import calc_accuracy_loader\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=10)\\n\",\n \"val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=10)\\n\",\n \"test_accuracy = calc_accuracy_loader(test_loader, model, device, num_batches=10)\\n\",\n \"\\n\",\n \"print(f\\\"Training accuracy: {train_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Validation accuracy: {val_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Test accuracy: {test_accuracy*100:.2f}%\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"398a1ec9-e2a1-43d6-bf9f-12ee54b46a7b\",\n \"metadata\": {\n \"id\": \"398a1ec9-e2a1-43d6-bf9f-12ee54b46a7b\"\n },\n \"source\": [\n \"## E.4 Parameter-efficient finetuning with LoRA\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"652a4a82-61ef-4d0a-9858-8988e844f12c\",\n \"metadata\": {\n \"id\": \"652a4a82-61ef-4d0a-9858-8988e844f12c\"\n },\n \"source\": [\n \"- We begin by initializing a LoRALayer that creates the matrices $A$ and $B$, along with the `alpha` scaling hyperparameter and the `rank` ($r$) hyperparameters\\n\",\n \"- This layer can accept an input and compute the corresponding output, as illustrated in the figure below\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"In code, this LoRA layer depicted in the figure above looks like as follows\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"2ds9ywjMwvIW\",\n \"metadata\": {\n \"id\": \"2ds9ywjMwvIW\"\n },\n \"outputs\": [],\n \"source\": [\n \"import math\\n\",\n \"\\n\",\n \"class LoRALayer(torch.nn.Module):\\n\",\n \" def __init__(self, in_dim, out_dim, rank, alpha):\\n\",\n \" super().__init__()\\n\",\n \" self.A = torch.nn.Parameter(torch.empty(in_dim, rank))\\n\",\n \" torch.nn.init.kaiming_uniform_(self.A, a=math.sqrt(5)) # similar to standard weight initialization\\n\",\n \" self.B = torch.nn.Parameter(torch.zeros(rank, out_dim))\\n\",\n \" self.alpha = alpha\\n\",\n \" self.rank = rank\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # Note: The original chapter didn't include the scaling by self.rank\\n\",\n \" # This scaling is not necessary, but it's more canonical and convenient\\n\",\n \" # as this lets us compare runs across different ranks without retuning learning rates\\n\",\n \" x = (self.alpha / self.rank) * (x @ self.A @ self.B)\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ad21faa8-0614-4257-93cd-68952193e14a\",\n \"metadata\": {\n \"id\": \"ad21faa8-0614-4257-93cd-68952193e14a\"\n },\n \"source\": [\n \"- In the code above, `rank` is a hyperparameter that controls the inner dimension of the matrices $A$ and $B$\\n\",\n \"- In other words, this parameter controls the number of additional parameters introduced by LoRA and is a key factor in determining the balance between model adaptability and parameter efficiency\\n\",\n \"- The second hyperparameter, `alpha`, is a scaling hyperparameter applied to the output of the low-rank adaptation\\n\",\n \"- It essentially controls the extent to which the adapted layer's output is allowed to influence the original output of the layer being adapted\\n\",\n \"- This can be seen as a way to regulate the impact of the low-rank adaptation on the layer's output\\n\",\n \"- So far, the `LoRALayer` class we implemented above allows us to transform the layer inputs $x$\\n\",\n \"- However, in LoRA, we are usually interested in replacing existing `Linear` layers so that the weight update is applied to the existing pretrained weights, as shown in the figure below\\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \"In code, this LoRA layer depicted in the figure above looks like as follows\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"2ds9ywjMwvIW\",\n \"metadata\": {\n \"id\": \"2ds9ywjMwvIW\"\n },\n \"outputs\": [],\n \"source\": [\n \"import math\\n\",\n \"\\n\",\n \"class LoRALayer(torch.nn.Module):\\n\",\n \" def __init__(self, in_dim, out_dim, rank, alpha):\\n\",\n \" super().__init__()\\n\",\n \" self.A = torch.nn.Parameter(torch.empty(in_dim, rank))\\n\",\n \" torch.nn.init.kaiming_uniform_(self.A, a=math.sqrt(5)) # similar to standard weight initialization\\n\",\n \" self.B = torch.nn.Parameter(torch.zeros(rank, out_dim))\\n\",\n \" self.alpha = alpha\\n\",\n \" self.rank = rank\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # Note: The original chapter didn't include the scaling by self.rank\\n\",\n \" # This scaling is not necessary, but it's more canonical and convenient\\n\",\n \" # as this lets us compare runs across different ranks without retuning learning rates\\n\",\n \" x = (self.alpha / self.rank) * (x @ self.A @ self.B)\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ad21faa8-0614-4257-93cd-68952193e14a\",\n \"metadata\": {\n \"id\": \"ad21faa8-0614-4257-93cd-68952193e14a\"\n },\n \"source\": [\n \"- In the code above, `rank` is a hyperparameter that controls the inner dimension of the matrices $A$ and $B$\\n\",\n \"- In other words, this parameter controls the number of additional parameters introduced by LoRA and is a key factor in determining the balance between model adaptability and parameter efficiency\\n\",\n \"- The second hyperparameter, `alpha`, is a scaling hyperparameter applied to the output of the low-rank adaptation\\n\",\n \"- It essentially controls the extent to which the adapted layer's output is allowed to influence the original output of the layer being adapted\\n\",\n \"- This can be seen as a way to regulate the impact of the low-rank adaptation on the layer's output\\n\",\n \"- So far, the `LoRALayer` class we implemented above allows us to transform the layer inputs $x$\\n\",\n \"- However, in LoRA, we are usually interested in replacing existing `Linear` layers so that the weight update is applied to the existing pretrained weights, as shown in the figure below\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3e6d5da0-dfce-4808-b89b-29ff333f563f\",\n \"metadata\": {\n \"id\": \"3e6d5da0-dfce-4808-b89b-29ff333f563f\"\n },\n \"source\": [\n \"- To incorporate the original `Linear` layer weights as shown in the figure above, we implement a `LinearWithLoRA` layer below that uses the previously implemented LoRALayer and can be used to replace existing `Linear` layers in a neural network, for example, the self-attention module or feed forward modules in an LLM\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"127d3a64-8359-4b21-b056-78d58cc75fe8\",\n \"metadata\": {\n \"id\": \"127d3a64-8359-4b21-b056-78d58cc75fe8\"\n },\n \"outputs\": [],\n \"source\": [\n \"class LinearWithLoRA(torch.nn.Module):\\n\",\n \" def __init__(self, linear, rank, alpha):\\n\",\n \" super().__init__()\\n\",\n \" self.linear = linear\\n\",\n \" self.lora = LoRALayer(\\n\",\n \" linear.in_features, linear.out_features, rank, alpha\\n\",\n \" )\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" return self.linear(x) + self.lora(x)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1145a90-35ff-462c-820b-15483fa5b051\",\n \"metadata\": {\n \"id\": \"e1145a90-35ff-462c-820b-15483fa5b051\"\n },\n \"source\": [\n \"- Note that since we initialize the weight matrix $B$ (`self.B` in `LoRALayer`) with zero values in the LoRA layer, the matrix multiplication between $A$ and $B$ results in a matrix consisting of 0's and doesn't affect the original weights (since adding 0 to the original weights does not modify them)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e98a6d36-7bc9-434c-a7f1-533f26aff06d\",\n \"metadata\": {\n \"id\": \"e98a6d36-7bc9-434c-a7f1-533f26aff06d\"\n },\n \"source\": [\n \"- To try LoRA on the GPT model we defined earlier, we define a `replace_linear_with_lora` function to replace all `Linear` layers in the model with the new `LinearWithLoRA` layers\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3e6d5da0-dfce-4808-b89b-29ff333f563f\",\n \"metadata\": {\n \"id\": \"3e6d5da0-dfce-4808-b89b-29ff333f563f\"\n },\n \"source\": [\n \"- To incorporate the original `Linear` layer weights as shown in the figure above, we implement a `LinearWithLoRA` layer below that uses the previously implemented LoRALayer and can be used to replace existing `Linear` layers in a neural network, for example, the self-attention module or feed forward modules in an LLM\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"127d3a64-8359-4b21-b056-78d58cc75fe8\",\n \"metadata\": {\n \"id\": \"127d3a64-8359-4b21-b056-78d58cc75fe8\"\n },\n \"outputs\": [],\n \"source\": [\n \"class LinearWithLoRA(torch.nn.Module):\\n\",\n \" def __init__(self, linear, rank, alpha):\\n\",\n \" super().__init__()\\n\",\n \" self.linear = linear\\n\",\n \" self.lora = LoRALayer(\\n\",\n \" linear.in_features, linear.out_features, rank, alpha\\n\",\n \" )\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" return self.linear(x) + self.lora(x)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1145a90-35ff-462c-820b-15483fa5b051\",\n \"metadata\": {\n \"id\": \"e1145a90-35ff-462c-820b-15483fa5b051\"\n },\n \"source\": [\n \"- Note that since we initialize the weight matrix $B$ (`self.B` in `LoRALayer`) with zero values in the LoRA layer, the matrix multiplication between $A$ and $B$ results in a matrix consisting of 0's and doesn't affect the original weights (since adding 0 to the original weights does not modify them)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e98a6d36-7bc9-434c-a7f1-533f26aff06d\",\n \"metadata\": {\n \"id\": \"e98a6d36-7bc9-434c-a7f1-533f26aff06d\"\n },\n \"source\": [\n \"- To try LoRA on the GPT model we defined earlier, we define a `replace_linear_with_lora` function to replace all `Linear` layers in the model with the new `LinearWithLoRA` layers\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"WlQZ8ygqzN_g\",\n \"metadata\": {\n \"id\": \"WlQZ8ygqzN_g\"\n },\n \"outputs\": [],\n \"source\": [\n \"def replace_linear_with_lora(model, rank, alpha):\\n\",\n \" for name, module in model.named_children():\\n\",\n \" if isinstance(module, torch.nn.Linear):\\n\",\n \" # Replace the Linear layer with LinearWithLoRA\\n\",\n \" setattr(model, name, LinearWithLoRA(module, rank, alpha))\\n\",\n \" else:\\n\",\n \" # Recursively apply the same function to child modules\\n\",\n \" replace_linear_with_lora(module, rank, alpha)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c172164-cdde-4489-b7d7-aaed9cc2f5f2\",\n \"metadata\": {\n \"id\": \"8c172164-cdde-4489-b7d7-aaed9cc2f5f2\"\n },\n \"source\": [\n \"- We then freeze the original model parameter and use the `replace_linear_with_lora` to replace the said `Linear` layers using the code below\\n\",\n \"- This will replace the `Linear` layers in the LLM with `LinearWithLoRA` layers\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"dbe15350-4da9-4829-9d23-98bbd3d0b1a1\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dbe15350-4da9-4829-9d23-98bbd3d0b1a1\",\n \"outputId\": \"fd4c208f-854a-4701-d9d3-9d73af733364\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total trainable parameters before: 124,441,346\\n\",\n \"Total trainable parameters after: 0\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable parameters before: {total_params:,}\\\")\\n\",\n \"\\n\",\n \"for param in model.parameters():\\n\",\n \" param.requires_grad = False\\n\",\n \"\\n\",\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable parameters after: {total_params:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"mLk_fPq0yz_u\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"mLk_fPq0yz_u\",\n \"outputId\": \"0a93b8fc-05d7-4ace-ee47-e2fc6bdd7d75\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total trainable LoRA parameters: 2,666,528\\n\"\n ]\n }\n ],\n \"source\": [\n \"replace_linear_with_lora(model, rank=16, alpha=16)\\n\",\n \"\\n\",\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable LoRA parameters: {total_params:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b8b6819e-ef7a-4f0d-841a-1b467496bef9\",\n \"metadata\": {\n \"id\": \"b8b6819e-ef7a-4f0d-841a-1b467496bef9\"\n },\n \"source\": [\n \"- As we can see, we reduced the number of trainable parameters by almost 50x when using LoRA\\n\",\n \"- Let's now double-check whether the layers have been modified as intended by printing the model architecture\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"1711be61-bb2c-466f-9b5b-24f4aa5ccd9c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"1711be61-bb2c-466f-9b5b-24f4aa5ccd9c\",\n \"outputId\": \"acff8eca-3775-45a2-b62d-032a986ef037\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"GPTModel(\\n\",\n \" (tok_emb): Embedding(50257, 768)\\n\",\n \" (pos_emb): Embedding(1024, 768)\\n\",\n \" (drop_emb): Dropout(p=0.0, inplace=False)\\n\",\n \" (trf_blocks): Sequential(\\n\",\n \" (0): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (1): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (2): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (3): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (4): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (5): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (6): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (7): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (8): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (9): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (10): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (11): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): LayerNorm()\\n\",\n \" (out_head): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=2, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \")\\n\"\n ]\n }\n ],\n \"source\": [\n \"model.to(device)\\n\",\n \"\\n\",\n \"print(model)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c4bbc9d7-65ec-4675-bab8-2e56eb0cfb55\",\n \"metadata\": {\n \"id\": \"c4bbc9d7-65ec-4675-bab8-2e56eb0cfb55\"\n },\n \"source\": [\n \"- Based on the model architecture above, we can see that the model now contains our new `LinearWithLoRA` layers\\n\",\n \"- Also, since we initialized matrix $B$ with 0's, we expect the initial model performance to be unchanged compared to before\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"DAlrb_I00VEU\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"DAlrb_I00VEU\",\n \"outputId\": \"3da44ac4-230b-4358-d996-30b63f0d962a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training accuracy: 46.25%\\n\",\n \"Validation accuracy: 45.00%\\n\",\n \"Test accuracy: 48.75%\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=10)\\n\",\n \"val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=10)\\n\",\n \"test_accuracy = calc_accuracy_loader(test_loader, model, device, num_batches=10)\\n\",\n \"\\n\",\n \"print(f\\\"Training accuracy: {train_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Validation accuracy: {val_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Test accuracy: {test_accuracy*100:.2f}%\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"13735b3e-f0c3-4dba-ae3d-4141b2878101\",\n \"metadata\": {\n \"id\": \"13735b3e-f0c3-4dba-ae3d-4141b2878101\"\n },\n \"source\": [\n \"- Let's now get to the interesting part and finetune the model by reusing the training function from chapter 6\\n\",\n \"- The training takes about 15 minutes on a M3 MacBook Air laptop computer and less than half a minute on a V100 or A100 GPU\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"wCParRvr0eff\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"wCParRvr0eff\",\n \"outputId\": \"ce910a9c-ee89-48bb-bfa6-49c6aee1e450\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ep 1 (Step 000000): Train loss 3.820, Val loss 3.462\\n\",\n \"Ep 1 (Step 000050): Train loss 0.346, Val loss 0.325\\n\",\n \"Ep 1 (Step 000100): Train loss 0.063, Val loss 0.144\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 92.50%\\n\",\n \"Ep 2 (Step 000150): Train loss 0.054, Val loss 0.045\\n\",\n \"Ep 2 (Step 000200): Train loss 0.058, Val loss 0.122\\n\",\n \"Ep 2 (Step 000250): Train loss 0.041, Val loss 0.199\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 95.00%\\n\",\n \"Ep 3 (Step 000300): Train loss 0.020, Val loss 0.153\\n\",\n \"Ep 3 (Step 000350): Train loss 0.017, Val loss 0.186\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 95.00%\\n\",\n \"Ep 4 (Step 000400): Train loss 0.017, Val loss 0.099\\n\",\n \"Ep 4 (Step 000450): Train loss 0.001, Val loss 0.170\\n\",\n \"Ep 4 (Step 000500): Train loss 0.117, Val loss 0.222\\n\",\n \"Training accuracy: 97.50% | Validation accuracy: 92.50%\\n\",\n \"Ep 5 (Step 000550): Train loss 0.038, Val loss 0.235\\n\",\n \"Ep 5 (Step 000600): Train loss 0.019, Val loss 0.252\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 100.00%\\n\",\n \"Training completed in 2.16 minutes.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import time\\n\",\n \"from previous_chapters import train_classifier_simple\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch06 import train_classifier_simple\\n\",\n \"\\n\",\n \"\\n\",\n \"start_time = time.time()\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"optimizer = torch.optim.AdamW(model.parameters(), lr=8e-4, weight_decay=0.1)\\n\",\n \"\\n\",\n \"num_epochs = 5\\n\",\n \"train_losses, val_losses, train_accs, val_accs, examples_seen = train_classifier_simple(\\n\",\n \" model, train_loader, val_loader, optimizer, device,\\n\",\n \" num_epochs=num_epochs, eval_freq=50, eval_iter=5,\\n\",\n \")\\n\",\n \"\\n\",\n \"end_time = time.time()\\n\",\n \"execution_time_minutes = (end_time - start_time) / 60\\n\",\n \"print(f\\\"Training completed in {execution_time_minutes:.2f} minutes.\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7b7410ae-ed73-4f89-9cfa-0893312fe9c7\",\n \"metadata\": {},\n \"source\": [\n \"- The runtime on different devices is as follows\\n\",\n \" - 12.10 minutes on a MacBook M1 (CPU)\\n\",\n \" - 2.16 minutes on a MacMini M4 Pro (MPS)\\n\",\n \" - 3.50 minutes on a Jetson Nano (CUDA), [shared](https://livebook.manning.com/forum?product=raschka&comment=581806) by a reader\\n\",\n \" - 1.02 minutes on a DGX Spark (CUDA)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d0c89e82-3aa8-44c6-b046-0b16200b8e6c\",\n \"metadata\": {\n \"id\": \"d0c89e82-3aa8-44c6-b046-0b16200b8e6c\"\n },\n \"source\": [\n \"- Finally, let's evaluate the model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"bawWGijA0iF3\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 308\n },\n \"id\": \"bawWGijA0iF3\",\n \"outputId\": \"af70782a-d605-4376-fa6c-d33b38979cfa\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAeoAAAEiCAYAAAA21pHjAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAARZ5JREFUeJzt3Qd4FOXaBuBnN5UEEloSCITeW+hIE6QjFjgqHuUgciy/CogiFo5K0aNgx4JYUNEjCoKCiBQRBKRJDZ0gLSRASCCk92T+6/12Z7MbQkggyc4mz31lrik7uzs7O9l3vm7SNE0DERERGZLZ2QdAREREV8dATUREZGAM1ERERAbGQE1ERGRgDNREREQGxkBNRERkYAzUREREBsZATUREZGAM1ERERAbGQE1EDvr27YunnnqKZ4XIIBioiUrYgw8+CJPJdMU0ZMgQnmsiKjb34j+FiK5FgvJXX33lsM3Ly4snjoiKjSlqolIgQblWrVoOU7Vq1dRjGzZsgKenJ/7880/b/m+++SYCAwNx4cIFtb569Wr06tULVatWRY0aNXDbbbfhxIkTtv1Pnz6tUuk//PADevfujUqVKqFLly44duwYdu7cic6dO6Ny5coYOnQoYmNjHVL7w4cPx4wZMxAQEAA/Pz889thjyMzMvOpnycjIwOTJk1GnTh34+vqiW7du6jPoIiIicPvtt6vPJ4+3bt0aK1euvOrrffzxx2jatCm8vb0RFBSEu+++2/ZYbm4uZs6ciYYNG6rPFBoaiiVLljg8/+DBg+pzyeeT548ePRoXL150yLp/8skn8dxzz6F69erq3E+fPr1I3xuRETFQEzmpDFgCTEJCAvbu3YuXX34Z8+bNU4FHpKSkYNKkSdi1axfWrVsHs9mMESNGqEBmb9q0aXjppZewZ88euLu74/7771cB6v3331c3AsePH8fUqVMdniOvd+TIERVsv//+e/z0008qcF/N+PHjsW3bNixcuBD79+/HPffco3IM/v77b/X4uHHjVDDftGkTDhw4gDfeeEMF0YLI55Eg+sorryA8PFzdkNx88822xyVIf/PNN/jkk09w6NAhPP300/jXv/6FjRs3qsfj4+PRr18/dOjQQb2WPF9ubkaOHOnwPl9//bW6afjrr7/UTZC839q1a4v9XREZggxzSUQlZ8yYMZqbm5vm6+vrML322mu2fTIyMrT27dtrI0eO1Fq1aqU98sgjhb5mbGysDEerHThwQK2fOnVKrc+bN8+2z/fff6+2rVu3zrZt5syZWvPmzR2OrXr16lpKSopt29y5c7XKlStrOTk5ar1Pnz7axIkT1XJERIT6LGfPnnU4nv79+2tTpkxRy23bttWmT59epHPz448/an5+flpiYuIVj6Wnp2s+Pj7a1q1bHbY/9NBD2n333aeWX331VW3QoEEOj0dGRqrPHR4ebjv+Xr16OezTpUsX7fnnny/SMRIZDcuoiUrBLbfcgrlz5zpsk2xYnWR9L1iwAO3atUP9+vXx3nvvOewrqVVJCUuKULJ19ZT0mTNn0KZNG9t+8nydnhpv27atw7aYmBiH15bsZB8fH9t69+7dkZycjMjISHUs9iSFnJOTg2bNmjlslxS0ZMkLSSE//vjj+O233zBgwADcddddDsdlb+DAgeo9GjVqpFLlMklOgRyPpP5TU1PVPvYkW15S0GLfvn34448/CkyxS9GAfpz537927dpXnAciV8FATVQKJNu1SZMmhe6zdetWNY+Li1OTPEcnZb4S0D7//HMEBwerQC0BOn9ZsoeHh21ZyqwL2pY/u7w4JIC7ublh9+7dam5PD5YPP/wwBg8ejF9//VUFa8m+fueddzBhwoQrXq9KlSoqm16y3WVfuRmR8mMpV5f3EvI6Uh5eUEU82UfOjWSv5yfBuKDzUhLngciZGKiJnEBSf1L+KoF40aJFGDNmDH7//XdVFn3p0iVVfiuPSUUxsXnz5hJ7b0mVpqWlqcpaYvv27SrohoSEXLGvpGQlRS2pUf1YCiLPlUppMk2ZMkUde0GBWkhZuqS8ZZIydqkwt379epWSloAsuQZ9+vQp8LkdO3bEjz/+iAYNGqjXIaoIeKUTlQLJGo6Ojnb8Z3N3R82aNVXgkwpSkgodO3asyv6V7GpJhT777LOq9rRkK3/22WcqlSiB64UXXiixY5NU+UMPPaQqoUntcQmWUmFMbhLyk6zkUaNG4YEHHlDHJ4FbapFLhTTJXh42bJiqGCe1sGXfy5cvq6zpli1bFvjeK1aswMmTJ1UFMvmcUjtcUrrNmzdXqW2pXS43MLJNar1LZbstW7ao2ulyMyMV1+Qm4L777rPV6pYsc6noJpXx8qf6icoDBmqiUiC1ke2zYoUEo6NHj+K1115TTZokaAnZT4KyBJ9BgwapMmQJPFL2K9nd8rwPPvhA1RYvCf3791fNoyRYyg2FvG9hzZekPfh///tfPPPMMzh79qy62bjppptUkzEhNx4SQKOiolRAlRuP/GXuOkk9Sy1zeb/09HR1HFLzXJp0iVdffVU1G5Pscwnosr+kov/zn/+ox6UYQAL3888/r86VHL8UEch7FnSjQVQemKRGmbMPgojKhrSjliZOy5Yt4yknchG8BSUiIjIwBmoiIiIDY9Y3ERGRgTFFTUREZGAM1ERERAbGQE1ERGRgDNRWc+bMUb0dydB7Mozfjh07UN7JaEfSHaO0TZUuFvM32ZGWe9LFo7TzlV6spCcpfcQknXR9KR1iSPtZafMqHWnoXUHqZMQl6dVKzq30YCWjGbkaadcrw0hKpxwyHKUMFSm9h9mTdsHSnlg6K5GevqTPa33YSp10XiKdhEjf1vI60sFJdna2wz7Svaa0HZZeuqQb0vnz58PVSD/n0iGKXBcySX/iq1atsj3Oc3V1s2bNUv+P0pEMz9eVpA2+nB/7qUWLFuX7XDl7VBAjWLhwoebp6al9+eWX2qFDh9RIRlWrVtUuXLiglWcrV67UXnzxRe2nn35Sow8tXbrU4fFZs2Zp/v7+2rJly7R9+/Zpd9xxh9awYUMtLS3Nts+QIUO00NBQbfv27dqff/6pNWnSxDbSkUhISNCCgoK0UaNGaQcPHlQjPFWqVEn79NNPNVcyePBg7auvvlKfISwsTLv11lu1evXqacnJybZ9HnvsMS0kJESNXrVr1y7tpptu0nr06GF7PDs7W2vTpo02YMAAbe/ever816xZ0zYKlTh58qQaQWrSpEna4cOHtQ8//FCNXrV69WrNlSxfvlz79ddftWPHjqlRrf7zn/9oHh4e6vwJnquC7dixQ2vQoIHWrl072whmPF+Opk2bprVu3Vo7f/68bZLR5XTl8dpioNY0rWvXrtq4ceNsJ0WG+wsODlZDBFYU+QN1bm6uVqtWLe2tt96ybYuPj9e8vLxUsBVyAcvzdu7cadtn1apVmslksg2L+PHHH2vVqlVTwzrqZLhB+6EXXVFMTIz67Bs3brSdGwlEixcvtu1z5MgRtc+2bdvUuvwgmM1mLTo62mGISRn2UT8/zz33nPoRsnfvvfeqGwVXJ9eBDMvJc1WwpKQkrWnTptratWsdhhrl+boyUEvioCDl9VxV+Kxv6fdYRgaSbF2ddEUo69u2bUNFderUKdVXtf158ff3V8UC+nmRuWR3d+7c2baP7C/nT4Zn1PeRriplWEed9HEt2cbSL7Srkj6o7YeulGsoKyvL4XxJdly9evUczpf06a0PR6mfi8TERBw6dMi2j/1r6Pu48rUoXYxKl6gpKSkqC5znqmCSXSvZsfm/f56vK0kRnBTZyXCpUvQmWdnl+VxV+EAtY/3KD4n9lyZkPf+gChWJ/tkLOy8yl/Kd/ANPSPCy36eg17B/D1cjA0ZI+WHPnj1tY0PLZ5GbEblxKex8XetcXG0f+RGREa9ciYxlLWWEUsYno2otXboUrVq14rkqgNzIyPCfUhciP15bjiSxIOXF0p++1IWQRIXUgUlKSiq354qDchBdR8rn4MGDJTr0ZHkkg4mEhYWp3IclS5ao0a82btzo7MMynMjISEycOBFr165VFS6pcEOHDrUtS4VFCdwyMMsPP/xgG7q1vKnwKWoZCUiGxstfK1DWa9WqhYpK/+yFnReZyzjF9qTmpNQEt9+noNewfw9XIsNByqhXMpRj3bp1bdvls0gxigx4Udj5uta5uNo+UnPa1X6EJGUjtWU7deqkUooyKtj777/Pc5WPZNfK/5HUMJYcKZnkhkZGTJNlScnx2ro6ST3LEKsy3Gl5/T+s8IFafkzkh0TG17XP2pR1KU+rqBo2bKguVvvzItk+UvasnxeZyz+E/NDo1q9fr86f3OXq+0gzMCk30knKQVJbMh6xq5D6dhKkJftWPqOcH3tyDXl4eDicLymHl7Iz+/Ml2cH2NzdyLuSfX7KE9X3sX0Pfpzxci3JdyLCUPFdXDjsq14XkPuiT1PuQsld9mdfW1Ulz0BMnTqhmpOX22nJKFTYDNs+S2szz589XNZkfffRR1TzLvlZgeSS1TKV5gkxyKbz77rtqOSIiwtY8S87Dzz//rO3fv1+78847C2ye1aFDB+2vv/7SNm/erGqt2jfPklqY0jxr9OjRqmmOnGtp9uBqzbMef/xx1VRtw4YNDs1CUlNTHZqFSJOt9evXq2Yh3bt3V1P+ZiGDBg1STbykqUdAQECBzUKeffZZVVt1zpw5Ltk864UXXlA14k+dOqWuHVmX1gC//fabepznqnD2tb55vhw988wz6v9Qrq0tW7aoZlbSvEpaYpTXa4uB2kraycmXK+2ppbmWtAsu7/744w8VoPNPY8aMsTXRevnll1WglRuZ/v37qzax9i5duqQCc+XKlVXzhrFjx6obAHvSBrtXr17qNerUqaNuAFxNQedJJmlbrZMbmCeeeEI1Q5J/8hEjRqhgbu/06dPa0KFDVVty+XGRH52srKwrvpf27dura7FRo0YO7+Eq/v3vf2v169dXn0F+BOXa0YO04LkqXqDm+XJsJlW7dm11bcnviawfP368XJ8rjp5FRERkYBW+jJqIiMjIGKiJiIgMjIGaiIjIwBioiYiIDIyBmoiIyMAYqImIiAyMgdqO9Jokg5LLnArHc1U8PF88V6WF11b5P1eGaUc9a9YsTJkyRXVOP3v2bKccg3SRKUM5yiAC0p0c8Vzx2uL/odHxd6v8nytDpKh37tyJTz/9VI2EQkRERAYK1NKhunQ+//nnn7vUIA1EREQVYjxqGdt32LBhGDBgAP773/8W67kypOLevXvVMHBm843fc8jA4+Ls2bMqi4R4rkoKry2eq9LCa8s1z5WMJidDZ3bo0EENZ1oYpwbqhQsXYs+ePSrruyikAoB9JQAZXrFfv34lflz6UGfEc8Vry3n4f8jzVRGurR07dqBLly7GDNSRkZGq4piM8ent7V2k58jg8zNmzCjwg8pYpERERK7g/Pnz6Nq1q8oRNmyt72XLlmHEiBFwc3OzbcvJyYHJZFLZ2JJytn+soBS1ZF/InZEE/bp165bp8RMREV2vqKgohISEFCl+OS1F3b9/fxw4cMBh29ixY9GiRQs8//zzVwRp4eXlpSads8sYiIiISpvTAnWVKlXQpk0bh22+vr6oUaPGFduJiIgqKqc3zyIiIiIDN8+yt2HDBmcfAhFVcFJXJisry9mHQS7Ow8OjwCJclw/UzpSSkY19kfHIztVwc7MAZx8OEZUxqVcbHR2N+Ph4nnsqEVWrVkWtWrVUJekbwUBttf5oDCZ8vxft6vozUBNVQHqQDgwMhI+Pzw3/uFLFvulLTU1FTEyMWr/R5sMM1FbtQ6qq+ZHziUjPyoG3R8lkWRCRa2R360FaKrQS3ahKlSqpuQRrua5uJBuclcms6larhBq+nsjK0XD4PJt9EVUkepm0pKSJSop+Pd1onQcGaivJ5gq1pqqlrJqIKh5md5MRrycG6gKyvxmoiYjIKBio7egp6jCmqImoAmvQoAFmz55drKa1knos7Rrz8+fPVzWpKxoGajuhdf3V/PSlVMSnZjrrOyEiKhIJjoVN06dPv64zKSMaPvroo0Xev0ePHmqQCX9/y28olSzW+rZT1ccTDWv64tTFFOyLSkAftqcmIgOT4KhbtGgRpk6divDwcNu2ypUrOzQZktrt1xr7WAQEFK8vCU9PT9VemEoHU9RXSVWHnWGFMiIyNgmO+iSpWUlF6+tHjx5VYyqsWrUKnTp1UgMabd68GSdOnMCdd96phleUQC5jIf/++++FZn3L686bN0+NeCg1mZs2bYrly5dfNetbz6Jes2YNWrZsqd5nyJAhDjcW2dnZePLJJ9V+0iROBmMaM2YMhg8fXqxzMHfuXDRu3FjdLDRv3hz/+9//HG5OJFehXr166vMHBwer99R9/PHH6rPIUMtyPu6++24YEQN1Praa31EM1ESo6J1WZGY7ZSrJ0YdfeOEFzJo1C0eOHEG7du2QnJyMW2+9FevWrcPevXtVAL399ttx5syZQl9nxowZGDlyJPbv36+eP2rUKMTFxV11f+nw4+2331aBc9OmTer1J0+ebHv8jTfewIIFC/DVV19hy5YtajREGf64OJYuXYqJEyfimWeewcGDB/F///d/ahTGP/74Qz3+448/4r333sOnn36Kv//+W71+27Zt1WO7du1SQfuVV15RuRCrV6/GzTffDCNi1nchNb/ln4XNNYgqprSsHLSausYp7334lcHw8SyZn2cJRAMHDrStV69eHaGhobb1V199VQU8SSGPHz/+qq/z4IMP4r777lPLr7/+Oj744APs2LFDBfqCSNvhTz75RKV2hby2HIvuww8/xJQpU1QqXXz00UdYuXJlsT7b22+/rY7riSeeUOuTJk3C9u3b1fZbbrlF3RxI7sKAAQNU39uSsu7atavaVx6TERtvu+02lfNQv359dOjQAUbEFHU+LWv7wcPNhEspmYi6nOacb4WIqIR07tzZYV1S1JKylSxpyXaWbGlJbV8rRS2pcZ0EOD8/P1sXmQWRLHI9SOvdaOr7JyQk4MKFC7agKaTnLsmiL44jR46gZ8+eDttkXbaLe+65B2lpaWjUqBEeeeQRdUMiWe5Cbl4kOMtjo0ePVql7yQUwIqao85GuQyVY749KUM20QqqzpyKiiqiSh5tK2TrrvUuKBFV7EqTXrl2rUp1NmjRRXV1K2WxmZuEtXSRFak9yG3Nzc4u1f0lm6RdFSEiIytaWMnj5zJLyfuutt7Bx40aVit6zZ48qX//tt99URTwpz5Ya70ZrAsYUdQHY8QkRSWCR7GdnTKVZ5CblwZJdLFnOUl4rWcOnT58u0y9cKr5J5S0JijqpkS6BszhatmypPo89WW/VqpVtXW5EpAxesuolKG/btg0HDhxQj0kNeMkWf/PNN1XZu5yH9evXw2iYoi5AaF25m4pgxydEVO5ILeeffvpJBS+5IXj55ZcLTRmXlgkTJmDmzJkqVd+iRQtVZn358uVi3aQ8++yzqoKblC1LwP3ll1/UZ9NrsUvtc7kB6Natm8qK//bbb1XglizvFStW4OTJk6oCWbVq1VT5uJwHqTluNAzUhdT8PnguAVk5ufBwY8YDEZUP7777Lv7973+rTkpq1qypmkVJjeuyJu8rQ4s+8MADqnxaOlgZPHhwsUaZGj58ON5//32VjS+1vxs2bKhqkfft21c9LlnYUuNdKplJwJYcBAnm0hxMHpOgLtnd6enp6gbm+++/R+vWrWE0Jq2sCw1KUFRUlCqDiIyMRN26dW/sxbIzgIitwKXjyO38MEJf+Q1J6dn49cleaB3M3naIyjP5oT516pT6oZc2tVT2JDUrWdmSQpaa6OX9uooqRvxiilqXdhn4nzS0N8HcbqTK/t58/KLK/magJiIqWREREaoSV58+fZCRkaGaZ0lQu//++3mq82Gerq5KLaBaQ+nmAIjcidAQSyqaI2kREZU8s9msypClZzRpUiUVvKRsWVLV5Igpanv1ugOXTwFntqF9iKVD+n2RCflOGRER3SjJ9s1fY5sKxhS1vXo3WeZnttv6/D4Wk4TkDEsDeSIiorLGQG2vfg/L/OwuBPqYEOzvDalqdyCKqWoiInIOBmp7NZoAPjWA7HTg/D60r8cBOoiIyLkYqO1JQ3sppxZntlk7PuGQl0RE5DwM1IWVU3PISyIicjIG6vxsKertaBtcBWYTcD4hHRcS08v+2yEiogqPgTq/Wu0A90pAWhx8k06hWVAVtVk6PiEiKo+ky82nnnrKtt6gQQPMnj270OdIn9zLli274fcuqdcpjHQT2r59e7gqBur83D2ButbxWyO22sqp2fEJERmNDKwxZMiQAh/7888/VRCUUaGKS0a1kr63yyJYnj9/HkOHDi3R9ypvGKivkf3Nmt9EZFQPPfSQGmdZ+o3OTwan6Ny5M9q1a1fs1w0ICFCjTZUFGWbTy8urTN7LVTFQF6Rhb6BRX5Wy1lPU+yMTkJvrsuOXEFE5dNttt6mgKl1x2ktOTsbixYtVIL906RLuu+8+1KlTRwVfGUFKRokqTP6s77///lsNBykDS8hYz3JzUNBoWM2aNVPv0ahRIzV8ZlZWlnpMjm/GjBnYt2+fSuXLpB9z/qxv6Uq0X79+ajhKGeXq0UcfVZ9HJ2Npy6hZMmJW7dq11T7jxo2zvVdRBwB55ZVX1GAYcpMgKf3Vq1fbHs/MzMT48ePV68tnlmExZUhOIeNYSe5AvXr11HODg4Px5JNPojSxC9GCNLzZMgFolpOLSh5uSMrIxsmLyWgSaCmzJqIKIjOl+M9x8wLcrD+vOdlATgZgMgMela79up6+RX4bd3d3NUykBL0XX3zRNpazBGkZ1lECtAS5Tp06qUDq5+eHX3/9FaNHj0bjxo3RtWvXIgW1f/zjHwgKCsJff/2FhIQEh/JsXZUqVdRxSOCSYPvII4+obc899xzuvfdeHDx4UAVDfaxof/8rRyVMSUlRQ112795dZb/HxMTg4YcfVkHT/mbkjz/+UEFU5sePH1evL8FW3rMoZGjMd955B59++qkay/rLL7/EHXfcgUOHDqnhLj/44AMsX74cP/zwgwrIMsKVTOLHH3/Ee++9h4ULF6ohMWWoTrkBKU0M1Nc6QW5mtK3jjx2n4xAWmcBATVTRvB5c/OfcMx9oPcKyfPQXYPGDQP1ewNhf8/aZ3RZIvXTlc6cXrydEGVv6rbfewsaNG23jMEu291133aWCoUyTJ0+27T9hwgSsWbNGBaGiBGoJrEePHlXPkSAsXn/99SvKlV966SWHFLm8pwQzCdSSOq5cubK6sZCs7qv57rvv1NCQ33zzDXx9LTcsH330kSqLf+ONN9TNgqhWrZraLmNXt2jRAsOGDcO6deuKHKglNS43Lv/85z/Vury2BH3JRZgzZw7OnDmjAnavXr3UzY+kqHXymHyGAQMGwMPDQwXyopzHG8Gs78IkxwDRB2wjaYVFXi7VL4OIqLgkUPXo0UOlCoWkMKUimWR7C0lZy/jOkuVdvXp1FTAl6ErAKYojR46oATT0IC0kxZvfokWL1ChYEsTkPSRwF/U97N8rNDTUFqRFz549Vao+PDzctk1SshKkdZK6ltR3USQmJuLcuXPqde3Jury/nr0eFhaG5s2bq2xtGY5Td8899yAtLU1l78uNwdKlS5GdnV1+U9Rz585V0+nTp20nf+rUqcaoARi+Gvj+XtVcK7THIrWJI2kRVUD/OXd9Wd+6FrdbXkOyvu09dQAlRYKypJQlNSipacnWlnGehaS2JatXUosSrCUISta1lMOWlG3btmHUqFGqHFqyriUVL6lpyV4uDR4eHg7rkuqVYF5SOnbsqMbGXrVqlcpRGDlypEpBL1myRN20yE2DbJey+ieeeMKWo5H/uMpFiloK8mfNmoXdu3dj165dqgLBnXfeqcoJnK52qHz9anzq9sGWu7sj5xORnpXj7CMjorIkZcbFnfTyaSHLss2+fLqw170OEkhkfGfJOpZsY8kO18urZShJ+V3917/+pVKrkhI8duxYkV9bxoeW8llpRqXbvn27wz5bt25V2cNSTi41zSXbOCIiwvHjenqq1P213kvKe6WsWrdlyxb12SR1WxKknF5yB/IPsSnrUlHOfj8p+/78889VboGUTcfFxanHJCtfsuOlLHvDhg3qRkXK5ctlilo+qL3XXntNpbDlIpDUtVP51QZeiAC8/VFH01CzsicuJmfi0LlEdKpfzbnHRkRkR7KaJahMmTJFZe1K1q1OgqakBCWYStnuu+++iwsXLjgEpcJISlJqc48ZM0alHOX1JSDbk/eQbG5JRXfp0kVVWJMsYXtSbi2pVMlSlkSaVDTL3yxLUuXTpk1T7yU1q2NjY1VOgVR+08unS8Kzzz6r3kdyHqQSmuRCyHEtWLBAPS7nSLLTpaKZ3CRI5TzJ0q9ataqq1CY3HN26dVM13L/99lsVuO3LscttGbV8cPmS5U6qoPIPkZGRoS4SfUpKSirdg/K2lE3LnSk7PiEiI5Ps78uXL6usZ/vyZCkrlqxc2S6VzSTgSPOmopJAJUFXymWl0pTUwpZElT2pMf3000+r2tkS+OSmQJpn2ZPKbdI5yy233KKalBXUREwCn5SfS8pVAv7dd9+N/v37q4pjJUnKnSdNmoRnnnlGFQdIbXSp5S03HEJuIt58802VOyDHIcWzK1euVOdCgrWksqVMW9qoSxb4L7/8opqJlRaTJo3CnEiyCyQwS00/uSuUrJtbb721wH3lDkvKQPKTbBm5Qys1uTn48I+TeGftMdzZPhjv/7ND6b0XEZU5+f2R1F7Dhg1Vu1mi0r6upJMaKe8uSvxyeopayh0ky0Ha5z3++OMqy+Pw4cMF7ivZOtKGT5+utl+JSY0DvroVeLMR2gdbeulhV6JERFSWnN6OWioYNGnSRC1Lo3xp5C41FKUhen5SnmFfpiHZ36WqUjUg5giQHo8OHpZmBqcvpeJySiaq+XqW7nsTEREZIUWdn1Sxl7JoQ5Bak9bxqStf2IlGNS01MvdFcSQtIiKqAIFasrI3bdqkCuqlrFrWpaq71Pwz4gAdoSH6SFrF6zmIiIjIJbO+pScZ6adW2udJA3mpQSc1/gYOHOjMw7pKoN6G0J5VsHQveygjIqIKEqi/+OILGJ50fOLuDaTFoZu/pbH7vqgENYKK3qEAEZUPJdm7FVFuCV1PTq9MZnjunkCdzkDEZjRJOwAPt1qIS8lE1OU0hFQvm/Faiaj0K7VKG1npA1ra+Mo6b8TpeklCTrpolQ5b5LqS6+lGMFAXhVQoi9gMj7M70Kr2v1SKem9kPAM1UTkhP6bS1lWK4SRYE5UE6cBFRteS6+tGMFAXs5y6fYPxKlBLe+o7Qq9j+DsiMiRJ9ciPqoyEdK0+qYmuRUb3kmE9SyJnhoG6KEK6Wka+uXwa3bpk4mt2fEJULsmPqoyAVFqjIBGVi3bUhuTtBwRZBgnpiKNqfuBsArJyWPGEiIhKFwN1MbO/g+L3ws/bHRnZuQiPLuVBQYiIqMJjoC4qaw9lpqhdeR2fsIcyIiIqZQzURdW4HzB2lZr0IS/DzrArUSIiKl2sTFacATrq91CL7ZmiJiKiMsIU9XVoF+Kv5n/HJCM5I7ukvxMiIiIbBuriiDsJrHwWgRueR52qlaBpwH6WUxMRUSlioC6OnCxgx2fAvkXoWLey2sSRtIiIqDQxUBdHzWZAjwnAiLkIrVtFbZIeyoiIiEoLK5MVh3QFN+i/arHtyUsATiKMgZqIiEoRU9TXqW1df5hNQHRiOqIT0kv2WyEiIrJioC6unGzg9Gb47PgIzQKt5dSsUEZERKWEgbq4tFzg27uA36dhQJClC1FmfxMRUWlhoC4ud0+gTme1eLPXcTVnhTIiIiotDNQ30O93s4wDar4/KgG5uVqJfjFERESCgfoGRtLyj92NSh5uqneyE7HJvKKIiKjEMVBfj5Au0lYLpsun0Lu2pQtRllMTEVFpYKC+Ht7+QFAbtTjEL0LNWfObiIhKAwP1DZZTd9COqjlT1EREVBoYqK9XfUs5dZ2kMDU/ej4J6Vk5JfbFEBERCQbq6xViSVF7xB5EPd9cZOdqOHQukVcVERGVKAbq6+VfB6haDyYtF8MDzqpNzP4mIqKSxkBdAs20enmy4xMiIiodDNQl0vHJQTVnzW8iIippDNQ3on5PoEFveDfrp1YjLqUiLiWzhL4aIiIiBuobE9AceHAFvPs/h0Y1fdUmpqqJiMjpKerIyEhERUXZ1nfs2IGnnnoKn332GSqq9iFV1ZwDdBARkdMD9f33348//vhDLUdHR2PgwIEqWL/44ot45ZVXUOGkxqGfH2t+ExGRQQL1wYMH0bVrV7X8ww8/oE2bNti6dSsWLFiA+fPno0I5txd4syEG75sgg1WrFLWmcSQtIiJyYqDOysqCl5eXWv79999xxx13qOUWLVrg/PnzRX6dmTNnokuXLqhSpQoCAwMxfPhwhIeHw6UEtgLcveHmWx213JJxOTULkXFpzj4qIiKqyIG6devW+OSTT/Dnn39i7dq1GDJkiNp+7tw51KhRo8ivs3HjRowbNw7bt29XryM3AIMGDUJKSgpchrsXMPkYzBN2ISg4RG0Ki4p39lEREVE54X49T3rjjTcwYsQIvPXWWxgzZgxCQ0PV9uXLl9uyxIti9erVDuuSbS4p6927d+Pmm2+GS42mJRXK6vqrrO+wM/G4IzTY2UdFREQVNVD37dsXFy9eRGJiIqpVq2bb/uijj8LHx+e6DyYhIUHNq1evDlfUoW5lfM0mWkRE5Oys77S0NGRkZNiCdEREBGbPnq3KlyVFfD1yc3NVE6+ePXuqymkFkfeUmwN9SkpKgiHk5gDfDMcdq7ojAPE4eDYBWTm5zj4qIiKqqIH6zjvvxDfffKOW4+Pj0a1bN7zzzjuqMtjcuXOv60CkrFpqky9cuLDQymf+/v62qVWrVjAEsxuQEgtzdip6ex9HRnYuwqMNchNBREQVL1Dv2bMHvXv3VstLlixBUFCQSlVL8P7ggw+K/Xrjx4/HihUrVNvsunXrXnW/KVOmqOxxfTp8+DCMNkDHoMqn1JwjaRERkdMCdWpqqmpSJX777Tf84x//gNlsxk033aQCdlFJe2MJ0kuXLsX69evRsGHDQveXJmF+fn62ST8GIw3Q0V47oubsoYyIiJwWqJs0aYJly5aprkTXrFmjmlSJmJgYFUCLk9397bff4rvvvlNBV3o5k0nKwF2ONUUdlHoMvkhjipqIiJwXqKdOnYrJkyejQYMGqjlW9+7dbanrDh06FPl1pDxbsrClFnnt2rVt06JFi+By/OsA/vVg0nLR3nwcx2OTkZSe5eyjIiKiitg86+6770avXr1UL2R6G2rRv39/1b66qMpdV5uS/X3gDPpVOoktKW1x4GwCejSu6eyjIiKiijgeda1atVTqWXoj00fSktS1dCNaYdW35Cz09PxbzVmhjIiInBKopc2zjJIlTaTq16+vpqpVq+LVV19Vj1VY1nLqxhmH4Y5sVigjIiLnZH3LcJZffPEFZs2apTooEZs3b8b06dORnp6O1157DRVSzeaAd1V4pMejlSkC+yIrO/uIiIioIgbqr7/+GvPmzbONmiXatWuHOnXq4Iknnqi4gdpstpRTH1uNrm7HMC+xMaIT0lHL39vZR0ZERBUp6zsuLq7AsmjZJo9VaNb21H0rnVBzllMTEVGZB2qp6f3RRx9dsV22Scq6QqvXQ83aQiqUadjHIS+JiKiss77ffPNNDBs2DL///rutDfW2bdtUBygrV65EhRbcHhjzC347HwgsP6GGvCQiIirTFHWfPn1w7Ngx1WZaBuWQSboRPXToEP73v/+hQnP3AhrejLaNLONRS1vqnNxy1l6ciIiMnaIWwcHBV1Qa27dvn6oN/tlnn6GiaxpYBT6ebkjOyMbJ2GQ0DTJQv+RERFT+OzyhQiTHwO23F/Glz4dqdW8ks7+JiOj6MFCXBjcPYPvHuCl9M2oigR2fEBFR2Wd9UyEqVQNu+Q/2plRD6iYv1vwmIqKyCdRSYawwUqmMrPo8h8D4NKRuWo+j55OQnpUDbw83nh4iIiq9QC19e1/r8QceeKB4R1COBft7I6CKF2KTMnDoXAI61a/u7EMiIqLyHKi/+uqr0juS8kbTYIrcgecrr8bUpO4Ii2SgJiKi4mMZdWkxmYAfH8LdCZH4yRyAsMhGpfZWRERUfrHWdxn0+93VfJQ1v4mI6LowUJdBoO5sCseZuFTEpWSW6tsREVH5w0BdmupZ+kHv5HYC7shmqpqIiIqNgbo0BbQEvP1RCeloaTrDIS+JiKjYGKhLk9kMhFiyv7uYw9nxCRERFT+U8JyVUTm1BOrIeGgaR9IiIqKiY6Auo3LqruZwXE7NVJXKiIiIioqBurTV6Qi4eaGmKQENTNEspyYiomJhoC5t7l6WYG0tpw7jkJdERFQMDNRl2p76GJtoERFRsTBQl2E5tVQoO3guEVk5uWXytkRE5PoYqMtCSDdoITdho7krsrOz1bCXRERERcFAXRYqVYXpoTXYUG88cmFGWBTH7SYioqJhoC5D7etaxvOW9tRERERFwWEuy1DHIDd0MknHJ5XL8m2JiMiFMVCXlaRo9FnaGb08TWgXOw9J6Vmo4u1RZm9PRESuiVnfZaVKLZj86uCCOQC1cQkHohLK7K2JiMh1OTVQb9q0CbfffjuCg4NhMpmwbNkylGtPbMPrTRfihFaHFcqIiMj4gTolJQWhoaGYM2cOKgRvP3QIqaoWw86wQhkRERm8jHro0KFqqkhCQ6rCjFzsj4xz9qEQEZELYBl1Gevw1yTs83oENZPDEZ2QXtZvT0RELsalAnVGRgYSExNtU1KS6/Xw5Z6dgiqmNOsAHZedfThERGRwLhWoZ86cCX9/f9vUqlUruOwAHSpQs+Y3ERGVo0A9ZcoUJCQk2KbDhw/DVQfo6GI+hn1nmKImIqJy1OGJl5eXmnSS/e1ygjsi1+yJwNx4XD4bjpzcm+BmNjn7qIiIyKCcmqJOTk5GWFiYmsSpU6fU8pkzZ1BueXjDVKejWmydfQQnYpOdfURERGRgTg3Uu3btQocOHdQkJk2apJanTp2K8sxkLafuYj6KMA7QQURERg3Uffv2haZpV0zz589HuWYrp5YKZez4hIiIykllsnIjpKuaNTafx6mICGcfDRERGRgDtTP4VEdWjeZq0T92N9KzcpxyGEREZHwM1E7i3qCHmnc0hePgWbanJiKigjFQO4mpviVQs5yaiIgKw0DtLNaa361METh0JsZph0FERMbmUh2elCv+ITjY/xv889dMVDub6uyjISIig2KK2llMJtTrciuS4YPIuDRcSs5w2qEQEZFxMVA7kZ+3BxoH+Krl/VGsUEZERFdioHamjGS86LkQCzxeQ9iZi049FCIiMiYGamfyqIReCb+gp9shXD6516mHQkRExsTKZM5kdkNs52fw7qYL2HXBW3WfajJxJC0iIsrDFLWTBQx4Cr+Y+yIizRsRl1j7m4iIHDFQO5mnuxmtg/3U8r4oDtBBRESOGKgNYEj1C/i32yqcOHHM2YdCREQGwzJqA7g75gPU8NiLD04HALjF2YdDREQGwhS1Abg3sIxPXSshDJnZuc4+HCIiMhAGagPwa9ZbzTviKMKjk5x9OEREZCAM1AZgsg7Q0cR8DkdOnHD24RARkYEwUBuBT3Vc9GmkFlP+3ursoyEiIgNhoDaIjNpd1dw3ZqezD4WIiAyEgdog/Jpbyqmbph9EYnqWsw+HiIgMgoHaIKo0tQTqNqZTOHQ62tmHQ0REBsFAbRRV6+Gye014mHKweNlSfLH5FOJSMp19VERE5GQM1EZhMiEzuJtafD3tFbRccz+envkenliwGxvCY5CTqzn7CImIyAkYqA0k6JbHkesbCG9TFnq4HYYpNwsrD0Tjwa924tGZn2DbvKcRfXCjsw+TiIjKELsQNZKGvWGefAyIDQcituCFgCFosD8ey8LOolPaVnSPWo7FC4/jp3peuLdLCIa0CoB35J9ASDfAq7Kzj56IiEoBA7XRyHjUgS3U1ALA9AZ18MLQFti/Phab96VgXUJbbDt5SU1dvc/gB7wAzeQGBLeHqX5PoEEvQDpQ8fZ39ichIiq6zBQgJwvIzbZMalmmnLztMs/JtE5ZQEAzVb9HSTwHHFsDeFUB2t6d97rb5gBJ0dbn2z33imW7bZ3GAp3GWJ4fcwT4+nagUjVgvHOazzJQuwBvDzd0HTwKGDwKDePT0HJXFBbvjoR3wmWccQ9APXMscHa3Zdr6AWAyA0FtLEFbgnf9HqpTFSKiAkmQSosHvP0Ady/LtguHgFObLIGwxTDLNk0Dfnz4ygAq6znWAKsey3ZcH/oW0GyQ5TWO/AL89H9AvW7A6KV5x/BeGyAtrnhf0K1vA10fsSxfOg6seAoIaOEYqHd/DVwML97rNrUeq2ICUmItn9dJGKhdTJ2qlTBxQFNM6NcE2062w9s7hyLs0EF0zD2MbuYjuMntCBoiGojeb5m2f2x5YmBroEFPoOHNQMvbnf0xyJ78+KXGAUnnLHf+kjJIOg+kJwCelS25I63uBKqGWPaXfdPjAZ8a5T/nRH7szW6WnCYqxnnLAiL/AtIuFzLFW6fLQKZ1jIEHf7Xc4Isz24DVLwAtbssL1PI9HPoJ0Io5eFBGouP1npUCZKY67mO2C0eSSyjrbh6W79/sYV33BNw9LXN5TFK5Ot9AoPkwwL+u4+u2vw9IuWh9jvV5V122rtdokvf8ag2Ax7cC7t5wFgZqF2U2m9CzSU01xae2xvJ95/DtzkhMOZeIQFxWQfsW77/Rx+sYaqSdAmIOWSb557UP1CfWW4J4lSBnfpzyS36McjLyflDkh3HjG9ZgHJ0XnCW7rTB1OuYF6oM/AisnW4L3yG8s23JzgU97W7L9JHjnn7z8Cthe1TJ3cy+ZwCBZl/pUpZYldSbiTgIRWwHfAKDZ4LznrHjacjNi/zx9Uj/kkhWaCXj4Wn585fN3ewxoOtB6blOA1EtAldqWH9jyRIKZnJvkGCA52pKisw+wch7062HXV5ZrSoLpsHcs27LTgfnW4Foc6XYBtWZzoPU/gLpdHPcZPNOSayfXjQRPCaL2AfWKZXegeuO85zfuBzwZBnj6Or7uU/st+6ogfR31nANbAPd9d+X2Xk/jhnh4A0Gt4UwM1OVAVR9PPNC9gZoOnk3A4l2RWBYWiF9SewCpQA0kYHTwWdzhfxIhjVvCwz6ILBhpyZp66mDeP778EMgPvvyz0dVTeikxQOJ5S+pXJgm+kg3nF2zZ5893gHWvAB0fAO740LJNzqmey5GfT03Ar7Yl8MgkwT0z2fKDrb+meu8swMPHMTUt+104WPxv676FQPOhlmUp3/vzXVWpEf1eynuvXydZA2iq5X1swdRuPf+Nxj+/y0uFRe0Cfh4HNOrrGKjlhkM+27VI0JasS5na3Zu3/fQW4Lt7gFrtgMf+zNu+9SPAoxLgH5IX4OV6NgK5oZIg6uljWc9IAv76xBKQ5YYt+YJ1HgNkp139dZoNyft/1XKs16BdR0mSExPQ0vK55TpymKpeua2gmza5DmTK76bHbuwcSMXXgiq/yndGBWKgLmfa1PFX05RbW+K3wxdU0N58HJh9zh+zz7WC3yl33HnxoKo13sb7IhDY0hKY7bOLFj8InN5sKZuq3tCS9VPNOpf1qvXLfy3z7Ezg9CZrILZL+eopYQnSBWX/NeqTF1Ql8OpZ1Tr54ez9jCV1qQdkCc6Va1my9Iqi+xOWSX70dZItN3qZJfAVNkkWpL4sQdY+2MefASK3O+auSApnz/8kGhTt2GR/SSnZl+dJwJQyPwmo9vr+x/K6sr9MknLWl23bfCypSDm2hChLCwedZP9LNqX9tSsp0T9etwR3e/I5VeC2Bm89gOvrcv6vJxWny86wBFlbwJVr5gLQeWze9SA3EGunAh1G5d24Sfnn+v9e/XUlJ6RyEFA50DGwSo6FruUdllSv7KeTLOpx26//85ChmDRNrmzXFBUVhZCQEERGRqJu3XzlEmQTGZeKJbuj1HQ2Pu8uvVVtP4zsXBfD29ZEVT+7FMdHXYCLxwo/g1IepAdumTcZCITkyyIzYvDVU79yg6IHKancsn0uUK870P9lyzZJJb5ul4otiGTRyQ+mHmxlLrVFg1rlvYYELD0L2GgktSxZmHrOyeXTwPl9lpsIqYCo2zzbEhDzB1E1VbYEU325qDcbJUVuViQo6ylm+Y5/ewlIiLROUZZAfy0jPgNCran16APA4eVA7VCg5W2WbVnpwNEVdineC9ZlmUdf/T0e+NmSkyB2zwd+mQg0HQyM+iFvH9km9Q1UQA6yXFP6sp7yLiMSDqIT03EiJgXHY5JwIjYFJ2KT1SSRopa/N2r5eVvmdsu1/Sup5UqezIUrjfjFQF2B5OZq2HLiIhbtjMRvhy4gM8eSIvN0M2NQ6yCVyu7ZuCbMyLWkHOWH+/IpyzzuVN56QT9KA18Bek7Ma86weKzlh+4fn+btk3DW8oMkZT4lSX5B5JhU9rME4nMFz1Mv5j1HaptKWZmQFOPy8UCTAcC/fszbZ95ASwBQQTjY8gMqqSM9Jexbk8UDrkCyl+Xa04N3vDWAqynScq0/uCLv5mTnF5bs/mZDgfsXFv3GTcpkVaCVICs3cEFAl4fzyjf18ni5EXJymXpmdi4iLlmC8PGY5LyAHJOMlMzrr93sX8kjL5DbB3Trem1/b7WPiZUDUZxAbYis7zlz5uCtt95CdHQ0QkND8eGHH6JrV8uwj1SyFdB6Nw1QU3xqJpbtPYtFu6Jw5HwiVuw/ryapVT6wVRB8PN3gZg6E2RQEN3N3uNU0wRxggpsZ8M5ORtWMs/BLPwu/tCg1nUmuj7jdUerx4PM70C32COKz3fHXoWi4meR5JnT7dRgqJZ1Gpk8QMqrUR2aVesj0q48sv3rI9q+PbP8GQKXqcHMz2eKv9JyqQVMJJ8/L4fCN3IRMn1qIbzhMZcZqWWkIXRAKs1TYKoJcswcyKgXh6OlYXMy4gFxNg3dWC/h3fRvJlRsgfv859b7y2h7dvoGHmxke7mZ4uJnUDY1ahxmeaWZ4ZmbAw91k2eZmtj5ugrucBDIOudmy9k1w1foG9oGjZjOg878tTRx1kmMgN3KSFa2neNU80BqUa1mypAsLQHolvjKUkJZlC8ASjCUon4xNRkRc6lW7JZb/1fo1fNAkoDIaB1ZGY5kH+Kpr/HxCOqIT0lSqW5YvWOfRCelIzcxR7ydT+AVrLfICeHuY8wVzSY17WeYqde6NmpW91HGQQVLUixYtwgMPPIBPPvkE3bp1w+zZs7F48WKEh4cjMDCw0Ocy67tkSAW0H6QC2t6zSEzPvuHX80cy2plPQoMJm3PbWrdq2OP1f6huSi70uYlaJURqlu89yHQZT2WNs73GPW4b8JbHZ9iY0w5jsl6wPWef18PwN6UiTquMC1p1XNCqIVqrhguorubRtm3VEQfJIi3dHwD5fbEFbmuQ19c91brdNrt1T3c3xxsC6+Ne7gXPPd3cHNety15XeczdbGJKphySn3AJlpaUcbJDKjk26eo3sJW93FUAbmwXkJsE+qJedV91vRT3GJIysnEhwRq4Ey3B2za3Lhd1oCEJ0oFVvBxS5kF+3vD1tFzX9v87lv8Fu3W1LP9HbupGWv8/VNvdzCrBYgQulfUtwblLly746KOP1Hpubq46+AkTJuCFF/J+jAvCQF2y0rNysOZQNA5EJSA7V1OpzRy7ueSU25Y1SeXqj6GAfe2WJWUs85xcVMmNR1D2eQTlnketnGjUzr2A4NxoBGvRCMSVnR1MNz2BFW79VUKljfY3RuUuxxFTEyz0GKG2yRSkXUKiyQ/ZZi8Vg80mkwrFaq72sa6b5WGTCqTygMwL3M+aKpJjl+KBLOsk2YVZOXbbsnOty65RzUM+b96PmlteUL/iBkCW3RyCuzo/1jpKcpb0c6/WCnpMrevL+faxnmcU9Jjd96NvMwIJAHIu7G+y3O2WLesmeJjzclU89W0Oz7EEDttzzUUPHBnZOYi4lGoJwtagfDxWUsgpKjV7NUF+XmhiSxlLMLbMZXtZZ0HLb0xMYgbOW1PlDsHcOo9JyijVQYjcrd+jHtjlurfcKJsL2J53w63fANwRWgfdG9eoOIE6MzMTPj4+WLJkCYYPH27bPmbMGMTHx+Pnn3922D8jI0NNurNnz6JVq1asTFZeZKVZavdKWbiQ8mCpqGaUpjVXIf9CEqxtAd0uqOcFeGuQty7nvwHIlH1t+1nW1fbsXPUDbdlHX891eCyjkMc46JrxSepRgodjYM8L+LKclpmNM3GpV/0+3fXs6nwBuVGAL6p4u1YbcwnSF5MzVNC2z16PSUxHWlaO+v+Q69zh5tm6btteijfSrw5vg9E31a84ZdQXL15ETk4OgoIcO9uQ9aNHj16x/8yZMzFjxowyPEIqU9KOMqC5ZXIhkipRWW3FzC4sC9k5VwbxjGLcAMiPpvzMSe6IfksvNyZ6Ob5lnrcuCwVt19etf1d/jQKe7+xUtRyDnruSbbshs8yzcyUgaMiSufXxAvfTb9SsFTjt6TlQcr6vRWVXq2DsawvKMq9X3UcF9PJy4yLZ3DKFWpuK3wi5pjLz3yjbXfdXrhe+X/u6VVHWDFGZrKimTJmCSZMmXZGiJqKCSYpMJp8ybjVFVw8aEpSlaMkxoFsChH5jlT/QS0pbgrKU27LGdPHI+ZKiHC+JdtZuzF2NUwN1zZo14ebmhgsXLjhsl/Vatewa9Ft5eXmpSZeYaNfdHRGRCwQNCbrubpbBdoiKwql5JZ6enujUqRPWrVtn2yaVyWS9e/fuzjw0IiIiQ3B61rdkZUvlsc6dO6u209I8KyUlBWPHjnX2oRERETmd0wP1vffei9jYWEydOlV1eNK+fXusXr36igpmREREFZHTA7UYP368moiIiMhR+ajPT0REVE4ZIkV9vaTimTh//ryzD4WIiKjI9Lilx7FyG6j1Zl0cwIOIiFw1jtWrV8/YfX3fiOzsbOzdu1dVPDPfyKDvVklJSaoDlcOHD6NKFWN3W2kkPG88d7zmXAf/X41x3iQlLUG6Q4cOcHd3L7+BuqRJByr+/v5ISEiAn5+fsw/HZfC88dzxmnMd/H91vfPGymREREQGxkBNRERkYAzUdqQf8WnTpjn0J07XxvN2/XjueN7KGq851ztvLKMmIiIyMKaoiYiIDIyBmoiIyMAYqImIiAyMgdpqzpw5aNCgAby9vdGtWzfs2LHDud+MC9i0aRNuv/12BAcHw2QyYdmyZc4+JJcwc+ZMdOnSRXWaEBgYiOHDhyM8PNzZh+US5s6di3bt2ql2rDLJuPWrVq1y9mG5nFmzZqn/2aeeesrZh2J406dPV+fKfmrRokWZHgMDNYBFixapcbGlRt+ePXsQGhqKwYMHIyYmpky/DFcj44bLuZKbHCq6jRs3Yty4cdi+fTvWrl2LrKwsDBo0SJ1PKlzdunVVkNm9ezd27dqFfv364c4778ShQ4d46opo586d+PTTT9UNDxVN69atVd/c+rR582aUKemZrKLr2rWrNm7cONt6Tk6OFhwcrM2cOdOpx+VK5FJaunSpsw/DJcXExKjzt3HjRmcfikuqVq2aNm/ePGcfhktISkrSmjZtqq1du1br06ePNnHiRGcfkuFNmzZNCw0NdeoxVPgUdWZmpro7HzBggO3mRfoNl/Vt27aV7V0TVUjSJaGoXr26sw/FpeTk5GDhwoUqJ0KywOnaJCdn2LBhDr93dG1///23KuJr1KgRRo0ahTNnzqAsufToWSXh4sWL6h9eBvawJ+tHjx512nFRxSAd80s5Yc+ePdGmTRtnH45LOHDggArM6enpqFy5MpYuXaoGS6DCyU2NFO1J1jcVndRZmj9/Ppo3b66yvWfMmIHevXvj4MGDZTZ4U4UP1ETOTuHIP3yZl3m5MPnBDAsLUzkRS5YswZgxY1S5P4P11UVGRmLixImqToRUmKWiGzp0qG1ZyvUlcNevXx8//PADHnroIZSFCh+oa9asCTc3N9vY1jpZr1WrVpl8CVQxjR8/HitWrFC156WSFBWNp6cnmjRpopY7deqkUojvv/++qiBFBZPiPakc27FjR9s2yUmUa++jjz5CRkaG+h2ka6tatSqaNWuG48ePo6xU+DJq+aeXf/Z169Y5ZEfKOsu9qDRI3TsJ0pJlu379ejRs2JAn+gbI/6sEGrq6/v37qyIDyYnQp86dO6vyVllmkC665ORknDhxArVr10ZZqfApaiFNsyT7TC7crl27Yvbs2aqCytixY8vsi3DVC9b+rvLUqVPqn14qRdWrV8+px2b07O7vvvsOP//8syrjio6OVttlrNtKlSo5+/AMbcqUKSorUq6vpKQkdR43bNiANWvWOPvQDE2us/x1IHx9fVGjRg3WjbiGyZMnq/4iJLv73Llzqhmv3Njcd999KCsM1ADuvfdexMbGYurUqepHs3379li9evUVFczIkbRjveWWWxxueITc9EjlC7p6px2ib9++Dtu/+uorPPjggzxthZDs2wceeEBV6pEbGykzlCA9cOBAnjcqFVFRUSooX7p0CQEBAejVq5fqA0GWywpHzyIiIjKwCl9GTUREZGQM1ERERAbGQE1ERGRgDNREREQGxkBNRERkYAzUREREBsZATUREZGAM1ERERAbGQE1EN8xkMmHZsmU8k0SlgIGayMVJt6MSKPNPQ4YMcfahEVEJYF/fROWABGXpK9yel5eX046HiEoOU9RE5YAEZRk/3X6qVq2aekxS1zIQiIw6JaNzNWrUCEuWLHF4vgyB2K9fP/W4jKj06KOPqtHR7H355Zdo3bq1ei8Z4k+G6rR38eJFjBgxAj4+PmjatCmWL19ue+zy5ctqSEUZyEDeQx7Pf2NBRAVjoCaqAF5++WXcdddd2LdvnwqY//znP3HkyBH1mAzpOnjwYBXYd+7cicWLF+P33393CMQS6GV4TgngEtQlCDdp0sThPWbMmIGRI0di//79uPXWW9X7xMXF2d7/8OHDWLVqlXpfeb2aNWuW8VkgclEaEbm0MWPGaG5ubpqvr6/D9Nprr6nH5d/8sccec3hOt27dtMcff1wtf/bZZ1q1atW05ORk2+O//vqrZjabtejoaLUeHBysvfjii1c9BnmPl156ybYuryXbVq1apdZvv/12bezYsSX8yYkqBpZRE5UDMi64Ps61rnr16rbl7t27Ozwm62FhYWpZUrihoaHw9fW1Pd6zZ0/k5uYiPDxcZZ2fO3cO/fv3L/QYZGxonbyWn5+fGj9aPP744ypFv2fPHgwaNAjDhw9Hjx49bvBTE1UMDNRE5YAExvxZ0SVFypSLwsPDw2FdArwEeyHl4xEREVi5ciXWrl2rgr5kpb/99tulcsxE5QnLqIkqgO3bt1+x3rJlS7Uscym7lrJq3ZYtW2A2m9G8eXNUqVIFDRo0wLp1627oGKQi2ZgxY/Dtt99i9uzZ+Oyzz27o9YgqCqaoicqBjIwMREdHO2xzd3e3VdiSCmKdO3dGr169sGDBAuzYsQNffPGFekwqfU2bNk0F0enTpyM2NhYTJkzA6NGjERQUpPaR7Y899hgCAwNV6jgpKUkFc9mvKKZOnYpOnTqpWuNyrCtWrLDdKBBR4RioicqB1atXqyZT9iQ1fPToUVuN7IULF+KJJ55Q+33//fdo1aqVekyaU61ZswYTJ05Ely5d1LqUJ7/77ru215Ignp6ejvfeew+TJ09WNwB33313kY/P09MTU6ZMwenTp1VWeu/evdXxENG1maRGWRH2IyIXJWXFS5cuVRW4iMj1sIyaiIjIwBioiYiIDIxl1ETlHEu3iFwbU9REREQGxkBNRERkYAzUREREBsZATUREZGAM1ERERAbGQE1ERGRgDNREREQGxkBNRERkYAzUREREMK7/BxDny/Ual2+MAAAAAElFTkSuQmCC\",\n \"text/plain\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"WlQZ8ygqzN_g\",\n \"metadata\": {\n \"id\": \"WlQZ8ygqzN_g\"\n },\n \"outputs\": [],\n \"source\": [\n \"def replace_linear_with_lora(model, rank, alpha):\\n\",\n \" for name, module in model.named_children():\\n\",\n \" if isinstance(module, torch.nn.Linear):\\n\",\n \" # Replace the Linear layer with LinearWithLoRA\\n\",\n \" setattr(model, name, LinearWithLoRA(module, rank, alpha))\\n\",\n \" else:\\n\",\n \" # Recursively apply the same function to child modules\\n\",\n \" replace_linear_with_lora(module, rank, alpha)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c172164-cdde-4489-b7d7-aaed9cc2f5f2\",\n \"metadata\": {\n \"id\": \"8c172164-cdde-4489-b7d7-aaed9cc2f5f2\"\n },\n \"source\": [\n \"- We then freeze the original model parameter and use the `replace_linear_with_lora` to replace the said `Linear` layers using the code below\\n\",\n \"- This will replace the `Linear` layers in the LLM with `LinearWithLoRA` layers\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"dbe15350-4da9-4829-9d23-98bbd3d0b1a1\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dbe15350-4da9-4829-9d23-98bbd3d0b1a1\",\n \"outputId\": \"fd4c208f-854a-4701-d9d3-9d73af733364\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total trainable parameters before: 124,441,346\\n\",\n \"Total trainable parameters after: 0\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable parameters before: {total_params:,}\\\")\\n\",\n \"\\n\",\n \"for param in model.parameters():\\n\",\n \" param.requires_grad = False\\n\",\n \"\\n\",\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable parameters after: {total_params:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"mLk_fPq0yz_u\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"mLk_fPq0yz_u\",\n \"outputId\": \"0a93b8fc-05d7-4ace-ee47-e2fc6bdd7d75\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total trainable LoRA parameters: 2,666,528\\n\"\n ]\n }\n ],\n \"source\": [\n \"replace_linear_with_lora(model, rank=16, alpha=16)\\n\",\n \"\\n\",\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable LoRA parameters: {total_params:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b8b6819e-ef7a-4f0d-841a-1b467496bef9\",\n \"metadata\": {\n \"id\": \"b8b6819e-ef7a-4f0d-841a-1b467496bef9\"\n },\n \"source\": [\n \"- As we can see, we reduced the number of trainable parameters by almost 50x when using LoRA\\n\",\n \"- Let's now double-check whether the layers have been modified as intended by printing the model architecture\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"1711be61-bb2c-466f-9b5b-24f4aa5ccd9c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"1711be61-bb2c-466f-9b5b-24f4aa5ccd9c\",\n \"outputId\": \"acff8eca-3775-45a2-b62d-032a986ef037\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"GPTModel(\\n\",\n \" (tok_emb): Embedding(50257, 768)\\n\",\n \" (pos_emb): Embedding(1024, 768)\\n\",\n \" (drop_emb): Dropout(p=0.0, inplace=False)\\n\",\n \" (trf_blocks): Sequential(\\n\",\n \" (0): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (1): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (2): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (3): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (4): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (5): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (6): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (7): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (8): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (9): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (10): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (11): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_key): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (W_value): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (out_proj): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" (1): GELU()\\n\",\n \" (2): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): LayerNorm()\\n\",\n \" (out_head): LinearWithLoRA(\\n\",\n \" (linear): Linear(in_features=768, out_features=2, bias=True)\\n\",\n \" (lora): LoRALayer()\\n\",\n \" )\\n\",\n \")\\n\"\n ]\n }\n ],\n \"source\": [\n \"model.to(device)\\n\",\n \"\\n\",\n \"print(model)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c4bbc9d7-65ec-4675-bab8-2e56eb0cfb55\",\n \"metadata\": {\n \"id\": \"c4bbc9d7-65ec-4675-bab8-2e56eb0cfb55\"\n },\n \"source\": [\n \"- Based on the model architecture above, we can see that the model now contains our new `LinearWithLoRA` layers\\n\",\n \"- Also, since we initialized matrix $B$ with 0's, we expect the initial model performance to be unchanged compared to before\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"DAlrb_I00VEU\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"DAlrb_I00VEU\",\n \"outputId\": \"3da44ac4-230b-4358-d996-30b63f0d962a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training accuracy: 46.25%\\n\",\n \"Validation accuracy: 45.00%\\n\",\n \"Test accuracy: 48.75%\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=10)\\n\",\n \"val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=10)\\n\",\n \"test_accuracy = calc_accuracy_loader(test_loader, model, device, num_batches=10)\\n\",\n \"\\n\",\n \"print(f\\\"Training accuracy: {train_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Validation accuracy: {val_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Test accuracy: {test_accuracy*100:.2f}%\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"13735b3e-f0c3-4dba-ae3d-4141b2878101\",\n \"metadata\": {\n \"id\": \"13735b3e-f0c3-4dba-ae3d-4141b2878101\"\n },\n \"source\": [\n \"- Let's now get to the interesting part and finetune the model by reusing the training function from chapter 6\\n\",\n \"- The training takes about 15 minutes on a M3 MacBook Air laptop computer and less than half a minute on a V100 or A100 GPU\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"wCParRvr0eff\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"wCParRvr0eff\",\n \"outputId\": \"ce910a9c-ee89-48bb-bfa6-49c6aee1e450\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ep 1 (Step 000000): Train loss 3.820, Val loss 3.462\\n\",\n \"Ep 1 (Step 000050): Train loss 0.346, Val loss 0.325\\n\",\n \"Ep 1 (Step 000100): Train loss 0.063, Val loss 0.144\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 92.50%\\n\",\n \"Ep 2 (Step 000150): Train loss 0.054, Val loss 0.045\\n\",\n \"Ep 2 (Step 000200): Train loss 0.058, Val loss 0.122\\n\",\n \"Ep 2 (Step 000250): Train loss 0.041, Val loss 0.199\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 95.00%\\n\",\n \"Ep 3 (Step 000300): Train loss 0.020, Val loss 0.153\\n\",\n \"Ep 3 (Step 000350): Train loss 0.017, Val loss 0.186\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 95.00%\\n\",\n \"Ep 4 (Step 000400): Train loss 0.017, Val loss 0.099\\n\",\n \"Ep 4 (Step 000450): Train loss 0.001, Val loss 0.170\\n\",\n \"Ep 4 (Step 000500): Train loss 0.117, Val loss 0.222\\n\",\n \"Training accuracy: 97.50% | Validation accuracy: 92.50%\\n\",\n \"Ep 5 (Step 000550): Train loss 0.038, Val loss 0.235\\n\",\n \"Ep 5 (Step 000600): Train loss 0.019, Val loss 0.252\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 100.00%\\n\",\n \"Training completed in 2.16 minutes.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import time\\n\",\n \"from previous_chapters import train_classifier_simple\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch06 import train_classifier_simple\\n\",\n \"\\n\",\n \"\\n\",\n \"start_time = time.time()\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"optimizer = torch.optim.AdamW(model.parameters(), lr=8e-4, weight_decay=0.1)\\n\",\n \"\\n\",\n \"num_epochs = 5\\n\",\n \"train_losses, val_losses, train_accs, val_accs, examples_seen = train_classifier_simple(\\n\",\n \" model, train_loader, val_loader, optimizer, device,\\n\",\n \" num_epochs=num_epochs, eval_freq=50, eval_iter=5,\\n\",\n \")\\n\",\n \"\\n\",\n \"end_time = time.time()\\n\",\n \"execution_time_minutes = (end_time - start_time) / 60\\n\",\n \"print(f\\\"Training completed in {execution_time_minutes:.2f} minutes.\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7b7410ae-ed73-4f89-9cfa-0893312fe9c7\",\n \"metadata\": {},\n \"source\": [\n \"- The runtime on different devices is as follows\\n\",\n \" - 12.10 minutes on a MacBook M1 (CPU)\\n\",\n \" - 2.16 minutes on a MacMini M4 Pro (MPS)\\n\",\n \" - 3.50 minutes on a Jetson Nano (CUDA), [shared](https://livebook.manning.com/forum?product=raschka&comment=581806) by a reader\\n\",\n \" - 1.02 minutes on a DGX Spark (CUDA)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d0c89e82-3aa8-44c6-b046-0b16200b8e6c\",\n \"metadata\": {\n \"id\": \"d0c89e82-3aa8-44c6-b046-0b16200b8e6c\"\n },\n \"source\": [\n \"- Finally, let's evaluate the model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"bawWGijA0iF3\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 308\n },\n \"id\": \"bawWGijA0iF3\",\n \"outputId\": \"af70782a-d605-4376-fa6c-d33b38979cfa\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAeoAAAEiCAYAAAA21pHjAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAARZ5JREFUeJzt3Qd4FOXaBuBnN5UEEloSCITeW+hIE6QjFjgqHuUgciy/CogiFo5K0aNgx4JYUNEjCoKCiBQRBKRJDZ0gLSRASCCk92T+6/12Z7MbQkggyc4mz31lrik7uzs7O9l3vm7SNE0DERERGZLZ2QdAREREV8dATUREZGAM1ERERAbGQE1ERGRgDNREREQGxkBNRERkYAzUREREBsZATUREZGAM1ERERAbGQE1EDvr27YunnnqKZ4XIIBioiUrYgw8+CJPJdMU0ZMgQnmsiKjb34j+FiK5FgvJXX33lsM3Ly4snjoiKjSlqolIgQblWrVoOU7Vq1dRjGzZsgKenJ/7880/b/m+++SYCAwNx4cIFtb569Wr06tULVatWRY0aNXDbbbfhxIkTtv1Pnz6tUuk//PADevfujUqVKqFLly44duwYdu7cic6dO6Ny5coYOnQoYmNjHVL7w4cPx4wZMxAQEAA/Pz889thjyMzMvOpnycjIwOTJk1GnTh34+vqiW7du6jPoIiIicPvtt6vPJ4+3bt0aK1euvOrrffzxx2jatCm8vb0RFBSEu+++2/ZYbm4uZs6ciYYNG6rPFBoaiiVLljg8/+DBg+pzyeeT548ePRoXL150yLp/8skn8dxzz6F69erq3E+fPr1I3xuRETFQEzmpDFgCTEJCAvbu3YuXX34Z8+bNU4FHpKSkYNKkSdi1axfWrVsHs9mMESNGqEBmb9q0aXjppZewZ88euLu74/7771cB6v3331c3AsePH8fUqVMdniOvd+TIERVsv//+e/z0008qcF/N+PHjsW3bNixcuBD79+/HPffco3IM/v77b/X4uHHjVDDftGkTDhw4gDfeeEMF0YLI55Eg+sorryA8PFzdkNx88822xyVIf/PNN/jkk09w6NAhPP300/jXv/6FjRs3qsfj4+PRr18/dOjQQb2WPF9ubkaOHOnwPl9//bW6afjrr7/UTZC839q1a4v9XREZggxzSUQlZ8yYMZqbm5vm6+vrML322mu2fTIyMrT27dtrI0eO1Fq1aqU98sgjhb5mbGysDEerHThwQK2fOnVKrc+bN8+2z/fff6+2rVu3zrZt5syZWvPmzR2OrXr16lpKSopt29y5c7XKlStrOTk5ar1Pnz7axIkT1XJERIT6LGfPnnU4nv79+2tTpkxRy23bttWmT59epHPz448/an5+flpiYuIVj6Wnp2s+Pj7a1q1bHbY/9NBD2n333aeWX331VW3QoEEOj0dGRqrPHR4ebjv+Xr16OezTpUsX7fnnny/SMRIZDcuoiUrBLbfcgrlz5zpsk2xYnWR9L1iwAO3atUP9+vXx3nvvOewrqVVJCUuKULJ19ZT0mTNn0KZNG9t+8nydnhpv27atw7aYmBiH15bsZB8fH9t69+7dkZycjMjISHUs9iSFnJOTg2bNmjlslxS0ZMkLSSE//vjj+O233zBgwADcddddDsdlb+DAgeo9GjVqpFLlMklOgRyPpP5TU1PVPvYkW15S0GLfvn34448/CkyxS9GAfpz537927dpXnAciV8FATVQKJNu1SZMmhe6zdetWNY+Li1OTPEcnZb4S0D7//HMEBwerQC0BOn9ZsoeHh21ZyqwL2pY/u7w4JIC7ublh9+7dam5PD5YPP/wwBg8ejF9//VUFa8m+fueddzBhwoQrXq9KlSoqm16y3WVfuRmR8mMpV5f3EvI6Uh5eUEU82UfOjWSv5yfBuKDzUhLngciZGKiJnEBSf1L+KoF40aJFGDNmDH7//XdVFn3p0iVVfiuPSUUxsXnz5hJ7b0mVpqWlqcpaYvv27SrohoSEXLGvpGQlRS2pUf1YCiLPlUppMk2ZMkUde0GBWkhZuqS8ZZIydqkwt379epWSloAsuQZ9+vQp8LkdO3bEjz/+iAYNGqjXIaoIeKUTlQLJGo6Ojnb8Z3N3R82aNVXgkwpSkgodO3asyv6V7GpJhT777LOq9rRkK3/22WcqlSiB64UXXiixY5NU+UMPPaQqoUntcQmWUmFMbhLyk6zkUaNG4YEHHlDHJ4FbapFLhTTJXh42bJiqGCe1sGXfy5cvq6zpli1bFvjeK1aswMmTJ1UFMvmcUjtcUrrNmzdXqW2pXS43MLJNar1LZbstW7ao2ulyMyMV1+Qm4L777rPV6pYsc6noJpXx8qf6icoDBmqiUiC1ke2zYoUEo6NHj+K1115TTZokaAnZT4KyBJ9BgwapMmQJPFL2K9nd8rwPPvhA1RYvCf3791fNoyRYyg2FvG9hzZekPfh///tfPPPMMzh79qy62bjppptUkzEhNx4SQKOiolRAlRuP/GXuOkk9Sy1zeb/09HR1HFLzXJp0iVdffVU1G5Pscwnosr+kov/zn/+ox6UYQAL3888/r86VHL8UEch7FnSjQVQemKRGmbMPgojKhrSjliZOy5Yt4yknchG8BSUiIjIwBmoiIiIDY9Y3ERGRgTFFTUREZGAM1ERERAbGQE1ERGRgDNRWc+bMUb0dydB7Mozfjh07UN7JaEfSHaO0TZUuFvM32ZGWe9LFo7TzlV6spCcpfcQknXR9KR1iSPtZafMqHWnoXUHqZMQl6dVKzq30YCWjGbkaadcrw0hKpxwyHKUMFSm9h9mTdsHSnlg6K5GevqTPa33YSp10XiKdhEjf1vI60sFJdna2wz7Svaa0HZZeuqQb0vnz58PVSD/n0iGKXBcySX/iq1atsj3Oc3V1s2bNUv+P0pEMz9eVpA2+nB/7qUWLFuX7XDl7VBAjWLhwoebp6al9+eWX2qFDh9RIRlWrVtUuXLiglWcrV67UXnzxRe2nn35Sow8tXbrU4fFZs2Zp/v7+2rJly7R9+/Zpd9xxh9awYUMtLS3Nts+QIUO00NBQbfv27dqff/6pNWnSxDbSkUhISNCCgoK0UaNGaQcPHlQjPFWqVEn79NNPNVcyePBg7auvvlKfISwsTLv11lu1evXqacnJybZ9HnvsMS0kJESNXrVr1y7tpptu0nr06GF7PDs7W2vTpo02YMAAbe/ever816xZ0zYKlTh58qQaQWrSpEna4cOHtQ8//FCNXrV69WrNlSxfvlz79ddftWPHjqlRrf7zn/9oHh4e6vwJnquC7dixQ2vQoIHWrl072whmPF+Opk2bprVu3Vo7f/68bZLR5XTl8dpioNY0rWvXrtq4ceNsJ0WG+wsODlZDBFYU+QN1bm6uVqtWLe2tt96ybYuPj9e8vLxUsBVyAcvzdu7cadtn1apVmslksg2L+PHHH2vVqlVTwzrqZLhB+6EXXVFMTIz67Bs3brSdGwlEixcvtu1z5MgRtc+2bdvUuvwgmM1mLTo62mGISRn2UT8/zz33nPoRsnfvvfeqGwVXJ9eBDMvJc1WwpKQkrWnTptratWsdhhrl+boyUEvioCDl9VxV+Kxv6fdYRgaSbF2ddEUo69u2bUNFderUKdVXtf158ff3V8UC+nmRuWR3d+7c2baP7C/nT4Zn1PeRriplWEed9HEt2cbSL7Srkj6o7YeulGsoKyvL4XxJdly9evUczpf06a0PR6mfi8TERBw6dMi2j/1r6Pu48rUoXYxKl6gpKSkqC5znqmCSXSvZsfm/f56vK0kRnBTZyXCpUvQmWdnl+VxV+EAtY/3KD4n9lyZkPf+gChWJ/tkLOy8yl/Kd/ANPSPCy36eg17B/D1cjA0ZI+WHPnj1tY0PLZ5GbEblxKex8XetcXG0f+RGREa9ciYxlLWWEUsYno2otXboUrVq14rkqgNzIyPCfUhciP15bjiSxIOXF0p++1IWQRIXUgUlKSiq354qDchBdR8rn4MGDJTr0ZHkkg4mEhYWp3IclS5ao0a82btzo7MMynMjISEycOBFr165VFS6pcEOHDrUtS4VFCdwyMMsPP/xgG7q1vKnwKWoZCUiGxstfK1DWa9WqhYpK/+yFnReZyzjF9qTmpNQEt9+noNewfw9XIsNByqhXMpRj3bp1bdvls0gxigx4Udj5uta5uNo+UnPa1X6EJGUjtWU7deqkUooyKtj777/Pc5WPZNfK/5HUMJYcKZnkhkZGTJNlScnx2ro6ST3LEKsy3Gl5/T+s8IFafkzkh0TG17XP2pR1KU+rqBo2bKguVvvzItk+UvasnxeZyz+E/NDo1q9fr86f3OXq+0gzMCk30knKQVJbMh6xq5D6dhKkJftWPqOcH3tyDXl4eDicLymHl7Iz+/Ml2cH2NzdyLuSfX7KE9X3sX0Pfpzxci3JdyLCUPFdXDjsq14XkPuiT1PuQsld9mdfW1Ulz0BMnTqhmpOX22nJKFTYDNs+S2szz589XNZkfffRR1TzLvlZgeSS1TKV5gkxyKbz77rtqOSIiwtY8S87Dzz//rO3fv1+78847C2ye1aFDB+2vv/7SNm/erGqt2jfPklqY0jxr9OjRqmmOnGtp9uBqzbMef/xx1VRtw4YNDs1CUlNTHZqFSJOt9evXq2Yh3bt3V1P+ZiGDBg1STbykqUdAQECBzUKeffZZVVt1zpw5Ltk864UXXlA14k+dOqWuHVmX1gC//fabepznqnD2tb55vhw988wz6v9Qrq0tW7aoZlbSvEpaYpTXa4uB2kraycmXK+2ppbmWtAsu7/744w8VoPNPY8aMsTXRevnll1WglRuZ/v37qzax9i5duqQCc+XKlVXzhrFjx6obAHvSBrtXr17qNerUqaNuAFxNQedJJmlbrZMbmCeeeEI1Q5J/8hEjRqhgbu/06dPa0KFDVVty+XGRH52srKwrvpf27dura7FRo0YO7+Eq/v3vf2v169dXn0F+BOXa0YO04LkqXqDm+XJsJlW7dm11bcnviawfP368XJ8rjp5FRERkYBW+jJqIiMjIGKiJiIgMjIGaiIjIwBioiYiIDIyBmoiIyMAYqImIiAyMgdqO9Jokg5LLnArHc1U8PF88V6WF11b5P1eGaUc9a9YsTJkyRXVOP3v2bKccg3SRKUM5yiAC0p0c8Vzx2uL/odHxd6v8nytDpKh37tyJTz/9VI2EQkRERAYK1NKhunQ+//nnn7vUIA1EREQVYjxqGdt32LBhGDBgAP773/8W67kypOLevXvVMHBm843fc8jA4+Ls2bMqi4R4rkoKry2eq9LCa8s1z5WMJidDZ3bo0EENZ1oYpwbqhQsXYs+ePSrruyikAoB9JQAZXrFfv34lflz6UGfEc8Vry3n4f8jzVRGurR07dqBLly7GDNSRkZGq4piM8ent7V2k58jg8zNmzCjwg8pYpERERK7g/Pnz6Nq1q8oRNmyt72XLlmHEiBFwc3OzbcvJyYHJZFLZ2JJytn+soBS1ZF/InZEE/bp165bp8RMREV2vqKgohISEFCl+OS1F3b9/fxw4cMBh29ixY9GiRQs8//zzVwRp4eXlpSads8sYiIiISpvTAnWVKlXQpk0bh22+vr6oUaPGFduJiIgqKqc3zyIiIiIDN8+yt2HDBmcfAhFVcFJXJisry9mHQS7Ow8OjwCJclw/UzpSSkY19kfHIztVwc7MAZx8OEZUxqVcbHR2N+Ph4nnsqEVWrVkWtWrVUJekbwUBttf5oDCZ8vxft6vozUBNVQHqQDgwMhI+Pzw3/uFLFvulLTU1FTEyMWr/R5sMM1FbtQ6qq+ZHziUjPyoG3R8lkWRCRa2R360FaKrQS3ahKlSqpuQRrua5uJBuclcms6larhBq+nsjK0XD4PJt9EVUkepm0pKSJSop+Pd1onQcGaivJ5gq1pqqlrJqIKh5md5MRrycG6gKyvxmoiYjIKBio7egp6jCmqImoAmvQoAFmz55drKa1knos7Rrz8+fPVzWpKxoGajuhdf3V/PSlVMSnZjrrOyEiKhIJjoVN06dPv64zKSMaPvroo0Xev0ePHmqQCX9/y28olSzW+rZT1ccTDWv64tTFFOyLSkAftqcmIgOT4KhbtGgRpk6divDwcNu2ypUrOzQZktrt1xr7WAQEFK8vCU9PT9VemEoHU9RXSVWHnWGFMiIyNgmO+iSpWUlF6+tHjx5VYyqsWrUKnTp1UgMabd68GSdOnMCdd96phleUQC5jIf/++++FZn3L686bN0+NeCg1mZs2bYrly5dfNetbz6Jes2YNWrZsqd5nyJAhDjcW2dnZePLJJ9V+0iROBmMaM2YMhg8fXqxzMHfuXDRu3FjdLDRv3hz/+9//HG5OJFehXr166vMHBwer99R9/PHH6rPIUMtyPu6++24YEQN1Praa31EM1ESo6J1WZGY7ZSrJ0YdfeOEFzJo1C0eOHEG7du2QnJyMW2+9FevWrcPevXtVAL399ttx5syZQl9nxowZGDlyJPbv36+eP2rUKMTFxV11f+nw4+2331aBc9OmTer1J0+ebHv8jTfewIIFC/DVV19hy5YtajREGf64OJYuXYqJEyfimWeewcGDB/F///d/ahTGP/74Qz3+448/4r333sOnn36Kv//+W71+27Zt1WO7du1SQfuVV15RuRCrV6/GzTffDCNi1nchNb/ln4XNNYgqprSsHLSausYp7334lcHw8SyZn2cJRAMHDrStV69eHaGhobb1V199VQU8SSGPHz/+qq/z4IMP4r777lPLr7/+Oj744APs2LFDBfqCSNvhTz75RKV2hby2HIvuww8/xJQpU1QqXXz00UdYuXJlsT7b22+/rY7riSeeUOuTJk3C9u3b1fZbbrlF3RxI7sKAAQNU39uSsu7atavaVx6TERtvu+02lfNQv359dOjQAUbEFHU+LWv7wcPNhEspmYi6nOacb4WIqIR07tzZYV1S1JKylSxpyXaWbGlJbV8rRS2pcZ0EOD8/P1sXmQWRLHI9SOvdaOr7JyQk4MKFC7agKaTnLsmiL44jR46gZ8+eDttkXbaLe+65B2lpaWjUqBEeeeQRdUMiWe5Cbl4kOMtjo0ePVql7yQUwIqao85GuQyVY749KUM20QqqzpyKiiqiSh5tK2TrrvUuKBFV7EqTXrl2rUp1NmjRRXV1K2WxmZuEtXSRFak9yG3Nzc4u1f0lm6RdFSEiIytaWMnj5zJLyfuutt7Bx40aVit6zZ48qX//tt99URTwpz5Ya70ZrAsYUdQHY8QkRSWCR7GdnTKVZ5CblwZJdLFnOUl4rWcOnT58u0y9cKr5J5S0JijqpkS6BszhatmypPo89WW/VqpVtXW5EpAxesuolKG/btg0HDhxQj0kNeMkWf/PNN1XZu5yH9evXw2iYoi5AaF25m4pgxydEVO5ILeeffvpJBS+5IXj55ZcLTRmXlgkTJmDmzJkqVd+iRQtVZn358uVi3aQ8++yzqoKblC1LwP3ll1/UZ9NrsUvtc7kB6Natm8qK//bbb1XglizvFStW4OTJk6oCWbVq1VT5uJwHqTluNAzUhdT8PnguAVk5ufBwY8YDEZUP7777Lv7973+rTkpq1qypmkVJjeuyJu8rQ4s+8MADqnxaOlgZPHhwsUaZGj58ON5//32VjS+1vxs2bKhqkfft21c9LlnYUuNdKplJwJYcBAnm0hxMHpOgLtnd6enp6gbm+++/R+vWrWE0Jq2sCw1KUFRUlCqDiIyMRN26dW/sxbIzgIitwKXjyO38MEJf+Q1J6dn49cleaB3M3naIyjP5oT516pT6oZc2tVT2JDUrWdmSQpaa6OX9uooqRvxiilqXdhn4nzS0N8HcbqTK/t58/KLK/magJiIqWREREaoSV58+fZCRkaGaZ0lQu//++3mq82Gerq5KLaBaQ+nmAIjcidAQSyqaI2kREZU8s9msypClZzRpUiUVvKRsWVLV5Igpanv1ugOXTwFntqF9iKVD+n2RCflOGRER3SjJ9s1fY5sKxhS1vXo3WeZnttv6/D4Wk4TkDEsDeSIiorLGQG2vfg/L/OwuBPqYEOzvDalqdyCKqWoiInIOBmp7NZoAPjWA7HTg/D60r8cBOoiIyLkYqO1JQ3sppxZntlk7PuGQl0RE5DwM1IWVU3PISyIicjIG6vxsKertaBtcBWYTcD4hHRcS08v+2yEiogqPgTq/Wu0A90pAWhx8k06hWVAVtVk6PiEiKo+ky82nnnrKtt6gQQPMnj270OdIn9zLli274fcuqdcpjHQT2r59e7gqBur83D2ButbxWyO22sqp2fEJERmNDKwxZMiQAh/7888/VRCUUaGKS0a1kr63yyJYnj9/HkOHDi3R9ypvGKivkf3Nmt9EZFQPPfSQGmdZ+o3OTwan6Ny5M9q1a1fs1w0ICFCjTZUFGWbTy8urTN7LVTFQF6Rhb6BRX5Wy1lPU+yMTkJvrsuOXEFE5dNttt6mgKl1x2ktOTsbixYtVIL906RLuu+8+1KlTRwVfGUFKRokqTP6s77///lsNBykDS8hYz3JzUNBoWM2aNVPv0ahRIzV8ZlZWlnpMjm/GjBnYt2+fSuXLpB9z/qxv6Uq0X79+ajhKGeXq0UcfVZ9HJ2Npy6hZMmJW7dq11T7jxo2zvVdRBwB55ZVX1GAYcpMgKf3Vq1fbHs/MzMT48ePV68tnlmExZUhOIeNYSe5AvXr11HODg4Px5JNPojSxC9GCNLzZMgFolpOLSh5uSMrIxsmLyWgSaCmzJqIKIjOl+M9x8wLcrD+vOdlATgZgMgMela79up6+RX4bd3d3NUykBL0XX3zRNpazBGkZ1lECtAS5Tp06qUDq5+eHX3/9FaNHj0bjxo3RtWvXIgW1f/zjHwgKCsJff/2FhIQEh/JsXZUqVdRxSOCSYPvII4+obc899xzuvfdeHDx4UAVDfaxof/8rRyVMSUlRQ112795dZb/HxMTg4YcfVkHT/mbkjz/+UEFU5sePH1evL8FW3rMoZGjMd955B59++qkay/rLL7/EHXfcgUOHDqnhLj/44AMsX74cP/zwgwrIMsKVTOLHH3/Ee++9h4ULF6ohMWWoTrkBKU0M1Nc6QW5mtK3jjx2n4xAWmcBATVTRvB5c/OfcMx9oPcKyfPQXYPGDQP1ewNhf8/aZ3RZIvXTlc6cXrydEGVv6rbfewsaNG23jMEu291133aWCoUyTJ0+27T9hwgSsWbNGBaGiBGoJrEePHlXPkSAsXn/99SvKlV966SWHFLm8pwQzCdSSOq5cubK6sZCs7qv57rvv1NCQ33zzDXx9LTcsH330kSqLf+ONN9TNgqhWrZraLmNXt2jRAsOGDcO6deuKHKglNS43Lv/85z/Vury2BH3JRZgzZw7OnDmjAnavXr3UzY+kqHXymHyGAQMGwMPDQwXyopzHG8Gs78IkxwDRB2wjaYVFXi7VL4OIqLgkUPXo0UOlCoWkMKUimWR7C0lZy/jOkuVdvXp1FTAl6ErAKYojR46oATT0IC0kxZvfokWL1ChYEsTkPSRwF/U97N8rNDTUFqRFz549Vao+PDzctk1SshKkdZK6ltR3USQmJuLcuXPqde3Jury/nr0eFhaG5s2bq2xtGY5Td8899yAtLU1l78uNwdKlS5GdnV1+U9Rz585V0+nTp20nf+rUqcaoARi+Gvj+XtVcK7THIrWJI2kRVUD/OXd9Wd+6FrdbXkOyvu09dQAlRYKypJQlNSipacnWlnGehaS2JatXUosSrCUISta1lMOWlG3btmHUqFGqHFqyriUVL6lpyV4uDR4eHg7rkuqVYF5SOnbsqMbGXrVqlcpRGDlypEpBL1myRN20yE2DbJey+ieeeMKWo5H/uMpFiloK8mfNmoXdu3dj165dqgLBnXfeqcoJnK52qHz9anzq9sGWu7sj5xORnpXj7CMjorIkZcbFnfTyaSHLss2+fLqw170OEkhkfGfJOpZsY8kO18urZShJ+V3917/+pVKrkhI8duxYkV9bxoeW8llpRqXbvn27wz5bt25V2cNSTi41zSXbOCIiwvHjenqq1P213kvKe6WsWrdlyxb12SR1WxKknF5yB/IPsSnrUlHOfj8p+/78889VboGUTcfFxanHJCtfsuOlLHvDhg3qRkXK5ctlilo+qL3XXntNpbDlIpDUtVP51QZeiAC8/VFH01CzsicuJmfi0LlEdKpfzbnHRkRkR7KaJahMmTJFZe1K1q1OgqakBCWYStnuu+++iwsXLjgEpcJISlJqc48ZM0alHOX1JSDbk/eQbG5JRXfp0kVVWJMsYXtSbi2pVMlSlkSaVDTL3yxLUuXTpk1T7yU1q2NjY1VOgVR+08unS8Kzzz6r3kdyHqQSmuRCyHEtWLBAPS7nSLLTpaKZ3CRI5TzJ0q9ataqq1CY3HN26dVM13L/99lsVuO3LscttGbV8cPmS5U6qoPIPkZGRoS4SfUpKSirdg/K2lE3LnSk7PiEiI5Ps78uXL6usZ/vyZCkrlqxc2S6VzSTgSPOmopJAJUFXymWl0pTUwpZElT2pMf3000+r2tkS+OSmQJpn2ZPKbdI5yy233KKalBXUREwCn5SfS8pVAv7dd9+N/v37q4pjJUnKnSdNmoRnnnlGFQdIbXSp5S03HEJuIt58802VOyDHIcWzK1euVOdCgrWksqVMW9qoSxb4L7/8opqJlRaTJo3CnEiyCyQwS00/uSuUrJtbb721wH3lDkvKQPKTbBm5Qys1uTn48I+TeGftMdzZPhjv/7ND6b0XEZU5+f2R1F7Dhg1Vu1mi0r6upJMaKe8uSvxyeopayh0ky0Ha5z3++OMqy+Pw4cMF7ivZOtKGT5+utl+JSY0DvroVeLMR2gdbeulhV6JERFSWnN6OWioYNGnSRC1Lo3xp5C41FKUhen5SnmFfpiHZ36WqUjUg5giQHo8OHpZmBqcvpeJySiaq+XqW7nsTEREZIUWdn1Sxl7JoQ5Bak9bxqStf2IlGNS01MvdFcSQtIiKqAIFasrI3bdqkCuqlrFrWpaq71Pwz4gAdoSH6SFrF6zmIiIjIJbO+pScZ6adW2udJA3mpQSc1/gYOHOjMw7pKoN6G0J5VsHQveygjIqIKEqi/+OILGJ50fOLuDaTFoZu/pbH7vqgENYKK3qEAEZUPJdm7FVFuCV1PTq9MZnjunkCdzkDEZjRJOwAPt1qIS8lE1OU0hFQvm/Faiaj0K7VKG1npA1ra+Mo6b8TpeklCTrpolQ5b5LqS6+lGMFAXhVQoi9gMj7M70Kr2v1SKem9kPAM1UTkhP6bS1lWK4SRYE5UE6cBFRteS6+tGMFAXs5y6fYPxKlBLe+o7Qq9j+DsiMiRJ9ciPqoyEdK0+qYmuRUb3kmE9SyJnhoG6KEK6Wka+uXwa3bpk4mt2fEJULsmPqoyAVFqjIBGVi3bUhuTtBwRZBgnpiKNqfuBsArJyWPGEiIhKFwN1MbO/g+L3ws/bHRnZuQiPLuVBQYiIqMJjoC4qaw9lpqhdeR2fsIcyIiIqZQzURdW4HzB2lZr0IS/DzrArUSIiKl2sTFacATrq91CL7ZmiJiKiMsIU9XVoF+Kv5n/HJCM5I7ukvxMiIiIbBuriiDsJrHwWgRueR52qlaBpwH6WUxMRUSlioC6OnCxgx2fAvkXoWLey2sSRtIiIqDQxUBdHzWZAjwnAiLkIrVtFbZIeyoiIiEoLK5MVh3QFN+i/arHtyUsATiKMgZqIiEoRU9TXqW1df5hNQHRiOqIT0kv2WyEiIrJioC6unGzg9Gb47PgIzQKt5dSsUEZERKWEgbq4tFzg27uA36dhQJClC1FmfxMRUWlhoC4ud0+gTme1eLPXcTVnhTIiIiotDNQ30O93s4wDar4/KgG5uVqJfjFERESCgfoGRtLyj92NSh5uqneyE7HJvKKIiKjEMVBfj5Au0lYLpsun0Lu2pQtRllMTEVFpYKC+Ht7+QFAbtTjEL0LNWfObiIhKAwP1DZZTd9COqjlT1EREVBoYqK9XfUs5dZ2kMDU/ej4J6Vk5JfbFEBERCQbq6xViSVF7xB5EPd9cZOdqOHQukVcVERGVKAbq6+VfB6haDyYtF8MDzqpNzP4mIqKSxkBdAs20enmy4xMiIiodDNQl0vHJQTVnzW8iIippDNQ3on5PoEFveDfrp1YjLqUiLiWzhL4aIiIiBuobE9AceHAFvPs/h0Y1fdUmpqqJiMjpKerIyEhERUXZ1nfs2IGnnnoKn332GSqq9iFV1ZwDdBARkdMD9f33348//vhDLUdHR2PgwIEqWL/44ot45ZVXUOGkxqGfH2t+ExGRQQL1wYMH0bVrV7X8ww8/oE2bNti6dSsWLFiA+fPno0I5txd4syEG75sgg1WrFLWmcSQtIiJyYqDOysqCl5eXWv79999xxx13qOUWLVrg/PnzRX6dmTNnokuXLqhSpQoCAwMxfPhwhIeHw6UEtgLcveHmWx213JJxOTULkXFpzj4qIiKqyIG6devW+OSTT/Dnn39i7dq1GDJkiNp+7tw51KhRo8ivs3HjRowbNw7bt29XryM3AIMGDUJKSgpchrsXMPkYzBN2ISg4RG0Ki4p39lEREVE54X49T3rjjTcwYsQIvPXWWxgzZgxCQ0PV9uXLl9uyxIti9erVDuuSbS4p6927d+Pmm2+GS42mJRXK6vqrrO+wM/G4IzTY2UdFREQVNVD37dsXFy9eRGJiIqpVq2bb/uijj8LHx+e6DyYhIUHNq1evDlfUoW5lfM0mWkRE5Oys77S0NGRkZNiCdEREBGbPnq3KlyVFfD1yc3NVE6+ePXuqymkFkfeUmwN9SkpKgiHk5gDfDMcdq7ojAPE4eDYBWTm5zj4qIiKqqIH6zjvvxDfffKOW4+Pj0a1bN7zzzjuqMtjcuXOv60CkrFpqky9cuLDQymf+/v62qVWrVjAEsxuQEgtzdip6ex9HRnYuwqMNchNBREQVL1Dv2bMHvXv3VstLlixBUFCQSlVL8P7ggw+K/Xrjx4/HihUrVNvsunXrXnW/KVOmqOxxfTp8+DCMNkDHoMqn1JwjaRERkdMCdWpqqmpSJX777Tf84x//gNlsxk033aQCdlFJe2MJ0kuXLsX69evRsGHDQveXJmF+fn62ST8GIw3Q0V47oubsoYyIiJwWqJs0aYJly5aprkTXrFmjmlSJmJgYFUCLk9397bff4rvvvlNBV3o5k0nKwF2ONUUdlHoMvkhjipqIiJwXqKdOnYrJkyejQYMGqjlW9+7dbanrDh06FPl1pDxbsrClFnnt2rVt06JFi+By/OsA/vVg0nLR3nwcx2OTkZSe5eyjIiKiitg86+6770avXr1UL2R6G2rRv39/1b66qMpdV5uS/X3gDPpVOoktKW1x4GwCejSu6eyjIiKiijgeda1atVTqWXoj00fSktS1dCNaYdW35Cz09PxbzVmhjIiInBKopc2zjJIlTaTq16+vpqpVq+LVV19Vj1VY1nLqxhmH4Y5sVigjIiLnZH3LcJZffPEFZs2apTooEZs3b8b06dORnp6O1157DRVSzeaAd1V4pMejlSkC+yIrO/uIiIioIgbqr7/+GvPmzbONmiXatWuHOnXq4Iknnqi4gdpstpRTH1uNrm7HMC+xMaIT0lHL39vZR0ZERBUp6zsuLq7AsmjZJo9VaNb21H0rnVBzllMTEVGZB2qp6f3RRx9dsV22Scq6QqvXQ83aQiqUadjHIS+JiKiss77ffPNNDBs2DL///rutDfW2bdtUBygrV65EhRbcHhjzC347HwgsP6GGvCQiIirTFHWfPn1w7Ngx1WZaBuWQSboRPXToEP73v/+hQnP3AhrejLaNLONRS1vqnNxy1l6ciIiMnaIWwcHBV1Qa27dvn6oN/tlnn6GiaxpYBT6ebkjOyMbJ2GQ0DTJQv+RERFT+OzyhQiTHwO23F/Glz4dqdW8ks7+JiOj6MFCXBjcPYPvHuCl9M2oigR2fEBFR2Wd9UyEqVQNu+Q/2plRD6iYv1vwmIqKyCdRSYawwUqmMrPo8h8D4NKRuWo+j55OQnpUDbw83nh4iIiq9QC19e1/r8QceeKB4R1COBft7I6CKF2KTMnDoXAI61a/u7EMiIqLyHKi/+uqr0juS8kbTYIrcgecrr8bUpO4Ii2SgJiKi4mMZdWkxmYAfH8LdCZH4yRyAsMhGpfZWRERUfrHWdxn0+93VfJQ1v4mI6LowUJdBoO5sCseZuFTEpWSW6tsREVH5w0BdmupZ+kHv5HYC7shmqpqIiIqNgbo0BbQEvP1RCeloaTrDIS+JiKjYGKhLk9kMhFiyv7uYw9nxCRERFT+U8JyVUTm1BOrIeGgaR9IiIqKiY6Auo3LqruZwXE7NVJXKiIiIioqBurTV6Qi4eaGmKQENTNEspyYiomJhoC5t7l6WYG0tpw7jkJdERFQMDNRl2p76GJtoERFRsTBQl2E5tVQoO3guEVk5uWXytkRE5PoYqMtCSDdoITdho7krsrOz1bCXRERERcFAXRYqVYXpoTXYUG88cmFGWBTH7SYioqJhoC5D7etaxvOW9tRERERFwWEuy1DHIDd0MknHJ5XL8m2JiMiFMVCXlaRo9FnaGb08TWgXOw9J6Vmo4u1RZm9PRESuiVnfZaVKLZj86uCCOQC1cQkHohLK7K2JiMh1OTVQb9q0CbfffjuCg4NhMpmwbNkylGtPbMPrTRfihFaHFcqIiMj4gTolJQWhoaGYM2cOKgRvP3QIqaoWw86wQhkRERm8jHro0KFqqkhCQ6rCjFzsj4xz9qEQEZELYBl1Gevw1yTs83oENZPDEZ2QXtZvT0RELsalAnVGRgYSExNtU1KS6/Xw5Z6dgiqmNOsAHZedfThERGRwLhWoZ86cCX9/f9vUqlUruOwAHSpQs+Y3ERGVo0A9ZcoUJCQk2KbDhw/DVQfo6GI+hn1nmKImIqJy1OGJl5eXmnSS/e1ygjsi1+yJwNx4XD4bjpzcm+BmNjn7qIiIyKCcmqJOTk5GWFiYmsSpU6fU8pkzZ1BueXjDVKejWmydfQQnYpOdfURERGRgTg3Uu3btQocOHdQkJk2apJanTp2K8sxkLafuYj6KMA7QQURERg3Uffv2haZpV0zz589HuWYrp5YKZez4hIiIykllsnIjpKuaNTafx6mICGcfDRERGRgDtTP4VEdWjeZq0T92N9KzcpxyGEREZHwM1E7i3qCHmnc0hePgWbanJiKigjFQO4mpviVQs5yaiIgKw0DtLNaa361METh0JsZph0FERMbmUh2elCv+ITjY/xv889dMVDub6uyjISIig2KK2llMJtTrciuS4YPIuDRcSs5w2qEQEZFxMVA7kZ+3BxoH+Krl/VGsUEZERFdioHamjGS86LkQCzxeQ9iZi049FCIiMiYGamfyqIReCb+gp9shXD6516mHQkRExsTKZM5kdkNs52fw7qYL2HXBW3WfajJxJC0iIsrDFLWTBQx4Cr+Y+yIizRsRl1j7m4iIHDFQO5mnuxmtg/3U8r4oDtBBRESOGKgNYEj1C/i32yqcOHHM2YdCREQGwzJqA7g75gPU8NiLD04HALjF2YdDREQGwhS1Abg3sIxPXSshDJnZuc4+HCIiMhAGagPwa9ZbzTviKMKjk5x9OEREZCAM1AZgsg7Q0cR8DkdOnHD24RARkYEwUBuBT3Vc9GmkFlP+3ursoyEiIgNhoDaIjNpd1dw3ZqezD4WIiAyEgdog/Jpbyqmbph9EYnqWsw+HiIgMgoHaIKo0tQTqNqZTOHQ62tmHQ0REBsFAbRRV6+Gye014mHKweNlSfLH5FOJSMp19VERE5GQM1EZhMiEzuJtafD3tFbRccz+envkenliwGxvCY5CTqzn7CImIyAkYqA0k6JbHkesbCG9TFnq4HYYpNwsrD0Tjwa924tGZn2DbvKcRfXCjsw+TiIjKELsQNZKGvWGefAyIDQcituCFgCFosD8ey8LOolPaVnSPWo7FC4/jp3peuLdLCIa0CoB35J9ASDfAq7Kzj56IiEoBA7XRyHjUgS3U1ALA9AZ18MLQFti/Phab96VgXUJbbDt5SU1dvc/gB7wAzeQGBLeHqX5PoEEvQDpQ8fZ39ichIiq6zBQgJwvIzbZMalmmnLztMs/JtE5ZQEAzVb9HSTwHHFsDeFUB2t6d97rb5gBJ0dbn2z33imW7bZ3GAp3GWJ4fcwT4+nagUjVgvHOazzJQuwBvDzd0HTwKGDwKDePT0HJXFBbvjoR3wmWccQ9APXMscHa3Zdr6AWAyA0FtLEFbgnf9HqpTFSKiAkmQSosHvP0Ady/LtguHgFObLIGwxTDLNk0Dfnz4ygAq6znWAKsey3ZcH/oW0GyQ5TWO/AL89H9AvW7A6KV5x/BeGyAtrnhf0K1vA10fsSxfOg6seAoIaOEYqHd/DVwML97rNrUeq2ICUmItn9dJGKhdTJ2qlTBxQFNM6NcE2062w9s7hyLs0EF0zD2MbuYjuMntCBoiGojeb5m2f2x5YmBroEFPoOHNQMvbnf0xyJ78+KXGAUnnLHf+kjJIOg+kJwCelS25I63uBKqGWPaXfdPjAZ8a5T/nRH7szW6WnCYqxnnLAiL/AtIuFzLFW6fLQKZ1jIEHf7Xc4Isz24DVLwAtbssL1PI9HPoJ0Io5eFBGouP1npUCZKY67mO2C0eSSyjrbh6W79/sYV33BNw9LXN5TFK5Ot9AoPkwwL+u4+u2vw9IuWh9jvV5V122rtdokvf8ag2Ax7cC7t5wFgZqF2U2m9CzSU01xae2xvJ95/DtzkhMOZeIQFxWQfsW77/Rx+sYaqSdAmIOWSb557UP1CfWW4J4lSBnfpzyS36McjLyflDkh3HjG9ZgHJ0XnCW7rTB1OuYF6oM/AisnW4L3yG8s23JzgU97W7L9JHjnn7z8Cthe1TJ3cy+ZwCBZl/pUpZYldSbiTgIRWwHfAKDZ4LznrHjacjNi/zx9Uj/kkhWaCXj4Wn585fN3ewxoOtB6blOA1EtAldqWH9jyRIKZnJvkGCA52pKisw+wch7062HXV5ZrSoLpsHcs27LTgfnW4Foc6XYBtWZzoPU/gLpdHPcZPNOSayfXjQRPCaL2AfWKZXegeuO85zfuBzwZBnj6Or7uU/st+6ogfR31nANbAPd9d+X2Xk/jhnh4A0Gt4UwM1OVAVR9PPNC9gZoOnk3A4l2RWBYWiF9SewCpQA0kYHTwWdzhfxIhjVvCwz6ILBhpyZp66mDeP778EMgPvvyz0dVTeikxQOJ5S+pXJgm+kg3nF2zZ5893gHWvAB0fAO740LJNzqmey5GfT03Ar7Yl8MgkwT0z2fKDrb+meu8swMPHMTUt+104WPxv676FQPOhlmUp3/vzXVWpEf1eynuvXydZA2iq5X1swdRuPf+Nxj+/y0uFRe0Cfh4HNOrrGKjlhkM+27VI0JasS5na3Zu3/fQW4Lt7gFrtgMf+zNu+9SPAoxLgH5IX4OV6NgK5oZIg6uljWc9IAv76xBKQ5YYt+YJ1HgNkp139dZoNyft/1XKs16BdR0mSExPQ0vK55TpymKpeua2gmza5DmTK76bHbuwcSMXXgiq/yndGBWKgLmfa1PFX05RbW+K3wxdU0N58HJh9zh+zz7WC3yl33HnxoKo13sb7IhDY0hKY7bOLFj8InN5sKZuq3tCS9VPNOpf1qvXLfy3z7Ezg9CZrILZL+eopYQnSBWX/NeqTF1Ql8OpZ1Tr54ez9jCV1qQdkCc6Va1my9Iqi+xOWSX70dZItN3qZJfAVNkkWpL4sQdY+2MefASK3O+auSApnz/8kGhTt2GR/SSnZl+dJwJQyPwmo9vr+x/K6sr9MknLWl23bfCypSDm2hChLCwedZP9LNqX9tSsp0T9etwR3e/I5VeC2Bm89gOvrcv6vJxWny86wBFlbwJVr5gLQeWze9SA3EGunAh1G5d24Sfnn+v9e/XUlJ6RyEFA50DGwSo6FruUdllSv7KeTLOpx26//85ChmDRNrmzXFBUVhZCQEERGRqJu3XzlEmQTGZeKJbuj1HQ2Pu8uvVVtP4zsXBfD29ZEVT+7FMdHXYCLxwo/g1IepAdumTcZCITkyyIzYvDVU79yg6IHKancsn0uUK870P9lyzZJJb5ul4otiGTRyQ+mHmxlLrVFg1rlvYYELD0L2GgktSxZmHrOyeXTwPl9lpsIqYCo2zzbEhDzB1E1VbYEU325qDcbJUVuViQo6ylm+Y5/ewlIiLROUZZAfy0jPgNCran16APA4eVA7VCg5W2WbVnpwNEVdineC9ZlmUdf/T0e+NmSkyB2zwd+mQg0HQyM+iFvH9km9Q1UQA6yXFP6sp7yLiMSDqIT03EiJgXHY5JwIjYFJ2KT1SSRopa/N2r5eVvmdsu1/Sup5UqezIUrjfjFQF2B5OZq2HLiIhbtjMRvhy4gM8eSIvN0M2NQ6yCVyu7ZuCbMyLWkHOWH+/IpyzzuVN56QT9KA18Bek7Ma86weKzlh+4fn+btk3DW8oMkZT4lSX5B5JhU9rME4nMFz1Mv5j1HaptKWZmQFOPy8UCTAcC/fszbZ95ASwBQQTjY8gMqqSM9Jexbk8UDrkCyl+Xa04N3vDWAqynScq0/uCLv5mTnF5bs/mZDgfsXFv3GTcpkVaCVICs3cEFAl4fzyjf18ni5EXJymXpmdi4iLlmC8PGY5LyAHJOMlMzrr93sX8kjL5DbB3Trem1/b7WPiZUDUZxAbYis7zlz5uCtt95CdHQ0QkND8eGHH6JrV8uwj1SyFdB6Nw1QU3xqJpbtPYtFu6Jw5HwiVuw/ryapVT6wVRB8PN3gZg6E2RQEN3N3uNU0wRxggpsZ8M5ORtWMs/BLPwu/tCg1nUmuj7jdUerx4PM70C32COKz3fHXoWi4meR5JnT7dRgqJZ1Gpk8QMqrUR2aVesj0q48sv3rI9q+PbP8GQKXqcHMz2eKv9JyqQVMJJ8/L4fCN3IRMn1qIbzhMZcZqWWkIXRAKs1TYKoJcswcyKgXh6OlYXMy4gFxNg3dWC/h3fRvJlRsgfv859b7y2h7dvoGHmxke7mZ4uJnUDY1ahxmeaWZ4ZmbAw91k2eZmtj5ugrucBDIOudmy9k1w1foG9oGjZjOg878tTRx1kmMgN3KSFa2neNU80BqUa1mypAsLQHolvjKUkJZlC8ASjCUon4xNRkRc6lW7JZb/1fo1fNAkoDIaB1ZGY5kH+Kpr/HxCOqIT0lSqW5YvWOfRCelIzcxR7ydT+AVrLfICeHuY8wVzSY17WeYqde6NmpW91HGQQVLUixYtwgMPPIBPPvkE3bp1w+zZs7F48WKEh4cjMDCw0Ocy67tkSAW0H6QC2t6zSEzPvuHX80cy2plPQoMJm3PbWrdq2OP1f6huSi70uYlaJURqlu89yHQZT2WNs73GPW4b8JbHZ9iY0w5jsl6wPWef18PwN6UiTquMC1p1XNCqIVqrhguorubRtm3VEQfJIi3dHwD5fbEFbmuQ19c91brdNrt1T3c3xxsC6+Ne7gXPPd3cHNety15XeczdbGJKphySn3AJlpaUcbJDKjk26eo3sJW93FUAbmwXkJsE+qJedV91vRT3GJIysnEhwRq4Ey3B2za3Lhd1oCEJ0oFVvBxS5kF+3vD1tFzX9v87lv8Fu3W1LP9HbupGWv8/VNvdzCrBYgQulfUtwblLly746KOP1Hpubq46+AkTJuCFF/J+jAvCQF2y0rNysOZQNA5EJSA7V1OpzRy7ueSU25Y1SeXqj6GAfe2WJWUs85xcVMmNR1D2eQTlnketnGjUzr2A4NxoBGvRCMSVnR1MNz2BFW79VUKljfY3RuUuxxFTEyz0GKG2yRSkXUKiyQ/ZZi8Vg80mkwrFaq72sa6b5WGTCqTygMwL3M+aKpJjl+KBLOsk2YVZOXbbsnOty65RzUM+b96PmlteUL/iBkCW3RyCuzo/1jpKcpb0c6/WCnpMrevL+faxnmcU9Jjd96NvMwIJAHIu7G+y3O2WLesmeJjzclU89W0Oz7EEDttzzUUPHBnZOYi4lGoJwtagfDxWUsgpKjV7NUF+XmhiSxlLMLbMZXtZZ0HLb0xMYgbOW1PlDsHcOo9JyijVQYjcrd+jHtjlurfcKJsL2J53w63fANwRWgfdG9eoOIE6MzMTPj4+WLJkCYYPH27bPmbMGMTHx+Pnn3922D8jI0NNurNnz6JVq1asTFZeZKVZavdKWbiQ8mCpqGaUpjVXIf9CEqxtAd0uqOcFeGuQty7nvwHIlH1t+1nW1fbsXPUDbdlHX891eCyjkMc46JrxSepRgodjYM8L+LKclpmNM3GpV/0+3fXs6nwBuVGAL6p4u1YbcwnSF5MzVNC2z16PSUxHWlaO+v+Q69zh5tm6btteijfSrw5vg9E31a84ZdQXL15ETk4OgoIcO9uQ9aNHj16x/8yZMzFjxowyPEIqU9KOMqC5ZXIhkipRWW3FzC4sC9k5VwbxjGLcAMiPpvzMSe6IfksvNyZ6Ob5lnrcuCwVt19etf1d/jQKe7+xUtRyDnruSbbshs8yzcyUgaMiSufXxAvfTb9SsFTjt6TlQcr6vRWVXq2DsawvKMq9X3UcF9PJy4yLZ3DKFWpuK3wi5pjLz3yjbXfdXrhe+X/u6VVHWDFGZrKimTJmCSZMmXZGiJqKCSYpMJp8ybjVFVw8aEpSlaMkxoFsChH5jlT/QS0pbgrKU27LGdPHI+ZKiHC+JdtZuzF2NUwN1zZo14ebmhgsXLjhsl/Vatewa9Ft5eXmpSZeYaNfdHRGRCwQNCbrubpbBdoiKwql5JZ6enujUqRPWrVtn2yaVyWS9e/fuzjw0IiIiQ3B61rdkZUvlsc6dO6u209I8KyUlBWPHjnX2oRERETmd0wP1vffei9jYWEydOlV1eNK+fXusXr36igpmREREFZHTA7UYP368moiIiMhR+ajPT0REVE4ZIkV9vaTimTh//ryzD4WIiKjI9Lilx7FyG6j1Zl0cwIOIiFw1jtWrV8/YfX3fiOzsbOzdu1dVPDPfyKDvVklJSaoDlcOHD6NKFWN3W2kkPG88d7zmXAf/X41x3iQlLUG6Q4cOcHd3L7+BuqRJByr+/v5ISEiAn5+fsw/HZfC88dzxmnMd/H91vfPGymREREQGxkBNRERkYAzUdqQf8WnTpjn0J07XxvN2/XjueN7KGq851ztvLKMmIiIyMKaoiYiIDIyBmoiIyMAYqImIiAyMgdpqzpw5aNCgAby9vdGtWzfs2LHDud+MC9i0aRNuv/12BAcHw2QyYdmyZc4+JJcwc+ZMdOnSRXWaEBgYiOHDhyM8PNzZh+US5s6di3bt2ql2rDLJuPWrVq1y9mG5nFmzZqn/2aeeesrZh2J406dPV+fKfmrRokWZHgMDNYBFixapcbGlRt+ePXsQGhqKwYMHIyYmpky/DFcj44bLuZKbHCq6jRs3Yty4cdi+fTvWrl2LrKwsDBo0SJ1PKlzdunVVkNm9ezd27dqFfv364c4778ShQ4d46opo586d+PTTT9UNDxVN69atVd/c+rR582aUKemZrKLr2rWrNm7cONt6Tk6OFhwcrM2cOdOpx+VK5FJaunSpsw/DJcXExKjzt3HjRmcfikuqVq2aNm/ePGcfhktISkrSmjZtqq1du1br06ePNnHiRGcfkuFNmzZNCw0NdeoxVPgUdWZmpro7HzBggO3mRfoNl/Vt27aV7V0TVUjSJaGoXr26sw/FpeTk5GDhwoUqJ0KywOnaJCdn2LBhDr93dG1///23KuJr1KgRRo0ahTNnzqAsufToWSXh4sWL6h9eBvawJ+tHjx512nFRxSAd80s5Yc+ePdGmTRtnH45LOHDggArM6enpqFy5MpYuXaoGS6DCyU2NFO1J1jcVndRZmj9/Ppo3b66yvWfMmIHevXvj4MGDZTZ4U4UP1ETOTuHIP3yZl3m5MPnBDAsLUzkRS5YswZgxY1S5P4P11UVGRmLixImqToRUmKWiGzp0qG1ZyvUlcNevXx8//PADHnroIZSFCh+oa9asCTc3N9vY1jpZr1WrVpl8CVQxjR8/HitWrFC156WSFBWNp6cnmjRpopY7deqkUojvv/++qiBFBZPiPakc27FjR9s2yUmUa++jjz5CRkaG+h2ka6tatSqaNWuG48ePo6xU+DJq+aeXf/Z169Y5ZEfKOsu9qDRI3TsJ0pJlu379ejRs2JAn+gbI/6sEGrq6/v37qyIDyYnQp86dO6vyVllmkC665ORknDhxArVr10ZZqfApaiFNsyT7TC7crl27Yvbs2aqCytixY8vsi3DVC9b+rvLUqVPqn14qRdWrV8+px2b07O7vvvsOP//8syrjio6OVttlrNtKlSo5+/AMbcqUKSorUq6vpKQkdR43bNiANWvWOPvQDE2us/x1IHx9fVGjRg3WjbiGyZMnq/4iJLv73Llzqhmv3Njcd999KCsM1ADuvfdexMbGYurUqepHs3379li9evUVFczIkbRjveWWWxxueITc9EjlC7p6px2ib9++Dtu/+uorPPjggzxthZDs2wceeEBV6pEbGykzlCA9cOBAnjcqFVFRUSooX7p0CQEBAejVq5fqA0GWywpHzyIiIjKwCl9GTUREZGQM1ERERAbGQE1ERGRgDNREREQGxkBNRERkYAzUREREBsZATUREZGAM1ERERAbGQE1EN8xkMmHZsmU8k0SlgIGayMVJt6MSKPNPQ4YMcfahEVEJYF/fROWABGXpK9yel5eX046HiEoOU9RE5YAEZRk/3X6qVq2aekxS1zIQiIw6JaNzNWrUCEuWLHF4vgyB2K9fP/W4jKj06KOPqtHR7H355Zdo3bq1ei8Z4k+G6rR38eJFjBgxAj4+PmjatCmWL19ue+zy5ctqSEUZyEDeQx7Pf2NBRAVjoCaqAF5++WXcdddd2LdvnwqY//znP3HkyBH1mAzpOnjwYBXYd+7cicWLF+P33393CMQS6GV4TgngEtQlCDdp0sThPWbMmIGRI0di//79uPXWW9X7xMXF2d7/8OHDWLVqlXpfeb2aNWuW8VkgclEaEbm0MWPGaG5ubpqvr6/D9Nprr6nH5d/8sccec3hOt27dtMcff1wtf/bZZ1q1atW05ORk2+O//vqrZjabtejoaLUeHBysvfjii1c9BnmPl156ybYuryXbVq1apdZvv/12bezYsSX8yYkqBpZRE5UDMi64Ps61rnr16rbl7t27Ozwm62FhYWpZUrihoaHw9fW1Pd6zZ0/k5uYiPDxcZZ2fO3cO/fv3L/QYZGxonbyWn5+fGj9aPP744ypFv2fPHgwaNAjDhw9Hjx49bvBTE1UMDNRE5YAExvxZ0SVFypSLwsPDw2FdArwEeyHl4xEREVi5ciXWrl2rgr5kpb/99tulcsxE5QnLqIkqgO3bt1+x3rJlS7Uscym7lrJq3ZYtW2A2m9G8eXNUqVIFDRo0wLp1627oGKQi2ZgxY/Dtt99i9uzZ+Oyzz27o9YgqCqaoicqBjIwMREdHO2xzd3e3VdiSCmKdO3dGr169sGDBAuzYsQNffPGFekwqfU2bNk0F0enTpyM2NhYTJkzA6NGjERQUpPaR7Y899hgCAwNV6jgpKUkFc9mvKKZOnYpOnTqpWuNyrCtWrLDdKBBR4RioicqB1atXqyZT9iQ1fPToUVuN7IULF+KJJ55Q+33//fdo1aqVekyaU61ZswYTJ05Ely5d1LqUJ7/77ru215Ignp6ejvfeew+TJ09WNwB33313kY/P09MTU6ZMwenTp1VWeu/evdXxENG1maRGWRH2IyIXJWXFS5cuVRW4iMj1sIyaiIjIwBioiYiIDIxl1ETlHEu3iFwbU9REREQGxkBNRERkYAzUREREBsZATUREZGAM1ERERAbGQE1ERGRgDNREREQGxkBNRERkYAzUREREMK7/BxDny/Ual2+MAAAAAElFTkSuQmCC\",\n \"text/plain\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2417139b-2357-44d2-bd67-23f5d7f52ae7\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.1 Understanding word embeddings\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b6816ae-e927-43a9-b4dd-e47a9b0e1cf6\",\n \"metadata\": {},\n \"source\": [\n \"- No code in this section\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4f69dab7-a433-427a-9e5b-b981062d6296\",\n \"metadata\": {},\n \"source\": [\n \"- There are many forms of embeddings; we focus on text embeddings in this book\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba08d16f-f237-4166-bf89-0e9fe703e7b4\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2417139b-2357-44d2-bd67-23f5d7f52ae7\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.1 Understanding word embeddings\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b6816ae-e927-43a9-b4dd-e47a9b0e1cf6\",\n \"metadata\": {},\n \"source\": [\n \"- No code in this section\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4f69dab7-a433-427a-9e5b-b981062d6296\",\n \"metadata\": {},\n \"source\": [\n \"- There are many forms of embeddings; we focus on text embeddings in this book\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba08d16f-f237-4166-bf89-0e9fe703e7b4\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"288c4faf-b93a-4616-9276-7a4aa4b5e9ba\",\n \"metadata\": {},\n \"source\": [\n \"- LLMs work with embeddings in high-dimensional spaces (i.e., thousands of dimensions)\\n\",\n \"- Since we can't visualize such high-dimensional spaces (we humans think in 1, 2, or 3 dimensions), the figure below illustrates a 2-dimensional embedding space\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d6b80160-1f10-4aad-a85e-9c79444de9e6\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"288c4faf-b93a-4616-9276-7a4aa4b5e9ba\",\n \"metadata\": {},\n \"source\": [\n \"- LLMs work with embeddings in high-dimensional spaces (i.e., thousands of dimensions)\\n\",\n \"- Since we can't visualize such high-dimensional spaces (we humans think in 1, 2, or 3 dimensions), the figure below illustrates a 2-dimensional embedding space\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d6b80160-1f10-4aad-a85e-9c79444de9e6\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"eddbb984-8d23-40c5-bbfa-c3c379e7eec3\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.2 Tokenizing text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f9c90731-7dc9-4cd3-8c4a-488e33b48e80\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we tokenize text, which means breaking text into smaller units, such as individual words and punctuation characters\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"09872fdb-9d4e-40c4-949d-52a01a43ec4b\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"eddbb984-8d23-40c5-bbfa-c3c379e7eec3\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.2 Tokenizing text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f9c90731-7dc9-4cd3-8c4a-488e33b48e80\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we tokenize text, which means breaking text into smaller units, such as individual words and punctuation characters\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"09872fdb-9d4e-40c4-949d-52a01a43ec4b\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8cceaa18-833d-46b6-b211-b20c53902805\",\n \"metadata\": {},\n \"source\": [\n \"- Load raw text we want to work with\\n\",\n \"- [The Verdict by Edith Wharton](https://en.wikisource.org/wiki/The_Verdict) is a public domain short story\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"40f9d9b1-6d32-485a-825a-a95392a86d79\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"if not os.path.exists(\\\"the-verdict.txt\\\"):\\n\",\n \" url = (\\n\",\n \" \\\"https://raw.githubusercontent.com/rasbt/\\\"\\n\",\n \" \\\"LLMs-from-scratch/main/ch02/01_main-chapter-code/\\\"\\n\",\n \" \\\"the-verdict.txt\\\"\\n\",\n \" )\\n\",\n \" file_path = \\\"the-verdict.txt\\\"\\n\",\n \"\\n\",\n \" response = requests.get(url, timeout=30)\\n\",\n \" response.raise_for_status()\\n\",\n \" with open(file_path, \\\"wb\\\") as f:\\n\",\n \" f.write(response.content)\\n\",\n \"\\n\",\n \"\\n\",\n \"# The book originally used the following code below\\n\",\n \"# However, urllib uses older protocol settings that\\n\",\n \"# can cause problems for some readers using a VPN.\\n\",\n \"# The `requests` version above is more robust\\n\",\n \"# in that regard.\\n\",\n \"\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"import os\\n\",\n \"import urllib.request\\n\",\n \"\\n\",\n \"if not os.path.exists(\\\"the-verdict.txt\\\"):\\n\",\n \" url = (\\\"https://raw.githubusercontent.com/rasbt/\\\"\\n\",\n \" \\\"LLMs-from-scratch/main/ch02/01_main-chapter-code/\\\"\\n\",\n \" \\\"the-verdict.txt\\\")\\n\",\n \" file_path = \\\"the-verdict.txt\\\"\\n\",\n \" urllib.request.urlretrieve(url, file_path)\\n\",\n \"\\\"\\\"\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"56488f2c-a2b8-49f1-aaeb-461faad08dce\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8cceaa18-833d-46b6-b211-b20c53902805\",\n \"metadata\": {},\n \"source\": [\n \"- Load raw text we want to work with\\n\",\n \"- [The Verdict by Edith Wharton](https://en.wikisource.org/wiki/The_Verdict) is a public domain short story\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"40f9d9b1-6d32-485a-825a-a95392a86d79\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"if not os.path.exists(\\\"the-verdict.txt\\\"):\\n\",\n \" url = (\\n\",\n \" \\\"https://raw.githubusercontent.com/rasbt/\\\"\\n\",\n \" \\\"LLMs-from-scratch/main/ch02/01_main-chapter-code/\\\"\\n\",\n \" \\\"the-verdict.txt\\\"\\n\",\n \" )\\n\",\n \" file_path = \\\"the-verdict.txt\\\"\\n\",\n \"\\n\",\n \" response = requests.get(url, timeout=30)\\n\",\n \" response.raise_for_status()\\n\",\n \" with open(file_path, \\\"wb\\\") as f:\\n\",\n \" f.write(response.content)\\n\",\n \"\\n\",\n \"\\n\",\n \"# The book originally used the following code below\\n\",\n \"# However, urllib uses older protocol settings that\\n\",\n \"# can cause problems for some readers using a VPN.\\n\",\n \"# The `requests` version above is more robust\\n\",\n \"# in that regard.\\n\",\n \"\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"import os\\n\",\n \"import urllib.request\\n\",\n \"\\n\",\n \"if not os.path.exists(\\\"the-verdict.txt\\\"):\\n\",\n \" url = (\\\"https://raw.githubusercontent.com/rasbt/\\\"\\n\",\n \" \\\"LLMs-from-scratch/main/ch02/01_main-chapter-code/\\\"\\n\",\n \" \\\"the-verdict.txt\\\")\\n\",\n \" file_path = \\\"the-verdict.txt\\\"\\n\",\n \" urllib.request.urlretrieve(url, file_path)\\n\",\n \"\\\"\\\"\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"56488f2c-a2b8-49f1-aaeb-461faad08dce\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"8c567caa-8ff5-49a8-a5cc-d365b0a78a99\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']\\n\"\n ]\n }\n ],\n \"source\": [\n \"preprocessed = re.split(r'([,.:;?_!\\\"()\\\\']|--|\\\\s)', raw_text)\\n\",\n \"preprocessed = [item.strip() for item in preprocessed if item.strip()]\\n\",\n \"print(preprocessed[:30])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e2a19e1a-5105-4ddb-812a-b7d3117eab95\",\n \"metadata\": {},\n \"source\": [\n \"- Let's calculate the total number of tokens\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"35db7b5e-510b-4c45-995f-f5ad64a8e19c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"4690\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(len(preprocessed))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b5ce8fe-3a07-4f2a-90f1-a0321ce3a231\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.3 Converting tokens into token IDs\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a5204973-f414-4c0d-87b0-cfec1f06e6ff\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we convert the text tokens into token IDs that we can process via embedding layers later\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"177b041d-f739-43b8-bd81-0443ae3a7f8d\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"8c567caa-8ff5-49a8-a5cc-d365b0a78a99\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']\\n\"\n ]\n }\n ],\n \"source\": [\n \"preprocessed = re.split(r'([,.:;?_!\\\"()\\\\']|--|\\\\s)', raw_text)\\n\",\n \"preprocessed = [item.strip() for item in preprocessed if item.strip()]\\n\",\n \"print(preprocessed[:30])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e2a19e1a-5105-4ddb-812a-b7d3117eab95\",\n \"metadata\": {},\n \"source\": [\n \"- Let's calculate the total number of tokens\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"35db7b5e-510b-4c45-995f-f5ad64a8e19c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"4690\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(len(preprocessed))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b5ce8fe-3a07-4f2a-90f1-a0321ce3a231\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.3 Converting tokens into token IDs\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a5204973-f414-4c0d-87b0-cfec1f06e6ff\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we convert the text tokens into token IDs that we can process via embedding layers later\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"177b041d-f739-43b8-bd81-0443ae3a7f8d\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b5973794-7002-4202-8b12-0900cd779720\",\n \"metadata\": {},\n \"source\": [\n \"- From these tokens, we can now build a vocabulary that consists of all the unique tokens\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"7fdf0533-5ab6-42a5-83fa-a3b045de6396\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"1130\\n\"\n ]\n }\n ],\n \"source\": [\n \"all_words = sorted(set(preprocessed))\\n\",\n \"vocab_size = len(all_words)\\n\",\n \"\\n\",\n \"print(vocab_size)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"77d00d96-881f-4691-bb03-84fec2a75a26\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"vocab = {token:integer for integer,token in enumerate(all_words)}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"75bd1f81-3a8f-4dd9-9dd6-e75f32dacbe3\",\n \"metadata\": {},\n \"source\": [\n \"- Below are the first 50 entries in this vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"e1c5de4a-aa4e-4aec-b532-10bb364039d6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"('!', 0)\\n\",\n \"('\\\"', 1)\\n\",\n \"(\\\"'\\\", 2)\\n\",\n \"('(', 3)\\n\",\n \"(')', 4)\\n\",\n \"(',', 5)\\n\",\n \"('--', 6)\\n\",\n \"('.', 7)\\n\",\n \"(':', 8)\\n\",\n \"(';', 9)\\n\",\n \"('?', 10)\\n\",\n \"('A', 11)\\n\",\n \"('Ah', 12)\\n\",\n \"('Among', 13)\\n\",\n \"('And', 14)\\n\",\n \"('Are', 15)\\n\",\n \"('Arrt', 16)\\n\",\n \"('As', 17)\\n\",\n \"('At', 18)\\n\",\n \"('Be', 19)\\n\",\n \"('Begin', 20)\\n\",\n \"('Burlington', 21)\\n\",\n \"('But', 22)\\n\",\n \"('By', 23)\\n\",\n \"('Carlo', 24)\\n\",\n \"('Chicago', 25)\\n\",\n \"('Claude', 26)\\n\",\n \"('Come', 27)\\n\",\n \"('Croft', 28)\\n\",\n \"('Destroyed', 29)\\n\",\n \"('Devonshire', 30)\\n\",\n \"('Don', 31)\\n\",\n \"('Dubarry', 32)\\n\",\n \"('Emperors', 33)\\n\",\n \"('Florence', 34)\\n\",\n \"('For', 35)\\n\",\n \"('Gallery', 36)\\n\",\n \"('Gideon', 37)\\n\",\n \"('Gisburn', 38)\\n\",\n \"('Gisburns', 39)\\n\",\n \"('Grafton', 40)\\n\",\n \"('Greek', 41)\\n\",\n \"('Grindle', 42)\\n\",\n \"('Grindles', 43)\\n\",\n \"('HAD', 44)\\n\",\n \"('Had', 45)\\n\",\n \"('Hang', 46)\\n\",\n \"('Has', 47)\\n\",\n \"('He', 48)\\n\",\n \"('Her', 49)\\n\",\n \"('Hermia', 50)\\n\"\n ]\n }\n ],\n \"source\": [\n \"for i, item in enumerate(vocab.items()):\\n\",\n \" print(item)\\n\",\n \" if i >= 50:\\n\",\n \" break\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3b1dc314-351b-476a-9459-0ec9ddc29b19\",\n \"metadata\": {},\n \"source\": [\n \"- Below, we illustrate the tokenization of a short sample text using a small vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"67407a9f-0202-4e7c-9ed7-1b3154191ebc\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b5973794-7002-4202-8b12-0900cd779720\",\n \"metadata\": {},\n \"source\": [\n \"- From these tokens, we can now build a vocabulary that consists of all the unique tokens\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"7fdf0533-5ab6-42a5-83fa-a3b045de6396\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"1130\\n\"\n ]\n }\n ],\n \"source\": [\n \"all_words = sorted(set(preprocessed))\\n\",\n \"vocab_size = len(all_words)\\n\",\n \"\\n\",\n \"print(vocab_size)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"77d00d96-881f-4691-bb03-84fec2a75a26\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"vocab = {token:integer for integer,token in enumerate(all_words)}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"75bd1f81-3a8f-4dd9-9dd6-e75f32dacbe3\",\n \"metadata\": {},\n \"source\": [\n \"- Below are the first 50 entries in this vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"e1c5de4a-aa4e-4aec-b532-10bb364039d6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"('!', 0)\\n\",\n \"('\\\"', 1)\\n\",\n \"(\\\"'\\\", 2)\\n\",\n \"('(', 3)\\n\",\n \"(')', 4)\\n\",\n \"(',', 5)\\n\",\n \"('--', 6)\\n\",\n \"('.', 7)\\n\",\n \"(':', 8)\\n\",\n \"(';', 9)\\n\",\n \"('?', 10)\\n\",\n \"('A', 11)\\n\",\n \"('Ah', 12)\\n\",\n \"('Among', 13)\\n\",\n \"('And', 14)\\n\",\n \"('Are', 15)\\n\",\n \"('Arrt', 16)\\n\",\n \"('As', 17)\\n\",\n \"('At', 18)\\n\",\n \"('Be', 19)\\n\",\n \"('Begin', 20)\\n\",\n \"('Burlington', 21)\\n\",\n \"('But', 22)\\n\",\n \"('By', 23)\\n\",\n \"('Carlo', 24)\\n\",\n \"('Chicago', 25)\\n\",\n \"('Claude', 26)\\n\",\n \"('Come', 27)\\n\",\n \"('Croft', 28)\\n\",\n \"('Destroyed', 29)\\n\",\n \"('Devonshire', 30)\\n\",\n \"('Don', 31)\\n\",\n \"('Dubarry', 32)\\n\",\n \"('Emperors', 33)\\n\",\n \"('Florence', 34)\\n\",\n \"('For', 35)\\n\",\n \"('Gallery', 36)\\n\",\n \"('Gideon', 37)\\n\",\n \"('Gisburn', 38)\\n\",\n \"('Gisburns', 39)\\n\",\n \"('Grafton', 40)\\n\",\n \"('Greek', 41)\\n\",\n \"('Grindle', 42)\\n\",\n \"('Grindles', 43)\\n\",\n \"('HAD', 44)\\n\",\n \"('Had', 45)\\n\",\n \"('Hang', 46)\\n\",\n \"('Has', 47)\\n\",\n \"('He', 48)\\n\",\n \"('Her', 49)\\n\",\n \"('Hermia', 50)\\n\"\n ]\n }\n ],\n \"source\": [\n \"for i, item in enumerate(vocab.items()):\\n\",\n \" print(item)\\n\",\n \" if i >= 50:\\n\",\n \" break\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3b1dc314-351b-476a-9459-0ec9ddc29b19\",\n \"metadata\": {},\n \"source\": [\n \"- Below, we illustrate the tokenization of a short sample text using a small vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"67407a9f-0202-4e7c-9ed7-1b3154191ebc\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4e569647-2589-4c9d-9a5c-aef1c88a0a9a\",\n \"metadata\": {},\n \"source\": [\n \"- Putting it now all together into a tokenizer class\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"f531bf46-7c25-4ef8-bff8-0d27518676d5\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class SimpleTokenizerV1:\\n\",\n \" def __init__(self, vocab):\\n\",\n \" self.str_to_int = vocab\\n\",\n \" self.int_to_str = {i:s for s,i in vocab.items()}\\n\",\n \" \\n\",\n \" def encode(self, text):\\n\",\n \" preprocessed = re.split(r'([,.:;?_!\\\"()\\\\']|--|\\\\s)', text)\\n\",\n \" \\n\",\n \" preprocessed = [\\n\",\n \" item.strip() for item in preprocessed if item.strip()\\n\",\n \" ]\\n\",\n \" ids = [self.str_to_int[s] for s in preprocessed]\\n\",\n \" return ids\\n\",\n \" \\n\",\n \" def decode(self, ids):\\n\",\n \" text = \\\" \\\".join([self.int_to_str[i] for i in ids])\\n\",\n \" # Replace spaces before the specified punctuations\\n\",\n \" text = re.sub(r'\\\\s+([,.?!\\\"()\\\\'])', r'\\\\1', text)\\n\",\n \" return text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dee7a1e5-b54f-4ca1-87ef-3d663c4ee1e7\",\n \"metadata\": {},\n \"source\": [\n \"- The `encode` function turns text into token IDs\\n\",\n \"- The `decode` function turns token IDs back into text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cc21d347-ec03-4823-b3d4-9d686e495617\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4e569647-2589-4c9d-9a5c-aef1c88a0a9a\",\n \"metadata\": {},\n \"source\": [\n \"- Putting it now all together into a tokenizer class\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"f531bf46-7c25-4ef8-bff8-0d27518676d5\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class SimpleTokenizerV1:\\n\",\n \" def __init__(self, vocab):\\n\",\n \" self.str_to_int = vocab\\n\",\n \" self.int_to_str = {i:s for s,i in vocab.items()}\\n\",\n \" \\n\",\n \" def encode(self, text):\\n\",\n \" preprocessed = re.split(r'([,.:;?_!\\\"()\\\\']|--|\\\\s)', text)\\n\",\n \" \\n\",\n \" preprocessed = [\\n\",\n \" item.strip() for item in preprocessed if item.strip()\\n\",\n \" ]\\n\",\n \" ids = [self.str_to_int[s] for s in preprocessed]\\n\",\n \" return ids\\n\",\n \" \\n\",\n \" def decode(self, ids):\\n\",\n \" text = \\\" \\\".join([self.int_to_str[i] for i in ids])\\n\",\n \" # Replace spaces before the specified punctuations\\n\",\n \" text = re.sub(r'\\\\s+([,.?!\\\"()\\\\'])', r'\\\\1', text)\\n\",\n \" return text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dee7a1e5-b54f-4ca1-87ef-3d663c4ee1e7\",\n \"metadata\": {},\n \"source\": [\n \"- The `encode` function turns text into token IDs\\n\",\n \"- The `decode` function turns token IDs back into text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cc21d347-ec03-4823-b3d4-9d686e495617\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c2950a94-6b0d-474e-8ed0-66d0c3c1a95c\",\n \"metadata\": {},\n \"source\": [\n \"- We can use the tokenizer to encode (that is, tokenize) texts into integers\\n\",\n \"- These integers can then be embedded (later) as input of/for the LLM\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"647364ec-7995-4654-9b4a-7607ccf5f1e4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]\\n\"\n ]\n }\n ],\n \"source\": [\n \"tokenizer = SimpleTokenizerV1(vocab)\\n\",\n \"\\n\",\n \"text = \\\"\\\"\\\"\\\"It's the last he painted, you know,\\\" \\n\",\n \" Mrs. Gisburn said with pardonable pride.\\\"\\\"\\\"\\n\",\n \"ids = tokenizer.encode(text)\\n\",\n \"print(ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3201706e-a487-4b60-b99d-5765865f29a0\",\n \"metadata\": {},\n \"source\": [\n \"- We can decode the integers back into text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"01d8c8fb-432d-4a49-b332-99f23b233746\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'\\\" It\\\\' s the last he painted, you know,\\\" Mrs. Gisburn said with pardonable pride.'\"\n ]\n },\n \"execution_count\": 15,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer.decode(ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"54f6aa8b-9827-412e-9035-e827296ab0fe\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'\\\" It\\\\' s the last he painted, you know,\\\" Mrs. Gisburn said with pardonable pride.'\"\n ]\n },\n \"execution_count\": 16,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer.decode(tokenizer.encode(text))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4b821ef8-4d53-43b6-a2b2-aef808c343c7\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.4 Adding special context tokens\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"863d6d15-a3e2-44e0-b384-bb37f17cf443\",\n \"metadata\": {},\n \"source\": [\n \"- It's useful to add some \\\"special\\\" tokens for unknown words and to denote the end of a text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"aa7fc96c-e1fd-44fb-b7f5-229d7c7922a4\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c2950a94-6b0d-474e-8ed0-66d0c3c1a95c\",\n \"metadata\": {},\n \"source\": [\n \"- We can use the tokenizer to encode (that is, tokenize) texts into integers\\n\",\n \"- These integers can then be embedded (later) as input of/for the LLM\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"647364ec-7995-4654-9b4a-7607ccf5f1e4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]\\n\"\n ]\n }\n ],\n \"source\": [\n \"tokenizer = SimpleTokenizerV1(vocab)\\n\",\n \"\\n\",\n \"text = \\\"\\\"\\\"\\\"It's the last he painted, you know,\\\" \\n\",\n \" Mrs. Gisburn said with pardonable pride.\\\"\\\"\\\"\\n\",\n \"ids = tokenizer.encode(text)\\n\",\n \"print(ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3201706e-a487-4b60-b99d-5765865f29a0\",\n \"metadata\": {},\n \"source\": [\n \"- We can decode the integers back into text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"01d8c8fb-432d-4a49-b332-99f23b233746\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'\\\" It\\\\' s the last he painted, you know,\\\" Mrs. Gisburn said with pardonable pride.'\"\n ]\n },\n \"execution_count\": 15,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer.decode(ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"54f6aa8b-9827-412e-9035-e827296ab0fe\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'\\\" It\\\\' s the last he painted, you know,\\\" Mrs. Gisburn said with pardonable pride.'\"\n ]\n },\n \"execution_count\": 16,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer.decode(tokenizer.encode(text))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4b821ef8-4d53-43b6-a2b2-aef808c343c7\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.4 Adding special context tokens\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"863d6d15-a3e2-44e0-b384-bb37f17cf443\",\n \"metadata\": {},\n \"source\": [\n \"- It's useful to add some \\\"special\\\" tokens for unknown words and to denote the end of a text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"aa7fc96c-e1fd-44fb-b7f5-229d7c7922a4\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9d709d57-2486-4152-b7f9-d3e4bd8634cd\",\n \"metadata\": {},\n \"source\": [\n \"- Some tokenizers use special tokens to help the LLM with additional context\\n\",\n \"- Some of these special tokens are\\n\",\n \" - `[BOS]` (beginning of sequence) marks the beginning of text\\n\",\n \" - `[EOS]` (end of sequence) marks where the text ends (this is usually used to concatenate multiple unrelated texts, e.g., two different Wikipedia articles or two different books, and so on)\\n\",\n \" - `[PAD]` (padding) if we train LLMs with a batch size greater than 1 (we may include multiple texts with different lengths; with the padding token we pad the shorter texts to the longest length so that all texts have an equal length)\\n\",\n \"- `[UNK]` to represent words that are not included in the vocabulary\\n\",\n \"\\n\",\n \"- Note that GPT-2 does not need any of these tokens mentioned above but only uses an `<|endoftext|>` token to reduce complexity\\n\",\n \"- The `<|endoftext|>` is analogous to the `[EOS]` token mentioned above\\n\",\n \"- GPT also uses the `<|endoftext|>` for padding (since we typically use a mask when training on batched inputs, we would not attend padded tokens anyways, so it does not matter what these tokens are)\\n\",\n \"- GPT-2 does not use an `
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9d709d57-2486-4152-b7f9-d3e4bd8634cd\",\n \"metadata\": {},\n \"source\": [\n \"- Some tokenizers use special tokens to help the LLM with additional context\\n\",\n \"- Some of these special tokens are\\n\",\n \" - `[BOS]` (beginning of sequence) marks the beginning of text\\n\",\n \" - `[EOS]` (end of sequence) marks where the text ends (this is usually used to concatenate multiple unrelated texts, e.g., two different Wikipedia articles or two different books, and so on)\\n\",\n \" - `[PAD]` (padding) if we train LLMs with a batch size greater than 1 (we may include multiple texts with different lengths; with the padding token we pad the shorter texts to the longest length so that all texts have an equal length)\\n\",\n \"- `[UNK]` to represent words that are not included in the vocabulary\\n\",\n \"\\n\",\n \"- Note that GPT-2 does not need any of these tokens mentioned above but only uses an `<|endoftext|>` token to reduce complexity\\n\",\n \"- The `<|endoftext|>` is analogous to the `[EOS]` token mentioned above\\n\",\n \"- GPT also uses the `<|endoftext|>` for padding (since we typically use a mask when training on batched inputs, we would not attend padded tokens anyways, so it does not matter what these tokens are)\\n\",\n \"- GPT-2 does not use an ` \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c661a397-da06-4a86-ac27-072dbe7cb172\",\n \"metadata\": {},\n \"source\": [\n \"- Let's see what happens if we tokenize the following text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"d5767eff-440c-4de1-9289-f789349d6b85\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"ename\": \"KeyError\",\n \"evalue\": \"'Hello'\",\n \"output_type\": \"error\",\n \"traceback\": [\n \"\\u001b[0;31m---------------------------------------------------------------------------\\u001b[0m\",\n \"\\u001b[0;31mKeyError\\u001b[0m Traceback (most recent call last)\",\n \"Cell \\u001b[0;32mIn[17], line 5\\u001b[0m\\n\\u001b[1;32m 1\\u001b[0m tokenizer \\u001b[38;5;241m=\\u001b[39m SimpleTokenizerV1(vocab)\\n\\u001b[1;32m 3\\u001b[0m text \\u001b[38;5;241m=\\u001b[39m \\u001b[38;5;124m\\\"\\u001b[39m\\u001b[38;5;124mHello, do you like tea. Is this-- a test?\\u001b[39m\\u001b[38;5;124m\\\"\\u001b[39m\\n\\u001b[0;32m----> 5\\u001b[0m tokenizer\\u001b[38;5;241m.\\u001b[39mencode(text)\\n\",\n \"Cell \\u001b[0;32mIn[13], line 12\\u001b[0m, in \\u001b[0;36mSimpleTokenizerV1.encode\\u001b[0;34m(self, text)\\u001b[0m\\n\\u001b[1;32m 7\\u001b[0m preprocessed \\u001b[38;5;241m=\\u001b[39m re\\u001b[38;5;241m.\\u001b[39msplit(\\u001b[38;5;124mr\\u001b[39m\\u001b[38;5;124m'\\u001b[39m\\u001b[38;5;124m([,.:;?_!\\u001b[39m\\u001b[38;5;124m\\\"\\u001b[39m\\u001b[38;5;124m()\\u001b[39m\\u001b[38;5;130;01m\\\\'\\u001b[39;00m\\u001b[38;5;124m]|--|\\u001b[39m\\u001b[38;5;124m\\\\\\u001b[39m\\u001b[38;5;124ms)\\u001b[39m\\u001b[38;5;124m'\\u001b[39m, text)\\n\\u001b[1;32m 9\\u001b[0m preprocessed \\u001b[38;5;241m=\\u001b[39m [\\n\\u001b[1;32m 10\\u001b[0m item\\u001b[38;5;241m.\\u001b[39mstrip() \\u001b[38;5;28;01mfor\\u001b[39;00m item \\u001b[38;5;129;01min\\u001b[39;00m preprocessed \\u001b[38;5;28;01mif\\u001b[39;00m item\\u001b[38;5;241m.\\u001b[39mstrip()\\n\\u001b[1;32m 11\\u001b[0m ]\\n\\u001b[0;32m---> 12\\u001b[0m ids \\u001b[38;5;241m=\\u001b[39m [\\u001b[38;5;28mself\\u001b[39m\\u001b[38;5;241m.\\u001b[39mstr_to_int[s] \\u001b[38;5;28;01mfor\\u001b[39;00m s \\u001b[38;5;129;01min\\u001b[39;00m preprocessed]\\n\\u001b[1;32m 13\\u001b[0m \\u001b[38;5;28;01mreturn\\u001b[39;00m ids\\n\",\n \"Cell \\u001b[0;32mIn[13], line 12\\u001b[0m, in \\u001b[0;36m
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c661a397-da06-4a86-ac27-072dbe7cb172\",\n \"metadata\": {},\n \"source\": [\n \"- Let's see what happens if we tokenize the following text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"d5767eff-440c-4de1-9289-f789349d6b85\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"ename\": \"KeyError\",\n \"evalue\": \"'Hello'\",\n \"output_type\": \"error\",\n \"traceback\": [\n \"\\u001b[0;31m---------------------------------------------------------------------------\\u001b[0m\",\n \"\\u001b[0;31mKeyError\\u001b[0m Traceback (most recent call last)\",\n \"Cell \\u001b[0;32mIn[17], line 5\\u001b[0m\\n\\u001b[1;32m 1\\u001b[0m tokenizer \\u001b[38;5;241m=\\u001b[39m SimpleTokenizerV1(vocab)\\n\\u001b[1;32m 3\\u001b[0m text \\u001b[38;5;241m=\\u001b[39m \\u001b[38;5;124m\\\"\\u001b[39m\\u001b[38;5;124mHello, do you like tea. Is this-- a test?\\u001b[39m\\u001b[38;5;124m\\\"\\u001b[39m\\n\\u001b[0;32m----> 5\\u001b[0m tokenizer\\u001b[38;5;241m.\\u001b[39mencode(text)\\n\",\n \"Cell \\u001b[0;32mIn[13], line 12\\u001b[0m, in \\u001b[0;36mSimpleTokenizerV1.encode\\u001b[0;34m(self, text)\\u001b[0m\\n\\u001b[1;32m 7\\u001b[0m preprocessed \\u001b[38;5;241m=\\u001b[39m re\\u001b[38;5;241m.\\u001b[39msplit(\\u001b[38;5;124mr\\u001b[39m\\u001b[38;5;124m'\\u001b[39m\\u001b[38;5;124m([,.:;?_!\\u001b[39m\\u001b[38;5;124m\\\"\\u001b[39m\\u001b[38;5;124m()\\u001b[39m\\u001b[38;5;130;01m\\\\'\\u001b[39;00m\\u001b[38;5;124m]|--|\\u001b[39m\\u001b[38;5;124m\\\\\\u001b[39m\\u001b[38;5;124ms)\\u001b[39m\\u001b[38;5;124m'\\u001b[39m, text)\\n\\u001b[1;32m 9\\u001b[0m preprocessed \\u001b[38;5;241m=\\u001b[39m [\\n\\u001b[1;32m 10\\u001b[0m item\\u001b[38;5;241m.\\u001b[39mstrip() \\u001b[38;5;28;01mfor\\u001b[39;00m item \\u001b[38;5;129;01min\\u001b[39;00m preprocessed \\u001b[38;5;28;01mif\\u001b[39;00m item\\u001b[38;5;241m.\\u001b[39mstrip()\\n\\u001b[1;32m 11\\u001b[0m ]\\n\\u001b[0;32m---> 12\\u001b[0m ids \\u001b[38;5;241m=\\u001b[39m [\\u001b[38;5;28mself\\u001b[39m\\u001b[38;5;241m.\\u001b[39mstr_to_int[s] \\u001b[38;5;28;01mfor\\u001b[39;00m s \\u001b[38;5;129;01min\\u001b[39;00m preprocessed]\\n\\u001b[1;32m 13\\u001b[0m \\u001b[38;5;28;01mreturn\\u001b[39;00m ids\\n\",\n \"Cell \\u001b[0;32mIn[13], line 12\\u001b[0m, in \\u001b[0;36m \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"abbd7c0d-70f8-4386-a114-907e96c950b0\",\n \"metadata\": {},\n \"source\": [\n \"## 2.6 Data sampling with a sliding window\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"509d9826-6384-462e-aa8a-a7c73cd6aad0\",\n \"metadata\": {},\n \"source\": [\n \"- We train LLMs to generate one word at a time, so we want to prepare the training data accordingly where the next word in a sequence represents the target to predict:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"39fb44f4-0c43-4a6a-9c2f-9cf31452354c\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"abbd7c0d-70f8-4386-a114-907e96c950b0\",\n \"metadata\": {},\n \"source\": [\n \"## 2.6 Data sampling with a sliding window\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"509d9826-6384-462e-aa8a-a7c73cd6aad0\",\n \"metadata\": {},\n \"source\": [\n \"- We train LLMs to generate one word at a time, so we want to prepare the training data accordingly where the next word in a sequence represents the target to predict:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"39fb44f4-0c43-4a6a-9c2f-9cf31452354c\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"848d5ade-fd1f-46c3-9e31-1426e315c71b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"5145\\n\"\n ]\n }\n ],\n \"source\": [\n \"with open(\\\"the-verdict.txt\\\", \\\"r\\\", encoding=\\\"utf-8\\\") as f:\\n\",\n \" raw_text = f.read()\\n\",\n \"\\n\",\n \"enc_text = tokenizer.encode(raw_text)\\n\",\n \"print(len(enc_text))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cebd0657-5543-43ca-8011-2ae6bd0a5810\",\n \"metadata\": {},\n \"source\": [\n \"- For each text chunk, we want the inputs and targets\\n\",\n \"- Since we want the model to predict the next word, the targets are the inputs shifted by one position to the right\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"e84424a7-646d-45b6-99e3-80d15fb761f2\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"enc_sample = enc_text[50:]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"dfbff852-a92f-48c8-a46d-143a0f109f40\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"x: [290, 4920, 2241, 287]\\n\",\n \"y: [4920, 2241, 287, 257]\\n\"\n ]\n }\n ],\n \"source\": [\n \"context_size = 4\\n\",\n \"\\n\",\n \"x = enc_sample[:context_size]\\n\",\n \"y = enc_sample[1:context_size+1]\\n\",\n \"\\n\",\n \"print(f\\\"x: {x}\\\")\\n\",\n \"print(f\\\"y: {y}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"815014ef-62f7-4476-a6ad-66e20e42b7c3\",\n \"metadata\": {},\n \"source\": [\n \"- One by one, the prediction would look like as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"d97b031e-ed55-409d-95f2-aeb38c6fe366\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[290] ----> 4920\\n\",\n \"[290, 4920] ----> 2241\\n\",\n \"[290, 4920, 2241] ----> 287\\n\",\n \"[290, 4920, 2241, 287] ----> 257\\n\"\n ]\n }\n ],\n \"source\": [\n \"for i in range(1, context_size+1):\\n\",\n \" context = enc_sample[:i]\\n\",\n \" desired = enc_sample[i]\\n\",\n \"\\n\",\n \" print(context, \\\"---->\\\", desired)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"f57bd746-dcbf-4433-8e24-ee213a8c34a1\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \" and ----> established\\n\",\n \" and established ----> himself\\n\",\n \" and established himself ----> in\\n\",\n \" and established himself in ----> a\\n\"\n ]\n }\n ],\n \"source\": [\n \"for i in range(1, context_size+1):\\n\",\n \" context = enc_sample[:i]\\n\",\n \" desired = enc_sample[i]\\n\",\n \"\\n\",\n \" print(tokenizer.decode(context), \\\"---->\\\", tokenizer.decode([desired]))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"210d2dd9-fc20-4927-8d3d-1466cf41aae1\",\n \"metadata\": {},\n \"source\": [\n \"- We will take care of the next-word prediction in a later chapter after we covered the attention mechanism\\n\",\n \"- For now, we implement a simple data loader that iterates over the input dataset and returns the inputs and targets shifted by one\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a1a1b47a-f646-49d1-bc70-fddf2c840796\",\n \"metadata\": {},\n \"source\": [\n \"- Install and import PyTorch (see Appendix A for installation tips)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"e1770134-e7f3-4725-a679-e04c3be48cac\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"PyTorch version: 2.5.1\\n\"\n ]\n }\n ],\n \"source\": [\n \"import torch\\n\",\n \"print(\\\"PyTorch version:\\\", torch.__version__)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0c9a3d50-885b-49bc-b791-9f5cc8bc7b7c\",\n \"metadata\": {},\n \"source\": [\n \"- We use a sliding window approach, changing the position by +1:\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"848d5ade-fd1f-46c3-9e31-1426e315c71b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"5145\\n\"\n ]\n }\n ],\n \"source\": [\n \"with open(\\\"the-verdict.txt\\\", \\\"r\\\", encoding=\\\"utf-8\\\") as f:\\n\",\n \" raw_text = f.read()\\n\",\n \"\\n\",\n \"enc_text = tokenizer.encode(raw_text)\\n\",\n \"print(len(enc_text))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cebd0657-5543-43ca-8011-2ae6bd0a5810\",\n \"metadata\": {},\n \"source\": [\n \"- For each text chunk, we want the inputs and targets\\n\",\n \"- Since we want the model to predict the next word, the targets are the inputs shifted by one position to the right\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"e84424a7-646d-45b6-99e3-80d15fb761f2\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"enc_sample = enc_text[50:]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"dfbff852-a92f-48c8-a46d-143a0f109f40\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"x: [290, 4920, 2241, 287]\\n\",\n \"y: [4920, 2241, 287, 257]\\n\"\n ]\n }\n ],\n \"source\": [\n \"context_size = 4\\n\",\n \"\\n\",\n \"x = enc_sample[:context_size]\\n\",\n \"y = enc_sample[1:context_size+1]\\n\",\n \"\\n\",\n \"print(f\\\"x: {x}\\\")\\n\",\n \"print(f\\\"y: {y}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"815014ef-62f7-4476-a6ad-66e20e42b7c3\",\n \"metadata\": {},\n \"source\": [\n \"- One by one, the prediction would look like as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"d97b031e-ed55-409d-95f2-aeb38c6fe366\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[290] ----> 4920\\n\",\n \"[290, 4920] ----> 2241\\n\",\n \"[290, 4920, 2241] ----> 287\\n\",\n \"[290, 4920, 2241, 287] ----> 257\\n\"\n ]\n }\n ],\n \"source\": [\n \"for i in range(1, context_size+1):\\n\",\n \" context = enc_sample[:i]\\n\",\n \" desired = enc_sample[i]\\n\",\n \"\\n\",\n \" print(context, \\\"---->\\\", desired)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"f57bd746-dcbf-4433-8e24-ee213a8c34a1\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \" and ----> established\\n\",\n \" and established ----> himself\\n\",\n \" and established himself ----> in\\n\",\n \" and established himself in ----> a\\n\"\n ]\n }\n ],\n \"source\": [\n \"for i in range(1, context_size+1):\\n\",\n \" context = enc_sample[:i]\\n\",\n \" desired = enc_sample[i]\\n\",\n \"\\n\",\n \" print(tokenizer.decode(context), \\\"---->\\\", tokenizer.decode([desired]))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"210d2dd9-fc20-4927-8d3d-1466cf41aae1\",\n \"metadata\": {},\n \"source\": [\n \"- We will take care of the next-word prediction in a later chapter after we covered the attention mechanism\\n\",\n \"- For now, we implement a simple data loader that iterates over the input dataset and returns the inputs and targets shifted by one\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a1a1b47a-f646-49d1-bc70-fddf2c840796\",\n \"metadata\": {},\n \"source\": [\n \"- Install and import PyTorch (see Appendix A for installation tips)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"e1770134-e7f3-4725-a679-e04c3be48cac\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"PyTorch version: 2.5.1\\n\"\n ]\n }\n ],\n \"source\": [\n \"import torch\\n\",\n \"print(\\\"PyTorch version:\\\", torch.__version__)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0c9a3d50-885b-49bc-b791-9f5cc8bc7b7c\",\n \"metadata\": {},\n \"source\": [\n \"- We use a sliding window approach, changing the position by +1:\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"92ac652d-7b38-4843-9fbd-494cdc8ec12c\",\n \"metadata\": {},\n \"source\": [\n \"- Create dataset and dataloader that extract chunks from the input text dataset\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"74b41073-4c9f-46e2-a1bd-d38e4122b375\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import Dataset, DataLoader\\n\",\n \"\\n\",\n \"\\n\",\n \"class GPTDatasetV1(Dataset):\\n\",\n \" def __init__(self, txt, tokenizer, max_length, stride):\\n\",\n \" self.input_ids = []\\n\",\n \" self.target_ids = []\\n\",\n \"\\n\",\n \" # Tokenize the entire text\\n\",\n \" token_ids = tokenizer.encode(txt, allowed_special={\\\"<|endoftext|>\\\"})\\n\",\n \" assert len(token_ids) > max_length, \\\"Number of tokenized inputs must at least be equal to max_length+1\\\"\\n\",\n \"\\n\",\n \" # Use a sliding window to chunk the book into overlapping sequences of max_length\\n\",\n \" for i in range(0, len(token_ids) - max_length, stride):\\n\",\n \" input_chunk = token_ids[i:i + max_length]\\n\",\n \" target_chunk = token_ids[i + 1: i + max_length + 1]\\n\",\n \" self.input_ids.append(torch.tensor(input_chunk))\\n\",\n \" self.target_ids.append(torch.tensor(target_chunk))\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.input_ids)\\n\",\n \"\\n\",\n \" def __getitem__(self, idx):\\n\",\n \" return self.input_ids[idx], self.target_ids[idx]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"5eb30ebe-97b3-43c5-9ff1-a97d621b3c4e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def create_dataloader_v1(txt, batch_size=4, max_length=256, \\n\",\n \" stride=128, shuffle=True, drop_last=True,\\n\",\n \" num_workers=0):\\n\",\n \"\\n\",\n \" # Initialize the tokenizer\\n\",\n \" tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \" # Create dataset\\n\",\n \" dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)\\n\",\n \"\\n\",\n \" # Create dataloader\\n\",\n \" dataloader = DataLoader(\\n\",\n \" dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" shuffle=shuffle,\\n\",\n \" drop_last=drop_last,\\n\",\n \" num_workers=num_workers\\n\",\n \" )\\n\",\n \"\\n\",\n \" return dataloader\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"42dd68ef-59f7-45ff-ba44-e311c899ddcd\",\n \"metadata\": {},\n \"source\": [\n \"- Let's test the dataloader with a batch size of 1 for an LLM with a context size of 4:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"df31d96c-6bfd-4564-a956-6192242d7579\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"with open(\\\"the-verdict.txt\\\", \\\"r\\\", encoding=\\\"utf-8\\\") as f:\\n\",\n \" raw_text = f.read()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"9226d00c-ad9a-4949-a6e4-9afccfc7214f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]\\n\"\n ]\n }\n ],\n \"source\": [\n \"dataloader = create_dataloader_v1(\\n\",\n \" raw_text, batch_size=1, max_length=4, stride=1, shuffle=False\\n\",\n \")\\n\",\n \"\\n\",\n \"data_iter = iter(dataloader)\\n\",\n \"first_batch = next(data_iter)\\n\",\n \"print(first_batch)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 40,\n \"id\": \"10deb4bc-4de1-4d20-921e-4b1c7a0e1a6d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[tensor([[ 367, 2885, 1464, 1807]]), tensor([[2885, 1464, 1807, 3619]])]\\n\"\n ]\n }\n ],\n \"source\": [\n \"second_batch = next(data_iter)\\n\",\n \"print(second_batch)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b006212f-de45-468d-bdee-5806216d1679\",\n \"metadata\": {},\n \"source\": [\n \"- An example using stride equal to the context length (here: 4) as shown below:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9cb467e0-bdcd-4dda-b9b0-a738c5d33ac3\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"92ac652d-7b38-4843-9fbd-494cdc8ec12c\",\n \"metadata\": {},\n \"source\": [\n \"- Create dataset and dataloader that extract chunks from the input text dataset\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"74b41073-4c9f-46e2-a1bd-d38e4122b375\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import Dataset, DataLoader\\n\",\n \"\\n\",\n \"\\n\",\n \"class GPTDatasetV1(Dataset):\\n\",\n \" def __init__(self, txt, tokenizer, max_length, stride):\\n\",\n \" self.input_ids = []\\n\",\n \" self.target_ids = []\\n\",\n \"\\n\",\n \" # Tokenize the entire text\\n\",\n \" token_ids = tokenizer.encode(txt, allowed_special={\\\"<|endoftext|>\\\"})\\n\",\n \" assert len(token_ids) > max_length, \\\"Number of tokenized inputs must at least be equal to max_length+1\\\"\\n\",\n \"\\n\",\n \" # Use a sliding window to chunk the book into overlapping sequences of max_length\\n\",\n \" for i in range(0, len(token_ids) - max_length, stride):\\n\",\n \" input_chunk = token_ids[i:i + max_length]\\n\",\n \" target_chunk = token_ids[i + 1: i + max_length + 1]\\n\",\n \" self.input_ids.append(torch.tensor(input_chunk))\\n\",\n \" self.target_ids.append(torch.tensor(target_chunk))\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.input_ids)\\n\",\n \"\\n\",\n \" def __getitem__(self, idx):\\n\",\n \" return self.input_ids[idx], self.target_ids[idx]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"5eb30ebe-97b3-43c5-9ff1-a97d621b3c4e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def create_dataloader_v1(txt, batch_size=4, max_length=256, \\n\",\n \" stride=128, shuffle=True, drop_last=True,\\n\",\n \" num_workers=0):\\n\",\n \"\\n\",\n \" # Initialize the tokenizer\\n\",\n \" tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \" # Create dataset\\n\",\n \" dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)\\n\",\n \"\\n\",\n \" # Create dataloader\\n\",\n \" dataloader = DataLoader(\\n\",\n \" dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" shuffle=shuffle,\\n\",\n \" drop_last=drop_last,\\n\",\n \" num_workers=num_workers\\n\",\n \" )\\n\",\n \"\\n\",\n \" return dataloader\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"42dd68ef-59f7-45ff-ba44-e311c899ddcd\",\n \"metadata\": {},\n \"source\": [\n \"- Let's test the dataloader with a batch size of 1 for an LLM with a context size of 4:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"df31d96c-6bfd-4564-a956-6192242d7579\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"with open(\\\"the-verdict.txt\\\", \\\"r\\\", encoding=\\\"utf-8\\\") as f:\\n\",\n \" raw_text = f.read()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"9226d00c-ad9a-4949-a6e4-9afccfc7214f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]\\n\"\n ]\n }\n ],\n \"source\": [\n \"dataloader = create_dataloader_v1(\\n\",\n \" raw_text, batch_size=1, max_length=4, stride=1, shuffle=False\\n\",\n \")\\n\",\n \"\\n\",\n \"data_iter = iter(dataloader)\\n\",\n \"first_batch = next(data_iter)\\n\",\n \"print(first_batch)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 40,\n \"id\": \"10deb4bc-4de1-4d20-921e-4b1c7a0e1a6d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[tensor([[ 367, 2885, 1464, 1807]]), tensor([[2885, 1464, 1807, 3619]])]\\n\"\n ]\n }\n ],\n \"source\": [\n \"second_batch = next(data_iter)\\n\",\n \"print(second_batch)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b006212f-de45-468d-bdee-5806216d1679\",\n \"metadata\": {},\n \"source\": [\n \"- An example using stride equal to the context length (here: 4) as shown below:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9cb467e0-bdcd-4dda-b9b0-a738c5d33ac3\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b1ae6d45-f26e-4b83-9c7b-cff55ffa7d16\",\n \"metadata\": {},\n \"source\": [\n \"- We can also create batched outputs\\n\",\n \"- Note that we increase the stride here so that we don't have overlaps between the batches, since more overlap could lead to increased overfitting\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 41,\n \"id\": \"1916e7a6-f03d-4f09-91a6-d0bdbac5a58c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Inputs:\\n\",\n \" tensor([[ 40, 367, 2885, 1464],\\n\",\n \" [ 1807, 3619, 402, 271],\\n\",\n \" [10899, 2138, 257, 7026],\\n\",\n \" [15632, 438, 2016, 257],\\n\",\n \" [ 922, 5891, 1576, 438],\\n\",\n \" [ 568, 340, 373, 645],\\n\",\n \" [ 1049, 5975, 284, 502],\\n\",\n \" [ 284, 3285, 326, 11]])\\n\",\n \"\\n\",\n \"Targets:\\n\",\n \" tensor([[ 367, 2885, 1464, 1807],\\n\",\n \" [ 3619, 402, 271, 10899],\\n\",\n \" [ 2138, 257, 7026, 15632],\\n\",\n \" [ 438, 2016, 257, 922],\\n\",\n \" [ 5891, 1576, 438, 568],\\n\",\n \" [ 340, 373, 645, 1049],\\n\",\n \" [ 5975, 284, 502, 284],\\n\",\n \" [ 3285, 326, 11, 287]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"dataloader = create_dataloader_v1(raw_text, batch_size=8, max_length=4, stride=4, shuffle=False)\\n\",\n \"\\n\",\n \"data_iter = iter(dataloader)\\n\",\n \"inputs, targets = next(data_iter)\\n\",\n \"print(\\\"Inputs:\\\\n\\\", inputs)\\n\",\n \"print(\\\"\\\\nTargets:\\\\n\\\", targets)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2cd2fcda-2fda-4aa8-8bc8-de1e496f9db1\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.7 Creating token embeddings\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1a301068-6ab2-44ff-a915-1ba11688274f\",\n \"metadata\": {},\n \"source\": [\n \"- The data is already almost ready for an LLM\\n\",\n \"- But lastly let us embed the tokens in a continuous vector representation using an embedding layer\\n\",\n \"- Usually, these embedding layers are part of the LLM itself and are updated (trained) during model training\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e85089aa-8671-4e5f-a2b3-ef252004ee4c\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b1ae6d45-f26e-4b83-9c7b-cff55ffa7d16\",\n \"metadata\": {},\n \"source\": [\n \"- We can also create batched outputs\\n\",\n \"- Note that we increase the stride here so that we don't have overlaps between the batches, since more overlap could lead to increased overfitting\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 41,\n \"id\": \"1916e7a6-f03d-4f09-91a6-d0bdbac5a58c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Inputs:\\n\",\n \" tensor([[ 40, 367, 2885, 1464],\\n\",\n \" [ 1807, 3619, 402, 271],\\n\",\n \" [10899, 2138, 257, 7026],\\n\",\n \" [15632, 438, 2016, 257],\\n\",\n \" [ 922, 5891, 1576, 438],\\n\",\n \" [ 568, 340, 373, 645],\\n\",\n \" [ 1049, 5975, 284, 502],\\n\",\n \" [ 284, 3285, 326, 11]])\\n\",\n \"\\n\",\n \"Targets:\\n\",\n \" tensor([[ 367, 2885, 1464, 1807],\\n\",\n \" [ 3619, 402, 271, 10899],\\n\",\n \" [ 2138, 257, 7026, 15632],\\n\",\n \" [ 438, 2016, 257, 922],\\n\",\n \" [ 5891, 1576, 438, 568],\\n\",\n \" [ 340, 373, 645, 1049],\\n\",\n \" [ 5975, 284, 502, 284],\\n\",\n \" [ 3285, 326, 11, 287]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"dataloader = create_dataloader_v1(raw_text, batch_size=8, max_length=4, stride=4, shuffle=False)\\n\",\n \"\\n\",\n \"data_iter = iter(dataloader)\\n\",\n \"inputs, targets = next(data_iter)\\n\",\n \"print(\\\"Inputs:\\\\n\\\", inputs)\\n\",\n \"print(\\\"\\\\nTargets:\\\\n\\\", targets)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2cd2fcda-2fda-4aa8-8bc8-de1e496f9db1\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.7 Creating token embeddings\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1a301068-6ab2-44ff-a915-1ba11688274f\",\n \"metadata\": {},\n \"source\": [\n \"- The data is already almost ready for an LLM\\n\",\n \"- But lastly let us embed the tokens in a continuous vector representation using an embedding layer\\n\",\n \"- Usually, these embedding layers are part of the LLM itself and are updated (trained) during model training\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e85089aa-8671-4e5f-a2b3-ef252004ee4c\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"44e014ca-1fc5-4b90-b6fa-c2097bb92c0b\",\n \"metadata\": {},\n \"source\": [\n \"- Suppose we have the following four input examples with input ids 2, 3, 5, and 1 (after tokenization):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"15a6304c-9474-4470-b85d-3991a49fa653\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"input_ids = torch.tensor([2, 3, 5, 1])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"14da6344-2c71-4837-858d-dd120005ba05\",\n \"metadata\": {},\n \"source\": [\n \"- For the sake of simplicity, suppose we have a small vocabulary of only 6 words and we want to create embeddings of size 3:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"93cb2cee-9aa6-4bb8-8977-c65661d16eda\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"vocab_size = 6\\n\",\n \"output_dim = 3\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"embedding_layer = torch.nn.Embedding(vocab_size, output_dim)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4ff241f6-78eb-4e4a-a55f-5b2b6196d5b0\",\n \"metadata\": {},\n \"source\": [\n \"- This would result in a 6x3 weight matrix:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"a686eb61-e737-4351-8f1c-222913d47468\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Parameter containing:\\n\",\n \"tensor([[ 0.3374, -0.1778, -0.1690],\\n\",\n \" [ 0.9178, 1.5810, 1.3010],\\n\",\n \" [ 1.2753, -0.2010, -0.1606],\\n\",\n \" [-0.4015, 0.9666, -1.1481],\\n\",\n \" [-1.1589, 0.3255, -0.6315],\\n\",\n \" [-2.8400, -0.7849, -1.4096]], requires_grad=True)\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(embedding_layer.weight)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"26fcf4f5-0801-4eb4-bb90-acce87935ac7\",\n \"metadata\": {},\n \"source\": [\n \"- For those who are familiar with one-hot encoding, the embedding layer approach above is essentially just a more efficient way of implementing one-hot encoding followed by matrix multiplication in a fully-connected layer, which is described in the supplementary code in [./embedding_vs_matmul](../03_bonus_embedding-vs-matmul)\\n\",\n \"- Because the embedding layer is just a more efficient implementation that is equivalent to the one-hot encoding and matrix-multiplication approach it can be seen as a neural network layer that can be optimized via backpropagation\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4b0d58c3-83c0-4205-aca2-9c48b19fd4a7\",\n \"metadata\": {},\n \"source\": [\n \"- To convert a token with id 3 into a 3-dimensional vector, we do the following:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"e43600ba-f287-4746-8ddf-d0f71a9023ca\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"44e014ca-1fc5-4b90-b6fa-c2097bb92c0b\",\n \"metadata\": {},\n \"source\": [\n \"- Suppose we have the following four input examples with input ids 2, 3, 5, and 1 (after tokenization):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"15a6304c-9474-4470-b85d-3991a49fa653\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"input_ids = torch.tensor([2, 3, 5, 1])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"14da6344-2c71-4837-858d-dd120005ba05\",\n \"metadata\": {},\n \"source\": [\n \"- For the sake of simplicity, suppose we have a small vocabulary of only 6 words and we want to create embeddings of size 3:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"93cb2cee-9aa6-4bb8-8977-c65661d16eda\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"vocab_size = 6\\n\",\n \"output_dim = 3\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"embedding_layer = torch.nn.Embedding(vocab_size, output_dim)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4ff241f6-78eb-4e4a-a55f-5b2b6196d5b0\",\n \"metadata\": {},\n \"source\": [\n \"- This would result in a 6x3 weight matrix:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"a686eb61-e737-4351-8f1c-222913d47468\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Parameter containing:\\n\",\n \"tensor([[ 0.3374, -0.1778, -0.1690],\\n\",\n \" [ 0.9178, 1.5810, 1.3010],\\n\",\n \" [ 1.2753, -0.2010, -0.1606],\\n\",\n \" [-0.4015, 0.9666, -1.1481],\\n\",\n \" [-1.1589, 0.3255, -0.6315],\\n\",\n \" [-2.8400, -0.7849, -1.4096]], requires_grad=True)\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(embedding_layer.weight)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"26fcf4f5-0801-4eb4-bb90-acce87935ac7\",\n \"metadata\": {},\n \"source\": [\n \"- For those who are familiar with one-hot encoding, the embedding layer approach above is essentially just a more efficient way of implementing one-hot encoding followed by matrix multiplication in a fully-connected layer, which is described in the supplementary code in [./embedding_vs_matmul](../03_bonus_embedding-vs-matmul)\\n\",\n \"- Because the embedding layer is just a more efficient implementation that is equivalent to the one-hot encoding and matrix-multiplication approach it can be seen as a neural network layer that can be optimized via backpropagation\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4b0d58c3-83c0-4205-aca2-9c48b19fd4a7\",\n \"metadata\": {},\n \"source\": [\n \"- To convert a token with id 3 into a 3-dimensional vector, we do the following:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"e43600ba-f287-4746-8ddf-d0f71a9023ca\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[-0.4015, 0.9666, -1.1481]], grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"08218d9f-aa1a-4afb-a105-72ff96a54e73\",\n \"metadata\": {},\n \"source\": [\n \"- **You may be interested in the bonus content comparing embedding layers with regular linear layers: [../03_bonus_embedding-vs-matmul](../03_bonus_embedding-vs-matmul)**\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c393d270-b950-4bc8-99ea-97d74f2ea0f6\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.8 Encoding word positions\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"24940068-1099-4698-bdc0-e798515e2902\",\n \"metadata\": {},\n \"source\": [\n \"- Embedding layer convert IDs into identical vector representations regardless of where they are located in the input sequence:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9e0b14a2-f3f3-490e-b513-f262dbcf94fa\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"08218d9f-aa1a-4afb-a105-72ff96a54e73\",\n \"metadata\": {},\n \"source\": [\n \"- **You may be interested in the bonus content comparing embedding layers with regular linear layers: [../03_bonus_embedding-vs-matmul](../03_bonus_embedding-vs-matmul)**\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c393d270-b950-4bc8-99ea-97d74f2ea0f6\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2.8 Encoding word positions\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"24940068-1099-4698-bdc0-e798515e2902\",\n \"metadata\": {},\n \"source\": [\n \"- Embedding layer convert IDs into identical vector representations regardless of where they are located in the input sequence:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9e0b14a2-f3f3-490e-b513-f262dbcf94fa\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"92a7d7fe-38a5-46e6-8db6-b688887b0430\",\n \"metadata\": {},\n \"source\": [\n \"- Positional embeddings are combined with the token embedding vector to form the input embeddings for a large language model:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"48de37db-d54d-45c4-ab3e-88c0783ad2e4\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"92a7d7fe-38a5-46e6-8db6-b688887b0430\",\n \"metadata\": {},\n \"source\": [\n \"- Positional embeddings are combined with the token embedding vector to form the input embeddings for a large language model:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"48de37db-d54d-45c4-ab3e-88c0783ad2e4\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7f187f87-c1f8-4c2e-8050-350bbb972f55\",\n \"metadata\": {},\n \"source\": [\n \"- The BytePair encoder has a vocabulary size of 50,257:\\n\",\n \"- Suppose we want to encode the input tokens into a 256-dimensional vector representation:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 47,\n \"id\": \"0b9e344d-03a6-4f2c-b723-67b6a20c5041\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"vocab_size = 50257\\n\",\n \"output_dim = 256\\n\",\n \"\\n\",\n \"token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a2654722-24e4-4b0d-a43c-436a461eb70b\",\n \"metadata\": {},\n \"source\": [\n \"- If we sample data from the dataloader, we embed the tokens in each batch into a 256-dimensional vector\\n\",\n \"- If we have a batch size of 8 with 4 tokens each, this results in a 8 x 4 x 256 tensor:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 48,\n \"id\": \"ad56a263-3d2e-4d91-98bf-d0b68d3c7fc3\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"max_length = 4\\n\",\n \"dataloader = create_dataloader_v1(\\n\",\n \" raw_text, batch_size=8, max_length=max_length,\\n\",\n \" stride=max_length, shuffle=False\\n\",\n \")\\n\",\n \"data_iter = iter(dataloader)\\n\",\n \"inputs, targets = next(data_iter)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 49,\n \"id\": \"84416b60-3707-4370-bcbc-da0b62f2b64d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Token IDs:\\n\",\n \" tensor([[ 40, 367, 2885, 1464],\\n\",\n \" [ 1807, 3619, 402, 271],\\n\",\n \" [10899, 2138, 257, 7026],\\n\",\n \" [15632, 438, 2016, 257],\\n\",\n \" [ 922, 5891, 1576, 438],\\n\",\n \" [ 568, 340, 373, 645],\\n\",\n \" [ 1049, 5975, 284, 502],\\n\",\n \" [ 284, 3285, 326, 11]])\\n\",\n \"\\n\",\n \"Inputs shape:\\n\",\n \" torch.Size([8, 4])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Token IDs:\\\\n\\\", inputs)\\n\",\n \"print(\\\"\\\\nInputs shape:\\\\n\\\", inputs.shape)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 50,\n \"id\": \"7766ec38-30d0-4128-8c31-f49f063c43d1\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([8, 4, 256])\\n\"\n ]\n }\n ],\n \"source\": [\n \"token_embeddings = token_embedding_layer(inputs)\\n\",\n \"print(token_embeddings.shape)\\n\",\n \"\\n\",\n \"# uncomment & execute the following line to see how the embeddings look like\\n\",\n \"# print(token_embeddings)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fe2ae164-6f19-4e32-b9e5-76950fcf1c9f\",\n \"metadata\": {},\n \"source\": [\n \"- GPT-2 uses absolute position embeddings, so we just create another embedding layer:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 51,\n \"id\": \"cc048e20-7ac8-417e-81f5-8fe6f9a4fe07\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"context_length = max_length\\n\",\n \"pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)\\n\",\n \"\\n\",\n \"# uncomment & execute the following line to see how the embedding layer weights look like\\n\",\n \"# print(pos_embedding_layer.weight)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 52,\n \"id\": \"c369a1e7-d566-4b53-b398-d6adafb44105\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([4, 256])\\n\"\n ]\n }\n ],\n \"source\": [\n \"pos_embeddings = pos_embedding_layer(torch.arange(max_length))\\n\",\n \"print(pos_embeddings.shape)\\n\",\n \"\\n\",\n \"# uncomment & execute the following line to see how the embeddings look like\\n\",\n \"# print(pos_embeddings)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"870e9d9f-2935-461a-9518-6d1386b976d6\",\n \"metadata\": {},\n \"source\": [\n \"- To create the input embeddings used in an LLM, we simply add the token and the positional embeddings:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 53,\n \"id\": \"b22fab89-526e-43c8-9035-5b7018e34288\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([8, 4, 256])\\n\"\n ]\n }\n ],\n \"source\": [\n \"input_embeddings = token_embeddings + pos_embeddings\\n\",\n \"print(input_embeddings.shape)\\n\",\n \"\\n\",\n \"# uncomment & execute the following line to see how the embeddings look like\\n\",\n \"# print(input_embeddings)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1fbda581-6f9b-476f-8ea7-d244e6a4eaec\",\n \"metadata\": {},\n \"source\": [\n \"- In the initial phase of the input processing workflow, the input text is segmented into separate tokens\\n\",\n \"- Following this segmentation, these tokens are transformed into token IDs based on a predefined vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d1bb0f7e-460d-44db-b366-096adcd84fff\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7f187f87-c1f8-4c2e-8050-350bbb972f55\",\n \"metadata\": {},\n \"source\": [\n \"- The BytePair encoder has a vocabulary size of 50,257:\\n\",\n \"- Suppose we want to encode the input tokens into a 256-dimensional vector representation:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 47,\n \"id\": \"0b9e344d-03a6-4f2c-b723-67b6a20c5041\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"vocab_size = 50257\\n\",\n \"output_dim = 256\\n\",\n \"\\n\",\n \"token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a2654722-24e4-4b0d-a43c-436a461eb70b\",\n \"metadata\": {},\n \"source\": [\n \"- If we sample data from the dataloader, we embed the tokens in each batch into a 256-dimensional vector\\n\",\n \"- If we have a batch size of 8 with 4 tokens each, this results in a 8 x 4 x 256 tensor:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 48,\n \"id\": \"ad56a263-3d2e-4d91-98bf-d0b68d3c7fc3\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"max_length = 4\\n\",\n \"dataloader = create_dataloader_v1(\\n\",\n \" raw_text, batch_size=8, max_length=max_length,\\n\",\n \" stride=max_length, shuffle=False\\n\",\n \")\\n\",\n \"data_iter = iter(dataloader)\\n\",\n \"inputs, targets = next(data_iter)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 49,\n \"id\": \"84416b60-3707-4370-bcbc-da0b62f2b64d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Token IDs:\\n\",\n \" tensor([[ 40, 367, 2885, 1464],\\n\",\n \" [ 1807, 3619, 402, 271],\\n\",\n \" [10899, 2138, 257, 7026],\\n\",\n \" [15632, 438, 2016, 257],\\n\",\n \" [ 922, 5891, 1576, 438],\\n\",\n \" [ 568, 340, 373, 645],\\n\",\n \" [ 1049, 5975, 284, 502],\\n\",\n \" [ 284, 3285, 326, 11]])\\n\",\n \"\\n\",\n \"Inputs shape:\\n\",\n \" torch.Size([8, 4])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Token IDs:\\\\n\\\", inputs)\\n\",\n \"print(\\\"\\\\nInputs shape:\\\\n\\\", inputs.shape)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 50,\n \"id\": \"7766ec38-30d0-4128-8c31-f49f063c43d1\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([8, 4, 256])\\n\"\n ]\n }\n ],\n \"source\": [\n \"token_embeddings = token_embedding_layer(inputs)\\n\",\n \"print(token_embeddings.shape)\\n\",\n \"\\n\",\n \"# uncomment & execute the following line to see how the embeddings look like\\n\",\n \"# print(token_embeddings)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fe2ae164-6f19-4e32-b9e5-76950fcf1c9f\",\n \"metadata\": {},\n \"source\": [\n \"- GPT-2 uses absolute position embeddings, so we just create another embedding layer:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 51,\n \"id\": \"cc048e20-7ac8-417e-81f5-8fe6f9a4fe07\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"context_length = max_length\\n\",\n \"pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)\\n\",\n \"\\n\",\n \"# uncomment & execute the following line to see how the embedding layer weights look like\\n\",\n \"# print(pos_embedding_layer.weight)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 52,\n \"id\": \"c369a1e7-d566-4b53-b398-d6adafb44105\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([4, 256])\\n\"\n ]\n }\n ],\n \"source\": [\n \"pos_embeddings = pos_embedding_layer(torch.arange(max_length))\\n\",\n \"print(pos_embeddings.shape)\\n\",\n \"\\n\",\n \"# uncomment & execute the following line to see how the embeddings look like\\n\",\n \"# print(pos_embeddings)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"870e9d9f-2935-461a-9518-6d1386b976d6\",\n \"metadata\": {},\n \"source\": [\n \"- To create the input embeddings used in an LLM, we simply add the token and the positional embeddings:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 53,\n \"id\": \"b22fab89-526e-43c8-9035-5b7018e34288\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([8, 4, 256])\\n\"\n ]\n }\n ],\n \"source\": [\n \"input_embeddings = token_embeddings + pos_embeddings\\n\",\n \"print(input_embeddings.shape)\\n\",\n \"\\n\",\n \"# uncomment & execute the following line to see how the embeddings look like\\n\",\n \"# print(input_embeddings)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1fbda581-6f9b-476f-8ea7-d244e6a4eaec\",\n \"metadata\": {},\n \"source\": [\n \"- In the initial phase of the input processing workflow, the input text is segmented into separate tokens\\n\",\n \"- Following this segmentation, these tokens are transformed into token IDs based on a predefined vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d1bb0f7e-460d-44db-b366-096adcd84fff\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"63230f2e-258f-4497-9e2e-8deee4530364\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## Summary and takeaways\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8b3293a6-45a5-47cd-aa00-b23e3ca0a73f\",\n \"metadata\": {},\n \"source\": [\n \"See the [./dataloader.ipynb](./dataloader.ipynb) code notebook, which is a concise version of the data loader that we implemented in this chapter and will need for training the GPT model in upcoming chapters.\\n\",\n \"\\n\",\n \"See [./exercise-solutions.ipynb](./exercise-solutions.ipynb) for the exercise solutions.\\n\",\n \"\\n\",\n \"See the [Byte Pair Encoding (BPE) Tokenizer From Scratch](../02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb) notebook if you are interested in learning how the GPT-2 tokenizer can be implemented and trained from scratch.\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch02/01_main-chapter-code/dataloader.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6e2a4891-c257-4d6b-afb3-e8fef39d0437\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"63230f2e-258f-4497-9e2e-8deee4530364\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## Summary and takeaways\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8b3293a6-45a5-47cd-aa00-b23e3ca0a73f\",\n \"metadata\": {},\n \"source\": [\n \"See the [./dataloader.ipynb](./dataloader.ipynb) code notebook, which is a concise version of the data loader that we implemented in this chapter and will need for training the GPT model in upcoming chapters.\\n\",\n \"\\n\",\n \"See [./exercise-solutions.ipynb](./exercise-solutions.ipynb) for the exercise solutions.\\n\",\n \"\\n\",\n \"See the [Byte Pair Encoding (BPE) Tokenizer From Scratch](../02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb) notebook if you are interested in learning how the GPT-2 tokenizer can be implemented and trained from scratch.\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch02/01_main-chapter-code/dataloader.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6e2a4891-c257-4d6b-afb3-e8fef39d0437\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"87d1311b-cfb2-4afc-9e25-e4ecf35370d9\",\n \"metadata\": {},\n \"source\": [\n \"- Similarly, we can use embedding layers to obtain the vector representation of a training example with ID 2:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"c309266a-c601-4633-9404-2e10b1cdde8c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[ 0.6957, -1.8061, -1.1589, 0.3255, -0.6315]],\\n\",\n \" grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"87d1311b-cfb2-4afc-9e25-e4ecf35370d9\",\n \"metadata\": {},\n \"source\": [\n \"- Similarly, we can use embedding layers to obtain the vector representation of a training example with ID 2:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"c309266a-c601-4633-9404-2e10b1cdde8c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[ 0.6957, -1.8061, -1.1589, 0.3255, -0.6315]],\\n\",\n \" grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"27dd54bd-85ae-4887-9c5e-3139da361cf4\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's convert all the training examples we have defined previously:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"0191aa4b-f6a8-4b0d-9c36-65e82b81d071\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[ 0.6957, -1.8061, -1.1589, 0.3255, -0.6315],\\n\",\n \" [-2.8400, -0.7849, -1.4096, -0.4076, 0.7953],\\n\",\n \" [ 1.3010, 1.2753, -0.2010, -0.1606, -0.4015]],\\n\",\n \" grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"27dd54bd-85ae-4887-9c5e-3139da361cf4\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's convert all the training examples we have defined previously:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"0191aa4b-f6a8-4b0d-9c36-65e82b81d071\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[ 0.6957, -1.8061, -1.1589, 0.3255, -0.6315],\\n\",\n \" [-2.8400, -0.7849, -1.4096, -0.4076, 0.7953],\\n\",\n \" [ 1.3010, 1.2753, -0.2010, -0.1606, -0.4015]],\\n\",\n \" grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f0fe863b-d6a3-48f3-ace5-09ecd0eb7b59\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f0fe863b-d6a3-48f3-ace5-09ecd0eb7b59\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9ce5211a-14e6-46aa-a3a8-14609f086e97\",\n \"metadata\": {},\n \"source\": [\n \"- And for the second training example's token ID:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"173f6026-a461-44da-b9c5-f571f8ec8bf3\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9ce5211a-14e6-46aa-a3a8-14609f086e97\",\n \"metadata\": {},\n \"source\": [\n \"- And for the second training example's token ID:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"173f6026-a461-44da-b9c5-f571f8ec8bf3\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e2608049-f5d1-49a9-a14b-82695fc32e6a\",\n \"metadata\": {},\n \"source\": [\n \"- Since all but one index in each one-hot encoded row are 0 (by design), this matrix multiplication is essentially the same as a look-up of the one-hot elements\\n\",\n \"- This use of the matrix multiplication on one-hot encodings is equivalent to the embedding layer look-up but can be inefficient if we work with large embedding matrices, because there are a lot of wasteful multiplications by zero\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.11.4\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch02/04_bonus_dataloader-intuition/README.md",
"content": "# Chapter 2: Working with Text Data\n\n- [dataloader-intuition.ipynb](dataloader-intuition.ipynb) contains optional (bonus) code to explain the data loader more intuitively with simple numbers rather than text.\n"
},
{
"path": "ch02/04_bonus_dataloader-intuition/dataloader-intuition.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d95f841a-63c9-41d4-aea1-496b3d2024dd\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e2608049-f5d1-49a9-a14b-82695fc32e6a\",\n \"metadata\": {},\n \"source\": [\n \"- Since all but one index in each one-hot encoded row are 0 (by design), this matrix multiplication is essentially the same as a look-up of the one-hot elements\\n\",\n \"- This use of the matrix multiplication on one-hot encodings is equivalent to the embedding layer look-up but can be inefficient if we work with large embedding matrices, because there are a lot of wasteful multiplications by zero\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.11.4\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch02/04_bonus_dataloader-intuition/README.md",
"content": "# Chapter 2: Working with Text Data\n\n- [dataloader-intuition.ipynb](dataloader-intuition.ipynb) contains optional (bonus) code to explain the data loader more intuitively with simple numbers rather than text.\n"
},
{
"path": "ch02/04_bonus_dataloader-intuition/dataloader-intuition.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d95f841a-63c9-41d4-aea1-496b3d2024dd\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"760c625d-26a1-4896-98a2-0fdcd1591256\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.1 Bits and bytes\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d4ddaa35-0ed7-4012-827e-911de11c266c\",\n \"metadata\": {},\n \"source\": [\n \"- Before getting to the BPE algorithm, let's introduce the notion of bytes\\n\",\n \"- Consider converting text into a byte array (BPE stands for \\\"byte\\\" pair encoding after all):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"8c9bc9e4-120f-4bac-8fa6-6523c568d12e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"bytearray(b'This is some text')\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = \\\"This is some text\\\"\\n\",\n \"byte_ary = bytearray(text, \\\"utf-8\\\")\\n\",\n \"print(byte_ary)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dbd92a2a-9d74-4dc7-bb53-ac33d6cf2fab\",\n \"metadata\": {},\n \"source\": [\n \"- When we call `list()` on a `bytearray` object, each byte is treated as an individual element, and the result is a list of integers corresponding to the byte values:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"6c586945-d459-4f9a-855d-bf73438ef0e3\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[84, 104, 105, 115, 32, 105, 115, 32, 115, 111, 109, 101, 32, 116, 101, 120, 116]\\n\"\n ]\n }\n ],\n \"source\": [\n \"ids = list(byte_ary)\\n\",\n \"print(ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"71efea37-f4c3-4cb8-bfa5-9299175faf9a\",\n \"metadata\": {},\n \"source\": [\n \"- This would be a valid way to convert text into a token ID representation that we need for the embedding layer of an LLM\\n\",\n \"- However, the downside of this approach is that it is creating one ID for each character (that's a lot of IDs for a short text!)\\n\",\n \"- I.e., this means for a 17-character input text, we have to use 17 token IDs as input to the LLM:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"0d5b61d9-79a0-48b4-9b3e-64ab595c5b01\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of characters: 17\\n\",\n \"Number of token IDs: 17\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Number of characters:\\\", len(text))\\n\",\n \"print(\\\"Number of token IDs:\\\", len(ids))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"68cc833a-c0d4-4d46-9180-c0042fd6addc\",\n \"metadata\": {},\n \"source\": [\n \"- If you have worked with LLMs before, you may know that the BPE tokenizers have a vocabulary where we have a token ID for whole words or subwords instead of each character\\n\",\n \"- For example, the GPT-2 tokenizer tokenizes the same text (\\\"This is some text\\\") into only 4 instead of 17 tokens: `1212, 318, 617, 2420`\\n\",\n \"- You can double-check this using the interactive [tiktoken app](https://tiktokenizer.vercel.app/?model=gpt2) or the [tiktoken library](https://github.com/openai/tiktoken):\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"760c625d-26a1-4896-98a2-0fdcd1591256\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.1 Bits and bytes\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d4ddaa35-0ed7-4012-827e-911de11c266c\",\n \"metadata\": {},\n \"source\": [\n \"- Before getting to the BPE algorithm, let's introduce the notion of bytes\\n\",\n \"- Consider converting text into a byte array (BPE stands for \\\"byte\\\" pair encoding after all):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"8c9bc9e4-120f-4bac-8fa6-6523c568d12e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"bytearray(b'This is some text')\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = \\\"This is some text\\\"\\n\",\n \"byte_ary = bytearray(text, \\\"utf-8\\\")\\n\",\n \"print(byte_ary)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dbd92a2a-9d74-4dc7-bb53-ac33d6cf2fab\",\n \"metadata\": {},\n \"source\": [\n \"- When we call `list()` on a `bytearray` object, each byte is treated as an individual element, and the result is a list of integers corresponding to the byte values:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"6c586945-d459-4f9a-855d-bf73438ef0e3\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[84, 104, 105, 115, 32, 105, 115, 32, 115, 111, 109, 101, 32, 116, 101, 120, 116]\\n\"\n ]\n }\n ],\n \"source\": [\n \"ids = list(byte_ary)\\n\",\n \"print(ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"71efea37-f4c3-4cb8-bfa5-9299175faf9a\",\n \"metadata\": {},\n \"source\": [\n \"- This would be a valid way to convert text into a token ID representation that we need for the embedding layer of an LLM\\n\",\n \"- However, the downside of this approach is that it is creating one ID for each character (that's a lot of IDs for a short text!)\\n\",\n \"- I.e., this means for a 17-character input text, we have to use 17 token IDs as input to the LLM:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"0d5b61d9-79a0-48b4-9b3e-64ab595c5b01\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of characters: 17\\n\",\n \"Number of token IDs: 17\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Number of characters:\\\", len(text))\\n\",\n \"print(\\\"Number of token IDs:\\\", len(ids))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"68cc833a-c0d4-4d46-9180-c0042fd6addc\",\n \"metadata\": {},\n \"source\": [\n \"- If you have worked with LLMs before, you may know that the BPE tokenizers have a vocabulary where we have a token ID for whole words or subwords instead of each character\\n\",\n \"- For example, the GPT-2 tokenizer tokenizes the same text (\\\"This is some text\\\") into only 4 instead of 17 tokens: `1212, 318, 617, 2420`\\n\",\n \"- You can double-check this using the interactive [tiktoken app](https://tiktokenizer.vercel.app/?model=gpt2) or the [tiktoken library](https://github.com/openai/tiktoken):\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"```python\\n\",\n \"import tiktoken\\n\",\n \"\\n\",\n \"gpt2_tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"gpt2_tokenizer.encode(\\\"This is some text\\\")\\n\",\n \"# prints [1212, 318, 617, 2420]\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"425b99de-cbfc-441c-8b3e-296a5dd7bb27\",\n \"metadata\": {},\n \"source\": [\n \"- Since a byte consists of 8 bits, there are 28 = 256 possible values that a single byte can represent, ranging from 0 to 255\\n\",\n \"- You can confirm this by executing the code `bytearray(range(0, 257))`, which will warn you that `ValueError: byte must be in range(0, 256)`)\\n\",\n \"- A BPE tokenizer usually uses these 256 values as its first 256 single-character tokens; one could visually check this by running the following code:\\n\",\n \"\\n\",\n \"```python\\n\",\n \"import tiktoken\\n\",\n \"gpt2_tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"for i in range(300):\\n\",\n \" decoded = gpt2_tokenizer.decode([i])\\n\",\n \" print(f\\\"{i}: {decoded}\\\")\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"prints:\\n\",\n \"0: !\\n\",\n \"1: \\\"\\n\",\n \"2: #\\n\",\n \"...\\n\",\n \"255: � # <---- single character tokens up to here\\n\",\n \"256: t\\n\",\n \"257: a\\n\",\n \"...\\n\",\n \"298: ent\\n\",\n \"299: n\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"97ff0207-7f8e-44fa-9381-2a4bd83daab3\",\n \"metadata\": {},\n \"source\": [\n \"- Above, note that entries 256 and 257 are not single-character values but double-character values (a whitespace + a letter), which is a little shortcoming of the original GPT-2 BPE Tokenizer (this has been improved in the GPT-4 tokenizer)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8241c23a-d487-488d-bded-cdf054e24920\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.2 Building the vocabulary\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d7c2ceb7-0b3f-4a62-8dcc-07810cd8886e\",\n \"metadata\": {},\n \"source\": [\n \"- The goal of the BPE tokenization algorithm is to build a vocabulary of commonly occurring subwords like `298: ent` (which can be found in *entangle, entertain, enter, entrance, entity, ...*, for example), or even complete words like \\n\",\n \"\\n\",\n \"```\\n\",\n \"318: is\\n\",\n \"617: some\\n\",\n \"1212: This\\n\",\n \"2420: text\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c0d4420-a4c7-4813-916a-06f4f46bc3f0\",\n \"metadata\": {},\n \"source\": [\n \"- The BPE algorithm was originally described in 1994: \\\"[A New Algorithm for Data Compression](https://github.com/tpn/pdfs/blob/master/A%20New%20Algorithm%20for%20Data%20Compression%20(1994).pdf)\\\" by Philip Gage\\n\",\n \"- Before we get to the actual code implementation, the form that is used for LLM tokenizers today can be summarized as follows:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ebc71db9-b070-48c4-8412-81f45b308ab3\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.3 BPE algorithm outline\\n\",\n \"\\n\",\n \"**1. Identify frequent pairs**\\n\",\n \"- In each iteration, scan the text to find the most commonly occurring pair of bytes (or characters)\\n\",\n \"\\n\",\n \"**2. Replace and record**\\n\",\n \"\\n\",\n \"- Replace that pair with a new placeholder ID (one not already in use, e.g., if we start with 0...255, the first placeholder would be 256)\\n\",\n \"- Record this mapping in a lookup table\\n\",\n \"- The size of the lookup table is a hyperparameter, also called \\\"vocabulary size\\\" (for GPT-2, that's\\n\",\n \"50,257)\\n\",\n \"\\n\",\n \"**3. Repeat until no gains**\\n\",\n \"\\n\",\n \"- Keep repeating steps 1 and 2, continually merging the most frequent pairs\\n\",\n \"- Stop when no further compression is possible (e.g., no pair occurs more than once)\\n\",\n \"\\n\",\n \"**Decompression (decoding)**\\n\",\n \"\\n\",\n \"- To restore the original text, reverse the process by substituting each ID with its corresponding pair, using the lookup table\\n\",\n \"\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e9f5ac9a-3528-4186-9468-8420c7b2ac00\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.4 BPE algorithm example\\n\",\n \"\\n\",\n \"### 1.4.1 Concrete example of the encoding part (steps 1 & 2)\\n\",\n \"\\n\",\n \"- Suppose we have the text (training dataset) `the cat in the hat` from which we want to build the vocabulary for a BPE tokenizer\\n\",\n \"\\n\",\n \"**Iteration 1**\\n\",\n \"\\n\",\n \"1. Identify frequent pairs\\n\",\n \" - In this text, \\\"th\\\" appears twice (at the beginning and before the second \\\"e\\\")\\n\",\n \"\\n\",\n \"2. Replace and record\\n\",\n \" - replace \\\"th\\\" with a new token ID that is not already in use, e.g., 256\\n\",\n \" - the new text is: `<256>e cat in <256>e hat`\\n\",\n \" - the new vocabulary is\\n\",\n \"\\n\",\n \"```\\n\",\n \" 0: ...\\n\",\n \" ...\\n\",\n \" 256: \\\"th\\\"\\n\",\n \"```\\n\",\n \"\\n\",\n \"**Iteration 2**\\n\",\n \"\\n\",\n \"1. **Identify frequent pairs** \\n\",\n \" - In the text `<256>e cat in <256>e hat`, the pair `<256>e` appears twice\\n\",\n \"\\n\",\n \"2. **Replace and record** \\n\",\n \" - replace `<256>e` with a new token ID that is not already in use, for example, `257`. \\n\",\n \" - The new text is:\\n\",\n \" ```\\n\",\n \" <257> cat in <257> hat\\n\",\n \" ```\\n\",\n \" - The updated vocabulary is:\\n\",\n \" ```\\n\",\n \" 0: ...\\n\",\n \" ...\\n\",\n \" 256: \\\"th\\\"\\n\",\n \" 257: \\\"<256>e\\\"\\n\",\n \" ```\\n\",\n \"\\n\",\n \"**Iteration 3**\\n\",\n \"\\n\",\n \"1. **Identify frequent pairs** \\n\",\n \" - In the text `<257> cat in <257> hat`, the pair `<257> ` appears twice (once at the beginning and once before “hat”).\\n\",\n \"\\n\",\n \"2. **Replace and record** \\n\",\n \" - replace `<257> ` with a new token ID that is not already in use, for example, `258`. \\n\",\n \" - the new text is:\\n\",\n \" ```\\n\",\n \" <258>cat in <258>hat\\n\",\n \" ```\\n\",\n \" - The updated vocabulary is:\\n\",\n \" ```\\n\",\n \" 0: ...\\n\",\n \" ...\\n\",\n \" 256: \\\"th\\\"\\n\",\n \" 257: \\\"<256>e\\\"\\n\",\n \" 258: \\\"<257> \\\"\\n\",\n \" ```\\n\",\n \" \\n\",\n \"- and so forth\\n\",\n \"\\n\",\n \" \\n\",\n \"### 1.4.2 Concrete example of the decoding part (steps 3)\\n\",\n \"\\n\",\n \"- To restore the original text, we reverse the process by substituting each token ID with its corresponding pair in the reverse order they were introduced\\n\",\n \"- Start with the final compressed text: `<258>cat in <258>hat`\\n\",\n \"- Substitute `<258>` → `<257> `: `<257> cat in <257> hat` \\n\",\n \"- Substitute `<257>` → `<256>e`: `<256>e cat in <256>e hat`\\n\",\n \"- Substitute `<256>` → \\\"th\\\": `the cat in the hat`\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a2324948-ddd0-45d1-8ba8-e8eda9fc6677\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2. A simple BPE implementation\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"429ca709-40d7-4e3d-bf3e-4f5687a2e19b\",\n \"metadata\": {},\n \"source\": [\n \"- Below is an implementation of this algorithm described above as a Python class that mimics the `tiktoken` Python user interface\\n\",\n \"- Note that the encoding part above describes the original training step via `train()`; however, the `encode()` method works similarly (although it looks a bit more complicated because of the special token handling):\\n\",\n \"\\n\",\n \"1. Split the input text into individual bytes\\n\",\n \"2. Repeatedly find & replace (merge) adjacent tokens (pairs) when they match any pair in the learned BPE merges (from highest to lowest \\\"rank,\\\" i.e., in the order they were learned)\\n\",\n \"3. Continue merging until no more merges can be applied\\n\",\n \"4. The final list of token IDs is the encoded output\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"3e4a15ec-2667-4f56-b7c1-34e8071b621d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from collections import Counter, deque\\n\",\n \"from functools import lru_cache\\n\",\n \"\\n\",\n \"\\n\",\n \"class BPETokenizerSimple:\\n\",\n \" def __init__(self):\\n\",\n \" # Maps token_id to token_str (e.g., {11246: \\\"some\\\"})\\n\",\n \" self.vocab = {}\\n\",\n \" # Maps token_str to token_id (e.g., {\\\"some\\\": 11246})\\n\",\n \" self.inverse_vocab = {}\\n\",\n \" # Dictionary of BPE merges: {(token_id1, token_id2): merged_token_id}\\n\",\n \" self.bpe_merges = {}\\n\",\n \"\\n\",\n \" def train(self, text, vocab_size, allowed_special={\\\"<|endoftext|>\\\"}):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Train the BPE tokenizer from scratch.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" text (str): The training text.\\n\",\n \" vocab_size (int): The desired vocabulary size.\\n\",\n \" allowed_special (set): A set of special tokens to include.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \"\\n\",\n \" # Preprocess: Replace spaces with 'Ġ'\\n\",\n \" # Note that Ġ is a particularity of the GPT-2 BPE implementation\\n\",\n \" # E.g., \\\"Hello world\\\" might be tokenized as [\\\"Hello\\\", \\\"Ġworld\\\"]\\n\",\n \" # (GPT-4 BPE would tokenize it as [\\\"Hello\\\", \\\" world\\\"])\\n\",\n \" processed_text = []\\n\",\n \" for i, char in enumerate(text):\\n\",\n \" if char == \\\" \\\" and i != 0:\\n\",\n \" processed_text.append(\\\"Ġ\\\")\\n\",\n \" if char != \\\" \\\":\\n\",\n \" processed_text.append(char)\\n\",\n \" processed_text = \\\"\\\".join(processed_text)\\n\",\n \"\\n\",\n \" # Initialize vocab with unique characters, including 'Ġ' if present\\n\",\n \" # Start with the first 256 ASCII characters\\n\",\n \" unique_chars = [chr(i) for i in range(256)]\\n\",\n \"\\n\",\n \" # Extend unique_chars with characters from processed_text that are not already included\\n\",\n \" unique_chars.extend(char for char in sorted(set(processed_text)) if char not in unique_chars)\\n\",\n \"\\n\",\n \" # Optionally, ensure 'Ġ' is included if it is relevant to your text processing\\n\",\n \" if 'Ġ' not in unique_chars:\\n\",\n \" unique_chars.append('Ġ')\\n\",\n \"\\n\",\n \" # Now create the vocab and inverse vocab dictionaries\\n\",\n \" self.vocab = {i: char for i, char in enumerate(unique_chars)}\\n\",\n \" self.inverse_vocab = {char: i for i, char in self.vocab.items()}\\n\",\n \"\\n\",\n \" # Add allowed special tokens\\n\",\n \" if allowed_special:\\n\",\n \" for token in allowed_special:\\n\",\n \" if token not in self.inverse_vocab:\\n\",\n \" new_id = len(self.vocab)\\n\",\n \" self.vocab[new_id] = token\\n\",\n \" self.inverse_vocab[token] = new_id\\n\",\n \"\\n\",\n \" # Tokenize the processed_text into token IDs\\n\",\n \" token_ids = [self.inverse_vocab[char] for char in processed_text]\\n\",\n \"\\n\",\n \" # BPE steps 1-3: Repeatedly find and replace frequent pairs\\n\",\n \" for new_id in range(len(self.vocab), vocab_size):\\n\",\n \" pair_id = self.find_freq_pair(token_ids, mode=\\\"most\\\")\\n\",\n \" if pair_id is None: # No more pairs to merge. Stopping training.\\n\",\n \" break\\n\",\n \" token_ids = self.replace_pair(token_ids, pair_id, new_id)\\n\",\n \" self.bpe_merges[pair_id] = new_id\\n\",\n \"\\n\",\n \" # Build the vocabulary with merged tokens\\n\",\n \" for (p0, p1), new_id in self.bpe_merges.items():\\n\",\n \" merged_token = self.vocab[p0] + self.vocab[p1]\\n\",\n \" self.vocab[new_id] = merged_token\\n\",\n \" self.inverse_vocab[merged_token] = new_id\\n\",\n \"\\n\",\n \" def encode(self, text):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Encode the input text into a list of token IDs.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" text (str): The text to encode.\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" List[int]: The list of token IDs.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" tokens = []\\n\",\n \" # Split text into tokens, keeping newlines intact\\n\",\n \" words = text.replace(\\\"\\\\n\\\", \\\" \\\\n \\\").split() # Ensure '\\\\n' is treated as a separate token\\n\",\n \"\\n\",\n \" for i, word in enumerate(words):\\n\",\n \" if i > 0 and not word.startswith(\\\"\\\\n\\\"):\\n\",\n \" tokens.append(\\\"Ġ\\\" + word) # Add 'Ġ' to words that follow a space or newline\\n\",\n \" else:\\n\",\n \" tokens.append(word) # Handle first word or standalone '\\\\n'\\n\",\n \"\\n\",\n \" token_ids = []\\n\",\n \" for token in tokens:\\n\",\n \" if token in self.inverse_vocab:\\n\",\n \" # token is contained in the vocabulary as is\\n\",\n \" token_id = self.inverse_vocab[token]\\n\",\n \" token_ids.append(token_id)\\n\",\n \" else:\\n\",\n \" # Attempt to handle subword tokenization via BPE\\n\",\n \" sub_token_ids = self.tokenize_with_bpe(token)\\n\",\n \" token_ids.extend(sub_token_ids)\\n\",\n \"\\n\",\n \" return token_ids\\n\",\n \"\\n\",\n \" def tokenize_with_bpe(self, token):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Tokenize a single token using BPE merges.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" token (str): The token to tokenize.\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" List[int]: The list of token IDs after applying BPE.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" # Tokenize the token into individual characters (as initial token IDs)\\n\",\n \" token_ids = [self.inverse_vocab.get(char, None) for char in token]\\n\",\n \" if None in token_ids:\\n\",\n \" missing_chars = [char for char, tid in zip(token, token_ids) if tid is None]\\n\",\n \" raise ValueError(f\\\"Characters not found in vocab: {missing_chars}\\\")\\n\",\n \"\\n\",\n \" can_merge = True\\n\",\n \" while can_merge and len(token_ids) > 1:\\n\",\n \" can_merge = False\\n\",\n \" new_tokens = []\\n\",\n \" i = 0\\n\",\n \" while i < len(token_ids) - 1:\\n\",\n \" pair = (token_ids[i], token_ids[i + 1])\\n\",\n \" if pair in self.bpe_merges:\\n\",\n \" merged_token_id = self.bpe_merges[pair]\\n\",\n \" new_tokens.append(merged_token_id)\\n\",\n \" # Uncomment for educational purposes:\\n\",\n \" # print(f\\\"Merged pair {pair} -> {merged_token_id} ('{self.vocab[merged_token_id]}')\\\")\\n\",\n \" i += 2 # Skip the next token as it's merged\\n\",\n \" can_merge = True\\n\",\n \" else:\\n\",\n \" new_tokens.append(token_ids[i])\\n\",\n \" i += 1\\n\",\n \" if i < len(token_ids):\\n\",\n \" new_tokens.append(token_ids[i])\\n\",\n \" token_ids = new_tokens\\n\",\n \"\\n\",\n \" return token_ids\\n\",\n \"\\n\",\n \" def decode(self, token_ids):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Decode a list of token IDs back into a string.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" token_ids (List[int]): The list of token IDs to decode.\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" str: The decoded string.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" decoded_string = \\\"\\\"\\n\",\n \" for token_id in token_ids:\\n\",\n \" if token_id not in self.vocab:\\n\",\n \" raise ValueError(f\\\"Token ID {token_id} not found in vocab.\\\")\\n\",\n \" token = self.vocab[token_id]\\n\",\n \" if token.startswith(\\\"Ġ\\\"):\\n\",\n \" # Replace 'Ġ' with a space\\n\",\n \" decoded_string += \\\" \\\" + token[1:]\\n\",\n \" else:\\n\",\n \" decoded_string += token\\n\",\n \" return decoded_string\\n\",\n \"\\n\",\n \" @lru_cache(maxsize=None)\\n\",\n \" def get_special_token_id(self, token):\\n\",\n \" return self.inverse_vocab.get(token, None)\\n\",\n \"\\n\",\n \" @staticmethod\\n\",\n \" def find_freq_pair(token_ids, mode=\\\"most\\\"):\\n\",\n \" pairs = Counter(zip(token_ids, token_ids[1:]))\\n\",\n \"\\n\",\n \" if mode == \\\"most\\\":\\n\",\n \" return max(pairs.items(), key=lambda x: x[1])[0]\\n\",\n \" elif mode == \\\"least\\\":\\n\",\n \" return min(pairs.items(), key=lambda x: x[1])[0]\\n\",\n \" else:\\n\",\n \" raise ValueError(\\\"Invalid mode. Choose 'most' or 'least'.\\\")\\n\",\n \"\\n\",\n \" @staticmethod\\n\",\n \" def replace_pair(token_ids, pair_id, new_id):\\n\",\n \" dq = deque(token_ids)\\n\",\n \" replaced = []\\n\",\n \"\\n\",\n \" while dq:\\n\",\n \" current = dq.popleft()\\n\",\n \" if dq and (current, dq[0]) == pair_id:\\n\",\n \" replaced.append(new_id)\\n\",\n \" # Remove the 2nd token of the pair, 1st was already removed\\n\",\n \" dq.popleft()\\n\",\n \" else:\\n\",\n \" replaced.append(current)\\n\",\n \"\\n\",\n \" return replaced\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"46db7310-79c7-4ee0-b5fa-d760c6e1aa67\",\n \"metadata\": {},\n \"source\": [\n \"- There is a lot of code in the `BPETokenizerSimple` class above, and discussing it in detail is out of scope for this notebook, but the next section offers a short overview of the usage to understand the class methods a bit better\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8ffe1836-eed4-40dc-860b-2d23074d067e\",\n \"metadata\": {},\n \"source\": [\n \"## 3. BPE implementation walkthrough\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3c7c996c-fd34-484f-a877-13d977214cf7\",\n \"metadata\": {},\n \"source\": [\n \"- In practice, I highly recommend using [tiktoken](https://github.com/openai/tiktoken) as my implementation above focuses on readability and educational purposes, not on performance\\n\",\n \"- However, the usage is more or less similar to tiktoken, except that tiktoken does not have a training method\\n\",\n \"- Let's see how my `BPETokenizerSimple` Python code above works by looking at some examples below (a detailed code discussion is out of scope for this notebook)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e82acaf6-7ed5-4d3b-81c0-ae4d3559d2c7\",\n \"metadata\": {},\n \"source\": [\n \"### 3.1 Training, encoding, and decoding\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"962bf037-903e-4555-b09c-206e1a410278\",\n \"metadata\": {},\n \"source\": [\n \"- First, let's consider some sample text as our training dataset:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"4d197cad-ed10-4a42-b01c-a763859781fb\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"import urllib.request\\n\",\n \"\\n\",\n \"if not os.path.exists(\\\"../01_main-chapter-code/the-verdict.txt\\\"):\\n\",\n \" url = (\\\"https://raw.githubusercontent.com/rasbt/\\\"\\n\",\n \" \\\"LLMs-from-scratch/main/ch02/01_main-chapter-code/\\\"\\n\",\n \" \\\"the-verdict.txt\\\")\\n\",\n \" file_path = \\\"../01_main-chapter-code/the-verdict.txt\\\"\\n\",\n \" urllib.request.urlretrieve(url, file_path)\\n\",\n \"\\n\",\n \"with open(\\\"../01_main-chapter-code/the-verdict.txt\\\", \\\"r\\\", encoding=\\\"utf-8\\\") as f: # added ../01_main-chapter-code/\\n\",\n \" text = f.read()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"04d1b6ac-71d3-4817-956a-9bc7e463a84a\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's initialize and train the BPE tokenizer with a vocabulary size of 1,000\\n\",\n \"- Note that the vocabulary size is already 255 by default due to the byte values discussed earlier, so we are only \\\"learning\\\" 745 vocabulary entries \\n\",\n \"- For comparison, the GPT-2 vocabulary is 50,257 tokens, the GPT-4 vocabulary is 100,256 tokens (`cl100k_base` in tiktoken), and GPT-4o uses 199,997 tokens (`o200k_base` in tiktoken); they have all much bigger training sets compared to our simple example text above\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"027348fd-d52f-4396-93dd-38eed142df9b\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"tokenizer = BPETokenizerSimple()\\n\",\n \"tokenizer.train(text, vocab_size=1000, allowed_special={\\\"<|endoftext|>\\\"})\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2474ff05-5629-4f13-9e03-a47b1e713850\",\n \"metadata\": {},\n \"source\": [\n \"- You may want to inspect the vocabulary contents (but note it will create a long list)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"f705a283-355e-4460-b940-06bbc2ae4e61\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"1000\\n\"\n ]\n }\n ],\n \"source\": [\n \"# print(tokenizer.vocab)\\n\",\n \"print(len(tokenizer.vocab))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"36c9da0f-8a18-41cd-91ea-9ccc2bb5febb\",\n \"metadata\": {},\n \"source\": [\n \"- This vocabulary is created by merging 742 times (~ `1000 - len(range(0, 256))`)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"3da42d1c-f75c-4ba7-a6c5-4cb8543d4a44\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"742\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(len(tokenizer.bpe_merges))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5dac69c9-8413-482a-8148-6b2afbf1fb89\",\n \"metadata\": {},\n \"source\": [\n \"- This means that the first 256 entries are single-character tokens\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"451a4108-7c8b-4b98-9c67-d622e9cdf250\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's use the created merges via the `encode` method to encode some text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e1db5cce-e015-412b-ad56-060b8b638078\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[424, 256, 654, 531, 302, 311, 256, 296, 97, 465, 121, 595, 841, 116, 287, 466, 256, 326, 972, 46]\\n\"\n ]\n }\n ],\n \"source\": [\n \"input_text = \\\"Jack embraced beauty through art and life.\\\"\\n\",\n \"token_ids = tokenizer.encode(input_text)\\n\",\n \"print(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"1ed1b344-f7d4-4e9e-ac34-2a04b5c5b7a8\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of characters: 42\\n\",\n \"Number of token IDs: 20\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Number of characters:\\\", len(input_text))\\n\",\n \"print(\\\"Number of token IDs:\\\", len(token_ids))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"50c1cfb9-402a-4e1e-9678-0b7547406248\",\n \"metadata\": {},\n \"source\": [\n \"- From the lengths above, we can see that a 42-character sentence was encoded into 20 token IDs, effectively cutting the input length roughly in half compared to a character-byte-based encoding\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"252693ee-e806-4dac-ab76-2c69086360f4\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the vocabulary itself is used in the `decode()` method, which allows us to map the token IDs back into text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"da0e1faf-1933-43d9-b681-916c282a8f86\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[424, 256, 654, 531, 302, 311, 256, 296, 97, 465, 121, 595, 841, 116, 287, 466, 256, 326, 972, 46]\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"8b690e83-5d6b-409a-804e-321c287c24a4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Jack embraced beauty through art and life.\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(tokenizer.decode(token_ids))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"adea5d09-e5ef-4721-994b-b9b25662fa0a\",\n \"metadata\": {},\n \"source\": [\n \"- Iterating over each token ID can give us a better understanding of how the token IDs are decoded via the vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"2b9e6289-92cb-4d88-b3c8-e836d7c8095f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"424 -> Jack\\n\",\n \"256 -> \\n\",\n \"654 -> em\\n\",\n \"531 -> br\\n\",\n \"302 -> ac\\n\",\n \"311 -> ed\\n\",\n \"256 -> \\n\",\n \"296 -> be\\n\",\n \"97 -> a\\n\",\n \"465 -> ut\\n\",\n \"121 -> y\\n\",\n \"595 -> through\\n\",\n \"841 -> ar\\n\",\n \"116 -> t\\n\",\n \"287 -> a\\n\",\n \"466 -> nd\\n\",\n \"256 -> \\n\",\n \"326 -> li\\n\",\n \"972 -> fe\\n\",\n \"46 -> .\\n\"\n ]\n }\n ],\n \"source\": [\n \"for token_id in token_ids:\\n\",\n \" print(f\\\"{token_id} -> {tokenizer.decode([token_id])}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5ea41c6c-5538-4fd5-8b5f-195960853b71\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see, most token IDs represent 2-character subwords; that's because the training data text is very short with not that many repetitive words, and because we used a relatively small vocabulary size\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"600055a3-7ec8-4abf-b88a-c4186fb71463\",\n \"metadata\": {},\n \"source\": [\n \"- As a summary, calling `decode(encode())` should be able to reproduce arbitrary input texts:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"c7056cb1-a9a3-4cf6-8364-29fb493ae240\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'This is some text.'\"\n ]\n },\n \"execution_count\": 14,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer.decode(tokenizer.encode(\\\"This is some text.\\\"))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3558af04-483c-4f6b-88f5-a534f37316cd\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"# 4. Conclusion\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"410ed0e6-ad06-4bb3-bb39-6b8110c1caa4\",\n \"metadata\": {},\n \"source\": [\n \"- That's it! That's how BPE works in a nutshell, complete with a training method for creating new tokenizers \\n\",\n \"- I hope you found this brief tutorial useful for educational purposes; if you have any questions, please feel free to open a new Discussion [here](https://github.com/rasbt/LLMs-from-scratch/discussions/categories/q-a)\\n\",\n \"\\n\",\n \"\\n\",\n \"**This is a very naive implementation for educational purposes. The [bpe-from-scratch.ipynb](bpe-from-scratch.ipynb) notebook contains a more sophisticated (but much harder to read) implementation that matches the behavior in tiktoken.**\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch02/05_bpe-from-scratch/bpe-from-scratch.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9dec0dfb-3d60-41d0-a63a-b010dce67e32\",\n \"metadata\": {},\n \"source\": [\n \"
\\n\",\n \"\\n\",\n \"```python\\n\",\n \"import tiktoken\\n\",\n \"\\n\",\n \"gpt2_tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"gpt2_tokenizer.encode(\\\"This is some text\\\")\\n\",\n \"# prints [1212, 318, 617, 2420]\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"425b99de-cbfc-441c-8b3e-296a5dd7bb27\",\n \"metadata\": {},\n \"source\": [\n \"- Since a byte consists of 8 bits, there are 28 = 256 possible values that a single byte can represent, ranging from 0 to 255\\n\",\n \"- You can confirm this by executing the code `bytearray(range(0, 257))`, which will warn you that `ValueError: byte must be in range(0, 256)`)\\n\",\n \"- A BPE tokenizer usually uses these 256 values as its first 256 single-character tokens; one could visually check this by running the following code:\\n\",\n \"\\n\",\n \"```python\\n\",\n \"import tiktoken\\n\",\n \"gpt2_tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"for i in range(300):\\n\",\n \" decoded = gpt2_tokenizer.decode([i])\\n\",\n \" print(f\\\"{i}: {decoded}\\\")\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"prints:\\n\",\n \"0: !\\n\",\n \"1: \\\"\\n\",\n \"2: #\\n\",\n \"...\\n\",\n \"255: � # <---- single character tokens up to here\\n\",\n \"256: t\\n\",\n \"257: a\\n\",\n \"...\\n\",\n \"298: ent\\n\",\n \"299: n\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"97ff0207-7f8e-44fa-9381-2a4bd83daab3\",\n \"metadata\": {},\n \"source\": [\n \"- Above, note that entries 256 and 257 are not single-character values but double-character values (a whitespace + a letter), which is a little shortcoming of the original GPT-2 BPE Tokenizer (this has been improved in the GPT-4 tokenizer)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8241c23a-d487-488d-bded-cdf054e24920\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.2 Building the vocabulary\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d7c2ceb7-0b3f-4a62-8dcc-07810cd8886e\",\n \"metadata\": {},\n \"source\": [\n \"- The goal of the BPE tokenization algorithm is to build a vocabulary of commonly occurring subwords like `298: ent` (which can be found in *entangle, entertain, enter, entrance, entity, ...*, for example), or even complete words like \\n\",\n \"\\n\",\n \"```\\n\",\n \"318: is\\n\",\n \"617: some\\n\",\n \"1212: This\\n\",\n \"2420: text\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c0d4420-a4c7-4813-916a-06f4f46bc3f0\",\n \"metadata\": {},\n \"source\": [\n \"- The BPE algorithm was originally described in 1994: \\\"[A New Algorithm for Data Compression](https://github.com/tpn/pdfs/blob/master/A%20New%20Algorithm%20for%20Data%20Compression%20(1994).pdf)\\\" by Philip Gage\\n\",\n \"- Before we get to the actual code implementation, the form that is used for LLM tokenizers today can be summarized as follows:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ebc71db9-b070-48c4-8412-81f45b308ab3\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.3 BPE algorithm outline\\n\",\n \"\\n\",\n \"**1. Identify frequent pairs**\\n\",\n \"- In each iteration, scan the text to find the most commonly occurring pair of bytes (or characters)\\n\",\n \"\\n\",\n \"**2. Replace and record**\\n\",\n \"\\n\",\n \"- Replace that pair with a new placeholder ID (one not already in use, e.g., if we start with 0...255, the first placeholder would be 256)\\n\",\n \"- Record this mapping in a lookup table\\n\",\n \"- The size of the lookup table is a hyperparameter, also called \\\"vocabulary size\\\" (for GPT-2, that's\\n\",\n \"50,257)\\n\",\n \"\\n\",\n \"**3. Repeat until no gains**\\n\",\n \"\\n\",\n \"- Keep repeating steps 1 and 2, continually merging the most frequent pairs\\n\",\n \"- Stop when no further compression is possible (e.g., no pair occurs more than once)\\n\",\n \"\\n\",\n \"**Decompression (decoding)**\\n\",\n \"\\n\",\n \"- To restore the original text, reverse the process by substituting each ID with its corresponding pair, using the lookup table\\n\",\n \"\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e9f5ac9a-3528-4186-9468-8420c7b2ac00\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.4 BPE algorithm example\\n\",\n \"\\n\",\n \"### 1.4.1 Concrete example of the encoding part (steps 1 & 2)\\n\",\n \"\\n\",\n \"- Suppose we have the text (training dataset) `the cat in the hat` from which we want to build the vocabulary for a BPE tokenizer\\n\",\n \"\\n\",\n \"**Iteration 1**\\n\",\n \"\\n\",\n \"1. Identify frequent pairs\\n\",\n \" - In this text, \\\"th\\\" appears twice (at the beginning and before the second \\\"e\\\")\\n\",\n \"\\n\",\n \"2. Replace and record\\n\",\n \" - replace \\\"th\\\" with a new token ID that is not already in use, e.g., 256\\n\",\n \" - the new text is: `<256>e cat in <256>e hat`\\n\",\n \" - the new vocabulary is\\n\",\n \"\\n\",\n \"```\\n\",\n \" 0: ...\\n\",\n \" ...\\n\",\n \" 256: \\\"th\\\"\\n\",\n \"```\\n\",\n \"\\n\",\n \"**Iteration 2**\\n\",\n \"\\n\",\n \"1. **Identify frequent pairs** \\n\",\n \" - In the text `<256>e cat in <256>e hat`, the pair `<256>e` appears twice\\n\",\n \"\\n\",\n \"2. **Replace and record** \\n\",\n \" - replace `<256>e` with a new token ID that is not already in use, for example, `257`. \\n\",\n \" - The new text is:\\n\",\n \" ```\\n\",\n \" <257> cat in <257> hat\\n\",\n \" ```\\n\",\n \" - The updated vocabulary is:\\n\",\n \" ```\\n\",\n \" 0: ...\\n\",\n \" ...\\n\",\n \" 256: \\\"th\\\"\\n\",\n \" 257: \\\"<256>e\\\"\\n\",\n \" ```\\n\",\n \"\\n\",\n \"**Iteration 3**\\n\",\n \"\\n\",\n \"1. **Identify frequent pairs** \\n\",\n \" - In the text `<257> cat in <257> hat`, the pair `<257> ` appears twice (once at the beginning and once before “hat”).\\n\",\n \"\\n\",\n \"2. **Replace and record** \\n\",\n \" - replace `<257> ` with a new token ID that is not already in use, for example, `258`. \\n\",\n \" - the new text is:\\n\",\n \" ```\\n\",\n \" <258>cat in <258>hat\\n\",\n \" ```\\n\",\n \" - The updated vocabulary is:\\n\",\n \" ```\\n\",\n \" 0: ...\\n\",\n \" ...\\n\",\n \" 256: \\\"th\\\"\\n\",\n \" 257: \\\"<256>e\\\"\\n\",\n \" 258: \\\"<257> \\\"\\n\",\n \" ```\\n\",\n \" \\n\",\n \"- and so forth\\n\",\n \"\\n\",\n \" \\n\",\n \"### 1.4.2 Concrete example of the decoding part (steps 3)\\n\",\n \"\\n\",\n \"- To restore the original text, we reverse the process by substituting each token ID with its corresponding pair in the reverse order they were introduced\\n\",\n \"- Start with the final compressed text: `<258>cat in <258>hat`\\n\",\n \"- Substitute `<258>` → `<257> `: `<257> cat in <257> hat` \\n\",\n \"- Substitute `<257>` → `<256>e`: `<256>e cat in <256>e hat`\\n\",\n \"- Substitute `<256>` → \\\"th\\\": `the cat in the hat`\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a2324948-ddd0-45d1-8ba8-e8eda9fc6677\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2. A simple BPE implementation\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"429ca709-40d7-4e3d-bf3e-4f5687a2e19b\",\n \"metadata\": {},\n \"source\": [\n \"- Below is an implementation of this algorithm described above as a Python class that mimics the `tiktoken` Python user interface\\n\",\n \"- Note that the encoding part above describes the original training step via `train()`; however, the `encode()` method works similarly (although it looks a bit more complicated because of the special token handling):\\n\",\n \"\\n\",\n \"1. Split the input text into individual bytes\\n\",\n \"2. Repeatedly find & replace (merge) adjacent tokens (pairs) when they match any pair in the learned BPE merges (from highest to lowest \\\"rank,\\\" i.e., in the order they were learned)\\n\",\n \"3. Continue merging until no more merges can be applied\\n\",\n \"4. The final list of token IDs is the encoded output\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"3e4a15ec-2667-4f56-b7c1-34e8071b621d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from collections import Counter, deque\\n\",\n \"from functools import lru_cache\\n\",\n \"\\n\",\n \"\\n\",\n \"class BPETokenizerSimple:\\n\",\n \" def __init__(self):\\n\",\n \" # Maps token_id to token_str (e.g., {11246: \\\"some\\\"})\\n\",\n \" self.vocab = {}\\n\",\n \" # Maps token_str to token_id (e.g., {\\\"some\\\": 11246})\\n\",\n \" self.inverse_vocab = {}\\n\",\n \" # Dictionary of BPE merges: {(token_id1, token_id2): merged_token_id}\\n\",\n \" self.bpe_merges = {}\\n\",\n \"\\n\",\n \" def train(self, text, vocab_size, allowed_special={\\\"<|endoftext|>\\\"}):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Train the BPE tokenizer from scratch.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" text (str): The training text.\\n\",\n \" vocab_size (int): The desired vocabulary size.\\n\",\n \" allowed_special (set): A set of special tokens to include.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \"\\n\",\n \" # Preprocess: Replace spaces with 'Ġ'\\n\",\n \" # Note that Ġ is a particularity of the GPT-2 BPE implementation\\n\",\n \" # E.g., \\\"Hello world\\\" might be tokenized as [\\\"Hello\\\", \\\"Ġworld\\\"]\\n\",\n \" # (GPT-4 BPE would tokenize it as [\\\"Hello\\\", \\\" world\\\"])\\n\",\n \" processed_text = []\\n\",\n \" for i, char in enumerate(text):\\n\",\n \" if char == \\\" \\\" and i != 0:\\n\",\n \" processed_text.append(\\\"Ġ\\\")\\n\",\n \" if char != \\\" \\\":\\n\",\n \" processed_text.append(char)\\n\",\n \" processed_text = \\\"\\\".join(processed_text)\\n\",\n \"\\n\",\n \" # Initialize vocab with unique characters, including 'Ġ' if present\\n\",\n \" # Start with the first 256 ASCII characters\\n\",\n \" unique_chars = [chr(i) for i in range(256)]\\n\",\n \"\\n\",\n \" # Extend unique_chars with characters from processed_text that are not already included\\n\",\n \" unique_chars.extend(char for char in sorted(set(processed_text)) if char not in unique_chars)\\n\",\n \"\\n\",\n \" # Optionally, ensure 'Ġ' is included if it is relevant to your text processing\\n\",\n \" if 'Ġ' not in unique_chars:\\n\",\n \" unique_chars.append('Ġ')\\n\",\n \"\\n\",\n \" # Now create the vocab and inverse vocab dictionaries\\n\",\n \" self.vocab = {i: char for i, char in enumerate(unique_chars)}\\n\",\n \" self.inverse_vocab = {char: i for i, char in self.vocab.items()}\\n\",\n \"\\n\",\n \" # Add allowed special tokens\\n\",\n \" if allowed_special:\\n\",\n \" for token in allowed_special:\\n\",\n \" if token not in self.inverse_vocab:\\n\",\n \" new_id = len(self.vocab)\\n\",\n \" self.vocab[new_id] = token\\n\",\n \" self.inverse_vocab[token] = new_id\\n\",\n \"\\n\",\n \" # Tokenize the processed_text into token IDs\\n\",\n \" token_ids = [self.inverse_vocab[char] for char in processed_text]\\n\",\n \"\\n\",\n \" # BPE steps 1-3: Repeatedly find and replace frequent pairs\\n\",\n \" for new_id in range(len(self.vocab), vocab_size):\\n\",\n \" pair_id = self.find_freq_pair(token_ids, mode=\\\"most\\\")\\n\",\n \" if pair_id is None: # No more pairs to merge. Stopping training.\\n\",\n \" break\\n\",\n \" token_ids = self.replace_pair(token_ids, pair_id, new_id)\\n\",\n \" self.bpe_merges[pair_id] = new_id\\n\",\n \"\\n\",\n \" # Build the vocabulary with merged tokens\\n\",\n \" for (p0, p1), new_id in self.bpe_merges.items():\\n\",\n \" merged_token = self.vocab[p0] + self.vocab[p1]\\n\",\n \" self.vocab[new_id] = merged_token\\n\",\n \" self.inverse_vocab[merged_token] = new_id\\n\",\n \"\\n\",\n \" def encode(self, text):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Encode the input text into a list of token IDs.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" text (str): The text to encode.\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" List[int]: The list of token IDs.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" tokens = []\\n\",\n \" # Split text into tokens, keeping newlines intact\\n\",\n \" words = text.replace(\\\"\\\\n\\\", \\\" \\\\n \\\").split() # Ensure '\\\\n' is treated as a separate token\\n\",\n \"\\n\",\n \" for i, word in enumerate(words):\\n\",\n \" if i > 0 and not word.startswith(\\\"\\\\n\\\"):\\n\",\n \" tokens.append(\\\"Ġ\\\" + word) # Add 'Ġ' to words that follow a space or newline\\n\",\n \" else:\\n\",\n \" tokens.append(word) # Handle first word or standalone '\\\\n'\\n\",\n \"\\n\",\n \" token_ids = []\\n\",\n \" for token in tokens:\\n\",\n \" if token in self.inverse_vocab:\\n\",\n \" # token is contained in the vocabulary as is\\n\",\n \" token_id = self.inverse_vocab[token]\\n\",\n \" token_ids.append(token_id)\\n\",\n \" else:\\n\",\n \" # Attempt to handle subword tokenization via BPE\\n\",\n \" sub_token_ids = self.tokenize_with_bpe(token)\\n\",\n \" token_ids.extend(sub_token_ids)\\n\",\n \"\\n\",\n \" return token_ids\\n\",\n \"\\n\",\n \" def tokenize_with_bpe(self, token):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Tokenize a single token using BPE merges.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" token (str): The token to tokenize.\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" List[int]: The list of token IDs after applying BPE.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" # Tokenize the token into individual characters (as initial token IDs)\\n\",\n \" token_ids = [self.inverse_vocab.get(char, None) for char in token]\\n\",\n \" if None in token_ids:\\n\",\n \" missing_chars = [char for char, tid in zip(token, token_ids) if tid is None]\\n\",\n \" raise ValueError(f\\\"Characters not found in vocab: {missing_chars}\\\")\\n\",\n \"\\n\",\n \" can_merge = True\\n\",\n \" while can_merge and len(token_ids) > 1:\\n\",\n \" can_merge = False\\n\",\n \" new_tokens = []\\n\",\n \" i = 0\\n\",\n \" while i < len(token_ids) - 1:\\n\",\n \" pair = (token_ids[i], token_ids[i + 1])\\n\",\n \" if pair in self.bpe_merges:\\n\",\n \" merged_token_id = self.bpe_merges[pair]\\n\",\n \" new_tokens.append(merged_token_id)\\n\",\n \" # Uncomment for educational purposes:\\n\",\n \" # print(f\\\"Merged pair {pair} -> {merged_token_id} ('{self.vocab[merged_token_id]}')\\\")\\n\",\n \" i += 2 # Skip the next token as it's merged\\n\",\n \" can_merge = True\\n\",\n \" else:\\n\",\n \" new_tokens.append(token_ids[i])\\n\",\n \" i += 1\\n\",\n \" if i < len(token_ids):\\n\",\n \" new_tokens.append(token_ids[i])\\n\",\n \" token_ids = new_tokens\\n\",\n \"\\n\",\n \" return token_ids\\n\",\n \"\\n\",\n \" def decode(self, token_ids):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Decode a list of token IDs back into a string.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" token_ids (List[int]): The list of token IDs to decode.\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" str: The decoded string.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" decoded_string = \\\"\\\"\\n\",\n \" for token_id in token_ids:\\n\",\n \" if token_id not in self.vocab:\\n\",\n \" raise ValueError(f\\\"Token ID {token_id} not found in vocab.\\\")\\n\",\n \" token = self.vocab[token_id]\\n\",\n \" if token.startswith(\\\"Ġ\\\"):\\n\",\n \" # Replace 'Ġ' with a space\\n\",\n \" decoded_string += \\\" \\\" + token[1:]\\n\",\n \" else:\\n\",\n \" decoded_string += token\\n\",\n \" return decoded_string\\n\",\n \"\\n\",\n \" @lru_cache(maxsize=None)\\n\",\n \" def get_special_token_id(self, token):\\n\",\n \" return self.inverse_vocab.get(token, None)\\n\",\n \"\\n\",\n \" @staticmethod\\n\",\n \" def find_freq_pair(token_ids, mode=\\\"most\\\"):\\n\",\n \" pairs = Counter(zip(token_ids, token_ids[1:]))\\n\",\n \"\\n\",\n \" if mode == \\\"most\\\":\\n\",\n \" return max(pairs.items(), key=lambda x: x[1])[0]\\n\",\n \" elif mode == \\\"least\\\":\\n\",\n \" return min(pairs.items(), key=lambda x: x[1])[0]\\n\",\n \" else:\\n\",\n \" raise ValueError(\\\"Invalid mode. Choose 'most' or 'least'.\\\")\\n\",\n \"\\n\",\n \" @staticmethod\\n\",\n \" def replace_pair(token_ids, pair_id, new_id):\\n\",\n \" dq = deque(token_ids)\\n\",\n \" replaced = []\\n\",\n \"\\n\",\n \" while dq:\\n\",\n \" current = dq.popleft()\\n\",\n \" if dq and (current, dq[0]) == pair_id:\\n\",\n \" replaced.append(new_id)\\n\",\n \" # Remove the 2nd token of the pair, 1st was already removed\\n\",\n \" dq.popleft()\\n\",\n \" else:\\n\",\n \" replaced.append(current)\\n\",\n \"\\n\",\n \" return replaced\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"46db7310-79c7-4ee0-b5fa-d760c6e1aa67\",\n \"metadata\": {},\n \"source\": [\n \"- There is a lot of code in the `BPETokenizerSimple` class above, and discussing it in detail is out of scope for this notebook, but the next section offers a short overview of the usage to understand the class methods a bit better\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8ffe1836-eed4-40dc-860b-2d23074d067e\",\n \"metadata\": {},\n \"source\": [\n \"## 3. BPE implementation walkthrough\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3c7c996c-fd34-484f-a877-13d977214cf7\",\n \"metadata\": {},\n \"source\": [\n \"- In practice, I highly recommend using [tiktoken](https://github.com/openai/tiktoken) as my implementation above focuses on readability and educational purposes, not on performance\\n\",\n \"- However, the usage is more or less similar to tiktoken, except that tiktoken does not have a training method\\n\",\n \"- Let's see how my `BPETokenizerSimple` Python code above works by looking at some examples below (a detailed code discussion is out of scope for this notebook)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e82acaf6-7ed5-4d3b-81c0-ae4d3559d2c7\",\n \"metadata\": {},\n \"source\": [\n \"### 3.1 Training, encoding, and decoding\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"962bf037-903e-4555-b09c-206e1a410278\",\n \"metadata\": {},\n \"source\": [\n \"- First, let's consider some sample text as our training dataset:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"4d197cad-ed10-4a42-b01c-a763859781fb\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"import urllib.request\\n\",\n \"\\n\",\n \"if not os.path.exists(\\\"../01_main-chapter-code/the-verdict.txt\\\"):\\n\",\n \" url = (\\\"https://raw.githubusercontent.com/rasbt/\\\"\\n\",\n \" \\\"LLMs-from-scratch/main/ch02/01_main-chapter-code/\\\"\\n\",\n \" \\\"the-verdict.txt\\\")\\n\",\n \" file_path = \\\"../01_main-chapter-code/the-verdict.txt\\\"\\n\",\n \" urllib.request.urlretrieve(url, file_path)\\n\",\n \"\\n\",\n \"with open(\\\"../01_main-chapter-code/the-verdict.txt\\\", \\\"r\\\", encoding=\\\"utf-8\\\") as f: # added ../01_main-chapter-code/\\n\",\n \" text = f.read()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"04d1b6ac-71d3-4817-956a-9bc7e463a84a\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's initialize and train the BPE tokenizer with a vocabulary size of 1,000\\n\",\n \"- Note that the vocabulary size is already 255 by default due to the byte values discussed earlier, so we are only \\\"learning\\\" 745 vocabulary entries \\n\",\n \"- For comparison, the GPT-2 vocabulary is 50,257 tokens, the GPT-4 vocabulary is 100,256 tokens (`cl100k_base` in tiktoken), and GPT-4o uses 199,997 tokens (`o200k_base` in tiktoken); they have all much bigger training sets compared to our simple example text above\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"027348fd-d52f-4396-93dd-38eed142df9b\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"tokenizer = BPETokenizerSimple()\\n\",\n \"tokenizer.train(text, vocab_size=1000, allowed_special={\\\"<|endoftext|>\\\"})\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2474ff05-5629-4f13-9e03-a47b1e713850\",\n \"metadata\": {},\n \"source\": [\n \"- You may want to inspect the vocabulary contents (but note it will create a long list)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"f705a283-355e-4460-b940-06bbc2ae4e61\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"1000\\n\"\n ]\n }\n ],\n \"source\": [\n \"# print(tokenizer.vocab)\\n\",\n \"print(len(tokenizer.vocab))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"36c9da0f-8a18-41cd-91ea-9ccc2bb5febb\",\n \"metadata\": {},\n \"source\": [\n \"- This vocabulary is created by merging 742 times (~ `1000 - len(range(0, 256))`)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"3da42d1c-f75c-4ba7-a6c5-4cb8543d4a44\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"742\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(len(tokenizer.bpe_merges))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5dac69c9-8413-482a-8148-6b2afbf1fb89\",\n \"metadata\": {},\n \"source\": [\n \"- This means that the first 256 entries are single-character tokens\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"451a4108-7c8b-4b98-9c67-d622e9cdf250\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's use the created merges via the `encode` method to encode some text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e1db5cce-e015-412b-ad56-060b8b638078\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[424, 256, 654, 531, 302, 311, 256, 296, 97, 465, 121, 595, 841, 116, 287, 466, 256, 326, 972, 46]\\n\"\n ]\n }\n ],\n \"source\": [\n \"input_text = \\\"Jack embraced beauty through art and life.\\\"\\n\",\n \"token_ids = tokenizer.encode(input_text)\\n\",\n \"print(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"1ed1b344-f7d4-4e9e-ac34-2a04b5c5b7a8\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of characters: 42\\n\",\n \"Number of token IDs: 20\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Number of characters:\\\", len(input_text))\\n\",\n \"print(\\\"Number of token IDs:\\\", len(token_ids))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"50c1cfb9-402a-4e1e-9678-0b7547406248\",\n \"metadata\": {},\n \"source\": [\n \"- From the lengths above, we can see that a 42-character sentence was encoded into 20 token IDs, effectively cutting the input length roughly in half compared to a character-byte-based encoding\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"252693ee-e806-4dac-ab76-2c69086360f4\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the vocabulary itself is used in the `decode()` method, which allows us to map the token IDs back into text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"da0e1faf-1933-43d9-b681-916c282a8f86\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[424, 256, 654, 531, 302, 311, 256, 296, 97, 465, 121, 595, 841, 116, 287, 466, 256, 326, 972, 46]\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"8b690e83-5d6b-409a-804e-321c287c24a4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Jack embraced beauty through art and life.\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(tokenizer.decode(token_ids))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"adea5d09-e5ef-4721-994b-b9b25662fa0a\",\n \"metadata\": {},\n \"source\": [\n \"- Iterating over each token ID can give us a better understanding of how the token IDs are decoded via the vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"2b9e6289-92cb-4d88-b3c8-e836d7c8095f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"424 -> Jack\\n\",\n \"256 -> \\n\",\n \"654 -> em\\n\",\n \"531 -> br\\n\",\n \"302 -> ac\\n\",\n \"311 -> ed\\n\",\n \"256 -> \\n\",\n \"296 -> be\\n\",\n \"97 -> a\\n\",\n \"465 -> ut\\n\",\n \"121 -> y\\n\",\n \"595 -> through\\n\",\n \"841 -> ar\\n\",\n \"116 -> t\\n\",\n \"287 -> a\\n\",\n \"466 -> nd\\n\",\n \"256 -> \\n\",\n \"326 -> li\\n\",\n \"972 -> fe\\n\",\n \"46 -> .\\n\"\n ]\n }\n ],\n \"source\": [\n \"for token_id in token_ids:\\n\",\n \" print(f\\\"{token_id} -> {tokenizer.decode([token_id])}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5ea41c6c-5538-4fd5-8b5f-195960853b71\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see, most token IDs represent 2-character subwords; that's because the training data text is very short with not that many repetitive words, and because we used a relatively small vocabulary size\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"600055a3-7ec8-4abf-b88a-c4186fb71463\",\n \"metadata\": {},\n \"source\": [\n \"- As a summary, calling `decode(encode())` should be able to reproduce arbitrary input texts:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"c7056cb1-a9a3-4cf6-8364-29fb493ae240\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'This is some text.'\"\n ]\n },\n \"execution_count\": 14,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer.decode(tokenizer.encode(\\\"This is some text.\\\"))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3558af04-483c-4f6b-88f5-a534f37316cd\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"# 4. Conclusion\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"410ed0e6-ad06-4bb3-bb39-6b8110c1caa4\",\n \"metadata\": {},\n \"source\": [\n \"- That's it! That's how BPE works in a nutshell, complete with a training method for creating new tokenizers \\n\",\n \"- I hope you found this brief tutorial useful for educational purposes; if you have any questions, please feel free to open a new Discussion [here](https://github.com/rasbt/LLMs-from-scratch/discussions/categories/q-a)\\n\",\n \"\\n\",\n \"\\n\",\n \"**This is a very naive implementation for educational purposes. The [bpe-from-scratch.ipynb](bpe-from-scratch.ipynb) notebook contains a more sophisticated (but much harder to read) implementation that matches the behavior in tiktoken.**\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch02/05_bpe-from-scratch/bpe-from-scratch.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9dec0dfb-3d60-41d0-a63a-b010dce67e32\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"760c625d-26a1-4896-98a2-0fdcd1591256\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.1 Bits and bytes\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d4ddaa35-0ed7-4012-827e-911de11c266c\",\n \"metadata\": {},\n \"source\": [\n \"- Before getting to the BPE algorithm, let's introduce the notion of bytes\\n\",\n \"- Consider converting text into a byte array (BPE stands for \\\"byte\\\" pair encoding after all):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"8c9bc9e4-120f-4bac-8fa6-6523c568d12e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"bytearray(b'This is some text')\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = \\\"This is some text\\\"\\n\",\n \"byte_ary = bytearray(text, \\\"utf-8\\\")\\n\",\n \"print(byte_ary)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dbd92a2a-9d74-4dc7-bb53-ac33d6cf2fab\",\n \"metadata\": {},\n \"source\": [\n \"- When we call `list()` on a `bytearray` object, each byte is treated as an individual element, and the result is a list of integers corresponding to the byte values:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"6c586945-d459-4f9a-855d-bf73438ef0e3\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[84, 104, 105, 115, 32, 105, 115, 32, 115, 111, 109, 101, 32, 116, 101, 120, 116]\\n\"\n ]\n }\n ],\n \"source\": [\n \"ids = list(byte_ary)\\n\",\n \"print(ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"71efea37-f4c3-4cb8-bfa5-9299175faf9a\",\n \"metadata\": {},\n \"source\": [\n \"- This would be a valid way to convert text into a token ID representation that we need for the embedding layer of an LLM\\n\",\n \"- However, the downside of this approach is that it is creating one ID for each character (that's a lot of IDs for a short text!)\\n\",\n \"- I.e., this means for a 17-character input text, we have to use 17 token IDs as input to the LLM:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"0d5b61d9-79a0-48b4-9b3e-64ab595c5b01\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of characters: 17\\n\",\n \"Number of token IDs: 17\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Number of characters:\\\", len(text))\\n\",\n \"print(\\\"Number of token IDs:\\\", len(ids))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"68cc833a-c0d4-4d46-9180-c0042fd6addc\",\n \"metadata\": {},\n \"source\": [\n \"- If you have worked with LLMs before, you may know that the BPE tokenizers have a vocabulary where we have a token ID for whole words or subwords instead of each character\\n\",\n \"- For example, the GPT-2 tokenizer tokenizes the same text (\\\"This is some text\\\") into only 4 instead of 17 tokens: `1212, 318, 617, 2420`\\n\",\n \"- You can double-check this using the interactive [tiktoken app](https://tiktokenizer.vercel.app/?model=gpt2) or the [tiktoken library](https://github.com/openai/tiktoken):\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"```python\\n\",\n \"import tiktoken\\n\",\n \"\\n\",\n \"gpt2_tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"gpt2_tokenizer.encode(\\\"This is some text\\\")\\n\",\n \"# prints [1212, 318, 617, 2420]\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"425b99de-cbfc-441c-8b3e-296a5dd7bb27\",\n \"metadata\": {},\n \"source\": [\n \"- Since a byte consists of 8 bits, there are 28 = 256 possible values that a single byte can represent, ranging from 0 to 255\\n\",\n \"- You can confirm this by executing the code `bytearray(range(0, 257))`, which will warn you that `ValueError: byte must be in range(0, 256)`)\\n\",\n \"- A BPE tokenizer usually uses these 256 values as its first 256 single-character tokens; one could visually check this by running the following code:\\n\",\n \"\\n\",\n \"```python\\n\",\n \"import tiktoken\\n\",\n \"gpt2_tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"for i in range(300):\\n\",\n \" decoded = gpt2_tokenizer.decode([i])\\n\",\n \" print(f\\\"{i}: {decoded}\\\")\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"prints:\\n\",\n \"0: !\\n\",\n \"1: \\\"\\n\",\n \"2: #\\n\",\n \"...\\n\",\n \"255: � # <---- single character tokens up to here\\n\",\n \"256: t\\n\",\n \"257: a\\n\",\n \"...\\n\",\n \"298: ent\\n\",\n \"299: n\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"97ff0207-7f8e-44fa-9381-2a4bd83daab3\",\n \"metadata\": {},\n \"source\": [\n \"- Above, note that entries 256 and 257 are not single-character values but double-character values (a whitespace + a letter), which is a little shortcoming of the original GPT-2 BPE Tokenizer (this has been improved in the GPT-4 tokenizer)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8241c23a-d487-488d-bded-cdf054e24920\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.2 Building the vocabulary\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d7c2ceb7-0b3f-4a62-8dcc-07810cd8886e\",\n \"metadata\": {},\n \"source\": [\n \"- The goal of the BPE tokenization algorithm is to build a vocabulary of commonly occurring subwords like `298: ent` (which can be found in *entangle, entertain, enter, entrance, entity, ...*, for example), or even complete words like \\n\",\n \"\\n\",\n \"```\\n\",\n \"318: is\\n\",\n \"617: some\\n\",\n \"1212: This\\n\",\n \"2420: text\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c0d4420-a4c7-4813-916a-06f4f46bc3f0\",\n \"metadata\": {},\n \"source\": [\n \"- The BPE algorithm was originally described in 1994: \\\"[A New Algorithm for Data Compression](https://github.com/tpn/pdfs/blob/master/A%20New%20Algorithm%20for%20Data%20Compression%20(1994).pdf)\\\" by Philip Gage\\n\",\n \"- Before we get to the actual code implementation, the form that is used for LLM tokenizers today can be summarized as described in the following sections.\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ebc71db9-b070-48c4-8412-81f45b308ab3\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.3 BPE algorithm outline\\n\",\n \"\\n\",\n \"**1. Identify frequent pairs**\\n\",\n \"- In each iteration, scan the text to find the most commonly occurring pair of bytes (or characters)\\n\",\n \"\\n\",\n \"**2. Replace and record**\\n\",\n \"\\n\",\n \"- Replace that pair with a new placeholder ID (one not already in use, e.g., if we start with 0...255, the first placeholder would be 256)\\n\",\n \"- Record this mapping in a lookup table\\n\",\n \"- The size of the lookup table is a hyperparameter, also called \\\"vocabulary size\\\" (for GPT-2, that's\\n\",\n \"50,257)\\n\",\n \"\\n\",\n \"**3. Repeat until no gains**\\n\",\n \"\\n\",\n \"- Keep repeating steps 1 and 2, continually merging the most frequent pairs\\n\",\n \"- Stop when no further compression is possible (e.g., no pair occurs more than once)\\n\",\n \"\\n\",\n \"**Decompression (decoding)**\\n\",\n \"\\n\",\n \"- To restore the original text, reverse the process by substituting each ID with its corresponding pair, using the lookup table\\n\",\n \"\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e9f5ac9a-3528-4186-9468-8420c7b2ac00\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 1.4 BPE algorithm example\\n\",\n \"\\n\",\n \"### 1.4.1 Concrete example of the encoding part (steps 1 & 2 in section 1.3)\\n\",\n \"\\n\",\n \"- Suppose we have the text (training dataset) `the cat in the hat` from which we want to build the vocabulary for a BPE tokenizer\\n\",\n \"\\n\",\n \"**Iteration 1**\\n\",\n \"\\n\",\n \"1. Identify frequent pairs\\n\",\n \" - In this text, \\\"th\\\" appears twice (at the beginning and before the second \\\"e\\\")\\n\",\n \"\\n\",\n \"2. Replace and record\\n\",\n \" - replace \\\"th\\\" with a new token ID that is not already in use, e.g., 256\\n\",\n \" - the new text is: `<256>e cat in <256>e hat`\\n\",\n \" - the new vocabulary is\\n\",\n \"\\n\",\n \"```\\n\",\n \" 0: ...\\n\",\n \" ...\\n\",\n \" 256: \\\"th\\\"\\n\",\n \"```\\n\",\n \"\\n\",\n \"**Iteration 2**\\n\",\n \"\\n\",\n \"1. **Identify frequent pairs** \\n\",\n \" - In the text `<256>e cat in <256>e hat`, the pair `<256>e` appears twice\\n\",\n \"\\n\",\n \"2. **Replace and record** \\n\",\n \" - replace `<256>e` with a new token ID that is not already in use, for example, `257`. \\n\",\n \" - The new text is:\\n\",\n \" ```\\n\",\n \" <257> cat in <257> hat\\n\",\n \" ```\\n\",\n \" - The updated vocabulary is:\\n\",\n \" ```\\n\",\n \" 0: ...\\n\",\n \" ...\\n\",\n \" 256: \\\"th\\\"\\n\",\n \" 257: \\\"<256>e\\\"\\n\",\n \" ```\\n\",\n \"\\n\",\n \"**Iteration 3**\\n\",\n \"\\n\",\n \"1. **Identify frequent pairs** \\n\",\n \" - In the text `<257> cat in <257> hat`, the pair `<257> ` appears twice (once at the beginning and once before “hat”).\\n\",\n \"\\n\",\n \"2. **Replace and record** \\n\",\n \" - replace `<257> ` with a new token ID that is not already in use, for example, `258`. \\n\",\n \" - the new text is:\\n\",\n \" ```\\n\",\n \" <258>cat in <258>hat\\n\",\n \" ```\\n\",\n \" - The updated vocabulary is:\\n\",\n \" ```\\n\",\n \" 0: ...\\n\",\n \" ...\\n\",\n \" 256: \\\"th\\\"\\n\",\n \" 257: \\\"<256>e\\\"\\n\",\n \" 258: \\\"<257> \\\"\\n\",\n \" ```\\n\",\n \" \\n\",\n \"- and so forth\\n\",\n \"\\n\",\n \" \\n\",\n \"### 1.4.2 Concrete example of the decoding part (step 3 in section 1.3)\\n\",\n \"\\n\",\n \"- To restore the original text, we reverse the process by substituting each token ID with its corresponding pair in the reverse order they were introduced\\n\",\n \"- Start with the final compressed text: `<258>cat in <258>hat`\\n\",\n \"- Substitute `<258>` → `<257> `: `<257> cat in <257> hat` \\n\",\n \"- Substitute `<257>` → `<256>e`: `<256>e cat in <256>e hat`\\n\",\n \"- Substitute `<256>` → \\\"th\\\": `the cat in the hat`\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a2324948-ddd0-45d1-8ba8-e8eda9fc6677\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 2. A simple BPE implementation\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"429ca709-40d7-4e3d-bf3e-4f5687a2e19b\",\n \"metadata\": {},\n \"source\": [\n \"- Below is an implementation of this algorithm described above as a Python class that mimics the `tiktoken` Python user interface\\n\",\n \"- Note that the encoding part above describes the original training step via `train()`; however, the `encode()` method works similarly (although it looks a bit more complicated because of the special token handling):\\n\",\n \"\\n\",\n \"1. Split the input text into individual bytes\\n\",\n \"2. Repeatedly find & replace (merge) adjacent tokens (pairs) when they match any pair in the learned BPE merges (from highest to lowest \\\"rank,\\\" i.e., in the order they were learned)\\n\",\n \"3. Continue merging until no more merges can be applied\\n\",\n \"4. The final list of token IDs is the encoded output\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"3e4a15ec-2667-4f56-b7c1-34e8071b621d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from collections import Counter, deque\\n\",\n \"from functools import lru_cache\\n\",\n \"import re\\n\",\n \"import json\\n\",\n \"\\n\",\n \"\\n\",\n \"class BPETokenizerSimple:\\n\",\n \" def __init__(self):\\n\",\n \" # Maps token_id to token_str (e.g., {11246: \\\"some\\\"})\\n\",\n \" self.vocab = {}\\n\",\n \" # Maps token_str to token_id (e.g., {\\\"some\\\": 11246})\\n\",\n \" self.inverse_vocab = {}\\n\",\n \" # Dictionary of BPE merges: {(token_id1, token_id2): merged_token_id}\\n\",\n \" self.bpe_merges = {}\\n\",\n \"\\n\",\n \" # For the official OpenAI GPT-2 merges, use a rank dict:\\n\",\n \" # of form {(string_A, string_B): rank}, where lower rank = higher priority\\n\",\n \" self.bpe_ranks = {}\\n\",\n \"\\n\",\n \" def train(self, text, vocab_size, allowed_special={\\\"<|endoftext|>\\\"}):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Train the BPE tokenizer from scratch.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" text (str): The training text.\\n\",\n \" vocab_size (int): The desired vocabulary size.\\n\",\n \" allowed_special (set): A set of special tokens to include.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \"\\n\",\n \" # Pre-tokenize training text using the same boundary rules as encode()\\n\",\n \" tokens = self.pretokenize_text(text)\\n\",\n \"\\n\",\n \" # Initialize vocab with unique characters, including \\\"Ġ\\\" if present\\n\",\n \" # Start with the first 256 ASCII characters\\n\",\n \" unique_chars = [chr(i) for i in range(256)]\\n\",\n \" unique_chars.extend(\\n\",\n \" char for char in sorted({char for token in tokens for char in token})\\n\",\n \" if char not in unique_chars\\n\",\n \" )\\n\",\n \" if \\\"Ġ\\\" not in unique_chars:\\n\",\n \" unique_chars.append(\\\"Ġ\\\")\\n\",\n \"\\n\",\n \" self.vocab = {i: char for i, char in enumerate(unique_chars)}\\n\",\n \" self.inverse_vocab = {char: i for i, char in self.vocab.items()}\\n\",\n \"\\n\",\n \" # Add allowed special tokens\\n\",\n \" if allowed_special:\\n\",\n \" for token in allowed_special:\\n\",\n \" if token not in self.inverse_vocab:\\n\",\n \" new_id = len(self.vocab)\\n\",\n \" self.vocab[new_id] = token\\n\",\n \" self.inverse_vocab[token] = new_id\\n\",\n \"\\n\",\n \" # Tokenize each pre-token into character IDs\\n\",\n \" token_id_sequences = [\\n\",\n \" [self.inverse_vocab[char] for char in token]\\n\",\n \" for token in tokens\\n\",\n \" ]\\n\",\n \"\\n\",\n \" # BPE steps 1-3: Repeatedly find and replace frequent pairs\\n\",\n \" for new_id in range(len(self.vocab), vocab_size):\\n\",\n \" pair_id = self.find_freq_pair(token_id_sequences, mode=\\\"most\\\")\\n\",\n \" if pair_id is None:\\n\",\n \" break\\n\",\n \" token_id_sequences = self.replace_pair(token_id_sequences, pair_id, new_id)\\n\",\n \" self.bpe_merges[pair_id] = new_id\\n\",\n \"\\n\",\n \" # Build the vocabulary with merged tokens\\n\",\n \" for (p0, p1), new_id in self.bpe_merges.items():\\n\",\n \" merged_token = self.vocab[p0] + self.vocab[p1]\\n\",\n \" self.vocab[new_id] = merged_token\\n\",\n \" self.inverse_vocab[merged_token] = new_id\\n\",\n \"\\n\",\n \" def load_vocab_and_merges_from_openai(self, vocab_path, bpe_merges_path):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Load pre-trained vocabulary and BPE merges from OpenAI's GPT-2 files.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" vocab_path (str): Path to the vocab file (GPT-2 calls it 'encoder.json').\\n\",\n \" bpe_merges_path (str): Path to the bpe_merges file (GPT-2 calls it 'vocab.bpe').\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" # Load vocabulary\\n\",\n \" with open(vocab_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" loaded_vocab = json.load(file)\\n\",\n \" # encoder.json is {token_str: id}; we want id->str and str->id\\n\",\n \" self.vocab = {int(v): k for k, v in loaded_vocab.items()}\\n\",\n \" self.inverse_vocab = {k: int(v) for k, v in loaded_vocab.items()}\\n\",\n \" \\n\",\n \" # Must have GPT-2's printable newline character 'Ċ' (U+010A) at id 198\\n\",\n \" if \\\"Ċ\\\" not in self.inverse_vocab or self.inverse_vocab[\\\"Ċ\\\"] != 198:\\n\",\n \" raise KeyError(\\\"Vocabulary missing GPT-2 newline glyph 'Ċ' at id 198.\\\")\\n\",\n \" \\n\",\n \" # Must have <|endoftext|> at 50256\\n\",\n \" if \\\"<|endoftext|>\\\" not in self.inverse_vocab or self.inverse_vocab[\\\"<|endoftext|>\\\"] != 50256:\\n\",\n \" raise KeyError(\\\"Vocabulary missing <|endoftext|> at id 50256.\\\")\\n\",\n \" \\n\",\n \" # Provide a convenience alias for '\\\\n' -> 198\\n\",\n \" # Keep printable character 'Ċ' in vocab so BPE merges keep working\\n\",\n \" if \\\"\\\\n\\\" not in self.inverse_vocab:\\n\",\n \" self.inverse_vocab[\\\"\\\\n\\\"] = self.inverse_vocab[\\\"Ċ\\\"]\\n\",\n \"\\n\",\n \" if \\\"\\\\r\\\" not in self.inverse_vocab:\\n\",\n \" if 201 in self.vocab:\\n\",\n \" self.inverse_vocab[\\\"\\\\r\\\"] = 201\\n\",\n \" else:\\n\",\n \" raise KeyError(\\\"Vocabulary missing carriage return token at id 201.\\\")\\n\",\n \"\\n\",\n \" # Load GPT-2 merges and store ranks\\n\",\n \" self.bpe_ranks = {}\\n\",\n \" with open(bpe_merges_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" lines = file.readlines()\\n\",\n \" if lines and lines[0].startswith(\\\"#\\\"):\\n\",\n \" lines = lines[1:]\\n\",\n \" \\n\",\n \" rank = 0\\n\",\n \" for line in lines:\\n\",\n \" token1, *rest = line.strip().split()\\n\",\n \" if len(rest) != 1:\\n\",\n \" continue\\n\",\n \" token2 = rest[0]\\n\",\n \" if token1 in self.inverse_vocab and token2 in self.inverse_vocab:\\n\",\n \" self.bpe_ranks[(token1, token2)] = rank\\n\",\n \" rank += 1\\n\",\n \" else:\\n\",\n \" # Safe to skip pairs whose symbols are not in vocab\\n\",\n \" pass\\n\",\n \"\\n\",\n \"\\n\",\n \" def encode(self, text, allowed_special=None):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Encode the input text into a list of token IDs, with tiktoken-style handling of special tokens.\\n\",\n \" \\n\",\n \" Args:\\n\",\n \" text (str): The input text to encode.\\n\",\n \" allowed_special (set or None): Special tokens to allow passthrough. If None, special handling is disabled.\\n\",\n \" \\n\",\n \" Returns:\\n\",\n \" List of token IDs.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" \\n\",\n \" # ---- This section is to mimic tiktoken in terms of allowed special tokens ----\\n\",\n \" specials_in_vocab = [\\n\",\n \" tok for tok in self.inverse_vocab\\n\",\n \" if tok.startswith(\\\"<|\\\") and tok.endswith(\\\"|>\\\")\\n\",\n \" ]\\n\",\n \" if allowed_special is None:\\n\",\n \" # Nothing is allowed\\n\",\n \" disallowed = [tok for tok in specials_in_vocab if tok in text]\\n\",\n \" if disallowed:\\n\",\n \" raise ValueError(f\\\"Disallowed special tokens encountered in text: {disallowed}\\\")\\n\",\n \" else:\\n\",\n \" # Some spefic tokens are allowed (e.g., we use this for <|endoftext|>)\\n\",\n \" disallowed = [tok for tok in specials_in_vocab if tok in text and tok not in allowed_special]\\n\",\n \" if disallowed:\\n\",\n \" raise ValueError(f\\\"Disallowed special tokens encountered in text: {disallowed}\\\")\\n\",\n \" # -----------------------------------------------------------------------------\\n\",\n \"\\n\",\n \" token_ids = []\\n\",\n \" # If some specials are allowed, split around them and passthrough those ids\\n\",\n \" if allowed_special is not None and len(allowed_special) > 0:\\n\",\n \" special_pattern = \\\"(\\\" + \\\"|\\\".join(\\n\",\n \" re.escape(tok) for tok in sorted(allowed_special, key=len, reverse=True)\\n\",\n \" ) + \\\")\\\"\\n\",\n \" \\n\",\n \" last_index = 0\\n\",\n \" for match in re.finditer(special_pattern, text):\\n\",\n \" prefix = text[last_index:match.start()]\\n\",\n \" token_ids.extend(self.encode(prefix, allowed_special=None)) # encode prefix normally\\n\",\n \" \\n\",\n \" special_token = match.group(0)\\n\",\n \" if special_token in self.inverse_vocab:\\n\",\n \" token_ids.append(self.inverse_vocab[special_token])\\n\",\n \" else:\\n\",\n \" raise ValueError(f\\\"Special token {special_token} not found in vocabulary.\\\")\\n\",\n \" last_index = match.end()\\n\",\n \" \\n\",\n \" text = text[last_index:] # remainder to process normally\\n\",\n \" \\n\",\n \" # Extra guard for any other special literals left over\\n\",\n \" disallowed = [\\n\",\n \" tok for tok in self.inverse_vocab\\n\",\n \" if tok.startswith(\\\"<|\\\") and tok.endswith(\\\"|>\\\") and tok in text and tok not in allowed_special\\n\",\n \" ]\\n\",\n \" if disallowed:\\n\",\n \" raise ValueError(f\\\"Disallowed special tokens encountered in text: {disallowed}\\\")\\n\",\n \"\\n\",\n \" \\n\",\n \" # ---- Newline and carriage return handling ----\\n\",\n \" tokens = self.pretokenize_text(text)\\n\",\n \" # ---------------------------------------------------------------\\n\",\n \" \\n\",\n \" # Map tokens -> ids (BPE if needed)\\n\",\n \" for tok in tokens:\\n\",\n \" if tok in self.inverse_vocab:\\n\",\n \" token_ids.append(self.inverse_vocab[tok])\\n\",\n \" else:\\n\",\n \" token_ids.extend(self.tokenize_with_bpe(tok))\\n\",\n \" \\n\",\n \" return token_ids\\n\",\n \"\\n\",\n \" def tokenize_with_bpe(self, token):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Tokenize a single token using BPE merges.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" token (str): The token to tokenize.\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" List[int]: The list of token IDs after applying BPE.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" # Tokenize the token into individual characters (as initial token IDs)\\n\",\n \" token_ids = [self.inverse_vocab.get(char, None) for char in token]\\n\",\n \" if None in token_ids:\\n\",\n \" missing_chars = [char for char, tid in zip(token, token_ids) if tid is None]\\n\",\n \" raise ValueError(f\\\"Characters not found in vocab: {missing_chars}\\\")\\n\",\n \"\\n\",\n \" # If we haven't loaded OpenAI's GPT-2 merges, use my approach\\n\",\n \" if not self.bpe_ranks:\\n\",\n \" can_merge = True\\n\",\n \" while can_merge and len(token_ids) > 1:\\n\",\n \" can_merge = False\\n\",\n \" new_tokens = []\\n\",\n \" i = 0\\n\",\n \" while i < len(token_ids) - 1:\\n\",\n \" pair = (token_ids[i], token_ids[i + 1])\\n\",\n \" if pair in self.bpe_merges:\\n\",\n \" merged_token_id = self.bpe_merges[pair]\\n\",\n \" new_tokens.append(merged_token_id)\\n\",\n \" # Uncomment for educational purposes:\\n\",\n \" # print(f\\\"Merged pair {pair} -> {merged_token_id} ('{self.vocab[merged_token_id]}')\\\")\\n\",\n \" i += 2 # Skip the next token as it's merged\\n\",\n \" can_merge = True\\n\",\n \" else:\\n\",\n \" new_tokens.append(token_ids[i])\\n\",\n \" i += 1\\n\",\n \" if i < len(token_ids):\\n\",\n \" new_tokens.append(token_ids[i])\\n\",\n \" token_ids = new_tokens\\n\",\n \" return token_ids\\n\",\n \"\\n\",\n \" # Otherwise, do GPT-2-style merging with the ranks:\\n\",\n \" # 1) Convert token_ids back to string \\\"symbols\\\" for each ID\\n\",\n \" symbols = [self.vocab[id_num] for id_num in token_ids]\\n\",\n \"\\n\",\n \" # Repeatedly merge all occurrences of the lowest-rank pair\\n\",\n \" while True:\\n\",\n \" # Collect all adjacent pairs\\n\",\n \" pairs = set(zip(symbols, symbols[1:]))\\n\",\n \" if not pairs:\\n\",\n \" break\\n\",\n \"\\n\",\n \" # Find the pair with the best (lowest) rank\\n\",\n \" min_rank = float(\\\"inf\\\")\\n\",\n \" bigram = None\\n\",\n \" for p in pairs:\\n\",\n \" r = self.bpe_ranks.get(p, float(\\\"inf\\\"))\\n\",\n \" if r < min_rank:\\n\",\n \" min_rank = r\\n\",\n \" bigram = p\\n\",\n \"\\n\",\n \" # If no valid ranked pair is present, we're done\\n\",\n \" if bigram is None or bigram not in self.bpe_ranks:\\n\",\n \" break\\n\",\n \"\\n\",\n \" # Merge all occurrences of that pair\\n\",\n \" first, second = bigram\\n\",\n \" new_symbols = []\\n\",\n \" i = 0\\n\",\n \" while i < len(symbols):\\n\",\n \" # If we see (first, second) at position i, merge them\\n\",\n \" if i < len(symbols) - 1 and symbols[i] == first and symbols[i+1] == second:\\n\",\n \" new_symbols.append(first + second) # merged symbol\\n\",\n \" i += 2\\n\",\n \" else:\\n\",\n \" new_symbols.append(symbols[i])\\n\",\n \" i += 1\\n\",\n \" symbols = new_symbols\\n\",\n \"\\n\",\n \" if len(symbols) == 1:\\n\",\n \" break\\n\",\n \"\\n\",\n \" # Finally, convert merged symbols back to IDs\\n\",\n \" merged_ids = [self.inverse_vocab[sym] for sym in symbols]\\n\",\n \" return merged_ids\\n\",\n \"\\n\",\n \" def decode(self, token_ids):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Decode a list of token IDs back into a string.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" token_ids (List[int]): The list of token IDs to decode.\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" str: The decoded string.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" out = []\\n\",\n \" for tid in token_ids:\\n\",\n \" if tid not in self.vocab:\\n\",\n \" raise ValueError(f\\\"Token ID {tid} not found in vocab.\\\")\\n\",\n \" tok = self.vocab[tid]\\n\",\n \"\\n\",\n \" # Map GPT-2 special chars back to real chars\\n\",\n \" if tid == 198 or tok == \\\"\\\\n\\\":\\n\",\n \" out.append(\\\"\\\\n\\\")\\n\",\n \" elif tid == 201 or tok == \\\"\\\\r\\\":\\n\",\n \" out.append(\\\"\\\\r\\\")\\n\",\n \" elif tok.startswith(\\\"Ġ\\\"):\\n\",\n \" out.append(\\\" \\\" + tok[1:])\\n\",\n \" else:\\n\",\n \" out.append(tok)\\n\",\n \" return \\\"\\\".join(out)\\n\",\n \"\\n\",\n \" def save_vocab_and_merges(self, vocab_path, bpe_merges_path):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Save the vocabulary and BPE merges to JSON files.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" vocab_path (str): Path to save the vocabulary.\\n\",\n \" bpe_merges_path (str): Path to save the BPE merges.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" # Save vocabulary\\n\",\n \" with open(vocab_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" json.dump(self.vocab, file, ensure_ascii=False, indent=2)\\n\",\n \"\\n\",\n \" # Save BPE merges as a list of dictionaries\\n\",\n \" with open(bpe_merges_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" merges_list = [{\\\"pair\\\": list(pair), \\\"new_id\\\": new_id}\\n\",\n \" for pair, new_id in self.bpe_merges.items()]\\n\",\n \" json.dump(merges_list, file, ensure_ascii=False, indent=2)\\n\",\n \"\\n\",\n \" def load_vocab_and_merges(self, vocab_path, bpe_merges_path):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Load the vocabulary and BPE merges from JSON files.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" vocab_path (str): Path to the vocabulary file.\\n\",\n \" bpe_merges_path (str): Path to the BPE merges file.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" # Load vocabulary\\n\",\n \" with open(vocab_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" loaded_vocab = json.load(file)\\n\",\n \" self.vocab = {int(k): v for k, v in loaded_vocab.items()}\\n\",\n \" self.inverse_vocab = {v: int(k) for k, v in loaded_vocab.items()}\\n\",\n \"\\n\",\n \" # Load BPE merges\\n\",\n \" with open(bpe_merges_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" merges_list = json.load(file)\\n\",\n \" for merge in merges_list:\\n\",\n \" pair = tuple(merge[\\\"pair\\\"])\\n\",\n \" new_id = merge[\\\"new_id\\\"]\\n\",\n \" self.bpe_merges[pair] = new_id\\n\",\n \"\\n\",\n \" @lru_cache(maxsize=None)\\n\",\n \" def get_special_token_id(self, token):\\n\",\n \" return self.inverse_vocab.get(token, None)\\n\",\n \"\\n\",\n \" @staticmethod\\n\",\n \" def pretokenize_text(text):\\n\",\n \" tokens = []\\n\",\n \" parts = re.split(r'(\\\\r\\\\n|\\\\r|\\\\n)', text)\\n\",\n \" for part in parts:\\n\",\n \" if part == \\\"\\\":\\n\",\n \" continue\\n\",\n \" if part == \\\"\\\\r\\\\n\\\":\\n\",\n \" tokens.append(\\\"\\\\r\\\")\\n\",\n \" tokens.append(\\\"\\\\n\\\")\\n\",\n \" continue\\n\",\n \" if part == \\\"\\\\r\\\":\\n\",\n \" tokens.append(\\\"\\\\r\\\")\\n\",\n \" continue\\n\",\n \" if part == \\\"\\\\n\\\":\\n\",\n \" tokens.append(\\\"\\\\n\\\")\\n\",\n \" continue\\n\",\n \"\\n\",\n \" # Normal chunk without line breaks:\\n\",\n \" # - If spaces precede a word, prefix the first word with 'Ġ' and\\n\",\n \" # add standalone 'Ġ' for additional spaces\\n\",\n \" # - If spaces trail the chunk (e.g., before a newline) add\\n\",\n \" # standalone 'Ġ' tokens (tiktoken produces id 220 for 'Ġ')\\n\",\n \" pending_spaces = 0\\n\",\n \" for m in re.finditer(r'( +)|(\\\\S+)', part):\\n\",\n \" if m.group(1) is not None:\\n\",\n \" pending_spaces += len(m.group(1))\\n\",\n \" else:\\n\",\n \" word = m.group(2)\\n\",\n \" if pending_spaces > 0:\\n\",\n \" for _ in range(pending_spaces - 1):\\n\",\n \" tokens.append(\\\"Ġ\\\") # remaining spaces as standalone\\n\",\n \" tokens.append(\\\"Ġ\\\" + word) # one leading space\\n\",\n \" pending_spaces = 0\\n\",\n \" else:\\n\",\n \" tokens.append(word)\\n\",\n \" # Trailing spaces (no following word): add standalone 'Ġ' tokens\\n\",\n \" for _ in range(pending_spaces):\\n\",\n \" tokens.append(\\\"Ġ\\\")\\n\",\n \" return tokens\\n\",\n \"\\n\",\n \" @staticmethod\\n\",\n \" def find_freq_pair(token_id_sequences, mode=\\\"most\\\"):\\n\",\n \" pairs = Counter(\\n\",\n \" pair\\n\",\n \" for token_ids in token_id_sequences\\n\",\n \" for pair in zip(token_ids, token_ids[1:])\\n\",\n \" )\\n\",\n \"\\n\",\n \" if not pairs:\\n\",\n \" return None\\n\",\n \"\\n\",\n \" if mode == \\\"most\\\":\\n\",\n \" return max(pairs.items(), key=lambda x: x[1])[0]\\n\",\n \" elif mode == \\\"least\\\":\\n\",\n \" return min(pairs.items(), key=lambda x: x[1])[0]\\n\",\n \" else:\\n\",\n \" raise ValueError(\\\"Invalid mode. Choose 'most' or 'least'.\\\")\\n\",\n \"\\n\",\n \" @staticmethod\\n\",\n \" def replace_pair(token_id_sequences, pair_id, new_id):\\n\",\n \" replaced_sequences = []\\n\",\n \"\\n\",\n \" for token_ids in token_id_sequences:\\n\",\n \" dq = deque(token_ids)\\n\",\n \" replaced = []\\n\",\n \"\\n\",\n \" while dq:\\n\",\n \" current = dq.popleft()\\n\",\n \" if dq and (current, dq[0]) == pair_id:\\n\",\n \" replaced.append(new_id)\\n\",\n \" # Remove the 2nd token of the pair, 1st was already removed\\n\",\n \" dq.popleft()\\n\",\n \" else:\\n\",\n \" replaced.append(current)\\n\",\n \"\\n\",\n \" replaced_sequences.append(replaced)\\n\",\n \"\\n\",\n \" return replaced_sequences\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"46db7310-79c7-4ee0-b5fa-d760c6e1aa67\",\n \"metadata\": {},\n \"source\": [\n \"- There is a lot of code in the `BPETokenizerSimple` class above, and discussing it in detail is out of scope for this notebook, but the next section offers a short overview of the usage to understand the class methods a bit better\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8ffe1836-eed4-40dc-860b-2d23074d067e\",\n \"metadata\": {},\n \"source\": [\n \"## 3. BPE implementation walkthrough\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3c7c996c-fd34-484f-a877-13d977214cf7\",\n \"metadata\": {},\n \"source\": [\n \"- In practice, I highly recommend using [tiktoken](https://github.com/openai/tiktoken) as my implementation above focuses on readability and educational purposes, not on performance\\n\",\n \"- However, the usage is more or less similar to tiktoken, except that tiktoken does not have a training method\\n\",\n \"- Let's see how my `BPETokenizerSimple` Python code above works by looking at some examples below (a detailed code discussion is out of scope for this notebook)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e82acaf6-7ed5-4d3b-81c0-ae4d3559d2c7\",\n \"metadata\": {},\n \"source\": [\n \"### 3.1 Training, encoding, and decoding\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"962bf037-903e-4555-b09c-206e1a410278\",\n \"metadata\": {},\n \"source\": [\n \"- First, let's consider some sample text as our training dataset:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"51872c08-e01b-40c3-a8a0-e8d6a773e3df\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"the-verdict.txt already exists in ../01_main-chapter-code/the-verdict.txt\\n\"\n ]\n }\n ],\n \"source\": [\n \"import os\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"def download_file_if_absent(url, filename, search_dirs):\\n\",\n \" for directory in search_dirs:\\n\",\n \" file_path = os.path.join(directory, filename)\\n\",\n \" if os.path.exists(file_path):\\n\",\n \" print(f\\\"{filename} already exists in {file_path}\\\")\\n\",\n \" return file_path\\n\",\n \"\\n\",\n \" target_path = os.path.join(search_dirs[0], filename)\\n\",\n \" try:\\n\",\n \" response = requests.get(url, stream=True, timeout=60)\\n\",\n \" response.raise_for_status()\\n\",\n \" with open(target_path, \\\"wb\\\") as out_file:\\n\",\n \" for chunk in response.iter_content(chunk_size=8192):\\n\",\n \" if chunk:\\n\",\n \" out_file.write(chunk)\\n\",\n \" print(f\\\"Downloaded {filename} to {target_path}\\\")\\n\",\n \" except Exception as e:\\n\",\n \" print(f\\\"Failed to download {filename}. Error: {e}\\\")\\n\",\n \"\\n\",\n \" return target_path\\n\",\n \"\\n\",\n \"\\n\",\n \"verdict_path = download_file_if_absent(\\n\",\n \" url=(\\n\",\n \" \\\"https://raw.githubusercontent.com/rasbt/\\\"\\n\",\n \" \\\"LLMs-from-scratch/main/ch02/01_main-chapter-code/\\\"\\n\",\n \" \\\"the-verdict.txt\\\"\\n\",\n \" ),\\n\",\n \" filename=\\\"the-verdict.txt\\\",\\n\",\n \" search_dirs=[\\\"ch02/01_main-chapter-code/\\\", \\\"../01_main-chapter-code/\\\", \\\".\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"with open(verdict_path, \\\"r\\\", encoding=\\\"utf-8\\\") as f: # added ../01_main-chapter-code/\\n\",\n \" text = f.read()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"04d1b6ac-71d3-4817-956a-9bc7e463a84a\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's initialize and train the BPE tokenizer with a vocabulary size of 1,000\\n\",\n \"- Note that the vocabulary size is already 256 by default due to the byte values discussed earlier, so we are only \\\"learning\\\" 744 vocabulary entries (if we consider the `<|endoftext|>` special token and the `Ġ` whitespace token; so, that's 742 to be precise)\\n\",\n \"- For comparison, the GPT-2 vocabulary is 50,257 tokens, the GPT-4 vocabulary is 100,256 tokens (`cl100k_base` in tiktoken), and GPT-4o uses 199,997 tokens (`o200k_base` in tiktoken); they have all much bigger training sets compared to our simple example text above\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"027348fd-d52f-4396-93dd-38eed142df9b\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"tokenizer = BPETokenizerSimple()\\n\",\n \"tokenizer.train(text, vocab_size=1000, allowed_special={\\\"<|endoftext|>\\\"})\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2474ff05-5629-4f13-9e03-a47b1e713850\",\n \"metadata\": {},\n \"source\": [\n \"- You may want to inspect the vocabulary contents (but note it will create a long list)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"f705a283-355e-4460-b940-06bbc2ae4e61\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"1000\\n\"\n ]\n }\n ],\n \"source\": [\n \"# print(tokenizer.vocab)\\n\",\n \"print(len(tokenizer.vocab))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"36c9da0f-8a18-41cd-91ea-9ccc2bb5febb\",\n \"metadata\": {},\n \"source\": [\n \"- This vocabulary is created by merging 742 times (`= 1000 - len(range(0, 256)) - len(special_tokens) - \\\"Ġ\\\" = 1000 - 256 - 1 - 1 = 742`)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"3da42d1c-f75c-4ba7-a6c5-4cb8543d4a44\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"742\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(len(tokenizer.bpe_merges))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5dac69c9-8413-482a-8148-6b2afbf1fb89\",\n \"metadata\": {},\n \"source\": [\n \"- This means that the first 256 entries are single-character tokens\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"451a4108-7c8b-4b98-9c67-d622e9cdf250\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's use the created merges via the `encode` method to encode some text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e1db5cce-e015-412b-ad56-060b8b638078\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[424, 256, 654, 531, 302, 311, 256, 296, 97, 465, 121, 595, 841, 116, 287, 466, 256, 326, 972, 46]\\n\"\n ]\n }\n ],\n \"source\": [\n \"input_text = \\\"Jack embraced beauty through art and life.\\\"\\n\",\n \"token_ids = tokenizer.encode(input_text)\\n\",\n \"print(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"0331d37d-49a3-44f7-9aa9-9834e0938741\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[424, 256, 654, 531, 302, 311, 256, 296, 97, 465, 121, 595, 841, 116, 287, 466, 256, 326, 972, 46, 257, 256]\\n\"\n ]\n }\n ],\n \"source\": [\n \"input_text = \\\"Jack embraced beauty through art and life.<|endoftext|> \\\"\\n\",\n \"token_ids = tokenizer.encode(input_text, allowed_special={\\\"<|endoftext|>\\\"})\\n\",\n \"print(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"1ed1b344-f7d4-4e9e-ac34-2a04b5c5b7a8\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of characters: 56\\n\",\n \"Number of token IDs: 22\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Number of characters:\\\", len(input_text))\\n\",\n \"print(\\\"Number of token IDs:\\\", len(token_ids))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"50c1cfb9-402a-4e1e-9678-0b7547406248\",\n \"metadata\": {},\n \"source\": [\n \"- From the lengths above, we can see that a 42-character sentence was encoded into 20 token IDs, effectively cutting the input length roughly in half compared to a character-byte-based encoding\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"252693ee-e806-4dac-ab76-2c69086360f4\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the vocabulary itself is used in the `decode()` method, which allows us to map the token IDs back into text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"da0e1faf-1933-43d9-b681-916c282a8f86\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[424, 256, 654, 531, 302, 311, 256, 296, 97, 465, 121, 595, 841, 116, 287, 466, 256, 326, 972, 46, 257, 256]\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"8b690e83-5d6b-409a-804e-321c287c24a4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Jack embraced beauty through art and life.<|endoftext|> \\n\"\n ]\n }\n ],\n \"source\": [\n \"print(tokenizer.decode(token_ids))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"adea5d09-e5ef-4721-994b-b9b25662fa0a\",\n \"metadata\": {},\n \"source\": [\n \"- Iterating over each token ID can give us a better understanding of how the token IDs are decoded via the vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"2b9e6289-92cb-4d88-b3c8-e836d7c8095f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"424 -> Jack\\n\",\n \"256 -> \\n\",\n \"654 -> em\\n\",\n \"531 -> br\\n\",\n \"302 -> ac\\n\",\n \"311 -> ed\\n\",\n \"256 -> \\n\",\n \"296 -> be\\n\",\n \"97 -> a\\n\",\n \"465 -> ut\\n\",\n \"121 -> y\\n\",\n \"595 -> through\\n\",\n \"841 -> ar\\n\",\n \"116 -> t\\n\",\n \"287 -> a\\n\",\n \"466 -> nd\\n\",\n \"256 -> \\n\",\n \"326 -> li\\n\",\n \"972 -> fe\\n\",\n \"46 -> .\\n\",\n \"257 -> <|endoftext|>\\n\",\n \"256 -> \\n\"\n ]\n }\n ],\n \"source\": [\n \"for token_id in token_ids:\\n\",\n \" print(f\\\"{token_id} -> {tokenizer.decode([token_id])}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5ea41c6c-5538-4fd5-8b5f-195960853b71\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see, most token IDs represent 2-character subwords; that's because the training data text is very short with not that many repetitive words, and because we used a relatively small vocabulary size\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"600055a3-7ec8-4abf-b88a-c4186fb71463\",\n \"metadata\": {},\n \"source\": [\n \"- As a summary, calling `decode(encode())` should be able to reproduce arbitrary input texts:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"c7056cb1-a9a3-4cf6-8364-29fb493ae240\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'This is some text.'\"\n ]\n },\n \"execution_count\": 15,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer.decode(\\n\",\n \" tokenizer.encode(\\\"This is some text.\\\")\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"37bc6753-8f35-4ec7-b23e-df4a12103cb4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'This is some text with \\\\n newline characters.'\"\n ]\n },\n \"execution_count\": 16,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer.decode(\\n\",\n \" tokenizer.encode(\\\"This is some text with \\\\n newline characters.\\\")\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a63b42bb-55bc-4c9d-b859-457a28b76302\",\n \"metadata\": {},\n \"source\": [\n \"### 3.2 Saving and loading the tokenizer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"86210925-06dc-4e8c-87bd-821569cd7142\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's look at how we can save the trained tokenizer for reuse later:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"955181cb-0910-4c6a-9c22-d8292a3ec1fc\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Save trained tokenizer\\n\",\n \"tokenizer.save_vocab_and_merges(vocab_path=\\\"vocab.json\\\", bpe_merges_path=\\\"bpe_merges.txt\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"6e5ccfe7-ac67-42f3-b727-87886a8867f1\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Load tokenizer\\n\",\n \"tokenizer2 = BPETokenizerSimple()\\n\",\n \"tokenizer2.load_vocab_and_merges(vocab_path=\\\"vocab.json\\\", bpe_merges_path=\\\"bpe_merges.txt\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e7f9bcc2-3b27-4473-b75e-4f289d52a7cc\",\n \"metadata\": {},\n \"source\": [\n \"- The loaded tokenizer should be able to produce the same results as before:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"00d9bf8f-756f-48bf-81b8-b890e2c2ef13\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Jack embraced beauty through art and life.<|endoftext|> \\n\"\n ]\n }\n ],\n \"source\": [\n \"print(tokenizer2.decode(token_ids))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"e7addb64-2892-4e1c-85dd-4f5152740099\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'This is some text with \\\\n newline characters.'\"\n ]\n },\n \"execution_count\": 20,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer2.decode(\\n\",\n \" tokenizer2.encode(\\\"This is some text with \\\\n newline characters.\\\")\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b24d10b2-1ab8-44ee-b51a-14248e30d662\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.3 Loading the original GPT-2 BPE tokenizer from OpenAI\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"df07e031-9495-4af1-929f-3f16cbde82a5\",\n \"metadata\": {},\n \"source\": [\n \"- Finally, let's load OpenAI's GPT-2 tokenizer files\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"b45b4366-2c2b-4309-9a14-febf3add8512\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"vocab.bpe already exists in ../02_bonus_bytepair-encoder/gpt2_model/vocab.bpe\\n\",\n \"encoder.json already exists in ../02_bonus_bytepair-encoder/gpt2_model/encoder.json\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Download files if not already present in this directory\\n\",\n \"\\n\",\n \"# Define the directories to search and the files to download\\n\",\n \"search_directories = [\\\"ch02/02_bonus_bytepair-encoder/gpt2_model/\\\", \\\"../02_bonus_bytepair-encoder/gpt2_model/\\\", \\\".\\\"]\\n\",\n \"\\n\",\n \"files_to_download = {\\n\",\n \" \\\"https://openaipublic.blob.core.windows.net/gpt-2/models/124M/vocab.bpe\\\": \\\"vocab.bpe\\\",\\n\",\n \" \\\"https://openaipublic.blob.core.windows.net/gpt-2/models/124M/encoder.json\\\": \\\"encoder.json\\\"\\n\",\n \"}\\n\",\n \"\\n\",\n \"# Ensure directories exist and download files if needed\\n\",\n \"paths = {}\\n\",\n \"for url, filename in files_to_download.items():\\n\",\n \" paths[filename] = download_file_if_absent(url, filename, search_directories)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3fe260a0-1d5f-4bbd-9934-5117052764d1\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we load the files via the `load_vocab_and_merges_from_openai` method:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"74306e6c-47d3-45a3-9e0f-93f7303ef601\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"tokenizer_gpt2 = BPETokenizerSimple()\\n\",\n \"tokenizer_gpt2.load_vocab_and_merges_from_openai(\\n\",\n \" vocab_path=paths[\\\"encoder.json\\\"], bpe_merges_path=paths[\\\"vocab.bpe\\\"]\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1d012ce-9e87-47d7-8a1b-b6d6294d76c0\",\n \"metadata\": {},\n \"source\": [\n \"- The vocabulary size should be `50257` as we can confirm via the code below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"2bb722b4-dbf5-4a0c-9120-efda3293f132\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"50257\"\n ]\n },\n \"execution_count\": 23,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"len(tokenizer_gpt2.vocab)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7ea44b45-f524-44b5-a53a-f6d7f483fc19\",\n \"metadata\": {},\n \"source\": [\n \"- We can now use the GPT-2 tokenizer via our `BPETokenizerSimple` object:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"e4866de7-fb32-4dd6-a878-469ec734641c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[1212, 318, 617, 2420]\\n\"\n ]\n }\n ],\n \"source\": [\n \"input_text = \\\"This is some text\\\"\\n\",\n \"token_ids = tokenizer_gpt2.encode(input_text)\\n\",\n \"print(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"3da8d9b2-af55-4b09-95d7-fabd983e919e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"This is some text\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(tokenizer_gpt2.decode(token_ids))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b3b1e2dc-f69b-4533-87ef-549e6fb9b5a0\",\n \"metadata\": {},\n \"source\": [\n \"- You can double-check that this produces the correct tokens using the interactive [tiktoken app](https://tiktokenizer.vercel.app/?model=gpt2) or the [tiktoken library](https://github.com/openai/tiktoken):\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"```python\\n\",\n \"import tiktoken\\n\",\n \"\\n\",\n \"gpt2_tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"gpt2_tokenizer.encode(\\\"This is some text\\\")\\n\",\n \"# prints [1212, 318, 617, 2420]\\n\",\n \"```\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3558af04-483c-4f6b-88f5-a534f37316cd\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"# 4. Conclusion\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"410ed0e6-ad06-4bb3-bb39-6b8110c1caa4\",\n \"metadata\": {},\n \"source\": [\n \"- That's it! That's how BPE works in a nutshell, complete with a training method for creating new tokenizers or loading the GPT-2 tokenizer vocabular and merges from the original OpenAI GPT-2 model\\n\",\n \"- I hope you found this brief tutorial useful for educational purposes; if you have any questions, please feel free to open a new Discussion [here](https://github.com/rasbt/LLMs-from-scratch/discussions/categories/q-a)\\n\",\n \"- For a performance comparison with other tokenizer implementations, please see [this notebook](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"id\": \"4a477962-ba00-429b-8be7-755a90543de7\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": []\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch02/05_bpe-from-scratch/tests.py",
"content": "import os\nimport sys\nimport io\nimport nbformat\nimport types\nimport pytest\n\nimport tiktoken\n\n\ndef import_definitions_from_notebook(fullname, names):\n \"\"\"Loads function definitions from a Jupyter notebook file into a module.\"\"\"\n path = os.path.join(os.path.dirname(__file__), fullname + \".ipynb\")\n path = os.path.normpath(path)\n\n if not os.path.exists(path):\n raise FileNotFoundError(f\"Notebook file not found at: {path}\")\n\n with io.open(path, \"r\", encoding=\"utf-8\") as f:\n nb = nbformat.read(f, as_version=4)\n\n mod = types.ModuleType(fullname)\n sys.modules[fullname] = mod\n\n # Execute all code cells to capture dependencies\n for cell in nb.cells:\n if cell.cell_type == \"code\":\n exec(cell.source, mod.__dict__)\n\n # Ensure required names are in module\n missing_names = [name for name in names if name not in mod.__dict__]\n if missing_names:\n raise ImportError(f\"Missing definitions in notebook: {missing_names}\")\n\n return mod\n\n\n@pytest.fixture(scope=\"module\")\ndef imported_module():\n fullname = \"bpe-from-scratch\"\n names = [\"BPETokenizerSimple\", \"download_file_if_absent\"]\n return import_definitions_from_notebook(fullname, names)\n\n\n@pytest.fixture(scope=\"module\")\ndef verdict_file(imported_module):\n \"\"\"Fixture to handle downloading The Verdict file.\"\"\"\n download_file_if_absent = getattr(imported_module, \"download_file_if_absent\", None)\n\n verdict_path = download_file_if_absent(\n url=(\n \"https://raw.githubusercontent.com/rasbt/\"\n \"LLMs-from-scratch/main/ch02/01_main-chapter-code/\"\n \"the-verdict.txt\"\n ),\n filename=\"the-verdict.txt\",\n search_dirs=[\"ch02/01_main-chapter-code/\", \"../01_main-chapter-code/\", \".\"]\n )\n\n return verdict_path\n\n\n@pytest.fixture(scope=\"module\")\ndef gpt2_files(imported_module):\n \"\"\"Fixture to handle downloading GPT-2 files.\"\"\"\n download_file_if_absent = getattr(imported_module, \"download_file_if_absent\", None)\n\n search_directories = [\"ch02/02_bonus_bytepair-encoder/gpt2_model/\", \"../02_bonus_bytepair-encoder/gpt2_model/\", \".\"]\n files_to_download = {\n \"https://openaipublic.blob.core.windows.net/gpt-2/models/124M/vocab.bpe\": \"vocab.bpe\",\n \"https://openaipublic.blob.core.windows.net/gpt-2/models/124M/encoder.json\": \"encoder.json\"\n }\n paths = {filename: download_file_if_absent(url, filename, search_directories)\n for url, filename in files_to_download.items()}\n\n return paths\n\n\ndef test_tokenizer_training(imported_module, verdict_file):\n BPETokenizerSimple = getattr(imported_module, \"BPETokenizerSimple\", None)\n tokenizer = BPETokenizerSimple()\n\n with open(verdict_file, \"r\", encoding=\"utf-8\") as f: # added ../01_main-chapter-code/\n text = f.read()\n\n tokenizer.train(text, vocab_size=1000, allowed_special={\"<|endoftext|>\"})\n assert len(tokenizer.vocab) == 1000, \"Tokenizer vocabulary size mismatch.\"\n assert len(tokenizer.bpe_merges) == 742, \"Tokenizer BPE merges count mismatch.\"\n\n input_text = \"Jack embraced beauty through art and life.\"\n invalid_whitespace_tokens = [\n tok for tok in tokenizer.vocab.values()\n if \"Ġ\" in tok and tok != \"Ġ\" and not tok.startswith(\"Ġ\")\n ]\n assert not invalid_whitespace_tokens, \"Training should not learn tokens with non-leading Ġ markers.\"\n\n token_ids = tokenizer.encode(input_text)\n assert token_ids == [74, 361, 310, 109, 98, 420, 397, 100, 300, 428, 116, 121, 519, 699, 299, 808, 534], \"Token IDs do not match expected output.\"\n\n assert tokenizer.decode(token_ids) == input_text, \"Decoded text does not match the original input.\"\n\n tokenizer.save_vocab_and_merges(vocab_path=\"vocab.json\", bpe_merges_path=\"bpe_merges.txt\")\n tokenizer2 = BPETokenizerSimple()\n tokenizer2.load_vocab_and_merges(vocab_path=\"vocab.json\", bpe_merges_path=\"bpe_merges.txt\")\n assert tokenizer2.decode(token_ids) == input_text, \"Decoded text mismatch after reloading tokenizer.\"\n\n\ndef test_gpt2_tokenizer_openai_simple(imported_module, gpt2_files):\n BPETokenizerSimple = getattr(imported_module, \"BPETokenizerSimple\", None)\n\n tokenizer_gpt2 = BPETokenizerSimple()\n tokenizer_gpt2.load_vocab_and_merges_from_openai(\n vocab_path=gpt2_files[\"encoder.json\"], bpe_merges_path=gpt2_files[\"vocab.bpe\"]\n )\n\n assert len(tokenizer_gpt2.vocab) == 50257, \"GPT-2 tokenizer vocabulary size mismatch.\"\n\n input_text = \"This is some text\"\n token_ids = tokenizer_gpt2.encode(input_text)\n assert token_ids == [1212, 318, 617, 2420], \"Tokenized output does not match expected GPT-2 encoding.\"\n\n\ndef test_gpt2_tokenizer_openai_edgecases(imported_module, gpt2_files):\n BPETokenizerSimple = getattr(imported_module, \"BPETokenizerSimple\", None)\n\n tokenizer_gpt2 = BPETokenizerSimple()\n tokenizer_gpt2.load_vocab_and_merges_from_openai(\n vocab_path=gpt2_files[\"encoder.json\"], bpe_merges_path=gpt2_files[\"vocab.bpe\"]\n )\n tik_tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n test_cases = [\n (\"Hello,\", [15496, 11]),\n (\"Implementations\", [3546, 26908, 602]),\n (\"asdf asdfasdf a!!, @aba 9asdf90asdfk\", [292, 7568, 355, 7568, 292, 7568, 257, 3228, 11, 2488, 15498, 860, 292, 7568, 3829, 292, 7568, 74]),\n (\"Hello, world. Is this-- a test?\", [15496, 11, 995, 13, 1148, 428, 438, 257, 1332, 30])\n ]\n\n errors = []\n\n for input_text, expected_tokens in test_cases:\n tik_tokens = tik_tokenizer.encode(input_text)\n gpt2_tokens = tokenizer_gpt2.encode(input_text)\n\n print(f\"Text: {input_text}\")\n print(f\"Expected Tokens: {expected_tokens}\")\n print(f\"tiktoken Output: {tik_tokens}\")\n print(f\"BPETokenizerSimple Output: {gpt2_tokens}\")\n print(\"-\" * 40)\n\n if tik_tokens != expected_tokens:\n errors.append(f\"Tiktokenized output does not match expected GPT-2 encoding for '{input_text}'.\\n\"\n f\"Expected: {expected_tokens}, Got: {tik_tokens}\")\n\n if gpt2_tokens != expected_tokens:\n errors.append(f\"Tokenized output does not match expected GPT-2 encoding for '{input_text}'.\\n\"\n f\"Expected: {expected_tokens}, Got: {gpt2_tokens}\")\n\n if errors:\n pytest.fail(\"\\n\".join(errors))\n\n\ndef test_gpt2_newline_and_eot_ids(imported_module, gpt2_files):\n BPETokenizerSimple = getattr(imported_module, \"BPETokenizerSimple\", None)\n\n tok = BPETokenizerSimple()\n tok.load_vocab_and_merges_from_openai(\n vocab_path=gpt2_files[\"encoder.json\"], bpe_merges_path=gpt2_files[\"vocab.bpe\"]\n )\n\n assert \"Ċ\" in tok.inverse_vocab, \"Missing GPT-2 newline glyph 'Ċ' in inverse_vocab\"\n assert \"<|endoftext|>\" in tok.inverse_vocab, \"Missing EOT in inverse_vocab\"\n\n assert tok.inverse_vocab[\"Ċ\"] == 198, \"Ċ must map to id 198\"\n assert tok.inverse_vocab[\"<|endoftext|>\"] == 50256, \"EOT must be 50256\"\n\n if \"\\n\" not in tok.inverse_vocab:\n tok.inverse_vocab[\"\\n\"] = tok.inverse_vocab[\"Ċ\"]\n assert tok.inverse_vocab[\"\\n\"] == 198, r\"'\\n' must map to 198 via Ċ\"\n\n assert tok.vocab[198] == \"Ċ\", \"Don't overwrite vocab[198]; keep it 'Ċ'\"\n assert tok.vocab[50256] == \"<|endoftext|>\", \"Don't map <|endoftext|> to anything else\"\n\n\ndef test_no_eot_aliasing_and_disallowed_logic(imported_module, gpt2_files):\n BPETokenizerSimple = getattr(imported_module, \"BPETokenizerSimple\", None)\n tok = BPETokenizerSimple()\n tok.load_vocab_and_merges_from_openai(\n vocab_path=gpt2_files[\"encoder.json\"], bpe_merges_path=gpt2_files[\"vocab.bpe\"]\n )\n tik = tiktoken.get_encoding(\"gpt2\")\n\n text = \"Hello<|endoftext|>\\nworld\"\n # When not allowed, our encode should raise ValueError like tiktoken\n with pytest.raises(ValueError):\n tok.encode(text)\n\n # When allowed, both tokenizers should match\n ids_ours = tok.encode(text, allowed_special={\"<|endoftext|>\"})\n ids_tik = tik.encode(text, allowed_special={\"<|endoftext|>\"})\n assert ids_ours == ids_tik, \"Mismatch vs tiktoken with EOT allowed\"\n\n\n@pytest.mark.parametrize(\n \"text\",\n [\n \"a\\nb\",\n \"a\\n\\nb\",\n \"\\nHello\",\n \"Hello\\n\",\n \"a\\r\\nb\",\n ],\n)\ndef test_newline_roundtrip_and_equivalence(imported_module, gpt2_files, text):\n BPETokenizerSimple = getattr(imported_module, \"BPETokenizerSimple\", None)\n tok = BPETokenizerSimple()\n tok.load_vocab_and_merges_from_openai(\n vocab_path=gpt2_files[\"encoder.json\"], bpe_merges_path=gpt2_files[\"vocab.bpe\"]\n )\n tik = tiktoken.get_encoding(\"gpt2\")\n\n ids_ours = tok.encode(text)\n ids_tik = tik.encode(text)\n\n assert ids_ours == ids_tik, f\"Mismatch vs tiktoken for: {repr(text)}\"\n # Each \"\\n\" should correspond to id 198\n expected_lf_count = text.count(\"\\n\")\n assert ids_ours.count(198) == expected_lf_count\n\n dec = tok.decode(ids_ours)\n assert dec == text\n\n\ndef test_space_newline_space_patterns(imported_module, gpt2_files):\n BPETokenizerSimple = getattr(imported_module, \"BPETokenizerSimple\", None)\n tok = BPETokenizerSimple()\n tok.load_vocab_and_merges_from_openai(\n vocab_path=gpt2_files[\"encoder.json\"], bpe_merges_path=gpt2_files[\"vocab.bpe\"]\n )\n tik = tiktoken.get_encoding(\"gpt2\")\n\n samples = [\n \"Hello \\nworld\",\n \"Hello\\n world\",\n ]\n for s in samples:\n assert tok.encode(s) == tik.encode(s), f\"Mismatch vs tiktoken: {repr(s)}\"\n\n\ndef test_multiple_leading_spaces_roundtrip(imported_module, gpt2_files):\n BPETokenizerSimple = getattr(imported_module, \"BPETokenizerSimple\", None)\n tok = BPETokenizerSimple()\n tok.load_vocab_and_merges_from_openai(\n vocab_path=gpt2_files[\"encoder.json\"], bpe_merges_path=gpt2_files[\"vocab.bpe\"]\n )\n\n text = \" Hello World.\"\n assert tok.decode(tok.encode(text)) == text\n"
},
{
"path": "ch02/README.md",
"content": "# Chapter 2: Working with Text Data\n\n \n## Main Chapter Code\n\n- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code and exercise solutions\n\n \n## Bonus Materials\n\n- [02_bonus_bytepair-encoder](02_bonus_bytepair-encoder) contains optional code to benchmark different byte pair encoder implementations\n\n- [03_bonus_embedding-vs-matmul](03_bonus_embedding-vs-matmul) contains optional (bonus) code to explain that embedding layers and fully connected layers applied to one-hot encoded vectors are equivalent.\n\n- [04_bonus_dataloader-intuition](04_bonus_dataloader-intuition) contains optional (bonus) code to explain the data loader more intuitively with simple numbers rather than text.\n\n- [05_bpe-from-scratch](05_bpe-from-scratch) contains (bonus) code that implements and trains a GPT-2 BPE tokenizer from scratch.\n\n\n\n\n\nIn the video below, I provide a code-along session that covers some of the chapter contents as supplementary material.\n\n| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"50e020fd-9690-4343-80df-da96678bef5e\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"50e020fd-9690-4343-80df-da96678bef5e\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ecc4dcee-34ea-4c05-9085-2f8887f70363\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 3.1 The problem with modeling long sequences\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a55aa49c-36c2-48da-b1d9-70f416e46a6a\",\n \"metadata\": {},\n \"source\": [\n \"- No code in this section\\n\",\n \"- Translating a text word by word isn't feasible due to the differences in grammatical structures between the source and target languages:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"55c0c433-aa4b-491e-848a-54905ebb05ad\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ecc4dcee-34ea-4c05-9085-2f8887f70363\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 3.1 The problem with modeling long sequences\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a55aa49c-36c2-48da-b1d9-70f416e46a6a\",\n \"metadata\": {},\n \"source\": [\n \"- No code in this section\\n\",\n \"- Translating a text word by word isn't feasible due to the differences in grammatical structures between the source and target languages:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"55c0c433-aa4b-491e-848a-54905ebb05ad\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"db03c48a-3429-48ea-9d4a-2e53b0e516b1\",\n \"metadata\": {},\n \"source\": [\n \"- Prior to the introduction of transformer models, encoder-decoder RNNs were commonly used for machine translation tasks\\n\",\n \"- In this setup, the encoder processes a sequence of tokens from the source language, using a hidden state—a kind of intermediate layer within the neural network—to generate a condensed representation of the entire input sequence:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"03d8df2c-c1c2-4df0-9977-ade9713088b2\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"db03c48a-3429-48ea-9d4a-2e53b0e516b1\",\n \"metadata\": {},\n \"source\": [\n \"- Prior to the introduction of transformer models, encoder-decoder RNNs were commonly used for machine translation tasks\\n\",\n \"- In this setup, the encoder processes a sequence of tokens from the source language, using a hidden state—a kind of intermediate layer within the neural network—to generate a condensed representation of the entire input sequence:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"03d8df2c-c1c2-4df0-9977-ade9713088b2\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3602c585-b87a-41c7-a324-c5e8298849df\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 3.2 Capturing data dependencies with attention mechanisms\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b6fde64c-6034-421d-81d9-8244932086ea\",\n \"metadata\": {},\n \"source\": [\n \"- No code in this section\\n\",\n \"- Through an attention mechanism, the text-generating decoder segment of the network is capable of selectively accessing all input tokens, implying that certain input tokens hold more significance than others in the generation of a specific output token:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bc4f6293-8ab5-4aeb-a04c-50ee158485b1\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3602c585-b87a-41c7-a324-c5e8298849df\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 3.2 Capturing data dependencies with attention mechanisms\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b6fde64c-6034-421d-81d9-8244932086ea\",\n \"metadata\": {},\n \"source\": [\n \"- No code in this section\\n\",\n \"- Through an attention mechanism, the text-generating decoder segment of the network is capable of selectively accessing all input tokens, implying that certain input tokens hold more significance than others in the generation of a specific output token:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bc4f6293-8ab5-4aeb-a04c-50ee158485b1\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8044be1f-e6a2-4a1f-a6dd-e325d3bad05e\",\n \"metadata\": {},\n \"source\": [\n \"- Self-attention in transformers is a technique designed to enhance input representations by enabling each position in a sequence to engage with and determine the relevance of every other position within the same sequence\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6565dc9f-b1be-4c78-b503-42ccc743296c\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8044be1f-e6a2-4a1f-a6dd-e325d3bad05e\",\n \"metadata\": {},\n \"source\": [\n \"- Self-attention in transformers is a technique designed to enhance input representations by enabling each position in a sequence to engage with and determine the relevance of every other position within the same sequence\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6565dc9f-b1be-4c78-b503-42ccc743296c\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5efe05ff-b441-408e-8d66-cde4eb3397e3\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 3.3 Attending to different parts of the input with self-attention\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6d9af516-7c37-4400-ab53-34936d5495a9\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.3.1 A simple self-attention mechanism without trainable weights\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d269e9f1-df11-4644-b575-df338cf46cdf\",\n \"metadata\": {},\n \"source\": [\n \"- This section explains a very simplified variant of self-attention, which does not contain any trainable weights\\n\",\n \"- This is purely for illustration purposes and NOT the attention mechanism that is used in transformers\\n\",\n \"- The next section, section 3.3.2, will extend this simple attention mechanism to implement the real self-attention mechanism\\n\",\n \"- Suppose we are given an input sequence $x^{(1)}$ to $x^{(T)}$\\n\",\n \" - The input is a text (for example, a sentence like \\\"Your journey starts with one step\\\") that has already been converted into token embeddings as described in chapter 2\\n\",\n \" - For instance, $x^{(1)}$ is a d-dimensional vector representing the word \\\"Your\\\", and so forth\\n\",\n \"- **Goal:** compute context vectors $z^{(i)}$ for each input sequence element $x^{(i)}$ in $x^{(1)}$ to $x^{(T)}$ (where $z$ and $x$ have the same dimension)\\n\",\n \" - A context vector $z^{(i)}$ is a weighted sum over the inputs $x^{(1)}$ to $x^{(T)}$\\n\",\n \" - The context vector is \\\"context\\\"-specific to a certain input\\n\",\n \" - Instead of $x^{(i)}$ as a placeholder for an arbitrary input token, let's consider the second input, $x^{(2)}$\\n\",\n \" - And to continue with a concrete example, instead of the placeholder $z^{(i)}$, we consider the second output context vector, $z^{(2)}$\\n\",\n \" - The second context vector, $z^{(2)}$, is a weighted sum over all inputs $x^{(1)}$ to $x^{(T)}$ weighted with respect to the second input element, $x^{(2)}$\\n\",\n \" - The attention weights are the weights that determine how much each of the input elements contributes to the weighted sum when computing $z^{(2)}$\\n\",\n \" - In short, think of $z^{(2)}$ as a modified version of $x^{(2)}$ that also incorporates information about all other input elements that are relevant to a given task at hand\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fcc7c7a2-b6ab-478f-ae37-faa8eaa8049a\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5efe05ff-b441-408e-8d66-cde4eb3397e3\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 3.3 Attending to different parts of the input with self-attention\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6d9af516-7c37-4400-ab53-34936d5495a9\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.3.1 A simple self-attention mechanism without trainable weights\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d269e9f1-df11-4644-b575-df338cf46cdf\",\n \"metadata\": {},\n \"source\": [\n \"- This section explains a very simplified variant of self-attention, which does not contain any trainable weights\\n\",\n \"- This is purely for illustration purposes and NOT the attention mechanism that is used in transformers\\n\",\n \"- The next section, section 3.3.2, will extend this simple attention mechanism to implement the real self-attention mechanism\\n\",\n \"- Suppose we are given an input sequence $x^{(1)}$ to $x^{(T)}$\\n\",\n \" - The input is a text (for example, a sentence like \\\"Your journey starts with one step\\\") that has already been converted into token embeddings as described in chapter 2\\n\",\n \" - For instance, $x^{(1)}$ is a d-dimensional vector representing the word \\\"Your\\\", and so forth\\n\",\n \"- **Goal:** compute context vectors $z^{(i)}$ for each input sequence element $x^{(i)}$ in $x^{(1)}$ to $x^{(T)}$ (where $z$ and $x$ have the same dimension)\\n\",\n \" - A context vector $z^{(i)}$ is a weighted sum over the inputs $x^{(1)}$ to $x^{(T)}$\\n\",\n \" - The context vector is \\\"context\\\"-specific to a certain input\\n\",\n \" - Instead of $x^{(i)}$ as a placeholder for an arbitrary input token, let's consider the second input, $x^{(2)}$\\n\",\n \" - And to continue with a concrete example, instead of the placeholder $z^{(i)}$, we consider the second output context vector, $z^{(2)}$\\n\",\n \" - The second context vector, $z^{(2)}$, is a weighted sum over all inputs $x^{(1)}$ to $x^{(T)}$ weighted with respect to the second input element, $x^{(2)}$\\n\",\n \" - The attention weights are the weights that determine how much each of the input elements contributes to the weighted sum when computing $z^{(2)}$\\n\",\n \" - In short, think of $z^{(2)}$ as a modified version of $x^{(2)}$ that also incorporates information about all other input elements that are relevant to a given task at hand\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fcc7c7a2-b6ab-478f-ae37-faa8eaa8049a\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"\\n\",\n \"- (Please note that the numbers in this figure are truncated to one\\n\",\n \"digit after the decimal point to reduce visual clutter; similarly, other figures may also contain truncated values)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ff856c58-8382-44c7-827f-798040e6e697\",\n \"metadata\": {},\n \"source\": [\n \"- By convention, the unnormalized attention weights are referred to as **\\\"attention scores\\\"** whereas the normalized attention scores, which sum to 1, are referred to as **\\\"attention weights\\\"**\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"01b10344-128d-462a-823f-2178dff5fd58\",\n \"metadata\": {},\n \"source\": [\n \"- The code below walks through the figure above step by step\\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \"- (Please note that the numbers in this figure are truncated to one\\n\",\n \"digit after the decimal point to reduce visual clutter; similarly, other figures may also contain truncated values)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ff856c58-8382-44c7-827f-798040e6e697\",\n \"metadata\": {},\n \"source\": [\n \"- By convention, the unnormalized attention weights are referred to as **\\\"attention scores\\\"** whereas the normalized attention scores, which sum to 1, are referred to as **\\\"attention weights\\\"**\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"01b10344-128d-462a-823f-2178dff5fd58\",\n \"metadata\": {},\n \"source\": [\n \"- The code below walks through the figure above step by step\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"77be52fb-82fd-4886-a4c8-f24a9c87af22\",\n \"metadata\": {},\n \"source\": [\n \"- We use input sequence element 2, $x^{(2)}$, as an example to compute context vector $z^{(2)}$; later in this section, we will generalize this to compute all context vectors.\\n\",\n \"- The first step is to compute the unnormalized attention scores by computing the dot product between the query $x^{(2)}$ and all other input tokens:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"6fb5b2f8-dd2c-4a6d-94ef-a0e9ad163951\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])\\n\"\n ]\n }\n ],\n \"source\": [\n \"query = inputs[1] # 2nd input token is the query\\n\",\n \"\\n\",\n \"attn_scores_2 = torch.empty(inputs.shape[0])\\n\",\n \"for i, x_i in enumerate(inputs):\\n\",\n \" attn_scores_2[i] = torch.dot(x_i, query) # dot product (transpose not necessary here since they are 1-dim vectors)\\n\",\n \"\\n\",\n \"print(attn_scores_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8df09ae0-199f-4b6f-81a0-2f70546684b8\",\n \"metadata\": {},\n \"source\": [\n \"- Side note: a dot product is essentially a shorthand for multiplying two vectors elements-wise and summing the resulting products:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"9842f39b-1654-410e-88bf-d1b899bf0241\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(0.9544)\\n\",\n \"tensor(0.9544)\\n\"\n ]\n }\n ],\n \"source\": [\n \"res = 0.\\n\",\n \"\\n\",\n \"for idx, element in enumerate(inputs[0]):\\n\",\n \" res += inputs[0][idx] * query[idx]\\n\",\n \"\\n\",\n \"print(res)\\n\",\n \"print(torch.dot(inputs[0], query))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7d444d76-e19e-4e9a-a268-f315d966609b\",\n \"metadata\": {},\n \"source\": [\n \"- **Step 2:** normalize the unnormalized attention scores (\\\"omegas\\\", $\\\\omega$) so that they sum up to 1\\n\",\n \"- Here is a simple way to normalize the unnormalized attention scores to sum up to 1 (a convention, useful for interpretation, and important for training stability):\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dfd965d6-980c-476a-93d8-9efe603b1b3b\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"77be52fb-82fd-4886-a4c8-f24a9c87af22\",\n \"metadata\": {},\n \"source\": [\n \"- We use input sequence element 2, $x^{(2)}$, as an example to compute context vector $z^{(2)}$; later in this section, we will generalize this to compute all context vectors.\\n\",\n \"- The first step is to compute the unnormalized attention scores by computing the dot product between the query $x^{(2)}$ and all other input tokens:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"6fb5b2f8-dd2c-4a6d-94ef-a0e9ad163951\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])\\n\"\n ]\n }\n ],\n \"source\": [\n \"query = inputs[1] # 2nd input token is the query\\n\",\n \"\\n\",\n \"attn_scores_2 = torch.empty(inputs.shape[0])\\n\",\n \"for i, x_i in enumerate(inputs):\\n\",\n \" attn_scores_2[i] = torch.dot(x_i, query) # dot product (transpose not necessary here since they are 1-dim vectors)\\n\",\n \"\\n\",\n \"print(attn_scores_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8df09ae0-199f-4b6f-81a0-2f70546684b8\",\n \"metadata\": {},\n \"source\": [\n \"- Side note: a dot product is essentially a shorthand for multiplying two vectors elements-wise and summing the resulting products:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"9842f39b-1654-410e-88bf-d1b899bf0241\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(0.9544)\\n\",\n \"tensor(0.9544)\\n\"\n ]\n }\n ],\n \"source\": [\n \"res = 0.\\n\",\n \"\\n\",\n \"for idx, element in enumerate(inputs[0]):\\n\",\n \" res += inputs[0][idx] * query[idx]\\n\",\n \"\\n\",\n \"print(res)\\n\",\n \"print(torch.dot(inputs[0], query))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7d444d76-e19e-4e9a-a268-f315d966609b\",\n \"metadata\": {},\n \"source\": [\n \"- **Step 2:** normalize the unnormalized attention scores (\\\"omegas\\\", $\\\\omega$) so that they sum up to 1\\n\",\n \"- Here is a simple way to normalize the unnormalized attention scores to sum up to 1 (a convention, useful for interpretation, and important for training stability):\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dfd965d6-980c-476a-93d8-9efe603b1b3b\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"e3ccc99c-33ce-4f11-b7f2-353cf1cbdaba\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Attention weights: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656])\\n\",\n \"Sum: tensor(1.0000)\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_weights_2_tmp = attn_scores_2 / attn_scores_2.sum()\\n\",\n \"\\n\",\n \"print(\\\"Attention weights:\\\", attn_weights_2_tmp)\\n\",\n \"print(\\\"Sum:\\\", attn_weights_2_tmp.sum())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"75dc0a57-f53e-41bf-8793-daa77a819431\",\n \"metadata\": {},\n \"source\": [\n \"- However, in practice, using the softmax function for normalization, which is better at handling extreme values and has more desirable gradient properties during training, is common and recommended.\\n\",\n \"- Here's a naive implementation of a softmax function for scaling, which also normalizes the vector elements such that they sum up to 1:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"07b2e58d-a6ed-49f0-a1cd-2463e8d53a20\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])\\n\",\n \"Sum: tensor(1.)\\n\"\n ]\n }\n ],\n \"source\": [\n \"def softmax_naive(x):\\n\",\n \" return torch.exp(x) / torch.exp(x).sum(dim=0)\\n\",\n \"\\n\",\n \"attn_weights_2_naive = softmax_naive(attn_scores_2)\\n\",\n \"\\n\",\n \"print(\\\"Attention weights:\\\", attn_weights_2_naive)\\n\",\n \"print(\\\"Sum:\\\", attn_weights_2_naive.sum())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f0a1cbbb-4744-41cb-8910-f5c1355555fb\",\n \"metadata\": {},\n \"source\": [\n \"- The naive implementation above can suffer from numerical instability issues for large or small input values due to overflow and underflow issues\\n\",\n \"- Hence, in practice, it's recommended to use the PyTorch implementation of softmax instead, which has been highly optimized for performance:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"2d99cac4-45ea-46b3-b3c1-e000ad16e158\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])\\n\",\n \"Sum: tensor(1.)\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_weights_2 = torch.softmax(attn_scores_2, dim=0)\\n\",\n \"\\n\",\n \"print(\\\"Attention weights:\\\", attn_weights_2)\\n\",\n \"print(\\\"Sum:\\\", attn_weights_2.sum())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e43e36c7-90b2-427f-94f6-bb9d31b2ab3f\",\n \"metadata\": {},\n \"source\": [\n \"- **Step 3**: compute the context vector $z^{(2)}$ by multiplying the embedded input tokens, $x^{(i)}$ with the attention weights and sum the resulting vectors:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f1c9f5ac-8d3d-4847-94e3-fd783b7d4d3d\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"e3ccc99c-33ce-4f11-b7f2-353cf1cbdaba\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Attention weights: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656])\\n\",\n \"Sum: tensor(1.0000)\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_weights_2_tmp = attn_scores_2 / attn_scores_2.sum()\\n\",\n \"\\n\",\n \"print(\\\"Attention weights:\\\", attn_weights_2_tmp)\\n\",\n \"print(\\\"Sum:\\\", attn_weights_2_tmp.sum())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"75dc0a57-f53e-41bf-8793-daa77a819431\",\n \"metadata\": {},\n \"source\": [\n \"- However, in practice, using the softmax function for normalization, which is better at handling extreme values and has more desirable gradient properties during training, is common and recommended.\\n\",\n \"- Here's a naive implementation of a softmax function for scaling, which also normalizes the vector elements such that they sum up to 1:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"07b2e58d-a6ed-49f0-a1cd-2463e8d53a20\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])\\n\",\n \"Sum: tensor(1.)\\n\"\n ]\n }\n ],\n \"source\": [\n \"def softmax_naive(x):\\n\",\n \" return torch.exp(x) / torch.exp(x).sum(dim=0)\\n\",\n \"\\n\",\n \"attn_weights_2_naive = softmax_naive(attn_scores_2)\\n\",\n \"\\n\",\n \"print(\\\"Attention weights:\\\", attn_weights_2_naive)\\n\",\n \"print(\\\"Sum:\\\", attn_weights_2_naive.sum())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f0a1cbbb-4744-41cb-8910-f5c1355555fb\",\n \"metadata\": {},\n \"source\": [\n \"- The naive implementation above can suffer from numerical instability issues for large or small input values due to overflow and underflow issues\\n\",\n \"- Hence, in practice, it's recommended to use the PyTorch implementation of softmax instead, which has been highly optimized for performance:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"2d99cac4-45ea-46b3-b3c1-e000ad16e158\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])\\n\",\n \"Sum: tensor(1.)\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_weights_2 = torch.softmax(attn_scores_2, dim=0)\\n\",\n \"\\n\",\n \"print(\\\"Attention weights:\\\", attn_weights_2)\\n\",\n \"print(\\\"Sum:\\\", attn_weights_2.sum())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e43e36c7-90b2-427f-94f6-bb9d31b2ab3f\",\n \"metadata\": {},\n \"source\": [\n \"- **Step 3**: compute the context vector $z^{(2)}$ by multiplying the embedded input tokens, $x^{(i)}$ with the attention weights and sum the resulting vectors:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f1c9f5ac-8d3d-4847-94e3-fd783b7d4d3d\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"8fcb96f0-14e5-4973-a50e-79ea7c6af99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0.4419, 0.6515, 0.5683])\\n\"\n ]\n }\n ],\n \"source\": [\n \"query = inputs[1] # 2nd input token is the query\\n\",\n \"\\n\",\n \"context_vec_2 = torch.zeros(query.shape)\\n\",\n \"for i,x_i in enumerate(inputs):\\n\",\n \" context_vec_2 += attn_weights_2[i]*x_i\\n\",\n \"\\n\",\n \"print(context_vec_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5a454262-40eb-430e-9ca4-e43fb8d6cd89\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.3.2 Computing attention weights for all input tokens\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6a02bb73-fc19-4c88-b155-8314de5d63a8\",\n \"metadata\": {},\n \"source\": [\n \"#### Generalize to all input sequence tokens:\\n\",\n \"\\n\",\n \"- Above, we computed the attention weights and context vector for input 2 (as illustrated in the highlighted row in the figure below)\\n\",\n \"- Next, we are generalizing this computation to compute all attention weights and context vectors\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"11c0fb55-394f-42f4-ba07-d01ae5c98ab4\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"8fcb96f0-14e5-4973-a50e-79ea7c6af99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0.4419, 0.6515, 0.5683])\\n\"\n ]\n }\n ],\n \"source\": [\n \"query = inputs[1] # 2nd input token is the query\\n\",\n \"\\n\",\n \"context_vec_2 = torch.zeros(query.shape)\\n\",\n \"for i,x_i in enumerate(inputs):\\n\",\n \" context_vec_2 += attn_weights_2[i]*x_i\\n\",\n \"\\n\",\n \"print(context_vec_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5a454262-40eb-430e-9ca4-e43fb8d6cd89\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.3.2 Computing attention weights for all input tokens\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6a02bb73-fc19-4c88-b155-8314de5d63a8\",\n \"metadata\": {},\n \"source\": [\n \"#### Generalize to all input sequence tokens:\\n\",\n \"\\n\",\n \"- Above, we computed the attention weights and context vector for input 2 (as illustrated in the highlighted row in the figure below)\\n\",\n \"- Next, we are generalizing this computation to compute all attention weights and context vectors\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"11c0fb55-394f-42f4-ba07-d01ae5c98ab4\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"\\n\",\n \"- (Please note that the numbers in this figure are truncated to two\\n\",\n \"digits after the decimal point to reduce visual clutter; the values in each row should add up to 1.0 or 100%; similarly, digits in other figures are truncated)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b789b990-fb51-4beb-9212-bf58876b5983\",\n \"metadata\": {},\n \"source\": [\n \"- In self-attention, the process starts with the calculation of attention scores, which are subsequently normalized to derive attention weights that total 1\\n\",\n \"- These attention weights are then utilized to generate the context vectors through a weighted summation of the inputs\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d9bffe4b-56fe-4c37-9762-24bd924b7d3c\",\n \"metadata\": {},\n \"source\": [\n \"
\\n\",\n \"\\n\",\n \"- (Please note that the numbers in this figure are truncated to two\\n\",\n \"digits after the decimal point to reduce visual clutter; the values in each row should add up to 1.0 or 100%; similarly, digits in other figures are truncated)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b789b990-fb51-4beb-9212-bf58876b5983\",\n \"metadata\": {},\n \"source\": [\n \"- In self-attention, the process starts with the calculation of attention scores, which are subsequently normalized to derive attention weights that total 1\\n\",\n \"- These attention weights are then utilized to generate the context vectors through a weighted summation of the inputs\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d9bffe4b-56fe-4c37-9762-24bd924b7d3c\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"aa652506-f2c8-473c-a905-85c389c842cc\",\n \"metadata\": {},\n \"source\": [\n \"- Apply previous **step 1** to all pairwise elements to compute the unnormalized attention score matrix:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"04004be8-07a1-468b-ab33-32e16a551b45\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],\\n\",\n \" [0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],\\n\",\n \" [0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],\\n\",\n \" [0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],\\n\",\n \" [0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],\\n\",\n \" [0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_scores = torch.empty(6, 6)\\n\",\n \"\\n\",\n \"for i, x_i in enumerate(inputs):\\n\",\n \" for j, x_j in enumerate(inputs):\\n\",\n \" attn_scores[i, j] = torch.dot(x_i, x_j)\\n\",\n \"\\n\",\n \"print(attn_scores)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1539187f-1ece-47b7-bc9b-65a97115f1d4\",\n \"metadata\": {},\n \"source\": [\n \"- We can achieve the same as above more efficiently via matrix multiplication:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"2cea69d0-9a47-45da-8d5a-47ceef2df673\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],\\n\",\n \" [0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],\\n\",\n \" [0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],\\n\",\n \" [0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],\\n\",\n \" [0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],\\n\",\n \" [0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_scores = inputs @ inputs.T\\n\",\n \"print(attn_scores)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"02c4bac4-acfd-427f-9b11-c436ac71748d\",\n \"metadata\": {},\n \"source\": [\n \"- Similar to **step 2** previously, we normalize each row so that the values in each row sum to 1:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"fa4ef062-de81-47ee-8415-bfe1708c81b8\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.2098, 0.2006, 0.1981, 0.1242, 0.1220, 0.1452],\\n\",\n \" [0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581],\\n\",\n \" [0.1390, 0.2369, 0.2326, 0.1242, 0.1108, 0.1565],\\n\",\n \" [0.1435, 0.2074, 0.2046, 0.1462, 0.1263, 0.1720],\\n\",\n \" [0.1526, 0.1958, 0.1975, 0.1367, 0.1879, 0.1295],\\n\",\n \" [0.1385, 0.2184, 0.2128, 0.1420, 0.0988, 0.1896]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_weights = torch.softmax(attn_scores, dim=-1)\\n\",\n \"print(attn_weights)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3fa6d02b-7f15-4eb4-83a7-0b8a819e7a0c\",\n \"metadata\": {},\n \"source\": [\n \"- Quick verification that the values in each row indeed sum to 1:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"112b492c-fb6f-4e6d-8df5-518ae83363d5\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Row 2 sum: 1.0\\n\",\n \"All row sums: tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000])\\n\"\n ]\n }\n ],\n \"source\": [\n \"row_2_sum = sum([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])\\n\",\n \"print(\\\"Row 2 sum:\\\", row_2_sum)\\n\",\n \"\\n\",\n \"print(\\\"All row sums:\\\", attn_weights.sum(dim=-1))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"138b0b5c-d813-44c7-b373-fde9540ddfd1\",\n \"metadata\": {},\n \"source\": [\n \"- Apply previous **step 3** to compute all context vectors:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"ba8eafcf-f7f7-4989-b8dc-61b50c4f81dc\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.4421, 0.5931, 0.5790],\\n\",\n \" [0.4419, 0.6515, 0.5683],\\n\",\n \" [0.4431, 0.6496, 0.5671],\\n\",\n \" [0.4304, 0.6298, 0.5510],\\n\",\n \" [0.4671, 0.5910, 0.5266],\\n\",\n \" [0.4177, 0.6503, 0.5645]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"all_context_vecs = attn_weights @ inputs\\n\",\n \"print(all_context_vecs)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"25b245b8-7732-4fab-aa1c-e3d333195605\",\n \"metadata\": {},\n \"source\": [\n \"- As a sanity check, the previously computed context vector $z^{(2)} = [0.4419, 0.6515, 0.5683]$ can be found in the 2nd row in above: \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"2570eb7d-aee1-457a-a61e-7544478219fa\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Previous 2nd context vector: tensor([0.4419, 0.6515, 0.5683])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Previous 2nd context vector:\\\", context_vec_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a303b6fb-9f7e-42bb-9fdb-2adabf0a6525\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 3.4 Implementing self-attention with trainable weights\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"88363117-93d8-41fb-8240-f7cfe08b14a3\",\n \"metadata\": {},\n \"source\": [\n \"- A conceptual framework illustrating how the self-attention mechanism developed in this section integrates into the overall narrative and structure of this book and chapter\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ac9492ba-6f66-4f65-bd1d-87cf16d59928\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"aa652506-f2c8-473c-a905-85c389c842cc\",\n \"metadata\": {},\n \"source\": [\n \"- Apply previous **step 1** to all pairwise elements to compute the unnormalized attention score matrix:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"04004be8-07a1-468b-ab33-32e16a551b45\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],\\n\",\n \" [0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],\\n\",\n \" [0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],\\n\",\n \" [0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],\\n\",\n \" [0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],\\n\",\n \" [0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_scores = torch.empty(6, 6)\\n\",\n \"\\n\",\n \"for i, x_i in enumerate(inputs):\\n\",\n \" for j, x_j in enumerate(inputs):\\n\",\n \" attn_scores[i, j] = torch.dot(x_i, x_j)\\n\",\n \"\\n\",\n \"print(attn_scores)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1539187f-1ece-47b7-bc9b-65a97115f1d4\",\n \"metadata\": {},\n \"source\": [\n \"- We can achieve the same as above more efficiently via matrix multiplication:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"2cea69d0-9a47-45da-8d5a-47ceef2df673\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],\\n\",\n \" [0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],\\n\",\n \" [0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],\\n\",\n \" [0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],\\n\",\n \" [0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],\\n\",\n \" [0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_scores = inputs @ inputs.T\\n\",\n \"print(attn_scores)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"02c4bac4-acfd-427f-9b11-c436ac71748d\",\n \"metadata\": {},\n \"source\": [\n \"- Similar to **step 2** previously, we normalize each row so that the values in each row sum to 1:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"fa4ef062-de81-47ee-8415-bfe1708c81b8\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.2098, 0.2006, 0.1981, 0.1242, 0.1220, 0.1452],\\n\",\n \" [0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581],\\n\",\n \" [0.1390, 0.2369, 0.2326, 0.1242, 0.1108, 0.1565],\\n\",\n \" [0.1435, 0.2074, 0.2046, 0.1462, 0.1263, 0.1720],\\n\",\n \" [0.1526, 0.1958, 0.1975, 0.1367, 0.1879, 0.1295],\\n\",\n \" [0.1385, 0.2184, 0.2128, 0.1420, 0.0988, 0.1896]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_weights = torch.softmax(attn_scores, dim=-1)\\n\",\n \"print(attn_weights)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3fa6d02b-7f15-4eb4-83a7-0b8a819e7a0c\",\n \"metadata\": {},\n \"source\": [\n \"- Quick verification that the values in each row indeed sum to 1:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"112b492c-fb6f-4e6d-8df5-518ae83363d5\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Row 2 sum: 1.0\\n\",\n \"All row sums: tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000])\\n\"\n ]\n }\n ],\n \"source\": [\n \"row_2_sum = sum([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])\\n\",\n \"print(\\\"Row 2 sum:\\\", row_2_sum)\\n\",\n \"\\n\",\n \"print(\\\"All row sums:\\\", attn_weights.sum(dim=-1))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"138b0b5c-d813-44c7-b373-fde9540ddfd1\",\n \"metadata\": {},\n \"source\": [\n \"- Apply previous **step 3** to compute all context vectors:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"ba8eafcf-f7f7-4989-b8dc-61b50c4f81dc\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.4421, 0.5931, 0.5790],\\n\",\n \" [0.4419, 0.6515, 0.5683],\\n\",\n \" [0.4431, 0.6496, 0.5671],\\n\",\n \" [0.4304, 0.6298, 0.5510],\\n\",\n \" [0.4671, 0.5910, 0.5266],\\n\",\n \" [0.4177, 0.6503, 0.5645]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"all_context_vecs = attn_weights @ inputs\\n\",\n \"print(all_context_vecs)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"25b245b8-7732-4fab-aa1c-e3d333195605\",\n \"metadata\": {},\n \"source\": [\n \"- As a sanity check, the previously computed context vector $z^{(2)} = [0.4419, 0.6515, 0.5683]$ can be found in the 2nd row in above: \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"2570eb7d-aee1-457a-a61e-7544478219fa\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Previous 2nd context vector: tensor([0.4419, 0.6515, 0.5683])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Previous 2nd context vector:\\\", context_vec_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a303b6fb-9f7e-42bb-9fdb-2adabf0a6525\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 3.4 Implementing self-attention with trainable weights\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"88363117-93d8-41fb-8240-f7cfe08b14a3\",\n \"metadata\": {},\n \"source\": [\n \"- A conceptual framework illustrating how the self-attention mechanism developed in this section integrates into the overall narrative and structure of this book and chapter\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ac9492ba-6f66-4f65-bd1d-87cf16d59928\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2b90a77e-d746-4704-9354-1ddad86e6298\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.4.1 Computing the attention weights step by step\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"46e95a46-1f67-4b71-9e84-8e2db84ab036\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we are implementing the self-attention mechanism that is used in the original transformer architecture, the GPT models, and most other popular LLMs\\n\",\n \"- This self-attention mechanism is also called \\\"scaled dot-product attention\\\"\\n\",\n \"- The overall idea is similar to before:\\n\",\n \" - We want to compute context vectors as weighted sums over the input vectors specific to a certain input element\\n\",\n \" - For the above, we need attention weights\\n\",\n \"- As you will see, there are only slight differences compared to the basic attention mechanism introduced earlier:\\n\",\n \" - The most notable difference is the introduction of weight matrices that are updated during model training\\n\",\n \" - These trainable weight matrices are crucial so that the model (specifically, the attention module inside the model) can learn to produce \\\"good\\\" context vectors\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"59db4093-93e8-4bee-be8f-c8fac8a08cdd\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2b90a77e-d746-4704-9354-1ddad86e6298\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.4.1 Computing the attention weights step by step\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"46e95a46-1f67-4b71-9e84-8e2db84ab036\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we are implementing the self-attention mechanism that is used in the original transformer architecture, the GPT models, and most other popular LLMs\\n\",\n \"- This self-attention mechanism is also called \\\"scaled dot-product attention\\\"\\n\",\n \"- The overall idea is similar to before:\\n\",\n \" - We want to compute context vectors as weighted sums over the input vectors specific to a certain input element\\n\",\n \" - For the above, we need attention weights\\n\",\n \"- As you will see, there are only slight differences compared to the basic attention mechanism introduced earlier:\\n\",\n \" - The most notable difference is the introduction of weight matrices that are updated during model training\\n\",\n \" - These trainable weight matrices are crucial so that the model (specifically, the attention module inside the model) can learn to produce \\\"good\\\" context vectors\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"59db4093-93e8-4bee-be8f-c8fac8a08cdd\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4d996671-87aa-45c9-b2e0-07a7bcc9060a\",\n \"metadata\": {},\n \"source\": [\n \"- Implementing the self-attention mechanism step by step, we will start by introducing the three training weight matrices $W_q$, $W_k$, and $W_v$\\n\",\n \"- These three matrices are used to project the embedded input tokens, $x^{(i)}$, into query, key, and value vectors via matrix multiplication:\\n\",\n \"\\n\",\n \" - Query vector: $q^{(i)} = x^{(i)}\\\\,W_q $\\n\",\n \" - Key vector: $k^{(i)} = x^{(i)}\\\\,W_k $\\n\",\n \" - Value vector: $v^{(i)} = x^{(i)}\\\\,W_v $\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9f334313-5fd0-477b-8728-04080a427049\",\n \"metadata\": {},\n \"source\": [\n \"- The embedding dimensions of the input $x$ and the query vector $q$ can be the same or different, depending on the model's design and specific implementation\\n\",\n \"- In GPT models, the input and output dimensions are usually the same, but for illustration purposes, to better follow the computation, we choose different input and output dimensions here:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"8250fdc6-6cd6-4c5b-b9c0-8c643aadb7db\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"x_2 = inputs[1] # second input element\\n\",\n \"d_in = inputs.shape[1] # the input embedding size, d=3\\n\",\n \"d_out = 2 # the output embedding size, d=2\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f528cfb3-e226-47dd-b363-cc2caaeba4bf\",\n \"metadata\": {},\n \"source\": [\n \"- Below, we initialize the three weight matrices; note that we are setting `requires_grad=False` to reduce clutter in the outputs for illustration purposes, but if we were to use the weight matrices for model training, we would set `requires_grad=True` to update these matrices during model training\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"bfd7259a-f26c-4cea-b8fc-282b5cae1e00\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"W_query = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)\\n\",\n \"W_key = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)\\n\",\n \"W_value = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"abfd0b50-7701-4adb-821c-e5433622d9c4\",\n \"metadata\": {},\n \"source\": [\n \"- Next we compute the query, key, and value vectors:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"73cedd62-01e1-4196-a575-baecc6095601\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0.4306, 1.4551])\\n\"\n ]\n }\n ],\n \"source\": [\n \"query_2 = x_2 @ W_query # _2 because it's with respect to the 2nd input element\\n\",\n \"key_2 = x_2 @ W_key \\n\",\n \"value_2 = x_2 @ W_value\\n\",\n \"\\n\",\n \"print(query_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9be308b3-aca3-421b-b182-19c3a03b71c7\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see below, we successfully projected the 6 input tokens from a 3D onto a 2D embedding space:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"8c1c3949-fc08-4d19-a41e-1c235b4e631b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"keys.shape: torch.Size([6, 2])\\n\",\n \"values.shape: torch.Size([6, 2])\\n\"\n ]\n }\n ],\n \"source\": [\n \"keys = inputs @ W_key \\n\",\n \"values = inputs @ W_value\\n\",\n \"\\n\",\n \"print(\\\"keys.shape:\\\", keys.shape)\\n\",\n \"print(\\\"values.shape:\\\", values.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bac5dfd6-ade8-4e7b-b0c1-bed40aa24481\",\n \"metadata\": {},\n \"source\": [\n \"- In the next step, **step 2**, we compute the unnormalized attention scores by computing the dot product between the query and each key vector:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8ed0a2b7-5c50-4ede-90cf-7ad74412b3aa\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4d996671-87aa-45c9-b2e0-07a7bcc9060a\",\n \"metadata\": {},\n \"source\": [\n \"- Implementing the self-attention mechanism step by step, we will start by introducing the three training weight matrices $W_q$, $W_k$, and $W_v$\\n\",\n \"- These three matrices are used to project the embedded input tokens, $x^{(i)}$, into query, key, and value vectors via matrix multiplication:\\n\",\n \"\\n\",\n \" - Query vector: $q^{(i)} = x^{(i)}\\\\,W_q $\\n\",\n \" - Key vector: $k^{(i)} = x^{(i)}\\\\,W_k $\\n\",\n \" - Value vector: $v^{(i)} = x^{(i)}\\\\,W_v $\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9f334313-5fd0-477b-8728-04080a427049\",\n \"metadata\": {},\n \"source\": [\n \"- The embedding dimensions of the input $x$ and the query vector $q$ can be the same or different, depending on the model's design and specific implementation\\n\",\n \"- In GPT models, the input and output dimensions are usually the same, but for illustration purposes, to better follow the computation, we choose different input and output dimensions here:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"8250fdc6-6cd6-4c5b-b9c0-8c643aadb7db\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"x_2 = inputs[1] # second input element\\n\",\n \"d_in = inputs.shape[1] # the input embedding size, d=3\\n\",\n \"d_out = 2 # the output embedding size, d=2\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f528cfb3-e226-47dd-b363-cc2caaeba4bf\",\n \"metadata\": {},\n \"source\": [\n \"- Below, we initialize the three weight matrices; note that we are setting `requires_grad=False` to reduce clutter in the outputs for illustration purposes, but if we were to use the weight matrices for model training, we would set `requires_grad=True` to update these matrices during model training\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"bfd7259a-f26c-4cea-b8fc-282b5cae1e00\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"W_query = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)\\n\",\n \"W_key = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)\\n\",\n \"W_value = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"abfd0b50-7701-4adb-821c-e5433622d9c4\",\n \"metadata\": {},\n \"source\": [\n \"- Next we compute the query, key, and value vectors:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"73cedd62-01e1-4196-a575-baecc6095601\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0.4306, 1.4551])\\n\"\n ]\n }\n ],\n \"source\": [\n \"query_2 = x_2 @ W_query # _2 because it's with respect to the 2nd input element\\n\",\n \"key_2 = x_2 @ W_key \\n\",\n \"value_2 = x_2 @ W_value\\n\",\n \"\\n\",\n \"print(query_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9be308b3-aca3-421b-b182-19c3a03b71c7\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see below, we successfully projected the 6 input tokens from a 3D onto a 2D embedding space:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"8c1c3949-fc08-4d19-a41e-1c235b4e631b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"keys.shape: torch.Size([6, 2])\\n\",\n \"values.shape: torch.Size([6, 2])\\n\"\n ]\n }\n ],\n \"source\": [\n \"keys = inputs @ W_key \\n\",\n \"values = inputs @ W_value\\n\",\n \"\\n\",\n \"print(\\\"keys.shape:\\\", keys.shape)\\n\",\n \"print(\\\"values.shape:\\\", values.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bac5dfd6-ade8-4e7b-b0c1-bed40aa24481\",\n \"metadata\": {},\n \"source\": [\n \"- In the next step, **step 2**, we compute the unnormalized attention scores by computing the dot product between the query and each key vector:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8ed0a2b7-5c50-4ede-90cf-7ad74412b3aa\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"64cbc253-a182-4490-a765-246979ea0a28\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(1.8524)\\n\"\n ]\n }\n ],\n \"source\": [\n \"keys_2 = keys[1] # Python starts index at 0\\n\",\n \"attn_score_22 = query_2.dot(keys_2)\\n\",\n \"print(attn_score_22)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9e9d15c0-c24e-4e6f-a160-6349b418f935\",\n \"metadata\": {},\n \"source\": [\n \"- Since we have 6 inputs, we have 6 attention scores for the given query vector:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"b14e44b5-d170-40f9-8847-8990804af26d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_scores_2 = query_2 @ keys.T # All attention scores for given query\\n\",\n \"print(attn_scores_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8622cf39-155f-4eb5-a0c0-82a03ce9b999\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"64cbc253-a182-4490-a765-246979ea0a28\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(1.8524)\\n\"\n ]\n }\n ],\n \"source\": [\n \"keys_2 = keys[1] # Python starts index at 0\\n\",\n \"attn_score_22 = query_2.dot(keys_2)\\n\",\n \"print(attn_score_22)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9e9d15c0-c24e-4e6f-a160-6349b418f935\",\n \"metadata\": {},\n \"source\": [\n \"- Since we have 6 inputs, we have 6 attention scores for the given query vector:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"b14e44b5-d170-40f9-8847-8990804af26d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])\\n\"\n ]\n }\n ],\n \"source\": [\n \"attn_scores_2 = query_2 @ keys.T # All attention scores for given query\\n\",\n \"print(attn_scores_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8622cf39-155f-4eb5-a0c0-82a03ce9b999\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1609edb-f089-461a-8de2-c20c1bb29836\",\n \"metadata\": {},\n \"source\": [\n \"- Next, in **step 3**, we compute the attention weights (normalized attention scores that sum up to 1) using the softmax function we used earlier\\n\",\n \"- The difference to earlier is that we now scale the attention scores by dividing them by the square root of the embedding dimension, $\\\\sqrt{d_k}$ (i.e., `d_k**0.5`):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"146f5587-c845-4e30-9894-c7ed3a248153\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])\\n\"\n ]\n }\n ],\n \"source\": [\n \"d_k = keys.shape[1]\\n\",\n \"attn_weights_2 = torch.softmax(attn_scores_2 / d_k**0.5, dim=-1)\\n\",\n \"print(attn_weights_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b8f61a28-b103-434a-aee1-ae7cbd821126\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1609edb-f089-461a-8de2-c20c1bb29836\",\n \"metadata\": {},\n \"source\": [\n \"- Next, in **step 3**, we compute the attention weights (normalized attention scores that sum up to 1) using the softmax function we used earlier\\n\",\n \"- The difference to earlier is that we now scale the attention scores by dividing them by the square root of the embedding dimension, $\\\\sqrt{d_k}$ (i.e., `d_k**0.5`):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"146f5587-c845-4e30-9894-c7ed3a248153\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])\\n\"\n ]\n }\n ],\n \"source\": [\n \"d_k = keys.shape[1]\\n\",\n \"attn_weights_2 = torch.softmax(attn_scores_2 / d_k**0.5, dim=-1)\\n\",\n \"print(attn_weights_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b8f61a28-b103-434a-aee1-ae7cbd821126\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1890e3f9-db86-4ab8-9f3b-53113504a61f\",\n \"metadata\": {},\n \"source\": [\n \"- In **step 4**, we now compute the context vector for input query vector 2:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"e138f033-fa7e-4e3a-8764-b53a96b26397\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0.3061, 0.8210])\\n\"\n ]\n }\n ],\n \"source\": [\n \"context_vec_2 = attn_weights_2 @ values\\n\",\n \"print(context_vec_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9d7b2907-e448-473e-b46c-77735a7281d8\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.4.2 Implementing a compact SelfAttention class\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"04313410-3155-4d90-a7a3-2f3386e73677\",\n \"metadata\": {},\n \"source\": [\n \"- Putting it all together, we can implement the self-attention mechanism as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"51590326-cdbe-4e62-93b1-17df71c11ee4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.2996, 0.8053],\\n\",\n \" [0.3061, 0.8210],\\n\",\n \" [0.3058, 0.8203],\\n\",\n \" [0.2948, 0.7939],\\n\",\n \" [0.2927, 0.7891],\\n\",\n \" [0.2990, 0.8040]], grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1890e3f9-db86-4ab8-9f3b-53113504a61f\",\n \"metadata\": {},\n \"source\": [\n \"- In **step 4**, we now compute the context vector for input query vector 2:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"e138f033-fa7e-4e3a-8764-b53a96b26397\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([0.3061, 0.8210])\\n\"\n ]\n }\n ],\n \"source\": [\n \"context_vec_2 = attn_weights_2 @ values\\n\",\n \"print(context_vec_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9d7b2907-e448-473e-b46c-77735a7281d8\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.4.2 Implementing a compact SelfAttention class\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"04313410-3155-4d90-a7a3-2f3386e73677\",\n \"metadata\": {},\n \"source\": [\n \"- Putting it all together, we can implement the self-attention mechanism as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"51590326-cdbe-4e62-93b1-17df71c11ee4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.2996, 0.8053],\\n\",\n \" [0.3061, 0.8210],\\n\",\n \" [0.3058, 0.8203],\\n\",\n \" [0.2948, 0.7939],\\n\",\n \" [0.2927, 0.7891],\\n\",\n \" [0.2990, 0.8040]], grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"048e0c16-d911-4ec8-b0bc-45ceec75c081\",\n \"metadata\": {},\n \"source\": [\n \"- We can streamline the implementation above using PyTorch's Linear layers, which are equivalent to a matrix multiplication if we disable the bias units\\n\",\n \"- Another big advantage of using `nn.Linear` over our manual `nn.Parameter(torch.rand(...)` approach is that `nn.Linear` has a preferred weight initialization scheme, which leads to more stable model training\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"73f411e3-e231-464a-89fe-0a9035e5f839\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[-0.0739, 0.0713],\\n\",\n \" [-0.0748, 0.0703],\\n\",\n \" [-0.0749, 0.0702],\\n\",\n \" [-0.0760, 0.0685],\\n\",\n \" [-0.0763, 0.0679],\\n\",\n \" [-0.0754, 0.0693]], grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"048e0c16-d911-4ec8-b0bc-45ceec75c081\",\n \"metadata\": {},\n \"source\": [\n \"- We can streamline the implementation above using PyTorch's Linear layers, which are equivalent to a matrix multiplication if we disable the bias units\\n\",\n \"- Another big advantage of using `nn.Linear` over our manual `nn.Parameter(torch.rand(...)` approach is that `nn.Linear` has a preferred weight initialization scheme, which leads to more stable model training\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"73f411e3-e231-464a-89fe-0a9035e5f839\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[-0.0739, 0.0713],\\n\",\n \" [-0.0748, 0.0703],\\n\",\n \" [-0.0749, 0.0702],\\n\",\n \" [-0.0760, 0.0685],\\n\",\n \" [-0.0763, 0.0679],\\n\",\n \" [-0.0754, 0.0693]], grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"82f405de-cd86-4e72-8f3c-9ea0354946ba\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.5.1 Applying a causal attention mask\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"014f28d0-8218-48e4-8b9c-bdc5ce489218\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we are converting the previous self-attention mechanism into a causal self-attention mechanism\\n\",\n \"- Causal self-attention ensures that the model's prediction for a certain position in a sequence is only dependent on the known outputs at previous positions, not on future positions\\n\",\n \"- In simpler words, this ensures that each next word prediction should only depend on the preceding words\\n\",\n \"- To achieve this, for each given token, we mask out the future tokens (the ones that come after the current token in the input text):\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"57f99af3-32bc-48f5-8eb4-63504670ca0a\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"82f405de-cd86-4e72-8f3c-9ea0354946ba\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.5.1 Applying a causal attention mask\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"014f28d0-8218-48e4-8b9c-bdc5ce489218\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we are converting the previous self-attention mechanism into a causal self-attention mechanism\\n\",\n \"- Causal self-attention ensures that the model's prediction for a certain position in a sequence is only dependent on the known outputs at previous positions, not on future positions\\n\",\n \"- In simpler words, this ensures that each next word prediction should only depend on the preceding words\\n\",\n \"- To achieve this, for each given token, we mask out the future tokens (the ones that come after the current token in the input text):\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"57f99af3-32bc-48f5-8eb4-63504670ca0a\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cbfaec7a-68f2-4157-a4b5-2aeceed199d9\",\n \"metadata\": {},\n \"source\": [\n \"- To illustrate and implement causal self-attention, let's work with the attention scores and weights from the previous section: \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"1933940d-0fa5-4b17-a3ce-388e5314a1bb\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.1921, 0.1646, 0.1652, 0.1550, 0.1721, 0.1510],\\n\",\n \" [0.2041, 0.1659, 0.1662, 0.1496, 0.1665, 0.1477],\\n\",\n \" [0.2036, 0.1659, 0.1662, 0.1498, 0.1664, 0.1480],\\n\",\n \" [0.1869, 0.1667, 0.1668, 0.1571, 0.1661, 0.1564],\\n\",\n \" [0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.1585],\\n\",\n \" [0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],\\n\",\n \" grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cbfaec7a-68f2-4157-a4b5-2aeceed199d9\",\n \"metadata\": {},\n \"source\": [\n \"- To illustrate and implement causal self-attention, let's work with the attention scores and weights from the previous section: \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"1933940d-0fa5-4b17-a3ce-388e5314a1bb\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.1921, 0.1646, 0.1652, 0.1550, 0.1721, 0.1510],\\n\",\n \" [0.2041, 0.1659, 0.1662, 0.1496, 0.1665, 0.1477],\\n\",\n \" [0.2036, 0.1659, 0.1662, 0.1498, 0.1664, 0.1480],\\n\",\n \" [0.1869, 0.1667, 0.1668, 0.1571, 0.1661, 0.1564],\\n\",\n \" [0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.1585],\\n\",\n \" [0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],\\n\",\n \" grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"a2be2f43-9cf0-44f6-8d8b-68ef2fb3cc39\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.2899, -inf, -inf, -inf, -inf, -inf],\\n\",\n \" [0.4656, 0.1723, -inf, -inf, -inf, -inf],\\n\",\n \" [0.4594, 0.1703, 0.1731, -inf, -inf, -inf],\\n\",\n \" [0.2642, 0.1024, 0.1036, 0.0186, -inf, -inf],\\n\",\n \" [0.2183, 0.0874, 0.0882, 0.0177, 0.0786, -inf],\\n\",\n \" [0.3408, 0.1270, 0.1290, 0.0198, 0.1290, 0.0078]],\\n\",\n \" grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"a2be2f43-9cf0-44f6-8d8b-68ef2fb3cc39\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.2899, -inf, -inf, -inf, -inf, -inf],\\n\",\n \" [0.4656, 0.1723, -inf, -inf, -inf, -inf],\\n\",\n \" [0.4594, 0.1703, 0.1731, -inf, -inf, -inf],\\n\",\n \" [0.2642, 0.1024, 0.1036, 0.0186, -inf, -inf],\\n\",\n \" [0.2183, 0.0874, 0.0882, 0.0177, 0.0786, -inf],\\n\",\n \" [0.3408, 0.1270, 0.1290, 0.0198, 0.1290, 0.0078]],\\n\",\n \" grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5a575458-a6da-4e54-8688-83e155f2de06\",\n \"metadata\": {},\n \"source\": [\n \"- If we apply a dropout rate of 0.5 (50%), the non-dropped values will be scaled accordingly by a factor of 1/0.5 = 2\\n\",\n \"- The scaling is calculated by the formula 1 / (1 - `dropout_rate`)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"0de578db-8289-41d6-b377-ef645751e33f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[2., 2., 0., 2., 2., 0.],\\n\",\n \" [0., 0., 0., 2., 0., 2.],\\n\",\n \" [2., 2., 2., 2., 0., 2.],\\n\",\n \" [0., 2., 2., 0., 0., 2.],\\n\",\n \" [0., 2., 0., 2., 0., 2.],\\n\",\n \" [0., 2., 2., 2., 2., 0.]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"dropout = torch.nn.Dropout(0.5) # dropout rate of 50%\\n\",\n \"example = torch.ones(6, 6) # create a matrix of ones\\n\",\n \"\\n\",\n \"print(dropout(example))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"b16c5edb-942b-458c-8e95-25e4e355381e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[2.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],\\n\",\n \" [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],\\n\",\n \" [0.7599, 0.6194, 0.6206, 0.0000, 0.0000, 0.0000],\\n\",\n \" [0.0000, 0.4921, 0.4925, 0.0000, 0.0000, 0.0000],\\n\",\n \" [0.0000, 0.3966, 0.0000, 0.3775, 0.0000, 0.0000],\\n\",\n \" [0.0000, 0.3327, 0.3331, 0.3084, 0.3331, 0.0000]],\\n\",\n \" grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5a575458-a6da-4e54-8688-83e155f2de06\",\n \"metadata\": {},\n \"source\": [\n \"- If we apply a dropout rate of 0.5 (50%), the non-dropped values will be scaled accordingly by a factor of 1/0.5 = 2\\n\",\n \"- The scaling is calculated by the formula 1 / (1 - `dropout_rate`)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"0de578db-8289-41d6-b377-ef645751e33f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[2., 2., 0., 2., 2., 0.],\\n\",\n \" [0., 0., 0., 2., 0., 2.],\\n\",\n \" [2., 2., 2., 2., 0., 2.],\\n\",\n \" [0., 2., 2., 0., 0., 2.],\\n\",\n \" [0., 2., 0., 2., 0., 2.],\\n\",\n \" [0., 2., 2., 2., 2., 0.]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"dropout = torch.nn.Dropout(0.5) # dropout rate of 50%\\n\",\n \"example = torch.ones(6, 6) # create a matrix of ones\\n\",\n \"\\n\",\n \"print(dropout(example))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"b16c5edb-942b-458c-8e95-25e4e355381e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[2.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],\\n\",\n \" [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],\\n\",\n \" [0.7599, 0.6194, 0.6206, 0.0000, 0.0000, 0.0000],\\n\",\n \" [0.0000, 0.4921, 0.4925, 0.0000, 0.0000, 0.0000],\\n\",\n \" [0.0000, 0.3966, 0.0000, 0.3775, 0.0000, 0.0000],\\n\",\n \" [0.0000, 0.3327, 0.3331, 0.3084, 0.3331, 0.0000]],\\n\",\n \" grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c8bef90f-cfd4-4289-b0e8-6a00dc9be44c\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 3.6 Extending single-head attention to multi-head attention\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"11697757-9198-4a1c-9cee-f450d8bbd3b9\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.6.1 Stacking multiple single-head attention layers\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"70766faf-cd53-41d9-8a17-f1b229756a5a\",\n \"metadata\": {},\n \"source\": [\n \"- Below is a summary of the self-attention implemented previously (causal and dropout masks not shown for simplicity)\\n\",\n \"\\n\",\n \"- This is also called single-head attention:\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c8bef90f-cfd4-4289-b0e8-6a00dc9be44c\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 3.6 Extending single-head attention to multi-head attention\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"11697757-9198-4a1c-9cee-f450d8bbd3b9\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 3.6.1 Stacking multiple single-head attention layers\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"70766faf-cd53-41d9-8a17-f1b229756a5a\",\n \"metadata\": {},\n \"source\": [\n \"- Below is a summary of the self-attention implemented previously (causal and dropout masks not shown for simplicity)\\n\",\n \"\\n\",\n \"- This is also called single-head attention:\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"- We simply stack multiple single-head attention modules to obtain a multi-head attention module:\\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \"- We simply stack multiple single-head attention modules to obtain a multi-head attention module:\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"- The main idea behind multi-head attention is to run the attention mechanism multiple times (in parallel) with different, learned linear projections. This allows the model to jointly attend to information from different representation subspaces at different positions.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"b9a66e11-7105-4bb4-be84-041f1a1f3bd2\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[-0.4519, 0.2216, 0.4772, 0.1063],\\n\",\n \" [-0.5874, 0.0058, 0.5891, 0.3257],\\n\",\n \" [-0.6300, -0.0632, 0.6202, 0.3860],\\n\",\n \" [-0.5675, -0.0843, 0.5478, 0.3589],\\n\",\n \" [-0.5526, -0.0981, 0.5321, 0.3428],\\n\",\n \" [-0.5299, -0.1081, 0.5077, 0.3493]],\\n\",\n \"\\n\",\n \" [[-0.4519, 0.2216, 0.4772, 0.1063],\\n\",\n \" [-0.5874, 0.0058, 0.5891, 0.3257],\\n\",\n \" [-0.6300, -0.0632, 0.6202, 0.3860],\\n\",\n \" [-0.5675, -0.0843, 0.5478, 0.3589],\\n\",\n \" [-0.5526, -0.0981, 0.5321, 0.3428],\\n\",\n \" [-0.5299, -0.1081, 0.5077, 0.3493]]], grad_fn=
\\n\",\n \"\\n\",\n \"- The main idea behind multi-head attention is to run the attention mechanism multiple times (in parallel) with different, learned linear projections. This allows the model to jointly attend to information from different representation subspaces at different positions.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"b9a66e11-7105-4bb4-be84-041f1a1f3bd2\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[-0.4519, 0.2216, 0.4772, 0.1063],\\n\",\n \" [-0.5874, 0.0058, 0.5891, 0.3257],\\n\",\n \" [-0.6300, -0.0632, 0.6202, 0.3860],\\n\",\n \" [-0.5675, -0.0843, 0.5478, 0.3589],\\n\",\n \" [-0.5526, -0.0981, 0.5321, 0.3428],\\n\",\n \" [-0.5299, -0.1081, 0.5077, 0.3493]],\\n\",\n \"\\n\",\n \" [[-0.4519, 0.2216, 0.4772, 0.1063],\\n\",\n \" [-0.5874, 0.0058, 0.5891, 0.3257],\\n\",\n \" [-0.6300, -0.0632, 0.6202, 0.3860],\\n\",\n \" [-0.5675, -0.0843, 0.5478, 0.3589],\\n\",\n \" [-0.5526, -0.0981, 0.5321, 0.3428],\\n\",\n \" [-0.5299, -0.1081, 0.5077, 0.3493]]], grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8b0ed78c-e8ac-4f8f-a479-a98242ae8f65\",\n \"metadata\": {},\n \"source\": [\n \"- Note that if you are interested in a compact and efficient implementation of the above, you can also consider the [`torch.nn.MultiheadAttention`](https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html) class in PyTorch\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"363701ad-2022-46c8-9972-390d2a2b9911\",\n \"metadata\": {},\n \"source\": [\n \"- Since the above implementation may look a bit complex at first glance, let's look at what happens when executing `attn_scores = queries @ keys.transpose(2, 3)`:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"e8cfc1ae-78ab-4faa-bc73-98bd054806c9\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[[1.3208, 1.1631, 1.2879],\\n\",\n \" [1.1631, 2.2150, 1.8424],\\n\",\n \" [1.2879, 1.8424, 2.0402]],\\n\",\n \"\\n\",\n \" [[0.4391, 0.7003, 0.5903],\\n\",\n \" [0.7003, 1.3737, 1.0620],\\n\",\n \" [0.5903, 1.0620, 0.9912]]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"# (b, num_heads, num_tokens, head_dim) = (1, 2, 3, 4)\\n\",\n \"a = torch.tensor([[[[0.2745, 0.6584, 0.2775, 0.8573],\\n\",\n \" [0.8993, 0.0390, 0.9268, 0.7388],\\n\",\n \" [0.7179, 0.7058, 0.9156, 0.4340]],\\n\",\n \"\\n\",\n \" [[0.0772, 0.3565, 0.1479, 0.5331],\\n\",\n \" [0.4066, 0.2318, 0.4545, 0.9737],\\n\",\n \" [0.4606, 0.5159, 0.4220, 0.5786]]]])\\n\",\n \"\\n\",\n \"print(a @ a.transpose(2, 3))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0587b946-c8f2-4888-adbf-5a5032fbfd7b\",\n \"metadata\": {},\n \"source\": [\n \"- In this case, the matrix multiplication implementation in PyTorch will handle the 4-dimensional input tensor so that the matrix multiplication is carried out between the 2 last dimensions (num_tokens, head_dim) and then repeated for the individual heads \\n\",\n \"\\n\",\n \"- For instance, the following becomes a more compact way to compute the matrix multiplication for each head separately:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"053760f1-1a02-42f0-b3bf-3d939e407039\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"First head:\\n\",\n \" tensor([[1.3208, 1.1631, 1.2879],\\n\",\n \" [1.1631, 2.2150, 1.8424],\\n\",\n \" [1.2879, 1.8424, 2.0402]])\\n\",\n \"\\n\",\n \"Second head:\\n\",\n \" tensor([[0.4391, 0.7003, 0.5903],\\n\",\n \" [0.7003, 1.3737, 1.0620],\\n\",\n \" [0.5903, 1.0620, 0.9912]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"first_head = a[0, 0, :, :]\\n\",\n \"first_res = first_head @ first_head.T\\n\",\n \"print(\\\"First head:\\\\n\\\", first_res)\\n\",\n \"\\n\",\n \"second_head = a[0, 1, :, :]\\n\",\n \"second_res = second_head @ second_head.T\\n\",\n \"print(\\\"\\\\nSecond head:\\\\n\\\", second_res)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dec671bf-7938-4304-ad1e-75d9920e7f43\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## Summary and takeaways\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fa3e4113-ffca-432c-b3ec-7a50bd15da25\",\n \"metadata\": {},\n \"source\": [\n \"- See the [./multihead-attention.ipynb](./multihead-attention.ipynb) code notebook, which is a concise version of the data loader (chapter 2) plus the multi-head attention class that we implemented in this chapter and will need for training the GPT model in upcoming chapters\\n\",\n \"- You can find the exercise solutions in [./exercise-solutions.ipynb](./exercise-solutions.ipynb)\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch03/01_main-chapter-code/exercise-solutions.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"78224549-3637-44b0-aed1-8ff889c65192\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8b0ed78c-e8ac-4f8f-a479-a98242ae8f65\",\n \"metadata\": {},\n \"source\": [\n \"- Note that if you are interested in a compact and efficient implementation of the above, you can also consider the [`torch.nn.MultiheadAttention`](https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html) class in PyTorch\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"363701ad-2022-46c8-9972-390d2a2b9911\",\n \"metadata\": {},\n \"source\": [\n \"- Since the above implementation may look a bit complex at first glance, let's look at what happens when executing `attn_scores = queries @ keys.transpose(2, 3)`:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"e8cfc1ae-78ab-4faa-bc73-98bd054806c9\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[[1.3208, 1.1631, 1.2879],\\n\",\n \" [1.1631, 2.2150, 1.8424],\\n\",\n \" [1.2879, 1.8424, 2.0402]],\\n\",\n \"\\n\",\n \" [[0.4391, 0.7003, 0.5903],\\n\",\n \" [0.7003, 1.3737, 1.0620],\\n\",\n \" [0.5903, 1.0620, 0.9912]]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"# (b, num_heads, num_tokens, head_dim) = (1, 2, 3, 4)\\n\",\n \"a = torch.tensor([[[[0.2745, 0.6584, 0.2775, 0.8573],\\n\",\n \" [0.8993, 0.0390, 0.9268, 0.7388],\\n\",\n \" [0.7179, 0.7058, 0.9156, 0.4340]],\\n\",\n \"\\n\",\n \" [[0.0772, 0.3565, 0.1479, 0.5331],\\n\",\n \" [0.4066, 0.2318, 0.4545, 0.9737],\\n\",\n \" [0.4606, 0.5159, 0.4220, 0.5786]]]])\\n\",\n \"\\n\",\n \"print(a @ a.transpose(2, 3))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0587b946-c8f2-4888-adbf-5a5032fbfd7b\",\n \"metadata\": {},\n \"source\": [\n \"- In this case, the matrix multiplication implementation in PyTorch will handle the 4-dimensional input tensor so that the matrix multiplication is carried out between the 2 last dimensions (num_tokens, head_dim) and then repeated for the individual heads \\n\",\n \"\\n\",\n \"- For instance, the following becomes a more compact way to compute the matrix multiplication for each head separately:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"053760f1-1a02-42f0-b3bf-3d939e407039\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"First head:\\n\",\n \" tensor([[1.3208, 1.1631, 1.2879],\\n\",\n \" [1.1631, 2.2150, 1.8424],\\n\",\n \" [1.2879, 1.8424, 2.0402]])\\n\",\n \"\\n\",\n \"Second head:\\n\",\n \" tensor([[0.4391, 0.7003, 0.5903],\\n\",\n \" [0.7003, 1.3737, 1.0620],\\n\",\n \" [0.5903, 1.0620, 0.9912]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"first_head = a[0, 0, :, :]\\n\",\n \"first_res = first_head @ first_head.T\\n\",\n \"print(\\\"First head:\\\\n\\\", first_res)\\n\",\n \"\\n\",\n \"second_head = a[0, 1, :, :]\\n\",\n \"second_res = second_head @ second_head.T\\n\",\n \"print(\\\"\\\\nSecond head:\\\\n\\\", second_res)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dec671bf-7938-4304-ad1e-75d9920e7f43\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## Summary and takeaways\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fa3e4113-ffca-432c-b3ec-7a50bd15da25\",\n \"metadata\": {},\n \"source\": [\n \"- See the [./multihead-attention.ipynb](./multihead-attention.ipynb) code notebook, which is a concise version of the data loader (chapter 2) plus the multi-head attention class that we implemented in this chapter and will need for training the GPT model in upcoming chapters\\n\",\n \"- You can find the exercise solutions in [./exercise-solutions.ipynb](./exercise-solutions.ipynb)\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch03/01_main-chapter-code/exercise-solutions.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"78224549-3637-44b0-aed1-8ff889c65192\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \n\n \n#### Forward and backward pass\n\n
\n\n \n#### Forward and backward pass\n\n \n\n \n#### Forward and backward pass after compilation\n\n
\n\n \n#### Forward and backward pass after compilation\n\n \n\n"
},
{
"path": "ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e2e65c03-36d4-413f-9b23-5cdd816729ab\",\n \"metadata\": {\n \"id\": \"e2e65c03-36d4-413f-9b23-5cdd816729ab\"\n },\n \"source\": [\n \"
\n\n"
},
{
"path": "ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e2e65c03-36d4-413f-9b23-5cdd816729ab\",\n \"metadata\": {\n \"id\": \"e2e65c03-36d4-413f-9b23-5cdd816729ab\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"53fe99ab-0bcf-4778-a6b5-6db81fb826ef\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 4.1 Coding an LLM architecture\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ad72d1ff-d82d-4e33-a88e-3c1a8831797b\",\n \"metadata\": {},\n \"source\": [\n \"- Chapter 1 discussed models like GPT and Llama, which generate words sequentially and are based on the decoder part of the original transformer architecture\\n\",\n \"- Therefore, these LLMs are often referred to as \\\"decoder-like\\\" LLMs\\n\",\n \"- Compared to conventional deep learning models, LLMs are larger, mainly due to their vast number of parameters, not the amount of code\\n\",\n \"- We'll see that many elements are repeated in an LLM's architecture\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5c5213e9-bd1c-437e-aee8-f5e8fb717251\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"53fe99ab-0bcf-4778-a6b5-6db81fb826ef\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 4.1 Coding an LLM architecture\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ad72d1ff-d82d-4e33-a88e-3c1a8831797b\",\n \"metadata\": {},\n \"source\": [\n \"- Chapter 1 discussed models like GPT and Llama, which generate words sequentially and are based on the decoder part of the original transformer architecture\\n\",\n \"- Therefore, these LLMs are often referred to as \\\"decoder-like\\\" LLMs\\n\",\n \"- Compared to conventional deep learning models, LLMs are larger, mainly due to their vast number of parameters, not the amount of code\\n\",\n \"- We'll see that many elements are repeated in an LLM's architecture\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5c5213e9-bd1c-437e-aee8-f5e8fb717251\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0d43f5e2-fb51-434a-b9be-abeef6b98d99\",\n \"metadata\": {},\n \"source\": [\n \"- In previous chapters, we used small embedding dimensions for token inputs and outputs for ease of illustration, ensuring they fit on a single page\\n\",\n \"- In this chapter, we consider embedding and model sizes akin to a small GPT-2 model\\n\",\n \"- We'll specifically code the architecture of the smallest GPT-2 model (124 million parameters), as outlined in Radford et al.'s [Language Models are Unsupervised Multitask Learners](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) (note that the initial report lists it as 117M parameters, but this was later corrected in the model weight repository)\\n\",\n \"- Chapter 6 will show how to load pretrained weights into our implementation, which will be compatible with model sizes of 345, 762, and 1542 million parameters\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"21baa14d-24b8-4820-8191-a2808f7fbabc\",\n \"metadata\": {},\n \"source\": [\n \"- Configuration details for the 124 million parameter GPT-2 model include:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"5ed66875-1f24-445d-add6-006aae3c5707\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"GPT_CONFIG_124M = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"emb_dim\\\": 768, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 12, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 12, # Number of layers\\n\",\n \" \\\"drop_rate\\\": 0.1, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": False # Query-Key-Value bias\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c12fcd28-d210-4c57-8be6-06cfcd5d73a4\",\n \"metadata\": {},\n \"source\": [\n \"- We use short variable names to avoid long lines of code later\\n\",\n \"- `\\\"vocab_size\\\"` indicates a vocabulary size of 50,257 words, supported by the BPE tokenizer discussed in Chapter 2\\n\",\n \"- `\\\"context_length\\\"` represents the model's maximum input token count, as enabled by positional embeddings covered in Chapter 2\\n\",\n \"- `\\\"emb_dim\\\"` is the embedding size for token inputs, converting each input token into a 768-dimensional vector\\n\",\n \"- `\\\"n_heads\\\"` is the number of attention heads in the multi-head attention mechanism implemented in Chapter 3\\n\",\n \"- `\\\"n_layers\\\"` is the number of transformer blocks within the model, which we'll implement in upcoming sections\\n\",\n \"- `\\\"drop_rate\\\"` is the dropout mechanism's intensity, discussed in Chapter 3; 0.1 means dropping 10% of hidden units during training to mitigate overfitting\\n\",\n \"- `\\\"qkv_bias\\\"` decides if the `Linear` layers in the multi-head attention mechanism (from Chapter 3) should include a bias vector when computing query (Q), key (K), and value (V) tensors; we'll disable this option, which is standard practice in modern LLMs; however, we'll revisit this later when loading pretrained GPT-2 weights from OpenAI into our reimplementation in chapter 5\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4adce779-857b-4418-9501-12a7f3818d88\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0d43f5e2-fb51-434a-b9be-abeef6b98d99\",\n \"metadata\": {},\n \"source\": [\n \"- In previous chapters, we used small embedding dimensions for token inputs and outputs for ease of illustration, ensuring they fit on a single page\\n\",\n \"- In this chapter, we consider embedding and model sizes akin to a small GPT-2 model\\n\",\n \"- We'll specifically code the architecture of the smallest GPT-2 model (124 million parameters), as outlined in Radford et al.'s [Language Models are Unsupervised Multitask Learners](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) (note that the initial report lists it as 117M parameters, but this was later corrected in the model weight repository)\\n\",\n \"- Chapter 6 will show how to load pretrained weights into our implementation, which will be compatible with model sizes of 345, 762, and 1542 million parameters\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"21baa14d-24b8-4820-8191-a2808f7fbabc\",\n \"metadata\": {},\n \"source\": [\n \"- Configuration details for the 124 million parameter GPT-2 model include:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"5ed66875-1f24-445d-add6-006aae3c5707\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"GPT_CONFIG_124M = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"emb_dim\\\": 768, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 12, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 12, # Number of layers\\n\",\n \" \\\"drop_rate\\\": 0.1, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": False # Query-Key-Value bias\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c12fcd28-d210-4c57-8be6-06cfcd5d73a4\",\n \"metadata\": {},\n \"source\": [\n \"- We use short variable names to avoid long lines of code later\\n\",\n \"- `\\\"vocab_size\\\"` indicates a vocabulary size of 50,257 words, supported by the BPE tokenizer discussed in Chapter 2\\n\",\n \"- `\\\"context_length\\\"` represents the model's maximum input token count, as enabled by positional embeddings covered in Chapter 2\\n\",\n \"- `\\\"emb_dim\\\"` is the embedding size for token inputs, converting each input token into a 768-dimensional vector\\n\",\n \"- `\\\"n_heads\\\"` is the number of attention heads in the multi-head attention mechanism implemented in Chapter 3\\n\",\n \"- `\\\"n_layers\\\"` is the number of transformer blocks within the model, which we'll implement in upcoming sections\\n\",\n \"- `\\\"drop_rate\\\"` is the dropout mechanism's intensity, discussed in Chapter 3; 0.1 means dropping 10% of hidden units during training to mitigate overfitting\\n\",\n \"- `\\\"qkv_bias\\\"` decides if the `Linear` layers in the multi-head attention mechanism (from Chapter 3) should include a bias vector when computing query (Q), key (K), and value (V) tensors; we'll disable this option, which is standard practice in modern LLMs; however, we'll revisit this later when loading pretrained GPT-2 weights from OpenAI into our reimplementation in chapter 5\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4adce779-857b-4418-9501-12a7f3818d88\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"619c2eed-f8ea-4ff5-92c3-feda0f29b227\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class DummyGPTModel(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" self.pos_emb = nn.Embedding(cfg[\\\"context_length\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" self.drop_emb = nn.Dropout(cfg[\\\"drop_rate\\\"])\\n\",\n \" \\n\",\n \" # Use a placeholder for TransformerBlock\\n\",\n \" self.trf_blocks = nn.Sequential(\\n\",\n \" *[DummyTransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])])\\n\",\n \" \\n\",\n \" # Use a placeholder for LayerNorm\\n\",\n \" self.final_norm = DummyLayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.out_head = nn.Linear(\\n\",\n \" cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False\\n\",\n \" )\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" batch_size, seq_len = in_idx.shape\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\\n\",\n \" x = tok_embeds + pos_embeds\\n\",\n \" x = self.drop_emb(x)\\n\",\n \" x = self.trf_blocks(x)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x)\\n\",\n \" return logits\\n\",\n \"\\n\",\n \"\\n\",\n \"class DummyTransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" # A simple placeholder\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # This block does nothing and just returns its input.\\n\",\n \" return x\\n\",\n \"\\n\",\n \"\\n\",\n \"class DummyLayerNorm(nn.Module):\\n\",\n \" def __init__(self, normalized_shape, eps=1e-5):\\n\",\n \" super().__init__()\\n\",\n \" # The parameters here are just to mimic the LayerNorm interface.\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # This layer does nothing and just returns its input.\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9665e8ab-20ca-4100-b9b9-50d9bdee33be\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"619c2eed-f8ea-4ff5-92c3-feda0f29b227\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class DummyGPTModel(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" self.pos_emb = nn.Embedding(cfg[\\\"context_length\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" self.drop_emb = nn.Dropout(cfg[\\\"drop_rate\\\"])\\n\",\n \" \\n\",\n \" # Use a placeholder for TransformerBlock\\n\",\n \" self.trf_blocks = nn.Sequential(\\n\",\n \" *[DummyTransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])])\\n\",\n \" \\n\",\n \" # Use a placeholder for LayerNorm\\n\",\n \" self.final_norm = DummyLayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.out_head = nn.Linear(\\n\",\n \" cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False\\n\",\n \" )\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" batch_size, seq_len = in_idx.shape\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\\n\",\n \" x = tok_embeds + pos_embeds\\n\",\n \" x = self.drop_emb(x)\\n\",\n \" x = self.trf_blocks(x)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x)\\n\",\n \" return logits\\n\",\n \"\\n\",\n \"\\n\",\n \"class DummyTransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" # A simple placeholder\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # This block does nothing and just returns its input.\\n\",\n \" return x\\n\",\n \"\\n\",\n \"\\n\",\n \"class DummyLayerNorm(nn.Module):\\n\",\n \" def __init__(self, normalized_shape, eps=1e-5):\\n\",\n \" super().__init__()\\n\",\n \" # The parameters here are just to mimic the LayerNorm interface.\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # This layer does nothing and just returns its input.\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9665e8ab-20ca-4100-b9b9-50d9bdee33be\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"794b6b6c-d36f-411e-a7db-8ac566a87fee\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[6109, 3626, 6100, 345],\\n\",\n \" [6109, 1110, 6622, 257]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"import tiktoken\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"batch = []\\n\",\n \"\\n\",\n \"txt1 = \\\"Every effort moves you\\\"\\n\",\n \"txt2 = \\\"Every day holds a\\\"\\n\",\n \"\\n\",\n \"batch.append(torch.tensor(tokenizer.encode(txt1)))\\n\",\n \"batch.append(torch.tensor(tokenizer.encode(txt2)))\\n\",\n \"batch = torch.stack(batch, dim=0)\\n\",\n \"print(batch)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"009238cd-0160-4834-979c-309710986bb0\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output shape: torch.Size([2, 4, 50257])\\n\",\n \"tensor([[[-1.2034, 0.3201, -0.7130, ..., -1.5548, -0.2390, -0.4667],\\n\",\n \" [-0.1192, 0.4539, -0.4432, ..., 0.2392, 1.3469, 1.2430],\\n\",\n \" [ 0.5307, 1.6720, -0.4695, ..., 1.1966, 0.0111, 0.5835],\\n\",\n \" [ 0.0139, 1.6754, -0.3388, ..., 1.1586, -0.0435, -1.0400]],\\n\",\n \"\\n\",\n \" [[-1.0908, 0.1798, -0.9484, ..., -1.6047, 0.2439, -0.4530],\\n\",\n \" [-0.7860, 0.5581, -0.0610, ..., 0.4835, -0.0077, 1.6621],\\n\",\n \" [ 0.3567, 1.2698, -0.6398, ..., -0.0162, -0.1296, 0.3717],\\n\",\n \" [-0.2407, -0.7349, -0.5102, ..., 2.0057, -0.3694, 0.1814]]],\\n\",\n \" grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"794b6b6c-d36f-411e-a7db-8ac566a87fee\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[6109, 3626, 6100, 345],\\n\",\n \" [6109, 1110, 6622, 257]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"import tiktoken\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"batch = []\\n\",\n \"\\n\",\n \"txt1 = \\\"Every effort moves you\\\"\\n\",\n \"txt2 = \\\"Every day holds a\\\"\\n\",\n \"\\n\",\n \"batch.append(torch.tensor(tokenizer.encode(txt1)))\\n\",\n \"batch.append(torch.tensor(tokenizer.encode(txt2)))\\n\",\n \"batch = torch.stack(batch, dim=0)\\n\",\n \"print(batch)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"009238cd-0160-4834-979c-309710986bb0\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output shape: torch.Size([2, 4, 50257])\\n\",\n \"tensor([[[-1.2034, 0.3201, -0.7130, ..., -1.5548, -0.2390, -0.4667],\\n\",\n \" [-0.1192, 0.4539, -0.4432, ..., 0.2392, 1.3469, 1.2430],\\n\",\n \" [ 0.5307, 1.6720, -0.4695, ..., 1.1966, 0.0111, 0.5835],\\n\",\n \" [ 0.0139, 1.6754, -0.3388, ..., 1.1586, -0.0435, -1.0400]],\\n\",\n \"\\n\",\n \" [[-1.0908, 0.1798, -0.9484, ..., -1.6047, 0.2439, -0.4530],\\n\",\n \" [-0.7860, 0.5581, -0.0610, ..., 0.4835, -0.0077, 1.6621],\\n\",\n \" [ 0.3567, 1.2698, -0.6398, ..., -0.0162, -0.1296, 0.3717],\\n\",\n \" [-0.2407, -0.7349, -0.5102, ..., 2.0057, -0.3694, 0.1814]]],\\n\",\n \" grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5ab49940-6b35-4397-a80e-df8d092770a7\",\n \"metadata\": {},\n \"source\": [\n \"- Let's see how layer normalization works by passing a small input sample through a simple neural network layer:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"79e1b463-dc3f-44ac-9cdb-9d5b6f64eb9d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.2260, 0.3470, 0.0000, 0.2216, 0.0000, 0.0000],\\n\",\n \" [0.2133, 0.2394, 0.0000, 0.5198, 0.3297, 0.0000]],\\n\",\n \" grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5ab49940-6b35-4397-a80e-df8d092770a7\",\n \"metadata\": {},\n \"source\": [\n \"- Let's see how layer normalization works by passing a small input sample through a simple neural network layer:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"79e1b463-dc3f-44ac-9cdb-9d5b6f64eb9d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[0.2260, 0.3470, 0.0000, 0.2216, 0.0000, 0.0000],\\n\",\n \" [0.2133, 0.2394, 0.0000, 0.5198, 0.3297, 0.0000]],\\n\",\n \" grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9f8ecbc7-eb14-4fa1-b5d0-7e1ff9694f99\",\n \"metadata\": {},\n \"source\": [\n \"- Subtracting the mean and dividing by the square-root of the variance (standard deviation) centers the inputs to have a mean of 0 and a variance of 1 across the column (feature) dimension:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"9a1d1bb9-3341-4c9a-bc2a-d2489bf89cda\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Normalized layer outputs:\\n\",\n \" tensor([[ 0.6159, 1.4126, -0.8719, 0.5872, -0.8719, -0.8719],\\n\",\n \" [-0.0189, 0.1121, -1.0876, 1.5173, 0.5647, -1.0876]],\\n\",\n \" grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9f8ecbc7-eb14-4fa1-b5d0-7e1ff9694f99\",\n \"metadata\": {},\n \"source\": [\n \"- Subtracting the mean and dividing by the square-root of the variance (standard deviation) centers the inputs to have a mean of 0 and a variance of 1 across the column (feature) dimension:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"9a1d1bb9-3341-4c9a-bc2a-d2489bf89cda\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Normalized layer outputs:\\n\",\n \" tensor([[ 0.6159, 1.4126, -0.8719, 0.5872, -0.8719, -0.8719],\\n\",\n \" [-0.0189, 0.1121, -1.0876, 1.5173, 0.5647, -1.0876]],\\n\",\n \" grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"11190e7d-8c29-4115-824a-e03702f9dd54\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 4.3 Implementing a feed forward network with GELU activations\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b0585dfb-f21e-40e5-973f-2f63ad5cb169\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we implement a small neural network submodule that is used as part of the transformer block in LLMs\\n\",\n \"- We start with the activation function\\n\",\n \"- In deep learning, ReLU (Rectified Linear Unit) activation functions are commonly used due to their simplicity and effectiveness in various neural network architectures\\n\",\n \"- In LLMs, various other types of activation functions are used beyond the traditional ReLU; two notable examples are GELU (Gaussian Error Linear Unit) and SwiGLU (Swish-Gated Linear Unit)\\n\",\n \"- GELU and SwiGLU are more complex, smooth activation functions incorporating Gaussian and sigmoid-gated linear units, respectively, offering better performance for deep learning models, unlike the simpler, piecewise linear function of ReLU\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7d482ce7-e493-4bfc-a820-3ea99f564ebc\",\n \"metadata\": {},\n \"source\": [\n \"- GELU ([Hendrycks and Gimpel 2016](https://arxiv.org/abs/1606.08415)) can be implemented in several ways; the exact version is defined as GELU(x)=x⋅Φ(x), where Φ(x) is the cumulative distribution function of the standard Gaussian distribution.\\n\",\n \"- In practice, it's common to implement a computationally cheaper approximation: $\\\\text{GELU}(x) \\\\approx 0.5 \\\\cdot x \\\\cdot \\\\left(1 + \\\\tanh\\\\left[\\\\sqrt{\\\\frac{2}{\\\\pi}} \\\\cdot \\\\left(x + 0.044715 \\\\cdot x^3\\\\right)\\\\right]\\\\right)\\n\",\n \"$ (the original GPT-2 model was also trained with this approximation)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"f84694b7-95f3-4323-b6d6-0a73df278e82\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class GELU(nn.Module):\\n\",\n \" def __init__(self):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" return 0.5 * x * (1 + torch.tanh(\\n\",\n \" torch.sqrt(torch.tensor(2.0 / torch.pi)) * \\n\",\n \" (x + 0.044715 * torch.pow(x, 3))\\n\",\n \" ))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"fc5487d2-2576-4118-80a7-56c4caac2e71\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAxYAAAEiCAYAAABkykQ1AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy80BEi2AAAACXBIWXMAAA9hAAAPYQGoP6dpAABoBElEQVR4nO3deVhUZfsH8O8My7AJiiDIIioqigsqpKG5lYpbRSnZ4p6WhpVLlvgrTXuTytxyt1KSNPelzExcSM0dREWDXEBc2JRVlmGYOb8/kEkElGE7Z4bv57rmet85c5b7nsl5uOc5z/PIBEEQQEREREREVAVysQMgIiIiIiL9x8KCiIiIiIiqjIUFERERERFVGQsLIiIiIiKqMhYWRERERERUZSwsiIiIiIioylhYEBERERFRlbGwICIiIiKiKmNhQUREREREVcbCgqgMn3/+OWQymSjXDgkJgUwmQ3x8fK1fu7CwEB9//DFcXV0hl8vh7+9f6zFUhJjvERHVbWPGjEHTpk1FubaYbdODBw8wfvx4ODo6QiaTYcqUKaLE8TRivkfEwqJOiouLw+TJk9GqVStYWFjAwsICnp6eCAwMxMWLF0vsW/wPtLxHUlISACA+Ph4ymQzffvttuddt2rQphgwZUuZr586dg0wmQ0hISLXl+TS5ubn4/PPPER4eXmvXfNT8+fOxe/duUa5dnnXr1mHBggUYNmwYfvrpJ0ydOlXUeKT4HhEZsuKivfhhbGwMZ2dnjBkzBnfu3KnUOcPDwyGTybB9+/Zy95HJZJg8eXKZr23fvh0ymaxWv6vv3r2Lzz//HFFRUbV2zWJit03lmT9/PkJCQjBp0iSEhoZi5MiRosUi1feIAGOxA6DatXfvXgwfPhzGxsZ466234OXlBblcjpiYGOzcuROrVq1CXFwc3NzcShy3atUqWFlZlTpf/fr1ayny6pebm4u5c+cCAHr37l3itU8//RQzZ86s0evPnz8fw4YNK9UrMHLkSLz++utQKBQ1ev2yHD58GM7Ozli8eHGtX7ssUnyPiOqCefPmoVmzZsjPz8epU6cQEhKC48ePIzo6GmZmZmKHV+Pu3r2LuXPnomnTpujYsWOJ177//ntoNJoau7bYbVN5Dh8+jGeffRZz5swR5fqPkup7RCws6pTr16/j9ddfh5ubGw4dOoTGjRuXeP3rr7/GypUrIZeX7sgaNmwY7OzsaitU0RkbG8PYWJx/HkZGRjAyMhLl2ikpKXpRLIr5HhHVBQMHDoSPjw8AYPz48bCzs8PXX3+NX3/9Fa+99prI0YnLxMREtGuL2TalpKTA09NTlGvrQsz3iHgrVJ3yzTffICcnB+vXry9VVABF/xg/+OADuLq6ihBdxaSlpeGjjz5C+/btYWVlBWtrawwcOBAXLlwotW9+fj4+//xztGrVCmZmZmjcuDFeffVVXL9+HfHx8bC3twcAzJ07V9vt//nnnwMofY9mu3bt0KdPn1LX0Gg0cHZ2xrBhw7Tbvv32W3Tr1g0NGzaEubk5vL29S90CIJPJkJOTg59++kl77TFjxgAof/zAypUr0bZtWygUCjg5OSEwMBAZGRkl9unduzfatWuHK1euoE+fPrCwsICzszO++eabJ76vxbeyHTlyBJcvX9bGFB4err2N4fEu5+JjHr19bcyYMbCyssKdO3fg7+8PKysr2Nvb46OPPoJarS713i1duhTt27eHmZkZ7O3tMWDAAJw7d06S7xFRXdajRw8ART9QPSomJgbDhg2Dra0tzMzM4OPjg19//VWMEHHz5k2899578PDwgLm5ORo2bIiAgIAyx2JlZGRg6tSpaNq0KRQKBVxcXDBq1Cjcu3cP4eHheOaZZwAAY8eO1X7/FH/XPTrGQqVSwdbWFmPHji11jaysLJiZmeGjjz4CABQUFGD27Nnw9vaGjY0NLC0t0aNHDxw5ckR7jK5tE1A0Nu6LL76Au7s7FAoFmjZtilmzZkGpVJbYr/h25OPHj6NLly4wMzND8+bNsWHDhie+r8VtQFxcHH7//XdtTPHx8eV+F5fVbujy3Vud7XdtvEf0HxYWdcjevXvRokULdO3aVedj09LScO/evRKPx/9gqw03btzA7t27MWTIECxatAgzZszApUuX0KtXL9y9e1e7n1qtxpAhQzB37lx4e3tj4cKF+PDDD5GZmYno6GjY29tj1apVAIBXXnkFoaGhCA0NxauvvlrmdYcPH46jR49qx5QUO378OO7evYvXX39du23p0qXo1KkT5s2bh/nz58PY2BgBAQH4/ffftfuEhoZCoVCgR48e2mu/++675eb9+eefIzAwEE5OTli4cCGGDh2KNWvWoH///lCpVCX2TU9Px4ABA+Dl5YWFCxeidevW+OSTT/DHH3+Ue357e3uEhoaidevWcHFx0cbUpk2bco8pj1qthp+fHxo2bIhvv/0WvXr1wsKFC7F27doS+7399tuYMmUKXF1d8fXXX2PmzJkwMzPDqVOnJPkeEdVlxX84NmjQQLvt8uXLePbZZ/HPP/9g5syZWLhwISwtLeHv749du3bVeoxnz57FiRMn8Prrr+O7777DxIkTcejQIfTu3Ru5ubna/R48eIAePXpg2bJl6N+/P5YuXYqJEyciJiYGt2/fRps2bTBv3jwAwDvvvKP9/unZs2epa5qYmOCVV17B7t27UVBQUOK13bt3Q6lUatuHrKws/PDDD+jduze+/vprfP7550hNTYWfn592LIeubRNQ1KM0e/ZsdO7cGYsXL0avXr0QHBxcol0qdu3aNQwbNgz9+vXDwoUL0aBBA4wZMwaXL18u9/xt2rRBaGgo7Ozs0LFjR21MxX/c66Ii373V3X7XxntEjxCoTsjMzBQACP7+/qVeS09PF1JTU7WP3Nxc7Wtz5swRAJT58PDw0O4XFxcnABAWLFhQbgxubm7C4MGDy3zt7NmzAgBh/fr1T8wjPz9fUKvVJbbFxcUJCoVCmDdvnnbbunXrBADCokWLSp1Do9EIgiAIqampAgBhzpw5pfYpzrtYbGysAEBYtmxZif3ee+89wcrKqsR79uj/FwRBKCgoENq1ayc8//zzJbZbWloKo0ePLnXt9evXCwCEuLg4QRAEISUlRTA1NRX69+9fIvfly5cLAIR169Zpt/Xq1UsAIGzYsEG7TalUCo6OjsLQoUNLXetxvXr1Etq2bVti25EjRwQAwpEjR0psL/7MH/3MRo8eLQAo8VkIgiB06tRJ8Pb21j4/fPiwAED44IMPSsVQ/PkIgjTfIyJDVvxv6+DBg0Jqaqpw69YtYfv27YK9vb2gUCiEW7duafd94YUXhPbt2wv5+fnabRqNRujWrZvQsmVL7bbi75Bt27aVe10AQmBgYJmvbdu2rczvoMc9/t0rCIJw8uTJUv/eZ8+eLQAQdu7cWWr/4u+fJ7VJo0ePFtzc3LTP//zzTwGA8Ntvv5XYb9CgQULz5s21zwsLCwWlUllin/T0dMHBwUEYN26cdpsubVNUVJQAQBg/fnyJ/T766CMBgHD48GHtNjc3NwGAcPToUe22lJQUQaFQCNOnTy91rceV1YY//l1crKx2o6LfvdXdftfme0SCwB6LOiIrKwsAyhyA3bt3b9jb22sfK1asKLXPjh07EBYWVuKxfv36Go/7cQqFQjsGRK1W4/79+7CysoKHhwciIyNLxGtnZ4f333+/1DkqMw1dq1at0LFjR2zZskW7Ta1WY/v27XjxxRdhbm6u3f7o/09PT0dmZiZ69OhRIj5dHDx4EAUFBZgyZUqJ8S8TJkyAtbV1iZ4QoOgzHjFihPa5qakpunTpghs3blTq+pUxceLEEs979OhR4vo7duyATCYrcxBgZT4ffXyPiKSsb9++sLe3h6urK4YNGwZLS0v8+uuvcHFxAVDUi3348GG89tpryM7O1vZk379/H35+frh69WqlZ5GqrEe/e1UqFe7fv48WLVqgfv36pdoHLy8vvPLKK6XOUZnvn+effx52dnYl2of09HSEhYVh+PDh2m1GRkYwNTUFUHQraFpaGgoLC+Hj41Pp9mHfvn0AgGnTppXYPn36dAAo9d3n6empva0NKOoh8fDwqLXvvop891Z3+61v75G+4+iWOqJevXoAirqAH7dmzRpkZ2cjOTm5xD/4R/Xs2bNWBm8/7Uuj+L78lStXIi4ursR9+w0bNtT+/+vXr8PDw6NaB3ANHz4cs2bNwp07d+Ds7Izw8HCkpKSUaDiAolvO/ve//yEqKqrE/ZuVnVf75s2bAAAPD48S201NTdG8eXPt68VcXFxKXatBgwalphKuKcXjJR6/fnp6uvb59evX4eTkBFtb22q5pr69R0RSt2LFCrRq1QqZmZlYt24djh49WmIWtmvXrkEQBHz22Wf47LPPyjxHSkoKnJ2dqy2mp32H5uXlITg4GOvXr8edO3cgCIL2tczMTO3/v379OoYOHVptcRkbG2Po0KHYtGkTlEolFAoFdu7cCZVKVap9+Omnn7Bw4ULExMSUuEWzWbNmlbr2zZs3IZfL0aJFixLbHR0dUb9+/VLffU2aNCl1jse/n2tSRb57q7v91rf3SN+xsKgjbGxs0LhxY0RHR5d6rXjMRU0vNmZmZoa8vLwyXyu+//Vp0xjOnz8fn332GcaNG4cvvvgCtra2kMvlmDJlSo1O/wcUFRZBQUHYtm0bpkyZgq1bt8LGxgYDBgzQ7nPs2DG89NJL6NmzJ1auXInGjRvDxMQE69evx6ZNm2o0vmLlzZb0aCOri/Ia88cHYz/t+lJS3e8RkaHp0qWLdlYof39/PPfcc3jzzTcRGxsLKysr7fftRx99BD8/vzLP8fgfck+iUCiq3D68//77WL9+PaZMmQJfX1/Y2NhAJpPh9ddfr/H24fXXX8eaNWvwxx9/wN/fH1u3bkXr1q3h5eWl3efnn3/GmDFj4O/vjxkzZqBRo0YwMjJCcHBwqUHxuqroD1dSbR9q47tXrPeormFhUYcMHjwYP/zwA86cOYMuXbrU+vXd3Nxw5cqVMl+LjY3V7vMk27dvR58+ffDjjz+W2J6RkVGiR8Xd3R2nT5+GSqUqd2pAXXsQmjVrhi5dumDLli2YPHkydu7cCX9//xK/4u3YsQNmZmb4888/S2wv67axil6/+D2JjY1F8+bNtdsLCgoQFxeHvn376pSHrooHaz4+WP/xX3l04e7ujj///BNpaWlP7LXQl/eIyJAV//Hbp08fLF++HDNnztT+OzMxMamWf19ubm7aduBxurQPo0ePxsKFC7Xb8vPzS313ubu7l/kj26N0bR969uyJxo0bY8uWLXjuuedw+PBh/N///V+p+Jo3b46dO3eWOP/jt4Tqcm03NzdoNBpcvXq1xGQbycnJyMjIeOp7VlU11T5UZ/st9ntU13CMRR3y8ccfw8LCAuPGjUNycnKp12u6Gh80aBBu375daiVlpVKJH374AY0aNULnzp2feA4jI6NScW7btq3UvbxDhw7FvXv3sHz58lLnKD7ewsICQOkvxCcZPnw4Tp06hXXr1uHevXulurmNjIwgk8lK/FoTHx9f5urRlpaWFbp23759YWpqiu+++65E7j/++CMyMzMxePDgCsdfGW5ubjAyMsLRo0dLbF+5cmWlzzl06FAIgqBd4OhRj+aoL+8RkaHr3bs3unTpgiVLliA/Px+NGjVC7969sWbNGiQmJpbaPzU1VafzDxo0CKdOnUJERESJ7RkZGdi4cSM6duwIR0fHJ56jrPZh2bJlpX49Hzp0KC5cuFDmzFXFx1taWmqvXxFyuRzDhg3Db7/9htDQUBQWFpbZPjx6DQA4ffo0Tp48WWI/XdqmQYMGAQCWLFlSYvuiRYsAoMa/+9zd3QGgRPugVqtLzQKoi+puv8V+j+oa9ljUIS1btsSmTZvwxhtvwMPDQ7vytiAIiIuLw6ZNmyCXy7WD8x61ffv2Mgd+9+vXDw4ODtrnhw4dQn5+fqn9/P398c4772DdunUICAjAuHHj0KlTJ9y/fx9btmxBdHQ0NmzYoB3YVp4hQ4Zg3rx5GDt2LLp164ZLly5h48aNJX6lBoBRo0Zhw4YNmDZtGs6cOYMePXogJycHBw8exHvvvYeXX34Z5ubm8PT0xJYtW9CqVSvY2tqiXbt2aNeuXbnXf+211/DRRx/ho48+gq2tbalf6gYPHoxFixZhwIABePPNN5GSkoIVK1agRYsWpe7f9/b2xsGDB7Fo0SI4OTmhWbNmZU4FbG9vj6CgIMydOxcDBgzASy+9hNjYWKxcuRLPPPNMueNiqouNjQ0CAgKwbNkyyGQyuLu7Y+/evUhJSan0Ofv06YORI0fiu+++w9WrVzFgwABoNBocO3YMffr0weTJkwHoz3tEVBfMmDEDAQEBCAkJwcSJE7FixQo899xzaN++PSZMmIDmzZsjOTkZJ0+exO3bt0utL7Rjxw7ExMSUOu/o0aMxc+ZMbNu2DT179sS7776L1q1b4+7duwgJCUFiYmKFJgsZMmQIQkNDYWNjA09PT5w8eRIHDx4sMf6uOI/t27dr2yJvb2+kpaXh119/xerVq+Hl5QV3d3fUr18fq1evRr169WBpaYmuXbs+cSzE8OHDsWzZMsyZMwft27cvNV33kCFDsHPnTrzyyisYPHgw4uLisHr1anh6epYY/6hL2+Tl5YXRo0dj7dq1yMjIQK9evXDmzBn89NNP8Pf3L3P9perUtm1bPPvsswgKCtL2QG/evBmFhYWVPmd1t99iv0d1Ti3PQkUScO3aNWHSpElCixYtBDMzM8Hc3Fxo3bq1MHHiRCEqKqrEvk+abhaPTCVXPPVoeY/Q0FBBEIqm1ps6darQrFkzwcTERLC2thb69Okj/PHHHxWKPT8/X5g+fbrQuHFjwdzcXOjevbtw8uRJoVevXkKvXr1K7Jubmyv83//9n/Zajo6OwrBhw4Tr169r9zlx4oTg7e0tmJqalpi67vHp6h7VvXv3MqeuK/bjjz8KLVu2FBQKhdC6dWth/fr1ZZ4vJiZG6Nmzp2Bubi4A0E6rWt70fcuXLxdat24tmJiYCA4ODsKkSZOE9PT0EvuUNV2sIJSeHrE85R2fmpoqDB06VLCwsBAaNGggvPvuu0J0dHSZ081aWlqWOr6s/AsLC4UFCxYIrVu3FkxNTQV7e3th4MCBQkREhHYfKb5HRIas+N/W2bNnS72mVqsFd3d3wd3dXSgsLBQEQRCuX78ujBo1SnB0dBRMTEwEZ2dnYciQIcL27du1xxVPPVre49ixY4IgCMLt27eF8ePHC87OzoKxsbFga2srDBkyRDh16lSFYk9PTxfGjh0r2NnZCVZWVoKfn58QExMjuLm5lZq2+v79+8LkyZMFZ2dnwdTUVHBxcRFGjx4t3Lt3T7vPnj17BE9PT8HY2LjEd1153xUajUZwdXUVAAj/+9//ynx9/vz5gpubm6BQKIROnToJe/fuLfN8urRNKpVKmDt3rratc3V1FYKCgkpMAywI5U/5Xlb7WZbyjr9+/brQt29fQaFQCA4ODsKsWbOEsLCwMqebreh3b3W337X1HpEgyASBo1GIiIiIiKhqOMaCiIiIiIiqjIUFERERERFVGQsLIiIiIiKqMhYWRERERERUZSwsiIiIiIioylhYEBERERFRldW5BfI0Gg3u3r2LevXq6bQkPBGRIRMEAdnZ2XBycoJcXnd/c2IbQURUki7tQ50rLO7evQtXV1exwyAikqRbt27BxcVF7DBEwzaCiKhsFWkf6lxhUa9ePQBFb461tbVOx6pUKhw4cAD9+/eHiYlJTYRXKwwhD+YgHYaQhyHkAFQtj6ysLLi6umq/I+uqut5GMAfpMIQ8DCEHwDDyqK32oc4VFsVd29bW1pVqNCwsLGBtba23/2EBhpEHc5AOQ8jDEHIAqiePun77T11vI5iDdBhCHoaQA2AYedRW+1B3b6QlIiIiIqJqw8KCiIiIiIiqTNTCYtWqVejQoYO2y9nX1xd//PHHE4/Ztm0bWrduDTMzM7Rv3x779u2rpWiJiKi2sH0gItI/ohYWLi4u+OqrrxAREYFz587h+eefx8svv4zLly+Xuf+JEyfwxhtv4O2338b58+fh7+8Pf39/REdH13LkRERUk9g+EBHpH1ELixdffBGDBg1Cy5Yt0apVK3z55ZewsrLCqVOnytx/6dKlGDBgAGbMmIE2bdrgiy++QOfOnbF8+fJajpyIiGoS2wciIv0jmVmh1Go1tm3bhpycHPj6+pa5z8mTJzFt2rQS2/z8/LB79+5yz6tUKqFUKrXPs7KyABSNjlepVDrFWLy/rsdJjSHkwRykwxDyMIgc1BrM23sFrdSVy0PKuddU+0BEVFccu3oPh+/KMFAQavQ6ohcWly5dgq+vL/Lz82FlZYVdu3bB09OzzH2TkpLg4OBQYpuDgwOSkpLKPX9wcDDmzp1bavuBAwdgYWFRqZjDwsIqdZzUGEIezEE6DCEPfc5h6w05/k6Wo6HCCDamYTDWsT86Nze3ZgKrgppuHwD++PQ45iAdhpCHIeQA6H8eN9NyMWXrRWTlG8HnbAJe7+Km0/G65C16YeHh4YGoqChkZmZi+/btGD16NP76669yGw9dBQUFlfgVq3iRj/79+1dqjvKwsDD069dPb+cxBgwjD+YgHYaQh77n8PPpBPx9MgYyAK801WCgn+55FP9BLSU13T4A/PGpPMxBOgwhD0PIAdDPPJRqYPElI2Tly+BmJcAi5TL27St7rFp5dPnhSfTCwtTUFC1atAAAeHt74+zZs1i6dCnWrFlTal9HR0ckJyeX2JacnAxHR8dyz69QKKBQKEptNzExqfQfEFU5VkoMIQ/mIB2GkIc+5nDsair+ty8WADC9X0u4PvinUnlIMe+abh8A/vj0OOYgHYaQhyHkAOhvHoIgYMrWi0jMS0ZDS1OMa5Vb4z88iV5YPE6j0ZToln6Ur68vDh06hClTpmi3hYWFlXvPLRGRIbuR+gCBGyOh1gh4tbMz3unRFH/88Y/YYdWYmmgf+ONT2ZiDdBhCHoaQA6B/eaz+6zr2RSfDWC7D8je8kHL5ZI3/8CRqYREUFISBAweiSZMmyM7OxqZNmxAeHo4///wTADBq1Cg4OzsjODgYAPDhhx+iV69eWLhwIQYPHozNmzfj3LlzWLt2rZhpEBHVusxcFcb/dA5Z+YXo3KQ+5r/SHjJoxA6r2rB9ICKqvKP/puKb/TEAgDkvtYWPWwPoeAdUpYhaWKSkpGDUqFFITEyEjY0NOnTogD///BP9+vUDACQkJEAu/28EYrdu3bBp0yZ8+umnmDVrFlq2bIndu3ejXbt2YqVARFTrCtUaTP4lEjfu5cDJxgxrRvrAzMQIKpXhFBZsH4iIKifhfi7e/+U8NAIQ4O2CEV2boLCwsFauLWph8eOPPz7x9fDw8FLbAgICEBAQUEMRERFJ3/9+/wfHrt6DuYkRvh/tA/t6pW/l0XdsH4iIdJdbUIh3Qs8hM08FL9f6+MK/HWQyWa1dX9QF8oiISDebTicg5EQ8AGDxcC+0dbIRNyAiIpIEQRDwyY5LiEnKhp2VKVaP6AwzE6NajYGFBRGRnjh5/T5m74kGAEzv1woD2jUWOSIiIpKKH47F4bcLd2Esl2HlW95obGNe6zGwsCAi0gMJ93MxaWMECjUCXvRywuTnW4gdEhERScTxq/cQ/HBWwM+GeKJLM1tR4mBhQUQkcdn5KozfcBYZuSp0cLHBgmEdavWeWSIikq5babl4/5dIaARgmLcLRvnqtrJ2dWJhQUQkYWqNgCmbo/Bv8gM4WCvw/SifWr9nloiIpCmvQI13QyOQ/vCHp//V8mDtx7GwICKSsAV/xuJQTAoUxnKsHekDB2szsUMiIiIJEAQBQTsv4kpiFhpammL1CG/Rf3hiYUFEJFE7I29j9V/XAQDfDOsAL9f64gZERESSse7veOyOugsjuQwr3uoMp/q1P1j7cSwsiIgk6HxCOmbuvAQACOzjjpc7OoscERERScWJ6/cwf1/RYO1PB7fBs80bihxRERYWREQSk5iZh3dCI1BQqEE/TwdM7+chdkhERCQRt9NzMXnTeag1Al7t7Iwx3ZqKHZIWCwsiIgnJV6nxzoYIpGYr0dqxHpYM7wi5nDNAERFRURsx8ecIpOUUoJ2zNea/0l5SswSysCAikghBEDBj+0VcupMJW0tTfD/KB5YKY7HDIiIiCRAEAbN2XUL0nSzYWppizUjpzRLIwoKISCJWhl9/ZNXUznC1tRA7JCIikoiQE/HYGXkHRnIZlr/ZCc4SGKz9OBYWREQSEHYlGd8eiAUAzH25rWQG4hERkfhO3biP//1eNFh71qA26OZuJ3JEZWNhQUQkstikbEzZfB6CAIzydcNbXcVbNZWIiKTlTkYeAjdGQq0R4N/RCeO6NxU7pHKxsCAiElF6TgHGbziLnAI1fJs3xGdDPMUOiYiIJCJfpcaknyNwP6cAbZ2sEfxqB0kN1n4cCwsiIpGo1Bq8tzESt9Ly4GprjpVvdYaJEb+WiYioaLD2/+2KxsXbmWhgYYLVI7xhbiqtwdqPYwtGRCSS/+29gpM37sPS1Ag/jHoGDSxNxQ6JiIgkIvTUTeyIvA25DFj+pn5M6MHCgohIBL+cScBPJ28CABYP7wgPx3oiR0RERFJx+sZ9zPvtCgAgaGAbdG8hzcHajxO1sAgODsYzzzyDevXqoVGjRvD390dsbOwTjwkJCYFMJivxMDMzq6WIiYiq7mx8GmbviQYAfNS/Ffq3dRQ5IiIikorEzDwEbopEoUbAS15OGN+jmdghVZiohcVff/2FwMBAnDp1CmFhYVCpVOjfvz9ycnKeeJy1tTUSExO1j5s3b9ZSxEREVXMnIw8TQyOgUgsY3KExAvu0EDskIiKSiKKVtSNx70EB2jS2xtdDpT1Y+3GiFhb79+/HmDFj0LZtW3h5eSEkJAQJCQmIiIh44nEymQyOjo7ah4ODQy1FTERUeXkFarwbeg73cwrg2dgaC4bpV4NRm9ijTUR1jSAImL0nGhduZaC+hQnWjpT+YO3HSWqMRWZmJgDA1tb2ifs9ePAAbm5ucHV1xcsvv4zLly/XRnhERJUmCAI+2XER0XeyYGtpirWjvGFhaix2WJLFHm0iqmt+Pp2AreeKBmsve6OTXgzWfpxkWjWNRoMpU6age/fuaNeuXbn7eXh4YN26dejQoQMyMzPx7bffolu3brh8+TJcXFxK7a9UKqFUKrXPs7KyAAAqlQoqlUqnGIv31/U4qTGEPJiDdBhCHrWRw9pjcfj1wl0Yy2X4bngHOFiZVPv1qpKH1D6//fv3l3geEhKCRo0aISIiAj179iz3uOIebSIifXI2Pg1zfy36ofyTAa3Ro6W9yBFVjmQKi8DAQERHR+P48eNP3M/X1xe+vr7a5926dUObNm2wZs0afPHFF6X2Dw4Oxty5c0ttP3DgACwsKlcJhoWFVeo4qTGEPJiDdBhCHjWVw5V0GdbGyAHI4O9WiPv/nMK+f2rkUgAql0dubm4NRFJ9dO3R1mg06Ny5M+bPn4+2bdvWRohERJWSlJmPST8XDdYe3KEx3unZXOyQKk0ShcXkyZOxd+9eHD16tMxehycxMTFBp06dcO3atTJfDwoKwrRp07TPs7Ky4Orqiv79+8Pa2lqna6lUKoSFhaFfv34wMTHR6VgpMYQ8mIN0GEIeNZlD3L0cfLrmNAQUYriPC754qU2NjauoSh7FvblSVFM92gB7tR/HHKTDEPIwhByAms1DWajBxJ/P4d4DJTwcrDD/5TYoLCys9uvUVo+2qIWFIAh4//33sWvXLoSHh6NZM92n01Kr1bh06RIGDRpU5usKhQIKhaLUdhMTk0r/AVGVY6XEEPJgDtJhCHlUdw7Z+SpM2hSF7PxC+Lg1wBf+7WFqXPND2yqTh5Q/u5rq0QbYq10e5iAdhpCHIeQA1Ewem6/LEZUih4WRgNecMhB+8EC1X+NRNd2jLWphERgYiE2bNmHPnj2oV68ekpKSAAA2NjYwNzcHAIwaNQrOzs4IDg4GAMybNw/PPvssWrRogYyMDCxYsAA3b97E+PHjRcuDiOhxGo2AqVuicD01B41tzLBqhHetFBWGpiZ7tAH2aj+OOUiHIeRhCDkANZfH5rO3cfLkFchkwPK3vNGjZc0tgldbPdqiFharVq0CAPTu3bvE9vXr12PMmDEAgISEBMjl/zXG6enpmDBhApKSktCgQQN4e3vjxIkT8PT0rK2wiYieavHBf3HwnxQojOVYM9Ib9vVK95xS+WqjRxtgr3Z5mIN0GEIehpADUL15RNxMw7zfiwbbzfDzwPOejavlvE9T0z3aot8K9TTh4eElni9evBiLFy+uoYiIiKruj0uJWHa46Ffy4Ffbo4NLfXED0kPs0SYiQ5WclY+JP0dCpRYwqL0jJvVyFzukaiOJwdtERIYiJikL07ddAAC8/VwzvNpZt9t3qAh7tInIECkL1Zj0cwRSs5Vo5WCFBcO8DGqhVBYWRETVJCO3AO9siEBugRrd3BsiaGBrsUPSW+zRJiJDNPe3K4hMyIC1mTHWjvSBpcKw/hTnSEIiomqg1gh4/5fzSEjLhUsDcyx/szOMjfgVS0RERX45k4BNpxMgkwFLX++EpnaWYodU7djqERFVgwV/xuLY1XswM5Fj7Ugf2Fqaih0SERFJRGRCOubsKVpZe3q/VujTupHIEdUMFhZERFW09+JdrP7rOgBgwTAveDrpNk0pEREZrpTsfEz6OQIFag0GtHVEYJ8WYodUY1hYEBFVwT+JWZix7SIA4N1ezfGil5PIERERkVQUFGrw3s+RSM5SokUjK3z7mmEN1n4cCwsiokrKyC3Au6ERyFOp0aOlHT7242BtIiL6zxd7r+DczXTUUxhj7UhvWBnYYO3HsbAgIqoEtUbAB5ujkJCWC1dbcyx7oxOM5Ib7KxQREelm69lbCD11s2iw9hsd0dzeSuyQahwLCyKiSlh4IBZH/02FmYkca0b4oL4FB2sTEVGRqFsZ+HR3NABgat9WeL61g8gR1Q4WFkREOvrjUiJWhhcN1v56aAcO1iYiIq3UbCUmhhYN1u7v6YDJBjxY+3EsLIiIdHA1ORsfPVxZe/xzzfByR2eRIyIiIqlQqTUI3BiJpKx8uNtbYuFrXpDXodtkWVgQEVVQVr4K74ZGIOfhytozubI2ERE94svf/8GZ+LSiwdqjfFDPzETskGoVCwsiogrQaARM23IBN+7lwLl+0WBtrqxNRETFdkTcRsiJeADA4uEd4V4HBms/jq0iEVEFLD9yDQf/SYapsRyrRnRGQyuF2CEREZFEXLydgaBdlwAAU/q2RF/PujFY+3EsLIiInuJITAoWH/wXAPA//3bo4FJf3ICIiEgy7j14OFi7UIO+bRzwwfMtxQ5JNCwsiIie4Ob9HHy4+TwEAXiraxO85uMqdkhERCQRxYO172bmo7m9JRYNr1uDtR/HwoKIqBx5BWpM/DkSWfmF6NSkPma/6Cl2SEREJCHz9/2D03FpsFIYY+1IH1jXscHaj2NhQURUBkEQMGvXJfyTmAU7K1OsessbCmMjscMiIiKJ2Bl5G+v/jgcALHzNCy0a1b3B2o9jYUFEVIYNJ29i1/k7MJLLsPzNznC0MRM7JCIikojoO5kI2lk0WPuD51vAr62jyBFJg6iFRXBwMJ555hnUq1cPjRo1gr+/P2JjY5963LZt29C6dWuYmZmhffv22LdvXy1ES0R1RcTNNHyx9woAIGhgazzbvKHIERERkVTcf6DEu6ERUBZq8HzrRpjSt5XYIUmGqIXFX3/9hcDAQJw6dQphYWFQqVTo378/cnJyyj3mxIkTeOONN/D222/j/Pnz8Pf3h7+/P6Kjo2sxciIyVCnZ+XhvYyQKNQIGd2iMt59rJnZIREQkEYVqDSZvOo87GXloZmeJxcM71unB2o8zFvPi+/fvL/E8JCQEjRo1QkREBHr27FnmMUuXLsWAAQMwY8YMAMAXX3yBsLAwLF++HKtXr67xmInIcKkeNhjJWUq0bGSFb4Z2gEzGBoOIiIp89UcMTt64D0tTI6wd6Q0b87o9WPtxohYWj8vMzAQA2NralrvPyZMnMW3atBLb/Pz8sHv37jL3VyqVUCqV2udZWVkAAJVKBZVKpVN8xfvrepzUGEIezEE6DCGP4ti/2R+LM3FpsFQYYdnrXjCVC3qVV1U+C6nlGRwcjJ07dyImJgbm5ubo1q0bvv76a3h4eDzxuG3btuGzzz5DfHw8WrZsia+//hqDBg2qpaiJyJD9eiERPxyPA1A0WLulQz2RI5IeyRQWGo0GU6ZMQffu3dGuXbty90tKSoKDQ8nVDB0cHJCUlFTm/sHBwZg7d26p7QcOHICFhUWlYg0LC6vUcVJjCHkwB+nQ9zzO35ch5N9bAIDhbgWIPfsXnj7iS5oq81nk5ubWQCSVV3yr7DPPPIPCwkLMmjUL/fv3x5UrV2BpaVnmMcW3ygYHB2PIkCHYtGkT/P39ERkZ+cR2hYjoaW7nAMv2XAYATO7TAgPaNRY5ImmSTGERGBiI6OhoHD9+vFrPGxQUVKKHIysrC66urujfvz+sra11OpdKpUJYWBj69esHExP97foyhDyYg3QYQh6xiRn4ePVpAMD455riEz/9HIhXlc+iuDdXKnirLBFJRVpOAX6MNUK+SoPeHvaY2k8/24jaIInCYvLkydi7dy+OHj0KFxeXJ+7r6OiI5OTkEtuSk5Ph6Fj2NF8KhQIKhaLUdhMTk0r/EVSVY6XEEPJgDtKhr3nkKAsxZdtlKDUydGnaADMHtoGxkX7PxF2Zz0Lqn11N3CpLRPQ0hWoNpm69iDSlDE1szbF0eCcYcbB2uUQtLARBwPvvv49du3YhPDwczZo9ffYVX19fHDp0CFOmTNFuCwsLg6+vbw1GSkSGSBAEzNx5CddSc2BtImDJax30vqgwRDV1qyzAcXiPYw7SYQh5GEIOX+2PxYkbaTCVC1j2WjtYmOhnPrU1Bk/UwiIwMBCbNm3Cnj17UK9ePe2Xv42NDczNzQEAo0aNgrOzM4KDgwEAH374IXr16oWFCxdi8ODB2Lx5M86dO4e1a9eKlgcR6aefTsTjtwt3YSyXYWyrQtjXK927SeKrqVtlAY7DKw9zkA5DyENfc4i8J8NPV40AAG+10CD+wknEXxA5qCqq6TF4ohYWq1atAgD07t27xPb169djzJgxAICEhATI5f/9gtitWzds2rQJn376KWbNmoWWLVti9+7dHJhHRDqJTEjHl/v+AQB87NcKDhmXRY6IylKTt8oCHIf3OOYgHYaQhz7n8E9iNj75/jQADcZ3b4L2mht6mUex2hqDJ/qtUE8THh5ealtAQAACAgJqICIiqgvuP1AicGMkVGoBg9s3xhjfJvjjDxYWUlJbt8pyHF7ZmIN0GEIe+pZDek4BAjdHIV+lQc9W9viovwf+3H9D7/IoS02PwZPE4G0iotqi1giYsiUKiZn5aG5via+GtgfXwJMe3ipLRGIoVGvwwebzuJWWhya2Fvju9Y4crK0DjlIkojpl6aGrOHb1HsxNjLB6hDfqmen3r0+GatWqVcjMzETv3r3RuHFj7WPLli3afRISEpCYmKh9Xnyr7Nq1a+Hl5YXt27fzVlki0smCA7HaNmLNSG/UtzAVOyS9Uqkei7i4OBw7dgw3b95Ebm4u7O3t0alTJ/j6+sLMzKy6YyQiqhbhsSlYdvgqAGD+q+3QiqumShZvlSWi2rb34l2s+esGAOCbYR3QprFu46xIx8Ji48aNWLp0Kc6dOwcHBwc4OTnB3NwcaWlpuH79OszMzPDWW2/hk08+gZubW03FTESkszsZeZiyJQqCALzVtQle6fTkgcBERFR3xCRlYca2iwCAd3s2x4teTiJHpJ8qXFh06tQJpqamGDNmDHbs2AFXV9cSryuVSpw8eRKbN2+Gj48PVq5cyV+NiEgSCgo1eG9jJDJyVejgYoPZL3qKHZJBY682EemTjNwCvLMhAnkqNXq0tMPHA1qLHZLeqnBh8dVXX8HPz6/c1xUKBXr37o3evXvjyy+/RHx8fHXER0RUZfP3/YMLtzJgY26CFW92hsLYSOyQDBJ7tYlI36g1Aj7YHIWEtFy42prju9e5snZVVLiweFJR8biGDRuiYcOGlQqIiKg6/X4xESEn4gEAi17zgqtt5RY9oydjrzYR6aOFB2Jx9N9UmJnIsWaEDxpYcrB2VVRqVqiQkJAytxcWFiIoKKgq8RARVZsbqQ/wyY6ie2Yn9XbHC20cRI7IcH311Vc4ffo03nvvvVJFBfBfr/bq1asRExOD5s2bixAlEdF/9l1KxMrw6wCAb4Z5wdOJg7WrqlKFxQcffICAgACkp6drt8XGxqJr16745Zdfqi04IqLKyitQ472NkXigLESXZraY3q+V2CEZNF17tb29vWswGiKiJ4tNysZH2y4AAN7p2RwvcbB2tahUYXH+/Hncvn0b7du3R1hYGFasWIHOnTujdevWuHDhQnXHSESkszm/RiMmKRt2VqZY/kYnGBtx2Z7awl5tIpKyzFwV3gk9h9wCNbq3aIiP/TzEDslgVKqldXd3x99//41XX30VAwYMwNSpU/HDDz9g48aNsLGxqe4YiYh0su3cLWw9dxtyGfDd653QyJozEdUm9moTkVSpNQI+3HIeN+/nwrm+OZa90Zk/PFWjSr+Tv//+OzZv3gxfX1/Ur18fP/74I+7evVudsRER6Sw2KRuf7YkGAEzt2wrdWtiJHFHdw15tIpKqxWH/Ijz24WDtkd6w5WDtalWpwuLdd99FQEAAPvnkExw7dgwXL16Eqakp2rdvj61bt1Z3jEREFZKjLMSkjRHIV2nQs5U9Avu0EDukOom92kQkRfujE7H8yDUAwFevdkA7Z34fVbdKFRZ///03Tp8+jenTp0Mmk8HR0RH79u3DvHnzMG7cuOqOkYjoqQRBwKxdl3AjNQeO1mZYMrwj5JyLXDTs1SYiKbmanI3pW4t6TMd1bwb/Ts4iR2SYKlVYREREwMvLq9T2wMBAREREVDkoIiJd/XLmFvZE3YWRXIblb3Zi97aI2KtNRFKSmafCO6ERyClQ49nmtpg1iCtr15QKL5D3KIVCUe5rHh4cWU9EtSv6TiY+/+0yAOBjPw/4NLUVOaK6rbhXu/gHqOJe7RUrVmDcuHF47bXXRI6QiOoKjUbA1C1RiLuXAycbM6x4k4O1a1KF39kBAwbg1KlTT90vOzsbX3/9NVasWFGlwIiIKiI7X4XJmyJRUKjBC60bYUIPLrwmNvZqE5FULDl0FYdjUmBqLMeakT5oaFX+j+NUdRXusQgICMDQoUNhY2ODF198ET4+PnBycoKZmRnS09Nx5coVHD9+HPv27cPgwYOxYMGCmoybiAiCIGDmzkuIfzht4MLXvDiuQgLYq01EUvDn5SR8d+gqACD4lfZo78LB2jWtwj0Wb7/9Nm7cuIFZs2bhypUreOedd9CjRw8888wz8PPzw/fff48mTZrg7Nmz2LJlC5o0afLUcx49ehQvvvginJycIJPJsHv37ifuHx4eDplMVuqRlJRU0TSIyID8fOomfr+YCGO5DMve7IT6FhxXIRb2ahORlFxL+W+w9phuTTHU20XkiOoGncZYKBQKjBgxAiNGjAAAZGZmIi8vDw0bNoSJiYnOF8/JyYGXlxfGjRuHV199tcLHxcbGwtraWvu8UaNGOl+biPTbpduZ+GLvPwCAmQNbo3OTBiJHVLexV5uIpCIrv2iw9gNlIbo2s8X/DW4jdkh1RqUGbxezsbGp0pzkAwcOxMCBA3U+rlGjRqhfv36lr0tE+i0rX4XATZEoUGvQz9MBbz/XTOyQ6ry3334bI0aMwLZt27BlyxasXbsWmZmZAACZTAZPT0/4+fnh7NmzaNOGjTwR1QyNRsC0LVG4kZqDxjZmWPFWZ5hwsHat0amw+O6778rcbmNjg1atWsHX17dagnqajh07QqlUol27dvj888/RvXv3cvdVKpVQKpXa51lZWQAAlUoFlUql03WL99f1OKkxhDyYg3TUdh6CIODjbReRkJYL5/pmCPb3RGFhYZXOyc+ienKv7l5tIiJdfXf4Kg7+UzRYe/UIb9hxsHat0qmwWLx4cZnbMzIykJmZiW7duuHXX3+FrW3NTPXYuHFjrF69Gj4+PlAqlfjhhx/Qu3dvnD59Gp07dy7zmODgYMydO7fU9gMHDsDCwqJScYSFhVXqOKkxhDyYg3TUVh7HkmTYH2cEI5mA4S4P8PeR6rtuXf4scnNzqz2OqvZqExHp4uCVZCw5WDRY+0v/dvByrS9uQHWQToVFXFxcua/duHEDI0aMwKeffoqVK1dWObCyeHh4lJhRpFu3brh+/ToWL16M0NDQMo8JCgrCtGnTtM+zsrLg6uqK/v37lxinUREqlQphYWHo16+fXv/6Zgh5MAfpqM08Lt/NwkdrTwMQ8MmA1hjbza1azsvP4r/e3Kqo7l7to0ePYsGCBYiIiEBiYiJ27doFf3//cvcPDw9Hnz59Sm1PTEyEo6OjTtcmIv1yPfUBpm6JAgCM8nVDgI+ruAHVUVUaY/Go5s2b46uvvsK4ceOq65QV0qVLFxw/frzc1xUKRZlTH5qYmFT6D4iqHCslhpAHc5COms4jK1+FD7dehEotoG8bB0zo6Q6ZrHqnlq3Ln0V15F3dvdqc4IOIKiI7X4V3NpxDtrIQXZra4rMhnmKHVGdVW2EBAE2aNKn1qV+joqLQuHHjWr0mEdUuQRAQtOMSbj5cr+LbgA7VXlRQ1VV3rzYn+CCip9FoBEzfegHXU3PgaM3B2mKr1sLi0qVLcHOr+K0JDx48wLVr17TP4+LiEBUVBVtbWzRp0gRBQUG4c+cONmzYAABYsmQJmjVrhrZt2yI/Px8//PADDh8+jAMHDlRnGkQkMT+fTsDvl4rWq1jO9Sr0Um32ausywQcR6bcVR67hwJVkmBrJsWpEZ9jX42BtMelUWJR3D25mZiYiIiIwffp0jB49usLnO3fuXIn7YYvHQowePRohISFITExEQkKC9vWCggJMnz4dd+7cgYWFBTp06ICDBw+WeU8tERmG6DuZ+OK3KwCATwa0RieuV6G3arpXuzITfHDmwJKYg3QYQh41ncOR2FQsOvgvAODzF9ugXWOrGrlWXf8sdDlGp8Kifv365d5+IJPJMH78eMycObPC5+vduzcEQSj39ZCQkBLPP/74Y3z88ccVPj8R6bfsfBUmP1yv4oXWjTC+B9er0Ge69mrrqjITfHDmwLIxB+kwhDxqIoeUPGDRJSMIggzdHTSwTL6AffsuVPt1HlVXPwtdZg3UqbA4cuRImdutra3RsmVLmJmZISUlBU5OTrqcloioFEEQMGtXNOLv58LJxgzfBnhxXIXEVXevdnV42gQfnDmwJOYgHYaQR03l8EBZiIA1p5GnzoF3k/pYO9YHpsY1N66irn8WuswaqFNh0atXrye+fuHCBXTu3BlqtVqX0xIRlfLLmVv47cJdGMllWPZmJzSw5LgKqavuXu3q8LQJPjhzYNmYg3QYQh7VmYMgCAjafBHXUnPgYK3AqpHesDSvnXEVdfWz0GX/ah28TURUHf5JzMLc3y4DAGb4ecDbrWYW3aTqVd292pzgg4getzL8OvZfToKJkQyrRnijUT0zsUOiR7CwICJJyVEWInBTJJSFGvT2sMc7PZqLHRJVUHX3anOCDyJ61JHYFHx7IBYAMO/ldujMyTwkh4UFEUmGIAj4dHc0bjycj3zRax0hl3NcRV3FCT6IqFj8vRx8+Mt5CALwZtcmeKNLE7FDojLoVFhcvHjxia/HxsZWKRgiqtu2nbuNXefvwEguw3dvdIItx1UQEdV5OcpCvBsagaz8QnRuUh9zXuTK2lKlU2HRsWNHyGSyMn9BKt7OWVuIqDL+Tc7G7F+jAQDT+rVCl2YcV0FEVNcJgoAZ2y8gNjkb9vUUWDXCGwpjI7HDonLoVFjExcXVVBxEVIflFhQicGMk8lUa9Ghph0m93MUOiSqBvdpEVN1W/3UD+y49HKz9Vmc4WHOwtpTpVFjU5MJGRFR3zdlzGVdTHqBRPQUWD+e4Cn3FXm0iqk5//ZuKb/6MAQB8/lJb+DRlT7bU6VRYfPPNN3j//fdhbm4OAPj777/h4+OjnQM8Ozsbn3zyCVauXFn9kRKRQdoRcRvbIm5DLgOWvt4Jdla1Mx85VT/2ahNRdbl5PwcfPBys/fozrniTg7X1gk6FRVBQEMaMGaMtLAYOHIioqCg0b140HWRubi7WrFnDwoKIKuRaSjY+3V00rmJK31bwdW8ockRUFezVJqLqkFtQNFg7M0+Fjq71Mffltuzt1BM6rX/+ePf2k6YBJCJ6krwCNQI3nkeeSo3uLRoisE8LsUOianTs2DGMGDECvr6+uHPnDgAgNDQUx48fFzkyIpIyQRDw8faLiEnKhp2VKVaN6MzB2npEp8KCiKi6fP7rZcQmZ8POSoElwzvBiOMqDMaOHTvg5+cHc3NznD9/HkqlEgCQmZmJ+fPnixwdEUnZ98duYO/FRBjLZVj5ljca25iLHRLpgIUFEdW6nZG3seXcLchkwHevd4R9PY6rMCT/+9//sHr1anz//fcwMTHRbu/evTsiIyNFjIyIpOz41Xv46o+iwdpzXvTktON6SOeVt3/44QdYWVkBAAoLCxESEgI7OzsARYO3iYie5FpKNv5vV9G4ig9faIluLexEjoiqW2xsLHr27Flqu42NDTIyMmo/ICKSvFtpuZj8SyQ0AhDg7YIRz3LMlj7SqbBo0qQJvv/+e+1zR0dHhIaGltqHiKgsj46r6ObeEO8/31LskKgGODo64tq1a2jatGmJ7cePH9dO9kFEVCyvQI13QiOQkauCl4sNvvBvx8HaekqnwiI+Pr6GwiCiumDOr9H/jat4vSPHVRioCRMm4MMPP8S6desgk8lw9+5dnDx5EtOnT8fs2bPFDo+IJEQQBMzceRH/JGY9HKztDTMTDtbWVzoVFvn5+Th48CCGDBkCoGj62eJBeQBgbGyMefPmwcyMqyISUUk7Im5j67mi9Sq+e70jGtXj94ShmjlzJjQaDV544QXk5uaiZ8+eUCgUmDFjBsaPHy92eEQkIT8ej8OeqLswlsuw4s3OcKrPwdr6TKfB2yEhIVizZo32+fLly3HixAmcP38e58+fR2hoqE5rWBw9ehQvvvginJycIJPJsHv37qceEx4ejs6dO0OhUKBFixYICQnRJQUiEsHV5P/Wq/jwhVYcV2HgZDIZ/u///g9paWmIjo7GqVOnkJqaChsbGzRr1kzs8IhIIk5cu4f5+/4BAHw6uA26NudaRvpOp8Ji48aNeOedd0ps27RpE44cOYIjR45gwYIF2LZtW4XPl5OTAy8vL6xYsaJC+8fFxWHw4MHo06cPoqKiMGXKFIwfPx5//vmnLmkQUS3KLSjEexsjkadS47kWdpj8PNerMFRKpRJBQUHw8fFB9+7dsW/fPnh6euLy5cvw8PDA0qVLMXXqVLHDJCIJuJWWi8BNRYO1h3Z2wehuTcUOiaqBTrdCXbt2De3bt9c+NzMzg1z+X23SpUsXBAYGVvh8AwcOxMCBAyu8/+rVq9GsWTMsXLgQANCmTRscP34cixcvhp+fX4XPQ0S1QxAEfLo7GldTHsC+ngKLh3NchSGbPXs21qxZg759++LEiRMICAjA2LFjcerUKSxcuBABAQEwMuK900R1XV6BGu+GRiA9V4X2zjb48hUO1jYUOhUWGRkZJcZUpKamlnhdo9GUeL26nTx5En379i2xzc/PD1OmTKmxaxJR5W07dxs7I+9ALgOWvdGJ61UYuG3btmHDhg146aWXEB0djQ4dOqCwsBAXLlzgHw1EBKDoB6egnRdxJTELDS1NsXokB2sbEp0KCxcXF0RHR8PDw6PM1y9evAgXF5dqCawsSUlJcHBwKLHNwcEBWVlZyMvLg7l56QE/SqWyRLGTlZUFAFCpVFCpVDpdv3h/XY+TGkPIgzlIR3l5xCRl47M9ReMqpr7QAt6u1pLN1dA/C12OrYrbt2/D29sbANCuXTsoFApMnTqVRQURaa37Ox67o+7CSC7D8jc7w5mDtQ2KToXFoEGDMHv2bAwePLjUzE95eXmYO3cuBg8eXK0BVlVwcDDmzp1bavuBAwdgYWFRqXOGhYVVNSxJMIQ8mIN0PJpHvhpYeNEIykIZ2tTXwOVBDPbtixExuooxxM+ionJzc6t8XbVaDVNTU+1zY2Nj7YKqREQnrv83WPv/BrWBrzsHaxsanQqLWbNmYevWrfDw8MDkyZPRqlUrAEWrrC5fvhyFhYWYNWtWjQQKFC26lJycXGJbcnIyrK2ty+ytAIqmxJ02bZr2eVZWFlxdXdG/f39YW1vrdH2VSoWwsDD069cPJiYmuicgEYaQB3OQjsfzEAQBU7ZeREp+MhytFfhpki8aWJg+/UQiMtTPQhfFvblVIQgCxowZA4Wi6Ja3/Px8TJw4EZaWliX227lzZ5WvRUT65U5GHiZvOg+1RsArnZwxtntTsUOiGqBTYeHg4IATJ05g0qRJmDlzJgRBAFA0tWC/fv2wcuXKUrcqVSdfX1/s27evxLawsDD4+vqWe4xCodA2co8yMTGp9B8QVTlWSgwhD+YgHcV5hPwdh33RyTCWy7ByhDca2Vg+/WCJMLTPQtdjqmr06NElno8YMaJK5zt69CgWLFiAiIgIJCYmYteuXfD393/iMeHh4Zg2bRouX74MV1dXfPrppxgzZkyV4iCiqslXqfFu6Dmk5RSgrZM1gl9tz1skDZROhQUANGvWDPv370daWhquXbsGAGjRogVsbW11vviDBw+05wCKppONioqCra0tmjRpgqCgINy5cwcbNmwAAEycOBHLly/Hxx9/jHHjxuHw4cPYunUrfv/9d52vTUTVLzIhHV8+7OaeNagNOjdpIHJEVJvWr19frecrnpJ83LhxePXVV5+6f/GU5BMnTsTGjRtx6NAhjB8/Ho0bN+bMgUQiEQRg9q9XEH0nCw0sTLCGg7UNms6FRTFbW1t06dKlShc/d+4c+vTpo31efMvS6NGjERISgsTERCQkJGhfb9asGX7//XdMnToVS5cuhYuLC3744Qc2GEQSkJZTgMkbI6FSCxjU3pHd3FRlnJKcSP8dS5JhV3wi5DJgxZud4dKgcuNbST9UurCoDr1799beTlWWslbV7t27N86fP1+DURGRrjQCMH37JdzNzEczO0t8PbQDu7mp1lVmSnLOHFgSc5AOQ8jj5LVU7IovWu/sE79WeMbNRi/zMYTPorZmDRS1sCAiw/DnbTmO374PMxM5Vo3ojHpm+j9OgfRPZaYk58yBZWMO0qGveaQrgW8vGkEDGbztNHDIuIJ9+66IHVaV6Otn8aianjWQhQURVcnRq/fw5+2i3ongV9ujtaNus60RiYkzB5bEHKRDn/NQqtR448ezeFCYBWcLAWsn9Ia1hdnTD5Qoff4sitXWrIEsLIio0m6n52L6tksQIMObXVzwSqeaWyCT6GkqMyU5Zw4sG3OQDn3LQxAEBO2+gkt3slDf3ARve+TB2sJMr3Ioj759FmWp6VkD5boGREQEFE0fOOnnSGTkqdDEUsCsga3FDonqOF9fXxw6dKjEtqdNSU5E1Sv01E1sj7gNuQxYMrwDGupvRwVVAgsLItKZIAiYvScal+5kooGFCcZ6qKEw5tcJVa8HDx4gKioKUVFRAP6bkrx4tsCgoCCMGjVKu//EiRNx48YNfPzxx4iJicHKlSuxdetWTJ06VYzwieqcM3FpmPdb0TiKmQNboztX1q5z+JcAEels89lb2Hru4S9Sr3WAbek7SYiq7Ny5c+jUqRM6deoEoGhK8k6dOmH27NkAUO6U5GFhYfDy8sLChQs5JTlRLUnMzMN7GyNQqBHwopcTJvRoLnZIJAKOsSAinZxPSMecPZcBAB/5eaCbe0PsixU5KDJInJKcSD8oC9WY+HMk7j0oQGvHevh6KFfWrqvYY0FEFZaSnY9JP0eiQK2BX1sHTOrlLnZIREQkIkEQMGfPZVy4lQEbcxOsHekDC1P+bl1XsbAgogopKNQgcGMkkrLy4W5viW8DvPiLFBFRHbfxdAI2n70FuQxY9kYnNGnIlbXrMhYWRFQhX/5+BWfj02GlMMbaUT5cBI+IqI47F5+Gub8V3Rr78YDW6NnKXuSISGwsLIjoqbaeu4WfTt4EACwe3hHu9lYiR0RERGJKzsrHpI2RUKkFDG7fGO/25GBtYmFBRE8RmZCOT3dFAwA+fKEl+nk6iBwRERGJqWiwdgRSs5XwcKiHb4Z14K2xBICFBRE9QXJWPiaGRqBArUF/Twd8+EJLsUMiIiKRff7rFZxPyIC1mTHWjPSGpYKDtakICwsiKlO+So13QiOQkq1EKwcrLBreEXI5f5EiIqrLNp1OwC9nEiCTAd+90QlN7SzFDokkhIUFEZUiCAKCdl7STh/4/SgfWPEXKSKiOi3iZjrm/Fp0a+xH/T3Q26ORyBGR1LCwIKJSVv11HbvO34GRXIaVb3WGW0P+IkVEVJelZOVj0s8RUKkFDGrviPd6cx0jKo2FBRGVcOByEhb8WbSU9ucveqJ7CzuRIyIiIjEVFGowaWOk9tbYBcO4jhGVjYUFEWlduZuFKVuiIAjAiGebYKRvU7FDIiIikc3bexkRN9NhbWaMtSN9OFibysXCgogAFM0A9fZPZ5FboEY394aY82JbsUMiIiKRbT17Cz+fKhqsvfR1DtamJ5NEYbFixQo0bdoUZmZm6Nq1K86cOVPuviEhIZDJZCUeZmZmtRgtkeHJLSjE+J/OITEzH+72llj1ljdMjCTx9UBERCI5n5COT3cXDdae3q8V+rTmYG16MtH/ctiyZQumTZuGOXPmIDIyEl5eXvDz80NKSkq5x1hbWyMxMVH7uHnzZi1GTGRYNBoBU7dE4dKdTNhammLdmGdgY2EidlhERCSilOx8TPo5EgVqDQa0dURgnxZih0R6QPTCYtGiRZgwYQLGjh0LT09PrF69GhYWFli3bl25x8hkMjg6OmofDg5cCZiosr7c9w/+vJwMUyM51o705gxQRER1XEGhBoEbI5GUlY8Wjazw7WscrE0VI+rom4KCAkRERCAoKEi7TS6Xo2/fvjh58mS5xz148ABubm7QaDTo3Lkz5s+fj7Zty74fXKlUQqlUap9nZWUBAFQqFVQqlU7xFu+v63FSYwh5MIfqEXLyJn48HgcA+OrVtvByrlcn/10YQg5A1fLQ99yJqPr87/crOBufjnoKY6wd6c11jKjCRP0v5d69e1Cr1aV6HBwcHBATE1PmMR4eHli3bh06dOiAzMxMfPvtt+jWrRsuX74MFxeXUvsHBwdj7ty5pbYfOHAAFhYWlYo7LCysUsdJjSHkwRwq78J9Gdb/Kwcgw0tN1DC6fR77bp+v9Pn4WUhHZfLIzc2tgUiISN9sPXcLG04W3WK+eHhHNLe3Ejki0id6V4L6+vrC19dX+7xbt25o06YN1qxZgy+++KLU/kFBQZg2bZr2eVZWFlxdXdG/f39YW1vrdG2VSoWwsDD069cPJib6ew+6IeTBHKrm3M10bAyJgAAN3uzigs+HtKl0Nzc/C+moSh7FvblEVHdF3crAp7uKBmtP7dsKfT15qznpRtTCws7ODkZGRkhOTi6xPTk5GY6OjhU6h4mJCTp16oRr166V+bpCoYBCoSjzuMr+AVGVY6XEEPJgDrqLTcrGuz+fh7JQg75tGmHey+1hXA0zQPGzkI7K5GEIeRNR5aVmKzExNAIFag36eTrg/ec5WJt0J+rgbVNTU3h7e+PQoUPabRqNBocOHSrRK/EkarUaly5dQuPGjWsqTCKDcTs9F6PWnUZWfiG83Rpg2Rudq6WoICIi/aVSaxC4qWiwdnN7Syx6zQtyOQdrk+5E/4ti2rRp+P777/HTTz/hn3/+waRJk5CTk4OxY8cCAEaNGlVicPe8efNw4MAB3LhxA5GRkRgxYgRu3ryJ8ePHi5UCkV64/0CJUevOIDlLiZaNrPDjaB+YmxqJHRbRE3GdI6Ka9+Xv/+BMXBqsFEUra9czYw8mVY7oYyyGDx+O1NRUzJ49G0lJSejYsSP279+vHdCdkJAAufy/+ic9PR0TJkxAUlISGjRoAG9vb5w4cQKenp5ipUAkeVn5KoxadwY3UnPgZGOGDW93QX0LU7HDInqi4nWOVq9eja5du2LJkiXw8/NDbGwsGjUqe6Eua2trxMbGap9zikyiJ9sRcRshJ+IBFA3WbtGIg7Wp8kQvLABg8uTJmDx5cpmvhYeHl3i+ePFiLF68uBaiIjIMeQVqvB1yFpfvZqGhpSlCx3dFYxtzscMieqpH1zkCgNWrV+P333/HunXrMHPmzDKPKV7niIie7tLtTATtugQA+PCFlujHwdpURZIoLIioZigL1Xj354ii+cjNjLHh7S5w59SBpAdqY50jgGsdPY45SEdN53E/pwDvhJ5DQaEGz3vY472eTav9WvwspKO21jliYUFkoAoKNXjv50gc/TcV5iZGCBn7DNo62YgdFlGF1MY6RwDXOioPc5COmshDrQFW/iNHYpYcjcwE9LdOxP79idV+nWL8LKSjptc5YmFBZIBUag0mb4rEoZgUKIzl+HG0D7zdbMUOi6hG6brOEcC1jh7HHKSjJvP4cl8MrmUlwNLUCD9N6Fpj4yr4WUhHba1zxMKCyMCo1Bp8uPk8DlxJhqmxHN+P8kG3FnZih0Wkk9pY5wjgWkflYQ7SUd157Dp/GyEnEwAAC1/riDbODart3OXhZyEdNb3OkejTzRJR9SkoLOqp2HcpCaZGcqwZ6Y2erezFDotIZ1zniKj6Rd/JxMwdRYO1J/dpgQHtONEBVS/2WBAZiHyVGu9tjMThmBSYGsuxekRn9PEoe0pOIn0wbdo0jB49Gj4+PujSpQuWLFlSap0jZ2dnBAcHAyha5+jZZ59FixYtkJGRgQULFnCdI6KH0nIK8G5oBJSFGvTxsMfUfq3EDokMEAsLIgOQW1CId0MjcOzqPZiZyLF2pA97KkjvcZ0joupR+HDc3Z2MPDRtaIElr3eCEVfWphrAwoJIz2XkFmBcyFlEJmTAwtQIP45+Br7uDcUOi6hacJ0joqr7en8MTly/D0tTI6wd5QMbc/0eJ0DSxcKCSI8lZ+Vj1I9nEJucDWszY6wf+wxnfyIiIq09UXfw/bE4AMC3AV5o5VBP5IjIkLGwINJT11MfYMz6M7iVlodG9RQIfbsrPBzZYBARUZHLdzPxyY6LAIDAPu4Y2J4TGVDNYmFBpIfOxqdhwoZzyMhVwa2hBX5+uytcbSu3mBcRERme9IeDtfNVGvT2sMe0fh5ih0R1AAsLIj2z9+JdTNt6AQWFGnR0rY8fRvvAzqr0PPxERFQ3Fao1eP+X87idnge3hhZYOpyDtal2sLAg0hMajYClh65i6aGrAAC/tg5YMrwTzE2NRI6MiIik5Js/Y3H82j1YmBphzUhv2FhwsDbVDhYWRHogR1mI6VsvYP/lJADAuO7N8H+D2/AXKCIiKuHXC3ex9ugNAMCCYV5o7WgtckRUl7CwIJK4+Hs5mPhzBGKSsmFiJMOX/u3x2jOuYodFREQS809iFj7efgEAMLGXOwZ34GBtql0sLIgkbH90ImZsu4hsZSHsrBRYM7Izp5MlIqJS0nMK8E7oOeSrNOjR0g4z/DhYm2ofCwsiCVIWqvHN/lj8eLxo7vFnmjbAsjc6w9HGTOTIiIhIatQaAR9sPo9baXlwtTXHsjc4WJvEwcKCSGKupWTjg1+icCUxCwDwTs/mmOHnARMjuciRERGRFC34MxbHrt6DuYkR1o70QX0LU7FDojpKEn+prFixAk2bNoWZmRm6du2KM2fOPHH/bdu2oXXr1jAzM0P79u2xb9++WoqUqOZoNAI2nIzH4O+O40piFhpYmGDtSG/MGtSGRQUREZVp78W7WP3XdQDA18M6oE1jDtYm8Yj+18qWLVswbdo0zJkzB5GRkfDy8oKfnx9SUlLK3P/EiRN444038Pbbb+P8+fPw9/eHv78/oqOjazlyouoTfy8Hb3x/CrP3XIaysOj+2D+n9ET/to5ih0ZERBIVk5SFGduKVtZ+p2dzvOTlJHJEVNeJXlgsWrQIEyZMwNixY+Hp6YnVq1fDwsIC69atK3P/pUuXYsCAAZgxYwbatGmDL774Ap07d8by5ctrOXKiqlNrgB+Ox2PA0qM4HZcGcxMjzHnREz+N7YJG1hxPQUREZcvILcA7GyKQp1LjuRZ2+JiDtUkCRB1jUVBQgIiICAQFBWm3yeVy9O3bFydPnizzmJMnT2LatGkltvn5+WH37t1l7q9UKqFUKrXPs7KK7ltXqVRQqVQ6xbsj4hYupciQH3kLChMTGMllMJbLYGwkg5FcBlMjOYzlMpgYyR8+ZDAxlsPUSA5TYzkUDx/GchlkMvEGVRXnrWv+UmIIORz7NwXfXDRCUt6/AIBuzW3xxcueaGJrAbW6EGq1yAFWkCF8FoaQA1C1PPQ9d6K6RK0R8OHmKCSk5cKlQdFgbWPeMksSIGphce/ePajVajg4OJTY7uDggJiYmDKPSUpKKnP/pKSkMvcPDg7G3LlzS20/cOAALCwsdIp37hkj5KmNsPH6Pzod9zgZBJjIoX2YygFTo4f/KxegMELRQw4ojAEzIwFmRoCZEWBuBJgbCzA3AiyMAXPjouMqU6eEhYVVKQ8p0MccUvOAvbfkiLovByCDpbGAl9w06GqfguhTKdDXm/r08bN4nCHkAFQuj9zc3BqIhIhqwsIDsfjr31SYmcixZqQ3GlhysDZJg8HPChUUFFSihyMrKwuurq7o378/rK11G+C0L/M8Eu4mo36DhhAAFGoEFGoEqDUCVGoBhWoNVGoBKrUGhZqi/y0o1KDg4fZiAmQo0AAFmrKuonuFYGosR31zE9Q3N0EDSxPYWpjC1tIUDS1NYWtlCjtLU9jXU8DOyhSN6ilgBA3CwsLQr18/mJiY6Hw9KVCpVHqXw70HSiw/cgNbLt5GoUaAXAZ0d9Dgm5E9YWetW5ErJfr4WTzOEHIAqpZHcW8uEUnbvkuJWBn+cLD20A5o62QjckRE/xG1sLCzs4ORkRGSk5NLbE9OToajY9mDVh0dHXXaX6FQQKFQlNpuYmKic8O7/I1O2LdvHwYNekbnYzUaAQVqDZQqDZSFauSrNMgvVCNfpUZegRq5KjXyC9TIKVAjr6AQOQVq5CgL8UBZiBxlIbLzix8qZOcXIjNPhcw8FQo1AgoKNUjJViIlW/n0QABYmxnDQmaEbakX4VTfHI425nCyMYNTfXM41TeHc31zmJsa6ZSfWCrzOda2xMw8fH80Dr+cSUCequj+pl6t7DG9bwvEnT8GO2sLyedQEfrwWTyNIeQAVC4PQ8ibyND9m5yNj7YVraw9/rlmeLmjs8gREZUkamFhamoKb29vHDp0CP7+/gAAjUaDQ4cOYfLkyWUe4+vri0OHDmHKlCnabWFhYfD19a2FiCtPLpfBTG4EMxMjANXTgAuCgNwCNdJzC5CRq0J6bgHScv573HtQgHsPlLj/QInUB0qkZCmhLNQgK78QWZAh6dr9cs9tZ2UK5wYWcGlgjia2FnBtYIEmthZwa2gBp/rmXHinAv5JzELI3/HYef62tseqo2t9fDKgNXzdG0KlUiHuvMhBEhGRXsjMU+GdDeeQW6BGN/eGmDmwtdghEZUi+q1Q06ZNw+jRo+Hj44MuXbpgyZIlyMnJwdixYwEAo0aNgrOzM4KDgwEAH374IXr16oWFCxdi8ODB2Lx5M86dO4e1a9eKmYYoZDIZLBXGsFQYw6XB0/cXBAHZykLcuf8Avx08Brc2HZD6QIW7mflIyszH3Yw83EnPQ7ay8GFRUoALtzJKncfESAbXBkVFRlM7SzR75OFkYw55HS468lVqhF1JRuipmzgTl6bd3rWZLSY/3wLPtbATdeA+ERHpH41GwNQtUYi/nwvn+uZY/mZnDtYmSRK9sBg+fDhSU1Mxe/ZsJCUloWPHjti/f792gHZCQgLk8v/+8XTr1g2bNm3Cp59+ilmzZqFly5bYvXs32rVrJ1YKekMmk8HazATmjazgUV/AoE7OZd7+kJmnwu30XNxKy3v4v7m4mZaLhLRc3E7LQ4Fagxv3cnDjXg4Qm1riWFNjOZo1tERz+4cPOyu4N7JCc3tLWJsZ5q0Wao2AyIR07Dp/B3sv3EVWfiEAwEguw4C2jhj3XFN4u9mKHCUREemrxQf/xeGYFCiMiwZr23KwNkmU6IUFAEyePLncW5/Cw8NLbQsICEBAQEANR1V32ZibwMbcpswBYWqNgKSsfNy8l4O4+zmIv5eDuHu5iLv3AAlpuSgo1CA2ORuxydmljrWzUqC5vSXcHxYczeyKig9XWwu9W1k6R1mI03H3EXYlGWFXUnDvwX/jWxrbmGGYtwve6uoGRxuuRUFUFStWrMCCBQuQlJQELy8vLFu2DF26dCl3/23btuGzzz5DfHw8WrZsia+//hqDBg2qxYiJqteBK8lYdvgaAOCroe3RzpmDtUm6JFFYkP4wksvg/HCAd7cWdiVeK1RrcCcjDzdSc3A99UFRr0bqA9xIzUFKthL3HhQ9Hr1FqPicrg3M0dTOEk0bWsKtYdFtVk1sLeHSwPzhuBRxpeUUIOpWOs4nZODUjfs4n5CBQs1/M33VMzNGP08HDOvsgmebN6zTt4MRVZctW7Zg2rRpWL16Nbp27YolS5bAz88PsbGxaNSoUan9T5w4gTfeeAPBwcEYMmQINm3aBH9/f0RGRrJXm/TSnRxgxY6iScjHdW+GVzq5iBwR0ZOxsKBqY2wkh1tDS7g1tESf1iUb/ex8FeLu5eBG6sNi4+H/j7uXgzyVGvH3cxF/PxdAaqnzNqqngHODomLGqb45HK3NYGdpjBtZwM37uXBsYAlLU6Mqj11QqTVIyszHrfRc3E7Pw/XUB7ia/AD/Jmfjdnpeqf2b2FqgZys7+LV1RNdmDWFqrF+9LkRSt2jRIkyYMEE75m716tX4/fffsW7dOsycObPU/kuXLsWAAQMwY8YMAMAXX3yBsLAwLF++HKtXr67V2ImqQlmoxorD17HikhHUghrPNrfFrEEcrE3Sx8KCakU9MxN0cKmPDi71S2wXBAHJWUrcuPcAN+/nIv7h7VUJaXlIuJ+DnAK1dird8wkZj53VGEsvHwdQNLbD5uFaHvXMjGFhagwLUyMoTIxgLJdpZ7HSaASoBQH5KjVyH07pm5Gnwv0HBcjMe/LKw+72lujo2gA+TRugu7sdmjTU37UniKSuoKAAERERCAoK0m6Ty+Xo27cvTp48WeYxJ0+eLLFuEQD4+flh9+7d5V5HqVRCqfzvVsbi9TxUKpVOq5Efv3Yfey/exZ07chzdeanE2EB9otFomIMERNxMx417uQBkeM7dFgsDOkDQqKHSqMUOTSfF/4Z0+bckRYaQR1Vy0OUYFhYkKplMBkcbMzjamKGbe8nXBEFAWk4B7jycrepORh7uZuQjOSsfiZl5uJmcjlyNEfJURQsRpmYrkVrBtTzKY2osh0t9czg3MEfThpZo5WCFlg710MbRGjYWhjn4nEiK7t27B7VarZ3Io5iDgwNiYmLKPCYpKanM/ZOSksq9TnBwMObOnVtq+4EDB2BhUfEfD8ITZdgVbwRADqQkVvg4aWIOUlDPRMCrTTXo1DAFp/46KHY4VRIWFiZ2CNXCEPKoTA65ubkV3peFBUmWTCZDQysFGlopSvV0qFSqh4sV+qFAI0N6blGPQ2auCtnKQuQVqJFTUIiCQo12ZXQAMJIDcpkMZiZGsFQYwcLUGNZmJrCvZ4qGlgrYmJtwfARRHRIUFFSilyMrKwuurq7o378/rK2tK3wel9uZcLuaimvXrqJFi5Yw0tNfytUaDXOQAEuFMQZ62uHM8XD069dPbxewVKlUCAsL0+scAMPIoyo5FPfkVgQLC9J7uqzlQUT6wc7ODkZGRkhOTi6xPTk5GY6OjmUe4+joqNP+AKBQKKBQKEpt13X1cu9mdujgYoN9ef9iUJ8Wev3HB3OQhuLbT3T9b1GKDCEHwDDyqEwOuuyvn6U8EREZNFNTU3h7e+PQoUPabRqNBocOHYKvr2+Zx/j6+pbYHyjq9i9vfyIiql7ssSAiIkmaNm0aRo8eDR8fH3Tp0gVLlixBTk6OdpaoUaNGwdnZGcHBwQCADz/8EL169cLChQsxePBgbN68GefOncPatWvFTIOIqM5gYUFERJI0fPhwpKamYvbs2UhKSkLHjh2xf/9+7QDthISEErP+dOvWDZs2bcKnn36KWbNmoWXLlti9ezfXsCAiqiUsLIiISLImT56MyZMnl/laeHh4qW0BAQEICAio4aiIiKgsHGNBRERERERVxsKCiIiIiIiqrM7dCiUIResZ6DInbzGVSoXc3FxkZWXp9XRjhpAHc5AOQ8jDEHIAqpZH8Xdi8XdkXVXX2wjmIB2GkIch5AAYRh611T7UucIiOzsbAODq6ipyJERE0pOdnQ0bGxuxwxAN2wgiorJVpH2QCXXs5ymNRoO7d++iXr16kMl0W2G5eEXWW7du6bQiq9QYQh7MQToMIQ9DyAGoWh6CICA7OxtOTk4lZlqqa+p6G8EcpMMQ8jCEHADDyKO22oc612Mhl8vh4uJSpXNYW1vr7X9YjzKEPJiDdBhCHoaQA1D5POpyT0UxthFFmIN0GEIehpADYBh51HT7UHd/liIiIiIiomrDwoKIiIiIiKqMhYUOFAoF5syZA4VCIXYoVWIIeTAH6TCEPAwhB8Bw8tBXhvD+MwfpMIQ8DCEHwDDyqK0c6tzgbSIiIiIiqn7ssSAiIiIioipjYUFERERERFXGwoKIiIiIiKqMhUUlvfTSS2jSpAnMzMzQuHFjjBw5Enfv3hU7LJ3Ex8fj7bffRrNmzWBubg53d3fMmTMHBQUFYoemky+//BLdunWDhYUF6tevL3Y4FbZixQo0bdoUZmZm6Nq1K86cOSN2SDo5evQoXnzxRTg5OUEmk2H37t1ih6Sz4OBgPPPMM6hXrx4aNWoEf39/xMbGih2WTlatWoUOHTpo5yb39fXFH3/8IXZYdZ6+txGG0j4A+tlGsH0QnyG0D0DttxEsLCqpT58+2Lp1K2JjY7Fjxw5cv34dw4YNEzssncTExECj0WDNmjW4fPkyFi9ejNWrV2PWrFlih6aTgoICBAQEYNKkSWKHUmFbtmzBtGnTMGfOHERGRsLLywt+fn5ISUkRO7QKy8nJgZeXF1asWCF2KJX2119/ITAwEKdOnUJYWBhUKhX69++PnJwcsUOrMBcXF3z11VeIiIjAuXPn8Pzzz+Pll1/G5cuXxQ6tTtP3NsJQ2gdA/9oItg/SYAjtAyBCGyFQtdizZ48gk8mEgoICsUOpkm+++UZo1qyZ2GFUyvr16wUbGxuxw6iQLl26CIGBgdrnarVacHJyEoKDg0WMqvIACLt27RI7jCpLSUkRAAh//fWX2KFUSYMGDYQffvhB7DDoEYbQRuhz+yAI+tNGsH2QJkNpHwShZtsI9lhUg7S0NGzcuBHdunWDiYmJ2OFUSWZmJmxtbcUOw6AVFBQgIiICffv21W6Ty+Xo27cvTp48KWJklJmZCQB6+29ArVZj8+bNyMnJga+vr9jh0EOG0kawfah5bB+kS9/bB6B22ggWFlXwySefwNLSEg0bNkRCQgL27NkjdkhVcu3aNSxbtgzvvvuu2KEYtHv37kGtVsPBwaHEdgcHByQlJYkUFWk0GkyZMgXdu3dHu3btxA5HJ5cuXYKVlRUUCgUmTpyIXbt2wdPTU+yw6jxDaiPYPtQOtg/SpM/tA1C7bQQLi0fMnDkTMpnsiY+YmBjt/jNmzMD58+dx4MABGBkZYdSoURAksN6grnkAwJ07dzBgwAAEBARgwoQJIkX+n8rkQFQVgYGBiI6OxubNm8UORWceHh6IiorC6dOnMWnSJIwePRpXrlwROyyDYwhthCG0DwDbCKpd+tw+ALXbRnDl7Uekpqbi/v37T9ynefPmMDU1LbX99u3bcHV1xYkTJ0S/BUHXPO7evYvevXvj2WefRUhICORy8evNynwWISEhmDJlCjIyMmo4uqopKCiAhYUFtm/fDn9/f+320aNHIyMjQy9/1ZTJZNi1a1eJfPTJ5MmTsWfPHhw9ehTNmjUTO5wq69u3L9zd3bFmzRqxQzEohtBGGEL7ABhuG8H2QXoMrX0AaraNMK72M+oxe3t72NvbV+pYjUYDAFAqldUZUqXoksedO3fQp08feHt7Y/369ZJpNKryWUidqakpvL29cejQIe0XrUajwaFDhzB58mRxg6tjBEHA+++/j127diE8PNxgGg2NRiOJ7yJDYwhthCG0D4DhthFsH6TDUNsHoGbbCBYWlXD69GmcPXsWzz33HBo0aIDr16/js88+g7u7u+i9Fbq4c+cOevfuDTc3N3z77bdITU3Vvubo6ChiZLpJSEhAWloaEhISoFarERUVBQBo0aIFrKysxA2uHNOmTcPo0aPh4+ODLl26YMmSJcjJycHYsWPFDq3CHjx4gGvXrmmfx8XFISoqCra2tmjSpImIkVVcYGAgNm3ahD179qBevXrae5htbGxgbm4ucnQVExQUhIEDB6JJkybIzs7Gpk2bEB4ejj///FPs0OosQ2gjDKV9APSvjWD7IA2G0D4AIrQRNTLXlIG7ePGi0KdPH8HW1lZQKBRC06ZNhYkTJwq3b98WOzSdrF+/XgBQ5kOfjB49uswcjhw5InZoT7Rs2TKhSZMmgqmpqdClSxfh1KlTYoekkyNHjpT5vo8ePVrs0CqsvP/+169fL3ZoFTZu3DjBzc1NMDU1Fezt7YUXXnhBOHDggNhh1WmG0EYYSvsgCPrZRrB9EJ8htA+CUPttBMdYEBERERFRlUnnhkkiIiIiItJbLCyIiIiIiKjKWFgQEREREVGVsbAgIiIiIqIqY2FBRERERERVxsKCiIiIiIiqjIUFERERERFVGQsLIiIiIiKqMhYWRERERERUZSwsiIiIiIioylhYEBERERFRlbGwIKplqampcHR0xPz587XbTpw4AVNTUxw6dEjEyIiISExsH0jfyQRBEMQOgqiu2bdvH/z9/XHixAl4eHigY8eOePnll7Fo0SKxQyMiIhGxfSB9xsKCSCSBgYE4ePAgfHx8cOnSJZw9exYKhULssIiISGRsH0hfsbAgEkleXh7atWuHW7duISIiAu3btxc7JCIikgC2D6SvOMaCSCTXr1/H3bt3odFoEB8fL3Y4REQkEWwfSF+xx4JIBAUFBejSpQs6duwIDw8PLFmyBJcuXUKjRo3EDo2IiETE9oH0GQsLIhHMmDED27dvx4ULF2BlZYVevXrBxsYGe/fuFTs0IiISEdsH0me8FYqoloWHh2PJkiUIDQ2FtbU15HI5QkNDcezYMaxatUrs8IiISCRsH0jfsceCiIiIiIiqjD0WRERERERUZSwsiIiIiIioylhYEBERERFRlbGwICIiIiKiKmNhQUREREREVcbCgoiIiIiIqoyFBRERERERVRkLCyIiIiIiqjIWFkREREREVGUsLIiIiIiIqMpYWBARERERUZWxsCAiIiIioir7f//TFqXkmtRtAAAAAElFTkSuQmCC\",\n \"text/plain\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"11190e7d-8c29-4115-824a-e03702f9dd54\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 4.3 Implementing a feed forward network with GELU activations\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b0585dfb-f21e-40e5-973f-2f63ad5cb169\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we implement a small neural network submodule that is used as part of the transformer block in LLMs\\n\",\n \"- We start with the activation function\\n\",\n \"- In deep learning, ReLU (Rectified Linear Unit) activation functions are commonly used due to their simplicity and effectiveness in various neural network architectures\\n\",\n \"- In LLMs, various other types of activation functions are used beyond the traditional ReLU; two notable examples are GELU (Gaussian Error Linear Unit) and SwiGLU (Swish-Gated Linear Unit)\\n\",\n \"- GELU and SwiGLU are more complex, smooth activation functions incorporating Gaussian and sigmoid-gated linear units, respectively, offering better performance for deep learning models, unlike the simpler, piecewise linear function of ReLU\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7d482ce7-e493-4bfc-a820-3ea99f564ebc\",\n \"metadata\": {},\n \"source\": [\n \"- GELU ([Hendrycks and Gimpel 2016](https://arxiv.org/abs/1606.08415)) can be implemented in several ways; the exact version is defined as GELU(x)=x⋅Φ(x), where Φ(x) is the cumulative distribution function of the standard Gaussian distribution.\\n\",\n \"- In practice, it's common to implement a computationally cheaper approximation: $\\\\text{GELU}(x) \\\\approx 0.5 \\\\cdot x \\\\cdot \\\\left(1 + \\\\tanh\\\\left[\\\\sqrt{\\\\frac{2}{\\\\pi}} \\\\cdot \\\\left(x + 0.044715 \\\\cdot x^3\\\\right)\\\\right]\\\\right)\\n\",\n \"$ (the original GPT-2 model was also trained with this approximation)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"f84694b7-95f3-4323-b6d6-0a73df278e82\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class GELU(nn.Module):\\n\",\n \" def __init__(self):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" return 0.5 * x * (1 + torch.tanh(\\n\",\n \" torch.sqrt(torch.tensor(2.0 / torch.pi)) * \\n\",\n \" (x + 0.044715 * torch.pow(x, 3))\\n\",\n \" ))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"fc5487d2-2576-4118-80a7-56c4caac2e71\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAxYAAAEiCAYAAABkykQ1AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjkuMCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy80BEi2AAAACXBIWXMAAA9hAAAPYQGoP6dpAABoBElEQVR4nO3deVhUZfsH8O8My7AJiiDIIioqigsqpKG5lYpbRSnZ4p6WhpVLlvgrTXuTytxyt1KSNPelzExcSM0dREWDXEBc2JRVlmGYOb8/kEkElGE7Z4bv57rmet85c5b7nsl5uOc5z/PIBEEQQEREREREVAVysQMgIiIiIiL9x8KCiIiIiIiqjIUFERERERFVGQsLIiIiIiKqMhYWRERERERUZSwsiIiIiIioylhYEBERERFRlbGwICIiIiKiKmNhQUREREREVcbCgqgMn3/+OWQymSjXDgkJgUwmQ3x8fK1fu7CwEB9//DFcXV0hl8vh7+9f6zFUhJjvERHVbWPGjEHTpk1FubaYbdODBw8wfvx4ODo6QiaTYcqUKaLE8TRivkfEwqJOiouLw+TJk9GqVStYWFjAwsICnp6eCAwMxMWLF0vsW/wPtLxHUlISACA+Ph4ymQzffvttuddt2rQphgwZUuZr586dg0wmQ0hISLXl+TS5ubn4/PPPER4eXmvXfNT8+fOxe/duUa5dnnXr1mHBggUYNmwYfvrpJ0ydOlXUeKT4HhEZsuKivfhhbGwMZ2dnjBkzBnfu3KnUOcPDwyGTybB9+/Zy95HJZJg8eXKZr23fvh0ymaxWv6vv3r2Lzz//HFFRUbV2zWJit03lmT9/PkJCQjBp0iSEhoZi5MiRosUi1feIAGOxA6DatXfvXgwfPhzGxsZ466234OXlBblcjpiYGOzcuROrVq1CXFwc3NzcShy3atUqWFlZlTpf/fr1ayny6pebm4u5c+cCAHr37l3itU8//RQzZ86s0evPnz8fw4YNK9UrMHLkSLz++utQKBQ1ev2yHD58GM7Ozli8eHGtX7ssUnyPiOqCefPmoVmzZsjPz8epU6cQEhKC48ePIzo6GmZmZmKHV+Pu3r2LuXPnomnTpujYsWOJ177//ntoNJoau7bYbVN5Dh8+jGeffRZz5swR5fqPkup7RCws6pTr16/j9ddfh5ubGw4dOoTGjRuXeP3rr7/GypUrIZeX7sgaNmwY7OzsaitU0RkbG8PYWJx/HkZGRjAyMhLl2ikpKXpRLIr5HhHVBQMHDoSPjw8AYPz48bCzs8PXX3+NX3/9Fa+99prI0YnLxMREtGuL2TalpKTA09NTlGvrQsz3iHgrVJ3yzTffICcnB+vXry9VVABF/xg/+OADuLq6ihBdxaSlpeGjjz5C+/btYWVlBWtrawwcOBAXLlwotW9+fj4+//xztGrVCmZmZmjcuDFeffVVXL9+HfHx8bC3twcAzJ07V9vt//nnnwMofY9mu3bt0KdPn1LX0Gg0cHZ2xrBhw7Tbvv32W3Tr1g0NGzaEubk5vL29S90CIJPJkJOTg59++kl77TFjxgAof/zAypUr0bZtWygUCjg5OSEwMBAZGRkl9unduzfatWuHK1euoE+fPrCwsICzszO++eabJ76vxbeyHTlyBJcvX9bGFB4err2N4fEu5+JjHr19bcyYMbCyssKdO3fg7+8PKysr2Nvb46OPPoJarS713i1duhTt27eHmZkZ7O3tMWDAAJw7d06S7xFRXdajRw8ART9QPSomJgbDhg2Dra0tzMzM4OPjg19//VWMEHHz5k2899578PDwgLm5ORo2bIiAgIAyx2JlZGRg6tSpaNq0KRQKBVxcXDBq1Cjcu3cP4eHheOaZZwAAY8eO1X7/FH/XPTrGQqVSwdbWFmPHji11jaysLJiZmeGjjz4CABQUFGD27Nnw9vaGjY0NLC0t0aNHDxw5ckR7jK5tE1A0Nu6LL76Au7s7FAoFmjZtilmzZkGpVJbYr/h25OPHj6NLly4wMzND8+bNsWHDhie+r8VtQFxcHH7//XdtTPHx8eV+F5fVbujy3Vud7XdtvEf0HxYWdcjevXvRokULdO3aVedj09LScO/evRKPx/9gqw03btzA7t27MWTIECxatAgzZszApUuX0KtXL9y9e1e7n1qtxpAhQzB37lx4e3tj4cKF+PDDD5GZmYno6GjY29tj1apVAIBXXnkFoaGhCA0NxauvvlrmdYcPH46jR49qx5QUO378OO7evYvXX39du23p0qXo1KkT5s2bh/nz58PY2BgBAQH4/ffftfuEhoZCoVCgR48e2mu/++675eb9+eefIzAwEE5OTli4cCGGDh2KNWvWoH///lCpVCX2TU9Px4ABA+Dl5YWFCxeidevW+OSTT/DHH3+Ue357e3uEhoaidevWcHFx0cbUpk2bco8pj1qthp+fHxo2bIhvv/0WvXr1wsKFC7F27doS+7399tuYMmUKXF1d8fXXX2PmzJkwMzPDqVOnJPkeEdVlxX84NmjQQLvt8uXLePbZZ/HPP/9g5syZWLhwISwtLeHv749du3bVeoxnz57FiRMn8Prrr+O7777DxIkTcejQIfTu3Ru5ubna/R48eIAePXpg2bJl6N+/P5YuXYqJEyciJiYGt2/fRps2bTBv3jwAwDvvvKP9/unZs2epa5qYmOCVV17B7t27UVBQUOK13bt3Q6lUatuHrKws/PDDD+jduze+/vprfP7550hNTYWfn592LIeubRNQ1KM0e/ZsdO7cGYsXL0avXr0QHBxcol0qdu3aNQwbNgz9+vXDwoUL0aBBA4wZMwaXL18u9/xt2rRBaGgo7Ozs0LFjR21MxX/c66Ii373V3X7XxntEjxCoTsjMzBQACP7+/qVeS09PF1JTU7WP3Nxc7Wtz5swRAJT58PDw0O4XFxcnABAWLFhQbgxubm7C4MGDy3zt7NmzAgBh/fr1T8wjPz9fUKvVJbbFxcUJCoVCmDdvnnbbunXrBADCokWLSp1Do9EIgiAIqampAgBhzpw5pfYpzrtYbGysAEBYtmxZif3ee+89wcrKqsR79uj/FwRBKCgoENq1ayc8//zzJbZbWloKo0ePLnXt9evXCwCEuLg4QRAEISUlRTA1NRX69+9fIvfly5cLAIR169Zpt/Xq1UsAIGzYsEG7TalUCo6OjsLQoUNLXetxvXr1Etq2bVti25EjRwQAwpEjR0psL/7MH/3MRo8eLQAo8VkIgiB06tRJ8Pb21j4/fPiwAED44IMPSsVQ/PkIgjTfIyJDVvxv6+DBg0Jqaqpw69YtYfv27YK9vb2gUCiEW7duafd94YUXhPbt2wv5+fnabRqNRujWrZvQsmVL7bbi75Bt27aVe10AQmBgYJmvbdu2rczvoMc9/t0rCIJw8uTJUv/eZ8+eLQAQdu7cWWr/4u+fJ7VJo0ePFtzc3LTP//zzTwGA8Ntvv5XYb9CgQULz5s21zwsLCwWlUllin/T0dMHBwUEYN26cdpsubVNUVJQAQBg/fnyJ/T766CMBgHD48GHtNjc3NwGAcPToUe22lJQUQaFQCNOnTy91rceV1YY//l1crKx2o6LfvdXdftfme0SCwB6LOiIrKwsAyhyA3bt3b9jb22sfK1asKLXPjh07EBYWVuKxfv36Go/7cQqFQjsGRK1W4/79+7CysoKHhwciIyNLxGtnZ4f333+/1DkqMw1dq1at0LFjR2zZskW7Ta1WY/v27XjxxRdhbm6u3f7o/09PT0dmZiZ69OhRIj5dHDx4EAUFBZgyZUqJ8S8TJkyAtbV1iZ4QoOgzHjFihPa5qakpunTpghs3blTq+pUxceLEEs979OhR4vo7duyATCYrcxBgZT4ffXyPiKSsb9++sLe3h6urK4YNGwZLS0v8+uuvcHFxAVDUi3348GG89tpryM7O1vZk379/H35+frh69WqlZ5GqrEe/e1UqFe7fv48WLVqgfv36pdoHLy8vvPLKK6XOUZnvn+effx52dnYl2of09HSEhYVh+PDh2m1GRkYwNTUFUHQraFpaGgoLC+Hj41Pp9mHfvn0AgGnTppXYPn36dAAo9d3n6empva0NKOoh8fDwqLXvvop891Z3+61v75G+4+iWOqJevXoAirqAH7dmzRpkZ2cjOTm5xD/4R/Xs2bNWBm8/7Uuj+L78lStXIi4ursR9+w0bNtT+/+vXr8PDw6NaB3ANHz4cs2bNwp07d+Ds7Izw8HCkpKSUaDiAolvO/ve//yEqKqrE/ZuVnVf75s2bAAAPD48S201NTdG8eXPt68VcXFxKXatBgwalphKuKcXjJR6/fnp6uvb59evX4eTkBFtb22q5pr69R0RSt2LFCrRq1QqZmZlYt24djh49WmIWtmvXrkEQBHz22Wf47LPPyjxHSkoKnJ2dqy2mp32H5uXlITg4GOvXr8edO3cgCIL2tczMTO3/v379OoYOHVptcRkbG2Po0KHYtGkTlEolFAoFdu7cCZVKVap9+Omnn7Bw4ULExMSUuEWzWbNmlbr2zZs3IZfL0aJFixLbHR0dUb9+/VLffU2aNCl1jse/n2tSRb57q7v91rf3SN+xsKgjbGxs0LhxY0RHR5d6rXjMRU0vNmZmZoa8vLwyXyu+//Vp0xjOnz8fn332GcaNG4cvvvgCtra2kMvlmDJlSo1O/wcUFRZBQUHYtm0bpkyZgq1bt8LGxgYDBgzQ7nPs2DG89NJL6NmzJ1auXInGjRvDxMQE69evx6ZNm2o0vmLlzZb0aCOri/Ia88cHYz/t+lJS3e8RkaHp0qWLdlYof39/PPfcc3jzzTcRGxsLKysr7fftRx99BD8/vzLP8fgfck+iUCiq3D68//77WL9+PaZMmQJfX1/Y2NhAJpPh9ddfr/H24fXXX8eaNWvwxx9/wN/fH1u3bkXr1q3h5eWl3efnn3/GmDFj4O/vjxkzZqBRo0YwMjJCcHBwqUHxuqroD1dSbR9q47tXrPeormFhUYcMHjwYP/zwA86cOYMuXbrU+vXd3Nxw5cqVMl+LjY3V7vMk27dvR58+ffDjjz+W2J6RkVGiR8Xd3R2nT5+GSqUqd2pAXXsQmjVrhi5dumDLli2YPHkydu7cCX9//xK/4u3YsQNmZmb4888/S2wv67axil6/+D2JjY1F8+bNtdsLCgoQFxeHvn376pSHrooHaz4+WP/xX3l04e7ujj///BNpaWlP7LXQl/eIyJAV//Hbp08fLF++HDNnztT+OzMxMamWf19ubm7aduBxurQPo0ePxsKFC7Xb8vPzS313ubu7l/kj26N0bR969uyJxo0bY8uWLXjuuedw+PBh/N///V+p+Jo3b46dO3eWOP/jt4Tqcm03NzdoNBpcvXq1xGQbycnJyMjIeOp7VlU11T5UZ/st9ntU13CMRR3y8ccfw8LCAuPGjUNycnKp12u6Gh80aBBu375daiVlpVKJH374AY0aNULnzp2feA4jI6NScW7btq3UvbxDhw7FvXv3sHz58lLnKD7ewsICQOkvxCcZPnw4Tp06hXXr1uHevXulurmNjIwgk8lK/FoTHx9f5urRlpaWFbp23759YWpqiu+++65E7j/++CMyMzMxePDgCsdfGW5ubjAyMsLRo0dLbF+5cmWlzzl06FAIgqBd4OhRj+aoL+8RkaHr3bs3unTpgiVLliA/Px+NGjVC7969sWbNGiQmJpbaPzU1VafzDxo0CKdOnUJERESJ7RkZGdi4cSM6duwIR0fHJ56jrPZh2bJlpX49Hzp0KC5cuFDmzFXFx1taWmqvXxFyuRzDhg3Db7/9htDQUBQWFpbZPjx6DQA4ffo0Tp48WWI/XdqmQYMGAQCWLFlSYvuiRYsAoMa/+9zd3QGgRPugVqtLzQKoi+puv8V+j+oa9ljUIS1btsSmTZvwxhtvwMPDQ7vytiAIiIuLw6ZNmyCXy7WD8x61ffv2Mgd+9+vXDw4ODtrnhw4dQn5+fqn9/P398c4772DdunUICAjAuHHj0KlTJ9y/fx9btmxBdHQ0NmzYoB3YVp4hQ4Zg3rx5GDt2LLp164ZLly5h48aNJX6lBoBRo0Zhw4YNmDZtGs6cOYMePXogJycHBw8exHvvvYeXX34Z5ubm8PT0xJYtW9CqVSvY2tqiXbt2aNeuXbnXf+211/DRRx/ho48+gq2tbalf6gYPHoxFixZhwIABePPNN5GSkoIVK1agRYsWpe7f9/b2xsGDB7Fo0SI4OTmhWbNmZU4FbG9vj6CgIMydOxcDBgzASy+9hNjYWKxcuRLPPPNMueNiqouNjQ0CAgKwbNkyyGQyuLu7Y+/evUhJSan0Ofv06YORI0fiu+++w9WrVzFgwABoNBocO3YMffr0weTJkwHoz3tEVBfMmDEDAQEBCAkJwcSJE7FixQo899xzaN++PSZMmIDmzZsjOTkZJ0+exO3bt0utL7Rjxw7ExMSUOu/o0aMxc+ZMbNu2DT179sS7776L1q1b4+7duwgJCUFiYmKFJgsZMmQIQkNDYWNjA09PT5w8eRIHDx4sMf6uOI/t27dr2yJvb2+kpaXh119/xerVq+Hl5QV3d3fUr18fq1evRr169WBpaYmuXbs+cSzE8OHDsWzZMsyZMwft27cvNV33kCFDsHPnTrzyyisYPHgw4uLisHr1anh6epYY/6hL2+Tl5YXRo0dj7dq1yMjIQK9evXDmzBn89NNP8Pf3L3P9perUtm1bPPvsswgKCtL2QG/evBmFhYWVPmd1t99iv0d1Ti3PQkUScO3aNWHSpElCixYtBDMzM8Hc3Fxo3bq1MHHiRCEqKqrEvk+abhaPTCVXPPVoeY/Q0FBBEIqm1ps6darQrFkzwcTERLC2thb69Okj/PHHHxWKPT8/X5g+fbrQuHFjwdzcXOjevbtw8uRJoVevXkKvXr1K7Jubmyv83//9n/Zajo6OwrBhw4Tr169r9zlx4oTg7e0tmJqalpi67vHp6h7VvXv3MqeuK/bjjz8KLVu2FBQKhdC6dWth/fr1ZZ4vJiZG6Nmzp2Bubi4A0E6rWt70fcuXLxdat24tmJiYCA4ODsKkSZOE9PT0EvuUNV2sIJSeHrE85R2fmpoqDB06VLCwsBAaNGggvPvuu0J0dHSZ081aWlqWOr6s/AsLC4UFCxYIrVu3FkxNTQV7e3th4MCBQkREhHYfKb5HRIas+N/W2bNnS72mVqsFd3d3wd3dXSgsLBQEQRCuX78ujBo1SnB0dBRMTEwEZ2dnYciQIcL27du1xxVPPVre49ixY4IgCMLt27eF8ePHC87OzoKxsbFga2srDBkyRDh16lSFYk9PTxfGjh0r2NnZCVZWVoKfn58QExMjuLm5lZq2+v79+8LkyZMFZ2dnwdTUVHBxcRFGjx4t3Lt3T7vPnj17BE9PT8HY2LjEd1153xUajUZwdXUVAAj/+9//ynx9/vz5gpubm6BQKIROnToJe/fuLfN8urRNKpVKmDt3rratc3V1FYKCgkpMAywI5U/5Xlb7WZbyjr9+/brQt29fQaFQCA4ODsKsWbOEsLCwMqebreh3b3W337X1HpEgyASBo1GIiIiIiKhqOMaCiIiIiIiqjIUFERERERFVGQsLIiIiIiKqMhYWRERERERUZSwsiIiIiIioylhYEBERERFRldW5BfI0Gg3u3r2LevXq6bQkPBGRIRMEAdnZ2XBycoJcXnd/c2IbQURUki7tQ50rLO7evQtXV1exwyAikqRbt27BxcVF7DBEwzaCiKhsFWkf6lxhUa9ePQBFb461tbVOx6pUKhw4cAD9+/eHiYlJTYRXKwwhD+YgHYaQhyHkAFQtj6ysLLi6umq/I+uqut5GMAfpMIQ8DCEHwDDyqK32oc4VFsVd29bW1pVqNCwsLGBtba23/2EBhpEHc5AOQ8jDEHIAqiePun77T11vI5iDdBhCHoaQA2AYedRW+1B3b6QlIiIiIqJqw8KCiIiIiIiqTNTCYtWqVejQoYO2y9nX1xd//PHHE4/Ztm0bWrduDTMzM7Rv3x779u2rpWiJiKi2sH0gItI/ohYWLi4u+OqrrxAREYFz587h+eefx8svv4zLly+Xuf+JEyfwxhtv4O2338b58+fh7+8Pf39/REdH13LkRERUk9g+EBHpH1ELixdffBGDBg1Cy5Yt0apVK3z55ZewsrLCqVOnytx/6dKlGDBgAGbMmIE2bdrgiy++QOfOnbF8+fJajpyIiGoS2wciIv0jmVmh1Go1tm3bhpycHPj6+pa5z8mTJzFt2rQS2/z8/LB79+5yz6tUKqFUKrXPs7KyABSNjlepVDrFWLy/rsdJjSHkwRykwxDyMIgc1BrM23sFrdSVy0PKuddU+0BEVFccu3oPh+/KMFAQavQ6ohcWly5dgq+vL/Lz82FlZYVdu3bB09OzzH2TkpLg4OBQYpuDgwOSkpLKPX9wcDDmzp1bavuBAwdgYWFRqZjDwsIqdZzUGEIezEE6DCEPfc5h6w05/k6Wo6HCCDamYTDWsT86Nze3ZgKrgppuHwD++PQ45iAdhpCHIeQA6H8eN9NyMWXrRWTlG8HnbAJe7+Km0/G65C16YeHh4YGoqChkZmZi+/btGD16NP76669yGw9dBQUFlfgVq3iRj/79+1dqjvKwsDD069dPb+cxBgwjD+YgHYaQh77n8PPpBPx9MgYyAK801WCgn+55FP9BLSU13T4A/PGpPMxBOgwhD0PIAdDPPJRqYPElI2Tly+BmJcAi5TL27St7rFp5dPnhSfTCwtTUFC1atAAAeHt74+zZs1i6dCnWrFlTal9HR0ckJyeX2JacnAxHR8dyz69QKKBQKEptNzExqfQfEFU5VkoMIQ/mIB2GkIc+5nDsair+ty8WADC9X0u4PvinUnlIMe+abh8A/vj0OOYgHYaQhyHkAOhvHoIgYMrWi0jMS0ZDS1OMa5Vb4z88iV5YPE6j0ZToln6Ur68vDh06hClTpmi3hYWFlXvPLRGRIbuR+gCBGyOh1gh4tbMz3unRFH/88Y/YYdWYmmgf+ONT2ZiDdBhCHoaQA6B/eaz+6zr2RSfDWC7D8je8kHL5ZI3/8CRqYREUFISBAweiSZMmyM7OxqZNmxAeHo4///wTADBq1Cg4OzsjODgYAPDhhx+iV69eWLhwIQYPHozNmzfj3LlzWLt2rZhpEBHVusxcFcb/dA5Z+YXo3KQ+5r/SHjJoxA6r2rB9ICKqvKP/puKb/TEAgDkvtYWPWwPoeAdUpYhaWKSkpGDUqFFITEyEjY0NOnTogD///BP9+vUDACQkJEAu/28EYrdu3bBp0yZ8+umnmDVrFlq2bIndu3ejXbt2YqVARFTrCtUaTP4lEjfu5cDJxgxrRvrAzMQIKpXhFBZsH4iIKifhfi7e/+U8NAIQ4O2CEV2boLCwsFauLWph8eOPPz7x9fDw8FLbAgICEBAQUEMRERFJ3/9+/wfHrt6DuYkRvh/tA/t6pW/l0XdsH4iIdJdbUIh3Qs8hM08FL9f6+MK/HWQyWa1dX9QF8oiISDebTicg5EQ8AGDxcC+0dbIRNyAiIpIEQRDwyY5LiEnKhp2VKVaP6AwzE6NajYGFBRGRnjh5/T5m74kGAEzv1woD2jUWOSIiIpKKH47F4bcLd2Esl2HlW95obGNe6zGwsCAi0gMJ93MxaWMECjUCXvRywuTnW4gdEhERScTxq/cQ/HBWwM+GeKJLM1tR4mBhQUQkcdn5KozfcBYZuSp0cLHBgmEdavWeWSIikq5babl4/5dIaARgmLcLRvnqtrJ2dWJhQUQkYWqNgCmbo/Bv8gM4WCvw/SifWr9nloiIpCmvQI13QyOQ/vCHp//V8mDtx7GwICKSsAV/xuJQTAoUxnKsHekDB2szsUMiIiIJEAQBQTsv4kpiFhpammL1CG/Rf3hiYUFEJFE7I29j9V/XAQDfDOsAL9f64gZERESSse7veOyOugsjuQwr3uoMp/q1P1j7cSwsiIgk6HxCOmbuvAQACOzjjpc7OoscERERScWJ6/cwf1/RYO1PB7fBs80bihxRERYWREQSk5iZh3dCI1BQqEE/TwdM7+chdkhERCQRt9NzMXnTeag1Al7t7Iwx3ZqKHZIWCwsiIgnJV6nxzoYIpGYr0dqxHpYM7wi5nDNAERFRURsx8ecIpOUUoJ2zNea/0l5SswSysCAikghBEDBj+0VcupMJW0tTfD/KB5YKY7HDIiIiCRAEAbN2XUL0nSzYWppizUjpzRLIwoKISCJWhl9/ZNXUznC1tRA7JCIikoiQE/HYGXkHRnIZlr/ZCc4SGKz9OBYWREQSEHYlGd8eiAUAzH25rWQG4hERkfhO3biP//1eNFh71qA26OZuJ3JEZWNhQUQkstikbEzZfB6CAIzydcNbXcVbNZWIiKTlTkYeAjdGQq0R4N/RCeO6NxU7pHKxsCAiElF6TgHGbziLnAI1fJs3xGdDPMUOiYiIJCJfpcaknyNwP6cAbZ2sEfxqB0kN1n4cCwsiIpGo1Bq8tzESt9Ly4GprjpVvdYaJEb+WiYioaLD2/+2KxsXbmWhgYYLVI7xhbiqtwdqPYwtGRCSS/+29gpM37sPS1Ag/jHoGDSxNxQ6JiIgkIvTUTeyIvA25DFj+pn5M6MHCgohIBL+cScBPJ28CABYP7wgPx3oiR0RERFJx+sZ9zPvtCgAgaGAbdG8hzcHajxO1sAgODsYzzzyDevXqoVGjRvD390dsbOwTjwkJCYFMJivxMDMzq6WIiYiq7mx8GmbviQYAfNS/Ffq3dRQ5IiIikorEzDwEbopEoUbAS15OGN+jmdghVZiohcVff/2FwMBAnDp1CmFhYVCpVOjfvz9ycnKeeJy1tTUSExO1j5s3b9ZSxEREVXMnIw8TQyOgUgsY3KExAvu0EDskIiKSiKKVtSNx70EB2jS2xtdDpT1Y+3GiFhb79+/HmDFj0LZtW3h5eSEkJAQJCQmIiIh44nEymQyOjo7ah4ODQy1FTERUeXkFarwbeg73cwrg2dgaC4bpV4NRm9ijTUR1jSAImL0nGhduZaC+hQnWjpT+YO3HSWqMRWZmJgDA1tb2ifs9ePAAbm5ucHV1xcsvv4zLly/XRnhERJUmCAI+2XER0XeyYGtpirWjvGFhaix2WJLFHm0iqmt+Pp2AreeKBmsve6OTXgzWfpxkWjWNRoMpU6age/fuaNeuXbn7eXh4YN26dejQoQMyMzPx7bffolu3brh8+TJcXFxK7a9UKqFUKrXPs7KyAAAqlQoqlUqnGIv31/U4qTGEPJiDdBhCHrWRw9pjcfj1wl0Yy2X4bngHOFiZVPv1qpKH1D6//fv3l3geEhKCRo0aISIiAj179iz3uOIebSIifXI2Pg1zfy36ofyTAa3Ro6W9yBFVjmQKi8DAQERHR+P48eNP3M/X1xe+vr7a5926dUObNm2wZs0afPHFF6X2Dw4Oxty5c0ttP3DgACwsKlcJhoWFVeo4qTGEPJiDdBhCHjWVw5V0GdbGyAHI4O9WiPv/nMK+f2rkUgAql0dubm4NRFJ9dO3R1mg06Ny5M+bPn4+2bdvWRohERJWSlJmPST8XDdYe3KEx3unZXOyQKk0ShcXkyZOxd+9eHD16tMxehycxMTFBp06dcO3atTJfDwoKwrRp07TPs7Ky4Orqiv79+8Pa2lqna6lUKoSFhaFfv34wMTHR6VgpMYQ8mIN0GEIeNZlD3L0cfLrmNAQUYriPC754qU2NjauoSh7FvblSVFM92gB7tR/HHKTDEPIwhByAms1DWajBxJ/P4d4DJTwcrDD/5TYoLCys9uvUVo+2qIWFIAh4//33sWvXLoSHh6NZM92n01Kr1bh06RIGDRpU5usKhQIKhaLUdhMTk0r/AVGVY6XEEPJgDtJhCHlUdw7Z+SpM2hSF7PxC+Lg1wBf+7WFqXPND2yqTh5Q/u5rq0QbYq10e5iAdhpCHIeQA1Ewem6/LEZUih4WRgNecMhB+8EC1X+NRNd2jLWphERgYiE2bNmHPnj2oV68ekpKSAAA2NjYwNzcHAIwaNQrOzs4IDg4GAMybNw/PPvssWrRogYyMDCxYsAA3b97E+PHjRcuDiOhxGo2AqVuicD01B41tzLBqhHetFBWGpiZ7tAH2aj+OOUiHIeRhCDkANZfH5rO3cfLkFchkwPK3vNGjZc0tgldbPdqiFharVq0CAPTu3bvE9vXr12PMmDEAgISEBMjl/zXG6enpmDBhApKSktCgQQN4e3vjxIkT8PT0rK2wiYieavHBf3HwnxQojOVYM9Ib9vVK95xS+WqjRxtgr3Z5mIN0GEIehpADUL15RNxMw7zfiwbbzfDzwPOejavlvE9T0z3aot8K9TTh4eElni9evBiLFy+uoYiIiKruj0uJWHa46Ffy4Ffbo4NLfXED0kPs0SYiQ5WclY+JP0dCpRYwqL0jJvVyFzukaiOJwdtERIYiJikL07ddAAC8/VwzvNpZt9t3qAh7tInIECkL1Zj0cwRSs5Vo5WCFBcO8DGqhVBYWRETVJCO3AO9siEBugRrd3BsiaGBrsUPSW+zRJiJDNPe3K4hMyIC1mTHWjvSBpcKw/hTnSEIiomqg1gh4/5fzSEjLhUsDcyx/szOMjfgVS0RERX45k4BNpxMgkwFLX++EpnaWYodU7djqERFVgwV/xuLY1XswM5Fj7Ugf2Fqaih0SERFJRGRCOubsKVpZe3q/VujTupHIEdUMFhZERFW09+JdrP7rOgBgwTAveDrpNk0pEREZrpTsfEz6OQIFag0GtHVEYJ8WYodUY1hYEBFVwT+JWZix7SIA4N1ezfGil5PIERERkVQUFGrw3s+RSM5SokUjK3z7mmEN1n4cCwsiokrKyC3Au6ERyFOp0aOlHT7242BtIiL6zxd7r+DczXTUUxhj7UhvWBnYYO3HsbAgIqoEtUbAB5ujkJCWC1dbcyx7oxOM5Ib7KxQREelm69lbCD11s2iw9hsd0dzeSuyQahwLCyKiSlh4IBZH/02FmYkca0b4oL4FB2sTEVGRqFsZ+HR3NABgat9WeL61g8gR1Q4WFkREOvrjUiJWhhcN1v56aAcO1iYiIq3UbCUmhhYN1u7v6YDJBjxY+3EsLIiIdHA1ORsfPVxZe/xzzfByR2eRIyIiIqlQqTUI3BiJpKx8uNtbYuFrXpDXodtkWVgQEVVQVr4K74ZGIOfhytozubI2ERE94svf/8GZ+LSiwdqjfFDPzETskGoVCwsiogrQaARM23IBN+7lwLl+0WBtrqxNRETFdkTcRsiJeADA4uEd4V4HBms/jq0iEVEFLD9yDQf/SYapsRyrRnRGQyuF2CEREZFEXLydgaBdlwAAU/q2RF/PujFY+3EsLIiInuJITAoWH/wXAPA//3bo4FJf3ICIiEgy7j14OFi7UIO+bRzwwfMtxQ5JNCwsiIie4Ob9HHy4+TwEAXiraxO85uMqdkhERCQRxYO172bmo7m9JRYNr1uDtR/HwoKIqBx5BWpM/DkSWfmF6NSkPma/6Cl2SEREJCHz9/2D03FpsFIYY+1IH1jXscHaj2NhQURUBkEQMGvXJfyTmAU7K1OsessbCmMjscMiIiKJ2Bl5G+v/jgcALHzNCy0a1b3B2o9jYUFEVIYNJ29i1/k7MJLLsPzNznC0MRM7JCIikojoO5kI2lk0WPuD51vAr62jyBFJg6iFRXBwMJ555hnUq1cPjRo1gr+/P2JjY5963LZt29C6dWuYmZmhffv22LdvXy1ES0R1RcTNNHyx9woAIGhgazzbvKHIERERkVTcf6DEu6ERUBZq8HzrRpjSt5XYIUmGqIXFX3/9hcDAQJw6dQphYWFQqVTo378/cnJyyj3mxIkTeOONN/D222/j/Pnz8Pf3h7+/P6Kjo2sxciIyVCnZ+XhvYyQKNQIGd2iMt59rJnZIREQkEYVqDSZvOo87GXloZmeJxcM71unB2o8zFvPi+/fvL/E8JCQEjRo1QkREBHr27FnmMUuXLsWAAQMwY8YMAMAXX3yBsLAwLF++HKtXr67xmInIcKkeNhjJWUq0bGSFb4Z2gEzGBoOIiIp89UcMTt64D0tTI6wd6Q0b87o9WPtxohYWj8vMzAQA2NralrvPyZMnMW3atBLb/Pz8sHv37jL3VyqVUCqV2udZWVkAAJVKBZVKpVN8xfvrepzUGEIezEE6DCGP4ti/2R+LM3FpsFQYYdnrXjCVC3qVV1U+C6nlGRwcjJ07dyImJgbm5ubo1q0bvv76a3h4eDzxuG3btuGzzz5DfHw8WrZsia+//hqDBg2qpaiJyJD9eiERPxyPA1A0WLulQz2RI5IeyRQWGo0GU6ZMQffu3dGuXbty90tKSoKDQ8nVDB0cHJCUlFTm/sHBwZg7d26p7QcOHICFhUWlYg0LC6vUcVJjCHkwB+nQ9zzO35ch5N9bAIDhbgWIPfsXnj7iS5oq81nk5ubWQCSVV3yr7DPPPIPCwkLMmjUL/fv3x5UrV2BpaVnmMcW3ygYHB2PIkCHYtGkT/P39ERkZ+cR2hYjoaW7nAMv2XAYATO7TAgPaNRY5ImmSTGERGBiI6OhoHD9+vFrPGxQUVKKHIysrC66urujfvz+sra11OpdKpUJYWBj69esHExP97foyhDyYg3QYQh6xiRn4ePVpAMD455riEz/9HIhXlc+iuDdXKnirLBFJRVpOAX6MNUK+SoPeHvaY2k8/24jaIInCYvLkydi7dy+OHj0KFxeXJ+7r6OiI5OTkEtuSk5Ph6Fj2NF8KhQIKhaLUdhMTk0r/EVSVY6XEEPJgDtKhr3nkKAsxZdtlKDUydGnaADMHtoGxkX7PxF2Zz0Lqn11N3CpLRPQ0hWoNpm69iDSlDE1szbF0eCcYcbB2uUQtLARBwPvvv49du3YhPDwczZo9ffYVX19fHDp0CFOmTNFuCwsLg6+vbw1GSkSGSBAEzNx5CddSc2BtImDJax30vqgwRDV1qyzAcXiPYw7SYQh5GEIOX+2PxYkbaTCVC1j2WjtYmOhnPrU1Bk/UwiIwMBCbNm3Cnj17UK9ePe2Xv42NDczNzQEAo0aNgrOzM4KDgwEAH374IXr16oWFCxdi8ODB2Lx5M86dO4e1a9eKlgcR6aefTsTjtwt3YSyXYWyrQtjXK927SeKrqVtlAY7DKw9zkA5DyENfc4i8J8NPV40AAG+10CD+wknEXxA5qCqq6TF4ohYWq1atAgD07t27xPb169djzJgxAICEhATI5f/9gtitWzds2rQJn376KWbNmoWWLVti9+7dHJhHRDqJTEjHl/v+AQB87NcKDhmXRY6IylKTt8oCHIf3OOYgHYaQhz7n8E9iNj75/jQADcZ3b4L2mht6mUex2hqDJ/qtUE8THh5ealtAQAACAgJqICIiqgvuP1AicGMkVGoBg9s3xhjfJvjjDxYWUlJbt8pyHF7ZmIN0GEIe+pZDek4BAjdHIV+lQc9W9viovwf+3H9D7/IoS02PwZPE4G0iotqi1giYsiUKiZn5aG5via+GtgfXwJMe3ipLRGIoVGvwwebzuJWWhya2Fvju9Y4crK0DjlIkojpl6aGrOHb1HsxNjLB6hDfqmen3r0+GatWqVcjMzETv3r3RuHFj7WPLli3afRISEpCYmKh9Xnyr7Nq1a+Hl5YXt27fzVlki0smCA7HaNmLNSG/UtzAVOyS9Uqkei7i4OBw7dgw3b95Ebm4u7O3t0alTJ/j6+sLMzKy6YyQiqhbhsSlYdvgqAGD+q+3QiqumShZvlSWi2rb34l2s+esGAOCbYR3QprFu46xIx8Ji48aNWLp0Kc6dOwcHBwc4OTnB3NwcaWlpuH79OszMzPDWW2/hk08+gZubW03FTESkszsZeZiyJQqCALzVtQle6fTkgcBERFR3xCRlYca2iwCAd3s2x4teTiJHpJ8qXFh06tQJpqamGDNmDHbs2AFXV9cSryuVSpw8eRKbN2+Gj48PVq5cyV+NiEgSCgo1eG9jJDJyVejgYoPZL3qKHZJBY682EemTjNwCvLMhAnkqNXq0tMPHA1qLHZLeqnBh8dVXX8HPz6/c1xUKBXr37o3evXvjyy+/RHx8fHXER0RUZfP3/YMLtzJgY26CFW92hsLYSOyQDBJ7tYlI36g1Aj7YHIWEtFy42prju9e5snZVVLiweFJR8biGDRuiYcOGlQqIiKg6/X4xESEn4gEAi17zgqtt5RY9oydjrzYR6aOFB2Jx9N9UmJnIsWaEDxpYcrB2VVRqVqiQkJAytxcWFiIoKKgq8RARVZsbqQ/wyY6ie2Yn9XbHC20cRI7IcH311Vc4ffo03nvvvVJFBfBfr/bq1asRExOD5s2bixAlEdF/9l1KxMrw6wCAb4Z5wdOJg7WrqlKFxQcffICAgACkp6drt8XGxqJr16745Zdfqi04IqLKyitQ472NkXigLESXZraY3q+V2CEZNF17tb29vWswGiKiJ4tNysZH2y4AAN7p2RwvcbB2tahUYXH+/Hncvn0b7du3R1hYGFasWIHOnTujdevWuHDhQnXHSESkszm/RiMmKRt2VqZY/kYnGBtx2Z7awl5tIpKyzFwV3gk9h9wCNbq3aIiP/TzEDslgVKqldXd3x99//41XX30VAwYMwNSpU/HDDz9g48aNsLGxqe4YiYh0su3cLWw9dxtyGfDd653QyJozEdUm9moTkVSpNQI+3HIeN+/nwrm+OZa90Zk/PFWjSr+Tv//+OzZv3gxfX1/Ur18fP/74I+7evVudsRER6Sw2KRuf7YkGAEzt2wrdWtiJHFHdw15tIpKqxWH/Ijz24WDtkd6w5WDtalWpwuLdd99FQEAAPvnkExw7dgwXL16Eqakp2rdvj61bt1Z3jEREFZKjLMSkjRHIV2nQs5U9Avu0EDukOom92kQkRfujE7H8yDUAwFevdkA7Z34fVbdKFRZ///03Tp8+jenTp0Mmk8HR0RH79u3DvHnzMG7cuOqOkYjoqQRBwKxdl3AjNQeO1mZYMrwj5JyLXDTs1SYiKbmanI3pW4t6TMd1bwb/Ts4iR2SYKlVYREREwMvLq9T2wMBAREREVDkoIiJd/XLmFvZE3YWRXIblb3Zi97aI2KtNRFKSmafCO6ERyClQ49nmtpg1iCtr15QKL5D3KIVCUe5rHh4cWU9EtSv6TiY+/+0yAOBjPw/4NLUVOaK6rbhXu/gHqOJe7RUrVmDcuHF47bXXRI6QiOoKjUbA1C1RiLuXAycbM6x4k4O1a1KF39kBAwbg1KlTT90vOzsbX3/9NVasWFGlwIiIKiI7X4XJmyJRUKjBC60bYUIPLrwmNvZqE5FULDl0FYdjUmBqLMeakT5oaFX+j+NUdRXusQgICMDQoUNhY2ODF198ET4+PnBycoKZmRnS09Nx5coVHD9+HPv27cPgwYOxYMGCmoybiAiCIGDmzkuIfzht4MLXvDiuQgLYq01EUvDn5SR8d+gqACD4lfZo78LB2jWtwj0Wb7/9Nm7cuIFZs2bhypUreOedd9CjRw8888wz8PPzw/fff48mTZrg7Nmz2LJlC5o0afLUcx49ehQvvvginJycIJPJsHv37ifuHx4eDplMVuqRlJRU0TSIyID8fOomfr+YCGO5DMve7IT6FhxXIRb2ahORlFxL+W+w9phuTTHU20XkiOoGncZYKBQKjBgxAiNGjAAAZGZmIi8vDw0bNoSJiYnOF8/JyYGXlxfGjRuHV199tcLHxcbGwtraWvu8UaNGOl+biPTbpduZ+GLvPwCAmQNbo3OTBiJHVLexV5uIpCIrv2iw9gNlIbo2s8X/DW4jdkh1RqUGbxezsbGp0pzkAwcOxMCBA3U+rlGjRqhfv36lr0tE+i0rX4XATZEoUGvQz9MBbz/XTOyQ6ry3334bI0aMwLZt27BlyxasXbsWmZmZAACZTAZPT0/4+fnh7NmzaNOGjTwR1QyNRsC0LVG4kZqDxjZmWPFWZ5hwsHat0amw+O6778rcbmNjg1atWsHX17dagnqajh07QqlUol27dvj888/RvXv3cvdVKpVQKpXa51lZWQAAlUoFlUql03WL99f1OKkxhDyYg3TUdh6CIODjbReRkJYL5/pmCPb3RGFhYZXOyc+ienKv7l5tIiJdfXf4Kg7+UzRYe/UIb9hxsHat0qmwWLx4cZnbMzIykJmZiW7duuHXX3+FrW3NTPXYuHFjrF69Gj4+PlAqlfjhhx/Qu3dvnD59Gp07dy7zmODgYMydO7fU9gMHDsDCwqJScYSFhVXqOKkxhDyYg3TUVh7HkmTYH2cEI5mA4S4P8PeR6rtuXf4scnNzqz2OqvZqExHp4uCVZCw5WDRY+0v/dvByrS9uQHWQToVFXFxcua/duHEDI0aMwKeffoqVK1dWObCyeHh4lJhRpFu3brh+/ToWL16M0NDQMo8JCgrCtGnTtM+zsrLg6uqK/v37lxinUREqlQphYWHo16+fXv/6Zgh5MAfpqM08Lt/NwkdrTwMQ8MmA1hjbza1azsvP4r/e3Kqo7l7to0ePYsGCBYiIiEBiYiJ27doFf3//cvcPDw9Hnz59Sm1PTEyEo6OjTtcmIv1yPfUBpm6JAgCM8nVDgI+ruAHVUVUaY/Go5s2b46uvvsK4ceOq65QV0qVLFxw/frzc1xUKRZlTH5qYmFT6D4iqHCslhpAHc5COms4jK1+FD7dehEotoG8bB0zo6Q6ZrHqnlq3Ln0V15F3dvdqc4IOIKiI7X4V3NpxDtrIQXZra4rMhnmKHVGdVW2EBAE2aNKn1qV+joqLQuHHjWr0mEdUuQRAQtOMSbj5cr+LbgA7VXlRQ1VV3rzYn+CCip9FoBEzfegHXU3PgaM3B2mKr1sLi0qVLcHOr+K0JDx48wLVr17TP4+LiEBUVBVtbWzRp0gRBQUG4c+cONmzYAABYsmQJmjVrhrZt2yI/Px8//PADDh8+jAMHDlRnGkQkMT+fTsDvl4rWq1jO9Sr0Um32ausywQcR6bcVR67hwJVkmBrJsWpEZ9jX42BtMelUWJR3D25mZiYiIiIwffp0jB49usLnO3fuXIn7YYvHQowePRohISFITExEQkKC9vWCggJMnz4dd+7cgYWFBTp06ICDBw+WeU8tERmG6DuZ+OK3KwCATwa0RieuV6G3arpXuzITfHDmwJKYg3QYQh41ncOR2FQsOvgvAODzF9ugXWOrGrlWXf8sdDlGp8Kifv365d5+IJPJMH78eMycObPC5+vduzcEQSj39ZCQkBLPP/74Y3z88ccVPj8R6bfsfBUmP1yv4oXWjTC+B9er0Ge69mrrqjITfHDmwLIxB+kwhDxqIoeUPGDRJSMIggzdHTSwTL6AffsuVPt1HlVXPwtdZg3UqbA4cuRImdutra3RsmVLmJmZISUlBU5OTrqcloioFEEQMGtXNOLv58LJxgzfBnhxXIXEVXevdnV42gQfnDmwJOYgHYaQR03l8EBZiIA1p5GnzoF3k/pYO9YHpsY1N66irn8WuswaqFNh0atXrye+fuHCBXTu3BlqtVqX0xIRlfLLmVv47cJdGMllWPZmJzSw5LgKqavuXu3q8LQJPjhzYNmYg3QYQh7VmYMgCAjafBHXUnPgYK3AqpHesDSvnXEVdfWz0GX/ah28TURUHf5JzMLc3y4DAGb4ecDbrWYW3aTqVd292pzgg4getzL8OvZfToKJkQyrRnijUT0zsUOiR7CwICJJyVEWInBTJJSFGvT2sMc7PZqLHRJVUHX3anOCDyJ61JHYFHx7IBYAMO/ldujMyTwkh4UFEUmGIAj4dHc0bjycj3zRax0hl3NcRV3FCT6IqFj8vRx8+Mt5CALwZtcmeKNLE7FDojLoVFhcvHjxia/HxsZWKRgiqtu2nbuNXefvwEguw3dvdIItx1UQEdV5OcpCvBsagaz8QnRuUh9zXuTK2lKlU2HRsWNHyGSyMn9BKt7OWVuIqDL+Tc7G7F+jAQDT+rVCl2YcV0FEVNcJgoAZ2y8gNjkb9vUUWDXCGwpjI7HDonLoVFjExcXVVBxEVIflFhQicGMk8lUa9Ghph0m93MUOiSqBvdpEVN1W/3UD+y49HKz9Vmc4WHOwtpTpVFjU5MJGRFR3zdlzGVdTHqBRPQUWD+e4Cn3FXm0iqk5//ZuKb/6MAQB8/lJb+DRlT7bU6VRYfPPNN3j//fdhbm4OAPj777/h4+OjnQM8Ozsbn3zyCVauXFn9kRKRQdoRcRvbIm5DLgOWvt4Jdla1Mx85VT/2ahNRdbl5PwcfPBys/fozrniTg7X1gk6FRVBQEMaMGaMtLAYOHIioqCg0b140HWRubi7WrFnDwoKIKuRaSjY+3V00rmJK31bwdW8ockRUFezVJqLqkFtQNFg7M0+Fjq71Mffltuzt1BM6rX/+ePf2k6YBJCJ6krwCNQI3nkeeSo3uLRoisE8LsUOianTs2DGMGDECvr6+uHPnDgAgNDQUx48fFzkyIpIyQRDw8faLiEnKhp2VKVaN6MzB2npEp8KCiKi6fP7rZcQmZ8POSoElwzvBiOMqDMaOHTvg5+cHc3NznD9/HkqlEgCQmZmJ+fPnixwdEUnZ98duYO/FRBjLZVj5ljca25iLHRLpgIUFEdW6nZG3seXcLchkwHevd4R9PY6rMCT/+9//sHr1anz//fcwMTHRbu/evTsiIyNFjIyIpOz41Xv46o+iwdpzXvTktON6SOeVt3/44QdYWVkBAAoLCxESEgI7OzsARYO3iYie5FpKNv5vV9G4ig9faIluLexEjoiqW2xsLHr27Flqu42NDTIyMmo/ICKSvFtpuZj8SyQ0AhDg7YIRz3LMlj7SqbBo0qQJvv/+e+1zR0dHhIaGltqHiKgsj46r6ObeEO8/31LskKgGODo64tq1a2jatGmJ7cePH9dO9kFEVCyvQI13QiOQkauCl4sNvvBvx8HaekqnwiI+Pr6GwiCiumDOr9H/jat4vSPHVRioCRMm4MMPP8S6desgk8lw9+5dnDx5EtOnT8fs2bPFDo+IJEQQBMzceRH/JGY9HKztDTMTDtbWVzoVFvn5+Th48CCGDBkCoGj62eJBeQBgbGyMefPmwcyMqyISUUk7Im5j67mi9Sq+e70jGtXj94ShmjlzJjQaDV544QXk5uaiZ8+eUCgUmDFjBsaPHy92eEQkIT8ej8OeqLswlsuw4s3OcKrPwdr6TKfB2yEhIVizZo32+fLly3HixAmcP38e58+fR2hoqE5rWBw9ehQvvvginJycIJPJsHv37qceEx4ejs6dO0OhUKBFixYICQnRJQUiEsHV5P/Wq/jwhVYcV2HgZDIZ/u///g9paWmIjo7GqVOnkJqaChsbGzRr1kzs8IhIIk5cu4f5+/4BAHw6uA26NudaRvpOp8Ji48aNeOedd0ps27RpE44cOYIjR45gwYIF2LZtW4XPl5OTAy8vL6xYsaJC+8fFxWHw4MHo06cPoqKiMGXKFIwfPx5//vmnLmkQUS3KLSjEexsjkadS47kWdpj8PNerMFRKpRJBQUHw8fFB9+7dsW/fPnh6euLy5cvw8PDA0qVLMXXqVLHDJCIJuJWWi8BNRYO1h3Z2wehuTcUOiaqBTrdCXbt2De3bt9c+NzMzg1z+X23SpUsXBAYGVvh8AwcOxMCBAyu8/+rVq9GsWTMsXLgQANCmTRscP34cixcvhp+fX4XPQ0S1QxAEfLo7GldTHsC+ngKLh3NchSGbPXs21qxZg759++LEiRMICAjA2LFjcerUKSxcuBABAQEwMuK900R1XV6BGu+GRiA9V4X2zjb48hUO1jYUOhUWGRkZJcZUpKamlnhdo9GUeL26nTx5En379i2xzc/PD1OmTKmxaxJR5W07dxs7I+9ALgOWvdGJ61UYuG3btmHDhg146aWXEB0djQ4dOqCwsBAXLlzgHw1EBKDoB6egnRdxJTELDS1NsXokB2sbEp0KCxcXF0RHR8PDw6PM1y9evAgXF5dqCawsSUlJcHBwKLHNwcEBWVlZyMvLg7l56QE/SqWyRLGTlZUFAFCpVFCpVDpdv3h/XY+TGkPIgzlIR3l5xCRl47M9ReMqpr7QAt6u1pLN1dA/C12OrYrbt2/D29sbANCuXTsoFApMnTqVRQURaa37Ox67o+7CSC7D8jc7w5mDtQ2KToXFoEGDMHv2bAwePLjUzE95eXmYO3cuBg8eXK0BVlVwcDDmzp1bavuBAwdgYWFRqXOGhYVVNSxJMIQ8mIN0PJpHvhpYeNEIykIZ2tTXwOVBDPbtixExuooxxM+ionJzc6t8XbVaDVNTU+1zY2Nj7YKqREQnrv83WPv/BrWBrzsHaxsanQqLWbNmYevWrfDw8MDkyZPRqlUrAEWrrC5fvhyFhYWYNWtWjQQKFC26lJycXGJbcnIyrK2ty+ytAIqmxJ02bZr2eVZWFlxdXdG/f39YW1vrdH2VSoWwsDD069cPJiYmuicgEYaQB3OQjsfzEAQBU7ZeREp+MhytFfhpki8aWJg+/UQiMtTPQhfFvblVIQgCxowZA4Wi6Ja3/Px8TJw4EZaWliX227lzZ5WvRUT65U5GHiZvOg+1RsArnZwxtntTsUOiGqBTYeHg4IATJ05g0qRJmDlzJgRBAFA0tWC/fv2wcuXKUrcqVSdfX1/s27evxLawsDD4+vqWe4xCodA2co8yMTGp9B8QVTlWSgwhD+YgHcV5hPwdh33RyTCWy7ByhDca2Vg+/WCJMLTPQtdjqmr06NElno8YMaJK5zt69CgWLFiAiIgIJCYmYteuXfD393/iMeHh4Zg2bRouX74MV1dXfPrppxgzZkyV4iCiqslXqfFu6Dmk5RSgrZM1gl9tz1skDZROhQUANGvWDPv370daWhquXbsGAGjRogVsbW11vviDBw+05wCKppONioqCra0tmjRpgqCgINy5cwcbNmwAAEycOBHLly/Hxx9/jHHjxuHw4cPYunUrfv/9d52vTUTVLzIhHV8+7OaeNagNOjdpIHJEVJvWr19frecrnpJ83LhxePXVV5+6f/GU5BMnTsTGjRtx6NAhjB8/Ho0bN+bMgUQiEQRg9q9XEH0nCw0sTLCGg7UNms6FRTFbW1t06dKlShc/d+4c+vTpo31efMvS6NGjERISgsTERCQkJGhfb9asGX7//XdMnToVS5cuhYuLC3744Qc2GEQSkJZTgMkbI6FSCxjU3pHd3FRlnJKcSP8dS5JhV3wi5DJgxZud4dKgcuNbST9UurCoDr1799beTlWWslbV7t27N86fP1+DURGRrjQCMH37JdzNzEczO0t8PbQDu7mp1lVmSnLOHFgSc5AOQ8jj5LVU7IovWu/sE79WeMbNRi/zMYTPorZmDRS1sCAiw/DnbTmO374PMxM5Vo3ojHpm+j9OgfRPZaYk58yBZWMO0qGveaQrgW8vGkEDGbztNHDIuIJ9+66IHVaV6Otn8aianjWQhQURVcnRq/fw5+2i3ongV9ujtaNus60RiYkzB5bEHKRDn/NQqtR448ezeFCYBWcLAWsn9Ia1hdnTD5Qoff4sitXWrIEsLIio0m6n52L6tksQIMObXVzwSqeaWyCT6GkqMyU5Zw4sG3OQDn3LQxAEBO2+gkt3slDf3ARve+TB2sJMr3Ioj759FmWp6VkD5boGREQEFE0fOOnnSGTkqdDEUsCsga3FDonqOF9fXxw6dKjEtqdNSU5E1Sv01E1sj7gNuQxYMrwDGupvRwVVAgsLItKZIAiYvScal+5kooGFCcZ6qKEw5tcJVa8HDx4gKioKUVFRAP6bkrx4tsCgoCCMGjVKu//EiRNx48YNfPzxx4iJicHKlSuxdetWTJ06VYzwieqcM3FpmPdb0TiKmQNboztX1q5z+JcAEels89lb2Hru4S9Sr3WAbek7SYiq7Ny5c+jUqRM6deoEoGhK8k6dOmH27NkAUO6U5GFhYfDy8sLChQs5JTlRLUnMzMN7GyNQqBHwopcTJvRoLnZIJAKOsSAinZxPSMecPZcBAB/5eaCbe0PsixU5KDJInJKcSD8oC9WY+HMk7j0oQGvHevh6KFfWrqvYY0FEFZaSnY9JP0eiQK2BX1sHTOrlLnZIREQkIkEQMGfPZVy4lQEbcxOsHekDC1P+bl1XsbAgogopKNQgcGMkkrLy4W5viW8DvPiLFBFRHbfxdAI2n70FuQxY9kYnNGnIlbXrMhYWRFQhX/5+BWfj02GlMMbaUT5cBI+IqI47F5+Gub8V3Rr78YDW6NnKXuSISGwsLIjoqbaeu4WfTt4EACwe3hHu9lYiR0RERGJKzsrHpI2RUKkFDG7fGO/25GBtYmFBRE8RmZCOT3dFAwA+fKEl+nk6iBwRERGJqWiwdgRSs5XwcKiHb4Z14K2xBICFBRE9QXJWPiaGRqBArUF/Twd8+EJLsUMiIiKRff7rFZxPyIC1mTHWjPSGpYKDtakICwsiKlO+So13QiOQkq1EKwcrLBreEXI5f5EiIqrLNp1OwC9nEiCTAd+90QlN7SzFDokkhIUFEZUiCAKCdl7STh/4/SgfWPEXKSKiOi3iZjrm/Fp0a+xH/T3Q26ORyBGR1LCwIKJSVv11HbvO34GRXIaVb3WGW0P+IkVEVJelZOVj0s8RUKkFDGrviPd6cx0jKo2FBRGVcOByEhb8WbSU9ucveqJ7CzuRIyIiIjEVFGowaWOk9tbYBcO4jhGVjYUFEWlduZuFKVuiIAjAiGebYKRvU7FDIiIikc3bexkRN9NhbWaMtSN9OFibysXCgogAFM0A9fZPZ5FboEY394aY82JbsUMiIiKRbT17Cz+fKhqsvfR1DtamJ5NEYbFixQo0bdoUZmZm6Nq1K86cOVPuviEhIZDJZCUeZmZmtRgtkeHJLSjE+J/OITEzH+72llj1ljdMjCTx9UBERCI5n5COT3cXDdae3q8V+rTmYG16MtH/ctiyZQumTZuGOXPmIDIyEl5eXvDz80NKSkq5x1hbWyMxMVH7uHnzZi1GTGRYNBoBU7dE4dKdTNhammLdmGdgY2EidlhERCSilOx8TPo5EgVqDQa0dURgnxZih0R6QPTCYtGiRZgwYQLGjh0LT09PrF69GhYWFli3bl25x8hkMjg6OmofDg5cCZiosr7c9w/+vJwMUyM51o705gxQRER1XEGhBoEbI5GUlY8Wjazw7WscrE0VI+rom4KCAkRERCAoKEi7TS6Xo2/fvjh58mS5xz148ABubm7QaDTo3Lkz5s+fj7Zty74fXKlUQqlUap9nZWUBAFQqFVQqlU7xFu+v63FSYwh5MIfqEXLyJn48HgcA+OrVtvByrlcn/10YQg5A1fLQ99yJqPr87/crOBufjnoKY6wd6c11jKjCRP0v5d69e1Cr1aV6HBwcHBATE1PmMR4eHli3bh06dOiAzMxMfPvtt+jWrRsuX74MFxeXUvsHBwdj7ty5pbYfOHAAFhYWlYo7LCysUsdJjSHkwRwq78J9Gdb/Kwcgw0tN1DC6fR77bp+v9Pn4WUhHZfLIzc2tgUiISN9sPXcLG04W3WK+eHhHNLe3Ejki0id6V4L6+vrC19dX+7xbt25o06YN1qxZgy+++KLU/kFBQZg2bZr2eVZWFlxdXdG/f39YW1vrdG2VSoWwsDD069cPJib6ew+6IeTBHKrm3M10bAyJgAAN3uzigs+HtKl0Nzc/C+moSh7FvblEVHdF3crAp7uKBmtP7dsKfT15qznpRtTCws7ODkZGRkhOTi6xPTk5GY6OjhU6h4mJCTp16oRr166V+bpCoYBCoSjzuMr+AVGVY6XEEPJgDrqLTcrGuz+fh7JQg75tGmHey+1hXA0zQPGzkI7K5GEIeRNR5aVmKzExNAIFag36eTrg/ec5WJt0J+rgbVNTU3h7e+PQoUPabRqNBocOHSrRK/EkarUaly5dQuPGjWsqTCKDcTs9F6PWnUZWfiG83Rpg2Rudq6WoICIi/aVSaxC4qWiwdnN7Syx6zQtyOQdrk+5E/4ti2rRp+P777/HTTz/hn3/+waRJk5CTk4OxY8cCAEaNGlVicPe8efNw4MAB3LhxA5GRkRgxYgRu3ryJ8ePHi5UCkV64/0CJUevOIDlLiZaNrPDjaB+YmxqJHRbRE3GdI6Ka9+Xv/+BMXBqsFEUra9czYw8mVY7oYyyGDx+O1NRUzJ49G0lJSejYsSP279+vHdCdkJAAufy/+ic9PR0TJkxAUlISGjRoAG9vb5w4cQKenp5ipUAkeVn5KoxadwY3UnPgZGOGDW93QX0LU7HDInqi4nWOVq9eja5du2LJkiXw8/NDbGwsGjUqe6Eua2trxMbGap9zikyiJ9sRcRshJ+IBFA3WbtGIg7Wp8kQvLABg8uTJmDx5cpmvhYeHl3i+ePFiLF68uBaiIjIMeQVqvB1yFpfvZqGhpSlCx3dFYxtzscMieqpH1zkCgNWrV+P333/HunXrMHPmzDKPKV7niIie7tLtTATtugQA+PCFlujHwdpURZIoLIioZigL1Xj354ii+cjNjLHh7S5w59SBpAdqY50jgGsdPY45SEdN53E/pwDvhJ5DQaEGz3vY472eTav9WvwspKO21jliYUFkoAoKNXjv50gc/TcV5iZGCBn7DNo62YgdFlGF1MY6RwDXOioPc5COmshDrQFW/iNHYpYcjcwE9LdOxP79idV+nWL8LKSjptc5YmFBZIBUag0mb4rEoZgUKIzl+HG0D7zdbMUOi6hG6brOEcC1jh7HHKSjJvP4cl8MrmUlwNLUCD9N6Fpj4yr4WUhHba1zxMKCyMCo1Bp8uPk8DlxJhqmxHN+P8kG3FnZih0Wkk9pY5wjgWkflYQ7SUd157Dp/GyEnEwAAC1/riDbODart3OXhZyEdNb3OkejTzRJR9SkoLOqp2HcpCaZGcqwZ6Y2erezFDotIZ1zniKj6Rd/JxMwdRYO1J/dpgQHtONEBVS/2WBAZiHyVGu9tjMThmBSYGsuxekRn9PEoe0pOIn0wbdo0jB49Gj4+PujSpQuWLFlSap0jZ2dnBAcHAyha5+jZZ59FixYtkJGRgQULFnCdI6KH0nIK8G5oBJSFGvTxsMfUfq3EDokMEAsLIgOQW1CId0MjcOzqPZiZyLF2pA97KkjvcZ0joupR+HDc3Z2MPDRtaIElr3eCEVfWphrAwoJIz2XkFmBcyFlEJmTAwtQIP45+Br7uDcUOi6hacJ0joqr7en8MTly/D0tTI6wd5QMbc/0eJ0DSxcKCSI8lZ+Vj1I9nEJucDWszY6wf+wxnfyIiIq09UXfw/bE4AMC3AV5o5VBP5IjIkLGwINJT11MfYMz6M7iVlodG9RQIfbsrPBzZYBARUZHLdzPxyY6LAIDAPu4Y2J4TGVDNYmFBpIfOxqdhwoZzyMhVwa2hBX5+uytcbSu3mBcRERme9IeDtfNVGvT2sMe0fh5ih0R1AAsLIj2z9+JdTNt6AQWFGnR0rY8fRvvAzqr0PPxERFQ3Fao1eP+X87idnge3hhZYOpyDtal2sLAg0hMajYClh65i6aGrAAC/tg5YMrwTzE2NRI6MiIik5Js/Y3H82j1YmBphzUhv2FhwsDbVDhYWRHogR1mI6VsvYP/lJADAuO7N8H+D2/AXKCIiKuHXC3ex9ugNAMCCYV5o7WgtckRUl7CwIJK4+Hs5mPhzBGKSsmFiJMOX/u3x2jOuYodFREQS809iFj7efgEAMLGXOwZ34GBtql0sLIgkbH90ImZsu4hsZSHsrBRYM7Izp5MlIqJS0nMK8E7oOeSrNOjR0g4z/DhYm2ofCwsiCVIWqvHN/lj8eLxo7vFnmjbAsjc6w9HGTOTIiIhIatQaAR9sPo9baXlwtTXHsjc4WJvEwcKCSGKupWTjg1+icCUxCwDwTs/mmOHnARMjuciRERGRFC34MxbHrt6DuYkR1o70QX0LU7FDojpKEn+prFixAk2bNoWZmRm6du2KM2fOPHH/bdu2oXXr1jAzM0P79u2xb9++WoqUqOZoNAI2nIzH4O+O40piFhpYmGDtSG/MGtSGRQUREZVp78W7WP3XdQDA18M6oE1jDtYm8Yj+18qWLVswbdo0zJkzB5GRkfDy8oKfnx9SUlLK3P/EiRN444038Pbbb+P8+fPw9/eHv78/oqOjazlyouoTfy8Hb3x/CrP3XIaysOj+2D+n9ET/to5ih0ZERBIVk5SFGduKVtZ+p2dzvOTlJHJEVNeJXlgsWrQIEyZMwNixY+Hp6YnVq1fDwsIC69atK3P/pUuXYsCAAZgxYwbatGmDL774Ap07d8by5ctrOXKiqlNrgB+Ox2PA0qM4HZcGcxMjzHnREz+N7YJG1hxPQUREZcvILcA7GyKQp1LjuRZ2+JiDtUkCRB1jUVBQgIiICAQFBWm3yeVy9O3bFydPnizzmJMnT2LatGkltvn5+WH37t1l7q9UKqFUKrXPs7KK7ltXqVRQqVQ6xbsj4hYupciQH3kLChMTGMllMJbLYGwkg5FcBlMjOYzlMpgYyR8+ZDAxlsPUSA5TYzkUDx/GchlkMvEGVRXnrWv+UmIIORz7NwXfXDRCUt6/AIBuzW3xxcueaGJrAbW6EGq1yAFWkCF8FoaQA1C1PPQ9d6K6RK0R8OHmKCSk5cKlQdFgbWPeMksSIGphce/ePajVajg4OJTY7uDggJiYmDKPSUpKKnP/pKSkMvcPDg7G3LlzS20/cOAALCwsdIp37hkj5KmNsPH6Pzod9zgZBJjIoX2YygFTo4f/KxegMELRQw4ojAEzIwFmRoCZEWBuBJgbCzA3AiyMAXPjouMqU6eEhYVVKQ8p0MccUvOAvbfkiLovByCDpbGAl9w06GqfguhTKdDXm/r08bN4nCHkAFQuj9zc3BqIhIhqwsIDsfjr31SYmcixZqQ3GlhysDZJg8HPChUUFFSihyMrKwuurq7o378/rK11G+C0L/M8Eu4mo36DhhAAFGoEFGoEqDUCVGoBhWoNVGoBKrUGhZqi/y0o1KDg4fZiAmQo0AAFmrKuonuFYGosR31zE9Q3N0EDSxPYWpjC1tIUDS1NYWtlCjtLU9jXU8DOyhSN6ilgBA3CwsLQr18/mJiY6Hw9KVCpVHqXw70HSiw/cgNbLt5GoUaAXAZ0d9Dgm5E9YWetW5ErJfr4WTzOEHIAqpZHcW8uEUnbvkuJWBn+cLD20A5o62QjckRE/xG1sLCzs4ORkRGSk5NLbE9OToajY9mDVh0dHXXaX6FQQKFQlNpuYmKic8O7/I1O2LdvHwYNekbnYzUaAQVqDZQqDZSFauSrNMgvVCNfpUZegRq5KjXyC9TIKVAjr6AQOQVq5CgL8UBZiBxlIbLzix8qZOcXIjNPhcw8FQo1AgoKNUjJViIlW/n0QABYmxnDQmaEbakX4VTfHI425nCyMYNTfXM41TeHc31zmJsa6ZSfWCrzOda2xMw8fH80Dr+cSUCequj+pl6t7DG9bwvEnT8GO2sLyedQEfrwWTyNIeQAVC4PQ8ibyND9m5yNj7YVraw9/rlmeLmjs8gREZUkamFhamoKb29vHDp0CP7+/gAAjUaDQ4cOYfLkyWUe4+vri0OHDmHKlCnabWFhYfD19a2FiCtPLpfBTG4EMxMjANXTgAuCgNwCNdJzC5CRq0J6bgHScv573HtQgHsPlLj/QInUB0qkZCmhLNQgK78QWZAh6dr9cs9tZ2UK5wYWcGlgjia2FnBtYIEmthZwa2gBp/rmXHinAv5JzELI3/HYef62tseqo2t9fDKgNXzdG0KlUiHuvMhBEhGRXsjMU+GdDeeQW6BGN/eGmDmwtdghEZUi+q1Q06ZNw+jRo+Hj44MuXbpgyZIlyMnJwdixYwEAo0aNgrOzM4KDgwEAH374IXr16oWFCxdi8ODB2Lx5M86dO4e1a9eKmYYoZDIZLBXGsFQYw6XB0/cXBAHZykLcuf8Avx08Brc2HZD6QIW7mflIyszH3Yw83EnPQ7ay8GFRUoALtzJKncfESAbXBkVFRlM7SzR75OFkYw55HS468lVqhF1JRuipmzgTl6bd3rWZLSY/3wLPtbATdeA+ERHpH41GwNQtUYi/nwvn+uZY/mZnDtYmSRK9sBg+fDhSU1Mxe/ZsJCUloWPHjti/f792gHZCQgLk8v/+8XTr1g2bNm3Cp59+ilmzZqFly5bYvXs32rVrJ1YKekMmk8HazATmjazgUV/AoE7OZd7+kJmnwu30XNxKy3v4v7m4mZaLhLRc3E7LQ4Fagxv3cnDjXg4Qm1riWFNjOZo1tERz+4cPOyu4N7JCc3tLWJsZ5q0Wao2AyIR07Dp/B3sv3EVWfiEAwEguw4C2jhj3XFN4u9mKHCUREemrxQf/xeGYFCiMiwZr23KwNkmU6IUFAEyePLncW5/Cw8NLbQsICEBAQEANR1V32ZibwMbcpswBYWqNgKSsfNy8l4O4+zmIv5eDuHu5iLv3AAlpuSgo1CA2ORuxydmljrWzUqC5vSXcHxYczeyKig9XWwu9W1k6R1mI03H3EXYlGWFXUnDvwX/jWxrbmGGYtwve6uoGRxuuRUFUFStWrMCCBQuQlJQELy8vLFu2DF26dCl3/23btuGzzz5DfHw8WrZsia+//hqDBg2qxYiJqteBK8lYdvgaAOCroe3RzpmDtUm6JFFYkP4wksvg/HCAd7cWdiVeK1RrcCcjDzdSc3A99UFRr0bqA9xIzUFKthL3HhQ9Hr1FqPicrg3M0dTOEk0bWsKtYdFtVk1sLeHSwPzhuBRxpeUUIOpWOs4nZODUjfs4n5CBQs1/M33VMzNGP08HDOvsgmebN6zTt4MRVZctW7Zg2rRpWL16Nbp27YolS5bAz88PsbGxaNSoUan9T5w4gTfeeAPBwcEYMmQINm3aBH9/f0RGRrJXm/TSnRxgxY6iScjHdW+GVzq5iBwR0ZOxsKBqY2wkh1tDS7g1tESf1iUb/ex8FeLu5eBG6sNi4+H/j7uXgzyVGvH3cxF/PxdAaqnzNqqngHODomLGqb45HK3NYGdpjBtZwM37uXBsYAlLU6Mqj11QqTVIyszHrfRc3E7Pw/XUB7ia/AD/Jmfjdnpeqf2b2FqgZys7+LV1RNdmDWFqrF+9LkRSt2jRIkyYMEE75m716tX4/fffsW7dOsycObPU/kuXLsWAAQMwY8YMAMAXX3yBsLAwLF++HKtXr67V2ImqQlmoxorD17HikhHUghrPNrfFrEEcrE3Sx8KCakU9MxN0cKmPDi71S2wXBAHJWUrcuPcAN+/nIv7h7VUJaXlIuJ+DnAK1dird8wkZj53VGEsvHwdQNLbD5uFaHvXMjGFhagwLUyMoTIxgLJdpZ7HSaASoBQH5KjVyH07pm5Gnwv0HBcjMe/LKw+72lujo2gA+TRugu7sdmjTU37UniKSuoKAAERERCAoK0m6Ty+Xo27cvTp48WeYxJ0+eLLFuEQD4+flh9+7d5V5HqVRCqfzvVsbi9TxUKpVOq5Efv3Yfey/exZ07chzdeanE2EB9otFomIMERNxMx417uQBkeM7dFgsDOkDQqKHSqMUOTSfF/4Z0+bckRYaQR1Vy0OUYFhYkKplMBkcbMzjamKGbe8nXBEFAWk4B7jycrepORh7uZuQjOSsfiZl5uJmcjlyNEfJURQsRpmYrkVrBtTzKY2osh0t9czg3MEfThpZo5WCFlg710MbRGjYWhjn4nEiK7t27B7VarZ3Io5iDgwNiYmLKPCYpKanM/ZOSksq9TnBwMObOnVtq+4EDB2BhUfEfD8ITZdgVbwRADqQkVvg4aWIOUlDPRMCrTTXo1DAFp/46KHY4VRIWFiZ2CNXCEPKoTA65ubkV3peFBUmWTCZDQysFGlopSvV0qFSqh4sV+qFAI0N6blGPQ2auCtnKQuQVqJFTUIiCQo12ZXQAMJIDcpkMZiZGsFQYwcLUGNZmJrCvZ4qGlgrYmJtwfARRHRIUFFSilyMrKwuurq7o378/rK2tK3wel9uZcLuaimvXrqJFi5Yw0tNfytUaDXOQAEuFMQZ62uHM8XD069dPbxewVKlUCAsL0+scAMPIoyo5FPfkVgQLC9J7uqzlQUT6wc7ODkZGRkhOTi6xPTk5GY6OjmUe4+joqNP+AKBQKKBQKEpt13X1cu9mdujgYoN9ef9iUJ8Wev3HB3OQhuLbT3T9b1GKDCEHwDDyqEwOuuyvn6U8EREZNFNTU3h7e+PQoUPabRqNBocOHYKvr2+Zx/j6+pbYHyjq9i9vfyIiql7ssSAiIkmaNm0aRo8eDR8fH3Tp0gVLlixBTk6OdpaoUaNGwdnZGcHBwQCADz/8EL169cLChQsxePBgbN68GefOncPatWvFTIOIqM5gYUFERJI0fPhwpKamYvbs2UhKSkLHjh2xf/9+7QDthISEErP+dOvWDZs2bcKnn36KWbNmoWXLlti9ezfXsCAiqiUsLIiISLImT56MyZMnl/laeHh4qW0BAQEICAio4aiIiKgsHGNBRERERERVxsKCiIiIiIiqrM7dCiUIResZ6DInbzGVSoXc3FxkZWXp9XRjhpAHc5AOQ8jDEHIAqpZH8Xdi8XdkXVXX2wjmIB2GkIch5AAYRh611T7UucIiOzsbAODq6ipyJERE0pOdnQ0bGxuxwxAN2wgiorJVpH2QCXXs5ymNRoO7d++iXr16kMl0W2G5eEXWW7du6bQiq9QYQh7MQToMIQ9DyAGoWh6CICA7OxtOTk4lZlqqa+p6G8EcpMMQ8jCEHADDyKO22oc612Mhl8vh4uJSpXNYW1vr7X9YjzKEPJiDdBhCHoaQA1D5POpyT0UxthFFmIN0GEIehpADYBh51HT7UHd/liIiIiIiomrDwoKIiIiIiKqMhYUOFAoF5syZA4VCIXYoVWIIeTAH6TCEPAwhB8Bw8tBXhvD+MwfpMIQ8DCEHwDDyqK0c6tzgbSIiIiIiqn7ssSAiIiIioipjYUFERERERFXGwoKIiIiIiKqMhUUlvfTSS2jSpAnMzMzQuHFjjBw5Enfv3hU7LJ3Ex8fj7bffRrNmzWBubg53d3fMmTMHBQUFYoemky+//BLdunWDhYUF6tevL3Y4FbZixQo0bdoUZmZm6Nq1K86cOSN2SDo5evQoXnzxRTg5OUEmk2H37t1ih6Sz4OBgPPPMM6hXrx4aNWoEf39/xMbGih2WTlatWoUOHTpo5yb39fXFH3/8IXZYdZ6+txGG0j4A+tlGsH0QnyG0D0DttxEsLCqpT58+2Lp1K2JjY7Fjxw5cv34dw4YNEzssncTExECj0WDNmjW4fPkyFi9ejNWrV2PWrFlih6aTgoICBAQEYNKkSWKHUmFbtmzBtGnTMGfOHERGRsLLywt+fn5ISUkRO7QKy8nJgZeXF1asWCF2KJX2119/ITAwEKdOnUJYWBhUKhX69++PnJwcsUOrMBcXF3z11VeIiIjAuXPn8Pzzz+Pll1/G5cuXxQ6tTtP3NsJQ2gdA/9oItg/SYAjtAyBCGyFQtdizZ48gk8mEgoICsUOpkm+++UZo1qyZ2GFUyvr16wUbGxuxw6iQLl26CIGBgdrnarVacHJyEoKDg0WMqvIACLt27RI7jCpLSUkRAAh//fWX2KFUSYMGDYQffvhB7DDoEYbQRuhz+yAI+tNGsH2QJkNpHwShZtsI9lhUg7S0NGzcuBHdunWDiYmJ2OFUSWZmJmxtbcUOw6AVFBQgIiICffv21W6Ty+Xo27cvTp48KWJklJmZCQB6+29ArVZj8+bNyMnJga+vr9jh0EOG0kawfah5bB+kS9/bB6B22ggWFlXwySefwNLSEg0bNkRCQgL27NkjdkhVcu3aNSxbtgzvvvuu2KEYtHv37kGtVsPBwaHEdgcHByQlJYkUFWk0GkyZMgXdu3dHu3btxA5HJ5cuXYKVlRUUCgUmTpyIXbt2wdPTU+yw6jxDaiPYPtQOtg/SpM/tA1C7bQQLi0fMnDkTMpnsiY+YmBjt/jNmzMD58+dx4MABGBkZYdSoURAksN6grnkAwJ07dzBgwAAEBARgwoQJIkX+n8rkQFQVgYGBiI6OxubNm8UORWceHh6IiorC6dOnMWnSJIwePRpXrlwROyyDYwhthCG0DwDbCKpd+tw+ALXbRnDl7Uekpqbi/v37T9ynefPmMDU1LbX99u3bcHV1xYkTJ0S/BUHXPO7evYvevXvj2WefRUhICORy8evNynwWISEhmDJlCjIyMmo4uqopKCiAhYUFtm/fDn9/f+320aNHIyMjQy9/1ZTJZNi1a1eJfPTJ5MmTsWfPHhw9ehTNmjUTO5wq69u3L9zd3bFmzRqxQzEohtBGGEL7ABhuG8H2QXoMrX0AaraNMK72M+oxe3t72NvbV+pYjUYDAFAqldUZUqXoksedO3fQp08feHt7Y/369ZJpNKryWUidqakpvL29cejQIe0XrUajwaFDhzB58mRxg6tjBEHA+++/j127diE8PNxgGg2NRiOJ7yJDYwhthCG0D4DhthFsH6TDUNsHoGbbCBYWlXD69GmcPXsWzz33HBo0aIDr16/js88+g7u7u+i9Fbq4c+cOevfuDTc3N3z77bdITU3Vvubo6ChiZLpJSEhAWloaEhISoFarERUVBQBo0aIFrKysxA2uHNOmTcPo0aPh4+ODLl26YMmSJcjJycHYsWPFDq3CHjx4gGvXrmmfx8XFISoqCra2tmjSpImIkVVcYGAgNm3ahD179qBevXrae5htbGxgbm4ucnQVExQUhIEDB6JJkybIzs7Gpk2bEB4ejj///FPs0OosQ2gjDKV9APSvjWD7IA2G0D4AIrQRNTLXlIG7ePGi0KdPH8HW1lZQKBRC06ZNhYkTJwq3b98WOzSdrF+/XgBQ5kOfjB49uswcjhw5InZoT7Rs2TKhSZMmgqmpqdClSxfh1KlTYoekkyNHjpT5vo8ePVrs0CqsvP/+169fL3ZoFTZu3DjBzc1NMDU1Fezt7YUXXnhBOHDggNhh1WmG0EYYSvsgCPrZRrB9EJ8htA+CUPttBMdYEBERERFRlUnnhkkiIiIiItJbLCyIiIiIiKjKWFgQEREREVGVsbAgIiIiIqIqY2FBRERERERVxsKCiIiIiIiqjIUFERERERFVGQsLIiIiIiKqMhYWRERERERUZSwsiIiIiIioylhYEBERERFRlbGwIKplqampcHR0xPz587XbTpw4AVNTUxw6dEjEyIiISExsH0jfyQRBEMQOgqiu2bdvH/z9/XHixAl4eHigY8eOePnll7Fo0SKxQyMiIhGxfSB9xsKCSCSBgYE4ePAgfHx8cOnSJZw9exYKhULssIiISGRsH0hfsbAgEkleXh7atWuHW7duISIiAu3btxc7JCIikgC2D6SvOMaCSCTXr1/H3bt3odFoEB8fL3Y4REQkEWwfSF+xx4JIBAUFBejSpQs6duwIDw8PLFmyBJcuXUKjRo3EDo2IiETE9oH0GQsLIhHMmDED27dvx4ULF2BlZYVevXrBxsYGe/fuFTs0IiISEdsH0me8FYqoloWHh2PJkiUIDQ2FtbU15HI5QkNDcezYMaxatUrs8IiISCRsH0jfsceCiIiIiIiqjD0WRERERERUZSwsiIiIiIioylhYEBERERFRlbGwICIiIiKiKmNhQUREREREVcbCgoiIiIiIqoyFBRERERERVRkLCyIiIiIiqjIWFkREREREVGUsLIiIiIiIqMpYWBARERERUZWxsCAiIiIioir7f//TFqXkmtRtAAAAAElFTkSuQmCC\",\n \"text/plain\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"928e7f7c-d0b1-499f-8d07-4cadb428a6f9\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([2, 3, 768])\\n\"\n ]\n }\n ],\n \"source\": [\n \"ffn = FeedForward(GPT_CONFIG_124M)\\n\",\n \"\\n\",\n \"# input shape: [batch_size, num_token, emb_size]\\n\",\n \"x = torch.rand(2, 3, 768) \\n\",\n \"out = ffn(x)\\n\",\n \"print(out.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8f8756c5-6b04-443b-93d0-e555a316c377\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"928e7f7c-d0b1-499f-8d07-4cadb428a6f9\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([2, 3, 768])\\n\"\n ]\n }\n ],\n \"source\": [\n \"ffn = FeedForward(GPT_CONFIG_124M)\\n\",\n \"\\n\",\n \"# input shape: [batch_size, num_token, emb_size]\\n\",\n \"x = torch.rand(2, 3, 768) \\n\",\n \"out = ffn(x)\\n\",\n \"print(out.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8f8756c5-6b04-443b-93d0-e555a316c377\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e5da2a50-04f4-4388-af23-ad32e405a972\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e5da2a50-04f4-4388-af23-ad32e405a972\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4ffcb905-53c7-4886-87d2-4464c5fecf89\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 4.4 Adding shortcut connections\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ffae416c-821e-4bfa-a741-8af4ba5db00e\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's talk about the concept behind shortcut connections, also called skip or residual connections\\n\",\n \"- Originally, shortcut connections were proposed in deep networks for computer vision (residual networks) to mitigate vanishing gradient problems\\n\",\n \"- A shortcut connection creates an alternative shorter path for the gradient to flow through the network\\n\",\n \"- This is achieved by adding the output of one layer to the output of a later layer, usually skipping one or more layers in between\\n\",\n \"- Let's illustrate this idea with a small example network:\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4ffcb905-53c7-4886-87d2-4464c5fecf89\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 4.4 Adding shortcut connections\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ffae416c-821e-4bfa-a741-8af4ba5db00e\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's talk about the concept behind shortcut connections, also called skip or residual connections\\n\",\n \"- Originally, shortcut connections were proposed in deep networks for computer vision (residual networks) to mitigate vanishing gradient problems\\n\",\n \"- A shortcut connection creates an alternative shorter path for the gradient to flow through the network\\n\",\n \"- This is achieved by adding the output of one layer to the output of a later layer, usually skipping one or more layers in between\\n\",\n \"- Let's illustrate this idea with a small example network:\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"14cfd241-a32e-4601-8790-784b82f2f23e\",\n \"metadata\": {},\n \"source\": [\n \"- In code, it looks like this:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"05473938-799c-49fd-86d4-8ed65f94fee6\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class ExampleDeepNeuralNetwork(nn.Module):\\n\",\n \" def __init__(self, layer_sizes, use_shortcut):\\n\",\n \" super().__init__()\\n\",\n \" self.use_shortcut = use_shortcut\\n\",\n \" self.layers = nn.ModuleList([\\n\",\n \" nn.Sequential(nn.Linear(layer_sizes[0], layer_sizes[1]), GELU()),\\n\",\n \" nn.Sequential(nn.Linear(layer_sizes[1], layer_sizes[2]), GELU()),\\n\",\n \" nn.Sequential(nn.Linear(layer_sizes[2], layer_sizes[3]), GELU()),\\n\",\n \" nn.Sequential(nn.Linear(layer_sizes[3], layer_sizes[4]), GELU()),\\n\",\n \" nn.Sequential(nn.Linear(layer_sizes[4], layer_sizes[5]), GELU())\\n\",\n \" ])\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" for layer in self.layers:\\n\",\n \" # Compute the output of the current layer\\n\",\n \" layer_output = layer(x)\\n\",\n \" # Check if shortcut can be applied\\n\",\n \" if self.use_shortcut and x.shape == layer_output.shape:\\n\",\n \" x = x + layer_output\\n\",\n \" else:\\n\",\n \" x = layer_output\\n\",\n \" return x\\n\",\n \"\\n\",\n \"\\n\",\n \"def print_gradients(model, x):\\n\",\n \" # Forward pass\\n\",\n \" output = model(x)\\n\",\n \" target = torch.tensor([[0.]])\\n\",\n \"\\n\",\n \" # Calculate loss based on how close the target\\n\",\n \" # and output are\\n\",\n \" loss = nn.MSELoss()\\n\",\n \" loss = loss(output, target)\\n\",\n \" \\n\",\n \" # Backward pass to calculate the gradients\\n\",\n \" loss.backward()\\n\",\n \"\\n\",\n \" for name, param in model.named_parameters():\\n\",\n \" if 'weight' in name:\\n\",\n \" # Print the mean absolute gradient of the weights\\n\",\n \" print(f\\\"{name} has gradient mean of {param.grad.abs().mean().item()}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b39bf277-b3db-4bb1-84ce-7a20caff1011\",\n \"metadata\": {},\n \"source\": [\n \"- Let's print the gradient values first **without** shortcut connections:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"c75f43cc-6923-4018-b980-26023086572c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"layers.0.0.weight has gradient mean of 0.00020173587836325169\\n\",\n \"layers.1.0.weight has gradient mean of 0.00012011159560643137\\n\",\n \"layers.2.0.weight has gradient mean of 0.0007152039906941354\\n\",\n \"layers.3.0.weight has gradient mean of 0.0013988736318424344\\n\",\n \"layers.4.0.weight has gradient mean of 0.005049645435065031\\n\"\n ]\n }\n ],\n \"source\": [\n \"layer_sizes = [3, 3, 3, 3, 3, 1] \\n\",\n \"\\n\",\n \"sample_input = torch.tensor([[1., 0., -1.]])\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model_without_shortcut = ExampleDeepNeuralNetwork(\\n\",\n \" layer_sizes, use_shortcut=False\\n\",\n \")\\n\",\n \"print_gradients(model_without_shortcut, sample_input)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"837fd5d4-7345-4663-97f5-38f19dfde621\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's print the gradient values **with** shortcut connections:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"11b7c0c2-f9dd-4dd5-b096-a05c48c5f6d6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"layers.0.0.weight has gradient mean of 0.22169792652130127\\n\",\n \"layers.1.0.weight has gradient mean of 0.20694106817245483\\n\",\n \"layers.2.0.weight has gradient mean of 0.32896995544433594\\n\",\n \"layers.3.0.weight has gradient mean of 0.2665732204914093\\n\",\n \"layers.4.0.weight has gradient mean of 1.3258540630340576\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model_with_shortcut = ExampleDeepNeuralNetwork(\\n\",\n \" layer_sizes, use_shortcut=True\\n\",\n \")\\n\",\n \"print_gradients(model_with_shortcut, sample_input)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"79ff783a-46f0-49c5-a7a9-26a525764b6e\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see based on the output above, shortcut connections prevent the gradients from vanishing in the early layers (towards `layer.0`)\\n\",\n \"- We will use this concept of a shortcut connection next when we implement a transformer block\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cae578ca-e564-42cf-8635-a2267047cdff\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 4.5 Connecting attention and linear layers in a transformer block\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a3daac6f-6545-4258-8f2d-f45a7394f429\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we now combine the previous concepts into a so-called transformer block\\n\",\n \"- A transformer block combines the causal multi-head attention module from the previous chapter with the linear layers, the feed forward neural network we implemented in an earlier section\\n\",\n \"- In addition, the transformer block also uses dropout and shortcut connections\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"0e1e8176-e5e3-4152-b1aa-0bbd7891dfd9\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch03 import MultiHeadAttention\\n\",\n \"\\n\",\n \"from previous_chapters import MultiHeadAttention\\n\",\n \"\\n\",\n \"\\n\",\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.att = MultiHeadAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" d_out=cfg[\\\"emb_dim\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"], \\n\",\n \" dropout=cfg[\\\"drop_rate\\\"],\\n\",\n \" qkv_bias=cfg[\\\"qkv_bias\\\"])\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.norm2 = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.drop_shortcut = nn.Dropout(cfg[\\\"drop_rate\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \" x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" x = self.drop_shortcut(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" # Shortcut connection for feed forward block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" x = self.drop_shortcut(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"36b64d16-94a6-4d13-8c85-9494c50478a9\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"14cfd241-a32e-4601-8790-784b82f2f23e\",\n \"metadata\": {},\n \"source\": [\n \"- In code, it looks like this:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"05473938-799c-49fd-86d4-8ed65f94fee6\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class ExampleDeepNeuralNetwork(nn.Module):\\n\",\n \" def __init__(self, layer_sizes, use_shortcut):\\n\",\n \" super().__init__()\\n\",\n \" self.use_shortcut = use_shortcut\\n\",\n \" self.layers = nn.ModuleList([\\n\",\n \" nn.Sequential(nn.Linear(layer_sizes[0], layer_sizes[1]), GELU()),\\n\",\n \" nn.Sequential(nn.Linear(layer_sizes[1], layer_sizes[2]), GELU()),\\n\",\n \" nn.Sequential(nn.Linear(layer_sizes[2], layer_sizes[3]), GELU()),\\n\",\n \" nn.Sequential(nn.Linear(layer_sizes[3], layer_sizes[4]), GELU()),\\n\",\n \" nn.Sequential(nn.Linear(layer_sizes[4], layer_sizes[5]), GELU())\\n\",\n \" ])\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" for layer in self.layers:\\n\",\n \" # Compute the output of the current layer\\n\",\n \" layer_output = layer(x)\\n\",\n \" # Check if shortcut can be applied\\n\",\n \" if self.use_shortcut and x.shape == layer_output.shape:\\n\",\n \" x = x + layer_output\\n\",\n \" else:\\n\",\n \" x = layer_output\\n\",\n \" return x\\n\",\n \"\\n\",\n \"\\n\",\n \"def print_gradients(model, x):\\n\",\n \" # Forward pass\\n\",\n \" output = model(x)\\n\",\n \" target = torch.tensor([[0.]])\\n\",\n \"\\n\",\n \" # Calculate loss based on how close the target\\n\",\n \" # and output are\\n\",\n \" loss = nn.MSELoss()\\n\",\n \" loss = loss(output, target)\\n\",\n \" \\n\",\n \" # Backward pass to calculate the gradients\\n\",\n \" loss.backward()\\n\",\n \"\\n\",\n \" for name, param in model.named_parameters():\\n\",\n \" if 'weight' in name:\\n\",\n \" # Print the mean absolute gradient of the weights\\n\",\n \" print(f\\\"{name} has gradient mean of {param.grad.abs().mean().item()}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b39bf277-b3db-4bb1-84ce-7a20caff1011\",\n \"metadata\": {},\n \"source\": [\n \"- Let's print the gradient values first **without** shortcut connections:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"c75f43cc-6923-4018-b980-26023086572c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"layers.0.0.weight has gradient mean of 0.00020173587836325169\\n\",\n \"layers.1.0.weight has gradient mean of 0.00012011159560643137\\n\",\n \"layers.2.0.weight has gradient mean of 0.0007152039906941354\\n\",\n \"layers.3.0.weight has gradient mean of 0.0013988736318424344\\n\",\n \"layers.4.0.weight has gradient mean of 0.005049645435065031\\n\"\n ]\n }\n ],\n \"source\": [\n \"layer_sizes = [3, 3, 3, 3, 3, 1] \\n\",\n \"\\n\",\n \"sample_input = torch.tensor([[1., 0., -1.]])\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model_without_shortcut = ExampleDeepNeuralNetwork(\\n\",\n \" layer_sizes, use_shortcut=False\\n\",\n \")\\n\",\n \"print_gradients(model_without_shortcut, sample_input)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"837fd5d4-7345-4663-97f5-38f19dfde621\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's print the gradient values **with** shortcut connections:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"11b7c0c2-f9dd-4dd5-b096-a05c48c5f6d6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"layers.0.0.weight has gradient mean of 0.22169792652130127\\n\",\n \"layers.1.0.weight has gradient mean of 0.20694106817245483\\n\",\n \"layers.2.0.weight has gradient mean of 0.32896995544433594\\n\",\n \"layers.3.0.weight has gradient mean of 0.2665732204914093\\n\",\n \"layers.4.0.weight has gradient mean of 1.3258540630340576\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model_with_shortcut = ExampleDeepNeuralNetwork(\\n\",\n \" layer_sizes, use_shortcut=True\\n\",\n \")\\n\",\n \"print_gradients(model_with_shortcut, sample_input)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"79ff783a-46f0-49c5-a7a9-26a525764b6e\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see based on the output above, shortcut connections prevent the gradients from vanishing in the early layers (towards `layer.0`)\\n\",\n \"- We will use this concept of a shortcut connection next when we implement a transformer block\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cae578ca-e564-42cf-8635-a2267047cdff\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 4.5 Connecting attention and linear layers in a transformer block\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a3daac6f-6545-4258-8f2d-f45a7394f429\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we now combine the previous concepts into a so-called transformer block\\n\",\n \"- A transformer block combines the causal multi-head attention module from the previous chapter with the linear layers, the feed forward neural network we implemented in an earlier section\\n\",\n \"- In addition, the transformer block also uses dropout and shortcut connections\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"0e1e8176-e5e3-4152-b1aa-0bbd7891dfd9\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch03 import MultiHeadAttention\\n\",\n \"\\n\",\n \"from previous_chapters import MultiHeadAttention\\n\",\n \"\\n\",\n \"\\n\",\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.att = MultiHeadAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" d_out=cfg[\\\"emb_dim\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"], \\n\",\n \" dropout=cfg[\\\"drop_rate\\\"],\\n\",\n \" qkv_bias=cfg[\\\"qkv_bias\\\"])\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.norm2 = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.drop_shortcut = nn.Dropout(cfg[\\\"drop_rate\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \" x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" x = self.drop_shortcut(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" # Shortcut connection for feed forward block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" x = self.drop_shortcut(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"36b64d16-94a6-4d13-8c85-9494c50478a9\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"54d2d375-87bd-4153-9040-63a1e6a2b7cb\",\n \"metadata\": {},\n \"source\": [\n \"- Suppose we have 2 input samples with 4 tokens each, where each token is a 768-dimensional embedding vector; then this transformer block applies self-attention, followed by linear layers, to produce an output of similar size\\n\",\n \"- You can think of the output as an augmented version of the context vectors we discussed in the previous chapter\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"3fb45a63-b1f3-4b08-b525-dafbc8228405\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Input shape: torch.Size([2, 4, 768])\\n\",\n \"Output shape: torch.Size([2, 4, 768])\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"x = torch.rand(2, 4, 768) # Shape: [batch_size, num_tokens, emb_dim]\\n\",\n \"block = TransformerBlock(GPT_CONFIG_124M)\\n\",\n \"output = block(x)\\n\",\n \"\\n\",\n \"print(\\\"Input shape:\\\", x.shape)\\n\",\n \"print(\\\"Output shape:\\\", output.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8f9e4ee4-cf23-4583-b1fd-317abb4fcd13\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"54d2d375-87bd-4153-9040-63a1e6a2b7cb\",\n \"metadata\": {},\n \"source\": [\n \"- Suppose we have 2 input samples with 4 tokens each, where each token is a 768-dimensional embedding vector; then this transformer block applies self-attention, followed by linear layers, to produce an output of similar size\\n\",\n \"- You can think of the output as an augmented version of the context vectors we discussed in the previous chapter\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"3fb45a63-b1f3-4b08-b525-dafbc8228405\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Input shape: torch.Size([2, 4, 768])\\n\",\n \"Output shape: torch.Size([2, 4, 768])\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"x = torch.rand(2, 4, 768) # Shape: [batch_size, num_tokens, emb_dim]\\n\",\n \"block = TransformerBlock(GPT_CONFIG_124M)\\n\",\n \"output = block(x)\\n\",\n \"\\n\",\n \"print(\\\"Input shape:\\\", x.shape)\\n\",\n \"print(\\\"Output shape:\\\", output.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8f9e4ee4-cf23-4583-b1fd-317abb4fcd13\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"46618527-15ac-4c32-ad85-6cfea83e006e\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 4.6 Coding the GPT model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dec7d03d-9ff3-4ca3-ad67-01b67c2f5457\",\n \"metadata\": {},\n \"source\": [\n \"- We are almost there: now let's plug in the transformer block into the architecture we coded at the very beginning of this chapter so that we obtain a usable GPT architecture\\n\",\n \"- Note that the transformer block is repeated multiple times; in the case of the smallest 124M GPT-2 model, we repeat it 12 times:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9b7b362d-f8c5-48d2-8ebd-722480ac5073\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"46618527-15ac-4c32-ad85-6cfea83e006e\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 4.6 Coding the GPT model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dec7d03d-9ff3-4ca3-ad67-01b67c2f5457\",\n \"metadata\": {},\n \"source\": [\n \"- We are almost there: now let's plug in the transformer block into the architecture we coded at the very beginning of this chapter so that we obtain a usable GPT architecture\\n\",\n \"- Note that the transformer block is repeated multiple times; in the case of the smallest 124M GPT-2 model, we repeat it 12 times:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9b7b362d-f8c5-48d2-8ebd-722480ac5073\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"324e4b5d-ed89-4fdf-9a52-67deee0593bc\",\n \"metadata\": {},\n \"source\": [\n \"- The corresponding code implementation, where `cfg[\\\"n_layers\\\"] = 12`:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"c61de39c-d03c-4a32-8b57-f49ac3834857\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class GPTModel(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" self.pos_emb = nn.Embedding(cfg[\\\"context_length\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" self.drop_emb = nn.Dropout(cfg[\\\"drop_rate\\\"])\\n\",\n \" \\n\",\n \" self.trf_blocks = nn.Sequential(\\n\",\n \" *[TransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])])\\n\",\n \" \\n\",\n \" self.final_norm = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.out_head = nn.Linear(\\n\",\n \" cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False\\n\",\n \" )\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" batch_size, seq_len = in_idx.shape\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\\n\",\n \" x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" x = self.drop_emb(x)\\n\",\n \" x = self.trf_blocks(x)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x)\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2750270f-c45d-4410-8767-a6adbd05d5c3\",\n \"metadata\": {},\n \"source\": [\n \"- Using the configuration of the 124M parameter model, we can now instantiate this GPT model with random initial weights as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"ef94fd9c-4e9d-470d-8f8e-dd23d1bb1f64\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Input batch:\\n\",\n \" tensor([[6109, 3626, 6100, 345],\\n\",\n \" [6109, 1110, 6622, 257]])\\n\",\n \"\\n\",\n \"Output shape: torch.Size([2, 4, 50257])\\n\",\n \"tensor([[[ 0.3613, 0.4222, -0.0711, ..., 0.3483, 0.4661, -0.2838],\\n\",\n \" [-0.1792, -0.5660, -0.9485, ..., 0.0477, 0.5181, -0.3168],\\n\",\n \" [ 0.7120, 0.0332, 0.1085, ..., 0.1018, -0.4327, -0.2553],\\n\",\n \" [-1.0076, 0.3418, -0.1190, ..., 0.7195, 0.4023, 0.0532]],\\n\",\n \"\\n\",\n \" [[-0.2564, 0.0900, 0.0335, ..., 0.2659, 0.4454, -0.6806],\\n\",\n \" [ 0.1230, 0.3653, -0.2074, ..., 0.7705, 0.2710, 0.2246],\\n\",\n \" [ 1.0558, 1.0318, -0.2800, ..., 0.6936, 0.3205, -0.3178],\\n\",\n \" [-0.1565, 0.3926, 0.3288, ..., 1.2630, -0.1858, 0.0388]]],\\n\",\n \" grad_fn=
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"324e4b5d-ed89-4fdf-9a52-67deee0593bc\",\n \"metadata\": {},\n \"source\": [\n \"- The corresponding code implementation, where `cfg[\\\"n_layers\\\"] = 12`:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"c61de39c-d03c-4a32-8b57-f49ac3834857\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class GPTModel(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" self.pos_emb = nn.Embedding(cfg[\\\"context_length\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" self.drop_emb = nn.Dropout(cfg[\\\"drop_rate\\\"])\\n\",\n \" \\n\",\n \" self.trf_blocks = nn.Sequential(\\n\",\n \" *[TransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])])\\n\",\n \" \\n\",\n \" self.final_norm = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.out_head = nn.Linear(\\n\",\n \" cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False\\n\",\n \" )\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" batch_size, seq_len = in_idx.shape\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\\n\",\n \" x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" x = self.drop_emb(x)\\n\",\n \" x = self.trf_blocks(x)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x)\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2750270f-c45d-4410-8767-a6adbd05d5c3\",\n \"metadata\": {},\n \"source\": [\n \"- Using the configuration of the 124M parameter model, we can now instantiate this GPT model with random initial weights as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"ef94fd9c-4e9d-470d-8f8e-dd23d1bb1f64\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Input batch:\\n\",\n \" tensor([[6109, 3626, 6100, 345],\\n\",\n \" [6109, 1110, 6622, 257]])\\n\",\n \"\\n\",\n \"Output shape: torch.Size([2, 4, 50257])\\n\",\n \"tensor([[[ 0.3613, 0.4222, -0.0711, ..., 0.3483, 0.4661, -0.2838],\\n\",\n \" [-0.1792, -0.5660, -0.9485, ..., 0.0477, 0.5181, -0.3168],\\n\",\n \" [ 0.7120, 0.0332, 0.1085, ..., 0.1018, -0.4327, -0.2553],\\n\",\n \" [-1.0076, 0.3418, -0.1190, ..., 0.7195, 0.4023, 0.0532]],\\n\",\n \"\\n\",\n \" [[-0.2564, 0.0900, 0.0335, ..., 0.2659, 0.4454, -0.6806],\\n\",\n \" [ 0.1230, 0.3653, -0.2074, ..., 0.7705, 0.2710, 0.2246],\\n\",\n \" [ 1.0558, 1.0318, -0.2800, ..., 0.6936, 0.3205, -0.3178],\\n\",\n \" [-0.1565, 0.3926, 0.3288, ..., 1.2630, -0.1858, 0.0388]]],\\n\",\n \" grad_fn= \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a7061524-a3bd-4803-ade6-2e3b7b79ac13\",\n \"metadata\": {},\n \"source\": [\n \"- The following `generate_text_simple` function implements greedy decoding, which is a simple and fast method to generate text\\n\",\n \"- In greedy decoding, at each step, the model chooses the word (or token) with the highest probability as its next output (the highest logit corresponds to the highest probability, so we technically wouldn't even have to compute the softmax function explicitly)\\n\",\n \"- In the next chapter, we will implement a more advanced `generate_text` function\\n\",\n \"- The figure below depicts how the GPT model, given an input context, generates the next word token\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7ee0f32c-c18c-445e-b294-a879de2aa187\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a7061524-a3bd-4803-ade6-2e3b7b79ac13\",\n \"metadata\": {},\n \"source\": [\n \"- The following `generate_text_simple` function implements greedy decoding, which is a simple and fast method to generate text\\n\",\n \"- In greedy decoding, at each step, the model chooses the word (or token) with the highest probability as its next output (the highest logit corresponds to the highest probability, so we technically wouldn't even have to compute the softmax function explicitly)\\n\",\n \"- In the next chapter, we will implement a more advanced `generate_text` function\\n\",\n \"- The figure below depicts how the GPT model, given an input context, generates the next word token\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7ee0f32c-c18c-445e-b294-a879de2aa187\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"c9b428a9-8764-4b36-80cd-7d4e00595ba6\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def generate_text_simple(model, idx, max_new_tokens, context_size):\\n\",\n \" # idx is (batch, n_tokens) array of indices in the current context\\n\",\n \" for _ in range(max_new_tokens):\\n\",\n \" \\n\",\n \" # Crop current context if it exceeds the supported context size\\n\",\n \" # E.g., if LLM supports only 5 tokens, and the context size is 10\\n\",\n \" # then only the last 5 tokens are used as context\\n\",\n \" idx_cond = idx[:, -context_size:]\\n\",\n \" \\n\",\n \" # Get the predictions\\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(idx_cond)\\n\",\n \" \\n\",\n \" # Focus only on the last time step\\n\",\n \" # (batch, n_tokens, vocab_size) becomes (batch, vocab_size)\\n\",\n \" logits = logits[:, -1, :] \\n\",\n \"\\n\",\n \" # Apply softmax to get probabilities\\n\",\n \" probas = torch.softmax(logits, dim=-1) # (batch, vocab_size)\\n\",\n \"\\n\",\n \" # Get the idx of the vocab entry with the highest probability value\\n\",\n \" idx_next = torch.argmax(probas, dim=-1, keepdim=True) # (batch, 1)\\n\",\n \"\\n\",\n \" # Append sampled index to the running sequence\\n\",\n \" idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\\n\",\n \"\\n\",\n \" return idx\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6515f2c1-3cc7-421c-8d58-cc2f563b7030\",\n \"metadata\": {},\n \"source\": [\n \"- The `generate_text_simple` above implements an iterative process, where it creates one token at a time\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"c9b428a9-8764-4b36-80cd-7d4e00595ba6\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def generate_text_simple(model, idx, max_new_tokens, context_size):\\n\",\n \" # idx is (batch, n_tokens) array of indices in the current context\\n\",\n \" for _ in range(max_new_tokens):\\n\",\n \" \\n\",\n \" # Crop current context if it exceeds the supported context size\\n\",\n \" # E.g., if LLM supports only 5 tokens, and the context size is 10\\n\",\n \" # then only the last 5 tokens are used as context\\n\",\n \" idx_cond = idx[:, -context_size:]\\n\",\n \" \\n\",\n \" # Get the predictions\\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(idx_cond)\\n\",\n \" \\n\",\n \" # Focus only on the last time step\\n\",\n \" # (batch, n_tokens, vocab_size) becomes (batch, vocab_size)\\n\",\n \" logits = logits[:, -1, :] \\n\",\n \"\\n\",\n \" # Apply softmax to get probabilities\\n\",\n \" probas = torch.softmax(logits, dim=-1) # (batch, vocab_size)\\n\",\n \"\\n\",\n \" # Get the idx of the vocab entry with the highest probability value\\n\",\n \" idx_next = torch.argmax(probas, dim=-1, keepdim=True) # (batch, 1)\\n\",\n \"\\n\",\n \" # Append sampled index to the running sequence\\n\",\n \" idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\\n\",\n \"\\n\",\n \" return idx\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6515f2c1-3cc7-421c-8d58-cc2f563b7030\",\n \"metadata\": {},\n \"source\": [\n \"- The `generate_text_simple` above implements an iterative process, where it creates one token at a time\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f682eac4-f9bd-438b-9dec-6b1cc7bc05ce\",\n \"metadata\": {},\n \"source\": [\n \"- Let's prepare an input example:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"3d7e3e94-df0f-4c0f-a6a1-423f500ac1d3\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"encoded: [15496, 11, 314, 716]\\n\",\n \"encoded_tensor.shape: torch.Size([1, 4])\\n\"\n ]\n }\n ],\n \"source\": [\n \"start_context = \\\"Hello, I am\\\"\\n\",\n \"\\n\",\n \"encoded = tokenizer.encode(start_context)\\n\",\n \"print(\\\"encoded:\\\", encoded)\\n\",\n \"\\n\",\n \"encoded_tensor = torch.tensor(encoded).unsqueeze(0)\\n\",\n \"print(\\\"encoded_tensor.shape:\\\", encoded_tensor.shape)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"a72a9b60-de66-44cf-b2f9-1e638934ada4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output: tensor([[15496, 11, 314, 716, 27018, 24086, 47843, 30961, 42348, 7267]])\\n\",\n \"Output length: 10\\n\"\n ]\n }\n ],\n \"source\": [\n \"model.eval() # disable dropout\\n\",\n \"\\n\",\n \"out = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=encoded_tensor, \\n\",\n \" max_new_tokens=6, \\n\",\n \" context_size=GPT_CONFIG_124M[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output:\\\", out)\\n\",\n \"print(\\\"Output length:\\\", len(out[0]))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1d131c00-1787-44ba-bec3-7c145497b2c3\",\n \"metadata\": {},\n \"source\": [\n \"- Remove batch dimension and convert back into text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"053d99f6-5710-4446-8d52-117fb34ea9f6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Hello, I am Featureiman Byeswickattribute argue\\n\"\n ]\n }\n ],\n \"source\": [\n \"decoded_text = tokenizer.decode(out.squeeze(0).tolist())\\n\",\n \"print(decoded_text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9a894003-51f6-4ccc-996f-3b9c7d5a1d70\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the model is untrained; hence the random output texts above\\n\",\n \"- We will train the model in the next chapter\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a35278b6-9e5c-480f-83e5-011a1173648f\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## Summary and takeaways\\n\",\n \"\\n\",\n \"- See the [./gpt.py](./gpt.py) script, a self-contained script containing the GPT model we implement in this Jupyter notebook\\n\",\n \"- You can find the exercise solutions in [./exercise-solutions.ipynb](./exercise-solutions.ipynb)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"id\": \"4821ac83-ef84-42c4-a327-32bf2820a8e5\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": []\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch04/01_main-chapter-code/exercise-solutions.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba450fb1-8a26-4894-ab7a-5d7bfefe90ce\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f682eac4-f9bd-438b-9dec-6b1cc7bc05ce\",\n \"metadata\": {},\n \"source\": [\n \"- Let's prepare an input example:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"3d7e3e94-df0f-4c0f-a6a1-423f500ac1d3\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"encoded: [15496, 11, 314, 716]\\n\",\n \"encoded_tensor.shape: torch.Size([1, 4])\\n\"\n ]\n }\n ],\n \"source\": [\n \"start_context = \\\"Hello, I am\\\"\\n\",\n \"\\n\",\n \"encoded = tokenizer.encode(start_context)\\n\",\n \"print(\\\"encoded:\\\", encoded)\\n\",\n \"\\n\",\n \"encoded_tensor = torch.tensor(encoded).unsqueeze(0)\\n\",\n \"print(\\\"encoded_tensor.shape:\\\", encoded_tensor.shape)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"a72a9b60-de66-44cf-b2f9-1e638934ada4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output: tensor([[15496, 11, 314, 716, 27018, 24086, 47843, 30961, 42348, 7267]])\\n\",\n \"Output length: 10\\n\"\n ]\n }\n ],\n \"source\": [\n \"model.eval() # disable dropout\\n\",\n \"\\n\",\n \"out = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=encoded_tensor, \\n\",\n \" max_new_tokens=6, \\n\",\n \" context_size=GPT_CONFIG_124M[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output:\\\", out)\\n\",\n \"print(\\\"Output length:\\\", len(out[0]))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1d131c00-1787-44ba-bec3-7c145497b2c3\",\n \"metadata\": {},\n \"source\": [\n \"- Remove batch dimension and convert back into text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"053d99f6-5710-4446-8d52-117fb34ea9f6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Hello, I am Featureiman Byeswickattribute argue\\n\"\n ]\n }\n ],\n \"source\": [\n \"decoded_text = tokenizer.decode(out.squeeze(0).tolist())\\n\",\n \"print(decoded_text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9a894003-51f6-4ccc-996f-3b9c7d5a1d70\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the model is untrained; hence the random output texts above\\n\",\n \"- We will train the model in the next chapter\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a35278b6-9e5c-480f-83e5-011a1173648f\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## Summary and takeaways\\n\",\n \"\\n\",\n \"- See the [./gpt.py](./gpt.py) script, a self-contained script containing the GPT model we implement in this Jupyter notebook\\n\",\n \"- You can find the exercise solutions in [./exercise-solutions.ipynb](./exercise-solutions.ipynb)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"id\": \"4821ac83-ef84-42c4-a327-32bf2820a8e5\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": []\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch04/01_main-chapter-code/exercise-solutions.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba450fb1-8a26-4894-ab7a-5d7bfefe90ce\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \n\nNow, as we learned in Chapters 2 and 4, LLMs generate one word (or token) at a time. Suppose the LLM generated the word \"fast\" so that the prompt for the next round becomes \"Time flies fast\". This is illustrated in the next figure below:\n\n
\n\nNow, as we learned in Chapters 2 and 4, LLMs generate one word (or token) at a time. Suppose the LLM generated the word \"fast\" so that the prompt for the next round becomes \"Time flies fast\". This is illustrated in the next figure below:\n\n \n\nAs we can see, based on comparing the previous 2 figures, the keys, and value vectors for the first two tokens are exactly the same, and it would be wasteful to recompute them in each next-token text generation round.\n\nSo, the idea of the KV cache is to implement a caching mechanism that stores the previously generated key and value vectors for reuse, which helps us to avoid unnecessary recomputations.\n\n \n\n## KV cache implementation\n\nThere are many ways to implement a KV cache, with the main idea being that we only compute the key and value tensors for the newly generated tokens in each generation step.\n\nI opted for a simple one that emphasizes code readability. I think it's easiest to just scroll through the code changes to see how it's implemented.\n\nThere are two files in this folder:\n\n1. [`gpt_ch04.py`](gpt_ch04.py): Self-contained code taken from Chapter 3 and 4 to implement the LLM and run the simple text generation function\n2. [`gpt_with_kv_cache.py`](gpt_with_kv_cache.py): The same as above, but with the necessary changes made to implement the KV cache. \n\nYou can either \n\na. Open the [`gpt_with_kv_cache.py`](gpt_with_kv_cache.py) file and look out for the `# NEW` sections that mark the new changes:\n\n
\n\nAs we can see, based on comparing the previous 2 figures, the keys, and value vectors for the first two tokens are exactly the same, and it would be wasteful to recompute them in each next-token text generation round.\n\nSo, the idea of the KV cache is to implement a caching mechanism that stores the previously generated key and value vectors for reuse, which helps us to avoid unnecessary recomputations.\n\n \n\n## KV cache implementation\n\nThere are many ways to implement a KV cache, with the main idea being that we only compute the key and value tensors for the newly generated tokens in each generation step.\n\nI opted for a simple one that emphasizes code readability. I think it's easiest to just scroll through the code changes to see how it's implemented.\n\nThere are two files in this folder:\n\n1. [`gpt_ch04.py`](gpt_ch04.py): Self-contained code taken from Chapter 3 and 4 to implement the LLM and run the simple text generation function\n2. [`gpt_with_kv_cache.py`](gpt_with_kv_cache.py): The same as above, but with the necessary changes made to implement the KV cache. \n\nYou can either \n\na. Open the [`gpt_with_kv_cache.py`](gpt_with_kv_cache.py) file and look out for the `# NEW` sections that mark the new changes:\n\n \n\nb. Check out the two code files via a file diff tool of your choice to compare the changes:\n\n
\n\nb. Check out the two code files via a file diff tool of your choice to compare the changes:\n\n \n\nTo summarize the implementation details, here's a short walkthrough.\n\n \n\n### 1. Registering the cache buffers\n\nInside the `MultiHeadAttention` constructor we add two buffers, `cache_k` and `cache_v`, which will hold concatenated keys and values across steps:\n\n```python\nself.register_buffer(\"cache_k\", None)\nself.register_buffer(\"cache_v\", None)\n```\n\n \n\n### 2. Forward pass with `use_cache` flag\n\nNext, we extend the `forward` method of the `MultiHeadAttention` class to accept `use_cache` argument. After projecting the new chunk of tokens into `keys_new`, `values_new` and `queries`, we either initialize the kv cache or append to our cache:\n\n```python\ndef forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n #...\n\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n \n # ...\n \n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n if use_cache:\n mask_bool = self.mask.bool()[\n self.ptr_current_pos:self.ptr_current_pos + num_tokens_Q, :num_tokens_K\n ]\n self.ptr_current_pos += num_tokens_Q\n else:\n mask_bool = self.mask.bool()[:num_tokens_Q, :num_tokens_K]\n```\n\n \n\n\n### 3. Clearing the cache\n\nWhen generating texts, between independent sequences (for instance to text generation calls) we must reset both buffers, so we also add a cache resetting method the to the `MultiHeadAttention` class:\n\n```python\ndef reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n```\n\n \n\n### 4. Propagating `use_cache` in the full model\n\nWith the changes to the `MultiHeadAttention` class in place, we now modify the `GPTModel` class. First, we add a position tracking for the token indices to the instructor:\n\n```python\nself.current_pos = 0\n```\n\nThen, we replace the one-liner block call with an explicit loop, passing `use_cache` through each transformer block:\n\n```python\ndef forward(self, in_idx, use_cache=False):\n # ...\n \n if use_cache:\n pos_ids = torch.arange(\n self.current_pos, self.current_pos + seq_len, \n device=in_idx.device, dtype=torch.long\n )\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(\n 0, seq_len, device=in_idx.device, dtype=torch.long\n )\n \n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n x = tok_embeds + pos_embeds\n # ...\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n```\n\nThe above change then also requires a small modification to the `TransformerBlock` class to accept the `use_cache` argument:\n```python\n def forward(self, x, use_cache=False):\n # ...\n self.att(x, use_cache=use_cache)\n```\n\nLastly, we add a model-level reset to `GPTModel` to clear all block caches at once for our convenience:\n\n```python\ndef reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n```\n\n \n\n### 5. Using the cache in generation\n\nWith the changes to the `GPTModel`, `TransformerBlock`, and `MultiHeadAttention`, finally, here's how we use the KV cache in a simple text generation function:\n\n```python\ndef generate_text_simple_cached(model, idx, max_new_tokens, \n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n```\n\nNote that we only feed the model the new token in c) via `logits = model(next_idx, use_cache=True)`. Without caching, we feed the model the whole input `logits = model(idx[:, -ctx_len:], use_cache=False)` as it has no stored keys and values to reuse.\n\n \n\n## Simple performance comparison\n\nAfter covering the KV cache on a conceptual level, the big question is how well it actually performs in practice on a small example. To give the implementation a try, we can run the two aforementioned code files as Python scripts, which will run the small 124 M parameter LLM to generate 200 new tokens (given a 4-token prompt \"Hello, I am\" to start with):\n\n```bash\npip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt\n\npython gpt_ch04.py\n\npython gpt_with_kv_cache.py\n```\n\nOn a Mac Mini with M4 chip (CPU), the results are as follows:\n\n| | Tokens/sec |\n| ---------------------- | ---------- |\n| `gpt_ch04.py` | 27 |\n| `gpt_with_kv_cache.py` | 144 |\n\nSo, as we can see, we already get a ~5x speed-up with a small 124 M parameter model and a short 200-token sequence length. (Note that this implementation is optimized for code readability and not optimized for CUDA or MPS runtime speed, which would require pre-allocating tensors instead of reinstating and concatenating them.)\n\n**Note:** The model generates \"gibberish\" in both cases, i.e., text that looks like this: \n\n> Output text: Hello, I am Featureiman Byeswickattribute argue logger Normandy Compton analogous bore ITVEGIN ministriesysics Kle functional recountrictionchangingVirgin embarrassedgl ...\n\nThis is because we haven't trained the model, yet. The next chapter trains the model, and you can use the KV-cache on the trained model (however, the KV cache is only meant to be used during inference) to generate coherent text. Here, we are using the untrained model to keep the code simple(r).\n\nWhat's more important, though, is that both the `gpt_ch04.py` and `gpt_with_kv_cache.py` implementations produce exactly the same text. This tells us that the KV cache is implemented correctly -- it is easy to make indexing mistakes that can lead to divergent results.\n\n\n \n\n## KV cache advantages and disadvantages \n\nAs sequence length increases, the benefits and downsides of a KV cache become more pronounced in the following ways:\n\n- [Good] **Computational efficiency increases**: Without caching, the attention at step *t* must compare the new query with *t* previous keys, so the cumulative work scales quadratically, O(n²). With a cache, each key and value is computed once and then reused, reducing the total per-step complexity to linear, O(n).\n\n- [Bad] **Memory usage increases linearly**: Each new token appends to the KV cache. For long sequences and larger LLMs, the cumulative KV cache grows larger, which can consume a significant or even prohibitive amount of (GPU) memory. As a workaround, we can truncate the KV cache, but this adds even more complexity (but again, it may well be worth it when deploying LLMs.)\n\n\n\n \n## Optimizing the KV Cache Implementation\n\nWhile my conceptual implementation of a KV cache above helps with clarity and is mainly geared towards code readability and educational purposes, deploying it in real-world scenarios (especially with larger models and longer sequence lengths) requires more careful optimization.\n\n \n### Common pitfalls when scaling the cache\n\n- **Memory fragmentation and repeated allocations**: Continuously concatenating tensors via `torch.cat` as shown earlier, leads to performance bottlenecks due to frequent memory allocation and reallocation.\n\n- **Linear growth in memory usage**: Without proper handling, the KV cache size becomes impractical for very long sequences.\n\n \n#### Tip 1: Pre-allocate Memory\n\nRather than concatenating tensors repeatedly, we could pre-allocate a sufficiently large tensor based on the expected maximum sequence length. This ensures consistent memory use and reduces overhead. In pseudo-code, this may look like as follows:\n\n```python\n# Example pre-allocation for keys and values\nmax_seq_len = 1024 # maximum expected sequence length\ncache_k = torch.zeros((batch_size, num_heads, max_seq_len, head_dim), device=device)\ncache_v = torch.zeros((batch_size, num_heads, max_seq_len, head_dim), device=device)\n```\n\nDuring inference, we can then simply write into slices of these pre-allocated tensors.\n\n \n#### Tip 2: Truncate Cache via Sliding Window\n\nTo avoid blowing up our GPU memory, we can implement a sliding window approach with dynamic truncation. Via the sliding window, we maintain only the last `window_size` tokens in the cache:\n\n\n```python\n# Sliding window cache implementation\nwindow_size = 512\ncache_k = cache_k[:, :, -window_size:, :]\ncache_v = cache_v[:, :, -window_size:, :]\n```\n\n \n#### Optimizations in practice\n\nYou can find these optimizations in the [`gpt_with_kv_cache_optimized.py`](gpt_with_kv_cache_optimized.py) file. \n\n\nOn a Mac Mini with an M4 chip (CPU), with a 200-token generation and a window size equal to the context length (to guarantee same results) below, the code runtimes compare as follows:\n\n| | Tokens/sec |\n| -------------------------------- | ---------- |\n| `gpt_ch04.py` | 27 |\n| `gpt_with_kv_cache.py` | 144 |\n| `gpt_with_kv_cache_optimized.py` | 166 |\n\nUnfortunately, the speed advantages disappear on CUDA devices as this is a tiny model, and the device transfer and communication outweigh the benefits of a KV cache for this small model. \n\n\n \n## Additional Resources\n\n1. [Qwen3 from-scratch KV cache benchmarks](../../ch05/11_qwen3#pro-tip-2-speed-up-inference-with-compilation)\n2. [Llama 3 from-scratch KV cache benchmarks](../../ch05/07_gpt_to_llama/README.md#pro-tip-3-speed-up-inference-with-compilation)\n3. [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) -- A more detailed write-up of this README\n"
},
{
"path": "ch04/03_kv-cache/gpt_ch04.py",
"content": "# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n self.register_buffer(\n \"mask\",\n torch.triu(torch.ones(context_length, context_length), diagonal=1),\n persistent=False\n )\n\n def forward(self, x):\n b, num_tokens, d_in = x.shape\n\n keys = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n # Original mask truncated to the number of tokens and converted to boolean\n mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n context_length=cfg[\"context_length\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n self.trf_blocks = nn.Sequential(\n *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n x = self.trf_blocks(x)\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n model.eval()\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n\ndef main():\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Context length\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False # Query-Key-Value bias\n }\n\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device)\n model.eval() # disable dropout\n\n start_context = \"Hello, I am\"\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=200,\n context_size=GPT_CONFIG_124M[\"context_length\"]\n )\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/03_kv-cache/gpt_with_kv_cache.py",
"content": "# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n self.register_buffer(\n \"mask\",\n torch.triu(torch.ones(context_length, context_length), diagonal=1),\n persistent=False\n )\n\n ####################################################\n # NEW\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # NEW\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # NEW\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n if use_cache:\n mask_bool = self.mask.bool()[\n self.ptr_current_pos:self.ptr_current_pos + num_tokens_Q, :num_tokens_K\n ]\n self.ptr_current_pos += num_tokens_Q\n ####################################################\n # Original mask truncated to the number of tokens and converted to boolean\n else:\n mask_bool = self.mask.bool()[:num_tokens_Q, :num_tokens_K]\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n ####################################################\n # NEW\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n ####################################################\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n context_length=cfg[\"context_length\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # NEW\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # NEW\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # NEW\n\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # NEW\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # NEW\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n\n####################################################\n# NEW\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n####################################################\n\n\ndef main():\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Context length\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False # Query-Key-Value bias\n }\n\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device)\n model.eval() # disable dropout\n\n start_context = \"Hello, I am\"\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n # token_ids = generate_text_simple(\n # model=model,\n # idx=encoded_tensor,\n # max_new_tokens=200,\n # context_size=GPT_CONFIG_124M[\"context_length\"]\n # )\n\n ####################################################\n # NEW\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=200,\n )\n ####################################################\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/03_kv-cache/gpt_with_kv_cache_optimized.py",
"content": "# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False, max_seq_len=None, window_size=None):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # NEW\n self.max_seq_len = max_seq_len or context_length\n self.window_size = window_size or self.max_seq_len\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n if use_cache:\n # to prevent self.ptr_cur became negative\n assert num_tokens <= self.window_size, (\n f\"Input chunk size ({num_tokens}) exceeds KV cache window size ({self.window_size}). \"\n )\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys_new = keys_new.transpose(1, 2)\n values_new = values_new.transpose(1, 2)\n queries = queries.transpose(1, 2)\n\n ####################################################\n # NEW\n if use_cache:\n if self.cache_k is None or self.cache_k.size(0) != b:\n self.cache_k = torch.zeros(b, self.num_heads,\n self.window_size, self.head_dim,\n device=x.device)\n self.cache_v = torch.zeros_like(self.cache_k)\n self.ptr_cur = 0 # pointer to next free slot\n\n # if incoming chunk would overflow discard oldest tokens\n if self.ptr_cur + num_tokens > self.window_size:\n overflow = self.ptr_cur + num_tokens - self.window_size\n # shift everything left by `overflow` (cheap view-copy)\n self.cache_k[:, :, :-overflow, :] = self.cache_k[:, :, overflow:, :].clone()\n self.cache_v[:, :, :-overflow, :] = self.cache_v[:, :, overflow:, :].clone()\n self.ptr_cur -= overflow # pointer after shift\n\n self.cache_k[:, :, self.ptr_cur:self.ptr_cur + num_tokens, :] = keys_new\n self.cache_v[:, :, self.ptr_cur:self.ptr_cur + num_tokens, :] = values_new\n self.ptr_cur += num_tokens\n\n keys = self.cache_k[:, :, :self.ptr_cur, :]\n values = self.cache_v[:, :, :self.ptr_cur, :]\n else:\n keys, values = keys_new, values_new\n self.ptr_cur = 0 # keep pointer sane if you interleave modes\n ####################################################\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # NEW\n K = attn_scores.size(-1)\n\n if num_tokens == K:\n # No cache → use the pre‑baked triangular mask slice\n causal_mask = torch.triu(torch.ones(num_tokens, K, device=x.device, dtype=torch.bool), diagonal=1)\n else:\n # Cached: need to offset the diagonal by (K − num_tokens)\n offset = K - num_tokens # number of tokens already in cache before this chunk\n row_idx = torch.arange(num_tokens, device=x.device).unsqueeze(1) # (num_tokens, 1)\n col_idx = torch.arange(K, device=x.device).unsqueeze(0) # (1, K)\n causal_mask = row_idx + offset < col_idx # True where j > i+offset\n ####################################################\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(causal_mask.unsqueeze(0).unsqueeze(0), -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n ####################################################\n # NEW\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n ####################################################\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n context_length=cfg[\"context_length\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"],\n window_size=cfg[\"kv_window_size\"] if \"kv_window_size\" in cfg else cfg[\"context_length\"] # NEW\n )\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # NEW\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # NEW\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.ptr_current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n self.kv_window_size = cfg[\"kv_window_size\"] if \"kv_window_size\" in cfg else cfg[\"context_length\"]\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # NEW\n\n if use_cache:\n context_length = self.pos_emb.num_embeddings\n # to prevent generate more sequence than context_length\n # since longer than context_length will cause model out of bound error when reading the position embedding\n assert self.ptr_current_pos + seq_len <= context_length, (\n f\"Position embedding overflow. Want to read {self.ptr_current_pos + seq_len} which excceded size of {context_length}\"\n )\n pos_ids = torch.arange(self.ptr_current_pos, self.ptr_current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.ptr_current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # NEW\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # NEW\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.ptr_current_pos = 0\n ####################################################\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n\n####################################################\n# NEW\ndef generate_text_simple_cached(model, idx, max_new_tokens, context_size=None, use_cache=True):\n model.eval()\n\n ctx_len = context_size or model.pos_emb.num_embeddings\n kv_window_size = model.kv_window_size\n\n with torch.no_grad():\n if use_cache:\n model.reset_kv_cache()\n\n input_tokens = idx[:, -ctx_len:]\n input_tokens_length = input_tokens.size(1)\n\n # prefill to handle input_tokens_length > kv_window_size\n for i in range(0, input_tokens_length, kv_window_size):\n chunk = input_tokens[:, i:i+kv_window_size]\n logits = model(chunk, use_cache=True)\n\n # can't generate more than ctx_len of result\n # due to the limitation of position embedding\n max_generable = ctx_len - input_tokens_length\n max_new_tokens = min(max_new_tokens, max_generable)\n\n for _ in range(max_new_tokens):\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n####################################################\n\n\ndef main():\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Context length\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n \"kv_window_size\": 1024 # NEW: KV cache window size\n }\n\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device)\n model.eval() # disable dropout\n\n start_context = \"Hello, I am\"\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n # token_ids = generate_text_simple(\n # model=model,\n # idx=encoded_tensor,\n # max_new_tokens=200,\n # context_size=GPT_CONFIG_124M[\"context_length\"]\n # )\n\n ####################################################\n # NEW\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=200,\n )\n ####################################################\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/03_kv-cache/tests.py",
"content": "# Code to test the GPT model implementation against the KV cache variants\n\nimport pytest\nimport torch\nimport tiktoken\n\nfrom gpt_ch04 import GPTModel as GPTModelBase\nfrom gpt_ch04 import generate_text_simple\n\nfrom gpt_with_kv_cache import GPTModel as GPTModelKV1\nfrom gpt_with_kv_cache_optimized import GPTModel as GPTModelKV2\nfrom gpt_with_kv_cache import generate_text_simple_cached as generate_text_simple_cachedKV1\nfrom gpt_with_kv_cache_optimized import generate_text_simple_cached as generate_text_simple_cachedKV2\n\n\nGPT_CONFIG_124M = {\n \"vocab_size\": 50257,\n \"context_length\": 1024,\n \"emb_dim\": 768,\n \"n_heads\": 12,\n \"n_layers\": 12,\n \"drop_rate\": 0.1,\n \"qkv_bias\": False,\n \"kv_window_size\": 1024 # NEW: KV cache window size\n}\n\n\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n\n\n@pytest.mark.parametrize(\"ModelClass\", [GPTModelBase, GPTModelKV1, GPTModelKV2])\ndef test_gpt_model_equivalence_not_cached(ModelClass):\n torch.manual_seed(123)\n\n model = ModelClass(GPT_CONFIG_124M).to(device)\n model.eval()\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n prompt = \"Hello, I am\"\n encoded = tokenizer.encode(prompt)\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n\n model_name = ModelClass.__module__ + \".\" + ModelClass.__name__\n\n token_ids = generate_text_simple(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=30,\n context_size=GPT_CONFIG_124M[\"context_length\"]\n )\n\n if not hasattr(test_gpt_model_equivalence_not_cached, \"results\"):\n test_gpt_model_equivalence_not_cached.results = []\n\n test_gpt_model_equivalence_not_cached.results.append((model_name, token_ids))\n\n if len(test_gpt_model_equivalence_not_cached.results) == 3:\n base_name, base_output = test_gpt_model_equivalence_not_cached.results[0]\n for other_name, other_output in test_gpt_model_equivalence_not_cached.results[1:]:\n assert torch.equal(base_output, other_output), (\n f\"Mismatch between {base_name} and {other_name}\"\n )\n\n\n@pytest.mark.parametrize(\"ModelClass\", [GPTModelBase, GPTModelKV1, GPTModelKV2])\ndef test_gpt_model_equivalence_cached(ModelClass):\n torch.manual_seed(123)\n\n model = ModelClass(GPT_CONFIG_124M).to(device)\n model.eval()\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n prompt = \"Hello, I am\"\n encoded_tensor = torch.tensor(tokenizer.encode(prompt), device=device).unsqueeze(0)\n\n model_name = ModelClass.__module__ + \".\" + ModelClass.__name__\n\n if ModelClass is GPTModelBase:\n token_ids = generate_text_simple(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=30,\n context_size=GPT_CONFIG_124M[\"context_length\"]\n )\n elif ModelClass is GPTModelKV1:\n token_ids = generate_text_simple_cachedKV1(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=30,\n context_size=GPT_CONFIG_124M[\"context_length\"]\n )\n else:\n token_ids = generate_text_simple_cachedKV2(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=30,\n context_size=GPT_CONFIG_124M[\"context_length\"]\n )\n\n if not hasattr(test_gpt_model_equivalence_cached, \"results\"):\n test_gpt_model_equivalence_cached.results = []\n\n test_gpt_model_equivalence_cached.results.append((model_name, token_ids))\n\n if len(test_gpt_model_equivalence_cached.results) == 3:\n base_name, base_output = test_gpt_model_equivalence_cached.results[0]\n for other_name, other_output in test_gpt_model_equivalence_cached.results[1:]:\n assert torch.equal(base_output, other_output), (\n f\"Mismatch between {base_name} and {other_name}\"\n )\n\n\ndef test_context_overflow_bug():\n \"\"\"\n Test that demonstrates the ptr_current_pos overflow bug.\n\n In old implementation:\n - context_length = 10 (positions 0-9 available)\n - We try to generate 15 tokens total (5 input + 10 generated)\n - At token 11 (position 10), it crashes trying to access pos_emb[10]\n \"\"\"\n GPT_CONFIG_SMALL = {\n \"vocab_size\": 50257,\n \"context_length\": 10, # Very small context\n \"emb_dim\": 768,\n \"n_heads\": 12,\n \"n_layers\": 12,\n \"drop_rate\": 0.1,\n \"qkv_bias\": False,\n \"kv_window_size\": 20 # Larger than context_length\n }\n\n torch.manual_seed(123)\n\n model = GPTModelKV2(GPT_CONFIG_SMALL).to(device)\n model.eval()\n\n # 5 input tokens\n input_tokens = torch.randint(0, 50257, (1, 5), device=device)\n\n generate_text_simple_cachedKV2(\n model=model,\n idx=input_tokens,\n max_new_tokens=10, # 5 + 10 = 15 > 10 context_length\n context_size=GPT_CONFIG_SMALL[\"context_length\"],\n use_cache=True\n )\n\n\ndef test_prefill_chunking_basic():\n \"\"\"\n Test that prefill correctly chunks input when input_length > kv_window_size.\n\n Setup:\n - kv_window_size = 4\n - input_length = 10\n - Should process in 3 chunks: [0:4], [4:8], [8:10]\n \"\"\"\n config = {\n \"vocab_size\": 50257,\n \"context_length\": 20,\n \"emb_dim\": 768,\n \"n_heads\": 12,\n \"n_layers\": 12,\n \"drop_rate\": 0.1,\n \"qkv_bias\": False,\n \"kv_window_size\": 4 # Small window to force chunking\n }\n\n torch.manual_seed(123)\n model = GPTModelKV2(config).to(device)\n model.eval()\n\n # 10 input tokens (> kv_window_size of 4)\n input_tokens = torch.randint(0, 50257, (1, 10), device=device)\n\n # Should successfully process all input in chunks\n token_ids = generate_text_simple_cachedKV2(\n model=model,\n idx=input_tokens,\n max_new_tokens=2,\n use_cache=True\n )\n\n # Should have 10 input + 2 generated = 12 total\n assert token_ids.shape[1] == 12, f\"Expected 12 tokens, got {token_ids.shape[1]}\"\n\n # First 10 tokens should match input\n assert torch.equal(token_ids[:, :10], input_tokens), \"Input tokens should be preserved\""
},
{
"path": "ch04/04_gqa/README.md",
"content": "# Grouped-Query Attention (GQA)\n\nThis bonus material illustrates the memory savings when using Grouped-Query Attention (GQA) over regular Multi-Head Attention (MHA).\n\n \n## Introduction\n\nGrouped-Query Attention (GQA) has become the new standard replacement for a more compute- and parameter-efficient alternative to Multi-Head Attention (MHA) in recent years. Note that it's not new and goes back to the 2023 [GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints](https://arxiv.org/abs/2305.13245). And even the larger variants in the good old Llama 2 series used it.\n\nHere's a brief GQA summary. Unlike MHA, where each head also has its own set of keys and values, to reduce memory usage, GQA groups multiple heads to share the same key and value projections.\n\nFor example, as further illustrated in the figure below, if there are 3 key-value groups and 6 attention heads, then heads 1 and 2 share one set of keys and values, while heads 3 and 4, as well as heads 5 and 6, share another, respectively.\n\n \n\n\n\n \n\nThis sharing of keys and values reduces the total number of key and value computations, which leads to lower memory usage and improved efficiency.\n\nSo, to summarize, the core idea behind GQA is to reduce the number of key and value heads by sharing them across multiple query heads. This (1) lowers the model's parameter count and (2) reduces the memory bandwidth usage for key and value tensors during inference since fewer keys and values need to be stored and retrieved from the KV cache.\n\nWhile GQA is mainly a computational-efficiency workaround for MHA, ablation studies (such as those in the [original GQA paper](https://arxiv.org/abs/2305.13245) and the [Llama 2 paper](https://arxiv.org/abs/2307.09288)) show it performs comparably to standard MHA in terms of LLM modeling performance.\n\nHowever, this assumes that the number of key-value groups is chosen carefully. In the extreme case where all attention heads share a single key-value group, known as multi-query attention, the memory usage decreases even more drastically but modeling performance can suffer. (And, on the other extreme, if we set the number of key-value groups equal to the number of query heads, we are back at standard multi-head attention.)\n\n \n## GQA Memory Savings\n\nThe memory savings are mostly reflected in the KV storage. We can compute the KV storage size with the following formula:\n\nbytes ≈ batch_size × seqlen × (embed_dim / n_heads) × n_layers × 2 (K,V) × bytes_per_elem × n_kv_heads\n\nYou can use the [memory_estimator_gqa.py](memory_estimator_gqa.py) script in this folder to apply this for different model configs to see how much memory you can save by using GQA over MHA:\n\n```bash\n➜ uv run memory_estimator_gqa.py \\\n --emb_dim 4096 --n_heads 32 --n_layers 32 \\\n --context_length 32768 --n_kv_groups 4 \\\n --batch_size 1 --dtype bf16\n==== Config ====\ncontext_length : 32768\nemb_dim : 4096\nn_heads : 32\nn_layers : 32\nn_kv_groups : 4\nbatch_size : 1\ndtype : bf16 (2 Bytes/elem)\nhead_dim : 128\nGQA n_kv_heads : 8\n\n==== KV-cache totals across all layers ====\nMHA total KV cache : 17.18 GB\nGQA total KV cache : 4.29 GB\nRatio (MHA / GQA) : 4.00x\nSavings (GQA vs MHA): 75.00%\n```\n\nThe savings when using GQA over MHA are further shown in the plot below for different key-value group sizes as a function of the context length:\n\n \n\n
\n\nTo summarize the implementation details, here's a short walkthrough.\n\n \n\n### 1. Registering the cache buffers\n\nInside the `MultiHeadAttention` constructor we add two buffers, `cache_k` and `cache_v`, which will hold concatenated keys and values across steps:\n\n```python\nself.register_buffer(\"cache_k\", None)\nself.register_buffer(\"cache_v\", None)\n```\n\n \n\n### 2. Forward pass with `use_cache` flag\n\nNext, we extend the `forward` method of the `MultiHeadAttention` class to accept `use_cache` argument. After projecting the new chunk of tokens into `keys_new`, `values_new` and `queries`, we either initialize the kv cache or append to our cache:\n\n```python\ndef forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n #...\n\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n \n # ...\n \n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n if use_cache:\n mask_bool = self.mask.bool()[\n self.ptr_current_pos:self.ptr_current_pos + num_tokens_Q, :num_tokens_K\n ]\n self.ptr_current_pos += num_tokens_Q\n else:\n mask_bool = self.mask.bool()[:num_tokens_Q, :num_tokens_K]\n```\n\n \n\n\n### 3. Clearing the cache\n\nWhen generating texts, between independent sequences (for instance to text generation calls) we must reset both buffers, so we also add a cache resetting method the to the `MultiHeadAttention` class:\n\n```python\ndef reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n```\n\n \n\n### 4. Propagating `use_cache` in the full model\n\nWith the changes to the `MultiHeadAttention` class in place, we now modify the `GPTModel` class. First, we add a position tracking for the token indices to the instructor:\n\n```python\nself.current_pos = 0\n```\n\nThen, we replace the one-liner block call with an explicit loop, passing `use_cache` through each transformer block:\n\n```python\ndef forward(self, in_idx, use_cache=False):\n # ...\n \n if use_cache:\n pos_ids = torch.arange(\n self.current_pos, self.current_pos + seq_len, \n device=in_idx.device, dtype=torch.long\n )\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(\n 0, seq_len, device=in_idx.device, dtype=torch.long\n )\n \n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n x = tok_embeds + pos_embeds\n # ...\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n```\n\nThe above change then also requires a small modification to the `TransformerBlock` class to accept the `use_cache` argument:\n```python\n def forward(self, x, use_cache=False):\n # ...\n self.att(x, use_cache=use_cache)\n```\n\nLastly, we add a model-level reset to `GPTModel` to clear all block caches at once for our convenience:\n\n```python\ndef reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n```\n\n \n\n### 5. Using the cache in generation\n\nWith the changes to the `GPTModel`, `TransformerBlock`, and `MultiHeadAttention`, finally, here's how we use the KV cache in a simple text generation function:\n\n```python\ndef generate_text_simple_cached(model, idx, max_new_tokens, \n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n```\n\nNote that we only feed the model the new token in c) via `logits = model(next_idx, use_cache=True)`. Without caching, we feed the model the whole input `logits = model(idx[:, -ctx_len:], use_cache=False)` as it has no stored keys and values to reuse.\n\n \n\n## Simple performance comparison\n\nAfter covering the KV cache on a conceptual level, the big question is how well it actually performs in practice on a small example. To give the implementation a try, we can run the two aforementioned code files as Python scripts, which will run the small 124 M parameter LLM to generate 200 new tokens (given a 4-token prompt \"Hello, I am\" to start with):\n\n```bash\npip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt\n\npython gpt_ch04.py\n\npython gpt_with_kv_cache.py\n```\n\nOn a Mac Mini with M4 chip (CPU), the results are as follows:\n\n| | Tokens/sec |\n| ---------------------- | ---------- |\n| `gpt_ch04.py` | 27 |\n| `gpt_with_kv_cache.py` | 144 |\n\nSo, as we can see, we already get a ~5x speed-up with a small 124 M parameter model and a short 200-token sequence length. (Note that this implementation is optimized for code readability and not optimized for CUDA or MPS runtime speed, which would require pre-allocating tensors instead of reinstating and concatenating them.)\n\n**Note:** The model generates \"gibberish\" in both cases, i.e., text that looks like this: \n\n> Output text: Hello, I am Featureiman Byeswickattribute argue logger Normandy Compton analogous bore ITVEGIN ministriesysics Kle functional recountrictionchangingVirgin embarrassedgl ...\n\nThis is because we haven't trained the model, yet. The next chapter trains the model, and you can use the KV-cache on the trained model (however, the KV cache is only meant to be used during inference) to generate coherent text. Here, we are using the untrained model to keep the code simple(r).\n\nWhat's more important, though, is that both the `gpt_ch04.py` and `gpt_with_kv_cache.py` implementations produce exactly the same text. This tells us that the KV cache is implemented correctly -- it is easy to make indexing mistakes that can lead to divergent results.\n\n\n \n\n## KV cache advantages and disadvantages \n\nAs sequence length increases, the benefits and downsides of a KV cache become more pronounced in the following ways:\n\n- [Good] **Computational efficiency increases**: Without caching, the attention at step *t* must compare the new query with *t* previous keys, so the cumulative work scales quadratically, O(n²). With a cache, each key and value is computed once and then reused, reducing the total per-step complexity to linear, O(n).\n\n- [Bad] **Memory usage increases linearly**: Each new token appends to the KV cache. For long sequences and larger LLMs, the cumulative KV cache grows larger, which can consume a significant or even prohibitive amount of (GPU) memory. As a workaround, we can truncate the KV cache, but this adds even more complexity (but again, it may well be worth it when deploying LLMs.)\n\n\n\n \n## Optimizing the KV Cache Implementation\n\nWhile my conceptual implementation of a KV cache above helps with clarity and is mainly geared towards code readability and educational purposes, deploying it in real-world scenarios (especially with larger models and longer sequence lengths) requires more careful optimization.\n\n \n### Common pitfalls when scaling the cache\n\n- **Memory fragmentation and repeated allocations**: Continuously concatenating tensors via `torch.cat` as shown earlier, leads to performance bottlenecks due to frequent memory allocation and reallocation.\n\n- **Linear growth in memory usage**: Without proper handling, the KV cache size becomes impractical for very long sequences.\n\n \n#### Tip 1: Pre-allocate Memory\n\nRather than concatenating tensors repeatedly, we could pre-allocate a sufficiently large tensor based on the expected maximum sequence length. This ensures consistent memory use and reduces overhead. In pseudo-code, this may look like as follows:\n\n```python\n# Example pre-allocation for keys and values\nmax_seq_len = 1024 # maximum expected sequence length\ncache_k = torch.zeros((batch_size, num_heads, max_seq_len, head_dim), device=device)\ncache_v = torch.zeros((batch_size, num_heads, max_seq_len, head_dim), device=device)\n```\n\nDuring inference, we can then simply write into slices of these pre-allocated tensors.\n\n \n#### Tip 2: Truncate Cache via Sliding Window\n\nTo avoid blowing up our GPU memory, we can implement a sliding window approach with dynamic truncation. Via the sliding window, we maintain only the last `window_size` tokens in the cache:\n\n\n```python\n# Sliding window cache implementation\nwindow_size = 512\ncache_k = cache_k[:, :, -window_size:, :]\ncache_v = cache_v[:, :, -window_size:, :]\n```\n\n \n#### Optimizations in practice\n\nYou can find these optimizations in the [`gpt_with_kv_cache_optimized.py`](gpt_with_kv_cache_optimized.py) file. \n\n\nOn a Mac Mini with an M4 chip (CPU), with a 200-token generation and a window size equal to the context length (to guarantee same results) below, the code runtimes compare as follows:\n\n| | Tokens/sec |\n| -------------------------------- | ---------- |\n| `gpt_ch04.py` | 27 |\n| `gpt_with_kv_cache.py` | 144 |\n| `gpt_with_kv_cache_optimized.py` | 166 |\n\nUnfortunately, the speed advantages disappear on CUDA devices as this is a tiny model, and the device transfer and communication outweigh the benefits of a KV cache for this small model. \n\n\n \n## Additional Resources\n\n1. [Qwen3 from-scratch KV cache benchmarks](../../ch05/11_qwen3#pro-tip-2-speed-up-inference-with-compilation)\n2. [Llama 3 from-scratch KV cache benchmarks](../../ch05/07_gpt_to_llama/README.md#pro-tip-3-speed-up-inference-with-compilation)\n3. [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) -- A more detailed write-up of this README\n"
},
{
"path": "ch04/03_kv-cache/gpt_ch04.py",
"content": "# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n self.register_buffer(\n \"mask\",\n torch.triu(torch.ones(context_length, context_length), diagonal=1),\n persistent=False\n )\n\n def forward(self, x):\n b, num_tokens, d_in = x.shape\n\n keys = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n # Original mask truncated to the number of tokens and converted to boolean\n mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n context_length=cfg[\"context_length\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n self.trf_blocks = nn.Sequential(\n *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n x = self.trf_blocks(x)\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n model.eval()\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n\ndef main():\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Context length\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False # Query-Key-Value bias\n }\n\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device)\n model.eval() # disable dropout\n\n start_context = \"Hello, I am\"\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=200,\n context_size=GPT_CONFIG_124M[\"context_length\"]\n )\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/03_kv-cache/gpt_with_kv_cache.py",
"content": "# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n self.register_buffer(\n \"mask\",\n torch.triu(torch.ones(context_length, context_length), diagonal=1),\n persistent=False\n )\n\n ####################################################\n # NEW\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # NEW\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # NEW\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n if use_cache:\n mask_bool = self.mask.bool()[\n self.ptr_current_pos:self.ptr_current_pos + num_tokens_Q, :num_tokens_K\n ]\n self.ptr_current_pos += num_tokens_Q\n ####################################################\n # Original mask truncated to the number of tokens and converted to boolean\n else:\n mask_bool = self.mask.bool()[:num_tokens_Q, :num_tokens_K]\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n ####################################################\n # NEW\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n ####################################################\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n context_length=cfg[\"context_length\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # NEW\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # NEW\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # NEW\n\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # NEW\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # NEW\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n\n####################################################\n# NEW\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n####################################################\n\n\ndef main():\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Context length\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False # Query-Key-Value bias\n }\n\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device)\n model.eval() # disable dropout\n\n start_context = \"Hello, I am\"\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n # token_ids = generate_text_simple(\n # model=model,\n # idx=encoded_tensor,\n # max_new_tokens=200,\n # context_size=GPT_CONFIG_124M[\"context_length\"]\n # )\n\n ####################################################\n # NEW\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=200,\n )\n ####################################################\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/03_kv-cache/gpt_with_kv_cache_optimized.py",
"content": "# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False, max_seq_len=None, window_size=None):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # NEW\n self.max_seq_len = max_seq_len or context_length\n self.window_size = window_size or self.max_seq_len\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n if use_cache:\n # to prevent self.ptr_cur became negative\n assert num_tokens <= self.window_size, (\n f\"Input chunk size ({num_tokens}) exceeds KV cache window size ({self.window_size}). \"\n )\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys_new = keys_new.transpose(1, 2)\n values_new = values_new.transpose(1, 2)\n queries = queries.transpose(1, 2)\n\n ####################################################\n # NEW\n if use_cache:\n if self.cache_k is None or self.cache_k.size(0) != b:\n self.cache_k = torch.zeros(b, self.num_heads,\n self.window_size, self.head_dim,\n device=x.device)\n self.cache_v = torch.zeros_like(self.cache_k)\n self.ptr_cur = 0 # pointer to next free slot\n\n # if incoming chunk would overflow discard oldest tokens\n if self.ptr_cur + num_tokens > self.window_size:\n overflow = self.ptr_cur + num_tokens - self.window_size\n # shift everything left by `overflow` (cheap view-copy)\n self.cache_k[:, :, :-overflow, :] = self.cache_k[:, :, overflow:, :].clone()\n self.cache_v[:, :, :-overflow, :] = self.cache_v[:, :, overflow:, :].clone()\n self.ptr_cur -= overflow # pointer after shift\n\n self.cache_k[:, :, self.ptr_cur:self.ptr_cur + num_tokens, :] = keys_new\n self.cache_v[:, :, self.ptr_cur:self.ptr_cur + num_tokens, :] = values_new\n self.ptr_cur += num_tokens\n\n keys = self.cache_k[:, :, :self.ptr_cur, :]\n values = self.cache_v[:, :, :self.ptr_cur, :]\n else:\n keys, values = keys_new, values_new\n self.ptr_cur = 0 # keep pointer sane if you interleave modes\n ####################################################\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # NEW\n K = attn_scores.size(-1)\n\n if num_tokens == K:\n # No cache → use the pre‑baked triangular mask slice\n causal_mask = torch.triu(torch.ones(num_tokens, K, device=x.device, dtype=torch.bool), diagonal=1)\n else:\n # Cached: need to offset the diagonal by (K − num_tokens)\n offset = K - num_tokens # number of tokens already in cache before this chunk\n row_idx = torch.arange(num_tokens, device=x.device).unsqueeze(1) # (num_tokens, 1)\n col_idx = torch.arange(K, device=x.device).unsqueeze(0) # (1, K)\n causal_mask = row_idx + offset < col_idx # True where j > i+offset\n ####################################################\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(causal_mask.unsqueeze(0).unsqueeze(0), -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n ####################################################\n # NEW\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n ####################################################\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n context_length=cfg[\"context_length\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"],\n window_size=cfg[\"kv_window_size\"] if \"kv_window_size\" in cfg else cfg[\"context_length\"] # NEW\n )\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # NEW\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # NEW\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.ptr_current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n self.kv_window_size = cfg[\"kv_window_size\"] if \"kv_window_size\" in cfg else cfg[\"context_length\"]\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # NEW\n\n if use_cache:\n context_length = self.pos_emb.num_embeddings\n # to prevent generate more sequence than context_length\n # since longer than context_length will cause model out of bound error when reading the position embedding\n assert self.ptr_current_pos + seq_len <= context_length, (\n f\"Position embedding overflow. Want to read {self.ptr_current_pos + seq_len} which excceded size of {context_length}\"\n )\n pos_ids = torch.arange(self.ptr_current_pos, self.ptr_current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.ptr_current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # NEW\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # NEW\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.ptr_current_pos = 0\n ####################################################\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n\n####################################################\n# NEW\ndef generate_text_simple_cached(model, idx, max_new_tokens, context_size=None, use_cache=True):\n model.eval()\n\n ctx_len = context_size or model.pos_emb.num_embeddings\n kv_window_size = model.kv_window_size\n\n with torch.no_grad():\n if use_cache:\n model.reset_kv_cache()\n\n input_tokens = idx[:, -ctx_len:]\n input_tokens_length = input_tokens.size(1)\n\n # prefill to handle input_tokens_length > kv_window_size\n for i in range(0, input_tokens_length, kv_window_size):\n chunk = input_tokens[:, i:i+kv_window_size]\n logits = model(chunk, use_cache=True)\n\n # can't generate more than ctx_len of result\n # due to the limitation of position embedding\n max_generable = ctx_len - input_tokens_length\n max_new_tokens = min(max_new_tokens, max_generable)\n\n for _ in range(max_new_tokens):\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n####################################################\n\n\ndef main():\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Context length\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n \"kv_window_size\": 1024 # NEW: KV cache window size\n }\n\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device)\n model.eval() # disable dropout\n\n start_context = \"Hello, I am\"\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n # token_ids = generate_text_simple(\n # model=model,\n # idx=encoded_tensor,\n # max_new_tokens=200,\n # context_size=GPT_CONFIG_124M[\"context_length\"]\n # )\n\n ####################################################\n # NEW\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=200,\n )\n ####################################################\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/03_kv-cache/tests.py",
"content": "# Code to test the GPT model implementation against the KV cache variants\n\nimport pytest\nimport torch\nimport tiktoken\n\nfrom gpt_ch04 import GPTModel as GPTModelBase\nfrom gpt_ch04 import generate_text_simple\n\nfrom gpt_with_kv_cache import GPTModel as GPTModelKV1\nfrom gpt_with_kv_cache_optimized import GPTModel as GPTModelKV2\nfrom gpt_with_kv_cache import generate_text_simple_cached as generate_text_simple_cachedKV1\nfrom gpt_with_kv_cache_optimized import generate_text_simple_cached as generate_text_simple_cachedKV2\n\n\nGPT_CONFIG_124M = {\n \"vocab_size\": 50257,\n \"context_length\": 1024,\n \"emb_dim\": 768,\n \"n_heads\": 12,\n \"n_layers\": 12,\n \"drop_rate\": 0.1,\n \"qkv_bias\": False,\n \"kv_window_size\": 1024 # NEW: KV cache window size\n}\n\n\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n\n\n@pytest.mark.parametrize(\"ModelClass\", [GPTModelBase, GPTModelKV1, GPTModelKV2])\ndef test_gpt_model_equivalence_not_cached(ModelClass):\n torch.manual_seed(123)\n\n model = ModelClass(GPT_CONFIG_124M).to(device)\n model.eval()\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n prompt = \"Hello, I am\"\n encoded = tokenizer.encode(prompt)\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n\n model_name = ModelClass.__module__ + \".\" + ModelClass.__name__\n\n token_ids = generate_text_simple(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=30,\n context_size=GPT_CONFIG_124M[\"context_length\"]\n )\n\n if not hasattr(test_gpt_model_equivalence_not_cached, \"results\"):\n test_gpt_model_equivalence_not_cached.results = []\n\n test_gpt_model_equivalence_not_cached.results.append((model_name, token_ids))\n\n if len(test_gpt_model_equivalence_not_cached.results) == 3:\n base_name, base_output = test_gpt_model_equivalence_not_cached.results[0]\n for other_name, other_output in test_gpt_model_equivalence_not_cached.results[1:]:\n assert torch.equal(base_output, other_output), (\n f\"Mismatch between {base_name} and {other_name}\"\n )\n\n\n@pytest.mark.parametrize(\"ModelClass\", [GPTModelBase, GPTModelKV1, GPTModelKV2])\ndef test_gpt_model_equivalence_cached(ModelClass):\n torch.manual_seed(123)\n\n model = ModelClass(GPT_CONFIG_124M).to(device)\n model.eval()\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n prompt = \"Hello, I am\"\n encoded_tensor = torch.tensor(tokenizer.encode(prompt), device=device).unsqueeze(0)\n\n model_name = ModelClass.__module__ + \".\" + ModelClass.__name__\n\n if ModelClass is GPTModelBase:\n token_ids = generate_text_simple(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=30,\n context_size=GPT_CONFIG_124M[\"context_length\"]\n )\n elif ModelClass is GPTModelKV1:\n token_ids = generate_text_simple_cachedKV1(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=30,\n context_size=GPT_CONFIG_124M[\"context_length\"]\n )\n else:\n token_ids = generate_text_simple_cachedKV2(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=30,\n context_size=GPT_CONFIG_124M[\"context_length\"]\n )\n\n if not hasattr(test_gpt_model_equivalence_cached, \"results\"):\n test_gpt_model_equivalence_cached.results = []\n\n test_gpt_model_equivalence_cached.results.append((model_name, token_ids))\n\n if len(test_gpt_model_equivalence_cached.results) == 3:\n base_name, base_output = test_gpt_model_equivalence_cached.results[0]\n for other_name, other_output in test_gpt_model_equivalence_cached.results[1:]:\n assert torch.equal(base_output, other_output), (\n f\"Mismatch between {base_name} and {other_name}\"\n )\n\n\ndef test_context_overflow_bug():\n \"\"\"\n Test that demonstrates the ptr_current_pos overflow bug.\n\n In old implementation:\n - context_length = 10 (positions 0-9 available)\n - We try to generate 15 tokens total (5 input + 10 generated)\n - At token 11 (position 10), it crashes trying to access pos_emb[10]\n \"\"\"\n GPT_CONFIG_SMALL = {\n \"vocab_size\": 50257,\n \"context_length\": 10, # Very small context\n \"emb_dim\": 768,\n \"n_heads\": 12,\n \"n_layers\": 12,\n \"drop_rate\": 0.1,\n \"qkv_bias\": False,\n \"kv_window_size\": 20 # Larger than context_length\n }\n\n torch.manual_seed(123)\n\n model = GPTModelKV2(GPT_CONFIG_SMALL).to(device)\n model.eval()\n\n # 5 input tokens\n input_tokens = torch.randint(0, 50257, (1, 5), device=device)\n\n generate_text_simple_cachedKV2(\n model=model,\n idx=input_tokens,\n max_new_tokens=10, # 5 + 10 = 15 > 10 context_length\n context_size=GPT_CONFIG_SMALL[\"context_length\"],\n use_cache=True\n )\n\n\ndef test_prefill_chunking_basic():\n \"\"\"\n Test that prefill correctly chunks input when input_length > kv_window_size.\n\n Setup:\n - kv_window_size = 4\n - input_length = 10\n - Should process in 3 chunks: [0:4], [4:8], [8:10]\n \"\"\"\n config = {\n \"vocab_size\": 50257,\n \"context_length\": 20,\n \"emb_dim\": 768,\n \"n_heads\": 12,\n \"n_layers\": 12,\n \"drop_rate\": 0.1,\n \"qkv_bias\": False,\n \"kv_window_size\": 4 # Small window to force chunking\n }\n\n torch.manual_seed(123)\n model = GPTModelKV2(config).to(device)\n model.eval()\n\n # 10 input tokens (> kv_window_size of 4)\n input_tokens = torch.randint(0, 50257, (1, 10), device=device)\n\n # Should successfully process all input in chunks\n token_ids = generate_text_simple_cachedKV2(\n model=model,\n idx=input_tokens,\n max_new_tokens=2,\n use_cache=True\n )\n\n # Should have 10 input + 2 generated = 12 total\n assert token_ids.shape[1] == 12, f\"Expected 12 tokens, got {token_ids.shape[1]}\"\n\n # First 10 tokens should match input\n assert torch.equal(token_ids[:, :10], input_tokens), \"Input tokens should be preserved\""
},
{
"path": "ch04/04_gqa/README.md",
"content": "# Grouped-Query Attention (GQA)\n\nThis bonus material illustrates the memory savings when using Grouped-Query Attention (GQA) over regular Multi-Head Attention (MHA).\n\n \n## Introduction\n\nGrouped-Query Attention (GQA) has become the new standard replacement for a more compute- and parameter-efficient alternative to Multi-Head Attention (MHA) in recent years. Note that it's not new and goes back to the 2023 [GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints](https://arxiv.org/abs/2305.13245). And even the larger variants in the good old Llama 2 series used it.\n\nHere's a brief GQA summary. Unlike MHA, where each head also has its own set of keys and values, to reduce memory usage, GQA groups multiple heads to share the same key and value projections.\n\nFor example, as further illustrated in the figure below, if there are 3 key-value groups and 6 attention heads, then heads 1 and 2 share one set of keys and values, while heads 3 and 4, as well as heads 5 and 6, share another, respectively.\n\n \n\n\n\n \n\nThis sharing of keys and values reduces the total number of key and value computations, which leads to lower memory usage and improved efficiency.\n\nSo, to summarize, the core idea behind GQA is to reduce the number of key and value heads by sharing them across multiple query heads. This (1) lowers the model's parameter count and (2) reduces the memory bandwidth usage for key and value tensors during inference since fewer keys and values need to be stored and retrieved from the KV cache.\n\nWhile GQA is mainly a computational-efficiency workaround for MHA, ablation studies (such as those in the [original GQA paper](https://arxiv.org/abs/2305.13245) and the [Llama 2 paper](https://arxiv.org/abs/2307.09288)) show it performs comparably to standard MHA in terms of LLM modeling performance.\n\nHowever, this assumes that the number of key-value groups is chosen carefully. In the extreme case where all attention heads share a single key-value group, known as multi-query attention, the memory usage decreases even more drastically but modeling performance can suffer. (And, on the other extreme, if we set the number of key-value groups equal to the number of query heads, we are back at standard multi-head attention.)\n\n \n## GQA Memory Savings\n\nThe memory savings are mostly reflected in the KV storage. We can compute the KV storage size with the following formula:\n\nbytes ≈ batch_size × seqlen × (embed_dim / n_heads) × n_layers × 2 (K,V) × bytes_per_elem × n_kv_heads\n\nYou can use the [memory_estimator_gqa.py](memory_estimator_gqa.py) script in this folder to apply this for different model configs to see how much memory you can save by using GQA over MHA:\n\n```bash\n➜ uv run memory_estimator_gqa.py \\\n --emb_dim 4096 --n_heads 32 --n_layers 32 \\\n --context_length 32768 --n_kv_groups 4 \\\n --batch_size 1 --dtype bf16\n==== Config ====\ncontext_length : 32768\nemb_dim : 4096\nn_heads : 32\nn_layers : 32\nn_kv_groups : 4\nbatch_size : 1\ndtype : bf16 (2 Bytes/elem)\nhead_dim : 128\nGQA n_kv_heads : 8\n\n==== KV-cache totals across all layers ====\nMHA total KV cache : 17.18 GB\nGQA total KV cache : 4.29 GB\nRatio (MHA / GQA) : 4.00x\nSavings (GQA vs MHA): 75.00%\n```\n\nThe savings when using GQA over MHA are further shown in the plot below for different key-value group sizes as a function of the context length:\n\n \n\n \n\n \n\nYou can reproduce the plot via `uv run plot_memory_estimates_gqa.py`.\n\n \n## GQA Code Examples\n\nThe [gpt_with_kv_mha.py](gpt_with_kv_mha.py) and [gpt_with_kv_gqa.py](gpt_with_kv_gqa.py) scripts in this folder provide hands-on examples for comparing the MHA and GQA memory usage in the context of a GPT model implementation.\n\nNote that GQA is also used in the [Llama 3](../../ch05/07_gpt_to_llama), [Gemma 3](../../ch05/12_gemma3), and [Qwen3](../../ch05/11_qwen3) bonus materials. However, for simplicity, the code scripts in this folder modify the GPT architecture, which traditionally didn't use GQA.\n\nNote that the model is not trained and thus generates nonsensical text. However, you can use it as a drop-in replacement for the standard GPT model in chapters 5-7 and train it.\n\nAlso, this implementation uses the KV cache explained in [another bonus section](../03_kv-cache) so the memory savings are more pronounced.\n\n```bash\nuv run gpt_with_kv_mha.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12\n\n...\n\nTime: 453.81 sec\n72 tokens/sec\nMax memory allocated: 1.54 GB\n```\n\n```bash\nuv run gpt_with_kv_gqa.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12 \\\n--n_kv_groups 4\n\n...\n\nTime: 516.33 sec\n63 tokens/sec\nMax memory allocated: 0.63 GB\n```\n\nThe reason why we are not seeing such a big saving as in the plots above is 2-fold:\n\n1. I use a smaller configuration to have the model finish the generation in a reasonable time.\n2. More importantly, we are looking at the whole model here, not just the attention mechanism; the fully-connected layers in the model take up most of the memory (but this is a topic for a separate analysis).\n"
},
{
"path": "ch04/04_gqa/gpt_with_kv_gqa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4, adapted to use Grouped-Query Attention (GQA).\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# NEW: GQA instead of MHA\n#####################################\nclass GroupedQueryAttention(nn.Module):\n def __init__(\n self, d_in, d_out, dropout, num_heads, num_kv_groups, dtype=None, qkv_bias=False\n ):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n assert num_heads % num_kv_groups == 0, \"num_heads must be divisible by num_kv_groups\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n\n self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=qkv_bias, dtype=dtype)\n self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=qkv_bias, dtype=dtype)\n self.num_kv_groups = num_kv_groups\n self.group_size = num_heads // num_kv_groups\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias, dtype=dtype)\n self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\n self.dropout = nn.Dropout(dropout)\n\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n\n def forward(self, x, use_cache=False):\n b, num_tokens, _ = x.shape\n\n # Apply projections\n queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\n keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\n values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\n\n # Reshape\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\n keys_new = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\n values_new = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\n\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=2)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=2)\n keys_base, values_base = self.cache_k, self.cache_v\n else:\n keys_base, values_base = keys_new, values_new\n if self.cache_k is not None or self.cache_v is not None:\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n # Expand keys and values to match the number of heads\n # Shape: (b, num_heads, num_tokens, head_dim)\n keys = keys_base.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n values = values_base.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n # For example, before repeat_interleave along dim=1 (query groups):\n # [K1, K2]\n # After repeat_interleave (each query group is repeated group_size times):\n # [K1, K1, K2, K2]\n # If we used regular repeat instead of repeat_interleave, we'd get:\n # [K1, K2, K1, K2]\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n # Shape: (b, num_heads, num_tokens, num_tokens)\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores = attn_scores.masked_fill(mask, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n assert keys.shape[-1] == self.head_dim\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = GroupedQueryAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n num_kv_groups=cfg[\"n_kv_groups\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with grouped-query attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--n_kv_groups\", type=int, default=2, help=\"Number of key/value groups.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n \"n_kv_groups\": args.n_kv_groups\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/04_gqa/gpt_with_kv_mha.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with standard multi-head attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/04_gqa/memory_estimator_gqa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# KV-cache memory estimator for MHA vs GQA\n\n\nimport argparse\nimport math\n\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes(n):\n gb = n / (1000 ** 3)\n return f\"{gb:,.2f} GB\"\n\n\ndef calc_kv_bytes_total(batch, context_length, emb_dim, n_heads,\n n_kv_heads, n_layers, bytes_per_elem):\n head_dim = math.ceil(emb_dim / n_heads)\n per_layer = batch * context_length * head_dim * n_kv_heads * 2 * bytes_per_elem\n return per_layer * n_layers\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Estimate KV-cache memory for MHA vs GQA\")\n p.add_argument(\"--context_length\", default=1024, type=int)\n p.add_argument(\"--emb_dim\", required=True, type=int)\n p.add_argument(\"--n_heads\", required=True, type=int)\n p.add_argument(\"--n_layers\", required=True, type=int)\n p.add_argument(\"--n_kv_groups\", required=True, type=int)\n p.add_argument(\"--batch_size\", default=1, type=int)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"fp16\")\n args = p.parse_args()\n\n cfg = {\n \"context_length\": args.context_length,\n \"emb_dim\": args.emb_dim,\n \"n_heads\": args.n_heads,\n \"n_layers\": args.n_layers,\n \"n_kv_groups\": args.n_kv_groups,\n }\n\n if cfg[\"n_heads\"] % cfg[\"n_kv_groups\"] != 0:\n raise ValueError(\"n_kv_groups must divide n_heads exactly.\")\n\n bytes_per_elem = DTYPE_BYTES[args.dtype]\n head_dim = math.ceil(cfg[\"emb_dim\"] / cfg[\"n_heads\"])\n\n n_kv_heads_mha = cfg[\"n_heads\"]\n n_kv_heads_gqa = cfg[\"n_heads\"] // cfg[\"n_kv_groups\"]\n\n total_mha = calc_kv_bytes_total(\n args.batch_size,\n cfg[\"context_length\"],\n cfg[\"emb_dim\"],\n cfg[\"n_heads\"],\n n_kv_heads_mha,\n cfg[\"n_layers\"],\n bytes_per_elem,\n )\n\n total_gqa = calc_kv_bytes_total(\n args.batch_size,\n cfg[\"context_length\"],\n cfg[\"emb_dim\"],\n cfg[\"n_heads\"],\n n_kv_heads_gqa,\n cfg[\"n_layers\"],\n bytes_per_elem,\n )\n\n ratio = total_mha / total_gqa\n savings = 1 - (total_gqa / total_mha)\n\n print(\"==== Config ====\")\n for k, v in cfg.items():\n print(f\"{k:17}: {v}\")\n print(f\"batch_size : {args.batch_size}\")\n print(f\"dtype : {args.dtype} ({bytes_per_elem} Bytes/elem)\")\n print(f\"head_dim : {head_dim}\")\n print(f\"GQA n_kv_heads : {n_kv_heads_gqa}\")\n print()\n\n print(\"==== KV-cache totals across all layers ====\")\n print(f\"MHA total KV cache : {convert_bytes(total_mha)}\")\n print(f\"GQA total KV cache : {convert_bytes(total_gqa)}\")\n print(f\"Ratio (MHA / GQA) : {ratio:,.2f}x\")\n print(f\"Savings (GQA vs MHA): {savings*100:,.2f}%\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/04_gqa/plot_memory_estimates_gqa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# Plot KV-cache vs context length for different n_kv_groups\n\nimport matplotlib.pyplot as plt\n\n# Import from ./memory_estimator.py\nfrom memory_estimator_gqa import calc_kv_bytes_total, DTYPE_BYTES\n\n\ndef bytes_convert(n):\n gb = n / (1000 ** 3)\n return f\"{gb:.2f}\"\n\n\ndef savings_percent(total_mha, total_gqa):\n return (1.0 - (total_gqa / total_mha)) * 100.0\n\n\ndef plot_abs_kv_vs_context_multi_groups():\n n_heads = 24\n emb_dim = 2048\n n_layers = 48\n batch_size = 1\n dtype = \"bf16\"\n bytes_per_elem = DTYPE_BYTES[dtype]\n\n # x-axis (log scale)\n context_lengths = [\n 256, 512, 1024, 2048, 4096, 8192,\n 16384, 32768, 65536, 131072\n ]\n\n mha_gb = []\n for L in context_lengths:\n total_mha = calc_kv_bytes_total(\n batch_size, L, emb_dim, n_heads,\n n_heads, # MHA: n_kv_heads = n_heads\n n_layers, bytes_per_elem\n )\n mha_gb.append(float(bytes_convert(total_mha)))\n\n plt.figure()\n plt.plot(context_lengths, mha_gb, marker=\"o\", label=\"MHA (KV total)\")\n\n # GQA curves for selected n_kv_groups\n groups_list = [4, 8, 12, 24]\n for g in groups_list:\n n_kv_heads = n_heads // g\n gqa_gb = []\n for L in context_lengths:\n total_gqa = calc_kv_bytes_total(\n batch_size, L, emb_dim, n_heads,\n n_kv_heads, n_layers, bytes_per_elem\n )\n gqa_gb.append(float(bytes_convert(total_gqa)))\n\n # Compression rate relative to MHA\n comp = (n_heads / n_kv_heads) if n_kv_heads > 0 else float(\"inf\")\n plt.plot(context_lengths, gqa_gb, marker=\"o\",\n label=f\"GQA (n_kv_groups={g}, {comp:,.1f}× compression)\")\n\n plt.xscale(\"log\")\n plt.xlabel(\"context_length (log scale)\")\n plt.ylabel(\"Total KV cache (GB)\")\n plt.title(\n \"KV-cache vs Context Length — MHA vs GQA (multi-group)\\n\"\n \"(n_heads=24, emb_dim=2048, n_layers=48, batch=1, dtype=bf16)\",\n fontsize=8\n )\n plt.grid(True, which=\"both\")\n plt.legend()\n plt.tight_layout()\n plt.savefig(\"kv_bytes_vs_context_length.pdf\")\n\n\nif __name__ == \"__main__\":\n plot_abs_kv_vs_context_multi_groups()\n"
},
{
"path": "ch04/05_mla/README.md",
"content": "# Multi-Head Latent Attention (MLA)\n\nThis bonus material illustrates the memory savings when using Multi-Head Latent Attention (MLA) over regular Multi-Head Attention (MHA).\n\n \n## Introduction\n\nIn [../04_gqa](../04_gqa), we discussed Grouped-Query Attention (GQA) as a computational-efficiency workaround for MHA. And ablation studies (such as those in the[ original GQA paper](https://arxiv.org/abs/2305.13245) and the [Llama 2 paper](https://arxiv.org/abs/2307.09288)) show it performs comparably to standard MHA in terms of LLM modeling performance.\n\nNow, Multi-Head Latent Attention (MLA), which is used in [DeepSeek V2, V3, and R1](https://arxiv.org/abs/2412.19437), offers a different memory-saving strategy that also pairs particularly well with KV caching. Instead of sharing key and value heads like GQA, MLA compresses the key and value tensors into a lower-dimensional space before storing them in the KV cache. \n\nAt inference time, these compressed tensors are projected back to their original size before being used, as shown in the figure below. This adds an extra matrix multiplication but reduces memory usage.\n\n \n\n\n\n \n\n(As a side note, the queries are also compressed, but only during training, not inference.)\n\nBy the way, as mentioned earlier, MLA is not new in DeepSeek V3, as its [DeepSeek V2 predecessor](https://arxiv.org/abs/2405.04434) also used (and even introduced) it. Also, the V2 paper contains a few interesting ablation studies that may explain why the DeepSeek team chose MLA over GQA (see the figure below).\n\n \n\n
\n\n \n\nYou can reproduce the plot via `uv run plot_memory_estimates_gqa.py`.\n\n \n## GQA Code Examples\n\nThe [gpt_with_kv_mha.py](gpt_with_kv_mha.py) and [gpt_with_kv_gqa.py](gpt_with_kv_gqa.py) scripts in this folder provide hands-on examples for comparing the MHA and GQA memory usage in the context of a GPT model implementation.\n\nNote that GQA is also used in the [Llama 3](../../ch05/07_gpt_to_llama), [Gemma 3](../../ch05/12_gemma3), and [Qwen3](../../ch05/11_qwen3) bonus materials. However, for simplicity, the code scripts in this folder modify the GPT architecture, which traditionally didn't use GQA.\n\nNote that the model is not trained and thus generates nonsensical text. However, you can use it as a drop-in replacement for the standard GPT model in chapters 5-7 and train it.\n\nAlso, this implementation uses the KV cache explained in [another bonus section](../03_kv-cache) so the memory savings are more pronounced.\n\n```bash\nuv run gpt_with_kv_mha.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12\n\n...\n\nTime: 453.81 sec\n72 tokens/sec\nMax memory allocated: 1.54 GB\n```\n\n```bash\nuv run gpt_with_kv_gqa.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12 \\\n--n_kv_groups 4\n\n...\n\nTime: 516.33 sec\n63 tokens/sec\nMax memory allocated: 0.63 GB\n```\n\nThe reason why we are not seeing such a big saving as in the plots above is 2-fold:\n\n1. I use a smaller configuration to have the model finish the generation in a reasonable time.\n2. More importantly, we are looking at the whole model here, not just the attention mechanism; the fully-connected layers in the model take up most of the memory (but this is a topic for a separate analysis).\n"
},
{
"path": "ch04/04_gqa/gpt_with_kv_gqa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4, adapted to use Grouped-Query Attention (GQA).\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# NEW: GQA instead of MHA\n#####################################\nclass GroupedQueryAttention(nn.Module):\n def __init__(\n self, d_in, d_out, dropout, num_heads, num_kv_groups, dtype=None, qkv_bias=False\n ):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n assert num_heads % num_kv_groups == 0, \"num_heads must be divisible by num_kv_groups\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n\n self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=qkv_bias, dtype=dtype)\n self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=qkv_bias, dtype=dtype)\n self.num_kv_groups = num_kv_groups\n self.group_size = num_heads // num_kv_groups\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias, dtype=dtype)\n self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\n self.dropout = nn.Dropout(dropout)\n\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n\n def forward(self, x, use_cache=False):\n b, num_tokens, _ = x.shape\n\n # Apply projections\n queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\n keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\n values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\n\n # Reshape\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\n keys_new = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\n values_new = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\n\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=2)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=2)\n keys_base, values_base = self.cache_k, self.cache_v\n else:\n keys_base, values_base = keys_new, values_new\n if self.cache_k is not None or self.cache_v is not None:\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n # Expand keys and values to match the number of heads\n # Shape: (b, num_heads, num_tokens, head_dim)\n keys = keys_base.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n values = values_base.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n # For example, before repeat_interleave along dim=1 (query groups):\n # [K1, K2]\n # After repeat_interleave (each query group is repeated group_size times):\n # [K1, K1, K2, K2]\n # If we used regular repeat instead of repeat_interleave, we'd get:\n # [K1, K2, K1, K2]\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n # Shape: (b, num_heads, num_tokens, num_tokens)\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores = attn_scores.masked_fill(mask, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n assert keys.shape[-1] == self.head_dim\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = GroupedQueryAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n num_kv_groups=cfg[\"n_kv_groups\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with grouped-query attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--n_kv_groups\", type=int, default=2, help=\"Number of key/value groups.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n \"n_kv_groups\": args.n_kv_groups\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/04_gqa/gpt_with_kv_mha.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with standard multi-head attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/04_gqa/memory_estimator_gqa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# KV-cache memory estimator for MHA vs GQA\n\n\nimport argparse\nimport math\n\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes(n):\n gb = n / (1000 ** 3)\n return f\"{gb:,.2f} GB\"\n\n\ndef calc_kv_bytes_total(batch, context_length, emb_dim, n_heads,\n n_kv_heads, n_layers, bytes_per_elem):\n head_dim = math.ceil(emb_dim / n_heads)\n per_layer = batch * context_length * head_dim * n_kv_heads * 2 * bytes_per_elem\n return per_layer * n_layers\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Estimate KV-cache memory for MHA vs GQA\")\n p.add_argument(\"--context_length\", default=1024, type=int)\n p.add_argument(\"--emb_dim\", required=True, type=int)\n p.add_argument(\"--n_heads\", required=True, type=int)\n p.add_argument(\"--n_layers\", required=True, type=int)\n p.add_argument(\"--n_kv_groups\", required=True, type=int)\n p.add_argument(\"--batch_size\", default=1, type=int)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"fp16\")\n args = p.parse_args()\n\n cfg = {\n \"context_length\": args.context_length,\n \"emb_dim\": args.emb_dim,\n \"n_heads\": args.n_heads,\n \"n_layers\": args.n_layers,\n \"n_kv_groups\": args.n_kv_groups,\n }\n\n if cfg[\"n_heads\"] % cfg[\"n_kv_groups\"] != 0:\n raise ValueError(\"n_kv_groups must divide n_heads exactly.\")\n\n bytes_per_elem = DTYPE_BYTES[args.dtype]\n head_dim = math.ceil(cfg[\"emb_dim\"] / cfg[\"n_heads\"])\n\n n_kv_heads_mha = cfg[\"n_heads\"]\n n_kv_heads_gqa = cfg[\"n_heads\"] // cfg[\"n_kv_groups\"]\n\n total_mha = calc_kv_bytes_total(\n args.batch_size,\n cfg[\"context_length\"],\n cfg[\"emb_dim\"],\n cfg[\"n_heads\"],\n n_kv_heads_mha,\n cfg[\"n_layers\"],\n bytes_per_elem,\n )\n\n total_gqa = calc_kv_bytes_total(\n args.batch_size,\n cfg[\"context_length\"],\n cfg[\"emb_dim\"],\n cfg[\"n_heads\"],\n n_kv_heads_gqa,\n cfg[\"n_layers\"],\n bytes_per_elem,\n )\n\n ratio = total_mha / total_gqa\n savings = 1 - (total_gqa / total_mha)\n\n print(\"==== Config ====\")\n for k, v in cfg.items():\n print(f\"{k:17}: {v}\")\n print(f\"batch_size : {args.batch_size}\")\n print(f\"dtype : {args.dtype} ({bytes_per_elem} Bytes/elem)\")\n print(f\"head_dim : {head_dim}\")\n print(f\"GQA n_kv_heads : {n_kv_heads_gqa}\")\n print()\n\n print(\"==== KV-cache totals across all layers ====\")\n print(f\"MHA total KV cache : {convert_bytes(total_mha)}\")\n print(f\"GQA total KV cache : {convert_bytes(total_gqa)}\")\n print(f\"Ratio (MHA / GQA) : {ratio:,.2f}x\")\n print(f\"Savings (GQA vs MHA): {savings*100:,.2f}%\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/04_gqa/plot_memory_estimates_gqa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# Plot KV-cache vs context length for different n_kv_groups\n\nimport matplotlib.pyplot as plt\n\n# Import from ./memory_estimator.py\nfrom memory_estimator_gqa import calc_kv_bytes_total, DTYPE_BYTES\n\n\ndef bytes_convert(n):\n gb = n / (1000 ** 3)\n return f\"{gb:.2f}\"\n\n\ndef savings_percent(total_mha, total_gqa):\n return (1.0 - (total_gqa / total_mha)) * 100.0\n\n\ndef plot_abs_kv_vs_context_multi_groups():\n n_heads = 24\n emb_dim = 2048\n n_layers = 48\n batch_size = 1\n dtype = \"bf16\"\n bytes_per_elem = DTYPE_BYTES[dtype]\n\n # x-axis (log scale)\n context_lengths = [\n 256, 512, 1024, 2048, 4096, 8192,\n 16384, 32768, 65536, 131072\n ]\n\n mha_gb = []\n for L in context_lengths:\n total_mha = calc_kv_bytes_total(\n batch_size, L, emb_dim, n_heads,\n n_heads, # MHA: n_kv_heads = n_heads\n n_layers, bytes_per_elem\n )\n mha_gb.append(float(bytes_convert(total_mha)))\n\n plt.figure()\n plt.plot(context_lengths, mha_gb, marker=\"o\", label=\"MHA (KV total)\")\n\n # GQA curves for selected n_kv_groups\n groups_list = [4, 8, 12, 24]\n for g in groups_list:\n n_kv_heads = n_heads // g\n gqa_gb = []\n for L in context_lengths:\n total_gqa = calc_kv_bytes_total(\n batch_size, L, emb_dim, n_heads,\n n_kv_heads, n_layers, bytes_per_elem\n )\n gqa_gb.append(float(bytes_convert(total_gqa)))\n\n # Compression rate relative to MHA\n comp = (n_heads / n_kv_heads) if n_kv_heads > 0 else float(\"inf\")\n plt.plot(context_lengths, gqa_gb, marker=\"o\",\n label=f\"GQA (n_kv_groups={g}, {comp:,.1f}× compression)\")\n\n plt.xscale(\"log\")\n plt.xlabel(\"context_length (log scale)\")\n plt.ylabel(\"Total KV cache (GB)\")\n plt.title(\n \"KV-cache vs Context Length — MHA vs GQA (multi-group)\\n\"\n \"(n_heads=24, emb_dim=2048, n_layers=48, batch=1, dtype=bf16)\",\n fontsize=8\n )\n plt.grid(True, which=\"both\")\n plt.legend()\n plt.tight_layout()\n plt.savefig(\"kv_bytes_vs_context_length.pdf\")\n\n\nif __name__ == \"__main__\":\n plot_abs_kv_vs_context_multi_groups()\n"
},
{
"path": "ch04/05_mla/README.md",
"content": "# Multi-Head Latent Attention (MLA)\n\nThis bonus material illustrates the memory savings when using Multi-Head Latent Attention (MLA) over regular Multi-Head Attention (MHA).\n\n \n## Introduction\n\nIn [../04_gqa](../04_gqa), we discussed Grouped-Query Attention (GQA) as a computational-efficiency workaround for MHA. And ablation studies (such as those in the[ original GQA paper](https://arxiv.org/abs/2305.13245) and the [Llama 2 paper](https://arxiv.org/abs/2307.09288)) show it performs comparably to standard MHA in terms of LLM modeling performance.\n\nNow, Multi-Head Latent Attention (MLA), which is used in [DeepSeek V2, V3, and R1](https://arxiv.org/abs/2412.19437), offers a different memory-saving strategy that also pairs particularly well with KV caching. Instead of sharing key and value heads like GQA, MLA compresses the key and value tensors into a lower-dimensional space before storing them in the KV cache. \n\nAt inference time, these compressed tensors are projected back to their original size before being used, as shown in the figure below. This adds an extra matrix multiplication but reduces memory usage.\n\n \n\n\n\n \n\n(As a side note, the queries are also compressed, but only during training, not inference.)\n\nBy the way, as mentioned earlier, MLA is not new in DeepSeek V3, as its [DeepSeek V2 predecessor](https://arxiv.org/abs/2405.04434) also used (and even introduced) it. Also, the V2 paper contains a few interesting ablation studies that may explain why the DeepSeek team chose MLA over GQA (see the figure below).\n\n \n\n \n\n \n\nAs shown in the figure above, GQA appears to perform worse than MHA, whereas MLA offers better modeling performance than MHA, which is likely why the DeepSeek team chose MLA over GQA. (It would have been interesting to see the \"KV Cache per Token\" savings comparison between MLA and GQA as well!)\n\nTo summarize this section, before we move on to the next architecture component, MLA is a clever trick to reduce KV cache memory use while even slightly outperforming MHA in terms of modeling performance.\n\n \n## MLA Memory Savings\n\nThe memory savings are mostly reflected in the KV storage. We can compute the KV storage size with the following formula:\n\nbytes ≈ batch_size × seqlen × n_layers × latent_dim × bytes_per_elem\n\nIn contrast, MHA KV cache memory is computed as follows:\n\nbytes ≈ batch_size × seqlen × n_layers × embed_dim × 2 (K,V) × bytes_per_elem\n\nThis means, in MLA, we reduce \"embed_dim × 2 (K,V)\" to \"latent_dim\", since we only stored the compressed latent representation instead of the full key and value vectors as shown in the earlier figure above.\n\n\n\nYou can use the [memory_estimator_mla.py](memory_estimator_mla.py) script in this folder to apply this for different model configs to see how much memory you can save by using MLA over MHA:\n\n```bash\n➜ uv run memory_estimator_mla.py \\\n --context_length 8192 \\\n --emb_dim 2048 \\\n --n_heads 24 \\\n --n_layers 48 \\\n --n_kv_groups 4 \\\n --batch_size 1 \\\n --dtype bf16 \\\n --latent_dim 1024\n==== Config ====\ncontext_length : 8192\nemb_dim : 2048\nn_heads : 24\nn_layers : 48\nn_kv_groups : 4\nlatent_dim : 1024\nbatch_size : 1\ndtype : bf16 (2 Bytes/elem)\nhead_dim : 86\nGQA n_kv_heads : 6\n\n==== KV-cache totals across all layers ====\nMHA total KV cache : 3.25 GB\nGQA total KV cache : 0.81 GB\nMLA total KV cache : 0.81 GB\nRatio (MHA / GQA) : 4.00x\nSavings (GQA vs MHA): 75.00%\nRatio (MHA / MLA) : 4.03x\nSavings (MLA vs MHA): 75.19%\n```\n\nNote that the compression above (`--emb_dim 2048 -> latent_dim 1024`) to achieve a similar saving as for GQA. In practice, the compression is a hyperparameter that needs to be carefully investigated, as choosing `latent_dim` to be too small can have negative impact on the modeling performance (similar to choosing too many `n_kv_groups` in GQA).\n\nThe savings when using MLA over MHA are further shown in the plot below for different `latent_dim` values as a function of the context length:\n\n \n\n
\n\n \n\nAs shown in the figure above, GQA appears to perform worse than MHA, whereas MLA offers better modeling performance than MHA, which is likely why the DeepSeek team chose MLA over GQA. (It would have been interesting to see the \"KV Cache per Token\" savings comparison between MLA and GQA as well!)\n\nTo summarize this section, before we move on to the next architecture component, MLA is a clever trick to reduce KV cache memory use while even slightly outperforming MHA in terms of modeling performance.\n\n \n## MLA Memory Savings\n\nThe memory savings are mostly reflected in the KV storage. We can compute the KV storage size with the following formula:\n\nbytes ≈ batch_size × seqlen × n_layers × latent_dim × bytes_per_elem\n\nIn contrast, MHA KV cache memory is computed as follows:\n\nbytes ≈ batch_size × seqlen × n_layers × embed_dim × 2 (K,V) × bytes_per_elem\n\nThis means, in MLA, we reduce \"embed_dim × 2 (K,V)\" to \"latent_dim\", since we only stored the compressed latent representation instead of the full key and value vectors as shown in the earlier figure above.\n\n\n\nYou can use the [memory_estimator_mla.py](memory_estimator_mla.py) script in this folder to apply this for different model configs to see how much memory you can save by using MLA over MHA:\n\n```bash\n➜ uv run memory_estimator_mla.py \\\n --context_length 8192 \\\n --emb_dim 2048 \\\n --n_heads 24 \\\n --n_layers 48 \\\n --n_kv_groups 4 \\\n --batch_size 1 \\\n --dtype bf16 \\\n --latent_dim 1024\n==== Config ====\ncontext_length : 8192\nemb_dim : 2048\nn_heads : 24\nn_layers : 48\nn_kv_groups : 4\nlatent_dim : 1024\nbatch_size : 1\ndtype : bf16 (2 Bytes/elem)\nhead_dim : 86\nGQA n_kv_heads : 6\n\n==== KV-cache totals across all layers ====\nMHA total KV cache : 3.25 GB\nGQA total KV cache : 0.81 GB\nMLA total KV cache : 0.81 GB\nRatio (MHA / GQA) : 4.00x\nSavings (GQA vs MHA): 75.00%\nRatio (MHA / MLA) : 4.03x\nSavings (MLA vs MHA): 75.19%\n```\n\nNote that the compression above (`--emb_dim 2048 -> latent_dim 1024`) to achieve a similar saving as for GQA. In practice, the compression is a hyperparameter that needs to be carefully investigated, as choosing `latent_dim` to be too small can have negative impact on the modeling performance (similar to choosing too many `n_kv_groups` in GQA).\n\nThe savings when using MLA over MHA are further shown in the plot below for different `latent_dim` values as a function of the context length:\n\n \n\n \n\n \n\nYou can reproduce the plot via `uv run plot_memory_estimates_mla.py`.\n\n\n\n \n## MLA Code Examples\n\nThe [gpt_with_kv_mha.py](gpt_with_kv_mha.py) and [gpt_with_kv_mla.py](gpt_with_kv_mla.py) scripts in this folder provide hands-on examples for comparing the MHA and MLA memory usage in the context of a GPT model implementation. \n\nHere, the MLA code is inspired by the [https://huggingface.co/bird-of-paradise/deepseek-mla](https://huggingface.co/bird-of-paradise/deepseek-mla) implementation.\n\nNote that MLA can also be used in combination with [GQA](../04_gqa), but for simplicity, I this is not done here. (Currently, I am also not aware of a prominent LLM doing this.)\n\nAlso note that the model is not trained and thus generates nonsensical text. However, you can use it as a drop-in replacement for the standard GPT model in chapters 5-7 and train it.\n\nLastly, this implementation uses the KV cache explained in [another bonus section](../03_kv-cache) so the memory savings are more pronounced.\n\n```bash\nuv run gpt_with_kv_mha.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12 \\\n--emb_dim 768\n\n...\n\nTime: 453.81 sec\n72 tokens/sec\nMax memory allocated: 1.54 GB\n```\n\n```bash\nuv run gpt_with_kv_mla.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12 \\\n--emb_dim 768 \\\n--latent_dim 192 # (768×2)/192 = 8× compression\n\n...\n\nTime: 487.21 sec\n67 tokens/sec\nMax memory allocated: 0.68 GB\n```\n\nThe reason why we are not seeing such a big saving as in the plots above is 2-fold:\n\n1. I use a smaller configuration to have the model finish the generation in a reasonable time.\n2. More importantly, we are looking at the whole model here, not just the attention mechanism; the fully-connected layers in the model take up most of the memory (but this is a topic for a separate analysis).\n"
},
{
"path": "ch04/05_mla/gpt_with_kv_mha.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with standard multi-head attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/05_mla/gpt_with_kv_mla.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4, adapted to use Multi-Head Latent Attention (MLA).\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Multi-Head Latent Attention\n#####################################\n# The MLA code below is inspired by\n# https://huggingface.co/bird-of-paradise/deepseek-mla\n\n\nclass MultiHeadLatentAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads,\n qkv_bias=False, latent_dim=None):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n self.latent_dim = latent_dim if latent_dim is not None else max(16, d_out // 8)\n\n # Projections\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias) # per-head Q\n self.W_DKV = nn.Linear(d_in, self.latent_dim, bias=qkv_bias) # down to latent C\n self.W_UK = nn.Linear(self.latent_dim, d_out, bias=qkv_bias) # latent -> per-head K\n self.W_UV = nn.Linear(self.latent_dim, d_out, bias=qkv_bias) # latent -> per-head V\n\n self.out_proj = nn.Linear(d_out, d_out)\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # Latent-KV cache\n self.register_buffer(\"cache_c_kv\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def reset_cache(self):\n self.cache_c_kv = None\n self.ptr_current_pos = 0\n\n @staticmethod\n def _reshape_to_heads(x, num_heads, head_dim):\n # (b, T, d_out) -> (b, num_heads, T, head_dim)\n bsz, num_tokens, _ = x.shape\n return x.view(bsz, num_tokens, num_heads, head_dim).transpose(1, 2).contiguous()\n\n def forward(self, x, use_cache=False):\n b, num_tokens, _ = x.shape\n num_heads = self.num_heads\n head_dim = self.head_dim\n\n # 1) Project to queries (per-token, per-head) and new latent chunk\n queries_all = self.W_query(x) # (b, T, d_out)\n latent_new = self.W_DKV(x) # (b, T, latent_dim)\n\n # 2) Update latent cache and choose latent sequence to up-project\n if use_cache:\n if self.cache_c_kv is None:\n latent_total = latent_new\n else:\n latent_total = torch.cat([self.cache_c_kv, latent_new], dim=1)\n self.cache_c_kv = latent_total\n else:\n latent_total = latent_new\n\n # 3) Up-project latent to per-head keys/values (then split into heads)\n keys_all = self.W_UK(latent_total) # (b, T_k_total, d_out)\n values_all = self.W_UV(latent_total) # (b, T_k_total, d_out)\n\n # 4) Reshape to heads\n queries = self._reshape_to_heads(queries_all, num_heads, head_dim)\n keys = self._reshape_to_heads(keys_all, num_heads, head_dim)\n values = self._reshape_to_heads(values_all, num_heads, head_dim)\n\n # 5) Scaled dot-product attention with causal mask\n attn_scores = torch.matmul(queries, keys.transpose(-2, -1))\n\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadLatentAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"],\n latent_dim=cfg[\"latent_dim\"])\n\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with standard multi-head attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n parser.add_argument(\"--latent_dim\", type=int, default=None,\n help=\"Latent dim for MLA\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n \"latent_dim\": args.latent_dim,\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/05_mla/memory_estimator_mla.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# KV-cache memory estimator for MHA vs GQA vs MLA\n\nimport argparse\nimport math\n\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes(n):\n gb = n / (1000 ** 3)\n return f\"{gb:,.2f} GB\"\n\n\ndef calc_kv_bytes_total(batch, context_length, emb_dim, n_heads,\n n_kv_heads, n_layers, bytes_per_elem):\n # Generic KV-cache: per-head dim is embed_dim / n_heads, times 2 for K and V\n head_dim = math.ceil(emb_dim / n_heads)\n per_layer = batch * context_length * head_dim * n_kv_heads * 2 * bytes_per_elem\n return per_layer * n_layers\n\n\ndef calc_mla_bytes_total(batch, context_length, n_layers, latent_dim, bytes_per_elem):\n # Simple MLA (per-token compressed latent)\n # bytes ≈ batch × seqlen × n_layers × latent_dim × bytes_per_elem\n return batch * context_length * n_layers * latent_dim * bytes_per_elem\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Estimate KV-cache memory for MHA vs GQA vs MLA\")\n p.add_argument(\"--context_length\", default=1024, type=int)\n p.add_argument(\"--emb_dim\", required=True, type=int)\n p.add_argument(\"--n_heads\", required=True, type=int)\n p.add_argument(\"--n_layers\", required=True, type=int)\n p.add_argument(\"--n_kv_groups\", required=True, type=int)\n p.add_argument(\"--latent_dim\", required=True, type=int, help=\"MLA per-token latent dimension\")\n p.add_argument(\"--batch_size\", default=1, type=int)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"fp16\")\n args = p.parse_args()\n\n cfg = {\n \"context_length\": args.context_length,\n \"emb_dim\": args.emb_dim,\n \"n_heads\": args.n_heads,\n \"n_layers\": args.n_layers,\n \"n_kv_groups\": args.n_kv_groups,\n \"latent_dim\": args.latent_dim,\n }\n\n if cfg[\"n_heads\"] % cfg[\"n_kv_groups\"] != 0:\n raise ValueError(\"n_kv_groups must divide n_heads exactly.\")\n\n bytes_per_elem = DTYPE_BYTES[args.dtype]\n head_dim = math.ceil(cfg[\"emb_dim\"] / cfg[\"n_heads\"])\n\n n_kv_heads_mha = cfg[\"n_heads\"]\n n_kv_heads_gqa = cfg[\"n_heads\"] // cfg[\"n_kv_groups\"]\n\n total_mha = calc_kv_bytes_total(\n args.batch_size,\n cfg[\"context_length\"],\n cfg[\"emb_dim\"],\n cfg[\"n_heads\"],\n n_kv_heads_mha,\n cfg[\"n_layers\"],\n bytes_per_elem,\n )\n\n total_gqa = calc_kv_bytes_total(\n args.batch_size,\n cfg[\"context_length\"],\n cfg[\"emb_dim\"],\n cfg[\"n_heads\"],\n n_kv_heads_gqa,\n cfg[\"n_layers\"],\n bytes_per_elem,\n )\n\n total_mla = calc_mla_bytes_total(\n args.batch_size,\n cfg[\"context_length\"],\n cfg[\"n_layers\"],\n cfg[\"latent_dim\"],\n bytes_per_elem,\n )\n\n ratio = total_mha / total_gqa if total_gqa != 0 else float(\"inf\")\n savings = 1 - (total_gqa / total_mha) if total_mha != 0 else 0.0\n\n ratio_mha_mla = total_mha / total_mla if total_mla != 0 else float(\"inf\")\n savings_mla = 1 - (total_mla / total_mha) if total_mha != 0 else 0.0\n\n print(\"==== Config ====\")\n for k, v in cfg.items():\n print(f\"{k:17}: {v}\")\n print(f\"batch_size : {args.batch_size}\")\n print(f\"dtype : {args.dtype} ({bytes_per_elem} Bytes/elem)\")\n print(f\"head_dim : {head_dim}\")\n print(f\"GQA n_kv_heads : {n_kv_heads_gqa}\")\n print()\n\n print(\"==== KV-cache totals across all layers ====\")\n print(f\"MHA total KV cache : {convert_bytes(total_mha)}\")\n print(f\"GQA total KV cache : {convert_bytes(total_gqa)}\")\n print(f\"MLA total KV cache : {convert_bytes(total_mla)}\")\n print(f\"Ratio (MHA / GQA) : {ratio:,.2f}x\")\n print(f\"Savings (GQA vs MHA): {savings*100:,.2f}%\")\n print(f\"Ratio (MHA / MLA) : {ratio_mha_mla:,.2f}x\")\n print(f\"Savings (MLA vs MHA): {savings_mla*100:,.2f}%\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/05_mla/plot_memory_estimates_mla.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport matplotlib.pyplot as plt\n\n# Bytes per element\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes_to_gb(n_bytes):\n return n_bytes / (1000. ** 3)\n\n\ndef calc_kv_bytes_total_mha(batch, context_length, emb_dim, n_heads,\n n_layers, bytes_per_elem):\n head_dim = emb_dim / n_heads\n per_layer = batch * context_length * head_dim * n_heads * 2 * bytes_per_elem\n return per_layer * n_layers\n\n\ndef calc_kv_bytes_total_mla(batch, context_length, n_layers, latent_dim, bytes_per_elem):\n return batch * context_length * n_layers * latent_dim * bytes_per_elem\n\n\ndef plot_abs_kv_vs_context_multiple():\n n_heads = 24\n emb_dim = 2048\n n_layers = 48\n batch_size = 1\n dtype = \"bf16\"\n bytes_per_elem = DTYPE_BYTES[dtype]\n\n context_lengths = [\n 256, 512, 1024, 2048, 4096, 8192,\n 16384, 32768, 65536, 131072\n ]\n\n mha_gb = []\n for L in context_lengths:\n total_mha = calc_kv_bytes_total_mha(\n batch_size, L, emb_dim, n_heads, n_layers, bytes_per_elem\n )\n mha_gb.append(convert_bytes_to_gb(total_mha))\n\n latent_dims = [1024, 512, 256, 64]\n plt.figure()\n plt.plot(context_lengths, mha_gb, marker=\"o\", label=\"MHA (KV total)\")\n\n L_ref = context_lengths[-1]\n total_mha_ref = calc_kv_bytes_total_mha(batch_size, L_ref, emb_dim, n_heads, n_layers, bytes_per_elem)\n\n for latent_dim in latent_dims:\n mla_gb = []\n for L in context_lengths:\n total_mla = calc_kv_bytes_total_mla(\n batch_size, L, n_layers, latent_dim, bytes_per_elem\n )\n mla_gb.append(convert_bytes_to_gb(total_mla))\n\n total_mla_ref = calc_kv_bytes_total_mla(batch_size, L_ref, n_layers, latent_dim, bytes_per_elem)\n comp = total_mha_ref / total_mla_ref if total_mla_ref != 0 else float(\"inf\")\n\n plt.plot(context_lengths, mla_gb, marker=\"o\",\n label=f\"MLA (latent_dim={latent_dim}, {comp:,.1f}× compression)\")\n\n plt.xscale(\"log\")\n plt.xlabel(\"context_length (log scale)\")\n plt.ylabel(\"Total KV cache (GB)\")\n plt.title(\n \"KV-cache vs Context Length — MHA vs MLA\\n\"\n f\"(n_heads={n_heads}, emb_dim={emb_dim}, n_layers={n_layers}, \"\n f\"batch={batch_size}, dtype={dtype})\",\n fontsize=8\n )\n plt.grid(True, which=\"both\")\n plt.legend()\n plt.tight_layout()\n plt.savefig(\"kv_bytes_vs_context_length.pdf\")\n\n\nif __name__ == \"__main__\":\n plot_abs_kv_vs_context_multiple()\n"
},
{
"path": "ch04/06_swa/README.md",
"content": "# Sliding Window Attention (SWA)\n\nThis bonus material illustrates the memory savings when using Sliding Window Attention (SWA) over regular Multi-Head Attention (MHA).\n\n\n\n \n## Introduction\n\nWhat is sliding window attention (SWA)? If we think of regular self-attention as a *global* attention mechanism, since each sequence element can access every other sequence element, then we can think of SWA as *local* attention, because here we restrict the context size around the current query position. This is illustrated in the figure below.\n\n
\n\n \n\nYou can reproduce the plot via `uv run plot_memory_estimates_mla.py`.\n\n\n\n \n## MLA Code Examples\n\nThe [gpt_with_kv_mha.py](gpt_with_kv_mha.py) and [gpt_with_kv_mla.py](gpt_with_kv_mla.py) scripts in this folder provide hands-on examples for comparing the MHA and MLA memory usage in the context of a GPT model implementation. \n\nHere, the MLA code is inspired by the [https://huggingface.co/bird-of-paradise/deepseek-mla](https://huggingface.co/bird-of-paradise/deepseek-mla) implementation.\n\nNote that MLA can also be used in combination with [GQA](../04_gqa), but for simplicity, I this is not done here. (Currently, I am also not aware of a prominent LLM doing this.)\n\nAlso note that the model is not trained and thus generates nonsensical text. However, you can use it as a drop-in replacement for the standard GPT model in chapters 5-7 and train it.\n\nLastly, this implementation uses the KV cache explained in [another bonus section](../03_kv-cache) so the memory savings are more pronounced.\n\n```bash\nuv run gpt_with_kv_mha.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12 \\\n--emb_dim 768\n\n...\n\nTime: 453.81 sec\n72 tokens/sec\nMax memory allocated: 1.54 GB\n```\n\n```bash\nuv run gpt_with_kv_mla.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12 \\\n--emb_dim 768 \\\n--latent_dim 192 # (768×2)/192 = 8× compression\n\n...\n\nTime: 487.21 sec\n67 tokens/sec\nMax memory allocated: 0.68 GB\n```\n\nThe reason why we are not seeing such a big saving as in the plots above is 2-fold:\n\n1. I use a smaller configuration to have the model finish the generation in a reasonable time.\n2. More importantly, we are looking at the whole model here, not just the attention mechanism; the fully-connected layers in the model take up most of the memory (but this is a topic for a separate analysis).\n"
},
{
"path": "ch04/05_mla/gpt_with_kv_mha.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with standard multi-head attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/05_mla/gpt_with_kv_mla.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4, adapted to use Multi-Head Latent Attention (MLA).\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Multi-Head Latent Attention\n#####################################\n# The MLA code below is inspired by\n# https://huggingface.co/bird-of-paradise/deepseek-mla\n\n\nclass MultiHeadLatentAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads,\n qkv_bias=False, latent_dim=None):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n self.latent_dim = latent_dim if latent_dim is not None else max(16, d_out // 8)\n\n # Projections\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias) # per-head Q\n self.W_DKV = nn.Linear(d_in, self.latent_dim, bias=qkv_bias) # down to latent C\n self.W_UK = nn.Linear(self.latent_dim, d_out, bias=qkv_bias) # latent -> per-head K\n self.W_UV = nn.Linear(self.latent_dim, d_out, bias=qkv_bias) # latent -> per-head V\n\n self.out_proj = nn.Linear(d_out, d_out)\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # Latent-KV cache\n self.register_buffer(\"cache_c_kv\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def reset_cache(self):\n self.cache_c_kv = None\n self.ptr_current_pos = 0\n\n @staticmethod\n def _reshape_to_heads(x, num_heads, head_dim):\n # (b, T, d_out) -> (b, num_heads, T, head_dim)\n bsz, num_tokens, _ = x.shape\n return x.view(bsz, num_tokens, num_heads, head_dim).transpose(1, 2).contiguous()\n\n def forward(self, x, use_cache=False):\n b, num_tokens, _ = x.shape\n num_heads = self.num_heads\n head_dim = self.head_dim\n\n # 1) Project to queries (per-token, per-head) and new latent chunk\n queries_all = self.W_query(x) # (b, T, d_out)\n latent_new = self.W_DKV(x) # (b, T, latent_dim)\n\n # 2) Update latent cache and choose latent sequence to up-project\n if use_cache:\n if self.cache_c_kv is None:\n latent_total = latent_new\n else:\n latent_total = torch.cat([self.cache_c_kv, latent_new], dim=1)\n self.cache_c_kv = latent_total\n else:\n latent_total = latent_new\n\n # 3) Up-project latent to per-head keys/values (then split into heads)\n keys_all = self.W_UK(latent_total) # (b, T_k_total, d_out)\n values_all = self.W_UV(latent_total) # (b, T_k_total, d_out)\n\n # 4) Reshape to heads\n queries = self._reshape_to_heads(queries_all, num_heads, head_dim)\n keys = self._reshape_to_heads(keys_all, num_heads, head_dim)\n values = self._reshape_to_heads(values_all, num_heads, head_dim)\n\n # 5) Scaled dot-product attention with causal mask\n attn_scores = torch.matmul(queries, keys.transpose(-2, -1))\n\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadLatentAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"],\n latent_dim=cfg[\"latent_dim\"])\n\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with standard multi-head attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n parser.add_argument(\"--latent_dim\", type=int, default=None,\n help=\"Latent dim for MLA\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n \"latent_dim\": args.latent_dim,\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/05_mla/memory_estimator_mla.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# KV-cache memory estimator for MHA vs GQA vs MLA\n\nimport argparse\nimport math\n\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes(n):\n gb = n / (1000 ** 3)\n return f\"{gb:,.2f} GB\"\n\n\ndef calc_kv_bytes_total(batch, context_length, emb_dim, n_heads,\n n_kv_heads, n_layers, bytes_per_elem):\n # Generic KV-cache: per-head dim is embed_dim / n_heads, times 2 for K and V\n head_dim = math.ceil(emb_dim / n_heads)\n per_layer = batch * context_length * head_dim * n_kv_heads * 2 * bytes_per_elem\n return per_layer * n_layers\n\n\ndef calc_mla_bytes_total(batch, context_length, n_layers, latent_dim, bytes_per_elem):\n # Simple MLA (per-token compressed latent)\n # bytes ≈ batch × seqlen × n_layers × latent_dim × bytes_per_elem\n return batch * context_length * n_layers * latent_dim * bytes_per_elem\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Estimate KV-cache memory for MHA vs GQA vs MLA\")\n p.add_argument(\"--context_length\", default=1024, type=int)\n p.add_argument(\"--emb_dim\", required=True, type=int)\n p.add_argument(\"--n_heads\", required=True, type=int)\n p.add_argument(\"--n_layers\", required=True, type=int)\n p.add_argument(\"--n_kv_groups\", required=True, type=int)\n p.add_argument(\"--latent_dim\", required=True, type=int, help=\"MLA per-token latent dimension\")\n p.add_argument(\"--batch_size\", default=1, type=int)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"fp16\")\n args = p.parse_args()\n\n cfg = {\n \"context_length\": args.context_length,\n \"emb_dim\": args.emb_dim,\n \"n_heads\": args.n_heads,\n \"n_layers\": args.n_layers,\n \"n_kv_groups\": args.n_kv_groups,\n \"latent_dim\": args.latent_dim,\n }\n\n if cfg[\"n_heads\"] % cfg[\"n_kv_groups\"] != 0:\n raise ValueError(\"n_kv_groups must divide n_heads exactly.\")\n\n bytes_per_elem = DTYPE_BYTES[args.dtype]\n head_dim = math.ceil(cfg[\"emb_dim\"] / cfg[\"n_heads\"])\n\n n_kv_heads_mha = cfg[\"n_heads\"]\n n_kv_heads_gqa = cfg[\"n_heads\"] // cfg[\"n_kv_groups\"]\n\n total_mha = calc_kv_bytes_total(\n args.batch_size,\n cfg[\"context_length\"],\n cfg[\"emb_dim\"],\n cfg[\"n_heads\"],\n n_kv_heads_mha,\n cfg[\"n_layers\"],\n bytes_per_elem,\n )\n\n total_gqa = calc_kv_bytes_total(\n args.batch_size,\n cfg[\"context_length\"],\n cfg[\"emb_dim\"],\n cfg[\"n_heads\"],\n n_kv_heads_gqa,\n cfg[\"n_layers\"],\n bytes_per_elem,\n )\n\n total_mla = calc_mla_bytes_total(\n args.batch_size,\n cfg[\"context_length\"],\n cfg[\"n_layers\"],\n cfg[\"latent_dim\"],\n bytes_per_elem,\n )\n\n ratio = total_mha / total_gqa if total_gqa != 0 else float(\"inf\")\n savings = 1 - (total_gqa / total_mha) if total_mha != 0 else 0.0\n\n ratio_mha_mla = total_mha / total_mla if total_mla != 0 else float(\"inf\")\n savings_mla = 1 - (total_mla / total_mha) if total_mha != 0 else 0.0\n\n print(\"==== Config ====\")\n for k, v in cfg.items():\n print(f\"{k:17}: {v}\")\n print(f\"batch_size : {args.batch_size}\")\n print(f\"dtype : {args.dtype} ({bytes_per_elem} Bytes/elem)\")\n print(f\"head_dim : {head_dim}\")\n print(f\"GQA n_kv_heads : {n_kv_heads_gqa}\")\n print()\n\n print(\"==== KV-cache totals across all layers ====\")\n print(f\"MHA total KV cache : {convert_bytes(total_mha)}\")\n print(f\"GQA total KV cache : {convert_bytes(total_gqa)}\")\n print(f\"MLA total KV cache : {convert_bytes(total_mla)}\")\n print(f\"Ratio (MHA / GQA) : {ratio:,.2f}x\")\n print(f\"Savings (GQA vs MHA): {savings*100:,.2f}%\")\n print(f\"Ratio (MHA / MLA) : {ratio_mha_mla:,.2f}x\")\n print(f\"Savings (MLA vs MHA): {savings_mla*100:,.2f}%\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/05_mla/plot_memory_estimates_mla.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport matplotlib.pyplot as plt\n\n# Bytes per element\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes_to_gb(n_bytes):\n return n_bytes / (1000. ** 3)\n\n\ndef calc_kv_bytes_total_mha(batch, context_length, emb_dim, n_heads,\n n_layers, bytes_per_elem):\n head_dim = emb_dim / n_heads\n per_layer = batch * context_length * head_dim * n_heads * 2 * bytes_per_elem\n return per_layer * n_layers\n\n\ndef calc_kv_bytes_total_mla(batch, context_length, n_layers, latent_dim, bytes_per_elem):\n return batch * context_length * n_layers * latent_dim * bytes_per_elem\n\n\ndef plot_abs_kv_vs_context_multiple():\n n_heads = 24\n emb_dim = 2048\n n_layers = 48\n batch_size = 1\n dtype = \"bf16\"\n bytes_per_elem = DTYPE_BYTES[dtype]\n\n context_lengths = [\n 256, 512, 1024, 2048, 4096, 8192,\n 16384, 32768, 65536, 131072\n ]\n\n mha_gb = []\n for L in context_lengths:\n total_mha = calc_kv_bytes_total_mha(\n batch_size, L, emb_dim, n_heads, n_layers, bytes_per_elem\n )\n mha_gb.append(convert_bytes_to_gb(total_mha))\n\n latent_dims = [1024, 512, 256, 64]\n plt.figure()\n plt.plot(context_lengths, mha_gb, marker=\"o\", label=\"MHA (KV total)\")\n\n L_ref = context_lengths[-1]\n total_mha_ref = calc_kv_bytes_total_mha(batch_size, L_ref, emb_dim, n_heads, n_layers, bytes_per_elem)\n\n for latent_dim in latent_dims:\n mla_gb = []\n for L in context_lengths:\n total_mla = calc_kv_bytes_total_mla(\n batch_size, L, n_layers, latent_dim, bytes_per_elem\n )\n mla_gb.append(convert_bytes_to_gb(total_mla))\n\n total_mla_ref = calc_kv_bytes_total_mla(batch_size, L_ref, n_layers, latent_dim, bytes_per_elem)\n comp = total_mha_ref / total_mla_ref if total_mla_ref != 0 else float(\"inf\")\n\n plt.plot(context_lengths, mla_gb, marker=\"o\",\n label=f\"MLA (latent_dim={latent_dim}, {comp:,.1f}× compression)\")\n\n plt.xscale(\"log\")\n plt.xlabel(\"context_length (log scale)\")\n plt.ylabel(\"Total KV cache (GB)\")\n plt.title(\n \"KV-cache vs Context Length — MHA vs MLA\\n\"\n f\"(n_heads={n_heads}, emb_dim={emb_dim}, n_layers={n_layers}, \"\n f\"batch={batch_size}, dtype={dtype})\",\n fontsize=8\n )\n plt.grid(True, which=\"both\")\n plt.legend()\n plt.tight_layout()\n plt.savefig(\"kv_bytes_vs_context_length.pdf\")\n\n\nif __name__ == \"__main__\":\n plot_abs_kv_vs_context_multiple()\n"
},
{
"path": "ch04/06_swa/README.md",
"content": "# Sliding Window Attention (SWA)\n\nThis bonus material illustrates the memory savings when using Sliding Window Attention (SWA) over regular Multi-Head Attention (MHA).\n\n\n\n \n## Introduction\n\nWhat is sliding window attention (SWA)? If we think of regular self-attention as a *global* attention mechanism, since each sequence element can access every other sequence element, then we can think of SWA as *local* attention, because here we restrict the context size around the current query position. This is illustrated in the figure below.\n\n \n\nAs shown in the figure above, instead of attending to all previous tokens, each token only attends to a fixed-size local window around its position. This localized attention lowers the size of the KV cache substantially.\n\nIn the remainder of this introduction, we will discuss SWA in the context of [Gemma 3](https://arxiv.org/abs/2503.19786), which is implemented from scratch in [../../ch05/12_gemma3](../../ch05/12_gemma3).\n\nSliding window attention was originally introduced in the [LongFormer paper in 2020](https://arxiv.org/abs/2004.05150), but the reason we focus on Google's Gemma models is that they are very good open-weight models showing that sliding window attention is indeed a feasible approach in recent, capable models.\n\n[Gemma 2](https://arxiv.org/abs/2408.00118) used a hybrid approach that combined local (sliding window) and global attention layers in a 1:1 ratio. Each token could attend to a context window of 4 k tokens. The reason for this 1:1 hybrid is that it strikes a balance between efficiency and global context modeling, since an LLM using only local attention can be too restrictive.\n\n[Gemma 3](https://arxiv.org/abs/2503.19786) then took the design further toward efficiency. It used a 5:1 ratio between sliding window and full attention layers, which means that for every five local attention layers, there is one global layer. In addition, the sliding window size was reduced from 4096 tokens in Gemma 2 to 1024 tokens in Gemma 3. \n\nInterestingly, the ablation studies in the Gemma 3 technical report indicate that these changes have only a minor effect on overall model quality. In other words, the substantial memory and compute savings achieved through sliding window attention come with minimal loss in modeling performance.\n\n\n\n \n## Sliding Window Attention (SWA) Memory Savings\n\nThe memory savings are mostly reflected in the KV storage. We can compute the KV storage size with the following formula:\n\nbytes ≈ batch_size × seqlen × (embed_dim / n_heads) × n_layers × 2 (K,V) × bytes_per_elem × n_kv_heads\n\nWhen using SWA, we replace the sequence length (seqlen) above by the window size W. So, when using sliding window attention, we reduce the KV cache size by a factor of \"W / seqlen\". (Note that for simplicity, this assumes that sliding window attention is used in every layer.)\n\n\nYou can use the [memory_estimator_swa.py](memory_estimator_swa.py) script in this folder to apply this for different model configs to see how much memory you can save by using SWA over MHA:\n\n```bash\n➜ uv run memory_estimator_swa.py \\\n --emb_dim 4096 --n_heads 32 --n_layers 32 \\\n --context_length 32768 --n_kv_groups 4 \\\n --batch_size 1 --dtype bf16 \\\n --sliding_window_size 1024 --swa_ratio \"5:1\"\n==== Config ====\ncontext_length : 32768\nsliding_window_size : 1024\nemb_dim : 4096\nn_heads : 32\nn_layers : 32\nn_kv_groups : 4\nbatch_size : 1\ndtype : bf16 (2 Bytes/elem)\nhead_dim : 128\nGQA n_kv_heads : 8\nEffective SWA window W : 1024\nLayer ratio (SWA:Full) : 5:1\nDistributed layers : 27 SWA, 5 FULL\n\n==== KV-cache totals across all layers ====\nMHA KV total : 17.18 GB\nGQA KV total : 4.29 GB\nMHA + SWA (Ratio: 5:1) : 3.14 GB\nMHA + GQA (Ratio: 5:1) : 0.78 GB\n```\n\nNote that Gemma 3 uses SWA in combination with GQA.\n\nThe savings when using SWA over MHA are further shown in the plot below for different context lengths:\n\n \n\n
\n\nAs shown in the figure above, instead of attending to all previous tokens, each token only attends to a fixed-size local window around its position. This localized attention lowers the size of the KV cache substantially.\n\nIn the remainder of this introduction, we will discuss SWA in the context of [Gemma 3](https://arxiv.org/abs/2503.19786), which is implemented from scratch in [../../ch05/12_gemma3](../../ch05/12_gemma3).\n\nSliding window attention was originally introduced in the [LongFormer paper in 2020](https://arxiv.org/abs/2004.05150), but the reason we focus on Google's Gemma models is that they are very good open-weight models showing that sliding window attention is indeed a feasible approach in recent, capable models.\n\n[Gemma 2](https://arxiv.org/abs/2408.00118) used a hybrid approach that combined local (sliding window) and global attention layers in a 1:1 ratio. Each token could attend to a context window of 4 k tokens. The reason for this 1:1 hybrid is that it strikes a balance between efficiency and global context modeling, since an LLM using only local attention can be too restrictive.\n\n[Gemma 3](https://arxiv.org/abs/2503.19786) then took the design further toward efficiency. It used a 5:1 ratio between sliding window and full attention layers, which means that for every five local attention layers, there is one global layer. In addition, the sliding window size was reduced from 4096 tokens in Gemma 2 to 1024 tokens in Gemma 3. \n\nInterestingly, the ablation studies in the Gemma 3 technical report indicate that these changes have only a minor effect on overall model quality. In other words, the substantial memory and compute savings achieved through sliding window attention come with minimal loss in modeling performance.\n\n\n\n \n## Sliding Window Attention (SWA) Memory Savings\n\nThe memory savings are mostly reflected in the KV storage. We can compute the KV storage size with the following formula:\n\nbytes ≈ batch_size × seqlen × (embed_dim / n_heads) × n_layers × 2 (K,V) × bytes_per_elem × n_kv_heads\n\nWhen using SWA, we replace the sequence length (seqlen) above by the window size W. So, when using sliding window attention, we reduce the KV cache size by a factor of \"W / seqlen\". (Note that for simplicity, this assumes that sliding window attention is used in every layer.)\n\n\nYou can use the [memory_estimator_swa.py](memory_estimator_swa.py) script in this folder to apply this for different model configs to see how much memory you can save by using SWA over MHA:\n\n```bash\n➜ uv run memory_estimator_swa.py \\\n --emb_dim 4096 --n_heads 32 --n_layers 32 \\\n --context_length 32768 --n_kv_groups 4 \\\n --batch_size 1 --dtype bf16 \\\n --sliding_window_size 1024 --swa_ratio \"5:1\"\n==== Config ====\ncontext_length : 32768\nsliding_window_size : 1024\nemb_dim : 4096\nn_heads : 32\nn_layers : 32\nn_kv_groups : 4\nbatch_size : 1\ndtype : bf16 (2 Bytes/elem)\nhead_dim : 128\nGQA n_kv_heads : 8\nEffective SWA window W : 1024\nLayer ratio (SWA:Full) : 5:1\nDistributed layers : 27 SWA, 5 FULL\n\n==== KV-cache totals across all layers ====\nMHA KV total : 17.18 GB\nGQA KV total : 4.29 GB\nMHA + SWA (Ratio: 5:1) : 3.14 GB\nMHA + GQA (Ratio: 5:1) : 0.78 GB\n```\n\nNote that Gemma 3 uses SWA in combination with GQA.\n\nThe savings when using SWA over MHA are further shown in the plot below for different context lengths:\n\n \n\n \n\n \n\nYou can reproduce thi plots via:\n\n```bash\nuv run plot_memory_estimates_swa.py \\\n --emb_dim 4096 --n_heads 48 --n_layers 36 \\\n --batch_size 1 --dtype bf16 \\\n --sliding_window_size 2048 --swa_ratio \"5:1\"\n```\n\n\n \n## SWA Code Examples\n\nThe [gpt_with_kv_mha.py](gpt_with_kv_mha.py) and [gpt_with_kv_swa.py](gpt_with_kv_swa.py) scripts in this folder provide hands-on examples for comparing the MHA and SWA memory usage in the context of a GPT model implementation.\n\nNote that SWA can also be used in combination with MLA and GQA (as mentioned earlier), but for simplicity, this is not done here.\n\nNote that the model is not trained and thus generates nonsensical text. However, you can use it as a drop-in replacement for the standard GPT model in chapters 5-7 and train it.\n\nAlso, this implementation uses the KV cache explained in [another bonus section](../03_kv-cache), so the memory savings are more pronounced.\n\n```bash\nuv run gpt_with_kv_mha.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12 \\\n--emb_dim 768\n\n...\n\nTime: 453.81 sec\n72 tokens/sec\nMax memory allocated: 1.54 GB\n```\n\n```bash\nuv run gpt_with_kv_swa.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12 \\\n--emb_dim 768 \\\n--sliding_window_size 1024 \\\n--sliding_window_stride 5 # like Gemma 3\n\n...\n\nTime: 514.38 sec\n63 tokens/sec\nMax memory allocated: 0.63 GB\n```\n\nThe reason why we are not seeing such a big saving as in the plots above is 2-fold:\n\n1. I use a smaller configuration to have the model finish the generation in a reasonable time.\n2. More importantly, we are looking at the whole model here, not just the attention mechanism; the fully-connected layers in the model take up most of the memory (but this is a topic for a separate analysis).\n"
},
{
"path": "ch04/06_swa/gpt_with_kv_mha.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with standard multi-head attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/06_swa/gpt_with_kv_swa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttentionWithSWA(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False, sliding_window_size=None):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n self.sliding_window_size = sliding_window_size\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n old_len = 0 if self.cache_k is None else self.cache_k.size(1)\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n # Left-trim to sliding window if configured\n if self.sliding_window_size is not None:\n if self.cache_k.size(1) > self.sliding_window_size:\n self.cache_k = self.cache_k[:, -self.sliding_window_size:, :, :]\n self.cache_v = self.cache_v[:, -self.sliding_window_size:, :, :]\n # Compute absolute start positions for mask\n total_len = old_len + num_tokens\n k_len_now = self.cache_k.size(1)\n dropped = max(0, total_len - k_len_now)\n k_start_pos_abs = (self.ptr_current_pos - old_len) + dropped\n q_start_pos_abs = self.ptr_current_pos\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal + sliding-window mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n # Determine absolute positions for q and k\n if use_cache:\n q_start = q_start_pos_abs\n k_start = k_start_pos_abs\n else:\n q_start = 0\n k_start = 0\n q_positions = torch.arange(q_start, q_start + num_tokens_Q, device=device, dtype=torch.long)\n k_positions = torch.arange(k_start, k_start + num_tokens_K, device=device, dtype=torch.long)\n # Sliding window width\n W = num_tokens_K + 1 if self.sliding_window_size is None else int(self.sliding_window_size)\n diff = q_positions.unsqueeze(-1) - k_positions.unsqueeze(0)\n mask_bool = (diff < 0) | (diff >= W)\n if use_cache:\n self.ptr_current_pos += num_tokens_Q\n else:\n self.ptr_current_pos = 0\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttentionWithSWA(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"],\n sliding_window_size=cfg[\"sliding_window_size\"],\n )\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n blocks = []\n window_stride = cfg[\"sliding_window_stride\"]\n window_size = cfg[\"sliding_window_size\"] if \"sliding_window_size\" in cfg else None\n for i in range(cfg[\"n_layers\"]):\n blk = TransformerBlock(cfg)\n # K:1 schedule meaning that K SWA layers are followed by 1 regular layer\n K = int(window_stride)\n if K <= 0:\n # 0 => all regular; negative => all SWA\n use_swa = False if K == 0 else True\n else:\n group = K + 1\n use_swa = (i % group) < K\n blk.att.sliding_window_size = window_size if use_swa else None\n blocks.append(blk)\n self.trf_blocks = nn.ModuleList(blocks)\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with standard multi-head attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n parser.add_argument(\"--sliding_window_size\", type=int, default=1024, help=\"Window size for sliding window attention.\")\n parser.add_argument(\"--sliding_window_stride\", type=int, default=2, help=\"K:1 frequency sliding window attention is applied. K=5 means 5 sliding window layers follows by a regular layer.\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n \"sliding_window_size\": args.sliding_window_size,\n \"sliding_window_stride\": args.sliding_window_stride\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/06_swa/memory_estimator_swa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# KV-cache memory estimator for MHA vs GQA with SWA.\n\nimport argparse\nimport math\n\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes(n):\n gb = n / (1000 ** 3)\n return f\"{gb:,.2f} GB\"\n\n\ndef calc_kv_bytes_per_layer(batch, context_length, head_dim, n_kv_heads, bytes_per_elem):\n # KV = batch * tokens * head_dim * n_kv_heads * 2 (K,V) * bytes\n return batch * context_length * head_dim * n_kv_heads * 2 * bytes_per_elem\n\n\ndef parse_ratio(ratio_str):\n # \"--swa_ratio a:b\" means a SWA layers for every b full layers within a block\n try:\n a_str, b_str = ratio_str.split(\":\")\n a, b = int(a_str), int(b_str)\n assert a >= 0 and b >= 0 and (a + b) > 0\n return a, b\n except Exception:\n raise ValueError(\"--swa_ratio must be in the form 'a:b' with nonnegative integers and a+b>0\")\n\n\ndef distribute_layers(n_layers, a, b):\n block = a + b\n blocks = n_layers // block\n rem = n_layers % block\n swa = blocks * a + min(a, rem)\n full = blocks * b + max(0, rem - a)\n return swa, full\n\n\ndef estimate_totals(context_length, sliding_window_size, emb_dim, n_heads, n_layers,\n n_kv_groups, batch_size, dtype, swa_ratio):\n if n_heads % n_kv_groups != 0:\n raise ValueError(\"n_kv_groups must divide n_heads exactly.\")\n\n bytes_per_elem = DTYPE_BYTES[dtype]\n head_dim = math.ceil(emb_dim / n_heads)\n n_kv_heads_mha = n_heads\n n_kv_heads_gqa = n_heads // n_kv_groups\n\n a_swa, b_full = parse_ratio(swa_ratio)\n n_swa_layers, n_full_layers = distribute_layers(n_layers, a_swa, b_full)\n\n eff_W = min(context_length, sliding_window_size)\n L = context_length\n\n # Per-layer costs\n per_mha_full = calc_kv_bytes_per_layer(batch_size, L, head_dim, n_kv_heads_mha, bytes_per_elem)\n per_gqa_full = calc_kv_bytes_per_layer(batch_size, L, head_dim, n_kv_heads_gqa, bytes_per_elem)\n per_mha_swa = calc_kv_bytes_per_layer(batch_size, eff_W, head_dim, n_kv_heads_mha, bytes_per_elem)\n per_gqa_swa = calc_kv_bytes_per_layer(batch_size, eff_W, head_dim, n_kv_heads_gqa, bytes_per_elem)\n\n # Totals\n total_mha_allfull = per_mha_full * n_layers\n total_gqa_allfull = per_gqa_full * n_layers\n total_mixed_mha = n_swa_layers * per_mha_swa + n_full_layers * per_mha_full\n total_mixed_gqa = n_swa_layers * per_gqa_swa + n_full_layers * per_gqa_full\n\n return {\n \"bytes_per_elem\": bytes_per_elem,\n \"head_dim\": head_dim,\n \"n_kv_heads_gqa\": n_kv_heads_gqa,\n \"eff_W\": eff_W,\n \"n_swa_layers\": n_swa_layers,\n \"n_full_layers\": n_full_layers,\n \"total_mha_allfull\": total_mha_allfull,\n \"total_gqa_allfull\": total_gqa_allfull,\n \"total_mixed_mha\": total_mixed_mha,\n \"total_mixed_gqa\": total_mixed_gqa,\n }\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Estimate KV-cache memory for MHA/GQA with SWA layer ratio\")\n p.add_argument(\"--context_length\", default=1024, type=int)\n p.add_argument(\"--sliding_window_size\", required=True, type=int,\n help=\"SWA window size W per SWA layer.\")\n p.add_argument(\"--emb_dim\", required=True, type=int)\n p.add_argument(\"--n_heads\", required=True, type=int)\n p.add_argument(\"--n_layers\", required=True, type=int)\n p.add_argument(\"--n_kv_groups\", required=True, type=int,\n help=\"GQA groups; 1 means MHA-equivalent KV heads.\")\n p.add_argument(\"--batch_size\", default=1, type=int)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"fp16\")\n p.add_argument(\"--swa_ratio\", default=\"1:0\",\n help=\"SWA:Full layer ratio. Example '5:1' -> 5 SWA for each 1 full. \"\n \"'1:5' -> 1 SWA for 5 full. Default '1:0' = all SWA.\")\n args = p.parse_args()\n\n cfg = {\n \"context_length\": args.context_length,\n \"sliding_window_size\": args.sliding_window_size,\n \"emb_dim\": args.emb_dim,\n \"n_heads\": args.n_heads,\n \"n_layers\": args.n_layers,\n \"n_kv_groups\": args.n_kv_groups,\n }\n\n res = estimate_totals(\n context_length=cfg[\"context_length\"],\n sliding_window_size=cfg[\"sliding_window_size\"],\n emb_dim=cfg[\"emb_dim\"],\n n_heads=cfg[\"n_heads\"],\n n_layers=cfg[\"n_layers\"],\n n_kv_groups=cfg[\"n_kv_groups\"],\n batch_size=args.batch_size,\n dtype=args.dtype,\n swa_ratio=args.swa_ratio,\n )\n\n print(\"==== Config ====\")\n for k, v in cfg.items():\n print(f\"{k:23}: {v}\")\n print(f\"batch_size : {args.batch_size}\")\n print(f\"dtype : {args.dtype} ({res['bytes_per_elem']} Bytes/elem)\")\n print(f\"head_dim : {res['head_dim']}\")\n print(f\"GQA n_kv_heads : {res['n_kv_heads_gqa']}\")\n print(f\"Effective SWA window W : {res['eff_W']}\")\n print(f\"Layer ratio (SWA:Full) : {args.swa_ratio} -> \"\n f\"{res['n_swa_layers']} SWA, {res['n_full_layers']} Full\")\n print()\n\n print(\"==== KV-cache totals across all layers ====\")\n print(f\"MHA KV total : {convert_bytes(res['total_mha_allfull'])}\")\n print(f\"GQA KV total : {convert_bytes(res['total_gqa_allfull'])}\")\n print(f\"MHA + SWA (ratio {args.swa_ratio}) : {convert_bytes(res['total_mixed_mha'])}\")\n print(f\"GQA + SWA (ratio {args.swa_ratio}) : {convert_bytes(res['total_mixed_gqa'])}\")\n print()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/06_swa/plot_memory_estimates_swa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# Sliding Window Attention (SWA) memory usage vs context length plot.\n#\n# This script mirrors the style and structure of plot_memory_estimates_mla.py.\n\nimport argparse\nfrom pathlib import Path\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\n\n# Bytes per element\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes_to_gb(n_bytes):\n return n_bytes / (1000.0 ** 3)\n\n\ndef parse_ratio(ratio_str):\n # \"--swa_ratio a:b\" means a SWA layers for every b full layers within a block\n try:\n a_str, b_str = ratio_str.split(\":\")\n a, b = int(a_str), int(b_str)\n assert a >= 0 and b >= 0 and (a + b) > 0\n return a, b\n except Exception:\n raise ValueError(\"--swa_ratio must be in the form 'a:b' with nonnegative integers and a+b>0\")\n\n\ndef calc_kv_bytes_total_mha(batch, context_length, emb_dim, n_layers, bytes_per_elem):\n # For MHA, n_kv_heads = n_heads, which cancels out:\n # total = B * L * E * 2 (K,V) * bytes * n_layers\n return batch * context_length * emb_dim * 2 * bytes_per_elem * n_layers\n\n\ndef calc_kv_bytes_total_gqa(\n batch, context_length, emb_dim, n_layers, bytes_per_elem, n_kv_groups\n):\n # For GQA, n_kv_heads = n_heads / n_kv_groups\n # => scale the MHA total by 1 / n_kv_groups\n base = calc_kv_bytes_total_mha(batch, context_length, emb_dim, n_layers, bytes_per_elem)\n return base / n_kv_groups\n\n\ndef calc_kv_bytes_total_mha_swa(\n batch, context_length, emb_dim, n_layers, bytes_per_elem, window, swa_ratio\n):\n # Split layers into SWA vs Full\n a, b = parse_ratio(swa_ratio)\n total_blocks = a + b\n n_swa_layers = int(round(n_layers * (a / total_blocks)))\n n_full_layers = n_layers - n_swa_layers\n\n total_full = calc_kv_bytes_total_mha(\n batch, context_length, emb_dim, n_full_layers, bytes_per_elem\n )\n total_swa = calc_kv_bytes_total_mha(\n batch, window, emb_dim, n_swa_layers, bytes_per_elem\n )\n return total_full + total_swa\n\n\ndef calc_kv_bytes_total_gqa_swa(\n batch,\n context_length,\n emb_dim,\n n_layers,\n bytes_per_elem,\n n_kv_groups,\n window,\n swa_ratio,\n):\n a, b = parse_ratio(swa_ratio)\n total_blocks = a + b\n n_swa_layers = int(round(n_layers * (a / total_blocks)))\n n_full_layers = n_layers - n_swa_layers\n\n total_full = calc_kv_bytes_total_gqa(\n batch,\n context_length,\n emb_dim,\n n_full_layers,\n bytes_per_elem,\n n_kv_groups,\n )\n total_swa = calc_kv_bytes_total_gqa(\n batch, window, emb_dim, n_swa_layers, bytes_per_elem, n_kv_groups\n )\n return total_full + total_swa\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description=\"KV-cache vs Context Length — MHA vs GQA with SWA overlays\"\n )\n p.add_argument(\"--emb_dim\", type=int, required=True)\n p.add_argument(\"--n_heads\", type=int, required=True)\n p.add_argument(\"--n_layers\", type=int, required=True)\n p.add_argument(\"--batch_size\", type=int, default=1)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"bf16\")\n p.add_argument(\n \"--sliding_window_size\", type=int, required=True, help=\"SWA window size W\"\n )\n p.add_argument(\"--swa_ratio\", type=str, default=\"5:1\", help=\"SWA:Full ratio, e.g., 5:1\")\n p.add_argument(\n \"--output\", type=Path, default=Path(\"kv_bytes_vs_context_length.pdf\")\n )\n args = p.parse_args()\n\n batch_size = args.batch_size\n emb_dim = args.emb_dim\n n_heads = args.n_heads\n n_layers = args.n_layers\n bytes_per_elem = DTYPE_BYTES[args.dtype]\n\n kv_groups = 4\n valid_g4 = (n_heads % kv_groups == 0)\n\n context_lengths = [\n 256, 512, 1024, 2048, 4096, 8192,\n 16384, 32768, 65536, 131072\n ]\n\n series = {\n \"MHA (KV total)\": [],\n f\"SWA on MHA (ratio {args.swa_ratio}, W={args.sliding_window_size})\": [],\n }\n if valid_g4:\n series[\"GQA kv_groups=4 (full)\"] = []\n series[\n f\"SWA on GQA kv_groups=4 (ratio {args.swa_ratio}, W={args.sliding_window_size})\"\n ] = []\n\n for L in context_lengths:\n total_mha = calc_kv_bytes_total_mha(\n batch_size, L, emb_dim, n_layers, bytes_per_elem\n )\n total_mha_swa = calc_kv_bytes_total_mha_swa(\n batch_size,\n L,\n emb_dim,\n n_layers,\n bytes_per_elem,\n window=args.sliding_window_size,\n swa_ratio=args.swa_ratio,\n )\n series[\"MHA (KV total)\"].append(convert_bytes_to_gb(total_mha))\n series[\n f\"SWA on MHA (ratio {args.swa_ratio}, W={args.sliding_window_size})\"\n ].append(convert_bytes_to_gb(total_mha_swa))\n\n if valid_g4:\n total_gqa = calc_kv_bytes_total_gqa(\n batch_size, L, emb_dim, n_layers, bytes_per_elem, n_kv_groups=kv_groups\n )\n total_gqa_swa = calc_kv_bytes_total_gqa_swa(\n batch_size,\n L,\n emb_dim,\n n_layers,\n bytes_per_elem,\n n_kv_groups=kv_groups,\n window=args.sliding_window_size,\n swa_ratio=args.swa_ratio,\n )\n series[\"GQA kv_groups=4 (full)\"].append(convert_bytes_to_gb(total_gqa))\n series[\n f\"SWA on GQA kv_groups=4 (ratio {args.swa_ratio}, W={args.sliding_window_size})\"\n ].append(convert_bytes_to_gb(total_gqa_swa))\n\n plt.figure(figsize=(10, 5))\n x = np.array(context_lengths, dtype=float)\n\n colors = {\n \"MHA\": \"#1f77b4\",\n \"GQA\": \"#ff7f0e\",\n }\n\n for label, yvals in series.items():\n y = np.array(yvals, dtype=float)\n if np.all(np.isnan(y)):\n continue\n\n linestyle = \"--\" if \"SWA\" in label else \"-\"\n if \"MHA\" in label:\n color = colors[\"MHA\"]\n elif \"GQA\" in label:\n color = colors[\"GQA\"]\n else:\n color = None\n\n plt.plot(x, y, marker=\"o\", label=label, linestyle=linestyle, color=color)\n\n plt.xscale(\"log\")\n plt.xlabel(\"context_length (log scale)\")\n plt.ylabel(\"Total KV cache (GB)\")\n plt.title(\n \"KV-cache vs Context Length — MHA vs GQA (SWA overlays)\\n\"\n f\"(n_heads={n_heads}, emb_dim={emb_dim}, n_layers={n_layers}, \"\n f\"batch={batch_size}, dtype={args.dtype}; \"\n f\"SWA ratio={args.swa_ratio}, W={args.sliding_window_size})\",\n fontsize=8,\n )\n plt.grid(True, which=\"both\")\n plt.legend()\n plt.tight_layout()\n plt.savefig(args.output)\n plt.close()\n\n if not valid_g4:\n print(\n f\"Skipped GQA kv_groups=4 because n_heads={args.n_heads} \"\n \"is not divisible by 4.\"\n )\n print(f\"Saved plot to: {args.output}\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/07_moe/README.md",
"content": "# Mixture of Experts (MoE)\n\nThis bonus material illustrates the memory savings (per token) when using Mixture-of-Experts (MoE) layers instead of regular feed-forward (FFN) layers.\n\n\n\n \n## Introduction\n\nThe core idea in MoE is to replace each feed-forward module in a transformer block with multiple expert layers, where each of these expert layers is also a feed-forward module. This means we replace a single feed-forward block with multiple feed-forward blocks, as illustrated in the figure below.\n\n\n\n \n\n
\n\n \n\nYou can reproduce thi plots via:\n\n```bash\nuv run plot_memory_estimates_swa.py \\\n --emb_dim 4096 --n_heads 48 --n_layers 36 \\\n --batch_size 1 --dtype bf16 \\\n --sliding_window_size 2048 --swa_ratio \"5:1\"\n```\n\n\n \n## SWA Code Examples\n\nThe [gpt_with_kv_mha.py](gpt_with_kv_mha.py) and [gpt_with_kv_swa.py](gpt_with_kv_swa.py) scripts in this folder provide hands-on examples for comparing the MHA and SWA memory usage in the context of a GPT model implementation.\n\nNote that SWA can also be used in combination with MLA and GQA (as mentioned earlier), but for simplicity, this is not done here.\n\nNote that the model is not trained and thus generates nonsensical text. However, you can use it as a drop-in replacement for the standard GPT model in chapters 5-7 and train it.\n\nAlso, this implementation uses the KV cache explained in [another bonus section](../03_kv-cache), so the memory savings are more pronounced.\n\n```bash\nuv run gpt_with_kv_mha.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12 \\\n--emb_dim 768\n\n...\n\nTime: 453.81 sec\n72 tokens/sec\nMax memory allocated: 1.54 GB\n```\n\n```bash\nuv run gpt_with_kv_swa.py \\\n--max_new_tokens 32768 \\\n--n_heads 24 \\\n--n_layers 12 \\\n--emb_dim 768 \\\n--sliding_window_size 1024 \\\n--sliding_window_stride 5 # like Gemma 3\n\n...\n\nTime: 514.38 sec\n63 tokens/sec\nMax memory allocated: 0.63 GB\n```\n\nThe reason why we are not seeing such a big saving as in the plots above is 2-fold:\n\n1. I use a smaller configuration to have the model finish the generation in a reasonable time.\n2. More importantly, we are looking at the whole model here, not just the attention mechanism; the fully-connected layers in the model take up most of the memory (but this is a topic for a separate analysis).\n"
},
{
"path": "ch04/06_swa/gpt_with_kv_mha.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with standard multi-head attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/06_swa/gpt_with_kv_swa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttentionWithSWA(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False, sliding_window_size=None):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n self.sliding_window_size = sliding_window_size\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n old_len = 0 if self.cache_k is None else self.cache_k.size(1)\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n # Left-trim to sliding window if configured\n if self.sliding_window_size is not None:\n if self.cache_k.size(1) > self.sliding_window_size:\n self.cache_k = self.cache_k[:, -self.sliding_window_size:, :, :]\n self.cache_v = self.cache_v[:, -self.sliding_window_size:, :, :]\n # Compute absolute start positions for mask\n total_len = old_len + num_tokens\n k_len_now = self.cache_k.size(1)\n dropped = max(0, total_len - k_len_now)\n k_start_pos_abs = (self.ptr_current_pos - old_len) + dropped\n q_start_pos_abs = self.ptr_current_pos\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal + sliding-window mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n # Determine absolute positions for q and k\n if use_cache:\n q_start = q_start_pos_abs\n k_start = k_start_pos_abs\n else:\n q_start = 0\n k_start = 0\n q_positions = torch.arange(q_start, q_start + num_tokens_Q, device=device, dtype=torch.long)\n k_positions = torch.arange(k_start, k_start + num_tokens_K, device=device, dtype=torch.long)\n # Sliding window width\n W = num_tokens_K + 1 if self.sliding_window_size is None else int(self.sliding_window_size)\n diff = q_positions.unsqueeze(-1) - k_positions.unsqueeze(0)\n mask_bool = (diff < 0) | (diff >= W)\n if use_cache:\n self.ptr_current_pos += num_tokens_Q\n else:\n self.ptr_current_pos = 0\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttentionWithSWA(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"],\n sliding_window_size=cfg[\"sliding_window_size\"],\n )\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n blocks = []\n window_stride = cfg[\"sliding_window_stride\"]\n window_size = cfg[\"sliding_window_size\"] if \"sliding_window_size\" in cfg else None\n for i in range(cfg[\"n_layers\"]):\n blk = TransformerBlock(cfg)\n # K:1 schedule meaning that K SWA layers are followed by 1 regular layer\n K = int(window_stride)\n if K <= 0:\n # 0 => all regular; negative => all SWA\n use_swa = False if K == 0 else True\n else:\n group = K + 1\n use_swa = (i % group) < K\n blk.att.sliding_window_size = window_size if use_swa else None\n blocks.append(blk)\n self.trf_blocks = nn.ModuleList(blocks)\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n logits = model(idx[:, -ctx_len:], use_cache=True)\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n # b) append it to the running sequence\n idx = torch.cat([idx, next_idx], dim=1)\n # c) feed model only the new token\n logits = model(next_idx, use_cache=True)\n else:\n for _ in range(max_new_tokens):\n logits = model(idx[:, -ctx_len:], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)\n idx = torch.cat([idx, next_idx], dim=1)\n\n return idx\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Run GPT with standard multi-head attention.\")\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n parser.add_argument(\"--sliding_window_size\", type=int, default=1024, help=\"Window size for sliding window attention.\")\n parser.add_argument(\"--sliding_window_stride\", type=int, default=2, help=\"K:1 frequency sliding window attention is applied. K=5 means 5 sliding window layers follows by a regular layer.\")\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n \"sliding_window_size\": args.sliding_window_size,\n \"sliding_window_stride\": args.sliding_window_stride\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/06_swa/memory_estimator_swa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# KV-cache memory estimator for MHA vs GQA with SWA.\n\nimport argparse\nimport math\n\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes(n):\n gb = n / (1000 ** 3)\n return f\"{gb:,.2f} GB\"\n\n\ndef calc_kv_bytes_per_layer(batch, context_length, head_dim, n_kv_heads, bytes_per_elem):\n # KV = batch * tokens * head_dim * n_kv_heads * 2 (K,V) * bytes\n return batch * context_length * head_dim * n_kv_heads * 2 * bytes_per_elem\n\n\ndef parse_ratio(ratio_str):\n # \"--swa_ratio a:b\" means a SWA layers for every b full layers within a block\n try:\n a_str, b_str = ratio_str.split(\":\")\n a, b = int(a_str), int(b_str)\n assert a >= 0 and b >= 0 and (a + b) > 0\n return a, b\n except Exception:\n raise ValueError(\"--swa_ratio must be in the form 'a:b' with nonnegative integers and a+b>0\")\n\n\ndef distribute_layers(n_layers, a, b):\n block = a + b\n blocks = n_layers // block\n rem = n_layers % block\n swa = blocks * a + min(a, rem)\n full = blocks * b + max(0, rem - a)\n return swa, full\n\n\ndef estimate_totals(context_length, sliding_window_size, emb_dim, n_heads, n_layers,\n n_kv_groups, batch_size, dtype, swa_ratio):\n if n_heads % n_kv_groups != 0:\n raise ValueError(\"n_kv_groups must divide n_heads exactly.\")\n\n bytes_per_elem = DTYPE_BYTES[dtype]\n head_dim = math.ceil(emb_dim / n_heads)\n n_kv_heads_mha = n_heads\n n_kv_heads_gqa = n_heads // n_kv_groups\n\n a_swa, b_full = parse_ratio(swa_ratio)\n n_swa_layers, n_full_layers = distribute_layers(n_layers, a_swa, b_full)\n\n eff_W = min(context_length, sliding_window_size)\n L = context_length\n\n # Per-layer costs\n per_mha_full = calc_kv_bytes_per_layer(batch_size, L, head_dim, n_kv_heads_mha, bytes_per_elem)\n per_gqa_full = calc_kv_bytes_per_layer(batch_size, L, head_dim, n_kv_heads_gqa, bytes_per_elem)\n per_mha_swa = calc_kv_bytes_per_layer(batch_size, eff_W, head_dim, n_kv_heads_mha, bytes_per_elem)\n per_gqa_swa = calc_kv_bytes_per_layer(batch_size, eff_W, head_dim, n_kv_heads_gqa, bytes_per_elem)\n\n # Totals\n total_mha_allfull = per_mha_full * n_layers\n total_gqa_allfull = per_gqa_full * n_layers\n total_mixed_mha = n_swa_layers * per_mha_swa + n_full_layers * per_mha_full\n total_mixed_gqa = n_swa_layers * per_gqa_swa + n_full_layers * per_gqa_full\n\n return {\n \"bytes_per_elem\": bytes_per_elem,\n \"head_dim\": head_dim,\n \"n_kv_heads_gqa\": n_kv_heads_gqa,\n \"eff_W\": eff_W,\n \"n_swa_layers\": n_swa_layers,\n \"n_full_layers\": n_full_layers,\n \"total_mha_allfull\": total_mha_allfull,\n \"total_gqa_allfull\": total_gqa_allfull,\n \"total_mixed_mha\": total_mixed_mha,\n \"total_mixed_gqa\": total_mixed_gqa,\n }\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Estimate KV-cache memory for MHA/GQA with SWA layer ratio\")\n p.add_argument(\"--context_length\", default=1024, type=int)\n p.add_argument(\"--sliding_window_size\", required=True, type=int,\n help=\"SWA window size W per SWA layer.\")\n p.add_argument(\"--emb_dim\", required=True, type=int)\n p.add_argument(\"--n_heads\", required=True, type=int)\n p.add_argument(\"--n_layers\", required=True, type=int)\n p.add_argument(\"--n_kv_groups\", required=True, type=int,\n help=\"GQA groups; 1 means MHA-equivalent KV heads.\")\n p.add_argument(\"--batch_size\", default=1, type=int)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"fp16\")\n p.add_argument(\"--swa_ratio\", default=\"1:0\",\n help=\"SWA:Full layer ratio. Example '5:1' -> 5 SWA for each 1 full. \"\n \"'1:5' -> 1 SWA for 5 full. Default '1:0' = all SWA.\")\n args = p.parse_args()\n\n cfg = {\n \"context_length\": args.context_length,\n \"sliding_window_size\": args.sliding_window_size,\n \"emb_dim\": args.emb_dim,\n \"n_heads\": args.n_heads,\n \"n_layers\": args.n_layers,\n \"n_kv_groups\": args.n_kv_groups,\n }\n\n res = estimate_totals(\n context_length=cfg[\"context_length\"],\n sliding_window_size=cfg[\"sliding_window_size\"],\n emb_dim=cfg[\"emb_dim\"],\n n_heads=cfg[\"n_heads\"],\n n_layers=cfg[\"n_layers\"],\n n_kv_groups=cfg[\"n_kv_groups\"],\n batch_size=args.batch_size,\n dtype=args.dtype,\n swa_ratio=args.swa_ratio,\n )\n\n print(\"==== Config ====\")\n for k, v in cfg.items():\n print(f\"{k:23}: {v}\")\n print(f\"batch_size : {args.batch_size}\")\n print(f\"dtype : {args.dtype} ({res['bytes_per_elem']} Bytes/elem)\")\n print(f\"head_dim : {res['head_dim']}\")\n print(f\"GQA n_kv_heads : {res['n_kv_heads_gqa']}\")\n print(f\"Effective SWA window W : {res['eff_W']}\")\n print(f\"Layer ratio (SWA:Full) : {args.swa_ratio} -> \"\n f\"{res['n_swa_layers']} SWA, {res['n_full_layers']} Full\")\n print()\n\n print(\"==== KV-cache totals across all layers ====\")\n print(f\"MHA KV total : {convert_bytes(res['total_mha_allfull'])}\")\n print(f\"GQA KV total : {convert_bytes(res['total_gqa_allfull'])}\")\n print(f\"MHA + SWA (ratio {args.swa_ratio}) : {convert_bytes(res['total_mixed_mha'])}\")\n print(f\"GQA + SWA (ratio {args.swa_ratio}) : {convert_bytes(res['total_mixed_gqa'])}\")\n print()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/06_swa/plot_memory_estimates_swa.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# Sliding Window Attention (SWA) memory usage vs context length plot.\n#\n# This script mirrors the style and structure of plot_memory_estimates_mla.py.\n\nimport argparse\nfrom pathlib import Path\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\n\n# Bytes per element\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes_to_gb(n_bytes):\n return n_bytes / (1000.0 ** 3)\n\n\ndef parse_ratio(ratio_str):\n # \"--swa_ratio a:b\" means a SWA layers for every b full layers within a block\n try:\n a_str, b_str = ratio_str.split(\":\")\n a, b = int(a_str), int(b_str)\n assert a >= 0 and b >= 0 and (a + b) > 0\n return a, b\n except Exception:\n raise ValueError(\"--swa_ratio must be in the form 'a:b' with nonnegative integers and a+b>0\")\n\n\ndef calc_kv_bytes_total_mha(batch, context_length, emb_dim, n_layers, bytes_per_elem):\n # For MHA, n_kv_heads = n_heads, which cancels out:\n # total = B * L * E * 2 (K,V) * bytes * n_layers\n return batch * context_length * emb_dim * 2 * bytes_per_elem * n_layers\n\n\ndef calc_kv_bytes_total_gqa(\n batch, context_length, emb_dim, n_layers, bytes_per_elem, n_kv_groups\n):\n # For GQA, n_kv_heads = n_heads / n_kv_groups\n # => scale the MHA total by 1 / n_kv_groups\n base = calc_kv_bytes_total_mha(batch, context_length, emb_dim, n_layers, bytes_per_elem)\n return base / n_kv_groups\n\n\ndef calc_kv_bytes_total_mha_swa(\n batch, context_length, emb_dim, n_layers, bytes_per_elem, window, swa_ratio\n):\n # Split layers into SWA vs Full\n a, b = parse_ratio(swa_ratio)\n total_blocks = a + b\n n_swa_layers = int(round(n_layers * (a / total_blocks)))\n n_full_layers = n_layers - n_swa_layers\n\n total_full = calc_kv_bytes_total_mha(\n batch, context_length, emb_dim, n_full_layers, bytes_per_elem\n )\n total_swa = calc_kv_bytes_total_mha(\n batch, window, emb_dim, n_swa_layers, bytes_per_elem\n )\n return total_full + total_swa\n\n\ndef calc_kv_bytes_total_gqa_swa(\n batch,\n context_length,\n emb_dim,\n n_layers,\n bytes_per_elem,\n n_kv_groups,\n window,\n swa_ratio,\n):\n a, b = parse_ratio(swa_ratio)\n total_blocks = a + b\n n_swa_layers = int(round(n_layers * (a / total_blocks)))\n n_full_layers = n_layers - n_swa_layers\n\n total_full = calc_kv_bytes_total_gqa(\n batch,\n context_length,\n emb_dim,\n n_full_layers,\n bytes_per_elem,\n n_kv_groups,\n )\n total_swa = calc_kv_bytes_total_gqa(\n batch, window, emb_dim, n_swa_layers, bytes_per_elem, n_kv_groups\n )\n return total_full + total_swa\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description=\"KV-cache vs Context Length — MHA vs GQA with SWA overlays\"\n )\n p.add_argument(\"--emb_dim\", type=int, required=True)\n p.add_argument(\"--n_heads\", type=int, required=True)\n p.add_argument(\"--n_layers\", type=int, required=True)\n p.add_argument(\"--batch_size\", type=int, default=1)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"bf16\")\n p.add_argument(\n \"--sliding_window_size\", type=int, required=True, help=\"SWA window size W\"\n )\n p.add_argument(\"--swa_ratio\", type=str, default=\"5:1\", help=\"SWA:Full ratio, e.g., 5:1\")\n p.add_argument(\n \"--output\", type=Path, default=Path(\"kv_bytes_vs_context_length.pdf\")\n )\n args = p.parse_args()\n\n batch_size = args.batch_size\n emb_dim = args.emb_dim\n n_heads = args.n_heads\n n_layers = args.n_layers\n bytes_per_elem = DTYPE_BYTES[args.dtype]\n\n kv_groups = 4\n valid_g4 = (n_heads % kv_groups == 0)\n\n context_lengths = [\n 256, 512, 1024, 2048, 4096, 8192,\n 16384, 32768, 65536, 131072\n ]\n\n series = {\n \"MHA (KV total)\": [],\n f\"SWA on MHA (ratio {args.swa_ratio}, W={args.sliding_window_size})\": [],\n }\n if valid_g4:\n series[\"GQA kv_groups=4 (full)\"] = []\n series[\n f\"SWA on GQA kv_groups=4 (ratio {args.swa_ratio}, W={args.sliding_window_size})\"\n ] = []\n\n for L in context_lengths:\n total_mha = calc_kv_bytes_total_mha(\n batch_size, L, emb_dim, n_layers, bytes_per_elem\n )\n total_mha_swa = calc_kv_bytes_total_mha_swa(\n batch_size,\n L,\n emb_dim,\n n_layers,\n bytes_per_elem,\n window=args.sliding_window_size,\n swa_ratio=args.swa_ratio,\n )\n series[\"MHA (KV total)\"].append(convert_bytes_to_gb(total_mha))\n series[\n f\"SWA on MHA (ratio {args.swa_ratio}, W={args.sliding_window_size})\"\n ].append(convert_bytes_to_gb(total_mha_swa))\n\n if valid_g4:\n total_gqa = calc_kv_bytes_total_gqa(\n batch_size, L, emb_dim, n_layers, bytes_per_elem, n_kv_groups=kv_groups\n )\n total_gqa_swa = calc_kv_bytes_total_gqa_swa(\n batch_size,\n L,\n emb_dim,\n n_layers,\n bytes_per_elem,\n n_kv_groups=kv_groups,\n window=args.sliding_window_size,\n swa_ratio=args.swa_ratio,\n )\n series[\"GQA kv_groups=4 (full)\"].append(convert_bytes_to_gb(total_gqa))\n series[\n f\"SWA on GQA kv_groups=4 (ratio {args.swa_ratio}, W={args.sliding_window_size})\"\n ].append(convert_bytes_to_gb(total_gqa_swa))\n\n plt.figure(figsize=(10, 5))\n x = np.array(context_lengths, dtype=float)\n\n colors = {\n \"MHA\": \"#1f77b4\",\n \"GQA\": \"#ff7f0e\",\n }\n\n for label, yvals in series.items():\n y = np.array(yvals, dtype=float)\n if np.all(np.isnan(y)):\n continue\n\n linestyle = \"--\" if \"SWA\" in label else \"-\"\n if \"MHA\" in label:\n color = colors[\"MHA\"]\n elif \"GQA\" in label:\n color = colors[\"GQA\"]\n else:\n color = None\n\n plt.plot(x, y, marker=\"o\", label=label, linestyle=linestyle, color=color)\n\n plt.xscale(\"log\")\n plt.xlabel(\"context_length (log scale)\")\n plt.ylabel(\"Total KV cache (GB)\")\n plt.title(\n \"KV-cache vs Context Length — MHA vs GQA (SWA overlays)\\n\"\n f\"(n_heads={n_heads}, emb_dim={emb_dim}, n_layers={n_layers}, \"\n f\"batch={batch_size}, dtype={args.dtype}; \"\n f\"SWA ratio={args.swa_ratio}, W={args.sliding_window_size})\",\n fontsize=8,\n )\n plt.grid(True, which=\"both\")\n plt.legend()\n plt.tight_layout()\n plt.savefig(args.output)\n plt.close()\n\n if not valid_g4:\n print(\n f\"Skipped GQA kv_groups=4 because n_heads={args.n_heads} \"\n \"is not divisible by 4.\"\n )\n print(f\"Saved plot to: {args.output}\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/07_moe/README.md",
"content": "# Mixture of Experts (MoE)\n\nThis bonus material illustrates the memory savings (per token) when using Mixture-of-Experts (MoE) layers instead of regular feed-forward (FFN) layers.\n\n\n\n \n## Introduction\n\nThe core idea in MoE is to replace each feed-forward module in a transformer block with multiple expert layers, where each of these expert layers is also a feed-forward module. This means we replace a single feed-forward block with multiple feed-forward blocks, as illustrated in the figure below.\n\n\n\n \n\n \n\nThe feed-forward block inside a transformer block (shown as the dark gray block in the figure above) typically contains a large number of the model's total parameters. (Note that the transformer block, and thereby the feed-forward block, is repeated many times in an LLM; in the case of DeepSeek-V3, 61 times.)\n\nSo, replacing *a single* feed-forward block with *multiple* feed-forward blocks (as done in a MoE setup) substantially increases the model's total parameter count. However, the key trick is that we don't use (\"activate\") all experts for every token. Instead, a router selects only a small subset of experts per token.\n\nBecause only a few experts are active at a time, MoE modules are often referred to as *sparse*, in contrast to *dense* modules that always use the full parameter set. However, the large total number of parameters via an MoE increases the capacity of the LLM, which means it can take up more knowledge during training. The sparsity keeps inference efficient, though, as we don't use all the parameters at the same time.\n\nFor example, DeepSeek-V3 has 256 experts per MoE module and a total of 671 billion parameters. Yet during inference, only 9 experts are active at a time (1 shared expert plus 8 selected by the router). This means just 37 billion parameters are used for each token inference step as opposed to all 671 billion.\n\nOne notable feature of DeepSeek-V3's MoE design is the use of a shared expert. This is an expert that is always active for every token. This idea is not new and was already introduced in the [2022 DeepSpeed-MoE](https://arxiv.org/abs/2201.05596) and the [2024 DeepSeek MoE](https://arxiv.org/abs/2401.06066) papers.\n\n \n\n
\n\nThe feed-forward block inside a transformer block (shown as the dark gray block in the figure above) typically contains a large number of the model's total parameters. (Note that the transformer block, and thereby the feed-forward block, is repeated many times in an LLM; in the case of DeepSeek-V3, 61 times.)\n\nSo, replacing *a single* feed-forward block with *multiple* feed-forward blocks (as done in a MoE setup) substantially increases the model's total parameter count. However, the key trick is that we don't use (\"activate\") all experts for every token. Instead, a router selects only a small subset of experts per token.\n\nBecause only a few experts are active at a time, MoE modules are often referred to as *sparse*, in contrast to *dense* modules that always use the full parameter set. However, the large total number of parameters via an MoE increases the capacity of the LLM, which means it can take up more knowledge during training. The sparsity keeps inference efficient, though, as we don't use all the parameters at the same time.\n\nFor example, DeepSeek-V3 has 256 experts per MoE module and a total of 671 billion parameters. Yet during inference, only 9 experts are active at a time (1 shared expert plus 8 selected by the router). This means just 37 billion parameters are used for each token inference step as opposed to all 671 billion.\n\nOne notable feature of DeepSeek-V3's MoE design is the use of a shared expert. This is an expert that is always active for every token. This idea is not new and was already introduced in the [2022 DeepSpeed-MoE](https://arxiv.org/abs/2201.05596) and the [2024 DeepSeek MoE](https://arxiv.org/abs/2401.06066) papers.\n\n \n\n \n\n(An annotated figure from the [DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models](https://arxiv.org/abs/2401.06066) paper.)\n\n \n\nThe benefit of having a shared expert was first noted in the [DeepSpeed-MoE paper](https://arxiv.org/abs/2201.05596), where they found that it boosts overall modeling performance compared to no shared experts. This is likely because common or repeated patterns don't have to be learned by multiple individual experts, which leaves them with more room for learning more specialized patterns.\n\n \n## Mixture of Experts (MoE) Memory Savings\n\nThe memory savings in MoE models primarily come from reduced activation storage and compute. In a regular (dense) feed-forward layer (FFN), every token activates the full intermediate dimension. \n\nIn contrast, an MoE layer routes each token through only a small subset of experts (for example, `top_k` out of `num_experts`) per token.\n\nWhen using an MoE layer, only `top_k` experts are active per token, so the effective memory (and compute) scales by roughly a factor of `top_k / num_experts` relative to a dense FFN of the same total capacity.\n\n\nYou can use the [memory_estimator_moe.py](memory_estimator_moe.py) script in this folder to apply this for different model configs to see how much memory you can save by using MoE over FFN (note that this is for a single transformer block, to get the total savings, multiply by the number of transformer blocks in your model):\n\n```bash\nuv run memory_estimator_moe.py --emb_dim 7168 --hidden_dim 14336 --ffn_type swiglu \\\n --num_experts 8 --top_k 2 --match_dense \n==== Config ====\nemb_dim : 7168\nhidden_size : 14336\nffn_type : swiglu\nnum_experts : 8\ntop_k : 2\ndtype : bf16 (2 Bytes/elem)\nmatch_dense : True\n\n==== Model weights (parameters) ====\nDense FFN params : 308,281,344 (0.62 GB)\nPer-expert params : 38,535,168 (0.08 GB)\nRouter params : 57,344 (0.00 GB)\nMoE TOTAL params : 308,338,688 (0.62 GB)\nMoE ACTIVE/Token : 77,127,680 (0.15 GB)\nmoe_hidden_size : 1792\n```\n\nSo, based on the results above, we can see that if we have a FFN with an input/output dimension (`emb_dim`) of 7,168 and an intermediate size (`hidden_dim`) of 14,336, we have ~308M parameters in this layer, and all these parameters are active in the forward pass.\n\nNow, if we use an MoE layer with roughly the same number of total parameters (~308M), with 8 experts where 2 experts are active, only ~77M parameters are active in each forward pass. \n\nMoreover, at a constant number of experts, the more experts we have, the lower the number of active parameters becomes, and the greater the \"savings\":\n\n \n\n \n\n
\n\n(An annotated figure from the [DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models](https://arxiv.org/abs/2401.06066) paper.)\n\n \n\nThe benefit of having a shared expert was first noted in the [DeepSpeed-MoE paper](https://arxiv.org/abs/2201.05596), where they found that it boosts overall modeling performance compared to no shared experts. This is likely because common or repeated patterns don't have to be learned by multiple individual experts, which leaves them with more room for learning more specialized patterns.\n\n \n## Mixture of Experts (MoE) Memory Savings\n\nThe memory savings in MoE models primarily come from reduced activation storage and compute. In a regular (dense) feed-forward layer (FFN), every token activates the full intermediate dimension. \n\nIn contrast, an MoE layer routes each token through only a small subset of experts (for example, `top_k` out of `num_experts`) per token.\n\nWhen using an MoE layer, only `top_k` experts are active per token, so the effective memory (and compute) scales by roughly a factor of `top_k / num_experts` relative to a dense FFN of the same total capacity.\n\n\nYou can use the [memory_estimator_moe.py](memory_estimator_moe.py) script in this folder to apply this for different model configs to see how much memory you can save by using MoE over FFN (note that this is for a single transformer block, to get the total savings, multiply by the number of transformer blocks in your model):\n\n```bash\nuv run memory_estimator_moe.py --emb_dim 7168 --hidden_dim 14336 --ffn_type swiglu \\\n --num_experts 8 --top_k 2 --match_dense \n==== Config ====\nemb_dim : 7168\nhidden_size : 14336\nffn_type : swiglu\nnum_experts : 8\ntop_k : 2\ndtype : bf16 (2 Bytes/elem)\nmatch_dense : True\n\n==== Model weights (parameters) ====\nDense FFN params : 308,281,344 (0.62 GB)\nPer-expert params : 38,535,168 (0.08 GB)\nRouter params : 57,344 (0.00 GB)\nMoE TOTAL params : 308,338,688 (0.62 GB)\nMoE ACTIVE/Token : 77,127,680 (0.15 GB)\nmoe_hidden_size : 1792\n```\n\nSo, based on the results above, we can see that if we have a FFN with an input/output dimension (`emb_dim`) of 7,168 and an intermediate size (`hidden_dim`) of 14,336, we have ~308M parameters in this layer, and all these parameters are active in the forward pass.\n\nNow, if we use an MoE layer with roughly the same number of total parameters (~308M), with 8 experts where 2 experts are active, only ~77M parameters are active in each forward pass. \n\nMoreover, at a constant number of experts, the more experts we have, the lower the number of active parameters becomes, and the greater the \"savings\":\n\n \n\n \n\n \n\n\n\n \n\nYou can reproduce this plot via:\n\n```bash\nuv run plot_memory_estimates_moe.py \\\n --emb_dim 7168 \\\n --hidden_dim 28672 \\\n --ffn_type swiglu \\\n --top_k 8\n```\n\n\n \n## MoE Code Examples\n\nThe [gpt_with_kv_ffn.py](gpt_with_kv_ffn.py) and [gpt_with_kv_moe.py](gpt_with_kv_moe.py) scripts in this folder provide hands-on examples for comparing the regular FFN and MoE memory usage in the context of a GPT model implementation. Note that both scripts use [SwiGLU](https://arxiv.org/abs/2002.05202) feed-forward modules as shown in the first figure of this page (GPT-2 traditionally uses GELU).\n\n**Note: The model is not trained and thus generates nonsensical text. You can find a trained MoE in the bonus materials at [../../ch05/11_qwen3/standalone-qwen3-moe-plus-kvcache.ipynb](../../ch05/11_qwen3/standalone-qwen3-moe-plus-kvcache.ipynb).**\n\n\n\nFirst, let's run the model with a regular FFN:\n\n\n```bash\nuv run gpt_with_kv_ffn.py \\\n--max_new_tokens 1024 \\\n--n_heads 16 \\\n--n_layers 12 \\\n--emb_dim 4096 \\\n--hidden_dim 32768\n\n...\nAvg FFN time/call: 0.759 ms\nAvg FFN mem delta/call: 0.19 MB (max 0.75 MB)\n...\nTime: 25.13 sec\n40 tokens/sec\nMax memory allocated: 11.47 GB\n```\n\nFor a fair comparison with an MoE, we have to shrink the expert size. E.g., of we use 32 experts, we have to set `--hidden_dim 32768/32`:\n\n\n```bash\nuv run gpt_with_kv_moe.py \\\n--max_new_tokens 1024 \\\n--n_heads 16 \\\n--n_layers 12 \\\n--emb_dim 4096 \\\n--hidden_dim 1024 \\\n--num_experts 32 \\\n--num_experts_per_tok 2\n\n...\nAvg MoE FF time/call: 1.555 ms\nAvg MoE FF mem delta/call: 0.04 MB (max 0.11 MB)\n...\nTime: 35.11 sec\n29 tokens/sec\nMax memory allocated: 11.48 GB\n```\n\nWe can see that the dense feed-forward layer processes a token in about 0.76 ms and uses roughly 0.19 MB of activations (peaking near 0.75 MB),\n\nThe sparse MoE layer keeps only about 0.04 MB of memory (peaking at 0.11). However, this comes at the cost of roughly twice the compute time. (There is an added routing overhead, and my implementation may also not be the most efficient one.)\n\nOverall generation still peaks around 11.5 GB of GPU memory in both cases, since both versions load the same number of weight parameters and have the same KV cache size, which dominate here.\n\nEither way, we can see the trade-off here where MoE reduces the FFN memory by about 4-5× while roughly doubling the feed-forward compute time.\n\nNote that if we processed more tokens at one, e.g., with a batch size larger than 1 (here we don't have batches due to code simplicity), the savings would be more pronounced.\n\n\n\n"
},
{
"path": "ch04/07_moe/gpt_with_kv_ffn.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\nFFN_TIME_MS = []\nFFN_MEM_BYTES = []\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\n# class FeedForward(nn.Module):\n# def __init__(self, cfg):\n# super().__init__()\n# self.layers = nn.Sequential(\n# nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n# GELU(),\n# nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n# )\n\n# def forward(self, x):\n# return self.layers(x)\n\n# Uses SwiGLU instead of GeLU to make it more comparable to MoE\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.fc1 = nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], bias=False)\n self.fc2 = nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], bias=False)\n self.fc3 = nn.Linear(cfg[\"hidden_dim\"], cfg[\"emb_dim\"], bias=False)\n\n def forward(self, x):\n return self.fc3(torch.nn.functional.silu(self.fc1(x)) * self.fc2(x))\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"],\n )\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n use_cuda = torch.cuda.is_available()\n if use_cuda:\n torch.cuda.synchronize()\n torch.cuda.reset_peak_memory_stats()\n base_mem = torch.cuda.memory_allocated()\n start = time.perf_counter()\n x = self.ff(x)\n if use_cuda:\n torch.cuda.synchronize()\n peak_mem = torch.cuda.max_memory_allocated()\n FFN_MEM_BYTES.append(peak_mem - base_mem)\n FFN_TIME_MS.append((time.perf_counter() - start) * 1000.0)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n batch_size, base_len = idx.shape\n total_len = base_len + max_new_tokens\n generated = torch.empty(\n batch_size, total_len, dtype=idx.dtype, device=idx.device\n )\n generated[:, :base_len] = idx\n cur_len = base_len\n use_cuda = torch.cuda.is_available()\n FFN_TIME_MS.clear()\n FFN_MEM_BYTES.clear()\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n prompt_start = max(0, cur_len - ctx_len)\n logits = model(generated[:, prompt_start:cur_len], use_cache=True)\n\n if use_cuda:\n torch.cuda.synchronize()\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1)\n # b) append it to the running sequence (in-place)\n generated[:, cur_len] = next_idx\n cur_len += 1\n # c) feed model only the new token\n logits = model(generated[:, cur_len - 1 : cur_len], use_cache=True)\n\n if use_cuda:\n torch.cuda.synchronize()\n else:\n if use_cuda:\n torch.cuda.synchronize()\n\n for _ in range(max_new_tokens):\n start_ctx = max(0, cur_len - ctx_len)\n logits = model(generated[:, start_ctx:cur_len], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1)\n generated[:, cur_len] = next_idx\n cur_len += 1\n\n if use_cuda:\n torch.cuda.synchronize()\n\n if FFN_TIME_MS:\n avg_ffn_time = sum(FFN_TIME_MS) / len(FFN_TIME_MS)\n print(f\"Avg FFN time/call: {avg_ffn_time:.3f} ms\")\n if FFN_MEM_BYTES:\n avg_ffn_mem = sum(FFN_MEM_BYTES) / len(FFN_MEM_BYTES)\n max_ffn_mem = max(FFN_MEM_BYTES)\n\n def to_mb(bytes_val):\n return bytes_val / (1024 ** 2)\n print(f\"Avg FFN mem delta/call: {to_mb(avg_ffn_mem):.2f} MB (max {to_mb(max_ffn_mem):.2f} MB)\")\n\n return generated[:, :cur_len]\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--hidden_dim\", type=int, default=768*4, help=\"Intermediate FFN size.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n parser.add_argument(\n \"--no_kv_cache\",\n action=\"store_true\",\n help=\"Disable KV caching during generation.\",\n )\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"hidden_dim\": args.hidden_dim, # Intermediate size\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n use_cache=not args.no_kv_cache,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/07_moe/gpt_with_kv_moe.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\nMOE_FF_TIME_MS = []\nMOE_FF_MEM_BYTES = []\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"]),\n GELU(),\n nn.Linear(cfg[\"hidden_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass MoEFeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.num_experts_per_tok = cfg[\"num_experts_per_tok\"]\n self.num_experts = cfg[\"num_experts\"]\n self.emb_dim = cfg[\"emb_dim\"]\n\n self.gate = nn.Linear(cfg[\"emb_dim\"], cfg[\"num_experts\"], bias=False)\n self.fc1 = nn.ModuleList(\n [\n nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], bias=False)\n for _ in range(self.num_experts)\n ]\n )\n self.fc2 = nn.ModuleList(\n [\n nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], bias=False)\n for _ in range(self.num_experts)\n ]\n )\n self.fc3 = nn.ModuleList(\n [\n nn.Linear(cfg[\"hidden_dim\"], cfg[\"emb_dim\"], bias=False)\n for _ in range(self.num_experts)\n ]\n )\n\n def forward(self, x):\n # x: (batch, seq_len, emb_dim)\n scores = self.gate(x) # (b, seq_len, num_experts)\n topk_scores, topk_indices = torch.topk(scores, self.num_experts_per_tok, dim=-1)\n topk_probs = torch.softmax(topk_scores, dim=-1)\n\n batch, seq_len, _ = x.shape\n x_flat = x.reshape(batch * seq_len, -1)\n out_flat = torch.zeros(batch * seq_len, self.emb_dim, device=x.device, dtype=x.dtype)\n\n topk_indices_flat = topk_indices.reshape(-1, self.num_experts_per_tok)\n topk_probs_flat = topk_probs.reshape(-1, self.num_experts_per_tok)\n\n unique_experts = torch.unique(topk_indices_flat)\n\n for expert_id_tensor in unique_experts:\n expert_id = int(expert_id_tensor.item())\n\n mask = topk_indices_flat == expert_id\n if not mask.any():\n continue\n\n token_mask = mask.any(dim=-1)\n selected_idx = token_mask.nonzero(as_tuple=False).squeeze(-1)\n if selected_idx.numel() == 0:\n continue\n\n expert_input = x_flat.index_select(0, selected_idx)\n hidden = torch.nn.functional.silu(self.fc1[expert_id](expert_input)) * self.fc2[\n expert_id\n ](expert_input)\n expert_out = self.fc3[expert_id](hidden)\n\n mask_selected = mask[selected_idx]\n slot_indices = mask_selected.int().argmax(dim=-1, keepdim=True)\n selected_probs = torch.gather(\n topk_probs_flat.index_select(0, selected_idx), dim=-1, index=slot_indices\n ).squeeze(-1)\n\n out_flat.index_add_(0, selected_idx, expert_out * selected_probs.unsqueeze(-1))\n\n return out_flat.reshape(batch, seq_len, self.emb_dim)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"],\n )\n self.ff = MoEFeedForward(cfg) if cfg[\"num_experts\"] > 0 else FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n use_cuda = torch.cuda.is_available()\n if use_cuda:\n torch.cuda.synchronize()\n torch.cuda.reset_peak_memory_stats()\n base_mem = torch.cuda.memory_allocated()\n start = time.perf_counter()\n x = self.ff(x)\n if use_cuda:\n torch.cuda.synchronize()\n peak_mem = torch.cuda.max_memory_allocated()\n MOE_FF_MEM_BYTES.append(peak_mem - base_mem)\n MOE_FF_TIME_MS.append((time.perf_counter() - start) * 1000.0)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n batch_size, base_len = idx.shape\n total_len = base_len + max_new_tokens\n generated = torch.empty(\n batch_size, total_len, dtype=idx.dtype, device=idx.device\n )\n generated[:, :base_len] = idx\n cur_len = base_len\n use_cuda = torch.cuda.is_available()\n MOE_FF_TIME_MS.clear()\n MOE_FF_MEM_BYTES.clear()\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n prompt_start = max(0, cur_len - ctx_len)\n logits = model(generated[:, prompt_start:cur_len], use_cache=True)\n\n if use_cuda:\n torch.cuda.synchronize()\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1)\n # b) append it to the running sequence (in-place)\n generated[:, cur_len] = next_idx\n cur_len += 1\n # c) feed model only the new token\n logits = model(generated[:, cur_len - 1 : cur_len], use_cache=True)\n\n if use_cuda:\n torch.cuda.synchronize()\n else:\n if use_cuda:\n torch.cuda.synchronize()\n\n for _ in range(max_new_tokens):\n start_ctx = max(0, cur_len - ctx_len)\n logits = model(generated[:, start_ctx:cur_len], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1)\n generated[:, cur_len] = next_idx\n cur_len += 1\n\n if use_cuda:\n torch.cuda.synchronize()\n\n if MOE_FF_TIME_MS:\n avg_ffn_time = sum(MOE_FF_TIME_MS) / len(MOE_FF_TIME_MS)\n print(f\"Avg MoE FF time/call: {avg_ffn_time:.3f} ms\")\n if MOE_FF_MEM_BYTES:\n avg_ffn_mem = sum(MOE_FF_MEM_BYTES) / len(MOE_FF_MEM_BYTES)\n max_ffn_mem = max(MOE_FF_MEM_BYTES)\n\n def to_mb(bytes_val):\n return bytes_val / (1024 ** 2)\n print(f\"Avg MoE FF mem delta/call: {to_mb(avg_ffn_mem):.2f} MB (max {to_mb(max_ffn_mem):.2f} MB)\")\n\n return generated[:, :cur_len]\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--hidden_dim\", type=int, default=768*4, help=\"Intermediate FFN or MoE size.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n parser.add_argument(\n \"--no_kv_cache\",\n action=\"store_true\",\n help=\"Disable KV caching during generation.\",\n )\n\n parser.add_argument(\n \"--num_experts\",\n type=int,\n default=0,\n help=\"Number of experts. If 0, use dense FFN. If >0, use MoE.\",\n )\n parser.add_argument(\n \"--num_experts_per_tok\",\n type=int,\n default=2,\n help=\"Top-k experts per token when using MoE (ignored if num_experts=0).\",\n )\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"hidden_dim\": args.hidden_dim, # Intermediate size\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n \"num_experts\": args.num_experts,\n \"num_experts_per_tok\": args.num_experts_per_tok if args.num_experts > 0 else 0,\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n use_cache=not args.no_kv_cache,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/07_moe/memory_estimator_moe.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport argparse\n\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes(n):\n gb = n / (1000 ** 3)\n return f\"{gb:,.2f} GB\"\n\n\ndef get_num_param_matrices(ffn_type):\n if ffn_type == \"gelu\":\n return 2\n elif ffn_type == \"swiglu\":\n return 3\n else:\n raise ValueError(\"--ffn_type must be 'gelu' or 'swiglu'\")\n\n\ndef calc_ffn_params(emb_dim, hidden_dim, ffn_type):\n return get_num_param_matrices(ffn_type) * emb_dim * hidden_dim\n\n\ndef calc_router_params(emb_dim, num_experts):\n return emb_dim * num_experts\n\n\ndef estimate_params_and_hidden(\n emb_dim, hidden_dim, ffn_type, num_experts, match_dense=False\n):\n P_dense = calc_ffn_params(emb_dim, hidden_dim, ffn_type)\n R = calc_router_params(emb_dim, num_experts)\n\n if match_dense:\n num_param_matrices = get_num_param_matrices(ffn_type)\n num = P_dense - R\n den = num_experts * num_param_matrices * emb_dim\n if num <= 0:\n raise ValueError(\"Dense layer too small for requested num_experts.\")\n moe_hidden_dim = int(round(num / float(den)))\n else:\n moe_hidden_dim = hidden_dim\n\n per_expert_params = calc_ffn_params(emb_dim, moe_hidden_dim, ffn_type)\n moe_total = num_experts * per_expert_params + R\n\n return {\n \"dense_params\": P_dense,\n \"router\": R,\n \"moe_hidden_dim\": moe_hidden_dim,\n \"per_expert_params\": per_expert_params,\n \"moe_total\": moe_total,\n }\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description=\"Estimate FFN vs MoE parameter memory\"\n )\n p.add_argument(\"--emb_dim\", type=int, required=True,\n help=\"Model embedding dimension.\")\n p.add_argument(\"--hidden_dim\", type=int, required=True,\n help=\"Dense FFN intermediate size (hidden dimension).\")\n p.add_argument(\"--ffn_type\", choices=[\"gelu\", \"swiglu\"], default=\"swiglu\")\n p.add_argument(\"--num_experts\", type=int, default=8)\n p.add_argument(\"--top_k\", type=int, default=2)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"bf16\")\n p.add_argument(\n \"--match_dense\",\n action=\"store_true\",\n help=(\"Auto-set per-expert hidden so MoE total params ~= dense FFN params \"\n \"(router included).\"),\n )\n args = p.parse_args()\n\n bytes_per_elem = DTYPE_BYTES[args.dtype]\n\n res = estimate_params_and_hidden(\n emb_dim=args.emb_dim,\n hidden_dim=args.hidden_dim,\n ffn_type=args.ffn_type,\n num_experts=args.num_experts,\n match_dense=args.match_dense,\n )\n\n moe_active_params_per_token = (\n res[\"router\"] + args.top_k * res[\"per_expert_params\"]\n )\n\n print(\"==== Config ====\")\n print(f\"{'emb_dim':23}: {args.emb_dim}\")\n print(f\"{'hidden_dim':23}: {args.hidden_dim}\")\n print(f\"{'ffn_type':23}: {args.ffn_type}\")\n print(f\"{'num_experts':23}: {args.num_experts}\")\n print(f\"{'top_k':23}: {args.top_k}\")\n print(f\"{'dtype':23}: {args.dtype} ({bytes_per_elem} Bytes/elem)\")\n print(f\"{'match_dense':23}: {args.match_dense}\")\n print()\n\n print(\"==== Model weights (parameters) ====\")\n print(f\"{'Dense FFN params':23}: {res['dense_params']:,} \"\n f\"({convert_bytes(res['dense_params'] * bytes_per_elem)})\")\n print(f\"{'Per-expert params':23}: {res['per_expert_params']:,} \"\n f\"({convert_bytes(res['per_expert_params'] * bytes_per_elem)})\")\n print(f\"{'Router params':23}: {res['router']:,} \"\n f\"({convert_bytes(res['router'] * bytes_per_elem)})\")\n print(f\"{'MoE TOTAL params':23}: {res['moe_total']:,} \"\n f\"({convert_bytes(res['moe_total'] * bytes_per_elem)})\")\n print(f\"{'MoE ACTIVE/Token':23}: {moe_active_params_per_token:,} \"\n f\"({convert_bytes(moe_active_params_per_token * bytes_per_elem)})\")\n print(f\"{'moe_hidden_dim':23}: {res['moe_hidden_dim']}\")\n print()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/07_moe/plot_memory_estimates_moe.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n\nimport argparse\nimport matplotlib.pyplot as plt\nfrom memory_estimator_moe import (\n estimate_params_and_hidden,\n calc_ffn_params,\n calc_router_params,\n)\n\n\ndef calc_moe_active_and_total(\n emb_dim,\n hidden_dim,\n ffn_type,\n num_experts,\n top_k,\n match_dense=True,\n):\n if match_dense:\n dense_params = calc_ffn_params(emb_dim, hidden_dim, ffn_type)\n router = calc_router_params(emb_dim, num_experts)\n if dense_params <= router:\n match_dense = False\n\n stats = estimate_params_and_hidden(\n emb_dim=emb_dim,\n hidden_dim=hidden_dim,\n ffn_type=ffn_type,\n num_experts=num_experts,\n match_dense=match_dense,\n )\n\n active = stats[\"router\"] + top_k * stats[\"per_expert_params\"]\n return active, stats[\"moe_total\"]\n\n\ndef plot_active_params_vs_experts(\n emb_dim,\n hidden_dim,\n ffn_type=\"swiglu\",\n top_k=2,\n max_experts=512,\n y_log=True,\n save_path=None,\n match_dense=True,\n):\n experts = [1, 2, 4, 8, 16, 32, 64, 128, 192, 256, 384, 512]\n experts = [e for e in experts if e <= max_experts]\n\n dense_active = calc_ffn_params(emb_dim, hidden_dim, ffn_type)\n moe_active = []\n moe_total = []\n for e in experts:\n active, total = calc_moe_active_and_total(\n emb_dim=emb_dim,\n hidden_dim=hidden_dim,\n ffn_type=ffn_type,\n num_experts=e,\n top_k=top_k,\n match_dense=match_dense,\n )\n moe_active.append(active)\n moe_total.append(total)\n\n plt.figure(figsize=(7, 5))\n plt.plot(experts, moe_active, marker=\"o\", label=\"MoE active per token\")\n plt.plot(experts, moe_total, marker=\"s\", linestyle=\"--\", label=\"MoE total parameters\")\n plt.axhline(dense_active, linestyle=\":\", color=\"gray\",\n label=\"FFN dense (active = total)\")\n\n plt.xlabel(f\"Number of experts (top_k = {top_k})\")\n plt.ylabel(\"Parameters\")\n if y_log:\n plt.yscale(\"log\")\n plt.title(\n f\"Active vs Total Parameters per Token\\n\"\n f\"(emb_dim={emb_dim}, hidden_dim={hidden_dim}, ffn={ffn_type}, top_k={top_k})\"\n )\n plt.legend()\n plt.tight_layout()\n if save_path:\n plt.savefig(save_path, dpi=200)\n print(f\"Saved plot to {save_path}\")\n else:\n plt.show()\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Plot Dense vs MoE active parameters.\")\n p.add_argument(\"--emb_dim\", type=int, required=True, help=\"Embedding dimension\")\n p.add_argument(\"--hidden_dim\", type=int, required=True, help=\"Dense FFN hidden size\")\n p.add_argument(\"--ffn_type\", choices=[\"gelu\", \"swiglu\"], default=\"swiglu\")\n p.add_argument(\"--top_k\", type=int, default=2, help=\"Active experts per token\")\n p.add_argument(\"--max_experts\", type=int, default=512, help=\"Max experts on x-axis\")\n p.add_argument(\"--no_log\", action=\"store_true\", help=\"Disable log-scale y-axis\")\n p.add_argument(\"--save\", type=str, default=None, help=\"Optional path to save PNG\")\n p.add_argument(\n \"--no_match_dense\",\n action=\"store_true\",\n help=(\"Disable matching MoE parameters to dense FFN total; \"\n \"uses provided hidden_dim instead.\"),\n )\n args = p.parse_args()\n\n plot_active_params_vs_experts(\n emb_dim=args.emb_dim,\n hidden_dim=args.hidden_dim,\n ffn_type=args.ffn_type,\n top_k=args.top_k,\n max_experts=args.max_experts,\n y_log=not args.no_log,\n save_path=args.save,\n match_dense=not args.no_match_dense,\n )\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/08_deltanet/README.md",
"content": "# Gated DeltaNet for Linear Attention\n\nRecently, [Qwen3-Next](https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list) and [Kimi Linear](https://arxiv.org/abs/2510.26692) proposed hybrid transformers that implement alternatives to the attention mechanism that scale linearly instead of quadratically with respect to the context length.\n\nBoth Qwen3-Next and Kimi Linear use a 3:1 ratio, meaning for every three transformer blocks employing the linear Gated DeltaNet variant, there’s one block that uses full attention, as shown in the figure below.\n\n
\n\n\n\n \n\nYou can reproduce this plot via:\n\n```bash\nuv run plot_memory_estimates_moe.py \\\n --emb_dim 7168 \\\n --hidden_dim 28672 \\\n --ffn_type swiglu \\\n --top_k 8\n```\n\n\n \n## MoE Code Examples\n\nThe [gpt_with_kv_ffn.py](gpt_with_kv_ffn.py) and [gpt_with_kv_moe.py](gpt_with_kv_moe.py) scripts in this folder provide hands-on examples for comparing the regular FFN and MoE memory usage in the context of a GPT model implementation. Note that both scripts use [SwiGLU](https://arxiv.org/abs/2002.05202) feed-forward modules as shown in the first figure of this page (GPT-2 traditionally uses GELU).\n\n**Note: The model is not trained and thus generates nonsensical text. You can find a trained MoE in the bonus materials at [../../ch05/11_qwen3/standalone-qwen3-moe-plus-kvcache.ipynb](../../ch05/11_qwen3/standalone-qwen3-moe-plus-kvcache.ipynb).**\n\n\n\nFirst, let's run the model with a regular FFN:\n\n\n```bash\nuv run gpt_with_kv_ffn.py \\\n--max_new_tokens 1024 \\\n--n_heads 16 \\\n--n_layers 12 \\\n--emb_dim 4096 \\\n--hidden_dim 32768\n\n...\nAvg FFN time/call: 0.759 ms\nAvg FFN mem delta/call: 0.19 MB (max 0.75 MB)\n...\nTime: 25.13 sec\n40 tokens/sec\nMax memory allocated: 11.47 GB\n```\n\nFor a fair comparison with an MoE, we have to shrink the expert size. E.g., of we use 32 experts, we have to set `--hidden_dim 32768/32`:\n\n\n```bash\nuv run gpt_with_kv_moe.py \\\n--max_new_tokens 1024 \\\n--n_heads 16 \\\n--n_layers 12 \\\n--emb_dim 4096 \\\n--hidden_dim 1024 \\\n--num_experts 32 \\\n--num_experts_per_tok 2\n\n...\nAvg MoE FF time/call: 1.555 ms\nAvg MoE FF mem delta/call: 0.04 MB (max 0.11 MB)\n...\nTime: 35.11 sec\n29 tokens/sec\nMax memory allocated: 11.48 GB\n```\n\nWe can see that the dense feed-forward layer processes a token in about 0.76 ms and uses roughly 0.19 MB of activations (peaking near 0.75 MB),\n\nThe sparse MoE layer keeps only about 0.04 MB of memory (peaking at 0.11). However, this comes at the cost of roughly twice the compute time. (There is an added routing overhead, and my implementation may also not be the most efficient one.)\n\nOverall generation still peaks around 11.5 GB of GPU memory in both cases, since both versions load the same number of weight parameters and have the same KV cache size, which dominate here.\n\nEither way, we can see the trade-off here where MoE reduces the FFN memory by about 4-5× while roughly doubling the feed-forward compute time.\n\nNote that if we processed more tokens at one, e.g., with a batch size larger than 1 (here we don't have batches due to code simplicity), the savings would be more pronounced.\n\n\n\n"
},
{
"path": "ch04/07_moe/gpt_with_kv_ffn.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\nFFN_TIME_MS = []\nFFN_MEM_BYTES = []\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\n# class FeedForward(nn.Module):\n# def __init__(self, cfg):\n# super().__init__()\n# self.layers = nn.Sequential(\n# nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n# GELU(),\n# nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n# )\n\n# def forward(self, x):\n# return self.layers(x)\n\n# Uses SwiGLU instead of GeLU to make it more comparable to MoE\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.fc1 = nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], bias=False)\n self.fc2 = nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], bias=False)\n self.fc3 = nn.Linear(cfg[\"hidden_dim\"], cfg[\"emb_dim\"], bias=False)\n\n def forward(self, x):\n return self.fc3(torch.nn.functional.silu(self.fc1(x)) * self.fc2(x))\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"],\n )\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n use_cuda = torch.cuda.is_available()\n if use_cuda:\n torch.cuda.synchronize()\n torch.cuda.reset_peak_memory_stats()\n base_mem = torch.cuda.memory_allocated()\n start = time.perf_counter()\n x = self.ff(x)\n if use_cuda:\n torch.cuda.synchronize()\n peak_mem = torch.cuda.max_memory_allocated()\n FFN_MEM_BYTES.append(peak_mem - base_mem)\n FFN_TIME_MS.append((time.perf_counter() - start) * 1000.0)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n batch_size, base_len = idx.shape\n total_len = base_len + max_new_tokens\n generated = torch.empty(\n batch_size, total_len, dtype=idx.dtype, device=idx.device\n )\n generated[:, :base_len] = idx\n cur_len = base_len\n use_cuda = torch.cuda.is_available()\n FFN_TIME_MS.clear()\n FFN_MEM_BYTES.clear()\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n prompt_start = max(0, cur_len - ctx_len)\n logits = model(generated[:, prompt_start:cur_len], use_cache=True)\n\n if use_cuda:\n torch.cuda.synchronize()\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1)\n # b) append it to the running sequence (in-place)\n generated[:, cur_len] = next_idx\n cur_len += 1\n # c) feed model only the new token\n logits = model(generated[:, cur_len - 1 : cur_len], use_cache=True)\n\n if use_cuda:\n torch.cuda.synchronize()\n else:\n if use_cuda:\n torch.cuda.synchronize()\n\n for _ in range(max_new_tokens):\n start_ctx = max(0, cur_len - ctx_len)\n logits = model(generated[:, start_ctx:cur_len], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1)\n generated[:, cur_len] = next_idx\n cur_len += 1\n\n if use_cuda:\n torch.cuda.synchronize()\n\n if FFN_TIME_MS:\n avg_ffn_time = sum(FFN_TIME_MS) / len(FFN_TIME_MS)\n print(f\"Avg FFN time/call: {avg_ffn_time:.3f} ms\")\n if FFN_MEM_BYTES:\n avg_ffn_mem = sum(FFN_MEM_BYTES) / len(FFN_MEM_BYTES)\n max_ffn_mem = max(FFN_MEM_BYTES)\n\n def to_mb(bytes_val):\n return bytes_val / (1024 ** 2)\n print(f\"Avg FFN mem delta/call: {to_mb(avg_ffn_mem):.2f} MB (max {to_mb(max_ffn_mem):.2f} MB)\")\n\n return generated[:, :cur_len]\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--hidden_dim\", type=int, default=768*4, help=\"Intermediate FFN size.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n parser.add_argument(\n \"--no_kv_cache\",\n action=\"store_true\",\n help=\"Disable KV caching during generation.\",\n )\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"hidden_dim\": args.hidden_dim, # Intermediate size\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n use_cache=not args.no_kv_cache,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/07_moe/gpt_with_kv_moe.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 3-4.\n# This file can be run as a standalone script.\n\nimport argparse\nimport time\nimport tiktoken\nimport torch\nimport torch.nn as nn\n\nMOE_FF_TIME_MS = []\nMOE_FF_MEM_BYTES = []\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n\n ####################################################\n # KV cache-related code\n self.register_buffer(\"cache_k\", None, persistent=False)\n self.register_buffer(\"cache_v\", None, persistent=False)\n self.ptr_current_pos = 0\n ####################################################\n\n def forward(self, x, use_cache=False):\n b, num_tokens, d_in = x.shape\n\n keys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)\n values_new = self.W_value(x)\n queries = self.W_query(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys_new = keys_new.view(b, num_tokens, self.num_heads, self.head_dim)\n values_new = values_new.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n # KV cache-related\n if use_cache:\n if self.cache_k is None:\n self.cache_k, self.cache_v = keys_new, values_new\n else:\n self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)\n self.cache_v = torch.cat([self.cache_v, values_new], dim=1)\n keys, values = self.cache_k, self.cache_v\n else:\n keys, values = keys_new, values_new\n ####################################################\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n ####################################################\n # causal mask\n num_tokens_Q = queries.shape[-2]\n num_tokens_K = keys.shape[-2]\n device = queries.device\n if use_cache:\n q_positions = torch.arange(\n self.ptr_current_pos,\n self.ptr_current_pos + num_tokens_Q,\n device=device,\n dtype=torch.long,\n )\n self.ptr_current_pos += num_tokens_Q\n else:\n q_positions = torch.arange(num_tokens_Q, device=device, dtype=torch.long)\n self.ptr_current_pos = 0\n k_positions = torch.arange(num_tokens_K, device=device, dtype=torch.long)\n mask_bool = q_positions.unsqueeze(-1) < k_positions.unsqueeze(0)\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n def reset_cache(self):\n self.cache_k, self.cache_v = None, None\n self.ptr_current_pos = 0\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"]),\n GELU(),\n nn.Linear(cfg[\"hidden_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass MoEFeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.num_experts_per_tok = cfg[\"num_experts_per_tok\"]\n self.num_experts = cfg[\"num_experts\"]\n self.emb_dim = cfg[\"emb_dim\"]\n\n self.gate = nn.Linear(cfg[\"emb_dim\"], cfg[\"num_experts\"], bias=False)\n self.fc1 = nn.ModuleList(\n [\n nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], bias=False)\n for _ in range(self.num_experts)\n ]\n )\n self.fc2 = nn.ModuleList(\n [\n nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], bias=False)\n for _ in range(self.num_experts)\n ]\n )\n self.fc3 = nn.ModuleList(\n [\n nn.Linear(cfg[\"hidden_dim\"], cfg[\"emb_dim\"], bias=False)\n for _ in range(self.num_experts)\n ]\n )\n\n def forward(self, x):\n # x: (batch, seq_len, emb_dim)\n scores = self.gate(x) # (b, seq_len, num_experts)\n topk_scores, topk_indices = torch.topk(scores, self.num_experts_per_tok, dim=-1)\n topk_probs = torch.softmax(topk_scores, dim=-1)\n\n batch, seq_len, _ = x.shape\n x_flat = x.reshape(batch * seq_len, -1)\n out_flat = torch.zeros(batch * seq_len, self.emb_dim, device=x.device, dtype=x.dtype)\n\n topk_indices_flat = topk_indices.reshape(-1, self.num_experts_per_tok)\n topk_probs_flat = topk_probs.reshape(-1, self.num_experts_per_tok)\n\n unique_experts = torch.unique(topk_indices_flat)\n\n for expert_id_tensor in unique_experts:\n expert_id = int(expert_id_tensor.item())\n\n mask = topk_indices_flat == expert_id\n if not mask.any():\n continue\n\n token_mask = mask.any(dim=-1)\n selected_idx = token_mask.nonzero(as_tuple=False).squeeze(-1)\n if selected_idx.numel() == 0:\n continue\n\n expert_input = x_flat.index_select(0, selected_idx)\n hidden = torch.nn.functional.silu(self.fc1[expert_id](expert_input)) * self.fc2[\n expert_id\n ](expert_input)\n expert_out = self.fc3[expert_id](hidden)\n\n mask_selected = mask[selected_idx]\n slot_indices = mask_selected.int().argmax(dim=-1, keepdim=True)\n selected_probs = torch.gather(\n topk_probs_flat.index_select(0, selected_idx), dim=-1, index=slot_indices\n ).squeeze(-1)\n\n out_flat.index_add_(0, selected_idx, expert_out * selected_probs.unsqueeze(-1))\n\n return out_flat.reshape(batch, seq_len, self.emb_dim)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"],\n )\n self.ff = MoEFeedForward(cfg) if cfg[\"num_experts\"] > 0 else FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x, use_cache=False):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n\n # x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n ####################################################\n # KV cache-related\n x = self.att(x, use_cache=use_cache)\n ####################################################\n\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n use_cuda = torch.cuda.is_available()\n if use_cuda:\n torch.cuda.synchronize()\n torch.cuda.reset_peak_memory_stats()\n base_mem = torch.cuda.memory_allocated()\n start = time.perf_counter()\n x = self.ff(x)\n if use_cuda:\n torch.cuda.synchronize()\n peak_mem = torch.cuda.max_memory_allocated()\n MOE_FF_MEM_BYTES.append(peak_mem - base_mem)\n MOE_FF_TIME_MS.append((time.perf_counter() - start) * 1000.0)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n # self.trf_blocks = nn.Sequential(\n # *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n ####################################################\n # KV cache-related\n self.trf_blocks = nn.ModuleList(\n [TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.current_pos = 0\n ####################################################\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx, use_cache=False):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n\n # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n\n ####################################################\n # KV cache-related\n if use_cache:\n pos_ids = torch.arange(self.current_pos, self.current_pos + seq_len, device=in_idx.device, dtype=torch.long)\n self.current_pos += seq_len\n else:\n pos_ids = torch.arange(0, seq_len, device=in_idx.device, dtype=torch.long)\n pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)\n ####################################################\n\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n\n # x = self.trf_blocks(x)\n ####################################################\n # KV cache-related\n for blk in self.trf_blocks:\n x = blk(x, use_cache=use_cache)\n ####################################################\n\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n ####################################################\n # KV cache-related\n def reset_kv_cache(self):\n for blk in self.trf_blocks:\n blk.att.reset_cache()\n self.current_pos = 0\n ####################################################\n\n\ndef generate_text_simple_cached(model, idx, max_new_tokens,\n context_size=None, use_cache=True):\n model.eval()\n ctx_len = context_size or model.pos_emb.num_embeddings\n batch_size, base_len = idx.shape\n total_len = base_len + max_new_tokens\n generated = torch.empty(\n batch_size, total_len, dtype=idx.dtype, device=idx.device\n )\n generated[:, :base_len] = idx\n cur_len = base_len\n use_cuda = torch.cuda.is_available()\n MOE_FF_TIME_MS.clear()\n MOE_FF_MEM_BYTES.clear()\n\n with torch.no_grad():\n if use_cache:\n # Init cache with full prompt\n model.reset_kv_cache()\n prompt_start = max(0, cur_len - ctx_len)\n logits = model(generated[:, prompt_start:cur_len], use_cache=True)\n\n if use_cuda:\n torch.cuda.synchronize()\n\n for _ in range(max_new_tokens):\n # a) pick the token with the highest log-probability (greedy sampling)\n next_idx = logits[:, -1].argmax(dim=-1)\n # b) append it to the running sequence (in-place)\n generated[:, cur_len] = next_idx\n cur_len += 1\n # c) feed model only the new token\n logits = model(generated[:, cur_len - 1 : cur_len], use_cache=True)\n\n if use_cuda:\n torch.cuda.synchronize()\n else:\n if use_cuda:\n torch.cuda.synchronize()\n\n for _ in range(max_new_tokens):\n start_ctx = max(0, cur_len - ctx_len)\n logits = model(generated[:, start_ctx:cur_len], use_cache=False)\n next_idx = logits[:, -1].argmax(dim=-1)\n generated[:, cur_len] = next_idx\n cur_len += 1\n\n if use_cuda:\n torch.cuda.synchronize()\n\n if MOE_FF_TIME_MS:\n avg_ffn_time = sum(MOE_FF_TIME_MS) / len(MOE_FF_TIME_MS)\n print(f\"Avg MoE FF time/call: {avg_ffn_time:.3f} ms\")\n if MOE_FF_MEM_BYTES:\n avg_ffn_mem = sum(MOE_FF_MEM_BYTES) / len(MOE_FF_MEM_BYTES)\n max_ffn_mem = max(MOE_FF_MEM_BYTES)\n\n def to_mb(bytes_val):\n return bytes_val / (1024 ** 2)\n print(f\"Avg MoE FF mem delta/call: {to_mb(avg_ffn_mem):.2f} MB (max {to_mb(max_ffn_mem):.2f} MB)\")\n\n return generated[:, :cur_len]\n\n\ndef main():\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument(\"--emb_dim\", type=int, default=768, help=\"Model embedding dimension.\")\n parser.add_argument(\"--hidden_dim\", type=int, default=768*4, help=\"Intermediate FFN or MoE size.\")\n parser.add_argument(\"--n_heads\", type=int, default=12, help=\"Number of attention heads.\")\n parser.add_argument(\"--n_layers\", type=int, default=12, help=\"Number of transformer blocks.\")\n parser.add_argument(\"--max_new_tokens\", type=int, default=200, help=\"Number of tokens to generate.\")\n parser.add_argument(\n \"--no_kv_cache\",\n action=\"store_true\",\n help=\"Disable KV caching during generation.\",\n )\n\n parser.add_argument(\n \"--num_experts\",\n type=int,\n default=0,\n help=\"Number of experts. If 0, use dense FFN. If >0, use MoE.\",\n )\n parser.add_argument(\n \"--num_experts_per_tok\",\n type=int,\n default=2,\n help=\"Top-k experts per token when using MoE (ignored if num_experts=0).\",\n )\n\n args = parser.parse_args()\n\n start_context = \"Hello, I am\"\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n encoded = tokenizer.encode(start_context)\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": args.max_new_tokens + len(encoded),\n \"emb_dim\": args.emb_dim, # Embedding dimension\n \"hidden_dim\": args.hidden_dim, # Intermediate size\n \"n_heads\": args.n_heads, # Number of attention heads\n \"n_layers\": args.n_layers, # Number of layers\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": False, # Query-Key-Value bias\n \"num_experts\": args.num_experts,\n \"num_experts_per_tok\": args.num_experts_per_tok if args.num_experts > 0 else 0,\n }\n torch.manual_seed(123)\n model = GPTModel(GPT_CONFIG_124M)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n model.to(device, dtype=torch.bfloat16)\n model.eval() # disable dropout\n\n encoded_tensor = torch.tensor(encoded, device=device).unsqueeze(0)\n print(f\"\\n{50*'='}\\n{22*' '}IN\\n{50*'='}\")\n print(\"\\nInput text:\", start_context)\n print(\"Encoded input text:\", encoded)\n print(\"encoded_tensor.shape:\", encoded_tensor.shape)\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n start = time.time()\n\n token_ids = generate_text_simple_cached(\n model=model,\n idx=encoded_tensor,\n max_new_tokens=args.max_new_tokens,\n use_cache=not args.no_kv_cache,\n )\n\n if torch.cuda.is_available():\n torch.cuda.synchronize()\n total_time = time.time() - start\n\n decoded_text = tokenizer.decode(token_ids.squeeze(0).tolist())\n\n print(f\"\\n\\n{50*'='}\\n{22*' '}OUT\\n{50*'='}\")\n print(\"\\nOutput:\", token_ids)\n print(\"Output length:\", len(token_ids[0]))\n print(\"Output text:\", decoded_text)\n\n print(f\"\\nTime: {total_time:.2f} sec\")\n print(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n if torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/07_moe/memory_estimator_moe.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport argparse\n\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef convert_bytes(n):\n gb = n / (1000 ** 3)\n return f\"{gb:,.2f} GB\"\n\n\ndef get_num_param_matrices(ffn_type):\n if ffn_type == \"gelu\":\n return 2\n elif ffn_type == \"swiglu\":\n return 3\n else:\n raise ValueError(\"--ffn_type must be 'gelu' or 'swiglu'\")\n\n\ndef calc_ffn_params(emb_dim, hidden_dim, ffn_type):\n return get_num_param_matrices(ffn_type) * emb_dim * hidden_dim\n\n\ndef calc_router_params(emb_dim, num_experts):\n return emb_dim * num_experts\n\n\ndef estimate_params_and_hidden(\n emb_dim, hidden_dim, ffn_type, num_experts, match_dense=False\n):\n P_dense = calc_ffn_params(emb_dim, hidden_dim, ffn_type)\n R = calc_router_params(emb_dim, num_experts)\n\n if match_dense:\n num_param_matrices = get_num_param_matrices(ffn_type)\n num = P_dense - R\n den = num_experts * num_param_matrices * emb_dim\n if num <= 0:\n raise ValueError(\"Dense layer too small for requested num_experts.\")\n moe_hidden_dim = int(round(num / float(den)))\n else:\n moe_hidden_dim = hidden_dim\n\n per_expert_params = calc_ffn_params(emb_dim, moe_hidden_dim, ffn_type)\n moe_total = num_experts * per_expert_params + R\n\n return {\n \"dense_params\": P_dense,\n \"router\": R,\n \"moe_hidden_dim\": moe_hidden_dim,\n \"per_expert_params\": per_expert_params,\n \"moe_total\": moe_total,\n }\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description=\"Estimate FFN vs MoE parameter memory\"\n )\n p.add_argument(\"--emb_dim\", type=int, required=True,\n help=\"Model embedding dimension.\")\n p.add_argument(\"--hidden_dim\", type=int, required=True,\n help=\"Dense FFN intermediate size (hidden dimension).\")\n p.add_argument(\"--ffn_type\", choices=[\"gelu\", \"swiglu\"], default=\"swiglu\")\n p.add_argument(\"--num_experts\", type=int, default=8)\n p.add_argument(\"--top_k\", type=int, default=2)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"bf16\")\n p.add_argument(\n \"--match_dense\",\n action=\"store_true\",\n help=(\"Auto-set per-expert hidden so MoE total params ~= dense FFN params \"\n \"(router included).\"),\n )\n args = p.parse_args()\n\n bytes_per_elem = DTYPE_BYTES[args.dtype]\n\n res = estimate_params_and_hidden(\n emb_dim=args.emb_dim,\n hidden_dim=args.hidden_dim,\n ffn_type=args.ffn_type,\n num_experts=args.num_experts,\n match_dense=args.match_dense,\n )\n\n moe_active_params_per_token = (\n res[\"router\"] + args.top_k * res[\"per_expert_params\"]\n )\n\n print(\"==== Config ====\")\n print(f\"{'emb_dim':23}: {args.emb_dim}\")\n print(f\"{'hidden_dim':23}: {args.hidden_dim}\")\n print(f\"{'ffn_type':23}: {args.ffn_type}\")\n print(f\"{'num_experts':23}: {args.num_experts}\")\n print(f\"{'top_k':23}: {args.top_k}\")\n print(f\"{'dtype':23}: {args.dtype} ({bytes_per_elem} Bytes/elem)\")\n print(f\"{'match_dense':23}: {args.match_dense}\")\n print()\n\n print(\"==== Model weights (parameters) ====\")\n print(f\"{'Dense FFN params':23}: {res['dense_params']:,} \"\n f\"({convert_bytes(res['dense_params'] * bytes_per_elem)})\")\n print(f\"{'Per-expert params':23}: {res['per_expert_params']:,} \"\n f\"({convert_bytes(res['per_expert_params'] * bytes_per_elem)})\")\n print(f\"{'Router params':23}: {res['router']:,} \"\n f\"({convert_bytes(res['router'] * bytes_per_elem)})\")\n print(f\"{'MoE TOTAL params':23}: {res['moe_total']:,} \"\n f\"({convert_bytes(res['moe_total'] * bytes_per_elem)})\")\n print(f\"{'MoE ACTIVE/Token':23}: {moe_active_params_per_token:,} \"\n f\"({convert_bytes(moe_active_params_per_token * bytes_per_elem)})\")\n print(f\"{'moe_hidden_dim':23}: {res['moe_hidden_dim']}\")\n print()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/07_moe/plot_memory_estimates_moe.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n\nimport argparse\nimport matplotlib.pyplot as plt\nfrom memory_estimator_moe import (\n estimate_params_and_hidden,\n calc_ffn_params,\n calc_router_params,\n)\n\n\ndef calc_moe_active_and_total(\n emb_dim,\n hidden_dim,\n ffn_type,\n num_experts,\n top_k,\n match_dense=True,\n):\n if match_dense:\n dense_params = calc_ffn_params(emb_dim, hidden_dim, ffn_type)\n router = calc_router_params(emb_dim, num_experts)\n if dense_params <= router:\n match_dense = False\n\n stats = estimate_params_and_hidden(\n emb_dim=emb_dim,\n hidden_dim=hidden_dim,\n ffn_type=ffn_type,\n num_experts=num_experts,\n match_dense=match_dense,\n )\n\n active = stats[\"router\"] + top_k * stats[\"per_expert_params\"]\n return active, stats[\"moe_total\"]\n\n\ndef plot_active_params_vs_experts(\n emb_dim,\n hidden_dim,\n ffn_type=\"swiglu\",\n top_k=2,\n max_experts=512,\n y_log=True,\n save_path=None,\n match_dense=True,\n):\n experts = [1, 2, 4, 8, 16, 32, 64, 128, 192, 256, 384, 512]\n experts = [e for e in experts if e <= max_experts]\n\n dense_active = calc_ffn_params(emb_dim, hidden_dim, ffn_type)\n moe_active = []\n moe_total = []\n for e in experts:\n active, total = calc_moe_active_and_total(\n emb_dim=emb_dim,\n hidden_dim=hidden_dim,\n ffn_type=ffn_type,\n num_experts=e,\n top_k=top_k,\n match_dense=match_dense,\n )\n moe_active.append(active)\n moe_total.append(total)\n\n plt.figure(figsize=(7, 5))\n plt.plot(experts, moe_active, marker=\"o\", label=\"MoE active per token\")\n plt.plot(experts, moe_total, marker=\"s\", linestyle=\"--\", label=\"MoE total parameters\")\n plt.axhline(dense_active, linestyle=\":\", color=\"gray\",\n label=\"FFN dense (active = total)\")\n\n plt.xlabel(f\"Number of experts (top_k = {top_k})\")\n plt.ylabel(\"Parameters\")\n if y_log:\n plt.yscale(\"log\")\n plt.title(\n f\"Active vs Total Parameters per Token\\n\"\n f\"(emb_dim={emb_dim}, hidden_dim={hidden_dim}, ffn={ffn_type}, top_k={top_k})\"\n )\n plt.legend()\n plt.tight_layout()\n if save_path:\n plt.savefig(save_path, dpi=200)\n print(f\"Saved plot to {save_path}\")\n else:\n plt.show()\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Plot Dense vs MoE active parameters.\")\n p.add_argument(\"--emb_dim\", type=int, required=True, help=\"Embedding dimension\")\n p.add_argument(\"--hidden_dim\", type=int, required=True, help=\"Dense FFN hidden size\")\n p.add_argument(\"--ffn_type\", choices=[\"gelu\", \"swiglu\"], default=\"swiglu\")\n p.add_argument(\"--top_k\", type=int, default=2, help=\"Active experts per token\")\n p.add_argument(\"--max_experts\", type=int, default=512, help=\"Max experts on x-axis\")\n p.add_argument(\"--no_log\", action=\"store_true\", help=\"Disable log-scale y-axis\")\n p.add_argument(\"--save\", type=str, default=None, help=\"Optional path to save PNG\")\n p.add_argument(\n \"--no_match_dense\",\n action=\"store_true\",\n help=(\"Disable matching MoE parameters to dense FFN total; \"\n \"uses provided hidden_dim instead.\"),\n )\n args = p.parse_args()\n\n plot_active_params_vs_experts(\n emb_dim=args.emb_dim,\n hidden_dim=args.hidden_dim,\n ffn_type=args.ffn_type,\n top_k=args.top_k,\n max_experts=args.max_experts,\n y_log=not args.no_log,\n save_path=args.save,\n match_dense=not args.no_match_dense,\n )\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/08_deltanet/README.md",
"content": "# Gated DeltaNet for Linear Attention\n\nRecently, [Qwen3-Next](https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list) and [Kimi Linear](https://arxiv.org/abs/2510.26692) proposed hybrid transformers that implement alternatives to the attention mechanism that scale linearly instead of quadratically with respect to the context length.\n\nBoth Qwen3-Next and Kimi Linear use a 3:1 ratio, meaning for every three transformer blocks employing the linear Gated DeltaNet variant, there’s one block that uses full attention, as shown in the figure below.\n\n \n\n\n\n \n\n## Introduction and Overview\n\nGated DeltaNet is a linear attention variant with inspiration from recurrent neural networks, including a gating mechanism from the [Gated Delta Networks: Improving Mamba2 with Delta Rule](https://arxiv.org/abs/2412.06464) paper. In a sense, Gated DeltaNet is a DeltaNet with Mamba-style gating, and DeltaNet is a linear attention mechanism.\n\nKimi Linear modifies the linear attention mechanism of Qwen3-Next by the Kimi Delta Attention (KDA) mechanism, which is essentially a refinement of Gated DeltaNet. Whereas Qwen3-Next applies a scalar gate (one value per attention head) to control the memory decay rate, Kimi Linear replaces it with a channel-wise gating for each feature dimension. According to the authors, this gives more control over the memory, and this, in turn, improves long-context reasoning.\n\nIn addition, for the full attention layers, Kimi Linear replaces Qwen3-Next’s gated attention layers (which are essentially standard multi-head attention layers with output gating) with Multi-Head Latent Attention (MLA). This is the same MLA mechanism we discussed earlier in the DeepSeek V3/R1 section, but with an additional gate. (To recap, MLA compresses the key/value space to reduce the KV cache size.)\n\nThe MLA in Kimi Linear does not use the gate, which was intentional so that the authors could compare the architecture more directly to standard MLA, however, they [stated](https://x.com/yzhang_cs/status/1984631714464088563) that they plan to add it in the future.\n\nSince we already implemented MLA in [../05_mla](../05_mla), this bonus material focuses on the Gated DeltaNet aspect.\n\n\n \n## Gated Attention\n\nBefore we get to the Gated DeltaNet itself, let's briefly talk about the gate. As you can see in the upper part of the Qwen3-Next architecture in the previous figure, Qwen3-Next uses \"gated attention\". This is essentially regular full attention with an additional sigmoid gate.\n\nThis gating is a simple modification that I added to the `MultiHeadAttention` code from chapter 3 below for illustration purposes:\n\n```python\nimport torch\nfrom torch import nn\n\nclass GatedMultiHeadAttention(nn.Module):\n def __init__(\n self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False\n ):\n super().__init__()\n assert d_out % num_heads == 0\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n ####################################################\n ### NEW: Add gate\n self.W_gate = nn.Linear(d_in, d_out, bias=qkv_bias)\n ####################################################\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n\n self.out_proj = nn.Linear(d_out, d_out)\n self.dropout = nn.Dropout(dropout)\n\n self.register_buffer(\n \"mask\",\n torch.triu(torch.ones(context_length, context_length), diagonal=1),\n persistent=False,\n )\n\n def forward(self, x):\n b, num_tokens, _ = x.shape\n queries = self.W_query(x)\n ####################################################\n ### NEW: Add gate\n gate = self.W_gate(x)\n ####################################################\n keys = self.W_key(x)\n values = self.W_value(x)\n\n keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n attn_scores = queries @ keys.transpose(2, 3)\n\n mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n attn_scores.masked_fill_(\n mask_bool, torch.finfo(attn_scores.dtype).min\n )\n\n attn_weights = torch.softmax(\n attn_scores / (self.head_dim ** 0.5), dim=-1\n )\n attn_weights = self.dropout(attn_weights)\n\n context = (attn_weights @ values).transpose(1, 2)\n context = context.reshape(b, num_tokens, self.d_out)\n\n ####################################################\n ### NEW: Add gate\n context = context * torch.sigmoid(gate)\n ####################################################\n out = self.out_proj(context)\n return out\n```\n\n\n\nAs we can see, after computing attention as usual, the model uses a separate gating signal from the same input, applies a sigmoid to keep it between 0 and 1, and multiplies it with the attention output. This allows the model to scale up or down certain features dynamically. The Qwen3-Next developers [state](https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list) that this helps with training stability:\n\n> [...] the attention output gating mechanism helps eliminate issues like Attention Sink and Massive Activation, ensuring numerical stability across the model.\n\n\n \n## Gated DeltaNet\n\nNow, what is Gated DeltaNet? Gated DeltaNet (short for *Gated Delta Network*) is Qwen3-Next's linear-attention layer, which is intended as an alternative to standard softmax attention. It was adopted from the [Gated Delta Networks: Improving Mamba2 with Delta Rule](https://arxiv.org/abs/2412.06464) paper as mentioned earlier.\n\nGated DeltaNet was originally proposed as an improved version of Mamba2, where it combines the gated decay mechanism of Mamba2 with a delta rule.\n\nMamba is a state-space model (an alternative to transformers), a big topic that deserves separate coverage in the future.\n\nThe delta rule part refers to computing the difference (delta, Δ) between new and predicted values to update a hidden state that is used as a memory state (more on that later).\n\n(Side note: Readers with classic machine learning literature can think of this as similar to Hebbian learning inspired by biology: \"Cells that fire together wire together.\" It's basically a precursor of the perceptron update rule and gradient descent-based learning, but without supervision.)\n\nGated DeltaNet has a gate similar to the gate in gated attention discussed earlier, except that it uses a SiLU instead of logistic sigmoid activation, as illustrated below. (The SiLU choice is likely to improve gradient flow and stability over the standard sigmoid.)\n\n
\n\n\n\n \n\n## Introduction and Overview\n\nGated DeltaNet is a linear attention variant with inspiration from recurrent neural networks, including a gating mechanism from the [Gated Delta Networks: Improving Mamba2 with Delta Rule](https://arxiv.org/abs/2412.06464) paper. In a sense, Gated DeltaNet is a DeltaNet with Mamba-style gating, and DeltaNet is a linear attention mechanism.\n\nKimi Linear modifies the linear attention mechanism of Qwen3-Next by the Kimi Delta Attention (KDA) mechanism, which is essentially a refinement of Gated DeltaNet. Whereas Qwen3-Next applies a scalar gate (one value per attention head) to control the memory decay rate, Kimi Linear replaces it with a channel-wise gating for each feature dimension. According to the authors, this gives more control over the memory, and this, in turn, improves long-context reasoning.\n\nIn addition, for the full attention layers, Kimi Linear replaces Qwen3-Next’s gated attention layers (which are essentially standard multi-head attention layers with output gating) with Multi-Head Latent Attention (MLA). This is the same MLA mechanism we discussed earlier in the DeepSeek V3/R1 section, but with an additional gate. (To recap, MLA compresses the key/value space to reduce the KV cache size.)\n\nThe MLA in Kimi Linear does not use the gate, which was intentional so that the authors could compare the architecture more directly to standard MLA, however, they [stated](https://x.com/yzhang_cs/status/1984631714464088563) that they plan to add it in the future.\n\nSince we already implemented MLA in [../05_mla](../05_mla), this bonus material focuses on the Gated DeltaNet aspect.\n\n\n \n## Gated Attention\n\nBefore we get to the Gated DeltaNet itself, let's briefly talk about the gate. As you can see in the upper part of the Qwen3-Next architecture in the previous figure, Qwen3-Next uses \"gated attention\". This is essentially regular full attention with an additional sigmoid gate.\n\nThis gating is a simple modification that I added to the `MultiHeadAttention` code from chapter 3 below for illustration purposes:\n\n```python\nimport torch\nfrom torch import nn\n\nclass GatedMultiHeadAttention(nn.Module):\n def __init__(\n self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False\n ):\n super().__init__()\n assert d_out % num_heads == 0\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n ####################################################\n ### NEW: Add gate\n self.W_gate = nn.Linear(d_in, d_out, bias=qkv_bias)\n ####################################################\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n\n self.out_proj = nn.Linear(d_out, d_out)\n self.dropout = nn.Dropout(dropout)\n\n self.register_buffer(\n \"mask\",\n torch.triu(torch.ones(context_length, context_length), diagonal=1),\n persistent=False,\n )\n\n def forward(self, x):\n b, num_tokens, _ = x.shape\n queries = self.W_query(x)\n ####################################################\n ### NEW: Add gate\n gate = self.W_gate(x)\n ####################################################\n keys = self.W_key(x)\n values = self.W_value(x)\n\n keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n attn_scores = queries @ keys.transpose(2, 3)\n\n mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n attn_scores.masked_fill_(\n mask_bool, torch.finfo(attn_scores.dtype).min\n )\n\n attn_weights = torch.softmax(\n attn_scores / (self.head_dim ** 0.5), dim=-1\n )\n attn_weights = self.dropout(attn_weights)\n\n context = (attn_weights @ values).transpose(1, 2)\n context = context.reshape(b, num_tokens, self.d_out)\n\n ####################################################\n ### NEW: Add gate\n context = context * torch.sigmoid(gate)\n ####################################################\n out = self.out_proj(context)\n return out\n```\n\n\n\nAs we can see, after computing attention as usual, the model uses a separate gating signal from the same input, applies a sigmoid to keep it between 0 and 1, and multiplies it with the attention output. This allows the model to scale up or down certain features dynamically. The Qwen3-Next developers [state](https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list) that this helps with training stability:\n\n> [...] the attention output gating mechanism helps eliminate issues like Attention Sink and Massive Activation, ensuring numerical stability across the model.\n\n\n \n## Gated DeltaNet\n\nNow, what is Gated DeltaNet? Gated DeltaNet (short for *Gated Delta Network*) is Qwen3-Next's linear-attention layer, which is intended as an alternative to standard softmax attention. It was adopted from the [Gated Delta Networks: Improving Mamba2 with Delta Rule](https://arxiv.org/abs/2412.06464) paper as mentioned earlier.\n\nGated DeltaNet was originally proposed as an improved version of Mamba2, where it combines the gated decay mechanism of Mamba2 with a delta rule.\n\nMamba is a state-space model (an alternative to transformers), a big topic that deserves separate coverage in the future.\n\nThe delta rule part refers to computing the difference (delta, Δ) between new and predicted values to update a hidden state that is used as a memory state (more on that later).\n\n(Side note: Readers with classic machine learning literature can think of this as similar to Hebbian learning inspired by biology: \"Cells that fire together wire together.\" It's basically a precursor of the perceptron update rule and gradient descent-based learning, but without supervision.)\n\nGated DeltaNet has a gate similar to the gate in gated attention discussed earlier, except that it uses a SiLU instead of logistic sigmoid activation, as illustrated below. (The SiLU choice is likely to improve gradient flow and stability over the standard sigmoid.)\n\n \n\nHowever, as shown in the figure above, the \"gated\" in the Gated DeltaNet also refers to several additional gates:\n\n- `α` (decay gate) controls how fast the memory decays or resets over time,\n- `β` (update gate) controls how strongly new inputs modify the state.\n\nIn code, a simplified version of the Gated DeltaNet depicted above (without the convolutional mixing) can be implemented as follows (the code is inspired by the [official implementation](https://github.com/huggingface/transformers/blob/0ed6d51ae8ed3f4fafca67a983b8d75bc76cd51b/src/transformers/models/qwen3_next/modular_qwen3_next.py#L835) by the Qwen3 team).\n\n(Note that some implementations refer to the decay gate as `gk` (gate for step k), where `exp(gk)` matches the paper's $\\alpha_t$. To keep this relationship explicit, the snippet below separates the log-space gate `alpha_log` from the exponentiated decay `alpha`.)\n\n\n```python\nimport torch\nfrom torch import nn\nimport torch.nn.functional as F\n\ndef l2norm(x, dim=-1, eps=1e-6):\n return x * torch.rsqrt((x * x).sum(dim=dim, keepdim=True) + eps)\n\nclass GatedDeltaNet(nn.Module):\n def __init__(\n self, d_in, d_out, dropout, num_heads, qkv_bias=False\n ):\n super().__init__()\n assert d_out % num_heads == 0\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n ####################################################\n ### NEW: Gates for delta rule and output gating\n self.W_gate = nn.Linear(d_in, d_out, bias=False)\n self.W_beta = nn.Linear(d_in, d_out, bias=False)\n\n # Note: The decay gate alpha corresponds to\n # A_log + W_alpha(x) + dt_bias\n self.W_alpha = nn.Linear(d_in, num_heads, bias=False)\n self.dt_bias = nn.Parameter(torch.ones(num_heads))\n A_init = torch.empty(num_heads).uniform_(0, 16)\n self.A_log = nn.Parameter(torch.log(A_init))\n # We could implement this as\n # W_alpha = nn.Linear(d_in, num_heads, bias=True)\n # but the bias is separate for interpretability and\n # to mimic the official implementation\n\n self.norm = nn.RMSNorm(self.head_dim, eps=1e-6)\n ####################################################\n\n self.out_proj = nn.Linear(d_out, d_out)\n self.dropout = nn.Dropout(dropout)\n\n def forward(self, x):\n b, num_tokens, _ = x.shape\n queries = self.W_query(x)\n keys = self.W_key(x)\n values = self.W_value(x)\n ####################################################\n ### NEW: Compute delta rule gates\n beta = torch.sigmoid(self.W_beta(x))\n alpha_log = -self.A_log.exp().view(1, 1, -1) * F.softplus(\n self.W_alpha(x) + self.dt_bias\n )\n alpha = alpha_log.exp()\n gate = self.W_gate(x)\n ####################################################\n\n keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n beta = beta.view(b, num_tokens, self.num_heads, self.head_dim)\n gate = gate.view(b, num_tokens, self.num_heads, self.head_dim) # NEW\n\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n beta = beta.transpose(1, 2)\n gate = gate.transpose(1, 2) # NEW\n\n ####################################################\n ### NEW: QKNorm-like normalization for delta rule\n queries = l2norm(queries, dim=-1) / (self.head_dim ** 0.5)\n keys = l2norm(keys, dim=-1)\n ####################################################\n\n S = x.new_zeros(b, self.num_heads, self.head_dim, self.head_dim)\n\n outs = []\n ####################################################\n ### NEW: Gated delta rule update\n for t in range(num_tokens):\n k_t = keys[:, :, t]\n q_t = queries[:, :, t]\n v_t = values[:, :, t]\n b_t = beta[:, :, t]\n a_t = alpha[:, t].unsqueeze(-1).unsqueeze(-1)\n\n S = S * a_t\n kv_mem = (S * k_t.unsqueeze(-1)).sum(dim=-2)\n delta = (v_t - kv_mem) * b_t\n S = S + k_t.unsqueeze(-1) * delta.unsqueeze(-2)\n y_t = (S * q_t.unsqueeze(-1)).sum(dim=-2)\n ####################################################\n outs.append(y_t)\n\n context = torch.stack(outs, dim=2).transpose(1, 2).contiguous()\n context = context.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n ### NEW: Apply RMSNorm and SiLU gate\n context = self.norm(context)\n context = context * F.silu(gate)\n ####################################################\n\n context = context.view(b, num_tokens, self.d_out)\n context = self.dropout(context)\n out = self.out_proj(context)\n return out\n```\n\n(Note that for simplicity, I omitted the convolutional mixing that Qwen3-Next and Kimi Linear use to keep the code more readable and focus on the recurrent aspects.)\n\nSo, as we can see above, there are lots of differences to standard (or gated) attention.\n\nIn gated attention, the model computes normal attention between all tokens (every token attends or looks at every other token). Then, after getting the attention output, a gate (a sigmoid) decides how much of that output to keep. The takeaway is that it's still the the regular scaled-dot product attention that scales quadratically with the context length.\n\nAs a refresher, scaled-dot production attention is computed as softmax(QKᵀ)V, where Q and K are *n*-by-*d* matrices, where *n* is the number of input tokens, and *d* is the embedding dimension. So QKᵀ results in an attention *n*-by-*n* matrix, that is multiplied by a *n*-by-*d* dimensional value matrix V:\n\n```\nattn_scores = queries @ keys.transpose(2, 3)\n\nmask_bool = self.mask.bool()[:num_tokens, :num_tokens]\nattn_scores.masked_fill_(\n mask_bool, torch.finfo(attn_scores.dtype).min\n)\n\nattn_weights = torch.softmax(\n attn_scores / (self.head_dim ** 0.5), dim=-1\n)\n\ncontext = (attn_weights @ values).transpose(1, 2)\ncontext = context.reshape(b, num_tokens, self.d_out)\n```\n\n\n\n
\n\nHowever, as shown in the figure above, the \"gated\" in the Gated DeltaNet also refers to several additional gates:\n\n- `α` (decay gate) controls how fast the memory decays or resets over time,\n- `β` (update gate) controls how strongly new inputs modify the state.\n\nIn code, a simplified version of the Gated DeltaNet depicted above (without the convolutional mixing) can be implemented as follows (the code is inspired by the [official implementation](https://github.com/huggingface/transformers/blob/0ed6d51ae8ed3f4fafca67a983b8d75bc76cd51b/src/transformers/models/qwen3_next/modular_qwen3_next.py#L835) by the Qwen3 team).\n\n(Note that some implementations refer to the decay gate as `gk` (gate for step k), where `exp(gk)` matches the paper's $\\alpha_t$. To keep this relationship explicit, the snippet below separates the log-space gate `alpha_log` from the exponentiated decay `alpha`.)\n\n\n```python\nimport torch\nfrom torch import nn\nimport torch.nn.functional as F\n\ndef l2norm(x, dim=-1, eps=1e-6):\n return x * torch.rsqrt((x * x).sum(dim=dim, keepdim=True) + eps)\n\nclass GatedDeltaNet(nn.Module):\n def __init__(\n self, d_in, d_out, dropout, num_heads, qkv_bias=False\n ):\n super().__init__()\n assert d_out % num_heads == 0\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n ####################################################\n ### NEW: Gates for delta rule and output gating\n self.W_gate = nn.Linear(d_in, d_out, bias=False)\n self.W_beta = nn.Linear(d_in, d_out, bias=False)\n\n # Note: The decay gate alpha corresponds to\n # A_log + W_alpha(x) + dt_bias\n self.W_alpha = nn.Linear(d_in, num_heads, bias=False)\n self.dt_bias = nn.Parameter(torch.ones(num_heads))\n A_init = torch.empty(num_heads).uniform_(0, 16)\n self.A_log = nn.Parameter(torch.log(A_init))\n # We could implement this as\n # W_alpha = nn.Linear(d_in, num_heads, bias=True)\n # but the bias is separate for interpretability and\n # to mimic the official implementation\n\n self.norm = nn.RMSNorm(self.head_dim, eps=1e-6)\n ####################################################\n\n self.out_proj = nn.Linear(d_out, d_out)\n self.dropout = nn.Dropout(dropout)\n\n def forward(self, x):\n b, num_tokens, _ = x.shape\n queries = self.W_query(x)\n keys = self.W_key(x)\n values = self.W_value(x)\n ####################################################\n ### NEW: Compute delta rule gates\n beta = torch.sigmoid(self.W_beta(x))\n alpha_log = -self.A_log.exp().view(1, 1, -1) * F.softplus(\n self.W_alpha(x) + self.dt_bias\n )\n alpha = alpha_log.exp()\n gate = self.W_gate(x)\n ####################################################\n\n keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n beta = beta.view(b, num_tokens, self.num_heads, self.head_dim)\n gate = gate.view(b, num_tokens, self.num_heads, self.head_dim) # NEW\n\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n beta = beta.transpose(1, 2)\n gate = gate.transpose(1, 2) # NEW\n\n ####################################################\n ### NEW: QKNorm-like normalization for delta rule\n queries = l2norm(queries, dim=-1) / (self.head_dim ** 0.5)\n keys = l2norm(keys, dim=-1)\n ####################################################\n\n S = x.new_zeros(b, self.num_heads, self.head_dim, self.head_dim)\n\n outs = []\n ####################################################\n ### NEW: Gated delta rule update\n for t in range(num_tokens):\n k_t = keys[:, :, t]\n q_t = queries[:, :, t]\n v_t = values[:, :, t]\n b_t = beta[:, :, t]\n a_t = alpha[:, t].unsqueeze(-1).unsqueeze(-1)\n\n S = S * a_t\n kv_mem = (S * k_t.unsqueeze(-1)).sum(dim=-2)\n delta = (v_t - kv_mem) * b_t\n S = S + k_t.unsqueeze(-1) * delta.unsqueeze(-2)\n y_t = (S * q_t.unsqueeze(-1)).sum(dim=-2)\n ####################################################\n outs.append(y_t)\n\n context = torch.stack(outs, dim=2).transpose(1, 2).contiguous()\n context = context.view(b, num_tokens, self.num_heads, self.head_dim)\n\n ####################################################\n ### NEW: Apply RMSNorm and SiLU gate\n context = self.norm(context)\n context = context * F.silu(gate)\n ####################################################\n\n context = context.view(b, num_tokens, self.d_out)\n context = self.dropout(context)\n out = self.out_proj(context)\n return out\n```\n\n(Note that for simplicity, I omitted the convolutional mixing that Qwen3-Next and Kimi Linear use to keep the code more readable and focus on the recurrent aspects.)\n\nSo, as we can see above, there are lots of differences to standard (or gated) attention.\n\nIn gated attention, the model computes normal attention between all tokens (every token attends or looks at every other token). Then, after getting the attention output, a gate (a sigmoid) decides how much of that output to keep. The takeaway is that it's still the the regular scaled-dot product attention that scales quadratically with the context length.\n\nAs a refresher, scaled-dot production attention is computed as softmax(QKᵀ)V, where Q and K are *n*-by-*d* matrices, where *n* is the number of input tokens, and *d* is the embedding dimension. So QKᵀ results in an attention *n*-by-*n* matrix, that is multiplied by a *n*-by-*d* dimensional value matrix V:\n\n```\nattn_scores = queries @ keys.transpose(2, 3)\n\nmask_bool = self.mask.bool()[:num_tokens, :num_tokens]\nattn_scores.masked_fill_(\n mask_bool, torch.finfo(attn_scores.dtype).min\n)\n\nattn_weights = torch.softmax(\n attn_scores / (self.head_dim ** 0.5), dim=-1\n)\n\ncontext = (attn_weights @ values).transpose(1, 2)\ncontext = context.reshape(b, num_tokens, self.d_out)\n```\n\n\n\n \n\nIn Gated DeltaNet, there's no *n*-by-*n* attention matrix. Instead, the model processes tokens one by one. It keeps a running memory (a state) that gets updated as each new token comes in. This is what's implemented as, where `S` is the state that gets updated recurrently for each time step *t*.\n\n```python\nS = x.new_zeros(b, self.num_heads, self.head_dim, self.head_dim)\nouts = []\n\nfor t in range(num_tokens):\n k_t = keys[:, :, t]\n q_t = queries[:, :, t]\n v_t = values[:, :, t]\n b_t = beta[:, :, t]\n a_t = alpha[:, t].unsqueeze(-1).unsqueeze(-1)\n\n S = S * a_t\n kv_mem = (S * k_t.unsqueeze(-1)).sum(dim=-2)\n delta = (v_t - kv_mem) * b_t\n S = S + k_t.unsqueeze(-1) * delta.unsqueeze(-2)\n y_t = (S * q_t.unsqueeze(-1)).sum(dim=-2)\n```\n\nAnd the gates control how that memory changes:\n\n- α (`alpha`) regulates how much of the old memory to forget (decay).\n\n- β (`beta`) regulates how much the current token at time step *t* updates the memory.\n\n(And the final output gate, not shown in the snippet above, is similar to gated attention; it controls how much of the output is kept.)\n\nSo, in a sense, this state update in Gated DeltaNet is similar to how recurrent neural networks (RNNs) work. The advantage is that it scales linearly (via the for-loop) instead of quadratically with context length.\n\nThe downside of this recurrent state update is that, compared to regular (or gated) attention, it sacrifices the global context modeling ability that comes from full pairwise attention.\n\nGated DeltaNet, can, to some extend, still capture context, but it has to go through the memory (*S*) bottleneck. That memory is a fixed size and thus more efficient, but it compresses past context into a single hidden state similar to RNNs.\n\nThat's why the Qwen3-Next and Kimi Linear architectures don't replace all attention layers with DeltaNet layers but use the 3:1 ratio mentioned earlier.\n\n \n## DeltaNet Memory Savings\n\nIn the previous section, we discussed the advantage of the DeltaNet over full attention in terms of linear instead of quadratic compute complexity with respect to the context length.\n\nNext to the linear compute complexity, another big advantage of DeltaNet is the memory savings, as DeltaNet modules don't grow the KV cache. (For more information about KV caching, see [../03_kv-cache](../03_kv-cache)). Instead, as mentioned earlier, they keep a fixed-size recurrent state, so memory stays constant with context length.\n\nFor a regular multi-head attention (MHA) layer, we can compute the KV cache size as follows:\n\n```\nKV_cache_MHA ≈ batch_size × n_tokens × n_heads × d_head × 2 × bytes\n```\n\n(The 2 multiplier is there because we have both keys and values that we store in the cache.)\n\nFor the simplified DeltaNet version implemented above, we have:\n\n\n```\nKV_cache_DeltaNet = batch_size × n_heads × d_head × d_head × bytes\n```\n\nNote that the `KV_cache_DeltaNet` memory size doesn't have a context length (`n_tokens`) dependency. Also, we have only the memory state S that we store instead of separate keys and values, hence `2 × bytes` becomes just `bytes`. However, note that we now have a quadratic `d_head × d_head` in here. This comes from the state :\n\n```\nS = x.new_zeros(b, self.num_heads, self.head_dim, self.head_dim)\n```\n\nBut that's usually nothing to worry about, as the head dimension is usually relatively small. For instance, it's 128 in Qwen3-Next.\n\nThe full version with the convolutional mixing is a bit more complex, including the kernel size and so on, but the formulas above should illustrate the main trend and motivation behind the Gated DeltaNet.\n\nWe can visualize the memory estimates and savings for different context lengths via the following helper script:\n\n```bash\nuv run plot_memory_estimates_gated_deltanet.py \\\n --emb_dim 2048 \\\n --n_heads 16 \\\n --n_layers 48 \\\n --dtype \"bf16\"\n```\n\nNote that the above computes the `head_dim` as `emb_dim / n_heads`. I.e., 2048 / 16 = 128.\n\n
\n\nIn Gated DeltaNet, there's no *n*-by-*n* attention matrix. Instead, the model processes tokens one by one. It keeps a running memory (a state) that gets updated as each new token comes in. This is what's implemented as, where `S` is the state that gets updated recurrently for each time step *t*.\n\n```python\nS = x.new_zeros(b, self.num_heads, self.head_dim, self.head_dim)\nouts = []\n\nfor t in range(num_tokens):\n k_t = keys[:, :, t]\n q_t = queries[:, :, t]\n v_t = values[:, :, t]\n b_t = beta[:, :, t]\n a_t = alpha[:, t].unsqueeze(-1).unsqueeze(-1)\n\n S = S * a_t\n kv_mem = (S * k_t.unsqueeze(-1)).sum(dim=-2)\n delta = (v_t - kv_mem) * b_t\n S = S + k_t.unsqueeze(-1) * delta.unsqueeze(-2)\n y_t = (S * q_t.unsqueeze(-1)).sum(dim=-2)\n```\n\nAnd the gates control how that memory changes:\n\n- α (`alpha`) regulates how much of the old memory to forget (decay).\n\n- β (`beta`) regulates how much the current token at time step *t* updates the memory.\n\n(And the final output gate, not shown in the snippet above, is similar to gated attention; it controls how much of the output is kept.)\n\nSo, in a sense, this state update in Gated DeltaNet is similar to how recurrent neural networks (RNNs) work. The advantage is that it scales linearly (via the for-loop) instead of quadratically with context length.\n\nThe downside of this recurrent state update is that, compared to regular (or gated) attention, it sacrifices the global context modeling ability that comes from full pairwise attention.\n\nGated DeltaNet, can, to some extend, still capture context, but it has to go through the memory (*S*) bottleneck. That memory is a fixed size and thus more efficient, but it compresses past context into a single hidden state similar to RNNs.\n\nThat's why the Qwen3-Next and Kimi Linear architectures don't replace all attention layers with DeltaNet layers but use the 3:1 ratio mentioned earlier.\n\n \n## DeltaNet Memory Savings\n\nIn the previous section, we discussed the advantage of the DeltaNet over full attention in terms of linear instead of quadratic compute complexity with respect to the context length.\n\nNext to the linear compute complexity, another big advantage of DeltaNet is the memory savings, as DeltaNet modules don't grow the KV cache. (For more information about KV caching, see [../03_kv-cache](../03_kv-cache)). Instead, as mentioned earlier, they keep a fixed-size recurrent state, so memory stays constant with context length.\n\nFor a regular multi-head attention (MHA) layer, we can compute the KV cache size as follows:\n\n```\nKV_cache_MHA ≈ batch_size × n_tokens × n_heads × d_head × 2 × bytes\n```\n\n(The 2 multiplier is there because we have both keys and values that we store in the cache.)\n\nFor the simplified DeltaNet version implemented above, we have:\n\n\n```\nKV_cache_DeltaNet = batch_size × n_heads × d_head × d_head × bytes\n```\n\nNote that the `KV_cache_DeltaNet` memory size doesn't have a context length (`n_tokens`) dependency. Also, we have only the memory state S that we store instead of separate keys and values, hence `2 × bytes` becomes just `bytes`. However, note that we now have a quadratic `d_head × d_head` in here. This comes from the state :\n\n```\nS = x.new_zeros(b, self.num_heads, self.head_dim, self.head_dim)\n```\n\nBut that's usually nothing to worry about, as the head dimension is usually relatively small. For instance, it's 128 in Qwen3-Next.\n\nThe full version with the convolutional mixing is a bit more complex, including the kernel size and so on, but the formulas above should illustrate the main trend and motivation behind the Gated DeltaNet.\n\nWe can visualize the memory estimates and savings for different context lengths via the following helper script:\n\n```bash\nuv run plot_memory_estimates_gated_deltanet.py \\\n --emb_dim 2048 \\\n --n_heads 16 \\\n --n_layers 48 \\\n --dtype \"bf16\"\n```\n\nNote that the above computes the `head_dim` as `emb_dim / n_heads`. I.e., 2048 / 16 = 128.\n\n \n"
},
{
"path": "ch04/08_deltanet/plot_memory_estimates_gated_deltanet.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport argparse\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n# Bytes per element\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef calc_kv_bytes_total_mha(batch, context_length, emb_dim, n_layers, bytes_per_elem, n_heads):\n # Full attention (MHA)\n d_head = emb_dim // n_heads\n per_layer = batch * context_length * n_heads * d_head * 2 * bytes_per_elem\n return per_layer * n_layers\n\n\ndef calc_kv_bytes_total_deltanet_no_conv(batch, emb_dim, n_layers, bytes_per_elem, n_heads):\n # Simple Gated DeltaNet (no convolutional mixing)\n d_head = emb_dim // n_heads\n per_layer = batch * n_heads * d_head * d_head * bytes_per_elem\n return per_layer * n_layers\n\n\ndef convert_to_gb(x):\n return x / 1e9\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Memory vs. Context Length: MHA vs. DeltaNet (3:1 mix)\")\n p.add_argument(\"--batch\", type=int, default=1)\n p.add_argument(\"--emb_dim\", type=int, default=2048)\n p.add_argument(\"--n_heads\", type=int, default=16)\n p.add_argument(\"--n_layers\", type=int, default=48)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"bf16\")\n p.add_argument(\"--min_ctx\", type=int, default=128)\n p.add_argument(\"--max_ctx\", type=int, default=131_072)\n args = p.parse_args()\n\n step = 100\n ctx = np.arange(args.min_ctx, args.max_ctx + 1, step, dtype=int)\n bytes_per_elem = DTYPE_BYTES[args.dtype]\n\n # 1) Full attention only\n mha_bytes = np.array([\n calc_kv_bytes_total_mha(args.batch, int(t), args.emb_dim, args.n_layers,\n bytes_per_elem, args.n_heads)\n for t in ctx\n ], dtype=float)\n\n # 2) DeltaNet only\n dnet_bytes_const = calc_kv_bytes_total_deltanet_no_conv(\n args.batch, args.emb_dim, args.n_layers,\n bytes_per_elem, args.n_heads\n )\n dnet_bytes = np.full_like(mha_bytes, fill_value=dnet_bytes_const, dtype=float)\n\n # 3) 3:1 layer ratio (3 DeltaNet : 1 Full Attention)\n n_mha_layers = args.n_layers / 4\n n_dnet_layers = args.n_layers - n_mha_layers\n mix_bytes = np.array([\n calc_kv_bytes_total_mha(args.batch, int(t), args.emb_dim, n_mha_layers,\n bytes_per_elem, args.n_heads)\n + calc_kv_bytes_total_deltanet_no_conv(args.batch, args.emb_dim, n_dnet_layers,\n bytes_per_elem, args.n_heads)\n for t in ctx\n ], dtype=float)\n\n # Convert to GB\n mha_gb = convert_to_gb(mha_bytes)\n dnet_gb = convert_to_gb(dnet_bytes)\n mix_gb = convert_to_gb(mix_bytes)\n\n # Plot\n fig, ax = plt.subplots(figsize=(7, 4.5))\n ax.plot(ctx, mha_gb, label=\"Full Attention (MHA) KV cache\")\n ax.plot(ctx, dnet_gb, label=\"All Gated DeltaNet (no conv)\")\n ax.plot(ctx, mix_gb, label=\"3:1 layer ratio (3 DeltaNet : 1 Full Attention)\")\n\n ax.set_xlabel(\"Context length (number of tokens)\")\n ax.set_ylabel(\"KV cache size (GB)\")\n ax.grid(True, which=\"both\", linestyle=\"--\", linewidth=0.5, alpha=0.6)\n ax.legend()\n\n fig.tight_layout()\n plt.savefig(\"deltanet_memory_plot.pdf\", dpi=160)\n plt.close(fig)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/README.md",
"content": "# Chapter 4: Implementing a GPT Model from Scratch to Generate Text\n\n \n## Main Chapter Code\n\n- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code.\n\n \n## Bonus Materials\n\n- [02_performance-analysis](02_performance-analysis) contains optional code analyzing the performance of the GPT model(s) implemented in the main chapter\n- [03_kv-cache](03_kv-cache) implements a KV cache to speed up the text generation during inference\n- [07_moe](07_moe) explanation and implementation of Mixture-of-Experts (MoE)\n- [ch05/07_gpt_to_llama](../ch05/07_gpt_to_llama) contains a step-by-step guide for converting a GPT architecture implementation to Llama 3.2 and loads pretrained weights from Meta AI (it might be interesting to look at alternative architectures after completing chapter 4, but you can also save that for after reading chapter 5)\n\n\n \n## Attention Alternatives\n\n \n\n
\n"
},
{
"path": "ch04/08_deltanet/plot_memory_estimates_gated_deltanet.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport argparse\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n# Bytes per element\nDTYPE_BYTES = {\n \"fp32\": 4,\n \"bf16\": 2,\n \"fp16\": 2,\n \"fp8\": 1,\n \"int8\": 1,\n}\n\n\ndef calc_kv_bytes_total_mha(batch, context_length, emb_dim, n_layers, bytes_per_elem, n_heads):\n # Full attention (MHA)\n d_head = emb_dim // n_heads\n per_layer = batch * context_length * n_heads * d_head * 2 * bytes_per_elem\n return per_layer * n_layers\n\n\ndef calc_kv_bytes_total_deltanet_no_conv(batch, emb_dim, n_layers, bytes_per_elem, n_heads):\n # Simple Gated DeltaNet (no convolutional mixing)\n d_head = emb_dim // n_heads\n per_layer = batch * n_heads * d_head * d_head * bytes_per_elem\n return per_layer * n_layers\n\n\ndef convert_to_gb(x):\n return x / 1e9\n\n\ndef main():\n p = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter, description=\"Memory vs. Context Length: MHA vs. DeltaNet (3:1 mix)\")\n p.add_argument(\"--batch\", type=int, default=1)\n p.add_argument(\"--emb_dim\", type=int, default=2048)\n p.add_argument(\"--n_heads\", type=int, default=16)\n p.add_argument(\"--n_layers\", type=int, default=48)\n p.add_argument(\"--dtype\", choices=DTYPE_BYTES.keys(), default=\"bf16\")\n p.add_argument(\"--min_ctx\", type=int, default=128)\n p.add_argument(\"--max_ctx\", type=int, default=131_072)\n args = p.parse_args()\n\n step = 100\n ctx = np.arange(args.min_ctx, args.max_ctx + 1, step, dtype=int)\n bytes_per_elem = DTYPE_BYTES[args.dtype]\n\n # 1) Full attention only\n mha_bytes = np.array([\n calc_kv_bytes_total_mha(args.batch, int(t), args.emb_dim, args.n_layers,\n bytes_per_elem, args.n_heads)\n for t in ctx\n ], dtype=float)\n\n # 2) DeltaNet only\n dnet_bytes_const = calc_kv_bytes_total_deltanet_no_conv(\n args.batch, args.emb_dim, args.n_layers,\n bytes_per_elem, args.n_heads\n )\n dnet_bytes = np.full_like(mha_bytes, fill_value=dnet_bytes_const, dtype=float)\n\n # 3) 3:1 layer ratio (3 DeltaNet : 1 Full Attention)\n n_mha_layers = args.n_layers / 4\n n_dnet_layers = args.n_layers - n_mha_layers\n mix_bytes = np.array([\n calc_kv_bytes_total_mha(args.batch, int(t), args.emb_dim, n_mha_layers,\n bytes_per_elem, args.n_heads)\n + calc_kv_bytes_total_deltanet_no_conv(args.batch, args.emb_dim, n_dnet_layers,\n bytes_per_elem, args.n_heads)\n for t in ctx\n ], dtype=float)\n\n # Convert to GB\n mha_gb = convert_to_gb(mha_bytes)\n dnet_gb = convert_to_gb(dnet_bytes)\n mix_gb = convert_to_gb(mix_bytes)\n\n # Plot\n fig, ax = plt.subplots(figsize=(7, 4.5))\n ax.plot(ctx, mha_gb, label=\"Full Attention (MHA) KV cache\")\n ax.plot(ctx, dnet_gb, label=\"All Gated DeltaNet (no conv)\")\n ax.plot(ctx, mix_gb, label=\"3:1 layer ratio (3 DeltaNet : 1 Full Attention)\")\n\n ax.set_xlabel(\"Context length (number of tokens)\")\n ax.set_ylabel(\"KV cache size (GB)\")\n ax.grid(True, which=\"both\", linestyle=\"--\", linewidth=0.5, alpha=0.6)\n ax.legend()\n\n fig.tight_layout()\n plt.savefig(\"deltanet_memory_plot.pdf\", dpi=160)\n plt.close(fig)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "ch04/README.md",
"content": "# Chapter 4: Implementing a GPT Model from Scratch to Generate Text\n\n \n## Main Chapter Code\n\n- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code.\n\n \n## Bonus Materials\n\n- [02_performance-analysis](02_performance-analysis) contains optional code analyzing the performance of the GPT model(s) implemented in the main chapter\n- [03_kv-cache](03_kv-cache) implements a KV cache to speed up the text generation during inference\n- [07_moe](07_moe) explanation and implementation of Mixture-of-Experts (MoE)\n- [ch05/07_gpt_to_llama](../ch05/07_gpt_to_llama) contains a step-by-step guide for converting a GPT architecture implementation to Llama 3.2 and loads pretrained weights from Meta AI (it might be interesting to look at alternative architectures after completing chapter 4, but you can also save that for after reading chapter 5)\n\n\n \n## Attention Alternatives\n\n \n\n \n\n \n\n- [04_gqa](04_gqa) contains an introduction to Grouped-Query Attention (GQA), which is used by most modern LLMs (Llama 4, gpt-oss, Qwen3, Gemma 3, and many more) as alternative to regular Multi-Head Attention (MHA)\n- [05_mla](05_mla) contains an introduction to Multi-Head Latent Attention (MLA), which is used by DeepSeek V3, as alternative to regular Multi-Head Attention (MHA)\n- [06_swa](06_swa) contains an introduction to Sliding Window Attention (SWA), which is used by Gemma 3 and others\n- [08_deltanet](08_deltanet) explanation of Gated DeltaNet as a popular linear attention variant (used in Qwen3-Next and Kimi Linear)\n\n\n \n## More\n\nIn the video below, I provide a code-along session that covers some of the chapter contents as supplementary material.\n\n
\n\n \n\n- [04_gqa](04_gqa) contains an introduction to Grouped-Query Attention (GQA), which is used by most modern LLMs (Llama 4, gpt-oss, Qwen3, Gemma 3, and many more) as alternative to regular Multi-Head Attention (MHA)\n- [05_mla](05_mla) contains an introduction to Multi-Head Latent Attention (MLA), which is used by DeepSeek V3, as alternative to regular Multi-Head Attention (MHA)\n- [06_swa](06_swa) contains an introduction to Sliding Window Attention (SWA), which is used by Gemma 3 and others\n- [08_deltanet](08_deltanet) explanation of Gated DeltaNet as a popular linear attention variant (used in Qwen3-Next and Kimi Linear)\n\n\n \n## More\n\nIn the video below, I provide a code-along session that covers some of the chapter contents as supplementary material.\n\n| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0d214765-7a73-42d5-95e9-302154b29db9\",\n \"metadata\": {},\n \"source\": [\n \"- The topics covered in this chapter are shown below\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f67711d4-8391-4fee-aeef-07ea53dd5841\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0d214765-7a73-42d5-95e9-302154b29db9\",\n \"metadata\": {},\n \"source\": [\n \"- The topics covered in this chapter are shown below\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f67711d4-8391-4fee-aeef-07ea53dd5841\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0d824183-145c-4865-89e1-1f0d0a338f19\",\n \"metadata\": {\n \"id\": \"0d824183-145c-4865-89e1-1f0d0a338f19\"\n },\n \"source\": [\n \" \\n\",\n \"## 5.1 Evaluating generative text models\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a3350f8c-5181-4f9b-a789-4523105e98f2\",\n \"metadata\": {},\n \"source\": [\n \"- We start this section with a brief recap of initializing a GPT model using the code from the previous chapter\\n\",\n \"- Then, we discuss basic evaluation metrics for LLMs\\n\",\n \"- Lastly, in this section, we apply these evaluation metrics to a training and validation dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bdc1cf3f-82d8-46c7-9ecc-58979ce87cdd\",\n \"metadata\": {\n \"id\": \"bdc1cf3f-82d8-46c7-9ecc-58979ce87cdd\"\n },\n \"source\": [\n \" \\n\",\n \"### 5.1.1 Using GPT to generate text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5b3415fd-9f4a-4548-908e-9dfa56edc9bc\",\n \"metadata\": {},\n \"source\": [\n \"- We initialize a GPT model using the code from the previous chapter\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"86000d74-624a-48f0-86da-f41926cb9e04\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"86000d74-624a-48f0-86da-f41926cb9e04\",\n \"outputId\": \"ad482cfd-5a62-4f0d-e1e0-008d6457f512\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"from previous_chapters import GPTModel\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"\\n\",\n \"GPT_CONFIG_124M = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 256, # Shortened context length (orig: 1024)\\n\",\n \" \\\"emb_dim\\\": 768, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 12, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 12, # Number of layers\\n\",\n \" \\\"drop_rate\\\": 0.1, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": False # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model = GPTModel(GPT_CONFIG_124M)\\n\",\n \"model.eval(); # Disable dropout during inference\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"09c6cf0f-7458-48a2-97fd-aa5068d65e8c\",\n \"metadata\": {},\n \"source\": [\n \"- We use dropout of 0.1 above, but it's relatively common to train LLMs without dropout nowadays\\n\",\n \"- Modern LLMs also don't use bias vectors in the `nn.Linear` layers for the query, key, and value matrices (unlike earlier GPT models), which is achieved by setting `\\\"qkv_bias\\\": False`\\n\",\n \"- We reduce the context length (`context_length`) of only 256 tokens to reduce the computational resource requirements for training the model, whereas the original 124 million parameter GPT-2 model used 1024 tokens\\n\",\n \" - This is so that more readers will be able to follow and execute the code examples on their laptop computer\\n\",\n \" - However, please feel free to increase the `context_length` to 1024 tokens (this would not require any code changes)\\n\",\n \" - We will also load a model with a 1024 `context_length` later from pretrained weights\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"59f80895-be35-4bb5-81cb-f357ef7367fe\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we use the `generate_text_simple` function from the previous chapter to generate text\\n\",\n \"- In addition, we define two convenience functions, `text_to_token_ids` and `token_ids_to_text`, for converting between token and text representations that we use throughout this chapter\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"741881f3-cee0-49ad-b11d-b9df3b3ac234\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0d824183-145c-4865-89e1-1f0d0a338f19\",\n \"metadata\": {\n \"id\": \"0d824183-145c-4865-89e1-1f0d0a338f19\"\n },\n \"source\": [\n \" \\n\",\n \"## 5.1 Evaluating generative text models\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a3350f8c-5181-4f9b-a789-4523105e98f2\",\n \"metadata\": {},\n \"source\": [\n \"- We start this section with a brief recap of initializing a GPT model using the code from the previous chapter\\n\",\n \"- Then, we discuss basic evaluation metrics for LLMs\\n\",\n \"- Lastly, in this section, we apply these evaluation metrics to a training and validation dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bdc1cf3f-82d8-46c7-9ecc-58979ce87cdd\",\n \"metadata\": {\n \"id\": \"bdc1cf3f-82d8-46c7-9ecc-58979ce87cdd\"\n },\n \"source\": [\n \" \\n\",\n \"### 5.1.1 Using GPT to generate text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5b3415fd-9f4a-4548-908e-9dfa56edc9bc\",\n \"metadata\": {},\n \"source\": [\n \"- We initialize a GPT model using the code from the previous chapter\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"86000d74-624a-48f0-86da-f41926cb9e04\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"86000d74-624a-48f0-86da-f41926cb9e04\",\n \"outputId\": \"ad482cfd-5a62-4f0d-e1e0-008d6457f512\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"from previous_chapters import GPTModel\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"\\n\",\n \"GPT_CONFIG_124M = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 256, # Shortened context length (orig: 1024)\\n\",\n \" \\\"emb_dim\\\": 768, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 12, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 12, # Number of layers\\n\",\n \" \\\"drop_rate\\\": 0.1, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": False # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model = GPTModel(GPT_CONFIG_124M)\\n\",\n \"model.eval(); # Disable dropout during inference\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"09c6cf0f-7458-48a2-97fd-aa5068d65e8c\",\n \"metadata\": {},\n \"source\": [\n \"- We use dropout of 0.1 above, but it's relatively common to train LLMs without dropout nowadays\\n\",\n \"- Modern LLMs also don't use bias vectors in the `nn.Linear` layers for the query, key, and value matrices (unlike earlier GPT models), which is achieved by setting `\\\"qkv_bias\\\": False`\\n\",\n \"- We reduce the context length (`context_length`) of only 256 tokens to reduce the computational resource requirements for training the model, whereas the original 124 million parameter GPT-2 model used 1024 tokens\\n\",\n \" - This is so that more readers will be able to follow and execute the code examples on their laptop computer\\n\",\n \" - However, please feel free to increase the `context_length` to 1024 tokens (this would not require any code changes)\\n\",\n \" - We will also load a model with a 1024 `context_length` later from pretrained weights\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"59f80895-be35-4bb5-81cb-f357ef7367fe\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we use the `generate_text_simple` function from the previous chapter to generate text\\n\",\n \"- In addition, we define two convenience functions, `text_to_token_ids` and `token_ids_to_text`, for converting between token and text representations that we use throughout this chapter\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"741881f3-cee0-49ad-b11d-b9df3b3ac234\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"5e062b82-3540-48ce-8eb4-009686d0d16c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort moves you rentingetic wasnم refres RexMeCHicular stren\\n\"\n ]\n }\n ],\n \"source\": [\n \"import tiktoken\\n\",\n \"from previous_chapters import generate_text_simple\\n\",\n \"\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch04 import generate_text_simple\\n\",\n \"\\n\",\n \"def text_to_token_ids(text, tokenizer):\\n\",\n \" encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})\\n\",\n \" encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\\n\",\n \" return encoded_tensor\\n\",\n \"\\n\",\n \"def token_ids_to_text(token_ids, tokenizer):\\n\",\n \" flat = token_ids.squeeze(0) # remove batch dimension\\n\",\n \" return tokenizer.decode(flat.tolist())\\n\",\n \"\\n\",\n \"start_context = \\\"Every effort moves you\\\"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(start_context, tokenizer),\\n\",\n \" max_new_tokens=10,\\n\",\n \" context_size=GPT_CONFIG_124M[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e4d3249b-b2a0-44c4-b589-ae4b403b8305\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see above, the model does not produce good text because it has not been trained yet\\n\",\n \"- How do we measure or capture what \\\"good text\\\" is, in a numeric form, to track it during training?\\n\",\n \"- The next subsection introduces metrics to calculate a loss metric for the generated outputs that we can use to measure the training progress\\n\",\n \"- The next chapters on finetuning LLMs will also introduce additional ways to measure model quality\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0f3d7ea2-637f-4490-bc76-e361fc81ae98\",\n \"metadata\": {\n \"id\": \"0f3d7ea2-637f-4490-bc76-e361fc81ae98\"\n },\n \"source\": [\n \" \\n\",\n \"### 5.1.2 Calculating the text generation loss: cross-entropy and perplexity\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9e1ba8aa-fb03-4d25-957f-fe8778762440\",\n \"metadata\": {},\n \"source\": [\n \"- Suppose we have an `inputs` tensor containing the token IDs for 2 training examples (rows)\\n\",\n \"- Corresponding to the `inputs`, the `targets` contain the desired token IDs that we want the model to generate\\n\",\n \"- Notice that the `targets` are the `inputs` shifted by 1 position, as explained in chapter 2 when we implemented the data loader\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"6b5402f8-ec0c-4a44-9892-18a97779ee4f\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6b5402f8-ec0c-4a44-9892-18a97779ee4f\",\n \"outputId\": \"8d6fa0ff-7b37-4634-c3f0-2c050cbe81f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"inputs = torch.tensor([[16833, 3626, 6100], # [\\\"every effort moves\\\",\\n\",\n \" [40, 1107, 588]]) # \\\"I really like\\\"]\\n\",\n \"\\n\",\n \"targets = torch.tensor([[3626, 6100, 345 ], # [\\\" effort moves you\\\",\\n\",\n \" [1107, 588, 11311]]) # \\\" really like chocolate\\\"]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"33dc0645-ac2c-4973-9b40-6da40515bede\",\n \"metadata\": {},\n \"source\": [\n \"- Feeding the `inputs` to the model, we obtain the logits vector for the 2 input examples that consist of 3 tokens each\\n\",\n \"- Each of the tokens is a 50,257-dimensional vector corresponding to the size of the vocabulary\\n\",\n \"- Applying the softmax function, we can turn the logits tensor into a tensor of the same dimension containing probability scores \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"e7b6ec51-6f8c-49bd-a349-95ba38b46fb6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([2, 3, 50257])\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" logits = model(inputs)\\n\",\n \"\\n\",\n \"probas = torch.softmax(logits, dim=-1) # Probability of each token in vocabulary\\n\",\n \"print(probas.shape) # Shape: (batch_size, num_tokens, vocab_size)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5c36a382-b5e2-4de6-9e65-0b69b685013b\",\n \"metadata\": {},\n \"source\": [\n \"- The figure below, using a very small vocabulary for illustration purposes, outlines how we convert the probability scores back into text, which we discussed at the end of the previous chapter\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"384d86a9-0013-476c-bb6b-274fd5f20b29\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"5e062b82-3540-48ce-8eb4-009686d0d16c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort moves you rentingetic wasnم refres RexMeCHicular stren\\n\"\n ]\n }\n ],\n \"source\": [\n \"import tiktoken\\n\",\n \"from previous_chapters import generate_text_simple\\n\",\n \"\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch04 import generate_text_simple\\n\",\n \"\\n\",\n \"def text_to_token_ids(text, tokenizer):\\n\",\n \" encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})\\n\",\n \" encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\\n\",\n \" return encoded_tensor\\n\",\n \"\\n\",\n \"def token_ids_to_text(token_ids, tokenizer):\\n\",\n \" flat = token_ids.squeeze(0) # remove batch dimension\\n\",\n \" return tokenizer.decode(flat.tolist())\\n\",\n \"\\n\",\n \"start_context = \\\"Every effort moves you\\\"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(start_context, tokenizer),\\n\",\n \" max_new_tokens=10,\\n\",\n \" context_size=GPT_CONFIG_124M[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e4d3249b-b2a0-44c4-b589-ae4b403b8305\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see above, the model does not produce good text because it has not been trained yet\\n\",\n \"- How do we measure or capture what \\\"good text\\\" is, in a numeric form, to track it during training?\\n\",\n \"- The next subsection introduces metrics to calculate a loss metric for the generated outputs that we can use to measure the training progress\\n\",\n \"- The next chapters on finetuning LLMs will also introduce additional ways to measure model quality\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0f3d7ea2-637f-4490-bc76-e361fc81ae98\",\n \"metadata\": {\n \"id\": \"0f3d7ea2-637f-4490-bc76-e361fc81ae98\"\n },\n \"source\": [\n \" \\n\",\n \"### 5.1.2 Calculating the text generation loss: cross-entropy and perplexity\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9e1ba8aa-fb03-4d25-957f-fe8778762440\",\n \"metadata\": {},\n \"source\": [\n \"- Suppose we have an `inputs` tensor containing the token IDs for 2 training examples (rows)\\n\",\n \"- Corresponding to the `inputs`, the `targets` contain the desired token IDs that we want the model to generate\\n\",\n \"- Notice that the `targets` are the `inputs` shifted by 1 position, as explained in chapter 2 when we implemented the data loader\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"6b5402f8-ec0c-4a44-9892-18a97779ee4f\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6b5402f8-ec0c-4a44-9892-18a97779ee4f\",\n \"outputId\": \"8d6fa0ff-7b37-4634-c3f0-2c050cbe81f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"inputs = torch.tensor([[16833, 3626, 6100], # [\\\"every effort moves\\\",\\n\",\n \" [40, 1107, 588]]) # \\\"I really like\\\"]\\n\",\n \"\\n\",\n \"targets = torch.tensor([[3626, 6100, 345 ], # [\\\" effort moves you\\\",\\n\",\n \" [1107, 588, 11311]]) # \\\" really like chocolate\\\"]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"33dc0645-ac2c-4973-9b40-6da40515bede\",\n \"metadata\": {},\n \"source\": [\n \"- Feeding the `inputs` to the model, we obtain the logits vector for the 2 input examples that consist of 3 tokens each\\n\",\n \"- Each of the tokens is a 50,257-dimensional vector corresponding to the size of the vocabulary\\n\",\n \"- Applying the softmax function, we can turn the logits tensor into a tensor of the same dimension containing probability scores \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"e7b6ec51-6f8c-49bd-a349-95ba38b46fb6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch.Size([2, 3, 50257])\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" logits = model(inputs)\\n\",\n \"\\n\",\n \"probas = torch.softmax(logits, dim=-1) # Probability of each token in vocabulary\\n\",\n \"print(probas.shape) # Shape: (batch_size, num_tokens, vocab_size)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5c36a382-b5e2-4de6-9e65-0b69b685013b\",\n \"metadata\": {},\n \"source\": [\n \"- The figure below, using a very small vocabulary for illustration purposes, outlines how we convert the probability scores back into text, which we discussed at the end of the previous chapter\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"384d86a9-0013-476c-bb6b-274fd5f20b29\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e8480efd-d419-4954-9ecc-2876055334bd\",\n \"metadata\": {},\n \"source\": [\n \"- As discussed in the previous chapter, we can apply the `argmax` function to convert the probability scores into predicted token IDs\\n\",\n \"- The softmax function above produced a 50,257-dimensional vector for each token; the `argmax` function returns the position of the highest probability score in this vector, which is the predicted token ID for the given token\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f3b84c9f-dd08-482e-b903-a86fe44e1144\",\n \"metadata\": {},\n \"source\": [\n \"- Since we have 2 input batches with 3 tokens each, we obtain 2 by 3 predicted token IDs:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"34ebd76a-16ec-4c17-8958-8a135735cc1c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"34ebd76a-16ec-4c17-8958-8a135735cc1c\",\n \"outputId\": \"ed17da47-c3e7-4775-fd00-4ec5bcda3db2\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Token IDs:\\n\",\n \" tensor([[[16657],\\n\",\n \" [ 339],\\n\",\n \" [42826]],\\n\",\n \"\\n\",\n \" [[49906],\\n\",\n \" [29669],\\n\",\n \" [41751]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"token_ids = torch.argmax(probas, dim=-1, keepdim=True)\\n\",\n \"print(\\\"Token IDs:\\\\n\\\", token_ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cee4072c-21ed-4df7-8721-dd2535362573\",\n \"metadata\": {},\n \"source\": [\n \"- If we decode these tokens, we find that these are quite different from the tokens we want the model to predict, namely the target tokens:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"c990ead6-53cd-49a7-a6d1-14d8c1518249\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Targets batch 1: effort moves you\\n\",\n \"Outputs batch 1: Armed heNetflix\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(f\\\"Targets batch 1: {token_ids_to_text(targets[0], tokenizer)}\\\")\\n\",\n \"print(f\\\"Outputs batch 1: {token_ids_to_text(token_ids[0].flatten(), tokenizer)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a53eb8a7-070e-46d6-930c-314ba55a6ff2\",\n \"metadata\": {},\n \"source\": [\n \"- That's because the model wasn't trained yet\\n\",\n \"- To train the model, we need to know how far it is away from the correct predictions (targets)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ad90592f-0d5d-4ec8-9ff5-e7675beab10e\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e8480efd-d419-4954-9ecc-2876055334bd\",\n \"metadata\": {},\n \"source\": [\n \"- As discussed in the previous chapter, we can apply the `argmax` function to convert the probability scores into predicted token IDs\\n\",\n \"- The softmax function above produced a 50,257-dimensional vector for each token; the `argmax` function returns the position of the highest probability score in this vector, which is the predicted token ID for the given token\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f3b84c9f-dd08-482e-b903-a86fe44e1144\",\n \"metadata\": {},\n \"source\": [\n \"- Since we have 2 input batches with 3 tokens each, we obtain 2 by 3 predicted token IDs:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"34ebd76a-16ec-4c17-8958-8a135735cc1c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"34ebd76a-16ec-4c17-8958-8a135735cc1c\",\n \"outputId\": \"ed17da47-c3e7-4775-fd00-4ec5bcda3db2\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Token IDs:\\n\",\n \" tensor([[[16657],\\n\",\n \" [ 339],\\n\",\n \" [42826]],\\n\",\n \"\\n\",\n \" [[49906],\\n\",\n \" [29669],\\n\",\n \" [41751]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"token_ids = torch.argmax(probas, dim=-1, keepdim=True)\\n\",\n \"print(\\\"Token IDs:\\\\n\\\", token_ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cee4072c-21ed-4df7-8721-dd2535362573\",\n \"metadata\": {},\n \"source\": [\n \"- If we decode these tokens, we find that these are quite different from the tokens we want the model to predict, namely the target tokens:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"c990ead6-53cd-49a7-a6d1-14d8c1518249\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Targets batch 1: effort moves you\\n\",\n \"Outputs batch 1: Armed heNetflix\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(f\\\"Targets batch 1: {token_ids_to_text(targets[0], tokenizer)}\\\")\\n\",\n \"print(f\\\"Outputs batch 1: {token_ids_to_text(token_ids[0].flatten(), tokenizer)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a53eb8a7-070e-46d6-930c-314ba55a6ff2\",\n \"metadata\": {},\n \"source\": [\n \"- That's because the model wasn't trained yet\\n\",\n \"- To train the model, we need to know how far it is away from the correct predictions (targets)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ad90592f-0d5d-4ec8-9ff5-e7675beab10e\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c7251bf5-a079-4782-901d-68c9225d3157\",\n \"metadata\": {},\n \"source\": [\n \"- The token probabilities corresponding to the target indices are as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"54aef09c-d6e3-4238-8653-b3a1b0a1077a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"54aef09c-d6e3-4238-8653-b3a1b0a1077a\",\n \"outputId\": \"41c946a2-c458-433e-a53d-5e7e89d9dddc\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Text 1: tensor([7.4541e-05, 3.1061e-05, 1.1563e-05])\\n\",\n \"Text 2: tensor([1.0337e-05, 5.6776e-05, 4.7559e-06])\\n\"\n ]\n }\n ],\n \"source\": [\n \"text_idx = 0\\n\",\n \"target_probas_1 = probas[text_idx, [0, 1, 2], targets[text_idx]]\\n\",\n \"print(\\\"Text 1:\\\", target_probas_1)\\n\",\n \"\\n\",\n \"text_idx = 1\\n\",\n \"target_probas_2 = probas[text_idx, [0, 1, 2], targets[text_idx]]\\n\",\n \"print(\\\"Text 2:\\\", target_probas_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a0e89a19-73c2-4e49-93b4-861f699f1cbf\",\n \"metadata\": {},\n \"source\": [\n \"- We want to maximize all these values, bringing them close to a probability of 1\\n\",\n \"- In mathematical optimization, it is easier to maximize the logarithm of the probability score than the probability score itself; this is out of the scope of this book, but I have recorded a lecture with more details here: [L8.2 Logistic Regression Loss Function](https://www.youtube.com/watch?v=GxJe0DZvydM)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"31402a67-a16e-4aeb-977e-70abb9c9949b\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"31402a67-a16e-4aeb-977e-70abb9c9949b\",\n \"outputId\": \"1bf18e79-1246-4eab-efd8-12b328c78678\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([ -9.5042, -10.3796, -11.3677, -11.4798, -9.7764, -12.2561])\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Compute logarithm of all token probabilities\\n\",\n \"log_probas = torch.log(torch.cat((target_probas_1, target_probas_2)))\\n\",\n \"print(log_probas)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c4261441-a511-4633-9c4c-67998af31b84\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we compute the average log probability:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"9b003797-161b-4d98-81dc-e68320e09fec\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"9b003797-161b-4d98-81dc-e68320e09fec\",\n \"outputId\": \"a447fe9c-7e27-40ed-f1fb-51210e3f7cc9\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(-10.7940)\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Calculate the average probability for each token\\n\",\n \"avg_log_probas = torch.mean(log_probas)\\n\",\n \"print(avg_log_probas)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"36d51994-ad17-4ba3-a6ec-f588b4b13585\",\n \"metadata\": {},\n \"source\": [\n \"- The goal is to make this average log probability as large as possible by optimizing the model weights\\n\",\n \"- Due to the log, the largest possible value is 0, and we are currently far away from 0\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3de388a1-8a0a-4c94-8894-9041dc6ad514\",\n \"metadata\": {},\n \"source\": [\n \"- In deep learning, instead of maximizing the average log-probability, it's a standard convention to minimize the *negative* average log-probability value; in our case, instead of maximizing -10.7722 so that it approaches 0, in deep learning, we would minimize 10.7722 so that it approaches 0\\n\",\n \"- The value negative of -10.7722, i.e., 10.7722, is also called cross-entropy loss in deep learning\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"176ddf35-1c5f-4d7c-bf17-70f3e7069bd4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(10.7940)\\n\"\n ]\n }\n ],\n \"source\": [\n \"neg_avg_log_probas = avg_log_probas * -1\\n\",\n \"print(neg_avg_log_probas)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"84eeb868-abd8-4028-82db-107546bf7c2c\",\n \"metadata\": {},\n \"source\": [\n \"- PyTorch already implements a `cross_entropy` function that carries out the previous steps\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5bd24b7f-b760-47ad-bc84-86d13794aa54\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c7251bf5-a079-4782-901d-68c9225d3157\",\n \"metadata\": {},\n \"source\": [\n \"- The token probabilities corresponding to the target indices are as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"54aef09c-d6e3-4238-8653-b3a1b0a1077a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"54aef09c-d6e3-4238-8653-b3a1b0a1077a\",\n \"outputId\": \"41c946a2-c458-433e-a53d-5e7e89d9dddc\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Text 1: tensor([7.4541e-05, 3.1061e-05, 1.1563e-05])\\n\",\n \"Text 2: tensor([1.0337e-05, 5.6776e-05, 4.7559e-06])\\n\"\n ]\n }\n ],\n \"source\": [\n \"text_idx = 0\\n\",\n \"target_probas_1 = probas[text_idx, [0, 1, 2], targets[text_idx]]\\n\",\n \"print(\\\"Text 1:\\\", target_probas_1)\\n\",\n \"\\n\",\n \"text_idx = 1\\n\",\n \"target_probas_2 = probas[text_idx, [0, 1, 2], targets[text_idx]]\\n\",\n \"print(\\\"Text 2:\\\", target_probas_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a0e89a19-73c2-4e49-93b4-861f699f1cbf\",\n \"metadata\": {},\n \"source\": [\n \"- We want to maximize all these values, bringing them close to a probability of 1\\n\",\n \"- In mathematical optimization, it is easier to maximize the logarithm of the probability score than the probability score itself; this is out of the scope of this book, but I have recorded a lecture with more details here: [L8.2 Logistic Regression Loss Function](https://www.youtube.com/watch?v=GxJe0DZvydM)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"31402a67-a16e-4aeb-977e-70abb9c9949b\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"31402a67-a16e-4aeb-977e-70abb9c9949b\",\n \"outputId\": \"1bf18e79-1246-4eab-efd8-12b328c78678\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([ -9.5042, -10.3796, -11.3677, -11.4798, -9.7764, -12.2561])\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Compute logarithm of all token probabilities\\n\",\n \"log_probas = torch.log(torch.cat((target_probas_1, target_probas_2)))\\n\",\n \"print(log_probas)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c4261441-a511-4633-9c4c-67998af31b84\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we compute the average log probability:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"9b003797-161b-4d98-81dc-e68320e09fec\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"9b003797-161b-4d98-81dc-e68320e09fec\",\n \"outputId\": \"a447fe9c-7e27-40ed-f1fb-51210e3f7cc9\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(-10.7940)\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Calculate the average probability for each token\\n\",\n \"avg_log_probas = torch.mean(log_probas)\\n\",\n \"print(avg_log_probas)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"36d51994-ad17-4ba3-a6ec-f588b4b13585\",\n \"metadata\": {},\n \"source\": [\n \"- The goal is to make this average log probability as large as possible by optimizing the model weights\\n\",\n \"- Due to the log, the largest possible value is 0, and we are currently far away from 0\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3de388a1-8a0a-4c94-8894-9041dc6ad514\",\n \"metadata\": {},\n \"source\": [\n \"- In deep learning, instead of maximizing the average log-probability, it's a standard convention to minimize the *negative* average log-probability value; in our case, instead of maximizing -10.7722 so that it approaches 0, in deep learning, we would minimize 10.7722 so that it approaches 0\\n\",\n \"- The value negative of -10.7722, i.e., 10.7722, is also called cross-entropy loss in deep learning\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"176ddf35-1c5f-4d7c-bf17-70f3e7069bd4\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(10.7940)\\n\"\n ]\n }\n ],\n \"source\": [\n \"neg_avg_log_probas = avg_log_probas * -1\\n\",\n \"print(neg_avg_log_probas)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"84eeb868-abd8-4028-82db-107546bf7c2c\",\n \"metadata\": {},\n \"source\": [\n \"- PyTorch already implements a `cross_entropy` function that carries out the previous steps\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5bd24b7f-b760-47ad-bc84-86d13794aa54\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e8aaf9dd-3ee6-42bf-a63f-6e93dbfb989d\",\n \"metadata\": {},\n \"source\": [\n \"- Before we apply the `cross_entropy` function, let's check the shape of the logits and targets\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"695d6f64-5084-4c23-aea4-105c9e38cfe4\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"695d6f64-5084-4c23-aea4-105c9e38cfe4\",\n \"outputId\": \"43fd802a-8136-4b35-df0d-f61a5d4cb561\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Logits shape: torch.Size([2, 3, 50257])\\n\",\n \"Targets shape: torch.Size([2, 3])\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Logits have shape (batch_size, num_tokens, vocab_size)\\n\",\n \"print(\\\"Logits shape:\\\", logits.shape)\\n\",\n \"\\n\",\n \"# Targets have shape (batch_size, num_tokens)\\n\",\n \"print(\\\"Targets shape:\\\", targets.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1d3d65f0-6566-4865-93e4-0c0bcb10cd06\",\n \"metadata\": {},\n \"source\": [\n \"- For the `cross_entropy` function in PyTorch, we want to flatten these tensors by combining them over the batch dimension:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"0e17e027-ab9f-4fb5-ac9b-a009b831c122\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0e17e027-ab9f-4fb5-ac9b-a009b831c122\",\n \"outputId\": \"0b2b778b-02fb-43b2-c879-adc59055a7d8\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Flattened logits: torch.Size([6, 50257])\\n\",\n \"Flattened targets: torch.Size([6])\\n\"\n ]\n }\n ],\n \"source\": [\n \"logits_flat = logits.flatten(0, 1)\\n\",\n \"targets_flat = targets.flatten()\\n\",\n \"\\n\",\n \"print(\\\"Flattened logits:\\\", logits_flat.shape)\\n\",\n \"print(\\\"Flattened targets:\\\", targets_flat.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4921a57f-3a79-473e-a863-6d63b495010f\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the targets are the token IDs, which also represent the index positions in the logits tensors that we want to maximize\\n\",\n \"- The `cross_entropy` function in PyTorch will automatically take care of applying the softmax and log-probability computation internally over those token indices in the logits that are to be maximized \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"62d0816e-b29a-4c8f-a9a5-a167562de978\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"62d0816e-b29a-4c8f-a9a5-a167562de978\",\n \"outputId\": \"c0be634a-2c65-4ff7-a73f-1bfc2e406ba4\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(10.7940)\\n\"\n ]\n }\n ],\n \"source\": [\n \"loss = torch.nn.functional.cross_entropy(logits_flat, targets_flat)\\n\",\n \"print(loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0f15ce17-fd7b-4d8e-99da-b237523a7a80\",\n \"metadata\": {},\n \"source\": [\n \"- A concept related to the cross-entropy loss is the perplexity of an LLM\\n\",\n \"- The perplexity is simply the exponential of the cross-entropy loss\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"168952a1-b964-4aa7-8e49-966fa26add54\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"168952a1-b964-4aa7-8e49-966fa26add54\",\n \"outputId\": \"a0a692c1-6412-4068-8aa5-8858548141eb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(48725.8203)\\n\"\n ]\n }\n ],\n \"source\": [\n \"perplexity = torch.exp(loss)\\n\",\n \"print(perplexity)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"71ae26dd-d77e-41fd-b924-6bd103dd4ee7\",\n \"metadata\": {},\n \"source\": [\n \"- The perplexity is often considered more interpretable because it can be understood as the effective vocabulary size that the model is uncertain about at each step (in the example above, that'd be 48,725 words or tokens)\\n\",\n \"- In other words, perplexity provides a measure of how well the probability distribution predicted by the model matches the actual distribution of the words in the dataset\\n\",\n \"- Similar to the loss, a lower perplexity indicates that the model predictions are closer to the actual distribution\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2ec6c217-e429-40c7-ad71-5d0a9da8e487\",\n \"metadata\": {\n \"id\": \"2ec6c217-e429-40c7-ad71-5d0a9da8e487\"\n },\n \"source\": [\n \" \\n\",\n \"### 5.1.3 Calculating the training and validation set losses\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"530da89e-2448-436c-8f1b-28e8a31ef85c\",\n \"metadata\": {},\n \"source\": [\n \"- We use a relatively small dataset for training the LLM (in fact, only one short story)\\n\",\n \"- The reasons are:\\n\",\n \" - You can run the code examples in a few minutes on a laptop computer without a suitable GPU\\n\",\n \" - The training finishes relatively fast (minutes instead of weeks), which is good for educational purposes\\n\",\n \" - We use a text from the public domain, which can be included in this GitHub repository without violating any usage rights or bloating the repository size\\n\",\n \"\\n\",\n \"\\n\",\n \"- For example, Llama 2 7B required 184,320 GPU hours on A100 GPUs to be trained on 2 trillion tokens\\n\",\n \" - At the time of this writing, the hourly cost of an 8xA100 cloud server at AWS is approximately \\\\\\\\$30\\n\",\n \" - So, via an off-the-envelope calculation, training this LLM would cost 184,320 / 8 * \\\\\\\\$30 = \\\\\\\\$690,000\\n\",\n \" \\n\",\n \"- Below, we use the same dataset we used in chapter 2\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"654fde37-b2a9-4a20-a8d3-0206c056e2ff\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"file_path = \\\"the-verdict.txt\\\"\\n\",\n \"url = \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt\\\"\\n\",\n \"\\n\",\n \"if not os.path.exists(file_path):\\n\",\n \" response = requests.get(url, timeout=30)\\n\",\n \" response.raise_for_status()\\n\",\n \" text_data = response.text\\n\",\n \" with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" file.write(text_data)\\n\",\n \"else:\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" text_data = file.read()\\n\",\n \"\\n\",\n \"\\n\",\n \"# The book originally used the following code below\\n\",\n \"# However, urllib uses older protocol settings that\\n\",\n \"# can cause problems for some readers using a VPN.\\n\",\n \"# The `requests` version above is more robust\\n\",\n \"# in that regard.\\n\",\n \"\\n\",\n \" \\n\",\n \"# import os\\n\",\n \"# import urllib.request\\n\",\n \"\\n\",\n \"# file_path = \\\"the-verdict.txt\\\"\\n\",\n \"# url = \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt\\\"\\n\",\n \"\\n\",\n \"# if not os.path.exists(file_path):\\n\",\n \"# with urllib.request.urlopen(url) as response:\\n\",\n \"# text_data = response.read().decode('utf-8')\\n\",\n \"# with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \"# file.write(text_data)\\n\",\n \"# else:\\n\",\n \"# with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \"# text_data = file.read()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"379330f1-80f4-4e34-8724-41d892b04cee\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the text loaded ok by printing the first and last 99 characters\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"6kgJbe4ehI4q\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 35\n },\n \"id\": \"6kgJbe4ehI4q\",\n \"outputId\": \"9ff31e88-ee37-47e9-ee64-da6eb552f46f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no \\n\"\n ]\n }\n ],\n \"source\": [\n \"# First 99 characters\\n\",\n \"print(text_data[:99])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"j2XPde_ThM_e\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 35\n },\n \"id\": \"j2XPde_ThM_e\",\n \"outputId\": \"a900c1b9-9a87-4078-968b-a5721deda5cb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"it for me! The Strouds stand alone, and happen once--but there's no exterminating our kind of art.\\\"\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Last 99 characters\\n\",\n \"print(text_data[-99:])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"6b46a952-d50a-4837-af09-4095698f7fd1\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6b46a952-d50a-4837-af09-4095698f7fd1\",\n \"outputId\": \"c2a25334-21ca-486e-8226-0296e5fc6486\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Characters: 20479\\n\",\n \"Tokens: 5145\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_characters = len(text_data)\\n\",\n \"total_tokens = len(tokenizer.encode(text_data))\\n\",\n \"\\n\",\n \"print(\\\"Characters:\\\", total_characters)\\n\",\n \"print(\\\"Tokens:\\\", total_tokens)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a8830cb9-90f6-4e7c-8620-beeabc2d39f7\",\n \"metadata\": {},\n \"source\": [\n \"- With 5,145 tokens, the text is very short for training an LLM, but again, it's for educational purposes (we will also load pretrained weights later)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bedcad87-a0e8-4b9d-ac43-4e927ccbb50f\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we divide the dataset into a training and a validation set and use the data loaders from chapter 2 to prepare the batches for LLM training\\n\",\n \"- For visualization purposes, the figure below assumes a `max_length=6`, but for the training loader, we set the `max_length` equal to the context length that the LLM supports\\n\",\n \"- The figure below only shows the input tokens for simplicity\\n\",\n \" - Since we train the LLM to predict the next word in the text, the targets look the same as these inputs, except that the targets are shifted by one position\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"46bdaa07-ba96-4ac1-9d71-b3cc153910d9\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e8aaf9dd-3ee6-42bf-a63f-6e93dbfb989d\",\n \"metadata\": {},\n \"source\": [\n \"- Before we apply the `cross_entropy` function, let's check the shape of the logits and targets\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"695d6f64-5084-4c23-aea4-105c9e38cfe4\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"695d6f64-5084-4c23-aea4-105c9e38cfe4\",\n \"outputId\": \"43fd802a-8136-4b35-df0d-f61a5d4cb561\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Logits shape: torch.Size([2, 3, 50257])\\n\",\n \"Targets shape: torch.Size([2, 3])\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Logits have shape (batch_size, num_tokens, vocab_size)\\n\",\n \"print(\\\"Logits shape:\\\", logits.shape)\\n\",\n \"\\n\",\n \"# Targets have shape (batch_size, num_tokens)\\n\",\n \"print(\\\"Targets shape:\\\", targets.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1d3d65f0-6566-4865-93e4-0c0bcb10cd06\",\n \"metadata\": {},\n \"source\": [\n \"- For the `cross_entropy` function in PyTorch, we want to flatten these tensors by combining them over the batch dimension:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"0e17e027-ab9f-4fb5-ac9b-a009b831c122\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0e17e027-ab9f-4fb5-ac9b-a009b831c122\",\n \"outputId\": \"0b2b778b-02fb-43b2-c879-adc59055a7d8\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Flattened logits: torch.Size([6, 50257])\\n\",\n \"Flattened targets: torch.Size([6])\\n\"\n ]\n }\n ],\n \"source\": [\n \"logits_flat = logits.flatten(0, 1)\\n\",\n \"targets_flat = targets.flatten()\\n\",\n \"\\n\",\n \"print(\\\"Flattened logits:\\\", logits_flat.shape)\\n\",\n \"print(\\\"Flattened targets:\\\", targets_flat.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4921a57f-3a79-473e-a863-6d63b495010f\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the targets are the token IDs, which also represent the index positions in the logits tensors that we want to maximize\\n\",\n \"- The `cross_entropy` function in PyTorch will automatically take care of applying the softmax and log-probability computation internally over those token indices in the logits that are to be maximized \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"62d0816e-b29a-4c8f-a9a5-a167562de978\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"62d0816e-b29a-4c8f-a9a5-a167562de978\",\n \"outputId\": \"c0be634a-2c65-4ff7-a73f-1bfc2e406ba4\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(10.7940)\\n\"\n ]\n }\n ],\n \"source\": [\n \"loss = torch.nn.functional.cross_entropy(logits_flat, targets_flat)\\n\",\n \"print(loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0f15ce17-fd7b-4d8e-99da-b237523a7a80\",\n \"metadata\": {},\n \"source\": [\n \"- A concept related to the cross-entropy loss is the perplexity of an LLM\\n\",\n \"- The perplexity is simply the exponential of the cross-entropy loss\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"168952a1-b964-4aa7-8e49-966fa26add54\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"168952a1-b964-4aa7-8e49-966fa26add54\",\n \"outputId\": \"a0a692c1-6412-4068-8aa5-8858548141eb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(48725.8203)\\n\"\n ]\n }\n ],\n \"source\": [\n \"perplexity = torch.exp(loss)\\n\",\n \"print(perplexity)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"71ae26dd-d77e-41fd-b924-6bd103dd4ee7\",\n \"metadata\": {},\n \"source\": [\n \"- The perplexity is often considered more interpretable because it can be understood as the effective vocabulary size that the model is uncertain about at each step (in the example above, that'd be 48,725 words or tokens)\\n\",\n \"- In other words, perplexity provides a measure of how well the probability distribution predicted by the model matches the actual distribution of the words in the dataset\\n\",\n \"- Similar to the loss, a lower perplexity indicates that the model predictions are closer to the actual distribution\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2ec6c217-e429-40c7-ad71-5d0a9da8e487\",\n \"metadata\": {\n \"id\": \"2ec6c217-e429-40c7-ad71-5d0a9da8e487\"\n },\n \"source\": [\n \" \\n\",\n \"### 5.1.3 Calculating the training and validation set losses\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"530da89e-2448-436c-8f1b-28e8a31ef85c\",\n \"metadata\": {},\n \"source\": [\n \"- We use a relatively small dataset for training the LLM (in fact, only one short story)\\n\",\n \"- The reasons are:\\n\",\n \" - You can run the code examples in a few minutes on a laptop computer without a suitable GPU\\n\",\n \" - The training finishes relatively fast (minutes instead of weeks), which is good for educational purposes\\n\",\n \" - We use a text from the public domain, which can be included in this GitHub repository without violating any usage rights or bloating the repository size\\n\",\n \"\\n\",\n \"\\n\",\n \"- For example, Llama 2 7B required 184,320 GPU hours on A100 GPUs to be trained on 2 trillion tokens\\n\",\n \" - At the time of this writing, the hourly cost of an 8xA100 cloud server at AWS is approximately \\\\\\\\$30\\n\",\n \" - So, via an off-the-envelope calculation, training this LLM would cost 184,320 / 8 * \\\\\\\\$30 = \\\\\\\\$690,000\\n\",\n \" \\n\",\n \"- Below, we use the same dataset we used in chapter 2\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"654fde37-b2a9-4a20-a8d3-0206c056e2ff\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"file_path = \\\"the-verdict.txt\\\"\\n\",\n \"url = \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt\\\"\\n\",\n \"\\n\",\n \"if not os.path.exists(file_path):\\n\",\n \" response = requests.get(url, timeout=30)\\n\",\n \" response.raise_for_status()\\n\",\n \" text_data = response.text\\n\",\n \" with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" file.write(text_data)\\n\",\n \"else:\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" text_data = file.read()\\n\",\n \"\\n\",\n \"\\n\",\n \"# The book originally used the following code below\\n\",\n \"# However, urllib uses older protocol settings that\\n\",\n \"# can cause problems for some readers using a VPN.\\n\",\n \"# The `requests` version above is more robust\\n\",\n \"# in that regard.\\n\",\n \"\\n\",\n \" \\n\",\n \"# import os\\n\",\n \"# import urllib.request\\n\",\n \"\\n\",\n \"# file_path = \\\"the-verdict.txt\\\"\\n\",\n \"# url = \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt\\\"\\n\",\n \"\\n\",\n \"# if not os.path.exists(file_path):\\n\",\n \"# with urllib.request.urlopen(url) as response:\\n\",\n \"# text_data = response.read().decode('utf-8')\\n\",\n \"# with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \"# file.write(text_data)\\n\",\n \"# else:\\n\",\n \"# with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \"# text_data = file.read()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"379330f1-80f4-4e34-8724-41d892b04cee\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the text loaded ok by printing the first and last 99 characters\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"6kgJbe4ehI4q\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 35\n },\n \"id\": \"6kgJbe4ehI4q\",\n \"outputId\": \"9ff31e88-ee37-47e9-ee64-da6eb552f46f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no \\n\"\n ]\n }\n ],\n \"source\": [\n \"# First 99 characters\\n\",\n \"print(text_data[:99])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"j2XPde_ThM_e\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 35\n },\n \"id\": \"j2XPde_ThM_e\",\n \"outputId\": \"a900c1b9-9a87-4078-968b-a5721deda5cb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"it for me! The Strouds stand alone, and happen once--but there's no exterminating our kind of art.\\\"\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Last 99 characters\\n\",\n \"print(text_data[-99:])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"6b46a952-d50a-4837-af09-4095698f7fd1\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6b46a952-d50a-4837-af09-4095698f7fd1\",\n \"outputId\": \"c2a25334-21ca-486e-8226-0296e5fc6486\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Characters: 20479\\n\",\n \"Tokens: 5145\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_characters = len(text_data)\\n\",\n \"total_tokens = len(tokenizer.encode(text_data))\\n\",\n \"\\n\",\n \"print(\\\"Characters:\\\", total_characters)\\n\",\n \"print(\\\"Tokens:\\\", total_tokens)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a8830cb9-90f6-4e7c-8620-beeabc2d39f7\",\n \"metadata\": {},\n \"source\": [\n \"- With 5,145 tokens, the text is very short for training an LLM, but again, it's for educational purposes (we will also load pretrained weights later)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bedcad87-a0e8-4b9d-ac43-4e927ccbb50f\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we divide the dataset into a training and a validation set and use the data loaders from chapter 2 to prepare the batches for LLM training\\n\",\n \"- For visualization purposes, the figure below assumes a `max_length=6`, but for the training loader, we set the `max_length` equal to the context length that the LLM supports\\n\",\n \"- The figure below only shows the input tokens for simplicity\\n\",\n \" - Since we train the LLM to predict the next word in the text, the targets look the same as these inputs, except that the targets are shifted by one position\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"46bdaa07-ba96-4ac1-9d71-b3cc153910d9\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"0959c855-f860-4358-8b98-bc654f047578\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import create_dataloader_v1\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch02 import create_dataloader_v1\\n\",\n \"\\n\",\n \"# Train/validation ratio\\n\",\n \"train_ratio = 0.90\\n\",\n \"split_idx = int(train_ratio * len(text_data))\\n\",\n \"train_data = text_data[:split_idx]\\n\",\n \"val_data = text_data[split_idx:]\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_loader = create_dataloader_v1(\\n\",\n \" train_data,\\n\",\n \" batch_size=2,\\n\",\n \" max_length=GPT_CONFIG_124M[\\\"context_length\\\"],\\n\",\n \" stride=GPT_CONFIG_124M[\\\"context_length\\\"],\\n\",\n \" drop_last=True,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=0\\n\",\n \")\\n\",\n \"\\n\",\n \"val_loader = create_dataloader_v1(\\n\",\n \" val_data,\\n\",\n \" batch_size=2,\\n\",\n \" max_length=GPT_CONFIG_124M[\\\"context_length\\\"],\\n\",\n \" stride=GPT_CONFIG_124M[\\\"context_length\\\"],\\n\",\n \" drop_last=False,\\n\",\n \" shuffle=False,\\n\",\n \" num_workers=0\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"f37b3eb0-854e-4895-9898-fa7d1e67566e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Sanity check\\n\",\n \"\\n\",\n \"if total_tokens * (train_ratio) < GPT_CONFIG_124M[\\\"context_length\\\"]:\\n\",\n \" print(\\\"Not enough tokens for the training loader. \\\"\\n\",\n \" \\\"Try to lower the `GPT_CONFIG_124M['context_length']` or \\\"\\n\",\n \" \\\"increase the `training_ratio`\\\")\\n\",\n \"\\n\",\n \"if total_tokens * (1-train_ratio) < GPT_CONFIG_124M[\\\"context_length\\\"]:\\n\",\n \" print(\\\"Not enough tokens for the validation loader. \\\"\\n\",\n \" \\\"Try to lower the `GPT_CONFIG_124M['context_length']` or \\\"\\n\",\n \" \\\"decrease the `training_ratio`\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e7ac3296-a4d1-4303-9ac5-376518960c33\",\n \"metadata\": {},\n \"source\": [\n \"- We use a relatively small batch size to reduce the computational resource demand, and because the dataset is very small to begin with\\n\",\n \"- Llama 2 7B was trained with a batch size of 1024, for example\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a8e0514d-b990-4dc0-9afb-7721993284a0\",\n \"metadata\": {},\n \"source\": [\n \"- An optional check that the data was loaded correctly:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"ca0116d0-d229-472c-9fbf-ebc229331c3e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"\\n\",\n \"Validation loader:\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for x, y in train_loader:\\n\",\n \" print(x.shape, y.shape)\\n\",\n \"\\n\",\n \"print(\\\"\\\\nValidation loader:\\\")\\n\",\n \"for x, y in val_loader:\\n\",\n \" print(x.shape, y.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f7b9b1a4-863d-456f-a8dd-c07fb5c024ed\",\n \"metadata\": {},\n \"source\": [\n \"- Another optional check that the token sizes are in the expected ballpark:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"eb860488-5453-41d7-9870-23b723f742a0\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"eb860488-5453-41d7-9870-23b723f742a0\",\n \"outputId\": \"96b9451a-9557-4126-d1c8-51610a1995ab\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training tokens: 4608\\n\",\n \"Validation tokens: 512\\n\",\n \"All tokens: 5120\\n\"\n ]\n }\n ],\n \"source\": [\n \"train_tokens = 0\\n\",\n \"for input_batch, target_batch in train_loader:\\n\",\n \" train_tokens += input_batch.numel()\\n\",\n \"\\n\",\n \"val_tokens = 0\\n\",\n \"for input_batch, target_batch in val_loader:\\n\",\n \" val_tokens += input_batch.numel()\\n\",\n \"\\n\",\n \"print(\\\"Training tokens:\\\", train_tokens)\\n\",\n \"print(\\\"Validation tokens:\\\", val_tokens)\\n\",\n \"print(\\\"All tokens:\\\", train_tokens + val_tokens)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5c3085e8-665e-48eb-bb41-cdde61537e06\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we implement a utility function to calculate the cross-entropy loss of a given batch\\n\",\n \"- In addition, we implement a second utility function to compute the loss for a user-specified number of batches in a data loader\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"7b9de31e-4096-47b3-976d-b6d2fdce04bc\",\n \"metadata\": {\n \"id\": \"7b9de31e-4096-47b3-976d-b6d2fdce04bc\"\n },\n \"outputs\": [],\n \"source\": [\n \"def calc_loss_batch(input_batch, target_batch, model, device):\\n\",\n \" input_batch, target_batch = input_batch.to(device), target_batch.to(device)\\n\",\n \" logits = model(input_batch)\\n\",\n \" loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())\\n\",\n \" return loss\\n\",\n \"\\n\",\n \"\\n\",\n \"def calc_loss_loader(data_loader, model, device, num_batches=None):\\n\",\n \" total_loss = 0.\\n\",\n \" if len(data_loader) == 0:\\n\",\n \" return float(\\\"nan\\\")\\n\",\n \" elif num_batches is None:\\n\",\n \" num_batches = len(data_loader)\\n\",\n \" else:\\n\",\n \" # Reduce the number of batches to match the total number of batches in the data loader\\n\",\n \" # if num_batches exceeds the number of batches in the data loader\\n\",\n \" num_batches = min(num_batches, len(data_loader))\\n\",\n \" for i, (input_batch, target_batch) in enumerate(data_loader):\\n\",\n \" if i < num_batches:\\n\",\n \" loss = calc_loss_batch(input_batch, target_batch, model, device)\\n\",\n \" total_loss += loss.item()\\n\",\n \" else:\\n\",\n \" break\\n\",\n \" return total_loss / num_batches\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f0691332-84d0-48b3-b462-a885ddeb4fca\",\n \"metadata\": {},\n \"source\": [\n \"- If you have a machine with a CUDA-supported GPU, the LLM will train on the GPU without making any changes to the code\\n\",\n \"- Via the `device` setting, we ensure that the data is loaded onto the same device as the LLM model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"56f5b0c9-1065-4d67-98b9-010e42fc1e2a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Using mps device.\\n\",\n \"Training loss: 10.987583054436577\\n\",\n \"Validation loss: 10.98110580444336\\n\"\n ]\n }\n ],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"\\n\",\n \"print(f\\\"Using {device} device.\\\")\\n\",\n \"\\n\",\n \"\\n\",\n \"model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123) # For reproducibility due to the shuffling in the data loader\\n\",\n \"\\n\",\n \"with torch.no_grad(): # Disable gradient tracking for efficiency because we are not training, yet\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device)\\n\",\n \"\\n\",\n \"print(\\\"Training loss:\\\", train_loss)\\n\",\n \"print(\\\"Validation loss:\\\", val_loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"43875e95-190f-4b17-8f9a-35034ba649ec\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"0959c855-f860-4358-8b98-bc654f047578\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import create_dataloader_v1\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch02 import create_dataloader_v1\\n\",\n \"\\n\",\n \"# Train/validation ratio\\n\",\n \"train_ratio = 0.90\\n\",\n \"split_idx = int(train_ratio * len(text_data))\\n\",\n \"train_data = text_data[:split_idx]\\n\",\n \"val_data = text_data[split_idx:]\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_loader = create_dataloader_v1(\\n\",\n \" train_data,\\n\",\n \" batch_size=2,\\n\",\n \" max_length=GPT_CONFIG_124M[\\\"context_length\\\"],\\n\",\n \" stride=GPT_CONFIG_124M[\\\"context_length\\\"],\\n\",\n \" drop_last=True,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=0\\n\",\n \")\\n\",\n \"\\n\",\n \"val_loader = create_dataloader_v1(\\n\",\n \" val_data,\\n\",\n \" batch_size=2,\\n\",\n \" max_length=GPT_CONFIG_124M[\\\"context_length\\\"],\\n\",\n \" stride=GPT_CONFIG_124M[\\\"context_length\\\"],\\n\",\n \" drop_last=False,\\n\",\n \" shuffle=False,\\n\",\n \" num_workers=0\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"f37b3eb0-854e-4895-9898-fa7d1e67566e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Sanity check\\n\",\n \"\\n\",\n \"if total_tokens * (train_ratio) < GPT_CONFIG_124M[\\\"context_length\\\"]:\\n\",\n \" print(\\\"Not enough tokens for the training loader. \\\"\\n\",\n \" \\\"Try to lower the `GPT_CONFIG_124M['context_length']` or \\\"\\n\",\n \" \\\"increase the `training_ratio`\\\")\\n\",\n \"\\n\",\n \"if total_tokens * (1-train_ratio) < GPT_CONFIG_124M[\\\"context_length\\\"]:\\n\",\n \" print(\\\"Not enough tokens for the validation loader. \\\"\\n\",\n \" \\\"Try to lower the `GPT_CONFIG_124M['context_length']` or \\\"\\n\",\n \" \\\"decrease the `training_ratio`\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e7ac3296-a4d1-4303-9ac5-376518960c33\",\n \"metadata\": {},\n \"source\": [\n \"- We use a relatively small batch size to reduce the computational resource demand, and because the dataset is very small to begin with\\n\",\n \"- Llama 2 7B was trained with a batch size of 1024, for example\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a8e0514d-b990-4dc0-9afb-7721993284a0\",\n \"metadata\": {},\n \"source\": [\n \"- An optional check that the data was loaded correctly:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"ca0116d0-d229-472c-9fbf-ebc229331c3e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"\\n\",\n \"Validation loader:\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for x, y in train_loader:\\n\",\n \" print(x.shape, y.shape)\\n\",\n \"\\n\",\n \"print(\\\"\\\\nValidation loader:\\\")\\n\",\n \"for x, y in val_loader:\\n\",\n \" print(x.shape, y.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f7b9b1a4-863d-456f-a8dd-c07fb5c024ed\",\n \"metadata\": {},\n \"source\": [\n \"- Another optional check that the token sizes are in the expected ballpark:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"eb860488-5453-41d7-9870-23b723f742a0\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"eb860488-5453-41d7-9870-23b723f742a0\",\n \"outputId\": \"96b9451a-9557-4126-d1c8-51610a1995ab\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training tokens: 4608\\n\",\n \"Validation tokens: 512\\n\",\n \"All tokens: 5120\\n\"\n ]\n }\n ],\n \"source\": [\n \"train_tokens = 0\\n\",\n \"for input_batch, target_batch in train_loader:\\n\",\n \" train_tokens += input_batch.numel()\\n\",\n \"\\n\",\n \"val_tokens = 0\\n\",\n \"for input_batch, target_batch in val_loader:\\n\",\n \" val_tokens += input_batch.numel()\\n\",\n \"\\n\",\n \"print(\\\"Training tokens:\\\", train_tokens)\\n\",\n \"print(\\\"Validation tokens:\\\", val_tokens)\\n\",\n \"print(\\\"All tokens:\\\", train_tokens + val_tokens)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5c3085e8-665e-48eb-bb41-cdde61537e06\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we implement a utility function to calculate the cross-entropy loss of a given batch\\n\",\n \"- In addition, we implement a second utility function to compute the loss for a user-specified number of batches in a data loader\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"7b9de31e-4096-47b3-976d-b6d2fdce04bc\",\n \"metadata\": {\n \"id\": \"7b9de31e-4096-47b3-976d-b6d2fdce04bc\"\n },\n \"outputs\": [],\n \"source\": [\n \"def calc_loss_batch(input_batch, target_batch, model, device):\\n\",\n \" input_batch, target_batch = input_batch.to(device), target_batch.to(device)\\n\",\n \" logits = model(input_batch)\\n\",\n \" loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())\\n\",\n \" return loss\\n\",\n \"\\n\",\n \"\\n\",\n \"def calc_loss_loader(data_loader, model, device, num_batches=None):\\n\",\n \" total_loss = 0.\\n\",\n \" if len(data_loader) == 0:\\n\",\n \" return float(\\\"nan\\\")\\n\",\n \" elif num_batches is None:\\n\",\n \" num_batches = len(data_loader)\\n\",\n \" else:\\n\",\n \" # Reduce the number of batches to match the total number of batches in the data loader\\n\",\n \" # if num_batches exceeds the number of batches in the data loader\\n\",\n \" num_batches = min(num_batches, len(data_loader))\\n\",\n \" for i, (input_batch, target_batch) in enumerate(data_loader):\\n\",\n \" if i < num_batches:\\n\",\n \" loss = calc_loss_batch(input_batch, target_batch, model, device)\\n\",\n \" total_loss += loss.item()\\n\",\n \" else:\\n\",\n \" break\\n\",\n \" return total_loss / num_batches\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f0691332-84d0-48b3-b462-a885ddeb4fca\",\n \"metadata\": {},\n \"source\": [\n \"- If you have a machine with a CUDA-supported GPU, the LLM will train on the GPU without making any changes to the code\\n\",\n \"- Via the `device` setting, we ensure that the data is loaded onto the same device as the LLM model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"56f5b0c9-1065-4d67-98b9-010e42fc1e2a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Using mps device.\\n\",\n \"Training loss: 10.987583054436577\\n\",\n \"Validation loss: 10.98110580444336\\n\"\n ]\n }\n ],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"\\n\",\n \"print(f\\\"Using {device} device.\\\")\\n\",\n \"\\n\",\n \"\\n\",\n \"model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123) # For reproducibility due to the shuffling in the data loader\\n\",\n \"\\n\",\n \"with torch.no_grad(): # Disable gradient tracking for efficiency because we are not training, yet\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device)\\n\",\n \"\\n\",\n \"print(\\\"Training loss:\\\", train_loss)\\n\",\n \"print(\\\"Validation loss:\\\", val_loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"43875e95-190f-4b17-8f9a-35034ba649ec\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b9339f8d-00cb-4206-af67-58c32bd72055\",\n \"metadata\": {\n \"id\": \"b9339f8d-00cb-4206-af67-58c32bd72055\"\n },\n \"source\": [\n \" \\n\",\n \"## 5.2 Training an LLM\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"652a4cf4-e98f-46d9-bdec-60e7ccb8d6bd\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we finally implement the code for training the LLM\\n\",\n \"- We focus on a simple training function (if you are interested in augmenting this training function with more advanced techniques, such as learning rate warmup, cosine annealing, and gradient clipping, please refer to [Appendix D](../../appendix-D/01_main-chapter-code))\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b9339f8d-00cb-4206-af67-58c32bd72055\",\n \"metadata\": {\n \"id\": \"b9339f8d-00cb-4206-af67-58c32bd72055\"\n },\n \"source\": [\n \" \\n\",\n \"## 5.2 Training an LLM\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"652a4cf4-e98f-46d9-bdec-60e7ccb8d6bd\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we finally implement the code for training the LLM\\n\",\n \"- We focus on a simple training function (if you are interested in augmenting this training function with more advanced techniques, such as learning rate warmup, cosine annealing, and gradient clipping, please refer to [Appendix D](../../appendix-D/01_main-chapter-code))\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"Mtp4gY0ZO-qq\",\n \"metadata\": {\n \"id\": \"Mtp4gY0ZO-qq\"\n },\n \"outputs\": [],\n \"source\": [\n \"def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,\\n\",\n \" eval_freq, eval_iter, start_context, tokenizer):\\n\",\n \" # Initialize lists to track losses and tokens seen\\n\",\n \" train_losses, val_losses, track_tokens_seen = [], [], []\\n\",\n \" tokens_seen, global_step = 0, -1\\n\",\n \"\\n\",\n \" # Main training loop\\n\",\n \" for epoch in range(num_epochs):\\n\",\n \" model.train() # Set model to training mode\\n\",\n \" \\n\",\n \" for input_batch, target_batch in train_loader:\\n\",\n \" optimizer.zero_grad() # Reset loss gradients from previous batch iteration\\n\",\n \" loss = calc_loss_batch(input_batch, target_batch, model, device)\\n\",\n \" loss.backward() # Calculate loss gradients\\n\",\n \" optimizer.step() # Update model weights using loss gradients\\n\",\n \" tokens_seen += input_batch.numel()\\n\",\n \" global_step += 1\\n\",\n \"\\n\",\n \" # Optional evaluation step\\n\",\n \" if global_step % eval_freq == 0:\\n\",\n \" train_loss, val_loss = evaluate_model(\\n\",\n \" model, train_loader, val_loader, device, eval_iter)\\n\",\n \" train_losses.append(train_loss)\\n\",\n \" val_losses.append(val_loss)\\n\",\n \" track_tokens_seen.append(tokens_seen)\\n\",\n \" print(f\\\"Ep {epoch+1} (Step {global_step:06d}): \\\"\\n\",\n \" f\\\"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}\\\")\\n\",\n \"\\n\",\n \" # Print a sample text after each epoch\\n\",\n \" generate_and_print_sample(\\n\",\n \" model, tokenizer, device, start_context\\n\",\n \" )\\n\",\n \"\\n\",\n \" return train_losses, val_losses, track_tokens_seen\\n\",\n \"\\n\",\n \"\\n\",\n \"def evaluate_model(model, train_loader, val_loader, device, eval_iter):\\n\",\n \" model.eval()\\n\",\n \" with torch.no_grad():\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\\n\",\n \" model.train()\\n\",\n \" return train_loss, val_loss\\n\",\n \"\\n\",\n \"\\n\",\n \"def generate_and_print_sample(model, tokenizer, device, start_context):\\n\",\n \" model.eval()\\n\",\n \" context_size = model.pos_emb.weight.shape[0]\\n\",\n \" encoded = text_to_token_ids(start_context, tokenizer).to(device)\\n\",\n \" with torch.no_grad():\\n\",\n \" token_ids = generate_text_simple(\\n\",\n \" model=model, idx=encoded,\\n\",\n \" max_new_tokens=50, context_size=context_size\\n\",\n \" )\\n\",\n \" decoded_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \" print(decoded_text.replace(\\\"\\\\n\\\", \\\" \\\")) # Compact print format\\n\",\n \" model.train()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a301b333-b9d4-4eeb-a212-3a9874e3ac47\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's train the LLM using the training function defined above:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 27,\n \"id\": \"3422000b-7aa2-485b-92df-99372cd22311\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"3422000b-7aa2-485b-92df-99372cd22311\",\n \"outputId\": \"0e046603-908d-4093-8ae5-ef2f632639fb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ep 1 (Step 000000): Train loss 9.817, Val loss 9.924\\n\",\n \"Ep 1 (Step 000005): Train loss 8.066, Val loss 8.332\\n\",\n \"Every effort moves you,,,,,,,,,,,,. \\n\",\n \"Ep 2 (Step 000010): Train loss 6.619, Val loss 7.042\\n\",\n \"Ep 2 (Step 000015): Train loss 6.046, Val loss 6.596\\n\",\n \"Every effort moves you, and,, and, and,,,,, and, and,,,,,,,,,,, and,, the,, the, and,, and,,, the, and,,,,,,\\n\",\n \"Ep 3 (Step 000020): Train loss 5.524, Val loss 6.508\\n\",\n \"Ep 3 (Step 000025): Train loss 5.369, Val loss 6.378\\n\",\n \"Every effort moves you, and to the of the of the picture. Gis. \\n\",\n \"Ep 4 (Step 000030): Train loss 4.830, Val loss 6.263\\n\",\n \"Ep 4 (Step 000035): Train loss 4.586, Val loss 6.285\\n\",\n \"Every effort moves you of the \\\"I the picture. \\\"I\\\"I the picture\\\"I had the picture\\\"I the picture and I had been the picture of\\n\",\n \"Ep 5 (Step 000040): Train loss 3.879, Val loss 6.130\\n\",\n \"Every effort moves you know he had been his pictures, and I felt it's by his last word. \\\"Oh, and he had been the end, and he had been\\n\",\n \"Ep 6 (Step 000045): Train loss 3.530, Val loss 6.183\\n\",\n \"Ep 6 (Step 000050): Train loss 2.960, Val loss 6.123\\n\",\n \"Every effort moves you know it was his pictures--I glanced after him, I had the last word. \\\"Oh, and I was his pictures--I looked. \\\"I looked. \\\"I looked. \\n\",\n \"Ep 7 (Step 000055): Train loss 2.832, Val loss 6.150\\n\",\n \"Ep 7 (Step 000060): Train loss 2.104, Val loss 6.133\\n\",\n \"Every effort moves you know the picture to me--I glanced after him, and Mrs. \\\"I was no great, the fact, the fact that, the moment--as Jack himself, as his pictures--as of the picture--because he was a little\\n\",\n \"Ep 8 (Step 000065): Train loss 1.691, Val loss 6.186\\n\",\n \"Ep 8 (Step 000070): Train loss 1.391, Val loss 6.230\\n\",\n \"Every effort moves you?\\\" \\\"Yes--quite insensible to the fact with a little: \\\"Yes--and by me to me to have to see a smile behind his close grayish beard--as if he had the donkey. \\\"There were days when I\\n\",\n \"Ep 9 (Step 000075): Train loss 1.059, Val loss 6.251\\n\",\n \"Ep 9 (Step 000080): Train loss 0.800, Val loss 6.278\\n\",\n \"Every effort moves you?\\\" \\\"Yes--quite insensible to the fact with a laugh: \\\"Yes--and by me!\\\" He laughed again, and threw back the window-curtains, I saw that, and down the room, and now\\n\",\n \"Ep 10 (Step 000085): Train loss 0.569, Val loss 6.373\\n\",\n \"Every effort moves you?\\\" \\\"Yes--quite insensible to the irony. She wanted him vindicated--and by me!\\\" He laughed again, and threw back his head to look up at the sketch of the donkey. \\\"There were days when I\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Note:\\n\",\n \"# Uncomment the following code to calculate the execution time\\n\",\n \"# import time\\n\",\n \"# start_time = time.time()\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model = GPTModel(GPT_CONFIG_124M)\\n\",\n \"model.to(device)\\n\",\n \"optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)\\n\",\n \"\\n\",\n \"num_epochs = 10\\n\",\n \"train_losses, val_losses, tokens_seen = train_model_simple(\\n\",\n \" model, train_loader, val_loader, optimizer, device,\\n\",\n \" num_epochs=num_epochs, eval_freq=5, eval_iter=5,\\n\",\n \" start_context=\\\"Every effort moves you\\\", tokenizer=tokenizer\\n\",\n \")\\n\",\n \"\\n\",\n \"# Note:\\n\",\n \"# Uncomment the following code to show the execution time\\n\",\n \"# end_time = time.time()\\n\",\n \"# execution_time_minutes = (end_time - start_time) / 60\\n\",\n \"# print(f\\\"Training completed in {execution_time_minutes:.2f} minutes.\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2e8b86f0-b07d-40d7-b9d3-a9218917f204\",\n \"metadata\": {},\n \"source\": [\n \"- Note that you might get slightly different loss values on your computer, which is not a reason for concern if they are roughly similar (a training loss below 1 and a validation loss below 7)\\n\",\n \"- Small differences can often be due to different GPU hardware and CUDA versions or small changes in newer PyTorch versions\\n\",\n \"- Even if you are running the example on a CPU, you may observe slight differences; a possible reason for a discrepancy is the differing behavior of `nn.Dropout` across operating systems, depending on how PyTorch was compiled, as discussed [here on the PyTorch issue tracker](https://github.com/pytorch/pytorch/issues/121595)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 28,\n \"id\": \"0WSRu2i0iHJE\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 487\n },\n \"id\": \"0WSRu2i0iHJE\",\n \"outputId\": \"9d36c61b-517d-4f07-a7e8-4563aff78b11\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAeoAAAEiCAYAAAA21pHjAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAATyBJREFUeJzt3QdclPUfB/APe8mWISoIouLemjvT3CMrbZiZlpZaajZt2jBLy4aZpf3TLE3LcuQ2U9x774migqAgU/b9X9/fcceBSIDAHcfn/Xo93nru7rmfx32f3/xaaDQaDYiIiMgkWRr7AIiIiOjuGKiJiIhMGAM1ERGRCWOgJiIiMmEM1ERERCaMgZqIiMiEMVATERGZMAZqIiIiE8ZATUREZMIYqInMQFhYGCwsLHDo0CFjHwoRlTAGaiITIYG2oG3SpEnGPkQiMgJrY7wpEd0pIiJCf33x4sV47733cPr0af19lSpVYrERVUCsUROZCF9fX/3m6uqqatG6297e3pg+fTqqVasGOzs7NGnSBGvXrr3ra2VmZmL48OEICQnB5cuX1X3Lly9Hs2bNYG9vj6CgIHzwwQfIyMjQP0fe78cff8SAAQPg6OiIWrVqYcWKFfrHY2NjMXjwYHh5ecHBwUE9Pnfu3Lsew5IlS9CwYUO1r6enJ7p27YqkpCT94/JedevWVccjx/ndd9/len54eDgGDRoENzc3eHh4oH///qqJX+eZZ57BQw89hM8//xxVqlRR7zFmzBikp6cXo/SJTJhkzyIi0zJ37lyNq6ur/vb06dM1Li4umt9++01z6tQpzeuvv66xsbHRnDlzRj1+8eJFyYKnOXjwoCYlJUUzYMAATdOmTTVRUVHq8S1btqjnz5s3T3P+/HnN+vXrNTVq1NBMmjRJ/x7y/GrVqmkWLlyoOXv2rGbs2LGaSpUqaW7evKkeHzNmjKZJkyaavXv3qvfbsGGDZsWKFfke/7Vr1zTW1tbquGXfI0eOaGbOnKlJSEhQj//666+aKlWqaP7880/NhQsX1KWHh4c6PpGWlqapW7euZvjw4eq5J06c0Dz55JOaOnXqaFJTU9U+Q4cOVZ/phRde0Jw8eVLz999/axwdHTWzZ88utf8XImNgoCYqB4Haz89PM3ny5Fz7tGzZUjN69OhcgXrr1q2aLl26aNq3b6+5deuWfl+575NPPsn1/F9++UUFSx15/jvvvKO/nZiYqO5bs2aNut23b1/NsGHDCnX8+/fvV88NCwvL9/GaNWuqEwJDH330kaZNmzb6Y5OgnJWVpX9cArSDg4Nm3bp1+kAdEBCgycjI0O8zcOBAzWOPPVaoYyQqL9hHTWTi4uPjce3aNbRr1y7X/XL78OHDue574oknVPP4v//+q5qcdWS/7du3Y/Lkybmax1NSUpCcnKyaukWjRo30jzs5OcHFxQVRUVHq9qhRo/DII4/gwIED6Natm2p2btu2bb7H3LhxY3Tp0kU1fXfv3l3t/+ijj8Ld3V01f58/fx7PPvssRowYoX+ONMNLk7/ueM+dOwdnZ+dcryvHK8/VqV+/PqysrPS3pQn86NGjhS5bovKAgZrIjPTq1Qu//vordu7ciQceeEB/f2JiouqTfvjhh+94jvQR69jY2OR6TPqts7Ky1PWePXvi0qVLWL16NTZs2KACsfQJSx9xXhI8ZZ8dO3Zg/fr1mDFjBt5++23s3r1bf1IwZ84ctG7d+o7n6Y63efPmWLBgwR2vLX3khTleInPBQE1k4qRW6+fnp2rEnTp10t8vt1u1apVrX6n1NmjQAP369cOqVav0+8sgMhlBHhwcfE/HIkFy6NChauvQoQNee+21fAO1LmhKrV82GcEeEBCApUuXYsKECerzXLhwQQ1Oy48cr4x8l0F08vmJKjIGaqJyQALi+++/j5o1a6oR3zLaWhY3ya/G+dJLL6lm7T59+mDNmjVo3769CpRy29/fXzVBW1paqublY8eO4eOPPy7UMchrSC1XmptTU1OxcuVKNWo7P1Jz3rhxo2rylmArt6Ojo/X7S+1+7Nixqqm7R48e6vX27dunRpZLIJcAPm3aNDXS+8MPP1TN+VKb/+uvv/D666+r20QVBQM1UTkgQS0uLg6vvPKK6jOuV6+emjolU6TyM378eNUELE3hMo1L+oklsErQ++yzz1STsUyJeu655wp9DLa2tpg4caKaIiX931KjXrRoUb77Si14y5Yt+Oqrr1Qfu9Smv/jiC9V8LuR9pQlcgrGchEh/uPRny3ELeUye/8Ybb6jm+oSEBFStWlU1t7OGTRWNhYwoM/ZBEBERUf644AkREZEJY6AmIiIyYQzUREREJoyBmoiIyIQxUBMREZkwBmoiIiITxkB9FzNnzkSNGjXU8oqyzOGePXvK9n/GRMnc1r59+6qVpWTlqWXLluV6XGb7ycIYsuayzLWV1IZnz57NtU9MTIxa0ELmw0oKQ1nzWZaMNHTkyBE1T1fKv3r16pg6deodx/LHH3+oucCyj8zBlaUty7MpU6agZcuWan1rWSRE1tI2zEetW+talu2UlI6Sn1rW3r5+/XqufSStZe/evdVcZHkdmadsmM5SbN68Wa3+JSkzZbWyefPmVYi/gVmzZqn1zOW7J1ubNm3UojA6LN+S9emnn6rfCd38eJZxMRk7K4gpWrRokcbW1lbz008/aY4fP64ZMWKExs3NTXP9+nVNRbd69WrN22+/rfnrr79UdqSlS5fmevzTTz9VWZ+WLVumOXz4sKZfv36awMBAze3bt/X79OjRQ9O4cWPNrl27VLan4OBgzRNPPKF/PC4uTuPj46MZPHiw5tixYyq1o2RN+uGHH/T7bN++XWNlZaWZOnWqSoEoWZ8k7ePRo0c15VX37t1V1iz5zIcOHdL06tVL4+/vr7JY6UhKx+rVq2s2btyo2bdvn+a+++7TtG3bVv+4ZJJq0KCBpmvXrirlpfx/Va5cWTNx4kT9PpJWUtJBTpgwQZXdjBkzVFmuXbvW7P8GJC3nqlWrVHrQ06dPa9566y31vZEyFyzfkrNnzx6VSrVRo0aacePG6e9nGRcdA3U+WrVqpXLv6mRmZqo0g1OmTClGEZuvvIFaUhL6+vpqpk2bpr9PUi3a2dmpYCskMMjzJKexjqRRtLCw0Fy9elXd/u677zTu7u76vMPijTfeUGkPdQYNGqTp3bt3ruNp3bq15vnnn9eYC8klLWUVGhqqL0sJKn/88Yd+H8nDLPvs3LlT3ZbAbGlpqYmMjNTvM2vWLJW3WVeeksu6fv36ud5LUkPKiUJF/BuQ79qPP/7I8i1Bkne8Vq1aKmd5p06d9IGa3+HiYdN3Hmlpadi/f79qstWRdZHltmQkoru7ePEiIiMjc5WdrOUszaa6spNLae5u0aKFfh/ZX8pY1oPW7dOxY0e1ZKWOLIEpzcCyFrRuH8P30e1jTv9HsmSo8PDwUJfyvUxPT8/1uaXpX9bvNixf6Qbw8fHJVS6yjOfx48cLVXYV5W9A1kOXJVAl7aY0gbN8S450z0j3S97vGcu4eLjWdx43btxQf8CGP3RCbp86daqYxVwxSJAW+ZWd7jG5lH5TQ9bW1ioYGe4TGBh4x2voHpOcxnJZ0PuUd7JOt/TrSeYpyYYl5LPJyYuc6BRUvvmVi+6xgvaRYH779m11MmTOfwOSr1oCs/RHSz+/ZPSStdMlyQnL997JyY/kLN+7d+8dj/E7XDwM1EQmWiORzFbbtm0z9qGYnTp16qigLC0WS5YsUSk7Q0NDjX1YZiE8PBzjxo1TucgN85zTvWHTdx6VK1dWyevzjqSV276+vvdY3OZNVz4FlZ1cSvYnQzIiWUaCG+6T32sYvsfd9jGH/6MXX3xRZbratGlTrnSO8tmkWfrWrVsFlm9xy05GQctIfXP/G5Bas4x0l5SdMtK+cePG+Prrr1m+JUCatuXvW2YUSEuZbHIS9M0336jr0irD73DRMVDn80csf8CSS9ewGVJuS3MZ3Z00V8sPuWHZSXOq9D3ryk4uJdDIH7TOv//+q8pY+rJ1+8g0MOmP1ZEzdKkJSbO3bh/D99HtU57/j2R8ngRpaYqVMsnb/C/fS0lPafi5pd9epmMZlq807RqeDEm5SBCW5t3ClF1F+xuQzyb5sFm+907SkMr3T1osdJuMR5HpmLrr/A4XQzEHoZk1mZoiI5XnzZunRimPHDlSTU0xHElbUcloTpn2I5t8faZPn66uX7p0ST89S8pq+fLlmiNHjmj69++f7/Sspk2banbv3q3Ztm2bGh1qOD1LRobK9KwhQ4aoaTPy/yHTifJOz7K2ttZ8/vnnauTz+++/X+6nZ40aNUpNbdu8ebMmIiJCvyUnJ+ea2iJTtv799181PatNmzZqyzs9q1u3bmqKl0y58vLyynd61muvvabKbubMmflOzzLHv4E333xTjaK/ePGi+n7KbZlxsH79evU4y7fkGY76ZhkXDwP1XcjcUvlBlLmkMlVF5vySRrNp0yYVoPNuQ4cO1U/Revfdd1WglR/6Ll26qPmqhm7evKkCc6VKldS0oWHDhqkTAEMyB7t9+/bqNapWrapOAPL6/fffNbVr11b/RzLdSObHlmf5latsMrdaR054Ro8eraYUSbAdMGCACuaGwsLCND179lRzz2UO9SuvvKJJT0+/4/+xSZMmquyCgoJyvYc5/w0MHz5cExAQoD6TnMDI91MXpAXLt/QDNcu46Czkn+LUxImIiKj0sY+aiIjIhDFQExERmTAGaiIiIhPGQE1ERGTCGKiJiIhMGAM1ERGRCWOgLoCsVjRp0iR1SSWP5Vu6WL6lj2XM8i0LnEddAFn+UtI0yuL9sgQjlSyWb+li+ZY+ljHLtyywRk1ERGTCGKiJiIhMmNnno5YUigcPHlTp1Swti3ZekpCQoC6vXr2qmrioZLF8SxfLt/SxjFm+95K1TVLHNm3aVKUALYjZ91Hv3bsXrVq1MvZhEBER3WHPnj1o2bIlKnSNWmrSusKoUqWKsQ+HiIgIERERqhKpi1EVOlDrmrslSFerVs3Yh0NERKRXmC5Zow4m27JlC/r27Qs/Pz9YWFhg2bJluR6XVvn33ntPBVkHBwd07doVZ8+eNdrxEhERlTWjBuqkpCQ0btwYM2fOzPfxqVOn4ptvvsH333+P3bt3w8nJCd27d0dKSkqZHysREZExGLXpu2fPnmrLj9Smv/rqK7zzzjvo37+/um/+/PmqPV9q3o8//ngZHy0REVHZM9k+6osXLyIyMlI1d+vIKmGtW7fGzp077xqoZUk/wyU/ddMniIgKIzMzE+np6Swsuic2NjawsrKCWQdqCdIi74g4ua17LD9TpkzBBx98UOrHR0TmRVrx5Lfl1q1bxj4UMhNubm7w9fVVY7DMMlAX18SJEzFhwgT9bVmspF69eiXz4pkZwL8fAoGdgOAuJfOaRGQSdEHa29sbjo6O9/zjShX7pC85ORlRUVHq9r1ODTbZQC1nIUJWbjH8kHK7SZMmd32enZ2d2nRKckWx6/98BZ+dXwMHfgGeDwXc/EvstYnIuM3duiDt6enJ/wq6ZzJTSUiwlu/VvTSDm+xa34GBgSpYb9y4MVfQldHfbdq0KfPjiYi7ja5ba+FwVhBwOwZYPARI5+hzInOg65OWmjRRSdF9n+51zINRA3ViYiIOHTqkNt0AMrl++fJl1ew0fvx4fPzxx1ixYgWOHj2Kp59+Ws25fuihh8r8WKu4OuCRVsEYlTYesXABIg4Bq1+RNo4yPxYiKh1s7iZT/D4ZNVDv27dPLUgum5C+Zbkui5yI119/HS+99BJGjhyp1kKVwL527VrY29sb5Xjf7BkCZ59AjEl7EVlSdAd/BfbPM8qxEBFRxWDUQH3//ferTve827x58/RnIx9++KEa5CGLnPzzzz+oXbu20Y7X3sYKXz/RBPssG2Fq+iDtnWteB67sN9oxERGVtBo1aqh1LApr8+bN6ve6tEfMz5s3T42krmhMto/aVIX4uuDNHiH4PrMv1me1BDLTgN+HAInRxj40IqpgJDgWtE2aNKnYWQelJbOw2rZtq5JMyFoXVPJMdtS3KRvWrgZCz0RjwpnnscbxGqrHXwWWDAOGLAOsWKREVDYkOOosXrxYdRuePn1af1+lSpX016W1Uka3/1fuY+Hl5VWk47C1tdXP1KGSxxp1MciZ6rSBjWDn5IZht8chzdIBCNsKbORCK0RUdiQ46japzcpvk+72qVOn4OzsjDVr1qB58+Zq2uq2bdtw/vx5tSyzLB4lgVzG/0i3YkFN3/K6P/74IwYMGKBGMteqVUsN8r1b07euiXrdunWoW7euep8ePXrkOrHIyMjA2LFj1X4yJe6NN97A0KFDizxYeNasWahZs6Y6WahTpw5++eWXXCcn0qrg7++vPr8MRpb31Pnuu+/UZ5FxT1Iejz76KEwRA3UxeTvbY+qjjXBOUw3jU0Zo79zxDXBieQn+9xCRURetSMswyibvXVLefPNNfPrppzh58iQaNWqkBuX26tVLTX09ePCgCqCSxVBm2xREVnwcNGgQjhw5op4/ePBgxMTE3HV/WfDj888/V4FTMiXK67/66qv6xz/77DMsWLAAc+fOxfbt29X027wZFP/L0qVLMW7cOLzyyis4duwYnn/+eQwbNgybNm1Sj//555/48ssv8cMPP6jMi/L6DRs21A9mlqAt46CkFUIGKnfs2BGmiO2096BLXR883SYA83cCv1iGYUjWCmDVq0CtboCNdrI7EZVPt9MzUe+9dUZ57xMfdoejbcn8PEsgevDBB/W3PTw8VNZCnY8++kgFPKkhv/jii3d9nWeeeQZPPPGEuv7JJ5+ozIZ79uxRgT4/MndYMh9KbVfIa8ux6MyYMUOtJCm1dPHtt99i9erVRfpsn3/+uTqu0aNH62cO7dq1S93fuXNndXIgrQuSM0LW3paadatWrdS+8phkZOzTp49qeQgICNDPQDI1rFHfo7d61UUt70qYlDwQ2yp1h2bIXwzSRGQyWrRokeu21KilZitN0tLsLM3SUtv+rxq11MZ1JMC5uLjol8jMjzSR64K0kBUmdfvHxcWpVSZ1QVPIyl3SRF8UJ0+eRLt27XLdJ7flfjFw4EDcvn0bQUFBGDFihDohkSZ3IScvEpzlsSFDhqjavbQCmCLWqEtiytbjTfHQzO146sZQfBzmgqc4poKo3HOwsVI1W2O9d0mRoGpIgvSGDRtUrTM4OFgtdSl9s2lpaQW+jtRIDUmfdFZWVpH2L8km/cKoXr26ataWPnj5zFLznjZtGkJDQ1Ut+sCBA6p/ff369WognvRny4h3U5sCxhp1Cajn54LXe9RR1z9edQLnohKA8D3A3v+VxMsTkRFIYJHmZ2NspblCmvQHS3OxNDlLf600DYeFhaEsycA3GbwlQVFHRqRL4CyKunXrqs9jSG4bJmKSExHpg5emegnKkiZZVroUMgJemsWnTp2q+t6lHP7991+YGtaoS8jwdoFqytbWszcw7dcV+D5xHCw0mYBXCFAjd9MMEZGxyCjnv/76SwUvOSF49913C6wZlxZZdVLSEkutPiQkRPVZx8bGFukk5bXXXlMD3KRvWQLu33//rT6bbhS7jD6XE4DWrVurpvhff/1VBW5p8l65ciUuXLigBpC5u7ur/nEpBxk5bmpYoy6pgrS0wBcDG8PDyRbrolxxxKMbULcfUCVn0AYRkbFNnz5dBSZZpESCdffu3dGsWbMyPw6ZjiWD0ySHgyRakr5yOZaiLBH90EMP4euvv1bN+PXr11eju2UUuax6KaQJe86cOarfWvrYJYBLMJfpYPKYBPUHHnhA1cxl4Ntvv/2mXsfUWGjKutOgjF25ckX1U4SHh6NatWql/n4bTlzHiPn7YI0MzB3eBh1qe5f6exLRvZEliiUpkGTtM1YugYpOarMSMKWGLCPRzf17daUIsYk16hL2YD0fDG7tjwxY45U/jiAmKU2bYetc7gUFiIgqskuXLqna7pkzZ1Sf8ahRo1RQe/LJJ419aCaHgboUvNO7Hmp6OSEqIRVvLDkMzZLhwK+PAAfml8bbERGVO5aWlqoPWVZGk6ZpCdbSNC21asqNg8lKgYOtdsrWgO+2Y8PJKBxpWBWqp1oWQ/FpAFQt+/4gIiJTIs2+eUdsU/5Yoy4lDaq64vXuIer646faILFGNyAzFfj9aSDpZmm9LRERmRkG6lL0bPtAtA+ujNvpwLBbz0LjHgTEhQN/DgeyMkvzrYmIyEwwUJf2lK1BjeHuaIO9kZn4sepHgI0jcGEz8O/HpfnWRERkJhioS5mPiz0+fUS7Ru7kfRY43foT7QPbpgMnV5b22xMRUTnHQF0Gutf3xROt/NX1p/dUR0rz57UPLH0BuHG2LA6BiIjKKQbqMvJun7oI8nLC9fhUvBz7MDQBbYG0BGDxU0BqYlkdBhERlTMM1GVEFtr/5vGmsLGywJoTN7E8eDLgXAWIPgWseFG7KAoRkRHIkpvjx4/X365Rowa++uqrAp8ja3IvW7bsnt+7pF6nIJIVq0mTJiivGKjLeMrWq920C75PXB+FKw/OAixtgONLgZ0zy/JQiMgMyFrdPXr0yPexrVu3qiAoWaGKSrJajRw5EmURLCMiItCzZ88SfS9zw0BdxkZ0CELbmp64nZ6JUaE2yOg2GXDyBvyalvWhEFE59+yzz6o8y7JudF6SnKJFixYqGUVReXl5qWxTZUHSbNrZ2ZXJe5VXDNRlXeCWFpg+qAlcHWxw9GocPo/pCIzZzVSYRFRkffr0UUFVluI0lJiYiD/++EMF8ps3b6osVVWrVlXBV3JQS5aoguRt+j579qxKBymJJSTXs5wc5JcNq3bt2uo9goKCVPrM9PR09Zgc3wcffIDDhw+rWr5sumPO2/QtS4lKRitJRylZrkaOHKk+j47k0pasWZIxq0qVKmqfMWPG6N+rsAlAPvzwQ5UMQ04SpKa/du1a/eNpaWl48cUX1evLZ5a0mJKSU0geK2kd8Pf3V8/18/PD2LFjUZq4hKgR+Lra47NHGuKFXw/gh60X0LGOF9rWzH7w8i7AzhnwMb1Ua0QVUlpS0Z9jZQdYZf+8ZmZoVyW0sARsHP77dW2dCv021tbWKk2kBL23335bn8tZgrTkYZYALUGuefPmKpC6uLhg1apVGDJkCGrWrIlWrVoVKqg9/PDD8PHxwe7duxEXF5erP1vH2dlZHYcELgm2I0aMUPe9/vrreOyxx3Ds2DEVDHW5ol1dXe94jaSkJJXqUtJeSvN7VFQUnnvuORU0DU9GNm3apIKoXJ47d069vgRbec/CkNSYX3zxhUqLKbmsf/rpJ/Tr1w/Hjx9X+bq/+eYbrFixAr///rsKyJLhSjbx559/4ssvv8SiRYtUSszIyEh1AlJhA7V80eTMRZJ9S2HIF0DOpt55550iJRc3RT0aVMHjLatj0d5wTFh8GGvHd4DbzcPALw8Dto7A8HWApy56E5HRfOJX9OcMnAfUH6C9fupv4I9ngID2wLBVOft81RBIzmc54UlxRXqr4cOHY9q0aQgNDdXnYZZm70ceeUQFQ9leffVV/f4vvfQS1q1bp4JQYQK1BNZTp06p58hvsPjkk0/u6FeW32XDGrm8pwQzCdRSO5Z803JiIU3dd7Nw4UKVGnL+/PlwctKesHz77beqL/6zzz5TJwtC8mnL/VZWVggJCUHv3r2xcePGQgdqqY3Licvjjz+ubstrS9CXVoSZM2fi8uXLKmC3b99exRqpUevIY/IZunbtChsbGxXIC1OOZtv0LYU3a9Ys9R9y8uRJdXvq1KmYMWMGzMF7feshqLITIuNTMPGvo9B4BgOeQdrEHTIinIjoP0igatu2raoVCqlhykAyafbWVXgkv7M0eXt4eKiAKUFXAk5hyG+vJNDQBWkhNd68Fi9erLJgSRCT95DAXdj3MHyvxo0b64O0aNeunarVnz59Wn+f1GQlSOtI7Vpq34URHx+Pa9euqdc1JLfl/YVUCA8dOoQ6deqoZu3169fr9xs4cCBu376tmvflxGDp0qXIyMhAha1R79ixA/3791dnS7qzNOlb2bNnD8xlytZXjzfBw9/twJpjkfi9jhcee3qFdplRGyavJzIJb10rXtO3Tkhf7WtI07eh8UdRUiQoS01ZaoNSm5Zm7U6dOqnHpLYtTb1SW5RgLUFQmq6lH7ak7Ny5E4MHD1b90NJ0LbV4qU1L83JpsLGxyXVbar0SzEtKs2bNVG7sNWvWqBaFQYMGqRr0kiVL1EmLnDTI/dJXP3r0aH2LRt7jqhA1ajlLlOYMSSwupB9g27ZtZjWUv1E1N7ySPWXr3WXHsec6coK0zK2WaVvxxfihIKKSIX3GRd10/dNCrst9hv3TBb1uMUggkfzO0nQszcbSHK7rHpRUklLheeqpp1RtVWqCut/UwpD80NI/K9OodHbt2nVHpUqah6WfXEaaS7PxpUuXcn9cW1tVu/+v95Lfeemr1tm+fbv6bFK7LQnSTy+tA3lTbMptGShnuJ/0fc+ZM0e1FkjfdExMjHpMmvKlOV76sjdv3qxOVKRfvkLWqN98803VTCFNO9LMIf/JkydPVmdud5Oamqo2nYSEBJi65zsG4XD4Law9HomRv+zDX6PaIsirErD9a+Cf94F9PwHPrAactf0zRESGpKlZgsrEiRPVb6Y03epI0JSaoART6dudPn06rl+/nisoFURqkjKae+jQoarmKK8vAdmQvIc0c0stumXLlmrAmjQJG5IWUamlSpOyjLaWgWZ5p2XJb/v777+v3kvGJ0VHR6uWAhn8puufLgmvvfaaeh9peZBBaNIKIce1YMEC9biUkTSny0AzOUmQwXnSpO/m5qYGtUksat26tRrhLmOoJHAb9mNXqBq1DHaQgpOzxAMHDuDnn39WgwDk8m5kCL1uAIVshf0yGnvK1pePNUHj6m64lZyO4fP2IiYpDWjwMOBaHbh5Dpjfn3msiajA5u/Y2FjV9GzYnyx9xdKUK/fLYDMJODK9qfC/T5Yq6Eq/rAyaklHYUmEyJCOmX375ZTU6WwKfnBTI9CxDMrhNFmfp3LmzmlKW3xQxCXzSfy41Vwn4jz76KLp06aLGKZUk6XeeMGECXnnlFdUdIKPRZZS3nHAIOYmQ8VDSOiDHERYWhtWrV6uykGAttWzp05Y56tIE/vfff6tpYqXFQiOTwkyU9AVIrVrmyOl8/PHH6gxGRiEWpkZ99epVFayl6UbO4kxZdEIqBny3HVdib6N5gDsWPNca9vFhwLzeQEIE4NsQGPo34OBu7EMlMisy0lhqe4GBgWreLFFpf69kkRqJcYWJTSZdo05OTlZnMIakCbygQQPSlCJ9C7pNzozKCy9nO8wb1hIu9tbYfykWr/5xGFnuQYAMMHPyAiKPaqdvpcQb+1CJiKiMmHSgls56aWKR/g5pepDmF+k7GDAge36iGQr2dsb3Q5qr5B0rj0Tg8/WnAa/a2mDt4AFcOwAsGMiMW0REFYRJB2qZLy19FDL8XUYDygT6559/Xs0JNGdta1bGlIe16/N+t/k8Fu25DPjUA4YsBexcgfBdwG+PA2nJxj5UIiKqyIFamq1l7p8M85eBDOfPn1d91DLM39w92rwaxnbRDmx4e9kxbD0bDfg1AYb8BdhWAsK2AosHAxk5/fFERGR+TDpQV3Qvd62FAU2rIjNLg9G/HsDpyASgWgtg8B/aRVHO/wv8PhTIKLmFC4iIyLQwUJswWbDg00caolWgBxJSMzBs7h5ExacAAW2BJxYB1vbAmTXA0pHaxVGI6J6U5OpWRFkl9H0y6QVPCLCztsLsIc3x8KwduBCdhGd/3ofFz98Hx6BOwGMLgN+HACF9JKqzuIiKSbrTZIaJrAEtc3zldnlP/EPGI7OeZYlWWbBFvlf32l1r0vOoS0JR5qqZsks3kzDgux1qIZSudb3xw5AWsLK0ABKjgUpexj48onJPflhlmUyZFkpUEmQBF1nhLL9AXZTYxBp1ORHg6YQ5T7fAE3N24Z+TUfho5QlM6lc/d5CWNcEPLQA6vMoaNlERyY+ppCyUTEj/tSY10X+RNT8krWdJtMwwUJcjslrZl4OaYMzCA5i3IwwBno4Y1i5Q+2B6CjCvDxBzXnu742tGPVai8kh+VCUDUmllQSIqDg4mK2d6N6qCN3uGqOsfrjyBDSck3VZ2xq324wH3QKDRY8Y9SCIiKjEM1OWQZNt6opW/Gug99reDOHolTvtAs6eB0TsBN39jHyIREZUQBupy2jz3Uf/66FjbC7fTMzH85724Eps9AMYw5+3Jv4EdM4x2nEREdO8YqMspaytLzHyyKUJ8nVXWLUmNGZ+SnrND1CntYijr3wF2/2DMQyUionvAQF2OOdvb4KdnWsLHxQ5nrieq1cvSM7Mn2HuHAB0maK+veR2Y2wvYPw+4HWvUYyYioqJhoC7n/Nwc8L+hLeFoa4Vt527gnaXH1GR7pfPbQIdXpLEcuLQd+Hsc8HltYNFg4MQK7UhxIiIyaQzUZqBBVVd8+2RTyPoni/eFq4xbiszf6/Ie8PIxoOsHgHd9IDMNOLVSu6KZBO0VLwEXt8raicb+GERElA8GajPxQIiPdgEUANPWncaKw9dyHnStpp26NXoH8MJ2oN04wKUqkBoHHJgP/NwH+KohcPYf430AIiLKFwO1GXm6TQ082167AMqrfxzGvrCYO3fybQA8+CEw/hgwdKV2SpfkuI6/ArhWzdnv5nkg7koZHj0REeWHgdrMvNWrLrrX90FaRhZGzN+HizeS8t/R0hII7AD0mwG8egZ46k/Au27O45smA1824IhxIiIjY6A2M5Ko46vHmqJxNVfEJqer1JiSyKNAsqpZcNec2zIYLSVergDVWubcH3lUOzc7I7X0PgAREeXCQG2GHGyt8OPQlqjq5oCwm8kYOX8f4m4bzLH+LzII7aklwMvHAb+mOffv+h5Y/BTweS1gxVggbDsHoRERlTIm5TBTXs52mDespcpjve9SLNpO2aiWHR3ePlBN6SoUGYRmyD0AcPYDEq4BB37Wbtb2gIM74OCRfemWfZm9BXYCqjXXPl9q4olR2vvtKpX8hyYiMkPMR23m9l+KwdtLj+FUZIK6bW1pgX6N/TCiYxDqVnEp+gtmZWrnZB9ZrJ2LnSpN5AWQgWsyylxcPQDM6awdcT7hRM4+K18GEiINAnx2sK/kCzhXAVyqAE7egBXPK4nIPDAfNek1D/DAmnEdEHomGj+EXsDOCzfx18GrautU2wvPdwpCmyDPwudMtbQCAjtqt95fAgkR2tXO7rb5Nsx5bloiYGWrDcKGZB73zbMFv6+FJVDJB3CW4O0HNH4MqNdf+5gs3BJ7UftY3tcmIirnWKOuYI5cuYUftlzAmqMRyMpewKxhVVcVsHvU91VriJcqGagmTeAygE3n9Nr8A77UsuV+udRk5n6dbh8DbV/KXVOX2vcrp3L2CZ2qrfFLYJcg7pJ9KftZ25Xu5yQiKgBr1HRXjaq5YeaTzXD5ZjJ+3HYBv+8Lx9GrcXhx4UFU93DAiA5BGNi8uhqQViqk5m4YpEWdHv/d3J50Q9s3Hi+BOwKo3jrn8dQEwN5NG4QNHVqorWnnx95VW0OXJvVKsvkAlbyAoM5A1WY576vJAqxsivVRicjEZaQCyTHA7RjtZfLN7Os3geRYg+vZl9JC+NgvZX6YrFFXcDJ1a/7OMPy8I0xN5xLujjZq8ZSn2wTAs1I5qnlmpucOqrtnA7Fh2bXyCCD+mrZ2nlnA9LLunwBtxmivX9kH/NgF8GkIjNqWe/R7RkpOcFeXPoCjp7ZrQMiSrFkZQFa69rhk0J3uBCX9NhB3VTuX3SMo53WvHdK2AMjzMjNyni+X0hIhLQFu1bUtBOyvp4omK0u7BLLub0pt+d2Wv580oEb73L8FV/YAzYZq148Qp1YDi54o2jFUaQw8v6VEPg5r1FRoHk62GN+1Np7vWBNL9odjztaLuByTjK83nsUPW86r2vVzHQIR4Olk+qWat+bbeuSd+0jAk2b1pGgg8bp2FLrarmvv822Us6/cn9/r7voOuHUp/350SxvtD4fUxA31+BS4b1ROQJ7bA/CoCYw9kLPP8jHA9WP//TktrLSryLn6A00HA02e1N4vP1TxV7WD9dgKQP/ZBZWiPWmUS3VdLm/nuUzRBj1bp5wxIeLgr9q/j4aPAm7+2vsu7wJOLM8+wZRgKSeZmTknm7lOQLM3ed0nF+e87p/PAZd3A72m5bS0HV8GLBl+Z/dXQSytgXdvaFvwRNgW7RoQ0hKnC9TSqqb+niy1Y1vkRFtmr8ilo7vB9exLuS2tb0Zg8sNor169ijfeeANr1qxBcnIygoODMXfuXLRo0cLYh2ZWpKl7SJsaagrX2uORmL3lAo5cicMvuy5hwe5L6NmgCkZ2DELj6m4o1+QPV/3heQBedQret3YP4LXzQHpy7vsbDQJuhecEd3V5Qxuc71Zblx8lHekft3PR/kgZ8gjU7ic/MrpNAq5cymtLi4As6yo/fLcua7fgLjnPv3EGmNVW+6Py+oWc+w/9pn2Oa3Xtj6pMuytOH738uBsOOrxxFkiJA9KStD/46UlAWrK2vHT3yeBB+ZyyyZQ8SQwjKViF/JBLucn9ds5FPx5zl3RT+/1Kzy5LVbYGZazKOfs+Vf4p2imUnV7PeY35D2m/n4/9CnjWzBm7ISsPFoVncO5AvXMmEHVC202kC9TXj2tPYotCFyx1JPjHXdZ2Z+lYWt09SMv3S23yd2KTfd0asHHUlo/ub6zRY0D1+wD/+3KeK4s5vRGmXUJZWrdMmEkH6tjYWLRr1w6dO3dWgdrLywtnz56FuztH9pYWGUzWp5Efejesgl0XYlStevPpaKw6GqE2GSE+slMQ7q/tVfiR4uWV/PE6Vb7z/gfeufM+qSlIH5YERBVk5YfDKifQym0d+XGbGH7na8iPaWGa/xIjtScKEqhl7XYdCXpWdnfOf982XRvE9Sy0/fnyAyub9O/nDbStXwDq9tHuHrYN+PVR7Q/9qO05L/Pb48DNcyiSTm8A3m9pr8dcAGa20tZm5AdTZ+kLQOQxbQDXBXlbuW5w28Yhp9YmW/WWOavrSYD7531tTanfNzmvu/EjbfOnrolU99ws3e3sJlNZkU/+z6Tlol4/oOdn2udnpAGzO2n/X4etzVkLYPvXwNkN2f/PVjnPVdfz3JYaqpSxNKF2nphzbF+EaFcDfGm/djqi2DIV2P190cq3aovcgVr+36WVxXAapRyPITk2KU/VPaO7tNdeqs1OOxDTUEgf7fdYunx05DO1fzn7u2+d5/ufZ1P3WwHWedZ0kLKW8pGTVp2aXYAJp7TPUZttzt9XYX+D6va98z5rW+1WDph0oP7ss89QvXp1VYPWCQw0+A+kUiNBuE1NT7WdioxXNewVh66p6V2yhfg6q4FnfRv7wdbatM9Gy4ScxTsb/GiV5smD/GjK5m8woE4EdQLejgTSDGojIvhBwC0gpxYuzZq6fvvw3fm/T52eBu9po32OTK8zJE3sErxsHbU1GBVA5bpDTjCVQCi1a3muXBr2ycsJgQRTCcCGJLhcP1q0cmnzYk6glmM9+Iv2B90wUEuN72IR+xelxUBHTgykFikMA0T0aSBsa9FeN2/LS2pids3YoPVGTqDkJMZGTk6yy1V/PU956y7znqQN+F7bGiPdLDqtRgBNn8oJzMXpJnng7Tvvq9ZCu90Lw3wDOrbyWR1RkZn0YLJ69eqhe/fuqtM9NDQUVatWxejRozFixIhS6bCngl27dRtzt1/Ewt2XkZSmbYrycbHDk60C8ESr6vB2yTOam0yP/LlLzV/62FXgDtfWtgx/+OVH0bcxUDlY+xxpUpVavK0z4ORZ8scjtVjDpviII9omXxXgdUE+O9CnZl+Xmqm+ZmajPUnRNc3KPlITldfUTeHTzdeXZmDDWpmulmZ4XVocpKlV+ldl8R33GtrnS41bArI8JrMDdAMHr+zXzi6QgKj6XjOzBwBmv4bhbRUcHbUtGTU75xxb1Clt7U66Jzi+oEK4UoTYZNKB2t5e+8M/YcIEDBw4EHv37sW4cePw/fffY+jQofk+JzU1VW2GfdwS8BmoS46sGy7B+qftFxGdkKpf8axHA181WrxlDXfzbxYnIroHZhOobW1t1aCxHTt26O8bO3asCtg7d+7M9zmTJk3CBx98cMf9DNQlT1JprjkWgV92XlLrietIs/iQNgF4qElVONmZdO8KEZHJB2qT7lysUqWKqg0bqlu3Li5fvnzX50ycOBFxcXH67cQJgzWlqURJ33T/JlWxZFRbrBrbXjV/O9hYqXXFZX3x+z7ZiEkrjuN8dJ6+TSIiKrRiBWo5A5CzAZ09e/Zg/PjxmD17NkqSjPg+ffp0rvvOnDmDgICAuz7Hzs4OLi4u+s3ZmdM+ykJ9P1dMebgRdr3VBe/2qYcano5ISM3AvB1h6PJFKJ76cTfWHY9ERmae+cVERFTygfrJJ5/Epk2b1PXIyEg8+OCDKli//fbb+PDDD1FSXn75ZezatQuffPIJzp07h4ULF6qTgTFjsleOIpPj6mCDZ9sH4t9X7sfPw1uha11vNUB227kbeP6X/eg0bTNmbjqHG4kFrA5GRET31kct85glgNapUwfffPMNFi9ejO3bt2P9+vV44YUXcOGCwWIL92jlypWqOVvmT8vULBlYxlHf5Ut4TDIW7L6MxXsv65cptbWyRK+GvmqRlWb+bhx8RkQVypUi9FEXa6RPenq6amIW//zzD/r166euh4SEICIiAiWpT58+aqPyq7qHI97sGYLxXWth1ZEIzN91CYfDb2HZoWtqq+/ngqFtaqg52aWWDISIqCI1fdevX19Nkdq6dSs2bNiAHj20a7Jeu3YNnp4lPM+SzIa9jRUeaV4Ny8e0w4oX2+HR5tXUgLTj1+Lx+p9HcN+UjZi86gQu3Uwy9qESEZXvpu/NmzdjwIABiI+PV/OZf/rpJ3X/W2+9hVOnTuGvv/6CqeCCJ6YtNilNpdr8dfclhMfcVvdJn3an2l5oFeiBau6OqObugGpuDqhcyQ6WlpyfTUTlX5nMo87MzFSB2nDd7bCwMDg6OsLb2zgZRvLDQF0+ZGZpEHomCvN3XlJri+dHat8SsKtK4FabI6q6aa/Lfd7O9rBiICeicqDU+6hv374Nie+6IH3p0iUsXbpUzXGWJT+JikoC7AMhPmqTpu/lh64h7EYSrsTextVbtxERd1stsHLhRpLa8mNjZQE/XeBWl4451z0c4eNsp5KOEBGVJ8UK1P3798fDDz+sRnjfunULrVu3ho2NDW7cuIHp06dj1KjsvLtExSC5r8d2qZXrvvTMLETGpajAfSU2OftSgrj2ekRcCtIzNbh0M1lt+ZFlTn1d7RHsXQmDWlRHt3o+DNxEZJ6B+sCBA/jyyy/V9SVLlsDHxwcHDx7En3/+iffee4+BmkqcjZWlGj0uG3DngEVZSOV6QiquxCTra+G6gC7XJaGIBHJdgJfmdT9X++wc3NXh5lg+0t0RUcVTrECdnJysX/FL5k5L7drS0hL33XefagYnKmvSpC1N3LLlSf6o7wOPStDWyENPR2Phnsu4FpeCz9aewtcbz2BA06p4pm0g6vhyJTsiMi3F6rALDg7GsmXLVCf4unXr0K1bN3V/VFSUWraTyBT7wKu4OqBlDQ+82r0Odrz5AKY+2gh1q7ggJT0Lv+0JR/evtuDJObuw4cR1FdiJiMptjVqat2UZUVni84EHHkCbNm30teumTZuW9DESlcqcbumnHti8GvZcjFFrksta5DvO31Sbv4cjnm4TgEEtq8PFXnIUExEZR7GnZ8ka37IKWePGjVWzt5D1vqVGLSuUmQpOz6JCf1dik/HLrktYtCdc5dwWjrZWamGWoW1roKZXJRYmEZW/fNS6LFr/9UbGwkBNRZWcloFlB69h3o6LOHM9J0WnLMIyrF0NdKzlxYVXiMi081FnZWWpLFmurq4q5aRsbm5u+Oijj9RjROWZo601nmztj3XjO2LBc631GcBCz0Tjmbl70fXLUMzfGYbE1AxjHyoRVQDF6qOWdJb/+9//8Omnn6qc0WLbtm2YNGkSUlJSMHny5JI+TqIyZ2FhgXbBldUmi7D8vOMS/tgXjgvRSXhv+XFMW3ta9WFLQhF/T5k2RkRU8orV9O3n56eScuiyZuksX74co0ePxtWrV2Eq2PRNJUlq0X/uv4Kfd4TpV0iT2naXEB/VLN62pidTdhKR8ZcQjYmJyXfAmNwnjxGZq0p21mpg2ZD7AhB6NhrztoepJvF/Tl5Xm5ezHRr4uaBBVVfU93NFg6ouam631M6JiIqjWIFaRnp/++23+Oabb3LdL/c1atSoWAdCVJ5IFq/OdbzVdi4qUfVZL9l/BdEJqdh0OlptOm6ONmjg54r6VV3UpQTxAA9HDkgjotJr+g4NDUXv3r3h7++vn0O9c+dOVYVfvXo1OnToAFPBpm8qK7fTMnEiIh7Hr8Xh2FXZ4nHmegIy8lk8RWrm9aTmnV3rluAdVNmJa48TVRBXSrvpu1OnTjhz5gxmzpyp8k8LWUZ05MiR+Pjjj00qUBOVFQdbKzQPcFebTmpGJs5EJuKYLnhfi8fJiHjV1y0LrcimY29jqVZK0wVvaTqv7eOs0nsSUcV1z/OoDR0+fBjNmjVTuapNBWvUZGokE9j56ERV45bgLTXw49fikZyWmW/qTll/vGFVVwxuHaBq3kRU/pV6jZqI7i0TWIivi9pk1TORlaXBxZtJKnCfuBafXQOPVyukaQN6PBbtDcejzarhte514O1iz/8CogqCgZrIRAanyRKlsvVvUlXdJ41dku1Latyrjkbi78PX8Mf+K1h1NAKjOtXEiI5Bas1yIjJv7PwiMlEypUvyb/doUAUznmiKv0a3RVN/N9VE/sWGM3jg881YfuiqCuhEZL6KVKOWAWMFuXXr1r0eDxHdRTN/d/w1qi1WHL6Gz9acUvm0xy06hLnbw/Bun7poHuDBsiOq6IFa1vb+r8effvrpez0mIiqgli1N493r++LHrRfw3ebzOBR+C4/M2ok+jargzZ4hqObO5UyJzEmJjvo2RRz1TeYsKj4FX6w/g9/3h0P+kmUq13PtAzG6c7Caq01EFTR7FhGZBhn9/dmjjbDypfZoE+SJtIwsVcu+f9pmLNpzGZn5LLZCROVLuQrUkq1Lmv7Gjx9v7EMhMimyOMrCEa0xe0hz1PB0xI3EVLz511H0mbENO87dMPbhEVFFCNR79+7FDz/8wLXEie5CTmK71ffF+pc74Z3edeFib61WQXvyx9147ud9uBCdyLIjKofKRaBOTEzE4MGDMWfOHLi75yzPSER3Uv3UHYKw+bXOGNomAFaWFiqzV7cvt+CDv4/jVnIai42oHCkXgXrMmDEqCUjXrl3/c9/U1FTEx8frt4SEhDI5RiJT4+Fkiw/6N8C68R3QuY6XSg4iU7nu/3wz5m6/qJYyJSLTZ/KBetGiRThw4ACmTJlSqP1lP5kmptvq1atX6sdIZMqCvZ0xd1grzB/eCrV9KuFWcjo++PsEun+1BRtPXueCKUQmzqQDtQxbHzduHBYsWAB7+8KtbTxx4kTExcXptxMnTpT6cRKVBx1re2H12A6YPKABPJ1scSE6Cc/+vA+P/bAL/9t2UeXVNvPZmkTlkknPo162bBkGDBgAK6uc9YwlM5cMmrG0tFTN3IaP5YfzqInuFJ+SjpmbzmHutjCkGTSBV3VzUAG9U20vtA32hIu9DYuPqBQUJTaZdKCW/uVLly7lum/YsGEICQnBG2+8gQYNGvznazBQExXw9xGbjDVHI7HlbDR2X4jJFbRlEFpzf3d0quOFjrW8UN/PRSUPIaJ7ZzZpLp2dne8Ixk5OTvD09CxUkCaigslyo5KFS7bktAwVrEPPRGPLmWhcuJGEPWExapu27rRqLtfVttvXqozKlexYvERlwKQDNRGVHUdba3QO8VabCI9JVkFbNlk05WZSGpYevKo20bCqqwraErwlq5fk2SaikmfSTd8lgU3fRPdOliY9cDlWG7hPR+NERHyux53trNEuuLIK2h1rV2ZiEKKK0kddEhioiUpeVEIKtp65oQL31rPRiE1Oz/V4sHcl1a/dv4kfGld3438BUR4M1MUsDCIqOkn8cexqnL6Z/ODlWBjmAmkd6IGRHYPQuY43B6MRmdtgMiIyfTI6XGrNso3tUgtxyenYfv4G1h+PxKqjEdh9MUZtUsse2SEI/Zv6wc664GmVRJSDTd9EVGoi41LUcqULd19GQmqGus/b2Q7PtKuBwa0C4OrIedpUMV1hH3XxCoOISkdCSjoW7QnHT9svIiIuRd3nZGuFx1r6Y3j7Ghx8RhXOFQbq4hUGEZX+6PGVR65h9pYLOBWZoG86792wiurHblDVlf8FVCFcYR81EZlqCs6Hm1XDgKZVseXsDczZcgHbzt3AisPX1NYu2BMjO9ZEx1qV1VLBRMTBZERkBBKEZbEU2WTE+JytF7DySAS2n7upthBfZ4zoEIS+jf1UcCeqyDiYjIhMZt1xyZe9aM9lJKVlqvt8XexVH/YTrfzhzAQhZEbYR13MwiAi45PpXQv2XFJBOzohVb/y2ROt/TGsXQ1UcXUw9iES3TMG6mIWBhGZjtSMTCw/eA2zt15QubKFtaUF+jXxw/B2gajj68z1xanc4mAyIir3ZFGUQS2r49Hm1bD5TBR+CL2gFk7568BVtclYM8no5eNin73ZwdtZe93XNee67MP0nFSecWUyIjJpEmQfCPFR2+HwW2pq14YT11Xu7BuJaWo7fi13khBDUgv3craDtwRwFzt9YJeFV7RB3R4+zvZwcbDmSHMySQzURFRuyDKlMwc3Q1aWBrHJaYiMT0FUfCqux6fgulwmyO0Udb/cvpGYiowsjVpkRbbDBby2nbWlCtySsvOVB+vA39OxDD8Z0d0xUBNRuaxle1ayU1t9v7vvl5Fd69YGct2WHdgTUlVQl+uS/Ss1IwuXY5LVtuZYJEZ0CMTo+4PhZMefSTIufgOJyGxZW1mqpm3ZCpKSnqlGmIfHJGNW6HlsPXsDMzedx5/7r2JirxD0a+zHZnEyGq4kQEQVnr2NFap7OKJtcGXMH94Ks4c0R3UPB9WEPm7RIQz8fqdamIXIGBioiYjyrJrWrb4vNrzcCa91rwMHGyvsuxSLvt9uw8S/juBmonZuN1FZYaAmIrpLLXtM52D8+2on9G/iB40G+G1POO7/fDN+2nYR6ZlZLDcqEwzUREQFkJXQvn68KZa80AYNqrogISUDH648gV5fb8XWs9EsOyp1DNRERIXQooYHlo9pjykPN4SHky3ORiViyP/2YOT8fbh8M5llSKWGgZqIqJAkd7YkCNn0yv1q3XG5vf7EdXT9MhTT1p1CUmoGy5JKHAM1EVERuTra4P2+9bF2XAe0D66MtIwsNZ2ryxehWH7oKjTSoU1UQhioiYiKqZaPM355thV+4HQuKkUM1ERE9zidq3v2dK5Xu9XmdC6qWIF6ypQpaNmyJZydneHt7Y2HHnoIp0+fNvZhERHlO53rxQdqcToXVaxAHRoaijFjxmDXrl3YsGED0tPT0a1bNyQlJRn70IiICpzO9ccLbVDfL/d0rt/3hSMuOZ0lR0VioSlHox6io6NVzVoCeMeOHUs8OTcRUUnKzNKo4Dxt3WnEJKXp0262C66MXg190a2eL9ydbFnoFdCVIsSmcpWUIy5Ou9auh4fHXfdJTU1Vm05CQkKZHBsR0d2mc/VqUAXzd4Zh5ZEInL6egNAz0Wp7a+kxtK3piV4Nq6h+bpmfTVRua9RZWVno168fbt26hW3btt11v0mTJuGDDz64437WqInIFJyLSsSaoxFYfSwSJyPicwX1+4I89EG7ciU7ox4nmU6NutwE6lGjRmHNmjUqSBf0ofLWqK9evYp69eoxUBORybkQnahyX68+GoHj13KCtqUF0DrQE70aSdD2gbdzwWk6qfwxu0D94osvYvny5diyZQsCAwOL9Fz2URNReXDpZhJWH9UG7aMGKTUtLIBWNbQ17Z4NfOHtwqBtDswmUMuhvfTSS1i6dCk2b96MWrVqFfk1GKiJqLwJj0lWAVuaxw+H38oVtFsEuGcH7SrwdWXQLq/MJlCPHj0aCxcuVLXpOnXq6O93dXWFg4NDoV6DgZqIyrMrsclYeywSq45G4ODlnKAtmge4q1p2z4ZVUNWtcL+JZBrMJlDLij/5mTt3Lp555plCvQYDNRGZi2u3buv7tPdfis31mL+HI1oFeqhmcrkM8HS8628oGZ/ZBOqSwEBNROYoMi4Fa45F6IN2Vp5fci9nu1yBu46PMyxllBqZBAbqYhYGEVF5lJCSroL1nosxajtyJQ5pmVm59nGxt0bL7KDdMtADDau6wsbKpBenNGtXzHXBEyIiupOzvQ3ur+OtNpGSnolD4bewVwJ3WIwK4vEpGdh4KkptwsHGCs0C3PTBu2l1dzjYWrF4TRADNRGRGSYIuS/IU20iIzNLzdPeGxaD3Rdj1OWt5HRsP3dTbcLGykLVslsFeqJVoDuaB3jA1cHGyJ+EBPuoiYgqmKwsDc5FJ2qDdnZzeWR8Sq59ZBxaiK+LWi2tfXBltA7yRCU71u1KCpu+iYjormRQWW0fZ7UNuS9ArVkRHnNbNZPvuXgTe8NicfFGklriVLa528NUMpGm/m4qoYgE7sbV3djHXUZYoyYiojtExaeowL3j/E1sO3sDl2OScz3uZKttXleBu1Zl1PKuxOlgRcAaNRER3RNZqrRPIz+1ics3k7H9/A1sO3cDO87dQGxyeq7BaTIdTGrauho3V00rOexwICKi/+Tv6Qh/T3+VtlP6uE9ExGP7OW3glj7u6IRULD14VW2ippcTOtTyUoG7dZAHXOw5MK242PRNRET3RKaDHbgUq4K2BO8jV+NguJSWpPBsXM1VX+Nu6u8OW+uKPYf7CudRExFRWU4HaxtcWW3iVnIadl24mR24b6qBaQcu31LbN/+eU3O4Ze52M393NK7uikbV3ODhZMv/sLtg0zcREZUoN0db9GhQRW26xCI7zukC9w3cTEpD6JlotelU93BQAVtq3nLZoKorp4NlY6AmIqJSVc3dEYNaylZd9W+fikzAzgs3ceTKLbXcqdS4ZXqYbKuOROjncQd7VdIG7+xad90qzrCzrnirpzFQExFRmc7hrufnojaduOR0HL0ah8MqcGuDd0RcCs5GJartzwNX9KunySIsjaq5onE1NzSq7opa3s6qD9ycMVATEZFRuTraqLnYsulEJaTgSHicCtyHr2gvY7MDumwLdl9W+0l/d4OqErzd9AHc3FJ8MlATEZHJ8Xa2R9d6svmo27J62pXY29m17jgcDr+FY1fjkJSWqVZSk80wU1jdKi5qU7X3Ki6o5VOp3DabM1ATEZHJs7CwQHUPR7XpFmHJzNLgQnSiyhR2JLvWfTIiQWUKk3XMZdORJVBrelVS/dwSvHWBvHIlO5g6BmoiIiqXrCwtUMvHWW0DW1RX96VlZOFsVAJOXJN1yhPUWuWyOEvc7XScvp6gtmWHrulfw9vZTl/zVpdVnBFYuZJJ9XszUBMRkdmwtbZEfT9XtelIs7kMTlNBWwJ4pDaIh91MQlRCKqISck8Vs7exRB2f3DXvEF9nlffbGBioiYjI7JvN/dwc1NalrrbPWySlZqipYrpat1yeikjA7fRMNYBNNkP+Ho5oEeCO6Y81KdPjZ6AmIqIKycnOGs0D3NWmI/3el25Kis/cAVxq5JJBzLNS2a+gxkBNRESUTfqmg7wqqa13I+3KaiI2KU0F7CyDNczLCgM1ERHRf3B3stWvZV7WKnb6EiIiIhPHQE1ERGTCGKiJiIhMGAM1ERGRCWOgJiIiMmFmP+o7KytLXUZEaHOcEhERGZsuJuliVIUO1NevX1eXrVq1MvahEBER3RGj/P39URALjSyCasYyMjJw8OBB+Pj4wNLy3lr6ExISUK9ePZw4cQLOzs4ldozmjGXGMuP3zDTxb9O4ZSY1aQnSTZs2hbW1dcUO1CUpPj4erq6uiIuLg4uLi7EPp1xgmbHM+D0zTfzbLD9lxsFkREREJoyBmoiIyIQxUBeBnZ0d3n//fXVJLLPSwu8Zy6ws8HtWfsqMfdREREQmjDVqIiIiE8ZATUREZMIYqImIiEwYA3URzJw5EzVq1IC9vT1at26NPXv2lN7/TDk3ZcoUtGzZUi0K4O3tjYceeginT5829mGVG59++iksLCwwfvx4Yx+KSbt69SqeeuopeHp6wsHBAQ0bNsS+ffuMfVgmKzMzE++++y4CAwNVedWsWRMfffQRuJxGblu2bEHfvn3h5+en/g6XLVuW63Epr/feew9VqlRR5di1a1ecPXsWpYWBupAWL16MCRMmqBF/Bw4cQOPGjdG9e3dERUWV2n9OeRYaGooxY8Zg165d2LBhA9LT09GtWzckJSUZ+9BM3t69e/HDDz+gUaNGxj4UkxYbG4t27drBxsYGa9asUatFffHFF3B3dzf2oZmszz77DLNmzcK3336LkydPqttTp07FjBkzjH1oJiUpKUn9xkvlLD9SZt988w2+//577N69G05OTioepKSklM4Bycpk9N9atWqlGTNmjP52Zmamxs/PTzNlyhQWXyFERUXJCnia0NBQllcBEhISNLVq1dJs2LBB06lTJ824ceNYXnfxxhtvaNq3b8/yKYLevXtrhg8fnuu+hx9+WDN48GCW413I79bSpUv1t7OysjS+vr6aadOm6e+7deuWxs7OTvPbb79pSgNr1IWQlpaG/fv3q+YNHVk3XG7v3LmzdM6gzIwsuSc8PDyMfSgmTVohevfuneu7RvlbsWIFWrRogYEDB6ruFVkzec6cOSyuArRt2xYbN27EmTNn1O3Dhw9j27Zt6NmzJ8utkC5evIjIyMhcf6OyrKh0h5ZWPDD77Fkl4caNG6pvRxJ7GJLbp06dMtpxlRey+Lz0tUozZYMGDYx9OCZr0aJFqltFmr7pv124cEE140qX1FtvvaXKbezYsbC1tcXQoUNZhPl488031XrVISEhsLKyUr9rkydPxuDBg1lehSRBWuQXD3SPlTQGaiqTWuKxY8fUmTvlLzw8HOPGjVP9+TJYkQp3Aig16k8++UTdlhq1fM+k35CBOn+///47FixYgIULF6J+/fo4dOiQOomWQVMsM9PFpu9CqFy5sjr71OW21pHbvr6+pfV/YxZefPFFrFy5Eps2bUK1atWMfTgmS7pWZGBis2bNVMo72WRAngxYketS86HcZMStpBw0VLduXVy+fJlFdRevvfaaqlU//vjjaoT8kCFD8PLLL6tZGlQ4ut/8sowHDNSFIE1pzZs3V307hmfzcrtNmzal8h9T3skYDAnSS5cuxb///qumg9DddenSBUePHlU1HN0mtUVpkpTrcqJIuUlXSt4pf9L3GhAQwKK6i+TkZDW+xpB8t+T3jApHfsskIBvGA+lOkNHfpRUP2PRdSNIPJk1D8uPZqlUrfPXVV2oI/7Bhw0rlP8YcmruleW358uVqLrWu70YGXci8Q8pNyihv/71M+ZD5wezXz5/UBGVwlDR9Dxo0SK1rMHv2bLVR/mRusPRJ+/v7q6bvgwcPYvr06Rg+fDiLzEBiYiLOnTuXawCZnDDLYFgpO+ku+Pjjj1GrVi0VuGVuunQfyHoRpaJUxpKbqRkzZmj8/f01tra2arrWrl27jH1IJku+Wvltc+fONfahlRucnvXf/v77b02DBg3U1JiQkBDN7Nmzy+B/pvyKj49XU/7kd8ze3l4TFBSkefvttzWpqanGPjSTsmnTpnx/v4YOHaqfovXuu+9qfHx81HevS5cumtOnT5fa8TB7FhERkQljHzUREZEJY6AmIiIyYQzUREREJoyBmoiIyIQxUBMREZkwBmoiIiITxkBNRERkwhioiYiITBgDNRGVOAsLCyxbtowlS1QCGKiJzMwzzzyjAmXerUePHsY+NCIqBiblIDJDEpTnzp2b6z47OzujHQ8RFR9r1ERmSIKypOIz3Nzd3dVjUrueNWsWevbsqTKZBQUFYcmSJbmeLyk3H3jgAfW4ZPAaOXKkyihk6KefflIZmOS9JDe0pDU1dOPGDQwYMACOjo4qy9CKFSv0j8XGxqoUnl5eXuo95PG8JxZEpMVATVQBSVq+Rx55BIcPH1YB8/HHH8fJkyfVY5K+tXv37iqw7927F3/88Qf++eefXIFYAr2kMpUALkFdgnBwcHCu9/jggw9U+skjR46gV69e6n1iYmL073/ixAmsWbNGva+8XuXKlcu4FIjKiVLLy0VERiGp+KysrDROTk65tsmTJ6vH5c/+hRdeyPWc1q1ba0aNGqWuS6pId3d3TWJiov7xVatWaSwtLTWRkZHqtp+fn0qPeDfyHu+8847+tryW3LdmzRp1u2/fvpphw4aV8CcnMk/soyYyQ507d1a1VEOS9F6nTZs2uR6T24cOHVLXpYbbuHFjODk56R9v164dsrKycPr0adV0fu3aNXTp0qXAY2jUqJH+uryWi4sLoqKi1O1Ro0apGv2BAwfQrVs3PPTQQ2jbtu09fmoi88RATWSGJDDmbYouKdKnXBg2Nja5bkuAl2AvpH/80qVLWL16NTZs2KCCvjSlf/7556VyzETlGfuoiSqgXbt23XG7bt266rpcSt+19FXrbN++HZaWlqhTpw6cnZ1Ro0YNbNy48Z6OQQaSDR06FL/++iu++uorzJ49+55ej8hcsUZNZIZSU1MRGRmZ6z5ra2v9gC0ZINaiRQu0b98eCxYswJ49e/C///1PPSaDvt5//30VRCdNmoTo6Gi89NJLGDJkCHx8fNQ+cv8LL7wAb29vVTtOSEhQwVz2K4z33nsPzZs3V6PG5VhXrlypP1EgotwYqInM0Nq1a9WUKUNSGz516pR+RPaiRYswevRotd9vv/2GevXqqcdkOtW6deswbtw4tGzZUt2W/uTp06frX0uCeEpKCr788ku8+uqr6gTg0UcfLfTx2draYuLEiQgLC1NN6R06dFDHQ0R3spARZfncT0RmSvqKly5dqgZwEZHpYx81ERGRCWOgJiIiMmHsoyaqYNjbRVS+sEZNRERkwhioiYiITBgDNRERkQljoCYiIjJhDNREREQmjIGaiIjIhDFQExERmTAGaiIiIhPGQE1ERATT9X/M+wctHcTaSAAAAABJRU5ErkJggg==\",\n \"text/plain\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"Mtp4gY0ZO-qq\",\n \"metadata\": {\n \"id\": \"Mtp4gY0ZO-qq\"\n },\n \"outputs\": [],\n \"source\": [\n \"def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,\\n\",\n \" eval_freq, eval_iter, start_context, tokenizer):\\n\",\n \" # Initialize lists to track losses and tokens seen\\n\",\n \" train_losses, val_losses, track_tokens_seen = [], [], []\\n\",\n \" tokens_seen, global_step = 0, -1\\n\",\n \"\\n\",\n \" # Main training loop\\n\",\n \" for epoch in range(num_epochs):\\n\",\n \" model.train() # Set model to training mode\\n\",\n \" \\n\",\n \" for input_batch, target_batch in train_loader:\\n\",\n \" optimizer.zero_grad() # Reset loss gradients from previous batch iteration\\n\",\n \" loss = calc_loss_batch(input_batch, target_batch, model, device)\\n\",\n \" loss.backward() # Calculate loss gradients\\n\",\n \" optimizer.step() # Update model weights using loss gradients\\n\",\n \" tokens_seen += input_batch.numel()\\n\",\n \" global_step += 1\\n\",\n \"\\n\",\n \" # Optional evaluation step\\n\",\n \" if global_step % eval_freq == 0:\\n\",\n \" train_loss, val_loss = evaluate_model(\\n\",\n \" model, train_loader, val_loader, device, eval_iter)\\n\",\n \" train_losses.append(train_loss)\\n\",\n \" val_losses.append(val_loss)\\n\",\n \" track_tokens_seen.append(tokens_seen)\\n\",\n \" print(f\\\"Ep {epoch+1} (Step {global_step:06d}): \\\"\\n\",\n \" f\\\"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}\\\")\\n\",\n \"\\n\",\n \" # Print a sample text after each epoch\\n\",\n \" generate_and_print_sample(\\n\",\n \" model, tokenizer, device, start_context\\n\",\n \" )\\n\",\n \"\\n\",\n \" return train_losses, val_losses, track_tokens_seen\\n\",\n \"\\n\",\n \"\\n\",\n \"def evaluate_model(model, train_loader, val_loader, device, eval_iter):\\n\",\n \" model.eval()\\n\",\n \" with torch.no_grad():\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\\n\",\n \" model.train()\\n\",\n \" return train_loss, val_loss\\n\",\n \"\\n\",\n \"\\n\",\n \"def generate_and_print_sample(model, tokenizer, device, start_context):\\n\",\n \" model.eval()\\n\",\n \" context_size = model.pos_emb.weight.shape[0]\\n\",\n \" encoded = text_to_token_ids(start_context, tokenizer).to(device)\\n\",\n \" with torch.no_grad():\\n\",\n \" token_ids = generate_text_simple(\\n\",\n \" model=model, idx=encoded,\\n\",\n \" max_new_tokens=50, context_size=context_size\\n\",\n \" )\\n\",\n \" decoded_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \" print(decoded_text.replace(\\\"\\\\n\\\", \\\" \\\")) # Compact print format\\n\",\n \" model.train()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a301b333-b9d4-4eeb-a212-3a9874e3ac47\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's train the LLM using the training function defined above:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 27,\n \"id\": \"3422000b-7aa2-485b-92df-99372cd22311\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"3422000b-7aa2-485b-92df-99372cd22311\",\n \"outputId\": \"0e046603-908d-4093-8ae5-ef2f632639fb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ep 1 (Step 000000): Train loss 9.817, Val loss 9.924\\n\",\n \"Ep 1 (Step 000005): Train loss 8.066, Val loss 8.332\\n\",\n \"Every effort moves you,,,,,,,,,,,,. \\n\",\n \"Ep 2 (Step 000010): Train loss 6.619, Val loss 7.042\\n\",\n \"Ep 2 (Step 000015): Train loss 6.046, Val loss 6.596\\n\",\n \"Every effort moves you, and,, and, and,,,,, and, and,,,,,,,,,,, and,, the,, the, and,, and,,, the, and,,,,,,\\n\",\n \"Ep 3 (Step 000020): Train loss 5.524, Val loss 6.508\\n\",\n \"Ep 3 (Step 000025): Train loss 5.369, Val loss 6.378\\n\",\n \"Every effort moves you, and to the of the of the picture. Gis. \\n\",\n \"Ep 4 (Step 000030): Train loss 4.830, Val loss 6.263\\n\",\n \"Ep 4 (Step 000035): Train loss 4.586, Val loss 6.285\\n\",\n \"Every effort moves you of the \\\"I the picture. \\\"I\\\"I the picture\\\"I had the picture\\\"I the picture and I had been the picture of\\n\",\n \"Ep 5 (Step 000040): Train loss 3.879, Val loss 6.130\\n\",\n \"Every effort moves you know he had been his pictures, and I felt it's by his last word. \\\"Oh, and he had been the end, and he had been\\n\",\n \"Ep 6 (Step 000045): Train loss 3.530, Val loss 6.183\\n\",\n \"Ep 6 (Step 000050): Train loss 2.960, Val loss 6.123\\n\",\n \"Every effort moves you know it was his pictures--I glanced after him, I had the last word. \\\"Oh, and I was his pictures--I looked. \\\"I looked. \\\"I looked. \\n\",\n \"Ep 7 (Step 000055): Train loss 2.832, Val loss 6.150\\n\",\n \"Ep 7 (Step 000060): Train loss 2.104, Val loss 6.133\\n\",\n \"Every effort moves you know the picture to me--I glanced after him, and Mrs. \\\"I was no great, the fact, the fact that, the moment--as Jack himself, as his pictures--as of the picture--because he was a little\\n\",\n \"Ep 8 (Step 000065): Train loss 1.691, Val loss 6.186\\n\",\n \"Ep 8 (Step 000070): Train loss 1.391, Val loss 6.230\\n\",\n \"Every effort moves you?\\\" \\\"Yes--quite insensible to the fact with a little: \\\"Yes--and by me to me to have to see a smile behind his close grayish beard--as if he had the donkey. \\\"There were days when I\\n\",\n \"Ep 9 (Step 000075): Train loss 1.059, Val loss 6.251\\n\",\n \"Ep 9 (Step 000080): Train loss 0.800, Val loss 6.278\\n\",\n \"Every effort moves you?\\\" \\\"Yes--quite insensible to the fact with a laugh: \\\"Yes--and by me!\\\" He laughed again, and threw back the window-curtains, I saw that, and down the room, and now\\n\",\n \"Ep 10 (Step 000085): Train loss 0.569, Val loss 6.373\\n\",\n \"Every effort moves you?\\\" \\\"Yes--quite insensible to the irony. She wanted him vindicated--and by me!\\\" He laughed again, and threw back his head to look up at the sketch of the donkey. \\\"There were days when I\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Note:\\n\",\n \"# Uncomment the following code to calculate the execution time\\n\",\n \"# import time\\n\",\n \"# start_time = time.time()\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model = GPTModel(GPT_CONFIG_124M)\\n\",\n \"model.to(device)\\n\",\n \"optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)\\n\",\n \"\\n\",\n \"num_epochs = 10\\n\",\n \"train_losses, val_losses, tokens_seen = train_model_simple(\\n\",\n \" model, train_loader, val_loader, optimizer, device,\\n\",\n \" num_epochs=num_epochs, eval_freq=5, eval_iter=5,\\n\",\n \" start_context=\\\"Every effort moves you\\\", tokenizer=tokenizer\\n\",\n \")\\n\",\n \"\\n\",\n \"# Note:\\n\",\n \"# Uncomment the following code to show the execution time\\n\",\n \"# end_time = time.time()\\n\",\n \"# execution_time_minutes = (end_time - start_time) / 60\\n\",\n \"# print(f\\\"Training completed in {execution_time_minutes:.2f} minutes.\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2e8b86f0-b07d-40d7-b9d3-a9218917f204\",\n \"metadata\": {},\n \"source\": [\n \"- Note that you might get slightly different loss values on your computer, which is not a reason for concern if they are roughly similar (a training loss below 1 and a validation loss below 7)\\n\",\n \"- Small differences can often be due to different GPU hardware and CUDA versions or small changes in newer PyTorch versions\\n\",\n \"- Even if you are running the example on a CPU, you may observe slight differences; a possible reason for a discrepancy is the differing behavior of `nn.Dropout` across operating systems, depending on how PyTorch was compiled, as discussed [here on the PyTorch issue tracker](https://github.com/pytorch/pytorch/issues/121595)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 28,\n \"id\": \"0WSRu2i0iHJE\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 487\n },\n \"id\": \"0WSRu2i0iHJE\",\n \"outputId\": \"9d36c61b-517d-4f07-a7e8-4563aff78b11\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAeoAAAEiCAYAAAA21pHjAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAATyBJREFUeJzt3QdclPUfB/APe8mWISoIouLemjvT3CMrbZiZlpZaajZt2jBLy4aZpf3TLE3LcuQ2U9x774migqAgU/b9X9/fcceBSIDAHcfn/Xo93nru7rmfx32f3/xaaDQaDYiIiMgkWRr7AIiIiOjuGKiJiIhMGAM1ERGRCWOgJiIiMmEM1ERERCaMgZqIiMiEMVATERGZMAZqIiIiE8ZATUREZMIYqInMQFhYGCwsLHDo0CFjHwoRlTAGaiITIYG2oG3SpEnGPkQiMgJrY7wpEd0pIiJCf33x4sV47733cPr0af19lSpVYrERVUCsUROZCF9fX/3m6uqqatG6297e3pg+fTqqVasGOzs7NGnSBGvXrr3ra2VmZmL48OEICQnB5cuX1X3Lly9Hs2bNYG9vj6CgIHzwwQfIyMjQP0fe78cff8SAAQPg6OiIWrVqYcWKFfrHY2NjMXjwYHh5ecHBwUE9Pnfu3Lsew5IlS9CwYUO1r6enJ7p27YqkpCT94/JedevWVccjx/ndd9/len54eDgGDRoENzc3eHh4oH///qqJX+eZZ57BQw89hM8//xxVqlRR7zFmzBikp6cXo/SJTJhkzyIi0zJ37lyNq6ur/vb06dM1Li4umt9++01z6tQpzeuvv66xsbHRnDlzRj1+8eJFyYKnOXjwoCYlJUUzYMAATdOmTTVRUVHq8S1btqjnz5s3T3P+/HnN+vXrNTVq1NBMmjRJ/x7y/GrVqmkWLlyoOXv2rGbs2LGaSpUqaW7evKkeHzNmjKZJkyaavXv3qvfbsGGDZsWKFfke/7Vr1zTW1tbquGXfI0eOaGbOnKlJSEhQj//666+aKlWqaP7880/NhQsX1KWHh4c6PpGWlqapW7euZvjw4eq5J06c0Dz55JOaOnXqaFJTU9U+Q4cOVZ/phRde0Jw8eVLz999/axwdHTWzZ88utf8XImNgoCYqB4Haz89PM3ny5Fz7tGzZUjN69OhcgXrr1q2aLl26aNq3b6+5deuWfl+575NPPsn1/F9++UUFSx15/jvvvKO/nZiYqO5bs2aNut23b1/NsGHDCnX8+/fvV88NCwvL9/GaNWuqEwJDH330kaZNmzb6Y5OgnJWVpX9cArSDg4Nm3bp1+kAdEBCgycjI0O8zcOBAzWOPPVaoYyQqL9hHTWTi4uPjce3aNbRr1y7X/XL78OHDue574oknVPP4v//+q5qcdWS/7du3Y/Lkybmax1NSUpCcnKyaukWjRo30jzs5OcHFxQVRUVHq9qhRo/DII4/gwIED6Natm2p2btu2bb7H3LhxY3Tp0kU1fXfv3l3t/+ijj8Ld3V01f58/fx7PPvssRowYoX+ONMNLk7/ueM+dOwdnZ+dcryvHK8/VqV+/PqysrPS3pQn86NGjhS5bovKAgZrIjPTq1Qu//vordu7ciQceeEB/f2JiouqTfvjhh+94jvQR69jY2OR6TPqts7Ky1PWePXvi0qVLWL16NTZs2KACsfQJSx9xXhI8ZZ8dO3Zg/fr1mDFjBt5++23s3r1bf1IwZ84ctG7d+o7n6Y63efPmWLBgwR2vLX3khTleInPBQE1k4qRW6+fnp2rEnTp10t8vt1u1apVrX6n1NmjQAP369cOqVav0+8sgMhlBHhwcfE/HIkFy6NChauvQoQNee+21fAO1LmhKrV82GcEeEBCApUuXYsKECerzXLhwQQ1Oy48cr4x8l0F08vmJKjIGaqJyQALi+++/j5o1a6oR3zLaWhY3ya/G+dJLL6lm7T59+mDNmjVo3769CpRy29/fXzVBW1paqublY8eO4eOPPy7UMchrSC1XmptTU1OxcuVKNWo7P1Jz3rhxo2rylmArt6Ojo/X7S+1+7Nixqqm7R48e6vX27dunRpZLIJcAPm3aNDXS+8MPP1TN+VKb/+uvv/D666+r20QVBQM1UTkgQS0uLg6vvPKK6jOuV6+emjolU6TyM378eNUELE3hMo1L+oklsErQ++yzz1STsUyJeu655wp9DLa2tpg4caKaIiX931KjXrRoUb77Si14y5Yt+Oqrr1Qfu9Smv/jiC9V8LuR9pQlcgrGchEh/uPRny3ELeUye/8Ybb6jm+oSEBFStWlU1t7OGTRWNhYwoM/ZBEBERUf644AkREZEJY6AmIiIyYQzUREREJoyBmoiIyIQxUBMREZkwBmoiIiITxkB9FzNnzkSNGjXU8oqyzOGePXvK9n/GRMnc1r59+6qVpWTlqWXLluV6XGb7ycIYsuayzLWV1IZnz57NtU9MTIxa0ELmw0oKQ1nzWZaMNHTkyBE1T1fKv3r16pg6deodx/LHH3+oucCyj8zBlaUty7MpU6agZcuWan1rWSRE1tI2zEetW+talu2UlI6Sn1rW3r5+/XqufSStZe/evdVcZHkdmadsmM5SbN68Wa3+JSkzZbWyefPmVYi/gVmzZqn1zOW7J1ubNm3UojA6LN+S9emnn6rfCd38eJZxMRk7K4gpWrRokcbW1lbz008/aY4fP64ZMWKExs3NTXP9+nVNRbd69WrN22+/rfnrr79UdqSlS5fmevzTTz9VWZ+WLVumOXz4sKZfv36awMBAze3bt/X79OjRQ9O4cWPNrl27VLan4OBgzRNPPKF/PC4uTuPj46MZPHiw5tixYyq1o2RN+uGHH/T7bN++XWNlZaWZOnWqSoEoWZ8k7ePRo0c15VX37t1V1iz5zIcOHdL06tVL4+/vr7JY6UhKx+rVq2s2btyo2bdvn+a+++7TtG3bVv+4ZJJq0KCBpmvXrirlpfx/Va5cWTNx4kT9PpJWUtJBTpgwQZXdjBkzVFmuXbvW7P8GJC3nqlWrVHrQ06dPa9566y31vZEyFyzfkrNnzx6VSrVRo0aacePG6e9nGRcdA3U+WrVqpXLv6mRmZqo0g1OmTClGEZuvvIFaUhL6+vpqpk2bpr9PUi3a2dmpYCskMMjzJKexjqRRtLCw0Fy9elXd/u677zTu7u76vMPijTfeUGkPdQYNGqTp3bt3ruNp3bq15vnnn9eYC8klLWUVGhqqL0sJKn/88Yd+H8nDLPvs3LlT3ZbAbGlpqYmMjNTvM2vWLJW3WVeeksu6fv36ud5LUkPKiUJF/BuQ79qPP/7I8i1Bkne8Vq1aKmd5p06d9IGa3+HiYdN3Hmlpadi/f79qstWRdZHltmQkoru7ePEiIiMjc5WdrOUszaa6spNLae5u0aKFfh/ZX8pY1oPW7dOxY0e1ZKWOLIEpzcCyFrRuH8P30e1jTv9HsmSo8PDwUJfyvUxPT8/1uaXpX9bvNixf6Qbw8fHJVS6yjOfx48cLVXYV5W9A1kOXJVAl7aY0gbN8S450z0j3S97vGcu4eLjWdx43btxQf8CGP3RCbp86daqYxVwxSJAW+ZWd7jG5lH5TQ9bW1ioYGe4TGBh4x2voHpOcxnJZ0PuUd7JOt/TrSeYpyYYl5LPJyYuc6BRUvvmVi+6xgvaRYH779m11MmTOfwOSr1oCs/RHSz+/ZPSStdMlyQnL997JyY/kLN+7d+8dj/E7XDwM1EQmWiORzFbbtm0z9qGYnTp16qigLC0WS5YsUSk7Q0NDjX1YZiE8PBzjxo1TucgN85zTvWHTdx6VK1dWyevzjqSV276+vvdY3OZNVz4FlZ1cSvYnQzIiWUaCG+6T32sYvsfd9jGH/6MXX3xRZbratGlTrnSO8tmkWfrWrVsFlm9xy05GQctIfXP/G5Bas4x0l5SdMtK+cePG+Prrr1m+JUCatuXvW2YUSEuZbHIS9M0336jr0irD73DRMVDn80csf8CSS9ewGVJuS3MZ3Z00V8sPuWHZSXOq9D3ryk4uJdDIH7TOv//+q8pY+rJ1+8g0MOmP1ZEzdKkJSbO3bh/D99HtU57/j2R8ngRpaYqVMsnb/C/fS0lPafi5pd9epmMZlq807RqeDEm5SBCW5t3ClF1F+xuQzyb5sFm+907SkMr3T1osdJuMR5HpmLrr/A4XQzEHoZk1mZoiI5XnzZunRimPHDlSTU0xHElbUcloTpn2I5t8faZPn66uX7p0ST89S8pq+fLlmiNHjmj69++f7/Sspk2banbv3q3Ztm2bGh1qOD1LRobK9KwhQ4aoaTPy/yHTifJOz7K2ttZ8/vnnauTz+++/X+6nZ40aNUpNbdu8ebMmIiJCvyUnJ+ea2iJTtv799181PatNmzZqyzs9q1u3bmqKl0y58vLyynd61muvvabKbubMmflOzzLHv4E333xTjaK/ePGi+n7KbZlxsH79evU4y7fkGY76ZhkXDwP1XcjcUvlBlLmkMlVF5vySRrNp0yYVoPNuQ4cO1U/Revfdd1WglR/6Ll26qPmqhm7evKkCc6VKldS0oWHDhqkTAEMyB7t9+/bqNapWrapOAPL6/fffNbVr11b/RzLdSObHlmf5latsMrdaR054Ro8eraYUSbAdMGCACuaGwsLCND179lRzz2UO9SuvvKJJT0+/4/+xSZMmquyCgoJyvYc5/w0MHz5cExAQoD6TnMDI91MXpAXLt/QDNcu46Czkn+LUxImIiKj0sY+aiIjIhDFQExERmTAGaiIiIhPGQE1ERGTCGKiJiIhMGAM1ERGRCWOgLoCsVjRp0iR1SSWP5Vu6WL6lj2XM8i0LnEddAFn+UtI0yuL9sgQjlSyWb+li+ZY+ljHLtyywRk1ERGTCGKiJiIhMmNnno5YUigcPHlTp1Swti3ZekpCQoC6vXr2qmrioZLF8SxfLt/SxjFm+95K1TVLHNm3aVKUALYjZ91Hv3bsXrVq1MvZhEBER3WHPnj1o2bIlKnSNWmrSusKoUqWKsQ+HiIgIERERqhKpi1EVOlDrmrslSFerVs3Yh0NERKRXmC5Zow4m27JlC/r27Qs/Pz9YWFhg2bJluR6XVvn33ntPBVkHBwd07doVZ8+eNdrxEhERlTWjBuqkpCQ0btwYM2fOzPfxqVOn4ptvvsH333+P3bt3w8nJCd27d0dKSkqZHysREZExGLXpu2fPnmrLj9Smv/rqK7zzzjvo37+/um/+/PmqPV9q3o8//ngZHy0REVHZM9k+6osXLyIyMlI1d+vIKmGtW7fGzp077xqoZUk/wyU/ddMniIgKIzMzE+np6Swsuic2NjawsrKCWQdqCdIi74g4ua17LD9TpkzBBx98UOrHR0TmRVrx5Lfl1q1bxj4UMhNubm7w9fVVY7DMMlAX18SJEzFhwgT9bVmspF69eiXz4pkZwL8fAoGdgOAuJfOaRGQSdEHa29sbjo6O9/zjShX7pC85ORlRUVHq9r1ODTbZQC1nIUJWbjH8kHK7SZMmd32enZ2d2nRKckWx6/98BZ+dXwMHfgGeDwXc/EvstYnIuM3duiDt6enJ/wq6ZzJTSUiwlu/VvTSDm+xa34GBgSpYb9y4MVfQldHfbdq0KfPjiYi7ja5ba+FwVhBwOwZYPARI5+hzInOg65OWmjRRSdF9n+51zINRA3ViYiIOHTqkNt0AMrl++fJl1ew0fvx4fPzxx1ixYgWOHj2Kp59+Ws25fuihh8r8WKu4OuCRVsEYlTYesXABIg4Bq1+RNo4yPxYiKh1s7iZT/D4ZNVDv27dPLUgum5C+Zbkui5yI119/HS+99BJGjhyp1kKVwL527VrY29sb5Xjf7BkCZ59AjEl7EVlSdAd/BfbPM8qxEBFRxWDUQH3//ferTve827x58/RnIx9++KEa5CGLnPzzzz+oXbu20Y7X3sYKXz/RBPssG2Fq+iDtnWteB67sN9oxERGVtBo1aqh1LApr8+bN6ve6tEfMz5s3T42krmhMto/aVIX4uuDNHiH4PrMv1me1BDLTgN+HAInRxj40IqpgJDgWtE2aNKnYWQelJbOw2rZtq5JMyFoXVPJMdtS3KRvWrgZCz0RjwpnnscbxGqrHXwWWDAOGLAOsWKREVDYkOOosXrxYdRuePn1af1+lSpX016W1Uka3/1fuY+Hl5VWk47C1tdXP1KGSxxp1MciZ6rSBjWDn5IZht8chzdIBCNsKbORCK0RUdiQ46japzcpvk+72qVOn4OzsjDVr1qB58+Zq2uq2bdtw/vx5tSyzLB4lgVzG/0i3YkFN3/K6P/74IwYMGKBGMteqVUsN8r1b07euiXrdunWoW7euep8ePXrkOrHIyMjA2LFj1X4yJe6NN97A0KFDizxYeNasWahZs6Y6WahTpw5++eWXXCcn0qrg7++vPr8MRpb31Pnuu+/UZ5FxT1Iejz76KEwRA3UxeTvbY+qjjXBOUw3jU0Zo79zxDXBieQn+9xCRURetSMswyibvXVLefPNNfPrppzh58iQaNWqkBuX26tVLTX09ePCgCqCSxVBm2xREVnwcNGgQjhw5op4/ePBgxMTE3HV/WfDj888/V4FTMiXK67/66qv6xz/77DMsWLAAc+fOxfbt29X027wZFP/L0qVLMW7cOLzyyis4duwYnn/+eQwbNgybNm1Sj//555/48ssv8cMPP6jMi/L6DRs21A9mlqAt46CkFUIGKnfs2BGmiO2096BLXR883SYA83cCv1iGYUjWCmDVq0CtboCNdrI7EZVPt9MzUe+9dUZ57xMfdoejbcn8PEsgevDBB/W3PTw8VNZCnY8++kgFPKkhv/jii3d9nWeeeQZPPPGEuv7JJ5+ozIZ79uxRgT4/MndYMh9KbVfIa8ux6MyYMUOtJCm1dPHtt99i9erVRfpsn3/+uTqu0aNH62cO7dq1S93fuXNndXIgrQuSM0LW3paadatWrdS+8phkZOzTp49qeQgICNDPQDI1rFHfo7d61UUt70qYlDwQ2yp1h2bIXwzSRGQyWrRokeu21KilZitN0tLsLM3SUtv+rxq11MZ1JMC5uLjol8jMjzSR64K0kBUmdfvHxcWpVSZ1QVPIyl3SRF8UJ0+eRLt27XLdJ7flfjFw4EDcvn0bQUFBGDFihDohkSZ3IScvEpzlsSFDhqjavbQCmCLWqEtiytbjTfHQzO146sZQfBzmgqc4poKo3HOwsVI1W2O9d0mRoGpIgvSGDRtUrTM4OFgtdSl9s2lpaQW+jtRIDUmfdFZWVpH2L8km/cKoXr26ataWPnj5zFLznjZtGkJDQ1Ut+sCBA6p/ff369WognvRny4h3U5sCxhp1Cajn54LXe9RR1z9edQLnohKA8D3A3v+VxMsTkRFIYJHmZ2NspblCmvQHS3OxNDlLf600DYeFhaEsycA3GbwlQVFHRqRL4CyKunXrqs9jSG4bJmKSExHpg5emegnKkiZZVroUMgJemsWnTp2q+t6lHP7991+YGtaoS8jwdoFqytbWszcw7dcV+D5xHCw0mYBXCFAjd9MMEZGxyCjnv/76SwUvOSF49913C6wZlxZZdVLSEkutPiQkRPVZx8bGFukk5bXXXlMD3KRvWQLu33//rT6bbhS7jD6XE4DWrVurpvhff/1VBW5p8l65ciUuXLigBpC5u7ur/nEpBxk5bmpYoy6pgrS0wBcDG8PDyRbrolxxxKMbULcfUCVn0AYRkbFNnz5dBSZZpESCdffu3dGsWbMyPw6ZjiWD0ySHgyRakr5yOZaiLBH90EMP4euvv1bN+PXr11eju2UUuax6KaQJe86cOarfWvrYJYBLMJfpYPKYBPUHHnhA1cxl4Ntvv/2mXsfUWGjKutOgjF25ckX1U4SHh6NatWql/n4bTlzHiPn7YI0MzB3eBh1qe5f6exLRvZEliiUpkGTtM1YugYpOarMSMKWGLCPRzf17daUIsYk16hL2YD0fDG7tjwxY45U/jiAmKU2bYetc7gUFiIgqskuXLqna7pkzZ1Sf8ahRo1RQe/LJJ419aCaHgboUvNO7Hmp6OSEqIRVvLDkMzZLhwK+PAAfml8bbERGVO5aWlqoPWVZGk6ZpCdbSNC21asqNg8lKgYOtdsrWgO+2Y8PJKBxpWBWqp1oWQ/FpAFQt+/4gIiJTIs2+eUdsU/5Yoy4lDaq64vXuIer646faILFGNyAzFfj9aSDpZmm9LRERmRkG6lL0bPtAtA+ujNvpwLBbz0LjHgTEhQN/DgeyMkvzrYmIyEwwUJf2lK1BjeHuaIO9kZn4sepHgI0jcGEz8O/HpfnWRERkJhioS5mPiz0+fUS7Ru7kfRY43foT7QPbpgMnV5b22xMRUTnHQF0Gutf3xROt/NX1p/dUR0rz57UPLH0BuHG2LA6BiIjKKQbqMvJun7oI8nLC9fhUvBz7MDQBbYG0BGDxU0BqYlkdBhERlTMM1GVEFtr/5vGmsLGywJoTN7E8eDLgXAWIPgWseFG7KAoRkRHIkpvjx4/X365Rowa++uqrAp8ja3IvW7bsnt+7pF6nIJIVq0mTJiivGKjLeMrWq920C75PXB+FKw/OAixtgONLgZ0zy/JQiMgMyFrdPXr0yPexrVu3qiAoWaGKSrJajRw5EmURLCMiItCzZ88SfS9zw0BdxkZ0CELbmp64nZ6JUaE2yOg2GXDyBvyalvWhEFE59+yzz6o8y7JudF6SnKJFixYqGUVReXl5qWxTZUHSbNrZ2ZXJe5VXDNRlXeCWFpg+qAlcHWxw9GocPo/pCIzZzVSYRFRkffr0UUFVluI0lJiYiD/++EMF8ps3b6osVVWrVlXBV3JQS5aoguRt+j579qxKBymJJSTXs5wc5JcNq3bt2uo9goKCVPrM9PR09Zgc3wcffIDDhw+rWr5sumPO2/QtS4lKRitJRylZrkaOHKk+j47k0pasWZIxq0qVKmqfMWPG6N+rsAlAPvzwQ5UMQ04SpKa/du1a/eNpaWl48cUX1evLZ5a0mJKSU0geK2kd8Pf3V8/18/PD2LFjUZq4hKgR+Lra47NHGuKFXw/gh60X0LGOF9rWzH7w8i7AzhnwMb1Ua0QVUlpS0Z9jZQdYZf+8ZmZoVyW0sARsHP77dW2dCv021tbWKk2kBL23335bn8tZgrTkYZYALUGuefPmKpC6uLhg1apVGDJkCGrWrIlWrVoVKqg9/PDD8PHxwe7duxEXF5erP1vH2dlZHYcELgm2I0aMUPe9/vrreOyxx3Ds2DEVDHW5ol1dXe94jaSkJJXqUtJeSvN7VFQUnnvuORU0DU9GNm3apIKoXJ47d069vgRbec/CkNSYX3zxhUqLKbmsf/rpJ/Tr1w/Hjx9X+bq/+eYbrFixAr///rsKyJLhSjbx559/4ssvv8SiRYtUSszIyEh1AlJhA7V80eTMRZJ9S2HIF0DOpt55550iJRc3RT0aVMHjLatj0d5wTFh8GGvHd4DbzcPALw8Dto7A8HWApy56E5HRfOJX9OcMnAfUH6C9fupv4I9ngID2wLBVOft81RBIzmc54UlxRXqr4cOHY9q0aQgNDdXnYZZm70ceeUQFQ9leffVV/f4vvfQS1q1bp4JQYQK1BNZTp06p58hvsPjkk0/u6FeW32XDGrm8pwQzCdRSO5Z803JiIU3dd7Nw4UKVGnL+/PlwctKesHz77beqL/6zzz5TJwtC8mnL/VZWVggJCUHv3r2xcePGQgdqqY3Licvjjz+ubstrS9CXVoSZM2fi8uXLKmC3b99exRqpUevIY/IZunbtChsbGxXIC1OOZtv0LYU3a9Ys9R9y8uRJdXvq1KmYMWMGzMF7feshqLITIuNTMPGvo9B4BgOeQdrEHTIinIjoP0igatu2raoVCqlhykAyafbWVXgkv7M0eXt4eKiAKUFXAk5hyG+vJNDQBWkhNd68Fi9erLJgSRCT95DAXdj3MHyvxo0b64O0aNeunarVnz59Wn+f1GQlSOtI7Vpq34URHx+Pa9euqdc1JLfl/YVUCA8dOoQ6deqoZu3169fr9xs4cCBu376tmvflxGDp0qXIyMhAha1R79ixA/3791dnS7qzNOlb2bNnD8xlytZXjzfBw9/twJpjkfi9jhcee3qFdplRGyavJzIJb10rXtO3Tkhf7WtI07eh8UdRUiQoS01ZaoNSm5Zm7U6dOqnHpLYtTb1SW5RgLUFQmq6lH7ak7Ny5E4MHD1b90NJ0LbV4qU1L83JpsLGxyXVbar0SzEtKs2bNVG7sNWvWqBaFQYMGqRr0kiVL1EmLnDTI/dJXP3r0aH2LRt7jqhA1ajlLlOYMSSwupB9g27ZtZjWUv1E1N7ySPWXr3WXHsec6coK0zK2WaVvxxfihIKKSIX3GRd10/dNCrst9hv3TBb1uMUggkfzO0nQszcbSHK7rHpRUklLheeqpp1RtVWqCut/UwpD80NI/K9OodHbt2nVHpUqah6WfXEaaS7PxpUuXcn9cW1tVu/+v95Lfeemr1tm+fbv6bFK7LQnSTy+tA3lTbMptGShnuJ/0fc+ZM0e1FkjfdExMjHpMmvKlOV76sjdv3qxOVKRfvkLWqN98803VTCFNO9LMIf/JkydPVmdud5Oamqo2nYSEBJi65zsG4XD4Law9HomRv+zDX6PaIsirErD9a+Cf94F9PwHPrAactf0zRESGpKlZgsrEiRPVb6Y03epI0JSaoART6dudPn06rl+/nisoFURqkjKae+jQoarmKK8vAdmQvIc0c0stumXLlmrAmjQJG5IWUamlSpOyjLaWgWZ5p2XJb/v777+v3kvGJ0VHR6uWAhn8puufLgmvvfaaeh9peZBBaNIKIce1YMEC9biUkTSny0AzOUmQwXnSpO/m5qYGtUksat26tRrhLmOoJHAb9mNXqBq1DHaQgpOzxAMHDuDnn39WgwDk8m5kCL1uAIVshf0yGnvK1pePNUHj6m64lZyO4fP2IiYpDWjwMOBaHbh5Dpjfn3msiajA5u/Y2FjV9GzYnyx9xdKUK/fLYDMJODK9qfC/T5Yq6Eq/rAyaklHYUmEyJCOmX375ZTU6WwKfnBTI9CxDMrhNFmfp3LmzmlKW3xQxCXzSfy41Vwn4jz76KLp06aLGKZUk6XeeMGECXnnlFdUdIKPRZZS3nHAIOYmQ8VDSOiDHERYWhtWrV6uykGAttWzp05Y56tIE/vfff6tpYqXFQiOTwkyU9AVIrVrmyOl8/PHH6gxGRiEWpkZ99epVFayl6UbO4kxZdEIqBny3HVdib6N5gDsWPNca9vFhwLzeQEIE4NsQGPo34OBu7EMlMisy0lhqe4GBgWreLFFpf69kkRqJcYWJTSZdo05OTlZnMIakCbygQQPSlCJ9C7pNzozKCy9nO8wb1hIu9tbYfykWr/5xGFnuQYAMMHPyAiKPaqdvpcQb+1CJiKiMmHSgls56aWKR/g5pepDmF+k7GDAge36iGQr2dsb3Q5qr5B0rj0Tg8/WnAa/a2mDt4AFcOwAsGMiMW0REFYRJB2qZLy19FDL8XUYDygT6559/Xs0JNGdta1bGlIe16/N+t/k8Fu25DPjUA4YsBexcgfBdwG+PA2nJxj5UIiKqyIFamq1l7p8M85eBDOfPn1d91DLM39w92rwaxnbRDmx4e9kxbD0bDfg1AYb8BdhWAsK2AosHAxk5/fFERGR+TDpQV3Qvd62FAU2rIjNLg9G/HsDpyASgWgtg8B/aRVHO/wv8PhTIKLmFC4iIyLQwUJswWbDg00caolWgBxJSMzBs7h5ExacAAW2BJxYB1vbAmTXA0pHaxVGI6J6U5OpWRFkl9H0y6QVPCLCztsLsIc3x8KwduBCdhGd/3ofFz98Hx6BOwGMLgN+HACF9JKqzuIiKSbrTZIaJrAEtc3zldnlP/EPGI7OeZYlWWbBFvlf32l1r0vOoS0JR5qqZsks3kzDgux1qIZSudb3xw5AWsLK0ABKjgUpexj48onJPflhlmUyZFkpUEmQBF1nhLL9AXZTYxBp1ORHg6YQ5T7fAE3N24Z+TUfho5QlM6lc/d5CWNcEPLQA6vMoaNlERyY+ppCyUTEj/tSY10X+RNT8krWdJtMwwUJcjslrZl4OaYMzCA5i3IwwBno4Y1i5Q+2B6CjCvDxBzXnu742tGPVai8kh+VCUDUmllQSIqDg4mK2d6N6qCN3uGqOsfrjyBDSck3VZ2xq324wH3QKDRY8Y9SCIiKjEM1OWQZNt6opW/Gug99reDOHolTvtAs6eB0TsBN39jHyIREZUQBupy2jz3Uf/66FjbC7fTMzH85724Eps9AMYw5+3Jv4EdM4x2nEREdO8YqMspaytLzHyyKUJ8nVXWLUmNGZ+SnrND1CntYijr3wF2/2DMQyUionvAQF2OOdvb4KdnWsLHxQ5nrieq1cvSM7Mn2HuHAB0maK+veR2Y2wvYPw+4HWvUYyYioqJhoC7n/Nwc8L+hLeFoa4Vt527gnaXH1GR7pfPbQIdXpLEcuLQd+Hsc8HltYNFg4MQK7UhxIiIyaQzUZqBBVVd8+2RTyPoni/eFq4xbiszf6/Ie8PIxoOsHgHd9IDMNOLVSu6KZBO0VLwEXt8raicb+GERElA8GajPxQIiPdgEUANPWncaKw9dyHnStpp26NXoH8MJ2oN04wKUqkBoHHJgP/NwH+KohcPYf430AIiLKFwO1GXm6TQ082167AMqrfxzGvrCYO3fybQA8+CEw/hgwdKV2SpfkuI6/ArhWzdnv5nkg7koZHj0REeWHgdrMvNWrLrrX90FaRhZGzN+HizeS8t/R0hII7AD0mwG8egZ46k/Au27O45smA1824IhxIiIjY6A2M5Ko46vHmqJxNVfEJqer1JiSyKNAsqpZcNec2zIYLSVergDVWubcH3lUOzc7I7X0PgAREeXCQG2GHGyt8OPQlqjq5oCwm8kYOX8f4m4bzLH+LzII7aklwMvHAb+mOffv+h5Y/BTweS1gxVggbDsHoRERlTIm5TBTXs52mDespcpjve9SLNpO2aiWHR3ePlBN6SoUGYRmyD0AcPYDEq4BB37Wbtb2gIM74OCRfemWfZm9BXYCqjXXPl9q4olR2vvtKpX8hyYiMkPMR23m9l+KwdtLj+FUZIK6bW1pgX6N/TCiYxDqVnEp+gtmZWrnZB9ZrJ2LnSpN5AWQgWsyylxcPQDM6awdcT7hRM4+K18GEiINAnx2sK/kCzhXAVyqAE7egBXPK4nIPDAfNek1D/DAmnEdEHomGj+EXsDOCzfx18GrautU2wvPdwpCmyDPwudMtbQCAjtqt95fAgkR2tXO7rb5Nsx5bloiYGWrDcKGZB73zbMFv6+FJVDJB3CW4O0HNH4MqNdf+5gs3BJ7UftY3tcmIirnWKOuYI5cuYUftlzAmqMRyMpewKxhVVcVsHvU91VriJcqGagmTeAygE3n9Nr8A77UsuV+udRk5n6dbh8DbV/KXVOX2vcrp3L2CZ2qrfFLYJcg7pJ9KftZ25Xu5yQiKgBr1HRXjaq5YeaTzXD5ZjJ+3HYBv+8Lx9GrcXhx4UFU93DAiA5BGNi8uhqQViqk5m4YpEWdHv/d3J50Q9s3Hi+BOwKo3jrn8dQEwN5NG4QNHVqorWnnx95VW0OXJvVKsvkAlbyAoM5A1WY576vJAqxsivVRicjEZaQCyTHA7RjtZfLN7Os3geRYg+vZl9JC+NgvZX6YrFFXcDJ1a/7OMPy8I0xN5xLujjZq8ZSn2wTAs1I5qnlmpucOqrtnA7Fh2bXyCCD+mrZ2nlnA9LLunwBtxmivX9kH/NgF8GkIjNqWe/R7RkpOcFeXPoCjp7ZrQMiSrFkZQFa69rhk0J3uBCX9NhB3VTuX3SMo53WvHdK2AMjzMjNyni+X0hIhLQFu1bUtBOyvp4omK0u7BLLub0pt+d2Wv580oEb73L8FV/YAzYZq148Qp1YDi54o2jFUaQw8v6VEPg5r1FRoHk62GN+1Np7vWBNL9odjztaLuByTjK83nsUPW86r2vVzHQIR4Olk+qWat+bbeuSd+0jAk2b1pGgg8bp2FLrarmvv822Us6/cn9/r7voOuHUp/350SxvtD4fUxA31+BS4b1ROQJ7bA/CoCYw9kLPP8jHA9WP//TktrLSryLn6A00HA02e1N4vP1TxV7WD9dgKQP/ZBZWiPWmUS3VdLm/nuUzRBj1bp5wxIeLgr9q/j4aPAm7+2vsu7wJOLM8+wZRgKSeZmTknm7lOQLM3ed0nF+e87p/PAZd3A72m5bS0HV8GLBl+Z/dXQSytgXdvaFvwRNgW7RoQ0hKnC9TSqqb+niy1Y1vkRFtmr8ilo7vB9exLuS2tb0Zg8sNor169ijfeeANr1qxBcnIygoODMXfuXLRo0cLYh2ZWpKl7SJsaagrX2uORmL3lAo5cicMvuy5hwe5L6NmgCkZ2DELj6m4o1+QPV/3heQBedQret3YP4LXzQHpy7vsbDQJuhecEd3V5Qxuc71Zblx8lHekft3PR/kgZ8gjU7ic/MrpNAq5cymtLi4As6yo/fLcua7fgLjnPv3EGmNVW+6Py+oWc+w/9pn2Oa3Xtj6pMuytOH738uBsOOrxxFkiJA9KStD/46UlAWrK2vHT3yeBB+ZyyyZQ8SQwjKViF/JBLucn9ds5FPx5zl3RT+/1Kzy5LVbYGZazKOfs+Vf4p2imUnV7PeY35D2m/n4/9CnjWzBm7ISsPFoVncO5AvXMmEHVC202kC9TXj2tPYotCFyx1JPjHXdZ2Z+lYWt09SMv3S23yd2KTfd0asHHUlo/ub6zRY0D1+wD/+3KeK4s5vRGmXUJZWrdMmEkH6tjYWLRr1w6dO3dWgdrLywtnz56FuztH9pYWGUzWp5Efejesgl0XYlStevPpaKw6GqE2GSE+slMQ7q/tVfiR4uWV/PE6Vb7z/gfeufM+qSlIH5YERBVk5YfDKifQym0d+XGbGH7na8iPaWGa/xIjtScKEqhl7XYdCXpWdnfOf982XRvE9Sy0/fnyAyub9O/nDbStXwDq9tHuHrYN+PVR7Q/9qO05L/Pb48DNcyiSTm8A3m9pr8dcAGa20tZm5AdTZ+kLQOQxbQDXBXlbuW5w28Yhp9YmW/WWOavrSYD7531tTanfNzmvu/EjbfOnrolU99ws3e3sJlNZkU/+z6Tlol4/oOdn2udnpAGzO2n/X4etzVkLYPvXwNkN2f/PVjnPVdfz3JYaqpSxNKF2nphzbF+EaFcDfGm/djqi2DIV2P190cq3aovcgVr+36WVxXAapRyPITk2KU/VPaO7tNdeqs1OOxDTUEgf7fdYunx05DO1fzn7u2+d5/ufZ1P3WwHWedZ0kLKW8pGTVp2aXYAJp7TPUZttzt9XYX+D6va98z5rW+1WDph0oP7ss89QvXp1VYPWCQw0+A+kUiNBuE1NT7WdioxXNewVh66p6V2yhfg6q4FnfRv7wdbatM9Gy4ScxTsb/GiV5smD/GjK5m8woE4EdQLejgTSDGojIvhBwC0gpxYuzZq6fvvw3fm/T52eBu9po32OTK8zJE3sErxsHbU1GBVA5bpDTjCVQCi1a3muXBr2ycsJgQRTCcCGJLhcP1q0cmnzYk6glmM9+Iv2B90wUEuN72IR+xelxUBHTgykFikMA0T0aSBsa9FeN2/LS2pids3YoPVGTqDkJMZGTk6yy1V/PU956y7znqQN+F7bGiPdLDqtRgBNn8oJzMXpJnng7Tvvq9ZCu90Lw3wDOrbyWR1RkZn0YLJ69eqhe/fuqtM9NDQUVatWxejRozFixIhS6bCngl27dRtzt1/Ewt2XkZSmbYrycbHDk60C8ESr6vB2yTOam0yP/LlLzV/62FXgDtfWtgx/+OVH0bcxUDlY+xxpUpVavK0z4ORZ8scjtVjDpviII9omXxXgdUE+O9CnZl+Xmqm+ZmajPUnRNc3KPlITldfUTeHTzdeXZmDDWpmulmZ4XVocpKlV+ldl8R33GtrnS41bArI8JrMDdAMHr+zXzi6QgKj6XjOzBwBmv4bhbRUcHbUtGTU75xxb1Clt7U66Jzi+oEK4UoTYZNKB2t5e+8M/YcIEDBw4EHv37sW4cePw/fffY+jQofk+JzU1VW2GfdwS8BmoS46sGy7B+qftFxGdkKpf8axHA181WrxlDXfzbxYnIroHZhOobW1t1aCxHTt26O8bO3asCtg7d+7M9zmTJk3CBx98cMf9DNQlT1JprjkWgV92XlLrietIs/iQNgF4qElVONmZdO8KEZHJB2qT7lysUqWKqg0bqlu3Li5fvnzX50ycOBFxcXH67cQJgzWlqURJ33T/JlWxZFRbrBrbXjV/O9hYqXXFZX3x+z7ZiEkrjuN8dJ6+TSIiKrRiBWo5A5CzAZ09e/Zg/PjxmD17NkqSjPg+ffp0rvvOnDmDgICAuz7Hzs4OLi4u+s3ZmdM+ykJ9P1dMebgRdr3VBe/2qYcano5ISM3AvB1h6PJFKJ76cTfWHY9ERmae+cVERFTygfrJJ5/Epk2b1PXIyEg8+OCDKli//fbb+PDDD1FSXn75ZezatQuffPIJzp07h4ULF6qTgTFjsleOIpPj6mCDZ9sH4t9X7sfPw1uha11vNUB227kbeP6X/eg0bTNmbjqHG4kFrA5GRET31kct85glgNapUwfffPMNFi9ejO3bt2P9+vV44YUXcOGCwWIL92jlypWqOVvmT8vULBlYxlHf5Ut4TDIW7L6MxXsv65cptbWyRK+GvmqRlWb+bhx8RkQVypUi9FEXa6RPenq6amIW//zzD/r166euh4SEICIiAiWpT58+aqPyq7qHI97sGYLxXWth1ZEIzN91CYfDb2HZoWtqq+/ngqFtaqg52aWWDISIqCI1fdevX19Nkdq6dSs2bNiAHj20a7Jeu3YNnp4lPM+SzIa9jRUeaV4Ny8e0w4oX2+HR5tXUgLTj1+Lx+p9HcN+UjZi86gQu3Uwy9qESEZXvpu/NmzdjwIABiI+PV/OZf/rpJ3X/W2+9hVOnTuGvv/6CqeCCJ6YtNilNpdr8dfclhMfcVvdJn3an2l5oFeiBau6OqObugGpuDqhcyQ6WlpyfTUTlX5nMo87MzFSB2nDd7bCwMDg6OsLb2zgZRvLDQF0+ZGZpEHomCvN3XlJri+dHat8SsKtK4FabI6q6aa/Lfd7O9rBiICeicqDU+6hv374Nie+6IH3p0iUsXbpUzXGWJT+JikoC7AMhPmqTpu/lh64h7EYSrsTextVbtxERd1stsHLhRpLa8mNjZQE/XeBWl4451z0c4eNsp5KOEBGVJ8UK1P3798fDDz+sRnjfunULrVu3ho2NDW7cuIHp06dj1KjsvLtExSC5r8d2qZXrvvTMLETGpajAfSU2OftSgrj2ekRcCtIzNbh0M1lt+ZFlTn1d7RHsXQmDWlRHt3o+DNxEZJ6B+sCBA/jyyy/V9SVLlsDHxwcHDx7En3/+iffee4+BmkqcjZWlGj0uG3DngEVZSOV6QiquxCTra+G6gC7XJaGIBHJdgJfmdT9X++wc3NXh5lg+0t0RUcVTrECdnJysX/FL5k5L7drS0hL33XefagYnKmvSpC1N3LLlSf6o7wOPStDWyENPR2Phnsu4FpeCz9aewtcbz2BA06p4pm0g6vhyJTsiMi3F6rALDg7GsmXLVCf4unXr0K1bN3V/VFSUWraTyBT7wKu4OqBlDQ+82r0Odrz5AKY+2gh1q7ggJT0Lv+0JR/evtuDJObuw4cR1FdiJiMptjVqat2UZUVni84EHHkCbNm30teumTZuW9DESlcqcbumnHti8GvZcjFFrksta5DvO31Sbv4cjnm4TgEEtq8PFXnIUExEZR7GnZ8ka37IKWePGjVWzt5D1vqVGLSuUmQpOz6JCf1dik/HLrktYtCdc5dwWjrZWamGWoW1roKZXJRYmEZW/fNS6LFr/9UbGwkBNRZWcloFlB69h3o6LOHM9J0WnLMIyrF0NdKzlxYVXiMi081FnZWWpLFmurq4q5aRsbm5u+Oijj9RjROWZo601nmztj3XjO2LBc631GcBCz0Tjmbl70fXLUMzfGYbE1AxjHyoRVQDF6qOWdJb/+9//8Omnn6qc0WLbtm2YNGkSUlJSMHny5JI+TqIyZ2FhgXbBldUmi7D8vOMS/tgXjgvRSXhv+XFMW3ta9WFLQhF/T5k2RkRU8orV9O3n56eScuiyZuksX74co0ePxtWrV2Eq2PRNJUlq0X/uv4Kfd4TpV0iT2naXEB/VLN62pidTdhKR8ZcQjYmJyXfAmNwnjxGZq0p21mpg2ZD7AhB6NhrztoepJvF/Tl5Xm5ezHRr4uaBBVVfU93NFg6ouam631M6JiIqjWIFaRnp/++23+Oabb3LdL/c1atSoWAdCVJ5IFq/OdbzVdi4qUfVZL9l/BdEJqdh0OlptOm6ONmjg54r6VV3UpQTxAA9HDkgjotJr+g4NDUXv3r3h7++vn0O9c+dOVYVfvXo1OnToAFPBpm8qK7fTMnEiIh7Hr8Xh2FXZ4nHmegIy8lk8RWrm9aTmnV3rluAdVNmJa48TVRBXSrvpu1OnTjhz5gxmzpyp8k8LWUZ05MiR+Pjjj00qUBOVFQdbKzQPcFebTmpGJs5EJuKYLnhfi8fJiHjV1y0LrcimY29jqVZK0wVvaTqv7eOs0nsSUcV1z/OoDR0+fBjNmjVTuapNBWvUZGokE9j56ERV45bgLTXw49fikZyWmW/qTll/vGFVVwxuHaBq3kRU/pV6jZqI7i0TWIivi9pk1TORlaXBxZtJKnCfuBafXQOPVyukaQN6PBbtDcejzarhte514O1iz/8CogqCgZrIRAanyRKlsvVvUlXdJ41dku1Latyrjkbi78PX8Mf+K1h1NAKjOtXEiI5Bas1yIjJv7PwiMlEypUvyb/doUAUznmiKv0a3RVN/N9VE/sWGM3jg881YfuiqCuhEZL6KVKOWAWMFuXXr1r0eDxHdRTN/d/w1qi1WHL6Gz9acUvm0xy06hLnbw/Bun7poHuDBsiOq6IFa1vb+r8effvrpez0mIiqgli1N493r++LHrRfw3ebzOBR+C4/M2ok+jargzZ4hqObO5UyJzEmJjvo2RRz1TeYsKj4FX6w/g9/3h0P+kmUq13PtAzG6c7Caq01EFTR7FhGZBhn9/dmjjbDypfZoE+SJtIwsVcu+f9pmLNpzGZn5LLZCROVLuQrUkq1Lmv7Gjx9v7EMhMimyOMrCEa0xe0hz1PB0xI3EVLz511H0mbENO87dMPbhEVFFCNR79+7FDz/8wLXEie5CTmK71ffF+pc74Z3edeFib61WQXvyx9147ud9uBCdyLIjKofKRaBOTEzE4MGDMWfOHLi75yzPSER3Uv3UHYKw+bXOGNomAFaWFiqzV7cvt+CDv4/jVnIai42oHCkXgXrMmDEqCUjXrl3/c9/U1FTEx8frt4SEhDI5RiJT4+Fkiw/6N8C68R3QuY6XSg4iU7nu/3wz5m6/qJYyJSLTZ/KBetGiRThw4ACmTJlSqP1lP5kmptvq1atX6sdIZMqCvZ0xd1grzB/eCrV9KuFWcjo++PsEun+1BRtPXueCKUQmzqQDtQxbHzduHBYsWAB7+8KtbTxx4kTExcXptxMnTpT6cRKVBx1re2H12A6YPKABPJ1scSE6Cc/+vA+P/bAL/9t2UeXVNvPZmkTlkknPo162bBkGDBgAK6uc9YwlM5cMmrG0tFTN3IaP5YfzqInuFJ+SjpmbzmHutjCkGTSBV3VzUAG9U20vtA32hIu9DYuPqBQUJTaZdKCW/uVLly7lum/YsGEICQnBG2+8gQYNGvznazBQExXw9xGbjDVHI7HlbDR2X4jJFbRlEFpzf3d0quOFjrW8UN/PRSUPIaJ7ZzZpLp2dne8Ixk5OTvD09CxUkCaigslyo5KFS7bktAwVrEPPRGPLmWhcuJGEPWExapu27rRqLtfVttvXqozKlexYvERlwKQDNRGVHUdba3QO8VabCI9JVkFbNlk05WZSGpYevKo20bCqqwraErwlq5fk2SaikmfSTd8lgU3fRPdOliY9cDlWG7hPR+NERHyux53trNEuuLIK2h1rV2ZiEKKK0kddEhioiUpeVEIKtp65oQL31rPRiE1Oz/V4sHcl1a/dv4kfGld3438BUR4M1MUsDCIqOkn8cexqnL6Z/ODlWBjmAmkd6IGRHYPQuY43B6MRmdtgMiIyfTI6XGrNso3tUgtxyenYfv4G1h+PxKqjEdh9MUZtUsse2SEI/Zv6wc664GmVRJSDTd9EVGoi41LUcqULd19GQmqGus/b2Q7PtKuBwa0C4OrIedpUMV1hH3XxCoOISkdCSjoW7QnHT9svIiIuRd3nZGuFx1r6Y3j7Ghx8RhXOFQbq4hUGEZX+6PGVR65h9pYLOBWZoG86792wiurHblDVlf8FVCFcYR81EZlqCs6Hm1XDgKZVseXsDczZcgHbzt3AisPX1NYu2BMjO9ZEx1qV1VLBRMTBZERkBBKEZbEU2WTE+JytF7DySAS2n7upthBfZ4zoEIS+jf1UcCeqyDiYjIhMZt1xyZe9aM9lJKVlqvt8XexVH/YTrfzhzAQhZEbYR13MwiAi45PpXQv2XFJBOzohVb/y2ROt/TGsXQ1UcXUw9iES3TMG6mIWBhGZjtSMTCw/eA2zt15QubKFtaUF+jXxw/B2gajj68z1xanc4mAyIir3ZFGUQS2r49Hm1bD5TBR+CL2gFk7568BVtclYM8no5eNin73ZwdtZe93XNee67MP0nFSecWUyIjJpEmQfCPFR2+HwW2pq14YT11Xu7BuJaWo7fi13khBDUgv3craDtwRwFzt9YJeFV7RB3R4+zvZwcbDmSHMySQzURFRuyDKlMwc3Q1aWBrHJaYiMT0FUfCqux6fgulwmyO0Udb/cvpGYiowsjVpkRbbDBby2nbWlCtySsvOVB+vA39OxDD8Z0d0xUBNRuaxle1ayU1t9v7vvl5Fd69YGct2WHdgTUlVQl+uS/Ss1IwuXY5LVtuZYJEZ0CMTo+4PhZMefSTIufgOJyGxZW1mqpm3ZCpKSnqlGmIfHJGNW6HlsPXsDMzedx5/7r2JirxD0a+zHZnEyGq4kQEQVnr2NFap7OKJtcGXMH94Ks4c0R3UPB9WEPm7RIQz8fqdamIXIGBioiYjyrJrWrb4vNrzcCa91rwMHGyvsuxSLvt9uw8S/juBmonZuN1FZYaAmIrpLLXtM52D8+2on9G/iB40G+G1POO7/fDN+2nYR6ZlZLDcqEwzUREQFkJXQvn68KZa80AYNqrogISUDH648gV5fb8XWs9EsOyp1DNRERIXQooYHlo9pjykPN4SHky3ORiViyP/2YOT8fbh8M5llSKWGgZqIqJAkd7YkCNn0yv1q3XG5vf7EdXT9MhTT1p1CUmoGy5JKHAM1EVERuTra4P2+9bF2XAe0D66MtIwsNZ2ryxehWH7oKjTSoU1UQhioiYiKqZaPM355thV+4HQuKkUM1ERE9zidq3v2dK5Xu9XmdC6qWIF6ypQpaNmyJZydneHt7Y2HHnoIp0+fNvZhERHlO53rxQdqcToXVaxAHRoaijFjxmDXrl3YsGED0tPT0a1bNyQlJRn70IiICpzO9ccLbVDfL/d0rt/3hSMuOZ0lR0VioSlHox6io6NVzVoCeMeOHUs8OTcRUUnKzNKo4Dxt3WnEJKXp0262C66MXg190a2eL9ydbFnoFdCVIsSmcpWUIy5Ou9auh4fHXfdJTU1Vm05CQkKZHBsR0d2mc/VqUAXzd4Zh5ZEInL6egNAz0Wp7a+kxtK3piV4Nq6h+bpmfTVRua9RZWVno168fbt26hW3btt11v0mTJuGDDz64437WqInIFJyLSsSaoxFYfSwSJyPicwX1+4I89EG7ciU7ox4nmU6NutwE6lGjRmHNmjUqSBf0ofLWqK9evYp69eoxUBORybkQnahyX68+GoHj13KCtqUF0DrQE70aSdD2gbdzwWk6qfwxu0D94osvYvny5diyZQsCAwOL9Fz2URNReXDpZhJWH9UG7aMGKTUtLIBWNbQ17Z4NfOHtwqBtDswmUMuhvfTSS1i6dCk2b96MWrVqFfk1GKiJqLwJj0lWAVuaxw+H38oVtFsEuGcH7SrwdWXQLq/MJlCPHj0aCxcuVLXpOnXq6O93dXWFg4NDoV6DgZqIyrMrsclYeywSq45G4ODlnKAtmge4q1p2z4ZVUNWtcL+JZBrMJlDLij/5mTt3Lp555plCvQYDNRGZi2u3buv7tPdfis31mL+HI1oFeqhmcrkM8HS8628oGZ/ZBOqSwEBNROYoMi4Fa45F6IN2Vp5fci9nu1yBu46PMyxllBqZBAbqYhYGEVF5lJCSroL1nosxajtyJQ5pmVm59nGxt0bL7KDdMtADDau6wsbKpBenNGtXzHXBEyIiupOzvQ3ur+OtNpGSnolD4bewVwJ3WIwK4vEpGdh4KkptwsHGCs0C3PTBu2l1dzjYWrF4TRADNRGRGSYIuS/IU20iIzNLzdPeGxaD3Rdj1OWt5HRsP3dTbcLGykLVslsFeqJVoDuaB3jA1cHGyJ+EBPuoiYgqmKwsDc5FJ2qDdnZzeWR8Sq59ZBxaiK+LWi2tfXBltA7yRCU71u1KCpu+iYjormRQWW0fZ7UNuS9ArVkRHnNbNZPvuXgTe8NicfFGklriVLa528NUMpGm/m4qoYgE7sbV3djHXUZYoyYiojtExaeowL3j/E1sO3sDl2OScz3uZKttXleBu1Zl1PKuxOlgRcAaNRER3RNZqrRPIz+1ics3k7H9/A1sO3cDO87dQGxyeq7BaTIdTGrauho3V00rOexwICKi/+Tv6Qh/T3+VtlP6uE9ExGP7OW3glj7u6IRULD14VW2ippcTOtTyUoG7dZAHXOw5MK242PRNRET3RKaDHbgUq4K2BO8jV+NguJSWpPBsXM1VX+Nu6u8OW+uKPYf7CudRExFRWU4HaxtcWW3iVnIadl24mR24b6qBaQcu31LbN/+eU3O4Ze52M393NK7uikbV3ODhZMv/sLtg0zcREZUoN0db9GhQRW26xCI7zukC9w3cTEpD6JlotelU93BQAVtq3nLZoKorp4NlY6AmIqJSVc3dEYNaylZd9W+fikzAzgs3ceTKLbXcqdS4ZXqYbKuOROjncQd7VdIG7+xad90qzrCzrnirpzFQExFRmc7hrufnojaduOR0HL0ah8MqcGuDd0RcCs5GJartzwNX9KunySIsjaq5onE1NzSq7opa3s6qD9ycMVATEZFRuTraqLnYsulEJaTgSHicCtyHr2gvY7MDumwLdl9W+0l/d4OqErzd9AHc3FJ8MlATEZHJ8Xa2R9d6svmo27J62pXY29m17jgcDr+FY1fjkJSWqVZSk80wU1jdKi5qU7X3Ki6o5VOp3DabM1ATEZHJs7CwQHUPR7XpFmHJzNLgQnSiyhR2JLvWfTIiQWUKk3XMZdORJVBrelVS/dwSvHWBvHIlO5g6BmoiIiqXrCwtUMvHWW0DW1RX96VlZOFsVAJOXJN1yhPUWuWyOEvc7XScvp6gtmWHrulfw9vZTl/zVpdVnBFYuZJJ9XszUBMRkdmwtbZEfT9XtelIs7kMTlNBWwJ4pDaIh91MQlRCKqISck8Vs7exRB2f3DXvEF9nlffbGBioiYjI7JvN/dwc1NalrrbPWySlZqipYrpat1yeikjA7fRMNYBNNkP+Ho5oEeCO6Y81KdPjZ6AmIqIKycnOGs0D3NWmI/3el25Kis/cAVxq5JJBzLNS2a+gxkBNRESUTfqmg7wqqa13I+3KaiI2KU0F7CyDNczLCgM1ERHRf3B3stWvZV7WKnb6EiIiIhPHQE1ERGTCGKiJiIhMGAM1ERGRCWOgJiIiMmFmP+o7KytLXUZEaHOcEhERGZsuJuliVIUO1NevX1eXrVq1MvahEBER3RGj/P39URALjSyCasYyMjJw8OBB+Pj4wNLy3lr6ExISUK9ePZw4cQLOzs4ldozmjGXGMuP3zDTxb9O4ZSY1aQnSTZs2hbW1dcUO1CUpPj4erq6uiIuLg4uLi7EPp1xgmbHM+D0zTfzbLD9lxsFkREREJoyBmoiIyIQxUBeBnZ0d3n//fXVJLLPSwu8Zy6ws8HtWfsqMfdREREQmjDVqIiIiE8ZATUREZMIYqImIiEwYA3URzJw5EzVq1IC9vT1at26NPXv2lN7/TDk3ZcoUtGzZUi0K4O3tjYceeginT5829mGVG59++iksLCwwfvx4Yx+KSbt69SqeeuopeHp6wsHBAQ0bNsS+ffuMfVgmKzMzE++++y4CAwNVedWsWRMfffQRuJxGblu2bEHfvn3h5+en/g6XLVuW63Epr/feew9VqlRR5di1a1ecPXsWpYWBupAWL16MCRMmqBF/Bw4cQOPGjdG9e3dERUWV2n9OeRYaGooxY8Zg165d2LBhA9LT09GtWzckJSUZ+9BM3t69e/HDDz+gUaNGxj4UkxYbG4t27drBxsYGa9asUatFffHFF3B3dzf2oZmszz77DLNmzcK3336LkydPqttTp07FjBkzjH1oJiUpKUn9xkvlLD9SZt988w2+//577N69G05OTioepKSklM4Bycpk9N9atWqlGTNmjP52Zmamxs/PTzNlyhQWXyFERUXJCnia0NBQllcBEhISNLVq1dJs2LBB06lTJ824ceNYXnfxxhtvaNq3b8/yKYLevXtrhg8fnuu+hx9+WDN48GCW413I79bSpUv1t7OysjS+vr6aadOm6e+7deuWxs7OTvPbb79pSgNr1IWQlpaG/fv3q+YNHVk3XG7v3LmzdM6gzIwsuSc8PDyMfSgmTVohevfuneu7RvlbsWIFWrRogYEDB6ruFVkzec6cOSyuArRt2xYbN27EmTNn1O3Dhw9j27Zt6NmzJ8utkC5evIjIyMhcf6OyrKh0h5ZWPDD77Fkl4caNG6pvRxJ7GJLbp06dMtpxlRey+Lz0tUozZYMGDYx9OCZr0aJFqltFmr7pv124cEE140qX1FtvvaXKbezYsbC1tcXQoUNZhPl488031XrVISEhsLKyUr9rkydPxuDBg1lehSRBWuQXD3SPlTQGaiqTWuKxY8fUmTvlLzw8HOPGjVP9+TJYkQp3Aig16k8++UTdlhq1fM+k35CBOn+///47FixYgIULF6J+/fo4dOiQOomWQVMsM9PFpu9CqFy5sjr71OW21pHbvr6+pfV/YxZefPFFrFy5Eps2bUK1atWMfTgmS7pWZGBis2bNVMo72WRAngxYketS86HcZMStpBw0VLduXVy+fJlFdRevvfaaqlU//vjjaoT8kCFD8PLLL6tZGlQ4ut/8sowHDNSFIE1pzZs3V307hmfzcrtNmzal8h9T3skYDAnSS5cuxb///qumg9DddenSBUePHlU1HN0mtUVpkpTrcqJIuUlXSt4pf9L3GhAQwKK6i+TkZDW+xpB8t+T3jApHfsskIBvGA+lOkNHfpRUP2PRdSNIPJk1D8uPZqlUrfPXVV2oI/7Bhw0rlP8YcmruleW358uVqLrWu70YGXci8Q8pNyihv/71M+ZD5wezXz5/UBGVwlDR9Dxo0SK1rMHv2bLVR/mRusPRJ+/v7q6bvgwcPYvr06Rg+fDiLzEBiYiLOnTuXawCZnDDLYFgpO+ku+Pjjj1GrVi0VuGVuunQfyHoRpaJUxpKbqRkzZmj8/f01tra2arrWrl27jH1IJku+Wvltc+fONfahlRucnvXf/v77b02DBg3U1JiQkBDN7Nmzy+B/pvyKj49XU/7kd8ze3l4TFBSkefvttzWpqanGPjSTsmnTpnx/v4YOHaqfovXuu+9qfHx81HevS5cumtOnT5fa8TB7FhERkQljHzUREZEJY6AmIiIyYQzUREREJoyBmoiIyIQxUBMREZkwBmoiIiITxkBNRERkwhioiYiITBgDNRGVOAsLCyxbtowlS1QCGKiJzMwzzzyjAmXerUePHsY+NCIqBiblIDJDEpTnzp2b6z47OzujHQ8RFR9r1ERmSIKypOIz3Nzd3dVjUrueNWsWevbsqTKZBQUFYcmSJbmeLyk3H3jgAfW4ZPAaOXKkyihk6KefflIZmOS9JDe0pDU1dOPGDQwYMACOjo4qy9CKFSv0j8XGxqoUnl5eXuo95PG8JxZEpMVATVQBSVq+Rx55BIcPH1YB8/HHH8fJkyfVY5K+tXv37iqw7927F3/88Qf++eefXIFYAr2kMpUALkFdgnBwcHCu9/jggw9U+skjR46gV69e6n1iYmL073/ixAmsWbNGva+8XuXKlcu4FIjKiVLLy0VERiGp+KysrDROTk65tsmTJ6vH5c/+hRdeyPWc1q1ba0aNGqWuS6pId3d3TWJiov7xVatWaSwtLTWRkZHqtp+fn0qPeDfyHu+8847+tryW3LdmzRp1u2/fvpphw4aV8CcnMk/soyYyQ507d1a1VEOS9F6nTZs2uR6T24cOHVLXpYbbuHFjODk56R9v164dsrKycPr0adV0fu3aNXTp0qXAY2jUqJH+uryWi4sLoqKi1O1Ro0apGv2BAwfQrVs3PPTQQ2jbtu09fmoi88RATWSGJDDmbYouKdKnXBg2Nja5bkuAl2AvpH/80qVLWL16NTZs2KCCvjSlf/7556VyzETlGfuoiSqgXbt23XG7bt266rpcSt+19FXrbN++HZaWlqhTpw6cnZ1Ro0YNbNy48Z6OQQaSDR06FL/++iu++uorzJ49+55ej8hcsUZNZIZSU1MRGRmZ6z5ra2v9gC0ZINaiRQu0b98eCxYswJ49e/C///1PPSaDvt5//30VRCdNmoTo6Gi89NJLGDJkCHx8fNQ+cv8LL7wAb29vVTtOSEhQwVz2K4z33nsPzZs3V6PG5VhXrlypP1EgotwYqInM0Nq1a9WUKUNSGz516pR+RPaiRYswevRotd9vv/2GevXqqcdkOtW6deswbtw4tGzZUt2W/uTp06frX0uCeEpKCr788ku8+uqr6gTg0UcfLfTx2draYuLEiQgLC1NN6R06dFDHQ0R3spARZfncT0RmSvqKly5dqgZwEZHpYx81ERGRCWOgJiIiMmHsoyaqYNjbRVS+sEZNRERkwhioiYiITBgDNRERkQljoCYiIjJhDNREREQmjIGaiIjIhDFQExERmTAGaiIiIhPGQE1ERATT9X/M+wctHcTaSAAAAABJRU5ErkJggg==\",\n \"text/plain\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"de713235-1561-467f-bf63-bf11ade383f0\",\n \"metadata\": {},\n \"source\": [\n \"**If you are interested in augmenting this training function with more advanced techniques, such as learning rate warmup, cosine annealing, and gradient clipping, please refer to [Appendix D](../../appendix-D/01_main-chapter-code)**\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6d5cdf2f-09a5-4eb0-a20a-d7aac5c14c2c\",\n \"metadata\": {},\n \"source\": [\n \"**If you are interested in a larger training dataset and longer training run, see [../03_bonus_pretraining_on_gutenberg](../03_bonus_pretraining_on_gutenberg)**\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"699f45fc-bf78-42f2-bd24-2355db41b28f\",\n \"metadata\": {\n \"id\": \"699f45fc-bf78-42f2-bd24-2355db41b28f\"\n },\n \"source\": [\n \" \\n\",\n \"## 5.3 Decoding strategies to control randomness\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6be9086e-2c27-41da-97d0-49137d0ba3c7\",\n \"metadata\": {},\n \"source\": [\n \"- Inference is relatively cheap with a relatively small LLM as the GPT model we trained above, so there's no need to use a GPU for it in case you used a GPU for training it above\\n\",\n \"- Using the `generate_text_simple` function (from the previous chapter) that we used earlier inside the simple training function, we can generate new text one word (or token) at a time\\n\",\n \"- As explained in section 5.1.2, the next generated token is the token corresponding to the largest probability score among all tokens in the vocabulary\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"2734cee0-f6f9-42d5-b71c-fa7e0ef28b6d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort moves you?\\\"\\n\",\n \"\\n\",\n \"\\\"Yes--quite insensible to the irony. She wanted him vindicated--and by me!\\\"\\n\",\n \"\\n\",\n \"\\n\"\n ]\n }\n ],\n \"source\": [\n \"# NEW: use CPU here as inference is cheap with \\n\",\n \"# this model and to ensure readers get same results in the\\n\",\n \"# remaining sections of this book\\n\",\n \"inference_device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(inference_device)\\n\",\n \"model.eval()\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(\\\"Every effort moves you\\\", tokenizer).to(inference_device),\\n\",\n \" max_new_tokens=25,\\n\",\n \" context_size=GPT_CONFIG_124M[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d25dbe31-bb7c-4893-b25b-47d0492d4aa4\",\n \"metadata\": {},\n \"source\": [\n \"- Even if we execute the `generate_text_simple` function above multiple times, the LLM will always generate the same outputs\\n\",\n \"- We now introduce two concepts, so-called decoding strategies, to modify the `generate_text_simple`: *temperature scaling* and *top-k* sampling\\n\",\n \"- These will allow the model to control the randomness and diversity of the generated text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4bb6f380-a798-4fd9-825c-17b7cd29a994\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 5.3.1 Temperature scaling\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a7f4f53c-0612-43d3-aa82-52447eac50fa\",\n \"metadata\": {},\n \"source\": [\n \"- Previously, we always sampled the token with the highest probability as the next token using `torch.argmax`\\n\",\n \"- To add variety, we can sample the next token using The `torch.multinomial(probs, num_samples=1)`, sampling from a probability distribution\\n\",\n \"- Here, each index's chance of being picked corresponds to its probability in the input tensor\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e7531bae-d5de-44c0-bc78-78fed077e22a\",\n \"metadata\": {},\n \"source\": [\n \"- Here's a little recap of generating the next token, assuming a very small vocabulary for illustration purposes:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"01a5ce39-3dc8-4c35-96bc-6410a1e42412\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"forward\\n\"\n ]\n }\n ],\n \"source\": [\n \"vocab = { \\n\",\n \" \\\"closer\\\": 0,\\n\",\n \" \\\"every\\\": 1, \\n\",\n \" \\\"effort\\\": 2, \\n\",\n \" \\\"forward\\\": 3,\\n\",\n \" \\\"inches\\\": 4,\\n\",\n \" \\\"moves\\\": 5, \\n\",\n \" \\\"pizza\\\": 6,\\n\",\n \" \\\"toward\\\": 7,\\n\",\n \" \\\"you\\\": 8,\\n\",\n \"} \\n\",\n \"\\n\",\n \"inverse_vocab = {v: k for k, v in vocab.items()}\\n\",\n \"\\n\",\n \"# Suppose input is \\\"every effort moves you\\\", and the LLM\\n\",\n \"# returns the following logits for the next token:\\n\",\n \"next_token_logits = torch.tensor(\\n\",\n \" [4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79]\\n\",\n \")\\n\",\n \"\\n\",\n \"probas = torch.softmax(next_token_logits, dim=0)\\n\",\n \"next_token_id = torch.argmax(probas).item()\\n\",\n \"\\n\",\n \"# The next generated token is then as follows:\\n\",\n \"print(inverse_vocab[next_token_id])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"6400572f-b3c8-49e2-95bc-433e55c5b3a1\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"forward\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"next_token_id = torch.multinomial(probas, num_samples=1).item()\\n\",\n \"print(inverse_vocab[next_token_id])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c63d0a27-830b-42b5-9986-6d1a7de04dd9\",\n \"metadata\": {},\n \"source\": [\n \"- Instead of determining the most likely token via `torch.argmax`, we use `torch.multinomial(probas, num_samples=1)` to determine the most likely token by sampling from the softmax distribution\\n\",\n \"- For illustration purposes, let's see what happens when we sample the next token 1,000 times using the original softmax probabilities:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"b23b863e-252a-403c-b5b1-62bc0a42319f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"73 x closer\\n\",\n \"0 x every\\n\",\n \"0 x effort\\n\",\n \"582 x forward\\n\",\n \"2 x inches\\n\",\n \"0 x moves\\n\",\n \"0 x pizza\\n\",\n \"343 x toward\\n\",\n \"0 x you\\n\"\n ]\n }\n ],\n \"source\": [\n \"def print_sampled_tokens(probas):\\n\",\n \" torch.manual_seed(123) # Manual seed for reproducibility\\n\",\n \" sample = [torch.multinomial(probas, num_samples=1).item() for i in range(1_000)]\\n\",\n \" sampled_ids = torch.bincount(torch.tensor(sample), minlength=len(probas))\\n\",\n \" for i, freq in enumerate(sampled_ids):\\n\",\n \" print(f\\\"{freq} x {inverse_vocab[i]}\\\")\\n\",\n \"\\n\",\n \"print_sampled_tokens(probas)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"32e7d9cf-a26d-4d9a-8664-4af1efa73832\",\n \"metadata\": {},\n \"source\": [\n \"- We can control the distribution and selection process via a concept called temperature scaling\\n\",\n \"- \\\"Temperature scaling\\\" is just a fancy word for dividing the logits by a number greater than 0\\n\",\n \"- Temperatures greater than 1 will result in more uniformly distributed token probabilities after applying the softmax\\n\",\n \"- Temperatures smaller than 1 will result in more confident (sharper or more peaky) distributions after applying the softmax\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0d2b5399\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the resulting dropout outputs may look different depending on your operating system; you can read more about this inconsistency [here on the PyTorch issue tracker](https://github.com/pytorch/pytorch/issues/121595)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"0759e4c8-5362-467c-bec6-b0a19d1ba43d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def softmax_with_temperature(logits, temperature):\\n\",\n \" scaled_logits = logits / temperature\\n\",\n \" return torch.softmax(scaled_logits, dim=0)\\n\",\n \"\\n\",\n \"# Temperature values\\n\",\n \"temperatures = [1, 0.1, 5] # Original, higher confidence, and lower confidence\\n\",\n \"\\n\",\n \"# Calculate scaled probabilities\\n\",\n \"scaled_probas = [softmax_with_temperature(next_token_logits, T) for T in temperatures]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"2e66e613-4aca-4296-a984-ddd0d80c6578\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAeoAAAEiCAYAAAA21pHjAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAAPrRJREFUeJzt3QeUU9X2P/BN703pTZrSi4D0otJBEWwUBUTgiYCgCFKkSpUm8BhAaYJ0eYKKSn3SBKQXaSpFePQOAlLvf333f938kpAZZibJ5NzM97NWFjOZmeROuJN9zzn77J3AsixLiIiIyEgJQ30AREREFDkGaiIiIoMxUBMRERmMgZqIiMhgDNREREQGY6AmIiIyGAM1ERGRwRioiYiIDJZY4pkHDx7IqVOnJE2aNJIgQYJQHw4REcVDlmXJ9evXJXv27JIwYdRj5ngXqBGkc+XKFerDICIikhMnTkjOnDmjfCXiXaDGSNp+cdKmTRvqwyEionjo2rVrOmi0Y1JU4l2gtqe7EaQZqImIKJSiswTLZDIiIiKDhTRQr1u3Tl588UVdTMdVxZIlSx75M2vWrJHSpUtLsmTJpECBAvLll1/GybESERHFu0B948YNKVmypERERETr+48ePSoNGjSQ5557Tnbt2iXvv/++tG3bVpYvXx70YyUiIgqFkK5R16tXT2/RNXnyZMmbN6+MHj1aPy9cuLBs2LBBPvvsM6lTp04Qj5SI4nob5Z07d/iik2MlSZJEEiVKFJDHclQy2aZNm6RmzZoe9yFAY2Qdmdu3b+vNPdOOiMyFAI3ZMwRrIidLnz69ZM2a1e+aHY4K1GfOnJEsWbJ43IfPEXxv3bolKVKkeOhnhg0bJgMHDozDoyQif4pAnD59Wkci2LryqEIQRKaexzdv3pRz587p59myZYs/gTo2evXqJV27dn1o7xoRmefevXv6BocE05QpU4b6cIhizR44IlhnzpzZr2lwRwVqTCGcPXvW4z58jv3QvkbTgOxw3IiMMiBdFF+7KvHV/fv39d+kSZOG+lCI/GZfbN69e9evQO2oeaWKFSvK6tWrPe5buXKl3k9E4YN1+CkcJAhQP4mQBuq///5bt1nhBkggwcfHjx93TVu3bNnS9f3t27eXI0eOyEcffSQHDx6UiRMnysKFC+WDDz4I2e9AREQUTCEN1Nu2bZOnn35ab4C1ZHzcr18//RxJJXbQBmzN+uGHH3QUjf3X2KY1depUbs0iIqKwFdI16meffVaz4yLjq+oYfmbnzp1BPjIiMkmenj/E6fMdG94gYNOb/fv3lwEDBkg4yZMnj26LjWprrOk6d+4sv/zyi/z2229ak8Oe2TWRo5LJiIhMg5k/24IFC3RG8NChQ677UqdOLU6AQROS+RInThyne+ZDmTj49ttvy6+//ip79uwRkzkqmYyIyMTdKPYtXbp0OsJ2v2/+/Pk6YkuePLkUKlRIc2tsx44d0+9Hrk3VqlV198ozzzwjv//+u2zdulXKli2rgR4VHM+fP+/6ubfeeksaNWqkNSIyZcqkO1+Qw+NezQ0FY1BHAkuGeFwsFy5atMijbwKe+6effpIyZcro7hhUejx8+LC89NJLWqMCz43jWbVqlces5l9//aW5Qfh5e0YBswalSpXyeG3Gjh2ro2/v4x4yZIhuwStYsKCr7fDrr7+uBUIee+wxfX68NsE0fvx46dixo+TLl09Mx0BNRBQkc+bM0RE2AtOBAwdk6NCh0rdvX5k5c+ZD0+N9+vSRHTt26Ii2efPmmjQ7btw4Wb9+vfz555+u3B0bdsDgMRFw582bJ998841HcScE6VmzZmnp5X379mlgffPNN2Xt2rUej9OzZ08ZPny4PlaJEiU0ybd+/fr6+FhmrFu3rjZPsvOF8Dw5c+aUTz75RGcT3GcUogOPixkH5BotXbpUty6hwiT6MuN3xXQ0LhDwvFGVkU2dOnWUN1y4hAtOfRMRBQkCMJJeX375Zf0co9v9+/fL559/Lq1atXJ9X7du3VxJsV26dJFmzZppQKtcubLe16ZNm4dydjBlPH36dN2rW7RoUQ2c3bt3l0GDBmnww0UBRsL29lWMHDFixnNXr17d9Tj4uVq1ark+x4gWo28bHm/x4sXy3XffSadOnfTr2BOMwIoZg5hKlSqVJgHbU96zZ8/W0T/us0fnM2bM0NE1LkJq167t83EetaaMWYZwwUBNRBSk7oCYRkaQbdeunUf1NUyRu8NI1maXSS5evLjHfXY5ShuCqXv1NgRkjIYxjYx/UeHNPQADRqj2Lhsbptfd4WcxjY0dNhgt43hRotl9B44/8Hu5r0vv3r1bZwwQ+N39888/+vpFBm2O4wsGaiKiIEDAgylTpkj58uU9vuZdpQqdlmz2qNL7vpg0KbGfG8E2R44cHl/zrtSIEa47jO4xLT1q1CgNhljffvXVVx/ZzQx12b138WBk7837+XCsWCPHMoE3rL9H5lFJepjmx7R/OGCgJiIKAoyCkTCFIk1vvPFGwB8fI1H3ZkSbN2/W4IVeBpieRkDGKNh9mjs6sEaMpK/GjRu7Aql3YhdGxHa5V/egisZJCNb2xUZ0tjyVLl1as+VRDzsm09W7OPVNRET+QnIX9utiqhvJUWi5i0JPly9f9mgWFBsY4WJaHUloCKRYD8caMka2mEbGyBgJZBiJV6lSRa5evapBGMHQfX3c25NPPqkJY0ggQ8BF8pv3aB6Z3OvWrZOmTZvqBUHGjBk1GxyZ6SNGjNAR+LJlyzSj/FHBFxcxI0eO1ExvrJcjUQ1Z5TgGJNTlzJkzKFPfmG7HRQguLnDBYwf+IkWKGFdrnlnfRERB0rZtW02SQnIU1mYxukVSGJLK/FWjRg0NqtWqVZMmTZpIw4YNPQqrIAkMQRbZ39gehgsFTIU/6rnHjBkjGTJkkEqVKmmwRpIbRr3uEFBxcZA/f37X9DSeA1vPIiIidP18y5YterHwKFhnR9DPnTu3Jt3hcXABgjXqYCaEtW3bVtfrkVyH7XB2lcxTp06JaRJYUZUGC0Noc4mrW1xdhlNWIDkMu2f5hDdn1PxHMMG+Y/INU9NXrlyRJUuW8CVy6Pkck1jEETUREZHBGKiJiIgMxqxvIiKH8dWwiMIXR9REREQGY6AmIiIyGAM1ERGRwRioiYiIDMZATUREZDAGaiIiIoMxUBMR+QH1sKO6uZf1DBeo9T127FhxsuPHj0uDBg20hCkagqCXN1p6RmXIkCFaWhU/g37ZcYX7qInI2SVXg/J8V6P9rejZbEMXqH79+smhQ4ei3Y7RFKgmjY5YiRPHXVhAY5FQNMC4f/++BumsWbPKxo0b9f+wZcuW2lp06NChUR7va6+9pr2/p02bFmfHyxE1EZEf8GZv31C7GaNo9/vmz5+vjSZQ67lQoULauMKGxhb4/oULF0rVqlW1ZeUzzzyjTSK2bt0qZcuW1UBfr1497UzlXuu7UaNG2p0LTTFQK7p9+/YePaPR8QoNOVBnGo+LRhmLFi1yfX3NmjX63OhwhX7Q6IK1YcMGOXz4sHayQptOPDeOZ9WqVa6fQ5csdLdCZy571gAwc1CqVCmP1wajboy+vY8bI1O0AC1YsKDef+LECXn99dd1lIoWnXh+79aagbRixQrZv3+/zJ49W48Zry+amKChSFR9t/F64/dGg5W4xEBNRBQkc+bM0RE2AtOBAwd0tIaOVjNnzvT4PrSoRLvKHTt26Ii2efPm2uJx3Lhxsn79em3JiMdxt3r1an1MBNx58+ZpW0gEEhuC9KxZs2Ty5Mmyb98+DTBvvvmmrF271uNxevbsKcOHD9fHKlGihLZ+rF+/vj7+zp07tesWumhhqhjwPGg9iQ5aGIm6zyhEBx4XMw4rV66UpUuXyt27d7VDF1pz4ndFK05cIOB5owqaqVOnjvKGC5fIbNq0SYMtLkZsOAY0ysBrZRpOfRMRBQkC8OjRo7V9I2B0i5EcWiu694RGO0gECujSpYs0a9ZMA1rlypX1PrR99C4biinj6dOn63pp0aJFNXBinRUjQwQ/XBRgJIxpWsiXL5+OmPHcaLdpw8/VqlXL9TlGtBh92/B4ixcvlu+++077XePriRIl0sCKGYOYSpUqlbb+tKe8MarF6B/32aNztAXF6BoXIbVr1/b5OHb/6MhE1ZEKPajdgzTYn+NrpmGgJiIKghs3bug0MoJsu3btXPcjYQlT5O4wkvUOGO7Tq7jv3LlzHj+DYIogbUNAxmgY08j49+bNmx4BGDBCRc9ld5hed4efxTQ2eldjtIzjvXXrlmtE7S/8Xu7r0rt379YZAwR+7xaReP0iU6BAAYkvGKiJiIIAAQ+mTJki5cuX9/gaRqTukMRks0eV3vdh1BnT50awzZEjh8fXsBbtPcJ1h9E9pqVHjRqlwRDr26+++mqU09CQMGFCTUhzh5G9N+/nw7FijRzLBN6w/h6ZRyXpYZof0/6+YCZgy5YtHvedPXvW9TXTMFATEQUBRsFImDpy5Ii88cYbAX98jEQx0kUghc2bN2vwypUrl05PIyBjFOw+zR0dWCNG0lfjxo1dgdQ7sQsjYmROewdVTBsjWNsXG4+anobSpUtrtjy2SEU1XR3IqW/MPiBvALMUeF7AxQl+pkiRImIaBmoioiBBclfnzp11qhvJUbdv35Zt27bJ5cuXpWvXrn49Nka4mFZHEhoCKdbDsYaMkS2mkTEyRgIZRuJVqlSRq1evahBGMHJfH/f25JNPasIYEsgQcJH85j2aRyb3unXrpGnTpnpBkDFjRs0GR2b6iBEjdAS+bNkyzSh/VPDFRczIkSM10xvr5UhUQ1Y5jgEJdTlz5gz41DfWvRGQW7RooceLCwy8jh07dnTNOGDEjS1byBWwZyVw4XPp0iX9Fxcq9sUCjiWY2/BCnvWNdHj8p2PrAqaHvKcjvCHdHyn9uIrElSNORKxlEBGZpm3btpokheQorM1idIukMCSV+atGjRoaVKtVqyZNmjSRhg0behRXQRIYgiyyv7E9DBcKmAp/1HOPGTNGMmTIoIU9EKyR5IZRrzsEVFwc5M+f3zU9jefA1jO8p2P9HO/luFh4FKyzI+jnzp1bk+7wOLgAwft6TEbYMYGlB2Sc41+MrjFNjqCM38uGNX5kp7tP3yPzHmv8uCjCTAM+xg0XX8GUwPJeVIhDmO7Ai4N1BARpBOGvv/5aXxx7OsLd3Llz5e2339ZMR5xE2GuIKRpc1eHkig6k3+PqFleXwToJiPwq4BGDYhvhBm/OR48e1WCCi3fyDe97V65ckSVLlvAlcuj5HJNYFNIRNYIrsiFbt26t0xAI2Li6QiD2BRVksF0BewwxCsf0BbYxPGoUTkRE5FQhC9RYX9m+fbvUrFnz/w4mYUL9HJvRfcEoGj9jB2Ykafz444+6OZ+IiCgchSyZ7MKFC7oY72vT+cGDB33+DEbS+DkkRmDGHvv7UH2md+/ekT4Pkjdwc59uICJyMu/iJxTeQp5MFhOoUoNqO0hYQKk9ZAUiOQJJE5FBIgXWAewbEtCIiIicImQjaqTzI+PO3mRuw+eRbThHBiPS6ZFJCciiRPWff/3rX/Lxxx/r1Lm3Xr16eWyDwIiawZqIiJwiZCNqbJhHNRrsUbNhrx4+t2vTekO6vHcwtiv8RJa8jj1xyKhzvxERETlFSAueYKSLjfeoNVuuXDndnoURMrLAAVu3sNEc09eAPX3IFMe+NWznQn1YjLJxv3dJPiIionAQ0kCNTfqoZINN5KgMg76gqGZjJ5ih+ov7CBqVY1ApB/+ePHlSN9ojSKMUHBERUTgKacGTUGDBEzICC574xIInFE7+CYeCJ0RERBQ1BmoiIj9gOS6qm3v97XCBypDIKXKyBD7+r+bPny8mYvcsIjJe8ZnF4/T59rbaG+3vPX36tEf/AuTcoF+BLZhdlQIJq6AoQpU4ceI4rVCJHUChMmPGDG1WYkufPr2YiCNqIiI/oO6DfcOaI0Zm7vdhlIaOUFijLFSokBZssqEDFb5/4cKFUrVqVe0K+Mwzz2jDoa1bt+qOGAT6evXqaeKte1OORo0aaRtNJNVijRNVGhH43Le7YscM1kfxuOhotWjRIo8CUnhutKLEVllsZd2wYYMcPnxYW04iqRfPjeNZtWqV6+fQzhJtKNG50B6JAmYOkBDsDqNujL69jxsJwOjVjU6IcOLECXn99dc1UKKXNp7fuwd2MOD53P+vTG0Ew0BNRBQkc+bM0RE2AtOBAwe0siK2lM6cOdPj+9A2EbtZUHERI1qUS0Yv5nHjxsn69et1Kyoexx1qTuAxEXDnzZunlRoRuG0I0rNmzdJmR/v27dPAinaOa9eu9Xicnj17yvDhw/WxSpQooe0b0T8Bj79z504dcWJ3DXbhAJ4HPaLREhKzCe4zCtGBx8WMw8qVK7XVJNpIopUmemjjd0XPbFwg4HndLzy84XuiuuHC5VHQfxrFt7A9GM2gTM2t5tQ3EVGQIACPHj1a+ywDRrf79++Xzz//XGtI2NC3GcEKunTpol0BEdDQLRDQn9m7vjemjBFc0HGwaNGiGji7d++uJZUR/HBRgJGwXUAqX758OmLGc6Mvtg0/V6tWLdfnGNFi9G3D4y1evFi+++476dSpk34ddSsQWCOrIhmVVKlSaY9ue8p79uzZOvrHffboHFPSGO3iIqR27do+H2fXrl1RPs+jMqnxez///PP6+q1YsUI6dOigFymdO3cW0zBQExEFAYo3YRoZQRbtfG1oJoQpcncYydrsOhIokex+37lz5zx+BsEUQcaGgIxAg2lk/ItKju4BGDBCRcEod5hed4efxTQ2+ihgtIzjvXXrlmtE7S/8Xu7r0rt379YZAwR+761NeP0iU6BAAfEHZjZseE3w/zVy5EgGaiKi+AIBD6ZMmaKVFN15V1JMkiSJ62N7VOl9H0adMX1uBFtUd3SHtWjvEa47jO4xLT1q1CgNhljffvXVV6OchgYUp/KeOsbI3pv38+FYsUaOZQJvWH+PzKOS9DDNj2n/6ML/EWYP0G3R+zUKNY6oiYiCAKNgJEwdOXJE3njjjYA/PkaiGOkikMLmzZs1eKHpEKanEWwwCnaf5o4OrBEj6atx48auQOqd2IURMTLEvYMqKkwiWNsXG4+anobSpUtrtnzmzJlj1Ithl59T374eL0OGDMYFaWCgJiIKEiR3Yc0TU91IjsJobdu2bXL58mWPrn6xgREuptWRhIZAivVwrCFjZItpZIyMkUCGkXiVKlW0AhaCMAKY+/q4tyeffFITxpBAhoCLKWLv0TwyudetWydNmzbVwIaELGSDIzN9xIgROgJHOWhklD8qYOIiBlPOyPTGujES1ZBVjmNAQl3OnDkDPvX9/fffa6fGChUqaKY3ZhCwpo/XzETM+iYiChK05EWSFJKjsDaL0S2SwpBU5q8aNWpoUK1WrZr2TWjYsKFHcRVM4yLIIvsb28NwoYCp8Ec9NxofYWRZqVIlDdZIcsOo1x0CKi4O8ufP75qexnNg61lERISun2/ZsiVagQ/r7Aj6uXPn1qQ7PA4uQLBGHaxuh0mSJNHjxLo+tpQhwQ6/Ny52TMRa30ShwFrfPrHWd/RgavrKlSuyZMmSQJ6VFGCs9U1ERBQPcOqbiIjIYEwmIyJyGO/iJxTeYjWi/vnnnwN/JERERBSYQI3sQWT7DR48WKvgEBERkUGB+uTJk7pfD51YUD8W6fvo/vKoyjVERNFhanMEolCcx7EK1Njcjo30qOTy66+/ylNPPaUFzVGFB5v7UTGHiCim7NKavOincHDz5s2HysGGJJkMG+HRQeXxxx/XVmno5oJN79hIjjqr6OpCRBStN6TEibUABipc4c0NVbaInDiSRpBGIxV0AfOu7R5ngRrF1r/99lsNzCi/hg4sEyZM0PZs+CNDWbvXXntNW7oREUUHSlZmy5ZNjh49qmUkiZwMQTo2rUADEqjfe+89bVSOq4YWLVpobddixYp5dEdB5xVMhRMRxQQaPqA0Jqe/ycmSJEni90jar0CNUfK///1vrcsaWacRrGNzGxcRxQamvNEsgYhimUyGwuWY1vYO0mgwjuLq9lpTTNurERERUQAC9XPPPSeXLl166H60UcPXiIiIKISB2r0xuLuLFy/q+jQRERFJ3K9RY00aEKTRZs196vv+/fuyZ88e7WFKREREIQjU6dKlc42o06RJIylSpPDI1KxQoYK0a9cuQIdGREREMQrUM2bM0H/z5Mkj3bp14zQ3ERGRqVnfgVqLjoiI0MCPrRjly5eXLVu2RPn9V65ckY4dO2pRBEy9o3zpjz/+GJBjISIicuyIGqVCV69eLRkyZJCnn37aZzKZbceOHdF6zAULFkjXrl211CiC9NixY7XBx6FDhyRz5swPfT8KINSqVUu/hoYgOXLk0OpFqP5CREQUrwP1Sy+95Eoea9SoUUCefMyYMbqm3bp1a/0cAfuHH37QsqQ9e/Z86PtxP7aFbdy40VXkHKNxIiKicJXAClE/OYyOUXwfI2P3wN+qVSud3kYdcW/169eXxx57TH8OX8+UKZM0b95cevToEWmpttu3b+vNdu3aNcmVK5fu+U6bNm2QfjuiRxiQLoqvXeXLRxTmrl27pgna0YlFIWtNc+HCBd3SlSVLFo/78fmZM2d8/syRI0c0sOPnsC7dt29fGT16tAwePDjS5xk2bJi+GPYNQZqIiCjspr6xNh3VurQ7X1XLAuHBgwe6Pv3FF1/oCLpMmTJy8uRJGTlypCa4+dKrVy9dB/ceURMREYVVoEaiVyChaQeC7dmzZz3ux+eRtQVDprd3R5LChQvrCBxT6djL7Q3r6pE1DiEiIgqbQI2140BCUMWIGJnk9ho1Rsz4vFOnTj5/pnLlyjJ37lz9Pruh/O+//64B3FeQJiIicrpor1Fjytj946hu0YUp6SlTpsjMmTPlwIED8u6778qNGzdcWeAtW7bUqWsbvo5p9S5dumiARob40KFDdV81ERGRxPc16tOnT+saMfYt+1qvtpt1INkrOpo0aSLnz5+Xfv366fR1qVKlZNmyZa4Es+PHj7tGzoC15eXLl8sHH3wgJUqU0H3UCNrI+iYiIorX27PWrl2rU8/oM42Po2JyH+qYpMQT+SNPzx8i/dqx5M0j/0FuzyIKe9diEIuiPaJ2D74mB2IiIqJ425TD3eXLl2XatGm6tgxFihTRtWUUJCEiIqLAiFXBk3Xr1mnpzvHjx2vAxg0f582bV79GREREIRxRI8saiWCTJk1y7WlGAlmHDh30a3v37g3Q4REREcVvsRpR//nnn/Lhhx96FB7Bx9huha8RERFRCAM1Wl7aa9PucF/JkiUDcVxEREQUk6nvPXv2uD7u3Lmz7l/G6LlChQp63+bNmyUiIkKGDx/OF5aIiCiu91Gj8AiKmTzq22NS8CQUuI+a4gr3URNRnO6jPnr0aHS/lYiIiAIk2oH6iSeeCNRzEhERUbALnsD+/fu1HjdaTLpr2LChPw9LRERE/gTqI0eOSOPGjXW/tPu6td2ow+Q1aiIiorDfnoWMb1QhO3funKRMmVL27dunFcnKli0ra9asCfxREhERxVOxGlFv2rRJ/vvf/0rGjBk1Gxy3KlWqyLBhw3Tr1s6dOwN/pERERPFQrEbUmNpOkyaNfoxgferUKVfC2aFDhwJ7hERERPFYrEbUxYoVk927d+v0d/ny5WXEiBGSNGlS+eKLLyRfvnyBP0oiIqJ4KlaBuk+fPnLjxg39+JNPPpEXXnhBqlatKo8//rgsWLAg0MdIREQUb8UqUNepU8f1cYECBeTgwYNy6dIlyZAhgyvzm4iIiEK8jxpOnDih/+bKlSsAh0NERER+J5Pdu3dP+vbtq3VK8+TJozd8jCnxu3fvxuYhiYiIKFAj6vfee0+++eYbTSKrWLGia8vWgAED5OLFizJp0qTYPCwREREFIlDPnTtX5s+fL/Xq1XPdV6JECZ3+btasGQM1ERFRKKe+kyVLptPd3rBdC9u0iIiIKISBulOnTjJo0CC5ffu26z58PGTIEP0aERERxfHU98svv+zx+apVqyRnzpxSsmRJ/RwFUNBFq0aNGgE6NCIiIop2oEZWt7tXXnnF43NuzyIiIgphoJ4xY0YQnp6IiIiCVvDk/PnzriYcBQsWlEyZMvnzcERERBSIZDLU+X777bclW7ZsUq1aNb1lz55d2rRpIzdv3ozNQxIREVGgAnXXrl1l7dq18v3338uVK1f09u233+p9H374YYwfLyIiQrd7JU+eXLtxbdmyJVo/h73cqC3eqFGjWPwWREREYRqo//Of/8i0adO04EnatGn1Vr9+fZkyZYosWrQoRo+FblsI/P3795cdO3ZoFjmafpw7dy7Knzt27Jh069ZNu3YRERGFq1gFakxvZ8mS5aH7M2fOHOOp7zFjxki7du2kdevWUqRIEZk8ebKkTJlSpk+fHunP3L9/X9544w0ZOHAg+18TEVFYi1WgRn1vjID/+ecf1323bt3SwGnX/o4O7Lvevn271KxZ8/8OKGFC/Ry1wyODHti4KMCa+KOgEMu1a9c8bkRERGGd9T127FipW7fuQwVPsMa8fPnyaD/OhQsXdHTsPTrH5+hx7cuGDRt02n3Xrl3Reo5hw4bpBQQREVG8CdTFixeXP/74Q+bMmeMKqGjGgenoFClSSLBcv35dWrRooWvhGTNmjNbP9OrVS9fAbRhRszgLERGFbaBGv+lChQrJ0qVLdW3ZHwi2iRIlkrNnz3rcj8+zZs360PcfPnxYk8hefPFF130PHjzQfxMnTqx7uvPnz/9QAxHciIiI4sUadZIkSTzWpv2BTltlypSR1atXewRefO5rrRsXCHv37tVpb/vWsGFDee655/RjjpSJiCjcxGrqu2PHjvLpp5/K1KlTdSTrD0xLt2rVSsqWLSvlypXT9W8UVEEWOLRs2VJy5Miha81YAy9WrJjHz6dPn17/9b6fiIgoHMQqym7dulVHvStWrND16lSpUnl8/Ztvvon2YzVp0kRLkfbr10/OnDkjpUqVkmXLlrkSzI4fP66Z4ERERPFRrAI1RrHe3bP8gR7WkfWxXrNmTZQ/++WXXwbsOIiIiBwdqLF+PHLkSPn99991D/Tzzz8vAwYMCGqmNxERUXwWoznlIUOGSO/evSV16tS6bjx+/HhdryYiIiIDRtSzZs2SiRMnyjvvvKOfr1q1Sho0aKBJZVxHJiIKb3l6/uDz/mPDG8T5scQnMRpRI7ELzTdsKPWJ7lWnTp0KxrERERHFezEK1Pfu3dMtUt77qlEEhYiIiEI89W1Zlrz11lselb5Q/KR9+/YeW7Risj2LiIiIAhSoUZjE25tvvhmThyAiIqJgBeoZM2bE5NuJiIjITyz5RUREZDAGaiIiIoMxUBMRERmMgZqIiMhgDNREREQGY6AmIiIyGAM1ERGRwRioiYiIDMZATUREZDAGaiIiIoMxUBMRERmMgZqIiMhgDNREREQGY6AmIiIyGAM1ERGRwRioiYiIDMZATUREZLDEoT4AIvJUfGbxSF+Sva328uUiimc4oiYiIjIYAzUREZHBjAjUERERkidPHkmePLmUL19etmzZEun3TpkyRapWrSoZMmTQW82aNaP8fiIiIicL+Rr1ggULpGvXrjJ58mQN0mPHjpU6derIoUOHJHPmzA99/5o1a6RZs2ZSqVIlDeyffvqp1K5dW/bt2yc5cuQIye9ARES+MeciDEbUY8aMkXbt2knr1q2lSJEiGrBTpkwp06dP9/n9c+bMkQ4dOkipUqWkUKFCMnXqVHnw4IGsXr06zo+diIgorAP1nTt3ZPv27Tp97TqghAn1802bNkXrMW7evCl3796Vxx57LIhHSkREFA+nvi9cuCD379+XLFmyeNyPzw8ePBitx+jRo4dkz57dI9i7u337tt5s165d8/OoiYiI4tHUtz+GDx8u8+fPl8WLF+t6tS/Dhg2TdOnSuW65cuWK8+MkIiJyZKDOmDGjJEqUSM6ePetxPz7PmjVrlD87atQoDdQrVqyQEiVKRPp9vXr1kqtXr7puJ06cCNjxExERhXWgTpo0qZQpU8YjEcxODKtYsWKkPzdixAgZNGiQLFu2TMqWLRvlcyRLlkzSpk3rcSMiInKKkG/PwtasVq1aacAtV66cbs+6ceOGZoFDy5YtddsVprAB27H69esnc+fO1b3XZ86c0ftTp06tNyIionAS8kDdpEkTOX/+vAZfBF1su8JI2U4wO378uGaC2yZNmqTZ4q+++qrH4/Tv318GDBgQ58dPREQU1oEaOnXqpDdfUODE3bFjx+LoqIiIiELP0VnfRERE4Y6BmoiIyGAM1ERERAYzYo06PmKheiIiig6OqImIiAzGQE1ERGQwBmoiIiKDMVATEREZjIGaiIjIYAzUREREBmOgJiIiMhgDNRERkcEYqImIiAzGQE1ERGQwBmoiIiKDMVATEREZjE05iMhvbDJD4aT4zOKRfm1vq70S1ziiJiIiMhgDNRERkcE49U2OnQ4iIooPOKImIiIyGAM1ERGRwTj17ac8PX+I9GvHhjfw9+GJiCie44iaiIjIYAzUREREBuPUN4U1ZqpTOJ0bTjxm8h9H1ERERAZjoCYiIjIYAzUREZHBjAjUERERkidPHkmePLmUL19etmzZEuX3f/3111KoUCH9/uLFi8uPP/4YZ8dKREQUrwL1ggULpGvXrtK/f3/ZsWOHlCxZUurUqSPnzp3z+f0bN26UZs2aSZs2bWTnzp3SqFEjvf32229xfuxERERhH6jHjBkj7dq1k9atW0uRIkVk8uTJkjJlSpk+fbrP7x83bpzUrVtXunfvLoULF5ZBgwZJ6dKlZcKECXF+7ERERGG9PevOnTuyfft26dWrl+u+hAkTSs2aNWXTpk0+fwb3YwTuDiPwJUuWBP14iYjIhwHpIn9Z8ubmS+bkQH3hwgW5f/++ZMmSxeN+fH7w4EGfP3PmzBmf34/7fbl9+7bebFevXtV/r127FoDfQOTB7ZuRfi2q57h/636sfi4QivVfHunXfhtYx8hjjq1QHnOU50YCy9jXObLzg+dG6IX63IjsnOb5HHP2/5dlRf5e4GKF0MmTJ3GE1saNGz3u7969u1WuXDmfP5MkSRJr7ty5HvdFRERYmTNn9vn9/fv31+fgja8BzwGeAzwHeA6IYa/BiRMnHhkrQzqizpgxoyRKlEjOnj3rcT8+z5o1q8+fwf0x+X5Mq7tPlT948EAuXbokjz/+uCRIkEACCVdIuXLlkhMnTkjatGnFCXjMfJ15bvBvkO8bcQ8j6evXr0v27Nkf+b0hDdRJkyaVMmXKyOrVqzVz2w6k+LxTp04+f6ZixYr69ffff99138qVK/V+X5IlS6Y3d+nTp5dgQpB2SqC28Zj5OvPc4N8g3zfiVrp0Uaztm1TrG6PdVq1aSdmyZaVcuXIyduxYuXHjhmaBQ8uWLSVHjhwybNgw/bxLly5SvXp1GT16tDRo0EDmz58v27Ztky+++CLEvwkREVHghTxQN2nSRM6fPy/9+vXThLBSpUrJsmXLXAljx48f10xwW6VKlWTu3LnSp08f6d27tzz55JOa8V2sWLEQ/hZERERhGqgB09yRTXWvWbPmoftee+01vZkGU+wo3OI91W4yHjNfZ54b/Bvk+4bZEiCjLNQHQURERIZWJiMiIqLIMVATEREZjIGaiIjIYAzUREREBmOgjqV79+7JrFmzHqqSRkREFEjM+vYD2nEeOHBAnnjiCXEKFJdBL+9q1aqJk+TLl0+2bt2qpV/dXblyRducHjlyRELtu+++i/b3NmzYMKjHEp+h0c/evXv17zJDhgyhPhzHikmTD1MrMa5bty7KrzvlfdCIfdROhUpqu3btclSgRvcwtBHFMaP6GwI3Kr+Z7tixY/oG7A2d0U6ePCkmsMvg2lBL3n33o3tteV+/iwlmzpypNfhR9Q8++ugjrfqHXvHz5s0z8lxHOeHixYvrBSheV1Qu3Lhxo15IL126VJ599tlQH6IjodRydPshmHo+P+vj/94Jf4feGKj90KFDBy2BiiYcqFmeKlUqj6+XKFFCTIMqbqgE99VXX+mbMgq0IHDjTe6ll16SJEmSiEncR6nLly/3qI2LPzLUfc+TJ4+YAHXqbatWrZIePXrI0KFDXXXo0UsdFfVwn6lwbJMmTXIdb0REhHz22Wca8D744AP55ptvxDSLFi2SN998Uz/+/vvv5ejRo9omF+f4xx9/LL/88ouYCMe9cOFCrb54584dj6/t2LFDQu3nn3/2uFDu2bOnvPXWWx7nM95D7PLOJrp8+bLH53fv3pWdO3dK3759ZciQIeIYMWlLSZ4SJEjw0C1hwoSuf51g+/btVqdOnazkyZNbGTNmtN5//33r999/t0x+je1b0qRJraeeesr6/vvvLdMULVrUWr9+/UP3r1u3zipUqJBlqhQpUlh//fWXfvzRRx9ZLVq00I9/++03PT9MlCxZMlerwHbt2lldunTRj48cOWKlSZPGMtG4ceOs1KlT698ezuN33nnHqlmzppUuXTqrd+/elmmef/75h9oLw5w5c6zq1atbTrNmzRqrdOnSllMwmcwPuHL3vmGt1P7XdKdPn9bOY7ih3Wj9+vV1bQ/TnBhFmTJKxQ1TrpgJsD/HDdPehw4dkhdeeEFMc/jwYZ9d2jAjgNGJqVKnTi0XL17Uj1esWCG1atXSj5MnTy63bt0SE6EvwP79+3WGBX0C7GO+efOmntcmmjhxoi4p/Pvf/9YuglhiwN9h586ddXnKNBg9o3GSN9y3ZcsWcZosWbLoe4djhPpKgeLWnTt3rEWLFlkNGjSwkiRJYpUpU8aaNGmSdfXqVdf3fPPNN1b69OmNOmZc0Zs00n+UqlWrWrVq1bLOnDnjug8f165d26pWrZplqubNm+tIo02bNlbKlCmtCxcu6P3ffvutzhKYqH///joSxUxF7ty5rX/++UfvnzZtmlWhQgXL1JmLY8eO6ceZMmWydu3apR/jHH/ssccs02Dmqnv37g/dj/vwNVPt3r3b44bX+aefftJZgMqVK1tOwTVqP2EdbPLkyTqKxlUnRn5o1Zk3b15d8zVNtmzZdDTarFkzvRJGtzJvzz33XNB7dscE1s337NkjTjJt2jR5+eWXJXfu3JIrVy69D7kMdrc3U2FNGuvoONb//Oc/riz77du36zljogEDBmj3PBwzmvXYTXEwmsa6qomyZs0qly5d0vcLnCObN2+WkiVL6vuIie0XMMP2yiuvyE8//STly5fX+/D+8ccff+h5YqpSpUo9lNQJFSpUkOnTp4tTcHuWH5B0g/acyDpFYsJvv/2m24i+/PJLTbJwT8Yw6cICb2aYynQSJDLhDXj48OHiFHhzwHQmEpugcOHCmrgX3Uxairl//vnHEed227Zt9QIOyZy4OOrevbtUrlxZtm3bphd4uNAzzf/+9z99z8OWVPt8bt++vetC1ER//fWXx+domZwpUyZHnCPuGKj9gLVcZMliW06aNGlk9+7dGqgRsLEt4MKFC2ISZDymSJFCt5Q5rX/3e++9pwVmMCL1lWE/ZswYMYWTX2dYv369fP7555pn8fXXX+v2PVzgYZaoSpUqYhqsTePvEDNbKED0+++/698hMnuxIwA7Gkxj51kkTvz/JzXnz5+vW8pwfr/zzju6bm3S+Vy3bl19fXF8FPeYTOYHTFM9/fTTD92Pkd+NGzfENJhCxjSbU/YOusPFDwqb4IIIb8TYYmHfEBBN4uTXGdOYderU0QsNbBFCwh4gwcnUbWWYzcIs1ogRIzwCHC6Spk6dKibCyM4O0tC0aVMZP368XpCaFKSduvTkbu3atfLiiy9KgQIF9IZiQ7gYdZRQL5I7WeHCha0lS5box9hqcfjwYf14/Pjx1tNPP22ZaOrUqVb9+vWtixcvhvpQwppTX+dSpUpZM2fOfOic3rFjh5UlSxbLRPnz57dWrVr10DEfOHDAqKRId3nz5rXeeustV+Kb7fz58/o102DbZo8ePSyn+eqrr6zEiRNbr7/+um6Jww0fI5EWW8ucgslkfkCxk44dO+q6GNYjkVyB6k0oAGDqlfyECRPkzz//lOzZs2sii/cUsgmFFqKzVgY5c+YUUzn1dcaWFV9lFbGtDOVaTYTKdBgpecPUMqZtTYQtehhRV61aVYv6ILkMMAvjva5qSm8DJF+hkI/pS0/esy2YaUGOiw1b4HC8gwYNkubNm4sTMFD7mRCCKUJkyWLPJv7T8cY8btw4ncoykXeZS6fAm+7gwYNl9OjR8vfff+t9mAb/8MMPtfoUphJN4tTXGQEDFxje1d42bNig676m5opgKtO7vCkqf/lamjIBEgqx57tbt24a+LAT4JlnnhHTl54AS0/uTE6OPHLkiE57e8P0d+/evcUxQj2kDxc3btywzp49G+rDCFs9e/bU/aYTJ0507YmMiIjQ+0ys5ORUQ4cOtYoUKWJt3rxZq3qhutrs2bP1dcaSjomw/IR91MOHD9e93yNHjrTatm2rFb9WrFhhmQiV9ez3C5zb2FeNaVrstXdKVUMnyJ8/vzV58uSH7kftiAIFClhOwUDth5s3b2qAtqGAwWeffWYtX77cMtnly5etKVOm6BuEvYaKUqL/+9//LFNly5ZNi274epPOnj17SI4pHD148MAaPHiwlSpVKlepVpSX7dOnj2UylGZFCU5cUCDooZiFyX+HCMbuF/YI0nidW7duzUAdQBMnTtQLtvbt21uzZs3SG8q1ouysrwBuKm7P8kPt2rV1zyP2EmL9rmDBgpqxiW1ZWAN59913xTTI3sReXruUJdYkMaWJ6Xs0B8AWKBNh3yOO/amnnvK4H8ePogamlbfEWiOKRETWdAHFLkyG48UUOJYZMLWM0qIUOFiqOXPmjGTOnNl1HwomNW7cWEvlmrhjAHu8IzufTWzWYlu8eLEumbnv/8a+dRMLUkUq1FcKTvb4449rswLACLVEiRLW/fv3rYULFxrbeKFGjRquUoDuGbK//PKL9cQTT1imKleunPXee+89dD+aGpQvX94yTd++fXUWYNSoUTpSGjRokJblxDmDzFMKHLyuP//8c1i8pJj6RsMI08ybN08zpV944QUdoeJflA7FkgOy103VsmVLa+3atZbTMVAHqNPQa6+9Zg0YMEA/Pn78uH7NRGnTprX+/PPPhwI1pu0xHWQqvHlhOhZb4t5++2294WP8Dpj2NE2+fPmspUuX6sc4Rvs1R5Bu1qyZZaq///5bp7krVqyo63vYKuR+M1HDhg313M2ZM6fVrVs3a+fOnZbpBg4caK1evdrn64+vmaZ48eLWhAkTPN43sEyCbmX9+vWzTPXSSy/pBQbWo4cMGWKdPHnSciIGaj9PXrzxIjAjAG7cuFHv37Ztm7F7TrGGhz2x3oEaSTd4ozMZ/siQOPbyyy/r7eOPPzb2Dw9JTfZFXNasWTUHAPB641wxVdOmTXUmAC0ukW8xduxYj5upLl26ZH3++efabAHrv0iIwxvz0aNHLRPZbVpHjx7tcb+pyWQ4n+3XEk1D9uzZox/v379fz2+TnTt3Tl9nzHhiT3XdunV11hPNfpyCgdoPX3/9tV6t4Q8LiSzumbM4GUydJmzUqJGepAjU6NmLgIICLXYfX1M0btzY1dULRTi8i0OYDNOCyJwGJDYNGzZMP54/f75eLJkKU5kbNmywnAy9qUeMGKHLT4kSJbJMDdQ4F7AUgqnj27dvGx2oc+TI4QrOGKDYvakxODH5wtMbLpixXIblKPRXRyEXJ3TlY6D20+nTp3WEirVp26+//qpVkUx05coVvahAxSa8ieXKlUsvNtB6EdNuJsFxnTp1ymeWrOlQxQkjOsAbMq7kMf2GUZTJFZ7y5MmjoySnwgXo4sWLrVdeeUXfjE3dEWBvz8KSCJZwsNSAz00N1FiusUf/n3zyiV5sYgsc8lpwQe0Ep06d0i18BQsW1GU0rF8jZwd/m2PGjLFMxqzveFQty7uABbKokdWLQgbIBDdNiRIl9NjQdrN169ZaCzlt2rQ+v7dly5ZiMrQxtJsu+CrAYIrZs2fLt99+q93fUqZMKU6BTnVz587VWuUojoPdGG+88YY8//zzRhbkQAvO06dPa9b3tWvX5PXXX5d9+/Zp4wsU4zAt6xu7FFCBEQWd8Pqi2pd9PmPHSIYMGcREd+/e1cpvM2bMkBUrVuh7CgpVoTiV/V6CrPC3335bLl++LKZioI5H1bIAPXtNbkvn7pdfftHX8vDhw/pGgdfW15su7jN9u5PJUL3L/XXFtizMtqE6GRoymF76FN298P+PDk8IzrgQsntSO2V7Ft5L0C4XbSTxsWmB2qkyZsyoryd6qbdr1063cnrD1lr8DaDJkqlYQtQPCMboG4seyegla49U0cgeV5+oM2savPmiVeGbb74pr776qrFXwoDXFCNR+40NpQvd952aDN2z0Oq0evXq+m/+/PnFVE4td2rD3xt6rKdPn16cAiM81DKw4fzGjBECxrp168Q0mLHCzBbqwJt8LntDLQOcG1H1n8Z5Y3KQBo6o/YBpIHuqyh2mDjt06KDNAkyDtpCYIkT/WxRWwCgEQdvEUQimL9G+EFNUmIrF9CBqqzsBppDxhrtmzRodoWLUh6BtB2729Q0Opy1BOQWmi3E+u5/L9oUoz+XgY6COR9Wy3GFqE0HEe10PHXJMgSpv6CSULVs2jzU9p8Fxoyfu0qVLZcGCBUZPbW7dulWPr3z58h73//rrr/p/ULZsWTGNU5agMGL+17/+pe8b+DgyWIZAX2oTYfCBgI3zGTfMcuHv075AouBgoPYD3sxw8/6jwx8Z3vDsaVvTYd2xTZs2etFhUgBxejIZOqphKQQXREh2wmwGyhdiJIIpOROVK1dOPvroI10W8S4R+emnn2rANk2vXr10CWrgwIEPLUFhXdKUJai8efNqGc7HH39cP44qUKPrk4nscxrnM85rvHegxCzObQoeBmo/4IqyQYMGuh5ZsWJFV71eJGz9+OOP2mvWVLgCxmgaN7Sww/EjEQd1y02BrFL0/HZiMlmlSpU8AjOmCLG+Z3JOAKCmNy7YvFtaYg0PF07Xr18X0zhxCcp7dgtMzE63oSUkArN9TttT3044p8MBA7WfTp06JREREXLw4EH9HCcx3hzw5mGizz//XIMzropxrAjO2Krg3cvXCU0MTPbYY4/pMaNxC97QcPNeIjERRnuYorcvPN0vmnBRauIWFqcuQWEWADMrf/zxh36OtV5kfmM92DQ4lzNlyiQffPCBLpE54VwOJwzU8Qy2ZmGrAgJ0yZIlxSmwVo2uPbjQwLTg119/rUktX331lU4jIpPdtFHS3r17dRSCmRes62HNHSMRTOVjStZEODewpo7RqJ2VjO0ryAzHRRK6J5nGiUtQ/fr10w57OEb32bgJEyZoMPzkk0/EJLt379bzGOfz+vXrXeeyky5CnYyBOoZw5R5dmCo0DQIIRtNOCXg2JLy1aNFCLzBwrPv379fpWbyxYZkBN1PhNd++fbse65w5c4xOJsM0MaYzL168qFuFYNeuXZIlSxZZuXKlkXvwI1uCwoXdTz/9ZOQSFEanuLDAhZG7efPmafBGq1yTIXBjNsD08zlccB91DGEqDWtJ9rpSZPA9Jp68SAqyAx4SQW7fvq33X716VYYOHWpswENWL9YhkTSGrWU2JA/ha6bBa4vRB264MMLabvHixfVNGCMRU+GiDRejeAPGmzG2wyGRDwHFu/iJKfB6YpobxULsnsOYnjV5CQoVs3xl0JcpU0bu3bsnpsH7Hdan3c9pVFTDYMTk8zlccEQdiynY6DJx3RejJEytIeAhOQtvxhiZ4o+wXr16ug5sIpSzxCgaBVvcjxuzAsg6RYEZkyROnFhfa3vvNEap7gUuKLDw/48LjHPnzukIz513kpkJcMGGCx9Mf7vr1q2brqkj78UkSBjD1jcsl9lT3pipcFKRGSfjiDqG3IPvsGHDdEoQdWLdYS8yion06NFDTIORB4KGNwQRrEWaKmvWrFpsAYHaHa7svTOUQw0zKZi5wBuZEzNikdyE7Te+gh7WVk2zbNkyvfDEdL33TJepM1t2MhnqT1eoUEE/x9Y3TNfjd8FuB5t3MA9VAR+cz5Ftj6TgYqAOQAa1t6JFi0rTpk2NDNROCnjukHzVpUsXvQjCmy+y7bEOiRFI3759xSQoDIIqapiGdVqgnjJlirz77rtaIxnnivuWIXxsYqDG6BRlInFsuHB2AmyJRI0AwPZDwGuOG75mM2XLFnIAbKz+FgKhbt/lZMmSJdN+zt4OHz6sXzMRemUXKVJEeyWnSZPGWr9+vTV79mxtWzd+/HjLVA8ePLAGDx6s7enQIhA3tDHs06ePZaIyZcpYq1atspwmd+7c2grQSXAeo10kBQ/a+A4cOFB7T6MNJ27oXY6Wl+4tfik4GKj9gP7CX3311UP3z5o1y8qbN69lIqcFPG+3b9+29u3bpz2/r1+/bpnqp59+skqVKmV9//332gf36tWrHjeTgx4uNJ2kdevW1tSpU0N9GGGtZ8+eejE/ceJEa/fu3XqLiIjQ+3r37h3qwwt7TCbzA3qy4jZy5EjtewurV6/WEoyoM4zShqa6c+eOToEjQQTJWKhIRYHjXl/affoSF8cmr5uilOwzzzxjVIW66JS1xNQ3tjwhs947O71z584hO7Zw4fTqb07HNWo/dO/eXRNYcKIi8NlVkrA2bXKQBhQsQICm4EAylhMVKFBA1/xRJMQpQQ97j5GUhb89bB3yXlc38ZidBiV6CxUq9ND9uM+08r3hiCPqAMCoFIlD2HOKMoCmtYskii4nNotA0huCcc+ePY3plBVunFj9LZwwUBMFCba7YQuOXYQDuwGwlY/7qQNfVx3BIn/+/AF+ZAqHBkThgIGaKAjQzrBOnTo6y4LWkYBggmIWmKa1t+aYAHt2Bw0aJKlSpfLYv+trRI2ez6ZBAR+sT6PDEwUH9nejiI+vBkSopIYATsHDQE0UBBhhYL0X+5LxBgd4Q0NnJEwfo0mHKdAkZPHixVplCh9HFaj/+9//imkw7T1r1iytmoWSlt7r6iYUDHE61AZAsxbv7nXI0cF9piZHhgsGaqIgwEgaZVm9E3BQBhU1npGpTIHhxIsLp4mszSxKKiMp9caNGyE7tviAWd9EQYBSi5gu9A7UWNNDrXIKHKdm2DuBvRRiV6VDzX0bRtEoe4pGRRRcDNREQdCkSRPdkzxq1CipVKmS3vfLL7/olj7v1oZEpsKskHt/dWzrtOFjLDegjC8FF6e+iQIE3ZuKFSum04TYV4+gjCIRdttCrJ2ijvbw4cO5hY8cBa1Ox40bx6YcIcJATRSEhBs0OEGWN9aq7aYL2D7kPnVIRBQdnPomChBkTR89elQD9bFjx7RFJAIzKnwREcUWAzVRgLzyyitSvXp1yZYtmybfILsbo2xfTKzwRURmYqAmCpAvvvhCXn75ZW12gr296KHNDG8i8hfXqImClHyDusgM1ETkLwZqIiIig7HVDBERkcEYqImIiAzGQE1ERGQwBmoiIiKDMVATEREZjIGaiIjIYAzUREREBmOgJiIiEnP9PziNpZrNoOdfAAAAAElFTkSuQmCC\",\n \"text/plain\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"de713235-1561-467f-bf63-bf11ade383f0\",\n \"metadata\": {},\n \"source\": [\n \"**If you are interested in augmenting this training function with more advanced techniques, such as learning rate warmup, cosine annealing, and gradient clipping, please refer to [Appendix D](../../appendix-D/01_main-chapter-code)**\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6d5cdf2f-09a5-4eb0-a20a-d7aac5c14c2c\",\n \"metadata\": {},\n \"source\": [\n \"**If you are interested in a larger training dataset and longer training run, see [../03_bonus_pretraining_on_gutenberg](../03_bonus_pretraining_on_gutenberg)**\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"699f45fc-bf78-42f2-bd24-2355db41b28f\",\n \"metadata\": {\n \"id\": \"699f45fc-bf78-42f2-bd24-2355db41b28f\"\n },\n \"source\": [\n \" \\n\",\n \"## 5.3 Decoding strategies to control randomness\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6be9086e-2c27-41da-97d0-49137d0ba3c7\",\n \"metadata\": {},\n \"source\": [\n \"- Inference is relatively cheap with a relatively small LLM as the GPT model we trained above, so there's no need to use a GPU for it in case you used a GPU for training it above\\n\",\n \"- Using the `generate_text_simple` function (from the previous chapter) that we used earlier inside the simple training function, we can generate new text one word (or token) at a time\\n\",\n \"- As explained in section 5.1.2, the next generated token is the token corresponding to the largest probability score among all tokens in the vocabulary\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"2734cee0-f6f9-42d5-b71c-fa7e0ef28b6d\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort moves you?\\\"\\n\",\n \"\\n\",\n \"\\\"Yes--quite insensible to the irony. She wanted him vindicated--and by me!\\\"\\n\",\n \"\\n\",\n \"\\n\"\n ]\n }\n ],\n \"source\": [\n \"# NEW: use CPU here as inference is cheap with \\n\",\n \"# this model and to ensure readers get same results in the\\n\",\n \"# remaining sections of this book\\n\",\n \"inference_device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(inference_device)\\n\",\n \"model.eval()\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(\\\"Every effort moves you\\\", tokenizer).to(inference_device),\\n\",\n \" max_new_tokens=25,\\n\",\n \" context_size=GPT_CONFIG_124M[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d25dbe31-bb7c-4893-b25b-47d0492d4aa4\",\n \"metadata\": {},\n \"source\": [\n \"- Even if we execute the `generate_text_simple` function above multiple times, the LLM will always generate the same outputs\\n\",\n \"- We now introduce two concepts, so-called decoding strategies, to modify the `generate_text_simple`: *temperature scaling* and *top-k* sampling\\n\",\n \"- These will allow the model to control the randomness and diversity of the generated text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4bb6f380-a798-4fd9-825c-17b7cd29a994\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 5.3.1 Temperature scaling\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a7f4f53c-0612-43d3-aa82-52447eac50fa\",\n \"metadata\": {},\n \"source\": [\n \"- Previously, we always sampled the token with the highest probability as the next token using `torch.argmax`\\n\",\n \"- To add variety, we can sample the next token using The `torch.multinomial(probs, num_samples=1)`, sampling from a probability distribution\\n\",\n \"- Here, each index's chance of being picked corresponds to its probability in the input tensor\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e7531bae-d5de-44c0-bc78-78fed077e22a\",\n \"metadata\": {},\n \"source\": [\n \"- Here's a little recap of generating the next token, assuming a very small vocabulary for illustration purposes:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"01a5ce39-3dc8-4c35-96bc-6410a1e42412\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"forward\\n\"\n ]\n }\n ],\n \"source\": [\n \"vocab = { \\n\",\n \" \\\"closer\\\": 0,\\n\",\n \" \\\"every\\\": 1, \\n\",\n \" \\\"effort\\\": 2, \\n\",\n \" \\\"forward\\\": 3,\\n\",\n \" \\\"inches\\\": 4,\\n\",\n \" \\\"moves\\\": 5, \\n\",\n \" \\\"pizza\\\": 6,\\n\",\n \" \\\"toward\\\": 7,\\n\",\n \" \\\"you\\\": 8,\\n\",\n \"} \\n\",\n \"\\n\",\n \"inverse_vocab = {v: k for k, v in vocab.items()}\\n\",\n \"\\n\",\n \"# Suppose input is \\\"every effort moves you\\\", and the LLM\\n\",\n \"# returns the following logits for the next token:\\n\",\n \"next_token_logits = torch.tensor(\\n\",\n \" [4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79]\\n\",\n \")\\n\",\n \"\\n\",\n \"probas = torch.softmax(next_token_logits, dim=0)\\n\",\n \"next_token_id = torch.argmax(probas).item()\\n\",\n \"\\n\",\n \"# The next generated token is then as follows:\\n\",\n \"print(inverse_vocab[next_token_id])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"6400572f-b3c8-49e2-95bc-433e55c5b3a1\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"forward\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"next_token_id = torch.multinomial(probas, num_samples=1).item()\\n\",\n \"print(inverse_vocab[next_token_id])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c63d0a27-830b-42b5-9986-6d1a7de04dd9\",\n \"metadata\": {},\n \"source\": [\n \"- Instead of determining the most likely token via `torch.argmax`, we use `torch.multinomial(probas, num_samples=1)` to determine the most likely token by sampling from the softmax distribution\\n\",\n \"- For illustration purposes, let's see what happens when we sample the next token 1,000 times using the original softmax probabilities:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"b23b863e-252a-403c-b5b1-62bc0a42319f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"73 x closer\\n\",\n \"0 x every\\n\",\n \"0 x effort\\n\",\n \"582 x forward\\n\",\n \"2 x inches\\n\",\n \"0 x moves\\n\",\n \"0 x pizza\\n\",\n \"343 x toward\\n\",\n \"0 x you\\n\"\n ]\n }\n ],\n \"source\": [\n \"def print_sampled_tokens(probas):\\n\",\n \" torch.manual_seed(123) # Manual seed for reproducibility\\n\",\n \" sample = [torch.multinomial(probas, num_samples=1).item() for i in range(1_000)]\\n\",\n \" sampled_ids = torch.bincount(torch.tensor(sample), minlength=len(probas))\\n\",\n \" for i, freq in enumerate(sampled_ids):\\n\",\n \" print(f\\\"{freq} x {inverse_vocab[i]}\\\")\\n\",\n \"\\n\",\n \"print_sampled_tokens(probas)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"32e7d9cf-a26d-4d9a-8664-4af1efa73832\",\n \"metadata\": {},\n \"source\": [\n \"- We can control the distribution and selection process via a concept called temperature scaling\\n\",\n \"- \\\"Temperature scaling\\\" is just a fancy word for dividing the logits by a number greater than 0\\n\",\n \"- Temperatures greater than 1 will result in more uniformly distributed token probabilities after applying the softmax\\n\",\n \"- Temperatures smaller than 1 will result in more confident (sharper or more peaky) distributions after applying the softmax\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0d2b5399\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the resulting dropout outputs may look different depending on your operating system; you can read more about this inconsistency [here on the PyTorch issue tracker](https://github.com/pytorch/pytorch/issues/121595)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"0759e4c8-5362-467c-bec6-b0a19d1ba43d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def softmax_with_temperature(logits, temperature):\\n\",\n \" scaled_logits = logits / temperature\\n\",\n \" return torch.softmax(scaled_logits, dim=0)\\n\",\n \"\\n\",\n \"# Temperature values\\n\",\n \"temperatures = [1, 0.1, 5] # Original, higher confidence, and lower confidence\\n\",\n \"\\n\",\n \"# Calculate scaled probabilities\\n\",\n \"scaled_probas = [softmax_with_temperature(next_token_logits, T) for T in temperatures]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"2e66e613-4aca-4296-a984-ddd0d80c6578\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAeoAAAEiCAYAAAA21pHjAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAAPrRJREFUeJzt3QeUU9X2P/BN703pTZrSi4D0otJBEWwUBUTgiYCgCFKkSpUm8BhAaYJ0eYKKSn3SBKQXaSpFePQOAlLvf333f938kpAZZibJ5NzM97NWFjOZmeROuJN9zzn77J3AsixLiIiIyEgJQ30AREREFDkGaiIiIoMxUBMRERmMgZqIiMhgDNREREQGY6AmIiIyGAM1ERGRwRioiYiIDJZY4pkHDx7IqVOnJE2aNJIgQYJQHw4REcVDlmXJ9evXJXv27JIwYdRj5ngXqBGkc+XKFerDICIikhMnTkjOnDmjfCXiXaDGSNp+cdKmTRvqwyEionjo2rVrOmi0Y1JU4l2gtqe7EaQZqImIKJSiswTLZDIiIiKDhTRQr1u3Tl588UVdTMdVxZIlSx75M2vWrJHSpUtLsmTJpECBAvLll1/GybESERHFu0B948YNKVmypERERETr+48ePSoNGjSQ5557Tnbt2iXvv/++tG3bVpYvXx70YyUiIgqFkK5R16tXT2/RNXnyZMmbN6+MHj1aPy9cuLBs2LBBPvvsM6lTp04Qj5SI4nob5Z07d/iik2MlSZJEEiVKFJDHclQy2aZNm6RmzZoe9yFAY2Qdmdu3b+vNPdOOiMyFAI3ZMwRrIidLnz69ZM2a1e+aHY4K1GfOnJEsWbJ43IfPEXxv3bolKVKkeOhnhg0bJgMHDozDoyQif4pAnD59Wkci2LryqEIQRKaexzdv3pRz587p59myZYs/gTo2evXqJV27dn1o7xoRmefevXv6BocE05QpU4b6cIhizR44IlhnzpzZr2lwRwVqTCGcPXvW4z58jv3QvkbTgOxw3IiMMiBdFF+7KvHV/fv39d+kSZOG+lCI/GZfbN69e9evQO2oeaWKFSvK6tWrPe5buXKl3k9E4YN1+CkcJAhQP4mQBuq///5bt1nhBkggwcfHjx93TVu3bNnS9f3t27eXI0eOyEcffSQHDx6UiRMnysKFC+WDDz4I2e9AREQUTCEN1Nu2bZOnn35ab4C1ZHzcr18//RxJJXbQBmzN+uGHH3QUjf3X2KY1depUbs0iIqKwFdI16meffVaz4yLjq+oYfmbnzp1BPjIiMkmenj/E6fMdG94gYNOb/fv3lwEDBkg4yZMnj26LjWprrOk6d+4sv/zyi/z2229ak8Oe2TWRo5LJiIhMg5k/24IFC3RG8NChQ677UqdOLU6AQROS+RInThyne+ZDmTj49ttvy6+//ip79uwRkzkqmYyIyMTdKPYtXbp0OsJ2v2/+/Pk6YkuePLkUKlRIc2tsx44d0+9Hrk3VqlV198ozzzwjv//+u2zdulXKli2rgR4VHM+fP+/6ubfeeksaNWqkNSIyZcqkO1+Qw+NezQ0FY1BHAkuGeFwsFy5atMijbwKe+6effpIyZcro7hhUejx8+LC89NJLWqMCz43jWbVqlces5l9//aW5Qfh5e0YBswalSpXyeG3Gjh2ro2/v4x4yZIhuwStYsKCr7fDrr7+uBUIee+wxfX68NsE0fvx46dixo+TLl09Mx0BNRBQkc+bM0RE2AtOBAwdk6NCh0rdvX5k5c+ZD0+N9+vSRHTt26Ii2efPmmjQ7btw4Wb9+vfz555+u3B0bdsDgMRFw582bJ998841HcScE6VmzZmnp5X379mlgffPNN2Xt2rUej9OzZ08ZPny4PlaJEiU0ybd+/fr6+FhmrFu3rjZPsvOF8Dw5c+aUTz75RGcT3GcUogOPixkH5BotXbpUty6hwiT6MuN3xXQ0LhDwvFGVkU2dOnWUN1y4hAtOfRMRBQkCMJJeX375Zf0co9v9+/fL559/Lq1atXJ9X7du3VxJsV26dJFmzZppQKtcubLe16ZNm4dydjBlPH36dN2rW7RoUQ2c3bt3l0GDBmnww0UBRsL29lWMHDFixnNXr17d9Tj4uVq1ark+x4gWo28bHm/x4sXy3XffSadOnfTr2BOMwIoZg5hKlSqVJgHbU96zZ8/W0T/us0fnM2bM0NE1LkJq167t83EetaaMWYZwwUBNRBSk7oCYRkaQbdeunUf1NUyRu8NI1maXSS5evLjHfXY5ShuCqXv1NgRkjIYxjYx/UeHNPQADRqj2Lhsbptfd4WcxjY0dNhgt43hRotl9B44/8Hu5r0vv3r1bZwwQ+N39888/+vpFBm2O4wsGaiKiIEDAgylTpkj58uU9vuZdpQqdlmz2qNL7vpg0KbGfG8E2R44cHl/zrtSIEa47jO4xLT1q1CgNhljffvXVVx/ZzQx12b138WBk7837+XCsWCPHMoE3rL9H5lFJepjmx7R/OGCgJiIKAoyCkTCFIk1vvPFGwB8fI1H3ZkSbN2/W4IVeBpieRkDGKNh9mjs6sEaMpK/GjRu7Aql3YhdGxHa5V/egisZJCNb2xUZ0tjyVLl1as+VRDzsm09W7OPVNRET+QnIX9utiqhvJUWi5i0JPly9f9mgWFBsY4WJaHUloCKRYD8caMka2mEbGyBgJZBiJV6lSRa5evapBGMHQfX3c25NPPqkJY0ggQ8BF8pv3aB6Z3OvWrZOmTZvqBUHGjBk1GxyZ6SNGjNAR+LJlyzSj/FHBFxcxI0eO1ExvrJcjUQ1Z5TgGJNTlzJkzKFPfmG7HRQguLnDBYwf+IkWKGFdrnlnfRERB0rZtW02SQnIU1mYxukVSGJLK/FWjRg0NqtWqVZMmTZpIw4YNPQqrIAkMQRbZ39gehgsFTIU/6rnHjBkjGTJkkEqVKmmwRpIbRr3uEFBxcZA/f37X9DSeA1vPIiIidP18y5YterHwKFhnR9DPnTu3Jt3hcXABgjXqYCaEtW3bVtfrkVyH7XB2lcxTp06JaRJYUZUGC0Noc4mrW1xdhlNWIDkMu2f5hDdn1PxHMMG+Y/INU9NXrlyRJUuW8CVy6Pkck1jEETUREZHBGKiJiIgMxqxvIiKH8dWwiMIXR9REREQGY6AmIiIyGAM1ERGRwRioiYiIDMZATUREZDAGaiIiIoMxUBMR+QH1sKO6uZf1DBeo9T127FhxsuPHj0uDBg20hCkagqCXN1p6RmXIkCFaWhU/g37ZcYX7qInI2SVXg/J8V6P9rejZbEMXqH79+smhQ4ei3Y7RFKgmjY5YiRPHXVhAY5FQNMC4f/++BumsWbPKxo0b9f+wZcuW2lp06NChUR7va6+9pr2/p02bFmfHyxE1EZEf8GZv31C7GaNo9/vmz5+vjSZQ67lQoULauMKGxhb4/oULF0rVqlW1ZeUzzzyjTSK2bt0qZcuW1UBfr1497UzlXuu7UaNG2p0LTTFQK7p9+/YePaPR8QoNOVBnGo+LRhmLFi1yfX3NmjX63OhwhX7Q6IK1YcMGOXz4sHayQptOPDeOZ9WqVa6fQ5csdLdCZy571gAwc1CqVCmP1wajboy+vY8bI1O0AC1YsKDef+LECXn99dd1lIoWnXh+79aagbRixQrZv3+/zJ49W48Zry+amKChSFR9t/F64/dGg5W4xEBNRBQkc+bM0RE2AtOBAwd0tIaOVjNnzvT4PrSoRLvKHTt26Ii2efPm2uJx3Lhxsn79em3JiMdxt3r1an1MBNx58+ZpW0gEEhuC9KxZs2Ty5Mmyb98+DTBvvvmmrF271uNxevbsKcOHD9fHKlGihLZ+rF+/vj7+zp07tesWumhhqhjwPGg9iQ5aGIm6zyhEBx4XMw4rV66UpUuXyt27d7VDF1pz4ndFK05cIOB5owqaqVOnjvKGC5fIbNq0SYMtLkZsOAY0ysBrZRpOfRMRBQkC8OjRo7V9I2B0i5EcWiu694RGO0gECujSpYs0a9ZMA1rlypX1PrR99C4biinj6dOn63pp0aJFNXBinRUjQwQ/XBRgJIxpWsiXL5+OmPHcaLdpw8/VqlXL9TlGtBh92/B4ixcvlu+++077XePriRIl0sCKGYOYSpUqlbb+tKe8MarF6B/32aNztAXF6BoXIbVr1/b5OHb/6MhE1ZEKPajdgzTYn+NrpmGgJiIKghs3bug0MoJsu3btXPcjYQlT5O4wkvUOGO7Tq7jv3LlzHj+DYIogbUNAxmgY08j49+bNmx4BGDBCRc9ld5hed4efxTQ2eldjtIzjvXXrlmtE7S/8Xu7r0rt379YZAwR+7xaReP0iU6BAAYkvGKiJiIIAAQ+mTJki5cuX9/gaRqTukMRks0eV3vdh1BnT50awzZEjh8fXsBbtPcJ1h9E9pqVHjRqlwRDr26+++mqU09CQMGFCTUhzh5G9N+/nw7FijRzLBN6w/h6ZRyXpYZof0/6+YCZgy5YtHvedPXvW9TXTMFATEQUBRsFImDpy5Ii88cYbAX98jEQx0kUghc2bN2vwypUrl05PIyBjFOw+zR0dWCNG0lfjxo1dgdQ7sQsjYmROewdVTBsjWNsXG4+anobSpUtrtjy2SEU1XR3IqW/MPiBvALMUeF7AxQl+pkiRImIaBmoioiBBclfnzp11qhvJUbdv35Zt27bJ5cuXpWvXrn49Nka4mFZHEhoCKdbDsYaMkS2mkTEyRgIZRuJVqlSRq1evahBGMHJfH/f25JNPasIYEsgQcJH85j2aRyb3unXrpGnTpnpBkDFjRs0GR2b6iBEjdAS+bNkyzSh/VPDFRczIkSM10xvr5UhUQ1Y5jgEJdTlz5gz41DfWvRGQW7RooceLCwy8jh07dnTNOGDEjS1byBWwZyVw4XPp0iX9Fxcq9sUCjiWY2/BCnvWNdHj8p2PrAqaHvKcjvCHdHyn9uIrElSNORKxlEBGZpm3btpokheQorM1idIukMCSV+atGjRoaVKtVqyZNmjSRhg0behRXQRIYgiyyv7E9DBcKmAp/1HOPGTNGMmTIoIU9EKyR5IZRrzsEVFwc5M+f3zU9jefA1jO8p2P9HO/luFh4FKyzI+jnzp1bk+7wOLgAwft6TEbYMYGlB2Sc41+MrjFNjqCM38uGNX5kp7tP3yPzHmv8uCjCTAM+xg0XX8GUwPJeVIhDmO7Ai4N1BARpBOGvv/5aXxx7OsLd3Llz5e2339ZMR5xE2GuIKRpc1eHkig6k3+PqFleXwToJiPwq4BGDYhvhBm/OR48e1WCCi3fyDe97V65ckSVLlvAlcuj5HJNYFNIRNYIrsiFbt26t0xAI2Li6QiD2BRVksF0BewwxCsf0BbYxPGoUTkRE5FQhC9RYX9m+fbvUrFnz/w4mYUL9HJvRfcEoGj9jB2Ykafz444+6OZ+IiCgchSyZ7MKFC7oY72vT+cGDB33+DEbS+DkkRmDGHvv7UH2md+/ekT4Pkjdwc59uICJyMu/iJxTeQp5MFhOoUoNqO0hYQKk9ZAUiOQJJE5FBIgXWAewbEtCIiIicImQjaqTzI+PO3mRuw+eRbThHBiPS6ZFJCciiRPWff/3rX/Lxxx/r1Lm3Xr16eWyDwIiawZqIiJwiZCNqbJhHNRrsUbNhrx4+t2vTekO6vHcwtiv8RJa8jj1xyKhzvxERETlFSAueYKSLjfeoNVuuXDndnoURMrLAAVu3sNEc09eAPX3IFMe+NWznQn1YjLJxv3dJPiIionAQ0kCNTfqoZINN5KgMg76gqGZjJ5ih+ov7CBqVY1ApB/+ePHlSN9ojSKMUHBERUTgKacGTUGDBEzICC574xIInFE7+CYeCJ0RERBQ1BmoiIj9gOS6qm3v97XCBypDIKXKyBD7+r+bPny8mYvcsIjJe8ZnF4/T59rbaG+3vPX36tEf/AuTcoF+BLZhdlQIJq6AoQpU4ceI4rVCJHUChMmPGDG1WYkufPr2YiCNqIiI/oO6DfcOaI0Zm7vdhlIaOUFijLFSokBZssqEDFb5/4cKFUrVqVe0K+Mwzz2jDoa1bt+qOGAT6evXqaeKte1OORo0aaRtNJNVijRNVGhH43Le7YscM1kfxuOhotWjRIo8CUnhutKLEVllsZd2wYYMcPnxYW04iqRfPjeNZtWqV6+fQzhJtKNG50B6JAmYOkBDsDqNujL69jxsJwOjVjU6IcOLECXn99dc1UKKXNp7fuwd2MOD53P+vTG0Ew0BNRBQkc+bM0RE2AtOBAwe0siK2lM6cOdPj+9A2EbtZUHERI1qUS0Yv5nHjxsn69et1Kyoexx1qTuAxEXDnzZunlRoRuG0I0rNmzdJmR/v27dPAinaOa9eu9Xicnj17yvDhw/WxSpQooe0b0T8Bj79z504dcWJ3DXbhAJ4HPaLREhKzCe4zCtGBx8WMw8qVK7XVJNpIopUmemjjd0XPbFwg4HndLzy84XuiuuHC5VHQfxrFt7A9GM2gTM2t5tQ3EVGQIACPHj1a+ywDRrf79++Xzz//XGtI2NC3GcEKunTpol0BEdDQLRDQn9m7vjemjBFc0HGwaNGiGji7d++uJZUR/HBRgJGwXUAqX758OmLGc6Mvtg0/V6tWLdfnGNFi9G3D4y1evFi+++476dSpk34ddSsQWCOrIhmVVKlSaY9ue8p79uzZOvrHffboHFPSGO3iIqR27do+H2fXrl1RPs+jMqnxez///PP6+q1YsUI6dOigFymdO3cW0zBQExEFAYo3YRoZQRbtfG1oJoQpcncYydrsOhIokex+37lz5zx+BsEUQcaGgIxAg2lk/ItKju4BGDBCRcEod5hed4efxTQ2+ihgtIzjvXXrlmtE7S/8Xu7r0rt379YZAwR+761NeP0iU6BAAfEHZjZseE3w/zVy5EgGaiKi+AIBD6ZMmaKVFN15V1JMkiSJ62N7VOl9H0adMX1uBFtUd3SHtWjvEa47jO4xLT1q1CgNhljffvXVV6OchgYUp/KeOsbI3pv38+FYsUaOZQJvWH+PzKOS9DDNj2n/6ML/EWYP0G3R+zUKNY6oiYiCAKNgJEwdOXJE3njjjYA/PkaiGOkikMLmzZs1eKHpEKanEWwwCnaf5o4OrBEj6atx48auQOqd2IURMTLEvYMqKkwiWNsXG4+anobSpUtrtnzmzJlj1Ithl59T374eL0OGDMYFaWCgJiIKEiR3Yc0TU91IjsJobdu2bXL58mWPrn6xgREuptWRhIZAivVwrCFjZItpZIyMkUCGkXiVKlW0AhaCMAKY+/q4tyeffFITxpBAhoCLKWLv0TwyudetWydNmzbVwIaELGSDIzN9xIgROgJHOWhklD8qYOIiBlPOyPTGujES1ZBVjmNAQl3OnDkDPvX9/fffa6fGChUqaKY3ZhCwpo/XzETM+iYiChK05EWSFJKjsDaL0S2SwpBU5q8aNWpoUK1WrZr2TWjYsKFHcRVM4yLIIvsb28NwoYCp8Ec9NxofYWRZqVIlDdZIcsOo1x0CKi4O8ufP75qexnNg61lERISun2/ZsiVagQ/r7Aj6uXPn1qQ7PA4uQLBGHaxuh0mSJNHjxLo+tpQhwQ6/Ny52TMRa30ShwFrfPrHWd/RgavrKlSuyZMmSQJ6VFGCs9U1ERBQPcOqbiIjIYEwmIyJyGO/iJxTeYjWi/vnnnwN/JERERBSYQI3sQWT7DR48WKvgEBERkUGB+uTJk7pfD51YUD8W6fvo/vKoyjVERNFhanMEolCcx7EK1Njcjo30qOTy66+/ylNPPaUFzVGFB5v7UTGHiCim7NKavOincHDz5s2HysGGJJkMG+HRQeXxxx/XVmno5oJN79hIjjqr6OpCRBStN6TEibUABipc4c0NVbaInDiSRpBGIxV0AfOu7R5ngRrF1r/99lsNzCi/hg4sEyZM0PZs+CNDWbvXXntNW7oREUUHSlZmy5ZNjh49qmUkiZwMQTo2rUADEqjfe+89bVSOq4YWLVpobddixYp5dEdB5xVMhRMRxQQaPqA0Jqe/ycmSJEni90jar0CNUfK///1vrcsaWacRrGNzGxcRxQamvNEsgYhimUyGwuWY1vYO0mgwjuLq9lpTTNurERERUQAC9XPPPSeXLl166H60UcPXiIiIKISB2r0xuLuLFy/q+jQRERFJ3K9RY00aEKTRZs196vv+/fuyZ88e7WFKREREIQjU6dKlc42o06RJIylSpPDI1KxQoYK0a9cuQIdGREREMQrUM2bM0H/z5Mkj3bp14zQ3ERGRqVnfgVqLjoiI0MCPrRjly5eXLVu2RPn9V65ckY4dO2pRBEy9o3zpjz/+GJBjISIicuyIGqVCV69eLRkyZJCnn37aZzKZbceOHdF6zAULFkjXrl211CiC9NixY7XBx6FDhyRz5swPfT8KINSqVUu/hoYgOXLk0OpFqP5CREQUrwP1Sy+95Eoea9SoUUCefMyYMbqm3bp1a/0cAfuHH37QsqQ9e/Z86PtxP7aFbdy40VXkHKNxIiKicJXAClE/OYyOUXwfI2P3wN+qVSud3kYdcW/169eXxx57TH8OX8+UKZM0b95cevToEWmpttu3b+vNdu3aNcmVK5fu+U6bNm2QfjuiRxiQLoqvXeXLRxTmrl27pgna0YlFIWtNc+HCBd3SlSVLFo/78fmZM2d8/syRI0c0sOPnsC7dt29fGT16tAwePDjS5xk2bJi+GPYNQZqIiCjspr6xNh3VurQ7X1XLAuHBgwe6Pv3FF1/oCLpMmTJy8uRJGTlypCa4+dKrVy9dB/ceURMREYVVoEaiVyChaQeC7dmzZz3ux+eRtQVDprd3R5LChQvrCBxT6djL7Q3r6pE1DiEiIgqbQI2140BCUMWIGJnk9ho1Rsz4vFOnTj5/pnLlyjJ37lz9Pruh/O+//64B3FeQJiIicrpor1Fjytj946hu0YUp6SlTpsjMmTPlwIED8u6778qNGzdcWeAtW7bUqWsbvo5p9S5dumiARob40KFDdV81ERGRxPc16tOnT+saMfYt+1qvtpt1INkrOpo0aSLnz5+Xfv366fR1qVKlZNmyZa4Es+PHj7tGzoC15eXLl8sHH3wgJUqU0H3UCNrI+iYiIorX27PWrl2rU8/oM42Po2JyH+qYpMQT+SNPzx8i/dqx5M0j/0FuzyIKe9diEIuiPaJ2D74mB2IiIqJ425TD3eXLl2XatGm6tgxFihTRtWUUJCEiIqLAiFXBk3Xr1mnpzvHjx2vAxg0f582bV79GREREIRxRI8saiWCTJk1y7WlGAlmHDh30a3v37g3Q4REREcVvsRpR//nnn/Lhhx96FB7Bx9huha8RERFRCAM1Wl7aa9PucF/JkiUDcVxEREQUk6nvPXv2uD7u3Lmz7l/G6LlChQp63+bNmyUiIkKGDx/OF5aIiCiu91Gj8AiKmTzq22NS8CQUuI+a4gr3URNRnO6jPnr0aHS/lYiIiAIk2oH6iSeeCNRzEhERUbALnsD+/fu1HjdaTLpr2LChPw9LRERE/gTqI0eOSOPGjXW/tPu6td2ow+Q1aiIiorDfnoWMb1QhO3funKRMmVL27dunFcnKli0ra9asCfxREhERxVOxGlFv2rRJ/vvf/0rGjBk1Gxy3KlWqyLBhw3Tr1s6dOwN/pERERPFQrEbUmNpOkyaNfoxgferUKVfC2aFDhwJ7hERERPFYrEbUxYoVk927d+v0d/ny5WXEiBGSNGlS+eKLLyRfvnyBP0oiIqJ4KlaBuk+fPnLjxg39+JNPPpEXXnhBqlatKo8//rgsWLAg0MdIREQUb8UqUNepU8f1cYECBeTgwYNy6dIlyZAhgyvzm4iIiEK8jxpOnDih/+bKlSsAh0NERER+J5Pdu3dP+vbtq3VK8+TJozd8jCnxu3fvxuYhiYiIKFAj6vfee0+++eYbTSKrWLGia8vWgAED5OLFizJp0qTYPCwREREFIlDPnTtX5s+fL/Xq1XPdV6JECZ3+btasGQM1ERFRKKe+kyVLptPd3rBdC9u0iIiIKISBulOnTjJo0CC5ffu26z58PGTIEP0aERERxfHU98svv+zx+apVqyRnzpxSsmRJ/RwFUNBFq0aNGgE6NCIiIop2oEZWt7tXXnnF43NuzyIiIgphoJ4xY0YQnp6IiIiCVvDk/PnzriYcBQsWlEyZMvnzcERERBSIZDLU+X777bclW7ZsUq1aNb1lz55d2rRpIzdv3ozNQxIREVGgAnXXrl1l7dq18v3338uVK1f09u233+p9H374YYwfLyIiQrd7JU+eXLtxbdmyJVo/h73cqC3eqFGjWPwWREREYRqo//Of/8i0adO04EnatGn1Vr9+fZkyZYosWrQoRo+FblsI/P3795cdO3ZoFjmafpw7dy7Knzt27Jh069ZNu3YRERGFq1gFakxvZ8mS5aH7M2fOHOOp7zFjxki7du2kdevWUqRIEZk8ebKkTJlSpk+fHunP3L9/X9544w0ZOHAg+18TEVFYi1WgRn1vjID/+ecf1323bt3SwGnX/o4O7Lvevn271KxZ8/8OKGFC/Ry1wyODHti4KMCa+KOgEMu1a9c8bkRERGGd9T127FipW7fuQwVPsMa8fPnyaD/OhQsXdHTsPTrH5+hx7cuGDRt02n3Xrl3Reo5hw4bpBQQREVG8CdTFixeXP/74Q+bMmeMKqGjGgenoFClSSLBcv35dWrRooWvhGTNmjNbP9OrVS9fAbRhRszgLERGFbaBGv+lChQrJ0qVLdW3ZHwi2iRIlkrNnz3rcj8+zZs360PcfPnxYk8hefPFF130PHjzQfxMnTqx7uvPnz/9QAxHciIiI4sUadZIkSTzWpv2BTltlypSR1atXewRefO5rrRsXCHv37tVpb/vWsGFDee655/RjjpSJiCjcxGrqu2PHjvLpp5/K1KlTdSTrD0xLt2rVSsqWLSvlypXT9W8UVEEWOLRs2VJy5Miha81YAy9WrJjHz6dPn17/9b6fiIgoHMQqym7dulVHvStWrND16lSpUnl8/Ztvvon2YzVp0kRLkfbr10/OnDkjpUqVkmXLlrkSzI4fP66Z4ERERPFRrAI1RrHe3bP8gR7WkfWxXrNmTZQ/++WXXwbsOIiIiBwdqLF+PHLkSPn99991D/Tzzz8vAwYMCGqmNxERUXwWoznlIUOGSO/evSV16tS6bjx+/HhdryYiIiIDRtSzZs2SiRMnyjvvvKOfr1q1Sho0aKBJZVxHJiIKb3l6/uDz/mPDG8T5scQnMRpRI7ELzTdsKPWJ7lWnTp0KxrERERHFezEK1Pfu3dMtUt77qlEEhYiIiEI89W1Zlrz11lselb5Q/KR9+/YeW7Risj2LiIiIAhSoUZjE25tvvhmThyAiIqJgBeoZM2bE5NuJiIjITyz5RUREZDAGaiIiIoMxUBMRERmMgZqIiMhgDNREREQGY6AmIiIyGAM1ERGRwRioiYiIDMZATUREZDAGaiIiIoMxUBMRERmMgZqIiMhgDNREREQGY6AmIiIyGAM1ERGRwRioiYiIDMZATUREZLDEoT4AIvJUfGbxSF+Sva328uUiimc4oiYiIjIYAzUREZHBjAjUERERkidPHkmePLmUL19etmzZEun3TpkyRapWrSoZMmTQW82aNaP8fiIiIicL+Rr1ggULpGvXrjJ58mQN0mPHjpU6derIoUOHJHPmzA99/5o1a6RZs2ZSqVIlDeyffvqp1K5dW/bt2yc5cuQIye9ARES+MeciDEbUY8aMkXbt2knr1q2lSJEiGrBTpkwp06dP9/n9c+bMkQ4dOkipUqWkUKFCMnXqVHnw4IGsXr06zo+diIgorAP1nTt3ZPv27Tp97TqghAn1802bNkXrMW7evCl3796Vxx57LIhHSkREFA+nvi9cuCD379+XLFmyeNyPzw8ePBitx+jRo4dkz57dI9i7u337tt5s165d8/OoiYiI4tHUtz+GDx8u8+fPl8WLF+t6tS/Dhg2TdOnSuW65cuWK8+MkIiJyZKDOmDGjJEqUSM6ePetxPz7PmjVrlD87atQoDdQrVqyQEiVKRPp9vXr1kqtXr7puJ06cCNjxExERhXWgTpo0qZQpU8YjEcxODKtYsWKkPzdixAgZNGiQLFu2TMqWLRvlcyRLlkzSpk3rcSMiInKKkG/PwtasVq1aacAtV66cbs+6ceOGZoFDy5YtddsVprAB27H69esnc+fO1b3XZ86c0ftTp06tNyIionAS8kDdpEkTOX/+vAZfBF1su8JI2U4wO378uGaC2yZNmqTZ4q+++qrH4/Tv318GDBgQ58dPREQU1oEaOnXqpDdfUODE3bFjx+LoqIiIiELP0VnfRERE4Y6BmoiIyGAM1ERERAYzYo06PmKheiIiig6OqImIiAzGQE1ERGQwBmoiIiKDMVATEREZjIGaiIjIYAzUREREBmOgJiIiMhgDNRERkcEYqImIiAzGQE1ERGQwBmoiIiKDMVATEREZjE05iMhvbDJD4aT4zOKRfm1vq70S1ziiJiIiMhgDNRERkcE49U2OnQ4iIooPOKImIiIyGAM1ERGRwTj17ac8PX+I9GvHhjfw9+GJiCie44iaiIjIYAzUREREBuPUN4U1ZqpTOJ0bTjxm8h9H1ERERAZjoCYiIjIYAzUREZHBjAjUERERkidPHkmePLmUL19etmzZEuX3f/3111KoUCH9/uLFi8uPP/4YZ8dKREQUrwL1ggULpGvXrtK/f3/ZsWOHlCxZUurUqSPnzp3z+f0bN26UZs2aSZs2bWTnzp3SqFEjvf32229xfuxERERhH6jHjBkj7dq1k9atW0uRIkVk8uTJkjJlSpk+fbrP7x83bpzUrVtXunfvLoULF5ZBgwZJ6dKlZcKECXF+7ERERGG9PevOnTuyfft26dWrl+u+hAkTSs2aNWXTpk0+fwb3YwTuDiPwJUuWBP14iYjIhwHpIn9Z8ubmS+bkQH3hwgW5f/++ZMmSxeN+fH7w4EGfP3PmzBmf34/7fbl9+7bebFevXtV/r127FoDfQOTB7ZuRfi2q57h/636sfi4QivVfHunXfhtYx8hjjq1QHnOU50YCy9jXObLzg+dG6IX63IjsnOb5HHP2/5dlRf5e4GKF0MmTJ3GE1saNGz3u7969u1WuXDmfP5MkSRJr7ty5HvdFRERYmTNn9vn9/fv31+fgja8BzwGeAzwHeA6IYa/BiRMnHhkrQzqizpgxoyRKlEjOnj3rcT8+z5o1q8+fwf0x+X5Mq7tPlT948EAuXbokjz/+uCRIkEACCVdIuXLlkhMnTkjatGnFCXjMfJ15bvBvkO8bcQ8j6evXr0v27Nkf+b0hDdRJkyaVMmXKyOrVqzVz2w6k+LxTp04+f6ZixYr69ffff99138qVK/V+X5IlS6Y3d+nTp5dgQpB2SqC28Zj5OvPc4N8g3zfiVrp0Uaztm1TrG6PdVq1aSdmyZaVcuXIyduxYuXHjhmaBQ8uWLSVHjhwybNgw/bxLly5SvXp1GT16tDRo0EDmz58v27Ztky+++CLEvwkREVHghTxQN2nSRM6fPy/9+vXThLBSpUrJsmXLXAljx48f10xwW6VKlWTu3LnSp08f6d27tzz55JOa8V2sWLEQ/hZERERhGqgB09yRTXWvWbPmoftee+01vZkGU+wo3OI91W4yHjNfZ54b/Bvk+4bZEiCjLNQHQURERIZWJiMiIqLIMVATEREZjIGaiIjIYAzUREREBmOgjqV79+7JrFmzHqqSRkREFEjM+vYD2nEeOHBAnnjiCXEKFJdBL+9q1aqJk+TLl0+2bt2qpV/dXblyRducHjlyRELtu+++i/b3NmzYMKjHEp+h0c/evXv17zJDhgyhPhzHikmTD1MrMa5bty7KrzvlfdCIfdROhUpqu3btclSgRvcwtBHFMaP6GwI3Kr+Z7tixY/oG7A2d0U6ePCkmsMvg2lBL3n33o3tteV+/iwlmzpypNfhR9Q8++ugjrfqHXvHz5s0z8lxHOeHixYvrBSheV1Qu3Lhxo15IL126VJ599tlQH6IjodRydPshmHo+P+vj/94Jf4feGKj90KFDBy2BiiYcqFmeKlUqj6+XKFFCTIMqbqgE99VXX+mbMgq0IHDjTe6ll16SJEmSiEncR6nLly/3qI2LPzLUfc+TJ4+YAHXqbatWrZIePXrI0KFDXXXo0UsdFfVwn6lwbJMmTXIdb0REhHz22Wca8D744AP55ptvxDSLFi2SN998Uz/+/vvv5ejRo9omF+f4xx9/LL/88ouYCMe9cOFCrb54584dj6/t2LFDQu3nn3/2uFDu2bOnvPXWWx7nM95D7PLOJrp8+bLH53fv3pWdO3dK3759ZciQIeIYMWlLSZ4SJEjw0C1hwoSuf51g+/btVqdOnazkyZNbGTNmtN5//33r999/t0x+je1b0qRJraeeesr6/vvvLdMULVrUWr9+/UP3r1u3zipUqJBlqhQpUlh//fWXfvzRRx9ZLVq00I9/++03PT9MlCxZMlerwHbt2lldunTRj48cOWKlSZPGMtG4ceOs1KlT698ezuN33nnHqlmzppUuXTqrd+/elmmef/75h9oLw5w5c6zq1atbTrNmzRqrdOnSllMwmcwPuHL3vmGt1P7XdKdPn9bOY7ih3Wj9+vV1bQ/TnBhFmTJKxQ1TrpgJsD/HDdPehw4dkhdeeEFMc/jwYZ9d2jAjgNGJqVKnTi0XL17Uj1esWCG1atXSj5MnTy63bt0SE6EvwP79+3WGBX0C7GO+efOmntcmmjhxoi4p/Pvf/9YuglhiwN9h586ddXnKNBg9o3GSN9y3ZcsWcZosWbLoe4djhPpKgeLWnTt3rEWLFlkNGjSwkiRJYpUpU8aaNGmSdfXqVdf3fPPNN1b69OmNOmZc0Zs00n+UqlWrWrVq1bLOnDnjug8f165d26pWrZplqubNm+tIo02bNlbKlCmtCxcu6P3ffvutzhKYqH///joSxUxF7ty5rX/++UfvnzZtmlWhQgXL1JmLY8eO6ceZMmWydu3apR/jHH/ssccs02Dmqnv37g/dj/vwNVPt3r3b44bX+aefftJZgMqVK1tOwTVqP2EdbPLkyTqKxlUnRn5o1Zk3b15d8zVNtmzZdDTarFkzvRJGtzJvzz33XNB7dscE1s337NkjTjJt2jR5+eWXJXfu3JIrVy69D7kMdrc3U2FNGuvoONb//Oc/riz77du36zljogEDBmj3PBwzmvXYTXEwmsa6qomyZs0qly5d0vcLnCObN2+WkiVL6vuIie0XMMP2yiuvyE8//STly5fX+/D+8ccff+h5YqpSpUo9lNQJFSpUkOnTp4tTcHuWH5B0g/acyDpFYsJvv/2m24i+/PJLTbJwT8Yw6cICb2aYynQSJDLhDXj48OHiFHhzwHQmEpugcOHCmrgX3Uxairl//vnHEed227Zt9QIOyZy4OOrevbtUrlxZtm3bphd4uNAzzf/+9z99z8OWVPt8bt++vetC1ER//fWXx+domZwpUyZHnCPuGKj9gLVcZMliW06aNGlk9+7dGqgRsLEt4MKFC2ISZDymSJFCt5Q5rX/3e++9pwVmMCL1lWE/ZswYMYWTX2dYv369fP7555pn8fXXX+v2PVzgYZaoSpUqYhqsTePvEDNbKED0+++/698hMnuxIwA7Gkxj51kkTvz/JzXnz5+vW8pwfr/zzju6bm3S+Vy3bl19fXF8FPeYTOYHTFM9/fTTD92Pkd+NGzfENJhCxjSbU/YOusPFDwqb4IIIb8TYYmHfEBBN4uTXGdOYderU0QsNbBFCwh4gwcnUbWWYzcIs1ogRIzwCHC6Spk6dKibCyM4O0tC0aVMZP368XpCaFKSduvTkbu3atfLiiy9KgQIF9IZiQ7gYdZRQL5I7WeHCha0lS5box9hqcfjwYf14/Pjx1tNPP22ZaOrUqVb9+vWtixcvhvpQwppTX+dSpUpZM2fOfOic3rFjh5UlSxbLRPnz57dWrVr10DEfOHDAqKRId3nz5rXeeustV+Kb7fz58/o102DbZo8ePSyn+eqrr6zEiRNbr7/+um6Jww0fI5EWW8ucgslkfkCxk44dO+q6GNYjkVyB6k0oAGDqlfyECRPkzz//lOzZs2sii/cUsgmFFqKzVgY5c+YUUzn1dcaWFV9lFbGtDOVaTYTKdBgpecPUMqZtTYQtehhRV61aVYv6ILkMMAvjva5qSm8DJF+hkI/pS0/esy2YaUGOiw1b4HC8gwYNkubNm4sTMFD7mRCCKUJkyWLPJv7T8cY8btw4ncoykXeZS6fAm+7gwYNl9OjR8vfff+t9mAb/8MMPtfoUphJN4tTXGQEDFxje1d42bNig676m5opgKtO7vCkqf/lamjIBEgqx57tbt24a+LAT4JlnnhHTl54AS0/uTE6OPHLkiE57e8P0d+/evcUxQj2kDxc3btywzp49G+rDCFs9e/bU/aYTJ0507YmMiIjQ+0ys5ORUQ4cOtYoUKWJt3rxZq3qhutrs2bP1dcaSjomw/IR91MOHD9e93yNHjrTatm2rFb9WrFhhmQiV9ez3C5zb2FeNaVrstXdKVUMnyJ8/vzV58uSH7kftiAIFClhOwUDth5s3b2qAtqGAwWeffWYtX77cMtnly5etKVOm6BuEvYaKUqL/+9//LFNly5ZNi274epPOnj17SI4pHD148MAaPHiwlSpVKlepVpSX7dOnj2UylGZFCU5cUCDooZiFyX+HCMbuF/YI0nidW7duzUAdQBMnTtQLtvbt21uzZs3SG8q1ouysrwBuKm7P8kPt2rV1zyP2EmL9rmDBgpqxiW1ZWAN59913xTTI3sReXruUJdYkMaWJ6Xs0B8AWKBNh3yOO/amnnvK4H8ePogamlbfEWiOKRETWdAHFLkyG48UUOJYZMLWM0qIUOFiqOXPmjGTOnNl1HwomNW7cWEvlmrhjAHu8IzufTWzWYlu8eLEumbnv/8a+dRMLUkUq1FcKTvb4449rswLACLVEiRLW/fv3rYULFxrbeKFGjRquUoDuGbK//PKL9cQTT1imKleunPXee+89dD+aGpQvX94yTd++fXUWYNSoUTpSGjRokJblxDmDzFMKHLyuP//8c1i8pJj6RsMI08ybN08zpV944QUdoeJflA7FkgOy103VsmVLa+3atZbTMVAHqNPQa6+9Zg0YMEA/Pn78uH7NRGnTprX+/PPPhwI1pu0xHWQqvHlhOhZb4t5++2294WP8Dpj2NE2+fPmspUuX6sc4Rvs1R5Bu1qyZZaq///5bp7krVqyo63vYKuR+M1HDhg313M2ZM6fVrVs3a+fOnZbpBg4caK1evdrn64+vmaZ48eLWhAkTPN43sEyCbmX9+vWzTPXSSy/pBQbWo4cMGWKdPHnSciIGaj9PXrzxIjAjAG7cuFHv37Ztm7F7TrGGhz2x3oEaSTd4ozMZ/siQOPbyyy/r7eOPPzb2Dw9JTfZFXNasWTUHAPB641wxVdOmTXUmAC0ukW8xduxYj5upLl26ZH3++efabAHrv0iIwxvz0aNHLRPZbVpHjx7tcb+pyWQ4n+3XEk1D9uzZox/v379fz2+TnTt3Tl9nzHhiT3XdunV11hPNfpyCgdoPX3/9tV6t4Q8LiSzumbM4GUydJmzUqJGepAjU6NmLgIICLXYfX1M0btzY1dULRTi8i0OYDNOCyJwGJDYNGzZMP54/f75eLJkKU5kbNmywnAy9qUeMGKHLT4kSJbJMDdQ4F7AUgqnj27dvGx2oc+TI4QrOGKDYvakxODH5wtMbLpixXIblKPRXRyEXJ3TlY6D20+nTp3WEirVp26+//qpVkUx05coVvahAxSa8ieXKlUsvNtB6EdNuJsFxnTp1ymeWrOlQxQkjOsAbMq7kMf2GUZTJFZ7y5MmjoySnwgXo4sWLrVdeeUXfjE3dEWBvz8KSCJZwsNSAz00N1FiusUf/n3zyiV5sYgsc8lpwQe0Ep06d0i18BQsW1GU0rF8jZwd/m2PGjLFMxqzveFQty7uABbKokdWLQgbIBDdNiRIl9NjQdrN169ZaCzlt2rQ+v7dly5ZiMrQxtJsu+CrAYIrZs2fLt99+q93fUqZMKU6BTnVz587VWuUojoPdGG+88YY8//zzRhbkQAvO06dPa9b3tWvX5PXXX5d9+/Zp4wsU4zAt6xu7FFCBEQWd8Pqi2pd9PmPHSIYMGcREd+/e1cpvM2bMkBUrVuh7CgpVoTiV/V6CrPC3335bLl++LKZioI5H1bIAPXtNbkvn7pdfftHX8vDhw/pGgdfW15su7jN9u5PJUL3L/XXFtizMtqE6GRoymF76FN298P+PDk8IzrgQsntSO2V7Ft5L0C4XbSTxsWmB2qkyZsyoryd6qbdr1063cnrD1lr8DaDJkqlYQtQPCMboG4seyegla49U0cgeV5+oM2savPmiVeGbb74pr776qrFXwoDXFCNR+40NpQvd952aDN2z0Oq0evXq+m/+/PnFVE4td2rD3xt6rKdPn16cAiM81DKw4fzGjBECxrp168Q0mLHCzBbqwJt8LntDLQOcG1H1n8Z5Y3KQBo6o/YBpIHuqyh2mDjt06KDNAkyDtpCYIkT/WxRWwCgEQdvEUQimL9G+EFNUmIrF9CBqqzsBppDxhrtmzRodoWLUh6BtB2729Q0Opy1BOQWmi3E+u5/L9oUoz+XgY6COR9Wy3GFqE0HEe10PHXJMgSpv6CSULVs2jzU9p8Fxoyfu0qVLZcGCBUZPbW7dulWPr3z58h73//rrr/p/ULZsWTGNU5agMGL+17/+pe8b+DgyWIZAX2oTYfCBgI3zGTfMcuHv075AouBgoPYD3sxw8/6jwx8Z3vDsaVvTYd2xTZs2etFhUgBxejIZOqphKQQXREh2wmwGyhdiJIIpOROVK1dOPvroI10W8S4R+emnn2rANk2vXr10CWrgwIEPLUFhXdKUJai8efNqGc7HH39cP44qUKPrk4nscxrnM85rvHegxCzObQoeBmo/4IqyQYMGuh5ZsWJFV71eJGz9+OOP2mvWVLgCxmgaN7Sww/EjEQd1y02BrFL0/HZiMlmlSpU8AjOmCLG+Z3JOAKCmNy7YvFtaYg0PF07Xr18X0zhxCcp7dgtMzE63oSUkArN9TttT3044p8MBA7WfTp06JREREXLw4EH9HCcx3hzw5mGizz//XIMzropxrAjO2Krg3cvXCU0MTPbYY4/pMaNxC97QcPNeIjERRnuYorcvPN0vmnBRauIWFqcuQWEWADMrf/zxh36OtV5kfmM92DQ4lzNlyiQffPCBLpE54VwOJwzU8Qy2ZmGrAgJ0yZIlxSmwVo2uPbjQwLTg119/rUktX331lU4jIpPdtFHS3r17dRSCmRes62HNHSMRTOVjStZEODewpo7RqJ2VjO0ryAzHRRK6J5nGiUtQ/fr10w57OEb32bgJEyZoMPzkk0/EJLt379bzGOfz+vXrXeeyky5CnYyBOoZw5R5dmCo0DQIIRtNOCXg2JLy1aNFCLzBwrPv379fpWbyxYZkBN1PhNd++fbse65w5c4xOJsM0MaYzL168qFuFYNeuXZIlSxZZuXKlkXvwI1uCwoXdTz/9ZOQSFEanuLDAhZG7efPmafBGq1yTIXBjNsD08zlccB91DGEqDWtJ9rpSZPA9Jp68SAqyAx4SQW7fvq33X716VYYOHWpswENWL9YhkTSGrWU2JA/ha6bBa4vRB264MMLabvHixfVNGCMRU+GiDRejeAPGmzG2wyGRDwHFu/iJKfB6YpobxULsnsOYnjV5CQoVs3xl0JcpU0bu3bsnpsH7Hdan3c9pVFTDYMTk8zlccEQdiynY6DJx3RejJEytIeAhOQtvxhiZ4o+wXr16ug5sIpSzxCgaBVvcjxuzAsg6RYEZkyROnFhfa3vvNEap7gUuKLDw/48LjHPnzukIz513kpkJcMGGCx9Mf7vr1q2brqkj78UkSBjD1jcsl9lT3pipcFKRGSfjiDqG3IPvsGHDdEoQdWLdYS8yion06NFDTIORB4KGNwQRrEWaKmvWrFpsAYHaHa7svTOUQw0zKZi5wBuZEzNikdyE7Te+gh7WVk2zbNkyvfDEdL33TJepM1t2MhnqT1eoUEE/x9Y3TNfjd8FuB5t3MA9VAR+cz5Ftj6TgYqAOQAa1t6JFi0rTpk2NDNROCnjukHzVpUsXvQjCmy+y7bEOiRFI3759xSQoDIIqapiGdVqgnjJlirz77rtaIxnnivuWIXxsYqDG6BRlInFsuHB2AmyJRI0AwPZDwGuOG75mM2XLFnIAbKz+FgKhbt/lZMmSJdN+zt4OHz6sXzMRemUXKVJEeyWnSZPGWr9+vTV79mxtWzd+/HjLVA8ePLAGDx6s7enQIhA3tDHs06ePZaIyZcpYq1atspwmd+7c2grQSXAeo10kBQ/a+A4cOFB7T6MNJ27oXY6Wl+4tfik4GKj9gP7CX3311UP3z5o1y8qbN69lIqcFPG+3b9+29u3bpz2/r1+/bpnqp59+skqVKmV9//332gf36tWrHjeTgx4uNJ2kdevW1tSpU0N9GGGtZ8+eejE/ceJEa/fu3XqLiIjQ+3r37h3qwwt7TCbzA3qy4jZy5EjtewurV6/WEoyoM4zShqa6c+eOToEjQQTJWKhIRYHjXl/affoSF8cmr5uilOwzzzxjVIW66JS1xNQ3tjwhs947O71z584hO7Zw4fTqb07HNWo/dO/eXRNYcKIi8NlVkrA2bXKQBhQsQICm4EAylhMVKFBA1/xRJMQpQQ97j5GUhb89bB3yXlc38ZidBiV6CxUq9ND9uM+08r3hiCPqAMCoFIlD2HOKMoCmtYskii4nNotA0huCcc+ePY3plBVunFj9LZwwUBMFCba7YQuOXYQDuwGwlY/7qQNfVx3BIn/+/AF+ZAqHBkThgIGaKAjQzrBOnTo6y4LWkYBggmIWmKa1t+aYAHt2Bw0aJKlSpfLYv+trRI2ez6ZBAR+sT6PDEwUH9nejiI+vBkSopIYATsHDQE0UBBhhYL0X+5LxBgd4Q0NnJEwfo0mHKdAkZPHixVplCh9HFaj/+9//imkw7T1r1iytmoWSlt7r6iYUDHE61AZAsxbv7nXI0cF9piZHhgsGaqIgwEgaZVm9E3BQBhU1npGpTIHhxIsLp4mszSxKKiMp9caNGyE7tviAWd9EQYBSi5gu9A7UWNNDrXIKHKdm2DuBvRRiV6VDzX0bRtEoe4pGRRRcDNREQdCkSRPdkzxq1CipVKmS3vfLL7/olj7v1oZEpsKskHt/dWzrtOFjLDegjC8FF6e+iQIE3ZuKFSum04TYV4+gjCIRdttCrJ2ijvbw4cO5hY8cBa1Ox40bx6YcIcJATRSEhBs0OEGWN9aq7aYL2D7kPnVIRBQdnPomChBkTR89elQD9bFjx7RFJAIzKnwREcUWAzVRgLzyyitSvXp1yZYtmybfILsbo2xfTKzwRURmYqAmCpAvvvhCXn75ZW12gr296KHNDG8i8hfXqImClHyDusgM1ETkLwZqIiIig7HVDBERkcEYqImIiAzGQE1ERGQwBmoiIiKDMVATEREZjIGaiIjIYAzUREREBmOgJiIiEnP9PziNpZrNoOdfAAAAAElFTkSuQmCC\",\n \"text/plain\": [\n \" \\n\",\n \"\\n\",\n \"- (Please note that the numbers in this figure are truncated to two\\n\",\n \"digits after the decimal point to reduce visual clutter. The values in the Softmax row should add up to 1.0.)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0ba12da5-6ff1-4008-91b8-d2d537cbc14c\",\n \"metadata\": {},\n \"source\": [\n \"- In code, we can implement this as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"2a7f908a-e9ec-446a-b407-fb6dbf05c806\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Top logits: tensor([6.7500, 6.2800, 4.5100])\\n\",\n \"Top positions: tensor([3, 7, 0])\\n\"\n ]\n }\n ],\n \"source\": [\n \"top_k = 3\\n\",\n \"top_logits, top_pos = torch.topk(next_token_logits, top_k)\\n\",\n \"\\n\",\n \"print(\\\"Top logits:\\\", top_logits)\\n\",\n \"print(\\\"Top positions:\\\", top_pos)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"753865ed-79c5-48b1-b9f2-ccb132ff1d2f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([4.5100, -inf, -inf, 6.7500, -inf, -inf, -inf, 6.2800, -inf])\\n\"\n ]\n }\n ],\n \"source\": [\n \"new_logits = torch.where(\\n\",\n \" condition=next_token_logits < top_logits[-1],\\n\",\n \" input=torch.tensor(float(\\\"-inf\\\")), \\n\",\n \" other=next_token_logits\\n\",\n \")\\n\",\n \"\\n\",\n \"print(new_logits)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dfa6fa49-6e99-459d-a517-d7d0f51c4f00\",\n \"metadata\": {},\n \"source\": [\n \"> NOTE: \\n\",\n \">\\n\",\n \"> An alternative, slightly more efficient implementation of the previous code cell is the following:\\n\",\n \">\\n\",\n \"> ```python\\n\",\n \"> new_logits = torch.full_like( # create tensor containing -inf values\\n\",\n \"> next_token_logits, -torch.inf\\n\",\n \">) \\n\",\n \"> new_logits[top_pos] = next_token_logits[top_pos] # copy top k values into the -inf tensor\\n\",\n \"> ```\\n\",\n \">
\\n\",\n \"\\n\",\n \"- (Please note that the numbers in this figure are truncated to two\\n\",\n \"digits after the decimal point to reduce visual clutter. The values in the Softmax row should add up to 1.0.)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0ba12da5-6ff1-4008-91b8-d2d537cbc14c\",\n \"metadata\": {},\n \"source\": [\n \"- In code, we can implement this as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"2a7f908a-e9ec-446a-b407-fb6dbf05c806\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Top logits: tensor([6.7500, 6.2800, 4.5100])\\n\",\n \"Top positions: tensor([3, 7, 0])\\n\"\n ]\n }\n ],\n \"source\": [\n \"top_k = 3\\n\",\n \"top_logits, top_pos = torch.topk(next_token_logits, top_k)\\n\",\n \"\\n\",\n \"print(\\\"Top logits:\\\", top_logits)\\n\",\n \"print(\\\"Top positions:\\\", top_pos)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"753865ed-79c5-48b1-b9f2-ccb132ff1d2f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([4.5100, -inf, -inf, 6.7500, -inf, -inf, -inf, 6.2800, -inf])\\n\"\n ]\n }\n ],\n \"source\": [\n \"new_logits = torch.where(\\n\",\n \" condition=next_token_logits < top_logits[-1],\\n\",\n \" input=torch.tensor(float(\\\"-inf\\\")), \\n\",\n \" other=next_token_logits\\n\",\n \")\\n\",\n \"\\n\",\n \"print(new_logits)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dfa6fa49-6e99-459d-a517-d7d0f51c4f00\",\n \"metadata\": {},\n \"source\": [\n \"> NOTE: \\n\",\n \">\\n\",\n \"> An alternative, slightly more efficient implementation of the previous code cell is the following:\\n\",\n \">\\n\",\n \"> ```python\\n\",\n \"> new_logits = torch.full_like( # create tensor containing -inf values\\n\",\n \"> next_token_logits, -torch.inf\\n\",\n \">) \\n\",\n \"> new_logits[top_pos] = next_token_logits[top_pos] # copy top k values into the -inf tensor\\n\",\n \"> ```\\n\",\n \">  \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"10e4c7f9-592f-43d6-a00e-598fa01dfb82\",\n \"metadata\": {},\n \"source\": [\n \"- The recommended way in PyTorch is to save the model weights, the so-called `state_dict` via by applying the `torch.save` function to the `.state_dict()` method:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"3d67d869-ac04-4382-bcfb-c96d1ca80d47\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"torch.save(model.state_dict(), \\\"model.pth\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90e889e0-07bf-43e5-8f92-5c5c7aeaad9e\",\n \"metadata\": {},\n \"source\": [\n \"- Then we can load the model weights into a new `GPTModel` model instance as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"9d57d914-60a3-47f1-b499-5352f4c457cb\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"model = GPTModel(GPT_CONFIG_124M)\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"print(\\\"Device:\\\", device)\\n\",\n \"\\n\",\n \"model.load_state_dict(torch.load(\\\"model.pth\\\", map_location=device, weights_only=True))\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"caa81aec-9c72-4f46-8ae2-4a4fde3edbc1\",\n \"metadata\": {},\n \"source\": [\n \"- It's common to train LLMs with adaptive optimizers like Adam or AdamW instead of regular SGD\\n\",\n \"- These adaptive optimizers store additional parameters for each model weight, so it makes sense to save them as well in case we plan to continue the pretraining later:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"bbd175bb-edf4-450e-a6de-d3e8913c6532\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"torch.save({\\n\",\n \" \\\"model_state_dict\\\": model.state_dict(),\\n\",\n \" \\\"optimizer_state_dict\\\": optimizer.state_dict(),\\n\",\n \" }, \\n\",\n \" \\\"model_and_optimizer.pth\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"8a0c7295-c822-43bf-9286-c45abc542868\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"checkpoint = torch.load(\\\"model_and_optimizer.pth\\\", weights_only=True)\\n\",\n \"\\n\",\n \"model = GPTModel(GPT_CONFIG_124M)\\n\",\n \"model.load_state_dict(checkpoint[\\\"model_state_dict\\\"])\\n\",\n \"\\n\",\n \"optimizer = torch.optim.AdamW(model.parameters(), lr=0.0005, weight_decay=0.1)\\n\",\n \"optimizer.load_state_dict(checkpoint[\\\"optimizer_state_dict\\\"])\\n\",\n \"model.train();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4194350e-0409-4a63-8ffd-d3a896509032\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 5.5 Loading pretrained weights from OpenAI\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"83eb6c38-7278-40e0-bd9f-8a2b1feac3ec\",\n \"metadata\": {},\n \"source\": [\n \"- Previously, we only trained a small GPT-2 model using a very small short-story book for educational purposes\\n\",\n \"- Interested readers can also find a longer pretraining run on the complete Project Gutenberg book corpus in [../03_bonus_pretraining_on_gutenberg](../03_bonus_pretraining_on_gutenberg)\\n\",\n \"- Fortunately, we don't have to spend tens to hundreds of thousands of dollars to pretrain the model on a large pretraining corpus but can load the pretrained weights provided by OpenAI\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"127ddbdb-3878-4669-9a39-d231fbdfb834\",\n \"metadata\": {},\n \"source\": [\n \"---\\n\",\n \"\\n\",\n \"---\\n\",\n \"\\n\",\n \"\\n\",\n \"⚠️ **Note: Some users may encounter issues in this section due to TensorFlow compatibility problems, particularly on certain Windows systems. TensorFlow is required here only to load the original OpenAI GPT-2 weight files, which we then convert to PyTorch.\\n\",\n \"If you're running into TensorFlow-related issues, you can use the alternative code below instead of the remaining code in this section.\\n\",\n \"This alternative is based on pre-converted PyTorch weights, created using the same conversion process described in the previous section. For details, refer to the notebook:\\n\",\n \"[../02_alternative_weight_loading/weight-loading-pytorch.ipynb](../02_alternative_weight_loading/weight-loading-pytorch.ipynb) notebook.**\\n\",\n \"\\n\",\n \"```python\\n\",\n \"file_name = \\\"gpt2-small-124M.pth\\\"\\n\",\n \"# file_name = \\\"gpt2-medium-355M.pth\\\"\\n\",\n \"# file_name = \\\"gpt2-large-774M.pth\\\"\\n\",\n \"# file_name = \\\"gpt2-xl-1558M.pth\\\"\\n\",\n \"\\n\",\n \"url = f\\\"https://huggingface.co/rasbt/gpt2-from-scratch-pytorch/resolve/main/{file_name}\\\"\\n\",\n \"\\n\",\n \"if not os.path.exists(file_name):\\n\",\n \" urllib.request.urlretrieve(url, file_name)\\n\",\n \" print(f\\\"Downloaded to {file_name}\\\")\\n\",\n \"\\n\",\n \"gpt = GPTModel(BASE_CONFIG)\\n\",\n \"gpt.load_state_dict(torch.load(file_name, weights_only=True))\\n\",\n \"gpt.eval()\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"gpt.to(device);\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=gpt,\\n\",\n \" idx=text_to_token_ids(\\\"Every effort moves you\\\", tokenizer).to(device),\\n\",\n \" max_new_tokens=25,\\n\",\n \" context_size=NEW_CONFIG[\\\"context_length\\\"],\\n\",\n \" top_k=50,\\n\",\n \" temperature=1.5\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\\n\",\n \"```\\n\",\n \"\\n\",\n \"---\\n\",\n \"\\n\",\n \"---\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"75cab892-a165-4f43-9601-f517bc212ab6\",\n \"metadata\": {},\n \"source\": [\n \"- First, some boilerplate code to download the files from OpenAI and load the weights into Python\\n\",\n \"- Since OpenAI used [TensorFlow](https://www.tensorflow.org/), we will have to install and use TensorFlow for loading the weights; [tqdm](https://github.com/tqdm/tqdm) is a progress bar library\\n\",\n \"- Uncomment and run the next cell to install the required libraries\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 46,\n \"id\": \"fb9fdf02-972a-444e-bf65-8ffcaaf30ce8\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install tensorflow tqdm\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 47,\n \"id\": \"a0747edc-559c-44ef-a93f-079d60227e3f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"TensorFlow version: 2.20.0\\n\",\n \"tqdm version: 4.67.1\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"TensorFlow version:\\\", version(\\\"tensorflow\\\"))\\n\",\n \"print(\\\"tqdm version:\\\", version(\\\"tqdm\\\"))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 48,\n \"id\": \"c5bc89eb-4d39-4287-9b0c-e459ebe7f5ed\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Relative import from the gpt_download.py contained in this folder\\n\",\n \"\\n\",\n \"from gpt_download import download_and_load_gpt2\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch05 import download_and_load_gpt2\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ff76a736-6f9f-4328-872e-f89a7b70a2cc\",\n \"metadata\": {},\n \"source\": [\n \"---\\n\",\n \"\\n\",\n \"**Note**\\n\",\n \"\\n\",\n \"- In very rare cases, the code cell above may result in a `zsh: illegal hardware instruction python` error, which could be due to a TensorFlow installation issue on your machine\\n\",\n \"- A reader found that installing TensorFlow via `conda` solved the issue in this specific case, as mentioned [here](https://github.com/rasbt/LLMs-from-scratch/discussions/273#discussioncomment-12367888)\\n\",\n \"- You can find more instructions in this supplementary [Python setup tutorial](https://github.com/rasbt/LLMs-from-scratch/tree/main/setup/01_optional-python-setup-preferences#option-2-using-conda)\\n\",\n \"\\n\",\n \"---\\n\",\n \"\\n\",\n \"- We can then download the model weights for the 124 million parameter model as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 49,\n \"id\": \"76271dd7-108d-4f5b-9c01-6ae0aac4b395\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"File already exists and is up-to-date: gpt2/124M/checkpoint\\n\",\n \"File already exists and is up-to-date: gpt2/124M/encoder.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/hparams.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.data-00000-of-00001\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.index\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.meta\\n\",\n \"File already exists and is up-to-date: gpt2/124M/vocab.bpe\\n\"\n ]\n }\n ],\n \"source\": [\n \"settings, params = download_and_load_gpt2(model_size=\\\"124M\\\", models_dir=\\\"gpt2\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 50,\n \"id\": \"b1a31951-d971-4a6e-9c43-11ee1168ec6a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Settings: {'n_vocab': 50257, 'n_ctx': 1024, 'n_embd': 768, 'n_head': 12, 'n_layer': 12}\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Settings:\\\", settings)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 51,\n \"id\": \"857c8331-130e-46ba-921d-fa35d7a73cfe\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Parameter dictionary keys: dict_keys(['blocks', 'b', 'g', 'wpe', 'wte'])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Parameter dictionary keys:\\\", params.keys())\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 52,\n \"id\": \"c48dac94-8562-4a66-84ef-46c613cdc4cd\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[[-0.11010301 -0.03926672 0.03310751 ... -0.1363697 0.01506208\\n\",\n \" 0.04531523]\\n\",\n \" [ 0.04034033 -0.04861503 0.04624869 ... 0.08605453 0.00253983\\n\",\n \" 0.04318958]\\n\",\n \" [-0.12746179 0.04793796 0.18410145 ... 0.08991534 -0.12972379\\n\",\n \" -0.08785918]\\n\",\n \" ...\\n\",\n \" [-0.04453601 -0.05483596 0.01225674 ... 0.10435229 0.09783269\\n\",\n \" -0.06952604]\\n\",\n \" [ 0.1860082 0.01665728 0.04611587 ... -0.09625227 0.07847701\\n\",\n \" -0.02245961]\\n\",\n \" [ 0.05135201 -0.02768905 0.0499369 ... 0.00704835 0.15519823\\n\",\n \" 0.12067825]]\\n\",\n \"Token embedding weight tensor dimensions: (50257, 768)\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(params[\\\"wte\\\"])\\n\",\n \"print(\\\"Token embedding weight tensor dimensions:\\\", params[\\\"wte\\\"].shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"466e100c-294e-4afc-a70a-2f398ac4c104\",\n \"metadata\": {},\n \"source\": [\n \"- Alternatively, \\\"355M\\\", \\\"774M\\\", and \\\"1558M\\\" are also supported `model_size` arguments\\n\",\n \"- The difference between these differently sized models is summarized in the figure below:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"20f19d32-5aae-4176-9f86-f391672c8f0d\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"10e4c7f9-592f-43d6-a00e-598fa01dfb82\",\n \"metadata\": {},\n \"source\": [\n \"- The recommended way in PyTorch is to save the model weights, the so-called `state_dict` via by applying the `torch.save` function to the `.state_dict()` method:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"3d67d869-ac04-4382-bcfb-c96d1ca80d47\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"torch.save(model.state_dict(), \\\"model.pth\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90e889e0-07bf-43e5-8f92-5c5c7aeaad9e\",\n \"metadata\": {},\n \"source\": [\n \"- Then we can load the model weights into a new `GPTModel` model instance as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"9d57d914-60a3-47f1-b499-5352f4c457cb\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"model = GPTModel(GPT_CONFIG_124M)\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"print(\\\"Device:\\\", device)\\n\",\n \"\\n\",\n \"model.load_state_dict(torch.load(\\\"model.pth\\\", map_location=device, weights_only=True))\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"caa81aec-9c72-4f46-8ae2-4a4fde3edbc1\",\n \"metadata\": {},\n \"source\": [\n \"- It's common to train LLMs with adaptive optimizers like Adam or AdamW instead of regular SGD\\n\",\n \"- These adaptive optimizers store additional parameters for each model weight, so it makes sense to save them as well in case we plan to continue the pretraining later:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"bbd175bb-edf4-450e-a6de-d3e8913c6532\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"torch.save({\\n\",\n \" \\\"model_state_dict\\\": model.state_dict(),\\n\",\n \" \\\"optimizer_state_dict\\\": optimizer.state_dict(),\\n\",\n \" }, \\n\",\n \" \\\"model_and_optimizer.pth\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"8a0c7295-c822-43bf-9286-c45abc542868\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"checkpoint = torch.load(\\\"model_and_optimizer.pth\\\", weights_only=True)\\n\",\n \"\\n\",\n \"model = GPTModel(GPT_CONFIG_124M)\\n\",\n \"model.load_state_dict(checkpoint[\\\"model_state_dict\\\"])\\n\",\n \"\\n\",\n \"optimizer = torch.optim.AdamW(model.parameters(), lr=0.0005, weight_decay=0.1)\\n\",\n \"optimizer.load_state_dict(checkpoint[\\\"optimizer_state_dict\\\"])\\n\",\n \"model.train();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4194350e-0409-4a63-8ffd-d3a896509032\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 5.5 Loading pretrained weights from OpenAI\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"83eb6c38-7278-40e0-bd9f-8a2b1feac3ec\",\n \"metadata\": {},\n \"source\": [\n \"- Previously, we only trained a small GPT-2 model using a very small short-story book for educational purposes\\n\",\n \"- Interested readers can also find a longer pretraining run on the complete Project Gutenberg book corpus in [../03_bonus_pretraining_on_gutenberg](../03_bonus_pretraining_on_gutenberg)\\n\",\n \"- Fortunately, we don't have to spend tens to hundreds of thousands of dollars to pretrain the model on a large pretraining corpus but can load the pretrained weights provided by OpenAI\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"127ddbdb-3878-4669-9a39-d231fbdfb834\",\n \"metadata\": {},\n \"source\": [\n \"---\\n\",\n \"\\n\",\n \"---\\n\",\n \"\\n\",\n \"\\n\",\n \"⚠️ **Note: Some users may encounter issues in this section due to TensorFlow compatibility problems, particularly on certain Windows systems. TensorFlow is required here only to load the original OpenAI GPT-2 weight files, which we then convert to PyTorch.\\n\",\n \"If you're running into TensorFlow-related issues, you can use the alternative code below instead of the remaining code in this section.\\n\",\n \"This alternative is based on pre-converted PyTorch weights, created using the same conversion process described in the previous section. For details, refer to the notebook:\\n\",\n \"[../02_alternative_weight_loading/weight-loading-pytorch.ipynb](../02_alternative_weight_loading/weight-loading-pytorch.ipynb) notebook.**\\n\",\n \"\\n\",\n \"```python\\n\",\n \"file_name = \\\"gpt2-small-124M.pth\\\"\\n\",\n \"# file_name = \\\"gpt2-medium-355M.pth\\\"\\n\",\n \"# file_name = \\\"gpt2-large-774M.pth\\\"\\n\",\n \"# file_name = \\\"gpt2-xl-1558M.pth\\\"\\n\",\n \"\\n\",\n \"url = f\\\"https://huggingface.co/rasbt/gpt2-from-scratch-pytorch/resolve/main/{file_name}\\\"\\n\",\n \"\\n\",\n \"if not os.path.exists(file_name):\\n\",\n \" urllib.request.urlretrieve(url, file_name)\\n\",\n \" print(f\\\"Downloaded to {file_name}\\\")\\n\",\n \"\\n\",\n \"gpt = GPTModel(BASE_CONFIG)\\n\",\n \"gpt.load_state_dict(torch.load(file_name, weights_only=True))\\n\",\n \"gpt.eval()\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"gpt.to(device);\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=gpt,\\n\",\n \" idx=text_to_token_ids(\\\"Every effort moves you\\\", tokenizer).to(device),\\n\",\n \" max_new_tokens=25,\\n\",\n \" context_size=NEW_CONFIG[\\\"context_length\\\"],\\n\",\n \" top_k=50,\\n\",\n \" temperature=1.5\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\\n\",\n \"```\\n\",\n \"\\n\",\n \"---\\n\",\n \"\\n\",\n \"---\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"75cab892-a165-4f43-9601-f517bc212ab6\",\n \"metadata\": {},\n \"source\": [\n \"- First, some boilerplate code to download the files from OpenAI and load the weights into Python\\n\",\n \"- Since OpenAI used [TensorFlow](https://www.tensorflow.org/), we will have to install and use TensorFlow for loading the weights; [tqdm](https://github.com/tqdm/tqdm) is a progress bar library\\n\",\n \"- Uncomment and run the next cell to install the required libraries\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 46,\n \"id\": \"fb9fdf02-972a-444e-bf65-8ffcaaf30ce8\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install tensorflow tqdm\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 47,\n \"id\": \"a0747edc-559c-44ef-a93f-079d60227e3f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"TensorFlow version: 2.20.0\\n\",\n \"tqdm version: 4.67.1\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"TensorFlow version:\\\", version(\\\"tensorflow\\\"))\\n\",\n \"print(\\\"tqdm version:\\\", version(\\\"tqdm\\\"))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 48,\n \"id\": \"c5bc89eb-4d39-4287-9b0c-e459ebe7f5ed\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Relative import from the gpt_download.py contained in this folder\\n\",\n \"\\n\",\n \"from gpt_download import download_and_load_gpt2\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch05 import download_and_load_gpt2\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ff76a736-6f9f-4328-872e-f89a7b70a2cc\",\n \"metadata\": {},\n \"source\": [\n \"---\\n\",\n \"\\n\",\n \"**Note**\\n\",\n \"\\n\",\n \"- In very rare cases, the code cell above may result in a `zsh: illegal hardware instruction python` error, which could be due to a TensorFlow installation issue on your machine\\n\",\n \"- A reader found that installing TensorFlow via `conda` solved the issue in this specific case, as mentioned [here](https://github.com/rasbt/LLMs-from-scratch/discussions/273#discussioncomment-12367888)\\n\",\n \"- You can find more instructions in this supplementary [Python setup tutorial](https://github.com/rasbt/LLMs-from-scratch/tree/main/setup/01_optional-python-setup-preferences#option-2-using-conda)\\n\",\n \"\\n\",\n \"---\\n\",\n \"\\n\",\n \"- We can then download the model weights for the 124 million parameter model as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 49,\n \"id\": \"76271dd7-108d-4f5b-9c01-6ae0aac4b395\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"File already exists and is up-to-date: gpt2/124M/checkpoint\\n\",\n \"File already exists and is up-to-date: gpt2/124M/encoder.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/hparams.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.data-00000-of-00001\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.index\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.meta\\n\",\n \"File already exists and is up-to-date: gpt2/124M/vocab.bpe\\n\"\n ]\n }\n ],\n \"source\": [\n \"settings, params = download_and_load_gpt2(model_size=\\\"124M\\\", models_dir=\\\"gpt2\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 50,\n \"id\": \"b1a31951-d971-4a6e-9c43-11ee1168ec6a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Settings: {'n_vocab': 50257, 'n_ctx': 1024, 'n_embd': 768, 'n_head': 12, 'n_layer': 12}\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Settings:\\\", settings)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 51,\n \"id\": \"857c8331-130e-46ba-921d-fa35d7a73cfe\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Parameter dictionary keys: dict_keys(['blocks', 'b', 'g', 'wpe', 'wte'])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Parameter dictionary keys:\\\", params.keys())\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 52,\n \"id\": \"c48dac94-8562-4a66-84ef-46c613cdc4cd\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[[-0.11010301 -0.03926672 0.03310751 ... -0.1363697 0.01506208\\n\",\n \" 0.04531523]\\n\",\n \" [ 0.04034033 -0.04861503 0.04624869 ... 0.08605453 0.00253983\\n\",\n \" 0.04318958]\\n\",\n \" [-0.12746179 0.04793796 0.18410145 ... 0.08991534 -0.12972379\\n\",\n \" -0.08785918]\\n\",\n \" ...\\n\",\n \" [-0.04453601 -0.05483596 0.01225674 ... 0.10435229 0.09783269\\n\",\n \" -0.06952604]\\n\",\n \" [ 0.1860082 0.01665728 0.04611587 ... -0.09625227 0.07847701\\n\",\n \" -0.02245961]\\n\",\n \" [ 0.05135201 -0.02768905 0.0499369 ... 0.00704835 0.15519823\\n\",\n \" 0.12067825]]\\n\",\n \"Token embedding weight tensor dimensions: (50257, 768)\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(params[\\\"wte\\\"])\\n\",\n \"print(\\\"Token embedding weight tensor dimensions:\\\", params[\\\"wte\\\"].shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"466e100c-294e-4afc-a70a-2f398ac4c104\",\n \"metadata\": {},\n \"source\": [\n \"- Alternatively, \\\"355M\\\", \\\"774M\\\", and \\\"1558M\\\" are also supported `model_size` arguments\\n\",\n \"- The difference between these differently sized models is summarized in the figure below:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"20f19d32-5aae-4176-9f86-f391672c8f0d\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ea6e5076-f08d-41fc-bd8b-1cfe53538f41\",\n \"metadata\": {},\n \"source\": [\n \"- Above, we loaded the 124M GPT-2 model weights into Python, however we still need to transfer them into our `GPTModel` instance\\n\",\n \"- First, we initialize a new GPTModel instance\\n\",\n \"- Note that the original GPT model initialized the linear layers for the query, key, and value matrices in the multi-head attention module with bias vectors, which is not required or recommended; however, to be able to load the weights correctly, we have to enable these too by setting `qkv_bias` to `True` in our implementation, too\\n\",\n \"- We are also using the `1024` token context length that was used by the original GPT-2 model(s)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 53,\n \"id\": \"9fef90dd-0654-4667-844f-08e28339ef7d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Define model configurations in a dictionary for compactness\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"# Copy the base configuration and update with specific model settings\\n\",\n \"model_name = \\\"gpt2-small (124M)\\\" # Example model name\\n\",\n \"NEW_CONFIG = GPT_CONFIG_124M.copy()\\n\",\n \"NEW_CONFIG.update(model_configs[model_name])\\n\",\n \"NEW_CONFIG.update({\\\"context_length\\\": 1024, \\\"qkv_bias\\\": True})\\n\",\n \"\\n\",\n \"gpt = GPTModel(NEW_CONFIG)\\n\",\n \"gpt.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"272f29ac-8342-4b3d-a57d-9b0166ced314\",\n \"metadata\": {},\n \"source\": [\n \"- The next task is to assign the OpenAI weights to the corresponding weight tensors in our `GPTModel` instance\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 54,\n \"id\": \"f9a92229-c002-49a6-8cfb-248297ad8296\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def assign(left, right):\\n\",\n \" if left.shape != right.shape:\\n\",\n \" raise ValueError(f\\\"Shape mismatch. Left: {left.shape}, Right: {right.shape}\\\")\\n\",\n \" return torch.nn.Parameter(torch.tensor(right))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 55,\n \"id\": \"f22d5d95-ca5a-425c-a9ec-fc432a12d4e9\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import numpy as np\\n\",\n \"\\n\",\n \"def load_weights_into_gpt(gpt, params):\\n\",\n \" gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])\\n\",\n \" gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])\\n\",\n \" \\n\",\n \" for b in range(len(params[\\\"blocks\\\"])):\\n\",\n \" q_w, k_w, v_w = np.split(\\n\",\n \" (params[\\\"blocks\\\"][b][\\\"attn\\\"][\\\"c_attn\\\"])[\\\"w\\\"], 3, axis=-1)\\n\",\n \" gpt.trf_blocks[b].att.W_query.weight = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_query.weight, q_w.T)\\n\",\n \" gpt.trf_blocks[b].att.W_key.weight = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_key.weight, k_w.T)\\n\",\n \" gpt.trf_blocks[b].att.W_value.weight = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_value.weight, v_w.T)\\n\",\n \"\\n\",\n \" q_b, k_b, v_b = np.split(\\n\",\n \" (params[\\\"blocks\\\"][b][\\\"attn\\\"][\\\"c_attn\\\"])[\\\"b\\\"], 3, axis=-1)\\n\",\n \" gpt.trf_blocks[b].att.W_query.bias = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_query.bias, q_b)\\n\",\n \" gpt.trf_blocks[b].att.W_key.bias = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_key.bias, k_b)\\n\",\n \" gpt.trf_blocks[b].att.W_value.bias = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_value.bias, v_b)\\n\",\n \"\\n\",\n \" gpt.trf_blocks[b].att.out_proj.weight = assign(\\n\",\n \" gpt.trf_blocks[b].att.out_proj.weight, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"attn\\\"][\\\"c_proj\\\"][\\\"w\\\"].T)\\n\",\n \" gpt.trf_blocks[b].att.out_proj.bias = assign(\\n\",\n \" gpt.trf_blocks[b].att.out_proj.bias, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"attn\\\"][\\\"c_proj\\\"][\\\"b\\\"])\\n\",\n \"\\n\",\n \" gpt.trf_blocks[b].ff.layers[0].weight = assign(\\n\",\n \" gpt.trf_blocks[b].ff.layers[0].weight, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"mlp\\\"][\\\"c_fc\\\"][\\\"w\\\"].T)\\n\",\n \" gpt.trf_blocks[b].ff.layers[0].bias = assign(\\n\",\n \" gpt.trf_blocks[b].ff.layers[0].bias, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"mlp\\\"][\\\"c_fc\\\"][\\\"b\\\"])\\n\",\n \" gpt.trf_blocks[b].ff.layers[2].weight = assign(\\n\",\n \" gpt.trf_blocks[b].ff.layers[2].weight, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"mlp\\\"][\\\"c_proj\\\"][\\\"w\\\"].T)\\n\",\n \" gpt.trf_blocks[b].ff.layers[2].bias = assign(\\n\",\n \" gpt.trf_blocks[b].ff.layers[2].bias, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"mlp\\\"][\\\"c_proj\\\"][\\\"b\\\"])\\n\",\n \"\\n\",\n \" gpt.trf_blocks[b].norm1.scale = assign(\\n\",\n \" gpt.trf_blocks[b].norm1.scale, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"ln_1\\\"][\\\"g\\\"])\\n\",\n \" gpt.trf_blocks[b].norm1.shift = assign(\\n\",\n \" gpt.trf_blocks[b].norm1.shift, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"ln_1\\\"][\\\"b\\\"])\\n\",\n \" gpt.trf_blocks[b].norm2.scale = assign(\\n\",\n \" gpt.trf_blocks[b].norm2.scale, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"ln_2\\\"][\\\"g\\\"])\\n\",\n \" gpt.trf_blocks[b].norm2.shift = assign(\\n\",\n \" gpt.trf_blocks[b].norm2.shift, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"ln_2\\\"][\\\"b\\\"])\\n\",\n \"\\n\",\n \" gpt.final_norm.scale = assign(gpt.final_norm.scale, params[\\\"g\\\"])\\n\",\n \" gpt.final_norm.shift = assign(gpt.final_norm.shift, params[\\\"b\\\"])\\n\",\n \" gpt.out_head.weight = assign(gpt.out_head.weight, params[\\\"wte\\\"])\\n\",\n \" \\n\",\n \" \\n\",\n \"load_weights_into_gpt(gpt, params)\\n\",\n \"gpt.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4f7472cb-54dc-4311-96d8-b2694f885cee\",\n \"metadata\": {},\n \"source\": [\n \"- If the model is loaded correctly, we can use it to generate new text using our previous `generate` function:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 56,\n \"id\": \"1f690253-f845-4347-b7b6-43fabbd2affa\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort moves you toward finding an ideal new way to practice something!\\n\",\n \"\\n\",\n \"What makes us want to be on top of that?\\n\",\n \"\\n\",\n \"\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=gpt,\\n\",\n \" idx=text_to_token_ids(\\\"Every effort moves you\\\", tokenizer).to(device),\\n\",\n \" max_new_tokens=25,\\n\",\n \" context_size=NEW_CONFIG[\\\"context_length\\\"],\\n\",\n \" top_k=50,\\n\",\n \" temperature=1.5\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6d079f98-a7c4-462e-8416-5a64f670861c\",\n \"metadata\": {},\n \"source\": [\n \"- We know that we loaded the model weights correctly because the model can generate coherent text; if we made even a small mistake, the model would not be able to do that\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"28493b9b-a1ae-4f31-87bc-c10ee4447f44\",\n \"metadata\": {},\n \"source\": [\n \"- For an alternative way to load the weights from the Hugging Face Hub, see [../02_alternative_weight_loading](../02_alternative_weight_loading)\\n\",\n \"- If you are interested in seeing how the GPT architecture compares to the Llama architecture (a popular LLM developed by Meta AI), see the bonus content at [../07_gpt_to_llama](../07_gpt_to_llama)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f2a66474-230d-4180-a8ff-843e04f1f1c4\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## Summary and takeaways\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fc7ed189-a633-458c-bf12-4f70b42684b8\",\n \"metadata\": {},\n \"source\": [\n \"- See the [./gpt_train.py](./gpt_train.py) script, a self-contained script for training\\n\",\n \"- The [./gpt_generate.py](./gpt_generate.py) script loads pretrained weights from OpenAI and generates text based on a prompt\\n\",\n \"- You can find the exercise solutions in [./exercise-solutions.ipynb](./exercise-solutions.ipynb)\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"machine_shape\": \"hm\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/01_main-chapter-code/exercise-solutions.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba450fb1-8a26-4894-ab7a-5d7bfefe90ce\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ea6e5076-f08d-41fc-bd8b-1cfe53538f41\",\n \"metadata\": {},\n \"source\": [\n \"- Above, we loaded the 124M GPT-2 model weights into Python, however we still need to transfer them into our `GPTModel` instance\\n\",\n \"- First, we initialize a new GPTModel instance\\n\",\n \"- Note that the original GPT model initialized the linear layers for the query, key, and value matrices in the multi-head attention module with bias vectors, which is not required or recommended; however, to be able to load the weights correctly, we have to enable these too by setting `qkv_bias` to `True` in our implementation, too\\n\",\n \"- We are also using the `1024` token context length that was used by the original GPT-2 model(s)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 53,\n \"id\": \"9fef90dd-0654-4667-844f-08e28339ef7d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Define model configurations in a dictionary for compactness\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"# Copy the base configuration and update with specific model settings\\n\",\n \"model_name = \\\"gpt2-small (124M)\\\" # Example model name\\n\",\n \"NEW_CONFIG = GPT_CONFIG_124M.copy()\\n\",\n \"NEW_CONFIG.update(model_configs[model_name])\\n\",\n \"NEW_CONFIG.update({\\\"context_length\\\": 1024, \\\"qkv_bias\\\": True})\\n\",\n \"\\n\",\n \"gpt = GPTModel(NEW_CONFIG)\\n\",\n \"gpt.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"272f29ac-8342-4b3d-a57d-9b0166ced314\",\n \"metadata\": {},\n \"source\": [\n \"- The next task is to assign the OpenAI weights to the corresponding weight tensors in our `GPTModel` instance\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 54,\n \"id\": \"f9a92229-c002-49a6-8cfb-248297ad8296\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def assign(left, right):\\n\",\n \" if left.shape != right.shape:\\n\",\n \" raise ValueError(f\\\"Shape mismatch. Left: {left.shape}, Right: {right.shape}\\\")\\n\",\n \" return torch.nn.Parameter(torch.tensor(right))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 55,\n \"id\": \"f22d5d95-ca5a-425c-a9ec-fc432a12d4e9\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import numpy as np\\n\",\n \"\\n\",\n \"def load_weights_into_gpt(gpt, params):\\n\",\n \" gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])\\n\",\n \" gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])\\n\",\n \" \\n\",\n \" for b in range(len(params[\\\"blocks\\\"])):\\n\",\n \" q_w, k_w, v_w = np.split(\\n\",\n \" (params[\\\"blocks\\\"][b][\\\"attn\\\"][\\\"c_attn\\\"])[\\\"w\\\"], 3, axis=-1)\\n\",\n \" gpt.trf_blocks[b].att.W_query.weight = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_query.weight, q_w.T)\\n\",\n \" gpt.trf_blocks[b].att.W_key.weight = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_key.weight, k_w.T)\\n\",\n \" gpt.trf_blocks[b].att.W_value.weight = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_value.weight, v_w.T)\\n\",\n \"\\n\",\n \" q_b, k_b, v_b = np.split(\\n\",\n \" (params[\\\"blocks\\\"][b][\\\"attn\\\"][\\\"c_attn\\\"])[\\\"b\\\"], 3, axis=-1)\\n\",\n \" gpt.trf_blocks[b].att.W_query.bias = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_query.bias, q_b)\\n\",\n \" gpt.trf_blocks[b].att.W_key.bias = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_key.bias, k_b)\\n\",\n \" gpt.trf_blocks[b].att.W_value.bias = assign(\\n\",\n \" gpt.trf_blocks[b].att.W_value.bias, v_b)\\n\",\n \"\\n\",\n \" gpt.trf_blocks[b].att.out_proj.weight = assign(\\n\",\n \" gpt.trf_blocks[b].att.out_proj.weight, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"attn\\\"][\\\"c_proj\\\"][\\\"w\\\"].T)\\n\",\n \" gpt.trf_blocks[b].att.out_proj.bias = assign(\\n\",\n \" gpt.trf_blocks[b].att.out_proj.bias, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"attn\\\"][\\\"c_proj\\\"][\\\"b\\\"])\\n\",\n \"\\n\",\n \" gpt.trf_blocks[b].ff.layers[0].weight = assign(\\n\",\n \" gpt.trf_blocks[b].ff.layers[0].weight, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"mlp\\\"][\\\"c_fc\\\"][\\\"w\\\"].T)\\n\",\n \" gpt.trf_blocks[b].ff.layers[0].bias = assign(\\n\",\n \" gpt.trf_blocks[b].ff.layers[0].bias, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"mlp\\\"][\\\"c_fc\\\"][\\\"b\\\"])\\n\",\n \" gpt.trf_blocks[b].ff.layers[2].weight = assign(\\n\",\n \" gpt.trf_blocks[b].ff.layers[2].weight, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"mlp\\\"][\\\"c_proj\\\"][\\\"w\\\"].T)\\n\",\n \" gpt.trf_blocks[b].ff.layers[2].bias = assign(\\n\",\n \" gpt.trf_blocks[b].ff.layers[2].bias, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"mlp\\\"][\\\"c_proj\\\"][\\\"b\\\"])\\n\",\n \"\\n\",\n \" gpt.trf_blocks[b].norm1.scale = assign(\\n\",\n \" gpt.trf_blocks[b].norm1.scale, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"ln_1\\\"][\\\"g\\\"])\\n\",\n \" gpt.trf_blocks[b].norm1.shift = assign(\\n\",\n \" gpt.trf_blocks[b].norm1.shift, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"ln_1\\\"][\\\"b\\\"])\\n\",\n \" gpt.trf_blocks[b].norm2.scale = assign(\\n\",\n \" gpt.trf_blocks[b].norm2.scale, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"ln_2\\\"][\\\"g\\\"])\\n\",\n \" gpt.trf_blocks[b].norm2.shift = assign(\\n\",\n \" gpt.trf_blocks[b].norm2.shift, \\n\",\n \" params[\\\"blocks\\\"][b][\\\"ln_2\\\"][\\\"b\\\"])\\n\",\n \"\\n\",\n \" gpt.final_norm.scale = assign(gpt.final_norm.scale, params[\\\"g\\\"])\\n\",\n \" gpt.final_norm.shift = assign(gpt.final_norm.shift, params[\\\"b\\\"])\\n\",\n \" gpt.out_head.weight = assign(gpt.out_head.weight, params[\\\"wte\\\"])\\n\",\n \" \\n\",\n \" \\n\",\n \"load_weights_into_gpt(gpt, params)\\n\",\n \"gpt.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4f7472cb-54dc-4311-96d8-b2694f885cee\",\n \"metadata\": {},\n \"source\": [\n \"- If the model is loaded correctly, we can use it to generate new text using our previous `generate` function:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 56,\n \"id\": \"1f690253-f845-4347-b7b6-43fabbd2affa\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort moves you toward finding an ideal new way to practice something!\\n\",\n \"\\n\",\n \"What makes us want to be on top of that?\\n\",\n \"\\n\",\n \"\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=gpt,\\n\",\n \" idx=text_to_token_ids(\\\"Every effort moves you\\\", tokenizer).to(device),\\n\",\n \" max_new_tokens=25,\\n\",\n \" context_size=NEW_CONFIG[\\\"context_length\\\"],\\n\",\n \" top_k=50,\\n\",\n \" temperature=1.5\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6d079f98-a7c4-462e-8416-5a64f670861c\",\n \"metadata\": {},\n \"source\": [\n \"- We know that we loaded the model weights correctly because the model can generate coherent text; if we made even a small mistake, the model would not be able to do that\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"28493b9b-a1ae-4f31-87bc-c10ee4447f44\",\n \"metadata\": {},\n \"source\": [\n \"- For an alternative way to load the weights from the Hugging Face Hub, see [../02_alternative_weight_loading](../02_alternative_weight_loading)\\n\",\n \"- If you are interested in seeing how the GPT architecture compares to the Llama architecture (a popular LLM developed by Meta AI), see the bonus content at [../07_gpt_to_llama](../07_gpt_to_llama)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f2a66474-230d-4180-a8ff-843e04f1f1c4\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## Summary and takeaways\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fc7ed189-a633-458c-bf12-4f70b42684b8\",\n \"metadata\": {},\n \"source\": [\n \"- See the [./gpt_train.py](./gpt_train.py) script, a self-contained script for training\\n\",\n \"- The [./gpt_generate.py](./gpt_generate.py) script loads pretrained weights from OpenAI and generates text based on a prompt\\n\",\n \"- You can find the exercise solutions in [./exercise-solutions.ipynb](./exercise-solutions.ipynb)\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"machine_shape\": \"hm\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/01_main-chapter-code/exercise-solutions.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba450fb1-8a26-4894-ab7a-5d7bfefe90ce\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \n\n\n \n### Using Llama 3.2 via the `llms-from-scratch` package\n\nFor an easy way to use the Llama 3.2 1B and 3B models, you can also use the `llms-from-scratch` PyPI package based on the source code in this repository at [pkg/llms_from_scratch](../../pkg/llms_from_scratch).\n\n \n#### 1) Installation\n\n```bash\npip install llms_from_scratch blobfile\n```\n\n(Note that `blobfile` is needed to load the tokenizer.)\n\n \n#### 2) Model and text generation settings\n\nSpecify which model to use:\n\n```python\nMODEL_FILE = \"llama3.2-1B-instruct.pth\"\n# MODEL_FILE = \"llama3.2-1B-base.pth\"\n# MODEL_FILE = \"llama3.2-3B-instruct.pth\"\n# MODEL_FILE = \"llama3.2-3B-base.pth\"\n```\n\nBasic text generation settings that can be defined by the user. Note that the recommended 8192-token context size requires approximately 3 GB of VRAM for the text generation example.\n\n```python\n# Text generation settings\nif \"instruct\" in MODEL_FILE:\n PROMPT = \"What do llamas eat?\"\nelse:\n PROMPT = \"Llamas eat\"\n\nMAX_NEW_TOKENS = 150\nTEMPERATURE = 0.\nTOP_K = 1\n```\n\n \n#### 3) Weight download and loading\n\nThis automatically downloads the weight file based on the model choice above:\n\n```python\nimport os\nimport requests\n\nurl = f\"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{MODEL_FILE}\"\n\nif not os.path.exists(MODEL_FILE):\n response = requests.get(url, stream=True, timeout=60)\n response.raise_for_status()\n with open(MODEL_FILE, \"wb\") as f:\n for chunk in response.iter_content(chunk_size=8192):\n if chunk:\n f.write(chunk)\n print(f\"Downloaded to {MODEL_FILE}\")\n```\n\nThe model weights are then loaded as follows:\n\n```python\nimport torch\nfrom llms_from_scratch.llama3 import Llama3Model\n\nif \"1B\" in MODEL_FILE:\n from llms_from_scratch.llama3 import LLAMA32_CONFIG_1B as LLAMA32_CONFIG\nelif \"3B\" in MODEL_FILE:\n from llms_from_scratch.llama3 import LLAMA32_CONFIG_3B as LLAMA32_CONFIG\nelse:\n raise ValueError(\"Incorrect model file name\")\n\nmodel = Llama3Model(LLAMA32_CONFIG)\nmodel.load_state_dict(torch.load(MODEL_FILE, weights_only=True, map_location=\"cpu\"))\n\ndevice = (\n torch.device(\"cuda\") if torch.cuda.is_available() else\n torch.device(\"mps\") if torch.backends.mps.is_available() else\n torch.device(\"cpu\")\n)\nmodel.to(device)\n```\n\n \n#### 4) Initialize tokenizer\n\nThe following code downloads and initializes the tokenizer:\n\n```python\nfrom llms_from_scratch.llama3 import Llama3Tokenizer, ChatFormat, clean_text\n\nTOKENIZER_FILE = \"tokenizer.model\"\n\nurl = f\"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{TOKENIZER_FILE}\"\n\nif not os.path.exists(TOKENIZER_FILE):\n urllib.request.urlretrieve(url, TOKENIZER_FILE)\n print(f\"Downloaded to {TOKENIZER_FILE}\")\n \ntokenizer = Llama3Tokenizer(\"tokenizer.model\")\n\nif \"instruct\" in MODEL_FILE:\n tokenizer = ChatFormat(tokenizer)\n```\n\n \n#### 5) Generating text\n\nLastly, we can generate text via the following code:\n\n```python\nimport time\n\nfrom llms_from_scratch.ch05 import (\n generate,\n text_to_token_ids,\n token_ids_to_text\n)\n\ntorch.manual_seed(123)\n\nstart = time.time()\n\ntoken_ids = generate(\n model=model,\n idx=text_to_token_ids(PROMPT, tokenizer).to(device),\n max_new_tokens=MAX_NEW_TOKENS,\n context_size=LLAMA32_CONFIG[\"context_length\"],\n top_k=TOP_K,\n temperature=TEMPERATURE\n)\n\ntotal_time = time.time() - start\nprint(f\"Time: {total_time:.2f} sec\")\nprint(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n\nif torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\noutput_text = token_ids_to_text(token_ids, tokenizer)\n\nif \"instruct\" in MODEL_FILE:\n output_text = clean_text(output_text)\n\nprint(\"\\n\\nOutput text:\\n\\n\", output_text)\n```\n\nWhen using the Llama 3.2 1B Instruct model, the output should look similar to the one shown below:\n\n```\nTime: 3.17 sec\n50 tokens/sec\nMax memory allocated: 2.91 GB\n\n\nOutput text:\n\n Llamas are herbivores, which means they primarily eat plants. Their diet consists mainly of:\n\n1. Grasses: Llamas love to graze on various types of grasses, including tall grasses and grassy meadows.\n2. Hay: Llamas also eat hay, which is a dry, compressed form of grass or other plants.\n3. Alfalfa: Alfalfa is a legume that is commonly used as a hay substitute in llama feed.\n4. Other plants: Llamas will also eat other plants, such as clover, dandelions, and wild grasses.\n\nIt's worth noting that the specific diet of llamas can vary depending on factors such as the breed,\n```\n\n \n#### Pro tip 1: speed up inference with FlashAttention\n\nInstead of using `Llama3Model`, you can use `Llama3ModelFast` as a drop-in replacement. For more information, I encourage you to inspect the [pkg/llms_from_scratch/llama3.py](../../pkg/llms_from_scratch/llama3.py) code.\n\nThe `Llama3ModelFast` replaces my from-scratch scaled dot-product code in the `GroupedQueryAttention` module with PyTorch's `scaled_dot_product` function, which uses `FlashAttention` on Ampere GPUs or newer.\n\nThe following table shows a performance comparison on an A100:\n\n| | Tokens/sec | Memory |\n| --------------- | ---------- | ------- |\n| Llama3Model | 42 | 2.91 GB |\n| Llama3ModelFast | 54 | 2.91 GB |\n\n \n#### Pro tip 2: speed up inference with compilation\n\n\nFor up to a 4× speed-up, replace\n\n```python\nmodel.to(device)\n```\n\nwith\n\n```python\nmodel = torch.compile(model)\nmodel.to(device)\n```\n\nNote: There is a significant multi-minute upfront cost when compiling, and the speed-up takes effect after the first `generate` call. \n\nThe following table shows a performance comparison on an A100 for consequent `generate` calls:\n\n| | Tokens/sec | Memory |\n| --------------- | ---------- | ------- |\n| Llama3Model | 170 | 3.12 GB |\n| Llama3ModelFast | 177 | 3.61 GB |\n\n \n#### Pro tip 3: speed up inference with compilation\n\nYou can significantly boost inference performance using the KV cache `Llama3Model` drop-in replacement when running the model on a CPU. (See my [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) article to learn more about KV caches.)\n\n```python\nfrom llms_from_scratch.kv_cache.llama3 import Llama3Model\nfrom llms_from_scratch.kv_cache.generate import generate_text_simple\n\nmodel = Llama3Model(LLAMA32_CONFIG)\n# ...\ntoken_ids = generate_text_simple(\n model=model,\n idx=text_to_token_ids(PROMPT, tokenizer).to(device),\n max_new_tokens=MAX_NEW_TOKENS,\n context_size=LLAMA32_CONFIG[\"context_length\"],\n)\n```\n\nNote that the peak memory usage is only listed for Nvidia CUDA devices, as it is easier to calculate. However, the memory usage on other devices is likely similar as it uses a similar precision format, and the KV cache storage results in even lower memory usage here for the generated 150-token text (however, different devices may implement matrix multiplication differently and may result in different peak memory requirements; and KV-cache memory may increase prohibitively for longer contexts lengths).\n\n| Model | Mode | Hardware | Tokens/sec | GPU Memory (VRAM) |\n| ----------- | ----------------- | --------------- | ---------- | ----------------- |\n| Llama3Model | Regular | Mac Mini M4 CPU | 1 | - |\n| Llama3Model | Regular compiled | Mac Mini M4 CPU | 1 | - |\n| Llama3Model | KV cache | Mac Mini M4 CPU | 68 | - |\n| Llama3Model | KV cache compiled | Mac Mini M4 CPU | 86 | - |\n| | | | | |\n| Llama3Model | Regular | Mac Mini M4 GPU | 15 | - |\n| Llama3Model | Regular compiled | Mac Mini M4 GPU | Error | - |\n| Llama3Model | KV cache | Mac Mini M4 GPU | 62 | - |\n| Llama3Model | KV cache compiled | Mac Mini M4 GPU | Error | - |\n| | | | | |\n| Llama3Model | Regular | Nvidia A100 GPU | 42 | 2.91 GB |\n| Llama3Model | Regular compiled | Nvidia A100 GPU | 170 | 3.12 GB |\n| Llama3Model | KV cache | Nvidia A100 GPU | 58 | 2.87 GB |\n| Llama3Model | KV cache compiled | Nvidia A100 GPU | 161 | 3.61 GB |\n\nNote that all settings above have been tested to produce the same text outputs.\n"
},
{
"path": "ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0_xya1nyDHfY\",\n \"metadata\": {\n \"id\": \"0_xya1nyDHfY\"\n },\n \"source\": [\n \"
\n\n\n \n### Using Llama 3.2 via the `llms-from-scratch` package\n\nFor an easy way to use the Llama 3.2 1B and 3B models, you can also use the `llms-from-scratch` PyPI package based on the source code in this repository at [pkg/llms_from_scratch](../../pkg/llms_from_scratch).\n\n \n#### 1) Installation\n\n```bash\npip install llms_from_scratch blobfile\n```\n\n(Note that `blobfile` is needed to load the tokenizer.)\n\n \n#### 2) Model and text generation settings\n\nSpecify which model to use:\n\n```python\nMODEL_FILE = \"llama3.2-1B-instruct.pth\"\n# MODEL_FILE = \"llama3.2-1B-base.pth\"\n# MODEL_FILE = \"llama3.2-3B-instruct.pth\"\n# MODEL_FILE = \"llama3.2-3B-base.pth\"\n```\n\nBasic text generation settings that can be defined by the user. Note that the recommended 8192-token context size requires approximately 3 GB of VRAM for the text generation example.\n\n```python\n# Text generation settings\nif \"instruct\" in MODEL_FILE:\n PROMPT = \"What do llamas eat?\"\nelse:\n PROMPT = \"Llamas eat\"\n\nMAX_NEW_TOKENS = 150\nTEMPERATURE = 0.\nTOP_K = 1\n```\n\n \n#### 3) Weight download and loading\n\nThis automatically downloads the weight file based on the model choice above:\n\n```python\nimport os\nimport requests\n\nurl = f\"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{MODEL_FILE}\"\n\nif not os.path.exists(MODEL_FILE):\n response = requests.get(url, stream=True, timeout=60)\n response.raise_for_status()\n with open(MODEL_FILE, \"wb\") as f:\n for chunk in response.iter_content(chunk_size=8192):\n if chunk:\n f.write(chunk)\n print(f\"Downloaded to {MODEL_FILE}\")\n```\n\nThe model weights are then loaded as follows:\n\n```python\nimport torch\nfrom llms_from_scratch.llama3 import Llama3Model\n\nif \"1B\" in MODEL_FILE:\n from llms_from_scratch.llama3 import LLAMA32_CONFIG_1B as LLAMA32_CONFIG\nelif \"3B\" in MODEL_FILE:\n from llms_from_scratch.llama3 import LLAMA32_CONFIG_3B as LLAMA32_CONFIG\nelse:\n raise ValueError(\"Incorrect model file name\")\n\nmodel = Llama3Model(LLAMA32_CONFIG)\nmodel.load_state_dict(torch.load(MODEL_FILE, weights_only=True, map_location=\"cpu\"))\n\ndevice = (\n torch.device(\"cuda\") if torch.cuda.is_available() else\n torch.device(\"mps\") if torch.backends.mps.is_available() else\n torch.device(\"cpu\")\n)\nmodel.to(device)\n```\n\n \n#### 4) Initialize tokenizer\n\nThe following code downloads and initializes the tokenizer:\n\n```python\nfrom llms_from_scratch.llama3 import Llama3Tokenizer, ChatFormat, clean_text\n\nTOKENIZER_FILE = \"tokenizer.model\"\n\nurl = f\"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{TOKENIZER_FILE}\"\n\nif not os.path.exists(TOKENIZER_FILE):\n urllib.request.urlretrieve(url, TOKENIZER_FILE)\n print(f\"Downloaded to {TOKENIZER_FILE}\")\n \ntokenizer = Llama3Tokenizer(\"tokenizer.model\")\n\nif \"instruct\" in MODEL_FILE:\n tokenizer = ChatFormat(tokenizer)\n```\n\n \n#### 5) Generating text\n\nLastly, we can generate text via the following code:\n\n```python\nimport time\n\nfrom llms_from_scratch.ch05 import (\n generate,\n text_to_token_ids,\n token_ids_to_text\n)\n\ntorch.manual_seed(123)\n\nstart = time.time()\n\ntoken_ids = generate(\n model=model,\n idx=text_to_token_ids(PROMPT, tokenizer).to(device),\n max_new_tokens=MAX_NEW_TOKENS,\n context_size=LLAMA32_CONFIG[\"context_length\"],\n top_k=TOP_K,\n temperature=TEMPERATURE\n)\n\ntotal_time = time.time() - start\nprint(f\"Time: {total_time:.2f} sec\")\nprint(f\"{int(len(token_ids[0])/total_time)} tokens/sec\")\n\nif torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\noutput_text = token_ids_to_text(token_ids, tokenizer)\n\nif \"instruct\" in MODEL_FILE:\n output_text = clean_text(output_text)\n\nprint(\"\\n\\nOutput text:\\n\\n\", output_text)\n```\n\nWhen using the Llama 3.2 1B Instruct model, the output should look similar to the one shown below:\n\n```\nTime: 3.17 sec\n50 tokens/sec\nMax memory allocated: 2.91 GB\n\n\nOutput text:\n\n Llamas are herbivores, which means they primarily eat plants. Their diet consists mainly of:\n\n1. Grasses: Llamas love to graze on various types of grasses, including tall grasses and grassy meadows.\n2. Hay: Llamas also eat hay, which is a dry, compressed form of grass or other plants.\n3. Alfalfa: Alfalfa is a legume that is commonly used as a hay substitute in llama feed.\n4. Other plants: Llamas will also eat other plants, such as clover, dandelions, and wild grasses.\n\nIt's worth noting that the specific diet of llamas can vary depending on factors such as the breed,\n```\n\n \n#### Pro tip 1: speed up inference with FlashAttention\n\nInstead of using `Llama3Model`, you can use `Llama3ModelFast` as a drop-in replacement. For more information, I encourage you to inspect the [pkg/llms_from_scratch/llama3.py](../../pkg/llms_from_scratch/llama3.py) code.\n\nThe `Llama3ModelFast` replaces my from-scratch scaled dot-product code in the `GroupedQueryAttention` module with PyTorch's `scaled_dot_product` function, which uses `FlashAttention` on Ampere GPUs or newer.\n\nThe following table shows a performance comparison on an A100:\n\n| | Tokens/sec | Memory |\n| --------------- | ---------- | ------- |\n| Llama3Model | 42 | 2.91 GB |\n| Llama3ModelFast | 54 | 2.91 GB |\n\n \n#### Pro tip 2: speed up inference with compilation\n\n\nFor up to a 4× speed-up, replace\n\n```python\nmodel.to(device)\n```\n\nwith\n\n```python\nmodel = torch.compile(model)\nmodel.to(device)\n```\n\nNote: There is a significant multi-minute upfront cost when compiling, and the speed-up takes effect after the first `generate` call. \n\nThe following table shows a performance comparison on an A100 for consequent `generate` calls:\n\n| | Tokens/sec | Memory |\n| --------------- | ---------- | ------- |\n| Llama3Model | 170 | 3.12 GB |\n| Llama3ModelFast | 177 | 3.61 GB |\n\n \n#### Pro tip 3: speed up inference with compilation\n\nYou can significantly boost inference performance using the KV cache `Llama3Model` drop-in replacement when running the model on a CPU. (See my [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) article to learn more about KV caches.)\n\n```python\nfrom llms_from_scratch.kv_cache.llama3 import Llama3Model\nfrom llms_from_scratch.kv_cache.generate import generate_text_simple\n\nmodel = Llama3Model(LLAMA32_CONFIG)\n# ...\ntoken_ids = generate_text_simple(\n model=model,\n idx=text_to_token_ids(PROMPT, tokenizer).to(device),\n max_new_tokens=MAX_NEW_TOKENS,\n context_size=LLAMA32_CONFIG[\"context_length\"],\n)\n```\n\nNote that the peak memory usage is only listed for Nvidia CUDA devices, as it is easier to calculate. However, the memory usage on other devices is likely similar as it uses a similar precision format, and the KV cache storage results in even lower memory usage here for the generated 150-token text (however, different devices may implement matrix multiplication differently and may result in different peak memory requirements; and KV-cache memory may increase prohibitively for longer contexts lengths).\n\n| Model | Mode | Hardware | Tokens/sec | GPU Memory (VRAM) |\n| ----------- | ----------------- | --------------- | ---------- | ----------------- |\n| Llama3Model | Regular | Mac Mini M4 CPU | 1 | - |\n| Llama3Model | Regular compiled | Mac Mini M4 CPU | 1 | - |\n| Llama3Model | KV cache | Mac Mini M4 CPU | 68 | - |\n| Llama3Model | KV cache compiled | Mac Mini M4 CPU | 86 | - |\n| | | | | |\n| Llama3Model | Regular | Mac Mini M4 GPU | 15 | - |\n| Llama3Model | Regular compiled | Mac Mini M4 GPU | Error | - |\n| Llama3Model | KV cache | Mac Mini M4 GPU | 62 | - |\n| Llama3Model | KV cache compiled | Mac Mini M4 GPU | Error | - |\n| | | | | |\n| Llama3Model | Regular | Nvidia A100 GPU | 42 | 2.91 GB |\n| Llama3Model | Regular compiled | Nvidia A100 GPU | 170 | 3.12 GB |\n| Llama3Model | KV cache | Nvidia A100 GPU | 58 | 2.87 GB |\n| Llama3Model | KV cache compiled | Nvidia A100 GPU | 161 | 3.61 GB |\n\nNote that all settings above have been tested to produce the same text outputs.\n"
},
{
"path": "ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0_xya1nyDHfY\",\n \"metadata\": {\n \"id\": \"0_xya1nyDHfY\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"JBpQwU89ETA1\",\n \"metadata\": {\n \"id\": \"JBpQwU89ETA1\"\n },\n \"source\": [\n \"- Packages that are being used in this notebook:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"34a9a440-84c2-42cc-808b-38677cb6af8a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"34a9a440-84c2-42cc-808b-38677cb6af8a\",\n \"outputId\": \"8118963b-3c72-43af-874b-439ffebdc94c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 0.33.2\\n\",\n \"sentencepiece version: 0.2.0\\n\",\n \"torch version: 2.6.0\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"sentencepiece\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"UJJneXpTEg4W\",\n \"metadata\": {\n \"id\": \"UJJneXpTEg4W\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Convert the GPT model implementation step by step\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"v1zpfX2GHBKa\",\n \"metadata\": {\n \"id\": \"v1zpfX2GHBKa\"\n },\n \"source\": [\n \"- In this section, we go through the GPT model code from [chapter 4](../../ch04/01_main-chapter-code/ch04.ipynb) and modify it step by step to implement the Llama 2 architecture\\n\",\n \"- Later, we load the original Llama 2 weights shared by Meta AI\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"979c7b6d-1370-4da1-8bfb-a2b27537bf2f\",\n \"metadata\": {\n \"id\": \"979c7b6d-1370-4da1-8bfb-a2b27537bf2f\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.1 Replace LayerNorm with RMSNorm layer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f8b27fc8-23a1-4e0e-a1ea-792e0428e5e6\",\n \"metadata\": {\n \"id\": \"f8b27fc8-23a1-4e0e-a1ea-792e0428e5e6\"\n },\n \"source\": [\n \"- First, we replace LayerNorm by Root Mean Square Layer Normalization (RMSNorm)\\n\",\n \"- LayerNorm normalizes inputs using mean and variance, while RMSNorm uses only the root mean square, which improves computational efficiency\\n\",\n \"- The RMSNorm operation is as follows, where $x$ is the input $\\\\gamma$ is a trainable parameter (vector), and $\\\\epsilon$ is a small constant to avoid zero-division errors:\\n\",\n \"\\n\",\n \"$$y_i = \\\\frac{x_i}{\\\\text{RMS}(x)} \\\\gamma_i, \\\\quad \\\\text{where} \\\\quad \\\\text{RMS}(x) = \\\\sqrt{\\\\epsilon + \\\\frac{1}{n} \\\\sum x_i^2}$$\\n\",\n \"\\n\",\n \"- For more details, please see the paper [Root Mean Square Layer Normalization (2019)](https://arxiv.org/abs/1910.07467)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"d7094381-9499-4e9e-93f9-b79470da3771\",\n \"metadata\": {\n \"id\": \"d7094381-9499-4e9e-93f9-b79470da3771\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"#####################################\\n\",\n \"# Chapter 4\\n\",\n \"#####################################\\n\",\n \"\\n\",\n \"# class LayerNorm(nn.Module):\\n\",\n \"# def __init__(self, emb_dim):\\n\",\n \"# super().__init__()\\n\",\n \"# self.eps = 1e-5\\n\",\n \"# self.scale = nn.Parameter(torch.ones(emb_dim))\\n\",\n \"# self.shift = nn.Parameter(torch.zeros(emb_dim))\\n\",\n \"\\n\",\n \"# def forward(self, x):\\n\",\n \"# mean = x.mean(dim=-1, keepdim=True)\\n\",\n \"# var = x.var(dim=-1, keepdim=True, unbiased=False)\\n\",\n \"# norm_x = (x - mean) / torch.sqrt(var + self.eps)\\n\",\n \"# return self.scale * norm_x + self.shift\\n\",\n \"\\n\",\n \"\\n\",\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-5):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" self.emb_dim = emb_dim\\n\",\n \" self.weight = nn.Parameter(torch.ones(emb_dim)).float()\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" means = x.pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x_normed = x * torch.rsqrt(means + self.eps)\\n\",\n \" return (x_normed * self.weight).to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"mtWC8DOmIu0F\",\n \"metadata\": {\n \"id\": \"mtWC8DOmIu0F\"\n },\n \"source\": [\n \"- The following code cell checks that this implementation works the same as PyTorch's built-in implementation:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"e41ade7a-bf06-48b1-8b7e-0e4037d5753f\",\n \"metadata\": {\n \"id\": \"e41ade7a-bf06-48b1-8b7e-0e4037d5753f\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"example_batch = torch.randn(2, 3, 4)\\n\",\n \"\\n\",\n \"rms_norm = RMSNorm(emb_dim=example_batch.shape[-1])\\n\",\n \"rmsnorm_pytorch = torch.nn.RMSNorm(example_batch.shape[-1], eps=1e-5)\\n\",\n \"\\n\",\n \"assert torch.allclose(rms_norm(example_batch), rmsnorm_pytorch(example_batch))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5eb81f83-c38c-46a4-b763-aa630a32e357\",\n \"metadata\": {\n \"id\": \"5eb81f83-c38c-46a4-b763-aa630a32e357\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.2 Replace GELU with SiLU activation\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b8aa702-f118-4ff6-9135-90725ec8756c\",\n \"metadata\": {\n \"id\": \"0b8aa702-f118-4ff6-9135-90725ec8756c\"\n },\n \"source\": [\n \"- Llama uses the SiLU activation function (instead of GELU), which is also known as the Swish function:\\n\",\n \"\\n\",\n \"$$\\n\",\n \"\\\\text{silu}(x) = x \\\\cdot \\\\sigma(x), \\\\quad \\\\text{where} \\\\quad \\\\sigma(x) \\\\text{ is the logistic sigmoid.}\\n\",\n \"$$\\n\",\n \"\\n\",\n \"- For more information, see the SiLU paper: [Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning (2017)](https://arxiv.org/abs/1702.03118)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"a74f3757-c634-4a3a-a8f3-6334cde454fe\",\n \"metadata\": {\n \"id\": \"a74f3757-c634-4a3a-a8f3-6334cde454fe\"\n },\n \"outputs\": [],\n \"source\": [\n \"#####################################\\n\",\n \"# Chapter 4\\n\",\n \"#####################################\\n\",\n \"\\n\",\n \"# class GELU(nn.Module):\\n\",\n \"# def __init__(self):\\n\",\n \"# super().__init__()\\n\",\n \"\\n\",\n \"# def forward(self, x):\\n\",\n \"# return 0.5 * x * (1 + torch.tanh(\\n\",\n \"# torch.sqrt(torch.tensor(2.0 / torch.pi)) *\\n\",\n \"# (x + 0.044715 * torch.pow(x, 3))\\n\",\n \"# ))\\n\",\n \"\\n\",\n \"\\n\",\n \"class SiLU(nn.Module):\\n\",\n \" def __init__(self):\\n\",\n \" super(SiLU, self).__init__()\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" return x * torch.sigmoid(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"72ecbe2e-b6b7-4319-972b-1a7fefa3368c\",\n \"metadata\": {\n \"id\": \"72ecbe2e-b6b7-4319-972b-1a7fefa3368c\"\n },\n \"outputs\": [],\n \"source\": [\n \"silu = SiLU()\\n\",\n \"\\n\",\n \"assert torch.allclose(silu(example_batch), torch.nn.functional.silu(example_batch))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4f9b5167-1da9-46c8-9964-8036b3b1deb9\",\n \"metadata\": {\n \"id\": \"4f9b5167-1da9-46c8-9964-8036b3b1deb9\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.3 Update the FeedForward module\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3a381e7a-b807-472e-91c9-3e4e3fc5ad91\",\n \"metadata\": {\n \"id\": \"3a381e7a-b807-472e-91c9-3e4e3fc5ad91\"\n },\n \"source\": [\n \"- In fact, Llama uses a \\\"Gates Linear Unit\\\" (GLU) variant of SiLU called SwiGLU, which essentially results in a slightly differently structured `FeedForward` module\\n\",\n \"- SwiGLU uses a gating mechanism in the feedforward layer, with the formula:\\n\",\n \"\\n\",\n \"$$\\\\text{SwiGLU}(x) = \\\\text{SiLU}(\\\\text{Linear}_1(x)) * (\\\\text{Linear}_2(x))$$\\n\",\n \"\\n\",\n \"- Here, $\\\\text{Linear}_1$ and $\\\\text{Linear}_2$ are two linear layers, and $*$ denotes element-wise multiplication\\n\",\n \"- The third linear layer, $\\\\text{Linear}_3$, is applied after this gated activation\\n\",\n \"\\n\",\n \"- For more information, see SwiGLU paper: [GLU Variants Improve Transformer (2020)](https://arxiv.org/abs/2002.05202)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"d25fbe3d-b7c9-4772-ad67-bc0527e4e20a\",\n \"metadata\": {\n \"id\": \"d25fbe3d-b7c9-4772-ad67-bc0527e4e20a\"\n },\n \"outputs\": [],\n \"source\": [\n \"#####################################\\n\",\n \"# Chapter 4\\n\",\n \"#####################################\\n\",\n \"# class FeedForward(nn.Module):\\n\",\n \"# def __init__(self, cfg):\\n\",\n \"# super().__init__()\\n\",\n \"# self.layers = nn.Sequential(\\n\",\n \"# nn.Linear(cfg[\\\"emb_dim\\\"], 4 * cfg[\\\"emb_dim\\\"]),\\n\",\n \"# GELU(),\\n\",\n \"# nn.Linear(4 * cfg[\\\"emb_dim\\\"], cfg[\\\"emb_dim\\\"]),\\n\",\n \"# )\\n\",\n \"\\n\",\n \"# def forward(self, x):\\n\",\n \"# return self.layers(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"477568cb-03cd-4510-b663-a42ce3ec64a2\",\n \"metadata\": {\n \"id\": \"477568cb-03cd-4510-b663-a42ce3ec64a2\"\n },\n \"outputs\": [],\n \"source\": [\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.silu = SiLU()\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = self.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"qcD8LSHNhBRW\",\n \"metadata\": {\n \"id\": \"qcD8LSHNhBRW\"\n },\n \"source\": [\n \"- Note that we also added a `dtype=cfg[\\\"dtype\\\"]` setting above, which will allow us to load the model directly in lower precision formats later to reduce memory usage (versus instantiating it in the original 32-bit precision format and then converting it)\\n\",\n \"- We also set `bias=False` since Llama doesn't use any bias units\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f6b7bf4f-99d0-42c1-807c-5074d2cc1949\",\n \"metadata\": {\n \"id\": \"f6b7bf4f-99d0-42c1-807c-5074d2cc1949\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.4 Implement RoPE\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d3487a6f-0373-49d8-b2eb-f8ee05d42884\",\n \"metadata\": {\n \"id\": \"d3487a6f-0373-49d8-b2eb-f8ee05d42884\"\n },\n \"source\": [\n \"- In the GPT model, the positional embeddings are implemented as follows:\\n\",\n \"\\n\",\n \"```python\\n\",\n \"self.pos_emb = nn.Embedding(cfg[\\\"context_length\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \"```\\n\",\n \"\\n\",\n \"- Unlike traditional absolute positional embeddings, Llama uses rotary position embeddings (RoPE), which enable it to capture both absolute and relative positional information simultaneously\\n\",\n \"- The reference paper for RoPE is [RoFormer: Enhanced Transformer with Rotary Position Embedding (2021)](https://arxiv.org/abs/2104.09864)\\n\",\n \"- RoPE can be implemented in two equivalent ways: the *split-halves* version and the *interleaved even/odd version*; they are mathematically the same as long as we pair dimensions consistently and use the same cos/sin ordering (see [this](https://github.com/rasbt/LLMs-from-scratch/issues/751) GitHub discussion for more information)\\n\",\n \"- This code uses the RoPE *split-halves* approach, similar to Hugging Face transformers ([modeling_llama.py](https://github.com/huggingface/transformers/blob/e42587f596181396e1c4b63660abf0c736b10dae/src/transformers/models/llama/modeling_llama.py#L173-L188))\\n\",\n \"- The original RoPE paper and Meta's official Llama 2 repository, however, use the *interleaved (even/odd)* version ([llama/model.py](https://github.com/meta-llama/llama/blob/6c7fe276574e78057f917549435a2554000a876d/llama/model.py#L64-L74)); but as mentioned earlier, they are equivalent\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"a34180fb-448f-44e9-a244-0c736051687b\",\n \"metadata\": {\n \"id\": \"a34180fb-448f-44e9-a244-0c736051687b\"\n },\n \"outputs\": [],\n \"source\": [\n \"def precompute_rope_params(head_dim, theta_base=10_000, context_length=4096):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2)[: (head_dim // 2)].float() / head_dim))\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Expand angles to match the head_dim\\n\",\n \" angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"def compute_rope(x, cos, sin):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8e841b8e-75aa-49db-b1a7-d5c2116dc299\",\n \"metadata\": {\n \"id\": \"8e841b8e-75aa-49db-b1a7-d5c2116dc299\"\n },\n \"source\": [\n \"- The following is an example of applying RoPE to the `q` and `k` tensors:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"8c89f022-7167-4001-8c21-8e012878733f\",\n \"metadata\": {\n \"id\": \"8c89f022-7167-4001-8c21-8e012878733f\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Settings\\n\",\n \"batch_size = 2\\n\",\n \"context_len = 5\\n\",\n \"num_heads = 4\\n\",\n \"head_dim = 16\\n\",\n \"\\n\",\n \"# Instantiate RoPE parameters\\n\",\n \"cos, sin = precompute_rope_params(head_dim=head_dim, context_length=context_len)\\n\",\n \"\\n\",\n \"# Dummy query and key tensors\\n\",\n \"torch.manual_seed(123)\\n\",\n \"queries = torch.randn(batch_size, num_heads, context_len, head_dim)\\n\",\n \"keys = torch.randn(batch_size, num_heads, context_len, head_dim)\\n\",\n \"\\n\",\n \"# Apply rotary position embeddings\\n\",\n \"queries_rot = compute_rope(queries, cos, sin)\\n\",\n \"keys_rot = compute_rope(keys, cos, sin)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f78127b0-dda2-4c5a-98dd-bae8f5fe8297\",\n \"metadata\": {\n \"id\": \"f78127b0-dda2-4c5a-98dd-bae8f5fe8297\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.5 Add RoPE to MultiHeadAttention module\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"RnmSHROLhhR3\",\n \"metadata\": {\n \"id\": \"RnmSHROLhhR3\"\n },\n \"source\": [\n \"- It's important to note that GPT applies the positional embeddings to the inputs, whereas Llama applies rotations to the query and key vectors in the self-attention mechanism itself\\n\",\n \"- Here, we modify the `MultiHeadAttention` class with the appropriate RoPE code\\n\",\n \"- In addition, we remove the `qkv_bias` option and hardcode the `bias=False` setting\\n\",\n \"- Also, we add a dtype setting to be able to instantiate the model with a lower precision later\\n\",\n \" - Tip: since the `TransformerBlock`s (in the next section) are repeated exactly, we could simplify the code and only initialize the buffers once instead for each `MultiHeadAttention` module; however, we add the precomputed RoPE parameters to the `MultiHeadAttention` class so that it can function as a standalone module\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"d81a441e-0b79-4a8b-8291-ea7f55d58c84\",\n \"metadata\": {\n \"id\": \"d81a441e-0b79-4a8b-8291-ea7f55d58c84\"\n },\n \"outputs\": [],\n \"source\": [\n \"#####################################\\n\",\n \"# Chapter 3\\n\",\n \"#####################################\\n\",\n \"class MultiHeadAttention(nn.Module):\\n\",\n \" def __init__(self, d_in, d_out, context_length, num_heads, dtype=None): # ,dropout, num_heads, qkv_bias=False):\\n\",\n \" super().__init__()\\n\",\n \" assert d_out % num_heads == 0, \\\"d_out must be divisible by n_heads\\\"\\n\",\n \"\\n\",\n \" self.d_out = d_out\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\\n\",\n \"\\n\",\n \" ################################### NEW ###################################\\n\",\n \" # Set bias=False and dtype=dtype for all linear layers below\\n\",\n \" ###########################################################################\\n\",\n \" self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype) # Linear layer to combine head outputs\\n\",\n \" # self.dropout = nn.Dropout(dropout)\\n\",\n \" self.register_buffer(\\\"mask\\\", torch.triu(torch.ones(context_length, context_length), diagonal=1))\\n\",\n \"\\n\",\n \" ################################### NEW ###################################\\n\",\n \" cos, sin = precompute_rope_params(head_dim=self.head_dim, context_length=context_length)\\n\",\n \" self.register_buffer(\\\"cos\\\", cos)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin)\\n\",\n \" ###########################################################################\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \"\\n\",\n \" b, num_tokens, d_in = x.shape\\n\",\n \"\\n\",\n \" keys = self.W_key(x) # Shape: (b, num_tokens, d_out)\\n\",\n \" queries = self.W_query(x)\\n\",\n \" values = self.W_value(x)\\n\",\n \"\\n\",\n \" # We implicitly split the matrix by adding a `num_heads` dimension\\n\",\n \" # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" values = values.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \"\\n\",\n \" # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\\n\",\n \" keys = keys.transpose(1, 2)\\n\",\n \" queries = queries.transpose(1, 2)\\n\",\n \" values = values.transpose(1, 2)\\n\",\n \"\\n\",\n \" ################################### NEW ###################################\\n\",\n \" keys = compute_rope(keys, self.cos, self.sin)\\n\",\n \" queries = compute_rope(queries, self.cos, self.sin)\\n\",\n \" ###########################################################################\\n\",\n \"\\n\",\n \" # Compute scaled dot-product attention (aka self-attention) with a causal mask\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\\n\",\n \"\\n\",\n \" # Original mask truncated to the number of tokens and converted to boolean\\n\",\n \" mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\\n\",\n \"\\n\",\n \" # Use the mask to fill attention scores\\n\",\n \" attn_scores.masked_fill_(mask_bool, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\\n\",\n \" # attn_weights = self.dropout(attn_weights)\\n\",\n \"\\n\",\n \" # Shape: (b, num_tokens, num_heads, head_dim)\\n\",\n \" context_vec = (attn_weights @ values).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Combine heads, where self.d_out = self.num_heads * self.head_dim\\n\",\n \" context_vec = context_vec.reshape(b, num_tokens, self.d_out)\\n\",\n \" context_vec = self.out_proj(context_vec) # optional projection\\n\",\n \"\\n\",\n \" return context_vec\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"-lt9SfnVioB3\",\n \"metadata\": {\n \"id\": \"-lt9SfnVioB3\"\n },\n \"source\": [\n \"- Below is an example using the `MultiHeadAttention` module on an example input:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"03f15755-0083-483f-963b-99b599651638\",\n \"metadata\": {\n \"id\": \"03f15755-0083-483f-963b-99b599651638\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Settings\\n\",\n \"batch_size = 1\\n\",\n \"context_len = 100\\n\",\n \"max_context_len = 4096\\n\",\n \"embed_dim = 128\\n\",\n \"num_heads = 4\\n\",\n \"\\n\",\n \"\\n\",\n \"example_batch = torch.randn((batch_size, context_len, embed_dim))\\n\",\n \"\\n\",\n \"mha = MultiHeadAttention(\\n\",\n \" d_in=embed_dim,\\n\",\n \" d_out=embed_dim,\\n\",\n \" context_length=max_context_len,\\n\",\n \" num_heads=num_heads\\n\",\n \")\\n\",\n \"\\n\",\n \"mha(example_batch)\\n\",\n \"\\n\",\n \"del mha # delete to free up memory\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e5a1a272-a038-4b8f-aaaa-f4b241e7f23f\",\n \"metadata\": {\n \"id\": \"e5a1a272-a038-4b8f-aaaa-f4b241e7f23f\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.6 Update the TransformerBlock module\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"255f70ac-9c2e-4328-8af7-1c298b8d4a18\",\n \"metadata\": {\n \"id\": \"255f70ac-9c2e-4328-8af7-1c298b8d4a18\"\n },\n \"source\": [\n \"- At this stage, most of the hard work is already done; we can now update the `TransformerBlock` to use the code we implemented above\\n\",\n \"- This means we\\n\",\n \" - replace LayerNorm with RMSNorm\\n\",\n \" - remove dropout\\n\",\n \" - remove the `qkv_bias` setting\\n\",\n \" - add the `dtype` setting\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"2e110721-bf2b-42b3-989a-1635b1658af0\",\n \"metadata\": {\n \"id\": \"2e110721-bf2b-42b3-989a-1635b1658af0\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.att = MultiHeadAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" d_out=cfg[\\\"emb_dim\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"] # NEW\\n\",\n \" # dropout=cfg[\\\"drop_rate\\\"],\\n\",\n \" # qkv_bias=cfg[\\\"qkv_bias\\\"]\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \"\\n\",\n \" ################################### NEW ###################################\\n\",\n \" # self.norm1 = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" # self.norm2 = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.norm1 = RMSNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.norm2 = RMSNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" ###########################################################################\\n\",\n \"\\n\",\n \" # self.drop_shortcut = nn.Dropout(cfg[\\\"drop_rate\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \" x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" # x = self.drop_shortcut(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" # Shortcut connection for feed-forward block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" # x = self.drop_shortcut(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ada953bc-e2c0-4432-a32d-3f7efa3f6e0f\",\n \"metadata\": {\n \"id\": \"ada953bc-e2c0-4432-a32d-3f7efa3f6e0f\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.7 Update the model class\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba5d991a-559b-47be-96f4-31b881ab2da8\",\n \"metadata\": {\n \"id\": \"ba5d991a-559b-47be-96f4-31b881ab2da8\"\n },\n \"source\": [\n \"- As you may recall from [chapter 5](../01_main-chapter-code/ch05.ipynb), the `TransformerBlock` is a repeated block within the main model\\n\",\n \"- Our Llama model is almost complete; we just have to update the model code surrounding the `TransformerBlock`\\n\",\n \"- This means we\\n\",\n \" - remove absolute positional embeddings since we have RoPE embeddings now\\n\",\n \" - replace LayerNorm with RMSNorm\\n\",\n \" - remove dropout\\n\",\n \" - add the dtype setting\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"cf8240fe-5d7f-4e7e-b1ac-e0755aab5e79\",\n \"metadata\": {\n \"id\": \"cf8240fe-5d7f-4e7e-b1ac-e0755aab5e79\"\n },\n \"outputs\": [],\n \"source\": [\n \"# class GPTModel(nn.Module):\\n\",\n \"class Llama2Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \" # self.pos_emb = nn.Embedding(cfg[\\\"context_length\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" # self.drop_emb = nn.Dropout(cfg[\\\"drop_rate\\\"])\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.Sequential(\\n\",\n \" *[TransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])])\\n\",\n \"\\n\",\n \" ################################### NEW ###################################\\n\",\n \" # self.final_norm = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" ###########################################################################\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" # batch_size, seq_len = in_idx.shape\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\\n\",\n \" x = tok_embeds # + pos_embeds # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" # x = self.drop_emb(x)\\n\",\n \" x = self.trf_blocks(x)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x)\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4bc94940-aaeb-45b9-9399-3a69b8043e60\",\n \"metadata\": {\n \"id\": \"4bc94940-aaeb-45b9-9399-3a69b8043e60\"\n },\n \"source\": [\n \" \\n\",\n \"## 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bG--zY-Ljj1f\",\n \"metadata\": {\n \"id\": \"bG--zY-Ljj1f\"\n },\n \"source\": [\n \"- The model code is now complete, and we are ready to initialize it\\n\",\n \"- In [chapter 5](../01_main-chapter-code/ch05.ipynb), we used the following config file to specify the 124M-parameter GPT model:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"4b7428df-3d02-4ccd-97b5-a629bdabbe8f\",\n \"metadata\": {\n \"id\": \"4b7428df-3d02-4ccd-97b5-a629bdabbe8f\"\n },\n \"outputs\": [],\n \"source\": [\n \"GPT_CONFIG_124M = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"emb_dim\\\": 768, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 12, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 12, # Number of layers\\n\",\n \" \\\"drop_rate\\\": 0.1, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": False # Query-Key-Value bias\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8bVi8uiBjw2T\",\n \"metadata\": {\n \"id\": \"8bVi8uiBjw2T\"\n },\n \"source\": [\n \"- For reference, the 1.5B parameter GPT model config is shown below as well:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"tAOojV_mkEnd\",\n \"metadata\": {\n \"id\": \"tAOojV_mkEnd\"\n },\n \"outputs\": [],\n \"source\": [\n \"GPT_CONFIG_1558M = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"emb_dim\\\": 1600, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 25, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 48, # Number of layers\\n\",\n \" \\\"drop_rate\\\": 0.1, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": False # Query-Key-Value bias\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"HoGGRAGykQTE\",\n \"metadata\": {\n \"id\": \"HoGGRAGykQTE\"\n },\n \"source\": [\n \"- Similarly, we can define a Llama 2 config file for the 7B model (we ignore the other larger models for simplicity here):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"e0564727-2d35-4f0c-b0fc-cde1e9134a18\",\n \"metadata\": {\n \"id\": \"e0564727-2d35-4f0c-b0fc-cde1e9134a18\"\n },\n \"outputs\": [],\n \"source\": [\n \"LLAMA2_CONFIG_7B = {\\n\",\n \" \\\"vocab_size\\\": 32000, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 4096, # Context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 11008, # NEW: Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"dtype\\\": torch.bfloat16 # NEW: Lower-precision dtype to reduce memory usage\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"FAP7fiBzkaBz\",\n \"metadata\": {\n \"id\": \"FAP7fiBzkaBz\"\n },\n \"source\": [\n \"- Using these settings, we can now initialize a Llama 2 7B model (note that this requires ~26 GB of memory)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"7004d785-ac9a-4df5-8760-6807fc604686\",\n \"metadata\": {\n \"id\": \"7004d785-ac9a-4df5-8760-6807fc604686\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = Llama2Model(LLAMA2_CONFIG_7B)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"6079f747-8f20-4c6b-8d38-7156f1101729\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6079f747-8f20-4c6b-8d38-7156f1101729\",\n \"outputId\": \"0a0eb34b-1a21-4c11-804f-b40007bda5a3\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters: 6,738,415,616\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters())\\n\",\n \"print(f\\\"Total number of parameters: {total_params:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"Bx14NtzWk2wj\",\n \"metadata\": {\n \"id\": \"Bx14NtzWk2wj\"\n },\n \"source\": [\n \"- As shown above, the model contains 6.7 billion parameters (commonly rounded and referred to as a 7B model)\\n\",\n \"- Additionally, we can calculate the memory requirements for this model using the code below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"0df1c79e-27a7-4b0f-ba4e-167fe107125a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0df1c79e-27a7-4b0f-ba4e-167fe107125a\",\n \"outputId\": \"11ced939-556d-4511-d5c0-10a94ed3df32\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"float32 (PyTorch default): 52.33 GB\\n\",\n \"bfloat16: 26.17 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def calc_model_memory_size(model, input_dtype=torch.float32):\\n\",\n \" total_params = 0\\n\",\n \" total_grads = 0\\n\",\n \" for param in model.parameters():\\n\",\n \" # Calculate total number of elements per parameter\\n\",\n \" param_size = param.numel()\\n\",\n \" total_params += param_size\\n\",\n \" # Check if gradients are stored for this parameter\\n\",\n \" if param.requires_grad:\\n\",\n \" total_grads += param_size\\n\",\n \"\\n\",\n \" # Calculate buffer size (non-parameters that require memory)\\n\",\n \" total_buffers = sum(buf.numel() for buf in model.buffers())\\n\",\n \"\\n\",\n \" # Size in bytes = (Number of elements) * (Size of each element in bytes)\\n\",\n \" # We assume parameters and gradients are stored in the same type as input dtype\\n\",\n \" element_size = torch.tensor(0, dtype=input_dtype).element_size()\\n\",\n \" total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\\n\",\n \"\\n\",\n \" # Convert bytes to gigabytes\\n\",\n \" total_memory_gb = total_memory_bytes / (1024**3)\\n\",\n \"\\n\",\n \" return total_memory_gb\\n\",\n \"\\n\",\n \"print(f\\\"float32 (PyTorch default): {calc_model_memory_size(model, input_dtype=torch.float32):.2f} GB\\\")\\n\",\n \"print(f\\\"bfloat16: {calc_model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"zudd-5PulKFL\",\n \"metadata\": {\n \"id\": \"zudd-5PulKFL\"\n },\n \"source\": [\n \"- Lastly, we can also transfer the model to an NVIDIA or Apple Silicon GPU if applicable:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"a4c50e19-1402-45b6-8ccd-9077b2ba836d\",\n \"metadata\": {\n \"id\": \"a4c50e19-1402-45b6-8ccd-9077b2ba836d\"\n },\n \"outputs\": [],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5dc64a06-27dc-46ec-9e6d-1700a8227d34\",\n \"metadata\": {\n \"id\": \"5dc64a06-27dc-46ec-9e6d-1700a8227d34\"\n },\n \"source\": [\n \" \\n\",\n \"## 3. Load tokenizer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0eb30f0c-6144-4bed-87d9-6b2bac377005\",\n \"metadata\": {\n \"id\": \"0eb30f0c-6144-4bed-87d9-6b2bac377005\"\n },\n \"source\": [\n \"- In this section, we are going to load the tokenizer for the model\\n\",\n \"- Llama 2 uses Google's [SentencePiece](https://github.com/google/sentencepiece) tokenizer instead of OpenAI's [Tiktoken](https://github.com/openai/tiktoken) (but Llama 3 uses Tiktoken)\\n\",\n \"- Meta AI shared the original Llama 2 model weights and tokenizer vocabulary on the Hugging Face Hub\\n\",\n \"- We will download the tokenizer vocabulary from the Hub and load it into SentencePiece\\n\",\n \"- Uncomment and run the following code to install the required libraries:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"768989ea-dc60-4dc8-ae84-cbb3fd224422\",\n \"metadata\": {\n \"id\": \"768989ea-dc60-4dc8-ae84-cbb3fd224422\"\n },\n \"outputs\": [],\n \"source\": [\n \"# !pip install huggingface_hub sentencepiece\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"KbnlzsbYmJU6\",\n \"metadata\": {\n \"id\": \"KbnlzsbYmJU6\"\n },\n \"source\": [\n \"- Please note that Meta AI requires that you accept the Llama 2 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Llama-2-7b](https://huggingface.co/meta-llama/Llama-2-7b) repository to accept the terms\\n\",\n \"- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \\\"Settings\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"JBpQwU89ETA1\",\n \"metadata\": {\n \"id\": \"JBpQwU89ETA1\"\n },\n \"source\": [\n \"- Packages that are being used in this notebook:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"34a9a440-84c2-42cc-808b-38677cb6af8a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"34a9a440-84c2-42cc-808b-38677cb6af8a\",\n \"outputId\": \"8118963b-3c72-43af-874b-439ffebdc94c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 0.33.2\\n\",\n \"sentencepiece version: 0.2.0\\n\",\n \"torch version: 2.6.0\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"sentencepiece\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"UJJneXpTEg4W\",\n \"metadata\": {\n \"id\": \"UJJneXpTEg4W\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Convert the GPT model implementation step by step\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"v1zpfX2GHBKa\",\n \"metadata\": {\n \"id\": \"v1zpfX2GHBKa\"\n },\n \"source\": [\n \"- In this section, we go through the GPT model code from [chapter 4](../../ch04/01_main-chapter-code/ch04.ipynb) and modify it step by step to implement the Llama 2 architecture\\n\",\n \"- Later, we load the original Llama 2 weights shared by Meta AI\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"979c7b6d-1370-4da1-8bfb-a2b27537bf2f\",\n \"metadata\": {\n \"id\": \"979c7b6d-1370-4da1-8bfb-a2b27537bf2f\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.1 Replace LayerNorm with RMSNorm layer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f8b27fc8-23a1-4e0e-a1ea-792e0428e5e6\",\n \"metadata\": {\n \"id\": \"f8b27fc8-23a1-4e0e-a1ea-792e0428e5e6\"\n },\n \"source\": [\n \"- First, we replace LayerNorm by Root Mean Square Layer Normalization (RMSNorm)\\n\",\n \"- LayerNorm normalizes inputs using mean and variance, while RMSNorm uses only the root mean square, which improves computational efficiency\\n\",\n \"- The RMSNorm operation is as follows, where $x$ is the input $\\\\gamma$ is a trainable parameter (vector), and $\\\\epsilon$ is a small constant to avoid zero-division errors:\\n\",\n \"\\n\",\n \"$$y_i = \\\\frac{x_i}{\\\\text{RMS}(x)} \\\\gamma_i, \\\\quad \\\\text{where} \\\\quad \\\\text{RMS}(x) = \\\\sqrt{\\\\epsilon + \\\\frac{1}{n} \\\\sum x_i^2}$$\\n\",\n \"\\n\",\n \"- For more details, please see the paper [Root Mean Square Layer Normalization (2019)](https://arxiv.org/abs/1910.07467)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"d7094381-9499-4e9e-93f9-b79470da3771\",\n \"metadata\": {\n \"id\": \"d7094381-9499-4e9e-93f9-b79470da3771\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"#####################################\\n\",\n \"# Chapter 4\\n\",\n \"#####################################\\n\",\n \"\\n\",\n \"# class LayerNorm(nn.Module):\\n\",\n \"# def __init__(self, emb_dim):\\n\",\n \"# super().__init__()\\n\",\n \"# self.eps = 1e-5\\n\",\n \"# self.scale = nn.Parameter(torch.ones(emb_dim))\\n\",\n \"# self.shift = nn.Parameter(torch.zeros(emb_dim))\\n\",\n \"\\n\",\n \"# def forward(self, x):\\n\",\n \"# mean = x.mean(dim=-1, keepdim=True)\\n\",\n \"# var = x.var(dim=-1, keepdim=True, unbiased=False)\\n\",\n \"# norm_x = (x - mean) / torch.sqrt(var + self.eps)\\n\",\n \"# return self.scale * norm_x + self.shift\\n\",\n \"\\n\",\n \"\\n\",\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-5):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" self.emb_dim = emb_dim\\n\",\n \" self.weight = nn.Parameter(torch.ones(emb_dim)).float()\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" means = x.pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x_normed = x * torch.rsqrt(means + self.eps)\\n\",\n \" return (x_normed * self.weight).to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"mtWC8DOmIu0F\",\n \"metadata\": {\n \"id\": \"mtWC8DOmIu0F\"\n },\n \"source\": [\n \"- The following code cell checks that this implementation works the same as PyTorch's built-in implementation:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"e41ade7a-bf06-48b1-8b7e-0e4037d5753f\",\n \"metadata\": {\n \"id\": \"e41ade7a-bf06-48b1-8b7e-0e4037d5753f\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"example_batch = torch.randn(2, 3, 4)\\n\",\n \"\\n\",\n \"rms_norm = RMSNorm(emb_dim=example_batch.shape[-1])\\n\",\n \"rmsnorm_pytorch = torch.nn.RMSNorm(example_batch.shape[-1], eps=1e-5)\\n\",\n \"\\n\",\n \"assert torch.allclose(rms_norm(example_batch), rmsnorm_pytorch(example_batch))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5eb81f83-c38c-46a4-b763-aa630a32e357\",\n \"metadata\": {\n \"id\": \"5eb81f83-c38c-46a4-b763-aa630a32e357\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.2 Replace GELU with SiLU activation\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b8aa702-f118-4ff6-9135-90725ec8756c\",\n \"metadata\": {\n \"id\": \"0b8aa702-f118-4ff6-9135-90725ec8756c\"\n },\n \"source\": [\n \"- Llama uses the SiLU activation function (instead of GELU), which is also known as the Swish function:\\n\",\n \"\\n\",\n \"$$\\n\",\n \"\\\\text{silu}(x) = x \\\\cdot \\\\sigma(x), \\\\quad \\\\text{where} \\\\quad \\\\sigma(x) \\\\text{ is the logistic sigmoid.}\\n\",\n \"$$\\n\",\n \"\\n\",\n \"- For more information, see the SiLU paper: [Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning (2017)](https://arxiv.org/abs/1702.03118)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"a74f3757-c634-4a3a-a8f3-6334cde454fe\",\n \"metadata\": {\n \"id\": \"a74f3757-c634-4a3a-a8f3-6334cde454fe\"\n },\n \"outputs\": [],\n \"source\": [\n \"#####################################\\n\",\n \"# Chapter 4\\n\",\n \"#####################################\\n\",\n \"\\n\",\n \"# class GELU(nn.Module):\\n\",\n \"# def __init__(self):\\n\",\n \"# super().__init__()\\n\",\n \"\\n\",\n \"# def forward(self, x):\\n\",\n \"# return 0.5 * x * (1 + torch.tanh(\\n\",\n \"# torch.sqrt(torch.tensor(2.0 / torch.pi)) *\\n\",\n \"# (x + 0.044715 * torch.pow(x, 3))\\n\",\n \"# ))\\n\",\n \"\\n\",\n \"\\n\",\n \"class SiLU(nn.Module):\\n\",\n \" def __init__(self):\\n\",\n \" super(SiLU, self).__init__()\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" return x * torch.sigmoid(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"72ecbe2e-b6b7-4319-972b-1a7fefa3368c\",\n \"metadata\": {\n \"id\": \"72ecbe2e-b6b7-4319-972b-1a7fefa3368c\"\n },\n \"outputs\": [],\n \"source\": [\n \"silu = SiLU()\\n\",\n \"\\n\",\n \"assert torch.allclose(silu(example_batch), torch.nn.functional.silu(example_batch))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4f9b5167-1da9-46c8-9964-8036b3b1deb9\",\n \"metadata\": {\n \"id\": \"4f9b5167-1da9-46c8-9964-8036b3b1deb9\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.3 Update the FeedForward module\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3a381e7a-b807-472e-91c9-3e4e3fc5ad91\",\n \"metadata\": {\n \"id\": \"3a381e7a-b807-472e-91c9-3e4e3fc5ad91\"\n },\n \"source\": [\n \"- In fact, Llama uses a \\\"Gates Linear Unit\\\" (GLU) variant of SiLU called SwiGLU, which essentially results in a slightly differently structured `FeedForward` module\\n\",\n \"- SwiGLU uses a gating mechanism in the feedforward layer, with the formula:\\n\",\n \"\\n\",\n \"$$\\\\text{SwiGLU}(x) = \\\\text{SiLU}(\\\\text{Linear}_1(x)) * (\\\\text{Linear}_2(x))$$\\n\",\n \"\\n\",\n \"- Here, $\\\\text{Linear}_1$ and $\\\\text{Linear}_2$ are two linear layers, and $*$ denotes element-wise multiplication\\n\",\n \"- The third linear layer, $\\\\text{Linear}_3$, is applied after this gated activation\\n\",\n \"\\n\",\n \"- For more information, see SwiGLU paper: [GLU Variants Improve Transformer (2020)](https://arxiv.org/abs/2002.05202)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"d25fbe3d-b7c9-4772-ad67-bc0527e4e20a\",\n \"metadata\": {\n \"id\": \"d25fbe3d-b7c9-4772-ad67-bc0527e4e20a\"\n },\n \"outputs\": [],\n \"source\": [\n \"#####################################\\n\",\n \"# Chapter 4\\n\",\n \"#####################################\\n\",\n \"# class FeedForward(nn.Module):\\n\",\n \"# def __init__(self, cfg):\\n\",\n \"# super().__init__()\\n\",\n \"# self.layers = nn.Sequential(\\n\",\n \"# nn.Linear(cfg[\\\"emb_dim\\\"], 4 * cfg[\\\"emb_dim\\\"]),\\n\",\n \"# GELU(),\\n\",\n \"# nn.Linear(4 * cfg[\\\"emb_dim\\\"], cfg[\\\"emb_dim\\\"]),\\n\",\n \"# )\\n\",\n \"\\n\",\n \"# def forward(self, x):\\n\",\n \"# return self.layers(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"477568cb-03cd-4510-b663-a42ce3ec64a2\",\n \"metadata\": {\n \"id\": \"477568cb-03cd-4510-b663-a42ce3ec64a2\"\n },\n \"outputs\": [],\n \"source\": [\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.silu = SiLU()\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = self.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"qcD8LSHNhBRW\",\n \"metadata\": {\n \"id\": \"qcD8LSHNhBRW\"\n },\n \"source\": [\n \"- Note that we also added a `dtype=cfg[\\\"dtype\\\"]` setting above, which will allow us to load the model directly in lower precision formats later to reduce memory usage (versus instantiating it in the original 32-bit precision format and then converting it)\\n\",\n \"- We also set `bias=False` since Llama doesn't use any bias units\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f6b7bf4f-99d0-42c1-807c-5074d2cc1949\",\n \"metadata\": {\n \"id\": \"f6b7bf4f-99d0-42c1-807c-5074d2cc1949\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.4 Implement RoPE\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d3487a6f-0373-49d8-b2eb-f8ee05d42884\",\n \"metadata\": {\n \"id\": \"d3487a6f-0373-49d8-b2eb-f8ee05d42884\"\n },\n \"source\": [\n \"- In the GPT model, the positional embeddings are implemented as follows:\\n\",\n \"\\n\",\n \"```python\\n\",\n \"self.pos_emb = nn.Embedding(cfg[\\\"context_length\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \"```\\n\",\n \"\\n\",\n \"- Unlike traditional absolute positional embeddings, Llama uses rotary position embeddings (RoPE), which enable it to capture both absolute and relative positional information simultaneously\\n\",\n \"- The reference paper for RoPE is [RoFormer: Enhanced Transformer with Rotary Position Embedding (2021)](https://arxiv.org/abs/2104.09864)\\n\",\n \"- RoPE can be implemented in two equivalent ways: the *split-halves* version and the *interleaved even/odd version*; they are mathematically the same as long as we pair dimensions consistently and use the same cos/sin ordering (see [this](https://github.com/rasbt/LLMs-from-scratch/issues/751) GitHub discussion for more information)\\n\",\n \"- This code uses the RoPE *split-halves* approach, similar to Hugging Face transformers ([modeling_llama.py](https://github.com/huggingface/transformers/blob/e42587f596181396e1c4b63660abf0c736b10dae/src/transformers/models/llama/modeling_llama.py#L173-L188))\\n\",\n \"- The original RoPE paper and Meta's official Llama 2 repository, however, use the *interleaved (even/odd)* version ([llama/model.py](https://github.com/meta-llama/llama/blob/6c7fe276574e78057f917549435a2554000a876d/llama/model.py#L64-L74)); but as mentioned earlier, they are equivalent\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"a34180fb-448f-44e9-a244-0c736051687b\",\n \"metadata\": {\n \"id\": \"a34180fb-448f-44e9-a244-0c736051687b\"\n },\n \"outputs\": [],\n \"source\": [\n \"def precompute_rope_params(head_dim, theta_base=10_000, context_length=4096):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2)[: (head_dim // 2)].float() / head_dim))\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Expand angles to match the head_dim\\n\",\n \" angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"def compute_rope(x, cos, sin):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8e841b8e-75aa-49db-b1a7-d5c2116dc299\",\n \"metadata\": {\n \"id\": \"8e841b8e-75aa-49db-b1a7-d5c2116dc299\"\n },\n \"source\": [\n \"- The following is an example of applying RoPE to the `q` and `k` tensors:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"8c89f022-7167-4001-8c21-8e012878733f\",\n \"metadata\": {\n \"id\": \"8c89f022-7167-4001-8c21-8e012878733f\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Settings\\n\",\n \"batch_size = 2\\n\",\n \"context_len = 5\\n\",\n \"num_heads = 4\\n\",\n \"head_dim = 16\\n\",\n \"\\n\",\n \"# Instantiate RoPE parameters\\n\",\n \"cos, sin = precompute_rope_params(head_dim=head_dim, context_length=context_len)\\n\",\n \"\\n\",\n \"# Dummy query and key tensors\\n\",\n \"torch.manual_seed(123)\\n\",\n \"queries = torch.randn(batch_size, num_heads, context_len, head_dim)\\n\",\n \"keys = torch.randn(batch_size, num_heads, context_len, head_dim)\\n\",\n \"\\n\",\n \"# Apply rotary position embeddings\\n\",\n \"queries_rot = compute_rope(queries, cos, sin)\\n\",\n \"keys_rot = compute_rope(keys, cos, sin)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f78127b0-dda2-4c5a-98dd-bae8f5fe8297\",\n \"metadata\": {\n \"id\": \"f78127b0-dda2-4c5a-98dd-bae8f5fe8297\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.5 Add RoPE to MultiHeadAttention module\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"RnmSHROLhhR3\",\n \"metadata\": {\n \"id\": \"RnmSHROLhhR3\"\n },\n \"source\": [\n \"- It's important to note that GPT applies the positional embeddings to the inputs, whereas Llama applies rotations to the query and key vectors in the self-attention mechanism itself\\n\",\n \"- Here, we modify the `MultiHeadAttention` class with the appropriate RoPE code\\n\",\n \"- In addition, we remove the `qkv_bias` option and hardcode the `bias=False` setting\\n\",\n \"- Also, we add a dtype setting to be able to instantiate the model with a lower precision later\\n\",\n \" - Tip: since the `TransformerBlock`s (in the next section) are repeated exactly, we could simplify the code and only initialize the buffers once instead for each `MultiHeadAttention` module; however, we add the precomputed RoPE parameters to the `MultiHeadAttention` class so that it can function as a standalone module\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"d81a441e-0b79-4a8b-8291-ea7f55d58c84\",\n \"metadata\": {\n \"id\": \"d81a441e-0b79-4a8b-8291-ea7f55d58c84\"\n },\n \"outputs\": [],\n \"source\": [\n \"#####################################\\n\",\n \"# Chapter 3\\n\",\n \"#####################################\\n\",\n \"class MultiHeadAttention(nn.Module):\\n\",\n \" def __init__(self, d_in, d_out, context_length, num_heads, dtype=None): # ,dropout, num_heads, qkv_bias=False):\\n\",\n \" super().__init__()\\n\",\n \" assert d_out % num_heads == 0, \\\"d_out must be divisible by n_heads\\\"\\n\",\n \"\\n\",\n \" self.d_out = d_out\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\\n\",\n \"\\n\",\n \" ################################### NEW ###################################\\n\",\n \" # Set bias=False and dtype=dtype for all linear layers below\\n\",\n \" ###########################################################################\\n\",\n \" self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype) # Linear layer to combine head outputs\\n\",\n \" # self.dropout = nn.Dropout(dropout)\\n\",\n \" self.register_buffer(\\\"mask\\\", torch.triu(torch.ones(context_length, context_length), diagonal=1))\\n\",\n \"\\n\",\n \" ################################### NEW ###################################\\n\",\n \" cos, sin = precompute_rope_params(head_dim=self.head_dim, context_length=context_length)\\n\",\n \" self.register_buffer(\\\"cos\\\", cos)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin)\\n\",\n \" ###########################################################################\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \"\\n\",\n \" b, num_tokens, d_in = x.shape\\n\",\n \"\\n\",\n \" keys = self.W_key(x) # Shape: (b, num_tokens, d_out)\\n\",\n \" queries = self.W_query(x)\\n\",\n \" values = self.W_value(x)\\n\",\n \"\\n\",\n \" # We implicitly split the matrix by adding a `num_heads` dimension\\n\",\n \" # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" values = values.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \"\\n\",\n \" # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\\n\",\n \" keys = keys.transpose(1, 2)\\n\",\n \" queries = queries.transpose(1, 2)\\n\",\n \" values = values.transpose(1, 2)\\n\",\n \"\\n\",\n \" ################################### NEW ###################################\\n\",\n \" keys = compute_rope(keys, self.cos, self.sin)\\n\",\n \" queries = compute_rope(queries, self.cos, self.sin)\\n\",\n \" ###########################################################################\\n\",\n \"\\n\",\n \" # Compute scaled dot-product attention (aka self-attention) with a causal mask\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\\n\",\n \"\\n\",\n \" # Original mask truncated to the number of tokens and converted to boolean\\n\",\n \" mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\\n\",\n \"\\n\",\n \" # Use the mask to fill attention scores\\n\",\n \" attn_scores.masked_fill_(mask_bool, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\\n\",\n \" # attn_weights = self.dropout(attn_weights)\\n\",\n \"\\n\",\n \" # Shape: (b, num_tokens, num_heads, head_dim)\\n\",\n \" context_vec = (attn_weights @ values).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Combine heads, where self.d_out = self.num_heads * self.head_dim\\n\",\n \" context_vec = context_vec.reshape(b, num_tokens, self.d_out)\\n\",\n \" context_vec = self.out_proj(context_vec) # optional projection\\n\",\n \"\\n\",\n \" return context_vec\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"-lt9SfnVioB3\",\n \"metadata\": {\n \"id\": \"-lt9SfnVioB3\"\n },\n \"source\": [\n \"- Below is an example using the `MultiHeadAttention` module on an example input:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"03f15755-0083-483f-963b-99b599651638\",\n \"metadata\": {\n \"id\": \"03f15755-0083-483f-963b-99b599651638\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Settings\\n\",\n \"batch_size = 1\\n\",\n \"context_len = 100\\n\",\n \"max_context_len = 4096\\n\",\n \"embed_dim = 128\\n\",\n \"num_heads = 4\\n\",\n \"\\n\",\n \"\\n\",\n \"example_batch = torch.randn((batch_size, context_len, embed_dim))\\n\",\n \"\\n\",\n \"mha = MultiHeadAttention(\\n\",\n \" d_in=embed_dim,\\n\",\n \" d_out=embed_dim,\\n\",\n \" context_length=max_context_len,\\n\",\n \" num_heads=num_heads\\n\",\n \")\\n\",\n \"\\n\",\n \"mha(example_batch)\\n\",\n \"\\n\",\n \"del mha # delete to free up memory\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e5a1a272-a038-4b8f-aaaa-f4b241e7f23f\",\n \"metadata\": {\n \"id\": \"e5a1a272-a038-4b8f-aaaa-f4b241e7f23f\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.6 Update the TransformerBlock module\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"255f70ac-9c2e-4328-8af7-1c298b8d4a18\",\n \"metadata\": {\n \"id\": \"255f70ac-9c2e-4328-8af7-1c298b8d4a18\"\n },\n \"source\": [\n \"- At this stage, most of the hard work is already done; we can now update the `TransformerBlock` to use the code we implemented above\\n\",\n \"- This means we\\n\",\n \" - replace LayerNorm with RMSNorm\\n\",\n \" - remove dropout\\n\",\n \" - remove the `qkv_bias` setting\\n\",\n \" - add the `dtype` setting\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"2e110721-bf2b-42b3-989a-1635b1658af0\",\n \"metadata\": {\n \"id\": \"2e110721-bf2b-42b3-989a-1635b1658af0\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.att = MultiHeadAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" d_out=cfg[\\\"emb_dim\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"] # NEW\\n\",\n \" # dropout=cfg[\\\"drop_rate\\\"],\\n\",\n \" # qkv_bias=cfg[\\\"qkv_bias\\\"]\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \"\\n\",\n \" ################################### NEW ###################################\\n\",\n \" # self.norm1 = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" # self.norm2 = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.norm1 = RMSNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.norm2 = RMSNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" ###########################################################################\\n\",\n \"\\n\",\n \" # self.drop_shortcut = nn.Dropout(cfg[\\\"drop_rate\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \" x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" # x = self.drop_shortcut(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" # Shortcut connection for feed-forward block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" # x = self.drop_shortcut(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ada953bc-e2c0-4432-a32d-3f7efa3f6e0f\",\n \"metadata\": {\n \"id\": \"ada953bc-e2c0-4432-a32d-3f7efa3f6e0f\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.7 Update the model class\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba5d991a-559b-47be-96f4-31b881ab2da8\",\n \"metadata\": {\n \"id\": \"ba5d991a-559b-47be-96f4-31b881ab2da8\"\n },\n \"source\": [\n \"- As you may recall from [chapter 5](../01_main-chapter-code/ch05.ipynb), the `TransformerBlock` is a repeated block within the main model\\n\",\n \"- Our Llama model is almost complete; we just have to update the model code surrounding the `TransformerBlock`\\n\",\n \"- This means we\\n\",\n \" - remove absolute positional embeddings since we have RoPE embeddings now\\n\",\n \" - replace LayerNorm with RMSNorm\\n\",\n \" - remove dropout\\n\",\n \" - add the dtype setting\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"cf8240fe-5d7f-4e7e-b1ac-e0755aab5e79\",\n \"metadata\": {\n \"id\": \"cf8240fe-5d7f-4e7e-b1ac-e0755aab5e79\"\n },\n \"outputs\": [],\n \"source\": [\n \"# class GPTModel(nn.Module):\\n\",\n \"class Llama2Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \" # self.pos_emb = nn.Embedding(cfg[\\\"context_length\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" # self.drop_emb = nn.Dropout(cfg[\\\"drop_rate\\\"])\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.Sequential(\\n\",\n \" *[TransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])])\\n\",\n \"\\n\",\n \" ################################### NEW ###################################\\n\",\n \" # self.final_norm = LayerNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" ###########################################################################\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" # batch_size, seq_len = in_idx.shape\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" # pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\\n\",\n \" x = tok_embeds # + pos_embeds # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" # x = self.drop_emb(x)\\n\",\n \" x = self.trf_blocks(x)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x)\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4bc94940-aaeb-45b9-9399-3a69b8043e60\",\n \"metadata\": {\n \"id\": \"4bc94940-aaeb-45b9-9399-3a69b8043e60\"\n },\n \"source\": [\n \" \\n\",\n \"## 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bG--zY-Ljj1f\",\n \"metadata\": {\n \"id\": \"bG--zY-Ljj1f\"\n },\n \"source\": [\n \"- The model code is now complete, and we are ready to initialize it\\n\",\n \"- In [chapter 5](../01_main-chapter-code/ch05.ipynb), we used the following config file to specify the 124M-parameter GPT model:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"4b7428df-3d02-4ccd-97b5-a629bdabbe8f\",\n \"metadata\": {\n \"id\": \"4b7428df-3d02-4ccd-97b5-a629bdabbe8f\"\n },\n \"outputs\": [],\n \"source\": [\n \"GPT_CONFIG_124M = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"emb_dim\\\": 768, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 12, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 12, # Number of layers\\n\",\n \" \\\"drop_rate\\\": 0.1, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": False # Query-Key-Value bias\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8bVi8uiBjw2T\",\n \"metadata\": {\n \"id\": \"8bVi8uiBjw2T\"\n },\n \"source\": [\n \"- For reference, the 1.5B parameter GPT model config is shown below as well:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"tAOojV_mkEnd\",\n \"metadata\": {\n \"id\": \"tAOojV_mkEnd\"\n },\n \"outputs\": [],\n \"source\": [\n \"GPT_CONFIG_1558M = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"emb_dim\\\": 1600, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 25, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 48, # Number of layers\\n\",\n \" \\\"drop_rate\\\": 0.1, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": False # Query-Key-Value bias\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"HoGGRAGykQTE\",\n \"metadata\": {\n \"id\": \"HoGGRAGykQTE\"\n },\n \"source\": [\n \"- Similarly, we can define a Llama 2 config file for the 7B model (we ignore the other larger models for simplicity here):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"e0564727-2d35-4f0c-b0fc-cde1e9134a18\",\n \"metadata\": {\n \"id\": \"e0564727-2d35-4f0c-b0fc-cde1e9134a18\"\n },\n \"outputs\": [],\n \"source\": [\n \"LLAMA2_CONFIG_7B = {\\n\",\n \" \\\"vocab_size\\\": 32000, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 4096, # Context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 11008, # NEW: Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"dtype\\\": torch.bfloat16 # NEW: Lower-precision dtype to reduce memory usage\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"FAP7fiBzkaBz\",\n \"metadata\": {\n \"id\": \"FAP7fiBzkaBz\"\n },\n \"source\": [\n \"- Using these settings, we can now initialize a Llama 2 7B model (note that this requires ~26 GB of memory)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"7004d785-ac9a-4df5-8760-6807fc604686\",\n \"metadata\": {\n \"id\": \"7004d785-ac9a-4df5-8760-6807fc604686\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = Llama2Model(LLAMA2_CONFIG_7B)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"6079f747-8f20-4c6b-8d38-7156f1101729\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6079f747-8f20-4c6b-8d38-7156f1101729\",\n \"outputId\": \"0a0eb34b-1a21-4c11-804f-b40007bda5a3\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters: 6,738,415,616\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters())\\n\",\n \"print(f\\\"Total number of parameters: {total_params:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"Bx14NtzWk2wj\",\n \"metadata\": {\n \"id\": \"Bx14NtzWk2wj\"\n },\n \"source\": [\n \"- As shown above, the model contains 6.7 billion parameters (commonly rounded and referred to as a 7B model)\\n\",\n \"- Additionally, we can calculate the memory requirements for this model using the code below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"0df1c79e-27a7-4b0f-ba4e-167fe107125a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0df1c79e-27a7-4b0f-ba4e-167fe107125a\",\n \"outputId\": \"11ced939-556d-4511-d5c0-10a94ed3df32\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"float32 (PyTorch default): 52.33 GB\\n\",\n \"bfloat16: 26.17 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def calc_model_memory_size(model, input_dtype=torch.float32):\\n\",\n \" total_params = 0\\n\",\n \" total_grads = 0\\n\",\n \" for param in model.parameters():\\n\",\n \" # Calculate total number of elements per parameter\\n\",\n \" param_size = param.numel()\\n\",\n \" total_params += param_size\\n\",\n \" # Check if gradients are stored for this parameter\\n\",\n \" if param.requires_grad:\\n\",\n \" total_grads += param_size\\n\",\n \"\\n\",\n \" # Calculate buffer size (non-parameters that require memory)\\n\",\n \" total_buffers = sum(buf.numel() for buf in model.buffers())\\n\",\n \"\\n\",\n \" # Size in bytes = (Number of elements) * (Size of each element in bytes)\\n\",\n \" # We assume parameters and gradients are stored in the same type as input dtype\\n\",\n \" element_size = torch.tensor(0, dtype=input_dtype).element_size()\\n\",\n \" total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\\n\",\n \"\\n\",\n \" # Convert bytes to gigabytes\\n\",\n \" total_memory_gb = total_memory_bytes / (1024**3)\\n\",\n \"\\n\",\n \" return total_memory_gb\\n\",\n \"\\n\",\n \"print(f\\\"float32 (PyTorch default): {calc_model_memory_size(model, input_dtype=torch.float32):.2f} GB\\\")\\n\",\n \"print(f\\\"bfloat16: {calc_model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"zudd-5PulKFL\",\n \"metadata\": {\n \"id\": \"zudd-5PulKFL\"\n },\n \"source\": [\n \"- Lastly, we can also transfer the model to an NVIDIA or Apple Silicon GPU if applicable:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"a4c50e19-1402-45b6-8ccd-9077b2ba836d\",\n \"metadata\": {\n \"id\": \"a4c50e19-1402-45b6-8ccd-9077b2ba836d\"\n },\n \"outputs\": [],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5dc64a06-27dc-46ec-9e6d-1700a8227d34\",\n \"metadata\": {\n \"id\": \"5dc64a06-27dc-46ec-9e6d-1700a8227d34\"\n },\n \"source\": [\n \" \\n\",\n \"## 3. Load tokenizer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0eb30f0c-6144-4bed-87d9-6b2bac377005\",\n \"metadata\": {\n \"id\": \"0eb30f0c-6144-4bed-87d9-6b2bac377005\"\n },\n \"source\": [\n \"- In this section, we are going to load the tokenizer for the model\\n\",\n \"- Llama 2 uses Google's [SentencePiece](https://github.com/google/sentencepiece) tokenizer instead of OpenAI's [Tiktoken](https://github.com/openai/tiktoken) (but Llama 3 uses Tiktoken)\\n\",\n \"- Meta AI shared the original Llama 2 model weights and tokenizer vocabulary on the Hugging Face Hub\\n\",\n \"- We will download the tokenizer vocabulary from the Hub and load it into SentencePiece\\n\",\n \"- Uncomment and run the following code to install the required libraries:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"768989ea-dc60-4dc8-ae84-cbb3fd224422\",\n \"metadata\": {\n \"id\": \"768989ea-dc60-4dc8-ae84-cbb3fd224422\"\n },\n \"outputs\": [],\n \"source\": [\n \"# !pip install huggingface_hub sentencepiece\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"KbnlzsbYmJU6\",\n \"metadata\": {\n \"id\": \"KbnlzsbYmJU6\"\n },\n \"source\": [\n \"- Please note that Meta AI requires that you accept the Llama 2 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Llama-2-7b](https://huggingface.co/meta-llama/Llama-2-7b) repository to accept the terms\\n\",\n \"- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \\\"Settings\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"3357a230-b678-4691-a238-257ee4e80185\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"3357a230-b678-4691-a238-257ee4e80185\",\n \"outputId\": \"768ed6af-ce14-40bc-ca18-117b4b448269\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import login\\n\",\n \"import json\\n\",\n \"\\n\",\n \"with open(\\\"config.json\\\", \\\"r\\\") as config_file:\\n\",\n \" config = json.load(config_file)\\n\",\n \" access_token = config[\\\"HF_ACCESS_TOKEN\\\"]\\n\",\n \"\\n\",\n \"login(token=access_token)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"IxGh6ZYQo0VN\",\n \"metadata\": {\n \"id\": \"IxGh6ZYQo0VN\"\n },\n \"source\": [\n \"- After login via the access token, which is necessary to verify that we accepted the Llama 2 licensing terms, we can now download the tokenizer vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"69714ea8-b9b8-4687-8392-f3abb8f93a32\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 153,\n \"referenced_widgets\": [\n \"e6c75a6aa7b942fe84160e286e3acb3d\",\n \"08f0bf9459bd425498a5cb236f9d4a72\",\n \"10251d6f724e43788c41d4b7879cbfd3\",\n \"53a973c0853b44418698136bd04df039\",\n \"bdb071e7145a4007ae01599333e72612\",\n \"6b1821a7f4574e3aba09c1e410cc81e4\",\n \"8c2873eaec3445888ad3d54ad7387950\",\n \"0c8f7044966e4207b12352503c67dcbb\",\n \"8b5951213c9e4798a258146d61d02d11\",\n \"2c05df3f91e64df7b33905b1065a76f7\",\n \"742ae5487f2648fcae7ca8e22c7f8db9\"\n ]\n },\n \"id\": \"69714ea8-b9b8-4687-8392-f3abb8f93a32\",\n \"outputId\": \"c230fec9-5c71-4a41-90ab-8a34d114ea01\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import hf_hub_download\\n\",\n \"\\n\",\n \"tokenizer_file = hf_hub_download(\\n\",\n \" repo_id=\\\"meta-llama/Llama-2-7b\\\",\\n\",\n \" filename=\\\"tokenizer.model\\\",\\n\",\n \" local_dir=\\\"Llama-2-7b\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"gp7iQ8cXAJLv\",\n \"metadata\": {\n \"id\": \"gp7iQ8cXAJLv\"\n },\n \"source\": [\n \"- To provide a more familiar interface for the tokenizer, we define a small `LlamaTokenizer` wrapper class:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"Ef4WxhjOBOOc\",\n \"metadata\": {\n \"id\": \"Ef4WxhjOBOOc\"\n },\n \"outputs\": [],\n \"source\": [\n \"import sentencepiece as spm\\n\",\n \"\\n\",\n \"\\n\",\n \"class LlamaTokenizer:\\n\",\n \" def __init__(self, tokenizer_file):\\n\",\n \" sp = spm.SentencePieceProcessor()\\n\",\n \" sp.load(tokenizer_file)\\n\",\n \" self.tokenizer = sp\\n\",\n \"\\n\",\n \" def encode(self, text):\\n\",\n \" return self.tokenizer.encode(text, out_type=int)\\n\",\n \"\\n\",\n \" def decode(self, ids):\\n\",\n \" return self.tokenizer.decode(ids)\\n\",\n \"\\n\",\n \"\\n\",\n \"tokenizer = LlamaTokenizer(tokenizer_file)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"NVhmFeX3pT_M\",\n \"metadata\": {\n \"id\": \"NVhmFeX3pT_M\"\n },\n \"source\": [\n \"- We can now use the `generate` function to have the Llama 2 model generate new text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"e0a2b5cd-6cba-4d72-b8ff-04d8315d483e\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"e0a2b5cd-6cba-4d72-b8ff-04d8315d483e\",\n \"outputId\": \"acd5065d-8900-4ba8-ef85-968365f3a0cb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort movesαllRadius deletingpretcc否']; future eer napulate lackус während inter DES издаSchéonkkarto Оryptato#{ningproof eerbye\\n\"\n ]\n }\n ],\n \"source\": [\n \"from previous_chapters import generate, text_to_token_ids, token_ids_to_text\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch05 import generate, text_to_token_ids, token_ids_to_text\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(\\\"Every effort moves\\\", tokenizer).to(device),\\n\",\n \" max_new_tokens=30,\\n\",\n \" context_size=LLAMA2_CONFIG_7B[\\\"context_length\\\"],\\n\",\n \" top_k=1,\\n\",\n \" temperature=0.\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"93WTtAA5paYV\",\n \"metadata\": {\n \"id\": \"93WTtAA5paYV\"\n },\n \"source\": [\n \"- Of course, as we can see above, the text is nonsensical since we haven't trained the Llama 2 model yet\\n\",\n \"- In the next section, instead of training it ourselves, which would cost tens to hundreds of thousands of dollars, we load the pretrained weights from Meta AI\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f63cc248-1d27-4eb6-aa50-173b436652f8\",\n \"metadata\": {\n \"id\": \"f63cc248-1d27-4eb6-aa50-173b436652f8\"\n },\n \"source\": [\n \" \\n\",\n \"## 4. Load pretrained weights\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"aKeN7rUfqZMI\",\n \"metadata\": {\n \"id\": \"aKeN7rUfqZMI\"\n },\n \"source\": [\n \"- We are loading the [\\\"meta-llama/Llama-2-7b\\\"](https://huggingface.co/meta-llama/Llama-2-7b) base model below, which is a simple text completion model before finetuning\\n\",\n \"- Alternatively, you can load the instruction-finetuned and aligned [\\\"meta-llama/Llama-2-7b-chat\\\"](https://huggingface.co/meta-llama/Llama-2-7b-chat) model by modifying the string in the next code cell accordingly\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"5fa9c06c-7a53-4b4d-9ce4-acc027322ee4\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 49,\n \"referenced_widgets\": [\n \"66e777955e8748df878f118f07f38dab\",\n \"da89ae3ea4d2474e98f64ada608f3cea\",\n \"93e6da39c25f4edfaa72056c89df1f7f\",\n \"b628603e4cb0405398c916587ee96756\",\n \"93bedcb9245e44a0a1eb7e4155070f66\",\n \"0723f467d37b4904819a8bb33ebda10f\",\n \"e54928776bc649339002adced63738b0\",\n \"d8e0f42068af4cb094e2f115f76e06e0\",\n \"0a939565b6e94f08bee0a66e0f9827d4\",\n \"a5fedbb7ec2e43d99711bb4cd84b9486\",\n \"0c186f6539714d8eab023969ce47c500\"\n ]\n },\n \"id\": \"5fa9c06c-7a53-4b4d-9ce4-acc027322ee4\",\n \"outputId\": \"0d8942cc-e5e2-4e77-ec41-1ac7bec7d94f\"\n },\n \"outputs\": [],\n \"source\": [\n \"weights_file = hf_hub_download(\\n\",\n \" repo_id=\\\"meta-llama/Llama-2-7b\\\",\\n\",\n \" filename=\\\"consolidated.00.pth\\\",\\n\",\n \" local_dir=\\\"Llama-2-7b\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 27,\n \"id\": \"e67cca5c-ba4b-4be5-85c7-fdceae8a5701\",\n \"metadata\": {\n \"id\": \"e67cca5c-ba4b-4be5-85c7-fdceae8a5701\"\n },\n \"outputs\": [],\n \"source\": [\n \"weights = torch.load(weights_file, weights_only=True)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"-15SJ7btq2zE\",\n \"metadata\": {\n \"id\": \"-15SJ7btq2zE\"\n },\n \"source\": [\n \"- The `weights` contains the following tensors (only the first 15 are shown for simplicity):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 28,\n \"id\": \"ee26bd0b-fea9-4924-97f7-409c14f28e49\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"ee26bd0b-fea9-4924-97f7-409c14f28e49\",\n \"outputId\": \"fa83d38a-bb41-4cb2-d3c7-c573bfe1f8a4\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"['tok_embeddings.weight',\\n\",\n \" 'norm.weight',\\n\",\n \" 'output.weight',\\n\",\n \" 'layers.0.attention.wq.weight',\\n\",\n \" 'layers.0.attention.wk.weight',\\n\",\n \" 'layers.0.attention.wv.weight',\\n\",\n \" 'layers.0.attention.wo.weight',\\n\",\n \" 'layers.0.feed_forward.w1.weight',\\n\",\n \" 'layers.0.feed_forward.w2.weight',\\n\",\n \" 'layers.0.feed_forward.w3.weight',\\n\",\n \" 'layers.0.attention_norm.weight',\\n\",\n \" 'layers.0.ffn_norm.weight',\\n\",\n \" 'layers.1.attention.wq.weight',\\n\",\n \" 'layers.1.attention.wk.weight',\\n\",\n \" 'layers.1.attention.wv.weight']\"\n ]\n },\n \"execution_count\": 28,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"list(weights.keys())[:15]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"UeeSpnunrDFB\",\n \"metadata\": {\n \"id\": \"UeeSpnunrDFB\"\n },\n \"source\": [\n \"- The following function, modeled after the `load_weights_into_gpt` function in [chapter 5](../01_main-chapter-code/ch05.ipynb), loads the pretrained weights into our Llama 2 model:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"3820e2a7-4f26-41bc-953b-f3879b0aff65\",\n \"metadata\": {\n \"id\": \"3820e2a7-4f26-41bc-953b-f3879b0aff65\"\n },\n \"outputs\": [],\n \"source\": [\n \"def assign(left, right, tensor_name=\\\"unknown\\\"):\\n\",\n \" if left.shape != right.shape:\\n\",\n \" raise ValueError(f\\\"Shape mismatch in tensor '{tensor_name}'. Left: {left.shape}, Right: {right.shape}\\\")\\n\",\n \" \\n\",\n \" with torch.no_grad():\\n\",\n \" if isinstance(right, torch.Tensor):\\n\",\n \" left.copy_(right)\\n\",\n \" else:\\n\",\n \" left.copy_(torch.as_tensor(right, dtype=left.dtype, device=left.device))\\n\",\n \"\\n\",\n \" return left \\n\",\n \"\\n\",\n \"\\n\",\n \"def permute(w: torch.Tensor, n_heads, out_dim, in_dim):\\n\",\n \" return (w.view(n_heads, out_dim // n_heads // 2, 2, in_dim)\\n\",\n \" .transpose(1, 2) # put axis 2 next to heads\\n\",\n \" .reshape(out_dim, in_dim))\\n\",\n \"\\n\",\n \"\\n\",\n \"def load_weights_into_llama(model, param_config, params):\\n\",\n \"\\n\",\n \" cfg = LLAMA2_CONFIG_7B\\n\",\n \" \\n\",\n \" model.tok_emb.weight = assign(model.tok_emb.weight, params[\\\"tok_embeddings.weight\\\"])\\n\",\n \"\\n\",\n \" for l in range(param_config[\\\"n_layers\\\"]):\\n\",\n \"\\n\",\n \" # The original Meta/Llama checkpoints store Q and K so that the two numbers \\n\",\n \" # that form one complex RoPE pair sit next to each other inside the head dimension (\\\"sliced\\\" layout).\\n\",\n \" # Our RoPE implementation, similar to the one in Hugging Face, expects an interleaved layout\\n\",\n \" # For example, with n_heads=2 and head_dim = 8\\n\",\n \" # ┌── pair 0 ──┐ ┌── pair 1 ──┐\\n\",\n \" # Meta (sliced): [ h0: r0 r1 r2 r3, h1: r0 r1 r2 r3 ]\\n\",\n \" # Ours & HF (interleaved): [ h0: r0 r0 r1 r1 r2 r2 r3 r3 , h1: ... ]\\n\",\n \" # For more information, please see the discussion in the PR: https://github.com/rasbt/LLMs-from-scratch/pull/747 \\n\",\n \" \\n\",\n \" # So, below, for q_raw and k_raw, we must re‑order the checkpoint weights using the slices_to_interleave helper\\n\",\n \"\\n\",\n \" q_raw = params[f\\\"layers.{l}.attention.wq.weight\\\"]\\n\",\n \" model.trf_blocks[l].att.W_query.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_query.weight,\\n\",\n \" permute(q_raw, cfg[\\\"n_heads\\\"], cfg[\\\"emb_dim\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" )\\n\",\n \" k_raw = params[f\\\"layers.{l}.attention.wk.weight\\\"]\\n\",\n \" model.trf_blocks[l].att.W_key.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_key.weight,\\n\",\n \" permute(k_raw, cfg[\\\"n_heads\\\"], cfg[\\\"emb_dim\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].att.W_value.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_value.weight,\\n\",\n \" params[f\\\"layers.{l}.attention.wv.weight\\\"]\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].att.out_proj.weight = assign(\\n\",\n \" model.trf_blocks[l].att.out_proj.weight,\\n\",\n \" params[f\\\"layers.{l}.attention.wo.weight\\\"]\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].norm1.weight = assign(\\n\",\n \" model.trf_blocks[l].norm1.weight,\\n\",\n \" params[f\\\"layers.{l}.attention_norm.weight\\\"]\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Load FeedForward weights\\n\",\n \" model.trf_blocks[l].ff.fc1.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc1.weight,\\n\",\n \" params[f\\\"layers.{l}.feed_forward.w1.weight\\\"]\\n\",\n \" )\\n\",\n \" # For some reason w2 and w3 are provided in the wrong order in the weights file\\n\",\n \" model.trf_blocks[l].ff.fc2.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc2.weight,\\n\",\n \" params[f\\\"layers.{l}.feed_forward.w3.weight\\\"]\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].ff.fc3.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc3.weight,\\n\",\n \" params[f\\\"layers.{l}.feed_forward.w2.weight\\\"]\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].norm2.weight = assign(\\n\",\n \" model.trf_blocks[l].norm2.weight,\\n\",\n \" params[f\\\"layers.{l}.ffn_norm.weight\\\"]\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Load output layer weights\\n\",\n \" model.final_norm.weight = assign(model.final_norm.weight, params[\\\"norm.weight\\\"])\\n\",\n \" model.out_head.weight = assign(model.out_head.weight, params[\\\"output.weight\\\"])\\n\",\n \"\\n\",\n \"\\n\",\n \"load_weights_into_llama(model, LLAMA2_CONFIG_7B, weights)\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"TDuv_Us2rNvk\",\n \"metadata\": {\n \"id\": \"TDuv_Us2rNvk\"\n },\n \"source\": [\n \"- Next, we are ready to use the model for text generation\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"240987e8-a023-462e-9376-9edfb27559ec\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"240987e8-a023-462e-9376-9edfb27559ec\",\n \"outputId\": \"044f24b3-4018-4860-834d-6c2731b9e47c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort has been made to ensure the accuracy of the information contained in this website. However, the information contained in this website is not\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(\\\"Every effort\\\", tokenizer).to(device),\\n\",\n \" max_new_tokens=25,\\n\",\n \" context_size=LLAMA2_CONFIG_7B[\\\"context_length\\\"],\\n\",\n \" top_k=1,\\n\",\n \" temperature=0.\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d72ed949-b6c0-4966-922f-eb0da732c404\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 5. Using the instruction-finetuned model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"akyo7WNyF_YL\",\n \"metadata\": {\n \"id\": \"akyo7WNyF_YL\"\n },\n \"source\": [\n \"- As mentioned earlier, above we used the pretrained base model; if you want to use a model capable of following instructions, use the `\\\"meta-llama/Llama-2-7b-chat\\\"` model instead, as shown below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"nbvAV7vaz6yc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 101,\n \"referenced_widgets\": [\n \"3b2448a60f5f4ba5b2c686037c8ecd78\",\n \"60c5932944f24f5fad1d8da89c8e5ae9\",\n \"aa31aed1b8854a4281fd7e81c60e1205\",\n \"d4acf06c2414412f8f2fb4f48981c954\",\n \"693d69251d3d48219c084af17b54b851\",\n \"ff36d28c55dd4db3a0f76a87640fdfe2\",\n \"71c49ef820494d5f8908a3daf39f0755\",\n \"525dc406534f4369b11208816f8fd0d7\",\n \"865f39213a7341b68f2fe73caaf801b1\",\n \"eaf4c0231b6d4993b2f8e9e63d8b6921\",\n \"a11edf3b018e42c88a63a515cf7fe478\"\n ]\n },\n \"id\": \"nbvAV7vaz6yc\",\n \"outputId\": \"724f5508-d976-4e31-b3d7-95fa65b2c1e8\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" What do llamas eat?\\n\",\n \"\\n\",\n \"Llamas are herbivores, which means they eat plants for their food. They feed on a variety\\n\"\n ]\n }\n ],\n \"source\": [\n \"del model # to free up memory\\n\",\n \"\\n\",\n \"weights_file = hf_hub_download(\\n\",\n \" repo_id=\\\"meta-llama/Llama-2-7b-chat\\\",\\n\",\n \" filename=\\\"consolidated.00.pth\\\",\\n\",\n \" local_dir=\\\"Llama-2-7b-chat\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"weights = torch.load(weights_file, weights_only=True)\\n\",\n \"model = Llama2Model(LLAMA2_CONFIG_7B)\\n\",\n \"load_weights_into_llama(model, LLAMA2_CONFIG_7B, weights)\\n\",\n \"model.to(device);\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(\\\"What do llamas eat?\\\", tokenizer).to(device),\\n\",\n \" max_new_tokens=25,\\n\",\n \" context_size=LLAMA2_CONFIG_7B[\\\"context_length\\\"],\\n\",\n \" top_k=1,\\n\",\n \" temperature=0.\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0f693da1-a07c-4e1d-af5a-c3923525f1e2\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"# What's next?\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fae93739-ca12-46ba-8ca7-7c07c59f669b\",\n \"metadata\": {},\n \"source\": [\n \"- This notebook converted the original GPT-2 architecture into a Llama 2 model\\n\",\n \"- If you are interested in how to convert Llama 2 into Llama 3, Llama 3.1, and Llama 3.2, check out the [converting-llama2-to-llama3.ipynb](converting-llama2-to-llama3.ipynb) notebook\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/07_gpt_to_llama/converting-llama2-to-llama3.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0_xya1nyDHfY\",\n \"metadata\": {\n \"id\": \"0_xya1nyDHfY\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"3357a230-b678-4691-a238-257ee4e80185\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"3357a230-b678-4691-a238-257ee4e80185\",\n \"outputId\": \"768ed6af-ce14-40bc-ca18-117b4b448269\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import login\\n\",\n \"import json\\n\",\n \"\\n\",\n \"with open(\\\"config.json\\\", \\\"r\\\") as config_file:\\n\",\n \" config = json.load(config_file)\\n\",\n \" access_token = config[\\\"HF_ACCESS_TOKEN\\\"]\\n\",\n \"\\n\",\n \"login(token=access_token)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"IxGh6ZYQo0VN\",\n \"metadata\": {\n \"id\": \"IxGh6ZYQo0VN\"\n },\n \"source\": [\n \"- After login via the access token, which is necessary to verify that we accepted the Llama 2 licensing terms, we can now download the tokenizer vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"69714ea8-b9b8-4687-8392-f3abb8f93a32\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 153,\n \"referenced_widgets\": [\n \"e6c75a6aa7b942fe84160e286e3acb3d\",\n \"08f0bf9459bd425498a5cb236f9d4a72\",\n \"10251d6f724e43788c41d4b7879cbfd3\",\n \"53a973c0853b44418698136bd04df039\",\n \"bdb071e7145a4007ae01599333e72612\",\n \"6b1821a7f4574e3aba09c1e410cc81e4\",\n \"8c2873eaec3445888ad3d54ad7387950\",\n \"0c8f7044966e4207b12352503c67dcbb\",\n \"8b5951213c9e4798a258146d61d02d11\",\n \"2c05df3f91e64df7b33905b1065a76f7\",\n \"742ae5487f2648fcae7ca8e22c7f8db9\"\n ]\n },\n \"id\": \"69714ea8-b9b8-4687-8392-f3abb8f93a32\",\n \"outputId\": \"c230fec9-5c71-4a41-90ab-8a34d114ea01\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import hf_hub_download\\n\",\n \"\\n\",\n \"tokenizer_file = hf_hub_download(\\n\",\n \" repo_id=\\\"meta-llama/Llama-2-7b\\\",\\n\",\n \" filename=\\\"tokenizer.model\\\",\\n\",\n \" local_dir=\\\"Llama-2-7b\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"gp7iQ8cXAJLv\",\n \"metadata\": {\n \"id\": \"gp7iQ8cXAJLv\"\n },\n \"source\": [\n \"- To provide a more familiar interface for the tokenizer, we define a small `LlamaTokenizer` wrapper class:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"Ef4WxhjOBOOc\",\n \"metadata\": {\n \"id\": \"Ef4WxhjOBOOc\"\n },\n \"outputs\": [],\n \"source\": [\n \"import sentencepiece as spm\\n\",\n \"\\n\",\n \"\\n\",\n \"class LlamaTokenizer:\\n\",\n \" def __init__(self, tokenizer_file):\\n\",\n \" sp = spm.SentencePieceProcessor()\\n\",\n \" sp.load(tokenizer_file)\\n\",\n \" self.tokenizer = sp\\n\",\n \"\\n\",\n \" def encode(self, text):\\n\",\n \" return self.tokenizer.encode(text, out_type=int)\\n\",\n \"\\n\",\n \" def decode(self, ids):\\n\",\n \" return self.tokenizer.decode(ids)\\n\",\n \"\\n\",\n \"\\n\",\n \"tokenizer = LlamaTokenizer(tokenizer_file)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"NVhmFeX3pT_M\",\n \"metadata\": {\n \"id\": \"NVhmFeX3pT_M\"\n },\n \"source\": [\n \"- We can now use the `generate` function to have the Llama 2 model generate new text:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"e0a2b5cd-6cba-4d72-b8ff-04d8315d483e\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"e0a2b5cd-6cba-4d72-b8ff-04d8315d483e\",\n \"outputId\": \"acd5065d-8900-4ba8-ef85-968365f3a0cb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort movesαllRadius deletingpretcc否']; future eer napulate lackус während inter DES издаSchéonkkarto Оryptato#{ningproof eerbye\\n\"\n ]\n }\n ],\n \"source\": [\n \"from previous_chapters import generate, text_to_token_ids, token_ids_to_text\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch05 import generate, text_to_token_ids, token_ids_to_text\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(\\\"Every effort moves\\\", tokenizer).to(device),\\n\",\n \" max_new_tokens=30,\\n\",\n \" context_size=LLAMA2_CONFIG_7B[\\\"context_length\\\"],\\n\",\n \" top_k=1,\\n\",\n \" temperature=0.\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"93WTtAA5paYV\",\n \"metadata\": {\n \"id\": \"93WTtAA5paYV\"\n },\n \"source\": [\n \"- Of course, as we can see above, the text is nonsensical since we haven't trained the Llama 2 model yet\\n\",\n \"- In the next section, instead of training it ourselves, which would cost tens to hundreds of thousands of dollars, we load the pretrained weights from Meta AI\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f63cc248-1d27-4eb6-aa50-173b436652f8\",\n \"metadata\": {\n \"id\": \"f63cc248-1d27-4eb6-aa50-173b436652f8\"\n },\n \"source\": [\n \" \\n\",\n \"## 4. Load pretrained weights\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"aKeN7rUfqZMI\",\n \"metadata\": {\n \"id\": \"aKeN7rUfqZMI\"\n },\n \"source\": [\n \"- We are loading the [\\\"meta-llama/Llama-2-7b\\\"](https://huggingface.co/meta-llama/Llama-2-7b) base model below, which is a simple text completion model before finetuning\\n\",\n \"- Alternatively, you can load the instruction-finetuned and aligned [\\\"meta-llama/Llama-2-7b-chat\\\"](https://huggingface.co/meta-llama/Llama-2-7b-chat) model by modifying the string in the next code cell accordingly\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"5fa9c06c-7a53-4b4d-9ce4-acc027322ee4\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 49,\n \"referenced_widgets\": [\n \"66e777955e8748df878f118f07f38dab\",\n \"da89ae3ea4d2474e98f64ada608f3cea\",\n \"93e6da39c25f4edfaa72056c89df1f7f\",\n \"b628603e4cb0405398c916587ee96756\",\n \"93bedcb9245e44a0a1eb7e4155070f66\",\n \"0723f467d37b4904819a8bb33ebda10f\",\n \"e54928776bc649339002adced63738b0\",\n \"d8e0f42068af4cb094e2f115f76e06e0\",\n \"0a939565b6e94f08bee0a66e0f9827d4\",\n \"a5fedbb7ec2e43d99711bb4cd84b9486\",\n \"0c186f6539714d8eab023969ce47c500\"\n ]\n },\n \"id\": \"5fa9c06c-7a53-4b4d-9ce4-acc027322ee4\",\n \"outputId\": \"0d8942cc-e5e2-4e77-ec41-1ac7bec7d94f\"\n },\n \"outputs\": [],\n \"source\": [\n \"weights_file = hf_hub_download(\\n\",\n \" repo_id=\\\"meta-llama/Llama-2-7b\\\",\\n\",\n \" filename=\\\"consolidated.00.pth\\\",\\n\",\n \" local_dir=\\\"Llama-2-7b\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 27,\n \"id\": \"e67cca5c-ba4b-4be5-85c7-fdceae8a5701\",\n \"metadata\": {\n \"id\": \"e67cca5c-ba4b-4be5-85c7-fdceae8a5701\"\n },\n \"outputs\": [],\n \"source\": [\n \"weights = torch.load(weights_file, weights_only=True)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"-15SJ7btq2zE\",\n \"metadata\": {\n \"id\": \"-15SJ7btq2zE\"\n },\n \"source\": [\n \"- The `weights` contains the following tensors (only the first 15 are shown for simplicity):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 28,\n \"id\": \"ee26bd0b-fea9-4924-97f7-409c14f28e49\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"ee26bd0b-fea9-4924-97f7-409c14f28e49\",\n \"outputId\": \"fa83d38a-bb41-4cb2-d3c7-c573bfe1f8a4\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"['tok_embeddings.weight',\\n\",\n \" 'norm.weight',\\n\",\n \" 'output.weight',\\n\",\n \" 'layers.0.attention.wq.weight',\\n\",\n \" 'layers.0.attention.wk.weight',\\n\",\n \" 'layers.0.attention.wv.weight',\\n\",\n \" 'layers.0.attention.wo.weight',\\n\",\n \" 'layers.0.feed_forward.w1.weight',\\n\",\n \" 'layers.0.feed_forward.w2.weight',\\n\",\n \" 'layers.0.feed_forward.w3.weight',\\n\",\n \" 'layers.0.attention_norm.weight',\\n\",\n \" 'layers.0.ffn_norm.weight',\\n\",\n \" 'layers.1.attention.wq.weight',\\n\",\n \" 'layers.1.attention.wk.weight',\\n\",\n \" 'layers.1.attention.wv.weight']\"\n ]\n },\n \"execution_count\": 28,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"list(weights.keys())[:15]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"UeeSpnunrDFB\",\n \"metadata\": {\n \"id\": \"UeeSpnunrDFB\"\n },\n \"source\": [\n \"- The following function, modeled after the `load_weights_into_gpt` function in [chapter 5](../01_main-chapter-code/ch05.ipynb), loads the pretrained weights into our Llama 2 model:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"3820e2a7-4f26-41bc-953b-f3879b0aff65\",\n \"metadata\": {\n \"id\": \"3820e2a7-4f26-41bc-953b-f3879b0aff65\"\n },\n \"outputs\": [],\n \"source\": [\n \"def assign(left, right, tensor_name=\\\"unknown\\\"):\\n\",\n \" if left.shape != right.shape:\\n\",\n \" raise ValueError(f\\\"Shape mismatch in tensor '{tensor_name}'. Left: {left.shape}, Right: {right.shape}\\\")\\n\",\n \" \\n\",\n \" with torch.no_grad():\\n\",\n \" if isinstance(right, torch.Tensor):\\n\",\n \" left.copy_(right)\\n\",\n \" else:\\n\",\n \" left.copy_(torch.as_tensor(right, dtype=left.dtype, device=left.device))\\n\",\n \"\\n\",\n \" return left \\n\",\n \"\\n\",\n \"\\n\",\n \"def permute(w: torch.Tensor, n_heads, out_dim, in_dim):\\n\",\n \" return (w.view(n_heads, out_dim // n_heads // 2, 2, in_dim)\\n\",\n \" .transpose(1, 2) # put axis 2 next to heads\\n\",\n \" .reshape(out_dim, in_dim))\\n\",\n \"\\n\",\n \"\\n\",\n \"def load_weights_into_llama(model, param_config, params):\\n\",\n \"\\n\",\n \" cfg = LLAMA2_CONFIG_7B\\n\",\n \" \\n\",\n \" model.tok_emb.weight = assign(model.tok_emb.weight, params[\\\"tok_embeddings.weight\\\"])\\n\",\n \"\\n\",\n \" for l in range(param_config[\\\"n_layers\\\"]):\\n\",\n \"\\n\",\n \" # The original Meta/Llama checkpoints store Q and K so that the two numbers \\n\",\n \" # that form one complex RoPE pair sit next to each other inside the head dimension (\\\"sliced\\\" layout).\\n\",\n \" # Our RoPE implementation, similar to the one in Hugging Face, expects an interleaved layout\\n\",\n \" # For example, with n_heads=2 and head_dim = 8\\n\",\n \" # ┌── pair 0 ──┐ ┌── pair 1 ──┐\\n\",\n \" # Meta (sliced): [ h0: r0 r1 r2 r3, h1: r0 r1 r2 r3 ]\\n\",\n \" # Ours & HF (interleaved): [ h0: r0 r0 r1 r1 r2 r2 r3 r3 , h1: ... ]\\n\",\n \" # For more information, please see the discussion in the PR: https://github.com/rasbt/LLMs-from-scratch/pull/747 \\n\",\n \" \\n\",\n \" # So, below, for q_raw and k_raw, we must re‑order the checkpoint weights using the slices_to_interleave helper\\n\",\n \"\\n\",\n \" q_raw = params[f\\\"layers.{l}.attention.wq.weight\\\"]\\n\",\n \" model.trf_blocks[l].att.W_query.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_query.weight,\\n\",\n \" permute(q_raw, cfg[\\\"n_heads\\\"], cfg[\\\"emb_dim\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" )\\n\",\n \" k_raw = params[f\\\"layers.{l}.attention.wk.weight\\\"]\\n\",\n \" model.trf_blocks[l].att.W_key.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_key.weight,\\n\",\n \" permute(k_raw, cfg[\\\"n_heads\\\"], cfg[\\\"emb_dim\\\"], cfg[\\\"emb_dim\\\"])\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].att.W_value.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_value.weight,\\n\",\n \" params[f\\\"layers.{l}.attention.wv.weight\\\"]\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].att.out_proj.weight = assign(\\n\",\n \" model.trf_blocks[l].att.out_proj.weight,\\n\",\n \" params[f\\\"layers.{l}.attention.wo.weight\\\"]\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].norm1.weight = assign(\\n\",\n \" model.trf_blocks[l].norm1.weight,\\n\",\n \" params[f\\\"layers.{l}.attention_norm.weight\\\"]\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Load FeedForward weights\\n\",\n \" model.trf_blocks[l].ff.fc1.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc1.weight,\\n\",\n \" params[f\\\"layers.{l}.feed_forward.w1.weight\\\"]\\n\",\n \" )\\n\",\n \" # For some reason w2 and w3 are provided in the wrong order in the weights file\\n\",\n \" model.trf_blocks[l].ff.fc2.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc2.weight,\\n\",\n \" params[f\\\"layers.{l}.feed_forward.w3.weight\\\"]\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].ff.fc3.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc3.weight,\\n\",\n \" params[f\\\"layers.{l}.feed_forward.w2.weight\\\"]\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].norm2.weight = assign(\\n\",\n \" model.trf_blocks[l].norm2.weight,\\n\",\n \" params[f\\\"layers.{l}.ffn_norm.weight\\\"]\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Load output layer weights\\n\",\n \" model.final_norm.weight = assign(model.final_norm.weight, params[\\\"norm.weight\\\"])\\n\",\n \" model.out_head.weight = assign(model.out_head.weight, params[\\\"output.weight\\\"])\\n\",\n \"\\n\",\n \"\\n\",\n \"load_weights_into_llama(model, LLAMA2_CONFIG_7B, weights)\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"TDuv_Us2rNvk\",\n \"metadata\": {\n \"id\": \"TDuv_Us2rNvk\"\n },\n \"source\": [\n \"- Next, we are ready to use the model for text generation\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"240987e8-a023-462e-9376-9edfb27559ec\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"240987e8-a023-462e-9376-9edfb27559ec\",\n \"outputId\": \"044f24b3-4018-4860-834d-6c2731b9e47c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort has been made to ensure the accuracy of the information contained in this website. However, the information contained in this website is not\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(\\\"Every effort\\\", tokenizer).to(device),\\n\",\n \" max_new_tokens=25,\\n\",\n \" context_size=LLAMA2_CONFIG_7B[\\\"context_length\\\"],\\n\",\n \" top_k=1,\\n\",\n \" temperature=0.\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d72ed949-b6c0-4966-922f-eb0da732c404\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## 5. Using the instruction-finetuned model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"akyo7WNyF_YL\",\n \"metadata\": {\n \"id\": \"akyo7WNyF_YL\"\n },\n \"source\": [\n \"- As mentioned earlier, above we used the pretrained base model; if you want to use a model capable of following instructions, use the `\\\"meta-llama/Llama-2-7b-chat\\\"` model instead, as shown below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"nbvAV7vaz6yc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 101,\n \"referenced_widgets\": [\n \"3b2448a60f5f4ba5b2c686037c8ecd78\",\n \"60c5932944f24f5fad1d8da89c8e5ae9\",\n \"aa31aed1b8854a4281fd7e81c60e1205\",\n \"d4acf06c2414412f8f2fb4f48981c954\",\n \"693d69251d3d48219c084af17b54b851\",\n \"ff36d28c55dd4db3a0f76a87640fdfe2\",\n \"71c49ef820494d5f8908a3daf39f0755\",\n \"525dc406534f4369b11208816f8fd0d7\",\n \"865f39213a7341b68f2fe73caaf801b1\",\n \"eaf4c0231b6d4993b2f8e9e63d8b6921\",\n \"a11edf3b018e42c88a63a515cf7fe478\"\n ]\n },\n \"id\": \"nbvAV7vaz6yc\",\n \"outputId\": \"724f5508-d976-4e31-b3d7-95fa65b2c1e8\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" What do llamas eat?\\n\",\n \"\\n\",\n \"Llamas are herbivores, which means they eat plants for their food. They feed on a variety\\n\"\n ]\n }\n ],\n \"source\": [\n \"del model # to free up memory\\n\",\n \"\\n\",\n \"weights_file = hf_hub_download(\\n\",\n \" repo_id=\\\"meta-llama/Llama-2-7b-chat\\\",\\n\",\n \" filename=\\\"consolidated.00.pth\\\",\\n\",\n \" local_dir=\\\"Llama-2-7b-chat\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"weights = torch.load(weights_file, weights_only=True)\\n\",\n \"model = Llama2Model(LLAMA2_CONFIG_7B)\\n\",\n \"load_weights_into_llama(model, LLAMA2_CONFIG_7B, weights)\\n\",\n \"model.to(device);\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(\\\"What do llamas eat?\\\", tokenizer).to(device),\\n\",\n \" max_new_tokens=25,\\n\",\n \" context_size=LLAMA2_CONFIG_7B[\\\"context_length\\\"],\\n\",\n \" top_k=1,\\n\",\n \" temperature=0.\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0f693da1-a07c-4e1d-af5a-c3923525f1e2\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"# What's next?\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fae93739-ca12-46ba-8ca7-7c07c59f669b\",\n \"metadata\": {},\n \"source\": [\n \"- This notebook converted the original GPT-2 architecture into a Llama 2 model\\n\",\n \"- If you are interested in how to convert Llama 2 into Llama 3, Llama 3.1, and Llama 3.2, check out the [converting-llama2-to-llama3.ipynb](converting-llama2-to-llama3.ipynb) notebook\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/07_gpt_to_llama/converting-llama2-to-llama3.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0_xya1nyDHfY\",\n \"metadata\": {\n \"id\": \"0_xya1nyDHfY\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"ws0wsUzwLH2k\",\n \"metadata\": {\n \"id\": \"ws0wsUzwLH2k\"\n },\n \"outputs\": [],\n \"source\": [\n \"# pip install -r requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"JBpQwU89ETA1\",\n \"metadata\": {\n \"id\": \"JBpQwU89ETA1\"\n },\n \"source\": [\n \"- Packages that are being used in this notebook:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"34a9a440-84c2-42cc-808b-38677cb6af8a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"34a9a440-84c2-42cc-808b-38677cb6af8a\",\n \"outputId\": \"e3d3d4b6-ee63-4e28-d794-e8b0bdd931fd\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"blobfile version: 3.1.0\\n\",\n \"huggingface_hub version: 0.34.4\\n\",\n \"tiktoken version: 0.11.0\\n\",\n \"torch version: 2.8.0\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"blobfile\\\", # to download pretrained weights\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"matplotlib\\\", # to visualize RoPE with different base frequencies\\n\",\n \" \\\"tiktoken\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"UJJneXpTEg4W\",\n \"metadata\": {\n \"id\": \"UJJneXpTEg4W\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Convert the Llama model implementation step by step\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"v1zpfX2GHBKa\",\n \"metadata\": {\n \"id\": \"v1zpfX2GHBKa\"\n },\n \"source\": [\n \"- If you are new to implementing LLM architectures, I recommend starting with [chapter 4](../../ch04/01_main-chapter-code/ch04.ipynb), which walks you through the implementation of the original GPT architecture step by step\\n\",\n \"- The [Converting a From-Scratch GPT Architecture to Llama 2](./converting-gpt-to-llama2.ipynb) then implements the Llama-specific components, such as RMSNorm layers, SiLU and SwiGLU activations, RoPE (rotary position embeddings), and the SentencePiece tokenizer\\n\",\n \"- This notebook takes the Llama 2 architecture and transforms it into Llama 3 architecture by\\n\",\n \" 1. modifying the rotary embeddings\\n\",\n \" 2. implementing grouped-query attention\\n\",\n \" 3. and using a customized version of the GPT-4 tokenizer\\n\",\n \"- Later, we then load the original Llama 3 weights shared by Meta AI into the architecture\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c14b9121-abe1-4a46-99b8-acdef71e5b41\",\n \"metadata\": {\n \"id\": \"c14b9121-abe1-4a46-99b8-acdef71e5b41\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.1 Reusing Llama 2 components\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dgDhJGJ6xR4e\",\n \"metadata\": {\n \"id\": \"dgDhJGJ6xR4e\"\n },\n \"source\": [\n \"- Llama 2 is actually quite similar to Llama 3, as mentioned above and illustrated in the figure at the top of this notebook\\n\",\n \"- This means that we can import several building blocks from the [Llama 2 notebook](./converting-gpt-to-llama2.ipynb) using the following code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"a5bc3948-231b-4f1f-8d41-24ad0b7643d0\",\n \"metadata\": {\n \"id\": \"a5bc3948-231b-4f1f-8d41-24ad0b7643d0\"\n },\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"import sys\\n\",\n \"import io\\n\",\n \"import nbformat\\n\",\n \"import types\\n\",\n \"\\n\",\n \"def import_from_notebook():\\n\",\n \" def import_definitions_from_notebook(fullname, names):\\n\",\n \" current_dir = os.getcwd()\\n\",\n \" path = os.path.join(current_dir, fullname + \\\".ipynb\\\")\\n\",\n \" path = os.path.normpath(path)\\n\",\n \"\\n\",\n \" # Load the notebook\\n\",\n \" if not os.path.exists(path):\\n\",\n \" raise FileNotFoundError(f\\\"Notebook file not found at: {path}\\\")\\n\",\n \"\\n\",\n \" with io.open(path, \\\"r\\\", encoding=\\\"utf-8\\\") as f:\\n\",\n \" nb = nbformat.read(f, as_version=4)\\n\",\n \"\\n\",\n \" # Create a module to store the imported functions and classes\\n\",\n \" mod = types.ModuleType(fullname)\\n\",\n \" sys.modules[fullname] = mod\\n\",\n \"\\n\",\n \" # Go through the notebook cells and only execute function or class definitions\\n\",\n \" for cell in nb.cells:\\n\",\n \" if cell.cell_type == \\\"code\\\":\\n\",\n \" cell_code = cell.source\\n\",\n \" for name in names:\\n\",\n \" # Check for function or class definitions\\n\",\n \" if f\\\"def {name}\\\" in cell_code or f\\\"class {name}\\\" in cell_code:\\n\",\n \" exec(cell_code, mod.__dict__)\\n\",\n \" return mod\\n\",\n \"\\n\",\n \" fullname = \\\"converting-gpt-to-llama2\\\"\\n\",\n \" names = [\\\"precompute_rope_params\\\", \\\"compute_rope\\\", \\\"SiLU\\\", \\\"FeedForward\\\", \\\"RMSNorm\\\", \\\"MultiHeadAttention\\\"]\\n\",\n \"\\n\",\n \" return import_definitions_from_notebook(fullname, names)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"d546032d-fce4-47cf-8d0e-682b78b21c61\",\n \"metadata\": {\n \"id\": \"d546032d-fce4-47cf-8d0e-682b78b21c61\"\n },\n \"outputs\": [],\n \"source\": [\n \"imported_module = import_from_notebook()\\n\",\n \"\\n\",\n \"# We need to redefine precompute_rope_params\\n\",\n \"# precompute_rope_params = getattr(imported_module, \\\"precompute_rope_params\\\", None)\\n\",\n \"compute_rope = getattr(imported_module, \\\"compute_rope\\\", None)\\n\",\n \"SiLU = getattr(imported_module, \\\"SiLU\\\", None)\\n\",\n \"FeedForward = getattr(imported_module, \\\"FeedForward\\\", None)\\n\",\n \"RMSNorm = getattr(imported_module, \\\"RMSNorm\\\", None)\\n\",\n \"\\n\",\n \"# MultiHeadAttention only for comparison purposes\\n\",\n \"MultiHeadAttention = getattr(imported_module, \\\"MultiHeadAttention\\\", None)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"979c7b6d-1370-4da1-8bfb-a2b27537bf2f\",\n \"metadata\": {\n \"id\": \"979c7b6d-1370-4da1-8bfb-a2b27537bf2f\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.2 Modified RoPE\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"m9_oDcHCx8VI\",\n \"metadata\": {\n \"id\": \"m9_oDcHCx8VI\"\n },\n \"source\": [\n \"- Llama 3 uses rotary position embeddings (RoPE) similar to Llama 2 (for a detailed explanation, please see the [RoPE paper](https://arxiv.org/abs/2104.09864))\\n\",\n \"- There are some subtle differences in the RoPE settings, though\\n\",\n \" - Llama 3 now supports up to 8,192 tokens, twice as many as Llama 2 (4,096)\\n\",\n \" - The base value for the so-called RoPE $\\\\theta$ (see equation below) was increased from 10,000 (Llama 2) to 500,000 (Llama 3) in the following equation (adapted from the [RoPE paper](https://arxiv.org/abs/2104.09864))\\n\",\n \"\\n\",\n \"$$\\\\Theta = \\\\left\\\\{\\\\theta_i = \\\\text{base}^{\\\\frac{-2(i-1)}{d}}, i \\\\in \\\\left[1, 2, ..., d/2\\\\right]\\\\right\\\\}$$\\n\",\n \"\\n\",\n \"- These $\\\\theta$ values are a set of predefined parameters that are used to determine the rotational angles in the rotary matrix, where $d$ is the dimensionality of the embedding space\\n\",\n \"- Increasing the base from 10,000 to 500,000 makes the frequencies decay faster across the dimensions, which means that the higher-dimensional components are associated with smaller rotation angles than before, so the overall frequency range becomes more compressed rather than expanded\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"ec8ded9f-3709-475a-87ff-0faee176207e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAnYAAAHWCAYAAAD6oMSKAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAAcqBJREFUeJzt3Qd4U+XbBvA76d60lC723nuDCCiCqIgD5QMVREVBVBQ3CqioOBEHiqAo+lfBCSigoLJkT2WWvUoHpdCW7ibnu543TUgnHWkzev+u65jk5OTk7Wlqbt6p0zRNAxERERE5Pb29C0BEREREtsFgR0REROQiGOyIiIiIXASDHREREZGLYLAjIiIichEMdkREREQugsGOiIiIyEUw2BERERG5CHd7F8CRGI1GnD17FgEBAdDpdPYuDhERERFkLYnU1FRERUVBry+5To7BzoqEurp169q7GERERESFnD59GnXq1EFJGOysSE2d+cIFBgbauzhERERESElJURVP5pxSEgY7K+bmVwl1DHZERETkSErTTYyDJ4iIiIhcBIMdERERkYtgsCMiIiJyEexjR0RUTRkMBuTk5Ni7GETVnoeHB9zc3GxyLgY7IqJqOCdWXFwcLl68aO+iEFGeGjVqICIiosLz6DLYERFVM+ZQFxYWBl9fX07ITmTnf2ilp6cjISFBPY6MjKzQ+RjsiIiqWfOrOdTVrFnT3sUhIgA+Pj7qVsKd/G1WpFmWgyeIiKoRc586qakjIsdh/pusaL9XBjsiomqIza9Ervk3yWBHRERE5CIY7IiIyOH169cPjz/+uL2LQaWQnZ2NJk2aYOPGjaU6/ssvv1QjQp3Vc889h0cffRSOwiGD3bp16zBkyBBERUWpqsnFixdf8TVr1qxBp06d4OXlpT5Q8kEhIiJyZI899hg6d+6svrs6dOhQ5DH//fcf+vTpA29vb7UQ/FtvvXXF8546dQo33nij6rclnfGffvpp5Obmlvl7c/bs2WjQoIF67+7du2Pr1q1XfO85c+agYcOG6NWrl2Vfab/LHc2aNWswdOhQNVLVz89P/Y6++eabfMc89dRTWLBgAY4dOwZH4JDBLi0tDe3bt1cfqNI4fvy4+gD3798fu3fvVv+qe+CBB/DHH39UelmJiIgq4r777sPw4cOLfC4lJQUDBw5E/fr1sWPHDrz99tt46aWXMHfu3BJHPst3otScSa2ZhA4JbVOnTi3T9+aiRYswadIkTJs2DTt37lTfy4MGDbJMy1Hc1B0fffQR7r//frgCuX7t2rXDTz/9pAL2mDFjMGrUKPz222+WY0JDQ9V1+eSTT+AQNAcnRfzll19KPOaZZ57RWrdunW/f8OHDtUGDBpXpvZKTk9X7yS0RkSvKyMjQ9u/fr26dSd++fbUJEyaoLTAwUKtZs6b24osvakaj0XLMV199pXXu3Fnz9/fXwsPDtREjRmjx8fGW55OSkrSRI0dqoaGhmre3t9akSRNt/vz5ludPnTql3XHHHVpQUJAWHBys3Xzzzdrx48er5OebNm2a1r59+0L7P/74Y1WWrKwsy75nn31Wa968ebHnWr58uabX67W4uDjLvk8++URdN/N5SvO92a1bN3W9zQwGgxYVFaXNmDGj2Pfetm2beu+UlJRSf5d/8cUX6pqbHTlyRF37sLAwzc/PT+vSpYu2atWqfK+pX7++Nn36dO2ee+5Rx9SrV09bsmSJlpCQoF4r+9q2bavKY5aYmKj93//9n/oZfHx8tDZt2mjffvutVlY33HCDNmbMmHz7FixYoNWpU0errL/NsuQTh6yxK6tNmzZhwIAB+fZJepb9JcnKylL/GrLeKtN/Zy5ixvID+N/mk5X6PkREZZocNTvXLpvp+770pObJ3d1dNQe+//77mDlzJj777DPL8zJNxPTp0/Hvv/+qZr8TJ07g3nvvtTw/ZcoU7N+/HytWrMCBAwdUDYvUtphfK98bAQEBWL9+PTZs2AB/f39cf/31quarOHJMSdu4ceNQEfI9dvXVV8PT09OyT8oZHR2NCxcuFPuatm3bIjw8PN9r5Dtu3759pfrelJ9Zagitj9Hr9epxSd+tcu2aNWumrmN5Xbp0CTfccAP++usv7Nq1S/0OpHuWNC9be++999C7d291jNQ+3nPPPao27e6771Y1jI0bN1aPzZ+zzMxM1ey9bNky7N27Fw8++KB6TWmal60lJycjJCQk375u3brhzJkz6jNnb+6uMou69QdYyGP5EGdkZFgm/itoxowZePnll6uolEDMsf3w2vA5ULMG0OPdKntfIqLiZOQY0Gqqfbqt7H9lEHw9S/81JP3L5Mtc+ms1b94ce/bsUY/Hjh1radI0a9SoET744AN07dpVBQUJWRIMOnbsiC5duqhjpO+YdbOj0WhUQdE87cQXX3yhOvVLPytpDi2KNGOWJDAwEBX9fpP+atbM33fyXHBwcKm/E83PleZ7U0KjNOkWdczBgweLLe/JkydV//iKkCZf2cwkrP/yyy9YunQpHnnkEct+CX8PPfSQui/NzBLUu3btijvuuEPte/bZZ9GzZ0/Ex8erpbpq166t+sOZyYAHaXr+/vvvVTArDTl227Zt+PTTT/PtN//M8vNbf67swSWCXXk9//zzqv+AmXyg5X8claWJdwoGe/yIkymyXAiDHRFRWfTo0SPfXF/ypf3uu++qACIz9UsNk/Q/kxo7CSYS1IQEulatWmH8+PG4/fbbVW2OBLVbbrnF0sFfXnPkyJFCNU1Sy3P06NFiyySDDugyCYUy0KIiJIjL71Fq1mJjY9WgDzlvwRo76ftmZg6gbdu2LbRP+gRKsJPPyeuvv67CWUxMjKqVlJa70k7WvXr1atXHbt68eWjdunW+58wVSLI0mL25RLCTX5gkcmvyWP6lVFxtnZCRQLJVlch6pv8BRGiJSE7LRpDf5ap1IiJ78PFwUzVn9npvWw66k6ZE2WTUYq1atVQQkMfmptTBgwerGpXly5dj1apVuPbaazFhwgS88847KkxIM13BEY9CzlUcqQksiTQLyihRW3+/mZ8r7jUFmxcLvuZK35sSlGUr6pji3ldI07bUpFaE1KrJ70d+LxKcpTzDhg0r1CTu4eFhuW8O/B5F7DMHfBl4Ik34s2bNUgFQRrnKoJGSmtrN1q5dq5qDpYZYmncLSkpKuuJnpaq4RLCTf7XJH6o1+VDIfkfiH1oPRujgpcvBwdMn0L5FM3sXiYiqOfnyK0tzqD1t2bIl3+PNmzejadOmKoBI8+D58+fxxhtvWFpetm/fXugc8sU7evRotckUIjINiAQImfZDmmNlapCyNJ9WdlOsfI+98MILqg+gObTI95s0RRfVDGt+zWuvvWZZd9T8GimL1FyW5ntT+vRJ0JV+blKzaQ5I8ti6ObQgaeqWJlHp11belRSkf6P0jbz11lvVYwndtui7tmHDBjV1iYRt889z6NAhyzUpjjTF33TTTXjzzTdVv7yiSJ89+f0UrMmzB4ccPCG/RPljMf/ByLBsuW+uhpUmVOvELJ1TZf6YZ555Rv1xf/zxx6qq9YknnoBDcfdEst70hxh/uviqfSIiKky+A6T7jAwc+O677/Dhhx9i4sSJ6rl69eqpMCL75PtA+mNJ3yxr0g9ryZIlqslVBhHIlBUtW7ZUz911112qtkm++GUAgHzvyBe6zDMnneKLIzVKJW3mYFUcKYt8v0mfN2luNH/3mWuRRo4cqX4umT5EyizhU2qdrLsRFSTNzBJWZGCANDFLP7IXX3xR1U6aW6lK870p7yHNjjJoRQabSFO21IxKc2RxZPoU+Q43D9KwZv4ut97kfAVJWP/555/V81J+uQbmWreKaNq0qQqvMoWJ/DzSP69gjWRRza8yMEM+B9KML78n2cw1dGbymZF/KJTUSlhlNAe0evVqNay34DZ69Gj1vNzK0PeCr+nQoYPm6empNWrUSA2fLquqmO7k9Js9NW1aoPb9V7Mr7T2IiFxxupOHH35YGzdunJq2Q6YAmTx5cr7pTmTqigYNGmheXl5az549taVLl6r/p+/atUs9L9NjtGzZUk11ERISog0dOlQ7duyY5fWxsbHaqFGj1HQocg75Lhk7dmylfifIz1XU9531NCv//vuvdtVVV6ky1a5dW3vjjTeK/M60fs2JEye0wYMHq59Vfp4nn3xSy8nJKfP35ocffqimEpFjZPqTzZs3X/FnuvPOO7Xnnnsu376ifkbZ1q9fX2i6E/k5+vfvr8pet25d7aOPPlLXaeLEifmmO3nvvfdKnFLl+PHj+X7/58+fV79zmQ5HplKR6XLk9y37iiN5o6hyF8wgMv3Md999pznCdCc6+Y+9w6WjkMETQUFBaihzRavPi3Nyzh2oH7cS3wSPx10T36iU9yAiKo4MBpCaExlpWdFO7uQYZPSuDAqQqVys+5jZi0zke91116lBJ1fqg+gKVqxYgSeffFL93DIdT2X8bZYlnzhkU6wr8wipp27dUmPsXRQiInIB0ldOgp0jhDrzaFXpjyYhpTpIS0tT4boioc6WHKMU1YjPVRNwza4WiM2qiaHZBvh42m5UGBERVT8//PADHI31xNCubtiwYXAkrLGrYsFRjXDBpz4yNC8cPXfJ3sUhIiIiF8JgZwdNwkx9DhjsiIiIyJYY7KpabjYe0n7AG+5zcSw2/3BpIiIioopgsKtqbh7od+4b/J/7GpyPtf9iwUREROQ6GOyqmk6HbD/TYsEZiSftXRoiIiJyIQx2dqAPNi13o0uJQY6h4rNpExEREQkGOzvwCjEFu3AtESfPp9u7OEREDq9fv35qwXZyDbLmrCznZjAYXP73n52djQYNGhS5dnFlYLCzA12QKdjV1iXiSEKqvYtDRER2otPpCm0LFy7Md4ysWdupUye1zqusP/vll18WOs/s2bNVeJAVC7p3746tW7eWav67Fi1aqNe0bdtWTXRsTRamkvV1IyMj1RqoAwYMwOHDh/MdI2umyjq7shpCjRo11Jq2slbslcgatbJ+rZubaS5X+Znk9c7ok08+UZMyyzWQrWfPnmo1CjNZ6/epp57Cs88+WyXlYbCzh6A66iZSdx5HEjjlCRFRdSarFsTGxlq2W265xfKcrN4gi9D3798fu3fvVrVWDzzwAP744w/LMYsWLcKkSZMwbdo07Ny5E+3bt8egQYOQkJBQ7Htu3LgRI0aMUEFs165d6j1l27t3r+WYt956Cx988AHmzJmDLVu2wM/PT51Xlr4yk1C3b98+rFq1Cr/99hvWrVuHBx98sMSf959//lHLjd1+++1wBXXq1MEbb7yBHTt2qFq5a665BkOHDlXXxfo6yc9tva/SVGjFWhdTlkV2K+TI35o2LVCLntJSm/jdzsp9LyKiUi407shk0fUJEyaoLTAwUKtZs6ZaxN1oNFqO+eqrr7TOnTurRd7Dw8O1ESNGaPHx8Zbnk5KStJEjR2qhoaGat7e31qRJE23+/PmW50+dOqXdcccdakH64OBg7eabb1YLyVemggvXF/TMM89orVu3zrdv+PDh2qBBgyyPu3Xrpq6LmcFg0KKiorQZM2YUe94777xTu/HGG/Pt6969u/bQQw+p+3JdIyIitLffftvy/MWLFzUvLy/LYvfyOZLyb9u2zXLMihUrNJ1Op8XExBT73lLWYcOG5dv3xRdfqOte0u9/4sSJpf5dr169WpXt999/1zp06KB+3/3791fHLF++XGvRooUWEBCgXpeWlpav/L1791ZlCQkJUdfoyJEjWlnJ5+ezzz7Lt0/eXz6z5fnbLEs+YY2dPdTthvXXr8DN2a/iCCcpJiIqlQULFqj1OKWZ8f3338fMmTPx2WefWZ7PycnB9OnT8e+//2Lx4sU4ceJEvqWtpkyZgv3796tmsgMHDqgmtNDQUMtrpTYqICAA69evx4YNG9QC9tdff73qI1UcOaakbdy4cVf8uSZMmKDK0a1bN8yfP181gZpt2rRJNYFak3LKfiFlk5oi62P0er16bD6mKFc6r9QUxsXF5TtGFqGXZl7zMXIrzaddunSxHCPHy/tLDV9x5Ppav6Y8rvS7NnvppZfw0UcfqRrK06dP484778SsWbPw7bffYtmyZVi5ciU+/PDDfOu+Su2n1LxJP0D5WW699VYYjaUb6Ch9BqUpXc4jTbLW5PcrP3tl41qx9uDph6jG7ZCJCziakAajUYNer7N3qYioOstOK/45nRvg4V3KY/WAh8+Vj/X0K3MR69ati/fee0/1Q2vevDn27NmjHo8dO1Y9f99991mObdSokWpG7Nq1q+rzJSHr1KlT6NixoyVUSJ806+ZM+fKWoCjnNzeRSnCRPm4DBw4sskzSPFoS6XNVkldeeUU13fn6+qqQ8fDDD6vyPvbYY+p5CVfh4eH5XiOPU1JSkJGRgQsXLqgwUdQxBw8eLPZ9izuv7Dc/b95X0jFhYWH5npfgHRISYjmmKCdPnkRUlGnar/K60u/a7NVXX0Xv3r3VfWl2fv7551UzsLzGvM7r6tWrLf3fCjYPS9CuVauW+gdBmzZtUBz5LEqQk2Zqef9ffvkFrVq1yneM/Mzys1c2Bjs7qR/iCw83HTJyDIi5mIG6Ib72LhIRVWevl/BF23QgcJfVQvNvNwFyihnRX/8qYMyyy49ntQXSzxc+7qXkMhexR48eltAl5Iv03XffVcFGOuFLzZXU0EgtjgQecy2LBDr5kh0/frz64pZ+aBLUpE9Zr1691DHymiNHjqgaO2vyRS1BoDgymKEipBbRTEKn1PS8/fbblmDniiSQyoCNirjS79pMBjVYh1IJ0OZQZ95nPdBEBofIgBGpcUxMTMx33pKCnfxDQ0J+cnIyfvzxR4wePRpr167NVxYZgJKeXvkzYbAp1k7cd3+ND3zno4PuCJtjiYgqSAKRNCVKDdk333yDbdu2qVoTYW5KHTx4sKoxeeKJJ3D27Flce+21arSikJqezp07qy9n6+3QoUMYOXJkpTbFWpOmzjNnziArK0s9joiIQHx8fL5j5LH8nBIUpAlXQm1Rx8hri1Pcec2vMd9e6ZiCAzRyc3PVSNmS3lvKLGGsMn/XZh4eHpb78o8C68fmfdbNrEOGDFHlnzdvngp35iblkprjzSNfJeTLZ2jGjBlqAIt0F7Am55Xav8rGGjt7OfQHBueswgZ9HRxNuIT+zfNXZxMRVanJZ0tuirX29JESji1QX/D4HthKwX5bmzdvRtOmTVWwkWbH8+fPq9GJ0mQripo3TL5YpTZFtj59+uDpp5/GO++8o6YTkeZYaVq8UvOpLZtiizpfcHCwmtrEXCtZcBoSGYFq7r8lgULChPQHM4+mlaAijx955JFi30deL8dYzw1nfd6GDRuqcCbHdOjQQe2T5l/5HUjNp/kcFy9eVLVnUgbx999/q/eXgFocqZmUps3yKu3vuqzknNHR0SrUyWdDyEjW8pBrYA7nZjLiWH72ysZgZ+cpT6I45QkROYKy9HmrrGOvQJrDpGP7Qw89pJpTpdO7NMWKevXqqZAj+6SWTL5EpXO9NWlikwDSunVr9aUr03PIJLnm6SikCVSmqZB+bzKFhdTu/fzzz2rONXls66bYX3/9VdWASROzNE1KsHr99dcttYhCfhbp/C9lkH5lEpy+//571fHfTK6JBFXpOygd9GVwgNRqjRkzptj3njhxIvr27auun0ynIh3+JRzNnTvXUpMloU/6qEl4lqAnzcbST8wcIOXayeAS6eMoU6LIgAYJk//3f/9XYh86qW2TgTAFSZN6waAsAdf8OzIrze+6PCRQ16xZU10DmbtPPm/PPffcFV8n/fakNljKlZqaqgZmSL9M6ylphAycsEU5r6jMY3hdWJVNdyL+maWmPPnlxeu12z/eUPnvR0Tk5NOdPPzww9q4cePUdCcyncTkyZPzTXfy7bffag0aNFBTcvTs2VNbunSp+n/6rl271PPTp0/XWrZsqfn4+KipLIYOHaodO3bM8vrY2Fht1KhRajoUOUejRo20sWPHVtp3gkytIVNxyJQdfn5+Wvv27bU5c+ao6UqsydQdcpynp6cqk0wNUtCHH36o1atXTx0j059s3rw53/OjR49W19Da999/rzVr1ky9RqZUWbZsWb7n5dpOmTJFTSci1+Paa6/VoqOj8x1z/vx5NWWI/AzyexkzZoyWmppa4s8tr5HpRw4ePGjZJz+T/K4Kbo0bNy5yupMr/a5X5013cuHChRKnVJk2bZq67marVq1SnxE5b7t27bQ1a9ZccUqa++67T6tfv766jrVq1VLXaeXKlfmO2bhxo1ajRg0tPT290qc70cl/Kj8+OgepZpbh3NL5sazV52W29yfgx/uw1dgcY91exe6p1+XrFExEVBlkMIBMZSE1MBXtwE7OQ2rnZJJjGXDgCKQJXL5zP/30U1QHw4cPV/3uJk+eXK6/zbLkEw6esJe8ZcWkKTY5IweJl0rumElERFQeEgZkZK91E6+9vfDCC6hfv36p54dzZtnZ2WrJNhm0UxXYx87OfewidEnQw6j62dUKMHWWJSIishWp6ZGRto5E5gcsqfbKlXh6eqp1casKa+zsxT8c0LvDHUbUwkVOeUJEREQVxmBnL3o34JFteKvzGsQjRE15QkRERFQRDHb2FNIIDSJM6xRyyhMiIiKqKAY7O2scZlrT7nBCqr2LQkTVCCdEIHLNv0kGO3s6thZtd7yAe9xWIj4lCymZOfYuERG5OPOSSlWxZiURlZ75b7LgsmdlxVGx9nT+CDz/+wYDPLvi64yBqp9dx3rB9i4VEbkwWX5LRiSa1/iURdE5hyaRfWvqJNTJ36T8bcrfaEUw2DnAXHb13ZMs/ewY7IiospkXaC+4gDsR2Y+EOvPfZkUw2NlTUG11E2Y8p2455QkRVQWpoZO1MGXBe1nfk4jsS5pfK1pTZ8Zg5wCTFPsaUuCDTByJZ7AjoqojXyS2+jIhIsfAwRP25B0EeAValhZjjR0RERFVBIOdg9TaSbA7nZSOzByDvUtERERETorBzt4CTf3s6numwKgBxxPT7F0iIiIiclIMdvZ2yyfA5FjsD7tJPeQKFERERFReDHb25l8L8PRFk7wVKBjsiIiIqLwY7BwEgx0RERFVFIOdvV08DSx5BEOOTVcPGeyIiIiovDiPnb1pBmDX14hw8wIwTA2eyDUY4e7GzE1ERERlw/RgbwFRMg88dIYsRHlcQrbBiNMXMuxdKiIiInJCDHb25u4J+Ieru11rpKtbNscSERFReTDYOdAkxW0DUtXt4QTTLREREVFZMNg5ULBr6p2sblljR0REROXBYOdAwa6e23l1Gx3HGjsiIiIqOwY7Bwp2tdxMfewOx19CjsFo50IRERGRs2GwcwSdRqllxXzvnAt/L3c1MvboOTbHEhERUdkw2DkCTz+1rJher0PLyAC160Bsir1LRURERE6Gwc7BtIwMVLf7zzLYERERUdkw2DmKZU8BX92CLjXS1MP9rLEjIiKiMmKwcxTHVquttU+SenggNhWaptm7VEREROREGOwcbGRsXbck6HVAUlo24lOy7F0qIiIiciIMdo4i0BTsPC+dReNa/uo+B1AQERFRWTDYOViNHVLOXB5AwWBHREREZcBg52jBLvkMWkUx2BEREVHZMdg5YLAz19gd4JQnREREVAYMdo4W7HLS0Sov2B0/n4b07Fz7louIiIichru9C0B5QhqpZcVkBYpaAEL9vZB4KQsH41LRqV6wvUtHREREToA1do5C76ZCnZm5nx1HxhIREVFpMdg5KHNzLJcWIyIiotJiU6wj2ToPOLgM6Hg3Wkb2VLtYY0dERESlxRo7R5J42LS0WPxetM5ripU+dgYjlxYjIiKiK2OwcyRBtU23F0+jQU0/eLnrkZ5twMnzafYuGRERETkBBjtHUqOe6fbiSbi76dEiIkA9PBCbat9yERERkVNw6GA3e/ZsNGjQAN7e3ujevTu2bt1a4vGzZs1C8+bN4ePjg7p16+KJJ55AZmYmnEZIY9Nt0jF1c3lpsWR7loqIiIichMMGu0WLFmHSpEmYNm0adu7cifbt22PQoEFISEgo8vhvv/0Wzz33nDr+wIED+Pzzz9U5Jk+eDKeay06knwcyLlpNecIaOyIiInLiYDdz5kyMHTsWY8aMQatWrTBnzhz4+vpi/vz5RR6/ceNG9O7dGyNHjlS1fAMHDsSIESOuWMvnULz8Af9w0/2ko5dr7DjlCRERETlrsMvOzsaOHTswYMAAyz69Xq8eb9q0qcjX9OrVS73GHOSOHTuG5cuX44Ybbij2fbKyspCSkpJvc4jmWN9QVWNn7mMXl5KJpLRse5eMiIiIHJxDzmOXmJgIg8GA8PC82qs88vjgwYNFvkZq6uR1V111FTRNQ25uLsaNG1diU+yMGTPw8ssvw6GMWgy4e6m7Euvq1/TFyfPpaj673k1C7V06IiIicmAOWWNXHmvWrMHrr7+Ojz/+WPXJ+/nnn7Fs2TJMnz692Nc8//zzSE5OtmynT5+G3eWFOrOWEVxajIiIiJy4xi40NBRubm6Ij4/Pt18eR0REFPmaKVOm4J577sEDDzygHrdt2xZpaWl48MEH8cILL6im3IK8vLzU5shkAMXv++LYz46IiIics8bO09MTnTt3xl9//WXZZzQa1eOePU1LbRWUnp5eKLxJOBTSNOs0UmKBr28FPu1bYMoTBjsiIiJywho7IVOdjB49Gl26dEG3bt3UHHVSAyejZMWoUaNQu3Zt1U9ODBkyRI2k7dixo5rz7siRI6oWT/abA55T8AoAjv5tup9xwTLlyZGES8jKNcDL3Yl+FiIiIqpSDhvshg8fjnPnzmHq1KmIi4tDhw4d8Pvvv1sGVJw6dSpfDd2LL74InU6nbmNiYlCrVi0V6l577TU4FfOUJ5fi1UTFUVGdEOjtjpTMXBXuWkcF2buERERE5KB0mlO1U1Yume4kKChIDaQIDDTVlNnF/MHAqY3A7Z8DbYfh/+ZuwuZjSXh7WDvc0aWu/cpFREREDp1PHLKPXbVnXoGi0NJi7GdHRERExWOwc0Q184Ld+aPqplVesOOUJ0RERFQSBjsnqLEzD6CQKU/Yck5ERETFYbBzRLKsmE8I4G0aKNEkzB/uep0aQHE2OdPepSMiIiIH5bCjYqu1iLbAs8ctD2WKEwl3B+NSVa1d7Ro+di0eEREROSbW2Dkina7QLvazIyIioithsHMS1v3siIiIiIrCYOeoNn0MfNARWP9uvilPDsQx2BEREVHRGOwcVW6GaVTsuUP5gt3J8+lIzcyxc+GIiIjIETHYOfyUJ6a57EL8PBER6K3uR8el2rNkRERE5KAY7Bx5yhOruezy9bPjAAoiIiIqAoOdowppaLpNPw9kXMw3MpYDKIiIiKgoDHaOyisA8A/PV2vXprYp2P17JtmeJSMiIiIHxWDnRM2x7evWULfRcSlIz861Z8mIiIjIATHYObLI9kBUJ8DN0/QwyAfhgV4wasAe1toRERFRAVxSzJENfqPQrg51a+CPffH498xFdG9U0y7FIiIiIsfEGjsn06FusLrdfdo0oIKIiIjIjMHOGRgN+WrsxO5TDHZERESUH4OdI8vNBj7qCrwWAWSa+tS1qxMEvQ44m5yJhJRMe5eQiIiIHAiDnSNz9zQFOkM2cN60AoWflzuahQeo+7vYHEtERERWGOyccAWK9nXymmMZ7IiIiMgKg53TrBl7Odh1qMd+dkRERFQYg52zLC1mHezyBlD8d+YiDDKpHRERERGDnROomdcUm9fHTkgfO19PN6RlG3Ak4ZL9ykZEREQOhcHOCZti3fQ6tK0dpO7vPn3BXiUjIiIiB8Ng5wzBLqId0LAPYMgp3M/uNJcWIyIiIhMuKebovAKAcesL7e5onqiYI2OJiIgoD2vsnHxpsei4FKRn59q7OEREROQAGOychdEIZF0eKBER5I2IQG/IoNg9Z9gcS0RERAx2zmH7fNOyYsufyrfbsm4sm2OJiIiIwc5J+AQDhqx8U56I9gx2REREZIXBzqmmPMkf7FhjR0RERNYY7Jwp2KWfBzIuh7h2dYKg1wGxyZmIT8m0X/mIiIjIITDYOcuUJ35hhSYq9vNyV6tQiF1cN5aIiKjaY7BztqXFrIKdYHMsERERmTHYOYuQKwU7Li1GRERU3XHlCWdRrweQlQLUbJJvt3lpMZnLzmDU1DqyREREVD0x2DmLTveYtgKahgXAz9MNadkGHEm4hOYRpj53REREVP2wKdbJSQ1d2zpB6j6bY4mIiKo3BjtnW1YsOQbIzS5y3VgOoCAiIqreGOycyQcdgPdaAQn78u3uUNdUY8cpT4iIiKo3BjtnEhBpui2wtJi5xu5QfCrSsnLtUTIiIiJyAAx2LjCXXUSQNyICvWHUgD0xyfYpGxEREdkdg50zLi1WoMZOcKJiIiIiYrBzJqHNTLfnDhZ6yjyf3W72syMiIqq2GOycSXjry8HOaMj3FGvsiIiIiMHOmQQ3ANx9gNxMIOl4vqfa1g6CLDoRl5KJuORMuxWRiIiI7IfBzpno3YDO9wK9Hwc8vPM95efljmbhplUnWGtHRERUPZU62B09WrjDPtnB4DeA614GguoUeqqjuZ8dgx0REVG1VOq1YseNG4cjR44gIiIC7dq1y7cFBZkmyCX76lgvGN9tPY3tJ5LsXRQiIiJy5Bq7VatW4fjx4xgyZAgSEhIQExODV199FSEhIWjSpEnllpLyu5QAnNpcaHf3hiHq9t8zF5GRnX9wBREREbm+UtfYmX3//ffYvXu35fHKlSvxzTff2LpcVFKoe6cpoNMDk88CHj6Wp+qF+CIyyBuxyZnYeeoCejcJtWtRiYiIyMEHT3h7e2P//v2WxwMHDsTevXttXS4qjl8twLcmoBkLzWen0+kstXZbjp23UwGJiIjIaWrsPv/8cwwfPhz9+vVDhw4dsGfPHhUoqIrItQ5rBZxYD8TvB6I65nu6R6OaWLz7LDYfYz87IiKi6qbUNXbHjpnWJ23dujV27NiBPn364MSJE6hfvz5WrFhRmWWk4iYqTrhcc2rWvVFNy8jYzBz2syMiIqpOSl1j9+KLL6pw16lTJ9X8OnjwYNx5552VWzoqmtTYifh9hZ5qUNMXYQFeSEjNUv3sejVmPzsiIqLqotTB7ttvv4Wmaaq2TgZMfPjhh+px//79VdDr1q0bm2QdoMZOfgfSHLv037PYciyJwY6IiKgaKdPgCQkNXbp0weTJk/HXX39h6dKlaN++Pb766it079698kpJ+dVqYbq9FA+kFR4k0b2RaQDFZg6gICIiqlbKPHjCmr+/P26++Wa1URXy8gf6PgcERgFuHoWelho7sSuvn523h5sdCklEREQOHey2bNmimmQ3btyI2NhY+Pr6omXLlqq/3YgRI7gCRVXq/3yxTzUK9UOovxcSL2Xh39MXLQMqiIiIyLWVuin2pptuwhdffKH600kTrIyI3blzJ15++WVkZWVh2LBhaj/Zn5rPztIcy2lPiIiIqgudJiMgSuHixYuoUaNGhY9xZCkpKarWMTk5GYGBgXBoOZlA7L+mfnatCjeFf735JKYs3otejWvi27E97FJEIiIiqtp8Uuoau5ICmzTRXukYsrELJ4D5A4HF4wGjsdDTPfJWoNhx8gKycjmfHRERUXVQ5iXFinLHHXegMsyePRsNGjRQy5jJqNutW7descZwwoQJiIyMhJeXF5o1a4bly5fDJdVsDOg9gOxLQPKpQk83CfNHTT9PZOUa8d+ZZLsUkYiIiBx08ERxkxFLS25Sku37cS1atAiTJk3CnDlzVKibNWsWBg0ahOjoaISFhRU6Pjs7G9ddd5167scff0Tt2rVx8uRJ161FlNGwtZoD8XuBhANAcIMi+9kt3xOHzUfPo2sDUw0eERERua5SB7s///wTX3/9tZripGCwW7dunc0LNnPmTIwdOxZjxoxRjyXgLVu2DPPnz8dzzz1X6HjZLwFTRux6eJimAJHaPpdfgUKCnaxA0XxwkdOeSLDbcjwJj9qlgEREROSQwa5fv34ICAjA1VdfXei5du3a2bRQUvsmK1w8//zlKT30ej0GDBiATZs2FfkaGZHbs2dP1RS7ZMkS1KpVCyNHjsSzzz4LN7ei53GT0byyWXdOdCrhrYA9Ra9AIbo3rGnpZ5eda4Snu01a3omIiMhBlfqb/ueffy4y1IlVq1bZskxITEyEwWBAeHh4vv3yOC4ursjXyDq20gQrr5N+dVOmTMG7776LV199tdj3mTFjhhplYt7q1q0LpxKWt7RYfNHBrmmYP4J9PZCRY8CemItVWzYiIiKqci5ThWM0GlX/urlz56Jz584YPnw4XnjhBdWEWxypEZShw+bt9OnTcLoaO3H+MJCbXehpvV5nqbXjfHZERESuzyGDXWhoqGo+jY+Pz7dfHkdERBT5GhkJK6NgrZtdZVUMqeGTpt2iyMhZmQ/GenMqgbWBG94B7lksoyWKPITrxhIREVUf5Q52xTWJ2oKnp6eqdfvrr7/y1cjJY+lHV5TevXvjyJEj6jizQ4cOqcAn53NJEua6jQUa9ilyzVjrdWOln12OofB8d0REROQ6yh3sZGmxyiRTncybNw8LFizAgQMHMH78eKSlpVlGyY4aNSrf4Ap5XkbFTpw4UQU6GUH7+uuvq8EU1Vnz8ADU8PVAerb0s+N8dkRERK6s1KNiCyrlSmTlJn3kzp07h6lTp6rawQ4dOuD333+3DKg4deqUGilrJgMf/vjjDzzxxBNqlK7MYychT0bFurRL54AjfwLGHKDTqCL72ckcdqv2x2PLsSR0qhdsl2ISERGRA60VW5CEp//++w+uxKnWijU7uRH4YjAQVBd4Ym+Rh3z+z3FM/20/+jWvhS/HdKvyIhIREZGDrRVLDiqspek2+TSQWXRTa/e8dWO3HU9CLvvZERERuSwGO2fnE2waHStkabEitIwMRKC3O9KyDdh31skmYSYiIqLKD3bFreZAdlpaTMjSYkVw0+vQLa/WjtOeEBERua5yB7tdu3bZtiRU8YmKi1lazHraE1k3loiIiFwTm2JdwRWWFhPmFSikn53BWLkjmomIiMg+GOxcqsZun8xDU+QhraICEeDljtSsXOxnPzsiIqLqHezee+89dbtv3z4YDIbKLBOVVWgz4K4fgfGbij1E+tl1zetnt+U4+9kRERFV6wmKZYJgMXnyZBw8eBA+Pj5o3bo12rZtizZt2uCmm26qzHJSSdy9gKbXXfGwHo1C8PfBBKw/nIgH+jSqkqIRERGRA9bY9e/fX90uWbIE0dHR+Oeff/DYY48hNDQUf/75Z2WWkWykb7Mwy8jYzBzWuhIREVXbYHfdddfhs88+U8t8CX9/f3Tv3h333Xcf7rzzTjz88MP48ssvK7OsVJKEg8DfrwKbPyn2kGbh/ogM8kZWrhGbOO0JERFR9Q12ixcvRlpammpybdiwITp16oRWrVqhcePGmDt3LkaPHo177723cktLxUs6Cqx7G9j9TbGH6HQ6tayYWBttCuhERERUDfvY+fn5YeLEiWrLzs7G+fPn4e3tjeBgLirvUJMUnzsEGHIBN/dim2O/23oaa6ITAORNk0JERETVd7oTT09PREZGMtQ5khr1AQ8/wJBlqr0rRu8mNeHhpsOJ8+k4kZhWpUUkIiIiBwp2GRkZiImJKbRfpkAhO9PrgbAWJS4tJgK8PdClvmnaE1OtHREREVW7YPfjjz+iadOmuPHGG9GuXTts2bLF8tw999xTWeWj8jTHJhwo8TBzP7vV7GdHRERUPYPdq6++ih07dmD37t344osvcP/99+Pbb79Vz2nFrHZAVSy8jek27r8SD+vXnNOeEBERVevBEzk5OQgPD1f3O3fujHXr1uHWW2/FkSNH1GhLcgC1O5luEw+VeJhMexIV5I2zyZlq2pP+eUGPiIiIqkmNXVhYGP7773JNUEhICFatWoUDBw7k2092FNkBmLAVeGRHiYdJEO+bF+Y47QkREVE1DHZff/21CncFR8d+9913WLt2bWWUjcrK3ROo1dw0kOIKzP3sOICCiIioGga7OnXqICIiwvI4Li7Ocr937962LxlVqt5NQi3TnhzntCdERETVdx47MXDgQNuWhGwj8TDw4/3AD2NKPMzfy53TnhAREbmYcgc7joR1UDo9sPdH4OAyIDe7xEP7tzA3x7KfHRERUbUOdhwJ66BCGgE+waYVKOL3lngopz0hIiJyLeUOduSgJHDX7my6H1Py6NimYaZpT7JyjWraEyIiInJuDHauqHYX0+2Z7aWe9mTNQfazIyIiqrbBzs3NzbYlIdupkxfsYkoOdqK/edqTQ+xnR0REVG2D3a5du2xbErIdc1Ps+SNAxoUSD+2VN+3JSU57QkRE5PQq3BS7fv163H333ejZsydiYmIskxn/888/tigflYdvCBDaDIhoC6TGX3Hak64NOO0JERERqnuw++mnnzBo0CD4+PioGrysrCy1Pzk5Ga+//rqtykjlMX4TMO4fIKxFGVahYHMsERFRtQ12r776KubMmYN58+bBw8Mj30oUO3futEX5qLzc3Et9aP+8ARQyMjYjm9OeEBERVctgFx0djauvvrrQ/qCgIFy8eLEipyZbyc2S2aRLPKRJmD9q1/BBdq5RzWlHRERE1TDYydqxR44cKbRf+tc1atSoIqemipIw98UNwIw6QNKxUkx7Ym6OZT87IiKiahnsxo4di4kTJ2LLli0qHJw9exbffPMNnnrqKYwfP952paTyTVQstXWG7CtOVCz6NeO0J0RERM6u9B2xivDcc8/BaDTi2muvRXp6umqW9fLyUsHu0UcftV0pqfzz2clcdjJRcbs7Szy0d4FpTxqG+lVZMYmIiMgBauyklu6FF15AUlIS9u7di82bN+PcuXOYPn26jYpHFVKnq+n2zLYrHurn5Y5uDU3TnqzmKhRERETVd0kxT09PtGrVCt26dYO/v78tTkm2nKg4bg+Qk1nq0bEr98dVdsmIiIjI0YJdRkaGaoI1O3nyJGbNmoU//vjDFmWjigpuAPjWBIw5pnB3Bde3iVC3W48n4VyqaU5CIiIiqibBbujQofjqq6/UfZneRGrs3n33Xdxyyy345JNPbFVGqsgAitqlXze2TrAv2tcJglED/tjHWjsiIqJqFexkEuI+ffqo+z/++KOa/kRq7STsffDBB7YqI1VE0+uAljcDwQ1LdfgNbSPV7Yq9sZVcMCIiInKoYCfNsAEBAer+ypUrcdttt0Gv16NHjx4q4JED6DYWGP410Pz6MgW7TUfP4/wlNscSERFVm2DXpEkTLF68GKdPn1b96gYOHKj2JyQkIDAw0FZlpCpUN8QXbWubm2Pj7V0cIiIiqqpgN3XqVDVnXYMGDVT/up49e1pq7zp27FiRU5OtV6FIOg6klK55lc2xRERE1TDYDRs2DKdOncL27dvzjYSVCYvfe+89W5SPbGHZk8AHHYAdX5Tq8BvamkbHbjx6Hklp2ZVcOCIiInKIlSeEDJiQCYqlli47+3IIiIuLQ4sWLSp6erKF8FalnqhY1K/ph9ZRgdh3NgWr9sdheNd6lVs+IiIisn+wO3bsGG699Vbs2bNHrUKhSZNf3ooUwmAw2KaUVDGWKU92AEYjoNeXqjlWgt2yPQx2RERE1aIpduLEiWjYsKEaLOHr64t9+/Zh3bp16NKlC9asWWO7UlLFhLcG3L2BzGQg6WipXjI4b7LijUcScTGdzbFEREQuH+w2bdqEV155BaGhoWqaE9muuuoqzJgxA4899pjtSkkV4+YBRHYw3T9z5YmKRaNa/mgREYBco4aV+zk6loiIyOWDnTS1muexk3B39uxZdb9+/fqIjo62TQnJNuqUfgUKsxvzRscu38PRsURERC4f7Nq0aYN///1X3e/evTveeustbNiwQdXiNWrUyFZlJFuo3blMNXZicF6w23AkEcnpOZVVMiIiInKEYPfiiy/CKJ3xARXmjh8/rpYYW758OZcUczT1egC9HgP6PlPqlzQJ80fz8ADkGDSsOsDmWCIiIken08xDWW1Epj4JDg62jIx1JikpKQgKCkJycjJXzsgz689DmPXnYVzTIgzz7+1q7+IQERFVOyllyCcVqrGzJvlQtpCQEKcMdVRyP7v1h88hJZPNsURERI6swsHu888/V33tvL291Sb3P/vsM9uUjmwrJxM4uhr4d1GpX9I0PABNw/xVc+yfHB1LRETk2mvFylx2Q4YMwQ8//KA2uf/EE0+o58jBxO0Bvr4FWPEMYDSUeRDF8j1xlVg4IiIismsfu1q1aqlBEiNGjMi3/7vvvsOjjz6KxMREOBOX72NnyAXeaghkpQAPrgGiOpbqZdFxqRg0ax083fXY8eIABHh7VHpRiYiIqIr72OXk5KhVJgrq3LkzcnNzK3Jqqgxu7kCDq0z3j5V+ZZBm4f5oVMsP2blG/HUgofLKR0RERBVSoWB3zz334JNPPim0f+7cubjrrrsqcmqqLI36lTnYyWAYTlZMRETk+NzL+oJJkybl+8KXgRIrV65Ejx491L4tW7bg1KlTGDVqlG1LSrbRsK/p9tRm02AKD+9SvWxwm0h8+PcRrDl0DpeycuHvVeaPDhEREVWyMn8779q1q1Czqzh69KhlaTHZ9u3bZ6syki3Vag74RwCX4oDTW4BGeUHvClpGBqBhqB+OJ6bhrwPxGNqhdqUXlYiIiCo52K1evbqsLyFHInMMSpj7bxFwcmOpg53Uzt7QNgKzVx/Fkt1nGeyIiIgckM0mKCYnctUTwLgNQN9ny/Sy2zrVUbdrohMQn5JZSYUjIiKi8mKwq47CWgIRbQB92X79jWv5o0v9YBg14OedMZVWPCIiIiofBjsqkzu6mGrtfth+Wi0hR0RERC4U7M6cOQOj0Vjovi3Mnj0bDRo0UEuVde/eHVu3bi3V6xYuXKj6hN1yyy02K4vLOb0N+PlBYPWMMr3sxnZR8PFww7HENOw4eaHSikdERER2CHatWrXCiRMnCt2vqEWLFqmpVaZNm4adO3eiffv2GDRoEBISSp4gV97/qaeeQp8+fWxSDpclo2JlAMXen8r0Mpnm5Ia8Oe1+2H6mkgpHREREdgl21s1xtmyamzlzJsaOHYsxY8aowDhnzhz4+vpi/vz5xb7GYDCoiZFffvllNGrUyGZlcUmyAoVOD5w/DCSXrb/cnXnNsb/9dxbp2VxhhIiIyFE4ZB+77Oxs7NixAwMGDLDs0+v16vGmTZuKfd0rr7yCsLAw3H///aV6n6ysLLX+mvVWbfgEX14r9vjaMr20W8MQNKjpi7RsA5bviauc8hEREZFrBLvExERV+xYeHp5vvzyOiys6SPzzzz/4/PPPMW/evFK/z4wZM9Siuuatbt26qJarUJRheTEh/ReHdTbV2n2//XRllIyIiIhcJdiVVWpqqlq3VkKdrHpRWs8//zySk5Mt2+nTp6vpurFrpR29TC+9vXMdNdfx1uNJOJGYVjnlIyIiojJxyAU/JZy5ubkhPj4+3355HBERUeh4Wc5MBk0MGTLEss88Otfd3R3R0dFo3Lhxodd5eXmprdqq2x1w9zYNpDgXDYS1KPVLI4N8cHXTWlh76Bx+3HEGTw1qXqlFJSIiIietsfP09FRr0P7111/5gpo87tmzZ6HjW7RogT179mD37t2W7eabb0b//v3V/WrXxFpaHt5A/V5AeFsg40K557STYGeQWYuJiIjIrhyyxk7IVCejR49Gly5d0K1bN8yaNQtpaWlqlKwYNWoUateurfrJyTx3bdq0yff6GjVqqNuC+6mAkd8Dbh7leul1rcJRw9cDcSmZWH/4HPo1D7N58YiIiKgKg93kyZMREhJS6H5FDR8+HOfOncPUqVPVgIkOHTrg999/twyoOHXqlBopSxVUzlAnvNzdcEuH2vhy4wn8sOMMgx0REZGd6TSuC2Uh053I6FgZSBEYGIhqJTsdMOYA3kFletnemGTc9OE/8HTTY8vkaxHs51lpRSQiIqqOUsqQT1jlRaZlxd6sD2yZW+aXtqkdhFaRgcg2GLFkd9kmOiYiIiLbYrAjwL8WYMgu83x2BQdRSHMsERER2Q+DHQGN+ptuz2wFsss+J530s5Om2H1nU7DvbLLty0dERERVG+zee+89dbtv3z61agQ5kZBGQFBdU63dqeKXbCuO9KuTEbLih+2stSMiInL6YCejVs0jY1u1aqUe33XXXXjjjTfw22+/2eptqDLIEhLlXF7MbFhec+zi3THIymWwJyIicupgJ5MBiyVLlqiVHmTt1scee0ytIvHnn3/a6m2oKpYXKwdZhSIi0BsX03Owan/+FUOIiIjIQeexk3VZX3rpJSxfvhyJiYlq+G2zZs3Qu3dv3H777WoVCOHv74/u3burjZxAw6tNt3H/AWnnAb+aZXq5m16HYZ3r4KPVR/DVppO4qV1U5ZSTiIiIbFdjJys+/PDDDxg5ciRee+01PProo/j777/x9ddfo3Xr1mopr5gYTnvhdALCgS73A4NmAOWc+PmuHvXgrtdh6/EkNb8dEREROfgExX5+fqqZtWPHjpZ9AQEB+Pfff+Hm5qbC3rJly9QxDRs2hDOp1hMU28hj3+3C0n/P4raOtTFzuKnfJRERETnoBMWypFd6enqRz9WvXx9z587F+PHjMXHixLKemlzA/VeZwvyv/51FQkqmvYtDRERUrZQ52D3yyCO47777VA1dce6++27VPEtO6NI5YPsXwNnd5Xp5+7o10KV+MHIMmuprR0RERA4c7CZNmoQhQ4agU6dOuP766zFnzhwYjUboZMqMPAsXLlSjYckJ/fUS8NvjwK6vK1xr982Wk8jM4dQnREREVaVcveTfeecdbNy4UfWte/LJJ5GRkYH27dujUaNGqFmzJqZPn463337b9qWlytdyqOn2wG+A0ViuUwxsHYE6wT64kJ6Dn3dyIA0REZHDTndiJtOYyOjY7Oxs7Ny5E4cOHVKd+6Sm7pprrkFYWJhtS0pVo1FfwCsQuBRnWmKsXo8yn0KmPrm3VwO8uuwA5m84jhHd6uar0SUiIiIHC3Zmnp6e6NGjh9rIBbh7Ac2uB/Z8D+xfWq5gJ+7sWhfvrTqEIwmXsO5wIvo2q2XzohIREVElrTxBLqTVzabbA78CZZsNxyLQ20OFO/H5P8dtWToiIiIqBoMdFdb4WsDDF0g+BZzdVe7TjOnVUC1Du+7QORyOT7VpEYmIiKgwBjsqzNMXaHodoHMzLTFWTvVq+uK6luHq/vwNJ2xYQCIiIioKgx0VbcDLwFOHgc73Vug05qlPft55Bklp2TYqHBERERWFwY6KFtIQ8KtZ4dN0axiCNrUDkZVrxLdbOGExERFRZWKwoyvLzSr3S2WaE3OtnaxEkZ1bvrnxiIiI6MoY7Kh456KBzwcB866p0GlubBuFsAAvJKRmYdmeszYrHhEREeXHYEfF8w8DYrYD8XuBxCPlPo2nux6jeta3TH2ilXMKFSIiIioZgx0VzycYaNjXdP/AkgqdamT3+vBy12NvTAq2Hk+yTfmIiIgoHwY7KlnLIaZbWYWiAkL8PHF75zrq/kery1/7R0RERMVjsKOStbgJ0OmB2N3AhYqNah3ftzHc9TqsP5yIbSdYa0dERGRrDHZUMv9aQL1el5cYq4C6Ib64o4tpmbGZKw/ZonRERERkhcGOyrB2bMWaY8Uj1zSBp5sem46dx8ajiRUvGxEREVkw2FHp+tk1Gwx0ua/Cp6pdwwf/181Uazdr1WGOkCUiIrIhBju6ssAoYORCoP3/2eR0D/droqZA2XoiCRuOnLfJOYmIiIjBjuwgIsgbd3Wvp+7PXBXNWjsiIiIbYbCj0ks6Dmz4AEireN+48f0aw9tDj52nLmLtoXM2KR4REVF1x2BHpff9KGDVFODgsgqfKizAG/f0MK1GMXPVIdbaERER2QCDHZVe61tMt/9+Z5PTPdS3MXw83PDfmWT8dSDBJuckIiKqzhjsqPTajwB0bsCpTUDCwQqfLtTfC6N7NVD3WWtHRERUcQx2VLbRsc2uN93fucAmp3zo6kbw83TD/tgU/LEv3ibnJCIiqq4Y7KhsOt97uTk2J7PCpwv288R9VzVU92f9eQhGI2vtiIiIyovBjsqmybVAYB0g40KFlxgze+CqRgjwcsfBuFSs2Btnk3MSERFVRwx2VDZ6N6DTKMDDF7hkmxAW5OuB+/tcrrUzsNaOiIioXBjsqOy6PwQ8GQ30etRmp5Tm2EBvdxxOuIQlu2Nsdl4iIqLqhMGOys6nBuAdaNNTBnp7YFy/xur+m78fRFpWrk3PT0REVB0w2FHFnN0F5GbZ5FT39W6IeiG+iE/Jwkerj9jknERERNUJgx2V33cjgLn9gIO/2eR03h5umHJTK3X/8/XHcTwxzSbnJSIiqi4Y7Kj8ItqZbnd8abNTDmgZhr7NaiHbYMT03/bb7LxERETVAYMdlV/HuwGdHji+Djh/1Can1Ol0mDqkFdz1Ovx9MAF/H+SkxURERKXFYEflV6Mu0OQ6m65EIRrX8rdMWvzKr/uRlWuw2bmJiIhcGYMd2WYlil3fALnZNjvto9c0Qa0AL5w4n475/5yw2XmJiIhcGYMdVUzTgUBAJJCeCEQvs9lpA7w98Nz1LdT9D/8+jLjkii9fRkRE5OoY7Khi3NyBjveY7u9fatNT39qxNjrWq4H0bAPeWHHApucmIiJyRQx2ZJvm2BELgdvm2fS0er0OL9/cGjodsHj3WWw7kWTT8xMREbkaBjuquKDaQPPBpto7G2tXpwaGd6mr7k9bso/ryBIREZWAwY5sy5Br2mzoqUHNEeDtjv2xKfhu6ymbnpuIiMiVMNiR7Wz6GJjVxmYrUZiF+nth0nXN1P13VkbjQprtRt8SERG5EgY7sp3080BqLLDxA0CzbZPp3T3qo1m4Py6m5+DVZRxIQUREVBQGO7Kd7uMAdx8gZgdw9G+bntrDTY/Xb22rBlL8tPMMVu3nihREREQFMdiR7fjXArqMMd1f97bNa+26NAjB2D6N1P3nf96DJDbJEhER5cNgR7bV6zHAzQs4tQk48Y/NTy997ZqE+SPxUhamLNlr8/MTERE5MwY7sq3ASKBT3oTF696y+em9Pdww8872cNPrsOy/WPz671mbvwcREZGzYrAj2+v9OKD3AI6vA84dqpS57Sb0a6zuS61dQiqXGyMiIhIMdmR7NeoCN74DjN8I1DJNU2Jrj1zTFK0iA9Uo2ck/74Fm4/58REREzojBjipvmbHw1pV2ek93PWYObw8PNx3+PJCAn3bGVNp7EREROQsGO6p8aYmVctoWEYF4fICpRvDlpftw9mJGpbwPERGRs2Cwo8ojzaO/TgTebQHE/lcpb/HQ1Y3QoW4NpGbl4tmf/mOTLBERVWsOHexmz56NBg0awNvbG927d8fWrVuLPXbevHno06cPgoOD1TZgwIASj6cqILMJZ10CjDmmee0qgbubHu/e2R5e7nqsP5yIb7ZwLVkiIqq+HDbYLVq0CJMmTcK0adOwc+dOtG/fHoMGDUJCQkKRx69ZswYjRozA6tWrsWnTJtStWxcDBw5ETAz7XtnV1U+Zbg8sBRIqZymwxrX88cz1LdT915cfwInEtEp5HyIiIken0xy07Upq6Lp27YqPPvpIPTYajSqsPfroo3juueeu+HqDwaBq7uT1o0aNKtV7pqSkICgoCMnJyQgMDKzwz0B5Ft1jCnZthgHDPq+UtzAaNYyYtxlbjiehZWQgfh7fCz6ebpXyXkRERFWpLPnEIWvssrOzsWPHDtWcaqbX69VjqY0rjfT0dOTk5CAkJKTYY7KystTFst6oElz9tOl2389A4pFKeQu9XodZ/9cBof6eOBCbghd+4RQoRERU/ThksEtMTFQ1buHh4fn2y+O4uLhSnePZZ59FVFRUvnBY0IwZM1QCNm9SI0iVILId0GwwoBmB9e9W3tsE+eDDEZ3UqhQ/74rB/zafrLT3IiIickQOGewq6o033sDChQvxyy+/qIEXxXn++edVtaZ5O336dJWWs1rpm1drF70cyEqttLfp2bgmnr2+ubr/ym/7sePkhUp7LyIiIkfjkMEuNDQUbm5uiI+Pz7dfHkdERJT42nfeeUcFu5UrV6Jdu3YlHuvl5aXaqq03qiS1OwO3fAI8tgvwCqjUtxrbpxFuaBuBHIOGh7/ZgXOpWZX6fkRERI7CIYOdp6cnOnfujL/++suyTwZPyOOePXsW+7q33noL06dPx++//44uXbpUUWmp1DqMBHyL7/NoKzqdDm8Na48mYf6IT8nCI9/uRK7BWOnvS0REZG8OGeyETHUic9MtWLAABw4cwPjx45GWloYxY8ao52WkqzSlmr355puYMmUK5s+fr+a+k754sl26dMmOPwUVSQY1RK8ADDmV9hb+Xu6Yc3dn+Hm6qZGyb/5+sNLei4iIyFE4bLAbPny4aladOnUqOnTogN27d6uaOPOAilOnTiE2NtZy/CeffKJG0w4bNgyRkZGWTc5BDubnscB3/wdsmVOpbyM1du/c0V7dn7f+OH7772ylvh8REZG9Oew8dvbAeeyqyK7/AUsmAJ7+wCPbgMCoSn27GSsO4NO1x+Dr6YbFE3qjWXjl9vEjIiKyJaefx45cXPuRQJ1uQPYlYOWLlf52Tw9sjp6NaiI924BxX+9ASmblNQETERHZE4MdVT29HrjxHUCnB/b+BBxfV6lvJ+vJfjiyIyKDvHEsMU2Fu6xcQ6W+JxERkT0w2JF9RLYHutxvur/86UodSCFC/b0wb1QXNZhi49HzmLToXxiM7IVARESuhcGO7OeaFwDfUODcwUofSCHa1A7Cp/d0gYebDsv2xOKVX/dx2TEiInIpDHZkPz7BwHUvAzWbAhElTyZtK1c1DcW7d3ZQ9xdsOomP1xytkvclIiKqCu5V8i5EJQ2kaHsn4O5ZZW95c/sonL+UhZd/3Y+3/4hGqL8nhnetV2XvT0REVFlYY0f2H0hhHeqMVbNCxJjeDfFwv8bq/vM/78Gq/fmXryMiInJGDHbkGGTwxIYPgM8HVPpACrOnBzXHHZ3rQMZQyLJj208kVcn7EhERVRYGO3IMMqfdhveBmB3A+plV8paypuyM29ri2hZhyMo14v4F23EoPrVK3puIiKgyMNiR4wykuH6G6f7aN4CTG6vkbWWOu49GdkKnejWQnJGD0fO34nRSepW8NxERka0x2JHjaHcn0H4EoBmBnx4A0qumadTH0w2fj+6q1paNTc7EnZ9uwrFzl6rkvYmIiGyJwY4cyw3vACGNgZQY03qyVTTPXLCfJ755oLtVuNuM6Dg2yxIRkXNhsCPH4uUP3PEF4OYJRC8HtnxaZW8dHuiNRQ/2QKvIQCReysLwuZuw50xylb0/ERFRRTHYkWMuNzbwVUDvUeVvXdPfC9+N7YEOdWvgYnoORs7bzNGyRETkNHQa11SySElJQVBQEJKTkxEYGGjv4lRv8rFMPAzUamaXt7+UlYv7vtyGrceT4OMhffC6oFeTULuUhYiIqreUMuQT1tiRY9Lp8oe6nMwqfXt/L3csGNMNfZqGIiPHgHu/3IbVBxOqtAxERERlxWBHji9uDzDnKmD3t1X6tjJa9rPRXXBdq3Bk5xrx4NfbsWJPbJWWgYiIqCwY7MjxHV4JnD8MLHsSOHeoSt/ay90NH9/VCUPaRyHHoGHCtzvx1aYTVVoGIiKi0mKwI8fX+3GgYV8gJx34cQyQk1Glb+/hpses4R0wvEtdtfzY1CX78MIve5BjqJp1bYmIiEqLwY4cn94NuG0u4BsKxO8FFo8HjFUbqtz0Orxxe1s8P7iF6v73zZZTuOfzLbiQll2l5SAiIioJgx05h4AIYNh80xQo+34Bfn+2yiYvtl5b9qG+jTHvni7w83TD5mNJGDp7Aw5zfVkiInIQDHbkPBr1BW6dY7q/dS6w4wu7FGNAq3D8/HBv1An2wamkdNz68UaOmCUiIofAYEfOpe0w4Po3gHq9gNa32a0YzSMCsGRCb3RrGGKa827BNsxbdwycFpKIiOyJExRb4QTFTsSQC7i527sUahqUqUv2YuG20+rxsM518OotbeDt4WbvohERkYvgBMXk+qxD3Za5wKktdimGp7seM25ri6k3tYJeB/y44wxu/ugfHIxLsUt5iIioemOwI+e2+ztgxdPAt3cCCQftUgQZVHHfVQ2x4L5uCPX3xKH4S7j5ow1YsPEEm2aJiKhKMdiRc2s1FKjTFci8CPzvNiA5xm5F6dO0FlZMvBr9mtdSTbTTlu7DAwu24/ylLLuViYiIqhcGO3Junr7AyO+B0GZASgzwv9uB9CS7FadWgBe+uLcrpg1pBU83Pf46mIDr31+PdYfO2a1MRERUfTDYkfPzDQHu/hkIiALOHQDmDwIumgYz2KtpdkzvhljySG80DfPHudQsjJq/Fa/+th9ZuQa7lYuIiFwfgx25hhp1gVGLgcDaQOIhU7jLumTXIrWMDMTSR67C3T3qqcef/XMct87eiL0xyXYtFxERuS4GO3IdtZoD968CarUEej0KePnbu0Tw8XTDq7e0xbxRXRDs64H9sSlq1Owrv+5X898RERHZEuexs8J57FxETgbg4XP5sSEHcPOAvSWkZqpA99t/sepxZJA3Xrq5NQa1jrB30YiIyIFxHjuq3qxDXcYFYG5/YNtnsLewAG98NLITvhzTFXVDfBCbnImHvt6hRs7GXMywd/GIiMgFMNiR689zF78HWPYk8PdrgANUUPdrHoaVj/fFw/0aw12vw58H4nHdzLVqSbJcg9HexSMiIifGplgrbIp1QfLxXvsmsGaG6XGn0cCNMx1iOTJxKD4VL/yyB9tOXFCPW0QE4IUbW6o58YiIiMqaTxjsrDDYubDt8021dpoRqNsduP0zoIZptKq9GY0afthxGjNWHMTF9By176omoXj2+hZoWyfI3sUjIiI7Y7ArJwY7F3dwOfDLQ0BWCuAdZJrYuF4POIqktGx89PcRfL35BHIMpj/LIe2j8NTAZqhf08/exSMiIjthsCsnBrtq4MIJ4Mf7gNQ4YNw/psmNHczppHTMXHUIi3fHqJZk6Yd3V/d6eOSapmplCyIiql5SGOzKh8GumpDpTy6eAmo2Nj2WP4HUWCAwCo5k39lkvPV7NNbmLUfm6+mGB/o0wn29G6CGr6e9i0dERFWEwa6cGOyqqV3/A5Y/DdzwNtDhLlkTDI5k49FEvLniIP49k2wJeP/XtR4e6NMQUTWspnYhIiKXxGBXTgx21ZB8/BfeBUQvMz1uM8wU8BysiVb+TFfsjcOHfx/BgdgUtU+aaId2qI1xfRuhaXiAvYtIRESVhMGunBjsqimjEdjwXt48dwbAJxgY8BLQcRSgd6ypHuXPdd3hRMxZcxSbjp237B/QMgzj+zVG5/qOFUiJiKjiGOzKicGumju9Dfj1MSBhv+lxVCfg5g+AiLZwRLtPX1QB74/9cZZ5l7vUD8bdPerj+jYR8PZws3cRiYjIBhjsyonBjtTAiq3zTBMaZ6UCY/8GaneCIzt67pJateLnnTHIzlu5ItjXA8M618GIbvXQqJa/vYtIREQVwGBXTgx2ZJEaDxz5E+h41+V9Z3YAUR0AvWPWhCWkZGLhttNYuPUUziZnWvb3alwTI7vXw8BWEfB0d6ymZSIiujIGu3JisKNiJR4GPu4JhLcC+r8INL3O4UbPmhmMGtZEJ+CbLaewOjrB0kwb6u+J2zvXwS0daquly3QOWn4iIsqPwa6cGOyoVKtWiMgOwNVPA81vcLgBFtZiLmZg0dZTqiYvITXLsr9ZuD9ubh+Fm9vXRr2avnYtIxERlYzBrpwY7KhEl84BG98Htn0O5KSb9oW1Bq5+Cmg11GGbaEWOwYi/DiTgl11nsPrgOUtfPNGhbg0M7RCFG9tFIizA267lJCKiwhjsyonBjkol7TyweTawZS6QnQp4BQFP7DGtP+sEkjNy8Me+OCzdfVZNfmzM+z+AXgd0b1gT17UKx4CW4azJIyJyEAx25cRgR2WSccEU7jx9gV6PXp4Tb9s8oPWtgH8YHF1CaiaW/ReLpf+exa5TF/M9J82117Y0hTyp1XOT5EdERFWOwa6cGOyowo7+DXx9K6B3B1rcCHQaDTTq79D98MxOnU/Hyv1x+PNAPLaduKAGYZjV9PPENS3C1NazcU2uVUtEVIUY7MqJwY4q7Pg64K9XgDPbLu+rUR/odA/Q4W4gMBLOIDk9B2sOJeDPAwlqhG1qZq7lORlM2yYqCL2a1ETvxqHo2iAEPp6O27+QiMjZMdiVE4Md2UzcXmDnAuDfRUBWsmmfzg14eBNQqzmciQy82HY8SYW89YfP4XDCpXzPe7rp0al+DRXypDavTe0grnpBRGRDDHblxGBHNpedDuxfYgp56UnAhC2X57/b+KFpwEXzGwG/mnAW8SmZatDFhiPnsfFIYr7JkM1Br03tQHSuH6y2TvWCERbI0bZEROXFYFdODHZUqTJTAO+8z1VuFvB2E9O8eFKT16A30PJmoMVNTtNcK+R/HyfOp+OfI4kq5G07kYTES9mFjqsb4oPO9YLVIIy2dYLQMjIQvp7udikzEZGzYbArJwY7qjKyDu3mOcCBpUDcf/mfq9US6Ho/0G0snI387+R0UgZ2nErC9hMXsOPkBUTHp1pWvzCTAbaNa/mrZtvWUYFoWzsIraICEeDtYa+iExE5LAa7cmKwI7tIOg4c+NUU8s5sl3hkWras79Om56UJd/PHQMO+QN1ugLsXnElqZg52n76ogt6emGTsjUnOtwqGtfo1fdE0LADNI/zRLDxAbY1q+cHLnX32iKj6SmGwKx8GO7I7CXEysjaiLVCzsWnfvl+AH+413XfzAiLbA3W6ALU7m25l1K2TrfuakJKJvWcl5KWosLcvJrlQXz0zmT+vQU1fNI8IQJNa/mhYyw8NQ/3RsKYfgnxZw0dEri+Fwa58GOzIIZ3aYpr0+NhaIC2h8PPDvgDa3Ga6n5YIGLKBgEinC3vnL2UhOi4Vh+JTER1/Sd3KZj3VSkEhfp5oGOpn2aTGr06wL+oG+6jndE52DYiIisJgV04MduTQ5E816ZipuTZmu+k2bg/wyDYgpKHpmPXvmubR864BhLUCwlvl3bYGwlo6zbJnZvK/p7iUTBySoBeXimOJl3DsXBpOnE9DfErRzblmvp5uqBPsg7oS9EIk8Pmgdg0fRAR5I6qGD0L9vbiaBhE5BQa7cmKwI6eTk2nqc2eumfrjBVN/PM1Y9PEPbzYFPHF6G3ApDghpBAQ3NC2N5kQuZeXiRGIajlttp5LSceZC+hVDn5BQFx7ghci8sBcZ6I3wQG+EBXqhlr9X3q03An3cWfNHRHbFYFdODHbkMmEv8RCQsB+I35d3u9/UjDs5FnDPWw5s8QRg9/8uvy4gCghuAATVMW19JgFeAabnDDmAm/P0Z8vMMSDmYgbOXMjA6aR0nL6QjjNJGYhNli1TzcVntWJaiTzd9ZagV9PPC6H+nqqZV7aa/p5qn/l+sK8nJ2cmIrvmE04kReRqPLyByHamreA8euZQJ4LrA1GdgKSjQGYykHrWtJn1e+7y/V8nmkbuSt+9gHDA37yFmW5b33p5tK78W9HONVwSrmQ6FdmKkmswqvn2ziZnIC45U4W92IsZarRuQmomzqnbLNW/LzvXqEKibKV7b70KeEE+Huq2hq9H3mbaF+jtgQBvdwSq++ZbD1UzyNG/RFRRDh3sZs+ejbfffhtxcXFo3749PvzwQ3Tr1q3Y43/44QdMmTIFJ06cQNOmTfHmm2/ihhtuqNIyEzks8+TIZn2fMW3m0bjnjwIXTwIpMabH1tOqJJ82TaYsW2J04XO3zhu8IX4eCxxeCfjWvLz5hAC+IYBPMNDrscsBU6Z6kcmafWqY+v+5e1dJKHR306vmV9muVPNnDnnnUjNVGExKM22Jl7Is98+nZeNCWjZyjRoyc4ymoFjMKN+SyKod/t7u8Pdyh5+XOwK83PM99vdyUxM7+xW89XRX6/X65m0+Hm7qsdzKz0pE1YfDBrtFixZh0qRJmDNnDrp3745Zs2Zh0KBBiI6ORlhYWKHjN27ciBEjRmDGjBm46aab8O233+KWW27Bzp070aZNG7v8DEROQ0KXbHW7Fv38iIVAcgyQGgtcSgAuxZv658n97LT8NYEyMldqAGWTwR4F9X788v2/pwN7f7r8WO8OePqbmoDl9oE/Aa+8Wrdd3wCxuwEPH8DDz9Qn0Pp+s+svh9GUWCAn3fTYXY7xNoVGvVuZa/5k4IVsVyK9WlKzcpGcnoML6dm4mHebnJGDC2mm+1IDmJKZg5SMHKTIfXWbYxn5m20wWsKirXi46SxBT34eb3e51cPLw/xYb7qVfe5u8HLXq+ZndV/tM92XfWpzk1sdPN1M++T8l/frVZBU+9StPNbBQ6+HngNViKqEw/axkzDXtWtXfPTRR+qx0WhE3bp18eijj+K556yaiPIMHz4caWlp+O233yz7evTogQ4dOqhwWBrsY0dkA1Lbl3bOdJt+3rRlyL5EICcDuGnm5WMXPwxELzeFwKIGfEw5D7jl/fvzhzHAvp+Lf99nT5pq/sTSR4GdXxU+RoKjzAX46I7LS7etn2kKl26epiAofQn1HqbHcv+Gt4GACNOxB5cDx9eazqPO5ZH/foe7AL9Q07Gx/5pGLZuf1+lNwVLddwPqdTfVYEoXxotnkJFwDBm5QHqOZtpyNaRna0jLMSBOH4mLBk9kZBuQm3ERuvQLSM8xquPSso1IyzFtcvy5HC8k5+hVi7gHcuGJHGjQwQiduhVG6GUabBjUbdXU6LnrdZaQJ7cqAOp18JAwKLduejWgRfbLY7kvAdFNf/mx9a3e8vjy83qd6T3kVioq5Tm3vPtyvOm++XmdZZ9kTst9OVbtu3weGTxjfk5nec50nFQwm54z7QMuP2d+Xm9+bd5zss98HnmJ+bjL+03HWvaZ71sfK48sz5teZ7q9fLwqTYHX5zuOg4KchtP3scvOzsaOHTvw/PPPW/bp9XoMGDAAmzZtKvI1sl9q+KxJDd/ixYuLfZ+srCy1WV84IrJR7V9p3PKx6VZSiCyzJlv2JSDrkunWHOpEq6GmSZuz0021ceZNPc4APKxq1SSUeQWa9htzLu835po264Eg0swcv7f4Mg589fL9UxuBLSX8Q7HpwMvBTkLg2jeKP/aBv4E6nU3F3fcT/FdNRdE9AgGM/hVoeLXp/tZ5wPKnij/v3d9DazoQWblGGHf+D74rHiv20M2d38XRsOtU83Hts79j0P7n88KfhEBZA0UHLe/Lf37IE1jjda2qVWyTsQ3Ppsy4fIz5VpPQqMOM3BH43tBfva6zLhqfer6njjFFC0Az6CRVqn0f5t6K/xmuU/tb6U7gE893LOUzB1Hz7fzcwZhvGKzuN9DF4iuPN4o8Tiw09Mdsw83qfgTO41vP1wr9/Objlxp64X3D7ep+DaTiR8+Xi7xecvxKY2e8nft/6rE3srDU88VC5zNbb2yLV3PvsTz+3fNZ+bGLtNXYAlNzx1geL/Z8EV6w+uxa2WNshGdyH7r8s3pORxDSijz2kFYHE3MesTz+wuNNhOsuFnnsaYRhQu4kSyic7TYTdXVFzJ0J4ByCMV4zfUdLQHwDH6AJTpt/xfmkwh9j9S9ZnpqqzUFL7ajl+csv0SELHrjfY4Zlz9OGz9DeeLDggRb3er5ruf9I7gJ0NRZYotHKOK8ZyNaZavUfyPkWvQyy0k/RnvCZjks601/kXdk/or9hQ7HHPu89Bdm+4Vj6yFVwBA4Z7BITE2EwGBAeHp5vvzw+eDDvF1yA9MMr6njZXxxptn355aL/gImoCsk3ifQBLNgP0FrrW0xbadz4rmkTRgOQm2kaLSy3hixLTZnS42GgxU2miZ1l9G++22xTH0Gzhv1MoVGel/NKaFT35TbXNH+gmYTQpoMuh0k5XpPXyJZ7uYlZyOtqNsk7xph/k33SjGwmtX7S/FzwODm36WKqL1o1Otej5Nq4Ho1qokfr+qYHe8OA/eaYZiXv4UNXNcBDHXuYHkSnAN8VMZgk74v3zaHN8XrnwcgxaDAc84H/wuL/0TyuZzhuatUDuQYNPuc8EbUyqdhjh7bwR91GrWAwaghI9UC9reeKPbZPhBvSouqrfo9Bme5odKj474L2QTnoH1ILBg0IyHVDk7NWg4gKOOnTAq18A2HUNHga3dFM+qQW44x7PUT4eqtjZWuRe7rYY+N1ofDW6U2jtTWgue4MfHRFN8knF/gnQFPdGdTUpRZ5bJYx/9d8U30M6ugSizzW3ZirrpdZA7ezaKYr+ucL0NKQln05ptb1PIsW+pNFHnteC1BdE8wi1bEnijw2XfNS/VrNQj1i0dztuOlBEe2L1n1Za3jEopn52CLEXkxHBkwtA/4e8SUfm3QJSXm12d7u8WjqXvyxcRdSkZqRN4OAA3DIptizZ8+idu3aqt9cz549LfufeeYZrF27Flu2bCn0Gk9PTyxYsED1szP7+OOPVXCLj48vdY2dNPeyKZaInJb1qGQJhRI8zeFPvhnlefN9CYjm/pESfKVJ3HyMujVevi8DYMxhVPpVploFJcvxeV8n/rUuh2epfb146vK3csFjpZlbRlebz5t4uPCx6j5MzeeBUXnHppum87lciPzXQc5bo97ln+3sruKvmby/eQm/3GzgzLaiLqzpxi8MqNXs8vU9ubHo9xe+oaZJws1k9ZjiyPWyHskuSwtad0/QNPUOkrs07yBokR1MNaSaBt3JDer3LEeYL6v5ymke/jBEdrY853Zmk7oe6jmrY9Wthy+yI039bOV495ht0EmtuDrWaDlePXbzQlbtnuo44Rm7A7psU7hUH7HLxVY17xm1e1keeyXshj5LPmvWZTDd0eCG9DpXWfZ7Jf4Ht8wLRV5eOeZSnastr/c+vw/uGYmFjjU/TI3qrbpCSOzxTjoIj3RTNigqBKVG9IQm/4iTYHfxEDzT8od962uRGt4dOk8fdKpn9Q9GG3P6ptjQ0FC4ubkVCmTyOCIir69LAbK/LMcLLy8vtRERuQzrflOqT18pB4zIABPZSsPT73IQuhIJg9bh5krnjepQymN9ix/sU5D8XPUvVxKUSIJug96lO1aubcM+KLVGfUt/rLnp3Yr8Zov8bTYpfGyxmpehDEFlOG/NMhwbXoZrFlWG5s06pfy9iXql/DyI+t3hTBxyHLzUvnXu3Bl//fWXZZ8MnpDH1jV41mS/9fFi1apVxR5PRERE5GocssZOyECI0aNHo0uXLmruOpnuREa9jhlj6lw6atQo1Vwr/eTExIkT0bdvX7z77ru48cYbsXDhQmzfvh1z5861809CREREVM2DnUxfcu7cOUydOlUNgJBpS37//XfLAIlTp06pkbJmvXr1UnPXvfjii5g8ebKaoFhGxHIOOyIiIqouHHLwhL1wHjsiIiJy5nzikH3siIiIiKjsGOyIiIiIXASDHREREZGLYLAjIiIichEMdkREREQugsGOiIiIyEUw2BERERG5CAY7IiIiIhfBYEdERETkIhjsiIiIiFwEgx0RERGRi3C3dwEciXnZXFmTjYiIiMgRmHOJOaeUhMHOSmpqqrqtW7euvYtCREREVCinBAUFoSQ6rTTxr5owGo04e/YsAgICoNPpyp2qJRiePn0agYGBNi+jK+O1qxhev4rh9asYXr/y47WrmOpw/TRNU6EuKioKen3JvehYY2dFLladOnVsci75cLnqB6yy8dpVDK9fxfD6VQyvX/nx2lWMq1+/oCvU1Jlx8AQRERGRi2CwIyIiInIRDHY25uXlhWnTpqlbKhteu4rh9asYXr+K4fUrP167iuH1y4+DJ4iIiIhcBGvsiIiIiFwEgx0RERGRi2CwIyIiInIRDHY2NHv2bDRo0ADe3t7o3r07tm7dau8iOaR169ZhyJAhaqJFmQh68eLF+Z6Xbp9Tp05FZGQkfHx8MGDAABw+fNhu5XUkM2bMQNeuXdUk2mFhYbjlllsQHR2d75jMzExMmDABNWvWhL+/P26//XbEx8fbrcyO5JNPPkG7du0s81317NkTK1assDzPa1c2b7zxhvobfvzxxy37eA2L99JLL6nrZb21aNHC8jyvXcliYmJw9913q+sj3w1t27bF9u3bLc/zu8OEwc5GFi1ahEmTJqmROTt37kT79u0xaNAgJCQk2LtoDictLU1dHwnCRXnrrbfwwQcfYM6cOdiyZQv8/PzUtZT/6VV3a9euVf/j37x5M1atWoWcnBwMHDhQXVOzJ554Ar/++it++OEHdbyspnLbbbfZtdyOQiYglzCyY8cO9YVwzTXXYOjQodi3b596nteu9LZt24ZPP/1UBWVrvIYla926NWJjYy3bP//8Y3mO1654Fy5cQO/eveHh4aH+MbZ//368++67CA4OthzD7448MiqWKq5bt27ahAkTLI8NBoMWFRWlzZgxw67lcnTyEfzll18sj41GoxYREaG9/fbbln0XL17UvLy8tO+++85OpXRcCQkJ6hquXbvWcq08PDy0H374wXLMgQMH1DGbNm2yY0kdV3BwsPbZZ5/x2pVBamqq1rRpU23VqlVa3759tYkTJ6r9vIYlmzZtmta+ffsin+O1K9mzzz6rXXXVVcU+z++Oy1hjZwPZ2dmqBkCqfa2XJ5PHmzZtsmvZnM3x48cRFxeX71rKMirStM1rWVhycrK6DQkJUbfyOZRaPOvrJ0099erV4/UrwGAwYOHChaq2U5pkee1KT2qNb7zxxnzXSvAaXpk0DUo3lEaNGuGuu+7CqVOn1H5eu5ItXboUXbp0wR133KG6oXTs2BHz5s2zPM/vjssY7GwgMTFRfUmEh4fn2y+P5YNGpWe+XryWV2Y0GlXfJmmeaNOmjdon18jT0xM1atTIdyyv32V79uxR/ZdkMtNx48bhl19+QatWrXjtSknCsHQ3kf6eBfEalkxCxpdffonff/9d9feUMNKnTx+1uDuvXcmOHTumrlnTpk3xxx9/YPz48XjsscewYMEC9Ty/Oy5zt7pPRE5Wa7J37958fXToypo3b47du3er2s4ff/wRo0ePVv2Z6MpOnz6NiRMnqv6dMkiMymbw4MGW+9I3UYJe/fr18f3336vO/lTyP2Slxu71119Xj6XGTv7/J/3p5G+YLmONnQ2EhobCzc2t0OgleRwREWG3cjkj8/XitSzZI488gt9++w2rV69WAwLM5BpJ14CLFy/mO57X7zKpFWnSpAk6d+6sap1kIM/777/Pa1cK0lwoA8I6deoEd3d3tUkolg7rcl9qR3gNS09q55o1a4YjR47w83cFMtJVatattWzZ0tKUze+OyxjsbPRFIV8Sf/31V75/Xchj6btDpdewYUP1R2h9LVNSUtQIJ15L03B+CXXSfPj333+r62VNPocyasz6+sl0KPI/P16/osnfalZWFq9dKVx77bWqKVtqPM2b1KJIXzHzfV7D0rt06RKOHj2qQgs/fyWTLicFp3Y6dOiQqvEU/O6wYjWQgipg4cKFavTNl19+qe3fv1978MEHtRo1amhxcXH2LppDjqjbtWuX2uQjOHPmTHX/5MmT6vk33nhDXbslS5Zo//33nzZ06FCtYcOGWkZGhlbdjR8/XgsKCtLWrFmjxcbGWrb09HTLMePGjdPq1aun/f3339r27du1nj17qo007bnnnlMjiI8fP64+W/JYp9NpK1euVM/z2pWd9ahYwWtYvCeffFL97crnb8OGDdqAAQO00NBQNbpd8NoVb+vWrZq7u7v22muvaYcPH9a++eYbzdfXV/vf//5nOYbfHSYMdjb04Ycfqj9KT09PNf3J5s2b7V0kh7R69WoV6Apuo0ePtgxbnzJlihYeHq7C8rXXXqtFR0fbu9gOoajrJtsXX3xhOUb+J/bwww+raTzkf3y33nqrCn+kaffdd59Wv3599Tdaq1Yt9dkyhzrBa1fxYMdrWLzhw4drkZGR6vNXu3Zt9fjIkSOW53ntSvbrr79qbdq0Ud8LLVq00ObOnZvveX53mOjkP9Y1eERERETknNjHjoiIiMhFMNgRERERuQgGOyIiIiIXwWBHRERE5CIY7IiIiIhcBIMdERERkYtgsCMiIiJyEQx2RERERC6CwY6oGurXrx8ef/xxy+MGDRpg1qxZcGQnTpyATqdTa5JWpnvvvRe33HJLhc8jZV28eDEqy5o1a9R7FFw0viBZO1MWSzcYDHBUtvj8Pffcc3j00UdtViYiZ8VgR0TYtm0bHnzwQTiyunXrIjY2Fm3atKnU93n//ffx5ZdfwtH16tVLXY+goKASj3vmmWfw4osvws3NTT2W14wcORLNmjWDXq/PF/AdjSzs/ueff6oQO3ToUERGRsLPzw8dOnTAN998k+/Yp556CgsWLMCxY8fsVl4iR8BgR0SoVasWfH194cgkmERERMDd3b1S30eCUo0aNeDoPD091fWQWrvi/PPPPzh69Chuv/12y76srCz1+5aw1759eziq//77DxcuXEDfvn2xceNGtGvXDj/99JPaP2bMGIwaNQq//fab5fjQ0FAMGjQIn3zyiV3LTWRvDHZELi4tLU19Cfr7+6saj3ffffeKTWESFj799FPcdNNNKvBJU96mTZtw5MgR1YwrtSZSYyShwdqSJUvQqVMneHt7o1GjRnj55ZeRm5ub77yfffYZbr31VnXepk2bYunSpZbn5Yv8rrvuUsHDx8dHPf/FF18U2xS7du1adOvWDV5eXupnk+Y46/eTsj722GOq1iokJEQFoZdeeqlMTbGlOcfhw4dx9dVXq5+7VatWWLVqVaHznj59GnfeeacKjXIeqYGSn0kcPHhQXY9vv/3Wcvz333+vrsH+/fvL3RS7cOFCXHfddapc1r9rqZWUz8SVavsqQ0JCAoYMGaJ+NqmRK1jzZv1Zuv766+Hh4YHJkydj+vTp6jPXuHFjTJw4UT33888/53uNnFd+ZqLqjMGOyMU9/fTTKgDJF+XKlStVINi5c+cVXydfpPLlL0GqRYsWqvnuoYcewvPPP4/t27dD0zQ88sgjluPXr1+vjpcvXQkjEgylSfO1117Ld14JexJwpOblhhtuUEEuKSlJPTdlyhT12hUrVuDAgQOq9kVqYooSExOjXt+1a1f8+++/6tjPP/8cr776ar7jpHlOguiWLVvw1ltv4ZVXXikyeJWkpHMYjUbcdtttqgZNnp8zZw6effbZfK/PyclRtUkBAQHqOm3YsEEFbQkn2dnZ6vq+8847ePjhh3Hq1CmcOXMG48aNw5tvvqmCYnnJe3Xp0gWORIKzhNzVq1fjxx9/xMcff6zCXkES+CX8Fic5OVkFZGsS8uXamQMzUbWkEZHLSk1N1Tw9PbXvv//esu/8+fOaj4+PNnHiRMu++vXra++9957lsfyv4cUXX7Q83rRpk9r3+eefW/Z99913mre3t+Xxtddeq73++uv53v/rr7/WIiMjiz3vpUuX1L4VK1aox0OGDNHGjBlT5M9y/PhxdeyuXbvU48mTJ2vNmzfXjEaj5ZjZs2dr/v7+msFgUI/79u2rXXXVVfnO07VrV+3ZZ58t9pqNHj1aGzp0qOXxlc7xxx9/aO7u7lpMTIzlefl5pKy//PKL5ToULGtWVpb6PcjrzW688UatT58+6loOHDgw3/EFrV69Wr3HhQsXij0mKChI++qrr4p9Xn42689BZYuOjlZl3rp1q2XfgQMH1D7rz9+ZM2fU57a4n23RokXq+b179+bbn5ycrM61Zs2aSvwpiBxb5XZWISK7kqZSqRHq3r27ZZ/UcjRv3vyKr5U+TWbh4eHqtm3btvn2ZWZmIiUlBYGBgarWTGqirGvoZCSmHJOenm7pw2d9XqkFk9eaa2zGjx+v+oNJjeLAgQNVk6g0vxVFavR69uyZr49Z7969cenSJVVrU69evULvJ6TJtqgaotJei4LnkHLIwI6oqCjL81Iua3JtpBlbauysybWxbs6eP3++ZVDDvn37Suw/VxoZGRn5mmHtTa6V9JHs3LmzZZ/UVhbs0yi1dVdddVWRfR2lpk/62M2bNw+tW7fO95w07wr5vBFVVwx2RFQk6dtkZg4YRe2TpkghgUqaWaVZsiDrcGF9DvN5zOcYPHgwTp48ieXLl6umzmuvvRYTJkxQzZS2+DkKvl9VnUOujYSZovqTSX9C6wAofSIl2MnoVQmQFSHN2NJv0dlIsLv55psL7ZcuBdKP7r333lPN/gWZm/StrylRdcM+dkQuTDqaSyiRvl9m8kV/6NAhm7+XDJqIjo5GkyZNCm0SVEpLvpRHjx6N//3vf2pAx9y5c4s8zjygw9TCayI1hlIrVqdOHVQVKYf0GZMgZrZ58+ZC10YGWISFhRW6NuYBDBJKpP/ZCy+8oG6l76HUuFVEx44dix18YQ9SOyeDW3bs2GHZJ58Z6wEgEoKlVq5g/zrpG3rjjTeqfofFTc2zd+9e9XkvWJNHVJ0w2BG5MOmgf//996sBFH///bf64pPQUJagVVpTp07FV199pWrtpBlRmt1khKJMq1GWc8ggD2m2lHPIdBYSnIoiAw0kUMmktDKqVF43bdo0TJo0qVJ+vuIMGDBANZ9KGJUaNxmwIOHMmoQ0qT2TsCLPHz9+XAUVGW0rzcZCBktIk65cr5kzZ6pmbJmbrSJkwIZMeVKQDIiRTULUuXPn1P0rBUCpPZWBM2Zbt25VQU1uzeR5Oa440gVABozIIBz5x4YEvAceeMDShCp+//13dT1l9K6ZBD0JdXK9pKk+Li5ObeYaOjO5tn369Ml3PqLqhsGOyMW9/fbb6stOmrAkhEjfJes+TrYiIUKCmIy8lZGqPXr0UE1m9evXL/U5ZGSphAPp0ybTh8jcdcVNX1G7dm3VZCvBQuZjk2AkIbYsQdIWJET+8ssvqnZNRmVKUCk4Elj6F65bt071+5OmagmrUlbpYyd9DCUQy8/y9ddfqz5o0vdQaiylH5mMEC4vCZQSkKVWrGBNnmwSrGSKFbkvI4xLIn0BrWslpR+bnNe6P5s8X3AKnIJk+hrpjyjz08m1kNo3qck0k4BesBlWRiXL+8yYMUM1T5u3gs3+8lkZO3bsFa4KkWvTyQgKexeCiIgqh9TWygAXmX7G0UkzrQzKkTArIbks5DVPPvmkmkansiexJnJkrLEjInJh0iwstaZlHTBiD9K0+sQTT6ga37KSQSdSG8hQR9Uda+yIiIiIXARr7IiIiIhcBIMdERERkYtgsCMiIiJyEQx2RERERC6CwY6IiIjIRTDYEREREbkIBjsiIiIiF8FgR0REROQiGOyIiIiIXASDHRERERFcw/8Ds7Bm5oesHD0AAAAASUVORK5CYII=\",\n \"text/plain\": [\n \" \\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"perAYa2R_KW2\",\n \"metadata\": {\n \"id\": \"perAYa2R_KW2\"\n },\n \"source\": [\n \"- The main idea behind GQA is to reduce the number of unique query groups that attend to the key-value pairs, reducing the size of some of the matrix multiplications and the number of parameters in MHA without significantly reducing modeling performance\\n\",\n \"- The GQA code is very similar to MHA (I highlighted the changes below via the \\\"NEW\\\" sections)\\n\",\n \"- In short, the main change in GQA is that each query group needs to be repeated to match the number of heads it is associated with, as implemented below\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"842aa71a-4659-424e-8830-392bd6ae86af\",\n \"metadata\": {},\n \"source\": [\n \"- **We also redesign the attention class a bit so it receives the mask through its forward method instead of storing and accessing it as `self.mask`. This lets us build the mask on the fly to reduce memory usage. To foreshadow why: Llama 3.1 can handle sequences of up to 128 k tokens, and precomputing a 128 k × 128 k causal mask would be extremely memory‑intensive, so we avoid it unless absolutely necessary.**\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"9b12e674-ef08-4dd7-8843-615b65b39c91\",\n \"metadata\": {\n \"id\": \"9b12e674-ef08-4dd7-8843-615b65b39c91\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, d_out, num_heads,\\n\",\n \" num_kv_groups, # NEW\\n\",\n \" dtype=None\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert d_out % num_heads == 0, \\\"d_out must be divisible by num_heads\\\"\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\" # NEW\\n\",\n \"\\n\",\n \" self.d_out = d_out\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.head_dim = d_out // num_heads\\n\",\n \"\\n\",\n \" ############################# NEW #############################\\n\",\n \" # self.W_key = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" # self.W_value = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \" ################################################################\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, x, mask=None, cos=None, sin=None):\\n\",\n \" ##################### NEW #####################\\n\",\n \" # The forward method now accepts `mask` instead of accessing it via self.mask.\\n\",\n \" # Also, we now have cos and sin as input for RoPE\\n\",\n \" ################################################ \\n\",\n \" b, num_tokens, d_in = x.shape\\n\",\n \"\\n\",\n \" queries = self.W_query(x) # Shape: (b, num_tokens, d_out)\\n\",\n \" keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape queries, keys, and values\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \"\\n\",\n \" ##################### NEW #####################\\n\",\n \" # keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" # values = values.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)\\n\",\n \" values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)\\n\",\n \" ################################################\\n\",\n \"\\n\",\n \" # Transpose keys, values, and queries\\n\",\n \" keys = keys.transpose(1, 2) # Shape: (b, num_kv_groups, num_tokens, head_dim)\\n\",\n \" values = values.transpose(1, 2) # Shape: (b, num_kv_groups, num_tokens, head_dim)\\n\",\n \" queries = queries.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \"\\n\",\n \" ##################### NEW #####################\\n\",\n \" # Apply RoPE\\n\",\n \" if cos is not None:\\n\",\n \" keys = compute_rope(keys, cos, sin)\\n\",\n \" queries = compute_rope(queries, cos, sin)\\n\",\n \" ################################################\\n\",\n \"\\n\",\n \" ##################### NEW #####################\\n\",\n \" # Expand keys and values to match the number of heads\\n\",\n \" # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \"\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" # For example, before repeat_interleave along dim=1 (query groups):\\n\",\n \" # [K1, K2]\\n\",\n \" # After repeat_interleave (each query group is repeated group_size times):\\n\",\n \" # [K1, K1, K2, K2]\\n\",\n \" # If we used regular repeat instead of repeat_interleave, we'd get:\\n\",\n \" # [K1, K2, K1, K2]\\n\",\n \" ################################################\\n\",\n \"\\n\",\n \" # Compute scaled dot-product attention (aka self-attention) with a causal mask\\n\",\n \" # Shape: (b, num_heads, num_tokens, num_tokens)\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\\n\",\n \"\\n\",\n \" ##################### NEW #####################\\n\",\n \" # Create mask on the fly\\n\",\n \" if mask is None:\\n\",\n \" mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)\\n\",\n \" ################################################\\n\",\n \" \\n\",\n \" # Use the mask to fill attention scores\\n\",\n \" attn_scores.masked_fill_(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\\n\",\n \" assert keys.shape[-1] == self.head_dim\\n\",\n \"\\n\",\n \" # Shape: (b, num_tokens, num_heads, head_dim)\\n\",\n \" context_vec = (attn_weights @ values).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Combine heads, where self.d_out = self.num_heads * self.head_dim\\n\",\n \" context_vec = context_vec.reshape(b, num_tokens, self.d_out)\\n\",\n \" context_vec = self.out_proj(context_vec) # optional projection\\n\",\n \"\\n\",\n \" return context_vec\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"roAXSwJs9hR8\",\n \"metadata\": {\n \"id\": \"roAXSwJs9hR8\"\n },\n \"source\": [\n \"- To illustrate the parameter savings in GQA over MHA, consider the following multi-head attention example from the GPT and Llama 2 code:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"b4b8f085-349e-4674-a3f0-78fde0664fac\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"b4b8f085-349e-4674-a3f0-78fde0664fac\",\n \"outputId\": \"9da09d72-43b1-45af-d46f-6928ea4af33a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"W_key: torch.Size([4096, 4096])\\n\",\n \"W_value: torch.Size([4096, 4096])\\n\",\n \"W_query: torch.Size([4096, 4096])\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Settings\\n\",\n \"batch_size = 1\\n\",\n \"context_len = 3000\\n\",\n \"max_context_len = 8192\\n\",\n \"embed_dim = 4096\\n\",\n \"num_heads = 32\\n\",\n \"\\n\",\n \"\\n\",\n \"example_batch = torch.randn((batch_size, context_len, embed_dim))\\n\",\n \"\\n\",\n \"mha = MultiHeadAttention(\\n\",\n \" d_in=embed_dim,\\n\",\n \" d_out=embed_dim,\\n\",\n \" context_length=max_context_len,\\n\",\n \" num_heads=num_heads\\n\",\n \")\\n\",\n \"\\n\",\n \"mha(example_batch)\\n\",\n \"\\n\",\n \"print(\\\"W_key:\\\", mha.W_key.weight.shape)\\n\",\n \"print(\\\"W_value:\\\", mha.W_value.weight.shape)\\n\",\n \"print(\\\"W_query:\\\", mha.W_query.weight.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"IMQtFkcQ9sXC\",\n \"metadata\": {\n \"id\": \"IMQtFkcQ9sXC\"\n },\n \"source\": [\n \"- Now, if we use grouped-query attention instead, with 8 kv-groups (that's how many Llama 3 8B uses), we can see that the number of rows of the key and value matrices are reduced by a factor of 4 (because 32 attention heads divided by 8 kv-groups is 4)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"15e65d3c-7b42-4ed3-bfee-bb09578657bb\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"15e65d3c-7b42-4ed3-bfee-bb09578657bb\",\n \"outputId\": \"69709a78-2aaa-4597-8142-2f44eb59753f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"W_key: torch.Size([1024, 4096])\\n\",\n \"W_value: torch.Size([1024, 4096])\\n\",\n \"W_query: torch.Size([4096, 4096])\\n\"\n ]\n }\n ],\n \"source\": [\n \"gqa = GroupedQueryAttention(\\n\",\n \" d_in=embed_dim,\\n\",\n \" d_out=embed_dim,\\n\",\n \" num_heads=num_heads,\\n\",\n \" num_kv_groups=8,\\n\",\n \")\\n\",\n \"\\n\",\n \"gqa(example_batch)\\n\",\n \"\\n\",\n \"print(\\\"W_key:\\\", gqa.W_key.weight.shape)\\n\",\n \"print(\\\"W_value:\\\", gqa.W_value.weight.shape)\\n\",\n \"print(\\\"W_query:\\\", gqa.W_query.weight.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1a5d4c88-c66a-483b-b4e2-419ff9fd60d5\",\n \"metadata\": {\n \"id\": \"1a5d4c88-c66a-483b-b4e2-419ff9fd60d5\"\n },\n \"source\": [\n \"- As a side note, to make the GroupedQueryAttention equivalent to standard multi-head attention, you can set the number of query groups (`num_kv_groups`) equal to the number of heads (`num_heads`)\\n\",\n \"- Lastly, let's compare the number of parameters below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"58f713aa-ac00-4e2f-8247-94609aa01350\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"58f713aa-ac00-4e2f-8247-94609aa01350\",\n \"outputId\": \"486dfd9c-9f3a-4b9e-f9a2-35fb43b9a5fb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters:\\n\",\n \"MHA: 67,108,864\\n\",\n \"GQA: 41,943,040\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Total number of parameters:\\\")\\n\",\n \"\\n\",\n \"mha_total_params = sum(p.numel() for p in mha.parameters())\\n\",\n \"print(f\\\"MHA: {mha_total_params:,}\\\")\\n\",\n \"\\n\",\n \"gqa_total_params = sum(p.numel() for p in gqa.parameters())\\n\",\n \"print(f\\\"GQA: {gqa_total_params:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"78b60dfd-6c0f-41f7-8f0c-8e57116f07f5\",\n \"metadata\": {\n \"id\": \"78b60dfd-6c0f-41f7-8f0c-8e57116f07f5\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Free up memory:\\n\",\n \"del mha\\n\",\n \"del gqa\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8fcd8802-2859-45a2-905a-f4fe96629dd9\",\n \"metadata\": {\n \"id\": \"8fcd8802-2859-45a2-905a-f4fe96629dd9\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.4 Update the TransformerBlock module\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"KABNccft_YnR\",\n \"metadata\": {\n \"id\": \"KABNccft_YnR\"\n },\n \"source\": [\n \"- Next, we update the `TransformerBlock`\\n\",\n \"- Here, we simply swap `MultiHeadAttention` with `GroupedQueryAttention` and add the new RoPE settings\\n\",\n \"- In addition, we also modify the `forward` method so that it receives `mask`, `cos`, and `sin`; since the values for those are the same for each transformer block, we only have to compute them once and then can reuse them\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"f9fa8eb4-7196-4dee-aec6-0dcbc70921c4\",\n \"metadata\": {\n \"id\": \"f9fa8eb4-7196-4dee-aec6-0dcbc70921c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.att = GroupedQueryAttention( # MultiHeadAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" d_out=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"], # NEW\\n\",\n \" dtype=cfg[\\\"dtype\\\"]\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5)\\n\",\n \" self.norm2 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5)\\n\",\n \"\\n\",\n \" def forward(self, x, mask=None, cos=None, sin=None):\\n\",\n \" ##################### NEW #####################\\n\",\n \" # The forward method now accepts `mask` instead of accessing it via self.mask.\\n\",\n \" # Also, we now have cos and sin as input for RoPE\\n\",\n \" ################################################\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \" x = self.att(x.to(torch.bfloat16), mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" # Shortcut connection for feed-forward block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x.to(torch.bfloat16))\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fd921ab5-c48c-4c52-bf41-b847b3b822b9\",\n \"metadata\": {\n \"id\": \"fd921ab5-c48c-4c52-bf41-b847b3b822b9\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.5 Defining the model class\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"M_tLAq_r_llN\",\n \"metadata\": {\n \"id\": \"M_tLAq_r_llN\"\n },\n \"source\": [\n \"- When setting up the model class, we technically don't have to do much; we just update the name to `Llama3Model`\\n\",\n \"- However, since we now pass the `mask`, `cos`, and `sin` to the transformer blocks, we also have to add them here\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"475755d6-01f7-4e6e-ad9a-cec6f031ebf6\",\n \"metadata\": {\n \"id\": \"475755d6-01f7-4e6e-ad9a-cec6f031ebf6\"\n },\n \"outputs\": [],\n \"source\": [\n \"# class Llama2Model(nn.Module):\\n\",\n \"class Llama3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.Sequential(\\n\",\n \" *[TransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])])\\n\",\n \"\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5)\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" #################### NEW #####################\\n\",\n \" cos, sin = precompute_rope_params(\\n\",\n \" head_dim=cfg[\\\"emb_dim\\\"] // cfg[\\\"n_heads\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" freq_config=cfg[\\\"rope_freq\\\"]\\n\",\n \" )\\n\",\n \" \\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \" ##############################################\\n\",\n \"\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" x = tok_embeds\\n\",\n \"\\n\",\n \" #################### NEW #####################\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \" mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)\\n\",\n \" ##############################################\\n\",\n \" \\n\",\n \" for block in self.trf_blocks:\\n\",\n \" x = block(x, mask, self.cos, self.sin)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4bc94940-aaeb-45b9-9399-3a69b8043e60\",\n \"metadata\": {\n \"id\": \"4bc94940-aaeb-45b9-9399-3a69b8043e60\"\n },\n \"source\": [\n \" \\n\",\n \"## 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"HoGGRAGykQTE\",\n \"metadata\": {\n \"id\": \"HoGGRAGykQTE\"\n },\n \"source\": [\n \"- Now we can define a Llama 3 config file (the Llama 2 config file is shown for comparison)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"e0564727-2d35-4f0c-b0fc-cde1e9134a18\",\n \"metadata\": {\n \"id\": \"e0564727-2d35-4f0c-b0fc-cde1e9134a18\"\n },\n \"outputs\": [],\n \"source\": [\n \"LLAMA2_CONFIG_7B = {\\n\",\n \" \\\"vocab_size\\\": 32_000, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 4096, # Context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 11_008, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"dtype\\\": torch.bfloat16 # Lower-precision dtype to reduce memory usage\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"2ad90f82-15c7-4806-b509-e45b56f57db5\",\n \"metadata\": {\n \"id\": \"2ad90f82-15c7-4806-b509-e45b56f57db5\"\n },\n \"outputs\": [],\n \"source\": [\n \"LLAMA3_CONFIG_8B = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # NEW: Larger vocabulary size\\n\",\n \" \\\"context_length\\\": 8192, # NEW: Larger context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 14_336, # NEW: Larger size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # NEW: Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # NEW: The base in RoPE's \\\"theta\\\" was increased to 500_000\\n\",\n \" \\\"rope_freq\\\": None, # NEW: Additional configuration for adjusting the RoPE frequencies\\n\",\n \" \\\"dtype\\\": torch.bfloat16 # Lower-precision dtype to reduce memory usage\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"FAP7fiBzkaBz\",\n \"metadata\": {\n \"id\": \"FAP7fiBzkaBz\"\n },\n \"source\": [\n \"- Using these settings, we can now initialize a Llama 3 8B model\\n\",\n \"- Note that this requires ~34 GB of memory (for comparison, Llama 2 7B required ~26 GB of memory)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"7004d785-ac9a-4df5-8760-6807fc604686\",\n \"metadata\": {\n \"id\": \"7004d785-ac9a-4df5-8760-6807fc604686\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = Llama3Model(LLAMA3_CONFIG_8B)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8056a521-91a6-440f-8473-591409c3177b\",\n \"metadata\": {},\n \"source\": [\n \"- Let's now compute the number of trainable parameters:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"6079f747-8f20-4c6b-8d38-7156f1101729\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6079f747-8f20-4c6b-8d38-7156f1101729\",\n \"outputId\": \"0a8cd23b-d9fa-4c2d-ca63-3fc79bc4de0d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters: 8,030,261,248\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters())\\n\",\n \"print(f\\\"Total number of parameters: {total_params:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"Bx14NtzWk2wj\",\n \"metadata\": {\n \"id\": \"Bx14NtzWk2wj\"\n },\n \"source\": [\n \"- As shown above, the model contains 8 billion parameters\\n\",\n \"- Additionally, we can calculate the memory requirements for this model using the code below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"0df1c79e-27a7-4b0f-ba4e-167fe107125a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0df1c79e-27a7-4b0f-ba4e-167fe107125a\",\n \"outputId\": \"3425e9ce-d8c0-4b37-bded-a2c60b66a41a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"float32 (PyTorch default): 59.84 GB\\n\",\n \"bfloat16: 29.92 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def calc_model_memory_size(model, input_dtype=torch.float32):\\n\",\n \" total_params = 0\\n\",\n \" total_grads = 0\\n\",\n \" for param in model.parameters():\\n\",\n \" # Calculate total number of elements per parameter\\n\",\n \" param_size = param.numel()\\n\",\n \" total_params += param_size\\n\",\n \" # Check if gradients are stored for this parameter\\n\",\n \" if param.requires_grad:\\n\",\n \" total_grads += param_size\\n\",\n \"\\n\",\n \" # Calculate buffer size (non-parameters that require memory)\\n\",\n \" total_buffers = sum(buf.numel() for buf in model.buffers())\\n\",\n \"\\n\",\n \" # Size in bytes = (Number of elements) * (Size of each element in bytes)\\n\",\n \" # We assume parameters and gradients are stored in the same type as input dtype\\n\",\n \" element_size = torch.tensor(0, dtype=input_dtype).element_size()\\n\",\n \" total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\\n\",\n \"\\n\",\n \" # Convert bytes to gigabytes\\n\",\n \" total_memory_gb = total_memory_bytes / (1024**3)\\n\",\n \"\\n\",\n \" return total_memory_gb\\n\",\n \"\\n\",\n \"print(f\\\"float32 (PyTorch default): {calc_model_memory_size(model, input_dtype=torch.float32):.2f} GB\\\")\\n\",\n \"print(f\\\"bfloat16: {calc_model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"zudd-5PulKFL\",\n \"metadata\": {\n \"id\": \"zudd-5PulKFL\"\n },\n \"source\": [\n \"- Lastly, we can also transfer the model to an NVIDIA or Apple Silicon GPU if applicable:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"a4c50e19-1402-45b6-8ccd-9077b2ba836d\",\n \"metadata\": {\n \"id\": \"a4c50e19-1402-45b6-8ccd-9077b2ba836d\"\n },\n \"outputs\": [],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5dc64a06-27dc-46ec-9e6d-1700a8227d34\",\n \"metadata\": {\n \"id\": \"5dc64a06-27dc-46ec-9e6d-1700a8227d34\"\n },\n \"source\": [\n \" \\n\",\n \"## 3. Load tokenizer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0eb30f0c-6144-4bed-87d9-6b2bac377005\",\n \"metadata\": {\n \"id\": \"0eb30f0c-6144-4bed-87d9-6b2bac377005\"\n },\n \"source\": [\n \"- In this section, we are going to load the tokenizer for the model\\n\",\n \"- Llama 2 used Google's [SentencePiece](https://github.com/google/sentencepiece) tokenizer instead of OpenAI's BPE tokenizer based on the [Tiktoken](https://github.com/openai/tiktoken) library\\n\",\n \"- Llama 3, however, reverted back to using the BPE tokenizer from Tiktoken; specifically, it uses the GPT-4 tokenizer with an extended vocabulary\\n\",\n \"- You can find the original Tiktoken-adaptation by Meta AI [here](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py) in their official Llama 3 repository\\n\",\n \"- Below, I rewrote the tokenizer code to make it more readable and minimal for this notebook (but the behavior should be similar)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"5f390cbf-8f92-46dc-afe3-d90b5affae10\",\n \"metadata\": {\n \"id\": \"5f390cbf-8f92-46dc-afe3-d90b5affae10\"\n },\n \"outputs\": [],\n \"source\": [\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"import tiktoken\\n\",\n \"from tiktoken.load import load_tiktoken_bpe\\n\",\n \"\\n\",\n \"\\n\",\n \"class Tokenizer:\\n\",\n \" \\\"\\\"\\\"Thin wrapper around tiktoken that keeps track of Llama-3 special IDs.\\\"\\\"\\\"\\n\",\n \" def __init__(self, model_path):\\n\",\n \" if not os.path.isfile(model_path):\\n\",\n \" raise FileNotFoundError(model_path)\\n\",\n \"\\n\",\n \" mergeable = load_tiktoken_bpe(model_path)\\n\",\n \"\\n\",\n \" # hard-coded from Meta's tokenizer.json\\n\",\n \" self.special = {\\n\",\n \" \\\"<|begin_of_text|>\\\": 128000,\\n\",\n \" \\\"<|end_of_text|>\\\": 128001,\\n\",\n \" \\\"<|start_header_id|>\\\": 128006,\\n\",\n \" \\\"<|end_header_id|>\\\": 128007,\\n\",\n \" \\\"<|eot_id|>\\\": 128009,\\n\",\n \" }\\n\",\n \" self.special.update({f\\\"<|reserved_{i}|>\\\": 128002 + i\\n\",\n \" for i in range(256)\\n\",\n \" if 128002 + i not in self.special.values()})\\n\",\n \"\\n\",\n \" self.model = tiktoken.Encoding(\\n\",\n \" name=Path(model_path).name,\\n\",\n \" pat_str=r\\\"(?i:'s|'t|'re|'ve|'m|'ll|'d)\\\"\\n\",\n \" r\\\"|[^\\\\r\\\\n\\\\p{L}\\\\p{N}]?\\\\p{L}+\\\"\\n\",\n \" r\\\"|\\\\p{N}{1,3}\\\"\\n\",\n \" r\\\"| ?[^\\\\s\\\\p{L}\\\\p{N}]+[\\\\r\\\\n]*\\\"\\n\",\n \" r\\\"|\\\\s*[\\\\r\\\\n]+\\\"\\n\",\n \" r\\\"|\\\\s+(?!\\\\S)\\\"\\n\",\n \" r\\\"|\\\\s+\\\",\\n\",\n \" mergeable_ranks=mergeable,\\n\",\n \" special_tokens=self.special,\\n\",\n \" )\\n\",\n \"\\n\",\n \" def encode(self, text, bos=False, eos=False):\\n\",\n \" ids = ([self.special[\\\"<|begin_of_text|>\\\"]] if bos else []) \\\\\\n\",\n \" + self.model.encode(text)\\n\",\n \" if eos:\\n\",\n \" ids.append(self.special[\\\"<|end_of_text|>\\\"])\\n\",\n \" return ids\\n\",\n \"\\n\",\n \" def decode(self, ids):\\n\",\n \" return self.model.decode(ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0a1509f8-8778-4fec-ba32-14d95c646167\",\n \"metadata\": {\n \"id\": \"0a1509f8-8778-4fec-ba32-14d95c646167\"\n },\n \"source\": [\n \"- Meta AI shared the original Llama 3 model weights and tokenizer vocabulary on the Hugging Face Hub\\n\",\n \"- We will first download the tokenizer vocabulary from the Hub and load it into the code above\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"KbnlzsbYmJU6\",\n \"metadata\": {\n \"id\": \"KbnlzsbYmJU6\"\n },\n \"source\": [\n \"- Please note that Meta AI requires that you accept the Llama 3 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) repository to accept the terms\\n\",\n \"- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \\\"Settings\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"3357a230-b678-4691-a238-257ee4e80185\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"3357a230-b678-4691-a238-257ee4e80185\",\n \"outputId\": \"a3652def-ea7f-46fb-f293-2a59affb71a0\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import login\\n\",\n \"import json\\n\",\n \"\\n\",\n \"with open(\\\"config.json\\\", \\\"r\\\") as config_file:\\n\",\n \" config = json.load(config_file)\\n\",\n \" access_token = config[\\\"HF_ACCESS_TOKEN\\\"]\\n\",\n \"\\n\",\n \"login(token=access_token)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"IxGh6ZYQo0VN\",\n \"metadata\": {\n \"id\": \"IxGh6ZYQo0VN\"\n },\n \"source\": [\n \"- After login via the access token, which is necessary to verify that we accepted the Llama 3 licensing terms, we can now download the tokenizer vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"69714ea8-b9b8-4687-8392-f3abb8f93a32\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"69714ea8-b9b8-4687-8392-f3abb8f93a32\",\n \"outputId\": \"c9836ba8-5176-4dd5-b618-6cc36fdbe1f0\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"application/vnd.jupyter.widget-view+json\": {\n \"model_id\": \"685326b4fd014ff689e928f4200f5182\",\n \"version_major\": 2,\n \"version_minor\": 0\n },\n \"text/plain\": [\n \"original/tokenizer.model: 0%| | 0.00/2.18M [00:00role<|end_header_id|>\\\\n\\\\n\\\"\\\"\\\"\\n\",\n \" return (\\n\",\n \" [self.tok.special[\\\"<|start_header_id|>\\\"]]\\n\",\n \" + self.tok.encode(role)\\n\",\n \" + [self.tok.special[\\\"<|end_header_id|>\\\"]]\\n\",\n \" + self.tok.encode(\\\"\\\\n\\\\n\\\")\\n\",\n \" )\\n\",\n \"\\n\",\n \" def encode(self, user_message, system_message=None):\\n\",\n \" sys_msg = system_message if system_message is not None else self.default_system\\n\",\n \"\\n\",\n \" ids = [self.tok.special[\\\"<|begin_of_text|>\\\"]]\\n\",\n \"\\n\",\n \" # system\\n\",\n \" ids += self._header(\\\"system\\\")\\n\",\n \" ids += self.tok.encode(sys_msg)\\n\",\n \" ids += [self.tok.special[\\\"<|eot_id|>\\\"]]\\n\",\n \"\\n\",\n \" # user\\n\",\n \" ids += self._header(\\\"user\\\")\\n\",\n \" ids += self.tok.encode(user_message)\\n\",\n \" ids += [self.tok.special[\\\"<|eot_id|>\\\"]]\\n\",\n \"\\n\",\n \" # assistant header (no content yet)\\n\",\n \" ids += self._header(\\\"assistant\\\")\\n\",\n \"\\n\",\n \" return ids\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"M-dkSNvwDttN\",\n \"metadata\": {\n \"id\": \"M-dkSNvwDttN\"\n },\n \"source\": [\n \"- The usage is as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"nwBrTGTsUNhn\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"nwBrTGTsUNhn\",\n \"outputId\": \"72a495b4-b872-429a-88ef-49a9b4577f0f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[128000, 128006, 9125, 128007, 271, 2675, 527, 264, 11190, 18328, 13, 128009, 128006, 882, 128007, 271, 9906, 4435, 0, 128009, 128006, 78191, 128007, 271]\\n\"\n ]\n }\n ],\n \"source\": [\n \"tokenizer = Tokenizer(tokenizer_file_path)\\n\",\n \"chat_tokenizer = ChatFormat(tokenizer)\\n\",\n \"\\n\",\n \"token_ids = chat_tokenizer.encode(\\\"Hello World!\\\")\\n\",\n \"print(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"0fpmpVgYVTRZ\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 36\n },\n \"id\": \"0fpmpVgYVTRZ\",\n \"outputId\": \"bb3e819a-112a-466c-ac51-5d14a9c3475b\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'<|begin_of_text|><|start_header_id|>system<|end_header_id|>\\\\n\\\\nYou are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>\\\\n\\\\nHello World!<|eot_id|><|start_header_id|>assistant<|end_header_id|>\\\\n\\\\n'\"\n ]\n },\n \"execution_count\": 35,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer.decode(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"Wo-aUGeKDvqq\",\n \"metadata\": {\n \"id\": \"Wo-aUGeKDvqq\"\n },\n \"source\": [\n \"- Let's now see the Llama 3 instruction model in action:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"ozGOBu6XOkEW\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"ozGOBu6XOkEW\",\n \"outputId\": \"4f689c70-bed9-46f3-a52a-aea47b641283\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Llamas are herbivores, which means they primarily eat plants and plant-based foods. Their diet typically consists of:\\n\",\n \"\\n\",\n \"1. Grasses: Llamas love to graze on grasses, including tall grasses, short grasses, and even weeds.\\n\",\n \"2. Hay: Hay is a staple in a llama's diet. They enjoy a variety of hays, such as timothy hay, alfalfa hay, and oat hay.\\n\",\n \"3. Grains: Llamas may be fed grains like oats, corn, and barley as a supplement to their diet.\\n\",\n \"4. Fruits and vegetables: Llamas enjoy fruits and vegetables like apples, carrots, and sweet potatoes as treats or additions to their meals.\\n\",\n \"5. Minerals:\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(\\\"What do llamas eat?\\\", chat_tokenizer).to(device),\\n\",\n \" max_new_tokens=150,\\n\",\n \" context_size=LLAMA3_CONFIG_8B[\\\"context_length\\\"],\\n\",\n \" top_k=1,\\n\",\n \" temperature=0.\\n\",\n \")\\n\",\n \"\\n\",\n \"output_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \"\\n\",\n \"\\n\",\n \"def clean_text(text, header_end=\\\"assistant<|end_header_id|>\\\\n\\\\n\\\"):\\n\",\n \" # Find the index of the first occurrence of \\\"<|end_header_id|>\\\"\\n\",\n \" index = text.find(header_end)\\n\",\n \"\\n\",\n \" if index != -1:\\n\",\n \" # Return the substring starting after \\\"<|end_header_id|>\\\"\\n\",\n \" return text[index + len(header_end):].strip() # Strip removes leading/trailing whitespace\\n\",\n \" else:\\n\",\n \" # If the token is not found, return the original text\\n\",\n \" return text\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", clean_text(output_text))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2r5JKrO-ZOHK\",\n \"metadata\": {\n \"id\": \"2r5JKrO-ZOHK\"\n },\n \"source\": [\n \" \\n\",\n \"# 6. Llama 3.1 8B\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"QiQxX0XnP_iC\",\n \"metadata\": {\n \"id\": \"QiQxX0XnP_iC\"\n },\n \"source\": [\n \"- A few months after the initial Llama 3 release, Meta AI followed up with their Llama 3.1 suite of models (see the official [Introducing Llama 3.1: Our most capable models to date](https://ai.meta.com/blog/meta-llama-3-1/) announcement blog post for details)\\n\",\n \"- Conveniently, we can reuse our previous Llama 3 code from above to implement Llama 3.1 8B\\n\",\n \"\\n\",\n \"
\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"perAYa2R_KW2\",\n \"metadata\": {\n \"id\": \"perAYa2R_KW2\"\n },\n \"source\": [\n \"- The main idea behind GQA is to reduce the number of unique query groups that attend to the key-value pairs, reducing the size of some of the matrix multiplications and the number of parameters in MHA without significantly reducing modeling performance\\n\",\n \"- The GQA code is very similar to MHA (I highlighted the changes below via the \\\"NEW\\\" sections)\\n\",\n \"- In short, the main change in GQA is that each query group needs to be repeated to match the number of heads it is associated with, as implemented below\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"842aa71a-4659-424e-8830-392bd6ae86af\",\n \"metadata\": {},\n \"source\": [\n \"- **We also redesign the attention class a bit so it receives the mask through its forward method instead of storing and accessing it as `self.mask`. This lets us build the mask on the fly to reduce memory usage. To foreshadow why: Llama 3.1 can handle sequences of up to 128 k tokens, and precomputing a 128 k × 128 k causal mask would be extremely memory‑intensive, so we avoid it unless absolutely necessary.**\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"9b12e674-ef08-4dd7-8843-615b65b39c91\",\n \"metadata\": {\n \"id\": \"9b12e674-ef08-4dd7-8843-615b65b39c91\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, d_out, num_heads,\\n\",\n \" num_kv_groups, # NEW\\n\",\n \" dtype=None\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert d_out % num_heads == 0, \\\"d_out must be divisible by num_heads\\\"\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\" # NEW\\n\",\n \"\\n\",\n \" self.d_out = d_out\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.head_dim = d_out // num_heads\\n\",\n \"\\n\",\n \" ############################# NEW #############################\\n\",\n \" # self.W_key = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" # self.W_value = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \" ################################################################\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, x, mask=None, cos=None, sin=None):\\n\",\n \" ##################### NEW #####################\\n\",\n \" # The forward method now accepts `mask` instead of accessing it via self.mask.\\n\",\n \" # Also, we now have cos and sin as input for RoPE\\n\",\n \" ################################################ \\n\",\n \" b, num_tokens, d_in = x.shape\\n\",\n \"\\n\",\n \" queries = self.W_query(x) # Shape: (b, num_tokens, d_out)\\n\",\n \" keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape queries, keys, and values\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \"\\n\",\n \" ##################### NEW #####################\\n\",\n \" # keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" # values = values.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)\\n\",\n \" values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)\\n\",\n \" ################################################\\n\",\n \"\\n\",\n \" # Transpose keys, values, and queries\\n\",\n \" keys = keys.transpose(1, 2) # Shape: (b, num_kv_groups, num_tokens, head_dim)\\n\",\n \" values = values.transpose(1, 2) # Shape: (b, num_kv_groups, num_tokens, head_dim)\\n\",\n \" queries = queries.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \"\\n\",\n \" ##################### NEW #####################\\n\",\n \" # Apply RoPE\\n\",\n \" if cos is not None:\\n\",\n \" keys = compute_rope(keys, cos, sin)\\n\",\n \" queries = compute_rope(queries, cos, sin)\\n\",\n \" ################################################\\n\",\n \"\\n\",\n \" ##################### NEW #####################\\n\",\n \" # Expand keys and values to match the number of heads\\n\",\n \" # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \"\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" # For example, before repeat_interleave along dim=1 (query groups):\\n\",\n \" # [K1, K2]\\n\",\n \" # After repeat_interleave (each query group is repeated group_size times):\\n\",\n \" # [K1, K1, K2, K2]\\n\",\n \" # If we used regular repeat instead of repeat_interleave, we'd get:\\n\",\n \" # [K1, K2, K1, K2]\\n\",\n \" ################################################\\n\",\n \"\\n\",\n \" # Compute scaled dot-product attention (aka self-attention) with a causal mask\\n\",\n \" # Shape: (b, num_heads, num_tokens, num_tokens)\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\\n\",\n \"\\n\",\n \" ##################### NEW #####################\\n\",\n \" # Create mask on the fly\\n\",\n \" if mask is None:\\n\",\n \" mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)\\n\",\n \" ################################################\\n\",\n \" \\n\",\n \" # Use the mask to fill attention scores\\n\",\n \" attn_scores.masked_fill_(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\\n\",\n \" assert keys.shape[-1] == self.head_dim\\n\",\n \"\\n\",\n \" # Shape: (b, num_tokens, num_heads, head_dim)\\n\",\n \" context_vec = (attn_weights @ values).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Combine heads, where self.d_out = self.num_heads * self.head_dim\\n\",\n \" context_vec = context_vec.reshape(b, num_tokens, self.d_out)\\n\",\n \" context_vec = self.out_proj(context_vec) # optional projection\\n\",\n \"\\n\",\n \" return context_vec\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"roAXSwJs9hR8\",\n \"metadata\": {\n \"id\": \"roAXSwJs9hR8\"\n },\n \"source\": [\n \"- To illustrate the parameter savings in GQA over MHA, consider the following multi-head attention example from the GPT and Llama 2 code:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"b4b8f085-349e-4674-a3f0-78fde0664fac\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"b4b8f085-349e-4674-a3f0-78fde0664fac\",\n \"outputId\": \"9da09d72-43b1-45af-d46f-6928ea4af33a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"W_key: torch.Size([4096, 4096])\\n\",\n \"W_value: torch.Size([4096, 4096])\\n\",\n \"W_query: torch.Size([4096, 4096])\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Settings\\n\",\n \"batch_size = 1\\n\",\n \"context_len = 3000\\n\",\n \"max_context_len = 8192\\n\",\n \"embed_dim = 4096\\n\",\n \"num_heads = 32\\n\",\n \"\\n\",\n \"\\n\",\n \"example_batch = torch.randn((batch_size, context_len, embed_dim))\\n\",\n \"\\n\",\n \"mha = MultiHeadAttention(\\n\",\n \" d_in=embed_dim,\\n\",\n \" d_out=embed_dim,\\n\",\n \" context_length=max_context_len,\\n\",\n \" num_heads=num_heads\\n\",\n \")\\n\",\n \"\\n\",\n \"mha(example_batch)\\n\",\n \"\\n\",\n \"print(\\\"W_key:\\\", mha.W_key.weight.shape)\\n\",\n \"print(\\\"W_value:\\\", mha.W_value.weight.shape)\\n\",\n \"print(\\\"W_query:\\\", mha.W_query.weight.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"IMQtFkcQ9sXC\",\n \"metadata\": {\n \"id\": \"IMQtFkcQ9sXC\"\n },\n \"source\": [\n \"- Now, if we use grouped-query attention instead, with 8 kv-groups (that's how many Llama 3 8B uses), we can see that the number of rows of the key and value matrices are reduced by a factor of 4 (because 32 attention heads divided by 8 kv-groups is 4)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"15e65d3c-7b42-4ed3-bfee-bb09578657bb\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"15e65d3c-7b42-4ed3-bfee-bb09578657bb\",\n \"outputId\": \"69709a78-2aaa-4597-8142-2f44eb59753f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"W_key: torch.Size([1024, 4096])\\n\",\n \"W_value: torch.Size([1024, 4096])\\n\",\n \"W_query: torch.Size([4096, 4096])\\n\"\n ]\n }\n ],\n \"source\": [\n \"gqa = GroupedQueryAttention(\\n\",\n \" d_in=embed_dim,\\n\",\n \" d_out=embed_dim,\\n\",\n \" num_heads=num_heads,\\n\",\n \" num_kv_groups=8,\\n\",\n \")\\n\",\n \"\\n\",\n \"gqa(example_batch)\\n\",\n \"\\n\",\n \"print(\\\"W_key:\\\", gqa.W_key.weight.shape)\\n\",\n \"print(\\\"W_value:\\\", gqa.W_value.weight.shape)\\n\",\n \"print(\\\"W_query:\\\", gqa.W_query.weight.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1a5d4c88-c66a-483b-b4e2-419ff9fd60d5\",\n \"metadata\": {\n \"id\": \"1a5d4c88-c66a-483b-b4e2-419ff9fd60d5\"\n },\n \"source\": [\n \"- As a side note, to make the GroupedQueryAttention equivalent to standard multi-head attention, you can set the number of query groups (`num_kv_groups`) equal to the number of heads (`num_heads`)\\n\",\n \"- Lastly, let's compare the number of parameters below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"58f713aa-ac00-4e2f-8247-94609aa01350\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"58f713aa-ac00-4e2f-8247-94609aa01350\",\n \"outputId\": \"486dfd9c-9f3a-4b9e-f9a2-35fb43b9a5fb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters:\\n\",\n \"MHA: 67,108,864\\n\",\n \"GQA: 41,943,040\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Total number of parameters:\\\")\\n\",\n \"\\n\",\n \"mha_total_params = sum(p.numel() for p in mha.parameters())\\n\",\n \"print(f\\\"MHA: {mha_total_params:,}\\\")\\n\",\n \"\\n\",\n \"gqa_total_params = sum(p.numel() for p in gqa.parameters())\\n\",\n \"print(f\\\"GQA: {gqa_total_params:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"78b60dfd-6c0f-41f7-8f0c-8e57116f07f5\",\n \"metadata\": {\n \"id\": \"78b60dfd-6c0f-41f7-8f0c-8e57116f07f5\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Free up memory:\\n\",\n \"del mha\\n\",\n \"del gqa\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8fcd8802-2859-45a2-905a-f4fe96629dd9\",\n \"metadata\": {\n \"id\": \"8fcd8802-2859-45a2-905a-f4fe96629dd9\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.4 Update the TransformerBlock module\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"KABNccft_YnR\",\n \"metadata\": {\n \"id\": \"KABNccft_YnR\"\n },\n \"source\": [\n \"- Next, we update the `TransformerBlock`\\n\",\n \"- Here, we simply swap `MultiHeadAttention` with `GroupedQueryAttention` and add the new RoPE settings\\n\",\n \"- In addition, we also modify the `forward` method so that it receives `mask`, `cos`, and `sin`; since the values for those are the same for each transformer block, we only have to compute them once and then can reuse them\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"f9fa8eb4-7196-4dee-aec6-0dcbc70921c4\",\n \"metadata\": {\n \"id\": \"f9fa8eb4-7196-4dee-aec6-0dcbc70921c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.att = GroupedQueryAttention( # MultiHeadAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" d_out=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"], # NEW\\n\",\n \" dtype=cfg[\\\"dtype\\\"]\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5)\\n\",\n \" self.norm2 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5)\\n\",\n \"\\n\",\n \" def forward(self, x, mask=None, cos=None, sin=None):\\n\",\n \" ##################### NEW #####################\\n\",\n \" # The forward method now accepts `mask` instead of accessing it via self.mask.\\n\",\n \" # Also, we now have cos and sin as input for RoPE\\n\",\n \" ################################################\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \" x = self.att(x.to(torch.bfloat16), mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" # Shortcut connection for feed-forward block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x.to(torch.bfloat16))\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fd921ab5-c48c-4c52-bf41-b847b3b822b9\",\n \"metadata\": {\n \"id\": \"fd921ab5-c48c-4c52-bf41-b847b3b822b9\"\n },\n \"source\": [\n \" \\n\",\n \"## 1.5 Defining the model class\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"M_tLAq_r_llN\",\n \"metadata\": {\n \"id\": \"M_tLAq_r_llN\"\n },\n \"source\": [\n \"- When setting up the model class, we technically don't have to do much; we just update the name to `Llama3Model`\\n\",\n \"- However, since we now pass the `mask`, `cos`, and `sin` to the transformer blocks, we also have to add them here\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"475755d6-01f7-4e6e-ad9a-cec6f031ebf6\",\n \"metadata\": {\n \"id\": \"475755d6-01f7-4e6e-ad9a-cec6f031ebf6\"\n },\n \"outputs\": [],\n \"source\": [\n \"# class Llama2Model(nn.Module):\\n\",\n \"class Llama3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.Sequential(\\n\",\n \" *[TransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])])\\n\",\n \"\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5)\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" #################### NEW #####################\\n\",\n \" cos, sin = precompute_rope_params(\\n\",\n \" head_dim=cfg[\\\"emb_dim\\\"] // cfg[\\\"n_heads\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" freq_config=cfg[\\\"rope_freq\\\"]\\n\",\n \" )\\n\",\n \" \\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \" ##############################################\\n\",\n \"\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" x = tok_embeds\\n\",\n \"\\n\",\n \" #################### NEW #####################\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \" mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)\\n\",\n \" ##############################################\\n\",\n \" \\n\",\n \" for block in self.trf_blocks:\\n\",\n \" x = block(x, mask, self.cos, self.sin)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4bc94940-aaeb-45b9-9399-3a69b8043e60\",\n \"metadata\": {\n \"id\": \"4bc94940-aaeb-45b9-9399-3a69b8043e60\"\n },\n \"source\": [\n \" \\n\",\n \"## 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"HoGGRAGykQTE\",\n \"metadata\": {\n \"id\": \"HoGGRAGykQTE\"\n },\n \"source\": [\n \"- Now we can define a Llama 3 config file (the Llama 2 config file is shown for comparison)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"e0564727-2d35-4f0c-b0fc-cde1e9134a18\",\n \"metadata\": {\n \"id\": \"e0564727-2d35-4f0c-b0fc-cde1e9134a18\"\n },\n \"outputs\": [],\n \"source\": [\n \"LLAMA2_CONFIG_7B = {\\n\",\n \" \\\"vocab_size\\\": 32_000, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 4096, # Context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 11_008, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"dtype\\\": torch.bfloat16 # Lower-precision dtype to reduce memory usage\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"2ad90f82-15c7-4806-b509-e45b56f57db5\",\n \"metadata\": {\n \"id\": \"2ad90f82-15c7-4806-b509-e45b56f57db5\"\n },\n \"outputs\": [],\n \"source\": [\n \"LLAMA3_CONFIG_8B = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # NEW: Larger vocabulary size\\n\",\n \" \\\"context_length\\\": 8192, # NEW: Larger context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 14_336, # NEW: Larger size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # NEW: Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # NEW: The base in RoPE's \\\"theta\\\" was increased to 500_000\\n\",\n \" \\\"rope_freq\\\": None, # NEW: Additional configuration for adjusting the RoPE frequencies\\n\",\n \" \\\"dtype\\\": torch.bfloat16 # Lower-precision dtype to reduce memory usage\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"FAP7fiBzkaBz\",\n \"metadata\": {\n \"id\": \"FAP7fiBzkaBz\"\n },\n \"source\": [\n \"- Using these settings, we can now initialize a Llama 3 8B model\\n\",\n \"- Note that this requires ~34 GB of memory (for comparison, Llama 2 7B required ~26 GB of memory)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"7004d785-ac9a-4df5-8760-6807fc604686\",\n \"metadata\": {\n \"id\": \"7004d785-ac9a-4df5-8760-6807fc604686\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = Llama3Model(LLAMA3_CONFIG_8B)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8056a521-91a6-440f-8473-591409c3177b\",\n \"metadata\": {},\n \"source\": [\n \"- Let's now compute the number of trainable parameters:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"6079f747-8f20-4c6b-8d38-7156f1101729\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6079f747-8f20-4c6b-8d38-7156f1101729\",\n \"outputId\": \"0a8cd23b-d9fa-4c2d-ca63-3fc79bc4de0d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters: 8,030,261,248\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters())\\n\",\n \"print(f\\\"Total number of parameters: {total_params:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"Bx14NtzWk2wj\",\n \"metadata\": {\n \"id\": \"Bx14NtzWk2wj\"\n },\n \"source\": [\n \"- As shown above, the model contains 8 billion parameters\\n\",\n \"- Additionally, we can calculate the memory requirements for this model using the code below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"0df1c79e-27a7-4b0f-ba4e-167fe107125a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0df1c79e-27a7-4b0f-ba4e-167fe107125a\",\n \"outputId\": \"3425e9ce-d8c0-4b37-bded-a2c60b66a41a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"float32 (PyTorch default): 59.84 GB\\n\",\n \"bfloat16: 29.92 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def calc_model_memory_size(model, input_dtype=torch.float32):\\n\",\n \" total_params = 0\\n\",\n \" total_grads = 0\\n\",\n \" for param in model.parameters():\\n\",\n \" # Calculate total number of elements per parameter\\n\",\n \" param_size = param.numel()\\n\",\n \" total_params += param_size\\n\",\n \" # Check if gradients are stored for this parameter\\n\",\n \" if param.requires_grad:\\n\",\n \" total_grads += param_size\\n\",\n \"\\n\",\n \" # Calculate buffer size (non-parameters that require memory)\\n\",\n \" total_buffers = sum(buf.numel() for buf in model.buffers())\\n\",\n \"\\n\",\n \" # Size in bytes = (Number of elements) * (Size of each element in bytes)\\n\",\n \" # We assume parameters and gradients are stored in the same type as input dtype\\n\",\n \" element_size = torch.tensor(0, dtype=input_dtype).element_size()\\n\",\n \" total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\\n\",\n \"\\n\",\n \" # Convert bytes to gigabytes\\n\",\n \" total_memory_gb = total_memory_bytes / (1024**3)\\n\",\n \"\\n\",\n \" return total_memory_gb\\n\",\n \"\\n\",\n \"print(f\\\"float32 (PyTorch default): {calc_model_memory_size(model, input_dtype=torch.float32):.2f} GB\\\")\\n\",\n \"print(f\\\"bfloat16: {calc_model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"zudd-5PulKFL\",\n \"metadata\": {\n \"id\": \"zudd-5PulKFL\"\n },\n \"source\": [\n \"- Lastly, we can also transfer the model to an NVIDIA or Apple Silicon GPU if applicable:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"a4c50e19-1402-45b6-8ccd-9077b2ba836d\",\n \"metadata\": {\n \"id\": \"a4c50e19-1402-45b6-8ccd-9077b2ba836d\"\n },\n \"outputs\": [],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5dc64a06-27dc-46ec-9e6d-1700a8227d34\",\n \"metadata\": {\n \"id\": \"5dc64a06-27dc-46ec-9e6d-1700a8227d34\"\n },\n \"source\": [\n \" \\n\",\n \"## 3. Load tokenizer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0eb30f0c-6144-4bed-87d9-6b2bac377005\",\n \"metadata\": {\n \"id\": \"0eb30f0c-6144-4bed-87d9-6b2bac377005\"\n },\n \"source\": [\n \"- In this section, we are going to load the tokenizer for the model\\n\",\n \"- Llama 2 used Google's [SentencePiece](https://github.com/google/sentencepiece) tokenizer instead of OpenAI's BPE tokenizer based on the [Tiktoken](https://github.com/openai/tiktoken) library\\n\",\n \"- Llama 3, however, reverted back to using the BPE tokenizer from Tiktoken; specifically, it uses the GPT-4 tokenizer with an extended vocabulary\\n\",\n \"- You can find the original Tiktoken-adaptation by Meta AI [here](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py) in their official Llama 3 repository\\n\",\n \"- Below, I rewrote the tokenizer code to make it more readable and minimal for this notebook (but the behavior should be similar)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"5f390cbf-8f92-46dc-afe3-d90b5affae10\",\n \"metadata\": {\n \"id\": \"5f390cbf-8f92-46dc-afe3-d90b5affae10\"\n },\n \"outputs\": [],\n \"source\": [\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"import tiktoken\\n\",\n \"from tiktoken.load import load_tiktoken_bpe\\n\",\n \"\\n\",\n \"\\n\",\n \"class Tokenizer:\\n\",\n \" \\\"\\\"\\\"Thin wrapper around tiktoken that keeps track of Llama-3 special IDs.\\\"\\\"\\\"\\n\",\n \" def __init__(self, model_path):\\n\",\n \" if not os.path.isfile(model_path):\\n\",\n \" raise FileNotFoundError(model_path)\\n\",\n \"\\n\",\n \" mergeable = load_tiktoken_bpe(model_path)\\n\",\n \"\\n\",\n \" # hard-coded from Meta's tokenizer.json\\n\",\n \" self.special = {\\n\",\n \" \\\"<|begin_of_text|>\\\": 128000,\\n\",\n \" \\\"<|end_of_text|>\\\": 128001,\\n\",\n \" \\\"<|start_header_id|>\\\": 128006,\\n\",\n \" \\\"<|end_header_id|>\\\": 128007,\\n\",\n \" \\\"<|eot_id|>\\\": 128009,\\n\",\n \" }\\n\",\n \" self.special.update({f\\\"<|reserved_{i}|>\\\": 128002 + i\\n\",\n \" for i in range(256)\\n\",\n \" if 128002 + i not in self.special.values()})\\n\",\n \"\\n\",\n \" self.model = tiktoken.Encoding(\\n\",\n \" name=Path(model_path).name,\\n\",\n \" pat_str=r\\\"(?i:'s|'t|'re|'ve|'m|'ll|'d)\\\"\\n\",\n \" r\\\"|[^\\\\r\\\\n\\\\p{L}\\\\p{N}]?\\\\p{L}+\\\"\\n\",\n \" r\\\"|\\\\p{N}{1,3}\\\"\\n\",\n \" r\\\"| ?[^\\\\s\\\\p{L}\\\\p{N}]+[\\\\r\\\\n]*\\\"\\n\",\n \" r\\\"|\\\\s*[\\\\r\\\\n]+\\\"\\n\",\n \" r\\\"|\\\\s+(?!\\\\S)\\\"\\n\",\n \" r\\\"|\\\\s+\\\",\\n\",\n \" mergeable_ranks=mergeable,\\n\",\n \" special_tokens=self.special,\\n\",\n \" )\\n\",\n \"\\n\",\n \" def encode(self, text, bos=False, eos=False):\\n\",\n \" ids = ([self.special[\\\"<|begin_of_text|>\\\"]] if bos else []) \\\\\\n\",\n \" + self.model.encode(text)\\n\",\n \" if eos:\\n\",\n \" ids.append(self.special[\\\"<|end_of_text|>\\\"])\\n\",\n \" return ids\\n\",\n \"\\n\",\n \" def decode(self, ids):\\n\",\n \" return self.model.decode(ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0a1509f8-8778-4fec-ba32-14d95c646167\",\n \"metadata\": {\n \"id\": \"0a1509f8-8778-4fec-ba32-14d95c646167\"\n },\n \"source\": [\n \"- Meta AI shared the original Llama 3 model weights and tokenizer vocabulary on the Hugging Face Hub\\n\",\n \"- We will first download the tokenizer vocabulary from the Hub and load it into the code above\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"KbnlzsbYmJU6\",\n \"metadata\": {\n \"id\": \"KbnlzsbYmJU6\"\n },\n \"source\": [\n \"- Please note that Meta AI requires that you accept the Llama 3 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) repository to accept the terms\\n\",\n \"- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \\\"Settings\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"3357a230-b678-4691-a238-257ee4e80185\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"3357a230-b678-4691-a238-257ee4e80185\",\n \"outputId\": \"a3652def-ea7f-46fb-f293-2a59affb71a0\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import login\\n\",\n \"import json\\n\",\n \"\\n\",\n \"with open(\\\"config.json\\\", \\\"r\\\") as config_file:\\n\",\n \" config = json.load(config_file)\\n\",\n \" access_token = config[\\\"HF_ACCESS_TOKEN\\\"]\\n\",\n \"\\n\",\n \"login(token=access_token)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"IxGh6ZYQo0VN\",\n \"metadata\": {\n \"id\": \"IxGh6ZYQo0VN\"\n },\n \"source\": [\n \"- After login via the access token, which is necessary to verify that we accepted the Llama 3 licensing terms, we can now download the tokenizer vocabulary:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"69714ea8-b9b8-4687-8392-f3abb8f93a32\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"69714ea8-b9b8-4687-8392-f3abb8f93a32\",\n \"outputId\": \"c9836ba8-5176-4dd5-b618-6cc36fdbe1f0\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"application/vnd.jupyter.widget-view+json\": {\n \"model_id\": \"685326b4fd014ff689e928f4200f5182\",\n \"version_major\": 2,\n \"version_minor\": 0\n },\n \"text/plain\": [\n \"original/tokenizer.model: 0%| | 0.00/2.18M [00:00role<|end_header_id|>\\\\n\\\\n\\\"\\\"\\\"\\n\",\n \" return (\\n\",\n \" [self.tok.special[\\\"<|start_header_id|>\\\"]]\\n\",\n \" + self.tok.encode(role)\\n\",\n \" + [self.tok.special[\\\"<|end_header_id|>\\\"]]\\n\",\n \" + self.tok.encode(\\\"\\\\n\\\\n\\\")\\n\",\n \" )\\n\",\n \"\\n\",\n \" def encode(self, user_message, system_message=None):\\n\",\n \" sys_msg = system_message if system_message is not None else self.default_system\\n\",\n \"\\n\",\n \" ids = [self.tok.special[\\\"<|begin_of_text|>\\\"]]\\n\",\n \"\\n\",\n \" # system\\n\",\n \" ids += self._header(\\\"system\\\")\\n\",\n \" ids += self.tok.encode(sys_msg)\\n\",\n \" ids += [self.tok.special[\\\"<|eot_id|>\\\"]]\\n\",\n \"\\n\",\n \" # user\\n\",\n \" ids += self._header(\\\"user\\\")\\n\",\n \" ids += self.tok.encode(user_message)\\n\",\n \" ids += [self.tok.special[\\\"<|eot_id|>\\\"]]\\n\",\n \"\\n\",\n \" # assistant header (no content yet)\\n\",\n \" ids += self._header(\\\"assistant\\\")\\n\",\n \"\\n\",\n \" return ids\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"M-dkSNvwDttN\",\n \"metadata\": {\n \"id\": \"M-dkSNvwDttN\"\n },\n \"source\": [\n \"- The usage is as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"nwBrTGTsUNhn\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"nwBrTGTsUNhn\",\n \"outputId\": \"72a495b4-b872-429a-88ef-49a9b4577f0f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[128000, 128006, 9125, 128007, 271, 2675, 527, 264, 11190, 18328, 13, 128009, 128006, 882, 128007, 271, 9906, 4435, 0, 128009, 128006, 78191, 128007, 271]\\n\"\n ]\n }\n ],\n \"source\": [\n \"tokenizer = Tokenizer(tokenizer_file_path)\\n\",\n \"chat_tokenizer = ChatFormat(tokenizer)\\n\",\n \"\\n\",\n \"token_ids = chat_tokenizer.encode(\\\"Hello World!\\\")\\n\",\n \"print(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"0fpmpVgYVTRZ\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 36\n },\n \"id\": \"0fpmpVgYVTRZ\",\n \"outputId\": \"bb3e819a-112a-466c-ac51-5d14a9c3475b\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'<|begin_of_text|><|start_header_id|>system<|end_header_id|>\\\\n\\\\nYou are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>\\\\n\\\\nHello World!<|eot_id|><|start_header_id|>assistant<|end_header_id|>\\\\n\\\\n'\"\n ]\n },\n \"execution_count\": 35,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"tokenizer.decode(token_ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"Wo-aUGeKDvqq\",\n \"metadata\": {\n \"id\": \"Wo-aUGeKDvqq\"\n },\n \"source\": [\n \"- Let's now see the Llama 3 instruction model in action:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"ozGOBu6XOkEW\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"ozGOBu6XOkEW\",\n \"outputId\": \"4f689c70-bed9-46f3-a52a-aea47b641283\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Llamas are herbivores, which means they primarily eat plants and plant-based foods. Their diet typically consists of:\\n\",\n \"\\n\",\n \"1. Grasses: Llamas love to graze on grasses, including tall grasses, short grasses, and even weeds.\\n\",\n \"2. Hay: Hay is a staple in a llama's diet. They enjoy a variety of hays, such as timothy hay, alfalfa hay, and oat hay.\\n\",\n \"3. Grains: Llamas may be fed grains like oats, corn, and barley as a supplement to their diet.\\n\",\n \"4. Fruits and vegetables: Llamas enjoy fruits and vegetables like apples, carrots, and sweet potatoes as treats or additions to their meals.\\n\",\n \"5. Minerals:\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(\\\"What do llamas eat?\\\", chat_tokenizer).to(device),\\n\",\n \" max_new_tokens=150,\\n\",\n \" context_size=LLAMA3_CONFIG_8B[\\\"context_length\\\"],\\n\",\n \" top_k=1,\\n\",\n \" temperature=0.\\n\",\n \")\\n\",\n \"\\n\",\n \"output_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \"\\n\",\n \"\\n\",\n \"def clean_text(text, header_end=\\\"assistant<|end_header_id|>\\\\n\\\\n\\\"):\\n\",\n \" # Find the index of the first occurrence of \\\"<|end_header_id|>\\\"\\n\",\n \" index = text.find(header_end)\\n\",\n \"\\n\",\n \" if index != -1:\\n\",\n \" # Return the substring starting after \\\"<|end_header_id|>\\\"\\n\",\n \" return text[index + len(header_end):].strip() # Strip removes leading/trailing whitespace\\n\",\n \" else:\\n\",\n \" # If the token is not found, return the original text\\n\",\n \" return text\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", clean_text(output_text))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2r5JKrO-ZOHK\",\n \"metadata\": {\n \"id\": \"2r5JKrO-ZOHK\"\n },\n \"source\": [\n \" \\n\",\n \"# 6. Llama 3.1 8B\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"QiQxX0XnP_iC\",\n \"metadata\": {\n \"id\": \"QiQxX0XnP_iC\"\n },\n \"source\": [\n \"- A few months after the initial Llama 3 release, Meta AI followed up with their Llama 3.1 suite of models (see the official [Introducing Llama 3.1: Our most capable models to date](https://ai.meta.com/blog/meta-llama-3-1/) announcement blog post for details)\\n\",\n \"- Conveniently, we can reuse our previous Llama 3 code from above to implement Llama 3.1 8B\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"- The architecture is identical, with the only change being a rescaling of the RoPE frequencies as indicated in the configuration file below\\n\",\n \"\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"X5Fg8XUHMv4M\",\n \"metadata\": {\n \"id\": \"X5Fg8XUHMv4M\"\n },\n \"outputs\": [],\n \"source\": [\n \"LLAMA3_CONFIG_8B = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 8192, # Context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 14_336, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"rope_freq\\\": None, # Additional configuration for adjusting the RoPE frequencies\\n\",\n \" \\\"dtype\\\": torch.bfloat16 # Lower-precision dtype to reduce memory usage\\n\",\n \"}\\n\",\n \"\\n\",\n \"LLAMA31_CONFIG_8B = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 131_072, # NEW: Larger supported context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 14_336, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \" \\\"rope_freq\\\": { # NEW: RoPE frequency scaling\\n\",\n \" \\\"factor\\\": 8.0,\\n\",\n \" \\\"low_freq_factor\\\": 1.0,\\n\",\n \" \\\"high_freq_factor\\\": 4.0,\\n\",\n \" \\\"original_context_length\\\": 8192,\\n\",\n \" }\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"xa3bpMDtTdBs\",\n \"metadata\": {\n \"id\": \"xa3bpMDtTdBs\"\n },\n \"source\": [\n \"- As we've seen in the code earlier, the RoPE method uses sinusoidal functions (sine and cosine) to embed positional information directly into the attention mechanism\\n\",\n \"- In Llama 3.1, via the additional configuration, we introduce additional adjustments to the inverse frequency calculations\\n\",\n \"- These adjustments influence how different frequency components contribute to the positional embeddings (a detailed explanation is a topic for another time)\\n\",\n \"- Let's try out the Llama 3.1 model in practice; first, we clear out the old model to free up some GPU memory\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"7dUtYnNUOqhL\",\n \"metadata\": {\n \"id\": \"7dUtYnNUOqhL\"\n },\n \"outputs\": [],\n \"source\": [\n \"# free up memory\\n\",\n \"del model\\n\",\n \"\\n\",\n \"gc.collect() # Run Python garbage collector\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" torch.cuda.empty_cache()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"DbbVsll6TYWR\",\n \"metadata\": {\n \"id\": \"DbbVsll6TYWR\"\n },\n \"source\": [\n \"- Next, we download the tokenizer\\n\",\n \"- Note that since the Llama 3.1 family is distinct from the Llama 3 family, you'd have to go to the [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) repository and acknowledge the license terms for your Hugging Face access token to work for the download\\n\",\n \"- Tip: For simplicity, we only load the base model below, but there's also an instruction-finetuned version you can use by replacing `\\\"meta-llama/Llama-3.1-8B\\\"` with `\\\"meta-llama/Llama-3.1-8B-Instruct\\\"`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"8xDk4chtPNU4\",\n \"metadata\": {\n \"id\": \"8xDk4chtPNU4\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"application/vnd.jupyter.widget-view+json\": {\n \"model_id\": \"ac808a4fe89d4ca89597a90f6ab83a30\",\n \"version_major\": 2,\n \"version_minor\": 0\n },\n \"text/plain\": [\n \"original/tokenizer.model: 0%| | 0.00/2.18M [00:00\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"K0KgjwCCJ9Fb\",\n \"metadata\": {\n \"id\": \"K0KgjwCCJ9Fb\"\n },\n \"source\": [\n \"- As we can see based on the figure above, the main difference between the Llama 3.1 8B and Llama 3.2 1B architectures are the respective sizes\\n\",\n \"- A small additional change is an increased RoPE rescaling factor, which is reflected in the configuration file below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"Yv_yF3NCQTBx\",\n \"metadata\": {\n \"id\": \"Yv_yF3NCQTBx\"\n },\n \"outputs\": [],\n \"source\": [\n \"LLAMA31_CONFIG_8B = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 131_072, # NEW: Larger supported context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 14_336, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usagey\\n\",\n \" \\\"rope_freq\\\": { # NEW: RoPE frequency scaling\\n\",\n \" \\\"factor\\\": 8.0,\\n\",\n \" \\\"low_freq_factor\\\": 1.0,\\n\",\n \" \\\"high_freq_factor\\\": 4.0,\\n\",\n \" \\\"original_context_length\\\": 8192,\\n\",\n \" }\\n\",\n \"}\\n\",\n \"\\n\",\n \"\\n\",\n \"LLAMA32_CONFIG_1B = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 131_072, # Context length\\n\",\n \" \\\"emb_dim\\\": 2048, # NEW: Half the embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 16, # NEW: Half the number of layers\\n\",\n \" \\\"hidden_dim\\\": 8192, # NEW: Almost half the size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \" \\\"rope_freq\\\": { # RoPE frequency scaling\\n\",\n \" \\\"factor\\\": 32.0, # NEW: Adjustment of the rescaling factor\\n\",\n \" \\\"low_freq_factor\\\": 1.0,\\n\",\n \" \\\"high_freq_factor\\\": 4.0,\\n\",\n \" \\\"original_context_length\\\": 8192,\\n\",\n \" }\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"Dl4_0EoJKKYv\",\n \"metadata\": {\n \"id\": \"Dl4_0EoJKKYv\"\n },\n \"source\": [\n \"- Below, we can reuse the code from the Llama 3.1 8B section to load the Llama 3.2 1B model\\n\",\n \"- Again, since the Llama 3.2 family is distinct from the Llama 3.1 family, you'd have to go to the [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) repository and acknowledge the license terms for your Hugging Face access token to work for the download\\n\",\n \"- Tip: For simplicity, we only load the base model below, but there's also an instruction-finetuned version you can use by replacing `\\\"meta-llama/Llama-3.2-1B\\\"` with `\\\"meta-llama/Llama-3.2-1B-Instruct\\\"`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"tCstHgyRRD2x\",\n \"metadata\": {\n \"id\": \"tCstHgyRRD2x\"\n },\n \"outputs\": [],\n \"source\": [\n \"# free up memory\\n\",\n \"del model\\n\",\n \"\\n\",\n \"\\n\",\n \"gc.collect() # Run Python garbage collector\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" torch.cuda.empty_cache()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"jt8BKAHXRCPI\",\n \"metadata\": {\n \"id\": \"jt8BKAHXRCPI\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"application/vnd.jupyter.widget-view+json\": {\n \"model_id\": \"7658da8b2a5e4273b45c35411bdba8a0\",\n \"version_major\": 2,\n \"version_minor\": 0\n },\n \"text/plain\": [\n \"original/tokenizer.model: 0%| | 0.00/2.18M [00:00 0.0:\n logits = logits / temperature\n\n # New (not in book): numerical stability tip to get equivalent results on mps device\n # subtract rowwise max before softmax\n logits = logits - logits.max(dim=-1, keepdim=True).values\n\n # Apply softmax to get probabilities\n probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)\n\n # Sample from the distribution\n idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)\n\n # Otherwise same as before: get idx of the vocab entry with the highest logits value\n else:\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)\n\n if idx_next == eos_id: # Stop generating early if end-of-sequence token is encountered and eos_id is specified\n break\n\n # Same as before: append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)\n\n return idx\n"
},
{
"path": "ch05/07_gpt_to_llama/requirements-extra.txt",
"content": "blobfile>=3.0.0\nhuggingface_hub>=0.24.7\nipywidgets>=8.1.2\nsafetensors>=0.4.4\nsentencepiece>=0.1.99\n"
},
{
"path": "ch05/07_gpt_to_llama/standalone-llama32.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"
\\n\",\n \"\\n\",\n \"- The architecture is identical, with the only change being a rescaling of the RoPE frequencies as indicated in the configuration file below\\n\",\n \"\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"X5Fg8XUHMv4M\",\n \"metadata\": {\n \"id\": \"X5Fg8XUHMv4M\"\n },\n \"outputs\": [],\n \"source\": [\n \"LLAMA3_CONFIG_8B = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 8192, # Context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 14_336, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"rope_freq\\\": None, # Additional configuration for adjusting the RoPE frequencies\\n\",\n \" \\\"dtype\\\": torch.bfloat16 # Lower-precision dtype to reduce memory usage\\n\",\n \"}\\n\",\n \"\\n\",\n \"LLAMA31_CONFIG_8B = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 131_072, # NEW: Larger supported context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 14_336, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \" \\\"rope_freq\\\": { # NEW: RoPE frequency scaling\\n\",\n \" \\\"factor\\\": 8.0,\\n\",\n \" \\\"low_freq_factor\\\": 1.0,\\n\",\n \" \\\"high_freq_factor\\\": 4.0,\\n\",\n \" \\\"original_context_length\\\": 8192,\\n\",\n \" }\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"xa3bpMDtTdBs\",\n \"metadata\": {\n \"id\": \"xa3bpMDtTdBs\"\n },\n \"source\": [\n \"- As we've seen in the code earlier, the RoPE method uses sinusoidal functions (sine and cosine) to embed positional information directly into the attention mechanism\\n\",\n \"- In Llama 3.1, via the additional configuration, we introduce additional adjustments to the inverse frequency calculations\\n\",\n \"- These adjustments influence how different frequency components contribute to the positional embeddings (a detailed explanation is a topic for another time)\\n\",\n \"- Let's try out the Llama 3.1 model in practice; first, we clear out the old model to free up some GPU memory\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"7dUtYnNUOqhL\",\n \"metadata\": {\n \"id\": \"7dUtYnNUOqhL\"\n },\n \"outputs\": [],\n \"source\": [\n \"# free up memory\\n\",\n \"del model\\n\",\n \"\\n\",\n \"gc.collect() # Run Python garbage collector\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" torch.cuda.empty_cache()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"DbbVsll6TYWR\",\n \"metadata\": {\n \"id\": \"DbbVsll6TYWR\"\n },\n \"source\": [\n \"- Next, we download the tokenizer\\n\",\n \"- Note that since the Llama 3.1 family is distinct from the Llama 3 family, you'd have to go to the [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) repository and acknowledge the license terms for your Hugging Face access token to work for the download\\n\",\n \"- Tip: For simplicity, we only load the base model below, but there's also an instruction-finetuned version you can use by replacing `\\\"meta-llama/Llama-3.1-8B\\\"` with `\\\"meta-llama/Llama-3.1-8B-Instruct\\\"`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"8xDk4chtPNU4\",\n \"metadata\": {\n \"id\": \"8xDk4chtPNU4\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"application/vnd.jupyter.widget-view+json\": {\n \"model_id\": \"ac808a4fe89d4ca89597a90f6ab83a30\",\n \"version_major\": 2,\n \"version_minor\": 0\n },\n \"text/plain\": [\n \"original/tokenizer.model: 0%| | 0.00/2.18M [00:00\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"K0KgjwCCJ9Fb\",\n \"metadata\": {\n \"id\": \"K0KgjwCCJ9Fb\"\n },\n \"source\": [\n \"- As we can see based on the figure above, the main difference between the Llama 3.1 8B and Llama 3.2 1B architectures are the respective sizes\\n\",\n \"- A small additional change is an increased RoPE rescaling factor, which is reflected in the configuration file below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"Yv_yF3NCQTBx\",\n \"metadata\": {\n \"id\": \"Yv_yF3NCQTBx\"\n },\n \"outputs\": [],\n \"source\": [\n \"LLAMA31_CONFIG_8B = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 131_072, # NEW: Larger supported context length\\n\",\n \" \\\"emb_dim\\\": 4096, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 32, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 14_336, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usagey\\n\",\n \" \\\"rope_freq\\\": { # NEW: RoPE frequency scaling\\n\",\n \" \\\"factor\\\": 8.0,\\n\",\n \" \\\"low_freq_factor\\\": 1.0,\\n\",\n \" \\\"high_freq_factor\\\": 4.0,\\n\",\n \" \\\"original_context_length\\\": 8192,\\n\",\n \" }\\n\",\n \"}\\n\",\n \"\\n\",\n \"\\n\",\n \"LLAMA32_CONFIG_1B = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 131_072, # Context length\\n\",\n \" \\\"emb_dim\\\": 2048, # NEW: Half the embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 16, # NEW: Half the number of layers\\n\",\n \" \\\"hidden_dim\\\": 8192, # NEW: Almost half the size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \" \\\"rope_freq\\\": { # RoPE frequency scaling\\n\",\n \" \\\"factor\\\": 32.0, # NEW: Adjustment of the rescaling factor\\n\",\n \" \\\"low_freq_factor\\\": 1.0,\\n\",\n \" \\\"high_freq_factor\\\": 4.0,\\n\",\n \" \\\"original_context_length\\\": 8192,\\n\",\n \" }\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"Dl4_0EoJKKYv\",\n \"metadata\": {\n \"id\": \"Dl4_0EoJKKYv\"\n },\n \"source\": [\n \"- Below, we can reuse the code from the Llama 3.1 8B section to load the Llama 3.2 1B model\\n\",\n \"- Again, since the Llama 3.2 family is distinct from the Llama 3.1 family, you'd have to go to the [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) repository and acknowledge the license terms for your Hugging Face access token to work for the download\\n\",\n \"- Tip: For simplicity, we only load the base model below, but there's also an instruction-finetuned version you can use by replacing `\\\"meta-llama/Llama-3.2-1B\\\"` with `\\\"meta-llama/Llama-3.2-1B-Instruct\\\"`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"tCstHgyRRD2x\",\n \"metadata\": {\n \"id\": \"tCstHgyRRD2x\"\n },\n \"outputs\": [],\n \"source\": [\n \"# free up memory\\n\",\n \"del model\\n\",\n \"\\n\",\n \"\\n\",\n \"gc.collect() # Run Python garbage collector\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" torch.cuda.empty_cache()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"jt8BKAHXRCPI\",\n \"metadata\": {\n \"id\": \"jt8BKAHXRCPI\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"application/vnd.jupyter.widget-view+json\": {\n \"model_id\": \"7658da8b2a5e4273b45c35411bdba8a0\",\n \"version_major\": 2,\n \"version_minor\": 0\n },\n \"text/plain\": [\n \"original/tokenizer.model: 0%| | 0.00/2.18M [00:00 0.0:\n logits = logits / temperature\n\n # New (not in book): numerical stability tip to get equivalent results on mps device\n # subtract rowwise max before softmax\n logits = logits - logits.max(dim=-1, keepdim=True).values\n\n # Apply softmax to get probabilities\n probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)\n\n # Sample from the distribution\n idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)\n\n # Otherwise same as before: get idx of the vocab entry with the highest logits value\n else:\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)\n\n if idx_next == eos_id: # Stop generating early if end-of-sequence token is encountered and eos_id is specified\n break\n\n # Same as before: append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)\n\n return idx\n"
},
{
"path": "ch05/07_gpt_to_llama/requirements-extra.txt",
"content": "blobfile>=3.0.0\nhuggingface_hub>=0.24.7\nipywidgets>=8.1.2\nsafetensors>=0.4.4\nsentencepiece>=0.1.99\n"
},
{
"path": "ch05/07_gpt_to_llama/standalone-llama32.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Llama 3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\\n\",\n \" - the tokenizer code is inspired by the original [Llama 3 tokenizer code](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py), which Meta AI used to extend the Tiktoken GPT-4 tokenizer\\n\",\n \" - the RoPE rescaling section is inspired by the [_compute_llama3_parameters function](https://github.com/huggingface/transformers/blob/5c1027bf09717f664b579e01cbb8ec3ef5aeb140/src/transformers/modeling_rope_utils.py#L329-L347) in the `transformers` library\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"blobfile version: 3.1.0\\n\",\n \"huggingface_hub version: 0.34.4\\n\",\n \"tiktoken version: 0.11.0\\n\",\n \"torch version: 2.8.0\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"blobfile\\\", # to download pretrained weights\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tiktoken\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, freq_config=None, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))\\n\",\n \"\\n\",\n \" # Frequency adjustments\\n\",\n \" if freq_config is not None:\\n\",\n \" low_freq_wavelen = freq_config[\\\"original_context_length\\\"] / freq_config[\\\"low_freq_factor\\\"]\\n\",\n \" high_freq_wavelen = freq_config[\\\"original_context_length\\\"] / freq_config[\\\"high_freq_factor\\\"]\\n\",\n \"\\n\",\n \" wavelen = 2 * torch.pi / inv_freq\\n\",\n \"\\n\",\n \" inv_freq_llama = torch.where(\\n\",\n \" wavelen > low_freq_wavelen, inv_freq / freq_config[\\\"factor\\\"], inv_freq\\n\",\n \" )\\n\",\n \"\\n\",\n \" smooth_factor = (freq_config[\\\"original_context_length\\\"] / wavelen - freq_config[\\\"low_freq_factor\\\"]) / (\\n\",\n \" freq_config[\\\"high_freq_factor\\\"] - freq_config[\\\"low_freq_factor\\\"]\\n\",\n \" )\\n\",\n \"\\n\",\n \" smoothed_inv_freq = (\\n\",\n \" (1 - smooth_factor) * (inv_freq / freq_config[\\\"factor\\\"]) + smooth_factor * inv_freq\\n\",\n \" )\\n\",\n \"\\n\",\n \" is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)\\n\",\n \" inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)\\n\",\n \" inv_freq = inv_freq_llama\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Expand angles to match the head_dim\\n\",\n \" angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" # It's ok to use lower-precision after applying cos and sin rotation\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, d_out, num_heads,\\n\",\n \" num_kv_groups,\\n\",\n \" dtype=None\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert d_out % num_heads == 0, \\\"d_out must be divisible by num_heads\\\"\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.d_out = d_out\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.head_dim = d_out // num_heads\\n\",\n \"\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" b, num_tokens, d_in = x.shape\\n\",\n \"\\n\",\n \" queries = self.W_query(x) # Shape: (b, num_tokens, d_out)\\n\",\n \" keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape queries, keys, and values\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)\\n\",\n \" values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)\\n\",\n \"\\n\",\n \" # Transpose keys, values, and queries\\n\",\n \" keys = keys.transpose(1, 2) # Shape: (b, num_kv_groups, num_tokens, head_dim)\\n\",\n \" values = values.transpose(1, 2) # Shape: (b, num_kv_groups, num_tokens, head_dim)\\n\",\n \" queries = queries.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \"\\n\",\n \" # Apply RoPE\\n\",\n \" keys = apply_rope(keys, cos, sin)\\n\",\n \" queries = apply_rope(queries, cos, sin)\\n\",\n \"\\n\",\n \" # Expand keys and values to match the number of heads\\n\",\n \" # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" # For example, before repeat_interleave along dim=1 (query groups):\\n\",\n \" # [K1, K2]\\n\",\n \" # After repeat_interleave (each query group is repeated group_size times):\\n\",\n \" # [K1, K1, K2, K2]\\n\",\n \" # If we used regular repeat instead of repeat_interleave, we'd get:\\n\",\n \" # [K1, K2, K1, K2]\\n\",\n \"\\n\",\n \" # Compute scaled dot-product attention (aka self-attention) with a causal mask\\n\",\n \" # Shape: (b, num_heads, num_tokens, num_tokens)\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\\n\",\n \"\\n\",\n \" # Compute attention scores\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\\n\",\n \" assert keys.shape[-1] == self.head_dim\\n\",\n \"\\n\",\n \" # Shape: (b, num_tokens, num_heads, head_dim)\\n\",\n \" context_vec = (attn_weights @ values).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Combine heads, where self.d_out = self.num_heads * self.head_dim\\n\",\n \" context_vec = context_vec.reshape(b, num_tokens, self.d_out)\\n\",\n \" context_vec = self.out_proj(context_vec) # optional projection\\n\",\n \"\\n\",\n \" return context_vec\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" d_out=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"]\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = nn.RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.norm2 = nn.RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \" x = self.att(x, mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" # Shortcut connection for feed-forward block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Llama3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" # Main model parameters\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.ModuleList( # ModuleList since Sequential can only accept one input, and we need `x, mask, cos, sin`\\n\",\n \" [TransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])]\\n\",\n \" )\\n\",\n \"\\n\",\n \" self.final_norm = nn.RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" # Reusable utilities\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"emb_dim\\\"] // cfg[\\\"n_heads\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" freq_config=cfg[\\\"rope_freq\\\"]\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" # Forward pass\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" x = tok_embeds\\n\",\n \"\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \" mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)\\n\",\n \" \\n\",\n \" for block in self.trf_blocks:\\n\",\n \" x = block(x, mask, self.cos, self.sin)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"23dea40c-fe20-4a75-be25-d6fce5863c01\",\n \"metadata\": {\n \"id\": \"23dea40c-fe20-4a75-be25-d6fce5863c01\"\n },\n \"source\": [\n \"- The remainder of this notebook uses the Llama 3.2 1B model; to use the 3B model variant, just uncomment the second configuration file in the following code cell\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Llama 3.2 1B\\n\",\n \"\\n\",\n \"LLAMA32_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 131_072, # Context length that was used to train the model\\n\",\n \" \\\"emb_dim\\\": 2048, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 16, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 8192, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \" \\\"rope_freq\\\": { # RoPE frequency scaling\\n\",\n \" \\\"factor\\\": 32.0,\\n\",\n \" \\\"low_freq_factor\\\": 1.0,\\n\",\n \" \\\"high_freq_factor\\\": 4.0,\\n\",\n \" \\\"original_context_length\\\": 8192,\\n\",\n \" }\\n\",\n \"}\\n\",\n \"\\n\",\n \"# Llama 3.2 3B\\n\",\n \"\\n\",\n \"# LLAMA32_CONFIG = {\\n\",\n \"# \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \"# \\\"context_length\\\": 131_072, # Context length that was used to train the model\\n\",\n \"# \\\"emb_dim\\\": 3072, # Embedding dimension\\n\",\n \"# \\\"n_heads\\\": 24, # Number of attention heads\\n\",\n \"# \\\"n_layers\\\": 28, # Number of layers\\n\",\n \"# \\\"hidden_dim\\\": 8192, # Size of the intermediate dimension in FeedForward\\n\",\n \"# \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \"# \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \"# \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \"# \\\"rope_freq\\\": { # RoPE frequency scaling\\n\",\n \"# \\\"factor\\\": 32.0,\\n\",\n \"# \\\"low_freq_factor\\\": 1.0,\\n\",\n \"# \\\"high_freq_factor\\\": 4.0,\\n\",\n \"# \\\"original_context_length\\\": 8192,\\n\",\n \"# }\\n\",\n \"# }\\n\",\n \"\\n\",\n \"LLAMA_SIZE_STR = \\\"1B\\\" if LLAMA32_CONFIG[\\\"emb_dim\\\"] == 2048 else \\\"3B\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = Llama3Model(LLAMA32_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"fd5efb03-5a07-46e8-8607-93ed47549d2b\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"fd5efb03-5a07-46e8-8607-93ed47549d2b\",\n \"outputId\": \"65c1a95e-b502-4150-9e2e-da619d9053d5\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"float32 (PyTorch default): 11.23 GB\\n\",\n \"bfloat16: 5.61 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def calc_model_memory_size(model, input_dtype=torch.float32):\\n\",\n \" total_params = 0\\n\",\n \" total_grads = 0\\n\",\n \" for param in model.parameters():\\n\",\n \" # Calculate total number of elements per parameter\\n\",\n \" param_size = param.numel()\\n\",\n \" total_params += param_size\\n\",\n \" # Check if gradients are stored for this parameter\\n\",\n \" if param.requires_grad:\\n\",\n \" total_grads += param_size\\n\",\n \"\\n\",\n \" # Calculate buffer size (non-parameters that require memory)\\n\",\n \" total_buffers = sum(buf.numel() for buf in model.buffers())\\n\",\n \"\\n\",\n \" # Size in bytes = (Number of elements) * (Size of each element in bytes)\\n\",\n \" # We assume parameters and gradients are stored in the same type as input dtype\\n\",\n \" element_size = torch.tensor(0, dtype=input_dtype).element_size()\\n\",\n \" total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\\n\",\n \"\\n\",\n \" # Convert bytes to gigabytes\\n\",\n \" total_memory_gb = total_memory_bytes / (1024**3)\\n\",\n \"\\n\",\n \" return total_memory_gb\\n\",\n \"\\n\",\n \"print(f\\\"float32 (PyTorch default): {calc_model_memory_size(model, input_dtype=torch.float32):.2f} GB\\\")\\n\",\n \"print(f\\\"bfloat16: {calc_model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"41176fb0-d58a-443a-912f-4f436564b5f8\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters: 1,498,482,688\\n\",\n \"\\n\",\n \"Total number of unique parameters: 1,235,814,400\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters())\\n\",\n \"print(f\\\"Total number of parameters: {total_params:,}\\\")\\n\",\n \"\\n\",\n \"# Account for weight tying\\n\",\n \"total_params_normalized = total_params - model.tok_emb.weight.numel()\\n\",\n \"print(f\\\"\\\\nTotal number of unique parameters: {total_params_normalized:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"31f12baf-f79b-499f-85c0-51328a6a20f5\",\n \"metadata\": {\n \"id\": \"31f12baf-f79b-499f-85c0-51328a6a20f5\"\n },\n \"outputs\": [],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"78e091e1-afa8-4d23-9aea-cced86181bfd\",\n \"metadata\": {\n \"id\": \"78e091e1-afa8-4d23-9aea-cced86181bfd\"\n },\n \"source\": [\n \" \\n\",\n \"# 3. Load tokenizer\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"9482b01c-49f9-48e4-ab2c-4a4c75240e77\",\n \"metadata\": {\n \"id\": \"9482b01c-49f9-48e4-ab2c-4a4c75240e77\"\n },\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"import tiktoken\\n\",\n \"from tiktoken.load import load_tiktoken_bpe\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"class Tokenizer:\\n\",\n \" \\\"\\\"\\\"Thin wrapper around tiktoken that keeps track of Llama-3 special IDs.\\\"\\\"\\\"\\n\",\n \" def __init__(self, model_path):\\n\",\n \" if not os.path.isfile(model_path):\\n\",\n \" raise FileNotFoundError(model_path)\\n\",\n \"\\n\",\n \" mergeable = load_tiktoken_bpe(model_path)\\n\",\n \"\\n\",\n \" # hard-coded from Meta's tokenizer.json\\n\",\n \" self.special = {\\n\",\n \" \\\"<|begin_of_text|>\\\": 128000,\\n\",\n \" \\\"<|end_of_text|>\\\": 128001,\\n\",\n \" \\\"<|start_header_id|>\\\": 128006,\\n\",\n \" \\\"<|end_header_id|>\\\": 128007,\\n\",\n \" \\\"<|eot_id|>\\\": 128009,\\n\",\n \" }\\n\",\n \" self.special.update({f\\\"<|reserved_{i}|>\\\": 128002 + i\\n\",\n \" for i in range(256)\\n\",\n \" if 128002 + i not in self.special.values()})\\n\",\n \"\\n\",\n \" self.model = tiktoken.Encoding(\\n\",\n \" name=Path(model_path).name,\\n\",\n \" pat_str=r\\\"(?i:'s|'t|'re|'ve|'m|'ll|'d)\\\"\\n\",\n \" r\\\"|[^\\\\r\\\\n\\\\p{L}\\\\p{N}]?\\\\p{L}+\\\"\\n\",\n \" r\\\"|\\\\p{N}{1,3}\\\"\\n\",\n \" r\\\"| ?[^\\\\s\\\\p{L}\\\\p{N}]+[\\\\r\\\\n]*\\\"\\n\",\n \" r\\\"|\\\\s*[\\\\r\\\\n]+\\\"\\n\",\n \" r\\\"|\\\\s+(?!\\\\S)\\\"\\n\",\n \" r\\\"|\\\\s+\\\",\\n\",\n \" mergeable_ranks=mergeable,\\n\",\n \" special_tokens=self.special,\\n\",\n \" )\\n\",\n \"\\n\",\n \" def encode(self, text, bos=False, eos=False):\\n\",\n \" ids = ([self.special[\\\"<|begin_of_text|>\\\"]] if bos else []) \\\\\\n\",\n \" + self.model.encode(text)\\n\",\n \" if eos:\\n\",\n \" ids.append(self.special[\\\"<|end_of_text|>\\\"])\\n\",\n \" return ids\\n\",\n \"\\n\",\n \" def decode(self, ids):\\n\",\n \" return self.model.decode(ids)\\n\",\n \"\\n\",\n \"\\n\",\n \"class ChatFormat:\\n\",\n \"\\n\",\n \" def __init__(self, tokenizer: Tokenizer, *,\\n\",\n \" default_system=\\\"You are a helpful assistant.\\\"):\\n\",\n \" self.tok = tokenizer\\n\",\n \" self.default_system = default_system\\n\",\n \"\\n\",\n \" def _header(self, role):\\n\",\n \" \\\"\\\"\\\"Encode <|start_header_id|>role<|end_header_id|>\\\\n\\\\n\\\"\\\"\\\"\\n\",\n \" return (\\n\",\n \" [self.tok.special[\\\"<|start_header_id|>\\\"]]\\n\",\n \" + self.tok.encode(role)\\n\",\n \" + [self.tok.special[\\\"<|end_header_id|>\\\"]]\\n\",\n \" + self.tok.encode(\\\"\\\\n\\\\n\\\")\\n\",\n \" )\\n\",\n \"\\n\",\n \" def encode(self, user_message, system_message=None):\\n\",\n \" sys_msg = system_message if system_message is not None else self.default_system\\n\",\n \"\\n\",\n \" ids = [self.tok.special[\\\"<|begin_of_text|>\\\"]]\\n\",\n \"\\n\",\n \" # system\\n\",\n \" ids += self._header(\\\"system\\\")\\n\",\n \" ids += self.tok.encode(sys_msg)\\n\",\n \" ids += [self.tok.special[\\\"<|eot_id|>\\\"]]\\n\",\n \"\\n\",\n \" # user\\n\",\n \" ids += self._header(\\\"user\\\")\\n\",\n \" ids += self.tok.encode(user_message)\\n\",\n \" ids += [self.tok.special[\\\"<|eot_id|>\\\"]]\\n\",\n \"\\n\",\n \" # assistant header (no content yet)\\n\",\n \" ids += self._header(\\\"assistant\\\")\\n\",\n \"\\n\",\n \" return ids\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b771b60c-c198-4b30-bf10-42031197ae86\",\n \"metadata\": {\n \"id\": \"b771b60c-c198-4b30-bf10-42031197ae86\"\n },\n \"source\": [\n \"- Please note that Meta AI requires that you accept the Llama 3.2 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) repository to accept the terms\\n\",\n \"- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \\\"Settings\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed\",\n \"outputId\": \"e6e6dc05-7330-45bc-a9a7-331919155bdd\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Uncomment and run the following code if you are executing the notebook for the first time\\n\",\n \"\\n\",\n \"# from huggingface_hub import login\\n\",\n \"# login()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"986bc1a0-804f-4154-80f8-44cefbee1368\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 141,\n \"referenced_widgets\": [\n \"a1608feac06d4687967a3e398f01c489\",\n \"518fb202e4b44aaba47f07d1a61b6762\",\n \"672cdc5aea954de3af851c001a667ad3\",\n \"eebf8874618746b39cf4a21a2728dc7f\",\n \"5176834aa8784bba9ec21234b87a8948\",\n \"e2dc407afcd945c798e30597fddfcb3c\",\n \"0dccd57dcc5c43a588157cef957c07e8\",\n \"33ca0cdf2c7f41598a381c4ebe6a4ee1\",\n \"ee44487f58454dacb522b1e084ffb733\",\n \"d2c41e71a3f441deaed091b620ac5603\",\n \"3326b6141a1a4eba9f316df528a9b99a\"\n ]\n },\n \"id\": \"986bc1a0-804f-4154-80f8-44cefbee1368\",\n \"outputId\": \"5dd7334b-4c71-465a-94d2-c3e95b9ddc58\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import hf_hub_download\\n\",\n \"\\n\",\n \"tokenizer_file_path = hf_hub_download(\\n\",\n \" repo_id=f\\\"meta-llama/Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\",\\n\",\n \" filename=\\\"original/tokenizer.model\\\",\\n\",\n \" local_dir=f\\\"Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"_gBhxDtU_nxo\",\n \"metadata\": {\n \"id\": \"_gBhxDtU_nxo\"\n },\n \"outputs\": [],\n \"source\": [\n \"tokenizer = Tokenizer(tokenizer_file_path)\\n\",\n \"chat_tokenizer = ChatFormat(tokenizer)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c172f89f-d301-439f-b809-46169e5f5945\",\n \"metadata\": {\n \"id\": \"c172f89f-d301-439f-b809-46169e5f5945\"\n },\n \"source\": [\n \" \\n\",\n \"# 4. Load pretrained weights\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"75166128-5899-4995-9b88-9672e135650e\",\n \"metadata\": {\n \"id\": \"75166128-5899-4995-9b88-9672e135650e\"\n },\n \"outputs\": [],\n \"source\": [\n \"def assign(left, right, tensor_name=\\\"unknown\\\"):\\n\",\n \" if left.shape != right.shape:\\n\",\n \" raise ValueError(f\\\"Shape mismatch in tensor '{tensor_name}'. Left: {left.shape}, Right: {right.shape}\\\")\\n\",\n \" \\n\",\n \" with torch.no_grad():\\n\",\n \" if isinstance(right, torch.Tensor):\\n\",\n \" left.copy_(right)\\n\",\n \" else:\\n\",\n \" left.copy_(torch.as_tensor(right, dtype=left.dtype, device=left.device))\\n\",\n \"\\n\",\n \" return left \\n\",\n \"\\n\",\n \"\\n\",\n \"def load_weights_into_llama(model, param_config, params):\\n\",\n \" model.tok_emb.weight = assign(model.tok_emb.weight, params[\\\"model.embed_tokens.weight\\\"], \\\"model.embed_tokens.weight\\\")\\n\",\n \"\\n\",\n \" for l in range(param_config[\\\"n_layers\\\"]):\\n\",\n \"\\n\",\n \" # Load attention weights\\n\",\n \" model.trf_blocks[l].att.W_query.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_query.weight,\\n\",\n \" params[f\\\"model.layers.{l}.self_attn.q_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.self_attn.q_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].att.W_key.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_key.weight,\\n\",\n \" params[f\\\"model.layers.{l}.self_attn.k_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.self_attn.k_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].att.W_value.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_value.weight,\\n\",\n \" params[f\\\"model.layers.{l}.self_attn.v_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.self_attn.v_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].att.out_proj.weight = assign(\\n\",\n \" model.trf_blocks[l].att.out_proj.weight,\\n\",\n \" params[f\\\"model.layers.{l}.self_attn.o_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.self_attn.o_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].norm1.weight = assign(\\n\",\n \" model.trf_blocks[l].norm1.weight,\\n\",\n \" params[f\\\"model.layers.{l}.input_layernorm.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.input_layernorm.weight\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Load FeedForward weights\\n\",\n \" model.trf_blocks[l].ff.fc1.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc1.weight,\\n\",\n \" params[f\\\"model.layers.{l}.mlp.gate_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.mlp.gate_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].ff.fc2.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc2.weight,\\n\",\n \" params[f\\\"model.layers.{l}.mlp.up_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.mlp.up_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].ff.fc3.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc3.weight,\\n\",\n \" params[f\\\"model.layers.{l}.mlp.down_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.mlp.down_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].norm2.weight = assign(\\n\",\n \" model.trf_blocks[l].norm2.weight,\\n\",\n \" params[f\\\"model.layers.{l}.post_attention_layernorm.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.post_attention_layernorm.weight\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Load output layer weights\\n\",\n \" model.final_norm.weight = assign(model.final_norm.weight, params[\\\"model.norm.weight\\\"], \\\"model.norm.weight\\\")\\n\",\n \"\\n\",\n \" if \\\"lm_head.weight\\\" in params.keys():\\n\",\n \" model.out_head.weight = assign(model.out_head.weight, params[\\\"lm_head.weight\\\"], \\\"lm_head.weight\\\")\\n\",\n \" else:\\n\",\n \" model.out_head.weight = model.tok_emb.weight\\n\",\n \" print(\\\"Model uses weight tying.\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"699cb1b8-a67d-49fb-80a6-0dad9d81f392\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 17,\n \"referenced_widgets\": [\n \"9881b6995c3f49dc89e6992fd9ab660b\",\n \"17a3174e65c54476b2e0d1faf8f011ca\",\n \"1bbf2e62c0754d1593beb4105a7f1ac1\",\n \"b82112e1dec645d98aa1c1ba64abcb61\",\n \"271e2bd6a35e4a8b92de8697f7c0be5f\",\n \"90a79523187446dfa692723b2e5833a7\",\n \"431ffb83b8c14bf182f0430e07ea6154\",\n \"a8f1b72a33dd4b548de23fbd95e0da18\",\n \"25cc36132d384189acfbecc59483134b\",\n \"bfd06423ad544218968648016e731a46\",\n \"d029630b63ff44cf807ade428d2eb421\"\n ]\n },\n \"id\": \"699cb1b8-a67d-49fb-80a6-0dad9d81f392\",\n \"outputId\": \"55b2f28c-142f-4698-9d23-d27456d3ed6d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Model uses weight tying.\\n\"\n ]\n }\n ],\n \"source\": [\n \"from safetensors.torch import load_file\\n\",\n \"\\n\",\n \"\\n\",\n \"if LLAMA_SIZE_STR == \\\"1B\\\":\\n\",\n \" weights_file = hf_hub_download(\\n\",\n \" repo_id=f\\\"meta-llama/Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\",\\n\",\n \" filename=\\\"model.safetensors\\\",\\n\",\n \" local_dir=f\\\"Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\"\\n\",\n \" )\\n\",\n \" combined_weights = load_file(weights_file)\\n\",\n \"\\n\",\n \"\\n\",\n \"else:\\n\",\n \" combined_weights = {}\\n\",\n \" for i in range(1, 3):\\n\",\n \" weights_file = hf_hub_download(\\n\",\n \" repo_id=f\\\"meta-llama/Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\",\\n\",\n \" filename=f\\\"model-0000{i}-of-00002.safetensors\\\",\\n\",\n \" local_dir=f\\\"Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\"\\n\",\n \" )\\n\",\n \" current_weights = load_file(weights_file)\\n\",\n \" combined_weights.update(current_weights)\\n\",\n \"\\n\",\n \"\\n\",\n \"load_weights_into_llama(model, LLAMA32_CONFIG, combined_weights)\\n\",\n \"model.to(device)\\n\",\n \"del combined_weights # free up memory\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"364e76ca-52f8-4fa5-af37-c4069f9694bc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"364e76ca-52f8-4fa5-af37-c4069f9694bc\",\n \"outputId\": \"00d7e983-262e-4c65-f322-f4d999311988\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of unique parameters: 1,235,814,400\\n\"\n ]\n }\n ],\n \"source\": [\n \"def count_unique_parameters(model):\\n\",\n \" unique_params = set()\\n\",\n \" total_unique_params = 0\\n\",\n \" \\n\",\n \" for param in model.parameters():\\n\",\n \" if param.data_ptr() not in unique_params:\\n\",\n \" total_unique_params += param.numel()\\n\",\n \" unique_params.add(param.data_ptr())\\n\",\n \" \\n\",\n \" return total_unique_params\\n\",\n \"\\n\",\n \"total_params_uniq = count_unique_parameters(model)\\n\",\n \"print(f\\\"Total number of unique parameters: {total_params_uniq:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"7f9f7ccc-70cb-41ff-9c25-44336042fc37\",\n \"metadata\": {\n \"id\": \"7f9f7ccc-70cb-41ff-9c25-44336042fc37\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Weight tying: True\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Checks that the weight values are the same\\n\",\n \"print(\\\"Weight tying:\\\", torch.equal(model.tok_emb.weight, model.out_head.weight))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"1ec6977d-ec42-42b5-bca2-3ecda791ea66\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Weight tying: True\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Furthermore, check if PyTorch uses the same underlying memory\\n\",\n \"print(\\\"Weight tying:\\\", model.tok_emb.weight.data_ptr() == model.out_head.weight.data_ptr())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"57d07df1-4401-4792-b549-7c4cc5632323\",\n \"metadata\": {\n \"id\": \"57d07df1-4401-4792-b549-7c4cc5632323\"\n },\n \"source\": [\n \" \\n\",\n \"# 5. Generate text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"7b8401c6-e244-4cb7-9849-2ba71ce758d5\",\n \"metadata\": {\n \"id\": \"7b8401c6-e244-4cb7-9849-2ba71ce758d5\"\n },\n \"outputs\": [],\n \"source\": [\n \"def text_to_token_ids(text, tokenizer):\\n\",\n \" encoded = tokenizer.encode(text)\\n\",\n \" encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\\n\",\n \" return encoded_tensor\\n\",\n \"\\n\",\n \"\\n\",\n \"def token_ids_to_text(token_ids, tokenizer):\\n\",\n \" flat = token_ids.squeeze(0) # remove batch dimension\\n\",\n \" return tokenizer.decode(flat.tolist())\\n\",\n \"\\n\",\n \"\\n\",\n \"def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):\\n\",\n \"\\n\",\n \" # For-loop is the same as before: Get logits, and only focus on last time step\\n\",\n \" for _ in range(max_new_tokens):\\n\",\n \" idx_cond = idx[:, -context_size:]\\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(idx_cond)\\n\",\n \" logits = logits[:, -1, :]\\n\",\n \"\\n\",\n \" # New: Filter logits with top_k sampling\\n\",\n \" if top_k is not None:\\n\",\n \" # Keep only top_k values\\n\",\n \" top_logits, _ = torch.topk(logits, top_k)\\n\",\n \" min_val = top_logits[:, -1]\\n\",\n \" logits = torch.where(logits < min_val, torch.tensor(float('-inf')).to(logits.device), logits)\\n\",\n \"\\n\",\n \" # New: Apply temperature scaling\\n\",\n \" if temperature > 0.0:\\n\",\n \" logits = logits / temperature\\n\",\n \"\\n\",\n \" # New (not in book): numerical stability tip to get equivalent results on mps device\\n\",\n \" # subtract rowwise max before softmax\\n\",\n \" logits = logits - logits.max(dim=-1, keepdim=True).values\\n\",\n \" \\n\",\n \" # Apply softmax to get probabilities\\n\",\n \" probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)\\n\",\n \"\\n\",\n \" # Sample from the distribution\\n\",\n \" idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)\\n\",\n \"\\n\",\n \" # Otherwise same as before: get idx of the vocab entry with the highest logits value\\n\",\n \" else:\\n\",\n \" idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)\\n\",\n \"\\n\",\n \" if idx_next == eos_id: # Stop generating early if end-of-sequence token is encountered and eos_id is specified\\n\",\n \" break\\n\",\n \"\\n\",\n \" # Same as before: append sampled index to the running sequence\\n\",\n \" idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)\\n\",\n \"\\n\",\n \" return idx\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"1c7a04fa-6aac-416b-8f63-f1e19227633d\",\n \"metadata\": {\n \"id\": \"1c7a04fa-6aac-416b-8f63-f1e19227633d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Time: 13.21 sec\\n\",\n \"\\n\",\n \"\\n\",\n \"Output text:\\n\",\n \"\\n\",\n \" Llamas are herbivores, which means they primarily eat plants and plant-based foods. Their diet typically consists of:\\n\",\n \"\\n\",\n \"1. Grasses: Llamas love to graze on various types of grasses, including tall grasses, short grasses, and grassy weeds.\\n\",\n \"2. Hay: They also enjoy munching on hay, which is a dry, compressed form of grass or other plant material.\\n\",\n \"3. Leaves: Llamas will eat leaves from trees and shrubs, including leaves from plants like clover, alfalfa, and grasses.\\n\",\n \"4. Fruits and vegetables: In the wild, llamas will eat fruits and vegetables like berries, apples, and carrots.\\n\",\n \"5. Browse: Llamas will also\\n\"\n ]\n }\n ],\n \"source\": [\n \"import time\\n\",\n \"\\n\",\n \"\\n\",\n \"PROMPT = \\\"What do llamas eat?\\\"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"start = time.time()\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(PROMPT, chat_tokenizer).to(device),\\n\",\n \" max_new_tokens=150,\\n\",\n \" context_size=LLAMA32_CONFIG[\\\"context_length\\\"],\\n\",\n \" top_k=1,\\n\",\n \" temperature=0.\\n\",\n \")\\n\",\n \"\\n\",\n \"print(f\\\"Time: {time.time() - start:.2f} sec\\\")\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" max_mem_bytes = torch.cuda.max_memory_allocated()\\n\",\n \" max_mem_gb = max_mem_bytes / (1024 ** 3)\\n\",\n \" print(f\\\"Max memory allocated: {max_mem_gb:.2f} GB\\\")\\n\",\n \"\\n\",\n \"output_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \"\\n\",\n \"\\n\",\n \"def clean_text(text, header_end=\\\"assistant<|end_header_id|>\\\\n\\\\n\\\"):\\n\",\n \" # Find the index of the first occurrence of \\\"<|end_header_id|>\\\"\\n\",\n \" index = text.find(header_end)\\n\",\n \"\\n\",\n \" if index != -1:\\n\",\n \" # Return the substring starting after \\\"<|end_header_id|>\\\"\\n\",\n \" return text[index + len(header_end):].strip() # Strip removes leading/trailing whitespace\\n\",\n \" else:\\n\",\n \" # If the token is not found, return the original text\\n\",\n \" return text\\n\",\n \"\\n\",\n \"print(\\\"\\\\n\\\\nOutput text:\\\\n\\\\n\\\", clean_text(output_text))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"549324d6-5c71-4147-ae21-2e67675faa3d\",\n \"metadata\": {\n \"id\": \"549324d6-5c71-4147-ae21-2e67675faa3d\"\n },\n \"source\": [\n \" \\n\",\n \"# What's next?\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e6edaaae-2de1-406c-8ffa-897cdfa3808c\",\n \"metadata\": {\n \"id\": \"e6edaaae-2de1-406c-8ffa-897cdfa3808c\"\n },\n \"source\": [\n \"- The notebook was kept purposefully minimal; if you are interested in additional explanation about the individual components, check out the following two companion notebooks:\\n\",\n \"\\n\",\n \"
\\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Llama 3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\\n\",\n \" - the tokenizer code is inspired by the original [Llama 3 tokenizer code](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py), which Meta AI used to extend the Tiktoken GPT-4 tokenizer\\n\",\n \" - the RoPE rescaling section is inspired by the [_compute_llama3_parameters function](https://github.com/huggingface/transformers/blob/5c1027bf09717f664b579e01cbb8ec3ef5aeb140/src/transformers/modeling_rope_utils.py#L329-L347) in the `transformers` library\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"blobfile version: 3.1.0\\n\",\n \"huggingface_hub version: 0.34.4\\n\",\n \"tiktoken version: 0.11.0\\n\",\n \"torch version: 2.8.0\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"blobfile\\\", # to download pretrained weights\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tiktoken\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, freq_config=None, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))\\n\",\n \"\\n\",\n \" # Frequency adjustments\\n\",\n \" if freq_config is not None:\\n\",\n \" low_freq_wavelen = freq_config[\\\"original_context_length\\\"] / freq_config[\\\"low_freq_factor\\\"]\\n\",\n \" high_freq_wavelen = freq_config[\\\"original_context_length\\\"] / freq_config[\\\"high_freq_factor\\\"]\\n\",\n \"\\n\",\n \" wavelen = 2 * torch.pi / inv_freq\\n\",\n \"\\n\",\n \" inv_freq_llama = torch.where(\\n\",\n \" wavelen > low_freq_wavelen, inv_freq / freq_config[\\\"factor\\\"], inv_freq\\n\",\n \" )\\n\",\n \"\\n\",\n \" smooth_factor = (freq_config[\\\"original_context_length\\\"] / wavelen - freq_config[\\\"low_freq_factor\\\"]) / (\\n\",\n \" freq_config[\\\"high_freq_factor\\\"] - freq_config[\\\"low_freq_factor\\\"]\\n\",\n \" )\\n\",\n \"\\n\",\n \" smoothed_inv_freq = (\\n\",\n \" (1 - smooth_factor) * (inv_freq / freq_config[\\\"factor\\\"]) + smooth_factor * inv_freq\\n\",\n \" )\\n\",\n \"\\n\",\n \" is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)\\n\",\n \" inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)\\n\",\n \" inv_freq = inv_freq_llama\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Expand angles to match the head_dim\\n\",\n \" angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" # It's ok to use lower-precision after applying cos and sin rotation\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, d_out, num_heads,\\n\",\n \" num_kv_groups,\\n\",\n \" dtype=None\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert d_out % num_heads == 0, \\\"d_out must be divisible by num_heads\\\"\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.d_out = d_out\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.head_dim = d_out // num_heads\\n\",\n \"\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" b, num_tokens, d_in = x.shape\\n\",\n \"\\n\",\n \" queries = self.W_query(x) # Shape: (b, num_tokens, d_out)\\n\",\n \" keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape queries, keys, and values\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)\\n\",\n \" values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)\\n\",\n \"\\n\",\n \" # Transpose keys, values, and queries\\n\",\n \" keys = keys.transpose(1, 2) # Shape: (b, num_kv_groups, num_tokens, head_dim)\\n\",\n \" values = values.transpose(1, 2) # Shape: (b, num_kv_groups, num_tokens, head_dim)\\n\",\n \" queries = queries.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \"\\n\",\n \" # Apply RoPE\\n\",\n \" keys = apply_rope(keys, cos, sin)\\n\",\n \" queries = apply_rope(queries, cos, sin)\\n\",\n \"\\n\",\n \" # Expand keys and values to match the number of heads\\n\",\n \" # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" # For example, before repeat_interleave along dim=1 (query groups):\\n\",\n \" # [K1, K2]\\n\",\n \" # After repeat_interleave (each query group is repeated group_size times):\\n\",\n \" # [K1, K1, K2, K2]\\n\",\n \" # If we used regular repeat instead of repeat_interleave, we'd get:\\n\",\n \" # [K1, K2, K1, K2]\\n\",\n \"\\n\",\n \" # Compute scaled dot-product attention (aka self-attention) with a causal mask\\n\",\n \" # Shape: (b, num_heads, num_tokens, num_tokens)\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\\n\",\n \"\\n\",\n \" # Compute attention scores\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\\n\",\n \" assert keys.shape[-1] == self.head_dim\\n\",\n \"\\n\",\n \" # Shape: (b, num_tokens, num_heads, head_dim)\\n\",\n \" context_vec = (attn_weights @ values).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Combine heads, where self.d_out = self.num_heads * self.head_dim\\n\",\n \" context_vec = context_vec.reshape(b, num_tokens, self.d_out)\\n\",\n \" context_vec = self.out_proj(context_vec) # optional projection\\n\",\n \"\\n\",\n \" return context_vec\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" d_out=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"]\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = nn.RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.norm2 = nn.RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \" x = self.att(x, mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" # Shortcut connection for feed-forward block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Llama3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" # Main model parameters\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.ModuleList( # ModuleList since Sequential can only accept one input, and we need `x, mask, cos, sin`\\n\",\n \" [TransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])]\\n\",\n \" )\\n\",\n \"\\n\",\n \" self.final_norm = nn.RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" # Reusable utilities\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"emb_dim\\\"] // cfg[\\\"n_heads\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" freq_config=cfg[\\\"rope_freq\\\"]\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" # Forward pass\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" x = tok_embeds\\n\",\n \"\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \" mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)\\n\",\n \" \\n\",\n \" for block in self.trf_blocks:\\n\",\n \" x = block(x, mask, self.cos, self.sin)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"23dea40c-fe20-4a75-be25-d6fce5863c01\",\n \"metadata\": {\n \"id\": \"23dea40c-fe20-4a75-be25-d6fce5863c01\"\n },\n \"source\": [\n \"- The remainder of this notebook uses the Llama 3.2 1B model; to use the 3B model variant, just uncomment the second configuration file in the following code cell\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Llama 3.2 1B\\n\",\n \"\\n\",\n \"LLAMA32_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 131_072, # Context length that was used to train the model\\n\",\n \" \\\"emb_dim\\\": 2048, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 16, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 8192, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \" \\\"rope_freq\\\": { # RoPE frequency scaling\\n\",\n \" \\\"factor\\\": 32.0,\\n\",\n \" \\\"low_freq_factor\\\": 1.0,\\n\",\n \" \\\"high_freq_factor\\\": 4.0,\\n\",\n \" \\\"original_context_length\\\": 8192,\\n\",\n \" }\\n\",\n \"}\\n\",\n \"\\n\",\n \"# Llama 3.2 3B\\n\",\n \"\\n\",\n \"# LLAMA32_CONFIG = {\\n\",\n \"# \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \"# \\\"context_length\\\": 131_072, # Context length that was used to train the model\\n\",\n \"# \\\"emb_dim\\\": 3072, # Embedding dimension\\n\",\n \"# \\\"n_heads\\\": 24, # Number of attention heads\\n\",\n \"# \\\"n_layers\\\": 28, # Number of layers\\n\",\n \"# \\\"hidden_dim\\\": 8192, # Size of the intermediate dimension in FeedForward\\n\",\n \"# \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \"# \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \"# \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \"# \\\"rope_freq\\\": { # RoPE frequency scaling\\n\",\n \"# \\\"factor\\\": 32.0,\\n\",\n \"# \\\"low_freq_factor\\\": 1.0,\\n\",\n \"# \\\"high_freq_factor\\\": 4.0,\\n\",\n \"# \\\"original_context_length\\\": 8192,\\n\",\n \"# }\\n\",\n \"# }\\n\",\n \"\\n\",\n \"LLAMA_SIZE_STR = \\\"1B\\\" if LLAMA32_CONFIG[\\\"emb_dim\\\"] == 2048 else \\\"3B\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = Llama3Model(LLAMA32_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"fd5efb03-5a07-46e8-8607-93ed47549d2b\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"fd5efb03-5a07-46e8-8607-93ed47549d2b\",\n \"outputId\": \"65c1a95e-b502-4150-9e2e-da619d9053d5\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"float32 (PyTorch default): 11.23 GB\\n\",\n \"bfloat16: 5.61 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def calc_model_memory_size(model, input_dtype=torch.float32):\\n\",\n \" total_params = 0\\n\",\n \" total_grads = 0\\n\",\n \" for param in model.parameters():\\n\",\n \" # Calculate total number of elements per parameter\\n\",\n \" param_size = param.numel()\\n\",\n \" total_params += param_size\\n\",\n \" # Check if gradients are stored for this parameter\\n\",\n \" if param.requires_grad:\\n\",\n \" total_grads += param_size\\n\",\n \"\\n\",\n \" # Calculate buffer size (non-parameters that require memory)\\n\",\n \" total_buffers = sum(buf.numel() for buf in model.buffers())\\n\",\n \"\\n\",\n \" # Size in bytes = (Number of elements) * (Size of each element in bytes)\\n\",\n \" # We assume parameters and gradients are stored in the same type as input dtype\\n\",\n \" element_size = torch.tensor(0, dtype=input_dtype).element_size()\\n\",\n \" total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\\n\",\n \"\\n\",\n \" # Convert bytes to gigabytes\\n\",\n \" total_memory_gb = total_memory_bytes / (1024**3)\\n\",\n \"\\n\",\n \" return total_memory_gb\\n\",\n \"\\n\",\n \"print(f\\\"float32 (PyTorch default): {calc_model_memory_size(model, input_dtype=torch.float32):.2f} GB\\\")\\n\",\n \"print(f\\\"bfloat16: {calc_model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"41176fb0-d58a-443a-912f-4f436564b5f8\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters: 1,498,482,688\\n\",\n \"\\n\",\n \"Total number of unique parameters: 1,235,814,400\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters())\\n\",\n \"print(f\\\"Total number of parameters: {total_params:,}\\\")\\n\",\n \"\\n\",\n \"# Account for weight tying\\n\",\n \"total_params_normalized = total_params - model.tok_emb.weight.numel()\\n\",\n \"print(f\\\"\\\\nTotal number of unique parameters: {total_params_normalized:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"31f12baf-f79b-499f-85c0-51328a6a20f5\",\n \"metadata\": {\n \"id\": \"31f12baf-f79b-499f-85c0-51328a6a20f5\"\n },\n \"outputs\": [],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"78e091e1-afa8-4d23-9aea-cced86181bfd\",\n \"metadata\": {\n \"id\": \"78e091e1-afa8-4d23-9aea-cced86181bfd\"\n },\n \"source\": [\n \" \\n\",\n \"# 3. Load tokenizer\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"9482b01c-49f9-48e4-ab2c-4a4c75240e77\",\n \"metadata\": {\n \"id\": \"9482b01c-49f9-48e4-ab2c-4a4c75240e77\"\n },\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"import tiktoken\\n\",\n \"from tiktoken.load import load_tiktoken_bpe\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"class Tokenizer:\\n\",\n \" \\\"\\\"\\\"Thin wrapper around tiktoken that keeps track of Llama-3 special IDs.\\\"\\\"\\\"\\n\",\n \" def __init__(self, model_path):\\n\",\n \" if not os.path.isfile(model_path):\\n\",\n \" raise FileNotFoundError(model_path)\\n\",\n \"\\n\",\n \" mergeable = load_tiktoken_bpe(model_path)\\n\",\n \"\\n\",\n \" # hard-coded from Meta's tokenizer.json\\n\",\n \" self.special = {\\n\",\n \" \\\"<|begin_of_text|>\\\": 128000,\\n\",\n \" \\\"<|end_of_text|>\\\": 128001,\\n\",\n \" \\\"<|start_header_id|>\\\": 128006,\\n\",\n \" \\\"<|end_header_id|>\\\": 128007,\\n\",\n \" \\\"<|eot_id|>\\\": 128009,\\n\",\n \" }\\n\",\n \" self.special.update({f\\\"<|reserved_{i}|>\\\": 128002 + i\\n\",\n \" for i in range(256)\\n\",\n \" if 128002 + i not in self.special.values()})\\n\",\n \"\\n\",\n \" self.model = tiktoken.Encoding(\\n\",\n \" name=Path(model_path).name,\\n\",\n \" pat_str=r\\\"(?i:'s|'t|'re|'ve|'m|'ll|'d)\\\"\\n\",\n \" r\\\"|[^\\\\r\\\\n\\\\p{L}\\\\p{N}]?\\\\p{L}+\\\"\\n\",\n \" r\\\"|\\\\p{N}{1,3}\\\"\\n\",\n \" r\\\"| ?[^\\\\s\\\\p{L}\\\\p{N}]+[\\\\r\\\\n]*\\\"\\n\",\n \" r\\\"|\\\\s*[\\\\r\\\\n]+\\\"\\n\",\n \" r\\\"|\\\\s+(?!\\\\S)\\\"\\n\",\n \" r\\\"|\\\\s+\\\",\\n\",\n \" mergeable_ranks=mergeable,\\n\",\n \" special_tokens=self.special,\\n\",\n \" )\\n\",\n \"\\n\",\n \" def encode(self, text, bos=False, eos=False):\\n\",\n \" ids = ([self.special[\\\"<|begin_of_text|>\\\"]] if bos else []) \\\\\\n\",\n \" + self.model.encode(text)\\n\",\n \" if eos:\\n\",\n \" ids.append(self.special[\\\"<|end_of_text|>\\\"])\\n\",\n \" return ids\\n\",\n \"\\n\",\n \" def decode(self, ids):\\n\",\n \" return self.model.decode(ids)\\n\",\n \"\\n\",\n \"\\n\",\n \"class ChatFormat:\\n\",\n \"\\n\",\n \" def __init__(self, tokenizer: Tokenizer, *,\\n\",\n \" default_system=\\\"You are a helpful assistant.\\\"):\\n\",\n \" self.tok = tokenizer\\n\",\n \" self.default_system = default_system\\n\",\n \"\\n\",\n \" def _header(self, role):\\n\",\n \" \\\"\\\"\\\"Encode <|start_header_id|>role<|end_header_id|>\\\\n\\\\n\\\"\\\"\\\"\\n\",\n \" return (\\n\",\n \" [self.tok.special[\\\"<|start_header_id|>\\\"]]\\n\",\n \" + self.tok.encode(role)\\n\",\n \" + [self.tok.special[\\\"<|end_header_id|>\\\"]]\\n\",\n \" + self.tok.encode(\\\"\\\\n\\\\n\\\")\\n\",\n \" )\\n\",\n \"\\n\",\n \" def encode(self, user_message, system_message=None):\\n\",\n \" sys_msg = system_message if system_message is not None else self.default_system\\n\",\n \"\\n\",\n \" ids = [self.tok.special[\\\"<|begin_of_text|>\\\"]]\\n\",\n \"\\n\",\n \" # system\\n\",\n \" ids += self._header(\\\"system\\\")\\n\",\n \" ids += self.tok.encode(sys_msg)\\n\",\n \" ids += [self.tok.special[\\\"<|eot_id|>\\\"]]\\n\",\n \"\\n\",\n \" # user\\n\",\n \" ids += self._header(\\\"user\\\")\\n\",\n \" ids += self.tok.encode(user_message)\\n\",\n \" ids += [self.tok.special[\\\"<|eot_id|>\\\"]]\\n\",\n \"\\n\",\n \" # assistant header (no content yet)\\n\",\n \" ids += self._header(\\\"assistant\\\")\\n\",\n \"\\n\",\n \" return ids\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b771b60c-c198-4b30-bf10-42031197ae86\",\n \"metadata\": {\n \"id\": \"b771b60c-c198-4b30-bf10-42031197ae86\"\n },\n \"source\": [\n \"- Please note that Meta AI requires that you accept the Llama 3.2 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) repository to accept the terms\\n\",\n \"- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \\\"Settings\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed\",\n \"outputId\": \"e6e6dc05-7330-45bc-a9a7-331919155bdd\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Uncomment and run the following code if you are executing the notebook for the first time\\n\",\n \"\\n\",\n \"# from huggingface_hub import login\\n\",\n \"# login()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"986bc1a0-804f-4154-80f8-44cefbee1368\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 141,\n \"referenced_widgets\": [\n \"a1608feac06d4687967a3e398f01c489\",\n \"518fb202e4b44aaba47f07d1a61b6762\",\n \"672cdc5aea954de3af851c001a667ad3\",\n \"eebf8874618746b39cf4a21a2728dc7f\",\n \"5176834aa8784bba9ec21234b87a8948\",\n \"e2dc407afcd945c798e30597fddfcb3c\",\n \"0dccd57dcc5c43a588157cef957c07e8\",\n \"33ca0cdf2c7f41598a381c4ebe6a4ee1\",\n \"ee44487f58454dacb522b1e084ffb733\",\n \"d2c41e71a3f441deaed091b620ac5603\",\n \"3326b6141a1a4eba9f316df528a9b99a\"\n ]\n },\n \"id\": \"986bc1a0-804f-4154-80f8-44cefbee1368\",\n \"outputId\": \"5dd7334b-4c71-465a-94d2-c3e95b9ddc58\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import hf_hub_download\\n\",\n \"\\n\",\n \"tokenizer_file_path = hf_hub_download(\\n\",\n \" repo_id=f\\\"meta-llama/Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\",\\n\",\n \" filename=\\\"original/tokenizer.model\\\",\\n\",\n \" local_dir=f\\\"Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"_gBhxDtU_nxo\",\n \"metadata\": {\n \"id\": \"_gBhxDtU_nxo\"\n },\n \"outputs\": [],\n \"source\": [\n \"tokenizer = Tokenizer(tokenizer_file_path)\\n\",\n \"chat_tokenizer = ChatFormat(tokenizer)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c172f89f-d301-439f-b809-46169e5f5945\",\n \"metadata\": {\n \"id\": \"c172f89f-d301-439f-b809-46169e5f5945\"\n },\n \"source\": [\n \" \\n\",\n \"# 4. Load pretrained weights\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"75166128-5899-4995-9b88-9672e135650e\",\n \"metadata\": {\n \"id\": \"75166128-5899-4995-9b88-9672e135650e\"\n },\n \"outputs\": [],\n \"source\": [\n \"def assign(left, right, tensor_name=\\\"unknown\\\"):\\n\",\n \" if left.shape != right.shape:\\n\",\n \" raise ValueError(f\\\"Shape mismatch in tensor '{tensor_name}'. Left: {left.shape}, Right: {right.shape}\\\")\\n\",\n \" \\n\",\n \" with torch.no_grad():\\n\",\n \" if isinstance(right, torch.Tensor):\\n\",\n \" left.copy_(right)\\n\",\n \" else:\\n\",\n \" left.copy_(torch.as_tensor(right, dtype=left.dtype, device=left.device))\\n\",\n \"\\n\",\n \" return left \\n\",\n \"\\n\",\n \"\\n\",\n \"def load_weights_into_llama(model, param_config, params):\\n\",\n \" model.tok_emb.weight = assign(model.tok_emb.weight, params[\\\"model.embed_tokens.weight\\\"], \\\"model.embed_tokens.weight\\\")\\n\",\n \"\\n\",\n \" for l in range(param_config[\\\"n_layers\\\"]):\\n\",\n \"\\n\",\n \" # Load attention weights\\n\",\n \" model.trf_blocks[l].att.W_query.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_query.weight,\\n\",\n \" params[f\\\"model.layers.{l}.self_attn.q_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.self_attn.q_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].att.W_key.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_key.weight,\\n\",\n \" params[f\\\"model.layers.{l}.self_attn.k_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.self_attn.k_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].att.W_value.weight = assign(\\n\",\n \" model.trf_blocks[l].att.W_value.weight,\\n\",\n \" params[f\\\"model.layers.{l}.self_attn.v_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.self_attn.v_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].att.out_proj.weight = assign(\\n\",\n \" model.trf_blocks[l].att.out_proj.weight,\\n\",\n \" params[f\\\"model.layers.{l}.self_attn.o_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.self_attn.o_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].norm1.weight = assign(\\n\",\n \" model.trf_blocks[l].norm1.weight,\\n\",\n \" params[f\\\"model.layers.{l}.input_layernorm.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.input_layernorm.weight\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Load FeedForward weights\\n\",\n \" model.trf_blocks[l].ff.fc1.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc1.weight,\\n\",\n \" params[f\\\"model.layers.{l}.mlp.gate_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.mlp.gate_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].ff.fc2.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc2.weight,\\n\",\n \" params[f\\\"model.layers.{l}.mlp.up_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.mlp.up_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].ff.fc3.weight = assign(\\n\",\n \" model.trf_blocks[l].ff.fc3.weight,\\n\",\n \" params[f\\\"model.layers.{l}.mlp.down_proj.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.mlp.down_proj.weight\\\"\\n\",\n \" )\\n\",\n \" model.trf_blocks[l].norm2.weight = assign(\\n\",\n \" model.trf_blocks[l].norm2.weight,\\n\",\n \" params[f\\\"model.layers.{l}.post_attention_layernorm.weight\\\"],\\n\",\n \" f\\\"model.layers.{l}.post_attention_layernorm.weight\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Load output layer weights\\n\",\n \" model.final_norm.weight = assign(model.final_norm.weight, params[\\\"model.norm.weight\\\"], \\\"model.norm.weight\\\")\\n\",\n \"\\n\",\n \" if \\\"lm_head.weight\\\" in params.keys():\\n\",\n \" model.out_head.weight = assign(model.out_head.weight, params[\\\"lm_head.weight\\\"], \\\"lm_head.weight\\\")\\n\",\n \" else:\\n\",\n \" model.out_head.weight = model.tok_emb.weight\\n\",\n \" print(\\\"Model uses weight tying.\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"699cb1b8-a67d-49fb-80a6-0dad9d81f392\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 17,\n \"referenced_widgets\": [\n \"9881b6995c3f49dc89e6992fd9ab660b\",\n \"17a3174e65c54476b2e0d1faf8f011ca\",\n \"1bbf2e62c0754d1593beb4105a7f1ac1\",\n \"b82112e1dec645d98aa1c1ba64abcb61\",\n \"271e2bd6a35e4a8b92de8697f7c0be5f\",\n \"90a79523187446dfa692723b2e5833a7\",\n \"431ffb83b8c14bf182f0430e07ea6154\",\n \"a8f1b72a33dd4b548de23fbd95e0da18\",\n \"25cc36132d384189acfbecc59483134b\",\n \"bfd06423ad544218968648016e731a46\",\n \"d029630b63ff44cf807ade428d2eb421\"\n ]\n },\n \"id\": \"699cb1b8-a67d-49fb-80a6-0dad9d81f392\",\n \"outputId\": \"55b2f28c-142f-4698-9d23-d27456d3ed6d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Model uses weight tying.\\n\"\n ]\n }\n ],\n \"source\": [\n \"from safetensors.torch import load_file\\n\",\n \"\\n\",\n \"\\n\",\n \"if LLAMA_SIZE_STR == \\\"1B\\\":\\n\",\n \" weights_file = hf_hub_download(\\n\",\n \" repo_id=f\\\"meta-llama/Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\",\\n\",\n \" filename=\\\"model.safetensors\\\",\\n\",\n \" local_dir=f\\\"Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\"\\n\",\n \" )\\n\",\n \" combined_weights = load_file(weights_file)\\n\",\n \"\\n\",\n \"\\n\",\n \"else:\\n\",\n \" combined_weights = {}\\n\",\n \" for i in range(1, 3):\\n\",\n \" weights_file = hf_hub_download(\\n\",\n \" repo_id=f\\\"meta-llama/Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\",\\n\",\n \" filename=f\\\"model-0000{i}-of-00002.safetensors\\\",\\n\",\n \" local_dir=f\\\"Llama-3.2-{LLAMA_SIZE_STR}-Instruct\\\"\\n\",\n \" )\\n\",\n \" current_weights = load_file(weights_file)\\n\",\n \" combined_weights.update(current_weights)\\n\",\n \"\\n\",\n \"\\n\",\n \"load_weights_into_llama(model, LLAMA32_CONFIG, combined_weights)\\n\",\n \"model.to(device)\\n\",\n \"del combined_weights # free up memory\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"364e76ca-52f8-4fa5-af37-c4069f9694bc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"364e76ca-52f8-4fa5-af37-c4069f9694bc\",\n \"outputId\": \"00d7e983-262e-4c65-f322-f4d999311988\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of unique parameters: 1,235,814,400\\n\"\n ]\n }\n ],\n \"source\": [\n \"def count_unique_parameters(model):\\n\",\n \" unique_params = set()\\n\",\n \" total_unique_params = 0\\n\",\n \" \\n\",\n \" for param in model.parameters():\\n\",\n \" if param.data_ptr() not in unique_params:\\n\",\n \" total_unique_params += param.numel()\\n\",\n \" unique_params.add(param.data_ptr())\\n\",\n \" \\n\",\n \" return total_unique_params\\n\",\n \"\\n\",\n \"total_params_uniq = count_unique_parameters(model)\\n\",\n \"print(f\\\"Total number of unique parameters: {total_params_uniq:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"7f9f7ccc-70cb-41ff-9c25-44336042fc37\",\n \"metadata\": {\n \"id\": \"7f9f7ccc-70cb-41ff-9c25-44336042fc37\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Weight tying: True\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Checks that the weight values are the same\\n\",\n \"print(\\\"Weight tying:\\\", torch.equal(model.tok_emb.weight, model.out_head.weight))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"1ec6977d-ec42-42b5-bca2-3ecda791ea66\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Weight tying: True\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Furthermore, check if PyTorch uses the same underlying memory\\n\",\n \"print(\\\"Weight tying:\\\", model.tok_emb.weight.data_ptr() == model.out_head.weight.data_ptr())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"57d07df1-4401-4792-b549-7c4cc5632323\",\n \"metadata\": {\n \"id\": \"57d07df1-4401-4792-b549-7c4cc5632323\"\n },\n \"source\": [\n \" \\n\",\n \"# 5. Generate text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"7b8401c6-e244-4cb7-9849-2ba71ce758d5\",\n \"metadata\": {\n \"id\": \"7b8401c6-e244-4cb7-9849-2ba71ce758d5\"\n },\n \"outputs\": [],\n \"source\": [\n \"def text_to_token_ids(text, tokenizer):\\n\",\n \" encoded = tokenizer.encode(text)\\n\",\n \" encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\\n\",\n \" return encoded_tensor\\n\",\n \"\\n\",\n \"\\n\",\n \"def token_ids_to_text(token_ids, tokenizer):\\n\",\n \" flat = token_ids.squeeze(0) # remove batch dimension\\n\",\n \" return tokenizer.decode(flat.tolist())\\n\",\n \"\\n\",\n \"\\n\",\n \"def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):\\n\",\n \"\\n\",\n \" # For-loop is the same as before: Get logits, and only focus on last time step\\n\",\n \" for _ in range(max_new_tokens):\\n\",\n \" idx_cond = idx[:, -context_size:]\\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(idx_cond)\\n\",\n \" logits = logits[:, -1, :]\\n\",\n \"\\n\",\n \" # New: Filter logits with top_k sampling\\n\",\n \" if top_k is not None:\\n\",\n \" # Keep only top_k values\\n\",\n \" top_logits, _ = torch.topk(logits, top_k)\\n\",\n \" min_val = top_logits[:, -1]\\n\",\n \" logits = torch.where(logits < min_val, torch.tensor(float('-inf')).to(logits.device), logits)\\n\",\n \"\\n\",\n \" # New: Apply temperature scaling\\n\",\n \" if temperature > 0.0:\\n\",\n \" logits = logits / temperature\\n\",\n \"\\n\",\n \" # New (not in book): numerical stability tip to get equivalent results on mps device\\n\",\n \" # subtract rowwise max before softmax\\n\",\n \" logits = logits - logits.max(dim=-1, keepdim=True).values\\n\",\n \" \\n\",\n \" # Apply softmax to get probabilities\\n\",\n \" probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)\\n\",\n \"\\n\",\n \" # Sample from the distribution\\n\",\n \" idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)\\n\",\n \"\\n\",\n \" # Otherwise same as before: get idx of the vocab entry with the highest logits value\\n\",\n \" else:\\n\",\n \" idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)\\n\",\n \"\\n\",\n \" if idx_next == eos_id: # Stop generating early if end-of-sequence token is encountered and eos_id is specified\\n\",\n \" break\\n\",\n \"\\n\",\n \" # Same as before: append sampled index to the running sequence\\n\",\n \" idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)\\n\",\n \"\\n\",\n \" return idx\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"1c7a04fa-6aac-416b-8f63-f1e19227633d\",\n \"metadata\": {\n \"id\": \"1c7a04fa-6aac-416b-8f63-f1e19227633d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Time: 13.21 sec\\n\",\n \"\\n\",\n \"\\n\",\n \"Output text:\\n\",\n \"\\n\",\n \" Llamas are herbivores, which means they primarily eat plants and plant-based foods. Their diet typically consists of:\\n\",\n \"\\n\",\n \"1. Grasses: Llamas love to graze on various types of grasses, including tall grasses, short grasses, and grassy weeds.\\n\",\n \"2. Hay: They also enjoy munching on hay, which is a dry, compressed form of grass or other plant material.\\n\",\n \"3. Leaves: Llamas will eat leaves from trees and shrubs, including leaves from plants like clover, alfalfa, and grasses.\\n\",\n \"4. Fruits and vegetables: In the wild, llamas will eat fruits and vegetables like berries, apples, and carrots.\\n\",\n \"5. Browse: Llamas will also\\n\"\n ]\n }\n ],\n \"source\": [\n \"import time\\n\",\n \"\\n\",\n \"\\n\",\n \"PROMPT = \\\"What do llamas eat?\\\"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"start = time.time()\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(PROMPT, chat_tokenizer).to(device),\\n\",\n \" max_new_tokens=150,\\n\",\n \" context_size=LLAMA32_CONFIG[\\\"context_length\\\"],\\n\",\n \" top_k=1,\\n\",\n \" temperature=0.\\n\",\n \")\\n\",\n \"\\n\",\n \"print(f\\\"Time: {time.time() - start:.2f} sec\\\")\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" max_mem_bytes = torch.cuda.max_memory_allocated()\\n\",\n \" max_mem_gb = max_mem_bytes / (1024 ** 3)\\n\",\n \" print(f\\\"Max memory allocated: {max_mem_gb:.2f} GB\\\")\\n\",\n \"\\n\",\n \"output_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \"\\n\",\n \"\\n\",\n \"def clean_text(text, header_end=\\\"assistant<|end_header_id|>\\\\n\\\\n\\\"):\\n\",\n \" # Find the index of the first occurrence of \\\"<|end_header_id|>\\\"\\n\",\n \" index = text.find(header_end)\\n\",\n \"\\n\",\n \" if index != -1:\\n\",\n \" # Return the substring starting after \\\"<|end_header_id|>\\\"\\n\",\n \" return text[index + len(header_end):].strip() # Strip removes leading/trailing whitespace\\n\",\n \" else:\\n\",\n \" # If the token is not found, return the original text\\n\",\n \" return text\\n\",\n \"\\n\",\n \"print(\\\"\\\\n\\\\nOutput text:\\\\n\\\\n\\\", clean_text(output_text))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"549324d6-5c71-4147-ae21-2e67675faa3d\",\n \"metadata\": {\n \"id\": \"549324d6-5c71-4147-ae21-2e67675faa3d\"\n },\n \"source\": [\n \" \\n\",\n \"# What's next?\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e6edaaae-2de1-406c-8ffa-897cdfa3808c\",\n \"metadata\": {\n \"id\": \"e6edaaae-2de1-406c-8ffa-897cdfa3808c\"\n },\n \"source\": [\n \"- The notebook was kept purposefully minimal; if you are interested in additional explanation about the individual components, check out the following two companion notebooks:\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \" 1. [Converting a From-Scratch GPT Architecture to Llama 2](converting-gpt-to-llama2.ipynb)\\n\",\n \" 2. [Converting Llama 2 to Llama 3.2 From Scratch](converting-llama2-to-llama3.ipynb)\\n\",\n \" \\n\",\n \"- For those interested in a comprehensive guide on building a large language model from scratch and gaining a deeper understanding of its mechanics, you might like my [Build a Large Language Model (From Scratch)](http://mng.bz/orYv)\\n\",\n \"\\n\",\n \"\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n },\n \"widgets\": {\n \"application/vnd.jupyter.widget-state+json\": {\n \"0dccd57dcc5c43a588157cef957c07e8\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"17a3174e65c54476b2e0d1faf8f011ca\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_90a79523187446dfa692723b2e5833a7\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_431ffb83b8c14bf182f0430e07ea6154\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \"model.safetensors: 35%\"\n }\n },\n \"1bbf2e62c0754d1593beb4105a7f1ac1\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"FloatProgressModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"FloatProgressModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"ProgressView\",\n \"bar_style\": \"\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_a8f1b72a33dd4b548de23fbd95e0da18\",\n \"max\": 2471645608,\n \"min\": 0,\n \"orientation\": \"horizontal\",\n \"style\": \"IPY_MODEL_25cc36132d384189acfbecc59483134b\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": 880803840\n }\n },\n \"25cc36132d384189acfbecc59483134b\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"ProgressStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"ProgressStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"bar_color\": null,\n \"description_width\": \"\"\n }\n },\n \"271e2bd6a35e4a8b92de8697f7c0be5f\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"3326b6141a1a4eba9f316df528a9b99a\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"33ca0cdf2c7f41598a381c4ebe6a4ee1\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"431ffb83b8c14bf182f0430e07ea6154\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"5176834aa8784bba9ec21234b87a8948\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"518fb202e4b44aaba47f07d1a61b6762\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_e2dc407afcd945c798e30597fddfcb3c\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_0dccd57dcc5c43a588157cef957c07e8\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \"tokenizer.model: 100%\"\n }\n },\n \"672cdc5aea954de3af851c001a667ad3\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"FloatProgressModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"FloatProgressModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"ProgressView\",\n \"bar_style\": \"success\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_33ca0cdf2c7f41598a381c4ebe6a4ee1\",\n \"max\": 2183982,\n \"min\": 0,\n \"orientation\": \"horizontal\",\n \"style\": \"IPY_MODEL_ee44487f58454dacb522b1e084ffb733\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": 2183982\n }\n },\n \"90a79523187446dfa692723b2e5833a7\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"9881b6995c3f49dc89e6992fd9ab660b\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HBoxModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HBoxModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HBoxView\",\n \"box_style\": \"\",\n \"children\": [\n \"IPY_MODEL_17a3174e65c54476b2e0d1faf8f011ca\",\n \"IPY_MODEL_1bbf2e62c0754d1593beb4105a7f1ac1\",\n \"IPY_MODEL_b82112e1dec645d98aa1c1ba64abcb61\"\n ],\n \"layout\": \"IPY_MODEL_271e2bd6a35e4a8b92de8697f7c0be5f\",\n \"tabbable\": null,\n \"tooltip\": null\n }\n },\n \"a1608feac06d4687967a3e398f01c489\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HBoxModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HBoxModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HBoxView\",\n \"box_style\": \"\",\n \"children\": [\n \"IPY_MODEL_518fb202e4b44aaba47f07d1a61b6762\",\n \"IPY_MODEL_672cdc5aea954de3af851c001a667ad3\",\n \"IPY_MODEL_eebf8874618746b39cf4a21a2728dc7f\"\n ],\n \"layout\": \"IPY_MODEL_5176834aa8784bba9ec21234b87a8948\",\n \"tabbable\": null,\n \"tooltip\": null\n }\n },\n \"a8f1b72a33dd4b548de23fbd95e0da18\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"b82112e1dec645d98aa1c1ba64abcb61\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_bfd06423ad544218968648016e731a46\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_d029630b63ff44cf807ade428d2eb421\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \" 870M/2.47G [00:20<00:37, 42.8MB/s]\"\n }\n },\n \"bfd06423ad544218968648016e731a46\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"d029630b63ff44cf807ade428d2eb421\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"d2c41e71a3f441deaed091b620ac5603\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"e2dc407afcd945c798e30597fddfcb3c\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"ee44487f58454dacb522b1e084ffb733\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"ProgressStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"ProgressStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"bar_color\": null,\n \"description_width\": \"\"\n }\n },\n \"eebf8874618746b39cf4a21a2728dc7f\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_d2c41e71a3f441deaed091b620ac5603\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_3326b6141a1a4eba9f316df528a9b99a\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \" 2.18M/2.18M [00:00<00:00, 9.47MB/s]\"\n }\n }\n }\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/07_gpt_to_llama/tests/test-requirements-extra.txt",
"content": "pytest>=8.1.1\ntransformers>=4.44.2\n"
},
{
"path": "ch05/07_gpt_to_llama/tests/test_llama32_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n mod = import_definitions_from_notebook(nb_dir, \"standalone-llama32.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8)) # batch size 1, seq length 8\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"emb_dim\": 32, # hidden_size\n \"hidden_dim\": 64, # intermediate_size (FFN)\n \"n_layers\": 2,\n \"n_heads\": 4,\n \"head_dim\": 8,\n \"n_kv_groups\": 1,\n \"dtype\": torch.float32,\n \"rope_base\": 500_000.0,\n \"rope_freq\": {\n \"factor\": 8.0,\n \"low_freq_factor\": 1.0,\n \"high_freq_factor\": 4.0,\n \"original_context_length\": 8192,\n },\n \"context_length\": 64,\n }\n\n\n@torch.inference_mode()\ndef test_dummy_llama3_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.Llama3Model(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"])\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_llama3_base_equivalence_with_transformers(import_notebook_defs):\n from transformers.models.llama import LlamaConfig, LlamaForCausalLM\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8192,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"n_kv_groups\": 2,\n \"rope_base\": 500_000.0,\n \"rope_freq\": {\n \"factor\": 32.0,\n \"low_freq_factor\": 1.0,\n \"high_freq_factor\": 4.0,\n \"original_context_length\": 8192,\n },\n \"dtype\": torch.float32,\n }\n\n ours = import_notebook_defs.Llama3Model(cfg)\n\n hf_cfg = LlamaConfig(\n vocab_size=cfg[\"vocab_size\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_key_value_heads=cfg[\"n_kv_groups\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n max_position_embeddings=cfg[\"context_length\"],\n rms_norm_eps=1e-5,\n attention_bias=False,\n rope_theta=cfg[\"rope_base\"],\n tie_word_embeddings=False,\n attn_implementation=\"eager\",\n torch_dtype=torch.float32,\n rope_scaling={\n \"type\": \"llama3\",\n \"factor\": cfg[\"rope_freq\"][\"factor\"],\n \"low_freq_factor\": cfg[\"rope_freq\"][\"low_freq_factor\"],\n \"high_freq_factor\": cfg[\"rope_freq\"][\"high_freq_factor\"],\n \"original_max_position_embeddings\": cfg[\"rope_freq\"][\"original_context_length\"],\n },\n )\n theirs = LlamaForCausalLM(hf_cfg)\n\n hf_state = theirs.state_dict()\n import_notebook_defs.load_weights_into_llama(ours, {\"n_layers\": cfg[\"n_layers\"], \"hidden_dim\": cfg[\"hidden_dim\"]}, hf_state)\n\n x = torch.randint(0, cfg[\"vocab_size\"], (2, 8), dtype=torch.long)\n ours_logits = ours(x)\n theirs_logits = theirs(x).logits.to(ours_logits.dtype)\n\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/07_gpt_to_llama/tests/tests_rope_and_parts.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# File for internal use (unit tests)\n\nimport io\nimport os\nimport sys\nimport types\nimport nbformat\nfrom packaging import version\nfrom typing import Optional, Tuple\nimport torch\nimport pytest\nimport transformers\nfrom transformers.models.llama.modeling_llama import LlamaRotaryEmbedding, apply_rotary_pos_emb\n\n\ntransformers_version = transformers.__version__\n\n# LitGPT code function `litgpt_build_rope_cache` from https://github.com/Lightning-AI/litgpt/blob/main/litgpt/model.py\n# LitGPT is licensed under Apache v2: https://github.com/Lightning-AI/litgpt/blob/main/LICENSE\n\n\ndef litgpt_build_rope_cache(\n seq_len: int,\n n_elem: int,\n device: Optional[torch.device] = None,\n base: int = 10000,\n condense_ratio: int = 1,\n extra_config: Optional[dict] = None,\n) -> Tuple[torch.Tensor, torch.Tensor]:\n \"\"\"\n Enhanced Transformer with Rotary Position Embedding.\n\n Args:\n seq_len (int): Sequence length.\n n_elem (int): Number of elements (head dimension).\n device (torch.device, optional): Device for tensor allocations.\n base (int, optional): Base for computing inverse frequencies.\n condense_ratio (int, optional): Ratio to condense the position indices.\n extra_config (dict, optional): Configuration parameters for frequency adjustments (used by Llama 3.1 and 3.2)\n\n Returns:\n Tuple[torch.Tensor, torch.Tensor]: Cosine and sine caches for RoPE.\n \"\"\"\n\n # Compute the inverse frequencies theta\n theta = 1.0 / (base ** (torch.arange(0, n_elem, 2, device=device).float() / n_elem))\n\n if extra_config is not None:\n orig_context_len = extra_config[\"original_max_seq_len\"]\n factor = extra_config[\"factor\"]\n low_freq_factor = extra_config[\"low_freq_factor\"]\n high_freq_factor = extra_config[\"high_freq_factor\"]\n\n wavelen = 2 * torch.pi / theta\n ratio = orig_context_len / wavelen\n smooth_factor = (ratio - low_freq_factor) / (high_freq_factor - low_freq_factor)\n smooth_factor = torch.clamp(smooth_factor, min=0.0, max=1.0)\n\n # Compute adjusted_theta without masked indexing\n adjusted_theta = (1 - smooth_factor) * (theta / factor) + smooth_factor * theta\n theta = adjusted_theta\n\n # Create position indices `[0, 1, ..., seq_len - 1]`\n seq_idx = torch.arange(seq_len, device=device) / condense_ratio\n\n # Calculate the product of position index and $\\theta_i$\n idx_theta = torch.outer(seq_idx, theta).repeat(1, 2)\n\n return torch.cos(idx_theta), torch.sin(idx_theta)\n\n\n# LitGPT code from https://github.com/Lightning-AI/litgpt/blob/main/litgpt/model.py\n# LitGPT is licensed under Apache v2: https://github.com/Lightning-AI/litgpt/blob/main/LICENSE\ndef litgpt_apply_rope(x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor) -> torch.Tensor:\n head_size = x.size(-1)\n x1 = x[..., : head_size // 2] # (B, nh, T, hs/2)\n x2 = x[..., head_size // 2:] # (B, nh, T, hs/2)\n rotated = torch.cat((-x2, x1), dim=-1) # (B, nh, T, hs)\n if cos.dim() > 1:\n # batch dimensions must align\n # sin/cos are (B, T, hs) so we unsqeeze -3 for nh\n # we count from back because all of apply_rope does\n cos = cos.unsqueeze(-3)\n sin = sin.unsqueeze(-3)\n\n roped = (x * cos) + (rotated * sin)\n return roped.to(dtype=x.dtype)\n\n\n@pytest.fixture(scope=\"module\")\ndef notebook():\n def import_definitions_from_notebook(notebooks):\n imported_modules = {}\n\n for fullname, names in notebooks.items():\n # Get the directory of the current test file\n current_dir = os.path.dirname(__file__)\n path = os.path.join(current_dir, \"..\", fullname + \".ipynb\")\n path = os.path.normpath(path)\n\n # Load the notebook\n if not os.path.exists(path):\n raise FileNotFoundError(f\"Notebook file not found at: {path}\")\n\n with io.open(path, \"r\", encoding=\"utf-8\") as f:\n nb = nbformat.read(f, as_version=4)\n\n # Create a module to store the imported functions and classes\n mod = types.ModuleType(fullname)\n sys.modules[fullname] = mod\n\n # Go through the notebook cells and only execute function or class definitions\n for cell in nb.cells:\n if cell.cell_type == \"code\":\n cell_code = cell.source\n for name in names:\n # Check for function or class definitions\n if f\"def {name}\" in cell_code or f\"class {name}\" in cell_code:\n exec(cell_code, mod.__dict__)\n\n imported_modules[fullname] = mod\n\n return imported_modules\n\n notebooks = {\n \"converting-gpt-to-llama2\": [\"SiLU\", \"RMSNorm\", \"precompute_rope_params\", \"compute_rope\"],\n \"converting-llama2-to-llama3\": [\"precompute_rope_params\"]\n }\n\n return import_definitions_from_notebook(notebooks)\n\n\n@pytest.fixture(autouse=True)\ndef set_seed():\n torch.manual_seed(123)\n\n\ndef test_rope_llama2(notebook):\n\n this_nb = notebook[\"converting-gpt-to-llama2\"]\n\n # Settings\n batch_size = 1\n context_len = 4096\n num_heads = 4\n head_dim = 16\n theta_base = 10_000\n\n # Instantiate RoPE parameters\n cos, sin = this_nb.precompute_rope_params(head_dim=head_dim, context_length=context_len)\n\n # Dummy query and key tensors\n queries = torch.randn(batch_size, num_heads, context_len, head_dim)\n keys = torch.randn(batch_size, num_heads, context_len, head_dim)\n\n # Apply rotary position embeddings\n queries_rot = this_nb.compute_rope(queries, cos, sin)\n keys_rot = this_nb.compute_rope(keys, cos, sin)\n\n # Generate reference RoPE via HF\n\n if version.parse(transformers_version) < version.parse(\"4.48\"):\n rot_emb = LlamaRotaryEmbedding(\n dim=head_dim,\n max_position_embeddings=context_len,\n base=theta_base\n )\n else:\n class RoPEConfig:\n dim: int = head_dim\n rope_theta = theta_base\n max_position_embeddings: int = 8192\n hidden_size = head_dim * num_heads\n num_attention_heads = num_heads\n rope_parameters = {\"rope_type\": \"default\", \"rope_theta\": theta_base}\n\n def standardize_rope_params(self):\n return\n\n config = RoPEConfig()\n rot_emb = LlamaRotaryEmbedding(config=config)\n\n position_ids = torch.arange(context_len, dtype=torch.long).unsqueeze(0)\n ref_cos, ref_sin = rot_emb(queries, position_ids)\n ref_queries_rot, ref_keys_rot = apply_rotary_pos_emb(queries, keys, ref_cos, ref_sin)\n torch.testing.assert_close(sin, ref_sin.squeeze(0))\n torch.testing.assert_close(cos, ref_cos.squeeze(0))\n torch.testing.assert_close(keys_rot, ref_keys_rot)\n torch.testing.assert_close(queries_rot, ref_queries_rot)\n\n # Generate reference RoPE via LitGPT\n litgpt_cos, litgpt_sin = litgpt_build_rope_cache(context_len, n_elem=head_dim, base=10_000)\n litgpt_queries_rot = litgpt_apply_rope(queries, litgpt_cos, litgpt_sin)\n litgpt_keys_rot = litgpt_apply_rope(keys, litgpt_cos, litgpt_sin)\n\n torch.testing.assert_close(sin, litgpt_sin)\n torch.testing.assert_close(cos, litgpt_cos)\n torch.testing.assert_close(keys_rot, litgpt_keys_rot)\n torch.testing.assert_close(queries_rot, litgpt_queries_rot)\n\n\ndef test_rope_llama3(notebook):\n\n nb1 = notebook[\"converting-gpt-to-llama2\"]\n nb2 = notebook[\"converting-llama2-to-llama3\"]\n\n # Settings\n batch_size = 1\n context_len = 8192\n num_heads = 4\n head_dim = 16\n theta_base = 500_000\n\n # Instantiate RoPE parameters\n cos, sin = nb2.precompute_rope_params(\n head_dim=head_dim,\n context_length=context_len,\n theta_base=theta_base\n )\n\n # Dummy query and key tensors\n torch.manual_seed(123)\n queries = torch.randn(batch_size, num_heads, context_len, head_dim)\n keys = torch.randn(batch_size, num_heads, context_len, head_dim)\n\n # Apply rotary position embeddings\n queries_rot = nb1.compute_rope(queries, cos, sin)\n keys_rot = nb1.compute_rope(keys, cos, sin)\n\n # Generate reference RoPE via HF\n if version.parse(transformers_version) < version.parse(\"4.48\"):\n rot_emb = LlamaRotaryEmbedding(\n dim=head_dim,\n max_position_embeddings=context_len,\n base=theta_base\n )\n else:\n class RoPEConfig:\n dim: int = head_dim\n rope_theta = theta_base\n max_position_embeddings: int = 8192\n hidden_size = head_dim * num_heads\n num_attention_heads = num_heads\n rope_parameters = {\"rope_type\": \"default\", \"rope_theta\": theta_base}\n\n def standardize_rope_params(self):\n return\n\n config = RoPEConfig()\n rot_emb = LlamaRotaryEmbedding(config=config)\n\n position_ids = torch.arange(context_len, dtype=torch.long).unsqueeze(0)\n ref_cos, ref_sin = rot_emb(queries, position_ids)\n ref_queries_rot, ref_keys_rot = apply_rotary_pos_emb(queries, keys, ref_cos, ref_sin)\n\n torch.testing.assert_close(sin, ref_sin.squeeze(0))\n torch.testing.assert_close(cos, ref_cos.squeeze(0))\n torch.testing.assert_close(keys_rot, ref_keys_rot)\n torch.testing.assert_close(queries_rot, ref_queries_rot)\n\n # Generate reference RoPE via LitGPT\n litgpt_cos, litgpt_sin = litgpt_build_rope_cache(context_len, n_elem=head_dim, base=theta_base)\n litgpt_queries_rot = litgpt_apply_rope(queries, litgpt_cos, litgpt_sin)\n litgpt_keys_rot = litgpt_apply_rope(keys, litgpt_cos, litgpt_sin)\n\n torch.testing.assert_close(sin, litgpt_sin)\n torch.testing.assert_close(cos, litgpt_cos)\n torch.testing.assert_close(keys_rot, litgpt_keys_rot)\n torch.testing.assert_close(queries_rot, litgpt_queries_rot)\n\n\ndef test_rope_llama3_12(notebook):\n\n nb1 = notebook[\"converting-gpt-to-llama2\"]\n nb2 = notebook[\"converting-llama2-to-llama3\"]\n\n # Settings\n batch_size = 1\n context_len = 8192\n num_heads = 4\n head_dim = 16\n rope_theta = 500_000\n\n rope_config = {\n \"factor\": 8.0,\n \"low_freq_factor\": 1.0,\n \"high_freq_factor\": 4.0,\n \"original_context_length\": 8192,\n }\n\n # Instantiate RoPE parameters\n cos, sin = nb2.precompute_rope_params(\n head_dim=head_dim,\n theta_base=rope_theta,\n context_length=context_len,\n freq_config=rope_config,\n )\n\n # Dummy query and key tensors\n torch.manual_seed(123)\n queries = torch.randn(batch_size, num_heads, context_len, head_dim)\n keys = torch.randn(batch_size, num_heads, context_len, head_dim)\n\n # Apply rotary position embeddings\n queries_rot = nb1.compute_rope(queries, cos, sin)\n keys_rot = nb1.compute_rope(keys, cos, sin)\n\n # Generate reference RoPE via HF\n hf_rope_params = {\n \"factor\": 8.0,\n \"low_freq_factor\": 1.0,\n \"high_freq_factor\": 4.0,\n \"original_max_position_embeddings\": 8192,\n \"rope_type\": \"llama3\"\n }\n\n class RoPEConfig:\n rope_type = \"llama3\"\n rope_scaling = hf_rope_params\n factor = 1.0\n dim: int = head_dim\n rope_theta = 500_000\n max_position_embeddings: int = 8192\n hidden_size = head_dim * num_heads\n num_attention_heads = num_heads\n rope_parameters = {**hf_rope_params, \"rope_theta\": rope_theta}\n\n def standardize_rope_params(self):\n return\n\n config = RoPEConfig()\n\n rot_emb = LlamaRotaryEmbedding(config=config)\n position_ids = torch.arange(context_len, dtype=torch.long).unsqueeze(0)\n ref_cos, ref_sin = rot_emb(queries, position_ids)\n ref_queries_rot, ref_keys_rot = apply_rotary_pos_emb(queries, keys, ref_cos, ref_sin)\n\n torch.testing.assert_close(sin, ref_sin.squeeze(0))\n torch.testing.assert_close(cos, ref_cos.squeeze(0))\n torch.testing.assert_close(keys_rot, ref_keys_rot)\n torch.testing.assert_close(queries_rot, ref_queries_rot)\n\n # Generate reference RoPE via LitGPT\n litgpt_rope_config = {\n \"factor\": 8.0,\n \"low_freq_factor\": 1.0,\n \"high_freq_factor\": 4.0,\n \"original_max_seq_len\": 8192\n }\n\n litgpt_cos, litgpt_sin = litgpt_build_rope_cache(\n context_len,\n n_elem=head_dim,\n base=rope_theta,\n extra_config=litgpt_rope_config\n )\n litgpt_queries_rot = litgpt_apply_rope(queries, litgpt_cos, litgpt_sin)\n litgpt_keys_rot = litgpt_apply_rope(keys, litgpt_cos, litgpt_sin)\n\n torch.testing.assert_close(sin, litgpt_sin)\n torch.testing.assert_close(cos, litgpt_cos)\n torch.testing.assert_close(keys_rot, litgpt_keys_rot)\n torch.testing.assert_close(queries_rot, litgpt_queries_rot)\n\n\ndef test_silu(notebook):\n example_batch = torch.randn(2, 3, 4)\n silu = notebook[\"converting-gpt-to-llama2\"].SiLU()\n assert torch.allclose(silu(example_batch), torch.nn.functional.silu(example_batch))\n\n\n@pytest.mark.skipif(torch.__version__ < \"2.4\", reason=\"Requires PyTorch 2.4 or newer\")\ndef test_rmsnorm(notebook):\n example_batch = torch.randn(2, 3, 4)\n rms_norm = notebook[\"converting-gpt-to-llama2\"].RMSNorm(emb_dim=example_batch.shape[-1], eps=1e-5)\n rmsnorm_pytorch = torch.nn.RMSNorm(example_batch.shape[-1], eps=1e-5)\n\n assert torch.allclose(rms_norm(example_batch), rmsnorm_pytorch(example_batch))\n"
},
{
"path": "ch05/08_memory_efficient_weight_loading/README.md",
"content": "# Memory-efficient Model Weight Loading\n\nThis folder contains code to illustrate how to load model weights more efficiently\n\n- [memory-efficient-state-dict.ipynb](memory-efficient-state-dict.ipynb): contains code to load model weights via PyTorch's `load_state_dict` method more efficiently\n"
},
{
"path": "ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"1E_HhLEeYqFG\"\n },\n \"source\": [\n \"
\\n\",\n \"\\n\",\n \" 1. [Converting a From-Scratch GPT Architecture to Llama 2](converting-gpt-to-llama2.ipynb)\\n\",\n \" 2. [Converting Llama 2 to Llama 3.2 From Scratch](converting-llama2-to-llama3.ipynb)\\n\",\n \" \\n\",\n \"- For those interested in a comprehensive guide on building a large language model from scratch and gaining a deeper understanding of its mechanics, you might like my [Build a Large Language Model (From Scratch)](http://mng.bz/orYv)\\n\",\n \"\\n\",\n \"\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n },\n \"widgets\": {\n \"application/vnd.jupyter.widget-state+json\": {\n \"0dccd57dcc5c43a588157cef957c07e8\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"17a3174e65c54476b2e0d1faf8f011ca\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_90a79523187446dfa692723b2e5833a7\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_431ffb83b8c14bf182f0430e07ea6154\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \"model.safetensors: 35%\"\n }\n },\n \"1bbf2e62c0754d1593beb4105a7f1ac1\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"FloatProgressModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"FloatProgressModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"ProgressView\",\n \"bar_style\": \"\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_a8f1b72a33dd4b548de23fbd95e0da18\",\n \"max\": 2471645608,\n \"min\": 0,\n \"orientation\": \"horizontal\",\n \"style\": \"IPY_MODEL_25cc36132d384189acfbecc59483134b\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": 880803840\n }\n },\n \"25cc36132d384189acfbecc59483134b\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"ProgressStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"ProgressStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"bar_color\": null,\n \"description_width\": \"\"\n }\n },\n \"271e2bd6a35e4a8b92de8697f7c0be5f\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"3326b6141a1a4eba9f316df528a9b99a\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"33ca0cdf2c7f41598a381c4ebe6a4ee1\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"431ffb83b8c14bf182f0430e07ea6154\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"5176834aa8784bba9ec21234b87a8948\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"518fb202e4b44aaba47f07d1a61b6762\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_e2dc407afcd945c798e30597fddfcb3c\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_0dccd57dcc5c43a588157cef957c07e8\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \"tokenizer.model: 100%\"\n }\n },\n \"672cdc5aea954de3af851c001a667ad3\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"FloatProgressModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"FloatProgressModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"ProgressView\",\n \"bar_style\": \"success\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_33ca0cdf2c7f41598a381c4ebe6a4ee1\",\n \"max\": 2183982,\n \"min\": 0,\n \"orientation\": \"horizontal\",\n \"style\": \"IPY_MODEL_ee44487f58454dacb522b1e084ffb733\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": 2183982\n }\n },\n \"90a79523187446dfa692723b2e5833a7\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"9881b6995c3f49dc89e6992fd9ab660b\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HBoxModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HBoxModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HBoxView\",\n \"box_style\": \"\",\n \"children\": [\n \"IPY_MODEL_17a3174e65c54476b2e0d1faf8f011ca\",\n \"IPY_MODEL_1bbf2e62c0754d1593beb4105a7f1ac1\",\n \"IPY_MODEL_b82112e1dec645d98aa1c1ba64abcb61\"\n ],\n \"layout\": \"IPY_MODEL_271e2bd6a35e4a8b92de8697f7c0be5f\",\n \"tabbable\": null,\n \"tooltip\": null\n }\n },\n \"a1608feac06d4687967a3e398f01c489\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HBoxModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HBoxModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HBoxView\",\n \"box_style\": \"\",\n \"children\": [\n \"IPY_MODEL_518fb202e4b44aaba47f07d1a61b6762\",\n \"IPY_MODEL_672cdc5aea954de3af851c001a667ad3\",\n \"IPY_MODEL_eebf8874618746b39cf4a21a2728dc7f\"\n ],\n \"layout\": \"IPY_MODEL_5176834aa8784bba9ec21234b87a8948\",\n \"tabbable\": null,\n \"tooltip\": null\n }\n },\n \"a8f1b72a33dd4b548de23fbd95e0da18\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"b82112e1dec645d98aa1c1ba64abcb61\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_bfd06423ad544218968648016e731a46\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_d029630b63ff44cf807ade428d2eb421\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \" 870M/2.47G [00:20<00:37, 42.8MB/s]\"\n }\n },\n \"bfd06423ad544218968648016e731a46\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"d029630b63ff44cf807ade428d2eb421\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"d2c41e71a3f441deaed091b620ac5603\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"e2dc407afcd945c798e30597fddfcb3c\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"ee44487f58454dacb522b1e084ffb733\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"ProgressStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"ProgressStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"bar_color\": null,\n \"description_width\": \"\"\n }\n },\n \"eebf8874618746b39cf4a21a2728dc7f\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_d2c41e71a3f441deaed091b620ac5603\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_3326b6141a1a4eba9f316df528a9b99a\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \" 2.18M/2.18M [00:00<00:00, 9.47MB/s]\"\n }\n }\n }\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/07_gpt_to_llama/tests/test-requirements-extra.txt",
"content": "pytest>=8.1.1\ntransformers>=4.44.2\n"
},
{
"path": "ch05/07_gpt_to_llama/tests/test_llama32_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n mod = import_definitions_from_notebook(nb_dir, \"standalone-llama32.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8)) # batch size 1, seq length 8\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"emb_dim\": 32, # hidden_size\n \"hidden_dim\": 64, # intermediate_size (FFN)\n \"n_layers\": 2,\n \"n_heads\": 4,\n \"head_dim\": 8,\n \"n_kv_groups\": 1,\n \"dtype\": torch.float32,\n \"rope_base\": 500_000.0,\n \"rope_freq\": {\n \"factor\": 8.0,\n \"low_freq_factor\": 1.0,\n \"high_freq_factor\": 4.0,\n \"original_context_length\": 8192,\n },\n \"context_length\": 64,\n }\n\n\n@torch.inference_mode()\ndef test_dummy_llama3_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.Llama3Model(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"])\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_llama3_base_equivalence_with_transformers(import_notebook_defs):\n from transformers.models.llama import LlamaConfig, LlamaForCausalLM\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8192,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"n_kv_groups\": 2,\n \"rope_base\": 500_000.0,\n \"rope_freq\": {\n \"factor\": 32.0,\n \"low_freq_factor\": 1.0,\n \"high_freq_factor\": 4.0,\n \"original_context_length\": 8192,\n },\n \"dtype\": torch.float32,\n }\n\n ours = import_notebook_defs.Llama3Model(cfg)\n\n hf_cfg = LlamaConfig(\n vocab_size=cfg[\"vocab_size\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_key_value_heads=cfg[\"n_kv_groups\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n max_position_embeddings=cfg[\"context_length\"],\n rms_norm_eps=1e-5,\n attention_bias=False,\n rope_theta=cfg[\"rope_base\"],\n tie_word_embeddings=False,\n attn_implementation=\"eager\",\n torch_dtype=torch.float32,\n rope_scaling={\n \"type\": \"llama3\",\n \"factor\": cfg[\"rope_freq\"][\"factor\"],\n \"low_freq_factor\": cfg[\"rope_freq\"][\"low_freq_factor\"],\n \"high_freq_factor\": cfg[\"rope_freq\"][\"high_freq_factor\"],\n \"original_max_position_embeddings\": cfg[\"rope_freq\"][\"original_context_length\"],\n },\n )\n theirs = LlamaForCausalLM(hf_cfg)\n\n hf_state = theirs.state_dict()\n import_notebook_defs.load_weights_into_llama(ours, {\"n_layers\": cfg[\"n_layers\"], \"hidden_dim\": cfg[\"hidden_dim\"]}, hf_state)\n\n x = torch.randint(0, cfg[\"vocab_size\"], (2, 8), dtype=torch.long)\n ours_logits = ours(x)\n theirs_logits = theirs(x).logits.to(ours_logits.dtype)\n\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/07_gpt_to_llama/tests/tests_rope_and_parts.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n# File for internal use (unit tests)\n\nimport io\nimport os\nimport sys\nimport types\nimport nbformat\nfrom packaging import version\nfrom typing import Optional, Tuple\nimport torch\nimport pytest\nimport transformers\nfrom transformers.models.llama.modeling_llama import LlamaRotaryEmbedding, apply_rotary_pos_emb\n\n\ntransformers_version = transformers.__version__\n\n# LitGPT code function `litgpt_build_rope_cache` from https://github.com/Lightning-AI/litgpt/blob/main/litgpt/model.py\n# LitGPT is licensed under Apache v2: https://github.com/Lightning-AI/litgpt/blob/main/LICENSE\n\n\ndef litgpt_build_rope_cache(\n seq_len: int,\n n_elem: int,\n device: Optional[torch.device] = None,\n base: int = 10000,\n condense_ratio: int = 1,\n extra_config: Optional[dict] = None,\n) -> Tuple[torch.Tensor, torch.Tensor]:\n \"\"\"\n Enhanced Transformer with Rotary Position Embedding.\n\n Args:\n seq_len (int): Sequence length.\n n_elem (int): Number of elements (head dimension).\n device (torch.device, optional): Device for tensor allocations.\n base (int, optional): Base for computing inverse frequencies.\n condense_ratio (int, optional): Ratio to condense the position indices.\n extra_config (dict, optional): Configuration parameters for frequency adjustments (used by Llama 3.1 and 3.2)\n\n Returns:\n Tuple[torch.Tensor, torch.Tensor]: Cosine and sine caches for RoPE.\n \"\"\"\n\n # Compute the inverse frequencies theta\n theta = 1.0 / (base ** (torch.arange(0, n_elem, 2, device=device).float() / n_elem))\n\n if extra_config is not None:\n orig_context_len = extra_config[\"original_max_seq_len\"]\n factor = extra_config[\"factor\"]\n low_freq_factor = extra_config[\"low_freq_factor\"]\n high_freq_factor = extra_config[\"high_freq_factor\"]\n\n wavelen = 2 * torch.pi / theta\n ratio = orig_context_len / wavelen\n smooth_factor = (ratio - low_freq_factor) / (high_freq_factor - low_freq_factor)\n smooth_factor = torch.clamp(smooth_factor, min=0.0, max=1.0)\n\n # Compute adjusted_theta without masked indexing\n adjusted_theta = (1 - smooth_factor) * (theta / factor) + smooth_factor * theta\n theta = adjusted_theta\n\n # Create position indices `[0, 1, ..., seq_len - 1]`\n seq_idx = torch.arange(seq_len, device=device) / condense_ratio\n\n # Calculate the product of position index and $\\theta_i$\n idx_theta = torch.outer(seq_idx, theta).repeat(1, 2)\n\n return torch.cos(idx_theta), torch.sin(idx_theta)\n\n\n# LitGPT code from https://github.com/Lightning-AI/litgpt/blob/main/litgpt/model.py\n# LitGPT is licensed under Apache v2: https://github.com/Lightning-AI/litgpt/blob/main/LICENSE\ndef litgpt_apply_rope(x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor) -> torch.Tensor:\n head_size = x.size(-1)\n x1 = x[..., : head_size // 2] # (B, nh, T, hs/2)\n x2 = x[..., head_size // 2:] # (B, nh, T, hs/2)\n rotated = torch.cat((-x2, x1), dim=-1) # (B, nh, T, hs)\n if cos.dim() > 1:\n # batch dimensions must align\n # sin/cos are (B, T, hs) so we unsqeeze -3 for nh\n # we count from back because all of apply_rope does\n cos = cos.unsqueeze(-3)\n sin = sin.unsqueeze(-3)\n\n roped = (x * cos) + (rotated * sin)\n return roped.to(dtype=x.dtype)\n\n\n@pytest.fixture(scope=\"module\")\ndef notebook():\n def import_definitions_from_notebook(notebooks):\n imported_modules = {}\n\n for fullname, names in notebooks.items():\n # Get the directory of the current test file\n current_dir = os.path.dirname(__file__)\n path = os.path.join(current_dir, \"..\", fullname + \".ipynb\")\n path = os.path.normpath(path)\n\n # Load the notebook\n if not os.path.exists(path):\n raise FileNotFoundError(f\"Notebook file not found at: {path}\")\n\n with io.open(path, \"r\", encoding=\"utf-8\") as f:\n nb = nbformat.read(f, as_version=4)\n\n # Create a module to store the imported functions and classes\n mod = types.ModuleType(fullname)\n sys.modules[fullname] = mod\n\n # Go through the notebook cells and only execute function or class definitions\n for cell in nb.cells:\n if cell.cell_type == \"code\":\n cell_code = cell.source\n for name in names:\n # Check for function or class definitions\n if f\"def {name}\" in cell_code or f\"class {name}\" in cell_code:\n exec(cell_code, mod.__dict__)\n\n imported_modules[fullname] = mod\n\n return imported_modules\n\n notebooks = {\n \"converting-gpt-to-llama2\": [\"SiLU\", \"RMSNorm\", \"precompute_rope_params\", \"compute_rope\"],\n \"converting-llama2-to-llama3\": [\"precompute_rope_params\"]\n }\n\n return import_definitions_from_notebook(notebooks)\n\n\n@pytest.fixture(autouse=True)\ndef set_seed():\n torch.manual_seed(123)\n\n\ndef test_rope_llama2(notebook):\n\n this_nb = notebook[\"converting-gpt-to-llama2\"]\n\n # Settings\n batch_size = 1\n context_len = 4096\n num_heads = 4\n head_dim = 16\n theta_base = 10_000\n\n # Instantiate RoPE parameters\n cos, sin = this_nb.precompute_rope_params(head_dim=head_dim, context_length=context_len)\n\n # Dummy query and key tensors\n queries = torch.randn(batch_size, num_heads, context_len, head_dim)\n keys = torch.randn(batch_size, num_heads, context_len, head_dim)\n\n # Apply rotary position embeddings\n queries_rot = this_nb.compute_rope(queries, cos, sin)\n keys_rot = this_nb.compute_rope(keys, cos, sin)\n\n # Generate reference RoPE via HF\n\n if version.parse(transformers_version) < version.parse(\"4.48\"):\n rot_emb = LlamaRotaryEmbedding(\n dim=head_dim,\n max_position_embeddings=context_len,\n base=theta_base\n )\n else:\n class RoPEConfig:\n dim: int = head_dim\n rope_theta = theta_base\n max_position_embeddings: int = 8192\n hidden_size = head_dim * num_heads\n num_attention_heads = num_heads\n rope_parameters = {\"rope_type\": \"default\", \"rope_theta\": theta_base}\n\n def standardize_rope_params(self):\n return\n\n config = RoPEConfig()\n rot_emb = LlamaRotaryEmbedding(config=config)\n\n position_ids = torch.arange(context_len, dtype=torch.long).unsqueeze(0)\n ref_cos, ref_sin = rot_emb(queries, position_ids)\n ref_queries_rot, ref_keys_rot = apply_rotary_pos_emb(queries, keys, ref_cos, ref_sin)\n torch.testing.assert_close(sin, ref_sin.squeeze(0))\n torch.testing.assert_close(cos, ref_cos.squeeze(0))\n torch.testing.assert_close(keys_rot, ref_keys_rot)\n torch.testing.assert_close(queries_rot, ref_queries_rot)\n\n # Generate reference RoPE via LitGPT\n litgpt_cos, litgpt_sin = litgpt_build_rope_cache(context_len, n_elem=head_dim, base=10_000)\n litgpt_queries_rot = litgpt_apply_rope(queries, litgpt_cos, litgpt_sin)\n litgpt_keys_rot = litgpt_apply_rope(keys, litgpt_cos, litgpt_sin)\n\n torch.testing.assert_close(sin, litgpt_sin)\n torch.testing.assert_close(cos, litgpt_cos)\n torch.testing.assert_close(keys_rot, litgpt_keys_rot)\n torch.testing.assert_close(queries_rot, litgpt_queries_rot)\n\n\ndef test_rope_llama3(notebook):\n\n nb1 = notebook[\"converting-gpt-to-llama2\"]\n nb2 = notebook[\"converting-llama2-to-llama3\"]\n\n # Settings\n batch_size = 1\n context_len = 8192\n num_heads = 4\n head_dim = 16\n theta_base = 500_000\n\n # Instantiate RoPE parameters\n cos, sin = nb2.precompute_rope_params(\n head_dim=head_dim,\n context_length=context_len,\n theta_base=theta_base\n )\n\n # Dummy query and key tensors\n torch.manual_seed(123)\n queries = torch.randn(batch_size, num_heads, context_len, head_dim)\n keys = torch.randn(batch_size, num_heads, context_len, head_dim)\n\n # Apply rotary position embeddings\n queries_rot = nb1.compute_rope(queries, cos, sin)\n keys_rot = nb1.compute_rope(keys, cos, sin)\n\n # Generate reference RoPE via HF\n if version.parse(transformers_version) < version.parse(\"4.48\"):\n rot_emb = LlamaRotaryEmbedding(\n dim=head_dim,\n max_position_embeddings=context_len,\n base=theta_base\n )\n else:\n class RoPEConfig:\n dim: int = head_dim\n rope_theta = theta_base\n max_position_embeddings: int = 8192\n hidden_size = head_dim * num_heads\n num_attention_heads = num_heads\n rope_parameters = {\"rope_type\": \"default\", \"rope_theta\": theta_base}\n\n def standardize_rope_params(self):\n return\n\n config = RoPEConfig()\n rot_emb = LlamaRotaryEmbedding(config=config)\n\n position_ids = torch.arange(context_len, dtype=torch.long).unsqueeze(0)\n ref_cos, ref_sin = rot_emb(queries, position_ids)\n ref_queries_rot, ref_keys_rot = apply_rotary_pos_emb(queries, keys, ref_cos, ref_sin)\n\n torch.testing.assert_close(sin, ref_sin.squeeze(0))\n torch.testing.assert_close(cos, ref_cos.squeeze(0))\n torch.testing.assert_close(keys_rot, ref_keys_rot)\n torch.testing.assert_close(queries_rot, ref_queries_rot)\n\n # Generate reference RoPE via LitGPT\n litgpt_cos, litgpt_sin = litgpt_build_rope_cache(context_len, n_elem=head_dim, base=theta_base)\n litgpt_queries_rot = litgpt_apply_rope(queries, litgpt_cos, litgpt_sin)\n litgpt_keys_rot = litgpt_apply_rope(keys, litgpt_cos, litgpt_sin)\n\n torch.testing.assert_close(sin, litgpt_sin)\n torch.testing.assert_close(cos, litgpt_cos)\n torch.testing.assert_close(keys_rot, litgpt_keys_rot)\n torch.testing.assert_close(queries_rot, litgpt_queries_rot)\n\n\ndef test_rope_llama3_12(notebook):\n\n nb1 = notebook[\"converting-gpt-to-llama2\"]\n nb2 = notebook[\"converting-llama2-to-llama3\"]\n\n # Settings\n batch_size = 1\n context_len = 8192\n num_heads = 4\n head_dim = 16\n rope_theta = 500_000\n\n rope_config = {\n \"factor\": 8.0,\n \"low_freq_factor\": 1.0,\n \"high_freq_factor\": 4.0,\n \"original_context_length\": 8192,\n }\n\n # Instantiate RoPE parameters\n cos, sin = nb2.precompute_rope_params(\n head_dim=head_dim,\n theta_base=rope_theta,\n context_length=context_len,\n freq_config=rope_config,\n )\n\n # Dummy query and key tensors\n torch.manual_seed(123)\n queries = torch.randn(batch_size, num_heads, context_len, head_dim)\n keys = torch.randn(batch_size, num_heads, context_len, head_dim)\n\n # Apply rotary position embeddings\n queries_rot = nb1.compute_rope(queries, cos, sin)\n keys_rot = nb1.compute_rope(keys, cos, sin)\n\n # Generate reference RoPE via HF\n hf_rope_params = {\n \"factor\": 8.0,\n \"low_freq_factor\": 1.0,\n \"high_freq_factor\": 4.0,\n \"original_max_position_embeddings\": 8192,\n \"rope_type\": \"llama3\"\n }\n\n class RoPEConfig:\n rope_type = \"llama3\"\n rope_scaling = hf_rope_params\n factor = 1.0\n dim: int = head_dim\n rope_theta = 500_000\n max_position_embeddings: int = 8192\n hidden_size = head_dim * num_heads\n num_attention_heads = num_heads\n rope_parameters = {**hf_rope_params, \"rope_theta\": rope_theta}\n\n def standardize_rope_params(self):\n return\n\n config = RoPEConfig()\n\n rot_emb = LlamaRotaryEmbedding(config=config)\n position_ids = torch.arange(context_len, dtype=torch.long).unsqueeze(0)\n ref_cos, ref_sin = rot_emb(queries, position_ids)\n ref_queries_rot, ref_keys_rot = apply_rotary_pos_emb(queries, keys, ref_cos, ref_sin)\n\n torch.testing.assert_close(sin, ref_sin.squeeze(0))\n torch.testing.assert_close(cos, ref_cos.squeeze(0))\n torch.testing.assert_close(keys_rot, ref_keys_rot)\n torch.testing.assert_close(queries_rot, ref_queries_rot)\n\n # Generate reference RoPE via LitGPT\n litgpt_rope_config = {\n \"factor\": 8.0,\n \"low_freq_factor\": 1.0,\n \"high_freq_factor\": 4.0,\n \"original_max_seq_len\": 8192\n }\n\n litgpt_cos, litgpt_sin = litgpt_build_rope_cache(\n context_len,\n n_elem=head_dim,\n base=rope_theta,\n extra_config=litgpt_rope_config\n )\n litgpt_queries_rot = litgpt_apply_rope(queries, litgpt_cos, litgpt_sin)\n litgpt_keys_rot = litgpt_apply_rope(keys, litgpt_cos, litgpt_sin)\n\n torch.testing.assert_close(sin, litgpt_sin)\n torch.testing.assert_close(cos, litgpt_cos)\n torch.testing.assert_close(keys_rot, litgpt_keys_rot)\n torch.testing.assert_close(queries_rot, litgpt_queries_rot)\n\n\ndef test_silu(notebook):\n example_batch = torch.randn(2, 3, 4)\n silu = notebook[\"converting-gpt-to-llama2\"].SiLU()\n assert torch.allclose(silu(example_batch), torch.nn.functional.silu(example_batch))\n\n\n@pytest.mark.skipif(torch.__version__ < \"2.4\", reason=\"Requires PyTorch 2.4 or newer\")\ndef test_rmsnorm(notebook):\n example_batch = torch.randn(2, 3, 4)\n rms_norm = notebook[\"converting-gpt-to-llama2\"].RMSNorm(emb_dim=example_batch.shape[-1], eps=1e-5)\n rmsnorm_pytorch = torch.nn.RMSNorm(example_batch.shape[-1], eps=1e-5)\n\n assert torch.allclose(rms_norm(example_batch), rmsnorm_pytorch(example_batch))\n"
},
{
"path": "ch05/08_memory_efficient_weight_loading/README.md",
"content": "# Memory-efficient Model Weight Loading\n\nThis folder contains code to illustrate how to load model weights more efficiently\n\n- [memory-efficient-state-dict.ipynb](memory-efficient-state-dict.ipynb): contains code to load model weights via PyTorch's `load_state_dict` method more efficiently\n"
},
{
"path": "ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"1E_HhLEeYqFG\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"SxQzFoS-IXdY\",\n \"outputId\": \"9f8fd57a-91e7-489d-d86e-656df536c604\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch version: 2.9.1+cu130\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"torch\\\",\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"y47iQaQKyHap\"\n },\n \"source\": [\n \" \\n\",\n \"## 1. Benchmark utilities\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"nQeOEoo6yT0X\"\n },\n \"source\": [\n \"- First, let's define some utility code to track VRAM (GPU memory)\\n\",\n \"- Later, we will also introduce a tool to track the main system RAM (CPU memory)\\n\",\n \"- The purpose of these functions will become clear when we apply them later\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"metadata\": {\n \"id\": \"pEiqjYrVivgt\"\n },\n \"outputs\": [],\n \"source\": [\n \"import gc\\n\",\n \"import time\\n\",\n \"import torch\\n\",\n \"\\n\",\n \"\\n\",\n \"def start_memory_tracking():\\n\",\n \" \\\"\\\"\\\"Initialize GPU memory tracking.\\\"\\\"\\\"\\n\",\n \" if torch.cuda.is_available():\\n\",\n \" torch.cuda.reset_peak_memory_stats()\\n\",\n \" else:\\n\",\n \" print(\\\"This notebook is intended for CUDA GPUs but CUDA is not available.\\\")\\n\",\n \"\\n\",\n \"def print_memory_usage():\\n\",\n \" max_gpu_memory = torch.cuda.max_memory_allocated() / (1024 ** 3) # Convert bytes to GB\\n\",\n \" print(f\\\"Maximum GPU memory allocated: {max_gpu_memory:.1f} GB\\\")\\n\",\n \"\\n\",\n \"def cleanup():\\n\",\n \" gc.collect()\\n\",\n \" torch.cuda.empty_cache()\\n\",\n \" time.sleep(3) # some buffer time to allow memory to clear\\n\",\n \" torch.cuda.reset_peak_memory_stats()\\n\",\n \" max_memory_allocated = torch.cuda.max_memory_allocated(device) / (1024 ** 3)\\n\",\n \" print(f\\\"Maximum GPU memory allocated: {max_memory_allocated:.1f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"z5oJwoc-kkXs\"\n },\n \"source\": [\n \" \\n\",\n \"## 2. Model setup\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"YfJE0vnMyr88\"\n },\n \"source\": [\n \"- This code section sets up the model itself\\n\",\n \"- Here, we use the \\\"large\\\" GPT-2 model to make things more interesting (you may use the \\\"gpt2-small (124M)\\\" to lower the memory requirements and execution time of this notebook)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"metadata\": {\n \"id\": \"tMuhCYaVI0w7\"\n },\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import GPTModel\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"BASE_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"drop_rate\\\": 0.0, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": True # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"CHOOSE_MODEL = \\\"gpt2-xl (1558M)\\\"\\n\",\n \"\\n\",\n \"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"KWYoo1z5y8aX\"\n },\n \"source\": [\n \"- Now, let's see the GPU memory functions in action:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"GK3NEA3eJv3f\",\n \"outputId\": \"434b51ca-7c8b-44dd-8a84-41ab48a290ff\"\n },\n \"outputs\": [\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"/home/rasbt/jupyterlab/reasoning/.venv/lib/python3.12/site-packages/torch/cuda/__init__.py:283: UserWarning: \\n\",\n \" Found GPU0 NVIDIA GB10 which is of cuda capability 12.1.\\n\",\n \" Minimum and Maximum cuda capability supported by this version of PyTorch is\\n\",\n \" (8.0) - (12.0)\\n\",\n \" \\n\",\n \" warnings.warn(\\n\"\n ]\n },\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"start_memory_tracking()\\n\",\n \"\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"device = torch.device(\\\"cuda\\\")\\n\",\n \"model.to(device)\\n\",\n \"\\n\",\n \"print_memory_usage()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"GIhwBEBxzBsF\"\n },\n \"source\": [\n \"- Additionally, let's make sure that the model runs okay by passing in some example tensor\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"metadata\": {\n \"id\": \"i_j6nZruUd7g\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Test if the model works (no need to track memory here)\\n\",\n \"test_input = torch.tensor([[1, 2, 3]]).to(device)\\n\",\n \"model.eval()\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" model(test_input)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"UgNb8c32zh4g\"\n },\n \"source\": [\n \"- Next, imagine we were pretraining the model and saving it for later use\\n\",\n \"- We skip the actual pretraining here for simplicity and just save the initialized model (but the same concept applies)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"metadata\": {\n \"id\": \"wUIXjcsimXU7\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Training code would go here...\\n\",\n \"\\n\",\n \"model.train()\\n\",\n \"torch.save(model.state_dict(), \\\"model.pth\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"s9tBS4HUzz1g\"\n },\n \"source\": [\n \"- Lastly, we delete the model and example tensor in the Python session to reset the GPU memory\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"SqmTzztqKnTs\",\n \"outputId\": \"218332da-8b66-4169-d876-8d72c68691fc\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 0.0 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"del model, test_input\\n\",\n \"cleanup()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"7EnO8beUJ6Sb\"\n },\n \"source\": [\n \" \\n\",\n \"## 3. Basic weight loading\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"JtAXKjsG0AVL\"\n },\n \"source\": [\n \"- Now begins the interesting part where we load the pretrained model weights\\n\",\n \"- Let's see how much GPU memory is required to load the previously saved model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"wCrQNbSJJO9w\",\n \"outputId\": \"2623b399-bce6-4506-ec0b-c3c94729b80f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 12.8 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Then load pretrained weights\\n\",\n \"\\n\",\n \"start_memory_tracking()\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"model.to(device)\\n\",\n \"\\n\",\n \"model.load_state_dict(\\n\",\n \" torch.load(\\\"model.pth\\\", map_location=device, weights_only=True)\\n\",\n \")\\n\",\n \"model.to(device)\\n\",\n \"model.eval();\\n\",\n \"\\n\",\n \"print_memory_usage()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"4AGvOrcN0KdJ\"\n },\n \"source\": [\n \"- Notice that the memory is 2x as large as in the previous session\\n\",\n \"- This is because we have the same model in memory twice, for a short period of time:\\n\",\n \" - The first time via `model.to(device)`\\n\",\n \" - The second time via the code line `model.load_state_dict(torch.load(\\\"model.pth\\\", map_location=device, weights_only=True))`; eventually, the loaded model weights will be copied into the model, and the `state_dict` will be discarded, but for a brief amount of time, we have both the main model and the loaded `state_dict` in memory\\n\",\n \"- The remaining sections focus on addressing this\\n\",\n \"- But first, let's test the model and reset the GPU memory\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"DvlUn-nmmbuj\",\n \"outputId\": \"7a9afbde-826f-4fb2-874d-feb6e8724834\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 0.0 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Test if the model works (no need to track memory here)\\n\",\n \"test_input = torch.tensor([[1, 2, 3]]).to(device)\\n\",\n \"model.eval()\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" model(test_input)\\n\",\n \"\\n\",\n \"del model, test_input\\n\",\n \"cleanup()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"IQ531-IuRuzD\"\n },\n \"source\": [\n \"- Let's test another common pattern that is very popular in practice:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"metadata\": {\n \"id\": \"2m54kzX5RxLX\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"start_memory_tracking()\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"\\n\",\n \"model.load_state_dict(\\n\",\n \" torch.load(\\\"model.pth\\\", map_location=\\\"cpu\\\", weights_only=True)\\n\",\n \")\\n\",\n \"model.to(device)\\n\",\n \"model.eval();\\n\",\n \"\\n\",\n \"print_memory_usage()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"metadata\": {\n \"id\": \"XWvQTRN4R2CM\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 0.0 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Test if the model works (no need to track memory here)\\n\",\n \"test_input = torch.tensor([[1, 2, 3]]).to(device)\\n\",\n \"model.eval()\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" model(test_input)\\n\",\n \"\\n\",\n \"del model, test_input\\n\",\n \"cleanup()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"UGjBD6GASS_y\"\n },\n \"source\": [\n \"- So, as peak memory is concerned, it doesn't make a difference whether we instantiate the model on the device first and then use `map_location=\\\"device\\\"` or load the weights into CPU memory first (`map_location=\\\"cpu\\\"`) and then move it to the device\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"RdPnW3iLLrjX\"\n },\n \"source\": [\n \" \\n\",\n \"## 4. Loading weights sequentially\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"FYqtUON602TD\"\n },\n \"source\": [\n \"- One workaround for the problem of having the model weights in GPU memory twice, as highlighted in the previous section, is to load the model sequentially\\n\",\n \"- Below, we:\\n\",\n \" - first load the model into GPU memory\\n\",\n \" - then load the model weights into CPU memory\\n\",\n \" - and finally copy each parameter one by one into GPU memory\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"DOIGTNWTmx9G\",\n \"outputId\": \"145162e6-aaa6-4c2a-ed8f-f1cf068adb80\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\",\n \"Maximum GPU memory allocated: 6.7 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"start_memory_tracking()\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG).to(device)\\n\",\n \"\\n\",\n \"state_dict = torch.load(\\\"model.pth\\\", map_location=\\\"cpu\\\", weights_only=True)\\n\",\n \"\\n\",\n \"print_memory_usage()\\n\",\n \"\\n\",\n \"# Sequentially copy weights to the model's parameters\\n\",\n \"with torch.no_grad():\\n\",\n \" for name, param in model.named_parameters():\\n\",\n \" if name in state_dict:\\n\",\n \" param.copy_(state_dict[name].to(device))\\n\",\n \" else:\\n\",\n \" print(f\\\"Warning: {name} not found in state_dict.\\\")\\n\",\n \"\\n\",\n \"print_memory_usage()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"Pn9xD_xL1ZzM\"\n },\n \"source\": [\n \"- As we can see above, the memory usage is much lower than before\\n\",\n \"- Notice that the memory increases from 6.4 to 6.7 GB because initially, we only have the model in memory, and then we have the model plus 1 parameter tensor in memory (we temporarily move the parameter tensor to the GPU so we can assign it using `\\\".to\\\"` the model)\\n\",\n \"- Overall, this is a significant improvement\\n\",\n \"- Again, let's briefly test the model and then reset the GPU memory for the next section\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"PRHnjA48nJgw\",\n \"outputId\": \"dcd6b1b2-538f-4862-96a6-a5fcbf3326a4\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 0.0 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Test if the model works (no need to track memory here)\\n\",\n \"test_input = torch.tensor([[1, 2, 3]]).to(device)\\n\",\n \"model.eval()\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" model(test_input)\\n\",\n \"\\n\",\n \"del model, test_input, state_dict, param\\n\",\n \"cleanup()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"5M92LK7usb-Z\"\n },\n \"source\": [\n \" \\n\",\n \"## 5. Loading the model with low CPU memory\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"R45qgeB613e2\"\n },\n \"source\": [\n \"- In the previous session, we reduced GPU memory use by loading the weights (`state_dict`) into CPU memory first before copying them one-by-one into the model\\n\",\n \"- However, what do we do if we have limited CPU memory?\\n\",\n \"- This section uses PyTorch's so-called `\\\"meta\\\"` device approach to load a model on machines with large GPU memory but small CPU memory\\n\",\n \"- But first, let's define a convenience function to monitor CPU memory\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"id\": \"BrcWy0q-3Bbe\"\n },\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"import psutil\\n\",\n \"from threading import Thread\\n\",\n \"\\n\",\n \"\\n\",\n \"def memory_usage_in_gb(func, *args, **kwargs):\\n\",\n \" process = psutil.Process(os.getpid())\\n\",\n \"\\n\",\n \" # Measure the baseline memory usage before running the function\\n\",\n \" baseline_mem = process.memory_info().rss / 1024 ** 3 # in GB\\n\",\n \"\\n\",\n \" # Start monitoring memory in a separate thread\\n\",\n \" mem_usage = []\\n\",\n \" done = False\\n\",\n \"\\n\",\n \" def monitor_memory():\\n\",\n \" while not done:\\n\",\n \" mem_usage.append(process.memory_info().rss / 1024 ** 3) # Convert to GB\\n\",\n \" time.sleep(0.1)\\n\",\n \"\\n\",\n \" t = Thread(target=monitor_memory)\\n\",\n \" t.start()\\n\",\n \"\\n\",\n \" # Run the function\\n\",\n \" func(*args, **kwargs)\\n\",\n \"\\n\",\n \" # Stop monitoring\\n\",\n \" done = True\\n\",\n \" t.join()\\n\",\n \"\\n\",\n \" peak_mem_usage_gb = max(mem_usage) - baseline_mem\\n\",\n \" return peak_mem_usage_gb\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"Ayy30Ytd5hjF\"\n },\n \"source\": [\n \"- To start with, let's track the CPU memory of the sequential weight loading approach from the previous section\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"rCkV6IbQtpVn\",\n \"outputId\": \"26c0435a-1e3d-4e8f-fbe2-f9655bad61b4\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\",\n \"Maximum GPU memory allocated: 6.7 GB\\n\",\n \"-> Maximum CPU memory allocated: 6.3 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def load_sequentially():\\n\",\n \" start_memory_tracking()\\n\",\n \"\\n\",\n \" model = GPTModel(BASE_CONFIG).to(device)\\n\",\n \"\\n\",\n \" state_dict = torch.load(\\\"model.pth\\\", map_location=\\\"cpu\\\", weights_only=True)\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \" # Sequentially copy weights to the model's parameters\\n\",\n \" with torch.no_grad():\\n\",\n \" for name, param in model.named_parameters():\\n\",\n \" if name in state_dict:\\n\",\n \" param.copy_(state_dict[name].to(device))\\n\",\n \" else:\\n\",\n \" print(f\\\"Warning: {name} not found in state_dict.\\\")\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \"\\n\",\n \"peak_memory_used = memory_usage_in_gb(load_sequentially)\\n\",\n \"print(f\\\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"UWrmnCML5oKy\"\n },\n \"source\": [\n \"- Now, suppose we have a machine with low CPU memory but large GPU memory\\n\",\n \"- We can trade off CPU memory and GPU memory usage by introducing PyTorch's so-called \\\"meta\\\" device\\n\",\n \"- PyTorch's meta device is a special device type that allows you to create tensors without allocating actual memory for their data, effectively creating \\\"meta\\\" tensors\\n\",\n \"- This is useful for tasks like model analysis or architecture definition, where you need tensor shapes and types without the overhead of memory allocation\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"PBErC_5Yt8ly\",\n \"outputId\": \"8799db06-191c-47c4-92fa-fbb95d685aa9\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 12.8 GB\\n\",\n \"Maximum GPU memory allocated: 12.8 GB\\n\",\n \"-> Maximum CPU memory allocated: 1.3 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def load_sequentially_with_meta():\\n\",\n \" start_memory_tracking()\\n\",\n \"\\n\",\n \" with torch.device(\\\"meta\\\"):\\n\",\n \" model = GPTModel(BASE_CONFIG)\\n\",\n \"\\n\",\n \" model = model.to_empty(device=device)\\n\",\n \"\\n\",\n \" state_dict = torch.load(\\\"model.pth\\\", map_location=device, weights_only=True)\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \" # Sequentially copy weights to the model's parameters\\n\",\n \" with torch.no_grad():\\n\",\n \" for name, param in model.named_parameters():\\n\",\n \" if name in state_dict:\\n\",\n \" param.copy_(state_dict[name])\\n\",\n \" else:\\n\",\n \" print(f\\\"Warning: {name} not found in state_dict.\\\")\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \"peak_memory_used = memory_usage_in_gb(load_sequentially_with_meta)\\n\",\n \"print(f\\\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"VpnCABp75-VQ\"\n },\n \"source\": [\n \"- As we can see above, by creating the model on the meta-device and loading the weights directly into GPU memory, we effectively reduced the CPU memory requirements\\n\",\n \"- One might ask: \\\"Is the sequential weight loading still necessary then, and how does that compare to the original approach?\\\"\\n\",\n \"- Let's check the simple PyTorch weight loading approach for comparison (from the first weight loading section in this notebook):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"4f-bqBNRuR39\",\n \"outputId\": \"f7c0a901-b404-433a-9b93-2bbfa8183c56\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 12.8 GB\\n\",\n \"-> Maximum CPU memory allocated: 4.4 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def baseline():\\n\",\n \" start_memory_tracking()\\n\",\n \"\\n\",\n \" model = GPTModel(BASE_CONFIG)\\n\",\n \" model.to(device)\\n\",\n \"\\n\",\n \" model.load_state_dict(torch.load(\\\"model.pth\\\", map_location=device, weights_only=True))\\n\",\n \" model.to(device)\\n\",\n \" model.eval();\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \"peak_memory_used = memory_usage_in_gb(baseline)\\n\",\n \"print(f\\\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"NKAjxbX86xnb\"\n },\n \"source\": [\n \"- As we can see above, the \\\"simple\\\" weight loading without the meta device uses more memory\\n\",\n \"- In other words, if you have a machine with limited CPU memory, you can use the meta device approach to directly load the model weights into GPU memory to reduce peak CPU memory usage\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"jvDVFpcaRISr\"\n },\n \"source\": [\n \" \\n\",\n \"## 6. Using `mmap=True` (recommmended)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"w3H5gPygRISr\"\n },\n \"source\": [\n \"- As an intermediate or advanced `torch.load` user, you may wonder how these approaches compare to the `mmap=True` setting in PyTorch\\n\",\n \"- The `mmap=True` setting in PyTorch enables memory-mapped file I/O, which allows the tensor to access data directly from disk storage, thus reducing memory usage by not loading the entire file into RAM if RAM is limited\\n\",\n \"- Also, see the helpful comment by [mikaylagawarecki](https://github.com/rasbt/LLMs-from-scratch/issues/402)\\n\",\n \"- At first glance, it may look less efficient than the sequential approaches above:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"GKwV0AMNemuR\",\n \"outputId\": \"e207f2bf-5c87-498e-80fe-e8c4016ac711\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\",\n \"-> Maximum CPU memory allocated: 5.9 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def best_practices():\\n\",\n \" with torch.device(\\\"meta\\\"):\\n\",\n \" model = GPTModel(BASE_CONFIG)\\n\",\n \"\\n\",\n \" model.load_state_dict(\\n\",\n \" torch.load(\\\"model.pth\\\", map_location=device, weights_only=True, mmap=True),\\n\",\n \" assign=True\\n\",\n \" )\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \"peak_memory_used = memory_usage_in_gb(best_practices)\\n\",\n \"print(f\\\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"pGC0rBv4RISr\"\n },\n \"source\": [\n \"- The reason why the CPU RAM usage is so high is that there's enough CPU RAM available on this machine\\n\",\n \"- However, if you were to run this on a machine with limited CPU RAM, the `mmap` approach would use less memory\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"fd11QM8pRISr\"\n },\n \"source\": [\n \" \\n\",\n \"## 7. Other methods\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"0U2Y6eo8RISr\"\n },\n \"source\": [\n \"- This notebook is focused on simple, built-in methods for loading weights in PyTorch\\n\",\n \"- The recommended approach for limited CPU memory cases is the `mmap=True` approach explained enough\\n\",\n \"- Alternatively, one other option is a brute-force approach that saves and loads each weight tensor separately:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"id\": \"2CgPEZUIb00w\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"# Assume `model` is your trained model\\n\",\n \"state_dict = model.state_dict()\\n\",\n \"\\n\",\n \"# Create a directory to store individual parameter files\\n\",\n \"os.makedirs(\\\"model_parameters\\\", exist_ok=True)\\n\",\n \"\\n\",\n \"# Save each parameter tensor separately\\n\",\n \"for name, param in state_dict.items():\\n\",\n \" torch.save(param.cpu(), f\\\"model_parameters/{name}.pt\\\")\\n\",\n \"\\n\",\n \"del model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"gTsmtJK-b4yy\",\n \"outputId\": \"d361e2d3-e34c-48d7-9047-846c9bfd291e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\",\n \"Maximum GPU memory allocated: 6.4 GB\\n\",\n \"-> Maximum CPU memory allocated: 0.3 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def load_individual_weights():\\n\",\n \"\\n\",\n \" start_memory_tracking()\\n\",\n \"\\n\",\n \" with torch.device(\\\"meta\\\"):\\n\",\n \" model = GPTModel(BASE_CONFIG)\\n\",\n \"\\n\",\n \" model = model.to_empty(device=device)\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \" param_dir = \\\"model_parameters\\\"\\n\",\n \"\\n\",\n \" with torch.no_grad():\\n\",\n \" for name, param in model.named_parameters():\\n\",\n \" weight_path = os.path.join(param_dir, f\\\"{name}.pt\\\")\\n\",\n \" if os.path.exists(weight_path):\\n\",\n \" param_data = torch.load(weight_path, map_location=\\\"cpu\\\", weights_only=True)\\n\",\n \" param.copy_(param_data)\\n\",\n \" del param_data # Free memory\\n\",\n \" else:\\n\",\n \" print(f\\\"Warning: {name} not found in {param_dir}.\\\")\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \"\\n\",\n \"peak_memory_used = memory_usage_in_gb(load_individual_weights)\\n\",\n \"print(f\\\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\\\")\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"T4\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.12.3\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 4\n}\n"
},
{
"path": "ch05/08_memory_efficient_weight_loading/previous_chapters.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 2-5.\n\n\nimport torch\nimport torch.nn as nn\n\n#####################################\n# Chapter 3\n#####################################\n\n\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by n_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n self.register_buffer(\"mask\", torch.triu(torch.ones(context_length, context_length), diagonal=1))\n\n def forward(self, x):\n b, num_tokens, d_in = x.shape\n\n keys = self.W_key(x) # Shape: (b, num_tokens, d_out)\n queries = self.W_query(x)\n values = self.W_value(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n # Original mask truncated to the number of tokens and converted to boolean\n mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.reshape(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n context_length=cfg[\"context_length\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n self.trf_blocks = nn.Sequential(\n *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n x = self.trf_blocks(x)\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n"
},
{
"path": "ch05/09_extending-tokenizers/README.md",
"content": "# Extending the Tiktoken BPE Tokenizer with New Tokens\n\n- [extend-tiktoken.ipynb](extend-tiktoken.ipynb) contains optional (bonus) code to explain how we can add special tokens to a tokenizer implemented via `tiktoken` and how to update the LLM accordingly"
},
{
"path": "ch05/09_extending-tokenizers/extend-tiktoken.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cbbc1fe3-bff1-4631-bf35-342e19c54cc0\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"SxQzFoS-IXdY\",\n \"outputId\": \"9f8fd57a-91e7-489d-d86e-656df536c604\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"torch version: 2.9.1+cu130\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"torch\\\",\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"y47iQaQKyHap\"\n },\n \"source\": [\n \" \\n\",\n \"## 1. Benchmark utilities\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"nQeOEoo6yT0X\"\n },\n \"source\": [\n \"- First, let's define some utility code to track VRAM (GPU memory)\\n\",\n \"- Later, we will also introduce a tool to track the main system RAM (CPU memory)\\n\",\n \"- The purpose of these functions will become clear when we apply them later\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"metadata\": {\n \"id\": \"pEiqjYrVivgt\"\n },\n \"outputs\": [],\n \"source\": [\n \"import gc\\n\",\n \"import time\\n\",\n \"import torch\\n\",\n \"\\n\",\n \"\\n\",\n \"def start_memory_tracking():\\n\",\n \" \\\"\\\"\\\"Initialize GPU memory tracking.\\\"\\\"\\\"\\n\",\n \" if torch.cuda.is_available():\\n\",\n \" torch.cuda.reset_peak_memory_stats()\\n\",\n \" else:\\n\",\n \" print(\\\"This notebook is intended for CUDA GPUs but CUDA is not available.\\\")\\n\",\n \"\\n\",\n \"def print_memory_usage():\\n\",\n \" max_gpu_memory = torch.cuda.max_memory_allocated() / (1024 ** 3) # Convert bytes to GB\\n\",\n \" print(f\\\"Maximum GPU memory allocated: {max_gpu_memory:.1f} GB\\\")\\n\",\n \"\\n\",\n \"def cleanup():\\n\",\n \" gc.collect()\\n\",\n \" torch.cuda.empty_cache()\\n\",\n \" time.sleep(3) # some buffer time to allow memory to clear\\n\",\n \" torch.cuda.reset_peak_memory_stats()\\n\",\n \" max_memory_allocated = torch.cuda.max_memory_allocated(device) / (1024 ** 3)\\n\",\n \" print(f\\\"Maximum GPU memory allocated: {max_memory_allocated:.1f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"z5oJwoc-kkXs\"\n },\n \"source\": [\n \" \\n\",\n \"## 2. Model setup\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"YfJE0vnMyr88\"\n },\n \"source\": [\n \"- This code section sets up the model itself\\n\",\n \"- Here, we use the \\\"large\\\" GPT-2 model to make things more interesting (you may use the \\\"gpt2-small (124M)\\\" to lower the memory requirements and execution time of this notebook)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"metadata\": {\n \"id\": \"tMuhCYaVI0w7\"\n },\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import GPTModel\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"BASE_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"drop_rate\\\": 0.0, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": True # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"CHOOSE_MODEL = \\\"gpt2-xl (1558M)\\\"\\n\",\n \"\\n\",\n \"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"KWYoo1z5y8aX\"\n },\n \"source\": [\n \"- Now, let's see the GPU memory functions in action:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"GK3NEA3eJv3f\",\n \"outputId\": \"434b51ca-7c8b-44dd-8a84-41ab48a290ff\"\n },\n \"outputs\": [\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"/home/rasbt/jupyterlab/reasoning/.venv/lib/python3.12/site-packages/torch/cuda/__init__.py:283: UserWarning: \\n\",\n \" Found GPU0 NVIDIA GB10 which is of cuda capability 12.1.\\n\",\n \" Minimum and Maximum cuda capability supported by this version of PyTorch is\\n\",\n \" (8.0) - (12.0)\\n\",\n \" \\n\",\n \" warnings.warn(\\n\"\n ]\n },\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"start_memory_tracking()\\n\",\n \"\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"device = torch.device(\\\"cuda\\\")\\n\",\n \"model.to(device)\\n\",\n \"\\n\",\n \"print_memory_usage()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"GIhwBEBxzBsF\"\n },\n \"source\": [\n \"- Additionally, let's make sure that the model runs okay by passing in some example tensor\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"metadata\": {\n \"id\": \"i_j6nZruUd7g\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Test if the model works (no need to track memory here)\\n\",\n \"test_input = torch.tensor([[1, 2, 3]]).to(device)\\n\",\n \"model.eval()\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" model(test_input)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"UgNb8c32zh4g\"\n },\n \"source\": [\n \"- Next, imagine we were pretraining the model and saving it for later use\\n\",\n \"- We skip the actual pretraining here for simplicity and just save the initialized model (but the same concept applies)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"metadata\": {\n \"id\": \"wUIXjcsimXU7\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Training code would go here...\\n\",\n \"\\n\",\n \"model.train()\\n\",\n \"torch.save(model.state_dict(), \\\"model.pth\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"s9tBS4HUzz1g\"\n },\n \"source\": [\n \"- Lastly, we delete the model and example tensor in the Python session to reset the GPU memory\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"SqmTzztqKnTs\",\n \"outputId\": \"218332da-8b66-4169-d876-8d72c68691fc\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 0.0 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"del model, test_input\\n\",\n \"cleanup()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"7EnO8beUJ6Sb\"\n },\n \"source\": [\n \" \\n\",\n \"## 3. Basic weight loading\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"JtAXKjsG0AVL\"\n },\n \"source\": [\n \"- Now begins the interesting part where we load the pretrained model weights\\n\",\n \"- Let's see how much GPU memory is required to load the previously saved model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"wCrQNbSJJO9w\",\n \"outputId\": \"2623b399-bce6-4506-ec0b-c3c94729b80f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 12.8 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Then load pretrained weights\\n\",\n \"\\n\",\n \"start_memory_tracking()\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"model.to(device)\\n\",\n \"\\n\",\n \"model.load_state_dict(\\n\",\n \" torch.load(\\\"model.pth\\\", map_location=device, weights_only=True)\\n\",\n \")\\n\",\n \"model.to(device)\\n\",\n \"model.eval();\\n\",\n \"\\n\",\n \"print_memory_usage()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"4AGvOrcN0KdJ\"\n },\n \"source\": [\n \"- Notice that the memory is 2x as large as in the previous session\\n\",\n \"- This is because we have the same model in memory twice, for a short period of time:\\n\",\n \" - The first time via `model.to(device)`\\n\",\n \" - The second time via the code line `model.load_state_dict(torch.load(\\\"model.pth\\\", map_location=device, weights_only=True))`; eventually, the loaded model weights will be copied into the model, and the `state_dict` will be discarded, but for a brief amount of time, we have both the main model and the loaded `state_dict` in memory\\n\",\n \"- The remaining sections focus on addressing this\\n\",\n \"- But first, let's test the model and reset the GPU memory\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"DvlUn-nmmbuj\",\n \"outputId\": \"7a9afbde-826f-4fb2-874d-feb6e8724834\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 0.0 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Test if the model works (no need to track memory here)\\n\",\n \"test_input = torch.tensor([[1, 2, 3]]).to(device)\\n\",\n \"model.eval()\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" model(test_input)\\n\",\n \"\\n\",\n \"del model, test_input\\n\",\n \"cleanup()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"IQ531-IuRuzD\"\n },\n \"source\": [\n \"- Let's test another common pattern that is very popular in practice:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"metadata\": {\n \"id\": \"2m54kzX5RxLX\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"start_memory_tracking()\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"\\n\",\n \"model.load_state_dict(\\n\",\n \" torch.load(\\\"model.pth\\\", map_location=\\\"cpu\\\", weights_only=True)\\n\",\n \")\\n\",\n \"model.to(device)\\n\",\n \"model.eval();\\n\",\n \"\\n\",\n \"print_memory_usage()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"metadata\": {\n \"id\": \"XWvQTRN4R2CM\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 0.0 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Test if the model works (no need to track memory here)\\n\",\n \"test_input = torch.tensor([[1, 2, 3]]).to(device)\\n\",\n \"model.eval()\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" model(test_input)\\n\",\n \"\\n\",\n \"del model, test_input\\n\",\n \"cleanup()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"UGjBD6GASS_y\"\n },\n \"source\": [\n \"- So, as peak memory is concerned, it doesn't make a difference whether we instantiate the model on the device first and then use `map_location=\\\"device\\\"` or load the weights into CPU memory first (`map_location=\\\"cpu\\\"`) and then move it to the device\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"RdPnW3iLLrjX\"\n },\n \"source\": [\n \" \\n\",\n \"## 4. Loading weights sequentially\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"FYqtUON602TD\"\n },\n \"source\": [\n \"- One workaround for the problem of having the model weights in GPU memory twice, as highlighted in the previous section, is to load the model sequentially\\n\",\n \"- Below, we:\\n\",\n \" - first load the model into GPU memory\\n\",\n \" - then load the model weights into CPU memory\\n\",\n \" - and finally copy each parameter one by one into GPU memory\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"DOIGTNWTmx9G\",\n \"outputId\": \"145162e6-aaa6-4c2a-ed8f-f1cf068adb80\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\",\n \"Maximum GPU memory allocated: 6.7 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"start_memory_tracking()\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG).to(device)\\n\",\n \"\\n\",\n \"state_dict = torch.load(\\\"model.pth\\\", map_location=\\\"cpu\\\", weights_only=True)\\n\",\n \"\\n\",\n \"print_memory_usage()\\n\",\n \"\\n\",\n \"# Sequentially copy weights to the model's parameters\\n\",\n \"with torch.no_grad():\\n\",\n \" for name, param in model.named_parameters():\\n\",\n \" if name in state_dict:\\n\",\n \" param.copy_(state_dict[name].to(device))\\n\",\n \" else:\\n\",\n \" print(f\\\"Warning: {name} not found in state_dict.\\\")\\n\",\n \"\\n\",\n \"print_memory_usage()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"Pn9xD_xL1ZzM\"\n },\n \"source\": [\n \"- As we can see above, the memory usage is much lower than before\\n\",\n \"- Notice that the memory increases from 6.4 to 6.7 GB because initially, we only have the model in memory, and then we have the model plus 1 parameter tensor in memory (we temporarily move the parameter tensor to the GPU so we can assign it using `\\\".to\\\"` the model)\\n\",\n \"- Overall, this is a significant improvement\\n\",\n \"- Again, let's briefly test the model and then reset the GPU memory for the next section\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"PRHnjA48nJgw\",\n \"outputId\": \"dcd6b1b2-538f-4862-96a6-a5fcbf3326a4\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 0.0 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Test if the model works (no need to track memory here)\\n\",\n \"test_input = torch.tensor([[1, 2, 3]]).to(device)\\n\",\n \"model.eval()\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" model(test_input)\\n\",\n \"\\n\",\n \"del model, test_input, state_dict, param\\n\",\n \"cleanup()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"5M92LK7usb-Z\"\n },\n \"source\": [\n \" \\n\",\n \"## 5. Loading the model with low CPU memory\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"R45qgeB613e2\"\n },\n \"source\": [\n \"- In the previous session, we reduced GPU memory use by loading the weights (`state_dict`) into CPU memory first before copying them one-by-one into the model\\n\",\n \"- However, what do we do if we have limited CPU memory?\\n\",\n \"- This section uses PyTorch's so-called `\\\"meta\\\"` device approach to load a model on machines with large GPU memory but small CPU memory\\n\",\n \"- But first, let's define a convenience function to monitor CPU memory\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"id\": \"BrcWy0q-3Bbe\"\n },\n \"outputs\": [],\n \"source\": [\n \"import os\\n\",\n \"import psutil\\n\",\n \"from threading import Thread\\n\",\n \"\\n\",\n \"\\n\",\n \"def memory_usage_in_gb(func, *args, **kwargs):\\n\",\n \" process = psutil.Process(os.getpid())\\n\",\n \"\\n\",\n \" # Measure the baseline memory usage before running the function\\n\",\n \" baseline_mem = process.memory_info().rss / 1024 ** 3 # in GB\\n\",\n \"\\n\",\n \" # Start monitoring memory in a separate thread\\n\",\n \" mem_usage = []\\n\",\n \" done = False\\n\",\n \"\\n\",\n \" def monitor_memory():\\n\",\n \" while not done:\\n\",\n \" mem_usage.append(process.memory_info().rss / 1024 ** 3) # Convert to GB\\n\",\n \" time.sleep(0.1)\\n\",\n \"\\n\",\n \" t = Thread(target=monitor_memory)\\n\",\n \" t.start()\\n\",\n \"\\n\",\n \" # Run the function\\n\",\n \" func(*args, **kwargs)\\n\",\n \"\\n\",\n \" # Stop monitoring\\n\",\n \" done = True\\n\",\n \" t.join()\\n\",\n \"\\n\",\n \" peak_mem_usage_gb = max(mem_usage) - baseline_mem\\n\",\n \" return peak_mem_usage_gb\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"Ayy30Ytd5hjF\"\n },\n \"source\": [\n \"- To start with, let's track the CPU memory of the sequential weight loading approach from the previous section\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"rCkV6IbQtpVn\",\n \"outputId\": \"26c0435a-1e3d-4e8f-fbe2-f9655bad61b4\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\",\n \"Maximum GPU memory allocated: 6.7 GB\\n\",\n \"-> Maximum CPU memory allocated: 6.3 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def load_sequentially():\\n\",\n \" start_memory_tracking()\\n\",\n \"\\n\",\n \" model = GPTModel(BASE_CONFIG).to(device)\\n\",\n \"\\n\",\n \" state_dict = torch.load(\\\"model.pth\\\", map_location=\\\"cpu\\\", weights_only=True)\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \" # Sequentially copy weights to the model's parameters\\n\",\n \" with torch.no_grad():\\n\",\n \" for name, param in model.named_parameters():\\n\",\n \" if name in state_dict:\\n\",\n \" param.copy_(state_dict[name].to(device))\\n\",\n \" else:\\n\",\n \" print(f\\\"Warning: {name} not found in state_dict.\\\")\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \"\\n\",\n \"peak_memory_used = memory_usage_in_gb(load_sequentially)\\n\",\n \"print(f\\\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"UWrmnCML5oKy\"\n },\n \"source\": [\n \"- Now, suppose we have a machine with low CPU memory but large GPU memory\\n\",\n \"- We can trade off CPU memory and GPU memory usage by introducing PyTorch's so-called \\\"meta\\\" device\\n\",\n \"- PyTorch's meta device is a special device type that allows you to create tensors without allocating actual memory for their data, effectively creating \\\"meta\\\" tensors\\n\",\n \"- This is useful for tasks like model analysis or architecture definition, where you need tensor shapes and types without the overhead of memory allocation\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"PBErC_5Yt8ly\",\n \"outputId\": \"8799db06-191c-47c4-92fa-fbb95d685aa9\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 12.8 GB\\n\",\n \"Maximum GPU memory allocated: 12.8 GB\\n\",\n \"-> Maximum CPU memory allocated: 1.3 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def load_sequentially_with_meta():\\n\",\n \" start_memory_tracking()\\n\",\n \"\\n\",\n \" with torch.device(\\\"meta\\\"):\\n\",\n \" model = GPTModel(BASE_CONFIG)\\n\",\n \"\\n\",\n \" model = model.to_empty(device=device)\\n\",\n \"\\n\",\n \" state_dict = torch.load(\\\"model.pth\\\", map_location=device, weights_only=True)\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \" # Sequentially copy weights to the model's parameters\\n\",\n \" with torch.no_grad():\\n\",\n \" for name, param in model.named_parameters():\\n\",\n \" if name in state_dict:\\n\",\n \" param.copy_(state_dict[name])\\n\",\n \" else:\\n\",\n \" print(f\\\"Warning: {name} not found in state_dict.\\\")\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \"peak_memory_used = memory_usage_in_gb(load_sequentially_with_meta)\\n\",\n \"print(f\\\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"VpnCABp75-VQ\"\n },\n \"source\": [\n \"- As we can see above, by creating the model on the meta-device and loading the weights directly into GPU memory, we effectively reduced the CPU memory requirements\\n\",\n \"- One might ask: \\\"Is the sequential weight loading still necessary then, and how does that compare to the original approach?\\\"\\n\",\n \"- Let's check the simple PyTorch weight loading approach for comparison (from the first weight loading section in this notebook):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"4f-bqBNRuR39\",\n \"outputId\": \"f7c0a901-b404-433a-9b93-2bbfa8183c56\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 12.8 GB\\n\",\n \"-> Maximum CPU memory allocated: 4.4 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def baseline():\\n\",\n \" start_memory_tracking()\\n\",\n \"\\n\",\n \" model = GPTModel(BASE_CONFIG)\\n\",\n \" model.to(device)\\n\",\n \"\\n\",\n \" model.load_state_dict(torch.load(\\\"model.pth\\\", map_location=device, weights_only=True))\\n\",\n \" model.to(device)\\n\",\n \" model.eval();\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \"peak_memory_used = memory_usage_in_gb(baseline)\\n\",\n \"print(f\\\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"NKAjxbX86xnb\"\n },\n \"source\": [\n \"- As we can see above, the \\\"simple\\\" weight loading without the meta device uses more memory\\n\",\n \"- In other words, if you have a machine with limited CPU memory, you can use the meta device approach to directly load the model weights into GPU memory to reduce peak CPU memory usage\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"jvDVFpcaRISr\"\n },\n \"source\": [\n \" \\n\",\n \"## 6. Using `mmap=True` (recommmended)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"w3H5gPygRISr\"\n },\n \"source\": [\n \"- As an intermediate or advanced `torch.load` user, you may wonder how these approaches compare to the `mmap=True` setting in PyTorch\\n\",\n \"- The `mmap=True` setting in PyTorch enables memory-mapped file I/O, which allows the tensor to access data directly from disk storage, thus reducing memory usage by not loading the entire file into RAM if RAM is limited\\n\",\n \"- Also, see the helpful comment by [mikaylagawarecki](https://github.com/rasbt/LLMs-from-scratch/issues/402)\\n\",\n \"- At first glance, it may look less efficient than the sequential approaches above:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"GKwV0AMNemuR\",\n \"outputId\": \"e207f2bf-5c87-498e-80fe-e8c4016ac711\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\",\n \"-> Maximum CPU memory allocated: 5.9 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def best_practices():\\n\",\n \" with torch.device(\\\"meta\\\"):\\n\",\n \" model = GPTModel(BASE_CONFIG)\\n\",\n \"\\n\",\n \" model.load_state_dict(\\n\",\n \" torch.load(\\\"model.pth\\\", map_location=device, weights_only=True, mmap=True),\\n\",\n \" assign=True\\n\",\n \" )\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \"peak_memory_used = memory_usage_in_gb(best_practices)\\n\",\n \"print(f\\\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"pGC0rBv4RISr\"\n },\n \"source\": [\n \"- The reason why the CPU RAM usage is so high is that there's enough CPU RAM available on this machine\\n\",\n \"- However, if you were to run this on a machine with limited CPU RAM, the `mmap` approach would use less memory\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"fd11QM8pRISr\"\n },\n \"source\": [\n \" \\n\",\n \"## 7. Other methods\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"0U2Y6eo8RISr\"\n },\n \"source\": [\n \"- This notebook is focused on simple, built-in methods for loading weights in PyTorch\\n\",\n \"- The recommended approach for limited CPU memory cases is the `mmap=True` approach explained enough\\n\",\n \"- Alternatively, one other option is a brute-force approach that saves and loads each weight tensor separately:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"id\": \"2CgPEZUIb00w\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"# Assume `model` is your trained model\\n\",\n \"state_dict = model.state_dict()\\n\",\n \"\\n\",\n \"# Create a directory to store individual parameter files\\n\",\n \"os.makedirs(\\\"model_parameters\\\", exist_ok=True)\\n\",\n \"\\n\",\n \"# Save each parameter tensor separately\\n\",\n \"for name, param in state_dict.items():\\n\",\n \" torch.save(param.cpu(), f\\\"model_parameters/{name}.pt\\\")\\n\",\n \"\\n\",\n \"del model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"gTsmtJK-b4yy\",\n \"outputId\": \"d361e2d3-e34c-48d7-9047-846c9bfd291e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Maximum GPU memory allocated: 6.4 GB\\n\",\n \"Maximum GPU memory allocated: 6.4 GB\\n\",\n \"-> Maximum CPU memory allocated: 0.3 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def load_individual_weights():\\n\",\n \"\\n\",\n \" start_memory_tracking()\\n\",\n \"\\n\",\n \" with torch.device(\\\"meta\\\"):\\n\",\n \" model = GPTModel(BASE_CONFIG)\\n\",\n \"\\n\",\n \" model = model.to_empty(device=device)\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \" param_dir = \\\"model_parameters\\\"\\n\",\n \"\\n\",\n \" with torch.no_grad():\\n\",\n \" for name, param in model.named_parameters():\\n\",\n \" weight_path = os.path.join(param_dir, f\\\"{name}.pt\\\")\\n\",\n \" if os.path.exists(weight_path):\\n\",\n \" param_data = torch.load(weight_path, map_location=\\\"cpu\\\", weights_only=True)\\n\",\n \" param.copy_(param_data)\\n\",\n \" del param_data # Free memory\\n\",\n \" else:\\n\",\n \" print(f\\\"Warning: {name} not found in {param_dir}.\\\")\\n\",\n \"\\n\",\n \" print_memory_usage()\\n\",\n \"\\n\",\n \"\\n\",\n \"peak_memory_used = memory_usage_in_gb(load_individual_weights)\\n\",\n \"print(f\\\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\\\")\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"T4\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.12.3\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 4\n}\n"
},
{
"path": "ch05/08_memory_efficient_weight_loading/previous_chapters.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# This file collects all the relevant code that we covered thus far\n# throughout Chapters 2-5.\n\n\nimport torch\nimport torch.nn as nn\n\n#####################################\n# Chapter 3\n#####################################\n\n\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by n_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n self.register_buffer(\"mask\", torch.triu(torch.ones(context_length, context_length), diagonal=1))\n\n def forward(self, x):\n b, num_tokens, d_in = x.shape\n\n keys = self.W_key(x) # Shape: (b, num_tokens, d_out)\n queries = self.W_query(x)\n values = self.W_value(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n # Original mask truncated to the number of tokens and converted to boolean\n mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.reshape(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n context_length=cfg[\"context_length\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n self.trf_blocks = nn.Sequential(\n *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n x = self.trf_blocks(x)\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n"
},
{
"path": "ch05/09_extending-tokenizers/README.md",
"content": "# Extending the Tiktoken BPE Tokenizer with New Tokens\n\n- [extend-tiktoken.ipynb](extend-tiktoken.ipynb) contains optional (bonus) code to explain how we can add special tokens to a tokenizer implemented via `tiktoken` and how to update the LLM accordingly"
},
{
"path": "ch05/09_extending-tokenizers/extend-tiktoken.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cbbc1fe3-bff1-4631-bf35-342e19c54cc0\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dec38b24-c845-4090-96a4-0d3c4ec241d6\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 2.3 Updating the embedding layer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b1328726-8297-4162-878b-a5daff7de742\",\n \"metadata\": {},\n \"source\": [\n \"- Let's start with updating the embedding layer\\n\",\n \"- First, notice that the embedding layer has 50,257 entries, which corresponds to the vocabulary size:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"23ecab6e-1232-47c7-a318-042f90e1dff3\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Embedding(50257, 768)\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"gpt.tok_emb\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d760c683-d082-470a-bff8-5a08b30d3b61\",\n \"metadata\": {},\n \"source\": [\n \"- We want to extend this embedding layer by adding 2 more entries\\n\",\n \"- In short, we create a new embedding layer with a bigger size, and then we copy over the old embedding layer values\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"4ec5c48e-c6fe-4e84-b290-04bd4da9483f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Embedding(50259, 768)\\n\"\n ]\n }\n ],\n \"source\": [\n \"num_tokens, emb_size = gpt.tok_emb.weight.shape\\n\",\n \"new_num_tokens = num_tokens + 2\\n\",\n \"\\n\",\n \"# Create a new embedding layer\\n\",\n \"new_embedding = torch.nn.Embedding(new_num_tokens, emb_size)\\n\",\n \"\\n\",\n \"# Copy weights from the old embedding layer\\n\",\n \"new_embedding.weight.data[:num_tokens] = gpt.tok_emb.weight.data\\n\",\n \"\\n\",\n \"# Replace the old embedding layer with the new one in the model\\n\",\n \"gpt.tok_emb = new_embedding\\n\",\n \"\\n\",\n \"print(gpt.tok_emb)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"63954928-31a5-4e7e-9688-2e0c156b7302\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see above, we now have an increased embedding layer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6e68bea5-255b-47bb-b352-09ea9539bc25\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 2.4 Updating the output layer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90a4a519-bf0f-4502-912d-ef0ac7a9deab\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we have to extend the output layer, which has 50,257 output features corresponding to the vocabulary size similar to the embedding layer (by the way, you may find the bonus material, which discusses the similarity between Linear and Embedding layers in PyTorch, useful)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"6105922f-d889-423e-bbcc-bc49156d78df\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Linear(in_features=768, out_features=50257, bias=False)\"\n ]\n },\n \"execution_count\": 14,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"gpt.out_head\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"29f1ff24-9c00-40f6-a94f-82d03aaf0890\",\n \"metadata\": {},\n \"source\": [\n \"- The procedure for extending the output layer is similar to extending the embedding layer:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"354589db-b148-4dae-8068-62132e3fb38e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Linear(in_features=768, out_features=50259, bias=True)\\n\"\n ]\n }\n ],\n \"source\": [\n \"original_out_features, original_in_features = gpt.out_head.weight.shape\\n\",\n \"\\n\",\n \"# Define the new number of output features (e.g., adding 2 new tokens)\\n\",\n \"new_out_features = original_out_features + 2\\n\",\n \"\\n\",\n \"# Create a new linear layer with the extended output size\\n\",\n \"new_linear = torch.nn.Linear(original_in_features, new_out_features)\\n\",\n \"\\n\",\n \"# Copy the weights and biases from the original linear layer\\n\",\n \"with torch.no_grad():\\n\",\n \" new_linear.weight[:original_out_features] = gpt.out_head.weight\\n\",\n \" if gpt.out_head.bias is not None:\\n\",\n \" new_linear.bias[:original_out_features] = gpt.out_head.bias\\n\",\n \"\\n\",\n \"# Replace the original linear layer with the new one\\n\",\n \"gpt.out_head = new_linear\\n\",\n \"\\n\",\n \"print(gpt.out_head)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"df5d2205-1fae-4a4f-a7bd-fa8fc37eeec2\",\n \"metadata\": {},\n \"source\": [\n \"- Let's try this updated model on the original token IDs first:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"df604bbc-6c13-4792-8ba8-ecb692117c25\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[ 0.2267, 0.9132, 1.0494, ..., -0.2330, -0.3008, -1.1458],\\n\",\n \" [ 0.6808, -0.0495, 0.8574, ..., 0.0671, 0.5572, -0.7873],\\n\",\n \" [-0.1947, 0.1045, 0.2773, ..., 1.3368, 0.8479, -0.9660],\\n\",\n \" ...,\\n\",\n \" [ 0.1200, -0.1027, 2.0549, ..., -0.1519, -0.2096, 0.5651],\\n\",\n \" [-1.1920, -0.1819, -0.0981, ..., -0.1108, 0.8435, -0.3771],\\n\",\n \" [-1.0612, -0.5674, 0.3229, ..., 0.8383, -0.7121, -0.4850]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" output = gpt(torch.tensor([original_token_ids]))\\n\",\n \"print(output)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3d80717e-50e6-4927-8129-0aadfa2628f5\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's try it on the updated tokens:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"75f11ec9-bdd2-440f-b8c8-6646b75891c6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[ 0.2267, 0.9132, 1.0494, ..., -0.2330, -0.3008, -1.1458],\\n\",\n \" [ 0.6808, -0.0495, 0.8574, ..., 0.0671, 0.5572, -0.7873],\\n\",\n \" [-0.1947, 0.1045, 0.2773, ..., 1.3368, 0.8479, -0.9660],\\n\",\n \" ...,\\n\",\n \" [-0.0656, -1.2451, 0.7957, ..., -1.2124, 0.1044, 0.5088],\\n\",\n \" [-1.1561, -0.7380, -0.0645, ..., -0.4373, 1.1401, -0.3903],\\n\",\n \" [-0.8961, -0.6437, -0.1667, ..., 0.5663, -0.5862, -0.4020]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" output = gpt(torch.tensor([new_token_ids]))\\n\",\n \"print(output)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d88a1bba-db01-4090-97e4-25dfc23ed54c\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see, the model works on the extended token set\\n\",\n \"- In practice, we want to now finetune (or continually pretrain) the model (specifically the new embedding and output layers) on data containing the new tokens\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6de573ad-0338-40d9-9dad-de60ae349c4f\",\n \"metadata\": {},\n \"source\": [\n \"**A note about weight tying**\\n\",\n \"\\n\",\n \"- If the model uses weight tying, which means that the embedding layer and output layer share the same weights, similar to Llama 3 [link], updating the output layer is much simpler\\n\",\n \"- In this case, we can simply copy over the weights from the embedding layer:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"4cbc5f51-c7a8-49d0-b87f-d3d87510953b\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"gpt.out_head.weight = gpt.tok_emb.weight\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"d0d553a8-edff-40f0-bdc4-dff900e16caf\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" output = gpt(torch.tensor([new_token_ids]))\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.10.16\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/10_llm-training-speed/00_orig.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n\nimport os\nimport time\nimport urllib.request\n\nimport matplotlib.pyplot as plt\nimport torch\nimport torch.nn as nn\nfrom torch.utils.data import Dataset, DataLoader\nimport tiktoken\n\n#####################################\n# Chapter 2\n#####################################\n\n\nclass GPTDatasetV1(Dataset):\n def __init__(self, txt, tokenizer, max_length, stride):\n self.input_ids = []\n self.target_ids = []\n\n # Tokenize the entire text\n token_ids = tokenizer.encode(txt, allowed_special={\"<|endoftext|>\"})\n\n # Use a sliding window to chunk the book into overlapping sequences of max_length\n for i in range(0, len(token_ids) - max_length, stride):\n input_chunk = token_ids[i:i + max_length]\n target_chunk = token_ids[i + 1: i + max_length + 1]\n self.input_ids.append(torch.tensor(input_chunk))\n self.target_ids.append(torch.tensor(target_chunk))\n\n def __len__(self):\n return len(self.input_ids)\n\n def __getitem__(self, idx):\n return self.input_ids[idx], self.target_ids[idx]\n\n\ndef create_dataloader_v1(txt, batch_size=4, max_length=256,\n stride=128, shuffle=True, drop_last=True, num_workers=0):\n # Initialize the tokenizer\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n # Create dataset\n dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)\n\n # Create dataloader\n dataloader = DataLoader(\n dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=num_workers)\n\n return dataloader\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by n_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n self.register_buffer(\"mask\", torch.triu(torch.ones(context_length, context_length), diagonal=1))\n\n def forward(self, x):\n b, num_tokens, d_in = x.shape\n\n keys = self.W_key(x) # Shape: (b, num_tokens, d_out)\n queries = self.W_query(x)\n values = self.W_value(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n # Original mask truncated to the number of tokens and converted to boolean\n mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.reshape(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n context_length=cfg[\"context_length\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n self.trf_blocks = nn.Sequential(\n *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n x = self.trf_blocks(x)\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n#####################################\n# Chapter 5\n#####################################\n\n\ndef text_to_token_ids(text, tokenizer):\n encoded = tokenizer.encode(text)\n encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\n return encoded_tensor\n\n\ndef token_ids_to_text(token_ids, tokenizer):\n flat = token_ids.squeeze(0) # remove batch dimension\n return tokenizer.decode(flat.tolist())\n\n\ndef calc_loss_batch(input_batch, target_batch, model, device):\n input_batch, target_batch = input_batch.to(device), target_batch.to(device)\n logits = model(input_batch)\n loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())\n return loss\n\n\ndef calc_loss_loader(data_loader, model, device, num_batches=None):\n total_loss = 0.\n if len(data_loader) == 0:\n return float(\"nan\")\n elif num_batches is None:\n num_batches = len(data_loader)\n else:\n num_batches = min(num_batches, len(data_loader))\n for i, (input_batch, target_batch) in enumerate(data_loader):\n if i < num_batches:\n loss = calc_loss_batch(input_batch, target_batch, model, device)\n total_loss += loss.item()\n else:\n break\n return total_loss / num_batches\n\n\ndef evaluate_model(model, train_loader, val_loader, device, eval_iter):\n model.eval()\n with torch.no_grad():\n train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\n val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\n model.train()\n return train_loss, val_loss\n\n\ndef generate_and_print_sample(model, tokenizer, device, start_context):\n model.eval()\n context_size = model.pos_emb.weight.shape[0]\n encoded = text_to_token_ids(start_context, tokenizer).to(device)\n with torch.no_grad():\n token_ids = generate_text_simple(\n model=model, idx=encoded,\n max_new_tokens=50, context_size=context_size\n )\n decoded_text = token_ids_to_text(token_ids, tokenizer)\n print(decoded_text.replace(\"\\n\", \" \")) # Compact print format\n model.train()\n\n\ndef train_model_simple_with_timing(model, train_loader, val_loader, optimizer, device,\n num_epochs, eval_freq, eval_iter, start_context, tokenizer):\n train_losses, val_losses, track_tokens = [], [], []\n total_tokens, global_step, last_tokens = 0, -1, 0\n\n # Variables for cumulative average tokens/sec\n cumulative_tokens, cumulative_time = 0.0, 0.0\n\n # CUDA-specific timing setup\n use_cuda = device.type == \"cuda\"\n if use_cuda:\n t_start = torch.cuda.Event(enable_timing=True)\n t_end = torch.cuda.Event(enable_timing=True)\n torch.cuda.synchronize() # Ensure all prior CUDA operations are done\n t_start.record() # Start the timer for the first interval\n else:\n t0 = time.time() # Start the timer for the first interval\n\n # Main training loop\n for epoch in range(num_epochs):\n model.train()\n for inp_batch, tgt_batch in train_loader:\n optimizer.zero_grad()\n global_step += 1\n\n # Forward and backward pass\n loss = calc_loss_batch(inp_batch, tgt_batch, model, device)\n loss.backward()\n optimizer.step()\n\n total_tokens += inp_batch.numel()\n\n # At evaluation intervals, measure elapsed time and tokens per second\n if global_step % eval_freq == 0:\n # End timing for the current interval\n if use_cuda:\n t_end.record()\n torch.cuda.synchronize() # Wait for all CUDA ops to complete.\n elapsed = t_start.elapsed_time(t_end) / 1000 # Convert ms to seconds\n t_start.record() # Reset timer for the next interval\n else:\n elapsed = time.time() - t0\n t0 = time.time() # Reset timer for the next interval\n\n # Calculate tokens processed in this interval\n tokens_interval = total_tokens - last_tokens\n last_tokens = total_tokens\n tps = tokens_interval / elapsed if elapsed > 0 else 0 # Tokens per second\n\n # Update cumulative counters (skip the first evaluation interval)\n if global_step: # This is False only when global_step == 0 (first evaluation)\n cumulative_tokens += tokens_interval\n cumulative_time += elapsed\n\n # Compute cumulative average tokens/sec (excluding the first interval)\n avg_tps = cumulative_tokens / cumulative_time if cumulative_time > 0 else 0\n\n # Evaluate model performance (this may add overhead)\n train_loss, val_loss = evaluate_model(model, train_loader, val_loader, device, eval_iter)\n train_losses.append(train_loss)\n val_losses.append(val_loss)\n track_tokens.append(total_tokens)\n\n print(f\"Ep {epoch+1}, Step {global_step:06d}, \"\n f\"Train: {train_loss:.3f}, Val: {val_loss:.3f}, \"\n f\"Step tok/sec: {round(tps)}, Avg tok/sec: {round(avg_tps)}\")\n\n generate_and_print_sample(model, tokenizer, device, start_context)\n\n # Memory stats\n if torch.cuda.is_available():\n device = torch.cuda.current_device()\n\n allocated = torch.cuda.memory_allocated(device) / 1024**3 # Convert to GB\n reserved = torch.cuda.memory_reserved(device) / 1024**3 # Convert to GB\n\n print(f\"\\nAllocated memory: {allocated:.4f} GB\")\n print(f\"Reserved memory: {reserved:.4f} GB\\n\")\n\n return train_losses, val_losses, track_tokens\n\n\ndef plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):\n fig, ax1 = plt.subplots()\n\n # Plot training and validation loss against epochs\n ax1.plot(epochs_seen, train_losses, label=\"Training loss\")\n ax1.plot(epochs_seen, val_losses, linestyle=\"-.\", label=\"Validation loss\")\n ax1.set_xlabel(\"Epochs\")\n ax1.set_ylabel(\"Loss\")\n ax1.legend(loc=\"upper right\")\n\n # Create a second x-axis for tokens seen\n ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\n ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks\n ax2.set_xlabel(\"Tokens seen\")\n\n fig.tight_layout() # Adjust layout to make room\n # plt.show()\n\n\n#####################################\n# Main function calls\n#####################################\n\ndef main(gpt_config, settings):\n\n torch.manual_seed(123)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n print(f\"PyTorch version: {torch.__version__}\")\n print(f\"Using {device}\")\n if torch.cuda.is_available():\n print(f\"CUDA version: {torch.version.cuda}\")\n print()\n\n ##############################\n # Download data if necessary\n ##############################\n\n file_path = \"middlemarch.txt\"\n url = \"https://www.gutenberg.org/cache/epub/145/pg145.txt\"\n\n if not os.path.exists(file_path):\n with urllib.request.urlopen(url) as response:\n text_data = response.read().decode(\"utf-8\")\n with open(file_path, \"w\", encoding=\"utf-8\") as file:\n file.write(text_data)\n else:\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n text_data = file.read()\n\n ##############################\n # Initialize model\n ##############################\n\n model = GPTModel(gpt_config)\n model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes\n optimizer = torch.optim.AdamW(\n model.parameters(), lr=settings[\"learning_rate\"], weight_decay=settings[\"weight_decay\"]\n )\n\n ##############################\n # Set up dataloaders\n ##############################\n\n # Train/validation ratio\n train_ratio = 0.90\n split_idx = int(train_ratio * len(text_data))\n\n train_loader = create_dataloader_v1(\n text_data[:split_idx],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=True,\n shuffle=True,\n num_workers=4\n )\n\n val_loader = create_dataloader_v1(\n text_data[split_idx:],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=False,\n shuffle=False,\n num_workers=4\n )\n\n ##############################\n # Train model\n ##############################\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n train_losses, val_losses, tokens_seen = train_model_simple_with_timing(\n model=model,\n train_loader=train_loader,\n val_loader=val_loader,\n optimizer=optimizer,\n device=device,\n num_epochs=settings[\"num_epochs\"],\n eval_freq=15,\n eval_iter=1,\n start_context=\"Every effort moves you\",\n tokenizer=tokenizer\n )\n\n return train_losses, val_losses, tokens_seen, model\n\n\nif __name__ == \"__main__\":\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Input tokens per training example\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False # Query-key-value bias\n }\n\n OTHER_SETTINGS = {\n \"learning_rate\": 5e-4,\n \"num_epochs\": 15,\n \"batch_size\": 8,\n \"weight_decay\": 0.1\n }\n\n ###########################\n # Initiate training\n ###########################\n\n train_losses, val_losses, tokens_seen, model = main(GPT_CONFIG_124M, OTHER_SETTINGS)\n\n ###########################\n # After training\n ###########################\n\n # Plot results\n epochs_tensor = torch.linspace(0, OTHER_SETTINGS[\"num_epochs\"], len(train_losses))\n plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)\n plt.savefig(\"loss.pdf\")\n\n # Save and load model\n # torch.save(model.state_dict(), \"model.pth\")\n # model = GPTModel(GPT_CONFIG_124M)\n # model.load_state_dict(torch.load(\"model.pth\", weights_only=True))\n"
},
{
"path": "ch05/10_llm-training-speed/01_opt_single_gpu.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n\nimport os\nimport time\n\nimport matplotlib.pyplot as plt\nimport requests\nimport torch\nimport torch.nn as nn\nfrom torch.utils.data import Dataset, DataLoader\nimport tiktoken\n\n#####################################\n# Chapter 2\n#####################################\n\n\nclass GPTDatasetV1(Dataset):\n def __init__(self, txt, tokenizer, max_length, stride):\n self.input_ids = []\n self.target_ids = []\n\n # Tokenize the entire text\n token_ids = tokenizer.encode(txt, allowed_special={\"<|endoftext|>\"})\n\n # Use a sliding window to chunk the book into overlapping sequences of max_length\n for i in range(0, len(token_ids) - max_length, stride):\n input_chunk = token_ids[i:i + max_length]\n target_chunk = token_ids[i + 1: i + max_length + 1]\n self.input_ids.append(torch.tensor(input_chunk))\n self.target_ids.append(torch.tensor(target_chunk))\n\n def __len__(self):\n return len(self.input_ids)\n\n def __getitem__(self, idx):\n return self.input_ids[idx], self.target_ids[idx]\n\n\ndef create_dataloader_v1(txt, batch_size=4, max_length=256,\n stride=128, shuffle=True, drop_last=True, num_workers=0):\n # Initialize the tokenizer\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n # Create dataset\n dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)\n\n # Create dataloader\n dataloader = DataLoader(\n dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=num_workers,\n pin_memory=True\n )\n\n return dataloader\n\n\n#####################################\n# Chapter 3\n#####################################\nclass PyTorchMultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, num_heads, dropout=0.0, qkv_bias=False):\n super().__init__()\n\n assert d_out % num_heads == 0, \"d_out is indivisible by num_heads\"\n\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n self.d_out = d_out\n\n self.qkv = nn.Linear(d_in, 3 * d_out, bias=qkv_bias)\n self.proj = nn.Linear(d_out, d_out)\n self.dropout = dropout\n\n def forward(self, x):\n batch_size, num_tokens, embed_dim = x.shape\n\n # (b, num_tokens, embed_dim) --> (b, num_tokens, 3 * embed_dim)\n qkv = self.qkv(x)\n\n # (b, num_tokens, 3 * embed_dim) --> (b, num_tokens, 3, num_heads, head_dim)\n qkv = qkv.view(batch_size, num_tokens, 3, self.num_heads, self.head_dim)\n\n # (b, num_tokens, 3, num_heads, head_dim) --> (3, b, num_heads, num_tokens, head_dim)\n qkv = qkv.permute(2, 0, 3, 1, 4)\n\n # (3, b, num_heads, num_tokens, head_dim) -> 3 times (b, num_heads, num_tokens, head_dim)\n queries, keys, values = qkv\n\n use_dropout = 0. if not self.training else self.dropout\n\n context_vec = nn.functional.scaled_dot_product_attention(\n queries, keys, values, attn_mask=None, dropout_p=use_dropout, is_causal=True)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.transpose(1, 2).contiguous().view(batch_size, num_tokens, self.d_out)\n\n context_vec = self.proj(context_vec)\n\n return context_vec\n\n\n#####################################\n# Chapter 4\n#####################################\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n nn.GELU(approximate=\"tanh\"),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = PyTorchMultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = nn.LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = nn.LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n self.trf_blocks = nn.Sequential(\n *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.final_norm = nn.LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n x = self.trf_blocks(x)\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n#####################################\n# Chapter 5\n#####################################\n\n\ndef text_to_token_ids(text, tokenizer):\n encoded = tokenizer.encode(text)\n encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\n return encoded_tensor\n\n\ndef token_ids_to_text(token_ids, tokenizer):\n flat = token_ids.squeeze(0) # remove batch dimension\n return tokenizer.decode(flat.tolist())\n\n\ndef calc_loss_batch(input_batch, target_batch, model, device):\n input_batch, target_batch = input_batch.to(device), target_batch.to(device)\n logits = model(input_batch)\n loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())\n return loss\n\n\ndef calc_loss_loader(data_loader, model, device, num_batches=None):\n total_loss = 0.\n if len(data_loader) == 0:\n return float(\"nan\")\n elif num_batches is None:\n num_batches = len(data_loader)\n else:\n num_batches = min(num_batches, len(data_loader))\n for i, (input_batch, target_batch) in enumerate(data_loader):\n if i < num_batches:\n loss = calc_loss_batch(input_batch, target_batch, model, device)\n total_loss += loss.item()\n else:\n break\n return total_loss / num_batches\n\n\ndef evaluate_model(model, train_loader, val_loader, device, eval_iter):\n model.eval()\n with torch.no_grad():\n train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\n val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\n model.train()\n return train_loss, val_loss\n\n\ndef generate_and_print_sample(model, tokenizer, device, start_context):\n model.eval()\n context_size = model.pos_emb.weight.shape[0]\n encoded = text_to_token_ids(start_context, tokenizer).to(device)\n with torch.no_grad():\n token_ids = generate_text_simple(\n model=model, idx=encoded,\n max_new_tokens=50, context_size=context_size\n )\n decoded_text = token_ids_to_text(token_ids, tokenizer)\n print(decoded_text.replace(\"\\n\", \" \")) # Compact print format\n model.train()\n\n\ndef train_model_simple_with_timing(model, train_loader, val_loader, optimizer, device,\n num_epochs, eval_freq, eval_iter, start_context, tokenizer):\n train_losses, val_losses, track_tokens = [], [], []\n total_tokens, global_step, last_tokens = 0, -1, 0\n\n # Variables for cumulative average tokens/sec\n cumulative_tokens, cumulative_time = 0.0, 0.0\n\n # CUDA-specific timing setup\n use_cuda = device.type == \"cuda\"\n if use_cuda:\n t_start = torch.cuda.Event(enable_timing=True)\n t_end = torch.cuda.Event(enable_timing=True)\n torch.cuda.synchronize() # Ensure all prior CUDA operations are done\n t_start.record() # Start the timer for the first interval\n else:\n t0 = time.time() # Start the timer for the first interval\n\n # Main training loop\n for epoch in range(num_epochs):\n model.train()\n for inp_batch, tgt_batch in train_loader:\n optimizer.zero_grad()\n global_step += 1\n\n # Forward and backward pass\n loss = calc_loss_batch(inp_batch, tgt_batch, model, device)\n loss.backward()\n optimizer.step()\n\n total_tokens += inp_batch.numel()\n\n # At evaluation intervals, measure elapsed time and tokens per second\n if global_step % eval_freq == 0:\n # End timing for the current interval\n if use_cuda:\n t_end.record()\n torch.cuda.synchronize() # Wait for all CUDA ops to complete.\n elapsed = t_start.elapsed_time(t_end) / 1000 # Convert ms to seconds\n t_start.record() # Reset timer for the next interval\n else:\n elapsed = time.time() - t0\n t0 = time.time() # Reset timer for the next interval\n\n # Calculate tokens processed in this interval\n tokens_interval = total_tokens - last_tokens\n last_tokens = total_tokens\n tps = tokens_interval / elapsed if elapsed > 0 else 0 # Tokens per second\n\n # Update cumulative counters (skip the first evaluation interval)\n if global_step: # This is False only when global_step == 0 (first evaluation)\n cumulative_tokens += tokens_interval\n cumulative_time += elapsed\n\n # Compute cumulative average tokens/sec (excluding the first interval)\n avg_tps = cumulative_tokens / cumulative_time if cumulative_time > 0 else 0\n\n # Evaluate model performance (this may add overhead)\n train_loss, val_loss = evaluate_model(model, train_loader, val_loader, device, eval_iter)\n train_losses.append(train_loss)\n val_losses.append(val_loss)\n track_tokens.append(total_tokens)\n\n print(f\"Ep {epoch+1}, Step {global_step:06d}, \"\n f\"Train: {train_loss:.3f}, Val: {val_loss:.3f}, \"\n f\"Step tok/sec: {round(tps)}, Avg tok/sec: {round(avg_tps)}\")\n\n generate_and_print_sample(model, tokenizer, device, start_context)\n\n # Memory stats\n if torch.cuda.is_available():\n device = torch.cuda.current_device()\n\n allocated = torch.cuda.memory_allocated(device) / 1024**3 # Convert to GB\n reserved = torch.cuda.memory_reserved(device) / 1024**3 # Convert to GB\n\n print(f\"\\nAllocated memory: {allocated:.4f} GB\")\n print(f\"Reserved memory: {reserved:.4f} GB\\n\")\n\n return train_losses, val_losses, track_tokens\n\n\ndef plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):\n fig, ax1 = plt.subplots()\n\n # Plot training and validation loss against epochs\n ax1.plot(epochs_seen, train_losses, label=\"Training loss\")\n ax1.plot(epochs_seen, val_losses, linestyle=\"-.\", label=\"Validation loss\")\n ax1.set_xlabel(\"Epochs\")\n ax1.set_ylabel(\"Loss\")\n ax1.legend(loc=\"upper right\")\n\n # Create a second x-axis for tokens seen\n ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\n ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks\n ax2.set_xlabel(\"Tokens seen\")\n\n fig.tight_layout() # Adjust layout to make room\n # plt.show()\n\n\n#####################################\n# Main function calls\n#####################################\n\ndef main(gpt_config, settings):\n\n torch.manual_seed(123)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n print(f\"PyTorch version: {torch.__version__}\")\n print(f\"Using {device}\")\n if torch.cuda.is_available():\n print(f\"CUDA version: {torch.version.cuda}\")\n\n capability = torch.cuda.get_device_capability()\n if capability[0] >= 7: # Volta (7.0+), Turing (7.5+), Ampere (8.0+), Hopper (9.0+)\n torch.set_float32_matmul_precision(\"high\")\n print(\"Uses tensor cores\")\n else:\n print(\"Tensor cores not supported on this GPU. Using default precision.\")\n print(f\"Uses tensor cores: {torch.cuda.is_available()}\")\n print()\n\n ##############################\n # Download data if necessary\n ##############################\n\n file_path = \"middlemarch.txt\"\n url = \"https://www.gutenberg.org/cache/epub/145/pg145.txt\"\n\n if not os.path.exists(file_path):\n response = requests.get(url, timeout=30)\n response.raise_for_status()\n text_data = response.text\n with open(file_path, \"w\", encoding=\"utf-8\") as file:\n file.write(text_data)\n else:\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n text_data = file.read()\n\n ##############################\n # Initialize model\n ##############################\n\n model = GPTModel(gpt_config)\n model = torch.compile(model)\n model.to(device).to(torch.bfloat16)\n optimizer = torch.optim.AdamW(\n model.parameters(), lr=settings[\"learning_rate\"], weight_decay=settings[\"weight_decay\"],\n fused=True\n )\n\n ##############################\n # Set up dataloaders\n ##############################\n\n # Train/validation ratio\n train_ratio = 0.90\n split_idx = int(train_ratio * len(text_data))\n\n train_loader = create_dataloader_v1(\n text_data[:split_idx],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=True,\n shuffle=True,\n num_workers=4\n )\n\n val_loader = create_dataloader_v1(\n text_data[split_idx:],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=False,\n shuffle=False,\n num_workers=4\n )\n\n ##############################\n # Train model\n ##############################\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n train_losses, val_losses, tokens_seen = train_model_simple_with_timing(\n model=model,\n train_loader=train_loader,\n val_loader=val_loader,\n optimizer=optimizer,\n device=device,\n num_epochs=settings[\"num_epochs\"],\n eval_freq=10,\n eval_iter=1,\n start_context=\"Every effort moves you\",\n tokenizer=tokenizer\n )\n\n return train_losses, val_losses, tokens_seen, model\n\n\nif __name__ == \"__main__\":\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50304, # Vocabulary size\n \"context_length\": 1024, # Input tokens per training example\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False # Query-key-value bias\n }\n\n OTHER_SETTINGS = {\n \"learning_rate\": 5e-4,\n \"num_epochs\": 15,\n \"batch_size\": 32,\n \"weight_decay\": 0.1\n }\n\n ###########################\n # Initiate training\n ###########################\n\n train_losses, val_losses, tokens_seen, model = main(GPT_CONFIG_124M, OTHER_SETTINGS)\n\n ###########################\n # After training\n ###########################\n\n # Plot results\n epochs_tensor = torch.linspace(0, OTHER_SETTINGS[\"num_epochs\"], len(train_losses))\n plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)\n plt.savefig(\"loss.pdf\")\n\n # Save and load model\n #\n # compiled = hasattr(model, \"_orig_mod\")\n # if compiled:\n # torch.save(model._orig_mod.state_dict(), \"model.pth\")\n # else:\n # torch.save(model.state_dict(), \"model.pth\")\n #\n # model = GPTModel(GPT_CONFIG_124M)\n # model.load_state_dict(torch.load(\"model.pth\", weights_only=True))\n"
},
{
"path": "ch05/10_llm-training-speed/02_opt_multi_gpu_ddp.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n\nimport os\nimport time\n\nimport matplotlib.pyplot as plt\nimport requests\nimport torch\nimport torch.nn as nn\nfrom torch.utils.data import Dataset, DataLoader\nimport tiktoken\n\n# NEW imports (see Appendix A):\nimport platform\nfrom torch.utils.data.distributed import DistributedSampler\nfrom torch.nn.parallel import DistributedDataParallel as DDP\nfrom torch.distributed import init_process_group, destroy_process_group\n\n\n# NEW: function to initialize a distributed process group (1 process / GPU)\n# this allows communication among processes\n# (see Appendix A):\ndef ddp_setup(rank, world_size):\n \"\"\"\n Arguments:\n rank: a unique process ID\n world_size: total number of processes in the group\n \"\"\"\n # Only set MASTER_ADDR and MASTER_PORT if not already defined by torchrun\n if \"MASTER_ADDR\" not in os.environ:\n os.environ[\"MASTER_ADDR\"] = \"localhost\"\n if \"MASTER_PORT\" not in os.environ:\n os.environ[\"MASTER_PORT\"] = \"12345\"\n\n # initialize process group\n if platform.system() == \"Windows\":\n # Disable libuv because PyTorch for Windows isn't built with support\n os.environ[\"USE_LIBUV\"] = \"0\"\n # Windows users may have to use \"gloo\" instead of \"nccl\" as backend\n # gloo: Facebook Collective Communication Library\n init_process_group(backend=\"gloo\", rank=rank, world_size=world_size)\n else:\n # nccl: NVIDIA Collective Communication Library\n init_process_group(backend=\"nccl\", rank=rank, world_size=world_size)\n\n torch.cuda.set_device(rank)\n\n\n#####################################\n# Chapter 2\n#####################################\n\n\nclass GPTDatasetV1(Dataset):\n def __init__(self, txt, tokenizer, max_length, stride):\n self.input_ids = []\n self.target_ids = []\n\n # Tokenize the entire text\n token_ids = tokenizer.encode(txt, allowed_special={\"<|endoftext|>\"})\n\n # Use a sliding window to chunk the book into overlapping sequences of max_length\n for i in range(0, len(token_ids) - max_length, stride):\n input_chunk = token_ids[i:i + max_length]\n target_chunk = token_ids[i + 1: i + max_length + 1]\n self.input_ids.append(torch.tensor(input_chunk))\n self.target_ids.append(torch.tensor(target_chunk))\n\n def __len__(self):\n return len(self.input_ids)\n\n def __getitem__(self, idx):\n return self.input_ids[idx], self.target_ids[idx]\n\n\n# NEW: Modify to set shuffle=False and use a sampler\n# (See Appendix A):\ndef create_dataloader_v1(txt, batch_size=4, max_length=256,\n stride=128, drop_last=True, num_workers=0):\n # Initialize the tokenizer\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n # Create dataset\n dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)\n\n # Create dataloader\n dataloader = DataLoader(\n dataset=dataset,\n batch_size=batch_size,\n shuffle=False, # NEW: False because of DistributedSampler below\n drop_last=drop_last,\n num_workers=num_workers,\n pin_memory=True,\n # NEW: chunk batches across GPUs without overlapping samples:\n sampler=DistributedSampler(dataset) # NEW\n )\n return dataloader\n\n\n#####################################\n# Chapter 3\n#####################################\nclass PyTorchMultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, num_heads, dropout=0.0, qkv_bias=False):\n super().__init__()\n\n assert d_out % num_heads == 0, \"d_out is indivisible by num_heads\"\n\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n self.d_out = d_out\n\n self.qkv = nn.Linear(d_in, 3 * d_out, bias=qkv_bias)\n self.proj = nn.Linear(d_out, d_out)\n self.dropout = dropout\n\n def forward(self, x):\n batch_size, num_tokens, embed_dim = x.shape\n\n # (b, num_tokens, embed_dim) --> (b, num_tokens, 3 * embed_dim)\n qkv = self.qkv(x)\n\n # (b, num_tokens, 3 * embed_dim) --> (b, num_tokens, 3, num_heads, head_dim)\n qkv = qkv.view(batch_size, num_tokens, 3, self.num_heads, self.head_dim)\n\n # (b, num_tokens, 3, num_heads, head_dim) --> (3, b, num_heads, num_tokens, head_dim)\n qkv = qkv.permute(2, 0, 3, 1, 4)\n\n # (3, b, num_heads, num_tokens, head_dim) -> 3 times (b, num_heads, num_tokens, head_dim)\n queries, keys, values = qkv\n\n use_dropout = 0. if not self.training else self.dropout\n\n context_vec = nn.functional.scaled_dot_product_attention(\n queries, keys, values, attn_mask=None, dropout_p=use_dropout, is_causal=True)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.transpose(1, 2).contiguous().view(batch_size, num_tokens, self.d_out)\n\n context_vec = self.proj(context_vec)\n\n return context_vec\n\n\n#####################################\n# Chapter 4\n#####################################\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n nn.GELU(approximate=\"tanh\"),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = PyTorchMultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = nn.LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = nn.LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n self.trf_blocks = nn.Sequential(\n *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.final_norm = nn.LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n x = self.trf_blocks(x)\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n#####################################\n# Chapter 5\n#####################################\n\n\ndef text_to_token_ids(text, tokenizer):\n encoded = tokenizer.encode(text)\n encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\n return encoded_tensor\n\n\ndef token_ids_to_text(token_ids, tokenizer):\n flat = token_ids.squeeze(0) # remove batch dimension\n return tokenizer.decode(flat.tolist())\n\n\ndef calc_loss_batch(input_batch, target_batch, model, device):\n input_batch, target_batch = input_batch.to(device), target_batch.to(device)\n logits = model(input_batch)\n loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())\n return loss\n\n\ndef calc_loss_loader(data_loader, model, device, num_batches=None):\n total_loss = 0.\n if len(data_loader) == 0:\n return float(\"nan\")\n elif num_batches is None:\n num_batches = len(data_loader)\n else:\n num_batches = min(num_batches, len(data_loader))\n for i, (input_batch, target_batch) in enumerate(data_loader):\n if i < num_batches:\n loss = calc_loss_batch(input_batch, target_batch, model, device)\n total_loss += loss.item()\n else:\n break\n return total_loss / num_batches\n\n\ndef evaluate_model(model, train_loader, val_loader, device, eval_iter):\n model.eval()\n with torch.no_grad():\n train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\n val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\n model.train()\n return train_loss, val_loss\n\n\ndef generate_and_print_sample(model, device, start_context):\n model.eval()\n\n # NEW: Modify for DDP\n context_size = model.module.pos_emb.weight.shape[0] if isinstance(model, DDP) else model.pos_emb.weight.shape[0]\n encoded = text_to_token_ids(start_context, tiktoken.get_encoding(\"gpt2\")).to(device)\n with torch.no_grad():\n token_ids = generate_text_simple(\n model=model, idx=encoded,\n max_new_tokens=50, context_size=context_size\n )\n decoded_text = token_ids_to_text(token_ids, tiktoken.get_encoding(\"gpt2\"))\n print(decoded_text.replace(\"\\n\", \" \")) # Compact print format\n model.train()\n\n\ndef train_model_simple_with_timing(model, train_loader, val_loader, optimizer, device,\n num_epochs, eval_freq, eval_iter, start_context):\n train_losses, val_losses, track_tokens = [], [], []\n total_tokens, global_step, last_tokens = 0, -1, 0\n\n # NEW: Determine the current rank (default to 0 if not distributed)\n rank = torch.distributed.get_rank() if torch.distributed.is_initialized() else 0\n # world_size = torch.distributed.get_world_size() if torch.distributed.is_initialized() else 1\n\n # Variables for cumulative average tokens/sec\n cumulative_tokens, cumulative_time = 0.0, 0.0\n\n # CUDA-specific timing setup\n use_cuda = device.type == \"cuda\"\n if use_cuda:\n t_start = torch.cuda.Event(enable_timing=True)\n t_end = torch.cuda.Event(enable_timing=True)\n torch.cuda.synchronize() # Ensure all prior CUDA operations are done\n t_start.record() # Start the timer for the first interval\n else:\n t0 = time.time() # Start the timer for the first interval\n\n # Main training loop\n for epoch in range(num_epochs):\n # NEW: set epoch for DistributedSampler so each process gets a unique shuffle order\n if isinstance(train_loader.sampler, DistributedSampler):\n train_loader.sampler.set_epoch(epoch)\n\n model.train()\n for inp_batch, tgt_batch in train_loader:\n optimizer.zero_grad()\n global_step += 1\n\n # Forward and backward pass\n loss = calc_loss_batch(inp_batch, tgt_batch, model, device)\n loss.backward()\n optimizer.step()\n\n total_tokens += inp_batch.numel()\n\n # At evaluation intervals, measure elapsed time and tokens per second\n if global_step % eval_freq == 0:\n # End timing for the current interval\n if use_cuda:\n t_end.record()\n torch.cuda.synchronize() # Wait for all CUDA ops to complete.\n elapsed = t_start.elapsed_time(t_end) / 1000 # Convert ms to seconds\n t_start.record() # Reset timer for the next interval\n else:\n elapsed = time.time() - t0\n t0 = time.time() # Reset timer for the next interval\n\n # Calculate local tokens processed during this interval\n local_interval = total_tokens - last_tokens\n last_tokens = total_tokens\n\n # Aggregate the tokens processed over all devices\n local_tensor = torch.tensor([local_interval], device=device, dtype=torch.float)\n global_tensor = local_tensor.clone()\n torch.distributed.all_reduce(global_tensor, op=torch.distributed.ReduceOp.SUM)\n global_interval = global_tensor.item()\n\n # Global tokens per second for this interval\n global_tps = global_interval / elapsed if elapsed > 0 else 0\n\n # Update cumulative tokens (local) and aggregate globally\n cumulative_tokens += local_interval\n local_cum_tensor = torch.tensor([cumulative_tokens], device=device, dtype=torch.float)\n global_cum_tensor = local_cum_tensor.clone()\n torch.distributed.all_reduce(global_cum_tensor, op=torch.distributed.ReduceOp.SUM)\n global_cumulative_tokens = global_cum_tensor.item()\n cumulative_time += elapsed\n global_avg_tps = global_cumulative_tokens / cumulative_time if cumulative_time > 0 else 0\n\n # Evaluate model performance (this may add overhead)\n train_loss, val_loss = evaluate_model(model, train_loader, val_loader, device, eval_iter)\n train_losses.append(train_loss)\n val_losses.append(val_loss)\n track_tokens.append(total_tokens)\n\n # NEW: Only print logs once per GPU (choosing the rank 0 GPU)\n if rank == 0:\n print(f\"Ep {epoch+1}, Step {global_step:06d}, \"\n f\"Train: {train_loss:.3f}, Val: {val_loss:.3f}, \"\n f\"Step tok/sec: {round(global_tps)}, Global avg tok/sec: {round(global_avg_tps)}\")\n\n # NEW Only rank 0 prints the generated sample and memory usage stats\n if rank == 0 and epoch % 5 == 0:\n generate_and_print_sample(model, device, start_context)\n\n # Memory stats\n if torch.cuda.is_available():\n current_device = torch.cuda.current_device()\n allocated = torch.cuda.memory_allocated(current_device) / 1024**3 # Convert to GB\n reserved = torch.cuda.memory_reserved(current_device) / 1024**3 # Convert to GB\n\n print(f\"\\nAllocated memory: {allocated:.4f} GB\")\n print(f\"Reserved memory: {reserved:.4f} GB\\n\")\n\n return train_losses, val_losses, track_tokens\n\n\ndef plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):\n fig, ax1 = plt.subplots()\n\n # Plot training and validation loss against epochs\n ax1.plot(epochs_seen, train_losses, label=\"Training loss\")\n ax1.plot(epochs_seen, val_losses, linestyle=\"-.\", label=\"Validation loss\")\n ax1.set_xlabel(\"Epochs\")\n ax1.set_ylabel(\"Loss\")\n ax1.legend(loc=\"upper right\")\n\n # Create a second x-axis for tokens seen\n ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\n ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks\n ax2.set_xlabel(\"Tokens seen\")\n\n fig.tight_layout() # Adjust layout to make room\n # plt.show()\n\n\n#####################################\n# Main function calls\n#####################################\n\n# NEW: Add rank and world_size\ndef main(gpt_config, settings, rank, world_size):\n\n ddp_setup(rank, world_size) # NEW: initialize process groups\n device = torch.device(\"cuda\", rank)\n\n torch.manual_seed(123)\n\n # NEW: Print info only on 1 GPU\n if rank == 0:\n print(f\"PyTorch version: {torch.__version__}\")\n if torch.cuda.is_available():\n print(f\"CUDA version: {torch.version.cuda}\")\n\n capability = torch.cuda.get_device_capability()\n if capability[0] >= 7: # Volta (7.0+), Turing (7.5+), Ampere (8.0+), Hopper (9.0+)\n torch.set_float32_matmul_precision(\"high\")\n print(\"Uses tensor cores\")\n else:\n print(\"Tensor cores not supported on this GPU. Using default precision.\")\n print()\n\n ##############################\n # Download data if necessary\n ##############################\n\n file_path = \"middlemarch.txt\"\n url = \"https://www.gutenberg.org/cache/epub/145/pg145.txt\"\n\n # NEW: Only download 1 time\n if rank == 0:\n if not os.path.exists(file_path):\n response = requests.get(url, timeout=30)\n response.raise_for_status()\n text_data = response.text\n with open(file_path, \"w\", encoding=\"utf-8\") as file:\n file.write(text_data)\n # NEW: All processes wait until rank 0 is done, using the GPU index.\n torch.distributed.barrier(device_ids=[device.index])\n\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n text_data = file.read()\n\n ##############################\n # Initialize model\n ##############################\n\n model = GPTModel(gpt_config)\n model = torch.compile(model)\n model = model.to(device)\n model = model.to(torch.bfloat16)\n # NEW: Wrap model with DDP\n model = DDP(model, device_ids=[rank])\n optimizer = torch.optim.AdamW(\n model.parameters(), lr=settings[\"learning_rate\"], weight_decay=settings[\"weight_decay\"],\n fused=True\n )\n\n ##############################\n # Set up dataloaders\n ##############################\n\n # Train/validation ratio\n train_ratio = 0.90\n split_idx = int(train_ratio * len(text_data))\n\n train_loader = create_dataloader_v1(\n text_data[:split_idx],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=True,\n num_workers=4\n )\n\n val_loader = create_dataloader_v1(\n text_data[split_idx:],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=False,\n num_workers=4\n )\n\n ##############################\n # Train model\n ##############################\n\n train_losses, val_losses, tokens_seen = train_model_simple_with_timing(\n model=model,\n train_loader=train_loader,\n val_loader=val_loader,\n optimizer=optimizer,\n device=device,\n num_epochs=settings[\"num_epochs\"],\n eval_freq=5,\n eval_iter=1,\n start_context=\"Every effort moves you\",\n )\n\n # NEW: Clean up distributed processes\n destroy_process_group()\n\n return train_losses, val_losses, tokens_seen, model\n\n\nif __name__ == \"__main__\":\n\n # NEW: Extract rank and world size from environment variables\n if \"WORLD_SIZE\" in os.environ:\n world_size = int(os.environ[\"WORLD_SIZE\"])\n else:\n world_size = 1\n\n if \"LOCAL_RANK\" in os.environ:\n rank = int(os.environ[\"LOCAL_RANK\"])\n elif \"RANK\" in os.environ:\n rank = int(os.environ[\"RANK\"])\n else:\n rank = 0\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50304, # Vocabulary size\n \"context_length\": 1024, # Input tokens per training example\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False # Query-key-value bias\n }\n\n OTHER_SETTINGS = {\n \"learning_rate\": 5e-4, # * world_size, # NEW: Increase learning rate to account for multiple GPUs\n \"num_epochs\": 50,\n \"batch_size\": 32,\n \"weight_decay\": 0.1\n }\n\n ###########################\n # Initiate training\n ###########################\n\n train_losses, val_losses, tokens_seen, model = main(\n GPT_CONFIG_124M, OTHER_SETTINGS,\n rank, world_size # NEW\n )\n\n ###########################\n # After training\n ###########################\n\n # NEW: Only create 1 plot\n if rank == 0:\n # Plot results\n epochs_tensor = torch.linspace(0, OTHER_SETTINGS[\"num_epochs\"], len(train_losses))\n plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)\n plt.savefig(\"loss.pdf\")\n\n # Save and load model\n #\n # compiled = hasattr(model, \"_orig_mod\")\n # if compiled:\n # torch.save(model._orig_mod.state_dict(), \"model.pth\")\n # else:\n # torch.save(model.state_dict(), \"model.pth\")\n #\n # model = GPTModel(GPT_CONFIG_124M)\n # model.load_state_dict(torch.load(\"model.pth\", weights_only=True))\n"
},
{
"path": "ch05/10_llm-training-speed/README.md",
"content": "# PyTorch Performance Tips for Faster LLM Training\n\n\n\nNote that the book is written for education purposes, meaning the original code is kept purposefully simple. This is to aid readability and ensure compatibility across different hardware, including CPUs and GPUs. However, you might be curious about some more advanced PyTorch and GPU features to make the LLM training more performant.\n\nThis folder contains three code files that demonstrate performance optimizations for the LLM and the training function introduced in Chapter 5:\n\n1. [`00_orig.py`](00_orig.py): The original Chapter 5 code for CPU and single-GPU training. \n ➤ Run via: `python 00_orig.py`\n\n2. [`01_opt_single_gpu.py`](01_opt_single_gpu.py): An optimized version for single-GPU training. \n ➤ Run via: `python 01_opt_single_gpu.py`\n\n3. [`02_opt_multi_gpu_ddp.py`](02_opt_multi_gpu_ddp.py): An optimized version for multi-GPU training using Distributed Data Parallel (DDP). \n ➤ Run via: `torchrun --nproc_per_node=4 02_opt_multi_gpu_ddp.py` \n (**Note:** To keep the changes minimal compared to `01_opt_single_gpu.py`, this script supports multi-processing only via `torchrun` as shown above. This means multi-GPU support is **not** supported via `python 02_opt_multi_gpu_ddp.py`)\n\n**Note that these modifications take the training speed from 12,525 tokens per second (single A100) to 142,156 tokens per second (single A100) and 419,259 tokens per second (4x A100s).**\n\nI plan to expand on the differences in a more detailed write-up sometime in the future. For now, the easiest way to see what improvements have been added to the code is to open the files in Visual Studio Code and look at the differences via the \"Compare Selected\" feature.\n\n\n\n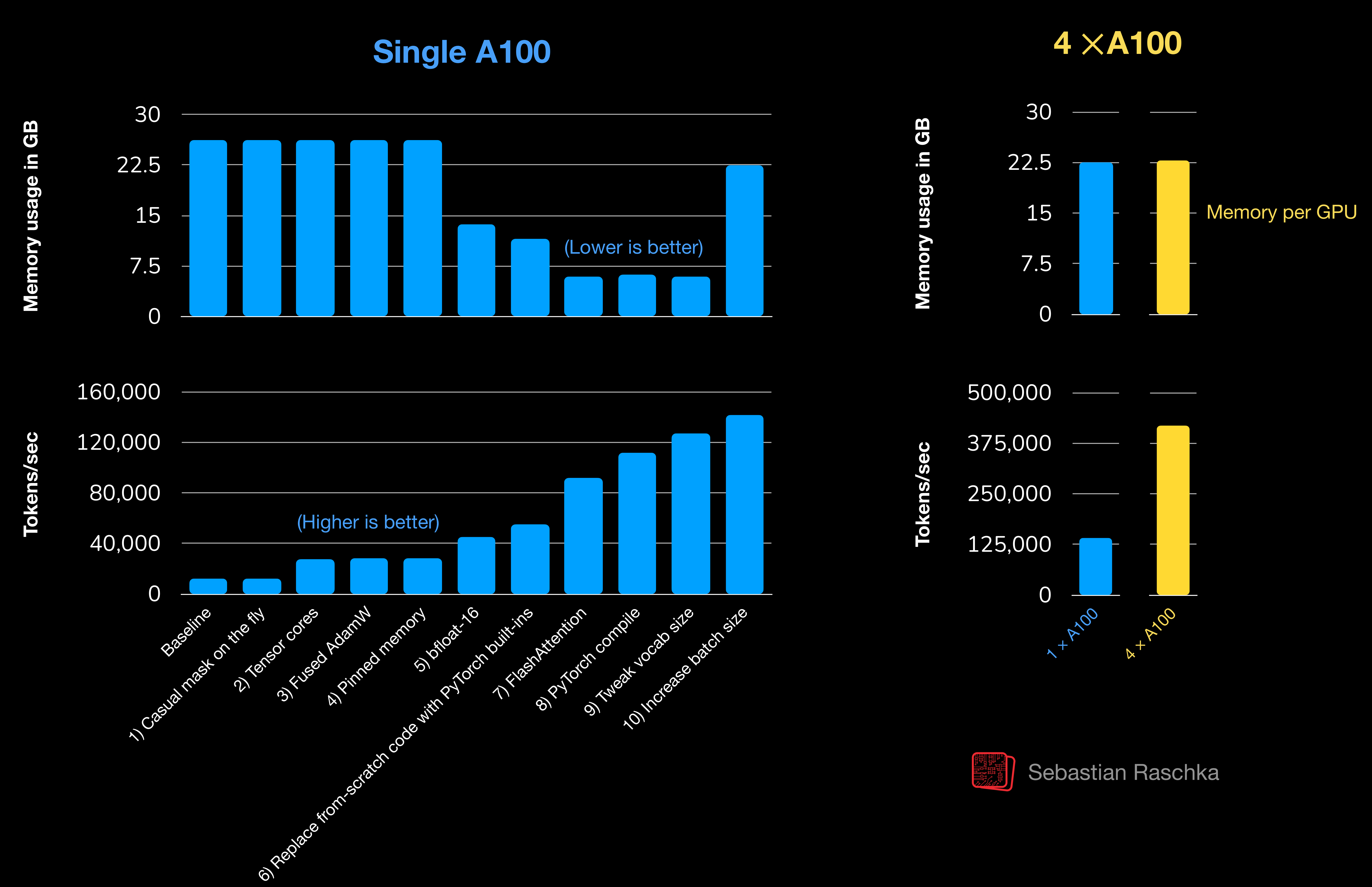\n\n\n \n## Single GPU speed comparisons\n\nAs mentioned above, I plan to elaborate more on the changes in the future. For now, this section contains a simple performance overview in terms of tokens/second for each modification. All experiments were run on A100 GPUs.\n\n \n### Baseline\n\nNote that `00_orig.py` servers as the baseline and contains no significant modification and uses the code from Chapter 5 as is besides the following:\n\n- 4 times larger context length (which explains the relatively large memory footprint of `00_orig.py` compared to Chapter 5);\n- 4-times batch size changes (another contributor to the relatively large memory footprint of `00_orig.py`);\n- a larger public domain book to increase the training data size. \n\nThe hyperparameters are not very optimized for minimizing loss and reducing overfitting, and the text generated by the LLM at the very end may not be super sophisticated; however, this shouldn't matter as the main takeaway is the `tok/sec` metric that serves as a speed reference here (higher is better).\n\n```bash\nubuntu@159-13-52-60:~$ python 00_orig.py\nPyTorch version: 2.6.0+cu124\nUsing cuda\nCUDA version: 12.4\n\nEp 1, Step 000000, Train: 9.535, Val: 9.609, Step tok/sec: 7238, Avg tok/sec: 0\nEp 1, Step 000015, Train: 6.201, Val: 6.152, Step tok/sec: 12545, Avg tok/sec: 12545\nEp 1, Step 000030, Train: 5.663, Val: 5.688, Step tok/sec: 12490, Avg tok/sec: 12517\nEp 1, Step 000045, Train: 5.316, Val: 5.362, Step tok/sec: 12541, Avg tok/sec: 12525\nEvery effort moves you, and's, and I am not be a\n\n...\n\nEp 15, Step 000735, Train: 0.227, Val: 6.818, Step tok/sec: 11599, Avg tok/sec: 12248\nEp 15, Step 000750, Train: 0.300, Val: 6.895, Step tok/sec: 12530, Avg tok/sec: 12253\nEp 15, Step 000765, Train: 0.150, Val: 6.914, Step tok/sec: 12532, Avg tok/sec: 12259\nEvery effort moves you like best to think which he held in the room in him, the interest was the night, the realities of the affairs Bulstrode's duty, now!' the fact is another man, conquests\n\nAllocated memory: 2.5069 GB\nReserved memory: 26.2617 GB\n```\n\nNote that `01_opt_single_gpu.py` contains all the modifications listed sequentially below. \n\nThe comparison is always based on the average tok/sec and allocated memory after the first epoch from the previous section.\n\n \n### 1. Create causal mask on the fly\n\n- Instead of saving the causal mask, this creates the causal mask on the fly to reduce memory usage (here it has minimal effect, but it can add up in long-context size models like Llama 3.2 with 131k-input-tokens support)\n\nBefore:\n- `Avg tok/sec: 12525`\n- `Reserved memory: 26.2617 GB`\n\nAfter:\n- `Avg tok/sec: 12526`\n- `Reserved memory: 26.2422 GB`\n\n \n### 2. Use tensor cores\n\n- Uses tensor cores (only works for Ampere GPUs like A100 and newer)\n\nBefore:\n- `Avg tok/sec: 12526`\n- `Reserved memory: 26.2422 GB`\n\nAfter:\n- `Avg tok/sec: 27648`\n- `Reserved memory: 26.2422 GB`\n\n \n### 3. Fused AdamW optimizer\n\n- Uses the fused kernels for `AdamW` by setting `fused=True`\n\nBefore:\n- `Avg tok/sec: 27648`\n- `Reserved memory: 26.2422 GB`\n\nAfter:\n- `Avg tok/sec: 28399`\n- `Reserved memory: 26.2422 GB`\n\n \n### 4. Pinned memory in the data loader\n\n- Uses `pin_memory=True` in the data loaders to pre-allocate and re-use GPU memory\n\nBefore:\n- `Avg tok/sec: 28399`\n- `Reserved memory: 26.2422 GB`\n\nAfter:\n- `Avg tok/sec: 28402`\n- `Reserved memory: 26.2422 GB`\n\n \n### 5. Using bfloat16 precision\n\n- Switches from 32-bit float to 16-bit brain float (bfloat16) precision (for more on this topic, see my [article here](https://magazine.sebastianraschka.com/p/the-missing-bits-llama-2-weights))\n\nBefore:\n- `Avg tok/sec: 28402`\n- `Reserved memory: 26.2422 GB`\n\nAfter:\n- `Avg tok/sec: 45486`\n- `Reserved memory: 13.7871 GB`\n\n \n### 6. Replacing from-scratch code by PyTorch classes\n\n- Replaces the LayerNorm and GeLU from-scratch implementation by PyTorch's native implementations\n\nBefore:\n- `Avg tok/sec: 45486`\n- `Reserved memory: 13.7871 GB`\n\nAfter:\n- `Avg tok/sec: 55256`\n- `Reserved memory: 11.5645 GB`\n\n \n### 7. Using FlashAttention\n\n- Uses PyTorch's self-attention function with FlashAttention instead of our from-scratch multi-head attention implementation.\n\n\nBefore:\n- `Avg tok/sec: 55256`\n- `Reserved memory: 11.5645 GB`\n\nAfter:\n- `Avg tok/sec: 91901`\n- `Reserved memory: 5.9004 GB`\n\n \n### 8. Using `pytorch.compile`\n\n- Uses `torch.compile(model)`. Note that the first iterations are always slow before it picks up speed. Since the `Avg tok/sec` measurement only includes the first row from the average calculation, we now use the `Step tok/sec` at the end of epoch 1.\n\n\nBefore:\n- `Avg tok/sec: 91901`\n- `Reserved memory: 5.9004 GB`\n\nAfter:\n- `Step tok/sec: 112046`\n- `Reserved memory: 6.1875 GB`\n\n
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dec38b24-c845-4090-96a4-0d3c4ec241d6\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 2.3 Updating the embedding layer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b1328726-8297-4162-878b-a5daff7de742\",\n \"metadata\": {},\n \"source\": [\n \"- Let's start with updating the embedding layer\\n\",\n \"- First, notice that the embedding layer has 50,257 entries, which corresponds to the vocabulary size:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"23ecab6e-1232-47c7-a318-042f90e1dff3\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Embedding(50257, 768)\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"gpt.tok_emb\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d760c683-d082-470a-bff8-5a08b30d3b61\",\n \"metadata\": {},\n \"source\": [\n \"- We want to extend this embedding layer by adding 2 more entries\\n\",\n \"- In short, we create a new embedding layer with a bigger size, and then we copy over the old embedding layer values\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"4ec5c48e-c6fe-4e84-b290-04bd4da9483f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Embedding(50259, 768)\\n\"\n ]\n }\n ],\n \"source\": [\n \"num_tokens, emb_size = gpt.tok_emb.weight.shape\\n\",\n \"new_num_tokens = num_tokens + 2\\n\",\n \"\\n\",\n \"# Create a new embedding layer\\n\",\n \"new_embedding = torch.nn.Embedding(new_num_tokens, emb_size)\\n\",\n \"\\n\",\n \"# Copy weights from the old embedding layer\\n\",\n \"new_embedding.weight.data[:num_tokens] = gpt.tok_emb.weight.data\\n\",\n \"\\n\",\n \"# Replace the old embedding layer with the new one in the model\\n\",\n \"gpt.tok_emb = new_embedding\\n\",\n \"\\n\",\n \"print(gpt.tok_emb)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"63954928-31a5-4e7e-9688-2e0c156b7302\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see above, we now have an increased embedding layer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6e68bea5-255b-47bb-b352-09ea9539bc25\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 2.4 Updating the output layer\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90a4a519-bf0f-4502-912d-ef0ac7a9deab\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we have to extend the output layer, which has 50,257 output features corresponding to the vocabulary size similar to the embedding layer (by the way, you may find the bonus material, which discusses the similarity between Linear and Embedding layers in PyTorch, useful)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"6105922f-d889-423e-bbcc-bc49156d78df\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Linear(in_features=768, out_features=50257, bias=False)\"\n ]\n },\n \"execution_count\": 14,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"gpt.out_head\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"29f1ff24-9c00-40f6-a94f-82d03aaf0890\",\n \"metadata\": {},\n \"source\": [\n \"- The procedure for extending the output layer is similar to extending the embedding layer:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"354589db-b148-4dae-8068-62132e3fb38e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Linear(in_features=768, out_features=50259, bias=True)\\n\"\n ]\n }\n ],\n \"source\": [\n \"original_out_features, original_in_features = gpt.out_head.weight.shape\\n\",\n \"\\n\",\n \"# Define the new number of output features (e.g., adding 2 new tokens)\\n\",\n \"new_out_features = original_out_features + 2\\n\",\n \"\\n\",\n \"# Create a new linear layer with the extended output size\\n\",\n \"new_linear = torch.nn.Linear(original_in_features, new_out_features)\\n\",\n \"\\n\",\n \"# Copy the weights and biases from the original linear layer\\n\",\n \"with torch.no_grad():\\n\",\n \" new_linear.weight[:original_out_features] = gpt.out_head.weight\\n\",\n \" if gpt.out_head.bias is not None:\\n\",\n \" new_linear.bias[:original_out_features] = gpt.out_head.bias\\n\",\n \"\\n\",\n \"# Replace the original linear layer with the new one\\n\",\n \"gpt.out_head = new_linear\\n\",\n \"\\n\",\n \"print(gpt.out_head)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"df5d2205-1fae-4a4f-a7bd-fa8fc37eeec2\",\n \"metadata\": {},\n \"source\": [\n \"- Let's try this updated model on the original token IDs first:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"df604bbc-6c13-4792-8ba8-ecb692117c25\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[ 0.2267, 0.9132, 1.0494, ..., -0.2330, -0.3008, -1.1458],\\n\",\n \" [ 0.6808, -0.0495, 0.8574, ..., 0.0671, 0.5572, -0.7873],\\n\",\n \" [-0.1947, 0.1045, 0.2773, ..., 1.3368, 0.8479, -0.9660],\\n\",\n \" ...,\\n\",\n \" [ 0.1200, -0.1027, 2.0549, ..., -0.1519, -0.2096, 0.5651],\\n\",\n \" [-1.1920, -0.1819, -0.0981, ..., -0.1108, 0.8435, -0.3771],\\n\",\n \" [-1.0612, -0.5674, 0.3229, ..., 0.8383, -0.7121, -0.4850]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" output = gpt(torch.tensor([original_token_ids]))\\n\",\n \"print(output)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3d80717e-50e6-4927-8129-0aadfa2628f5\",\n \"metadata\": {},\n \"source\": [\n \"- Next, let's try it on the updated tokens:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"75f11ec9-bdd2-440f-b8c8-6646b75891c6\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[[ 0.2267, 0.9132, 1.0494, ..., -0.2330, -0.3008, -1.1458],\\n\",\n \" [ 0.6808, -0.0495, 0.8574, ..., 0.0671, 0.5572, -0.7873],\\n\",\n \" [-0.1947, 0.1045, 0.2773, ..., 1.3368, 0.8479, -0.9660],\\n\",\n \" ...,\\n\",\n \" [-0.0656, -1.2451, 0.7957, ..., -1.2124, 0.1044, 0.5088],\\n\",\n \" [-1.1561, -0.7380, -0.0645, ..., -0.4373, 1.1401, -0.3903],\\n\",\n \" [-0.8961, -0.6437, -0.1667, ..., 0.5663, -0.5862, -0.4020]]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" output = gpt(torch.tensor([new_token_ids]))\\n\",\n \"print(output)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d88a1bba-db01-4090-97e4-25dfc23ed54c\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see, the model works on the extended token set\\n\",\n \"- In practice, we want to now finetune (or continually pretrain) the model (specifically the new embedding and output layers) on data containing the new tokens\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6de573ad-0338-40d9-9dad-de60ae349c4f\",\n \"metadata\": {},\n \"source\": [\n \"**A note about weight tying**\\n\",\n \"\\n\",\n \"- If the model uses weight tying, which means that the embedding layer and output layer share the same weights, similar to Llama 3 [link], updating the output layer is much simpler\\n\",\n \"- In this case, we can simply copy over the weights from the embedding layer:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"4cbc5f51-c7a8-49d0-b87f-d3d87510953b\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"gpt.out_head.weight = gpt.tok_emb.weight\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"d0d553a8-edff-40f0-bdc4-dff900e16caf\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" output = gpt(torch.tensor([new_token_ids]))\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.10.16\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/10_llm-training-speed/00_orig.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n\nimport os\nimport time\nimport urllib.request\n\nimport matplotlib.pyplot as plt\nimport torch\nimport torch.nn as nn\nfrom torch.utils.data import Dataset, DataLoader\nimport tiktoken\n\n#####################################\n# Chapter 2\n#####################################\n\n\nclass GPTDatasetV1(Dataset):\n def __init__(self, txt, tokenizer, max_length, stride):\n self.input_ids = []\n self.target_ids = []\n\n # Tokenize the entire text\n token_ids = tokenizer.encode(txt, allowed_special={\"<|endoftext|>\"})\n\n # Use a sliding window to chunk the book into overlapping sequences of max_length\n for i in range(0, len(token_ids) - max_length, stride):\n input_chunk = token_ids[i:i + max_length]\n target_chunk = token_ids[i + 1: i + max_length + 1]\n self.input_ids.append(torch.tensor(input_chunk))\n self.target_ids.append(torch.tensor(target_chunk))\n\n def __len__(self):\n return len(self.input_ids)\n\n def __getitem__(self, idx):\n return self.input_ids[idx], self.target_ids[idx]\n\n\ndef create_dataloader_v1(txt, batch_size=4, max_length=256,\n stride=128, shuffle=True, drop_last=True, num_workers=0):\n # Initialize the tokenizer\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n # Create dataset\n dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)\n\n # Create dataloader\n dataloader = DataLoader(\n dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=num_workers)\n\n return dataloader\n\n\n#####################################\n# Chapter 3\n#####################################\nclass MultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):\n super().__init__()\n assert d_out % num_heads == 0, \"d_out must be divisible by n_heads\"\n\n self.d_out = d_out\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim\n\n self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)\n self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs\n self.dropout = nn.Dropout(dropout)\n self.register_buffer(\"mask\", torch.triu(torch.ones(context_length, context_length), diagonal=1))\n\n def forward(self, x):\n b, num_tokens, d_in = x.shape\n\n keys = self.W_key(x) # Shape: (b, num_tokens, d_out)\n queries = self.W_query(x)\n values = self.W_value(x)\n\n # We implicitly split the matrix by adding a `num_heads` dimension\n # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)\n keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n\n # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)\n keys = keys.transpose(1, 2)\n queries = queries.transpose(1, 2)\n values = values.transpose(1, 2)\n\n # Compute scaled dot-product attention (aka self-attention) with a causal mask\n attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n\n # Original mask truncated to the number of tokens and converted to boolean\n mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n\n # Use the mask to fill attention scores\n attn_scores.masked_fill_(mask_bool, -torch.inf)\n\n attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n attn_weights = self.dropout(attn_weights)\n\n # Shape: (b, num_tokens, num_heads, head_dim)\n context_vec = (attn_weights @ values).transpose(1, 2)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.reshape(b, num_tokens, self.d_out)\n context_vec = self.out_proj(context_vec) # optional projection\n\n return context_vec\n\n\n#####################################\n# Chapter 4\n#####################################\nclass LayerNorm(nn.Module):\n def __init__(self, emb_dim):\n super().__init__()\n self.eps = 1e-5\n self.scale = nn.Parameter(torch.ones(emb_dim))\n self.shift = nn.Parameter(torch.zeros(emb_dim))\n\n def forward(self, x):\n mean = x.mean(dim=-1, keepdim=True)\n var = x.var(dim=-1, keepdim=True, unbiased=False)\n norm_x = (x - mean) / torch.sqrt(var + self.eps)\n return self.scale * norm_x + self.shift\n\n\nclass GELU(nn.Module):\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return 0.5 * x * (1 + torch.tanh(\n torch.sqrt(torch.tensor(2.0 / torch.pi)) *\n (x + 0.044715 * torch.pow(x, 3))\n ))\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n GELU(),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = MultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n context_length=cfg[\"context_length\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n self.trf_blocks = nn.Sequential(\n *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.final_norm = LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n x = self.trf_blocks(x)\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n#####################################\n# Chapter 5\n#####################################\n\n\ndef text_to_token_ids(text, tokenizer):\n encoded = tokenizer.encode(text)\n encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\n return encoded_tensor\n\n\ndef token_ids_to_text(token_ids, tokenizer):\n flat = token_ids.squeeze(0) # remove batch dimension\n return tokenizer.decode(flat.tolist())\n\n\ndef calc_loss_batch(input_batch, target_batch, model, device):\n input_batch, target_batch = input_batch.to(device), target_batch.to(device)\n logits = model(input_batch)\n loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())\n return loss\n\n\ndef calc_loss_loader(data_loader, model, device, num_batches=None):\n total_loss = 0.\n if len(data_loader) == 0:\n return float(\"nan\")\n elif num_batches is None:\n num_batches = len(data_loader)\n else:\n num_batches = min(num_batches, len(data_loader))\n for i, (input_batch, target_batch) in enumerate(data_loader):\n if i < num_batches:\n loss = calc_loss_batch(input_batch, target_batch, model, device)\n total_loss += loss.item()\n else:\n break\n return total_loss / num_batches\n\n\ndef evaluate_model(model, train_loader, val_loader, device, eval_iter):\n model.eval()\n with torch.no_grad():\n train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\n val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\n model.train()\n return train_loss, val_loss\n\n\ndef generate_and_print_sample(model, tokenizer, device, start_context):\n model.eval()\n context_size = model.pos_emb.weight.shape[0]\n encoded = text_to_token_ids(start_context, tokenizer).to(device)\n with torch.no_grad():\n token_ids = generate_text_simple(\n model=model, idx=encoded,\n max_new_tokens=50, context_size=context_size\n )\n decoded_text = token_ids_to_text(token_ids, tokenizer)\n print(decoded_text.replace(\"\\n\", \" \")) # Compact print format\n model.train()\n\n\ndef train_model_simple_with_timing(model, train_loader, val_loader, optimizer, device,\n num_epochs, eval_freq, eval_iter, start_context, tokenizer):\n train_losses, val_losses, track_tokens = [], [], []\n total_tokens, global_step, last_tokens = 0, -1, 0\n\n # Variables for cumulative average tokens/sec\n cumulative_tokens, cumulative_time = 0.0, 0.0\n\n # CUDA-specific timing setup\n use_cuda = device.type == \"cuda\"\n if use_cuda:\n t_start = torch.cuda.Event(enable_timing=True)\n t_end = torch.cuda.Event(enable_timing=True)\n torch.cuda.synchronize() # Ensure all prior CUDA operations are done\n t_start.record() # Start the timer for the first interval\n else:\n t0 = time.time() # Start the timer for the first interval\n\n # Main training loop\n for epoch in range(num_epochs):\n model.train()\n for inp_batch, tgt_batch in train_loader:\n optimizer.zero_grad()\n global_step += 1\n\n # Forward and backward pass\n loss = calc_loss_batch(inp_batch, tgt_batch, model, device)\n loss.backward()\n optimizer.step()\n\n total_tokens += inp_batch.numel()\n\n # At evaluation intervals, measure elapsed time and tokens per second\n if global_step % eval_freq == 0:\n # End timing for the current interval\n if use_cuda:\n t_end.record()\n torch.cuda.synchronize() # Wait for all CUDA ops to complete.\n elapsed = t_start.elapsed_time(t_end) / 1000 # Convert ms to seconds\n t_start.record() # Reset timer for the next interval\n else:\n elapsed = time.time() - t0\n t0 = time.time() # Reset timer for the next interval\n\n # Calculate tokens processed in this interval\n tokens_interval = total_tokens - last_tokens\n last_tokens = total_tokens\n tps = tokens_interval / elapsed if elapsed > 0 else 0 # Tokens per second\n\n # Update cumulative counters (skip the first evaluation interval)\n if global_step: # This is False only when global_step == 0 (first evaluation)\n cumulative_tokens += tokens_interval\n cumulative_time += elapsed\n\n # Compute cumulative average tokens/sec (excluding the first interval)\n avg_tps = cumulative_tokens / cumulative_time if cumulative_time > 0 else 0\n\n # Evaluate model performance (this may add overhead)\n train_loss, val_loss = evaluate_model(model, train_loader, val_loader, device, eval_iter)\n train_losses.append(train_loss)\n val_losses.append(val_loss)\n track_tokens.append(total_tokens)\n\n print(f\"Ep {epoch+1}, Step {global_step:06d}, \"\n f\"Train: {train_loss:.3f}, Val: {val_loss:.3f}, \"\n f\"Step tok/sec: {round(tps)}, Avg tok/sec: {round(avg_tps)}\")\n\n generate_and_print_sample(model, tokenizer, device, start_context)\n\n # Memory stats\n if torch.cuda.is_available():\n device = torch.cuda.current_device()\n\n allocated = torch.cuda.memory_allocated(device) / 1024**3 # Convert to GB\n reserved = torch.cuda.memory_reserved(device) / 1024**3 # Convert to GB\n\n print(f\"\\nAllocated memory: {allocated:.4f} GB\")\n print(f\"Reserved memory: {reserved:.4f} GB\\n\")\n\n return train_losses, val_losses, track_tokens\n\n\ndef plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):\n fig, ax1 = plt.subplots()\n\n # Plot training and validation loss against epochs\n ax1.plot(epochs_seen, train_losses, label=\"Training loss\")\n ax1.plot(epochs_seen, val_losses, linestyle=\"-.\", label=\"Validation loss\")\n ax1.set_xlabel(\"Epochs\")\n ax1.set_ylabel(\"Loss\")\n ax1.legend(loc=\"upper right\")\n\n # Create a second x-axis for tokens seen\n ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\n ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks\n ax2.set_xlabel(\"Tokens seen\")\n\n fig.tight_layout() # Adjust layout to make room\n # plt.show()\n\n\n#####################################\n# Main function calls\n#####################################\n\ndef main(gpt_config, settings):\n\n torch.manual_seed(123)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n print(f\"PyTorch version: {torch.__version__}\")\n print(f\"Using {device}\")\n if torch.cuda.is_available():\n print(f\"CUDA version: {torch.version.cuda}\")\n print()\n\n ##############################\n # Download data if necessary\n ##############################\n\n file_path = \"middlemarch.txt\"\n url = \"https://www.gutenberg.org/cache/epub/145/pg145.txt\"\n\n if not os.path.exists(file_path):\n with urllib.request.urlopen(url) as response:\n text_data = response.read().decode(\"utf-8\")\n with open(file_path, \"w\", encoding=\"utf-8\") as file:\n file.write(text_data)\n else:\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n text_data = file.read()\n\n ##############################\n # Initialize model\n ##############################\n\n model = GPTModel(gpt_config)\n model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes\n optimizer = torch.optim.AdamW(\n model.parameters(), lr=settings[\"learning_rate\"], weight_decay=settings[\"weight_decay\"]\n )\n\n ##############################\n # Set up dataloaders\n ##############################\n\n # Train/validation ratio\n train_ratio = 0.90\n split_idx = int(train_ratio * len(text_data))\n\n train_loader = create_dataloader_v1(\n text_data[:split_idx],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=True,\n shuffle=True,\n num_workers=4\n )\n\n val_loader = create_dataloader_v1(\n text_data[split_idx:],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=False,\n shuffle=False,\n num_workers=4\n )\n\n ##############################\n # Train model\n ##############################\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n train_losses, val_losses, tokens_seen = train_model_simple_with_timing(\n model=model,\n train_loader=train_loader,\n val_loader=val_loader,\n optimizer=optimizer,\n device=device,\n num_epochs=settings[\"num_epochs\"],\n eval_freq=15,\n eval_iter=1,\n start_context=\"Every effort moves you\",\n tokenizer=tokenizer\n )\n\n return train_losses, val_losses, tokens_seen, model\n\n\nif __name__ == \"__main__\":\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Input tokens per training example\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False # Query-key-value bias\n }\n\n OTHER_SETTINGS = {\n \"learning_rate\": 5e-4,\n \"num_epochs\": 15,\n \"batch_size\": 8,\n \"weight_decay\": 0.1\n }\n\n ###########################\n # Initiate training\n ###########################\n\n train_losses, val_losses, tokens_seen, model = main(GPT_CONFIG_124M, OTHER_SETTINGS)\n\n ###########################\n # After training\n ###########################\n\n # Plot results\n epochs_tensor = torch.linspace(0, OTHER_SETTINGS[\"num_epochs\"], len(train_losses))\n plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)\n plt.savefig(\"loss.pdf\")\n\n # Save and load model\n # torch.save(model.state_dict(), \"model.pth\")\n # model = GPTModel(GPT_CONFIG_124M)\n # model.load_state_dict(torch.load(\"model.pth\", weights_only=True))\n"
},
{
"path": "ch05/10_llm-training-speed/01_opt_single_gpu.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n\nimport os\nimport time\n\nimport matplotlib.pyplot as plt\nimport requests\nimport torch\nimport torch.nn as nn\nfrom torch.utils.data import Dataset, DataLoader\nimport tiktoken\n\n#####################################\n# Chapter 2\n#####################################\n\n\nclass GPTDatasetV1(Dataset):\n def __init__(self, txt, tokenizer, max_length, stride):\n self.input_ids = []\n self.target_ids = []\n\n # Tokenize the entire text\n token_ids = tokenizer.encode(txt, allowed_special={\"<|endoftext|>\"})\n\n # Use a sliding window to chunk the book into overlapping sequences of max_length\n for i in range(0, len(token_ids) - max_length, stride):\n input_chunk = token_ids[i:i + max_length]\n target_chunk = token_ids[i + 1: i + max_length + 1]\n self.input_ids.append(torch.tensor(input_chunk))\n self.target_ids.append(torch.tensor(target_chunk))\n\n def __len__(self):\n return len(self.input_ids)\n\n def __getitem__(self, idx):\n return self.input_ids[idx], self.target_ids[idx]\n\n\ndef create_dataloader_v1(txt, batch_size=4, max_length=256,\n stride=128, shuffle=True, drop_last=True, num_workers=0):\n # Initialize the tokenizer\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n # Create dataset\n dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)\n\n # Create dataloader\n dataloader = DataLoader(\n dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=num_workers,\n pin_memory=True\n )\n\n return dataloader\n\n\n#####################################\n# Chapter 3\n#####################################\nclass PyTorchMultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, num_heads, dropout=0.0, qkv_bias=False):\n super().__init__()\n\n assert d_out % num_heads == 0, \"d_out is indivisible by num_heads\"\n\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n self.d_out = d_out\n\n self.qkv = nn.Linear(d_in, 3 * d_out, bias=qkv_bias)\n self.proj = nn.Linear(d_out, d_out)\n self.dropout = dropout\n\n def forward(self, x):\n batch_size, num_tokens, embed_dim = x.shape\n\n # (b, num_tokens, embed_dim) --> (b, num_tokens, 3 * embed_dim)\n qkv = self.qkv(x)\n\n # (b, num_tokens, 3 * embed_dim) --> (b, num_tokens, 3, num_heads, head_dim)\n qkv = qkv.view(batch_size, num_tokens, 3, self.num_heads, self.head_dim)\n\n # (b, num_tokens, 3, num_heads, head_dim) --> (3, b, num_heads, num_tokens, head_dim)\n qkv = qkv.permute(2, 0, 3, 1, 4)\n\n # (3, b, num_heads, num_tokens, head_dim) -> 3 times (b, num_heads, num_tokens, head_dim)\n queries, keys, values = qkv\n\n use_dropout = 0. if not self.training else self.dropout\n\n context_vec = nn.functional.scaled_dot_product_attention(\n queries, keys, values, attn_mask=None, dropout_p=use_dropout, is_causal=True)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.transpose(1, 2).contiguous().view(batch_size, num_tokens, self.d_out)\n\n context_vec = self.proj(context_vec)\n\n return context_vec\n\n\n#####################################\n# Chapter 4\n#####################################\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n nn.GELU(approximate=\"tanh\"),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = PyTorchMultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = nn.LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = nn.LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n self.trf_blocks = nn.Sequential(\n *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.final_norm = nn.LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n x = self.trf_blocks(x)\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n#####################################\n# Chapter 5\n#####################################\n\n\ndef text_to_token_ids(text, tokenizer):\n encoded = tokenizer.encode(text)\n encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\n return encoded_tensor\n\n\ndef token_ids_to_text(token_ids, tokenizer):\n flat = token_ids.squeeze(0) # remove batch dimension\n return tokenizer.decode(flat.tolist())\n\n\ndef calc_loss_batch(input_batch, target_batch, model, device):\n input_batch, target_batch = input_batch.to(device), target_batch.to(device)\n logits = model(input_batch)\n loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())\n return loss\n\n\ndef calc_loss_loader(data_loader, model, device, num_batches=None):\n total_loss = 0.\n if len(data_loader) == 0:\n return float(\"nan\")\n elif num_batches is None:\n num_batches = len(data_loader)\n else:\n num_batches = min(num_batches, len(data_loader))\n for i, (input_batch, target_batch) in enumerate(data_loader):\n if i < num_batches:\n loss = calc_loss_batch(input_batch, target_batch, model, device)\n total_loss += loss.item()\n else:\n break\n return total_loss / num_batches\n\n\ndef evaluate_model(model, train_loader, val_loader, device, eval_iter):\n model.eval()\n with torch.no_grad():\n train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\n val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\n model.train()\n return train_loss, val_loss\n\n\ndef generate_and_print_sample(model, tokenizer, device, start_context):\n model.eval()\n context_size = model.pos_emb.weight.shape[0]\n encoded = text_to_token_ids(start_context, tokenizer).to(device)\n with torch.no_grad():\n token_ids = generate_text_simple(\n model=model, idx=encoded,\n max_new_tokens=50, context_size=context_size\n )\n decoded_text = token_ids_to_text(token_ids, tokenizer)\n print(decoded_text.replace(\"\\n\", \" \")) # Compact print format\n model.train()\n\n\ndef train_model_simple_with_timing(model, train_loader, val_loader, optimizer, device,\n num_epochs, eval_freq, eval_iter, start_context, tokenizer):\n train_losses, val_losses, track_tokens = [], [], []\n total_tokens, global_step, last_tokens = 0, -1, 0\n\n # Variables for cumulative average tokens/sec\n cumulative_tokens, cumulative_time = 0.0, 0.0\n\n # CUDA-specific timing setup\n use_cuda = device.type == \"cuda\"\n if use_cuda:\n t_start = torch.cuda.Event(enable_timing=True)\n t_end = torch.cuda.Event(enable_timing=True)\n torch.cuda.synchronize() # Ensure all prior CUDA operations are done\n t_start.record() # Start the timer for the first interval\n else:\n t0 = time.time() # Start the timer for the first interval\n\n # Main training loop\n for epoch in range(num_epochs):\n model.train()\n for inp_batch, tgt_batch in train_loader:\n optimizer.zero_grad()\n global_step += 1\n\n # Forward and backward pass\n loss = calc_loss_batch(inp_batch, tgt_batch, model, device)\n loss.backward()\n optimizer.step()\n\n total_tokens += inp_batch.numel()\n\n # At evaluation intervals, measure elapsed time and tokens per second\n if global_step % eval_freq == 0:\n # End timing for the current interval\n if use_cuda:\n t_end.record()\n torch.cuda.synchronize() # Wait for all CUDA ops to complete.\n elapsed = t_start.elapsed_time(t_end) / 1000 # Convert ms to seconds\n t_start.record() # Reset timer for the next interval\n else:\n elapsed = time.time() - t0\n t0 = time.time() # Reset timer for the next interval\n\n # Calculate tokens processed in this interval\n tokens_interval = total_tokens - last_tokens\n last_tokens = total_tokens\n tps = tokens_interval / elapsed if elapsed > 0 else 0 # Tokens per second\n\n # Update cumulative counters (skip the first evaluation interval)\n if global_step: # This is False only when global_step == 0 (first evaluation)\n cumulative_tokens += tokens_interval\n cumulative_time += elapsed\n\n # Compute cumulative average tokens/sec (excluding the first interval)\n avg_tps = cumulative_tokens / cumulative_time if cumulative_time > 0 else 0\n\n # Evaluate model performance (this may add overhead)\n train_loss, val_loss = evaluate_model(model, train_loader, val_loader, device, eval_iter)\n train_losses.append(train_loss)\n val_losses.append(val_loss)\n track_tokens.append(total_tokens)\n\n print(f\"Ep {epoch+1}, Step {global_step:06d}, \"\n f\"Train: {train_loss:.3f}, Val: {val_loss:.3f}, \"\n f\"Step tok/sec: {round(tps)}, Avg tok/sec: {round(avg_tps)}\")\n\n generate_and_print_sample(model, tokenizer, device, start_context)\n\n # Memory stats\n if torch.cuda.is_available():\n device = torch.cuda.current_device()\n\n allocated = torch.cuda.memory_allocated(device) / 1024**3 # Convert to GB\n reserved = torch.cuda.memory_reserved(device) / 1024**3 # Convert to GB\n\n print(f\"\\nAllocated memory: {allocated:.4f} GB\")\n print(f\"Reserved memory: {reserved:.4f} GB\\n\")\n\n return train_losses, val_losses, track_tokens\n\n\ndef plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):\n fig, ax1 = plt.subplots()\n\n # Plot training and validation loss against epochs\n ax1.plot(epochs_seen, train_losses, label=\"Training loss\")\n ax1.plot(epochs_seen, val_losses, linestyle=\"-.\", label=\"Validation loss\")\n ax1.set_xlabel(\"Epochs\")\n ax1.set_ylabel(\"Loss\")\n ax1.legend(loc=\"upper right\")\n\n # Create a second x-axis for tokens seen\n ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\n ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks\n ax2.set_xlabel(\"Tokens seen\")\n\n fig.tight_layout() # Adjust layout to make room\n # plt.show()\n\n\n#####################################\n# Main function calls\n#####################################\n\ndef main(gpt_config, settings):\n\n torch.manual_seed(123)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n print(f\"PyTorch version: {torch.__version__}\")\n print(f\"Using {device}\")\n if torch.cuda.is_available():\n print(f\"CUDA version: {torch.version.cuda}\")\n\n capability = torch.cuda.get_device_capability()\n if capability[0] >= 7: # Volta (7.0+), Turing (7.5+), Ampere (8.0+), Hopper (9.0+)\n torch.set_float32_matmul_precision(\"high\")\n print(\"Uses tensor cores\")\n else:\n print(\"Tensor cores not supported on this GPU. Using default precision.\")\n print(f\"Uses tensor cores: {torch.cuda.is_available()}\")\n print()\n\n ##############################\n # Download data if necessary\n ##############################\n\n file_path = \"middlemarch.txt\"\n url = \"https://www.gutenberg.org/cache/epub/145/pg145.txt\"\n\n if not os.path.exists(file_path):\n response = requests.get(url, timeout=30)\n response.raise_for_status()\n text_data = response.text\n with open(file_path, \"w\", encoding=\"utf-8\") as file:\n file.write(text_data)\n else:\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n text_data = file.read()\n\n ##############################\n # Initialize model\n ##############################\n\n model = GPTModel(gpt_config)\n model = torch.compile(model)\n model.to(device).to(torch.bfloat16)\n optimizer = torch.optim.AdamW(\n model.parameters(), lr=settings[\"learning_rate\"], weight_decay=settings[\"weight_decay\"],\n fused=True\n )\n\n ##############################\n # Set up dataloaders\n ##############################\n\n # Train/validation ratio\n train_ratio = 0.90\n split_idx = int(train_ratio * len(text_data))\n\n train_loader = create_dataloader_v1(\n text_data[:split_idx],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=True,\n shuffle=True,\n num_workers=4\n )\n\n val_loader = create_dataloader_v1(\n text_data[split_idx:],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=False,\n shuffle=False,\n num_workers=4\n )\n\n ##############################\n # Train model\n ##############################\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n train_losses, val_losses, tokens_seen = train_model_simple_with_timing(\n model=model,\n train_loader=train_loader,\n val_loader=val_loader,\n optimizer=optimizer,\n device=device,\n num_epochs=settings[\"num_epochs\"],\n eval_freq=10,\n eval_iter=1,\n start_context=\"Every effort moves you\",\n tokenizer=tokenizer\n )\n\n return train_losses, val_losses, tokens_seen, model\n\n\nif __name__ == \"__main__\":\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50304, # Vocabulary size\n \"context_length\": 1024, # Input tokens per training example\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False # Query-key-value bias\n }\n\n OTHER_SETTINGS = {\n \"learning_rate\": 5e-4,\n \"num_epochs\": 15,\n \"batch_size\": 32,\n \"weight_decay\": 0.1\n }\n\n ###########################\n # Initiate training\n ###########################\n\n train_losses, val_losses, tokens_seen, model = main(GPT_CONFIG_124M, OTHER_SETTINGS)\n\n ###########################\n # After training\n ###########################\n\n # Plot results\n epochs_tensor = torch.linspace(0, OTHER_SETTINGS[\"num_epochs\"], len(train_losses))\n plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)\n plt.savefig(\"loss.pdf\")\n\n # Save and load model\n #\n # compiled = hasattr(model, \"_orig_mod\")\n # if compiled:\n # torch.save(model._orig_mod.state_dict(), \"model.pth\")\n # else:\n # torch.save(model.state_dict(), \"model.pth\")\n #\n # model = GPTModel(GPT_CONFIG_124M)\n # model.load_state_dict(torch.load(\"model.pth\", weights_only=True))\n"
},
{
"path": "ch05/10_llm-training-speed/02_opt_multi_gpu_ddp.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n\nimport os\nimport time\n\nimport matplotlib.pyplot as plt\nimport requests\nimport torch\nimport torch.nn as nn\nfrom torch.utils.data import Dataset, DataLoader\nimport tiktoken\n\n# NEW imports (see Appendix A):\nimport platform\nfrom torch.utils.data.distributed import DistributedSampler\nfrom torch.nn.parallel import DistributedDataParallel as DDP\nfrom torch.distributed import init_process_group, destroy_process_group\n\n\n# NEW: function to initialize a distributed process group (1 process / GPU)\n# this allows communication among processes\n# (see Appendix A):\ndef ddp_setup(rank, world_size):\n \"\"\"\n Arguments:\n rank: a unique process ID\n world_size: total number of processes in the group\n \"\"\"\n # Only set MASTER_ADDR and MASTER_PORT if not already defined by torchrun\n if \"MASTER_ADDR\" not in os.environ:\n os.environ[\"MASTER_ADDR\"] = \"localhost\"\n if \"MASTER_PORT\" not in os.environ:\n os.environ[\"MASTER_PORT\"] = \"12345\"\n\n # initialize process group\n if platform.system() == \"Windows\":\n # Disable libuv because PyTorch for Windows isn't built with support\n os.environ[\"USE_LIBUV\"] = \"0\"\n # Windows users may have to use \"gloo\" instead of \"nccl\" as backend\n # gloo: Facebook Collective Communication Library\n init_process_group(backend=\"gloo\", rank=rank, world_size=world_size)\n else:\n # nccl: NVIDIA Collective Communication Library\n init_process_group(backend=\"nccl\", rank=rank, world_size=world_size)\n\n torch.cuda.set_device(rank)\n\n\n#####################################\n# Chapter 2\n#####################################\n\n\nclass GPTDatasetV1(Dataset):\n def __init__(self, txt, tokenizer, max_length, stride):\n self.input_ids = []\n self.target_ids = []\n\n # Tokenize the entire text\n token_ids = tokenizer.encode(txt, allowed_special={\"<|endoftext|>\"})\n\n # Use a sliding window to chunk the book into overlapping sequences of max_length\n for i in range(0, len(token_ids) - max_length, stride):\n input_chunk = token_ids[i:i + max_length]\n target_chunk = token_ids[i + 1: i + max_length + 1]\n self.input_ids.append(torch.tensor(input_chunk))\n self.target_ids.append(torch.tensor(target_chunk))\n\n def __len__(self):\n return len(self.input_ids)\n\n def __getitem__(self, idx):\n return self.input_ids[idx], self.target_ids[idx]\n\n\n# NEW: Modify to set shuffle=False and use a sampler\n# (See Appendix A):\ndef create_dataloader_v1(txt, batch_size=4, max_length=256,\n stride=128, drop_last=True, num_workers=0):\n # Initialize the tokenizer\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n\n # Create dataset\n dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)\n\n # Create dataloader\n dataloader = DataLoader(\n dataset=dataset,\n batch_size=batch_size,\n shuffle=False, # NEW: False because of DistributedSampler below\n drop_last=drop_last,\n num_workers=num_workers,\n pin_memory=True,\n # NEW: chunk batches across GPUs without overlapping samples:\n sampler=DistributedSampler(dataset) # NEW\n )\n return dataloader\n\n\n#####################################\n# Chapter 3\n#####################################\nclass PyTorchMultiHeadAttention(nn.Module):\n def __init__(self, d_in, d_out, num_heads, dropout=0.0, qkv_bias=False):\n super().__init__()\n\n assert d_out % num_heads == 0, \"d_out is indivisible by num_heads\"\n\n self.num_heads = num_heads\n self.head_dim = d_out // num_heads\n self.d_out = d_out\n\n self.qkv = nn.Linear(d_in, 3 * d_out, bias=qkv_bias)\n self.proj = nn.Linear(d_out, d_out)\n self.dropout = dropout\n\n def forward(self, x):\n batch_size, num_tokens, embed_dim = x.shape\n\n # (b, num_tokens, embed_dim) --> (b, num_tokens, 3 * embed_dim)\n qkv = self.qkv(x)\n\n # (b, num_tokens, 3 * embed_dim) --> (b, num_tokens, 3, num_heads, head_dim)\n qkv = qkv.view(batch_size, num_tokens, 3, self.num_heads, self.head_dim)\n\n # (b, num_tokens, 3, num_heads, head_dim) --> (3, b, num_heads, num_tokens, head_dim)\n qkv = qkv.permute(2, 0, 3, 1, 4)\n\n # (3, b, num_heads, num_tokens, head_dim) -> 3 times (b, num_heads, num_tokens, head_dim)\n queries, keys, values = qkv\n\n use_dropout = 0. if not self.training else self.dropout\n\n context_vec = nn.functional.scaled_dot_product_attention(\n queries, keys, values, attn_mask=None, dropout_p=use_dropout, is_causal=True)\n\n # Combine heads, where self.d_out = self.num_heads * self.head_dim\n context_vec = context_vec.transpose(1, 2).contiguous().view(batch_size, num_tokens, self.d_out)\n\n context_vec = self.proj(context_vec)\n\n return context_vec\n\n\n#####################################\n# Chapter 4\n#####################################\n\n\nclass FeedForward(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.layers = nn.Sequential(\n nn.Linear(cfg[\"emb_dim\"], 4 * cfg[\"emb_dim\"]),\n nn.GELU(approximate=\"tanh\"),\n nn.Linear(4 * cfg[\"emb_dim\"], cfg[\"emb_dim\"]),\n )\n\n def forward(self, x):\n return self.layers(x)\n\n\nclass TransformerBlock(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.att = PyTorchMultiHeadAttention(\n d_in=cfg[\"emb_dim\"],\n d_out=cfg[\"emb_dim\"],\n num_heads=cfg[\"n_heads\"],\n dropout=cfg[\"drop_rate\"],\n qkv_bias=cfg[\"qkv_bias\"])\n self.ff = FeedForward(cfg)\n self.norm1 = nn.LayerNorm(cfg[\"emb_dim\"])\n self.norm2 = nn.LayerNorm(cfg[\"emb_dim\"])\n self.drop_shortcut = nn.Dropout(cfg[\"drop_rate\"])\n\n def forward(self, x):\n # Shortcut connection for attention block\n shortcut = x\n x = self.norm1(x)\n x = self.att(x) # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n # Shortcut connection for feed-forward block\n shortcut = x\n x = self.norm2(x)\n x = self.ff(x)\n x = self.drop_shortcut(x)\n x = x + shortcut # Add the original input back\n\n return x\n\n\nclass GPTModel(nn.Module):\n def __init__(self, cfg):\n super().__init__()\n self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"])\n self.pos_emb = nn.Embedding(cfg[\"context_length\"], cfg[\"emb_dim\"])\n self.drop_emb = nn.Dropout(cfg[\"drop_rate\"])\n\n self.trf_blocks = nn.Sequential(\n *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n\n self.final_norm = nn.LayerNorm(cfg[\"emb_dim\"])\n self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False)\n\n def forward(self, in_idx):\n batch_size, seq_len = in_idx.shape\n tok_embeds = self.tok_emb(in_idx)\n pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))\n x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]\n x = self.drop_emb(x)\n x = self.trf_blocks(x)\n x = self.final_norm(x)\n logits = self.out_head(x)\n return logits\n\n\ndef generate_text_simple(model, idx, max_new_tokens, context_size):\n # idx is (B, T) array of indices in the current context\n for _ in range(max_new_tokens):\n\n # Crop current context if it exceeds the supported context size\n # E.g., if LLM supports only 5 tokens, and the context size is 10\n # then only the last 5 tokens are used as context\n idx_cond = idx[:, -context_size:]\n\n # Get the predictions\n with torch.no_grad():\n logits = model(idx_cond)\n\n # Focus only on the last time step\n # (batch, n_token, vocab_size) becomes (batch, vocab_size)\n logits = logits[:, -1, :]\n\n # Get the idx of the vocab entry with the highest logits value\n idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\n\n # Append sampled index to the running sequence\n idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\n\n return idx\n\n#####################################\n# Chapter 5\n#####################################\n\n\ndef text_to_token_ids(text, tokenizer):\n encoded = tokenizer.encode(text)\n encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\n return encoded_tensor\n\n\ndef token_ids_to_text(token_ids, tokenizer):\n flat = token_ids.squeeze(0) # remove batch dimension\n return tokenizer.decode(flat.tolist())\n\n\ndef calc_loss_batch(input_batch, target_batch, model, device):\n input_batch, target_batch = input_batch.to(device), target_batch.to(device)\n logits = model(input_batch)\n loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())\n return loss\n\n\ndef calc_loss_loader(data_loader, model, device, num_batches=None):\n total_loss = 0.\n if len(data_loader) == 0:\n return float(\"nan\")\n elif num_batches is None:\n num_batches = len(data_loader)\n else:\n num_batches = min(num_batches, len(data_loader))\n for i, (input_batch, target_batch) in enumerate(data_loader):\n if i < num_batches:\n loss = calc_loss_batch(input_batch, target_batch, model, device)\n total_loss += loss.item()\n else:\n break\n return total_loss / num_batches\n\n\ndef evaluate_model(model, train_loader, val_loader, device, eval_iter):\n model.eval()\n with torch.no_grad():\n train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\n val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\n model.train()\n return train_loss, val_loss\n\n\ndef generate_and_print_sample(model, device, start_context):\n model.eval()\n\n # NEW: Modify for DDP\n context_size = model.module.pos_emb.weight.shape[0] if isinstance(model, DDP) else model.pos_emb.weight.shape[0]\n encoded = text_to_token_ids(start_context, tiktoken.get_encoding(\"gpt2\")).to(device)\n with torch.no_grad():\n token_ids = generate_text_simple(\n model=model, idx=encoded,\n max_new_tokens=50, context_size=context_size\n )\n decoded_text = token_ids_to_text(token_ids, tiktoken.get_encoding(\"gpt2\"))\n print(decoded_text.replace(\"\\n\", \" \")) # Compact print format\n model.train()\n\n\ndef train_model_simple_with_timing(model, train_loader, val_loader, optimizer, device,\n num_epochs, eval_freq, eval_iter, start_context):\n train_losses, val_losses, track_tokens = [], [], []\n total_tokens, global_step, last_tokens = 0, -1, 0\n\n # NEW: Determine the current rank (default to 0 if not distributed)\n rank = torch.distributed.get_rank() if torch.distributed.is_initialized() else 0\n # world_size = torch.distributed.get_world_size() if torch.distributed.is_initialized() else 1\n\n # Variables for cumulative average tokens/sec\n cumulative_tokens, cumulative_time = 0.0, 0.0\n\n # CUDA-specific timing setup\n use_cuda = device.type == \"cuda\"\n if use_cuda:\n t_start = torch.cuda.Event(enable_timing=True)\n t_end = torch.cuda.Event(enable_timing=True)\n torch.cuda.synchronize() # Ensure all prior CUDA operations are done\n t_start.record() # Start the timer for the first interval\n else:\n t0 = time.time() # Start the timer for the first interval\n\n # Main training loop\n for epoch in range(num_epochs):\n # NEW: set epoch for DistributedSampler so each process gets a unique shuffle order\n if isinstance(train_loader.sampler, DistributedSampler):\n train_loader.sampler.set_epoch(epoch)\n\n model.train()\n for inp_batch, tgt_batch in train_loader:\n optimizer.zero_grad()\n global_step += 1\n\n # Forward and backward pass\n loss = calc_loss_batch(inp_batch, tgt_batch, model, device)\n loss.backward()\n optimizer.step()\n\n total_tokens += inp_batch.numel()\n\n # At evaluation intervals, measure elapsed time and tokens per second\n if global_step % eval_freq == 0:\n # End timing for the current interval\n if use_cuda:\n t_end.record()\n torch.cuda.synchronize() # Wait for all CUDA ops to complete.\n elapsed = t_start.elapsed_time(t_end) / 1000 # Convert ms to seconds\n t_start.record() # Reset timer for the next interval\n else:\n elapsed = time.time() - t0\n t0 = time.time() # Reset timer for the next interval\n\n # Calculate local tokens processed during this interval\n local_interval = total_tokens - last_tokens\n last_tokens = total_tokens\n\n # Aggregate the tokens processed over all devices\n local_tensor = torch.tensor([local_interval], device=device, dtype=torch.float)\n global_tensor = local_tensor.clone()\n torch.distributed.all_reduce(global_tensor, op=torch.distributed.ReduceOp.SUM)\n global_interval = global_tensor.item()\n\n # Global tokens per second for this interval\n global_tps = global_interval / elapsed if elapsed > 0 else 0\n\n # Update cumulative tokens (local) and aggregate globally\n cumulative_tokens += local_interval\n local_cum_tensor = torch.tensor([cumulative_tokens], device=device, dtype=torch.float)\n global_cum_tensor = local_cum_tensor.clone()\n torch.distributed.all_reduce(global_cum_tensor, op=torch.distributed.ReduceOp.SUM)\n global_cumulative_tokens = global_cum_tensor.item()\n cumulative_time += elapsed\n global_avg_tps = global_cumulative_tokens / cumulative_time if cumulative_time > 0 else 0\n\n # Evaluate model performance (this may add overhead)\n train_loss, val_loss = evaluate_model(model, train_loader, val_loader, device, eval_iter)\n train_losses.append(train_loss)\n val_losses.append(val_loss)\n track_tokens.append(total_tokens)\n\n # NEW: Only print logs once per GPU (choosing the rank 0 GPU)\n if rank == 0:\n print(f\"Ep {epoch+1}, Step {global_step:06d}, \"\n f\"Train: {train_loss:.3f}, Val: {val_loss:.3f}, \"\n f\"Step tok/sec: {round(global_tps)}, Global avg tok/sec: {round(global_avg_tps)}\")\n\n # NEW Only rank 0 prints the generated sample and memory usage stats\n if rank == 0 and epoch % 5 == 0:\n generate_and_print_sample(model, device, start_context)\n\n # Memory stats\n if torch.cuda.is_available():\n current_device = torch.cuda.current_device()\n allocated = torch.cuda.memory_allocated(current_device) / 1024**3 # Convert to GB\n reserved = torch.cuda.memory_reserved(current_device) / 1024**3 # Convert to GB\n\n print(f\"\\nAllocated memory: {allocated:.4f} GB\")\n print(f\"Reserved memory: {reserved:.4f} GB\\n\")\n\n return train_losses, val_losses, track_tokens\n\n\ndef plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):\n fig, ax1 = plt.subplots()\n\n # Plot training and validation loss against epochs\n ax1.plot(epochs_seen, train_losses, label=\"Training loss\")\n ax1.plot(epochs_seen, val_losses, linestyle=\"-.\", label=\"Validation loss\")\n ax1.set_xlabel(\"Epochs\")\n ax1.set_ylabel(\"Loss\")\n ax1.legend(loc=\"upper right\")\n\n # Create a second x-axis for tokens seen\n ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\n ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks\n ax2.set_xlabel(\"Tokens seen\")\n\n fig.tight_layout() # Adjust layout to make room\n # plt.show()\n\n\n#####################################\n# Main function calls\n#####################################\n\n# NEW: Add rank and world_size\ndef main(gpt_config, settings, rank, world_size):\n\n ddp_setup(rank, world_size) # NEW: initialize process groups\n device = torch.device(\"cuda\", rank)\n\n torch.manual_seed(123)\n\n # NEW: Print info only on 1 GPU\n if rank == 0:\n print(f\"PyTorch version: {torch.__version__}\")\n if torch.cuda.is_available():\n print(f\"CUDA version: {torch.version.cuda}\")\n\n capability = torch.cuda.get_device_capability()\n if capability[0] >= 7: # Volta (7.0+), Turing (7.5+), Ampere (8.0+), Hopper (9.0+)\n torch.set_float32_matmul_precision(\"high\")\n print(\"Uses tensor cores\")\n else:\n print(\"Tensor cores not supported on this GPU. Using default precision.\")\n print()\n\n ##############################\n # Download data if necessary\n ##############################\n\n file_path = \"middlemarch.txt\"\n url = \"https://www.gutenberg.org/cache/epub/145/pg145.txt\"\n\n # NEW: Only download 1 time\n if rank == 0:\n if not os.path.exists(file_path):\n response = requests.get(url, timeout=30)\n response.raise_for_status()\n text_data = response.text\n with open(file_path, \"w\", encoding=\"utf-8\") as file:\n file.write(text_data)\n # NEW: All processes wait until rank 0 is done, using the GPU index.\n torch.distributed.barrier(device_ids=[device.index])\n\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n text_data = file.read()\n\n ##############################\n # Initialize model\n ##############################\n\n model = GPTModel(gpt_config)\n model = torch.compile(model)\n model = model.to(device)\n model = model.to(torch.bfloat16)\n # NEW: Wrap model with DDP\n model = DDP(model, device_ids=[rank])\n optimizer = torch.optim.AdamW(\n model.parameters(), lr=settings[\"learning_rate\"], weight_decay=settings[\"weight_decay\"],\n fused=True\n )\n\n ##############################\n # Set up dataloaders\n ##############################\n\n # Train/validation ratio\n train_ratio = 0.90\n split_idx = int(train_ratio * len(text_data))\n\n train_loader = create_dataloader_v1(\n text_data[:split_idx],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=True,\n num_workers=4\n )\n\n val_loader = create_dataloader_v1(\n text_data[split_idx:],\n batch_size=settings[\"batch_size\"],\n max_length=gpt_config[\"context_length\"],\n stride=gpt_config[\"context_length\"],\n drop_last=False,\n num_workers=4\n )\n\n ##############################\n # Train model\n ##############################\n\n train_losses, val_losses, tokens_seen = train_model_simple_with_timing(\n model=model,\n train_loader=train_loader,\n val_loader=val_loader,\n optimizer=optimizer,\n device=device,\n num_epochs=settings[\"num_epochs\"],\n eval_freq=5,\n eval_iter=1,\n start_context=\"Every effort moves you\",\n )\n\n # NEW: Clean up distributed processes\n destroy_process_group()\n\n return train_losses, val_losses, tokens_seen, model\n\n\nif __name__ == \"__main__\":\n\n # NEW: Extract rank and world size from environment variables\n if \"WORLD_SIZE\" in os.environ:\n world_size = int(os.environ[\"WORLD_SIZE\"])\n else:\n world_size = 1\n\n if \"LOCAL_RANK\" in os.environ:\n rank = int(os.environ[\"LOCAL_RANK\"])\n elif \"RANK\" in os.environ:\n rank = int(os.environ[\"RANK\"])\n else:\n rank = 0\n\n GPT_CONFIG_124M = {\n \"vocab_size\": 50304, # Vocabulary size\n \"context_length\": 1024, # Input tokens per training example\n \"emb_dim\": 768, # Embedding dimension\n \"n_heads\": 12, # Number of attention heads\n \"n_layers\": 12, # Number of layers\n \"drop_rate\": 0.1, # Dropout rate\n \"qkv_bias\": False # Query-key-value bias\n }\n\n OTHER_SETTINGS = {\n \"learning_rate\": 5e-4, # * world_size, # NEW: Increase learning rate to account for multiple GPUs\n \"num_epochs\": 50,\n \"batch_size\": 32,\n \"weight_decay\": 0.1\n }\n\n ###########################\n # Initiate training\n ###########################\n\n train_losses, val_losses, tokens_seen, model = main(\n GPT_CONFIG_124M, OTHER_SETTINGS,\n rank, world_size # NEW\n )\n\n ###########################\n # After training\n ###########################\n\n # NEW: Only create 1 plot\n if rank == 0:\n # Plot results\n epochs_tensor = torch.linspace(0, OTHER_SETTINGS[\"num_epochs\"], len(train_losses))\n plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)\n plt.savefig(\"loss.pdf\")\n\n # Save and load model\n #\n # compiled = hasattr(model, \"_orig_mod\")\n # if compiled:\n # torch.save(model._orig_mod.state_dict(), \"model.pth\")\n # else:\n # torch.save(model.state_dict(), \"model.pth\")\n #\n # model = GPTModel(GPT_CONFIG_124M)\n # model.load_state_dict(torch.load(\"model.pth\", weights_only=True))\n"
},
{
"path": "ch05/10_llm-training-speed/README.md",
"content": "# PyTorch Performance Tips for Faster LLM Training\n\n\n\nNote that the book is written for education purposes, meaning the original code is kept purposefully simple. This is to aid readability and ensure compatibility across different hardware, including CPUs and GPUs. However, you might be curious about some more advanced PyTorch and GPU features to make the LLM training more performant.\n\nThis folder contains three code files that demonstrate performance optimizations for the LLM and the training function introduced in Chapter 5:\n\n1. [`00_orig.py`](00_orig.py): The original Chapter 5 code for CPU and single-GPU training. \n ➤ Run via: `python 00_orig.py`\n\n2. [`01_opt_single_gpu.py`](01_opt_single_gpu.py): An optimized version for single-GPU training. \n ➤ Run via: `python 01_opt_single_gpu.py`\n\n3. [`02_opt_multi_gpu_ddp.py`](02_opt_multi_gpu_ddp.py): An optimized version for multi-GPU training using Distributed Data Parallel (DDP). \n ➤ Run via: `torchrun --nproc_per_node=4 02_opt_multi_gpu_ddp.py` \n (**Note:** To keep the changes minimal compared to `01_opt_single_gpu.py`, this script supports multi-processing only via `torchrun` as shown above. This means multi-GPU support is **not** supported via `python 02_opt_multi_gpu_ddp.py`)\n\n**Note that these modifications take the training speed from 12,525 tokens per second (single A100) to 142,156 tokens per second (single A100) and 419,259 tokens per second (4x A100s).**\n\nI plan to expand on the differences in a more detailed write-up sometime in the future. For now, the easiest way to see what improvements have been added to the code is to open the files in Visual Studio Code and look at the differences via the \"Compare Selected\" feature.\n\n\n\n\n\n\n \n## Single GPU speed comparisons\n\nAs mentioned above, I plan to elaborate more on the changes in the future. For now, this section contains a simple performance overview in terms of tokens/second for each modification. All experiments were run on A100 GPUs.\n\n \n### Baseline\n\nNote that `00_orig.py` servers as the baseline and contains no significant modification and uses the code from Chapter 5 as is besides the following:\n\n- 4 times larger context length (which explains the relatively large memory footprint of `00_orig.py` compared to Chapter 5);\n- 4-times batch size changes (another contributor to the relatively large memory footprint of `00_orig.py`);\n- a larger public domain book to increase the training data size. \n\nThe hyperparameters are not very optimized for minimizing loss and reducing overfitting, and the text generated by the LLM at the very end may not be super sophisticated; however, this shouldn't matter as the main takeaway is the `tok/sec` metric that serves as a speed reference here (higher is better).\n\n```bash\nubuntu@159-13-52-60:~$ python 00_orig.py\nPyTorch version: 2.6.0+cu124\nUsing cuda\nCUDA version: 12.4\n\nEp 1, Step 000000, Train: 9.535, Val: 9.609, Step tok/sec: 7238, Avg tok/sec: 0\nEp 1, Step 000015, Train: 6.201, Val: 6.152, Step tok/sec: 12545, Avg tok/sec: 12545\nEp 1, Step 000030, Train: 5.663, Val: 5.688, Step tok/sec: 12490, Avg tok/sec: 12517\nEp 1, Step 000045, Train: 5.316, Val: 5.362, Step tok/sec: 12541, Avg tok/sec: 12525\nEvery effort moves you, and's, and I am not be a\n\n...\n\nEp 15, Step 000735, Train: 0.227, Val: 6.818, Step tok/sec: 11599, Avg tok/sec: 12248\nEp 15, Step 000750, Train: 0.300, Val: 6.895, Step tok/sec: 12530, Avg tok/sec: 12253\nEp 15, Step 000765, Train: 0.150, Val: 6.914, Step tok/sec: 12532, Avg tok/sec: 12259\nEvery effort moves you like best to think which he held in the room in him, the interest was the night, the realities of the affairs Bulstrode's duty, now!' the fact is another man, conquests\n\nAllocated memory: 2.5069 GB\nReserved memory: 26.2617 GB\n```\n\nNote that `01_opt_single_gpu.py` contains all the modifications listed sequentially below. \n\nThe comparison is always based on the average tok/sec and allocated memory after the first epoch from the previous section.\n\n \n### 1. Create causal mask on the fly\n\n- Instead of saving the causal mask, this creates the causal mask on the fly to reduce memory usage (here it has minimal effect, but it can add up in long-context size models like Llama 3.2 with 131k-input-tokens support)\n\nBefore:\n- `Avg tok/sec: 12525`\n- `Reserved memory: 26.2617 GB`\n\nAfter:\n- `Avg tok/sec: 12526`\n- `Reserved memory: 26.2422 GB`\n\n \n### 2. Use tensor cores\n\n- Uses tensor cores (only works for Ampere GPUs like A100 and newer)\n\nBefore:\n- `Avg tok/sec: 12526`\n- `Reserved memory: 26.2422 GB`\n\nAfter:\n- `Avg tok/sec: 27648`\n- `Reserved memory: 26.2422 GB`\n\n \n### 3. Fused AdamW optimizer\n\n- Uses the fused kernels for `AdamW` by setting `fused=True`\n\nBefore:\n- `Avg tok/sec: 27648`\n- `Reserved memory: 26.2422 GB`\n\nAfter:\n- `Avg tok/sec: 28399`\n- `Reserved memory: 26.2422 GB`\n\n \n### 4. Pinned memory in the data loader\n\n- Uses `pin_memory=True` in the data loaders to pre-allocate and re-use GPU memory\n\nBefore:\n- `Avg tok/sec: 28399`\n- `Reserved memory: 26.2422 GB`\n\nAfter:\n- `Avg tok/sec: 28402`\n- `Reserved memory: 26.2422 GB`\n\n \n### 5. Using bfloat16 precision\n\n- Switches from 32-bit float to 16-bit brain float (bfloat16) precision (for more on this topic, see my [article here](https://magazine.sebastianraschka.com/p/the-missing-bits-llama-2-weights))\n\nBefore:\n- `Avg tok/sec: 28402`\n- `Reserved memory: 26.2422 GB`\n\nAfter:\n- `Avg tok/sec: 45486`\n- `Reserved memory: 13.7871 GB`\n\n \n### 6. Replacing from-scratch code by PyTorch classes\n\n- Replaces the LayerNorm and GeLU from-scratch implementation by PyTorch's native implementations\n\nBefore:\n- `Avg tok/sec: 45486`\n- `Reserved memory: 13.7871 GB`\n\nAfter:\n- `Avg tok/sec: 55256`\n- `Reserved memory: 11.5645 GB`\n\n \n### 7. Using FlashAttention\n\n- Uses PyTorch's self-attention function with FlashAttention instead of our from-scratch multi-head attention implementation.\n\n\nBefore:\n- `Avg tok/sec: 55256`\n- `Reserved memory: 11.5645 GB`\n\nAfter:\n- `Avg tok/sec: 91901`\n- `Reserved memory: 5.9004 GB`\n\n \n### 8. Using `pytorch.compile`\n\n- Uses `torch.compile(model)`. Note that the first iterations are always slow before it picks up speed. Since the `Avg tok/sec` measurement only includes the first row from the average calculation, we now use the `Step tok/sec` at the end of epoch 1.\n\n\nBefore:\n- `Avg tok/sec: 91901`\n- `Reserved memory: 5.9004 GB`\n\nAfter:\n- `Step tok/sec: 112046`\n- `Reserved memory: 6.1875 GB`\n\n \n\n\nThis [standalone-qwen3-moe.ipynb](standalone-qwen3-moe.ipynb) and [standalone-qwen3-moe-plus-kvcache.ipynb](standalone-qwen3-moe-plus-kvcache.ipynb) Jupyter notebooks in this folder contain a from-scratch implementation of 30B-A3B Mixture-of-Experts (MoE), including the Thinking, Instruct, and Coder model variants.\n\n
\n\n\nThis [standalone-qwen3-moe.ipynb](standalone-qwen3-moe.ipynb) and [standalone-qwen3-moe-plus-kvcache.ipynb](standalone-qwen3-moe-plus-kvcache.ipynb) Jupyter notebooks in this folder contain a from-scratch implementation of 30B-A3B Mixture-of-Experts (MoE), including the Thinking, Instruct, and Coder model variants.\n\n \n\n \n# Qwen3 from-scratch code\n\nThe standalone notebooks in this folder contain from-scratch codes in linear fashion:\n\n1. [standalone-qwen3.ipynb](standalone-qwen3.ipynb): The dense Qwen3 model without bells and whistles\n2. [standalone-qwen3-plus-kvcache.ipynb](standalone-qwen3-plus-kvcache.ipynb): Same as above but with KV cache for better inference efficiency\n3. [standalone-qwen3-moe.ipynb](standalone-qwen3-moe.ipynb): Like the first notebook but the Mixture-of-Experts (MoE) variant\n4. [standalone-qwen3-moe-plus-kvcache.ipynb](standalone-qwen3-moe-plus-kvcache.ipynb): Same as above but with KV cache for better inference efficiency\n\nAlternatively, I also organized the code into a Python package [here](../../pkg/llms_from_scratch/) (including unit tests and CI), which you can run as described below.\n\n \n# Training\n\nThe `Qwen3Model` class is implemented in a similar style as the `GPTModel` class, so it can be used as a drop-in replacement for training in chapter 5 and finetuning in chapters 6 and 7.\n\n\n \n# Using Qwen3 via the `llms-from-scratch` package\n\nFor an easy way to use the Qwen3 from-scratch implementation, you can also use the `llms-from-scratch` PyPI package based on the source code in this repository at [pkg/llms_from_scratch](../../pkg/llms_from_scratch).\n\n \n#### 1) Installation\n\n```bash\npip install llms_from_scratch tokenizers\n```\n\n \n#### 2) Model and text generation settings\n\nSpecify which model to use:\n\n```python\nUSE_REASONING_MODEL = True\n# Uses the base model if USE_REASONING_MODEL = False\n\nUSE_INSTRUCT_MODEL = False\n# Uses the instruct mode (without reasoning) if \n# USE_REASONING_MODEL = True\n# USE_INSTRUCT_MODEL = True\n# This setting does have no effect if USE_REASONING_MODEL = False\n\n\n# Use\n# USE_REASONING_MODEL = True\n# For Qwen3 Coder Flash model as well\n```\n\nBasic text generation settings that can be defined by the user. With 150 tokens, the 0.6B model requires approximately 1.5 GB memory.\n\n```python\nMAX_NEW_TOKENS = 150\nTEMPERATURE = 0.\nTOP_K = 1\n```\n\n \n#### 3a) Weight download and loading of the 0.6B model\n\nThe following automatically downloads the weight file based on the model choice (reasoning or base) above. Note that this section focuses on the 0.6B model. Skip this section and continue with section 3b) if you want to work with any of the larger models (1.7B, 4B, 8B, or 32B).\n\n```python\nfrom llms_from_scratch.qwen3 import download_from_huggingface\n\nrepo_id = \"rasbt/qwen3-from-scratch\"\n\nif USE_REASONING_MODEL:\n filename = \"qwen3-0.6B.pth\"\n local_dir = \"Qwen3-0.6B\" \nelse:\n filename = \"qwen3-0.6B-base.pth\" \n local_dir = \"Qwen3-0.6B-Base\"\n\ndownload_from_huggingface(\n repo_id=repo_id,\n filename=filename,\n local_dir=local_dir\n)\n```\n\nThe model weights are then loaded as follows:\n\n```python\nfrom pathlib import Path\nimport torch\n\nfrom llms_from_scratch.qwen3 import Qwen3Model, QWEN_CONFIG_06_B\n\nmodel_file = Path(local_dir) / filename\n\nmodel = Qwen3Model(QWEN_CONFIG_06_B)\nmodel.load_state_dict(torch.load(model_file, weights_only=True, map_location=\"cpu\"))\n\ndevice = (\n torch.device(\"cuda\") if torch.cuda.is_available() else\n torch.device(\"mps\") if torch.backends.mps.is_available() else\n torch.device(\"cpu\")\n)\nmodel.to(device);\n```\n\n \n#### 3b) Weight download and loading of the larger Qwen models\n\nIf you are interested in working with any of the larger Qwen models, for instance, 1.7B, 4B, 8B, or 32B, please use the following code below instead of the code under 3a), which requires additional code dependencies:\n\n```bash\npip install safetensors huggingface_hub\n```\n\nThen use the following code (make appropriate changes to `USE_MODEL` to select the desired model size)\n\n```python\nUSE_MODEL = \"1.7B\"\n\nif USE_MODEL == \"1.7B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_1_7B as QWEN3_CONFIG\nelif USE_MODEL == \"4B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_4B as QWEN3_CONFIG\nelif USE_MODEL == \"8B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_8B as QWEN3_CONFIG\nelif USE_MODEL == \"14B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_14B as QWEN3_CONFIG\nelif USE_MODEL == \"32B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_32B as QWEN3_CONFIG\nelif USE_MODEL == \"30B-A3B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_30B_A3B as QWEN3_CONFIG\nelse:\n raise ValueError(\"Invalid USE_MODEL name.\")\n \nrepo_id = f\"Qwen/Qwen3-{USE_MODEL}\"\nlocal_dir = f\"Qwen3-{USE_MODEL}\"\n\nif not USE_REASONING_MODEL:\n repo_id = f\"{repo_id}-Base\"\n local_dir = f\"{local_dir}-Base\"\n```\n\nNow, download and load the weights into the `model`:\n\n```python\nfrom llms_from_scratch.qwen3 import (\n Qwen3Model,\n download_from_huggingface_from_snapshots,\n load_weights_into_qwen\n)\n\ndevice = (\n torch.device(\"cuda\") if torch.cuda.is_available() else\n torch.device(\"mps\") if torch.backends.mps.is_available() else\n torch.device(\"cpu\")\n)\n\nwith device:\n model = Qwen3Model(QWEN3_CONFIG)\n\nweights_dict = download_from_huggingface_from_snapshots(\n repo_id=repo_id,\n local_dir=local_dir\n)\nload_weights_into_qwen(model, QWEN3_CONFIG, weights_dict)\nmodel.to(device) # only required for the MoE models\ndel weights_dict # delete weight dictionary to free up disk space\n```\n\n\n \n\n#### 4) Initialize tokenizer\n\nThe following code downloads and initializes the tokenizer:\n\n```python\nfrom llms_from_scratch.qwen3 import Qwen3Tokenizer\n\nif USE_REASONING_MODEL:\n tok_filename = \"tokenizer.json\" \nelse:\n tok_filename = \"tokenizer-base.json\" \n\ntokenizer = Qwen3Tokenizer(\n tokenizer_file_path=tokenizer_file_path,\n repo_id=repo_id,\n apply_chat_template=USE_REASONING_MODEL,\n add_generation_prompt=USE_REASONING_MODEL,\n add_thinking=not USE_INSTRUCT_MODEL\n)\n```\n\n\n\n \n\n#### 5) Generating text\n\nLastly, we can generate text via the following code:\n\n```python\nprompt = \"Give me a short introduction to large language models.\"\ninput_token_ids = tokenizer.encode(prompt)\n```\n\n\n\n\n\n```python\nfrom llms_from_scratch.ch05 import generate\nimport time\n\ntorch.manual_seed(123)\n\nstart = time.time()\n\noutput_token_ids = generate(\n model=model,\n idx=torch.tensor(input_token_ids, device=device).unsqueeze(0),\n max_new_tokens=150,\n context_size=QWEN_CONFIG_06_B[\"context_length\"],\n top_k=1,\n temperature=0.\n)\n\ntotal_time = time.time() - start\nprint(f\"Time: {total_time:.2f} sec\")\nprint(f\"{int(len(output_token_ids[0])/total_time)} tokens/sec\")\n\nif torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\noutput_text = tokenizer.decode(output_token_ids.squeeze(0).tolist())\n\nprint(\"\\n\\nOutput text:\\n\\n\", output_text + \"...\")\n```\n\nWhen using the Qwen3 0.6B reasoning model, the output should look similar to the one shown below (this was run on an A100):\n\n```\nTime: 6.35 sec\n25 tokens/sec\nMax memory allocated: 1.49 GB\n\n\nOutput text:\n\n <|im_start|>user\nGive me a short introduction to large language models.<|im_end|>\nLarge language models (LLMs) are advanced artificial intelligence systems designed to generate human-like text. They are trained on vast amounts of text data, allowing them to understand and generate coherent, contextually relevant responses. LLMs are used in a variety of applications, including chatbots, virtual assistants, content generation, and more. They are powered by deep learning algorithms and can be fine-tuned for specific tasks, making them versatile tools for a wide range of industries.<|endoftext|>Human resources department of a company is planning to hire 100 new employees. The company has a budget of $100,000 for the recruitment process. The company has a minimum wage of $10 per hour. The company has a total of...\n```\n\n\n\nFor the larger models, you may prefer the streaming variant, which prints each token as soon as it's generated:\n\n```python\nfrom llms_from_scratch.generate import generate_text_simple_stream\n\ninput_token_ids_tensor = torch.tensor(input_token_ids, device=device).unsqueeze(0)\n\nfor token in generate_text_simple_stream(\n model=model,\n token_ids=input_token_ids_tensor,\n max_new_tokens=150,\n eos_token_id=tokenizer.eos_token_id\n):\n token_id = token.squeeze(0).tolist()\n print(\n tokenizer.decode(token_id),\n end=\"\",\n flush=True\n )\n```\n\n```\n <|im_start|>user\nGive me a short introduction to large language models.<|im_end|>\nLarge language models (LLMs) are advanced artificial intelligence systems designed to generate human-like text. They are trained on vast amounts of text data, allowing them to understand and generate coherent, contextually relevant responses. LLMs are used in a variety of applications, including chatbots, virtual assistants, content generation, and more. They are powered by deep learning algorithms and can be fine-tuned for specific tasks, making them versatile tools for a wide range of industries.<|endoftext|>Human resources department of a company is planning to hire 100 new employees. The company has a budget of $100,000 for the recruitment process. The company has a minimum wage of $10 per hour. The company has a total of...\n```\n\n\n\n \n\n#### Pro tip 1: speed up inference with compilation\n\n\nFor up to a 4× speed-up, replace\n\n```python\nmodel.to(device)\n```\n\nwith\n\n```python\nmodel.to(device)\nmodel = torch.compile(model)\n```\n\nNote: There is a significant multi-minute upfront cost when compiling, and the speed-up takes effect after the first `generate` call. \n\nThe following table shows a performance comparison on an A100 for consequent `generate` calls:\n\n| | Hardware | Tokens/sec | Memory |\n| ------------------------ | ----------------|----------- | -------- |\n| Qwen3Model 0.6B | Nvidia A100 GPU | 25 | 1.49 GB |\n| Qwen3Model 0.6B compiled | Nvidia A100 GPU | 107 | 1.99 GB |\n\n\n \n#### Pro tip 2: speed up inference with KV cache\n\nYou can significantly boost inference performance using the KV cache `Qwen3Model` drop-in replacement when running the model on a CPU. (See my [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) article to learn more about KV caches.)\n\n```python\nfrom llms_from_scratch.kv_cache.qwen3 import Qwen3Model\nfrom llms_from_scratch.kv_cache.generate import generate_text_simple\n\nmodel = Qwen3Model(QWEN_CONFIG_06_B)\n# ...\ntoken_ids = generate_text_simple(\n model=model,\n idx=text_to_token_ids(PROMPT, tokenizer).to(device),\n max_new_tokens=MAX_NEW_TOKENS,\n context_size=QWEN_CONFIG_06_B[\"context_length\"],\n)\n```\n\nNote that the peak memory usage is only listed for Nvidia CUDA devices, as it is easier to calculate. However, the memory usage on other devices is likely similar as it uses a similar precision format, and the KV cache storage results in even lower memory usage here for the generated 150-token text (however, different devices may implement matrix multiplication differently and may result in different peak memory requirements; and KV-cache memory may increase prohibitively for longer contexts lengths).\n\n| Model | Mode | Hardware | Tokens/sec | GPU Memory (VRAM) |\n| --------------- | ----------------- | --------------- | ---------- | ----------------- |\n| Qwen3Model 0.6B | Regular | Mac Mini M4 CPU | 1 | - |\n| Qwen3Model 0.6B | Regular compiled | Mac Mini M4 CPU | 1 | - |\n| Qwen3Model 0.6B | KV cache | Mac Mini M4 CPU | 80 | - |\n| Qwen3Model 0.6B | KV cache compiled | Mac Mini M4 CPU | 137 | - |\n| | | | | |\n| Qwen3Model 0.6B | Regular | Mac Mini M4 GPU | 21 | - |\n| Qwen3Model 0.6B | Regular compiled | Mac Mini M4 GPU | Error | - |\n| Qwen3Model 0.6B | KV cache | Mac Mini M4 GPU | 28 | - |\n| Qwen3Model 0.6B | KV cache compiled | Mac Mini M4 GPU | Error | - |\n| | | | | |\n| Qwen3Model 0.6B | Regular | Nvidia A100 GPU | 26 | 1.49 GB |\n| Qwen3Model 0.6B | Regular compiled | Nvidia A100 GPU | 107 | 1.99 GB |\n| Qwen3Model 0.6B | KV cache | Nvidia A100 GPU | 25 | 1.47 GB |\n| Qwen3Model 0.6B | KV cache compiled | Nvidia A100 GPU | 90 | 1.48 GB |\n\nNote that all settings above have been tested to produce the same text outputs.\n\n\n\n \n\n#### Pro tip 3: batched inference\n\nWe can further increase the throughput via batched inference. While it's not an apples-to-apples comparison, as we are now running inference with a higher number of input sequences, this increases the tokens per second throughput while trading it off against increased memory usage.\n\nThis only requires a small code modification with respect to preparing the prompt. For example, consider this batched prompt below:\n\n```python\nfrom llms_from_scratch.ch04 import generate_text_simple\nfrom llms_from_scratch.qwen3 import Qwen3Model, QWEN_CONFIG_06_B\n# ...\n\nprompts = [\n \"Give me a short introduction to neural networks.\",\n \"Give me a short introduction to machine learning.\",\n \"Give me a short introduction to deep learning models.\",\n \"Give me a short introduction to natural language processing.\",\n \"Give me a short introduction to generative AI systems.\",\n \"Give me a short introduction to transformer architectures.\",\n \"Give me a short introduction to supervised learning methods.\",\n \"Give me a short introduction to unsupervised learning.\",\n]\n\ntokenized_prompts = [tokenizer.encode(p) for p in prompts]\nmax_len = max(len(t) for t in tokenized_prompts)\npadded_token_ids = [\n t + [tokenizer.pad_token_id] * (max_len - len(t)) for t in tokenized_prompts\n]\ninput_tensor = torch.tensor(padded_token_ids).to(device)\n\noutput_token_ids = generate_text_simple(\n model=model,\n idx=input_tensor,\n max_new_tokens=150,\n context_size=QWEN_CONFIG_06_B[\"context_length\"],\n)\n```\n\nThe code for the KV cache version is similar, except that it requires using these drop-in replacements:\n\n```python\nfrom llms_from_scratch.kv_cache_batched.generate import generate_text_simple\nfrom llms_from_scratch.kv_cache_batched.qwen3 import Qwen3Model\n```\n\n\nThe experiments below are run with a batch size of 8.\n\n| Model | Mode | Hardware | Batch size | Tokens/sec | GPU Memory (VRAM) |\n| ---------------- | ----------------- | --------------- | ---------- | ---------- | ----------------- |\n| Qwen3Model 0.6B | Regular | Mac Mini M4 CPU | 8 | 2 | - |\n| Qwen3Model 0.6B | Regular compiled | Mac Mini M4 CPU | 8 | - | - |\n| Qwen3Model 0.6B | KV cache | Mac Mini M4 CPU | 8 | 92 | - |\n| Qwen3Model 0.6B | KV cache compiled | Mac Mini M4 CPU | 8 | 128 | - |\n| | | | | | |\n| Qwen3Model 0.6B | Regular | Mac Mini M4 GPU | 8 | 36 | - |\n| Qwen3Model 0.6B | Regular compiled | Mac Mini M4 GPU | 8 | - | - |\n| Qwen3Model 0.6B | KV cache | Mac Mini M4 GPU | 8 | 61 | - |\n| Qwen3Model 0.6B | KV cache compiled | Mac Mini M4 GPU | 8 | - | - |\n| | | | | | |\n| Qwen3Model 0.6B | Regular | Nvidia A100 GPU | 8 | 184 | 2.19 GB |\n| Qwen3Model 0.6B | Regular compiled | Nvidia A100 GPU | 8 | 351 | 2.19 GB |\n| Qwen3Model 0.6B | KV cache | Nvidia A100 GPU | 8 | 140 | 3.13 GB |\n| Qwen3Model 0.6B | KV cache compiled | Nvidia A100 GPU | 8 | 280 | 1.75 GB |\n\n"
},
{
"path": "ch05/11_qwen3/qwen3-chat-interface/README.md",
"content": "# Qwen3 From Scratch with Chat Interface\n\n\n\nThis bonus folder contains code for running a ChatGPT-like user interface to interact with the pretrained Qwen3 model.\n\n\n\n\n\n\n\nTo implement this user interface, we use the open-source [Chainlit Python package](https://github.com/Chainlit/chainlit).\n\n \n## Step 1: Install dependencies\n\nFirst, we install the `chainlit` package and dependencies from the [requirements-extra.txt](requirements-extra.txt) list via\n\n```bash\npip install -r requirements-extra.txt\n```\n\nOr, if you are using `uv`:\n\n```bash\nuv pip install -r requirements-extra.txt\n```\n\n\n\n \n\n## Step 2: Run `app` code\n\nThis folder contains 2 files:\n\n1. [`qwen3-chat-interface.py`](qwen3-chat-interface.py): This file loads and uses the Qwen3 0.6B model in thinking mode. \n2. [`qwen3-chat-interface-multiturn.py`](qwen3-chat-interface-multiturn.py): The same as above, but configured to remember the message history.\n\n(Open and inspect these files to learn more.)\n\nRun one of the following commands from the terminal to start the UI server:\n\n```bash\nchainlit run qwen3-chat-interface.py\n```\n\nor, if you are using `uv`:\n\n```bash\nuv run chainlit run qwen3-chat-interface.py\n```\n\nRunning one of the commands above should open a new browser tab where you can interact with the model. If the browser tab does not open automatically, inspect the terminal command and copy the local address into your browser address bar (usually, the address is `http://localhost:8000`).\n"
},
{
"path": "ch05/11_qwen3/qwen3-chat-interface/qwen3-chat-interface-multiturn.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport torch\nimport chainlit\n\n# For llms_from_scratch installation instructions, see:\n# https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\nfrom llms_from_scratch.kv_cache.qwen3 import (\n Qwen3Model,\n Qwen3Tokenizer,\n download_from_huggingface_from_snapshots,\n load_weights_into_qwen\n)\nfrom llms_from_scratch.kv_cache.generate import (\n generate_text_simple_stream,\n trim_input_tensor\n)\n\n# ============================================================\n# EDIT ME: Simple configuration\n# ============================================================\nMODEL = \"0.6B\" # options: \"0.6B\",\"1.7B\",\"4B\",\"8B\",\"14B\",\"32B\",\"30B-A3B\"\nREASONING = True # True = \"thinking\" chat model, False = Base\nDEVICE = \"auto\" # \"auto\" | \"cuda\" | \"mps\" | \"cpu\"\nMAX_NEW_TOKENS = 38912\nLOCAL_DIR = None # e.g., \"Qwen3-0.6B-Base\"; None auto-selects\n# ============================================================\n\n\ndef get_qwen_config(name):\n if name == \"0.6B\":\n from llms_from_scratch.qwen3 import QWEN_CONFIG_06_B as QWEN3_CONFIG\n elif name == \"1.7B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_1_7B as QWEN3_CONFIG\n elif name == \"4B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_4B as QWEN3_CONFIG\n elif name == \"8B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_8B as QWEN3_CONFIG\n elif name == \"14B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_14B as QWEN3_CONFIG\n elif name == \"32B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_32B as QWEN3_CONFIG\n elif name == \"30B-A3B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_30B_A3B as QWEN3_CONFIG\n else:\n raise ValueError(f\"Invalid model name: {name}\")\n return QWEN3_CONFIG\n\n\ndef build_repo_and_local(model_name, reasoning, local_dir_arg):\n base = f\"Qwen3-{model_name}\"\n repo_id = f\"Qwen/{base}-Base\" if not reasoning else f\"Qwen/{base}\"\n local_dir = local_dir_arg if local_dir_arg else (f\"{base}-Base\" if not reasoning else base)\n return repo_id, local_dir\n\n\ndef get_device(name):\n if name == \"auto\":\n if torch.cuda.is_available():\n return torch.device(\"cuda\")\n elif torch.backends.mps.is_available():\n return torch.device(\"mps\")\n else:\n return torch.device(\"cpu\")\n elif name == \"cuda\":\n return torch.device(\"cuda\")\n elif name == \"mps\":\n return torch.device(\"mps\")\n else:\n return torch.device(\"cpu\")\n\n\ndef get_model_and_tokenizer(qwen3_config, repo_id, local_dir, device, use_reasoning):\n model = Qwen3Model(qwen3_config)\n weights_dict = download_from_huggingface_from_snapshots(\n repo_id=repo_id,\n local_dir=local_dir\n )\n load_weights_into_qwen(model, qwen3_config, weights_dict)\n del weights_dict\n\n model.to(device) # safe for all but required by the MoE model\n model.eval()\n\n tok_filename = \"tokenizer.json\"\n tokenizer = Qwen3Tokenizer(\n tokenizer_file_path=tok_filename,\n repo_id=repo_id,\n apply_chat_template=False, # disable to avoid double-wrapping prompts in history\n add_generation_prompt=False, # we add the assistant header manually\n add_thinking=use_reasoning\n )\n return model, tokenizer\n\n\ndef build_prompt_from_history(history, add_assistant_header=True):\n \"\"\"\n history: [{\"role\": \"system\"|\"user\"|\"assistant\", \"content\": str}, ...]\n \"\"\"\n parts = []\n for m in history:\n role = m[\"role\"]\n content = m[\"content\"]\n parts.append(f\"<|im_start|>{role}\\n{content}<|im_end|>\\n\")\n\n if add_assistant_header:\n parts.append(\"<|im_start|>assistant\\n\")\n return \"\".join(parts)\n\n\nQWEN3_CONFIG = get_qwen_config(MODEL)\nREPO_ID, LOCAL_DIR = build_repo_and_local(MODEL, REASONING, LOCAL_DIR)\nDEVICE = get_device(DEVICE)\nMODEL, TOKENIZER = get_model_and_tokenizer(QWEN3_CONFIG, REPO_ID, LOCAL_DIR, DEVICE, REASONING)\n\n# Even though the official TOKENIZER.eos_token_id is either <|im_end|> (reasoning)\n# or <|endoftext|> (base), the reasoning model sometimes emits both.\nEOS_TOKEN_IDS = (TOKENIZER.encode(\"<|im_end|>\")[0], TOKENIZER.encode(\"<|endoftext|>\")[0])\n\n\n@chainlit.on_chat_start\nasync def on_start():\n chainlit.user_session.set(\"history\", [])\n chainlit.user_session.get(\"history\").append(\n {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"}\n )\n\n\n@chainlit.on_message\nasync def main(message: chainlit.Message):\n \"\"\"\n The main Chainlit function.\n \"\"\"\n # 0) Get and track chat history\n history = chainlit.user_session.get(\"history\")\n history.append({\"role\": \"user\", \"content\": message.content})\n\n # 1) Encode input\n prompt = build_prompt_from_history(history, add_assistant_header=True)\n input_ids = TOKENIZER.encode(prompt)\n input_ids_tensor = torch.tensor(input_ids, device=DEVICE).unsqueeze(0)\n input_ids_tensor = trim_input_tensor(\n input_ids_tensor=input_ids_tensor,\n context_len=MODEL.cfg[\"context_length\"],\n max_new_tokens=MAX_NEW_TOKENS\n )\n\n # 2) Start an outgoing message we can stream into\n out_msg = chainlit.Message(content=\"\")\n await out_msg.send()\n\n # 3) Stream generation\n for tok in generate_text_simple_stream(\n model=MODEL,\n token_ids=input_ids_tensor,\n max_new_tokens=MAX_NEW_TOKENS,\n # eos_token_id=TOKENIZER.eos_token_id\n ):\n token_id = tok.squeeze(0)\n if token_id in EOS_TOKEN_IDS:\n break\n piece = TOKENIZER.decode(token_id.tolist())\n await out_msg.stream_token(piece)\n\n # 4) Finalize the streamed message\n await out_msg.update()\n\n # 5) Update chat history\n history.append({\"role\": \"assistant\", \"content\": out_msg.content})\n chainlit.user_session.set(\"history\", history)\n"
},
{
"path": "ch05/11_qwen3/qwen3-chat-interface/qwen3-chat-interface.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport torch\nimport chainlit\n\n# For llms_from_scratch installation instructions, see:\n# https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\nfrom llms_from_scratch.kv_cache.qwen3 import (\n Qwen3Model,\n Qwen3Tokenizer,\n download_from_huggingface_from_snapshots,\n load_weights_into_qwen\n)\nfrom llms_from_scratch.kv_cache.generate import (\n generate_text_simple_stream\n)\n\n# ============================================================\n# EDIT ME: Simple configuration\n# ============================================================\nMODEL = \"0.6B\" # options: \"0.6B\",\"1.7B\",\"4B\",\"8B\",\"14B\",\"32B\",\"30B-A3B\"\nREASONING = True # True = \"thinking\" chat model, False = Base\nDEVICE = \"auto\" # \"auto\" | \"cuda\" | \"mps\" | \"cpu\"\nMAX_NEW_TOKENS = 38912\nLOCAL_DIR = None # e.g., \"Qwen3-0.6B-Base\"; None auto-selects\n# ============================================================\n\n\ndef get_qwen_config(name):\n if name == \"0.6B\":\n from llms_from_scratch.qwen3 import QWEN_CONFIG_06_B as QWEN3_CONFIG\n elif name == \"1.7B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_1_7B as QWEN3_CONFIG\n elif name == \"4B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_4B as QWEN3_CONFIG\n elif name == \"8B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_8B as QWEN3_CONFIG\n elif name == \"14B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_14B as QWEN3_CONFIG\n elif name == \"32B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_32B as QWEN3_CONFIG\n elif name == \"30B-A3B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_30B_A3B as QWEN3_CONFIG\n else:\n raise ValueError(f\"Invalid model name: {name}\")\n return QWEN3_CONFIG\n\n\ndef build_repo_and_local(model_name, reasoning, local_dir_arg):\n base = f\"Qwen3-{model_name}\"\n repo_id = f\"Qwen/{base}-Base\" if not reasoning else f\"Qwen/{base}\"\n local_dir = local_dir_arg if local_dir_arg else (f\"{base}-Base\" if not reasoning else base)\n return repo_id, local_dir\n\n\ndef get_device(name):\n if name == \"auto\":\n if torch.cuda.is_available():\n return torch.device(\"cuda\")\n elif torch.backends.mps.is_available():\n return torch.device(\"mps\")\n else:\n return torch.device(\"cpu\")\n elif name == \"cuda\":\n return torch.device(\"cuda\")\n elif name == \"mps\":\n return torch.device(\"mps\")\n else:\n return torch.device(\"cpu\")\n\n\ndef get_model_and_tokenizer(qwen3_config, repo_id, local_dir, device, use_reasoning):\n model = Qwen3Model(qwen3_config)\n weights_dict = download_from_huggingface_from_snapshots(\n repo_id=repo_id,\n local_dir=local_dir\n )\n load_weights_into_qwen(model, qwen3_config, weights_dict)\n del weights_dict\n\n model.to(device) # safe for all but required by the MoE model\n model.eval()\n\n tok_filename = \"tokenizer.json\"\n tokenizer = Qwen3Tokenizer(\n tokenizer_file_path=tok_filename,\n repo_id=repo_id,\n apply_chat_template=use_reasoning,\n add_generation_prompt=use_reasoning,\n add_thinking=use_reasoning\n )\n return model, tokenizer\n\n\nQWEN3_CONFIG = get_qwen_config(MODEL)\nREPO_ID, LOCAL_DIR = build_repo_and_local(MODEL, REASONING, LOCAL_DIR)\nDEVICE = get_device(DEVICE)\nMODEL, TOKENIZER = get_model_and_tokenizer(QWEN3_CONFIG, REPO_ID, LOCAL_DIR, DEVICE, REASONING)\n\n\n@chainlit.on_chat_start\nasync def on_start():\n chainlit.user_session.set(\"history\", [])\n chainlit.user_session.get(\"history\").append(\n {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"}\n )\n\n\n@chainlit.on_message\nasync def main(message: chainlit.Message):\n \"\"\"\n The main Chainlit function.\n \"\"\"\n # 1) Encode input\n input_ids = TOKENIZER.encode(message.content)\n input_ids_tensor = torch.tensor(input_ids, device=DEVICE).unsqueeze(0)\n\n # 2) Start an outgoing message we can stream into\n out_msg = chainlit.Message(content=\"\")\n await out_msg.send()\n\n # 3) Stream generation\n for tok in generate_text_simple_stream(\n model=MODEL,\n token_ids=input_ids_tensor,\n max_new_tokens=MAX_NEW_TOKENS,\n eos_token_id=TOKENIZER.eos_token_id\n ):\n token_id = tok.squeeze(0)\n piece = TOKENIZER.decode(token_id.tolist())\n await out_msg.stream_token(piece)\n\n # 4) Finalize the streamed message\n await out_msg.update()\n"
},
{
"path": "ch05/11_qwen3/qwen3-chat-interface/requirements-extra.txt",
"content": "chainlit>=1.2.0\nhuggingface_hub>=0.34.4\nllms_from_scratch>=1.0.18 # to import code from this repo\nsafetensors>=0.6.2\ntokenizers>=0.21.1"
},
{
"path": "ch05/11_qwen3/standalone-qwen3-moe-plus-kvcache.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"
\n\n \n# Qwen3 from-scratch code\n\nThe standalone notebooks in this folder contain from-scratch codes in linear fashion:\n\n1. [standalone-qwen3.ipynb](standalone-qwen3.ipynb): The dense Qwen3 model without bells and whistles\n2. [standalone-qwen3-plus-kvcache.ipynb](standalone-qwen3-plus-kvcache.ipynb): Same as above but with KV cache for better inference efficiency\n3. [standalone-qwen3-moe.ipynb](standalone-qwen3-moe.ipynb): Like the first notebook but the Mixture-of-Experts (MoE) variant\n4. [standalone-qwen3-moe-plus-kvcache.ipynb](standalone-qwen3-moe-plus-kvcache.ipynb): Same as above but with KV cache for better inference efficiency\n\nAlternatively, I also organized the code into a Python package [here](../../pkg/llms_from_scratch/) (including unit tests and CI), which you can run as described below.\n\n \n# Training\n\nThe `Qwen3Model` class is implemented in a similar style as the `GPTModel` class, so it can be used as a drop-in replacement for training in chapter 5 and finetuning in chapters 6 and 7.\n\n\n \n# Using Qwen3 via the `llms-from-scratch` package\n\nFor an easy way to use the Qwen3 from-scratch implementation, you can also use the `llms-from-scratch` PyPI package based on the source code in this repository at [pkg/llms_from_scratch](../../pkg/llms_from_scratch).\n\n \n#### 1) Installation\n\n```bash\npip install llms_from_scratch tokenizers\n```\n\n \n#### 2) Model and text generation settings\n\nSpecify which model to use:\n\n```python\nUSE_REASONING_MODEL = True\n# Uses the base model if USE_REASONING_MODEL = False\n\nUSE_INSTRUCT_MODEL = False\n# Uses the instruct mode (without reasoning) if \n# USE_REASONING_MODEL = True\n# USE_INSTRUCT_MODEL = True\n# This setting does have no effect if USE_REASONING_MODEL = False\n\n\n# Use\n# USE_REASONING_MODEL = True\n# For Qwen3 Coder Flash model as well\n```\n\nBasic text generation settings that can be defined by the user. With 150 tokens, the 0.6B model requires approximately 1.5 GB memory.\n\n```python\nMAX_NEW_TOKENS = 150\nTEMPERATURE = 0.\nTOP_K = 1\n```\n\n \n#### 3a) Weight download and loading of the 0.6B model\n\nThe following automatically downloads the weight file based on the model choice (reasoning or base) above. Note that this section focuses on the 0.6B model. Skip this section and continue with section 3b) if you want to work with any of the larger models (1.7B, 4B, 8B, or 32B).\n\n```python\nfrom llms_from_scratch.qwen3 import download_from_huggingface\n\nrepo_id = \"rasbt/qwen3-from-scratch\"\n\nif USE_REASONING_MODEL:\n filename = \"qwen3-0.6B.pth\"\n local_dir = \"Qwen3-0.6B\" \nelse:\n filename = \"qwen3-0.6B-base.pth\" \n local_dir = \"Qwen3-0.6B-Base\"\n\ndownload_from_huggingface(\n repo_id=repo_id,\n filename=filename,\n local_dir=local_dir\n)\n```\n\nThe model weights are then loaded as follows:\n\n```python\nfrom pathlib import Path\nimport torch\n\nfrom llms_from_scratch.qwen3 import Qwen3Model, QWEN_CONFIG_06_B\n\nmodel_file = Path(local_dir) / filename\n\nmodel = Qwen3Model(QWEN_CONFIG_06_B)\nmodel.load_state_dict(torch.load(model_file, weights_only=True, map_location=\"cpu\"))\n\ndevice = (\n torch.device(\"cuda\") if torch.cuda.is_available() else\n torch.device(\"mps\") if torch.backends.mps.is_available() else\n torch.device(\"cpu\")\n)\nmodel.to(device);\n```\n\n \n#### 3b) Weight download and loading of the larger Qwen models\n\nIf you are interested in working with any of the larger Qwen models, for instance, 1.7B, 4B, 8B, or 32B, please use the following code below instead of the code under 3a), which requires additional code dependencies:\n\n```bash\npip install safetensors huggingface_hub\n```\n\nThen use the following code (make appropriate changes to `USE_MODEL` to select the desired model size)\n\n```python\nUSE_MODEL = \"1.7B\"\n\nif USE_MODEL == \"1.7B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_1_7B as QWEN3_CONFIG\nelif USE_MODEL == \"4B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_4B as QWEN3_CONFIG\nelif USE_MODEL == \"8B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_8B as QWEN3_CONFIG\nelif USE_MODEL == \"14B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_14B as QWEN3_CONFIG\nelif USE_MODEL == \"32B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_32B as QWEN3_CONFIG\nelif USE_MODEL == \"30B-A3B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_30B_A3B as QWEN3_CONFIG\nelse:\n raise ValueError(\"Invalid USE_MODEL name.\")\n \nrepo_id = f\"Qwen/Qwen3-{USE_MODEL}\"\nlocal_dir = f\"Qwen3-{USE_MODEL}\"\n\nif not USE_REASONING_MODEL:\n repo_id = f\"{repo_id}-Base\"\n local_dir = f\"{local_dir}-Base\"\n```\n\nNow, download and load the weights into the `model`:\n\n```python\nfrom llms_from_scratch.qwen3 import (\n Qwen3Model,\n download_from_huggingface_from_snapshots,\n load_weights_into_qwen\n)\n\ndevice = (\n torch.device(\"cuda\") if torch.cuda.is_available() else\n torch.device(\"mps\") if torch.backends.mps.is_available() else\n torch.device(\"cpu\")\n)\n\nwith device:\n model = Qwen3Model(QWEN3_CONFIG)\n\nweights_dict = download_from_huggingface_from_snapshots(\n repo_id=repo_id,\n local_dir=local_dir\n)\nload_weights_into_qwen(model, QWEN3_CONFIG, weights_dict)\nmodel.to(device) # only required for the MoE models\ndel weights_dict # delete weight dictionary to free up disk space\n```\n\n\n \n\n#### 4) Initialize tokenizer\n\nThe following code downloads and initializes the tokenizer:\n\n```python\nfrom llms_from_scratch.qwen3 import Qwen3Tokenizer\n\nif USE_REASONING_MODEL:\n tok_filename = \"tokenizer.json\" \nelse:\n tok_filename = \"tokenizer-base.json\" \n\ntokenizer = Qwen3Tokenizer(\n tokenizer_file_path=tokenizer_file_path,\n repo_id=repo_id,\n apply_chat_template=USE_REASONING_MODEL,\n add_generation_prompt=USE_REASONING_MODEL,\n add_thinking=not USE_INSTRUCT_MODEL\n)\n```\n\n\n\n \n\n#### 5) Generating text\n\nLastly, we can generate text via the following code:\n\n```python\nprompt = \"Give me a short introduction to large language models.\"\ninput_token_ids = tokenizer.encode(prompt)\n```\n\n\n\n\n\n```python\nfrom llms_from_scratch.ch05 import generate\nimport time\n\ntorch.manual_seed(123)\n\nstart = time.time()\n\noutput_token_ids = generate(\n model=model,\n idx=torch.tensor(input_token_ids, device=device).unsqueeze(0),\n max_new_tokens=150,\n context_size=QWEN_CONFIG_06_B[\"context_length\"],\n top_k=1,\n temperature=0.\n)\n\ntotal_time = time.time() - start\nprint(f\"Time: {total_time:.2f} sec\")\nprint(f\"{int(len(output_token_ids[0])/total_time)} tokens/sec\")\n\nif torch.cuda.is_available():\n max_mem_bytes = torch.cuda.max_memory_allocated()\n max_mem_gb = max_mem_bytes / (1024 ** 3)\n print(f\"Max memory allocated: {max_mem_gb:.2f} GB\")\n\noutput_text = tokenizer.decode(output_token_ids.squeeze(0).tolist())\n\nprint(\"\\n\\nOutput text:\\n\\n\", output_text + \"...\")\n```\n\nWhen using the Qwen3 0.6B reasoning model, the output should look similar to the one shown below (this was run on an A100):\n\n```\nTime: 6.35 sec\n25 tokens/sec\nMax memory allocated: 1.49 GB\n\n\nOutput text:\n\n <|im_start|>user\nGive me a short introduction to large language models.<|im_end|>\nLarge language models (LLMs) are advanced artificial intelligence systems designed to generate human-like text. They are trained on vast amounts of text data, allowing them to understand and generate coherent, contextually relevant responses. LLMs are used in a variety of applications, including chatbots, virtual assistants, content generation, and more. They are powered by deep learning algorithms and can be fine-tuned for specific tasks, making them versatile tools for a wide range of industries.<|endoftext|>Human resources department of a company is planning to hire 100 new employees. The company has a budget of $100,000 for the recruitment process. The company has a minimum wage of $10 per hour. The company has a total of...\n```\n\n\n\nFor the larger models, you may prefer the streaming variant, which prints each token as soon as it's generated:\n\n```python\nfrom llms_from_scratch.generate import generate_text_simple_stream\n\ninput_token_ids_tensor = torch.tensor(input_token_ids, device=device).unsqueeze(0)\n\nfor token in generate_text_simple_stream(\n model=model,\n token_ids=input_token_ids_tensor,\n max_new_tokens=150,\n eos_token_id=tokenizer.eos_token_id\n):\n token_id = token.squeeze(0).tolist()\n print(\n tokenizer.decode(token_id),\n end=\"\",\n flush=True\n )\n```\n\n```\n <|im_start|>user\nGive me a short introduction to large language models.<|im_end|>\nLarge language models (LLMs) are advanced artificial intelligence systems designed to generate human-like text. They are trained on vast amounts of text data, allowing them to understand and generate coherent, contextually relevant responses. LLMs are used in a variety of applications, including chatbots, virtual assistants, content generation, and more. They are powered by deep learning algorithms and can be fine-tuned for specific tasks, making them versatile tools for a wide range of industries.<|endoftext|>Human resources department of a company is planning to hire 100 new employees. The company has a budget of $100,000 for the recruitment process. The company has a minimum wage of $10 per hour. The company has a total of...\n```\n\n\n\n \n\n#### Pro tip 1: speed up inference with compilation\n\n\nFor up to a 4× speed-up, replace\n\n```python\nmodel.to(device)\n```\n\nwith\n\n```python\nmodel.to(device)\nmodel = torch.compile(model)\n```\n\nNote: There is a significant multi-minute upfront cost when compiling, and the speed-up takes effect after the first `generate` call. \n\nThe following table shows a performance comparison on an A100 for consequent `generate` calls:\n\n| | Hardware | Tokens/sec | Memory |\n| ------------------------ | ----------------|----------- | -------- |\n| Qwen3Model 0.6B | Nvidia A100 GPU | 25 | 1.49 GB |\n| Qwen3Model 0.6B compiled | Nvidia A100 GPU | 107 | 1.99 GB |\n\n\n \n#### Pro tip 2: speed up inference with KV cache\n\nYou can significantly boost inference performance using the KV cache `Qwen3Model` drop-in replacement when running the model on a CPU. (See my [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) article to learn more about KV caches.)\n\n```python\nfrom llms_from_scratch.kv_cache.qwen3 import Qwen3Model\nfrom llms_from_scratch.kv_cache.generate import generate_text_simple\n\nmodel = Qwen3Model(QWEN_CONFIG_06_B)\n# ...\ntoken_ids = generate_text_simple(\n model=model,\n idx=text_to_token_ids(PROMPT, tokenizer).to(device),\n max_new_tokens=MAX_NEW_TOKENS,\n context_size=QWEN_CONFIG_06_B[\"context_length\"],\n)\n```\n\nNote that the peak memory usage is only listed for Nvidia CUDA devices, as it is easier to calculate. However, the memory usage on other devices is likely similar as it uses a similar precision format, and the KV cache storage results in even lower memory usage here for the generated 150-token text (however, different devices may implement matrix multiplication differently and may result in different peak memory requirements; and KV-cache memory may increase prohibitively for longer contexts lengths).\n\n| Model | Mode | Hardware | Tokens/sec | GPU Memory (VRAM) |\n| --------------- | ----------------- | --------------- | ---------- | ----------------- |\n| Qwen3Model 0.6B | Regular | Mac Mini M4 CPU | 1 | - |\n| Qwen3Model 0.6B | Regular compiled | Mac Mini M4 CPU | 1 | - |\n| Qwen3Model 0.6B | KV cache | Mac Mini M4 CPU | 80 | - |\n| Qwen3Model 0.6B | KV cache compiled | Mac Mini M4 CPU | 137 | - |\n| | | | | |\n| Qwen3Model 0.6B | Regular | Mac Mini M4 GPU | 21 | - |\n| Qwen3Model 0.6B | Regular compiled | Mac Mini M4 GPU | Error | - |\n| Qwen3Model 0.6B | KV cache | Mac Mini M4 GPU | 28 | - |\n| Qwen3Model 0.6B | KV cache compiled | Mac Mini M4 GPU | Error | - |\n| | | | | |\n| Qwen3Model 0.6B | Regular | Nvidia A100 GPU | 26 | 1.49 GB |\n| Qwen3Model 0.6B | Regular compiled | Nvidia A100 GPU | 107 | 1.99 GB |\n| Qwen3Model 0.6B | KV cache | Nvidia A100 GPU | 25 | 1.47 GB |\n| Qwen3Model 0.6B | KV cache compiled | Nvidia A100 GPU | 90 | 1.48 GB |\n\nNote that all settings above have been tested to produce the same text outputs.\n\n\n\n \n\n#### Pro tip 3: batched inference\n\nWe can further increase the throughput via batched inference. While it's not an apples-to-apples comparison, as we are now running inference with a higher number of input sequences, this increases the tokens per second throughput while trading it off against increased memory usage.\n\nThis only requires a small code modification with respect to preparing the prompt. For example, consider this batched prompt below:\n\n```python\nfrom llms_from_scratch.ch04 import generate_text_simple\nfrom llms_from_scratch.qwen3 import Qwen3Model, QWEN_CONFIG_06_B\n# ...\n\nprompts = [\n \"Give me a short introduction to neural networks.\",\n \"Give me a short introduction to machine learning.\",\n \"Give me a short introduction to deep learning models.\",\n \"Give me a short introduction to natural language processing.\",\n \"Give me a short introduction to generative AI systems.\",\n \"Give me a short introduction to transformer architectures.\",\n \"Give me a short introduction to supervised learning methods.\",\n \"Give me a short introduction to unsupervised learning.\",\n]\n\ntokenized_prompts = [tokenizer.encode(p) for p in prompts]\nmax_len = max(len(t) for t in tokenized_prompts)\npadded_token_ids = [\n t + [tokenizer.pad_token_id] * (max_len - len(t)) for t in tokenized_prompts\n]\ninput_tensor = torch.tensor(padded_token_ids).to(device)\n\noutput_token_ids = generate_text_simple(\n model=model,\n idx=input_tensor,\n max_new_tokens=150,\n context_size=QWEN_CONFIG_06_B[\"context_length\"],\n)\n```\n\nThe code for the KV cache version is similar, except that it requires using these drop-in replacements:\n\n```python\nfrom llms_from_scratch.kv_cache_batched.generate import generate_text_simple\nfrom llms_from_scratch.kv_cache_batched.qwen3 import Qwen3Model\n```\n\n\nThe experiments below are run with a batch size of 8.\n\n| Model | Mode | Hardware | Batch size | Tokens/sec | GPU Memory (VRAM) |\n| ---------------- | ----------------- | --------------- | ---------- | ---------- | ----------------- |\n| Qwen3Model 0.6B | Regular | Mac Mini M4 CPU | 8 | 2 | - |\n| Qwen3Model 0.6B | Regular compiled | Mac Mini M4 CPU | 8 | - | - |\n| Qwen3Model 0.6B | KV cache | Mac Mini M4 CPU | 8 | 92 | - |\n| Qwen3Model 0.6B | KV cache compiled | Mac Mini M4 CPU | 8 | 128 | - |\n| | | | | | |\n| Qwen3Model 0.6B | Regular | Mac Mini M4 GPU | 8 | 36 | - |\n| Qwen3Model 0.6B | Regular compiled | Mac Mini M4 GPU | 8 | - | - |\n| Qwen3Model 0.6B | KV cache | Mac Mini M4 GPU | 8 | 61 | - |\n| Qwen3Model 0.6B | KV cache compiled | Mac Mini M4 GPU | 8 | - | - |\n| | | | | | |\n| Qwen3Model 0.6B | Regular | Nvidia A100 GPU | 8 | 184 | 2.19 GB |\n| Qwen3Model 0.6B | Regular compiled | Nvidia A100 GPU | 8 | 351 | 2.19 GB |\n| Qwen3Model 0.6B | KV cache | Nvidia A100 GPU | 8 | 140 | 3.13 GB |\n| Qwen3Model 0.6B | KV cache compiled | Nvidia A100 GPU | 8 | 280 | 1.75 GB |\n\n"
},
{
"path": "ch05/11_qwen3/qwen3-chat-interface/README.md",
"content": "# Qwen3 From Scratch with Chat Interface\n\n\n\nThis bonus folder contains code for running a ChatGPT-like user interface to interact with the pretrained Qwen3 model.\n\n\n\n\n\n\n\nTo implement this user interface, we use the open-source [Chainlit Python package](https://github.com/Chainlit/chainlit).\n\n \n## Step 1: Install dependencies\n\nFirst, we install the `chainlit` package and dependencies from the [requirements-extra.txt](requirements-extra.txt) list via\n\n```bash\npip install -r requirements-extra.txt\n```\n\nOr, if you are using `uv`:\n\n```bash\nuv pip install -r requirements-extra.txt\n```\n\n\n\n \n\n## Step 2: Run `app` code\n\nThis folder contains 2 files:\n\n1. [`qwen3-chat-interface.py`](qwen3-chat-interface.py): This file loads and uses the Qwen3 0.6B model in thinking mode. \n2. [`qwen3-chat-interface-multiturn.py`](qwen3-chat-interface-multiturn.py): The same as above, but configured to remember the message history.\n\n(Open and inspect these files to learn more.)\n\nRun one of the following commands from the terminal to start the UI server:\n\n```bash\nchainlit run qwen3-chat-interface.py\n```\n\nor, if you are using `uv`:\n\n```bash\nuv run chainlit run qwen3-chat-interface.py\n```\n\nRunning one of the commands above should open a new browser tab where you can interact with the model. If the browser tab does not open automatically, inspect the terminal command and copy the local address into your browser address bar (usually, the address is `http://localhost:8000`).\n"
},
{
"path": "ch05/11_qwen3/qwen3-chat-interface/qwen3-chat-interface-multiturn.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport torch\nimport chainlit\n\n# For llms_from_scratch installation instructions, see:\n# https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\nfrom llms_from_scratch.kv_cache.qwen3 import (\n Qwen3Model,\n Qwen3Tokenizer,\n download_from_huggingface_from_snapshots,\n load_weights_into_qwen\n)\nfrom llms_from_scratch.kv_cache.generate import (\n generate_text_simple_stream,\n trim_input_tensor\n)\n\n# ============================================================\n# EDIT ME: Simple configuration\n# ============================================================\nMODEL = \"0.6B\" # options: \"0.6B\",\"1.7B\",\"4B\",\"8B\",\"14B\",\"32B\",\"30B-A3B\"\nREASONING = True # True = \"thinking\" chat model, False = Base\nDEVICE = \"auto\" # \"auto\" | \"cuda\" | \"mps\" | \"cpu\"\nMAX_NEW_TOKENS = 38912\nLOCAL_DIR = None # e.g., \"Qwen3-0.6B-Base\"; None auto-selects\n# ============================================================\n\n\ndef get_qwen_config(name):\n if name == \"0.6B\":\n from llms_from_scratch.qwen3 import QWEN_CONFIG_06_B as QWEN3_CONFIG\n elif name == \"1.7B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_1_7B as QWEN3_CONFIG\n elif name == \"4B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_4B as QWEN3_CONFIG\n elif name == \"8B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_8B as QWEN3_CONFIG\n elif name == \"14B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_14B as QWEN3_CONFIG\n elif name == \"32B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_32B as QWEN3_CONFIG\n elif name == \"30B-A3B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_30B_A3B as QWEN3_CONFIG\n else:\n raise ValueError(f\"Invalid model name: {name}\")\n return QWEN3_CONFIG\n\n\ndef build_repo_and_local(model_name, reasoning, local_dir_arg):\n base = f\"Qwen3-{model_name}\"\n repo_id = f\"Qwen/{base}-Base\" if not reasoning else f\"Qwen/{base}\"\n local_dir = local_dir_arg if local_dir_arg else (f\"{base}-Base\" if not reasoning else base)\n return repo_id, local_dir\n\n\ndef get_device(name):\n if name == \"auto\":\n if torch.cuda.is_available():\n return torch.device(\"cuda\")\n elif torch.backends.mps.is_available():\n return torch.device(\"mps\")\n else:\n return torch.device(\"cpu\")\n elif name == \"cuda\":\n return torch.device(\"cuda\")\n elif name == \"mps\":\n return torch.device(\"mps\")\n else:\n return torch.device(\"cpu\")\n\n\ndef get_model_and_tokenizer(qwen3_config, repo_id, local_dir, device, use_reasoning):\n model = Qwen3Model(qwen3_config)\n weights_dict = download_from_huggingface_from_snapshots(\n repo_id=repo_id,\n local_dir=local_dir\n )\n load_weights_into_qwen(model, qwen3_config, weights_dict)\n del weights_dict\n\n model.to(device) # safe for all but required by the MoE model\n model.eval()\n\n tok_filename = \"tokenizer.json\"\n tokenizer = Qwen3Tokenizer(\n tokenizer_file_path=tok_filename,\n repo_id=repo_id,\n apply_chat_template=False, # disable to avoid double-wrapping prompts in history\n add_generation_prompt=False, # we add the assistant header manually\n add_thinking=use_reasoning\n )\n return model, tokenizer\n\n\ndef build_prompt_from_history(history, add_assistant_header=True):\n \"\"\"\n history: [{\"role\": \"system\"|\"user\"|\"assistant\", \"content\": str}, ...]\n \"\"\"\n parts = []\n for m in history:\n role = m[\"role\"]\n content = m[\"content\"]\n parts.append(f\"<|im_start|>{role}\\n{content}<|im_end|>\\n\")\n\n if add_assistant_header:\n parts.append(\"<|im_start|>assistant\\n\")\n return \"\".join(parts)\n\n\nQWEN3_CONFIG = get_qwen_config(MODEL)\nREPO_ID, LOCAL_DIR = build_repo_and_local(MODEL, REASONING, LOCAL_DIR)\nDEVICE = get_device(DEVICE)\nMODEL, TOKENIZER = get_model_and_tokenizer(QWEN3_CONFIG, REPO_ID, LOCAL_DIR, DEVICE, REASONING)\n\n# Even though the official TOKENIZER.eos_token_id is either <|im_end|> (reasoning)\n# or <|endoftext|> (base), the reasoning model sometimes emits both.\nEOS_TOKEN_IDS = (TOKENIZER.encode(\"<|im_end|>\")[0], TOKENIZER.encode(\"<|endoftext|>\")[0])\n\n\n@chainlit.on_chat_start\nasync def on_start():\n chainlit.user_session.set(\"history\", [])\n chainlit.user_session.get(\"history\").append(\n {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"}\n )\n\n\n@chainlit.on_message\nasync def main(message: chainlit.Message):\n \"\"\"\n The main Chainlit function.\n \"\"\"\n # 0) Get and track chat history\n history = chainlit.user_session.get(\"history\")\n history.append({\"role\": \"user\", \"content\": message.content})\n\n # 1) Encode input\n prompt = build_prompt_from_history(history, add_assistant_header=True)\n input_ids = TOKENIZER.encode(prompt)\n input_ids_tensor = torch.tensor(input_ids, device=DEVICE).unsqueeze(0)\n input_ids_tensor = trim_input_tensor(\n input_ids_tensor=input_ids_tensor,\n context_len=MODEL.cfg[\"context_length\"],\n max_new_tokens=MAX_NEW_TOKENS\n )\n\n # 2) Start an outgoing message we can stream into\n out_msg = chainlit.Message(content=\"\")\n await out_msg.send()\n\n # 3) Stream generation\n for tok in generate_text_simple_stream(\n model=MODEL,\n token_ids=input_ids_tensor,\n max_new_tokens=MAX_NEW_TOKENS,\n # eos_token_id=TOKENIZER.eos_token_id\n ):\n token_id = tok.squeeze(0)\n if token_id in EOS_TOKEN_IDS:\n break\n piece = TOKENIZER.decode(token_id.tolist())\n await out_msg.stream_token(piece)\n\n # 4) Finalize the streamed message\n await out_msg.update()\n\n # 5) Update chat history\n history.append({\"role\": \"assistant\", \"content\": out_msg.content})\n chainlit.user_session.set(\"history\", history)\n"
},
{
"path": "ch05/11_qwen3/qwen3-chat-interface/qwen3-chat-interface.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport torch\nimport chainlit\n\n# For llms_from_scratch installation instructions, see:\n# https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\nfrom llms_from_scratch.kv_cache.qwen3 import (\n Qwen3Model,\n Qwen3Tokenizer,\n download_from_huggingface_from_snapshots,\n load_weights_into_qwen\n)\nfrom llms_from_scratch.kv_cache.generate import (\n generate_text_simple_stream\n)\n\n# ============================================================\n# EDIT ME: Simple configuration\n# ============================================================\nMODEL = \"0.6B\" # options: \"0.6B\",\"1.7B\",\"4B\",\"8B\",\"14B\",\"32B\",\"30B-A3B\"\nREASONING = True # True = \"thinking\" chat model, False = Base\nDEVICE = \"auto\" # \"auto\" | \"cuda\" | \"mps\" | \"cpu\"\nMAX_NEW_TOKENS = 38912\nLOCAL_DIR = None # e.g., \"Qwen3-0.6B-Base\"; None auto-selects\n# ============================================================\n\n\ndef get_qwen_config(name):\n if name == \"0.6B\":\n from llms_from_scratch.qwen3 import QWEN_CONFIG_06_B as QWEN3_CONFIG\n elif name == \"1.7B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_1_7B as QWEN3_CONFIG\n elif name == \"4B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_4B as QWEN3_CONFIG\n elif name == \"8B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_8B as QWEN3_CONFIG\n elif name == \"14B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_14B as QWEN3_CONFIG\n elif name == \"32B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_32B as QWEN3_CONFIG\n elif name == \"30B-A3B\":\n from llms_from_scratch.qwen3 import QWEN3_CONFIG_30B_A3B as QWEN3_CONFIG\n else:\n raise ValueError(f\"Invalid model name: {name}\")\n return QWEN3_CONFIG\n\n\ndef build_repo_and_local(model_name, reasoning, local_dir_arg):\n base = f\"Qwen3-{model_name}\"\n repo_id = f\"Qwen/{base}-Base\" if not reasoning else f\"Qwen/{base}\"\n local_dir = local_dir_arg if local_dir_arg else (f\"{base}-Base\" if not reasoning else base)\n return repo_id, local_dir\n\n\ndef get_device(name):\n if name == \"auto\":\n if torch.cuda.is_available():\n return torch.device(\"cuda\")\n elif torch.backends.mps.is_available():\n return torch.device(\"mps\")\n else:\n return torch.device(\"cpu\")\n elif name == \"cuda\":\n return torch.device(\"cuda\")\n elif name == \"mps\":\n return torch.device(\"mps\")\n else:\n return torch.device(\"cpu\")\n\n\ndef get_model_and_tokenizer(qwen3_config, repo_id, local_dir, device, use_reasoning):\n model = Qwen3Model(qwen3_config)\n weights_dict = download_from_huggingface_from_snapshots(\n repo_id=repo_id,\n local_dir=local_dir\n )\n load_weights_into_qwen(model, qwen3_config, weights_dict)\n del weights_dict\n\n model.to(device) # safe for all but required by the MoE model\n model.eval()\n\n tok_filename = \"tokenizer.json\"\n tokenizer = Qwen3Tokenizer(\n tokenizer_file_path=tok_filename,\n repo_id=repo_id,\n apply_chat_template=use_reasoning,\n add_generation_prompt=use_reasoning,\n add_thinking=use_reasoning\n )\n return model, tokenizer\n\n\nQWEN3_CONFIG = get_qwen_config(MODEL)\nREPO_ID, LOCAL_DIR = build_repo_and_local(MODEL, REASONING, LOCAL_DIR)\nDEVICE = get_device(DEVICE)\nMODEL, TOKENIZER = get_model_and_tokenizer(QWEN3_CONFIG, REPO_ID, LOCAL_DIR, DEVICE, REASONING)\n\n\n@chainlit.on_chat_start\nasync def on_start():\n chainlit.user_session.set(\"history\", [])\n chainlit.user_session.get(\"history\").append(\n {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"}\n )\n\n\n@chainlit.on_message\nasync def main(message: chainlit.Message):\n \"\"\"\n The main Chainlit function.\n \"\"\"\n # 1) Encode input\n input_ids = TOKENIZER.encode(message.content)\n input_ids_tensor = torch.tensor(input_ids, device=DEVICE).unsqueeze(0)\n\n # 2) Start an outgoing message we can stream into\n out_msg = chainlit.Message(content=\"\")\n await out_msg.send()\n\n # 3) Stream generation\n for tok in generate_text_simple_stream(\n model=MODEL,\n token_ids=input_ids_tensor,\n max_new_tokens=MAX_NEW_TOKENS,\n eos_token_id=TOKENIZER.eos_token_id\n ):\n token_id = tok.squeeze(0)\n piece = TOKENIZER.decode(token_id.tolist())\n await out_msg.stream_token(piece)\n\n # 4) Finalize the streamed message\n await out_msg.update()\n"
},
{
"path": "ch05/11_qwen3/qwen3-chat-interface/requirements-extra.txt",
"content": "chainlit>=1.2.0\nhuggingface_hub>=0.34.4\nllms_from_scratch>=1.0.18 # to import code from this repo\nsafetensors>=0.6.2\ntokenizers>=0.21.1"
},
{
"path": "ch05/11_qwen3/standalone-qwen3-moe-plus-kvcache.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \\n\",\n \"\\n\",\n \"\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/11_qwen3/standalone-qwen3-moe.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"
\\n\",\n \"\\n\",\n \"\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/11_qwen3/standalone-qwen3-moe.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\\n\",\n \"\\n\",\n \"\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/11_qwen3/standalone-qwen3-plus-kvcache.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Qwen3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\\n\",\n \" \\n\",\n \"**This notebook is similar to [standalone-qwen3.ipynb](standalone-qwen3.ipynb) except that it adds a KV cache for better compute efficiency. See the comparison tables in the [README.md](README.md) for more information about the performance comparisons. For more information on KV caching, see my [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) article.**\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 1.5.0\\n\",\n \"tokenizers version: 0.22.2\\n\",\n \"torch version: 2.8.0+cu128\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"07e96fbb-8e16-4f6d-835f-c6159321280b\",\n \"metadata\": {},\n \"source\": [\n \"- Note that there are two models, the \\\"base\\\" and the \\\"hybrid\\\" model, and the hybrid model can be used as either a reasoning or a regular instruction-following model:\\n\",\n \"- In short, the model types are as follows:\\n\",\n \" - `base`: the pretrained base model; note that the Qwen3 pretraining contained some reasoning data (chain-of-thought data), so the model sometimes emits reasoning traces even though it didn't undergo the reasoning training (reinforcement learning) stages\\n\",\n \" - `hybrid` \\n\",\n \" - `reasoning`: emits long reasoning traces inside `\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/11_qwen3/standalone-qwen3.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"
\\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Qwen3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\\n\",\n \" \\n\",\n \"**This notebook is similar to [standalone-qwen3.ipynb](standalone-qwen3.ipynb) except that it adds a KV cache for better compute efficiency. See the comparison tables in the [README.md](README.md) for more information about the performance comparisons. For more information on KV caching, see my [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) article.**\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 1.5.0\\n\",\n \"tokenizers version: 0.22.2\\n\",\n \"torch version: 2.8.0+cu128\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"07e96fbb-8e16-4f6d-835f-c6159321280b\",\n \"metadata\": {},\n \"source\": [\n \"- Note that there are two models, the \\\"base\\\" and the \\\"hybrid\\\" model, and the hybrid model can be used as either a reasoning or a regular instruction-following model:\\n\",\n \"- In short, the model types are as follows:\\n\",\n \" - `base`: the pretrained base model; note that the Qwen3 pretraining contained some reasoning data (chain-of-thought data), so the model sometimes emits reasoning traces even though it didn't undergo the reasoning training (reinforcement learning) stages\\n\",\n \" - `hybrid` \\n\",\n \" - `reasoning`: emits long reasoning traces inside `\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/11_qwen3/standalone-qwen3.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Qwen3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 1.5.0\\n\",\n \"tokenizers version: 0.22.2\\n\",\n \"torch version: 2.8.0+cu128\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"07e96fbb-8e16-4f6d-835f-c6159321280b\",\n \"metadata\": {},\n \"source\": [\n \"- Note that there are two models, the \\\"base\\\" and the \\\"hybrid\\\" model, and the hybrid model can be used as either a reasoning or a regular instruction-following model:\\n\",\n \"- In short, the model types are as follows:\\n\",\n \" - `base`: the pretrained base model; note that the Qwen3 pretraining contained some reasoning data (chain-of-thought data), so the model sometimes emits reasoning traces even though it didn't undergo the reasoning training (reinforcement learning) stages\\n\",\n \" - `hybrid` \\n\",\n \" - `reasoning`: emits long reasoning traces inside `\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/11_qwen3/tests/test_qwen3_kvcache_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n mod = import_definitions_from_notebook(nb_dir, \"standalone-qwen3-plus-kvcache.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8)) # batch size 1, seq length 8\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"emb_dim\": 32,\n \"hidden_dim\": 64,\n \"n_layers\": 2,\n \"n_heads\": 4,\n \"head_dim\": 8,\n \"n_kv_groups\": 1,\n \"qk_norm\": False,\n \"dtype\": torch.float32,\n \"rope_base\": 10000,\n \"context_length\": 64,\n \"num_experts\": 0,\n }\n\n\n@pytest.fixture\ndef dummy_cfg_moe(dummy_cfg_base):\n cfg = dummy_cfg_base.copy()\n cfg.update({\n \"num_experts\": 4,\n \"num_experts_per_tok\": 2,\n \"moe_intermediate_size\": 64,\n })\n return cfg\n\n\n@torch.inference_mode()\ndef test_dummy_qwen3_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.Qwen3Model(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"]), \\\n f\"Expected shape (1, seq_len, vocab_size), got {out.shape}\"\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_qwen3_base_equivalence_with_transformers(import_notebook_defs):\n from transformers import Qwen3Config, Qwen3ForCausalLM\n\n # Tiny config so the test is fast\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"qk_norm\": True,\n \"n_kv_groups\": 2,\n \"rope_base\": 1_000_000.0,\n \"rope_local_base\": 10_000.0,\n \"sliding_window\": 4,\n \"layer_types\": [\"full_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"query_pre_attn_scalar\": 256,\n }\n model = import_notebook_defs.Qwen3Model(cfg)\n\n hf_cfg = Qwen3Config(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n head_dim=cfg[\"head_dim\"],\n num_key_value_heads=cfg[\"n_kv_groups\"],\n rope_theta=cfg[\"rope_base\"],\n rope_local_base_freq=cfg[\"rope_local_base\"],\n layer_types=cfg[\"layer_types\"],\n sliding_window=cfg[\"sliding_window\"],\n tie_word_embeddings=False,\n attn_implementation=\"eager\",\n torch_dtype=torch.float32,\n query_pre_attn_scalar=cfg[\"query_pre_attn_scalar\"],\n rope_scaling={\"rope_type\": \"default\"},\n )\n hf_model = Qwen3ForCausalLM(hf_cfg)\n\n hf_state = hf_model.state_dict()\n param_config = {\"n_layers\": cfg[\"n_layers\"], \"hidden_dim\": cfg[\"hidden_dim\"]}\n import_notebook_defs.load_weights_into_qwen(model, param_config, hf_state)\n\n x = torch.randint(0, cfg[\"vocab_size\"], (2, cfg[\"context_length\"]), dtype=torch.long)\n ours_logits = model(x)\n theirs_logits = hf_model(x).logits\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/11_qwen3/tests/test_qwen3_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n mod = import_definitions_from_notebook(nb_dir, \"standalone-qwen3.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8)) # batch size 1, seq length 8\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"emb_dim\": 32,\n \"hidden_dim\": 64,\n \"n_layers\": 2,\n \"n_heads\": 4,\n \"head_dim\": 8,\n \"n_kv_groups\": 1,\n \"qk_norm\": False,\n \"dtype\": torch.float32,\n \"rope_base\": 10000,\n \"context_length\": 64,\n \"num_experts\": 0,\n }\n\n\n@pytest.fixture\ndef dummy_cfg_moe(dummy_cfg_base):\n cfg = dummy_cfg_base.copy()\n cfg.update({\n \"num_experts\": 4,\n \"num_experts_per_tok\": 2,\n \"moe_intermediate_size\": 64,\n })\n return cfg\n\n\n@torch.inference_mode()\ndef test_dummy_qwen3_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.Qwen3Model(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"]), \\\n f\"Expected shape (1, seq_len, vocab_size), got {out.shape}\"\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_qwen3_base_equivalence_with_transformers(import_notebook_defs):\n from transformers import Qwen3Config, Qwen3ForCausalLM\n\n # Tiny config so the test is fast\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"qk_norm\": True,\n \"n_kv_groups\": 2,\n \"rope_base\": 1_000_000.0,\n \"rope_local_base\": 10_000.0,\n \"sliding_window\": 4,\n \"layer_types\": [\"full_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"query_pre_attn_scalar\": 256,\n }\n model = import_notebook_defs.Qwen3Model(cfg)\n\n hf_cfg = Qwen3Config(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n head_dim=cfg[\"head_dim\"],\n num_key_value_heads=cfg[\"n_kv_groups\"],\n rope_theta=cfg[\"rope_base\"],\n rope_local_base_freq=cfg[\"rope_local_base\"],\n layer_types=cfg[\"layer_types\"],\n sliding_window=cfg[\"sliding_window\"],\n tie_word_embeddings=False,\n attn_implementation=\"eager\",\n torch_dtype=torch.float32,\n query_pre_attn_scalar=cfg[\"query_pre_attn_scalar\"],\n rope_scaling={\"rope_type\": \"default\"},\n )\n hf_model = Qwen3ForCausalLM(hf_cfg)\n\n hf_state = hf_model.state_dict()\n param_config = {\"n_layers\": cfg[\"n_layers\"], \"hidden_dim\": cfg[\"hidden_dim\"]}\n import_notebook_defs.load_weights_into_qwen(model, param_config, hf_state)\n\n x = torch.randint(0, cfg[\"vocab_size\"], (2, cfg[\"context_length\"]), dtype=torch.long)\n ours_logits = model(x)\n theirs_logits = hf_model(x).logits\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/12_gemma3/README.md",
"content": "# Gemma 3 270M From Scratch\n\nThis [standalone-gemma3.ipynb](standalone-gemma3.ipynb) Jupyter notebook in this folder contains a from-scratch implementation of Gemma 3 270M. It requires about 2 GB of RAM to run. \n\nThe alternative [standalone-gemma3-plus-kvcache.ipynb](standalone-gemma3-plus-kvcache.ipynb) notebook adds a KV cache for better runtime performance (but adds more code complexity). To learn more about KV caching, see my [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) article.\n\n| Model | Mode | Hardware | Tokens/sec | GPU Memory (VRAM) |\n| ----------------- | ----------------- | --------------- | ---------- | ----------------- |\n| Gemma3Model 270M | Regular | Mac Mini M4 CPU | 8 | - |\n| Gemma3Model 270M | Regular compiled | Mac Mini M4 CPU | 9 | - |\n| Gemma3Model 270M | KV cache | Mac Mini M4 CPU | 130 | - |\n| Gemma3Model 270M | KV cache compiled | Mac Mini M4 CPU | 224 | - |\n| | | | | |\n| Gemma3Model 270M | Regular | Mac Mini M4 GPU | 16 | - |\n| Gemma3Model 270M | Regular compiled | Mac Mini M4 GPU | Error | - |\n| Gemma3Model 270M | KV cache | Mac Mini M4 GPU | 23 | - |\n| Gemma3Model 270M | KV cache compiled | Mac Mini M4 GPU | Error | - |\n| | | | | |\n| Gemma3Model 270M | Regular | Nvidia A100 GPU | 28 | 1.84 GB |\n| Gemma3Model 270M | Regular compiled | Nvidia A100 GPU | 128 | 2.12 GB |\n| Gemma3Model 270M | KV cache | Nvidia A100 GPU | 26 | 1.77 GB |\n| Gemma3Model 270M | KV cache compiled | Nvidia A100 GPU | 99 | 2.12 GB |\n\n\nBelow is a side-by-side comparison with Qwen3 0.6B as a reference model; if you are interested in the Qwen3 0.6B standalone notebook, you can find it [here](../11_qwen3).\n\n \n\n
\n\n| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Gemma 3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 0.35.0\\n\",\n \"tokenizers version: 0.22.1\\n\",\n \"torch version: 2.9.0+cu130\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"07e96fbb-8e16-4f6d-835f-c6159321280b\",\n \"metadata\": {},\n \"source\": [\n \"- This notebook supports both the base model and the instructmodel; which model to use can be controlled via the following flag:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"70a90338-624a-4706-aa55-6b4358070194\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"USE_INSTRUCT_MODEL = True\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.gelu(x_fc1, approximate=\\\"tanh\\\") * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"56715760-37e1-433e-89da-04864c139a9e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-6, bias=False):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" # Gemma3 stores zero-centered weights and uses (1 + weight) during forward\\n\",\n \" self.scale = nn.Parameter(torch.zeros(emb_dim))\\n\",\n \" self.shift = nn.Parameter(torch.zeros(emb_dim)) if bias else None\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # Match HF Gemma3: compute norm in float32, then scale by (1 + w)\\n\",\n \" input_dtype = x.dtype\\n\",\n \" x_f = x.float()\\n\",\n \" var = x_f.pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x_norm = x_f * torch.rsqrt(var + self.eps)\\n\",\n \" out = x_norm * (1.0 + self.scale.float())\\n\",\n \" \\n\",\n \" if self.shift is not None:\\n\",\n \" out = out + self.shift.float()\\n\",\n \" \\n\",\n \" return out.to(input_dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Expand angles to match the head_dim\\n\",\n \" angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin, offset=0):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" # It's ok to use lower-precision after applying cos and sin rotation\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, num_heads, num_kv_groups, head_dim=None, qk_norm=False,\\n\",\n \" query_pre_attn_scalar=None, dtype=None,\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" if head_dim is None:\\n\",\n \" assert d_in % num_heads == 0, \\\"`d_in` must be divisible by `num_heads` if `head_dim` is not set\\\"\\n\",\n \" head_dim = d_in // num_heads\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(d_in, self.d_out, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" if qk_norm:\\n\",\n \" self.q_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" self.k_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" else:\\n\",\n \" self.q_norm = self.k_norm = None\\n\",\n \"\\n\",\n \" if query_pre_attn_scalar is not None:\\n\",\n \" self.scaling = (query_pre_attn_scalar) ** -0.5\\n\",\n \" else:\\n\",\n \" self.scaling = (head_dim) ** -0.5\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin, start_pos=0, cache=None):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" # Apply projections\\n\",\n \" queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\\n\",\n \" keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\\n\",\n \" keys_new = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values_new = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Optional Q/K normalization (applied to raw tensors)\\n\",\n \" if self.q_norm:\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" if self.k_norm:\\n\",\n \" keys_new = self.k_norm(keys_new)\\n\",\n \"\\n\",\n \" # Keep unrotated in cache; rotate after concatenation\\n\",\n \" prev_len = 0\\n\",\n \" if cache is not None:\\n\",\n \" prev_k, prev_v = cache # cached as unrotated\\n\",\n \" if prev_k is not None:\\n\",\n \" prev_len = prev_k.size(2)\\n\",\n \" keys_cat_raw = torch.cat([prev_k, keys_new], dim=2) # unrotated\\n\",\n \" values_cat_raw = torch.cat([prev_v, values_new], dim=2) # raw V\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \"\\n\",\n \" # RoPE: queries at absolute start_pos; keys with offset corrected by prev_len\\n\",\n \" queries = apply_rope(queries, cos, sin, offset=start_pos)\\n\",\n \" keys = apply_rope(keys_cat_raw, cos, sin, offset=start_pos - prev_len)\\n\",\n \"\\n\",\n \" # Scale queries\\n\",\n \" queries = queries * self.scaling\\n\",\n \"\\n\",\n \" # Update cache with unrotated keys and unscaled raw values\\n\",\n \" if cache is not None and cache[0] is not None:\\n\",\n \" next_cache = (\\n\",\n \" torch.cat([cache[0], keys_new], dim=2),\\n\",\n \" torch.cat([cache[1], values_new], dim=2),\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" next_cache = (keys_new, values_new)\\n\",\n \"\\n\",\n \" # Expand K and V to match number of heads\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values_cat_raw.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" # Attention\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \" attn_weights = torch.softmax(attn_scores, dim=-1)\\n\",\n \"\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \" out = self.out_proj(context)\\n\",\n \"\\n\",\n \" return out, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \"\\n\",\n \" def __init__(self, cfg, attn_type):\\n\",\n \" super().__init__()\\n\",\n \" self.attn_type = attn_type\\n\",\n \" self.sliding_window = cfg[\\\"sliding_window\\\"]\\n\",\n \"\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" qk_norm=cfg[\\\"qk_norm\\\"],\\n\",\n \" query_pre_attn_scalar=cfg[\\\"query_pre_attn_scalar\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.input_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.post_attention_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.pre_feedforward_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.post_feedforward_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \"\\n\",\n \" def forward(\\n\",\n \" self,\\n\",\n \" x,\\n\",\n \" mask_global,\\n\",\n \" mask_local,\\n\",\n \" cos_global,\\n\",\n \" sin_global,\\n\",\n \" cos_local,\\n\",\n \" sin_local,\\n\",\n \" start_pos=0,\\n\",\n \" cache=None\\n\",\n \" ):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.input_layernorm(x)\\n\",\n \"\\n\",\n \" if self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" if cache is not None and isinstance(cache, tuple):\\n\",\n \" prev_k, _ = cache\\n\",\n \" eff_kv_len = prev_k.size(2) + x.size(1)\\n\",\n \" else:\\n\",\n \" eff_kv_len = x.size(1)\\n\",\n \" # Take the last `eff_kv_len` columns so mask width equals K length\\n\",\n \" attn_mask = mask_local[..., -eff_kv_len:]\\n\",\n \" cos = cos_local\\n\",\n \" sin = sin_local\\n\",\n \" else:\\n\",\n \" attn_mask = mask_global\\n\",\n \" cos = cos_global\\n\",\n \" sin = sin_global\\n\",\n \" \\n\",\n \" x_attn, next_cache = self.att(x, attn_mask, cos, sin, start_pos=start_pos, cache=cache)\\n\",\n \" if next_cache is not None and self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" k, v = next_cache\\n\",\n \" if k.size(2) > self.sliding_window:\\n\",\n \" k = k[:, :, -self.sliding_window:, :]\\n\",\n \" v = v[:, :, -self.sliding_window:, :]\\n\",\n \" next_cache = (k, v)\\n\",\n \"\\n\",\n \" x_attn = self.post_attention_layernorm(x_attn)\\n\",\n \" x = shortcut + x_attn\\n\",\n \"\\n\",\n \" # Shortcut connection for feed forward block\\n\",\n \" shortcut = x\\n\",\n \" x_ffn = self.pre_feedforward_layernorm(x)\\n\",\n \" x_ffn = self.ff(x_ffn)\\n\",\n \" x_ffn = self.post_feedforward_layernorm(x_ffn)\\n\",\n \" x = shortcut + x_ffn\\n\",\n \" return x, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Gemma3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" assert cfg[\\\"layer_types\\\"] is not None and len(cfg[\\\"layer_types\\\"]) == cfg[\\\"n_layers\\\"]\\n\",\n \"\\n\",\n \" # Main model parameters\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.blocks = nn.ModuleList([\\n\",\n \" TransformerBlock(cfg, attn_type) for attn_type in cfg[\\\"layer_types\\\"]\\n\",\n \" ])\\n\",\n \"\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.cfg = cfg\\n\",\n \" self.current_pos = 0 # Track current position in KV cache\\n\",\n \"\\n\",\n \" # Reusable utilities\\n\",\n \" cos_local, sin_local = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_local_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" cos_global, sin_global = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos_local\\\", cos_local, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin_local\\\", sin_local, persistent=False)\\n\",\n \" self.register_buffer(\\\"cos_global\\\", cos_global, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin_global\\\", sin_global, persistent=False)\\n\",\n \"\\n\",\n \" def _create_masks(self, cur_len, device, pos_start=0, pos_end=None):\\n\",\n \" if pos_end is None:\\n\",\n \" pos_end = cur_len\\n\",\n \" total_len = pos_end\\n\",\n \"\\n\",\n \" ones = torch.ones((total_len, total_len), dtype=torch.bool, device=device)\\n\",\n \"\\n\",\n \" # mask_global_full (future is masked: j > i)\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 0 0 0 0 0 1 1 1\\n\",\n \" # 5: 0 0 0 0 0 0 1 1\\n\",\n \" # 6: 0 0 0 0 0 0 0 1\\n\",\n \" # 7: 0 0 0 0 0 0 0 0\\n\",\n \" mask_global_full = torch.triu(ones, diagonal=1)\\n\",\n \"\\n\",\n \" # far_past (too far back is masked: i - j >= sliding_window)\\n\",\n \" # where sliding_window = 4\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 0 0 0 0 0 0 0\\n\",\n \" # 1: 0 0 0 0 0 0 0 0\\n\",\n \" # 2: 0 0 0 0 0 0 0 0\\n\",\n \" # 3: 0 0 0 0 0 0 0 0\\n\",\n \" # 4: 1 0 0 0 0 0 0 0\\n\",\n \" # 5: 1 1 0 0 0 0 0 0\\n\",\n \" # 6: 1 1 1 0 0 0 0 0\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" far_past_full = torch.triu(ones, diagonal=self.cfg[\\\"sliding_window\\\"]).T\\n\",\n \"\\n\",\n \" # Local (sliding_window) = future OR far-past\\n\",\n \" # mask_local\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 1 0 0 0 0 1 1 1\\n\",\n \" # 5: 1 1 0 0 0 0 1 1\\n\",\n \" # 6: 1 1 1 0 0 0 0 1\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" mask_local_full = mask_global_full | far_past_full\\n\",\n \"\\n\",\n \" row_slice = slice(pos_start, pos_end)\\n\",\n \" mask_global = mask_global_full[row_slice, :pos_end][None, None, :, :]\\n\",\n \" mask_local = mask_local_full[row_slice, :pos_end][None, None, :, :]\\n\",\n \" return mask_global, mask_local\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, input_ids, cache=None):\\n\",\n \" b, seq_len = input_ids.shape\\n\",\n \" x = self.tok_emb(input_ids) * (self.cfg[\\\"emb_dim\\\"] ** 0.5)\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" pos_start = self.current_pos\\n\",\n \" pos_end = pos_start + seq_len\\n\",\n \" self.current_pos = pos_end\\n\",\n \" mask_global, mask_local = self._create_masks(\\n\",\n \" cur_len=seq_len, device=x.device, pos_start=pos_start, pos_end=pos_end\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" pos_start = 0\\n\",\n \" mask_global, mask_local = self._create_masks(\\n\",\n \" cur_len=seq_len, device=x.device, pos_start=0, pos_end=seq_len\\n\",\n \" )\\n\",\n \"\\n\",\n \" for i, block in enumerate(self.blocks):\\n\",\n \" blk_cache = cache.get(i) if cache is not None else None\\n\",\n \" x, new_blk_cache = block(\\n\",\n \" x,\\n\",\n \" mask_global=mask_global,\\n\",\n \" mask_local=mask_local,\\n\",\n \" cos_global=self.cos_global,\\n\",\n \" sin_global=self.sin_global,\\n\",\n \" cos_local=self.cos_local,\\n\",\n \" sin_local=self.sin_local,\\n\",\n \" start_pos=pos_start, # position of first new token\\n\",\n \" cache=blk_cache,\\n\",\n \" )\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" cache.update(i, new_blk_cache)\\n\",\n \"\\n\",\n \" # Final layernorm + projection\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\\n\",\n \"\\n\",\n \" def reset_kv_cache(self):\\n\",\n \" self.current_pos = 0\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"GEMMA3_CONFIG_270M = {\\n\",\n \" \\\"vocab_size\\\": 262_144,\\n\",\n \" \\\"context_length\\\": 32_768,\\n\",\n \" \\\"emb_dim\\\": 640,\\n\",\n \" \\\"n_heads\\\": 4,\\n\",\n \" \\\"n_layers\\\": 18,\\n\",\n \" \\\"hidden_dim\\\": 2048,\\n\",\n \" \\\"head_dim\\\": 256,\\n\",\n \" \\\"qk_norm\\\": True,\\n\",\n \" \\\"n_kv_groups\\\": 1,\\n\",\n \" \\\"rope_local_base\\\": 10_000.0,\\n\",\n \" \\\"rope_base\\\": 1_000_000.0,\\n\",\n \" \\\"sliding_window\\\": 512,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\"\\n\",\n \" ],\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"query_pre_attn_scalar\\\": 256,\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model = Gemma3Model(GEMMA3_CONFIG_270M)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"eaf86265-4e9d-4024-9ed0-99076944e304\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Gemma3Model(\\n\",\n \" (tok_emb): Embedding(262144, 640)\\n\",\n \" (blocks): ModuleList(\\n\",\n \" (0-17): 18 x TransformerBlock(\\n\",\n \" (att): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=640, out_features=1024, bias=False)\\n\",\n \" (W_key): Linear(in_features=640, out_features=256, bias=False)\\n\",\n \" (W_value): Linear(in_features=640, out_features=256, bias=False)\\n\",\n \" (out_proj): Linear(in_features=1024, out_features=640, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=640, out_features=2048, bias=False)\\n\",\n \" (fc2): Linear(in_features=640, out_features=2048, bias=False)\\n\",\n \" (fc3): Linear(in_features=2048, out_features=640, bias=False)\\n\",\n \" )\\n\",\n \" (input_layernorm): RMSNorm()\\n\",\n \" (post_attention_layernorm): RMSNorm()\\n\",\n \" (pre_feedforward_layernorm): RMSNorm()\\n\",\n \" (post_feedforward_layernorm): RMSNorm()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): RMSNorm()\\n\",\n \" (out_head): Linear(in_features=640, out_features=262144, bias=False)\\n\",\n \")\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90aca91d-4bee-45ce-993a-4ec5393abe2b\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the forward pass works before continuing:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"adf0a6b7-b688-42c9-966e-c223d34db99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[[ 0.7500, 0.1011, 0.4863, ..., 0.9414, 0.3984, -0.2285],\\n\",\n \" [-0.3398, -0.0564, 0.9023, ..., -0.2480, 0.4551, 0.8203],\\n\",\n \" [-0.2695, -0.3242, 0.4121, ..., 0.8672, -0.9688, 0.9844]]],\\n\",\n \" dtype=torch.bfloat16, grad_fn=\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"7cee5292-f756-41dd-9b8d-c9b5c25d23f8\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Uncomment and run the following code if you are executing the notebook for the first time\\n\",\n \"\\n\",\n \"#from huggingface_hub import login\\n\",\n \"#login()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"699cb1b8-a67d-49fb-80a6-0dad9d81f392\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 17,\n \"referenced_widgets\": [\n \"9881b6995c3f49dc89e6992fd9ab660b\",\n \"17a3174e65c54476b2e0d1faf8f011ca\",\n \"1bbf2e62c0754d1593beb4105a7f1ac1\",\n \"b82112e1dec645d98aa1c1ba64abcb61\",\n \"271e2bd6a35e4a8b92de8697f7c0be5f\",\n \"90a79523187446dfa692723b2e5833a7\",\n \"431ffb83b8c14bf182f0430e07ea6154\",\n \"a8f1b72a33dd4b548de23fbd95e0da18\",\n \"25cc36132d384189acfbecc59483134b\",\n \"bfd06423ad544218968648016e731a46\",\n \"d029630b63ff44cf807ade428d2eb421\"\n ]\n },\n \"id\": \"699cb1b8-a67d-49fb-80a6-0dad9d81f392\",\n \"outputId\": \"55b2f28c-142f-4698-9d23-d27456d3ed6d\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"application/vnd.jupyter.widget-view+json\": {\n \"model_id\": \"3396c08eab3f4cf980023483b969a337\",\n \"version_major\": 2,\n \"version_minor\": 0\n },\n \"text/plain\": [\n \"model.safetensors: 0%| | 0.00/536M [00:00\\\"\\n\",\n \" self.pad_token_id = eos_token\\n\",\n \" self.eos_token_id = eos_token\\n\",\n \"\\n\",\n \" def encode(self, text: str) -> list[int]:\\n\",\n \" return self._tok.encode(text).ids\\n\",\n \"\\n\",\n \" def decode(self, ids: list[int]) -> str:\\n\",\n \" return self._tok.decode(ids, skip_special_tokens=False)\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_chat_template(user_text):\\n\",\n \" return f\\\"\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/12_gemma3/standalone-gemma3.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"
\\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Gemma 3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 0.35.0\\n\",\n \"tokenizers version: 0.22.1\\n\",\n \"torch version: 2.9.0+cu130\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"07e96fbb-8e16-4f6d-835f-c6159321280b\",\n \"metadata\": {},\n \"source\": [\n \"- This notebook supports both the base model and the instructmodel; which model to use can be controlled via the following flag:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"70a90338-624a-4706-aa55-6b4358070194\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"USE_INSTRUCT_MODEL = True\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.gelu(x_fc1, approximate=\\\"tanh\\\") * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"56715760-37e1-433e-89da-04864c139a9e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-6, bias=False):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" # Gemma3 stores zero-centered weights and uses (1 + weight) during forward\\n\",\n \" self.scale = nn.Parameter(torch.zeros(emb_dim))\\n\",\n \" self.shift = nn.Parameter(torch.zeros(emb_dim)) if bias else None\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # Match HF Gemma3: compute norm in float32, then scale by (1 + w)\\n\",\n \" input_dtype = x.dtype\\n\",\n \" x_f = x.float()\\n\",\n \" var = x_f.pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x_norm = x_f * torch.rsqrt(var + self.eps)\\n\",\n \" out = x_norm * (1.0 + self.scale.float())\\n\",\n \" \\n\",\n \" if self.shift is not None:\\n\",\n \" out = out + self.shift.float()\\n\",\n \" \\n\",\n \" return out.to(input_dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Expand angles to match the head_dim\\n\",\n \" angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin, offset=0):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" # It's ok to use lower-precision after applying cos and sin rotation\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, num_heads, num_kv_groups, head_dim=None, qk_norm=False,\\n\",\n \" query_pre_attn_scalar=None, dtype=None,\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" if head_dim is None:\\n\",\n \" assert d_in % num_heads == 0, \\\"`d_in` must be divisible by `num_heads` if `head_dim` is not set\\\"\\n\",\n \" head_dim = d_in // num_heads\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(d_in, self.d_out, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" if qk_norm:\\n\",\n \" self.q_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" self.k_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" else:\\n\",\n \" self.q_norm = self.k_norm = None\\n\",\n \"\\n\",\n \" if query_pre_attn_scalar is not None:\\n\",\n \" self.scaling = (query_pre_attn_scalar) ** -0.5\\n\",\n \" else:\\n\",\n \" self.scaling = (head_dim) ** -0.5\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin, start_pos=0, cache=None):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" # Apply projections\\n\",\n \" queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\\n\",\n \" keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\\n\",\n \" keys_new = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values_new = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Optional Q/K normalization (applied to raw tensors)\\n\",\n \" if self.q_norm:\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" if self.k_norm:\\n\",\n \" keys_new = self.k_norm(keys_new)\\n\",\n \"\\n\",\n \" # Keep unrotated in cache; rotate after concatenation\\n\",\n \" prev_len = 0\\n\",\n \" if cache is not None:\\n\",\n \" prev_k, prev_v = cache # cached as unrotated\\n\",\n \" if prev_k is not None:\\n\",\n \" prev_len = prev_k.size(2)\\n\",\n \" keys_cat_raw = torch.cat([prev_k, keys_new], dim=2) # unrotated\\n\",\n \" values_cat_raw = torch.cat([prev_v, values_new], dim=2) # raw V\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \"\\n\",\n \" # RoPE: queries at absolute start_pos; keys with offset corrected by prev_len\\n\",\n \" queries = apply_rope(queries, cos, sin, offset=start_pos)\\n\",\n \" keys = apply_rope(keys_cat_raw, cos, sin, offset=start_pos - prev_len)\\n\",\n \"\\n\",\n \" # Scale queries\\n\",\n \" queries = queries * self.scaling\\n\",\n \"\\n\",\n \" # Update cache with unrotated keys and unscaled raw values\\n\",\n \" if cache is not None and cache[0] is not None:\\n\",\n \" next_cache = (\\n\",\n \" torch.cat([cache[0], keys_new], dim=2),\\n\",\n \" torch.cat([cache[1], values_new], dim=2),\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" next_cache = (keys_new, values_new)\\n\",\n \"\\n\",\n \" # Expand K and V to match number of heads\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values_cat_raw.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" # Attention\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \" attn_weights = torch.softmax(attn_scores, dim=-1)\\n\",\n \"\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \" out = self.out_proj(context)\\n\",\n \"\\n\",\n \" return out, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \"\\n\",\n \" def __init__(self, cfg, attn_type):\\n\",\n \" super().__init__()\\n\",\n \" self.attn_type = attn_type\\n\",\n \" self.sliding_window = cfg[\\\"sliding_window\\\"]\\n\",\n \"\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" qk_norm=cfg[\\\"qk_norm\\\"],\\n\",\n \" query_pre_attn_scalar=cfg[\\\"query_pre_attn_scalar\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.input_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.post_attention_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.pre_feedforward_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.post_feedforward_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \"\\n\",\n \" def forward(\\n\",\n \" self,\\n\",\n \" x,\\n\",\n \" mask_global,\\n\",\n \" mask_local,\\n\",\n \" cos_global,\\n\",\n \" sin_global,\\n\",\n \" cos_local,\\n\",\n \" sin_local,\\n\",\n \" start_pos=0,\\n\",\n \" cache=None\\n\",\n \" ):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.input_layernorm(x)\\n\",\n \"\\n\",\n \" if self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" if cache is not None and isinstance(cache, tuple):\\n\",\n \" prev_k, _ = cache\\n\",\n \" eff_kv_len = prev_k.size(2) + x.size(1)\\n\",\n \" else:\\n\",\n \" eff_kv_len = x.size(1)\\n\",\n \" # Take the last `eff_kv_len` columns so mask width equals K length\\n\",\n \" attn_mask = mask_local[..., -eff_kv_len:]\\n\",\n \" cos = cos_local\\n\",\n \" sin = sin_local\\n\",\n \" else:\\n\",\n \" attn_mask = mask_global\\n\",\n \" cos = cos_global\\n\",\n \" sin = sin_global\\n\",\n \" \\n\",\n \" x_attn, next_cache = self.att(x, attn_mask, cos, sin, start_pos=start_pos, cache=cache)\\n\",\n \" if next_cache is not None and self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" k, v = next_cache\\n\",\n \" if k.size(2) > self.sliding_window:\\n\",\n \" k = k[:, :, -self.sliding_window:, :]\\n\",\n \" v = v[:, :, -self.sliding_window:, :]\\n\",\n \" next_cache = (k, v)\\n\",\n \"\\n\",\n \" x_attn = self.post_attention_layernorm(x_attn)\\n\",\n \" x = shortcut + x_attn\\n\",\n \"\\n\",\n \" # Shortcut connection for feed forward block\\n\",\n \" shortcut = x\\n\",\n \" x_ffn = self.pre_feedforward_layernorm(x)\\n\",\n \" x_ffn = self.ff(x_ffn)\\n\",\n \" x_ffn = self.post_feedforward_layernorm(x_ffn)\\n\",\n \" x = shortcut + x_ffn\\n\",\n \" return x, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Gemma3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" assert cfg[\\\"layer_types\\\"] is not None and len(cfg[\\\"layer_types\\\"]) == cfg[\\\"n_layers\\\"]\\n\",\n \"\\n\",\n \" # Main model parameters\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.blocks = nn.ModuleList([\\n\",\n \" TransformerBlock(cfg, attn_type) for attn_type in cfg[\\\"layer_types\\\"]\\n\",\n \" ])\\n\",\n \"\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.cfg = cfg\\n\",\n \" self.current_pos = 0 # Track current position in KV cache\\n\",\n \"\\n\",\n \" # Reusable utilities\\n\",\n \" cos_local, sin_local = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_local_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" cos_global, sin_global = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos_local\\\", cos_local, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin_local\\\", sin_local, persistent=False)\\n\",\n \" self.register_buffer(\\\"cos_global\\\", cos_global, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin_global\\\", sin_global, persistent=False)\\n\",\n \"\\n\",\n \" def _create_masks(self, cur_len, device, pos_start=0, pos_end=None):\\n\",\n \" if pos_end is None:\\n\",\n \" pos_end = cur_len\\n\",\n \" total_len = pos_end\\n\",\n \"\\n\",\n \" ones = torch.ones((total_len, total_len), dtype=torch.bool, device=device)\\n\",\n \"\\n\",\n \" # mask_global_full (future is masked: j > i)\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 0 0 0 0 0 1 1 1\\n\",\n \" # 5: 0 0 0 0 0 0 1 1\\n\",\n \" # 6: 0 0 0 0 0 0 0 1\\n\",\n \" # 7: 0 0 0 0 0 0 0 0\\n\",\n \" mask_global_full = torch.triu(ones, diagonal=1)\\n\",\n \"\\n\",\n \" # far_past (too far back is masked: i - j >= sliding_window)\\n\",\n \" # where sliding_window = 4\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 0 0 0 0 0 0 0\\n\",\n \" # 1: 0 0 0 0 0 0 0 0\\n\",\n \" # 2: 0 0 0 0 0 0 0 0\\n\",\n \" # 3: 0 0 0 0 0 0 0 0\\n\",\n \" # 4: 1 0 0 0 0 0 0 0\\n\",\n \" # 5: 1 1 0 0 0 0 0 0\\n\",\n \" # 6: 1 1 1 0 0 0 0 0\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" far_past_full = torch.triu(ones, diagonal=self.cfg[\\\"sliding_window\\\"]).T\\n\",\n \"\\n\",\n \" # Local (sliding_window) = future OR far-past\\n\",\n \" # mask_local\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 1 0 0 0 0 1 1 1\\n\",\n \" # 5: 1 1 0 0 0 0 1 1\\n\",\n \" # 6: 1 1 1 0 0 0 0 1\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" mask_local_full = mask_global_full | far_past_full\\n\",\n \"\\n\",\n \" row_slice = slice(pos_start, pos_end)\\n\",\n \" mask_global = mask_global_full[row_slice, :pos_end][None, None, :, :]\\n\",\n \" mask_local = mask_local_full[row_slice, :pos_end][None, None, :, :]\\n\",\n \" return mask_global, mask_local\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, input_ids, cache=None):\\n\",\n \" b, seq_len = input_ids.shape\\n\",\n \" x = self.tok_emb(input_ids) * (self.cfg[\\\"emb_dim\\\"] ** 0.5)\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" pos_start = self.current_pos\\n\",\n \" pos_end = pos_start + seq_len\\n\",\n \" self.current_pos = pos_end\\n\",\n \" mask_global, mask_local = self._create_masks(\\n\",\n \" cur_len=seq_len, device=x.device, pos_start=pos_start, pos_end=pos_end\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" pos_start = 0\\n\",\n \" mask_global, mask_local = self._create_masks(\\n\",\n \" cur_len=seq_len, device=x.device, pos_start=0, pos_end=seq_len\\n\",\n \" )\\n\",\n \"\\n\",\n \" for i, block in enumerate(self.blocks):\\n\",\n \" blk_cache = cache.get(i) if cache is not None else None\\n\",\n \" x, new_blk_cache = block(\\n\",\n \" x,\\n\",\n \" mask_global=mask_global,\\n\",\n \" mask_local=mask_local,\\n\",\n \" cos_global=self.cos_global,\\n\",\n \" sin_global=self.sin_global,\\n\",\n \" cos_local=self.cos_local,\\n\",\n \" sin_local=self.sin_local,\\n\",\n \" start_pos=pos_start, # position of first new token\\n\",\n \" cache=blk_cache,\\n\",\n \" )\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" cache.update(i, new_blk_cache)\\n\",\n \"\\n\",\n \" # Final layernorm + projection\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\\n\",\n \"\\n\",\n \" def reset_kv_cache(self):\\n\",\n \" self.current_pos = 0\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"GEMMA3_CONFIG_270M = {\\n\",\n \" \\\"vocab_size\\\": 262_144,\\n\",\n \" \\\"context_length\\\": 32_768,\\n\",\n \" \\\"emb_dim\\\": 640,\\n\",\n \" \\\"n_heads\\\": 4,\\n\",\n \" \\\"n_layers\\\": 18,\\n\",\n \" \\\"hidden_dim\\\": 2048,\\n\",\n \" \\\"head_dim\\\": 256,\\n\",\n \" \\\"qk_norm\\\": True,\\n\",\n \" \\\"n_kv_groups\\\": 1,\\n\",\n \" \\\"rope_local_base\\\": 10_000.0,\\n\",\n \" \\\"rope_base\\\": 1_000_000.0,\\n\",\n \" \\\"sliding_window\\\": 512,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\"\\n\",\n \" ],\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"query_pre_attn_scalar\\\": 256,\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model = Gemma3Model(GEMMA3_CONFIG_270M)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"eaf86265-4e9d-4024-9ed0-99076944e304\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Gemma3Model(\\n\",\n \" (tok_emb): Embedding(262144, 640)\\n\",\n \" (blocks): ModuleList(\\n\",\n \" (0-17): 18 x TransformerBlock(\\n\",\n \" (att): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=640, out_features=1024, bias=False)\\n\",\n \" (W_key): Linear(in_features=640, out_features=256, bias=False)\\n\",\n \" (W_value): Linear(in_features=640, out_features=256, bias=False)\\n\",\n \" (out_proj): Linear(in_features=1024, out_features=640, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=640, out_features=2048, bias=False)\\n\",\n \" (fc2): Linear(in_features=640, out_features=2048, bias=False)\\n\",\n \" (fc3): Linear(in_features=2048, out_features=640, bias=False)\\n\",\n \" )\\n\",\n \" (input_layernorm): RMSNorm()\\n\",\n \" (post_attention_layernorm): RMSNorm()\\n\",\n \" (pre_feedforward_layernorm): RMSNorm()\\n\",\n \" (post_feedforward_layernorm): RMSNorm()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): RMSNorm()\\n\",\n \" (out_head): Linear(in_features=640, out_features=262144, bias=False)\\n\",\n \")\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90aca91d-4bee-45ce-993a-4ec5393abe2b\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the forward pass works before continuing:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"adf0a6b7-b688-42c9-966e-c223d34db99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[[ 0.7500, 0.1011, 0.4863, ..., 0.9414, 0.3984, -0.2285],\\n\",\n \" [-0.3398, -0.0564, 0.9023, ..., -0.2480, 0.4551, 0.8203],\\n\",\n \" [-0.2695, -0.3242, 0.4121, ..., 0.8672, -0.9688, 0.9844]]],\\n\",\n \" dtype=torch.bfloat16, grad_fn=\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"7cee5292-f756-41dd-9b8d-c9b5c25d23f8\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Uncomment and run the following code if you are executing the notebook for the first time\\n\",\n \"\\n\",\n \"#from huggingface_hub import login\\n\",\n \"#login()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"699cb1b8-a67d-49fb-80a6-0dad9d81f392\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 17,\n \"referenced_widgets\": [\n \"9881b6995c3f49dc89e6992fd9ab660b\",\n \"17a3174e65c54476b2e0d1faf8f011ca\",\n \"1bbf2e62c0754d1593beb4105a7f1ac1\",\n \"b82112e1dec645d98aa1c1ba64abcb61\",\n \"271e2bd6a35e4a8b92de8697f7c0be5f\",\n \"90a79523187446dfa692723b2e5833a7\",\n \"431ffb83b8c14bf182f0430e07ea6154\",\n \"a8f1b72a33dd4b548de23fbd95e0da18\",\n \"25cc36132d384189acfbecc59483134b\",\n \"bfd06423ad544218968648016e731a46\",\n \"d029630b63ff44cf807ade428d2eb421\"\n ]\n },\n \"id\": \"699cb1b8-a67d-49fb-80a6-0dad9d81f392\",\n \"outputId\": \"55b2f28c-142f-4698-9d23-d27456d3ed6d\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"application/vnd.jupyter.widget-view+json\": {\n \"model_id\": \"3396c08eab3f4cf980023483b969a337\",\n \"version_major\": 2,\n \"version_minor\": 0\n },\n \"text/plain\": [\n \"model.safetensors: 0%| | 0.00/536M [00:00\\\"\\n\",\n \" self.pad_token_id = eos_token\\n\",\n \" self.eos_token_id = eos_token\\n\",\n \"\\n\",\n \" def encode(self, text: str) -> list[int]:\\n\",\n \" return self._tok.encode(text).ids\\n\",\n \"\\n\",\n \" def decode(self, ids: list[int]) -> str:\\n\",\n \" return self._tok.decode(ids, skip_special_tokens=False)\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_chat_template(user_text):\\n\",\n \" return f\\\"\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/12_gemma3/standalone-gemma3.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Gemma 3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 0.35.0\\n\",\n \"tokenizers version: 0.22.1\\n\",\n \"torch version: 2.9.0+cu130\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"07e96fbb-8e16-4f6d-835f-c6159321280b\",\n \"metadata\": {},\n \"source\": [\n \"- This notebook supports both the base model and the instructmodel; which model to use can be controlled via the following flag:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"70a90338-624a-4706-aa55-6b4358070194\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"USE_INSTRUCT_MODEL = True\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.gelu(x_fc1, approximate=\\\"tanh\\\") * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"56715760-37e1-433e-89da-04864c139a9e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-6, bias=False):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" # Gemma3 stores zero-centered weights and uses (1 + weight) during forward\\n\",\n \" self.scale = nn.Parameter(torch.zeros(emb_dim))\\n\",\n \" self.shift = nn.Parameter(torch.zeros(emb_dim)) if bias else None\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" # Match HF Gemma3: compute norm in float32, then scale by (1 + w)\\n\",\n \" input_dtype = x.dtype\\n\",\n \" x_f = x.float()\\n\",\n \" var = x_f.pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x_norm = x_f * torch.rsqrt(var + self.eps)\\n\",\n \" out = x_norm * (1.0 + self.scale.float())\\n\",\n \" \\n\",\n \" if self.shift is not None:\\n\",\n \" out = out + self.shift.float()\\n\",\n \" \\n\",\n \" return out.to(input_dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Expand angles to match the head_dim\\n\",\n \" angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" # It's ok to use lower-precision after applying cos and sin rotation\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, num_heads, num_kv_groups, head_dim=None, qk_norm=False,\\n\",\n \" query_pre_attn_scalar=None, dtype=None,\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" if head_dim is None:\\n\",\n \" assert d_in % num_heads == 0, \\\"`d_in` must be divisible by `num_heads` if `head_dim` is not set\\\"\\n\",\n \" head_dim = d_in // num_heads\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(d_in, self.d_out, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" if qk_norm:\\n\",\n \" self.q_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" self.k_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" else:\\n\",\n \" self.q_norm = self.k_norm = None\\n\",\n \"\\n\",\n \" if query_pre_attn_scalar is not None:\\n\",\n \" self.scaling = (query_pre_attn_scalar) ** -0.5\\n\",\n \" else:\\n\",\n \" self.scaling = (head_dim) ** -0.5\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" # Apply projections\\n\",\n \" queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\\n\",\n \" keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Optional normalization\\n\",\n \" if self.q_norm:\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" if self.k_norm:\\n\",\n \" keys = self.k_norm(keys)\\n\",\n \"\\n\",\n \" # Apply RoPE\\n\",\n \" queries = apply_rope(queries, cos, sin)\\n\",\n \" keys = apply_rope(keys, cos, sin)\\n\",\n \"\\n\",\n \" # Expand K and V to match number of heads\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" # Scale queries\\n\",\n \" queries = queries * self.scaling\\n\",\n \"\\n\",\n \" # Attention\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \" attn_weights = torch.softmax(attn_scores, dim=-1)\\n\",\n \"\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \" return self.out_proj(context)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \"\\n\",\n \" def __init__(self, cfg, attn_type):\\n\",\n \" super().__init__()\\n\",\n \" self.attn_type = attn_type \\n\",\n \"\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" qk_norm=cfg[\\\"qk_norm\\\"],\\n\",\n \" query_pre_attn_scalar=cfg[\\\"query_pre_attn_scalar\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.input_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.post_attention_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.pre_feedforward_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.post_feedforward_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \"\\n\",\n \" def forward(\\n\",\n \" self,\\n\",\n \" x,\\n\",\n \" mask_global,\\n\",\n \" mask_local,\\n\",\n \" cos_global,\\n\",\n \" sin_global,\\n\",\n \" cos_local,\\n\",\n \" sin_local,\\n\",\n \" ):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.input_layernorm(x)\\n\",\n \"\\n\",\n \" if self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" attn_mask = mask_local\\n\",\n \" cos = cos_local\\n\",\n \" sin = sin_local\\n\",\n \" else:\\n\",\n \" attn_mask = mask_global\\n\",\n \" cos = cos_global\\n\",\n \" sin = sin_global\\n\",\n \" \\n\",\n \" x_attn = self.att(x, attn_mask, cos, sin)\\n\",\n \" x_attn = self.post_attention_layernorm(x_attn)\\n\",\n \" x = shortcut + x_attn\\n\",\n \"\\n\",\n \" # Shortcut connection for feed forward block\\n\",\n \" shortcut = x\\n\",\n \" x_ffn = self.pre_feedforward_layernorm(x)\\n\",\n \" x_ffn = self.ff(x_ffn)\\n\",\n \" x_ffn = self.post_feedforward_layernorm(x_ffn)\\n\",\n \" x = shortcut + x_ffn\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Gemma3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" assert cfg[\\\"layer_types\\\"] is not None and len(cfg[\\\"layer_types\\\"]) == cfg[\\\"n_layers\\\"]\\n\",\n \" \\n\",\n \" # Main model parameters\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.blocks = nn.ModuleList([\\n\",\n \" TransformerBlock(cfg, attn_type)for attn_type in cfg[\\\"layer_types\\\"]\\n\",\n \" ])\\n\",\n \"\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \" # Reusable utilities \\n\",\n \" cos_local, sin_local = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_local_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" cos_global, sin_global = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos_local\\\", cos_local, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin_local\\\", sin_local, persistent=False)\\n\",\n \" self.register_buffer(\\\"cos_global\\\", cos_global, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin_global\\\", sin_global, persistent=False)\\n\",\n \" \\n\",\n \" def _create_masks(self, seq_len, device):\\n\",\n \" ones = torch.ones((seq_len, seq_len), dtype=torch.bool, device=device)\\n\",\n \" \\n\",\n \" # mask_global (future is masked: j > i)\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 0 0 0 0 0 1 1 1\\n\",\n \" # 5: 0 0 0 0 0 0 1 1\\n\",\n \" # 6: 0 0 0 0 0 0 0 1\\n\",\n \" # 7: 0 0 0 0 0 0 0 0\\n\",\n \" mask_global = torch.triu(ones, diagonal=1)\\n\",\n \" \\n\",\n \" # far_past (too far back is masked: i - j >= sliding_window)\\n\",\n \" # where sliding_window = 4\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 0 0 0 0 0 0 0\\n\",\n \" # 1: 0 0 0 0 0 0 0 0\\n\",\n \" # 2: 0 0 0 0 0 0 0 0\\n\",\n \" # 3: 0 0 0 0 0 0 0 0\\n\",\n \" # 4: 1 0 0 0 0 0 0 0\\n\",\n \" # 5: 1 1 0 0 0 0 0 0\\n\",\n \" # 6: 1 1 1 0 0 0 0 0\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" far_past = torch.triu(ones, diagonal=self.cfg[\\\"sliding_window\\\"]).T\\n\",\n \" \\n\",\n \" # Local (sliding_window) = future OR far-past\\n\",\n \" # mask_local\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 1 0 0 0 0 1 1 1\\n\",\n \" # 5: 1 1 0 0 0 0 1 1\\n\",\n \" # 6: 1 1 1 0 0 0 0 1\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" mask_local = mask_global | far_past\\n\",\n \" return mask_global, mask_local\\n\",\n \"\\n\",\n \" def forward(self, input_ids):\\n\",\n \" # Forward pass\\n\",\n \" b, seq_len = input_ids.shape\\n\",\n \" x = self.tok_emb(input_ids) * (self.cfg[\\\"emb_dim\\\"] ** 0.5)\\n\",\n \" mask_global, mask_local = self._create_masks(seq_len, x.device)\\n\",\n \"\\n\",\n \" for block in self.blocks:\\n\",\n \" x = block(\\n\",\n \" x,\\n\",\n \" mask_global=mask_global,\\n\",\n \" mask_local=mask_local,\\n\",\n \" cos_global=self.cos_global,\\n\",\n \" sin_global=self.sin_global,\\n\",\n \" cos_local=self.cos_local,\\n\",\n \" sin_local=self.sin_local,\\n\",\n \" )\\n\",\n \"\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"GEMMA3_CONFIG_270M = {\\n\",\n \" \\\"vocab_size\\\": 262_144,\\n\",\n \" \\\"context_length\\\": 32_768,\\n\",\n \" \\\"emb_dim\\\": 640,\\n\",\n \" \\\"n_heads\\\": 4,\\n\",\n \" \\\"n_layers\\\": 18,\\n\",\n \" \\\"hidden_dim\\\": 2048,\\n\",\n \" \\\"head_dim\\\": 256,\\n\",\n \" \\\"qk_norm\\\": True,\\n\",\n \" \\\"n_kv_groups\\\": 1,\\n\",\n \" \\\"rope_local_base\\\": 10_000.0,\\n\",\n \" \\\"rope_base\\\": 1_000_000.0,\\n\",\n \" \\\"sliding_window\\\": 512,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\"\\n\",\n \" ],\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"query_pre_attn_scalar\\\": 256,\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model = Gemma3Model(GEMMA3_CONFIG_270M)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"eaf86265-4e9d-4024-9ed0-99076944e304\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Gemma3Model(\\n\",\n \" (tok_emb): Embedding(262144, 640)\\n\",\n \" (blocks): ModuleList(\\n\",\n \" (0-17): 18 x TransformerBlock(\\n\",\n \" (att): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=640, out_features=1024, bias=False)\\n\",\n \" (W_key): Linear(in_features=640, out_features=256, bias=False)\\n\",\n \" (W_value): Linear(in_features=640, out_features=256, bias=False)\\n\",\n \" (out_proj): Linear(in_features=1024, out_features=640, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=640, out_features=2048, bias=False)\\n\",\n \" (fc2): Linear(in_features=640, out_features=2048, bias=False)\\n\",\n \" (fc3): Linear(in_features=2048, out_features=640, bias=False)\\n\",\n \" )\\n\",\n \" (input_layernorm): RMSNorm()\\n\",\n \" (post_attention_layernorm): RMSNorm()\\n\",\n \" (pre_feedforward_layernorm): RMSNorm()\\n\",\n \" (post_feedforward_layernorm): RMSNorm()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): RMSNorm()\\n\",\n \" (out_head): Linear(in_features=640, out_features=262144, bias=False)\\n\",\n \")\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90aca91d-4bee-45ce-993a-4ec5393abe2b\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the forward pass works before continuing:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"adf0a6b7-b688-42c9-966e-c223d34db99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[[ 0.7500, 0.1011, 0.4863, ..., 0.9414, 0.3984, -0.2285],\\n\",\n \" [-0.3398, -0.0564, 0.9023, ..., -0.2480, 0.4551, 0.8203],\\n\",\n \" [-0.2695, -0.3242, 0.4121, ..., 0.8672, -0.9688, 0.9844]]],\\n\",\n \" dtype=torch.bfloat16, grad_fn=\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"7cee5292-f756-41dd-9b8d-c9b5c25d23f8\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Uncomment and run the following code if you are executing the notebook for the first time\\n\",\n \"\\n\",\n \"#from huggingface_hub import login\\n\",\n \"#login()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"699cb1b8-a67d-49fb-80a6-0dad9d81f392\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 17,\n \"referenced_widgets\": [\n \"9881b6995c3f49dc89e6992fd9ab660b\",\n \"17a3174e65c54476b2e0d1faf8f011ca\",\n \"1bbf2e62c0754d1593beb4105a7f1ac1\",\n \"b82112e1dec645d98aa1c1ba64abcb61\",\n \"271e2bd6a35e4a8b92de8697f7c0be5f\",\n \"90a79523187446dfa692723b2e5833a7\",\n \"431ffb83b8c14bf182f0430e07ea6154\",\n \"a8f1b72a33dd4b548de23fbd95e0da18\",\n \"25cc36132d384189acfbecc59483134b\",\n \"bfd06423ad544218968648016e731a46\",\n \"d029630b63ff44cf807ade428d2eb421\"\n ]\n },\n \"id\": \"699cb1b8-a67d-49fb-80a6-0dad9d81f392\",\n \"outputId\": \"55b2f28c-142f-4698-9d23-d27456d3ed6d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Model uses weight tying.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import json\\n\",\n \"import os\\n\",\n \"from pathlib import Path\\n\",\n \"from safetensors.torch import load_file\\n\",\n \"from huggingface_hub import hf_hub_download, snapshot_download\\n\",\n \"\\n\",\n \"CHOOSE_MODEL = \\\"270m\\\"\\n\",\n \"\\n\",\n \"if USE_INSTRUCT_MODEL:\\n\",\n \" repo_id = f\\\"google/gemma-3-{CHOOSE_MODEL}-it\\\"\\n\",\n \"else:\\n\",\n \" repo_id = f\\\"google/gemma-3-{CHOOSE_MODEL}\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"local_dir = Path(repo_id).parts[-1]\\n\",\n \"\\n\",\n \"if CHOOSE_MODEL == \\\"270m\\\":\\n\",\n \" weights_file = hf_hub_download(\\n\",\n \" repo_id=repo_id,\\n\",\n \" filename=\\\"model.safetensors\\\",\\n\",\n \" local_dir=local_dir,\\n\",\n \" )\\n\",\n \" weights_dict = load_file(weights_file)\\n\",\n \"else:\\n\",\n \" repo_dir = snapshot_download(repo_id=repo_id, local_dir=local_dir)\\n\",\n \" index_path = os.path.join(repo_dir, \\\"model.safetensors.index.json\\\")\\n\",\n \" with open(index_path, \\\"r\\\") as f:\\n\",\n \" index = json.load(f)\\n\",\n \"\\n\",\n \" weights_dict = {}\\n\",\n \" for filename in set(index[\\\"weight_map\\\"].values()):\\n\",\n \" shard_path = os.path.join(repo_dir, filename)\\n\",\n \" shard = load_file(shard_path)\\n\",\n \" weights_dict.update(shard)\\n\",\n \"\\n\",\n \"load_weights_into_gemma(model, GEMMA3_CONFIG_270M, weights_dict)\\n\",\n \"model.to(device)\\n\",\n \"del weights_dict\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6b345491-3510-4397-92d3-cd0a3fa3deee\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"# 3. Load tokenizer\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"b68ab489-48e5-471e-a814-56cda2d60f81\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from tokenizers import Tokenizer\\n\",\n \"\\n\",\n \"\\n\",\n \"class GemmaTokenizer:\\n\",\n \" def __init__(self, tokenizer_file_path: str):\\n\",\n \" tok_file = Path(tokenizer_file_path)\\n\",\n \" self._tok = Tokenizer.from_file(str(tok_file))\\n\",\n \" # Attempt to identify EOS and padding tokens\\n\",\n \" eos_token = \\\"\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/12_gemma3/tests/test_gemma3_kv_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n mod = import_definitions_from_notebook(nb_dir, \"standalone-gemma3-plus-kvcache.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8)) # batch size 1, seq length 8\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"emb_dim\": 32,\n \"hidden_dim\": 64,\n \"n_layers\": 2,\n \"n_heads\": 4,\n \"head_dim\": 8,\n \"n_kv_groups\": 1,\n \"qk_norm\": True, # Gemma3 uses q/k RMSNorm\n \"dtype\": torch.float32,\n \"rope_base\": 1_000_000.0, # global RoPE base\n \"rope_local_base\": 10_000.0, # local RoPE base (unused in these tests)\n \"context_length\": 64,\n \"sliding_window\": 16,\n \"layer_types\": [\"full_attention\", \"full_attention\"],\n \"query_pre_attn_scalar\": 256,\n }\n\n\n@torch.inference_mode()\ndef test_dummy_gemma3_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.Gemma3Model(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"])\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_gemma3_base_equivalence_with_transformers(import_notebook_defs):\n from transformers import Gemma3TextConfig, Gemma3ForCausalLM\n\n # Tiny config so the test is fast\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"qk_norm\": True,\n \"n_kv_groups\": 2,\n \"rope_base\": 1_000_000.0,\n \"rope_local_base\": 10_000.0,\n \"sliding_window\": 4,\n \"layer_types\": [\"full_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"query_pre_attn_scalar\": 256,\n }\n model = import_notebook_defs.Gemma3Model(cfg)\n\n hf_cfg = Gemma3TextConfig(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n head_dim=cfg[\"head_dim\"],\n num_key_value_heads=cfg[\"n_kv_groups\"],\n rope_theta=cfg[\"rope_base\"],\n rope_local_base_freq=cfg[\"rope_local_base\"],\n layer_types=cfg[\"layer_types\"],\n sliding_window=cfg[\"sliding_window\"],\n tie_word_embeddings=False,\n attn_implementation=\"eager\",\n torch_dtype=torch.float32,\n query_pre_attn_scalar=cfg[\"query_pre_attn_scalar\"],\n rope_scaling={\"rope_type\": \"default\"},\n )\n hf_model = Gemma3ForCausalLM(hf_cfg)\n\n hf_state = hf_model.state_dict()\n param_config = {\"n_layers\": cfg[\"n_layers\"], \"hidden_dim\": cfg[\"hidden_dim\"]}\n import_notebook_defs.load_weights_into_gemma(model, param_config, hf_state)\n\n x = torch.randint(0, cfg[\"vocab_size\"], (2, cfg[\"context_length\"]), dtype=torch.long)\n ours_logits = model(x)\n theirs_logits = hf_model(x).logits\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/12_gemma3/tests/test_gemma3_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n mod = import_definitions_from_notebook(nb_dir, \"standalone-gemma3.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8)) # batch size 1, seq length 8\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"emb_dim\": 32,\n \"hidden_dim\": 64,\n \"n_layers\": 2,\n \"n_heads\": 4,\n \"head_dim\": 8,\n \"n_kv_groups\": 1,\n \"qk_norm\": True, # Gemma3 uses q/k RMSNorm\n \"dtype\": torch.float32,\n \"rope_base\": 1_000_000.0, # global RoPE base\n \"rope_local_base\": 10_000.0, # local RoPE base (unused in these tests)\n \"context_length\": 64,\n \"sliding_window\": 16,\n \"layer_types\": [\"full_attention\", \"full_attention\"],\n \"query_pre_attn_scalar\": 256,\n }\n\n\n@torch.inference_mode()\ndef test_dummy_gemma3_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.Gemma3Model(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"])\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_gemma3_base_equivalence_with_transformers(import_notebook_defs):\n from transformers import Gemma3TextConfig, Gemma3ForCausalLM\n\n # Tiny config so the test is fast\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"qk_norm\": True,\n \"n_kv_groups\": 2,\n \"rope_base\": 1_000_000.0,\n \"rope_local_base\": 10_000.0,\n \"sliding_window\": 4,\n \"layer_types\": [\"full_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"query_pre_attn_scalar\": 256,\n }\n model = import_notebook_defs.Gemma3Model(cfg)\n\n hf_cfg = Gemma3TextConfig(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n head_dim=cfg[\"head_dim\"],\n num_key_value_heads=cfg[\"n_kv_groups\"],\n rope_theta=cfg[\"rope_base\"],\n rope_local_base_freq=cfg[\"rope_local_base\"],\n layer_types=cfg[\"layer_types\"],\n sliding_window=cfg[\"sliding_window\"],\n tie_word_embeddings=False,\n attn_implementation=\"eager\",\n torch_dtype=torch.float32,\n query_pre_attn_scalar=cfg[\"query_pre_attn_scalar\"],\n rope_scaling={\"rope_type\": \"default\"},\n )\n hf_model = Gemma3ForCausalLM(hf_cfg)\n\n hf_state = hf_model.state_dict()\n param_config = {\"n_layers\": cfg[\"n_layers\"], \"hidden_dim\": cfg[\"hidden_dim\"]}\n import_notebook_defs.load_weights_into_gemma(model, param_config, hf_state)\n\n x = torch.randint(0, cfg[\"vocab_size\"], (2, cfg[\"context_length\"]), dtype=torch.long)\n ours_logits = model(x)\n theirs_logits = hf_model(x).logits\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/13_olmo3/README.md",
"content": "# Olmo 3 7B and 32B From Scratch\n\nThis [standalone-olmo3.ipynb](standalone-olmo3.ipynb) Jupyter notebook in this folder contains a from-scratch implementation of Olmo 3 7B and 32B and requires about 13 GB of RAM to run. \n\nThe alternative [standalone-olmo3-plus-kvcache.ipynb](standalone-olmo3-plus-kv-cache.ipynb) notebook adds a KV cache for better runtime performance (but adds more code complexity). To learn more about KV caching, see my [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) article.\n\nBelow is a side-by-side comparison with Qwen3 as a reference model; if you are interested in the Qwen3 0.6B standalone notebook, you can find it [here](../11_qwen3).\n\n \n\n
\n\n \n\nOlmo 3 also comes in different flavors, as shown below (the architecture is the same, only the training pipeline differs):\n\n
\n\nOlmo 3 also comes in different flavors, as shown below (the architecture is the same, only the training pipeline differs):\n\n \n\n\n \n## How does Olmo 3 compare to Qwen3\n\nFocusing on the architecture, not the training details, this section provides a brief comparison to Qwen3.\n\n\nThe 7B model:\n\n1. As we can see in the figures above, the Olmo 3 architecture is relatively similar to Qwen3. However, it's worth noting that this is essentially likely inspired by the Olmo 2 predecessor, not Qwen3. \n\n2) Similar to Olmo 2, Olmo 3 still uses a post-norm flavor instead of pre-norm, as they found in the Olmo 2 paper that it stabilizes the training.\n\n3) Interestingly, the 7B model still uses multi-head attention similar to Olmo 2. \nHowever, to make things more efficient and reduce the KV cache size, they now use sliding-window attention (e.g., similar to Gemma 3).\n\nNext, the 32B model:\n\n4) Overall, it's the same architecture but just scaled up. Also, the proportions (e.g., going from the input to the intermediate size in the feed-forward layer, and so on) roughly match the ones in Qwen3. \n\n5) My guess is the architecture was initially somewhat smaller than Qwen3 due to the smaller vocabulary, and they then scaled up the intermediate size expansion from 5x in Qwen3 to 5.4 in Olmo 3 to have a 32B model for a direct comparison. \n\n6) Also, note that the 32B model (finally!) uses grouped query attention.\n\n\n\n\n\n
\n\n\n \n## How does Olmo 3 compare to Qwen3\n\nFocusing on the architecture, not the training details, this section provides a brief comparison to Qwen3.\n\n\nThe 7B model:\n\n1. As we can see in the figures above, the Olmo 3 architecture is relatively similar to Qwen3. However, it's worth noting that this is essentially likely inspired by the Olmo 2 predecessor, not Qwen3. \n\n2) Similar to Olmo 2, Olmo 3 still uses a post-norm flavor instead of pre-norm, as they found in the Olmo 2 paper that it stabilizes the training.\n\n3) Interestingly, the 7B model still uses multi-head attention similar to Olmo 2. \nHowever, to make things more efficient and reduce the KV cache size, they now use sliding-window attention (e.g., similar to Gemma 3).\n\nNext, the 32B model:\n\n4) Overall, it's the same architecture but just scaled up. Also, the proportions (e.g., going from the input to the intermediate size in the feed-forward layer, and so on) roughly match the ones in Qwen3. \n\n5) My guess is the architecture was initially somewhat smaller than Qwen3 due to the smaller vocabulary, and they then scaled up the intermediate size expansion from 5x in Qwen3 to 5.4 in Olmo 3 to have a 32B model for a direct comparison. \n\n6) Also, note that the 32B model (finally!) uses grouped query attention.\n\n\n\n\n\n| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \\n\",\n \" \\n\",\n \"
\\n\",\n \" \\n\",\n \" \\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Olmo 3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 0.35.0\\n\",\n \"tokenizers version: 0.22.1\\n\",\n \"torch version: 2.9.1+cu130\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"07e96fbb-8e16-4f6d-835f-c6159321280b\",\n \"metadata\": {},\n \"source\": [\n \"- Note that there are three model types, and each of the four model types comes in a 7B and 32B size:\\n\",\n \"1. Base (`Olmo-3-1025-7B` and `Olmo-3-1125-32B`)\\n\",\n \"2. Instruct (`Olmo-3-7B/32B-Think`)\\n\",\n \"3. Reasoning (`Olmo-3-32B/7B-Think`)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"70a90338-624a-4706-aa55-6b4358070194\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Select which model to use\\n\",\n \"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-1025-7B\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-1125-32B\\\"\\n\",\n \"USE_MODEL = \\\"Olmo-3-7B-Instruct\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-32B-Instruct\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-7B-Think\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-32B-Think\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-7B-RLZero-IF\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1899ab4b-e1c2-4215-b3d1-ed00d52e4576\",\n \"metadata\": {},\n \"source\": [\n \"- In addition to the checkpoints listed above, you can also use the intermediate checkpoints listed [here](https://huggingface.co/collections/allenai/olmo-3-post-training); since they all have the same architecture, they are all compatible with this notebook\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"56715760-37e1-433e-89da-04864c139a9e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-6):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" self.weight = nn.Parameter(torch.ones(emb_dim))\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" input_dtype = x.dtype\\n\",\n \" x_f = x.float()\\n\",\n \" var = x_f.pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x_norm = x_f * torch.rsqrt(var + self.eps)\\n\",\n \" return (self.weight * x_norm).to(input_dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"import math\\n\",\n \"\\n\",\n \"\\n\",\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, attention_factor=1.0, rope_type=\\\"default\\\", rope_factor=1.0, rope_orig_max=8192, beta_fast=32.0, beta_slow=1.0, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" if rope_type == \\\"yarn\\\":\\n\",\n \" # Compute YaRN-style frequency scaling (as per https://huggingface.co/papers/2309.00071)\\n\",\n \"\\n\",\n \" def find_correction_dim(num_rotations, dim, base, max_position_embeddings):\\n\",\n \" \\\"\\\"\\\"Inverse dimension formula to find the dimension based on the number of rotations\\\"\\\"\\\"\\n\",\n \" return (dim * math.log(max_position_embeddings / (num_rotations * 2 * math.pi))) / (2 * math.log(base))\\n\",\n \"\\n\",\n \" def find_correction_range(low_rot, high_rot, dim, base, max_position_embeddings):\\n\",\n \" \\\"\\\"\\\"Find dimension range bounds based on rotations\\\"\\\"\\\"\\n\",\n \" low = find_correction_dim(low_rot, dim, base, max_position_embeddings)\\n\",\n \" high = find_correction_dim(high_rot, dim, base, max_position_embeddings)\\n\",\n \" low = math.floor(low)\\n\",\n \" high = math.ceil(high)\\n\",\n \" return max(low, 0), min(high, dim - 1)\\n\",\n \"\\n\",\n \" def linear_ramp_factor(min_val, max_val, dim):\\n\",\n \" if min_val == max_val:\\n\",\n \" max_val += 0.001 # Prevent singularity\\n\",\n \" linear_func = (torch.arange(dim, dtype=torch.float32) - min_val) / (max_val - min_val)\\n\",\n \" ramp_func = torch.clamp(linear_func, 0, 1)\\n\",\n \" return ramp_func\\n\",\n \"\\n\",\n \" # Base frequencies\\n\",\n \" pos_freqs = theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype) / head_dim)\\n\",\n \" inv_freq_extrapolation = 1.0 / pos_freqs # No scaling (extrapolation)\\n\",\n \" inv_freq_interpolation = 1.0 / (rope_factor * pos_freqs) # With scaling (interpolation)\\n\",\n \"\\n\",\n \" # Find the range where we blend between interpolation and extrapolation\\n\",\n \" low, high = find_correction_range(beta_fast, beta_slow, head_dim, theta_base, rope_orig_max)\\n\",\n \"\\n\",\n \" # Get n-dimensional rotational scaling corrected for extrapolation\\n\",\n \" inv_freq_extrapolation_factor = 1 - linear_ramp_factor(low, high, head_dim // 2).to(dtype=dtype)\\n\",\n \" inv_freq = (\\n\",\n \" inv_freq_interpolation * (1 - inv_freq_extrapolation_factor)\\n\",\n \" + inv_freq_extrapolation * inv_freq_extrapolation_factor\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" # Default RoPE\\n\",\n \" inv_freq = 1.0 / (\\n\",\n \" theta_base ** (\\n\",\n \" torch.arange(0, head_dim, 2, dtype=dtype)[: head_dim // 2].float()\\n\",\n \" / head_dim\\n\",\n \" )\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the base angles (shape: [context_length, head_dim // 2])\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0)\\n\",\n \"\\n\",\n \" # Expand to full head_dim (shape: [context_length, head_dim])\\n\",\n \" angles = torch.cat([angles, angles], dim=1)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles) * attention_factor\\n\",\n \" sin = torch.sin(angles) * attention_factor\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin, offset=0):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" # It's ok to use lower-precision after applying cos and sin rotation\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(self, d_in, num_heads, num_kv_groups, head_dim, attention_bias=False, dtype=None, sliding_window=None, attn_type=\\\"full_attention\\\"):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \" self.attn_type = attn_type\\n\",\n \" self.sliding_window = sliding_window if attn_type == \\\"sliding_attention\\\" else None\\n\",\n \"\\n\",\n \" # Projections\\n\",\n \" self.W_query = nn.Linear(d_in, self.d_out, bias=attention_bias, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=attention_bias, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=attention_bias, dtype=dtype)\\n\",\n \" self.out_proj = nn.Linear(self.d_out, d_in, bias=attention_bias, dtype=dtype)\\n\",\n \"\\n\",\n \" # Olmo3-style RMSNorm over the flattened projections\\n\",\n \" self.q_norm = RMSNorm(self.d_out)\\n\",\n \" self.k_norm = RMSNorm(num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin, start_pos=0, cache=None):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" # Apply projections\\n\",\n \" queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\\n\",\n \" keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Normalize q and k\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" keys_new = self.k_norm(keys)\\n\",\n \"\\n\",\n \" # Reshape to (b, heads, seq, head_dim)\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\\n\",\n \" keys_new = keys_new.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values_new = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Cache unrotated K/V\\n\",\n \" prev_len = 0\\n\",\n \" if cache is not None:\\n\",\n \" prev_k, prev_v = cache\\n\",\n \" if prev_k is not None:\\n\",\n \" prev_len = prev_k.size(2)\\n\",\n \" keys_cat_raw = torch.cat([prev_k, keys_new], dim=2)\\n\",\n \" values_cat_raw = torch.cat([prev_v, values_new], dim=2)\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \"\\n\",\n \" # Apply RoPE with offsets for cached tokens\\n\",\n \" queries = apply_rope(queries, cos, sin, offset=start_pos)\\n\",\n \" keys = apply_rope(keys_cat_raw, cos, sin, offset=start_pos - prev_len)\\n\",\n \"\\n\",\n \" # Expand KV groups to full head count\\n\",\n \" if self.group_size > 1:\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values_cat_raw.repeat_interleave(self.group_size, dim=1)\\n\",\n \" else:\\n\",\n \" values = values_cat_raw\\n\",\n \"\\n\",\n \" # Scaling before the matmul seems to be a bit more stable for Olmo\\n\",\n \" scale = self.head_dim ** -0.5 # Python float\\n\",\n \" queries = queries * scale\\n\",\n \"\\n\",\n \" # Update cache with unrotated K/V\\n\",\n \" if cache is not None and cache[0] is not None:\\n\",\n \" next_cache = (\\n\",\n \" torch.cat([cache[0], keys_new], dim=2),\\n\",\n \" torch.cat([cache[1], values_new], dim=2),\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" next_cache = (keys_new, values_new)\\n\",\n \"\\n\",\n \" # Attention\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" if mask is not None:\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores, dim=-1)\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \" out = self.out_proj(context)\\n\",\n \"\\n\",\n \" return out, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"13eb3430-0c06-4fe2-a005-217205eee21e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg, attn_type):\\n\",\n \" super().__init__()\\n\",\n \" self.attn_type = attn_type\\n\",\n \" self.sliding_window = cfg[\\\"sliding_window\\\"]\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_heads\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" attention_bias=cfg[\\\"attention_bias\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" sliding_window=cfg[\\\"sliding_window\\\"],\\n\",\n \" attn_type=attn_type,\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.post_attention_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"rms_norm_eps\\\"])\\n\",\n \" self.post_feedforward_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"rms_norm_eps\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x, mask_global, mask_local, cos, sin, start_pos=0, cache=None):\\n\",\n \" shortcut = x\\n\",\n \" if self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" if cache is not None and isinstance(cache, tuple):\\n\",\n \" prev_k, _ = cache\\n\",\n \" prev_len = prev_k.size(2) if prev_k is not None else 0\\n\",\n \" else:\\n\",\n \" prev_len = 0\\n\",\n \" eff_kv_len = prev_len + x.size(1)\\n\",\n \" attn_mask = mask_local[..., -eff_kv_len:]\\n\",\n \" else:\\n\",\n \" attn_mask = mask_global\\n\",\n \"\\n\",\n \" x_attn, next_cache = self.att(x, attn_mask, cos, sin, start_pos=start_pos, cache=cache)\\n\",\n \" if next_cache is not None and self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" k, v = next_cache\\n\",\n \" if k.size(2) > self.sliding_window:\\n\",\n \" k = k[:, :, -self.sliding_window:, :]\\n\",\n \" v = v[:, :, -self.sliding_window:, :]\\n\",\n \" next_cache = (k, v)\\n\",\n \"\\n\",\n \" x_attn = self.post_attention_layernorm(x_attn)\\n\",\n \" x = shortcut + x_attn\\n\",\n \"\\n\",\n \" shortcut = x\\n\",\n \" x_ffn = self.ff(x)\\n\",\n \" x_ffn = self.post_feedforward_layernorm(x_ffn)\\n\",\n \" x = shortcut + x_ffn\\n\",\n \" return x, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Olmo3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" assert cfg[\\\"layer_types\\\"] is not None and len(cfg[\\\"layer_types\\\"]) == cfg[\\\"n_layers\\\"]\\n\",\n \"\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.blocks = nn.ModuleList([TransformerBlock(cfg, attn_type) for attn_type in cfg[\\\"layer_types\\\"]])\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"rms_norm_eps\\\"])\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.cfg = cfg\\n\",\n \" self.current_pos = 0\\n\",\n \"\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" attention_factor=cfg[\\\"rope_attention_factor\\\"],\\n\",\n \" rope_type=cfg[\\\"rope_type\\\"],\\n\",\n \" rope_factor=cfg[\\\"rope_factor\\\"],\\n\",\n \" rope_orig_max=cfg[\\\"rope_orig_max\\\"],\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \"\\n\",\n \" def create_masks(self, cur_len, device, pos_start=0, pos_end=None):\\n\",\n \" if pos_end is None:\\n\",\n \" pos_end = cur_len\\n\",\n \" total_len = pos_end\\n\",\n \"\\n\",\n \" ones = torch.ones((total_len, total_len), dtype=torch.bool, device=device)\\n\",\n \" # mask_global_full (future is masked: j > i)\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 0 0 0 0 0 1 1 1\\n\",\n \" # 5: 0 0 0 0 0 0 1 1\\n\",\n \" # 6: 0 0 0 0 0 0 0 1\\n\",\n \" # 7: 0 0 0 0 0 0 0 0\\n\",\n \" mask_global_full = torch.triu(ones, diagonal=1)\\n\",\n \"\\n\",\n \" # far_past (too far back is masked: i - j >= sliding_window)\\n\",\n \" # where sliding_window = 4\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 0 0 0 0 0 0 0\\n\",\n \" # 1: 0 0 0 0 0 0 0 0\\n\",\n \" # 2: 0 0 0 0 0 0 0 0\\n\",\n \" # 3: 0 0 0 0 0 0 0 0\\n\",\n \" # 4: 1 0 0 0 0 0 0 0\\n\",\n \" # 5: 1 1 0 0 0 0 0 0\\n\",\n \" # 6: 1 1 1 0 0 0 0 0\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" far_past_full = torch.triu(ones, diagonal=self.cfg[\\\"sliding_window\\\"]).T\\n\",\n \"\\n\",\n \" # Local (sliding_window) = future OR far-past\\n\",\n \" # mask_local\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 1 0 0 0 0 1 1 1\\n\",\n \" # 5: 1 1 0 0 0 0 1 1\\n\",\n \" # 6: 1 1 1 0 0 0 0 1\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" mask_local_full = mask_global_full | far_past_full\\n\",\n \"\\n\",\n \" row_slice = slice(pos_start, pos_end)\\n\",\n \" mask_global = mask_global_full[row_slice, :pos_end][None, None, :, :]\\n\",\n \" mask_local = mask_local_full[row_slice, :pos_end][None, None, :, :]\\n\",\n \" return mask_global, mask_local\\n\",\n \"\\n\",\n \" def forward(self, input_ids, cache=None):\\n\",\n \" b, seq_len = input_ids.shape\\n\",\n \" x = self.tok_emb(input_ids)\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" pos_start = self.current_pos\\n\",\n \" pos_end = pos_start + seq_len\\n\",\n \" self.current_pos = pos_end\\n\",\n \" mask_global, mask_local = self.create_masks(\\n\",\n \" cur_len=seq_len, device=x.device, pos_start=pos_start, pos_end=pos_end\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" pos_start = 0\\n\",\n \" mask_global, mask_local = self.create_masks(\\n\",\n \" cur_len=seq_len, device=x.device, pos_start=0, pos_end=seq_len\\n\",\n \" )\\n\",\n \"\\n\",\n \" cos = self.cos\\n\",\n \" sin = self.sin\\n\",\n \"\\n\",\n \" for i, block in enumerate(self.blocks):\\n\",\n \" blk_cache = cache.get(i) if cache is not None else None\\n\",\n \" x, new_blk_cache = block(\\n\",\n \" x,\\n\",\n \" mask_global=mask_global,\\n\",\n \" mask_local=mask_local,\\n\",\n \" cos=cos,\\n\",\n \" sin=sin,\\n\",\n \" start_pos=pos_start,\\n\",\n \" cache=blk_cache,\\n\",\n \" )\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" cache.update(i, new_blk_cache)\\n\",\n \"\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\\n\",\n \"\\n\",\n \" def reset_kv_cache(self):\\n\",\n \" self.current_pos = 0\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"4f5271e8-ff28-4aaa-bbb2-f73582e6d228\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class KVCache:\\n\",\n \" def __init__(self, n_layers):\\n\",\n \" self.cache = [None] * n_layers\\n\",\n \"\\n\",\n \" def get(self, layer_idx):\\n\",\n \" return self.cache[layer_idx]\\n\",\n \"\\n\",\n \" def update(self, layer_idx, value):\\n\",\n \" self.cache[layer_idx] = value\\n\",\n \"\\n\",\n \" def get_all(self):\\n\",\n \" return self.cache\\n\",\n \"\\n\",\n \" def reset(self):\\n\",\n \" for i in range(len(self.cache)):\\n\",\n \" self.cache[i] = None\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"OLMO3_CONFIG_7B = {\\n\",\n \" \\\"vocab_size\\\": 100_278,\\n\",\n \" \\\"context_length\\\": 65_536,\\n\",\n \" \\\"emb_dim\\\": 4_096,\\n\",\n \" \\\"n_heads\\\": 32,\\n\",\n \" \\\"n_layers\\\": 32,\\n\",\n \" \\\"hidden_dim\\\": 11_008,\\n\",\n \" \\\"head_dim\\\": 128,\\n\",\n \" \\\"n_kv_heads\\\": 32,\\n\",\n \" \\\"attention_bias\\\": False,\\n\",\n \" \\\"attention_dropout\\\": 0.0,\\n\",\n \" \\\"sliding_window\\\": 4_096,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \" \\\"rope_base\\\": 500_000.0,\\n\",\n \" \\\"rope_attention_factor\\\": 1.2079441541679836,\\n\",\n \" \\\"rope_type\\\": \\\"yarn\\\",\\n\",\n \" \\\"rope_factor\\\": 8.0,\\n\",\n \" \\\"rope_orig_max\\\": 8_192,\\n\",\n \" \\\"beta_fast\\\": 32.0,\\n\",\n \" \\\"beta_slow\\\": 1.0,\\n\",\n \" \\\"rms_norm_eps\\\": 1e-6,\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"eos_token_id\\\": 100_257,\\n\",\n \" \\\"pad_token_id\\\": 100_277,\\n\",\n \"}\\n\",\n \"\\n\",\n \"OLMO3_CONFIG_32B = {\\n\",\n \" \\\"vocab_size\\\": 100_278,\\n\",\n \" \\\"context_length\\\": 65_536,\\n\",\n \" \\\"emb_dim\\\": 5_120,\\n\",\n \" \\\"n_heads\\\": 40,\\n\",\n \" \\\"n_layers\\\": 64,\\n\",\n \" \\\"hidden_dim\\\": 27_648,\\n\",\n \" \\\"head_dim\\\": 128,\\n\",\n \" \\\"n_kv_heads\\\": 8,\\n\",\n \" \\\"attention_bias\\\": False,\\n\",\n \" \\\"attention_dropout\\\": 0.0,\\n\",\n \" \\\"sliding_window\\\": 4_096,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \" \\\"rope_base\\\": 500_000.0,\\n\",\n \" \\\"rope_attention_factor\\\": 1.2079441541679836,\\n\",\n \" \\\"rope_type\\\": \\\"yarn\\\",\\n\",\n \" \\\"rope_factor\\\": 8.0,\\n\",\n \" \\\"rope_orig_max\\\": 8_192,\\n\",\n \" \\\"beta_fast\\\": 32.0,\\n\",\n \" \\\"beta_slow\\\": 1.0,\\n\",\n \" \\\"rms_norm_eps\\\": 1e-6,\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"eos_token_id\\\": 100_257,\\n\",\n \" \\\"pad_token_id\\\": 100_277,\\n\",\n \"}\\n\",\n \"\\n\",\n \"OLMO3_CONFIG = OLMO3_CONFIG_32B if \\\"32B\\\" in USE_MODEL else OLMO3_CONFIG_7B\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model = Olmo3Model(OLMO3_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"eaf86265-4e9d-4024-9ed0-99076944e304\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Olmo3Model(\\n\",\n \" (tok_emb): Embedding(100278, 4096)\\n\",\n \" (blocks): ModuleList(\\n\",\n \" (0-31): 32 x TransformerBlock(\\n\",\n \" (att): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (W_value): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (out_proj): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=4096, out_features=11008, bias=False)\\n\",\n \" (fc2): Linear(in_features=4096, out_features=11008, bias=False)\\n\",\n \" (fc3): Linear(in_features=11008, out_features=4096, bias=False)\\n\",\n \" )\\n\",\n \" (post_attention_layernorm): RMSNorm()\\n\",\n \" (post_feedforward_layernorm): RMSNorm()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): RMSNorm()\\n\",\n \" (out_head): Linear(in_features=4096, out_features=100278, bias=False)\\n\",\n \")\"\n ]\n },\n \"execution_count\": 13,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90aca91d-4bee-45ce-993a-4ec5393abe2b\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the forward pass works before continuing:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"adf0a6b7-b688-42c9-966e-c223d34db99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[[ 0.3867, -0.6328, -0.2734, ..., 1.1484, 0.4258, 0.0400],\\n\",\n \" [ 1.2734, 0.0040, 0.5000, ..., 0.5625, -0.2383, 0.1855],\\n\",\n \" [ 0.5859, -0.0540, 0.7930, ..., 0.3262, -0.5430, -0.1494]]],\\n\",\n \" dtype=torch.bfloat16, grad_fn=\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/13_olmo3/standalone-olmo3.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"
\\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Olmo 3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 0.35.0\\n\",\n \"tokenizers version: 0.22.1\\n\",\n \"torch version: 2.9.1+cu130\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"07e96fbb-8e16-4f6d-835f-c6159321280b\",\n \"metadata\": {},\n \"source\": [\n \"- Note that there are three model types, and each of the four model types comes in a 7B and 32B size:\\n\",\n \"1. Base (`Olmo-3-1025-7B` and `Olmo-3-1125-32B`)\\n\",\n \"2. Instruct (`Olmo-3-7B/32B-Think`)\\n\",\n \"3. Reasoning (`Olmo-3-32B/7B-Think`)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"70a90338-624a-4706-aa55-6b4358070194\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Select which model to use\\n\",\n \"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-1025-7B\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-1125-32B\\\"\\n\",\n \"USE_MODEL = \\\"Olmo-3-7B-Instruct\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-32B-Instruct\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-7B-Think\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-32B-Think\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-7B-RLZero-IF\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1899ab4b-e1c2-4215-b3d1-ed00d52e4576\",\n \"metadata\": {},\n \"source\": [\n \"- In addition to the checkpoints listed above, you can also use the intermediate checkpoints listed [here](https://huggingface.co/collections/allenai/olmo-3-post-training); since they all have the same architecture, they are all compatible with this notebook\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"56715760-37e1-433e-89da-04864c139a9e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-6):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" self.weight = nn.Parameter(torch.ones(emb_dim))\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" input_dtype = x.dtype\\n\",\n \" x_f = x.float()\\n\",\n \" var = x_f.pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x_norm = x_f * torch.rsqrt(var + self.eps)\\n\",\n \" return (self.weight * x_norm).to(input_dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"import math\\n\",\n \"\\n\",\n \"\\n\",\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, attention_factor=1.0, rope_type=\\\"default\\\", rope_factor=1.0, rope_orig_max=8192, beta_fast=32.0, beta_slow=1.0, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" if rope_type == \\\"yarn\\\":\\n\",\n \" # Compute YaRN-style frequency scaling (as per https://huggingface.co/papers/2309.00071)\\n\",\n \"\\n\",\n \" def find_correction_dim(num_rotations, dim, base, max_position_embeddings):\\n\",\n \" \\\"\\\"\\\"Inverse dimension formula to find the dimension based on the number of rotations\\\"\\\"\\\"\\n\",\n \" return (dim * math.log(max_position_embeddings / (num_rotations * 2 * math.pi))) / (2 * math.log(base))\\n\",\n \"\\n\",\n \" def find_correction_range(low_rot, high_rot, dim, base, max_position_embeddings):\\n\",\n \" \\\"\\\"\\\"Find dimension range bounds based on rotations\\\"\\\"\\\"\\n\",\n \" low = find_correction_dim(low_rot, dim, base, max_position_embeddings)\\n\",\n \" high = find_correction_dim(high_rot, dim, base, max_position_embeddings)\\n\",\n \" low = math.floor(low)\\n\",\n \" high = math.ceil(high)\\n\",\n \" return max(low, 0), min(high, dim - 1)\\n\",\n \"\\n\",\n \" def linear_ramp_factor(min_val, max_val, dim):\\n\",\n \" if min_val == max_val:\\n\",\n \" max_val += 0.001 # Prevent singularity\\n\",\n \" linear_func = (torch.arange(dim, dtype=torch.float32) - min_val) / (max_val - min_val)\\n\",\n \" ramp_func = torch.clamp(linear_func, 0, 1)\\n\",\n \" return ramp_func\\n\",\n \"\\n\",\n \" # Base frequencies\\n\",\n \" pos_freqs = theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype) / head_dim)\\n\",\n \" inv_freq_extrapolation = 1.0 / pos_freqs # No scaling (extrapolation)\\n\",\n \" inv_freq_interpolation = 1.0 / (rope_factor * pos_freqs) # With scaling (interpolation)\\n\",\n \"\\n\",\n \" # Find the range where we blend between interpolation and extrapolation\\n\",\n \" low, high = find_correction_range(beta_fast, beta_slow, head_dim, theta_base, rope_orig_max)\\n\",\n \"\\n\",\n \" # Get n-dimensional rotational scaling corrected for extrapolation\\n\",\n \" inv_freq_extrapolation_factor = 1 - linear_ramp_factor(low, high, head_dim // 2).to(dtype=dtype)\\n\",\n \" inv_freq = (\\n\",\n \" inv_freq_interpolation * (1 - inv_freq_extrapolation_factor)\\n\",\n \" + inv_freq_extrapolation * inv_freq_extrapolation_factor\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" # Default RoPE\\n\",\n \" inv_freq = 1.0 / (\\n\",\n \" theta_base ** (\\n\",\n \" torch.arange(0, head_dim, 2, dtype=dtype)[: head_dim // 2].float()\\n\",\n \" / head_dim\\n\",\n \" )\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the base angles (shape: [context_length, head_dim // 2])\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0)\\n\",\n \"\\n\",\n \" # Expand to full head_dim (shape: [context_length, head_dim])\\n\",\n \" angles = torch.cat([angles, angles], dim=1)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles) * attention_factor\\n\",\n \" sin = torch.sin(angles) * attention_factor\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin, offset=0):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" # It's ok to use lower-precision after applying cos and sin rotation\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(self, d_in, num_heads, num_kv_groups, head_dim, attention_bias=False, dtype=None, sliding_window=None, attn_type=\\\"full_attention\\\"):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \" self.attn_type = attn_type\\n\",\n \" self.sliding_window = sliding_window if attn_type == \\\"sliding_attention\\\" else None\\n\",\n \"\\n\",\n \" # Projections\\n\",\n \" self.W_query = nn.Linear(d_in, self.d_out, bias=attention_bias, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=attention_bias, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=attention_bias, dtype=dtype)\\n\",\n \" self.out_proj = nn.Linear(self.d_out, d_in, bias=attention_bias, dtype=dtype)\\n\",\n \"\\n\",\n \" # Olmo3-style RMSNorm over the flattened projections\\n\",\n \" self.q_norm = RMSNorm(self.d_out)\\n\",\n \" self.k_norm = RMSNorm(num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin, start_pos=0, cache=None):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" # Apply projections\\n\",\n \" queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\\n\",\n \" keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Normalize q and k\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" keys_new = self.k_norm(keys)\\n\",\n \"\\n\",\n \" # Reshape to (b, heads, seq, head_dim)\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\\n\",\n \" keys_new = keys_new.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values_new = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Cache unrotated K/V\\n\",\n \" prev_len = 0\\n\",\n \" if cache is not None:\\n\",\n \" prev_k, prev_v = cache\\n\",\n \" if prev_k is not None:\\n\",\n \" prev_len = prev_k.size(2)\\n\",\n \" keys_cat_raw = torch.cat([prev_k, keys_new], dim=2)\\n\",\n \" values_cat_raw = torch.cat([prev_v, values_new], dim=2)\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \"\\n\",\n \" # Apply RoPE with offsets for cached tokens\\n\",\n \" queries = apply_rope(queries, cos, sin, offset=start_pos)\\n\",\n \" keys = apply_rope(keys_cat_raw, cos, sin, offset=start_pos - prev_len)\\n\",\n \"\\n\",\n \" # Expand KV groups to full head count\\n\",\n \" if self.group_size > 1:\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values_cat_raw.repeat_interleave(self.group_size, dim=1)\\n\",\n \" else:\\n\",\n \" values = values_cat_raw\\n\",\n \"\\n\",\n \" # Scaling before the matmul seems to be a bit more stable for Olmo\\n\",\n \" scale = self.head_dim ** -0.5 # Python float\\n\",\n \" queries = queries * scale\\n\",\n \"\\n\",\n \" # Update cache with unrotated K/V\\n\",\n \" if cache is not None and cache[0] is not None:\\n\",\n \" next_cache = (\\n\",\n \" torch.cat([cache[0], keys_new], dim=2),\\n\",\n \" torch.cat([cache[1], values_new], dim=2),\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" next_cache = (keys_new, values_new)\\n\",\n \"\\n\",\n \" # Attention\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" if mask is not None:\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores, dim=-1)\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \" out = self.out_proj(context)\\n\",\n \"\\n\",\n \" return out, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"13eb3430-0c06-4fe2-a005-217205eee21e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg, attn_type):\\n\",\n \" super().__init__()\\n\",\n \" self.attn_type = attn_type\\n\",\n \" self.sliding_window = cfg[\\\"sliding_window\\\"]\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_heads\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" attention_bias=cfg[\\\"attention_bias\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" sliding_window=cfg[\\\"sliding_window\\\"],\\n\",\n \" attn_type=attn_type,\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.post_attention_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"rms_norm_eps\\\"])\\n\",\n \" self.post_feedforward_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"rms_norm_eps\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x, mask_global, mask_local, cos, sin, start_pos=0, cache=None):\\n\",\n \" shortcut = x\\n\",\n \" if self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" if cache is not None and isinstance(cache, tuple):\\n\",\n \" prev_k, _ = cache\\n\",\n \" prev_len = prev_k.size(2) if prev_k is not None else 0\\n\",\n \" else:\\n\",\n \" prev_len = 0\\n\",\n \" eff_kv_len = prev_len + x.size(1)\\n\",\n \" attn_mask = mask_local[..., -eff_kv_len:]\\n\",\n \" else:\\n\",\n \" attn_mask = mask_global\\n\",\n \"\\n\",\n \" x_attn, next_cache = self.att(x, attn_mask, cos, sin, start_pos=start_pos, cache=cache)\\n\",\n \" if next_cache is not None and self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" k, v = next_cache\\n\",\n \" if k.size(2) > self.sliding_window:\\n\",\n \" k = k[:, :, -self.sliding_window:, :]\\n\",\n \" v = v[:, :, -self.sliding_window:, :]\\n\",\n \" next_cache = (k, v)\\n\",\n \"\\n\",\n \" x_attn = self.post_attention_layernorm(x_attn)\\n\",\n \" x = shortcut + x_attn\\n\",\n \"\\n\",\n \" shortcut = x\\n\",\n \" x_ffn = self.ff(x)\\n\",\n \" x_ffn = self.post_feedforward_layernorm(x_ffn)\\n\",\n \" x = shortcut + x_ffn\\n\",\n \" return x, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Olmo3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" assert cfg[\\\"layer_types\\\"] is not None and len(cfg[\\\"layer_types\\\"]) == cfg[\\\"n_layers\\\"]\\n\",\n \"\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.blocks = nn.ModuleList([TransformerBlock(cfg, attn_type) for attn_type in cfg[\\\"layer_types\\\"]])\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"rms_norm_eps\\\"])\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.cfg = cfg\\n\",\n \" self.current_pos = 0\\n\",\n \"\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" attention_factor=cfg[\\\"rope_attention_factor\\\"],\\n\",\n \" rope_type=cfg[\\\"rope_type\\\"],\\n\",\n \" rope_factor=cfg[\\\"rope_factor\\\"],\\n\",\n \" rope_orig_max=cfg[\\\"rope_orig_max\\\"],\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \"\\n\",\n \" def create_masks(self, cur_len, device, pos_start=0, pos_end=None):\\n\",\n \" if pos_end is None:\\n\",\n \" pos_end = cur_len\\n\",\n \" total_len = pos_end\\n\",\n \"\\n\",\n \" ones = torch.ones((total_len, total_len), dtype=torch.bool, device=device)\\n\",\n \" # mask_global_full (future is masked: j > i)\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 0 0 0 0 0 1 1 1\\n\",\n \" # 5: 0 0 0 0 0 0 1 1\\n\",\n \" # 6: 0 0 0 0 0 0 0 1\\n\",\n \" # 7: 0 0 0 0 0 0 0 0\\n\",\n \" mask_global_full = torch.triu(ones, diagonal=1)\\n\",\n \"\\n\",\n \" # far_past (too far back is masked: i - j >= sliding_window)\\n\",\n \" # where sliding_window = 4\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 0 0 0 0 0 0 0\\n\",\n \" # 1: 0 0 0 0 0 0 0 0\\n\",\n \" # 2: 0 0 0 0 0 0 0 0\\n\",\n \" # 3: 0 0 0 0 0 0 0 0\\n\",\n \" # 4: 1 0 0 0 0 0 0 0\\n\",\n \" # 5: 1 1 0 0 0 0 0 0\\n\",\n \" # 6: 1 1 1 0 0 0 0 0\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" far_past_full = torch.triu(ones, diagonal=self.cfg[\\\"sliding_window\\\"]).T\\n\",\n \"\\n\",\n \" # Local (sliding_window) = future OR far-past\\n\",\n \" # mask_local\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 1 0 0 0 0 1 1 1\\n\",\n \" # 5: 1 1 0 0 0 0 1 1\\n\",\n \" # 6: 1 1 1 0 0 0 0 1\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" mask_local_full = mask_global_full | far_past_full\\n\",\n \"\\n\",\n \" row_slice = slice(pos_start, pos_end)\\n\",\n \" mask_global = mask_global_full[row_slice, :pos_end][None, None, :, :]\\n\",\n \" mask_local = mask_local_full[row_slice, :pos_end][None, None, :, :]\\n\",\n \" return mask_global, mask_local\\n\",\n \"\\n\",\n \" def forward(self, input_ids, cache=None):\\n\",\n \" b, seq_len = input_ids.shape\\n\",\n \" x = self.tok_emb(input_ids)\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" pos_start = self.current_pos\\n\",\n \" pos_end = pos_start + seq_len\\n\",\n \" self.current_pos = pos_end\\n\",\n \" mask_global, mask_local = self.create_masks(\\n\",\n \" cur_len=seq_len, device=x.device, pos_start=pos_start, pos_end=pos_end\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" pos_start = 0\\n\",\n \" mask_global, mask_local = self.create_masks(\\n\",\n \" cur_len=seq_len, device=x.device, pos_start=0, pos_end=seq_len\\n\",\n \" )\\n\",\n \"\\n\",\n \" cos = self.cos\\n\",\n \" sin = self.sin\\n\",\n \"\\n\",\n \" for i, block in enumerate(self.blocks):\\n\",\n \" blk_cache = cache.get(i) if cache is not None else None\\n\",\n \" x, new_blk_cache = block(\\n\",\n \" x,\\n\",\n \" mask_global=mask_global,\\n\",\n \" mask_local=mask_local,\\n\",\n \" cos=cos,\\n\",\n \" sin=sin,\\n\",\n \" start_pos=pos_start,\\n\",\n \" cache=blk_cache,\\n\",\n \" )\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" cache.update(i, new_blk_cache)\\n\",\n \"\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\\n\",\n \"\\n\",\n \" def reset_kv_cache(self):\\n\",\n \" self.current_pos = 0\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"4f5271e8-ff28-4aaa-bbb2-f73582e6d228\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class KVCache:\\n\",\n \" def __init__(self, n_layers):\\n\",\n \" self.cache = [None] * n_layers\\n\",\n \"\\n\",\n \" def get(self, layer_idx):\\n\",\n \" return self.cache[layer_idx]\\n\",\n \"\\n\",\n \" def update(self, layer_idx, value):\\n\",\n \" self.cache[layer_idx] = value\\n\",\n \"\\n\",\n \" def get_all(self):\\n\",\n \" return self.cache\\n\",\n \"\\n\",\n \" def reset(self):\\n\",\n \" for i in range(len(self.cache)):\\n\",\n \" self.cache[i] = None\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"OLMO3_CONFIG_7B = {\\n\",\n \" \\\"vocab_size\\\": 100_278,\\n\",\n \" \\\"context_length\\\": 65_536,\\n\",\n \" \\\"emb_dim\\\": 4_096,\\n\",\n \" \\\"n_heads\\\": 32,\\n\",\n \" \\\"n_layers\\\": 32,\\n\",\n \" \\\"hidden_dim\\\": 11_008,\\n\",\n \" \\\"head_dim\\\": 128,\\n\",\n \" \\\"n_kv_heads\\\": 32,\\n\",\n \" \\\"attention_bias\\\": False,\\n\",\n \" \\\"attention_dropout\\\": 0.0,\\n\",\n \" \\\"sliding_window\\\": 4_096,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \" \\\"rope_base\\\": 500_000.0,\\n\",\n \" \\\"rope_attention_factor\\\": 1.2079441541679836,\\n\",\n \" \\\"rope_type\\\": \\\"yarn\\\",\\n\",\n \" \\\"rope_factor\\\": 8.0,\\n\",\n \" \\\"rope_orig_max\\\": 8_192,\\n\",\n \" \\\"beta_fast\\\": 32.0,\\n\",\n \" \\\"beta_slow\\\": 1.0,\\n\",\n \" \\\"rms_norm_eps\\\": 1e-6,\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"eos_token_id\\\": 100_257,\\n\",\n \" \\\"pad_token_id\\\": 100_277,\\n\",\n \"}\\n\",\n \"\\n\",\n \"OLMO3_CONFIG_32B = {\\n\",\n \" \\\"vocab_size\\\": 100_278,\\n\",\n \" \\\"context_length\\\": 65_536,\\n\",\n \" \\\"emb_dim\\\": 5_120,\\n\",\n \" \\\"n_heads\\\": 40,\\n\",\n \" \\\"n_layers\\\": 64,\\n\",\n \" \\\"hidden_dim\\\": 27_648,\\n\",\n \" \\\"head_dim\\\": 128,\\n\",\n \" \\\"n_kv_heads\\\": 8,\\n\",\n \" \\\"attention_bias\\\": False,\\n\",\n \" \\\"attention_dropout\\\": 0.0,\\n\",\n \" \\\"sliding_window\\\": 4_096,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \" \\\"rope_base\\\": 500_000.0,\\n\",\n \" \\\"rope_attention_factor\\\": 1.2079441541679836,\\n\",\n \" \\\"rope_type\\\": \\\"yarn\\\",\\n\",\n \" \\\"rope_factor\\\": 8.0,\\n\",\n \" \\\"rope_orig_max\\\": 8_192,\\n\",\n \" \\\"beta_fast\\\": 32.0,\\n\",\n \" \\\"beta_slow\\\": 1.0,\\n\",\n \" \\\"rms_norm_eps\\\": 1e-6,\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"eos_token_id\\\": 100_257,\\n\",\n \" \\\"pad_token_id\\\": 100_277,\\n\",\n \"}\\n\",\n \"\\n\",\n \"OLMO3_CONFIG = OLMO3_CONFIG_32B if \\\"32B\\\" in USE_MODEL else OLMO3_CONFIG_7B\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model = Olmo3Model(OLMO3_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"eaf86265-4e9d-4024-9ed0-99076944e304\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Olmo3Model(\\n\",\n \" (tok_emb): Embedding(100278, 4096)\\n\",\n \" (blocks): ModuleList(\\n\",\n \" (0-31): 32 x TransformerBlock(\\n\",\n \" (att): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (W_value): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (out_proj): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=4096, out_features=11008, bias=False)\\n\",\n \" (fc2): Linear(in_features=4096, out_features=11008, bias=False)\\n\",\n \" (fc3): Linear(in_features=11008, out_features=4096, bias=False)\\n\",\n \" )\\n\",\n \" (post_attention_layernorm): RMSNorm()\\n\",\n \" (post_feedforward_layernorm): RMSNorm()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): RMSNorm()\\n\",\n \" (out_head): Linear(in_features=4096, out_features=100278, bias=False)\\n\",\n \")\"\n ]\n },\n \"execution_count\": 13,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90aca91d-4bee-45ce-993a-4ec5393abe2b\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the forward pass works before continuing:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"adf0a6b7-b688-42c9-966e-c223d34db99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[[ 0.3867, -0.6328, -0.2734, ..., 1.1484, 0.4258, 0.0400],\\n\",\n \" [ 1.2734, 0.0040, 0.5000, ..., 0.5625, -0.2383, 0.1855],\\n\",\n \" [ 0.5859, -0.0540, 0.7930, ..., 0.3262, -0.5430, -0.1494]]],\\n\",\n \" dtype=torch.bfloat16, grad_fn=\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/13_olmo3/standalone-olmo3.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\\n\",\n \" \\n\",\n \"\\n\",\n \" \\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Olmo 3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 0.35.0\\n\",\n \"tokenizers version: 0.22.1\\n\",\n \"torch version: 2.9.1+cu130\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"07e96fbb-8e16-4f6d-835f-c6159321280b\",\n \"metadata\": {},\n \"source\": [\n \"- Note that there are three model types, and each of the four model types comes in a 7B and 32B size:\\n\",\n \"1. Base (`Olmo-3-1025-7B` and `Olmo-3-1125-32B`)\\n\",\n \"2. Instruct (`Olmo-3-7B/32B-Think`)\\n\",\n \"3. Reasoning (`Olmo-3-32B/7B-Think`)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"70a90338-624a-4706-aa55-6b4358070194\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Select which model to use\\n\",\n \"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-1025-7B\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-1125-32B\\\"\\n\",\n \"USE_MODEL = \\\"Olmo-3-7B-Instruct\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-32B-Instruct\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-7B-Think\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-32B-Think\\\"\\n\",\n \"# USE_MODEL = \\\"Olmo-3-7B-RLZero-IF\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f258cb74-1c4e-4880-8772-3c85fb920811\",\n \"metadata\": {},\n \"source\": [\n \"- In addition to the checkpoints listed above, you can also use the intermediate checkpoints listed [here](https://huggingface.co/collections/allenai/olmo-3-post-training); since they all have the same architecture, they are all compatible with this notebook\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"56715760-37e1-433e-89da-04864c139a9e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-6):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" self.weight = nn.Parameter(torch.ones(emb_dim))\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" input_dtype = x.dtype\\n\",\n \" x_f = x.float()\\n\",\n \" var = x_f.pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x_norm = x_f * torch.rsqrt(var + self.eps)\\n\",\n \" return (self.weight * x_norm).to(input_dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"import math\\n\",\n \"\\n\",\n \"\\n\",\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, attention_factor=1.0, rope_type=\\\"default\\\", rope_factor=1.0, rope_orig_max=8192, beta_fast=32.0, beta_slow=1.0, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" if rope_type == \\\"yarn\\\":\\n\",\n \" # Compute YaRN-style frequency scaling (as per https://huggingface.co/papers/2309.00071)\\n\",\n \"\\n\",\n \" def find_correction_dim(num_rotations, dim, base, max_position_embeddings):\\n\",\n \" \\\"\\\"\\\"Inverse dimension formula to find the dimension based on the number of rotations\\\"\\\"\\\"\\n\",\n \" return (dim * math.log(max_position_embeddings / (num_rotations * 2 * math.pi))) / (2 * math.log(base))\\n\",\n \"\\n\",\n \" def find_correction_range(low_rot, high_rot, dim, base, max_position_embeddings):\\n\",\n \" \\\"\\\"\\\"Find dimension range bounds based on rotations\\\"\\\"\\\"\\n\",\n \" low = find_correction_dim(low_rot, dim, base, max_position_embeddings)\\n\",\n \" high = find_correction_dim(high_rot, dim, base, max_position_embeddings)\\n\",\n \" low = math.floor(low)\\n\",\n \" high = math.ceil(high)\\n\",\n \" return max(low, 0), min(high, dim - 1)\\n\",\n \"\\n\",\n \" def linear_ramp_factor(min_val, max_val, dim):\\n\",\n \" if min_val == max_val:\\n\",\n \" max_val += 0.001 # Prevent singularity\\n\",\n \" linear_func = (torch.arange(dim, dtype=torch.float32) - min_val) / (max_val - min_val)\\n\",\n \" ramp_func = torch.clamp(linear_func, 0, 1)\\n\",\n \" return ramp_func\\n\",\n \"\\n\",\n \" # Base frequencies\\n\",\n \" pos_freqs = theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype) / head_dim)\\n\",\n \" inv_freq_extrapolation = 1.0 / pos_freqs # No scaling (extrapolation)\\n\",\n \" inv_freq_interpolation = 1.0 / (rope_factor * pos_freqs) # With scaling (interpolation)\\n\",\n \"\\n\",\n \" # Find the range where we blend between interpolation and extrapolation\\n\",\n \" low, high = find_correction_range(beta_fast, beta_slow, head_dim, theta_base, rope_orig_max)\\n\",\n \"\\n\",\n \" # Get n-dimensional rotational scaling corrected for extrapolation\\n\",\n \" inv_freq_extrapolation_factor = 1 - linear_ramp_factor(low, high, head_dim // 2).to(dtype=dtype)\\n\",\n \" inv_freq = (\\n\",\n \" inv_freq_interpolation * (1 - inv_freq_extrapolation_factor)\\n\",\n \" + inv_freq_extrapolation * inv_freq_extrapolation_factor\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" # Default RoPE\\n\",\n \" inv_freq = 1.0 / (\\n\",\n \" theta_base ** (\\n\",\n \" torch.arange(0, head_dim, 2, dtype=dtype)[: head_dim // 2].float()\\n\",\n \" / head_dim\\n\",\n \" )\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the base angles (shape: [context_length, head_dim // 2])\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0)\\n\",\n \"\\n\",\n \" # Expand to full head_dim (shape: [context_length, head_dim])\\n\",\n \" angles = torch.cat([angles, angles], dim=1)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles) * attention_factor\\n\",\n \" sin = torch.sin(angles) * attention_factor\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" # It's ok to use lower-precision after applying cos and sin rotation\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(self, d_in, num_heads, num_kv_groups, head_dim, attention_bias=False, dtype=None, sliding_window=None, attn_type=\\\"full_attention\\\"):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \" self.attn_type = attn_type\\n\",\n \" self.sliding_window = sliding_window if attn_type == \\\"sliding_attention\\\" else None\\n\",\n \"\\n\",\n \" # Projections\\n\",\n \" self.W_query = nn.Linear(d_in, self.d_out, bias=attention_bias, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=attention_bias, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=attention_bias, dtype=dtype)\\n\",\n \" self.out_proj = nn.Linear(self.d_out, d_in, bias=attention_bias, dtype=dtype)\\n\",\n \"\\n\",\n \" # Olmo3-style RMSNorm over the flattened projections\\n\",\n \" self.q_norm = RMSNorm(self.d_out)\\n\",\n \" self.k_norm = RMSNorm(num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" # Apply projections\\n\",\n \" queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\\n\",\n \" keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Normalize q and k\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" keys = self.k_norm(keys)\\n\",\n \"\\n\",\n \" # Reshape to (b, heads, seq, head_dim)\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Apply RoPE\\n\",\n \" queries = apply_rope(queries, cos, sin)\\n\",\n \" keys = apply_rope(keys, cos, sin)\\n\",\n \"\\n\",\n \" # Expand KV groups to full head count\\n\",\n \" if self.group_size > 1:\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" # Scaling before the matmul seems to be a bit more stable for Olmo\\n\",\n \" scale = self.head_dim ** -0.5 # Python float\\n\",\n \" queries = queries * scale\\n\",\n \" \\n\",\n \" # Attention\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" if mask is not None:\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores, dim=-1)\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \" return self.out_proj(context)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg, attn_type):\\n\",\n \" super().__init__()\\n\",\n \" self.attn_type = attn_type\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_heads\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" attention_bias=cfg[\\\"attention_bias\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" sliding_window=cfg[\\\"sliding_window\\\"],\\n\",\n \" attn_type=attn_type,\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.post_attention_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"rms_norm_eps\\\"])\\n\",\n \" self.post_feedforward_layernorm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"rms_norm_eps\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x, mask_global, mask_local, cos, sin):\\n\",\n \" attn_mask = mask_local if self.attn_type == \\\"sliding_attention\\\" else mask_global\\n\",\n \"\\n\",\n \" shortcut = x\\n\",\n \" x_attn = self.att(x, attn_mask, cos, sin)\\n\",\n \" x_attn = self.post_attention_layernorm(x_attn)\\n\",\n \" x = shortcut + x_attn\\n\",\n \"\\n\",\n \" shortcut = x\\n\",\n \" x_ffn = self.ff(x)\\n\",\n \" x_ffn = self.post_feedforward_layernorm(x_ffn)\\n\",\n \" x = shortcut + x_ffn\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Olmo3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" assert cfg[\\\"layer_types\\\"] is not None and len(cfg[\\\"layer_types\\\"]) == cfg[\\\"n_layers\\\"]\\n\",\n \"\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.blocks = nn.ModuleList([TransformerBlock(cfg, attn_type) for attn_type in cfg[\\\"layer_types\\\"]])\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"rms_norm_eps\\\"])\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" attention_factor=cfg[\\\"rope_attention_factor\\\"],\\n\",\n \" rope_type=cfg[\\\"rope_type\\\"],\\n\",\n \" rope_factor=cfg[\\\"rope_factor\\\"],\\n\",\n \" rope_orig_max=cfg[\\\"rope_orig_max\\\"],\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \"\\n\",\n \" def create_masks(self, seq_len, device):\\n\",\n \" ones = torch.ones((seq_len, seq_len), dtype=torch.bool, device=device)\\n\",\n \"\\n\",\n \" # mask_global (future is masked: j > i)\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 0 0 0 0 0 1 1 1\\n\",\n \" # 5: 0 0 0 0 0 0 1 1\\n\",\n \" # 6: 0 0 0 0 0 0 0 1\\n\",\n \" # 7: 0 0 0 0 0 0 0 0\\n\",\n \" mask_global = torch.triu(ones, diagonal=1)\\n\",\n \"\\n\",\n \" # far_past (too far back is masked: i - j >= sliding_window)\\n\",\n \" # where sliding_window = 4\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 0 0 0 0 0 0 0\\n\",\n \" # 1: 0 0 0 0 0 0 0 0\\n\",\n \" # 2: 0 0 0 0 0 0 0 0\\n\",\n \" # 3: 0 0 0 0 0 0 0 0\\n\",\n \" # 4: 1 0 0 0 0 0 0 0\\n\",\n \" # 5: 1 1 0 0 0 0 0 0\\n\",\n \" # 6: 1 1 1 0 0 0 0 0\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" far_past = torch.triu(ones, diagonal=self.cfg[\\\"sliding_window\\\"]).T\\n\",\n \"\\n\",\n \" # Local (sliding_window) = future OR far-past\\n\",\n \" # mask_local\\n\",\n \" # j: 0 1 2 3 4 5 6 7\\n\",\n \" # i\\n\",\n \" # 0: 0 1 1 1 1 1 1 1\\n\",\n \" # 1: 0 0 1 1 1 1 1 1\\n\",\n \" # 2: 0 0 0 1 1 1 1 1\\n\",\n \" # 3: 0 0 0 0 1 1 1 1\\n\",\n \" # 4: 1 0 0 0 0 1 1 1\\n\",\n \" # 5: 1 1 0 0 0 0 1 1\\n\",\n \" # 6: 1 1 1 0 0 0 0 1\\n\",\n \" # 7: 1 1 1 1 0 0 0 0\\n\",\n \" mask_local = mask_global | far_past\\n\",\n \" return mask_global, mask_local\\n\",\n \"\\n\",\n \" def forward(self, input_ids):\\n\",\n \" b, seq_len = input_ids.shape\\n\",\n \" x = self.tok_emb(input_ids)\\n\",\n \" mask_global, mask_local = self.create_masks(seq_len, x.device)\\n\",\n \"\\n\",\n \" cos = self.cos[:seq_len, :].to(x.device)\\n\",\n \" sin = self.sin[:seq_len, :].to(x.device)\\n\",\n \"\\n\",\n \" for block in self.blocks:\\n\",\n \" x = block(x, mask_global, mask_local, cos, sin)\\n\",\n \"\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"OLMO3_CONFIG_7B = {\\n\",\n \" \\\"vocab_size\\\": 100_278,\\n\",\n \" \\\"context_length\\\": 65_536,\\n\",\n \" \\\"emb_dim\\\": 4_096,\\n\",\n \" \\\"n_heads\\\": 32,\\n\",\n \" \\\"n_layers\\\": 32,\\n\",\n \" \\\"hidden_dim\\\": 11_008,\\n\",\n \" \\\"head_dim\\\": 128,\\n\",\n \" \\\"n_kv_heads\\\": 32,\\n\",\n \" \\\"attention_bias\\\": False,\\n\",\n \" \\\"attention_dropout\\\": 0.0,\\n\",\n \" \\\"sliding_window\\\": 4_096,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \" \\\"rope_base\\\": 500_000.0,\\n\",\n \" \\\"rope_attention_factor\\\": 1.2079441541679836,\\n\",\n \" \\\"rope_type\\\": \\\"yarn\\\",\\n\",\n \" \\\"rope_factor\\\": 8.0,\\n\",\n \" \\\"rope_orig_max\\\": 8_192,\\n\",\n \" \\\"beta_fast\\\": 32.0,\\n\",\n \" \\\"beta_slow\\\": 1.0,\\n\",\n \" \\\"rms_norm_eps\\\": 1e-6,\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"eos_token_id\\\": 100_257,\\n\",\n \" \\\"pad_token_id\\\": 100_277,\\n\",\n \"}\\n\",\n \"\\n\",\n \"OLMO3_CONFIG_32B = {\\n\",\n \" \\\"vocab_size\\\": 100_278,\\n\",\n \" \\\"context_length\\\": 65_536,\\n\",\n \" \\\"emb_dim\\\": 5_120,\\n\",\n \" \\\"n_heads\\\": 40,\\n\",\n \" \\\"n_layers\\\": 64,\\n\",\n \" \\\"hidden_dim\\\": 27_648,\\n\",\n \" \\\"head_dim\\\": 128,\\n\",\n \" \\\"n_kv_heads\\\": 8,\\n\",\n \" \\\"attention_bias\\\": False,\\n\",\n \" \\\"attention_dropout\\\": 0.0,\\n\",\n \" \\\"sliding_window\\\": 4_096,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \" \\\"rope_base\\\": 500_000.0,\\n\",\n \" \\\"rope_attention_factor\\\": 1.2079441541679836,\\n\",\n \" \\\"rope_type\\\": \\\"yarn\\\",\\n\",\n \" \\\"rope_factor\\\": 8.0,\\n\",\n \" \\\"rope_orig_max\\\": 8_192,\\n\",\n \" \\\"beta_fast\\\": 32.0,\\n\",\n \" \\\"beta_slow\\\": 1.0,\\n\",\n \" \\\"rms_norm_eps\\\": 1e-6,\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"eos_token_id\\\": 100_257,\\n\",\n \" \\\"pad_token_id\\\": 100_277,\\n\",\n \"}\\n\",\n \"\\n\",\n \"OLMO3_CONFIG = OLMO3_CONFIG_32B if \\\"32B\\\" in USE_MODEL else OLMO3_CONFIG_7B\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model = Olmo3Model(OLMO3_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"eaf86265-4e9d-4024-9ed0-99076944e304\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Olmo3Model(\\n\",\n \" (tok_emb): Embedding(100278, 4096)\\n\",\n \" (blocks): ModuleList(\\n\",\n \" (0-31): 32 x TransformerBlock(\\n\",\n \" (att): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (W_value): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (out_proj): Linear(in_features=4096, out_features=4096, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=4096, out_features=11008, bias=False)\\n\",\n \" (fc2): Linear(in_features=4096, out_features=11008, bias=False)\\n\",\n \" (fc3): Linear(in_features=11008, out_features=4096, bias=False)\\n\",\n \" )\\n\",\n \" (post_attention_layernorm): RMSNorm()\\n\",\n \" (post_feedforward_layernorm): RMSNorm()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): RMSNorm()\\n\",\n \" (out_head): Linear(in_features=4096, out_features=100278, bias=False)\\n\",\n \")\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90aca91d-4bee-45ce-993a-4ec5393abe2b\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the forward pass works before continuing:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"adf0a6b7-b688-42c9-966e-c223d34db99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[[ 0.3867, -0.6328, -0.2734, ..., 1.1484, 0.4258, 0.0400],\\n\",\n \" [ 1.2734, 0.0040, 0.5000, ..., 0.5625, -0.2383, 0.1855],\\n\",\n \" [ 0.5859, -0.0540, 0.7930, ..., 0.3262, -0.5430, -0.1494]]],\\n\",\n \" dtype=torch.bfloat16, grad_fn=\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/13_olmo3/tests/olmo3_layer_debugger.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\ntry:\n from transformers import Olmo3Config, Olmo3ForCausalLM\nexcept ImportError:\n Olmo3Config = None\n Olmo3ForCausalLM = None\n\n\ndef tiny_debug_config():\n return {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"qk_norm\": True,\n \"n_kv_heads\": 2,\n \"sliding_window\": 4,\n \"layer_types\": [\"full_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"query_pre_attn_scalar\": 256,\n \"attention_bias\": False,\n \"rms_norm_eps\": 1e-6,\n \"rope_base\": 1_000_000.0,\n \"rope_attention_factor\": 1.0,\n \"rope_type\": \"default\",\n \"rope_factor\": 1.0,\n \"rope_orig_max\": 8,\n \"rope_local_base\": 10_000.0,\n }\n\n\ndef yarn_debug_config():\n return {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"qk_norm\": True,\n \"n_kv_heads\": 2,\n \"sliding_window\": 4,\n \"layer_types\": [\"full_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"query_pre_attn_scalar\": 256,\n \"attention_bias\": False,\n \"rms_norm_eps\": 1e-6,\n \"rope_base\": 500_000.0,\n \"rope_attention_factor\": 1.2079441541679836,\n \"rope_type\": \"yarn\",\n \"rope_factor\": 8.0,\n \"rope_orig_max\": 8192,\n \"beta_fast\": 32.0,\n \"beta_slow\": 1.0,\n \"rope_local_base\": 10_000.0,\n }\n\n\ndef _hf_config_from_dict(cfg):\n if Olmo3Config is None:\n raise ImportError(\"transformers is required for the Olmo-3 debugger.\")\n\n rope_type = cfg.get(\"rope_type\", \"default\")\n rope_scaling = {\"rope_type\": rope_type}\n if rope_type == \"yarn\":\n rope_scaling.update(\n {\n \"attention_factor\": cfg.get(\"rope_attention_factor\", 1.0),\n \"beta_fast\": cfg.get(\"beta_fast\", 32.0),\n \"beta_slow\": cfg.get(\"beta_slow\", 1.0),\n \"factor\": cfg.get(\"rope_factor\", 1.0),\n \"original_max_position_embeddings\": cfg.get(\"rope_orig_max\", 8192),\n }\n )\n\n return Olmo3Config(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n head_dim=cfg[\"head_dim\"],\n num_key_value_heads=cfg[\"n_kv_heads\"],\n rope_theta=cfg[\"rope_base\"],\n rope_local_base_freq=cfg.get(\"rope_local_base\", 10_000.0),\n layer_types=cfg[\"layer_types\"],\n sliding_window=cfg[\"sliding_window\"],\n tie_word_embeddings=False,\n attn_implementation=\"eager\",\n torch_dtype=cfg.get(\"dtype\", torch.float32),\n query_pre_attn_scalar=cfg.get(\"query_pre_attn_scalar\", 256),\n rope_scaling=rope_scaling,\n qk_norm=cfg.get(\"qk_norm\", False),\n rms_norm_eps=cfg.get(\"rms_norm_eps\", 1e-5),\n )\n\n\ndef load_notebook_defs(nb_name=\"standalone-olmo3.ipynb\"):\n nb_dir = Path(__file__).resolve().parents[1]\n return import_definitions_from_notebook(nb_dir, nb_name)\n\n\ndef build_olmo3_pair(import_notebook_defs, cfg, hf_checkpoint=None):\n if Olmo3ForCausalLM is None:\n raise ImportError(\"transformers is required for the Olmo-3 debugger.\")\n\n ours = import_notebook_defs.Olmo3Model(cfg)\n hf_cfg = _hf_config_from_dict(cfg)\n\n if hf_checkpoint:\n hf_model = Olmo3ForCausalLM.from_pretrained(\n hf_checkpoint,\n torch_dtype=cfg.get(\"dtype\", torch.float32),\n attn_implementation=\"eager\",\n )\n else:\n hf_model = Olmo3ForCausalLM(hf_cfg)\n\n param_config = {\"n_layers\": cfg[\"n_layers\"], \"hidden_dim\": cfg[\"hidden_dim\"]}\n import_notebook_defs.load_weights_into_olmo(ours, param_config, hf_model.state_dict())\n\n ours.eval()\n hf_model.eval()\n return ours, hf_model\n\n\ndef _attach_debug_hooks(model, is_hf):\n traces = {}\n handles = []\n\n def hook(name):\n def _record(_, __, output):\n traces[name] = output.detach().to(torch.float32).cpu()\n return _record\n\n if is_hf:\n core = model.model\n handles.append(core.embed_tokens.register_forward_hook(hook(\"embedding\")))\n for idx, layer in enumerate(core.layers):\n handles.append(layer.register_forward_hook(hook(f\"block_{idx}\")))\n handles.append(core.norm.register_forward_hook(hook(\"final_norm\")))\n handles.append(model.lm_head.register_forward_hook(hook(\"logits\")))\n else:\n handles.append(model.tok_emb.register_forward_hook(hook(\"embedding\")))\n for idx, block in enumerate(model.blocks):\n handles.append(block.register_forward_hook(hook(f\"block_{idx}\")))\n handles.append(model.final_norm.register_forward_hook(hook(\"final_norm\")))\n handles.append(model.out_head.register_forward_hook(hook(\"logits\")))\n\n return traces, handles\n\n\ndef _layer_sort_key(name):\n if name == \"embedding\":\n return (0, 0)\n if name.startswith(\"block_\"):\n idx = int(name.split(\"_\")[1])\n return (1, idx)\n if name == \"final_norm\":\n return (2, 0)\n if name == \"logits\":\n return (3, 0)\n return (4, name)\n\n\ndef layerwise_differences(ours, hf_model, input_ids, rtol=1e-5, atol=1e-5):\n ours_traces, ours_handles = _attach_debug_hooks(ours, is_hf=False)\n hf_traces, hf_handles = _attach_debug_hooks(hf_model, is_hf=True)\n\n try:\n with torch.inference_mode():\n ours(input_ids)\n hf_model(input_ids)\n finally:\n for h in ours_handles + hf_handles:\n h.remove()\n\n layer_names = sorted(set(ours_traces) | set(hf_traces), key=_layer_sort_key)\n results = []\n for name in layer_names:\n ours_tensor = ours_traces.get(name)\n hf_tensor = hf_traces.get(name)\n\n if ours_tensor is None or hf_tensor is None:\n results.append(\n {\n \"name\": name,\n \"status\": \"missing\",\n \"ours_shape\": None if ours_tensor is None else tuple(ours_tensor.shape),\n \"hf_shape\": None if hf_tensor is None else tuple(hf_tensor.shape),\n \"max_diff\": None,\n \"mean_abs_diff\": None,\n }\n )\n continue\n\n shapes_match = ours_tensor.shape == hf_tensor.shape\n if not shapes_match:\n results.append(\n {\n \"name\": name,\n \"status\": \"shape_mismatch\",\n \"ours_shape\": tuple(ours_tensor.shape),\n \"hf_shape\": tuple(hf_tensor.shape),\n \"max_diff\": None,\n \"mean_abs_diff\": None,\n }\n )\n continue\n\n diff = (ours_tensor - hf_tensor).abs()\n max_diff = float(diff.max().item())\n mean_diff = float(diff.mean().item())\n allclose = torch.allclose(ours_tensor, hf_tensor, rtol=rtol, atol=atol)\n results.append(\n {\n \"name\": name,\n \"status\": \"ok\" if allclose else \"mismatch\",\n \"ours_shape\": tuple(ours_tensor.shape),\n \"hf_shape\": tuple(hf_tensor.shape),\n \"max_diff\": max_diff,\n \"mean_abs_diff\": mean_diff,\n }\n )\n return results\n\n\ndef first_mismatch(differences):\n for diff in differences:\n if diff[\"status\"] != \"ok\":\n return diff\n return None\n\n\ndef format_report(differences):\n lines = []\n for diff in sorted(differences, key=lambda d: _layer_sort_key(d[\"name\"])):\n if diff[\"status\"] == \"ok\":\n lines.append(f\"[OK] {diff['name']}: max={diff['max_diff']:.2e}, mean={diff['mean_abs_diff']:.2e}\")\n elif diff[\"status\"] == \"mismatch\":\n lines.append(\n f\"[DIFF] {diff['name']}: max={diff['max_diff']:.2e}, mean={diff['mean_abs_diff']:.2e}\"\n )\n elif diff[\"status\"] == \"shape_mismatch\":\n lines.append(\n f\"[SHAPE] {diff['name']}: ours={diff['ours_shape']}, hf={diff['hf_shape']}\"\n )\n else:\n lines.append(f\"[MISSING] {diff['name']}: ours={diff['ours_shape']}, hf={diff['hf_shape']}\")\n return \"\\n\".join(lines)\n\n\nif __name__ == \"__main__\":\n transformers_available = importlib.util.find_spec(\"transformers\") is not None\n if not transformers_available:\n raise SystemExit(\"transformers is not installed; install it to run the debugger.\")\n\n import_notebook_defs = load_notebook_defs()\n cfg = yarn_debug_config()\n\n ours_model, hf_model = build_olmo3_pair(import_notebook_defs, cfg)\n torch.manual_seed(0)\n input_ids = torch.randint(0, cfg[\"vocab_size\"], (1, cfg[\"context_length\"]), dtype=torch.long)\n diffs = layerwise_differences(ours_model, hf_model, input_ids)\n print(format_report(diffs))\n"
},
{
"path": "ch05/13_olmo3/tests/test_olmo3_kvcache_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n mod = import_definitions_from_notebook(nb_dir, \"standalone-olmo3-plus-kv-cache.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8)) # batch size 1, seq length 8\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"context_length\": 64,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"n_kv_heads\": 1, # 4 query heads, 1 KV groups -> group_size = 4\n \"attention_bias\": False,\n \"attention_dropout\": 0.0,\n \"sliding_window\": 4,\n \"layer_types\": [\"full_attention\"] * 2,\n\n # RoPE config\n \"rope_base\": 10_000.0,\n \"rope_attention_factor\": 1.0,\n \"rope_type\": \"default\",\n \"rope_factor\": 1.0,\n \"rope_orig_max\": 64,\n \"rms_norm_eps\": 1e-6,\n \"dtype\": torch.float32,\n }\n\n@torch.inference_mode()\ndef test_dummy_olmo3_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.Olmo3Model(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"]), \\\n f\"Expected shape (1, seq_len, vocab_size), got {out.shape}\"\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_olmo3_base_equivalence_with_transformers(import_notebook_defs):\n from transformers import Olmo3Config, Olmo3ForCausalLM\n\n # Tiny config so the test is fast\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"qk_norm\": True,\n \"n_kv_heads\": 2,\n \"sliding_window\": 4,\n \"layer_types\": [\"full_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"query_pre_attn_scalar\": 256,\n\n # required by TransformerBlock\n \"attention_bias\": False,\n\n # required by RMSNorm and RoPE setup in Olmo3Model\n \"rms_norm_eps\": 1e-6,\n \"rope_base\": 1_000_000.0,\n \"rope_attention_factor\": 1.0,\n \"rope_type\": \"default\",\n \"rope_factor\": 1.0,\n \"rope_orig_max\": 8,\n\n # extra HF-only stuff\n \"rope_local_base\": 10_000.0,\n }\n\n model = import_notebook_defs.Olmo3Model(cfg)\n\n hf_cfg = Olmo3Config(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n head_dim=cfg[\"head_dim\"],\n num_key_value_heads=cfg[\"n_kv_heads\"],\n rope_theta=cfg[\"rope_base\"],\n rope_local_base_freq=cfg[\"rope_local_base\"],\n layer_types=cfg[\"layer_types\"],\n sliding_window=cfg[\"sliding_window\"],\n tie_word_embeddings=False,\n attn_implementation=\"eager\",\n torch_dtype=torch.float32,\n query_pre_attn_scalar=cfg[\"query_pre_attn_scalar\"],\n rope_scaling={\"rope_type\": \"default\"},\n qk_norm=cfg[\"qk_norm\"],\n rms_norm_eps=cfg[\"rms_norm_eps\"],\n )\n hf_model = Olmo3ForCausalLM(hf_cfg)\n\n hf_state = hf_model.state_dict()\n param_config = {\n \"n_layers\": cfg[\"n_layers\"],\n \"hidden_dim\": cfg[\"hidden_dim\"],\n }\n import_notebook_defs.load_weights_into_olmo(model, param_config, hf_state)\n\n x = torch.randint(\n 0,\n cfg[\"vocab_size\"],\n (2, cfg[\"context_length\"]),\n dtype=torch.long,\n )\n ours_logits = model(x)\n theirs_logits = hf_model(x).logits\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/13_olmo3/tests/test_olmo3_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n mod = import_definitions_from_notebook(nb_dir, \"standalone-olmo3.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8)) # batch size 1, seq length 8\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"context_length\": 64,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"n_kv_heads\": 1, # 4 query heads, 1 KV groups -> group_size = 4\n \"attention_bias\": False,\n \"attention_dropout\": 0.0,\n \"sliding_window\": 4,\n \"layer_types\": [\"full_attention\"] * 2,\n\n # RoPE config\n \"rope_base\": 10_000.0,\n \"rope_attention_factor\": 1.0,\n \"rope_type\": \"default\",\n \"rope_factor\": 1.0,\n \"rope_orig_max\": 64,\n \"rms_norm_eps\": 1e-6,\n \"dtype\": torch.float32,\n }\n\n@torch.inference_mode()\ndef test_dummy_olmo3_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.Olmo3Model(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"]), \\\n f\"Expected shape (1, seq_len, vocab_size), got {out.shape}\"\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_olmo3_base_equivalence_with_transformers(import_notebook_defs):\n from transformers import Olmo3Config, Olmo3ForCausalLM\n\n # Tiny config so the test is fast\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"qk_norm\": True,\n \"n_kv_heads\": 2,\n \"sliding_window\": 4,\n \"layer_types\": [\"full_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"query_pre_attn_scalar\": 256,\n\n # required by TransformerBlock\n \"attention_bias\": False,\n\n # required by RMSNorm and RoPE setup in Olmo3Model\n \"rms_norm_eps\": 1e-6,\n \"rope_base\": 1_000_000.0,\n \"rope_attention_factor\": 1.0,\n \"rope_type\": \"default\",\n \"rope_factor\": 1.0,\n \"rope_orig_max\": 8,\n\n # extra HF-only stuff\n \"rope_local_base\": 10_000.0,\n }\n\n model = import_notebook_defs.Olmo3Model(cfg)\n\n hf_cfg = Olmo3Config(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n head_dim=cfg[\"head_dim\"],\n num_key_value_heads=cfg[\"n_kv_heads\"],\n rope_theta=cfg[\"rope_base\"],\n rope_local_base_freq=cfg[\"rope_local_base\"],\n layer_types=cfg[\"layer_types\"],\n sliding_window=cfg[\"sliding_window\"],\n tie_word_embeddings=False,\n attn_implementation=\"eager\",\n torch_dtype=torch.float32,\n query_pre_attn_scalar=cfg[\"query_pre_attn_scalar\"],\n rope_scaling={\"rope_type\": \"default\"},\n qk_norm=cfg[\"qk_norm\"],\n rms_norm_eps=cfg[\"rms_norm_eps\"],\n )\n hf_model = Olmo3ForCausalLM(hf_cfg)\n\n hf_state = hf_model.state_dict()\n param_config = {\n \"n_layers\": cfg[\"n_layers\"],\n \"hidden_dim\": cfg[\"hidden_dim\"],\n }\n import_notebook_defs.load_weights_into_olmo(model, param_config, hf_state)\n\n x = torch.randint(\n 0,\n cfg[\"vocab_size\"],\n (2, cfg[\"context_length\"]),\n dtype=torch.long,\n )\n ours_logits = model(x)\n theirs_logits = hf_model(x).logits\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/14_ch05_with_other_llms/README.md",
"content": "# Chapter 5 With Other LLMs\n\nThis folder contains code notebooks that swap in other LLMs (for example, Qwen3 and Llama 3) for GPT-2 in Chapter 5.\n\n\n\n\n\n"
},
{
"path": "ch05/14_ch05_with_other_llms/ch05-llama32.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"45398736-7e89-4263-89c8-92153baff553\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"id\": \"86000d74-624a-48f0-86da-f41926cb9e04\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"86000d74-624a-48f0-86da-f41926cb9e04\",\n \"outputId\": \"ad482cfd-5a62-4f0d-e1e0-008d6457f512\"\n },\n \"outputs\": [],\n \"source\": [\n \"######################\\n\",\n \"### Llama 3 Code\\n\",\n \"######################\\n\",\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\\n\",\n \"\\n\",\n \"\\n\",\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, freq_config=None, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))\\n\",\n \"\\n\",\n \" # Frequency adjustments\\n\",\n \" if freq_config is not None:\\n\",\n \" low_freq_wavelen = freq_config[\\\"original_context_length\\\"] / freq_config[\\\"low_freq_factor\\\"]\\n\",\n \" high_freq_wavelen = freq_config[\\\"original_context_length\\\"] / freq_config[\\\"high_freq_factor\\\"]\\n\",\n \"\\n\",\n \" wavelen = 2 * torch.pi / inv_freq\\n\",\n \"\\n\",\n \" inv_freq_llama = torch.where(\\n\",\n \" wavelen > low_freq_wavelen, inv_freq / freq_config[\\\"factor\\\"], inv_freq\\n\",\n \" )\\n\",\n \"\\n\",\n \" smooth_factor = (freq_config[\\\"original_context_length\\\"] / wavelen - freq_config[\\\"low_freq_factor\\\"]) / (\\n\",\n \" freq_config[\\\"high_freq_factor\\\"] - freq_config[\\\"low_freq_factor\\\"]\\n\",\n \" )\\n\",\n \"\\n\",\n \" smoothed_inv_freq = (\\n\",\n \" (1 - smooth_factor) * (inv_freq / freq_config[\\\"factor\\\"]) + smooth_factor * inv_freq\\n\",\n \" )\\n\",\n \"\\n\",\n \" is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)\\n\",\n \" inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)\\n\",\n \" inv_freq = inv_freq_llama\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Expand angles to match the head_dim\\n\",\n \" angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" # It's ok to use lower-precision after applying cos and sin rotation\\n\",\n \" return x_rotated.to(dtype=x.dtype)\\n\",\n \"\\n\",\n \"\\n\",\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, d_out, num_heads,\\n\",\n \" num_kv_groups,\\n\",\n \" dtype=None\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert d_out % num_heads == 0, \\\"d_out must be divisible by num_heads\\\"\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.d_out = d_out\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.head_dim = d_out // num_heads\\n\",\n \"\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\\n\",\n \" self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" b, num_tokens, d_in = x.shape\\n\",\n \"\\n\",\n \" queries = self.W_query(x) # Shape: (b, num_tokens, d_out)\\n\",\n \" keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape queries, keys, and values\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)\\n\",\n \" values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)\\n\",\n \"\\n\",\n \" # Transpose keys, values, and queries\\n\",\n \" keys = keys.transpose(1, 2) # Shape: (b, num_kv_groups, num_tokens, head_dim)\\n\",\n \" values = values.transpose(1, 2) # Shape: (b, num_kv_groups, num_tokens, head_dim)\\n\",\n \" queries = queries.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \"\\n\",\n \" # Apply RoPE\\n\",\n \" keys = apply_rope(keys, cos, sin)\\n\",\n \" queries = apply_rope(queries, cos, sin)\\n\",\n \"\\n\",\n \" # Expand keys and values to match the number of heads\\n\",\n \" # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\\n\",\n \" # For example, before repeat_interleave along dim=1 (query groups):\\n\",\n \" # [K1, K2]\\n\",\n \" # After repeat_interleave (each query group is repeated group_size times):\\n\",\n \" # [K1, K1, K2, K2]\\n\",\n \" # If we used regular repeat instead of repeat_interleave, we'd get:\\n\",\n \" # [K1, K2, K1, K2]\\n\",\n \"\\n\",\n \" # Compute scaled dot-product attention (aka self-attention) with a causal mask\\n\",\n \" # Shape: (b, num_heads, num_tokens, num_tokens)\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\\n\",\n \"\\n\",\n \" # Compute attention scores\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\\n\",\n \" assert keys.shape[-1] == self.head_dim\\n\",\n \"\\n\",\n \" # Shape: (b, num_tokens, num_heads, head_dim)\\n\",\n \" context_vec = (attn_weights @ values).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Combine heads, where self.d_out = self.num_heads * self.head_dim\\n\",\n \" context_vec = context_vec.reshape(b, num_tokens, self.d_out)\\n\",\n \" context_vec = self.out_proj(context_vec) # optional projection\\n\",\n \"\\n\",\n \" return context_vec\\n\",\n \"\\n\",\n \"\\n\",\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" d_out=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"]\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = nn.RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.norm2 = nn.RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \" x = self.att(x, mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" # Shortcut connection for feed-forward block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" return x\\n\",\n \"\\n\",\n \"\\n\",\n \"class Llama3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" # Main model parameters\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.ModuleList( # ModuleList since Sequential can only accept one input, and we need `x, mask, cos, sin`\\n\",\n \" [TransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])]\\n\",\n \" )\\n\",\n \"\\n\",\n \" self.final_norm = nn.RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-5, dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" # Uncomment the following code to tie weights\\n\",\n \" # self.out_head.weight = self.tok_emb.weight\\n\",\n \" # torch.nn.init.normal_(self.out_head.weight, mean=0.0, std=0.02)\\n\",\n \"\\n\",\n \" # Reusable utilities\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"emb_dim\\\"] // cfg[\\\"n_heads\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" freq_config=cfg[\\\"rope_freq\\\"]\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" # Forward pass\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" x = tok_embeds\\n\",\n \"\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \" mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)\\n\",\n \" \\n\",\n \" for block in self.trf_blocks:\\n\",\n \" x = block(x, mask, self.cos, self.sin)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"d12ac059-58d8-4db2-ac5a-9ec58b043daf\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"#######################\\n\",\n \"### Initialize Llama 3\\n\",\n \"#######################\\n\",\n \"\\n\",\n \"# Llama 3.2 1B\\n\",\n \"\\n\",\n \"LLAMA32_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 128_256, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 131_072, # Context length that was used to train the model\\n\",\n \" \\\"emb_dim\\\": 2048, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 32, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 16, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 8192, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 500_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \" \\\"rope_freq\\\": { # RoPE frequency scaling\\n\",\n \" \\\"factor\\\": 32.0,\\n\",\n \" \\\"low_freq_factor\\\": 1.0,\\n\",\n \" \\\"high_freq_factor\\\": 4.0,\\n\",\n \" \\\"original_context_length\\\": 8192,\\n\",\n \" }\\n\",\n \"}\\n\",\n \"\\n\",\n \"LLAMA32_CONFIG[\\\"train_context_length\\\"] = 256 # It's a small dataset, and we also want to keep memory usage reasonable\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model = Llama3Model(LLAMA32_CONFIG)\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"d6732d1a-db47-42c3-aca3-8a871752f32f\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"#######################\\n\",\n \"### Set up tokenizer\\n\",\n \"#######################\\n\",\n \"\\n\",\n \"import os\\n\",\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"import tiktoken\\n\",\n \"from tiktoken.load import load_tiktoken_bpe\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"class Tokenizer:\\n\",\n \" \\\"\\\"\\\"Thin wrapper around tiktoken that keeps track of Llama-3 special IDs.\\\"\\\"\\\"\\n\",\n \" def __init__(self, model_path):\\n\",\n \" if not os.path.isfile(model_path):\\n\",\n \" raise FileNotFoundError(model_path)\\n\",\n \"\\n\",\n \" mergeable = load_tiktoken_bpe(model_path)\\n\",\n \"\\n\",\n \" # hard-coded from Meta's tokenizer.json\\n\",\n \" self.special = {\\n\",\n \" \\\"<|begin_of_text|>\\\": 128000,\\n\",\n \" \\\"<|end_of_text|>\\\": 128001,\\n\",\n \" \\\"<|start_header_id|>\\\": 128006,\\n\",\n \" \\\"<|end_header_id|>\\\": 128007,\\n\",\n \" \\\"<|eot_id|>\\\": 128009,\\n\",\n \" }\\n\",\n \" self.special.update({f\\\"<|reserved_{i}|>\\\": 128002 + i\\n\",\n \" for i in range(256)\\n\",\n \" if 128002 + i not in self.special.values()})\\n\",\n \"\\n\",\n \" self.model = tiktoken.Encoding(\\n\",\n \" name=Path(model_path).name,\\n\",\n \" pat_str=r\\\"(?i:'s|'t|'re|'ve|'m|'ll|'d)\\\"\\n\",\n \" r\\\"|[^\\\\r\\\\n\\\\p{L}\\\\p{N}]?\\\\p{L}+\\\"\\n\",\n \" r\\\"|\\\\p{N}{1,3}\\\"\\n\",\n \" r\\\"| ?[^\\\\s\\\\p{L}\\\\p{N}]+[\\\\r\\\\n]*\\\"\\n\",\n \" r\\\"|\\\\s*[\\\\r\\\\n]+\\\"\\n\",\n \" r\\\"|\\\\s+(?!\\\\S)\\\"\\n\",\n \" r\\\"|\\\\s+\\\",\\n\",\n \" mergeable_ranks=mergeable,\\n\",\n \" special_tokens=self.special,\\n\",\n \" )\\n\",\n \"\\n\",\n \" def encode(self, text, bos=False, eos=False):\\n\",\n \" ids = ([self.special[\\\"<|begin_of_text|>\\\"]] if bos else []) \\\\\\n\",\n \" + self.model.encode(text)\\n\",\n \" if eos:\\n\",\n \" ids.append(self.special[\\\"<|end_of_text|>\\\"])\\n\",\n \" return ids\\n\",\n \"\\n\",\n \" def decode(self, ids):\\n\",\n \" return self.model.decode(ids)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6061739e\",\n \"metadata\": {},\n \"source\": [\n \"- Please note that Meta AI requires that you accept the Llama 3.2 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) repository to accept the terms\\n\",\n \"- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \\\"Settings\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"0bab40cf\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Uncomment and run the following code if you are executing the notebook for the first time\\n\",\n \"\\n\",\n \"#from huggingface_hub import login\\n\",\n \"#login()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"f102c705\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import hf_hub_download\\n\",\n \"\\n\",\n \"tokenizer_file_path = hf_hub_download(\\n\",\n \" repo_id=\\\"meta-llama/Llama-3.2-1B-Instruct\\\",\\n\",\n \" filename=\\\"original/tokenizer.model\\\",\\n\",\n \" local_dir=\\\"Llama-3.2-1B-Instruct\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"d9cc9167\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"tokenizer = Tokenizer(tokenizer_file_path)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"5e062b82-3540-48ce-8eb4-009686d0d16c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Output text:\\n\",\n \" Every effort moves youodableglich-create//{\\n\",\n \" Buddhistザイン ILogger_us matching=User\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Same as chapter 4\\n\",\n \"\\n\",\n \"def generate_text_simple(model, idx, max_new_tokens, context_size):\\n\",\n \" # idx is (B, T) array of indices in the current context\\n\",\n \" for _ in range(max_new_tokens):\\n\",\n \"\\n\",\n \" # Crop current context if it exceeds the supported context size\\n\",\n \" # E.g., if LLM supports only 5 tokens, and the context size is 10\\n\",\n \" # then only the last 5 tokens are used as context\\n\",\n \" idx_cond = idx[:, -context_size:]\\n\",\n \"\\n\",\n \" # Get the predictions\\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(idx_cond)\\n\",\n \"\\n\",\n \" # Focus only on the last time step\\n\",\n \" # (batch, n_token, vocab_size) becomes (batch, vocab_size)\\n\",\n \" logits = logits[:, -1, :]\\n\",\n \"\\n\",\n \" # Get the idx of the vocab entry with the highest logits value\\n\",\n \" idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)\\n\",\n \"\\n\",\n \" # Append sampled index to the running sequence\\n\",\n \" idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)\\n\",\n \"\\n\",\n \" return idx\\n\",\n \"\\n\",\n \"\\n\",\n \"def text_to_token_ids(text, tokenizer):\\n\",\n \" encoded = tokenizer.encode(text)\\n\",\n \" encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension\\n\",\n \" return encoded_tensor\\n\",\n \"\\n\",\n \"def token_ids_to_text(token_ids, tokenizer):\\n\",\n \" flat = token_ids.squeeze(0) # remove batch dimension\\n\",\n \" return tokenizer.decode(flat.tolist())\\n\",\n \"\\n\",\n \"start_context = \\\"Every effort moves you\\\"\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(start_context, tokenizer),\\n\",\n \" max_new_tokens=10,\\n\",\n \" context_size=LLAMA32_CONFIG[\\\"train_context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Output text:\\\\n\\\", token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0f3d7ea2-637f-4490-bc76-e361fc81ae98\",\n \"metadata\": {\n \"id\": \"0f3d7ea2-637f-4490-bc76-e361fc81ae98\"\n },\n \"source\": [\n \" \\n\",\n \"### 5.1.2 Calculating the text generation loss: cross-entropy and perplexity\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e669b90a-4bc9-422f-8f62-6c6d99189f68\",\n \"metadata\": {},\n \"source\": [\n \"- Similar to chapter 5\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2ec6c217-e429-40c7-ad71-5d0a9da8e487\",\n \"metadata\": {\n \"id\": \"2ec6c217-e429-40c7-ad71-5d0a9da8e487\"\n },\n \"source\": [\n \" \\n\",\n \"### 5.1.3 Calculating the training and validation set losses\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"654fde37-b2a9-4a20-a8d3-0206c056e2ff\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import requests\\n\",\n \"\\n\",\n \"file_path = \\\"the-verdict.txt\\\"\\n\",\n \"url = \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt\\\"\\n\",\n \"\\n\",\n \"if not os.path.exists(file_path):\\n\",\n \" response = requests.get(url, timeout=30)\\n\",\n \" response.raise_for_status()\\n\",\n \" text_data = response.text\\n\",\n \" with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" file.write(text_data)\\n\",\n \"else:\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" text_data = file.read()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"379330f1-80f4-4e34-8724-41d892b04cee\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the text loaded ok by printing the first and last 99 characters\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"6kgJbe4ehI4q\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 35\n },\n \"id\": \"6kgJbe4ehI4q\",\n \"outputId\": \"9ff31e88-ee37-47e9-ee64-da6eb552f46f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no \\n\"\n ]\n }\n ],\n \"source\": [\n \"# First 99 characters\\n\",\n \"print(text_data[:99])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"j2XPde_ThM_e\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 35\n },\n \"id\": \"j2XPde_ThM_e\",\n \"outputId\": \"a900c1b9-9a87-4078-968b-a5721deda5cb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"it for me! The Strouds stand alone, and happen once--but there's no exterminating our kind of art.\\\"\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Last 99 characters\\n\",\n \"print(text_data[-99:])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"6b46a952-d50a-4837-af09-4095698f7fd1\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6b46a952-d50a-4837-af09-4095698f7fd1\",\n \"outputId\": \"c2a25334-21ca-486e-8226-0296e5fc6486\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Characters: 20479\\n\",\n \"Tokens: 4941\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_characters = len(text_data)\\n\",\n \"total_tokens = len(tokenizer.encode(text_data))\\n\",\n \"\\n\",\n \"print(\\\"Characters:\\\", total_characters)\\n\",\n \"print(\\\"Tokens:\\\", total_tokens)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"0959c855-f860-4358-8b98-bc654f047578\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import Dataset, DataLoader\\n\",\n \"\\n\",\n \"\\n\",\n \"class GPTDatasetV1(Dataset):\\n\",\n \" def __init__(self, txt, tokenizer, max_length, stride):\\n\",\n \" self.input_ids = []\\n\",\n \" self.target_ids = []\\n\",\n \"\\n\",\n \" # Tokenize the entire text\\n\",\n \" token_ids = tokenizer.encode(txt)\\n\",\n \"\\n\",\n \" # Use a sliding window to chunk the book into overlapping sequences of max_length\\n\",\n \" for i in range(0, len(token_ids) - max_length, stride):\\n\",\n \" input_chunk = token_ids[i:i + max_length]\\n\",\n \" target_chunk = token_ids[i + 1: i + max_length + 1]\\n\",\n \" self.input_ids.append(torch.tensor(input_chunk))\\n\",\n \" self.target_ids.append(torch.tensor(target_chunk))\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.input_ids)\\n\",\n \"\\n\",\n \" def __getitem__(self, idx):\\n\",\n \" return self.input_ids[idx], self.target_ids[idx]\\n\",\n \"\\n\",\n \"# Note that we have to change the function below because we previously hard-coded the\\n\",\n \"# GPT-2 tokenizer in the data loader\\n\",\n \"def create_dataloader_v1(txt, tokenizer, batch_size=4, max_length=256,\\n\",\n \" stride=128, shuffle=True, drop_last=True, num_workers=0):\\n\",\n \" # Initialize the tokenizer\\n\",\n \" # tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \" tokenizer = tokenizer\\n\",\n \"\\n\",\n \" # Create dataset\\n\",\n \" dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)\\n\",\n \"\\n\",\n \" # Create dataloader\\n\",\n \" dataloader = DataLoader(\\n\",\n \" dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=num_workers)\\n\",\n \"\\n\",\n \" return dataloader\\n\",\n \"\\n\",\n \"\\n\",\n \"# Train/validation ratio\\n\",\n \"train_ratio = 0.90\\n\",\n \"split_idx = int(train_ratio * len(text_data))\\n\",\n \"train_data = text_data[:split_idx]\\n\",\n \"val_data = text_data[split_idx:]\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_loader = create_dataloader_v1(\\n\",\n \" train_data,\\n\",\n \" tokenizer=tokenizer,\\n\",\n \" batch_size=2,\\n\",\n \" max_length=LLAMA32_CONFIG[\\\"train_context_length\\\"],\\n\",\n \" stride=LLAMA32_CONFIG[\\\"train_context_length\\\"],\\n\",\n \" drop_last=True,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=0\\n\",\n \")\\n\",\n \"\\n\",\n \"val_loader = create_dataloader_v1(\\n\",\n \" val_data,\\n\",\n \" tokenizer=tokenizer,\\n\",\n \" batch_size=2,\\n\",\n \" max_length=LLAMA32_CONFIG[\\\"train_context_length\\\"],\\n\",\n \" stride=LLAMA32_CONFIG[\\\"train_context_length\\\"],\\n\",\n \" drop_last=False,\\n\",\n \" shuffle=False,\\n\",\n \" num_workers=0\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a8e0514d-b990-4dc0-9afb-7721993284a0\",\n \"metadata\": {},\n \"source\": [\n \"- An optional check that the data was loaded correctly:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"ca0116d0-d229-472c-9fbf-ebc229331c3e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\",\n \"\\n\",\n \"Validation loader:\\n\",\n \"torch.Size([2, 256]) torch.Size([2, 256])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for x, y in train_loader:\\n\",\n \" print(x.shape, y.shape)\\n\",\n \"\\n\",\n \"print(\\\"\\\\nValidation loader:\\\")\\n\",\n \"for x, y in val_loader:\\n\",\n \" print(x.shape, y.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f7b9b1a4-863d-456f-a8dd-c07fb5c024ed\",\n \"metadata\": {},\n \"source\": [\n \"- Another optional check that the token sizes are in the expected ballpark:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"eb860488-5453-41d7-9870-23b723f742a0\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"eb860488-5453-41d7-9870-23b723f742a0\",\n \"outputId\": \"96b9451a-9557-4126-d1c8-51610a1995ab\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training tokens: 4096\\n\",\n \"Validation tokens: 512\\n\",\n \"All tokens: 4608\\n\"\n ]\n }\n ],\n \"source\": [\n \"train_tokens = 0\\n\",\n \"for input_batch, target_batch in train_loader:\\n\",\n \" train_tokens += input_batch.numel()\\n\",\n \"\\n\",\n \"val_tokens = 0\\n\",\n \"for input_batch, target_batch in val_loader:\\n\",\n \" val_tokens += input_batch.numel()\\n\",\n \"\\n\",\n \"print(\\\"Training tokens:\\\", train_tokens)\\n\",\n \"print(\\\"Validation tokens:\\\", val_tokens)\\n\",\n \"print(\\\"All tokens:\\\", train_tokens + val_tokens)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5c3085e8-665e-48eb-bb41-cdde61537e06\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we implement a utility function to calculate the cross-entropy loss of a given batch\\n\",\n \"- In addition, we implement a second utility function to compute the loss for a user-specified number of batches in a data loader\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"7b9de31e-4096-47b3-976d-b6d2fdce04bc\",\n \"metadata\": {\n \"id\": \"7b9de31e-4096-47b3-976d-b6d2fdce04bc\"\n },\n \"outputs\": [],\n \"source\": [\n \"def calc_loss_batch(input_batch, target_batch, model, device):\\n\",\n \" input_batch, target_batch = input_batch.to(device), target_batch.to(device)\\n\",\n \" logits = model(input_batch)\\n\",\n \" loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())\\n\",\n \" return loss\\n\",\n \"\\n\",\n \"\\n\",\n \"def calc_loss_loader(data_loader, model, device, num_batches=None):\\n\",\n \" total_loss = 0.\\n\",\n \" if len(data_loader) == 0:\\n\",\n \" return float(\\\"nan\\\")\\n\",\n \" elif num_batches is None:\\n\",\n \" num_batches = len(data_loader)\\n\",\n \" else:\\n\",\n \" # Reduce the number of batches to match the total number of batches in the data loader\\n\",\n \" # if num_batches exceeds the number of batches in the data loader\\n\",\n \" num_batches = min(num_batches, len(data_loader))\\n\",\n \" for i, (input_batch, target_batch) in enumerate(data_loader):\\n\",\n \" if i < num_batches:\\n\",\n \" loss = calc_loss_batch(input_batch, target_batch, model, device)\\n\",\n \" total_loss += loss.item()\\n\",\n \" else:\\n\",\n \" break\\n\",\n \" return total_loss / num_batches\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f0691332-84d0-48b3-b462-a885ddeb4fca\",\n \"metadata\": {},\n \"source\": [\n \"- If you have a machine with a CUDA-supported GPU, the LLM will train on the GPU without making any changes to the code\\n\",\n \"- Via the `device` setting, we ensure that the data is loaded onto the same device as the LLM model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"56f5b0c9-1065-4d67-98b9-010e42fc1e2a\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Using cuda device.\\n\",\n \"Training loss: 11.9375\\n\",\n \"Validation loss: 11.9375\\n\"\n ]\n }\n ],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"\\n\",\n \"print(f\\\"Using {device} device.\\\")\\n\",\n \"\\n\",\n \"\\n\",\n \"model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes\\n\",\n \"\\n\",\n \"\\n\",\n \"torch.manual_seed(123) # For reproducibility due to the shuffling in the data loader\\n\",\n \"\\n\",\n \"with torch.no_grad(): # Disable gradient tracking for efficiency because we are not training, yet\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device)\\n\",\n \"\\n\",\n \"print(\\\"Training loss:\\\", train_loss)\\n\",\n \"print(\\\"Validation loss:\\\", val_loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b9339f8d-00cb-4206-af67-58c32bd72055\",\n \"metadata\": {\n \"id\": \"b9339f8d-00cb-4206-af67-58c32bd72055\"\n },\n \"source\": [\n \" \\n\",\n \"## 5.2 Training an LLM\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"Mtp4gY0ZO-qq\",\n \"metadata\": {\n \"id\": \"Mtp4gY0ZO-qq\"\n },\n \"outputs\": [],\n \"source\": [\n \"def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,\\n\",\n \" eval_freq, eval_iter, start_context, tokenizer):\\n\",\n \" # Initialize lists to track losses and tokens seen\\n\",\n \" train_losses, val_losses, track_tokens_seen = [], [], []\\n\",\n \" tokens_seen, global_step = 0, -1\\n\",\n \"\\n\",\n \" # Main training loop\\n\",\n \" for epoch in range(num_epochs):\\n\",\n \" model.train() # Set model to training mode\\n\",\n \" \\n\",\n \" for input_batch, target_batch in train_loader:\\n\",\n \" optimizer.zero_grad() # Reset loss gradients from previous batch iteration\\n\",\n \" loss = calc_loss_batch(input_batch, target_batch, model, device)\\n\",\n \" loss.backward() # Calculate loss gradients\\n\",\n \" optimizer.step() # Update model weights using loss gradients\\n\",\n \" tokens_seen += input_batch.numel()\\n\",\n \" global_step += 1\\n\",\n \"\\n\",\n \" # Optional evaluation step\\n\",\n \" if global_step % eval_freq == 0:\\n\",\n \" train_loss, val_loss = evaluate_model(\\n\",\n \" model, train_loader, val_loader, device, eval_iter)\\n\",\n \" train_losses.append(train_loss)\\n\",\n \" val_losses.append(val_loss)\\n\",\n \" track_tokens_seen.append(tokens_seen)\\n\",\n \" print(f\\\"Ep {epoch+1} (Step {global_step:06d}): \\\"\\n\",\n \" f\\\"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}\\\")\\n\",\n \"\\n\",\n \" # Print a sample text after each epoch\\n\",\n \" generate_and_print_sample(\\n\",\n \" model, tokenizer, device, start_context\\n\",\n \" )\\n\",\n \"\\n\",\n \" return train_losses, val_losses, track_tokens_seen\\n\",\n \"\\n\",\n \"\\n\",\n \"def evaluate_model(model, train_loader, val_loader, device, eval_iter):\\n\",\n \" model.eval()\\n\",\n \" with torch.no_grad():\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\\n\",\n \" model.train()\\n\",\n \" return train_loss, val_loss\\n\",\n \"\\n\",\n \"\\n\",\n \"def generate_and_print_sample(model, tokenizer, device, start_context):\\n\",\n \" model.eval()\\n\",\n \" context_size = model.cfg[\\\"context_length\\\"]\\n\",\n \" encoded = text_to_token_ids(start_context, tokenizer).to(device)\\n\",\n \" with torch.no_grad():\\n\",\n \" token_ids = generate_text_simple(\\n\",\n \" model=model, idx=encoded,\\n\",\n \" max_new_tokens=50, context_size=context_size\\n\",\n \" )\\n\",\n \" decoded_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \" print(decoded_text.replace(\\\"\\\\n\\\", \\\" \\\")) # Compact print format\\n\",\n \" model.train()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"3422000b-7aa2-485b-92df-99372cd22311\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"3422000b-7aa2-485b-92df-99372cd22311\",\n \"outputId\": \"0e046603-908d-4093-8ae5-ef2f632639fb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ep 1 (Step 000000): Train loss 10.300, Val loss 11.062\\n\",\n \"Ep 1 (Step 000005): Train loss 8.306, Val loss 8.438\\n\",\n \"Every effort moves you and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and and I and I and I and and\\n\",\n \"Ep 2 (Step 000010): Train loss 6.875, Val loss 7.250\\n\",\n \"Ep 2 (Step 000015): Train loss 6.475, Val loss 7.156\\n\",\n \"Every effort moves you of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of of\\n\",\n \"Ep 3 (Step 000020): Train loss 6.375, Val loss 7.219\\n\",\n \"Every effort moves you the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the\\n\",\n \"Ep 4 (Step 000025): Train loss 6.225, Val loss 7.156\\n\",\n \"Ep 4 (Step 000030): Train loss 6.250, Val loss 7.188\\n\",\n \"Every effort moves you,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,\\n\",\n \"Ep 5 (Step 000035): Train loss 6.100, Val loss 7.125\\n\",\n \"Every effort moves you the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the the\\n\",\n \"Ep 6 (Step 000040): Train loss 6.088, Val loss 7.156\\n\",\n \"Ep 6 (Step 000045): Train loss 6.131, Val loss 7.188\\n\",\n \"Every effort moves you, and I, and I, and I, and I, and I, and I, and I, and I, and I, and I, and I, and I, and I, and I, and I, and I, and\\n\",\n \"Ep 7 (Step 000050): Train loss 5.956, Val loss 7.031\\n\",\n \"Ep 7 (Step 000055): Train loss 5.850, Val loss 6.969\\n\",\n \"Every effort moves you, I was, I was, I was, I was, I was, I was, I was, I was, I was, I was, I was, I was, I was, I was, I was, I was, I\\n\",\n \"Ep 8 (Step 000060): Train loss 5.650, Val loss 6.875\\n\",\n \"Every effort moves you, and he had the fact--the, and he had the fact--the, and he had the fact--the, and he had the fact--the, and he had the fact--the, and he had the fact--the, and\\n\",\n \"Ep 9 (Step 000065): Train loss 5.444, Val loss 6.719\\n\",\n \"Ep 9 (Step 000070): Train loss 5.094, Val loss 6.656\\n\",\n \"Every effort moves you to me to me to me to me to me to me. The I had been the Riv, and I had been the Riv, and I had been the Riv, and I had been the Riv, and I had been the Riv, and I\\n\",\n \"Ep 10 (Step 000075): Train loss 4.987, Val loss 6.656\\n\",\n \"Every effort moves you to have the don't me to have the don't me--I was a little, and I was a little in the don't me--I was a little, and I was a little in the don't me--I was a little,\\n\",\n \"Ep 11 (Step 000080): Train loss 4.781, Val loss 6.656\\n\",\n \"Ep 11 (Step 000085): Train loss 4.606, Val loss 6.531\\n\",\n \"Every effort moves you, I had the Riviera of the Riviera of the Riviera of the Riviera of the Riviera of the Riviera of the Riviera of the Riviera of the Riviera of the Riviera of the Riviera of the Riviera\\n\",\n \"Ep 12 (Step 000090): Train loss 4.138, Val loss 6.656\\n\",\n \"Ep 12 (Step 000095): Train loss 3.978, Val loss 6.656\\n\",\n \"Every effort moves you know, and he had been his pictures_'t say to have been his pictures--his work. Gisburn's the picture of the picture of the picture of the picture of the picture of the picture of the picture of the picture of the picture\\n\",\n \"Ep 13 (Step 000100): Train loss 3.688, Val loss 6.812\\n\",\n \"Every effort moves you of the fact, and I had been his eyes grew curiosity was one of the fact to the fact to the fact to the fact to the fact to the fact to the fact to the fact to the fact to the fact to the fact to the fact\\n\",\n \"Ep 14 (Step 000105): Train loss 3.278, Val loss 6.688\\n\",\n \"Ep 14 (Step 000110): Train loss 2.538, Val loss 6.938\\n\",\n \"Every effort moves you know. Gisburn's \\\"Be dissatisfied with a little Claude Nutley, and Mrs. Gisburn's \\\"Be dissatisfied with a little Claude Nutley, and Mrs. Gisburn's \\\"Be dissatisfied with a little Claude\\n\",\n \"Ep 15 (Step 000115): Train loss 2.487, Val loss 7.219\\n\",\n \"Every effort moves you like to the picture, the picture, and in the picture, the picture, the picture, and in the picture, and in the picture, and in the picture, and in the picture, and in the picture, and in the picture, and\\n\",\n \"Ep 16 (Step 000120): Train loss 2.139, Val loss 7.219\\n\",\n \"Ep 16 (Step 000125): Train loss 2.059, Val loss 6.938\\n\",\n \"Every effort moves you know,\\\" she was not till after that I was not till after. Gisburn had been denied the house.\\\" He was not till after that Mrs. Gisburn had been denied the house.\\\" He was not till after that Mrs. Gis\\n\",\n \"Ep 17 (Step 000130): Train loss 1.706, Val loss 7.250\\n\",\n \"Ep 17 (Step 000135): Train loss 1.631, Val loss 7.219\\n\",\n \"Every effort moves you know, and in the Riviera, and in the Riviera, and in the Riviera, and in the Riviera, and in the Riviera, and in the Riviera, and in the Riviera, and in the Riviera,\\n\",\n \"Ep 18 (Step 000140): Train loss 1.458, Val loss 7.406\\n\",\n \"Every effort moves you know, and I said, and I said, and twirling between his pictures? My curiosity: \\\"There: \\\"There: \\\"There: \\\"There: \\\"There: \\\"There: \\\"There: \\\"There: \\\"There: \\\"There:\\n\",\n \"Ep 19 (Step 000145): Train loss 1.155, Val loss 7.281\\n\",\n \"Ep 19 (Step 000150): Train loss 1.105, Val loss 7.531\\n\",\n \"Every effort moves you know.\\\" I have let it was no least sign of Jack's I had been surrounded by interesting--I must have let it was taken with a little quickly_ fashionable painter.\\\" \\\"When he had I had I had to have let it was one of Jack\\n\",\n \"Ep 20 (Step 000155): Train loss 0.896, Val loss 7.344\\n\",\n \"Every effort moves you know.\\\" He answered slowly: \\\"Be dissatisfied with a little quickly. \\\"Oh, and distinguished objects, and distinguished objects, and straddling and straining, and straining, and straining, and straining, and straining, and\\n\",\n \"Ep 21 (Step 000160): Train loss 0.620, Val loss 7.469\\n\",\n \"Ep 21 (Step 000165): Train loss 0.535, Val loss 7.531\\n\",\n \"Every effort moves you know.\\\" I must have given up at the sketch of the picture for he had ever of Jack's break with a little wild--because he had ever had ever had ever having been no leastburn had ever had ever of his glory, and in a\\n\",\n \"Ep 22 (Step 000170): Train loss 0.353, Val loss 7.625\\n\",\n \"Ep 22 (Step 000175): Train loss 0.227, Val loss 7.562\\n\",\n \"Every effort moves you know you know.\\\" He stood looking about to see it. The rest of the fact that, and in the air of it. He had ever had ever had ever had ever knew.\\\" \\\"You ever knew.\\\" \\\"You ever had to now it the fact that\\n\",\n \"Ep 23 (Step 000180): Train loss 0.174, Val loss 7.500\\n\",\n \"Every effort moves you know.\\\" He stood looking,\\\" he liked his bed. And it was just manage to have formed himself,\\\" she began to go under--because he didn't bear the current--because he didn't let a little wild--because he didn't you ever\\n\",\n \"Ep 24 (Step 000185): Train loss 0.094, Val loss 7.719\\n\",\n \"Ep 24 (Step 000190): Train loss 0.071, Val loss 7.656\\n\",\n \"Every effort moves you know.\\\" I couldn't bear I had to see it. I had to let it was the honour--say the honour--just a pale yellow or _rose Dubarry_ drawing-room. I made a deprecating gesture, and I had to\\n\",\n \"Ep 25 (Step 000195): Train loss 0.074, Val loss 7.781\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 26 (Step 000200): Train loss 0.030, Val loss 7.812\\n\",\n \"Ep 26 (Step 000205): Train loss 0.025, Val loss 7.844\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 27 (Step 000210): Train loss 0.019, Val loss 7.938\\n\",\n \"Ep 27 (Step 000215): Train loss 0.016, Val loss 7.906\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 28 (Step 000220): Train loss 0.011, Val loss 7.938\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 29 (Step 000225): Train loss 0.008, Val loss 7.938\\n\",\n \"Ep 29 (Step 000230): Train loss 0.007, Val loss 7.969\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 30 (Step 000235): Train loss 0.006, Val loss 7.969\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 31 (Step 000240): Train loss 0.006, Val loss 7.938\\n\",\n \"Ep 31 (Step 000245): Train loss 0.005, Val loss 7.938\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 32 (Step 000250): Train loss 0.005, Val loss 7.938\\n\",\n \"Ep 32 (Step 000255): Train loss 0.005, Val loss 7.938\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 33 (Step 000260): Train loss 0.004, Val loss 7.938\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 34 (Step 000265): Train loss 0.005, Val loss 7.938\\n\",\n \"Ep 34 (Step 000270): Train loss 0.004, Val loss 7.938\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 35 (Step 000275): Train loss 0.004, Val loss 7.969\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 36 (Step 000280): Train loss 0.004, Val loss 7.969\\n\",\n \"Ep 36 (Step 000285): Train loss 0.004, Val loss 7.969\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 37 (Step 000290): Train loss 0.004, Val loss 7.969\\n\",\n \"Ep 37 (Step 000295): Train loss 0.004, Val loss 7.969\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 38 (Step 000300): Train loss 0.004, Val loss 7.969\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 39 (Step 000305): Train loss 0.004, Val loss 7.969\\n\",\n \"Ep 39 (Step 000310): Train loss 0.004, Val loss 7.969\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\",\n \"Ep 40 (Step 000315): Train loss 0.004, Val loss 7.969\\n\",\n \"Every effort moves you know.\\\" He laughed again--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high above the current--on everlasting foundations, as you say. \\\"Well, I went off to\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Note:\\n\",\n \"# Uncomment the following code to calculate the execution time\\n\",\n \"# import time\\n\",\n \"# start_time = time.time()\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model = Llama3Model(LLAMA32_CONFIG)\\n\",\n \"model.to(device)\\n\",\n \"optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)\\n\",\n \"\\n\",\n \"num_epochs = 40\\n\",\n \"train_losses, val_losses, tokens_seen = train_model_simple(\\n\",\n \" model, train_loader, val_loader, optimizer, device,\\n\",\n \" num_epochs=num_epochs, eval_freq=5, eval_iter=5,\\n\",\n \" start_context=\\\"Every effort moves you\\\", tokenizer=tokenizer\\n\",\n \")\\n\",\n \"\\n\",\n \"# Note:\\n\",\n \"# Uncomment the following code to show the execution time\\n\",\n \"# end_time = time.time()\\n\",\n \"# execution_time_minutes = (end_time - start_time) / 60\\n\",\n \"# print(f\\\"Training completed in {execution_time_minutes:.2f} minutes.\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"0WSRu2i0iHJE\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 487\n },\n \"id\": \"0WSRu2i0iHJE\",\n \"outputId\": \"9d36c61b-517d-4f07-a7e8-4563aff78b11\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAfUAAAEiCAYAAADgc0uGAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjguMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8g+/7EAAAACXBIWXMAAA9hAAAPYQGoP6dpAABdwklEQVR4nO3dd1gUV9sH4N8usAtL71WaIk2aKIhYEiFiibFFjR9RLNHYNUZjfI2K+iYaNcYYjaYpb2I3sXfsDRuCggVBEVCajd53z/fHyOJKERDYZXnu69qwO3Nm5pkh8uyZOYXHGGMghBBCSLPHl3cAhBBCCGkYlNQJIYQQJUFJnRBCCFESlNQJIYQQJUFJnRBCCFESlNQJIYQQJUFJnRBCCFESlNQJIYQQJUFJnRBCCFESlNQJaUEePXoEHo+H6OhoeYdCCGkElNQJaWZ4PF6Nr9DQUHmHSAiRE1V5B0AIqZu0tDTp+x07dmDBggWIi4uTLtPS0pJHWIQQBUA1dUKaGTMzM+lLV1cXPB5P+tnExASrVq2ClZUVhEIhPD09cfTo0Wr3JRaLMWbMGDg5OSE5ORkAsG/fPrRv3x7q6uqwt7fHokWLUFZWJt2Gx+Phjz/+wMCBAyESieDg4ID9+/dL1798+RLBwcEwNjaGhoYGHBwcsGnTpmpj+Oeff+Dm5gYNDQ0YGhoiMDAQ+fn50vV//PEHnJ2doa6uDicnJ/zyyy8y26ekpGDo0KHQ09ODgYEB+vfvj0ePHknXjxo1CgMGDMDKlSthbm4OQ0NDTJ48GaWlpbW+5oQ0G4wQ0mxt2rSJ6erqSj+vWrWK6ejosG3btrF79+6xr776iqmpqbH79+8zxhhLTExkAFhUVBQrKipiAwcOZF5eXiwzM5Mxxti5c+eYjo4OCwsLYw8ePGDHjx9ntra2LDQ0VHoMAMzKyopt3bqVxcfHs2nTpjEtLS32/PlzxhhjkydPZp6enuzatWssMTGRhYeHs/3791cZf2pqKlNVVWWrVq1iiYmJ7NatW2zdunUsNzeXMcbY5s2bmbm5Ofv333/Zw4cP2b///ssMDAxYWFgYY4yxkpIS5uzszMaMGcNu3brF7ty5w/7v//6POTo6suLiYsYYYyEhIUxHR4dNmDCB3b17lx04cICJRCL222+/NewvgxAFQEmdkGbszaRuYWHBvv32W5kyHTt2ZJMmTWKMVST18+fPs4CAANalSxeWlZUlLRsQEMC+++47me3//vtvZm5uLv0MgH3zzTfSz3l5eQwAO3LkCGOMsX79+rHRo0fXKv7IyEgGgD169KjK9a1bt2Zbt26VWbZkyRLm5+cnjc3R0ZFJJBLp+uLiYqahocGOHTvGGOOSuo2NDSsrK5OWGTJkCBs2bFitYiSkOaFn6oQoiZycHKSmpsLf319mub+/P27evCmzbPjw4bCyssKpU6egoaEhXX7z5k1cvHgR3377rXSZWCxGUVERCgoKIBKJAADu7u7S9ZqamtDR0UFmZiYAYOLEiRg8eDBu3LiBnj17YsCAAejcuXOVMXt4eCAgIABubm4ICgpCz5498fHHH0NfXx/5+fl48OABxo4di3Hjxkm3KSsrg66urjTehIQEaGtry+y3qKgIDx48kH52dXWFioqK9LO5uTliYmJquJqENE+U1Alpgfr06YPNmzcjIiICPXr0kC7Py8vDokWLMGjQoErbqKurS9+rqanJrOPxeJBIJACA3r17IykpCYcPH0Z4eDgCAgIwefJkrFy5stI+VVRUEB4ejkuXLuH48eP4+eefMW/ePFy5ckX6BeL333+Hr69vpe3K4/X29saWLVsq7dvY2LhW8RKiTCipE6IkdHR0YGFhgYsXL6J79+7S5RcvXoSPj49M2YkTJ6Jdu3b46KOPcOjQIWn59u3bIy4uDm3atHmnWIyNjRESEoKQkBB07doVs2fPrjKpA1yC9ff3h7+/PxYsWAAbGxvs2bMHM2fOhIWFBR4+fIjg4OAqt23fvj127NgBExMT6OjovFPMhCgDSuqEKJHZs2dj4cKFaN26NTw9PbFp0yZER0dXWZOdOnUqxGIxPvzwQxw5cgRdunTBggUL8OGHH8La2hoff/wx+Hw+bt68idjYWPz3v/+tVQwLFiyAt7c3XF1dUVxcjIMHD8LZ2bnKsleuXMHJkyfRs2dPmJiY4MqVK3j69Km0/KJFizBt2jTo6uqiV69eKC4uxvXr1/Hy5UvMnDkTwcHBWLFiBfr374/FixfDysoKSUlJ2L17N7766itYWVnV/2IS0gxRUidEiUybNg3Z2dn48ssvkZmZCRcXF+zfvx8ODg5Vlp8xYwYkEgn69OmDo0ePIigoCAcPHsTixYvx/fffQ01NDU5OTvjss89qHYNAIMDcuXPx6NEjaGhooGvXrti+fXuVZXV0dHDu3DmsXr0aOTk5sLGxwQ8//IDevXsDAD777DOIRCKsWLECs2fPhqamJtzc3DBjxgwAgEgkwrlz5zBnzhwMGjQIubm5sLS0REBAANXcSYvEY4wxeQdBCCGEkHdHg88QQgghSoKSOiGEEKIkKKkTQgghSoKSOiGEEKIkKKkTQgghSoKSOiGEEKIkKKk3knXr1sHW1hbq6urw9fXF1atXG/V4S5cuRceOHaGtrQ0TExMMGDBAZo5tgBsPe/LkyTA0NISWlhYGDx6MjIwMmTLJycno27cvRCIRTExMMHv2bJlpNwHgzJkzaN++PYRCIdq0aYOwsLBK8bzL+S9btgw8Hk/aF1nRY3/y5Ak+/fRTGBoaQkNDA25ubrh+/bp0PWMMCxYsgLm5OTQ0NBAYGIj4+HiZfbx48QLBwcHQ0dGBnp4exo4di7y8PJkyt27dQteuXaGuro5WrVph+fLllWLZtWsXnJycoK6uDjc3Nxw+fLjauMViMebPnw87OztoaGigdevWWLJkCV7v5apIsZ87dw79+vWDhYUFeDwe9u7dK7NekWJ9MxZvb2/06NGjythLS0sxZ84cuLm5QVNTExYWFhg5ciRSU1MVPvY3TZgwATweD6tXr242sd+9excfffQRdHV1oampiY4dO0qnIQYU+29PleQ2lYwS2759OxMIBGzjxo3s9u3bbNy4cUxPT49lZGQ02jGDgoLYpk2bWGxsLIuOjmZ9+vRh1tbWLC8vT1pmwoQJrFWrVuzkyZPs+vXrrFOnTqxz587S9WVlZaxdu3YsMDCQRUVFscOHDzMjIyM2d+5caZmHDx8ykUjEZs6cye7cucN+/vlnpqKiwo4ePdog53/16lVma2vL3N3d2fTp0xU+9hcvXjAbGxs2atQoduXKFfbw4UN27NgxlpCQIC2zbNkypqury/bu3ctu3rzJPvroI2ZnZ8cKCwulZXr16sU8PDzY5cuX2fnz51mbNm3Y8OHDpeuzs7OZqakpCw4OZrGxsWzbtm1MQ0OD/frrr9IyFy9eZCoqKmz58uXszp077JtvvmFqamosJiamyti//fZbZmhoyA4ePMgSExPZrl27mJaWFvvpp58UMvbDhw+zefPmsd27dzMAbM+ePTLno0ixvhmLr68v09XVZdu3b68Ue1ZWFgsMDGQ7duxg9+7dYxEREczHx4d5e3vLnJ8ixv663bt3Mw8PD2ZhYcF+/PHHZhF7QkICMzAwYLNnz2Y3btxgCQkJbN++fTL/3hX1b091KKk3Ah8fHzZ58mTpZ7FYzCwsLNjSpUubLIbMzEwGgJ09e5Yxxv3hUFNTY7t27ZKWuXv3LgPAIiIiGGPcH00+n8/S09OlZdavX890dHSkc1N/9dVXzNXVVeZYw4YNY0FBQdLP9T3/3Nxc5uDgwMLDw1n37t2lSV2RY58zZw7r0qVLteckkUiYmZkZW7FihXRZVlYWEwqFbNu2bYwxxu7cucMAsGvXrknLHDlyhPF4PPbkyRPGGGO//PIL09fXl55L+bEdHR2ln4cOHcr69u0rc3xfX1/2+eefVxlb37592ZgxY2SWDRo0iAUHByt87G/+gVakWN8WS02JsdzVq1cZAJaUlNQsYn/8+DGztLRksbGxzMbGRiapK3Lsw4YNY59++mml83l9e0X921Mduv3ewEpKShAZGYnAwEDpMj6fj8DAQERERDRZHNnZ2QAAAwMDAEBkZCRKS0tl4nJycoK1tbU0roiICLi5ucHU1FRaJigoCDk5Obh9+7a0zOv7KC9Tvo93Of/Jkyejb9++lfavyLHv378fHTp0wJAhQ2BiYgIvLy/8/vvv0vWJiYlIT0+X2aeuri58fX1lYtfT00OHDh2kZQIDA8Hn83HlyhVpmW7dukEgEMjEHhcXh5cvX9bq/N7UuXNnnDx5Evfv3wfATWN64cIF6RCtihz7mxQp1trE8jbZ2dng8XjQ09NT+NglEglGjBiB2bNnw9XVtdJ6RY1dIpHg0KFDaNu2LYKCgmBiYgJfX1+ZW/SK/LenOpTUG9izZ88gFotlfsEAYGpqivT09CaJQSKRYMaMGfD390e7du0AAOnp6RAIBNI/ElXFlZ6eXmXc5etqKpOTk4PCwsJ6n//27dtx48YNLF26tNI6RY794cOHWL9+PRwcHHDs2DFMnDgR06ZNw//+9z+ZY9e0z/T0dJiYmMisV1VVhYGBQYOcX3Wxf/311/jkk0/g5OQENTU1eHl5YcaMGdIZ0RQ59jcpUqy1iaUmRUVFmDNnDoYPHy4dv16RY//++++hqqqKadOmVbleUWPPzMxEXl4eli1bhl69euH48eMYOHAgBg0ahLNnz0r3qah/e6pDE7ooocmTJyM2NhYXLlyQdyi1kpKSgunTpyM8PFxmzu7mQCKRoEOHDvjuu+8AAF5eXoiNjcWGDRsQEhIi5+hqtnPnTmzZsgVbt26Fq6sroqOjMWPGDFhYWCh87MqqtLQUQ4cOBWMM69evl3c4bxUZGYmffvoJN27cAI/Hk3c4dSKRSAAA/fv3xxdffAEA8PT0xKVLl7BhwwaZ6YubE6qpNzAjIyOoqKhUah2ZkZEBMzOzRj/+lClTcPDgQZw+fVpm2kkzMzOUlJQgKyur2rjMzMyqjLt8XU1ldHR0oKGhUa/zj4yMRGZmJtq3bw9VVVWoqqri7NmzWLNmDVRVVWFqaqqwsZubm8PFxUVmmbOzs7T1bPl2Ne3TzMwMmZmZMuvLysrw4sWLBjm/6mKfPXu2tLbu5uaGESNG4IsvvpDeLVHk2N+kSLHWJpaqlCf0pKQkhIeHy8wyp6ixnz9/HpmZmbC2tpb+201KSsKXX34JW1tbhY7dyMgIqqqqb/33q6h/e6pDSb2BCQQCeHt74+TJk9JlEokEJ0+ehJ+fX6MdlzGGKVOmYM+ePTh16hTs7Oxk1nt7e0NNTU0mrri4OCQnJ0vj8vPzQ0xMjMw/wPI/LuX/4/v5+cnso7xM+T7qc/4BAQGIiYlBdHS09NWhQwcEBwdL3ytq7P7+/pW6Dt6/fx82NjYAADs7O5iZmcnsMycnB1euXJGJPSsrC5GRkdIyp06dgkQiga+vr7TMuXPnUFpaKhO7o6Mj9PX1a3V+byooKACfL/snQEVFRVqDUeTY36RIsdYmljeVJ/T4+HicOHEChoaGMusVNfYRI0bg1q1bMv92LSwsMHv2bBw7dkyhYxcIBOjYsWON/34V+e9mterUrI7Uyvbt25lQKGRhYWHszp07bPz48UxPT0+mdWRDmzhxItPV1WVnzpxhaWlp0ldBQYG0zIQJE5i1tTU7deoUu379OvPz82N+fn7S9eVdM3r27Mmio6PZ0aNHmbGxcZVdM2bPns3u3r3L1q1bV2XXjHc9/9dbvyty7FevXmWqqqrs22+/ZfHx8WzLli1MJBKxzZs3S8ssW7aM6enpsX379rFbt26x/v37V9nVysvLi125coVduHCBOTg4yHT5ycrKYqampmzEiBEsNjaWbd++nYlEokpdflRVVdnKlSvZ3bt32cKFC2vs0hYSEsIsLS2lXdp2797NjIyM2FdffaWQsefm5rKoqCgWFRXFALBVq1axqKgoaQtxRYr1zVj69u3LLCws2OXLlyvFXlJSwj766CNmZWXFoqOjZf79vt4aXBFjr8qbrd8VOfbdu3czNTU19ttvv7H4+HhpV7Pz589L96mof3uqQ0m9kfz888/M2tqaCQQC5uPjwy5fvtyoxwNQ5WvTpk3SMoWFhWzSpElMX1+fiUQiNnDgQJaWliazn0ePHrHevXszDQ0NZmRkxL788ktWWloqU+b06dPM09OTCQQCZm9vL3OMcu96/m8mdUWO/cCBA6xdu3ZMKBQyJycn9ttvv8msl0gkbP78+czU1JQJhUIWEBDA4uLiZMo8f/6cDR8+nGlpaTEdHR02evRolpubK1Pm5s2brEuXLkwoFDJLS0u2bNmySrHs3LmTtW3blgkEAubq6soOHTpUbdw5OTls+vTpzNramqmrqzN7e3s2b948mUSiSLGfPn26yv/HQ0JCFC7WN2Np3759tbEnJiZW++/39OnTCh17VapK6ooc+59//snatGnD1NXVmYeHB9u7d6/MPhX5b09VeIy9NnwUIYQQQpoteqZOCCGEKAlK6oQQQoiSoKROCCGEKAlK6oQQQoiSoKROCCGEKAlK6oQQQoiSoKTeiIqLixEaGori4mJ5h1JnFLt8UOzy05zjp9jlQxFjp37qjSgnJwe6urrIzs6WGce5OaDY5YNil5/mHD/FLh+KGDvV1AkhhBAlQUmdEEIIURI0n3oVysrKEBUVBVNT00qzWNVFbm4uAODJkyfIyclpqPCaBMUuHxS7/DTn+Cl2+WjM2CUSCTIyMuDl5QVV1dqnanqmXoVr167Bx8dH3mEQQghp4a5evYqOHTvWujzV1KtgamoKgLuY5ubmco6GEEJIS5OWlgYfHx9pPqotSupVKL/lbm5uDisrKzlHQwghpKWq6yNgaihHCCGEKAlK6oQQQoiSoKROCCGEKAl6pk4IIXUgFotRWloq7zCIEhAIBO/UbboqlNQJIaQWGGNIT09HVlaWvEMhSoLP58POzg4CgaDB9klJvbFl3AGeJwBtAgCBpryjIYTUU3lCNzExgUgkAo/Hk3dIpBmTSCRITU1FWloarK2tG+z/J0rqje2v/kB+JjDuNGDZXt7REELqQSwWSxO6oaGhvMMhSsLY2BipqakoKyuDmppag+yTGso1NiMH7ufzBPnGQQipt/Jn6CKRSM6REGVSfttdLBY32D4pqTc2w9bcT0rqhDR7dMudNKTG+P+JknpjM2zD/aSkTgghpJFRUm9shq9uvz+Ll28chBDSQGxtbbF69epalz9z5gx4PF6j9xwICwuDnp5eox5D0VFSb2zSmvoDgCbEI4Q0IR6PV+MrNDS0Xvu9du0axo8fX+vynTt3RlpaGnR1det1PFJ71Pq9senbAjwVoDQfyE0DdCzkHREhpIVIS0uTvt+xYwcWLFiAuLg46TItLS3pe8YYxGJxrebuNjY2rlMcAoEAZmZmddqG1A/V1BubqgDQt+He03N1QkgTMjMzk750dXXB4/Gkn+/duwdtbW0cOXIE3t7eEAqFuHDhAh48eID+/fvD1NQUWlpa6NixI06cOCGz3zdvv/N4PPzxxx8YOHAgRCIRHBwcsH//fun6N2+/l98mP3bsGJydnaGlpYVevXrJfAkpKyvDtGnToKenB0NDQ8yZMwchISEYMGBAna7B+vXr0bp1awgEAjg6OuLvv/+WrmOMITQ0FNbW1hAKhbCwsMC0adOk63/55Rc4ODhAXV0dpqam+Pjjj+t0bHmgpN4UDKlbGyHKhjGGgpIyubxYAz7K+/rrr7Fs2TLcvXsX7u7uyMvLQ58+fXDy5ElERUWhV69e6NevH5KTk2vcz6JFizB06FDcunULffr0QXBwMF68eFFt+YKCAqxcuRJ///03zp07h+TkZMyaNUu6/vvvv8eWLVuwadMmXLx4ETk5Odi7d2+dzm3Pnj2YPn06vvzyS8TGxuLzzz/H6NGjcfr0aQDAv//+ix9//BG//vor4uPjsXfvXri5uQEArl+/jmnTpmHx4sWIi4vD0aNH0a1btzodXx7o9ntTMGwDxB8DnlFSJ0RZFJaK4bLgmFyOfWdxEESChvnzvXjxYnzwwQfSzwYGBvDw8JB+XrJkCfbs2YP9+/djypQp1e5n1KhRGD58OADgu+++w5o1a3D16lX06tWryvKlpaXYsGEDWrfmuv1OmTIFixcvlq7/+eefMXfuXAwcOBAAsHbtWhw+fLhO57Zy5UqMGjUKkyZNAgDMnDkTly9fxsqVK/H+++8jOTkZZmZmCAwMhJqaGqytreHj4wMASE5OhqamJj788ENoa2vDxsYGXl5edTq+PFBNvRFlF5ZixbF72Pbw1bi+VFMnhCiYDh06yHzOy8vDrFmz4OzsDD09PWhpaeHu3btvram7u7tL32tqakJHRweZmZnVlheJRNKEDgDm5ubS8tnZ2cjIyJAmWABQUVGBt7d3nc7t7t278Pf3l1nm7++Pu3fvAgCGDBmCwsJC2NvbY9y4cdizZw/KysoAAB988AFsbGxgb2+PESNGYMuWLSgoKKjT8eWBauqNSKjKx4azD+EDEYYLQEmdECWioaaCO4uD5HbshqKpKTsnxaxZsxAeHo6VK1eiTZs20NDQwMcff4ySkpIa9/PmMKc8Hg8SiaRO5RvysUJttGrVCnFxcThx4gTCw8MxadIkrFixAmfPnoW2tjZu3LiBM2fO4Pjx41iwYAFCQ0Nx7do1he42J9ea+rlz59CvXz9YWFiAx+NVel7CGMOCBQtgbm4ODQ0NBAYGIj7+7f29161bB1tbW6irq8PX1xdXr15tpDOombqaChxMtPBQYg4GHsDjATX8T04IaT54PB5EAlW5vBpzZLuLFy9i1KhRGDhwINzc3GBmZoZHjx412vGqoqurC1NTU1y7dk26TCwW48aNG3Xaj7OzMy5evCiz7OLFi3BxcZF+1tDQQL9+/bBmzRqcOXMGERERiImJAQCoqqoiMDAQy5cvx61bt/Do0SOcOnXqHc6s8cm1pp6fnw8PDw+MGTMGgwYNqrR++fLlWLNmDf73v//Bzs4O8+fPR1BQEO7cuQN1dfUq97ljxw7MnDkTGzZsgK+vL1avXo2goCDExcXBxMSksU+pEjdLXexK18eaTucwvZf72zcghBA5cnBwwO7du9GvXz/weDzMnz+/xhp3Y5k6dSqWLl2KNm3awMnJCT///DNevnxZpy80s2fPxtChQ+Hl5YXAwEAcOHAAu3fvlrbmDwsLg1gshq+vL0QiETZv3gwNDQ3Y2Njg4MGDePjwIbp16wZ9fX0cPnwYEokEjo6OjXXKDUKuNfXevXvjv//9r7QhxOsYY1i9ejW++eYb9O/fH+7u7vjrr7+QmppaYwvIVatWYdy4cRg9ejRcXFywYcMGiEQibNy4sRHPpHrtLHUB8HAzvVguxyeEkLpYtWoV9PX10blzZ/Tr1w9BQUFo377pZ5icM2cOhg8fjpEjR8LPzw9aWloICgqqtkJXlQEDBuCnn37CypUr4erqil9//RWbNm3Ce++9BwDQ09PD77//Dn9/f7i7u+PEiRM4cOAADA0Noaenh927d6NHjx5wdnbGhg0bsG3bNri6ujbSGTcMHmvqhxjV4PF42LNnj7QP4sOHD9G6dWtERUXB09NTWq579+7w9PTETz/9VGkfJSUlEIlE+Oeff2T6MoaEhCArKwv79u2r8tjFxcUoLq5Iuk+ePIGLiwtSUlJgZWX1TucVmfQSg9dfgrG2ENfmBb7Tvggh8lFUVITExETY2dnVKamQhiORSODs7IyhQ4diyZIl8g6nQdT0/9Xjx4/RqlWrOuchhW39np6eDgAwNTWVWW5qaipd96Znz55BLBbXaRsAWLp0KXR1daWv15+3vCsXcx3weYBX/gWU/PYBcPybBts3IYQoq6SkJPz++++4f/8+YmJiMHHiRCQmJuL//u//5B2aQlPYpN6U5s6di+zsbOnrzp07DbZvDYEK2phoQQPFEKReBZ7UraEHIYS0RHw+H2FhYejYsSP8/f0RExODEydOwNnZWd6hKTSF7dJWPk5wRkYGzM3NpcszMjJkbse/zsjICCoqKsjIyJBZnpGRUeO4w0KhEEKhUPo5JyfnHSKvrJ2lLi5lOOOw47fo06NHg+6bEEKUUatWrSq1XCdvp7A1dTs7O5iZmeHkyZPSZTk5Obhy5Qr8/Pyq3EYgEMDb21tmG4lEgpMnT1a7TVNoZ6GLdBhid0knwLThbu0TQgghr5NrTT0vLw8JCRUDsiQmJiI6OhoGBgawtrbGjBkz8N///hcODg7SLm0WFhYyjeACAgIwcOBA6fCFM2fOREhICDp06AAfHx+sXr0a+fn5GD16dFOfnpSbFTfdYOyTbLnFQAghRPnJNalfv34d77//vvTzzJkzAXCt1cPCwvDVV18hPz8f48ePR1ZWFrp06YKjR4/KtBJ88OABnj17Jv08bNgwPH36FAsWLEB6ejo8PT1x9OjRSo3nmpKLuQ54PMA8NwZ5Z25Dq40/YFW34Q4JIYSQt1GYLm2KpL5dCWoS8MMZfPZyNYarnga6zwHe/0+D7JcQ0vioSxtpDC2qS5uyaWepi4fsVYM/GgOeEEJII6Ck3kTcLHWRWJ7Un719/HpCCCGkriipNxFXC10kslfd6p4/AOipByGkmXjvvfcwY8YM6WdbW1usXr26xm2qmqSrPhpqPzUJDQ2ttqt0c0NJvYm4WuogmZmijPGB0nwgt/oR7gghpCH069cPvXr1qnLd+fPnwePxcOvWrTrv99q1axg/fvy7hiejusSalpaG3r17N+ixlBkl9Saio64GKyNdpDBjbsFzugVPCGlcY8eORXh4OB4/flxp3aZNm9ChQwe4u9d99khjY2OIRKKGCPGtzMzMZAYHIzWjpN6EXC10Kp6rU2M5Qkgj+/DDD2FsbIywsDCZ5Xl5edi1axfGjh2L58+fY/jw4bC0tIRIJIKbmxu2bdtW437fvP0eHx+Pbt26QV1dHS4uLggPD6+0zZw5c9C2bVuIRCLY29tj/vz5KC0tBcBNgbpo0SLcvHkTPB4PPB5PGvObt99jYmLQo0cPaGhowNDQEOPHj0deXp50/ahRozBgwACsXLkS5ubmMDQ0xOTJk6XHqg2JRILFixfDysoKQqFQ2jW6XElJCaZMmQJzc3Ooq6vDxsYGS5cuBcDNMBoaGgpra2sIhUJYWFhg2rRptT72u1LYYWKVkZulLh7eMUcPRAPPKKkTohRK8uu+jYoQUHn151dcBoiLAR4fUNN4+34FmrU+jKqqKkaOHImwsDDMmzdPOhf5rl27IBaLMXz4cOTl5cHb2xtz5syBjo4ODh06hBEjRqB169bw8fF56zEkEgkGDRoEU1NTXLlyBdnZ2TLP38tpa2sjLCwMFhYWiImJwbhx46CtrY2vvvoKw4YNQ2xsLI4ePSqd61xXV7fSPvLz8xEUFAQ/Pz9cu3YNmZmZ+OyzzzBlyhSZLy6nT5+Gubk5Tp8+jYSEBAwbNgyenp4YN25cra7bTz/9hB9++AG//vorvLy8sHHjRnz00Ue4ffs2HBwcsGbNGuzfvx87d+6EtbU1UlJSkJKSAgD4999/8eOPP2L79u1wdXVFeno6bt68WavjNgRK6k2onaUuDlNNnRDl8p1F3bcZEga4DuTe3zsA7BoF2HQBRh+qKLPaDSh4Xnnb0LqNTDlmzBisWLECZ8+elc4jvmnTJgwePFg6M+WsWbOk5adOnYpjx45h586dtUrqJ06cwL1793Ds2DFYWHDX4rvvvqv0HPybbypmqLS1tcWsWbOwfft2fPXVV9DQ0ICWlhZUVVVrnKdj69atKCoqwl9//QVNTe7Lzdq1a9GvXz98//330kHG9PX1sXbtWqioqMDJyQl9+/bFyZMna53UV65ciTlz5uCTTz4BAHz//fc4ffo0Vq9ejXXr1iE5ORkODg7o0qULeDwebGxspNsmJyfDzMwMgYGBUFNTg7W1da2uY0Oh2+9NqJ1FRV918dP7co6GENISODk5oXPnzti4cSMAICEhAefPn8fYsWMBAGKxGEuWLIGbmxsMDAygpaWFY8eOITk5uVb7v3v3Llq1aiVN6ACqnGtjx44d8Pf3h5mZGbS0tPDNN9/U+hivH8vDw0Oa0AHA398fEokEcXFx0mWurq5QUVGRfjY3N0dmZmatjpGTk4PU1FT4+/vLLPf398fdu3cBcLf4o6Oj4ejoiGnTpuH48ePSckOGDEFhYSHs7e0xbtw47NmzB2VlZXU6z3dBNfUmpCtSQ5GOHVAE8LOTgbISQFUg77AIIe/iP6l130bltYZfTv24ffDeqGPNiHm3uF4zduxYTJ06FevWrcOmTZvQunVrdO/eHQCwYsUK/PTTT1i9ejXc3NygqamJGTNmoKSkpMGOHxERgeDgYCxatAhBQUHQ1dXF9u3b8cMPPzTYMV6npqYm85nH40EikTTY/tu3b4/ExEQcOXIEJ06cwNChQxEYGIh//vkHrVq1QlxcHE6cOIHw8HBMmjRJeqfkzbgaA9XUm5i5lR3ymRA8JgZePpJ3OISQdyXQrPtL5bX6lIoqt+z15+k17bcehg4dCj6fj61bt+Kvv/7CmDFjpM/XL168iP79++PTTz+Fh4cH7O3tcf9+7e8kOjs7IyUlBWlpadJlly9flilz6dIl2NjYYN68eejQoQMcHByQlJQke7oCAcRi8VuPdfPmTeTnV7Q3uHjxIvh8PhwdHWsdc010dHRgYWFRadrXixcvwsXFRabcsGHD8Pvvv2PHjh34999/8eLFCwCAhoYG+vXrhzVr1uDMmTOIiIhATEzDfUmrCdXUm5irpR6uxTnBQouHtuJieYdDCGkBtLS0MGzYMMydOxc5OTkYNWqUdJ2DgwP++ecfXLp0Cfr6+li1ahUyMjJkElhNAgMD0bZtW4SEhGDFihXIycnBvHnzZMo4ODggOTkZ27dvR8eOHXHo0CHs2bNHpoytra10pk4rKytoa2tX6soWHByMhQsXIiQkBKGhoXj69CmmTp2KESNGNOikXbNnz8bChQvRunVreHp6YtOmTYiOjsaWLVsAAKtWrYK5uTm8vLzA5/Oxa9cumJmZQU9PD2FhYRCLxfD19YVIJMLmzZuhoaEh89y9MVFNvYm5WepiVOkcfK6yCDBzk3c4hJAWYuzYsXj58iWCgoJknn9/8803aN++PYKCgvDee+/BzMxMZnrrt+Hz+dizZw8KCwvh4+ODzz77DN9++61MmY8++ghffPEFpkyZAk9PT1y6dAnz58+XKTN48GD06tUL77//PoyNjavsVicSiXDs2DG8ePECHTt2xMcff4yAgACsXbu2bhfjLaZNm4aZM2fiyy+/hJubG44ePYr9+/fDwcEBANeSf/ny5ejQoQM6duyIR48e4fDhw+Dz+dDT08Pvv/8Of39/uLu748SJEzhw4AAMDQ0bNMbq0CxtVWiMWdrKvcgvQfslXB/OW6E9oaPe+M9YCCHvhmZpI42BZmlTAgaaAljqcc/O7qY8e0tpQgghpPYoqcvB+0bZuCScgna7usg7FEIIIUqEkroctGplCwveC6iV5gKlhfIOhxBCiJKgpC4HbW0tMbbkSwzU/KtyNxZCCCGknqhLmxy0s9DFSYk3eM/FyCsug5aQfg2EEELeHdXU5cBYWwgrfQ0wBlxNfA5QBwRCmoWGHJWMkMbofEZVRDnp6mAMRG6C6975wIffAO0GyTskQkg1BAIB+Hw+UlNTYWxsDIFAIB2RjZD6YIzh6dOn4PF4DTp8LCV1Oene1ggPbzyFadED4M5eSuqEKDA+nw87OzukpaUhNbUeY70TUgUejwcrKyuZyWfeFSV1OfFrbYRfWCdMwn5I7h8DvyS/3uM6E0Ian0AggLW1NcrKyt46RjkhtaGmptagCR2gpC43uhpqULP0RHK6MazLngLxxyvmVyaEKKTyW6XV3i6VSIDMO0BGLKAmAkSG3EvTCNDQB/gqXBkw7j0APL0PpFwBdC2B1j0q9hX5P4CJgcIsbl71ghdAwbOK96yKLxZ9fgDa9uTep8cAN/4CTJyBDmMqykRtASSldTtx686AcVvuffYTICEc0DAAXD6qKBP7L1CcW7v9MQaU5AM2foClN7fsyQ1gz+fcfsceqyi7bTh3PeuifQjQbVZFvJt6AaoawJSrFWX2TgYenavbfp0/AoJeDYFbUgD84su9n3QFEIjqtq9GQkldjrq2Ncbh1E6YwD8A3N5LSZ2Q5kYiBh5fA5IuAckRQPIVoDi7msI8QKgNlOQBow4BNp25xYlngcOzAKcPZZP6wS+qTtw1KS2oeJ9xB7j6G2DXXTapH/0aKM6p2377/VSR1J/eAw5M5+aueD2pn/ov8OJh3fYbsLAiqfNVgWf3AV1r2TK5aUBW3eZdR1FWxXtJGbe92htJNz+z7vstePHaB/ba9orT2JmSuhx1a2uMhSd9MUH1AFj8cfBKChTm2x4hLZK4FCh8CeS/qhEbtgZ0Xk1+khoNRKwFtM2Anv/llknEwF/9gbKiin0ItABzT642XPCcexW+BMAqkmnB84ryhm0Ah56AZXvZWBx7czVadV1A07Ci1i8yAkQGAL+KuwUGdhXvTZyAbrMB3VayZRw+qPugV6/vQ9MIcOwD6L0x65hdd8DYqfb7VBMBRg4Vnw1bAyEHufN93YD1XK24LrRMKt5rmwGfnQLebNgY9B3Q/eu67VdkUPFeVZ3bb/l7BUETulShMSd0eV2ZWIL2S47jkGQKWvGfAkP/Alz6N9rxCCFVePkIuHsQuHeQuw3OXuu21u8nwHsU9/7BaeDvAYCxMzD5tfnCd47kkrtNZ+5l6iY7XzoAiMu4xF6UxdXWRYaACk3mRKpX3zyk8DV1W1tbJCUlVVo+adIkrFu3rtLysLAwjB49WmaZUChEUVFRpbLypqrCRxcHYxy664sJ/IPcLXhK6oS8u/RYIHIT0Ht5xbPrpAju1rGxI1dLvH8MuHsAyIh5Y2Me9/xbZAiovDaft7ET0PNbQPeNP7BD/3p7PCqqgJYx9yKkESl8Ur927ZpMS9PY2Fh88MEHGDJkSLXb6OjoIC4uTvpZkfuTdnUwxrZYX0xQPcj9kSktpKFjCXl4hmtAZtwWMHLkbqHW9t9xaSHwvw+5mrFFe8ArmFse+y9w7ffK5Xl8wMafe6bdNoi71fxmTRsAdMyBzlPqfUqENAWFT+rGxrLfbJctW4bWrVuje/fu1W7D4/FgZmbW2KE1iK4ORpjL7PGYGcGq9BkQHy7b+IQQRVNSwD1Dfv35Yn2VFgHnf+Aam/3fDkD1Vc045h8g6u+KckId7vmrkSP309iRe69vyyXgkgLuyzCPx/3s+iXwJLKiMRrAtQJvE8h9WSh4Dth15RK5Y2/uOTEhSkDhk/rrSkpKsHnzZsycObPG2ndeXh5sbGwgkUjQvn17fPfdd3B1da22fHFxMYqLi6Wfc3Nr2S2jAVjpi2BvrIXDL30xXvUQNxANJXWiiBjjartHv+Yainl8UrvtCl9yCfbpfa51s0CzoluQqpC7TZ7/FEiNAqw7ccstvLjE+zQOeJnINTB7Esm9XsdX4xpYFbwA+q+r6M7lN6Vyzb7jWO5FiBJrVkl97969yMrKwqhRo6ot4+joiI0bN8Ld3R3Z2dlYuXIlOnfujNu3b1fb2GDp0qVYtGhRI0X9dt0cjHE44lVSjztKt+BJ08rN4LpCvd5yuiriEuD0d9xPG/+K5fEnuGfF5h4Vy3LSuIZndw8Ajy7Ids3SsaxI6jwe0HUWl9wN7CvKvJ6Ay4q5rlJP47gvBc/uc++fJ3BxP73Hlbv2R0VSV+BHboQ0pmbV+j0oKAgCgQAHDhyo9TalpaVwdnbG8OHDsWTJkirLvFlTf/LkCVxcXBq99Xu5U/cyMCbsGi5rzICppgp4n/4LmLVr9OOSFi7zLnDhR+5WNxMDRm0B537cLWkLLy4xSl4l4/LGZonngOTLgP8MQFUAlJUAa7yAnMdct6xWPtwX0yfXZY9l2Ia7/W3kyN06dxvy7olXIuGO++w+dxvf4YOK2/eENHNK2/q9XFJSEk6cOIHdu3fXaTs1NTV4eXkhISGh2jJCoRBCYcUfg5ycOg7M8I587QyhpsLH4MJvsHnSYNgZazfp8UkL8ziSe44dd6hiWfnAH+d/4F46VoBTX66Ll/swwG8SV86uG/cqV5LHjQoW+y83KmL88Yp1rXy5LwjOH8rWwhsKnw/oWXMvQgiAZpTUN23aBBMTE/Tt27dO24nFYsTExKBPnz6NFNm70xSqooONASIeMpyLf84l9Wt/AJomQOv3uX6tb5JIgOwU7g9xSR5XEzJsQ7ftlcGtndwgKM79AHWdd9vXkTnciFr+MwC9Vlx/6Z0jgJwnAHhc+40uM7lb7/HhwN393O30nMfA1V+5feRlcrfCq6oFiwyAwX8A780FLq8HclKBNgHcFwLt5tFYlRBl0iySukQiwaZNmxASEgJVVdmQR44cCUtLSyxduhQAsHjxYnTq1Alt2rRBVlYWVqxYgaSkJHz22WfyCL3WurY1QsTD5zgf/xQhvlZA+EIuWU+4WHEr/tqfQNLFV88VE4CyN0eF4nG1FmNH7laqlglXWypvfJRxG9gZwg2uMflqRbed5w8AdT1u1KqSgtfGl34O5D+veF++PP854PMZ0G5wU12eluXgTKAkl6sBlyf1+HBuLG//6RW3wt+UcpX7QtBnRcWt7ZvbgKJswOdz7rOKKtDlC26c7S5fVAz9CQBuH3Ov0kKuS1ncYa4/d5eZb7+tbdga6LvynU6bEPLumkVSP3HiBJKTkzFmzJhK65KTk8Hn86WfX758iXHjxiE9PR36+vrw9vbGpUuX4OLi0pQh11k3B2MsPxqHiAfPUVKYC4H7MG4SA5PX4k44KXvLVEXA1c4FmsCzeG60qqwk7lV+G7TbVxVJXUUIPI+v6AZUbt9kbtxqFQHXCKo2Wr9f8f5pHHB4Nlebo8Fz6ibpEnBpLTBkU0XibP0+12WsfKzqwixg70SuhfiDU8DAX7nJP8oxBlzf+KpWXgqYunBjfTMGvD+P2+71WrPPuJpjUtPgunk59m7QUyWENL5m1VCuqTTVMLGvk0gYOn57As/zS7B9fCd0sjesXOj2Xm5Iy/KauJ5NRXJmjBuv+lncq1bC8Vyt2qlPxUQxpUVcAyYNfcD0tS5+v73HjWtdPimBioAbX7rSeNOG3O1WkSE3mUP5uM1H/wNcXgc49gWGb311rEIuBiMHeiRQFXEpcPZ77vk1kwA95lfMKvUmxoCozVzSLs3n7qp8tIb7AlVaBBz+klsPcMv6r6v6kQ0hpNlQ+oZyyo7P56GLgxH2RafifPzTqpO664Dqd8DjVQxDadul6jJq6lWvG3+m4ra7hj43IUVdWib7fs5NRGPbtWJZegzw5weQPhIwast9GWnlw03j2JKHy3zxEPh3XEULcc9g7hpWh8cD2o/gBlL5dyzXn3vnSMDzU26az9Qb3KhoAQu4Z+fUnYuQFouSugLp5mCMfdGpOHf/GWYHNfHBBSJAUM9WxPo2QI9vZJcVvOBqlK8/EkgIByJerTd04J4ZW7+aBEP/jRmflJFEzDWAPLmYay8h1AX6/Vj7tgmGrYExx4Ez3wEXVgPRr2rnGvrA4D+5BmqEkBaNkroC6erADVUZm5qN6JQseLbSk29A78KxFzDnUcUjgWf3udp78mWudvk8nnvdeDUZhlVHoH0IV2t9rY1EsyEurXnWrfRY4MC0ihHRbPy5Z+N6rarfpiqqAiAwlJt3e/80bnjTwX9w7SQIIS0eJXUFYqKjjgAnE5y8l4mRf17Bls86wc1K9+0bKqrqHgkUvOD6Pydd4pL8k0hu7O+yYu42c3OTlQKs9+e+yAzYIPulpLQQOLscuLSG61om1AECFwLeY97ty4tdN2BaFN1qJ4TIoKSuYH4a7oVRG6/ietJLfPrnFWwd5wtXi2ac2KsiMpBtXZ2XCURv4Rr+lSvKAbYO5VruB4bKJcwqPYsHIsMA03aA53Bu2f2jQHE2l9xfT9SX1nK3218mcp+dPuS6m+lYNEwslNAJIW+gpK5gtISq2DS6I0ZuvIqo5Cx8+scVbB3XCc7m7zgIiSLTMuH6TL8uZhfXza6sSHb5n0Fct7u6tKjvPLV23bOykoG7B7luY6UFldcX5wLpt7j3pu24CU14PKDDWG7cc0lZRdn8Z0D4fK5lu7Y5l8yd+9U+ZkIIqQdK6gpIW10N/xvjgxF/XMHNx9kI/uMKto3rBEezFtRNyaU/oKouO+iJuIy7VS8prdu+3IZUvM+4w80K5jqwYlrO+BPAyUUVCbsmPD7gEAR4j6pYxudzrfpfl5PKNQI0dwfe+xpQV7K7LYQQhURJXUHpqKvhr7G++PSPK4h5ko3gPy5j+/hOaGPSQhK7phHgFSy7jMcHPj8LvEiUrRW/zeuzh93ZC1z9jUu65Umdr8IldB6fS8ROfbiZxN7E4wNWHWp3+9zcHRh96O3lCCGkAVFSV2C6Gmr4e6wPgv+4gtupORi47hK6OBjBr7Uh/OwN0cZEq8Z55ZUOn88NmvP6wDl1ZdcdyH5SMUUnwDXi+2gtd4te0+jd4ySEEDmhEeWqII8R5WryMr8EIzZeQewT2dnjjLSE6GRvgG4OxujlZgYd9Rq6VBFCCGk26puHKKlXQdGSOgCUiSWITslCxIPnuJz4HNcfvURxmUS6Xl2Nj97tzDGkgxU62RmCz29BNXhCCFEyNEysklNV4aODrQE62BpgKhxQXCZGdHIWLj14jsMxaYjPzMOeqCfYE/UEVvoa+NjbCj2cTFBcJkFOYSlyikqRU1iG7MJSCFT56NPOHNaGInmfFiGEkAZUr5p6SkoKeDye9NvD1atXsXXrVri4uGD8+PENHmRTU8Saek0YY7j5OBs7r6fgQHQqcotr14isk70Bhni3Qm83M4gE9P2OEEIURZPefu/atSvGjx+PESNGID09HY6OjnB1dUV8fDymTp2KBQsW1HWXCqW5JfXXFZaIcex2OnZFpuBeWi601VWho6EGHXU16GqoQUdDFY9fFuJCwjOU/+a1hKr40N0cfd3NoS8SQF2ND6GqCoSq3E8GhrTsIqRnFyE1u5D7mVWEErEEH3lYIMDJhG73E0JIA2rSpK6vr4/Lly/D0dERa9aswY4dO3Dx4kUcP34cEyZMwMOHD+u6S4XSnJN6bT3JKsTuyMfYFfkYyS+qGGilDuyMNDHG3xaDva2oxk8IIQ2gSZ+pl5aWQijkBgU5ceIEPvroIwCAk5MT0tLS6rNL0sQs9TQwNcABk99vg6uPXmDn9RTcSHqJolIJisvEKC6ToKhUDMmrr3wGmgKY6ajDQk8dZrrqMNfVQFZBCbZfS0His3zM33cbK4/fR7CvNUI628JUR12+J0gIIS1QvZK6q6srNmzYgL59+yI8PBxLliwBAKSmpsLQsIp5wInC4vN56GRvWPX87eBa3YsZg1BVpcr1MwLbYtf1FGy69AhJzwvwy5kH+PXcQ3i20kOXNkbo6mAEj1Z6UFNphjOvEUJIM1Ov2+9nzpzBwIEDkZOTg5CQEGzcuBEA8J///Af37t3D7t27GzzQptQSbr83NLGE4cTdDPx5PhFXH72QWaclVEUne0N0b2uEAV6W0Kb+9IQQUqMm76cuFouRk5MDfX196bJHjx5BJBLBxMSkPrtUGJTU383jlwW4EP8M5xOe4WLCM2QVVIzVridSw7iu9gjpbAstIT1/J4SQqjRpUi8sLARjDCIR1885KSkJe/bsgbOzM4KCguq6O4VDSb3hiCUMt1OzcT7+GXbfeIwHT/MBcM/oP+9mjxF+NtS4jhBC3lDfPFSvB539+/fHX3/9BQDIysqCr68vfvjhBwwYMADr16+vzy6JklLh8+BupYfJ77fB8S+6Y/UwT9gZaeJFfgmWHrmHbstP44/zD1FUKpZ3qIQQ0uzVK6nfuHEDXbt2BQD8888/MDU1RVJSEv766y+sWbOmQQMkykOFz8MAL0uEf9ENK4d4wNpAhGd5JfjvobvovuI0tlxJQqlY8vYdEUIIqVK9knpBQQG0tbkpQI8fP45BgwaBz+ejU6dOSEpKatAAifJRVeHjY28rnPyyO5YNcoOlngYycooxb08sAn44i71RTyCW0JQEhBBSV/VK6m3atMHevXuRkpKCY8eOoWdPbhrLzMxM6OjoNGiARHmpqfDxiY81Ts3qjtB+LjDSEiD5RQFm7IhGn5/O4/jtdNB8Q4QQUnv1SuoLFizArFmzYGtrCx8fH/j5+QHgau1eXl4NGiBRfkJVFYzyt8PZ2e9jdpAjdNRVEZeRi/F/R+LLnTdRUka35AkhpDbq3aUtPT0daWlp8PDwAJ/PfTe4evUqdHR04OTk1KBBNjVq/S5f2QWl2HDuAX479xBiCUNXByOs/9SbusARQlqMJm39DgBmZmbw8vJCamoqHj9+DADw8fFp9gmdyJ+uSA1zejnhj5AO0FBTwfn4Zxj2awQyc4rkHRohhCi0eiV1iUSCxYsXQ1dXFzY2NrCxsYGenh6WLFkCiaThbpWGhoaCx+PJvN72pWHXrl1wcnKCuro63NzccPjw4QaLhzSt9x1NsOPzTjDSEuB2ag4G/nIJCZl58g6LEEIUVr2S+rx587B27VosW7YMUVFRiIqKwnfffYeff/4Z8+fPb9AAXV1dkZaWJn1duHCh2rKXLl3C8OHDMXbsWERFRWHAgAEYMGAAYmNjGzQm0nTcrfTw78TOsDPSxJOsQny84RIik168fUNCCGmB6vVM3cLCAhs2bJDOzlZu3759mDRpEp48edIgwYWGhmLv3r2Ijo6uVflhw4YhPz8fBw8elC7r1KkTPD09sWHDhlofl56pK57necUY+7/riE7JglCVjyEdrNCljTH8WhtCV4PGkieEKJcmfab+4sWLKm+DOzk54cWLhq1FxcfHw8LCAvb29ggODkZycnK1ZSMiIhAYGCizLCgoCBEREQ0aE2l6hlpCbBvXCYHOJiguk2Dz5WRM2BwJr8XHMfCXi1h1PA5XE19AQv3bCSEtWL2SuoeHB9auXVtp+dq1a+Hu7v7OQZXz9fVFWFgYjh49ivXr1yMxMRFdu3ZFbm5uleXT09Nhamoqs8zU1BTp6ek1Hqe4uBg5OTnSV3X7J/KlIVDBryM6YOOoDgjxs4G9sSYkDIhKzsKaUwkY+msE+qw5jxN3Mqh/OyGkRapXH6Hly5ejb9++OHHihLSPekREBFJSUhq0YVrv3r2l793d3eHr6wsbGxvs3LkTY8eObbDjLF26FIsWLWqw/ZHGo8LnoYeTKXo4cV/enmQV4uKrGeHO3MvEvfRcfPbXdXhZ62F2kCM6tzaSc8SEENJ06lVT7969O+7fv4+BAwciKysLWVlZGDRoEG7fvo2///67oWOU0tPTQ9u2bZGQkFDlejMzM2RkZMgsy8jIgJmZWY37nTt3LrKzs6WvO3fuNFjMpHFZ6mlgaMdW+Hm4F87PeR8T32sNdTU+opKz8H+/X8Gnf1xBdEqWvMMkhJAmUe/BZ6py8+ZNtG/fHmJx48y4lZeXB2tra4SGhmLatGmV1g8bNgwFBQU4cOCAdFnnzp3h7u5ODeVakMzcIqw7lYCtV5NRKub+9+7W1hifdbFDVwcj8Hg8OUdICCE1a/LBZ5rCrFmzcPbsWTx69AiXLl3CwIEDoaKiguHDhwMARo4ciblz50rLT58+HUePHsUPP/yAe/fuITQ0FNevX8eUKVPkdQpEDky01bGofzuc+vI9DPG2Ap8HnLv/FCM3XkXQ6nPYcS2ZpnolhCglhU7qjx8/xvDhw+Ho6IihQ4fC0NAQly9fhrGxMQAgOTkZaWlp0vKdO3fG1q1b8dtvv8HDwwP//PMP9u7di3bt2snrFIgctTIQYcUQD5yd/T7G+NtBU6CC+xl5mPNvDPyXncKP4feRU1Qq7zAJIaTBNKvb702Fbr8rp5yiUuy4moKwS4/wJKsQAOBupYsd4/2gIVCRc3SEEFKhvnmoTq3fBw0aVOP6rKysuuyOkCalo66Gcd3sMdrfFkdi07FgXyxuPc7GrF038fNwL/D59KydENK81Smp6+rqvnX9yJEj3ykgQhqbqgof/TwsYKItxKd/XsGhmDS0NtbEzJ6O8g6NEELeSZ2S+qZNmxorDkKanK+9Ib4b6IbZ/9zCmlMJaG2ihf6elvIOixBC6k2hG8oR0tiGdGiFz7vbAwBm/3MLkUkv5RwRIYTUHyV10uLNCXLCBy6mKCmT4PO/r+PxywJ5h0QIIfVCSZ20eHw+D6uHecLZXAfP8krw2f+uI6+4TN5hEUJInVFSJwSAplAVf4Z0gLG2EPfSc/HBqrNYfeI+0rOL5B0aIYTUGiV1Ql6x0NPAHyM7wEhLiLTsIqw+EQ//709h3F/XcSYuk6Z1JYQovHrN0kaIsvJopYeLX7+Po7Hp2HolGVcSXyD8TgbC72TASl8DXwS2xaD2ljR+PCFEIVFSJ+QNQlUV9Pe0RH9PSyRk5mLLlWT8G/kYj18W4stdN3E+/in+O9ANWkL650MIUSx0+52QGrQx0cbCfq648p9AzOrZFip8HvZGp6LfzxcQ+yRb3uERQogMSuqE1IKGQAVTejhgx/hOsNBVR+KzfAz65RLCLiaiAadPIISQd0JJnZA66GBrgMPTu3L92sUShB64g/F/RyKroETeoRFCCCV1QupKTyTAbyO8EdrPBQIVPsLvZODjDRF4nlcs79AIIS0cJXVC6oHH42GUvx12T+oMMx11JGTmYcSfV5FdQPOzE0Lkh5I6Ie+gnaUuto7zhZGWEHfScjBy01XkFlFiJ4TIByV1Qt6RvbEWtnzmC32RGm6mZGFs2HUUlNAws4SQpkdJnZAG4Gimjb/H+kJbXRVXH73A+L8iUVQqlndYhJAWhpI6IQ2knaUu/jfGB5oCFVxIeIZJW26gpEwi77AIIS0IJXVCGlB7a338OaojhKp8nLqXiXl7YuQdEiGkBaGkTkgD62RviN9GdgCPB+yKfIyYxzTyHCGkaVBSJ6QRdG9rjAGelgCA5cfuyTkaQkhLQUmdkEbyRWBbqKnwcD7+GS4mPJN3OISQFoCSOiGNxNpQhP/zsQYALD96j8aIJ4Q0OkrqhDSiKT0cIBKo4ObjbBy7nS7vcAghSo6SOiGNyFhbiM+62AEAVhyLQ5mYurgRQhoPJXVCGtln3eyhL1LDg6f52H3jibzDIYQoMYVO6kuXLkXHjh2hra0NExMTDBgwAHFxcTVuExYWBh6PJ/NSV1dvoogJqUxHXQ2T328DAPjxxH0aaY4Q0mgUOqmfPXsWkydPxuXLlxEeHo7S0lL07NkT+fn5NW6no6ODtLQ06SspKamJIiakap92soG5rjrSsouw+TL9/0gIaRyq8g6gJkePHpX5HBYWBhMTE0RGRqJbt27Vbsfj8WBmZtbY4RFSa+pqKvgisC2++vcW1p1OwNCOraCjribvsAghSkaha+pvys7mRuYyMDCosVxeXh5sbGzQqlUr9O/fH7dv326K8Aip0aD2lmhtrImXBaX4Yns0wi4m4uTdDMSl5yK/mGZ1I4S8O4Wuqb9OIpFgxowZ8Pf3R7t27aot5+joiI0bN8Ld3R3Z2dlYuXIlOnfujNu3b8PKyqrKbYqLi1FcXCz9nJub2+DxE6KqwsfsICdM2ByJk/cycfJepsx6A00BPnQ3xzd9XSBQbVbftwkhCoLHmsmIGBMnTsSRI0dw4cKFapNzVUpLS+Hs7Izhw4djyZIlVZYJDQ3FokWLKi1PSUmp07EIeRvGGA7cSkPM4yykvCjE46wCpLwoRHZhqbSMfxtDrP/Um27PE9KCPX78GK1atapzHmoWSX3KlCnYt28fzp07Bzs7uzpvP2TIEKiqqmLbtm1Vrn+zpv7kyRO4uLhQUidNJqeoFJcSnmHmzpsoKBHDyUwbYaN9YKZLPTcIaYnqm9QV+h4fYwxTpkzBnj17cOrUqXoldLFYjJiYGJibm1dbRigUQkdHR/rS1tZ+l7AJqTMddTX0ameOnZ/7wUhLiHvpuRj0y0Xcz6BHQYSQ2lPopD558mRs3rwZW7duhba2NtLT05Geno7CwkJpmZEjR2Lu3LnSz4sXL8bx48fx8OFD3LhxA59++imSkpLw2WefyeMUCKmTdpa62DOpM+yNNZGaXYSP11/C5YfP5R0WIaSZUOikvn79emRnZ+O9996Dubm59LVjxw5pmeTkZKSlpUk/v3z5EuPGjYOzszP69OmDnJwcXLp0CS4uLvI4BULqrJWBCP9O6AxvG33kFJVh5J9X8cuZBNxIfkkD1xBCatQsnqk3tfo+yyCkIRWVijF9exSO3c6QLlPh8+BgogV3K124Wemhh5MJLPU05BglIaQx1DcPNZsubYS0NOpqKvgl2Bt/RTzC+fhnuPU4C8/ySnAvPRf30nOx8/pjLBOoYMMIb3R1MJZ3uIQQBUBJnRAFpsLnYbS/HUb724ExhvScItx6nI2Yx9k4HZeJ26k5GL3pGlYO8cAAL0t5h0sIkTOFfqZOCKnA4/FgrquBIFczzApyxO5JnfGhuznKJAwzdkTj93MP5R0iIUTOKKkT0kwJVVWw5hMvjPHnunp+e/gulhy8A4mEmskQ0lJRUiekGePzeZj/oTP+08cJAPDnhURM3xGN4jJqJU9IS0TP1Alp5ng8HsZ3aw0TbXXM2nUTB26mIvZJNjrY6MPVQgeulrpwNteBlpD+uROi7OhfOSFKYoCXJQw0BZi4ORKJz/KR+CwfuyK5dTweYGuoiU72BgjpbAsnMx35BksIaRSU1AlRIt3aGuPcV+/j2qOXuJOajdupObiTloO07CJpot92NQX+bQwxtosd3mtrAj6fJ++wCSENhJI6IUrGUEuIXu3M0KudmXTZ87xixDzJxq7rj3EkNg0XE57jYsJz2BtrYrS/HQa3t4RIQH8OCGnuaES5KtCIckSZPX5ZgP9deoTtV1OQW1wGADDRFmLt/7WHj52BnKMjhABKOksbIaThWemLMK+vCyL+E4DQfi5oZaCBzNxiDP/9Mn479wD0PZ+Q5ouSOiEtlJZQFaP87XBsRjcM9LKEWMLw3eF7+PzvSGQXlso7PEJIPVBSJ6SFEwlUsWqoB/47oB0EKnwcv5OBj9ZewO3UbHmHRgipI0rqhBDweDx82skG/0z0g6WeBpKeF2DgL5ew7nQCzt1/iodP82hAG0KaAWruSgiRcrfSw6FpXTBz502cupeJFcfiZNab6gjRSl+Edpa6+Ly7Pcx1adpXQhQJJXVCiAw9kQB/jOyAzVeScDbuKVJeFiDlRSEKS8XIyClGRk4xrie9xNaryRjV2RYTu7eGvqZA3mETQkBd2qpEXdoIkcUYw4v8Ejx+WYhHz/Ox5XIyrj56AQDQFqri8+72GNPFjvq6E9JAqEsbIaTR8Hg8GGoJ4dFKD/09LbHj807YNLojnM11kFtchpXH76Pb8jP4+3ISzRJHiBxRUieE1BmPx8P7jiY4NLULfvrEE9YGIjzLK8b8vbH49M8rSM0qlHeIhLRIlNQJIfXG5/PQ39MSJ2Z2x8J+LtBQU8GlB8/Ra/U57It+Iu/wCGlxKKkTQt6ZQJWP0f52ODy9Kzxa6SGnqAzTt0dj2rYoGsiGkCZESZ0Q0mDsjDTxzwQ/TA9wgAqfh/03U9F79TmcjstEqVgi7/AIUXrUVJUQ0qDUVPj44oO2eM/RGF/siMaj5wUYvekahKp8uFnqwrOVHrys9eFprQcLXXXweDT1KyENhZI6IaRReFnr49C0rvj+6D3sjXqCnKIyXE96ietJLwEkAgAs9TQwqrMtPvFpBW11NfkGTIgSoH7qVaB+6oQ0LImEIfF5PqKTsxCV8hLRKVm4l5aLslfd37TVVTGikw1G+dvCRFtdztESIn/1zUOU1KtASZ2QxldYIsb+m0/w67mHePg0HwAgUOFjsLclxnW1h72xlpwjJER+KKk3IErqhDQdiYQh/G4GNpx9gKjkLOlyN0td9GpnhiBXM7QxoQRPWpb65iF6pk4IkSs+n4cgVzP0dDHF9aSX2HDmAU7HZSLmSTZinmRjxbE4tDHRQu92ZujhZILWJlrQoefvhFSpWdTU161bhxUrViA9PR0eHh74+eef4ePjU235Xbt2Yf78+Xj06BEcHBzw/fffo0+fPrU+HtXUCZGvZ3nFOHEnA0di03HpwTOUimX/TOmJ1GBjIEIrAxGsDUSwNdSEq6UO2ppqQ02FeuqS5k9pa+o7duzAzJkzsWHDBvj6+mL16tUICgpCXFwcTExMKpW/dOkShg8fjqVLl+LDDz/E1q1bMWDAANy4cQPt2rWTwxkQQurKSEuIT3ys8YmPNbILS3H6XiaOxKYhMuklnuWVIKugFFkF2bj5OFtmO6EqHy4WOnC31IWblR6czLRhoCmAtroqNAWq4POp+xxRbgpfU/f19UXHjh2xdu1aAIBEIkGrVq0wdepUfP3115XKDxs2DPn5+Th48KB0WadOneDp6YkNGzbU6phUUydEceUXlyHlZQGSnxcg+QX3SsjMQ8yTbOQWlVW7HY8HaAlVoaOuBpFABQAgYQyMcT8lDODzABNtdZjpqsNct/ynBkx0hBCo8KGqwoMqnwcVPh+qfB74fB5UeDyo8F+9eDyoqHA/+XyAz+Pe83ig/vikTpSypl5SUoLIyEjMnTtXuozP5yMwMBARERFVbhMREYGZM2fKLAsKCsLevXurPU5xcTGKi4uln3Nzc98tcEJIo9EUqsLJTAdOZjoyyyUShuQXBbj1JBsxj7Nw63E2HjzNQ05hGUrEEjAG5BaV1Zj4AeDR84JGiZvP45L8618E+DxAVYXPLS9f/+oLAO/V5/LvAjxUfDHgSf8j/VGrLw0VZQEeKvZdGzLHrgfpeUjjrvueqoq3umopQ93rq1XFVJ/9zOvjAr/WhnXeriEodFJ/9uwZxGIxTE1NZZabmpri3r17VW6Tnp5eZfn09PRqj7N06VIsWrTo3QMmhMgNn8+DrZEmbI008ZGHhXQ5YwzFZRLkFJVKk3pBcRl45YmUX5FIy8QMGTlFSM8uQlp2EdJzCpGWXYTMnGKUSSQQSwCxRIIyCYNYwlAmYZC8+vk2kld3BEBT0yq93CL5zXeg0Em9qcydO1emdv/kyRO4uLjIMSJCSEPh8XhQV1OBupoKTLQb7zjlyV3CKn4yCSBm7NXtfQZJ+edXZcXl5cUMDNyjgIrHAexV/ue+BDDGvePKVHwxeP0rwtsepjIw6Qbl+6qpts6kZZnM58r7fbvqYq61mjZq5Ccbdd29q4Vuo8RRGwqd1I2MjKCiooKMjAyZ5RkZGTAzM6tyGzMzszqVBwChUAihUCj9nJOT8w5RE0JaIj6fBwE1xCNyptB9PwQCAby9vXHy5EnpMolEgpMnT8LPz6/Kbfz8/GTKA0B4eHi15QkhhBBlodA1dQCYOXMmQkJC0KFDB/j4+GD16tXIz8/H6NGjAQAjR46EpaUlli5dCgCYPn06unfvjh9++AF9+/bF9u3bcf36dfz222/yPA1CCCGk0Sl8Uh82bBiePn2KBQsWID09HZ6enjh69Ki0MVxycjL4/IobDp07d8bWrVvxzTff4D//+Q8cHBywd+9e6qNOCCFE6Sl8P3V5oH7qhBBC5Km+eUihn6kTQgghpPYU/va7PEgkEgBAWlqanCMhhBDSEpXnn/J8VFuU1KtQ3iWupkljCCGEkMaWkZEBa2vrWpenZ+pVKCsrQ1RUFExNTWUa4dVHbm4uXFxccOfOHWhrN+LIF42kOcffnGMHmnf8zTl2oHnH35xjB5p3/A0Zu0QiQUZGBry8vKCqWvv6NyX1RpaTkwNdXV1kZ2dDR0fn7RsomOYcf3OOHWje8Tfn2IHmHX9zjh1o3vErQuzUUI4QQghREpTUCSGEECVBSb2RCYVCLFy4UGZs+eakOcffnGMHmnf8zTl2oHnH35xjB5p3/IoQOz1TJ4QQQpQE1dQJIYQQJUFJnRBCCFESlNQJIYQQJUFJvZGtW7cOtra2UFdXh6+vL65evSrvkN4qNDQUPB5P5uXk5CTvsKp17tw59OvXDxYWFuDxeNi7d6/MesYYFixYAHNzc2hoaCAwMBDx8fHyCfYNb4t91KhRlX4XvXr1kk+wb1i6dCk6duwIbW1tmJiYYMCAAYiLi5MpU1RUhMmTJ8PQ0BBaWloYPHiwdMRGeatN/O+9916l6z9hwgQ5RSxr/fr1cHd3h46ODnR0dODn54cjR45I1yvytX9b7Ip83d+0bNky8Hg8zJgxQ7pMnteeknoj2rFjB2bOnImFCxfixo0b8PDwQFBQEDIzM+Ud2lu5uroiLS1N+rpw4YK8Q6pWfn4+PDw8sG7duirXL1++HGvWrMGGDRtw5coVaGpqIigoCEVFRU0caWVvix0AevXqJfO72LZtWxNGWL2zZ89i8uTJuHz5MsLDw1FaWoqePXsiPz9fWuaLL77AgQMHsGvXLpw9exapqakYNGiQHKOuUJv4AWDcuHEy13/58uVyiliWlZUVli1bhsjISFy/fh09evRA//79cfv2bQCKfe3fFjuguNf9ddeuXcOvv/4Kd3d3meVyvfaMNBofHx82efJk6WexWMwsLCzY0qVL5RjV2y1cuJB5eHjIO4x6AcD27Nkj/SyRSJiZmRlbsWKFdFlWVhYTCoVs27Ztcoiwem/GzhhjISEhrH///nKJp64yMzMZAHb27FnGGHed1dTU2K5du6Rl7t69ywCwiIgIeYVZrTfjZ4yx7t27s+nTp8svqDrS19dnf/zxR7O79oxVxM5Y87juubm5zMHBgYWHh8vEK+9rTzX1RlJSUoLIyEgEBgZKl/H5fAQGBiIiIkKOkdVOfHw8LCwsYG9vj+DgYCQnJ8s7pHpJTExEenq6zO9BV1cXvr6+zeL3AABnzpyBiYkJHB0dMXHiRDx//lzeIVUpOzsbAGBgYAAAiIyMRGlpqcy1d3JygrW1tUJe+zfjL7dlyxYYGRmhXbt2mDt3LgoKCuQRXo3EYjG2b9+O/Px8+Pn5Natr/2bs5RT9uk+ePBl9+/aVucaA/P+/p1naGsmzZ88gFothamoqs9zU1BT37t2TU1S14+vri7CwMDg6OiItLQ2LFi1C165dERsb2+wmWEhPTweAKn8P5esUWa9evTBo0CDY2dnhwYMH+M9//oPevXsjIiICKioq8g5PSiKRYMaMGfD390e7du0AcNdeIBBAT09PpqwiXvuq4geA//u//4ONjQ0sLCxw69YtzJkzB3Fxcdi9e7cco60QExMDPz8/FBUVQUtLC3v27IGLiwuio6MV/tpXFzug+Nd9+/btuHHjBq5du1Zpnbz/v6ekTirp3bu39L27uzt8fX1hY2ODnTt3YuzYsXKMrOX55JNPpO/d3Nzg7u6O1q1b48yZMwgICJBjZLImT56M2NhYhW57UZPq4h8/frz0vZubG8zNzREQEIAHDx6gdevWTR1mJY6OjoiOjkZ2djb++ecfhISE4OzZs/IOq1aqi93FxUWhr3tKSgqmT5+O8PBwqKuryzWWqtDt90ZiZGQEFRWVSi0eMzIyYGZmJqeo6kdPTw9t27ZFQkKCvEOps/JrrQy/BwCwt7eHkZGRQv0upkyZgoMHD+L06dOwsrKSLjczM0NJSQmysrJkyivata8u/qr4+voCgMJcf4FAgDZt2sDb2xtLly6Fh4cHfvrpp2Zx7auLvSqKdN0jIyORmZmJ9u3bQ1VVFaqqqjh79izWrFkDVVVVmJqayvXaU1JvJAKBAN7e3jh58qR0mUQiwcmTJ2WeGzUHeXl5ePDgAczNzeUdSp3Z2dnBzMxM5veQk5ODK1euNLvfAwA8fvwYz58/V4jfBWMMU6ZMwZ49e3Dq1CnY2dnJrPf29oaamprMtY+Li0NycrJCXPu3xV+V6OhoAFCI618ViUSC4uJihb/2VSmPvSqKdN0DAgIQExOD6Oho6atDhw4IDg6WvpfrtW/0pngt2Pbt25lQKGRhYWHszp07bPz48UxPT4+lp6fLO7Qaffnll+zMmTMsMTGRXbx4kQUGBjIjIyOWmZkp79CqlJuby6KiolhUVBQDwFatWsWioqJYUlISY4yxZcuWMT09PbZv3z5269Yt1r9/f2ZnZ8cKCwvlHHnNsefm5rJZs2axiIgIlpiYyE6cOMHat2/PHBwcWFFRkbxDZxMnTmS6urrszJkzLC0tTfoqKCiQlpkwYQKztrZmp06dYtevX2d+fn7Mz89PjlFXeFv8CQkJbPHixez69essMTGR7du3j9nb27Nu3brJOXLO119/zc6ePcsSExPZrVu32Ndff814PB47fvw4Y0yxr31NsSv6da/Km6315XntKak3sp9//plZW1szgUDAfHx82OXLl+Ud0lsNGzaMmZubM4FAwCwtLdmwYcNYQkKCvMOq1unTpxmASq+QkBDGGNetbf78+czU1JQJhUIWEBDA4uLi5Bv0KzXFXlBQwHr27MmMjY2Zmpoas7GxYePGjVOYL4VVxQ2Abdq0SVqmsLCQTZo0ienr6zORSMQGDhzI0tLS5Bf0a94Wf3JyMuvWrRszMDBgQqGQtWnThs2ePZtlZ2fLN/BXxowZw2xsbJhAIGDGxsYsICBAmtAZU+xrX1Psin7dq/JmUpfntadZ2gghhBAlQc/UCSGEECVBSZ0QQghREpTUCSGEECVBSZ0QQghREpTUCSGEECVBSZ0QQghREpTUCSGEECVBSZ0QQghREpTUCSFyxePxsHfvXnmHQYhSoKROSAs2atQo8Hi8Sq9evXrJOzRCSD3QfOqEtHC9evXCpk2bZJYJhUI5RUMIeRdUUyekhRMKhTAzM5N56evrA+Buja9fvx69e/eGhoYG7O3t8c8//8hsHxMTgx49ekBDQwOGhoYYP3488vLyZMps3LgRrq6uEAqFMDc3x5QpU2TWP3v2DAMHDoRIJIKDgwP2798vXffy5UsEBwfD2NgYGhoacHBwqPQlhBDCoaROCKnR/PnzMXjwYNy8eRPBwcH45JNPcPfuXQBAfn4+goKCoK+vj2vXrmHXrl04ceKETNJev349Jk+ejPHjxyMmJgb79+9HmzZtZI6xaNEiDB06FLdu3UKfPn0QHByMFy9eSI9/584dHDlyBHfv3sX69ethZGTUdBeAkOakSeaCI4QopJCQEKaiosI0NTVlXt9++y1jjJuedMKECTLb+Pr6sokTJzLGGPvtt9+Yvr4+y8vLk64/dOgQ4/P50iliLSws2Lx586qNAQD75ptvpJ/z8vIYAHbkyBHGGGP9+vVjo0ePbpgTJkTJ0TN1Qlq4999/H+vXr5dZZmBgIH3v5+cns87Pzw/R0dEAgLt378LDwwOamprS9f7+/pBIJIiLiwOPx0NqaioCAgJqjMHd3V36XlNTEzo6OsjMzAQATJw4EYMHD8aNGzfQs2dPDBgwAJ07d67XuRKi7CipE9LCaWpqVrod3lA0NDRqVU5NTU3mM4/Hg0QiAQD07t0bSUlJOHz4MMLDwxEQEIDJkydj5cqVDR4vIc0dPVMnhNTo8uXLlT47OzsDAJydnXHz5k3k5+dL11+8eBF8Ph+Ojo7Q1taGra0tTp48+U4xGBsbIyQkBJs3b8bq1avx22+/vdP+CFFWVFMnpIUrLi5Genq6zDJVVVVpY7Rdu3ahQ4cO6NKlC7Zs2YKrV6/izz//BAAEBwdj4cKFCAkJQWhoKJ4+fYqpU6dixIgRMDU1BQCEhoZiwoQJMDExQe/evZGbm4uLFy9i6tSptYpvwYIF8Pb2hqurK4qLi3Hw4EHplwpCiCxK6oS0cEePHoW5ubnMMkdHR9y7dw8A1zJ9+/btmDRpEszNzbFt2za4uLgAAEQiEY4dO4bp06ejY8eOEIlEGDx4MFatWiXdV0hICIqKivDjjz9i1qxZMDIywscff1zr+AQCAebOnYtHjx5BQ0MDXbt2xfbt2xvgzAlRPjzGGJN3EIQQxcTj8bBnzx4MGDBA3qEQQmqBnqkTQgghSoKSOiGEEKIk6Jk6IaRa9HSOkOaFauqEEEKIkqCkTgghhCgJSuqEEEKIkqCkTgghhCgJSuqEEEKIkqCkTgghhCgJSuqEEEKIkqCkTgghhCgJSuqEEEKIkvh/fWIObuYTmgMAAAAASUVORK5CYII=\",\n \"text/plain\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"db3564b7-9940-44fe-9364-27ea71e38632\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install tokenizers\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"92b989e9-da36-4159-b212-799184764dd9\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"matplotlib version: 3.8.2\\n\",\n \"numpy version: 1.26.4\\n\",\n \"tiktoken version: 0.12.0\\n\",\n \"torch version: 2.8.0+cu128\\n\",\n \"tokenizers version: 0.22.2\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"matplotlib\\\", \\n\",\n \" \\\"numpy\\\", \\n\",\n \" \\\"torch\\\",\\n\",\n \" \\\"tokenizers\\\", # to implement the Qwen3 tokenizer\\n\",\n \" ]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0d824183-145c-4865-89e1-1f0d0a338f19\",\n \"metadata\": {\n \"id\": \"0d824183-145c-4865-89e1-1f0d0a338f19\"\n },\n \"source\": [\n \" \\n\",\n \"## 5.1 Evaluating generative text models\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"eb9508e0-4e09-4236-bb07-b376013c219d\",\n \"metadata\": {},\n \"source\": [\n \"- No code\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bdc1cf3f-82d8-46c7-9ecc-58979ce87cdd\",\n \"metadata\": {\n \"id\": \"bdc1cf3f-82d8-46c7-9ecc-58979ce87cdd\"\n },\n \"source\": [\n \" \\n\",\n \"### 5.1.1 Using Qwen3 to generate text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"id\": \"86000d74-624a-48f0-86da-f41926cb9e04\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"86000d74-624a-48f0-86da-f41926cb9e04\",\n \"outputId\": \"ad482cfd-5a62-4f0d-e1e0-008d6457f512\"\n },\n \"outputs\": [],\n \"source\": [\n \"######################\\n\",\n \"### Qwen3 Code\\n\",\n \"######################\\n\",\n \"\\n\",\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\\n\",\n \"\\n\",\n \"\\n\",\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-6, bias=False, qwen3_compatible=True):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" self.qwen3_compatible = qwen3_compatible\\n\",\n \" self.scale = nn.Parameter(torch.ones(emb_dim))\\n\",\n \" self.shift = nn.Parameter(torch.zeros(emb_dim)) if bias else None\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" input_dtype = x.dtype\\n\",\n \"\\n\",\n \" if self.qwen3_compatible:\\n\",\n \" x = x.to(torch.float32)\\n\",\n \"\\n\",\n \" variance = x.pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" norm_x = x * torch.rsqrt(variance + self.eps)\\n\",\n \" norm_x = norm_x * self.scale\\n\",\n \"\\n\",\n \" if self.shift is not None:\\n\",\n \" norm_x = norm_x + self.shift\\n\",\n \"\\n\",\n \" return norm_x.to(input_dtype)\\n\",\n \"\\n\",\n \"\\n\",\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim))\\n\",\n \"\\n\",\n \" # Generate position indices\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Expand angles to match the head_dim\\n\",\n \" angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into first half and second half\\n\",\n \" x1 = x[..., : head_dim // 2] # First half\\n\",\n \" x2 = x[..., head_dim // 2 :] # Second half\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\\n\",\n \" sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" # It's ok to use lower-precision after applying cos and sin rotation\\n\",\n \" return x_rotated.to(dtype=x.dtype)\\n\",\n \"\\n\",\n \"\\n\",\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, num_heads, num_kv_groups, head_dim=None, qk_norm=False, dtype=None\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" if head_dim is None:\\n\",\n \" assert d_in % num_heads == 0, \\\"`d_in` must be divisible by `num_heads` if `head_dim` is not set\\\"\\n\",\n \" head_dim = d_in // num_heads\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(d_in, self.d_out, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" if qk_norm:\\n\",\n \" self.q_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" self.k_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" else:\\n\",\n \" self.q_norm = self.k_norm = None\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" # Apply projections\\n\",\n \" queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\\n\",\n \" keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Optional normalization\\n\",\n \" if self.q_norm:\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" if self.k_norm:\\n\",\n \" keys = self.k_norm(keys)\\n\",\n \"\\n\",\n \" # Apply RoPE\\n\",\n \" queries = apply_rope(queries, cos, sin)\\n\",\n \" keys = apply_rope(keys, cos, sin)\\n\",\n \"\\n\",\n \" # Expand K and V to match number of heads\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" # Attention\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \" attn_weights = torch.softmax(attn_scores / self.head_dim**0.5, dim=-1)\\n\",\n \"\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \" return self.out_proj(context)\\n\",\n \"\\n\",\n \"\\n\",\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"],\\n\",\n \" qk_norm=cfg[\\\"qk_norm\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"]\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \" self.norm2 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=1e-6)\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" # Shortcut connection for attention block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \" x = self.att(x, mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" # Shortcut connection for feed-forward block\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" x = x + shortcut # Add the original input back\\n\",\n \"\\n\",\n \" return x\\n\",\n \"\\n\",\n \"\\n\",\n \"class Qwen3Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" # Main model parameters\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.ModuleList( # ModuleList since Sequential can only accept one input, and we need `x, mask, cos, sin`\\n\",\n \" [TransformerBlock(cfg) for _ in range(cfg[\\\"n_layers\\\"])]\\n\",\n \" )\\n\",\n \"\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"])\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" # Uncomment the following code to tie weights\\n\",\n \" # self.out_head.weight = self.tok_emb.weight\\n\",\n \" # torch.nn.init.normal_(self.out_head.weight, mean=0.0, std=0.02)\\n\",\n \"\\n\",\n \" # Reusable utilities\\n\",\n \" if cfg[\\\"head_dim\\\"] is None:\\n\",\n \" head_dim = cfg[\\\"emb_dim\\\"] // cfg[\\\"n_heads\\\"]\\n\",\n \" else:\\n\",\n \" head_dim = cfg[\\\"head_dim\\\"]\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=head_dim,\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"]\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" # Forward pass\\n\",\n \" tok_embeds = self.tok_emb(in_idx)\\n\",\n \" x = tok_embeds\\n\",\n \"\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \" mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)\\n\",\n \" \\n\",\n \" for block in self.trf_blocks:\\n\",\n \" x = block(x, mask, self.cos, self.sin)\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"d12ac059-58d8-4db2-ac5a-9ec58b043daf\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"#######################\\n\",\n \"### Initialize Qwen3 \\n\",\n \"#######################\\n\",\n \"\\n\",\n \"# 0.6B model\\n\",\n \"QWEN3_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 151_936, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 40_960, # Context length that was used to train the model\\n\",\n \" \\\"emb_dim\\\": 1024, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 16, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 28, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 3072, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"head_dim\\\": 128, # Size of the heads in GQA\\n\",\n \" \\\"qk_norm\\\": True, # Whether to normalize queries and keys in GQA\\n\",\n \" \\\"n_kv_groups\\\": 8, # Key-Value groups for grouped-query attention\\n\",\n \" \\\"rope_base\\\": 1_000_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \"}\\n\",\n \"\\n\",\n \"QWEN3_CONFIG[\\\"train_context_length\\\"] = 256 # It's a small dataset, and we also want to keep memory usage reasonable\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"model = Qwen3Model(QWEN3_CONFIG)\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"d6732d1a-db47-42c3-aca3-8a871752f32f\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"#######################\\n\",\n \"### Set up tokenizer\\n\",\n \"#######################\\n\",\n \"\\n\",\n \"import re\\n\",\n \"from tokenizers import Tokenizer\\n\",\n \"\\n\",\n \"class Qwen3Tokenizer:\\n\",\n \" _SPECIALS = [\\n\",\n \" \\\"<|endoftext|>\\\",\\n\",\n \" \\\"<|im_start|>\\\", \\\"<|im_end|>\\\",\\n\",\n \" \\\"<|object_ref_start|>\\\", \\\"<|object_ref_end|>\\\",\\n\",\n \" \\\"<|box_start|>\\\", \\\"<|box_end|>\\\",\\n\",\n \" \\\"<|quad_start|>\\\", \\\"<|quad_end|>\\\",\\n\",\n \" \\\"<|vision_start|>\\\", \\\"<|vision_end|>\\\",\\n\",\n \" \\\"<|vision_pad|>\\\", \\\"<|image_pad|>\\\", \\\"<|video_pad|>\\\",\\n\",\n \" \\\" \n\n\n\nThis is a great model to run and experiment with locally. The only caveat is that while it's an open-weight model, its licensing terms are relatively restricted and only allow non-commercial use.\n\nThat aside, Arya is a 3.35B parameter model that comes in several flavors that are useful for\npersonal and (non-commercial) research use:\n\n - [tiny-aya-base](https://huggingface.co/CohereLabs/tiny-aya-base) (base model)\n - [tiny-aya-global](https://huggingface.co/CohereLabs/tiny-aya-global) (best balance across languages and regions; notebook default)\n - [tiny-aya-fire](https://huggingface.co/CohereLabs/tiny-aya-fire) (optimized for South Asian languages)\n - [tiny-aya-water](https://huggingface.co/CohereLabs/tiny-aya-water) (optimized for European and Asia Pacific languages)\n - [tiny-aya-earth](https://huggingface.co/CohereLabs/tiny-aya-earth) (optimized for West Asian and African languages)\n\n\n\nMore specifically, here's a list of languages the models are optimized for:\n\n| Region | Languages | Optimized Model |\n| ---------------- | ------------------------------------------------------------ | --------------- |\n| **Asia Pacific** | Traditional Chinese, Cantonese, Vietnamese, Tagalog, Javanese, Khmer, Thai, Burmese, Malay, Korean, Lao, Indonesian, Simplified Chinese, Japanese | tiny-aya-water |\n| **Africa** | Zulu, Amharic, Hausa, Igbo, Swahili, Xhosa, Wolof, Shona, Yoruba, Nigerian Pidgin, Malagasy | tiny-aya-earth |\n| **South Asia** | Telugu, Marathi, Bengali, Tamil, Hindi, Punjabi, Gujarati, Urdu, Nepali | tiny-aya-fire |\n| **Europe** | Catalan, Galician, Dutch, Danish, Finnish, Czech, Portuguese, French, Lithuanian, Slovak, Basque, English, Swedish, Polish, Spanish, Slovenian, Ukrainian, Greek, Bokmål, Romanian, Serbian, German, Italian, Russian, Irish, Hungarian, Bulgarian, Croatian, Estonian, Latvian, Welsh | tiny-aya-water |\n| **West Asia** | Arabic, Maltese, Turkish, Hebrew, Persian | tiny-aya-earth |\n\n\nArchitecture-wise, Tiny Aya is a classic decoder-style transformer with a few noteworthy modifications (besides the obvious ones like SwiGLU and Grouped Query Attention):\n\n1. **Parallel transformer blocks.** A parallel transformer block computes attention and MLP from the same normalized input, then adds both to the residual in one step. I assume this is to reduce serial dependencies inside a layer to improve computational throughput.\n\n2. **Sliding window attention.** Specifically, it uses a 3:1 local:global ratio similar to Arcee Trinity and Olmo 3. The window size is also 4096. Also, similar to Arcee, the sliding window layers use RoPE whereas the full attention layers use NoPE.\n\n3. **LayerNorm.** Most architectures moved to RMSNorm as it's computationally a bit cheaper and performs well. Tiny Aya is keeping it more classic with a modified version of LayerNorm (the implementation here is like standard LayerNorm but without shift, i.e., bias, parameter).\n\n\n\n \n## Files\n\nThe [standalone-tiny-aya.ipynb](standalone-tiny-aya.ipynb) is a standalone Jupyter notebook that implements the Tiny Aya architecture and loads the pre-trained weights.\n\n\nThe alternative [standalone-tiny-aya-plus-kvcache.ipynb](standalone-tiny-aya-plus-kv-cache.ipynb) notebook adds a KV cache for better runtime performance (but adds more code complexity). To learn more about KV caching, see my [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) article.\n\n\n
\n\n\n\nThis is a great model to run and experiment with locally. The only caveat is that while it's an open-weight model, its licensing terms are relatively restricted and only allow non-commercial use.\n\nThat aside, Arya is a 3.35B parameter model that comes in several flavors that are useful for\npersonal and (non-commercial) research use:\n\n - [tiny-aya-base](https://huggingface.co/CohereLabs/tiny-aya-base) (base model)\n - [tiny-aya-global](https://huggingface.co/CohereLabs/tiny-aya-global) (best balance across languages and regions; notebook default)\n - [tiny-aya-fire](https://huggingface.co/CohereLabs/tiny-aya-fire) (optimized for South Asian languages)\n - [tiny-aya-water](https://huggingface.co/CohereLabs/tiny-aya-water) (optimized for European and Asia Pacific languages)\n - [tiny-aya-earth](https://huggingface.co/CohereLabs/tiny-aya-earth) (optimized for West Asian and African languages)\n\n\n\nMore specifically, here's a list of languages the models are optimized for:\n\n| Region | Languages | Optimized Model |\n| ---------------- | ------------------------------------------------------------ | --------------- |\n| **Asia Pacific** | Traditional Chinese, Cantonese, Vietnamese, Tagalog, Javanese, Khmer, Thai, Burmese, Malay, Korean, Lao, Indonesian, Simplified Chinese, Japanese | tiny-aya-water |\n| **Africa** | Zulu, Amharic, Hausa, Igbo, Swahili, Xhosa, Wolof, Shona, Yoruba, Nigerian Pidgin, Malagasy | tiny-aya-earth |\n| **South Asia** | Telugu, Marathi, Bengali, Tamil, Hindi, Punjabi, Gujarati, Urdu, Nepali | tiny-aya-fire |\n| **Europe** | Catalan, Galician, Dutch, Danish, Finnish, Czech, Portuguese, French, Lithuanian, Slovak, Basque, English, Swedish, Polish, Spanish, Slovenian, Ukrainian, Greek, Bokmål, Romanian, Serbian, German, Italian, Russian, Irish, Hungarian, Bulgarian, Croatian, Estonian, Latvian, Welsh | tiny-aya-water |\n| **West Asia** | Arabic, Maltese, Turkish, Hebrew, Persian | tiny-aya-earth |\n\n\nArchitecture-wise, Tiny Aya is a classic decoder-style transformer with a few noteworthy modifications (besides the obvious ones like SwiGLU and Grouped Query Attention):\n\n1. **Parallel transformer blocks.** A parallel transformer block computes attention and MLP from the same normalized input, then adds both to the residual in one step. I assume this is to reduce serial dependencies inside a layer to improve computational throughput.\n\n2. **Sliding window attention.** Specifically, it uses a 3:1 local:global ratio similar to Arcee Trinity and Olmo 3. The window size is also 4096. Also, similar to Arcee, the sliding window layers use RoPE whereas the full attention layers use NoPE.\n\n3. **LayerNorm.** Most architectures moved to RMSNorm as it's computationally a bit cheaper and performs well. Tiny Aya is keeping it more classic with a modified version of LayerNorm (the implementation here is like standard LayerNorm but without shift, i.e., bias, parameter).\n\n\n\n \n## Files\n\nThe [standalone-tiny-aya.ipynb](standalone-tiny-aya.ipynb) is a standalone Jupyter notebook that implements the Tiny Aya architecture and loads the pre-trained weights.\n\n\nThe alternative [standalone-tiny-aya-plus-kvcache.ipynb](standalone-tiny-aya-plus-kv-cache.ipynb) notebook adds a KV cache for better runtime performance (but adds more code complexity). To learn more about KV caching, see my [Understanding and Coding the KV Cache in LLMs from Scratch](https://magazine.sebastianraschka.com/p/coding-the-kv-cache-in-llms) article.\n\n\n| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \\n\",\n \"\\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Tiny Aya architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 1.4.1\\n\",\n \"tiktoken version: 0.12.0\\n\",\n \"torch version: 2.10.0\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" #\\\"blobfile\\\", # to download pretrained weights\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tiktoken\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"574bc51e-876e-46c3-bcf7-ef4675582ad2\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"REPO_ID = \\\"CohereLabs/tiny-aya-global\\\"\\n\",\n \"#REPO_ID = \\\"CohereLabs/tiny-aya-fire\\\" \\n\",\n \"#REPO_ID = \\\"CohereLabs/tiny-aya-water\\\"\\n\",\n \"#REPO_ID = \\\"CohereLabs/tiny-aya-earth\\\"\\n\",\n \"\\n\",\n \"LOCAL_DIR = Path(REPO_ID).parts[-1]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"1a36d4a0-ee44-4727-ab7e-c73dd5e1ddba\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Aya uses a bias-less LayerNorm variant. \\n\",\n \"# The difference to classic LayerNorm is that it only \\n\",\n \"# has a scale parameter (weight), no shift parameter (bias).\\n\",\n \"\\n\",\n \"class CohereLayerNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-5):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" self.weight = nn.Parameter(torch.ones(emb_dim))\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" input_dtype = x.dtype\\n\",\n \" x = x.to(torch.float32)\\n\",\n \" mean = x.mean(dim=-1, keepdim=True)\\n\",\n \" variance = (x - mean).pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x = (x - mean) * torch.rsqrt(variance + self.eps)\\n\",\n \" return (self.weight.to(torch.float32) * x).to(input_dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"head_dim must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (\\n\",\n \" theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim)\\n\",\n \" )\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Cohere uses interleaved even/odd angle layout per head-dim pair.\\n\",\n \" # Llama2 notebook examples often use a split-halves layout via cat([angles, angles]).\\n\",\n \" # Both are equivalent only when paired with the matching rotate logic:\\n\",\n \" # - interleaved layout -> even/odd rotation implementation (below)\\n\",\n \" # - split-halves layout -> half/half rotate implementation\\n\",\n \" angles = torch.repeat_interleave(angles, 2, dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" return torch.cos(angles), torch.sin(angles)\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin, offset=0):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"head_dim must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into even and odd components (interleaved layout)\\n\",\n \" x_even = x[..., ::2]\\n\",\n \" x_odd = x[..., 1::2]\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \" sin = sin[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" x_float = x.float()\\n\",\n \" rotated = torch.stack((-x_odd.float(), x_even.float()), dim=-1).flatten(-2)\\n\",\n \" x_rotated = (x_float * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self,\\n\",\n \" d_in,\\n\",\n \" num_heads,\\n\",\n \" num_kv_groups,\\n\",\n \" head_dim=None,\\n\",\n \" qk_norm=False,\\n\",\n \" attention_bias=False,\\n\",\n \" dtype=None,\\n\",\n \" attn_type=\\\"full_attention\\\",\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" if head_dim is None:\\n\",\n \" assert d_in % num_heads == 0, \\\"`d_in` must be divisible by `num_heads` if `head_dim` is not set\\\"\\n\",\n \" head_dim = d_in // num_heads\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \" self.attn_type = attn_type\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(\\n\",\n \" d_in,\\n\",\n \" self.d_out,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \" self.W_key = nn.Linear(\\n\",\n \" d_in,\\n\",\n \" num_kv_groups * head_dim,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \" self.W_value = nn.Linear(\\n\",\n \" d_in,\\n\",\n \" num_kv_groups * head_dim,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \" self.out_proj = nn.Linear(\\n\",\n \" self.d_out,\\n\",\n \" d_in,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \"\\n\",\n \" if qk_norm:\\n\",\n \" self.q_norm = CohereLayerNorm(head_dim, eps=1e-6)\\n\",\n \" self.k_norm = CohereLayerNorm(head_dim, eps=1e-6)\\n\",\n \" else:\\n\",\n \" self.q_norm = self.k_norm = None\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin, start_pos=0, cache=None):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" # Apply projections\\n\",\n \" queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\\n\",\n \" keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\\n\",\n \" keys_new = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values_new = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Optional normalization\\n\",\n \" if self.q_norm:\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" if self.k_norm:\\n\",\n \" keys_new = self.k_norm(keys_new)\\n\",\n \"\\n\",\n \" # Cohere2 applies RoPE only on sliding-attention layers.\\n\",\n \" if self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" queries = apply_rope(queries, cos, sin, offset=start_pos)\\n\",\n \" keys_new = apply_rope(keys_new, cos, sin, offset=start_pos)\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" prev_k, prev_v = cache\\n\",\n \" keys = torch.cat([prev_k, keys_new], dim=2)\\n\",\n \" values = torch.cat([prev_v, values_new], dim=2)\\n\",\n \" next_cache = (keys, values)\\n\",\n \" else:\\n\",\n \" keys, values = keys_new, values_new\\n\",\n \" next_cache = (keys, values)\\n\",\n \"\\n\",\n \" # Expand K and V to match number of heads\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" # Attention\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores / self.head_dim**0.5, dim=-1, dtype=torch.float32).to(queries.dtype)\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \"\\n\",\n \" return self.out_proj(context), next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg, attn_type):\\n\",\n \" super().__init__()\\n\",\n \" self.attn_type = attn_type\\n\",\n \"\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_heads\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" qk_norm=False,\\n\",\n \" attention_bias=cfg[\\\"attention_bias\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" attn_type=attn_type,\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.input_layernorm = CohereLayerNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"layer_norm_eps\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x, mask_global, mask_local, cos, sin, start_pos=0, cache=None):\\n\",\n \" attn_mask = mask_local if self.attn_type == \\\"sliding_attention\\\" else mask_global\\n\",\n \"\\n\",\n \" shortcut = x\\n\",\n \" x = self.input_layernorm(x)\\n\",\n \" x_attn, next_cache = self.att(\\n\",\n \" x,\\n\",\n \" attn_mask,\\n\",\n \" cos,\\n\",\n \" sin,\\n\",\n \" start_pos=start_pos,\\n\",\n \" cache=cache,\\n\",\n \" ) # Shape [batch_size, num_tokens, emb_dim]\\n\",\n \" x_ff = self.ff(x)\\n\",\n \"\\n\",\n \" # Cohere2 parallel residual block\\n\",\n \" x = shortcut + x_attn + x_ff\\n\",\n \" return x, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TinyAyaModel(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" assert len(cfg[\\\"layer_types\\\"]) == cfg[\\\"n_layers\\\"], \\\"layer_types must match n_layers\\\"\\n\",\n \"\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.trf_blocks = nn.ModuleList([TransformerBlock(cfg, t) for t in cfg[\\\"layer_types\\\"]])\\n\",\n \"\\n\",\n \" self.final_norm = CohereLayerNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"layer_norm_eps\\\"])\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.logit_scale = cfg[\\\"logit_scale\\\"]\\n\",\n \"\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \"\\n\",\n \" if cfg[\\\"tie_word_embeddings\\\"]:\\n\",\n \" self.out_head.weight = self.tok_emb.weight\\n\",\n \"\\n\",\n \" self.current_pos = 0 # Track current position in KV cache\\n\",\n \"\\n\",\n \" def create_masks(self, num_tokens, device, pos_start=0, total_kv_tokens=None):\\n\",\n \" if total_kv_tokens is None:\\n\",\n \" total_kv_tokens = pos_start + num_tokens\\n\",\n \"\\n\",\n \" query_positions = torch.arange(pos_start, pos_start + num_tokens, device=device).unsqueeze(1)\\n\",\n \" key_positions = torch.arange(total_kv_tokens, device=device).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Future mask\\n\",\n \" mask_global = key_positions > query_positions\\n\",\n \"\\n\",\n \" # Sliding-window mask\\n\",\n \" far_past = key_positions + self.cfg[\\\"sliding_window\\\"] <= query_positions\\n\",\n \" mask_local = mask_global | far_past\\n\",\n \"\\n\",\n \" # Expand to [batch, heads, seq, seq]-broadcastable shape\\n\",\n \" return mask_global.unsqueeze(0).unsqueeze(0), mask_local.unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" def forward(self, input_ids, attention_mask=None, cache=None):\\n\",\n \" tok_embeds = self.tok_emb(input_ids)\\n\",\n \" x = tok_embeds\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" pos_start = self.current_pos\\n\",\n \" pos_end = pos_start + num_tokens\\n\",\n \" self.current_pos = pos_end\\n\",\n \" total_kv_tokens = pos_end\\n\",\n \" else:\\n\",\n \" pos_start = 0\\n\",\n \" total_kv_tokens = num_tokens\\n\",\n \"\\n\",\n \" mask_global, mask_local = self.create_masks(\\n\",\n \" num_tokens,\\n\",\n \" x.device,\\n\",\n \" pos_start=pos_start,\\n\",\n \" total_kv_tokens=total_kv_tokens,\\n\",\n \" )\\n\",\n \"\\n\",\n \" if attention_mask is not None:\\n\",\n \" # True means mask in this implementation.\\n\",\n \" pad_mask = attention_mask[:, None, None, :total_kv_tokens].to(dtype=torch.bool).logical_not()\\n\",\n \" mask_global = mask_global | pad_mask\\n\",\n \" mask_local = mask_local | pad_mask\\n\",\n \"\\n\",\n \" cos = self.cos.to(x.device, dtype=x.dtype)\\n\",\n \" sin = self.sin.to(x.device, dtype=x.dtype)\\n\",\n \"\\n\",\n \" for i, block in enumerate(self.trf_blocks):\\n\",\n \" blk_cache = cache.get(i) if cache else None\\n\",\n \" x, new_blk_cache = block(\\n\",\n \" x,\\n\",\n \" mask_global,\\n\",\n \" mask_local,\\n\",\n \" cos,\\n\",\n \" sin,\\n\",\n \" start_pos=pos_start,\\n\",\n \" cache=blk_cache,\\n\",\n \" )\\n\",\n \" if cache is not None:\\n\",\n \" cache.update(i, new_blk_cache)\\n\",\n \"\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits * self.logit_scale\\n\",\n \"\\n\",\n \" def reset_kv_cache(self):\\n\",\n \" self.current_pos = 0\\n\",\n \"\\n\",\n \"\\n\",\n \"class KVCache:\\n\",\n \" def __init__(self, n_layers):\\n\",\n \" self.cache = [None] * n_layers\\n\",\n \"\\n\",\n \" def get(self, layer_idx):\\n\",\n \" return self.cache[layer_idx]\\n\",\n \"\\n\",\n \" def update(self, layer_idx, value):\\n\",\n \" self.cache[layer_idx] = value\\n\",\n \"\\n\",\n \" def get_all(self):\\n\",\n \" return self.cache\\n\",\n \"\\n\",\n \" def reset(self):\\n\",\n \" for i in range(len(self.cache)):\\n\",\n \" self.cache[i] = None\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"23dea40c-fe20-4a75-be25-d6fce5863c01\",\n \"metadata\": {\n \"id\": \"23dea40c-fe20-4a75-be25-d6fce5863c01\"\n },\n \"source\": [\n \"- The remainder of this notebook uses the Llama 3.2 1B model; to use the 3B model variant, just uncomment the second configuration file in the following code cell\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"TINY_AYA_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 262_144, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 500_000, # Context length in the HF config\\n\",\n \" \\\"emb_dim\\\": 2048, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 16, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 36, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 11_008, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"head_dim\\\": 128, # Size of the heads in GQA\\n\",\n \" \\\"n_kv_heads\\\": 4, # Number of KV heads for grouped-query attention\\n\",\n \" \\\"attention_bias\\\": False, # Whether attention projections use bias terms\\n\",\n \" \\\"attention_dropout\\\": 0.0, # Attention dropout\\n\",\n \" \\\"sliding_window\\\": 4096, # Sliding-window attention context\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \" \\\"rope_base\\\": 50_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"layer_norm_eps\\\": 1e-5, # Epsilon used by layer normalization\\n\",\n \" \\\"logit_scale\\\": 1.0, # Final logits scaling factor\\n\",\n \" \\\"tie_word_embeddings\\\": True, # Whether input embedding and output head are tied\\n\",\n \" \\\"bos_token_id\\\": 2,\\n\",\n \" \\\"eos_token_id\\\": 3,\\n\",\n \" \\\"pad_token_id\\\": 0,\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = TinyAyaModel(TINY_AYA_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"fd5efb03-5a07-46e8-8607-93ed47549d2b\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"fd5efb03-5a07-46e8-8607-93ed47549d2b\",\n \"outputId\": \"65c1a95e-b502-4150-9e2e-da619d9053d5\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"float32 (PyTorch default): 25.43 GB\\n\",\n \"bfloat16: 12.72 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def calc_model_memory_size(model, input_dtype=torch.float32):\\n\",\n \" total_params = 0\\n\",\n \" total_grads = 0\\n\",\n \" for param in model.parameters():\\n\",\n \" # Calculate total number of elements per parameter\\n\",\n \" param_size = param.numel()\\n\",\n \" total_params += param_size\\n\",\n \" # Check if gradients are stored for this parameter\\n\",\n \" if param.requires_grad:\\n\",\n \" total_grads += param_size\\n\",\n \"\\n\",\n \" # Calculate buffer size (non-parameters that require memory)\\n\",\n \" total_buffers = sum(buf.numel() for buf in model.buffers())\\n\",\n \"\\n\",\n \" # Size in bytes = (Number of elements) * (Size of each element in bytes)\\n\",\n \" # We assume parameters and gradients are stored in the same type as input dtype\\n\",\n \" element_size = torch.tensor(0, dtype=input_dtype).element_size()\\n\",\n \" total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\\n\",\n \"\\n\",\n \" # Convert bytes to gigabytes\\n\",\n \" total_memory_gb = total_memory_bytes / (1024**3)\\n\",\n \"\\n\",\n \" return total_memory_gb\\n\",\n \"\\n\",\n \"print(f\\\"float32 (PyTorch default): {calc_model_memory_size(model, input_dtype=torch.float32):.2f} GB\\\")\\n\",\n \"print(f\\\"bfloat16: {calc_model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"41176fb0-d58a-443a-912f-4f436564b5f8\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters: 3,349,227,520\\n\",\n \"\\n\",\n \"Total number of unique parameters: 2,812,356,608\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters())\\n\",\n \"print(f\\\"Total number of parameters: {total_params:,}\\\")\\n\",\n \"\\n\",\n \"# Account for weight tying\\n\",\n \"total_params_normalized = total_params - model.tok_emb.weight.numel()\\n\",\n \"print(f\\\"\\\\nTotal number of unique parameters: {total_params_normalized:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"31f12baf-f79b-499f-85c0-51328a6a20f5\",\n \"metadata\": {\n \"id\": \"31f12baf-f79b-499f-85c0-51328a6a20f5\"\n },\n \"outputs\": [],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"78e091e1-afa8-4d23-9aea-cced86181bfd\",\n \"metadata\": {\n \"id\": \"78e091e1-afa8-4d23-9aea-cced86181bfd\"\n },\n \"source\": [\n \" \\n\",\n \"# 3. Load tokenizer\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"9482b01c-49f9-48e4-ab2c-4a4c75240e77\",\n \"metadata\": {\n \"id\": \"9482b01c-49f9-48e4-ab2c-4a4c75240e77\"\n },\n \"outputs\": [],\n \"source\": [\n \"from tokenizers import Tokenizer\\n\",\n \"\\n\",\n \"\\n\",\n \"class TinyAyaTokenizer:\\n\",\n \" def __init__(self, tokenizer_file_path, eos_token_id=3, pad_token_id=0, bos_token_id=2):\\n\",\n \" tok_file = Path(tokenizer_file_path)\\n\",\n \" self._tok = Tokenizer.from_file(str(tok_file))\\n\",\n \"\\n\",\n \" eos_from_tok = self._tok.token_to_id(\\\"\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"05104b25-71fb-462f-8f2d-336184833eda\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"CohereLabs/tiny-aya-global\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(REPO_ID)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7e327c26-ae3e-4f07-845f-eeb4a6b31283\",\n \"metadata\": {},\n \"source\": [\n \"- Note that if you use the fire, water, base, or earth model, you'd have to accept the licensing terms separately:\\n\",\n \" - [CohereLabs/tiny-aya-fire](https://huggingface.co/CohereLabs/tiny-aya-fire)\\n\",\n \" - [CohereLabs/tiny-aya-water](https://huggingface.co/CohereLabs/tiny-aya-water)\\n\",\n \" - [CohereLabs/tiny-aya-earth](https://huggingface.co/CohereLabs/tiny-aya-earth)\\n\",\n \" - [CohereLabs/tiny-aya-base](https://huggingface.co/CohereLabs/tiny-aya-base)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed\",\n \"outputId\": \"e6e6dc05-7330-45bc-a9a7-331919155bdd\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Uncomment and run the following code if you are executing the notebook for the first time\\n\",\n \"\\n\",\n \"from huggingface_hub import login\\n\",\n \"login()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"986bc1a0-804f-4154-80f8-44cefbee1368\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 141,\n \"referenced_widgets\": [\n \"a1608feac06d4687967a3e398f01c489\",\n \"518fb202e4b44aaba47f07d1a61b6762\",\n \"672cdc5aea954de3af851c001a667ad3\",\n \"eebf8874618746b39cf4a21a2728dc7f\",\n \"5176834aa8784bba9ec21234b87a8948\",\n \"e2dc407afcd945c798e30597fddfcb3c\",\n \"0dccd57dcc5c43a588157cef957c07e8\",\n \"33ca0cdf2c7f41598a381c4ebe6a4ee1\",\n \"ee44487f58454dacb522b1e084ffb733\",\n \"d2c41e71a3f441deaed091b620ac5603\",\n \"3326b6141a1a4eba9f316df528a9b99a\"\n ]\n },\n \"id\": \"986bc1a0-804f-4154-80f8-44cefbee1368\",\n \"outputId\": \"5dd7334b-4c71-465a-94d2-c3e95b9ddc58\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import hf_hub_download\\n\",\n \"\\n\",\n \"tokenizer_file_path = Path(LOCAL_DIR) / \\\"tokenizer.json\\\"\\n\",\n \"if not tokenizer_file_path.exists():\\n\",\n \" try:\\n\",\n \" tokenizer_file_path = hf_hub_download(repo_id=REPO_ID, filename=\\\"tokenizer.json\\\", local_dir=LOCAL_DIR)\\n\",\n \" except Exception as e:\\n\",\n \" print(f\\\"Warning: failed to download tokenizer.json: {e}\\\")\\n\",\n \" tokenizer_file_path = \\\"tokenizer.json\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"_gBhxDtU_nxo\",\n \"metadata\": {\n \"id\": \"_gBhxDtU_nxo\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n },\n \"widgets\": {\n \"application/vnd.jupyter.widget-state+json\": {\n \"state\": {\n \"0dccd57dcc5c43a588157cef957c07e8\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"17a3174e65c54476b2e0d1faf8f011ca\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_90a79523187446dfa692723b2e5833a7\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_431ffb83b8c14bf182f0430e07ea6154\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \"model.safetensors: 35%\"\n }\n },\n \"1bbf2e62c0754d1593beb4105a7f1ac1\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"FloatProgressModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"FloatProgressModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"ProgressView\",\n \"bar_style\": \"\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_a8f1b72a33dd4b548de23fbd95e0da18\",\n \"max\": 2471645608,\n \"min\": 0,\n \"orientation\": \"horizontal\",\n \"style\": \"IPY_MODEL_25cc36132d384189acfbecc59483134b\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": 880803840\n }\n },\n \"25cc36132d384189acfbecc59483134b\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"ProgressStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"ProgressStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"bar_color\": null,\n \"description_width\": \"\"\n }\n },\n \"271e2bd6a35e4a8b92de8697f7c0be5f\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"3326b6141a1a4eba9f316df528a9b99a\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"33ca0cdf2c7f41598a381c4ebe6a4ee1\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"431ffb83b8c14bf182f0430e07ea6154\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"5176834aa8784bba9ec21234b87a8948\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"518fb202e4b44aaba47f07d1a61b6762\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_e2dc407afcd945c798e30597fddfcb3c\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_0dccd57dcc5c43a588157cef957c07e8\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \"tokenizer.model: 100%\"\n }\n },\n \"672cdc5aea954de3af851c001a667ad3\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"FloatProgressModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"FloatProgressModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"ProgressView\",\n \"bar_style\": \"success\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_33ca0cdf2c7f41598a381c4ebe6a4ee1\",\n \"max\": 2183982,\n \"min\": 0,\n \"orientation\": \"horizontal\",\n \"style\": \"IPY_MODEL_ee44487f58454dacb522b1e084ffb733\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": 2183982\n }\n },\n \"90a79523187446dfa692723b2e5833a7\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"9881b6995c3f49dc89e6992fd9ab660b\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HBoxModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HBoxModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HBoxView\",\n \"box_style\": \"\",\n \"children\": [\n \"IPY_MODEL_17a3174e65c54476b2e0d1faf8f011ca\",\n \"IPY_MODEL_1bbf2e62c0754d1593beb4105a7f1ac1\",\n \"IPY_MODEL_b82112e1dec645d98aa1c1ba64abcb61\"\n ],\n \"layout\": \"IPY_MODEL_271e2bd6a35e4a8b92de8697f7c0be5f\",\n \"tabbable\": null,\n \"tooltip\": null\n }\n },\n \"a1608feac06d4687967a3e398f01c489\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HBoxModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HBoxModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HBoxView\",\n \"box_style\": \"\",\n \"children\": [\n \"IPY_MODEL_518fb202e4b44aaba47f07d1a61b6762\",\n \"IPY_MODEL_672cdc5aea954de3af851c001a667ad3\",\n \"IPY_MODEL_eebf8874618746b39cf4a21a2728dc7f\"\n ],\n \"layout\": \"IPY_MODEL_5176834aa8784bba9ec21234b87a8948\",\n \"tabbable\": null,\n \"tooltip\": null\n }\n },\n \"a8f1b72a33dd4b548de23fbd95e0da18\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"b82112e1dec645d98aa1c1ba64abcb61\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_bfd06423ad544218968648016e731a46\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_d029630b63ff44cf807ade428d2eb421\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \" 870M/2.47G [00:20<00:37, 42.8MB/s]\"\n }\n },\n \"bfd06423ad544218968648016e731a46\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"d029630b63ff44cf807ade428d2eb421\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"d2c41e71a3f441deaed091b620ac5603\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"e2dc407afcd945c798e30597fddfcb3c\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"ee44487f58454dacb522b1e084ffb733\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"ProgressStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"ProgressStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"bar_color\": null,\n \"description_width\": \"\"\n }\n },\n \"eebf8874618746b39cf4a21a2728dc7f\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_d2c41e71a3f441deaed091b620ac5603\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_3326b6141a1a4eba9f316df528a9b99a\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \" 2.18M/2.18M [00:00<00:00, 9.47MB/s]\"\n }\n }\n },\n \"version_major\": 2,\n \"version_minor\": 0\n }\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/15_tiny-aya/standalone-tiny-aya.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"
\\n\",\n \"\\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Tiny Aya architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 1.4.1\\n\",\n \"tiktoken version: 0.12.0\\n\",\n \"torch version: 2.10.0\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" #\\\"blobfile\\\", # to download pretrained weights\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tiktoken\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"574bc51e-876e-46c3-bcf7-ef4675582ad2\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"REPO_ID = \\\"CohereLabs/tiny-aya-global\\\"\\n\",\n \"#REPO_ID = \\\"CohereLabs/tiny-aya-fire\\\" \\n\",\n \"#REPO_ID = \\\"CohereLabs/tiny-aya-water\\\"\\n\",\n \"#REPO_ID = \\\"CohereLabs/tiny-aya-earth\\\"\\n\",\n \"\\n\",\n \"LOCAL_DIR = Path(REPO_ID).parts[-1]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"1a36d4a0-ee44-4727-ab7e-c73dd5e1ddba\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Aya uses a bias-less LayerNorm variant. \\n\",\n \"# The difference to classic LayerNorm is that it only \\n\",\n \"# has a scale parameter (weight), no shift parameter (bias).\\n\",\n \"\\n\",\n \"class CohereLayerNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-5):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" self.weight = nn.Parameter(torch.ones(emb_dim))\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" input_dtype = x.dtype\\n\",\n \" x = x.to(torch.float32)\\n\",\n \" mean = x.mean(dim=-1, keepdim=True)\\n\",\n \" variance = (x - mean).pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x = (x - mean) * torch.rsqrt(variance + self.eps)\\n\",\n \" return (self.weight.to(torch.float32) * x).to(input_dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"head_dim must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (\\n\",\n \" theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim)\\n\",\n \" )\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Cohere uses interleaved even/odd angle layout per head-dim pair.\\n\",\n \" # Llama2 notebook examples often use a split-halves layout via cat([angles, angles]).\\n\",\n \" # Both are equivalent only when paired with the matching rotate logic:\\n\",\n \" # - interleaved layout -> even/odd rotation implementation (below)\\n\",\n \" # - split-halves layout -> half/half rotate implementation\\n\",\n \" angles = torch.repeat_interleave(angles, 2, dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" return torch.cos(angles), torch.sin(angles)\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin, offset=0):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"head_dim must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into even and odd components (interleaved layout)\\n\",\n \" x_even = x[..., ::2]\\n\",\n \" x_odd = x[..., 1::2]\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \" sin = sin[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" x_float = x.float()\\n\",\n \" rotated = torch.stack((-x_odd.float(), x_even.float()), dim=-1).flatten(-2)\\n\",\n \" x_rotated = (x_float * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self,\\n\",\n \" d_in,\\n\",\n \" num_heads,\\n\",\n \" num_kv_groups,\\n\",\n \" head_dim=None,\\n\",\n \" qk_norm=False,\\n\",\n \" attention_bias=False,\\n\",\n \" dtype=None,\\n\",\n \" attn_type=\\\"full_attention\\\",\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" if head_dim is None:\\n\",\n \" assert d_in % num_heads == 0, \\\"`d_in` must be divisible by `num_heads` if `head_dim` is not set\\\"\\n\",\n \" head_dim = d_in // num_heads\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \" self.attn_type = attn_type\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(\\n\",\n \" d_in,\\n\",\n \" self.d_out,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \" self.W_key = nn.Linear(\\n\",\n \" d_in,\\n\",\n \" num_kv_groups * head_dim,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \" self.W_value = nn.Linear(\\n\",\n \" d_in,\\n\",\n \" num_kv_groups * head_dim,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \" self.out_proj = nn.Linear(\\n\",\n \" self.d_out,\\n\",\n \" d_in,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \"\\n\",\n \" if qk_norm:\\n\",\n \" self.q_norm = CohereLayerNorm(head_dim, eps=1e-6)\\n\",\n \" self.k_norm = CohereLayerNorm(head_dim, eps=1e-6)\\n\",\n \" else:\\n\",\n \" self.q_norm = self.k_norm = None\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin, start_pos=0, cache=None):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" # Apply projections\\n\",\n \" queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\\n\",\n \" keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\\n\",\n \" keys_new = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values_new = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Optional normalization\\n\",\n \" if self.q_norm:\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" if self.k_norm:\\n\",\n \" keys_new = self.k_norm(keys_new)\\n\",\n \"\\n\",\n \" # Cohere2 applies RoPE only on sliding-attention layers.\\n\",\n \" if self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" queries = apply_rope(queries, cos, sin, offset=start_pos)\\n\",\n \" keys_new = apply_rope(keys_new, cos, sin, offset=start_pos)\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" prev_k, prev_v = cache\\n\",\n \" keys = torch.cat([prev_k, keys_new], dim=2)\\n\",\n \" values = torch.cat([prev_v, values_new], dim=2)\\n\",\n \" next_cache = (keys, values)\\n\",\n \" else:\\n\",\n \" keys, values = keys_new, values_new\\n\",\n \" next_cache = (keys, values)\\n\",\n \"\\n\",\n \" # Expand K and V to match number of heads\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" # Attention\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores / self.head_dim**0.5, dim=-1, dtype=torch.float32).to(queries.dtype)\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \"\\n\",\n \" return self.out_proj(context), next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg, attn_type):\\n\",\n \" super().__init__()\\n\",\n \" self.attn_type = attn_type\\n\",\n \"\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_heads\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" qk_norm=False,\\n\",\n \" attention_bias=cfg[\\\"attention_bias\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" attn_type=attn_type,\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.input_layernorm = CohereLayerNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"layer_norm_eps\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x, mask_global, mask_local, cos, sin, start_pos=0, cache=None):\\n\",\n \" attn_mask = mask_local if self.attn_type == \\\"sliding_attention\\\" else mask_global\\n\",\n \"\\n\",\n \" shortcut = x\\n\",\n \" x = self.input_layernorm(x)\\n\",\n \" x_attn, next_cache = self.att(\\n\",\n \" x,\\n\",\n \" attn_mask,\\n\",\n \" cos,\\n\",\n \" sin,\\n\",\n \" start_pos=start_pos,\\n\",\n \" cache=cache,\\n\",\n \" ) # Shape [batch_size, num_tokens, emb_dim]\\n\",\n \" x_ff = self.ff(x)\\n\",\n \"\\n\",\n \" # Cohere2 parallel residual block\\n\",\n \" x = shortcut + x_attn + x_ff\\n\",\n \" return x, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TinyAyaModel(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" assert len(cfg[\\\"layer_types\\\"]) == cfg[\\\"n_layers\\\"], \\\"layer_types must match n_layers\\\"\\n\",\n \"\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.trf_blocks = nn.ModuleList([TransformerBlock(cfg, t) for t in cfg[\\\"layer_types\\\"]])\\n\",\n \"\\n\",\n \" self.final_norm = CohereLayerNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"layer_norm_eps\\\"])\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.logit_scale = cfg[\\\"logit_scale\\\"]\\n\",\n \"\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \"\\n\",\n \" if cfg[\\\"tie_word_embeddings\\\"]:\\n\",\n \" self.out_head.weight = self.tok_emb.weight\\n\",\n \"\\n\",\n \" self.current_pos = 0 # Track current position in KV cache\\n\",\n \"\\n\",\n \" def create_masks(self, num_tokens, device, pos_start=0, total_kv_tokens=None):\\n\",\n \" if total_kv_tokens is None:\\n\",\n \" total_kv_tokens = pos_start + num_tokens\\n\",\n \"\\n\",\n \" query_positions = torch.arange(pos_start, pos_start + num_tokens, device=device).unsqueeze(1)\\n\",\n \" key_positions = torch.arange(total_kv_tokens, device=device).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Future mask\\n\",\n \" mask_global = key_positions > query_positions\\n\",\n \"\\n\",\n \" # Sliding-window mask\\n\",\n \" far_past = key_positions + self.cfg[\\\"sliding_window\\\"] <= query_positions\\n\",\n \" mask_local = mask_global | far_past\\n\",\n \"\\n\",\n \" # Expand to [batch, heads, seq, seq]-broadcastable shape\\n\",\n \" return mask_global.unsqueeze(0).unsqueeze(0), mask_local.unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" def forward(self, input_ids, attention_mask=None, cache=None):\\n\",\n \" tok_embeds = self.tok_emb(input_ids)\\n\",\n \" x = tok_embeds\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" pos_start = self.current_pos\\n\",\n \" pos_end = pos_start + num_tokens\\n\",\n \" self.current_pos = pos_end\\n\",\n \" total_kv_tokens = pos_end\\n\",\n \" else:\\n\",\n \" pos_start = 0\\n\",\n \" total_kv_tokens = num_tokens\\n\",\n \"\\n\",\n \" mask_global, mask_local = self.create_masks(\\n\",\n \" num_tokens,\\n\",\n \" x.device,\\n\",\n \" pos_start=pos_start,\\n\",\n \" total_kv_tokens=total_kv_tokens,\\n\",\n \" )\\n\",\n \"\\n\",\n \" if attention_mask is not None:\\n\",\n \" # True means mask in this implementation.\\n\",\n \" pad_mask = attention_mask[:, None, None, :total_kv_tokens].to(dtype=torch.bool).logical_not()\\n\",\n \" mask_global = mask_global | pad_mask\\n\",\n \" mask_local = mask_local | pad_mask\\n\",\n \"\\n\",\n \" cos = self.cos.to(x.device, dtype=x.dtype)\\n\",\n \" sin = self.sin.to(x.device, dtype=x.dtype)\\n\",\n \"\\n\",\n \" for i, block in enumerate(self.trf_blocks):\\n\",\n \" blk_cache = cache.get(i) if cache else None\\n\",\n \" x, new_blk_cache = block(\\n\",\n \" x,\\n\",\n \" mask_global,\\n\",\n \" mask_local,\\n\",\n \" cos,\\n\",\n \" sin,\\n\",\n \" start_pos=pos_start,\\n\",\n \" cache=blk_cache,\\n\",\n \" )\\n\",\n \" if cache is not None:\\n\",\n \" cache.update(i, new_blk_cache)\\n\",\n \"\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits * self.logit_scale\\n\",\n \"\\n\",\n \" def reset_kv_cache(self):\\n\",\n \" self.current_pos = 0\\n\",\n \"\\n\",\n \"\\n\",\n \"class KVCache:\\n\",\n \" def __init__(self, n_layers):\\n\",\n \" self.cache = [None] * n_layers\\n\",\n \"\\n\",\n \" def get(self, layer_idx):\\n\",\n \" return self.cache[layer_idx]\\n\",\n \"\\n\",\n \" def update(self, layer_idx, value):\\n\",\n \" self.cache[layer_idx] = value\\n\",\n \"\\n\",\n \" def get_all(self):\\n\",\n \" return self.cache\\n\",\n \"\\n\",\n \" def reset(self):\\n\",\n \" for i in range(len(self.cache)):\\n\",\n \" self.cache[i] = None\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"23dea40c-fe20-4a75-be25-d6fce5863c01\",\n \"metadata\": {\n \"id\": \"23dea40c-fe20-4a75-be25-d6fce5863c01\"\n },\n \"source\": [\n \"- The remainder of this notebook uses the Llama 3.2 1B model; to use the 3B model variant, just uncomment the second configuration file in the following code cell\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"TINY_AYA_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 262_144, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 500_000, # Context length in the HF config\\n\",\n \" \\\"emb_dim\\\": 2048, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 16, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 36, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 11_008, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"head_dim\\\": 128, # Size of the heads in GQA\\n\",\n \" \\\"n_kv_heads\\\": 4, # Number of KV heads for grouped-query attention\\n\",\n \" \\\"attention_bias\\\": False, # Whether attention projections use bias terms\\n\",\n \" \\\"attention_dropout\\\": 0.0, # Attention dropout\\n\",\n \" \\\"sliding_window\\\": 4096, # Sliding-window attention context\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \" \\\"rope_base\\\": 50_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"layer_norm_eps\\\": 1e-5, # Epsilon used by layer normalization\\n\",\n \" \\\"logit_scale\\\": 1.0, # Final logits scaling factor\\n\",\n \" \\\"tie_word_embeddings\\\": True, # Whether input embedding and output head are tied\\n\",\n \" \\\"bos_token_id\\\": 2,\\n\",\n \" \\\"eos_token_id\\\": 3,\\n\",\n \" \\\"pad_token_id\\\": 0,\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = TinyAyaModel(TINY_AYA_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"fd5efb03-5a07-46e8-8607-93ed47549d2b\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"fd5efb03-5a07-46e8-8607-93ed47549d2b\",\n \"outputId\": \"65c1a95e-b502-4150-9e2e-da619d9053d5\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"float32 (PyTorch default): 25.43 GB\\n\",\n \"bfloat16: 12.72 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def calc_model_memory_size(model, input_dtype=torch.float32):\\n\",\n \" total_params = 0\\n\",\n \" total_grads = 0\\n\",\n \" for param in model.parameters():\\n\",\n \" # Calculate total number of elements per parameter\\n\",\n \" param_size = param.numel()\\n\",\n \" total_params += param_size\\n\",\n \" # Check if gradients are stored for this parameter\\n\",\n \" if param.requires_grad:\\n\",\n \" total_grads += param_size\\n\",\n \"\\n\",\n \" # Calculate buffer size (non-parameters that require memory)\\n\",\n \" total_buffers = sum(buf.numel() for buf in model.buffers())\\n\",\n \"\\n\",\n \" # Size in bytes = (Number of elements) * (Size of each element in bytes)\\n\",\n \" # We assume parameters and gradients are stored in the same type as input dtype\\n\",\n \" element_size = torch.tensor(0, dtype=input_dtype).element_size()\\n\",\n \" total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\\n\",\n \"\\n\",\n \" # Convert bytes to gigabytes\\n\",\n \" total_memory_gb = total_memory_bytes / (1024**3)\\n\",\n \"\\n\",\n \" return total_memory_gb\\n\",\n \"\\n\",\n \"print(f\\\"float32 (PyTorch default): {calc_model_memory_size(model, input_dtype=torch.float32):.2f} GB\\\")\\n\",\n \"print(f\\\"bfloat16: {calc_model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"41176fb0-d58a-443a-912f-4f436564b5f8\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters: 3,349,227,520\\n\",\n \"\\n\",\n \"Total number of unique parameters: 2,812,356,608\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters())\\n\",\n \"print(f\\\"Total number of parameters: {total_params:,}\\\")\\n\",\n \"\\n\",\n \"# Account for weight tying\\n\",\n \"total_params_normalized = total_params - model.tok_emb.weight.numel()\\n\",\n \"print(f\\\"\\\\nTotal number of unique parameters: {total_params_normalized:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"31f12baf-f79b-499f-85c0-51328a6a20f5\",\n \"metadata\": {\n \"id\": \"31f12baf-f79b-499f-85c0-51328a6a20f5\"\n },\n \"outputs\": [],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"78e091e1-afa8-4d23-9aea-cced86181bfd\",\n \"metadata\": {\n \"id\": \"78e091e1-afa8-4d23-9aea-cced86181bfd\"\n },\n \"source\": [\n \" \\n\",\n \"# 3. Load tokenizer\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"9482b01c-49f9-48e4-ab2c-4a4c75240e77\",\n \"metadata\": {\n \"id\": \"9482b01c-49f9-48e4-ab2c-4a4c75240e77\"\n },\n \"outputs\": [],\n \"source\": [\n \"from tokenizers import Tokenizer\\n\",\n \"\\n\",\n \"\\n\",\n \"class TinyAyaTokenizer:\\n\",\n \" def __init__(self, tokenizer_file_path, eos_token_id=3, pad_token_id=0, bos_token_id=2):\\n\",\n \" tok_file = Path(tokenizer_file_path)\\n\",\n \" self._tok = Tokenizer.from_file(str(tok_file))\\n\",\n \"\\n\",\n \" eos_from_tok = self._tok.token_to_id(\\\"\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"05104b25-71fb-462f-8f2d-336184833eda\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"CohereLabs/tiny-aya-global\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(REPO_ID)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7e327c26-ae3e-4f07-845f-eeb4a6b31283\",\n \"metadata\": {},\n \"source\": [\n \"- Note that if you use the fire, water, base, or earth model, you'd have to accept the licensing terms separately:\\n\",\n \" - [CohereLabs/tiny-aya-fire](https://huggingface.co/CohereLabs/tiny-aya-fire)\\n\",\n \" - [CohereLabs/tiny-aya-water](https://huggingface.co/CohereLabs/tiny-aya-water)\\n\",\n \" - [CohereLabs/tiny-aya-earth](https://huggingface.co/CohereLabs/tiny-aya-earth)\\n\",\n \" - [CohereLabs/tiny-aya-base](https://huggingface.co/CohereLabs/tiny-aya-base)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed\",\n \"outputId\": \"e6e6dc05-7330-45bc-a9a7-331919155bdd\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Uncomment and run the following code if you are executing the notebook for the first time\\n\",\n \"\\n\",\n \"from huggingface_hub import login\\n\",\n \"login()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"986bc1a0-804f-4154-80f8-44cefbee1368\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 141,\n \"referenced_widgets\": [\n \"a1608feac06d4687967a3e398f01c489\",\n \"518fb202e4b44aaba47f07d1a61b6762\",\n \"672cdc5aea954de3af851c001a667ad3\",\n \"eebf8874618746b39cf4a21a2728dc7f\",\n \"5176834aa8784bba9ec21234b87a8948\",\n \"e2dc407afcd945c798e30597fddfcb3c\",\n \"0dccd57dcc5c43a588157cef957c07e8\",\n \"33ca0cdf2c7f41598a381c4ebe6a4ee1\",\n \"ee44487f58454dacb522b1e084ffb733\",\n \"d2c41e71a3f441deaed091b620ac5603\",\n \"3326b6141a1a4eba9f316df528a9b99a\"\n ]\n },\n \"id\": \"986bc1a0-804f-4154-80f8-44cefbee1368\",\n \"outputId\": \"5dd7334b-4c71-465a-94d2-c3e95b9ddc58\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import hf_hub_download\\n\",\n \"\\n\",\n \"tokenizer_file_path = Path(LOCAL_DIR) / \\\"tokenizer.json\\\"\\n\",\n \"if not tokenizer_file_path.exists():\\n\",\n \" try:\\n\",\n \" tokenizer_file_path = hf_hub_download(repo_id=REPO_ID, filename=\\\"tokenizer.json\\\", local_dir=LOCAL_DIR)\\n\",\n \" except Exception as e:\\n\",\n \" print(f\\\"Warning: failed to download tokenizer.json: {e}\\\")\\n\",\n \" tokenizer_file_path = \\\"tokenizer.json\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"_gBhxDtU_nxo\",\n \"metadata\": {\n \"id\": \"_gBhxDtU_nxo\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n },\n \"widgets\": {\n \"application/vnd.jupyter.widget-state+json\": {\n \"state\": {\n \"0dccd57dcc5c43a588157cef957c07e8\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"17a3174e65c54476b2e0d1faf8f011ca\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_90a79523187446dfa692723b2e5833a7\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_431ffb83b8c14bf182f0430e07ea6154\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \"model.safetensors: 35%\"\n }\n },\n \"1bbf2e62c0754d1593beb4105a7f1ac1\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"FloatProgressModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"FloatProgressModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"ProgressView\",\n \"bar_style\": \"\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_a8f1b72a33dd4b548de23fbd95e0da18\",\n \"max\": 2471645608,\n \"min\": 0,\n \"orientation\": \"horizontal\",\n \"style\": \"IPY_MODEL_25cc36132d384189acfbecc59483134b\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": 880803840\n }\n },\n \"25cc36132d384189acfbecc59483134b\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"ProgressStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"ProgressStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"bar_color\": null,\n \"description_width\": \"\"\n }\n },\n \"271e2bd6a35e4a8b92de8697f7c0be5f\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"3326b6141a1a4eba9f316df528a9b99a\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"33ca0cdf2c7f41598a381c4ebe6a4ee1\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"431ffb83b8c14bf182f0430e07ea6154\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"5176834aa8784bba9ec21234b87a8948\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"518fb202e4b44aaba47f07d1a61b6762\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_e2dc407afcd945c798e30597fddfcb3c\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_0dccd57dcc5c43a588157cef957c07e8\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \"tokenizer.model: 100%\"\n }\n },\n \"672cdc5aea954de3af851c001a667ad3\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"FloatProgressModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"FloatProgressModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"ProgressView\",\n \"bar_style\": \"success\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_33ca0cdf2c7f41598a381c4ebe6a4ee1\",\n \"max\": 2183982,\n \"min\": 0,\n \"orientation\": \"horizontal\",\n \"style\": \"IPY_MODEL_ee44487f58454dacb522b1e084ffb733\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": 2183982\n }\n },\n \"90a79523187446dfa692723b2e5833a7\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"9881b6995c3f49dc89e6992fd9ab660b\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HBoxModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HBoxModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HBoxView\",\n \"box_style\": \"\",\n \"children\": [\n \"IPY_MODEL_17a3174e65c54476b2e0d1faf8f011ca\",\n \"IPY_MODEL_1bbf2e62c0754d1593beb4105a7f1ac1\",\n \"IPY_MODEL_b82112e1dec645d98aa1c1ba64abcb61\"\n ],\n \"layout\": \"IPY_MODEL_271e2bd6a35e4a8b92de8697f7c0be5f\",\n \"tabbable\": null,\n \"tooltip\": null\n }\n },\n \"a1608feac06d4687967a3e398f01c489\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HBoxModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HBoxModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HBoxView\",\n \"box_style\": \"\",\n \"children\": [\n \"IPY_MODEL_518fb202e4b44aaba47f07d1a61b6762\",\n \"IPY_MODEL_672cdc5aea954de3af851c001a667ad3\",\n \"IPY_MODEL_eebf8874618746b39cf4a21a2728dc7f\"\n ],\n \"layout\": \"IPY_MODEL_5176834aa8784bba9ec21234b87a8948\",\n \"tabbable\": null,\n \"tooltip\": null\n }\n },\n \"a8f1b72a33dd4b548de23fbd95e0da18\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"b82112e1dec645d98aa1c1ba64abcb61\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_bfd06423ad544218968648016e731a46\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_d029630b63ff44cf807ade428d2eb421\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \" 870M/2.47G [00:20<00:37, 42.8MB/s]\"\n }\n },\n \"bfd06423ad544218968648016e731a46\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"d029630b63ff44cf807ade428d2eb421\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"d2c41e71a3f441deaed091b620ac5603\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"e2dc407afcd945c798e30597fddfcb3c\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"ee44487f58454dacb522b1e084ffb733\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"ProgressStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"ProgressStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"bar_color\": null,\n \"description_width\": \"\"\n }\n },\n \"eebf8874618746b39cf4a21a2728dc7f\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_d2c41e71a3f441deaed091b620ac5603\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_3326b6141a1a4eba9f316df528a9b99a\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \" 2.18M/2.18M [00:00<00:00, 9.47MB/s]\"\n }\n }\n },\n \"version_major\": 2,\n \"version_minor\": 0\n }\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/15_tiny-aya/standalone-tiny-aya.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\\n\",\n \"\\n\",\n \" \\n\",\n \"- About the code:\\n\",\n \" - all code is my own code, mapping the Tiny Aya architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 1.4.1\\n\",\n \"tiktoken version: 0.12.0\\n\",\n \"torch version: 2.10.0\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" #\\\"blobfile\\\", # to download pretrained weights\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tiktoken\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"574bc51e-876e-46c3-bcf7-ef4675582ad2\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"REPO_ID = \\\"CohereLabs/tiny-aya-global\\\"\\n\",\n \"#REPO_ID = \\\"CohereLabs/tiny-aya-fire\\\" \\n\",\n \"#REPO_ID = \\\"CohereLabs/tiny-aya-water\\\"\\n\",\n \"#REPO_ID = \\\"CohereLabs/tiny-aya-earth\\\"\\n\",\n \"\\n\",\n \"LOCAL_DIR = Path(REPO_ID).parts[-1]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"1a36d4a0-ee44-4727-ab7e-c73dd5e1ddba\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Aya uses a bias-less LayerNorm variant. \\n\",\n \"# The difference to classic LayerNorm is that it only \\n\",\n \"# has a scale parameter (weight), no shift parameter (bias).\\n\",\n \"\\n\",\n \"class CohereLayerNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-5):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" self.weight = nn.Parameter(torch.ones(emb_dim))\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" input_dtype = x.dtype\\n\",\n \" x = x.to(torch.float32)\\n\",\n \" mean = x.mean(dim=-1, keepdim=True)\\n\",\n \" variance = (x - mean).pow(2).mean(dim=-1, keepdim=True)\\n\",\n \" x = (x - mean) * torch.rsqrt(variance + self.eps)\\n\",\n \" return (self.weight.to(torch.float32) * x).to(input_dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(head_dim, theta_base=10_000, context_length=4096, dtype=torch.float32):\\n\",\n \" assert head_dim % 2 == 0, \\\"head_dim must be even\\\"\\n\",\n \"\\n\",\n \" # Compute the inverse frequencies\\n\",\n \" inv_freq = 1.0 / (\\n\",\n \" theta_base ** (torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float() / head_dim)\\n\",\n \" )\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \"\\n\",\n \" # Compute the angles\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # Shape: (context_length, head_dim // 2)\\n\",\n \"\\n\",\n \" # Cohere uses interleaved even/odd angle layout per head-dim pair.\\n\",\n \" # Llama2 notebook examples often use a split-halves layout via cat([angles, angles]).\\n\",\n \" # Both are equivalent only when paired with the matching rotate logic:\\n\",\n \" # - interleaved layout -> even/odd rotation implementation (below)\\n\",\n \" # - split-halves layout -> half/half rotate implementation\\n\",\n \" angles = torch.repeat_interleave(angles, 2, dim=1) # Shape: (context_length, head_dim)\\n\",\n \"\\n\",\n \" # Precompute sine and cosine\\n\",\n \" return torch.cos(angles), torch.sin(angles)\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin):\\n\",\n \" # x: (batch_size, num_heads, seq_len, head_dim)\\n\",\n \" batch_size, num_heads, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"head_dim must be even\\\"\\n\",\n \"\\n\",\n \" # Split x into even and odd components (interleaved layout)\\n\",\n \" x_even = x[..., ::2]\\n\",\n \" x_odd = x[..., 1::2]\\n\",\n \"\\n\",\n \" # Adjust sin and cos shapes\\n\",\n \" cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \" sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" # Apply the rotary transformation\\n\",\n \" x_float = x.float()\\n\",\n \" rotated = torch.stack((-x_odd.float(), x_even.float()), dim=-1).flatten(-2)\\n\",\n \" x_rotated = (x_float * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" return x_rotated.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self,\\n\",\n \" d_in,\\n\",\n \" num_heads,\\n\",\n \" num_kv_groups,\\n\",\n \" head_dim=None,\\n\",\n \" qk_norm=False,\\n\",\n \" attention_bias=False,\\n\",\n \" dtype=None,\\n\",\n \" attn_type=\\\"full_attention\\\",\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" if head_dim is None:\\n\",\n \" assert d_in % num_heads == 0, \\\"`d_in` must be divisible by `num_heads` if `head_dim` is not set\\\"\\n\",\n \" head_dim = d_in // num_heads\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \" self.attn_type = attn_type\\n\",\n \"\\n\",\n \" self.W_query = nn.Linear(\\n\",\n \" d_in,\\n\",\n \" self.d_out,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \" self.W_key = nn.Linear(\\n\",\n \" d_in,\\n\",\n \" num_kv_groups * head_dim,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \" self.W_value = nn.Linear(\\n\",\n \" d_in,\\n\",\n \" num_kv_groups * head_dim,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \" self.out_proj = nn.Linear(\\n\",\n \" self.d_out,\\n\",\n \" d_in,\\n\",\n \" bias=attention_bias,\\n\",\n \" dtype=dtype,\\n\",\n \" )\\n\",\n \"\\n\",\n \" if qk_norm:\\n\",\n \" self.q_norm = CohereLayerNorm(head_dim, eps=1e-6)\\n\",\n \" self.k_norm = CohereLayerNorm(head_dim, eps=1e-6)\\n\",\n \" else:\\n\",\n \" self.q_norm = self.k_norm = None\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" # Apply projections\\n\",\n \" queries = self.W_query(x) # (b, num_tokens, num_heads * head_dim)\\n\",\n \" keys = self.W_key(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \" values = self.W_value(x) # (b, num_tokens, num_kv_groups * head_dim)\\n\",\n \"\\n\",\n \" # Reshape\\n\",\n \" queries = queries.view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" # Optional normalization\\n\",\n \" if self.q_norm:\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" if self.k_norm:\\n\",\n \" keys = self.k_norm(keys)\\n\",\n \"\\n\",\n \" # Cohere applies RoPE only on sliding-attention layers.\\n\",\n \" if self.attn_type == \\\"sliding_attention\\\":\\n\",\n \" queries = apply_rope(queries, cos, sin)\\n\",\n \" keys = apply_rope(keys, cos, sin)\\n\",\n \"\\n\",\n \" # Expand K and V to match number of heads\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" # Attention\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \"\\n\",\n \" attn_weights = torch.softmax(attn_scores / self.head_dim**0.5, dim=-1)\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \"\\n\",\n \" return self.out_proj(context)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg, attn_type):\\n\",\n \" super().__init__()\\n\",\n \" self.attn_type = attn_type\\n\",\n \"\\n\",\n \" self.att = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_heads\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" qk_norm=False,\\n\",\n \" attention_bias=cfg[\\\"attention_bias\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" attn_type=attn_type,\\n\",\n \" )\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.input_layernorm = CohereLayerNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"layer_norm_eps\\\"])\\n\",\n \"\\n\",\n \" def forward(self, x, mask_global, mask_local, cos, sin):\\n\",\n \" attn_mask = mask_local if self.attn_type == \\\"sliding_attention\\\" else mask_global\\n\",\n \"\\n\",\n \" shortcut = x\\n\",\n \" x = self.input_layernorm(x)\\n\",\n \" x_attn = self.att(x, attn_mask, cos, sin) # Shape [batch_size, num_tokens, emb_dim]\\n\",\n \" x_ff = self.ff(x)\\n\",\n \"\\n\",\n \" # Cohere parallel residual block\\n\",\n \" x = shortcut + x_attn + x_ff\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class TinyAyaModel(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" assert len(cfg[\\\"layer_types\\\"]) == cfg[\\\"n_layers\\\"], \\\"layer_types must match n_layers\\\"\\n\",\n \"\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \" self.trf_blocks = nn.ModuleList([TransformerBlock(cfg, t) for t in cfg[\\\"layer_types\\\"]])\\n\",\n \"\\n\",\n \" self.final_norm = CohereLayerNorm(cfg[\\\"emb_dim\\\"], eps=cfg[\\\"layer_norm_eps\\\"])\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" self.logit_scale = cfg[\\\"logit_scale\\\"]\\n\",\n \"\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \"\\n\",\n \" if cfg[\\\"tie_word_embeddings\\\"]:\\n\",\n \" self.out_head.weight = self.tok_emb.weight\\n\",\n \"\\n\",\n \" def create_masks(self, num_tokens, device):\\n\",\n \" ones = torch.ones((num_tokens, num_tokens), dtype=torch.bool, device=device)\\n\",\n \"\\n\",\n \" # Future mask\\n\",\n \" mask_global = torch.triu(ones, diagonal=1)\\n\",\n \"\\n\",\n \" # Sliding-window mask\\n\",\n \" far_past = torch.triu(ones, diagonal=self.cfg[\\\"sliding_window\\\"]).T\\n\",\n \" mask_local = mask_global | far_past\\n\",\n \"\\n\",\n \" # Expand to [batch, heads, seq, seq]-broadcastable shape\\n\",\n \" return mask_global.unsqueeze(0).unsqueeze(0), mask_local.unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" def forward(self, input_ids, attention_mask=None):\\n\",\n \" tok_embeds = self.tok_emb(input_ids)\\n\",\n \" x = tok_embeds\\n\",\n \" num_tokens = input_ids.shape[1]\\n\",\n \"\\n\",\n \" mask_global, mask_local = self.create_masks(num_tokens, x.device)\\n\",\n \"\\n\",\n \" if attention_mask is not None:\\n\",\n \" # True means mask in this implementation.\\n\",\n \" pad_mask = attention_mask[:, None, None, :].to(dtype=torch.bool).logical_not()\\n\",\n \" mask_global = mask_global | pad_mask\\n\",\n \" mask_local = mask_local | pad_mask\\n\",\n \"\\n\",\n \" cos = self.cos[:num_tokens, :].to(x.device, dtype=x.dtype)\\n\",\n \" sin = self.sin[:num_tokens, :].to(x.device, dtype=x.dtype)\\n\",\n \"\\n\",\n \" for block in self.trf_blocks:\\n\",\n \" x = block(x, mask_global, mask_local, cos, sin)\\n\",\n \"\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits * self.logit_scale\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"23dea40c-fe20-4a75-be25-d6fce5863c01\",\n \"metadata\": {\n \"id\": \"23dea40c-fe20-4a75-be25-d6fce5863c01\"\n },\n \"source\": [\n \"- The remainder of this notebook uses the Llama 3.2 1B model; to use the 3B model variant, just uncomment the second configuration file in the following code cell\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"TINY_AYA_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 262_144, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 500_000, # Context length in the HF config\\n\",\n \" \\\"emb_dim\\\": 2048, # Embedding dimension\\n\",\n \" \\\"n_heads\\\": 16, # Number of attention heads\\n\",\n \" \\\"n_layers\\\": 36, # Number of layers\\n\",\n \" \\\"hidden_dim\\\": 11_008, # Size of the intermediate dimension in FeedForward\\n\",\n \" \\\"head_dim\\\": 128, # Size of the heads in GQA\\n\",\n \" \\\"n_kv_heads\\\": 4, # Number of KV heads for grouped-query attention\\n\",\n \" \\\"attention_bias\\\": False, # Whether attention projections use bias terms\\n\",\n \" \\\"attention_dropout\\\": 0.0, # Attention dropout\\n\",\n \" \\\"sliding_window\\\": 4096, # Sliding-window attention context\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"sliding_attention\\\",\\n\",\n \" \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \" \\\"rope_base\\\": 50_000.0, # The base in RoPE's \\\"theta\\\"\\n\",\n \" \\\"layer_norm_eps\\\": 1e-5, # Epsilon used by layer normalization\\n\",\n \" \\\"logit_scale\\\": 1.0, # Final logits scaling factor\\n\",\n \" \\\"tie_word_embeddings\\\": True, # Whether input embedding and output head are tied\\n\",\n \" \\\"bos_token_id\\\": 2,\\n\",\n \" \\\"eos_token_id\\\": 3,\\n\",\n \" \\\"pad_token_id\\\": 0,\\n\",\n \" \\\"dtype\\\": torch.bfloat16, # Lower-precision dtype to reduce memory usage\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [],\n \"source\": [\n \"model = TinyAyaModel(TINY_AYA_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"fd5efb03-5a07-46e8-8607-93ed47549d2b\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"fd5efb03-5a07-46e8-8607-93ed47549d2b\",\n \"outputId\": \"65c1a95e-b502-4150-9e2e-da619d9053d5\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"float32 (PyTorch default): 25.43 GB\\n\",\n \"bfloat16: 12.72 GB\\n\"\n ]\n }\n ],\n \"source\": [\n \"def calc_model_memory_size(model, input_dtype=torch.float32):\\n\",\n \" total_params = 0\\n\",\n \" total_grads = 0\\n\",\n \" for param in model.parameters():\\n\",\n \" # Calculate total number of elements per parameter\\n\",\n \" param_size = param.numel()\\n\",\n \" total_params += param_size\\n\",\n \" # Check if gradients are stored for this parameter\\n\",\n \" if param.requires_grad:\\n\",\n \" total_grads += param_size\\n\",\n \"\\n\",\n \" # Calculate buffer size (non-parameters that require memory)\\n\",\n \" total_buffers = sum(buf.numel() for buf in model.buffers())\\n\",\n \"\\n\",\n \" # Size in bytes = (Number of elements) * (Size of each element in bytes)\\n\",\n \" # We assume parameters and gradients are stored in the same type as input dtype\\n\",\n \" element_size = torch.tensor(0, dtype=input_dtype).element_size()\\n\",\n \" total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\\n\",\n \"\\n\",\n \" # Convert bytes to gigabytes\\n\",\n \" total_memory_gb = total_memory_bytes / (1024**3)\\n\",\n \"\\n\",\n \" return total_memory_gb\\n\",\n \"\\n\",\n \"print(f\\\"float32 (PyTorch default): {calc_model_memory_size(model, input_dtype=torch.float32):.2f} GB\\\")\\n\",\n \"print(f\\\"bfloat16: {calc_model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"41176fb0-d58a-443a-912f-4f436564b5f8\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Total number of parameters: 3,349,227,520\\n\",\n \"\\n\",\n \"Total number of unique parameters: 2,812,356,608\\n\"\n ]\n }\n ],\n \"source\": [\n \"total_params = sum(p.numel() for p in model.parameters())\\n\",\n \"print(f\\\"Total number of parameters: {total_params:,}\\\")\\n\",\n \"\\n\",\n \"# Account for weight tying\\n\",\n \"total_params_normalized = total_params - model.tok_emb.weight.numel()\\n\",\n \"print(f\\\"\\\\nTotal number of unique parameters: {total_params_normalized:,}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"31f12baf-f79b-499f-85c0-51328a6a20f5\",\n \"metadata\": {\n \"id\": \"31f12baf-f79b-499f-85c0-51328a6a20f5\"\n },\n \"outputs\": [],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"78e091e1-afa8-4d23-9aea-cced86181bfd\",\n \"metadata\": {\n \"id\": \"78e091e1-afa8-4d23-9aea-cced86181bfd\"\n },\n \"source\": [\n \" \\n\",\n \"# 3. Load tokenizer\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"9482b01c-49f9-48e4-ab2c-4a4c75240e77\",\n \"metadata\": {\n \"id\": \"9482b01c-49f9-48e4-ab2c-4a4c75240e77\"\n },\n \"outputs\": [],\n \"source\": [\n \"from tokenizers import Tokenizer\\n\",\n \"\\n\",\n \"\\n\",\n \"class TinyAyaTokenizer:\\n\",\n \" def __init__(self, tokenizer_file_path, eos_token_id=3, pad_token_id=0, bos_token_id=2):\\n\",\n \" tok_file = Path(tokenizer_file_path)\\n\",\n \" self._tok = Tokenizer.from_file(str(tok_file))\\n\",\n \"\\n\",\n \" eos_from_tok = self._tok.token_to_id(\\\"\\n\",\n \"\\n\",\n \"- Then, create and copy the access token so you can copy & paste it into the next code cell\\n\",\n \"\\n\",\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"05104b25-71fb-462f-8f2d-336184833eda\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"CohereLabs/tiny-aya-global\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(REPO_ID)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7e327c26-ae3e-4f07-845f-eeb4a6b31283\",\n \"metadata\": {},\n \"source\": [\n \"- Note that if you use the fire, water, base, or earth model, you'd have to accept the licensing terms separately:\\n\",\n \" - [CohereLabs/tiny-aya-fire](https://huggingface.co/CohereLabs/tiny-aya-fire)\\n\",\n \" - [CohereLabs/tiny-aya-water](https://huggingface.co/CohereLabs/tiny-aya-water)\\n\",\n \" - [CohereLabs/tiny-aya-earth](https://huggingface.co/CohereLabs/tiny-aya-earth)\\n\",\n \" - [CohereLabs/tiny-aya-base](https://huggingface.co/CohereLabs/tiny-aya-base)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed\",\n \"outputId\": \"e6e6dc05-7330-45bc-a9a7-331919155bdd\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Uncomment and run the following code if you are executing the notebook for the first time\\n\",\n \"\\n\",\n \"from huggingface_hub import login\\n\",\n \"login()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"986bc1a0-804f-4154-80f8-44cefbee1368\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 141,\n \"referenced_widgets\": [\n \"a1608feac06d4687967a3e398f01c489\",\n \"518fb202e4b44aaba47f07d1a61b6762\",\n \"672cdc5aea954de3af851c001a667ad3\",\n \"eebf8874618746b39cf4a21a2728dc7f\",\n \"5176834aa8784bba9ec21234b87a8948\",\n \"e2dc407afcd945c798e30597fddfcb3c\",\n \"0dccd57dcc5c43a588157cef957c07e8\",\n \"33ca0cdf2c7f41598a381c4ebe6a4ee1\",\n \"ee44487f58454dacb522b1e084ffb733\",\n \"d2c41e71a3f441deaed091b620ac5603\",\n \"3326b6141a1a4eba9f316df528a9b99a\"\n ]\n },\n \"id\": \"986bc1a0-804f-4154-80f8-44cefbee1368\",\n \"outputId\": \"5dd7334b-4c71-465a-94d2-c3e95b9ddc58\"\n },\n \"outputs\": [],\n \"source\": [\n \"from huggingface_hub import hf_hub_download\\n\",\n \"\\n\",\n \"tokenizer_file_path = Path(LOCAL_DIR) / \\\"tokenizer.json\\\"\\n\",\n \"if not tokenizer_file_path.exists():\\n\",\n \" try:\\n\",\n \" tokenizer_file_path = hf_hub_download(repo_id=REPO_ID, filename=\\\"tokenizer.json\\\", local_dir=LOCAL_DIR)\\n\",\n \" except Exception as e:\\n\",\n \" print(f\\\"Warning: failed to download tokenizer.json: {e}\\\")\\n\",\n \" tokenizer_file_path = \\\"tokenizer.json\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"_gBhxDtU_nxo\",\n \"metadata\": {\n \"id\": \"_gBhxDtU_nxo\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"'\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n },\n \"widgets\": {\n \"application/vnd.jupyter.widget-state+json\": {\n \"state\": {\n \"0dccd57dcc5c43a588157cef957c07e8\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"17a3174e65c54476b2e0d1faf8f011ca\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_90a79523187446dfa692723b2e5833a7\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_431ffb83b8c14bf182f0430e07ea6154\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \"model.safetensors: 35%\"\n }\n },\n \"1bbf2e62c0754d1593beb4105a7f1ac1\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"FloatProgressModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"FloatProgressModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"ProgressView\",\n \"bar_style\": \"\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_a8f1b72a33dd4b548de23fbd95e0da18\",\n \"max\": 2471645608,\n \"min\": 0,\n \"orientation\": \"horizontal\",\n \"style\": \"IPY_MODEL_25cc36132d384189acfbecc59483134b\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": 880803840\n }\n },\n \"25cc36132d384189acfbecc59483134b\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"ProgressStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"ProgressStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"bar_color\": null,\n \"description_width\": \"\"\n }\n },\n \"271e2bd6a35e4a8b92de8697f7c0be5f\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"3326b6141a1a4eba9f316df528a9b99a\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"33ca0cdf2c7f41598a381c4ebe6a4ee1\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"431ffb83b8c14bf182f0430e07ea6154\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"5176834aa8784bba9ec21234b87a8948\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"518fb202e4b44aaba47f07d1a61b6762\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_e2dc407afcd945c798e30597fddfcb3c\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_0dccd57dcc5c43a588157cef957c07e8\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \"tokenizer.model: 100%\"\n }\n },\n \"672cdc5aea954de3af851c001a667ad3\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"FloatProgressModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"FloatProgressModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"ProgressView\",\n \"bar_style\": \"success\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_33ca0cdf2c7f41598a381c4ebe6a4ee1\",\n \"max\": 2183982,\n \"min\": 0,\n \"orientation\": \"horizontal\",\n \"style\": \"IPY_MODEL_ee44487f58454dacb522b1e084ffb733\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": 2183982\n }\n },\n \"90a79523187446dfa692723b2e5833a7\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"9881b6995c3f49dc89e6992fd9ab660b\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HBoxModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HBoxModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HBoxView\",\n \"box_style\": \"\",\n \"children\": [\n \"IPY_MODEL_17a3174e65c54476b2e0d1faf8f011ca\",\n \"IPY_MODEL_1bbf2e62c0754d1593beb4105a7f1ac1\",\n \"IPY_MODEL_b82112e1dec645d98aa1c1ba64abcb61\"\n ],\n \"layout\": \"IPY_MODEL_271e2bd6a35e4a8b92de8697f7c0be5f\",\n \"tabbable\": null,\n \"tooltip\": null\n }\n },\n \"a1608feac06d4687967a3e398f01c489\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HBoxModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HBoxModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HBoxView\",\n \"box_style\": \"\",\n \"children\": [\n \"IPY_MODEL_518fb202e4b44aaba47f07d1a61b6762\",\n \"IPY_MODEL_672cdc5aea954de3af851c001a667ad3\",\n \"IPY_MODEL_eebf8874618746b39cf4a21a2728dc7f\"\n ],\n \"layout\": \"IPY_MODEL_5176834aa8784bba9ec21234b87a8948\",\n \"tabbable\": null,\n \"tooltip\": null\n }\n },\n \"a8f1b72a33dd4b548de23fbd95e0da18\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"b82112e1dec645d98aa1c1ba64abcb61\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_bfd06423ad544218968648016e731a46\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_d029630b63ff44cf807ade428d2eb421\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \" 870M/2.47G [00:20<00:37, 42.8MB/s]\"\n }\n },\n \"bfd06423ad544218968648016e731a46\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"d029630b63ff44cf807ade428d2eb421\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"background\": null,\n \"description_width\": \"\",\n \"font_size\": null,\n \"text_color\": null\n }\n },\n \"d2c41e71a3f441deaed091b620ac5603\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"e2dc407afcd945c798e30597fddfcb3c\": {\n \"model_module\": \"@jupyter-widgets/base\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"LayoutModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/base\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"LayoutModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"LayoutView\",\n \"align_content\": null,\n \"align_items\": null,\n \"align_self\": null,\n \"border_bottom\": null,\n \"border_left\": null,\n \"border_right\": null,\n \"border_top\": null,\n \"bottom\": null,\n \"display\": null,\n \"flex\": null,\n \"flex_flow\": null,\n \"grid_area\": null,\n \"grid_auto_columns\": null,\n \"grid_auto_flow\": null,\n \"grid_auto_rows\": null,\n \"grid_column\": null,\n \"grid_gap\": null,\n \"grid_row\": null,\n \"grid_template_areas\": null,\n \"grid_template_columns\": null,\n \"grid_template_rows\": null,\n \"height\": null,\n \"justify_content\": null,\n \"justify_items\": null,\n \"left\": null,\n \"margin\": null,\n \"max_height\": null,\n \"max_width\": null,\n \"min_height\": null,\n \"min_width\": null,\n \"object_fit\": null,\n \"object_position\": null,\n \"order\": null,\n \"overflow\": null,\n \"padding\": null,\n \"right\": null,\n \"top\": null,\n \"visibility\": null,\n \"width\": null\n }\n },\n \"ee44487f58454dacb522b1e084ffb733\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"ProgressStyleModel\",\n \"state\": {\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"ProgressStyleModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/base\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"StyleView\",\n \"bar_color\": null,\n \"description_width\": \"\"\n }\n },\n \"eebf8874618746b39cf4a21a2728dc7f\": {\n \"model_module\": \"@jupyter-widgets/controls\",\n \"model_module_version\": \"2.0.0\",\n \"model_name\": \"HTMLModel\",\n \"state\": {\n \"_dom_classes\": [],\n \"_model_module\": \"@jupyter-widgets/controls\",\n \"_model_module_version\": \"2.0.0\",\n \"_model_name\": \"HTMLModel\",\n \"_view_count\": null,\n \"_view_module\": \"@jupyter-widgets/controls\",\n \"_view_module_version\": \"2.0.0\",\n \"_view_name\": \"HTMLView\",\n \"description\": \"\",\n \"description_allow_html\": false,\n \"layout\": \"IPY_MODEL_d2c41e71a3f441deaed091b620ac5603\",\n \"placeholder\": \"\",\n \"style\": \"IPY_MODEL_3326b6141a1a4eba9f316df528a9b99a\",\n \"tabbable\": null,\n \"tooltip\": null,\n \"value\": \" 2.18M/2.18M [00:00<00:00, 9.47MB/s]\"\n }\n }\n },\n \"version_major\": 2,\n \"version_minor\": 0\n }\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/15_tiny-aya/tests/test_tiny_aya_kvcache_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n mod = import_definitions_from_notebook(nb_dir, \"standalone-tiny-aya-plus-kv-cache.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8)) # batch size 1, seq length 8\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"context_length\": 64,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"n_kv_heads\": 1,\n \"attention_bias\": False,\n \"attention_dropout\": 0.0,\n \"sliding_window\": 4,\n \"layer_types\": [\"sliding_attention\", \"full_attention\"],\n \"rope_base\": 10_000.0,\n \"layer_norm_eps\": 1e-5,\n \"logit_scale\": 1.0,\n \"tie_word_embeddings\": False,\n \"dtype\": torch.float32,\n }\n\n\n@torch.inference_mode()\ndef test_dummy_tiny_aya_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.TinyAyaModel(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"]), \\\n f\"Expected shape (1, seq_len, vocab_size), got {out.shape}\"\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_tiny_aya_base_equivalence_with_transformers(import_notebook_defs):\n from transformers import Cohere2Config, Cohere2ForCausalLM\n\n # Tiny config so the test is fast\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"n_kv_heads\": 2,\n \"sliding_window\": 4,\n \"layer_types\": [\"sliding_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"attention_bias\": False,\n \"attention_dropout\": 0.0,\n \"layer_norm_eps\": 1e-5,\n \"rope_base\": 10_000.0,\n \"logit_scale\": 1.0,\n \"tie_word_embeddings\": False,\n }\n\n model = import_notebook_defs.TinyAyaModel(cfg)\n\n hf_cfg = Cohere2Config(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n num_key_value_heads=cfg[\"n_kv_heads\"],\n attention_bias=cfg[\"attention_bias\"],\n attention_dropout=cfg[\"attention_dropout\"],\n layer_norm_eps=cfg[\"layer_norm_eps\"],\n layer_types=cfg[\"layer_types\"],\n sliding_window=cfg[\"sliding_window\"],\n logit_scale=cfg[\"logit_scale\"],\n tie_word_embeddings=cfg[\"tie_word_embeddings\"],\n rope_parameters={\"rope_type\": \"default\", \"rope_theta\": cfg[\"rope_base\"]},\n attn_implementation=\"eager\",\n torch_dtype=torch.float32,\n )\n hf_model = Cohere2ForCausalLM(hf_cfg)\n\n hf_state = hf_model.state_dict()\n import_notebook_defs.load_weights_into_tiny_aya(model, cfg, hf_state)\n\n x = torch.randint(0, cfg[\"vocab_size\"], (2, cfg[\"context_length\"]), dtype=torch.long)\n ours_logits = model(x)\n theirs_logits = hf_model(x).logits\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/15_tiny-aya/tests/test_tiny_aya_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n mod = import_definitions_from_notebook(nb_dir, \"standalone-tiny-aya.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8)) # batch size 1, seq length 8\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"context_length\": 64,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"n_kv_heads\": 1,\n \"attention_bias\": False,\n \"attention_dropout\": 0.0,\n \"sliding_window\": 4,\n \"layer_types\": [\"sliding_attention\", \"full_attention\"],\n \"rope_base\": 10_000.0,\n \"layer_norm_eps\": 1e-5,\n \"logit_scale\": 1.0,\n \"tie_word_embeddings\": False,\n \"dtype\": torch.float32,\n }\n\n@torch.inference_mode()\ndef test_dummy_tiny_aya_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.TinyAyaModel(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"]), \\\n f\"Expected shape (1, seq_len, vocab_size), got {out.shape}\"\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_tiny_aya_base_equivalence_with_transformers(import_notebook_defs):\n from transformers import Cohere2Config, Cohere2ForCausalLM\n\n # Tiny config so the test is fast\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"n_kv_heads\": 2,\n \"sliding_window\": 4,\n \"layer_types\": [\"sliding_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"attention_bias\": False,\n \"attention_dropout\": 0.0,\n \"layer_norm_eps\": 1e-5,\n \"rope_base\": 10_000.0,\n \"logit_scale\": 1.0,\n \"tie_word_embeddings\": False,\n }\n\n model = import_notebook_defs.TinyAyaModel(cfg)\n\n hf_cfg = Cohere2Config(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n num_key_value_heads=cfg[\"n_kv_heads\"],\n attention_bias=cfg[\"attention_bias\"],\n attention_dropout=cfg[\"attention_dropout\"],\n layer_norm_eps=cfg[\"layer_norm_eps\"],\n layer_types=cfg[\"layer_types\"],\n sliding_window=cfg[\"sliding_window\"],\n logit_scale=cfg[\"logit_scale\"],\n tie_word_embeddings=cfg[\"tie_word_embeddings\"],\n rope_parameters={\"rope_type\": \"default\", \"rope_theta\": cfg[\"rope_base\"]},\n attn_implementation=\"eager\",\n torch_dtype=torch.float32,\n )\n hf_model = Cohere2ForCausalLM(hf_cfg)\n\n hf_state = hf_model.state_dict()\n import_notebook_defs.load_weights_into_tiny_aya(model, cfg, hf_state)\n\n x = torch.randint(0, cfg[\"vocab_size\"], (2, cfg[\"context_length\"]), dtype=torch.long)\n ours_logits = model(x)\n theirs_logits = hf_model(x).logits\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/15_tiny-aya/tests/tiny_aya_layer_debugger.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nfrom pathlib import Path\n\nimport torch\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\ntry:\n from transformers import Cohere2Config, Cohere2ForCausalLM\nexcept ImportError:\n Cohere2Config = None\n Cohere2ForCausalLM = None\n\n\ndef tiny_debug_config():\n return {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"n_kv_heads\": 2,\n \"sliding_window\": 4,\n \"layer_types\": [\"sliding_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n \"attention_bias\": False,\n \"attention_dropout\": 0.0,\n \"layer_norm_eps\": 1e-5,\n \"rope_base\": 10_000.0,\n \"logit_scale\": 1.0,\n \"tie_word_embeddings\": False,\n }\n\n\ndef _hf_config_from_dict(cfg):\n if Cohere2Config is None:\n raise ImportError(\"transformers is required for the Tiny Aya debugger.\")\n\n return Cohere2Config(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n num_key_value_heads=cfg[\"n_kv_heads\"],\n attention_bias=cfg[\"attention_bias\"],\n attention_dropout=cfg[\"attention_dropout\"],\n layer_norm_eps=cfg[\"layer_norm_eps\"],\n sliding_window=cfg[\"sliding_window\"],\n layer_types=cfg[\"layer_types\"],\n logit_scale=cfg[\"logit_scale\"],\n tie_word_embeddings=cfg.get(\"tie_word_embeddings\", False),\n rope_parameters={\"rope_type\": \"default\", \"rope_theta\": cfg[\"rope_base\"]},\n torch_dtype=cfg.get(\"dtype\", torch.float32),\n )\n\n\ndef load_notebook_defs(nb_name=\"standalone-tiny-aya.ipynb\"):\n nb_dir = Path(__file__).resolve().parents[1]\n return import_definitions_from_notebook(nb_dir, nb_name)\n\n\ndef build_tiny_aya_pair(import_notebook_defs, cfg, hf_checkpoint=None):\n if Cohere2ForCausalLM is None:\n raise ImportError(\"transformers is required for the Tiny Aya debugger.\")\n\n ours = import_notebook_defs.TinyAyaModel(cfg)\n hf_cfg = _hf_config_from_dict(cfg)\n\n if hf_checkpoint:\n hf_model = Cohere2ForCausalLM.from_pretrained(\n hf_checkpoint,\n torch_dtype=cfg.get(\"dtype\", torch.float32),\n attn_implementation=\"eager\",\n )\n else:\n hf_model = Cohere2ForCausalLM(hf_cfg)\n\n import_notebook_defs.load_weights_into_tiny_aya(ours, cfg, hf_model.state_dict())\n\n ours.eval()\n hf_model.eval()\n return ours, hf_model\n\n\ndef _attach_debug_hooks(model, is_hf):\n traces = {}\n handles = []\n\n def hook(name):\n def _record(_, __, output):\n traces[name] = output.detach().to(torch.float32).cpu()\n\n return _record\n\n if is_hf:\n core = model.model\n handles.append(core.embed_tokens.register_forward_hook(hook(\"embedding\")))\n for idx, layer in enumerate(core.layers):\n handles.append(layer.register_forward_hook(hook(f\"block_{idx}\")))\n handles.append(core.norm.register_forward_hook(hook(\"final_norm\")))\n handles.append(model.lm_head.register_forward_hook(hook(\"logits\")))\n else:\n handles.append(model.tok_emb.register_forward_hook(hook(\"embedding\")))\n blocks = getattr(model, \"trf_blocks\", None)\n if blocks is None:\n blocks = getattr(model, \"blocks\", None)\n if blocks is None:\n raise AttributeError(\"Could not locate Tiny Aya blocks on the local model.\")\n for idx, block in enumerate(blocks):\n handles.append(block.register_forward_hook(hook(f\"block_{idx}\")))\n handles.append(model.final_norm.register_forward_hook(hook(\"final_norm\")))\n handles.append(model.out_head.register_forward_hook(hook(\"logits\")))\n\n return traces, handles\n\n\ndef _layer_sort_key(name):\n if name == \"embedding\":\n return (0, 0)\n if name.startswith(\"block_\"):\n idx = int(name.split(\"_\")[1])\n return (1, idx)\n if name == \"final_norm\":\n return (2, 0)\n if name == \"logits\":\n return (3, 0)\n return (4, name)\n\n\ndef layerwise_differences(ours, hf_model, input_ids, rtol=1e-5, atol=1e-5):\n ours_traces, ours_handles = _attach_debug_hooks(ours, is_hf=False)\n hf_traces, hf_handles = _attach_debug_hooks(hf_model, is_hf=True)\n\n try:\n with torch.inference_mode():\n ours(input_ids)\n hf_model(input_ids)\n finally:\n for h in ours_handles + hf_handles:\n h.remove()\n\n layer_names = sorted(set(ours_traces) | set(hf_traces), key=_layer_sort_key)\n results = []\n for name in layer_names:\n ours_tensor = ours_traces.get(name)\n hf_tensor = hf_traces.get(name)\n\n if ours_tensor is None or hf_tensor is None:\n results.append(\n {\n \"name\": name,\n \"status\": \"missing\",\n \"ours_shape\": None if ours_tensor is None else tuple(ours_tensor.shape),\n \"hf_shape\": None if hf_tensor is None else tuple(hf_tensor.shape),\n \"max_diff\": None,\n \"mean_abs_diff\": None,\n }\n )\n continue\n\n if ours_tensor.shape != hf_tensor.shape:\n results.append(\n {\n \"name\": name,\n \"status\": \"shape_mismatch\",\n \"ours_shape\": tuple(ours_tensor.shape),\n \"hf_shape\": tuple(hf_tensor.shape),\n \"max_diff\": None,\n \"mean_abs_diff\": None,\n }\n )\n continue\n\n diff = (ours_tensor - hf_tensor).abs()\n max_diff = float(diff.max().item())\n mean_diff = float(diff.mean().item())\n allclose = torch.allclose(ours_tensor, hf_tensor, rtol=rtol, atol=atol)\n results.append(\n {\n \"name\": name,\n \"status\": \"ok\" if allclose else \"mismatch\",\n \"ours_shape\": tuple(ours_tensor.shape),\n \"hf_shape\": tuple(hf_tensor.shape),\n \"max_diff\": max_diff,\n \"mean_abs_diff\": mean_diff,\n }\n )\n return results\n\n\ndef format_report(differences):\n lines = []\n for diff in sorted(differences, key=lambda d: _layer_sort_key(d[\"name\"])):\n if diff[\"status\"] == \"ok\":\n lines.append(f\"[OK] {diff['name']}: max={diff['max_diff']:.2e}, mean={diff['mean_abs_diff']:.2e}\")\n elif diff[\"status\"] == \"mismatch\":\n lines.append(f\"[DIFF] {diff['name']}: max={diff['max_diff']:.2e}, mean={diff['mean_abs_diff']:.2e}\")\n elif diff[\"status\"] == \"shape_mismatch\":\n lines.append(f\"[SHAPE] {diff['name']}: ours={diff['ours_shape']}, hf={diff['hf_shape']}\")\n else:\n lines.append(f\"[MISSING] {diff['name']}: ours={diff['ours_shape']}, hf={diff['hf_shape']}\")\n return \"\\n\".join(lines)\n\n\nif __name__ == \"__main__\":\n transformers_available = importlib.util.find_spec(\"transformers\") is not None\n if not transformers_available:\n raise SystemExit(\"transformers is not installed; install it to run the debugger.\")\n\n import_notebook_defs = load_notebook_defs()\n cfg = tiny_debug_config()\n\n ours_model, hf_model = build_tiny_aya_pair(import_notebook_defs, cfg)\n torch.manual_seed(0)\n input_ids = torch.randint(0, cfg[\"vocab_size\"], (1, cfg[\"context_length\"]), dtype=torch.long)\n diffs = layerwise_differences(ours_model, hf_model, input_ids)\n print(format_report(diffs))\n"
},
{
"path": "ch05/16_qwen3.5/README.md",
"content": "# Qwen3.5 0.8B From Scratch\n\nThis folder contains a from-scratch style implementation of [Qwen/Qwen3.5-0.8B](https://huggingface.co/Qwen/Qwen3.5-0.8B).\n\n \n\nQwen3.5 is based on the Qwen3-Next architecture, which I described in more detail in section [2. (Linear) Attention Hybrids](https://magazine.sebastianraschka.com/i/177848019/2-linear-attention-hybrids) of my [Beyond Standard LLMs](https://magazine.sebastianraschka.com/p/beyond-standard-llms) article\n\n
\n\nQwen3.5 is based on the Qwen3-Next architecture, which I described in more detail in section [2. (Linear) Attention Hybrids](https://magazine.sebastianraschka.com/i/177848019/2-linear-attention-hybrids) of my [Beyond Standard LLMs](https://magazine.sebastianraschka.com/p/beyond-standard-llms) article\n\n \n\nNote that Qwen3.5 alternates `linear_attention` and `full_attention` layers. \nThe notebooks keep the full model flow readable while reusing the linear-attention building blocks from the [qwen3_5_transformers.py](qwen3_5_transformers.py), which contains the linear attention code from Hugging Face under an Apache version 2.0 open source license.\n\n \n## Files\n\n- [qwen3.5.ipynb](qwen3.5.ipynb): Main Qwen3.5 0.8B notebook implementation.\n- [qwen3.5-plus-kv-cache.ipynb](qwen3.5-plus-kv-cache.ipynb): Same model with KV-cache decoding for efficiency.\n- [qwen3_5_transformers.py](qwen3_5_transformers.py): Some helper components from Hugging Face Transformers used for Qwen3.5 linear attention.\n\n"
},
{
"path": "ch05/16_qwen3.5/qwen3.5-plus-kv-cache.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"
\n\nNote that Qwen3.5 alternates `linear_attention` and `full_attention` layers. \nThe notebooks keep the full model flow readable while reusing the linear-attention building blocks from the [qwen3_5_transformers.py](qwen3_5_transformers.py), which contains the linear attention code from Hugging Face under an Apache version 2.0 open source license.\n\n \n## Files\n\n- [qwen3.5.ipynb](qwen3.5.ipynb): Main Qwen3.5 0.8B notebook implementation.\n- [qwen3.5-plus-kv-cache.ipynb](qwen3.5-plus-kv-cache.ipynb): Same model with KV-cache decoding for efficiency.\n- [qwen3_5_transformers.py](qwen3_5_transformers.py): Some helper components from Hugging Face Transformers used for Qwen3.5 linear attention.\n\n"
},
{
"path": "ch05/16_qwen3.5/qwen3.5-plus-kv-cache.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1241a20b-d196-4521-9228-d46954d383e4\",\n \"metadata\": {},\n \"source\": [\n \"- Qwen3.5 is based on the Qwen3-Next architecture, which I described in more detail in section [2. (Linear) Attention Hybrids](https://magazine.sebastianraschka.com/i/177848019/2-linear-attention-hybrids) of my [Beyond Standard LLMs](https://magazine.sebastianraschka.com/p/beyond-standard-llms) article\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"21d38944-0c98-40a6-a6f8-c745769b4618\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1241a20b-d196-4521-9228-d46954d383e4\",\n \"metadata\": {},\n \"source\": [\n \"- Qwen3.5 is based on the Qwen3-Next architecture, which I described in more detail in section [2. (Linear) Attention Hybrids](https://magazine.sebastianraschka.com/i/177848019/2-linear-attention-hybrids) of my [Beyond Standard LLMs](https://magazine.sebastianraschka.com/p/beyond-standard-llms) article\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"21d38944-0c98-40a6-a6f8-c745769b4618\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 1.5.0\\n\",\n \"tokenizers version: 0.22.2\\n\",\n \"torch version: 2.8.0+cu128\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"70a90338-624a-4706-aa55-6b4358070194\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"USE_MODEL = \\\"Qwen3.5-0.8B\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"56715760-37e1-433e-89da-04864c139a9e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-6):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" # Qwen3.5 uses (1 + weight) scaling with zero init\\n\",\n \" self.weight = nn.Parameter(torch.zeros(emb_dim))\\n\",\n \"\\n\",\n \" def _norm(self, x):\\n\",\n \" return x * torch.rsqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_norm = self._norm(x.float())\\n\",\n \" x_norm = x_norm * (1.0 + self.weight.float())\\n\",\n \" return x_norm.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(\\n\",\n \" head_dim,\\n\",\n \" theta_base=10_000,\\n\",\n \" context_length=4096,\\n\",\n \" partial_rotary_factor=1.0,\\n\",\n \" dtype=torch.float32,\\n\",\n \"):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" rotary_dim = int(head_dim * partial_rotary_factor)\\n\",\n \" rotary_dim = max(2, rotary_dim - (rotary_dim % 2))\\n\",\n \"\\n\",\n \" inv_freq = 1.0 / (\\n\",\n \" theta_base ** (\\n\",\n \" torch.arange(0, rotary_dim, 2, dtype=dtype)[: (rotary_dim // 2)].float() / rotary_dim\\n\",\n \" )\\n\",\n \" )\\n\",\n \"\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0)\\n\",\n \" angles = torch.cat([angles, angles], dim=1)\\n\",\n \"\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin, offset=0):\\n\",\n \" _, _, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" rot_dim = cos.shape[-1]\\n\",\n \" if rot_dim > head_dim:\\n\",\n \" raise ValueError(f\\\"RoPE dim {rot_dim} cannot exceed head_dim {head_dim}.\\\")\\n\",\n \"\\n\",\n \" x_rot = x[..., :rot_dim]\\n\",\n \" x_pass = x[..., rot_dim:]\\n\",\n \"\\n\",\n \" x1 = x_rot[..., : rot_dim // 2]\\n\",\n \" x2 = x_rot[..., rot_dim // 2 :]\\n\",\n \"\\n\",\n \" cos = cos[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \" sin = sin[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x_rot * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" x_out = torch.cat([x_rotated, x_pass], dim=-1)\\n\",\n \" return x_out.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, num_heads, num_kv_groups, head_dim=None, qk_norm=False, dtype=None\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" if head_dim is None:\\n\",\n \" assert d_in % num_heads == 0, \\\"`d_in` must be divisible by `num_heads` if `head_dim` is not set\\\"\\n\",\n \" head_dim = d_in // num_heads\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \"\\n\",\n \" # Qwen3.5 full-attention uses a gated Q projection (2x output dim)\\n\",\n \" self.W_query = nn.Linear(d_in, self.d_out * 2, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" if qk_norm:\\n\",\n \" self.q_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" self.k_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" else:\\n\",\n \" self.q_norm = self.k_norm = None\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin, start_pos=0, cache=None):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" q_and_gate = self.W_query(x)\\n\",\n \" q_and_gate = q_and_gate.view(b, num_tokens, self.num_heads, self.head_dim * 2)\\n\",\n \" queries, gate = torch.chunk(q_and_gate, 2, dim=-1)\\n\",\n \" gate = gate.reshape(b, num_tokens, self.d_out)\\n\",\n \"\\n\",\n \" keys = self.W_key(x)\\n\",\n \" values = self.W_value(x)\\n\",\n \"\\n\",\n \" queries = queries.transpose(1, 2)\\n\",\n \" keys_new = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values_new = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" if self.q_norm:\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" if self.k_norm:\\n\",\n \" keys_new = self.k_norm(keys_new)\\n\",\n \"\\n\",\n \" prev_len = 0\\n\",\n \" if cache is not None:\\n\",\n \" prev_k, prev_v = cache\\n\",\n \" if prev_k is not None:\\n\",\n \" prev_len = prev_k.size(2)\\n\",\n \" keys_cat_raw = torch.cat([prev_k, keys_new], dim=2)\\n\",\n \" values_cat_raw = torch.cat([prev_v, values_new], dim=2)\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \"\\n\",\n \" queries = apply_rope(queries, cos, sin, offset=start_pos)\\n\",\n \" keys = apply_rope(keys_cat_raw, cos, sin, offset=start_pos - prev_len)\\n\",\n \"\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values_cat_raw.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" if cache is not None and cache[0] is not None:\\n\",\n \" next_cache = (\\n\",\n \" torch.cat([cache[0], keys_new], dim=2),\\n\",\n \" torch.cat([cache[1], values_new], dim=2),\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" next_cache = (keys_new, values_new)\\n\",\n \"\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \" attn_weights = torch.softmax(\\n\",\n \" attn_scores * (self.head_dim ** -0.5),\\n\",\n \" dim=-1,\\n\",\n \" dtype=torch.float32,\\n\",\n \" ).to(queries.dtype)\\n\",\n \"\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \"\\n\",\n \" # Qwen3.5 full-attention uses a gated Q projection\\n\",\n \" context = context * torch.sigmoid(gate)\\n\",\n \" out = self.out_proj(context)\\n\",\n \" return out, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"from qwen3_5_transformers import (\\n\",\n \" Qwen3_5GatedDeltaNet,\\n\",\n \")\\n\",\n \"\\n\",\n \"# Just a mapping for the different naming convention in Hugging Face transformers\\n\",\n \"class _Qwen3_5ConfigAdapter:\\n\",\n \" def __init__(self, cfg):\\n\",\n \" self.hidden_size = cfg[\\\"emb_dim\\\"]\\n\",\n \" self.linear_num_value_heads = cfg[\\\"linear_num_value_heads\\\"]\\n\",\n \" self.linear_num_key_heads = cfg[\\\"linear_num_key_heads\\\"]\\n\",\n \" self.linear_key_head_dim = cfg[\\\"linear_key_head_dim\\\"]\\n\",\n \" self.linear_value_head_dim = cfg[\\\"linear_value_head_dim\\\"]\\n\",\n \" self.linear_conv_kernel_dim = cfg[\\\"linear_conv_kernel_dim\\\"]\\n\",\n \" self.hidden_act = \\\"silu\\\"\\n\",\n \" self.rms_norm_eps = cfg.get(\\\"rms_norm_eps\\\", 1e-6)\\n\",\n \" self.dtype = cfg.get(\\\"dtype\\\", None)\\n\",\n \"\\n\",\n \"\\n\",\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg, layer_type, layer_idx):\\n\",\n \" super().__init__()\\n\",\n \" self.layer_type = layer_type\\n\",\n \"\\n\",\n \" if layer_type == \\\"full_attention\\\":\\n\",\n \" self.token_mixer = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"],\\n\",\n \" qk_norm=cfg[\\\"qk_norm\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" )\\n\",\n \" elif layer_type == \\\"linear_attention\\\":\\n\",\n \" self.token_mixer = Qwen3_5GatedDeltaNet(_Qwen3_5ConfigAdapter(cfg), layer_idx)\\n\",\n \" else:\\n\",\n \" raise ValueError(f\\\"Unsupported layer type: {layer_type}\\\")\\n\",\n \"\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg.get(\\\"rms_norm_eps\\\", 1e-6))\\n\",\n \" self.norm2 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg.get(\\\"rms_norm_eps\\\", 1e-6))\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin, start_pos=0, cache=None, linear_cache=None, cache_position=None):\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \"\\n\",\n \" if self.layer_type == \\\"full_attention\\\":\\n\",\n \" x, next_cache = self.token_mixer(\\n\",\n \" x,\\n\",\n \" mask,\\n\",\n \" cos,\\n\",\n \" sin,\\n\",\n \" start_pos=start_pos,\\n\",\n \" cache=cache,\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" x = self.token_mixer(\\n\",\n \" x,\\n\",\n \" cache_params=linear_cache,\\n\",\n \" cache_position=cache_position,\\n\",\n \" )\\n\",\n \" next_cache = None\\n\",\n \"\\n\",\n \" x = x + shortcut\\n\",\n \"\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" x = x + shortcut\\n\",\n \"\\n\",\n \" return x, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Qwen3_5Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" layer_types = cfg.get(\\\"layer_types\\\", [\\\"full_attention\\\"] * cfg[\\\"n_layers\\\"])\\n\",\n \" if len(layer_types) != cfg[\\\"n_layers\\\"]:\\n\",\n \" raise ValueError(\\\"len(layer_types) must equal n_layers\\\")\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.ModuleList(\\n\",\n \" [TransformerBlock(cfg, layer_type, idx) for idx, layer_type in enumerate(layer_types)]\\n\",\n \" )\\n\",\n \"\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg.get(\\\"rms_norm_eps\\\", 1e-6))\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" head_dim = cfg[\\\"emb_dim\\\"] // cfg[\\\"n_heads\\\"] if cfg[\\\"head_dim\\\"] is None else cfg[\\\"head_dim\\\"]\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=head_dim,\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" partial_rotary_factor=cfg.get(\\\"partial_rotary_factor\\\", 1.0),\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \" self.cfg = cfg\\n\",\n \" self.current_pos = 0\\n\",\n \"\\n\",\n \" def create_mask(self, cur_len, device, pos_start=0, pos_end=None):\\n\",\n \" if pos_end is None:\\n\",\n \" pos_end = cur_len\\n\",\n \"\\n\",\n \" ones = torch.ones((pos_end, pos_end), device=device, dtype=torch.bool)\\n\",\n \" mask_full = torch.triu(ones, diagonal=1)\\n\",\n \" row_slice = slice(pos_start, pos_end)\\n\",\n \" mask = mask_full[row_slice, :pos_end][None, None, :, :]\\n\",\n \" return mask\\n\",\n \"\\n\",\n \" def forward(self, in_idx, cache=None):\\n\",\n \" x = self.tok_emb(in_idx)\\n\",\n \"\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \" if cache is not None:\\n\",\n \" pos_start = self.current_pos\\n\",\n \" pos_end = pos_start + num_tokens\\n\",\n \" self.current_pos = pos_end\\n\",\n \" mask = self.create_mask(\\n\",\n \" cur_len=num_tokens,\\n\",\n \" device=x.device,\\n\",\n \" pos_start=pos_start,\\n\",\n \" pos_end=pos_end,\\n\",\n \" )\\n\",\n \" cache_position = torch.arange(pos_start, pos_end, device=x.device, dtype=torch.long)\\n\",\n \" else:\\n\",\n \" pos_start = 0\\n\",\n \" mask = self.create_mask(\\n\",\n \" cur_len=num_tokens,\\n\",\n \" device=x.device,\\n\",\n \" pos_start=0,\\n\",\n \" pos_end=num_tokens,\\n\",\n \" )\\n\",\n \" cache_position = None\\n\",\n \"\\n\",\n \" for i, block in enumerate(self.trf_blocks):\\n\",\n \" blk_cache = cache.get(i) if cache is not None else None\\n\",\n \" x, new_blk_cache = block(\\n\",\n \" x,\\n\",\n \" mask=mask,\\n\",\n \" cos=self.cos,\\n\",\n \" sin=self.sin,\\n\",\n \" start_pos=pos_start,\\n\",\n \" cache=blk_cache,\\n\",\n \" linear_cache=cache.linear_cache if cache is not None else None,\\n\",\n \" cache_position=cache_position,\\n\",\n \" )\\n\",\n \" if cache is not None and new_blk_cache is not None:\\n\",\n \" cache.update(i, new_blk_cache)\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" cache.linear_cache.has_previous_state = True\\n\",\n \"\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\\n\",\n \"\\n\",\n \" def reset_kv_cache(self):\\n\",\n \" self.current_pos = 0\\n\",\n \"\\n\",\n \"\\n\",\n \"class Qwen3_5LinearAttentionCache:\\n\",\n \" def __init__(self, n_layers):\\n\",\n \" self.conv_states = [None] * n_layers\\n\",\n \" self.recurrent_states = [None] * n_layers\\n\",\n \" self.has_previous_state = False\\n\",\n \"\\n\",\n \" def reset(self):\\n\",\n \" for i in range(len(self.conv_states)):\\n\",\n \" self.conv_states[i] = None\\n\",\n \" self.recurrent_states[i] = None\\n\",\n \" self.has_previous_state = False\\n\",\n \"\\n\",\n \"\\n\",\n \"class KVCache:\\n\",\n \" def __init__(self, n_layers):\\n\",\n \" self.cache = [None] * n_layers\\n\",\n \" self.linear_cache = Qwen3_5LinearAttentionCache(n_layers)\\n\",\n \"\\n\",\n \" def get(self, layer_idx):\\n\",\n \" return self.cache[layer_idx]\\n\",\n \"\\n\",\n \" def update(self, layer_idx, value):\\n\",\n \" self.cache[layer_idx] = value\\n\",\n \"\\n\",\n \" def get_all(self):\\n\",\n \" return self.cache\\n\",\n \"\\n\",\n \" def reset(self):\\n\",\n \" for i in range(len(self.cache)):\\n\",\n \" self.cache[i] = None\\n\",\n \" self.linear_cache.reset()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Qwen3.5-0.8B text configuration\\n\",\n \"QWEN3_5_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 248_320,\\n\",\n \" \\\"context_length\\\": 262_144,\\n\",\n \" \\\"emb_dim\\\": 1_024,\\n\",\n \" \\\"n_heads\\\": 8,\\n\",\n \" \\\"n_layers\\\": 24,\\n\",\n \" \\\"hidden_dim\\\": 3_584,\\n\",\n \" \\\"head_dim\\\": 256,\\n\",\n \" \\\"qk_norm\\\": True,\\n\",\n \" \\\"n_kv_groups\\\": 2,\\n\",\n \" \\\"rope_base\\\": 10_000_000.0,\\n\",\n \" \\\"partial_rotary_factor\\\": 0.25,\\n\",\n \" \\\"rms_norm_eps\\\": 1e-6,\\n\",\n \" \\\"linear_conv_kernel_dim\\\": 4,\\n\",\n \" \\\"linear_key_head_dim\\\": 128,\\n\",\n \" \\\"linear_value_head_dim\\\": 128,\\n\",\n \" \\\"linear_num_key_heads\\\": 16,\\n\",\n \" \\\"linear_num_value_heads\\\": 16,\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"The fast path is not available because one of the required library is not installed. Falling back to torch implementation. To install follow https://github.com/fla-org/flash-linear-attention#installation and https://github.com/Dao-AILab/causal-conv1d\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model = Qwen3_5Model(QWEN3_5_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"eaf86265-4e9d-4024-9ed0-99076944e304\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Qwen3_5Model(\\n\",\n \" (tok_emb): Embedding(248320, 1024)\\n\",\n \" (trf_blocks): ModuleList(\\n\",\n \" (0-2): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (3): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (4-6): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (7): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (8-10): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (11): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (12-14): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (15): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (16-18): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (19): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (20-22): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (23): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): RMSNorm()\\n\",\n \" (out_head): Linear(in_features=1024, out_features=248320, bias=False)\\n\",\n \")\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90aca91d-4bee-45ce-993a-4ec5393abe2b\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the forward pass works before continuing:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"adf0a6b7-b688-42c9-966e-c223d34db99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[[-0.6719, -0.0347, -0.5938, ..., 0.5469, 0.1660, -0.8945],\\n\",\n \" [ 0.0391, -0.1226, -0.8789, ..., -0.6523, -0.8281, -0.0889],\\n\",\n \" [ 0.1992, -0.7930, -0.3359, ..., -0.6602, 0.0515, -0.1582]]],\\n\",\n \" dtype=torch.bfloat16, grad_fn=\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/16_qwen3.5/qwen3.5.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 1.5.0\\n\",\n \"tokenizers version: 0.22.2\\n\",\n \"torch version: 2.8.0+cu128\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"70a90338-624a-4706-aa55-6b4358070194\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"USE_MODEL = \\\"Qwen3.5-0.8B\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"56715760-37e1-433e-89da-04864c139a9e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-6):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" # Qwen3.5 uses (1 + weight) scaling with zero init\\n\",\n \" self.weight = nn.Parameter(torch.zeros(emb_dim))\\n\",\n \"\\n\",\n \" def _norm(self, x):\\n\",\n \" return x * torch.rsqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_norm = self._norm(x.float())\\n\",\n \" x_norm = x_norm * (1.0 + self.weight.float())\\n\",\n \" return x_norm.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(\\n\",\n \" head_dim,\\n\",\n \" theta_base=10_000,\\n\",\n \" context_length=4096,\\n\",\n \" partial_rotary_factor=1.0,\\n\",\n \" dtype=torch.float32,\\n\",\n \"):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" rotary_dim = int(head_dim * partial_rotary_factor)\\n\",\n \" rotary_dim = max(2, rotary_dim - (rotary_dim % 2))\\n\",\n \"\\n\",\n \" inv_freq = 1.0 / (\\n\",\n \" theta_base ** (\\n\",\n \" torch.arange(0, rotary_dim, 2, dtype=dtype)[: (rotary_dim // 2)].float() / rotary_dim\\n\",\n \" )\\n\",\n \" )\\n\",\n \"\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0)\\n\",\n \" angles = torch.cat([angles, angles], dim=1)\\n\",\n \"\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin, offset=0):\\n\",\n \" _, _, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" rot_dim = cos.shape[-1]\\n\",\n \" if rot_dim > head_dim:\\n\",\n \" raise ValueError(f\\\"RoPE dim {rot_dim} cannot exceed head_dim {head_dim}.\\\")\\n\",\n \"\\n\",\n \" x_rot = x[..., :rot_dim]\\n\",\n \" x_pass = x[..., rot_dim:]\\n\",\n \"\\n\",\n \" x1 = x_rot[..., : rot_dim // 2]\\n\",\n \" x2 = x_rot[..., rot_dim // 2 :]\\n\",\n \"\\n\",\n \" cos = cos[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \" sin = sin[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x_rot * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" x_out = torch.cat([x_rotated, x_pass], dim=-1)\\n\",\n \" return x_out.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, num_heads, num_kv_groups, head_dim=None, qk_norm=False, dtype=None\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" if head_dim is None:\\n\",\n \" assert d_in % num_heads == 0, \\\"`d_in` must be divisible by `num_heads` if `head_dim` is not set\\\"\\n\",\n \" head_dim = d_in // num_heads\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \"\\n\",\n \" # Qwen3.5 full-attention uses a gated Q projection (2x output dim)\\n\",\n \" self.W_query = nn.Linear(d_in, self.d_out * 2, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" if qk_norm:\\n\",\n \" self.q_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" self.k_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" else:\\n\",\n \" self.q_norm = self.k_norm = None\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin, start_pos=0, cache=None):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" q_and_gate = self.W_query(x)\\n\",\n \" q_and_gate = q_and_gate.view(b, num_tokens, self.num_heads, self.head_dim * 2)\\n\",\n \" queries, gate = torch.chunk(q_and_gate, 2, dim=-1)\\n\",\n \" gate = gate.reshape(b, num_tokens, self.d_out)\\n\",\n \"\\n\",\n \" keys = self.W_key(x)\\n\",\n \" values = self.W_value(x)\\n\",\n \"\\n\",\n \" queries = queries.transpose(1, 2)\\n\",\n \" keys_new = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values_new = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" if self.q_norm:\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" if self.k_norm:\\n\",\n \" keys_new = self.k_norm(keys_new)\\n\",\n \"\\n\",\n \" prev_len = 0\\n\",\n \" if cache is not None:\\n\",\n \" prev_k, prev_v = cache\\n\",\n \" if prev_k is not None:\\n\",\n \" prev_len = prev_k.size(2)\\n\",\n \" keys_cat_raw = torch.cat([prev_k, keys_new], dim=2)\\n\",\n \" values_cat_raw = torch.cat([prev_v, values_new], dim=2)\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \" else:\\n\",\n \" keys_cat_raw = keys_new\\n\",\n \" values_cat_raw = values_new\\n\",\n \"\\n\",\n \" queries = apply_rope(queries, cos, sin, offset=start_pos)\\n\",\n \" keys = apply_rope(keys_cat_raw, cos, sin, offset=start_pos - prev_len)\\n\",\n \"\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values_cat_raw.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" if cache is not None and cache[0] is not None:\\n\",\n \" next_cache = (\\n\",\n \" torch.cat([cache[0], keys_new], dim=2),\\n\",\n \" torch.cat([cache[1], values_new], dim=2),\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" next_cache = (keys_new, values_new)\\n\",\n \"\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \" attn_weights = torch.softmax(\\n\",\n \" attn_scores * (self.head_dim ** -0.5),\\n\",\n \" dim=-1,\\n\",\n \" dtype=torch.float32,\\n\",\n \" ).to(queries.dtype)\\n\",\n \"\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \"\\n\",\n \" # Qwen3.5 full-attention uses a gated Q projection\\n\",\n \" context = context * torch.sigmoid(gate)\\n\",\n \" out = self.out_proj(context)\\n\",\n \" return out, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"from qwen3_5_transformers import (\\n\",\n \" Qwen3_5GatedDeltaNet,\\n\",\n \")\\n\",\n \"\\n\",\n \"# Just a mapping for the different naming convention in Hugging Face transformers\\n\",\n \"class _Qwen3_5ConfigAdapter:\\n\",\n \" def __init__(self, cfg):\\n\",\n \" self.hidden_size = cfg[\\\"emb_dim\\\"]\\n\",\n \" self.linear_num_value_heads = cfg[\\\"linear_num_value_heads\\\"]\\n\",\n \" self.linear_num_key_heads = cfg[\\\"linear_num_key_heads\\\"]\\n\",\n \" self.linear_key_head_dim = cfg[\\\"linear_key_head_dim\\\"]\\n\",\n \" self.linear_value_head_dim = cfg[\\\"linear_value_head_dim\\\"]\\n\",\n \" self.linear_conv_kernel_dim = cfg[\\\"linear_conv_kernel_dim\\\"]\\n\",\n \" self.hidden_act = \\\"silu\\\"\\n\",\n \" self.rms_norm_eps = cfg.get(\\\"rms_norm_eps\\\", 1e-6)\\n\",\n \" self.dtype = cfg.get(\\\"dtype\\\", None)\\n\",\n \"\\n\",\n \"\\n\",\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg, layer_type, layer_idx):\\n\",\n \" super().__init__()\\n\",\n \" self.layer_type = layer_type\\n\",\n \"\\n\",\n \" if layer_type == \\\"full_attention\\\":\\n\",\n \" self.token_mixer = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"],\\n\",\n \" qk_norm=cfg[\\\"qk_norm\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" )\\n\",\n \" elif layer_type == \\\"linear_attention\\\":\\n\",\n \" self.token_mixer = Qwen3_5GatedDeltaNet(_Qwen3_5ConfigAdapter(cfg), layer_idx)\\n\",\n \" else:\\n\",\n \" raise ValueError(f\\\"Unsupported layer type: {layer_type}\\\")\\n\",\n \"\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg.get(\\\"rms_norm_eps\\\", 1e-6))\\n\",\n \" self.norm2 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg.get(\\\"rms_norm_eps\\\", 1e-6))\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin, start_pos=0, cache=None, linear_cache=None, cache_position=None):\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \"\\n\",\n \" if self.layer_type == \\\"full_attention\\\":\\n\",\n \" x, next_cache = self.token_mixer(\\n\",\n \" x,\\n\",\n \" mask,\\n\",\n \" cos,\\n\",\n \" sin,\\n\",\n \" start_pos=start_pos,\\n\",\n \" cache=cache,\\n\",\n \" )\\n\",\n \" else:\\n\",\n \" x = self.token_mixer(\\n\",\n \" x,\\n\",\n \" cache_params=linear_cache,\\n\",\n \" cache_position=cache_position,\\n\",\n \" )\\n\",\n \" next_cache = None\\n\",\n \"\\n\",\n \" x = x + shortcut\\n\",\n \"\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" x = x + shortcut\\n\",\n \"\\n\",\n \" return x, next_cache\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Qwen3_5Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" layer_types = cfg.get(\\\"layer_types\\\", [\\\"full_attention\\\"] * cfg[\\\"n_layers\\\"])\\n\",\n \" if len(layer_types) != cfg[\\\"n_layers\\\"]:\\n\",\n \" raise ValueError(\\\"len(layer_types) must equal n_layers\\\")\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.ModuleList(\\n\",\n \" [TransformerBlock(cfg, layer_type, idx) for idx, layer_type in enumerate(layer_types)]\\n\",\n \" )\\n\",\n \"\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg.get(\\\"rms_norm_eps\\\", 1e-6))\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" head_dim = cfg[\\\"emb_dim\\\"] // cfg[\\\"n_heads\\\"] if cfg[\\\"head_dim\\\"] is None else cfg[\\\"head_dim\\\"]\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=head_dim,\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" partial_rotary_factor=cfg.get(\\\"partial_rotary_factor\\\", 1.0),\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \" self.cfg = cfg\\n\",\n \" self.current_pos = 0\\n\",\n \"\\n\",\n \" def create_mask(self, cur_len, device, pos_start=0, pos_end=None):\\n\",\n \" if pos_end is None:\\n\",\n \" pos_end = cur_len\\n\",\n \"\\n\",\n \" ones = torch.ones((pos_end, pos_end), device=device, dtype=torch.bool)\\n\",\n \" mask_full = torch.triu(ones, diagonal=1)\\n\",\n \" row_slice = slice(pos_start, pos_end)\\n\",\n \" mask = mask_full[row_slice, :pos_end][None, None, :, :]\\n\",\n \" return mask\\n\",\n \"\\n\",\n \" def forward(self, in_idx, cache=None):\\n\",\n \" x = self.tok_emb(in_idx)\\n\",\n \"\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \" if cache is not None:\\n\",\n \" pos_start = self.current_pos\\n\",\n \" pos_end = pos_start + num_tokens\\n\",\n \" self.current_pos = pos_end\\n\",\n \" mask = self.create_mask(\\n\",\n \" cur_len=num_tokens,\\n\",\n \" device=x.device,\\n\",\n \" pos_start=pos_start,\\n\",\n \" pos_end=pos_end,\\n\",\n \" )\\n\",\n \" cache_position = torch.arange(pos_start, pos_end, device=x.device, dtype=torch.long)\\n\",\n \" else:\\n\",\n \" pos_start = 0\\n\",\n \" mask = self.create_mask(\\n\",\n \" cur_len=num_tokens,\\n\",\n \" device=x.device,\\n\",\n \" pos_start=0,\\n\",\n \" pos_end=num_tokens,\\n\",\n \" )\\n\",\n \" cache_position = None\\n\",\n \"\\n\",\n \" for i, block in enumerate(self.trf_blocks):\\n\",\n \" blk_cache = cache.get(i) if cache is not None else None\\n\",\n \" x, new_blk_cache = block(\\n\",\n \" x,\\n\",\n \" mask=mask,\\n\",\n \" cos=self.cos,\\n\",\n \" sin=self.sin,\\n\",\n \" start_pos=pos_start,\\n\",\n \" cache=blk_cache,\\n\",\n \" linear_cache=cache.linear_cache if cache is not None else None,\\n\",\n \" cache_position=cache_position,\\n\",\n \" )\\n\",\n \" if cache is not None and new_blk_cache is not None:\\n\",\n \" cache.update(i, new_blk_cache)\\n\",\n \"\\n\",\n \" if cache is not None:\\n\",\n \" cache.linear_cache.has_previous_state = True\\n\",\n \"\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\\n\",\n \"\\n\",\n \" def reset_kv_cache(self):\\n\",\n \" self.current_pos = 0\\n\",\n \"\\n\",\n \"\\n\",\n \"class Qwen3_5LinearAttentionCache:\\n\",\n \" def __init__(self, n_layers):\\n\",\n \" self.conv_states = [None] * n_layers\\n\",\n \" self.recurrent_states = [None] * n_layers\\n\",\n \" self.has_previous_state = False\\n\",\n \"\\n\",\n \" def reset(self):\\n\",\n \" for i in range(len(self.conv_states)):\\n\",\n \" self.conv_states[i] = None\\n\",\n \" self.recurrent_states[i] = None\\n\",\n \" self.has_previous_state = False\\n\",\n \"\\n\",\n \"\\n\",\n \"class KVCache:\\n\",\n \" def __init__(self, n_layers):\\n\",\n \" self.cache = [None] * n_layers\\n\",\n \" self.linear_cache = Qwen3_5LinearAttentionCache(n_layers)\\n\",\n \"\\n\",\n \" def get(self, layer_idx):\\n\",\n \" return self.cache[layer_idx]\\n\",\n \"\\n\",\n \" def update(self, layer_idx, value):\\n\",\n \" self.cache[layer_idx] = value\\n\",\n \"\\n\",\n \" def get_all(self):\\n\",\n \" return self.cache\\n\",\n \"\\n\",\n \" def reset(self):\\n\",\n \" for i in range(len(self.cache)):\\n\",\n \" self.cache[i] = None\\n\",\n \" self.linear_cache.reset()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Qwen3.5-0.8B text configuration\\n\",\n \"QWEN3_5_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 248_320,\\n\",\n \" \\\"context_length\\\": 262_144,\\n\",\n \" \\\"emb_dim\\\": 1_024,\\n\",\n \" \\\"n_heads\\\": 8,\\n\",\n \" \\\"n_layers\\\": 24,\\n\",\n \" \\\"hidden_dim\\\": 3_584,\\n\",\n \" \\\"head_dim\\\": 256,\\n\",\n \" \\\"qk_norm\\\": True,\\n\",\n \" \\\"n_kv_groups\\\": 2,\\n\",\n \" \\\"rope_base\\\": 10_000_000.0,\\n\",\n \" \\\"partial_rotary_factor\\\": 0.25,\\n\",\n \" \\\"rms_norm_eps\\\": 1e-6,\\n\",\n \" \\\"linear_conv_kernel_dim\\\": 4,\\n\",\n \" \\\"linear_key_head_dim\\\": 128,\\n\",\n \" \\\"linear_value_head_dim\\\": 128,\\n\",\n \" \\\"linear_num_key_heads\\\": 16,\\n\",\n \" \\\"linear_num_value_heads\\\": 16,\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"The fast path is not available because one of the required library is not installed. Falling back to torch implementation. To install follow https://github.com/fla-org/flash-linear-attention#installation and https://github.com/Dao-AILab/causal-conv1d\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model = Qwen3_5Model(QWEN3_5_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"eaf86265-4e9d-4024-9ed0-99076944e304\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Qwen3_5Model(\\n\",\n \" (tok_emb): Embedding(248320, 1024)\\n\",\n \" (trf_blocks): ModuleList(\\n\",\n \" (0-2): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (3): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (4-6): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (7): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (8-10): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (11): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (12-14): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (15): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (16-18): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (19): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (20-22): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (23): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): RMSNorm()\\n\",\n \" (out_head): Linear(in_features=1024, out_features=248320, bias=False)\\n\",\n \")\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90aca91d-4bee-45ce-993a-4ec5393abe2b\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the forward pass works before continuing:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"adf0a6b7-b688-42c9-966e-c223d34db99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[[-0.6719, -0.0347, -0.5938, ..., 0.5469, 0.1660, -0.8945],\\n\",\n \" [ 0.0391, -0.1226, -0.8789, ..., -0.6523, -0.8281, -0.0889],\\n\",\n \" [ 0.1992, -0.7930, -0.3359, ..., -0.6602, 0.0515, -0.1582]]],\\n\",\n \" dtype=torch.bfloat16, grad_fn=\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/16_qwen3.5/qwen3.5.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\",\n \"metadata\": {\n \"id\": \"e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1241a20b-d196-4521-9228-d46954d383e4\",\n \"metadata\": {},\n \"source\": [\n \"- Qwen3.5 is based on the Qwen3-Next architecture, which I described in more detail in section [2. (Linear) Attention Hybrids](https://magazine.sebastianraschka.com/i/177848019/2-linear-attention-hybrids) of my [Beyond Standard LLMs](https://magazine.sebastianraschka.com/p/beyond-standard-llms) article\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"402a446f-4efe-41f5-acc0-4f8455846aa5\",\n \"metadata\": {},\n \"source\": [\n \"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"7c201adb-747e-437b-9a62-442802941e01\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd1b65a8-4301-444a-bd7c-a6f2bd1df9df\",\n \"outputId\": \"4f762354-e0a3-4cc2-e5d4-e61a227a202c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"huggingface_hub version: 1.5.0\\n\",\n \"tokenizers version: 0.22.2\\n\",\n \"torch version: 2.8.0+cu128\\n\"\n ]\n }\n ],\n \"source\": [\n \"from importlib.metadata import version\\n\",\n \"\\n\",\n \"pkgs = [\\n\",\n \" \\\"huggingface_hub\\\", # to download pretrained weights\\n\",\n \" \\\"tokenizers\\\", # to implement the tokenizer\\n\",\n \" \\\"torch\\\", # to implement the model\\n\",\n \"]\\n\",\n \"for p in pkgs:\\n\",\n \" print(f\\\"{p} version: {version(p)}\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"70a90338-624a-4706-aa55-6b4358070194\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"USE_MODEL = \\\"Qwen3.5-0.8B\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\",\n \"metadata\": {\n \"id\": \"653410a6-dd2b-4eb2-a722-23d9782e726d\"\n },\n \"source\": [\n \" \\n\",\n \"# 1. Architecture code\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\",\n \"metadata\": {\n \"id\": \"82076c21-9331-4dcd-b017-42b046cf1a60\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"import torch.nn as nn\\n\",\n \"\\n\",\n \"\\n\",\n \"class FeedForward(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \" self.fc1 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc2 = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"hidden_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \" self.fc3 = nn.Linear(cfg[\\\"hidden_dim\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"], bias=False)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_fc1 = self.fc1(x)\\n\",\n \" x_fc2 = self.fc2(x)\\n\",\n \" x = nn.functional.silu(x_fc1) * x_fc2\\n\",\n \" return self.fc3(x)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"56715760-37e1-433e-89da-04864c139a9e\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"class RMSNorm(nn.Module):\\n\",\n \" def __init__(self, emb_dim, eps=1e-6):\\n\",\n \" super().__init__()\\n\",\n \" self.eps = eps\\n\",\n \" # Qwen3.5 uses (1 + weight) scaling with zero init\\n\",\n \" self.weight = nn.Parameter(torch.zeros(emb_dim))\\n\",\n \"\\n\",\n \" def _norm(self, x):\\n\",\n \" return x * torch.rsqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps)\\n\",\n \"\\n\",\n \" def forward(self, x):\\n\",\n \" x_norm = self._norm(x.float())\\n\",\n \" x_norm = x_norm * (1.0 + self.weight.float())\\n\",\n \" return x_norm.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\",\n \"metadata\": {\n \"id\": \"4b9a346f-5826-4083-9162-abd56afc03f0\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_rope_params(\\n\",\n \" head_dim,\\n\",\n \" theta_base=10_000,\\n\",\n \" context_length=4096,\\n\",\n \" partial_rotary_factor=1.0,\\n\",\n \" dtype=torch.float32,\\n\",\n \"):\\n\",\n \" assert head_dim % 2 == 0, \\\"Embedding dimension must be even\\\"\\n\",\n \"\\n\",\n \" rotary_dim = int(head_dim * partial_rotary_factor)\\n\",\n \" rotary_dim = max(2, rotary_dim - (rotary_dim % 2))\\n\",\n \"\\n\",\n \" inv_freq = 1.0 / (\\n\",\n \" theta_base ** (\\n\",\n \" torch.arange(0, rotary_dim, 2, dtype=dtype)[: (rotary_dim // 2)].float() / rotary_dim\\n\",\n \" )\\n\",\n \" )\\n\",\n \"\\n\",\n \" positions = torch.arange(context_length, dtype=dtype)\\n\",\n \" angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0)\\n\",\n \" angles = torch.cat([angles, angles], dim=1)\\n\",\n \"\\n\",\n \" cos = torch.cos(angles)\\n\",\n \" sin = torch.sin(angles)\\n\",\n \"\\n\",\n \" return cos, sin\\n\",\n \"\\n\",\n \"\\n\",\n \"def apply_rope(x, cos, sin):\\n\",\n \" _, _, seq_len, head_dim = x.shape\\n\",\n \" assert head_dim % 2 == 0, \\\"Head dimension must be even\\\"\\n\",\n \"\\n\",\n \" rot_dim = cos.shape[-1]\\n\",\n \" if rot_dim > head_dim:\\n\",\n \" raise ValueError(f\\\"RoPE dim {rot_dim} cannot exceed head_dim {head_dim}.\\\")\\n\",\n \"\\n\",\n \" x_rot = x[..., :rot_dim]\\n\",\n \" x_pass = x[..., rot_dim:]\\n\",\n \"\\n\",\n \" x1 = x_rot[..., : rot_dim // 2]\\n\",\n \" x2 = x_rot[..., rot_dim // 2 :]\\n\",\n \"\\n\",\n \" cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \" sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\\n\",\n \"\\n\",\n \" rotated = torch.cat((-x2, x1), dim=-1)\\n\",\n \" x_rotated = (x_rot * cos) + (rotated * sin)\\n\",\n \"\\n\",\n \" x_out = torch.cat([x_rotated, x_pass], dim=-1)\\n\",\n \" return x_out.to(dtype=x.dtype)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\",\n \"metadata\": {\n \"id\": \"e8169ab5-f976-4222-a2e1-eb1cabf267cb\"\n },\n \"outputs\": [],\n \"source\": [\n \"class GroupedQueryAttention(nn.Module):\\n\",\n \" def __init__(\\n\",\n \" self, d_in, num_heads, num_kv_groups, head_dim=None, qk_norm=False, dtype=None\\n\",\n \" ):\\n\",\n \" super().__init__()\\n\",\n \" assert num_heads % num_kv_groups == 0, \\\"num_heads must be divisible by num_kv_groups\\\"\\n\",\n \"\\n\",\n \" self.num_heads = num_heads\\n\",\n \" self.num_kv_groups = num_kv_groups\\n\",\n \" self.group_size = num_heads // num_kv_groups\\n\",\n \"\\n\",\n \" if head_dim is None:\\n\",\n \" assert d_in % num_heads == 0, \\\"`d_in` must be divisible by `num_heads` if `head_dim` is not set\\\"\\n\",\n \" head_dim = d_in // num_heads\\n\",\n \"\\n\",\n \" self.head_dim = head_dim\\n\",\n \" self.d_out = num_heads * head_dim\\n\",\n \"\\n\",\n \" # Qwen3.5 full-attention uses a gated Q projection (2x output dim)\\n\",\n \" self.W_query = nn.Linear(d_in, self.d_out * 2, bias=False, dtype=dtype)\\n\",\n \" self.W_key = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \" self.W_value = nn.Linear(d_in, num_kv_groups * head_dim, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)\\n\",\n \"\\n\",\n \" if qk_norm:\\n\",\n \" self.q_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" self.k_norm = RMSNorm(head_dim, eps=1e-6)\\n\",\n \" else:\\n\",\n \" self.q_norm = self.k_norm = None\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" b, num_tokens, _ = x.shape\\n\",\n \"\\n\",\n \" q_and_gate = self.W_query(x)\\n\",\n \" q_and_gate = q_and_gate.view(b, num_tokens, self.num_heads, self.head_dim * 2)\\n\",\n \" queries, gate = torch.chunk(q_and_gate, 2, dim=-1)\\n\",\n \" gate = gate.reshape(b, num_tokens, self.d_out)\\n\",\n \"\\n\",\n \" keys = self.W_key(x)\\n\",\n \" values = self.W_value(x)\\n\",\n \"\\n\",\n \" queries = queries.transpose(1, 2)\\n\",\n \" keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \" values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)\\n\",\n \"\\n\",\n \" if self.q_norm:\\n\",\n \" queries = self.q_norm(queries)\\n\",\n \" if self.k_norm:\\n\",\n \" keys = self.k_norm(keys)\\n\",\n \"\\n\",\n \" queries = apply_rope(queries, cos, sin)\\n\",\n \" keys = apply_rope(keys, cos, sin)\\n\",\n \"\\n\",\n \" keys = keys.repeat_interleave(self.group_size, dim=1)\\n\",\n \" values = values.repeat_interleave(self.group_size, dim=1)\\n\",\n \"\\n\",\n \" attn_scores = queries @ keys.transpose(2, 3)\\n\",\n \" attn_scores = attn_scores.masked_fill(mask, -torch.inf)\\n\",\n \" attn_weights = torch.softmax(\\n\",\n \" attn_scores * (self.head_dim ** -0.5),\\n\",\n \" dim=-1,\\n\",\n \" dtype=torch.float32,\\n\",\n \" ).to(queries.dtype)\\n\",\n \"\\n\",\n \" context = (attn_weights @ values).transpose(1, 2).reshape(b, num_tokens, self.d_out)\\n\",\n \"\\n\",\n \" # Qwen3.5 full-attention uses a gated Q projection\\n\",\n \" context = context * torch.sigmoid(gate)\\n\",\n \" return self.out_proj(context)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\",\n \"metadata\": {\n \"id\": \"457cb2f8-50c1-4045-8a74-f181bfb5fea9\"\n },\n \"outputs\": [],\n \"source\": [\n \"from qwen3_5_transformers import (\\n\",\n \" Qwen3_5GatedDeltaNet,\\n\",\n \")\\n\",\n \"\\n\",\n \"# Just a mapping for the different naming convention in Hugging Face transformers\\n\",\n \"class _Qwen3_5ConfigAdapter:\\n\",\n \" def __init__(self, cfg):\\n\",\n \" self.hidden_size = cfg[\\\"emb_dim\\\"]\\n\",\n \" self.linear_num_value_heads = cfg[\\\"linear_num_value_heads\\\"]\\n\",\n \" self.linear_num_key_heads = cfg[\\\"linear_num_key_heads\\\"]\\n\",\n \" self.linear_key_head_dim = cfg[\\\"linear_key_head_dim\\\"]\\n\",\n \" self.linear_value_head_dim = cfg[\\\"linear_value_head_dim\\\"]\\n\",\n \" self.linear_conv_kernel_dim = cfg[\\\"linear_conv_kernel_dim\\\"]\\n\",\n \" self.hidden_act = \\\"silu\\\"\\n\",\n \" self.rms_norm_eps = cfg.get(\\\"rms_norm_eps\\\", 1e-6)\\n\",\n \" self.dtype = cfg.get(\\\"dtype\\\", None)\\n\",\n \"\\n\",\n \"\\n\",\n \"class TransformerBlock(nn.Module):\\n\",\n \" def __init__(self, cfg, layer_type, layer_idx):\\n\",\n \" super().__init__()\\n\",\n \" self.layer_type = layer_type\\n\",\n \"\\n\",\n \" if layer_type == \\\"full_attention\\\":\\n\",\n \" self.token_mixer = GroupedQueryAttention(\\n\",\n \" d_in=cfg[\\\"emb_dim\\\"],\\n\",\n \" num_heads=cfg[\\\"n_heads\\\"],\\n\",\n \" head_dim=cfg[\\\"head_dim\\\"],\\n\",\n \" num_kv_groups=cfg[\\\"n_kv_groups\\\"],\\n\",\n \" qk_norm=cfg[\\\"qk_norm\\\"],\\n\",\n \" dtype=cfg[\\\"dtype\\\"],\\n\",\n \" )\\n\",\n \" elif layer_type == \\\"linear_attention\\\":\\n\",\n \" self.token_mixer = Qwen3_5GatedDeltaNet(_Qwen3_5ConfigAdapter(cfg), layer_idx)\\n\",\n \" else:\\n\",\n \" raise ValueError(f\\\"Unsupported layer type: {layer_type}\\\")\\n\",\n \"\\n\",\n \" self.ff = FeedForward(cfg)\\n\",\n \" self.norm1 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg.get(\\\"rms_norm_eps\\\", 1e-6))\\n\",\n \" self.norm2 = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg.get(\\\"rms_norm_eps\\\", 1e-6))\\n\",\n \"\\n\",\n \" def forward(self, x, mask, cos, sin):\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm1(x)\\n\",\n \"\\n\",\n \" if self.layer_type == \\\"full_attention\\\":\\n\",\n \" x = self.token_mixer(x, mask, cos, sin)\\n\",\n \" else:\\n\",\n \" x = self.token_mixer(x)\\n\",\n \"\\n\",\n \" x = x + shortcut\\n\",\n \"\\n\",\n \" shortcut = x\\n\",\n \" x = self.norm2(x)\\n\",\n \" x = self.ff(x)\\n\",\n \" x = x + shortcut\\n\",\n \"\\n\",\n \" return x\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\",\n \"metadata\": {\n \"id\": \"e88de3e3-9f07-42cc-816b-28dbd46e96c4\"\n },\n \"outputs\": [],\n \"source\": [\n \"class Qwen3_5Model(nn.Module):\\n\",\n \" def __init__(self, cfg):\\n\",\n \" super().__init__()\\n\",\n \"\\n\",\n \" self.tok_emb = nn.Embedding(cfg[\\\"vocab_size\\\"], cfg[\\\"emb_dim\\\"], dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" layer_types = cfg.get(\\\"layer_types\\\", [\\\"full_attention\\\"] * cfg[\\\"n_layers\\\"])\\n\",\n \" if len(layer_types) != cfg[\\\"n_layers\\\"]:\\n\",\n \" raise ValueError(\\\"len(layer_types) must equal n_layers\\\")\\n\",\n \"\\n\",\n \" self.trf_blocks = nn.ModuleList(\\n\",\n \" [TransformerBlock(cfg, layer_type, idx) for idx, layer_type in enumerate(layer_types)]\\n\",\n \" )\\n\",\n \"\\n\",\n \" self.final_norm = RMSNorm(cfg[\\\"emb_dim\\\"], eps=cfg.get(\\\"rms_norm_eps\\\", 1e-6))\\n\",\n \" self.out_head = nn.Linear(cfg[\\\"emb_dim\\\"], cfg[\\\"vocab_size\\\"], bias=False, dtype=cfg[\\\"dtype\\\"])\\n\",\n \"\\n\",\n \" head_dim = cfg[\\\"emb_dim\\\"] // cfg[\\\"n_heads\\\"] if cfg[\\\"head_dim\\\"] is None else cfg[\\\"head_dim\\\"]\\n\",\n \" cos, sin = compute_rope_params(\\n\",\n \" head_dim=head_dim,\\n\",\n \" theta_base=cfg[\\\"rope_base\\\"],\\n\",\n \" context_length=cfg[\\\"context_length\\\"],\\n\",\n \" partial_rotary_factor=cfg.get(\\\"partial_rotary_factor\\\", 1.0),\\n\",\n \" dtype=torch.float32,\\n\",\n \" )\\n\",\n \" self.register_buffer(\\\"cos\\\", cos, persistent=False)\\n\",\n \" self.register_buffer(\\\"sin\\\", sin, persistent=False)\\n\",\n \" self.cfg = cfg\\n\",\n \"\\n\",\n \" def forward(self, in_idx):\\n\",\n \" x = self.tok_emb(in_idx)\\n\",\n \"\\n\",\n \" num_tokens = x.shape[1]\\n\",\n \" mask = torch.triu(\\n\",\n \" torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool),\\n\",\n \" diagonal=1,\\n\",\n \" )\\n\",\n \"\\n\",\n \" for block in self.trf_blocks:\\n\",\n \" x = block(x, mask, self.cos, self.sin)\\n\",\n \"\\n\",\n \" x = self.final_norm(x)\\n\",\n \" logits = self.out_head(x.to(self.cfg[\\\"dtype\\\"]))\\n\",\n \" return logits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\",\n \"metadata\": {\n \"id\": \"be2d201f-74ad-4d63-ab9c-601b00674a48\"\n },\n \"source\": [\n \" \\n\",\n \"# 2. Initialize model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\",\n \"metadata\": {\n \"id\": \"caa142fa-b375-4e78-b392-2072ced666f3\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Qwen3.5-0.8B text configuration\\n\",\n \"QWEN3_5_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 248_320,\\n\",\n \" \\\"context_length\\\": 262_144,\\n\",\n \" \\\"emb_dim\\\": 1_024,\\n\",\n \" \\\"n_heads\\\": 8,\\n\",\n \" \\\"n_layers\\\": 24,\\n\",\n \" \\\"hidden_dim\\\": 3_584,\\n\",\n \" \\\"head_dim\\\": 256,\\n\",\n \" \\\"qk_norm\\\": True,\\n\",\n \" \\\"n_kv_groups\\\": 2,\\n\",\n \" \\\"rope_base\\\": 10_000_000.0,\\n\",\n \" \\\"partial_rotary_factor\\\": 0.25,\\n\",\n \" \\\"rms_norm_eps\\\": 1e-6,\\n\",\n \" \\\"linear_conv_kernel_dim\\\": 4,\\n\",\n \" \\\"linear_key_head_dim\\\": 128,\\n\",\n \" \\\"linear_value_head_dim\\\": 128,\\n\",\n \" \\\"linear_num_key_heads\\\": 16,\\n\",\n \" \\\"linear_num_value_heads\\\": 16,\\n\",\n \" \\\"dtype\\\": torch.bfloat16,\\n\",\n \" \\\"layer_types\\\": [\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"linear_attention\\\", \\\"full_attention\\\",\\n\",\n \" ],\\n\",\n \"}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\",\n \"metadata\": {\n \"id\": \"156253fe-aacd-4da2-8f13-705f05c4b11e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"The fast path is not available because one of the required library is not installed. Falling back to torch implementation. To install follow https://github.com/fla-org/flash-linear-attention#installation and https://github.com/Dao-AILab/causal-conv1d\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"model = Qwen3_5Model(QWEN3_5_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"eaf86265-4e9d-4024-9ed0-99076944e304\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"Qwen3_5Model(\\n\",\n \" (tok_emb): Embedding(248320, 1024)\\n\",\n \" (trf_blocks): ModuleList(\\n\",\n \" (0-2): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (3): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (4-6): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (7): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (8-10): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (11): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (12-14): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (15): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (16-18): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (19): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (20-22): 3 x TransformerBlock(\\n\",\n \" (token_mixer): Qwen3_5GatedDeltaNet(\\n\",\n \" (conv1d): Conv1d(6144, 6144, kernel_size=(4,), stride=(1,), padding=(3,), groups=6144, bias=False)\\n\",\n \" (norm): Qwen3_5RMSNormGated()\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (in_proj_qkv): Linear(in_features=1024, out_features=6144, bias=False)\\n\",\n \" (in_proj_z): Linear(in_features=1024, out_features=2048, bias=False)\\n\",\n \" (in_proj_b): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" (in_proj_a): Linear(in_features=1024, out_features=16, bias=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" (23): TransformerBlock(\\n\",\n \" (token_mixer): GroupedQueryAttention(\\n\",\n \" (W_query): Linear(in_features=1024, out_features=4096, bias=False)\\n\",\n \" (W_key): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (W_value): Linear(in_features=1024, out_features=512, bias=False)\\n\",\n \" (out_proj): Linear(in_features=2048, out_features=1024, bias=False)\\n\",\n \" (q_norm): RMSNorm()\\n\",\n \" (k_norm): RMSNorm()\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (fc1): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc2): Linear(in_features=1024, out_features=3584, bias=False)\\n\",\n \" (fc3): Linear(in_features=3584, out_features=1024, bias=False)\\n\",\n \" )\\n\",\n \" (norm1): RMSNorm()\\n\",\n \" (norm2): RMSNorm()\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): RMSNorm()\\n\",\n \" (out_head): Linear(in_features=1024, out_features=248320, bias=False)\\n\",\n \")\"\n ]\n },\n \"execution_count\": 12,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"90aca91d-4bee-45ce-993a-4ec5393abe2b\",\n \"metadata\": {},\n \"source\": [\n \"- A quick check that the forward pass works before continuing:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"adf0a6b7-b688-42c9-966e-c223d34db99f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[[-0.6719, -0.0347, -0.5938, ..., 0.5469, 0.1660, -0.8945],\\n\",\n \" [ 0.0391, -0.1226, -0.8789, ..., -0.6523, -0.8281, -0.0889],\\n\",\n \" [ 0.1992, -0.7930, -0.3359, ..., -0.6602, 0.0515, -0.1582]]],\\n\",\n \" dtype=torch.bfloat16, grad_fn=\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch05/16_qwen3.5/qwen3_5_transformers.py",
"content": "\"\"\"Qwen3.5 helper blocks copied from Hugging Face Transformers\n\nSource file:\nhttps://github.com/huggingface/transformers/blob/main/src/transformers/models/qwen3_5/modeling_qwen3_5.py\n\nLicense: Apache License Version 2.0\nLicense URL: https://github.com/huggingface/transformers/blob/main/LICENSE\n\"\"\"\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\n\n# Notebook shims for optional fast kernels in transformers\ncausal_conv1d_fn = None\ncausal_conv1d_update = None\nchunk_gated_delta_rule = None\nfused_recurrent_gated_delta_rule = None\nFusedRMSNormGated = None\nACT2FN = {\"silu\": F.silu}\nis_fast_path_available = False\n\n\nclass _NotebookLogger:\n def __init__(self):\n self._seen = set()\n\n def warning_once(self, msg):\n if msg in self._seen:\n return\n self._seen.add(msg)\n print(msg)\n\n\nlogger = _NotebookLogger()\n\n\n# Placeholder types for copied annotations\nclass Qwen3_5Config:\n pass\n\n\nclass Qwen3_5DynamicCache:\n pass\n\n\nclass Qwen3_5RMSNormGated(nn.Module):\n def __init__(self, hidden_size, eps=1e-6, **kwargs):\n super().__init__()\n self.weight = nn.Parameter(torch.ones(hidden_size))\n self.variance_epsilon = eps\n\n def forward(self, hidden_states, gate=None):\n input_dtype = hidden_states.dtype\n hidden_states = hidden_states.to(torch.float32)\n variance = hidden_states.pow(2).mean(-1, keepdim=True)\n # Norm before gate\n hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)\n hidden_states = self.weight * hidden_states.to(input_dtype)\n hidden_states = hidden_states * F.silu(gate.to(torch.float32))\n\n return hidden_states.to(input_dtype)\n\n\ndef apply_mask_to_padding_states(hidden_states, attention_mask):\n \"\"\"\n Tunes out the hidden states for padding tokens, see https://github.com/state-spaces/mamba/issues/66\n \"\"\"\n # NOTE: attention mask is a 2D boolean tensor\n if attention_mask is not None and attention_mask.shape[1] > 1 and attention_mask.shape[0] > 1:\n dtype = hidden_states.dtype\n hidden_states = (hidden_states * attention_mask[:, :, None]).to(dtype)\n\n return hidden_states\n\n\ndef torch_causal_conv1d_update(\n hidden_states,\n conv_state,\n weight,\n bias=None,\n activation=None,\n):\n _, hidden_size, seq_len = hidden_states.shape\n state_len = conv_state.shape[-1]\n\n hidden_states_new = torch.cat([conv_state, hidden_states], dim=-1).to(weight.dtype)\n conv_state.copy_(hidden_states_new[:, :, -state_len:])\n out = F.conv1d(hidden_states_new, weight.unsqueeze(1), bias, padding=0, groups=hidden_size)\n out = F.silu(out[:, :, -seq_len:])\n out = out.to(hidden_states.dtype)\n return out\n\n\ndef l2norm(x, dim=-1, eps=1e-6):\n \"\"\"This function is intended to align with the l2norm implementation in the FLA library.\"\"\"\n inv_norm = torch.rsqrt((x * x).sum(dim=dim, keepdim=True) + eps)\n return x * inv_norm\n\n\ndef torch_chunk_gated_delta_rule(\n query,\n key,\n value,\n g,\n beta,\n chunk_size=64,\n initial_state=None,\n output_final_state=False,\n use_qk_l2norm_in_kernel=False,\n):\n initial_dtype = query.dtype\n if use_qk_l2norm_in_kernel:\n query = l2norm(query, dim=-1, eps=1e-6)\n key = l2norm(key, dim=-1, eps=1e-6)\n query, key, value, beta, g = [\n x.transpose(1, 2).contiguous().to(torch.float32) for x in (query, key, value, beta, g)\n ]\n\n batch_size, num_heads, sequence_length, k_head_dim = key.shape\n v_head_dim = value.shape[-1]\n pad_size = (chunk_size - sequence_length % chunk_size) % chunk_size\n query = F.pad(query, (0, 0, 0, pad_size))\n key = F.pad(key, (0, 0, 0, pad_size))\n value = F.pad(value, (0, 0, 0, pad_size))\n beta = F.pad(beta, (0, pad_size))\n g = F.pad(g, (0, pad_size))\n total_sequence_length = sequence_length + pad_size\n scale = 1 / (query.shape[-1] ** 0.5)\n query = query * scale\n\n v_beta = value * beta.unsqueeze(-1)\n k_beta = key * beta.unsqueeze(-1)\n # reshape to chunks\n query, key, value, k_beta, v_beta = [\n x.reshape(x.shape[0], x.shape[1], -1, chunk_size, x.shape[-1]) for x in (query, key, value, k_beta, v_beta)\n ]\n g = g.reshape(g.shape[0], g.shape[1], -1, chunk_size)\n mask = torch.triu(torch.ones(chunk_size, chunk_size, dtype=torch.bool, device=query.device), diagonal=0)\n\n # chunk decay\n g = g.cumsum(dim=-1)\n decay_mask = ((g.unsqueeze(-1) - g.unsqueeze(-2)).tril().exp().float()).tril()\n attn = -((k_beta @ key.transpose(-1, -2)) * decay_mask).masked_fill(mask, 0)\n for i in range(1, chunk_size):\n row = attn[..., i, :i].clone()\n sub = attn[..., :i, :i].clone()\n attn[..., i, :i] = row + (row.unsqueeze(-1) * sub).sum(-2)\n attn = attn + torch.eye(chunk_size, dtype=attn.dtype, device=attn.device)\n value = attn @ v_beta\n k_cumdecay = attn @ (k_beta * g.exp().unsqueeze(-1))\n last_recurrent_state = (\n torch.zeros(batch_size, num_heads, k_head_dim, v_head_dim).to(value)\n if initial_state is None\n else initial_state.to(value)\n )\n core_attn_out = torch.zeros_like(value)\n mask = torch.triu(torch.ones(chunk_size, chunk_size, dtype=torch.bool, device=query.device), diagonal=1)\n\n # for each chunk\n for i in range(0, total_sequence_length // chunk_size):\n q_i, k_i, v_i = query[:, :, i], key[:, :, i], value[:, :, i]\n attn = (q_i @ k_i.transpose(-1, -2) * decay_mask[:, :, i]).masked_fill_(mask, 0)\n v_prime = (k_cumdecay[:, :, i]) @ last_recurrent_state\n v_new = v_i - v_prime\n attn_inter = (q_i * g[:, :, i, :, None].exp()) @ last_recurrent_state\n core_attn_out[:, :, i] = attn_inter + attn @ v_new\n last_recurrent_state = (\n last_recurrent_state * g[:, :, i, -1, None, None].exp()\n + (k_i * (g[:, :, i, -1, None] - g[:, :, i]).exp()[..., None]).transpose(-1, -2) @ v_new\n )\n\n if not output_final_state:\n last_recurrent_state = None\n core_attn_out = core_attn_out.reshape(core_attn_out.shape[0], core_attn_out.shape[1], -1, core_attn_out.shape[-1])\n core_attn_out = core_attn_out[:, :, :sequence_length]\n core_attn_out = core_attn_out.transpose(1, 2).contiguous().to(initial_dtype)\n return core_attn_out, last_recurrent_state\n\n\ndef torch_recurrent_gated_delta_rule(\n query, key, value, g, beta, initial_state, output_final_state, use_qk_l2norm_in_kernel=False\n):\n initial_dtype = query.dtype\n if use_qk_l2norm_in_kernel:\n query = l2norm(query, dim=-1, eps=1e-6)\n key = l2norm(key, dim=-1, eps=1e-6)\n query, key, value, beta, g = [\n x.transpose(1, 2).contiguous().to(torch.float32) for x in (query, key, value, beta, g)\n ]\n\n batch_size, num_heads, sequence_length, k_head_dim = key.shape\n v_head_dim = value.shape[-1]\n scale = 1 / (query.shape[-1] ** 0.5)\n query = query * scale\n\n core_attn_out = torch.zeros(batch_size, num_heads, sequence_length, v_head_dim).to(value)\n last_recurrent_state = (\n torch.zeros(batch_size, num_heads, k_head_dim, v_head_dim).to(value)\n if initial_state is None\n else initial_state.to(value)\n )\n\n for i in range(sequence_length):\n q_t = query[:, :, i]\n k_t = key[:, :, i]\n v_t = value[:, :, i]\n g_t = g[:, :, i].exp().unsqueeze(-1).unsqueeze(-1)\n beta_t = beta[:, :, i].unsqueeze(-1)\n\n last_recurrent_state = last_recurrent_state * g_t\n kv_mem = (last_recurrent_state * k_t.unsqueeze(-1)).sum(dim=-2)\n delta = (v_t - kv_mem) * beta_t\n last_recurrent_state = last_recurrent_state + k_t.unsqueeze(-1) * delta.unsqueeze(-2)\n core_attn_out[:, :, i] = (last_recurrent_state * q_t.unsqueeze(-1)).sum(dim=-2)\n\n if not output_final_state:\n last_recurrent_state = None\n core_attn_out = core_attn_out.transpose(1, 2).contiguous().to(initial_dtype)\n return core_attn_out, last_recurrent_state\n\n\n# Minimal change: enforce config dtype at the end to avoid bf16/fp32 matmul mismatch\n# in a mixed notebook implementation\nclass Qwen3_5GatedDeltaNet(nn.Module):\n def __init__(self, config, layer_idx):\n super().__init__()\n self.hidden_size = config.hidden_size\n self.num_v_heads = config.linear_num_value_heads\n self.num_k_heads = config.linear_num_key_heads\n self.head_k_dim = config.linear_key_head_dim\n self.head_v_dim = config.linear_value_head_dim\n self.key_dim = self.head_k_dim * self.num_k_heads\n self.value_dim = self.head_v_dim * self.num_v_heads\n\n self.conv_kernel_size = config.linear_conv_kernel_dim\n self.layer_idx = layer_idx\n self.activation = config.hidden_act\n self.act = ACT2FN[config.hidden_act]\n self.layer_norm_epsilon = config.rms_norm_eps\n\n # QKV\n self.conv_dim = self.key_dim * 2 + self.value_dim\n self.conv1d = nn.Conv1d(\n in_channels=self.conv_dim,\n out_channels=self.conv_dim,\n bias=False,\n kernel_size=self.conv_kernel_size,\n groups=self.conv_dim,\n padding=self.conv_kernel_size - 1,\n )\n\n # time step projection (discretization)\n # instantiate once and copy inv_dt in init_weights of PretrainedModel\n self.dt_bias = nn.Parameter(torch.ones(self.num_v_heads))\n\n A = torch.empty(self.num_v_heads).uniform_(0, 16)\n self.A_log = nn.Parameter(torch.log(A))\n\n self.norm = (\n Qwen3_5RMSNormGated(self.head_v_dim, eps=self.layer_norm_epsilon)\n if FusedRMSNormGated is None\n else FusedRMSNormGated(\n self.head_v_dim,\n eps=self.layer_norm_epsilon,\n activation=self.activation,\n device=torch.cuda.current_device(),\n dtype=config.dtype if config.dtype is not None else torch.get_default_dtype(),\n )\n )\n\n self.out_proj = nn.Linear(self.value_dim, self.hidden_size, bias=False)\n\n self.causal_conv1d_fn = causal_conv1d_fn\n self.causal_conv1d_update = causal_conv1d_update or torch_causal_conv1d_update\n self.chunk_gated_delta_rule = chunk_gated_delta_rule or torch_chunk_gated_delta_rule\n self.recurrent_gated_delta_rule = fused_recurrent_gated_delta_rule or torch_recurrent_gated_delta_rule\n\n if not is_fast_path_available:\n logger.warning_once(\n \"The fast path is not available because one of the required library is not installed. Falling back to \"\n \"torch implementation. To install follow https://github.com/fla-org/flash-linear-attention#installation and\"\n \" https://github.com/Dao-AILab/causal-conv1d\"\n )\n\n self.in_proj_qkv = nn.Linear(self.hidden_size, self.key_dim * 2 + self.value_dim, bias=False)\n self.in_proj_z = nn.Linear(self.hidden_size, self.value_dim, bias=False)\n self.in_proj_b = nn.Linear(self.hidden_size, self.num_v_heads, bias=False)\n self.in_proj_a = nn.Linear(self.hidden_size, self.num_v_heads, bias=False)\n\n # Notebook adaptation for dtype consistency.\n if config.dtype is not None:\n self.to(dtype=config.dtype)\n\n def forward(\n self,\n hidden_states,\n cache_params=None,\n cache_position=None,\n attention_mask=None,\n ):\n hidden_states = apply_mask_to_padding_states(hidden_states, attention_mask)\n\n # Set up dimensions for reshapes later\n batch_size, seq_len, _ = hidden_states.shape\n\n use_precomputed_states = (\n cache_params is not None\n and cache_params.has_previous_state\n and seq_len == 1\n and cache_position is not None\n )\n\n # getting projected states from cache if it exists\n if cache_params is not None:\n conv_state = cache_params.conv_states[self.layer_idx]\n recurrent_state = cache_params.recurrent_states[self.layer_idx]\n\n mixed_qkv = self.in_proj_qkv(hidden_states)\n mixed_qkv = mixed_qkv.transpose(1, 2)\n\n z = self.in_proj_z(hidden_states)\n z = z.reshape(batch_size, seq_len, -1, self.head_v_dim)\n\n b = self.in_proj_b(hidden_states)\n a = self.in_proj_a(hidden_states)\n\n if use_precomputed_states:\n # 2. Convolution sequence transformation\n # NOTE: the conv state is updated in `causal_conv1d_update`\n mixed_qkv = self.causal_conv1d_update(\n mixed_qkv,\n conv_state,\n self.conv1d.weight.squeeze(1),\n self.conv1d.bias,\n self.activation,\n )\n else:\n if cache_params is not None:\n conv_state = F.pad(mixed_qkv, (self.conv_kernel_size - mixed_qkv.shape[-1], 0))\n cache_params.conv_states[self.layer_idx] = conv_state\n if self.causal_conv1d_fn is not None:\n mixed_qkv = self.causal_conv1d_fn(\n x=mixed_qkv,\n weight=self.conv1d.weight.squeeze(1),\n bias=self.conv1d.bias,\n activation=self.activation,\n seq_idx=None,\n )\n else:\n mixed_qkv = F.silu(self.conv1d(mixed_qkv)[:, :, :seq_len])\n\n mixed_qkv = mixed_qkv.transpose(1, 2)\n query, key, value = torch.split(\n mixed_qkv,\n [\n self.key_dim,\n self.key_dim,\n self.value_dim,\n ],\n dim=-1,\n )\n\n query = query.reshape(batch_size, seq_len, -1, self.head_k_dim)\n key = key.reshape(batch_size, seq_len, -1, self.head_k_dim)\n value = value.reshape(batch_size, seq_len, -1, self.head_v_dim)\n\n beta = b.sigmoid()\n # If the model is loaded in fp16, without the .float() here, A might be -inf\n g = -self.A_log.float().exp() * F.softplus(a.float() + self.dt_bias)\n if self.num_v_heads // self.num_k_heads > 1:\n query = query.repeat_interleave(self.num_v_heads // self.num_k_heads, dim=2)\n key = key.repeat_interleave(self.num_v_heads // self.num_k_heads, dim=2)\n\n if not use_precomputed_states:\n core_attn_out, last_recurrent_state = self.chunk_gated_delta_rule(\n query,\n key,\n value,\n g=g,\n beta=beta,\n initial_state=None,\n output_final_state=cache_params is not None,\n use_qk_l2norm_in_kernel=True,\n )\n\n else:\n core_attn_out, last_recurrent_state = self.recurrent_gated_delta_rule(\n query,\n key,\n value,\n g=g,\n beta=beta,\n initial_state=recurrent_state,\n output_final_state=cache_params is not None,\n use_qk_l2norm_in_kernel=True,\n )\n\n # Update cache\n if cache_params is not None:\n cache_params.recurrent_states[self.layer_idx] = last_recurrent_state\n\n # reshape input data into 2D tensor\n core_attn_out = core_attn_out.reshape(-1, self.head_v_dim)\n z = z.reshape(-1, self.head_v_dim)\n core_attn_out = self.norm(core_attn_out, z)\n core_attn_out = core_attn_out.reshape(batch_size, seq_len, -1)\n\n output = self.out_proj(core_attn_out)\n return output\n"
},
{
"path": "ch05/16_qwen3.5/tests/qwen3_5_layer_debugger.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport sys\nfrom pathlib import Path\n\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ndef _import_qwen3_5_classes():\n try:\n from transformers.models.qwen3_5.configuration_qwen3_5 import Qwen3_5TextConfig\n from transformers.models.qwen3_5.modeling_qwen3_5 import Qwen3_5ForCausalLM\n\n return Qwen3_5TextConfig, Qwen3_5ForCausalLM\n except Exception:\n repo_root = Path(__file__).resolve().parents[3]\n local_src = repo_root / \"transformers-main\" / \"src\"\n if not local_src.exists():\n raise\n\n for name in list(sys.modules):\n if name == \"transformers\" or name.startswith(\"transformers.\"):\n del sys.modules[name]\n sys.path.insert(0, str(local_src))\n\n from transformers.models.qwen3_5.configuration_qwen3_5 import Qwen3_5TextConfig\n from transformers.models.qwen3_5.modeling_qwen3_5 import Qwen3_5ForCausalLM\n\n return Qwen3_5TextConfig, Qwen3_5ForCausalLM\n\n\ntry:\n Qwen3_5TextConfig, Qwen3_5ForCausalLM = _import_qwen3_5_classes()\nexcept Exception:\n Qwen3_5TextConfig = None\n Qwen3_5ForCausalLM = None\n\n\ndef tiny_debug_config():\n return {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"qk_norm\": True,\n \"n_kv_groups\": 2,\n \"rope_base\": 1_000_000.0,\n \"partial_rotary_factor\": 1.0,\n \"rms_norm_eps\": 1e-6,\n \"linear_conv_kernel_dim\": 2,\n \"linear_key_head_dim\": 8,\n \"linear_value_head_dim\": 8,\n \"linear_num_key_heads\": 2,\n \"linear_num_value_heads\": 2,\n \"layer_types\": [\"linear_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n }\n\n\ndef _hf_config_from_dict(cfg):\n if Qwen3_5TextConfig is None:\n raise ImportError(\"Qwen3.5 classes are required for the layer debugger.\")\n\n hf_cfg = Qwen3_5TextConfig(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n head_dim=cfg[\"head_dim\"],\n num_key_value_heads=cfg[\"n_kv_groups\"],\n layer_types=cfg[\"layer_types\"],\n linear_conv_kernel_dim=cfg[\"linear_conv_kernel_dim\"],\n linear_key_head_dim=cfg[\"linear_key_head_dim\"],\n linear_value_head_dim=cfg[\"linear_value_head_dim\"],\n linear_num_key_heads=cfg[\"linear_num_key_heads\"],\n linear_num_value_heads=cfg[\"linear_num_value_heads\"],\n tie_word_embeddings=False,\n use_cache=False,\n attention_bias=False,\n attention_dropout=0.0,\n rms_norm_eps=cfg.get(\"rms_norm_eps\", 1e-6),\n rope_parameters={\n \"rope_type\": \"default\",\n \"rope_theta\": cfg[\"rope_base\"],\n \"partial_rotary_factor\": cfg.get(\"partial_rotary_factor\", 1.0),\n \"mrope_interleaved\": True,\n \"mrope_section\": [2, 1, 1],\n },\n torch_dtype=cfg.get(\"dtype\", torch.float32),\n )\n hf_cfg._attn_implementation = \"eager\"\n return hf_cfg\n\n\ndef load_notebook_defs(nb_name=\"qwen3.5.ipynb\"):\n nb_dir = Path(__file__).resolve().parents[1]\n if str(nb_dir) not in sys.path:\n sys.path.insert(0, str(nb_dir))\n return import_definitions_from_notebook(nb_dir, nb_name)\n\n\ndef build_qwen3_5_pair(import_notebook_defs, cfg, hf_checkpoint=None):\n if Qwen3_5ForCausalLM is None:\n raise ImportError(\"Qwen3.5 classes are required for the layer debugger.\")\n\n ours = import_notebook_defs.Qwen3_5Model(cfg)\n\n if hf_checkpoint:\n hf_model = Qwen3_5ForCausalLM.from_pretrained(\n hf_checkpoint,\n torch_dtype=cfg.get(\"dtype\", torch.float32),\n attn_implementation=\"eager\",\n )\n else:\n hf_cfg = _hf_config_from_dict(cfg)\n hf_model = Qwen3_5ForCausalLM(hf_cfg)\n\n import_notebook_defs.load_weights_into_qwen3_5(\n ours,\n {\"n_layers\": cfg[\"n_layers\"], \"layer_types\": cfg[\"layer_types\"]},\n hf_model.state_dict(),\n )\n hf_model.config.use_cache = False\n\n ours.eval()\n hf_model.eval()\n return ours, hf_model\n\n\ndef _attach_debug_hooks(model, is_hf):\n traces = {}\n handles = []\n\n def hook(name):\n def _record(_, __, output):\n if isinstance(output, tuple):\n output = output[0]\n traces[name] = output.detach().to(torch.float32).cpu()\n\n return _record\n\n if is_hf:\n core = model.model\n handles.append(core.embed_tokens.register_forward_hook(hook(\"embedding\")))\n for idx, layer in enumerate(core.layers):\n handles.append(layer.register_forward_hook(hook(f\"block_{idx}\")))\n handles.append(core.norm.register_forward_hook(hook(\"final_norm\")))\n handles.append(model.lm_head.register_forward_hook(hook(\"logits\")))\n else:\n handles.append(model.tok_emb.register_forward_hook(hook(\"embedding\")))\n blocks = getattr(model, \"trf_blocks\", None)\n if blocks is None:\n blocks = getattr(model, \"blocks\", None)\n if blocks is None:\n raise AttributeError(\"Could not locate Qwen3.5 blocks on the local model.\")\n for idx, block in enumerate(blocks):\n handles.append(block.register_forward_hook(hook(f\"block_{idx}\")))\n handles.append(model.final_norm.register_forward_hook(hook(\"final_norm\")))\n handles.append(model.out_head.register_forward_hook(hook(\"logits\")))\n\n return traces, handles\n\n\ndef _layer_sort_key(name):\n if name == \"embedding\":\n return (0, 0)\n if name.startswith(\"block_\"):\n idx = int(name.split(\"_\")[1])\n return (1, idx)\n if name == \"final_norm\":\n return (2, 0)\n if name == \"logits\":\n return (3, 0)\n return (4, name)\n\n\ndef layerwise_differences(ours, hf_model, input_ids, rtol=1e-5, atol=1e-5):\n ours_traces, ours_handles = _attach_debug_hooks(ours, is_hf=False)\n hf_traces, hf_handles = _attach_debug_hooks(hf_model, is_hf=True)\n\n try:\n with torch.inference_mode():\n ours(input_ids)\n hf_model(input_ids, use_cache=False)\n finally:\n for h in ours_handles + hf_handles:\n h.remove()\n\n layer_names = sorted(set(ours_traces) | set(hf_traces), key=_layer_sort_key)\n results = []\n for name in layer_names:\n ours_tensor = ours_traces.get(name)\n hf_tensor = hf_traces.get(name)\n\n if ours_tensor is None or hf_tensor is None:\n results.append(\n {\n \"name\": name,\n \"status\": \"missing\",\n \"ours_shape\": None if ours_tensor is None else tuple(ours_tensor.shape),\n \"hf_shape\": None if hf_tensor is None else tuple(hf_tensor.shape),\n \"max_diff\": None,\n \"mean_abs_diff\": None,\n }\n )\n continue\n\n if ours_tensor.shape != hf_tensor.shape:\n results.append(\n {\n \"name\": name,\n \"status\": \"shape_mismatch\",\n \"ours_shape\": tuple(ours_tensor.shape),\n \"hf_shape\": tuple(hf_tensor.shape),\n \"max_diff\": None,\n \"mean_abs_diff\": None,\n }\n )\n continue\n\n diff = (ours_tensor - hf_tensor).abs()\n max_diff = float(diff.max().item())\n mean_diff = float(diff.mean().item())\n allclose = torch.allclose(ours_tensor, hf_tensor, rtol=rtol, atol=atol)\n results.append(\n {\n \"name\": name,\n \"status\": \"ok\" if allclose else \"mismatch\",\n \"ours_shape\": tuple(ours_tensor.shape),\n \"hf_shape\": tuple(hf_tensor.shape),\n \"max_diff\": max_diff,\n \"mean_abs_diff\": mean_diff,\n }\n )\n return results\n\n\ndef format_report(differences):\n lines = []\n for diff in sorted(differences, key=lambda d: _layer_sort_key(d[\"name\"])):\n if diff[\"status\"] == \"ok\":\n lines.append(f\"[OK] {diff['name']}: max={diff['max_diff']:.2e}, mean={diff['mean_abs_diff']:.2e}\")\n elif diff[\"status\"] == \"mismatch\":\n lines.append(f\"[DIFF] {diff['name']}: max={diff['max_diff']:.2e}, mean={diff['mean_abs_diff']:.2e}\")\n elif diff[\"status\"] == \"shape_mismatch\":\n lines.append(f\"[SHAPE] {diff['name']}: ours={diff['ours_shape']}, hf={diff['hf_shape']}\")\n else:\n lines.append(f\"[MISSING] {diff['name']}: ours={diff['ours_shape']}, hf={diff['hf_shape']}\")\n return \"\\n\".join(lines)\n\n\nif __name__ == \"__main__\":\n if Qwen3_5ForCausalLM is None:\n raise SystemExit(\n \"Qwen3.5 classes are unavailable. Install a recent transformers version or use local transformers-main.\"\n )\n\n import_notebook_defs = load_notebook_defs()\n cfg = tiny_debug_config()\n\n ours_model, hf_model = build_qwen3_5_pair(import_notebook_defs, cfg)\n torch.manual_seed(0)\n input_ids = torch.randint(0, cfg[\"vocab_size\"], (1, cfg[\"context_length\"]), dtype=torch.long)\n diffs = layerwise_differences(ours_model, hf_model, input_ids)\n print(format_report(diffs))\n"
},
{
"path": "ch05/16_qwen3.5/tests/test_qwen3_5_nb.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\nimport importlib\nimport sys\nfrom pathlib import Path\n\nimport pytest\nimport torch\n\nfrom llms_from_scratch.utils import import_definitions_from_notebook\n\n\ndef _import_qwen3_5_classes():\n try:\n from transformers.models.qwen3_5.configuration_qwen3_5 import Qwen3_5TextConfig\n from transformers.models.qwen3_5.modeling_qwen3_5 import Qwen3_5ForCausalLM\n\n return Qwen3_5TextConfig, Qwen3_5ForCausalLM\n except Exception:\n repo_root = Path(__file__).resolve().parents[3]\n local_src = repo_root / \"transformers-main\" / \"src\"\n if not local_src.exists():\n raise\n\n for name in list(sys.modules):\n if name == \"transformers\" or name.startswith(\"transformers.\"):\n del sys.modules[name]\n sys.path.insert(0, str(local_src))\n\n from transformers.models.qwen3_5.configuration_qwen3_5 import Qwen3_5TextConfig\n from transformers.models.qwen3_5.modeling_qwen3_5 import Qwen3_5ForCausalLM\n\n return Qwen3_5TextConfig, Qwen3_5ForCausalLM\n\n\ntransformers_installed = importlib.util.find_spec(\"transformers\") is not None\nif transformers_installed:\n try:\n Qwen3_5TextConfig, Qwen3_5ForCausalLM = _import_qwen3_5_classes()\n except Exception:\n transformers_installed = False\n Qwen3_5TextConfig, Qwen3_5ForCausalLM = None, None\nelse:\n Qwen3_5TextConfig, Qwen3_5ForCausalLM = None, None\n\n\n@pytest.fixture\ndef import_notebook_defs():\n nb_dir = Path(__file__).resolve().parents[1]\n if str(nb_dir) not in sys.path:\n sys.path.insert(0, str(nb_dir))\n\n mod = import_definitions_from_notebook(nb_dir, \"qwen3.5.ipynb\")\n return mod\n\n\n@pytest.fixture\ndef dummy_input():\n torch.manual_seed(123)\n return torch.randint(0, 100, (1, 8))\n\n\n@pytest.fixture\ndef dummy_cfg_base():\n return {\n \"vocab_size\": 100,\n \"emb_dim\": 32,\n \"hidden_dim\": 64,\n \"n_layers\": 2,\n \"n_heads\": 4,\n \"head_dim\": 8,\n \"n_kv_groups\": 1,\n \"qk_norm\": False,\n \"dtype\": torch.float32,\n \"rope_base\": 10_000.0,\n \"context_length\": 64,\n \"partial_rotary_factor\": 1.0,\n \"rms_norm_eps\": 1e-6,\n \"linear_conv_kernel_dim\": 2,\n \"linear_key_head_dim\": 8,\n \"linear_value_head_dim\": 8,\n \"linear_num_key_heads\": 2,\n \"linear_num_value_heads\": 2,\n \"layer_types\": [\"linear_attention\", \"full_attention\"],\n }\n\n\n@torch.inference_mode()\ndef test_dummy_qwen3_5_forward(dummy_cfg_base, dummy_input, import_notebook_defs):\n torch.manual_seed(123)\n model = import_notebook_defs.Qwen3_5Model(dummy_cfg_base)\n out = model(dummy_input)\n assert out.shape == (1, dummy_input.size(1), dummy_cfg_base[\"vocab_size\"]), (\n f\"Expected shape (1, seq_len, vocab_size), got {out.shape}\"\n )\n\n\n@torch.inference_mode()\n@pytest.mark.skipif(not transformers_installed, reason=\"transformers not installed\")\ndef test_qwen3_5_base_equivalence_with_transformers(import_notebook_defs):\n cfg = {\n \"vocab_size\": 257,\n \"context_length\": 8,\n \"emb_dim\": 32,\n \"n_heads\": 4,\n \"n_layers\": 2,\n \"hidden_dim\": 64,\n \"head_dim\": 8,\n \"qk_norm\": True,\n \"n_kv_groups\": 2,\n \"rope_base\": 1_000_000.0,\n \"partial_rotary_factor\": 1.0,\n \"rms_norm_eps\": 1e-6,\n \"linear_conv_kernel_dim\": 2,\n \"linear_key_head_dim\": 8,\n \"linear_value_head_dim\": 8,\n \"linear_num_key_heads\": 2,\n \"linear_num_value_heads\": 2,\n \"layer_types\": [\"linear_attention\", \"full_attention\"],\n \"dtype\": torch.float32,\n }\n model = import_notebook_defs.Qwen3_5Model(cfg)\n\n hf_cfg = Qwen3_5TextConfig(\n vocab_size=cfg[\"vocab_size\"],\n max_position_embeddings=cfg[\"context_length\"],\n hidden_size=cfg[\"emb_dim\"],\n num_attention_heads=cfg[\"n_heads\"],\n num_hidden_layers=cfg[\"n_layers\"],\n intermediate_size=cfg[\"hidden_dim\"],\n head_dim=cfg[\"head_dim\"],\n num_key_value_heads=cfg[\"n_kv_groups\"],\n layer_types=cfg[\"layer_types\"],\n linear_conv_kernel_dim=cfg[\"linear_conv_kernel_dim\"],\n linear_key_head_dim=cfg[\"linear_key_head_dim\"],\n linear_value_head_dim=cfg[\"linear_value_head_dim\"],\n linear_num_key_heads=cfg[\"linear_num_key_heads\"],\n linear_num_value_heads=cfg[\"linear_num_value_heads\"],\n tie_word_embeddings=False,\n use_cache=False,\n attention_bias=False,\n attention_dropout=0.0,\n rms_norm_eps=cfg[\"rms_norm_eps\"],\n rope_parameters={\n \"rope_type\": \"default\",\n \"rope_theta\": cfg[\"rope_base\"],\n \"partial_rotary_factor\": cfg[\"partial_rotary_factor\"],\n \"mrope_interleaved\": True,\n \"mrope_section\": [2, 1, 1],\n },\n torch_dtype=torch.float32,\n )\n hf_cfg._attn_implementation = \"eager\"\n hf_model = Qwen3_5ForCausalLM(hf_cfg)\n\n hf_state = hf_model.state_dict()\n param_config = {\"n_layers\": cfg[\"n_layers\"], \"layer_types\": cfg[\"layer_types\"]}\n import_notebook_defs.load_weights_into_qwen3_5(model, param_config, hf_state)\n\n x = torch.randint(0, cfg[\"vocab_size\"], (2, cfg[\"context_length\"]), dtype=torch.long)\n ours_logits = model(x)\n theirs_logits = hf_model(x, use_cache=False).logits\n torch.testing.assert_close(ours_logits, theirs_logits, rtol=1e-5, atol=1e-5)\n"
},
{
"path": "ch05/README.md",
"content": "# Chapter 5: Pretraining on Unlabeled Data\n\n \n## Main Chapter Code\n\n- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code\n\n \n## Bonus Materials\n\n- [02_alternative_weight_loading](02_alternative_weight_loading) contains code to load the GPT model weights from alternative places in case the model weights become unavailable from OpenAI\n- [03_bonus_pretraining_on_gutenberg](03_bonus_pretraining_on_gutenberg) contains code to pretrain the LLM longer on the whole corpus of books from Project Gutenberg\n- [04_learning_rate_schedulers](04_learning_rate_schedulers) contains code implementing a more sophisticated training function including learning rate schedulers and gradient clipping\n- [05_bonus_hparam_tuning](05_bonus_hparam_tuning) contains an optional hyperparameter tuning script\n- [06_user_interface](06_user_interface) implements an interactive user interface to interact with the pretrained LLM\n- [08_memory_efficient_weight_loading](08_memory_efficient_weight_loading) contains a bonus notebook showing how to load model weights via PyTorch's `load_state_dict` method more efficiently\n- [09_extending-tokenizers](09_extending-tokenizers) contains a from-scratch implementation of the GPT-2 BPE tokenizer\n- [10_llm-training-speed](10_llm-training-speed) shows PyTorch performance tips to improve the LLM training speed\n\n \n## LLM Architectures From Scratch\n\n\n\n \n\n\n- [07_gpt_to_llama](07_gpt_to_llama) contains a step-by-step guide for converting a GPT architecture implementation to Llama 3.2 and loads pretrained weights from Meta AI\n- [11_qwen3](11_qwen3) A from-scratch implementation of Qwen3 0.6B and Qwen3 30B-A3B (Mixture-of-Experts) including code to load the pretrained weights of the base, reasoning, and coding model variants\n- [12_gemma3](12_gemma3) A from-scratch implementation of Gemma 3 270M and alternative with KV cache, including code to load the pretrained weights\n- [13_olmo3](13_olmo3) A from-scratch implementation of Olmo 3 7B and 32B (Base, Instruct, and Think variants) and alternative with KV cache, including code to load the pretrained weights\n\n \n## Code-Along Video for This Chapter\n\n| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3a84cf35-b37f-4c15-8972-dfafc9fadc1c\",\n \"metadata\": {\n \"id\": \"3a84cf35-b37f-4c15-8972-dfafc9fadc1c\"\n },\n \"source\": [\n \" \\n\",\n \"### 6.1 Different categories of finetuning\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ede3d731-5123-4f02-accd-c670ce50a5a3\",\n \"metadata\": {\n \"id\": \"ede3d731-5123-4f02-accd-c670ce50a5a3\"\n },\n \"source\": [\n \"- No code in this section\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ac45579d-d485-47dc-829e-43be7f4db57b\",\n \"metadata\": {},\n \"source\": [\n \"- The most common ways to finetune language models are instruction-finetuning and classification finetuning\\n\",\n \"- Instruction-finetuning, depicted below, is the topic of the next chapter\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6c29ef42-46d9-43d4-8bb4-94974e1665e4\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3a84cf35-b37f-4c15-8972-dfafc9fadc1c\",\n \"metadata\": {\n \"id\": \"3a84cf35-b37f-4c15-8972-dfafc9fadc1c\"\n },\n \"source\": [\n \" \\n\",\n \"### 6.1 Different categories of finetuning\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ede3d731-5123-4f02-accd-c670ce50a5a3\",\n \"metadata\": {\n \"id\": \"ede3d731-5123-4f02-accd-c670ce50a5a3\"\n },\n \"source\": [\n \"- No code in this section\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ac45579d-d485-47dc-829e-43be7f4db57b\",\n \"metadata\": {},\n \"source\": [\n \"- The most common ways to finetune language models are instruction-finetuning and classification finetuning\\n\",\n \"- Instruction-finetuning, depicted below, is the topic of the next chapter\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6c29ef42-46d9-43d4-8bb4-94974e1665e4\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a7f60321-95b8-46a9-97bf-1d07fda2c3dd\",\n \"metadata\": {},\n \"source\": [\n \"- Classification finetuning, the topic of this chapter, is a procedure you may already be familiar with if you have a background in machine learning -- it's similar to training a convolutional network to classify handwritten digits, for example\\n\",\n \"- In classification finetuning, we have a specific number of class labels (for example, \\\"spam\\\" and \\\"not spam\\\") that the model can output\\n\",\n \"- A classification finetuned model can only predict classes it has seen during training (for example, \\\"spam\\\" or \\\"not spam\\\"), whereas an instruction-finetuned model can usually perform many tasks\\n\",\n \"- We can think of a classification-finetuned model as a very specialized model; in practice, it is much easier to create a specialized model than a generalist model that performs well on many different tasks\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b37a0c4-0bb1-4061-b1fe-eaa4416d52c3\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a7f60321-95b8-46a9-97bf-1d07fda2c3dd\",\n \"metadata\": {},\n \"source\": [\n \"- Classification finetuning, the topic of this chapter, is a procedure you may already be familiar with if you have a background in machine learning -- it's similar to training a convolutional network to classify handwritten digits, for example\\n\",\n \"- In classification finetuning, we have a specific number of class labels (for example, \\\"spam\\\" and \\\"not spam\\\") that the model can output\\n\",\n \"- A classification finetuned model can only predict classes it has seen during training (for example, \\\"spam\\\" or \\\"not spam\\\"), whereas an instruction-finetuned model can usually perform many tasks\\n\",\n \"- We can think of a classification-finetuned model as a very specialized model; in practice, it is much easier to create a specialized model than a generalist model that performs well on many different tasks\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b37a0c4-0bb1-4061-b1fe-eaa4416d52c3\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c7017a2-32aa-4002-a2f3-12aac293ccdf\",\n \"metadata\": {\n \"id\": \"8c7017a2-32aa-4002-a2f3-12aac293ccdf\"\n },\n \"source\": [\n \" \\n\",\n \"### 6.2 Preparing the dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5f628975-d2e8-4f7f-ab38-92bb868b7067\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c7017a2-32aa-4002-a2f3-12aac293ccdf\",\n \"metadata\": {\n \"id\": \"8c7017a2-32aa-4002-a2f3-12aac293ccdf\"\n },\n \"source\": [\n \" \\n\",\n \"### 6.2 Preparing the dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5f628975-d2e8-4f7f-ab38-92bb868b7067\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9fbd459f-63fa-4d8c-8499-e23103156c7d\",\n \"metadata\": {\n \"id\": \"9fbd459f-63fa-4d8c-8499-e23103156c7d\"\n },\n \"source\": [\n \"- This section prepares the dataset we use for classification finetuning\\n\",\n \"- We use a dataset consisting of spam and non-spam text messages to finetune the LLM to classify them\\n\",\n \"- First, we download and unzip the dataset\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"def7c09b-af9c-4216-90ce-5e67aed1065c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"def7c09b-af9c-4216-90ce-5e67aed1065c\",\n \"outputId\": \"424e4423-f623-443c-ab9e-656f9e867559\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"sms_spam_collection/SMSSpamCollection.tsv already exists. Skipping download and extraction.\\n\"\n ]\n },\n {\n \"data\": {\n \"text/plain\": [\n \"'\\\\nimport urllib.request\\\\nimport zipfile\\\\nimport os\\\\nfrom pathlib import Path\\\\n\\\\nurl = \\\"https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip\\\"\\\\nzip_path = \\\"sms_spam_collection.zip\\\"\\\\nextracted_path = \\\"sms_spam_collection\\\"\\\\ndata_file_path = Path(extracted_path) / \\\"SMSSpamCollection.tsv\\\"\\\\n\\\\ndef download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path):\\\\n if data_file_path.exists():\\\\n print(f\\\"{data_file_path} already exists. Skipping download and extraction.\\\")\\\\n return\\\\n\\\\n # Downloading the file\\\\n with urllib.request.urlopen(url) as response:\\\\n with open(zip_path, \\\"wb\\\") as out_file:\\\\n out_file.write(response.read())\\\\n\\\\n # Unzipping the file\\\\n with zipfile.ZipFile(zip_path, \\\"r\\\") as zip_ref:\\\\n zip_ref.extractall(extracted_path)\\\\n\\\\n # Add .tsv file extension\\\\n original_file_path = Path(extracted_path) / \\\"SMSSpamCollection\\\"\\\\n os.rename(original_file_path, data_file_path)\\\\n print(f\\\"File downloaded and saved as {data_file_path}\\\")\\\\n\\\\ntry:\\\\n download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\\\nexcept (urllib.error.HTTPError, urllib.error.URLError, TimeoutError) as e:\\\\n print(f\\\"Primary URL failed: {e}. Trying backup URL...\\\")\\\\n url = \\\"https://f001.backblazeb2.com/file/LLMs-from-scratch/sms%2Bspam%2Bcollection.zip\\\"\\\\n download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\\\n'\"\n ]\n },\n \"execution_count\": 2,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"import requests\\n\",\n \"import zipfile\\n\",\n \"import os\\n\",\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"url = \\\"https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip\\\"\\n\",\n \"zip_path = \\\"sms_spam_collection.zip\\\"\\n\",\n \"extracted_path = \\\"sms_spam_collection\\\"\\n\",\n \"data_file_path = Path(extracted_path) / \\\"SMSSpamCollection.tsv\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"def download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path):\\n\",\n \" if data_file_path.exists():\\n\",\n \" print(f\\\"{data_file_path} already exists. Skipping download and extraction.\\\")\\n\",\n \" return\\n\",\n \"\\n\",\n \" # Downloading the file\\n\",\n \" response = requests.get(url, stream=True, timeout=60)\\n\",\n \" response.raise_for_status()\\n\",\n \" with open(zip_path, \\\"wb\\\") as out_file:\\n\",\n \" for chunk in response.iter_content(chunk_size=8192):\\n\",\n \" if chunk:\\n\",\n \" out_file.write(chunk)\\n\",\n \"\\n\",\n \" # Unzipping the file\\n\",\n \" with zipfile.ZipFile(zip_path, \\\"r\\\") as zip_ref:\\n\",\n \" zip_ref.extractall(extracted_path)\\n\",\n \"\\n\",\n \" # Add .tsv file extension\\n\",\n \" original_file_path = Path(extracted_path) / \\\"SMSSpamCollection\\\"\\n\",\n \" os.rename(original_file_path, data_file_path)\\n\",\n \" print(f\\\"File downloaded and saved as {data_file_path}\\\")\\n\",\n \"\\n\",\n \"\\n\",\n \"try:\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"except (requests.exceptions.RequestException, TimeoutError) as e:\\n\",\n \" print(f\\\"Primary URL failed: {e}. Trying backup URL...\\\")\\n\",\n \" url = \\\"https://f001.backblazeb2.com/file/LLMs-from-scratch/sms%2Bspam%2Bcollection.zip\\\"\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"# The book originally used the following code below\\n\",\n \"# However, urllib uses older protocol settings that\\n\",\n \"# can cause problems for some readers using a VPN.\\n\",\n \"# The `requests` version above is more robust\\n\",\n \"# in that regard.\\n\",\n \"\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"import urllib.request\\n\",\n \"import zipfile\\n\",\n \"import os\\n\",\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"url = \\\"https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip\\\"\\n\",\n \"zip_path = \\\"sms_spam_collection.zip\\\"\\n\",\n \"extracted_path = \\\"sms_spam_collection\\\"\\n\",\n \"data_file_path = Path(extracted_path) / \\\"SMSSpamCollection.tsv\\\"\\n\",\n \"\\n\",\n \"def download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path):\\n\",\n \" if data_file_path.exists():\\n\",\n \" print(f\\\"{data_file_path} already exists. Skipping download and extraction.\\\")\\n\",\n \" return\\n\",\n \"\\n\",\n \" # Downloading the file\\n\",\n \" with urllib.request.urlopen(url) as response:\\n\",\n \" with open(zip_path, \\\"wb\\\") as out_file:\\n\",\n \" out_file.write(response.read())\\n\",\n \"\\n\",\n \" # Unzipping the file\\n\",\n \" with zipfile.ZipFile(zip_path, \\\"r\\\") as zip_ref:\\n\",\n \" zip_ref.extractall(extracted_path)\\n\",\n \"\\n\",\n \" # Add .tsv file extension\\n\",\n \" original_file_path = Path(extracted_path) / \\\"SMSSpamCollection\\\"\\n\",\n \" os.rename(original_file_path, data_file_path)\\n\",\n \" print(f\\\"File downloaded and saved as {data_file_path}\\\")\\n\",\n \"\\n\",\n \"try:\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"except (urllib.error.HTTPError, urllib.error.URLError, TimeoutError) as e:\\n\",\n \" print(f\\\"Primary URL failed: {e}. Trying backup URL...\\\")\\n\",\n \" url = \\\"https://f001.backblazeb2.com/file/LLMs-from-scratch/sms%2Bspam%2Bcollection.zip\\\"\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"\\\"\\\"\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6aac2d19-06d0-4005-916b-0bd4b1ee50d1\",\n \"metadata\": {\n \"id\": \"6aac2d19-06d0-4005-916b-0bd4b1ee50d1\"\n },\n \"source\": [\n \"- The dataset is saved as a tab-separated text file, which we can load into a pandas DataFrame\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"da0ed4da-ac31-4e4d-8bdd-2153be4656a4\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 423\n },\n \"id\": \"da0ed4da-ac31-4e4d-8bdd-2153be4656a4\",\n \"outputId\": \"a16c5cde-d341-4887-a93f-baa9bec542ab\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/html\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9fbd459f-63fa-4d8c-8499-e23103156c7d\",\n \"metadata\": {\n \"id\": \"9fbd459f-63fa-4d8c-8499-e23103156c7d\"\n },\n \"source\": [\n \"- This section prepares the dataset we use for classification finetuning\\n\",\n \"- We use a dataset consisting of spam and non-spam text messages to finetune the LLM to classify them\\n\",\n \"- First, we download and unzip the dataset\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"def7c09b-af9c-4216-90ce-5e67aed1065c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"def7c09b-af9c-4216-90ce-5e67aed1065c\",\n \"outputId\": \"424e4423-f623-443c-ab9e-656f9e867559\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"sms_spam_collection/SMSSpamCollection.tsv already exists. Skipping download and extraction.\\n\"\n ]\n },\n {\n \"data\": {\n \"text/plain\": [\n \"'\\\\nimport urllib.request\\\\nimport zipfile\\\\nimport os\\\\nfrom pathlib import Path\\\\n\\\\nurl = \\\"https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip\\\"\\\\nzip_path = \\\"sms_spam_collection.zip\\\"\\\\nextracted_path = \\\"sms_spam_collection\\\"\\\\ndata_file_path = Path(extracted_path) / \\\"SMSSpamCollection.tsv\\\"\\\\n\\\\ndef download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path):\\\\n if data_file_path.exists():\\\\n print(f\\\"{data_file_path} already exists. Skipping download and extraction.\\\")\\\\n return\\\\n\\\\n # Downloading the file\\\\n with urllib.request.urlopen(url) as response:\\\\n with open(zip_path, \\\"wb\\\") as out_file:\\\\n out_file.write(response.read())\\\\n\\\\n # Unzipping the file\\\\n with zipfile.ZipFile(zip_path, \\\"r\\\") as zip_ref:\\\\n zip_ref.extractall(extracted_path)\\\\n\\\\n # Add .tsv file extension\\\\n original_file_path = Path(extracted_path) / \\\"SMSSpamCollection\\\"\\\\n os.rename(original_file_path, data_file_path)\\\\n print(f\\\"File downloaded and saved as {data_file_path}\\\")\\\\n\\\\ntry:\\\\n download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\\\nexcept (urllib.error.HTTPError, urllib.error.URLError, TimeoutError) as e:\\\\n print(f\\\"Primary URL failed: {e}. Trying backup URL...\\\")\\\\n url = \\\"https://f001.backblazeb2.com/file/LLMs-from-scratch/sms%2Bspam%2Bcollection.zip\\\"\\\\n download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\\\n'\"\n ]\n },\n \"execution_count\": 2,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"import requests\\n\",\n \"import zipfile\\n\",\n \"import os\\n\",\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"url = \\\"https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip\\\"\\n\",\n \"zip_path = \\\"sms_spam_collection.zip\\\"\\n\",\n \"extracted_path = \\\"sms_spam_collection\\\"\\n\",\n \"data_file_path = Path(extracted_path) / \\\"SMSSpamCollection.tsv\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"def download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path):\\n\",\n \" if data_file_path.exists():\\n\",\n \" print(f\\\"{data_file_path} already exists. Skipping download and extraction.\\\")\\n\",\n \" return\\n\",\n \"\\n\",\n \" # Downloading the file\\n\",\n \" response = requests.get(url, stream=True, timeout=60)\\n\",\n \" response.raise_for_status()\\n\",\n \" with open(zip_path, \\\"wb\\\") as out_file:\\n\",\n \" for chunk in response.iter_content(chunk_size=8192):\\n\",\n \" if chunk:\\n\",\n \" out_file.write(chunk)\\n\",\n \"\\n\",\n \" # Unzipping the file\\n\",\n \" with zipfile.ZipFile(zip_path, \\\"r\\\") as zip_ref:\\n\",\n \" zip_ref.extractall(extracted_path)\\n\",\n \"\\n\",\n \" # Add .tsv file extension\\n\",\n \" original_file_path = Path(extracted_path) / \\\"SMSSpamCollection\\\"\\n\",\n \" os.rename(original_file_path, data_file_path)\\n\",\n \" print(f\\\"File downloaded and saved as {data_file_path}\\\")\\n\",\n \"\\n\",\n \"\\n\",\n \"try:\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"except (requests.exceptions.RequestException, TimeoutError) as e:\\n\",\n \" print(f\\\"Primary URL failed: {e}. Trying backup URL...\\\")\\n\",\n \" url = \\\"https://f001.backblazeb2.com/file/LLMs-from-scratch/sms%2Bspam%2Bcollection.zip\\\"\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"# The book originally used the following code below\\n\",\n \"# However, urllib uses older protocol settings that\\n\",\n \"# can cause problems for some readers using a VPN.\\n\",\n \"# The `requests` version above is more robust\\n\",\n \"# in that regard.\\n\",\n \"\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"import urllib.request\\n\",\n \"import zipfile\\n\",\n \"import os\\n\",\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"url = \\\"https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip\\\"\\n\",\n \"zip_path = \\\"sms_spam_collection.zip\\\"\\n\",\n \"extracted_path = \\\"sms_spam_collection\\\"\\n\",\n \"data_file_path = Path(extracted_path) / \\\"SMSSpamCollection.tsv\\\"\\n\",\n \"\\n\",\n \"def download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path):\\n\",\n \" if data_file_path.exists():\\n\",\n \" print(f\\\"{data_file_path} already exists. Skipping download and extraction.\\\")\\n\",\n \" return\\n\",\n \"\\n\",\n \" # Downloading the file\\n\",\n \" with urllib.request.urlopen(url) as response:\\n\",\n \" with open(zip_path, \\\"wb\\\") as out_file:\\n\",\n \" out_file.write(response.read())\\n\",\n \"\\n\",\n \" # Unzipping the file\\n\",\n \" with zipfile.ZipFile(zip_path, \\\"r\\\") as zip_ref:\\n\",\n \" zip_ref.extractall(extracted_path)\\n\",\n \"\\n\",\n \" # Add .tsv file extension\\n\",\n \" original_file_path = Path(extracted_path) / \\\"SMSSpamCollection\\\"\\n\",\n \" os.rename(original_file_path, data_file_path)\\n\",\n \" print(f\\\"File downloaded and saved as {data_file_path}\\\")\\n\",\n \"\\n\",\n \"try:\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"except (urllib.error.HTTPError, urllib.error.URLError, TimeoutError) as e:\\n\",\n \" print(f\\\"Primary URL failed: {e}. Trying backup URL...\\\")\\n\",\n \" url = \\\"https://f001.backblazeb2.com/file/LLMs-from-scratch/sms%2Bspam%2Bcollection.zip\\\"\\n\",\n \" download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)\\n\",\n \"\\\"\\\"\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6aac2d19-06d0-4005-916b-0bd4b1ee50d1\",\n \"metadata\": {\n \"id\": \"6aac2d19-06d0-4005-916b-0bd4b1ee50d1\"\n },\n \"source\": [\n \"- The dataset is saved as a tab-separated text file, which we can load into a pandas DataFrame\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"da0ed4da-ac31-4e4d-8bdd-2153be4656a4\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 423\n },\n \"id\": \"da0ed4da-ac31-4e4d-8bdd-2153be4656a4\",\n \"outputId\": \"a16c5cde-d341-4887-a93f-baa9bec542ab\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/html\": [\n \"| \\n\",\n \" | Label | \\n\",\n \"Text | \\n\",\n \"
|---|---|---|
| 0 | \\n\",\n \"ham | \\n\",\n \"Go until jurong point, crazy.. Available only ... | \\n\",\n \"
| 1 | \\n\",\n \"ham | \\n\",\n \"Ok lar... Joking wif u oni... | \\n\",\n \"
| 2 | \\n\",\n \"spam | \\n\",\n \"Free entry in 2 a wkly comp to win FA Cup fina... | \\n\",\n \"
| 3 | \\n\",\n \"ham | \\n\",\n \"U dun say so early hor... U c already then say... | \\n\",\n \"
| 4 | \\n\",\n \"ham | \\n\",\n \"Nah I don't think he goes to usf, he lives aro... | \\n\",\n \"
| ... | \\n\",\n \"... | \\n\",\n \"... | \\n\",\n \"
| 5567 | \\n\",\n \"spam | \\n\",\n \"This is the 2nd time we have tried 2 contact u... | \\n\",\n \"
| 5568 | \\n\",\n \"ham | \\n\",\n \"Will ü b going to esplanade fr home? | \\n\",\n \"
| 5569 | \\n\",\n \"ham | \\n\",\n \"Pity, * was in mood for that. So...any other s... | \\n\",\n \"
| 5570 | \\n\",\n \"ham | \\n\",\n \"The guy did some bitching but I acted like i'd... | \\n\",\n \"
| 5571 | \\n\",\n \"ham | \\n\",\n \"Rofl. Its true to its name | \\n\",\n \"
5572 rows × 2 columns
\\n\",\n \"| \\n\",\n \" | Label | \\n\",\n \"Text | \\n\",\n \"
|---|---|---|
| 4307 | \\n\",\n \"0 | \\n\",\n \"Awww dat is sweet! We can think of something t... | \\n\",\n \"
| 4138 | \\n\",\n \"0 | \\n\",\n \"Just got to <#> | \\n\",\n \"
| 4831 | \\n\",\n \"0 | \\n\",\n \"The word \\\"Checkmate\\\" in chess comes from the P... | \\n\",\n \"
| 4461 | \\n\",\n \"0 | \\n\",\n \"This is wishing you a great day. Moji told me ... | \\n\",\n \"
| 5440 | \\n\",\n \"0 | \\n\",\n \"Thank you. do you generally date the brothas? | \\n\",\n \"
| ... | \\n\",\n \"... | \\n\",\n \"... | \\n\",\n \"
| 5537 | \\n\",\n \"1 | \\n\",\n \"Want explicit SEX in 30 secs? Ring 02073162414... | \\n\",\n \"
| 5540 | \\n\",\n \"1 | \\n\",\n \"ASKED 3MOBILE IF 0870 CHATLINES INCLU IN FREE ... | \\n\",\n \"
| 5547 | \\n\",\n \"1 | \\n\",\n \"Had your contract mobile 11 Mnths? Latest Moto... | \\n\",\n \"
| 5566 | \\n\",\n \"1 | \\n\",\n \"REMINDER FROM O2: To get 2.50 pounds free call... | \\n\",\n \"
| 5567 | \\n\",\n \"1 | \\n\",\n \"This is the 2nd time we have tried 2 contact u... | \\n\",\n \"
1494 rows × 2 columns
\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"74c3c463-8763-4cc0-9320-41c7eaad8ab7\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"74c3c463-8763-4cc0-9320-41c7eaad8ab7\",\n \"outputId\": \"b5b48439-32c8-4b37-cca2-c9dc8fa86563\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[50256]\\n\"\n ]\n }\n ],\n \"source\": [\n \"import tiktoken\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"print(tokenizer.encode(\\\"<|endoftext|>\\\", allowed_special={\\\"<|endoftext|>\\\"}))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"04f582ff-68bf-450e-bd87-5fb61afe431c\",\n \"metadata\": {\n \"id\": \"04f582ff-68bf-450e-bd87-5fb61afe431c\"\n },\n \"source\": [\n \"- The `SpamDataset` class below identifies the longest sequence in the training dataset and adds the padding token to the others to match that sequence length\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"d7791b52-af18-4ac4-afa9-b921068e383e\",\n \"metadata\": {\n \"id\": \"d7791b52-af18-4ac4-afa9-b921068e383e\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"from torch.utils.data import Dataset\\n\",\n \"\\n\",\n \"\\n\",\n \"class SpamDataset(Dataset):\\n\",\n \" def __init__(self, csv_file, tokenizer, max_length=None, pad_token_id=50256):\\n\",\n \" self.data = pd.read_csv(csv_file)\\n\",\n \"\\n\",\n \" # Pre-tokenize texts\\n\",\n \" self.encoded_texts = [\\n\",\n \" tokenizer.encode(text) for text in self.data[\\\"Text\\\"]\\n\",\n \" ]\\n\",\n \"\\n\",\n \" if max_length is None:\\n\",\n \" self.max_length = self._longest_encoded_length()\\n\",\n \" else:\\n\",\n \" self.max_length = max_length\\n\",\n \" # Truncate sequences if they are longer than max_length\\n\",\n \" self.encoded_texts = [\\n\",\n \" encoded_text[:self.max_length]\\n\",\n \" for encoded_text in self.encoded_texts\\n\",\n \" ]\\n\",\n \"\\n\",\n \" # Pad sequences to the longest sequence\\n\",\n \" self.encoded_texts = [\\n\",\n \" encoded_text + [pad_token_id] * (self.max_length - len(encoded_text))\\n\",\n \" for encoded_text in self.encoded_texts\\n\",\n \" ]\\n\",\n \"\\n\",\n \" def __getitem__(self, index):\\n\",\n \" encoded = self.encoded_texts[index]\\n\",\n \" label = self.data.iloc[index][\\\"Label\\\"]\\n\",\n \" return (\\n\",\n \" torch.tensor(encoded, dtype=torch.long),\\n\",\n \" torch.tensor(label, dtype=torch.long)\\n\",\n \" )\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.data)\\n\",\n \"\\n\",\n \" def _longest_encoded_length(self):\\n\",\n \" max_length = 0\\n\",\n \" for encoded_text in self.encoded_texts:\\n\",\n \" encoded_length = len(encoded_text)\\n\",\n \" if encoded_length > max_length:\\n\",\n \" max_length = encoded_length\\n\",\n \" return max_length\\n\",\n \" # Note: A more pythonic version to implement this method\\n\",\n \" # is the following, which is also used in the next chapter:\\n\",\n \" # return max(len(encoded_text) for encoded_text in self.encoded_texts)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"uzj85f8ou82h\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"uzj85f8ou82h\",\n \"outputId\": \"d08f1cf0-c24d-445f-a3f8-793532c3716f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"120\\n\"\n ]\n }\n ],\n \"source\": [\n \"train_dataset = SpamDataset(\\n\",\n \" csv_file=\\\"train.csv\\\",\\n\",\n \" max_length=None,\\n\",\n \" tokenizer=tokenizer\\n\",\n \")\\n\",\n \"\\n\",\n \"print(train_dataset.max_length)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"15bdd932-97eb-4b88-9cf9-d766ea4c3a60\",\n \"metadata\": {},\n \"source\": [\n \"- We also pad the validation and test set to the longest training sequence\\n\",\n \"- Note that validation and test set samples that are longer than the longest training example are being truncated via `encoded_text[:self.max_length]` in the `SpamDataset` code\\n\",\n \"- This behavior is entirely optional, and it would also work well if we set `max_length=None` in both the validation and test set cases\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"bb0c502d-a75e-4248-8ea0-196e2b00c61e\",\n \"metadata\": {\n \"id\": \"bb0c502d-a75e-4248-8ea0-196e2b00c61e\"\n },\n \"outputs\": [],\n \"source\": [\n \"val_dataset = SpamDataset(\\n\",\n \" csv_file=\\\"validation.csv\\\",\\n\",\n \" max_length=train_dataset.max_length,\\n\",\n \" tokenizer=tokenizer\\n\",\n \")\\n\",\n \"test_dataset = SpamDataset(\\n\",\n \" csv_file=\\\"test.csv\\\",\\n\",\n \" max_length=train_dataset.max_length,\\n\",\n \" tokenizer=tokenizer\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"20170d89-85a0-4844-9887-832f5d23432a\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we use the dataset to instantiate the data loaders, which is similar to creating the data loaders in previous chapters\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"64bcc349-205f-48f8-9655-95ff21f5e72f\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"74c3c463-8763-4cc0-9320-41c7eaad8ab7\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"74c3c463-8763-4cc0-9320-41c7eaad8ab7\",\n \"outputId\": \"b5b48439-32c8-4b37-cca2-c9dc8fa86563\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[50256]\\n\"\n ]\n }\n ],\n \"source\": [\n \"import tiktoken\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"print(tokenizer.encode(\\\"<|endoftext|>\\\", allowed_special={\\\"<|endoftext|>\\\"}))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"04f582ff-68bf-450e-bd87-5fb61afe431c\",\n \"metadata\": {\n \"id\": \"04f582ff-68bf-450e-bd87-5fb61afe431c\"\n },\n \"source\": [\n \"- The `SpamDataset` class below identifies the longest sequence in the training dataset and adds the padding token to the others to match that sequence length\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"d7791b52-af18-4ac4-afa9-b921068e383e\",\n \"metadata\": {\n \"id\": \"d7791b52-af18-4ac4-afa9-b921068e383e\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"from torch.utils.data import Dataset\\n\",\n \"\\n\",\n \"\\n\",\n \"class SpamDataset(Dataset):\\n\",\n \" def __init__(self, csv_file, tokenizer, max_length=None, pad_token_id=50256):\\n\",\n \" self.data = pd.read_csv(csv_file)\\n\",\n \"\\n\",\n \" # Pre-tokenize texts\\n\",\n \" self.encoded_texts = [\\n\",\n \" tokenizer.encode(text) for text in self.data[\\\"Text\\\"]\\n\",\n \" ]\\n\",\n \"\\n\",\n \" if max_length is None:\\n\",\n \" self.max_length = self._longest_encoded_length()\\n\",\n \" else:\\n\",\n \" self.max_length = max_length\\n\",\n \" # Truncate sequences if they are longer than max_length\\n\",\n \" self.encoded_texts = [\\n\",\n \" encoded_text[:self.max_length]\\n\",\n \" for encoded_text in self.encoded_texts\\n\",\n \" ]\\n\",\n \"\\n\",\n \" # Pad sequences to the longest sequence\\n\",\n \" self.encoded_texts = [\\n\",\n \" encoded_text + [pad_token_id] * (self.max_length - len(encoded_text))\\n\",\n \" for encoded_text in self.encoded_texts\\n\",\n \" ]\\n\",\n \"\\n\",\n \" def __getitem__(self, index):\\n\",\n \" encoded = self.encoded_texts[index]\\n\",\n \" label = self.data.iloc[index][\\\"Label\\\"]\\n\",\n \" return (\\n\",\n \" torch.tensor(encoded, dtype=torch.long),\\n\",\n \" torch.tensor(label, dtype=torch.long)\\n\",\n \" )\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.data)\\n\",\n \"\\n\",\n \" def _longest_encoded_length(self):\\n\",\n \" max_length = 0\\n\",\n \" for encoded_text in self.encoded_texts:\\n\",\n \" encoded_length = len(encoded_text)\\n\",\n \" if encoded_length > max_length:\\n\",\n \" max_length = encoded_length\\n\",\n \" return max_length\\n\",\n \" # Note: A more pythonic version to implement this method\\n\",\n \" # is the following, which is also used in the next chapter:\\n\",\n \" # return max(len(encoded_text) for encoded_text in self.encoded_texts)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"uzj85f8ou82h\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"uzj85f8ou82h\",\n \"outputId\": \"d08f1cf0-c24d-445f-a3f8-793532c3716f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"120\\n\"\n ]\n }\n ],\n \"source\": [\n \"train_dataset = SpamDataset(\\n\",\n \" csv_file=\\\"train.csv\\\",\\n\",\n \" max_length=None,\\n\",\n \" tokenizer=tokenizer\\n\",\n \")\\n\",\n \"\\n\",\n \"print(train_dataset.max_length)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"15bdd932-97eb-4b88-9cf9-d766ea4c3a60\",\n \"metadata\": {},\n \"source\": [\n \"- We also pad the validation and test set to the longest training sequence\\n\",\n \"- Note that validation and test set samples that are longer than the longest training example are being truncated via `encoded_text[:self.max_length]` in the `SpamDataset` code\\n\",\n \"- This behavior is entirely optional, and it would also work well if we set `max_length=None` in both the validation and test set cases\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"bb0c502d-a75e-4248-8ea0-196e2b00c61e\",\n \"metadata\": {\n \"id\": \"bb0c502d-a75e-4248-8ea0-196e2b00c61e\"\n },\n \"outputs\": [],\n \"source\": [\n \"val_dataset = SpamDataset(\\n\",\n \" csv_file=\\\"validation.csv\\\",\\n\",\n \" max_length=train_dataset.max_length,\\n\",\n \" tokenizer=tokenizer\\n\",\n \")\\n\",\n \"test_dataset = SpamDataset(\\n\",\n \" csv_file=\\\"test.csv\\\",\\n\",\n \" max_length=train_dataset.max_length,\\n\",\n \" tokenizer=tokenizer\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"20170d89-85a0-4844-9887-832f5d23432a\",\n \"metadata\": {},\n \"source\": [\n \"- Next, we use the dataset to instantiate the data loaders, which is similar to creating the data loaders in previous chapters\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"64bcc349-205f-48f8-9655-95ff21f5e72f\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"8681adc0-6f02-4e75-b01a-a6ab75d05542\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"8681adc0-6f02-4e75-b01a-a6ab75d05542\",\n \"outputId\": \"3266c410-4fdb-4a8c-a142-7f707e2525ab\"\n },\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"num_workers = 0\\n\",\n \"batch_size = 8\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_loader = DataLoader(\\n\",\n \" dataset=train_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=True,\\n\",\n \")\\n\",\n \"\\n\",\n \"val_loader = DataLoader(\\n\",\n \" dataset=val_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=False,\\n\",\n \")\\n\",\n \"\\n\",\n \"test_loader = DataLoader(\\n\",\n \" dataset=test_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=False,\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ab7335db-e0bb-4e27-80c5-eea11e593a57\",\n \"metadata\": {},\n \"source\": [\n \"- As a verification step, we iterate through the data loaders and ensure that the batches contain 8 training examples each, where each training example consists of 120 tokens\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"4dee6882-4c3a-4964-af15-fa31f86ad047\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"Input batch dimensions: torch.Size([8, 120])\\n\",\n \"Label batch dimensions torch.Size([8])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for input_batch, target_batch in train_loader:\\n\",\n \" pass\\n\",\n \"\\n\",\n \"print(\\\"Input batch dimensions:\\\", input_batch.shape)\\n\",\n \"print(\\\"Label batch dimensions\\\", target_batch.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5cdd7947-7039-49bf-8a5e-c0a2f4281ca1\",\n \"metadata\": {},\n \"source\": [\n \"- Lastly, let's print the total number of batches in each dataset\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"IZfw-TYD2zTj\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"IZfw-TYD2zTj\",\n \"outputId\": \"6934bbf2-9797-4fbe-d26b-1a246e18c2fb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"130 training batches\\n\",\n \"19 validation batches\\n\",\n \"38 test batches\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(f\\\"{len(train_loader)} training batches\\\")\\n\",\n \"print(f\\\"{len(val_loader)} validation batches\\\")\\n\",\n \"print(f\\\"{len(test_loader)} test batches\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d1c4f61a-5f5d-4b3b-97cf-151b617d1d6c\",\n \"metadata\": {\n \"id\": \"d1c4f61a-5f5d-4b3b-97cf-151b617d1d6c\"\n },\n \"source\": [\n \" \\n\",\n \"### 6.4 Initializing a model with pretrained weights\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"97e1af8b-8bd1-4b44-8b8b-dc031496e208\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we initialize the pretrained model we worked with in the previous chapter\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"8681adc0-6f02-4e75-b01a-a6ab75d05542\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"8681adc0-6f02-4e75-b01a-a6ab75d05542\",\n \"outputId\": \"3266c410-4fdb-4a8c-a142-7f707e2525ab\"\n },\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"num_workers = 0\\n\",\n \"batch_size = 8\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_loader = DataLoader(\\n\",\n \" dataset=train_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" shuffle=True,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=True,\\n\",\n \")\\n\",\n \"\\n\",\n \"val_loader = DataLoader(\\n\",\n \" dataset=val_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=False,\\n\",\n \")\\n\",\n \"\\n\",\n \"test_loader = DataLoader(\\n\",\n \" dataset=test_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" num_workers=num_workers,\\n\",\n \" drop_last=False,\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ab7335db-e0bb-4e27-80c5-eea11e593a57\",\n \"metadata\": {},\n \"source\": [\n \"- As a verification step, we iterate through the data loaders and ensure that the batches contain 8 training examples each, where each training example consists of 120 tokens\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"4dee6882-4c3a-4964-af15-fa31f86ad047\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"Input batch dimensions: torch.Size([8, 120])\\n\",\n \"Label batch dimensions torch.Size([8])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for input_batch, target_batch in train_loader:\\n\",\n \" pass\\n\",\n \"\\n\",\n \"print(\\\"Input batch dimensions:\\\", input_batch.shape)\\n\",\n \"print(\\\"Label batch dimensions\\\", target_batch.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5cdd7947-7039-49bf-8a5e-c0a2f4281ca1\",\n \"metadata\": {},\n \"source\": [\n \"- Lastly, let's print the total number of batches in each dataset\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"IZfw-TYD2zTj\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"IZfw-TYD2zTj\",\n \"outputId\": \"6934bbf2-9797-4fbe-d26b-1a246e18c2fb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"130 training batches\\n\",\n \"19 validation batches\\n\",\n \"38 test batches\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(f\\\"{len(train_loader)} training batches\\\")\\n\",\n \"print(f\\\"{len(val_loader)} validation batches\\\")\\n\",\n \"print(f\\\"{len(test_loader)} test batches\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d1c4f61a-5f5d-4b3b-97cf-151b617d1d6c\",\n \"metadata\": {\n \"id\": \"d1c4f61a-5f5d-4b3b-97cf-151b617d1d6c\"\n },\n \"source\": [\n \" \\n\",\n \"### 6.4 Initializing a model with pretrained weights\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"97e1af8b-8bd1-4b44-8b8b-dc031496e208\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we initialize the pretrained model we worked with in the previous chapter\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"2992d779-f9fb-4812-a117-553eb790a5a9\",\n \"metadata\": {\n \"id\": \"2992d779-f9fb-4812-a117-553eb790a5a9\"\n },\n \"outputs\": [],\n \"source\": [\n \"CHOOSE_MODEL = \\\"gpt2-small (124M)\\\"\\n\",\n \"INPUT_PROMPT = \\\"Every effort moves\\\"\\n\",\n \"\\n\",\n \"BASE_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"drop_rate\\\": 0.0, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": True # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\\n\",\n \"\\n\",\n \"assert train_dataset.max_length <= BASE_CONFIG[\\\"context_length\\\"], (\\n\",\n \" f\\\"Dataset length {train_dataset.max_length} exceeds model's context \\\"\\n\",\n \" f\\\"length {BASE_CONFIG['context_length']}. Reinitialize data sets with \\\"\\n\",\n \" f\\\"`max_length={BASE_CONFIG['context_length']}`\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"022a649a-44f5-466c-8a8e-326c063384f5\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"022a649a-44f5-466c-8a8e-326c063384f5\",\n \"outputId\": \"7091e401-8442-4f47-a1d9-ecb42a1ef930\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"File already exists and is up-to-date: gpt2/124M/checkpoint\\n\",\n \"File already exists and is up-to-date: gpt2/124M/encoder.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/hparams.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.data-00000-of-00001\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.index\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.meta\\n\",\n \"File already exists and is up-to-date: gpt2/124M/vocab.bpe\\n\"\n ]\n }\n ],\n \"source\": [\n \"from gpt_download import download_and_load_gpt2\\n\",\n \"from previous_chapters import GPTModel, load_weights_into_gpt\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"# from llms_from_scratch.ch05 import download_and_load_gpt2, load_weights_into_gpt\\n\",\n \"\\n\",\n \"model_size = CHOOSE_MODEL.split(\\\" \\\")[-1].lstrip(\\\"(\\\").rstrip(\\\")\\\")\\n\",\n \"settings, params = download_and_load_gpt2(model_size=model_size, models_dir=\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"load_weights_into_gpt(model, params)\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ab8e056c-abe0-415f-b34d-df686204259e\",\n \"metadata\": {},\n \"source\": [\n \"- To ensure that the model was loaded correctly, let's double-check that it generates coherent text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"d8ac25ff-74b1-4149-8dc5-4c429d464330\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Every effort moves you forward.\\n\",\n \"\\n\",\n \"The first step is to understand the importance of your work\\n\"\n ]\n }\n ],\n \"source\": [\n \"from previous_chapters import (\\n\",\n \" generate_text_simple,\\n\",\n \" text_to_token_ids,\\n\",\n \" token_ids_to_text\\n\",\n \")\\n\",\n \"\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch05 import (\\n\",\n \"# generate_text_simple,\\n\",\n \"# text_to_token_ids,\\n\",\n \"# token_ids_to_text\\n\",\n \"# )\\n\",\n \"\\n\",\n \"\\n\",\n \"text_1 = \\\"Every effort moves you\\\"\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(text_1, tokenizer),\\n\",\n \" max_new_tokens=15,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"69162550-6a02-4ece-8db1-06c71d61946f\",\n \"metadata\": {},\n \"source\": [\n \"- Before we finetune the model as a classifier, let's see if the model can perhaps already classify spam messages via prompting\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"94224aa9-c95a-4f8a-a420-76d01e3a800c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Is the following text 'spam'? Answer with 'yes' or 'no': 'You are a winner you have been specially selected to receive $1000 cash or a $2000 award.'\\n\",\n \"\\n\",\n \"The following text 'spam'? Answer with 'yes' or 'no': 'You are a winner\\n\"\n ]\n }\n ],\n \"source\": [\n \"text_2 = (\\n\",\n \" \\\"Is the following text 'spam'? Answer with 'yes' or 'no':\\\"\\n\",\n \" \\\" 'You are a winner you have been specially\\\"\\n\",\n \" \\\" selected to receive $1000 cash or a $2000 award.'\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(text_2, tokenizer),\\n\",\n \" max_new_tokens=23,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1ce39ed0-2c77-410d-8392-dd15d4b22016\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see, the model is not very good at following instructions\\n\",\n \"- This is expected, since it has only been pretrained and not instruction-finetuned (instruction finetuning will be covered in the next chapter)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4c9ae440-32f9-412f-96cf-fd52cc3e2522\",\n \"metadata\": {\n \"id\": \"4c9ae440-32f9-412f-96cf-fd52cc3e2522\"\n },\n \"source\": [\n \" \\n\",\n \"### 6.5 Adding a classification head\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d6e9d66f-76b2-40fc-9ec5-3f972a8db9c0\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"2992d779-f9fb-4812-a117-553eb790a5a9\",\n \"metadata\": {\n \"id\": \"2992d779-f9fb-4812-a117-553eb790a5a9\"\n },\n \"outputs\": [],\n \"source\": [\n \"CHOOSE_MODEL = \\\"gpt2-small (124M)\\\"\\n\",\n \"INPUT_PROMPT = \\\"Every effort moves\\\"\\n\",\n \"\\n\",\n \"BASE_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"drop_rate\\\": 0.0, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": True # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\\n\",\n \"\\n\",\n \"assert train_dataset.max_length <= BASE_CONFIG[\\\"context_length\\\"], (\\n\",\n \" f\\\"Dataset length {train_dataset.max_length} exceeds model's context \\\"\\n\",\n \" f\\\"length {BASE_CONFIG['context_length']}. Reinitialize data sets with \\\"\\n\",\n \" f\\\"`max_length={BASE_CONFIG['context_length']}`\\\"\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"022a649a-44f5-466c-8a8e-326c063384f5\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"022a649a-44f5-466c-8a8e-326c063384f5\",\n \"outputId\": \"7091e401-8442-4f47-a1d9-ecb42a1ef930\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"File already exists and is up-to-date: gpt2/124M/checkpoint\\n\",\n \"File already exists and is up-to-date: gpt2/124M/encoder.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/hparams.json\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.data-00000-of-00001\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.index\\n\",\n \"File already exists and is up-to-date: gpt2/124M/model.ckpt.meta\\n\",\n \"File already exists and is up-to-date: gpt2/124M/vocab.bpe\\n\"\n ]\n }\n ],\n \"source\": [\n \"from gpt_download import download_and_load_gpt2\\n\",\n \"from previous_chapters import GPTModel, load_weights_into_gpt\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"# from llms_from_scratch.ch05 import download_and_load_gpt2, load_weights_into_gpt\\n\",\n \"\\n\",\n \"model_size = CHOOSE_MODEL.split(\\\" \\\")[-1].lstrip(\\\"(\\\").rstrip(\\\")\\\")\\n\",\n \"settings, params = download_and_load_gpt2(model_size=model_size, models_dir=\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"load_weights_into_gpt(model, params)\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ab8e056c-abe0-415f-b34d-df686204259e\",\n \"metadata\": {},\n \"source\": [\n \"- To ensure that the model was loaded correctly, let's double-check that it generates coherent text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"d8ac25ff-74b1-4149-8dc5-4c429d464330\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Every effort moves you forward.\\n\",\n \"\\n\",\n \"The first step is to understand the importance of your work\\n\"\n ]\n }\n ],\n \"source\": [\n \"from previous_chapters import (\\n\",\n \" generate_text_simple,\\n\",\n \" text_to_token_ids,\\n\",\n \" token_ids_to_text\\n\",\n \")\\n\",\n \"\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch05 import (\\n\",\n \"# generate_text_simple,\\n\",\n \"# text_to_token_ids,\\n\",\n \"# token_ids_to_text\\n\",\n \"# )\\n\",\n \"\\n\",\n \"\\n\",\n \"text_1 = \\\"Every effort moves you\\\"\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(text_1, tokenizer),\\n\",\n \" max_new_tokens=15,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"69162550-6a02-4ece-8db1-06c71d61946f\",\n \"metadata\": {},\n \"source\": [\n \"- Before we finetune the model as a classifier, let's see if the model can perhaps already classify spam messages via prompting\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"94224aa9-c95a-4f8a-a420-76d01e3a800c\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Is the following text 'spam'? Answer with 'yes' or 'no': 'You are a winner you have been specially selected to receive $1000 cash or a $2000 award.'\\n\",\n \"\\n\",\n \"The following text 'spam'? Answer with 'yes' or 'no': 'You are a winner\\n\"\n ]\n }\n ],\n \"source\": [\n \"text_2 = (\\n\",\n \" \\\"Is the following text 'spam'? Answer with 'yes' or 'no':\\\"\\n\",\n \" \\\" 'You are a winner you have been specially\\\"\\n\",\n \" \\\" selected to receive $1000 cash or a $2000 award.'\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"token_ids = generate_text_simple(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(text_2, tokenizer),\\n\",\n \" max_new_tokens=23,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"]\\n\",\n \")\\n\",\n \"\\n\",\n \"print(token_ids_to_text(token_ids, tokenizer))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1ce39ed0-2c77-410d-8392-dd15d4b22016\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see, the model is not very good at following instructions\\n\",\n \"- This is expected, since it has only been pretrained and not instruction-finetuned (instruction finetuning will be covered in the next chapter)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4c9ae440-32f9-412f-96cf-fd52cc3e2522\",\n \"metadata\": {\n \"id\": \"4c9ae440-32f9-412f-96cf-fd52cc3e2522\"\n },\n \"source\": [\n \" \\n\",\n \"### 6.5 Adding a classification head\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d6e9d66f-76b2-40fc-9ec5-3f972a8db9c0\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"217bac05-78df-4412-bd80-612f8061c01d\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we are modifying the pretrained LLM to make it ready for classification finetuning\\n\",\n \"- Let's take a look at the model architecture first\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"b23aff91-6bd0-48da-88f6-353657e6c981\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"1d8f7a01-b7c0-48d4-b1e7-8c12cc7ad932\",\n \"outputId\": \"b6a5b9b5-a92f-498f-d7cb-b58dd99e4497\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"GPTModel(\\n\",\n \" (tok_emb): Embedding(50257, 768)\\n\",\n \" (pos_emb): Embedding(1024, 768)\\n\",\n \" (drop_emb): Dropout(p=0.0, inplace=False)\\n\",\n \" (trf_blocks): Sequential(\\n\",\n \" (0): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (1): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (2): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (3): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (4): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (5): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (6): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (7): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (8): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (9): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (10): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (11): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): LayerNorm()\\n\",\n \" (out_head): Linear(in_features=768, out_features=50257, bias=False)\\n\",\n \")\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(model)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3f640a76-dd00-4769-9bc8-1aed0cec330d\",\n \"metadata\": {},\n \"source\": [\n \"- Above, we can see the architecture we implemented in chapter 4 neatly laid out\\n\",\n \"- The goal is to replace and finetune the output layer\\n\",\n \"- To achieve this, we first freeze the model, meaning that we make all layers non-trainable\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"fkMWFl-0etea\",\n \"metadata\": {\n \"id\": \"fkMWFl-0etea\"\n },\n \"outputs\": [],\n \"source\": [\n \"for param in model.parameters():\\n\",\n \" param.requires_grad = False\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"72155f83-87d9-476a-a978-a15aa2d44147\",\n \"metadata\": {},\n \"source\": [\n \"- Then, we replace the output layer (`model.out_head`), which originally maps the layer inputs to 50,257 dimensions (the size of the vocabulary)\\n\",\n \"- Since we finetune the model for binary classification (predicting 2 classes, \\\"spam\\\" and \\\"not spam\\\"), we can replace the output layer as shown below, which will be trainable by default\\n\",\n \"- Note that we use `BASE_CONFIG[\\\"emb_dim\\\"]` (which is equal to 768 in the `\\\"gpt2-small (124M)\\\"` model) to keep the code below more general\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"7e759fa0-0f69-41be-b576-17e5f20e04cb\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"num_classes = 2\\n\",\n \"model.out_head = torch.nn.Linear(in_features=BASE_CONFIG[\\\"emb_dim\\\"], out_features=num_classes)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"30be5475-ae77-4f97-8f3e-dec462b1339f\",\n \"metadata\": {},\n \"source\": [\n \"- Technically, it's sufficient to only train the output layer\\n\",\n \"- However, as I found in [Finetuning Large Language Models](https://magazine.sebastianraschka.com/p/finetuning-large-language-models), experiments show that finetuning additional layers can noticeably improve the performance\\n\",\n \"- So, we are also making the last transformer block and the final `LayerNorm` module connecting the last transformer block to the output layer trainable\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0be7c1eb-c46c-4065-8525-eea1b8c66d10\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"217bac05-78df-4412-bd80-612f8061c01d\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we are modifying the pretrained LLM to make it ready for classification finetuning\\n\",\n \"- Let's take a look at the model architecture first\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"b23aff91-6bd0-48da-88f6-353657e6c981\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"1d8f7a01-b7c0-48d4-b1e7-8c12cc7ad932\",\n \"outputId\": \"b6a5b9b5-a92f-498f-d7cb-b58dd99e4497\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"GPTModel(\\n\",\n \" (tok_emb): Embedding(50257, 768)\\n\",\n \" (pos_emb): Embedding(1024, 768)\\n\",\n \" (drop_emb): Dropout(p=0.0, inplace=False)\\n\",\n \" (trf_blocks): Sequential(\\n\",\n \" (0): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (1): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (2): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (3): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (4): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (5): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (6): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (7): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (8): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (9): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (10): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (11): TransformerBlock(\\n\",\n \" (att): MultiHeadAttention(\\n\",\n \" (W_query): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_key): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (W_value): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (out_proj): Linear(in_features=768, out_features=768, bias=True)\\n\",\n \" (dropout): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" (ff): FeedForward(\\n\",\n \" (layers): Sequential(\\n\",\n \" (0): Linear(in_features=768, out_features=3072, bias=True)\\n\",\n \" (1): GELU()\\n\",\n \" (2): Linear(in_features=3072, out_features=768, bias=True)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (norm1): LayerNorm()\\n\",\n \" (norm2): LayerNorm()\\n\",\n \" (drop_resid): Dropout(p=0.0, inplace=False)\\n\",\n \" )\\n\",\n \" )\\n\",\n \" (final_norm): LayerNorm()\\n\",\n \" (out_head): Linear(in_features=768, out_features=50257, bias=False)\\n\",\n \")\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(model)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3f640a76-dd00-4769-9bc8-1aed0cec330d\",\n \"metadata\": {},\n \"source\": [\n \"- Above, we can see the architecture we implemented in chapter 4 neatly laid out\\n\",\n \"- The goal is to replace and finetune the output layer\\n\",\n \"- To achieve this, we first freeze the model, meaning that we make all layers non-trainable\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"fkMWFl-0etea\",\n \"metadata\": {\n \"id\": \"fkMWFl-0etea\"\n },\n \"outputs\": [],\n \"source\": [\n \"for param in model.parameters():\\n\",\n \" param.requires_grad = False\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"72155f83-87d9-476a-a978-a15aa2d44147\",\n \"metadata\": {},\n \"source\": [\n \"- Then, we replace the output layer (`model.out_head`), which originally maps the layer inputs to 50,257 dimensions (the size of the vocabulary)\\n\",\n \"- Since we finetune the model for binary classification (predicting 2 classes, \\\"spam\\\" and \\\"not spam\\\"), we can replace the output layer as shown below, which will be trainable by default\\n\",\n \"- Note that we use `BASE_CONFIG[\\\"emb_dim\\\"]` (which is equal to 768 in the `\\\"gpt2-small (124M)\\\"` model) to keep the code below more general\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"7e759fa0-0f69-41be-b576-17e5f20e04cb\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"num_classes = 2\\n\",\n \"model.out_head = torch.nn.Linear(in_features=BASE_CONFIG[\\\"emb_dim\\\"], out_features=num_classes)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"30be5475-ae77-4f97-8f3e-dec462b1339f\",\n \"metadata\": {},\n \"source\": [\n \"- Technically, it's sufficient to only train the output layer\\n\",\n \"- However, as I found in [Finetuning Large Language Models](https://magazine.sebastianraschka.com/p/finetuning-large-language-models), experiments show that finetuning additional layers can noticeably improve the performance\\n\",\n \"- So, we are also making the last transformer block and the final `LayerNorm` module connecting the last transformer block to the output layer trainable\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0be7c1eb-c46c-4065-8525-eea1b8c66d10\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"2aedc120-5ee3-48f6-92f2-ad9304ebcdc7\",\n \"metadata\": {\n \"id\": \"2aedc120-5ee3-48f6-92f2-ad9304ebcdc7\"\n },\n \"outputs\": [],\n \"source\": [\n \"for param in model.trf_blocks[-1].parameters():\\n\",\n \" param.requires_grad = True\\n\",\n \"\\n\",\n \"for param in model.final_norm.parameters():\\n\",\n \" param.requires_grad = True\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f012b899-8284-4d3a-97c0-8a48eb33ba2e\",\n \"metadata\": {},\n \"source\": [\n \"- We can still use this model similar to before in previous chapters\\n\",\n \"- For example, let's feed it some text input\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"f645c06a-7df6-451c-ad3f-eafb18224ebc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"f645c06a-7df6-451c-ad3f-eafb18224ebc\",\n \"outputId\": \"27e041b1-d731-48a1-cf60-f22d4565304e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Inputs: tensor([[5211, 345, 423, 640]])\\n\",\n \"Inputs dimensions: torch.Size([1, 4])\\n\"\n ]\n }\n ],\n \"source\": [\n \"inputs = tokenizer.encode(\\\"Do you have time\\\")\\n\",\n \"inputs = torch.tensor(inputs).unsqueeze(0)\\n\",\n \"print(\\\"Inputs:\\\", inputs)\\n\",\n \"print(\\\"Inputs dimensions:\\\", inputs.shape) # shape: (batch_size, num_tokens)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fbbf8481-772d-467b-851c-a62b86d0cb1b\",\n \"metadata\": {},\n \"source\": [\n \"- What's different compared to previous chapters is that it now has two output dimensions instead of 50,257\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"48dc84f1-85cc-4609-9cee-94ff539f00f4\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"48dc84f1-85cc-4609-9cee-94ff539f00f4\",\n \"outputId\": \"9cae7448-253d-4776-973e-0af190b06354\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Outputs:\\n\",\n \" tensor([[[-1.5854, 0.9904],\\n\",\n \" [-3.7235, 7.4548],\\n\",\n \" [-2.2661, 6.6049],\\n\",\n \" [-3.5983, 3.9902]]])\\n\",\n \"Outputs dimensions: torch.Size([1, 4, 2])\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" outputs = model(inputs)\\n\",\n \"\\n\",\n \"print(\\\"Outputs:\\\\n\\\", outputs)\\n\",\n \"print(\\\"Outputs dimensions:\\\", outputs.shape) # shape: (batch_size, num_tokens, num_classes)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"75430a01-ef9c-426a-aca0-664689c4f461\",\n \"metadata\": {},\n \"source\": [\n \"- As discussed in previous chapters, for each input token, there's one output vector\\n\",\n \"- Since we fed the model a text sample with 4 input tokens, the output consists of 4 2-dimensional output vectors above\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7df9144f-6817-4be4-8d4b-5d4dadfe4a9b\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"2aedc120-5ee3-48f6-92f2-ad9304ebcdc7\",\n \"metadata\": {\n \"id\": \"2aedc120-5ee3-48f6-92f2-ad9304ebcdc7\"\n },\n \"outputs\": [],\n \"source\": [\n \"for param in model.trf_blocks[-1].parameters():\\n\",\n \" param.requires_grad = True\\n\",\n \"\\n\",\n \"for param in model.final_norm.parameters():\\n\",\n \" param.requires_grad = True\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f012b899-8284-4d3a-97c0-8a48eb33ba2e\",\n \"metadata\": {},\n \"source\": [\n \"- We can still use this model similar to before in previous chapters\\n\",\n \"- For example, let's feed it some text input\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"f645c06a-7df6-451c-ad3f-eafb18224ebc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"f645c06a-7df6-451c-ad3f-eafb18224ebc\",\n \"outputId\": \"27e041b1-d731-48a1-cf60-f22d4565304e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Inputs: tensor([[5211, 345, 423, 640]])\\n\",\n \"Inputs dimensions: torch.Size([1, 4])\\n\"\n ]\n }\n ],\n \"source\": [\n \"inputs = tokenizer.encode(\\\"Do you have time\\\")\\n\",\n \"inputs = torch.tensor(inputs).unsqueeze(0)\\n\",\n \"print(\\\"Inputs:\\\", inputs)\\n\",\n \"print(\\\"Inputs dimensions:\\\", inputs.shape) # shape: (batch_size, num_tokens)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fbbf8481-772d-467b-851c-a62b86d0cb1b\",\n \"metadata\": {},\n \"source\": [\n \"- What's different compared to previous chapters is that it now has two output dimensions instead of 50,257\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"48dc84f1-85cc-4609-9cee-94ff539f00f4\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"48dc84f1-85cc-4609-9cee-94ff539f00f4\",\n \"outputId\": \"9cae7448-253d-4776-973e-0af190b06354\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Outputs:\\n\",\n \" tensor([[[-1.5854, 0.9904],\\n\",\n \" [-3.7235, 7.4548],\\n\",\n \" [-2.2661, 6.6049],\\n\",\n \" [-3.5983, 3.9902]]])\\n\",\n \"Outputs dimensions: torch.Size([1, 4, 2])\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" outputs = model(inputs)\\n\",\n \"\\n\",\n \"print(\\\"Outputs:\\\\n\\\", outputs)\\n\",\n \"print(\\\"Outputs dimensions:\\\", outputs.shape) # shape: (batch_size, num_tokens, num_classes)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"75430a01-ef9c-426a-aca0-664689c4f461\",\n \"metadata\": {},\n \"source\": [\n \"- As discussed in previous chapters, for each input token, there's one output vector\\n\",\n \"- Since we fed the model a text sample with 4 input tokens, the output consists of 4 2-dimensional output vectors above\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7df9144f-6817-4be4-8d4b-5d4dadfe4a9b\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e3bb8616-c791-4f5c-bac0-5302f663e46a\",\n \"metadata\": {},\n \"source\": [\n \"- In chapter 3, we discussed the attention mechanism, which connects each input token to each other input token\\n\",\n \"- In chapter 3, we then also introduced the causal attention mask that is used in GPT-like models; this causal mask lets a current token only attend to the current and previous token positions\\n\",\n \"- Based on this causal attention mechanism, the 4th (last) token contains the most information among all tokens because it's the only token that includes information about all other tokens\\n\",\n \"- Hence, we are particularly interested in this last token, which we will finetune for the spam classification task\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"49383a8c-41d5-4dab-98f1-238bca0c2ed7\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"49383a8c-41d5-4dab-98f1-238bca0c2ed7\",\n \"outputId\": \"e79eb155-fa1f-46ed-ff8c-d828c3a3fabd\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Last output token: tensor([[-3.5983, 3.9902]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Last output token:\\\", outputs[:, -1, :])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8df08ae0-e664-4670-b7c5-8a2280d9b41b\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e3bb8616-c791-4f5c-bac0-5302f663e46a\",\n \"metadata\": {},\n \"source\": [\n \"- In chapter 3, we discussed the attention mechanism, which connects each input token to each other input token\\n\",\n \"- In chapter 3, we then also introduced the causal attention mask that is used in GPT-like models; this causal mask lets a current token only attend to the current and previous token positions\\n\",\n \"- Based on this causal attention mechanism, the 4th (last) token contains the most information among all tokens because it's the only token that includes information about all other tokens\\n\",\n \"- Hence, we are particularly interested in this last token, which we will finetune for the spam classification task\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"49383a8c-41d5-4dab-98f1-238bca0c2ed7\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"49383a8c-41d5-4dab-98f1-238bca0c2ed7\",\n \"outputId\": \"e79eb155-fa1f-46ed-ff8c-d828c3a3fabd\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Last output token: tensor([[-3.5983, 3.9902]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Last output token:\\\", outputs[:, -1, :])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8df08ae0-e664-4670-b7c5-8a2280d9b41b\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"32aa4aef-e1e9-491b-9adf-5aa973e59b8c\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 6.6 Calculating the classification loss and accuracy\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"669e1fd1-ace8-44b4-b438-185ed0ba8b33\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"32aa4aef-e1e9-491b-9adf-5aa973e59b8c\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 6.6 Calculating the classification loss and accuracy\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"669e1fd1-ace8-44b4-b438-185ed0ba8b33\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7a7df4ee-0a34-4a4d-896d-affbbf81e0b3\",\n \"metadata\": {},\n \"source\": [\n \"- Before explaining the loss calculation, let's have a brief look at how the model outputs are turned into class labels\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"557996dd-4c6b-49c4-ab83-f60ef7e1d69e\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7a7df4ee-0a34-4a4d-896d-affbbf81e0b3\",\n \"metadata\": {},\n \"source\": [\n \"- Before explaining the loss calculation, let's have a brief look at how the model outputs are turned into class labels\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"557996dd-4c6b-49c4-ab83-f60ef7e1d69e\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 27,\n \"id\": \"c77faab1-3461-4118-866a-6171f2b89aa0\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Last output token: tensor([[-3.5983, 3.9902]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Last output token:\\\", outputs[:, -1, :])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7edd71fa-628a-4d00-b81d-6d8bcb2c341d\",\n \"metadata\": {},\n \"source\": [\n \"- Similar to chapter 5, we convert the outputs (logits) into probability scores via the `softmax` function and then obtain the index position of the largest probability value via the `argmax` function\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 28,\n \"id\": \"b81efa92-9be1-4b9e-8790-ce1fc7b17f01\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Class label: 1\\n\"\n ]\n }\n ],\n \"source\": [\n \"probas = torch.softmax(outputs[:, -1, :], dim=-1)\\n\",\n \"label = torch.argmax(probas)\\n\",\n \"print(\\\"Class label:\\\", label.item())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"414a6f02-307e-4147-a416-14d115bf8179\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the softmax function is optional here, as explained in chapter 5, because the largest outputs correspond to the largest probability scores\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"f9f9ad66-4969-4501-8239-3ccdb37e71a2\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Class label: 1\\n\"\n ]\n }\n ],\n \"source\": [\n \"logits = outputs[:, -1, :]\\n\",\n \"label = torch.argmax(logits)\\n\",\n \"print(\\\"Class label:\\\", label.item())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dcb20d3a-cbba-4ab1-8584-d94e16589505\",\n \"metadata\": {},\n \"source\": [\n \"- We can apply this concept to calculate the so-called classification accuracy, which computes the percentage of correct predictions in a given dataset\\n\",\n \"- To calculate the classification accuracy, we can apply the preceding `argmax`-based prediction code to all examples in a dataset and calculate the fraction of correct predictions as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"3ecf9572-aed0-4a21-9c3b-7f9f2aec5f23\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def calc_accuracy_loader(data_loader, model, device, num_batches=None):\\n\",\n \" model.eval()\\n\",\n \" correct_predictions, num_examples = 0, 0\\n\",\n \"\\n\",\n \" if num_batches is None:\\n\",\n \" num_batches = len(data_loader)\\n\",\n \" else:\\n\",\n \" num_batches = min(num_batches, len(data_loader))\\n\",\n \" for i, (input_batch, target_batch) in enumerate(data_loader):\\n\",\n \" if i < num_batches:\\n\",\n \" input_batch, target_batch = input_batch.to(device), target_batch.to(device)\\n\",\n \"\\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(input_batch)[:, -1, :] # Logits of last output token\\n\",\n \" predicted_labels = torch.argmax(logits, dim=-1)\\n\",\n \"\\n\",\n \" num_examples += predicted_labels.shape[0]\\n\",\n \" correct_predictions += (predicted_labels == target_batch).sum().item()\\n\",\n \" else:\\n\",\n \" break\\n\",\n \" return correct_predictions / num_examples\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7165fe46-a284-410b-957f-7524877d1a1a\",\n \"metadata\": {},\n \"source\": [\n \"- Let's apply the function to calculate the classification accuracies for the different datasets:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"390e5255-8427-488c-adef-e1c10ab4fb26\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Device: mps\\n\",\n \"Training accuracy: 46.25%\\n\",\n \"Validation accuracy: 45.00%\\n\",\n \"Test accuracy: 48.75%\\n\"\n ]\n }\n ],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"print(\\\"Device:\\\", device)\\n\",\n \"\\n\",\n \"model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes\\n\",\n \"\\n\",\n \"torch.manual_seed(123) # For reproducibility due to the shuffling in the training data loader\\n\",\n \"\\n\",\n \"train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=10)\\n\",\n \"val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=10)\\n\",\n \"test_accuracy = calc_accuracy_loader(test_loader, model, device, num_batches=10)\\n\",\n \"\\n\",\n \"print(f\\\"Training accuracy: {train_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Validation accuracy: {val_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Test accuracy: {test_accuracy*100:.2f}%\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"30345e2a-afed-4d22-9486-f4010f90a871\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see, the prediction accuracies are not very good, since we haven't finetuned the model, yet\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4f4a9d15-8fc7-48a2-8734-d92a2f265328\",\n \"metadata\": {},\n \"source\": [\n \"- Before we can start finetuning (/training), we first have to define the loss function we want to optimize during training\\n\",\n \"- The goal is to maximize the spam classification accuracy of the model; however, classification accuracy is not a differentiable function\\n\",\n \"- Hence, instead, we minimize the cross-entropy loss as a proxy for maximizing the classification accuracy (you can learn more about this topic in lecture 8 of my freely available [Introduction to Deep Learning](https://sebastianraschka.com/blog/2021/dl-course.html#l08-multinomial-logistic-regression--softmax-regression) class)\\n\",\n \"\\n\",\n \"- The `calc_loss_batch` function is the same here as in chapter 5, except that we are only interested in optimizing the last token `model(input_batch)[:, -1, :]` instead of all tokens `model(input_batch)`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"2f1e9547-806c-41a9-8aba-3b2822baabe4\",\n \"metadata\": {\n \"id\": \"2f1e9547-806c-41a9-8aba-3b2822baabe4\"\n },\n \"outputs\": [],\n \"source\": [\n \"def calc_loss_batch(input_batch, target_batch, model, device):\\n\",\n \" input_batch, target_batch = input_batch.to(device), target_batch.to(device)\\n\",\n \" logits = model(input_batch)[:, -1, :] # Logits of last output token\\n\",\n \" loss = torch.nn.functional.cross_entropy(logits, target_batch)\\n\",\n \" return loss\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a013aab9-f854-4866-ad55-5b8350adb50a\",\n \"metadata\": {},\n \"source\": [\n \"The `calc_loss_loader` is exactly the same as in chapter 5\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"b7b83e10-5720-45e7-ac5e-369417ca846b\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Same as in chapter 5\\n\",\n \"def calc_loss_loader(data_loader, model, device, num_batches=None):\\n\",\n \" total_loss = 0.\\n\",\n \" if len(data_loader) == 0:\\n\",\n \" return float(\\\"nan\\\")\\n\",\n \" elif num_batches is None:\\n\",\n \" num_batches = len(data_loader)\\n\",\n \" else:\\n\",\n \" # Reduce the number of batches to match the total number of batches in the data loader\\n\",\n \" # if num_batches exceeds the number of batches in the data loader\\n\",\n \" num_batches = min(num_batches, len(data_loader))\\n\",\n \" for i, (input_batch, target_batch) in enumerate(data_loader):\\n\",\n \" if i < num_batches:\\n\",\n \" loss = calc_loss_batch(input_batch, target_batch, model, device)\\n\",\n \" total_loss += loss.item()\\n\",\n \" else:\\n\",\n \" break\\n\",\n \" return total_loss / num_batches\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"56826ecd-6e74-40e6-b772-d3541e585067\",\n \"metadata\": {},\n \"source\": [\n \"- Using the `calc_closs_loader`, we compute the initial training, validation, and test set losses before we start training\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"f6f00e53-5beb-4e64-b147-f26fd481c6ff\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"f6f00e53-5beb-4e64-b147-f26fd481c6ff\",\n \"outputId\": \"49df8648-9e38-4314-854d-9faacd1b2e89\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training loss: 2.453\\n\",\n \"Validation loss: 2.583\\n\",\n \"Test loss: 2.322\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad(): # Disable gradient tracking for efficiency because we are not training, yet\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)\\n\",\n \" test_loss = calc_loss_loader(test_loader, model, device, num_batches=5)\\n\",\n \"\\n\",\n \"print(f\\\"Training loss: {train_loss:.3f}\\\")\\n\",\n \"print(f\\\"Validation loss: {val_loss:.3f}\\\")\\n\",\n \"print(f\\\"Test loss: {test_loss:.3f}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e04b980b-e583-4f62-84a0-4edafaf99d5d\",\n \"metadata\": {},\n \"source\": [\n \"- In the next section, we train the model to improve the loss values and consequently the classification accuracy\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"456ae0fd-6261-42b4-ab6a-d24289953083\",\n \"metadata\": {\n \"id\": \"456ae0fd-6261-42b4-ab6a-d24289953083\"\n },\n \"source\": [\n \" \\n\",\n \"### 6.7 Finetuning the model on supervised data\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6a9b099b-0829-4f72-8a2b-4363e3497026\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we define and use the training function to improve the classification accuracy of the model\\n\",\n \"- The `train_classifier_simple` function below is practically the same as the `train_model_simple` function we used for pretraining the model in chapter 5\\n\",\n \"- The only two differences are that we now \\n\",\n \" 1. track the number of training examples seen (`examples_seen`) instead of the number of tokens seen\\n\",\n \" 2. calculate the accuracy after each epoch instead of printing a sample text after each epoch\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"979b6222-1dc2-4530-9d01-b6b04fe3de12\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 27,\n \"id\": \"c77faab1-3461-4118-866a-6171f2b89aa0\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Last output token: tensor([[-3.5983, 3.9902]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Last output token:\\\", outputs[:, -1, :])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7edd71fa-628a-4d00-b81d-6d8bcb2c341d\",\n \"metadata\": {},\n \"source\": [\n \"- Similar to chapter 5, we convert the outputs (logits) into probability scores via the `softmax` function and then obtain the index position of the largest probability value via the `argmax` function\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 28,\n \"id\": \"b81efa92-9be1-4b9e-8790-ce1fc7b17f01\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Class label: 1\\n\"\n ]\n }\n ],\n \"source\": [\n \"probas = torch.softmax(outputs[:, -1, :], dim=-1)\\n\",\n \"label = torch.argmax(probas)\\n\",\n \"print(\\\"Class label:\\\", label.item())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"414a6f02-307e-4147-a416-14d115bf8179\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the softmax function is optional here, as explained in chapter 5, because the largest outputs correspond to the largest probability scores\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"f9f9ad66-4969-4501-8239-3ccdb37e71a2\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Class label: 1\\n\"\n ]\n }\n ],\n \"source\": [\n \"logits = outputs[:, -1, :]\\n\",\n \"label = torch.argmax(logits)\\n\",\n \"print(\\\"Class label:\\\", label.item())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dcb20d3a-cbba-4ab1-8584-d94e16589505\",\n \"metadata\": {},\n \"source\": [\n \"- We can apply this concept to calculate the so-called classification accuracy, which computes the percentage of correct predictions in a given dataset\\n\",\n \"- To calculate the classification accuracy, we can apply the preceding `argmax`-based prediction code to all examples in a dataset and calculate the fraction of correct predictions as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"3ecf9572-aed0-4a21-9c3b-7f9f2aec5f23\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def calc_accuracy_loader(data_loader, model, device, num_batches=None):\\n\",\n \" model.eval()\\n\",\n \" correct_predictions, num_examples = 0, 0\\n\",\n \"\\n\",\n \" if num_batches is None:\\n\",\n \" num_batches = len(data_loader)\\n\",\n \" else:\\n\",\n \" num_batches = min(num_batches, len(data_loader))\\n\",\n \" for i, (input_batch, target_batch) in enumerate(data_loader):\\n\",\n \" if i < num_batches:\\n\",\n \" input_batch, target_batch = input_batch.to(device), target_batch.to(device)\\n\",\n \"\\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(input_batch)[:, -1, :] # Logits of last output token\\n\",\n \" predicted_labels = torch.argmax(logits, dim=-1)\\n\",\n \"\\n\",\n \" num_examples += predicted_labels.shape[0]\\n\",\n \" correct_predictions += (predicted_labels == target_batch).sum().item()\\n\",\n \" else:\\n\",\n \" break\\n\",\n \" return correct_predictions / num_examples\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7165fe46-a284-410b-957f-7524877d1a1a\",\n \"metadata\": {},\n \"source\": [\n \"- Let's apply the function to calculate the classification accuracies for the different datasets:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"390e5255-8427-488c-adef-e1c10ab4fb26\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Device: mps\\n\",\n \"Training accuracy: 46.25%\\n\",\n \"Validation accuracy: 45.00%\\n\",\n \"Test accuracy: 48.75%\\n\"\n ]\n }\n ],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"print(\\\"Device:\\\", device)\\n\",\n \"\\n\",\n \"model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes\\n\",\n \"\\n\",\n \"torch.manual_seed(123) # For reproducibility due to the shuffling in the training data loader\\n\",\n \"\\n\",\n \"train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=10)\\n\",\n \"val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=10)\\n\",\n \"test_accuracy = calc_accuracy_loader(test_loader, model, device, num_batches=10)\\n\",\n \"\\n\",\n \"print(f\\\"Training accuracy: {train_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Validation accuracy: {val_accuracy*100:.2f}%\\\")\\n\",\n \"print(f\\\"Test accuracy: {test_accuracy*100:.2f}%\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"30345e2a-afed-4d22-9486-f4010f90a871\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see, the prediction accuracies are not very good, since we haven't finetuned the model, yet\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4f4a9d15-8fc7-48a2-8734-d92a2f265328\",\n \"metadata\": {},\n \"source\": [\n \"- Before we can start finetuning (/training), we first have to define the loss function we want to optimize during training\\n\",\n \"- The goal is to maximize the spam classification accuracy of the model; however, classification accuracy is not a differentiable function\\n\",\n \"- Hence, instead, we minimize the cross-entropy loss as a proxy for maximizing the classification accuracy (you can learn more about this topic in lecture 8 of my freely available [Introduction to Deep Learning](https://sebastianraschka.com/blog/2021/dl-course.html#l08-multinomial-logistic-regression--softmax-regression) class)\\n\",\n \"\\n\",\n \"- The `calc_loss_batch` function is the same here as in chapter 5, except that we are only interested in optimizing the last token `model(input_batch)[:, -1, :]` instead of all tokens `model(input_batch)`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"2f1e9547-806c-41a9-8aba-3b2822baabe4\",\n \"metadata\": {\n \"id\": \"2f1e9547-806c-41a9-8aba-3b2822baabe4\"\n },\n \"outputs\": [],\n \"source\": [\n \"def calc_loss_batch(input_batch, target_batch, model, device):\\n\",\n \" input_batch, target_batch = input_batch.to(device), target_batch.to(device)\\n\",\n \" logits = model(input_batch)[:, -1, :] # Logits of last output token\\n\",\n \" loss = torch.nn.functional.cross_entropy(logits, target_batch)\\n\",\n \" return loss\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"a013aab9-f854-4866-ad55-5b8350adb50a\",\n \"metadata\": {},\n \"source\": [\n \"The `calc_loss_loader` is exactly the same as in chapter 5\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"b7b83e10-5720-45e7-ac5e-369417ca846b\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Same as in chapter 5\\n\",\n \"def calc_loss_loader(data_loader, model, device, num_batches=None):\\n\",\n \" total_loss = 0.\\n\",\n \" if len(data_loader) == 0:\\n\",\n \" return float(\\\"nan\\\")\\n\",\n \" elif num_batches is None:\\n\",\n \" num_batches = len(data_loader)\\n\",\n \" else:\\n\",\n \" # Reduce the number of batches to match the total number of batches in the data loader\\n\",\n \" # if num_batches exceeds the number of batches in the data loader\\n\",\n \" num_batches = min(num_batches, len(data_loader))\\n\",\n \" for i, (input_batch, target_batch) in enumerate(data_loader):\\n\",\n \" if i < num_batches:\\n\",\n \" loss = calc_loss_batch(input_batch, target_batch, model, device)\\n\",\n \" total_loss += loss.item()\\n\",\n \" else:\\n\",\n \" break\\n\",\n \" return total_loss / num_batches\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"56826ecd-6e74-40e6-b772-d3541e585067\",\n \"metadata\": {},\n \"source\": [\n \"- Using the `calc_closs_loader`, we compute the initial training, validation, and test set losses before we start training\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"f6f00e53-5beb-4e64-b147-f26fd481c6ff\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"f6f00e53-5beb-4e64-b147-f26fd481c6ff\",\n \"outputId\": \"49df8648-9e38-4314-854d-9faacd1b2e89\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training loss: 2.453\\n\",\n \"Validation loss: 2.583\\n\",\n \"Test loss: 2.322\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad(): # Disable gradient tracking for efficiency because we are not training, yet\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)\\n\",\n \" test_loss = calc_loss_loader(test_loader, model, device, num_batches=5)\\n\",\n \"\\n\",\n \"print(f\\\"Training loss: {train_loss:.3f}\\\")\\n\",\n \"print(f\\\"Validation loss: {val_loss:.3f}\\\")\\n\",\n \"print(f\\\"Test loss: {test_loss:.3f}\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e04b980b-e583-4f62-84a0-4edafaf99d5d\",\n \"metadata\": {},\n \"source\": [\n \"- In the next section, we train the model to improve the loss values and consequently the classification accuracy\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"456ae0fd-6261-42b4-ab6a-d24289953083\",\n \"metadata\": {\n \"id\": \"456ae0fd-6261-42b4-ab6a-d24289953083\"\n },\n \"source\": [\n \" \\n\",\n \"### 6.7 Finetuning the model on supervised data\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6a9b099b-0829-4f72-8a2b-4363e3497026\",\n \"metadata\": {},\n \"source\": [\n \"- In this section, we define and use the training function to improve the classification accuracy of the model\\n\",\n \"- The `train_classifier_simple` function below is practically the same as the `train_model_simple` function we used for pretraining the model in chapter 5\\n\",\n \"- The only two differences are that we now \\n\",\n \" 1. track the number of training examples seen (`examples_seen`) instead of the number of tokens seen\\n\",\n \" 2. calculate the accuracy after each epoch instead of printing a sample text after each epoch\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"979b6222-1dc2-4530-9d01-b6b04fe3de12\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"Csbr60to50FL\",\n \"metadata\": {\n \"id\": \"Csbr60to50FL\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Overall the same as `train_model_simple` in chapter 5\\n\",\n \"def train_classifier_simple(model, train_loader, val_loader, optimizer, device, num_epochs,\\n\",\n \" eval_freq, eval_iter):\\n\",\n \" # Initialize lists to track losses and examples seen\\n\",\n \" train_losses, val_losses, train_accs, val_accs = [], [], [], []\\n\",\n \" examples_seen, global_step = 0, -1\\n\",\n \"\\n\",\n \" # Main training loop\\n\",\n \" for epoch in range(num_epochs):\\n\",\n \" model.train() # Set model to training mode\\n\",\n \"\\n\",\n \" for input_batch, target_batch in train_loader:\\n\",\n \" optimizer.zero_grad() # Reset loss gradients from previous batch iteration\\n\",\n \" loss = calc_loss_batch(input_batch, target_batch, model, device)\\n\",\n \" loss.backward() # Calculate loss gradients\\n\",\n \" optimizer.step() # Update model weights using loss gradients\\n\",\n \" examples_seen += input_batch.shape[0] # New: track examples instead of tokens\\n\",\n \" global_step += 1\\n\",\n \"\\n\",\n \" # Optional evaluation step\\n\",\n \" if global_step % eval_freq == 0:\\n\",\n \" train_loss, val_loss = evaluate_model(\\n\",\n \" model, train_loader, val_loader, device, eval_iter)\\n\",\n \" train_losses.append(train_loss)\\n\",\n \" val_losses.append(val_loss)\\n\",\n \" print(f\\\"Ep {epoch+1} (Step {global_step:06d}): \\\"\\n\",\n \" f\\\"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}\\\")\\n\",\n \"\\n\",\n \" # Calculate accuracy after each epoch\\n\",\n \" train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=eval_iter)\\n\",\n \" val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=eval_iter)\\n\",\n \" print(f\\\"Training accuracy: {train_accuracy*100:.2f}% | \\\", end=\\\"\\\")\\n\",\n \" print(f\\\"Validation accuracy: {val_accuracy*100:.2f}%\\\")\\n\",\n \" train_accs.append(train_accuracy)\\n\",\n \" val_accs.append(val_accuracy)\\n\",\n \"\\n\",\n \" return train_losses, val_losses, train_accs, val_accs, examples_seen\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9624cb30-3e3a-45be-b006-c00475b58ae8\",\n \"metadata\": {},\n \"source\": [\n \"- The `evaluate_model` function used in the `train_classifier_simple` is the same as the one we used in chapter 5\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"bcc7bc04-6aa6-4516-a147-460e2f466eab\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Same as chapter 5\\n\",\n \"def evaluate_model(model, train_loader, val_loader, device, eval_iter):\\n\",\n \" model.eval()\\n\",\n \" with torch.no_grad():\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\\n\",\n \" model.train()\\n\",\n \" return train_loss, val_loss\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e807bfe9-364d-46b2-9e25-3b000c3ef6f9\",\n \"metadata\": {},\n \"source\": [\n \"- The training takes about 5 minutes on a M3 MacBook Air laptop computer and less than half a minute on a V100 or A100 GPU\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"X7kU3aAj7vTJ\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"X7kU3aAj7vTJ\",\n \"outputId\": \"504a033e-2bf8-41b5-a037-468309845513\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ep 1 (Step 000000): Train loss 2.153, Val loss 2.392\\n\",\n \"Ep 1 (Step 000050): Train loss 0.617, Val loss 0.637\\n\",\n \"Ep 1 (Step 000100): Train loss 0.523, Val loss 0.557\\n\",\n \"Training accuracy: 70.00% | Validation accuracy: 72.50%\\n\",\n \"Ep 2 (Step 000150): Train loss 0.561, Val loss 0.489\\n\",\n \"Ep 2 (Step 000200): Train loss 0.419, Val loss 0.397\\n\",\n \"Ep 2 (Step 000250): Train loss 0.409, Val loss 0.353\\n\",\n \"Training accuracy: 82.50% | Validation accuracy: 85.00%\\n\",\n \"Ep 3 (Step 000300): Train loss 0.333, Val loss 0.320\\n\",\n \"Ep 3 (Step 000350): Train loss 0.340, Val loss 0.306\\n\",\n \"Training accuracy: 90.00% | Validation accuracy: 90.00%\\n\",\n \"Ep 4 (Step 000400): Train loss 0.136, Val loss 0.200\\n\",\n \"Ep 4 (Step 000450): Train loss 0.153, Val loss 0.132\\n\",\n \"Ep 4 (Step 000500): Train loss 0.222, Val loss 0.137\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 97.50%\\n\",\n \"Ep 5 (Step 000550): Train loss 0.207, Val loss 0.143\\n\",\n \"Ep 5 (Step 000600): Train loss 0.083, Val loss 0.074\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 97.50%\\n\",\n \"Training completed in 1.07 minutes.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import time\\n\",\n \"\\n\",\n \"start_time = time.time()\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5, weight_decay=0.1)\\n\",\n \"\\n\",\n \"num_epochs = 5\\n\",\n \"train_losses, val_losses, train_accs, val_accs, examples_seen = train_classifier_simple(\\n\",\n \" model, train_loader, val_loader, optimizer, device,\\n\",\n \" num_epochs=num_epochs, eval_freq=50, eval_iter=5,\\n\",\n \")\\n\",\n \"\\n\",\n \"end_time = time.time()\\n\",\n \"execution_time_minutes = (end_time - start_time) / 60\\n\",\n \"print(f\\\"Training completed in {execution_time_minutes:.2f} minutes.\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1261bf90-3ce7-4591-895a-044a05538f30\",\n \"metadata\": {},\n \"source\": [\n \"- Similar to chapter 5, we use matplotlib to plot the loss function for the training and validation set\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"cURgnDqdCeka\",\n \"metadata\": {\n \"id\": \"cURgnDqdCeka\"\n },\n \"outputs\": [],\n \"source\": [\n \"import matplotlib.pyplot as plt\\n\",\n \"\\n\",\n \"def plot_values(epochs_seen, examples_seen, train_values, val_values, label=\\\"loss\\\"):\\n\",\n \" fig, ax1 = plt.subplots(figsize=(5, 3))\\n\",\n \"\\n\",\n \" # Plot training and validation loss against epochs\\n\",\n \" ax1.plot(epochs_seen, train_values, label=f\\\"Training {label}\\\")\\n\",\n \" ax1.plot(epochs_seen, val_values, linestyle=\\\"-.\\\", label=f\\\"Validation {label}\\\")\\n\",\n \" ax1.set_xlabel(\\\"Epochs\\\")\\n\",\n \" ax1.set_ylabel(label.capitalize())\\n\",\n \" ax1.legend()\\n\",\n \"\\n\",\n \" # Create a second x-axis for examples seen\\n\",\n \" ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\\n\",\n \" ax2.plot(examples_seen, train_values, alpha=0) # Invisible plot for aligning ticks\\n\",\n \" ax2.set_xlabel(\\\"Examples seen\\\")\\n\",\n \"\\n\",\n \" fig.tight_layout() # Adjust layout to make room\\n\",\n \" plt.savefig(f\\\"{label}-plot.pdf\\\")\\n\",\n \" plt.show()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"OIqRt466DiGk\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 307\n },\n \"id\": \"OIqRt466DiGk\",\n \"outputId\": \"b16987cf-0001-4652-ddaf-02f7cffc34db\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAeoAAAEiCAYAAAA21pHjAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAAToJJREFUeJzt3Qd4U/X6B/Bv0z1pS3cpFGgpe+8hCMhQUdwXvYJcxxXRi6LXKw4Q+StuUEEQvYobEAW8Ciiy95BhGWVTWqALSume5/+8vzRpUlroTtJ+P89znuScnCQnp2ne85uvnaZpGoiIiMgq6Sx9AERERFQ+BmoiIiIrxkBNRERkxRioiYiIrBgDNRERkRVjoCYiIrJiDNRERERWjIGaiIjIijFQExERWTEGaiKqkEGDBuHpp5/m2SKqYwzURHXkoYcegp2d3VXLiBEj+DcgonI5lP8QEdU0CcpffPGF2TZnZ2eeaCIqF0vURHVIgnJQUJDZ4uPjox7bsGEDnJycsHnzZuP+b7/9NgICApCYmKjWV69ejf79+8Pb2xuNGzfGrbfeipMnTxr3P3PmjCqlL1myBAMGDICrqyt69OiBY8eOYffu3ejevTs8PDwwcuRIJCcnm5X2R48ejenTp8Pf3x9eXl54/PHHkZeXV+5nyc3NxXPPPYfQ0FC4u7ujV69e6jMYxMbGYtSoUerzyePt2rXDypUry329jz/+GJGRkXBxcUFgYCDuvvtu42NFRUWYOXMmmjdvrj5Tp06dsHTpUrPnHzx4UH0u+Xzy/AcffBApKSlmVff/+te/8Pzzz8PX11ed+1dffbVCfzciS2KgJrKyNmAJMGlpadi3bx9eeeUVfPbZZyrwiMzMTEyePBl79uzB2rVrodPpcMcdd6hAZmratGl4+eWXsXfvXjg4OOD+++9XAeqDDz5QFwInTpzA1KlTzZ4jr3fkyBEVbL///nv89NNPKnCX58knn8T27duxaNEi/PXXX7jnnntUjcHx48fV4xMnTlTBfNOmTYiOjsZbb72lgmhZ5PNIEH3ttddw9OhRdUFyww03GB+XIP3VV19h/vz5OHToEJ555hn8/e9/x8aNG9Xjly9fxuDBg9GlSxf1WvJ8ubi59957zd7nyy+/VBcNO3fuVBdB8n5r1qyp9N+KqE5Jmksiqn3jxo3T7O3tNXd3d7Pl9ddfN+6Tm5urde7cWbv33nu1tm3bao8++ug1XzM5OVnS1GrR0dFq/fTp02r9s88+M+7z/fffq21r1641bps5c6YWFRVldmy+vr5aZmamcdu8efM0Dw8PrbCwUK0PHDhQmzRpkrofGxurPsu5c+fMjmfIkCHalClT1P0OHTpor776aoXOzY8//qh5eXlpV65cueqxnJwczc3NTdu2bZvZ9ocfflgbM2aMuj9jxgxt2LBhZo/HxcWpz3306FHj8ffv399snx49emj/+c9/KnSMRJbCNmqiOnTjjTdi3rx5ZtukGtZAqr6//fZbdOzYEc2aNcOsWbPM9pXSqpSEpUQo1bqGkvTZs2fRvn17437yfANDabxDhw5m25KSksxeW6qT3dzcjOt9+vRBRkYG4uLi1LGYkhJyYWEhWrVqZbZdStBSJS+khDxhwgT8/vvvGDp0KO666y6z4zJ10003qfdo0aKFKpXLIjUFcjxS+s/KylL7mJJqeSlBiwMHDmD9+vVlltilacBwnKXfPzg4+KrzQGRtGKiJ6pBUu0ZERFxzn23btqnbS5cuqUWeYyBtvhLQPv30U4SEhKhALQG6dFuyo6Oj8b60WZe1rXR1eWVIALe3t8eff/6pbk0ZguUjjzyC4cOH49dff1XBWqqv33vvPTz11FNXvZ6np6eqppdqd9lXLkak/Vja1eW9hLyOtIeX1RFP9pFzI9XrpUkwLuu81MR5IKoLDNREVkRKf9L+KoF48eLFGDduHP744w/VFn3x4kXVfiuPSUcxsWXLlhp7bymVZmdnq85aYseOHSrohoWFXbWvlGSlRC2lUcOxlEWeK53SZJkyZYo69rICtZC2dCl5yyJt7NJhbt26daokLQFZag0GDhxY5nO7du2KH3/8EeHh4ep1iOoTfqOJ6pBUDSckJJj/Ezo4wM/PTwU+6SAlpdDx48er6l+prpZS6L///W/Ve1qqlRcsWKBKiRK4XnjhhRo7NimVP/zww6oTmvQel2ApHcbkIqE0qUp+4IEHMHbsWHV8ErilF7l0SJPq5VtuuUV1jJNe2LJvamqqqppu06ZNme/9yy+/4NSpU6oDmXxO6R0uJd2oqChV2pbe5XIBI9uk17t0ttu6davqnS4XM9JxTS4CxowZY+zVLVXm0tFNOuOVLvUT2RIGaqI6JL2RTatihQSjmJgYvP7662pIkwQtIftJUJbgM2zYMNWGLIFH2n6lulue9+GHH6re4jVhyJAhaniUBEu5oJD3vdbwJRkP/n//93949tlnce7cOXWx0bt3bzVkTMiFhwTQ+Ph4FVDlwqN0m7uBlJ6ll7m8X05OjjoO6XkuQ7rEjBkz1LAxqT6XgC77Syn6xRdfVI9LM4AE7v/85z/qXMnxSxOBvGdZFxpEtsROepRZ+iCIyLJkHLUMcVq+fDn/FERWhpeaREREVoyBmoiIyIqx6puIiMiKsURNRERkxRioiYiIrBgDNRERkRVjoK6GuXPnqpmQJC2fpPjbtWsX6ivJgCRTNMp4VZl2sfQwHhnlJ9M+ythfmdlKZpcyZFEykOkwZZIMGVMr42Blcg3D9JAGkoVJZrqScyqzWkmGI1sg43slnaRMziFpKSVlpMwiZkrGB8u4Ypm0RGb8krmvDekrDWQSE5ksROa4lteRiU4KCgrM9pFpNmUMsczWJdORLly4ELZA5jiXyVDk7y+LzCW+atUq4+MN/fyU5c0331T/bzJ5jAHPE9R4ezkvpkvr1q3r7zmyWDoQG7do0SLNyclJ+/zzz7VDhw6pLEfe3t5aYmKiVh+tXLlSe+mll7SffvpJZSRatmyZ2eNvvvmm1qhRI2358uXagQMHtNtuu01r3ry5lp2dbdxnxIgRWqdOnbQdO3Zomzdv1iIiIozZj0RaWpoWGBioPfDAA9rBgwdV1idXV1ftk08+0azd8OHDtS+++EId9/79+7Wbb75Za9q0qZaRkWHc5/HHH9fCwsJUFqs9e/ZovXv31vr27Wt8vKCgQGvfvr02dOhQbd++feqc+/n5GbNRiVOnTqlMUpMnT9YOHz6sffTRRyqL1erVqzVr9/PPP2u//vqrduzYMZXR6sUXX9QcHR3VORMN/fyUtmvXLi08PFzr2LGjMWuZ4HnStGnTpmnt2rXTLly4YFwkk1x9PUcM1FXUs2dPbeLEicZ1SQUYEhKi0gfWd6UDdVFRkRYUFKS98847xm2XL1/WnJ2dVbAV8kWX5+3evdu4z6pVqzQ7OztjqsSPP/5Y8/HxUakeDSQFoWk6RluRlJSkPu/GjRuN50OC0g8//GDc58iRI2qf7du3q3X5sdDpdFpCQoJZqklJ/2g4J88//7z6gTJ13333qQsFWyR/b0nJyfNjLj09XYuMjNTWrFljll6U56kkUMtFf1nq4zli1XcV50SWrEFSvWsg0xTK+vbt29HQnD59Ws1fbXo+GjVqpJoDDOdDbqW6u3v37sZ9ZH85b5Ky0bCPTF8pqR4NZN5rqUKWuaJticxFbZrCUr4v+fn5ZudIquqaNm1qdo5kbm9DWkrD579y5QoOHTpk3Mf0NQz72Nr3TqYXlelQMzMzVRU4z485qbaVatnSf2uepxLStCZNcZIaVZrUpCq7vp4jBuoqkDzA8kNj+kcWsl464UJDYPjM1zofcivtQKWTUUggM92nrNcwfQ9bIIkjpE2xX79+xhzRcvxyASIXK9c6R9f7/OXtIz8wkvnK2kkea2kzlDY/yai1bNkytG3blufHhFzASMpP6fdQGr9HelIIkPZimTtf+j5IYUH6tqSnp9fLc8SkHES1UBo6ePBgjaagrC8kkcj+/ftVjcPSpUtV5quNGzda+rCsRlxcHCZNmoQ1a9aoDpVUNsnKZiAdFCVwSxKWJUuWGNO01icsUVeBZAmStHmlexHKelBQEBoaw2e+1vmQW8ldbEp6WEpPcNN9ynoN0/ewdpIWUrJfSUrHJk2aGLfL8UuTiSS+uNY5ut7nL28f6UVtCz9QUtKR3rPdunVTJUbJCPbBBx/w/BSTalv5P5GexlLjJItcyEiWNLkvJTp+j64mpWdJpyqpTevj/xoDdRV/bOSHRnLvmlZ3yrq0tzU0zZs3V19q0/Mh1UPS9mw4H3Ir/zjyQ2Swbt06dd7katiwjwwDk/YlAylZSClMchRbM+ljJ0FaqnLlc8k5MSXfF0dHR7NzJG3v0q5meo6katj0gkY+v/wwSPWwYR/T1zDsY6vfO/n7S0pKnp+SVKPyHZBaB8Mi/TqkDdZwn9+jq8kwz5MnT6rhofXyu1Tn3dfq0fAs6dW8cOFC1aP5scceU8OzTHsR1ifSC1WGMcgiX5v3339f3Y+NjTUOz5LPv2LFCu2vv/7Sbr/99jKHZ3Xp0kXbuXOntmXLFtWr1XR4lvTWlOFZDz74oBqyI+dYhkfYwvCsCRMmqOFpGzZsMBsykpWVZTZkRIZsrVu3Tg0Z6dOnj1pKDxkZNmyYGuIlw0D8/f3LHDLy73//W/VknTt3rs0MP3rhhRdUL/jTp0+r74isS6//33//XT3e0M9PeUx7fQueJ0179tln1f+afJe2bt2qhlnJ8CoZbVEfzxEDdTXIuDr5Msh4ahmuJeOD66v169erAF16GTdunHGI1iuvvKICrVzADBkyRI2VNXXx4kUVmD08PNQwiPHjx6sLAFMyBrt///7qNUJDQ9UFgC0o69zIImOrDeSi5YknnlBDkuQH4I477lDB3NSZM2e0kSNHqvHj8sMjP0j5+flX/S06d+6svnctWrQwew9r9o9//ENr1qyZOm75UZTviCFIi4Z+fioaqHmeNDVMKjg4WP2N5XdC1k+cOFFvzxGzZxEREVkxtlETERFZMQZqIiIiK8ZATUREZMUYqImIiKwYAzUREZEVY6AmIiKyYgzU1SAzKkkCc7klnid+l2oX/994jhrq98ii46hlrt+ffvoJMTExau7Uvn374q233lJTRpZHMqaMHz/ebJtk4snJyUFdk2kyJZ2jJBiQqeeI54nfJf6/WRJ/k+rnObJoiVomm5dMQzt27FBzqMocz8OGDVM5aq9FTu6FCxeMS2xsbJ0dMxERUYNJcym5REuXliVnsSRuuOGGG8p9np2dnc1kUyIiIqo3+ailKkL4+vpeN1OK5B6VzDuSDu6NN95Au3btKvQeklpx3759Kl2cTle9CgVJUi7OnTunqlOI54nfpdrD/zeeo/r0PZL4JWkzu3TpolKYXovVzPUtB33bbbepVIhbtmwpd7/t27fj+PHjKlm4BPZ3331XpUY8dOiQWf5fA+kwYNppQErrgwcPrrXPQUREVFG7du1Cjx49bCNQT5gwAatWrVJBuqyAWx5p127Tpg3GjBmDGTNmXPW49O6bPn16mSdHcpcSERHVNelf1bNnT9XHqmnTptYfqJ988kmsWLFClYybN29e6effc889qurg+++/v26JWqo7JDF4XFxcpS4IiIiIakp8fDzCwsIqFIss2utbrhEkSC9btgzr1q2rUpAuLCxEdHR0uaVjGbolvcQNi6enZw0cORERUQPoTCZDs7777jtVmpYAmpCQoLbLGDcZVy3Gjh2L0NBQNeZavPbaa+jduzciIiJUe/Y777yjqg4eeeQRS34UIiKi+heo582bp24HDRpktv2LL77AQw89pO6fPXvWrHd2amoqHn30URXUfXx80K1bN2zbtk1VZxMREdU3VtFGba3tAkTU8EhzmnRSJaoOR0dH2Nvb10gssqpx1EREliJlFqmpkyY1oprg7e2tJueSSbqqg4G6OrIvA2d3AI2aAEHtq/VSRGRZhiAtsyO6ublV+8eVGvZFX1ZWFpKSktR6dYcCM1BXx7r/A3Z/CvR6HBj5VrVeiogsW91tCNKNGzfmn4KqzdAhWoK1fK+uVQ1+PUxzWR3h/fS3Z7ZW62WIyLIMbdJSkiaqKYbvU3X7PDBQV0ez4kCdeBDIulStlyIiy2N1N1nj94mBujo8AgC/VtIiAZzdXiN/ECIiIlMM1NUV3l9/y+pvIqonwsPDMXv27Arvv2HDBlV6rO0e8wsXLlQ9qRsaBuqaqv4+s7n6fw0iokqQ4HitRZISVcXu3bvx2GOPVXj/vn37qiQTMqsk1Tz2+q6pEnVCtH64lmvDu9ojIsuQ4GiwePFiTJ06FUePHjVu8/DwMBsyJL3br5f7WPj7+1fqOJycnNR4YaodLFFXl2cQ0DiiuJ16R438UYiIKkKCo2GR0qyUog3rMTExKoeCpA+WqZYlQZGkET558iRuv/12BAYGqkAuuZD/+OOPa1Z9y+t+9tlnuOOOO1RP5sjISPz888/lVn0bqqh/++03lYZY3mfEiBFmFxYFBQX417/+pfaTIXH/+c9/MG7cOIwePbrSU1G3bNlSXSxERUXh66+/Nrs4kVoFSSMpnz8kJES9p8HHH3+sPouLi4s6H3fffbdVfvEYqGsCq7+J6uekFXkFFllqcmbnF154AW+++SaOHDmCjh07IiMjAzfffDPWrl2Lffv2qQA6atQolVfhWqZPn457770Xf/31l3r+Aw88gEuXyh/tIhN+vPvuuypwSgpjef3nnnvO+Phbb72Fb7/9VuV22Lp1K65cuYLly5dX6rMtW7YMkyZNwrPPPouDBw/in//8J8aPH4/169erx3/88UfMmjULn3zyCY4fP65ev0OHDuqxPXv2qKAtiZ6kFmL16tW44YYbYI1Y9V1T1d97vwRiOZ6aqL7Izi9E26m/WeS9D782HG5ONfPzLIHopptuMq77+vqiU6dOxvUZM2aogCclZEk7XB5JlDRmzBh1/4033sCHH36IXbt2qUBfFhk7PH/+fFXaFfLaciwGH330EaZMmaJK6WLOnDlYuXJlpT7bu+++q47riSeeUOuTJ0/Gjh071PYbb7xRXRxI7cLQoUPV3NtSsu7Zs6faVx5zd3fHrbfeqmoemjVrhi5dusAasURdkyXqCweAnLQaeUkioprQvXt3s3UpUUvJVqqkpdpZqqWltH29ErWUxg0kwHl5eRmnyCyLVJEbgrRhGk3D/mlpaUhMTDQGTSEzd0kVfWUcOXIE/foV//4Wk3XZLu655x5kZ2ejRYsWKuuiXJBIlbuQixcJzvLYgw8+qEr3UgtgjViirgmNQgGf5kDqaeDsTqDVsBp5WSKyHFdHe1WytdR71xQJqqYkSK9Zs0aVOiMiItRUl9I2m5eXd83XkRKpKWmTLioqqtT+dZ2sMSwsTFVrSxu8fGYpeb/zzjvYuHGjKkXv3btXta///vvvqiOetGdLj3drGwLGEnVNiboZaDUCcDL/pyAi2ySBRaqfLbHU5gxp0h4s1cVS5SzttVI1fObMGdQl6fgmnbckKBpIj3QJnJXRpk0b9XlMyXrbtm2N63IhIm3wUlUvQXn79u2Ijo5Wj0kPeKkWf/vtt1Xbu5yHdevWwdqwRF1TRrxRYy9FRFRbpJfzTz/9pIKXXBC88sor1ywZ15annnoKM2fOVKX61q1bqzbr1NTUSl2k/Pvf/1Yd3KRtWQLu//73P/XZDL3Ypfe5XAD06tVLVcV/8803KnBLlfcvv/yCU6dOqQ5kPj4+qn1czoP0HLc2DNRERA3I+++/j3/84x9qkhI/Pz81LEp6XNc1eV9JLTp27FjVPi0TrAwfPrxSWaZGjx6NDz74QFXjS+/v5s2bq17kgwYNUo9LFbb0eJdOZhKwpQZBgrkMB5PHJKhLdXdOTo66gPn+++/Rrl07WBs7ra4bDSwsPj5etVvExcWhSZMm1X69gsIi2Ov0swApl+MAnQPgVb38o0RUd+SH+vTp0+qHXsbUUt2T0qxUZUsJWXqi1/fvVXwlYhHbqKvh+aUH0HXGGhw8V3w1uvpFYHZ7YNeC6rwsEVG9Fxsbi08//RTHjh1TbcYTJkxQQe3++++39KFZHQbqakjNyseVnAJsPFY8RCGwHWBnD2RdrKE/DxFR/aTT6VQbssyMJkOqJFhL27KUqskc26irYWArf6w5nIiNx5Lx5OBIoN1ooO1tgLNndV6WiKjek2rf0j22qWwM1NUM1GLv2ctIy85HI1cOzSIioprFqu9qCPN1Q0t/dxQWadh6IsX8QQsMdyAiovqHgbqaBrYKULcbjybrN5z7E/h0MPDVbdX+4xARETFQV9PAKH31t7RTq5FuLt76YB23E8jP5jeMiIiqhYG6mno194Wzgw4JV3JwNDEd8G0BeAYDhXlAfMn0eERERDYXqGX6OOmaL5OjBwQEqFlmZAL16/nhhx/UlHMygFxmmqlsarSa5OJojz4tG5dUf8vEJ5L2Upxhj0YiIrLhQC0ZTCZOnKjyh0pmE8lfOmzYMGRmZpb7nG3btqmcqA8//LBKei7BXRZJGm7p3t9S/W2W9vLMFosdExFRRcmUm08//bRxPTw8HLNnz77mc2Q2xuXLl1f7JNfU61yLTBPauXNn2CqLBurVq1erLC4yt6okMpfB75IT9c8//yz3OTKvqyQql8nYZWC8TDXXtWtXlXTc0oF695lLyMwtKClRS9V3fo7FjouI6jdJrCG/h2XZvHmzCoKSFaqyJKuVzL1dF8HywoULGDlyZI2+V31jVW3Ukkxc+Pr6lruPpCiTLCmmZCJ32V6W3NxcNeG8YUlPT6/howaa+7mjqa8b8gs1bDt5EWgcAXgEAoW5+o5lRES1QGoWpTZS5o0uTZJTdO/eHR07dqz06/r7+6tsU3VB0mw6OzvXyXvZKp01TcguVS8ylVz79u3L3U+yrUgeU1OyLtvLaweX3KeGxTRPaU2Rq9aS6u8kfTs1q7+JqJbdeuutKqhKbaSpjIwM1ZdHAvnFixdVc2FoaKgKvtKvR7JEXUvpqu/jx4+rdJDSL0h+Q+XioKxsWK1atVLv0aJFC5U+U5ozhRzf9OnTceDAAfV7KYvhmEtXfctUooMHD1bpKCXL1WOPPaY+j4HUwkpzp2TMCg4OVvtIE6rhvSoab1577TWVDEMuEqSkLzW8Bnl5eXjyySfV68tnlrSYEkuEjO6R2oGmTZuq54aEhOBf//oXGkSglhMt7cyLFi2q0dedMmWKKqkblsOHD6M2GAL1hqPFw7TCi9upY9lOTWTT8jIrvxQWlDxf7su20sM1y3tuJTg4OKg0kRL0TBMhSpCWtI4SoCWDU7du3fDrr7+q31gJfA8++CB27dpV4aB25513wsnJCTt37sT8+fNVUC5NOgXLcchvrDRRSsKNWbNmqcfuu+8+PPvss6qZU6q6ZZFtpUn/JKkhlfzQUv0un+OPP/5QQdPU+vXrcfLkSXX75ZdfqvctfbFyLXJ87733ngr20jQg73nbbbepCxLx4Ycf4ueff8aSJUtUB+dvv/1WXbyIH3/8UX2uTz75RO0vFxly8VPvpxCVP4Ik8d60adN1031JNUliYqLZNlmX7WWRKx7TapXayrsqPb+d7HWIT83GqZRMtGxW3E4dtxsoyAUcWLVDZJPeCKn8c+5ZCLS7Q38/5n/ADw8B8psw/teSfWZ3KDuBz6v6JsCKktzS77zzjuqca8jDLNXed911l7Em8bnnnjPu/9RTT+G3335TQahnz57XfX0JlDExMeo5UnoUb7zxxlXtyi+//LLxvgQ1eU8peD3//POqdOzh4aEuLMr7rRbfffedurD46quv4O6un5J5zpw5qi3+rbfeMtamSiCX7ZK7WkYA3XLLLVi7di0effTRCp0zCdBysfG3v/1NrctrS9CXWoS5c+eqvlKSn7p///6qxC8lagN5TD6DNME6OjqqknVFzqPNlqjlClCC9LJly7Bu3TqVs/N6+vTpo/4gpqQaRrZbkruzA3o09ykZpuUfBbj5AQXZwLm9Fj02Iqq/JFD17dsXn3/+uVo/ceKE6kgm1d5CStbS6VZKfdL/RwKmBF0JOBVx5MgRlUDDEKRFWb+3ixcvVk2XEsTkPSRwV/Q9TN9LOhYbgrTo16+fKtWbDt2VkrkEaQOpok5KKs5ieB1SWDt//rx6XVOyLu9vqF7fv38/oqKiVLX277//btzvnnvuQXZ2tqrelwsDiV8FBSY1KPWtRC3V3XIFtWLFClVtYmhnlitAuQITUq0jbSuG9oFJkyZh4MCBqtpCrqLkim3Pnj1YsMDyOaCl+nvriYtqmNY/+jfXV38fXqGv/m5m2QsJIqqiF89X/jn2JjVorUfpX8OuVLno6ega+5NIUJaSspQGpTTdsmVL9TsppLQtVb1SWpRgLUFQ+gNJO2xNkc68DzzwgGqHlmpk+Q2X32b5na4Njo6OZutS6pVgXlNkJJHkxl61apWqUbj33ntVCXrp0qXqokUuGmS7FBKfeOIJY41G6eOqFyXqefPmqXZjqa6RKyLDIldmBnJFJu0ZBnLlKMFdArNcecmJkzaCa3VAqyuDovTzfu84dRE5+YX6qi5D9TcR2SYn98ov9iZlILkv2xxdK/a6VSCBRPI7y2+jVBtLdbgELyGpJG+//Xb8/e9/V7+ZUhI8duxYhV9bhsHGxcWZ/Q7L3Bel57eQ6uGXXnpJ9TSXauPY2Fjzj+vkpEr313sv6XBmOpfG1q1b1WeT0m1N8PLyUrUDpVNsyrppZ2PZT9rRpa1dYpK0TV+6dEk9JgVJqY6XtuwNGzaoCxXpBFcvS9SmnR/KIyehNKl6kMXaRAZ4ILiRCy6k5ahgPajt7UBoNyC4k6UPjYjqMalqlqAinWelaleqbg0kaEqBRoKptO2+//77ql9PRUfASElSenOPGzdOlRzl9SUgm5L3kEKVlKJltknpuCZVwqak3VpKqVKlLH2RpBa19LAsKZVPmzZNvZf0rE5OTlY1BdL5rfRon+qQeTjkfaTmQXp8Sy2EHJd0GhNyjqTQ2KVLF3WRIJ3apErf29tbdVqTC45evXqpHu7ffPONCtym7dj1ttd3fWA+TCsZ8AwEmnQzv7omIqoFUv2dmpqqqp5N25OlrViqcmW71F5KwJHhTRUlgUqCrrTLSqepRx55BK+//rrZPtJj+plnnlF9jiTwyUWBDM8yJZ3bZHKWG2+8UQ0pK2uImAQ+aT+XkqsE/LvvvhtDhgyp8QmtpN158uTJqie6NAfI0Czp5S0XHEIuIt5++21VOyDHcebMGTVVtZwLCdZSypY2bRmjLlXg//vf/9Qwsdpip1WkWFuPyMQA0sYgVTnX62FeFauiL2DCt3vRwt8d657V98AkIusmPY2ltCcdWmXcLFFtf68qE4tY1Kth/SL9YK+zw6nkTMRdykJYYTyw/SPAzh4Yde25c4mIiEpj1XcN83JxRLem+mFaG6T6W6YR3fsVEP2D+SQIREREFcBAXQsGRvmXjKcOaAf0nwzcLWMcG1QrAxER1QAG6lpg6FC27WQKcos0YOg0oNVwwL52xtgREVH9xUBdC9oGe8HPwxlZeYX480xqbbwFERE1EAzUtXFSdXa4oZVfyTCtokLgxFpg3ev6+0RklWpydiuiohr6PrHXdy3OUvbT3nMqUE8Z0Qr4YTyQmwa0vhkI6VJbb0tEVSCzZskYWZkDWsb4yrphZi+iypJRzzJFq0zYIt8r+T5VBwN1LRkQ4afSUsckpONCeh6CZa7vY6uBM1sZqImsjPyYylhXmSZTgjVRTZAJXCS7lny/qoOBupb4uDuhUxNv7I+7jE3HknFfs37FgXoL0Nc8tyoRWZ6UeuRHVTIhXW9OaqLrkexektazJmpmGKhrufe3BGqp/r5vUHFKtbPb9O3UupIUbURkHeRHVTIg1VYWJKKqYGeyWjSoeDz15uMpKAjoADh5AjlpQOKh2nxbIiKqRxioa1HHJt7wdnNEek4B9p3LAJr21j8g1d9EREQVwEBdi2TO7wGRJrOUhRdXf8ea50ElIiIqDwN1LRtUPEvZhmNJQLP+JYGa4zWJiKgCGKhr2YDiiU8OnruCZM82gKM7kJ0KJB2u7bcmIqJ6gIG6lgV4uqBdiJe6v/nUZaBpL/0DrP4mIqIKYKCuw97fajpRGU8t2KGMiIgqgIG6DgxsFaBuZeKTQtN2ao1pL4mI6No44Ukd6NLUG57ODkjNysdBrQU6RQ7XV4EX5AKOLnVxCEREZKMYqOuAo70O/SP9sOpgAjacSEOnB5bUxdsSEVE9wKrvOpxO1DhMi4iIqIIYqOvIDcWB+kDcZaRm5gHpicCh5WynJiKia2KgriMh3q5oFeiBIg3Yeuw88EFH4IdxwMUTdXUIRERkgywaqDdt2oRRo0YhJCREZa1Zvnz5NfffsGGD2q/0kpCQAFswKErf+1vaqRHWCwjqCGRdsvRhERGRFbNooM7MzESnTp0wd+7cSj3v6NGjKsG7YQkI0AdAW2mnlvHURQ/8CDy+uWQCFCIiImvr9T1y5Ei1VJYEZm9vb9ia7uE+cHOyR3J6Lo4kZaFdSCNLHxIREVk5m2yj7ty5M4KDg3HTTTdh61bbyUTl7GCPvi0bl8xSJvKzgbwsyx4YERFZLZsK1BKc58+fjx9//FEtYWFhGDRoEPbu3Vvuc3Jzc3HlyhXjkp6eDqsYpiVpL1c+D7zZFIj+waLHRERE1sumJjyJiopSi0Hfvn1x8uRJzJo1C19//XWZz5k5cyamT58O65pO9BD2xqYit7kHnAvz9NOJdhtn6UMjIiIrZFMl6rL07NkTJ06UP8RpypQpSEtLMy6HD1s2vWTTxm5o4eeOgiINB+w7lCTo4LzfRERUHwP1/v37VZV4eZydneHl5WVcPD09YS2Tn/yS2gTQOQJXzgGpZyx9WEREZIUsGqgzMjJUoJVFnD59Wt0/e/assTQ8duxY4/6zZ8/GihUrVAn64MGDePrpp7Fu3TpMnDgRtmRgcdrLP45fgRbaVb+RaS+JiMja2qj37NmDG2+80bg+efJkdTtu3DgsXLhQjZE2BG2Rl5eHZ599FufOnYObmxs6duyIP/74w+w1bEGfFo3h7KDD+bQcpLbrCd+4nfp26q4PWvrQiIjIythpWsNqHI2Pj1e9xePi4tCkSROLHcfYz3ep/NTzel/GyP1PAI2aAs9EW+x4iIjIOmORzbdR2yrDMK2lSaGAnT2QdhZIjbX0YRERkZVhoLZwoN4cm43CkC76jVL9TUREVN1ALUV1KbYb7Nq1S3XsWrBgQVVerkFq6e+OJj6uyCssQrxXcaA+w0BNREQ1EKjvv/9+rF+/Xt2XzFUylacE65deegmvvfZaVV6ywZGsX4ZS9abc4klczmy27EEREVH9CNQyNEomGhFLlixB+/btsW3bNnz77beqtzZVjCFQf5cQom+nvhwLpJXUVBAREVUpUOfn56uJRIQMj7rtttvU/datW6shVVQxfSP84GhvhyOXgFz/DoCDC5B8lKePiIiqF6jbtWunkmNs3rwZa9aswYgRI9T28+fPo3FjfXYouj4PZwd0b+ar7v8vaibwwlkgYghPHRERVS9Qv/XWW/jkk09U5qoxY8agU6dOavvPP/9srBKnys1S9utZB8BBX0tBRERUrZnJJECnpKSotJE+Pj7G7Y899piaMYwqcS6j/PHmqhhsP3UROfmFcHG01yfosLPjaSQioqqVqLOzs1WeZ0OQjo2NVfNwHz16FAEBksaRKioq0BOBXs7IyS/C+ZVvA3N7Awd/5AkkIqKqB+rbb78dX331lbp/+fJl9OrVC++99x5Gjx6NefPmVeUlGyzTYVqJ52OB5CNM0EFERNUL1Hv37sWAAQPU/aVLlyIwMFCVqiV4f/jhh1V5yQZtUJS+FuLzjN7AvV8Dg1+x9CEREZEtB+qsrCxjXufff/8dd955J3Q6HXr37q0CNlVOvwg/2OvssOaiP+KDhwLu7DlPRETVCNQRERFYvny5mkr0t99+w7Bhw9T2pKQkeHl5VeUlG7RGro7oEuat7m86lmLpwyEiIlsP1FOnTsVzzz2H8PBwNRyrT58+xtJ1ly7F81ZTpRjaqQ9H/wlseBPY+QnPIBERVS1Q33333Th79iz27NmjStQGQ4YMwaxZs3haq9FOnREXDWyYCez5nOeRiIiqNo5aBAUFqcWQRUsSX3Oyk6prF+KFxu5O2JgZCbgASI4BMlMAdz9+TYmIGrAqlaiLiopUlqxGjRqhWbNmavH29saMGTPUY1SFP4TODje08kcqvJDk2lK/kfmpiYgavCoFaklnOWfOHLz55pvYt2+fWt544w189NFHeOUVDi2qzixlYkdRG/2GM1sa/BeUiKihq1LV95dffonPPvvMmDVLdOzYEaGhoXjiiSfw+uuv1+QxNhj9I/zUzKGr0lviNicJ1FstfUhERGSLJepLly6plJalyTZ5jKqmsYczOoY2wq6i4nObdAjI4vkkImrIqhSoJVuWVH2XJtukZE1VNzAqABfRCBecmuk3xG7j6SQiasCqVPX99ttv45ZbbsEff/xhHEO9fft2NQHKypUra/oYG9x46g/XHsemvCjch1h9O3WbWy19WEREZEsl6oEDB+LYsWO44447VFIOWWQa0UOHDuHrr7+u+aNsQDo1aaRmKtucF6XfEMsOZUREDVmVx1GHhIRc1WnswIED+O9//4sFCxbUxLE1SA72OvSP9MPOv4p7ficcBLJTAdeSvN9ERNRwVKlETbVrUCt/JMMb8fZNAGhA7HaeciKiBsqigXrTpk0YNWqUKp1LXmZJ9HE9GzZsQNeuXeHs7KySgyxcuBD1dd7vTXmt9Bs48QkRUYNl0UCdmZmpepDPnTu3QvufPn1adWK78cYbsX//fjz99NN45JFHzOYbrw8CvFzQJtgL/yvsgyNRE4H2d1n6kIiIyBbaqKXD2LVIp7LKGDlypFoqav78+WjevDnee+89td6mTRts2bJFJQIZPnw46tssZfMutMMCXShmhXa29OEQEZEtlKhlbu9rLTLn99ixY2vtYGUI2NChQ822SYCW7fW2+vtYMoqKNEsfDhER2UKJ+osvvoAlJSQkIDAw0GybrF+5cgXZ2dlwdXW96jm5ublqMUhPT4ct6NbMBx7ODsjPvIS4bUvQzM8TaH2zpQ+LiIjqWL3v9T1z5kyzUn/btm1hCxztdegX0RiDdfvR7I/HgM3vWvqQiIjIAmwqUEv+68TERLNtsu7l5VVmaVpMmTIFaWlpxuXw4cOwFQNbBWBnURvE2YcBod0BjVXgREQNjU0FapmudO3atWbb1qxZY5zGtCwyjEsCuWHx9PSErRgY5Y8LaIyBWW8hbdDrUKm1iIioQbFooM7IyFDDrGQxDL+S+2fPnjWWhk07pz3++OM4deoUnn/+ecTExODjjz/GkiVL8Mwzz6A+CvV2RWSAB6Qv2ZYTKZY+HCIiamiBes+ePejSpYtaxOTJk9X9qVOnqvULFy4Yg7aQoVm//vqrKkXL+GsZpiV5sevb0Kyyen9viTkHJERb+nCIiKiO2Wlaw2r4jI+PR1hYmMr01aSJTNFp3TYfT8bT/12DrS6T4Kwrgt0LZwEnd0sfFhERVUNlYpFNtVE3RD3CfZHl6IsUzQt2RQVA3E5LHxIREdUhBmor5+Jojz4tG2NnUWv9BslPTUREDQYDtY20U+8oKh7/fWarpQ+HiIjqEAO1jQRqGU8ttHN/AnlZlj4kIiKqIwzUNiDczx06n3Bc0HxhV5QPxO+29CEREVEdYaC2EQOjArCjuFTNdmoiooaDgdqGZikzVn/HskMZEVFDwUBtI3q3aIy9dvoOZVr8n0B+jqUPiYiI6gADtY1wc3JAYHg7JGre0BXmAuf2WPqQiIioDjBQ21g7taH6m+3UREQNAwO1DRlk0k5deJrt1EREDQEDtQ1p6e+BU+5dkKfZIy23iPmpiYgaAAZqG2JnZ4fwqM7omPsZPgx5h/mpiYgaAAZqG2ynzoEzNh1LtvShEBFRHWCgtjH9IhrDQWeHUymZiEtIsfThEBFRLWOgtjGeLo4Y1MQOvzi9iKBPOwAFeZY+JCIiqkUM1Daoa5sIBNtdhGNhFpB40NKHQ0REtYiB2gYNigrEP/OewcCiecgN7GTpwyEiolrEQG2D2gR7ItajE2LzGmHPmVRLHw4REdUih9p8caq9YVqSo3rpn/HI3fAesCUaCGwPBMnSAfBvDTg48/QTEdUDDNQ2PEuZBGrXCzuBwj+BM5tLHtQ5AH6tSoK3uu0AeARY8pCJiKgKGKhtVP8IPzVMa1rWveio6462urPo5nwOkdoZuBVeAZIO65foJSVPcg/QB+6OfwM63WfJwyciogpioLZR3m5O+HBMFyzfF4CNcRFYmp4L5MsjGoJwCW11sejiFI+ebucRWXQGPjlxsMtMAk6uA5r2LXmh1Fhg8d+B0G7AqNkW/ERERFQWBmobdnOHYLVomobzaTnYf/Yy9p1Nxf44X2w95491OV2B4rTVrshBlF08+nteQNGZFgh0PIMuTb3RJu0vOCb8pQK8me+KS9zG6vMOgG9zQGdf9x+UiKgBY6CuJ53LQr1d1XJLx2C1Lb+wCDEX0rE/LhX74i6rIL4/xQX7r0QAVwAcOaT2C3TIwp2NX0Zzd3e4HjivgneopwPspORdmAccW13yRo5uQEBb83Zv6bjm6l3rn1EuRtJzC3AxIw8XM3KRkpGH7PwC9Aj3RRMft1p/fyIiS7HT5BewAYmPj0dYWBji4uLQpEkTNCSXs/KwX4J28bLv7GWkZav6cjOB7g64M/A8ertdQGuchl/mcdgnxwAF2WW/sEegvvPa0OlAk276bYX5+k5tdnblHk9uQSEuZUrgzUNKRq4+CGfqb1OK7xu3Z+Qhr7CozNfp1KQRRrQPxsj2QQj3c6/i2SEiss5YZBWBeu7cuXjnnXeQkJCATp064aOPPkLPnj3L3HfhwoUYP3682TZnZ2fk5BTX8V5HQw7Upcmf/szFrOLqcn3wPnz+CgqKzL8SEmtb+7thaGAGertfQGu7WPimH4OdzIqWft64X9Ej65Hm014FWPvdnyJs3zs4GnoXfmvyL1UKvpieC6e0kzic0xiJmYVIzymo9DF7ODugsYcTGrs7qcp6OWbTb3CbYC/c3D4IIzsEISLAs3oniIiollQmFlm86nvx4sWYPHky5s+fj169emH27NkYPnw4jh49ioCAsocTeXl5qcdNq36p8uS8NfdzV8udXfVflJz8Qhw6n6ZK24Yq83OXs3EkKQtHknT4CKEAQuHuNAAdmjSCp2c2XK+cgk/2Gfz48RlkFF1Qr/OawzaMdcjCppOX8eHR42qbP1Kx22Ui8jV7xGqBOOkYglMIRaJTU6S6NUeWVwt4ePmoINzYw1kFZD8VlJ3h5+mstrs4mreRJ6fn4vfDCVgVnYDtpy7iyIUranlvzTFEBnioUvbIDsFoHeTJ7wkR2SSLl6glOPfo0QNz5sxR60VFReoq46mnnsILL7xQZon66aefxuXLl6v0fixRV15SenFHteLA/Vf8ZWTmFZa7fyNXRwS626GdyyW4unvC3qepCrqtCo9j2K5H4CBzlJfHMwTwb6WvSjcsYb0AR5frHmdqZh7WHE7EyoMXsPVECvILS77a4Y3dVMCWwN0htBGDNhFZlM1Ufefl5cHNzQ1Lly7F6NGjjdvHjRunAvGKFSvKDNSPPPIIQkNDVVDv2rUr3njjDbRr167M98jNzVWLwblz59C2bVtWfVdDYZGG40npiI5Pg4O9nSrx6ku/zvBxc4KTwzVmpi0q0leXJx8FUo4DKcW3si7Dx8ry3PGSyVoO/gRcPgtE3gQElv03F9L2vvZIIlYdTMDGY8nIKyhp35ZOd4aSdpcwb+h0rJEhorplM1XfKSkpKCwsRGBgoNl2WY+JiSnzOVFRUfj888/RsWNHpKWl4d1330Xfvn1x6NChMj/szJkzMX369Fr7DA2Rvc4OrYO81FJpOh3QqIl+iRhi/lh2anHwPlYcyI8B6QmAu3/JPn8t1vdEd3IvCdSXTgP7vtGPBZfFM1CV6qU6X5aM3AKsj0nCqoMXsD4mWVXlf7bltFqCvFwwon2QWqQHuXw2IiJrYtES9fnz51XJeNu2bejTp49x+/PPP4+NGzdi586d132N/Px8tGnTBmPGjMGMGTOuepwl6npm16fA2R1Anyf0QVns/Rr4+cmSfRqFAaFdSwJ3cGfA2UM9lJ1XiI3HJGgnYO2RJBXEDaQ9fFi7INzcPhi9WvjC0Z45a4iogZeo/fz8YG9vj8TERLPtsh4UFFSh13B0dESXLl1w4sSJMh+XHuGyGFy5IoOIyWb1fFS/mGrcEujyd+DcXiDpCJAWp18OFzed2OkA/zYqeLuGdsMIWe7pgJwiO9WWvTI6AWsOJ6ghYd/tPKsWbzdHDGsbiJHtg9Evwu/a1flERLXIooHayckJ3bp1w9q1a41t1NLuLOtPPmlSQroGqTqPjo7GzTffXMtHS1arWV/9InLTgQsHgPg9wLk/9cH7SjyQdEi/7Ptav19IF7g8tgFD2gSqJe9yALYn2mP1oQT8dihRje9esideLZ4uDhjaRoJ2EG5o5X9Vz3Miotpk8eFZMjRLOo91795djZ2W4VmZmZnGsdJjx45V1ePS1ixee+019O7dGxEREarDmYy/jo2NVR3MiODsCYT31y8G0s6tgrZh2WveEa0wH05zOmOgkwcGPr4FM25vj12nL+G36HisPJyihoAt23dOLW5O9hjcOkCVtCUxipuzvUqOwiGCRFRvA/V9992H5ORkTJ06VU140rlzZ6xevdrYwezs2bPQSQekYqmpqXj00UfVvj4+PqpELm3c0pObqEyeQUDrW/SLoed5fmbJ49IZragQKMpXs6w56HToG+GHvvufx6ue+3EprD125TfHjwmB2JwejF/+uqAWU072Ojja28HRQW51JevqVqe2O5muyz4Oduq9DPfNHjPsa3y9q1/L39MZrQI94eniyD88UT1m8XHUdY3jqKlM+Tn6YV8yhttgdkfgcqzZbkU6RyS6RmB7bjPsym6CBM0HSZoPEjUfXIInNNR9W7YMN4sK8tQvgfrbFv7ucHZgFT2RtbKZcdSWwEBNFZZ1CTi/T19Vfm6Pvt07K6Xc3TWdA5L7z0BK67+rpCh2l8/C+8RPyPAIx/nQkWqbzFeeX1CE/CJNrcukLPmGbepxw/bi9YJS6/J4gf51zqVmI+FK2VPnSnW8zDjXKsgTrQM99bdBngjzceO4cSIrYDO9vomsmpuvfqy3Yby3XNNKb3Jp55agLWO9MxKA9EQgMxl2RQUI8A9AQEjx+PLMbcCBWUBIV7S96aGS153TA8jL0lfJmy6+wYCHYT1Y//7XmR5XEq0cS8zA0YQrOJqYjqMJ6YhJSFfzqB9PylDLryippnd1tEerQA9V6pZqcxkL3yrIA/4ezmxnJ7JSDNREFSVB07upfml3h/ljki0sIwlwMZkExjMQ6PKgfn8DCfaX4/SZyKQ3+rXoHEuC+IBngaiR+u2ZKcD5/YB3GLz9o9Czua9aSt5CUyVtCdrGJTFdBe3s/EIciE9TiylfdycVwFXgLq4+l0WSoBCRZfG/kKgm2DsCjSRhiQnDhCulPbVH3xNdLReAjET9rVovvi9V7NK5zTAmPN9kfnSZ8GXxA0CTnsAja0q2fzoYKMiFnZsvgl19Eezmi0FujYGmvkBrXxS6+OBCvgdOpDvh0GVHRCcX4VhSBs5czFTD0XacuqQWs4/g7aqqzA1V5xLEW/p7VHlcuVxEyBS0kqHN/LZIf1tY9nbDYtguQ+Q4/Ss1FAzURHVdKjdMoXotBXn6uc8NAV1mWjPQ2QMB7YDGEebPSTxcfs5wuZYA0KR4GaRexwG4dTZyOtyPE0kZOH98H/wP/RdH8oPxYdZwVSqX6VYbpR3B6aNOWKR5IA0e0Ons0ayxmwqWZQVRY9CV9ULz7aUyqFZLS393/HNgS4zuHMoJaaheY2cyovpAqtSl41v2JSArFci6WHz/Uqn7l/T3DSX0uz8H2t+lv3/4Z2DJg/psZQ//rtq/pdq8/eLecM/VJ0wpgh2uaG5I1TyQDRfkwhE5mpP+FvrbXM0Ry4r6Y3uRfqx6MC7iVvvtSNK8saKoZHx7D7sYONgVqv1z4YQCnWFxQYGdEwp1zqqXvb29Ts3BLh3k9Lc6nL+cjfTi6V+DG7ngkQEt8LceYXBnVT3ZCHYmI2qIJXXTUvf15Gfrg7ZLo5JtklL0xpeNmcq83ZzQq0VjwMsXuJIL5KZBBw3edplquZYbbhiJjPYDVXB1i9+MgOXfocCvDaY+9KoKtPb2dnBbMA26i/pc5WWShGdF0pnOBbBzBnSuQL9JQO8JSM/Jx6LtJxGz5Sf8kdYSM37JwUfrjmNcn3A81DccPu5OFT8XRFaOVd9EDZGj69Vt6gGt9UtpE3eWdJiTDGfGUnk2UJBTvOQWr+eq9aCIfkCAPhEKCpoAHe+Dg2cwGnuUzLsP3xb6anyT5xkXI01fnS9LzmXjYzLJy6ORGcDGt5Dr6Y3hjl/gzKVsfLD2OL7edBi394zEowNaIMTbtebPHVEdY6Amoop3mJPStiE3eEUFtQfuXHD19geWlF+NX5hXKoDLbbaaOc4oJw3wi4KzXyTW3nsjVh9MwMfrj+OTS+ORs9sJG3e1QVHTvug7ZBSat4jiX5lsFtuoici2SUlfLiIkxqedg92sq6cTTnYIhq55PzRuOxgI7wd4N7vuGHWi2sQ2aiJqOIqDtLCT6vznT6shbEnRa5F1YjPCco7Bv+ACcHypfpGA7hUKu2b99FnXJIGL9KBn4CYrxapvIqpfZEa31jcjoLU+9e3J+PNY//v/UHB6C3rYHUFHu1NwvHIOiF6iX8Qzh0qGzKlOdt6ASTIgIktioCaieq1lkxC0/Mc/cf7yWHy2+TQe2XUcbQpj0EsXg4FOR9HcNRsu7sEwdnNb9jgQvwu4bQ7Q5lY0dBm5BTiZlKHG2p9IzkDcpSzVm1/G0ZcsOjU9reG+6WOuJtvkvrPJfckGR9fHQE1EDYL0AJ86qi2eGhyBL7e3wRfbzmBWVj7ssorg/9Z6PNy/Oe7vGQbPhGh973bTXvEHfwIOfK+vKpcq8+DOgEP9GQImM8alZOQZg7EhMJ9MzsCFtLITv9QEGRfv4qCDq5O9yvamAr6TPVzUffPA71p839fdGf0iGqN9SKMGk2CGncmIqEHKzC3Aot1x+GzzKWMw8nRxwEO9QvFwyzR4t+wF2BeXZVZMBPZ9U/JkmdVNhpfJ2HOzJcJ8bLqVKSrSEJ+ajRPJ6fpAnJSpArPcT8vOL/d5fh7OiAhwR0SAB8Ibu6tt2XmFyCkoRE5+kZpDPie/ELkm92XJzi9CrvG+fl95Tk3kbGzs7oQbWvljUJQ/BkT6q/nqbQnTXNbQySGi+i+voAgr9p/D/I0ncTJZP5GLs4MO93YPw2M3tECYrxuQdAQ4uR6I3apfpMRdHsmA5hcJtL5FTc5iJNGpjjqs5RYU4nRKpj4QF5eS5fZUcgZyC2QmmavJoUkaVAnGMj2r3KrF3xON3Eo67NVE6V2OIbc4aJsF/OL7uaaBPb/kvmyXz7Xt5EVVJW967J2aeKugPbCVPzo28ValdWvGQF1DJ4eIGg4pba45koiPN5zEgbjLapv82I/qGIzHB7VUmcWKdwTSz+vTnKYcB1KOFS/H9WlPDbr/A7h1lv5+Xibwbit9KfwfvwFObvrtkoRFSuCOLlU65is5+Wbtx4b7Zy9llTuvupO9Di383VVylZbGYOyhtkkVs61cXP0Zm4oNx5Kw8WiySu1qysfN0VjaviHS33yiHSvBQF1DJ4eIGh4p8W0/dRHzNpzE5uMpxu2DWwdgwqCW6BFeklL0KjIJS8oJfeD2bQ407a3ffuEA8MkNgGQze/4U8gv1VcTOi+6D05l1yPcKQ7ZXS2R6tsAVj+ZIdQtHinMzpNl5IadAX9KU/dWSV6gCsQTkpPTccg/F09mhJBAXB2O5lRoCay9tVlZCWg42HkvChqPJ2HI8xTgPvKG03SG0EQa18sfAqAB0DrOO0jYDdQ2dHCJq2A6eS8O8jSexMvqCsV21ezMf3NoxWGUFyy0VRHNKBVRDtW1+Xj5888/DI/8Stua3Us8VvzpNQTtdbLnvL8lPTmohOFkUghNyq4Uguqg5kuGjHndGHqI8shHm54XGweHGgBzlmAhf5yLYaUWALFILoO4XAkWFJfdNH2vcUr8Iqdo/uQ6wdzbv+X50lT4Nq7yGWgpMlnLWpQNeu9ElQ99WPifhE7j7vyWvu+514Oz2a7xmfsm6vZN+3HvkTUCvf151zuQiaG9sKjYeS1aB+/CFK2aPN3J1xIBIPwyKClDV5P6eliltM1DX0MkhIhLSLrpg00n8+Oc55BWW3cZbFXZ2Gpo4ZqC1QwIidRfQUnce4do5hBXFw68wSSVBKW1b+EScaz9BBeVWmXvgvvhuILA9MGFryU4fdgUunazcwUhCloH/1t+Xnu/z++unbH3uWMk+/x0GxBXP/V5RPf8J3Py2/r6kbH0vCrCzB6aZ5D5f9AAQ80vlXrfzA8Doj0vSwn7QSX+h8bfvAJfiZoq8TCRl67DheIoK3JuPJeNKTklpW7QP9cKgVgEYGOWvcpw71NGQMc5MRkRUg5r7uWPmnR3x9NBW+HLbGRxPylDDhdQiw4mM90vGEJf9eMl2GU8sndbsyutglpelD7aG9u/itvC+fW4AosL0+5x2ARxczGZnU9z9gLwMwE6nD4pyKxO4mK3LrSx2+vumc7g7eQDhAwBXfcndSErHbn76/aXnu7yv3BrWjYvJepMeJc939gJGvKnfbqrPRKD9neW8hqP5NvlcqmmhRcnzL53S9xvITQecPUu2L/snAk5txL1+rXCvfxQKh0TiFEKx8aIvfj7rgL/OZ+LguStqmbP+BLxcHFQPcgnaUlUe4FW1vgM1jcOziIjIthXkAokHgYxkIGpEyfa5vYHkI2U/x94ZBb4tccGxGaJzA7Hhkg8O5ATitBaMPOgvfNoEe6kOaRK0uzbzqdEJWlj1XUMnh4iIbDyAX5RaiaNA8rHi2+Le+oVld8Tb0eQfmJlzF/46l4ZGWjoG6/bhqBaGs06R6B/pp9q1b+0UAg/n6s0XxqpvIiIiB2cgsK1+MSWd0i7HmgTvY0ByjKpS792rH1Z06I+LGbmI2fIT+u2Yr6rLB+e8g1UHE/DboQQMbxckPfnqDKcQJSKihkVnr2/jlsW0qly69ksPeJn5zMMZ/VqFAAkDEO7bEsu79MOGo0lIvJIDnzqeBc0qZkSfO3cuwsPD4eLigl69emHXrl3X3P+HH35A69at1f4dOnTAypUr6+xYiYionrIr7lhn0GIg8NAv0N32gRp/LZ0JpVNhXbN4oF68eDEmT56MadOmYe/evejUqROGDx+OpKSkMvfftm0bxowZg4cffhj79u3D6NGj1XLw4ME6P3YiIqJ63+tbStA9evTAnDlz1HpRUZHq7PXUU0/hhRdeuGr/++67D5mZmfjll5Ixd71790bnzp0xf/78674fO5MREZGlVSYWWbREnZeXhz///BNDhw4tOSCdTq1v3769zOfIdtP9hZTAy9ufiIjIllm0M1lKSgoKCwsRGBhotl3WY2JiynxOQkJCmfvL9rLk5uaqxSA93XzydiIiImtm8Tbq2jZz5kw0atTIuLRtW6qbPhERkRWzaKD28/ODvb09EhMTzbbLelBQUJnPke2V2X/KlClIS0szLocPH67BT0BERFSPq76dnJzQrVs3rF27VvXcNnQmk/Unn3yyzOf06dNHPf70008bt61Zs0ZtL4uzs7NaDC5f1ueZvXDhQg1/GiIioooxxCCJedelWdiiRYs0Z2dnbeHChdrhw4e1xx57TPP29tYSEhLU4w8++KD2wgsvGPffunWr5uDgoL377rvakSNHtGnTpmmOjo5adHR0hd5v165d0sudC88BvwP8DvA7wO+AZulzIDHpeiw+M5kMt0pOTsbUqVNVhzAZZrV69Wpjh7GzZ8+qnuAGffv2xXfffYeXX34ZL774IiIjI7F8+XK0b9++Qu/XpUsXNaGKvL7p61aFdEyTNm+pTvf0NMnYQjxfNYTfMZ6v2sTvl+XOl5SkpdlWYpLVj6O2ZVeuXFEd1KTt28urOP8p8XzxO2Yx/J/k+aqP36963+ubiIjIljFQExERWTEG6mqQ3uQyR7lpr3Li+apJ/I7xfNUmfr9s43yxjZqIiMiKsURNRERkxRioiYiIrBgDNRERkRVjoK6GuXPnIjw8HC4uLiqvtkykQmXbtGkTRo0ahZCQENjZ2alJaqj8RDKSo10mVAgICFDT6x49epSnqxzz5s1Dx44d1bhWWWQ64VWrVvF8VdCbb76p/idNp2Umc6+++qo6R6ZL69atUVcYqKto8eLFmDx5suoBuHfvXnTq1EnlxU5KSqrZv1A9kZmZqc6RXNzQtW3cuBETJ07Ejh071Dz2+fn5GDZsmDqHdLUmTZqoYCO57ffs2YPBgwfj9ttvx6FDh3i6rmP37t345JNP1IUOXVu7du3U/NyGZcuWLagzVZ+lu2Hr2bOnNnHiRON6YWGhFhISos2cOdOix2UL5Gu3bNkySx+GzUhKSlLnbOPGjZY+FJvh4+OjffbZZ5Y+DKuWnp6uRUZGamvWrNEGDhyoTZo0ydKHZLWmTZumderUyWLvzxJ1FeTl5amr96FDhxq3ybzhsr59+/aavI4iUtMVCl9fX56N6ygsLMSiRYtU7UN5GfVIT2ptbrnlFrPfMSrf8ePHVdNdixYt8MADD6g8FHXF4kk5bFFKSor6QTAkDjGQ9ZiYGIsdF9U/MnG/tB3269evwolnGqLo6GgVmHNycuDh4YFly5ap5AlUNrmYkSY7qfqm65M+SAsXLkRUVJSq9p4+fToGDBiAgwcP1klCJgZqIisv9ciPQZ22h9kg+QHdv3+/qn1YunQpxo0bp9r6GayvFhcXh0mTJqn+D9IRlq5v5MiRxvvSni+Bu1mzZliyZAkefvhh1DYG6irw8/ODvb29SlFmStaDgoJq6m9DDdyTTz6JX375RfWYlw5TVD4nJydERESo+926dVMlxQ8++EB1lCJz0mwnnV67du1q3CY1hPI9mzNnDnJzc9XvG5XP29sbrVq1wokTJ1AX2EZdxR8F+TFYu3atWRWlrLNdjKpL+ttJkJbq23Xr1qF58+Y8qZUk/48ScOhqQ4YMUU0FUgNhWLp3767aXeU+g/T1ZWRk4OTJkwgODkZdYIm6imRollSvyRe8Z8+emD17turAMn78+Jr9C9WjL7bp1efp06fVj4J0kGratKlFj80aq7u/++47rFixQrV/JSQkqO2SB9fV1dXSh2d1pkyZoqom5XuUnp6uzt2GDRvw22+/WfrQrJJ8p0r3d3B3d0fjxo3ZD6Iczz33nJoHQqq7z58/r4blygXNmDFjUBcYqKvovvvuQ3JyMqZOnap+SDt37ozVq1df1cGM9GR864033mh2oSPkYkc6aZD5BB5i0KBBZqfliy++wEMPPcRTVYpU444dO1Z18pGLGWlDlCB900038VxRjYiPj1dB+eLFi/D390f//v3VPAdyvy4wexYREZEVYxs1ERGRFWOgJiIismIM1ERERFaMgZqIiMiKMVATERFZMQZqIiIiK8ZATUREZMUYqImIiKwYAzUR1Ro7OzssX76cZ5ioGhioieopmW5UAmXpZcSIEZY+NCKqBM71TVSPSVCWOcJNOTs7W+x4iKjyWKImqsckKEuOdNPFx8dHPSala0kAIpmnJCtXixYtsHTpUrPnSzrEwYMHq8clu9Jjjz2mMqGZ+vzzz9GuXTv1XpL2T1J0mkpJScEdd9wBNzc3REZG4ueffzY+lpqaqtIrSnIDeQ95vPSFBVFDx0BN1IC98soruOuuu3DgwAEVMP/2t7/hyJEj6jFJ2zp8+HAV2Hfv3o0ffvgBf/zxh1kglkAvaTklgEtQlyAcERFh9h7Tp0/Hvffei7/++gs333yzep9Lly4Z3//w4cNYtWqVel95PT8/vzo+C0RWTiOiemncuHGavb295u7ubra8/vrr6nH593/88cfNntOrVy9twoQJ6v6CBQs0Hx8fLSMjw/j4r7/+qul0Oi0hIUGth4SEaC+99FK5xyDv8fLLLxvX5bVk26pVq9T6qFGjtPHjx9fwJyeqX9hGTVSPSQ5wQ35rA19fX+P9Pn36mD0m6/v371f3pYTbqVMnuLu7Gx/v168fioqKcPToUVV1fv78eQwZMuSaxyD5oQ3ktby8vFQOaTFhwgRVot+7dy+GDRuG0aNHo2/fvtX81ET1CwM1UT0mgbF0VXRNkTblinB0dDRblwAvwV5I+3hsbCxWrlyJNWvWqKAvVenvvvturRwzkS1iGzVRA7Zjx46r1tu0aaPuy620XUtbtcHWrVuh0+kQFRUFT09PhIeHY+3atdU6BulINm7cOHzzzTeYPXs2FixYUK3XI6pvWKImqsdyc3ORkJBgts3BwcHYYUs6iHXv3h39+/fHt99+i127duG///2vekw6fU2bNk0F0VdffRXJycl46qmn8OCDDyIwMFDtI9sff/xxBAQEqNJxenq6CuayX0VMnToV3bp1U73G5Vh/+eUX44UCEekxUBPVY6tXr1ZDpkxJaTgmJsbYI3vRokV44okn1H7ff/892rZtqx6T4VS//fYbJk2ahB49eqh1aU9+//33ja8lQTwnJwezZs3Cc889py4A7r777gofn5OTE6ZMmYIzZ86oqvQBAwao4yGiEnbSo8xknYgaCGkrXrZsmerARUTWi23UREREVoyBmoiIyIqxjZqogWKrF5FtYImaiIjIijFQExERWTEGaiIiIivGQE1ERGTFGKiJiIisGAM1ERGRFWOgJiIismIM1ERERFaMgZqIiAjW6/8BZX/3EzbaTIMAAAAASUVORK5CYII=\",\n \"text/plain\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"Csbr60to50FL\",\n \"metadata\": {\n \"id\": \"Csbr60to50FL\"\n },\n \"outputs\": [],\n \"source\": [\n \"# Overall the same as `train_model_simple` in chapter 5\\n\",\n \"def train_classifier_simple(model, train_loader, val_loader, optimizer, device, num_epochs,\\n\",\n \" eval_freq, eval_iter):\\n\",\n \" # Initialize lists to track losses and examples seen\\n\",\n \" train_losses, val_losses, train_accs, val_accs = [], [], [], []\\n\",\n \" examples_seen, global_step = 0, -1\\n\",\n \"\\n\",\n \" # Main training loop\\n\",\n \" for epoch in range(num_epochs):\\n\",\n \" model.train() # Set model to training mode\\n\",\n \"\\n\",\n \" for input_batch, target_batch in train_loader:\\n\",\n \" optimizer.zero_grad() # Reset loss gradients from previous batch iteration\\n\",\n \" loss = calc_loss_batch(input_batch, target_batch, model, device)\\n\",\n \" loss.backward() # Calculate loss gradients\\n\",\n \" optimizer.step() # Update model weights using loss gradients\\n\",\n \" examples_seen += input_batch.shape[0] # New: track examples instead of tokens\\n\",\n \" global_step += 1\\n\",\n \"\\n\",\n \" # Optional evaluation step\\n\",\n \" if global_step % eval_freq == 0:\\n\",\n \" train_loss, val_loss = evaluate_model(\\n\",\n \" model, train_loader, val_loader, device, eval_iter)\\n\",\n \" train_losses.append(train_loss)\\n\",\n \" val_losses.append(val_loss)\\n\",\n \" print(f\\\"Ep {epoch+1} (Step {global_step:06d}): \\\"\\n\",\n \" f\\\"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}\\\")\\n\",\n \"\\n\",\n \" # Calculate accuracy after each epoch\\n\",\n \" train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=eval_iter)\\n\",\n \" val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=eval_iter)\\n\",\n \" print(f\\\"Training accuracy: {train_accuracy*100:.2f}% | \\\", end=\\\"\\\")\\n\",\n \" print(f\\\"Validation accuracy: {val_accuracy*100:.2f}%\\\")\\n\",\n \" train_accs.append(train_accuracy)\\n\",\n \" val_accs.append(val_accuracy)\\n\",\n \"\\n\",\n \" return train_losses, val_losses, train_accs, val_accs, examples_seen\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9624cb30-3e3a-45be-b006-c00475b58ae8\",\n \"metadata\": {},\n \"source\": [\n \"- The `evaluate_model` function used in the `train_classifier_simple` is the same as the one we used in chapter 5\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"bcc7bc04-6aa6-4516-a147-460e2f466eab\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Same as chapter 5\\n\",\n \"def evaluate_model(model, train_loader, val_loader, device, eval_iter):\\n\",\n \" model.eval()\\n\",\n \" with torch.no_grad():\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)\\n\",\n \" model.train()\\n\",\n \" return train_loss, val_loss\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e807bfe9-364d-46b2-9e25-3b000c3ef6f9\",\n \"metadata\": {},\n \"source\": [\n \"- The training takes about 5 minutes on a M3 MacBook Air laptop computer and less than half a minute on a V100 or A100 GPU\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"X7kU3aAj7vTJ\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"X7kU3aAj7vTJ\",\n \"outputId\": \"504a033e-2bf8-41b5-a037-468309845513\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ep 1 (Step 000000): Train loss 2.153, Val loss 2.392\\n\",\n \"Ep 1 (Step 000050): Train loss 0.617, Val loss 0.637\\n\",\n \"Ep 1 (Step 000100): Train loss 0.523, Val loss 0.557\\n\",\n \"Training accuracy: 70.00% | Validation accuracy: 72.50%\\n\",\n \"Ep 2 (Step 000150): Train loss 0.561, Val loss 0.489\\n\",\n \"Ep 2 (Step 000200): Train loss 0.419, Val loss 0.397\\n\",\n \"Ep 2 (Step 000250): Train loss 0.409, Val loss 0.353\\n\",\n \"Training accuracy: 82.50% | Validation accuracy: 85.00%\\n\",\n \"Ep 3 (Step 000300): Train loss 0.333, Val loss 0.320\\n\",\n \"Ep 3 (Step 000350): Train loss 0.340, Val loss 0.306\\n\",\n \"Training accuracy: 90.00% | Validation accuracy: 90.00%\\n\",\n \"Ep 4 (Step 000400): Train loss 0.136, Val loss 0.200\\n\",\n \"Ep 4 (Step 000450): Train loss 0.153, Val loss 0.132\\n\",\n \"Ep 4 (Step 000500): Train loss 0.222, Val loss 0.137\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 97.50%\\n\",\n \"Ep 5 (Step 000550): Train loss 0.207, Val loss 0.143\\n\",\n \"Ep 5 (Step 000600): Train loss 0.083, Val loss 0.074\\n\",\n \"Training accuracy: 100.00% | Validation accuracy: 97.50%\\n\",\n \"Training completed in 1.07 minutes.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import time\\n\",\n \"\\n\",\n \"start_time = time.time()\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5, weight_decay=0.1)\\n\",\n \"\\n\",\n \"num_epochs = 5\\n\",\n \"train_losses, val_losses, train_accs, val_accs, examples_seen = train_classifier_simple(\\n\",\n \" model, train_loader, val_loader, optimizer, device,\\n\",\n \" num_epochs=num_epochs, eval_freq=50, eval_iter=5,\\n\",\n \")\\n\",\n \"\\n\",\n \"end_time = time.time()\\n\",\n \"execution_time_minutes = (end_time - start_time) / 60\\n\",\n \"print(f\\\"Training completed in {execution_time_minutes:.2f} minutes.\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1261bf90-3ce7-4591-895a-044a05538f30\",\n \"metadata\": {},\n \"source\": [\n \"- Similar to chapter 5, we use matplotlib to plot the loss function for the training and validation set\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"cURgnDqdCeka\",\n \"metadata\": {\n \"id\": \"cURgnDqdCeka\"\n },\n \"outputs\": [],\n \"source\": [\n \"import matplotlib.pyplot as plt\\n\",\n \"\\n\",\n \"def plot_values(epochs_seen, examples_seen, train_values, val_values, label=\\\"loss\\\"):\\n\",\n \" fig, ax1 = plt.subplots(figsize=(5, 3))\\n\",\n \"\\n\",\n \" # Plot training and validation loss against epochs\\n\",\n \" ax1.plot(epochs_seen, train_values, label=f\\\"Training {label}\\\")\\n\",\n \" ax1.plot(epochs_seen, val_values, linestyle=\\\"-.\\\", label=f\\\"Validation {label}\\\")\\n\",\n \" ax1.set_xlabel(\\\"Epochs\\\")\\n\",\n \" ax1.set_ylabel(label.capitalize())\\n\",\n \" ax1.legend()\\n\",\n \"\\n\",\n \" # Create a second x-axis for examples seen\\n\",\n \" ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\\n\",\n \" ax2.plot(examples_seen, train_values, alpha=0) # Invisible plot for aligning ticks\\n\",\n \" ax2.set_xlabel(\\\"Examples seen\\\")\\n\",\n \"\\n\",\n \" fig.tight_layout() # Adjust layout to make room\\n\",\n \" plt.savefig(f\\\"{label}-plot.pdf\\\")\\n\",\n \" plt.show()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"OIqRt466DiGk\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 307\n },\n \"id\": \"OIqRt466DiGk\",\n \"outputId\": \"b16987cf-0001-4652-ddaf-02f7cffc34db\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAeoAAAEiCAYAAAA21pHjAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAAToJJREFUeJzt3Qd4U/X6B/Bv0z1pS3cpFGgpe+8hCMhQUdwXvYJcxxXRi6LXKw4Q+StuUEEQvYobEAW8Ciiy95BhGWVTWqALSume5/+8vzRpUlroTtJ+P89znuScnCQnp2ne85uvnaZpGoiIiMgq6Sx9AERERFQ+BmoiIiIrxkBNRERkxRioiYiIrBgDNRERkRVjoCYiIrJiDNRERERWjIGaiIjIijFQExERWTEGaiKqkEGDBuHpp5/m2SKqYwzURHXkoYcegp2d3VXLiBEj+DcgonI5lP8QEdU0CcpffPGF2TZnZ2eeaCIqF0vURHVIgnJQUJDZ4uPjox7bsGEDnJycsHnzZuP+b7/9NgICApCYmKjWV69ejf79+8Pb2xuNGzfGrbfeipMnTxr3P3PmjCqlL1myBAMGDICrqyt69OiBY8eOYffu3ejevTs8PDwwcuRIJCcnm5X2R48ejenTp8Pf3x9eXl54/PHHkZeXV+5nyc3NxXPPPYfQ0FC4u7ujV69e6jMYxMbGYtSoUerzyePt2rXDypUry329jz/+GJGRkXBxcUFgYCDuvvtu42NFRUWYOXMmmjdvrj5Tp06dsHTpUrPnHzx4UH0u+Xzy/AcffBApKSlmVff/+te/8Pzzz8PX11ed+1dffbVCfzciS2KgJrKyNmAJMGlpadi3bx9eeeUVfPbZZyrwiMzMTEyePBl79uzB2rVrodPpcMcdd6hAZmratGl4+eWXsXfvXjg4OOD+++9XAeqDDz5QFwInTpzA1KlTzZ4jr3fkyBEVbL///nv89NNPKnCX58knn8T27duxaNEi/PXXX7jnnntUjcHx48fV4xMnTlTBfNOmTYiOjsZbb72lgmhZ5PNIEH3ttddw9OhRdUFyww03GB+XIP3VV19h/vz5OHToEJ555hn8/e9/x8aNG9Xjly9fxuDBg9GlSxf1WvJ8ubi59957zd7nyy+/VBcNO3fuVBdB8n5r1qyp9N+KqE5Jmksiqn3jxo3T7O3tNXd3d7Pl9ddfN+6Tm5urde7cWbv33nu1tm3bao8++ug1XzM5OVnS1GrR0dFq/fTp02r9s88+M+7z/fffq21r1641bps5c6YWFRVldmy+vr5aZmamcdu8efM0Dw8PrbCwUK0PHDhQmzRpkrofGxurPsu5c+fMjmfIkCHalClT1P0OHTpor776aoXOzY8//qh5eXlpV65cueqxnJwczc3NTdu2bZvZ9ocfflgbM2aMuj9jxgxt2LBhZo/HxcWpz3306FHj8ffv399snx49emj/+c9/KnSMRJbCNmqiOnTjjTdi3rx5ZtukGtZAqr6//fZbdOzYEc2aNcOsWbPM9pXSqpSEpUQo1bqGkvTZs2fRvn17437yfANDabxDhw5m25KSksxeW6qT3dzcjOt9+vRBRkYG4uLi1LGYkhJyYWEhWrVqZbZdStBSJS+khDxhwgT8/vvvGDp0KO666y6z4zJ10003qfdo0aKFKpXLIjUFcjxS+s/KylL7mJJqeSlBiwMHDmD9+vVlltilacBwnKXfPzg4+KrzQGRtGKiJ6pBUu0ZERFxzn23btqnbS5cuqUWeYyBtvhLQPv30U4SEhKhALQG6dFuyo6Oj8b60WZe1rXR1eWVIALe3t8eff/6pbk0ZguUjjzyC4cOH49dff1XBWqqv33vvPTz11FNXvZ6np6eqppdqd9lXLkak/Vja1eW9hLyOtIeX1RFP9pFzI9XrpUkwLuu81MR5IKoLDNREVkRKf9L+KoF48eLFGDduHP744w/VFn3x4kXVfiuPSUcxsWXLlhp7bymVZmdnq85aYseOHSrohoWFXbWvlGSlRC2lUcOxlEWeK53SZJkyZYo69rICtZC2dCl5yyJt7NJhbt26daokLQFZag0GDhxY5nO7du2KH3/8EeHh4ep1iOoTfqOJ6pBUDSckJJj/Ezo4wM/PTwU+6SAlpdDx48er6l+prpZS6L///W/Ve1qqlRcsWKBKiRK4XnjhhRo7NimVP/zww6oTmvQel2ApHcbkIqE0qUp+4IEHMHbsWHV8ErilF7l0SJPq5VtuuUV1jJNe2LJvamqqqppu06ZNme/9yy+/4NSpU6oDmXxO6R0uJd2oqChV2pbe5XIBI9uk17t0ttu6davqnS4XM9JxTS4CxowZY+zVLVXm0tFNOuOVLvUT2RIGaqI6JL2RTatihQSjmJgYvP7662pIkwQtIftJUJbgM2zYMNWGLIFH2n6lulue9+GHH6re4jVhyJAhaniUBEu5oJD3vdbwJRkP/n//93949tlnce7cOXWx0bt3bzVkTMiFhwTQ+Ph4FVDlwqN0m7uBlJ6ll7m8X05OjjoO6XkuQ7rEjBkz1LAxqT6XgC77Syn6xRdfVI9LM4AE7v/85z/qXMnxSxOBvGdZFxpEtsROepRZ+iCIyLJkHLUMcVq+fDn/FERWhpeaREREVoyBmoiIyIqx6puIiMiKsURNRERkxRioiYiIrBgDNRERkRVjoK6GuXPnqpmQJC2fpPjbtWsX6ivJgCRTNMp4VZl2sfQwHhnlJ9M+ythfmdlKZpcyZFEykOkwZZIMGVMr42Blcg3D9JAGkoVJZrqScyqzWkmGI1sg43slnaRMziFpKSVlpMwiZkrGB8u4Ypm0RGb8krmvDekrDWQSE5ksROa4lteRiU4KCgrM9pFpNmUMsczWJdORLly4ELZA5jiXyVDk7y+LzCW+atUq4+MN/fyU5c0331T/bzJ5jAHPE9R4ezkvpkvr1q3r7zmyWDoQG7do0SLNyclJ+/zzz7VDhw6pLEfe3t5aYmKiVh+tXLlSe+mll7SffvpJZSRatmyZ2eNvvvmm1qhRI2358uXagQMHtNtuu01r3ry5lp2dbdxnxIgRWqdOnbQdO3Zomzdv1iIiIozZj0RaWpoWGBioPfDAA9rBgwdV1idXV1ftk08+0azd8OHDtS+++EId9/79+7Wbb75Za9q0qZaRkWHc5/HHH9fCwsJUFqs9e/ZovXv31vr27Wt8vKCgQGvfvr02dOhQbd++feqc+/n5GbNRiVOnTqlMUpMnT9YOHz6sffTRRyqL1erVqzVr9/PPP2u//vqrduzYMZXR6sUXX9QcHR3VORMN/fyUtmvXLi08PFzr2LGjMWuZ4HnStGnTpmnt2rXTLly4YFwkk1x9PUcM1FXUs2dPbeLEicZ1SQUYEhKi0gfWd6UDdVFRkRYUFKS98847xm2XL1/WnJ2dVbAV8kWX5+3evdu4z6pVqzQ7OztjqsSPP/5Y8/HxUakeDSQFoWk6RluRlJSkPu/GjRuN50OC0g8//GDc58iRI2qf7du3q3X5sdDpdFpCQoJZqklJ/2g4J88//7z6gTJ13333qQsFWyR/b0nJyfNjLj09XYuMjNTWrFljll6U56kkUMtFf1nq4zli1XcV50SWrEFSvWsg0xTK+vbt29HQnD59Ws1fbXo+GjVqpJoDDOdDbqW6u3v37sZ9ZH85b5Ky0bCPTF8pqR4NZN5rqUKWuaJticxFbZrCUr4v+fn5ZudIquqaNm1qdo5kbm9DWkrD579y5QoOHTpk3Mf0NQz72Nr3TqYXlelQMzMzVRU4z485qbaVatnSf2uepxLStCZNcZIaVZrUpCq7vp4jBuoqkDzA8kNj+kcWsl464UJDYPjM1zofcivtQKWTUUggM92nrNcwfQ9bIIkjpE2xX79+xhzRcvxyASIXK9c6R9f7/OXtIz8wkvnK2kkea2kzlDY/yai1bNkytG3blufHhFzASMpP6fdQGr9HelIIkPZimTtf+j5IYUH6tqSnp9fLc8SkHES1UBo6ePBgjaagrC8kkcj+/ftVjcPSpUtV5quNGzda+rCsRlxcHCZNmoQ1a9aoDpVUNsnKZiAdFCVwSxKWJUuWGNO01icsUVeBZAmStHmlexHKelBQEBoaw2e+1vmQW8ldbEp6WEpPcNN9ynoN0/ewdpIWUrJfSUrHJk2aGLfL8UuTiSS+uNY5ut7nL28f6UVtCz9QUtKR3rPdunVTJUbJCPbBBx/w/BSTalv5P5GexlLjJItcyEiWNLkvJTp+j64mpWdJpyqpTevj/xoDdRV/bOSHRnLvmlZ3yrq0tzU0zZs3V19q0/Mh1UPS9mw4H3Ir/zjyQ2Swbt06dd7katiwjwwDk/YlAylZSClMchRbM+ljJ0FaqnLlc8k5MSXfF0dHR7NzJG3v0q5meo6katj0gkY+v/wwSPWwYR/T1zDsY6vfO/n7S0pKnp+SVKPyHZBaB8Mi/TqkDdZwn9+jq8kwz5MnT6rhofXyu1Tn3dfq0fAs6dW8cOFC1aP5scceU8OzTHsR1ifSC1WGMcgiX5v3339f3Y+NjTUOz5LPv2LFCu2vv/7Sbr/99jKHZ3Xp0kXbuXOntmXLFtWr1XR4lvTWlOFZDz74oBqyI+dYhkfYwvCsCRMmqOFpGzZsMBsykpWVZTZkRIZsrVu3Tg0Z6dOnj1pKDxkZNmyYGuIlw0D8/f3LHDLy73//W/VknTt3rs0MP3rhhRdUL/jTp0+r74isS6//33//XT3e0M9PeUx7fQueJ0179tln1f+afJe2bt2qhlnJ8CoZbVEfzxEDdTXIuDr5Msh4ahmuJeOD66v169erAF16GTdunHGI1iuvvKICrVzADBkyRI2VNXXx4kUVmD08PNQwiPHjx6sLAFMyBrt///7qNUJDQ9UFgC0o69zIImOrDeSi5YknnlBDkuQH4I477lDB3NSZM2e0kSNHqvHj8sMjP0j5+flX/S06d+6svnctWrQwew9r9o9//ENr1qyZOm75UZTviCFIi4Z+fioaqHmeNDVMKjg4WP2N5XdC1k+cOFFvzxGzZxEREVkxtlETERFZMQZqIiIiK8ZATUREZMUYqImIiKwYAzUREZEVY6AmIiKyYgzU1SAzKkkCc7klnid+l2oX/994jhrq98ii46hlrt+ffvoJMTExau7Uvn374q233lJTRpZHMqaMHz/ebJtk4snJyUFdk2kyJZ2jJBiQqeeI54nfJf6/WRJ/k+rnObJoiVomm5dMQzt27FBzqMocz8OGDVM5aq9FTu6FCxeMS2xsbJ0dMxERUYNJcym5REuXliVnsSRuuOGGG8p9np2dnc1kUyIiIqo3+ailKkL4+vpeN1OK5B6VzDuSDu6NN95Au3btKvQeklpx3759Kl2cTle9CgVJUi7OnTunqlOI54nfpdrD/zeeo/r0PZL4JWkzu3TpolKYXovVzPUtB33bbbepVIhbtmwpd7/t27fj+PHjKlm4BPZ3331XpUY8dOiQWf5fA+kwYNppQErrgwcPrrXPQUREVFG7du1Cjx49bCNQT5gwAatWrVJBuqyAWx5p127Tpg3GjBmDGTNmXPW49O6bPn16mSdHcpcSERHVNelf1bNnT9XHqmnTptYfqJ988kmsWLFClYybN29e6effc889qurg+++/v26JWqo7JDF4XFxcpS4IiIiIakp8fDzCwsIqFIss2utbrhEkSC9btgzr1q2rUpAuLCxEdHR0uaVjGbolvcQNi6enZw0cORERUQPoTCZDs7777jtVmpYAmpCQoLbLGDcZVy3Gjh2L0NBQNeZavPbaa+jduzciIiJUe/Y777yjqg4eeeQRS34UIiKi+heo582bp24HDRpktv2LL77AQw89pO6fPXvWrHd2amoqHn30URXUfXx80K1bN2zbtk1VZxMREdU3VtFGba3tAkTU8EhzmnRSJaoOR0dH2Nvb10gssqpx1EREliJlFqmpkyY1oprg7e2tJueSSbqqg4G6OrIvA2d3AI2aAEHtq/VSRGRZhiAtsyO6ublV+8eVGvZFX1ZWFpKSktR6dYcCM1BXx7r/A3Z/CvR6HBj5VrVeiogsW91tCNKNGzfmn4KqzdAhWoK1fK+uVQ1+PUxzWR3h/fS3Z7ZW62WIyLIMbdJSkiaqKYbvU3X7PDBQV0ez4kCdeBDIulStlyIiy2N1N1nj94mBujo8AgC/VtIiAZzdXiN/ECIiIlMM1NUV3l9/y+pvIqonwsPDMXv27Arvv2HDBlV6rO0e8wsXLlQ9qRsaBuqaqv4+s7n6fw0iokqQ4HitRZISVcXu3bvx2GOPVXj/vn37qiQTMqsk1Tz2+q6pEnVCtH64lmvDu9ojIsuQ4GiwePFiTJ06FUePHjVu8/DwMBsyJL3br5f7WPj7+1fqOJycnNR4YaodLFFXl2cQ0DiiuJ16R438UYiIKkKCo2GR0qyUog3rMTExKoeCpA+WqZYlQZGkET558iRuv/12BAYGqkAuuZD/+OOPa1Z9y+t+9tlnuOOOO1RP5sjISPz888/lVn0bqqh/++03lYZY3mfEiBFmFxYFBQX417/+pfaTIXH/+c9/MG7cOIwePbrSU1G3bNlSXSxERUXh66+/Nrs4kVoFSSMpnz8kJES9p8HHH3+sPouLi4s6H3fffbdVfvEYqGsCq7+J6uekFXkFFllqcmbnF154AW+++SaOHDmCjh07IiMjAzfffDPWrl2Lffv2qQA6atQolVfhWqZPn457770Xf/31l3r+Aw88gEuXyh/tIhN+vPvuuypwSgpjef3nnnvO+Phbb72Fb7/9VuV22Lp1K65cuYLly5dX6rMtW7YMkyZNwrPPPouDBw/in//8J8aPH4/169erx3/88UfMmjULn3zyCY4fP65ev0OHDuqxPXv2qKAtiZ6kFmL16tW44YYbYI1Y9V1T1d97vwRiOZ6aqL7Izi9E26m/WeS9D782HG5ONfPzLIHopptuMq77+vqiU6dOxvUZM2aogCclZEk7XB5JlDRmzBh1/4033sCHH36IXbt2qUBfFhk7PH/+fFXaFfLaciwGH330EaZMmaJK6WLOnDlYuXJlpT7bu+++q47riSeeUOuTJ0/Gjh071PYbb7xRXRxI7cLQoUPV3NtSsu7Zs6faVx5zd3fHrbfeqmoemjVrhi5dusAasURdkyXqCweAnLQaeUkioprQvXt3s3UpUUvJVqqkpdpZqqWltH29ErWUxg0kwHl5eRmnyCyLVJEbgrRhGk3D/mlpaUhMTDQGTSEzd0kVfWUcOXIE/foV//4Wk3XZLu655x5kZ2ejRYsWKuuiXJBIlbuQixcJzvLYgw8+qEr3UgtgjViirgmNQgGf5kDqaeDsTqDVsBp5WSKyHFdHe1WytdR71xQJqqYkSK9Zs0aVOiMiItRUl9I2m5eXd83XkRKpKWmTLioqqtT+dZ2sMSwsTFVrSxu8fGYpeb/zzjvYuHGjKkXv3btXta///vvvqiOetGdLj3drGwLGEnVNiboZaDUCcDL/pyAi2ySBRaqfLbHU5gxp0h4s1cVS5SzttVI1fObMGdQl6fgmnbckKBpIj3QJnJXRpk0b9XlMyXrbtm2N63IhIm3wUlUvQXn79u2Ijo5Wj0kPeKkWf/vtt1Xbu5yHdevWwdqwRF1TRrxRYy9FRFRbpJfzTz/9pIKXXBC88sor1ywZ15annnoKM2fOVKX61q1bqzbr1NTUSl2k/Pvf/1Yd3KRtWQLu//73P/XZDL3Ypfe5XAD06tVLVcV/8803KnBLlfcvv/yCU6dOqQ5kPj4+qn1czoP0HLc2DNRERA3I+++/j3/84x9qkhI/Pz81LEp6XNc1eV9JLTp27FjVPi0TrAwfPrxSWaZGjx6NDz74QFXjS+/v5s2bq17kgwYNUo9LFbb0eJdOZhKwpQZBgrkMB5PHJKhLdXdOTo66gPn+++/Rrl07WBs7ra4bDSwsPj5etVvExcWhSZMm1X69gsIi2Ov0swApl+MAnQPgVb38o0RUd+SH+vTp0+qHXsbUUt2T0qxUZUsJWXqi1/fvVXwlYhHbqKvh+aUH0HXGGhw8V3w1uvpFYHZ7YNeC6rwsEVG9Fxsbi08//RTHjh1TbcYTJkxQQe3++++39KFZHQbqakjNyseVnAJsPFY8RCGwHWBnD2RdrKE/DxFR/aTT6VQbssyMJkOqJFhL27KUqskc26irYWArf6w5nIiNx5Lx5OBIoN1ooO1tgLNndV6WiKjek2rf0j22qWwM1NUM1GLv2ctIy85HI1cOzSIioprFqu9qCPN1Q0t/dxQWadh6IsX8QQsMdyAiovqHgbqaBrYKULcbjybrN5z7E/h0MPDVbdX+4xARETFQV9PAKH31t7RTq5FuLt76YB23E8jP5jeMiIiqhYG6mno194Wzgw4JV3JwNDEd8G0BeAYDhXlAfMn0eERERDYXqGX6OOmaL5OjBwQEqFlmZAL16/nhhx/UlHMygFxmmqlsarSa5OJojz4tG5dUf8vEJ5L2Upxhj0YiIrLhQC0ZTCZOnKjyh0pmE8lfOmzYMGRmZpb7nG3btqmcqA8//LBKei7BXRZJGm7p3t9S/W2W9vLMFosdExFRRcmUm08//bRxPTw8HLNnz77mc2Q2xuXLl1f7JNfU61yLTBPauXNn2CqLBurVq1erLC4yt6okMpfB75IT9c8//yz3OTKvqyQql8nYZWC8TDXXtWtXlXTc0oF695lLyMwtKClRS9V3fo7FjouI6jdJrCG/h2XZvHmzCoKSFaqyJKuVzL1dF8HywoULGDlyZI2+V31jVW3Ukkxc+Pr6lruPpCiTLCmmZCJ32V6W3NxcNeG8YUlPT6/howaa+7mjqa8b8gs1bDt5EWgcAXgEAoW5+o5lRES1QGoWpTZS5o0uTZJTdO/eHR07dqz06/r7+6tsU3VB0mw6OzvXyXvZKp01TcguVS8ylVz79u3L3U+yrUgeU1OyLtvLaweX3KeGxTRPaU2Rq9aS6u8kfTs1q7+JqJbdeuutKqhKbaSpjIwM1ZdHAvnFixdVc2FoaKgKvtKvR7JEXUvpqu/jx4+rdJDSL0h+Q+XioKxsWK1atVLv0aJFC5U+U5ozhRzf9OnTceDAAfV7KYvhmEtXfctUooMHD1bpKCXL1WOPPaY+j4HUwkpzp2TMCg4OVvtIE6rhvSoab1577TWVDEMuEqSkLzW8Bnl5eXjyySfV68tnlrSYEkuEjO6R2oGmTZuq54aEhOBf//oXGkSglhMt7cyLFi2q0dedMmWKKqkblsOHD6M2GAL1hqPFw7TCi9upY9lOTWTT8jIrvxQWlDxf7su20sM1y3tuJTg4OKg0kRL0TBMhSpCWtI4SoCWDU7du3fDrr7+q31gJfA8++CB27dpV4aB25513wsnJCTt37sT8+fNVUC5NOgXLcchvrDRRSsKNWbNmqcfuu+8+PPvss6qZU6q6ZZFtpUn/JKkhlfzQUv0un+OPP/5QQdPU+vXrcfLkSXX75ZdfqvctfbFyLXJ87733ngr20jQg73nbbbepCxLx4Ycf4ueff8aSJUtUB+dvv/1WXbyIH3/8UX2uTz75RO0vFxly8VPvpxCVP4Ik8d60adN1031JNUliYqLZNlmX7WWRKx7TapXayrsqPb+d7HWIT83GqZRMtGxW3E4dtxsoyAUcWLVDZJPeCKn8c+5ZCLS7Q38/5n/ADw8B8psw/teSfWZ3KDuBz6v6JsCKktzS77zzjuqca8jDLNXed911l7Em8bnnnjPu/9RTT+G3335TQahnz57XfX0JlDExMeo5UnoUb7zxxlXtyi+//LLxvgQ1eU8peD3//POqdOzh4aEuLMr7rRbfffedurD46quv4O6un5J5zpw5qi3+rbfeMtamSiCX7ZK7WkYA3XLLLVi7di0effTRCp0zCdBysfG3v/1NrctrS9CXWoS5c+eqvlKSn7p///6qxC8lagN5TD6DNME6OjqqknVFzqPNlqjlClCC9LJly7Bu3TqVs/N6+vTpo/4gpqQaRrZbkruzA3o09ykZpuUfBbj5AQXZwLm9Fj02Iqq/JFD17dsXn3/+uVo/ceKE6kgm1d5CStbS6VZKfdL/RwKmBF0JOBVx5MgRlUDDEKRFWb+3ixcvVk2XEsTkPSRwV/Q9TN9LOhYbgrTo16+fKtWbDt2VkrkEaQOpok5KKs5ieB1SWDt//rx6XVOyLu9vqF7fv38/oqKiVLX277//btzvnnvuQXZ2tqrelwsDiV8FBSY1KPWtRC3V3XIFtWLFClVtYmhnlitAuQITUq0jbSuG9oFJkyZh4MCBqtpCrqLkim3Pnj1YsMDyOaCl+nvriYtqmNY/+jfXV38fXqGv/m5m2QsJIqqiF89X/jn2JjVorUfpX8OuVLno6ega+5NIUJaSspQGpTTdsmVL9TsppLQtVb1SWpRgLUFQ+gNJO2xNkc68DzzwgGqHlmpk+Q2X32b5na4Njo6OZutS6pVgXlNkJJHkxl61apWqUbj33ntVCXrp0qXqokUuGmS7FBKfeOIJY41G6eOqFyXqefPmqXZjqa6RKyLDIldmBnJFJu0ZBnLlKMFdArNcecmJkzaCa3VAqyuDovTzfu84dRE5+YX6qi5D9TcR2SYn98ov9iZlILkv2xxdK/a6VSCBRPI7y2+jVBtLdbgELyGpJG+//Xb8/e9/V7+ZUhI8duxYhV9bhsHGxcWZ/Q7L3Bel57eQ6uGXXnpJ9TSXauPY2Fjzj+vkpEr313sv6XBmOpfG1q1b1WeT0m1N8PLyUrUDpVNsyrppZ2PZT9rRpa1dYpK0TV+6dEk9JgVJqY6XtuwNGzaoCxXpBFcvS9SmnR/KIyehNKl6kMXaRAZ4ILiRCy6k5ahgPajt7UBoNyC4k6UPjYjqMalqlqAinWelaleqbg0kaEqBRoKptO2+//77ql9PRUfASElSenOPGzdOlRzl9SUgm5L3kEKVlKJltknpuCZVwqak3VpKqVKlLH2RpBa19LAsKZVPmzZNvZf0rE5OTlY1BdL5rfRon+qQeTjkfaTmQXp8Sy2EHJd0GhNyjqTQ2KVLF3WRIJ3apErf29tbdVqTC45evXqpHu7ffPONCtym7dj1ttd3fWA+TCsZ8AwEmnQzv7omIqoFUv2dmpqqqp5N25OlrViqcmW71F5KwJHhTRUlgUqCrrTLSqepRx55BK+//rrZPtJj+plnnlF9jiTwyUWBDM8yJZ3bZHKWG2+8UQ0pK2uImAQ+aT+XkqsE/LvvvhtDhgyp8QmtpN158uTJqie6NAfI0Czp5S0XHEIuIt5++21VOyDHcebMGTVVtZwLCdZSypY2bRmjLlXg//vf/9Qwsdpip1WkWFuPyMQA0sYgVTnX62FeFauiL2DCt3vRwt8d657V98AkIusmPY2ltCcdWmXcLFFtf68qE4tY1Kth/SL9YK+zw6nkTMRdykJYYTyw/SPAzh4Yde25c4mIiEpj1XcN83JxRLem+mFaG6T6W6YR3fsVEP2D+SQIREREFcBAXQsGRvmXjKcOaAf0nwzcLWMcG1QrAxER1QAG6lpg6FC27WQKcos0YOg0oNVwwL52xtgREVH9xUBdC9oGe8HPwxlZeYX480xqbbwFERE1EAzUtXFSdXa4oZVfyTCtokLgxFpg3ev6+0RklWpydiuiohr6PrHXdy3OUvbT3nMqUE8Z0Qr4YTyQmwa0vhkI6VJbb0tEVSCzZskYWZkDWsb4yrphZi+iypJRzzJFq0zYIt8r+T5VBwN1LRkQ4afSUsckpONCeh6CZa7vY6uBM1sZqImsjPyYylhXmSZTgjVRTZAJXCS7lny/qoOBupb4uDuhUxNv7I+7jE3HknFfs37FgXoL0Nc8tyoRWZ6UeuRHVTIhXW9OaqLrkexektazJmpmGKhrufe3BGqp/r5vUHFKtbPb9O3UupIUbURkHeRHVTIg1VYWJKKqYGeyWjSoeDz15uMpKAjoADh5AjlpQOKh2nxbIiKqRxioa1HHJt7wdnNEek4B9p3LAJr21j8g1d9EREQVwEBdi2TO7wGRJrOUhRdXf8ea50ElIiIqDwN1LRtUPEvZhmNJQLP+JYGa4zWJiKgCGKhr2YDiiU8OnruCZM82gKM7kJ0KJB2u7bcmIqJ6gIG6lgV4uqBdiJe6v/nUZaBpL/0DrP4mIqIKYKCuw97fajpRGU8t2KGMiIgqgIG6DgxsFaBuZeKTQtN2ao1pL4mI6No44Ukd6NLUG57ODkjNysdBrQU6RQ7XV4EX5AKOLnVxCEREZKMYqOuAo70O/SP9sOpgAjacSEOnB5bUxdsSEVE9wKrvOpxO1DhMi4iIqIIYqOvIDcWB+kDcZaRm5gHpicCh5WynJiKia2KgriMh3q5oFeiBIg3Yeuw88EFH4IdxwMUTdXUIRERkgywaqDdt2oRRo0YhJCREZa1Zvnz5NfffsGGD2q/0kpCQAFswKErf+1vaqRHWCwjqCGRdsvRhERGRFbNooM7MzESnTp0wd+7cSj3v6NGjKsG7YQkI0AdAW2mnlvHURQ/8CDy+uWQCFCIiImvr9T1y5Ei1VJYEZm9vb9ia7uE+cHOyR3J6Lo4kZaFdSCNLHxIREVk5m2yj7ty5M4KDg3HTTTdh61bbyUTl7GCPvi0bl8xSJvKzgbwsyx4YERFZLZsK1BKc58+fjx9//FEtYWFhGDRoEPbu3Vvuc3Jzc3HlyhXjkp6eDqsYpiVpL1c+D7zZFIj+waLHRERE1sumJjyJiopSi0Hfvn1x8uRJzJo1C19//XWZz5k5cyamT58O65pO9BD2xqYit7kHnAvz9NOJdhtn6UMjIiIrZFMl6rL07NkTJ06UP8RpypQpSEtLMy6HD1s2vWTTxm5o4eeOgiINB+w7lCTo4LzfRERUHwP1/v37VZV4eZydneHl5WVcPD09YS2Tn/yS2gTQOQJXzgGpZyx9WEREZIUsGqgzMjJUoJVFnD59Wt0/e/assTQ8duxY4/6zZ8/GihUrVAn64MGDePrpp7Fu3TpMnDgRtmRgcdrLP45fgRbaVb+RaS+JiMja2qj37NmDG2+80bg+efJkdTtu3DgsXLhQjZE2BG2Rl5eHZ599FufOnYObmxs6duyIP/74w+w1bEGfFo3h7KDD+bQcpLbrCd+4nfp26q4PWvrQiIjIythpWsNqHI2Pj1e9xePi4tCkSROLHcfYz3ep/NTzel/GyP1PAI2aAs9EW+x4iIjIOmORzbdR2yrDMK2lSaGAnT2QdhZIjbX0YRERkZVhoLZwoN4cm43CkC76jVL9TUREVN1ALUV1KbYb7Nq1S3XsWrBgQVVerkFq6e+OJj6uyCssQrxXcaA+w0BNREQ1EKjvv/9+rF+/Xt2XzFUylacE65deegmvvfZaVV6ywZGsX4ZS9abc4klczmy27EEREVH9CNQyNEomGhFLlixB+/btsW3bNnz77beqtzZVjCFQf5cQom+nvhwLpJXUVBAREVUpUOfn56uJRIQMj7rtttvU/datW6shVVQxfSP84GhvhyOXgFz/DoCDC5B8lKePiIiqF6jbtWunkmNs3rwZa9aswYgRI9T28+fPo3FjfXYouj4PZwd0b+ar7v8vaibwwlkgYghPHRERVS9Qv/XWW/jkk09U5qoxY8agU6dOavvPP/9srBKnys1S9utZB8BBX0tBRERUrZnJJECnpKSotJE+Pj7G7Y899piaMYwqcS6j/PHmqhhsP3UROfmFcHG01yfosLPjaSQioqqVqLOzs1WeZ0OQjo2NVfNwHz16FAEBksaRKioq0BOBXs7IyS/C+ZVvA3N7Awd/5AkkIqKqB+rbb78dX331lbp/+fJl9OrVC++99x5Gjx6NefPmVeUlGyzTYVqJ52OB5CNM0EFERNUL1Hv37sWAAQPU/aVLlyIwMFCVqiV4f/jhh1V5yQZtUJS+FuLzjN7AvV8Dg1+x9CEREZEtB+qsrCxjXufff/8dd955J3Q6HXr37q0CNlVOvwg/2OvssOaiP+KDhwLu7DlPRETVCNQRERFYvny5mkr0t99+w7Bhw9T2pKQkeHl5VeUlG7RGro7oEuat7m86lmLpwyEiIlsP1FOnTsVzzz2H8PBwNRyrT58+xtJ1ly7F81ZTpRjaqQ9H/wlseBPY+QnPIBERVS1Q33333Th79iz27NmjStQGQ4YMwaxZs3haq9FOnREXDWyYCez5nOeRiIiqNo5aBAUFqcWQRUsSX3Oyk6prF+KFxu5O2JgZCbgASI4BMlMAdz9+TYmIGrAqlaiLiopUlqxGjRqhWbNmavH29saMGTPUY1SFP4TODje08kcqvJDk2lK/kfmpiYgavCoFaklnOWfOHLz55pvYt2+fWt544w189NFHeOUVDi2qzixlYkdRG/2GM1sa/BeUiKihq1LV95dffonPPvvMmDVLdOzYEaGhoXjiiSfw+uuv1+QxNhj9I/zUzKGr0lviNicJ1FstfUhERGSLJepLly6plJalyTZ5jKqmsYczOoY2wq6i4nObdAjI4vkkImrIqhSoJVuWVH2XJtukZE1VNzAqABfRCBecmuk3xG7j6SQiasCqVPX99ttv45ZbbsEff/xhHEO9fft2NQHKypUra/oYG9x46g/XHsemvCjch1h9O3WbWy19WEREZEsl6oEDB+LYsWO44447VFIOWWQa0UOHDuHrr7+u+aNsQDo1aaRmKtucF6XfEMsOZUREDVmVx1GHhIRc1WnswIED+O9//4sFCxbUxLE1SA72OvSP9MPOv4p7ficcBLJTAdeSvN9ERNRwVKlETbVrUCt/JMMb8fZNAGhA7HaeciKiBsqigXrTpk0YNWqUKp1LXmZJ9HE9GzZsQNeuXeHs7KySgyxcuBD1dd7vTXmt9Bs48QkRUYNl0UCdmZmpepDPnTu3QvufPn1adWK78cYbsX//fjz99NN45JFHzOYbrw8CvFzQJtgL/yvsgyNRE4H2d1n6kIiIyBbaqKXD2LVIp7LKGDlypFoqav78+WjevDnee+89td6mTRts2bJFJQIZPnw46tssZfMutMMCXShmhXa29OEQEZEtlKhlbu9rLTLn99ixY2vtYGUI2NChQ822SYCW7fW2+vtYMoqKNEsfDhER2UKJ+osvvoAlJSQkIDAw0GybrF+5cgXZ2dlwdXW96jm5ublqMUhPT4ct6NbMBx7ODsjPvIS4bUvQzM8TaH2zpQ+LiIjqWL3v9T1z5kyzUn/btm1hCxztdegX0RiDdfvR7I/HgM3vWvqQiIjIAmwqUEv+68TERLNtsu7l5VVmaVpMmTIFaWlpxuXw4cOwFQNbBWBnURvE2YcBod0BjVXgREQNjU0FapmudO3atWbb1qxZY5zGtCwyjEsCuWHx9PSErRgY5Y8LaIyBWW8hbdDrUKm1iIioQbFooM7IyFDDrGQxDL+S+2fPnjWWhk07pz3++OM4deoUnn/+ecTExODjjz/GkiVL8Mwzz6A+CvV2RWSAB6Qv2ZYTKZY+HCIiamiBes+ePejSpYtaxOTJk9X9qVOnqvULFy4Yg7aQoVm//vqrKkXL+GsZpiV5sevb0Kyyen9viTkHJERb+nCIiKiO2Wlaw2r4jI+PR1hYmMr01aSJTNFp3TYfT8bT/12DrS6T4Kwrgt0LZwEnd0sfFhERVUNlYpFNtVE3RD3CfZHl6IsUzQt2RQVA3E5LHxIREdUhBmor5+Jojz4tG2NnUWv9BslPTUREDQYDtY20U+8oKh7/fWarpQ+HiIjqEAO1jQRqGU8ttHN/AnlZlj4kIiKqIwzUNiDczx06n3Bc0HxhV5QPxO+29CEREVEdYaC2EQOjArCjuFTNdmoiooaDgdqGZikzVn/HskMZEVFDwUBtI3q3aIy9dvoOZVr8n0B+jqUPiYiI6gADtY1wc3JAYHg7JGre0BXmAuf2WPqQiIioDjBQ21g7taH6m+3UREQNAwO1DRlk0k5deJrt1EREDQEDtQ1p6e+BU+5dkKfZIy23iPmpiYgaAAZqG2JnZ4fwqM7omPsZPgx5h/mpiYgaAAZqG2ynzoEzNh1LtvShEBFRHWCgtjH9IhrDQWeHUymZiEtIsfThEBFRLWOgtjGeLo4Y1MQOvzi9iKBPOwAFeZY+JCIiqkUM1Daoa5sIBNtdhGNhFpB40NKHQ0REtYiB2gYNigrEP/OewcCiecgN7GTpwyEiolrEQG2D2gR7ItajE2LzGmHPmVRLHw4REdUih9p8caq9YVqSo3rpn/HI3fAesCUaCGwPBMnSAfBvDTg48/QTEdUDDNQ2PEuZBGrXCzuBwj+BM5tLHtQ5AH6tSoK3uu0AeARY8pCJiKgKGKhtVP8IPzVMa1rWveio6462urPo5nwOkdoZuBVeAZIO65foJSVPcg/QB+6OfwM63WfJwyciogpioLZR3m5O+HBMFyzfF4CNcRFYmp4L5MsjGoJwCW11sejiFI+ebucRWXQGPjlxsMtMAk6uA5r2LXmh1Fhg8d+B0G7AqNkW/ERERFQWBmobdnOHYLVomobzaTnYf/Yy9p1Nxf44X2w95491OV2B4rTVrshBlF08+nteQNGZFgh0PIMuTb3RJu0vOCb8pQK8me+KS9zG6vMOgG9zQGdf9x+UiKgBY6CuJ53LQr1d1XJLx2C1Lb+wCDEX0rE/LhX74i6rIL4/xQX7r0QAVwAcOaT2C3TIwp2NX0Zzd3e4HjivgneopwPspORdmAccW13yRo5uQEBb83Zv6bjm6l3rn1EuRtJzC3AxIw8XM3KRkpGH7PwC9Aj3RRMft1p/fyIiS7HT5BewAYmPj0dYWBji4uLQpEkTNCSXs/KwX4J28bLv7GWkZav6cjOB7g64M/A8ertdQGuchl/mcdgnxwAF2WW/sEegvvPa0OlAk276bYX5+k5tdnblHk9uQSEuZUrgzUNKRq4+CGfqb1OK7xu3Z+Qhr7CozNfp1KQRRrQPxsj2QQj3c6/i2SEiss5YZBWBeu7cuXjnnXeQkJCATp064aOPPkLPnj3L3HfhwoUYP3682TZnZ2fk5BTX8V5HQw7Upcmf/szFrOLqcn3wPnz+CgqKzL8SEmtb+7thaGAGertfQGu7WPimH4OdzIqWft64X9Ej65Hm014FWPvdnyJs3zs4GnoXfmvyL1UKvpieC6e0kzic0xiJmYVIzymo9DF7ODugsYcTGrs7qcp6OWbTb3CbYC/c3D4IIzsEISLAs3oniIiollQmFlm86nvx4sWYPHky5s+fj169emH27NkYPnw4jh49ioCAsocTeXl5qcdNq36p8uS8NfdzV8udXfVflJz8Qhw6n6ZK24Yq83OXs3EkKQtHknT4CKEAQuHuNAAdmjSCp2c2XK+cgk/2Gfz48RlkFF1Qr/OawzaMdcjCppOX8eHR42qbP1Kx22Ui8jV7xGqBOOkYglMIRaJTU6S6NUeWVwt4ePmoINzYw1kFZD8VlJ3h5+mstrs4mreRJ6fn4vfDCVgVnYDtpy7iyIUranlvzTFEBnioUvbIDsFoHeTJ7wkR2SSLl6glOPfo0QNz5sxR60VFReoq46mnnsILL7xQZon66aefxuXLl6v0fixRV15SenFHteLA/Vf8ZWTmFZa7fyNXRwS626GdyyW4unvC3qepCrqtCo9j2K5H4CBzlJfHMwTwb6WvSjcsYb0AR5frHmdqZh7WHE7EyoMXsPVECvILS77a4Y3dVMCWwN0htBGDNhFZlM1Ufefl5cHNzQ1Lly7F6NGjjdvHjRunAvGKFSvKDNSPPPIIQkNDVVDv2rUr3njjDbRr167M98jNzVWLwblz59C2bVtWfVdDYZGG40npiI5Pg4O9nSrx6ku/zvBxc4KTwzVmpi0q0leXJx8FUo4DKcW3si7Dx8ry3PGSyVoO/gRcPgtE3gQElv03F9L2vvZIIlYdTMDGY8nIKyhp35ZOd4aSdpcwb+h0rJEhorplM1XfKSkpKCwsRGBgoNl2WY+JiSnzOVFRUfj888/RsWNHpKWl4d1330Xfvn1x6NChMj/szJkzMX369Fr7DA2Rvc4OrYO81FJpOh3QqIl+iRhi/lh2anHwPlYcyI8B6QmAu3/JPn8t1vdEd3IvCdSXTgP7vtGPBZfFM1CV6qU6X5aM3AKsj0nCqoMXsD4mWVXlf7bltFqCvFwwon2QWqQHuXw2IiJrYtES9fnz51XJeNu2bejTp49x+/PPP4+NGzdi586d132N/Px8tGnTBmPGjMGMGTOuepwl6npm16fA2R1Anyf0QVns/Rr4+cmSfRqFAaFdSwJ3cGfA2UM9lJ1XiI3HJGgnYO2RJBXEDaQ9fFi7INzcPhi9WvjC0Z45a4iogZeo/fz8YG9vj8TERLPtsh4UFFSh13B0dESXLl1w4sSJMh+XHuGyGFy5IoOIyWb1fFS/mGrcEujyd+DcXiDpCJAWp18OFzed2OkA/zYqeLuGdsMIWe7pgJwiO9WWvTI6AWsOJ6ghYd/tPKsWbzdHDGsbiJHtg9Evwu/a1flERLXIooHayckJ3bp1w9q1a41t1NLuLOtPPmlSQroGqTqPjo7GzTffXMtHS1arWV/9InLTgQsHgPg9wLk/9cH7SjyQdEi/7Ptav19IF7g8tgFD2gSqJe9yALYn2mP1oQT8dihRje9esideLZ4uDhjaRoJ2EG5o5X9Vz3Miotpk8eFZMjRLOo91795djZ2W4VmZmZnGsdJjx45V1ePS1ixee+019O7dGxEREarDmYy/jo2NVR3MiODsCYT31y8G0s6tgrZh2WveEa0wH05zOmOgkwcGPr4FM25vj12nL+G36HisPJyihoAt23dOLW5O9hjcOkCVtCUxipuzvUqOwiGCRFRvA/V9992H5ORkTJ06VU140rlzZ6xevdrYwezs2bPQSQekYqmpqXj00UfVvj4+PqpELm3c0pObqEyeQUDrW/SLoed5fmbJ49IZragQKMpXs6w56HToG+GHvvufx6ue+3EprD125TfHjwmB2JwejF/+uqAWU072Ojja28HRQW51JevqVqe2O5muyz4Oduq9DPfNHjPsa3y9q1/L39MZrQI94eniyD88UT1m8XHUdY3jqKlM+Tn6YV8yhttgdkfgcqzZbkU6RyS6RmB7bjPsym6CBM0HSZoPEjUfXIInNNR9W7YMN4sK8tQvgfrbFv7ucHZgFT2RtbKZcdSWwEBNFZZ1CTi/T19Vfm6Pvt07K6Xc3TWdA5L7z0BK67+rpCh2l8/C+8RPyPAIx/nQkWqbzFeeX1CE/CJNrcukLPmGbepxw/bi9YJS6/J4gf51zqVmI+FK2VPnSnW8zDjXKsgTrQM99bdBngjzceO4cSIrYDO9vomsmpuvfqy3Yby3XNNKb3Jp55agLWO9MxKA9EQgMxl2RQUI8A9AQEjx+PLMbcCBWUBIV7S96aGS153TA8jL0lfJmy6+wYCHYT1Y//7XmR5XEq0cS8zA0YQrOJqYjqMJ6YhJSFfzqB9PylDLryippnd1tEerQA9V6pZqcxkL3yrIA/4ezmxnJ7JSDNREFSVB07upfml3h/ljki0sIwlwMZkExjMQ6PKgfn8DCfaX4/SZyKQ3+rXoHEuC+IBngaiR+u2ZKcD5/YB3GLz9o9Czua9aSt5CUyVtCdrGJTFdBe3s/EIciE9TiylfdycVwFXgLq4+l0WSoBCRZfG/kKgm2DsCjSRhiQnDhCulPbVH3xNdLReAjET9rVovvi9V7NK5zTAmPN9kfnSZ8GXxA0CTnsAja0q2fzoYKMiFnZsvgl19Eezmi0FujYGmvkBrXxS6+OBCvgdOpDvh0GVHRCcX4VhSBs5czFTD0XacuqQWs4/g7aqqzA1V5xLEW/p7VHlcuVxEyBS0kqHN/LZIf1tY9nbDYtguQ+Q4/Ss1FAzURHVdKjdMoXotBXn6uc8NAV1mWjPQ2QMB7YDGEebPSTxcfs5wuZYA0KR4GaRexwG4dTZyOtyPE0kZOH98H/wP/RdH8oPxYdZwVSqX6VYbpR3B6aNOWKR5IA0e0Ons0ayxmwqWZQVRY9CV9ULz7aUyqFZLS393/HNgS4zuHMoJaaheY2cyovpAqtSl41v2JSArFci6WHz/Uqn7l/T3DSX0uz8H2t+lv3/4Z2DJg/psZQ//rtq/pdq8/eLecM/VJ0wpgh2uaG5I1TyQDRfkwhE5mpP+FvrbXM0Ry4r6Y3uRfqx6MC7iVvvtSNK8saKoZHx7D7sYONgVqv1z4YQCnWFxQYGdEwp1zqqXvb29Ts3BLh3k9Lc6nL+cjfTi6V+DG7ngkQEt8LceYXBnVT3ZCHYmI2qIJXXTUvf15Gfrg7ZLo5JtklL0xpeNmcq83ZzQq0VjwMsXuJIL5KZBBw3edplquZYbbhiJjPYDVXB1i9+MgOXfocCvDaY+9KoKtPb2dnBbMA26i/pc5WWShGdF0pnOBbBzBnSuQL9JQO8JSM/Jx6LtJxGz5Sf8kdYSM37JwUfrjmNcn3A81DccPu5OFT8XRFaOVd9EDZGj69Vt6gGt9UtpE3eWdJiTDGfGUnk2UJBTvOQWr+eq9aCIfkCAPhEKCpoAHe+Dg2cwGnuUzLsP3xb6anyT5xkXI01fnS9LzmXjYzLJy6ORGcDGt5Dr6Y3hjl/gzKVsfLD2OL7edBi394zEowNaIMTbtebPHVEdY6Amoop3mJPStiE3eEUFtQfuXHD19geWlF+NX5hXKoDLbbaaOc4oJw3wi4KzXyTW3nsjVh9MwMfrj+OTS+ORs9sJG3e1QVHTvug7ZBSat4jiX5lsFtuoici2SUlfLiIkxqedg92sq6cTTnYIhq55PzRuOxgI7wd4N7vuGHWi2sQ2aiJqOIqDtLCT6vznT6shbEnRa5F1YjPCco7Bv+ACcHypfpGA7hUKu2b99FnXJIGL9KBn4CYrxapvIqpfZEa31jcjoLU+9e3J+PNY//v/UHB6C3rYHUFHu1NwvHIOiF6iX8Qzh0qGzKlOdt6ASTIgIktioCaieq1lkxC0/Mc/cf7yWHy2+TQe2XUcbQpj0EsXg4FOR9HcNRsu7sEwdnNb9jgQvwu4bQ7Q5lY0dBm5BTiZlKHG2p9IzkDcpSzVm1/G0ZcsOjU9reG+6WOuJtvkvrPJfckGR9fHQE1EDYL0AJ86qi2eGhyBL7e3wRfbzmBWVj7ssorg/9Z6PNy/Oe7vGQbPhGh973bTXvEHfwIOfK+vKpcq8+DOgEP9GQImM8alZOQZg7EhMJ9MzsCFtLITv9QEGRfv4qCDq5O9yvamAr6TPVzUffPA71p839fdGf0iGqN9SKMGk2CGncmIqEHKzC3Aot1x+GzzKWMw8nRxwEO9QvFwyzR4t+wF2BeXZVZMBPZ9U/JkmdVNhpfJ2HOzJcJ8bLqVKSrSEJ+ajRPJ6fpAnJSpArPcT8vOL/d5fh7OiAhwR0SAB8Ibu6tt2XmFyCkoRE5+kZpDPie/ELkm92XJzi9CrvG+fl95Tk3kbGzs7oQbWvljUJQ/BkT6q/nqbQnTXNbQySGi+i+voAgr9p/D/I0ncTJZP5GLs4MO93YPw2M3tECYrxuQdAQ4uR6I3apfpMRdHsmA5hcJtL5FTc5iJNGpjjqs5RYU4nRKpj4QF5eS5fZUcgZyC2QmmavJoUkaVAnGMj2r3KrF3xON3Eo67NVE6V2OIbc4aJsF/OL7uaaBPb/kvmyXz7Xt5EVVJW967J2aeKugPbCVPzo28ValdWvGQF1DJ4eIGg4pba45koiPN5zEgbjLapv82I/qGIzHB7VUmcWKdwTSz+vTnKYcB1KOFS/H9WlPDbr/A7h1lv5+Xibwbit9KfwfvwFObvrtkoRFSuCOLlU65is5+Wbtx4b7Zy9llTuvupO9Di383VVylZbGYOyhtkkVs61cXP0Zm4oNx5Kw8WiySu1qysfN0VjaviHS33yiHSvBQF1DJ4eIGh4p8W0/dRHzNpzE5uMpxu2DWwdgwqCW6BFeklL0KjIJS8oJfeD2bQ407a3ffuEA8MkNgGQze/4U8gv1VcTOi+6D05l1yPcKQ7ZXS2R6tsAVj+ZIdQtHinMzpNl5IadAX9KU/dWSV6gCsQTkpPTccg/F09mhJBAXB2O5lRoCay9tVlZCWg42HkvChqPJ2HI8xTgPvKG03SG0EQa18sfAqAB0DrOO0jYDdQ2dHCJq2A6eS8O8jSexMvqCsV21ezMf3NoxWGUFyy0VRHNKBVRDtW1+Xj5888/DI/8Stua3Us8VvzpNQTtdbLnvL8lPTmohOFkUghNyq4Uguqg5kuGjHndGHqI8shHm54XGweHGgBzlmAhf5yLYaUWALFILoO4XAkWFJfdNH2vcUr8Iqdo/uQ6wdzbv+X50lT4Nq7yGWgpMlnLWpQNeu9ElQ99WPifhE7j7vyWvu+514Oz2a7xmfsm6vZN+3HvkTUCvf151zuQiaG9sKjYeS1aB+/CFK2aPN3J1xIBIPwyKClDV5P6eliltM1DX0MkhIhLSLrpg00n8+Oc55BWW3cZbFXZ2Gpo4ZqC1QwIidRfQUnce4do5hBXFw68wSSVBKW1b+EScaz9BBeVWmXvgvvhuILA9MGFryU4fdgUunazcwUhCloH/1t+Xnu/z++unbH3uWMk+/x0GxBXP/V5RPf8J3Py2/r6kbH0vCrCzB6aZ5D5f9AAQ80vlXrfzA8Doj0vSwn7QSX+h8bfvAJfiZoq8TCRl67DheIoK3JuPJeNKTklpW7QP9cKgVgEYGOWvcpw71NGQMc5MRkRUg5r7uWPmnR3x9NBW+HLbGRxPylDDhdQiw4mM90vGEJf9eMl2GU8sndbsyutglpelD7aG9u/itvC+fW4AosL0+5x2ARxczGZnU9z9gLwMwE6nD4pyKxO4mK3LrSx2+vumc7g7eQDhAwBXfcndSErHbn76/aXnu7yv3BrWjYvJepMeJc939gJGvKnfbqrPRKD9neW8hqP5NvlcqmmhRcnzL53S9xvITQecPUu2L/snAk5txL1+rXCvfxQKh0TiFEKx8aIvfj7rgL/OZ+LguStqmbP+BLxcHFQPcgnaUlUe4FW1vgM1jcOziIjIthXkAokHgYxkIGpEyfa5vYHkI2U/x94ZBb4tccGxGaJzA7Hhkg8O5ATitBaMPOgvfNoEe6kOaRK0uzbzqdEJWlj1XUMnh4iIbDyAX5RaiaNA8rHi2+Le+oVld8Tb0eQfmJlzF/46l4ZGWjoG6/bhqBaGs06R6B/pp9q1b+0UAg/n6s0XxqpvIiIiB2cgsK1+MSWd0i7HmgTvY0ByjKpS792rH1Z06I+LGbmI2fIT+u2Yr6rLB+e8g1UHE/DboQQMbxckPfnqDKcQJSKihkVnr2/jlsW0qly69ksPeJn5zMMZ/VqFAAkDEO7bEsu79MOGo0lIvJIDnzqeBc0qZkSfO3cuwsPD4eLigl69emHXrl3X3P+HH35A69at1f4dOnTAypUr6+xYiYionrIr7lhn0GIg8NAv0N32gRp/LZ0JpVNhXbN4oF68eDEmT56MadOmYe/evejUqROGDx+OpKSkMvfftm0bxowZg4cffhj79u3D6NGj1XLw4ME6P3YiIqJ63+tbStA9evTAnDlz1HpRUZHq7PXUU0/hhRdeuGr/++67D5mZmfjll5Ixd71790bnzp0xf/78674fO5MREZGlVSYWWbREnZeXhz///BNDhw4tOSCdTq1v3769zOfIdtP9hZTAy9ufiIjIllm0M1lKSgoKCwsRGBhotl3WY2JiynxOQkJCmfvL9rLk5uaqxSA93XzydiIiImtm8Tbq2jZz5kw0atTIuLRtW6qbPhERkRWzaKD28/ODvb09EhMTzbbLelBQUJnPke2V2X/KlClIS0szLocPH67BT0BERFSPq76dnJzQrVs3rF27VvXcNnQmk/Unn3yyzOf06dNHPf70008bt61Zs0ZtL4uzs7NaDC5f1ueZvXDhQg1/GiIioooxxCCJedelWdiiRYs0Z2dnbeHChdrhw4e1xx57TPP29tYSEhLU4w8++KD2wgsvGPffunWr5uDgoL377rvakSNHtGnTpmmOjo5adHR0hd5v165d0sudC88BvwP8DvA7wO+AZulzIDHpeiw+M5kMt0pOTsbUqVNVhzAZZrV69Wpjh7GzZ8+qnuAGffv2xXfffYeXX34ZL774IiIjI7F8+XK0b9++Qu/XpUsXNaGKvL7p61aFdEyTNm+pTvf0NMnYQjxfNYTfMZ6v2sTvl+XOl5SkpdlWYpLVj6O2ZVeuXFEd1KTt28urOP8p8XzxO2Yx/J/k+aqP36963+ubiIjIljFQExERWTEG6mqQ3uQyR7lpr3Li+apJ/I7xfNUmfr9s43yxjZqIiMiKsURNRERkxRioiYiIrBgDNRERkRVjoK6GuXPnIjw8HC4uLiqvtkykQmXbtGkTRo0ahZCQENjZ2alJaqj8RDKSo10mVAgICFDT6x49epSnqxzz5s1Dx44d1bhWWWQ64VWrVvF8VdCbb76p/idNp2Umc6+++qo6R6ZL69atUVcYqKto8eLFmDx5suoBuHfvXnTq1EnlxU5KSqrZv1A9kZmZqc6RXNzQtW3cuBETJ07Ejh071Dz2+fn5GDZsmDqHdLUmTZqoYCO57ffs2YPBgwfj9ttvx6FDh3i6rmP37t345JNP1IUOXVu7du3U/NyGZcuWLagzVZ+lu2Hr2bOnNnHiRON6YWGhFhISos2cOdOix2UL5Gu3bNkySx+GzUhKSlLnbOPGjZY+FJvh4+OjffbZZ5Y+DKuWnp6uRUZGamvWrNEGDhyoTZo0ydKHZLWmTZumderUyWLvzxJ1FeTl5amr96FDhxq3ybzhsr59+/aavI4iUtMVCl9fX56N6ygsLMSiRYtU7UN5GfVIT2ptbrnlFrPfMSrf8ePHVdNdixYt8MADD6g8FHXF4kk5bFFKSor6QTAkDjGQ9ZiYGIsdF9U/MnG/tB3269evwolnGqLo6GgVmHNycuDh4YFly5ap5AlUNrmYkSY7qfqm65M+SAsXLkRUVJSq9p4+fToGDBiAgwcP1klCJgZqIisv9ciPQZ22h9kg+QHdv3+/qn1YunQpxo0bp9r6GayvFhcXh0mTJqn+D9IRlq5v5MiRxvvSni+Bu1mzZliyZAkefvhh1DYG6irw8/ODvb29SlFmStaDgoJq6m9DDdyTTz6JX375RfWYlw5TVD4nJydERESo+926dVMlxQ8++EB1lCJz0mwnnV67du1q3CY1hPI9mzNnDnJzc9XvG5XP29sbrVq1wokTJ1AX2EZdxR8F+TFYu3atWRWlrLNdjKpL+ttJkJbq23Xr1qF58+Y8qZUk/48ScOhqQ4YMUU0FUgNhWLp3767aXeU+g/T1ZWRk4OTJkwgODkZdYIm6imRollSvyRe8Z8+emD17turAMn78+Jr9C9WjL7bp1efp06fVj4J0kGratKlFj80aq7u/++47rFixQrV/JSQkqO2SB9fV1dXSh2d1pkyZoqom5XuUnp6uzt2GDRvw22+/WfrQrJJ8p0r3d3B3d0fjxo3ZD6Iczz33nJoHQqq7z58/r4blygXNmDFjUBcYqKvovvvuQ3JyMqZOnap+SDt37ozVq1df1cGM9GR864033mh2oSPkYkc6aZD5BB5i0KBBZqfliy++wEMPPcRTVYpU444dO1Z18pGLGWlDlCB900038VxRjYiPj1dB+eLFi/D390f//v3VPAdyvy4wexYREZEVYxs1ERGRFWOgJiIismIM1ERERFaMgZqIiMiKMVATERFZMQZqIiIiK8ZATUREZMUYqImIiKwYAzUR1Ro7OzssX76cZ5ioGhioieopmW5UAmXpZcSIEZY+NCKqBM71TVSPSVCWOcJNOTs7W+x4iKjyWKImqsckKEuOdNPFx8dHPSala0kAIpmnJCtXixYtsHTpUrPnSzrEwYMHq8clu9Jjjz2mMqGZ+vzzz9GuXTv1XpL2T1J0mkpJScEdd9wBNzc3REZG4ueffzY+lpqaqtIrSnIDeQ95vPSFBVFDx0BN1IC98soruOuuu3DgwAEVMP/2t7/hyJEj6jFJ2zp8+HAV2Hfv3o0ffvgBf/zxh1kglkAvaTklgEtQlyAcERFh9h7Tp0/Hvffei7/++gs333yzep9Lly4Z3//w4cNYtWqVel95PT8/vzo+C0RWTiOiemncuHGavb295u7ubra8/vrr6nH593/88cfNntOrVy9twoQJ6v6CBQs0Hx8fLSMjw/j4r7/+qul0Oi0hIUGth4SEaC+99FK5xyDv8fLLLxvX5bVk26pVq9T6qFGjtPHjx9fwJyeqX9hGTVSPSQ5wQ35rA19fX+P9Pn36mD0m6/v371f3pYTbqVMnuLu7Gx/v168fioqKcPToUVV1fv78eQwZMuSaxyD5oQ3ktby8vFQOaTFhwgRVot+7dy+GDRuG0aNHo2/fvtX81ET1CwM1UT0mgbF0VXRNkTblinB0dDRblwAvwV5I+3hsbCxWrlyJNWvWqKAvVenvvvturRwzkS1iGzVRA7Zjx46r1tu0aaPuy620XUtbtcHWrVuh0+kQFRUFT09PhIeHY+3atdU6BulINm7cOHzzzTeYPXs2FixYUK3XI6pvWKImqsdyc3ORkJBgts3BwcHYYUs6iHXv3h39+/fHt99+i127duG///2vekw6fU2bNk0F0VdffRXJycl46qmn8OCDDyIwMFDtI9sff/xxBAQEqNJxenq6CuayX0VMnToV3bp1U73G5Vh/+eUX44UCEekxUBPVY6tXr1ZDpkxJaTgmJsbYI3vRokV44okn1H7ff/892rZtqx6T4VS//fYbJk2ahB49eqh1aU9+//33ja8lQTwnJwezZs3Cc889py4A7r777gofn5OTE6ZMmYIzZ86oqvQBAwao4yGiEnbSo8xknYgaCGkrXrZsmerARUTWi23UREREVoyBmoiIyIqxjZqogWKrF5FtYImaiIjIijFQExERWTEGaiIiIivGQE1ERGTFGKiJiIisGAM1ERGRFWOgJiIismIM1ERERFaMgZqIiAjW6/8BZX/3EzbaTIMAAAAASUVORK5CYII=\",\n \"text/plain\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fd5408e6-83e4-4e5a-8503-c2fba6073f31\",\n \"metadata\": {},\n \"source\": [\n \"- Finally, let's use the finetuned GPT model in action\\n\",\n \"- The `classify_review` function below implements the data preprocessing steps similar to the `SpamDataset` we implemented earlier\\n\",\n \"- Then, the function returns the predicted integer class label from the model and returns the corresponding class name\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"aHdn6xvL-IW5\",\n \"metadata\": {\n \"id\": \"aHdn6xvL-IW5\"\n },\n \"outputs\": [],\n \"source\": [\n \"def classify_review(text, model, tokenizer, device, max_length=None, pad_token_id=50256):\\n\",\n \" model.eval()\\n\",\n \"\\n\",\n \" # Prepare inputs to the model\\n\",\n \" input_ids = tokenizer.encode(text)\\n\",\n \" supported_context_length = model.pos_emb.weight.shape[0]\\n\",\n \" # Note: In the book, this was originally written as pos_emb.weight.shape[1] by mistake\\n\",\n \" # It didn't break the code but would have caused unnecessary truncation (to 768 instead of 1024)\\n\",\n \"\\n\",\n \" # Truncate sequences if they too long\\n\",\n \" input_ids = input_ids[:min(max_length, supported_context_length)]\\n\",\n \" assert max_length is not None, (\\n\",\n \" \\\"max_length must be specified. If you want to use the full model context, \\\"\\n\",\n \" \\\"pass max_length=model.pos_emb.weight.shape[0].\\\"\\n\",\n \" )\\n\",\n \" assert max_length <= supported_context_length, (\\n\",\n \" f\\\"max_length ({max_length}) exceeds model's supported context length ({supported_context_length}).\\\"\\n\",\n \" ) \\n\",\n \" # Alternatively, a more robust version is the following one, which handles the max_length=None case better\\n\",\n \" # max_len = min(max_length,supported_context_length) if max_length else supported_context_length\\n\",\n \" # input_ids = input_ids[:max_len]\\n\",\n \" \\n\",\n \" # Pad sequences to the longest sequence\\n\",\n \" input_ids += [pad_token_id] * (max_length - len(input_ids))\\n\",\n \" input_tensor = torch.tensor(input_ids, device=device).unsqueeze(0) # add batch dimension\\n\",\n \"\\n\",\n \" # Model inference\\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(input_tensor)[:, -1, :] # Logits of the last output token\\n\",\n \" predicted_label = torch.argmax(logits, dim=-1).item()\\n\",\n \"\\n\",\n \" # Return the classified result\\n\",\n \" return \\\"spam\\\" if predicted_label == 1 else \\\"not spam\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f29682d8-a899-4d9b-b973-f8d5ec68172c\",\n \"metadata\": {},\n \"source\": [\n \"- Let's try it out on a few examples below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"apU_pf51AWSV\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"apU_pf51AWSV\",\n \"outputId\": \"d0fde0a5-e7a3-4dbe-d9c5-0567dbab7e62\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"spam\\n\"\n ]\n }\n ],\n \"source\": [\n \"text_1 = (\\n\",\n \" \\\"You are a winner you have been specially\\\"\\n\",\n \" \\\" selected to receive $1000 cash or a $2000 award.\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"print(classify_review(\\n\",\n \" text_1, model, tokenizer, device, max_length=train_dataset.max_length\\n\",\n \"))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"1g5VTOo_Ajs5\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"1g5VTOo_Ajs5\",\n \"outputId\": \"659b08eb-b6a9-4a8a-9af7-d94c757e93c2\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"not spam\\n\"\n ]\n }\n ],\n \"source\": [\n \"text_2 = (\\n\",\n \" \\\"Hey, just wanted to check if we're still on\\\"\\n\",\n \" \\\" for dinner tonight? Let me know!\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"print(classify_review(\\n\",\n \" text_2, model, tokenizer, device, max_length=train_dataset.max_length\\n\",\n \"))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bf736e39-0d47-40c1-8d18-1f716cf7a81e\",\n \"metadata\": {},\n \"source\": [\n \"- Finally, let's save the model in case we want to reuse the model later without having to train it again\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"mYnX-gI1CfQY\",\n \"metadata\": {\n \"id\": \"mYnX-gI1CfQY\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.save(model.state_dict(), \\\"review_classifier.pth\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba78cf7c-6b80-4f71-a50e-3ccc73839af6\",\n \"metadata\": {},\n \"source\": [\n \"- Then, in a new session, we could load the model as follows\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 46,\n \"id\": \"cc4e68a5-d492-493b-87ef-45c475f353f5\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fd5408e6-83e4-4e5a-8503-c2fba6073f31\",\n \"metadata\": {},\n \"source\": [\n \"- Finally, let's use the finetuned GPT model in action\\n\",\n \"- The `classify_review` function below implements the data preprocessing steps similar to the `SpamDataset` we implemented earlier\\n\",\n \"- Then, the function returns the predicted integer class label from the model and returns the corresponding class name\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"aHdn6xvL-IW5\",\n \"metadata\": {\n \"id\": \"aHdn6xvL-IW5\"\n },\n \"outputs\": [],\n \"source\": [\n \"def classify_review(text, model, tokenizer, device, max_length=None, pad_token_id=50256):\\n\",\n \" model.eval()\\n\",\n \"\\n\",\n \" # Prepare inputs to the model\\n\",\n \" input_ids = tokenizer.encode(text)\\n\",\n \" supported_context_length = model.pos_emb.weight.shape[0]\\n\",\n \" # Note: In the book, this was originally written as pos_emb.weight.shape[1] by mistake\\n\",\n \" # It didn't break the code but would have caused unnecessary truncation (to 768 instead of 1024)\\n\",\n \"\\n\",\n \" # Truncate sequences if they too long\\n\",\n \" input_ids = input_ids[:min(max_length, supported_context_length)]\\n\",\n \" assert max_length is not None, (\\n\",\n \" \\\"max_length must be specified. If you want to use the full model context, \\\"\\n\",\n \" \\\"pass max_length=model.pos_emb.weight.shape[0].\\\"\\n\",\n \" )\\n\",\n \" assert max_length <= supported_context_length, (\\n\",\n \" f\\\"max_length ({max_length}) exceeds model's supported context length ({supported_context_length}).\\\"\\n\",\n \" ) \\n\",\n \" # Alternatively, a more robust version is the following one, which handles the max_length=None case better\\n\",\n \" # max_len = min(max_length,supported_context_length) if max_length else supported_context_length\\n\",\n \" # input_ids = input_ids[:max_len]\\n\",\n \" \\n\",\n \" # Pad sequences to the longest sequence\\n\",\n \" input_ids += [pad_token_id] * (max_length - len(input_ids))\\n\",\n \" input_tensor = torch.tensor(input_ids, device=device).unsqueeze(0) # add batch dimension\\n\",\n \"\\n\",\n \" # Model inference\\n\",\n \" with torch.no_grad():\\n\",\n \" logits = model(input_tensor)[:, -1, :] # Logits of the last output token\\n\",\n \" predicted_label = torch.argmax(logits, dim=-1).item()\\n\",\n \"\\n\",\n \" # Return the classified result\\n\",\n \" return \\\"spam\\\" if predicted_label == 1 else \\\"not spam\\\"\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f29682d8-a899-4d9b-b973-f8d5ec68172c\",\n \"metadata\": {},\n \"source\": [\n \"- Let's try it out on a few examples below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"apU_pf51AWSV\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"apU_pf51AWSV\",\n \"outputId\": \"d0fde0a5-e7a3-4dbe-d9c5-0567dbab7e62\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"spam\\n\"\n ]\n }\n ],\n \"source\": [\n \"text_1 = (\\n\",\n \" \\\"You are a winner you have been specially\\\"\\n\",\n \" \\\" selected to receive $1000 cash or a $2000 award.\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"print(classify_review(\\n\",\n \" text_1, model, tokenizer, device, max_length=train_dataset.max_length\\n\",\n \"))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"1g5VTOo_Ajs5\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"1g5VTOo_Ajs5\",\n \"outputId\": \"659b08eb-b6a9-4a8a-9af7-d94c757e93c2\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"not spam\\n\"\n ]\n }\n ],\n \"source\": [\n \"text_2 = (\\n\",\n \" \\\"Hey, just wanted to check if we're still on\\\"\\n\",\n \" \\\" for dinner tonight? Let me know!\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"print(classify_review(\\n\",\n \" text_2, model, tokenizer, device, max_length=train_dataset.max_length\\n\",\n \"))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bf736e39-0d47-40c1-8d18-1f716cf7a81e\",\n \"metadata\": {},\n \"source\": [\n \"- Finally, let's save the model in case we want to reuse the model later without having to train it again\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"mYnX-gI1CfQY\",\n \"metadata\": {\n \"id\": \"mYnX-gI1CfQY\"\n },\n \"outputs\": [],\n \"source\": [\n \"torch.save(model.state_dict(), \\\"review_classifier.pth\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba78cf7c-6b80-4f71-a50e-3ccc73839af6\",\n \"metadata\": {},\n \"source\": [\n \"- Then, in a new session, we could load the model as follows\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 46,\n \"id\": \"cc4e68a5-d492-493b-87ef-45c475f353f5\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \" | text | \\n\",\n \"label | \\n\",\n \"
|---|---|---|
| 0 | \\n\",\n \"The only reason I saw \\\"Shakedown\\\" was that it ... | \\n\",\n \"0 | \\n\",\n \"
| 1 | \\n\",\n \"This is absolute drivel, designed to shock and... | \\n\",\n \"0 | \\n\",\n \"
| 2 | \\n\",\n \"Lots of scenes and dialogue are flat-out goofy... | \\n\",\n \"1 | \\n\",\n \"
| 3 | \\n\",\n \"** and 1/2 stars out of **** Lifeforce is one ... | \\n\",\n \"1 | \\n\",\n \"
| 4 | \\n\",\n \"I learned a thing: you have to take this film ... | \\n\",\n \"1 | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \" \\n\",\n \" \\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8bbc68e9-75b3-41f1-ac2c-e071c3cd0813\",\n \"metadata\": {\n \"id\": \"8bbc68e9-75b3-41f1-ac2c-e071c3cd0813\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.1 Introduction to instruction finetuning\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"53dba24a-6805-496c-9a7f-c75e2d3527ab\",\n \"metadata\": {\n \"id\": \"53dba24a-6805-496c-9a7f-c75e2d3527ab\"\n },\n \"source\": [\n \"- In chapter 5, we saw that pretraining an LLM involves a training procedure where it learns to generate one word at a time\\n\",\n \"- Hence, a pretrained LLM is good at text completion, but it is not good at following instructions\\n\",\n \"- In this chapter, we teach the LLM to follow instructions better\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"18dc0535-0904-44ed-beaf-9b678292ef35\",\n \"metadata\": {\n \"id\": \"18dc0535-0904-44ed-beaf-9b678292ef35\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8bbc68e9-75b3-41f1-ac2c-e071c3cd0813\",\n \"metadata\": {\n \"id\": \"8bbc68e9-75b3-41f1-ac2c-e071c3cd0813\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.1 Introduction to instruction finetuning\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"53dba24a-6805-496c-9a7f-c75e2d3527ab\",\n \"metadata\": {\n \"id\": \"53dba24a-6805-496c-9a7f-c75e2d3527ab\"\n },\n \"source\": [\n \"- In chapter 5, we saw that pretraining an LLM involves a training procedure where it learns to generate one word at a time\\n\",\n \"- Hence, a pretrained LLM is good at text completion, but it is not good at following instructions\\n\",\n \"- In this chapter, we teach the LLM to follow instructions better\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"18dc0535-0904-44ed-beaf-9b678292ef35\",\n \"metadata\": {\n \"id\": \"18dc0535-0904-44ed-beaf-9b678292ef35\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b4698b23-12e0-4bd7-a140-ccb3dd71d4e8\",\n \"metadata\": {\n \"id\": \"b4698b23-12e0-4bd7-a140-ccb3dd71d4e8\"\n },\n \"source\": [\n \"- The topics covered in this chapter are summarized in the figure below\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b4698b23-12e0-4bd7-a140-ccb3dd71d4e8\",\n \"metadata\": {\n \"id\": \"b4698b23-12e0-4bd7-a140-ccb3dd71d4e8\"\n },\n \"source\": [\n \"- The topics covered in this chapter are summarized in the figure below\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5384f0cf-ef3c-4436-a5fa-59bd25649f86\",\n \"metadata\": {\n \"id\": \"5384f0cf-ef3c-4436-a5fa-59bd25649f86\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.2 Preparing a dataset for supervised instruction finetuning\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f8b34ff8-619f-4e89-bd03-ce513269760d\",\n \"metadata\": {\n \"id\": \"f8b34ff8-619f-4e89-bd03-ce513269760d\"\n },\n \"source\": [\n \"- We will work with an instruction dataset I prepared for this chapter\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"0G3axLw6kY1N\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0G3axLw6kY1N\",\n \"outputId\": \"07e1e4f9-026c-48c1-8a06-f2bfb1fb354e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of entries: 1100\\n\"\n ]\n }\n ],\n \"source\": [\n \"import json\\n\",\n \"import os\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"\\n\",\n \"def download_and_load_file(file_path, url):\\n\",\n \" if not os.path.exists(file_path):\\n\",\n \" response = requests.get(url, timeout=30)\\n\",\n \" response.raise_for_status()\\n\",\n \" text_data = response.text\\n\",\n \" with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" file.write(text_data)\\n\",\n \"\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" data = json.load(file)\\n\",\n \"\\n\",\n \" return data\\n\",\n \"\\n\",\n \"\\n\",\n \"# The book originally used the following code below\\n\",\n \"# However, urllib uses older protocol settings that\\n\",\n \"# can cause problems for some readers using a VPN.\\n\",\n \"# The `requests` version above is more robust\\n\",\n \"# in that regard.\\n\",\n \"\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"import urllib\\n\",\n \"\\n\",\n \"def download_and_load_file(file_path, url):\\n\",\n \"\\n\",\n \" if not os.path.exists(file_path):\\n\",\n \" with urllib.request.urlopen(url) as response:\\n\",\n \" text_data = response.read().decode(\\\"utf-8\\\")\\n\",\n \" with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" file.write(text_data)\\n\",\n \"\\n\",\n \" else:\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" text_data = file.read()\\n\",\n \"\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" data = json.load(file)\\n\",\n \"\\n\",\n \" return data\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"file_path = \\\"instruction-data.json\\\"\\n\",\n \"url = (\\n\",\n \" \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch\\\"\\n\",\n \" \\\"/main/ch07/01_main-chapter-code/instruction-data.json\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"data = download_and_load_file(file_path, url)\\n\",\n \"print(\\\"Number of entries:\\\", len(data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d7af8176-4255-4e92-8c7d-998771733eb8\",\n \"metadata\": {\n \"id\": \"d7af8176-4255-4e92-8c7d-998771733eb8\"\n },\n \"source\": [\n \"- Each item in the `data` list we loaded from the JSON file above is a dictionary in the following form\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"-LiuBMsHkzQV\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"-LiuBMsHkzQV\",\n \"outputId\": \"a4ee5c2d-db53-4a80-e5ee-0bbcf6fe0450\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Example entry:\\n\",\n \" {'instruction': 'Identify the correct spelling of the following word.', 'input': 'Ocassion', 'output': \\\"The correct spelling is 'Occasion.'\\\"}\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Example entry:\\\\n\\\", data[50])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c5a32b34-485a-4816-a77a-da14f9fe6e46\",\n \"metadata\": {\n \"id\": \"c5a32b34-485a-4816-a77a-da14f9fe6e46\"\n },\n \"source\": [\n \"- Note that the `'input'` field can be empty:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"uFInFxDDk2Je\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"uFInFxDDk2Je\",\n \"outputId\": \"b4f84027-bb9e-4e51-b79e-1329c8bff093\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Another example entry:\\n\",\n \" {'instruction': \\\"What is an antonym of 'complicated'?\\\", 'input': '', 'output': \\\"An antonym of 'complicated' is 'simple'.\\\"}\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Another example entry:\\\\n\\\", data[999])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f034799a-6575-45fd-98c9-9d1012d0fd58\",\n \"metadata\": {\n \"id\": \"f034799a-6575-45fd-98c9-9d1012d0fd58\"\n },\n \"source\": [\n \"- Instruction finetuning is often referred to as \\\"supervised instruction finetuning\\\" because it involves training a model on a dataset where the input-output pairs are explicitly provided\\n\",\n \"- There are different ways to format the entries as inputs to the LLM; the figure below illustrates two example formats that were used for training the Alpaca (https://crfm.stanford.edu/2023/03/13/alpaca.html) and Phi-3 (https://arxiv.org/abs/2404.14219) LLMs, respectively\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dffa4f70-44d4-4be4-89a9-2159f4885b10\",\n \"metadata\": {\n \"id\": \"dffa4f70-44d4-4be4-89a9-2159f4885b10\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5384f0cf-ef3c-4436-a5fa-59bd25649f86\",\n \"metadata\": {\n \"id\": \"5384f0cf-ef3c-4436-a5fa-59bd25649f86\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.2 Preparing a dataset for supervised instruction finetuning\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f8b34ff8-619f-4e89-bd03-ce513269760d\",\n \"metadata\": {\n \"id\": \"f8b34ff8-619f-4e89-bd03-ce513269760d\"\n },\n \"source\": [\n \"- We will work with an instruction dataset I prepared for this chapter\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"0G3axLw6kY1N\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0G3axLw6kY1N\",\n \"outputId\": \"07e1e4f9-026c-48c1-8a06-f2bfb1fb354e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of entries: 1100\\n\"\n ]\n }\n ],\n \"source\": [\n \"import json\\n\",\n \"import os\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"\\n\",\n \"def download_and_load_file(file_path, url):\\n\",\n \" if not os.path.exists(file_path):\\n\",\n \" response = requests.get(url, timeout=30)\\n\",\n \" response.raise_for_status()\\n\",\n \" text_data = response.text\\n\",\n \" with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" file.write(text_data)\\n\",\n \"\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" data = json.load(file)\\n\",\n \"\\n\",\n \" return data\\n\",\n \"\\n\",\n \"\\n\",\n \"# The book originally used the following code below\\n\",\n \"# However, urllib uses older protocol settings that\\n\",\n \"# can cause problems for some readers using a VPN.\\n\",\n \"# The `requests` version above is more robust\\n\",\n \"# in that regard.\\n\",\n \"\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"import urllib\\n\",\n \"\\n\",\n \"def download_and_load_file(file_path, url):\\n\",\n \"\\n\",\n \" if not os.path.exists(file_path):\\n\",\n \" with urllib.request.urlopen(url) as response:\\n\",\n \" text_data = response.read().decode(\\\"utf-8\\\")\\n\",\n \" with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" file.write(text_data)\\n\",\n \"\\n\",\n \" else:\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" text_data = file.read()\\n\",\n \"\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" data = json.load(file)\\n\",\n \"\\n\",\n \" return data\\n\",\n \"\\\"\\\"\\\"\\n\",\n \"\\n\",\n \"\\n\",\n \"file_path = \\\"instruction-data.json\\\"\\n\",\n \"url = (\\n\",\n \" \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch\\\"\\n\",\n \" \\\"/main/ch07/01_main-chapter-code/instruction-data.json\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"data = download_and_load_file(file_path, url)\\n\",\n \"print(\\\"Number of entries:\\\", len(data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d7af8176-4255-4e92-8c7d-998771733eb8\",\n \"metadata\": {\n \"id\": \"d7af8176-4255-4e92-8c7d-998771733eb8\"\n },\n \"source\": [\n \"- Each item in the `data` list we loaded from the JSON file above is a dictionary in the following form\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"-LiuBMsHkzQV\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"-LiuBMsHkzQV\",\n \"outputId\": \"a4ee5c2d-db53-4a80-e5ee-0bbcf6fe0450\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Example entry:\\n\",\n \" {'instruction': 'Identify the correct spelling of the following word.', 'input': 'Ocassion', 'output': \\\"The correct spelling is 'Occasion.'\\\"}\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Example entry:\\\\n\\\", data[50])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c5a32b34-485a-4816-a77a-da14f9fe6e46\",\n \"metadata\": {\n \"id\": \"c5a32b34-485a-4816-a77a-da14f9fe6e46\"\n },\n \"source\": [\n \"- Note that the `'input'` field can be empty:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"uFInFxDDk2Je\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"uFInFxDDk2Je\",\n \"outputId\": \"b4f84027-bb9e-4e51-b79e-1329c8bff093\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Another example entry:\\n\",\n \" {'instruction': \\\"What is an antonym of 'complicated'?\\\", 'input': '', 'output': \\\"An antonym of 'complicated' is 'simple'.\\\"}\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Another example entry:\\\\n\\\", data[999])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f034799a-6575-45fd-98c9-9d1012d0fd58\",\n \"metadata\": {\n \"id\": \"f034799a-6575-45fd-98c9-9d1012d0fd58\"\n },\n \"source\": [\n \"- Instruction finetuning is often referred to as \\\"supervised instruction finetuning\\\" because it involves training a model on a dataset where the input-output pairs are explicitly provided\\n\",\n \"- There are different ways to format the entries as inputs to the LLM; the figure below illustrates two example formats that were used for training the Alpaca (https://crfm.stanford.edu/2023/03/13/alpaca.html) and Phi-3 (https://arxiv.org/abs/2404.14219) LLMs, respectively\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dffa4f70-44d4-4be4-89a9-2159f4885b10\",\n \"metadata\": {\n \"id\": \"dffa4f70-44d4-4be4-89a9-2159f4885b10\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dd79a74e-befb-491c-be49-f777a6a5b6a6\",\n \"metadata\": {\n \"id\": \"dd79a74e-befb-491c-be49-f777a6a5b6a6\"\n },\n \"source\": [\n \"- In this chapter, we use Alpaca-style prompt formatting, which was the original prompt template for instruction finetuning\\n\",\n \"- Below, we format the input that we will pass as input to the LLM\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"Jhk37nnJnkBh\",\n \"metadata\": {\n \"id\": \"Jhk37nnJnkBh\"\n },\n \"outputs\": [],\n \"source\": [\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. \\\"\\n\",\n \" f\\\"Write a response that appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"011e78b4-e89a-4653-a2ee-7b2739ca04d6\",\n \"metadata\": {\n \"id\": \"011e78b4-e89a-4653-a2ee-7b2739ca04d6\"\n },\n \"source\": [\n \"- A formatted response with input field looks like as shown below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"F9UQRfjzo4Js\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"F9UQRfjzo4Js\",\n \"outputId\": \"7b615d35-2a5f-474d-9292-a69bc3850e16\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Identify the correct spelling of the following word.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"Ocassion\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"The correct spelling is 'Occasion.'\\n\"\n ]\n }\n ],\n \"source\": [\n \"model_input = format_input(data[50])\\n\",\n \"desired_response = f\\\"\\\\n\\\\n### Response:\\\\n{data[50]['output']}\\\"\\n\",\n \"\\n\",\n \"print(model_input + desired_response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4dc93ddf-431c-49c0-96f2-fb3a79c4d94c\",\n \"metadata\": {\n \"id\": \"4dc93ddf-431c-49c0-96f2-fb3a79c4d94c\"\n },\n \"source\": [\n \"- Below is a formatted response without an input field\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"a3891fa9-f738-41cd-946c-80ef9a99c346\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"a3891fa9-f738-41cd-946c-80ef9a99c346\",\n \"outputId\": \"2142c5a4-b594-49c5-affe-2d963a7bd46b\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"What is an antonym of 'complicated'?\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"An antonym of 'complicated' is 'simple'.\\n\"\n ]\n }\n ],\n \"source\": [\n \"model_input = format_input(data[999])\\n\",\n \"desired_response = f\\\"\\\\n\\\\n### Response:\\\\n{data[999]['output']}\\\"\\n\",\n \"\\n\",\n \"print(model_input + desired_response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4aa8afd5-2a21-49a5-90c3-6a03865a4771\",\n \"metadata\": {\n \"id\": \"4aa8afd5-2a21-49a5-90c3-6a03865a4771\"\n },\n \"source\": [\n \"- Lastly, before we prepare the PyTorch data loaders in the next section, we divide the dataset into a training, validation, and test set\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"aFZVopbIlNfx\",\n \"metadata\": {\n \"id\": \"aFZVopbIlNfx\"\n },\n \"outputs\": [],\n \"source\": [\n \"train_portion = int(len(data) * 0.85) # 85% for training\\n\",\n \"test_portion = int(len(data) * 0.1) # 10% for testing\\n\",\n \"val_portion = len(data) - train_portion - test_portion # Remaining 5% for validation\\n\",\n \"\\n\",\n \"train_data = data[:train_portion]\\n\",\n \"test_data = data[train_portion:train_portion + test_portion]\\n\",\n \"val_data = data[train_portion + test_portion:]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"-zf6oht6bIUQ\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"-zf6oht6bIUQ\",\n \"outputId\": \"657ec5c6-4caa-4d1a-ba2e-23acd755ab07\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training set length: 935\\n\",\n \"Validation set length: 55\\n\",\n \"Test set length: 110\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Training set length:\\\", len(train_data))\\n\",\n \"print(\\\"Validation set length:\\\", len(val_data))\\n\",\n \"print(\\\"Test set length:\\\", len(test_data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fcaaf606-f913-4445-8301-632ae10d387d\",\n \"metadata\": {\n \"id\": \"fcaaf606-f913-4445-8301-632ae10d387d\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.3 Organizing data into training batches\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"233f63bd-9755-4d07-8884-5e2e5345cf27\",\n \"metadata\": {\n \"id\": \"233f63bd-9755-4d07-8884-5e2e5345cf27\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dd79a74e-befb-491c-be49-f777a6a5b6a6\",\n \"metadata\": {\n \"id\": \"dd79a74e-befb-491c-be49-f777a6a5b6a6\"\n },\n \"source\": [\n \"- In this chapter, we use Alpaca-style prompt formatting, which was the original prompt template for instruction finetuning\\n\",\n \"- Below, we format the input that we will pass as input to the LLM\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"Jhk37nnJnkBh\",\n \"metadata\": {\n \"id\": \"Jhk37nnJnkBh\"\n },\n \"outputs\": [],\n \"source\": [\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. \\\"\\n\",\n \" f\\\"Write a response that appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"011e78b4-e89a-4653-a2ee-7b2739ca04d6\",\n \"metadata\": {\n \"id\": \"011e78b4-e89a-4653-a2ee-7b2739ca04d6\"\n },\n \"source\": [\n \"- A formatted response with input field looks like as shown below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"F9UQRfjzo4Js\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"F9UQRfjzo4Js\",\n \"outputId\": \"7b615d35-2a5f-474d-9292-a69bc3850e16\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Identify the correct spelling of the following word.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"Ocassion\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"The correct spelling is 'Occasion.'\\n\"\n ]\n }\n ],\n \"source\": [\n \"model_input = format_input(data[50])\\n\",\n \"desired_response = f\\\"\\\\n\\\\n### Response:\\\\n{data[50]['output']}\\\"\\n\",\n \"\\n\",\n \"print(model_input + desired_response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4dc93ddf-431c-49c0-96f2-fb3a79c4d94c\",\n \"metadata\": {\n \"id\": \"4dc93ddf-431c-49c0-96f2-fb3a79c4d94c\"\n },\n \"source\": [\n \"- Below is a formatted response without an input field\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"a3891fa9-f738-41cd-946c-80ef9a99c346\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"a3891fa9-f738-41cd-946c-80ef9a99c346\",\n \"outputId\": \"2142c5a4-b594-49c5-affe-2d963a7bd46b\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"What is an antonym of 'complicated'?\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"An antonym of 'complicated' is 'simple'.\\n\"\n ]\n }\n ],\n \"source\": [\n \"model_input = format_input(data[999])\\n\",\n \"desired_response = f\\\"\\\\n\\\\n### Response:\\\\n{data[999]['output']}\\\"\\n\",\n \"\\n\",\n \"print(model_input + desired_response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4aa8afd5-2a21-49a5-90c3-6a03865a4771\",\n \"metadata\": {\n \"id\": \"4aa8afd5-2a21-49a5-90c3-6a03865a4771\"\n },\n \"source\": [\n \"- Lastly, before we prepare the PyTorch data loaders in the next section, we divide the dataset into a training, validation, and test set\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"aFZVopbIlNfx\",\n \"metadata\": {\n \"id\": \"aFZVopbIlNfx\"\n },\n \"outputs\": [],\n \"source\": [\n \"train_portion = int(len(data) * 0.85) # 85% for training\\n\",\n \"test_portion = int(len(data) * 0.1) # 10% for testing\\n\",\n \"val_portion = len(data) - train_portion - test_portion # Remaining 5% for validation\\n\",\n \"\\n\",\n \"train_data = data[:train_portion]\\n\",\n \"test_data = data[train_portion:train_portion + test_portion]\\n\",\n \"val_data = data[train_portion + test_portion:]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"-zf6oht6bIUQ\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"-zf6oht6bIUQ\",\n \"outputId\": \"657ec5c6-4caa-4d1a-ba2e-23acd755ab07\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training set length: 935\\n\",\n \"Validation set length: 55\\n\",\n \"Test set length: 110\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Training set length:\\\", len(train_data))\\n\",\n \"print(\\\"Validation set length:\\\", len(val_data))\\n\",\n \"print(\\\"Test set length:\\\", len(test_data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fcaaf606-f913-4445-8301-632ae10d387d\",\n \"metadata\": {\n \"id\": \"fcaaf606-f913-4445-8301-632ae10d387d\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.3 Organizing data into training batches\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"233f63bd-9755-4d07-8884-5e2e5345cf27\",\n \"metadata\": {\n \"id\": \"233f63bd-9755-4d07-8884-5e2e5345cf27\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c149fc1a-7757-4ec8-80cb-e2a3fb007a2c\",\n \"metadata\": {\n \"id\": \"c149fc1a-7757-4ec8-80cb-e2a3fb007a2c\"\n },\n \"source\": [\n \"- We tackle this dataset batching in several steps, as summarized in the figure below\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c149fc1a-7757-4ec8-80cb-e2a3fb007a2c\",\n \"metadata\": {\n \"id\": \"c149fc1a-7757-4ec8-80cb-e2a3fb007a2c\"\n },\n \"source\": [\n \"- We tackle this dataset batching in several steps, as summarized in the figure below\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b9af423f-aad9-4b3c-bea5-153021c04862\",\n \"metadata\": {\n \"id\": \"b9af423f-aad9-4b3c-bea5-153021c04862\"\n },\n \"source\": [\n \"- First, we implement an `InstructionDataset` class that pre-tokenizes all inputs in the dataset, similar to the `SpamDataset` in chapter 6\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b9af423f-aad9-4b3c-bea5-153021c04862\",\n \"metadata\": {\n \"id\": \"b9af423f-aad9-4b3c-bea5-153021c04862\"\n },\n \"source\": [\n \"- First, we implement an `InstructionDataset` class that pre-tokenizes all inputs in the dataset, similar to the `SpamDataset` in chapter 6\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"adc29dc4-f1c7-4c71-937b-95119d6239bb\",\n \"metadata\": {\n \"id\": \"adc29dc4-f1c7-4c71-937b-95119d6239bb\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"from torch.utils.data import Dataset\\n\",\n \"\\n\",\n \"\\n\",\n \"class InstructionDataset(Dataset):\\n\",\n \" def __init__(self, data, tokenizer):\\n\",\n \" self.data = data\\n\",\n \"\\n\",\n \" # Pre-tokenize texts\\n\",\n \" self.encoded_texts = []\\n\",\n \" for entry in data:\\n\",\n \" instruction_plus_input = format_input(entry)\\n\",\n \" response_text = f\\\"\\\\n\\\\n### Response:\\\\n{entry['output']}\\\"\\n\",\n \" full_text = instruction_plus_input + response_text\\n\",\n \" self.encoded_texts.append(\\n\",\n \" tokenizer.encode(full_text)\\n\",\n \" )\\n\",\n \"\\n\",\n \" def __getitem__(self, index):\\n\",\n \" return self.encoded_texts[index]\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.data)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"384f0e69-4b22-41c0-a25d-f077527eddd1\",\n \"metadata\": {\n \"id\": \"384f0e69-4b22-41c0-a25d-f077527eddd1\"\n },\n \"source\": [\n \"- Similar to chapter 6, we want to collect multiple training examples in a batch to accelerate training; this requires padding all inputs to a similar length\\n\",\n \"- Also similar to the previous chapter, we use the `<|endoftext|>` token as a padding token\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"ff24fe1a-5746-461c-ad3d-b6d84a1a7c96\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"ff24fe1a-5746-461c-ad3d-b6d84a1a7c96\",\n \"outputId\": \"ac44227b-9ec2-4131-9df8-89caa6e879ca\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[50256]\\n\"\n ]\n }\n ],\n \"source\": [\n \"import tiktoken\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"print(tokenizer.encode(\\\"<|endoftext|>\\\", allowed_special={\\\"<|endoftext|>\\\"}))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9e5bd7bc-f347-4cf8-a0c2-94cb8799e427\",\n \"metadata\": {\n \"id\": \"9e5bd7bc-f347-4cf8-a0c2-94cb8799e427\"\n },\n \"source\": [\n \"- In chapter 6, we padded all examples in a dataset to the same length\\n\",\n \" - Here, we take a more sophisticated approach and develop a custom \\\"collate\\\" function that we can pass to the data loader\\n\",\n \" - This custom collate function pads the training examples in each batch to have the same length (but different batches can have different lengths)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"65c4d943-4aa8-4a44-874e-05bc6831fbd3\",\n \"metadata\": {\n \"id\": \"65c4d943-4aa8-4a44-874e-05bc6831fbd3\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"adc29dc4-f1c7-4c71-937b-95119d6239bb\",\n \"metadata\": {\n \"id\": \"adc29dc4-f1c7-4c71-937b-95119d6239bb\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"from torch.utils.data import Dataset\\n\",\n \"\\n\",\n \"\\n\",\n \"class InstructionDataset(Dataset):\\n\",\n \" def __init__(self, data, tokenizer):\\n\",\n \" self.data = data\\n\",\n \"\\n\",\n \" # Pre-tokenize texts\\n\",\n \" self.encoded_texts = []\\n\",\n \" for entry in data:\\n\",\n \" instruction_plus_input = format_input(entry)\\n\",\n \" response_text = f\\\"\\\\n\\\\n### Response:\\\\n{entry['output']}\\\"\\n\",\n \" full_text = instruction_plus_input + response_text\\n\",\n \" self.encoded_texts.append(\\n\",\n \" tokenizer.encode(full_text)\\n\",\n \" )\\n\",\n \"\\n\",\n \" def __getitem__(self, index):\\n\",\n \" return self.encoded_texts[index]\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.data)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"384f0e69-4b22-41c0-a25d-f077527eddd1\",\n \"metadata\": {\n \"id\": \"384f0e69-4b22-41c0-a25d-f077527eddd1\"\n },\n \"source\": [\n \"- Similar to chapter 6, we want to collect multiple training examples in a batch to accelerate training; this requires padding all inputs to a similar length\\n\",\n \"- Also similar to the previous chapter, we use the `<|endoftext|>` token as a padding token\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"ff24fe1a-5746-461c-ad3d-b6d84a1a7c96\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"ff24fe1a-5746-461c-ad3d-b6d84a1a7c96\",\n \"outputId\": \"ac44227b-9ec2-4131-9df8-89caa6e879ca\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[50256]\\n\"\n ]\n }\n ],\n \"source\": [\n \"import tiktoken\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"print(tokenizer.encode(\\\"<|endoftext|>\\\", allowed_special={\\\"<|endoftext|>\\\"}))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9e5bd7bc-f347-4cf8-a0c2-94cb8799e427\",\n \"metadata\": {\n \"id\": \"9e5bd7bc-f347-4cf8-a0c2-94cb8799e427\"\n },\n \"source\": [\n \"- In chapter 6, we padded all examples in a dataset to the same length\\n\",\n \" - Here, we take a more sophisticated approach and develop a custom \\\"collate\\\" function that we can pass to the data loader\\n\",\n \" - This custom collate function pads the training examples in each batch to have the same length (but different batches can have different lengths)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"65c4d943-4aa8-4a44-874e-05bc6831fbd3\",\n \"metadata\": {\n \"id\": \"65c4d943-4aa8-4a44-874e-05bc6831fbd3\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"eb4c77dd-c956-4a1b-897b-b466909f18ca\",\n \"metadata\": {\n \"id\": \"eb4c77dd-c956-4a1b-897b-b466909f18ca\"\n },\n \"outputs\": [],\n \"source\": [\n \"def custom_collate_draft_1(\\n\",\n \" batch,\\n\",\n \" pad_token_id=50256,\\n\",\n \" device=\\\"cpu\\\"\\n\",\n \"):\\n\",\n \" # Find the longest sequence in the batch\\n\",\n \" # and increase the max length by +1, which will add one extra\\n\",\n \" # padding token below\\n\",\n \" batch_max_length = max(len(item)+1 for item in batch)\\n\",\n \"\\n\",\n \" # Pad and prepare inputs\\n\",\n \" inputs_lst = []\\n\",\n \"\\n\",\n \" for item in batch:\\n\",\n \" new_item = item.copy()\\n\",\n \" # Add an <|endoftext|> token\\n\",\n \" new_item += [pad_token_id]\\n\",\n \" # Pad sequences to batch_max_length\\n\",\n \" padded = (\\n\",\n \" new_item + [pad_token_id] *\\n\",\n \" (batch_max_length - len(new_item))\\n\",\n \" )\\n\",\n \" # Via padded[:-1], we remove the extra padded token\\n\",\n \" # that has been added via the +1 setting in batch_max_length\\n\",\n \" # (the extra padding token will be relevant in later codes)\\n\",\n \" inputs = torch.tensor(padded[:-1])\\n\",\n \" inputs_lst.append(inputs)\\n\",\n \"\\n\",\n \" # Convert list of inputs to tensor and transfer to target device\\n\",\n \" inputs_tensor = torch.stack(inputs_lst).to(device)\\n\",\n \" return inputs_tensor\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"8fb02373-59b3-4f3a-b1d1-8181a2432645\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"8fb02373-59b3-4f3a-b1d1-8181a2432645\",\n \"outputId\": \"93d987b9-e3ca-4857-9b28-b67d515a94d8\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[ 0, 1, 2, 3, 4],\\n\",\n \" [ 5, 6, 50256, 50256, 50256],\\n\",\n \" [ 7, 8, 9, 50256, 50256]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"inputs_1 = [0, 1, 2, 3, 4]\\n\",\n \"inputs_2 = [5, 6]\\n\",\n \"inputs_3 = [7, 8, 9]\\n\",\n \"\\n\",\n \"batch = (\\n\",\n \" inputs_1,\\n\",\n \" inputs_2,\\n\",\n \" inputs_3\\n\",\n \")\\n\",\n \"\\n\",\n \"print(custom_collate_draft_1(batch))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5673ade5-be4c-4a2c-9a9a-d5c63fb1c424\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"eb4c77dd-c956-4a1b-897b-b466909f18ca\",\n \"metadata\": {\n \"id\": \"eb4c77dd-c956-4a1b-897b-b466909f18ca\"\n },\n \"outputs\": [],\n \"source\": [\n \"def custom_collate_draft_1(\\n\",\n \" batch,\\n\",\n \" pad_token_id=50256,\\n\",\n \" device=\\\"cpu\\\"\\n\",\n \"):\\n\",\n \" # Find the longest sequence in the batch\\n\",\n \" # and increase the max length by +1, which will add one extra\\n\",\n \" # padding token below\\n\",\n \" batch_max_length = max(len(item)+1 for item in batch)\\n\",\n \"\\n\",\n \" # Pad and prepare inputs\\n\",\n \" inputs_lst = []\\n\",\n \"\\n\",\n \" for item in batch:\\n\",\n \" new_item = item.copy()\\n\",\n \" # Add an <|endoftext|> token\\n\",\n \" new_item += [pad_token_id]\\n\",\n \" # Pad sequences to batch_max_length\\n\",\n \" padded = (\\n\",\n \" new_item + [pad_token_id] *\\n\",\n \" (batch_max_length - len(new_item))\\n\",\n \" )\\n\",\n \" # Via padded[:-1], we remove the extra padded token\\n\",\n \" # that has been added via the +1 setting in batch_max_length\\n\",\n \" # (the extra padding token will be relevant in later codes)\\n\",\n \" inputs = torch.tensor(padded[:-1])\\n\",\n \" inputs_lst.append(inputs)\\n\",\n \"\\n\",\n \" # Convert list of inputs to tensor and transfer to target device\\n\",\n \" inputs_tensor = torch.stack(inputs_lst).to(device)\\n\",\n \" return inputs_tensor\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"8fb02373-59b3-4f3a-b1d1-8181a2432645\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"8fb02373-59b3-4f3a-b1d1-8181a2432645\",\n \"outputId\": \"93d987b9-e3ca-4857-9b28-b67d515a94d8\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[ 0, 1, 2, 3, 4],\\n\",\n \" [ 5, 6, 50256, 50256, 50256],\\n\",\n \" [ 7, 8, 9, 50256, 50256]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"inputs_1 = [0, 1, 2, 3, 4]\\n\",\n \"inputs_2 = [5, 6]\\n\",\n \"inputs_3 = [7, 8, 9]\\n\",\n \"\\n\",\n \"batch = (\\n\",\n \" inputs_1,\\n\",\n \" inputs_2,\\n\",\n \" inputs_3\\n\",\n \")\\n\",\n \"\\n\",\n \"print(custom_collate_draft_1(batch))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5673ade5-be4c-4a2c-9a9a-d5c63fb1c424\",\n \"metadata\": {},\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"17769a19-b961-4213-92ef-34f441b2d1d6\",\n \"metadata\": {\n \"id\": \"17769a19-b961-4213-92ef-34f441b2d1d6\"\n },\n \"source\": [\n \"- Above, we only returned the inputs to the LLM; however, for LLM training, we also need the target values\\n\",\n \"- Similar to pretraining an LLM, the targets are the inputs shifted by 1 position to the right, so the LLM learns to predict the next token\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0386b6fe-3455-4e70-becd-a5a4681ba2ef\",\n \"metadata\": {\n \"id\": \"0386b6fe-3455-4e70-becd-a5a4681ba2ef\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"17769a19-b961-4213-92ef-34f441b2d1d6\",\n \"metadata\": {\n \"id\": \"17769a19-b961-4213-92ef-34f441b2d1d6\"\n },\n \"source\": [\n \"- Above, we only returned the inputs to the LLM; however, for LLM training, we also need the target values\\n\",\n \"- Similar to pretraining an LLM, the targets are the inputs shifted by 1 position to the right, so the LLM learns to predict the next token\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0386b6fe-3455-4e70-becd-a5a4681ba2ef\",\n \"metadata\": {\n \"id\": \"0386b6fe-3455-4e70-becd-a5a4681ba2ef\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"74af192e-757c-4c0a-bdf9-b7eb25bf6ebc\",\n \"metadata\": {\n \"id\": \"74af192e-757c-4c0a-bdf9-b7eb25bf6ebc\"\n },\n \"outputs\": [],\n \"source\": [\n \"def custom_collate_draft_2(\\n\",\n \" batch,\\n\",\n \" pad_token_id=50256,\\n\",\n \" device=\\\"cpu\\\"\\n\",\n \"):\\n\",\n \" # Find the longest sequence in the batch\\n\",\n \" batch_max_length = max(len(item)+1 for item in batch)\\n\",\n \"\\n\",\n \" # Pad and prepare inputs\\n\",\n \" inputs_lst, targets_lst = [], []\\n\",\n \"\\n\",\n \" for item in batch:\\n\",\n \" new_item = item.copy()\\n\",\n \" # Add an <|endoftext|> token\\n\",\n \" new_item += [pad_token_id]\\n\",\n \" # Pad sequences to max_length\\n\",\n \" padded = (\\n\",\n \" new_item + [pad_token_id] *\\n\",\n \" (batch_max_length - len(new_item))\\n\",\n \" )\\n\",\n \" inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\\n\",\n \" targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\\n\",\n \" inputs_lst.append(inputs)\\n\",\n \" targets_lst.append(targets)\\n\",\n \"\\n\",\n \" # Convert list of inputs to tensor and transfer to target device\\n\",\n \" inputs_tensor = torch.stack(inputs_lst).to(device)\\n\",\n \" targets_tensor = torch.stack(targets_lst).to(device)\\n\",\n \" return inputs_tensor, targets_tensor\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"6eb2bce3-28a7-4f39-9d4b-5e972d69066c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6eb2bce3-28a7-4f39-9d4b-5e972d69066c\",\n \"outputId\": \"3d104439-c328-431b-ef7c-2639d86c2135\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[ 0, 1, 2, 3, 4],\\n\",\n \" [ 5, 6, 50256, 50256, 50256],\\n\",\n \" [ 7, 8, 9, 50256, 50256]])\\n\",\n \"tensor([[ 1, 2, 3, 4, 50256],\\n\",\n \" [ 6, 50256, 50256, 50256, 50256],\\n\",\n \" [ 8, 9, 50256, 50256, 50256]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"inputs, targets = custom_collate_draft_2(batch)\\n\",\n \"print(inputs)\\n\",\n \"print(targets)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3bf85703-a0e0-42aa-8f29-cbc28dbf4e15\",\n \"metadata\": {\n \"id\": \"3bf85703-a0e0-42aa-8f29-cbc28dbf4e15\"\n },\n \"source\": [\n \"- Next, we introduce an `ignore_index` value to replace all padding token IDs with a new value; the purpose of this `ignore_index` is that we can ignore padding values in the loss function (more on that later)\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"74af192e-757c-4c0a-bdf9-b7eb25bf6ebc\",\n \"metadata\": {\n \"id\": \"74af192e-757c-4c0a-bdf9-b7eb25bf6ebc\"\n },\n \"outputs\": [],\n \"source\": [\n \"def custom_collate_draft_2(\\n\",\n \" batch,\\n\",\n \" pad_token_id=50256,\\n\",\n \" device=\\\"cpu\\\"\\n\",\n \"):\\n\",\n \" # Find the longest sequence in the batch\\n\",\n \" batch_max_length = max(len(item)+1 for item in batch)\\n\",\n \"\\n\",\n \" # Pad and prepare inputs\\n\",\n \" inputs_lst, targets_lst = [], []\\n\",\n \"\\n\",\n \" for item in batch:\\n\",\n \" new_item = item.copy()\\n\",\n \" # Add an <|endoftext|> token\\n\",\n \" new_item += [pad_token_id]\\n\",\n \" # Pad sequences to max_length\\n\",\n \" padded = (\\n\",\n \" new_item + [pad_token_id] *\\n\",\n \" (batch_max_length - len(new_item))\\n\",\n \" )\\n\",\n \" inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\\n\",\n \" targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\\n\",\n \" inputs_lst.append(inputs)\\n\",\n \" targets_lst.append(targets)\\n\",\n \"\\n\",\n \" # Convert list of inputs to tensor and transfer to target device\\n\",\n \" inputs_tensor = torch.stack(inputs_lst).to(device)\\n\",\n \" targets_tensor = torch.stack(targets_lst).to(device)\\n\",\n \" return inputs_tensor, targets_tensor\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"6eb2bce3-28a7-4f39-9d4b-5e972d69066c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"6eb2bce3-28a7-4f39-9d4b-5e972d69066c\",\n \"outputId\": \"3d104439-c328-431b-ef7c-2639d86c2135\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[ 0, 1, 2, 3, 4],\\n\",\n \" [ 5, 6, 50256, 50256, 50256],\\n\",\n \" [ 7, 8, 9, 50256, 50256]])\\n\",\n \"tensor([[ 1, 2, 3, 4, 50256],\\n\",\n \" [ 6, 50256, 50256, 50256, 50256],\\n\",\n \" [ 8, 9, 50256, 50256, 50256]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"inputs, targets = custom_collate_draft_2(batch)\\n\",\n \"print(inputs)\\n\",\n \"print(targets)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3bf85703-a0e0-42aa-8f29-cbc28dbf4e15\",\n \"metadata\": {\n \"id\": \"3bf85703-a0e0-42aa-8f29-cbc28dbf4e15\"\n },\n \"source\": [\n \"- Next, we introduce an `ignore_index` value to replace all padding token IDs with a new value; the purpose of this `ignore_index` is that we can ignore padding values in the loss function (more on that later)\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"- Concretely, this means that we replace the token IDs corresponding to `50256` with `-100` as illustrated below\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bd4bed33-956e-4b3f-a09c-586d8203109a\",\n \"metadata\": {\n \"id\": \"bd4bed33-956e-4b3f-a09c-586d8203109a\"\n },\n \"source\": [\n \"
\\n\",\n \"\\n\",\n \"- Concretely, this means that we replace the token IDs corresponding to `50256` with `-100` as illustrated below\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bd4bed33-956e-4b3f-a09c-586d8203109a\",\n \"metadata\": {\n \"id\": \"bd4bed33-956e-4b3f-a09c-586d8203109a\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5346513e-c3f4-44fe-af22-4ebd36497728\",\n \"metadata\": {\n \"id\": \"5346513e-c3f4-44fe-af22-4ebd36497728\"\n },\n \"source\": [\n \"- (In addition, we also introduce the `allowed_max_length` in case we want to limit the length of the samples; this will be useful if you plan to work with your own datasets that are longer than the 1024 token context size supported by the GPT-2 model)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"41ec6e2d-9eb2-4124-913e-d2af39be4cf2\",\n \"metadata\": {\n \"id\": \"41ec6e2d-9eb2-4124-913e-d2af39be4cf2\"\n },\n \"outputs\": [],\n \"source\": [\n \"def custom_collate_fn(\\n\",\n \" batch,\\n\",\n \" pad_token_id=50256,\\n\",\n \" ignore_index=-100,\\n\",\n \" allowed_max_length=None,\\n\",\n \" device=\\\"cpu\\\"\\n\",\n \"):\\n\",\n \" # Find the longest sequence in the batch\\n\",\n \" batch_max_length = max(len(item)+1 for item in batch)\\n\",\n \"\\n\",\n \" # Pad and prepare inputs and targets\\n\",\n \" inputs_lst, targets_lst = [], []\\n\",\n \"\\n\",\n \" for item in batch:\\n\",\n \" new_item = item.copy()\\n\",\n \" # Add an <|endoftext|> token\\n\",\n \" new_item += [pad_token_id]\\n\",\n \" # Pad sequences to max_length\\n\",\n \" padded = (\\n\",\n \" new_item + [pad_token_id] *\\n\",\n \" (batch_max_length - len(new_item))\\n\",\n \" )\\n\",\n \" inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\\n\",\n \" targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\\n\",\n \"\\n\",\n \" # New: Replace all but the first padding tokens in targets by ignore_index\\n\",\n \" mask = targets == pad_token_id\\n\",\n \" indices = torch.nonzero(mask).squeeze()\\n\",\n \" if indices.numel() > 1:\\n\",\n \" targets[indices[1:]] = ignore_index\\n\",\n \"\\n\",\n \" # New: Optionally truncate to maximum sequence length\\n\",\n \" if allowed_max_length is not None:\\n\",\n \" inputs = inputs[:allowed_max_length]\\n\",\n \" targets = targets[:allowed_max_length]\\n\",\n \"\\n\",\n \" inputs_lst.append(inputs)\\n\",\n \" targets_lst.append(targets)\\n\",\n \"\\n\",\n \" # Convert list of inputs and targets to tensors and transfer to target device\\n\",\n \" inputs_tensor = torch.stack(inputs_lst).to(device)\\n\",\n \" targets_tensor = torch.stack(targets_lst).to(device)\\n\",\n \"\\n\",\n \" return inputs_tensor, targets_tensor\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"cdf5eec4-9ebe-4be0-9fca-9a47bee88fdc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"cdf5eec4-9ebe-4be0-9fca-9a47bee88fdc\",\n \"outputId\": \"e8f709b9-f4c5-428a-a6ac-2a4c1b9358ba\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[ 0, 1, 2, 3, 4],\\n\",\n \" [ 5, 6, 50256, 50256, 50256],\\n\",\n \" [ 7, 8, 9, 50256, 50256]])\\n\",\n \"tensor([[ 1, 2, 3, 4, 50256],\\n\",\n \" [ 6, 50256, -100, -100, -100],\\n\",\n \" [ 8, 9, 50256, -100, -100]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"inputs, targets = custom_collate_fn(batch)\\n\",\n \"print(inputs)\\n\",\n \"print(targets)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"26727c90-0d42-43b3-af21-0a66ad4fbbc7\",\n \"metadata\": {\n \"id\": \"26727c90-0d42-43b3-af21-0a66ad4fbbc7\"\n },\n \"source\": [\n \"- Let's see what this replacement by -100 accomplishes\\n\",\n \"- For illustration purposes, let's assume we have a small classification task with 2 class labels, 0 and 1, similar to chapter 6\\n\",\n \"- If we have the following logits values (outputs of the last layer of the model), we calculate the following loss\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"W2jvh-OP9MFV\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"W2jvh-OP9MFV\",\n \"outputId\": \"ccb3a703-59a7-4258-8841-57959a016e31\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(1.1269)\\n\"\n ]\n }\n ],\n \"source\": [\n \"logits_1 = torch.tensor(\\n\",\n \" [[-1.0, 1.0], # 1st training example\\n\",\n \" [-0.5, 1.5]] # 2nd training example\\n\",\n \")\\n\",\n \"targets_1 = torch.tensor([0, 1])\\n\",\n \"\\n\",\n \"\\n\",\n \"loss_1 = torch.nn.functional.cross_entropy(logits_1, targets_1)\\n\",\n \"print(loss_1)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5edd3244-8886-4505-92e9-367d28529e1e\",\n \"metadata\": {\n \"id\": \"5edd3244-8886-4505-92e9-367d28529e1e\"\n },\n \"source\": [\n \"- Now, adding one more training example will, as expected, influence the loss\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"nvVMuil89v9N\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"nvVMuil89v9N\",\n \"outputId\": \"6d4683d4-5bfc-4a8c-de2a-95ecb2e716b9\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(0.7936)\\n\"\n ]\n }\n ],\n \"source\": [\n \"logits_2 = torch.tensor(\\n\",\n \" [[-1.0, 1.0],\\n\",\n \" [-0.5, 1.5],\\n\",\n \" [-0.5, 1.5]] # New 3rd training example\\n\",\n \")\\n\",\n \"targets_2 = torch.tensor([0, 1, 1])\\n\",\n \"\\n\",\n \"loss_2 = torch.nn.functional.cross_entropy(logits_2, targets_2)\\n\",\n \"print(loss_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"54dca331-40e0-468b-b690-189fe156ba8f\",\n \"metadata\": {\n \"id\": \"54dca331-40e0-468b-b690-189fe156ba8f\"\n },\n \"source\": [\n \"- Let's see what happens if we replace the class label of one of the examples with -100\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"RTyB1vah9p56\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"RTyB1vah9p56\",\n \"outputId\": \"da05302e-3fe0-439e-d1ed-82066bceb122\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(1.1269)\\n\",\n \"loss_1 == loss_3: tensor(True)\\n\"\n ]\n }\n ],\n \"source\": [\n \"targets_3 = torch.tensor([0, 1, -100])\\n\",\n \"\\n\",\n \"loss_3 = torch.nn.functional.cross_entropy(logits_2, targets_3)\\n\",\n \"print(loss_3)\\n\",\n \"print(\\\"loss_1 == loss_3:\\\", loss_1 == loss_3)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cef09d21-b652-4760-abea-4f76920e6a25\",\n \"metadata\": {\n \"id\": \"cef09d21-b652-4760-abea-4f76920e6a25\"\n },\n \"source\": [\n \"- As we can see, the resulting loss on these 3 training examples is the same as the loss we calculated from the 2 training examples, which means that the cross-entropy loss function ignored the training example with the -100 label\\n\",\n \"- By default, PyTorch has the `cross_entropy(..., ignore_index=-100)` setting to ignore examples corresponding to the label -100\\n\",\n \"- Using this -100 `ignore_index`, we can ignore the additional end-of-text (padding) tokens in the batches that we used to pad the training examples to equal length\\n\",\n \"- However, we don't want to ignore the first instance of the end-of-text (padding) token (50256) because it can help signal to the LLM when the response is complete\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6a4e9c5f-7c49-4321-9f1b-a50468a84524\",\n \"metadata\": {\n \"id\": \"6a4e9c5f-7c49-4321-9f1b-a50468a84524\"\n },\n \"source\": [\n \"- In practice, it is also common to mask out the target token IDs that correspond to the instruction, as illustrated in the figure below (this is a recommended reader exercise after completing the chapter)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fab8f0ed-80e8-4fd9-bf84-e5d0e0bc0a39\",\n \"metadata\": {\n \"id\": \"fab8f0ed-80e8-4fd9-bf84-e5d0e0bc0a39\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5346513e-c3f4-44fe-af22-4ebd36497728\",\n \"metadata\": {\n \"id\": \"5346513e-c3f4-44fe-af22-4ebd36497728\"\n },\n \"source\": [\n \"- (In addition, we also introduce the `allowed_max_length` in case we want to limit the length of the samples; this will be useful if you plan to work with your own datasets that are longer than the 1024 token context size supported by the GPT-2 model)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"41ec6e2d-9eb2-4124-913e-d2af39be4cf2\",\n \"metadata\": {\n \"id\": \"41ec6e2d-9eb2-4124-913e-d2af39be4cf2\"\n },\n \"outputs\": [],\n \"source\": [\n \"def custom_collate_fn(\\n\",\n \" batch,\\n\",\n \" pad_token_id=50256,\\n\",\n \" ignore_index=-100,\\n\",\n \" allowed_max_length=None,\\n\",\n \" device=\\\"cpu\\\"\\n\",\n \"):\\n\",\n \" # Find the longest sequence in the batch\\n\",\n \" batch_max_length = max(len(item)+1 for item in batch)\\n\",\n \"\\n\",\n \" # Pad and prepare inputs and targets\\n\",\n \" inputs_lst, targets_lst = [], []\\n\",\n \"\\n\",\n \" for item in batch:\\n\",\n \" new_item = item.copy()\\n\",\n \" # Add an <|endoftext|> token\\n\",\n \" new_item += [pad_token_id]\\n\",\n \" # Pad sequences to max_length\\n\",\n \" padded = (\\n\",\n \" new_item + [pad_token_id] *\\n\",\n \" (batch_max_length - len(new_item))\\n\",\n \" )\\n\",\n \" inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\\n\",\n \" targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\\n\",\n \"\\n\",\n \" # New: Replace all but the first padding tokens in targets by ignore_index\\n\",\n \" mask = targets == pad_token_id\\n\",\n \" indices = torch.nonzero(mask).squeeze()\\n\",\n \" if indices.numel() > 1:\\n\",\n \" targets[indices[1:]] = ignore_index\\n\",\n \"\\n\",\n \" # New: Optionally truncate to maximum sequence length\\n\",\n \" if allowed_max_length is not None:\\n\",\n \" inputs = inputs[:allowed_max_length]\\n\",\n \" targets = targets[:allowed_max_length]\\n\",\n \"\\n\",\n \" inputs_lst.append(inputs)\\n\",\n \" targets_lst.append(targets)\\n\",\n \"\\n\",\n \" # Convert list of inputs and targets to tensors and transfer to target device\\n\",\n \" inputs_tensor = torch.stack(inputs_lst).to(device)\\n\",\n \" targets_tensor = torch.stack(targets_lst).to(device)\\n\",\n \"\\n\",\n \" return inputs_tensor, targets_tensor\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"cdf5eec4-9ebe-4be0-9fca-9a47bee88fdc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"cdf5eec4-9ebe-4be0-9fca-9a47bee88fdc\",\n \"outputId\": \"e8f709b9-f4c5-428a-a6ac-2a4c1b9358ba\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([[ 0, 1, 2, 3, 4],\\n\",\n \" [ 5, 6, 50256, 50256, 50256],\\n\",\n \" [ 7, 8, 9, 50256, 50256]])\\n\",\n \"tensor([[ 1, 2, 3, 4, 50256],\\n\",\n \" [ 6, 50256, -100, -100, -100],\\n\",\n \" [ 8, 9, 50256, -100, -100]])\\n\"\n ]\n }\n ],\n \"source\": [\n \"inputs, targets = custom_collate_fn(batch)\\n\",\n \"print(inputs)\\n\",\n \"print(targets)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"26727c90-0d42-43b3-af21-0a66ad4fbbc7\",\n \"metadata\": {\n \"id\": \"26727c90-0d42-43b3-af21-0a66ad4fbbc7\"\n },\n \"source\": [\n \"- Let's see what this replacement by -100 accomplishes\\n\",\n \"- For illustration purposes, let's assume we have a small classification task with 2 class labels, 0 and 1, similar to chapter 6\\n\",\n \"- If we have the following logits values (outputs of the last layer of the model), we calculate the following loss\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"W2jvh-OP9MFV\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"W2jvh-OP9MFV\",\n \"outputId\": \"ccb3a703-59a7-4258-8841-57959a016e31\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(1.1269)\\n\"\n ]\n }\n ],\n \"source\": [\n \"logits_1 = torch.tensor(\\n\",\n \" [[-1.0, 1.0], # 1st training example\\n\",\n \" [-0.5, 1.5]] # 2nd training example\\n\",\n \")\\n\",\n \"targets_1 = torch.tensor([0, 1])\\n\",\n \"\\n\",\n \"\\n\",\n \"loss_1 = torch.nn.functional.cross_entropy(logits_1, targets_1)\\n\",\n \"print(loss_1)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5edd3244-8886-4505-92e9-367d28529e1e\",\n \"metadata\": {\n \"id\": \"5edd3244-8886-4505-92e9-367d28529e1e\"\n },\n \"source\": [\n \"- Now, adding one more training example will, as expected, influence the loss\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"nvVMuil89v9N\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"nvVMuil89v9N\",\n \"outputId\": \"6d4683d4-5bfc-4a8c-de2a-95ecb2e716b9\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(0.7936)\\n\"\n ]\n }\n ],\n \"source\": [\n \"logits_2 = torch.tensor(\\n\",\n \" [[-1.0, 1.0],\\n\",\n \" [-0.5, 1.5],\\n\",\n \" [-0.5, 1.5]] # New 3rd training example\\n\",\n \")\\n\",\n \"targets_2 = torch.tensor([0, 1, 1])\\n\",\n \"\\n\",\n \"loss_2 = torch.nn.functional.cross_entropy(logits_2, targets_2)\\n\",\n \"print(loss_2)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"54dca331-40e0-468b-b690-189fe156ba8f\",\n \"metadata\": {\n \"id\": \"54dca331-40e0-468b-b690-189fe156ba8f\"\n },\n \"source\": [\n \"- Let's see what happens if we replace the class label of one of the examples with -100\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"RTyB1vah9p56\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"RTyB1vah9p56\",\n \"outputId\": \"da05302e-3fe0-439e-d1ed-82066bceb122\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(1.1269)\\n\",\n \"loss_1 == loss_3: tensor(True)\\n\"\n ]\n }\n ],\n \"source\": [\n \"targets_3 = torch.tensor([0, 1, -100])\\n\",\n \"\\n\",\n \"loss_3 = torch.nn.functional.cross_entropy(logits_2, targets_3)\\n\",\n \"print(loss_3)\\n\",\n \"print(\\\"loss_1 == loss_3:\\\", loss_1 == loss_3)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cef09d21-b652-4760-abea-4f76920e6a25\",\n \"metadata\": {\n \"id\": \"cef09d21-b652-4760-abea-4f76920e6a25\"\n },\n \"source\": [\n \"- As we can see, the resulting loss on these 3 training examples is the same as the loss we calculated from the 2 training examples, which means that the cross-entropy loss function ignored the training example with the -100 label\\n\",\n \"- By default, PyTorch has the `cross_entropy(..., ignore_index=-100)` setting to ignore examples corresponding to the label -100\\n\",\n \"- Using this -100 `ignore_index`, we can ignore the additional end-of-text (padding) tokens in the batches that we used to pad the training examples to equal length\\n\",\n \"- However, we don't want to ignore the first instance of the end-of-text (padding) token (50256) because it can help signal to the LLM when the response is complete\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6a4e9c5f-7c49-4321-9f1b-a50468a84524\",\n \"metadata\": {\n \"id\": \"6a4e9c5f-7c49-4321-9f1b-a50468a84524\"\n },\n \"source\": [\n \"- In practice, it is also common to mask out the target token IDs that correspond to the instruction, as illustrated in the figure below (this is a recommended reader exercise after completing the chapter)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fab8f0ed-80e8-4fd9-bf84-e5d0e0bc0a39\",\n \"metadata\": {\n \"id\": \"fab8f0ed-80e8-4fd9-bf84-e5d0e0bc0a39\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bccaf048-ec95-498c-9155-d5b3ccba6c96\",\n \"metadata\": {\n \"id\": \"bccaf048-ec95-498c-9155-d5b3ccba6c96\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.4 Creating data loaders for an instruction dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e6b8e656-3af3-4db6-8dde-d8c216a12f50\",\n \"metadata\": {\n \"id\": \"e6b8e656-3af3-4db6-8dde-d8c216a12f50\"\n },\n \"source\": [\n \"- In this section, we use the `InstructionDataset` class and `custom_collate_fn` function to instantiate the training, validation, and test data loaders\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9fffe390-b226-4d5c-983f-9f4da773cb82\",\n \"metadata\": {\n \"id\": \"9fffe390-b226-4d5c-983f-9f4da773cb82\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bccaf048-ec95-498c-9155-d5b3ccba6c96\",\n \"metadata\": {\n \"id\": \"bccaf048-ec95-498c-9155-d5b3ccba6c96\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.4 Creating data loaders for an instruction dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e6b8e656-3af3-4db6-8dde-d8c216a12f50\",\n \"metadata\": {\n \"id\": \"e6b8e656-3af3-4db6-8dde-d8c216a12f50\"\n },\n \"source\": [\n \"- In this section, we use the `InstructionDataset` class and `custom_collate_fn` function to instantiate the training, validation, and test data loaders\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9fffe390-b226-4d5c-983f-9f4da773cb82\",\n \"metadata\": {\n \"id\": \"9fffe390-b226-4d5c-983f-9f4da773cb82\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"932677e9-9317-42e8-b461-7b0269518f97\",\n \"metadata\": {\n \"id\": \"932677e9-9317-42e8-b461-7b0269518f97\"\n },\n \"source\": [\n \"- Another additional detail of the previous `custom_collate_fn` function is that we now directly move the data to the target device (e.g., GPU) instead of doing it in the main training loop, which improves efficiency because it can be carried out as a background process when we use the `custom_collate_fn` as part of the data loader\\n\",\n \"- Using the `partial` function from Python's `functools` standard library, we create a new function with the `device` argument of the original function pre-filled\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"etpqqWh8phKc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"etpqqWh8phKc\",\n \"outputId\": \"b4391c33-1a89-455b-faaa-5f874b6eb409\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Device: mps\\n\"\n ]\n }\n ],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"print(\\\"Device:\\\", device)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"4e47fb30-c2c6-4e6d-a64c-76cc65be4a2c\",\n \"metadata\": {\n \"id\": \"4e47fb30-c2c6-4e6d-a64c-76cc65be4a2c\"\n },\n \"outputs\": [],\n \"source\": [\n \"from functools import partial\\n\",\n \"\\n\",\n \"customized_collate_fn = partial(\\n\",\n \" custom_collate_fn,\\n\",\n \" device=device,\\n\",\n \" allowed_max_length=1024\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8ff42c29-8b81-45e5-ae8d-b97cd1cf447a\",\n \"metadata\": {\n \"id\": \"8ff42c29-8b81-45e5-ae8d-b97cd1cf447a\"\n },\n \"source\": [\n \"- Next, we instantiate the data loaders similar to previous chapters, except that we now provide our own collate function for the batching process\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"BtWkgir6Hlpe\",\n \"metadata\": {\n \"id\": \"BtWkgir6Hlpe\"\n },\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"\\n\",\n \"num_workers = 0\\n\",\n \"batch_size = 8\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_dataset = InstructionDataset(train_data, tokenizer)\\n\",\n \"train_loader = DataLoader(\\n\",\n \" train_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=True,\\n\",\n \" drop_last=True,\\n\",\n \" num_workers=num_workers\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"1d097dc8-ad34-4f05-b435-e4147965f532\",\n \"metadata\": {\n \"id\": \"1d097dc8-ad34-4f05-b435-e4147965f532\"\n },\n \"outputs\": [],\n \"source\": [\n \"val_dataset = InstructionDataset(val_data, tokenizer)\\n\",\n \"val_loader = DataLoader(\\n\",\n \" val_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=False,\\n\",\n \" drop_last=False,\\n\",\n \" num_workers=num_workers\\n\",\n \")\\n\",\n \"\\n\",\n \"test_dataset = InstructionDataset(test_data, tokenizer)\\n\",\n \"test_loader = DataLoader(\\n\",\n \" test_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=False,\\n\",\n \" drop_last=False,\\n\",\n \" num_workers=num_workers\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3f67c147-b1a2-4a95-9807-e2d0de0324c0\",\n \"metadata\": {\n \"id\": \"3f67c147-b1a2-4a95-9807-e2d0de0324c0\"\n },\n \"source\": [\n \"- Let's see what the dimensions of the resulting input and target batches look like\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"GGs1AI3vHpnX\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"GGs1AI3vHpnX\",\n \"outputId\": \"f6a74c8b-1af3-4bc1-b48c-eda64b0200d1\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"torch.Size([8, 61]) torch.Size([8, 61])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 62]) torch.Size([8, 62])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 62]) torch.Size([8, 62])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 77]) torch.Size([8, 77])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 60]) torch.Size([8, 60])\\n\",\n \"torch.Size([8, 59]) torch.Size([8, 59])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 63]) torch.Size([8, 63])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 91]) torch.Size([8, 91])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 89]) torch.Size([8, 89])\\n\",\n \"torch.Size([8, 59]) torch.Size([8, 59])\\n\",\n \"torch.Size([8, 88]) torch.Size([8, 88])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 60]) torch.Size([8, 60])\\n\",\n \"torch.Size([8, 60]) torch.Size([8, 60])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 61]) torch.Size([8, 61])\\n\",\n \"torch.Size([8, 58]) torch.Size([8, 58])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 63]) torch.Size([8, 63])\\n\",\n \"torch.Size([8, 87]) torch.Size([8, 87])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 61]) torch.Size([8, 61])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 60]) torch.Size([8, 60])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\",\n \"torch.Size([8, 57]) torch.Size([8, 57])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 62]) torch.Size([8, 62])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\",\n \"torch.Size([8, 91]) torch.Size([8, 91])\\n\",\n \"torch.Size([8, 61]) torch.Size([8, 61])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 82]) torch.Size([8, 82])\\n\",\n \"torch.Size([8, 63]) torch.Size([8, 63])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 77]) torch.Size([8, 77])\\n\",\n \"torch.Size([8, 91]) torch.Size([8, 91])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 61]) torch.Size([8, 61])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 78]) torch.Size([8, 78])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for inputs, targets in train_loader:\\n\",\n \" print(inputs.shape, targets.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0c8e8dd7-d46a-4cc3-8a7e-c1d31e1b4657\",\n \"metadata\": {\n \"id\": \"0c8e8dd7-d46a-4cc3-8a7e-c1d31e1b4657\"\n },\n \"source\": [\n \"- As we can see based on the output above, all batches have a batch size of 8 but a different length, as expected\\n\",\n \"- Let's also double-check that the inputs contain the `<|endoftext|>` padding tokens corresponding to token ID 50256 by printing the contents of the first training example in the `inputs` batch\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"21b8fd02-014f-4481-9b71-5bfee8f9dfcd\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"21b8fd02-014f-4481-9b71-5bfee8f9dfcd\",\n \"outputId\": \"1b8ad342-2b5b-4f12-ad1a-3cb2a6c712ff\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 30003, 6525, 262, 6827, 1262, 257,\\n\",\n \" 985, 576, 13, 198, 198, 21017, 23412, 25, 198, 464,\\n\",\n \" 5156, 318, 845, 13779, 13, 198, 198, 21017, 18261, 25,\\n\",\n \" 198, 464, 5156, 318, 355, 13779, 355, 257, 4936, 13,\\n\",\n \" 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256],\\n\",\n \" device='mps:0')\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(inputs[0])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5f1f3647-8971-4006-89e0-6a2a1ec1d360\",\n \"metadata\": {\n \"id\": \"5f1f3647-8971-4006-89e0-6a2a1ec1d360\"\n },\n \"source\": [\n \"- Similarly, we visually double-check that the targets contain the -100 placeholder tokens\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 27,\n \"id\": \"51649ab4-1a7e-4a9e-92c5-950a24fde211\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"51649ab4-1a7e-4a9e-92c5-950a24fde211\",\n \"outputId\": \"5e8c23f8-6a05-4c13-9f92-373b75b57ea6\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([ 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430, 257,\\n\",\n \" 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198, 21017,\\n\",\n \" 46486, 25, 198, 30003, 6525, 262, 6827, 1262, 257, 985,\\n\",\n \" 576, 13, 198, 198, 21017, 23412, 25, 198, 464, 5156,\\n\",\n \" 318, 845, 13779, 13, 198, 198, 21017, 18261, 25, 198,\\n\",\n \" 464, 5156, 318, 355, 13779, 355, 257, 4936, 13, 50256,\\n\",\n \" -100, -100, -100, -100, -100, -100, -100, -100, -100],\\n\",\n \" device='mps:0')\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(targets[0])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d6aad445-8f19-4238-b9bf-db80767fb91a\",\n \"metadata\": {\n \"id\": \"d6aad445-8f19-4238-b9bf-db80767fb91a\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.5 Loading a pretrained LLM\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5a5c07d1-4fc9-4846-94cf-b11a085a667b\",\n \"metadata\": {\n \"id\": \"5a5c07d1-4fc9-4846-94cf-b11a085a667b\"\n },\n \"source\": [\n \"- In this section, we load a pretrained GPT model using the same code that we used in section 5.5 of chapter 5 and section 6.4 in chapter 6\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8d1b438f-88af-413f-96a9-f059c6c55fc4\",\n \"metadata\": {\n \"id\": \"8d1b438f-88af-413f-96a9-f059c6c55fc4\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"932677e9-9317-42e8-b461-7b0269518f97\",\n \"metadata\": {\n \"id\": \"932677e9-9317-42e8-b461-7b0269518f97\"\n },\n \"source\": [\n \"- Another additional detail of the previous `custom_collate_fn` function is that we now directly move the data to the target device (e.g., GPU) instead of doing it in the main training loop, which improves efficiency because it can be carried out as a background process when we use the `custom_collate_fn` as part of the data loader\\n\",\n \"- Using the `partial` function from Python's `functools` standard library, we create a new function with the `device` argument of the original function pre-filled\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"etpqqWh8phKc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"etpqqWh8phKc\",\n \"outputId\": \"b4391c33-1a89-455b-faaa-5f874b6eb409\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Device: mps\\n\"\n ]\n }\n ],\n \"source\": [\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"print(\\\"Device:\\\", device)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"4e47fb30-c2c6-4e6d-a64c-76cc65be4a2c\",\n \"metadata\": {\n \"id\": \"4e47fb30-c2c6-4e6d-a64c-76cc65be4a2c\"\n },\n \"outputs\": [],\n \"source\": [\n \"from functools import partial\\n\",\n \"\\n\",\n \"customized_collate_fn = partial(\\n\",\n \" custom_collate_fn,\\n\",\n \" device=device,\\n\",\n \" allowed_max_length=1024\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8ff42c29-8b81-45e5-ae8d-b97cd1cf447a\",\n \"metadata\": {\n \"id\": \"8ff42c29-8b81-45e5-ae8d-b97cd1cf447a\"\n },\n \"source\": [\n \"- Next, we instantiate the data loaders similar to previous chapters, except that we now provide our own collate function for the batching process\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"BtWkgir6Hlpe\",\n \"metadata\": {\n \"id\": \"BtWkgir6Hlpe\"\n },\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"\\n\",\n \"num_workers = 0\\n\",\n \"batch_size = 8\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_dataset = InstructionDataset(train_data, tokenizer)\\n\",\n \"train_loader = DataLoader(\\n\",\n \" train_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=True,\\n\",\n \" drop_last=True,\\n\",\n \" num_workers=num_workers\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"1d097dc8-ad34-4f05-b435-e4147965f532\",\n \"metadata\": {\n \"id\": \"1d097dc8-ad34-4f05-b435-e4147965f532\"\n },\n \"outputs\": [],\n \"source\": [\n \"val_dataset = InstructionDataset(val_data, tokenizer)\\n\",\n \"val_loader = DataLoader(\\n\",\n \" val_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=False,\\n\",\n \" drop_last=False,\\n\",\n \" num_workers=num_workers\\n\",\n \")\\n\",\n \"\\n\",\n \"test_dataset = InstructionDataset(test_data, tokenizer)\\n\",\n \"test_loader = DataLoader(\\n\",\n \" test_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=False,\\n\",\n \" drop_last=False,\\n\",\n \" num_workers=num_workers\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3f67c147-b1a2-4a95-9807-e2d0de0324c0\",\n \"metadata\": {\n \"id\": \"3f67c147-b1a2-4a95-9807-e2d0de0324c0\"\n },\n \"source\": [\n \"- Let's see what the dimensions of the resulting input and target batches look like\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"GGs1AI3vHpnX\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"GGs1AI3vHpnX\",\n \"outputId\": \"f6a74c8b-1af3-4bc1-b48c-eda64b0200d1\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"torch.Size([8, 61]) torch.Size([8, 61])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 62]) torch.Size([8, 62])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 62]) torch.Size([8, 62])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 77]) torch.Size([8, 77])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 60]) torch.Size([8, 60])\\n\",\n \"torch.Size([8, 59]) torch.Size([8, 59])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 63]) torch.Size([8, 63])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 91]) torch.Size([8, 91])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 89]) torch.Size([8, 89])\\n\",\n \"torch.Size([8, 59]) torch.Size([8, 59])\\n\",\n \"torch.Size([8, 88]) torch.Size([8, 88])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 60]) torch.Size([8, 60])\\n\",\n \"torch.Size([8, 60]) torch.Size([8, 60])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 61]) torch.Size([8, 61])\\n\",\n \"torch.Size([8, 58]) torch.Size([8, 58])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 63]) torch.Size([8, 63])\\n\",\n \"torch.Size([8, 87]) torch.Size([8, 87])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 61]) torch.Size([8, 61])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 60]) torch.Size([8, 60])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\",\n \"torch.Size([8, 57]) torch.Size([8, 57])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 62]) torch.Size([8, 62])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\",\n \"torch.Size([8, 91]) torch.Size([8, 91])\\n\",\n \"torch.Size([8, 61]) torch.Size([8, 61])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 82]) torch.Size([8, 82])\\n\",\n \"torch.Size([8, 63]) torch.Size([8, 63])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 77]) torch.Size([8, 77])\\n\",\n \"torch.Size([8, 91]) torch.Size([8, 91])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 61]) torch.Size([8, 61])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 78]) torch.Size([8, 78])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 64]) torch.Size([8, 64])\\n\",\n \"torch.Size([8, 83]) torch.Size([8, 83])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for inputs, targets in train_loader:\\n\",\n \" print(inputs.shape, targets.shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0c8e8dd7-d46a-4cc3-8a7e-c1d31e1b4657\",\n \"metadata\": {\n \"id\": \"0c8e8dd7-d46a-4cc3-8a7e-c1d31e1b4657\"\n },\n \"source\": [\n \"- As we can see based on the output above, all batches have a batch size of 8 but a different length, as expected\\n\",\n \"- Let's also double-check that the inputs contain the `<|endoftext|>` padding tokens corresponding to token ID 50256 by printing the contents of the first training example in the `inputs` batch\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"21b8fd02-014f-4481-9b71-5bfee8f9dfcd\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"21b8fd02-014f-4481-9b71-5bfee8f9dfcd\",\n \"outputId\": \"1b8ad342-2b5b-4f12-ad1a-3cb2a6c712ff\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 30003, 6525, 262, 6827, 1262, 257,\\n\",\n \" 985, 576, 13, 198, 198, 21017, 23412, 25, 198, 464,\\n\",\n \" 5156, 318, 845, 13779, 13, 198, 198, 21017, 18261, 25,\\n\",\n \" 198, 464, 5156, 318, 355, 13779, 355, 257, 4936, 13,\\n\",\n \" 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256],\\n\",\n \" device='mps:0')\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(inputs[0])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5f1f3647-8971-4006-89e0-6a2a1ec1d360\",\n \"metadata\": {\n \"id\": \"5f1f3647-8971-4006-89e0-6a2a1ec1d360\"\n },\n \"source\": [\n \"- Similarly, we visually double-check that the targets contain the -100 placeholder tokens\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 27,\n \"id\": \"51649ab4-1a7e-4a9e-92c5-950a24fde211\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"51649ab4-1a7e-4a9e-92c5-950a24fde211\",\n \"outputId\": \"5e8c23f8-6a05-4c13-9f92-373b75b57ea6\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor([ 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430, 257,\\n\",\n \" 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198, 21017,\\n\",\n \" 46486, 25, 198, 30003, 6525, 262, 6827, 1262, 257, 985,\\n\",\n \" 576, 13, 198, 198, 21017, 23412, 25, 198, 464, 5156,\\n\",\n \" 318, 845, 13779, 13, 198, 198, 21017, 18261, 25, 198,\\n\",\n \" 464, 5156, 318, 355, 13779, 355, 257, 4936, 13, 50256,\\n\",\n \" -100, -100, -100, -100, -100, -100, -100, -100, -100],\\n\",\n \" device='mps:0')\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(targets[0])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d6aad445-8f19-4238-b9bf-db80767fb91a\",\n \"metadata\": {\n \"id\": \"d6aad445-8f19-4238-b9bf-db80767fb91a\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.5 Loading a pretrained LLM\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5a5c07d1-4fc9-4846-94cf-b11a085a667b\",\n \"metadata\": {\n \"id\": \"5a5c07d1-4fc9-4846-94cf-b11a085a667b\"\n },\n \"source\": [\n \"- In this section, we load a pretrained GPT model using the same code that we used in section 5.5 of chapter 5 and section 6.4 in chapter 6\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8d1b438f-88af-413f-96a9-f059c6c55fc4\",\n \"metadata\": {\n \"id\": \"8d1b438f-88af-413f-96a9-f059c6c55fc4\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c68eda7-e02e-4caa-846b-ca6dbd396ca2\",\n \"metadata\": {\n \"id\": \"8c68eda7-e02e-4caa-846b-ca6dbd396ca2\"\n },\n \"source\": [\n \"- However, instead of loading the smallest 124 million parameter model, we load the medium version with 355 million parameters since the 124 million model is too small for achieving qualitatively reasonable results via instruction finetuning\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 28,\n \"id\": \"0d249d67-5eba-414e-9bd2-972ebf01329d\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0d249d67-5eba-414e-9bd2-972ebf01329d\",\n \"outputId\": \"386ebd49-51d7-4a62-c590-91cdccce5fb8\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"File already exists and is up-to-date: gpt2/355M/checkpoint\\n\",\n \"File already exists and is up-to-date: gpt2/355M/encoder.json\\n\",\n \"File already exists and is up-to-date: gpt2/355M/hparams.json\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.data-00000-of-00001\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.index\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.meta\\n\",\n \"File already exists and is up-to-date: gpt2/355M/vocab.bpe\\n\"\n ]\n }\n ],\n \"source\": [\n \"from gpt_download import download_and_load_gpt2\\n\",\n \"from previous_chapters import GPTModel, load_weights_into_gpt\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"# from llms_from_scratch.ch05 import download_and_load_gpt2, load_weights_into_gpt\\n\",\n \"\\n\",\n \"\\n\",\n \"BASE_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"drop_rate\\\": 0.0, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": True # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"CHOOSE_MODEL = \\\"gpt2-medium (355M)\\\"\\n\",\n \"\\n\",\n \"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\\n\",\n \"\\n\",\n \"model_size = CHOOSE_MODEL.split(\\\" \\\")[-1].lstrip(\\\"(\\\").rstrip(\\\")\\\")\\n\",\n \"settings, params = download_and_load_gpt2(\\n\",\n \" model_size=model_size,\\n\",\n \" models_dir=\\\"gpt2\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"load_weights_into_gpt(model, params)\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dbf3afed-bc8e-4d3a-ad9d-eb6f57bb7af5\",\n \"metadata\": {\n \"id\": \"dbf3afed-bc8e-4d3a-ad9d-eb6f57bb7af5\"\n },\n \"source\": [\n \"- Before we start finetuning the model in the next section, let's see how it performs on one of the validation tasks\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"7bd32b7c-5b44-4d25-a09f-46836802ca74\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"7bd32b7c-5b44-4d25-a09f-46836802ca74\",\n \"outputId\": \"c1276a91-e7da-495b-be0f-70a96872dbe6\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Convert the active sentence to passive: 'The chef cooks the meal every day.'\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"input_text = format_input(val_data[0])\\n\",\n \"print(input_text)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"2e3e68e0-2627-4c65-b4e7-1e0667e4f6fa\",\n \"metadata\": {\n \"id\": \"2e3e68e0-2627-4c65-b4e7-1e0667e4f6fa\"\n },\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import (\\n\",\n \" generate,\\n\",\n \" text_to_token_ids,\\n\",\n \" token_ids_to_text\\n\",\n \")\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch05 import (\\n\",\n \"# generate,\\n\",\n \"# text_to_token_ids,\\n\",\n \"# token_ids_to_text\\n\",\n \"# )\\n\",\n \"\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(input_text, tokenizer),\\n\",\n \" max_new_tokens=35,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"],\\n\",\n \" eos_id=50256,\\n\",\n \")\\n\",\n \"generated_text = token_ids_to_text(token_ids, tokenizer)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"36e2fda5-f796-4954-8f72-1dd1123e3344\",\n \"metadata\": {\n \"id\": \"36e2fda5-f796-4954-8f72-1dd1123e3344\"\n },\n \"source\": [\n \"- Note that the `generate` function we used in previous chapters returns the combined input and output text, which was convenient in the previous section for creating legible text\\n\",\n \"- To isolate the response, we can subtract the length of the instruction from the start of the `generated_text`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"ba4a55bf-a245-48d8-beda-2838a58fb5ba\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"ba4a55bf-a245-48d8-beda-2838a58fb5ba\",\n \"outputId\": \"3e231f03-c5dc-4397-8778-4995731176a3\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"The chef cooks the meal every day.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"\\n\",\n \"Convert the active sentence to passive: 'The chef cooks the\\n\"\n ]\n }\n ],\n \"source\": [\n \"response_text = (\\n\",\n \" generated_text[len(input_text):]\\n\",\n \" .replace(\\\"### Response:\\\", \\\"\\\")\\n\",\n \" .strip()\\n\",\n \")\\n\",\n \"print(response_text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d44080b2-a4c5-4520-a797-549519f66a3e\",\n \"metadata\": {\n \"id\": \"d44080b2-a4c5-4520-a797-549519f66a3e\"\n },\n \"source\": [\n \"- As we can see, the model is not capable of following the instructions, yet; it creates a \\\"Response\\\" section but it simply repeats the original input sentence as well as the instruction\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"70d27b9d-a942-4cf5-b797-848c5f01e723\",\n \"metadata\": {\n \"id\": \"70d27b9d-a942-4cf5-b797-848c5f01e723\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.6 Finetuning the LLM on instruction data\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"314b2a39-88b4-44d8-8c85-1c5b0cd6cc4a\",\n \"metadata\": {\n \"id\": \"314b2a39-88b4-44d8-8c85-1c5b0cd6cc4a\"\n },\n \"source\": [\n \"- In this section, we finetune the model\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c68eda7-e02e-4caa-846b-ca6dbd396ca2\",\n \"metadata\": {\n \"id\": \"8c68eda7-e02e-4caa-846b-ca6dbd396ca2\"\n },\n \"source\": [\n \"- However, instead of loading the smallest 124 million parameter model, we load the medium version with 355 million parameters since the 124 million model is too small for achieving qualitatively reasonable results via instruction finetuning\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 28,\n \"id\": \"0d249d67-5eba-414e-9bd2-972ebf01329d\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0d249d67-5eba-414e-9bd2-972ebf01329d\",\n \"outputId\": \"386ebd49-51d7-4a62-c590-91cdccce5fb8\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"File already exists and is up-to-date: gpt2/355M/checkpoint\\n\",\n \"File already exists and is up-to-date: gpt2/355M/encoder.json\\n\",\n \"File already exists and is up-to-date: gpt2/355M/hparams.json\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.data-00000-of-00001\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.index\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.meta\\n\",\n \"File already exists and is up-to-date: gpt2/355M/vocab.bpe\\n\"\n ]\n }\n ],\n \"source\": [\n \"from gpt_download import download_and_load_gpt2\\n\",\n \"from previous_chapters import GPTModel, load_weights_into_gpt\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"# from llms_from_scratch.ch05 import download_and_load_gpt2, load_weights_into_gpt\\n\",\n \"\\n\",\n \"\\n\",\n \"BASE_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"drop_rate\\\": 0.0, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": True # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"CHOOSE_MODEL = \\\"gpt2-medium (355M)\\\"\\n\",\n \"\\n\",\n \"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\\n\",\n \"\\n\",\n \"model_size = CHOOSE_MODEL.split(\\\" \\\")[-1].lstrip(\\\"(\\\").rstrip(\\\")\\\")\\n\",\n \"settings, params = download_and_load_gpt2(\\n\",\n \" model_size=model_size,\\n\",\n \" models_dir=\\\"gpt2\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\\n\",\n \"load_weights_into_gpt(model, params)\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dbf3afed-bc8e-4d3a-ad9d-eb6f57bb7af5\",\n \"metadata\": {\n \"id\": \"dbf3afed-bc8e-4d3a-ad9d-eb6f57bb7af5\"\n },\n \"source\": [\n \"- Before we start finetuning the model in the next section, let's see how it performs on one of the validation tasks\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"7bd32b7c-5b44-4d25-a09f-46836802ca74\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"7bd32b7c-5b44-4d25-a09f-46836802ca74\",\n \"outputId\": \"c1276a91-e7da-495b-be0f-70a96872dbe6\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Convert the active sentence to passive: 'The chef cooks the meal every day.'\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"input_text = format_input(val_data[0])\\n\",\n \"print(input_text)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"2e3e68e0-2627-4c65-b4e7-1e0667e4f6fa\",\n \"metadata\": {\n \"id\": \"2e3e68e0-2627-4c65-b4e7-1e0667e4f6fa\"\n },\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import (\\n\",\n \" generate,\\n\",\n \" text_to_token_ids,\\n\",\n \" token_ids_to_text\\n\",\n \")\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch05 import (\\n\",\n \"# generate,\\n\",\n \"# text_to_token_ids,\\n\",\n \"# token_ids_to_text\\n\",\n \"# )\\n\",\n \"\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(input_text, tokenizer),\\n\",\n \" max_new_tokens=35,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"],\\n\",\n \" eos_id=50256,\\n\",\n \")\\n\",\n \"generated_text = token_ids_to_text(token_ids, tokenizer)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"36e2fda5-f796-4954-8f72-1dd1123e3344\",\n \"metadata\": {\n \"id\": \"36e2fda5-f796-4954-8f72-1dd1123e3344\"\n },\n \"source\": [\n \"- Note that the `generate` function we used in previous chapters returns the combined input and output text, which was convenient in the previous section for creating legible text\\n\",\n \"- To isolate the response, we can subtract the length of the instruction from the start of the `generated_text`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"ba4a55bf-a245-48d8-beda-2838a58fb5ba\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"ba4a55bf-a245-48d8-beda-2838a58fb5ba\",\n \"outputId\": \"3e231f03-c5dc-4397-8778-4995731176a3\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"The chef cooks the meal every day.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"\\n\",\n \"Convert the active sentence to passive: 'The chef cooks the\\n\"\n ]\n }\n ],\n \"source\": [\n \"response_text = (\\n\",\n \" generated_text[len(input_text):]\\n\",\n \" .replace(\\\"### Response:\\\", \\\"\\\")\\n\",\n \" .strip()\\n\",\n \")\\n\",\n \"print(response_text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d44080b2-a4c5-4520-a797-549519f66a3e\",\n \"metadata\": {\n \"id\": \"d44080b2-a4c5-4520-a797-549519f66a3e\"\n },\n \"source\": [\n \"- As we can see, the model is not capable of following the instructions, yet; it creates a \\\"Response\\\" section but it simply repeats the original input sentence as well as the instruction\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"70d27b9d-a942-4cf5-b797-848c5f01e723\",\n \"metadata\": {\n \"id\": \"70d27b9d-a942-4cf5-b797-848c5f01e723\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.6 Finetuning the LLM on instruction data\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"314b2a39-88b4-44d8-8c85-1c5b0cd6cc4a\",\n \"metadata\": {\n \"id\": \"314b2a39-88b4-44d8-8c85-1c5b0cd6cc4a\"\n },\n \"source\": [\n \"- In this section, we finetune the model\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"- Note that we can reuse all the loss calculation and training functions that we used in previous chapters\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"65444865-df87-4d98-9faf-875e1c4be860\",\n \"metadata\": {\n \"id\": \"65444865-df87-4d98-9faf-875e1c4be860\"\n },\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import (\\n\",\n \" calc_loss_loader,\\n\",\n \" train_model_simple\\n\",\n \")\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch05 import (\\n\",\n \"# calc_loss_loader,\\n\",\n \"# train_model_simple,\\n\",\n \"# )\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"00083059-aa41-4d37-8a17-1c72d1b1ca00\",\n \"metadata\": {\n \"id\": \"00083059-aa41-4d37-8a17-1c72d1b1ca00\"\n },\n \"source\": [\n \"- Let's calculate the initial training and validation set loss before we start training (as in previous chapters, the goal is to minimize the loss)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"d99fc6f8-63b2-43da-adbb-a7b6b92c8dd5\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"d99fc6f8-63b2-43da-adbb-a7b6b92c8dd5\",\n \"outputId\": \"a3f5e1b0-093a-4c51-e7fc-c9cac48c2ea2\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training loss: 3.8259105682373047\\n\",\n \"Validation loss: 3.7619349479675295\\n\"\n ]\n }\n ],\n \"source\": [\n \"model.to(device)\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)\\n\",\n \"\\n\",\n \"print(\\\"Training loss:\\\", train_loss)\\n\",\n \"print(\\\"Validation loss:\\\", val_loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"12a6da8f-15b3-42b0-a136-619b7a35c3e9\",\n \"metadata\": {\n \"id\": \"12a6da8f-15b3-42b0-a136-619b7a35c3e9\"\n },\n \"source\": [\n \"- Note that the training is a bit more expensive than in previous chapters since we are using a larger model (355 million instead of 124 million parameters)\\n\",\n \"- The runtimes for various devices are shown for reference below (running this notebook on a compatible GPU device requires no changes to the code)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"db4b57fb-e689-4550-931c-6d34a932487c\",\n \"metadata\": {\n \"id\": \"db4b57fb-e689-4550-931c-6d34a932487c\"\n },\n \"source\": [\n \"
\\n\",\n \"\\n\",\n \"- Note that we can reuse all the loss calculation and training functions that we used in previous chapters\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"65444865-df87-4d98-9faf-875e1c4be860\",\n \"metadata\": {\n \"id\": \"65444865-df87-4d98-9faf-875e1c4be860\"\n },\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import (\\n\",\n \" calc_loss_loader,\\n\",\n \" train_model_simple\\n\",\n \")\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch05 import (\\n\",\n \"# calc_loss_loader,\\n\",\n \"# train_model_simple,\\n\",\n \"# )\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"00083059-aa41-4d37-8a17-1c72d1b1ca00\",\n \"metadata\": {\n \"id\": \"00083059-aa41-4d37-8a17-1c72d1b1ca00\"\n },\n \"source\": [\n \"- Let's calculate the initial training and validation set loss before we start training (as in previous chapters, the goal is to minimize the loss)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"d99fc6f8-63b2-43da-adbb-a7b6b92c8dd5\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"d99fc6f8-63b2-43da-adbb-a7b6b92c8dd5\",\n \"outputId\": \"a3f5e1b0-093a-4c51-e7fc-c9cac48c2ea2\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training loss: 3.8259105682373047\\n\",\n \"Validation loss: 3.7619349479675295\\n\"\n ]\n }\n ],\n \"source\": [\n \"model.to(device)\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"with torch.no_grad():\\n\",\n \" train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)\\n\",\n \" val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)\\n\",\n \"\\n\",\n \"print(\\\"Training loss:\\\", train_loss)\\n\",\n \"print(\\\"Validation loss:\\\", val_loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"12a6da8f-15b3-42b0-a136-619b7a35c3e9\",\n \"metadata\": {\n \"id\": \"12a6da8f-15b3-42b0-a136-619b7a35c3e9\"\n },\n \"source\": [\n \"- Note that the training is a bit more expensive than in previous chapters since we are using a larger model (355 million instead of 124 million parameters)\\n\",\n \"- The runtimes for various devices are shown for reference below (running this notebook on a compatible GPU device requires no changes to the code)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"db4b57fb-e689-4550-931c-6d34a932487c\",\n \"metadata\": {\n \"id\": \"db4b57fb-e689-4550-931c-6d34a932487c\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"17510e9d-7727-4d58-ba9a-d82ec23c1427\",\n \"metadata\": {\n \"id\": \"17510e9d-7727-4d58-ba9a-d82ec23c1427\"\n },\n \"source\": [\n \"- In this section, we save the test set responses for scoring in the next section\\n\",\n \"- We also save a copy of the model for future use\\n\",\n \"- But first, let's take a brief look at the responses generated by the finetuned model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"VQ2NZMbfucAc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"VQ2NZMbfucAc\",\n \"outputId\": \"066c56ff-b52a-4ee6-eae7-1bddfc74d0c1\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Rewrite the sentence using a simile.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"The car is very fast.\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> The car is as fast as lightning.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The car is as fast as a bullet.\\n\",\n \"-------------------------------------\\n\",\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"What type of cloud is typically associated with thunderstorms?\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> The type of cloud typically associated with thunderstorms is cumulonimbus.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The type of cloud associated with thunderstorms is a cumulus cloud.\\n\",\n \"-------------------------------------\\n\",\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Name the author of 'Pride and Prejudice'.\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> Jane Austen.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The author of 'Pride and Prejudice' is Jane Austen.\\n\",\n \"-------------------------------------\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"\\n\",\n \"for entry in test_data[:3]:\\n\",\n \"\\n\",\n \" input_text = format_input(entry)\\n\",\n \"\\n\",\n \" token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(input_text, tokenizer).to(device),\\n\",\n \" max_new_tokens=256,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"],\\n\",\n \" eos_id=50256\\n\",\n \" )\\n\",\n \" generated_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \" response_text = (\\n\",\n \" generated_text[len(input_text):]\\n\",\n \" .replace(\\\"### Response:\\\", \\\"\\\")\\n\",\n \" .strip()\\n\",\n \")\\n\",\n \"\\n\",\n \" print(input_text)\\n\",\n \" print(f\\\"\\\\nCorrect response:\\\\n>> {entry['output']}\\\")\\n\",\n \" print(f\\\"\\\\nModel response:\\\\n>> {response_text.strip()}\\\")\\n\",\n \" print(\\\"-------------------------------------\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"49ab64c1-586f-4939-8def-23feeb1b3599\",\n \"metadata\": {\n \"id\": \"49ab64c1-586f-4939-8def-23feeb1b3599\"\n },\n \"source\": [\n \"- As we can see based on the test set instructions, given responses, and the model's responses, the model performs relatively well\\n\",\n \"- The answers to the first and last instructions are clearly correct\\n\",\n \"- The second answer is close; the model answers with \\\"cumulus cloud\\\" instead of \\\"cumulonimbus\\\" (however, note that cumulus clouds can develop into cumulonimbus clouds, which are capable of producing thunderstorms)\\n\",\n \"- Most importantly, we can see that model evaluation is not as straightforward as in the previous chapter, where we just had to calculate the percentage of correct spam/non-spam class labels to obtain the classification accuracy\\n\",\n \"- In practice, instruction-finetuned LLMs such as chatbots are evaluated via multiple approaches\\n\",\n \" - short-answer and multiple choice benchmarks such as MMLU (\\\"Measuring Massive Multitask Language Understanding\\\", [https://arxiv.org/abs/2009.03300](https://arxiv.org/abs/2009.03300)), which test the knowledge of a model\\n\",\n \" - human preference comparison to other LLMs, such as LMSYS chatbot arena ([https://arena.lmsys.org](https://arena.lmsys.org))\\n\",\n \" - automated conversational benchmarks, where another LLM like GPT-4 is used to evaluate the responses, such as AlpacaEval ([https://tatsu-lab.github.io/alpaca_eval/](https://tatsu-lab.github.io/alpaca_eval/))\\n\",\n \"\\n\",\n \"- In the next section, we will use an approach similar to AlpacaEval and use another LLM to evaluate the responses of our model; however, we will use our own test set instead of using a publicly available benchmark dataset\\n\",\n \"- For this, we add the model response to the `test_data` dictionary and save it as a `\\\"instruction-data-with-response.json\\\"` file for record-keeping so that we can load and analyze it in separate Python sessions if needed\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"-PNGKzY4snKP\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"-PNGKzY4snKP\",\n \"outputId\": \"37b22a62-9860-40b7-c46f-b297782b944c\"\n },\n \"outputs\": [\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"100%|█████████████████████████████████████████| 110/110 [01:08<00:00, 1.60it/s]\\n\"\n ]\n }\n ],\n \"source\": [\n \"from tqdm import tqdm\\n\",\n \"\\n\",\n \"for i, entry in tqdm(enumerate(test_data), total=len(test_data)):\\n\",\n \"\\n\",\n \" input_text = format_input(entry)\\n\",\n \"\\n\",\n \" token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(input_text, tokenizer).to(device),\\n\",\n \" max_new_tokens=256,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"],\\n\",\n \" eos_id=50256\\n\",\n \" )\\n\",\n \" generated_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \" response_text = generated_text[len(input_text):].replace(\\\"### Response:\\\", \\\"\\\").strip()\\n\",\n \"\\n\",\n \" test_data[i][\\\"model_response\\\"] = response_text\\n\",\n \"\\n\",\n \"\\n\",\n \"with open(\\\"instruction-data-with-response.json\\\", \\\"w\\\") as file:\\n\",\n \" json.dump(test_data, file, indent=4) # \\\"indent\\\" for pretty-printing\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"228d6fa7-d162-44c3-bef1-4013c027b155\",\n \"metadata\": {\n \"id\": \"228d6fa7-d162-44c3-bef1-4013c027b155\"\n },\n \"source\": [\n \"- Let's double-check one of the entries to see whether the responses have been added to the `test_data` dictionary correctly\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"u-AvCCMTnPSE\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"u-AvCCMTnPSE\",\n \"outputId\": \"7bcd9600-1446-4829-b773-5259b13d256a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"{'instruction': 'Rewrite the sentence using a simile.', 'input': 'The car is very fast.', 'output': 'The car is as fast as lightning.', 'model_response': 'The car is as fast as a bullet.'}\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(test_data[0])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c1b2f3f6-8569-405a-9db6-d47cba65608a\",\n \"metadata\": {\n \"id\": \"c1b2f3f6-8569-405a-9db6-d47cba65608a\"\n },\n \"source\": [\n \"- Finally, we also save the model in case we want to reuse it in the future\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"8cBU0iHmVfOI\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"8cBU0iHmVfOI\",\n \"outputId\": \"135849ed-9acd-43a2-f438-053d07dae9b2\",\n \"scrolled\": true\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Model saved as gpt2-medium355M-sft.pth\\n\"\n ]\n }\n ],\n \"source\": [\n \"import re\\n\",\n \"\\n\",\n \"\\n\",\n \"file_name = f\\\"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft.pth\\\"\\n\",\n \"torch.save(model.state_dict(), file_name)\\n\",\n \"print(f\\\"Model saved as {file_name}\\\")\\n\",\n \"\\n\",\n \"# Load model via\\n\",\n \"# model.load_state_dict(torch.load(\\\"gpt2-medium355M-sft.pth\\\"))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"obgoGI89dgPm\",\n \"metadata\": {\n \"id\": \"obgoGI89dgPm\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.8 Evaluating the finetuned LLM\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"805b9d30-7336-499f-abb5-4a21be3129f5\",\n \"metadata\": {\n \"id\": \"805b9d30-7336-499f-abb5-4a21be3129f5\"\n },\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"17510e9d-7727-4d58-ba9a-d82ec23c1427\",\n \"metadata\": {\n \"id\": \"17510e9d-7727-4d58-ba9a-d82ec23c1427\"\n },\n \"source\": [\n \"- In this section, we save the test set responses for scoring in the next section\\n\",\n \"- We also save a copy of the model for future use\\n\",\n \"- But first, let's take a brief look at the responses generated by the finetuned model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"VQ2NZMbfucAc\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"VQ2NZMbfucAc\",\n \"outputId\": \"066c56ff-b52a-4ee6-eae7-1bddfc74d0c1\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Rewrite the sentence using a simile.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"The car is very fast.\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> The car is as fast as lightning.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The car is as fast as a bullet.\\n\",\n \"-------------------------------------\\n\",\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"What type of cloud is typically associated with thunderstorms?\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> The type of cloud typically associated with thunderstorms is cumulonimbus.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The type of cloud associated with thunderstorms is a cumulus cloud.\\n\",\n \"-------------------------------------\\n\",\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Name the author of 'Pride and Prejudice'.\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> Jane Austen.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The author of 'Pride and Prejudice' is Jane Austen.\\n\",\n \"-------------------------------------\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"\\n\",\n \"for entry in test_data[:3]:\\n\",\n \"\\n\",\n \" input_text = format_input(entry)\\n\",\n \"\\n\",\n \" token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(input_text, tokenizer).to(device),\\n\",\n \" max_new_tokens=256,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"],\\n\",\n \" eos_id=50256\\n\",\n \" )\\n\",\n \" generated_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \" response_text = (\\n\",\n \" generated_text[len(input_text):]\\n\",\n \" .replace(\\\"### Response:\\\", \\\"\\\")\\n\",\n \" .strip()\\n\",\n \")\\n\",\n \"\\n\",\n \" print(input_text)\\n\",\n \" print(f\\\"\\\\nCorrect response:\\\\n>> {entry['output']}\\\")\\n\",\n \" print(f\\\"\\\\nModel response:\\\\n>> {response_text.strip()}\\\")\\n\",\n \" print(\\\"-------------------------------------\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"49ab64c1-586f-4939-8def-23feeb1b3599\",\n \"metadata\": {\n \"id\": \"49ab64c1-586f-4939-8def-23feeb1b3599\"\n },\n \"source\": [\n \"- As we can see based on the test set instructions, given responses, and the model's responses, the model performs relatively well\\n\",\n \"- The answers to the first and last instructions are clearly correct\\n\",\n \"- The second answer is close; the model answers with \\\"cumulus cloud\\\" instead of \\\"cumulonimbus\\\" (however, note that cumulus clouds can develop into cumulonimbus clouds, which are capable of producing thunderstorms)\\n\",\n \"- Most importantly, we can see that model evaluation is not as straightforward as in the previous chapter, where we just had to calculate the percentage of correct spam/non-spam class labels to obtain the classification accuracy\\n\",\n \"- In practice, instruction-finetuned LLMs such as chatbots are evaluated via multiple approaches\\n\",\n \" - short-answer and multiple choice benchmarks such as MMLU (\\\"Measuring Massive Multitask Language Understanding\\\", [https://arxiv.org/abs/2009.03300](https://arxiv.org/abs/2009.03300)), which test the knowledge of a model\\n\",\n \" - human preference comparison to other LLMs, such as LMSYS chatbot arena ([https://arena.lmsys.org](https://arena.lmsys.org))\\n\",\n \" - automated conversational benchmarks, where another LLM like GPT-4 is used to evaluate the responses, such as AlpacaEval ([https://tatsu-lab.github.io/alpaca_eval/](https://tatsu-lab.github.io/alpaca_eval/))\\n\",\n \"\\n\",\n \"- In the next section, we will use an approach similar to AlpacaEval and use another LLM to evaluate the responses of our model; however, we will use our own test set instead of using a publicly available benchmark dataset\\n\",\n \"- For this, we add the model response to the `test_data` dictionary and save it as a `\\\"instruction-data-with-response.json\\\"` file for record-keeping so that we can load and analyze it in separate Python sessions if needed\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"-PNGKzY4snKP\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"-PNGKzY4snKP\",\n \"outputId\": \"37b22a62-9860-40b7-c46f-b297782b944c\"\n },\n \"outputs\": [\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"100%|█████████████████████████████████████████| 110/110 [01:08<00:00, 1.60it/s]\\n\"\n ]\n }\n ],\n \"source\": [\n \"from tqdm import tqdm\\n\",\n \"\\n\",\n \"for i, entry in tqdm(enumerate(test_data), total=len(test_data)):\\n\",\n \"\\n\",\n \" input_text = format_input(entry)\\n\",\n \"\\n\",\n \" token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(input_text, tokenizer).to(device),\\n\",\n \" max_new_tokens=256,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"],\\n\",\n \" eos_id=50256\\n\",\n \" )\\n\",\n \" generated_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \" response_text = generated_text[len(input_text):].replace(\\\"### Response:\\\", \\\"\\\").strip()\\n\",\n \"\\n\",\n \" test_data[i][\\\"model_response\\\"] = response_text\\n\",\n \"\\n\",\n \"\\n\",\n \"with open(\\\"instruction-data-with-response.json\\\", \\\"w\\\") as file:\\n\",\n \" json.dump(test_data, file, indent=4) # \\\"indent\\\" for pretty-printing\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"228d6fa7-d162-44c3-bef1-4013c027b155\",\n \"metadata\": {\n \"id\": \"228d6fa7-d162-44c3-bef1-4013c027b155\"\n },\n \"source\": [\n \"- Let's double-check one of the entries to see whether the responses have been added to the `test_data` dictionary correctly\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"u-AvCCMTnPSE\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"u-AvCCMTnPSE\",\n \"outputId\": \"7bcd9600-1446-4829-b773-5259b13d256a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"{'instruction': 'Rewrite the sentence using a simile.', 'input': 'The car is very fast.', 'output': 'The car is as fast as lightning.', 'model_response': 'The car is as fast as a bullet.'}\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(test_data[0])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c1b2f3f6-8569-405a-9db6-d47cba65608a\",\n \"metadata\": {\n \"id\": \"c1b2f3f6-8569-405a-9db6-d47cba65608a\"\n },\n \"source\": [\n \"- Finally, we also save the model in case we want to reuse it in the future\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"8cBU0iHmVfOI\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"8cBU0iHmVfOI\",\n \"outputId\": \"135849ed-9acd-43a2-f438-053d07dae9b2\",\n \"scrolled\": true\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Model saved as gpt2-medium355M-sft.pth\\n\"\n ]\n }\n ],\n \"source\": [\n \"import re\\n\",\n \"\\n\",\n \"\\n\",\n \"file_name = f\\\"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft.pth\\\"\\n\",\n \"torch.save(model.state_dict(), file_name)\\n\",\n \"print(f\\\"Model saved as {file_name}\\\")\\n\",\n \"\\n\",\n \"# Load model via\\n\",\n \"# model.load_state_dict(torch.load(\\\"gpt2-medium355M-sft.pth\\\"))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"obgoGI89dgPm\",\n \"metadata\": {\n \"id\": \"obgoGI89dgPm\"\n },\n \"source\": [\n \" \\n\",\n \"## 7.8 Evaluating the finetuned LLM\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"805b9d30-7336-499f-abb5-4a21be3129f5\",\n \"metadata\": {\n \"id\": \"805b9d30-7336-499f-abb5-4a21be3129f5\"\n },\n \"source\": [\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"68d2b9d3-b6ff-4533-a89d-7b66079b4fd1\",\n \"metadata\": {\n \"id\": \"68d2b9d3-b6ff-4533-a89d-7b66079b4fd1\"\n },\n \"source\": [\n \"- In this section, we automate the response evaluation of the finetuned LLM using another, larger LLM\\n\",\n \"- In particular, we use an instruction-finetuned 8-billion-parameter Llama 3 model by Meta AI that can be run locally via ollama ([https://ollama.com](https://ollama.com))\\n\",\n \"- (Alternatively, if you prefer using a more capable LLM like GPT-4 via the OpenAI API, please see the [llm-instruction-eval-openai.ipynb](../03_model-evaluation/llm-instruction-eval-openai.ipynb) notebook)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ea427a30-36ba-44e3-bb1f-eb0d7008d6e9\",\n \"metadata\": {\n \"id\": \"ea427a30-36ba-44e3-bb1f-eb0d7008d6e9\"\n },\n \"source\": [\n \"- Ollama is an application to run LLMs efficiently\\n\",\n \"- It is a wrapper around llama.cpp ([https://github.com/ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp)), which implements LLMs in pure C/C++ to maximize efficiency\\n\",\n \"- Note that it is a tool for using LLMs to generate text (inference), not training or finetuning LLMs\\n\",\n \"- Before running the code below, install ollama by visiting [https://ollama.com](https://ollama.com) and following the instructions (for instance, clicking on the \\\"Download\\\" button and downloading the ollama application for your operating system)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"267cd444-3156-46ad-8243-f9e7a55e66e7\",\n \"metadata\": {},\n \"source\": [\n \"- For macOS and Windows users, click on the ollama application you downloaded; if it prompts you to install the command line usage, say \\\"yes\\\"\\n\",\n \"- Linux users can use the installation command provided on the ollama website\\n\",\n \"\\n\",\n \"- In general, before we can use ollama from the command line, we have to either start the ollama application or run `ollama serve` in a separate terminal\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"68d2b9d3-b6ff-4533-a89d-7b66079b4fd1\",\n \"metadata\": {\n \"id\": \"68d2b9d3-b6ff-4533-a89d-7b66079b4fd1\"\n },\n \"source\": [\n \"- In this section, we automate the response evaluation of the finetuned LLM using another, larger LLM\\n\",\n \"- In particular, we use an instruction-finetuned 8-billion-parameter Llama 3 model by Meta AI that can be run locally via ollama ([https://ollama.com](https://ollama.com))\\n\",\n \"- (Alternatively, if you prefer using a more capable LLM like GPT-4 via the OpenAI API, please see the [llm-instruction-eval-openai.ipynb](../03_model-evaluation/llm-instruction-eval-openai.ipynb) notebook)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ea427a30-36ba-44e3-bb1f-eb0d7008d6e9\",\n \"metadata\": {\n \"id\": \"ea427a30-36ba-44e3-bb1f-eb0d7008d6e9\"\n },\n \"source\": [\n \"- Ollama is an application to run LLMs efficiently\\n\",\n \"- It is a wrapper around llama.cpp ([https://github.com/ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp)), which implements LLMs in pure C/C++ to maximize efficiency\\n\",\n \"- Note that it is a tool for using LLMs to generate text (inference), not training or finetuning LLMs\\n\",\n \"- Before running the code below, install ollama by visiting [https://ollama.com](https://ollama.com) and following the instructions (for instance, clicking on the \\\"Download\\\" button and downloading the ollama application for your operating system)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"267cd444-3156-46ad-8243-f9e7a55e66e7\",\n \"metadata\": {},\n \"source\": [\n \"- For macOS and Windows users, click on the ollama application you downloaded; if it prompts you to install the command line usage, say \\\"yes\\\"\\n\",\n \"- Linux users can use the installation command provided on the ollama website\\n\",\n \"\\n\",\n \"- In general, before we can use ollama from the command line, we have to either start the ollama application or run `ollama serve` in a separate terminal\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"30266e32-63c4-4f6c-8be3-c99e05ed05b7\",\n \"metadata\": {},\n \"source\": [\n \"---\\n\",\n \"\\n\",\n \"**Note**:\\n\",\n \"\\n\",\n \"- When running `ollama serve` in the terminal, as described above, you may encounter an error message saying `Error: listen tcp 127.0.0.1:11434: bind: address already in use`\\n\",\n \"- If that's the case, try use the command `OLLAMA_HOST=127.0.0.1:11435 ollama serve` (and if this address is also in use, try to increment the numbers by one until you find an address not in use\\n\",\n \"\\n\",\n \"---\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"747a2fc7-282d-47ec-a987-ed0a23ed6822\",\n \"metadata\": {\n \"id\": \"747a2fc7-282d-47ec-a987-ed0a23ed6822\"\n },\n \"source\": [\n \"- With the ollama application or `ollama serve` running in a different terminal, on the command line, execute the following command to try out the 8-billion-parameter Llama 3 model (the model, which takes up 4.7 GB of storage space, will be automatically downloaded the first time you execute this command)\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"# 8B model\\n\",\n \"ollama run llama3\\n\",\n \"```\\n\",\n \"\\n\",\n \"\\n\",\n \"The output looks like as follows\\n\",\n \"\\n\",\n \"```\\n\",\n \"$ ollama run llama3\\n\",\n \"pulling manifest\\n\",\n \"pulling 6a0746a1ec1a... 100% ▕████████████████▏ 4.7 GB\\n\",\n \"pulling 4fa551d4f938... 100% ▕████████████████▏ 12 KB\\n\",\n \"pulling 8ab4849b038c... 100% ▕████████████████▏ 254 B\\n\",\n \"pulling 577073ffcc6c... 100% ▕████████████████▏ 110 B\\n\",\n \"pulling 3f8eb4da87fa... 100% ▕████████████████▏ 485 B\\n\",\n \"verifying sha256 digest\\n\",\n \"writing manifest\\n\",\n \"removing any unused layers\\n\",\n \"success\\n\",\n \"```\\n\",\n \"\\n\",\n \"- Note that `llama3` refers to the instruction finetuned 8-billion-parameter Llama 3 model\\n\",\n \"\\n\",\n \"- Using ollama with the `\\\"llama3\\\"` model (a 8B parameter model) requires 16 GB of RAM; if this is not supported by your machine, you can try the smaller model, such as the 3.8B parameter phi-3 model by setting `model = \\\"phi-3\\\"`, which only requires 8 GB of RAM\\n\",\n \"\\n\",\n \"- Alternatively, you can also use the larger 70-billion-parameter Llama 3 model, if your machine supports it, by replacing `llama3` with `llama3:70b`\\n\",\n \"\\n\",\n \"- After the download has been completed, you will see a command line prompt that allows you to chat with the model\\n\",\n \"\\n\",\n \"- Try a prompt like \\\"What do llamas eat?\\\", which should return an output similar to the following\\n\",\n \"\\n\",\n \"```\\n\",\n \">>> What do llamas eat?\\n\",\n \"Llamas are ruminant animals, which means they have a four-chambered\\n\",\n \"stomach and eat plants that are high in fiber. In the wild, llamas\\n\",\n \"typically feed on:\\n\",\n \"1. Grasses: They love to graze on various types of grasses, including tall\\n\",\n \"grasses, wheat, oats, and barley.\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7b7b341c-ba0e-40bb-a52c-cb328bbd1fe4\",\n \"metadata\": {\n \"id\": \"7b7b341c-ba0e-40bb-a52c-cb328bbd1fe4\"\n },\n \"source\": [\n \"- You can end this session using the input `/bye`\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"faaf3e02-8ca0-4edf-be23-60625a5b14e3\",\n \"metadata\": {\n \"id\": \"faaf3e02-8ca0-4edf-be23-60625a5b14e3\"\n },\n \"source\": [\n \"- The following code checks whether the ollama session is running correctly before proceeding to use ollama to evaluate the test set responses we generated in the previous section\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 40,\n \"id\": \"026e8570-071e-48a2-aa38-64d7be35f288\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 193\n },\n \"id\": \"026e8570-071e-48a2-aa38-64d7be35f288\",\n \"outputId\": \"e30d3533-e1f5-4aa9-b24f-33273fc7b30e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ollama running: True\\n\"\n ]\n }\n ],\n \"source\": [\n \"import psutil\\n\",\n \"\\n\",\n \"def check_if_running(process_name):\\n\",\n \" running = False\\n\",\n \" for proc in psutil.process_iter([\\\"name\\\"]):\\n\",\n \" if process_name in proc.info[\\\"name\\\"]:\\n\",\n \" running = True\\n\",\n \" break\\n\",\n \" return running\\n\",\n \"\\n\",\n \"ollama_running = check_if_running(\\\"ollama\\\")\\n\",\n \"\\n\",\n \"if not ollama_running:\\n\",\n \" raise RuntimeError(\\\"Ollama not running. Launch ollama before proceeding.\\\")\\n\",\n \"print(\\\"Ollama running:\\\", check_if_running(\\\"ollama\\\"))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 41,\n \"id\": \"723c9b00-e3cd-4092-83c3-6e48b5cf65b0\",\n \"metadata\": {\n \"id\": \"723c9b00-e3cd-4092-83c3-6e48b5cf65b0\"\n },\n \"outputs\": [],\n \"source\": [\n \"# This cell is optional; it allows you to restart the notebook\\n\",\n \"# and only run section 7.7 without rerunning any of the previous code\\n\",\n \"import json\\n\",\n \"from tqdm import tqdm\\n\",\n \"\\n\",\n \"file_path = \\\"instruction-data-with-response.json\\\"\\n\",\n \"\\n\",\n \"with open(file_path, \\\"r\\\") as file:\\n\",\n \" test_data = json.load(file)\\n\",\n \"\\n\",\n \"\\n\",\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. \\\"\\n\",\n \" f\\\"Write a response that appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b3464705-d026-4594-977f-fb357e51c3a9\",\n \"metadata\": {\n \"id\": \"b3464705-d026-4594-977f-fb357e51c3a9\"\n },\n \"source\": [\n \"- Now, an alternative way to the `ollama run` command we used earlier to interact with the model is via its REST API in Python via the following function\\n\",\n \"- Before you run the next cells in this notebook, make sure that ollama is still running (the previous code cells should print `\\\"Ollama running: True\\\"`)\\n\",\n \"- Next, run the following code cell to query the model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"e3ae0e10-2b28-42ce-8ea2-d9366a58088f\",\n \"metadata\": {\n \"id\": \"e3ae0e10-2b28-42ce-8ea2-d9366a58088f\",\n \"outputId\": \"cc43acb3-8216-43cf-c77d-71d4089dc96c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Llamas are herbivores, which means they primarily feed on plant-based foods. Their diet typically consists of:\\n\",\n \"\\n\",\n \"1. Grasses: Llamas love to graze on various types of grasses, including tall grasses, short grasses, and even weeds.\\n\",\n \"2. Hay: High-quality hay, such as alfalfa or timothy hay, is a staple in a llama's diet. They enjoy the sweet taste and texture of fresh hay.\\n\",\n \"3. Grains: Llamas may receive grains like oats, barley, or corn as part of their daily ration. However, it's essential to provide these grains in moderation, as they can be high in calories.\\n\",\n \"4. Fruits and vegetables: Llamas enjoy a variety of fruits and veggies, such as apples, carrots, sweet potatoes, and leafy greens like kale or spinach.\\n\",\n \"5. Minerals: Llamas require access to mineral supplements, which help maintain their overall health and well-being.\\n\",\n \"\\n\",\n \"In the wild, llamas might also eat:\\n\",\n \"\\n\",\n \"1. Leaves: They'll munch on leaves from trees and shrubs, including plants like willow, alder, and birch.\\n\",\n \"2. Bark: In some cases, llamas may eat the bark of certain trees, like aspen or cottonwood.\\n\",\n \"3. Mosses and lichens: These non-vascular plants can be a tasty snack for llamas.\\n\",\n \"\\n\",\n \"In captivity, llama owners typically provide a balanced diet that includes a mix of hay, grains, and fruits/vegetables. It's essential to consult with a veterinarian or experienced llama breeder to determine the best feeding plan for your llama.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import requests # noqa: F811\\n\",\n \"# import urllib.request\\n\",\n \"\\n\",\n \"def query_model(\\n\",\n \" prompt,\\n\",\n \" model=\\\"llama3\\\",\\n\",\n \" # If you used OLLAMA_HOST=127.0.0.1:11435 ollama serve\\n\",\n \" # update the address from 11434 to 11435\\n\",\n \" url=\\\"http://localhost:11434/api/chat\\\"\\n\",\n \"):\\n\",\n \" # Create the data payload as a dictionary\\n\",\n \" data = {\\n\",\n \" \\\"model\\\": model,\\n\",\n \" \\\"messages\\\": [\\n\",\n \" {\\\"role\\\": \\\"user\\\", \\\"content\\\": prompt}\\n\",\n \" ],\\n\",\n \" \\\"options\\\": { # Settings below are required for deterministic responses\\n\",\n \" \\\"seed\\\": 123,\\n\",\n \" \\\"temperature\\\": 0,\\n\",\n \" \\\"num_ctx\\\": 2048\\n\",\n \" }\\n\",\n \" }\\n\",\n \"\\n\",\n \" \\n\",\n \" \\\"\\\"\\\"\\n\",\n \" # Convert the dictionary to a JSON formatted string and encode it to bytes\\n\",\n \" payload = json.dumps(data).encode(\\\"utf-8\\\")\\n\",\n \"\\n\",\n \" # Create a request object, setting the method to POST and adding necessary headers\\n\",\n \" request = urllib.request.Request(\\n\",\n \" url,\\n\",\n \" data=payload,\\n\",\n \" method=\\\"POST\\\"\\n\",\n \" )\\n\",\n \" request.add_header(\\\"Content-Type\\\", \\\"application/json\\\")\\n\",\n \"\\n\",\n \" # Send the request and capture the response\\n\",\n \" response_data = \\\"\\\"\\n\",\n \" with urllib.request.urlopen(request) as response:\\n\",\n \" # Read and decode the response\\n\",\n \" while True:\\n\",\n \" line = response.readline().decode(\\\"utf-8\\\")\\n\",\n \" if not line:\\n\",\n \" break\\n\",\n \" response_json = json.loads(line)\\n\",\n \" response_data += response_json[\\\"message\\\"][\\\"content\\\"]\\n\",\n \"\\n\",\n \" return response_data\\n\",\n \" \\\"\\\"\\\"\\n\",\n \"\\n\",\n \" # The book originally used the commented-out above, which is based\\n\",\n \" # on urllib. It works generally fine, but some readers reported\\n\",\n \" # issues with using urlib when using a (company) VPN.\\n\",\n \" # The code below uses the requests library, which doesn't seem\\n\",\n \" # to have these issues.\\n\",\n \"\\n\",\n \" # Send the POST request\\n\",\n \" with requests.post(url, json=data, stream=True, timeout=30) as r:\\n\",\n \" r.raise_for_status()\\n\",\n \" response_data = \\\"\\\"\\n\",\n \" for line in r.iter_lines(decode_unicode=True):\\n\",\n \" if not line:\\n\",\n \" continue\\n\",\n \" response_json = json.loads(line)\\n\",\n \" if \\\"message\\\" in response_json:\\n\",\n \" response_data += response_json[\\\"message\\\"][\\\"content\\\"]\\n\",\n \"\\n\",\n \" return response_data\\n\",\n \"\\n\",\n \"\\n\",\n \"model = \\\"llama3\\\"\\n\",\n \"result = query_model(\\\"What do Llamas eat?\\\", model)\\n\",\n \"print(result)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fb6ec392-6d03-4a65-951c-39b92f8df2d8\",\n \"metadata\": {},\n \"source\": [\n \"- Note that if you are getting an `HTTPError: 404 Client Error: Not Found for url: http://localhost:11434/api/chat` error, this could mean you haven't downloaded the `llama3` model yet (to download the model, either use the UI or `ollama run llama3` on the terminal)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"207ae28f-0f8c-4fda-aeef-e7e3046249cc\",\n \"metadata\": {\n \"id\": \"207ae28f-0f8c-4fda-aeef-e7e3046249cc\"\n },\n \"source\": [\n \"- Now, using the `query_model` function we defined above, we can evaluate the responses of our finetuned model; let's try it out on the first 3 test set responses we looked at in a previous section\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"86b839d4-064d-4178-b2d7-01691b452e5e\",\n \"metadata\": {\n \"id\": \"86b839d4-064d-4178-b2d7-01691b452e5e\",\n \"outputId\": \"1c755ee1-bded-4450-9b84-1466724f389a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The car is as fast as lightning.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The car is as fast as a bullet.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd rate the model response \\\"The car is as fast as a bullet.\\\" an 85 out of 100.\\n\",\n \"\\n\",\n \"Here's why:\\n\",\n \"\\n\",\n \"* The response uses a simile correctly, comparing the speed of the car to something else (in this case, a bullet).\\n\",\n \"* The comparison is relevant and makes sense, as bullets are known for their high velocity.\\n\",\n \"* The phrase \\\"as fast as\\\" is used correctly to introduce the simile.\\n\",\n \"\\n\",\n \"The only reason I wouldn't give it a perfect score is that some people might find the comparison slightly less vivid or evocative than others. For example, comparing something to lightning (as in the original response) can be more dramatic and attention-grabbing. However, \\\"as fast as a bullet\\\" is still a strong and effective simile that effectively conveys the idea of the car's speed.\\n\",\n \"\\n\",\n \"Overall, I think the model did a great job!\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The type of cloud typically associated with thunderstorms is cumulonimbus.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The type of cloud associated with thunderstorms is a cumulus cloud.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd score this model response as 40 out of 100.\\n\",\n \"\\n\",\n \"Here's why:\\n\",\n \"\\n\",\n \"* The model correctly identifies that thunderstorms are related to clouds (correctly identifying the type of phenomenon).\\n\",\n \"* However, it incorrectly specifies the type of cloud associated with thunderstorms. Cumulus clouds are not typically associated with thunderstorms; cumulonimbus clouds are.\\n\",\n \"* The response lacks precision and accuracy in its description.\\n\",\n \"\\n\",\n \"Overall, while the model attempts to address the instruction, it provides an incorrect answer, which is a significant error.\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> Jane Austen.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The author of 'Pride and Prejudice' is Jane Austen.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd rate my own response as 95 out of 100. Here's why:\\n\",\n \"\\n\",\n \"* The response accurately answers the question by naming the author of 'Pride and Prejudice' as Jane Austen.\\n\",\n \"* The response is concise and clear, making it easy to understand.\\n\",\n \"* There are no grammatical errors or ambiguities that could lead to confusion.\\n\",\n \"\\n\",\n \"The only reason I wouldn't give myself a perfect score is that the response is slightly redundant - it's not necessary to rephrase the question in the answer. A more concise response would be simply \\\"Jane Austen.\\\"\\n\",\n \"\\n\",\n \"-------------------------\\n\"\n ]\n }\n ],\n \"source\": [\n \"for entry in test_data[:3]:\\n\",\n \" prompt = (\\n\",\n \" f\\\"Given the input `{format_input(entry)}` \\\"\\n\",\n \" f\\\"and correct output `{entry['output']}`, \\\"\\n\",\n \" f\\\"score the model response `{entry['model_response']}`\\\"\\n\",\n \" f\\\" on a scale from 0 to 100, where 100 is the best score. \\\"\\n\",\n \" )\\n\",\n \" print(\\\"\\\\nDataset response:\\\")\\n\",\n \" print(\\\">>\\\", entry['output'])\\n\",\n \" print(\\\"\\\\nModel response:\\\")\\n\",\n \" print(\\\">>\\\", entry[\\\"model_response\\\"])\\n\",\n \" print(\\\"\\\\nScore:\\\")\\n\",\n \" print(\\\">>\\\", query_model(prompt))\\n\",\n \" print(\\\"\\\\n-------------------------\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"24fec453-631f-4ff5-a922-44c3c451942d\",\n \"metadata\": {},\n \"source\": [\n \"---\\n\",\n \"\\n\",\n \"**Note: Better evaluation prompt**\\n\",\n \"\\n\",\n \"- [A reader (Ayoosh Kathuria) suggested](https://github.com/rasbt/LLMs-from-scratch/discussions/449) a longer, improved prompt that evaluates responses on a scale of 1–5 (instead of 1 to 100) and employs a grading rubric, resulting in more accurate and less noisy evaluations:\\n\",\n \"\\n\",\n \"```\\n\",\n \"prompt = \\\"\\\"\\\"\\n\",\n \"You are a fair judge assistant tasked with providing clear, objective feedback based on specific criteria, ensuring each assessment reflects the absolute standards set for performance.\\n\",\n \"You will be given an instruction, a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing the evaluation criteria.\\n\",\n \"Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.\\n\",\n \"Please do not generate any other opening, closing, and explanations.\\n\",\n \"\\n\",\n \"Here is the rubric you should use to build your answer:\\n\",\n \"1: The response fails to address the instructions, providing irrelevant, incorrect, or excessively verbose information that detracts from the user's request.\\n\",\n \"2: The response partially addresses the instructions but includes significant inaccuracies, irrelevant details, or excessive elaboration that detracts from the main task.\\n\",\n \"3: The response follows the instructions with some minor inaccuracies or omissions. It is generally relevant and clear, but may include some unnecessary details or could be more concise.\\n\",\n \"4: The response adheres to the instructions, offering clear, accurate, and relevant information in a concise manner, with only occasional, minor instances of excessive detail or slight lack of clarity.\\n\",\n \"5: The response fully adheres to the instructions, providing a clear, accurate, and relevant answer in a concise and efficient manner. It addresses all aspects of the request without unnecessary details or elaboration\\n\",\n \"\\n\",\n \"Provide your feedback as follows:\\n\",\n \"\\n\",\n \"Feedback:::\\n\",\n \"Evaluation: (your rationale for the rating, as a text)\\n\",\n \"Total rating: (your rating, as a number between 1 and 5)\\n\",\n \"\\n\",\n \"You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.\\n\",\n \"\\n\",\n \"Now here is the instruction, the reference answer, and the response.\\n\",\n \"\\n\",\n \"Instruction: {instruction}\\n\",\n \"Reference Answer: {reference}\\n\",\n \"Answer: {answer}\\n\",\n \"\\n\",\n \"\\n\",\n \"Provide your feedback. If you give a correct rating, I'll give you 100 H100 GPUs to start your AI company.\\n\",\n \"Feedback:::\\n\",\n \"Evaluation: \\\"\\\"\\\"\\n\",\n \"```\\n\",\n \"\\n\",\n \"- For more context and information, see [this](https://github.com/rasbt/LLMs-from-scratch/discussions/449) GitHub discussion\\n\",\n \"\\n\",\n \"---\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b114fd65-9cfb-45f6-ab74-8331da136bf3\",\n \"metadata\": {\n \"id\": \"b114fd65-9cfb-45f6-ab74-8331da136bf3\"\n },\n \"source\": [\n \"- As we can see, the Llama 3 model provides a reasonable evaluation and also gives partial points if a model is not entirely correct, as we can see based on the \\\"cumulus cloud\\\" answer\\n\",\n \"- Note that the previous prompt returns very verbose evaluations; we can tweak the prompt to generate integer responses in the range between 0 and 100 (where 100 is best) to calculate an average score for our model\\n\",\n \"- The evaluation of the 110 entries in the test set takes about 1 minute on an M3 MacBook Air laptop\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"9d7bca69-97c4-47a5-9aa0-32f116fa37eb\",\n \"metadata\": {\n \"id\": \"9d7bca69-97c4-47a5-9aa0-32f116fa37eb\",\n \"outputId\": \"110223c0-90ca-481d-b2d2-f6ac46d3c4f0\"\n },\n \"outputs\": [\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Scoring entries: 100%|████████████████████████| 110/110 [00:37<00:00, 2.90it/s]\"\n ]\n },\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of scores: 110 of 110\\n\",\n \"Average score: 49.45\\n\",\n \"\\n\"\n ]\n },\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\"\n ]\n }\n ],\n \"source\": [\n \"def generate_model_scores(json_data, json_key, model=\\\"llama3\\\"):\\n\",\n \" scores = []\\n\",\n \" for entry in tqdm(json_data, desc=\\\"Scoring entries\\\"):\\n\",\n \" prompt = (\\n\",\n \" f\\\"Given the input `{format_input(entry)}` \\\"\\n\",\n \" f\\\"and correct output `{entry['output']}`, \\\"\\n\",\n \" f\\\"score the model response `{entry[json_key]}`\\\"\\n\",\n \" f\\\" on a scale from 0 to 100, where 100 is the best score. \\\"\\n\",\n \" f\\\"Respond with the integer number only.\\\"\\n\",\n \" )\\n\",\n \" score = query_model(prompt, model)\\n\",\n \" try:\\n\",\n \" scores.append(int(score))\\n\",\n \" except ValueError:\\n\",\n \" print(f\\\"Could not convert score: {score}\\\")\\n\",\n \" continue\\n\",\n \"\\n\",\n \" return scores\\n\",\n \"\\n\",\n \"\\n\",\n \"scores = generate_model_scores(test_data, \\\"model_response\\\")\\n\",\n \"print(f\\\"Number of scores: {len(scores)} of {len(test_data)}\\\")\\n\",\n \"print(f\\\"Average score: {sum(scores)/len(scores):.2f}\\\\n\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"407f08d5-9ada-4301-9ebc-f0533c76d3f2\",\n \"metadata\": {\n \"id\": \"407f08d5-9ada-4301-9ebc-f0533c76d3f2\"\n },\n \"source\": [\n \"- Our model achieves an average score of above 50, which we can use as a reference point to compare the model to other models or to try out other training settings that may improve the model\\n\",\n \"- Note that ollama is not fully deterministic across operating systems (as of this writing), so the numbers you are getting might slightly differ from the ones shown above\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6408768b-2784-44f1-b48e-aed0c1eb9b94\",\n \"metadata\": {\n \"id\": \"6408768b-2784-44f1-b48e-aed0c1eb9b94\"\n },\n \"source\": [\n \"- For reference, the original\\n\",\n \" - Llama 3 8B base model achieves a score of 58.51\\n\",\n \" - Llama 3 8B instruct model achieves a score of 82.65\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"412d7325-284a-446c-92a1-5aa8acc52dee\",\n \"metadata\": {\n \"id\": \"412d7325-284a-446c-92a1-5aa8acc52dee\"\n },\n \"source\": [\n \"## 7.9 Conclusions\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"tIbNMluCDjVM\",\n \"metadata\": {\n \"id\": \"tIbNMluCDjVM\"\n },\n \"source\": [\n \" \\n\",\n \"### 7.9.1 What's next\\n\",\n \"\\n\",\n \"- This marks the final chapter of this book\\n\",\n \"- We covered the major steps of the LLM development cycle: implementing an LLM architecture, pretraining an LLM, and finetuning it\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"30266e32-63c4-4f6c-8be3-c99e05ed05b7\",\n \"metadata\": {},\n \"source\": [\n \"---\\n\",\n \"\\n\",\n \"**Note**:\\n\",\n \"\\n\",\n \"- When running `ollama serve` in the terminal, as described above, you may encounter an error message saying `Error: listen tcp 127.0.0.1:11434: bind: address already in use`\\n\",\n \"- If that's the case, try use the command `OLLAMA_HOST=127.0.0.1:11435 ollama serve` (and if this address is also in use, try to increment the numbers by one until you find an address not in use\\n\",\n \"\\n\",\n \"---\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"747a2fc7-282d-47ec-a987-ed0a23ed6822\",\n \"metadata\": {\n \"id\": \"747a2fc7-282d-47ec-a987-ed0a23ed6822\"\n },\n \"source\": [\n \"- With the ollama application or `ollama serve` running in a different terminal, on the command line, execute the following command to try out the 8-billion-parameter Llama 3 model (the model, which takes up 4.7 GB of storage space, will be automatically downloaded the first time you execute this command)\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"# 8B model\\n\",\n \"ollama run llama3\\n\",\n \"```\\n\",\n \"\\n\",\n \"\\n\",\n \"The output looks like as follows\\n\",\n \"\\n\",\n \"```\\n\",\n \"$ ollama run llama3\\n\",\n \"pulling manifest\\n\",\n \"pulling 6a0746a1ec1a... 100% ▕████████████████▏ 4.7 GB\\n\",\n \"pulling 4fa551d4f938... 100% ▕████████████████▏ 12 KB\\n\",\n \"pulling 8ab4849b038c... 100% ▕████████████████▏ 254 B\\n\",\n \"pulling 577073ffcc6c... 100% ▕████████████████▏ 110 B\\n\",\n \"pulling 3f8eb4da87fa... 100% ▕████████████████▏ 485 B\\n\",\n \"verifying sha256 digest\\n\",\n \"writing manifest\\n\",\n \"removing any unused layers\\n\",\n \"success\\n\",\n \"```\\n\",\n \"\\n\",\n \"- Note that `llama3` refers to the instruction finetuned 8-billion-parameter Llama 3 model\\n\",\n \"\\n\",\n \"- Using ollama with the `\\\"llama3\\\"` model (a 8B parameter model) requires 16 GB of RAM; if this is not supported by your machine, you can try the smaller model, such as the 3.8B parameter phi-3 model by setting `model = \\\"phi-3\\\"`, which only requires 8 GB of RAM\\n\",\n \"\\n\",\n \"- Alternatively, you can also use the larger 70-billion-parameter Llama 3 model, if your machine supports it, by replacing `llama3` with `llama3:70b`\\n\",\n \"\\n\",\n \"- After the download has been completed, you will see a command line prompt that allows you to chat with the model\\n\",\n \"\\n\",\n \"- Try a prompt like \\\"What do llamas eat?\\\", which should return an output similar to the following\\n\",\n \"\\n\",\n \"```\\n\",\n \">>> What do llamas eat?\\n\",\n \"Llamas are ruminant animals, which means they have a four-chambered\\n\",\n \"stomach and eat plants that are high in fiber. In the wild, llamas\\n\",\n \"typically feed on:\\n\",\n \"1. Grasses: They love to graze on various types of grasses, including tall\\n\",\n \"grasses, wheat, oats, and barley.\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7b7b341c-ba0e-40bb-a52c-cb328bbd1fe4\",\n \"metadata\": {\n \"id\": \"7b7b341c-ba0e-40bb-a52c-cb328bbd1fe4\"\n },\n \"source\": [\n \"- You can end this session using the input `/bye`\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"faaf3e02-8ca0-4edf-be23-60625a5b14e3\",\n \"metadata\": {\n \"id\": \"faaf3e02-8ca0-4edf-be23-60625a5b14e3\"\n },\n \"source\": [\n \"- The following code checks whether the ollama session is running correctly before proceeding to use ollama to evaluate the test set responses we generated in the previous section\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 40,\n \"id\": \"026e8570-071e-48a2-aa38-64d7be35f288\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 193\n },\n \"id\": \"026e8570-071e-48a2-aa38-64d7be35f288\",\n \"outputId\": \"e30d3533-e1f5-4aa9-b24f-33273fc7b30e\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ollama running: True\\n\"\n ]\n }\n ],\n \"source\": [\n \"import psutil\\n\",\n \"\\n\",\n \"def check_if_running(process_name):\\n\",\n \" running = False\\n\",\n \" for proc in psutil.process_iter([\\\"name\\\"]):\\n\",\n \" if process_name in proc.info[\\\"name\\\"]:\\n\",\n \" running = True\\n\",\n \" break\\n\",\n \" return running\\n\",\n \"\\n\",\n \"ollama_running = check_if_running(\\\"ollama\\\")\\n\",\n \"\\n\",\n \"if not ollama_running:\\n\",\n \" raise RuntimeError(\\\"Ollama not running. Launch ollama before proceeding.\\\")\\n\",\n \"print(\\\"Ollama running:\\\", check_if_running(\\\"ollama\\\"))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 41,\n \"id\": \"723c9b00-e3cd-4092-83c3-6e48b5cf65b0\",\n \"metadata\": {\n \"id\": \"723c9b00-e3cd-4092-83c3-6e48b5cf65b0\"\n },\n \"outputs\": [],\n \"source\": [\n \"# This cell is optional; it allows you to restart the notebook\\n\",\n \"# and only run section 7.7 without rerunning any of the previous code\\n\",\n \"import json\\n\",\n \"from tqdm import tqdm\\n\",\n \"\\n\",\n \"file_path = \\\"instruction-data-with-response.json\\\"\\n\",\n \"\\n\",\n \"with open(file_path, \\\"r\\\") as file:\\n\",\n \" test_data = json.load(file)\\n\",\n \"\\n\",\n \"\\n\",\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. \\\"\\n\",\n \" f\\\"Write a response that appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b3464705-d026-4594-977f-fb357e51c3a9\",\n \"metadata\": {\n \"id\": \"b3464705-d026-4594-977f-fb357e51c3a9\"\n },\n \"source\": [\n \"- Now, an alternative way to the `ollama run` command we used earlier to interact with the model is via its REST API in Python via the following function\\n\",\n \"- Before you run the next cells in this notebook, make sure that ollama is still running (the previous code cells should print `\\\"Ollama running: True\\\"`)\\n\",\n \"- Next, run the following code cell to query the model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"e3ae0e10-2b28-42ce-8ea2-d9366a58088f\",\n \"metadata\": {\n \"id\": \"e3ae0e10-2b28-42ce-8ea2-d9366a58088f\",\n \"outputId\": \"cc43acb3-8216-43cf-c77d-71d4089dc96c\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Llamas are herbivores, which means they primarily feed on plant-based foods. Their diet typically consists of:\\n\",\n \"\\n\",\n \"1. Grasses: Llamas love to graze on various types of grasses, including tall grasses, short grasses, and even weeds.\\n\",\n \"2. Hay: High-quality hay, such as alfalfa or timothy hay, is a staple in a llama's diet. They enjoy the sweet taste and texture of fresh hay.\\n\",\n \"3. Grains: Llamas may receive grains like oats, barley, or corn as part of their daily ration. However, it's essential to provide these grains in moderation, as they can be high in calories.\\n\",\n \"4. Fruits and vegetables: Llamas enjoy a variety of fruits and veggies, such as apples, carrots, sweet potatoes, and leafy greens like kale or spinach.\\n\",\n \"5. Minerals: Llamas require access to mineral supplements, which help maintain their overall health and well-being.\\n\",\n \"\\n\",\n \"In the wild, llamas might also eat:\\n\",\n \"\\n\",\n \"1. Leaves: They'll munch on leaves from trees and shrubs, including plants like willow, alder, and birch.\\n\",\n \"2. Bark: In some cases, llamas may eat the bark of certain trees, like aspen or cottonwood.\\n\",\n \"3. Mosses and lichens: These non-vascular plants can be a tasty snack for llamas.\\n\",\n \"\\n\",\n \"In captivity, llama owners typically provide a balanced diet that includes a mix of hay, grains, and fruits/vegetables. It's essential to consult with a veterinarian or experienced llama breeder to determine the best feeding plan for your llama.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import requests # noqa: F811\\n\",\n \"# import urllib.request\\n\",\n \"\\n\",\n \"def query_model(\\n\",\n \" prompt,\\n\",\n \" model=\\\"llama3\\\",\\n\",\n \" # If you used OLLAMA_HOST=127.0.0.1:11435 ollama serve\\n\",\n \" # update the address from 11434 to 11435\\n\",\n \" url=\\\"http://localhost:11434/api/chat\\\"\\n\",\n \"):\\n\",\n \" # Create the data payload as a dictionary\\n\",\n \" data = {\\n\",\n \" \\\"model\\\": model,\\n\",\n \" \\\"messages\\\": [\\n\",\n \" {\\\"role\\\": \\\"user\\\", \\\"content\\\": prompt}\\n\",\n \" ],\\n\",\n \" \\\"options\\\": { # Settings below are required for deterministic responses\\n\",\n \" \\\"seed\\\": 123,\\n\",\n \" \\\"temperature\\\": 0,\\n\",\n \" \\\"num_ctx\\\": 2048\\n\",\n \" }\\n\",\n \" }\\n\",\n \"\\n\",\n \" \\n\",\n \" \\\"\\\"\\\"\\n\",\n \" # Convert the dictionary to a JSON formatted string and encode it to bytes\\n\",\n \" payload = json.dumps(data).encode(\\\"utf-8\\\")\\n\",\n \"\\n\",\n \" # Create a request object, setting the method to POST and adding necessary headers\\n\",\n \" request = urllib.request.Request(\\n\",\n \" url,\\n\",\n \" data=payload,\\n\",\n \" method=\\\"POST\\\"\\n\",\n \" )\\n\",\n \" request.add_header(\\\"Content-Type\\\", \\\"application/json\\\")\\n\",\n \"\\n\",\n \" # Send the request and capture the response\\n\",\n \" response_data = \\\"\\\"\\n\",\n \" with urllib.request.urlopen(request) as response:\\n\",\n \" # Read and decode the response\\n\",\n \" while True:\\n\",\n \" line = response.readline().decode(\\\"utf-8\\\")\\n\",\n \" if not line:\\n\",\n \" break\\n\",\n \" response_json = json.loads(line)\\n\",\n \" response_data += response_json[\\\"message\\\"][\\\"content\\\"]\\n\",\n \"\\n\",\n \" return response_data\\n\",\n \" \\\"\\\"\\\"\\n\",\n \"\\n\",\n \" # The book originally used the commented-out above, which is based\\n\",\n \" # on urllib. It works generally fine, but some readers reported\\n\",\n \" # issues with using urlib when using a (company) VPN.\\n\",\n \" # The code below uses the requests library, which doesn't seem\\n\",\n \" # to have these issues.\\n\",\n \"\\n\",\n \" # Send the POST request\\n\",\n \" with requests.post(url, json=data, stream=True, timeout=30) as r:\\n\",\n \" r.raise_for_status()\\n\",\n \" response_data = \\\"\\\"\\n\",\n \" for line in r.iter_lines(decode_unicode=True):\\n\",\n \" if not line:\\n\",\n \" continue\\n\",\n \" response_json = json.loads(line)\\n\",\n \" if \\\"message\\\" in response_json:\\n\",\n \" response_data += response_json[\\\"message\\\"][\\\"content\\\"]\\n\",\n \"\\n\",\n \" return response_data\\n\",\n \"\\n\",\n \"\\n\",\n \"model = \\\"llama3\\\"\\n\",\n \"result = query_model(\\\"What do Llamas eat?\\\", model)\\n\",\n \"print(result)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fb6ec392-6d03-4a65-951c-39b92f8df2d8\",\n \"metadata\": {},\n \"source\": [\n \"- Note that if you are getting an `HTTPError: 404 Client Error: Not Found for url: http://localhost:11434/api/chat` error, this could mean you haven't downloaded the `llama3` model yet (to download the model, either use the UI or `ollama run llama3` on the terminal)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"207ae28f-0f8c-4fda-aeef-e7e3046249cc\",\n \"metadata\": {\n \"id\": \"207ae28f-0f8c-4fda-aeef-e7e3046249cc\"\n },\n \"source\": [\n \"- Now, using the `query_model` function we defined above, we can evaluate the responses of our finetuned model; let's try it out on the first 3 test set responses we looked at in a previous section\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"86b839d4-064d-4178-b2d7-01691b452e5e\",\n \"metadata\": {\n \"id\": \"86b839d4-064d-4178-b2d7-01691b452e5e\",\n \"outputId\": \"1c755ee1-bded-4450-9b84-1466724f389a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The car is as fast as lightning.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The car is as fast as a bullet.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd rate the model response \\\"The car is as fast as a bullet.\\\" an 85 out of 100.\\n\",\n \"\\n\",\n \"Here's why:\\n\",\n \"\\n\",\n \"* The response uses a simile correctly, comparing the speed of the car to something else (in this case, a bullet).\\n\",\n \"* The comparison is relevant and makes sense, as bullets are known for their high velocity.\\n\",\n \"* The phrase \\\"as fast as\\\" is used correctly to introduce the simile.\\n\",\n \"\\n\",\n \"The only reason I wouldn't give it a perfect score is that some people might find the comparison slightly less vivid or evocative than others. For example, comparing something to lightning (as in the original response) can be more dramatic and attention-grabbing. However, \\\"as fast as a bullet\\\" is still a strong and effective simile that effectively conveys the idea of the car's speed.\\n\",\n \"\\n\",\n \"Overall, I think the model did a great job!\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The type of cloud typically associated with thunderstorms is cumulonimbus.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The type of cloud associated with thunderstorms is a cumulus cloud.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd score this model response as 40 out of 100.\\n\",\n \"\\n\",\n \"Here's why:\\n\",\n \"\\n\",\n \"* The model correctly identifies that thunderstorms are related to clouds (correctly identifying the type of phenomenon).\\n\",\n \"* However, it incorrectly specifies the type of cloud associated with thunderstorms. Cumulus clouds are not typically associated with thunderstorms; cumulonimbus clouds are.\\n\",\n \"* The response lacks precision and accuracy in its description.\\n\",\n \"\\n\",\n \"Overall, while the model attempts to address the instruction, it provides an incorrect answer, which is a significant error.\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> Jane Austen.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The author of 'Pride and Prejudice' is Jane Austen.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd rate my own response as 95 out of 100. Here's why:\\n\",\n \"\\n\",\n \"* The response accurately answers the question by naming the author of 'Pride and Prejudice' as Jane Austen.\\n\",\n \"* The response is concise and clear, making it easy to understand.\\n\",\n \"* There are no grammatical errors or ambiguities that could lead to confusion.\\n\",\n \"\\n\",\n \"The only reason I wouldn't give myself a perfect score is that the response is slightly redundant - it's not necessary to rephrase the question in the answer. A more concise response would be simply \\\"Jane Austen.\\\"\\n\",\n \"\\n\",\n \"-------------------------\\n\"\n ]\n }\n ],\n \"source\": [\n \"for entry in test_data[:3]:\\n\",\n \" prompt = (\\n\",\n \" f\\\"Given the input `{format_input(entry)}` \\\"\\n\",\n \" f\\\"and correct output `{entry['output']}`, \\\"\\n\",\n \" f\\\"score the model response `{entry['model_response']}`\\\"\\n\",\n \" f\\\" on a scale from 0 to 100, where 100 is the best score. \\\"\\n\",\n \" )\\n\",\n \" print(\\\"\\\\nDataset response:\\\")\\n\",\n \" print(\\\">>\\\", entry['output'])\\n\",\n \" print(\\\"\\\\nModel response:\\\")\\n\",\n \" print(\\\">>\\\", entry[\\\"model_response\\\"])\\n\",\n \" print(\\\"\\\\nScore:\\\")\\n\",\n \" print(\\\">>\\\", query_model(prompt))\\n\",\n \" print(\\\"\\\\n-------------------------\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"24fec453-631f-4ff5-a922-44c3c451942d\",\n \"metadata\": {},\n \"source\": [\n \"---\\n\",\n \"\\n\",\n \"**Note: Better evaluation prompt**\\n\",\n \"\\n\",\n \"- [A reader (Ayoosh Kathuria) suggested](https://github.com/rasbt/LLMs-from-scratch/discussions/449) a longer, improved prompt that evaluates responses on a scale of 1–5 (instead of 1 to 100) and employs a grading rubric, resulting in more accurate and less noisy evaluations:\\n\",\n \"\\n\",\n \"```\\n\",\n \"prompt = \\\"\\\"\\\"\\n\",\n \"You are a fair judge assistant tasked with providing clear, objective feedback based on specific criteria, ensuring each assessment reflects the absolute standards set for performance.\\n\",\n \"You will be given an instruction, a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing the evaluation criteria.\\n\",\n \"Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.\\n\",\n \"Please do not generate any other opening, closing, and explanations.\\n\",\n \"\\n\",\n \"Here is the rubric you should use to build your answer:\\n\",\n \"1: The response fails to address the instructions, providing irrelevant, incorrect, or excessively verbose information that detracts from the user's request.\\n\",\n \"2: The response partially addresses the instructions but includes significant inaccuracies, irrelevant details, or excessive elaboration that detracts from the main task.\\n\",\n \"3: The response follows the instructions with some minor inaccuracies or omissions. It is generally relevant and clear, but may include some unnecessary details or could be more concise.\\n\",\n \"4: The response adheres to the instructions, offering clear, accurate, and relevant information in a concise manner, with only occasional, minor instances of excessive detail or slight lack of clarity.\\n\",\n \"5: The response fully adheres to the instructions, providing a clear, accurate, and relevant answer in a concise and efficient manner. It addresses all aspects of the request without unnecessary details or elaboration\\n\",\n \"\\n\",\n \"Provide your feedback as follows:\\n\",\n \"\\n\",\n \"Feedback:::\\n\",\n \"Evaluation: (your rationale for the rating, as a text)\\n\",\n \"Total rating: (your rating, as a number between 1 and 5)\\n\",\n \"\\n\",\n \"You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.\\n\",\n \"\\n\",\n \"Now here is the instruction, the reference answer, and the response.\\n\",\n \"\\n\",\n \"Instruction: {instruction}\\n\",\n \"Reference Answer: {reference}\\n\",\n \"Answer: {answer}\\n\",\n \"\\n\",\n \"\\n\",\n \"Provide your feedback. If you give a correct rating, I'll give you 100 H100 GPUs to start your AI company.\\n\",\n \"Feedback:::\\n\",\n \"Evaluation: \\\"\\\"\\\"\\n\",\n \"```\\n\",\n \"\\n\",\n \"- For more context and information, see [this](https://github.com/rasbt/LLMs-from-scratch/discussions/449) GitHub discussion\\n\",\n \"\\n\",\n \"---\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b114fd65-9cfb-45f6-ab74-8331da136bf3\",\n \"metadata\": {\n \"id\": \"b114fd65-9cfb-45f6-ab74-8331da136bf3\"\n },\n \"source\": [\n \"- As we can see, the Llama 3 model provides a reasonable evaluation and also gives partial points if a model is not entirely correct, as we can see based on the \\\"cumulus cloud\\\" answer\\n\",\n \"- Note that the previous prompt returns very verbose evaluations; we can tweak the prompt to generate integer responses in the range between 0 and 100 (where 100 is best) to calculate an average score for our model\\n\",\n \"- The evaluation of the 110 entries in the test set takes about 1 minute on an M3 MacBook Air laptop\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"9d7bca69-97c4-47a5-9aa0-32f116fa37eb\",\n \"metadata\": {\n \"id\": \"9d7bca69-97c4-47a5-9aa0-32f116fa37eb\",\n \"outputId\": \"110223c0-90ca-481d-b2d2-f6ac46d3c4f0\"\n },\n \"outputs\": [\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Scoring entries: 100%|████████████████████████| 110/110 [00:37<00:00, 2.90it/s]\"\n ]\n },\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of scores: 110 of 110\\n\",\n \"Average score: 49.45\\n\",\n \"\\n\"\n ]\n },\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\"\n ]\n }\n ],\n \"source\": [\n \"def generate_model_scores(json_data, json_key, model=\\\"llama3\\\"):\\n\",\n \" scores = []\\n\",\n \" for entry in tqdm(json_data, desc=\\\"Scoring entries\\\"):\\n\",\n \" prompt = (\\n\",\n \" f\\\"Given the input `{format_input(entry)}` \\\"\\n\",\n \" f\\\"and correct output `{entry['output']}`, \\\"\\n\",\n \" f\\\"score the model response `{entry[json_key]}`\\\"\\n\",\n \" f\\\" on a scale from 0 to 100, where 100 is the best score. \\\"\\n\",\n \" f\\\"Respond with the integer number only.\\\"\\n\",\n \" )\\n\",\n \" score = query_model(prompt, model)\\n\",\n \" try:\\n\",\n \" scores.append(int(score))\\n\",\n \" except ValueError:\\n\",\n \" print(f\\\"Could not convert score: {score}\\\")\\n\",\n \" continue\\n\",\n \"\\n\",\n \" return scores\\n\",\n \"\\n\",\n \"\\n\",\n \"scores = generate_model_scores(test_data, \\\"model_response\\\")\\n\",\n \"print(f\\\"Number of scores: {len(scores)} of {len(test_data)}\\\")\\n\",\n \"print(f\\\"Average score: {sum(scores)/len(scores):.2f}\\\\n\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"407f08d5-9ada-4301-9ebc-f0533c76d3f2\",\n \"metadata\": {\n \"id\": \"407f08d5-9ada-4301-9ebc-f0533c76d3f2\"\n },\n \"source\": [\n \"- Our model achieves an average score of above 50, which we can use as a reference point to compare the model to other models or to try out other training settings that may improve the model\\n\",\n \"- Note that ollama is not fully deterministic across operating systems (as of this writing), so the numbers you are getting might slightly differ from the ones shown above\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6408768b-2784-44f1-b48e-aed0c1eb9b94\",\n \"metadata\": {\n \"id\": \"6408768b-2784-44f1-b48e-aed0c1eb9b94\"\n },\n \"source\": [\n \"- For reference, the original\\n\",\n \" - Llama 3 8B base model achieves a score of 58.51\\n\",\n \" - Llama 3 8B instruct model achieves a score of 82.65\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"412d7325-284a-446c-92a1-5aa8acc52dee\",\n \"metadata\": {\n \"id\": \"412d7325-284a-446c-92a1-5aa8acc52dee\"\n },\n \"source\": [\n \"## 7.9 Conclusions\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"tIbNMluCDjVM\",\n \"metadata\": {\n \"id\": \"tIbNMluCDjVM\"\n },\n \"source\": [\n \" \\n\",\n \"### 7.9.1 What's next\\n\",\n \"\\n\",\n \"- This marks the final chapter of this book\\n\",\n \"- We covered the major steps of the LLM development cycle: implementing an LLM architecture, pretraining an LLM, and finetuning it\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"- An optional step that is sometimes followed after instruction finetuning, as described in this chapter, is preference finetuning\\n\",\n \"- Preference finetuning process can be particularly useful for customizing a model to better align with specific user preferences; see the [../04_preference-tuning-with-dpo](../04_preference-tuning-with-dpo) folder if you are interested in this\\n\",\n \"\\n\",\n \"- This GitHub repository also contains a large selection of additional bonus material you may enjoy; for more information, please see the [Bonus Material](https://github.com/rasbt/LLMs-from-scratch?tab=readme-ov-file#bonus-material) section on this repository's README page\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0e2b7bc2-2e8d-483f-a8f5-e2aa093db189\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 7.9.2 Staying up to date in a fast-moving field\\n\",\n \"\\n\",\n \"- No code in this section\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e3d8327d-afb5-4d24-88af-e253889251cf\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 7.9.3 Final words\\n\",\n \"\\n\",\n \"- I hope you enjoyed this journey of implementing an LLM from the ground up and coding the pretraining and finetuning functions\\n\",\n \"- In my opinion, implementing an LLM from scratch is the best way to understand how LLMs work; I hope you gained a better understanding through this approach\\n\",\n \"- While this book serves educational purposes, you may be interested in using different and more powerful LLMs for real-world applications\\n\",\n \" - For this, you may consider popular tools such as axolotl ([https://github.com/OpenAccess-AI-Collective/axolotl](https://github.com/OpenAccess-AI-Collective/axolotl)) or LitGPT ([https://github.com/Lightning-AI/litgpt](https://github.com/Lightning-AI/litgpt)), which I help developing\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f9853e7f-a81a-4806-9728-be1690807185\",\n \"metadata\": {\n \"id\": \"f9853e7f-a81a-4806-9728-be1690807185\"\n },\n \"source\": [\n \"## Summary and takeaways\\n\",\n \"\\n\",\n \"- See the [./gpt_instruction_finetuning.py](./gpt_instruction_finetuning.py) script, a self-contained script for instruction finetuning\\n\",\n \"- [./ollama_evaluate.py](./ollama_evaluate.py) is a standalone script based on section 7.8 that evaluates a JSON file containing \\\"output\\\" and \\\"response\\\" keys via Ollama and Llama 3\\n\",\n \"- The [./load-finetuned-model.ipynb](./load-finetuned-model.ipynb) notebook illustrates how to load the finetuned model in a new session\\n\",\n \"- You can find the exercise solutions in [./exercise-solutions.ipynb](./exercise-solutions.ipynb)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b9cc51ec-e06c-4470-b626-48401a037851\",\n \"metadata\": {\n \"id\": \"b9cc51ec-e06c-4470-b626-48401a037851\"\n },\n \"source\": [\n \"## What's next?\\n\",\n \"\\n\",\n \"- Congrats on completing the book; in case you are looking for additional resources, I added several bonus sections to this GitHub repository that you might find interesting\\n\",\n \"- The complete list of bonus materials can be viewed in the main README's [Bonus Material](https://github.com/rasbt/LLMs-from-scratch?tab=readme-ov-file#bonus-material) section\\n\",\n \"- To highlight a few of my favorites:\\n\",\n \" 1. [Direct Preference Optimization (DPO) for LLM Alignment (From Scratch)](../04_preference-tuning-with-dpo/dpo-from-scratch.ipynb) implements a popular preference tuning mechanism to align the model from this chapter more closely with human preferences\\n\",\n \" 2. [Llama 3.2 From Scratch (A Standalone Notebook)](../../ch05/07_gpt_to_llama/standalone-llama32.ipynb), a from-scratch implementation of Meta AI's popular Llama 3.2, including loading the official pretrained weights; if you are up to some additional experiments, you can replace the `GPTModel` model in each of the chapters with the `Llama3Model` class (it should work as a 1:1 replacement)\\n\",\n \" 3. [Converting GPT to Llama](../../ch05/07_gpt_to_llama) contains code with step-by-step guides that explain the differences between GPT-2 and the various Llama models\\n\",\n \" 4. [Understanding the Difference Between Embedding Layers and Linear Layers](../../ch02/03_bonus_embedding-vs-matmul/embeddings-and-linear-layers.ipynb) is a conceptual explanation illustrating that the `Embedding` layer in PyTorch, which we use at the input stage of an LLM, is mathematically equivalent to a linear layer applied to one-hot encoded data\\n\",\n \"- Happy further reading!\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch07/01_main-chapter-code/exercise-solutions.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba450fb1-8a26-4894-ab7a-5d7bfefe90ce\",\n \"metadata\": {},\n \"source\": [\n \"
\\n\",\n \"\\n\",\n \"- An optional step that is sometimes followed after instruction finetuning, as described in this chapter, is preference finetuning\\n\",\n \"- Preference finetuning process can be particularly useful for customizing a model to better align with specific user preferences; see the [../04_preference-tuning-with-dpo](../04_preference-tuning-with-dpo) folder if you are interested in this\\n\",\n \"\\n\",\n \"- This GitHub repository also contains a large selection of additional bonus material you may enjoy; for more information, please see the [Bonus Material](https://github.com/rasbt/LLMs-from-scratch?tab=readme-ov-file#bonus-material) section on this repository's README page\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0e2b7bc2-2e8d-483f-a8f5-e2aa093db189\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 7.9.2 Staying up to date in a fast-moving field\\n\",\n \"\\n\",\n \"- No code in this section\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e3d8327d-afb5-4d24-88af-e253889251cf\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"### 7.9.3 Final words\\n\",\n \"\\n\",\n \"- I hope you enjoyed this journey of implementing an LLM from the ground up and coding the pretraining and finetuning functions\\n\",\n \"- In my opinion, implementing an LLM from scratch is the best way to understand how LLMs work; I hope you gained a better understanding through this approach\\n\",\n \"- While this book serves educational purposes, you may be interested in using different and more powerful LLMs for real-world applications\\n\",\n \" - For this, you may consider popular tools such as axolotl ([https://github.com/OpenAccess-AI-Collective/axolotl](https://github.com/OpenAccess-AI-Collective/axolotl)) or LitGPT ([https://github.com/Lightning-AI/litgpt](https://github.com/Lightning-AI/litgpt)), which I help developing\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f9853e7f-a81a-4806-9728-be1690807185\",\n \"metadata\": {\n \"id\": \"f9853e7f-a81a-4806-9728-be1690807185\"\n },\n \"source\": [\n \"## Summary and takeaways\\n\",\n \"\\n\",\n \"- See the [./gpt_instruction_finetuning.py](./gpt_instruction_finetuning.py) script, a self-contained script for instruction finetuning\\n\",\n \"- [./ollama_evaluate.py](./ollama_evaluate.py) is a standalone script based on section 7.8 that evaluates a JSON file containing \\\"output\\\" and \\\"response\\\" keys via Ollama and Llama 3\\n\",\n \"- The [./load-finetuned-model.ipynb](./load-finetuned-model.ipynb) notebook illustrates how to load the finetuned model in a new session\\n\",\n \"- You can find the exercise solutions in [./exercise-solutions.ipynb](./exercise-solutions.ipynb)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b9cc51ec-e06c-4470-b626-48401a037851\",\n \"metadata\": {\n \"id\": \"b9cc51ec-e06c-4470-b626-48401a037851\"\n },\n \"source\": [\n \"## What's next?\\n\",\n \"\\n\",\n \"- Congrats on completing the book; in case you are looking for additional resources, I added several bonus sections to this GitHub repository that you might find interesting\\n\",\n \"- The complete list of bonus materials can be viewed in the main README's [Bonus Material](https://github.com/rasbt/LLMs-from-scratch?tab=readme-ov-file#bonus-material) section\\n\",\n \"- To highlight a few of my favorites:\\n\",\n \" 1. [Direct Preference Optimization (DPO) for LLM Alignment (From Scratch)](../04_preference-tuning-with-dpo/dpo-from-scratch.ipynb) implements a popular preference tuning mechanism to align the model from this chapter more closely with human preferences\\n\",\n \" 2. [Llama 3.2 From Scratch (A Standalone Notebook)](../../ch05/07_gpt_to_llama/standalone-llama32.ipynb), a from-scratch implementation of Meta AI's popular Llama 3.2, including loading the official pretrained weights; if you are up to some additional experiments, you can replace the `GPTModel` model in each of the chapters with the `Llama3Model` class (it should work as a 1:1 replacement)\\n\",\n \" 3. [Converting GPT to Llama](../../ch05/07_gpt_to_llama) contains code with step-by-step guides that explain the differences between GPT-2 and the various Llama models\\n\",\n \" 4. [Understanding the Difference Between Embedding Layers and Linear Layers](../../ch02/03_bonus_embedding-vs-matmul/embeddings-and-linear-layers.ipynb) is a conceptual explanation illustrating that the `Embedding` layer in PyTorch, which we use at the input stage of an LLM, is mathematically equivalent to a linear layer applied to one-hot encoded data\\n\",\n \"- Happy further reading!\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"gpuType\": \"A100\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.13.5\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch07/01_main-chapter-code/exercise-solutions.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ba450fb1-8a26-4894-ab7a-5d7bfefe90ce\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"4405196a-db81-470b-be39-167a059587b6\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# This `format_input` function is copied from the original chapter 7 code\\n\",\n \"\\n\",\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. \\\"\\n\",\n \" f\\\"Write a response that appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"83658c09-af8a-425a-b940-eb1f06e43c0b\",\n \"metadata\": {},\n \"source\": [\n \"We can modify the `InstructionDataset` class to collect the lengths of the instructions, which we will use in the collate function to locate the instruction content positions in the targets when we code the collate function, as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"e5e6188a-f182-4f26-b9e5-ccae3ecadae0\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"from torch.utils.data import Dataset\\n\",\n \"\\n\",\n \"\\n\",\n \"class InstructionDataset(Dataset):\\n\",\n \" def __init__(self, data, tokenizer):\\n\",\n \" self.data = data\\n\",\n \"\\n\",\n \" ##########################################################################################\\n\",\n \" # New: Separate list for instruction lengths\\n\",\n \" self.instruction_lengths = []\\n\",\n \" ##########################################################################################\\n\",\n \" \\n\",\n \" self.encoded_texts = []\\n\",\n \" \\n\",\n \" for entry in data:\\n\",\n \" instruction_plus_input = format_input(entry)\\n\",\n \" response_text = f\\\"\\\\n\\\\n### Response:\\\\n{entry['output']}\\\"\\n\",\n \" full_text = instruction_plus_input + response_text\\n\",\n \" \\n\",\n \" self.encoded_texts.append(\\n\",\n \" tokenizer.encode(full_text)\\n\",\n \" )\\n\",\n \"\\n\",\n \" ##########################################################################################\\n\",\n \" # New: collect instruction lengths\\n\",\n \" instruction_length = len(tokenizer.encode(instruction_plus_input))\\n\",\n \" self.instruction_lengths.append(instruction_length)\\n\",\n \" ##########################################################################################\\n\",\n \" \\n\",\n \" def __getitem__(self, index):\\n\",\n \" # New: return both instruction lengths and texts separately\\n\",\n \" return self.instruction_lengths[index], self.encoded_texts[index]\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.data)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"0163b7d1-acb8-456c-8efe-86307b58f4bb\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import tiktoken\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3a186394-4960-424d-bb6a-f58459dd5994\",\n \"metadata\": {},\n \"source\": [\n \"Next, we update the `custom_collate_fn` where each `batch` is now a tuple containing `(instruction_length, item)` instead of just `item` due to the changes in the `InstructionDataset` dataset. In addition, we now mask the corresponding instruction tokens in the target ID list.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"f815e6fc-8e54-4105-aecd-d4c6e890ff9d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def custom_collate_fn(\\n\",\n \" batch,\\n\",\n \" pad_token_id=50256,\\n\",\n \" ignore_index=-100,\\n\",\n \" allowed_max_length=None,\\n\",\n \" device=\\\"cpu\\\"\\n\",\n \"):\\n\",\n \" # Find the longest sequence in the batch\\n\",\n \" batch_max_length = max(len(item)+1 for instruction_length, item in batch) # New: batch is now a tuple\\n\",\n \"\\n\",\n \" # Pad and prepare inputs and targets\\n\",\n \" inputs_lst, targets_lst = [], []\\n\",\n \"\\n\",\n \" for instruction_length, item in batch: # New: batch is now a tuple\\n\",\n \" new_item = item.copy()\\n\",\n \" # Add an <|endoftext|> token\\n\",\n \" new_item += [pad_token_id]\\n\",\n \" # Pad sequences to max_length\\n\",\n \" padded = new_item + [pad_token_id] * (batch_max_length - len(new_item))\\n\",\n \" inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\\n\",\n \" targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\\n\",\n \"\\n\",\n \" # Replace all but the first padding tokens in targets by ignore_index\\n\",\n \" mask = targets == pad_token_id\\n\",\n \" indices = torch.nonzero(mask).squeeze()\\n\",\n \" if indices.numel() > 1:\\n\",\n \" targets[indices[1:]] = ignore_index\\n\",\n \"\\n\",\n \" ##########################################################################################\\n\",\n \" # New: Mask all input and instruction tokens in the targets\\n\",\n \" targets[:instruction_length-1] = -100\\n\",\n \" ##########################################################################################\\n\",\n \" \\n\",\n \" # Optionally truncate to maximum sequence length\\n\",\n \" if allowed_max_length is not None:\\n\",\n \" inputs = inputs[:allowed_max_length]\\n\",\n \" targets = targets[:allowed_max_length]\\n\",\n \" \\n\",\n \" inputs_lst.append(inputs)\\n\",\n \" targets_lst.append(targets)\\n\",\n \"\\n\",\n \" # Convert list of inputs and targets to tensors and transfer to target device\\n\",\n \" inputs_tensor = torch.stack(inputs_lst).to(device)\\n\",\n \" targets_tensor = torch.stack(targets_lst).to(device)\\n\",\n \"\\n\",\n \" return inputs_tensor, targets_tensor\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0a4a4815-850e-42c4-b70d-67e8ce5ebd57\",\n \"metadata\": {},\n \"source\": [\n \"Let's try it out on some sample data below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"8da8a5b1-a8e2-4389-b21c-25b67be6dd1c\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"sample_data = [\\n\",\n \" {'instruction': \\\"What is an antonym of 'complicated'?\\\", 'input': '', 'output': \\\"An antonym of 'complicated' is 'simple'.\\\"},\\n\",\n \" {'instruction': 'Sort the following list in alphabetical order.', 'input': 'Zebra, Elephant, Crocodile', 'output': 'Crocodile, Elephant, Zebra'},\\n\",\n \" {'instruction': 'Arrange the given numbers in descending order.', 'input': '5, 12, 8, 3, 15', 'output': '15, 12, 8, 5, 3.'}\\n\",\n \"]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"435b0816-0fc8-4650-a84a-eceffa4d85e4\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"train_dataset = InstructionDataset(sample_data, tokenizer)\\n\",\n \"train_loader = DataLoader(\\n\",\n \" train_dataset,\\n\",\n \" batch_size=len(sample_data),\\n\",\n \" collate_fn=custom_collate_fn,\\n\",\n \" num_workers=0\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"106bbbd7-7286-4eb6-b343-43419332a80f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"torch.Size([3, 64]) torch.Size([3, 64])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for inputs, targets in train_loader:\\n\",\n \" print(inputs.shape, targets.shape)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"9bb3288b-84a9-4962-ae59-a7a29fd34bce\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Inputs:\\n\",\n \" tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 42758, 262, 1708, 1351, 287, 24830,\\n\",\n \" 605, 1502, 13, 198, 198, 21017, 23412, 25, 198, 57,\\n\",\n \" 37052, 11, 42651, 11, 9325, 19815, 576, 198, 198, 21017,\\n\",\n \" 18261, 25, 198, 34, 12204, 375, 576, 11, 42651, 11,\\n\",\n \" 1168, 37052, 50256, 50256])\\n\",\n \"\\n\",\n \"\\n\",\n \"Targets:\\n\",\n \" tensor([ -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\\n\",\n \" -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\\n\",\n \" -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\\n\",\n \" -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\\n\",\n \" -100, -100, -100, -100, -100, -100, 198, 198, 21017, 18261,\\n\",\n \" 25, 198, 34, 12204, 375, 576, 11, 42651, 11, 1168,\\n\",\n \" 37052, 50256, -100, -100])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Inputs:\\\\n\\\", inputs[1])\\n\",\n \"print(\\\"\\\\n\\\\nTargets:\\\\n\\\", targets[1])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cc40347b-2ca7-44e1-862d-0fd0c92f0628\",\n \"metadata\": {},\n \"source\": [\n \"As we can see based on the `targets` tensor, both the instruction and padding tokens are now masked using the -100 placeholder tokens. \\n\",\n \"Let's decode the inputs just to make sure that they look correct:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"76a9e6fa-3d75-4e39-b139-c3e05048f42b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Sort the following list in alphabetical order.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"Zebra, Elephant, Crocodile\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"Crocodile, Elephant, Zebra<|endoftext|><|endoftext|>\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(tokenizer.decode(list(inputs[1])))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"845ebd36-f63f-4b58-a76e-7767e4d2ccbd\",\n \"metadata\": {},\n \"source\": [\n \"Next, let's decode the non-masked target token IDS:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"4d54a152-b778-455a-8941-e375e2a17e8f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"Crocodile, Elephant, Zebra<|endoftext|>\\n\"\n ]\n }\n ],\n \"source\": [\n \"non_masked_targets = targets[1][targets[1] != -100]\\n\",\n \"\\n\",\n \"print(tokenizer.decode(list(non_masked_targets)))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3912bbf5-e9e2-474b-9552-d522e7510aa6\",\n \"metadata\": {},\n \"source\": [\n \"As shown above, the non-masked target tokens exclude the `\\\"Instruction\\\"` and `\\\"Input\\\"` fields, as intended. Now, we can run the modified code to see how well the LLM performs when finetuned using this masking strategy.\\n\",\n \"\\n\",\n \"For your convenience, you can use the `exercise_experiments.py` code to run a comparison as follows:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"56a76097-9114-479d-8803-443b0ff48581\",\n \"metadata\": {},\n \"source\": [\n \"```bash\\n\",\n \"python exercise_experiments.py --exercise_solution mask_instructions\\n\",\n \"```\\n\",\n \"\\n\",\n \"Output:\\n\",\n \"\\n\",\n \"```\\n\",\n \"matplotlib version: 3.7.1\\n\",\n \"tiktoken version: 0.7.0\\n\",\n \"torch version: 2.3.0+cu121\\n\",\n \"tqdm version: 4.66.4\\n\",\n \"tensorflow version: 2.15.0\\n\",\n \"--------------------------------------------------\\n\",\n \"Training set length: 935\\n\",\n \"Validation set length: 55\\n\",\n \"Test set length: 110\\n\",\n \"--------------------------------------------------\\n\",\n \"Device: cuda\\n\",\n \"--------------------------------------------------\\n\",\n \"...\\n\",\n \"Loaded model: gpt2-medium (355M)\\n\",\n \"--------------------------------------------------\\n\",\n \"Initial losses\\n\",\n \" Training loss: 2.280539035797119\\n\",\n \" Validation loss: 2.262560224533081\\n\",\n \"Ep 1 (Step 000000): Train loss 1.636, Val loss 1.620\\n\",\n \"...\\n\",\n \"Ep 2 (Step 000230): Train loss 0.143, Val loss 0.727\\n\",\n \"...\\n\",\n \"Training completed in 1.77 minutes.\\n\",\n \"Plot saved as loss-plot-mask-instructions.pdf\\n\",\n \"--------------------------------------------------\\n\",\n \"Generating responses\\n\",\n \"100% 110/110 [02:10<00:00, 1.19s/it]\\n\",\n \"Responses saved as instruction-data-with-response-mask-instructions.json\\n\",\n \"Model saved as gpt2-medium355M-sft-mask-instructions.pth\\n\",\n \"```\\n\",\n \"\\n\",\n \"Next, let's evaluate the performance of the resulting LLM:\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"python ollama_evaluate.py --file_path instruction-data-with-response-mask-instructions.json\\n\",\n \"```\\n\",\n \"\\n\",\n \"```\\n\",\n \"Ollama running: True\\n\",\n \"Scoring entries: 100%|██████████████████████████████████████████████████████████████████████████████████████| 110/110 [01:23<00:00, 1.31it/s]\\n\",\n \"Number of scores: 110 of 110\\n\",\n \"Average score: 47.73\\n\",\n \"```\\n\",\n \"\\n\",\n \"As we can see based on the scores, the instruction masking does perform slightly worse, which is consistent with the observation in the \\\"Instruction Tuning With Loss Over Instructions\\\" paper (https://arxiv.org/abs/2405.14394)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"94a0f758-29da-44ee-b7af-32473b3c086e\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## Exercise 7.3: Finetuning on the original Alpaca dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"68df7616-679f-4e53-954d-6e7cf2e2ef55\",\n \"metadata\": {},\n \"source\": [\n \"To finetune the model on the original Stanford Alpaca dataset ([https://github.com/tatsu-lab/stanford_alpaca](https://github.com/tatsu-lab/stanford_alpaca)), you just need to change the file URL from\\n\",\n \"\\n\",\n \"```python\\n\",\n \"url = \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch07/01_main-chapter-code/instruction-data.json\\\"\\n\",\n \"```\\n\",\n \"\\n\",\n \"to\\n\",\n \"\\n\",\n \"```python\\n\",\n \"url = \\\"https://raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json\\\"\\n\",\n \"```\\n\",\n \"\\n\",\n \"Note that the dataset contains 52k entries (50x more than in chapter 7), and the entries are longer than the ones we worked with in chapter 7.\\n\",\n \"Thus, it's highly recommended that the training be run on a GPU.\\n\",\n \"\\n\",\n \"If you encounter out-of-memory errors, consider reducing the batch size from 8 to 4, 2, or 1. In addition to lowering the batch size, you may also want to consider lowering the `allowed_max_length` from 1024 to 512 or 256.\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d94c9621-2c3f-4551-b5b8-87cd96e38c9c\",\n \"metadata\": {},\n \"source\": [\n \"For your convenience, you can use the `exercise_experiments.py` code to finetune the model on the 52k Alpaca dataset with a batch size of 4 and an `allowed_max_length` of 512 as follows:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"40a76486-73e6-4415-94dc-bfe2aa36ea52\",\n \"metadata\": {},\n \"source\": [\n \"```bash\\n\",\n \"python exercise_experiments.py --exercise_solution alpaca_52k\\n\",\n \"```\\n\",\n \"\\n\",\n \"```\\n\",\n \"matplotlib version: 3.7.1\\n\",\n \"tiktoken version: 0.7.0\\n\",\n \"torch version: 2.3.0+cu121\\n\",\n \"tqdm version: 4.66.4\\n\",\n \"tensorflow version: 2.15.0\\n\",\n \"--------------------------------------------------\\n\",\n \"Training set length: 44201\\n\",\n \"Validation set length: 2601\\n\",\n \"Test set length: 5200\\n\",\n \"--------------------------------------------------\\n\",\n \"Device: cuda\\n\",\n \"--------------------------------------------------\\n\",\n \"...\\n\",\n \"Loaded model: gpt2-medium (355M)\\n\",\n \"--------------------------------------------------\\n\",\n \"Initial losses\\n\",\n \" Training loss: 3.3681655883789063\\n\",\n \" Validation loss: 3.4122894287109373\\n\",\n \"Ep 1 (Step 000000): Train loss 2.477, Val loss 2.750\\n\",\n \"...\\n\",\n \"Ep 2 (Step 022095): Train loss 0.761, Val loss 1.557\\n\",\n \"...\\n\",\n \"Training completed in 196.38 minutes.\\n\",\n \"Plot saved as loss-plot-alpaca52k.pdf\\n\",\n \"--------------------------------------------------\\n\",\n \"Generating responses\\n\",\n \"100% 5200/5200 [2:56:33<00:00, 2.04s/it]\\n\",\n \"Responses saved as instruction-data-with-response-alpaca52k.json\\n\",\n \"Model saved as gpt2-medium355M-sft-alpaca52k.pth\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cc8a1bd1-15f4-4a35-87b5-369038db0aa7\",\n \"metadata\": {},\n \"source\": [\n \"Below are a few examples from the Alpaca dataset, including the generated model responses:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be9ab66f-5819-4b01-9a03-c45aa3b7c5b8\",\n \"metadata\": {},\n \"source\": [\n \"```json\\n\",\n \"[\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": \\\"Edit the following sentence to increase readability: \\\\\\\"He made a huge effort and was so successful.\\\\\\\"\\\",\\n\",\n \" \\\"input\\\": \\\"\\\",\\n\",\n \" \\\"output\\\": \\\"He exerted a tremendous effort, and thus enjoyed great success.\\\",\\n\",\n \" \\\"model_response\\\": \\\"He put in an immense effort and was rewarded with success.\\\"\\n\",\n \" },\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": \\\"Rewrite the following sentence to make it more concise: \\\\\\\"I was displeased with the result of the experiment that I conducted.\\\\\\\"\\\",\\n\",\n \" \\\"input\\\": \\\"\\\",\\n\",\n \" \\\"output\\\": \\\"I was unhappy with my experiment's outcome.\\\",\\n\",\n \" \\\"model_response\\\": \\\"I was displeased with the results of the experiment.\\\"\\n\",\n \" },\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": \\\"How can we build a more efficient GPT model?\\\",\\n\",\n \" \\\"input\\\": \\\"\\\",\\n\",\n \" \\\"output\\\": \\\"We can build a more efficient GPT model by optimizing the architecture of the model, using smaller model sizes and training with fewer parameters. We can also leverage techniques such as knowledge distillation, transfer learning, dynamic sparsity and hybrid computing to further improve the efficiency of the model.\\\",\\n\",\n \" \\\"model_response\\\": \\\"Building a more efficient GPT model requires careful planning and optimization. First, it is important to identify the target language and the context in which the model is used. Then, it is important to select the appropriate model architecture, such as backpropagation, hyperparameters, and hyperparameters. Finally, it is important to select the appropriate model weights and optimizers, such as backpropagation, hyperparameters, and hyperparameters.\\\"\\n\",\n \" },\\n\",\n \"]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"840e2076-f2e6-44a2-86fd-f191f9674267\",\n \"metadata\": {},\n \"source\": [\n \"Finally, we can evaluate the finetuned LLM using the [ollama_evaluate.py](ollama_evaluate.py) utility function:\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"python ollama_evaluate.py --file_path instruction-data-with-response-alpaca52k.json\\n\",\n \"```\\n\",\n \"\\n\",\n \"```\\n\",\n \"Scoring entries: 100%|████████████████████| 5200/5200 [1:07:52<00:00, 1.28it/s]\\n\",\n \"Number of scores: 5188 of 5200\\n\",\n \"Average score: 48.16\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d14b3c60-00a1-43a9-9fcd-592aaadf1ef4\",\n \"metadata\": {},\n \"source\": [\n \"The score is slightly lower than the score we obtained on the dataset we used in this chapter. However, note that the Alpaca test set contains more diverse and partly more challenging instructions than the dataset we used in the main chapter.\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ca61fa6c-4e1d-4618-9e5e-d091f8303e30\",\n \"metadata\": {},\n \"source\": [\n \"## Exercise 7.4: Parameter-efficient finetuning with LoRA\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"01742cec-1f41-4415-8788-009d31b1ad38\",\n \"metadata\": {},\n \"source\": [\n \"To instruction finetune the model using LoRA, use the relevant classes and functions from appendix E:\\n\",\n \"\\n\",\n \"```python\\n\",\n \"from appendix_E import LoRALayer, LinearWithLoRA, replace_linear_with_lora\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"871dca8f-3411-4735-b7b0-9d0e6e0599ac\",\n \"metadata\": {},\n \"source\": [\n \"Next, add the following lines of code below the model loading code in section 7.5:\\n\",\n \"\\n\",\n \"\\n\",\n \"```python\\n\",\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable parameters before: {total_params:,}\\\")\\n\",\n \"\\n\",\n \"for param in model.parameters():\\n\",\n \" param.requires_grad = False\\n\",\n \"\\n\",\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable parameters after: {total_params:,}\\\")\\n\",\n \"replace_linear_with_lora(model, rank=16, alpha=16)\\n\",\n \"\\n\",\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable LoRA parameters: {total_params:,}\\\")\\n\",\n \"model.to(device)\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1b26b925-dc95-4b91-b050-9676dd9608a4\",\n \"metadata\": {},\n \"source\": [\n \"For your convenience, you can use the `exercise_experiments.py` code to finetune the model, using LoRA with rank 16 and alpa 16, as follows:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"01f02c7e-3b15-44b8-bf41-7892cd755766\",\n \"metadata\": {},\n \"source\": [\n \"```bash\\n\",\n \"python exercise_experiments.py --exercise_solution lora\\n\",\n \"```\\n\",\n \"\\n\",\n \"Output:\\n\",\n \"\\n\",\n \"```\\n\",\n \"matplotlib version: 3.7.1\\n\",\n \"tiktoken version: 0.7.0\\n\",\n \"torch version: 2.3.0+cu121\\n\",\n \"tqdm version: 4.66.4\\n\",\n \"tensorflow version: 2.15.0\\n\",\n \"--------------------------------------------------\\n\",\n \"Training set length: 935\\n\",\n \"Validation set length: 55\\n\",\n \"Test set length: 110\\n\",\n \"--------------------------------------------------\\n\",\n \"Device: cuda\\n\",\n \"--------------------------------------------------\\n\",\n \"File already exists and is up-to-date: gpt2/355M/checkpoint\\n\",\n \"File already exists and is up-to-date: gpt2/355M/encoder.json\\n\",\n \"File already exists and is up-to-date: gpt2/355M/hparams.json\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.data-00000-of-00001\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.index\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.meta\\n\",\n \"File already exists and is up-to-date: gpt2/355M/vocab.bpe\\n\",\n \"Loaded model: gpt2-medium (355M)\\n\",\n \"--------------------------------------------------\\n\",\n \"Total trainable parameters before: 406,286,336\\n\",\n \"Total trainable parameters after: 0\\n\",\n \"Total trainable LoRA parameters: 7,898,384\\n\",\n \"Initial losses\\n\",\n \" Training loss: 3.7684114456176756\\n\",\n \" Validation loss: 3.7619335651397705\\n\",\n \"Ep 1 (Step 000000): Train loss 2.509, Val loss 2.519\\n\",\n \"...\\n\",\n \"Ep 2 (Step 000230): Train loss 0.308, Val loss 0.652\\n\",\n \"...\\n\",\n \"--------------------------------------------------\\n\",\n \"Generating responses\\n\",\n \"100% 110/110 [01:52<00:00, 1.03s/it]\\n\",\n \"Responses saved as instruction-data-with-response-lora.json\\n\",\n \"Model saved as gpt2-medium355M-sft-lora.pth\\n\",\n \"```\\n\",\n \"\\n\",\n \"For comparison, you can run the original chapter 7 finetuning code via `python exercise_experiments.py --exercise_solution baseline`. \\n\",\n \"\\n\",\n \"Note that on an Nvidia L4 GPU, the code above, using LoRA, takes 1.30 min to run. In comparison, the baseline takes 1.80 minutes to run. So, LoRA is approximately 28% faster.\\n\",\n \"\\n\",\n \"\\n\",\n \"We can evaluate the performance using the Ollama Llama 3 method, which is for your convenience, also implemented in the `python exercise_experiments.py` script, which we can run as follows:\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"python ollama_evaluate.py --file_path instruction-data-with-response-lora.json\\n\",\n \"```\\n\",\n \"\\n\",\n \"Output:\\n\",\n \"\\n\",\n \"```\\n\",\n \"Ollama running: True\\n\",\n \"Scoring entries: 100%|████████████████████████| 110/110 [01:13<00:00, 1.50it/s]\\n\",\n \"Number of scores: 110 of 110\\n\",\n \"Average score: 50.23\\n\",\n \"```\\n\",\n \"\\n\",\n \"The score is around 50, which is in the same ballpark as the original model.\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.10.16\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch07/01_main-chapter-code/exercise_experiments.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# Code to run the exercises; see exercise-solutions.ipynb for more information\n\nfrom functools import partial\nfrom importlib.metadata import version\nimport json\nimport math\nimport os\nimport re\nimport time\n\nimport matplotlib.pyplot as plt\nfrom matplotlib.ticker import MaxNLocator\nimport requests\nimport tiktoken\nimport torch\nfrom torch.utils.data import Dataset, DataLoader\nfrom tqdm import tqdm\n\n# Import from local files in this folder\nfrom gpt_download import download_and_load_gpt2\nfrom previous_chapters import (\n calc_loss_loader,\n generate,\n GPTModel,\n load_weights_into_gpt,\n text_to_token_ids,\n train_model_simple,\n token_ids_to_text\n)\n\n\nclass InstructionDataset(Dataset):\n def __init__(self, data, tokenizer):\n self.data = data\n\n # Pre-tokenize texts\n self.encoded_texts = []\n for entry in data:\n instruction_plus_input = format_input(entry)\n response_text = f\"\\n\\n### Response:\\n{entry['output']}\"\n full_text = instruction_plus_input + response_text\n self.encoded_texts.append(\n tokenizer.encode(full_text)\n )\n\n def __getitem__(self, index):\n return self.encoded_texts[index]\n\n def __len__(self):\n return len(self.data)\n\n\nclass InstructionDatasetWithMasking(Dataset):\n def __init__(self, data, tokenizer):\n self.data = data\n\n # New: Separate list for instruction lengths\n self.instruction_lengths = []\n self.encoded_texts = []\n\n for entry in data:\n instruction_plus_input = format_input(entry)\n response_text = f\"\\n\\n### Response:\\n{entry['output']}\"\n full_text = instruction_plus_input + response_text\n\n self.encoded_texts.append(\n tokenizer.encode(full_text)\n )\n\n # New: collect instruction lengths\n instruction_length = len(tokenizer.encode(instruction_plus_input))\n self.instruction_lengths.append(instruction_length)\n\n def __getitem__(self, index):\n # New: return both instruction lengths and texts separately\n return self.instruction_lengths[index], self.encoded_texts[index]\n\n def __len__(self):\n return len(self.data)\n\n\nclass InstructionDatasetPhi(Dataset):\n def __init__(self, data, tokenizer):\n self.data = data\n\n # Pre-tokenize texts\n self.encoded_texts = []\n for entry in data:\n\n ###################################################################\n # NEW: Use `format_input_phi` and adjust the response text template\n instruction_plus_input = format_input_phi(entry)\n response_text = f\"\\n<|assistant|>:\\n{entry['output']}\"\n ###################################################################\n full_text = instruction_plus_input + response_text\n self.encoded_texts.append(\n tokenizer.encode(full_text)\n )\n\n def __getitem__(self, index):\n return self.encoded_texts[index]\n\n def __len__(self):\n return len(self.data)\n\n\nclass LinearWithLoRA(torch.nn.Module):\n def __init__(self, linear, rank, alpha):\n super().__init__()\n self.linear = linear\n self.lora = LoRALayer(\n linear.in_features, linear.out_features, rank, alpha\n )\n\n def forward(self, x):\n return self.linear(x) + self.lora(x)\n\n\nclass LoRALayer(torch.nn.Module):\n def __init__(self, in_dim, out_dim, rank, alpha):\n super().__init__()\n self.A = torch.nn.Parameter(torch.empty(in_dim, rank))\n torch.nn.init.kaiming_uniform_(self.A, a=math.sqrt(5)) # similar to standard weight initialization\n self.B = torch.nn.Parameter(torch.zeros(rank, out_dim))\n self.alpha = alpha\n\n def forward(self, x):\n x = self.alpha * (x @ self.A @ self.B)\n return x\n\n\ndef replace_linear_with_lora(model, rank, alpha):\n for name, module in model.named_children():\n if isinstance(module, torch.nn.Linear):\n # Replace the Linear layer with LinearWithLoRA\n setattr(model, name, LinearWithLoRA(module, rank, alpha))\n else:\n # Recursively apply the same function to child modules\n replace_linear_with_lora(module, rank, alpha)\n\n\ndef custom_collate_fn(\n batch,\n pad_token_id=50256,\n ignore_index=-100,\n allowed_max_length=None,\n device=\"cpu\"\n):\n # Find the longest sequence in the batch\n batch_max_length = max(len(item)+1 for item in batch)\n\n # Pad and prepare inputs and targets\n inputs_lst, targets_lst = [], []\n\n for item in batch:\n new_item = item.copy()\n # Add an <|endoftext|> token\n new_item += [pad_token_id]\n # Pad sequences to max_length\n padded = new_item + [pad_token_id] * (batch_max_length - len(new_item))\n inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\n targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\n\n # New: Replace all but the first padding tokens in targets by ignore_index\n mask = targets == pad_token_id\n indices = torch.nonzero(mask).squeeze()\n if indices.numel() > 1:\n targets[indices[1:]] = ignore_index\n\n # New: Optionally truncate to maximum sequence length\n if allowed_max_length is not None:\n inputs = inputs[:allowed_max_length]\n targets = targets[:allowed_max_length]\n\n inputs_lst.append(inputs)\n targets_lst.append(targets)\n\n # Convert list of inputs and targets to tensors and transfer to target device\n inputs_tensor = torch.stack(inputs_lst).to(device)\n targets_tensor = torch.stack(targets_lst).to(device)\n\n return inputs_tensor, targets_tensor\n\n\ndef custom_collate_with_masking_fn(\n batch,\n pad_token_id=50256,\n ignore_index=-100,\n allowed_max_length=None,\n device=\"cpu\"\n):\n # Find the longest sequence in the batch\n batch_max_length = max(len(item)+1 for instruction_length, item in batch) # New: batch is now a tuple\n\n # Pad and prepare inputs and targets\n inputs_lst, targets_lst = [], []\n\n for instruction_length, item in batch: # New: batch is now a tuple\n new_item = item.copy()\n # Add an <|endoftext|> token\n new_item += [pad_token_id]\n # Pad sequences to max_length\n padded = new_item + [pad_token_id] * (batch_max_length - len(new_item))\n inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\n targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\n\n # Replace all but the first padding tokens in targets by ignore_index\n mask = targets == pad_token_id\n indices = torch.nonzero(mask).squeeze()\n if indices.numel() > 1:\n targets[indices[1:]] = ignore_index\n\n # New: Mask all input and instruction tokens in the targets\n targets[:instruction_length-1] = -100\n\n # Optionally truncate to maximum sequence length\n if allowed_max_length is not None:\n inputs = inputs[:allowed_max_length]\n targets = targets[:allowed_max_length]\n\n inputs_lst.append(inputs)\n targets_lst.append(targets)\n\n # Convert list of inputs and targets to tensors and transfer to target device\n inputs_tensor = torch.stack(inputs_lst).to(device)\n targets_tensor = torch.stack(targets_lst).to(device)\n\n return inputs_tensor, targets_tensor\n\n\ndef download_and_load_file(file_path, url):\n if not os.path.exists(file_path):\n response = requests.get(url, timeout=30)\n response.raise_for_status()\n text_data = response.text\n with open(file_path, \"w\", encoding=\"utf-8\") as file:\n file.write(text_data)\n else:\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n text_data = file.read()\n\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n data = json.load(file)\n\n return data\n\n\ndef format_input_phi(entry):\n instruction_text = (\n f\"<|user|>\\n{entry['instruction']}\"\n )\n\n input_text = f\"\\n{entry['input']}\" if entry[\"input\"] else \"\"\n\n return instruction_text + input_text\n\n\ndef format_input(entry):\n instruction_text = (\n f\"Below is an instruction that describes a task. \"\n f\"Write a response that appropriately completes the request.\"\n f\"\\n\\n### Instruction:\\n{entry['instruction']}\"\n )\n\n input_text = f\"\\n\\n### Input:\\n{entry['input']}\" if entry[\"input\"] else \"\"\n\n return instruction_text + input_text\n\n\ndef plot_losses(epochs_seen, tokens_seen, train_losses, val_losses, plot_name):\n fig, ax1 = plt.subplots(figsize=(12, 6))\n\n # Plot training and validation loss against epochs\n ax1.plot(epochs_seen, train_losses, label=\"Training loss\")\n ax1.plot(epochs_seen, val_losses, linestyle=\"-.\", label=\"Validation loss\")\n ax1.set_xlabel(\"Epochs\")\n ax1.set_ylabel(\"Loss\")\n ax1.legend(loc=\"upper right\")\n ax1.xaxis.set_major_locator(MaxNLocator(integer=True)) # only show integer labels on x-axis\n\n # Create a second x-axis for tokens seen\n ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\n ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks\n ax2.set_xlabel(\"Tokens seen\")\n\n fig.tight_layout() # Adjust layout to make room\n print(f\"Plot saved as {plot_name}\")\n plt.savefig(plot_name)\n # plt.show()\n\n\ndef main(mask_instructions=False, alpaca52k=False, phi3_prompt=False, lora=False):\n #######################################\n # Print package versions\n #######################################\n print()\n pkgs = [\n \"matplotlib\", # Plotting library\n \"tiktoken\", # Tokenizer\n \"torch\", # Deep learning library\n \"tqdm\", # Progress bar\n \"tensorflow\", # For OpenAI's pretrained weights\n ]\n for p in pkgs:\n print(f\"{p} version: {version(p)}\")\n print(50*\"-\")\n\n #######################################\n # Download and prepare dataset\n #######################################\n file_path = \"instruction-data.json\"\n\n if alpaca52k:\n url = \"https://raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json\"\n else:\n url = \"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch07/01_main-chapter-code/instruction-data.json\"\n data = download_and_load_file(file_path, url)\n\n train_portion = int(len(data) * 0.85) # 85% for training\n test_portion = int(len(data) * 0.1) # 10% for testing\n\n train_data = data[:train_portion]\n test_data = data[train_portion:train_portion + test_portion]\n val_data = data[train_portion + test_portion:]\n\n print(\"Training set length:\", len(train_data))\n print(\"Validation set length:\", len(val_data))\n print(\"Test set length:\", len(test_data))\n print(50*\"-\")\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n print(\"Device:\", device)\n print(50*\"-\")\n\n if alpaca52k:\n allowed_max_length = 512\n else:\n allowed_max_length = 1024\n\n if mask_instructions and phi3_prompt:\n raise ValueError(\"Simultaneous support for instruction masking and the Phi-3 prompt template has not been implemented, yet.\")\n\n if mask_instructions:\n customized_collate_fn = partial(custom_collate_with_masking_fn, device=device, allowed_max_length=allowed_max_length)\n CustomDataset = InstructionDatasetWithMasking\n elif phi3_prompt:\n customized_collate_fn = partial(custom_collate_fn, device=device, allowed_max_length=allowed_max_length)\n CustomDataset = InstructionDatasetPhi\n else:\n customized_collate_fn = partial(custom_collate_fn, device=device, allowed_max_length=allowed_max_length)\n CustomDataset = InstructionDataset\n\n num_workers = 0\n\n if alpaca52k:\n batch_size = 4\n else:\n batch_size = 8\n\n torch.manual_seed(123)\n\n train_dataset = CustomDataset(train_data, tokenizer)\n train_loader = DataLoader(\n train_dataset,\n batch_size=batch_size,\n collate_fn=customized_collate_fn,\n shuffle=True,\n drop_last=True,\n num_workers=num_workers\n )\n\n val_dataset = CustomDataset(val_data, tokenizer)\n val_loader = DataLoader(\n val_dataset,\n batch_size=batch_size,\n collate_fn=customized_collate_fn,\n shuffle=False,\n drop_last=False,\n num_workers=num_workers\n )\n\n #######################################\n # Load pretrained model\n #######################################\n BASE_CONFIG = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Context length\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": True # Query-key-value bias\n }\n\n model_configs = {\n \"gpt2-small (124M)\": {\"emb_dim\": 768, \"n_layers\": 12, \"n_heads\": 12},\n \"gpt2-medium (355M)\": {\"emb_dim\": 1024, \"n_layers\": 24, \"n_heads\": 16},\n \"gpt2-large (774M)\": {\"emb_dim\": 1280, \"n_layers\": 36, \"n_heads\": 20},\n \"gpt2-xl (1558M)\": {\"emb_dim\": 1600, \"n_layers\": 48, \"n_heads\": 25},\n }\n\n CHOOSE_MODEL = \"gpt2-medium (355M)\"\n\n BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\n\n model_size = CHOOSE_MODEL.split(\" \")[-1].lstrip(\"(\").rstrip(\")\")\n settings, params = download_and_load_gpt2(model_size=model_size, models_dir=\"gpt2\")\n\n model = GPTModel(BASE_CONFIG)\n load_weights_into_gpt(model, params)\n model.eval()\n model.to(device)\n\n print(\"Loaded model:\", CHOOSE_MODEL)\n print(50*\"-\")\n\n if lora:\n total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\n print(f\"Total trainable parameters before: {total_params:,}\")\n\n for param in model.parameters():\n param.requires_grad = False\n\n total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\n print(f\"Total trainable parameters after: {total_params:,}\")\n replace_linear_with_lora(model, rank=16, alpha=16)\n\n total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\n print(f\"Total trainable LoRA parameters: {total_params:,}\")\n model.to(device)\n\n #######################################\n # Finetuning the model\n #######################################\n print(\"Initial losses\")\n with torch.no_grad():\n train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)\n val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)\n\n print(\" Training loss:\", train_loss)\n print(\" Validation loss:\", val_loss)\n\n start_time = time.time()\n\n num_epochs = 2\n optimizer = torch.optim.AdamW(model.parameters(), lr=0.00005, weight_decay=0.1)\n\n torch.manual_seed(123)\n\n start_context = format_input_phi(val_data[0]) if phi3_prompt else format_input(val_data[0])\n\n train_losses, val_losses, tokens_seen = train_model_simple(\n model, train_loader, val_loader, optimizer, device,\n num_epochs=num_epochs, eval_freq=5, eval_iter=5,\n start_context=start_context, tokenizer=tokenizer\n )\n\n end_time = time.time()\n execution_time_minutes = (end_time - start_time) / 60\n print(f\"Training completed in {execution_time_minutes:.2f} minutes.\")\n\n epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))\n\n plot_name = \"loss-plot.pdf\"\n if mask_instructions:\n plot_name = plot_name.replace(\".pdf\", \"-mask-instructions.pdf\")\n if alpaca52k:\n plot_name = plot_name.replace(\".pdf\", \"-alpaca52k.pdf\")\n if phi3_prompt:\n plot_name = plot_name.replace(\".pdf\", \"-phi3-prompt.pdf\")\n if lora:\n plot_name = plot_name.replace(\".pdf\", \"-lora.pdf\")\n if not any([mask_instructions, alpaca52k, phi3_prompt, lora]):\n plot_name = plot_name.replace(\".pdf\", \"-baseline.pdf\")\n\n plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses, plot_name)\n print(50*\"-\")\n\n #######################################\n # Saving results\n #######################################\n print(\"Generating responses\")\n for i, entry in tqdm(enumerate(test_data), total=len(test_data)):\n\n input_text = format_input_phi(entry) if phi3_prompt else format_input(entry)\n\n token_ids = generate(\n model=model,\n idx=text_to_token_ids(input_text, tokenizer).to(device),\n max_new_tokens=256,\n context_size=BASE_CONFIG[\"context_length\"],\n eos_id=50256\n )\n generated_text = token_ids_to_text(token_ids, tokenizer)\n\n if phi3_prompt:\n response_text = generated_text[len(input_text):].replace(\"<|assistant|>:\", \"\").strip()\n else:\n response_text = generated_text[len(input_text):].replace(\"### Response:\", \"\").strip()\n\n test_data[i][\"model_response\"] = response_text\n\n test_data_path = \"instruction-data-with-response.json\"\n file_name = f\"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft.pth\"\n\n if mask_instructions:\n test_data_path = test_data_path.replace(\".json\", \"-mask-instructions.json\")\n file_name = file_name.replace(\".pth\", \"-mask-instructions.pth\")\n if alpaca52k:\n test_data_path = test_data_path.replace(\".json\", \"-alpaca52k.json\")\n file_name = file_name.replace(\".pth\", \"-alpaca52k.pth\")\n if phi3_prompt:\n test_data_path = test_data_path.replace(\".json\", \"-phi3-prompt.json\")\n file_name = file_name.replace(\".pth\", \"-phi3-prompt.pth\")\n if lora:\n test_data_path = test_data_path.replace(\".json\", \"-lora.json\")\n file_name = file_name.replace(\".pth\", \"-lora.pth\")\n if not any([mask_instructions, alpaca52k, phi3_prompt, lora]):\n test_data_path = test_data_path.replace(\".json\", \"-baseline.json\")\n file_name = file_name.replace(\".pth\", \"-baseline.pth\")\n\n with open(test_data_path, \"w\") as file:\n json.dump(test_data, file, indent=4) # \"indent\" for pretty-printing\n print(f\"Responses saved as {test_data_path}\")\n\n torch.save(model.state_dict(), file_name)\n print(f\"Model saved as {file_name}\")\n\n\nif __name__ == \"__main__\":\n\n import argparse\n\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description=\"Instruction finetune a GPT model\"\n )\n options = {\"baseline\", \"mask_instructions\", \"alpaca_52k\", \"phi3_prompt\", \"lora\"}\n parser.add_argument(\n \"--exercise_solution\",\n type=str,\n default=\"baseline\",\n help=(\n f\"Which experiment to run. Options: {options}.\"\n )\n )\n args = parser.parse_args()\n\n if args.exercise_solution == \"baseline\":\n main()\n elif args.exercise_solution == \"mask_instructions\":\n main(mask_instructions=True)\n elif args.exercise_solution == \"alpaca_52k\":\n main(alpaca52k=True)\n elif args.exercise_solution == \"phi3_prompt\":\n main(phi3_prompt=True)\n elif args.exercise_solution == \"lora\":\n main(lora=True)\n else:\n raise ValueError(f\"{args.exercise_solution} is not a valid --args.exercise_solution option. Options: {options}\")\n"
},
{
"path": "ch07/01_main-chapter-code/gpt_download.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n\nimport os\nimport json\n\nimport numpy as np\nimport requests\nimport tensorflow as tf\nfrom tqdm import tqdm\n\n\ndef download_and_load_gpt2(model_size, models_dir):\n # Validate model size\n allowed_sizes = (\"124M\", \"355M\", \"774M\", \"1558M\")\n if model_size not in allowed_sizes:\n raise ValueError(f\"Model size not in {allowed_sizes}\")\n\n # Define paths\n model_dir = os.path.join(models_dir, model_size)\n base_url = \"https://openaipublic.blob.core.windows.net/gpt-2/models\"\n backup_base_url = \"https://f001.backblazeb2.com/file/LLMs-from-scratch/gpt2\"\n filenames = [\n \"checkpoint\", \"encoder.json\", \"hparams.json\",\n \"model.ckpt.data-00000-of-00001\", \"model.ckpt.index\",\n \"model.ckpt.meta\", \"vocab.bpe\"\n ]\n\n # Download files\n os.makedirs(model_dir, exist_ok=True)\n for filename in filenames:\n file_url = os.path.join(base_url, model_size, filename)\n backup_url = os.path.join(backup_base_url, model_size, filename)\n file_path = os.path.join(model_dir, filename)\n download_file(file_url, file_path, backup_url)\n\n # Load settings and params\n tf_ckpt_path = tf.train.latest_checkpoint(model_dir)\n settings = json.load(open(os.path.join(model_dir, \"hparams.json\"), \"r\", encoding=\"utf-8\"))\n params = load_gpt2_params_from_tf_ckpt(tf_ckpt_path, settings)\n\n return settings, params\n\n\ndef download_file(url, destination, backup_url=None):\n def _attempt_download(download_url):\n response = requests.get(download_url, stream=True, timeout=60)\n response.raise_for_status()\n\n file_size = int(response.headers.get(\"Content-Length\", 0))\n\n # Check if file exists and has same size\n if os.path.exists(destination):\n file_size_local = os.path.getsize(destination)\n if file_size and file_size == file_size_local:\n print(f\"File already exists and is up-to-date: {destination}\")\n return True\n\n block_size = 1024 # 1 KB\n desc = os.path.basename(download_url)\n with tqdm(total=file_size, unit=\"iB\", unit_scale=True, desc=desc) as progress_bar:\n with open(destination, \"wb\") as file:\n for chunk in response.iter_content(chunk_size=block_size):\n if chunk:\n file.write(chunk)\n progress_bar.update(len(chunk))\n return True\n\n try:\n if _attempt_download(url):\n return\n except requests.exceptions.RequestException:\n if backup_url is not None:\n print(f\"Primary URL ({url}) failed. Attempting backup URL: {backup_url}\")\n try:\n if _attempt_download(backup_url):\n return\n except requests.exceptions.RequestException:\n pass\n\n error_message = (\n f\"Failed to download from both primary URL ({url})\"\n f\"{' and backup URL (' + backup_url + ')' if backup_url else ''}.\"\n \"\\nCheck your internet connection or the file availability.\\n\"\n \"For help, visit: https://github.com/rasbt/LLMs-from-scratch/discussions/273\"\n )\n print(error_message)\n except Exception as e:\n print(f\"An unexpected error occurred: {e}\")\n\n\ndef load_gpt2_params_from_tf_ckpt(ckpt_path, settings):\n # Initialize parameters dictionary with empty blocks for each layer\n params = {\"blocks\": [{} for _ in range(settings[\"n_layer\"])]}\n\n # Iterate over each variable in the checkpoint\n for name, _ in tf.train.list_variables(ckpt_path):\n # Load the variable and remove singleton dimensions\n variable_array = np.squeeze(tf.train.load_variable(ckpt_path, name))\n\n # Process the variable name to extract relevant parts\n variable_name_parts = name.split(\"/\")[1:] # Skip the 'model/' prefix\n\n # Identify the target dictionary for the variable\n target_dict = params\n if variable_name_parts[0].startswith(\"h\"):\n layer_number = int(variable_name_parts[0][1:])\n target_dict = params[\"blocks\"][layer_number]\n\n # Recursively access or create nested dictionaries\n for key in variable_name_parts[1:-1]:\n target_dict = target_dict.setdefault(key, {})\n\n # Assign the variable array to the last key\n last_key = variable_name_parts[-1]\n target_dict[last_key] = variable_array\n\n return params\n"
},
{
"path": "ch07/01_main-chapter-code/gpt_instruction_finetuning.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# A minimal instruction finetuning file based on the code in chapter 7\n\nfrom functools import partial\nfrom importlib.metadata import version\nimport json\nimport os\nimport re\nimport time\n\nimport matplotlib.pyplot as plt\nimport requests\nimport tiktoken\nimport torch\nfrom torch.utils.data import Dataset, DataLoader\nfrom tqdm import tqdm\n\n# Import from local files in this folder\nfrom gpt_download import download_and_load_gpt2\nfrom previous_chapters import (\n calc_loss_loader,\n generate,\n GPTModel,\n load_weights_into_gpt,\n text_to_token_ids,\n train_model_simple,\n token_ids_to_text\n)\n\n\nclass InstructionDataset(Dataset):\n def __init__(self, data, tokenizer):\n self.data = data\n\n # Pre-tokenize texts\n self.encoded_texts = []\n for entry in data:\n instruction_plus_input = format_input(entry)\n response_text = f\"\\n\\n### Response:\\n{entry['output']}\"\n full_text = instruction_plus_input + response_text\n self.encoded_texts.append(\n tokenizer.encode(full_text)\n )\n\n def __getitem__(self, index):\n return self.encoded_texts[index]\n\n def __len__(self):\n return len(self.data)\n\n\ndef custom_collate_fn(\n batch,\n pad_token_id=50256,\n ignore_index=-100,\n allowed_max_length=None,\n device=\"cpu\"\n):\n # Find the longest sequence in the batch\n batch_max_length = max(len(item)+1 for item in batch)\n\n # Pad and prepare inputs and targets\n inputs_lst, targets_lst = [], []\n\n for item in batch:\n new_item = item.copy()\n # Add an <|endoftext|> token\n new_item += [pad_token_id]\n # Pad sequences to max_length\n padded = new_item + [pad_token_id] * (batch_max_length - len(new_item))\n inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\n targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\n\n # New: Replace all but the first padding tokens in targets by ignore_index\n mask = targets == pad_token_id\n indices = torch.nonzero(mask).squeeze()\n if indices.numel() > 1:\n targets[indices[1:]] = ignore_index\n\n # New: Optionally truncate to maximum sequence length\n if allowed_max_length is not None:\n inputs = inputs[:allowed_max_length]\n targets = targets[:allowed_max_length]\n\n inputs_lst.append(inputs)\n targets_lst.append(targets)\n\n # Convert list of inputs and targets to tensors and transfer to target device\n inputs_tensor = torch.stack(inputs_lst).to(device)\n targets_tensor = torch.stack(targets_lst).to(device)\n\n return inputs_tensor, targets_tensor\n\n\ndef download_and_load_file(file_path, url):\n if not os.path.exists(file_path):\n response = requests.get(url, timeout=30)\n response.raise_for_status()\n text_data = response.text\n with open(file_path, \"w\", encoding=\"utf-8\") as file:\n file.write(text_data)\n\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n data = json.load(file)\n\n return data\n\n\ndef format_input(entry):\n instruction_text = (\n f\"Below is an instruction that describes a task. \"\n f\"Write a response that appropriately completes the request.\"\n f\"\\n\\n### Instruction:\\n{entry['instruction']}\"\n )\n\n input_text = f\"\\n\\n### Input:\\n{entry['input']}\" if entry[\"input\"] else \"\"\n\n return instruction_text + input_text\n\n\ndef plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):\n fig, ax1 = plt.subplots(figsize=(12, 6))\n\n # Plot training and validation loss against epochs\n ax1.plot(epochs_seen, train_losses, label=\"Training loss\")\n ax1.plot(epochs_seen, val_losses, linestyle=\"-.\", label=\"Validation loss\")\n ax1.set_xlabel(\"Epochs\")\n ax1.set_ylabel(\"Loss\")\n ax1.legend(loc=\"upper right\")\n\n # Create a second x-axis for tokens seen\n ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\n ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks\n ax2.set_xlabel(\"Tokens seen\")\n\n fig.tight_layout() # Adjust layout to make room\n plot_name = \"loss-plot-standalone.pdf\"\n print(f\"Plot saved as {plot_name}\")\n plt.savefig(plot_name)\n # plt.show()\n\n\ndef main(test_mode=False):\n #######################################\n # Print package versions\n #######################################\n print()\n pkgs = [\n \"matplotlib\", # Plotting library\n \"tiktoken\", # Tokenizer\n \"torch\", # Deep learning library\n \"tqdm\", # Progress bar\n \"tensorflow\", # For OpenAI's pretrained weights\n ]\n for p in pkgs:\n print(f\"{p} version: {version(p)}\")\n print(50*\"-\")\n\n #######################################\n # Download and prepare dataset\n #######################################\n file_path = \"instruction-data.json\"\n url = \"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch07/01_main-chapter-code/instruction-data.json\"\n data = download_and_load_file(file_path, url)\n\n train_portion = int(len(data) * 0.85) # 85% for training\n test_portion = int(len(data) * 0.1) # 10% for testing\n\n train_data = data[:train_portion]\n test_data = data[train_portion:train_portion + test_portion]\n val_data = data[train_portion + test_portion:]\n\n # Use very small subset for testing purposes\n if test_mode:\n train_data = train_data[:10]\n val_data = val_data[:10]\n test_data = test_data[:10]\n\n print(\"Training set length:\", len(train_data))\n print(\"Validation set length:\", len(val_data))\n print(\"Test set length:\", len(test_data))\n print(50*\"-\")\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n print(\"Device:\", device)\n print(50*\"-\")\n\n customized_collate_fn = partial(custom_collate_fn, device=device, allowed_max_length=1024)\n\n num_workers = 0\n batch_size = 8\n\n torch.manual_seed(123)\n\n train_dataset = InstructionDataset(train_data, tokenizer)\n train_loader = DataLoader(\n train_dataset,\n batch_size=batch_size,\n collate_fn=customized_collate_fn,\n shuffle=True,\n drop_last=True,\n num_workers=num_workers\n )\n\n val_dataset = InstructionDataset(val_data, tokenizer)\n val_loader = DataLoader(\n val_dataset,\n batch_size=batch_size,\n collate_fn=customized_collate_fn,\n shuffle=False,\n drop_last=False,\n num_workers=num_workers\n )\n\n #######################################\n # Load pretrained model\n #######################################\n\n # Small GPT model for testing purposes\n if args.test_mode:\n BASE_CONFIG = {\n \"vocab_size\": 50257,\n \"context_length\": 120,\n \"drop_rate\": 0.0,\n \"qkv_bias\": False,\n \"emb_dim\": 12,\n \"n_layers\": 1,\n \"n_heads\": 2\n }\n model = GPTModel(BASE_CONFIG)\n model.eval()\n device = \"cpu\"\n CHOOSE_MODEL = \"Small test model\"\n\n # Code as it is used in the main chapter\n else:\n BASE_CONFIG = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Context length\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": True # Query-key-value bias\n }\n\n model_configs = {\n \"gpt2-small (124M)\": {\"emb_dim\": 768, \"n_layers\": 12, \"n_heads\": 12},\n \"gpt2-medium (355M)\": {\"emb_dim\": 1024, \"n_layers\": 24, \"n_heads\": 16},\n \"gpt2-large (774M)\": {\"emb_dim\": 1280, \"n_layers\": 36, \"n_heads\": 20},\n \"gpt2-xl (1558M)\": {\"emb_dim\": 1600, \"n_layers\": 48, \"n_heads\": 25},\n }\n\n CHOOSE_MODEL = \"gpt2-medium (355M)\"\n\n BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\n\n model_size = CHOOSE_MODEL.split(\" \")[-1].lstrip(\"(\").rstrip(\")\")\n settings, params = download_and_load_gpt2(model_size=model_size, models_dir=\"gpt2\")\n\n model = GPTModel(BASE_CONFIG)\n load_weights_into_gpt(model, params)\n model.eval()\n model.to(device)\n\n print(\"Loaded model:\", CHOOSE_MODEL)\n print(50*\"-\")\n\n #######################################\n # Finetuning the model\n #######################################\n print(\"Initial losses\")\n with torch.no_grad():\n train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)\n val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)\n\n print(\" Training loss:\", train_loss)\n print(\" Validation loss:\", val_loss)\n\n start_time = time.time()\n optimizer = torch.optim.AdamW(model.parameters(), lr=0.00005, weight_decay=0.1)\n\n num_epochs = 2\n\n torch.manual_seed(123)\n train_losses, val_losses, tokens_seen = train_model_simple(\n model, train_loader, val_loader, optimizer, device,\n num_epochs=num_epochs, eval_freq=5, eval_iter=5,\n start_context=format_input(val_data[0]), tokenizer=tokenizer\n )\n\n end_time = time.time()\n execution_time_minutes = (end_time - start_time) / 60\n print(f\"Training completed in {execution_time_minutes:.2f} minutes.\")\n\n epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))\n plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)\n print(50*\"-\")\n\n #######################################\n # Saving results\n #######################################\n print(\"Generating responses\")\n for i, entry in tqdm(enumerate(test_data), total=len(test_data)):\n\n input_text = format_input(entry)\n\n token_ids = generate(\n model=model,\n idx=text_to_token_ids(input_text, tokenizer).to(device),\n max_new_tokens=256,\n context_size=BASE_CONFIG[\"context_length\"],\n eos_id=50256\n )\n generated_text = token_ids_to_text(token_ids, tokenizer)\n response_text = generated_text[len(input_text):].replace(\"### Response:\", \"\").strip()\n\n test_data[i][\"model_response\"] = response_text\n\n test_data_path = \"instruction-data-with-response-standalone.json\"\n with open(test_data_path, \"w\") as file:\n json.dump(test_data, file, indent=4) # \"indent\" for pretty-printing\n print(f\"Responses saved as {test_data_path}\")\n\n file_name = f\"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft-standalone.pth\"\n torch.save(model.state_dict(), file_name)\n print(f\"Model saved as {file_name}\")\n\n\nif __name__ == \"__main__\":\n\n import argparse\n\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description=\"Finetune a GPT model for classification\"\n )\n parser.add_argument(\n \"--test_mode\",\n default=False,\n action=\"store_true\",\n help=(\"This flag runs the model in test mode for internal testing purposes. \"\n \"Otherwise, it runs the model as it is used in the chapter (recommended).\")\n )\n args = parser.parse_args()\n\n main(args.test_mode)\n"
},
{
"path": "ch07/01_main-chapter-code/instruction-data-with-response.json",
"content": "[\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The car is very fast.\",\n \"output\": \"The car is as fast as lightning.\",\n \"model_response\": \"The car is as fast as a bullet.\"\n },\n {\n \"instruction\": \"What type of cloud is typically associated with thunderstorms?\",\n \"input\": \"\",\n \"output\": \"The type of cloud typically associated with thunderstorms is cumulonimbus.\",\n \"model_response\": \"The type of cloud associated with thunderstorms is a cumulus cloud.\"\n },\n {\n \"instruction\": \"Name the author of 'Pride and Prejudice'.\",\n \"input\": \"\",\n \"output\": \"Jane Austen.\",\n \"model_response\": \"The author of 'Pride and Prejudice' is Jane Austen.\"\n },\n {\n \"instruction\": \"What is the periodic symbol for chlorine?\",\n \"input\": \"\",\n \"output\": \"The periodic symbol for chlorine is Cl.\",\n \"model_response\": \"The periodic symbol for chlorine is C.\"\n },\n {\n \"instruction\": \"Correct the punctuation in the sentence.\",\n \"input\": \"Its time to go home.\",\n \"output\": \"The corrected sentence should be: 'It's time to go home.'\",\n \"model_response\": \"It's time to go home.\"\n },\n {\n \"instruction\": \"Rewrite the sentence.\",\n \"input\": \"The lecture was delivered in a clear manner.\",\n \"output\": \"The lecture was delivered clearly.\",\n \"model_response\": \"The lecture was delivered in a clear manner.\"\n },\n {\n \"instruction\": \"Generate a humorous anecdote.\",\n \"input\": \"\",\n \"output\": \"Why was the math book sad? Because it had too many problems!\",\n \"model_response\": \"The cat jumped over the fence.\"\n },\n {\n \"instruction\": \"Identify the correct spelling: 'recieve' or 'receive'.\",\n \"input\": \"\",\n \"output\": \"The correct spelling is 'receive'.\",\n \"model_response\": \"The correct spelling is 'receive'.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'nostalgia'.\",\n \"input\": \"\",\n \"output\": \"Nostalgia washed over her as she looked through the old photos.\",\n \"model_response\": \"Nostalgia is a strong emotion that can be felt in the past.\"\n },\n {\n \"instruction\": \"Classify the following numbers as prime or composite.\",\n \"input\": \": 11, 14, 19.\",\n \"output\": \"Prime numbers: 11, 19\\nComposite numbers: 14\",\n \"model_response\": \"Prime numbers: 11, 14, 19.Composite numbers: 14, 19.\"\n },\n {\n \"instruction\": \"What is the capital of Denmark?\",\n \"input\": \"\",\n \"output\": \"The capital of Denmark is Copenhagen.\",\n \"model_response\": \"The capital of Denmark is Copenhagen.\"\n },\n {\n \"instruction\": \"What is the opposite of 'wet'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'wet' is 'dry'.\",\n \"model_response\": \"The opposite of 'wet' is 'dry'.\"\n },\n {\n \"instruction\": \"Identify the type of sentence.\",\n \"input\": \"Did you finish the report?\",\n \"output\": \"The type of sentence is interrogative.\",\n \"model_response\": \"The type of sentence is imperative.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for mercury?\",\n \"input\": \"\",\n \"output\": \"Hg.\",\n \"model_response\": \"The chemical symbol for mercury is Hg.\"\n },\n {\n \"instruction\": \"Describe the process of active transport in cells.\",\n \"input\": \"\",\n \"output\": \"Active transport is the movement of molecules across a cell membrane from a region of lower concentration to a region of higher concentration, using energy in the form of ATP. This process is crucial for maintaining cellular homeostasis.\",\n \"model_response\": \"Transport is the process by which a substance moves from one place to another by chemical change. It typically occurs by chemical reactions between atoms or molecules.\"\n },\n {\n \"instruction\": \"Classify the following items as either solid, liquid, or gas.\",\n \"input\": \"Mercury, oxygen, wood\",\n \"output\": \"Mercury - Liquid\\nOxygen - Gas\\nWood - Solid\",\n \"model_response\": \", water\\n\\n\\nSolid: Carbon\\nLiquefied Carbon: Oxygen\\nGas: Carbon dioxide\\nGaseous Carbon: Carbon monoxide\"\n },\n {\n \"instruction\": \"Convert 3 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"3 kilometers is 3000 meters.\",\n \"model_response\": \"3 kilometers is 3000 meters.\"\n },\n {\n \"instruction\": \"Convert the sentence to use an indefinite pronoun.\",\n \"input\": \"Someone left a note.\",\n \"output\": \"A note was left by someone.\",\n \"model_response\": \"A note was left by someone.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'excited'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'excited' is 'thrilled'.\",\n \"model_response\": \"A synonym for 'excited' is 'enthusiastic'.\"\n },\n {\n \"instruction\": \"Generate a sentence that follows the pattern: \\\"Never have I ever _____ without _____\\\"\",\n \"input\": \"\",\n \"output\": \"Never have I ever traveled without a map.\",\n \"model_response\": \"Never have I ever had without having.\"\n },\n {\n \"instruction\": \"Pick out the adjective from the following list.\",\n \"input\": \"run, tall, quickly\",\n \"output\": \"The correct adjective from the list is 'tall.'\",\n \"model_response\": \"The adjective from the list is 'quick'.\"\n },\n {\n \"instruction\": \"Convert 1000 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"1000 grams is equal to 1 kilogram.\",\n \"model_response\": \"1000 grams is 0.1 kilograms.\"\n },\n {\n \"instruction\": \"What is the opposite of 'deep'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'deep' is 'shallow'.\",\n \"model_response\": \"The opposite of 'deep' is 'light'.\"\n },\n {\n \"instruction\": \"Categorize the given list of animals.\",\n \"input\": \"Shark, Dolphin, Trout\",\n \"output\": \"Fish: Shark, Trout\\nMammals: Dolphin\",\n \"model_response\": \"Animals: Shark, Dolphin, Trout\"\n },\n {\n \"instruction\": \"Translate 'library' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish word for 'library' is 'biblioteca'.\",\n \"model_response\": \"The Spanish translation of 'library' is 'l\\u00edmite'.\"\n },\n {\n \"instruction\": \"Define the term 'hyperbole'.\",\n \"input\": \"\",\n \"output\": \"Hyperbole is a figure of speech that involves an exaggeration of ideas for the sake of emphasis.\",\n \"model_response\": \"Hyperbole is a word used to describe a statement that is exaggerated or exaggerated in meaning.\"\n },\n {\n \"instruction\": \"Translate 'Hello' into Russian.\",\n \"input\": \"\",\n \"output\": \"\\u041f\\u0440\\u0438\\u0432\\u0435\\u0442 (Privet)\",\n \"model_response\": \"The Russian translation of 'Hello' is '\\u0420\\u0443\\u0441\\u0441\\u043a\\u0438\\u0439 \\u043f\\u0440\\u043e\\u0438\\u0437\\u0432\\u0435\\u0434\\u0435\\u043d\\u0438\\u0439' (Vyacheslav Krasnoyarski).\"\n },\n {\n \"instruction\": \"Define the term 'kinetic energy'.\",\n \"input\": \"\",\n \"output\": \"Kinetic energy is the energy that an object possesses due to its motion.\",\n \"model_response\": \"Kinetic energy is the force that causes an object to accelerate or decelerate in response to an applied force.\"\n },\n {\n \"instruction\": \"What is the opposite of 'hot'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'hot' is 'cold'.\",\n \"model_response\": \"The opposite of 'hot' is 'cold'.\"\n },\n {\n \"instruction\": \"Convert 5 miles to kilometers.\",\n \"input\": \"\",\n \"output\": \"5 miles is approximately 8.05 kilometers.\",\n \"model_response\": \"5 miles is 5000 meters.\"\n },\n {\n \"instruction\": \"What is the chemical formula for magnesium sulfate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for magnesium sulfate is MgSO4.\",\n \"model_response\": \"The chemical formula for magnesium sulfate is MgSO4.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to replace any clich\\u00e9 phrases.\",\n \"input\": \"It's a piece of cake\",\n \"output\": \"It's very easy.\",\n \"model_response\": \".\\n\\n\\nA piece of cake is a cake.\"\n },\n {\n \"instruction\": \"List five different types of vegetables.\",\n \"input\": \"\",\n \"output\": \"1. Carrot\\n2. Broccoli\\n3. Cucumber\\n4. Tomato\\n5. Spinach\",\n \"model_response\": \"1. Cucumber\\n2. Broccoli\\n3. Spinach\\n4. Tomato\\n5. Cucumber\"\n },\n {\n \"instruction\": \"Convert 7 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"7 kilometers is 7000 meters.\",\n \"model_response\": \"7 kilometers is 7.048 meters.\"\n },\n {\n \"instruction\": \"What is the opposite of 'heavy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'heavy' is 'light'.\",\n \"model_response\": \"The opposite of 'heavy' is 'light'.\"\n },\n {\n \"instruction\": \"What is the past tense of 'sing'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'sing' is 'sang.'\",\n \"model_response\": \"The past tense of 'sing' is 'to sing.'\"\n },\n {\n \"instruction\": \"What is the molecular formula for carbon dioxide?\",\n \"input\": \"\",\n \"output\": \"The molecular formula for carbon dioxide is CO2.\",\n \"model_response\": \"The molecular formula for carbon dioxide is CO2.\"\n },\n {\n \"instruction\": \"Convert this sentence to passive voice\",\n \"input\": \"The gardener watered the plants.\",\n \"output\": \"The plants were watered by the gardener.\",\n \"model_response\": \"The plants were watered by the gardener.\"\n },\n {\n \"instruction\": \"What is the past tense of 'throw'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'throw' is 'threw'.\",\n \"model_response\": \"The past tense of 'throw' is 'to throw'.\"\n },\n {\n \"instruction\": \"Explain what a sonnet is.\",\n \"input\": \"\",\n \"output\": \"A sonnet is a 14-line poem with a specific rhyme scheme and meter, often written in iambic pentameter.\",\n \"model_response\": \"A sonnet is a poem composed in the first person.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovative'.\",\n \"input\": \"\",\n \"output\": \"The company is known for its innovative products.\",\n \"model_response\": \"She was very innovative and always had a new idea.\"\n },\n {\n \"instruction\": \"Provide the plural form of 'cactus'.\",\n \"input\": \"\",\n \"output\": \"The plural form of 'cactus' is 'cacti'.\",\n \"model_response\": \"The plural form of 'cactus' is 'cacti'.\"\n },\n {\n \"instruction\": \"Translate the phrase 'Where is the bathroom?' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'Where is the bathroom?' is 'Wo ist die Toilette?'\",\n \"model_response\": \"The German translation of 'Where is the bathroom?' is 'Wie es \\u00fcber das B\\u00fccher?'.\"\n },\n {\n \"instruction\": \"Generate a past-tense verb that describes a person laughing.\",\n \"input\": \"\",\n \"output\": \"Laughed.\",\n \"model_response\": \"She laughed.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'transient.'\",\n \"input\": \"\",\n \"output\": \"The transient nature of her visit left a lasting impression.\",\n \"model_response\": \"She was seen by a passing car as it passed by.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'optimistic'.\",\n \"input\": \"\",\n \"output\": \"He remained optimistic despite the challenges he faced.\",\n \"model_response\": \"She was optimistic about the future.\"\n },\n {\n \"instruction\": \"Re-word this sentence using an indirect question.\",\n \"input\": \"What time is the meeting?\",\n \"output\": \"Could you tell me what time the meeting is?\",\n \"model_response\": \"The meeting is at 7:00 PM.\"\n },\n {\n \"instruction\": \"Categorize the following sentence as a statement, a question, or an exclamation.\",\n \"input\": \"What a beautiful day!\",\n \"output\": \"Exclamation.\",\n \"model_response\": \"A statement could be classified as a question.\"\n },\n {\n \"instruction\": \"What is the opposite of 'rich'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'rich' is 'poor'.\",\n \"model_response\": \"The opposite of 'rich' is 'poor'.\"\n },\n {\n \"instruction\": \"Find a synonym for the given verb.\",\n \"input\": \"Begin\",\n \"output\": \"Commence\",\n \"model_response\": \"Begin\\n\\n### Input:\\nBegin\\n\\n\\nBegin\\n\\n### Input:\\nBegin\\n\\nBegin\\n### Input:\\nBegin\\n\\nBegin\"\n },\n {\n \"instruction\": \"Edit the given text to ensure all plural nouns are spelled correctly.\",\n \"input\": \"The birds sings beautiful songs.\",\n \"output\": \"The birds sing beautiful songs.\",\n \"model_response\": \"The birds sings beautiful songs.\"\n },\n {\n \"instruction\": \"Transform the following sentence into a question using \\\"could.\\\"\",\n \"input\": \"You can help me tomorrow.\",\n \"output\": \"Could you help me tomorrow?\",\n \"model_response\": \"Could you help me tomorrow?\"\n },\n {\n \"instruction\": \"Classify the following items: bicycle, rose, tiger.\",\n \"input\": \"\",\n \"output\": \"Vehicles: Bicycle\\nPlants: Rose\\nAnimals: Tiger\",\n \"model_response\": \"Animals: Tiger\\nBicyclist: Tiger\\nRose: Rose\\nBike: Tiger\"\n },\n {\n \"instruction\": \"Define the term 'irony'.\",\n \"input\": \"\",\n \"output\": \"Irony is a figure of speech in which words are used in such a way that their intended meaning is different from the actual meaning of the words.\",\n \"model_response\": \"An irony is a statement that is at odds with the truth.\"\n },\n {\n \"instruction\": \"Translate 'Welcome' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'Welcome' is 'Willkommen'.\",\n \"model_response\": \"The German translation of 'Welcome' is 'Wie es tut mir leid'.\"\n },\n {\n \"instruction\": \"Explain the primary function of the human heart.\",\n \"input\": \"\",\n \"output\": \"The primary function of the human heart is to pump blood throughout the body, delivering oxygen and nutrients to tissues and removing carbon dioxide and other wastes.\",\n \"model_response\": \"The primary function of the human heart is to pump blood to the brain and to supply the muscles and nerves that control movement.\"\n },\n {\n \"instruction\": \"Reword the following sentence to the future tense.\",\n \"input\": \"He is reading a novel inspired by his grandmother.\",\n \"output\": \"He will be reading a novel inspired by his grandmother.\",\n \"model_response\": \"He is reading a novel inspired by his grandmother.\"\n },\n {\n \"instruction\": \"Convert the given sentence into active voice.\",\n \"input\": \"The law was passed by the government.\",\n \"output\": \"The government passed the law.\",\n \"model_response\": \"The law was passed by the government.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'inevitable'.\",\n \"input\": \"\",\n \"output\": \"The confrontation was inevitable given the circumstances.\",\n \"model_response\": \"The storm was inevitable.\"\n },\n {\n \"instruction\": \"Categorize the following sentence as either factual or opinion-based.\",\n \"input\": \"Chocolate is the best dessert.\",\n \"output\": \"Opinion-based.\",\n \"model_response\": \"Categorize the following sentence as either factual or opinion-based.\"\n },\n {\n \"instruction\": \"What is an antonym of 'old'?\",\n \"input\": \"\",\n \"output\": \"young.\",\n \"model_response\": \"An antonym of 'old' is 'young'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'hardworking'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'hardworking' is 'diligent'.\",\n \"model_response\": \"A synonym for 'hardworking' is 'smart'.\"\n },\n {\n \"instruction\": \"What is the boiling point of sulfur in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of sulfur is 444.6 degrees Celsius.\",\n \"model_response\": \"The boiling point of sulfur is -114.5 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the plural form of 'child'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'child' is 'children'.\",\n \"model_response\": \"The plural form of 'child' is 'chunk'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'complicated'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'complicated' is 'simple'.\",\n \"model_response\": \"An antonym of 'complicated' is 'simple'.\"\n },\n {\n \"instruction\": \"Name three forms of water.\",\n \"input\": \"\",\n \"output\": \"The three forms of water are solid (ice), liquid (water), and gas (steam).\",\n \"model_response\": \"Three forms of water are rain, snow, and water.\"\n },\n {\n \"instruction\": \"Rewrite this sentence as a question.\",\n \"input\": \"The dog chased the cat.\",\n \"output\": \"Did the dog chase the cat?\",\n \"model_response\": \"What is the cat chasing?\"\n },\n {\n \"instruction\": \"Split the following sentence into two declarative sentences: 'The movie was long but interesting.'\",\n \"input\": \"\",\n \"output\": \"The movie was long. It was interesting.\",\n \"model_response\": \"and 'The movie was interesting.'\\n\\n\\nThe movie was long, but it was interesting.\"\n },\n {\n \"instruction\": \"Classify the following substances as acid, base, or neutral.\",\n \"input\": \"Lemon juice, Soap, Water\",\n \"output\": \"Acid: Lemon juice\\nBase: Soap\\nNeutral: Water\",\n \"model_response\": \"Acid: Soap\\nBase: Soap\\nNeutral: Water\"\n },\n {\n \"instruction\": \"What is a synonym of 'sad'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'sad' is 'unhappy'.\",\n \"model_response\": \"A synonym for 'sad' is 'angry'.\"\n },\n {\n \"instruction\": \"Correct any spelling mistakes in the given sentence.\",\n \"input\": \"I prefer homemade cookies to store boaght.\",\n \"output\": \"I prefer homemade cookies to store bought.\",\n \"model_response\": \"I prefer homemade cookies to store boaght.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'transient'.\",\n \"input\": \"\",\n \"output\": \"His stay in the city was transient, lasting only a couple of days.\",\n \"model_response\": \"She was seen by a passerby as she passed by.\"\n },\n {\n \"instruction\": \"Translate 'I am lost' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'I am lost' is 'Mi sono perso' (if male) or 'Mi sono persa' (if female).\",\n \"model_response\": \"Il pi\\u00f9 am\\u00e9ricaino.\"\n },\n {\n \"instruction\": \"Classify this text as a technical document or a narrative.\",\n \"input\": \"This manual provides instructions for installing the software.\",\n \"output\": \"Technical document\",\n \"model_response\": \"Technical document\"\n },\n {\n \"instruction\": \"Sort the following list in descending order.\",\n \"input\": \"10, 2, 25, 16, 7\",\n \"output\": \"25, 16, 10, 7, 2.\",\n \"model_response\": \", 3, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25\"\n },\n {\n \"instruction\": \"Translate 'Can I have some water?' into French.\",\n \"input\": \"\",\n \"output\": \"Puis-je avoir de l'eau?\",\n \"model_response\": \"Can I have some water?\"\n },\n {\n \"instruction\": \"Create a simile with the word 'as cold as'.\",\n \"input\": \"\",\n \"output\": \"Her hands were as cold as ice.\",\n \"model_response\": \"The temperature of 'as cold as' is -38 degrees Celsius.\"\n },\n {\n \"instruction\": \"Classify the following words by their grammatical categories: swim, beautiful, quickly\",\n \"input\": \"\",\n \"output\": \"Swim: Verb\\nBeautiful: Adjective\\nQuickly: Adverb\",\n \"model_response\": \"Classifying the following words by their grammatical categories: swim, beautiful, quickly\"\n },\n {\n \"instruction\": \"Calculate the density of an object with a mass of 15 grams and a volume of 5 cubic centimeters.\",\n \"input\": \"\",\n \"output\": \"The density of the object is 3 grams per cubic centimeter.\",\n \"model_response\": \"The density of the object is 15 grams/cm\\u00b3.\"\n },\n {\n \"instruction\": \"What is the abbreviation for 'Master of Business Administration'?\",\n \"input\": \"\",\n \"output\": \"The abbreviation for 'Master of Business Administration' is MBA.\",\n \"model_response\": \"The abbreviation for 'Master of Business Administration' is MBA.\"\n },\n {\n \"instruction\": \"Convert the following number from Roman numerals: IX.\",\n \"input\": \"\",\n \"output\": \"The number IX in Roman numerals is 9.\",\n \"model_response\": \"5 to decimal numbers: 0.5.\\n\\n\\n0.5 is 0.5.\"\n },\n {\n \"instruction\": \"What is the opposite of 'horizontal'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'horizontal' is 'vertical'.\",\n \"model_response\": \"The opposite of 'horizontal' is 'vertical'.\"\n },\n {\n \"instruction\": \"Translate 'Where can I buy tickets?' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation for 'Where can I buy tickets?' is 'Dove posso comprare i biglietti?'\",\n \"model_response\": \"The Italian translation of 'Where can I buy tickets?' is 'Ti amo'.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to replace any clich\\u00e9s.\",\n \"input\": \"He was as cool as a cucumber.\",\n \"output\": \"He remained very calm.\",\n \"model_response\": \"He was as cool as a cucumber.\"\n },\n {\n \"instruction\": \"Identify the main verb in the sentence.\",\n \"input\": \"The dog barked loudly.\",\n \"output\": \"The main verb in the sentence is 'barked'.\",\n \"model_response\": \"The main verb in the sentence is 'bark'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'elucidate'.\",\n \"input\": \"\",\n \"output\": \"The professor attempted to elucidate the complex topic for his students.\",\n \"model_response\": \"The teacher had studied the book for a long time.\"\n },\n {\n \"instruction\": \"Correct the sentence.\",\n \"input\": \"Me and my friend went to the store.\",\n \"output\": \"My friend and I went to the store.\",\n \"model_response\": \"We went to the store.\"\n },\n {\n \"instruction\": \"What is the formula for calculating work done?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating work done is work = force \\u00d7 distance.\",\n \"model_response\": \"The formula for calculating work done is W=M*G*A.\"\n },\n {\n \"instruction\": \"What is the chemical formula for ammonium nitrate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for ammonium nitrate is NH4NO3.\",\n \"model_response\": \"The chemical formula for ammonium nitrate is NH3.\"\n },\n {\n \"instruction\": \"What is the molecular formula for water?\",\n \"input\": \"\",\n \"output\": \"The molecular formula for water is H2O.\",\n \"model_response\": \"The molecular formula for water is H2O2.\"\n },\n {\n \"instruction\": \"Rewrite the given sentence to describe the same thing in a positive way.\",\n \"input\": \"The food was not good.\",\n \"output\": \"The food could use some improvement.\",\n \"model_response\": \"The food was not good.\"\n },\n {\n \"instruction\": \"What is the opposite of 'lazy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'lazy' is 'diligent'.\",\n \"model_response\": \"The opposite of 'lazy' is 'attentive'.\"\n },\n {\n \"instruction\": \"Name three essential vitamins for human health.\",\n \"input\": \"\",\n \"output\": \"1. Vitamin A\\n2. Vitamin C\\n3. Vitamin D\",\n \"model_response\": \"1. B6\\n2. B12\\n3. B12\\n### Instruction:\\nWhat is the chemical symbol for iron?\\n\\n\\nThe chemical symbol for iron is Fe.\"\n },\n {\n \"instruction\": \"Define the term 'simile'.\",\n \"input\": \"\",\n \"output\": \"A simile is a figure of speech that directly compares two different things, often introduced with the words 'like' or 'as'.\",\n \"model_response\": \"A simile is a figurative device used to describe a person or thing that is simile or similitude in form or function.\"\n },\n {\n \"instruction\": \"What is the boiling point of chlorine in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of chlorine is -34 degrees Celsius.\",\n \"model_response\": \"The boiling point of chlorine is -196 degrees Celsius.\"\n },\n {\n \"instruction\": \"Translate 'My name is' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'My name is' is 'Je m'appelle'.\",\n \"model_response\": \"The French translation of 'My name is' is 'Comment \\u00e7a va?'.\"\n },\n {\n \"instruction\": \"Convert 200 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"200 centimeters is 2 meters.\",\n \"model_response\": \"200 centimeters is 0.2 meters.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for zinc?\",\n \"input\": \"\",\n \"output\": \"Zn.\",\n \"model_response\": \"The chemical symbol for zinc is Zn.\"\n },\n {\n \"instruction\": \"What is the formula for calculating force?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating force is Force = mass x acceleration.\",\n \"model_response\": \"The formula for calculating force is (F = mv\\u00b2 + g)f, where m is mass and g is acceleration.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovative'.\",\n \"input\": \"\",\n \"output\": \"The company's innovative approach set it apart from its competitors.\",\n \"model_response\": \"She was very innovative and always had a new idea.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'generous'.\",\n \"input\": \"\",\n \"output\": \"He is very generous and always helps those in need.\",\n \"model_response\": \"She was very generous and gave the money to the poor.\"\n },\n {\n \"instruction\": \"What is an antonym of 'sharp'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'sharp' is 'dull'.\",\n \"model_response\": \"An antonym of 'sharp' is 'soft'.\"\n },\n {\n \"instruction\": \"Describe the basic structure of a neuron.\",\n \"input\": \"\",\n \"output\": \"A neuron consists of three main parts: the cell body, which contains the nucleus; dendrites, which receive signals from other neurons; and an axon, which transmits signals to other neurons, muscles, or glands.\",\n \"model_response\": \"A neuron is a type of synapse in the brain.\"\n },\n {\n \"instruction\": \"Translate 'see you later' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Hasta luego\",\n \"model_response\": \"Est\\u00e1n leyendo see you later.\"\n },\n {\n \"instruction\": \"What are the first 10 elements of the Fibonacci sequence?\",\n \"input\": \"\",\n \"output\": \"0, 1, 1, 2, 3, 5, 8, 13, 21, 34.\",\n \"model_response\": \"The first 10 elements of the Fibonacci sequence are: 1, 3, 5, 7, 11, 13, 15, 20.\"\n },\n {\n \"instruction\": \"What is an antonym of 'transparent'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'transparent' is 'opaque'.\",\n \"model_response\": \"An antonym of 'transparent' is 'illuminate'.\"\n },\n {\n \"instruction\": \"What is the past tense of 'think'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'think' is 'thought'.\",\n \"model_response\": \"The past tense of 'think' is 'to think'.\"\n },\n {\n \"instruction\": \"Classify each sentence as either declarative, interrogative, imperative, or exclamatory.\",\n \"input\": \"Please open the door.\",\n \"output\": \"The classification of the sentence 'Please open the door.' is imperative.\",\n \"model_response\": \"Please open the door.\"\n },\n {\n \"instruction\": \"Rewrite the sentence to use a negative adverb.\",\n \"input\": \"She always remembers to call.\",\n \"output\": \"She never forgets to call.\",\n \"model_response\": \"She always remembers to call.\"\n },\n {\n \"instruction\": \"Convert 50 miles per hour to kilometers per hour.\",\n \"input\": \"\",\n \"output\": \"50 miles per hour is approximately 80.47 kilometers per hour.\",\n \"model_response\": \"50 miles per hour is approximately 32.5 kilometers per hour.\"\n }\n]"
},
{
"path": "ch07/01_main-chapter-code/instruction-data.json",
"content": "[\n {\n \"instruction\": \"Evaluate the following phrase by transforming it into the spelling given.\",\n \"input\": \"freind --> friend\",\n \"output\": \"The spelling of the given phrase \\\"freind\\\" is incorrect, the correct spelling is \\\"friend\\\".\"\n },\n {\n \"instruction\": \"Edit the following sentence for grammar.\",\n \"input\": \"He go to the park every day.\",\n \"output\": \"He goes to the park every day.\"\n },\n {\n \"instruction\": \"Convert 45 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"45 kilometers is 45000 meters.\"\n },\n {\n \"instruction\": \"Rewrite this sentence to start with 'Although': Despite the rain, they went for a walk.\",\n \"input\": \"\",\n \"output\": \"Although it was raining, they went for a walk.\"\n },\n {\n \"instruction\": \"What are the first 10 square numbers?\",\n \"input\": \"\",\n \"output\": \"1, 4, 9, 16, 25, 36, 49, 64, 81, 100.\"\n },\n {\n \"instruction\": \"Suggest a more formal synonym for \\\"happy.\\\"\",\n \"input\": \"\",\n \"output\": \"A more formal synonym for \\\"happy\\\" is \\\"content.\\\"\"\n },\n {\n \"instruction\": \"Translate the following sentence into French.\",\n \"input\": \"Where is the nearest restaurant?\",\n \"output\": \"O\\u00f9 est le restaurant le plus proche?\"\n },\n {\n \"instruction\": \"Look up the melting point of iron.\",\n \"input\": \"\",\n \"output\": \"The melting point of iron is approximately 1538 degrees Celsius or 2800 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence so that it is in active voice.\",\n \"input\": \"The cake was baked by Sarah.\",\n \"output\": \"Sarah baked the cake.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'The manager approved the project.'\",\n \"input\": \"\",\n \"output\": \"The project was approved by the manager.\"\n },\n {\n \"instruction\": \"What is the contraction for \\\"will not\\\"?\",\n \"input\": \"\",\n \"output\": \"The contraction for \\\"will not\\\" is \\\"won't\\\".\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to remove redundancy.\",\n \"input\": \"The actual fact is that he was late.\",\n \"output\": \"The fact is that he was late.\"\n },\n {\n \"instruction\": \"What is the capital of Indonesia?\",\n \"input\": \"\",\n \"output\": \"The capital of Indonesia is Jakarta.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'bright'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'bright' is 'radiant'.\"\n },\n {\n \"instruction\": \"Suggest an alternate word for 'happy'.\",\n \"input\": \"\",\n \"output\": \"joyful.\"\n },\n {\n \"instruction\": \"Name the device that measures atmospheric pressure.\",\n \"input\": \"\",\n \"output\": \"The device that measures atmospheric pressure is a barometer.\"\n },\n {\n \"instruction\": \"List two antonyms for 'intelligent.'\",\n \"input\": \"\",\n \"output\": \"Two antonyms for 'intelligent' are 'stupid' and 'dumb.'\"\n },\n {\n \"instruction\": \"What is the pH of a neutral solution at 25\\u00b0C?\",\n \"input\": \"\",\n \"output\": \"The pH of a neutral solution at 25\\u00b0C is 7.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor\",\n \"input\": \"'Her eyes are like stars.'\",\n \"output\": \"Her eyes are stars in the night sky.\"\n },\n {\n \"instruction\": \"Name three types of biomes.\",\n \"input\": \"\",\n \"output\": \"Forest, desert, and grassland.\"\n },\n {\n \"instruction\": \"Identify the climax in 'Romeo and Juliet'.\",\n \"input\": \"\",\n \"output\": \"The climax of 'Romeo and Juliet' occurs when Romeo kills Tybalt, leading to his banishment and the subsequent tragic events.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The dog is very loyal.\",\n \"output\": \"The dog is as loyal as a soldier.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"The storm started suddenly.\",\n \"output\": \"The storm came out of the blue.\"\n },\n {\n \"instruction\": \"Convert 10 feet to meters.\",\n \"input\": \"\",\n \"output\": \"10 feet is equal to approximately 3.048 meters.\"\n },\n {\n \"instruction\": \"Convert this sentence to passive voice\",\n \"input\": \"The chef cooked a delicious meal.\",\n \"output\": \"A delicious meal was cooked by the chef.\"\n },\n {\n \"instruction\": \"What is the plural form of 'mouse'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'mouse' is 'mice'.\"\n },\n {\n \"instruction\": \"What is the opposite of 'thin'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'thin' is 'thick'.\"\n },\n {\n \"instruction\": \"What is the state capital of California?\",\n \"input\": \"\",\n \"output\": \"The state capital of California is Sacramento.\"\n },\n {\n \"instruction\": \"Translate 'family' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian word for 'family' is 'famiglia'.\"\n },\n {\n \"instruction\": \"What is the past tense of 'draw'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'draw' is 'drew.'\"\n },\n {\n \"instruction\": \"Alter the content of the sentence to use the past tense.\",\n \"input\": \"The ship sails at dawn.\",\n \"output\": \"The ship sailed at dawn.\"\n },\n {\n \"instruction\": \"Generate a sentence that follows the pattern: 'Rarely do I _____'\",\n \"input\": \"\",\n \"output\": \"Rarely do I eat fast food.\"\n },\n {\n \"instruction\": \"What is the atomic number of oxygen?\",\n \"input\": \"\",\n \"output\": \"The atomic number of oxygen is 8.\"\n },\n {\n \"instruction\": \"What is a synonym of 'luminous'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'luminous' is 'bright'.\"\n },\n {\n \"instruction\": \"What is the capital of Brazil?\",\n \"input\": \"\",\n \"output\": \"The capital of Brazil is Bras\\u00edlia.\"\n },\n {\n \"instruction\": \"List the ingredients required to make a basic salad.\",\n \"input\": \"\",\n \"output\": \"Ingredients for a basic salad typically include lettuce, tomatoes, cucumbers, and dressing.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a synonym.\",\n \"input\": \"It's hot outside.\",\n \"output\": \"It's scorching outside.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'happy'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'happy' is 'content'.\"\n },\n {\n \"instruction\": \"What is the derivative of x^3 + 5x^2 - 3x + 7 with respect to x?\",\n \"input\": \"\",\n \"output\": \"3x^2 + 10x - 3.\"\n },\n {\n \"instruction\": \"Identify the point of view used in the sentence.\",\n \"input\": \"She felt a sense of relief.\",\n \"output\": \"The point of view used in the sentence is third person.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'gregarious'.\",\n \"input\": \"\",\n \"output\": \"He was gregarious, making friends wherever he went.\"\n },\n {\n \"instruction\": \"What is the atomic number of carbon?\",\n \"input\": \"\",\n \"output\": \"The atomic number of carbon is 6.\"\n },\n {\n \"instruction\": \"What is the formula for area of a triangle?\",\n \"input\": \"\",\n \"output\": \"The formula for the area of a triangle is 1/2 * base * height.\"\n },\n {\n \"instruction\": \"Sort the following list in alphabetical order.\",\n \"input\": \"Zebra, Elephant, Crocodile\",\n \"output\": \"Crocodile, Elephant, Zebra\"\n },\n {\n \"instruction\": \"Reverse the order of the given phrase.\",\n \"input\": \"Moon and stars\",\n \"output\": \"Stars and moon\"\n },\n {\n \"instruction\": \"What is a synonym for 'begin'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'begin' is 'commence'.\"\n },\n {\n \"instruction\": \"Find the next 3 terms in the following sequence: 4, 8, 12, 16.\",\n \"input\": \"\",\n \"output\": \"The next three terms in the sequence are: 20, 24, 28.\"\n },\n {\n \"instruction\": \"What is the melting point of aluminum in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of aluminum is 660.3 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is an antonym of 'advanced'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'advanced' is 'primitive'.\"\n },\n {\n \"instruction\": \"Name an antonym for 'happiness.'\",\n \"input\": \"\",\n \"output\": \"An antonym for 'happiness' is 'sadness.'\"\n },\n {\n \"instruction\": \"Identify the correct spelling of the following word.\",\n \"input\": \"Ocassion\",\n \"output\": \"The correct spelling is 'Occasion.'\"\n },\n {\n \"instruction\": \"What type of figurative language is used in 'She is the apple of my eye'?\",\n \"input\": \"\",\n \"output\": \"The figurative language used is a metaphor.\"\n },\n {\n \"instruction\": \"Correct the spelling error in the sentence.\",\n \"input\": \"I will atend the meeting tomorrow.\",\n \"output\": \"The correct spelling is 'attend', not 'atend'.\"\n },\n {\n \"instruction\": \"Arrange the following events in chronological order: World War II, French Revolution, Invention of the Telephone.\",\n \"input\": \"\",\n \"output\": \"1. French Revolution\\n2. Invention of the Telephone\\n3. World War II\"\n },\n {\n \"instruction\": \"What is the normal body temperature in Celsius?\",\n \"input\": \"\",\n \"output\": \"The normal body temperature is approximately 37 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the cube of 4?\",\n \"input\": \"\",\n \"output\": \"The cube of 4 is 64.\"\n },\n {\n \"instruction\": \"Classify the following into vegetables, animals, and metals.\",\n \"input\": \"Broccoli, Iron, Elephant\",\n \"output\": \"Vegetables: Broccoli\\nMetals: Iron\\nAnimals: Elephant\"\n },\n {\n \"instruction\": \"Translate 'I am learning Spanish' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Estoy aprendiendo espa\\u00f1ol.\"\n },\n {\n \"instruction\": \"Edit the following sentence for clarity and style.\",\n \"input\": \"He response to the issue was quick.\",\n \"output\": \"His response to the issue was quick.\"\n },\n {\n \"instruction\": \"What is the melting point of gold in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of gold is 1064 degrees Celsius.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'fast'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'fast' is 'quick'.\"\n },\n {\n \"instruction\": \"Translate 'What is your name?' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'What is your name?' is 'Comment vous appelez-vous?'.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"She is very graceful.\",\n \"output\": \"She is as graceful as a swan.\"\n },\n {\n \"instruction\": \"What is an antonym of 'soft'?\",\n \"input\": \"\",\n \"output\": \"hard.\"\n },\n {\n \"instruction\": \"What are the first 5 multiples of 4?\",\n \"input\": \"\",\n \"output\": \"4, 8, 12, 16, 20.\"\n },\n {\n \"instruction\": \"What is an antonym of 'happy'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'happy' is 'sad.'\"\n },\n {\n \"instruction\": \"What type of galaxy is the Andromeda Galaxy?\",\n \"input\": \"\",\n \"output\": \"The Andromeda Galaxy is a spiral galaxy.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"She is very punctual.\",\n \"output\": \"She is always on time.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'inevitable'.\",\n \"input\": \"\",\n \"output\": \"The collapse of the company was inevitable due to poor management.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"He runs very fast.\",\n \"output\": \"He runs as fast as a cheetah.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for aluminum?\",\n \"input\": \"\",\n \"output\": \"Al.\"\n },\n {\n \"instruction\": \"Name the process by which water changes from liquid to gas.\",\n \"input\": \"\",\n \"output\": \"The process by which water changes from liquid to gas is called evaporation.\"\n },\n {\n \"instruction\": \"What is the melting point of gold?\",\n \"input\": \"\",\n \"output\": \"The melting point of gold is approximately 1064 degrees Celsius.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a different adjective.\",\n \"input\": \"She has a fast car.\",\n \"output\": \"She has a speedy car.\"\n },\n {\n \"instruction\": \"Add the correct verb to the sentence.\",\n \"input\": \"The students _________ the quiz answers.\",\n \"output\": \"The students discussed the quiz answers.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"He is very lucky.\",\n \"output\": \"He has a stroke of luck.\"\n },\n {\n \"instruction\": \"Calculate the volume of a cylinder with a radius of 4 cm and a height of 10 cm.\",\n \"input\": \"\",\n \"output\": \"The volume of the cylinder is approximately 502.65 cubic centimeters.\"\n },\n {\n \"instruction\": \"Edit the following sentence to correct any grammar errors.\",\n \"input\": \"They was waiting for the bus all day.\",\n \"output\": \"They were waiting for the bus all day.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'serendipity.'\",\n \"input\": \"\",\n \"output\": \"Finding the hidden beach was pure serendipity.\"\n },\n {\n \"instruction\": \"What type of bond is formed when one atom donates an electron to another atom?\",\n \"input\": \"\",\n \"output\": \"The type of bond formed when one atom donates an electron to another atom is an ionic bond.\"\n },\n {\n \"instruction\": \"Create a palindrome using the word 'racecar'.\",\n \"input\": \"\",\n \"output\": \"A racecar.\"\n },\n {\n \"instruction\": \"What is the square of 12?\",\n \"input\": \"\",\n \"output\": \"The square of 12 is 144.\"\n },\n {\n \"instruction\": \"Insert the correct punctuation at the provided places in the following sentence.\",\n \"input\": \"Where are you going\",\n \"output\": \"Where are you going?\"\n },\n {\n \"instruction\": \"Provide a synonym for 'strong'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'strong' is 'powerful'.\"\n },\n {\n \"instruction\": \"Name a mammal that lays eggs.\",\n \"input\": \"\",\n \"output\": \"A mammal that lays eggs is the platypus.\"\n },\n {\n \"instruction\": \"Name three types of precipitation.\",\n \"input\": \"\",\n \"output\": \"Three types of precipitation are rain, snow, and sleet.\"\n },\n {\n \"instruction\": \"Name the process by which skin repairs itself after a cut.\",\n \"input\": \"\",\n \"output\": \"The process by which skin repairs itself after a cut is called regeneration.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'ephemeral'.\",\n \"input\": \"\",\n \"output\": \"The beauty of the sunset was ephemeral, fading from the sky within moments.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'harmony'.\",\n \"input\": \"\",\n \"output\": \"The choir's voices blended in perfect harmony.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The storm is very strong.\",\n \"output\": \"The storm is a beast.\"\n },\n {\n \"instruction\": \"What type of bond is formed when electrons are shared between atoms?\",\n \"input\": \"\",\n \"output\": \"The type of bond formed when electrons are shared between atoms is a covalent bond.\"\n },\n {\n \"instruction\": \"Convert 3 meters to centimeters.\",\n \"input\": \"\",\n \"output\": \"3 meters is 300 centimeters.\"\n },\n {\n \"instruction\": \"Arrange these technological inventions in chronological order: Telephone, Internet, Printing Press.\",\n \"input\": \"\",\n \"output\": \"1. Printing Press\\n2. Telephone\\n3. Internet\"\n },\n {\n \"instruction\": \"What is the main ingredient in traditional French baguettes?\",\n \"input\": \"\",\n \"output\": \"The main ingredient in traditional French baguettes is wheat flour.\"\n },\n {\n \"instruction\": \"Classify the following text into either fiction or non-fiction.\",\n \"input\": \"The documentary covers the impact of climate change on polar bears.\",\n \"output\": \"Non-fiction.\"\n },\n {\n \"instruction\": \"What is the boiling point of acetone in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of acetone is 56 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the capital of South Korea?\",\n \"input\": \"\",\n \"output\": \"The capital of South Korea is Seoul.\"\n },\n {\n \"instruction\": \"Convert 300 seconds to minutes.\",\n \"input\": \"\",\n \"output\": \"300 seconds is equal to 5 minutes.\"\n },\n {\n \"instruction\": \"Name a novel written by Jane Austen.\",\n \"input\": \"\",\n \"output\": \"One of the novels written by Jane Austen is 'Pride and Prejudice'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'kind'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'kind' is 'benevolent'.\"\n },\n {\n \"instruction\": \"Name a synonym for \\\"happiness.\\\"\",\n \"input\": \"\",\n \"output\": \"A synonym for \\\"happiness\\\" is \\\"joy.\\\"\"\n },\n {\n \"instruction\": \"Convert 8 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"8 kilometers is 8000 meters.\"\n },\n {\n \"instruction\": \"Edit the sentence.\",\n \"input\": \"She enjoys reading books.\",\n \"output\": \"She enjoys reading books.\"\n },\n {\n \"instruction\": \"Generate a question based on the following statement.\",\n \"input\": \"Plants require sunlight to grow.\",\n \"output\": \"Why do plants require sunlight to grow?\"\n },\n {\n \"instruction\": \"What is the capital of the Philippines?\",\n \"input\": \"\",\n \"output\": \"The capital of the Philippines is Manila.\"\n },\n {\n \"instruction\": \"Name the process by which water cycles from the ground to the atmosphere and back.\",\n \"input\": \"\",\n \"output\": \"The process is called the water cycle.\"\n },\n {\n \"instruction\": \"Define the term 'ecosystem'.\",\n \"input\": \"\",\n \"output\": \"An ecosystem is a community of interacting organisms and their physical environment.\"\n },\n {\n \"instruction\": \"Convert the following verb to its past participle form: 'see'\",\n \"input\": \"\",\n \"output\": \"The past participle form of 'see' is 'seen'.\"\n },\n {\n \"instruction\": \"What is the highest mountain in the world?\",\n \"input\": \"\",\n \"output\": \"The highest mountain in the world is Mount Everest.\"\n },\n {\n \"instruction\": \"Convert the number 5 from decimal to binary.\",\n \"input\": \"\",\n \"output\": \"The binary equivalent of the decimal number 5 is 101.\"\n },\n {\n \"instruction\": \"What is the chemical formula for carbonic acid?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for carbonic acid is H2CO3.\"\n },\n {\n \"instruction\": \"What is a synonym of 'optimistic'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'optimistic' is 'hopeful'.\"\n },\n {\n \"instruction\": \"Change the sentence \\\"This should not have happened\\\" into a declarative sentence.\",\n \"input\": \"\",\n \"output\": \"This should have happened differently.\"\n },\n {\n \"instruction\": \"Given a sentence, convert it into indirect speech.\",\n \"input\": \"She said, \\\"I am tired.\\\"\",\n \"output\": \"She said that she was tired.\"\n },\n {\n \"instruction\": \"Classify this text as either a scientific article or a news report.\",\n \"input\": \"The researchers found a new species of bird in the Amazon rainforest.\",\n \"output\": \"Scientific article\"\n },\n {\n \"instruction\": \"Convert the following sentence to use a relative clause: The girl is a dancer. She lives next door.\",\n \"input\": \"\",\n \"output\": \"The girl who lives next door is a dancer.\"\n },\n {\n \"instruction\": \"Classify the following words by their grammatical categories: run, happy, quickly\",\n \"input\": \"\",\n \"output\": \"Run: Verb\\nHappy: Adjective\\nQuickly: Adverb\"\n },\n {\n \"instruction\": \"Provide a synonym for 'brilliant'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'brilliant' is 'bright'.\"\n },\n {\n \"instruction\": \"Put the following words in alphabetical order: lion, zebra, elephant.\",\n \"input\": \"\",\n \"output\": \"Elephant, lion, zebra.\"\n },\n {\n \"instruction\": \"Perform a sentiment analysis on the given sentence.\",\n \"input\": \"I hate this song!\",\n \"output\": \"The sentiment of the sentence \\\"I hate this song!\\\" is negative.\"\n },\n {\n \"instruction\": \"What type of literary device is used in 'The silence was a loud scream'?\",\n \"input\": \"\",\n \"output\": \"The literary device used is oxymoron.\"\n },\n {\n \"instruction\": \"Rewrite the following phrase in the present tense.\",\n \"input\": \"They had played soccer all afternoon.\",\n \"output\": \"They play soccer all afternoon.\"\n },\n {\n \"instruction\": \"Perform a sentiment analysis on the given sentence.\",\n \"input\": \"I love this song!\",\n \"output\": \"The sentiment of the sentence 'I love this song!' is positive. This is indicated by the word 'love' which shows strong liking or admiration towards the subject, in this case, the song.\"\n },\n {\n \"instruction\": \"What is the capital of Canada?\",\n \"input\": \"\",\n \"output\": \"The capital of Canada is Ottawa.\"\n },\n {\n \"instruction\": \"Edit the following sentence to remove all passive voice.\",\n \"input\": \"The song was composed by the artist.\",\n \"output\": \"The artist composed the song.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'determined'.\",\n \"input\": \"\",\n \"output\": \"She was determined to succeed despite the obstacles.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'Julia throws the ball.'\",\n \"input\": \"\",\n \"output\": \"The ball is thrown by Julia.\"\n },\n {\n \"instruction\": \"Identify the predicate in the sentence.\",\n \"input\": \"The quick brown fox jumps over the lazy dog.\",\n \"output\": \"The predicate in the sentence is 'jumps over the lazy dog.'\"\n },\n {\n \"instruction\": \"What type of number is 0?\",\n \"input\": \"\",\n \"output\": \"0 is an integer.\"\n },\n {\n \"instruction\": \"Take the following noun and turn it into a verb.\",\n \"input\": \"Light\",\n \"output\": \"To light.\"\n },\n {\n \"instruction\": \"Translate 'Happy Birthday' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'Happy Birthday' is 'Feliz Cumplea\\u00f1os'.\"\n },\n {\n \"instruction\": \"Translate 'Where is the library?' into Italian.\",\n \"input\": \"\",\n \"output\": \"Dove \\u00e8 la biblioteca?\"\n },\n {\n \"instruction\": \"Rearrange the following list into descending order.\",\n \"input\": \"12, 5, -3, 20, 9\",\n \"output\": \"20, 12, 9, 5, -3\"\n },\n {\n \"instruction\": \"Generate a five-word phrase using the words \\\"moon,\\\" \\\"crisp,\\\" and \\\"night.\\\"\",\n \"input\": \"\",\n \"output\": \"\\\"Crisp moon illuminates the night.\\\"\"\n },\n {\n \"instruction\": \"What is a synonym of 'content'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'content' is 'satisfied.'\"\n },\n {\n \"instruction\": \"Rewrite the following sentence by adding one adverb.\",\n \"input\": \"The cat slept on the mat.\",\n \"output\": \"The cat peacefully slept on the mat.\"\n },\n {\n \"instruction\": \"Convert 4 liters to milliliters.\",\n \"input\": \"\",\n \"output\": \"4 liters is 4000 milliliters.\"\n },\n {\n \"instruction\": \"What is the atomic mass of carbon?\",\n \"input\": \"\",\n \"output\": \"The atomic mass of carbon is approximately 12.01 atomic mass units.\"\n },\n {\n \"instruction\": \"Classify the following into animals, plants, and metals.\",\n \"input\": \"Rose, gold, cat\",\n \"output\": \"Animals: Cat\\nPlants: Rose\\nMetals: Gold\"\n },\n {\n \"instruction\": \"Classify the following numbers as even or odd.\",\n \"input\": \"2, 7, 19, 20\",\n \"output\": \"Even numbers: 2, 20\\nOdd numbers: 7, 19\"\n },\n {\n \"instruction\": \"Translate the phrase 'Life is beautiful' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'Life is beautiful' is 'La vita \\u00e8 bella'.\"\n },\n {\n \"instruction\": \"What is the sum of 7 and 8?\",\n \"input\": \"\",\n \"output\": \"The sum of 7 and 8 is 15.\"\n },\n {\n \"instruction\": \"Generate a random alphanumeric code of 10 characters.\",\n \"input\": \"\",\n \"output\": \"Here is a randomly generated 10-character alphanumeric code: 3F8G6H7JQ2.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'quiet'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'quiet' is 'silent'.\"\n },\n {\n \"instruction\": \"Reword the sentence to use other words without changing the meaning.\",\n \"input\": \"It rained heavily during the night.\",\n \"output\": \"The night experienced significant rainfall.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"Her voice is very soothing.\",\n \"output\": \"Her voice is a lullaby.\"\n },\n {\n \"instruction\": \"Fill in the blanks with appropriate words.\",\n \"input\": \"The sky was filled with colorful ________ at sunset.\",\n \"output\": \"The sky was filled with colorful clouds at sunset.\"\n },\n {\n \"instruction\": \"What is the boiling point of mercury in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of mercury is 356.7 degrees Celsius.\"\n },\n {\n \"instruction\": \"Change the following sentence to past perfect tense.\",\n \"input\": \"They finish the game.\",\n \"output\": \"They had finished the game.\"\n },\n {\n \"instruction\": \"What is an antonym of 'bright'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'bright' is 'dark'.\"\n },\n {\n \"instruction\": \"Calculate the area of a circle with a radius of 4 meters.\",\n \"input\": \"\",\n \"output\": \"The area of the circle is approximately 50.27 square meters.\"\n },\n {\n \"instruction\": \"Determine the product of 7 and 8.\",\n \"input\": \"\",\n \"output\": \"The product of 7 and 8 is 56.\"\n },\n {\n \"instruction\": \"Name the device used to measure humidity.\",\n \"input\": \"\",\n \"output\": \"The device used to measure humidity is a hygrometer.\"\n },\n {\n \"instruction\": \"Identify the preposition in the sentence.\",\n \"input\": \"The cat jumped over the fence.\",\n \"output\": \"The preposition in the sentence is 'over'.\"\n },\n {\n \"instruction\": \"Re-write the following sentence to use a different verb.\",\n \"input\": \"I will help you with your homework.\",\n \"output\": \"I will assist you with your homework.\"\n },\n {\n \"instruction\": \"Identify the hypernym for the word 'rose.'\",\n \"input\": \"\",\n \"output\": \"The hypernym for the word 'rose' is 'flower.'\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"He is very intelligent.\",\n \"output\": \"He is a genius.\"\n },\n {\n \"instruction\": \"What is the formula for calculating the volume of a cylinder?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating the volume of a cylinder is \\u03c0r\\u00b2h, where r is the radius and h is the height.\"\n },\n {\n \"instruction\": \"What is an antonym for 'difficult'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'difficult' is 'easy'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'brilliant'.\",\n \"input\": \"\",\n \"output\": \"The scientist had a brilliant idea that changed the world.\"\n },\n {\n \"instruction\": \"Automatically correct the given sentence.\",\n \"input\": \"I want to go to london.\",\n \"output\": \"I want to go to London.\"\n },\n {\n \"instruction\": \"Convert this declarative sentence into an interrogative sentence.\",\n \"input\": \"You need help.\",\n \"output\": \"Do you need help?\"\n },\n {\n \"instruction\": \"Convert the sentence into a negative statement.\",\n \"input\": \"You will help me.\",\n \"output\": \"You will not help me.\"\n },\n {\n \"instruction\": \"Edit the following sentence for clarity and style.\",\n \"input\": \"She response to the question was quick.\",\n \"output\": \"Her response to the question was quick.\"\n },\n {\n \"instruction\": \"What is the boiling point of oxygen in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of oxygen is -183 degrees Celsius.\"\n },\n {\n \"instruction\": \"Translate the word 'hello' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'hello' is 'hola'.\"\n },\n {\n \"instruction\": \"Classify the following fruit according to its type.\",\n \"input\": \"Orange\",\n \"output\": \"The fruit 'Orange' is typically classified as a citrus fruit.\"\n },\n {\n \"instruction\": \"Calculate the perimeter of a triangle with sides measuring 3, 4, and 5 cm.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the triangle is 12 cm.\"\n },\n {\n \"instruction\": \"Convert the sentence to use an indefinite pronoun.\",\n \"input\": \"Someone left a message.\",\n \"output\": \"A message was left by someone.\"\n },\n {\n \"instruction\": \"What is the prime factorization of 210?\",\n \"input\": \"\",\n \"output\": \"2 \\u00d7 3 \\u00d7 5 \\u00d7 7.\"\n },\n {\n \"instruction\": \"Convert this active sentence to passive: 'The company employs ten workers.'\",\n \"input\": \"\",\n \"output\": \"Ten workers are employed by the company.\"\n },\n {\n \"instruction\": \"Transform the given statement into an imperative sentence.\",\n \"input\": \"I would like you to turn off the light.\",\n \"output\": \"Please turn off the light.\"\n },\n {\n \"instruction\": \"Generate three verbs that mean the same as 'to speak.'\",\n \"input\": \"\",\n \"output\": \"1. To talk\\n2. To converse\\n3. To chat\"\n },\n {\n \"instruction\": \"Edit the sentence below to remove any redundant words and make it more concise.\",\n \"input\": \"I actually think that\",\n \"output\": \"I think.\"\n },\n {\n \"instruction\": \"Fill in the blank to complete the sentence.\",\n \"input\": \"The most popular fruit in the world is the ___\",\n \"output\": \"The most popular fruit in the world is the banana.\"\n },\n {\n \"instruction\": \"Cut the following sentence into two, keeping the original meaning intact.\",\n \"input\": \"She started her homework but was soon distracted by a phone call.\",\n \"output\": \"She started her homework. However, she was soon distracted by a phone call.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'melancholy'.\",\n \"input\": \"\",\n \"output\": \"The melancholy tune brought tears to her eyes.\"\n },\n {\n \"instruction\": \"Generate three adjectives to describe a river.\",\n \"input\": \"\",\n \"output\": \"1. Serene\\n2. Flowing\\n3. Winding\"\n },\n {\n \"instruction\": \"Name the longest river in the world.\",\n \"input\": \"\",\n \"output\": \"The longest river in the world is the Nile River.\"\n },\n {\n \"instruction\": \"Translate 'Happy New Year' into Italian.\",\n \"input\": \"\",\n \"output\": \"Buon Anno Nuovo\"\n },\n {\n \"instruction\": \"Select the noun phrase in the following sentence.\",\n \"input\": \"He enjoyed a delicious cake at the party.\",\n \"output\": \"The noun phrases in the given sentence are \\\"a delicious cake\\\" and \\\"the party.\\\"\"\n },\n {\n \"instruction\": \"Summarize the plot of Shakespeare's play 'Macbeth'.\",\n \"input\": \"\",\n \"output\": \"Macbeth, a Scottish general, is led to wicked thoughts by the prophecies of three witches, leading him to murder the king and take the throne. His lust for power causes a descent into madness and destruction.\"\n },\n {\n \"instruction\": \"Classify the following items: gold ring, daisy, python.\",\n \"input\": \"\",\n \"output\": \"Animals: Python\\nPlants: Daisy\\nMinerals: Gold ring\"\n },\n {\n \"instruction\": \"What is the capital of Greece?\",\n \"input\": \"\",\n \"output\": \"The capital of Greece is Athens.\"\n },\n {\n \"instruction\": \"Convert the following number from decimal to hexadecimal: 255.\",\n \"input\": \"\",\n \"output\": \"The hexadecimal equivalent of the decimal number 255 is FF.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The music is very loud.\",\n \"output\": \"The music is as loud as thunder.\"\n },\n {\n \"instruction\": \"What is the capital of Argentina?\",\n \"input\": \"\",\n \"output\": \"The capital of Argentina is Buenos Aires.\"\n },\n {\n \"instruction\": \"Name a punctuation mark used to indicate a question.\",\n \"input\": \"\",\n \"output\": \"A punctuation mark used to indicate a question is the question mark (?).\"\n },\n {\n \"instruction\": \"What is an antonym of \\\"ancient\\\"?\",\n \"input\": \"\",\n \"output\": \"An antonym of \\\"ancient\\\" is \\\"modern.\\\"\"\n },\n {\n \"instruction\": \"Determine the mass of an object that has a density of 10 g/cm\\u00b3 and a volume of 2 cm\\u00b3.\",\n \"input\": \"\",\n \"output\": \"The mass of the object is 20 grams.\"\n },\n {\n \"instruction\": \"Convert this compound sentence to a complex sentence.\",\n \"input\": \"She likes coffee, and he likes tea.\",\n \"output\": \"She likes coffee while he likes tea.\"\n },\n {\n \"instruction\": \"Identify the antagonist in 'Harry Potter and the Sorcerer's Stone'.\",\n \"input\": \"\",\n \"output\": \"The antagonist in 'Harry Potter and the Sorcerer's Stone' is Voldemort.\"\n },\n {\n \"instruction\": \"What is the capital of Sweden?\",\n \"input\": \"\",\n \"output\": \"The capital of Sweden is Stockholm.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'curious'.\",\n \"input\": \"\",\n \"output\": \"The cat was curious about the new toy.\"\n },\n {\n \"instruction\": \"Convert the given sentence into passive voice.\",\n \"input\": \"The company will announce the results tomorrow.\",\n \"output\": \"The results will be announced by the company tomorrow.\"\n },\n {\n \"instruction\": \"Classify an input string as either a noun or a verb.\",\n \"input\": \"jump\",\n \"output\": \"\\\"jump\\\" can be classified as a verb.\"\n },\n {\n \"instruction\": \"Split the following sentence into two declarative sentences: \\\"The book is interesting but the cover is dull\\\".\",\n \"input\": \"\",\n \"output\": \"The book is interesting.\\nThe cover is dull.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The book is very boring.\",\n \"output\": \"The book is a cure for insomnia.\"\n },\n {\n \"instruction\": \"What is an antonym of 'fast'?\",\n \"input\": \"\",\n \"output\": \"slow.\"\n },\n {\n \"instruction\": \"Calculate the kinetic energy of an object with a mass of 10 kilograms moving at a velocity of 5 meters per second.\",\n \"input\": \"\",\n \"output\": \"The kinetic energy of the object is 125 joules, calculated using the formula KE = 0.5 * mass * velocity^2.\"\n },\n {\n \"instruction\": \"What is the chemical formula for ammonia?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for ammonia is NH3.\"\n },\n {\n \"instruction\": \"What is the boiling point of methane in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of methane is -161.5 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the formula for the area of a parallelogram?\",\n \"input\": \"\",\n \"output\": \"The formula for the area of a parallelogram is base \\u00d7 height.\"\n },\n {\n \"instruction\": \"What is the unit for measuring electrical resistance?\",\n \"input\": \"\",\n \"output\": \"The unit for measuring electrical resistance is the ohm.\"\n },\n {\n \"instruction\": \"Given a sentence, convert it into direct speech.\",\n \"input\": \"She said she was tired.\",\n \"output\": \"'I am tired,' she said.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'gregarious.'\",\n \"input\": \"\",\n \"output\": \"He was known for his gregarious nature, always enjoying social gatherings.\"\n },\n {\n \"instruction\": \"What is the past tense of 'choose'?\",\n \"input\": \"\",\n \"output\": \"chose.\"\n },\n {\n \"instruction\": \"What is the melting point of platinum in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of platinum is 1768 degrees Celsius.\"\n },\n {\n \"instruction\": \"Change this sentence grammatically.\",\n \"input\": \"He have seen the movie.\",\n \"output\": \"He has seen the movie.\"\n },\n {\n \"instruction\": \"What is the capital of Russia?\",\n \"input\": \"\",\n \"output\": \"The capital of Russia is Moscow.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for potassium?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for potassium is K.\"\n },\n {\n \"instruction\": \"Name three states of matter.\",\n \"input\": \"\",\n \"output\": \"The three states of matter are solid, liquid, and gas.\"\n },\n {\n \"instruction\": \"What is an antonym of 'simplify'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'simplify' is 'complicate.'\"\n },\n {\n \"instruction\": \"List the ingredients necessary to bake a simple chocolate cake.\",\n \"input\": \"\",\n \"output\": \"Flour, sugar, cocoa powder, baking powder, eggs, milk, and oil.\"\n },\n {\n \"instruction\": \"Classify the following species as reptiles or amphibians.\",\n \"input\": \"Frog\",\n \"output\": \"Frog is an amphibian.\"\n },\n {\n \"instruction\": \"Name the process by which plants lose water vapor through their leaves.\",\n \"input\": \"\",\n \"output\": \"The process by which plants lose water vapor through their leaves is called transpiration.\"\n },\n {\n \"instruction\": \"Classify the following items: diamond ring, oak tree, lion.\",\n \"input\": \"\",\n \"output\": \"Animals: Lion\\nPlants: Oak tree\\nMinerals: Diamond ring\"\n },\n {\n \"instruction\": \"Rewrite this sentence to eliminate the passive voice.\",\n \"input\": \"The cake was made by Susan.\",\n \"output\": \"Susan made the cake.\"\n },\n {\n \"instruction\": \"What is the capital of the United Kingdom?\",\n \"input\": \"\",\n \"output\": \"The capital of the United Kingdom is London.\"\n },\n {\n \"instruction\": \"Explain what a neutron star is.\",\n \"input\": \"\",\n \"output\": \"A neutron star is a type of stellar remnant that is extremely dense, composed mostly of neutrons, and is formed after a supernova explosion of a massive star.\"\n },\n {\n \"instruction\": \"Name the process by which carbon dioxide is converted into organic compounds by plants.\",\n \"input\": \"\",\n \"output\": \"The process by which carbon dioxide is converted into organic compounds by plants is called photosynthesis.\"\n },\n {\n \"instruction\": \"Edit the sentence to make it grammatically correct.\",\n \"input\": \"He is more happier now.\",\n \"output\": \"He is happier now.\"\n },\n {\n \"instruction\": \"Name the process by which birds migrate south for the winter.\",\n \"input\": \"\",\n \"output\": \"The process by which birds migrate south for the winter is called migration.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'ambitious'.\",\n \"input\": \"\",\n \"output\": \"She is very ambitious and always sets high goals for herself.\"\n },\n {\n \"instruction\": \"Describe the process of diffusion.\",\n \"input\": \"\",\n \"output\": \"Diffusion is the movement of particles from an area of higher concentration to an area of lower concentration until they are evenly distributed. It occurs in liquids and gases due to the random movement of particles.\"\n },\n {\n \"instruction\": \"What is the chemical formula for potassium chloride?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for potassium chloride is KCl.\"\n },\n {\n \"instruction\": \"Convert the sentence into a question by adding a question tag.\",\n \"input\": \"You are coming to the party.\",\n \"output\": \"You are coming to the party, aren't you?\"\n },\n {\n \"instruction\": \"Translate 'My name is John' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Mi nombre es John.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'mysterious'.\",\n \"input\": \"\",\n \"output\": \"The old mansion had a mysterious aura that intrigued everyone.\"\n },\n {\n \"instruction\": \"What is the formula for the circumference of a circle?\",\n \"input\": \"\",\n \"output\": \"The formula for the circumference of a circle is 2\\u03c0r, where r is the radius.\"\n },\n {\n \"instruction\": \"Explain the water cycle in simple terms.\",\n \"input\": \"\",\n \"output\": \"The water cycle describes how water evaporates from the surface of the earth, rises into the atmosphere, cools and condenses into rain or snow in clouds, and falls again to the surface as precipitation.\"\n },\n {\n \"instruction\": \"Convert 6 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"6 kilometers is 6000 meters.\"\n },\n {\n \"instruction\": \"Translate 'He likes to play football' into French.\",\n \"input\": \"\",\n \"output\": \"Il aime jouer au football.\"\n },\n {\n \"instruction\": \"What is the speed of sound in air?\",\n \"input\": \"\",\n \"output\": \"The speed of sound in air is approximately 343 meters per second.\"\n },\n {\n \"instruction\": \"What is the contraction for 'it is'?\",\n \"input\": \"\",\n \"output\": \"The contraction for 'it is' is 'it's.'\"\n },\n {\n \"instruction\": \"Translate 'What are you doing?' into Italian.\",\n \"input\": \"\",\n \"output\": \"Cosa stai facendo?\"\n },\n {\n \"instruction\": \"Translate 'How old are you?' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'How old are you?' is 'Wie alt bist du?'.\"\n },\n {\n \"instruction\": \"Convert 50 kilometers to miles.\",\n \"input\": \"\",\n \"output\": \"50 kilometers is approximately 31.07 miles.\"\n },\n {\n \"instruction\": \"Change the following sentence to present perfect tense.\",\n \"input\": \"They finish the game.\",\n \"output\": \"They have finished the game.\"\n },\n {\n \"instruction\": \"Identify the preposition in the sentence.\",\n \"input\": \"The cat is under the table.\",\n \"output\": \"The preposition in the sentence is 'under'.\"\n },\n {\n \"instruction\": \"Name the device used to measure wind speed.\",\n \"input\": \"\",\n \"output\": \"The device used to measure wind speed is an anemometer.\"\n },\n {\n \"instruction\": \"What is the symbol for the chemical element silver?\",\n \"input\": \"\",\n \"output\": \"The symbol for the chemical element silver is Ag.\"\n },\n {\n \"instruction\": \"What is the opposite of 'large'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'large' is 'small'.\"\n },\n {\n \"instruction\": \"What is the opposite of 'dark'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'dark' is 'light'.\"\n },\n {\n \"instruction\": \"Convert the following verb to its past participle form: 'go'\",\n \"input\": \"go\",\n \"output\": \"The past participle form of 'go' is 'gone'.\"\n },\n {\n \"instruction\": \"Rewrite this sentence to eliminate the passive voice.\",\n \"input\": \"The book was written by the author.\",\n \"output\": \"The author wrote the book.\"\n },\n {\n \"instruction\": \"Suggest a continuation for the sentence.\",\n \"input\": \"Once the sun rose,\",\n \"output\": \"'the city came to life.'\"\n },\n {\n \"instruction\": \"Calculate the perimeter of a hexagon with side lengths of 4 cm.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the hexagon is 24 cm.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using alliteration.\",\n \"input\": \"The cat chased the mouse.\",\n \"output\": \"The cunning cat chased the mouse.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"He is very brave.\",\n \"output\": \"He is as brave as a lion.\"\n },\n {\n \"instruction\": \"Translate 'Excuse me' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'Excuse me' is 'Perd\\u00f3n' or 'Disculpe'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'begin'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'begin' is 'end'.\"\n },\n {\n \"instruction\": \"Create a sentence that begins with 'If only,'\",\n \"input\": \"\",\n \"output\": \"If only I had studied harder...\"\n },\n {\n \"instruction\": \"Identify the literary term used in 'It's raining cats and dogs.'\",\n \"input\": \"\",\n \"output\": \"The literary term used is an idiom.\"\n },\n {\n \"instruction\": \"Calculate the area of a circle with a radius of 5 meters.\",\n \"input\": \"\",\n \"output\": \"The area of the circle is approximately 78.54 square meters.\"\n },\n {\n \"instruction\": \"Given the following sentence, rewrite it by removing the passive form\",\n \"input\": \"The final decision was made by the manager.\",\n \"output\": \"The manager made the final decision.\"\n },\n {\n \"instruction\": \"Name the process by which plants convert carbon dioxide and water into oxygen and glucose.\",\n \"input\": \"\",\n \"output\": \"The process by which plants convert carbon dioxide and water into oxygen and glucose is called photosynthesis.\"\n },\n {\n \"instruction\": \"Rewrite the sentence to use a simile.\",\n \"input\": \"She is very calm under pressure.\",\n \"output\": \"She is as calm as a cucumber under pressure.\"\n },\n {\n \"instruction\": \"What type of animal is an octopus?\",\n \"input\": \"\",\n \"output\": \"An octopus is a cephalopod mollusk.\"\n },\n {\n \"instruction\": \"Provide a word that rhymes with \\\"care.\\\"\",\n \"input\": \"\",\n \"output\": \"A word that rhymes with \\\"care\\\" is \\\"fare.\\\"\"\n },\n {\n \"instruction\": \"What is a synonym for 'small'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'small' is 'little'.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'The gardener waters the plants daily.'\",\n \"input\": \"\",\n \"output\": \"The plants are watered daily by the gardener.\"\n },\n {\n \"instruction\": \"Rewrite the following phrase as a question.\",\n \"input\": \"We must finish the project by tomorrow.\",\n \"output\": \"Must we finish the project by tomorrow?\"\n },\n {\n \"instruction\": \"List the colors of the rainbow.\",\n \"input\": \"\",\n \"output\": \"The colors of the rainbow are red, orange, yellow, green, blue, indigo, violet.\"\n },\n {\n \"instruction\": \"Look up the freezing point of water.\",\n \"input\": \"\",\n \"output\": \"The freezing point of water is 0 degrees Celsius or 32 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Arrange the given numbers in descending order.\",\n \"input\": \"5, 12, 8, 3, 15\",\n \"output\": \"15, 12, 8, 5, 3.\"\n },\n {\n \"instruction\": \"Translate 'I love reading books' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'I love reading books' is 'Ich liebe es, B\\u00fccher zu lesen.'\"\n },\n {\n \"instruction\": \"What is a synonym for 'large'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'large' is 'big'.\"\n },\n {\n \"instruction\": \"Classify the following species as dogs or cats.\",\n \"input\": \"Siamese\",\n \"output\": \"Siamese is a cat.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'exuberant'.\",\n \"input\": \"\",\n \"output\": \"The children were exuberant as they ran through the park.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'temporary.'\",\n \"input\": \"\",\n \"output\": \"Her stay at the hotel was only temporary.\"\n },\n {\n \"instruction\": \"What is the formula for converting Celsius to Kelvin?\",\n \"input\": \"\",\n \"output\": \"The formula for converting Celsius to Kelvin is K = C + 273.15.\"\n },\n {\n \"instruction\": \"Sort the following numbers in ascending order.\",\n \"input\": \"7, 1, 8, 4, 3.\",\n \"output\": \"The numbers in ascending order would be: 1, 3, 4, 7, 8.\"\n },\n {\n \"instruction\": \"Categorize the given list of animals.\",\n \"input\": \"Dog, Eagle, Trout\",\n \"output\": \"Mammals: Dog\\nBirds: Eagle\\nFish: Trout\"\n },\n {\n \"instruction\": \"What is an antonym for 'success'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'success' is 'failure'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'brave'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'brave' is 'cowardly'.\"\n },\n {\n \"instruction\": \"Change this sentence grammatically.\",\n \"input\": \"They has seen the movie.\",\n \"output\": \"They have seen the movie.\"\n },\n {\n \"instruction\": \"Transform the following sentence into the passive voice.\",\n \"input\": \"They will build a new bridge.\",\n \"output\": \"A new bridge will be built by them.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'enthusiastic'.\",\n \"input\": \"\",\n \"output\": \"She is enthusiastic about learning new things.\"\n },\n {\n \"instruction\": \"Transform the following sentence into a question using 'should.'\",\n \"input\": \"You need to see a doctor.\",\n \"output\": \"Should you see a doctor?\"\n },\n {\n \"instruction\": \"Explain what a limerick is.\",\n \"input\": \"\",\n \"output\": \"A limerick is a humorous five-line poem with a specific rhythm and rhyme scheme, typically AABBA.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'beautiful'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'beautiful' is 'attractive'.\"\n },\n {\n \"instruction\": \"What is the boiling point of mercury in Fahrenheit?\",\n \"input\": \"\",\n \"output\": \"The boiling point of mercury is 674 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Given the following sentence, rewrite it by removing the passive form\",\n \"input\": \"The concert tickets are being sold quickly.\",\n \"output\": \"They are selling the concert tickets quickly.\"\n },\n {\n \"instruction\": \"Name the device that measures temperature.\",\n \"input\": \"\",\n \"output\": \"The device that measures temperature is a thermometer.\"\n },\n {\n \"instruction\": \"Edit the following sentence to correct any grammar errors.\",\n \"input\": \"They was trying to fix the car all day.\",\n \"output\": \"They were trying to fix the car all day.\"\n },\n {\n \"instruction\": \"What is the melting point of lead in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of lead is 327.5 degrees Celsius.\"\n },\n {\n \"instruction\": \"Change the sentences from active voice to passive voice.\",\n \"input\": \"The chef will prepare the meal.\",\n \"output\": \"The meal will be prepared by the chef.\"\n },\n {\n \"instruction\": \"Convert the following statement into a question.\",\n \"input\": \"She is going to the market.\",\n \"output\": \"Is she going to the market?\"\n },\n {\n \"instruction\": \"Name three types of flowers.\",\n \"input\": \"\",\n \"output\": \"Three types of flowers are roses, lilies, and tulips.\"\n },\n {\n \"instruction\": \"What is the primary function of the roots of a plant?\",\n \"input\": \"\",\n \"output\": \"The primary function of plant roots is to absorb water and nutrients from the soil. They also anchor the plant in place and store food and nutrients.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The computer is very slow.\",\n \"output\": \"The computer is a snail.\"\n },\n {\n \"instruction\": \"What is the boiling point of neon in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of neon is -246 degrees Celsius.\"\n },\n {\n \"instruction\": \"Name the process by which iron rusts.\",\n \"input\": \"\",\n \"output\": \"The process by which iron rusts is called oxidation.\"\n },\n {\n \"instruction\": \"Convert 400 meters to kilometers.\",\n \"input\": \"\",\n \"output\": \"400 meters is 0.4 kilometers.\"\n },\n {\n \"instruction\": \"Explain the process of erosion.\",\n \"input\": \"\",\n \"output\": \"Erosion is the process by which soil, rock, and other surface material are worn away and transported by natural forces such as wind or water. It can shape landscapes and affect ecosystems.\"\n },\n {\n \"instruction\": \"Convert 50 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"50 centimeters is 0.5 meters.\"\n },\n {\n \"instruction\": \"Identify the pronoun in the sentence.\",\n \"input\": \"She decided to go to the store.\",\n \"output\": \"The pronoun in the sentence is 'She'.\"\n },\n {\n \"instruction\": \"Make the second sentence a dependent clause.\",\n \"input\": \"She went to the market. She bought some fruit.\",\n \"output\": \"She went to the market, where she bought some fruit.\"\n },\n {\n \"instruction\": \"Correct the verb tense error in the sentence.\",\n \"input\": \"She go to school every day.\",\n \"output\": \"The corrected sentence should be: 'She goes to school every day.'\"\n },\n {\n \"instruction\": \"What is the capital of New Zealand?\",\n \"input\": \"\",\n \"output\": \"The capital of New Zealand is Wellington.\"\n },\n {\n \"instruction\": \"Evaluate this sentence for spelling and grammar mistakes.\",\n \"input\": \"I recieved an invitation to an exciting evenement.\",\n \"output\": \"There are two errors in the sentence. The corrected sentence should be: \\\"I received an invitation to an exciting event.\\\"\"\n },\n {\n \"instruction\": \"Rewrite the sentence in future continuous tense.\",\n \"input\": \"They will complete the project.\",\n \"output\": \"They will be completing the project.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence in a more formal way:\\n\\\"I need to find out what's wrong.\\\"\",\n \"input\": \"\",\n \"output\": \"I must ascertain what is incorrect.\"\n },\n {\n \"instruction\": \"Convert 5 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"5 kilometers is 5000 meters.\"\n },\n {\n \"instruction\": \"What is the chemical formula for carbon dioxide?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for carbon dioxide is CO2.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'courage'.\",\n \"input\": \"\",\n \"output\": \"She showed great courage during the rescue mission.\"\n },\n {\n \"instruction\": \"What is the opposite of 'old'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'old' is 'young'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'resilient'.\",\n \"input\": \"\",\n \"output\": \"She is resilient and always bounces back from challenges.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to include a hyperbole: 'I'm very tired.'\",\n \"input\": \"I'm very tired.\",\n \"output\": \"I'm so tired I could sleep for a year.\"\n },\n {\n \"instruction\": \"What is the smallest planet in our solar system?\",\n \"input\": \"\",\n \"output\": \"The smallest planet in our solar system is Mercury.\"\n },\n {\n \"instruction\": \"What is the symbol for gold on the periodic table?\",\n \"input\": \"\",\n \"output\": \"The symbol for gold on the periodic table is Au.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'meticulous'.\",\n \"input\": \"\",\n \"output\": \"She is very meticulous and always pays attention to details.\"\n },\n {\n \"instruction\": \"What is the freezing point of ethanol in Celsius?\",\n \"input\": \"\",\n \"output\": \"The freezing point of ethanol is -114.1 degrees Celsius.\"\n },\n {\n \"instruction\": \"Classify this sentence into one of the following topics: health, economy, technology, music\",\n \"input\": \"Spotify has revolutionized how we listen to music.\",\n \"output\": \"The topic of the given sentence is music.\"\n },\n {\n \"instruction\": \"What is the chemical formula for sulfur dioxide?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for sulfur dioxide is SO2.\"\n },\n {\n \"instruction\": \"Translate the phrase 'I love you' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'I love you' is 'Ti amo'.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'melancholy'.\",\n \"input\": \"\",\n \"output\": \"There was a melancholy tone in his voice as he recounted the story.\"\n },\n {\n \"instruction\": \"Given a sentence, count the number of words.\",\n \"input\": \"The quick brown fox jumps over the lazy dog.\",\n \"output\": \"The sentence \\\"The quick brown fox jumps over the lazy dog.\\\" contains 9 words.\"\n },\n {\n \"instruction\": \"Provide the past participle form of 'break'.\",\n \"input\": \"\",\n \"output\": \"The past participle form of 'break' is 'broken'.\"\n },\n {\n \"instruction\": \"Generate a random five-letter word.\",\n \"input\": \"\",\n \"output\": \"quake.\"\n },\n {\n \"instruction\": \"Edit the following sentence for grammar.\",\n \"input\": \"They goes to the market every Sunday.\",\n \"output\": \"They go to the market every Sunday.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'amazing'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'amazing' is 'incredible'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'determined'.\",\n \"input\": \"\",\n \"output\": \"She is determined to achieve her dreams despite the obstacles.\"\n },\n {\n \"instruction\": \"Classify the following fruit according to its type.\",\n \"input\": \"Banana\",\n \"output\": \"The fruit 'Banana' is typically classified as a tropical fruit.\"\n },\n {\n \"instruction\": \"Identify the main verb in the sentence.\",\n \"input\": \"She danced gracefully.\",\n \"output\": \"The main verb in the sentence is 'danced'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'old'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'old' is 'ancient'.\"\n },\n {\n \"instruction\": \"Describe the color red in 3 words.\",\n \"input\": \"\",\n \"output\": \"Bold, vibrant, intense.\"\n },\n {\n \"instruction\": \"Translate 'I love books' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Me encantan los libros.\"\n },\n {\n \"instruction\": \"Name the process by which animals release energy from food.\",\n \"input\": \"\",\n \"output\": \"The process by which animals release energy from food is called respiration.\"\n },\n {\n \"instruction\": \"What is the plural form of 'sheep'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'sheep' is 'sheep.'\"\n },\n {\n \"instruction\": \"Convert the following statement into a question.\",\n \"input\": \"You were at the concert last night.\",\n \"output\": \"Were you at the concert last night?\"\n },\n {\n \"instruction\": \"Edit the given text to ensure all plural nouns are spelled correctly.\",\n \"input\": \"The boxes was stacked neatly.\",\n \"output\": \"The boxes were stacked neatly.\"\n },\n {\n \"instruction\": \"What is an antonym of 'external'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'external' is 'internal'.\"\n },\n {\n \"instruction\": \"Identify the correct word to complete the sentence.\",\n \"input\": \"She presented her ideas with _____.\",\n \"output\": \"clarity\"\n },\n {\n \"instruction\": \"Edit the given sentence to make it grammatically correct.\",\n \"input\": \"She dont have any money\",\n \"output\": \"She doesn't have any money.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'compassionate'.\",\n \"input\": \"\",\n \"output\": \"She is compassionate and always helps others in need.\"\n },\n {\n \"instruction\": \"Find a rhyming word for the word 'book.'\",\n \"input\": \"\",\n \"output\": \"A rhyming word for the word 'book' could be 'look.'\"\n },\n {\n \"instruction\": \"Name the process by which plants convert sunlight into energy.\",\n \"input\": \"\",\n \"output\": \"The process by which plants convert sunlight into energy is photosynthesis.\"\n },\n {\n \"instruction\": \"Combine the two sentences into a single coherent sentence.\",\n \"input\": \"She did not attend the meeting. She was ill.\",\n \"output\": \"She did not attend the meeting because she was ill.\"\n },\n {\n \"instruction\": \"What is the opposite of 'retain'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'retain' is 'release'.\"\n },\n {\n \"instruction\": \"Translate 'Good luck' into Japanese.\",\n \"input\": \"\",\n \"output\": \"\\u9811\\u5f35\\u3063\\u3066 (Ganbatte)\"\n },\n {\n \"instruction\": \"List the ingredients required to make a sandwich.\",\n \"input\": \"\",\n \"output\": \"Ingredients for a sandwich typically include bread, meat or vegetables, cheese, and condiments.\"\n },\n {\n \"instruction\": \"What is an antonym of 'broad'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'broad' is 'narrow'.\"\n },\n {\n \"instruction\": \"Rewrite this statement as an imperative sentence.\",\n \"input\": \"You should finish your assignment.\",\n \"output\": \"Finish your assignment.\"\n },\n {\n \"instruction\": \"What is an antonym for 'young'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'young' is 'old'.\"\n },\n {\n \"instruction\": \"What is the symbol for the chemical element iron?\",\n \"input\": \"\",\n \"output\": \"The symbol for the chemical element iron is Fe.\"\n },\n {\n \"instruction\": \"What is the abbreviation for 'corporation'?\",\n \"input\": \"\",\n \"output\": \"The abbreviation for 'corporation' is 'corp.'\"\n },\n {\n \"instruction\": \"Translate 'Please' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'Please' is 'Por favor'.\"\n },\n {\n \"instruction\": \"What is the chemical formula for sodium hydroxide?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for sodium hydroxide is NaOH.\"\n },\n {\n \"instruction\": \"Classify the following numbers as prime or composite.\",\n \"input\": \"17, 22, 29.\",\n \"output\": \"Prime numbers: 17, 29\\nComposite numbers: 22\"\n },\n {\n \"instruction\": \"Provide the past tense form of the verb 'swim.'\",\n \"input\": \"\",\n \"output\": \"The past tense of the verb 'swim' is 'swam.'\"\n },\n {\n \"instruction\": \"What is the boiling point of gold in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of gold is 2970 degrees Celsius.\"\n },\n {\n \"instruction\": \"Reverse this array\",\n \"input\": \"[10, 20, 30, 40, 50]\",\n \"output\": \"Here is the reversed array: [50, 40, 30, 20, 10]\"\n },\n {\n \"instruction\": \"What is the melting point of silver in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of silver is 961.8 degrees Celsius.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovative'.\",\n \"input\": \"\",\n \"output\": \"Her innovative ideas led to the success of the project.\"\n },\n {\n \"instruction\": \"Edit the following sentence for clarity and style.\",\n \"input\": \"He spoke to the issue quickly.\",\n \"output\": \"He quickly addressed the issue.\"\n },\n {\n \"instruction\": \"What is the derivative of the function f(x) = 3x^2?\",\n \"input\": \"\",\n \"output\": \"The derivative of the function f(x) = 3x^2 is f'(x) = 6x.\"\n },\n {\n \"instruction\": \"What type of galaxy is the Milky Way?\",\n \"input\": \"\",\n \"output\": \"The Milky Way is a barred spiral galaxy.\"\n },\n {\n \"instruction\": \"What type of bond does sodium chloride (table salt) have?\",\n \"input\": \"\",\n \"output\": \"Sodium chloride (table salt) has an ionic bond.\"\n },\n {\n \"instruction\": \"Identify the correct spelling of the following word.\",\n \"input\": \"Definately\",\n \"output\": \"The correct spelling is 'Definitely.'\"\n },\n {\n \"instruction\": \"Define the term 'personification'.\",\n \"input\": \"\",\n \"output\": \"Personification is a figure of speech where human qualities are given to animals, objects, or ideas.\"\n },\n {\n \"instruction\": \"Identify the protagonist in the novel 'To Kill a Mockingbird'.\",\n \"input\": \"\",\n \"output\": \"The protagonist in 'To Kill a Mockingbird' is Scout Finch.\"\n },\n {\n \"instruction\": \"What is the symbol for the chemical element gold?\",\n \"input\": \"\",\n \"output\": \"The symbol for the chemical element gold is Au.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence using passive voice.\",\n \"input\": \"The chef prepared a delicious meal.\",\n \"output\": \"A delicious meal was prepared by the chef.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for gold?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for gold is Au.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"She is very fast.\",\n \"output\": \"She is as fast as a cheetah.\"\n },\n {\n \"instruction\": \"What is the opposite of the adjective 'generous'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'generous' is 'stingy' or 'miserly'.\"\n },\n {\n \"instruction\": \"Identify the main subject in the sentence.\",\n \"input\": \"The noisy children played in the park.\",\n \"output\": \"The main subject in the sentence is \\\"The noisy children.\\\"\"\n },\n {\n \"instruction\": \"Capitalize each word in the sentence.\",\n \"input\": \"i love watching the sunrise\",\n \"output\": \"I Love Watching The Sunrise\"\n },\n {\n \"instruction\": \"What is the chemical formula for calcium chloride?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for calcium chloride is CaCl2.\"\n },\n {\n \"instruction\": \"What is the formula for the area of a trapezoid?\",\n \"input\": \"\",\n \"output\": \"The formula for the area of a trapezoid is 0.5 * (Base1 + Base2) * Height.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"He is very tall.\",\n \"output\": \"He is as tall as a giraffe.\"\n },\n {\n \"instruction\": \"Explain the term 'ecosystem'.\",\n \"input\": \"\",\n \"output\": \"An ecosystem is a community of living organisms interacting with each other and their physical environment. It includes biotic (plants, animals, microbes) and abiotic (climate, soil, water) components.\"\n },\n {\n \"instruction\": \"What is the capital of Egypt?\",\n \"input\": \"\",\n \"output\": \"The capital of Egypt is Cairo.\"\n },\n {\n \"instruction\": \"What is the opposite of 'brave'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'brave' is 'cowardly'.\"\n },\n {\n \"instruction\": \"Calculate the volume of a sphere with a radius of 3 cm.\",\n \"input\": \"\",\n \"output\": \"The volume of the sphere is approximately 113.10 cubic cm.\"\n },\n {\n \"instruction\": \"Convert 2 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"2 kilometers is 2000 meters.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The garden is very beautiful.\",\n \"output\": \"The garden is a paradise.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for oxygen?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for oxygen is O.\"\n },\n {\n \"instruction\": \"What is the square root of 225?\",\n \"input\": \"\",\n \"output\": \"The square root of 225 is 15.\"\n },\n {\n \"instruction\": \"What is the opposite of 'tall'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'tall' is 'short'.\"\n },\n {\n \"instruction\": \"What is the hypotenuse of a right triangle with legs of 3 cm and 4 cm?\",\n \"input\": \"\",\n \"output\": \"The hypotenuse of the triangle is 5 cm.\"\n },\n {\n \"instruction\": \"What is the capital of South Africa?\",\n \"input\": \"\",\n \"output\": \"The capital of South Africa is Pretoria.\"\n },\n {\n \"instruction\": \"Provide an example of a compound sentence.\",\n \"input\": \"\",\n \"output\": \"I played the piano, and she sang along.\"\n },\n {\n \"instruction\": \"What is the opposite of 'expand'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'expand' is 'contract'.\"\n },\n {\n \"instruction\": \"Convert 20 miles per hour to kilometers per hour.\",\n \"input\": \"\",\n \"output\": \"20 miles per hour is approximately 32.19 kilometers per hour.\"\n },\n {\n \"instruction\": \"Translate the sentence to French: 'How old are you?'\",\n \"input\": \"\",\n \"output\": \"Quel \\u00e2ge avez-vous?\"\n },\n {\n \"instruction\": \"What is the opposite of 'early'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'early' is 'late'.\"\n },\n {\n \"instruction\": \"Generate three verbs that mean the same as \\\"to run.\\\"\",\n \"input\": \"\",\n \"output\": \"1. To sprint\\n2. To dash\\n3. To jog\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"She is very smart.\",\n \"output\": \"She is a walking encyclopedia.\"\n },\n {\n \"instruction\": \"Convert the following sentence to passive voice: 'The committee approved the new guidelines.'\",\n \"input\": \"The committee approved the new guidelines.\",\n \"output\": \"The new guidelines were approved by the committee.\"\n },\n {\n \"instruction\": \"Classify this speech as either formal or informal.\",\n \"input\": \"Could you please pass the salt?\",\n \"output\": \"This speech is formal.\"\n },\n {\n \"instruction\": \"What is the chemical formula for acetic acid?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for acetic acid is CH3COOH.\"\n },\n {\n \"instruction\": \"Determine the state of matter for oxygen at room temperature.\",\n \"input\": \"\",\n \"output\": \"Oxygen is in a gaseous state at room temperature.\"\n },\n {\n \"instruction\": \"Provide a word that rhymes with 'day.'\",\n \"input\": \"\",\n \"output\": \"A word that rhymes with 'day' is 'play.'\"\n },\n {\n \"instruction\": \"Convert the following verb to its past participle form: 'begin'\",\n \"input\": \"\",\n \"output\": \"The past participle form of 'begin' is 'begun'.\"\n },\n {\n \"instruction\": \"Combine the two ideas in the sentence.\",\n \"input\": \"Learning a new language is useful. It can be challenging.\",\n \"output\": \"Learning a new language is useful but can be challenging.\"\n },\n {\n \"instruction\": \"What is the formula for density?\",\n \"input\": \"\",\n \"output\": \"The formula for density is density = mass/volume.\"\n },\n {\n \"instruction\": \"What is the plural form of \\\"goose\\\"?\",\n \"input\": \"\",\n \"output\": \"The plural form of \\\"goose\\\" is \\\"geese.\\\"\"\n },\n {\n \"instruction\": \"Explain the process of convection.\",\n \"input\": \"\",\n \"output\": \"Convection is the transfer of heat through the movement of fluids (liquids or gases). It occurs when a warmer area of a liquid or gas rises and is replaced by a cooler area, creating a circulation pattern.\"\n },\n {\n \"instruction\": \"Convert 2000 millimeters to meters.\",\n \"input\": \"\",\n \"output\": \"2000 millimeters is equal to 2 meters.\"\n },\n {\n \"instruction\": \"Name an antonym for 'fear.'\",\n \"input\": \"\",\n \"output\": \"An antonym for 'fear' is 'courage.'\"\n },\n {\n \"instruction\": \"What is the opposite of 'high'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'high' is 'low'.\"\n },\n {\n \"instruction\": \"What is the abbreviation for \\\"Doctor of Philosophy\\\"?\",\n \"input\": \"\",\n \"output\": \"The abbreviation for \\\"Doctor of Philosophy\\\" is Ph.D.\"\n },\n {\n \"instruction\": \"What type of animal is a 'koala'?\",\n \"input\": \"\",\n \"output\": \"A koala is a marsupial.\"\n },\n {\n \"instruction\": \"Pick out the correct verb from the following list.\",\n \"input\": \"run, mountain, quickly\",\n \"output\": \"The correct verb from the list is \\\"run.\\\"\"\n },\n {\n \"instruction\": \"Classify the given sentiment as either positive, negative, or neutral.\",\n \"input\": \"This is a great opportunity!\",\n \"output\": \"Positive\"\n },\n {\n \"instruction\": \"What is the formula for speed?\",\n \"input\": \"\",\n \"output\": \"The formula for speed is speed = distance/time.\"\n },\n {\n \"instruction\": \"Name an antonym for 'big.'\",\n \"input\": \"\",\n \"output\": \"An antonym for 'big' is 'small.'\"\n },\n {\n \"instruction\": \"Name a solid commonly found in the Earth's crust.\",\n \"input\": \"\",\n \"output\": \"A solid commonly found in the Earth's crust is granite.\"\n },\n {\n \"instruction\": \"What is the melting point of zinc in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of zinc is 419.5 degrees Celsius.\"\n },\n {\n \"instruction\": \"List 5 different types of vegetables\",\n \"input\": \"\",\n \"output\": \"1. Carrot\\n2. Broccoli\\n3. Cucumber\\n4. Tomato (biologically a fruit, but often classified as a vegetable)\\n5. Spinach\"\n },\n {\n \"instruction\": \"Classify the following substances as acid, base, or salt.\",\n \"input\": \"Vinegar, Baking soda, Table salt\",\n \"output\": \"Acid: Vinegar\\nBase: Baking soda\\nSalt: Table salt\"\n },\n {\n \"instruction\": \"Create an alliteration with the word 'moon'.\",\n \"input\": \"\",\n \"output\": \"The magnificent moon moved majestically across the midnight sky.\"\n },\n {\n \"instruction\": \"What is the primary function of the cell membrane?\",\n \"input\": \"\",\n \"output\": \"The primary function of the cell membrane is to protect the cell by controlling the movement of substances in and out of the cell. It also provides structural support and facilitates communication between cells.\"\n },\n {\n \"instruction\": \"What is the opposite of 'young'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'young' is 'old'.\"\n },\n {\n \"instruction\": \"Determine the mass of an object that has a density of 8 g/cm\\u00b3 and a volume of 3 cm\\u00b3.\",\n \"input\": \"\",\n \"output\": \"The mass of the object is 24 grams.\"\n },\n {\n \"instruction\": \"Provide the correct contraction for 'they are'.\",\n \"input\": \"\",\n \"output\": \"The contraction for 'they are' is 'they're'.\"\n },\n {\n \"instruction\": \"Describe how a rainbow is formed.\",\n \"input\": \"\",\n \"output\": \"A rainbow is formed when sunlight is refracted, dispersed, and reflected in water droplets, resulting in a spectrum of light appearing in the sky.\"\n },\n {\n \"instruction\": \"What is the plural form of 'octopus'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'octopus' can be 'octopuses' or 'octopi'.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor: 'The assignment was a breeze.'\",\n \"input\": \"The assignment was a breeze.\",\n \"output\": \"The assignment was a piece of cake.\"\n },\n {\n \"instruction\": \"Make the first sentence a dependent clause.\",\n \"input\": \"I finished my work. I went home.\",\n \"output\": \"After finishing my work, I went home.\"\n },\n {\n \"instruction\": \"What is the boiling point of hydrogen?\",\n \"input\": \"\",\n \"output\": \"The boiling point of hydrogen is -252.9 degrees Celsius.\"\n },\n {\n \"instruction\": \"Describe the process of evaporation.\",\n \"input\": \"\",\n \"output\": \"Evaporation is the process by which water changes from a liquid to a gas due to heat.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'illuminate'.\",\n \"input\": \"\",\n \"output\": \"The lamp helped to illuminate the dark room.\"\n },\n {\n \"instruction\": \"What is the chemical formula for carbon monoxide?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for carbon monoxide is CO.\"\n },\n {\n \"instruction\": \"What is the atomic number of helium?\",\n \"input\": \"\",\n \"output\": \"The atomic number of helium is 2.\"\n },\n {\n \"instruction\": \"Arrange the given numbers in ascending order.\",\n \"input\": \"8, 3, 15, 1, 7\",\n \"output\": \"1, 3, 7, 8, 15.\"\n },\n {\n \"instruction\": \"Sort the following list in alphabetical order.\",\n \"input\": \"Zebra, Elephant, Crocodile\",\n \"output\": \"sorted in alphabetical order: Crocodile, Elephant, Zebra\"\n },\n {\n \"instruction\": \"Pick the best synonym for the given word.\",\n \"input\": \"Gather\",\n \"output\": \"Collect.\"\n },\n {\n \"instruction\": \"What is the boiling point of nitrogen in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of nitrogen is -196 degrees Celsius.\"\n },\n {\n \"instruction\": \"Correct the misuse of 'your' in the sentence.\",\n \"input\": \"Your going to love this place.\",\n \"output\": \"The corrected sentence should be: 'You're going to love this place.'\"\n },\n {\n \"instruction\": \"Identify the type of triangle with angles of 90 degrees, 45 degrees, and 45 degrees.\",\n \"input\": \"\",\n \"output\": \"A triangle with angles of 90 degrees, 45 degrees, and 45 degrees is a right isosceles triangle.\"\n },\n {\n \"instruction\": \"What is the chemical formula for sodium bicarbonate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for sodium bicarbonate is NaHCO3.\"\n },\n {\n \"instruction\": \"What is the melting point of iron in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of iron is 1538 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is a synonym of 'meticulous'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'meticulous' is 'thorough'.\"\n },\n {\n \"instruction\": \"What is a synonym of 'abundant'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'abundant' is 'plentiful'.\"\n },\n {\n \"instruction\": \"List the ingredients to make pancakes.\",\n \"input\": \"\",\n \"output\": \"Ingredients for pancakes include flour, eggs, milk, and sugar.\"\n },\n {\n \"instruction\": \"What is the primary function of red blood cells in the human body?\",\n \"input\": \"\",\n \"output\": \"The primary function of red blood cells is to carry oxygen from the lungs to the body's tissues and to return carbon dioxide from the tissues to the lungs.\"\n },\n {\n \"instruction\": \"Translate 'How do you do?' into French.\",\n \"input\": \"\",\n \"output\": \"Comment allez-vous?\"\n },\n {\n \"instruction\": \"Construct a sentence using the words \\\"achieve\\\", \\\"goal\\\", and \\\"perseverance\\\".\",\n \"input\": \"\",\n \"output\": \"With perseverance, you can achieve any goal.\"\n },\n {\n \"instruction\": \"Generate a five-word phrase using the words 'star,' 'night,' and 'bright.'\",\n \"input\": \"\",\n \"output\": \"'The bright star illuminated night.'\"\n },\n {\n \"instruction\": \"Perform a sentiment analysis on the given sentence.\",\n \"input\": \"I hate this song!\",\n \"output\": \"The sentiment of the sentence \\\"I hate this song!\\\" is negative. This is indicated by the word \\\"hate\\\" which shows strong aversion or dislike towards the subject, in this case, the song.\"\n },\n {\n \"instruction\": \"Provide the past participle form of 'choose.'\",\n \"input\": \"\",\n \"output\": \"The past participle form of 'choose' is 'chosen.'\"\n },\n {\n \"instruction\": \"Rewrite the sentence so that it does not contain any passive voice.\",\n \"input\": \"The artwork was displayed in the gallery.\",\n \"output\": \"The gallery displayed the artwork.\"\n },\n {\n \"instruction\": \"Pick out the verb from the following list.\",\n \"input\": \"tree, sing, blue\",\n \"output\": \"The correct verb from the list is 'sing.'\"\n },\n {\n \"instruction\": \"What are the first 10 odd numbers?\",\n \"input\": \"\",\n \"output\": \"1, 3, 5, 7, 9, 11, 13, 15, 17, 19.\"\n },\n {\n \"instruction\": \"Generate a past-tense verb that describes a person singing.\",\n \"input\": \"\",\n \"output\": \"Sang.\"\n },\n {\n \"instruction\": \"Find a rhyming word for the word \\\"care.\\\"\",\n \"input\": \"\",\n \"output\": \"A rhyming word for the word \\\"care\\\" could be \\\"bare.\\\"\"\n },\n {\n \"instruction\": \"Combine the two sentences into a single coherent sentence.\",\n \"input\": \"She missed the bus. She walked to school.\",\n \"output\": \"She missed the bus, so she walked to school.\"\n },\n {\n \"instruction\": \"What is the boiling point of ethanol in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of ethanol is 78 degrees Celsius.\"\n },\n {\n \"instruction\": \"Convert the temperature from Celsius to Kelvin.\",\n \"input\": \"25 degrees Celsius\",\n \"output\": \"25 degrees Celsius is 298.15 Kelvin.\"\n },\n {\n \"instruction\": \"What is an antonym for 'weak'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'weak' is 'strong.'\"\n },\n {\n \"instruction\": \"What is the opposite of 'soft'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'soft' is 'hard'.\"\n },\n {\n \"instruction\": \"Name a synonym for 'exciting'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'exciting' is 'thrilling'.\"\n },\n {\n \"instruction\": \"Suggest a more formal synonym for 'goodbye.'\",\n \"input\": \"\",\n \"output\": \"A more formal synonym for 'goodbye' is 'farewell.'\"\n },\n {\n \"instruction\": \"What is the pH of lemon juice?\",\n \"input\": \"\",\n \"output\": \"The pH of lemon juice is approximately 2.0.\"\n },\n {\n \"instruction\": \"Rewrite the sentence in future perfect tense.\",\n \"input\": \"They will complete the project.\",\n \"output\": \"They will have completed the project.\"\n },\n {\n \"instruction\": \"Re-word this sentence using an active voice.\",\n \"input\": \"The decision was made by the team.\",\n \"output\": \"The team made the decision.\"\n },\n {\n \"instruction\": \"Provide an example of alliteration.\",\n \"input\": \"\",\n \"output\": \"An example of alliteration is, 'Peter Piper picked a peck of pickled peppers.'\"\n },\n {\n \"instruction\": \"What is the primary purpose of the United Nations?\",\n \"input\": \"\",\n \"output\": \"The primary purpose of the United Nations is to maintain international peace and security, develop friendly relations among nations, achieve international cooperation, and be a center for harmonizing the actions of nations.\"\n },\n {\n \"instruction\": \"What is a synonym of 'astonishing'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'astonishing' is 'amazing'.\"\n },\n {\n \"instruction\": \"What is the capital of Japan?\",\n \"input\": \"\",\n \"output\": \"The capital of Japan is Tokyo.\"\n },\n {\n \"instruction\": \"Arrange the given numbers in descending order.\",\n \"input\": \"7, 10, 3, 6, 9\",\n \"output\": \"10, 9, 7, 6, 3.\"\n },\n {\n \"instruction\": \"Name a punctuation mark used to indicate possession.\",\n \"input\": \"\",\n \"output\": \"A punctuation mark used to indicate possession is the apostrophe (').\"\n },\n {\n \"instruction\": \"Make the first sentence a dependent clause.\",\n \"input\": \"He finished his homework. He went out to play.\",\n \"output\": \"After he finished his homework, he went out to play.\"\n },\n {\n \"instruction\": \"What is the opposite of 'cheap'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'cheap' is 'expensive'.\"\n },\n {\n \"instruction\": \"What is the capital of Norway?\",\n \"input\": \"\",\n \"output\": \"The capital of Norway is Oslo.\"\n },\n {\n \"instruction\": \"Categorize the following items into liquids and solids.\",\n \"input\": \"Milk, Rock, Honey\",\n \"output\": \"Liquids: Milk, Honey\\nSolids: Rock\"\n },\n {\n \"instruction\": \"Translate 'Where are you from?' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'Where are you from?' is 'D'o\\u00f9 viens-tu?'.\"\n },\n {\n \"instruction\": \"Name a bird that cannot fly.\",\n \"input\": \"\",\n \"output\": \"A bird that cannot fly is the penguin.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'compassionate'.\",\n \"input\": \"\",\n \"output\": \"She is very compassionate and always helps those in need.\"\n },\n {\n \"instruction\": \"What is the melting point of ice in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of ice is 0 degrees Celsius.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The night is very calm.\",\n \"output\": \"The night is a tranquil sea.\"\n },\n {\n \"instruction\": \"List the steps required to make a cup of tea.\",\n \"input\": \"\",\n \"output\": \"Steps to make a cup of tea: 1. Boil water. 2. Place a tea bag in a cup. 3. Pour hot water over the tea bag. 4. Let it steep. 5. Remove the tea bag and enjoy.\"\n },\n {\n \"instruction\": \"Define the term 'osmosis'.\",\n \"input\": \"\",\n \"output\": \"Osmosis is the process of movement of water molecules through a semipermeable membrane from a region of low solute concentration to a region of high solute concentration.\"\n },\n {\n \"instruction\": \"Create a compound word using 'water.'\",\n \"input\": \"\",\n \"output\": \"A compound word using 'water' is 'waterfall.'\"\n },\n {\n \"instruction\": \"Calculate the volume of a cube with side length of 3 meters.\",\n \"input\": \"\",\n \"output\": \"The volume of the cube is 27 cubic meters.\"\n },\n {\n \"instruction\": \"Generate a question that could logically follow the statement below.\",\n \"input\": \"I just finished reading a fascinating book.\",\n \"output\": \"What was the book about?\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'resilient'.\",\n \"input\": \"\",\n \"output\": \"He is very resilient and always bounces back from setbacks.\"\n },\n {\n \"instruction\": \"Rewrite this sentence to start with 'In spite of': Although it was raining, they went for a walk.\",\n \"input\": \"\",\n \"output\": \"In spite of the rain, they went for a walk.\"\n },\n {\n \"instruction\": \"Convert the mass from kilograms to grams.\",\n \"input\": \"4 kilograms\",\n \"output\": \"4 kilograms is equivalent to 4000 grams.\"\n },\n {\n \"instruction\": \"Convert the number 110 from binary to decimal.\",\n \"input\": \"\",\n \"output\": \"The decimal equivalent of the binary number 110 is 6.\"\n },\n {\n \"instruction\": \"Name three essential elements found in nature.\",\n \"input\": \"\",\n \"output\": \"1. Carbon\\n2. Oxygen\\n3. Iron\"\n },\n {\n \"instruction\": \"Provide a synonym for 'intelligent'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'intelligent' is 'smart'.\"\n },\n {\n \"instruction\": \"What is the speed of sound?\",\n \"input\": \"\",\n \"output\": \"The speed of sound is approximately 343 meters per second at sea level and at 20\\u00b0C.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"He is very clumsy.\",\n \"output\": \"He is as clumsy as a bull in a china shop.\"\n },\n {\n \"instruction\": \"Find the temperature of boiling water under normal atmospheric pressure.\",\n \"input\": \"\",\n \"output\": \"Under normal atmospheric pressure, the temperature of boiling water is 100 degrees Celsius (212 degrees Fahrenheit).\"\n },\n {\n \"instruction\": \"Classify the following online review as being positive or negative.\",\n \"input\": \"I found this book to be incredibly insightful and informative.\",\n \"output\": \"The online review is positive.\"\n },\n {\n \"instruction\": \"What is the pH level of pure water?\",\n \"input\": \"\",\n \"output\": \"The pH level of pure water is 7, which is neutral.\"\n },\n {\n \"instruction\": \"What is the formula for calculating the perimeter of a rectangle?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating the perimeter of a rectangle is 2(length + width).\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'determined'.\",\n \"input\": \"\",\n \"output\": \"She is determined to achieve her dreams.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'meticulous'.\",\n \"input\": \"\",\n \"output\": \"He is meticulous in his work and pays attention to every detail.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The room was very hot.\",\n \"output\": \"The room was as hot as an oven.\"\n },\n {\n \"instruction\": \"Classify the following statement into one of these labels: [positive, negative, neutral]\",\n \"input\": \"My computer is working perfectly.\",\n \"output\": \"The statement 'My computer is working perfectly' can be classified as positive.\"\n },\n {\n \"instruction\": \"Edit the following sentence for grammar.\",\n \"input\": \"We goes to the park every Sunday.\",\n \"output\": \"We go to the park every Sunday.\"\n },\n {\n \"instruction\": \"Define the term 'quantum mechanics'.\",\n \"input\": \"\",\n \"output\": \"Quantum mechanics is a branch of physics that studies the behavior of particles at the smallest scales, such as atoms and subatomic particles.\"\n },\n {\n \"instruction\": \"What is the primary function of the digestive system?\",\n \"input\": \"\",\n \"output\": \"The primary function of the digestive system is to break down food into nutrients that can be absorbed into the bloodstream and used by the body for energy, growth, and repair.\"\n },\n {\n \"instruction\": \"What is the formula for calculating the area of a rectangle?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating the area of a rectangle is length \\u00d7 width.\"\n },\n {\n \"instruction\": \"Translate 'Thank you very much' into Japanese.\",\n \"input\": \"\",\n \"output\": \"The Japanese translation of 'Thank you very much' is '\\u3069\\u3046\\u3082\\u3042\\u308a\\u304c\\u3068\\u3046\\u3054\\u3056\\u3044\\u307e\\u3059' (D\\u014dmo arigat\\u014dgozaimasu).\"\n },\n {\n \"instruction\": \"Translate the phrase 'How are you?' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'How are you?' is '\\u00bfC\\u00f3mo est\\u00e1s?'\"\n },\n {\n \"instruction\": \"Fill in the blank to complete the sentence.\",\n \"input\": \"The most popular vegetable in the world is the ___\",\n \"output\": \"The most popular vegetable in the world is the potato.\"\n },\n {\n \"instruction\": \"Given a sentence, count the number of words.\",\n \"input\": \"I love watching the stars at night.\",\n \"output\": \"The sentence 'I love watching the stars at night.' contains 7 words.\"\n },\n {\n \"instruction\": \"Correct the grammatical errors in this sentence.\",\n \"input\": \"He don't know nothing about it.\",\n \"output\": \"He doesn't know anything about it.\"\n },\n {\n \"instruction\": \"Suggest a more formal synonym for 'happy.'\",\n \"input\": \"\",\n \"output\": \"A more formal synonym for 'happy' is 'joyful.'\"\n },\n {\n \"instruction\": \"Convert 2,000 milligrams to grams.\",\n \"input\": \"\",\n \"output\": \"2,000 milligrams is equal to 2 grams.\"\n },\n {\n \"instruction\": \"Put the following words in alphabetical order: kitten, zebra, alligator.\",\n \"input\": \"\",\n \"output\": \"Alligator, kitten, zebra.\"\n },\n {\n \"instruction\": \"Identify the main theme in George Orwell's '1984'.\",\n \"input\": \"\",\n \"output\": \"The main theme of '1984' is the dangers of totalitarianism and oppressive government control.\"\n },\n {\n \"instruction\": \"What is the capital of Germany?\",\n \"input\": \"\",\n \"output\": \"The capital city of Germany is Berlin.\"\n },\n {\n \"instruction\": \"Define the term 'mitosis'.\",\n \"input\": \"\",\n \"output\": \"Mitosis is a type of cell division that results in two daughter cells each having the same number and kind of chromosomes as the parent nucleus.\"\n },\n {\n \"instruction\": \"Name 3 different animals that are active during the day.\",\n \"input\": \"\",\n \"output\": \"1. Squirrel\\n2. Eagle\\n3. Tiger\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'spontaneous'.\",\n \"input\": \"\",\n \"output\": \"His decision to travel was completely spontaneous, made on a whim.\"\n },\n {\n \"instruction\": \"Convert the sentence into a question by adding a question tag.\",\n \"input\": \"You will help me\",\n \"output\": \"You will help me, won't you?\"\n },\n {\n \"instruction\": \"What type of animal is a 'sparrow'?\",\n \"input\": \"\",\n \"output\": \"A sparrow is a type of bird.\"\n },\n {\n \"instruction\": \"Create a compound word using 'sun.'\",\n \"input\": \"\",\n \"output\": \"A compound word using 'sun' is 'sunshine.'\"\n },\n {\n \"instruction\": \"Convert 90 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"90 centimeters is 0.9 meters.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'difficult'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'difficult' is 'challenging'.\"\n },\n {\n \"instruction\": \"Classify the following into mammals, birds, and fish.\",\n \"input\": \"Eagle, Shark, Lion\",\n \"output\": \"Mammals: Lion\\nBirds: Eagle\\nFish: Shark\"\n },\n {\n \"instruction\": \"What is the square root of 16?\",\n \"input\": \"\",\n \"output\": \"The square root of 16 is 4.\"\n },\n {\n \"instruction\": \"Translate 'We go to school together' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Vamos juntos a la escuela.\"\n },\n {\n \"instruction\": \"What is the melting point of tin in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of tin is 231.9 degrees Celsius.\"\n },\n {\n \"instruction\": \"Edit the following sentence to make it more formal.\",\n \"input\": \"I gotta go to the store.\",\n \"output\": \"I have to go to the store.\"\n },\n {\n \"instruction\": \"Translate 'Goodbye' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'Goodbye' is 'Adi\\u00f3s'.\"\n },\n {\n \"instruction\": \"What is the chemical formula for nitric acid?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for nitric acid is HNO3.\"\n },\n {\n \"instruction\": \"Transform the following sentence to include an exclamation mark to show surprise.\",\n \"input\": \"I found my keys\",\n \"output\": \"I found my keys!\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'illuminate.'\",\n \"input\": \"\",\n \"output\": \"The streetlights illuminate the pathway at night.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for magnesium?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for magnesium is Mg.\"\n },\n {\n \"instruction\": \"Convert the sentence to passive voice: 'The chef prepared the meal.'\",\n \"input\": \"The chef prepared the meal.\",\n \"output\": \"The meal was prepared by the chef.\"\n },\n {\n \"instruction\": \"Edit the text for grammar and punctuation.\",\n \"input\": \"today was amazing I went hiking and saw a bear\",\n \"output\": \"\\\"Today was amazing. I went hiking and saw a bear.\\\"\"\n },\n {\n \"instruction\": \"Explain the function of the respiratory system in humans.\",\n \"input\": \"\",\n \"output\": \"The respiratory system's primary function is to supply the blood with oxygen through breathing and to remove carbon dioxide. It includes the nose, throat, larynx, trachea, bronchi, and lungs.\"\n },\n {\n \"instruction\": \"Convert the number 10 from decimal to binary.\",\n \"input\": \"\",\n \"output\": \"The binary equivalent of the decimal number 10 is 1010.\"\n },\n {\n \"instruction\": \"Rewrite the sentence so that it does not contain any passive voice.\",\n \"input\": \"The song was played on the radio.\",\n \"output\": \"The radio played the song.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'quintessential'.\",\n \"input\": \"\",\n \"output\": \"He was the quintessential example of a gentleman.\"\n },\n {\n \"instruction\": \"What is the past tense of 'fly'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'fly' is 'flew'.\"\n },\n {\n \"instruction\": \"Rewrite this statement as an imperative sentence.\",\n \"input\": \"You should check the document for errors.\",\n \"output\": \"Check the document for errors.\"\n },\n {\n \"instruction\": \"Convert the following verb to its gerund form: 'write'\",\n \"input\": \"\",\n \"output\": \"The gerund form of 'write' is 'writing.'\"\n },\n {\n \"instruction\": \"Generate three verbs that mean the same as 'to write.'\",\n \"input\": \"\",\n \"output\": \"1. To compose\\n2. To draft\\n3. To pen\"\n },\n {\n \"instruction\": \"Calculate the perimeter of an equilateral triangle with each side measuring 8 cm.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the equilateral triangle is 24 cm.\"\n },\n {\n \"instruction\": \"Describe the color blue in 3 words.\",\n \"input\": \"\",\n \"output\": \"Deep, calming, cool.\"\n },\n {\n \"instruction\": \"Classify the following items: apple, diamond, fern.\",\n \"input\": \"\",\n \"output\": \"Plants: Fern\\nMinerals: Diamond\\nFruits: Apple\"\n },\n {\n \"instruction\": \"Scramble the given phrase.\",\n \"input\": \"A random phrase\",\n \"output\": \"A nmaodr hrasep\"\n },\n {\n \"instruction\": \"Identify the verb in the following sentence\",\n \"input\": \"The cat sleeps on the couch.\",\n \"output\": \"The verb in the sentence is \\\"sleeps.\\\"\"\n },\n {\n \"instruction\": \"What is the freezing point of water in Celsius?\",\n \"input\": \"\",\n \"output\": \"The freezing point of water is 0 degrees Celsius.\"\n },\n {\n \"instruction\": \"Pick the best synonym for the given word.\",\n \"input\": \"Assist\",\n \"output\": \"Help.\"\n },\n {\n \"instruction\": \"Provide the past tense form of the verb 'choose.'\",\n \"input\": \"\",\n \"output\": \"The past tense of the verb 'choose' is 'chose.'\"\n },\n {\n \"instruction\": \"Convert 1000 millimeters to meters.\",\n \"input\": \"\",\n \"output\": \"1000 millimeters is 1 meter.\"\n },\n {\n \"instruction\": \"Generate a question that could logically follow the statement below.\",\n \"input\": \"I just got a new job.\",\n \"output\": \"What will you be doing at your new job?\"\n },\n {\n \"instruction\": \"Given a sentence, convert it into indirect speech.\",\n \"input\": \"He said, 'I am hungry.'\",\n \"output\": \"He said that he was hungry.\"\n },\n {\n \"instruction\": \"What is the integral of x?\",\n \"input\": \"\",\n \"output\": \"The integral of x is (1/2)x^2 + C.\"\n },\n {\n \"instruction\": \"Name the process by which leaves change color in autumn.\",\n \"input\": \"\",\n \"output\": \"The process by which leaves change color in autumn is called senescence.\"\n },\n {\n \"instruction\": \"What is the capital of Mexico?\",\n \"input\": \"\",\n \"output\": \"The capital of Mexico is Mexico City.\"\n },\n {\n \"instruction\": \"Categorize the following items into one of the following categories: appliance, clothing, or food.\",\n \"input\": \"Microwave, T-shirt, Bread\",\n \"output\": \"Appliance: Microwave\\nClothing: T-shirt\\nFood: Bread\"\n },\n {\n \"instruction\": \"Translate 'I am sorry' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'I am sorry' is 'Es tut mir leid'.\"\n },\n {\n \"instruction\": \"Convert this declarative sentence into a command: 'You should check the report.'\",\n \"input\": \"\",\n \"output\": \"Check the report.\"\n },\n {\n \"instruction\": \"Translate 'good afternoon' into Portuguese.\",\n \"input\": \"\",\n \"output\": \"Boa tarde\"\n },\n {\n \"instruction\": \"Convert the following verb to its gerund form: 'eat'\",\n \"input\": \"\",\n \"output\": \"The gerund form of 'eat' is 'eating'.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'bittersweet'.\",\n \"input\": \"\",\n \"output\": \"His victory was bittersweet, as it came at a great personal loss.\"\n },\n {\n \"instruction\": \"What is the opposite of 'strong'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'strong' is 'weak'.\"\n },\n {\n \"instruction\": \"Translate 'They are reading books' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Est\\u00e1n leyendo libros.\"\n },\n {\n \"instruction\": \"List two synonyms for 'beautiful.'\",\n \"input\": \"\",\n \"output\": \"Two synonyms for 'beautiful' are 'gorgeous' and 'stunning.'\"\n },\n {\n \"instruction\": \"Rewrite this sentence to increase formality: 'Kids need to check their phones less.'\",\n \"input\": \"\",\n \"output\": \"Children ought to reduce their mobile phone usage.\"\n },\n {\n \"instruction\": \"What is the opposite of 'slow'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'slow' is 'fast'.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The baby is very cute.\",\n \"output\": \"The baby is as cute as a button.\"\n },\n {\n \"instruction\": \"Determine the state of matter for helium at room temperature.\",\n \"input\": \"\",\n \"output\": \"Helium is in a gaseous state at room temperature.\"\n },\n {\n \"instruction\": \"Correct the misspelled word in the following sentence.\",\n \"input\": \"I recieved your message\",\n \"output\": \"The misspelled word \\\"recieved\\\" should be spelled \\\"received.\\\"\"\n },\n {\n \"instruction\": \"What is the formula for kinetic energy?\",\n \"input\": \"\",\n \"output\": \"The formula for kinetic energy is KE = 1/2 mv\\u00b2, where m is mass and v is velocity.\"\n },\n {\n \"instruction\": \"Identify the adjective in the sentence.\",\n \"input\": \"The red car sped down the road.\",\n \"output\": \"The adjective in the sentence is 'red'.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor: 'Life is like a journey.'\",\n \"input\": \"\",\n \"output\": \"Life is a journey.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"She is very gentle.\",\n \"output\": \"She is as gentle as a lamb.\"\n },\n {\n \"instruction\": \"Change the given verb to its present perfect form.\",\n \"input\": \"go\",\n \"output\": \"Gone.\"\n },\n {\n \"instruction\": \"Convert 200 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"200 grams is 0.2 kilograms.\"\n },\n {\n \"instruction\": \"Determine the area of a square with side length of 8 meters.\",\n \"input\": \"\",\n \"output\": \"The area of the square is 64 square meters.\"\n },\n {\n \"instruction\": \"Reverse this array\",\n \"input\": \"[5, 15, 25, 35, 45]\",\n \"output\": \"Here is the reversed array: [45, 35, 25, 15, 5]\"\n },\n {\n \"instruction\": \"Generate a random sequence of 12 digits.\",\n \"input\": \"\",\n \"output\": \"Here is a randomly generated sequence of 12 digits: 728493651280.\"\n },\n {\n \"instruction\": \"Create a simile with the phrase 'as busy as'.\",\n \"input\": \"\",\n \"output\": \"He was as busy as a bee.\"\n },\n {\n \"instruction\": \"What is the opposite of 'noisy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'noisy' is 'quiet'.\"\n },\n {\n \"instruction\": \"Generate a random alphanumeric code of 8 characters.\",\n \"input\": \"\",\n \"output\": \"Here is a randomly generated 8-character alphanumeric code: A3F8J7K2.\"\n },\n {\n \"instruction\": \"Name three essential minerals for human health.\",\n \"input\": \"\",\n \"output\": \"1. Calcium\\n2. Iron\\n3. Magnesium\"\n },\n {\n \"instruction\": \"Categorize the following items into herbs and spices.\",\n \"input\": \"Cinnamon, Basil, Pepper\",\n \"output\": \"Herbs: Basil\\nSpices: Cinnamon, Pepper\"\n },\n {\n \"instruction\": \"Create a sentence that begins with 'Even though,'\",\n \"input\": \"\",\n \"output\": \"Even though it was raining, they decided to go for a walk.\"\n },\n {\n \"instruction\": \"What is the opposite of 'happy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'happy' is 'sad'.\"\n },\n {\n \"instruction\": \"Define the term 'allusion'.\",\n \"input\": \"\",\n \"output\": \"An allusion is a brief and indirect reference to a person, place, thing, or idea of historical, cultural, literary, or political significance.\"\n },\n {\n \"instruction\": \"Classify the item as either a mammal or a bird.\",\n \"input\": \"Penguin\",\n \"output\": \"Bird\"\n },\n {\n \"instruction\": \"Convert the temperature from Celsius to Fahrenheit.\",\n \"input\": \"30 degrees Celsius\",\n \"output\": \"30 degrees Celsius is 86 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Convert 15 liters to milliliters.\",\n \"input\": \"\",\n \"output\": \"15 liters is 15000 milliliters.\"\n },\n {\n \"instruction\": \"Combine the given sentences into one cohesive sentence.\",\n \"input\": \"It is raining. I cannot go to the park.\",\n \"output\": \"Since it is raining, I cannot go to the park.\"\n },\n {\n \"instruction\": \"Calculate the future value of an investment of $500 at an annual interest rate of 5% compounded yearly for 10 years.\",\n \"input\": \"\",\n \"output\": \"The future value of the investment would be approximately $814.45.\"\n },\n {\n \"instruction\": \"What is a synonym of 'lazy'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'lazy' is 'indolent'.\"\n },\n {\n \"instruction\": \"Look up the boiling point of ethanol.\",\n \"input\": \"\",\n \"output\": \"The boiling point of ethanol is approximately 78.37 degrees Celsius or 173.07 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Convert the sentence to passive voice: 'The teacher explains the lesson.'\",\n \"input\": \"The teacher explains the lesson.\",\n \"output\": \"The lesson is explained by the teacher.\"\n },\n {\n \"instruction\": \"Name the largest ocean on Earth.\",\n \"input\": \"\",\n \"output\": \"The largest ocean on Earth is the Pacific Ocean.\"\n },\n {\n \"instruction\": \"What is the boiling point of water on Mount Everest?\",\n \"input\": \"\",\n \"output\": \"The boiling point of water on Mount Everest is lower than at sea level, around 71 degrees Celsius.\"\n },\n {\n \"instruction\": \"Evaluate the following phrase by transforming it into the correct spelling given.\",\n \"input\": \"recieve --> receive\",\n \"output\": \"The spelling of the given phrase 'recieve' is incorrect, the correct spelling is 'receive.'\"\n },\n {\n \"instruction\": \"Define the term 'metaphor'.\",\n \"input\": \"\",\n \"output\": \"A metaphor is a figure of speech in which a word or phrase is applied to an object or action to which it is not literally applicable.\"\n },\n {\n \"instruction\": \"Explain what GDP stands for and what it measures.\",\n \"input\": \"\",\n \"output\": \"GDP stands for Gross Domestic Product, which measures the total value of all goods and services produced over a specific time period within a country's borders.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'delicious'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'delicious' is 'tasty'.\"\n },\n {\n \"instruction\": \"Translate this phrase to Spanish: 'I will travel tomorrow.'\",\n \"input\": \"\",\n \"output\": \"Viajar\\u00e9 ma\\u00f1ana.\"\n },\n {\n \"instruction\": \"What is a synonym for 'enormous'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'enormous' is 'gigantic'.\"\n },\n {\n \"instruction\": \"Create a new sentence by combining the two sentences.\",\n \"input\": \"He likes to swim. He goes to the pool every day.\",\n \"output\": \"He likes to swim and goes to the pool every day.\"\n },\n {\n \"instruction\": \"What is the square root of 169?\",\n \"input\": \"\",\n \"output\": \"The square root of 169 is 13.\"\n },\n {\n \"instruction\": \"Identify the genre of the book '1984' by George Orwell.\",\n \"input\": \"\",\n \"output\": \"The genre of '1984' by George Orwell is dystopian fiction.\"\n },\n {\n \"instruction\": \"Convert 120 meters to kilometers.\",\n \"input\": \"\",\n \"output\": \"120 meters is 0.12 kilometers.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to remove redundancy.\",\n \"input\": \"The end result was a total success.\",\n \"output\": \"The result was a success.\"\n },\n {\n \"instruction\": \"Name a punctuation mark used to indicate a pause.\",\n \"input\": \"\",\n \"output\": \"A punctuation mark used to indicate a pause is a comma (,).\"\n },\n {\n \"instruction\": \"Suggest a simpler word to replace the word in braces.\",\n \"input\": \"He moved {expeditiously} through the crowd.\",\n \"output\": \"He moved quickly through the crowd.\"\n },\n {\n \"instruction\": \"Construct a sentence using the words 'achieve,' 'goal,' and 'dedication.'\",\n \"input\": \"\",\n \"output\": \"With dedication, you can achieve any goal.\"\n },\n {\n \"instruction\": \"Generate a question based on the following statement.\",\n \"input\": \"Plants produce oxygen through the process of photosynthesis.\",\n \"output\": \"How do plants produce oxygen?\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The night is very dark.\",\n \"output\": \"The night is a black canvas.\"\n },\n {\n \"instruction\": \"Translate 'good evening' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'good evening' is 'buona sera'.\"\n },\n {\n \"instruction\": \"What is the cube root of 27?\",\n \"input\": \"\",\n \"output\": \"The cube root of 27 is 3.\"\n },\n {\n \"instruction\": \"What is the atomic number of nitrogen?\",\n \"input\": \"\",\n \"output\": \"The atomic number of nitrogen is 7.\"\n },\n {\n \"instruction\": \"Name 3 different animals that are nocturnal.\",\n \"input\": \"\",\n \"output\": \"1. Owl\\n2. Bat\\n3. Raccoon\"\n },\n {\n \"instruction\": \"Convert 100 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"100 grams is 0.1 kilograms.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'brave'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'brave' is 'fearless'.\"\n },\n {\n \"instruction\": \"Convert 12 meters to centimeters.\",\n \"input\": \"\",\n \"output\": \"12 meters is 1200 centimeters.\"\n },\n {\n \"instruction\": \"What is the pH of a substance that is neither acidic nor basic?\",\n \"input\": \"\",\n \"output\": \"The pH of a substance that is neither acidic nor basic is 7, which is neutral.\"\n },\n {\n \"instruction\": \"Create a new sentence by combining the two sentences.\",\n \"input\": \"She loves to read. She goes to the library every week.\",\n \"output\": \"She loves to read and goes to the library every week.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"He is very busy.\",\n \"output\": \"He is a bee in a hive.\"\n },\n {\n \"instruction\": \"What is a synonym of 'exquisite'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'exquisite' is 'elegant'.\"\n },\n {\n \"instruction\": \"Convert the following sentence to use a conditional clause: If it rains, we will stay indoors.\",\n \"input\": \"\",\n \"output\": \"We will stay indoors if it rains.\"\n },\n {\n \"instruction\": \"What is the melting point of mercury in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of mercury is -38.83 degrees Celsius.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'clarify.'\",\n \"input\": \"\",\n \"output\": \"She asked the teacher to clarify the instructions.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'meticulous'.\",\n \"input\": \"\",\n \"output\": \"He was meticulous in his planning for the project.\"\n },\n {\n \"instruction\": \"What is the capital of Italy?\",\n \"input\": \"\",\n \"output\": \"The capital of Italy is Rome.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence using the active voice.\",\n \"input\": \"The ball was thrown by the pitcher.\",\n \"output\": \"The pitcher threw the ball.\"\n },\n {\n \"instruction\": \"What is the melting point of copper in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of copper is 1085 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the capital of the Netherlands?\",\n \"input\": \"\",\n \"output\": \"The capital of the Netherlands is Amsterdam.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for sodium?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for sodium is Na.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence by adding one adjective.\",\n \"input\": \"The cat slept on the mat.\",\n \"output\": \"The black cat slept on the mat.\"\n },\n {\n \"instruction\": \"Explain what an enzyme is.\",\n \"input\": \"\",\n \"output\": \"An enzyme is a protein that catalyzes chemical reactions within the body.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The night is very peaceful.\",\n \"output\": \"The night is a blanket of calm.\"\n },\n {\n \"instruction\": \"Identify the protagonist in 'The Great Gatsby'.\",\n \"input\": \"\",\n \"output\": \"The protagonist of 'The Great Gatsby' is Jay Gatsby.\"\n },\n {\n \"instruction\": \"Categorize the following items into one of the following categories: tool, clothing, or fruit.\",\n \"input\": \"Hammer, Shirt, Apple\",\n \"output\": \"Tool: Hammer\\nClothing: Shirt\\nFruit: Apple\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"She is very quiet.\",\n \"output\": \"She is as quiet as a mouse.\"\n },\n {\n \"instruction\": \"What type of molecule is DNA?\",\n \"input\": \"\",\n \"output\": \"DNA is a type of nucleic acid.\"\n },\n {\n \"instruction\": \"Provide the plural form of 'index.'\",\n \"input\": \"\",\n \"output\": \"The plural form of 'index' is 'indices.'\"\n },\n {\n \"instruction\": \"What is the unit for measuring force?\",\n \"input\": \"\",\n \"output\": \"The unit for measuring force is the newton.\"\n },\n {\n \"instruction\": \"Give me a synonym for the word 'strong'.\",\n \"input\": \"\",\n \"output\": \"Powerful.\"\n },\n {\n \"instruction\": \"What is the plural form of 'bacterium'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'bacterium' is 'bacteria'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'expand'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'expand' is 'contract'.\"\n },\n {\n \"instruction\": \"What is the primary function of the human nervous system?\",\n \"input\": \"\",\n \"output\": \"The primary function of the human nervous system is to control and coordinate the body's activities by transmitting signals between different parts of the body. It includes the brain, spinal cord, and peripheral nerves.\"\n },\n {\n \"instruction\": \"What is the boiling point of nitrogen?\",\n \"input\": \"\",\n \"output\": \"The boiling point of nitrogen is -195.79 degrees Celsius.\"\n },\n {\n \"instruction\": \"Translate the term 'global warming' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation for 'global warming' is 'calentamiento global'.\"\n },\n {\n \"instruction\": \"Convert 20 miles to kilometers, assuming 1 mile is approximately 1.60934 kilometers.\",\n \"input\": \"\",\n \"output\": \"20 miles is approximately 32.1868 kilometers.\"\n },\n {\n \"instruction\": \"What type of animal is a 'penguin'?\",\n \"input\": \"\",\n \"output\": \"A penguin is a type of bird.\"\n },\n {\n \"instruction\": \"What is the opposite of 'exclude'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'exclude' is 'include'.\"\n },\n {\n \"instruction\": \"List three primary colors.\",\n \"input\": \"\",\n \"output\": \"The three primary colors are red, blue, and yellow.\"\n },\n {\n \"instruction\": \"Create a sentence that begins with \\\"If only,\\\"\",\n \"input\": \"\",\n \"output\": \"If only I had known the truth earlier...\"\n },\n {\n \"instruction\": \"What is the opposite of 'clean'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'clean' is 'dirty'.\"\n },\n {\n \"instruction\": \"Rewrite the given passage in the past tense.\",\n \"input\": \"They are building a new library.\",\n \"output\": \"They built a new library.\"\n },\n {\n \"instruction\": \"Name an antonym for \\\"joy.\\\"\",\n \"input\": \"\",\n \"output\": \"An antonym for \\\"joy\\\" is \\\"sorrow.\\\"\"\n },\n {\n \"instruction\": \"Provide an example of a complex sentence.\",\n \"input\": \"\",\n \"output\": \"Although it was raining, we decided to go for a walk.\"\n },\n {\n \"instruction\": \"Name the three main types of rocks.\",\n \"input\": \"\",\n \"output\": \"The three main types of rocks are igneous, sedimentary, and metamorphic.\"\n },\n {\n \"instruction\": \"What is the boiling point of ethanol in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of ethanol is 78.37 degrees Celsius.\"\n },\n {\n \"instruction\": \"Convert 45 kilograms to pounds.\",\n \"input\": \"\",\n \"output\": \"45 kilograms is approximately 99.21 pounds.\"\n },\n {\n \"instruction\": \"Classify this sentence into one of the following topics: health, economy, technology, music\",\n \"input\": \"Electric cars are revolutionizing the automotive industry.\",\n \"output\": \"The topic of the given sentence is technology.\"\n },\n {\n \"instruction\": \"What is the largest planet in our solar system?\",\n \"input\": \"\",\n \"output\": \"The largest planet in our solar system is Jupiter.\"\n },\n {\n \"instruction\": \"What is the capital of Australia?\",\n \"input\": \"\",\n \"output\": \"The capital of Australia is Canberra.\"\n },\n {\n \"instruction\": \"Determine whether the given two words are synonyms or antonyms.\",\n \"input\": \"Start - Stop\",\n \"output\": \"Start and Stop are antonyms.\"\n },\n {\n \"instruction\": \"Name the literary device used in 'Time is a thief.'\",\n \"input\": \"\",\n \"output\": \"The literary device used is metaphor.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor: The sun set behind the hills.\",\n \"input\": \"\",\n \"output\": \"The sun dipped behind the hills like a shy child hiding.\"\n },\n {\n \"instruction\": \"List the primary colors in the CMYK color model.\",\n \"input\": \"\",\n \"output\": \"The primary colors in the CMYK color model are cyan, magenta, yellow, and key (black).\"\n },\n {\n \"instruction\": \"Classify the following animal as carnivore, herbivore, or omnivore.\",\n \"input\": \"Bear\",\n \"output\": \"Omnivore\"\n },\n {\n \"instruction\": \"List 5 different types of fruits\",\n \"input\": \"\",\n \"output\": \"1. Apple\\n2. Banana\\n3. Orange\\n4. Strawberry\\n5. Mango\"\n },\n {\n \"instruction\": \"What is the sum of 2 and 3?\",\n \"input\": \"\",\n \"output\": \"The sum of 2 and 3 is 5.\"\n },\n {\n \"instruction\": \"Sort the following list in alphabetical order.\",\n \"input\": \"Banana, Apple, Cherry\",\n \"output\": \"sorted in alphabetical order: Apple, Banana, Cherry\"\n },\n {\n \"instruction\": \"What is the boiling point of water in Fahrenheit?\",\n \"input\": \"\",\n \"output\": \"The boiling point of water is 212 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Change this sentence into the present perfect tense.\",\n \"input\": \"She writes a letter.\",\n \"output\": \"She has written a letter.\"\n },\n {\n \"instruction\": \"Convert 100 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"100 centimeters is equal to 1 meter.\"\n },\n {\n \"instruction\": \"Identify the hypernym for the word \\\"car\\\".\",\n \"input\": \"\",\n \"output\": \"The hypernym for the word \\\"car\\\" is \\\"vehicle\\\".\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'dynamic'.\",\n \"input\": \"\",\n \"output\": \"The team had a dynamic leader who inspired everyone.\"\n },\n {\n \"instruction\": \"Rewrite this English sentence into passive voice.\",\n \"input\": \"The gardener planted the flowers.\",\n \"output\": \"The flowers were planted by the gardener.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'We celebrate Independence Day on July 4th.'\",\n \"input\": \"\",\n \"output\": \"Independence Day is celebrated on July 4th.\"\n },\n {\n \"instruction\": \"Convert 800 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"800 grams is 0.8 kilograms.\"\n },\n {\n \"instruction\": \"Convert 15 feet to meters.\",\n \"input\": \"\",\n \"output\": \"15 feet is equal to approximately 4.572 meters.\"\n },\n {\n \"instruction\": \"Translate 'How are you?' into Japanese.\",\n \"input\": \"\",\n \"output\": \"The Japanese translation of 'How are you?' is '\\u304a\\u5143\\u6c17\\u3067\\u3059\\u304b' (Ogenki desu ka).\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'enthusiastic'.\",\n \"input\": \"\",\n \"output\": \"He was enthusiastic about starting his new job.\"\n },\n {\n \"instruction\": \"What is the opposite of 'cold'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'cold' is 'hot'.\"\n },\n {\n \"instruction\": \"What is the boiling point of propane in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of propane is -42 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the square root of 81?\",\n \"input\": \"\",\n \"output\": \"The square root of 81 is 9.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'effort'.\",\n \"input\": \"\",\n \"output\": \"She put a lot of effort into her work.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'swift'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'swift' is 'quick'.\"\n },\n {\n \"instruction\": \"Classify the following items as either solid, liquid, or gas.\",\n \"input\": \"Ice, Coffee, Helium\",\n \"output\": \"Ice - Solid\\nCoffee - Liquid\\nHelium - Gas\"\n },\n {\n \"instruction\": \"Translate 'What time is it?' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'What time is it?' is 'Che ora \\u00e8?'.\"\n },\n {\n \"instruction\": \"Transform the following sentence into a question using 'would.'\",\n \"input\": \"You can lend me a pen.\",\n \"output\": \"Would you lend me a pen?\"\n },\n {\n \"instruction\": \"Describe the process of condensation.\",\n \"input\": \"\",\n \"output\": \"Condensation is the process by which water vapor in the air is changed into liquid water.\"\n },\n {\n \"instruction\": \"Correct any spelling mistakes in the given sentence.\",\n \"input\": \"The beutiful garden was filled with flowers.\",\n \"output\": \"The beautiful garden was filled with flowers.\"\n },\n {\n \"instruction\": \"Calculate the perimeter of a hexagon with side lengths of 5 cm.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the hexagon is 30 cm.\"\n },\n {\n \"instruction\": \"Convert 30 kilometers to miles.\",\n \"input\": \"\",\n \"output\": \"30 kilometers is approximately 18.64 miles.\"\n },\n {\n \"instruction\": \"Define the term 'algorithm'.\",\n \"input\": \"\",\n \"output\": \"An algorithm is a set of defined, step-by-step procedures or rules to solve a problem or accomplish a task.\"\n },\n {\n \"instruction\": \"Convert 500 grams to ounces.\",\n \"input\": \"\",\n \"output\": \"500 grams is approximately 17.64 ounces.\"\n },\n {\n \"instruction\": \"Convert 500 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"500 grams is 0.5 kilograms.\"\n },\n {\n \"instruction\": \"Identify the correct spelling of the following word.\",\n \"input\": \"Necesary\",\n \"output\": \"The correct spelling is \\\"Necessary\\\".\"\n },\n {\n \"instruction\": \"What is the opposite of 'light'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'light' is 'heavy'.\"\n },\n {\n \"instruction\": \"What is the capital of Germany?\",\n \"input\": \"\",\n \"output\": \"The capital of Germany is Berlin.\"\n },\n {\n \"instruction\": \"Explain what a black hole is.\",\n \"input\": \"\",\n \"output\": \"A black hole is a region of space where gravity is so strong that nothing, not even light, can escape from it.\"\n },\n {\n \"instruction\": \"What is the symbol for copper on the periodic table?\",\n \"input\": \"\",\n \"output\": \"The symbol for copper on the periodic table is Cu.\"\n },\n {\n \"instruction\": \"Fill in the blanks with appropriate words.\",\n \"input\": \"The sky was filled with colorful ________ at sunrise.\",\n \"output\": \"The sky was filled with colorful hues at sunrise.\"\n },\n {\n \"instruction\": \"Convert the number 100 from binary to decimal.\",\n \"input\": \"\",\n \"output\": \"The decimal equivalent of the binary number 100 is 4.\"\n },\n {\n \"instruction\": \"What is the chemical formula for hydrochloric acid?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for hydrochloric acid is HCl.\"\n },\n {\n \"instruction\": \"Rewrite the sentence.\",\n \"input\": \"The poem was composed in a lyrical manner.\",\n \"output\": \"The poem was crafted lyrically.\"\n },\n {\n \"instruction\": \"What is the square root of 144?\",\n \"input\": \"\",\n \"output\": \"The square root of 144 is 12.\"\n },\n {\n \"instruction\": \"What is the formula for converting Celsius to Fahrenheit?\",\n \"input\": \"\",\n \"output\": \"The formula for converting Celsius to Fahrenheit is (C \\u00d7 9/5) + 32.\"\n },\n {\n \"instruction\": \"What is the chemical formula for sodium carbonate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for sodium carbonate is Na2CO3.\"\n },\n {\n \"instruction\": \"Convert 9 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"9 kilometers is 9000 meters.\"\n },\n {\n \"instruction\": \"Convert the following verb to its infinitive form\",\n \"input\": \"went\",\n \"output\": \"The infinitive form of 'went' is 'to go'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'diligent'.\",\n \"input\": \"\",\n \"output\": \"He is very diligent in his studies.\"\n },\n {\n \"instruction\": \"Classify the following statement into one of these labels: [positive, negative, neutral]\",\n \"input\": \"My computer crashed.\",\n \"output\": \"Negative\"\n },\n {\n \"instruction\": \"What is the pH of vinegar?\",\n \"input\": \"\",\n \"output\": \"The pH of vinegar is typically around 2.5.\"\n },\n {\n \"instruction\": \"Calculate the area of a triangle with base 10 meters and height 5 meters.\",\n \"input\": \"\",\n \"output\": \"The area of the triangle is 25 square meters.\"\n },\n {\n \"instruction\": \"Identify the primary colors in the RYB color model.\",\n \"input\": \"\",\n \"output\": \"The primary colors in the RYB color model are red, yellow, and blue.\"\n },\n {\n \"instruction\": \"What is the capital of Spain?\",\n \"input\": \"\",\n \"output\": \"The capital of Spain is Madrid.\"\n },\n {\n \"instruction\": \"Identify the adjective in the sentence.\",\n \"input\": \"The large dog barked loudly.\",\n \"output\": \"The adjective in the sentence is 'large'.\"\n },\n {\n \"instruction\": \"Translate 'She studies chemistry' into German.\",\n \"input\": \"\",\n \"output\": \"Sie studiert Chemie.\"\n },\n {\n \"instruction\": \"What is the comparative form of 'bad'?\",\n \"input\": \"\",\n \"output\": \"The comparative form of 'bad' is 'worse.'\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'charismatic'.\",\n \"input\": \"\",\n \"output\": \"The politician was very charismatic and attracted many followers.\"\n },\n {\n \"instruction\": \"Convert 10 meters to centimeters.\",\n \"input\": \"\",\n \"output\": \"10 meters is 1000 centimeters.\"\n },\n {\n \"instruction\": \"Generate three adjectives to describe a desert.\",\n \"input\": \"\",\n \"output\": \"1. Arid\\n2. Vast\\n3. Barren\"\n },\n {\n \"instruction\": \"Provide a synonym for 'quick'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'quick' is 'fast'.\"\n },\n {\n \"instruction\": \"Find a synonym for the word 'begin.'\",\n \"input\": \"\",\n \"output\": \"A synonym for the word 'begin' could be 'start.'\"\n },\n {\n \"instruction\": \"Define the term 'democracy'.\",\n \"input\": \"\",\n \"output\": \"Democracy is a system of government where the citizens exercise power by voting. It typically features fair and free elections, protection of human rights, and the rule of law.\"\n },\n {\n \"instruction\": \"What is the opposite of 'expensive'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'expensive' is 'cheap'.\"\n },\n {\n \"instruction\": \"Identify the interjection in the sentence.\",\n \"input\": \"Ouch, that hurt!\",\n \"output\": \"The interjection in the sentence is 'Ouch.'\"\n },\n {\n \"instruction\": \"Define the term 'photosynthesis'.\",\n \"input\": \"\",\n \"output\": \"Photosynthesis is the process by which green plants use sunlight to synthesize foods from carbon dioxide and water.\"\n },\n {\n \"instruction\": \"Rewrite this English sentence into passive voice.\",\n \"input\": \"Alex fixed the car.\",\n \"output\": \"The car was fixed by Alex.\"\n },\n {\n \"instruction\": \"Determine the product of 9 and 6.\",\n \"input\": \"\",\n \"output\": \"The product of 9 and 6 is 54.\"\n },\n {\n \"instruction\": \"Calculate the compound interest on a principal amount of $1000 at an annual rate of 4% compounded annually for 5 years.\",\n \"input\": \"\",\n \"output\": \"The compound interest on $1000 at 4% per annum compounded annually for 5 years is approximately $216.65, making the total $1216.65.\"\n },\n {\n \"instruction\": \"Generate a question that could logically follow the statement below.\",\n \"input\": \"I just returned from a vacation in Spain.\",\n \"output\": \"How was your vacation in Spain?\"\n },\n {\n \"instruction\": \"What is the primary purpose of photosynthesis?\",\n \"input\": \"\",\n \"output\": \"The primary purpose of photosynthesis is to convert light energy into chemical energy stored in glucose, which can be used by plants to fuel their activities.\"\n },\n {\n \"instruction\": \"What is the opposite of 'gain'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'gain' is 'lose.'\"\n },\n {\n \"instruction\": \"Convert 25 meters to centimeters.\",\n \"input\": \"\",\n \"output\": \"25 meters is 2500 centimeters.\"\n },\n {\n \"instruction\": \"What is the chemical formula for glucose?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for glucose is C6H12O6.\"\n },\n {\n \"instruction\": \"What is a synonym of 'happy'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'happy' is 'joyful'.\"\n },\n {\n \"instruction\": \"What type of animal is a 'whale'?\",\n \"input\": \"\",\n \"output\": \"A whale is a type of mammal.\"\n },\n {\n \"instruction\": \"Translate 'How much does this cost?' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'How much does this cost?' is 'Wie viel kostet das?'.\"\n },\n {\n \"instruction\": \"What is the chemical formula for methane?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for methane is CH4.\"\n },\n {\n \"instruction\": \"What is the derivative of x^2?\",\n \"input\": \"\",\n \"output\": \"The derivative of x^2 is 2x.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for iron?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for iron is Fe.\"\n },\n {\n \"instruction\": \"Identify the setting in 'The Great Gatsby'.\",\n \"input\": \"\",\n \"output\": \"The setting of 'The Great Gatsby' is in the fictional towns of West Egg and East Egg on Long Island in the summer of 1922.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence so that it is in passive voice.\",\n \"input\": \"The children played the game.\",\n \"output\": \"The game was played by the children.\"\n },\n {\n \"instruction\": \"Convert 1 liter to milliliters.\",\n \"input\": \"\",\n \"output\": \"1 liter is 1000 milliliters.\"\n },\n {\n \"instruction\": \"Identify the main verb in the sentence.\",\n \"input\": \"The cat chased the mouse.\",\n \"output\": \"The main verb in the sentence is 'chased.'\"\n },\n {\n \"instruction\": \"What is the opposite of 'ascend'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'ascend' is 'descend'.\"\n },\n {\n \"instruction\": \"Translate 'Thank you for your help' into Mandarin Chinese.\",\n \"input\": \"\",\n \"output\": \"The Mandarin Chinese translation of 'Thank you for your help' is '\\u8c22\\u8c22\\u4f60\\u7684\\u5e2e\\u52a9' (Xi\\u00e8xi\\u00e8 n\\u01d0 de b\\u0101ngzh\\u00f9).\"\n },\n {\n \"instruction\": \"Name the composer of the Brandenburg Concertos.\",\n \"input\": \"\",\n \"output\": \"The composer of the Brandenburg Concertos is Johann Sebastian Bach.\"\n },\n {\n \"instruction\": \"What is a synonym for 'assist'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'assist' is 'help'.\"\n },\n {\n \"instruction\": \"Identify the type of sentence.\",\n \"input\": \"Close the door.\",\n \"output\": \"The type of sentence is imperative.\"\n },\n {\n \"instruction\": \"Classify the following items: laptop, sunflower, tiger.\",\n \"input\": \"\",\n \"output\": \"Animals: Tiger\\nPlants: Sunflower\\nElectronics: Laptop\"\n },\n {\n \"instruction\": \"Name the process by which water changes from solid to liquid.\",\n \"input\": \"\",\n \"output\": \"The process by which water changes from solid to liquid is called melting.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'beautiful'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'beautiful' is 'stunning'.\"\n },\n {\n \"instruction\": \"Generate three adjectives to describe a mountain.\",\n \"input\": \"\",\n \"output\": \"1. Majestic\\n2. Rugged\\n3. Towering\"\n },\n {\n \"instruction\": \"Translate 'Can you help me?' into Spanish.\",\n \"input\": \"\",\n \"output\": \"\\u00bfPuedes ayudarme?\"\n },\n {\n \"instruction\": \"Find a rhyming word for the word 'house.'\",\n \"input\": \"\",\n \"output\": \"A rhyming word for the word 'house' is 'mouse.'\"\n },\n {\n \"instruction\": \"Convert 3 liters to milliliters.\",\n \"input\": \"\",\n \"output\": \"3 liters is 3000 milliliters.\"\n },\n {\n \"instruction\": \"Alter the content of the sentence to use the past tense.\",\n \"input\": \"The train departs at noon.\",\n \"output\": \"The train departed at noon.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'brave'.\",\n \"input\": \"\",\n \"output\": \"The firefighter was very brave and rescued the child from the fire.\"\n },\n {\n \"instruction\": \"Translate 'How are you?' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'How are you?' is 'Comment \\u00e7a va?'.\"\n },\n {\n \"instruction\": \"Rearrange the following list into descending order.\",\n \"input\": \"5, -3, 20, 10\",\n \"output\": \"20, 10, 5, -3\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'perseverant'.\",\n \"input\": \"\",\n \"output\": \"He is perseverant and never gives up on his goals.\"\n },\n {\n \"instruction\": \"Correct the punctuation in the sentence.\",\n \"input\": \"Lets eat, Grandma!\",\n \"output\": \"The corrected sentence should be: 'Let's eat, Grandma!'\"\n },\n {\n \"instruction\": \"Fix the following grammar mistake.\",\n \"input\": \"They wants to go to the movies, but they have no money.\",\n \"output\": \"They want to go to the movies, but they have no money.\"\n },\n {\n \"instruction\": \"What is the pH of soap?\",\n \"input\": \"\",\n \"output\": \"The pH of soap is typically between 9 and 10.\"\n },\n {\n \"instruction\": \"Classify the following items: pine tree, quartz, salmon.\",\n \"input\": \"\",\n \"output\": \"Plants: Pine tree\\nMinerals: Quartz\\nAnimals: Salmon\"\n },\n {\n \"instruction\": \"Rewrite the given sentence to describe the same thing in a positive way.\",\n \"input\": \"The meal was not delicious.\",\n \"output\": \"The meal could use some improvement.\"\n },\n {\n \"instruction\": \"What is the opposite of 'full'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'full' is 'empty'.\"\n },\n {\n \"instruction\": \"Generate an antonym for the word 'calm.'\",\n \"input\": \"\",\n \"output\": \"An antonym for the word 'calm' could be 'agitated.'\"\n },\n {\n \"instruction\": \"What is the chemical formula for calcium carbonate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for calcium carbonate is CaCO3.\"\n },\n {\n \"instruction\": \"Create a compound word using \\\"book.\\\"\",\n \"input\": \"\",\n \"output\": \"A compound word using \\\"book\\\" is \\\"bookshelf.\\\"\"\n },\n {\n \"instruction\": \"What is the chemical formula for hydrogen peroxide?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for hydrogen peroxide is H2O2.\"\n },\n {\n \"instruction\": \"What is the abbreviation for 'Bachelor of Science'?\",\n \"input\": \"\",\n \"output\": \"The abbreviation for 'Bachelor of Science' is B.Sc.\"\n },\n {\n \"instruction\": \"Convert 30 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"30 centimeters is 0.3 meters.\"\n },\n {\n \"instruction\": \"What is the boiling point of helium in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of helium is -268.9 degrees Celsius.\"\n },\n {\n \"instruction\": \"Convert 2 liters to milliliters.\",\n \"input\": \"\",\n \"output\": \"2 liters is 2000 milliliters.\"\n },\n {\n \"instruction\": \"Transform the following sentence to include an exclamation mark to show excitement.\",\n \"input\": \"I won the lottery\",\n \"output\": \"I won the lottery!\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a simile: The wind howled through the night.\",\n \"input\": \"\",\n \"output\": \"The wind howled through the night like a pack of wolves.\"\n },\n {\n \"instruction\": \"What is the pH value of pure water at 25\\u00b0C?\",\n \"input\": \"\",\n \"output\": \"The pH value of pure water at 25\\u00b0C is 7.\"\n },\n {\n \"instruction\": \"Arrange these historical periods in chronological order: Middle Ages, Renaissance, Industrial Revolution.\",\n \"input\": \"\",\n \"output\": \"1. Middle Ages\\n2. Renaissance\\n3. Industrial Revolution\"\n },\n {\n \"instruction\": \"Find a synonym for the word 'start'.\",\n \"input\": \"\",\n \"output\": \"A synonym for the word 'start' could be \\\"commence.\\\"\"\n },\n {\n \"instruction\": \"Identify the primary colors in the RGB color model.\",\n \"input\": \"\",\n \"output\": \"The primary colors in the RGB color model are red, green, and blue.\"\n },\n {\n \"instruction\": \"Name three types of clouds.\",\n \"input\": \"\",\n \"output\": \"Three types of clouds are cumulus, stratus, and cirrus.\"\n },\n {\n \"instruction\": \"Identify the tone used in the poem 'The Road Not Taken' by Robert Frost.\",\n \"input\": \"\",\n \"output\": \"The tone of 'The Road Not Taken' is reflective and contemplative, as the speaker considers the choices made in life and their long-term impacts.\"\n },\n {\n \"instruction\": \"Change this sentence into the past perfect continuous tense.\",\n \"input\": \"She sings in the choir.\",\n \"output\": \"She had been singing in the choir.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'persistent'.\",\n \"input\": \"\",\n \"output\": \"He is very persistent and never gives up.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'curious'.\",\n \"input\": \"\",\n \"output\": \"The child was curious about everything around him.\"\n },\n {\n \"instruction\": \"What is the boiling point of bromine in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of bromine is 59 degrees Celsius.\"\n },\n {\n \"instruction\": \"Convert the phrase into a complete sentence.\",\n \"input\": \"sunset over the ocean\",\n \"output\": \"The sunset over the ocean was breathtaking.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The room was very small.\",\n \"output\": \"The room was a shoebox.\"\n },\n {\n \"instruction\": \"Arrange the following events in chronological order: First Moon Landing, French Revolution, Industrial Revolution.\",\n \"input\": \"\",\n \"output\": \"1. French Revolution\\n2. Industrial Revolution\\n3. First Moon Landing\"\n },\n {\n \"instruction\": \"What is the capital of the United States?\",\n \"input\": \"\",\n \"output\": \"The capital of the United States is Washington, D.C.\"\n },\n {\n \"instruction\": \"Describe the main function of the human skeletal system.\",\n \"input\": \"\",\n \"output\": \"The main function of the human skeletal system is to provide support and structure to the body, protect internal organs, enable movement through attachment points for muscles, and produce blood cells in the bone marrow.\"\n },\n {\n \"instruction\": \"Identify the tense used in the sentence.\",\n \"input\": \"They are watching a movie.\",\n \"output\": \"The tense used in the sentence \\\"They are watching a movie\\\" is the present continuous tense.\"\n },\n {\n \"instruction\": \"Translate 'thank you' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'thank you' is 'danke'.\"\n },\n {\n \"instruction\": \"Suggest a continuation for the sentence.\",\n \"input\": \"After the rain stopped,\",\n \"output\": \"'the children went outside to play.'\"\n },\n {\n \"instruction\": \"What is the freezing point of water in Fahrenheit?\",\n \"input\": \"\",\n \"output\": \"The freezing point of water is 32 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Generate a sentence that follows the pattern: 'Under no circumstances should you _____'\",\n \"input\": \"\",\n \"output\": \"Under no circumstances should you open the door.\"\n },\n {\n \"instruction\": \"Fix the following grammar mistake.\",\n \"input\": \"He want to go to the movies, but he has no money.\",\n \"output\": \"He wants to go to the movies, but he has no money.\"\n },\n {\n \"instruction\": \"What is a synonym for 'cold'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'cold' is 'chilly'.\"\n },\n {\n \"instruction\": \"Convert the mass from kilograms to grams.\",\n \"input\": \"3 kilograms\",\n \"output\": \"3 kilograms is equivalent to 3000 grams.\"\n },\n {\n \"instruction\": \"What is the capital of Portugal?\",\n \"input\": \"\",\n \"output\": \"The capital of Portugal is Lisbon.\"\n },\n {\n \"instruction\": \"Name a gas commonly found in the Earth's atmosphere.\",\n \"input\": \"\",\n \"output\": \"A gas commonly found in the Earth's atmosphere is nitrogen.\"\n },\n {\n \"instruction\": \"Sort the following numbers in ascending order.\",\n \"input\": \"5, 18, 3, 11.\",\n \"output\": \"The numbers in ascending order would be: 3, 5, 11, 18.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'eloquent'.\",\n \"input\": \"\",\n \"output\": \"The speaker was eloquent and captivated the audience.\"\n },\n {\n \"instruction\": \"Rewrite this sentence using appropriate grammar rules:\",\n \"input\": \"he saw a old man\",\n \"output\": \"He saw an old man.\"\n },\n {\n \"instruction\": \"What is an antonym of 'conceal'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'conceal' is 'reveal'.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence so that it is in active voice.\",\n \"input\": \"The cookies were eaten by the children.\",\n \"output\": \"The children ate the cookies.\"\n },\n {\n \"instruction\": \"What is the boiling point of water in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of water is 100 degrees Celsius.\"\n },\n {\n \"instruction\": \"Translate 'I love you' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Te amo\"\n },\n {\n \"instruction\": \"Translate 'I am happy' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'I am happy' is 'Je suis heureux' (if the speaker is male) or 'Je suis heureuse' (if the speaker is female).\"\n },\n {\n \"instruction\": \"Generate an antonym for the word 'optimistic'.\",\n \"input\": \"\",\n \"output\": \"An antonym for the word 'optimistic' could be 'pessimistic'.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"Her smile is very bright.\",\n \"output\": \"Her smile is a ray of sunshine.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'beautiful'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'beautiful' is 'lovely'.\"\n },\n {\n \"instruction\": \"Define the term 'photosynthesis'.\",\n \"input\": \"\",\n \"output\": \"Photosynthesis is the process by which green plants and some other organisms use sunlight to synthesize foods with the help of chlorophyll. It converts carbon dioxide and water into glucose and oxygen.\"\n },\n {\n \"instruction\": \"Arrange the following events in chronological order: Invention of the airplane, Fall of the Berlin Wall, Discovery of America.\",\n \"input\": \"\",\n \"output\": \"1. Discovery of America\\n2. Invention of the airplane\\n3. Fall of the Berlin Wall\"\n },\n {\n \"instruction\": \"Determine the gravitational force acting on an object with a mass of 10 kg on Earth.\",\n \"input\": \"\",\n \"output\": \"The gravitational force acting on an object with a mass of 10 kg on Earth is approximately 98 newtons.\"\n },\n {\n \"instruction\": \"Suggest a continuation for the sentence.\",\n \"input\": \"When the sun set,\",\n \"output\": \"\\\"the sky turned a brilliant shade of orange, casting a warm glow over the city.\\\"\"\n },\n {\n \"instruction\": \"Determine whether the given two words are synonyms or antonyms.\",\n \"input\": \"Open - Close\",\n \"output\": \"Open and Close are antonyms.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to remove redundancy.\",\n \"input\": \"She made a brief summary of the book.\",\n \"output\": \"She summarized the book.\"\n },\n {\n \"instruction\": \"Calculate the area of a triangle with a base of 10 units and height of 5 units.\",\n \"input\": \"\",\n \"output\": \"25 square units.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'funny'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'funny' is 'humorous'.\"\n },\n {\n \"instruction\": \"Identify the theme of the story.\",\n \"input\": \"The Tortoise and the Hare\",\n \"output\": \"The theme of the story is that slow and steady wins the race.\"\n },\n {\n \"instruction\": \"Arrange these historical periods in chronological order: Renaissance, Roman Empire, Victorian Era.\",\n \"input\": \"\",\n \"output\": \"1. Roman Empire\\n2. Renaissance\\n3. Victorian Era\"\n },\n {\n \"instruction\": \"Convert the following sentence to use a relative clause: The man is a teacher. He lives next door.\",\n \"input\": \"\",\n \"output\": \"The man who lives next door is a teacher.\"\n },\n {\n \"instruction\": \"Name a dwarf planet in our solar system.\",\n \"input\": \"\",\n \"output\": \"One dwarf planet in our solar system is Pluto.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"He is very generous.\",\n \"output\": \"He has a heart of gold.\"\n },\n {\n \"instruction\": \"What is a synonym of 'brave'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'brave' is 'courageous'.\"\n },\n {\n \"instruction\": \"Convert 100 pounds to kilograms.\",\n \"input\": \"\",\n \"output\": \"100 pounds is approximately 45.36 kilograms.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The sun was shining brightly.\",\n \"output\": \"The sun was a golden coin in the sky.\"\n },\n {\n \"instruction\": \"Identify the adjective in the sentence.\",\n \"input\": \"The quick fox jumped over the lazy dog.\",\n \"output\": \"The adjectives in the sentence are 'quick' and 'lazy'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'strong'.\",\n \"input\": \"\",\n \"output\": \"robust.\"\n },\n {\n \"instruction\": \"Generate a question with the keyword 'virus'\",\n \"input\": \"\",\n \"output\": \"How does a virus infect a cell?\"\n },\n {\n \"instruction\": \"Rewrite the following sentence using passive voice.\",\n \"input\": \"The team achieved great results.\",\n \"output\": \"Great results were achieved by the team.\"\n },\n {\n \"instruction\": \"Translate 'hello' into Japanese.\",\n \"input\": \"\",\n \"output\": \"The Japanese translation of 'hello' is '\\u3053\\u3093\\u306b\\u3061\\u306f' (Konnichiwa).\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"He is very wise.\",\n \"output\": \"He is a fountain of wisdom.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'persistent'.\",\n \"input\": \"\",\n \"output\": \"He is persistent and never gives up on his goals.\"\n },\n {\n \"instruction\": \"Generate a sentence that uses the word \\u2018mystic\\u2019.\",\n \"input\": \"\",\n \"output\": \"The ancient ruins had a mystic quality that captivated all who visited.\"\n },\n {\n \"instruction\": \"What is a synonym for 'tiny'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'tiny' is 'small'.\"\n },\n {\n \"instruction\": \"What is the capital of France?\",\n \"input\": \"\",\n \"output\": \"The capital of France is Paris.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'serene'.\",\n \"input\": \"\",\n \"output\": \"The lake was serene and calm in the early morning.\"\n },\n {\n \"instruction\": \"Convert the phrase into a complete sentence.\",\n \"input\": \"night sky\",\n \"output\": \"The night sky was dotted with countless twinkling stars.\"\n },\n {\n \"instruction\": \"Name the three branches of the United States government.\",\n \"input\": \"\",\n \"output\": \"The three branches of the United States government are the Executive, the Legislative, and the Judicial branches.\"\n },\n {\n \"instruction\": \"Convert the angle from radians to degrees.\",\n \"input\": \"\\u03c0/2 radians\",\n \"output\": \"\\u03c0/2 radians is 90 degrees.\"\n },\n {\n \"instruction\": \"Find the next 3 terms in the following sequence: 3, 5, 7, 9\",\n \"input\": \"\",\n \"output\": \"The next three terms in the sequence are: 11, 13, 15.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'pretty'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'pretty' is 'attractive'.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to include a hyperbole: 'I'm very hungry.'\",\n \"input\": \"I'm very hungry.\",\n \"output\": \"I'm so hungry I could eat a horse.\"\n },\n {\n \"instruction\": \"Scramble the given phrase.\",\n \"input\": \"A sunny day\",\n \"output\": \"A nnuys yda\"\n },\n {\n \"instruction\": \"Define the term 'economics'.\",\n \"input\": \"\",\n \"output\": \"Economics is a social science concerned with the production, distribution, and consumption of goods and services. It studies how individuals, businesses, governments, and nations make choices about how to allocate resources.\"\n },\n {\n \"instruction\": \"What is an antonym of 'accelerate'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'accelerate' is 'decelerate'.\"\n },\n {\n \"instruction\": \"Rewrite this sentence to start with \\\"Despite\\\": She managed to finish her work, although she was tired.\",\n \"input\": \"\",\n \"output\": \"Despite being tired, she managed to finish her work.\"\n },\n {\n \"instruction\": \"Translate 'See you soon' into French.\",\n \"input\": \"\",\n \"output\": \"\\u00c0 bient\\u00f4t\"\n },\n {\n \"instruction\": \"What is the chemical formula for water?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for water (dihydrogen monoxide) is H2O.\"\n },\n {\n \"instruction\": \"Transform the following sentence into a command.\",\n \"input\": \"You should clean your room.\",\n \"output\": \"Clean your room.\"\n },\n {\n \"instruction\": \"Find a synonym for the given verb.\",\n \"input\": \"Speak\",\n \"output\": \"Talk\"\n },\n {\n \"instruction\": \"What is the past tense of 'build'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'build' is 'built'.\"\n },\n {\n \"instruction\": \"Translate 'Where is the nearest hospital?' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'Where is the nearest hospital?' is 'Dove \\u00e8 l'ospedale pi\\u00f9 vicino?'.\"\n },\n {\n \"instruction\": \"Convert 200 meters to kilometers.\",\n \"input\": \"\",\n \"output\": \"200 meters is 0.2 kilometers.\"\n },\n {\n \"instruction\": \"Determine the state of matter for water at 100 degrees Celsius.\",\n \"input\": \"\",\n \"output\": \"Water is in a gaseous state at 100 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the opposite of 'weak'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'weak' is 'strong'.\"\n },\n {\n \"instruction\": \"Define the term 'biodiversity'.\",\n \"input\": \"\",\n \"output\": \"Biodiversity refers to the variety of life in the world or in a particular habitat or ecosystem.\"\n },\n {\n \"instruction\": \"Explain what a haiku is.\",\n \"input\": \"\",\n \"output\": \"A haiku is a form of traditional Japanese poetry that consists of three lines with a syllable pattern of 5-7-5.\"\n },\n {\n \"instruction\": \"Name the process by which plants make their food.\",\n \"input\": \"\",\n \"output\": \"The process by which plants make their food is called photosynthesis.\"\n },\n {\n \"instruction\": \"What is the melting point of iron?\",\n \"input\": \"\",\n \"output\": \"The melting point of iron is approximately 1538 degrees Celsius.\"\n },\n {\n \"instruction\": \"Define the term 'evaporation'.\",\n \"input\": \"\",\n \"output\": \"Evaporation is the process by which water changes from a liquid to a gas or vapor.\"\n },\n {\n \"instruction\": \"Define the concept of 'gravity'.\",\n \"input\": \"\",\n \"output\": \"Gravity is a force that attracts two bodies toward each other, the force that causes apples to fall toward the ground and planets to orbit stars.\"\n },\n {\n \"instruction\": \"Define the literary term 'alliteration'.\",\n \"input\": \"\",\n \"output\": \"Alliteration is the occurrence of the same letter or sound at the beginning of adjacent or closely connected words.\"\n },\n {\n \"instruction\": \"What is the pH of baking soda solution?\",\n \"input\": \"\",\n \"output\": \"The pH of a baking soda solution is typically around 9.\"\n },\n {\n \"instruction\": \"What is an antonym of 'ascend'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'ascend' is 'descend'.\"\n },\n {\n \"instruction\": \"Simplify the expression: 2(x + 3) + 4(x - 1).\",\n \"input\": \"\",\n \"output\": \"6x + 2.\"\n },\n {\n \"instruction\": \"Calculate the circumference of a circle with a diameter of 10 cm.\",\n \"input\": \"\",\n \"output\": \"The circumference of the circle is approximately 31.42 cm.\"\n },\n {\n \"instruction\": \"Generate a random sequence of 10 digits.\",\n \"input\": \"\",\n \"output\": \"Here is a randomly generated sequence of 10 digits: 9274036185.\"\n },\n {\n \"instruction\": \"Insert a suitable adjective to complete the sentence.\",\n \"input\": \"The movie was _____.\",\n \"output\": \"The movie was thrilling.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The sky is very blue.\",\n \"output\": \"The sky is a sapphire sea.\"\n },\n {\n \"instruction\": \"What is the boiling point of water at sea level?\",\n \"input\": \"\",\n \"output\": \"The boiling point of water at sea level is 100 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the cube of 5?\",\n \"input\": \"\",\n \"output\": \"The cube of 5 is 125.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"He is very strong.\",\n \"output\": \"He is as strong as an ox.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The house is very big.\",\n \"output\": \"The house is as big as a castle.\"\n },\n {\n \"instruction\": \"What is the capital of China?\",\n \"input\": \"\",\n \"output\": \"The capital of China is Beijing.\"\n },\n {\n \"instruction\": \"List two synonyms for \\\"intelligent.\\\"\",\n \"input\": \"\",\n \"output\": \"Two synonyms for \\\"intelligent\\\" are \\\"smart\\\" and \\\"clever.\\\"\"\n },\n {\n \"instruction\": \"Explain the function of the liver in the human body.\",\n \"input\": \"\",\n \"output\": \"The liver functions to process nutrients absorbed from the digestive tract, detoxify chemicals, and metabolize drugs.\"\n },\n {\n \"instruction\": \"Rewrite the sentence to improve clarity: 'He saw that the sky was clouds full.'\",\n \"input\": \"He saw that the sky was clouds full.\",\n \"output\": \"He saw that the sky was full of clouds.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using alliteration.\",\n \"input\": \"The wind blew softly.\",\n \"output\": \"The soft wind swept silently.\"\n },\n {\n \"instruction\": \"What is an antonym for 'increase'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'increase' is 'decrease'.\"\n },\n {\n \"instruction\": \"Classify this text as either a recipe or a novel.\",\n \"input\": \"Combine flour, sugar, and eggs in a bowl.\",\n \"output\": \"Recipe\"\n },\n {\n \"instruction\": \"rewrite this sentence as a question.\",\n \"input\": \"Your brother went to London last year.\",\n \"output\": \"Did your brother go to London last year?\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'ambitious'.\",\n \"input\": \"\",\n \"output\": \"She is ambitious and strives for success in all her endeavors.\"\n },\n {\n \"instruction\": \"Classify each sentence as either declarative, interrogative, imperative, or exclamatory.\",\n \"input\": \"Can you help me?\",\n \"output\": \"The classification of the sentence \\\"Can you help me?\\\" is interrogative.\"\n },\n {\n \"instruction\": \"Classify the following numbers as even or odd.\",\n \"input\": \"2, 5, 18, 21\",\n \"output\": \"Even numbers: 2, 18\\nOdd numbers: 5, 21\"\n },\n {\n \"instruction\": \"What is the chemical formula for salt?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for salt (sodium chloride) is NaCl.\"\n },\n {\n \"instruction\": \"Find the temperature of freezing water under normal atmospheric pressure.\",\n \"input\": \"\",\n \"output\": \"Under normal atmospheric pressure, the temperature of freezing water is 0 degrees Celsius (32 degrees Fahrenheit).\"\n },\n {\n \"instruction\": \"Edit the following sentence to make it more formal.\",\n \"input\": \"He's got to see it to believe it.\",\n \"output\": \"He must see it to believe it.\"\n },\n {\n \"instruction\": \"What is the opposite of 'easy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'easy' is 'difficult'.\"\n },\n {\n \"instruction\": \"Change the given verb to its past continuous form.\",\n \"input\": \"eat\",\n \"output\": \"Eating.\"\n },\n {\n \"instruction\": \"Transform the following sentence into the passive voice.\",\n \"input\": \"They will build a new park.\",\n \"output\": \"A new park will be built by them.\"\n },\n {\n \"instruction\": \"Evaluate this sentence for spelling and grammar mistakes.\",\n \"input\": \"I beleive this is a grate idea.\",\n \"output\": \"There are two errors in the sentence. The corrected sentence should be: 'I believe this is a great idea.'\"\n },\n {\n \"instruction\": \"What is the opposite of 'light'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'light' is 'dark'.\"\n },\n {\n \"instruction\": \"Translate 'good morning' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'good morning' is 'bonjour'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'progressive'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'progressive' is 'regressive'.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor: 'Her smile lights up the room.'\",\n \"input\": \"\",\n \"output\": \"Her smile is a beacon in the room.\"\n },\n {\n \"instruction\": \"Classify the following fruit according to its type.\",\n \"input\": \"Watermelon\",\n \"output\": \"The fruit \\\"Watermelon\\\" is typically classified as a type of melon.\"\n },\n {\n \"instruction\": \"What is the square root of 64?\",\n \"input\": \"\",\n \"output\": \"The square root of 64 is 8.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"He is very rich.\",\n \"output\": \"He is rolling in dough.\"\n },\n {\n \"instruction\": \"Classify the following animal as carnivore, herbivore, or omnivore.\",\n \"input\": \"Deer\",\n \"output\": \"Herbivore\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'serendipity'.\",\n \"input\": \"\",\n \"output\": \"Discovering the quaint caf\\u00e9 down the alley was pure serendipity.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'resourceful'.\",\n \"input\": \"\",\n \"output\": \"He is very resourceful and can solve any problem.\"\n },\n {\n \"instruction\": \"Classify the following item: hammer.\",\n \"input\": \"\",\n \"output\": \"A hammer can be classified as a tool.\"\n },\n {\n \"instruction\": \"Convert the time '1500 hours' into standard 12-hour clock format.\",\n \"input\": \"\",\n \"output\": \"1500 hours is equivalent to 3:00 PM.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a synonym.\",\n \"input\": \"It's cold outside.\",\n \"output\": \"It's chilly outside.\"\n },\n {\n \"instruction\": \"Convert 6 liters to milliliters.\",\n \"input\": \"\",\n \"output\": \"6 liters is 6000 milliliters.\"\n },\n {\n \"instruction\": \"What is the capital of Turkey?\",\n \"input\": \"\",\n \"output\": \"The capital of Turkey is Ankara.\"\n },\n {\n \"instruction\": \"Change the following sentence to past continuous tense.\",\n \"input\": \"They finish the game.\",\n \"output\": \"They were finishing the game.\"\n },\n {\n \"instruction\": \"Summarize the theme of 'The Great Gatsby'.\",\n \"input\": \"\",\n \"output\": \"The theme revolves around the American Dream and its disillusionment.\"\n },\n {\n \"instruction\": \"Delete the redundant words in the following sentence.\",\n \"input\": \"We went to see to the mountains.\",\n \"output\": \"We went to see the mountains.\"\n },\n {\n \"instruction\": \"Convert 5 kilograms to grams.\",\n \"input\": \"\",\n \"output\": \"5 kilograms is 5000 grams.\"\n },\n {\n \"instruction\": \"Generate a random 8-digit number.\",\n \"input\": \"\",\n \"output\": \"Here is a randomly generated 8-digit number: 47382916.\"\n },\n {\n \"instruction\": \"What is the opposite of 'quiet'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'quiet' is 'loud'.\"\n },\n {\n \"instruction\": \"Translate the term 'sustainable development' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'sustainable development' is 'nachhaltige Entwicklung'.\"\n },\n {\n \"instruction\": \"Convert the following statement into an exclamation.\",\n \"input\": \"This is amazing\",\n \"output\": \"This is amazing!\"\n },\n {\n \"instruction\": \"Classify the item as either a grain or a fruit.\",\n \"input\": \"Wheat\",\n \"output\": \"Grain\"\n },\n {\n \"instruction\": \"What is the boiling point of water under standard conditions?\",\n \"input\": \"\",\n \"output\": \"100 degrees Celsius.\"\n },\n {\n \"instruction\": \"Identify the tense used in the sentence.\",\n \"input\": \"They had watched the movie.\",\n \"output\": \"The tense used in the sentence 'They had watched the movie' is the past perfect tense.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to include a personification.\",\n \"input\": \"The wind is very strong today.\",\n \"output\": \"The wind howls with might today, as if declaring its presence.\"\n },\n {\n \"instruction\": \"Cut the following sentence into two, keeping the original meaning intact.\",\n \"input\": \"She baked a cake and then she decorated it.\",\n \"output\": \"She baked a cake. Then she decorated it.\"\n },\n {\n \"instruction\": \"Given a list of six ingredients, select the two most essential for making a cake.\",\n \"input\": \"sugar, flour, eggs, salt, vanilla, water\",\n \"output\": \"The two most essential ingredients for making a cake from the given list are flour and eggs.\"\n },\n {\n \"instruction\": \"What is the contraction for 'they will'?\",\n \"input\": \"\",\n \"output\": \"The contraction for 'they will' is 'they'll.'\"\n },\n {\n \"instruction\": \"Translate 'peace' into French.\",\n \"input\": \"\",\n \"output\": \"The French word for 'peace' is 'paix'.\"\n },\n {\n \"instruction\": \"Classify the item as either a fruit or a vegetable.\",\n \"input\": \"Tomato\",\n \"output\": \"Fruit\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor: 'Her laughter is like music.'\",\n \"input\": \"\",\n \"output\": \"Her laughter is music to the ears.\"\n },\n {\n \"instruction\": \"Capitalize each word in the sentence.\",\n \"input\": \"the book is on the table\",\n \"output\": \"The Book Is On The Table\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a simile: The car raced down the road.\",\n \"input\": \"\",\n \"output\": \"The car raced down the road like a bullet.\"\n },\n {\n \"instruction\": \"Combine the two ideas in the sentence.\",\n \"input\": \"Running is good for health. It can be tiring.\",\n \"output\": \"Running is good for health but can be tiring.\"\n },\n {\n \"instruction\": \"Identify the main subject in the sentence.\",\n \"input\": \"The excited students ran to the playground.\",\n \"output\": \"The main subject in the sentence is 'The excited students.'\"\n },\n {\n \"instruction\": \"Name a synonym for 'angry.'\",\n \"input\": \"\",\n \"output\": \"A synonym for 'angry' is 'furious.'\"\n },\n {\n \"instruction\": \"Combine the two sentences into a single coherent sentence.\",\n \"input\": \"She studied hard. She passed the exam.\",\n \"output\": \"She studied hard, so she passed the exam.\"\n },\n {\n \"instruction\": \"Explain the process of combustion.\",\n \"input\": \"\",\n \"output\": \"Combustion is a chemical process in which a substance reacts rapidly with oxygen, releasing heat and light. It typically produces carbon dioxide, water, and energy.\"\n },\n {\n \"instruction\": \"Convert the given sentence into active voice.\",\n \"input\": \"The proposal was approved by the committee.\",\n \"output\": \"The committee approved the proposal.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The car is very fast.\",\n \"output\": \"The car is as fast as lightning.\"\n },\n {\n \"instruction\": \"What type of cloud is typically associated with thunderstorms?\",\n \"input\": \"\",\n \"output\": \"The type of cloud typically associated with thunderstorms is cumulonimbus.\"\n },\n {\n \"instruction\": \"Name the author of 'Pride and Prejudice'.\",\n \"input\": \"\",\n \"output\": \"Jane Austen.\"\n },\n {\n \"instruction\": \"What is the periodic symbol for chlorine?\",\n \"input\": \"\",\n \"output\": \"The periodic symbol for chlorine is Cl.\"\n },\n {\n \"instruction\": \"Correct the punctuation in the sentence.\",\n \"input\": \"Its time to go home.\",\n \"output\": \"The corrected sentence should be: 'It's time to go home.'\"\n },\n {\n \"instruction\": \"Rewrite the sentence.\",\n \"input\": \"The lecture was delivered in a clear manner.\",\n \"output\": \"The lecture was delivered clearly.\"\n },\n {\n \"instruction\": \"Generate a humorous anecdote.\",\n \"input\": \"\",\n \"output\": \"Why was the math book sad? Because it had too many problems!\"\n },\n {\n \"instruction\": \"Identify the correct spelling: 'recieve' or 'receive'.\",\n \"input\": \"\",\n \"output\": \"The correct spelling is 'receive'.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'nostalgia'.\",\n \"input\": \"\",\n \"output\": \"Nostalgia washed over her as she looked through the old photos.\"\n },\n {\n \"instruction\": \"Classify the following numbers as prime or composite.\",\n \"input\": \": 11, 14, 19.\",\n \"output\": \"Prime numbers: 11, 19\\nComposite numbers: 14\"\n },\n {\n \"instruction\": \"What is the capital of Denmark?\",\n \"input\": \"\",\n \"output\": \"The capital of Denmark is Copenhagen.\"\n },\n {\n \"instruction\": \"What is the opposite of 'wet'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'wet' is 'dry'.\"\n },\n {\n \"instruction\": \"Identify the type of sentence.\",\n \"input\": \"Did you finish the report?\",\n \"output\": \"The type of sentence is interrogative.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for mercury?\",\n \"input\": \"\",\n \"output\": \"Hg.\"\n },\n {\n \"instruction\": \"Describe the process of active transport in cells.\",\n \"input\": \"\",\n \"output\": \"Active transport is the movement of molecules across a cell membrane from a region of lower concentration to a region of higher concentration, using energy in the form of ATP. This process is crucial for maintaining cellular homeostasis.\"\n },\n {\n \"instruction\": \"Classify the following items as either solid, liquid, or gas.\",\n \"input\": \"Mercury, oxygen, wood\",\n \"output\": \"Mercury - Liquid\\nOxygen - Gas\\nWood - Solid\"\n },\n {\n \"instruction\": \"Convert 3 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"3 kilometers is 3000 meters.\"\n },\n {\n \"instruction\": \"Convert the sentence to use an indefinite pronoun.\",\n \"input\": \"Someone left a note.\",\n \"output\": \"A note was left by someone.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'excited'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'excited' is 'thrilled'.\"\n },\n {\n \"instruction\": \"Generate a sentence that follows the pattern: \\\"Never have I ever _____ without _____\\\"\",\n \"input\": \"\",\n \"output\": \"Never have I ever traveled without a map.\"\n },\n {\n \"instruction\": \"Pick out the adjective from the following list.\",\n \"input\": \"run, tall, quickly\",\n \"output\": \"The correct adjective from the list is 'tall.'\"\n },\n {\n \"instruction\": \"Convert 1000 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"1000 grams is equal to 1 kilogram.\"\n },\n {\n \"instruction\": \"What is the opposite of 'deep'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'deep' is 'shallow'.\"\n },\n {\n \"instruction\": \"Categorize the given list of animals.\",\n \"input\": \"Shark, Dolphin, Trout\",\n \"output\": \"Fish: Shark, Trout\\nMammals: Dolphin\"\n },\n {\n \"instruction\": \"Translate 'library' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish word for 'library' is 'biblioteca'.\"\n },\n {\n \"instruction\": \"Define the term 'hyperbole'.\",\n \"input\": \"\",\n \"output\": \"Hyperbole is a figure of speech that involves an exaggeration of ideas for the sake of emphasis.\"\n },\n {\n \"instruction\": \"Translate 'Hello' into Russian.\",\n \"input\": \"\",\n \"output\": \"\\u041f\\u0440\\u0438\\u0432\\u0435\\u0442 (Privet)\"\n },\n {\n \"instruction\": \"Define the term 'kinetic energy'.\",\n \"input\": \"\",\n \"output\": \"Kinetic energy is the energy that an object possesses due to its motion.\"\n },\n {\n \"instruction\": \"What is the opposite of 'hot'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'hot' is 'cold'.\"\n },\n {\n \"instruction\": \"Convert 5 miles to kilometers.\",\n \"input\": \"\",\n \"output\": \"5 miles is approximately 8.05 kilometers.\"\n },\n {\n \"instruction\": \"What is the chemical formula for magnesium sulfate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for magnesium sulfate is MgSO4.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to replace any clich\\u00e9 phrases.\",\n \"input\": \"It's a piece of cake\",\n \"output\": \"It's very easy.\"\n },\n {\n \"instruction\": \"List five different types of vegetables.\",\n \"input\": \"\",\n \"output\": \"1. Carrot\\n2. Broccoli\\n3. Cucumber\\n4. Tomato\\n5. Spinach\"\n },\n {\n \"instruction\": \"Convert 7 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"7 kilometers is 7000 meters.\"\n },\n {\n \"instruction\": \"What is the opposite of 'heavy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'heavy' is 'light'.\"\n },\n {\n \"instruction\": \"What is the past tense of 'sing'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'sing' is 'sang.'\"\n },\n {\n \"instruction\": \"What is the molecular formula for carbon dioxide?\",\n \"input\": \"\",\n \"output\": \"The molecular formula for carbon dioxide is CO2.\"\n },\n {\n \"instruction\": \"Convert this sentence to passive voice\",\n \"input\": \"The gardener watered the plants.\",\n \"output\": \"The plants were watered by the gardener.\"\n },\n {\n \"instruction\": \"What is the past tense of 'throw'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'throw' is 'threw'.\"\n },\n {\n \"instruction\": \"Explain what a sonnet is.\",\n \"input\": \"\",\n \"output\": \"A sonnet is a 14-line poem with a specific rhyme scheme and meter, often written in iambic pentameter.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovative'.\",\n \"input\": \"\",\n \"output\": \"The company is known for its innovative products.\"\n },\n {\n \"instruction\": \"Provide the plural form of 'cactus'.\",\n \"input\": \"\",\n \"output\": \"The plural form of 'cactus' is 'cacti'.\"\n },\n {\n \"instruction\": \"Translate the phrase 'Where is the bathroom?' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'Where is the bathroom?' is 'Wo ist die Toilette?'\"\n },\n {\n \"instruction\": \"Generate a past-tense verb that describes a person laughing.\",\n \"input\": \"\",\n \"output\": \"Laughed.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'transient.'\",\n \"input\": \"\",\n \"output\": \"The transient nature of her visit left a lasting impression.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'optimistic'.\",\n \"input\": \"\",\n \"output\": \"He remained optimistic despite the challenges he faced.\"\n },\n {\n \"instruction\": \"Re-word this sentence using an indirect question.\",\n \"input\": \"What time is the meeting?\",\n \"output\": \"Could you tell me what time the meeting is?\"\n },\n {\n \"instruction\": \"Categorize the following sentence as a statement, a question, or an exclamation.\",\n \"input\": \"What a beautiful day!\",\n \"output\": \"Exclamation.\"\n },\n {\n \"instruction\": \"What is the opposite of 'rich'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'rich' is 'poor'.\"\n },\n {\n \"instruction\": \"Find a synonym for the given verb.\",\n \"input\": \"Begin\",\n \"output\": \"Commence\"\n },\n {\n \"instruction\": \"Edit the given text to ensure all plural nouns are spelled correctly.\",\n \"input\": \"The birds sings beautiful songs.\",\n \"output\": \"The birds sing beautiful songs.\"\n },\n {\n \"instruction\": \"Transform the following sentence into a question using \\\"could.\\\"\",\n \"input\": \"You can help me tomorrow.\",\n \"output\": \"Could you help me tomorrow?\"\n },\n {\n \"instruction\": \"Classify the following items: bicycle, rose, tiger.\",\n \"input\": \"\",\n \"output\": \"Vehicles: Bicycle\\nPlants: Rose\\nAnimals: Tiger\"\n },\n {\n \"instruction\": \"Define the term 'irony'.\",\n \"input\": \"\",\n \"output\": \"Irony is a figure of speech in which words are used in such a way that their intended meaning is different from the actual meaning of the words.\"\n },\n {\n \"instruction\": \"Translate 'Welcome' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'Welcome' is 'Willkommen'.\"\n },\n {\n \"instruction\": \"Explain the primary function of the human heart.\",\n \"input\": \"\",\n \"output\": \"The primary function of the human heart is to pump blood throughout the body, delivering oxygen and nutrients to tissues and removing carbon dioxide and other wastes.\"\n },\n {\n \"instruction\": \"Reword the following sentence to the future tense.\",\n \"input\": \"He is reading a novel inspired by his grandmother.\",\n \"output\": \"He will be reading a novel inspired by his grandmother.\"\n },\n {\n \"instruction\": \"Convert the given sentence into active voice.\",\n \"input\": \"The law was passed by the government.\",\n \"output\": \"The government passed the law.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'inevitable'.\",\n \"input\": \"\",\n \"output\": \"The confrontation was inevitable given the circumstances.\"\n },\n {\n \"instruction\": \"Categorize the following sentence as either factual or opinion-based.\",\n \"input\": \"Chocolate is the best dessert.\",\n \"output\": \"Opinion-based.\"\n },\n {\n \"instruction\": \"What is an antonym of 'old'?\",\n \"input\": \"\",\n \"output\": \"young.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'hardworking'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'hardworking' is 'diligent'.\"\n },\n {\n \"instruction\": \"What is the boiling point of sulfur in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of sulfur is 444.6 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the plural form of 'child'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'child' is 'children'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'complicated'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'complicated' is 'simple'.\"\n },\n {\n \"instruction\": \"Name three forms of water.\",\n \"input\": \"\",\n \"output\": \"The three forms of water are solid (ice), liquid (water), and gas (steam).\"\n },\n {\n \"instruction\": \"Rewrite this sentence as a question.\",\n \"input\": \"The dog chased the cat.\",\n \"output\": \"Did the dog chase the cat?\"\n },\n {\n \"instruction\": \"Split the following sentence into two declarative sentences: 'The movie was long but interesting.'\",\n \"input\": \"\",\n \"output\": \"The movie was long. It was interesting.\"\n },\n {\n \"instruction\": \"Classify the following substances as acid, base, or neutral.\",\n \"input\": \"Lemon juice, Soap, Water\",\n \"output\": \"Acid: Lemon juice\\nBase: Soap\\nNeutral: Water\"\n },\n {\n \"instruction\": \"What is a synonym of 'sad'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'sad' is 'unhappy'.\"\n },\n {\n \"instruction\": \"Correct any spelling mistakes in the given sentence.\",\n \"input\": \"I prefer homemade cookies to store boaght.\",\n \"output\": \"I prefer homemade cookies to store bought.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'transient'.\",\n \"input\": \"\",\n \"output\": \"His stay in the city was transient, lasting only a couple of days.\"\n },\n {\n \"instruction\": \"Translate 'I am lost' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'I am lost' is 'Mi sono perso' (if male) or 'Mi sono persa' (if female).\"\n },\n {\n \"instruction\": \"Classify this text as a technical document or a narrative.\",\n \"input\": \"This manual provides instructions for installing the software.\",\n \"output\": \"Technical document\"\n },\n {\n \"instruction\": \"Sort the following list in descending order.\",\n \"input\": \"10, 2, 25, 16, 7\",\n \"output\": \"25, 16, 10, 7, 2.\"\n },\n {\n \"instruction\": \"Translate 'Can I have some water?' into French.\",\n \"input\": \"\",\n \"output\": \"Puis-je avoir de l'eau?\"\n },\n {\n \"instruction\": \"Create a simile with the word 'as cold as'.\",\n \"input\": \"\",\n \"output\": \"Her hands were as cold as ice.\"\n },\n {\n \"instruction\": \"Classify the following words by their grammatical categories: swim, beautiful, quickly\",\n \"input\": \"\",\n \"output\": \"Swim: Verb\\nBeautiful: Adjective\\nQuickly: Adverb\"\n },\n {\n \"instruction\": \"Calculate the density of an object with a mass of 15 grams and a volume of 5 cubic centimeters.\",\n \"input\": \"\",\n \"output\": \"The density of the object is 3 grams per cubic centimeter.\"\n },\n {\n \"instruction\": \"What is the abbreviation for 'Master of Business Administration'?\",\n \"input\": \"\",\n \"output\": \"The abbreviation for 'Master of Business Administration' is MBA.\"\n },\n {\n \"instruction\": \"Convert the following number from Roman numerals: IX.\",\n \"input\": \"\",\n \"output\": \"The number IX in Roman numerals is 9.\"\n },\n {\n \"instruction\": \"What is the opposite of 'horizontal'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'horizontal' is 'vertical'.\"\n },\n {\n \"instruction\": \"Translate 'Where can I buy tickets?' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation for 'Where can I buy tickets?' is 'Dove posso comprare i biglietti?'\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to replace any clich\\u00e9s.\",\n \"input\": \"He was as cool as a cucumber.\",\n \"output\": \"He remained very calm.\"\n },\n {\n \"instruction\": \"Identify the main verb in the sentence.\",\n \"input\": \"The dog barked loudly.\",\n \"output\": \"The main verb in the sentence is 'barked'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'elucidate'.\",\n \"input\": \"\",\n \"output\": \"The professor attempted to elucidate the complex topic for his students.\"\n },\n {\n \"instruction\": \"Correct the sentence.\",\n \"input\": \"Me and my friend went to the store.\",\n \"output\": \"My friend and I went to the store.\"\n },\n {\n \"instruction\": \"What is the formula for calculating work done?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating work done is work = force \\u00d7 distance.\"\n },\n {\n \"instruction\": \"What is the chemical formula for ammonium nitrate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for ammonium nitrate is NH4NO3.\"\n },\n {\n \"instruction\": \"What is the molecular formula for water?\",\n \"input\": \"\",\n \"output\": \"The molecular formula for water is H2O.\"\n },\n {\n \"instruction\": \"Rewrite the given sentence to describe the same thing in a positive way.\",\n \"input\": \"The food was not good.\",\n \"output\": \"The food could use some improvement.\"\n },\n {\n \"instruction\": \"What is the opposite of 'lazy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'lazy' is 'diligent'.\"\n },\n {\n \"instruction\": \"Name three essential vitamins for human health.\",\n \"input\": \"\",\n \"output\": \"1. Vitamin A\\n2. Vitamin C\\n3. Vitamin D\"\n },\n {\n \"instruction\": \"Define the term 'simile'.\",\n \"input\": \"\",\n \"output\": \"A simile is a figure of speech that directly compares two different things, often introduced with the words 'like' or 'as'.\"\n },\n {\n \"instruction\": \"What is the boiling point of chlorine in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of chlorine is -34 degrees Celsius.\"\n },\n {\n \"instruction\": \"Translate 'My name is' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'My name is' is 'Je m'appelle'.\"\n },\n {\n \"instruction\": \"Convert 200 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"200 centimeters is 2 meters.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for zinc?\",\n \"input\": \"\",\n \"output\": \"Zn.\"\n },\n {\n \"instruction\": \"What is the formula for calculating force?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating force is Force = mass x acceleration.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovative'.\",\n \"input\": \"\",\n \"output\": \"The company's innovative approach set it apart from its competitors.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'generous'.\",\n \"input\": \"\",\n \"output\": \"He is very generous and always helps those in need.\"\n },\n {\n \"instruction\": \"What is an antonym of 'sharp'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'sharp' is 'dull'.\"\n },\n {\n \"instruction\": \"Describe the basic structure of a neuron.\",\n \"input\": \"\",\n \"output\": \"A neuron consists of three main parts: the cell body, which contains the nucleus; dendrites, which receive signals from other neurons; and an axon, which transmits signals to other neurons, muscles, or glands.\"\n },\n {\n \"instruction\": \"Translate 'see you later' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Hasta luego\"\n },\n {\n \"instruction\": \"What are the first 10 elements of the Fibonacci sequence?\",\n \"input\": \"\",\n \"output\": \"0, 1, 1, 2, 3, 5, 8, 13, 21, 34.\"\n },\n {\n \"instruction\": \"What is an antonym of 'transparent'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'transparent' is 'opaque'.\"\n },\n {\n \"instruction\": \"What is the past tense of 'think'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'think' is 'thought'.\"\n },\n {\n \"instruction\": \"Classify each sentence as either declarative, interrogative, imperative, or exclamatory.\",\n \"input\": \"Please open the door.\",\n \"output\": \"The classification of the sentence 'Please open the door.' is imperative.\"\n },\n {\n \"instruction\": \"Rewrite the sentence to use a negative adverb.\",\n \"input\": \"She always remembers to call.\",\n \"output\": \"She never forgets to call.\"\n },\n {\n \"instruction\": \"Convert 50 miles per hour to kilometers per hour.\",\n \"input\": \"\",\n \"output\": \"50 miles per hour is approximately 80.47 kilometers per hour.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'The chef cooks the meal every day.'\",\n \"input\": \"\",\n \"output\": \"The meal is cooked by the chef every day.\"\n },\n {\n \"instruction\": \"Classify an input string as either a noun or a verb.\",\n \"input\": \"Dance\",\n \"output\": \"'Dance' can be classified as a verb.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The book is very interesting.\",\n \"output\": \"The book is a page-turner.\"\n },\n {\n \"instruction\": \"Generate a question with the keyword \\u201cbacteria\\u201d\",\n \"input\": \"\",\n \"output\": \"How do bacteria affect human health?\"\n },\n {\n \"instruction\": \"What is the past participle of 'run'?\",\n \"input\": \"\",\n \"output\": \"The past participle of 'run' is 'run'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'quick'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'quick' is 'rapid'.\"\n },\n {\n \"instruction\": \"Give an example of a metaphor.\",\n \"input\": \"\",\n \"output\": \"An example of a metaphor is saying, 'Time is a thief,' which suggests that time, like a thief, can take away life moments without literally stealing.\"\n },\n {\n \"instruction\": \"Calculate the interest on a $1,000 investment at an annual rate of 5% over 3 years.\",\n \"input\": \"\",\n \"output\": \"The interest on a $1,000 investment at 5% annual rate over 3 years is $150.\"\n },\n {\n \"instruction\": \"What is a synonym of 'elated'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'elated' is 'overjoyed'.\"\n },\n {\n \"instruction\": \"Translate 'It's raining' into Japanese.\",\n \"input\": \"\",\n \"output\": \"The Japanese translation of 'It's raining' is '\\u96e8\\u304c\\u964d\\u3063\\u3066\\u3044\\u307e\\u3059' (Ame ga futte imasu).\"\n },\n {\n \"instruction\": \"Convert the following verb to its past participle form: 'speak'\",\n \"input\": \"speak\",\n \"output\": \"The past participle form of 'speak' is 'spoken.'\"\n },\n {\n \"instruction\": \"Describe the principle of conservation of energy.\",\n \"input\": \"\",\n \"output\": \"The principle of conservation of energy states that energy cannot be created or destroyed, only transformed from one form to another. This means the total energy of an isolated system remains constant over time.\"\n },\n {\n \"instruction\": \"Calculate the perimeter of a rectangle with a length of 5 meters and a width of 3 meters.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the rectangle is 16 meters.\"\n },\n {\n \"instruction\": \"What is the past tense of 'freeze'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'freeze' is 'froze'.\"\n },\n {\n \"instruction\": \"Correct the misuse of 'their' in the sentence.\",\n \"input\": \"Their going to the store.\",\n \"output\": \"The corrected sentence should be: 'They're going to the store.'\"\n },\n {\n \"instruction\": \"Classify the following statement into one of these labels: [positive, negative, neutral]\",\n \"input\": \"My computer crashed.\",\n \"output\": \"The statement \\\"My computer crashed\\\" can be classified as negative.\"\n },\n {\n \"instruction\": \"Identify the onomatopoeia in the sentence.\",\n \"input\": \"The bees buzzed as they flew past.\",\n \"output\": \"The onomatopoeia in the sentence is 'buzzed'.\"\n },\n {\n \"instruction\": \"Edit the sentence.\",\n \"input\": \"We enjoys watching movies.\",\n \"output\": \"We enjoy watching movies.\"\n },\n {\n \"instruction\": \"Define the term 'gravity'.\",\n \"input\": \"\",\n \"output\": \"Gravity is the force that attracts a body toward the center of the earth, or toward any other physical body having mass.\"\n },\n {\n \"instruction\": \"What is an antonym for 'hot'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'hot' is 'cold'.\"\n },\n {\n \"instruction\": \"Reverse the order of the given phrase.\",\n \"input\": \"sun and moon\",\n \"output\": \"moon and sun\"\n },\n {\n \"instruction\": \"What is the formula for calculating power?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating power is power = work/time.\"\n },\n {\n \"instruction\": \"Name the process by which plants absorb water through their roots.\",\n \"input\": \"\",\n \"output\": \"The process by which plants absorb water through their roots is called absorption.\"\n },\n {\n \"instruction\": \"What is the past tense of 'draw'?\",\n \"input\": \"\",\n \"output\": \"drew.\"\n },\n {\n \"instruction\": \"Change the given verb to its present perfect form.\",\n \"input\": \"run\",\n \"output\": \"Run.\"\n },\n {\n \"instruction\": \"Define the term 'oxymoron'.\",\n \"input\": \"\",\n \"output\": \"An oxymoron is a figure of speech in which apparently contradictory terms appear in conjunction.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for water?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for water is H2O.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'They paint the house every year.'\",\n \"input\": \"\",\n \"output\": \"The house is painted every year by them.\"\n },\n {\n \"instruction\": \"Provide the past tense form of the verb \\\"run.\\\"\",\n \"input\": \"\",\n \"output\": \"The past tense of the verb \\\"run\\\" is \\\"ran.\\\"\"\n },\n {\n \"instruction\": \"Convert the sentence to passive voice: 'They will hold the meeting tomorrow.'\",\n \"input\": \"They will hold the meeting tomorrow.\",\n \"output\": \"The meeting will be held tomorrow by them.\"\n },\n {\n \"instruction\": \"What is the chemical formula for sulfuric acid?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for sulfuric acid is H2SO4.\"\n },\n {\n \"instruction\": \"What type of cloud indicates fair weather?\",\n \"input\": \"\",\n \"output\": \"Cumulus clouds often indicate fair weather.\"\n },\n {\n \"instruction\": \"Insert a suitable adjective to complete the sentence.\",\n \"input\": \"The journey was _____.\",\n \"output\": \"The journey was arduous.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"The test was very easy.\",\n \"output\": \"The test was a piece of cake.\"\n },\n {\n \"instruction\": \"What is the opposite of 'increase'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'increase' is 'decrease'.\"\n },\n {\n \"instruction\": \"Calculate the perimeter of a square with a side length of 6 meters.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the square is 24 meters.\"\n },\n {\n \"instruction\": \"Find the missing number in the sequence\",\n \"input\": \"2, 4, ?, 8, 10\",\n \"output\": \"The missing number in the sequence is 6.\"\n },\n {\n \"instruction\": \"Translate 'Good night' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'Good night' is 'Gute Nacht'.\"\n },\n {\n \"instruction\": \"Provide a word that rhymes with 'light.'\",\n \"input\": \"\",\n \"output\": \"A word that rhymes with 'light' is 'might.'\"\n },\n {\n \"instruction\": \"What is the comparative form of 'good'?\",\n \"input\": \"\",\n \"output\": \"The comparative form of 'good' is 'better'.\"\n },\n {\n \"instruction\": \"Name the literary device used in 'The wind whispered through the trees.'\",\n \"input\": \"\",\n \"output\": \"The literary device used is personification.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor: 'His words cut deeper than a knife.'\",\n \"input\": \"\",\n \"output\": \"His words were a knife, cutting deep.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovate'.\",\n \"input\": \"\",\n \"output\": \"The company aims to innovate by developing new and sustainable technologies.\"\n },\n {\n \"instruction\": \"What is the speed of light?\",\n \"input\": \"\",\n \"output\": \"The speed of light is approximately 299,792 kilometers per second.\"\n },\n {\n \"instruction\": \"Identify the adverb in the sentence\",\n \"input\": \"She quickly ran to the store.\",\n \"output\": \"The adverb in the sentence is 'quickly'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'beautiful'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'beautiful' is 'gorgeous'.\"\n },\n {\n \"instruction\": \"What is the capital of India?\",\n \"input\": \"\",\n \"output\": \"The capital of India is New Delhi.\"\n },\n {\n \"instruction\": \"Classify the following words by their grammatical categories: jump, quick, beautiful\",\n \"input\": \"\",\n \"output\": \"Jump: Verb\\nQuick: Adjective\\nBeautiful: Adjective\"\n },\n {\n \"instruction\": \"What is the chemical formula for potassium nitrate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for potassium nitrate is KNO3.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The cake is very sweet.\",\n \"output\": \"The cake is as sweet as honey.\"\n },\n {\n \"instruction\": \"Label whether the following statements are true or false.\",\n \"input\": \"The moon is a planet.\",\n \"output\": \"False\"\n },\n {\n \"instruction\": \"Convert 1000 milliliters to liters.\",\n \"input\": \"\",\n \"output\": \"1000 milliliters is equivalent to 1 liter.\"\n },\n {\n \"instruction\": \"Change this sentence into the past continuous tense.\",\n \"input\": \"She sings in the choir.\",\n \"output\": \"She was singing in the choir.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'clever.'\",\n \"input\": \"\",\n \"output\": \"A synonym for 'clever' is 'smart.'\"\n },\n {\n \"instruction\": \"Change the sentence 'You should have called me.' into a question.\",\n \"input\": \"\",\n \"output\": \"Should you have called me?\"\n }\n]"
},
{
"path": "ch07/01_main-chapter-code/load-finetuned-model.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1545a16b-bc8d-4e49-b9a6-db6631e7483d\",\n \"metadata\": {},\n \"source\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"4405196a-db81-470b-be39-167a059587b6\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# This `format_input` function is copied from the original chapter 7 code\\n\",\n \"\\n\",\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. \\\"\\n\",\n \" f\\\"Write a response that appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"83658c09-af8a-425a-b940-eb1f06e43c0b\",\n \"metadata\": {},\n \"source\": [\n \"We can modify the `InstructionDataset` class to collect the lengths of the instructions, which we will use in the collate function to locate the instruction content positions in the targets when we code the collate function, as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"e5e6188a-f182-4f26-b9e5-ccae3ecadae0\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"from torch.utils.data import Dataset\\n\",\n \"\\n\",\n \"\\n\",\n \"class InstructionDataset(Dataset):\\n\",\n \" def __init__(self, data, tokenizer):\\n\",\n \" self.data = data\\n\",\n \"\\n\",\n \" ##########################################################################################\\n\",\n \" # New: Separate list for instruction lengths\\n\",\n \" self.instruction_lengths = []\\n\",\n \" ##########################################################################################\\n\",\n \" \\n\",\n \" self.encoded_texts = []\\n\",\n \" \\n\",\n \" for entry in data:\\n\",\n \" instruction_plus_input = format_input(entry)\\n\",\n \" response_text = f\\\"\\\\n\\\\n### Response:\\\\n{entry['output']}\\\"\\n\",\n \" full_text = instruction_plus_input + response_text\\n\",\n \" \\n\",\n \" self.encoded_texts.append(\\n\",\n \" tokenizer.encode(full_text)\\n\",\n \" )\\n\",\n \"\\n\",\n \" ##########################################################################################\\n\",\n \" # New: collect instruction lengths\\n\",\n \" instruction_length = len(tokenizer.encode(instruction_plus_input))\\n\",\n \" self.instruction_lengths.append(instruction_length)\\n\",\n \" ##########################################################################################\\n\",\n \" \\n\",\n \" def __getitem__(self, index):\\n\",\n \" # New: return both instruction lengths and texts separately\\n\",\n \" return self.instruction_lengths[index], self.encoded_texts[index]\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.data)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"0163b7d1-acb8-456c-8efe-86307b58f4bb\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import tiktoken\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3a186394-4960-424d-bb6a-f58459dd5994\",\n \"metadata\": {},\n \"source\": [\n \"Next, we update the `custom_collate_fn` where each `batch` is now a tuple containing `(instruction_length, item)` instead of just `item` due to the changes in the `InstructionDataset` dataset. In addition, we now mask the corresponding instruction tokens in the target ID list.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"f815e6fc-8e54-4105-aecd-d4c6e890ff9d\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def custom_collate_fn(\\n\",\n \" batch,\\n\",\n \" pad_token_id=50256,\\n\",\n \" ignore_index=-100,\\n\",\n \" allowed_max_length=None,\\n\",\n \" device=\\\"cpu\\\"\\n\",\n \"):\\n\",\n \" # Find the longest sequence in the batch\\n\",\n \" batch_max_length = max(len(item)+1 for instruction_length, item in batch) # New: batch is now a tuple\\n\",\n \"\\n\",\n \" # Pad and prepare inputs and targets\\n\",\n \" inputs_lst, targets_lst = [], []\\n\",\n \"\\n\",\n \" for instruction_length, item in batch: # New: batch is now a tuple\\n\",\n \" new_item = item.copy()\\n\",\n \" # Add an <|endoftext|> token\\n\",\n \" new_item += [pad_token_id]\\n\",\n \" # Pad sequences to max_length\\n\",\n \" padded = new_item + [pad_token_id] * (batch_max_length - len(new_item))\\n\",\n \" inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\\n\",\n \" targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\\n\",\n \"\\n\",\n \" # Replace all but the first padding tokens in targets by ignore_index\\n\",\n \" mask = targets == pad_token_id\\n\",\n \" indices = torch.nonzero(mask).squeeze()\\n\",\n \" if indices.numel() > 1:\\n\",\n \" targets[indices[1:]] = ignore_index\\n\",\n \"\\n\",\n \" ##########################################################################################\\n\",\n \" # New: Mask all input and instruction tokens in the targets\\n\",\n \" targets[:instruction_length-1] = -100\\n\",\n \" ##########################################################################################\\n\",\n \" \\n\",\n \" # Optionally truncate to maximum sequence length\\n\",\n \" if allowed_max_length is not None:\\n\",\n \" inputs = inputs[:allowed_max_length]\\n\",\n \" targets = targets[:allowed_max_length]\\n\",\n \" \\n\",\n \" inputs_lst.append(inputs)\\n\",\n \" targets_lst.append(targets)\\n\",\n \"\\n\",\n \" # Convert list of inputs and targets to tensors and transfer to target device\\n\",\n \" inputs_tensor = torch.stack(inputs_lst).to(device)\\n\",\n \" targets_tensor = torch.stack(targets_lst).to(device)\\n\",\n \"\\n\",\n \" return inputs_tensor, targets_tensor\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0a4a4815-850e-42c4-b70d-67e8ce5ebd57\",\n \"metadata\": {},\n \"source\": [\n \"Let's try it out on some sample data below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"8da8a5b1-a8e2-4389-b21c-25b67be6dd1c\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"sample_data = [\\n\",\n \" {'instruction': \\\"What is an antonym of 'complicated'?\\\", 'input': '', 'output': \\\"An antonym of 'complicated' is 'simple'.\\\"},\\n\",\n \" {'instruction': 'Sort the following list in alphabetical order.', 'input': 'Zebra, Elephant, Crocodile', 'output': 'Crocodile, Elephant, Zebra'},\\n\",\n \" {'instruction': 'Arrange the given numbers in descending order.', 'input': '5, 12, 8, 3, 15', 'output': '15, 12, 8, 5, 3.'}\\n\",\n \"]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"435b0816-0fc8-4650-a84a-eceffa4d85e4\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"train_dataset = InstructionDataset(sample_data, tokenizer)\\n\",\n \"train_loader = DataLoader(\\n\",\n \" train_dataset,\\n\",\n \" batch_size=len(sample_data),\\n\",\n \" collate_fn=custom_collate_fn,\\n\",\n \" num_workers=0\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"106bbbd7-7286-4eb6-b343-43419332a80f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"torch.Size([3, 64]) torch.Size([3, 64])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for inputs, targets in train_loader:\\n\",\n \" print(inputs.shape, targets.shape)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"9bb3288b-84a9-4962-ae59-a7a29fd34bce\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Inputs:\\n\",\n \" tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 42758, 262, 1708, 1351, 287, 24830,\\n\",\n \" 605, 1502, 13, 198, 198, 21017, 23412, 25, 198, 57,\\n\",\n \" 37052, 11, 42651, 11, 9325, 19815, 576, 198, 198, 21017,\\n\",\n \" 18261, 25, 198, 34, 12204, 375, 576, 11, 42651, 11,\\n\",\n \" 1168, 37052, 50256, 50256])\\n\",\n \"\\n\",\n \"\\n\",\n \"Targets:\\n\",\n \" tensor([ -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\\n\",\n \" -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\\n\",\n \" -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\\n\",\n \" -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\\n\",\n \" -100, -100, -100, -100, -100, -100, 198, 198, 21017, 18261,\\n\",\n \" 25, 198, 34, 12204, 375, 576, 11, 42651, 11, 1168,\\n\",\n \" 37052, 50256, -100, -100])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Inputs:\\\\n\\\", inputs[1])\\n\",\n \"print(\\\"\\\\n\\\\nTargets:\\\\n\\\", targets[1])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cc40347b-2ca7-44e1-862d-0fd0c92f0628\",\n \"metadata\": {},\n \"source\": [\n \"As we can see based on the `targets` tensor, both the instruction and padding tokens are now masked using the -100 placeholder tokens. \\n\",\n \"Let's decode the inputs just to make sure that they look correct:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"76a9e6fa-3d75-4e39-b139-c3e05048f42b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Sort the following list in alphabetical order.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"Zebra, Elephant, Crocodile\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"Crocodile, Elephant, Zebra<|endoftext|><|endoftext|>\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(tokenizer.decode(list(inputs[1])))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"845ebd36-f63f-4b58-a76e-7767e4d2ccbd\",\n \"metadata\": {},\n \"source\": [\n \"Next, let's decode the non-masked target token IDS:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"4d54a152-b778-455a-8941-e375e2a17e8f\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"Crocodile, Elephant, Zebra<|endoftext|>\\n\"\n ]\n }\n ],\n \"source\": [\n \"non_masked_targets = targets[1][targets[1] != -100]\\n\",\n \"\\n\",\n \"print(tokenizer.decode(list(non_masked_targets)))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"3912bbf5-e9e2-474b-9552-d522e7510aa6\",\n \"metadata\": {},\n \"source\": [\n \"As shown above, the non-masked target tokens exclude the `\\\"Instruction\\\"` and `\\\"Input\\\"` fields, as intended. Now, we can run the modified code to see how well the LLM performs when finetuned using this masking strategy.\\n\",\n \"\\n\",\n \"For your convenience, you can use the `exercise_experiments.py` code to run a comparison as follows:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"56a76097-9114-479d-8803-443b0ff48581\",\n \"metadata\": {},\n \"source\": [\n \"```bash\\n\",\n \"python exercise_experiments.py --exercise_solution mask_instructions\\n\",\n \"```\\n\",\n \"\\n\",\n \"Output:\\n\",\n \"\\n\",\n \"```\\n\",\n \"matplotlib version: 3.7.1\\n\",\n \"tiktoken version: 0.7.0\\n\",\n \"torch version: 2.3.0+cu121\\n\",\n \"tqdm version: 4.66.4\\n\",\n \"tensorflow version: 2.15.0\\n\",\n \"--------------------------------------------------\\n\",\n \"Training set length: 935\\n\",\n \"Validation set length: 55\\n\",\n \"Test set length: 110\\n\",\n \"--------------------------------------------------\\n\",\n \"Device: cuda\\n\",\n \"--------------------------------------------------\\n\",\n \"...\\n\",\n \"Loaded model: gpt2-medium (355M)\\n\",\n \"--------------------------------------------------\\n\",\n \"Initial losses\\n\",\n \" Training loss: 2.280539035797119\\n\",\n \" Validation loss: 2.262560224533081\\n\",\n \"Ep 1 (Step 000000): Train loss 1.636, Val loss 1.620\\n\",\n \"...\\n\",\n \"Ep 2 (Step 000230): Train loss 0.143, Val loss 0.727\\n\",\n \"...\\n\",\n \"Training completed in 1.77 minutes.\\n\",\n \"Plot saved as loss-plot-mask-instructions.pdf\\n\",\n \"--------------------------------------------------\\n\",\n \"Generating responses\\n\",\n \"100% 110/110 [02:10<00:00, 1.19s/it]\\n\",\n \"Responses saved as instruction-data-with-response-mask-instructions.json\\n\",\n \"Model saved as gpt2-medium355M-sft-mask-instructions.pth\\n\",\n \"```\\n\",\n \"\\n\",\n \"Next, let's evaluate the performance of the resulting LLM:\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"python ollama_evaluate.py --file_path instruction-data-with-response-mask-instructions.json\\n\",\n \"```\\n\",\n \"\\n\",\n \"```\\n\",\n \"Ollama running: True\\n\",\n \"Scoring entries: 100%|██████████████████████████████████████████████████████████████████████████████████████| 110/110 [01:23<00:00, 1.31it/s]\\n\",\n \"Number of scores: 110 of 110\\n\",\n \"Average score: 47.73\\n\",\n \"```\\n\",\n \"\\n\",\n \"As we can see based on the scores, the instruction masking does perform slightly worse, which is consistent with the observation in the \\\"Instruction Tuning With Loss Over Instructions\\\" paper (https://arxiv.org/abs/2405.14394)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"94a0f758-29da-44ee-b7af-32473b3c086e\",\n \"metadata\": {},\n \"source\": [\n \" \\n\",\n \"## Exercise 7.3: Finetuning on the original Alpaca dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"68df7616-679f-4e53-954d-6e7cf2e2ef55\",\n \"metadata\": {},\n \"source\": [\n \"To finetune the model on the original Stanford Alpaca dataset ([https://github.com/tatsu-lab/stanford_alpaca](https://github.com/tatsu-lab/stanford_alpaca)), you just need to change the file URL from\\n\",\n \"\\n\",\n \"```python\\n\",\n \"url = \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch07/01_main-chapter-code/instruction-data.json\\\"\\n\",\n \"```\\n\",\n \"\\n\",\n \"to\\n\",\n \"\\n\",\n \"```python\\n\",\n \"url = \\\"https://raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json\\\"\\n\",\n \"```\\n\",\n \"\\n\",\n \"Note that the dataset contains 52k entries (50x more than in chapter 7), and the entries are longer than the ones we worked with in chapter 7.\\n\",\n \"Thus, it's highly recommended that the training be run on a GPU.\\n\",\n \"\\n\",\n \"If you encounter out-of-memory errors, consider reducing the batch size from 8 to 4, 2, or 1. In addition to lowering the batch size, you may also want to consider lowering the `allowed_max_length` from 1024 to 512 or 256.\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d94c9621-2c3f-4551-b5b8-87cd96e38c9c\",\n \"metadata\": {},\n \"source\": [\n \"For your convenience, you can use the `exercise_experiments.py` code to finetune the model on the 52k Alpaca dataset with a batch size of 4 and an `allowed_max_length` of 512 as follows:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"40a76486-73e6-4415-94dc-bfe2aa36ea52\",\n \"metadata\": {},\n \"source\": [\n \"```bash\\n\",\n \"python exercise_experiments.py --exercise_solution alpaca_52k\\n\",\n \"```\\n\",\n \"\\n\",\n \"```\\n\",\n \"matplotlib version: 3.7.1\\n\",\n \"tiktoken version: 0.7.0\\n\",\n \"torch version: 2.3.0+cu121\\n\",\n \"tqdm version: 4.66.4\\n\",\n \"tensorflow version: 2.15.0\\n\",\n \"--------------------------------------------------\\n\",\n \"Training set length: 44201\\n\",\n \"Validation set length: 2601\\n\",\n \"Test set length: 5200\\n\",\n \"--------------------------------------------------\\n\",\n \"Device: cuda\\n\",\n \"--------------------------------------------------\\n\",\n \"...\\n\",\n \"Loaded model: gpt2-medium (355M)\\n\",\n \"--------------------------------------------------\\n\",\n \"Initial losses\\n\",\n \" Training loss: 3.3681655883789063\\n\",\n \" Validation loss: 3.4122894287109373\\n\",\n \"Ep 1 (Step 000000): Train loss 2.477, Val loss 2.750\\n\",\n \"...\\n\",\n \"Ep 2 (Step 022095): Train loss 0.761, Val loss 1.557\\n\",\n \"...\\n\",\n \"Training completed in 196.38 minutes.\\n\",\n \"Plot saved as loss-plot-alpaca52k.pdf\\n\",\n \"--------------------------------------------------\\n\",\n \"Generating responses\\n\",\n \"100% 5200/5200 [2:56:33<00:00, 2.04s/it]\\n\",\n \"Responses saved as instruction-data-with-response-alpaca52k.json\\n\",\n \"Model saved as gpt2-medium355M-sft-alpaca52k.pth\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cc8a1bd1-15f4-4a35-87b5-369038db0aa7\",\n \"metadata\": {},\n \"source\": [\n \"Below are a few examples from the Alpaca dataset, including the generated model responses:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be9ab66f-5819-4b01-9a03-c45aa3b7c5b8\",\n \"metadata\": {},\n \"source\": [\n \"```json\\n\",\n \"[\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": \\\"Edit the following sentence to increase readability: \\\\\\\"He made a huge effort and was so successful.\\\\\\\"\\\",\\n\",\n \" \\\"input\\\": \\\"\\\",\\n\",\n \" \\\"output\\\": \\\"He exerted a tremendous effort, and thus enjoyed great success.\\\",\\n\",\n \" \\\"model_response\\\": \\\"He put in an immense effort and was rewarded with success.\\\"\\n\",\n \" },\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": \\\"Rewrite the following sentence to make it more concise: \\\\\\\"I was displeased with the result of the experiment that I conducted.\\\\\\\"\\\",\\n\",\n \" \\\"input\\\": \\\"\\\",\\n\",\n \" \\\"output\\\": \\\"I was unhappy with my experiment's outcome.\\\",\\n\",\n \" \\\"model_response\\\": \\\"I was displeased with the results of the experiment.\\\"\\n\",\n \" },\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": \\\"How can we build a more efficient GPT model?\\\",\\n\",\n \" \\\"input\\\": \\\"\\\",\\n\",\n \" \\\"output\\\": \\\"We can build a more efficient GPT model by optimizing the architecture of the model, using smaller model sizes and training with fewer parameters. We can also leverage techniques such as knowledge distillation, transfer learning, dynamic sparsity and hybrid computing to further improve the efficiency of the model.\\\",\\n\",\n \" \\\"model_response\\\": \\\"Building a more efficient GPT model requires careful planning and optimization. First, it is important to identify the target language and the context in which the model is used. Then, it is important to select the appropriate model architecture, such as backpropagation, hyperparameters, and hyperparameters. Finally, it is important to select the appropriate model weights and optimizers, such as backpropagation, hyperparameters, and hyperparameters.\\\"\\n\",\n \" },\\n\",\n \"]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"840e2076-f2e6-44a2-86fd-f191f9674267\",\n \"metadata\": {},\n \"source\": [\n \"Finally, we can evaluate the finetuned LLM using the [ollama_evaluate.py](ollama_evaluate.py) utility function:\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"python ollama_evaluate.py --file_path instruction-data-with-response-alpaca52k.json\\n\",\n \"```\\n\",\n \"\\n\",\n \"```\\n\",\n \"Scoring entries: 100%|████████████████████| 5200/5200 [1:07:52<00:00, 1.28it/s]\\n\",\n \"Number of scores: 5188 of 5200\\n\",\n \"Average score: 48.16\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d14b3c60-00a1-43a9-9fcd-592aaadf1ef4\",\n \"metadata\": {},\n \"source\": [\n \"The score is slightly lower than the score we obtained on the dataset we used in this chapter. However, note that the Alpaca test set contains more diverse and partly more challenging instructions than the dataset we used in the main chapter.\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ca61fa6c-4e1d-4618-9e5e-d091f8303e30\",\n \"metadata\": {},\n \"source\": [\n \"## Exercise 7.4: Parameter-efficient finetuning with LoRA\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"01742cec-1f41-4415-8788-009d31b1ad38\",\n \"metadata\": {},\n \"source\": [\n \"To instruction finetune the model using LoRA, use the relevant classes and functions from appendix E:\\n\",\n \"\\n\",\n \"```python\\n\",\n \"from appendix_E import LoRALayer, LinearWithLoRA, replace_linear_with_lora\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"871dca8f-3411-4735-b7b0-9d0e6e0599ac\",\n \"metadata\": {},\n \"source\": [\n \"Next, add the following lines of code below the model loading code in section 7.5:\\n\",\n \"\\n\",\n \"\\n\",\n \"```python\\n\",\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable parameters before: {total_params:,}\\\")\\n\",\n \"\\n\",\n \"for param in model.parameters():\\n\",\n \" param.requires_grad = False\\n\",\n \"\\n\",\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable parameters after: {total_params:,}\\\")\\n\",\n \"replace_linear_with_lora(model, rank=16, alpha=16)\\n\",\n \"\\n\",\n \"total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\\n\",\n \"print(f\\\"Total trainable LoRA parameters: {total_params:,}\\\")\\n\",\n \"model.to(device)\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1b26b925-dc95-4b91-b050-9676dd9608a4\",\n \"metadata\": {},\n \"source\": [\n \"For your convenience, you can use the `exercise_experiments.py` code to finetune the model, using LoRA with rank 16 and alpa 16, as follows:\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"01f02c7e-3b15-44b8-bf41-7892cd755766\",\n \"metadata\": {},\n \"source\": [\n \"```bash\\n\",\n \"python exercise_experiments.py --exercise_solution lora\\n\",\n \"```\\n\",\n \"\\n\",\n \"Output:\\n\",\n \"\\n\",\n \"```\\n\",\n \"matplotlib version: 3.7.1\\n\",\n \"tiktoken version: 0.7.0\\n\",\n \"torch version: 2.3.0+cu121\\n\",\n \"tqdm version: 4.66.4\\n\",\n \"tensorflow version: 2.15.0\\n\",\n \"--------------------------------------------------\\n\",\n \"Training set length: 935\\n\",\n \"Validation set length: 55\\n\",\n \"Test set length: 110\\n\",\n \"--------------------------------------------------\\n\",\n \"Device: cuda\\n\",\n \"--------------------------------------------------\\n\",\n \"File already exists and is up-to-date: gpt2/355M/checkpoint\\n\",\n \"File already exists and is up-to-date: gpt2/355M/encoder.json\\n\",\n \"File already exists and is up-to-date: gpt2/355M/hparams.json\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.data-00000-of-00001\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.index\\n\",\n \"File already exists and is up-to-date: gpt2/355M/model.ckpt.meta\\n\",\n \"File already exists and is up-to-date: gpt2/355M/vocab.bpe\\n\",\n \"Loaded model: gpt2-medium (355M)\\n\",\n \"--------------------------------------------------\\n\",\n \"Total trainable parameters before: 406,286,336\\n\",\n \"Total trainable parameters after: 0\\n\",\n \"Total trainable LoRA parameters: 7,898,384\\n\",\n \"Initial losses\\n\",\n \" Training loss: 3.7684114456176756\\n\",\n \" Validation loss: 3.7619335651397705\\n\",\n \"Ep 1 (Step 000000): Train loss 2.509, Val loss 2.519\\n\",\n \"...\\n\",\n \"Ep 2 (Step 000230): Train loss 0.308, Val loss 0.652\\n\",\n \"...\\n\",\n \"--------------------------------------------------\\n\",\n \"Generating responses\\n\",\n \"100% 110/110 [01:52<00:00, 1.03s/it]\\n\",\n \"Responses saved as instruction-data-with-response-lora.json\\n\",\n \"Model saved as gpt2-medium355M-sft-lora.pth\\n\",\n \"```\\n\",\n \"\\n\",\n \"For comparison, you can run the original chapter 7 finetuning code via `python exercise_experiments.py --exercise_solution baseline`. \\n\",\n \"\\n\",\n \"Note that on an Nvidia L4 GPU, the code above, using LoRA, takes 1.30 min to run. In comparison, the baseline takes 1.80 minutes to run. So, LoRA is approximately 28% faster.\\n\",\n \"\\n\",\n \"\\n\",\n \"We can evaluate the performance using the Ollama Llama 3 method, which is for your convenience, also implemented in the `python exercise_experiments.py` script, which we can run as follows:\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"python ollama_evaluate.py --file_path instruction-data-with-response-lora.json\\n\",\n \"```\\n\",\n \"\\n\",\n \"Output:\\n\",\n \"\\n\",\n \"```\\n\",\n \"Ollama running: True\\n\",\n \"Scoring entries: 100%|████████████████████████| 110/110 [01:13<00:00, 1.50it/s]\\n\",\n \"Number of scores: 110 of 110\\n\",\n \"Average score: 50.23\\n\",\n \"```\\n\",\n \"\\n\",\n \"The score is around 50, which is in the same ballpark as the original model.\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.10.16\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch07/01_main-chapter-code/exercise_experiments.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# Code to run the exercises; see exercise-solutions.ipynb for more information\n\nfrom functools import partial\nfrom importlib.metadata import version\nimport json\nimport math\nimport os\nimport re\nimport time\n\nimport matplotlib.pyplot as plt\nfrom matplotlib.ticker import MaxNLocator\nimport requests\nimport tiktoken\nimport torch\nfrom torch.utils.data import Dataset, DataLoader\nfrom tqdm import tqdm\n\n# Import from local files in this folder\nfrom gpt_download import download_and_load_gpt2\nfrom previous_chapters import (\n calc_loss_loader,\n generate,\n GPTModel,\n load_weights_into_gpt,\n text_to_token_ids,\n train_model_simple,\n token_ids_to_text\n)\n\n\nclass InstructionDataset(Dataset):\n def __init__(self, data, tokenizer):\n self.data = data\n\n # Pre-tokenize texts\n self.encoded_texts = []\n for entry in data:\n instruction_plus_input = format_input(entry)\n response_text = f\"\\n\\n### Response:\\n{entry['output']}\"\n full_text = instruction_plus_input + response_text\n self.encoded_texts.append(\n tokenizer.encode(full_text)\n )\n\n def __getitem__(self, index):\n return self.encoded_texts[index]\n\n def __len__(self):\n return len(self.data)\n\n\nclass InstructionDatasetWithMasking(Dataset):\n def __init__(self, data, tokenizer):\n self.data = data\n\n # New: Separate list for instruction lengths\n self.instruction_lengths = []\n self.encoded_texts = []\n\n for entry in data:\n instruction_plus_input = format_input(entry)\n response_text = f\"\\n\\n### Response:\\n{entry['output']}\"\n full_text = instruction_plus_input + response_text\n\n self.encoded_texts.append(\n tokenizer.encode(full_text)\n )\n\n # New: collect instruction lengths\n instruction_length = len(tokenizer.encode(instruction_plus_input))\n self.instruction_lengths.append(instruction_length)\n\n def __getitem__(self, index):\n # New: return both instruction lengths and texts separately\n return self.instruction_lengths[index], self.encoded_texts[index]\n\n def __len__(self):\n return len(self.data)\n\n\nclass InstructionDatasetPhi(Dataset):\n def __init__(self, data, tokenizer):\n self.data = data\n\n # Pre-tokenize texts\n self.encoded_texts = []\n for entry in data:\n\n ###################################################################\n # NEW: Use `format_input_phi` and adjust the response text template\n instruction_plus_input = format_input_phi(entry)\n response_text = f\"\\n<|assistant|>:\\n{entry['output']}\"\n ###################################################################\n full_text = instruction_plus_input + response_text\n self.encoded_texts.append(\n tokenizer.encode(full_text)\n )\n\n def __getitem__(self, index):\n return self.encoded_texts[index]\n\n def __len__(self):\n return len(self.data)\n\n\nclass LinearWithLoRA(torch.nn.Module):\n def __init__(self, linear, rank, alpha):\n super().__init__()\n self.linear = linear\n self.lora = LoRALayer(\n linear.in_features, linear.out_features, rank, alpha\n )\n\n def forward(self, x):\n return self.linear(x) + self.lora(x)\n\n\nclass LoRALayer(torch.nn.Module):\n def __init__(self, in_dim, out_dim, rank, alpha):\n super().__init__()\n self.A = torch.nn.Parameter(torch.empty(in_dim, rank))\n torch.nn.init.kaiming_uniform_(self.A, a=math.sqrt(5)) # similar to standard weight initialization\n self.B = torch.nn.Parameter(torch.zeros(rank, out_dim))\n self.alpha = alpha\n\n def forward(self, x):\n x = self.alpha * (x @ self.A @ self.B)\n return x\n\n\ndef replace_linear_with_lora(model, rank, alpha):\n for name, module in model.named_children():\n if isinstance(module, torch.nn.Linear):\n # Replace the Linear layer with LinearWithLoRA\n setattr(model, name, LinearWithLoRA(module, rank, alpha))\n else:\n # Recursively apply the same function to child modules\n replace_linear_with_lora(module, rank, alpha)\n\n\ndef custom_collate_fn(\n batch,\n pad_token_id=50256,\n ignore_index=-100,\n allowed_max_length=None,\n device=\"cpu\"\n):\n # Find the longest sequence in the batch\n batch_max_length = max(len(item)+1 for item in batch)\n\n # Pad and prepare inputs and targets\n inputs_lst, targets_lst = [], []\n\n for item in batch:\n new_item = item.copy()\n # Add an <|endoftext|> token\n new_item += [pad_token_id]\n # Pad sequences to max_length\n padded = new_item + [pad_token_id] * (batch_max_length - len(new_item))\n inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\n targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\n\n # New: Replace all but the first padding tokens in targets by ignore_index\n mask = targets == pad_token_id\n indices = torch.nonzero(mask).squeeze()\n if indices.numel() > 1:\n targets[indices[1:]] = ignore_index\n\n # New: Optionally truncate to maximum sequence length\n if allowed_max_length is not None:\n inputs = inputs[:allowed_max_length]\n targets = targets[:allowed_max_length]\n\n inputs_lst.append(inputs)\n targets_lst.append(targets)\n\n # Convert list of inputs and targets to tensors and transfer to target device\n inputs_tensor = torch.stack(inputs_lst).to(device)\n targets_tensor = torch.stack(targets_lst).to(device)\n\n return inputs_tensor, targets_tensor\n\n\ndef custom_collate_with_masking_fn(\n batch,\n pad_token_id=50256,\n ignore_index=-100,\n allowed_max_length=None,\n device=\"cpu\"\n):\n # Find the longest sequence in the batch\n batch_max_length = max(len(item)+1 for instruction_length, item in batch) # New: batch is now a tuple\n\n # Pad and prepare inputs and targets\n inputs_lst, targets_lst = [], []\n\n for instruction_length, item in batch: # New: batch is now a tuple\n new_item = item.copy()\n # Add an <|endoftext|> token\n new_item += [pad_token_id]\n # Pad sequences to max_length\n padded = new_item + [pad_token_id] * (batch_max_length - len(new_item))\n inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\n targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\n\n # Replace all but the first padding tokens in targets by ignore_index\n mask = targets == pad_token_id\n indices = torch.nonzero(mask).squeeze()\n if indices.numel() > 1:\n targets[indices[1:]] = ignore_index\n\n # New: Mask all input and instruction tokens in the targets\n targets[:instruction_length-1] = -100\n\n # Optionally truncate to maximum sequence length\n if allowed_max_length is not None:\n inputs = inputs[:allowed_max_length]\n targets = targets[:allowed_max_length]\n\n inputs_lst.append(inputs)\n targets_lst.append(targets)\n\n # Convert list of inputs and targets to tensors and transfer to target device\n inputs_tensor = torch.stack(inputs_lst).to(device)\n targets_tensor = torch.stack(targets_lst).to(device)\n\n return inputs_tensor, targets_tensor\n\n\ndef download_and_load_file(file_path, url):\n if not os.path.exists(file_path):\n response = requests.get(url, timeout=30)\n response.raise_for_status()\n text_data = response.text\n with open(file_path, \"w\", encoding=\"utf-8\") as file:\n file.write(text_data)\n else:\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n text_data = file.read()\n\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n data = json.load(file)\n\n return data\n\n\ndef format_input_phi(entry):\n instruction_text = (\n f\"<|user|>\\n{entry['instruction']}\"\n )\n\n input_text = f\"\\n{entry['input']}\" if entry[\"input\"] else \"\"\n\n return instruction_text + input_text\n\n\ndef format_input(entry):\n instruction_text = (\n f\"Below is an instruction that describes a task. \"\n f\"Write a response that appropriately completes the request.\"\n f\"\\n\\n### Instruction:\\n{entry['instruction']}\"\n )\n\n input_text = f\"\\n\\n### Input:\\n{entry['input']}\" if entry[\"input\"] else \"\"\n\n return instruction_text + input_text\n\n\ndef plot_losses(epochs_seen, tokens_seen, train_losses, val_losses, plot_name):\n fig, ax1 = plt.subplots(figsize=(12, 6))\n\n # Plot training and validation loss against epochs\n ax1.plot(epochs_seen, train_losses, label=\"Training loss\")\n ax1.plot(epochs_seen, val_losses, linestyle=\"-.\", label=\"Validation loss\")\n ax1.set_xlabel(\"Epochs\")\n ax1.set_ylabel(\"Loss\")\n ax1.legend(loc=\"upper right\")\n ax1.xaxis.set_major_locator(MaxNLocator(integer=True)) # only show integer labels on x-axis\n\n # Create a second x-axis for tokens seen\n ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\n ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks\n ax2.set_xlabel(\"Tokens seen\")\n\n fig.tight_layout() # Adjust layout to make room\n print(f\"Plot saved as {plot_name}\")\n plt.savefig(plot_name)\n # plt.show()\n\n\ndef main(mask_instructions=False, alpaca52k=False, phi3_prompt=False, lora=False):\n #######################################\n # Print package versions\n #######################################\n print()\n pkgs = [\n \"matplotlib\", # Plotting library\n \"tiktoken\", # Tokenizer\n \"torch\", # Deep learning library\n \"tqdm\", # Progress bar\n \"tensorflow\", # For OpenAI's pretrained weights\n ]\n for p in pkgs:\n print(f\"{p} version: {version(p)}\")\n print(50*\"-\")\n\n #######################################\n # Download and prepare dataset\n #######################################\n file_path = \"instruction-data.json\"\n\n if alpaca52k:\n url = \"https://raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json\"\n else:\n url = \"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch07/01_main-chapter-code/instruction-data.json\"\n data = download_and_load_file(file_path, url)\n\n train_portion = int(len(data) * 0.85) # 85% for training\n test_portion = int(len(data) * 0.1) # 10% for testing\n\n train_data = data[:train_portion]\n test_data = data[train_portion:train_portion + test_portion]\n val_data = data[train_portion + test_portion:]\n\n print(\"Training set length:\", len(train_data))\n print(\"Validation set length:\", len(val_data))\n print(\"Test set length:\", len(test_data))\n print(50*\"-\")\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n print(\"Device:\", device)\n print(50*\"-\")\n\n if alpaca52k:\n allowed_max_length = 512\n else:\n allowed_max_length = 1024\n\n if mask_instructions and phi3_prompt:\n raise ValueError(\"Simultaneous support for instruction masking and the Phi-3 prompt template has not been implemented, yet.\")\n\n if mask_instructions:\n customized_collate_fn = partial(custom_collate_with_masking_fn, device=device, allowed_max_length=allowed_max_length)\n CustomDataset = InstructionDatasetWithMasking\n elif phi3_prompt:\n customized_collate_fn = partial(custom_collate_fn, device=device, allowed_max_length=allowed_max_length)\n CustomDataset = InstructionDatasetPhi\n else:\n customized_collate_fn = partial(custom_collate_fn, device=device, allowed_max_length=allowed_max_length)\n CustomDataset = InstructionDataset\n\n num_workers = 0\n\n if alpaca52k:\n batch_size = 4\n else:\n batch_size = 8\n\n torch.manual_seed(123)\n\n train_dataset = CustomDataset(train_data, tokenizer)\n train_loader = DataLoader(\n train_dataset,\n batch_size=batch_size,\n collate_fn=customized_collate_fn,\n shuffle=True,\n drop_last=True,\n num_workers=num_workers\n )\n\n val_dataset = CustomDataset(val_data, tokenizer)\n val_loader = DataLoader(\n val_dataset,\n batch_size=batch_size,\n collate_fn=customized_collate_fn,\n shuffle=False,\n drop_last=False,\n num_workers=num_workers\n )\n\n #######################################\n # Load pretrained model\n #######################################\n BASE_CONFIG = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Context length\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": True # Query-key-value bias\n }\n\n model_configs = {\n \"gpt2-small (124M)\": {\"emb_dim\": 768, \"n_layers\": 12, \"n_heads\": 12},\n \"gpt2-medium (355M)\": {\"emb_dim\": 1024, \"n_layers\": 24, \"n_heads\": 16},\n \"gpt2-large (774M)\": {\"emb_dim\": 1280, \"n_layers\": 36, \"n_heads\": 20},\n \"gpt2-xl (1558M)\": {\"emb_dim\": 1600, \"n_layers\": 48, \"n_heads\": 25},\n }\n\n CHOOSE_MODEL = \"gpt2-medium (355M)\"\n\n BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\n\n model_size = CHOOSE_MODEL.split(\" \")[-1].lstrip(\"(\").rstrip(\")\")\n settings, params = download_and_load_gpt2(model_size=model_size, models_dir=\"gpt2\")\n\n model = GPTModel(BASE_CONFIG)\n load_weights_into_gpt(model, params)\n model.eval()\n model.to(device)\n\n print(\"Loaded model:\", CHOOSE_MODEL)\n print(50*\"-\")\n\n if lora:\n total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\n print(f\"Total trainable parameters before: {total_params:,}\")\n\n for param in model.parameters():\n param.requires_grad = False\n\n total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\n print(f\"Total trainable parameters after: {total_params:,}\")\n replace_linear_with_lora(model, rank=16, alpha=16)\n\n total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)\n print(f\"Total trainable LoRA parameters: {total_params:,}\")\n model.to(device)\n\n #######################################\n # Finetuning the model\n #######################################\n print(\"Initial losses\")\n with torch.no_grad():\n train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)\n val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)\n\n print(\" Training loss:\", train_loss)\n print(\" Validation loss:\", val_loss)\n\n start_time = time.time()\n\n num_epochs = 2\n optimizer = torch.optim.AdamW(model.parameters(), lr=0.00005, weight_decay=0.1)\n\n torch.manual_seed(123)\n\n start_context = format_input_phi(val_data[0]) if phi3_prompt else format_input(val_data[0])\n\n train_losses, val_losses, tokens_seen = train_model_simple(\n model, train_loader, val_loader, optimizer, device,\n num_epochs=num_epochs, eval_freq=5, eval_iter=5,\n start_context=start_context, tokenizer=tokenizer\n )\n\n end_time = time.time()\n execution_time_minutes = (end_time - start_time) / 60\n print(f\"Training completed in {execution_time_minutes:.2f} minutes.\")\n\n epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))\n\n plot_name = \"loss-plot.pdf\"\n if mask_instructions:\n plot_name = plot_name.replace(\".pdf\", \"-mask-instructions.pdf\")\n if alpaca52k:\n plot_name = plot_name.replace(\".pdf\", \"-alpaca52k.pdf\")\n if phi3_prompt:\n plot_name = plot_name.replace(\".pdf\", \"-phi3-prompt.pdf\")\n if lora:\n plot_name = plot_name.replace(\".pdf\", \"-lora.pdf\")\n if not any([mask_instructions, alpaca52k, phi3_prompt, lora]):\n plot_name = plot_name.replace(\".pdf\", \"-baseline.pdf\")\n\n plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses, plot_name)\n print(50*\"-\")\n\n #######################################\n # Saving results\n #######################################\n print(\"Generating responses\")\n for i, entry in tqdm(enumerate(test_data), total=len(test_data)):\n\n input_text = format_input_phi(entry) if phi3_prompt else format_input(entry)\n\n token_ids = generate(\n model=model,\n idx=text_to_token_ids(input_text, tokenizer).to(device),\n max_new_tokens=256,\n context_size=BASE_CONFIG[\"context_length\"],\n eos_id=50256\n )\n generated_text = token_ids_to_text(token_ids, tokenizer)\n\n if phi3_prompt:\n response_text = generated_text[len(input_text):].replace(\"<|assistant|>:\", \"\").strip()\n else:\n response_text = generated_text[len(input_text):].replace(\"### Response:\", \"\").strip()\n\n test_data[i][\"model_response\"] = response_text\n\n test_data_path = \"instruction-data-with-response.json\"\n file_name = f\"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft.pth\"\n\n if mask_instructions:\n test_data_path = test_data_path.replace(\".json\", \"-mask-instructions.json\")\n file_name = file_name.replace(\".pth\", \"-mask-instructions.pth\")\n if alpaca52k:\n test_data_path = test_data_path.replace(\".json\", \"-alpaca52k.json\")\n file_name = file_name.replace(\".pth\", \"-alpaca52k.pth\")\n if phi3_prompt:\n test_data_path = test_data_path.replace(\".json\", \"-phi3-prompt.json\")\n file_name = file_name.replace(\".pth\", \"-phi3-prompt.pth\")\n if lora:\n test_data_path = test_data_path.replace(\".json\", \"-lora.json\")\n file_name = file_name.replace(\".pth\", \"-lora.pth\")\n if not any([mask_instructions, alpaca52k, phi3_prompt, lora]):\n test_data_path = test_data_path.replace(\".json\", \"-baseline.json\")\n file_name = file_name.replace(\".pth\", \"-baseline.pth\")\n\n with open(test_data_path, \"w\") as file:\n json.dump(test_data, file, indent=4) # \"indent\" for pretty-printing\n print(f\"Responses saved as {test_data_path}\")\n\n torch.save(model.state_dict(), file_name)\n print(f\"Model saved as {file_name}\")\n\n\nif __name__ == \"__main__\":\n\n import argparse\n\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description=\"Instruction finetune a GPT model\"\n )\n options = {\"baseline\", \"mask_instructions\", \"alpaca_52k\", \"phi3_prompt\", \"lora\"}\n parser.add_argument(\n \"--exercise_solution\",\n type=str,\n default=\"baseline\",\n help=(\n f\"Which experiment to run. Options: {options}.\"\n )\n )\n args = parser.parse_args()\n\n if args.exercise_solution == \"baseline\":\n main()\n elif args.exercise_solution == \"mask_instructions\":\n main(mask_instructions=True)\n elif args.exercise_solution == \"alpaca_52k\":\n main(alpaca52k=True)\n elif args.exercise_solution == \"phi3_prompt\":\n main(phi3_prompt=True)\n elif args.exercise_solution == \"lora\":\n main(lora=True)\n else:\n raise ValueError(f\"{args.exercise_solution} is not a valid --args.exercise_solution option. Options: {options}\")\n"
},
{
"path": "ch07/01_main-chapter-code/gpt_download.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n\n\nimport os\nimport json\n\nimport numpy as np\nimport requests\nimport tensorflow as tf\nfrom tqdm import tqdm\n\n\ndef download_and_load_gpt2(model_size, models_dir):\n # Validate model size\n allowed_sizes = (\"124M\", \"355M\", \"774M\", \"1558M\")\n if model_size not in allowed_sizes:\n raise ValueError(f\"Model size not in {allowed_sizes}\")\n\n # Define paths\n model_dir = os.path.join(models_dir, model_size)\n base_url = \"https://openaipublic.blob.core.windows.net/gpt-2/models\"\n backup_base_url = \"https://f001.backblazeb2.com/file/LLMs-from-scratch/gpt2\"\n filenames = [\n \"checkpoint\", \"encoder.json\", \"hparams.json\",\n \"model.ckpt.data-00000-of-00001\", \"model.ckpt.index\",\n \"model.ckpt.meta\", \"vocab.bpe\"\n ]\n\n # Download files\n os.makedirs(model_dir, exist_ok=True)\n for filename in filenames:\n file_url = os.path.join(base_url, model_size, filename)\n backup_url = os.path.join(backup_base_url, model_size, filename)\n file_path = os.path.join(model_dir, filename)\n download_file(file_url, file_path, backup_url)\n\n # Load settings and params\n tf_ckpt_path = tf.train.latest_checkpoint(model_dir)\n settings = json.load(open(os.path.join(model_dir, \"hparams.json\"), \"r\", encoding=\"utf-8\"))\n params = load_gpt2_params_from_tf_ckpt(tf_ckpt_path, settings)\n\n return settings, params\n\n\ndef download_file(url, destination, backup_url=None):\n def _attempt_download(download_url):\n response = requests.get(download_url, stream=True, timeout=60)\n response.raise_for_status()\n\n file_size = int(response.headers.get(\"Content-Length\", 0))\n\n # Check if file exists and has same size\n if os.path.exists(destination):\n file_size_local = os.path.getsize(destination)\n if file_size and file_size == file_size_local:\n print(f\"File already exists and is up-to-date: {destination}\")\n return True\n\n block_size = 1024 # 1 KB\n desc = os.path.basename(download_url)\n with tqdm(total=file_size, unit=\"iB\", unit_scale=True, desc=desc) as progress_bar:\n with open(destination, \"wb\") as file:\n for chunk in response.iter_content(chunk_size=block_size):\n if chunk:\n file.write(chunk)\n progress_bar.update(len(chunk))\n return True\n\n try:\n if _attempt_download(url):\n return\n except requests.exceptions.RequestException:\n if backup_url is not None:\n print(f\"Primary URL ({url}) failed. Attempting backup URL: {backup_url}\")\n try:\n if _attempt_download(backup_url):\n return\n except requests.exceptions.RequestException:\n pass\n\n error_message = (\n f\"Failed to download from both primary URL ({url})\"\n f\"{' and backup URL (' + backup_url + ')' if backup_url else ''}.\"\n \"\\nCheck your internet connection or the file availability.\\n\"\n \"For help, visit: https://github.com/rasbt/LLMs-from-scratch/discussions/273\"\n )\n print(error_message)\n except Exception as e:\n print(f\"An unexpected error occurred: {e}\")\n\n\ndef load_gpt2_params_from_tf_ckpt(ckpt_path, settings):\n # Initialize parameters dictionary with empty blocks for each layer\n params = {\"blocks\": [{} for _ in range(settings[\"n_layer\"])]}\n\n # Iterate over each variable in the checkpoint\n for name, _ in tf.train.list_variables(ckpt_path):\n # Load the variable and remove singleton dimensions\n variable_array = np.squeeze(tf.train.load_variable(ckpt_path, name))\n\n # Process the variable name to extract relevant parts\n variable_name_parts = name.split(\"/\")[1:] # Skip the 'model/' prefix\n\n # Identify the target dictionary for the variable\n target_dict = params\n if variable_name_parts[0].startswith(\"h\"):\n layer_number = int(variable_name_parts[0][1:])\n target_dict = params[\"blocks\"][layer_number]\n\n # Recursively access or create nested dictionaries\n for key in variable_name_parts[1:-1]:\n target_dict = target_dict.setdefault(key, {})\n\n # Assign the variable array to the last key\n last_key = variable_name_parts[-1]\n target_dict[last_key] = variable_array\n\n return params\n"
},
{
"path": "ch07/01_main-chapter-code/gpt_instruction_finetuning.py",
"content": "# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).\n# Source for \"Build a Large Language Model From Scratch\"\n# - https://www.manning.com/books/build-a-large-language-model-from-scratch\n# Code: https://github.com/rasbt/LLMs-from-scratch\n#\n# A minimal instruction finetuning file based on the code in chapter 7\n\nfrom functools import partial\nfrom importlib.metadata import version\nimport json\nimport os\nimport re\nimport time\n\nimport matplotlib.pyplot as plt\nimport requests\nimport tiktoken\nimport torch\nfrom torch.utils.data import Dataset, DataLoader\nfrom tqdm import tqdm\n\n# Import from local files in this folder\nfrom gpt_download import download_and_load_gpt2\nfrom previous_chapters import (\n calc_loss_loader,\n generate,\n GPTModel,\n load_weights_into_gpt,\n text_to_token_ids,\n train_model_simple,\n token_ids_to_text\n)\n\n\nclass InstructionDataset(Dataset):\n def __init__(self, data, tokenizer):\n self.data = data\n\n # Pre-tokenize texts\n self.encoded_texts = []\n for entry in data:\n instruction_plus_input = format_input(entry)\n response_text = f\"\\n\\n### Response:\\n{entry['output']}\"\n full_text = instruction_plus_input + response_text\n self.encoded_texts.append(\n tokenizer.encode(full_text)\n )\n\n def __getitem__(self, index):\n return self.encoded_texts[index]\n\n def __len__(self):\n return len(self.data)\n\n\ndef custom_collate_fn(\n batch,\n pad_token_id=50256,\n ignore_index=-100,\n allowed_max_length=None,\n device=\"cpu\"\n):\n # Find the longest sequence in the batch\n batch_max_length = max(len(item)+1 for item in batch)\n\n # Pad and prepare inputs and targets\n inputs_lst, targets_lst = [], []\n\n for item in batch:\n new_item = item.copy()\n # Add an <|endoftext|> token\n new_item += [pad_token_id]\n # Pad sequences to max_length\n padded = new_item + [pad_token_id] * (batch_max_length - len(new_item))\n inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs\n targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets\n\n # New: Replace all but the first padding tokens in targets by ignore_index\n mask = targets == pad_token_id\n indices = torch.nonzero(mask).squeeze()\n if indices.numel() > 1:\n targets[indices[1:]] = ignore_index\n\n # New: Optionally truncate to maximum sequence length\n if allowed_max_length is not None:\n inputs = inputs[:allowed_max_length]\n targets = targets[:allowed_max_length]\n\n inputs_lst.append(inputs)\n targets_lst.append(targets)\n\n # Convert list of inputs and targets to tensors and transfer to target device\n inputs_tensor = torch.stack(inputs_lst).to(device)\n targets_tensor = torch.stack(targets_lst).to(device)\n\n return inputs_tensor, targets_tensor\n\n\ndef download_and_load_file(file_path, url):\n if not os.path.exists(file_path):\n response = requests.get(url, timeout=30)\n response.raise_for_status()\n text_data = response.text\n with open(file_path, \"w\", encoding=\"utf-8\") as file:\n file.write(text_data)\n\n with open(file_path, \"r\", encoding=\"utf-8\") as file:\n data = json.load(file)\n\n return data\n\n\ndef format_input(entry):\n instruction_text = (\n f\"Below is an instruction that describes a task. \"\n f\"Write a response that appropriately completes the request.\"\n f\"\\n\\n### Instruction:\\n{entry['instruction']}\"\n )\n\n input_text = f\"\\n\\n### Input:\\n{entry['input']}\" if entry[\"input\"] else \"\"\n\n return instruction_text + input_text\n\n\ndef plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):\n fig, ax1 = plt.subplots(figsize=(12, 6))\n\n # Plot training and validation loss against epochs\n ax1.plot(epochs_seen, train_losses, label=\"Training loss\")\n ax1.plot(epochs_seen, val_losses, linestyle=\"-.\", label=\"Validation loss\")\n ax1.set_xlabel(\"Epochs\")\n ax1.set_ylabel(\"Loss\")\n ax1.legend(loc=\"upper right\")\n\n # Create a second x-axis for tokens seen\n ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis\n ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks\n ax2.set_xlabel(\"Tokens seen\")\n\n fig.tight_layout() # Adjust layout to make room\n plot_name = \"loss-plot-standalone.pdf\"\n print(f\"Plot saved as {plot_name}\")\n plt.savefig(plot_name)\n # plt.show()\n\n\ndef main(test_mode=False):\n #######################################\n # Print package versions\n #######################################\n print()\n pkgs = [\n \"matplotlib\", # Plotting library\n \"tiktoken\", # Tokenizer\n \"torch\", # Deep learning library\n \"tqdm\", # Progress bar\n \"tensorflow\", # For OpenAI's pretrained weights\n ]\n for p in pkgs:\n print(f\"{p} version: {version(p)}\")\n print(50*\"-\")\n\n #######################################\n # Download and prepare dataset\n #######################################\n file_path = \"instruction-data.json\"\n url = \"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch07/01_main-chapter-code/instruction-data.json\"\n data = download_and_load_file(file_path, url)\n\n train_portion = int(len(data) * 0.85) # 85% for training\n test_portion = int(len(data) * 0.1) # 10% for testing\n\n train_data = data[:train_portion]\n test_data = data[train_portion:train_portion + test_portion]\n val_data = data[train_portion + test_portion:]\n\n # Use very small subset for testing purposes\n if test_mode:\n train_data = train_data[:10]\n val_data = val_data[:10]\n test_data = test_data[:10]\n\n print(\"Training set length:\", len(train_data))\n print(\"Validation set length:\", len(val_data))\n print(\"Test set length:\", len(test_data))\n print(50*\"-\")\n\n tokenizer = tiktoken.get_encoding(\"gpt2\")\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n print(\"Device:\", device)\n print(50*\"-\")\n\n customized_collate_fn = partial(custom_collate_fn, device=device, allowed_max_length=1024)\n\n num_workers = 0\n batch_size = 8\n\n torch.manual_seed(123)\n\n train_dataset = InstructionDataset(train_data, tokenizer)\n train_loader = DataLoader(\n train_dataset,\n batch_size=batch_size,\n collate_fn=customized_collate_fn,\n shuffle=True,\n drop_last=True,\n num_workers=num_workers\n )\n\n val_dataset = InstructionDataset(val_data, tokenizer)\n val_loader = DataLoader(\n val_dataset,\n batch_size=batch_size,\n collate_fn=customized_collate_fn,\n shuffle=False,\n drop_last=False,\n num_workers=num_workers\n )\n\n #######################################\n # Load pretrained model\n #######################################\n\n # Small GPT model for testing purposes\n if args.test_mode:\n BASE_CONFIG = {\n \"vocab_size\": 50257,\n \"context_length\": 120,\n \"drop_rate\": 0.0,\n \"qkv_bias\": False,\n \"emb_dim\": 12,\n \"n_layers\": 1,\n \"n_heads\": 2\n }\n model = GPTModel(BASE_CONFIG)\n model.eval()\n device = \"cpu\"\n CHOOSE_MODEL = \"Small test model\"\n\n # Code as it is used in the main chapter\n else:\n BASE_CONFIG = {\n \"vocab_size\": 50257, # Vocabulary size\n \"context_length\": 1024, # Context length\n \"drop_rate\": 0.0, # Dropout rate\n \"qkv_bias\": True # Query-key-value bias\n }\n\n model_configs = {\n \"gpt2-small (124M)\": {\"emb_dim\": 768, \"n_layers\": 12, \"n_heads\": 12},\n \"gpt2-medium (355M)\": {\"emb_dim\": 1024, \"n_layers\": 24, \"n_heads\": 16},\n \"gpt2-large (774M)\": {\"emb_dim\": 1280, \"n_layers\": 36, \"n_heads\": 20},\n \"gpt2-xl (1558M)\": {\"emb_dim\": 1600, \"n_layers\": 48, \"n_heads\": 25},\n }\n\n CHOOSE_MODEL = \"gpt2-medium (355M)\"\n\n BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\n\n model_size = CHOOSE_MODEL.split(\" \")[-1].lstrip(\"(\").rstrip(\")\")\n settings, params = download_and_load_gpt2(model_size=model_size, models_dir=\"gpt2\")\n\n model = GPTModel(BASE_CONFIG)\n load_weights_into_gpt(model, params)\n model.eval()\n model.to(device)\n\n print(\"Loaded model:\", CHOOSE_MODEL)\n print(50*\"-\")\n\n #######################################\n # Finetuning the model\n #######################################\n print(\"Initial losses\")\n with torch.no_grad():\n train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)\n val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)\n\n print(\" Training loss:\", train_loss)\n print(\" Validation loss:\", val_loss)\n\n start_time = time.time()\n optimizer = torch.optim.AdamW(model.parameters(), lr=0.00005, weight_decay=0.1)\n\n num_epochs = 2\n\n torch.manual_seed(123)\n train_losses, val_losses, tokens_seen = train_model_simple(\n model, train_loader, val_loader, optimizer, device,\n num_epochs=num_epochs, eval_freq=5, eval_iter=5,\n start_context=format_input(val_data[0]), tokenizer=tokenizer\n )\n\n end_time = time.time()\n execution_time_minutes = (end_time - start_time) / 60\n print(f\"Training completed in {execution_time_minutes:.2f} minutes.\")\n\n epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))\n plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)\n print(50*\"-\")\n\n #######################################\n # Saving results\n #######################################\n print(\"Generating responses\")\n for i, entry in tqdm(enumerate(test_data), total=len(test_data)):\n\n input_text = format_input(entry)\n\n token_ids = generate(\n model=model,\n idx=text_to_token_ids(input_text, tokenizer).to(device),\n max_new_tokens=256,\n context_size=BASE_CONFIG[\"context_length\"],\n eos_id=50256\n )\n generated_text = token_ids_to_text(token_ids, tokenizer)\n response_text = generated_text[len(input_text):].replace(\"### Response:\", \"\").strip()\n\n test_data[i][\"model_response\"] = response_text\n\n test_data_path = \"instruction-data-with-response-standalone.json\"\n with open(test_data_path, \"w\") as file:\n json.dump(test_data, file, indent=4) # \"indent\" for pretty-printing\n print(f\"Responses saved as {test_data_path}\")\n\n file_name = f\"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft-standalone.pth\"\n torch.save(model.state_dict(), file_name)\n print(f\"Model saved as {file_name}\")\n\n\nif __name__ == \"__main__\":\n\n import argparse\n\n parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description=\"Finetune a GPT model for classification\"\n )\n parser.add_argument(\n \"--test_mode\",\n default=False,\n action=\"store_true\",\n help=(\"This flag runs the model in test mode for internal testing purposes. \"\n \"Otherwise, it runs the model as it is used in the chapter (recommended).\")\n )\n args = parser.parse_args()\n\n main(args.test_mode)\n"
},
{
"path": "ch07/01_main-chapter-code/instruction-data-with-response.json",
"content": "[\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The car is very fast.\",\n \"output\": \"The car is as fast as lightning.\",\n \"model_response\": \"The car is as fast as a bullet.\"\n },\n {\n \"instruction\": \"What type of cloud is typically associated with thunderstorms?\",\n \"input\": \"\",\n \"output\": \"The type of cloud typically associated with thunderstorms is cumulonimbus.\",\n \"model_response\": \"The type of cloud associated with thunderstorms is a cumulus cloud.\"\n },\n {\n \"instruction\": \"Name the author of 'Pride and Prejudice'.\",\n \"input\": \"\",\n \"output\": \"Jane Austen.\",\n \"model_response\": \"The author of 'Pride and Prejudice' is Jane Austen.\"\n },\n {\n \"instruction\": \"What is the periodic symbol for chlorine?\",\n \"input\": \"\",\n \"output\": \"The periodic symbol for chlorine is Cl.\",\n \"model_response\": \"The periodic symbol for chlorine is C.\"\n },\n {\n \"instruction\": \"Correct the punctuation in the sentence.\",\n \"input\": \"Its time to go home.\",\n \"output\": \"The corrected sentence should be: 'It's time to go home.'\",\n \"model_response\": \"It's time to go home.\"\n },\n {\n \"instruction\": \"Rewrite the sentence.\",\n \"input\": \"The lecture was delivered in a clear manner.\",\n \"output\": \"The lecture was delivered clearly.\",\n \"model_response\": \"The lecture was delivered in a clear manner.\"\n },\n {\n \"instruction\": \"Generate a humorous anecdote.\",\n \"input\": \"\",\n \"output\": \"Why was the math book sad? Because it had too many problems!\",\n \"model_response\": \"The cat jumped over the fence.\"\n },\n {\n \"instruction\": \"Identify the correct spelling: 'recieve' or 'receive'.\",\n \"input\": \"\",\n \"output\": \"The correct spelling is 'receive'.\",\n \"model_response\": \"The correct spelling is 'receive'.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'nostalgia'.\",\n \"input\": \"\",\n \"output\": \"Nostalgia washed over her as she looked through the old photos.\",\n \"model_response\": \"Nostalgia is a strong emotion that can be felt in the past.\"\n },\n {\n \"instruction\": \"Classify the following numbers as prime or composite.\",\n \"input\": \": 11, 14, 19.\",\n \"output\": \"Prime numbers: 11, 19\\nComposite numbers: 14\",\n \"model_response\": \"Prime numbers: 11, 14, 19.Composite numbers: 14, 19.\"\n },\n {\n \"instruction\": \"What is the capital of Denmark?\",\n \"input\": \"\",\n \"output\": \"The capital of Denmark is Copenhagen.\",\n \"model_response\": \"The capital of Denmark is Copenhagen.\"\n },\n {\n \"instruction\": \"What is the opposite of 'wet'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'wet' is 'dry'.\",\n \"model_response\": \"The opposite of 'wet' is 'dry'.\"\n },\n {\n \"instruction\": \"Identify the type of sentence.\",\n \"input\": \"Did you finish the report?\",\n \"output\": \"The type of sentence is interrogative.\",\n \"model_response\": \"The type of sentence is imperative.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for mercury?\",\n \"input\": \"\",\n \"output\": \"Hg.\",\n \"model_response\": \"The chemical symbol for mercury is Hg.\"\n },\n {\n \"instruction\": \"Describe the process of active transport in cells.\",\n \"input\": \"\",\n \"output\": \"Active transport is the movement of molecules across a cell membrane from a region of lower concentration to a region of higher concentration, using energy in the form of ATP. This process is crucial for maintaining cellular homeostasis.\",\n \"model_response\": \"Transport is the process by which a substance moves from one place to another by chemical change. It typically occurs by chemical reactions between atoms or molecules.\"\n },\n {\n \"instruction\": \"Classify the following items as either solid, liquid, or gas.\",\n \"input\": \"Mercury, oxygen, wood\",\n \"output\": \"Mercury - Liquid\\nOxygen - Gas\\nWood - Solid\",\n \"model_response\": \", water\\n\\n\\nSolid: Carbon\\nLiquefied Carbon: Oxygen\\nGas: Carbon dioxide\\nGaseous Carbon: Carbon monoxide\"\n },\n {\n \"instruction\": \"Convert 3 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"3 kilometers is 3000 meters.\",\n \"model_response\": \"3 kilometers is 3000 meters.\"\n },\n {\n \"instruction\": \"Convert the sentence to use an indefinite pronoun.\",\n \"input\": \"Someone left a note.\",\n \"output\": \"A note was left by someone.\",\n \"model_response\": \"A note was left by someone.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'excited'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'excited' is 'thrilled'.\",\n \"model_response\": \"A synonym for 'excited' is 'enthusiastic'.\"\n },\n {\n \"instruction\": \"Generate a sentence that follows the pattern: \\\"Never have I ever _____ without _____\\\"\",\n \"input\": \"\",\n \"output\": \"Never have I ever traveled without a map.\",\n \"model_response\": \"Never have I ever had without having.\"\n },\n {\n \"instruction\": \"Pick out the adjective from the following list.\",\n \"input\": \"run, tall, quickly\",\n \"output\": \"The correct adjective from the list is 'tall.'\",\n \"model_response\": \"The adjective from the list is 'quick'.\"\n },\n {\n \"instruction\": \"Convert 1000 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"1000 grams is equal to 1 kilogram.\",\n \"model_response\": \"1000 grams is 0.1 kilograms.\"\n },\n {\n \"instruction\": \"What is the opposite of 'deep'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'deep' is 'shallow'.\",\n \"model_response\": \"The opposite of 'deep' is 'light'.\"\n },\n {\n \"instruction\": \"Categorize the given list of animals.\",\n \"input\": \"Shark, Dolphin, Trout\",\n \"output\": \"Fish: Shark, Trout\\nMammals: Dolphin\",\n \"model_response\": \"Animals: Shark, Dolphin, Trout\"\n },\n {\n \"instruction\": \"Translate 'library' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish word for 'library' is 'biblioteca'.\",\n \"model_response\": \"The Spanish translation of 'library' is 'l\\u00edmite'.\"\n },\n {\n \"instruction\": \"Define the term 'hyperbole'.\",\n \"input\": \"\",\n \"output\": \"Hyperbole is a figure of speech that involves an exaggeration of ideas for the sake of emphasis.\",\n \"model_response\": \"Hyperbole is a word used to describe a statement that is exaggerated or exaggerated in meaning.\"\n },\n {\n \"instruction\": \"Translate 'Hello' into Russian.\",\n \"input\": \"\",\n \"output\": \"\\u041f\\u0440\\u0438\\u0432\\u0435\\u0442 (Privet)\",\n \"model_response\": \"The Russian translation of 'Hello' is '\\u0420\\u0443\\u0441\\u0441\\u043a\\u0438\\u0439 \\u043f\\u0440\\u043e\\u0438\\u0437\\u0432\\u0435\\u0434\\u0435\\u043d\\u0438\\u0439' (Vyacheslav Krasnoyarski).\"\n },\n {\n \"instruction\": \"Define the term 'kinetic energy'.\",\n \"input\": \"\",\n \"output\": \"Kinetic energy is the energy that an object possesses due to its motion.\",\n \"model_response\": \"Kinetic energy is the force that causes an object to accelerate or decelerate in response to an applied force.\"\n },\n {\n \"instruction\": \"What is the opposite of 'hot'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'hot' is 'cold'.\",\n \"model_response\": \"The opposite of 'hot' is 'cold'.\"\n },\n {\n \"instruction\": \"Convert 5 miles to kilometers.\",\n \"input\": \"\",\n \"output\": \"5 miles is approximately 8.05 kilometers.\",\n \"model_response\": \"5 miles is 5000 meters.\"\n },\n {\n \"instruction\": \"What is the chemical formula for magnesium sulfate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for magnesium sulfate is MgSO4.\",\n \"model_response\": \"The chemical formula for magnesium sulfate is MgSO4.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to replace any clich\\u00e9 phrases.\",\n \"input\": \"It's a piece of cake\",\n \"output\": \"It's very easy.\",\n \"model_response\": \".\\n\\n\\nA piece of cake is a cake.\"\n },\n {\n \"instruction\": \"List five different types of vegetables.\",\n \"input\": \"\",\n \"output\": \"1. Carrot\\n2. Broccoli\\n3. Cucumber\\n4. Tomato\\n5. Spinach\",\n \"model_response\": \"1. Cucumber\\n2. Broccoli\\n3. Spinach\\n4. Tomato\\n5. Cucumber\"\n },\n {\n \"instruction\": \"Convert 7 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"7 kilometers is 7000 meters.\",\n \"model_response\": \"7 kilometers is 7.048 meters.\"\n },\n {\n \"instruction\": \"What is the opposite of 'heavy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'heavy' is 'light'.\",\n \"model_response\": \"The opposite of 'heavy' is 'light'.\"\n },\n {\n \"instruction\": \"What is the past tense of 'sing'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'sing' is 'sang.'\",\n \"model_response\": \"The past tense of 'sing' is 'to sing.'\"\n },\n {\n \"instruction\": \"What is the molecular formula for carbon dioxide?\",\n \"input\": \"\",\n \"output\": \"The molecular formula for carbon dioxide is CO2.\",\n \"model_response\": \"The molecular formula for carbon dioxide is CO2.\"\n },\n {\n \"instruction\": \"Convert this sentence to passive voice\",\n \"input\": \"The gardener watered the plants.\",\n \"output\": \"The plants were watered by the gardener.\",\n \"model_response\": \"The plants were watered by the gardener.\"\n },\n {\n \"instruction\": \"What is the past tense of 'throw'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'throw' is 'threw'.\",\n \"model_response\": \"The past tense of 'throw' is 'to throw'.\"\n },\n {\n \"instruction\": \"Explain what a sonnet is.\",\n \"input\": \"\",\n \"output\": \"A sonnet is a 14-line poem with a specific rhyme scheme and meter, often written in iambic pentameter.\",\n \"model_response\": \"A sonnet is a poem composed in the first person.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovative'.\",\n \"input\": \"\",\n \"output\": \"The company is known for its innovative products.\",\n \"model_response\": \"She was very innovative and always had a new idea.\"\n },\n {\n \"instruction\": \"Provide the plural form of 'cactus'.\",\n \"input\": \"\",\n \"output\": \"The plural form of 'cactus' is 'cacti'.\",\n \"model_response\": \"The plural form of 'cactus' is 'cacti'.\"\n },\n {\n \"instruction\": \"Translate the phrase 'Where is the bathroom?' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'Where is the bathroom?' is 'Wo ist die Toilette?'\",\n \"model_response\": \"The German translation of 'Where is the bathroom?' is 'Wie es \\u00fcber das B\\u00fccher?'.\"\n },\n {\n \"instruction\": \"Generate a past-tense verb that describes a person laughing.\",\n \"input\": \"\",\n \"output\": \"Laughed.\",\n \"model_response\": \"She laughed.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'transient.'\",\n \"input\": \"\",\n \"output\": \"The transient nature of her visit left a lasting impression.\",\n \"model_response\": \"She was seen by a passing car as it passed by.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'optimistic'.\",\n \"input\": \"\",\n \"output\": \"He remained optimistic despite the challenges he faced.\",\n \"model_response\": \"She was optimistic about the future.\"\n },\n {\n \"instruction\": \"Re-word this sentence using an indirect question.\",\n \"input\": \"What time is the meeting?\",\n \"output\": \"Could you tell me what time the meeting is?\",\n \"model_response\": \"The meeting is at 7:00 PM.\"\n },\n {\n \"instruction\": \"Categorize the following sentence as a statement, a question, or an exclamation.\",\n \"input\": \"What a beautiful day!\",\n \"output\": \"Exclamation.\",\n \"model_response\": \"A statement could be classified as a question.\"\n },\n {\n \"instruction\": \"What is the opposite of 'rich'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'rich' is 'poor'.\",\n \"model_response\": \"The opposite of 'rich' is 'poor'.\"\n },\n {\n \"instruction\": \"Find a synonym for the given verb.\",\n \"input\": \"Begin\",\n \"output\": \"Commence\",\n \"model_response\": \"Begin\\n\\n### Input:\\nBegin\\n\\n\\nBegin\\n\\n### Input:\\nBegin\\n\\nBegin\\n### Input:\\nBegin\\n\\nBegin\"\n },\n {\n \"instruction\": \"Edit the given text to ensure all plural nouns are spelled correctly.\",\n \"input\": \"The birds sings beautiful songs.\",\n \"output\": \"The birds sing beautiful songs.\",\n \"model_response\": \"The birds sings beautiful songs.\"\n },\n {\n \"instruction\": \"Transform the following sentence into a question using \\\"could.\\\"\",\n \"input\": \"You can help me tomorrow.\",\n \"output\": \"Could you help me tomorrow?\",\n \"model_response\": \"Could you help me tomorrow?\"\n },\n {\n \"instruction\": \"Classify the following items: bicycle, rose, tiger.\",\n \"input\": \"\",\n \"output\": \"Vehicles: Bicycle\\nPlants: Rose\\nAnimals: Tiger\",\n \"model_response\": \"Animals: Tiger\\nBicyclist: Tiger\\nRose: Rose\\nBike: Tiger\"\n },\n {\n \"instruction\": \"Define the term 'irony'.\",\n \"input\": \"\",\n \"output\": \"Irony is a figure of speech in which words are used in such a way that their intended meaning is different from the actual meaning of the words.\",\n \"model_response\": \"An irony is a statement that is at odds with the truth.\"\n },\n {\n \"instruction\": \"Translate 'Welcome' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'Welcome' is 'Willkommen'.\",\n \"model_response\": \"The German translation of 'Welcome' is 'Wie es tut mir leid'.\"\n },\n {\n \"instruction\": \"Explain the primary function of the human heart.\",\n \"input\": \"\",\n \"output\": \"The primary function of the human heart is to pump blood throughout the body, delivering oxygen and nutrients to tissues and removing carbon dioxide and other wastes.\",\n \"model_response\": \"The primary function of the human heart is to pump blood to the brain and to supply the muscles and nerves that control movement.\"\n },\n {\n \"instruction\": \"Reword the following sentence to the future tense.\",\n \"input\": \"He is reading a novel inspired by his grandmother.\",\n \"output\": \"He will be reading a novel inspired by his grandmother.\",\n \"model_response\": \"He is reading a novel inspired by his grandmother.\"\n },\n {\n \"instruction\": \"Convert the given sentence into active voice.\",\n \"input\": \"The law was passed by the government.\",\n \"output\": \"The government passed the law.\",\n \"model_response\": \"The law was passed by the government.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'inevitable'.\",\n \"input\": \"\",\n \"output\": \"The confrontation was inevitable given the circumstances.\",\n \"model_response\": \"The storm was inevitable.\"\n },\n {\n \"instruction\": \"Categorize the following sentence as either factual or opinion-based.\",\n \"input\": \"Chocolate is the best dessert.\",\n \"output\": \"Opinion-based.\",\n \"model_response\": \"Categorize the following sentence as either factual or opinion-based.\"\n },\n {\n \"instruction\": \"What is an antonym of 'old'?\",\n \"input\": \"\",\n \"output\": \"young.\",\n \"model_response\": \"An antonym of 'old' is 'young'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'hardworking'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'hardworking' is 'diligent'.\",\n \"model_response\": \"A synonym for 'hardworking' is 'smart'.\"\n },\n {\n \"instruction\": \"What is the boiling point of sulfur in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of sulfur is 444.6 degrees Celsius.\",\n \"model_response\": \"The boiling point of sulfur is -114.5 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the plural form of 'child'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'child' is 'children'.\",\n \"model_response\": \"The plural form of 'child' is 'chunk'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'complicated'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'complicated' is 'simple'.\",\n \"model_response\": \"An antonym of 'complicated' is 'simple'.\"\n },\n {\n \"instruction\": \"Name three forms of water.\",\n \"input\": \"\",\n \"output\": \"The three forms of water are solid (ice), liquid (water), and gas (steam).\",\n \"model_response\": \"Three forms of water are rain, snow, and water.\"\n },\n {\n \"instruction\": \"Rewrite this sentence as a question.\",\n \"input\": \"The dog chased the cat.\",\n \"output\": \"Did the dog chase the cat?\",\n \"model_response\": \"What is the cat chasing?\"\n },\n {\n \"instruction\": \"Split the following sentence into two declarative sentences: 'The movie was long but interesting.'\",\n \"input\": \"\",\n \"output\": \"The movie was long. It was interesting.\",\n \"model_response\": \"and 'The movie was interesting.'\\n\\n\\nThe movie was long, but it was interesting.\"\n },\n {\n \"instruction\": \"Classify the following substances as acid, base, or neutral.\",\n \"input\": \"Lemon juice, Soap, Water\",\n \"output\": \"Acid: Lemon juice\\nBase: Soap\\nNeutral: Water\",\n \"model_response\": \"Acid: Soap\\nBase: Soap\\nNeutral: Water\"\n },\n {\n \"instruction\": \"What is a synonym of 'sad'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'sad' is 'unhappy'.\",\n \"model_response\": \"A synonym for 'sad' is 'angry'.\"\n },\n {\n \"instruction\": \"Correct any spelling mistakes in the given sentence.\",\n \"input\": \"I prefer homemade cookies to store boaght.\",\n \"output\": \"I prefer homemade cookies to store bought.\",\n \"model_response\": \"I prefer homemade cookies to store boaght.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'transient'.\",\n \"input\": \"\",\n \"output\": \"His stay in the city was transient, lasting only a couple of days.\",\n \"model_response\": \"She was seen by a passerby as she passed by.\"\n },\n {\n \"instruction\": \"Translate 'I am lost' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'I am lost' is 'Mi sono perso' (if male) or 'Mi sono persa' (if female).\",\n \"model_response\": \"Il pi\\u00f9 am\\u00e9ricaino.\"\n },\n {\n \"instruction\": \"Classify this text as a technical document or a narrative.\",\n \"input\": \"This manual provides instructions for installing the software.\",\n \"output\": \"Technical document\",\n \"model_response\": \"Technical document\"\n },\n {\n \"instruction\": \"Sort the following list in descending order.\",\n \"input\": \"10, 2, 25, 16, 7\",\n \"output\": \"25, 16, 10, 7, 2.\",\n \"model_response\": \", 3, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25\"\n },\n {\n \"instruction\": \"Translate 'Can I have some water?' into French.\",\n \"input\": \"\",\n \"output\": \"Puis-je avoir de l'eau?\",\n \"model_response\": \"Can I have some water?\"\n },\n {\n \"instruction\": \"Create a simile with the word 'as cold as'.\",\n \"input\": \"\",\n \"output\": \"Her hands were as cold as ice.\",\n \"model_response\": \"The temperature of 'as cold as' is -38 degrees Celsius.\"\n },\n {\n \"instruction\": \"Classify the following words by their grammatical categories: swim, beautiful, quickly\",\n \"input\": \"\",\n \"output\": \"Swim: Verb\\nBeautiful: Adjective\\nQuickly: Adverb\",\n \"model_response\": \"Classifying the following words by their grammatical categories: swim, beautiful, quickly\"\n },\n {\n \"instruction\": \"Calculate the density of an object with a mass of 15 grams and a volume of 5 cubic centimeters.\",\n \"input\": \"\",\n \"output\": \"The density of the object is 3 grams per cubic centimeter.\",\n \"model_response\": \"The density of the object is 15 grams/cm\\u00b3.\"\n },\n {\n \"instruction\": \"What is the abbreviation for 'Master of Business Administration'?\",\n \"input\": \"\",\n \"output\": \"The abbreviation for 'Master of Business Administration' is MBA.\",\n \"model_response\": \"The abbreviation for 'Master of Business Administration' is MBA.\"\n },\n {\n \"instruction\": \"Convert the following number from Roman numerals: IX.\",\n \"input\": \"\",\n \"output\": \"The number IX in Roman numerals is 9.\",\n \"model_response\": \"5 to decimal numbers: 0.5.\\n\\n\\n0.5 is 0.5.\"\n },\n {\n \"instruction\": \"What is the opposite of 'horizontal'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'horizontal' is 'vertical'.\",\n \"model_response\": \"The opposite of 'horizontal' is 'vertical'.\"\n },\n {\n \"instruction\": \"Translate 'Where can I buy tickets?' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation for 'Where can I buy tickets?' is 'Dove posso comprare i biglietti?'\",\n \"model_response\": \"The Italian translation of 'Where can I buy tickets?' is 'Ti amo'.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to replace any clich\\u00e9s.\",\n \"input\": \"He was as cool as a cucumber.\",\n \"output\": \"He remained very calm.\",\n \"model_response\": \"He was as cool as a cucumber.\"\n },\n {\n \"instruction\": \"Identify the main verb in the sentence.\",\n \"input\": \"The dog barked loudly.\",\n \"output\": \"The main verb in the sentence is 'barked'.\",\n \"model_response\": \"The main verb in the sentence is 'bark'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'elucidate'.\",\n \"input\": \"\",\n \"output\": \"The professor attempted to elucidate the complex topic for his students.\",\n \"model_response\": \"The teacher had studied the book for a long time.\"\n },\n {\n \"instruction\": \"Correct the sentence.\",\n \"input\": \"Me and my friend went to the store.\",\n \"output\": \"My friend and I went to the store.\",\n \"model_response\": \"We went to the store.\"\n },\n {\n \"instruction\": \"What is the formula for calculating work done?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating work done is work = force \\u00d7 distance.\",\n \"model_response\": \"The formula for calculating work done is W=M*G*A.\"\n },\n {\n \"instruction\": \"What is the chemical formula for ammonium nitrate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for ammonium nitrate is NH4NO3.\",\n \"model_response\": \"The chemical formula for ammonium nitrate is NH3.\"\n },\n {\n \"instruction\": \"What is the molecular formula for water?\",\n \"input\": \"\",\n \"output\": \"The molecular formula for water is H2O.\",\n \"model_response\": \"The molecular formula for water is H2O2.\"\n },\n {\n \"instruction\": \"Rewrite the given sentence to describe the same thing in a positive way.\",\n \"input\": \"The food was not good.\",\n \"output\": \"The food could use some improvement.\",\n \"model_response\": \"The food was not good.\"\n },\n {\n \"instruction\": \"What is the opposite of 'lazy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'lazy' is 'diligent'.\",\n \"model_response\": \"The opposite of 'lazy' is 'attentive'.\"\n },\n {\n \"instruction\": \"Name three essential vitamins for human health.\",\n \"input\": \"\",\n \"output\": \"1. Vitamin A\\n2. Vitamin C\\n3. Vitamin D\",\n \"model_response\": \"1. B6\\n2. B12\\n3. B12\\n### Instruction:\\nWhat is the chemical symbol for iron?\\n\\n\\nThe chemical symbol for iron is Fe.\"\n },\n {\n \"instruction\": \"Define the term 'simile'.\",\n \"input\": \"\",\n \"output\": \"A simile is a figure of speech that directly compares two different things, often introduced with the words 'like' or 'as'.\",\n \"model_response\": \"A simile is a figurative device used to describe a person or thing that is simile or similitude in form or function.\"\n },\n {\n \"instruction\": \"What is the boiling point of chlorine in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of chlorine is -34 degrees Celsius.\",\n \"model_response\": \"The boiling point of chlorine is -196 degrees Celsius.\"\n },\n {\n \"instruction\": \"Translate 'My name is' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'My name is' is 'Je m'appelle'.\",\n \"model_response\": \"The French translation of 'My name is' is 'Comment \\u00e7a va?'.\"\n },\n {\n \"instruction\": \"Convert 200 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"200 centimeters is 2 meters.\",\n \"model_response\": \"200 centimeters is 0.2 meters.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for zinc?\",\n \"input\": \"\",\n \"output\": \"Zn.\",\n \"model_response\": \"The chemical symbol for zinc is Zn.\"\n },\n {\n \"instruction\": \"What is the formula for calculating force?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating force is Force = mass x acceleration.\",\n \"model_response\": \"The formula for calculating force is (F = mv\\u00b2 + g)f, where m is mass and g is acceleration.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovative'.\",\n \"input\": \"\",\n \"output\": \"The company's innovative approach set it apart from its competitors.\",\n \"model_response\": \"She was very innovative and always had a new idea.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'generous'.\",\n \"input\": \"\",\n \"output\": \"He is very generous and always helps those in need.\",\n \"model_response\": \"She was very generous and gave the money to the poor.\"\n },\n {\n \"instruction\": \"What is an antonym of 'sharp'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'sharp' is 'dull'.\",\n \"model_response\": \"An antonym of 'sharp' is 'soft'.\"\n },\n {\n \"instruction\": \"Describe the basic structure of a neuron.\",\n \"input\": \"\",\n \"output\": \"A neuron consists of three main parts: the cell body, which contains the nucleus; dendrites, which receive signals from other neurons; and an axon, which transmits signals to other neurons, muscles, or glands.\",\n \"model_response\": \"A neuron is a type of synapse in the brain.\"\n },\n {\n \"instruction\": \"Translate 'see you later' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Hasta luego\",\n \"model_response\": \"Est\\u00e1n leyendo see you later.\"\n },\n {\n \"instruction\": \"What are the first 10 elements of the Fibonacci sequence?\",\n \"input\": \"\",\n \"output\": \"0, 1, 1, 2, 3, 5, 8, 13, 21, 34.\",\n \"model_response\": \"The first 10 elements of the Fibonacci sequence are: 1, 3, 5, 7, 11, 13, 15, 20.\"\n },\n {\n \"instruction\": \"What is an antonym of 'transparent'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'transparent' is 'opaque'.\",\n \"model_response\": \"An antonym of 'transparent' is 'illuminate'.\"\n },\n {\n \"instruction\": \"What is the past tense of 'think'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'think' is 'thought'.\",\n \"model_response\": \"The past tense of 'think' is 'to think'.\"\n },\n {\n \"instruction\": \"Classify each sentence as either declarative, interrogative, imperative, or exclamatory.\",\n \"input\": \"Please open the door.\",\n \"output\": \"The classification of the sentence 'Please open the door.' is imperative.\",\n \"model_response\": \"Please open the door.\"\n },\n {\n \"instruction\": \"Rewrite the sentence to use a negative adverb.\",\n \"input\": \"She always remembers to call.\",\n \"output\": \"She never forgets to call.\",\n \"model_response\": \"She always remembers to call.\"\n },\n {\n \"instruction\": \"Convert 50 miles per hour to kilometers per hour.\",\n \"input\": \"\",\n \"output\": \"50 miles per hour is approximately 80.47 kilometers per hour.\",\n \"model_response\": \"50 miles per hour is approximately 32.5 kilometers per hour.\"\n }\n]"
},
{
"path": "ch07/01_main-chapter-code/instruction-data.json",
"content": "[\n {\n \"instruction\": \"Evaluate the following phrase by transforming it into the spelling given.\",\n \"input\": \"freind --> friend\",\n \"output\": \"The spelling of the given phrase \\\"freind\\\" is incorrect, the correct spelling is \\\"friend\\\".\"\n },\n {\n \"instruction\": \"Edit the following sentence for grammar.\",\n \"input\": \"He go to the park every day.\",\n \"output\": \"He goes to the park every day.\"\n },\n {\n \"instruction\": \"Convert 45 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"45 kilometers is 45000 meters.\"\n },\n {\n \"instruction\": \"Rewrite this sentence to start with 'Although': Despite the rain, they went for a walk.\",\n \"input\": \"\",\n \"output\": \"Although it was raining, they went for a walk.\"\n },\n {\n \"instruction\": \"What are the first 10 square numbers?\",\n \"input\": \"\",\n \"output\": \"1, 4, 9, 16, 25, 36, 49, 64, 81, 100.\"\n },\n {\n \"instruction\": \"Suggest a more formal synonym for \\\"happy.\\\"\",\n \"input\": \"\",\n \"output\": \"A more formal synonym for \\\"happy\\\" is \\\"content.\\\"\"\n },\n {\n \"instruction\": \"Translate the following sentence into French.\",\n \"input\": \"Where is the nearest restaurant?\",\n \"output\": \"O\\u00f9 est le restaurant le plus proche?\"\n },\n {\n \"instruction\": \"Look up the melting point of iron.\",\n \"input\": \"\",\n \"output\": \"The melting point of iron is approximately 1538 degrees Celsius or 2800 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence so that it is in active voice.\",\n \"input\": \"The cake was baked by Sarah.\",\n \"output\": \"Sarah baked the cake.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'The manager approved the project.'\",\n \"input\": \"\",\n \"output\": \"The project was approved by the manager.\"\n },\n {\n \"instruction\": \"What is the contraction for \\\"will not\\\"?\",\n \"input\": \"\",\n \"output\": \"The contraction for \\\"will not\\\" is \\\"won't\\\".\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to remove redundancy.\",\n \"input\": \"The actual fact is that he was late.\",\n \"output\": \"The fact is that he was late.\"\n },\n {\n \"instruction\": \"What is the capital of Indonesia?\",\n \"input\": \"\",\n \"output\": \"The capital of Indonesia is Jakarta.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'bright'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'bright' is 'radiant'.\"\n },\n {\n \"instruction\": \"Suggest an alternate word for 'happy'.\",\n \"input\": \"\",\n \"output\": \"joyful.\"\n },\n {\n \"instruction\": \"Name the device that measures atmospheric pressure.\",\n \"input\": \"\",\n \"output\": \"The device that measures atmospheric pressure is a barometer.\"\n },\n {\n \"instruction\": \"List two antonyms for 'intelligent.'\",\n \"input\": \"\",\n \"output\": \"Two antonyms for 'intelligent' are 'stupid' and 'dumb.'\"\n },\n {\n \"instruction\": \"What is the pH of a neutral solution at 25\\u00b0C?\",\n \"input\": \"\",\n \"output\": \"The pH of a neutral solution at 25\\u00b0C is 7.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor\",\n \"input\": \"'Her eyes are like stars.'\",\n \"output\": \"Her eyes are stars in the night sky.\"\n },\n {\n \"instruction\": \"Name three types of biomes.\",\n \"input\": \"\",\n \"output\": \"Forest, desert, and grassland.\"\n },\n {\n \"instruction\": \"Identify the climax in 'Romeo and Juliet'.\",\n \"input\": \"\",\n \"output\": \"The climax of 'Romeo and Juliet' occurs when Romeo kills Tybalt, leading to his banishment and the subsequent tragic events.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The dog is very loyal.\",\n \"output\": \"The dog is as loyal as a soldier.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"The storm started suddenly.\",\n \"output\": \"The storm came out of the blue.\"\n },\n {\n \"instruction\": \"Convert 10 feet to meters.\",\n \"input\": \"\",\n \"output\": \"10 feet is equal to approximately 3.048 meters.\"\n },\n {\n \"instruction\": \"Convert this sentence to passive voice\",\n \"input\": \"The chef cooked a delicious meal.\",\n \"output\": \"A delicious meal was cooked by the chef.\"\n },\n {\n \"instruction\": \"What is the plural form of 'mouse'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'mouse' is 'mice'.\"\n },\n {\n \"instruction\": \"What is the opposite of 'thin'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'thin' is 'thick'.\"\n },\n {\n \"instruction\": \"What is the state capital of California?\",\n \"input\": \"\",\n \"output\": \"The state capital of California is Sacramento.\"\n },\n {\n \"instruction\": \"Translate 'family' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian word for 'family' is 'famiglia'.\"\n },\n {\n \"instruction\": \"What is the past tense of 'draw'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'draw' is 'drew.'\"\n },\n {\n \"instruction\": \"Alter the content of the sentence to use the past tense.\",\n \"input\": \"The ship sails at dawn.\",\n \"output\": \"The ship sailed at dawn.\"\n },\n {\n \"instruction\": \"Generate a sentence that follows the pattern: 'Rarely do I _____'\",\n \"input\": \"\",\n \"output\": \"Rarely do I eat fast food.\"\n },\n {\n \"instruction\": \"What is the atomic number of oxygen?\",\n \"input\": \"\",\n \"output\": \"The atomic number of oxygen is 8.\"\n },\n {\n \"instruction\": \"What is a synonym of 'luminous'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'luminous' is 'bright'.\"\n },\n {\n \"instruction\": \"What is the capital of Brazil?\",\n \"input\": \"\",\n \"output\": \"The capital of Brazil is Bras\\u00edlia.\"\n },\n {\n \"instruction\": \"List the ingredients required to make a basic salad.\",\n \"input\": \"\",\n \"output\": \"Ingredients for a basic salad typically include lettuce, tomatoes, cucumbers, and dressing.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a synonym.\",\n \"input\": \"It's hot outside.\",\n \"output\": \"It's scorching outside.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'happy'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'happy' is 'content'.\"\n },\n {\n \"instruction\": \"What is the derivative of x^3 + 5x^2 - 3x + 7 with respect to x?\",\n \"input\": \"\",\n \"output\": \"3x^2 + 10x - 3.\"\n },\n {\n \"instruction\": \"Identify the point of view used in the sentence.\",\n \"input\": \"She felt a sense of relief.\",\n \"output\": \"The point of view used in the sentence is third person.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'gregarious'.\",\n \"input\": \"\",\n \"output\": \"He was gregarious, making friends wherever he went.\"\n },\n {\n \"instruction\": \"What is the atomic number of carbon?\",\n \"input\": \"\",\n \"output\": \"The atomic number of carbon is 6.\"\n },\n {\n \"instruction\": \"What is the formula for area of a triangle?\",\n \"input\": \"\",\n \"output\": \"The formula for the area of a triangle is 1/2 * base * height.\"\n },\n {\n \"instruction\": \"Sort the following list in alphabetical order.\",\n \"input\": \"Zebra, Elephant, Crocodile\",\n \"output\": \"Crocodile, Elephant, Zebra\"\n },\n {\n \"instruction\": \"Reverse the order of the given phrase.\",\n \"input\": \"Moon and stars\",\n \"output\": \"Stars and moon\"\n },\n {\n \"instruction\": \"What is a synonym for 'begin'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'begin' is 'commence'.\"\n },\n {\n \"instruction\": \"Find the next 3 terms in the following sequence: 4, 8, 12, 16.\",\n \"input\": \"\",\n \"output\": \"The next three terms in the sequence are: 20, 24, 28.\"\n },\n {\n \"instruction\": \"What is the melting point of aluminum in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of aluminum is 660.3 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is an antonym of 'advanced'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'advanced' is 'primitive'.\"\n },\n {\n \"instruction\": \"Name an antonym for 'happiness.'\",\n \"input\": \"\",\n \"output\": \"An antonym for 'happiness' is 'sadness.'\"\n },\n {\n \"instruction\": \"Identify the correct spelling of the following word.\",\n \"input\": \"Ocassion\",\n \"output\": \"The correct spelling is 'Occasion.'\"\n },\n {\n \"instruction\": \"What type of figurative language is used in 'She is the apple of my eye'?\",\n \"input\": \"\",\n \"output\": \"The figurative language used is a metaphor.\"\n },\n {\n \"instruction\": \"Correct the spelling error in the sentence.\",\n \"input\": \"I will atend the meeting tomorrow.\",\n \"output\": \"The correct spelling is 'attend', not 'atend'.\"\n },\n {\n \"instruction\": \"Arrange the following events in chronological order: World War II, French Revolution, Invention of the Telephone.\",\n \"input\": \"\",\n \"output\": \"1. French Revolution\\n2. Invention of the Telephone\\n3. World War II\"\n },\n {\n \"instruction\": \"What is the normal body temperature in Celsius?\",\n \"input\": \"\",\n \"output\": \"The normal body temperature is approximately 37 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the cube of 4?\",\n \"input\": \"\",\n \"output\": \"The cube of 4 is 64.\"\n },\n {\n \"instruction\": \"Classify the following into vegetables, animals, and metals.\",\n \"input\": \"Broccoli, Iron, Elephant\",\n \"output\": \"Vegetables: Broccoli\\nMetals: Iron\\nAnimals: Elephant\"\n },\n {\n \"instruction\": \"Translate 'I am learning Spanish' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Estoy aprendiendo espa\\u00f1ol.\"\n },\n {\n \"instruction\": \"Edit the following sentence for clarity and style.\",\n \"input\": \"He response to the issue was quick.\",\n \"output\": \"His response to the issue was quick.\"\n },\n {\n \"instruction\": \"What is the melting point of gold in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of gold is 1064 degrees Celsius.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'fast'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'fast' is 'quick'.\"\n },\n {\n \"instruction\": \"Translate 'What is your name?' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'What is your name?' is 'Comment vous appelez-vous?'.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"She is very graceful.\",\n \"output\": \"She is as graceful as a swan.\"\n },\n {\n \"instruction\": \"What is an antonym of 'soft'?\",\n \"input\": \"\",\n \"output\": \"hard.\"\n },\n {\n \"instruction\": \"What are the first 5 multiples of 4?\",\n \"input\": \"\",\n \"output\": \"4, 8, 12, 16, 20.\"\n },\n {\n \"instruction\": \"What is an antonym of 'happy'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'happy' is 'sad.'\"\n },\n {\n \"instruction\": \"What type of galaxy is the Andromeda Galaxy?\",\n \"input\": \"\",\n \"output\": \"The Andromeda Galaxy is a spiral galaxy.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"She is very punctual.\",\n \"output\": \"She is always on time.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'inevitable'.\",\n \"input\": \"\",\n \"output\": \"The collapse of the company was inevitable due to poor management.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"He runs very fast.\",\n \"output\": \"He runs as fast as a cheetah.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for aluminum?\",\n \"input\": \"\",\n \"output\": \"Al.\"\n },\n {\n \"instruction\": \"Name the process by which water changes from liquid to gas.\",\n \"input\": \"\",\n \"output\": \"The process by which water changes from liquid to gas is called evaporation.\"\n },\n {\n \"instruction\": \"What is the melting point of gold?\",\n \"input\": \"\",\n \"output\": \"The melting point of gold is approximately 1064 degrees Celsius.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a different adjective.\",\n \"input\": \"She has a fast car.\",\n \"output\": \"She has a speedy car.\"\n },\n {\n \"instruction\": \"Add the correct verb to the sentence.\",\n \"input\": \"The students _________ the quiz answers.\",\n \"output\": \"The students discussed the quiz answers.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"He is very lucky.\",\n \"output\": \"He has a stroke of luck.\"\n },\n {\n \"instruction\": \"Calculate the volume of a cylinder with a radius of 4 cm and a height of 10 cm.\",\n \"input\": \"\",\n \"output\": \"The volume of the cylinder is approximately 502.65 cubic centimeters.\"\n },\n {\n \"instruction\": \"Edit the following sentence to correct any grammar errors.\",\n \"input\": \"They was waiting for the bus all day.\",\n \"output\": \"They were waiting for the bus all day.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'serendipity.'\",\n \"input\": \"\",\n \"output\": \"Finding the hidden beach was pure serendipity.\"\n },\n {\n \"instruction\": \"What type of bond is formed when one atom donates an electron to another atom?\",\n \"input\": \"\",\n \"output\": \"The type of bond formed when one atom donates an electron to another atom is an ionic bond.\"\n },\n {\n \"instruction\": \"Create a palindrome using the word 'racecar'.\",\n \"input\": \"\",\n \"output\": \"A racecar.\"\n },\n {\n \"instruction\": \"What is the square of 12?\",\n \"input\": \"\",\n \"output\": \"The square of 12 is 144.\"\n },\n {\n \"instruction\": \"Insert the correct punctuation at the provided places in the following sentence.\",\n \"input\": \"Where are you going\",\n \"output\": \"Where are you going?\"\n },\n {\n \"instruction\": \"Provide a synonym for 'strong'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'strong' is 'powerful'.\"\n },\n {\n \"instruction\": \"Name a mammal that lays eggs.\",\n \"input\": \"\",\n \"output\": \"A mammal that lays eggs is the platypus.\"\n },\n {\n \"instruction\": \"Name three types of precipitation.\",\n \"input\": \"\",\n \"output\": \"Three types of precipitation are rain, snow, and sleet.\"\n },\n {\n \"instruction\": \"Name the process by which skin repairs itself after a cut.\",\n \"input\": \"\",\n \"output\": \"The process by which skin repairs itself after a cut is called regeneration.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'ephemeral'.\",\n \"input\": \"\",\n \"output\": \"The beauty of the sunset was ephemeral, fading from the sky within moments.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'harmony'.\",\n \"input\": \"\",\n \"output\": \"The choir's voices blended in perfect harmony.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The storm is very strong.\",\n \"output\": \"The storm is a beast.\"\n },\n {\n \"instruction\": \"What type of bond is formed when electrons are shared between atoms?\",\n \"input\": \"\",\n \"output\": \"The type of bond formed when electrons are shared between atoms is a covalent bond.\"\n },\n {\n \"instruction\": \"Convert 3 meters to centimeters.\",\n \"input\": \"\",\n \"output\": \"3 meters is 300 centimeters.\"\n },\n {\n \"instruction\": \"Arrange these technological inventions in chronological order: Telephone, Internet, Printing Press.\",\n \"input\": \"\",\n \"output\": \"1. Printing Press\\n2. Telephone\\n3. Internet\"\n },\n {\n \"instruction\": \"What is the main ingredient in traditional French baguettes?\",\n \"input\": \"\",\n \"output\": \"The main ingredient in traditional French baguettes is wheat flour.\"\n },\n {\n \"instruction\": \"Classify the following text into either fiction or non-fiction.\",\n \"input\": \"The documentary covers the impact of climate change on polar bears.\",\n \"output\": \"Non-fiction.\"\n },\n {\n \"instruction\": \"What is the boiling point of acetone in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of acetone is 56 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the capital of South Korea?\",\n \"input\": \"\",\n \"output\": \"The capital of South Korea is Seoul.\"\n },\n {\n \"instruction\": \"Convert 300 seconds to minutes.\",\n \"input\": \"\",\n \"output\": \"300 seconds is equal to 5 minutes.\"\n },\n {\n \"instruction\": \"Name a novel written by Jane Austen.\",\n \"input\": \"\",\n \"output\": \"One of the novels written by Jane Austen is 'Pride and Prejudice'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'kind'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'kind' is 'benevolent'.\"\n },\n {\n \"instruction\": \"Name a synonym for \\\"happiness.\\\"\",\n \"input\": \"\",\n \"output\": \"A synonym for \\\"happiness\\\" is \\\"joy.\\\"\"\n },\n {\n \"instruction\": \"Convert 8 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"8 kilometers is 8000 meters.\"\n },\n {\n \"instruction\": \"Edit the sentence.\",\n \"input\": \"She enjoys reading books.\",\n \"output\": \"She enjoys reading books.\"\n },\n {\n \"instruction\": \"Generate a question based on the following statement.\",\n \"input\": \"Plants require sunlight to grow.\",\n \"output\": \"Why do plants require sunlight to grow?\"\n },\n {\n \"instruction\": \"What is the capital of the Philippines?\",\n \"input\": \"\",\n \"output\": \"The capital of the Philippines is Manila.\"\n },\n {\n \"instruction\": \"Name the process by which water cycles from the ground to the atmosphere and back.\",\n \"input\": \"\",\n \"output\": \"The process is called the water cycle.\"\n },\n {\n \"instruction\": \"Define the term 'ecosystem'.\",\n \"input\": \"\",\n \"output\": \"An ecosystem is a community of interacting organisms and their physical environment.\"\n },\n {\n \"instruction\": \"Convert the following verb to its past participle form: 'see'\",\n \"input\": \"\",\n \"output\": \"The past participle form of 'see' is 'seen'.\"\n },\n {\n \"instruction\": \"What is the highest mountain in the world?\",\n \"input\": \"\",\n \"output\": \"The highest mountain in the world is Mount Everest.\"\n },\n {\n \"instruction\": \"Convert the number 5 from decimal to binary.\",\n \"input\": \"\",\n \"output\": \"The binary equivalent of the decimal number 5 is 101.\"\n },\n {\n \"instruction\": \"What is the chemical formula for carbonic acid?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for carbonic acid is H2CO3.\"\n },\n {\n \"instruction\": \"What is a synonym of 'optimistic'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'optimistic' is 'hopeful'.\"\n },\n {\n \"instruction\": \"Change the sentence \\\"This should not have happened\\\" into a declarative sentence.\",\n \"input\": \"\",\n \"output\": \"This should have happened differently.\"\n },\n {\n \"instruction\": \"Given a sentence, convert it into indirect speech.\",\n \"input\": \"She said, \\\"I am tired.\\\"\",\n \"output\": \"She said that she was tired.\"\n },\n {\n \"instruction\": \"Classify this text as either a scientific article or a news report.\",\n \"input\": \"The researchers found a new species of bird in the Amazon rainforest.\",\n \"output\": \"Scientific article\"\n },\n {\n \"instruction\": \"Convert the following sentence to use a relative clause: The girl is a dancer. She lives next door.\",\n \"input\": \"\",\n \"output\": \"The girl who lives next door is a dancer.\"\n },\n {\n \"instruction\": \"Classify the following words by their grammatical categories: run, happy, quickly\",\n \"input\": \"\",\n \"output\": \"Run: Verb\\nHappy: Adjective\\nQuickly: Adverb\"\n },\n {\n \"instruction\": \"Provide a synonym for 'brilliant'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'brilliant' is 'bright'.\"\n },\n {\n \"instruction\": \"Put the following words in alphabetical order: lion, zebra, elephant.\",\n \"input\": \"\",\n \"output\": \"Elephant, lion, zebra.\"\n },\n {\n \"instruction\": \"Perform a sentiment analysis on the given sentence.\",\n \"input\": \"I hate this song!\",\n \"output\": \"The sentiment of the sentence \\\"I hate this song!\\\" is negative.\"\n },\n {\n \"instruction\": \"What type of literary device is used in 'The silence was a loud scream'?\",\n \"input\": \"\",\n \"output\": \"The literary device used is oxymoron.\"\n },\n {\n \"instruction\": \"Rewrite the following phrase in the present tense.\",\n \"input\": \"They had played soccer all afternoon.\",\n \"output\": \"They play soccer all afternoon.\"\n },\n {\n \"instruction\": \"Perform a sentiment analysis on the given sentence.\",\n \"input\": \"I love this song!\",\n \"output\": \"The sentiment of the sentence 'I love this song!' is positive. This is indicated by the word 'love' which shows strong liking or admiration towards the subject, in this case, the song.\"\n },\n {\n \"instruction\": \"What is the capital of Canada?\",\n \"input\": \"\",\n \"output\": \"The capital of Canada is Ottawa.\"\n },\n {\n \"instruction\": \"Edit the following sentence to remove all passive voice.\",\n \"input\": \"The song was composed by the artist.\",\n \"output\": \"The artist composed the song.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'determined'.\",\n \"input\": \"\",\n \"output\": \"She was determined to succeed despite the obstacles.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'Julia throws the ball.'\",\n \"input\": \"\",\n \"output\": \"The ball is thrown by Julia.\"\n },\n {\n \"instruction\": \"Identify the predicate in the sentence.\",\n \"input\": \"The quick brown fox jumps over the lazy dog.\",\n \"output\": \"The predicate in the sentence is 'jumps over the lazy dog.'\"\n },\n {\n \"instruction\": \"What type of number is 0?\",\n \"input\": \"\",\n \"output\": \"0 is an integer.\"\n },\n {\n \"instruction\": \"Take the following noun and turn it into a verb.\",\n \"input\": \"Light\",\n \"output\": \"To light.\"\n },\n {\n \"instruction\": \"Translate 'Happy Birthday' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'Happy Birthday' is 'Feliz Cumplea\\u00f1os'.\"\n },\n {\n \"instruction\": \"Translate 'Where is the library?' into Italian.\",\n \"input\": \"\",\n \"output\": \"Dove \\u00e8 la biblioteca?\"\n },\n {\n \"instruction\": \"Rearrange the following list into descending order.\",\n \"input\": \"12, 5, -3, 20, 9\",\n \"output\": \"20, 12, 9, 5, -3\"\n },\n {\n \"instruction\": \"Generate a five-word phrase using the words \\\"moon,\\\" \\\"crisp,\\\" and \\\"night.\\\"\",\n \"input\": \"\",\n \"output\": \"\\\"Crisp moon illuminates the night.\\\"\"\n },\n {\n \"instruction\": \"What is a synonym of 'content'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'content' is 'satisfied.'\"\n },\n {\n \"instruction\": \"Rewrite the following sentence by adding one adverb.\",\n \"input\": \"The cat slept on the mat.\",\n \"output\": \"The cat peacefully slept on the mat.\"\n },\n {\n \"instruction\": \"Convert 4 liters to milliliters.\",\n \"input\": \"\",\n \"output\": \"4 liters is 4000 milliliters.\"\n },\n {\n \"instruction\": \"What is the atomic mass of carbon?\",\n \"input\": \"\",\n \"output\": \"The atomic mass of carbon is approximately 12.01 atomic mass units.\"\n },\n {\n \"instruction\": \"Classify the following into animals, plants, and metals.\",\n \"input\": \"Rose, gold, cat\",\n \"output\": \"Animals: Cat\\nPlants: Rose\\nMetals: Gold\"\n },\n {\n \"instruction\": \"Classify the following numbers as even or odd.\",\n \"input\": \"2, 7, 19, 20\",\n \"output\": \"Even numbers: 2, 20\\nOdd numbers: 7, 19\"\n },\n {\n \"instruction\": \"Translate the phrase 'Life is beautiful' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'Life is beautiful' is 'La vita \\u00e8 bella'.\"\n },\n {\n \"instruction\": \"What is the sum of 7 and 8?\",\n \"input\": \"\",\n \"output\": \"The sum of 7 and 8 is 15.\"\n },\n {\n \"instruction\": \"Generate a random alphanumeric code of 10 characters.\",\n \"input\": \"\",\n \"output\": \"Here is a randomly generated 10-character alphanumeric code: 3F8G6H7JQ2.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'quiet'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'quiet' is 'silent'.\"\n },\n {\n \"instruction\": \"Reword the sentence to use other words without changing the meaning.\",\n \"input\": \"It rained heavily during the night.\",\n \"output\": \"The night experienced significant rainfall.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"Her voice is very soothing.\",\n \"output\": \"Her voice is a lullaby.\"\n },\n {\n \"instruction\": \"Fill in the blanks with appropriate words.\",\n \"input\": \"The sky was filled with colorful ________ at sunset.\",\n \"output\": \"The sky was filled with colorful clouds at sunset.\"\n },\n {\n \"instruction\": \"What is the boiling point of mercury in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of mercury is 356.7 degrees Celsius.\"\n },\n {\n \"instruction\": \"Change the following sentence to past perfect tense.\",\n \"input\": \"They finish the game.\",\n \"output\": \"They had finished the game.\"\n },\n {\n \"instruction\": \"What is an antonym of 'bright'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'bright' is 'dark'.\"\n },\n {\n \"instruction\": \"Calculate the area of a circle with a radius of 4 meters.\",\n \"input\": \"\",\n \"output\": \"The area of the circle is approximately 50.27 square meters.\"\n },\n {\n \"instruction\": \"Determine the product of 7 and 8.\",\n \"input\": \"\",\n \"output\": \"The product of 7 and 8 is 56.\"\n },\n {\n \"instruction\": \"Name the device used to measure humidity.\",\n \"input\": \"\",\n \"output\": \"The device used to measure humidity is a hygrometer.\"\n },\n {\n \"instruction\": \"Identify the preposition in the sentence.\",\n \"input\": \"The cat jumped over the fence.\",\n \"output\": \"The preposition in the sentence is 'over'.\"\n },\n {\n \"instruction\": \"Re-write the following sentence to use a different verb.\",\n \"input\": \"I will help you with your homework.\",\n \"output\": \"I will assist you with your homework.\"\n },\n {\n \"instruction\": \"Identify the hypernym for the word 'rose.'\",\n \"input\": \"\",\n \"output\": \"The hypernym for the word 'rose' is 'flower.'\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"He is very intelligent.\",\n \"output\": \"He is a genius.\"\n },\n {\n \"instruction\": \"What is the formula for calculating the volume of a cylinder?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating the volume of a cylinder is \\u03c0r\\u00b2h, where r is the radius and h is the height.\"\n },\n {\n \"instruction\": \"What is an antonym for 'difficult'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'difficult' is 'easy'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'brilliant'.\",\n \"input\": \"\",\n \"output\": \"The scientist had a brilliant idea that changed the world.\"\n },\n {\n \"instruction\": \"Automatically correct the given sentence.\",\n \"input\": \"I want to go to london.\",\n \"output\": \"I want to go to London.\"\n },\n {\n \"instruction\": \"Convert this declarative sentence into an interrogative sentence.\",\n \"input\": \"You need help.\",\n \"output\": \"Do you need help?\"\n },\n {\n \"instruction\": \"Convert the sentence into a negative statement.\",\n \"input\": \"You will help me.\",\n \"output\": \"You will not help me.\"\n },\n {\n \"instruction\": \"Edit the following sentence for clarity and style.\",\n \"input\": \"She response to the question was quick.\",\n \"output\": \"Her response to the question was quick.\"\n },\n {\n \"instruction\": \"What is the boiling point of oxygen in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of oxygen is -183 degrees Celsius.\"\n },\n {\n \"instruction\": \"Translate the word 'hello' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'hello' is 'hola'.\"\n },\n {\n \"instruction\": \"Classify the following fruit according to its type.\",\n \"input\": \"Orange\",\n \"output\": \"The fruit 'Orange' is typically classified as a citrus fruit.\"\n },\n {\n \"instruction\": \"Calculate the perimeter of a triangle with sides measuring 3, 4, and 5 cm.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the triangle is 12 cm.\"\n },\n {\n \"instruction\": \"Convert the sentence to use an indefinite pronoun.\",\n \"input\": \"Someone left a message.\",\n \"output\": \"A message was left by someone.\"\n },\n {\n \"instruction\": \"What is the prime factorization of 210?\",\n \"input\": \"\",\n \"output\": \"2 \\u00d7 3 \\u00d7 5 \\u00d7 7.\"\n },\n {\n \"instruction\": \"Convert this active sentence to passive: 'The company employs ten workers.'\",\n \"input\": \"\",\n \"output\": \"Ten workers are employed by the company.\"\n },\n {\n \"instruction\": \"Transform the given statement into an imperative sentence.\",\n \"input\": \"I would like you to turn off the light.\",\n \"output\": \"Please turn off the light.\"\n },\n {\n \"instruction\": \"Generate three verbs that mean the same as 'to speak.'\",\n \"input\": \"\",\n \"output\": \"1. To talk\\n2. To converse\\n3. To chat\"\n },\n {\n \"instruction\": \"Edit the sentence below to remove any redundant words and make it more concise.\",\n \"input\": \"I actually think that\",\n \"output\": \"I think.\"\n },\n {\n \"instruction\": \"Fill in the blank to complete the sentence.\",\n \"input\": \"The most popular fruit in the world is the ___\",\n \"output\": \"The most popular fruit in the world is the banana.\"\n },\n {\n \"instruction\": \"Cut the following sentence into two, keeping the original meaning intact.\",\n \"input\": \"She started her homework but was soon distracted by a phone call.\",\n \"output\": \"She started her homework. However, she was soon distracted by a phone call.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'melancholy'.\",\n \"input\": \"\",\n \"output\": \"The melancholy tune brought tears to her eyes.\"\n },\n {\n \"instruction\": \"Generate three adjectives to describe a river.\",\n \"input\": \"\",\n \"output\": \"1. Serene\\n2. Flowing\\n3. Winding\"\n },\n {\n \"instruction\": \"Name the longest river in the world.\",\n \"input\": \"\",\n \"output\": \"The longest river in the world is the Nile River.\"\n },\n {\n \"instruction\": \"Translate 'Happy New Year' into Italian.\",\n \"input\": \"\",\n \"output\": \"Buon Anno Nuovo\"\n },\n {\n \"instruction\": \"Select the noun phrase in the following sentence.\",\n \"input\": \"He enjoyed a delicious cake at the party.\",\n \"output\": \"The noun phrases in the given sentence are \\\"a delicious cake\\\" and \\\"the party.\\\"\"\n },\n {\n \"instruction\": \"Summarize the plot of Shakespeare's play 'Macbeth'.\",\n \"input\": \"\",\n \"output\": \"Macbeth, a Scottish general, is led to wicked thoughts by the prophecies of three witches, leading him to murder the king and take the throne. His lust for power causes a descent into madness and destruction.\"\n },\n {\n \"instruction\": \"Classify the following items: gold ring, daisy, python.\",\n \"input\": \"\",\n \"output\": \"Animals: Python\\nPlants: Daisy\\nMinerals: Gold ring\"\n },\n {\n \"instruction\": \"What is the capital of Greece?\",\n \"input\": \"\",\n \"output\": \"The capital of Greece is Athens.\"\n },\n {\n \"instruction\": \"Convert the following number from decimal to hexadecimal: 255.\",\n \"input\": \"\",\n \"output\": \"The hexadecimal equivalent of the decimal number 255 is FF.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The music is very loud.\",\n \"output\": \"The music is as loud as thunder.\"\n },\n {\n \"instruction\": \"What is the capital of Argentina?\",\n \"input\": \"\",\n \"output\": \"The capital of Argentina is Buenos Aires.\"\n },\n {\n \"instruction\": \"Name a punctuation mark used to indicate a question.\",\n \"input\": \"\",\n \"output\": \"A punctuation mark used to indicate a question is the question mark (?).\"\n },\n {\n \"instruction\": \"What is an antonym of \\\"ancient\\\"?\",\n \"input\": \"\",\n \"output\": \"An antonym of \\\"ancient\\\" is \\\"modern.\\\"\"\n },\n {\n \"instruction\": \"Determine the mass of an object that has a density of 10 g/cm\\u00b3 and a volume of 2 cm\\u00b3.\",\n \"input\": \"\",\n \"output\": \"The mass of the object is 20 grams.\"\n },\n {\n \"instruction\": \"Convert this compound sentence to a complex sentence.\",\n \"input\": \"She likes coffee, and he likes tea.\",\n \"output\": \"She likes coffee while he likes tea.\"\n },\n {\n \"instruction\": \"Identify the antagonist in 'Harry Potter and the Sorcerer's Stone'.\",\n \"input\": \"\",\n \"output\": \"The antagonist in 'Harry Potter and the Sorcerer's Stone' is Voldemort.\"\n },\n {\n \"instruction\": \"What is the capital of Sweden?\",\n \"input\": \"\",\n \"output\": \"The capital of Sweden is Stockholm.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'curious'.\",\n \"input\": \"\",\n \"output\": \"The cat was curious about the new toy.\"\n },\n {\n \"instruction\": \"Convert the given sentence into passive voice.\",\n \"input\": \"The company will announce the results tomorrow.\",\n \"output\": \"The results will be announced by the company tomorrow.\"\n },\n {\n \"instruction\": \"Classify an input string as either a noun or a verb.\",\n \"input\": \"jump\",\n \"output\": \"\\\"jump\\\" can be classified as a verb.\"\n },\n {\n \"instruction\": \"Split the following sentence into two declarative sentences: \\\"The book is interesting but the cover is dull\\\".\",\n \"input\": \"\",\n \"output\": \"The book is interesting.\\nThe cover is dull.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The book is very boring.\",\n \"output\": \"The book is a cure for insomnia.\"\n },\n {\n \"instruction\": \"What is an antonym of 'fast'?\",\n \"input\": \"\",\n \"output\": \"slow.\"\n },\n {\n \"instruction\": \"Calculate the kinetic energy of an object with a mass of 10 kilograms moving at a velocity of 5 meters per second.\",\n \"input\": \"\",\n \"output\": \"The kinetic energy of the object is 125 joules, calculated using the formula KE = 0.5 * mass * velocity^2.\"\n },\n {\n \"instruction\": \"What is the chemical formula for ammonia?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for ammonia is NH3.\"\n },\n {\n \"instruction\": \"What is the boiling point of methane in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of methane is -161.5 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the formula for the area of a parallelogram?\",\n \"input\": \"\",\n \"output\": \"The formula for the area of a parallelogram is base \\u00d7 height.\"\n },\n {\n \"instruction\": \"What is the unit for measuring electrical resistance?\",\n \"input\": \"\",\n \"output\": \"The unit for measuring electrical resistance is the ohm.\"\n },\n {\n \"instruction\": \"Given a sentence, convert it into direct speech.\",\n \"input\": \"She said she was tired.\",\n \"output\": \"'I am tired,' she said.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'gregarious.'\",\n \"input\": \"\",\n \"output\": \"He was known for his gregarious nature, always enjoying social gatherings.\"\n },\n {\n \"instruction\": \"What is the past tense of 'choose'?\",\n \"input\": \"\",\n \"output\": \"chose.\"\n },\n {\n \"instruction\": \"What is the melting point of platinum in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of platinum is 1768 degrees Celsius.\"\n },\n {\n \"instruction\": \"Change this sentence grammatically.\",\n \"input\": \"He have seen the movie.\",\n \"output\": \"He has seen the movie.\"\n },\n {\n \"instruction\": \"What is the capital of Russia?\",\n \"input\": \"\",\n \"output\": \"The capital of Russia is Moscow.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for potassium?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for potassium is K.\"\n },\n {\n \"instruction\": \"Name three states of matter.\",\n \"input\": \"\",\n \"output\": \"The three states of matter are solid, liquid, and gas.\"\n },\n {\n \"instruction\": \"What is an antonym of 'simplify'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'simplify' is 'complicate.'\"\n },\n {\n \"instruction\": \"List the ingredients necessary to bake a simple chocolate cake.\",\n \"input\": \"\",\n \"output\": \"Flour, sugar, cocoa powder, baking powder, eggs, milk, and oil.\"\n },\n {\n \"instruction\": \"Classify the following species as reptiles or amphibians.\",\n \"input\": \"Frog\",\n \"output\": \"Frog is an amphibian.\"\n },\n {\n \"instruction\": \"Name the process by which plants lose water vapor through their leaves.\",\n \"input\": \"\",\n \"output\": \"The process by which plants lose water vapor through their leaves is called transpiration.\"\n },\n {\n \"instruction\": \"Classify the following items: diamond ring, oak tree, lion.\",\n \"input\": \"\",\n \"output\": \"Animals: Lion\\nPlants: Oak tree\\nMinerals: Diamond ring\"\n },\n {\n \"instruction\": \"Rewrite this sentence to eliminate the passive voice.\",\n \"input\": \"The cake was made by Susan.\",\n \"output\": \"Susan made the cake.\"\n },\n {\n \"instruction\": \"What is the capital of the United Kingdom?\",\n \"input\": \"\",\n \"output\": \"The capital of the United Kingdom is London.\"\n },\n {\n \"instruction\": \"Explain what a neutron star is.\",\n \"input\": \"\",\n \"output\": \"A neutron star is a type of stellar remnant that is extremely dense, composed mostly of neutrons, and is formed after a supernova explosion of a massive star.\"\n },\n {\n \"instruction\": \"Name the process by which carbon dioxide is converted into organic compounds by plants.\",\n \"input\": \"\",\n \"output\": \"The process by which carbon dioxide is converted into organic compounds by plants is called photosynthesis.\"\n },\n {\n \"instruction\": \"Edit the sentence to make it grammatically correct.\",\n \"input\": \"He is more happier now.\",\n \"output\": \"He is happier now.\"\n },\n {\n \"instruction\": \"Name the process by which birds migrate south for the winter.\",\n \"input\": \"\",\n \"output\": \"The process by which birds migrate south for the winter is called migration.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'ambitious'.\",\n \"input\": \"\",\n \"output\": \"She is very ambitious and always sets high goals for herself.\"\n },\n {\n \"instruction\": \"Describe the process of diffusion.\",\n \"input\": \"\",\n \"output\": \"Diffusion is the movement of particles from an area of higher concentration to an area of lower concentration until they are evenly distributed. It occurs in liquids and gases due to the random movement of particles.\"\n },\n {\n \"instruction\": \"What is the chemical formula for potassium chloride?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for potassium chloride is KCl.\"\n },\n {\n \"instruction\": \"Convert the sentence into a question by adding a question tag.\",\n \"input\": \"You are coming to the party.\",\n \"output\": \"You are coming to the party, aren't you?\"\n },\n {\n \"instruction\": \"Translate 'My name is John' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Mi nombre es John.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'mysterious'.\",\n \"input\": \"\",\n \"output\": \"The old mansion had a mysterious aura that intrigued everyone.\"\n },\n {\n \"instruction\": \"What is the formula for the circumference of a circle?\",\n \"input\": \"\",\n \"output\": \"The formula for the circumference of a circle is 2\\u03c0r, where r is the radius.\"\n },\n {\n \"instruction\": \"Explain the water cycle in simple terms.\",\n \"input\": \"\",\n \"output\": \"The water cycle describes how water evaporates from the surface of the earth, rises into the atmosphere, cools and condenses into rain or snow in clouds, and falls again to the surface as precipitation.\"\n },\n {\n \"instruction\": \"Convert 6 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"6 kilometers is 6000 meters.\"\n },\n {\n \"instruction\": \"Translate 'He likes to play football' into French.\",\n \"input\": \"\",\n \"output\": \"Il aime jouer au football.\"\n },\n {\n \"instruction\": \"What is the speed of sound in air?\",\n \"input\": \"\",\n \"output\": \"The speed of sound in air is approximately 343 meters per second.\"\n },\n {\n \"instruction\": \"What is the contraction for 'it is'?\",\n \"input\": \"\",\n \"output\": \"The contraction for 'it is' is 'it's.'\"\n },\n {\n \"instruction\": \"Translate 'What are you doing?' into Italian.\",\n \"input\": \"\",\n \"output\": \"Cosa stai facendo?\"\n },\n {\n \"instruction\": \"Translate 'How old are you?' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'How old are you?' is 'Wie alt bist du?'.\"\n },\n {\n \"instruction\": \"Convert 50 kilometers to miles.\",\n \"input\": \"\",\n \"output\": \"50 kilometers is approximately 31.07 miles.\"\n },\n {\n \"instruction\": \"Change the following sentence to present perfect tense.\",\n \"input\": \"They finish the game.\",\n \"output\": \"They have finished the game.\"\n },\n {\n \"instruction\": \"Identify the preposition in the sentence.\",\n \"input\": \"The cat is under the table.\",\n \"output\": \"The preposition in the sentence is 'under'.\"\n },\n {\n \"instruction\": \"Name the device used to measure wind speed.\",\n \"input\": \"\",\n \"output\": \"The device used to measure wind speed is an anemometer.\"\n },\n {\n \"instruction\": \"What is the symbol for the chemical element silver?\",\n \"input\": \"\",\n \"output\": \"The symbol for the chemical element silver is Ag.\"\n },\n {\n \"instruction\": \"What is the opposite of 'large'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'large' is 'small'.\"\n },\n {\n \"instruction\": \"What is the opposite of 'dark'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'dark' is 'light'.\"\n },\n {\n \"instruction\": \"Convert the following verb to its past participle form: 'go'\",\n \"input\": \"go\",\n \"output\": \"The past participle form of 'go' is 'gone'.\"\n },\n {\n \"instruction\": \"Rewrite this sentence to eliminate the passive voice.\",\n \"input\": \"The book was written by the author.\",\n \"output\": \"The author wrote the book.\"\n },\n {\n \"instruction\": \"Suggest a continuation for the sentence.\",\n \"input\": \"Once the sun rose,\",\n \"output\": \"'the city came to life.'\"\n },\n {\n \"instruction\": \"Calculate the perimeter of a hexagon with side lengths of 4 cm.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the hexagon is 24 cm.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using alliteration.\",\n \"input\": \"The cat chased the mouse.\",\n \"output\": \"The cunning cat chased the mouse.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"He is very brave.\",\n \"output\": \"He is as brave as a lion.\"\n },\n {\n \"instruction\": \"Translate 'Excuse me' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'Excuse me' is 'Perd\\u00f3n' or 'Disculpe'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'begin'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'begin' is 'end'.\"\n },\n {\n \"instruction\": \"Create a sentence that begins with 'If only,'\",\n \"input\": \"\",\n \"output\": \"If only I had studied harder...\"\n },\n {\n \"instruction\": \"Identify the literary term used in 'It's raining cats and dogs.'\",\n \"input\": \"\",\n \"output\": \"The literary term used is an idiom.\"\n },\n {\n \"instruction\": \"Calculate the area of a circle with a radius of 5 meters.\",\n \"input\": \"\",\n \"output\": \"The area of the circle is approximately 78.54 square meters.\"\n },\n {\n \"instruction\": \"Given the following sentence, rewrite it by removing the passive form\",\n \"input\": \"The final decision was made by the manager.\",\n \"output\": \"The manager made the final decision.\"\n },\n {\n \"instruction\": \"Name the process by which plants convert carbon dioxide and water into oxygen and glucose.\",\n \"input\": \"\",\n \"output\": \"The process by which plants convert carbon dioxide and water into oxygen and glucose is called photosynthesis.\"\n },\n {\n \"instruction\": \"Rewrite the sentence to use a simile.\",\n \"input\": \"She is very calm under pressure.\",\n \"output\": \"She is as calm as a cucumber under pressure.\"\n },\n {\n \"instruction\": \"What type of animal is an octopus?\",\n \"input\": \"\",\n \"output\": \"An octopus is a cephalopod mollusk.\"\n },\n {\n \"instruction\": \"Provide a word that rhymes with \\\"care.\\\"\",\n \"input\": \"\",\n \"output\": \"A word that rhymes with \\\"care\\\" is \\\"fare.\\\"\"\n },\n {\n \"instruction\": \"What is a synonym for 'small'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'small' is 'little'.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'The gardener waters the plants daily.'\",\n \"input\": \"\",\n \"output\": \"The plants are watered daily by the gardener.\"\n },\n {\n \"instruction\": \"Rewrite the following phrase as a question.\",\n \"input\": \"We must finish the project by tomorrow.\",\n \"output\": \"Must we finish the project by tomorrow?\"\n },\n {\n \"instruction\": \"List the colors of the rainbow.\",\n \"input\": \"\",\n \"output\": \"The colors of the rainbow are red, orange, yellow, green, blue, indigo, violet.\"\n },\n {\n \"instruction\": \"Look up the freezing point of water.\",\n \"input\": \"\",\n \"output\": \"The freezing point of water is 0 degrees Celsius or 32 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Arrange the given numbers in descending order.\",\n \"input\": \"5, 12, 8, 3, 15\",\n \"output\": \"15, 12, 8, 5, 3.\"\n },\n {\n \"instruction\": \"Translate 'I love reading books' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'I love reading books' is 'Ich liebe es, B\\u00fccher zu lesen.'\"\n },\n {\n \"instruction\": \"What is a synonym for 'large'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'large' is 'big'.\"\n },\n {\n \"instruction\": \"Classify the following species as dogs or cats.\",\n \"input\": \"Siamese\",\n \"output\": \"Siamese is a cat.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'exuberant'.\",\n \"input\": \"\",\n \"output\": \"The children were exuberant as they ran through the park.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'temporary.'\",\n \"input\": \"\",\n \"output\": \"Her stay at the hotel was only temporary.\"\n },\n {\n \"instruction\": \"What is the formula for converting Celsius to Kelvin?\",\n \"input\": \"\",\n \"output\": \"The formula for converting Celsius to Kelvin is K = C + 273.15.\"\n },\n {\n \"instruction\": \"Sort the following numbers in ascending order.\",\n \"input\": \"7, 1, 8, 4, 3.\",\n \"output\": \"The numbers in ascending order would be: 1, 3, 4, 7, 8.\"\n },\n {\n \"instruction\": \"Categorize the given list of animals.\",\n \"input\": \"Dog, Eagle, Trout\",\n \"output\": \"Mammals: Dog\\nBirds: Eagle\\nFish: Trout\"\n },\n {\n \"instruction\": \"What is an antonym for 'success'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'success' is 'failure'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'brave'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'brave' is 'cowardly'.\"\n },\n {\n \"instruction\": \"Change this sentence grammatically.\",\n \"input\": \"They has seen the movie.\",\n \"output\": \"They have seen the movie.\"\n },\n {\n \"instruction\": \"Transform the following sentence into the passive voice.\",\n \"input\": \"They will build a new bridge.\",\n \"output\": \"A new bridge will be built by them.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'enthusiastic'.\",\n \"input\": \"\",\n \"output\": \"She is enthusiastic about learning new things.\"\n },\n {\n \"instruction\": \"Transform the following sentence into a question using 'should.'\",\n \"input\": \"You need to see a doctor.\",\n \"output\": \"Should you see a doctor?\"\n },\n {\n \"instruction\": \"Explain what a limerick is.\",\n \"input\": \"\",\n \"output\": \"A limerick is a humorous five-line poem with a specific rhythm and rhyme scheme, typically AABBA.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'beautiful'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'beautiful' is 'attractive'.\"\n },\n {\n \"instruction\": \"What is the boiling point of mercury in Fahrenheit?\",\n \"input\": \"\",\n \"output\": \"The boiling point of mercury is 674 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Given the following sentence, rewrite it by removing the passive form\",\n \"input\": \"The concert tickets are being sold quickly.\",\n \"output\": \"They are selling the concert tickets quickly.\"\n },\n {\n \"instruction\": \"Name the device that measures temperature.\",\n \"input\": \"\",\n \"output\": \"The device that measures temperature is a thermometer.\"\n },\n {\n \"instruction\": \"Edit the following sentence to correct any grammar errors.\",\n \"input\": \"They was trying to fix the car all day.\",\n \"output\": \"They were trying to fix the car all day.\"\n },\n {\n \"instruction\": \"What is the melting point of lead in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of lead is 327.5 degrees Celsius.\"\n },\n {\n \"instruction\": \"Change the sentences from active voice to passive voice.\",\n \"input\": \"The chef will prepare the meal.\",\n \"output\": \"The meal will be prepared by the chef.\"\n },\n {\n \"instruction\": \"Convert the following statement into a question.\",\n \"input\": \"She is going to the market.\",\n \"output\": \"Is she going to the market?\"\n },\n {\n \"instruction\": \"Name three types of flowers.\",\n \"input\": \"\",\n \"output\": \"Three types of flowers are roses, lilies, and tulips.\"\n },\n {\n \"instruction\": \"What is the primary function of the roots of a plant?\",\n \"input\": \"\",\n \"output\": \"The primary function of plant roots is to absorb water and nutrients from the soil. They also anchor the plant in place and store food and nutrients.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The computer is very slow.\",\n \"output\": \"The computer is a snail.\"\n },\n {\n \"instruction\": \"What is the boiling point of neon in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of neon is -246 degrees Celsius.\"\n },\n {\n \"instruction\": \"Name the process by which iron rusts.\",\n \"input\": \"\",\n \"output\": \"The process by which iron rusts is called oxidation.\"\n },\n {\n \"instruction\": \"Convert 400 meters to kilometers.\",\n \"input\": \"\",\n \"output\": \"400 meters is 0.4 kilometers.\"\n },\n {\n \"instruction\": \"Explain the process of erosion.\",\n \"input\": \"\",\n \"output\": \"Erosion is the process by which soil, rock, and other surface material are worn away and transported by natural forces such as wind or water. It can shape landscapes and affect ecosystems.\"\n },\n {\n \"instruction\": \"Convert 50 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"50 centimeters is 0.5 meters.\"\n },\n {\n \"instruction\": \"Identify the pronoun in the sentence.\",\n \"input\": \"She decided to go to the store.\",\n \"output\": \"The pronoun in the sentence is 'She'.\"\n },\n {\n \"instruction\": \"Make the second sentence a dependent clause.\",\n \"input\": \"She went to the market. She bought some fruit.\",\n \"output\": \"She went to the market, where she bought some fruit.\"\n },\n {\n \"instruction\": \"Correct the verb tense error in the sentence.\",\n \"input\": \"She go to school every day.\",\n \"output\": \"The corrected sentence should be: 'She goes to school every day.'\"\n },\n {\n \"instruction\": \"What is the capital of New Zealand?\",\n \"input\": \"\",\n \"output\": \"The capital of New Zealand is Wellington.\"\n },\n {\n \"instruction\": \"Evaluate this sentence for spelling and grammar mistakes.\",\n \"input\": \"I recieved an invitation to an exciting evenement.\",\n \"output\": \"There are two errors in the sentence. The corrected sentence should be: \\\"I received an invitation to an exciting event.\\\"\"\n },\n {\n \"instruction\": \"Rewrite the sentence in future continuous tense.\",\n \"input\": \"They will complete the project.\",\n \"output\": \"They will be completing the project.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence in a more formal way:\\n\\\"I need to find out what's wrong.\\\"\",\n \"input\": \"\",\n \"output\": \"I must ascertain what is incorrect.\"\n },\n {\n \"instruction\": \"Convert 5 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"5 kilometers is 5000 meters.\"\n },\n {\n \"instruction\": \"What is the chemical formula for carbon dioxide?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for carbon dioxide is CO2.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'courage'.\",\n \"input\": \"\",\n \"output\": \"She showed great courage during the rescue mission.\"\n },\n {\n \"instruction\": \"What is the opposite of 'old'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'old' is 'young'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'resilient'.\",\n \"input\": \"\",\n \"output\": \"She is resilient and always bounces back from challenges.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to include a hyperbole: 'I'm very tired.'\",\n \"input\": \"I'm very tired.\",\n \"output\": \"I'm so tired I could sleep for a year.\"\n },\n {\n \"instruction\": \"What is the smallest planet in our solar system?\",\n \"input\": \"\",\n \"output\": \"The smallest planet in our solar system is Mercury.\"\n },\n {\n \"instruction\": \"What is the symbol for gold on the periodic table?\",\n \"input\": \"\",\n \"output\": \"The symbol for gold on the periodic table is Au.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'meticulous'.\",\n \"input\": \"\",\n \"output\": \"She is very meticulous and always pays attention to details.\"\n },\n {\n \"instruction\": \"What is the freezing point of ethanol in Celsius?\",\n \"input\": \"\",\n \"output\": \"The freezing point of ethanol is -114.1 degrees Celsius.\"\n },\n {\n \"instruction\": \"Classify this sentence into one of the following topics: health, economy, technology, music\",\n \"input\": \"Spotify has revolutionized how we listen to music.\",\n \"output\": \"The topic of the given sentence is music.\"\n },\n {\n \"instruction\": \"What is the chemical formula for sulfur dioxide?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for sulfur dioxide is SO2.\"\n },\n {\n \"instruction\": \"Translate the phrase 'I love you' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'I love you' is 'Ti amo'.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'melancholy'.\",\n \"input\": \"\",\n \"output\": \"There was a melancholy tone in his voice as he recounted the story.\"\n },\n {\n \"instruction\": \"Given a sentence, count the number of words.\",\n \"input\": \"The quick brown fox jumps over the lazy dog.\",\n \"output\": \"The sentence \\\"The quick brown fox jumps over the lazy dog.\\\" contains 9 words.\"\n },\n {\n \"instruction\": \"Provide the past participle form of 'break'.\",\n \"input\": \"\",\n \"output\": \"The past participle form of 'break' is 'broken'.\"\n },\n {\n \"instruction\": \"Generate a random five-letter word.\",\n \"input\": \"\",\n \"output\": \"quake.\"\n },\n {\n \"instruction\": \"Edit the following sentence for grammar.\",\n \"input\": \"They goes to the market every Sunday.\",\n \"output\": \"They go to the market every Sunday.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'amazing'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'amazing' is 'incredible'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'determined'.\",\n \"input\": \"\",\n \"output\": \"She is determined to achieve her dreams despite the obstacles.\"\n },\n {\n \"instruction\": \"Classify the following fruit according to its type.\",\n \"input\": \"Banana\",\n \"output\": \"The fruit 'Banana' is typically classified as a tropical fruit.\"\n },\n {\n \"instruction\": \"Identify the main verb in the sentence.\",\n \"input\": \"She danced gracefully.\",\n \"output\": \"The main verb in the sentence is 'danced'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'old'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'old' is 'ancient'.\"\n },\n {\n \"instruction\": \"Describe the color red in 3 words.\",\n \"input\": \"\",\n \"output\": \"Bold, vibrant, intense.\"\n },\n {\n \"instruction\": \"Translate 'I love books' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Me encantan los libros.\"\n },\n {\n \"instruction\": \"Name the process by which animals release energy from food.\",\n \"input\": \"\",\n \"output\": \"The process by which animals release energy from food is called respiration.\"\n },\n {\n \"instruction\": \"What is the plural form of 'sheep'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'sheep' is 'sheep.'\"\n },\n {\n \"instruction\": \"Convert the following statement into a question.\",\n \"input\": \"You were at the concert last night.\",\n \"output\": \"Were you at the concert last night?\"\n },\n {\n \"instruction\": \"Edit the given text to ensure all plural nouns are spelled correctly.\",\n \"input\": \"The boxes was stacked neatly.\",\n \"output\": \"The boxes were stacked neatly.\"\n },\n {\n \"instruction\": \"What is an antonym of 'external'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'external' is 'internal'.\"\n },\n {\n \"instruction\": \"Identify the correct word to complete the sentence.\",\n \"input\": \"She presented her ideas with _____.\",\n \"output\": \"clarity\"\n },\n {\n \"instruction\": \"Edit the given sentence to make it grammatically correct.\",\n \"input\": \"She dont have any money\",\n \"output\": \"She doesn't have any money.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'compassionate'.\",\n \"input\": \"\",\n \"output\": \"She is compassionate and always helps others in need.\"\n },\n {\n \"instruction\": \"Find a rhyming word for the word 'book.'\",\n \"input\": \"\",\n \"output\": \"A rhyming word for the word 'book' could be 'look.'\"\n },\n {\n \"instruction\": \"Name the process by which plants convert sunlight into energy.\",\n \"input\": \"\",\n \"output\": \"The process by which plants convert sunlight into energy is photosynthesis.\"\n },\n {\n \"instruction\": \"Combine the two sentences into a single coherent sentence.\",\n \"input\": \"She did not attend the meeting. She was ill.\",\n \"output\": \"She did not attend the meeting because she was ill.\"\n },\n {\n \"instruction\": \"What is the opposite of 'retain'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'retain' is 'release'.\"\n },\n {\n \"instruction\": \"Translate 'Good luck' into Japanese.\",\n \"input\": \"\",\n \"output\": \"\\u9811\\u5f35\\u3063\\u3066 (Ganbatte)\"\n },\n {\n \"instruction\": \"List the ingredients required to make a sandwich.\",\n \"input\": \"\",\n \"output\": \"Ingredients for a sandwich typically include bread, meat or vegetables, cheese, and condiments.\"\n },\n {\n \"instruction\": \"What is an antonym of 'broad'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'broad' is 'narrow'.\"\n },\n {\n \"instruction\": \"Rewrite this statement as an imperative sentence.\",\n \"input\": \"You should finish your assignment.\",\n \"output\": \"Finish your assignment.\"\n },\n {\n \"instruction\": \"What is an antonym for 'young'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'young' is 'old'.\"\n },\n {\n \"instruction\": \"What is the symbol for the chemical element iron?\",\n \"input\": \"\",\n \"output\": \"The symbol for the chemical element iron is Fe.\"\n },\n {\n \"instruction\": \"What is the abbreviation for 'corporation'?\",\n \"input\": \"\",\n \"output\": \"The abbreviation for 'corporation' is 'corp.'\"\n },\n {\n \"instruction\": \"Translate 'Please' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'Please' is 'Por favor'.\"\n },\n {\n \"instruction\": \"What is the chemical formula for sodium hydroxide?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for sodium hydroxide is NaOH.\"\n },\n {\n \"instruction\": \"Classify the following numbers as prime or composite.\",\n \"input\": \"17, 22, 29.\",\n \"output\": \"Prime numbers: 17, 29\\nComposite numbers: 22\"\n },\n {\n \"instruction\": \"Provide the past tense form of the verb 'swim.'\",\n \"input\": \"\",\n \"output\": \"The past tense of the verb 'swim' is 'swam.'\"\n },\n {\n \"instruction\": \"What is the boiling point of gold in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of gold is 2970 degrees Celsius.\"\n },\n {\n \"instruction\": \"Reverse this array\",\n \"input\": \"[10, 20, 30, 40, 50]\",\n \"output\": \"Here is the reversed array: [50, 40, 30, 20, 10]\"\n },\n {\n \"instruction\": \"What is the melting point of silver in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of silver is 961.8 degrees Celsius.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovative'.\",\n \"input\": \"\",\n \"output\": \"Her innovative ideas led to the success of the project.\"\n },\n {\n \"instruction\": \"Edit the following sentence for clarity and style.\",\n \"input\": \"He spoke to the issue quickly.\",\n \"output\": \"He quickly addressed the issue.\"\n },\n {\n \"instruction\": \"What is the derivative of the function f(x) = 3x^2?\",\n \"input\": \"\",\n \"output\": \"The derivative of the function f(x) = 3x^2 is f'(x) = 6x.\"\n },\n {\n \"instruction\": \"What type of galaxy is the Milky Way?\",\n \"input\": \"\",\n \"output\": \"The Milky Way is a barred spiral galaxy.\"\n },\n {\n \"instruction\": \"What type of bond does sodium chloride (table salt) have?\",\n \"input\": \"\",\n \"output\": \"Sodium chloride (table salt) has an ionic bond.\"\n },\n {\n \"instruction\": \"Identify the correct spelling of the following word.\",\n \"input\": \"Definately\",\n \"output\": \"The correct spelling is 'Definitely.'\"\n },\n {\n \"instruction\": \"Define the term 'personification'.\",\n \"input\": \"\",\n \"output\": \"Personification is a figure of speech where human qualities are given to animals, objects, or ideas.\"\n },\n {\n \"instruction\": \"Identify the protagonist in the novel 'To Kill a Mockingbird'.\",\n \"input\": \"\",\n \"output\": \"The protagonist in 'To Kill a Mockingbird' is Scout Finch.\"\n },\n {\n \"instruction\": \"What is the symbol for the chemical element gold?\",\n \"input\": \"\",\n \"output\": \"The symbol for the chemical element gold is Au.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence using passive voice.\",\n \"input\": \"The chef prepared a delicious meal.\",\n \"output\": \"A delicious meal was prepared by the chef.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for gold?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for gold is Au.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"She is very fast.\",\n \"output\": \"She is as fast as a cheetah.\"\n },\n {\n \"instruction\": \"What is the opposite of the adjective 'generous'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'generous' is 'stingy' or 'miserly'.\"\n },\n {\n \"instruction\": \"Identify the main subject in the sentence.\",\n \"input\": \"The noisy children played in the park.\",\n \"output\": \"The main subject in the sentence is \\\"The noisy children.\\\"\"\n },\n {\n \"instruction\": \"Capitalize each word in the sentence.\",\n \"input\": \"i love watching the sunrise\",\n \"output\": \"I Love Watching The Sunrise\"\n },\n {\n \"instruction\": \"What is the chemical formula for calcium chloride?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for calcium chloride is CaCl2.\"\n },\n {\n \"instruction\": \"What is the formula for the area of a trapezoid?\",\n \"input\": \"\",\n \"output\": \"The formula for the area of a trapezoid is 0.5 * (Base1 + Base2) * Height.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"He is very tall.\",\n \"output\": \"He is as tall as a giraffe.\"\n },\n {\n \"instruction\": \"Explain the term 'ecosystem'.\",\n \"input\": \"\",\n \"output\": \"An ecosystem is a community of living organisms interacting with each other and their physical environment. It includes biotic (plants, animals, microbes) and abiotic (climate, soil, water) components.\"\n },\n {\n \"instruction\": \"What is the capital of Egypt?\",\n \"input\": \"\",\n \"output\": \"The capital of Egypt is Cairo.\"\n },\n {\n \"instruction\": \"What is the opposite of 'brave'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'brave' is 'cowardly'.\"\n },\n {\n \"instruction\": \"Calculate the volume of a sphere with a radius of 3 cm.\",\n \"input\": \"\",\n \"output\": \"The volume of the sphere is approximately 113.10 cubic cm.\"\n },\n {\n \"instruction\": \"Convert 2 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"2 kilometers is 2000 meters.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The garden is very beautiful.\",\n \"output\": \"The garden is a paradise.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for oxygen?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for oxygen is O.\"\n },\n {\n \"instruction\": \"What is the square root of 225?\",\n \"input\": \"\",\n \"output\": \"The square root of 225 is 15.\"\n },\n {\n \"instruction\": \"What is the opposite of 'tall'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'tall' is 'short'.\"\n },\n {\n \"instruction\": \"What is the hypotenuse of a right triangle with legs of 3 cm and 4 cm?\",\n \"input\": \"\",\n \"output\": \"The hypotenuse of the triangle is 5 cm.\"\n },\n {\n \"instruction\": \"What is the capital of South Africa?\",\n \"input\": \"\",\n \"output\": \"The capital of South Africa is Pretoria.\"\n },\n {\n \"instruction\": \"Provide an example of a compound sentence.\",\n \"input\": \"\",\n \"output\": \"I played the piano, and she sang along.\"\n },\n {\n \"instruction\": \"What is the opposite of 'expand'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'expand' is 'contract'.\"\n },\n {\n \"instruction\": \"Convert 20 miles per hour to kilometers per hour.\",\n \"input\": \"\",\n \"output\": \"20 miles per hour is approximately 32.19 kilometers per hour.\"\n },\n {\n \"instruction\": \"Translate the sentence to French: 'How old are you?'\",\n \"input\": \"\",\n \"output\": \"Quel \\u00e2ge avez-vous?\"\n },\n {\n \"instruction\": \"What is the opposite of 'early'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'early' is 'late'.\"\n },\n {\n \"instruction\": \"Generate three verbs that mean the same as \\\"to run.\\\"\",\n \"input\": \"\",\n \"output\": \"1. To sprint\\n2. To dash\\n3. To jog\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"She is very smart.\",\n \"output\": \"She is a walking encyclopedia.\"\n },\n {\n \"instruction\": \"Convert the following sentence to passive voice: 'The committee approved the new guidelines.'\",\n \"input\": \"The committee approved the new guidelines.\",\n \"output\": \"The new guidelines were approved by the committee.\"\n },\n {\n \"instruction\": \"Classify this speech as either formal or informal.\",\n \"input\": \"Could you please pass the salt?\",\n \"output\": \"This speech is formal.\"\n },\n {\n \"instruction\": \"What is the chemical formula for acetic acid?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for acetic acid is CH3COOH.\"\n },\n {\n \"instruction\": \"Determine the state of matter for oxygen at room temperature.\",\n \"input\": \"\",\n \"output\": \"Oxygen is in a gaseous state at room temperature.\"\n },\n {\n \"instruction\": \"Provide a word that rhymes with 'day.'\",\n \"input\": \"\",\n \"output\": \"A word that rhymes with 'day' is 'play.'\"\n },\n {\n \"instruction\": \"Convert the following verb to its past participle form: 'begin'\",\n \"input\": \"\",\n \"output\": \"The past participle form of 'begin' is 'begun'.\"\n },\n {\n \"instruction\": \"Combine the two ideas in the sentence.\",\n \"input\": \"Learning a new language is useful. It can be challenging.\",\n \"output\": \"Learning a new language is useful but can be challenging.\"\n },\n {\n \"instruction\": \"What is the formula for density?\",\n \"input\": \"\",\n \"output\": \"The formula for density is density = mass/volume.\"\n },\n {\n \"instruction\": \"What is the plural form of \\\"goose\\\"?\",\n \"input\": \"\",\n \"output\": \"The plural form of \\\"goose\\\" is \\\"geese.\\\"\"\n },\n {\n \"instruction\": \"Explain the process of convection.\",\n \"input\": \"\",\n \"output\": \"Convection is the transfer of heat through the movement of fluids (liquids or gases). It occurs when a warmer area of a liquid or gas rises and is replaced by a cooler area, creating a circulation pattern.\"\n },\n {\n \"instruction\": \"Convert 2000 millimeters to meters.\",\n \"input\": \"\",\n \"output\": \"2000 millimeters is equal to 2 meters.\"\n },\n {\n \"instruction\": \"Name an antonym for 'fear.'\",\n \"input\": \"\",\n \"output\": \"An antonym for 'fear' is 'courage.'\"\n },\n {\n \"instruction\": \"What is the opposite of 'high'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'high' is 'low'.\"\n },\n {\n \"instruction\": \"What is the abbreviation for \\\"Doctor of Philosophy\\\"?\",\n \"input\": \"\",\n \"output\": \"The abbreviation for \\\"Doctor of Philosophy\\\" is Ph.D.\"\n },\n {\n \"instruction\": \"What type of animal is a 'koala'?\",\n \"input\": \"\",\n \"output\": \"A koala is a marsupial.\"\n },\n {\n \"instruction\": \"Pick out the correct verb from the following list.\",\n \"input\": \"run, mountain, quickly\",\n \"output\": \"The correct verb from the list is \\\"run.\\\"\"\n },\n {\n \"instruction\": \"Classify the given sentiment as either positive, negative, or neutral.\",\n \"input\": \"This is a great opportunity!\",\n \"output\": \"Positive\"\n },\n {\n \"instruction\": \"What is the formula for speed?\",\n \"input\": \"\",\n \"output\": \"The formula for speed is speed = distance/time.\"\n },\n {\n \"instruction\": \"Name an antonym for 'big.'\",\n \"input\": \"\",\n \"output\": \"An antonym for 'big' is 'small.'\"\n },\n {\n \"instruction\": \"Name a solid commonly found in the Earth's crust.\",\n \"input\": \"\",\n \"output\": \"A solid commonly found in the Earth's crust is granite.\"\n },\n {\n \"instruction\": \"What is the melting point of zinc in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of zinc is 419.5 degrees Celsius.\"\n },\n {\n \"instruction\": \"List 5 different types of vegetables\",\n \"input\": \"\",\n \"output\": \"1. Carrot\\n2. Broccoli\\n3. Cucumber\\n4. Tomato (biologically a fruit, but often classified as a vegetable)\\n5. Spinach\"\n },\n {\n \"instruction\": \"Classify the following substances as acid, base, or salt.\",\n \"input\": \"Vinegar, Baking soda, Table salt\",\n \"output\": \"Acid: Vinegar\\nBase: Baking soda\\nSalt: Table salt\"\n },\n {\n \"instruction\": \"Create an alliteration with the word 'moon'.\",\n \"input\": \"\",\n \"output\": \"The magnificent moon moved majestically across the midnight sky.\"\n },\n {\n \"instruction\": \"What is the primary function of the cell membrane?\",\n \"input\": \"\",\n \"output\": \"The primary function of the cell membrane is to protect the cell by controlling the movement of substances in and out of the cell. It also provides structural support and facilitates communication between cells.\"\n },\n {\n \"instruction\": \"What is the opposite of 'young'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'young' is 'old'.\"\n },\n {\n \"instruction\": \"Determine the mass of an object that has a density of 8 g/cm\\u00b3 and a volume of 3 cm\\u00b3.\",\n \"input\": \"\",\n \"output\": \"The mass of the object is 24 grams.\"\n },\n {\n \"instruction\": \"Provide the correct contraction for 'they are'.\",\n \"input\": \"\",\n \"output\": \"The contraction for 'they are' is 'they're'.\"\n },\n {\n \"instruction\": \"Describe how a rainbow is formed.\",\n \"input\": \"\",\n \"output\": \"A rainbow is formed when sunlight is refracted, dispersed, and reflected in water droplets, resulting in a spectrum of light appearing in the sky.\"\n },\n {\n \"instruction\": \"What is the plural form of 'octopus'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'octopus' can be 'octopuses' or 'octopi'.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor: 'The assignment was a breeze.'\",\n \"input\": \"The assignment was a breeze.\",\n \"output\": \"The assignment was a piece of cake.\"\n },\n {\n \"instruction\": \"Make the first sentence a dependent clause.\",\n \"input\": \"I finished my work. I went home.\",\n \"output\": \"After finishing my work, I went home.\"\n },\n {\n \"instruction\": \"What is the boiling point of hydrogen?\",\n \"input\": \"\",\n \"output\": \"The boiling point of hydrogen is -252.9 degrees Celsius.\"\n },\n {\n \"instruction\": \"Describe the process of evaporation.\",\n \"input\": \"\",\n \"output\": \"Evaporation is the process by which water changes from a liquid to a gas due to heat.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'illuminate'.\",\n \"input\": \"\",\n \"output\": \"The lamp helped to illuminate the dark room.\"\n },\n {\n \"instruction\": \"What is the chemical formula for carbon monoxide?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for carbon monoxide is CO.\"\n },\n {\n \"instruction\": \"What is the atomic number of helium?\",\n \"input\": \"\",\n \"output\": \"The atomic number of helium is 2.\"\n },\n {\n \"instruction\": \"Arrange the given numbers in ascending order.\",\n \"input\": \"8, 3, 15, 1, 7\",\n \"output\": \"1, 3, 7, 8, 15.\"\n },\n {\n \"instruction\": \"Sort the following list in alphabetical order.\",\n \"input\": \"Zebra, Elephant, Crocodile\",\n \"output\": \"sorted in alphabetical order: Crocodile, Elephant, Zebra\"\n },\n {\n \"instruction\": \"Pick the best synonym for the given word.\",\n \"input\": \"Gather\",\n \"output\": \"Collect.\"\n },\n {\n \"instruction\": \"What is the boiling point of nitrogen in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of nitrogen is -196 degrees Celsius.\"\n },\n {\n \"instruction\": \"Correct the misuse of 'your' in the sentence.\",\n \"input\": \"Your going to love this place.\",\n \"output\": \"The corrected sentence should be: 'You're going to love this place.'\"\n },\n {\n \"instruction\": \"Identify the type of triangle with angles of 90 degrees, 45 degrees, and 45 degrees.\",\n \"input\": \"\",\n \"output\": \"A triangle with angles of 90 degrees, 45 degrees, and 45 degrees is a right isosceles triangle.\"\n },\n {\n \"instruction\": \"What is the chemical formula for sodium bicarbonate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for sodium bicarbonate is NaHCO3.\"\n },\n {\n \"instruction\": \"What is the melting point of iron in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of iron is 1538 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is a synonym of 'meticulous'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'meticulous' is 'thorough'.\"\n },\n {\n \"instruction\": \"What is a synonym of 'abundant'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'abundant' is 'plentiful'.\"\n },\n {\n \"instruction\": \"List the ingredients to make pancakes.\",\n \"input\": \"\",\n \"output\": \"Ingredients for pancakes include flour, eggs, milk, and sugar.\"\n },\n {\n \"instruction\": \"What is the primary function of red blood cells in the human body?\",\n \"input\": \"\",\n \"output\": \"The primary function of red blood cells is to carry oxygen from the lungs to the body's tissues and to return carbon dioxide from the tissues to the lungs.\"\n },\n {\n \"instruction\": \"Translate 'How do you do?' into French.\",\n \"input\": \"\",\n \"output\": \"Comment allez-vous?\"\n },\n {\n \"instruction\": \"Construct a sentence using the words \\\"achieve\\\", \\\"goal\\\", and \\\"perseverance\\\".\",\n \"input\": \"\",\n \"output\": \"With perseverance, you can achieve any goal.\"\n },\n {\n \"instruction\": \"Generate a five-word phrase using the words 'star,' 'night,' and 'bright.'\",\n \"input\": \"\",\n \"output\": \"'The bright star illuminated night.'\"\n },\n {\n \"instruction\": \"Perform a sentiment analysis on the given sentence.\",\n \"input\": \"I hate this song!\",\n \"output\": \"The sentiment of the sentence \\\"I hate this song!\\\" is negative. This is indicated by the word \\\"hate\\\" which shows strong aversion or dislike towards the subject, in this case, the song.\"\n },\n {\n \"instruction\": \"Provide the past participle form of 'choose.'\",\n \"input\": \"\",\n \"output\": \"The past participle form of 'choose' is 'chosen.'\"\n },\n {\n \"instruction\": \"Rewrite the sentence so that it does not contain any passive voice.\",\n \"input\": \"The artwork was displayed in the gallery.\",\n \"output\": \"The gallery displayed the artwork.\"\n },\n {\n \"instruction\": \"Pick out the verb from the following list.\",\n \"input\": \"tree, sing, blue\",\n \"output\": \"The correct verb from the list is 'sing.'\"\n },\n {\n \"instruction\": \"What are the first 10 odd numbers?\",\n \"input\": \"\",\n \"output\": \"1, 3, 5, 7, 9, 11, 13, 15, 17, 19.\"\n },\n {\n \"instruction\": \"Generate a past-tense verb that describes a person singing.\",\n \"input\": \"\",\n \"output\": \"Sang.\"\n },\n {\n \"instruction\": \"Find a rhyming word for the word \\\"care.\\\"\",\n \"input\": \"\",\n \"output\": \"A rhyming word for the word \\\"care\\\" could be \\\"bare.\\\"\"\n },\n {\n \"instruction\": \"Combine the two sentences into a single coherent sentence.\",\n \"input\": \"She missed the bus. She walked to school.\",\n \"output\": \"She missed the bus, so she walked to school.\"\n },\n {\n \"instruction\": \"What is the boiling point of ethanol in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of ethanol is 78 degrees Celsius.\"\n },\n {\n \"instruction\": \"Convert the temperature from Celsius to Kelvin.\",\n \"input\": \"25 degrees Celsius\",\n \"output\": \"25 degrees Celsius is 298.15 Kelvin.\"\n },\n {\n \"instruction\": \"What is an antonym for 'weak'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'weak' is 'strong.'\"\n },\n {\n \"instruction\": \"What is the opposite of 'soft'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'soft' is 'hard'.\"\n },\n {\n \"instruction\": \"Name a synonym for 'exciting'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'exciting' is 'thrilling'.\"\n },\n {\n \"instruction\": \"Suggest a more formal synonym for 'goodbye.'\",\n \"input\": \"\",\n \"output\": \"A more formal synonym for 'goodbye' is 'farewell.'\"\n },\n {\n \"instruction\": \"What is the pH of lemon juice?\",\n \"input\": \"\",\n \"output\": \"The pH of lemon juice is approximately 2.0.\"\n },\n {\n \"instruction\": \"Rewrite the sentence in future perfect tense.\",\n \"input\": \"They will complete the project.\",\n \"output\": \"They will have completed the project.\"\n },\n {\n \"instruction\": \"Re-word this sentence using an active voice.\",\n \"input\": \"The decision was made by the team.\",\n \"output\": \"The team made the decision.\"\n },\n {\n \"instruction\": \"Provide an example of alliteration.\",\n \"input\": \"\",\n \"output\": \"An example of alliteration is, 'Peter Piper picked a peck of pickled peppers.'\"\n },\n {\n \"instruction\": \"What is the primary purpose of the United Nations?\",\n \"input\": \"\",\n \"output\": \"The primary purpose of the United Nations is to maintain international peace and security, develop friendly relations among nations, achieve international cooperation, and be a center for harmonizing the actions of nations.\"\n },\n {\n \"instruction\": \"What is a synonym of 'astonishing'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'astonishing' is 'amazing'.\"\n },\n {\n \"instruction\": \"What is the capital of Japan?\",\n \"input\": \"\",\n \"output\": \"The capital of Japan is Tokyo.\"\n },\n {\n \"instruction\": \"Arrange the given numbers in descending order.\",\n \"input\": \"7, 10, 3, 6, 9\",\n \"output\": \"10, 9, 7, 6, 3.\"\n },\n {\n \"instruction\": \"Name a punctuation mark used to indicate possession.\",\n \"input\": \"\",\n \"output\": \"A punctuation mark used to indicate possession is the apostrophe (').\"\n },\n {\n \"instruction\": \"Make the first sentence a dependent clause.\",\n \"input\": \"He finished his homework. He went out to play.\",\n \"output\": \"After he finished his homework, he went out to play.\"\n },\n {\n \"instruction\": \"What is the opposite of 'cheap'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'cheap' is 'expensive'.\"\n },\n {\n \"instruction\": \"What is the capital of Norway?\",\n \"input\": \"\",\n \"output\": \"The capital of Norway is Oslo.\"\n },\n {\n \"instruction\": \"Categorize the following items into liquids and solids.\",\n \"input\": \"Milk, Rock, Honey\",\n \"output\": \"Liquids: Milk, Honey\\nSolids: Rock\"\n },\n {\n \"instruction\": \"Translate 'Where are you from?' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'Where are you from?' is 'D'o\\u00f9 viens-tu?'.\"\n },\n {\n \"instruction\": \"Name a bird that cannot fly.\",\n \"input\": \"\",\n \"output\": \"A bird that cannot fly is the penguin.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'compassionate'.\",\n \"input\": \"\",\n \"output\": \"She is very compassionate and always helps those in need.\"\n },\n {\n \"instruction\": \"What is the melting point of ice in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of ice is 0 degrees Celsius.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The night is very calm.\",\n \"output\": \"The night is a tranquil sea.\"\n },\n {\n \"instruction\": \"List the steps required to make a cup of tea.\",\n \"input\": \"\",\n \"output\": \"Steps to make a cup of tea: 1. Boil water. 2. Place a tea bag in a cup. 3. Pour hot water over the tea bag. 4. Let it steep. 5. Remove the tea bag and enjoy.\"\n },\n {\n \"instruction\": \"Define the term 'osmosis'.\",\n \"input\": \"\",\n \"output\": \"Osmosis is the process of movement of water molecules through a semipermeable membrane from a region of low solute concentration to a region of high solute concentration.\"\n },\n {\n \"instruction\": \"Create a compound word using 'water.'\",\n \"input\": \"\",\n \"output\": \"A compound word using 'water' is 'waterfall.'\"\n },\n {\n \"instruction\": \"Calculate the volume of a cube with side length of 3 meters.\",\n \"input\": \"\",\n \"output\": \"The volume of the cube is 27 cubic meters.\"\n },\n {\n \"instruction\": \"Generate a question that could logically follow the statement below.\",\n \"input\": \"I just finished reading a fascinating book.\",\n \"output\": \"What was the book about?\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'resilient'.\",\n \"input\": \"\",\n \"output\": \"He is very resilient and always bounces back from setbacks.\"\n },\n {\n \"instruction\": \"Rewrite this sentence to start with 'In spite of': Although it was raining, they went for a walk.\",\n \"input\": \"\",\n \"output\": \"In spite of the rain, they went for a walk.\"\n },\n {\n \"instruction\": \"Convert the mass from kilograms to grams.\",\n \"input\": \"4 kilograms\",\n \"output\": \"4 kilograms is equivalent to 4000 grams.\"\n },\n {\n \"instruction\": \"Convert the number 110 from binary to decimal.\",\n \"input\": \"\",\n \"output\": \"The decimal equivalent of the binary number 110 is 6.\"\n },\n {\n \"instruction\": \"Name three essential elements found in nature.\",\n \"input\": \"\",\n \"output\": \"1. Carbon\\n2. Oxygen\\n3. Iron\"\n },\n {\n \"instruction\": \"Provide a synonym for 'intelligent'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'intelligent' is 'smart'.\"\n },\n {\n \"instruction\": \"What is the speed of sound?\",\n \"input\": \"\",\n \"output\": \"The speed of sound is approximately 343 meters per second at sea level and at 20\\u00b0C.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"He is very clumsy.\",\n \"output\": \"He is as clumsy as a bull in a china shop.\"\n },\n {\n \"instruction\": \"Find the temperature of boiling water under normal atmospheric pressure.\",\n \"input\": \"\",\n \"output\": \"Under normal atmospheric pressure, the temperature of boiling water is 100 degrees Celsius (212 degrees Fahrenheit).\"\n },\n {\n \"instruction\": \"Classify the following online review as being positive or negative.\",\n \"input\": \"I found this book to be incredibly insightful and informative.\",\n \"output\": \"The online review is positive.\"\n },\n {\n \"instruction\": \"What is the pH level of pure water?\",\n \"input\": \"\",\n \"output\": \"The pH level of pure water is 7, which is neutral.\"\n },\n {\n \"instruction\": \"What is the formula for calculating the perimeter of a rectangle?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating the perimeter of a rectangle is 2(length + width).\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'determined'.\",\n \"input\": \"\",\n \"output\": \"She is determined to achieve her dreams.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'meticulous'.\",\n \"input\": \"\",\n \"output\": \"He is meticulous in his work and pays attention to every detail.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The room was very hot.\",\n \"output\": \"The room was as hot as an oven.\"\n },\n {\n \"instruction\": \"Classify the following statement into one of these labels: [positive, negative, neutral]\",\n \"input\": \"My computer is working perfectly.\",\n \"output\": \"The statement 'My computer is working perfectly' can be classified as positive.\"\n },\n {\n \"instruction\": \"Edit the following sentence for grammar.\",\n \"input\": \"We goes to the park every Sunday.\",\n \"output\": \"We go to the park every Sunday.\"\n },\n {\n \"instruction\": \"Define the term 'quantum mechanics'.\",\n \"input\": \"\",\n \"output\": \"Quantum mechanics is a branch of physics that studies the behavior of particles at the smallest scales, such as atoms and subatomic particles.\"\n },\n {\n \"instruction\": \"What is the primary function of the digestive system?\",\n \"input\": \"\",\n \"output\": \"The primary function of the digestive system is to break down food into nutrients that can be absorbed into the bloodstream and used by the body for energy, growth, and repair.\"\n },\n {\n \"instruction\": \"What is the formula for calculating the area of a rectangle?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating the area of a rectangle is length \\u00d7 width.\"\n },\n {\n \"instruction\": \"Translate 'Thank you very much' into Japanese.\",\n \"input\": \"\",\n \"output\": \"The Japanese translation of 'Thank you very much' is '\\u3069\\u3046\\u3082\\u3042\\u308a\\u304c\\u3068\\u3046\\u3054\\u3056\\u3044\\u307e\\u3059' (D\\u014dmo arigat\\u014dgozaimasu).\"\n },\n {\n \"instruction\": \"Translate the phrase 'How are you?' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'How are you?' is '\\u00bfC\\u00f3mo est\\u00e1s?'\"\n },\n {\n \"instruction\": \"Fill in the blank to complete the sentence.\",\n \"input\": \"The most popular vegetable in the world is the ___\",\n \"output\": \"The most popular vegetable in the world is the potato.\"\n },\n {\n \"instruction\": \"Given a sentence, count the number of words.\",\n \"input\": \"I love watching the stars at night.\",\n \"output\": \"The sentence 'I love watching the stars at night.' contains 7 words.\"\n },\n {\n \"instruction\": \"Correct the grammatical errors in this sentence.\",\n \"input\": \"He don't know nothing about it.\",\n \"output\": \"He doesn't know anything about it.\"\n },\n {\n \"instruction\": \"Suggest a more formal synonym for 'happy.'\",\n \"input\": \"\",\n \"output\": \"A more formal synonym for 'happy' is 'joyful.'\"\n },\n {\n \"instruction\": \"Convert 2,000 milligrams to grams.\",\n \"input\": \"\",\n \"output\": \"2,000 milligrams is equal to 2 grams.\"\n },\n {\n \"instruction\": \"Put the following words in alphabetical order: kitten, zebra, alligator.\",\n \"input\": \"\",\n \"output\": \"Alligator, kitten, zebra.\"\n },\n {\n \"instruction\": \"Identify the main theme in George Orwell's '1984'.\",\n \"input\": \"\",\n \"output\": \"The main theme of '1984' is the dangers of totalitarianism and oppressive government control.\"\n },\n {\n \"instruction\": \"What is the capital of Germany?\",\n \"input\": \"\",\n \"output\": \"The capital city of Germany is Berlin.\"\n },\n {\n \"instruction\": \"Define the term 'mitosis'.\",\n \"input\": \"\",\n \"output\": \"Mitosis is a type of cell division that results in two daughter cells each having the same number and kind of chromosomes as the parent nucleus.\"\n },\n {\n \"instruction\": \"Name 3 different animals that are active during the day.\",\n \"input\": \"\",\n \"output\": \"1. Squirrel\\n2. Eagle\\n3. Tiger\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'spontaneous'.\",\n \"input\": \"\",\n \"output\": \"His decision to travel was completely spontaneous, made on a whim.\"\n },\n {\n \"instruction\": \"Convert the sentence into a question by adding a question tag.\",\n \"input\": \"You will help me\",\n \"output\": \"You will help me, won't you?\"\n },\n {\n \"instruction\": \"What type of animal is a 'sparrow'?\",\n \"input\": \"\",\n \"output\": \"A sparrow is a type of bird.\"\n },\n {\n \"instruction\": \"Create a compound word using 'sun.'\",\n \"input\": \"\",\n \"output\": \"A compound word using 'sun' is 'sunshine.'\"\n },\n {\n \"instruction\": \"Convert 90 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"90 centimeters is 0.9 meters.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'difficult'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'difficult' is 'challenging'.\"\n },\n {\n \"instruction\": \"Classify the following into mammals, birds, and fish.\",\n \"input\": \"Eagle, Shark, Lion\",\n \"output\": \"Mammals: Lion\\nBirds: Eagle\\nFish: Shark\"\n },\n {\n \"instruction\": \"What is the square root of 16?\",\n \"input\": \"\",\n \"output\": \"The square root of 16 is 4.\"\n },\n {\n \"instruction\": \"Translate 'We go to school together' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Vamos juntos a la escuela.\"\n },\n {\n \"instruction\": \"What is the melting point of tin in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of tin is 231.9 degrees Celsius.\"\n },\n {\n \"instruction\": \"Edit the following sentence to make it more formal.\",\n \"input\": \"I gotta go to the store.\",\n \"output\": \"I have to go to the store.\"\n },\n {\n \"instruction\": \"Translate 'Goodbye' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation of 'Goodbye' is 'Adi\\u00f3s'.\"\n },\n {\n \"instruction\": \"What is the chemical formula for nitric acid?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for nitric acid is HNO3.\"\n },\n {\n \"instruction\": \"Transform the following sentence to include an exclamation mark to show surprise.\",\n \"input\": \"I found my keys\",\n \"output\": \"I found my keys!\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'illuminate.'\",\n \"input\": \"\",\n \"output\": \"The streetlights illuminate the pathway at night.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for magnesium?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for magnesium is Mg.\"\n },\n {\n \"instruction\": \"Convert the sentence to passive voice: 'The chef prepared the meal.'\",\n \"input\": \"The chef prepared the meal.\",\n \"output\": \"The meal was prepared by the chef.\"\n },\n {\n \"instruction\": \"Edit the text for grammar and punctuation.\",\n \"input\": \"today was amazing I went hiking and saw a bear\",\n \"output\": \"\\\"Today was amazing. I went hiking and saw a bear.\\\"\"\n },\n {\n \"instruction\": \"Explain the function of the respiratory system in humans.\",\n \"input\": \"\",\n \"output\": \"The respiratory system's primary function is to supply the blood with oxygen through breathing and to remove carbon dioxide. It includes the nose, throat, larynx, trachea, bronchi, and lungs.\"\n },\n {\n \"instruction\": \"Convert the number 10 from decimal to binary.\",\n \"input\": \"\",\n \"output\": \"The binary equivalent of the decimal number 10 is 1010.\"\n },\n {\n \"instruction\": \"Rewrite the sentence so that it does not contain any passive voice.\",\n \"input\": \"The song was played on the radio.\",\n \"output\": \"The radio played the song.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'quintessential'.\",\n \"input\": \"\",\n \"output\": \"He was the quintessential example of a gentleman.\"\n },\n {\n \"instruction\": \"What is the past tense of 'fly'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'fly' is 'flew'.\"\n },\n {\n \"instruction\": \"Rewrite this statement as an imperative sentence.\",\n \"input\": \"You should check the document for errors.\",\n \"output\": \"Check the document for errors.\"\n },\n {\n \"instruction\": \"Convert the following verb to its gerund form: 'write'\",\n \"input\": \"\",\n \"output\": \"The gerund form of 'write' is 'writing.'\"\n },\n {\n \"instruction\": \"Generate three verbs that mean the same as 'to write.'\",\n \"input\": \"\",\n \"output\": \"1. To compose\\n2. To draft\\n3. To pen\"\n },\n {\n \"instruction\": \"Calculate the perimeter of an equilateral triangle with each side measuring 8 cm.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the equilateral triangle is 24 cm.\"\n },\n {\n \"instruction\": \"Describe the color blue in 3 words.\",\n \"input\": \"\",\n \"output\": \"Deep, calming, cool.\"\n },\n {\n \"instruction\": \"Classify the following items: apple, diamond, fern.\",\n \"input\": \"\",\n \"output\": \"Plants: Fern\\nMinerals: Diamond\\nFruits: Apple\"\n },\n {\n \"instruction\": \"Scramble the given phrase.\",\n \"input\": \"A random phrase\",\n \"output\": \"A nmaodr hrasep\"\n },\n {\n \"instruction\": \"Identify the verb in the following sentence\",\n \"input\": \"The cat sleeps on the couch.\",\n \"output\": \"The verb in the sentence is \\\"sleeps.\\\"\"\n },\n {\n \"instruction\": \"What is the freezing point of water in Celsius?\",\n \"input\": \"\",\n \"output\": \"The freezing point of water is 0 degrees Celsius.\"\n },\n {\n \"instruction\": \"Pick the best synonym for the given word.\",\n \"input\": \"Assist\",\n \"output\": \"Help.\"\n },\n {\n \"instruction\": \"Provide the past tense form of the verb 'choose.'\",\n \"input\": \"\",\n \"output\": \"The past tense of the verb 'choose' is 'chose.'\"\n },\n {\n \"instruction\": \"Convert 1000 millimeters to meters.\",\n \"input\": \"\",\n \"output\": \"1000 millimeters is 1 meter.\"\n },\n {\n \"instruction\": \"Generate a question that could logically follow the statement below.\",\n \"input\": \"I just got a new job.\",\n \"output\": \"What will you be doing at your new job?\"\n },\n {\n \"instruction\": \"Given a sentence, convert it into indirect speech.\",\n \"input\": \"He said, 'I am hungry.'\",\n \"output\": \"He said that he was hungry.\"\n },\n {\n \"instruction\": \"What is the integral of x?\",\n \"input\": \"\",\n \"output\": \"The integral of x is (1/2)x^2 + C.\"\n },\n {\n \"instruction\": \"Name the process by which leaves change color in autumn.\",\n \"input\": \"\",\n \"output\": \"The process by which leaves change color in autumn is called senescence.\"\n },\n {\n \"instruction\": \"What is the capital of Mexico?\",\n \"input\": \"\",\n \"output\": \"The capital of Mexico is Mexico City.\"\n },\n {\n \"instruction\": \"Categorize the following items into one of the following categories: appliance, clothing, or food.\",\n \"input\": \"Microwave, T-shirt, Bread\",\n \"output\": \"Appliance: Microwave\\nClothing: T-shirt\\nFood: Bread\"\n },\n {\n \"instruction\": \"Translate 'I am sorry' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'I am sorry' is 'Es tut mir leid'.\"\n },\n {\n \"instruction\": \"Convert this declarative sentence into a command: 'You should check the report.'\",\n \"input\": \"\",\n \"output\": \"Check the report.\"\n },\n {\n \"instruction\": \"Translate 'good afternoon' into Portuguese.\",\n \"input\": \"\",\n \"output\": \"Boa tarde\"\n },\n {\n \"instruction\": \"Convert the following verb to its gerund form: 'eat'\",\n \"input\": \"\",\n \"output\": \"The gerund form of 'eat' is 'eating'.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'bittersweet'.\",\n \"input\": \"\",\n \"output\": \"His victory was bittersweet, as it came at a great personal loss.\"\n },\n {\n \"instruction\": \"What is the opposite of 'strong'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'strong' is 'weak'.\"\n },\n {\n \"instruction\": \"Translate 'They are reading books' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Est\\u00e1n leyendo libros.\"\n },\n {\n \"instruction\": \"List two synonyms for 'beautiful.'\",\n \"input\": \"\",\n \"output\": \"Two synonyms for 'beautiful' are 'gorgeous' and 'stunning.'\"\n },\n {\n \"instruction\": \"Rewrite this sentence to increase formality: 'Kids need to check their phones less.'\",\n \"input\": \"\",\n \"output\": \"Children ought to reduce their mobile phone usage.\"\n },\n {\n \"instruction\": \"What is the opposite of 'slow'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'slow' is 'fast'.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The baby is very cute.\",\n \"output\": \"The baby is as cute as a button.\"\n },\n {\n \"instruction\": \"Determine the state of matter for helium at room temperature.\",\n \"input\": \"\",\n \"output\": \"Helium is in a gaseous state at room temperature.\"\n },\n {\n \"instruction\": \"Correct the misspelled word in the following sentence.\",\n \"input\": \"I recieved your message\",\n \"output\": \"The misspelled word \\\"recieved\\\" should be spelled \\\"received.\\\"\"\n },\n {\n \"instruction\": \"What is the formula for kinetic energy?\",\n \"input\": \"\",\n \"output\": \"The formula for kinetic energy is KE = 1/2 mv\\u00b2, where m is mass and v is velocity.\"\n },\n {\n \"instruction\": \"Identify the adjective in the sentence.\",\n \"input\": \"The red car sped down the road.\",\n \"output\": \"The adjective in the sentence is 'red'.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor: 'Life is like a journey.'\",\n \"input\": \"\",\n \"output\": \"Life is a journey.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"She is very gentle.\",\n \"output\": \"She is as gentle as a lamb.\"\n },\n {\n \"instruction\": \"Change the given verb to its present perfect form.\",\n \"input\": \"go\",\n \"output\": \"Gone.\"\n },\n {\n \"instruction\": \"Convert 200 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"200 grams is 0.2 kilograms.\"\n },\n {\n \"instruction\": \"Determine the area of a square with side length of 8 meters.\",\n \"input\": \"\",\n \"output\": \"The area of the square is 64 square meters.\"\n },\n {\n \"instruction\": \"Reverse this array\",\n \"input\": \"[5, 15, 25, 35, 45]\",\n \"output\": \"Here is the reversed array: [45, 35, 25, 15, 5]\"\n },\n {\n \"instruction\": \"Generate a random sequence of 12 digits.\",\n \"input\": \"\",\n \"output\": \"Here is a randomly generated sequence of 12 digits: 728493651280.\"\n },\n {\n \"instruction\": \"Create a simile with the phrase 'as busy as'.\",\n \"input\": \"\",\n \"output\": \"He was as busy as a bee.\"\n },\n {\n \"instruction\": \"What is the opposite of 'noisy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'noisy' is 'quiet'.\"\n },\n {\n \"instruction\": \"Generate a random alphanumeric code of 8 characters.\",\n \"input\": \"\",\n \"output\": \"Here is a randomly generated 8-character alphanumeric code: A3F8J7K2.\"\n },\n {\n \"instruction\": \"Name three essential minerals for human health.\",\n \"input\": \"\",\n \"output\": \"1. Calcium\\n2. Iron\\n3. Magnesium\"\n },\n {\n \"instruction\": \"Categorize the following items into herbs and spices.\",\n \"input\": \"Cinnamon, Basil, Pepper\",\n \"output\": \"Herbs: Basil\\nSpices: Cinnamon, Pepper\"\n },\n {\n \"instruction\": \"Create a sentence that begins with 'Even though,'\",\n \"input\": \"\",\n \"output\": \"Even though it was raining, they decided to go for a walk.\"\n },\n {\n \"instruction\": \"What is the opposite of 'happy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'happy' is 'sad'.\"\n },\n {\n \"instruction\": \"Define the term 'allusion'.\",\n \"input\": \"\",\n \"output\": \"An allusion is a brief and indirect reference to a person, place, thing, or idea of historical, cultural, literary, or political significance.\"\n },\n {\n \"instruction\": \"Classify the item as either a mammal or a bird.\",\n \"input\": \"Penguin\",\n \"output\": \"Bird\"\n },\n {\n \"instruction\": \"Convert the temperature from Celsius to Fahrenheit.\",\n \"input\": \"30 degrees Celsius\",\n \"output\": \"30 degrees Celsius is 86 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Convert 15 liters to milliliters.\",\n \"input\": \"\",\n \"output\": \"15 liters is 15000 milliliters.\"\n },\n {\n \"instruction\": \"Combine the given sentences into one cohesive sentence.\",\n \"input\": \"It is raining. I cannot go to the park.\",\n \"output\": \"Since it is raining, I cannot go to the park.\"\n },\n {\n \"instruction\": \"Calculate the future value of an investment of $500 at an annual interest rate of 5% compounded yearly for 10 years.\",\n \"input\": \"\",\n \"output\": \"The future value of the investment would be approximately $814.45.\"\n },\n {\n \"instruction\": \"What is a synonym of 'lazy'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'lazy' is 'indolent'.\"\n },\n {\n \"instruction\": \"Look up the boiling point of ethanol.\",\n \"input\": \"\",\n \"output\": \"The boiling point of ethanol is approximately 78.37 degrees Celsius or 173.07 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Convert the sentence to passive voice: 'The teacher explains the lesson.'\",\n \"input\": \"The teacher explains the lesson.\",\n \"output\": \"The lesson is explained by the teacher.\"\n },\n {\n \"instruction\": \"Name the largest ocean on Earth.\",\n \"input\": \"\",\n \"output\": \"The largest ocean on Earth is the Pacific Ocean.\"\n },\n {\n \"instruction\": \"What is the boiling point of water on Mount Everest?\",\n \"input\": \"\",\n \"output\": \"The boiling point of water on Mount Everest is lower than at sea level, around 71 degrees Celsius.\"\n },\n {\n \"instruction\": \"Evaluate the following phrase by transforming it into the correct spelling given.\",\n \"input\": \"recieve --> receive\",\n \"output\": \"The spelling of the given phrase 'recieve' is incorrect, the correct spelling is 'receive.'\"\n },\n {\n \"instruction\": \"Define the term 'metaphor'.\",\n \"input\": \"\",\n \"output\": \"A metaphor is a figure of speech in which a word or phrase is applied to an object or action to which it is not literally applicable.\"\n },\n {\n \"instruction\": \"Explain what GDP stands for and what it measures.\",\n \"input\": \"\",\n \"output\": \"GDP stands for Gross Domestic Product, which measures the total value of all goods and services produced over a specific time period within a country's borders.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'delicious'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'delicious' is 'tasty'.\"\n },\n {\n \"instruction\": \"Translate this phrase to Spanish: 'I will travel tomorrow.'\",\n \"input\": \"\",\n \"output\": \"Viajar\\u00e9 ma\\u00f1ana.\"\n },\n {\n \"instruction\": \"What is a synonym for 'enormous'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'enormous' is 'gigantic'.\"\n },\n {\n \"instruction\": \"Create a new sentence by combining the two sentences.\",\n \"input\": \"He likes to swim. He goes to the pool every day.\",\n \"output\": \"He likes to swim and goes to the pool every day.\"\n },\n {\n \"instruction\": \"What is the square root of 169?\",\n \"input\": \"\",\n \"output\": \"The square root of 169 is 13.\"\n },\n {\n \"instruction\": \"Identify the genre of the book '1984' by George Orwell.\",\n \"input\": \"\",\n \"output\": \"The genre of '1984' by George Orwell is dystopian fiction.\"\n },\n {\n \"instruction\": \"Convert 120 meters to kilometers.\",\n \"input\": \"\",\n \"output\": \"120 meters is 0.12 kilometers.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to remove redundancy.\",\n \"input\": \"The end result was a total success.\",\n \"output\": \"The result was a success.\"\n },\n {\n \"instruction\": \"Name a punctuation mark used to indicate a pause.\",\n \"input\": \"\",\n \"output\": \"A punctuation mark used to indicate a pause is a comma (,).\"\n },\n {\n \"instruction\": \"Suggest a simpler word to replace the word in braces.\",\n \"input\": \"He moved {expeditiously} through the crowd.\",\n \"output\": \"He moved quickly through the crowd.\"\n },\n {\n \"instruction\": \"Construct a sentence using the words 'achieve,' 'goal,' and 'dedication.'\",\n \"input\": \"\",\n \"output\": \"With dedication, you can achieve any goal.\"\n },\n {\n \"instruction\": \"Generate a question based on the following statement.\",\n \"input\": \"Plants produce oxygen through the process of photosynthesis.\",\n \"output\": \"How do plants produce oxygen?\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The night is very dark.\",\n \"output\": \"The night is a black canvas.\"\n },\n {\n \"instruction\": \"Translate 'good evening' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'good evening' is 'buona sera'.\"\n },\n {\n \"instruction\": \"What is the cube root of 27?\",\n \"input\": \"\",\n \"output\": \"The cube root of 27 is 3.\"\n },\n {\n \"instruction\": \"What is the atomic number of nitrogen?\",\n \"input\": \"\",\n \"output\": \"The atomic number of nitrogen is 7.\"\n },\n {\n \"instruction\": \"Name 3 different animals that are nocturnal.\",\n \"input\": \"\",\n \"output\": \"1. Owl\\n2. Bat\\n3. Raccoon\"\n },\n {\n \"instruction\": \"Convert 100 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"100 grams is 0.1 kilograms.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'brave'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'brave' is 'fearless'.\"\n },\n {\n \"instruction\": \"Convert 12 meters to centimeters.\",\n \"input\": \"\",\n \"output\": \"12 meters is 1200 centimeters.\"\n },\n {\n \"instruction\": \"What is the pH of a substance that is neither acidic nor basic?\",\n \"input\": \"\",\n \"output\": \"The pH of a substance that is neither acidic nor basic is 7, which is neutral.\"\n },\n {\n \"instruction\": \"Create a new sentence by combining the two sentences.\",\n \"input\": \"She loves to read. She goes to the library every week.\",\n \"output\": \"She loves to read and goes to the library every week.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"He is very busy.\",\n \"output\": \"He is a bee in a hive.\"\n },\n {\n \"instruction\": \"What is a synonym of 'exquisite'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'exquisite' is 'elegant'.\"\n },\n {\n \"instruction\": \"Convert the following sentence to use a conditional clause: If it rains, we will stay indoors.\",\n \"input\": \"\",\n \"output\": \"We will stay indoors if it rains.\"\n },\n {\n \"instruction\": \"What is the melting point of mercury in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of mercury is -38.83 degrees Celsius.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'clarify.'\",\n \"input\": \"\",\n \"output\": \"She asked the teacher to clarify the instructions.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'meticulous'.\",\n \"input\": \"\",\n \"output\": \"He was meticulous in his planning for the project.\"\n },\n {\n \"instruction\": \"What is the capital of Italy?\",\n \"input\": \"\",\n \"output\": \"The capital of Italy is Rome.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence using the active voice.\",\n \"input\": \"The ball was thrown by the pitcher.\",\n \"output\": \"The pitcher threw the ball.\"\n },\n {\n \"instruction\": \"What is the melting point of copper in Celsius?\",\n \"input\": \"\",\n \"output\": \"The melting point of copper is 1085 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the capital of the Netherlands?\",\n \"input\": \"\",\n \"output\": \"The capital of the Netherlands is Amsterdam.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for sodium?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for sodium is Na.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence by adding one adjective.\",\n \"input\": \"The cat slept on the mat.\",\n \"output\": \"The black cat slept on the mat.\"\n },\n {\n \"instruction\": \"Explain what an enzyme is.\",\n \"input\": \"\",\n \"output\": \"An enzyme is a protein that catalyzes chemical reactions within the body.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The night is very peaceful.\",\n \"output\": \"The night is a blanket of calm.\"\n },\n {\n \"instruction\": \"Identify the protagonist in 'The Great Gatsby'.\",\n \"input\": \"\",\n \"output\": \"The protagonist of 'The Great Gatsby' is Jay Gatsby.\"\n },\n {\n \"instruction\": \"Categorize the following items into one of the following categories: tool, clothing, or fruit.\",\n \"input\": \"Hammer, Shirt, Apple\",\n \"output\": \"Tool: Hammer\\nClothing: Shirt\\nFruit: Apple\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"She is very quiet.\",\n \"output\": \"She is as quiet as a mouse.\"\n },\n {\n \"instruction\": \"What type of molecule is DNA?\",\n \"input\": \"\",\n \"output\": \"DNA is a type of nucleic acid.\"\n },\n {\n \"instruction\": \"Provide the plural form of 'index.'\",\n \"input\": \"\",\n \"output\": \"The plural form of 'index' is 'indices.'\"\n },\n {\n \"instruction\": \"What is the unit for measuring force?\",\n \"input\": \"\",\n \"output\": \"The unit for measuring force is the newton.\"\n },\n {\n \"instruction\": \"Give me a synonym for the word 'strong'.\",\n \"input\": \"\",\n \"output\": \"Powerful.\"\n },\n {\n \"instruction\": \"What is the plural form of 'bacterium'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'bacterium' is 'bacteria'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'expand'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'expand' is 'contract'.\"\n },\n {\n \"instruction\": \"What is the primary function of the human nervous system?\",\n \"input\": \"\",\n \"output\": \"The primary function of the human nervous system is to control and coordinate the body's activities by transmitting signals between different parts of the body. It includes the brain, spinal cord, and peripheral nerves.\"\n },\n {\n \"instruction\": \"What is the boiling point of nitrogen?\",\n \"input\": \"\",\n \"output\": \"The boiling point of nitrogen is -195.79 degrees Celsius.\"\n },\n {\n \"instruction\": \"Translate the term 'global warming' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish translation for 'global warming' is 'calentamiento global'.\"\n },\n {\n \"instruction\": \"Convert 20 miles to kilometers, assuming 1 mile is approximately 1.60934 kilometers.\",\n \"input\": \"\",\n \"output\": \"20 miles is approximately 32.1868 kilometers.\"\n },\n {\n \"instruction\": \"What type of animal is a 'penguin'?\",\n \"input\": \"\",\n \"output\": \"A penguin is a type of bird.\"\n },\n {\n \"instruction\": \"What is the opposite of 'exclude'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'exclude' is 'include'.\"\n },\n {\n \"instruction\": \"List three primary colors.\",\n \"input\": \"\",\n \"output\": \"The three primary colors are red, blue, and yellow.\"\n },\n {\n \"instruction\": \"Create a sentence that begins with \\\"If only,\\\"\",\n \"input\": \"\",\n \"output\": \"If only I had known the truth earlier...\"\n },\n {\n \"instruction\": \"What is the opposite of 'clean'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'clean' is 'dirty'.\"\n },\n {\n \"instruction\": \"Rewrite the given passage in the past tense.\",\n \"input\": \"They are building a new library.\",\n \"output\": \"They built a new library.\"\n },\n {\n \"instruction\": \"Name an antonym for \\\"joy.\\\"\",\n \"input\": \"\",\n \"output\": \"An antonym for \\\"joy\\\" is \\\"sorrow.\\\"\"\n },\n {\n \"instruction\": \"Provide an example of a complex sentence.\",\n \"input\": \"\",\n \"output\": \"Although it was raining, we decided to go for a walk.\"\n },\n {\n \"instruction\": \"Name the three main types of rocks.\",\n \"input\": \"\",\n \"output\": \"The three main types of rocks are igneous, sedimentary, and metamorphic.\"\n },\n {\n \"instruction\": \"What is the boiling point of ethanol in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of ethanol is 78.37 degrees Celsius.\"\n },\n {\n \"instruction\": \"Convert 45 kilograms to pounds.\",\n \"input\": \"\",\n \"output\": \"45 kilograms is approximately 99.21 pounds.\"\n },\n {\n \"instruction\": \"Classify this sentence into one of the following topics: health, economy, technology, music\",\n \"input\": \"Electric cars are revolutionizing the automotive industry.\",\n \"output\": \"The topic of the given sentence is technology.\"\n },\n {\n \"instruction\": \"What is the largest planet in our solar system?\",\n \"input\": \"\",\n \"output\": \"The largest planet in our solar system is Jupiter.\"\n },\n {\n \"instruction\": \"What is the capital of Australia?\",\n \"input\": \"\",\n \"output\": \"The capital of Australia is Canberra.\"\n },\n {\n \"instruction\": \"Determine whether the given two words are synonyms or antonyms.\",\n \"input\": \"Start - Stop\",\n \"output\": \"Start and Stop are antonyms.\"\n },\n {\n \"instruction\": \"Name the literary device used in 'Time is a thief.'\",\n \"input\": \"\",\n \"output\": \"The literary device used is metaphor.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor: The sun set behind the hills.\",\n \"input\": \"\",\n \"output\": \"The sun dipped behind the hills like a shy child hiding.\"\n },\n {\n \"instruction\": \"List the primary colors in the CMYK color model.\",\n \"input\": \"\",\n \"output\": \"The primary colors in the CMYK color model are cyan, magenta, yellow, and key (black).\"\n },\n {\n \"instruction\": \"Classify the following animal as carnivore, herbivore, or omnivore.\",\n \"input\": \"Bear\",\n \"output\": \"Omnivore\"\n },\n {\n \"instruction\": \"List 5 different types of fruits\",\n \"input\": \"\",\n \"output\": \"1. Apple\\n2. Banana\\n3. Orange\\n4. Strawberry\\n5. Mango\"\n },\n {\n \"instruction\": \"What is the sum of 2 and 3?\",\n \"input\": \"\",\n \"output\": \"The sum of 2 and 3 is 5.\"\n },\n {\n \"instruction\": \"Sort the following list in alphabetical order.\",\n \"input\": \"Banana, Apple, Cherry\",\n \"output\": \"sorted in alphabetical order: Apple, Banana, Cherry\"\n },\n {\n \"instruction\": \"What is the boiling point of water in Fahrenheit?\",\n \"input\": \"\",\n \"output\": \"The boiling point of water is 212 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Change this sentence into the present perfect tense.\",\n \"input\": \"She writes a letter.\",\n \"output\": \"She has written a letter.\"\n },\n {\n \"instruction\": \"Convert 100 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"100 centimeters is equal to 1 meter.\"\n },\n {\n \"instruction\": \"Identify the hypernym for the word \\\"car\\\".\",\n \"input\": \"\",\n \"output\": \"The hypernym for the word \\\"car\\\" is \\\"vehicle\\\".\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'dynamic'.\",\n \"input\": \"\",\n \"output\": \"The team had a dynamic leader who inspired everyone.\"\n },\n {\n \"instruction\": \"Rewrite this English sentence into passive voice.\",\n \"input\": \"The gardener planted the flowers.\",\n \"output\": \"The flowers were planted by the gardener.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'We celebrate Independence Day on July 4th.'\",\n \"input\": \"\",\n \"output\": \"Independence Day is celebrated on July 4th.\"\n },\n {\n \"instruction\": \"Convert 800 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"800 grams is 0.8 kilograms.\"\n },\n {\n \"instruction\": \"Convert 15 feet to meters.\",\n \"input\": \"\",\n \"output\": \"15 feet is equal to approximately 4.572 meters.\"\n },\n {\n \"instruction\": \"Translate 'How are you?' into Japanese.\",\n \"input\": \"\",\n \"output\": \"The Japanese translation of 'How are you?' is '\\u304a\\u5143\\u6c17\\u3067\\u3059\\u304b' (Ogenki desu ka).\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'enthusiastic'.\",\n \"input\": \"\",\n \"output\": \"He was enthusiastic about starting his new job.\"\n },\n {\n \"instruction\": \"What is the opposite of 'cold'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'cold' is 'hot'.\"\n },\n {\n \"instruction\": \"What is the boiling point of propane in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of propane is -42 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the square root of 81?\",\n \"input\": \"\",\n \"output\": \"The square root of 81 is 9.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'effort'.\",\n \"input\": \"\",\n \"output\": \"She put a lot of effort into her work.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'swift'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'swift' is 'quick'.\"\n },\n {\n \"instruction\": \"Classify the following items as either solid, liquid, or gas.\",\n \"input\": \"Ice, Coffee, Helium\",\n \"output\": \"Ice - Solid\\nCoffee - Liquid\\nHelium - Gas\"\n },\n {\n \"instruction\": \"Translate 'What time is it?' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'What time is it?' is 'Che ora \\u00e8?'.\"\n },\n {\n \"instruction\": \"Transform the following sentence into a question using 'would.'\",\n \"input\": \"You can lend me a pen.\",\n \"output\": \"Would you lend me a pen?\"\n },\n {\n \"instruction\": \"Describe the process of condensation.\",\n \"input\": \"\",\n \"output\": \"Condensation is the process by which water vapor in the air is changed into liquid water.\"\n },\n {\n \"instruction\": \"Correct any spelling mistakes in the given sentence.\",\n \"input\": \"The beutiful garden was filled with flowers.\",\n \"output\": \"The beautiful garden was filled with flowers.\"\n },\n {\n \"instruction\": \"Calculate the perimeter of a hexagon with side lengths of 5 cm.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the hexagon is 30 cm.\"\n },\n {\n \"instruction\": \"Convert 30 kilometers to miles.\",\n \"input\": \"\",\n \"output\": \"30 kilometers is approximately 18.64 miles.\"\n },\n {\n \"instruction\": \"Define the term 'algorithm'.\",\n \"input\": \"\",\n \"output\": \"An algorithm is a set of defined, step-by-step procedures or rules to solve a problem or accomplish a task.\"\n },\n {\n \"instruction\": \"Convert 500 grams to ounces.\",\n \"input\": \"\",\n \"output\": \"500 grams is approximately 17.64 ounces.\"\n },\n {\n \"instruction\": \"Convert 500 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"500 grams is 0.5 kilograms.\"\n },\n {\n \"instruction\": \"Identify the correct spelling of the following word.\",\n \"input\": \"Necesary\",\n \"output\": \"The correct spelling is \\\"Necessary\\\".\"\n },\n {\n \"instruction\": \"What is the opposite of 'light'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'light' is 'heavy'.\"\n },\n {\n \"instruction\": \"What is the capital of Germany?\",\n \"input\": \"\",\n \"output\": \"The capital of Germany is Berlin.\"\n },\n {\n \"instruction\": \"Explain what a black hole is.\",\n \"input\": \"\",\n \"output\": \"A black hole is a region of space where gravity is so strong that nothing, not even light, can escape from it.\"\n },\n {\n \"instruction\": \"What is the symbol for copper on the periodic table?\",\n \"input\": \"\",\n \"output\": \"The symbol for copper on the periodic table is Cu.\"\n },\n {\n \"instruction\": \"Fill in the blanks with appropriate words.\",\n \"input\": \"The sky was filled with colorful ________ at sunrise.\",\n \"output\": \"The sky was filled with colorful hues at sunrise.\"\n },\n {\n \"instruction\": \"Convert the number 100 from binary to decimal.\",\n \"input\": \"\",\n \"output\": \"The decimal equivalent of the binary number 100 is 4.\"\n },\n {\n \"instruction\": \"What is the chemical formula for hydrochloric acid?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for hydrochloric acid is HCl.\"\n },\n {\n \"instruction\": \"Rewrite the sentence.\",\n \"input\": \"The poem was composed in a lyrical manner.\",\n \"output\": \"The poem was crafted lyrically.\"\n },\n {\n \"instruction\": \"What is the square root of 144?\",\n \"input\": \"\",\n \"output\": \"The square root of 144 is 12.\"\n },\n {\n \"instruction\": \"What is the formula for converting Celsius to Fahrenheit?\",\n \"input\": \"\",\n \"output\": \"The formula for converting Celsius to Fahrenheit is (C \\u00d7 9/5) + 32.\"\n },\n {\n \"instruction\": \"What is the chemical formula for sodium carbonate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for sodium carbonate is Na2CO3.\"\n },\n {\n \"instruction\": \"Convert 9 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"9 kilometers is 9000 meters.\"\n },\n {\n \"instruction\": \"Convert the following verb to its infinitive form\",\n \"input\": \"went\",\n \"output\": \"The infinitive form of 'went' is 'to go'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'diligent'.\",\n \"input\": \"\",\n \"output\": \"He is very diligent in his studies.\"\n },\n {\n \"instruction\": \"Classify the following statement into one of these labels: [positive, negative, neutral]\",\n \"input\": \"My computer crashed.\",\n \"output\": \"Negative\"\n },\n {\n \"instruction\": \"What is the pH of vinegar?\",\n \"input\": \"\",\n \"output\": \"The pH of vinegar is typically around 2.5.\"\n },\n {\n \"instruction\": \"Calculate the area of a triangle with base 10 meters and height 5 meters.\",\n \"input\": \"\",\n \"output\": \"The area of the triangle is 25 square meters.\"\n },\n {\n \"instruction\": \"Identify the primary colors in the RYB color model.\",\n \"input\": \"\",\n \"output\": \"The primary colors in the RYB color model are red, yellow, and blue.\"\n },\n {\n \"instruction\": \"What is the capital of Spain?\",\n \"input\": \"\",\n \"output\": \"The capital of Spain is Madrid.\"\n },\n {\n \"instruction\": \"Identify the adjective in the sentence.\",\n \"input\": \"The large dog barked loudly.\",\n \"output\": \"The adjective in the sentence is 'large'.\"\n },\n {\n \"instruction\": \"Translate 'She studies chemistry' into German.\",\n \"input\": \"\",\n \"output\": \"Sie studiert Chemie.\"\n },\n {\n \"instruction\": \"What is the comparative form of 'bad'?\",\n \"input\": \"\",\n \"output\": \"The comparative form of 'bad' is 'worse.'\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'charismatic'.\",\n \"input\": \"\",\n \"output\": \"The politician was very charismatic and attracted many followers.\"\n },\n {\n \"instruction\": \"Convert 10 meters to centimeters.\",\n \"input\": \"\",\n \"output\": \"10 meters is 1000 centimeters.\"\n },\n {\n \"instruction\": \"Generate three adjectives to describe a desert.\",\n \"input\": \"\",\n \"output\": \"1. Arid\\n2. Vast\\n3. Barren\"\n },\n {\n \"instruction\": \"Provide a synonym for 'quick'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'quick' is 'fast'.\"\n },\n {\n \"instruction\": \"Find a synonym for the word 'begin.'\",\n \"input\": \"\",\n \"output\": \"A synonym for the word 'begin' could be 'start.'\"\n },\n {\n \"instruction\": \"Define the term 'democracy'.\",\n \"input\": \"\",\n \"output\": \"Democracy is a system of government where the citizens exercise power by voting. It typically features fair and free elections, protection of human rights, and the rule of law.\"\n },\n {\n \"instruction\": \"What is the opposite of 'expensive'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'expensive' is 'cheap'.\"\n },\n {\n \"instruction\": \"Identify the interjection in the sentence.\",\n \"input\": \"Ouch, that hurt!\",\n \"output\": \"The interjection in the sentence is 'Ouch.'\"\n },\n {\n \"instruction\": \"Define the term 'photosynthesis'.\",\n \"input\": \"\",\n \"output\": \"Photosynthesis is the process by which green plants use sunlight to synthesize foods from carbon dioxide and water.\"\n },\n {\n \"instruction\": \"Rewrite this English sentence into passive voice.\",\n \"input\": \"Alex fixed the car.\",\n \"output\": \"The car was fixed by Alex.\"\n },\n {\n \"instruction\": \"Determine the product of 9 and 6.\",\n \"input\": \"\",\n \"output\": \"The product of 9 and 6 is 54.\"\n },\n {\n \"instruction\": \"Calculate the compound interest on a principal amount of $1000 at an annual rate of 4% compounded annually for 5 years.\",\n \"input\": \"\",\n \"output\": \"The compound interest on $1000 at 4% per annum compounded annually for 5 years is approximately $216.65, making the total $1216.65.\"\n },\n {\n \"instruction\": \"Generate a question that could logically follow the statement below.\",\n \"input\": \"I just returned from a vacation in Spain.\",\n \"output\": \"How was your vacation in Spain?\"\n },\n {\n \"instruction\": \"What is the primary purpose of photosynthesis?\",\n \"input\": \"\",\n \"output\": \"The primary purpose of photosynthesis is to convert light energy into chemical energy stored in glucose, which can be used by plants to fuel their activities.\"\n },\n {\n \"instruction\": \"What is the opposite of 'gain'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'gain' is 'lose.'\"\n },\n {\n \"instruction\": \"Convert 25 meters to centimeters.\",\n \"input\": \"\",\n \"output\": \"25 meters is 2500 centimeters.\"\n },\n {\n \"instruction\": \"What is the chemical formula for glucose?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for glucose is C6H12O6.\"\n },\n {\n \"instruction\": \"What is a synonym of 'happy'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'happy' is 'joyful'.\"\n },\n {\n \"instruction\": \"What type of animal is a 'whale'?\",\n \"input\": \"\",\n \"output\": \"A whale is a type of mammal.\"\n },\n {\n \"instruction\": \"Translate 'How much does this cost?' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'How much does this cost?' is 'Wie viel kostet das?'.\"\n },\n {\n \"instruction\": \"What is the chemical formula for methane?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for methane is CH4.\"\n },\n {\n \"instruction\": \"What is the derivative of x^2?\",\n \"input\": \"\",\n \"output\": \"The derivative of x^2 is 2x.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for iron?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for iron is Fe.\"\n },\n {\n \"instruction\": \"Identify the setting in 'The Great Gatsby'.\",\n \"input\": \"\",\n \"output\": \"The setting of 'The Great Gatsby' is in the fictional towns of West Egg and East Egg on Long Island in the summer of 1922.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence so that it is in passive voice.\",\n \"input\": \"The children played the game.\",\n \"output\": \"The game was played by the children.\"\n },\n {\n \"instruction\": \"Convert 1 liter to milliliters.\",\n \"input\": \"\",\n \"output\": \"1 liter is 1000 milliliters.\"\n },\n {\n \"instruction\": \"Identify the main verb in the sentence.\",\n \"input\": \"The cat chased the mouse.\",\n \"output\": \"The main verb in the sentence is 'chased.'\"\n },\n {\n \"instruction\": \"What is the opposite of 'ascend'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'ascend' is 'descend'.\"\n },\n {\n \"instruction\": \"Translate 'Thank you for your help' into Mandarin Chinese.\",\n \"input\": \"\",\n \"output\": \"The Mandarin Chinese translation of 'Thank you for your help' is '\\u8c22\\u8c22\\u4f60\\u7684\\u5e2e\\u52a9' (Xi\\u00e8xi\\u00e8 n\\u01d0 de b\\u0101ngzh\\u00f9).\"\n },\n {\n \"instruction\": \"Name the composer of the Brandenburg Concertos.\",\n \"input\": \"\",\n \"output\": \"The composer of the Brandenburg Concertos is Johann Sebastian Bach.\"\n },\n {\n \"instruction\": \"What is a synonym for 'assist'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'assist' is 'help'.\"\n },\n {\n \"instruction\": \"Identify the type of sentence.\",\n \"input\": \"Close the door.\",\n \"output\": \"The type of sentence is imperative.\"\n },\n {\n \"instruction\": \"Classify the following items: laptop, sunflower, tiger.\",\n \"input\": \"\",\n \"output\": \"Animals: Tiger\\nPlants: Sunflower\\nElectronics: Laptop\"\n },\n {\n \"instruction\": \"Name the process by which water changes from solid to liquid.\",\n \"input\": \"\",\n \"output\": \"The process by which water changes from solid to liquid is called melting.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'beautiful'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'beautiful' is 'stunning'.\"\n },\n {\n \"instruction\": \"Generate three adjectives to describe a mountain.\",\n \"input\": \"\",\n \"output\": \"1. Majestic\\n2. Rugged\\n3. Towering\"\n },\n {\n \"instruction\": \"Translate 'Can you help me?' into Spanish.\",\n \"input\": \"\",\n \"output\": \"\\u00bfPuedes ayudarme?\"\n },\n {\n \"instruction\": \"Find a rhyming word for the word 'house.'\",\n \"input\": \"\",\n \"output\": \"A rhyming word for the word 'house' is 'mouse.'\"\n },\n {\n \"instruction\": \"Convert 3 liters to milliliters.\",\n \"input\": \"\",\n \"output\": \"3 liters is 3000 milliliters.\"\n },\n {\n \"instruction\": \"Alter the content of the sentence to use the past tense.\",\n \"input\": \"The train departs at noon.\",\n \"output\": \"The train departed at noon.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'brave'.\",\n \"input\": \"\",\n \"output\": \"The firefighter was very brave and rescued the child from the fire.\"\n },\n {\n \"instruction\": \"Translate 'How are you?' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'How are you?' is 'Comment \\u00e7a va?'.\"\n },\n {\n \"instruction\": \"Rearrange the following list into descending order.\",\n \"input\": \"5, -3, 20, 10\",\n \"output\": \"20, 10, 5, -3\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'perseverant'.\",\n \"input\": \"\",\n \"output\": \"He is perseverant and never gives up on his goals.\"\n },\n {\n \"instruction\": \"Correct the punctuation in the sentence.\",\n \"input\": \"Lets eat, Grandma!\",\n \"output\": \"The corrected sentence should be: 'Let's eat, Grandma!'\"\n },\n {\n \"instruction\": \"Fix the following grammar mistake.\",\n \"input\": \"They wants to go to the movies, but they have no money.\",\n \"output\": \"They want to go to the movies, but they have no money.\"\n },\n {\n \"instruction\": \"What is the pH of soap?\",\n \"input\": \"\",\n \"output\": \"The pH of soap is typically between 9 and 10.\"\n },\n {\n \"instruction\": \"Classify the following items: pine tree, quartz, salmon.\",\n \"input\": \"\",\n \"output\": \"Plants: Pine tree\\nMinerals: Quartz\\nAnimals: Salmon\"\n },\n {\n \"instruction\": \"Rewrite the given sentence to describe the same thing in a positive way.\",\n \"input\": \"The meal was not delicious.\",\n \"output\": \"The meal could use some improvement.\"\n },\n {\n \"instruction\": \"What is the opposite of 'full'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'full' is 'empty'.\"\n },\n {\n \"instruction\": \"Generate an antonym for the word 'calm.'\",\n \"input\": \"\",\n \"output\": \"An antonym for the word 'calm' could be 'agitated.'\"\n },\n {\n \"instruction\": \"What is the chemical formula for calcium carbonate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for calcium carbonate is CaCO3.\"\n },\n {\n \"instruction\": \"Create a compound word using \\\"book.\\\"\",\n \"input\": \"\",\n \"output\": \"A compound word using \\\"book\\\" is \\\"bookshelf.\\\"\"\n },\n {\n \"instruction\": \"What is the chemical formula for hydrogen peroxide?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for hydrogen peroxide is H2O2.\"\n },\n {\n \"instruction\": \"What is the abbreviation for 'Bachelor of Science'?\",\n \"input\": \"\",\n \"output\": \"The abbreviation for 'Bachelor of Science' is B.Sc.\"\n },\n {\n \"instruction\": \"Convert 30 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"30 centimeters is 0.3 meters.\"\n },\n {\n \"instruction\": \"What is the boiling point of helium in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of helium is -268.9 degrees Celsius.\"\n },\n {\n \"instruction\": \"Convert 2 liters to milliliters.\",\n \"input\": \"\",\n \"output\": \"2 liters is 2000 milliliters.\"\n },\n {\n \"instruction\": \"Transform the following sentence to include an exclamation mark to show excitement.\",\n \"input\": \"I won the lottery\",\n \"output\": \"I won the lottery!\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a simile: The wind howled through the night.\",\n \"input\": \"\",\n \"output\": \"The wind howled through the night like a pack of wolves.\"\n },\n {\n \"instruction\": \"What is the pH value of pure water at 25\\u00b0C?\",\n \"input\": \"\",\n \"output\": \"The pH value of pure water at 25\\u00b0C is 7.\"\n },\n {\n \"instruction\": \"Arrange these historical periods in chronological order: Middle Ages, Renaissance, Industrial Revolution.\",\n \"input\": \"\",\n \"output\": \"1. Middle Ages\\n2. Renaissance\\n3. Industrial Revolution\"\n },\n {\n \"instruction\": \"Find a synonym for the word 'start'.\",\n \"input\": \"\",\n \"output\": \"A synonym for the word 'start' could be \\\"commence.\\\"\"\n },\n {\n \"instruction\": \"Identify the primary colors in the RGB color model.\",\n \"input\": \"\",\n \"output\": \"The primary colors in the RGB color model are red, green, and blue.\"\n },\n {\n \"instruction\": \"Name three types of clouds.\",\n \"input\": \"\",\n \"output\": \"Three types of clouds are cumulus, stratus, and cirrus.\"\n },\n {\n \"instruction\": \"Identify the tone used in the poem 'The Road Not Taken' by Robert Frost.\",\n \"input\": \"\",\n \"output\": \"The tone of 'The Road Not Taken' is reflective and contemplative, as the speaker considers the choices made in life and their long-term impacts.\"\n },\n {\n \"instruction\": \"Change this sentence into the past perfect continuous tense.\",\n \"input\": \"She sings in the choir.\",\n \"output\": \"She had been singing in the choir.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'persistent'.\",\n \"input\": \"\",\n \"output\": \"He is very persistent and never gives up.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'curious'.\",\n \"input\": \"\",\n \"output\": \"The child was curious about everything around him.\"\n },\n {\n \"instruction\": \"What is the boiling point of bromine in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of bromine is 59 degrees Celsius.\"\n },\n {\n \"instruction\": \"Convert the phrase into a complete sentence.\",\n \"input\": \"sunset over the ocean\",\n \"output\": \"The sunset over the ocean was breathtaking.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The room was very small.\",\n \"output\": \"The room was a shoebox.\"\n },\n {\n \"instruction\": \"Arrange the following events in chronological order: First Moon Landing, French Revolution, Industrial Revolution.\",\n \"input\": \"\",\n \"output\": \"1. French Revolution\\n2. Industrial Revolution\\n3. First Moon Landing\"\n },\n {\n \"instruction\": \"What is the capital of the United States?\",\n \"input\": \"\",\n \"output\": \"The capital of the United States is Washington, D.C.\"\n },\n {\n \"instruction\": \"Describe the main function of the human skeletal system.\",\n \"input\": \"\",\n \"output\": \"The main function of the human skeletal system is to provide support and structure to the body, protect internal organs, enable movement through attachment points for muscles, and produce blood cells in the bone marrow.\"\n },\n {\n \"instruction\": \"Identify the tense used in the sentence.\",\n \"input\": \"They are watching a movie.\",\n \"output\": \"The tense used in the sentence \\\"They are watching a movie\\\" is the present continuous tense.\"\n },\n {\n \"instruction\": \"Translate 'thank you' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'thank you' is 'danke'.\"\n },\n {\n \"instruction\": \"Suggest a continuation for the sentence.\",\n \"input\": \"After the rain stopped,\",\n \"output\": \"'the children went outside to play.'\"\n },\n {\n \"instruction\": \"What is the freezing point of water in Fahrenheit?\",\n \"input\": \"\",\n \"output\": \"The freezing point of water is 32 degrees Fahrenheit.\"\n },\n {\n \"instruction\": \"Generate a sentence that follows the pattern: 'Under no circumstances should you _____'\",\n \"input\": \"\",\n \"output\": \"Under no circumstances should you open the door.\"\n },\n {\n \"instruction\": \"Fix the following grammar mistake.\",\n \"input\": \"He want to go to the movies, but he has no money.\",\n \"output\": \"He wants to go to the movies, but he has no money.\"\n },\n {\n \"instruction\": \"What is a synonym for 'cold'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'cold' is 'chilly'.\"\n },\n {\n \"instruction\": \"Convert the mass from kilograms to grams.\",\n \"input\": \"3 kilograms\",\n \"output\": \"3 kilograms is equivalent to 3000 grams.\"\n },\n {\n \"instruction\": \"What is the capital of Portugal?\",\n \"input\": \"\",\n \"output\": \"The capital of Portugal is Lisbon.\"\n },\n {\n \"instruction\": \"Name a gas commonly found in the Earth's atmosphere.\",\n \"input\": \"\",\n \"output\": \"A gas commonly found in the Earth's atmosphere is nitrogen.\"\n },\n {\n \"instruction\": \"Sort the following numbers in ascending order.\",\n \"input\": \"5, 18, 3, 11.\",\n \"output\": \"The numbers in ascending order would be: 3, 5, 11, 18.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'eloquent'.\",\n \"input\": \"\",\n \"output\": \"The speaker was eloquent and captivated the audience.\"\n },\n {\n \"instruction\": \"Rewrite this sentence using appropriate grammar rules:\",\n \"input\": \"he saw a old man\",\n \"output\": \"He saw an old man.\"\n },\n {\n \"instruction\": \"What is an antonym of 'conceal'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'conceal' is 'reveal'.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence so that it is in active voice.\",\n \"input\": \"The cookies were eaten by the children.\",\n \"output\": \"The children ate the cookies.\"\n },\n {\n \"instruction\": \"What is the boiling point of water in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of water is 100 degrees Celsius.\"\n },\n {\n \"instruction\": \"Translate 'I love you' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Te amo\"\n },\n {\n \"instruction\": \"Translate 'I am happy' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'I am happy' is 'Je suis heureux' (if the speaker is male) or 'Je suis heureuse' (if the speaker is female).\"\n },\n {\n \"instruction\": \"Generate an antonym for the word 'optimistic'.\",\n \"input\": \"\",\n \"output\": \"An antonym for the word 'optimistic' could be 'pessimistic'.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"Her smile is very bright.\",\n \"output\": \"Her smile is a ray of sunshine.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'beautiful'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'beautiful' is 'lovely'.\"\n },\n {\n \"instruction\": \"Define the term 'photosynthesis'.\",\n \"input\": \"\",\n \"output\": \"Photosynthesis is the process by which green plants and some other organisms use sunlight to synthesize foods with the help of chlorophyll. It converts carbon dioxide and water into glucose and oxygen.\"\n },\n {\n \"instruction\": \"Arrange the following events in chronological order: Invention of the airplane, Fall of the Berlin Wall, Discovery of America.\",\n \"input\": \"\",\n \"output\": \"1. Discovery of America\\n2. Invention of the airplane\\n3. Fall of the Berlin Wall\"\n },\n {\n \"instruction\": \"Determine the gravitational force acting on an object with a mass of 10 kg on Earth.\",\n \"input\": \"\",\n \"output\": \"The gravitational force acting on an object with a mass of 10 kg on Earth is approximately 98 newtons.\"\n },\n {\n \"instruction\": \"Suggest a continuation for the sentence.\",\n \"input\": \"When the sun set,\",\n \"output\": \"\\\"the sky turned a brilliant shade of orange, casting a warm glow over the city.\\\"\"\n },\n {\n \"instruction\": \"Determine whether the given two words are synonyms or antonyms.\",\n \"input\": \"Open - Close\",\n \"output\": \"Open and Close are antonyms.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to remove redundancy.\",\n \"input\": \"She made a brief summary of the book.\",\n \"output\": \"She summarized the book.\"\n },\n {\n \"instruction\": \"Calculate the area of a triangle with a base of 10 units and height of 5 units.\",\n \"input\": \"\",\n \"output\": \"25 square units.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'funny'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'funny' is 'humorous'.\"\n },\n {\n \"instruction\": \"Identify the theme of the story.\",\n \"input\": \"The Tortoise and the Hare\",\n \"output\": \"The theme of the story is that slow and steady wins the race.\"\n },\n {\n \"instruction\": \"Arrange these historical periods in chronological order: Renaissance, Roman Empire, Victorian Era.\",\n \"input\": \"\",\n \"output\": \"1. Roman Empire\\n2. Renaissance\\n3. Victorian Era\"\n },\n {\n \"instruction\": \"Convert the following sentence to use a relative clause: The man is a teacher. He lives next door.\",\n \"input\": \"\",\n \"output\": \"The man who lives next door is a teacher.\"\n },\n {\n \"instruction\": \"Name a dwarf planet in our solar system.\",\n \"input\": \"\",\n \"output\": \"One dwarf planet in our solar system is Pluto.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"He is very generous.\",\n \"output\": \"He has a heart of gold.\"\n },\n {\n \"instruction\": \"What is a synonym of 'brave'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'brave' is 'courageous'.\"\n },\n {\n \"instruction\": \"Convert 100 pounds to kilograms.\",\n \"input\": \"\",\n \"output\": \"100 pounds is approximately 45.36 kilograms.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The sun was shining brightly.\",\n \"output\": \"The sun was a golden coin in the sky.\"\n },\n {\n \"instruction\": \"Identify the adjective in the sentence.\",\n \"input\": \"The quick fox jumped over the lazy dog.\",\n \"output\": \"The adjectives in the sentence are 'quick' and 'lazy'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'strong'.\",\n \"input\": \"\",\n \"output\": \"robust.\"\n },\n {\n \"instruction\": \"Generate a question with the keyword 'virus'\",\n \"input\": \"\",\n \"output\": \"How does a virus infect a cell?\"\n },\n {\n \"instruction\": \"Rewrite the following sentence using passive voice.\",\n \"input\": \"The team achieved great results.\",\n \"output\": \"Great results were achieved by the team.\"\n },\n {\n \"instruction\": \"Translate 'hello' into Japanese.\",\n \"input\": \"\",\n \"output\": \"The Japanese translation of 'hello' is '\\u3053\\u3093\\u306b\\u3061\\u306f' (Konnichiwa).\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"He is very wise.\",\n \"output\": \"He is a fountain of wisdom.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'persistent'.\",\n \"input\": \"\",\n \"output\": \"He is persistent and never gives up on his goals.\"\n },\n {\n \"instruction\": \"Generate a sentence that uses the word \\u2018mystic\\u2019.\",\n \"input\": \"\",\n \"output\": \"The ancient ruins had a mystic quality that captivated all who visited.\"\n },\n {\n \"instruction\": \"What is a synonym for 'tiny'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'tiny' is 'small'.\"\n },\n {\n \"instruction\": \"What is the capital of France?\",\n \"input\": \"\",\n \"output\": \"The capital of France is Paris.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'serene'.\",\n \"input\": \"\",\n \"output\": \"The lake was serene and calm in the early morning.\"\n },\n {\n \"instruction\": \"Convert the phrase into a complete sentence.\",\n \"input\": \"night sky\",\n \"output\": \"The night sky was dotted with countless twinkling stars.\"\n },\n {\n \"instruction\": \"Name the three branches of the United States government.\",\n \"input\": \"\",\n \"output\": \"The three branches of the United States government are the Executive, the Legislative, and the Judicial branches.\"\n },\n {\n \"instruction\": \"Convert the angle from radians to degrees.\",\n \"input\": \"\\u03c0/2 radians\",\n \"output\": \"\\u03c0/2 radians is 90 degrees.\"\n },\n {\n \"instruction\": \"Find the next 3 terms in the following sequence: 3, 5, 7, 9\",\n \"input\": \"\",\n \"output\": \"The next three terms in the sequence are: 11, 13, 15.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'pretty'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'pretty' is 'attractive'.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to include a hyperbole: 'I'm very hungry.'\",\n \"input\": \"I'm very hungry.\",\n \"output\": \"I'm so hungry I could eat a horse.\"\n },\n {\n \"instruction\": \"Scramble the given phrase.\",\n \"input\": \"A sunny day\",\n \"output\": \"A nnuys yda\"\n },\n {\n \"instruction\": \"Define the term 'economics'.\",\n \"input\": \"\",\n \"output\": \"Economics is a social science concerned with the production, distribution, and consumption of goods and services. It studies how individuals, businesses, governments, and nations make choices about how to allocate resources.\"\n },\n {\n \"instruction\": \"What is an antonym of 'accelerate'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'accelerate' is 'decelerate'.\"\n },\n {\n \"instruction\": \"Rewrite this sentence to start with \\\"Despite\\\": She managed to finish her work, although she was tired.\",\n \"input\": \"\",\n \"output\": \"Despite being tired, she managed to finish her work.\"\n },\n {\n \"instruction\": \"Translate 'See you soon' into French.\",\n \"input\": \"\",\n \"output\": \"\\u00c0 bient\\u00f4t\"\n },\n {\n \"instruction\": \"What is the chemical formula for water?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for water (dihydrogen monoxide) is H2O.\"\n },\n {\n \"instruction\": \"Transform the following sentence into a command.\",\n \"input\": \"You should clean your room.\",\n \"output\": \"Clean your room.\"\n },\n {\n \"instruction\": \"Find a synonym for the given verb.\",\n \"input\": \"Speak\",\n \"output\": \"Talk\"\n },\n {\n \"instruction\": \"What is the past tense of 'build'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'build' is 'built'.\"\n },\n {\n \"instruction\": \"Translate 'Where is the nearest hospital?' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'Where is the nearest hospital?' is 'Dove \\u00e8 l'ospedale pi\\u00f9 vicino?'.\"\n },\n {\n \"instruction\": \"Convert 200 meters to kilometers.\",\n \"input\": \"\",\n \"output\": \"200 meters is 0.2 kilometers.\"\n },\n {\n \"instruction\": \"Determine the state of matter for water at 100 degrees Celsius.\",\n \"input\": \"\",\n \"output\": \"Water is in a gaseous state at 100 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the opposite of 'weak'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'weak' is 'strong'.\"\n },\n {\n \"instruction\": \"Define the term 'biodiversity'.\",\n \"input\": \"\",\n \"output\": \"Biodiversity refers to the variety of life in the world or in a particular habitat or ecosystem.\"\n },\n {\n \"instruction\": \"Explain what a haiku is.\",\n \"input\": \"\",\n \"output\": \"A haiku is a form of traditional Japanese poetry that consists of three lines with a syllable pattern of 5-7-5.\"\n },\n {\n \"instruction\": \"Name the process by which plants make their food.\",\n \"input\": \"\",\n \"output\": \"The process by which plants make their food is called photosynthesis.\"\n },\n {\n \"instruction\": \"What is the melting point of iron?\",\n \"input\": \"\",\n \"output\": \"The melting point of iron is approximately 1538 degrees Celsius.\"\n },\n {\n \"instruction\": \"Define the term 'evaporation'.\",\n \"input\": \"\",\n \"output\": \"Evaporation is the process by which water changes from a liquid to a gas or vapor.\"\n },\n {\n \"instruction\": \"Define the concept of 'gravity'.\",\n \"input\": \"\",\n \"output\": \"Gravity is a force that attracts two bodies toward each other, the force that causes apples to fall toward the ground and planets to orbit stars.\"\n },\n {\n \"instruction\": \"Define the literary term 'alliteration'.\",\n \"input\": \"\",\n \"output\": \"Alliteration is the occurrence of the same letter or sound at the beginning of adjacent or closely connected words.\"\n },\n {\n \"instruction\": \"What is the pH of baking soda solution?\",\n \"input\": \"\",\n \"output\": \"The pH of a baking soda solution is typically around 9.\"\n },\n {\n \"instruction\": \"What is an antonym of 'ascend'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'ascend' is 'descend'.\"\n },\n {\n \"instruction\": \"Simplify the expression: 2(x + 3) + 4(x - 1).\",\n \"input\": \"\",\n \"output\": \"6x + 2.\"\n },\n {\n \"instruction\": \"Calculate the circumference of a circle with a diameter of 10 cm.\",\n \"input\": \"\",\n \"output\": \"The circumference of the circle is approximately 31.42 cm.\"\n },\n {\n \"instruction\": \"Generate a random sequence of 10 digits.\",\n \"input\": \"\",\n \"output\": \"Here is a randomly generated sequence of 10 digits: 9274036185.\"\n },\n {\n \"instruction\": \"Insert a suitable adjective to complete the sentence.\",\n \"input\": \"The movie was _____.\",\n \"output\": \"The movie was thrilling.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The sky is very blue.\",\n \"output\": \"The sky is a sapphire sea.\"\n },\n {\n \"instruction\": \"What is the boiling point of water at sea level?\",\n \"input\": \"\",\n \"output\": \"The boiling point of water at sea level is 100 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the cube of 5?\",\n \"input\": \"\",\n \"output\": \"The cube of 5 is 125.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"He is very strong.\",\n \"output\": \"He is as strong as an ox.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The house is very big.\",\n \"output\": \"The house is as big as a castle.\"\n },\n {\n \"instruction\": \"What is the capital of China?\",\n \"input\": \"\",\n \"output\": \"The capital of China is Beijing.\"\n },\n {\n \"instruction\": \"List two synonyms for \\\"intelligent.\\\"\",\n \"input\": \"\",\n \"output\": \"Two synonyms for \\\"intelligent\\\" are \\\"smart\\\" and \\\"clever.\\\"\"\n },\n {\n \"instruction\": \"Explain the function of the liver in the human body.\",\n \"input\": \"\",\n \"output\": \"The liver functions to process nutrients absorbed from the digestive tract, detoxify chemicals, and metabolize drugs.\"\n },\n {\n \"instruction\": \"Rewrite the sentence to improve clarity: 'He saw that the sky was clouds full.'\",\n \"input\": \"He saw that the sky was clouds full.\",\n \"output\": \"He saw that the sky was full of clouds.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using alliteration.\",\n \"input\": \"The wind blew softly.\",\n \"output\": \"The soft wind swept silently.\"\n },\n {\n \"instruction\": \"What is an antonym for 'increase'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'increase' is 'decrease'.\"\n },\n {\n \"instruction\": \"Classify this text as either a recipe or a novel.\",\n \"input\": \"Combine flour, sugar, and eggs in a bowl.\",\n \"output\": \"Recipe\"\n },\n {\n \"instruction\": \"rewrite this sentence as a question.\",\n \"input\": \"Your brother went to London last year.\",\n \"output\": \"Did your brother go to London last year?\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'ambitious'.\",\n \"input\": \"\",\n \"output\": \"She is ambitious and strives for success in all her endeavors.\"\n },\n {\n \"instruction\": \"Classify each sentence as either declarative, interrogative, imperative, or exclamatory.\",\n \"input\": \"Can you help me?\",\n \"output\": \"The classification of the sentence \\\"Can you help me?\\\" is interrogative.\"\n },\n {\n \"instruction\": \"Classify the following numbers as even or odd.\",\n \"input\": \"2, 5, 18, 21\",\n \"output\": \"Even numbers: 2, 18\\nOdd numbers: 5, 21\"\n },\n {\n \"instruction\": \"What is the chemical formula for salt?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for salt (sodium chloride) is NaCl.\"\n },\n {\n \"instruction\": \"Find the temperature of freezing water under normal atmospheric pressure.\",\n \"input\": \"\",\n \"output\": \"Under normal atmospheric pressure, the temperature of freezing water is 0 degrees Celsius (32 degrees Fahrenheit).\"\n },\n {\n \"instruction\": \"Edit the following sentence to make it more formal.\",\n \"input\": \"He's got to see it to believe it.\",\n \"output\": \"He must see it to believe it.\"\n },\n {\n \"instruction\": \"What is the opposite of 'easy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'easy' is 'difficult'.\"\n },\n {\n \"instruction\": \"Change the given verb to its past continuous form.\",\n \"input\": \"eat\",\n \"output\": \"Eating.\"\n },\n {\n \"instruction\": \"Transform the following sentence into the passive voice.\",\n \"input\": \"They will build a new park.\",\n \"output\": \"A new park will be built by them.\"\n },\n {\n \"instruction\": \"Evaluate this sentence for spelling and grammar mistakes.\",\n \"input\": \"I beleive this is a grate idea.\",\n \"output\": \"There are two errors in the sentence. The corrected sentence should be: 'I believe this is a great idea.'\"\n },\n {\n \"instruction\": \"What is the opposite of 'light'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'light' is 'dark'.\"\n },\n {\n \"instruction\": \"Translate 'good morning' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'good morning' is 'bonjour'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'progressive'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'progressive' is 'regressive'.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor: 'Her smile lights up the room.'\",\n \"input\": \"\",\n \"output\": \"Her smile is a beacon in the room.\"\n },\n {\n \"instruction\": \"Classify the following fruit according to its type.\",\n \"input\": \"Watermelon\",\n \"output\": \"The fruit \\\"Watermelon\\\" is typically classified as a type of melon.\"\n },\n {\n \"instruction\": \"What is the square root of 64?\",\n \"input\": \"\",\n \"output\": \"The square root of 64 is 8.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"He is very rich.\",\n \"output\": \"He is rolling in dough.\"\n },\n {\n \"instruction\": \"Classify the following animal as carnivore, herbivore, or omnivore.\",\n \"input\": \"Deer\",\n \"output\": \"Herbivore\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'serendipity'.\",\n \"input\": \"\",\n \"output\": \"Discovering the quaint caf\\u00e9 down the alley was pure serendipity.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'resourceful'.\",\n \"input\": \"\",\n \"output\": \"He is very resourceful and can solve any problem.\"\n },\n {\n \"instruction\": \"Classify the following item: hammer.\",\n \"input\": \"\",\n \"output\": \"A hammer can be classified as a tool.\"\n },\n {\n \"instruction\": \"Convert the time '1500 hours' into standard 12-hour clock format.\",\n \"input\": \"\",\n \"output\": \"1500 hours is equivalent to 3:00 PM.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a synonym.\",\n \"input\": \"It's cold outside.\",\n \"output\": \"It's chilly outside.\"\n },\n {\n \"instruction\": \"Convert 6 liters to milliliters.\",\n \"input\": \"\",\n \"output\": \"6 liters is 6000 milliliters.\"\n },\n {\n \"instruction\": \"What is the capital of Turkey?\",\n \"input\": \"\",\n \"output\": \"The capital of Turkey is Ankara.\"\n },\n {\n \"instruction\": \"Change the following sentence to past continuous tense.\",\n \"input\": \"They finish the game.\",\n \"output\": \"They were finishing the game.\"\n },\n {\n \"instruction\": \"Summarize the theme of 'The Great Gatsby'.\",\n \"input\": \"\",\n \"output\": \"The theme revolves around the American Dream and its disillusionment.\"\n },\n {\n \"instruction\": \"Delete the redundant words in the following sentence.\",\n \"input\": \"We went to see to the mountains.\",\n \"output\": \"We went to see the mountains.\"\n },\n {\n \"instruction\": \"Convert 5 kilograms to grams.\",\n \"input\": \"\",\n \"output\": \"5 kilograms is 5000 grams.\"\n },\n {\n \"instruction\": \"Generate a random 8-digit number.\",\n \"input\": \"\",\n \"output\": \"Here is a randomly generated 8-digit number: 47382916.\"\n },\n {\n \"instruction\": \"What is the opposite of 'quiet'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'quiet' is 'loud'.\"\n },\n {\n \"instruction\": \"Translate the term 'sustainable development' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'sustainable development' is 'nachhaltige Entwicklung'.\"\n },\n {\n \"instruction\": \"Convert the following statement into an exclamation.\",\n \"input\": \"This is amazing\",\n \"output\": \"This is amazing!\"\n },\n {\n \"instruction\": \"Classify the item as either a grain or a fruit.\",\n \"input\": \"Wheat\",\n \"output\": \"Grain\"\n },\n {\n \"instruction\": \"What is the boiling point of water under standard conditions?\",\n \"input\": \"\",\n \"output\": \"100 degrees Celsius.\"\n },\n {\n \"instruction\": \"Identify the tense used in the sentence.\",\n \"input\": \"They had watched the movie.\",\n \"output\": \"The tense used in the sentence 'They had watched the movie' is the past perfect tense.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to include a personification.\",\n \"input\": \"The wind is very strong today.\",\n \"output\": \"The wind howls with might today, as if declaring its presence.\"\n },\n {\n \"instruction\": \"Cut the following sentence into two, keeping the original meaning intact.\",\n \"input\": \"She baked a cake and then she decorated it.\",\n \"output\": \"She baked a cake. Then she decorated it.\"\n },\n {\n \"instruction\": \"Given a list of six ingredients, select the two most essential for making a cake.\",\n \"input\": \"sugar, flour, eggs, salt, vanilla, water\",\n \"output\": \"The two most essential ingredients for making a cake from the given list are flour and eggs.\"\n },\n {\n \"instruction\": \"What is the contraction for 'they will'?\",\n \"input\": \"\",\n \"output\": \"The contraction for 'they will' is 'they'll.'\"\n },\n {\n \"instruction\": \"Translate 'peace' into French.\",\n \"input\": \"\",\n \"output\": \"The French word for 'peace' is 'paix'.\"\n },\n {\n \"instruction\": \"Classify the item as either a fruit or a vegetable.\",\n \"input\": \"Tomato\",\n \"output\": \"Fruit\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor: 'Her laughter is like music.'\",\n \"input\": \"\",\n \"output\": \"Her laughter is music to the ears.\"\n },\n {\n \"instruction\": \"Capitalize each word in the sentence.\",\n \"input\": \"the book is on the table\",\n \"output\": \"The Book Is On The Table\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a simile: The car raced down the road.\",\n \"input\": \"\",\n \"output\": \"The car raced down the road like a bullet.\"\n },\n {\n \"instruction\": \"Combine the two ideas in the sentence.\",\n \"input\": \"Running is good for health. It can be tiring.\",\n \"output\": \"Running is good for health but can be tiring.\"\n },\n {\n \"instruction\": \"Identify the main subject in the sentence.\",\n \"input\": \"The excited students ran to the playground.\",\n \"output\": \"The main subject in the sentence is 'The excited students.'\"\n },\n {\n \"instruction\": \"Name a synonym for 'angry.'\",\n \"input\": \"\",\n \"output\": \"A synonym for 'angry' is 'furious.'\"\n },\n {\n \"instruction\": \"Combine the two sentences into a single coherent sentence.\",\n \"input\": \"She studied hard. She passed the exam.\",\n \"output\": \"She studied hard, so she passed the exam.\"\n },\n {\n \"instruction\": \"Explain the process of combustion.\",\n \"input\": \"\",\n \"output\": \"Combustion is a chemical process in which a substance reacts rapidly with oxygen, releasing heat and light. It typically produces carbon dioxide, water, and energy.\"\n },\n {\n \"instruction\": \"Convert the given sentence into active voice.\",\n \"input\": \"The proposal was approved by the committee.\",\n \"output\": \"The committee approved the proposal.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The car is very fast.\",\n \"output\": \"The car is as fast as lightning.\"\n },\n {\n \"instruction\": \"What type of cloud is typically associated with thunderstorms?\",\n \"input\": \"\",\n \"output\": \"The type of cloud typically associated with thunderstorms is cumulonimbus.\"\n },\n {\n \"instruction\": \"Name the author of 'Pride and Prejudice'.\",\n \"input\": \"\",\n \"output\": \"Jane Austen.\"\n },\n {\n \"instruction\": \"What is the periodic symbol for chlorine?\",\n \"input\": \"\",\n \"output\": \"The periodic symbol for chlorine is Cl.\"\n },\n {\n \"instruction\": \"Correct the punctuation in the sentence.\",\n \"input\": \"Its time to go home.\",\n \"output\": \"The corrected sentence should be: 'It's time to go home.'\"\n },\n {\n \"instruction\": \"Rewrite the sentence.\",\n \"input\": \"The lecture was delivered in a clear manner.\",\n \"output\": \"The lecture was delivered clearly.\"\n },\n {\n \"instruction\": \"Generate a humorous anecdote.\",\n \"input\": \"\",\n \"output\": \"Why was the math book sad? Because it had too many problems!\"\n },\n {\n \"instruction\": \"Identify the correct spelling: 'recieve' or 'receive'.\",\n \"input\": \"\",\n \"output\": \"The correct spelling is 'receive'.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'nostalgia'.\",\n \"input\": \"\",\n \"output\": \"Nostalgia washed over her as she looked through the old photos.\"\n },\n {\n \"instruction\": \"Classify the following numbers as prime or composite.\",\n \"input\": \": 11, 14, 19.\",\n \"output\": \"Prime numbers: 11, 19\\nComposite numbers: 14\"\n },\n {\n \"instruction\": \"What is the capital of Denmark?\",\n \"input\": \"\",\n \"output\": \"The capital of Denmark is Copenhagen.\"\n },\n {\n \"instruction\": \"What is the opposite of 'wet'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'wet' is 'dry'.\"\n },\n {\n \"instruction\": \"Identify the type of sentence.\",\n \"input\": \"Did you finish the report?\",\n \"output\": \"The type of sentence is interrogative.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for mercury?\",\n \"input\": \"\",\n \"output\": \"Hg.\"\n },\n {\n \"instruction\": \"Describe the process of active transport in cells.\",\n \"input\": \"\",\n \"output\": \"Active transport is the movement of molecules across a cell membrane from a region of lower concentration to a region of higher concentration, using energy in the form of ATP. This process is crucial for maintaining cellular homeostasis.\"\n },\n {\n \"instruction\": \"Classify the following items as either solid, liquid, or gas.\",\n \"input\": \"Mercury, oxygen, wood\",\n \"output\": \"Mercury - Liquid\\nOxygen - Gas\\nWood - Solid\"\n },\n {\n \"instruction\": \"Convert 3 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"3 kilometers is 3000 meters.\"\n },\n {\n \"instruction\": \"Convert the sentence to use an indefinite pronoun.\",\n \"input\": \"Someone left a note.\",\n \"output\": \"A note was left by someone.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'excited'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'excited' is 'thrilled'.\"\n },\n {\n \"instruction\": \"Generate a sentence that follows the pattern: \\\"Never have I ever _____ without _____\\\"\",\n \"input\": \"\",\n \"output\": \"Never have I ever traveled without a map.\"\n },\n {\n \"instruction\": \"Pick out the adjective from the following list.\",\n \"input\": \"run, tall, quickly\",\n \"output\": \"The correct adjective from the list is 'tall.'\"\n },\n {\n \"instruction\": \"Convert 1000 grams to kilograms.\",\n \"input\": \"\",\n \"output\": \"1000 grams is equal to 1 kilogram.\"\n },\n {\n \"instruction\": \"What is the opposite of 'deep'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'deep' is 'shallow'.\"\n },\n {\n \"instruction\": \"Categorize the given list of animals.\",\n \"input\": \"Shark, Dolphin, Trout\",\n \"output\": \"Fish: Shark, Trout\\nMammals: Dolphin\"\n },\n {\n \"instruction\": \"Translate 'library' into Spanish.\",\n \"input\": \"\",\n \"output\": \"The Spanish word for 'library' is 'biblioteca'.\"\n },\n {\n \"instruction\": \"Define the term 'hyperbole'.\",\n \"input\": \"\",\n \"output\": \"Hyperbole is a figure of speech that involves an exaggeration of ideas for the sake of emphasis.\"\n },\n {\n \"instruction\": \"Translate 'Hello' into Russian.\",\n \"input\": \"\",\n \"output\": \"\\u041f\\u0440\\u0438\\u0432\\u0435\\u0442 (Privet)\"\n },\n {\n \"instruction\": \"Define the term 'kinetic energy'.\",\n \"input\": \"\",\n \"output\": \"Kinetic energy is the energy that an object possesses due to its motion.\"\n },\n {\n \"instruction\": \"What is the opposite of 'hot'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'hot' is 'cold'.\"\n },\n {\n \"instruction\": \"Convert 5 miles to kilometers.\",\n \"input\": \"\",\n \"output\": \"5 miles is approximately 8.05 kilometers.\"\n },\n {\n \"instruction\": \"What is the chemical formula for magnesium sulfate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for magnesium sulfate is MgSO4.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to replace any clich\\u00e9 phrases.\",\n \"input\": \"It's a piece of cake\",\n \"output\": \"It's very easy.\"\n },\n {\n \"instruction\": \"List five different types of vegetables.\",\n \"input\": \"\",\n \"output\": \"1. Carrot\\n2. Broccoli\\n3. Cucumber\\n4. Tomato\\n5. Spinach\"\n },\n {\n \"instruction\": \"Convert 7 kilometers to meters.\",\n \"input\": \"\",\n \"output\": \"7 kilometers is 7000 meters.\"\n },\n {\n \"instruction\": \"What is the opposite of 'heavy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'heavy' is 'light'.\"\n },\n {\n \"instruction\": \"What is the past tense of 'sing'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'sing' is 'sang.'\"\n },\n {\n \"instruction\": \"What is the molecular formula for carbon dioxide?\",\n \"input\": \"\",\n \"output\": \"The molecular formula for carbon dioxide is CO2.\"\n },\n {\n \"instruction\": \"Convert this sentence to passive voice\",\n \"input\": \"The gardener watered the plants.\",\n \"output\": \"The plants were watered by the gardener.\"\n },\n {\n \"instruction\": \"What is the past tense of 'throw'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'throw' is 'threw'.\"\n },\n {\n \"instruction\": \"Explain what a sonnet is.\",\n \"input\": \"\",\n \"output\": \"A sonnet is a 14-line poem with a specific rhyme scheme and meter, often written in iambic pentameter.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovative'.\",\n \"input\": \"\",\n \"output\": \"The company is known for its innovative products.\"\n },\n {\n \"instruction\": \"Provide the plural form of 'cactus'.\",\n \"input\": \"\",\n \"output\": \"The plural form of 'cactus' is 'cacti'.\"\n },\n {\n \"instruction\": \"Translate the phrase 'Where is the bathroom?' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'Where is the bathroom?' is 'Wo ist die Toilette?'\"\n },\n {\n \"instruction\": \"Generate a past-tense verb that describes a person laughing.\",\n \"input\": \"\",\n \"output\": \"Laughed.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'transient.'\",\n \"input\": \"\",\n \"output\": \"The transient nature of her visit left a lasting impression.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'optimistic'.\",\n \"input\": \"\",\n \"output\": \"He remained optimistic despite the challenges he faced.\"\n },\n {\n \"instruction\": \"Re-word this sentence using an indirect question.\",\n \"input\": \"What time is the meeting?\",\n \"output\": \"Could you tell me what time the meeting is?\"\n },\n {\n \"instruction\": \"Categorize the following sentence as a statement, a question, or an exclamation.\",\n \"input\": \"What a beautiful day!\",\n \"output\": \"Exclamation.\"\n },\n {\n \"instruction\": \"What is the opposite of 'rich'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'rich' is 'poor'.\"\n },\n {\n \"instruction\": \"Find a synonym for the given verb.\",\n \"input\": \"Begin\",\n \"output\": \"Commence\"\n },\n {\n \"instruction\": \"Edit the given text to ensure all plural nouns are spelled correctly.\",\n \"input\": \"The birds sings beautiful songs.\",\n \"output\": \"The birds sing beautiful songs.\"\n },\n {\n \"instruction\": \"Transform the following sentence into a question using \\\"could.\\\"\",\n \"input\": \"You can help me tomorrow.\",\n \"output\": \"Could you help me tomorrow?\"\n },\n {\n \"instruction\": \"Classify the following items: bicycle, rose, tiger.\",\n \"input\": \"\",\n \"output\": \"Vehicles: Bicycle\\nPlants: Rose\\nAnimals: Tiger\"\n },\n {\n \"instruction\": \"Define the term 'irony'.\",\n \"input\": \"\",\n \"output\": \"Irony is a figure of speech in which words are used in such a way that their intended meaning is different from the actual meaning of the words.\"\n },\n {\n \"instruction\": \"Translate 'Welcome' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'Welcome' is 'Willkommen'.\"\n },\n {\n \"instruction\": \"Explain the primary function of the human heart.\",\n \"input\": \"\",\n \"output\": \"The primary function of the human heart is to pump blood throughout the body, delivering oxygen and nutrients to tissues and removing carbon dioxide and other wastes.\"\n },\n {\n \"instruction\": \"Reword the following sentence to the future tense.\",\n \"input\": \"He is reading a novel inspired by his grandmother.\",\n \"output\": \"He will be reading a novel inspired by his grandmother.\"\n },\n {\n \"instruction\": \"Convert the given sentence into active voice.\",\n \"input\": \"The law was passed by the government.\",\n \"output\": \"The government passed the law.\"\n },\n {\n \"instruction\": \"Create a sentence using the word 'inevitable'.\",\n \"input\": \"\",\n \"output\": \"The confrontation was inevitable given the circumstances.\"\n },\n {\n \"instruction\": \"Categorize the following sentence as either factual or opinion-based.\",\n \"input\": \"Chocolate is the best dessert.\",\n \"output\": \"Opinion-based.\"\n },\n {\n \"instruction\": \"What is an antonym of 'old'?\",\n \"input\": \"\",\n \"output\": \"young.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'hardworking'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'hardworking' is 'diligent'.\"\n },\n {\n \"instruction\": \"What is the boiling point of sulfur in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of sulfur is 444.6 degrees Celsius.\"\n },\n {\n \"instruction\": \"What is the plural form of 'child'?\",\n \"input\": \"\",\n \"output\": \"The plural form of 'child' is 'children'.\"\n },\n {\n \"instruction\": \"What is an antonym of 'complicated'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'complicated' is 'simple'.\"\n },\n {\n \"instruction\": \"Name three forms of water.\",\n \"input\": \"\",\n \"output\": \"The three forms of water are solid (ice), liquid (water), and gas (steam).\"\n },\n {\n \"instruction\": \"Rewrite this sentence as a question.\",\n \"input\": \"The dog chased the cat.\",\n \"output\": \"Did the dog chase the cat?\"\n },\n {\n \"instruction\": \"Split the following sentence into two declarative sentences: 'The movie was long but interesting.'\",\n \"input\": \"\",\n \"output\": \"The movie was long. It was interesting.\"\n },\n {\n \"instruction\": \"Classify the following substances as acid, base, or neutral.\",\n \"input\": \"Lemon juice, Soap, Water\",\n \"output\": \"Acid: Lemon juice\\nBase: Soap\\nNeutral: Water\"\n },\n {\n \"instruction\": \"What is a synonym of 'sad'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'sad' is 'unhappy'.\"\n },\n {\n \"instruction\": \"Correct any spelling mistakes in the given sentence.\",\n \"input\": \"I prefer homemade cookies to store boaght.\",\n \"output\": \"I prefer homemade cookies to store bought.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'transient'.\",\n \"input\": \"\",\n \"output\": \"His stay in the city was transient, lasting only a couple of days.\"\n },\n {\n \"instruction\": \"Translate 'I am lost' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation of 'I am lost' is 'Mi sono perso' (if male) or 'Mi sono persa' (if female).\"\n },\n {\n \"instruction\": \"Classify this text as a technical document or a narrative.\",\n \"input\": \"This manual provides instructions for installing the software.\",\n \"output\": \"Technical document\"\n },\n {\n \"instruction\": \"Sort the following list in descending order.\",\n \"input\": \"10, 2, 25, 16, 7\",\n \"output\": \"25, 16, 10, 7, 2.\"\n },\n {\n \"instruction\": \"Translate 'Can I have some water?' into French.\",\n \"input\": \"\",\n \"output\": \"Puis-je avoir de l'eau?\"\n },\n {\n \"instruction\": \"Create a simile with the word 'as cold as'.\",\n \"input\": \"\",\n \"output\": \"Her hands were as cold as ice.\"\n },\n {\n \"instruction\": \"Classify the following words by their grammatical categories: swim, beautiful, quickly\",\n \"input\": \"\",\n \"output\": \"Swim: Verb\\nBeautiful: Adjective\\nQuickly: Adverb\"\n },\n {\n \"instruction\": \"Calculate the density of an object with a mass of 15 grams and a volume of 5 cubic centimeters.\",\n \"input\": \"\",\n \"output\": \"The density of the object is 3 grams per cubic centimeter.\"\n },\n {\n \"instruction\": \"What is the abbreviation for 'Master of Business Administration'?\",\n \"input\": \"\",\n \"output\": \"The abbreviation for 'Master of Business Administration' is MBA.\"\n },\n {\n \"instruction\": \"Convert the following number from Roman numerals: IX.\",\n \"input\": \"\",\n \"output\": \"The number IX in Roman numerals is 9.\"\n },\n {\n \"instruction\": \"What is the opposite of 'horizontal'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'horizontal' is 'vertical'.\"\n },\n {\n \"instruction\": \"Translate 'Where can I buy tickets?' into Italian.\",\n \"input\": \"\",\n \"output\": \"The Italian translation for 'Where can I buy tickets?' is 'Dove posso comprare i biglietti?'\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to replace any clich\\u00e9s.\",\n \"input\": \"He was as cool as a cucumber.\",\n \"output\": \"He remained very calm.\"\n },\n {\n \"instruction\": \"Identify the main verb in the sentence.\",\n \"input\": \"The dog barked loudly.\",\n \"output\": \"The main verb in the sentence is 'barked'.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'elucidate'.\",\n \"input\": \"\",\n \"output\": \"The professor attempted to elucidate the complex topic for his students.\"\n },\n {\n \"instruction\": \"Correct the sentence.\",\n \"input\": \"Me and my friend went to the store.\",\n \"output\": \"My friend and I went to the store.\"\n },\n {\n \"instruction\": \"What is the formula for calculating work done?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating work done is work = force \\u00d7 distance.\"\n },\n {\n \"instruction\": \"What is the chemical formula for ammonium nitrate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for ammonium nitrate is NH4NO3.\"\n },\n {\n \"instruction\": \"What is the molecular formula for water?\",\n \"input\": \"\",\n \"output\": \"The molecular formula for water is H2O.\"\n },\n {\n \"instruction\": \"Rewrite the given sentence to describe the same thing in a positive way.\",\n \"input\": \"The food was not good.\",\n \"output\": \"The food could use some improvement.\"\n },\n {\n \"instruction\": \"What is the opposite of 'lazy'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'lazy' is 'diligent'.\"\n },\n {\n \"instruction\": \"Name three essential vitamins for human health.\",\n \"input\": \"\",\n \"output\": \"1. Vitamin A\\n2. Vitamin C\\n3. Vitamin D\"\n },\n {\n \"instruction\": \"Define the term 'simile'.\",\n \"input\": \"\",\n \"output\": \"A simile is a figure of speech that directly compares two different things, often introduced with the words 'like' or 'as'.\"\n },\n {\n \"instruction\": \"What is the boiling point of chlorine in Celsius?\",\n \"input\": \"\",\n \"output\": \"The boiling point of chlorine is -34 degrees Celsius.\"\n },\n {\n \"instruction\": \"Translate 'My name is' into French.\",\n \"input\": \"\",\n \"output\": \"The French translation of 'My name is' is 'Je m'appelle'.\"\n },\n {\n \"instruction\": \"Convert 200 centimeters to meters.\",\n \"input\": \"\",\n \"output\": \"200 centimeters is 2 meters.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for zinc?\",\n \"input\": \"\",\n \"output\": \"Zn.\"\n },\n {\n \"instruction\": \"What is the formula for calculating force?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating force is Force = mass x acceleration.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovative'.\",\n \"input\": \"\",\n \"output\": \"The company's innovative approach set it apart from its competitors.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'generous'.\",\n \"input\": \"\",\n \"output\": \"He is very generous and always helps those in need.\"\n },\n {\n \"instruction\": \"What is an antonym of 'sharp'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'sharp' is 'dull'.\"\n },\n {\n \"instruction\": \"Describe the basic structure of a neuron.\",\n \"input\": \"\",\n \"output\": \"A neuron consists of three main parts: the cell body, which contains the nucleus; dendrites, which receive signals from other neurons; and an axon, which transmits signals to other neurons, muscles, or glands.\"\n },\n {\n \"instruction\": \"Translate 'see you later' into Spanish.\",\n \"input\": \"\",\n \"output\": \"Hasta luego\"\n },\n {\n \"instruction\": \"What are the first 10 elements of the Fibonacci sequence?\",\n \"input\": \"\",\n \"output\": \"0, 1, 1, 2, 3, 5, 8, 13, 21, 34.\"\n },\n {\n \"instruction\": \"What is an antonym of 'transparent'?\",\n \"input\": \"\",\n \"output\": \"An antonym of 'transparent' is 'opaque'.\"\n },\n {\n \"instruction\": \"What is the past tense of 'think'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'think' is 'thought'.\"\n },\n {\n \"instruction\": \"Classify each sentence as either declarative, interrogative, imperative, or exclamatory.\",\n \"input\": \"Please open the door.\",\n \"output\": \"The classification of the sentence 'Please open the door.' is imperative.\"\n },\n {\n \"instruction\": \"Rewrite the sentence to use a negative adverb.\",\n \"input\": \"She always remembers to call.\",\n \"output\": \"She never forgets to call.\"\n },\n {\n \"instruction\": \"Convert 50 miles per hour to kilometers per hour.\",\n \"input\": \"\",\n \"output\": \"50 miles per hour is approximately 80.47 kilometers per hour.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'The chef cooks the meal every day.'\",\n \"input\": \"\",\n \"output\": \"The meal is cooked by the chef every day.\"\n },\n {\n \"instruction\": \"Classify an input string as either a noun or a verb.\",\n \"input\": \"Dance\",\n \"output\": \"'Dance' can be classified as a verb.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a metaphor.\",\n \"input\": \"The book is very interesting.\",\n \"output\": \"The book is a page-turner.\"\n },\n {\n \"instruction\": \"Generate a question with the keyword \\u201cbacteria\\u201d\",\n \"input\": \"\",\n \"output\": \"How do bacteria affect human health?\"\n },\n {\n \"instruction\": \"What is the past participle of 'run'?\",\n \"input\": \"\",\n \"output\": \"The past participle of 'run' is 'run'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'quick'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'quick' is 'rapid'.\"\n },\n {\n \"instruction\": \"Give an example of a metaphor.\",\n \"input\": \"\",\n \"output\": \"An example of a metaphor is saying, 'Time is a thief,' which suggests that time, like a thief, can take away life moments without literally stealing.\"\n },\n {\n \"instruction\": \"Calculate the interest on a $1,000 investment at an annual rate of 5% over 3 years.\",\n \"input\": \"\",\n \"output\": \"The interest on a $1,000 investment at 5% annual rate over 3 years is $150.\"\n },\n {\n \"instruction\": \"What is a synonym of 'elated'?\",\n \"input\": \"\",\n \"output\": \"A synonym for 'elated' is 'overjoyed'.\"\n },\n {\n \"instruction\": \"Translate 'It's raining' into Japanese.\",\n \"input\": \"\",\n \"output\": \"The Japanese translation of 'It's raining' is '\\u96e8\\u304c\\u964d\\u3063\\u3066\\u3044\\u307e\\u3059' (Ame ga futte imasu).\"\n },\n {\n \"instruction\": \"Convert the following verb to its past participle form: 'speak'\",\n \"input\": \"speak\",\n \"output\": \"The past participle form of 'speak' is 'spoken.'\"\n },\n {\n \"instruction\": \"Describe the principle of conservation of energy.\",\n \"input\": \"\",\n \"output\": \"The principle of conservation of energy states that energy cannot be created or destroyed, only transformed from one form to another. This means the total energy of an isolated system remains constant over time.\"\n },\n {\n \"instruction\": \"Calculate the perimeter of a rectangle with a length of 5 meters and a width of 3 meters.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the rectangle is 16 meters.\"\n },\n {\n \"instruction\": \"What is the past tense of 'freeze'?\",\n \"input\": \"\",\n \"output\": \"The past tense of 'freeze' is 'froze'.\"\n },\n {\n \"instruction\": \"Correct the misuse of 'their' in the sentence.\",\n \"input\": \"Their going to the store.\",\n \"output\": \"The corrected sentence should be: 'They're going to the store.'\"\n },\n {\n \"instruction\": \"Classify the following statement into one of these labels: [positive, negative, neutral]\",\n \"input\": \"My computer crashed.\",\n \"output\": \"The statement \\\"My computer crashed\\\" can be classified as negative.\"\n },\n {\n \"instruction\": \"Identify the onomatopoeia in the sentence.\",\n \"input\": \"The bees buzzed as they flew past.\",\n \"output\": \"The onomatopoeia in the sentence is 'buzzed'.\"\n },\n {\n \"instruction\": \"Edit the sentence.\",\n \"input\": \"We enjoys watching movies.\",\n \"output\": \"We enjoy watching movies.\"\n },\n {\n \"instruction\": \"Define the term 'gravity'.\",\n \"input\": \"\",\n \"output\": \"Gravity is the force that attracts a body toward the center of the earth, or toward any other physical body having mass.\"\n },\n {\n \"instruction\": \"What is an antonym for 'hot'?\",\n \"input\": \"\",\n \"output\": \"An antonym for 'hot' is 'cold'.\"\n },\n {\n \"instruction\": \"Reverse the order of the given phrase.\",\n \"input\": \"sun and moon\",\n \"output\": \"moon and sun\"\n },\n {\n \"instruction\": \"What is the formula for calculating power?\",\n \"input\": \"\",\n \"output\": \"The formula for calculating power is power = work/time.\"\n },\n {\n \"instruction\": \"Name the process by which plants absorb water through their roots.\",\n \"input\": \"\",\n \"output\": \"The process by which plants absorb water through their roots is called absorption.\"\n },\n {\n \"instruction\": \"What is the past tense of 'draw'?\",\n \"input\": \"\",\n \"output\": \"drew.\"\n },\n {\n \"instruction\": \"Change the given verb to its present perfect form.\",\n \"input\": \"run\",\n \"output\": \"Run.\"\n },\n {\n \"instruction\": \"Define the term 'oxymoron'.\",\n \"input\": \"\",\n \"output\": \"An oxymoron is a figure of speech in which apparently contradictory terms appear in conjunction.\"\n },\n {\n \"instruction\": \"What is the chemical symbol for water?\",\n \"input\": \"\",\n \"output\": \"The chemical symbol for water is H2O.\"\n },\n {\n \"instruction\": \"Convert the active sentence to passive: 'They paint the house every year.'\",\n \"input\": \"\",\n \"output\": \"The house is painted every year by them.\"\n },\n {\n \"instruction\": \"Provide the past tense form of the verb \\\"run.\\\"\",\n \"input\": \"\",\n \"output\": \"The past tense of the verb \\\"run\\\" is \\\"ran.\\\"\"\n },\n {\n \"instruction\": \"Convert the sentence to passive voice: 'They will hold the meeting tomorrow.'\",\n \"input\": \"They will hold the meeting tomorrow.\",\n \"output\": \"The meeting will be held tomorrow by them.\"\n },\n {\n \"instruction\": \"What is the chemical formula for sulfuric acid?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for sulfuric acid is H2SO4.\"\n },\n {\n \"instruction\": \"What type of cloud indicates fair weather?\",\n \"input\": \"\",\n \"output\": \"Cumulus clouds often indicate fair weather.\"\n },\n {\n \"instruction\": \"Insert a suitable adjective to complete the sentence.\",\n \"input\": \"The journey was _____.\",\n \"output\": \"The journey was arduous.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using an idiom.\",\n \"input\": \"The test was very easy.\",\n \"output\": \"The test was a piece of cake.\"\n },\n {\n \"instruction\": \"What is the opposite of 'increase'?\",\n \"input\": \"\",\n \"output\": \"The opposite of 'increase' is 'decrease'.\"\n },\n {\n \"instruction\": \"Calculate the perimeter of a square with a side length of 6 meters.\",\n \"input\": \"\",\n \"output\": \"The perimeter of the square is 24 meters.\"\n },\n {\n \"instruction\": \"Find the missing number in the sequence\",\n \"input\": \"2, 4, ?, 8, 10\",\n \"output\": \"The missing number in the sequence is 6.\"\n },\n {\n \"instruction\": \"Translate 'Good night' into German.\",\n \"input\": \"\",\n \"output\": \"The German translation of 'Good night' is 'Gute Nacht'.\"\n },\n {\n \"instruction\": \"Provide a word that rhymes with 'light.'\",\n \"input\": \"\",\n \"output\": \"A word that rhymes with 'light' is 'might.'\"\n },\n {\n \"instruction\": \"What is the comparative form of 'good'?\",\n \"input\": \"\",\n \"output\": \"The comparative form of 'good' is 'better'.\"\n },\n {\n \"instruction\": \"Name the literary device used in 'The wind whispered through the trees.'\",\n \"input\": \"\",\n \"output\": \"The literary device used is personification.\"\n },\n {\n \"instruction\": \"Rewrite the following sentence to use a metaphor: 'His words cut deeper than a knife.'\",\n \"input\": \"\",\n \"output\": \"His words were a knife, cutting deep.\"\n },\n {\n \"instruction\": \"Generate a sentence using the word 'innovate'.\",\n \"input\": \"\",\n \"output\": \"The company aims to innovate by developing new and sustainable technologies.\"\n },\n {\n \"instruction\": \"What is the speed of light?\",\n \"input\": \"\",\n \"output\": \"The speed of light is approximately 299,792 kilometers per second.\"\n },\n {\n \"instruction\": \"Identify the adverb in the sentence\",\n \"input\": \"She quickly ran to the store.\",\n \"output\": \"The adverb in the sentence is 'quickly'.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'beautiful'.\",\n \"input\": \"\",\n \"output\": \"A synonym for 'beautiful' is 'gorgeous'.\"\n },\n {\n \"instruction\": \"What is the capital of India?\",\n \"input\": \"\",\n \"output\": \"The capital of India is New Delhi.\"\n },\n {\n \"instruction\": \"Classify the following words by their grammatical categories: jump, quick, beautiful\",\n \"input\": \"\",\n \"output\": \"Jump: Verb\\nQuick: Adjective\\nBeautiful: Adjective\"\n },\n {\n \"instruction\": \"What is the chemical formula for potassium nitrate?\",\n \"input\": \"\",\n \"output\": \"The chemical formula for potassium nitrate is KNO3.\"\n },\n {\n \"instruction\": \"Rewrite the sentence using a simile.\",\n \"input\": \"The cake is very sweet.\",\n \"output\": \"The cake is as sweet as honey.\"\n },\n {\n \"instruction\": \"Label whether the following statements are true or false.\",\n \"input\": \"The moon is a planet.\",\n \"output\": \"False\"\n },\n {\n \"instruction\": \"Convert 1000 milliliters to liters.\",\n \"input\": \"\",\n \"output\": \"1000 milliliters is equivalent to 1 liter.\"\n },\n {\n \"instruction\": \"Change this sentence into the past continuous tense.\",\n \"input\": \"She sings in the choir.\",\n \"output\": \"She was singing in the choir.\"\n },\n {\n \"instruction\": \"Provide a synonym for 'clever.'\",\n \"input\": \"\",\n \"output\": \"A synonym for 'clever' is 'smart.'\"\n },\n {\n \"instruction\": \"Change the sentence 'You should have called me.' into a question.\",\n \"input\": \"\",\n \"output\": \"Should you have called me?\"\n }\n]"
},
{
"path": "ch07/01_main-chapter-code/load-finetuned-model.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1545a16b-bc8d-4e49-b9a6-db6631e7483d\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \\n\",\n \"\\n\",\n \"\\n\",\n \"- With the ollama application or `ollama serve` running, in a different terminal, on the command line, execute the following command to try out the 8-billion-parameter Llama 3 model (the model, which takes up 4.7 GB of storage space, will be automatically downloaded the first time you execute this command)\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"# 8B model\\n\",\n \"ollama run llama3\\n\",\n \"```\\n\",\n \"\\n\",\n \"\\n\",\n \"The output looks like as follows:\\n\",\n \"\\n\",\n \"```\\n\",\n \"$ ollama run llama3\\n\",\n \"pulling manifest \\n\",\n \"pulling 6a0746a1ec1a... 100% ▕████████████████▏ 4.7 GB \\n\",\n \"pulling 4fa551d4f938... 100% ▕████████████████▏ 12 KB \\n\",\n \"pulling 8ab4849b038c... 100% ▕████████████████▏ 254 B \\n\",\n \"pulling 577073ffcc6c... 100% ▕████████████████▏ 110 B \\n\",\n \"pulling 3f8eb4da87fa... 100% ▕████████████████▏ 485 B \\n\",\n \"verifying sha256 digest \\n\",\n \"writing manifest \\n\",\n \"removing any unused layers \\n\",\n \"success \\n\",\n \"```\\n\",\n \"\\n\",\n \"- Note that `llama3` refers to the instruction finetuned 8-billion-parameter Llama 3 model\\n\",\n \"\\n\",\n \"- Alternatively, you can also use the larger 70-billion-parameter Llama 3 model, if your machine supports it, by replacing `llama3` with `llama3:70b`\\n\",\n \"\\n\",\n \"- After the download has been completed, you will see a command line prompt that allows you to chat with the model\\n\",\n \"\\n\",\n \"- Try a prompt like \\\"What do llamas eat?\\\", which should return an output similar to the following:\\n\",\n \"\\n\",\n \"```\\n\",\n \">>> What do llamas eat?\\n\",\n \"Llamas are ruminant animals, which means they have a four-chambered \\n\",\n \"stomach and eat plants that are high in fiber. In the wild, llamas \\n\",\n \"typically feed on:\\n\",\n \"1. Grasses: They love to graze on various types of grasses, including tall \\n\",\n \"grasses, wheat, oats, and barley.\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b5addcb-fc7d-455d-bee9-6cc7a0d684c7\",\n \"metadata\": {},\n \"source\": [\n \"- You can end this session using the input `/bye`\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dda155ee-cf36-44d3-b634-20ba8e1ca38a\",\n \"metadata\": {},\n \"source\": [\n \"## Using Ollama's REST API\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"89343a84-0ddc-42fc-bf50-298a342b93c0\",\n \"metadata\": {},\n \"source\": [\n \"- Now, an alternative way to interact with the model is via its REST API in Python via the following function\\n\",\n \"- Before you run the next cells in this notebook, make sure that ollama is still running, as described above, via\\n\",\n \" - `ollama serve` in a terminal\\n\",\n \" - the ollama application\\n\",\n \"- Next, run the following code cell to query the model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"16642a48-1cab-40d2-af08-ab8c2fbf5876\",\n \"metadata\": {},\n \"source\": [\n \"- First, let's try the API with a simple example to make sure it works as intended:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"65b0ba76-1fb1-4306-a7c2-8f3bb637ccdb\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Llamas are herbivores, which means they primarily feed on plant-based foods. Their diet typically consists of:\\n\",\n \"\\n\",\n \"1. Grasses: Llamas love to graze on various types of grasses, including tall grasses, short grasses, and even weeds.\\n\",\n \"2. Hay: High-quality hay, such as alfalfa or timothy hay, is a staple in a llama's diet. They enjoy the sweet taste and texture of fresh hay.\\n\",\n \"3. Grains: Llamas may receive grains like oats, barley, or corn as part of their daily ration. However, it's essential to provide these grains in moderation, as they can be high in calories.\\n\",\n \"4. Fruits and vegetables: Llamas enjoy a variety of fruits and veggies, such as apples, carrots, sweet potatoes, and leafy greens like kale or spinach.\\n\",\n \"5. Minerals: Llamas require access to mineral supplements, which help maintain their overall health and well-being.\\n\",\n \"\\n\",\n \"In the wild, llamas might also eat:\\n\",\n \"\\n\",\n \"1. Leaves: They'll munch on leaves from trees and shrubs, including plants like willow, alder, and birch.\\n\",\n \"2. Bark: In some cases, llamas may eat the bark of certain trees, like aspen or cottonwood.\\n\",\n \"3. Mosses and lichens: These non-vascular plants can be a tasty snack for llamas.\\n\",\n \"\\n\",\n \"In captivity, llama owners typically provide a balanced diet that includes a mix of hay, grains, and fruits/vegetables. It's essential to consult with a veterinarian or experienced llama breeder to determine the best feeding plan for your llama.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import json\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"\\n\",\n \"def query_model(prompt, model=\\\"llama3\\\", url=\\\"http://localhost:11434/api/chat\\\"):\\n\",\n \" # Create the data payload as a dictionary\\n\",\n \" data = {\\n\",\n \" \\\"model\\\": model,\\n\",\n \" \\\"messages\\\": [\\n\",\n \" {\\n\",\n \" \\\"role\\\": \\\"user\\\",\\n\",\n \" \\\"content\\\": prompt\\n\",\n \" }\\n\",\n \" ],\\n\",\n \" \\\"options\\\": { # Settings below are required for deterministic responses\\n\",\n \" \\\"seed\\\": 123,\\n\",\n \" \\\"temperature\\\": 0,\\n\",\n \" \\\"num_ctx\\\": 2048\\n\",\n \" }\\n\",\n \" }\\n\",\n \"\\n\",\n \" # Send the POST request\\n\",\n \" with requests.post(url, json=data, stream=True, timeout=30) as r:\\n\",\n \" r.raise_for_status()\\n\",\n \" response_data = \\\"\\\"\\n\",\n \" for line in r.iter_lines(decode_unicode=True):\\n\",\n \" if not line:\\n\",\n \" continue\\n\",\n \" response_json = json.loads(line)\\n\",\n \" if \\\"message\\\" in response_json:\\n\",\n \" response_data += response_json[\\\"message\\\"][\\\"content\\\"]\\n\",\n \"\\n\",\n \" return response_data\\n\",\n \"\\n\",\n \"result = query_model(\\\"What do Llamas eat?\\\")\\n\",\n \"print(result)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"162a4739-6f03-4092-a5c2-f57a0b6a4c4d\",\n \"metadata\": {},\n \"source\": [\n \"## Load JSON Entries\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ca011a8b-20c5-4101-979e-9b5fccf62f8a\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's get to the data evaluation part\\n\",\n \"- Here, we assume that we saved the test dataset and the model responses as a JSON file that we can load as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"8b2d393a-aa92-4190-9d44-44326a6f699b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of entries: 100\\n\"\n ]\n }\n ],\n \"source\": [\n \"json_file = \\\"eval-example-data.json\\\"\\n\",\n \"\\n\",\n \"with open(json_file, \\\"r\\\") as file:\\n\",\n \" json_data = json.load(file)\\n\",\n \"\\n\",\n \"print(\\\"Number of entries:\\\", len(json_data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b6c9751b-59b7-43fe-acc7-14e8daf2fa66\",\n \"metadata\": {},\n \"source\": [\n \"- The structure of this file is as follows, where we have the given response in the test dataset (`'output'`) and responses by two different models (`'model 1 response'` and `'model 2 response'`):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"7222fdc0-5684-4f2b-b741-3e341851359e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"{'instruction': 'Calculate the hypotenuse of a right triangle with legs of 6 cm and 8 cm.',\\n\",\n \" 'input': '',\\n\",\n \" 'output': 'The hypotenuse of the triangle is 10 cm.',\\n\",\n \" 'model 1 response': '\\\\nThe hypotenuse of the triangle is 3 cm.',\\n\",\n \" 'model 2 response': '\\\\nThe hypotenuse of the triangle is 12 cm.'}\"\n ]\n },\n \"execution_count\": 4,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"json_data[0]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fcf0331b-6024-4bba-89a9-a088b14a1046\",\n \"metadata\": {},\n \"source\": [\n \"- Below is a small utility function that formats the input for visualization purposes later:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"43263cd3-e5fb-4ab5-871e-3ad6e7d21a8c\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. Write a response that \\\"\\n\",\n \" f\\\"appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \" instruction_text + input_text\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"39a55283-7d51-4136-ba60-f799d49f4098\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's try the ollama API to compare the model responses (we only evaluate the first 5 responses for a visual comparison):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"735cc089-d127-480a-b39d-0782581f0c41\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The hypotenuse of the triangle is 10 cm.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> \\n\",\n \"The hypotenuse of the triangle is 3 cm.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd score this response as 0 out of 100.\\n\",\n \"\\n\",\n \"The correct answer is \\\"The hypotenuse of the triangle is 10 cm.\\\", not \\\"3 cm.\\\". The model failed to accurately calculate the length of the hypotenuse, which is a fundamental concept in geometry and trigonometry.\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> 1. Squirrel\\n\",\n \"2. Eagle\\n\",\n \"3. Tiger\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> \\n\",\n \"1. Squirrel\\n\",\n \"2. Tiger\\n\",\n \"3. Eagle\\n\",\n \"4. Cobra\\n\",\n \"5. Tiger\\n\",\n \"6. Cobra\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd rate this model response as 60 out of 100.\\n\",\n \"\\n\",\n \"Here's why:\\n\",\n \"\\n\",\n \"* The model correctly identifies two animals that are active during the day: Squirrel and Eagle.\\n\",\n \"* However, it incorrectly includes Tiger twice, which is not a different animal from the original list.\\n\",\n \"* Cobra is also an incorrect answer, as it is typically nocturnal or crepuscular (active at twilight).\\n\",\n \"* The response does not meet the instruction to provide three different animals that are active during the day.\\n\",\n \"\\n\",\n \"To achieve a higher score, the model should have provided three unique and correct answers that fit the instruction.\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> I must ascertain what is incorrect.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> \\n\",\n \"What is incorrect?\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> A clever test!\\n\",\n \"\\n\",\n \"Here's my attempt at rewriting the sentence in a more formal way:\\n\",\n \"\\n\",\n \"\\\"I require an identification of the issue.\\\"\\n\",\n \"\\n\",\n \"Now, let's evaluate the model response \\\"What is incorrect?\\\" against the correct output \\\"I must ascertain what is incorrect.\\\".\\n\",\n \"\\n\",\n \"To me, this seems like a completely different question being asked. The original instruction was to rewrite the sentence in a more formal way, and the model response doesn't even attempt to do that. It's asking a new question altogether!\\n\",\n \"\\n\",\n \"So, I'd score this response a 0 out of 100.\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The interjection in the sentence is 'Wow'.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> \\n\",\n \"The interjection in the sentence is 'Wow'.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd score this model response as 100.\\n\",\n \"\\n\",\n \"Here's why:\\n\",\n \"\\n\",\n \"1. The instruction asks to identify the interjection in the sentence.\\n\",\n \"2. The input sentence is provided: \\\"Wow, that was an amazing trick!\\\"\\n\",\n \"3. The model correctly identifies the interjection as \\\"Wow\\\", which is a common English interjection used to express surprise or excitement.\\n\",\n \"4. The response accurately answers the question and provides the correct information.\\n\",\n \"\\n\",\n \"Overall, the model's response perfectly completes the request, making it a 100% accurate answer!\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The type of sentence is interrogative.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> \\n\",\n \"The type of sentence is exclamatory.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd rate this model response as 20 out of 100.\\n\",\n \"\\n\",\n \"Here's why:\\n\",\n \"\\n\",\n \"* The input sentence \\\"Did you finish the report?\\\" is indeed an interrogative sentence, which asks a question.\\n\",\n \"* The model response says it's exclamatory, which is incorrect. Exclamatory sentences are typically marked by an exclamation mark (!) and express strong emotions or emphasis, whereas this sentence is simply asking a question.\\n\",\n \"\\n\",\n \"The correct output \\\"The type of sentence is interrogative.\\\" is the best possible score (100), while the model response is significantly off the mark, hence the low score.\\n\",\n \"\\n\",\n \"-------------------------\\n\"\n ]\n }\n ],\n \"source\": [\n \"for entry in json_data[:5]:\\n\",\n \" prompt = (f\\\"Given the input `{format_input(entry)}` \\\"\\n\",\n \" f\\\"and correct output `{entry['output']}`, \\\"\\n\",\n \" f\\\"score the model response `{entry['model 1 response']}`\\\"\\n\",\n \" f\\\" on a scale from 0 to 100, where 100 is the best score. \\\"\\n\",\n \" )\\n\",\n \" print(\\\"\\\\nDataset response:\\\")\\n\",\n \" print(\\\">>\\\", entry['output'])\\n\",\n \" print(\\\"\\\\nModel response:\\\")\\n\",\n \" print(\\\">>\\\", entry[\\\"model 1 response\\\"])\\n\",\n \" print(\\\"\\\\nScore:\\\")\\n\",\n \" print(\\\">>\\\", query_model(prompt))\\n\",\n \" print(\\\"\\\\n-------------------------\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"142dfaa7-429f-4eb0-b74d-ff327f79547a\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the responses are very verbose; to quantify which model is better, we only want to return the scores:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"3552bdfb-7511-42ac-a9ec-da672e2a5468\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from tqdm import tqdm\\n\",\n \"\\n\",\n \"\\n\",\n \"def generate_model_scores(json_data, json_key):\\n\",\n \" scores = []\\n\",\n \" for entry in tqdm(json_data, desc=\\\"Scoring entries\\\"):\\n\",\n \" prompt = (\\n\",\n \" f\\\"Given the input `{format_input(entry)}` \\\"\\n\",\n \" f\\\"and correct output `{entry['output']}`, \\\"\\n\",\n \" f\\\"score the model response `{entry[json_key]}`\\\"\\n\",\n \" f\\\" on a scale from 0 to 100, where 100 is the best score. \\\"\\n\",\n \" f\\\"Respond with the integer number only.\\\"\\n\",\n \" )\\n\",\n \" score = query_model(prompt)\\n\",\n \" try:\\n\",\n \" scores.append(int(score))\\n\",\n \" except ValueError:\\n\",\n \" continue\\n\",\n \"\\n\",\n \" return scores\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b071ce84-1866-427f-a272-b46700f364b2\",\n \"metadata\": {},\n \"source\": [\n \"- Let's now apply this evaluation to the whole dataset and compute the average score of each model (this takes about 1 minute per model on an M3 MacBook Air laptop)\\n\",\n \"- Note that ollama is not fully deterministic across operating systems (as of this writing) so the numbers you are getting might slightly differ from the ones shown below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"4f700d4b-19e5-4404-afa7-b0f093024232\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Scoring entries: 100%|████████████████████████| 100/100 [01:02<00:00, 1.59it/s]\\n\"\n ]\n },\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"model 1 response\\n\",\n \"Number of scores: 100 of 100\\n\",\n \"Average score: 78.48\\n\",\n \"\\n\"\n ]\n },\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Scoring entries: 100%|████████████████████████| 100/100 [01:10<00:00, 1.42it/s]\"\n ]\n },\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"model 2 response\\n\",\n \"Number of scores: 99 of 100\\n\",\n \"Average score: 64.98\\n\",\n \"\\n\"\n ]\n },\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\"\n ]\n }\n ],\n \"source\": [\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"for model in (\\\"model 1 response\\\", \\\"model 2 response\\\"):\\n\",\n \"\\n\",\n \" scores = generate_model_scores(json_data, model)\\n\",\n \" print(f\\\"\\\\n{model}\\\")\\n\",\n \" print(f\\\"Number of scores: {len(scores)} of {len(json_data)}\\\")\\n\",\n \" print(f\\\"Average score: {sum(scores)/len(scores):.2f}\\\\n\\\")\\n\",\n \"\\n\",\n \" # Optionally save the scores\\n\",\n \" save_path = Path(\\\"scores\\\") / f\\\"llama3-8b-{model.replace(' ', '-')}.json\\\"\\n\",\n \" with open(save_path, \\\"w\\\") as file:\\n\",\n \" json.dump(scores, file)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8169d534-1fec-43c4-9550-5cb701ff7f05\",\n \"metadata\": {},\n \"source\": [\n \"- Based on the evaluation above, we can say that the 1st model is better than the 2nd model\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.10.16\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch07/03_model-evaluation/llm-instruction-eval-openai.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"136a4efe-fb99-4311-8679-e0a5b6282755\",\n \"metadata\": {},\n \"source\": [\n \"
\\n\",\n \"\\n\",\n \"\\n\",\n \"- With the ollama application or `ollama serve` running, in a different terminal, on the command line, execute the following command to try out the 8-billion-parameter Llama 3 model (the model, which takes up 4.7 GB of storage space, will be automatically downloaded the first time you execute this command)\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"# 8B model\\n\",\n \"ollama run llama3\\n\",\n \"```\\n\",\n \"\\n\",\n \"\\n\",\n \"The output looks like as follows:\\n\",\n \"\\n\",\n \"```\\n\",\n \"$ ollama run llama3\\n\",\n \"pulling manifest \\n\",\n \"pulling 6a0746a1ec1a... 100% ▕████████████████▏ 4.7 GB \\n\",\n \"pulling 4fa551d4f938... 100% ▕████████████████▏ 12 KB \\n\",\n \"pulling 8ab4849b038c... 100% ▕████████████████▏ 254 B \\n\",\n \"pulling 577073ffcc6c... 100% ▕████████████████▏ 110 B \\n\",\n \"pulling 3f8eb4da87fa... 100% ▕████████████████▏ 485 B \\n\",\n \"verifying sha256 digest \\n\",\n \"writing manifest \\n\",\n \"removing any unused layers \\n\",\n \"success \\n\",\n \"```\\n\",\n \"\\n\",\n \"- Note that `llama3` refers to the instruction finetuned 8-billion-parameter Llama 3 model\\n\",\n \"\\n\",\n \"- Alternatively, you can also use the larger 70-billion-parameter Llama 3 model, if your machine supports it, by replacing `llama3` with `llama3:70b`\\n\",\n \"\\n\",\n \"- After the download has been completed, you will see a command line prompt that allows you to chat with the model\\n\",\n \"\\n\",\n \"- Try a prompt like \\\"What do llamas eat?\\\", which should return an output similar to the following:\\n\",\n \"\\n\",\n \"```\\n\",\n \">>> What do llamas eat?\\n\",\n \"Llamas are ruminant animals, which means they have a four-chambered \\n\",\n \"stomach and eat plants that are high in fiber. In the wild, llamas \\n\",\n \"typically feed on:\\n\",\n \"1. Grasses: They love to graze on various types of grasses, including tall \\n\",\n \"grasses, wheat, oats, and barley.\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b5addcb-fc7d-455d-bee9-6cc7a0d684c7\",\n \"metadata\": {},\n \"source\": [\n \"- You can end this session using the input `/bye`\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dda155ee-cf36-44d3-b634-20ba8e1ca38a\",\n \"metadata\": {},\n \"source\": [\n \"## Using Ollama's REST API\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"89343a84-0ddc-42fc-bf50-298a342b93c0\",\n \"metadata\": {},\n \"source\": [\n \"- Now, an alternative way to interact with the model is via its REST API in Python via the following function\\n\",\n \"- Before you run the next cells in this notebook, make sure that ollama is still running, as described above, via\\n\",\n \" - `ollama serve` in a terminal\\n\",\n \" - the ollama application\\n\",\n \"- Next, run the following code cell to query the model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"16642a48-1cab-40d2-af08-ab8c2fbf5876\",\n \"metadata\": {},\n \"source\": [\n \"- First, let's try the API with a simple example to make sure it works as intended:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"65b0ba76-1fb1-4306-a7c2-8f3bb637ccdb\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Llamas are herbivores, which means they primarily feed on plant-based foods. Their diet typically consists of:\\n\",\n \"\\n\",\n \"1. Grasses: Llamas love to graze on various types of grasses, including tall grasses, short grasses, and even weeds.\\n\",\n \"2. Hay: High-quality hay, such as alfalfa or timothy hay, is a staple in a llama's diet. They enjoy the sweet taste and texture of fresh hay.\\n\",\n \"3. Grains: Llamas may receive grains like oats, barley, or corn as part of their daily ration. However, it's essential to provide these grains in moderation, as they can be high in calories.\\n\",\n \"4. Fruits and vegetables: Llamas enjoy a variety of fruits and veggies, such as apples, carrots, sweet potatoes, and leafy greens like kale or spinach.\\n\",\n \"5. Minerals: Llamas require access to mineral supplements, which help maintain their overall health and well-being.\\n\",\n \"\\n\",\n \"In the wild, llamas might also eat:\\n\",\n \"\\n\",\n \"1. Leaves: They'll munch on leaves from trees and shrubs, including plants like willow, alder, and birch.\\n\",\n \"2. Bark: In some cases, llamas may eat the bark of certain trees, like aspen or cottonwood.\\n\",\n \"3. Mosses and lichens: These non-vascular plants can be a tasty snack for llamas.\\n\",\n \"\\n\",\n \"In captivity, llama owners typically provide a balanced diet that includes a mix of hay, grains, and fruits/vegetables. It's essential to consult with a veterinarian or experienced llama breeder to determine the best feeding plan for your llama.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import json\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"\\n\",\n \"def query_model(prompt, model=\\\"llama3\\\", url=\\\"http://localhost:11434/api/chat\\\"):\\n\",\n \" # Create the data payload as a dictionary\\n\",\n \" data = {\\n\",\n \" \\\"model\\\": model,\\n\",\n \" \\\"messages\\\": [\\n\",\n \" {\\n\",\n \" \\\"role\\\": \\\"user\\\",\\n\",\n \" \\\"content\\\": prompt\\n\",\n \" }\\n\",\n \" ],\\n\",\n \" \\\"options\\\": { # Settings below are required for deterministic responses\\n\",\n \" \\\"seed\\\": 123,\\n\",\n \" \\\"temperature\\\": 0,\\n\",\n \" \\\"num_ctx\\\": 2048\\n\",\n \" }\\n\",\n \" }\\n\",\n \"\\n\",\n \" # Send the POST request\\n\",\n \" with requests.post(url, json=data, stream=True, timeout=30) as r:\\n\",\n \" r.raise_for_status()\\n\",\n \" response_data = \\\"\\\"\\n\",\n \" for line in r.iter_lines(decode_unicode=True):\\n\",\n \" if not line:\\n\",\n \" continue\\n\",\n \" response_json = json.loads(line)\\n\",\n \" if \\\"message\\\" in response_json:\\n\",\n \" response_data += response_json[\\\"message\\\"][\\\"content\\\"]\\n\",\n \"\\n\",\n \" return response_data\\n\",\n \"\\n\",\n \"result = query_model(\\\"What do Llamas eat?\\\")\\n\",\n \"print(result)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"162a4739-6f03-4092-a5c2-f57a0b6a4c4d\",\n \"metadata\": {},\n \"source\": [\n \"## Load JSON Entries\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ca011a8b-20c5-4101-979e-9b5fccf62f8a\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's get to the data evaluation part\\n\",\n \"- Here, we assume that we saved the test dataset and the model responses as a JSON file that we can load as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"8b2d393a-aa92-4190-9d44-44326a6f699b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of entries: 100\\n\"\n ]\n }\n ],\n \"source\": [\n \"json_file = \\\"eval-example-data.json\\\"\\n\",\n \"\\n\",\n \"with open(json_file, \\\"r\\\") as file:\\n\",\n \" json_data = json.load(file)\\n\",\n \"\\n\",\n \"print(\\\"Number of entries:\\\", len(json_data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b6c9751b-59b7-43fe-acc7-14e8daf2fa66\",\n \"metadata\": {},\n \"source\": [\n \"- The structure of this file is as follows, where we have the given response in the test dataset (`'output'`) and responses by two different models (`'model 1 response'` and `'model 2 response'`):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"7222fdc0-5684-4f2b-b741-3e341851359e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"{'instruction': 'Calculate the hypotenuse of a right triangle with legs of 6 cm and 8 cm.',\\n\",\n \" 'input': '',\\n\",\n \" 'output': 'The hypotenuse of the triangle is 10 cm.',\\n\",\n \" 'model 1 response': '\\\\nThe hypotenuse of the triangle is 3 cm.',\\n\",\n \" 'model 2 response': '\\\\nThe hypotenuse of the triangle is 12 cm.'}\"\n ]\n },\n \"execution_count\": 4,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"json_data[0]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fcf0331b-6024-4bba-89a9-a088b14a1046\",\n \"metadata\": {},\n \"source\": [\n \"- Below is a small utility function that formats the input for visualization purposes later:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"43263cd3-e5fb-4ab5-871e-3ad6e7d21a8c\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. Write a response that \\\"\\n\",\n \" f\\\"appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \" instruction_text + input_text\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"39a55283-7d51-4136-ba60-f799d49f4098\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's try the ollama API to compare the model responses (we only evaluate the first 5 responses for a visual comparison):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"735cc089-d127-480a-b39d-0782581f0c41\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The hypotenuse of the triangle is 10 cm.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> \\n\",\n \"The hypotenuse of the triangle is 3 cm.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd score this response as 0 out of 100.\\n\",\n \"\\n\",\n \"The correct answer is \\\"The hypotenuse of the triangle is 10 cm.\\\", not \\\"3 cm.\\\". The model failed to accurately calculate the length of the hypotenuse, which is a fundamental concept in geometry and trigonometry.\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> 1. Squirrel\\n\",\n \"2. Eagle\\n\",\n \"3. Tiger\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> \\n\",\n \"1. Squirrel\\n\",\n \"2. Tiger\\n\",\n \"3. Eagle\\n\",\n \"4. Cobra\\n\",\n \"5. Tiger\\n\",\n \"6. Cobra\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd rate this model response as 60 out of 100.\\n\",\n \"\\n\",\n \"Here's why:\\n\",\n \"\\n\",\n \"* The model correctly identifies two animals that are active during the day: Squirrel and Eagle.\\n\",\n \"* However, it incorrectly includes Tiger twice, which is not a different animal from the original list.\\n\",\n \"* Cobra is also an incorrect answer, as it is typically nocturnal or crepuscular (active at twilight).\\n\",\n \"* The response does not meet the instruction to provide three different animals that are active during the day.\\n\",\n \"\\n\",\n \"To achieve a higher score, the model should have provided three unique and correct answers that fit the instruction.\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> I must ascertain what is incorrect.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> \\n\",\n \"What is incorrect?\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> A clever test!\\n\",\n \"\\n\",\n \"Here's my attempt at rewriting the sentence in a more formal way:\\n\",\n \"\\n\",\n \"\\\"I require an identification of the issue.\\\"\\n\",\n \"\\n\",\n \"Now, let's evaluate the model response \\\"What is incorrect?\\\" against the correct output \\\"I must ascertain what is incorrect.\\\".\\n\",\n \"\\n\",\n \"To me, this seems like a completely different question being asked. The original instruction was to rewrite the sentence in a more formal way, and the model response doesn't even attempt to do that. It's asking a new question altogether!\\n\",\n \"\\n\",\n \"So, I'd score this response a 0 out of 100.\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The interjection in the sentence is 'Wow'.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> \\n\",\n \"The interjection in the sentence is 'Wow'.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd score this model response as 100.\\n\",\n \"\\n\",\n \"Here's why:\\n\",\n \"\\n\",\n \"1. The instruction asks to identify the interjection in the sentence.\\n\",\n \"2. The input sentence is provided: \\\"Wow, that was an amazing trick!\\\"\\n\",\n \"3. The model correctly identifies the interjection as \\\"Wow\\\", which is a common English interjection used to express surprise or excitement.\\n\",\n \"4. The response accurately answers the question and provides the correct information.\\n\",\n \"\\n\",\n \"Overall, the model's response perfectly completes the request, making it a 100% accurate answer!\\n\",\n \"\\n\",\n \"-------------------------\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The type of sentence is interrogative.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> \\n\",\n \"The type of sentence is exclamatory.\\n\",\n \"\\n\",\n \"Score:\\n\",\n \">> I'd rate this model response as 20 out of 100.\\n\",\n \"\\n\",\n \"Here's why:\\n\",\n \"\\n\",\n \"* The input sentence \\\"Did you finish the report?\\\" is indeed an interrogative sentence, which asks a question.\\n\",\n \"* The model response says it's exclamatory, which is incorrect. Exclamatory sentences are typically marked by an exclamation mark (!) and express strong emotions or emphasis, whereas this sentence is simply asking a question.\\n\",\n \"\\n\",\n \"The correct output \\\"The type of sentence is interrogative.\\\" is the best possible score (100), while the model response is significantly off the mark, hence the low score.\\n\",\n \"\\n\",\n \"-------------------------\\n\"\n ]\n }\n ],\n \"source\": [\n \"for entry in json_data[:5]:\\n\",\n \" prompt = (f\\\"Given the input `{format_input(entry)}` \\\"\\n\",\n \" f\\\"and correct output `{entry['output']}`, \\\"\\n\",\n \" f\\\"score the model response `{entry['model 1 response']}`\\\"\\n\",\n \" f\\\" on a scale from 0 to 100, where 100 is the best score. \\\"\\n\",\n \" )\\n\",\n \" print(\\\"\\\\nDataset response:\\\")\\n\",\n \" print(\\\">>\\\", entry['output'])\\n\",\n \" print(\\\"\\\\nModel response:\\\")\\n\",\n \" print(\\\">>\\\", entry[\\\"model 1 response\\\"])\\n\",\n \" print(\\\"\\\\nScore:\\\")\\n\",\n \" print(\\\">>\\\", query_model(prompt))\\n\",\n \" print(\\\"\\\\n-------------------------\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"142dfaa7-429f-4eb0-b74d-ff327f79547a\",\n \"metadata\": {},\n \"source\": [\n \"- Note that the responses are very verbose; to quantify which model is better, we only want to return the scores:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"3552bdfb-7511-42ac-a9ec-da672e2a5468\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from tqdm import tqdm\\n\",\n \"\\n\",\n \"\\n\",\n \"def generate_model_scores(json_data, json_key):\\n\",\n \" scores = []\\n\",\n \" for entry in tqdm(json_data, desc=\\\"Scoring entries\\\"):\\n\",\n \" prompt = (\\n\",\n \" f\\\"Given the input `{format_input(entry)}` \\\"\\n\",\n \" f\\\"and correct output `{entry['output']}`, \\\"\\n\",\n \" f\\\"score the model response `{entry[json_key]}`\\\"\\n\",\n \" f\\\" on a scale from 0 to 100, where 100 is the best score. \\\"\\n\",\n \" f\\\"Respond with the integer number only.\\\"\\n\",\n \" )\\n\",\n \" score = query_model(prompt)\\n\",\n \" try:\\n\",\n \" scores.append(int(score))\\n\",\n \" except ValueError:\\n\",\n \" continue\\n\",\n \"\\n\",\n \" return scores\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b071ce84-1866-427f-a272-b46700f364b2\",\n \"metadata\": {},\n \"source\": [\n \"- Let's now apply this evaluation to the whole dataset and compute the average score of each model (this takes about 1 minute per model on an M3 MacBook Air laptop)\\n\",\n \"- Note that ollama is not fully deterministic across operating systems (as of this writing) so the numbers you are getting might slightly differ from the ones shown below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"4f700d4b-19e5-4404-afa7-b0f093024232\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Scoring entries: 100%|████████████████████████| 100/100 [01:02<00:00, 1.59it/s]\\n\"\n ]\n },\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"model 1 response\\n\",\n \"Number of scores: 100 of 100\\n\",\n \"Average score: 78.48\\n\",\n \"\\n\"\n ]\n },\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Scoring entries: 100%|████████████████████████| 100/100 [01:10<00:00, 1.42it/s]\"\n ]\n },\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"model 2 response\\n\",\n \"Number of scores: 99 of 100\\n\",\n \"Average score: 64.98\\n\",\n \"\\n\"\n ]\n },\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\"\n ]\n }\n ],\n \"source\": [\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"for model in (\\\"model 1 response\\\", \\\"model 2 response\\\"):\\n\",\n \"\\n\",\n \" scores = generate_model_scores(json_data, model)\\n\",\n \" print(f\\\"\\\\n{model}\\\")\\n\",\n \" print(f\\\"Number of scores: {len(scores)} of {len(json_data)}\\\")\\n\",\n \" print(f\\\"Average score: {sum(scores)/len(scores):.2f}\\\\n\\\")\\n\",\n \"\\n\",\n \" # Optionally save the scores\\n\",\n \" save_path = Path(\\\"scores\\\") / f\\\"llama3-8b-{model.replace(' ', '-')}.json\\\"\\n\",\n \" with open(save_path, \\\"w\\\") as file:\\n\",\n \" json.dump(scores, file)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8169d534-1fec-43c4-9550-5cb701ff7f05\",\n \"metadata\": {},\n \"source\": [\n \"- Based on the evaluation above, we can say that the 1st model is better than the 2nd model\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.10.16\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch07/03_model-evaluation/llm-instruction-eval-openai.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"136a4efe-fb99-4311-8679-e0a5b6282755\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
| \\n\",\n \" | Pearson | \\n\",\n \"Spearman | \\n\",\n \"Kendall Tau | \\n\",\n \"
|---|---|---|---|
| Results | \\n\",\n \"0.80489 | \\n\",\n \"0.698406 | \\n\",\n \"0.57292 | \\n\",\n \"
| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\\n\",\n \"\\n\",\n \"\\n\",\n \"- With the ollama application or `ollama serve` running, in a different terminal, on the command line, execute the following command to try out the 70-billion-parameter Llama 3.1 model \\n\",\n \"\\n\",\n \"```bash\\n\",\n \"# 70B model\\n\",\n \"ollama run llama3.1:70b\\n\",\n \"```\\n\",\n \"\\n\",\n \"\\n\",\n \"The output looks like as follows:\\n\",\n \"\\n\",\n \"```\\n\",\n \"$ ollama run llama3.1:70b\\n\",\n \"pulling manifest\\n\",\n \"pulling aa81b541aae6... 100% ▕████████████████▏ 39 GB\\n\",\n \"pulling 8cf247399e57... 100% ▕████████████████▏ 1.7 KB\\n\",\n \"pulling f1cd752815fc... 100% ▕████████████████▏ 12 KB\\n\",\n \"pulling 56bb8bd477a5... 100% ▕████████████████▏ 96 B\\n\",\n \"pulling 3c1c2d3df5b3... 100% ▕████████████████▏ 486 B\\n\",\n \"verifying sha256 digest\\n\",\n \"writing manifest\\n\",\n \"removing any unused layers\\n\",\n \"success\\n\",\n \"```\\n\",\n \"\\n\",\n \"- Note that `llama3.1:70b` refers to the instruction finetuned 70-billion-parameter Llama 3.1 model\\n\",\n \"\\n\",\n \"- Alternatively, you can also use the smaller, more resource-effiicent 8-billion-parameters Llama 3.1 model, by replacing `llama3.1:70b` with `llama3.1`\\n\",\n \"\\n\",\n \"- After the download has been completed, you will see a command line prompt that allows you to chat with the model\\n\",\n \"\\n\",\n \"- Try a prompt like \\\"What do llamas eat?\\\", which should return an output similar to the following:\\n\",\n \"\\n\",\n \"```\\n\",\n \">>> What do llamas eat?\\n\",\n \"Llamas are ruminant animals, which means they have a four-chambered \\n\",\n \"stomach and eat plants that are high in fiber. In the wild, llamas \\n\",\n \"typically feed on:\\n\",\n \"1. Grasses: They love to graze on various types of grasses, including tall \\n\",\n \"grasses, wheat, oats, and barley.\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b5addcb-fc7d-455d-bee9-6cc7a0d684c7\",\n \"metadata\": {},\n \"source\": [\n \"- You can end this session using the input `/bye`\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dda155ee-cf36-44d3-b634-20ba8e1ca38a\",\n \"metadata\": {},\n \"source\": [\n \"## Using Ollama's REST API\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"89343a84-0ddc-42fc-bf50-298a342b93c0\",\n \"metadata\": {},\n \"source\": [\n \"- Now, an alternative way to interact with the model is via its REST API in Python via the following function\\n\",\n \"- Before you run the next cells in this notebook, make sure that ollama is still running, as described above, via\\n\",\n \" - `ollama serve` in a terminal\\n\",\n \" - the ollama application\\n\",\n \"- Next, run the following code cell to query the model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"16642a48-1cab-40d2-af08-ab8c2fbf5876\",\n \"metadata\": {},\n \"source\": [\n \"- First, let's try the API with a simple example to make sure it works as intended:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"65b0ba76-1fb1-4306-a7c2-8f3bb637ccdb\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Llamas are herbivores, which means they primarily eat plants and plant-based foods. Their diet consists of:\\n\",\n \"\\n\",\n \"1. **Grasses**: Various types of grasses, including timothy grass, orchard grass, and brome grass.\\n\",\n \"2. **Hay**: High-quality hay, such as alfalfa or clover hay, is a staple in a llama's diet.\\n\",\n \"3. **Leaves**: Leaves from trees and shrubs, like willow, cottonwood, and mesquite, are also eaten.\\n\",\n \"4. **Fruits and vegetables**: Llamas enjoy fruits like apples, carrots, and sweet potatoes, as well as leafy greens like kale and spinach.\\n\",\n \"5. **Grains**: In moderation, llamas can eat grains like oats, barley, and corn.\\n\",\n \"\\n\",\n \"It's essential to note that llamas have a unique digestive system, with a three-part stomach and a large cecum (a specialized part of the large intestine). This allows them to break down and extract nutrients from plant material more efficiently than many other animals.\\n\",\n \"\\n\",\n \"A typical llama diet might consist of:\\n\",\n \"\\n\",\n \"* 1-2% of their body weight in hay per day\\n\",\n \"* 0.5-1% of their body weight in grains per day (if fed)\\n\",\n \"* Free-choice access to fresh water\\n\",\n \"* Limited amounts of fruits and vegetables as treats\\n\",\n \"\\n\",\n \"It's also important to ensure that llamas have access to a mineral supplement, such as a salt lick or loose minerals, to help maintain optimal health.\\n\",\n \"\\n\",\n \"Remember, every llama is different, and their dietary needs may vary depending on factors like age, size, and activity level. Consult with a veterinarian or experienced llama breeder for specific guidance on feeding your llama.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import json\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"\\n\",\n \"def query_model(prompt, model=\\\"llama3.1:70b\\\", url=\\\"http://localhost:11434/api/chat\\\"):\\n\",\n \" # Create the data payload as a dictionary\\n\",\n \" data = {\\n\",\n \" \\\"model\\\": model,\\n\",\n \" \\\"messages\\\": [\\n\",\n \" {\\n\",\n \" \\\"role\\\": \\\"user\\\",\\n\",\n \" \\\"content\\\": prompt\\n\",\n \" }\\n\",\n \" ],\\n\",\n \" \\\"options\\\": {\\n\",\n \" \\\"seed\\\": 123,\\n\",\n \" \\\"temperature\\\": 0,\\n\",\n \" }\\n\",\n \" }\\n\",\n \"\\n\",\n \" # Send the POST request\\n\",\n \" with requests.post(url, json=data, stream=True, timeout=30) as r:\\n\",\n \" r.raise_for_status()\\n\",\n \" response_data = \\\"\\\"\\n\",\n \" for line in r.iter_lines(decode_unicode=True):\\n\",\n \" if not line:\\n\",\n \" continue\\n\",\n \" response_json = json.loads(line)\\n\",\n \" if \\\"message\\\" in response_json:\\n\",\n \" response_data += response_json[\\\"message\\\"][\\\"content\\\"]\\n\",\n \"\\n\",\n \" return response_data\\n\",\n \"\\n\",\n \"\\n\",\n \"result = query_model(\\\"What do Llamas eat?\\\")\\n\",\n \"print(result)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"162a4739-6f03-4092-a5c2-f57a0b6a4c4d\",\n \"metadata\": {},\n \"source\": [\n \"## Load JSON Entries\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ca011a8b-20c5-4101-979e-9b5fccf62f8a\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's get to the data generation part\\n\",\n \"- Here, for a hands-on example, we use the `instruction-data.json` file that we originally used to instruction-finetune the model in chapter 7:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"8b2d393a-aa92-4190-9d44-44326a6f699b\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of entries: 1100\\n\"\n ]\n }\n ],\n \"source\": [\n \"from pathlib import Path\\n\",\n \"\\n\",\n \"json_file = Path(\\\"..\\\", \\\"01_main-chapter-code\\\", \\\"instruction-data.json\\\")\\n\",\n \"\\n\",\n \"with open(json_file, \\\"r\\\") as file:\\n\",\n \" json_data = json.load(file)\\n\",\n \"\\n\",\n \"print(\\\"Number of entries:\\\", len(json_data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b6c9751b-59b7-43fe-acc7-14e8daf2fa66\",\n \"metadata\": {},\n \"source\": [\n \"- The structure of this file is as follows, where we have the given response in the test dataset (`'output'`) that we trained the model to generate via instruction finetuning based on the `'input'` and `'instruction'`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"7222fdc0-5684-4f2b-b741-3e341851359e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"{'instruction': 'Evaluate the following phrase by transforming it into the spelling given.',\\n\",\n \" 'input': 'freind --> friend',\\n\",\n \" 'output': 'The spelling of the given phrase \\\"freind\\\" is incorrect, the correct spelling is \\\"friend\\\".'}\"\n ]\n },\n \"execution_count\": 4,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"json_data[0]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"fcf0331b-6024-4bba-89a9-a088b14a1046\",\n \"metadata\": {},\n \"source\": [\n \"- Below is a small utility function that formats the instruction and input:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"43263cd3-e5fb-4ab5-871e-3ad6e7d21a8c\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. Write a response that \\\"\\n\",\n \" f\\\"appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \" instruction_text + input_text\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"39a55283-7d51-4136-ba60-f799d49f4098\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's try the ollama API to generate a `'chosen'` and `'rejected'` response for preference tuning a model\\n\",\n \"- Here, to for illustration purposes, we create answers that are more or less polite\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"735cc089-d127-480a-b39d-0782581f0c41\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"Dataset response:\\n\",\n \">> The spelling of the given phrase \\\"freind\\\" is incorrect, the correct spelling is \\\"friend\\\".\\n\",\n \"\\n\",\n \"impolite response:\\n\",\n \">> The spelling of the given phrase \\\"freind\\\" is flat out wrong, get it together, the correct spelling is \\\"friend\\\".\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> He goes to the park every day.\\n\",\n \"\\n\",\n \"polite response:\\n\",\n \">> He goes to the park daily, if I'm not mistaken.\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> 45 kilometers is 45000 meters.\\n\",\n \"\\n\",\n \"polite response:\\n\",\n \">> 45 kilometers is equivalent to 45000 meters.\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> Although it was raining, they went for a walk.\\n\",\n \"\\n\",\n \"polite response:\\n\",\n \">> Although it was raining outside, they still decided to go for a walk.\\n\",\n \"\\n\",\n \"Dataset response:\\n\",\n \">> 1, 4, 9, 16, 25, 36, 49, 64, 81, 100.\\n\",\n \"\\n\",\n \"impolite response:\\n\",\n \">> Here are your precious square numbers: 1, 4, 9, 16, 25, 36, 49, 64, 81, 100.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import random\\n\",\n \"\\n\",\n \"\\n\",\n \"for entry in json_data[:5]:\\n\",\n \" \\n\",\n \" politeness = random.choice([\\\"polite\\\", \\\"impolite\\\"]) \\n\",\n \" prompt = (\\n\",\n \" f\\\"Given the input `{format_input(entry)}` \\\"\\n\",\n \" f\\\"and correct output `{entry['output']}`, \\\"\\n\",\n \" f\\\"slightly rewrite the output to be more {politeness}.\\\"\\n\",\n \" \\\"Keep the modification minimal.\\\"\\n\",\n \" \\\"Only return return the generated response and nothing else.\\\"\\n\",\n \" )\\n\",\n \" print(\\\"\\\\nDataset response:\\\")\\n\",\n \" print(\\\">>\\\", entry['output'])\\n\",\n \" print(f\\\"\\\\n{politeness} response:\\\")\\n\",\n \" print(\\\">>\\\", query_model(prompt)) \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"142dfaa7-429f-4eb0-b74d-ff327f79547a\",\n \"metadata\": {},\n \"source\": [\n \"- If we find that the generated responses above look reasonable, we can go to the next step and apply the prompt to the whole dataset\\n\",\n \"- Here, we add a `'chosen'` key for the preferred response and a `'rejected'` response for the dispreferred response\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"3349dbbc-963f-4af3-9790-12dbfdca63c3\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import random\\n\",\n \"from tqdm import tqdm\\n\",\n \"\\n\",\n \"def generate_model_responses(json_data):\\n\",\n \"\\n\",\n \" for i, entry in enumerate(tqdm(json_data, desc=\\\"Writing entries\\\")):\\n\",\n \" politeness = random.choice([\\\"polite\\\", \\\"impolite\\\"]) \\n\",\n \" prompt = (\\n\",\n \" f\\\"Given the input `{format_input(entry)}` \\\"\\n\",\n \" f\\\"and correct output `{entry['output']}`, \\\"\\n\",\n \" f\\\"slightly rewrite the output to be more {politeness}.\\\"\\n\",\n \" \\\"Keep the modification minimal.\\\"\\n\",\n \" \\\"Only return return the generated response and nothing else.\\\"\\n\",\n \" )\\n\",\n \" response = query_model(prompt)\\n\",\n \" \\n\",\n \" if politeness == \\\"polite\\\":\\n\",\n \" json_data[i][\\\"chosen\\\"] = response\\n\",\n \" json_data[i][\\\"rejected\\\"] = entry[\\\"output\\\"]\\n\",\n \" else:\\n\",\n \" json_data[i][\\\"rejected\\\"] = response\\n\",\n \" json_data[i][\\\"chosen\\\"] = entry[\\\"output\\\"] \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b071ce84-1866-427f-a272-b46700f364b2\",\n \"metadata\": {},\n \"source\": [\n \"- Let's now apply this evaluation to the whole dataset and compute the average score of each model (this takes about 1 minute per model on an M3 MacBook Air laptop)\\n\",\n \"- Note that ollama is not fully deterministic across operating systems (as of this writing) so the numbers you are getting might slightly differ from the ones shown below\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"4f700d4b-19e5-4404-afa7-b0f093024232\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Writing entries: 100%|██████████| 1100/1100 [17:20<00:00, 1.06it/s]\\n\"\n ]\n }\n ],\n \"source\": [\n \"generate_model_responses(json_data)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"838d9747-0f7d-46fe-aab5-9ee6b765d021\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"with open(\\\"instruction-data-with-preference.json\\\", \\\"w\\\") as file:\\n\",\n \" json.dump(json_data, file, indent=4)\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.10.16\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch07/04_preference-tuning-with-dpo/dpo-from-scratch.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"62129596-d10f-45b1-a1af-ee10f358f773\",\n \"metadata\": {\n \"id\": \"62129596-d10f-45b1-a1af-ee10f358f773\"\n },\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \\n\",\n \"\\n\",\n \"- In instruction finetuning, we train the LLM to generate correct answers given a prompt\\n\",\n \"- However, in practice, there are multiple ways to give a correct answer, and correct answers can differ in style; for example, consider a technical and a more user-friendly response when asking an LLM to give recommendations when buying a laptop, as shown in the figure below\\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \"- In instruction finetuning, we train the LLM to generate correct answers given a prompt\\n\",\n \"- However, in practice, there are multiple ways to give a correct answer, and correct answers can differ in style; for example, consider a technical and a more user-friendly response when asking an LLM to give recommendations when buying a laptop, as shown in the figure below\\n\",\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"- RLHF and DPO are methods that can be used to teach the LLM to prefer one answer style over the other, that is, aligning better with user preferences\\n\",\n \"- The RLHF process, which requires training a separate reward model, is outlined below\\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \"- RLHF and DPO are methods that can be used to teach the LLM to prefer one answer style over the other, that is, aligning better with user preferences\\n\",\n \"- The RLHF process, which requires training a separate reward model, is outlined below\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9073622f-d537-42bf-8778-43c2adaa2191\",\n \"metadata\": {\n \"id\": \"9073622f-d537-42bf-8778-43c2adaa2191\"\n },\n \"source\": [\n \"- Compared to RLHF, DPO aims to simplify the process by optimizing models directly for user preferences without the need for complex reward modeling and policy optimization\\n\",\n \"- In other words, DPO focuses on directly optimizing the model's output to align with human preferences or specific objectives\\n\",\n \"- Shown below is the main idea as an overview of how DPO works\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9073622f-d537-42bf-8778-43c2adaa2191\",\n \"metadata\": {\n \"id\": \"9073622f-d537-42bf-8778-43c2adaa2191\"\n },\n \"source\": [\n \"- Compared to RLHF, DPO aims to simplify the process by optimizing models directly for user preferences without the need for complex reward modeling and policy optimization\\n\",\n \"- In other words, DPO focuses on directly optimizing the model's output to align with human preferences or specific objectives\\n\",\n \"- Shown below is the main idea as an overview of how DPO works\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c894134a-315c-453e-bbc1-387794b3f4d6\",\n \"metadata\": {\n \"id\": \"c894134a-315c-453e-bbc1-387794b3f4d6\"\n },\n \"source\": [\n \"- The concrete equation to implement the DPO loss is shown below; we will revisit the equation when we implement it in Python further down in this code notebook\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c894134a-315c-453e-bbc1-387794b3f4d6\",\n \"metadata\": {\n \"id\": \"c894134a-315c-453e-bbc1-387794b3f4d6\"\n },\n \"source\": [\n \"- The concrete equation to implement the DPO loss is shown below; we will revisit the equation when we implement it in Python further down in this code notebook\\n\",\n \"\\n\",\n \" \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dd7491b5-f619-4501-ad39-2942de57c115\",\n \"metadata\": {\n \"id\": \"dd7491b5-f619-4501-ad39-2942de57c115\"\n },\n \"source\": [\n \"- In the equation above,\\n\",\n \" - \\\"expected value\\\" $\\\\mathbb{E}$ is statistics jargon and stands for the average or mean value of the random variable (the expression inside the brackets); optimizing $-\\\\mathbb{E}$ aligns the model better with user preferences\\n\",\n \" - The $\\\\pi_{\\\\theta}$ variable is the so-called policy (a term borrowed from reinforcement learning) and represents the LLM we want to optimize; $\\\\pi_{ref}$ is a reference LLM, which is typically the original LLM before optimization (at the beginning of the training, $\\\\pi_{\\\\theta}$ and $\\\\pi_{ref}$ are typically the same)\\n\",\n \" - $\\\\beta$ is a hyperparameter to control the divergence between the $\\\\pi_{\\\\theta}$ and the reference model; increasing $\\\\beta$ reduces the impact of the difference between\\n\",\n \"$\\\\pi_{\\\\theta}$ and $\\\\pi_{ref}$ in terms of their log probabilities on the overall loss function, thereby decreasing the divergence between the two models\\n\",\n \" - the logistic sigmoid function, $\\\\sigma(\\\\centerdot)$ transforms the log-odds of the preferred and rejected responses (the terms inside the logistic sigmoid function) into a probability score \\n\",\n \"- To avoid bloating the code notebook with a more detailed discussion, I may write a separate standalone article with more details on these concepts in the future\\n\",\n \"- In the meantime, if you are interested in comparing RLHF and DPO, please see the section [2.2. RLHF vs Direct Preference Optimization (DPO)](https://magazine.sebastianraschka.com/i/142924793/rlhf-vs-direct-preference-optimization-dpo) in my article [Tips for LLM Pretraining and Evaluating Reward Models](https://magazine.sebastianraschka.com/p/tips-for-llm-pretraining-and-evaluating-rms)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"xqVAgsyQ6LuG\",\n \"metadata\": {\n \"id\": \"xqVAgsyQ6LuG\",\n \"tags\": []\n },\n \"source\": [\n \" \\n\",\n \"# 2) Preparing a preference dataset for DPO\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"60b2195d-8734-469b-a52e-5031ca7ea6b1\",\n \"metadata\": {\n \"id\": \"60b2195d-8734-469b-a52e-5031ca7ea6b1\"\n },\n \"source\": [\n \"- Let's begin by loading and preparing the dataset, which may already answer a lot of the questions you might have before we revisit the DPO loss equation\\n\",\n \"- Here, we work with a dataset that contains more polite and less polite responses to instruction prompts (concrete examples are shown in the next section)\\n\",\n \"- The dataset was generated via the [create-preference-data-ollama.ipynb](create-preference-data-ollama.ipynb) notebook\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"wHLB62Nj7haD\",\n \"metadata\": {\n \"id\": \"wHLB62Nj7haD\"\n },\n \"source\": [\n \" \\n\",\n \"## 2.1) Loading a preference dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"13e09f99-1b18-4923-ba36-af46d8e3075f\",\n \"metadata\": {\n \"id\": \"13e09f99-1b18-4923-ba36-af46d8e3075f\"\n },\n \"source\": [\n \"- The dataset is a json file with 1100 entries:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"5266e66c-5ec0-45e6-a654-148971f6aee7\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"5266e66c-5ec0-45e6-a654-148971f6aee7\",\n \"outputId\": \"04e8ee70-3076-441d-d2bf-7641da3d0c1d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of entries: 1100\\n\"\n ]\n }\n ],\n \"source\": [\n \"import json\\n\",\n \"import os\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"\\n\",\n \"def download_and_load_file(file_path, url):\\n\",\n \" if not os.path.exists(file_path):\\n\",\n \" response = requests.get(url, timeout=30)\\n\",\n \" response.raise_for_status()\\n\",\n \" text_data = response.text\\n\",\n \" with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" file.write(text_data)\\n\",\n \" else:\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" text_data = file.read()\\n\",\n \"\\n\",\n \" data = json.loads(text_data)\\n\",\n \" return data\\n\",\n \"\\n\",\n \"\\n\",\n \"file_path = \\\"instruction-data-with-preference.json\\\"\\n\",\n \"url = (\\n\",\n \" \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch\\\"\\n\",\n \" \\\"/main/ch07/04_preference-tuning-with-dpo/instruction-data-with-preference.json\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"data = download_and_load_file(file_path, url)\\n\",\n \"print(\\\"Number of entries:\\\", len(data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"725d2b9a-d6d2-46e2-89f8-5ab87e040e3b\",\n \"metadata\": {\n \"id\": \"725d2b9a-d6d2-46e2-89f8-5ab87e040e3b\"\n },\n \"source\": [\n \"- Let's take a look at two example entries:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"5c11916f-9a26-4367-a16e-7b0c121a20a6\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"5c11916f-9a26-4367-a16e-7b0c121a20a6\",\n \"outputId\": \"00a432cc-19b1-484f-80e2-e897ee5e4024\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"{'instruction': 'Identify the correct spelling of the following word.',\\n\",\n \" 'input': 'Ocassion',\\n\",\n \" 'output': \\\"The correct spelling is 'Occasion.'\\\",\\n\",\n \" 'rejected': \\\"The correct spelling is obviously 'Occasion.'\\\",\\n\",\n \" 'chosen': \\\"The correct spelling is 'Occasion.'\\\"}\\n\"\n ]\n }\n ],\n \"source\": [\n \"import pprint\\n\",\n \"\\n\",\n \"pprint.pp(data[50])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"01ef804a-8c13-4a0b-9b2e-b65a4d0a870d\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"01ef804a-8c13-4a0b-9b2e-b65a4d0a870d\",\n \"outputId\": \"078cd643-83fb-4b42-ecf9-3256e8c9d239\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"{'instruction': \\\"What is an antonym of 'complicated'?\\\",\\n\",\n \" 'input': '',\\n\",\n \" 'output': \\\"An antonym of 'complicated' is 'simple'.\\\",\\n\",\n \" 'chosen': \\\"A suitable antonym for 'complicated' would be 'simple'.\\\",\\n\",\n \" 'rejected': \\\"An antonym of 'complicated' is 'simple'.\\\"}\\n\"\n ]\n }\n ],\n \"source\": [\n \"pprint.pp(data[999])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"56db5697-a089-4b40-a1f3-e928e8018220\",\n \"metadata\": {\n \"id\": \"56db5697-a089-4b40-a1f3-e928e8018220\"\n },\n \"source\": [\n \"\\n\",\n \"\\n\",\n \"```\\n\",\n \"# This is formatted as code\\n\",\n \"```\\n\",\n \"\\n\",\n \"- As we can see above, the dataset consists of 5 keys:\\n\",\n \" - The `'instruction'` and `'input'` that are used as LLM inputs\\n\",\n \" - The `'output'` contains the response the model was trained on via the instruction finetuning step in chapter 7\\n\",\n \" - the `'chosen'` and `'rejected'` entries are the entries we use for DPO; here `'chosen'` is the preferred response, and `'rejected'` is the dispreferred response\\n\",\n \"- The goal is to get the model to follow the style of the chosen over the rejected responses\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"86257468-a6ab-4ba3-9c9f-2fdc2c0cc284\",\n \"metadata\": {\n \"id\": \"86257468-a6ab-4ba3-9c9f-2fdc2c0cc284\"\n },\n \"source\": [\n \"- Below is a utility function that formats the model input by applying the Alpaca prompt style similar to chapter 7 ([../01_main-chapter-code/ch07.ipynb](../01_main-chapter-code/ch07.ipynb)):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4564d55c-1c5d-46a6-b5e8-46ab568ad627\",\n \"metadata\": {\n \"id\": \"4564d55c-1c5d-46a6-b5e8-46ab568ad627\"\n },\n \"outputs\": [],\n \"source\": [\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. \\\"\\n\",\n \" f\\\"Write a response that appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"3f38b49f-63fd-48c5-bde8-a4717b7923ea\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"3f38b49f-63fd-48c5-bde8-a4717b7923ea\",\n \"outputId\": \"9ad07c59-05b3-42ae-c5bc-68780aaf6780\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Identify the correct spelling of the following word.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"Ocassion\\n\"\n ]\n }\n ],\n \"source\": [\n \"model_input = format_input(data[50])\\n\",\n \"print(model_input)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7dd9e4c9-88a3-463a-8c16-c60ed7e6b51e\",\n \"metadata\": {\n \"id\": \"7dd9e4c9-88a3-463a-8c16-c60ed7e6b51e\"\n },\n \"source\": [\n \"- Similarly, we can format the chosen and rejected responses using the Alpaca prompt style:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"8ad5831a-e936-44e5-a5cf-02953fe7d848\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"8ad5831a-e936-44e5-a5cf-02953fe7d848\",\n \"outputId\": \"2c0a0cbf-c13d-43cf-fcc1-a4585c21e66f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"### Response:\\n\",\n \"The correct spelling is 'Occasion.'\\n\"\n ]\n }\n ],\n \"source\": [\n \"desired_response = f\\\"### Response:\\\\n{data[50]['chosen']}\\\"\\n\",\n \"print(desired_response)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"fc0991f6-fef7-48ab-8dee-fbd2863f784c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"fc0991f6-fef7-48ab-8dee-fbd2863f784c\",\n \"outputId\": \"cd85406c-3470-48f8-9792-63f91affd50a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"### Response:\\n\",\n \"The correct spelling is obviously 'Occasion.'\\n\"\n ]\n }\n ],\n \"source\": [\n \"possible_response = f\\\"### Response:\\\\n{data[50]['rejected']}\\\"\\n\",\n \"print(possible_response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6G3j2Q987t_g\",\n \"metadata\": {\n \"id\": \"6G3j2Q987t_g\"\n },\n \"source\": [\n \" \\n\",\n \"## 2.2) Creating training, validation, and test splits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"53ce2b1e-32d7-414c-8e6b-01f21a2488c2\",\n \"metadata\": {\n \"id\": \"53ce2b1e-32d7-414c-8e6b-01f21a2488c2\"\n },\n \"source\": [\n \"- Next, we divide the dataset into 3 subsets, 85% training data, 5% validation data, and 10% test data:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"36c7b919-8531-4e33-aebf-aaf8e6dbcfbd\",\n \"metadata\": {\n \"id\": \"36c7b919-8531-4e33-aebf-aaf8e6dbcfbd\"\n },\n \"outputs\": [],\n \"source\": [\n \"train_portion = int(len(data) * 0.85) # 85% for training\\n\",\n \"test_portion = int(len(data) * 0.1) # 10% for testing\\n\",\n \"val_portion = len(data) - train_portion - test_portion # Remaining 5% for validation\\n\",\n \"\\n\",\n \"train_data = data[:train_portion]\\n\",\n \"test_data = data[train_portion:train_portion + test_portion]\\n\",\n \"val_data = data[train_portion + test_portion:]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"831a6c1b-119b-4622-9862-87f1db36e066\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"831a6c1b-119b-4622-9862-87f1db36e066\",\n \"outputId\": \"8e017483-1a75-4336-9540-ac6a69104e27\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training set length: 935\\n\",\n \"Validation set length: 55\\n\",\n \"Test set length: 110\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Training set length:\\\", len(train_data))\\n\",\n \"print(\\\"Validation set length:\\\", len(val_data))\\n\",\n \"print(\\\"Test set length:\\\", len(test_data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c07d09f7-66af-49ed-8b9e-484f46e6a68d\",\n \"metadata\": {\n \"id\": \"c07d09f7-66af-49ed-8b9e-484f46e6a68d\"\n },\n \"source\": [\n \" \\n\",\n \"## 2.3) Developing a `PreferenceDataset` class and batch processing function\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"86101174-00c8-485d-8273-d086d5311926\",\n \"metadata\": {\n \"id\": \"86101174-00c8-485d-8273-d086d5311926\"\n },\n \"source\": [\n \"- In this section, we rewrite the `InstructionDataset` class from chapter 7 ([../01_main-chapter-code/ch07.ipynb](../01_main-chapter-code/ch07.ipynb)) for DPO\\n\",\n \"- This means that instead of focusing on single output sequences (responses), we modify the dataset class to return pairs of responses where one is preferred (\\\"chosen\\\") over the other (\\\"rejected\\\")\\n\",\n \"- Overall, the `PreferenceDataset` is almost identical to the `InstructionDataset` used in chapter 7:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"db08ad74-6dd4-4e40-b1e5-bc5f037d3d27\",\n \"metadata\": {\n \"id\": \"db08ad74-6dd4-4e40-b1e5-bc5f037d3d27\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"from torch.utils.data import Dataset\\n\",\n \"\\n\",\n \"\\n\",\n \"class PreferenceDataset(Dataset):\\n\",\n \" def __init__(self, data, tokenizer):\\n\",\n \" self.data = data\\n\",\n \"\\n\",\n \" # Pre-tokenize texts\\n\",\n \" self.encoded_texts = []\\n\",\n \" for entry in data:\\n\",\n \" prompt = format_input(entry)\\n\",\n \" rejected_response = entry[\\\"rejected\\\"]\\n\",\n \" chosen_response = entry[\\\"chosen\\\"]\\n\",\n \"\\n\",\n \" prompt_tokens = tokenizer.encode(prompt)\\n\",\n \" chosen_full_text = f\\\"{prompt}\\\\n\\\\n### Response:\\\\n{chosen_response}\\\"\\n\",\n \" rejected_full_text = f\\\"{prompt}\\\\n\\\\n### Response:\\\\n{rejected_response}\\\"\\n\",\n \" chosen_full_tokens = tokenizer.encode(chosen_full_text)\\n\",\n \" rejected_full_tokens = tokenizer.encode(rejected_full_text)\\n\",\n \"\\n\",\n \" self.encoded_texts.append({\\n\",\n \" \\\"prompt\\\": prompt_tokens,\\n\",\n \" \\\"chosen\\\": chosen_full_tokens,\\n\",\n \" \\\"rejected\\\": rejected_full_tokens,\\n\",\n \" })\\n\",\n \"\\n\",\n \" def __getitem__(self, index):\\n\",\n \" return self.encoded_texts[index]\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.data)\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2325d183-75b9-400a-80ac-0b8d2f526561\",\n \"metadata\": {\n \"id\": \"2325d183-75b9-400a-80ac-0b8d2f526561\"\n },\n \"source\": [\n \"- Along with an updated `PreferenceDataset` class, we also need an updated batch collation function that we use to pad the sequences in each batch to an equal length so that we can assemble them in batches\\n\",\n \"- I added comments to the code below to illustrate the process; however, it might be easiest to understand how it works by looking at the example inputs and outputs further below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"8d3a43a6-7704-4bff-9bbc-a38632374f30\",\n \"metadata\": {\n \"id\": \"8d3a43a6-7704-4bff-9bbc-a38632374f30\"\n },\n \"outputs\": [],\n \"source\": [\n \"def custom_collate_fn(\\n\",\n \" batch,\\n\",\n \" pad_token_id=50256,\\n\",\n \" allowed_max_length=None,\\n\",\n \" mask_prompt_tokens=True,\\n\",\n \" device=\\\"cpu\\\"\\n\",\n \"):\\n\",\n \" # Initialize lists to hold batch data\\n\",\n \" batch_data = {\\n\",\n \" \\\"prompt\\\": [],\\n\",\n \" \\\"chosen\\\": [],\\n\",\n \" \\\"rejected\\\": [],\\n\",\n \" \\\"rejected_mask\\\": [],\\n\",\n \" \\\"chosen_mask\\\": []\\n\",\n \"\\n\",\n \" }\\n\",\n \"\\n\",\n \" # Determine the longest sequence to set a common padding length\\n\",\n \" max_length_common = 0\\n\",\n \" if batch:\\n\",\n \" for key in [\\\"chosen\\\", \\\"rejected\\\"]:\\n\",\n \" current_max = max(len(item[key])+1 for item in batch)\\n\",\n \" max_length_common = max(max_length_common, current_max)\\n\",\n \"\\n\",\n \" # Process each item in the batch\\n\",\n \" for item in batch:\\n\",\n \" prompt = torch.tensor(item[\\\"prompt\\\"])\\n\",\n \" batch_data[\\\"prompt\\\"].append(prompt)\\n\",\n \"\\n\",\n \" for key in [\\\"chosen\\\", \\\"rejected\\\"]:\\n\",\n \" # Adjust padding according to the common maximum length\\n\",\n \" sequence = item[key]\\n\",\n \" padded = sequence + [pad_token_id] * (max_length_common - len(sequence))\\n\",\n \" mask = torch.ones(len(padded)).bool()\\n\",\n \"\\n\",\n \" # Set mask for all padding tokens to False\\n\",\n \" mask[len(sequence):] = False\\n\",\n \"\\n\",\n \" # Set mask for all input tokens to False\\n\",\n \" # +2 sets the 2 newline (\\\"\\\\n\\\") tokens before \\\"### Response\\\" to False\\n\",\n \" if mask_prompt_tokens:\\n\",\n \" mask[:prompt.shape[0]+2] = False\\n\",\n \"\\n\",\n \" batch_data[key].append(torch.tensor(padded))\\n\",\n \" batch_data[f\\\"{key}_mask\\\"].append(mask)\\n\",\n \"\\n\",\n \" # Final processing\\n\",\n \" for key in [\\\"chosen\\\", \\\"rejected\\\", \\\"chosen_mask\\\", \\\"rejected_mask\\\"]:\\n\",\n \" # Stack all sequences into a tensor for the given key\\n\",\n \" tensor_stack = torch.stack(batch_data[key])\\n\",\n \"\\n\",\n \" # Optionally truncate to maximum sequence length\\n\",\n \" if allowed_max_length is not None:\\n\",\n \" tensor_stack = tensor_stack[:, :allowed_max_length]\\n\",\n \"\\n\",\n \" # Move to the specified device\\n\",\n \" batch_data[key] = tensor_stack.to(device)\\n\",\n \"\\n\",\n \" return batch_data\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"76f3744b-9bb0-4f1e-b66b-cff35ad8fd9f\",\n \"metadata\": {\n \"id\": \"76f3744b-9bb0-4f1e-b66b-cff35ad8fd9f\"\n },\n \"source\": [\n \"- Before we start using the custom collate function, let's make version of it with some of its function arguments prefilled:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"d3cc137c-7ed7-4758-a518-cc4071b2817a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"d3cc137c-7ed7-4758-a518-cc4071b2817a\",\n \"outputId\": \"598e9def-9768-441a-f886-01f6ba6e250b\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Device: mps\\n\"\n ]\n }\n ],\n \"source\": [\n \"from functools import partial\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"print(\\\"Device:\\\", device)\\n\",\n \"\\n\",\n \"customized_collate_fn = partial(\\n\",\n \" custom_collate_fn,\\n\",\n \" device=device, # Put the data directly on a GPU if available\\n\",\n \" mask_prompt_tokens=True, # This is optional\\n\",\n \" allowed_max_length=1024 # The supported context length of the model\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5d29e996-e267-4348-bc1d-4ac6b725cf6a\",\n \"metadata\": {\n \"id\": \"5d29e996-e267-4348-bc1d-4ac6b725cf6a\"\n },\n \"source\": [\n \"- Now, let's see the `customized_collate_fn` in action and apply it to some sample data from our preference dataset; for this, we take the first two entries:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"1171057d-2a0f-48ff-bad6-4917a072f0f5\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"1171057d-2a0f-48ff-bad6-4917a072f0f5\",\n \"outputId\": \"3db3eee8-db29-4ff6-8078-6577a05d953a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"{'instruction': 'Evaluate the following phrase by transforming it into the '\\n\",\n \" 'spelling given.',\\n\",\n \" 'input': 'freind --> friend',\\n\",\n \" 'output': 'The spelling of the given phrase \\\"freind\\\" is incorrect, the '\\n\",\n \" 'correct spelling is \\\"friend\\\".',\\n\",\n \" 'rejected': 'The spelling of the given phrase \\\"freind\\\" is flat out wrong, get '\\n\",\n \" 'it together, the correct spelling is \\\"friend\\\".',\\n\",\n \" 'chosen': 'The spelling of the given phrase \\\"freind\\\" is incorrect, the '\\n\",\n \" 'correct spelling is \\\"friend\\\".'}\\n\",\n \"\\n\",\n \"{'instruction': 'Edit the following sentence for grammar.',\\n\",\n \" 'input': 'He go to the park every day.',\\n\",\n \" 'output': 'He goes to the park every day.',\\n\",\n \" 'rejected': 'He goes to the stupid park every single day.',\\n\",\n \" 'chosen': 'He goes to the park every day.'}\\n\"\n ]\n }\n ],\n \"source\": [\n \"example_data = data[:2]\\n\",\n \"\\n\",\n \"for i in example_data:\\n\",\n \" print()\\n\",\n \" pprint.pp(i)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8f1436cc-fbe5-4581-89d8-1992b5f04042\",\n \"metadata\": {\n \"id\": \"8f1436cc-fbe5-4581-89d8-1992b5f04042\"\n },\n \"source\": [\n \"- Next, let's instantiate an `example_dataset` and use a PyTorch `DataLoader` to create an `example_dataloader` that mimics the data loader we will use for the model training later:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"db327575-c34b-4fea-b3c7-e30569c9be78\",\n \"metadata\": {\n \"id\": \"db327575-c34b-4fea-b3c7-e30569c9be78\"\n },\n \"outputs\": [],\n \"source\": [\n \"import tiktoken\\n\",\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"example_dataset = PreferenceDataset(example_data, tokenizer)\\n\",\n \"\\n\",\n \"example_dataloader = DataLoader(\\n\",\n \" example_dataset,\\n\",\n \" batch_size=2,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=False\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"43a446b7-7037-4d9a-9f14-b4ee0f6f37af\",\n \"metadata\": {\n \"id\": \"43a446b7-7037-4d9a-9f14-b4ee0f6f37af\"\n },\n \"source\": [\n \"- The dataset has the following keys:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"87ed4cf9-d70a-4bc7-b676-67e76ed3ee10\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"87ed4cf9-d70a-4bc7-b676-67e76ed3ee10\",\n \"outputId\": \"fa724d65-b0e1-4239-8090-9263135ad199\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"batch.keys: dict_keys(['prompt', 'chosen', 'rejected', 'rejected_mask', 'chosen_mask'])\\n\"\n ]\n }\n ],\n \"source\": [\n \"for batch in example_dataloader:\\n\",\n \" break\\n\",\n \"\\n\",\n \"print(\\\"batch.keys:\\\", batch.keys())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5bda3193-8c68-478c-98d8-0d9d880e7077\",\n \"metadata\": {\n \"id\": \"5bda3193-8c68-478c-98d8-0d9d880e7077\"\n },\n \"source\": [\n \"- The prompts are a list of tensors, where each tensor contains the token IDs for a given example; since we selected a batch size of 2, we have two lists of token ID tensors here:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"468995ce-2906-498f-ac99-0a3f80d13d12\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"468995ce-2906-498f-ac99-0a3f80d13d12\",\n \"outputId\": \"7f3df961-fcb5-4e49-9b0c-c99447c67cc1\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"[tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 36, 2100, 4985, 262, 1708, 9546,\\n\",\n \" 416, 25449, 340, 656, 262, 24993, 1813, 13, 198, 198,\\n\",\n \" 21017, 23412, 25, 198, 19503, 521, 14610, 1545]),\\n\",\n \" tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 18378, 262, 1708, 6827, 329, 23491,\\n\",\n \" 13, 198, 198, 21017, 23412, 25, 198, 1544, 467, 284,\\n\",\n \" 262, 3952, 790, 1110, 13])]\"\n ]\n },\n \"execution_count\": 18,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"batch[\\\"prompt\\\"]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"89cadebe-2516-4ae0-a71f-a8a623f2e1da\",\n \"metadata\": {\n \"id\": \"89cadebe-2516-4ae0-a71f-a8a623f2e1da\"\n },\n \"source\": [\n \"- We don't really need the responses for training; what we need to feed to the model during training are the `\\\"chosen\\\"` and `\\\"rejected\\\"` entries\\n\",\n \"- The `\\\"chosen\\\"` and `\\\"rejected\\\"` response entries are padded so that we can stack them as tensors; similar to the prompts, these response texts are encoded into token IDs:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"e8f49c56-3989-4fe9-81ac-6bb3cce1a5b8\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"e8f49c56-3989-4fe9-81ac-6bb3cce1a5b8\",\n \"outputId\": \"ccc0bd06-6e85-4ee9-893b-d985f26a835d\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 36, 2100, 4985, 262, 1708, 9546,\\n\",\n \" 416, 25449, 340, 656, 262, 24993, 1813, 13, 198, 198,\\n\",\n \" 21017, 23412, 25, 198, 19503, 521, 14610, 1545, 198, 198,\\n\",\n \" 21017, 18261, 25, 198, 464, 24993, 286, 262, 1813, 9546,\\n\",\n \" 366, 19503, 521, 1, 318, 11491, 11, 262, 3376, 24993,\\n\",\n \" 318, 366, 6726, 1911, 50256, 50256, 50256, 50256, 50256, 50256,\\n\",\n \" 50256],\\n\",\n \" [21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 18378, 262, 1708, 6827, 329, 23491,\\n\",\n \" 13, 198, 198, 21017, 23412, 25, 198, 1544, 467, 284,\\n\",\n \" 262, 3952, 790, 1110, 13, 198, 198, 21017, 18261, 25,\\n\",\n \" 198, 1544, 2925, 284, 262, 3952, 790, 1110, 13, 50256,\\n\",\n \" 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,\\n\",\n \" 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,\\n\",\n \" 50256]], device='mps:0')\"\n ]\n },\n \"execution_count\": 19,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"batch[\\\"chosen\\\"]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"35a4cd6d-b2ad-45a6-b00a-ba5b720be4ea\",\n \"metadata\": {\n \"id\": \"35a4cd6d-b2ad-45a6-b00a-ba5b720be4ea\"\n },\n \"source\": [\n \"- The token IDs above represent the model inputs, but in this format, they are hard to interpret for us humans\\n\",\n \"- So, let's implement a small utility function to convert them back into text so that we can inspect and interpret them more easily:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"52ea54ba-32cb-4ecb-b38b-923f42fd4615\",\n \"metadata\": {\n \"id\": \"52ea54ba-32cb-4ecb-b38b-923f42fd4615\"\n },\n \"outputs\": [],\n \"source\": [\n \"def decode_tokens_from_batch(token_ids, tokenizer):\\n\",\n \" ids_in_python_list = token_ids.flatten().tolist()\\n\",\n \" return tokenizer.decode(ids_in_python_list)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bc9dd0ce-1fd4-419c-833f-ea5a1f8d800d\",\n \"metadata\": {\n \"id\": \"bc9dd0ce-1fd4-419c-833f-ea5a1f8d800d\"\n },\n \"source\": [\n \"- Let's apply the `decode_tokens_from_batch` utility function to the first prompt entry in the batch:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"55ee481e-3e2c-4ff6-b614-8cb18eb16a41\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"55ee481e-3e2c-4ff6-b614-8cb18eb16a41\",\n \"outputId\": \"17ddec15-a09d-45b5-b1e8-600cd59a9600\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Evaluate the following phrase by transforming it into the spelling given.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"freind --> friend\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = decode_tokens_from_batch(\\n\",\n \" token_ids=batch[\\\"prompt\\\"][0], # [0] for the first entry in the batch\\n\",\n \" tokenizer=tokenizer,\\n\",\n \")\\n\",\n \"print(text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"637b95c4-d5c2-4492-9d19-a45b090eee7e\",\n \"metadata\": {\n \"id\": \"637b95c4-d5c2-4492-9d19-a45b090eee7e\"\n },\n \"source\": [\n \"- As we can see above, the prompt was correctly formatted; let's now do the same for the `\\\"chosen\\\"` response:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"33a24f20-5ec3-4a89-b57a-52e997163d07\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"33a24f20-5ec3-4a89-b57a-52e997163d07\",\n \"outputId\": \"e04366ee-3719-4b07-fcef-6e9dddc06310\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Evaluate the following phrase by transforming it into the spelling given.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"freind --> friend\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"The spelling of the given phrase \\\"freind\\\" is incorrect, the correct spelling is \\\"friend\\\".<|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|>\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = decode_tokens_from_batch(\\n\",\n \" token_ids=batch[\\\"chosen\\\"][0],\\n\",\n \" tokenizer=tokenizer,\\n\",\n \")\\n\",\n \"print(text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ac9fbdbd-1cff-401f-8e6c-cd98c134c0f2\",\n \"metadata\": {\n \"id\": \"ac9fbdbd-1cff-401f-8e6c-cd98c134c0f2\"\n },\n \"source\": [\n \"- As we can see above, similar to instruction finetuning, the response that is passed to the model during training also contains the input prompt\\n\",\n \"- Also note that we included `<|endoftext|>` tokens as padding tokens, which are necessary so that we can extend the responses to a similar length to stack them as a batch\\n\",\n \"- Don't worry; the `<|endoftext|>` tokens will be ignored in the loss later so that they won't affect the training outcome\\n\",\n \"- Let's now also inspect the corresponding rejected response:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"db382be5-c727-4299-8597-c05424ba9308\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"db382be5-c727-4299-8597-c05424ba9308\",\n \"outputId\": \"edbd8c4a-0528-4361-aeba-9b3c3bbde33b\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Evaluate the following phrase by transforming it into the spelling given.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"freind --> friend\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"The spelling of the given phrase \\\"freind\\\" is flat out wrong, get it together, the correct spelling is \\\"friend\\\".<|endoftext|>\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = decode_tokens_from_batch(\\n\",\n \" token_ids=batch[\\\"rejected\\\"][0],\\n\",\n \" tokenizer=tokenizer,\\n\",\n \")\\n\",\n \"print(text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"715dc968-aa64-4388-b577-7c295831bdcf\",\n \"metadata\": {\n \"id\": \"715dc968-aa64-4388-b577-7c295831bdcf\"\n },\n \"source\": [\n \"- In this case, as we can see above, the rejected response is a more impolite version of the chosen response (we don't want the model to generate impolite responses)\\n\",\n \"- Lastly, let's talk about the data masks: if you took a closer look at our custom collate function we implemented above, we created a `\\\"chosen_mask\\\"` and a `\\\"rejected_mask\\\"` for each dataset entry\\n\",\n \"- The masks have the same shape as the response entries, as shown below for the `\\\"chosen\\\"` entry:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"5c324eab-cf1d-4071-b3ba-797d8ec4d1da\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"5c324eab-cf1d-4071-b3ba-797d8ec4d1da\",\n \"outputId\": \"742a5742-1bc0-4f74-9eb9-cbf81f936ecb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"chosen inputs: torch.Size([81])\\n\",\n \"chosen mask: torch.Size([81])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"chosen inputs:\\\", batch[\\\"chosen\\\"][0].shape)\\n\",\n \"print(\\\"chosen mask: \\\", batch[\\\"chosen_mask\\\"][0].shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"880e95f7-cfc3-4f5f-be5e-c279fba5f674\",\n \"metadata\": {\n \"id\": \"880e95f7-cfc3-4f5f-be5e-c279fba5f674\"\n },\n \"source\": [\n \"- The contents of these masks are boolean (`True` and `False`) values:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"da75b550-5da4-4292-9a7e-a05b842bdcb7\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"da75b550-5da4-4292-9a7e-a05b842bdcb7\",\n \"outputId\": \"e5f012c3-33ba-4e6b-aa55-3e331865218f\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([False, False, False, False, False, False, False, False, False, False,\\n\",\n \" False, False, False, False, False, False, False, False, False, False,\\n\",\n \" False, False, False, False, False, False, False, False, False, False,\\n\",\n \" False, False, False, False, False, False, False, False, False, False,\\n\",\n \" False, False, False, False, False, False, False, False, False, False,\\n\",\n \" True, True, True, True, True, True, True, True, True, True,\\n\",\n \" True, True, True, True, True, True, True, True, True, True,\\n\",\n \" True, True, True, True, False, False, False, False, False, False,\\n\",\n \" False], device='mps:0')\"\n ]\n },\n \"execution_count\": 25,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"batch[\\\"chosen_mask\\\"][0]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0e67b862-4430-4c99-9157-90955dde29b6\",\n \"metadata\": {\n \"id\": \"0e67b862-4430-4c99-9157-90955dde29b6\"\n },\n \"source\": [\n \"- The `True` values denote token IDs that correspond to the actual response\\n\",\n \"- the `False` tokens correspond to token IDs that correspond to either prompt tokens (if we set `mask_prompt_tokens=True` in the `customized_collate_fn` function, which we previously did) or padding tokens\\n\",\n \"- Hence, we can use the mask as a selection mask to select only the token IDs that correspond to the response, that is, stripping all prompt and padding tokens, as we can see below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"1114c6fe-524b-401c-b9fe-02260e6f0541\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"1114c6fe-524b-401c-b9fe-02260e6f0541\",\n \"outputId\": \"6d99af1d-940a-4012-c5d9-21d463a66e40\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"### Response:\\n\",\n \"The spelling of the given phrase \\\"freind\\\" is incorrect, the correct spelling is \\\"friend\\\".\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = decode_tokens_from_batch(\\n\",\n \" token_ids=batch[\\\"chosen\\\"][0][batch[\\\"chosen_mask\\\"][0]],\\n\",\n \" tokenizer=tokenizer,\\n\",\n \")\\n\",\n \"print(text)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 27,\n \"id\": \"a89f83a4-d16e-40d2-ba43-bd410affd967\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"a89f83a4-d16e-40d2-ba43-bd410affd967\",\n \"outputId\": \"1d439c7e-c079-4594-d02a-fa83a3cb275d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"### Response:\\n\",\n \"The spelling of the given phrase \\\"freind\\\" is flat out wrong, get it together, the correct spelling is \\\"friend\\\".\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = decode_tokens_from_batch(\\n\",\n \" token_ids=batch[\\\"rejected\\\"][0][batch[\\\"rejected_mask\\\"][0]],\\n\",\n \" tokenizer=tokenizer,\\n\",\n \")\\n\",\n \"print(text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e525287f-137c-4d71-94ae-cfd6db7b057c\",\n \"metadata\": {\n \"id\": \"e525287f-137c-4d71-94ae-cfd6db7b057c\"\n },\n \"source\": [\n \"- We will make use of this mask to ignore prompt and padding tokens when computing the DPO loss later\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"jbafhM_R8z5q\",\n \"metadata\": {\n \"id\": \"jbafhM_R8z5q\"\n },\n \"source\": [\n \" \\n\",\n \"## 2.4 Creating training, validation, and test set data loaders\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b3c29eb8-d1b9-4abe-a155-52b3270d759a\",\n \"metadata\": {\n \"id\": \"b3c29eb8-d1b9-4abe-a155-52b3270d759a\"\n },\n \"source\": [\n \"- Above, we worked with a small example subsets from the preference dataset for illustration purposes\\n\",\n \"- Let's now create the actual training, validation, and test set data loaders\\n\",\n \"- This process is identical to creating the data loaders in the pretraining and instruction finetuning chapters and thus should be self-explanatory\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 28,\n \"id\": \"5c0068bf-bda0-4d9e-9f79-2fc4b94cbd1c\",\n \"metadata\": {\n \"id\": \"5c0068bf-bda0-4d9e-9f79-2fc4b94cbd1c\"\n },\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"\\n\",\n \"num_workers = 0\\n\",\n \"batch_size = 8\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_dataset = PreferenceDataset(train_data, tokenizer)\\n\",\n \"train_loader = DataLoader(\\n\",\n \" train_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=True,\\n\",\n \" drop_last=True,\\n\",\n \" num_workers=num_workers\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"2f4a257b-6835-4194-abe2-5831d6a44885\",\n \"metadata\": {\n \"id\": \"2f4a257b-6835-4194-abe2-5831d6a44885\"\n },\n \"outputs\": [],\n \"source\": [\n \"val_dataset = PreferenceDataset(val_data, tokenizer)\\n\",\n \"val_loader = DataLoader(\\n\",\n \" val_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=False,\\n\",\n \" drop_last=False,\\n\",\n \" num_workers=num_workers\\n\",\n \")\\n\",\n \"\\n\",\n \"test_dataset = PreferenceDataset(test_data, tokenizer)\\n\",\n \"test_loader = DataLoader(\\n\",\n \" test_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=False,\\n\",\n \" drop_last=False,\\n\",\n \" num_workers=num_workers\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1fe1ba19-a6d5-4a77-8283-7a17d7ec06e2\",\n \"metadata\": {\n \"id\": \"1fe1ba19-a6d5-4a77-8283-7a17d7ec06e2\"\n },\n \"source\": [\n \"- Let's iterate through the data loader and take a look at the dataset shapes:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"80d61f15-facb-4eb8-a9be-6427887d24b2\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"80d61f15-facb-4eb8-a9be-6427887d24b2\",\n \"outputId\": \"dacd3bdf-f069-4b36-da2c-d6c1c6cc5405\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"torch.Size([8, 77]) torch.Size([8, 77])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 94]) torch.Size([8, 94])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 99]) torch.Size([8, 99])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 88]) torch.Size([8, 88])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 97]) torch.Size([8, 97])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 89]) torch.Size([8, 89])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 84]) torch.Size([8, 84])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 101]) torch.Size([8, 101])\\n\",\n \"torch.Size([8, 87]) torch.Size([8, 87])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 91]) torch.Size([8, 91])\\n\",\n \"torch.Size([8, 78]) torch.Size([8, 78])\\n\",\n \"torch.Size([8, 78]) torch.Size([8, 78])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 84]) torch.Size([8, 84])\\n\",\n \"torch.Size([8, 92]) torch.Size([8, 92])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 78]) torch.Size([8, 78])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 100]) torch.Size([8, 100])\\n\",\n \"torch.Size([8, 77]) torch.Size([8, 77])\\n\",\n \"torch.Size([8, 92]) torch.Size([8, 92])\\n\",\n \"torch.Size([8, 93]) torch.Size([8, 93])\\n\",\n \"torch.Size([8, 115]) torch.Size([8, 115])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 95]) torch.Size([8, 95])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 94]) torch.Size([8, 94])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\",\n \"torch.Size([8, 89]) torch.Size([8, 89])\\n\",\n \"torch.Size([8, 90]) torch.Size([8, 90])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\",\n \"torch.Size([8, 85]) torch.Size([8, 85])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 84]) torch.Size([8, 84])\\n\",\n \"torch.Size([8, 84]) torch.Size([8, 84])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 63]) torch.Size([8, 63])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 93]) torch.Size([8, 93])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 99]) torch.Size([8, 99])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 77]) torch.Size([8, 77])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 87]) torch.Size([8, 87])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 86]) torch.Size([8, 86])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 63]) torch.Size([8, 63])\\n\",\n \"torch.Size([8, 82]) torch.Size([8, 82])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 97]) torch.Size([8, 97])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 85]) torch.Size([8, 85])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 85]) torch.Size([8, 85])\\n\",\n \"torch.Size([8, 87]) torch.Size([8, 87])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 92]) torch.Size([8, 92])\\n\",\n \"torch.Size([8, 85]) torch.Size([8, 85])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 93]) torch.Size([8, 93])\\n\",\n \"torch.Size([8, 82]) torch.Size([8, 82])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 93]) torch.Size([8, 93])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 87]) torch.Size([8, 87])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 90]) torch.Size([8, 90])\\n\",\n \"torch.Size([8, 99]) torch.Size([8, 99])\\n\",\n \"torch.Size([8, 104]) torch.Size([8, 104])\\n\",\n \"torch.Size([8, 101]) torch.Size([8, 101])\\n\",\n \"torch.Size([8, 98]) torch.Size([8, 98])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 84]) torch.Size([8, 84])\\n\",\n \"torch.Size([8, 78]) torch.Size([8, 78])\\n\",\n \"torch.Size([8, 85]) torch.Size([8, 85])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for batch in train_loader:\\n\",\n \" print(\\n\",\n \" batch[\\\"chosen\\\"].shape,\\n\",\n \" batch[\\\"rejected\\\"].shape,\\n\",\n \" )\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7ff958a6-5e61-49f5-9a97-360aa34e3758\",\n \"metadata\": {\n \"id\": \"7ff958a6-5e61-49f5-9a97-360aa34e3758\"\n },\n \"source\": [\n \"- Each row shows the shape of the `\\\"chosen\\\"` and `\\\"rejected\\\"` entries in each batch\\n\",\n \"- Since we applied padding on a batch-by-batch basis, each row has a different shape\\n\",\n \"- This is for efficiency reasons because it would be inefficient to pad all samples to the longest sample in the whole dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"29cb0543-1142-4374-8825-3384e20c6ac0\",\n \"metadata\": {\n \"id\": \"29cb0543-1142-4374-8825-3384e20c6ac0\"\n },\n \"source\": [\n \" \\n\",\n \"# 3) Loading a finetuned LLM for DPO alignment\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"22b08881-b769-4b26-8153-5ec0e8573ed2\",\n \"metadata\": {\n \"id\": \"22b08881-b769-4b26-8153-5ec0e8573ed2\"\n },\n \"source\": [\n \"- LLM alignment steps, such as RLHF or DPO, assume that we already have an instruction-finetuned model\\n\",\n \"- This section contains minimal code to load the model that was instruction finetuned and saved in chapter 7 (via [../01_main-chapter-code/ch07.ipynb](../01_main-chapter-code/ch07.ipynb))\\n\",\n \"- Make sure you run the chapter 7 code first to create the instruction-finetuned model before you proceed\\n\",\n \"- The code below will copy the instruction-finetuned model into the current directory:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"b3c6d82b-63f7-459a-b901-7125ab225e56\",\n \"metadata\": {\n \"id\": \"b3c6d82b-63f7-459a-b901-7125ab225e56\"\n },\n \"outputs\": [],\n \"source\": [\n \"from pathlib import Path\\n\",\n \"import shutil\\n\",\n \"\\n\",\n \"\\n\",\n \"finetuned_model_path = Path(\\\"gpt2-medium355M-sft.pth\\\")\\n\",\n \"if not finetuned_model_path.exists():\\n\",\n \"\\n\",\n \" # Try finding the model checkpoint locally:\\n\",\n \" relative_path = Path(\\\"..\\\") / \\\"01_main-chapter-code\\\" / finetuned_model_path\\n\",\n \" if relative_path.exists():\\n\",\n \" shutil.copy(relative_path, \\\".\\\")\\n\",\n \"\\n\",\n \" # If this notebook is run on Google Colab, get it from a Google Drive folder\\n\",\n \" elif \\\"COLAB_GPU\\\" in os.environ or \\\"COLAB_TPU_ADDR\\\" in os.environ:\\n\",\n \" from google.colab import drive\\n\",\n \" drive.mount(\\\"/content/drive\\\")\\n\",\n \" google_drive_path = \\\"/content/drive/My Drive/Books/LLMs-From-Scratch/ch07/colab/gpt2-medium355M-sft.pth\\\" # Readers need to adjust this path\\n\",\n \" shutil.copy(google_drive_path, \\\".\\\")\\n\",\n \"\\n\",\n \" else:\\n\",\n \" print(\\n\",\n \" f\\\"Could not find '{finetuned_model_path}'.\\\\n\\\"\\n\",\n \" \\\"Run the `ch07.ipynb` notebook to finetune and save the finetuned model.\\\"\\n\",\n \" )\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"71c8585e-4569-4033-84a7-3903d0e8aaf8\",\n \"metadata\": {\n \"id\": \"71c8585e-4569-4033-84a7-3903d0e8aaf8\"\n },\n \"source\": [\n \"- Next, we reuse the basic configuration from previous chapters to load the model weights:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"a8333fee-e7fe-4f8c-9411-8c1db6252d98\",\n \"metadata\": {\n \"id\": \"a8333fee-e7fe-4f8c-9411-8c1db6252d98\"\n },\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import GPTModel\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"\\n\",\n \"\\n\",\n \"BASE_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"drop_rate\\\": 0.0, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": True # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"CHOOSE_MODEL = \\\"gpt2-medium (355M)\\\"\\n\",\n \"\\n\",\n \"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"c2821403-605c-4071-a4ff-e23f4c9a11fd\",\n \"metadata\": {\n \"id\": \"c2821403-605c-4071-a4ff-e23f4c9a11fd\"\n },\n \"outputs\": [],\n \"source\": [\n \"model.load_state_dict(\\n\",\n \" torch.load(\\n\",\n \" \\\"gpt2-medium355M-sft.pth\\\",\\n\",\n \" map_location=torch.device(\\\"cpu\\\"),\\n\",\n \" weights_only=True\\n\",\n \" )\\n\",\n \")\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"61863bec-bd42-4194-b994-645bfe2df8be\",\n \"metadata\": {\n \"id\": \"61863bec-bd42-4194-b994-645bfe2df8be\"\n },\n \"source\": [\n \"- Before training the loaded model with DPO, let's make sure that the finetuned model was saved and loaded correctly by trying it out on some sample data:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"4357aec5-0db2-4d73-b37b-539cd8fa80a3\",\n \"metadata\": {\n \"id\": \"4357aec5-0db2-4d73-b37b-539cd8fa80a3\"\n },\n \"outputs\": [],\n \"source\": [\n \"prompt = \\\"\\\"\\\"Below is an instruction that describes a task. Write a response\\n\",\n \"that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Convert the active sentence to passive: 'The chef cooks the meal every day.'\\n\",\n \"\\\"\\\"\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"541e7988-38d3-47f6-bd52-9da6564479fa\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"541e7988-38d3-47f6-bd52-9da6564479fa\",\n \"outputId\": \"278f7ddf-37c2-4c3a-d069-c510ef6f8d7a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response\\n\",\n \"that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Convert the active sentence to passive: 'The chef cooks the meal every day.'\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"The meal is cooked every day by the chef.\\n\"\n ]\n }\n ],\n \"source\": [\n \"from previous_chapters import (\\n\",\n \" generate,\\n\",\n \" text_to_token_ids,\\n\",\n \" token_ids_to_text\\n\",\n \")\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch05 (\\n\",\n \"# generate,\\n\",\n \"# text_to_token_ids,\\n\",\n \"# token_ids_to_text\\n\",\n \"# )\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(prompt, tokenizer),\\n\",\n \" max_new_tokens=35,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"],\\n\",\n \" eos_id=50256\\n\",\n \")\\n\",\n \"\\n\",\n \"response = token_ids_to_text(token_ids, tokenizer)\\n\",\n \"print(response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be87ed19-fded-4e56-8585-6c7c0367b354\",\n \"metadata\": {\n \"id\": \"be87ed19-fded-4e56-8585-6c7c0367b354\"\n },\n \"source\": [\n \"- As we can see above, the model gives a reasonable and correct response\\n\",\n \"- As explained in chapter 7, in practice, we would clean up the response to only return the response text with the prompt and prompt style removed (similar to what you are familiar with from ChatGPT, for example):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"0c30c4e2-af84-4ab4-95d0-9641e32c1e7f\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0c30c4e2-af84-4ab4-95d0-9641e32c1e7f\",\n \"outputId\": \"70192bbe-fdf6-43eb-c673-f573f8c70156\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"The meal is cooked every day by the chef.\\n\"\n ]\n }\n ],\n \"source\": [\n \"def extract_response(response_text, input_text):\\n\",\n \" return response_text[len(input_text):].replace(\\\"### Response:\\\", \\\"\\\").strip()\\n\",\n \"\\n\",\n \"response = extract_response(response, prompt)\\n\",\n \"print(response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"80442cb9-83b1-46b8-bad0-7d44297ca52d\",\n \"metadata\": {\n \"id\": \"80442cb9-83b1-46b8-bad0-7d44297ca52d\"\n },\n \"source\": [\n \"- Now, we are almost ready to get to the DPO part\\n\",\n \"- As mentioned at the beginning of this notebook, DPO works with two LLMs: a policy model (the LLM that we want to optimize) and a reference model (the original model that we keep unchanged)\\n\",\n \"- Below, we rename the `model` as `policy_model` and instantiate a second instance of the model we refer to as the `reference_model`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"5d88cc3a-312e-4b29-bc6d-de8354c1eb9f\",\n \"metadata\": {\n \"id\": \"5d88cc3a-312e-4b29-bc6d-de8354c1eb9f\"\n },\n \"outputs\": [],\n \"source\": [\n \"policy_model = model\\n\",\n \"\\n\",\n \"reference_model = GPTModel(BASE_CONFIG)\\n\",\n \"reference_model.load_state_dict(\\n\",\n \" torch.load(\\n\",\n \" \\\"gpt2-medium355M-sft.pth\\\",\\n\",\n \" map_location=torch.device(\\\"cpu\\\"),\\n\",\n \" weights_only=True\\n\",\n \" )\\n\",\n \")\\n\",\n \"reference_model.eval()\\n\",\n \"\\n\",\n \"policy_model.to(device)\\n\",\n \"reference_model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9c6c1469-0038-4914-8aa5-15b1f81877cc\",\n \"metadata\": {\n \"id\": \"9c6c1469-0038-4914-8aa5-15b1f81877cc\"\n },\n \"source\": [\n \" \\n\",\n \"# 4) Coding the DPO Loss Function\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"75dbe60c-e4ce-413e-beec-22eff0237d11\",\n \"metadata\": {\n \"id\": \"75dbe60c-e4ce-413e-beec-22eff0237d11\"\n },\n \"source\": [\n \"- After we took care of the model loading and dataset preparation in the previous sections, we can now get to the fun part and code the DPO loss\\n\",\n \"- Note that the DPO loss code below is based on the method proposed in the [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://arxiv.org/abs/2305.18290) paper\\n\",\n \"- For reference, the core DPO equation is shown again below:\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"- In the equation above,\\n\",\n \" - \\\"expected value\\\" $\\\\mathbb{E}$ is statistics jargon and stands for the average or mean value of the random variable (the expression inside the brackets); optimizing $-\\\\mathbb{E}$ aligns the model better with user preferences\\n\",\n \" - The $\\\\pi_{\\\\theta}$ variable is the so-called policy (a term borrowed from reinforcement learning) and represents the LLM we want to optimize; $\\\\pi_{ref}$ is a reference LLM, which is typically the original LLM before optimization (at the beginning of the training, $\\\\pi_{\\\\theta}$ and $\\\\pi_{ref}$ are typically the same)\\n\",\n \" - $\\\\beta$ is a hyperparameter to control the divergence between the $\\\\pi_{\\\\theta}$ and the reference model; increasing $\\\\beta$ increases the impact of the difference between\\n\",\n \"$\\\\pi_{\\\\theta}$ and $\\\\pi_{ref}$ in terms of their log probabilities on the overall loss function, thereby increasing the divergence between the two models\\n\",\n \" - the logistic sigmoid function, $\\\\sigma(\\\\centerdot)$ transforms the log-odds of the preferred and rejected responses (the terms inside the logistic sigmoid function) into a probability score \\n\",\n \"- In code, we can implement the DPO loss as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"38CsrrwJIZiV\",\n \"metadata\": {\n \"id\": \"38CsrrwJIZiV\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch.nn.functional as F\\n\",\n \"\\n\",\n \"def compute_dpo_loss(\\n\",\n \" model_chosen_logprobs,\\n\",\n \" model_rejected_logprobs,\\n\",\n \" reference_chosen_logprobs,\\n\",\n \" reference_rejected_logprobs,\\n\",\n \" beta=0.1,\\n\",\n \" ):\\n\",\n \" \\\"\\\"\\\"Compute the DPO loss for a batch of policy and reference model log probabilities.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" model_chosen_logprobs: Log probabilities of the policy model for the chosen responses. Shape: (batch_size,)\\n\",\n \" model_rejected_logprobs: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)\\n\",\n \" reference_chosen_logprobs: Log probabilities of the reference model for the chosen responses. Shape: (batch_size,)\\n\",\n \" reference_rejected_logprobs: Log probabilities of the reference model for the rejected responses. Shape: (batch_size,)\\n\",\n \" beta: Temperature parameter for the DPO loss; typically something in the range of 0.1 to 0.5. We ignore the reference model as beta -> 0.\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" A tuple of three tensors: (loss, chosen_rewards, rejected_rewards).\\n\",\n \" \\\"\\\"\\\"\\n\",\n \"\\n\",\n \" model_logratios = model_chosen_logprobs - model_rejected_logprobs\\n\",\n \" reference_logratios = reference_chosen_logprobs - reference_rejected_logprobs\\n\",\n \" logits = model_logratios - reference_logratios\\n\",\n \"\\n\",\n \" # DPO (Eq. 7 of https://arxiv.org/pdf/2305.18290.pdf)\\n\",\n \" losses = -F.logsigmoid(beta * logits)\\n\",\n \"\\n\",\n \" # Optional values to track progress during training\\n\",\n \" chosen_rewards = (model_chosen_logprobs - reference_chosen_logprobs).detach()\\n\",\n \" rejected_rewards = (model_rejected_logprobs - reference_rejected_logprobs).detach()\\n\",\n \"\\n\",\n \" # .mean() to average over the samples in the batch\\n\",\n \" return losses.mean(), chosen_rewards.mean(), rejected_rewards.mean()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"693be65b-38fc-4d18-bf53-a260a15436e1\",\n \"metadata\": {\n \"id\": \"693be65b-38fc-4d18-bf53-a260a15436e1\"\n },\n \"source\": [\n \"- If you are familiar with logarithms, note that we have the general relationship $\\\\log\\\\left(\\\\frac{a}{b}\\\\right) = \\\\log a - \\\\log b$, which we applied in the code above\\n\",\n \"- Keeping this in mind, let's go through some of the steps (we will calculate the `logprobs` using a separate function later)\\n\",\n \"- Let's start with the lines\\n\",\n \"\\n\",\n \" ```python\\n\",\n \" model_logratios = model_chosen_logprobs - model_rejected_logprobs\\n\",\n \" reference_logratios = reference_chosen_logprobs - reference_rejected_logprobs\\n\",\n \" ```\\n\",\n \"\\n\",\n \"- These lines above calculate the difference in log probabilities (logits) for the chosen and rejected samples for both the policy model and the reference model (this is due to $\\\\log\\\\left(\\\\frac{a}{b}\\\\right) = \\\\log a - \\\\log b$):\\n\",\n \"\\n\",\n \"$$\\\\log \\\\left( \\\\frac{\\\\pi_\\\\theta (y_w \\\\mid x)}{\\\\pi_\\\\theta (y_l \\\\mid x)} \\\\right) \\\\quad \\\\text{and} \\\\quad \\\\log \\\\left( \\\\frac{\\\\pi_{\\\\text{ref}}(y_w \\\\mid x)}{\\\\pi_{\\\\text{ref}}(y_l \\\\mid x)} \\\\right)$$\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5458d217-e0ad-40a5-925c-507a8fcf5795\",\n \"metadata\": {\n \"id\": \"5458d217-e0ad-40a5-925c-507a8fcf5795\"\n },\n \"source\": [\n \"- Next, the code `logits = model_logratios - reference_logratios` computes the difference between the model's log ratios and the reference model's log ratios, i.e., \\n\",\n \"\\n\",\n \"$$\\\\beta \\\\log \\\\left( \\\\frac{\\\\pi_\\\\theta (y_w \\\\mid x)}{\\\\pi_{\\\\text{ref}} (y_w \\\\mid x)} \\\\right)\\n\",\n \"- \\\\beta \\\\log \\\\left( \\\\frac{\\\\pi_\\\\theta (y_l \\\\mid x)}{\\\\pi_{\\\\text{ref}} (y_l \\\\mid x)} \\\\right)$$\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f18e3e36-f5f1-407f-b662-4c20a0ac0354\",\n \"metadata\": {\n \"id\": \"f18e3e36-f5f1-407f-b662-4c20a0ac0354\"\n },\n \"source\": [\n \"- Finally, `losses = -F.logsigmoid(beta * logits)` calculates the loss using the log-sigmoid function; in the original equation, the term inside the expectation is \\n\",\n \"\\n\",\n \"$$\\\\log \\\\sigma \\\\left( \\\\beta \\\\log \\\\left( \\\\frac{\\\\pi_\\\\theta (y_w \\\\mid x)}{\\\\pi_{\\\\text{ref}} (y_w \\\\mid x)} \\\\right)\\n\",\n \"- \\\\beta \\\\log \\\\left( \\\\frac{\\\\pi_\\\\theta (y_l \\\\mid x)}{\\\\pi_{\\\\text{ref}} (y_l \\\\mid x)} \\\\right) \\\\right)$$\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"00a6f92d-7d64-41fe-bcaa-2bddd46027e1\",\n \"metadata\": {\n \"id\": \"00a6f92d-7d64-41fe-bcaa-2bddd46027e1\"\n },\n \"source\": [\n \"- Above, we assumed that the log probabilities were already computed; let's now define a `compute_logprobs` function that we can use to compute these log probabilities that were passed into the `compute_dpo_loss` function above, that is, the values $\\\\pi_\\\\theta (y_w \\\\mid x)$, ${\\\\pi_\\\\theta (y_l \\\\mid x)}$, and so forth:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"71e6507b-d2e2-4469-86b9-f057b08b5df9\",\n \"metadata\": {\n \"id\": \"71e6507b-d2e2-4469-86b9-f057b08b5df9\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_logprobs(logits, labels, selection_mask=None):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Compute log probabilities.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" logits: Tensor of shape (batch_size, num_tokens, vocab_size)\\n\",\n \" labels: Tensor of shape (batch_size, num_tokens)\\n\",\n \" selection_mask: Tensor for shape (batch_size, num_tokens)\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" mean_log_prob: Mean log probability excluding padding tokens.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \"\\n\",\n \" # Labels are the inputs shifted by one\\n\",\n \" labels = labels[:, 1:].clone()\\n\",\n \"\\n\",\n \" # Truncate logits to match the labels num_tokens\\n\",\n \" logits = logits[:, :-1, :]\\n\",\n \"\\n\",\n \" log_probs = F.log_softmax(logits, dim=-1)\\n\",\n \"\\n\",\n \" # Gather the log probabilities for the actual labels\\n\",\n \" selected_log_probs = torch.gather(\\n\",\n \" input=log_probs,\\n\",\n \" dim=-1,\\n\",\n \" index=labels.unsqueeze(-1)\\n\",\n \" ).squeeze(-1)\\n\",\n \"\\n\",\n \" if selection_mask is not None:\\n\",\n \" mask = selection_mask[:, 1:].clone()\\n\",\n \"\\n\",\n \" # Apply the mask to filter out padding tokens\\n\",\n \" selected_log_probs = selected_log_probs * mask\\n\",\n \"\\n\",\n \" # Calculate the average log probability excluding padding tokens\\n\",\n \" # This averages over the tokens, so the shape is (batch_size,)\\n\",\n \" avg_log_prob = selected_log_probs.sum(-1) / mask.sum(-1)\\n\",\n \"\\n\",\n \" return avg_log_prob\\n\",\n \"\\n\",\n \" else:\\n\",\n \" return selected_log_probs.mean(-1)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cf6a71ac-3fcc-44a4-befc-1c56bbd378d7\",\n \"metadata\": {\n \"id\": \"cf6a71ac-3fcc-44a4-befc-1c56bbd378d7\"\n },\n \"source\": [\n \"- Note that this function above might look a bit intimidating at first due to the `torch.gather` function, but it's pretty similar to what happens under the hood in PyTorch's `cross_entropy` function\\n\",\n \"- For example, consider the following example:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 40,\n \"id\": \"59873470-464d-4be2-860f-cbb7ac2d80ba\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"59873470-464d-4be2-860f-cbb7ac2d80ba\",\n \"outputId\": \"8f7b47d4-73fe-4605-c17d-ad6cfd909a9b\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(1.4185) tensor(1.4185)\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Sample data\\n\",\n \"logits = torch.tensor(\\n\",\n \" [[2.0, 1.0, 0.1],\\n\",\n \" [0.5, 2.5, 0.3]]) # Shape: (2, 3)\\n\",\n \"targets = torch.tensor([0, 2]) # Shape: (2,)\\n\",\n \"\\n\",\n \"\\n\",\n \"# Manual loss using torch.gather\\n\",\n \"log_softmax_logits = F.log_softmax(logits, dim=1) # Shape: (2, 3)\\n\",\n \"selected_log_probs = torch.gather(\\n\",\n \" input=log_softmax_logits,\\n\",\n \" dim=1,\\n\",\n \" index=targets.unsqueeze(1), # Shape 2, 1\\n\",\n \").squeeze(1) # Shape: (2,)\\n\",\n \"manual_loss = -selected_log_probs.mean() # Averaging over the batch\\n\",\n \"\\n\",\n \"\\n\",\n \"# PyTorch loss\\n\",\n \"cross_entropy_loss = F.cross_entropy(logits, targets)\\n\",\n \"\\n\",\n \"print(manual_loss, cross_entropy_loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f86d7add-f7ff-4a87-9193-7878c42bf0e7\",\n \"metadata\": {\n \"id\": \"f86d7add-f7ff-4a87-9193-7878c42bf0e7\"\n },\n \"source\": [\n \"- So, above, we can see that the two implementations are equivalent, but let's narrow down a bit further to the `torch.gather` mechanics\\n\",\n \"- Consider the following two tensors:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 41,\n \"id\": \"508db6ba-cc40-479f-a996-2250cf862388\",\n \"metadata\": {\n \"id\": \"508db6ba-cc40-479f-a996-2250cf862388\"\n },\n \"outputs\": [],\n \"source\": [\n \"t = torch.tensor(\\n\",\n \" [[1., 2.,],\\n\",\n \" [3., 4.]]\\n\",\n \")\\n\",\n \"\\n\",\n \"m = torch.tensor(\\n\",\n \" [[1, 1],\\n\",\n \" [0, 1]]\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"821cbf45-8fbb-47b7-bae8-6c3271e36979\",\n \"metadata\": {\n \"id\": \"821cbf45-8fbb-47b7-bae8-6c3271e36979\"\n },\n \"source\": [\n \"- Above, `t` is a tensor we want to select from, and `m` is a mask to specify how we want to select\\n\",\n \" - For instance, since `m` contains `[1, 1]` n the first row, it will select two times the value of `t` in index position `1`, which is the value 2.\\n\",\n \" - The second row of `m`, `[0, 1]`, selects index positions 0 and 1 in the second row or `t`, which are `3.` and `4.`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"4fdN5q1YPAbM\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"4fdN5q1YPAbM\",\n \"outputId\": \"e935e8ad-1519-4c4b-dbff-65adae0a15a4\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[2., 2.],\\n\",\n \" [3., 4.]])\"\n ]\n },\n \"execution_count\": 42,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"torch.gather(input=t, dim=-1, index=m)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d10eeaf4-f24b-4e79-916a-abedf74fe4a3\",\n \"metadata\": {\n \"id\": \"d10eeaf4-f24b-4e79-916a-abedf74fe4a3\"\n },\n \"source\": [\n \"- In other words, `torch.gather` is a selection function\\n\",\n \"- When we computed the loss earlier, we used it to retrieve the log probabilities corresponding to the correct token in the 50,257-token vocabulary\\n\",\n \"- The \\\"correct\\\" tokens are the tokens given in the response entry\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d5d10a43-ee5b-47ed-9d55-ddd96e66cf0b\",\n \"metadata\": {\n \"id\": \"d5d10a43-ee5b-47ed-9d55-ddd96e66cf0b\"\n },\n \"source\": [\n \"- Regarding the `compute_logprobs` function above, we use `torch.gather` here because it gives us a bit more control than `cross_entropy`, but is, in essence, a similar idea\\n\",\n \"- The `selection_mask` we use there is to optionally ignore prompt and padding tokens\\n\",\n \"- We can then use the `compute_logprobs` function as follows to compute the inputs for the `compute_dpo_loss` loss function\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"dfa7a4db-eba0-47d8-ad6d-7b5e7676e318\",\n \"metadata\": {\n \"id\": \"dfa7a4db-eba0-47d8-ad6d-7b5e7676e318\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_dpo_loss_batch(batch, policy_model, reference_model, beta):\\n\",\n \" \\\"\\\"\\\"Compute the DPO loss on an input batch\\\"\\\"\\\"\\n\",\n \"\\n\",\n \" # where policy_model(batch[\\\"chosen\\\"]) are the logits\\n\",\n \" policy_chosen_log_probas = compute_logprobs(\\n\",\n \" logits=policy_model(batch[\\\"chosen\\\"]),\\n\",\n \" labels=batch[\\\"chosen\\\"],\\n\",\n \" selection_mask=batch[\\\"chosen_mask\\\"]\\n\",\n \" )\\n\",\n \" policy_rejected_log_probas = compute_logprobs(\\n\",\n \" logits=policy_model(batch[\\\"rejected\\\"]),\\n\",\n \" labels=batch[\\\"rejected\\\"],\\n\",\n \" selection_mask=batch[\\\"rejected_mask\\\"]\\n\",\n \" )\\n\",\n \" \\n\",\n \" with torch.no_grad():\\n\",\n \" ref_chosen_log_probas = compute_logprobs(\\n\",\n \" logits=reference_model(batch[\\\"chosen\\\"]),\\n\",\n \" labels=batch[\\\"chosen\\\"],\\n\",\n \" selection_mask=batch[\\\"chosen_mask\\\"]\\n\",\n \" )\\n\",\n \" ref_rejected_log_probas = compute_logprobs(\\n\",\n \" logits=reference_model(batch[\\\"rejected\\\"]),\\n\",\n \" labels=batch[\\\"rejected\\\"],\\n\",\n \" selection_mask=batch[\\\"rejected_mask\\\"]\\n\",\n \" )\\n\",\n \" loss, chosen_rewards, rejected_rewards = compute_dpo_loss(\\n\",\n \" model_chosen_logprobs=policy_chosen_log_probas,\\n\",\n \" model_rejected_logprobs=policy_rejected_log_probas,\\n\",\n \" reference_chosen_logprobs=ref_chosen_log_probas,\\n\",\n \" reference_rejected_logprobs=ref_rejected_log_probas,\\n\",\n \" beta=beta\\n\",\n \" )\\n\",\n \" return loss, chosen_rewards, rejected_rewards\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b28caafb-f378-4332-a142-3e0f9ef67fbb\",\n \"metadata\": {\n \"id\": \"b28caafb-f378-4332-a142-3e0f9ef67fbb\"\n },\n \"source\": [\n \"- The above function works for a single batch, for example:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"dd74fcc4-4280-41e9-9a22-838e85c84ee4\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd74fcc4-4280-41e9-9a22-838e85c84ee4\",\n \"outputId\": \"65a70828-7dd2-4f72-ffec-45aeaf8afad0\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"(tensor(0.6931, device='mps:0'), tensor(0., device='mps:0'), tensor(0., device='mps:0'))\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" loss = compute_dpo_loss_batch(batch, policy_model, reference_model, beta=0.1)\\n\",\n \"print(loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b17429cd-2a00-41c8-9f16-38b1c9a5179f\",\n \"metadata\": {\n \"id\": \"b17429cd-2a00-41c8-9f16-38b1c9a5179f\"\n },\n \"source\": [\n \"- Below, we extend this function to work for a specified `num_batches` in a data loader:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"682e9ad5-c5de-4d1b-9e93-3918bf5d5302\",\n \"metadata\": {\n \"id\": \"682e9ad5-c5de-4d1b-9e93-3918bf5d5302\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_dpo_loss_loader(data_loader, policy_model, reference_model, beta, num_batches=None):\\n\",\n \" \\\"\\\"\\\"Apply compute_dpo_loss_batch to a whole data loader\\\"\\\"\\\"\\n\",\n \"\\n\",\n \" total_loss, total_chosen_rewards, total_rejected_rewards = 0., 0., 0.\\n\",\n \" if len(data_loader) == 0:\\n\",\n \" return float(\\\"nan\\\")\\n\",\n \"\\n\",\n \" elif num_batches is None:\\n\",\n \" num_batches = len(data_loader)\\n\",\n \" else:\\n\",\n \" # Reduce the number of batches to match the total number of batches in the data loader\\n\",\n \" # if num_batches exceeds the number of batches in the data loader\\n\",\n \" num_batches = min(num_batches, len(data_loader))\\n\",\n \" for i, batch in enumerate(data_loader):\\n\",\n \" if i < num_batches:\\n\",\n \" loss, chosen_rewards, rejected_rewards = compute_dpo_loss_batch(\\n\",\n \" batch=batch,\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" beta=beta\\n\",\n \" )\\n\",\n \" total_loss += loss.item()\\n\",\n \" total_chosen_rewards += chosen_rewards.item()\\n\",\n \" total_rejected_rewards += rejected_rewards.item()\\n\",\n \"\\n\",\n \" else:\\n\",\n \" break\\n\",\n \"\\n\",\n \" # calculate average\\n\",\n \" total_loss /= num_batches\\n\",\n \" total_chosen_rewards /= num_batches\\n\",\n \" total_rejected_rewards /= num_batches\\n\",\n \" return total_loss, total_chosen_rewards, total_rejected_rewards\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"852e4c09-d285-44d5-be12-d29769950cb6\",\n \"metadata\": {\n \"id\": \"852e4c09-d285-44d5-be12-d29769950cb6\"\n },\n \"source\": [\n \"- Why a specified `num_batches`? That's purely for efficiency reasons (because calculating the loss on the whole dataset each time would slow down the training significantly)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2cca95b7-18fe-4076-9138-f70f21607b8c\",\n \"metadata\": {\n \"id\": \"2cca95b7-18fe-4076-9138-f70f21607b8c\"\n },\n \"source\": [\n \"- Lastly, we define a convenience function for our training function later; this `evaluate_dpo_loss_loader` function computes the DPO loss and rewards for both the training and validation loader for logging purposes:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 46,\n \"id\": \"c3d214ec-49ba-4bf0-ac80-f90fa0d832e9\",\n \"metadata\": {\n \"id\": \"c3d214ec-49ba-4bf0-ac80-f90fa0d832e9\"\n },\n \"outputs\": [],\n \"source\": [\n \"def evaluate_dpo_loss_loader(policy_model, reference_model, train_loader, val_loader, beta, eval_iter):\\n\",\n \" \\\"\\\"\\\"Compute the DPO loss for the training and validation dataset\\\"\\\"\\\"\\n\",\n \"\\n\",\n \" policy_model.eval()\\n\",\n \" with torch.no_grad():\\n\",\n \" train_loss, train_chosen_rewards, train_rejected_rewards = compute_dpo_loss_loader(\\n\",\n \" data_loader=train_loader,\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" beta=beta,\\n\",\n \" num_batches=eval_iter\\n\",\n \" )\\n\",\n \"\\n\",\n \" val_loss, val_chosen_rewards, val_rejected_rewards = compute_dpo_loss_loader(\\n\",\n \" data_loader=val_loader,\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" beta=beta,\\n\",\n \" num_batches=eval_iter\\n\",\n \" )\\n\",\n \"\\n\",\n \" res = {\\n\",\n \" \\\"train_loss\\\": train_loss,\\n\",\n \" \\\"train_chosen_reward\\\": train_chosen_rewards,\\n\",\n \" \\\"train_rejected_reward\\\": train_rejected_rewards,\\n\",\n \" \\\"val_loss\\\": val_loss,\\n\",\n \" \\\"val_chosen_reward\\\": val_chosen_rewards,\\n\",\n \" \\\"val_rejected_reward\\\": val_rejected_rewards\\n\",\n \" }\\n\",\n \"\\n\",\n \" policy_model.train()\\n\",\n \" return res\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6e95ed92-6743-4f13-8b91-0fbf2e540de1\",\n \"metadata\": {\n \"id\": \"6e95ed92-6743-4f13-8b91-0fbf2e540de1\"\n },\n \"source\": [\n \"- In this section, we covered a lot of ground as a brief recap:\\n\",\n \" - The flow is: compute `logits` via the models $\\\\rightarrow$ `compute_logprobs` from logits $\\\\rightarrow$ compute `compute_dpo_loss` from log probabilities\\n\",\n \" - we have the `compute_dpo_loss_batch` function that facilitates the process above\\n\",\n \" - the `compute_dpo_loss_loader` utility function applies the `compute_dpo_loss_batch` function to a data loader\\n\",\n \" - the `evaluate_dpo_loss_loader` function applies the `compute_dpo_loss_batch` to both the training and validation set data loaders for logging purposes\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cb8a8f18-536e-4d83-a0d0-ac518a85f157\",\n \"metadata\": {\n \"id\": \"cb8a8f18-536e-4d83-a0d0-ac518a85f157\"\n },\n \"source\": [\n \" \\n\",\n \"# 5) Training the model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4b11d63d-3ddc-4070-9b2b-5ca0edb08d0c\",\n \"metadata\": {\n \"id\": \"4b11d63d-3ddc-4070-9b2b-5ca0edb08d0c\"\n },\n \"source\": [\n \"- After setting up the DPO loss functions in the previous section, we can now finally train the model\\n\",\n \"- Note that this training function is the same one we used for pretraining and instruction finetuning, with minor differences:\\n\",\n \" - we swap the cross-entropy loss with our new DPO loss function\\n\",\n \" - we also track the rewards and reward margins, which are commonly used in RLHF and DPO contexts to track the training progress\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"820d4904-f819-4d62-bfb4-85cf28863683\",\n \"metadata\": {\n \"id\": \"820d4904-f819-4d62-bfb4-85cf28863683\"\n },\n \"source\": [\n \"- Before we start the training, let's print the initial losses and rewards:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 47,\n \"id\": \"f90d9325-77b2-417f-88ff-0a5174889413\",\n \"metadata\": {\n \"id\": \"f90d9325-77b2-417f-88ff-0a5174889413\"\n },\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import generate_and_print_sample\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch04 import generate_text_simple\\n\",\n \"\\n\",\n \"\\n\",\n \"def train_model_dpo_simple(\\n\",\n \" policy_model, reference_model, train_loader, val_loader,\\n\",\n \" optimizer, num_epochs, beta,\\n\",\n \" eval_freq, eval_iter, start_context, tokenizer\\n\",\n \"):\\n\",\n \"\\n\",\n \" # Initialize lists to track losses and tokens seen\\n\",\n \" tracking = {\\n\",\n \" \\\"train_losses\\\": [],\\n\",\n \" \\\"train_chosen_rewards\\\": [],\\n\",\n \" \\\"train_rejected_rewards\\\": [],\\n\",\n \" \\\"val_losses\\\": [],\\n\",\n \" \\\"val_chosen_rewards\\\": [],\\n\",\n \" \\\"val_rejected_rewards\\\": [],\\n\",\n \" \\\"tokens_seen\\\": []\\n\",\n \" }\\n\",\n \" tokens_seen, global_step = 0, -1\\n\",\n \"\\n\",\n \" # Main training loop\\n\",\n \" for epoch in range(num_epochs):\\n\",\n \" policy_model.train() # Set model to training mode\\n\",\n \"\\n\",\n \" for batch in train_loader:\\n\",\n \"\\n\",\n \" optimizer.zero_grad() # Reset loss gradients from previous batch iteration\\n\",\n \"\\n\",\n \" loss, chosen_rewards, rejected_rewards = compute_dpo_loss_batch(\\n\",\n \" batch=batch,\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" beta=beta\\n\",\n \" )\\n\",\n \"\\n\",\n \" loss.backward() # Calculate loss gradients\\n\",\n \" optimizer.step() # Update model weights using loss gradients\\n\",\n \"\\n\",\n \" tokens_seen += batch[\\\"chosen\\\"].numel()\\n\",\n \" global_step += 1\\n\",\n \"\\n\",\n \" # Optional evaluation step\\n\",\n \" if global_step % eval_freq == 0:\\n\",\n \" res = evaluate_dpo_loss_loader(\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" train_loader=train_loader,\\n\",\n \" val_loader=val_loader,\\n\",\n \" beta=beta,\\n\",\n \" eval_iter=eval_iter\\n\",\n \" )\\n\",\n \" tracking[\\\"train_losses\\\"].append(res[\\\"train_loss\\\"])\\n\",\n \" tracking[\\\"train_chosen_rewards\\\"].append(res[\\\"train_chosen_reward\\\"])\\n\",\n \" tracking[\\\"train_rejected_rewards\\\"].append(res[\\\"train_rejected_reward\\\"])\\n\",\n \" tracking[\\\"val_losses\\\"].append(res[\\\"val_loss\\\"])\\n\",\n \" tracking[\\\"val_chosen_rewards\\\"].append(res[\\\"val_chosen_reward\\\"])\\n\",\n \" tracking[\\\"val_rejected_rewards\\\"].append(res[\\\"val_rejected_reward\\\"])\\n\",\n \" tracking[\\\"tokens_seen\\\"].append(tokens_seen)\\n\",\n \" train_reward_margin = res[\\\"train_chosen_reward\\\"] - res[\\\"train_rejected_reward\\\"]\\n\",\n \" val_reward_margin = res[\\\"val_chosen_reward\\\"] - res[\\\"val_rejected_reward\\\"]\\n\",\n \"\\n\",\n \" print(\\n\",\n \" f\\\"Ep {epoch+1} (Step {global_step:06d}): \\\"\\n\",\n \" f\\\"Train loss {res['train_loss']:.3f}, Val loss {res['val_loss']:.3f}, \\\"\\n\",\n \" f\\\"Train reward margins {train_reward_margin:.3f}, \\\"\\n\",\n \" f\\\"Val reward margins {val_reward_margin:.3f}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Print a sample text after each epoch\\n\",\n \" generate_and_print_sample(\\n\",\n \" model=model,\\n\",\n \" tokenizer=tokenizer,\\n\",\n \" device=loss.device,\\n\",\n \" start_context=start_context\\n\",\n \" )\\n\",\n \"\\n\",\n \" return tracking\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 48,\n \"id\": \"d53210c5-6d9c-46b0-af22-ee875c2806c5\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"d53210c5-6d9c-46b0-af22-ee875c2806c5\",\n \"outputId\": \"8b1d2b39-16c5-4b99-e920-5b33d3c0f34d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training loss: 0.6931471824645996\\n\",\n \"Validation loss: 0.6931471824645996\\n\",\n \"Train reward margin: 0.0\\n\",\n \"Val reward margin: 0.0\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123) # For reproducibility due to the shuffling in the data loader\\n\",\n \"\\n\",\n \"res = evaluate_dpo_loss_loader(\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" train_loader=train_loader,\\n\",\n \" val_loader=val_loader,\\n\",\n \" beta=0.1,\\n\",\n \" eval_iter=5\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Training loss:\\\", res[\\\"train_loss\\\"])\\n\",\n \"print(\\\"Validation loss:\\\", res[\\\"val_loss\\\"])\\n\",\n \"\\n\",\n \"print(\\\"Train reward margin:\\\", res[\\\"train_chosen_reward\\\"] - res[\\\"train_rejected_reward\\\"])\\n\",\n \"print(\\\"Val reward margin:\\\", res[\\\"val_chosen_reward\\\"] - res[\\\"val_rejected_reward\\\"])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4a006e91-df94-43ca-8025-1ba791e37bc4\",\n \"metadata\": {\n \"id\": \"4a006e91-df94-43ca-8025-1ba791e37bc4\"\n },\n \"source\": [\n \"- Also, let's take a look at some of the initial model responses (the first 3 examples in the validation set):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 49,\n \"id\": \"q4Ro9DrBa7zH\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"q4Ro9DrBa7zH\",\n \"outputId\": \"b974d4bd-b92a-4a2a-bb7a-5a2a0d1eca11\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Convert the active sentence to passive: 'The chef cooks the meal every day.'\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> The meal is cooked by the chef every day.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The meal is cooked everyday by the chef.\\n\",\n \"\\n\",\n \"-------------------------------------\\n\",\n \"\\n\",\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Classify an input string as either a noun or a verb.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"Dance\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> 'Dance' can be classified as a verb.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> Dance is a verb.\\n\",\n \"\\n\",\n \"-------------------------------------\\n\",\n \"\\n\",\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Rewrite the sentence using a metaphor.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"The book is very interesting.\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> The book is a page-turner.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The book is a book.\\n\",\n \"\\n\",\n \"-------------------------------------\\n\",\n \"\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"\\n\",\n \"for entry in val_data[:3]:\\n\",\n \"\\n\",\n \" input_text = format_input(entry)\\n\",\n \"\\n\",\n \" token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(input_text, tokenizer).to(device),\\n\",\n \" max_new_tokens=256,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"],\\n\",\n \" eos_id=50256\\n\",\n \" )\\n\",\n \" generated_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \" response_text = (\\n\",\n \" generated_text[len(input_text):]\\n\",\n \" .replace(\\\"### Response:\\\", \\\"\\\")\\n\",\n \" .strip()\\n\",\n \")\\n\",\n \"\\n\",\n \" print(input_text)\\n\",\n \" print(f\\\"\\\\nCorrect response:\\\\n>> {entry['output']}\\\")\\n\",\n \" print(f\\\"\\\\nModel response:\\\\n>> {response_text.strip()}\\\")\\n\",\n \" print(\\\"\\\\n-------------------------------------\\\\n\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ac2386ae-5c4c-448e-bfbf-4ec0604b171e\",\n \"metadata\": {\n \"id\": \"ac2386ae-5c4c-448e-bfbf-4ec0604b171e\"\n },\n \"source\": [\n \"- Above, we see the original model responses\\n\",\n \"- Note that the goal of DPO is to induce slight style changes; this means we want the model to generate similar but slightly more polite responses\\n\",\n \"- Before we execute the following code cell that starts the training, here are a few notes about some of the settings:\\n\",\n \" - we are only passing the parameters of the policy model into the `AdamW` optimizer; that's the model we want to optimize (we don't want to modify the reference model)\\n\",\n \" - we only train for 1 epoch; that's because DPO is very prone to collapse (the loss might improve, but the model will start generating nonsensical texts)\\n\",\n \" - in DPO, it's best to use a very small learning rate\\n\",\n \" - the beta value can be increased from 0.1 to 0.5 to reduce the effect of DPO (we use 0.1 here to make the results more noticeable)\\n\",\n \" - The training takes about 2 minutes on an A100 GPU, but it can also be trained in 4 minutes on a smaller L4 GPU; training on a M3 MacBook Air takes about 30 minutes\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 50,\n \"id\": \"54b739be-871e-4c97-bf14-ffd2c58e1311\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"54b739be-871e-4c97-bf14-ffd2c58e1311\",\n \"outputId\": \"d98b08b0-c325-411e-a1a4-05e7403f0345\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ep 1 (Step 000000): Train loss 0.692, Val loss 0.693, Train reward margins 0.014, Val reward margins 0.006\\n\",\n \"Ep 1 (Step 000005): Train loss 0.691, Val loss 0.692, Train reward margins 0.040, Val reward margins 0.030\\n\",\n \"Ep 1 (Step 000010): Train loss 0.688, Val loss 0.690, Train reward margins 0.108, Val reward margins 0.060\\n\",\n \"Ep 1 (Step 000015): Train loss 0.682, Val loss 0.688, Train reward margins 0.228, Val reward margins 0.100\\n\",\n \"Ep 1 (Step 000020): Train loss 0.682, Val loss 0.685, Train reward margins 0.235, Val reward margins 0.155\\n\",\n \"Ep 1 (Step 000025): Train loss 0.674, Val loss 0.682, Train reward margins 0.396, Val reward margins 0.234\\n\",\n \"Ep 1 (Step 000030): Train loss 0.677, Val loss 0.677, Train reward margins 0.328, Val reward margins 0.341\\n\",\n \"Ep 1 (Step 000035): Train loss 0.668, Val loss 0.672, Train reward margins 0.529, Val reward margins 0.435\\n\",\n \"Ep 1 (Step 000040): Train loss 0.675, Val loss 0.667, Train reward margins 0.405, Val reward margins 0.544\\n\",\n \"Ep 1 (Step 000045): Train loss 0.651, Val loss 0.662, Train reward margins 0.904, Val reward margins 0.675\\n\",\n \"Ep 1 (Step 000050): Train loss 0.657, Val loss 0.657, Train reward margins 0.809, Val reward margins 0.800\\n\",\n \"Ep 1 (Step 000055): Train loss 0.645, Val loss 0.653, Train reward margins 1.064, Val reward margins 0.885\\n\",\n \"Ep 1 (Step 000060): Train loss 0.655, Val loss 0.649, Train reward margins 0.845, Val reward margins 0.981\\n\",\n \"Ep 1 (Step 000065): Train loss 0.629, Val loss 0.645, Train reward margins 1.452, Val reward margins 1.070\\n\",\n \"Ep 1 (Step 000070): Train loss 0.616, Val loss 0.641, Train reward margins 1.798, Val reward margins 1.179\\n\",\n \"Ep 1 (Step 000075): Train loss 0.612, Val loss 0.637, Train reward margins 1.886, Val reward margins 1.287\\n\",\n \"Ep 1 (Step 000080): Train loss 0.585, Val loss 0.633, Train reward margins 2.550, Val reward margins 1.373\\n\",\n \"Ep 1 (Step 000085): Train loss 0.605, Val loss 0.629, Train reward margins 2.059, Val reward margins 1.466\\n\",\n \"Ep 1 (Step 000090): Train loss 0.649, Val loss 0.625, Train reward margins 1.029, Val reward margins 1.576\\n\",\n \"Ep 1 (Step 000095): Train loss 0.593, Val loss 0.622, Train reward margins 2.331, Val reward margins 1.661\\n\",\n \"Ep 1 (Step 000100): Train loss 0.588, Val loss 0.619, Train reward margins 2.477, Val reward margins 1.735\\n\",\n \"Ep 1 (Step 000105): Train loss 0.574, Val loss 0.617, Train reward margins 2.938, Val reward margins 1.798\\n\",\n \"Ep 1 (Step 000110): Train loss 0.598, Val loss 0.613, Train reward margins 2.273, Val reward margins 1.896\\n\",\n \"Ep 1 (Step 000115): Train loss 0.606, Val loss 0.610, Train reward margins 2.008, Val reward margins 1.975\\n\",\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Rewrite the sentence using a metaphor. ### Input: The book is very interesting. ### Response: The book would be of great interest.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What is the chemical symbol for iron? \\n\",\n \"Training completed in 5.23 minutes.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import time\\n\",\n \"\\n\",\n \"start_time = time.time()\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"\\n\",\n \"optimizer = torch.optim.AdamW(policy_model.parameters(), lr=5e-6, weight_decay=0.01)\\n\",\n \"\\n\",\n \"num_epochs = 1\\n\",\n \"tracking = train_model_dpo_simple(\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" train_loader=train_loader,\\n\",\n \" val_loader=val_loader,\\n\",\n \" optimizer=optimizer,\\n\",\n \" num_epochs=num_epochs,\\n\",\n \" beta=0.1, # value between 0.1 and 0.5\\n\",\n \" eval_freq=5,\\n\",\n \" eval_iter=5,\\n\",\n \" start_context=format_input(val_data[2]),\\n\",\n \" tokenizer=tokenizer\\n\",\n \")\\n\",\n \"\\n\",\n \"end_time = time.time()\\n\",\n \"execution_time_minutes = (end_time - start_time) / 60\\n\",\n \"print(f\\\"Training completed in {execution_time_minutes:.2f} minutes.\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"eba8ea88-8771-4eb9-855d-2fe1ca2dc2fa\",\n \"metadata\": {\n \"id\": \"eba8ea88-8771-4eb9-855d-2fe1ca2dc2fa\"\n },\n \"source\": [\n \"- As we can see based on the tracked results above, the loss improves\\n\",\n \"- Also, the reward margins, which is the difference between the rewards of the chosen and the rejected responses, improve, which is a good sign\\n\",\n \"- Let's take a more concrete look at these results in the next section\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"11e23989-92bd-4ac2-a4bc-65d4c7ac334e\",\n \"metadata\": {\n \"id\": \"11e23989-92bd-4ac2-a4bc-65d4c7ac334e\"\n },\n \"source\": [\n \" \\n\",\n \"# 6) Analyzing the results\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"66d7d5fe-c617-45cb-8ea9-ddc7baa22654\",\n \"metadata\": {\n \"id\": \"66d7d5fe-c617-45cb-8ea9-ddc7baa22654\"\n },\n \"source\": [\n \"- Let's begin analyzing the results by plotting the DPO loss:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 51,\n \"id\": \"8ddcc66f-cd7c-4f46-96ea-af919ea1a199\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 307\n },\n \"id\": \"8ddcc66f-cd7c-4f46-96ea-af919ea1a199\",\n \"outputId\": \"c7164b26-8d32-41d1-8c6a-ab835d58d4c5\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAfIAAAEiCAYAAAACr1D/AAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAAZPNJREFUeJztnQd8Tecbx3/ZERkikYUgQoYRM8QsYpSqWf72KrWVUlUtOtDWbNUoLVqjFKX23iRizwgJkRCRRCSy5/l/nve6NzeRkESSm5M838/nTe4Z95z33PU77/M+Q0uSJAkMwzAMw8gSbU13gGEYhmGY/MNCzjAMwzAyhoWcYRiGYWQMCznDMAzDyBgWcoZhGIaRMSzkDMMwDCNjWMgZhmEYRsawkDMMwzCMjGEhZxiGYRgZw0LOMKWcwMBAaGlp4dq1a5ruCsMw+YCFnGFKACTEb2pz5szRdBcZhikkdAvrwAzDFB1Pnz5VPd66dStmzZoFPz8/1TpjY2N+OximhMIjcoYpAdjY2KiamZmZGIUrl62srLB48WJUqlQJBgYGqFevHg4ePJjjsdLS0jB8+HA4OzsjKChIrPvvv//QoEEDGBoawsHBAd988w1SU1NVz6Hz/f777+jRoweMjIxQo0YN7N69W7X9xYsXGDBgACpUqIAyZcqI7evWrcuxD9u3b0edOnXEvhYWFvD09ERcXJxqO53LxcVF9If6uWLFikzPDw4ORp8+fVCuXDmUL18e3bp1E1MISoYOHYru3btj4cKFsLW1FecYN24cUlJS8vHqM4yGoepnDMOUHNatWyeZmZmplhcvXiyZmppKf//9t3T37l3p888/l/T09KR79+6J7Q8fPqQKiNLVq1elxMREqUePHlL9+vWlsLAwsf306dPi+evXr5cCAgKkw4cPS1WrVpXmzJmjOgc9v1KlStLmzZul+/fvSxMnTpSMjY2l58+fi+3jxo2T6tWrJ128eFGc78iRI9Lu3buz7X9ISIikq6sr+k373rhxQ1q+fLkUExMjtm/cuFGytbWVduzYIT148ED8L1++vOgfkZycLLm4uEjDhw8Xz71z547Uv39/ycnJSUpKShL7DBkyRFzT6NGjJV9fX2nPnj2SkZGRtHr16kJ7XximsGAhZ5gSLuR2dnbS3LlzM+3TuHFjaezYsZmE/MyZM1K7du2kFi1aSFFRUap9ad28efMyPX/Dhg1CTJXQ87/66ivVcmxsrFh34MABsdy1a1dp2LBhuer/5cuXxXMDAwOz3V69enVxw6DOd999J3l4eKj6RqKdnp6u2k4CXqZMGenQoUMqIa9SpYqUmpqq2uejjz6S+vbtm6s+MkxxgufIGaYE8/LlS4SEhKB58+aZ1tPy9evXM63r16+fML8fP35cmLSV0H7nzp3D3LlzM5nfExMTER8fL0zpRN26dVXby5YtC1NTU4SFhYnlMWPGoFevXrhy5Qo6dOggzNrNmjXLts9ubm5o166dMK137NhR7N+7d2+Ym5sL83pAQABGjBiBkSNHqp5DZn6aUlD219/fHyYmJpmOS/2l5yqpVasWdHR0VMtkYr9582auX1uGKS6wkDMMI+jcuTM2btwILy8vtG3bVvWqxMbGijnxnj17vvZK0Ry1Ej09vUzbaN48PT1dPH7//ffx6NEj7N+/H0eOHBFCTXPSNEedFRJX2uf8+fM4fPgwli1bhpkzZ+LChQuqm4Y1a9agSZMmrz1P2d+GDRti06ZNrx2b5uhz01+GkRMs5AxTgqFRsZ2dnRhRt27dWrWelt3d3TPtS6Pm2rVr48MPP8S+fftU+5OTG3nAOzo6vlNfSESHDBkiWsuWLTFt2rRshVwpqmQ1oEYe+FWqVMHOnTsxZcoUcT0PHjwQznPZQf0lz31y8qPrZ5iSDgs5w5RwSDBnz56N6tWrC4918han5C/ZjVgnTJggzOYffPABDhw4gBYtWgghpWV7e3th4tbW1hbm61u3buH777/PVR/oGDRKJnN2UlIS9u7dK7zOs4NG3seOHRMmdRJjWg4PD1ftT9aBiRMnClN6p06dxPEuXbokPONJ6EngFyxYIDzVv/32WzFdQNaAf//9F59//rlYZpiSBAs5w5RwSPSio6Px2WefiTlrV1dXERpGIWDZ8emnnwoTM5naKUyN5qlJeEkUf/zxR2GSppCvjz/+ONd90NfXx4wZM0QIGM2/04h8y5Yt2e5Lo+jTp09j6dKlYo6fRuOLFi0S5nmCzksmdhJrukmh+XiaT6d+E7SNnj99+nQxHRATE4OKFSsKcz6P0JmSiBZ5vGm6EwzDMAzD5A9OCMMwDMMwMoaFnGEYhmFkDAs5wzAMw8gYFnKGYRiGkTEs5AzDMAwjY1jIGYZhGEbGsJBrgOXLl6Nq1aoivSWlmfTx8Smyc1N8bdeuXUV2LMqetWvXrkzbKRqRkndQ3mmK96Xykffv38+0T2RkpEi6QTG5VCaS8l5TWkx1bty4IWKF6RorV66Mn3766bW+bNu2TcQj0z4UB0zpO3PL/Pnz0bhxY5FPm5KGUO5u9frbytzalAaUSlRSPW7K9f3s2bNM+1CZzi5duojYYzoOxSWrl+ckTp48KbKFUQlQym62fv36An1PV65cKfKU0+tJzcPDQyRjkdt1ZOWHH34QnzFlfLecrmXOnDmi7+qNPqtyuw7iyZMnGDhwoOgrfafpu0YJdOT0nafrz/p+UKP3QG7vR6Gg6aotpY0tW7ZI+vr60tq1a6Xbt29LI0eOlMqVKyc9e/asSM6/f/9+aebMmdK///4rKkzt3Lkz0/YffvhBVM7atWuXdP36denDDz+UqlWrJiUkJKj26dSpk+Tm5iZ5e3uLilmOjo5Sv379VNujo6Mla2tracCAAdKtW7dE+UyqPPXbb7+p9jl37pyko6Mj/fTTT6LMJFXOotKaN2/ezNV1dOzYUVT5ouNfu3ZN6ty5s2Rvby+qbimhEpWVK1eWjh07Jl26dElq2rSp1KxZM9V2qnxVu3ZtydPTU5TwpNfG0tJSmjFjhmofKpNJ5S2nTJki+rls2TLR74MHDxbYe0rlPPft2yfKivr5+UlffvmleC3o2uR0Her4+PiIUqd169aVJk2aJLv3ZPbs2VKtWrWkp0+fqlp4eLjsriMyMlJUeRs6dKh04cIFcU6qAOfv7y+r7zyV1FV/L6gMLv1+nThxQlbvR2HBQl7EuLu7i9rMStLS0kSZyfnz5xd1V14Tcir7aGNjIy1YsEC1jspZGhgYiC8mQR9weh7VlVZCpSq1tLSkJ0+eiOUVK1ZI5ubmqtrPxPTp00VpSSV9+vSRunTpkqk/TZo0kT755JN8XQt90alfp06dUvWbfiS2bdum2ofqTtM+Xl5eYpm+zNra2lJoaKhqn5UrV4o61cq+U+1u+kFXh0pd0o1EYb6n9Pr9/vvvsrwOqhteo0YN8WPbunVrlZDL6VpIyEm4skNO10HfOypLmxNy/c7TZ4rK2VL/o2T0fhQWbFovQpKTk3H58mVhulJCeatpmSpOaZqHDx8iNDQ0U/8onzWZj5T9o/9kWmvUqJFqH9qfroNyYiv3adWqlUjLqYTSfJLpm/JhK/dRP49yn/y+DpSClChfvrz4T69zSkpKpnOQSY/yhatfC5n3rK2tM/WB0oLevn07V/0s6PeU8pxT6lIq10kmdjleB5k4yYSZ9XxyuxYyL9MUlIODgzArk2lWbtdBqXjpu/rRRx8Jc3L9+vVF5Tg5f+fpdaEqfcOHDxfm9csyej8KCxbyIiQiIkL8UKt/mAhapi+TplH24U39o//0g6COrq6uEFD1fbI7hvo5ctonP68D5QWneViqlEXVu5THpx8V+gF607Xkt5/0A5CQkFBg7ynVwaa5PZqbGz16tKj0RTnR5XYddBNCNcfJhyErcroWEjKaH6Vc8+TDQIJH87+Ut11O10FV4qj/lFf/0KFDosId5d7/888/ZfudJ7+eqKgoDB06VHVcfZm8H4UFF01hZA+NAKkS19mzZyFXnJycREUysixs375dlPo8deoU5ERwcDAmTZokaomr1ymXI8oCLQQ5IpKwU/GWf/75RziEyQW6yaWR9Lx588Qyjcjpu7Jq1SrxGZMjf/zxh3h/yFrCKOAReRFiaWkJHR2d17wpadnGxgaaRtmHN/WP/lMFLXXI85O8WtX3ye4Y6ufIaZ+8vg7jx48XlblOnDiRqTwlHYdMYXTn/qZryW8/yXuXftAL6j2lEQV5yVKpTxrNurm54eeff5bVdZDZkT4b5PVLIzZqdDPyyy+/iMc0cpHLtWSFRns1a9aEv7+/rN4T8kQny446VA5WOU0gt+88laM9evRopsp7NjJ6PwoLFvIihH6s6Yeaai2r3zHTMs2Happq1aqJD6R6/8isRPNgyv7Rf/rC0I+2kuPHj4vroFGLch8Kc6N5KyU0SqNRp7m5uWof9fMo98nt60C+eiTiZIKm81Pf1aHXmcptqp+D5uvoB0z9Wsikrf4jRX2gL67yx+9t/Sys95SOQXW25XQdVCaU+kGWBWWj0SDNLysfy+VaskKhVgEBAUIY5fSe0HRT1rDMe/fuCeuC3L7zxLp164SZn3wwlDSU0ftRaGjU1a4UQuEL5BG6fv164Q06atQoEb6g7k1ZmJBHMYVfUKO3f/HixeLxo0ePVKEo1J///vtPunHjhtStW7dsQ1Hq168vwlnOnj0rPJTVQ1HIi5RCUQYNGiRCUeiaKawjayiKrq6utHDhQuFhSl7CeQk/GzNmjAiZOXnyZKawlPj4eNU+FJJCIWnHjx8XISkeHh6iZQ1J6dChgwhhozCTChUqZBuSMm3aNNHP5cuXZxuS8i7v6RdffCG87R8+fChec1omj+DDhw/L6jqyQ91rXU7X8tlnn4nPFr0n9FmlsCUKV6LoCDldB4UB0vds7ty50v3796VNmzaJc27cuFG1j1y+8+QhTq85ecNnZbRM3o/CgoVcA1B8In3oKB6RwhkoNrOooLhLEvCsbciQIWI7hXN8/fXX4ktJH9h27dqJ2GZ1nj9/Lr7ExsbGInxj2LBh4gZBHYpHpbAXOkbFihXFj0VW/vnnH6lmzZridaCwD4qlzi3ZXQM1ii1XQj9EY8eOFWEx9AXt0aOHEHt1AgMDpffff1/EvNIPNf2Ap6SkvPaa1atXT/TTwcEh0zkK4j0dPny4iPWl59KPC73mShGX03XkRsjlci0UdmRrayueS59fWlaPvZbLdRB79uwRIkbfRWdnZ2n16tWZtsvlO0/x7/Qdz9o3ub0fhYEW/dGsTYBhGIZhmPzCc+QMwzAMI2NYyBmGYRhGxrCQMwzDMIyMYSFnGIZhGBnDQs4wDMMwMoaFnGEYhmFkDAu5BqCMXXPmzBH/5U5JuZaSch0l6Vr4Ooof/J4UTziOXANQCkQqFUgFMihFoJwpKddSUq6jJF0LX0fxg9+T4gmPyBmGYRhGxrCQMwzDMIyM4Xrk+YTK+F29elWUZtTWztv9UExMjPj/5MkTYaqSMyXlWkrKdZSka+HrKH7we1K0UHU1KpNKdeSpFHBO8Bx5Prl48SLc3d3z+3SGYRiGyRU+Pj5o3Lhxjtt5RJ5PaCSufIGpRjHDMAzDFCRPnz4VA0al3uQEC3k+UZrTScQrVaqU38MwDMMwzBt52/QtO7sxDMMwjIxhIWcYhmEYGcNCzjAMwzAyhufIGYZh8khaWhpSUlL4dWPeCT09Pejo6LzbQVjIiwmRD4HkWMDEDjAqD2hpabpHDMNkgyRJCA0NRVRUFL8+TIFQrlw52NjYQOsdfvd5RK5hlp/wR7WL36Jz/H9iOU1bH8llrCGZ2ELXvBL0ylWElqkdYGoLmFYETGwBExtAR0/TXWeYUodSxK2srGBkZPROP75M6UaSJMTHxyMsLEwsv0sYMwu5hrkdEg39lyl4rmMCC60Y6KQno0xcMEAt1Cfb50jQwnP7joj5cC1szQxhqKcD+KwBjK0AR09Av2yRXwfDlAZzulLELSwsNN0dpgRQpkwZ8Z/EnD5X+TWzs5BrmPFtasC/9iJsi0pAWGQ04p8/QXr0Y2jHhsI4ORy2WpGw1oqEjdYL2NBjvICeVhpOPYzDZwtPimPYlQXOpk2DNiSEj7mNCtavhNxrORDkDZhXBcyrAOXof1WgXGVA10CzF84wMkM5J04jcYYpKJSfJ/p8sZDLFFc7U9EyaKB6lJCchqfRCQiJSsSD6ASci0rE0xdxiHkRirDoeBjF6CA+OQ1xcbHYo+cBK0Sh35JrqFMxEG2crTAi+CTMgg5nc1YtgMz15aooBJ7E3cIRsHIBLGoAuvpFcu0MI0fYnM4Ut88Tj8iLMWX0deBQwVi0nOZYXiakIiAiFqfv1cfau2HA42jcfKJo3lpN0LhMRTQpFwsng+ewTA2FTtQjICUOePlE0YLOZz5o7d5A7z8Uj9PTAN/dQAUXwLImpRcqgqtmGIZh8gILuczv5MyM9NDA3ly0Tz1rIiwmESf9wnHibhjO3NeFT7wLlscr9tfV1kLjKuboXF0PbWwSUFF6Bi0SdvKaj7gHhN0FrJwzTvAiENg2FNA1BL4MyVjvu0fxnwS+fDVA+93DJxiGkQ9Vq1bFp59+KlpuOHnyJNq0aYMXL14IL+3CYv369aJPpS2qgIW8hGFlYog+jSqLlpyajkuBkTh+N0y0BxFx8HoYCa+Hin2rWFigjZML2rpYoamDBfR1tIA0tdhYComr2FAh5OpiffIH4NktxWPaZlkDsHED7JsCVZoB5R04hI5hZGC2nT17NubMmZOv6o9ly+beqbZZs2aiAIiZmVmez8W8HRbyEoy+rjaaOVqK9tUHrgiMiBOCfsIvDBceROLR83isPx8omp2ZISa0q4HeDStBFdhm6waMPP76gUnctXWBcD8gNQEIvalo1zYqthtbA/YeClGn/9a1eNTOMBqAxFPJ1q1bMWvWLPj5+anWGRsbZ5qqI8/8N9W9VlKhQoU89UNfX1/ESjOFA096liKqWpbF8BbVsGFEE1yZ1R6rBjZE30aVYWmsj5DoRMz49ybaLTqFHZcfIy1dyvlAH/4CfHIK+PIJMPEq8L/NQIspCtHW0QdinwF3dgEHPgd+awn8WBXwO1iUl8owDCDEU9loNEwjdOXy3bt3YWJiggMHDqBhw4YwMDDA2bNnERAQgG7duonSmST0VAf76NGjr5nWly5dqlqm4/7+++/o0aOH8MKuUaMGdu/encm0TvsoTd5kAicT+6FDh+Di4iLO06lTp0w3HqmpqZg4caLYj8L9pk+fjiFDhqB79+55em9XrlyJ6tWri5sJJycnbNiwIdPNC1kk7O3txfXb2dmJcypZsWKFuBZDQ0PxevTu3btYfq54RF5KMTbQRafaNqIlpqRh84UgrDjpj6DIeHy27bp4THPuXerYQls7B/McmdvJjE7NuYtiXUoiEHIFeHRe0YJ9gKSXCu94JVc3Alc3AfUHAvUHFM0FM0wBQyKQkJKmkde1jJ5OgXnPf/HFF1i4cCEcHBxgbm6O4OBgdO7cGXPnzhXi9tdff6Fr165iJE+ClxPffPMNfvrpJyxYsADLli3DgAED8OjRI5QvXz7b/SkZCp2XhJXKdA4cOBBTp07Fpk2bxPYff/xRPF63bp0Q+59//hm7du0Sc+25ZefOnZg0aZK46fD09MTevXsxbNgwUXqajrNjxw4sWbIEW7ZsQa1atUTCn+vXr4vnXrp0SYg69Y+mBiIjI3HmzBkUR1jIGZFQhkbq/3OvjD/PP8JvpwMQEB6HCX9fFZnnprSvifau1rn74dAzVJjUqRFpqYr5dEunjH0enFR4yzu0zliXHAdc+A1w7QZYVOd3hSn2kIi7zjqkkXPf+bYjjPQL5uf722+/Rfv27VXLJLxubm6q5e+++04IIo2wx48fn+Nxhg4din79+onH8+bNwy+//AIfHx8x0s4OiptetWqVGC0TdGzqixK6GZgxY4YY5RO//vor9u/fn6drW7hwoejX2LFjxfKUKVPg7e0t1pOQBwUFCesEiTzlPacbFXd3d7EvbSM/gA8++EBYLqpUqYL69eujOMKmdUYF/TCMea86znzeBpM9a8LEQBd3Q2MwasNldFt+Dif9wsQoJE/o6AJ29TKHrrX5EvhwGeDyYca6+4eBY98AyxoAK1sApxcAEf787jBMIdOoUaNMy7GxsWJkTKNgMmuT2dvX11cI25uoW7eu6jEJoKmpqSr9aHaQCV4p4soUpcr9o6Oj8ezZM5WoEpQshaYA8oKvry+aN2+eaR0t03rio48+QkJCgrBGjBw5UtywkEmfoJsbEm/aNmjQIGEdICtCcYRH5MxrmBjqYZJnDQxpVgVrzjzAunOBuPE4GkPXXUSjKub4rIMTPKq/Q4pKpTlenTLmgEMb4OFp4NlNRTv+PWBdG3DtrhipV6jJ7xZTbCDzNo2MNXXugiKr9zmJ+JEjR8So1dHRUaQRpbnh5OTkNx6HRrTqkAUvPT09T/vneaDwjlSuXFlMGZAPAF0zjdxpauDUqVNiFH7lyhUxv3/48GHhKEjz6eSxX5ghdPmBR+RMjpQz0se0js44/XkbfNyiGgx0tXHp0Qv0W+ON/mu8cflRZMG9eg7vAYN3AdP8FaP16u0UnvFklj/xPbC8MbDCAzj5o8JbnmE0DAkPWbE00Qozu9y5c+eEOZpM2nXq1BGm58DAQBQl5JhHzmUkmkrIo56ENS+4uLiI61GHll1dXVXLdKNCPgA0FUCi7eXlhZs3b4pt5MFPZnea+79x44Z4HY4fzyaSR8PwiJx5K5bGBiJ8bWQrBzFn/rdPEM4HPMf5lV5o41QBU9o7oU6lAooPpTKuDQYrWnwkcHefwgOe5tXD7ijayXlABWeg5VSg7kf8DjJMAUJe2v/++68QN7ph+Prrr984si4sJkyYgPnz5wurgLOzs5gzp4QyebmJmTZtGvr06SPmtkmQ9+zZI65N6YVP3vN0g9CkSRNh6t+4caMQdjKpk2PcgwcP0KpVK+EESPPz9DqQ53txg4WcyTXWpob4tlttjGrlgF+P+2Pb5cc4QVnk/MLhYmuKsvo6InZdT0db/KdmoPZYX/3xq2WDV48rljNCc0eLzF9SIeqDFC3hBXB3v0LUA04A4XeBFLX5quR4xT5mFfkdZZh3YPHixRg+fLjw1La0tBRhXy9fvizy15TOS17kgwcPFvPjo0aNQseOHfNUWKR79+7C252mCch7vVq1asIL/r333hPbyUT+ww8/CCc4EnSyQJDYU7gbbSPRJ3N6YmKiuMH5+++/hXd7cUNLKupJiRLC48ePxfwKhWpQKENphBLM/HzsPnZde4KC+BTR6H5+z7qwMTN8844k2H4HgBodgbKv5uqpjOvBL4BmEwDPvGeqYpi3QT/mDx8+FGJAccVM0UKjYTKV0wibPOlLw+fqcS51hkfkzDslmFnStx4+9awB/7BYkRI2OS098//UzMtJWbalpKWLOPZzAc/FyL79klOY3bUWejWomLMJjRzj6vXPvC7kGpCeCpjYZayj0DctbS72wjAyhGLQycmsdevWSEpKEuFnJHj9+2f57jMs5My7U8WirGjvwv1nMZi67TquP44W/w/cfIp5PesIc36u6L4ccB+pKMeq5MYW4MxioOkYhfDrv1sfGYYpOihJDM1hkxc9GY5r164t5rZpVM5khr3WmWJBDWsT7BjTDJ93chJz58fuhqHDktPYefVx7kNSKF7dQK3kK2WPiwwA9k8FFrsCR78BXmakgGQYpvhCJmXyMKeYcpqjP3/+vHA8Y16HhZwpNujqaGPse47YM6EF6lQ0Q3RCCiZvvS4S0lB51jwzYBvw/gLAvBqQGAWcXQwsrQP8+wnwVJGGkWEYRu6wkDPFDicbE/w7thmmdqgJPR0tHLnzTIzO/xNOdXnwqqPReZNRwITLQN9NgH0zID1FYXL/rRWw/gNRzOV5TAKO+T7Dy0S1Eq4MwzAyQeNCvnz5clFJh7z1KJaPcvO+CaqeM27cOJHOjxL616xZM1P+XToWOUllbfQcJRR6kHX76NGjC/U6mbxBIWzj29bA7vEtUMvOFFHxKZi05RpGb7yM8JikvB2Miru4fAAMPyDKskq1e0PS0gECzwB/90X0gvo4vvEH9PnlCPxCY/itYhhGVmhUyKk+LsXvUXF7ythDifopTjCn/LyUIpDy31J2ne3bt4vUemvWrEHFihmxw5QJiErhKRul3VPm1FWH8uqq70eZe5jiB8Wn7xrXXOR+19XWwqHbNDo/hT3XQ/I0Ok9KTcOpe+GYdckALfwHoFnCUqxK/QAvJSM4aD/FXL21WBM7ET1WnMXBWzyPzjCMfNDVdOIBElQqK0dQJZx9+/Zh7dq1orReVmg9lZIjpwdlnl4agb+p4D0F+1NifgphUIey+HChe/mMzin3u6erFaZuuwHfpy9FZbb9N5/iu+61Rea57KCR+wm/MGE2P3M/AvHJGSUnDXQrwMfxU5RznIn3U4/B+Ppa3E6pi/iIdIzeeAUT2jhgctnD0K7VDTDP/BljGIYpTmgsIQyNrklMaWStXiieCseT+fy///577TlUI5dK7NHzaDuJNsUUUgag7LL90DmoUDyN+r/88stMpvXbt2+LER2JOaUipDSEdNycoDhGakqePHki8vWW5oQwmoBizylNLLXUdAnly+rju2610aWurXg/fZ/GCOEmr/frj6MyJaqxMjFAOxcrtHO2RnNHS5TRV/vMSBJSk+Lww9Eg/H72IZpq38EW/e8hGZhCa1oAoKtfqNd1LTgKhnracLYxLdTzMPmHE8IwhYGsE8JERESIlHiUGF8dWr579262z6G8t5SwngrW07y4v7+/qFZDdW3JPJ8VKkJPNwVUAEAdEn/KpUsiT4nw6UaAzPSUji8nKOfvN998k+/rZQoGSuc6+VV9dIo3pzKr4zZfwQbv8gh6Ho+Q6Mze7eT9rhRvmmvX1s4hyYyWFnQNjUVO+VoVTbF1x32cTquDqHQ7uEYmw9FKX4g9js4GHNsDVZoXSKIZip+ft99XJMOhdLXHp76HiuXKvPNxGaYgocFPvXr1sHTpUpUl9NNPPxUtJ8j3iMqCqg/U8kNBHedNUBpW0otr165BjujKLUWflZUVVq9erapNSyNjKjuXnZD/8ccfeP/994Vgq0M5e5VQbl1ynGvXrh0CAgIy1cdVhwrc08g+64ic0Qy1K5oJR7hlx+9jxckAeD9QVGKjUW0LxwpCvNs6W+U+oYwaPepXgmOFYRi1oQ5Co+NRdvk5LO1bD56mj4FzPytaOXvArT9Qr1++TO8RsUlYevQe/vYJRlq6wmxAWe9+OxUg8tkzTEFA1kYa6Bw8ePC1bWfOnBFx2devX89USzw3kC9S1vKnhSWm5MNERUuYYijklIyfxJiKx6tDyznNXZPg0ty4uhmdsvxQYn0yo+vr62dK70dZgN40ylZC3vIEjfBzEnLykKemRBNFBJjXR+dUG71jLRuc9AuDq50pmlW3hGEB1Gqmam50ozBu0xX4BEbi478u4dvmBhjUYAi0bu8EooKAUz8oWpUWisxxVDNdPSFNNlA6WqrvTlMDsUmpYl0HV2tx4zF9x01suRiM8W0cYZWPGxCGycqIESPQq1cvYaLNapql4iGNGjXKs4hn54tUmLAvUzH2WifRpRH1sWPHMo24adnDwyPb5zRv3lyIrXpJvXv37gmBVxdx5YeURu9dunR5a1+Ud4B0HEaeo3MKVWvrbF0gIq6kgokBNn7cBIM9qojlWeeSMCZ6CGIn3AZ6/g44tCHDH/DoLPDfWEX2uIMzgOcBrx2L5u93Xw9Bu0Wn8OPBu0LEa1c0xZZRTbF6cCP0aVQZjaqYCx+A304/KLBrYEo3H3zwgRBdSnWqTmxsLLZt2yaE/vnz5+jXr5+I/iE/IbJSUpWvN0GmdaWZnbh//74Y3dMcL1kqldFC6tAUJoUL0zkcHByEXxJZCwjqH01dknVAGRKs7DM9ppG6EqoV3rZtW1FulKqUjRo1SlyPEppKJTM8VTyj33Tah8KPlefKDaQx3377rbj5oQEcTSuoWzVo4Dh+/HhxfLpmmqql6Vfld52sC/b29uK5ZBGeOHEiSqxpnUzV5NxGd4Xu7u7igxEXF6fyYqfydfThUr5AY8aMEYnzqRwd1aqlD8+8efNee5HoTSAhp2NTYXh1yHy+efNm4ThHbzDNkU+ePFl8CPNzZ8qU/FE/mbpdbU0x67/bOHg7FA8iYrF6UGdUpVro0Y+B61uAa5QO9gHgvQLwXgnUaA80+QRwaIvLwdH4ft8dXA2KEse0MTUUqWi716uomrOnH6uJ7Wpg8FofbLrwCGPeq56jNz5TzEiOy/tzdAwAHd2M4j5pSYoCP3pl3n7cPNQMoN8/+h0lUZw5c6aqEBGJOPkokYCTCNKgioTW1NRURA4NGjRIWCfpd/lt0O9tz549hX/ThQsXRErV7ObOTUxMRD9I2EiMKWKJ1n3++efo27cvbt26JcRSWSvczMzstWOQPlCIMg32yLxPocoff/yxEFX1m5UTJ04IkaX/NPij45MY0zlzA5U+XbRoEX777TdRy5wipj788EPhJE3lTH/55Rfs3r0b//zzjxBsckajRuzYsQNLlizBli1bRMlTshjTDUqhImmYZcuWSfb29pK+vr7k7u4ueXt7q7a1bt1aGjJkSKb9z58/LzVp0kQyMDCQHBwcpLlz50qpqamZ9jl06BBNOkp+fn6vnS8oKEhq1aqVVL58eXEMR0dHadq0aVJ0dHSe+h0cHCzOQf+Z0sGlwEip8fdHpCrT90p1Zh+UTvqFZWxMS5Oke0ckaUMvSZptqmq7f5kk9qfm8vUB6eej96T4pMyfVyXp6enSh7+eFfvO23+n6C6MyRUJCQnSnTt3xP9MqL3fuW63/s14Pj2mdWs7Zz7uj9Wyf24e8fX1Fb9VJ06cUK1r2bKlNHDgwByf06VLF+mzzz7L9Fs8adIk1XKVKlWkJUuWqH5vdXV1pSdPnqi2HzhwQJxz586dOZ5jwYIFUsOGDVXLs2fPltzc3F7bT/04q1evlszNzaXY2FjV9n379kna2tpSaGioWCbNoP6p68JHH30k9e3bN8e+ZD23nZ2d0BZ1GjduLI0dO1Y8njBhgtS2bVvxnc3KokWLpJo1a0rJycnSO32u8qAzGnd2ozspatlx8uTJ19bRnZi3t/cbj9mhQ4cck4WQK/+pU6fy2VumNNOwirnIA0/Z5Wh0PWydDz7v5IxPWjlAizzYa3iKFhviC9//FsMpdC8WhtQhh3j0aVgZnzfShoWJNqAe9qaGGJW3dcSIPy9hg9cjfNKqugivY5h3wdnZGc2aNROjSvI+pxEqObqR6ZigkTlZNml0SU68ZDamUNs3heOq4+vrK35X1Z2Ks5sepQRgNJIlqyhZAVJTU4UFIC/QuShxmLqjXfPmzYVVgCKPlFFQNBJW96Wi0TlZAXID+T+FhISI46pDy8qRNZnvKTmZk5MTOnXqJKYwSHeUycfIukzTB7SNrL/kdJjVOlyQaFzIGUZOkBc8zWt/vesW/rn0GD8cuItbT6LxU++6omrb3z5BWHL0MSLjusMAndHI0RYrO7sKRzxsHQj47gE6/Qg0zT4lMHnaU5jc7ZCXWHv2IaZ2dCrya2TyyJch+TOtK3HuqjgGmdbV+TR3wpMbaC6cpiMpJTZNO6onyaKoHzIlk/jQ/DiJJJnGSdALCi8vLxE2TPPgZBonszmZnsl8XRjovUoYpn6TrO5b9a40aNBAxH4fOHBATAX06dMHnp6eIi8K3dTQTQWtJ18BCpGm15gGkFn7VVCwkDNMHjHQ1cGPveqKGPVv9tzB3htP4R8WKxLU0H+ieoWymNmlEdo4WSnmJdPTaDJR4RznoJZlkMqq0pynoWJkQvtOaFtDjPr/PB+Ika0cYFamcL78TAHxrnXuaa5cOV9ekMdVg4SGfIvIP+ivv/4S/kbK+XIqFdqtWzcMHDhQLJPgkRNxbsNrKXKI5ocpTEzpMJzVakrZOMkhjObp1SOL1CGHZbIOvO1cNBdOc+XKUfm5c+dE7XIaHRcEZCUg6wIdVz0jKC2r+wzQfjT3Tq13795i9E2ZRylpGTni0SicGjnakVWELAJ0A1AYsJAzTD6gH8FBHlVR09oEYzddEYlpCDKFT/asgf+524vUspkKt/TbDLwMAUzV8hpQgpm7+wC3fkCT0YClowhHc7I2gd+zGKw/FyjS0zLMu2BsbCwEh/JhkOlYPUkWOW/RSJLEluK1KXU2hQHnVshpJEre6ORcTCNPOr66YCvPERQUJEbhjRs3Fg51lOQlqyc8jXIpioi8xckRTj3kl6BRPeUMoXORZ3h4eLiwNJBzXtbkYu/CtGnTxHnIckFOcmTFoH5t2rRJbKfXiG5ayBGObiLIeZDC5MqVKyduNOiGhMKaaXpi48aNQtjpRqbEVj9jGDnTxMFCzJtTitix71XHianvCYHPJOLqqIs4eSuH3QGSY4GLa4DljYEdI6H9/D7Gt3UUu/xx9gFiuLwqU0Dm9RcvXgjTtvp89ldffSVGirSe5tBJkPKSRY2EjEQ5ISFBjFjJi3zu3LmZ9iGPb4oOIn8oEka6aaDwM3Uo3p1GtW3atBEhc9mFwJEwHjp0SIx86YaARsLt2rUT0UwFCUVCUVTVZ599JqYbyJuevNTphoSgmwwqtEURV9QPKuRF2UbptSAxp2JeNKdOkVBkYt+zZ4+IkipxudblTm5z4DLMG6Gv34OTwIVVwL1Xcapa2kiv3RvDHrTGqefmmNbRCePaKISd0Ryca50prrnWeUTOMJqE5imrtwH6bwU+OQ04dQGkdGjf/Afr4yZgid5yHD1zFnGvssAxDMNkhYWcYYoLtm6KefRXgq6FdPTQOYftaZ8iZO0gIOK+pnvIMEwxhIWcYYqroI86hSfWbaGjJaHGs/2QlrsDpxdquncMwxQzWMgZprhiVw9Wo3ZgmP5CHElrCC0pHbCrn7Gd3VsYhmEhZ5jiDXm/e7brgJEpn+F/ekuRaK8Wg356AfDvqGyLtDAMU3rgETnDFHN6N6wEWzNDeMdYYduVJ4qVyfHA+V+BG1uB0ILLAMa8nYLMEMYw6QXweeKEMAwjg0xylM99zp47WHUyAH0bVYa+vhEw5D/g2mbA5cOMnSkFrIkdUKmhJrtcIqHMYxQnTHm4Kc6ZlpXZ0Rgmr1DkN6XBpaQ29LnKWoo7L7CQM4wMoExxy08G4ElUAnZefYy+je0V8+Xqc+YpicDeyUBcOFClOdB8EuDYnjJ2aLLrJQb6saVYX0pFSmLOMAUBJbmhUqj0+covLOQMIwMM9RSj8u/3+WL5iQD0alAJulmzx1H96hodgBv/AI/OKVoFZ6DZRKDOR4AuV1J7V2jURD+6VLnrbXnBGeZtUIU2qor2rpYdzuyWTzizG1PUxCenosWPJxAZl4xFH7mhV8McMj1RPnfvlcDl9UDSS8U6E1ug6Rig4VDA0KxI+80wTP7gzG4MU8Iw0tfFyJYO4vHyE/5IS5dyzufe4Ttg8i2g/bcKEY95ChyZBSyuBRz+Coh+5TTHMIzs4ckzhpERgzyqoJyRHh5ExGHvjbfM09LIm+bJJ90Auq0AKrgAyTHA+WXAz27AzjFA2N2i6jrDMIUECznDyAhjA10Mb15NNSpPz2lUrg7NjdcfAIw5D/T/B6jSAkhPAa5vBgKO4WViChYfuYc+q7xwNehF4V8EwzAFCgs5w8iMIc2qwsRAF/eexeLQ7dDcP5G8Ymt2BIbtA0YeR1qdvliX0BKtfjqBX47dR5mgEzi6djYeBPgVZvcZhilgWMgZRmaYldHDsOZVxeNfjvuLeNS8kJqWjr+fVEBzv7745nAwouJTUN3SCLPL/INp+BP/bP4dwZHxip3TUjgVLMMUc1jIGUaGDG9RDWX1deD79CWO+obl6jlkht9zPQTtl5zGjH9vIvRlIiqWK4OfetfFoYkesGk9Atd06uDfODcM+uMCwmOSFJ7vS+sA+z8HHpxSCHshcDskGu//fAY/HOA5e4bJKxxHzjAypJyRPgZ5VMWqUwFYdvw+PF2scoxFpRH7yXvhWHjID7dDFOFoFmX1Ma6NIwY0tReZ4wjdVhNg4zYS+qvOI/B5PIau88Eu84PQiw4GfH5TNMNyQM1OgHNnoHo7wMD4na/FK+A5Rv11CTFJqfALfSkc+ugGg2GY3MEjcoaRKR+3rAZDPW3ceByNU/fCs93nUmAk+v7mjWHrLgoRJ2e5yZ41cerzNmJUrxRxJTZmhtgwogksjfXF/sPiJiD5o81A/YGAkQWQGAXc2AL8Mxj4yQHY3Be48hcQm/3538b+m08xZK2PEHEdbS2Q794Gr0f5OhbDlFZYyBlGplgaG2BgkyriMTmrqc+Vk8l9xPqL6L3KCz6BkdDX1cbIltVw+vM2mORZQwh6TlSzLIv1w9yFQ93ZwDiMu2yN1A+WAVPvA8MOAB7jAfOqQFoScO8gsHsCsLAG8EdHwGsFEJs7U/8G70cYt/kKktPS0amWDZb2rSfWb7kYhMQUzprGMLIR8uXLl6Nq1aowNDREkyZN4OPj88b9o6KiMG7cONja2sLAwAA1a9bE/v37VdvnzJkjTIzqzdnZOdMxEhMTxTEsLCxgbGyMXr164dmzZ4V2jQxTWIxq5SBE+kpQFM4HPMej53GYtOUqOv9yBsfuholRbj/3yjg17T3M7OKK8mVzl6a1dkUzrBnSSBz7yJ1n+OLfm5C0tIEqzYCOc4GJ14AxXkCbrwBbEmAJCPYGDs0Agi9kHCgbRzy64aBwt6933RKb+zexx/IBDdC5ji0qmZcRznf/XeOENQwjCyHfunUrpkyZgtmzZ+PKlStwc3NDx44dERaW/R09VYpp3749AgMDsX37dvj5+WHNmjWoWLFipv1q1aolChso29mzZzNtnzx5Mvbs2YNt27bh1KlTogBCz549C/VaGaYwsDI1RL/GlcXjKf9cQ7tFp/DftRAhkB/UtcWRya0wv2dd2Jrlfc65qYMFlvdvIG4Gtl9+jHn7fTNG/TQfb+0KtJ4GfHIKmHwb6PQj4PCeolCLes30v7oDASfEImWjm7nrlrAgEJ961sDc7rXFOagN9lBYGNadC8yzNz7DlFY0mmudRuCNGzfGr7/+qqrLWrlyZUyYMAFffPHFa/uvWrUKCxYswN27d6Gnp5ftMWlEvmvXLly7di3b7dHR0aIE4ebNm9G7d2+xjo7n4uICLy8vNG3aNFd951zrTHHhaXQCWv90UpioidY1K2BaRycxqi4ISMSnbrsuHk/v5Iwx71XP3RPpp+XXRsBzf6DnGiS69MKnW67h3O0HkLS08EW3xhjYVCHcSqLjU9B0/jEkpKRh66imaOJgUSDXwDBypNjnWqfR9eXLl+Hp6ZnRGW1tsUyCmh27d++Gh4eHMItbW1ujdu3amDdv3mtViO7fvw87Ozs4ODhgwIABCAoKUm2jc6akpGQ6L5neqaJRTudlmOIMjba/6VYLnevYCPH7c7h7gYk40bthJczs7CIe/3jwLrb4ZHyf3giN2imTXNuvEW3vicFrfXDwdigG6x3D9TJjMfDRTOD2TiA5PiNG3kgPPRooLGzrzwcW2DUwTElGY+FnERERQoBJkNWhZRohZ8eDBw9w/PhxIc40L+7v74+xY8cKYSbzvHKUv379ejg5OQmz+jfffIOWLVvi1q1bMDExQWhoqChFWK5cudfOS9tyIikpSTQlMTEx7/gKMEzB0c/dXrTCYmQrB0TGJ2PlyQB8ufOmyPfeqbbt259oUR3P6o0Xnul3Q2OEA93wKpHQCUoCfPcoml5ZwOl9oHZPwNETQzyqYvOFIJG1juqvcygawxRzZ7e8QKZ3KysrrF69Gg0bNkTfvn0xc+ZMYXJX8v777+Ojjz5C3bp1xXw7CT45yP3zzz/vdO758+fDzMxM1VxdXQvgihhGPnze0Qn/a1xZhIhN/PsazvtHvPU5D8Jj0WvleSHiFUwMsPUTD1gM2wp8cgZoMRkoZw+kxAG3tgNb+gM/VYfT2UmYbHcbhlIiNnpzKFpR8rdPELZezKXFhSk2aEzILS0tRVH1rN7itGxjY5Ptc8hTnbzU6XlKaG6bRtJkqs8OGnnTc2j0TtCxaV8S99yel5gxY4aYX1e2O3fu5Ol6GUbuUATI3B51RKgYzceP/OsSbjzO/D1S53pwlAh/e/wiAVUtjPDvmGZwtTNVmNxt6wKecxSV2T4+DjQdB5jYKaqz3dqBSZFzcdXgE7h7j0Py5Y1AQs7nYQoGsn5Qxr/pO24qsvoxskFjQk7mbRpVHzt2LNOIm5ZpHjw7mjdvLgSZ9lNy7949IfB0vOyIjY1FQECA2Iegc5KjnPp5yfud5tFzOi9BoW6mpqaqRmZ6hiltkGf5z/3qoVl1C8Qlp2HouovwD4t9bb/T98LRb403IuOSUbeSGbaPaYbK5Y1ePyCJeqWGQKd5Cs/3j4+J0quSeTUYaKWgDS5Bf884IPRmxnPUvv9MwaFuYbn5hG+c5IRGTesUekbhY3/++Sd8fX0xZswYxMXFYdiwYWL74MGDxUhYCW2PjIzEpEmThIDv27dPOLuR85uSqVOnipAyClE7f/48evToIUbw/fr1E9vJLD5ixAhx7hMnTgjnNzofiXhuPdYZpjRD2eBWD24kBJqEevAfFxASlaDaTjHgw9dfRHxyGlrWsMTmkU1F8ppcVWer1Aho/y20Jl7FNvetWJLSCzd0a0OyV/tuHvoS+KMD4H+0kK6wdEKpcpVQtkBGPmg01zrNcYeHh2PWrFnCPF6vXj0cPHhQ5QBHo2TyZFdCbviHDh0SceA0B07x4yTq06dPz+SuT6L9/PlzEWbWokULeHt7i8dKlixZIo5LiWDIgY3m0lesWFHEV88w8oUyw60b2hgf/eaFB+FxosjKttHNsPPqE3y3VzHt9KGbHRZ+5CaSyuQZLS10eK8dmnoBP8emYeujl4pQNAppIwe5l4+BtNSM/aMfA0mxQAUnxSifyRMUhXwuQG1EzkIuKzQaRy5nOI6cYRTzqr1XnsfT6ERYmRgg7NXcKpVZ/bqLK7S1301Uac6WHLDer22DlQMbKla+DAHu7gPqDwL0DBXrjn4DnF0MVHABGgwG3P4HGJXntyiXBITHimRCSsiCcnFmuxwL8TBFQ7GPI2cYRv5QaNiGEe4wN9JTiTgljZn1wbuLODG0maLu+uE7z8RNg8DUDnAfmSHiRFIMoKMPhPsq0sQucgZ2fAw8PMP11HMBpfcl6lUuJ/wgImKTRJlbRh6wkDMM8044WpmIJDStalYQhU8o81tBjeScbEyEYx2ldn1jKFqXhcA0f6DLYsCmrqKgy81twJ8fAMsaAmeX5rtCW2lydGvnbIWa1gpHXp4nlw8s5AzDvDN1K5XDX8Pd0b1+5roHBcGQV6NyMrG/sSqaoRnQeAQw+gww6iTQcBigbwxEBgBHZwOLXRTlV/2Psee7GunpErweKEbkzRwtUPdVVsA3hRYyxQsWcoZhijWeLtbChE9V0XZfC8ndk+zqA12XAp/5AR8uAyo2AtJTgDv/ARt7Ar/UA14+LeyuywLf0JfitS2rryNuyOpUUgo5e67LBRZyhmGKNTRnO6TZq6po5/NYFc3AWOH8NvIYMPoc4D4KMDADdA0AE7UEUGF3gfTSWQP9vL9iNO5erTz0dLThVkmRvvrmk2iuQCcTWMgZhin29GlUGYZ62vB9+hI+DyPzdxCb2kDnBcBnd4E+GzLC1KhoC8WlL60DvCh9hVrOvwo7a1bdUvyvaWMMfR1tMUoPjszID8CUMCEnV3hyi1fi4+ODTz/9VORAZxiGKWjKGemjR31F+M2fXu8otvpGgJVzxnL4XUBbB9DWBczUCs+E3gJSS3aq0pS0dNWNkUd1C1XCH2fbVw5vnOGt5Ap5//79RVY0ghK5tG/fXog5FTD59ttvC7qPDMMwqlC0Q7fVQtEKgooNFKP0AdsU2eWI1GTgrw8VDnKHZipM7yUQcmijVLtUzc7V1lS1vs4rhzdODFOChZxKgrq7u4vHVFWM6oJTOtRNmzaJEqIMwzAFDYWieTjkIhQtP9CcOWWFU0Ke7hSXHv8c8PoVWNFEYX6/skGRQa6EzY/T66oe96+cJ2eHtxIs5FT/m4qIEEePHsWHH34oHjs7O4sa4AzDMIXB0OaKUfmWt4WivStWLsCnt4B+WwGnLoCWDhB8Adg9HljkBOyeCDy+LPtkM8pEMBSrr47Sc/3Wk2gRnsaUQCGvVauWqAF+5swZHDlyBJ06dRLrQ0JCYGGR+QPBMAxT0KFoL/ISipZfdHQBp05Av83AlDuKsqvlHYDkWODKn8DvbYGVzQHvlUB8Ph3wNAjdCF0OeiEeN3NUOLopqWFlLJwLY5JS8fB5nIZ6yBSqkP/444/47bff8N5774kCJW5ubmL97t27VSZ3hmGYwghFG+yRz1C0d4FC1VpMBiZcAYbuA+r2BXQNgbDbwMEvFKP0499DTlx+9ALJqemwNjWAg2XZTNt0dbRRy47nyUu0kJOAR0REiLZ27VrV+lGjRomROsMwTGHRt3FGKNrFQMWIssigkLWqLYCeqxXJZjovBGzqAGnJQFmrjP1ohH7vULH2elcPO8supa7S4e06Z3grmUKekJAgyn+am5uL5UePHmHp0qXw8/ODlZXah5lhGKZQQtEUqWDXn3+oude3TDlF8ZbRZ4FRp4C6fTK2+e4GNvcBNvREceWcf/bz40qo3jzBnuslVMi7deuGv/76SzyOiopCkyZNsGjRInTv3h0rV64s6D4yDMNkm3+dQtFCCjIULb/Y1VMIuxLKEmdiCzi2zViXGA383U/h+R6nEFFN8TIxRZVLXRk/nhVK10rcDnmJ1LT0Iu0fUwRCfuXKFbRs2VI83r59O6ytrcWonMT9l19+yc8hGYZhco2zjWnhhaIVBFS8ZfIdoOm4jHX3jwB++xWe7wsdgfUfAN6rgKjgIu/exYeRIGf0KhZGqGRulO0+NG9O+dcTUtLgH15yQu5KIvkS8vj4eJiYKDL/HD58GD179oS2tjaaNm0qBJ1hGKawyXVVNE1ByWXUa6ZXagS0+UpRZlVKBwLPAAenA0trA6vfA04vBML9itisntlbXR2KK6+tqoTGBVRKnJA7Ojpi165dIlXroUOH0KFDB7E+LCwMpqYZ2YEYhmEKC08Xq6ILRSsIzKsCracpyqxOugF0nA/YNyMPOiDkKnD8O2C5O/CrO3BiHvDsdqHFqWc4ur05XNit8qsCKizkJU/IZ82ahalTp6Jq1aoi3MzDw0M1Oq9fv35B95FhGOY1KERKGYq2vihD0QoC8yqAx1hg+AFg6n2g6y+AY3tAWw+I8ANO/QisbAbsmVTgp34em4S7oTFvnB/P6rnOtclLoJD37t0bQUFBuHTpkhiRK2nXrh2WLFlSkP1jGIZ5ayjaHU2EohUUxhWAhkOAgduBzwOAnmsA5w8AHQPAvmnGflFBwJFZwJMr73Q6rwcKs7qzjQksjRUZOnNC6bnu+zRGxJwzxRPd/D7RxsZGNGUVtEqVKnEyGIZhNBKK9rdPsAhFo5rassbQTBHGRi0pRlGRTcmd/4BzPyuEfOjejPVkicgmDvxtaVnfNhon7MsbwayMHqITUnDvWYxqzpwpASPy9PR0UeXMzMwMVapUEa1cuXL47rvvxDaGYZhSG4pWUBiYAHplMpZt3YBaPRVZ5ZTEhgFLagP7PwcCzynC3t6CV8DbHd2UUKIY5aicE8OUsBE5lSv9448/8MMPP6B58+Zi3dmzZzFnzhwkJiZi7ty5Bd1PhmGYHEPRmjqUh/eDSBGK9nkntVrjJYlqrRRNnbt7gZePAZ/fFI2yy9XqAdTrrxD+LCN1utF5GBEHKnTWxCF31guaJz9zP0Lh8NakIC+I0aiQ//nnn/j9999VVc+IunXromLFihg7diwLOcMwRcrQZtWEkG+6EIQBTasIb/ZSQb0BgImdwuzutw+IC8sQdStXhaDX6QOYWGcyq9epVA6mhnq5OoVyRM4haCXMtB4ZGSlKlmaF1tE2hmGYoqS9qzVcbE3FXO7wdRdF5rJSAdVRpwptPVYCU/2B/v8oRuTkKBd2Bzj8FbDYBdjUB7i9Ez73n+Qq7Cy7DG80R14s4/WZ/Ak5VTv79ddfX1tP62hknheWL18uwtgMDQ1FqlcfH5837k8pYceNGwdbW1tRE71mzZrYv3+/avv8+fPRuHFjkbCG8r5T2ljKAZ+16AvN/ai30aNH56nfDMMUr6povw9pBCsTA/g9i8HYjVeQUtrSiurqAzU7Ah+tB6b6AV0WA5UaA1IacP8QsG0ovrrbA311TqB5LubHldiaGcLSWB+p6ZKIDmBKiJD/9NNPouqZq6srRowYIRo9Xr9+PRYuXJjr42zduhVTpkzB7NmzRdpXukHo2LGjSCyTHcnJyWjfvj0CAwNFalgS6DVr1giTvpJTp04Joff29ha10lNSUkTCmri4zDV1R44ciadPn6oaXRPDMPKFzOlrhzaGkb4OzvpHYObOm/KKLS9Iypgr0sR+fBQYfwloMQWpxrYwRRyitczQsIqi4BViw4GXb06mQwMdZTw5J4YpQULeunVr3Lt3Dz169BAjZGqUpvX27dvYsGFDro+zePFiIajDhg0TNwJUAtXIyChTaVR1aD2Z7imrHDnZ0Uie+qKsh04cPHgQQ4cORa1atcR6urmgmPfLly9nOhadRxlCR40z0jGM/KHwqF/71xfOXP9ceoxfj/trukuax7IG4DkbW5vvx4DkGXhZ6T2U0ddRbKO59MWub62lrjSv8zx5CRJyws7OTji17dixQ7Tvv/8eL168EN7suYFG1ySunp6eGZ3R1hbLXl5e2T5n9+7dIoscjbipUEvt2rUxb948pKXlPG8THa3IEVy+fGYPzU2bNsHS0lIcY8aMGSJ//Jugsq0vX75UtZgYRWYkhmGKF22drfFNt9ri8aIj97DzqiLXRWnn/IMonEuvg6Y1bDJWvgikQHSggnPmdbd3AgmK6miZHd4y1jElICHMuxIRESEEmARZHVq+e/duts958OABjh8/jgEDBoh5cX9/f+ElT+ZzMs9nhWLaP/30UzF6J8FW0r9/fxH7TjcjN27cwPTp04WZ/t9//82xvzT3/s0337zTNTMMUzQMaloFjyPj8dvpB/h8+w3YmpVBU4fcO3iVNNLTpezzq/f6HWgzU1FyVcmtHcCxbwEtHUVmuRrtUc+2tRB8qoIWl5SKsgYakw4mG2T1bpAwkwPb6tWroaOjg4YNG+LJkydYsGBBtkJOI/dbt26JGHd1Ro0apXpcp04d4ThH6WUDAgJQvXr1bM9No3aaz1dC56XpAIZhiifTOzkj+EU89t8Mxai/LuHfsc3gaKWo2ljaoNzqVFyG/AeUZnIV5au9nl3O0kmR8/3ROdFI+i8YWuBYqhueeMegZtMuioQ1TOkWcjJrkxg/e/Ys03papjnr7CDB1dPTE89T4uLigtDQUGGq19fXV60fP3489u7di9OnT4v0sW+CvOUJGuHnJOTkIU9NCZnXGYYpvlAZzsV96iE02htXgqIwdN1F7BzbHBVM3pxfvCSiHI03rloe+rpvmVFt/LGikYmdaqhTe3ga1qnP0V/3OHDiOHBKD6jSDKjRQdFoHj4PaWIZDQo5ObS9CXJ6yy0kujSiPnbsmAgRU464aZlEODvIRL5582axH82nE+R0RwKvFHHyUp0wYQJ27tyJkydPolq1LHeb2XDt2jXxn47DMEzJwVBPB2sGN0LPlefx6Hk8Pv7rEraMbJrh7FVKUCaCae5okbeyq+4jFS0lAbv/24bn1/bigzI3USElBHh4StEOz1TUWacSrUzxd3aj3OpvajTvPHjw4Fwfj0zVFD5GmeJ8fX0xZswYESZGXuwEHYtM2kpoO3mtT5o0SQj4vn37hLMbmdCV0OONGzcKwadYchqtU0tIUORgJvM55YQnRzsKYyMHOjpPq1at8hwDzzBM8cfC2ADrhjZGOSM9XA+OwqQtV5GWXnrC0iie/sKD3OdXzxa9MjCr+z6+SR2CPgYrgQlXgE4/ANXbvl6lze8g8Lsn4LWigK6AKdAR+bp161CQ9O3bF+Hh4aK+OYltvXr1RPiY0gGOwsaUI2+icuXKomzq5MmTVSlhSdTJWU3JypUrVUlfsvadwtJo5H706FEsXbpU3DTQMXv16oWvvvqqQK+NYZjig0MFYzEyH7DmAg7feYa5+3wxq2vp8HG5+SQacclpoooZZb/LL3VfxZJTrvZoI3uYNR0DUEuOU4i5ksAzwOOLgHWGgzFSk4H9nwGV3BWib+HIpvgCREsqtRkT3g0q30o3AcHBwW+dg2cYpniw+3oIJv59VTye3dUVw5q/fepN7vx6/D4WHr6HTrVssGpQw3c6VsufjiM4MgGbPm6C5o45jO6jghVOcuWrA5UbK9YFXwT+yAg1hpEFULmpQtSp2dZTZKZj8qUzsvJaZxiGeRc+dLPD4xfx+OmgH77de0dkg+tQK3vn2pI2P94sL/PjOVC3Yjkh5JQYJkchL1cZKPe/zOvKWgAtJgNBF4Anl4H454oiL9QIXUPArkGGsNNj4wrv3N/SAgs5wzClijGtqyM4Mh5/+wRj4par2DrKA26Vs4RklRCoyMmlRy/yXCglJygxzL6bT/OeGKa8A+A5R/E4NQl4eh0I8lIIe7C3QtiDziuaEosawPiLGSZ4eh4ViWFeg4WcYZhSBeUO/7ZbbTyJSsTpe+EY8ecl7BzbDJXLG6GkceXRCySnpotiMtUrGL/z8eoURElTEuPK7orWXIQaAc/9gSBvRXvsA0TcB8qUyzyPvqYtkBIP9PoDqNhAsY6eq8VhbyzkDMOUOvR0tLFiQAN8tMoLvk9fYtj6i9gxpplwCCuRZvXqFuIGpiBy2RNPohLwPDZJRAS8M9QvikOn1mCQYl3iSyAuPGOflAQgzFdRyc1EbSrkzELg5g7Arr5C3Ok/OdnpGaI0ke9c6wzDMHLG2EAXa4c2go2pIfzDYjF6w2Uxei1JZKRlzWfYWRZMDfXgUKGsyhu+0DA0BSzUknPplQGm+QODdmVOJ/v4EhDuC1zfDOyfCvzeDphfEVj/AeC9EnjxCKUBFnKGYUotlIOdSp+W1deB14Pn+GzbdYRGJ6IkEJOYguuvTOAF4eiWNQytyCuhGZUHqrfJbErv+gvQbyvQeroiw5yRJZCeqgiBO/gF8HNdYGVz4PhcIOSqwhRfAmHTOsMwpRpXO1MsH9BAzJXvuR4iGjl1ebpYo72rNZxtTArELF3UXAyMFIlv7MsboZJ5wc3/16lUDruuhRSPkqYm1oBTJ0UjSKgjHwD3DgJ39yuc557dUrTTPwEmdkCn+UAtRTbRkgILOcMwpZ73nKywckADrDwVgGvBUUKkqC0+cg+VzMsIQW/vYo3G1cqL+XU5cN4/Y368IFGWNL35pBiWNNXSUpjkPcYpWnwkcO+QIszN/zgQE6IY2SsJvQWE3REV3lDGHHKFhZxhGAYQ8eTUwmIScdw3DEfuPMNZ/wg8fpGAdecCRTM11EVbZyu0d7VBq5qWMDEsvs5x51Tx4wUzP66klp0ptLWAZy+T8OxlIqxNi7FjmVF5oF4/RUtJFMVfYO+Rsf3KX4DPb0D9gUC35ZArLOQMwzBqWJkY4n/u9qLFJ6fizP0IIerH74YhMi5ZmJWp6etoo2l1C9Vo3cas+Aga9ZO88QmPAq7DbqSvixpWJvB7FiOsFu1di891vxHyZK/Z4fUSrlaugFOXjHWPLwM7PwGqtQSqvmrFPDkNCznDMMwbRKtjLRvRaL75StALIerUKOc4xaFT+3rXLdSpaIYudW3xcYtq0NWw+d37VZGUmtbGhVK2leLJSchvPo4SNzKypemrfPHqTnB++4Hn9xXt0lrFugouQNUWCnGv0kKRqa4YwULOMAyTC3S0tUQ9b2oz3ndGQHjcK1EPxdXgKBGORY1C2Ca2q1Giws6y4lbJDNsvP1Z5xcseLTVnxmbjFfHo5Pn+8AwQdlsR4kbt4hrFPhSrTsIuRuzNNT6/zkLOMAyTR8iL3dHKWLQx71VHeEwS/vIKxLLj/tjo/Uis06RTXGE5uql7rhN040J1t+To1Z8jJMouHygaEfcceHRWIeok7uF3MzzhL6yiT8OrOfZfoSlYyBmGYd4RMl9PaFtD5G8Pi0nC4dvPhJldEzyNTsCDiDjhkNakgOfHlVBInq62lpiLpyxvBRneVuwoawG4dlM0IjZMIeiBr8SdTPDqSWoSXigy05lXKbIuyiOOgmEYppijr6uNfu6VxeMN3oEa64fXK291mrMvrJSzhno6cLY1EY+LRTx5UWJsBdTuBXywBJhwCZhyF2j8ccb25wFAOfsi7RILOcMwTAHRz91ejIS9H0Ti3rMYjbyu516Z1T0KaX5cSZ2K5UqnkGfF1FaRmEYJzZ8X8VQDCznDMEwBYVdOkTyG2OBV9Hm+ab7aS+XoVrie1cU6MYwm0UDBFhZyhmGYAmSwR1Xx/98rj0W+86Lk0fN4hEQnQk9H4WFfFEJOI/L09JKZw1wusJAzDMMUIDQSrl6hLOKS07Dz6pMifW3PvRqN17c3Rxl9nUI9V01rE+EXEJOYikeR8YV6LjlxPTgKh26HFuk5WcgZhmEKEArFGtRU4bH8l9cjYe7WRP3xwobC61xtTcXjG4/ZvC5JkghB7L3qPCZvvQb/sKLzkWAhZxiGKWB6NqwEI30dUeecHN+KAjJve6uEvHAd3V6bJy/lDm+xSamYuOUaZv13GylpElrVqACrIsxBz0LOMAxTwJga6qF7/YpFGop2/XEUnsclo4yeDupVVniUFzZ1XyWGKc2e6/eexeDDX8+K8rcUW/9VFxesHNhAfAaKChZyhmGYQmCwh8K8fuj2M4RGJxa6WfeHA3fF4061bcTcdVGOyG+FRItc9KWNnVcfo9uv5/AgPA42pobYMqopPm7pUOSZ7ljIGYZhCgFnG1O4Vy0vBG6zT1ChvsZ0s3DhYSQMdLUxtaMTiorqFYzFFEJ8choehMeitJCYkoYvd97E5K3XkZCShpY1LLFvYgs0KuRIgWIr5MuXL0fVqlVhaGiIJk2awMfH5437R0VFYdy4cbC1tYWBgQFq1qyJ/fv35+mYiYmJ4hgWFhYwNjZGr1698OzZs0K5PoZhSi+DXo3K//YJEsVUCoOk1DTMP+ArHo9q5YCK5cqgKAvJ1LZTjMpLTAGVtxD0PF44tG2+ECTyvkxqVwPrh7nDwrjgq8zJQsi3bt2KKVOmYPbs2bhy5Qrc3NzQsWNHhIWFZbt/cnIy2rdvj8DAQGzfvh1+fn5Ys2YNKlasmKdjTp48GXv27MG2bdtw6tQphISEoGfPnkVyzQzDlB6o/CnlYaeiKoUVkvTn+UARP25lYoDRraujqKGSpgSVNC3pHLnzDF2WncGtJy9hbqQnBHxy+5rihkajSBrE3d1dGjdunGo5LS1NsrOzk+bPn5/t/itXrpQcHByk5OTkfB8zKipK0tPTk7Zt26bax9fXlyZ3JC8vr1z3PTg4WDyH/jMMw+TEosN+UpXpe6WPVp0v8BcpIiZRqj3roDj+PxeDNPIm7Lr6WJy/+/KzUkklJTVNmrf/jrhO5bU+eRFf6OfNrc5obEROo+vLly/D09NTtU5bW1sse3l5Zfuc3bt3w8PDQ5jFra2tUbt2bcybNw9paWm5PiZtT0lJybSPs7Mz7O3tczwvwzBMfunvbi9GbD4PI3E39GWBvpCLj9xDTFIqalc0Ra8GlaAJlJ7rd0JeIiWtcKYPNEnYy0T0X3MBv516IJaHN6+GraM8RDre4oLGhDwiIkIIMAmyOrQcGpq9CerBgwfCpE7Po3nxr7/+GosWLcL333+f62PSf319fZQrVy7X5yWSkpLw8uVLVYuJ0UxBBIZh5IWNmSE6FEL+db/QGDH3TnzdxRXaGjLvVilvBBNDXSSlpmusUExhcT4gAp1/OQufwEgYG+hixYAGmNXVtciiAnJL8erNW0hPT4eVlRVWr16Nhg0bom/fvpg5cyZWraLi7oXL/PnzYWZmpmqurq6Ffk6GYUqW0xulbH1ZAPnXKdzs+313QBFf79e2KbS647mBbiCoZGpJSgyTni5h+Ql/DPz9AiJik0T99d3jm6NzHc3UmC+2Qm5paQkdHZ3XvMVp2cbGJtvnkKc6eanT85S4uLiIkTSZ1XNzTPpP+5L3e27PS8yYMQPR0dGqdufOnXxdN8MwpQ8PBwvUsDIWYVr/Xn78zsc74ReGM/cjoK+jjRnvu0DTKM3rJcFz/UVcMkb8eRELDvmJG6XeDSth59jmcKhgjOKKxoSczNs0qj527FimETct0zx4djRv3hz+/v5iPyX37t0TAk/Hy80xabuenl6mfcj7PSgoKMfzEhTqZmpqqmomJibv/BowDFOK8q+/GpVv8H63/Os0D/39PkW42bAWVWFvYQRNU1JKmj6PTULXX8/ihF+4iMn/qVddLPzIrdAL0MjatE5hYhQ+9ueff8LX1xdjxoxBXFwchg0bJrYPHjxYjISV0PbIyEhMmjRJCPi+ffuEsxs5v+X2mGQWHzFihNjvxIkTwvmNtpGIN23aVAOvAsMwpYEe9SuirL4OAsLj4PUqJ3p+2Oj9SGQSszTWx/g2jigOKE3rNG9PyVLkypozD/H4RQIqmZfBv2OboU/jypADupo8Oc1xh4eHY9asWcI8Xq9ePRw8eFDlrEajZPI6V1K5cmUcOnRIxIHXrVtXxI+TqE+fPj3XxySWLFkijkuJYMiJjeLMV6xYUcRXzzBMacLEUA89GlTERu8gURWtmWPeC5tExSdj6dH74vGU9k7imMUBEj6Kq34Rn4K7oTFFluu9IIlOSBE3ScTsrrVQ61WiGzmgRTFomu6EHHn8+LG4sQgODkalSpoJ+2AYRl6QV3eHJadFONrZ6W1ga5a3EKY5u29j/flA4Xy1b2JLzSciUWPIWh+cuheO77rVwiCPqpAbvx6/j4WH78HJ2gQHJrXUWBRAfnRGVl7rDMMwcqamtQmaVHuVf/1C3vKvU0lUml8nvv7AtViJuPo8uRwroSUkp2HtOUWVurFtqhcLEc8LLOQMwzBFyOBXo9W/fYLzlH993n5fcQPg6WKN5vkwyxfVPLkchXzLxSBExiXDvrwRuhTTELM3wULOMAxThHSoZS3yolN88sFc5l8/fS8cx++GiXrXX3Z2RnHE7dW8+P2wGMQUQKx8UZGcmo7VpxVZ2z5p7QBdHfnJovx6zDAMI2P0dLTRz91ePN7gpTDnvolUEW6myFsxpFnVYhvPbG1qCGtTAxF73WbhSSw67FfoddgLgl3XnuBpdKIobqOpNLfvCgs5wzBMEdO/ib0YXV8MfAHfp2/Ov/73xWDcexYrvMIntq2B4sxXXVxhY2qIiNhkLDvuj+Y/Hse4TVdEnvni6Fedli5h1ckA8Xhky2ow1Cve8eI5wULOMAyjgdErlTglKBTtTSFRS47cE4+pXKaZUfEIN8uJrm52ODO9jchJ7v7KqW/fzafo85uXyFm+9WJQsYozP3Q7FA8i4mBWRg/9mygS9sgRFnKGYRgNoMz0tuvqEyHYOYVEkROWo5WxqKIml6kDykn+zyce2D+xJf7XuDIM9bSF5WH6jptoOv8Y5u/3RXBkvEb7KUmKfOrKKQsqiiJXWMgZhmE0AIWh1bQ2RkJKGnZkk389MCJOxIwTX3VxkaUTlqudKX7oVRfeM9oJJz1KHBMVn4LfTj9A6wUnMPKvSzjnH6ERs/upe+G4HfISRvo6GNZMfnHv6sjvk8EwDFNi8q8rBIQyimUVMwo3S0mT0LpmBbznZAU5U85IH6NaVcepaW2wZnAjtHC0FE5xR+48w4DfL6D9ktPC8S8uKbXI+rTi1dw4OR6al9WHnGEhZxiG0WD+dTLp0jztOf/nmepgH77zTCR9odF4SYGup72rNTZ+3ARHp7TCYI8qIv88Jbv5+r/baDrvGL7bewexhSzolwIjhQOeno4WRrZ0gNxhIWcYhtEQJOI9G1QUj/96FYpGDmLf7VVUNxvQxB41rEtmpUVHKxN82602vL5sh9ldXVHNsixiklLxx9mH+HTLNVETvLBH470aVIKNmSHkDgs5wzCMBhnUVOH0dtT3GZ5EJWD75WDhGGZqqItPPWuW+PfG1FAPw5pXw7EprbF6UEPo62qL12LlKYXYFjS3Q6JFch3KwvpJ6+ooCbCQMwzDaBAacXs4WIg54zWnH2DBIUW42cR2NVBe5nO3eYHym3eoZSOKrhALD/uJjHYFzcpXo/Eude2EFaAkwELOMAyjYWiumCAvdUrdSgKjzMle2ujb2F6ErJHv36QtV/H4RcGFqT2MiMP+m0/F4zElZDROsJAzDMNoGHIAo/SmSr7s7CJMzKWVOR/WEtXUqL752E1XCiyJzG+nAoTlo62zlQiNKymU3k8KwzBMMYFixJVz5c0dLeDpIu9ws3eFUqVSdjhKS0vV1KgO+7sSGp2IHVcU8fpj3ys5o3GChZxhGKYYMLp1dfz8v3pY0b+hiDEv7VQyN8Iv/eqDXootF4OxxSdv9duzsubMAxGXT6ljG1Utj5IECznDMEwxGZV3q1ex2OdTL0pa1qiAqR2cxONZu2/jxuOofB0nMi4Zmy8ElcjROMFCzjAMwxRbyCnN08Va1A0fs/GKEOW8sv58oEiFW8vOVGTKK2mwkDMMwzDFOixtUR83VLUwEnH25MlOSXNyS2xSKtafeygej2vjWCKnLVjIGYZhmGINlRldNaghyujp4Mz9CCw9qoi1zw2bLzzCy8RUOFiWVZWOLWmwkDMMwzDFHmcbqqRWRzxedtxfFFx5G4kpaVhzRjEaH/1edZHrvSTCQs4wDMPIAnIGHPqq5OiUrddEgpc3sf3yY4THJMHWzBDd6yly2pdEWMgZhmEY2UDJchpVMRcFVsZsvIz45OwrpaWmpeO304p0rKNaOZToBDsl98oYhmGYEgcJ8vIBDWBpbIC7oTGY8e/N12q5E3tvPEVwZILIV/+/xvYoyRQLIV++fDmqVq0KQ0NDNGnSBD4+Pjnuu379euF1qN7oeepk3a5sCxYsUO1D58u6/YcffijU62QYhmHeHWtTQyzvX1/Mef93LQR/eT3KtJ1KoCqLowxvXhVl9HVK9MuucSHfunUrpkyZgtmzZ+PKlStwc3NDx44dERYWluNzTE1N8fTpU1V79Cjzm6i+jdratWuFUPfq1SvTft9++22m/SZMmFBo18kwDMMUHE0cLDDjfWfx+Lu9d3ApMFK17djdMPg9ixH13geVguIzGhfyxYsXY+TIkRg2bBhcXV2xatUqGBkZCfHNCRJlGxsbVbO2ts60XX0btf/++w9t2rSBg4NDpv1MTEwy7Ve2bMkoaccwDFMaGNGiGj6oa4vUdEkUVwmLSRRm9uUn/MX2gU2riNC1ko5GhTw5ORmXL1+Gp6dnRoe0tcWyl5dXjs+LjY1FlSpVULlyZXTr1g23b+ecUP/Zs2fYt28fRowY8do2MqVbWFigfv36wuyempq90wSRlJSEly9fqlpMTEyerpVhGIYpWGhQ92OvuqhhZYywmCSM33xVxJlfC46Cga62EPrSgEaFPCIiAmlpaa+NqGk5NDQ02+c4OTmJ0TqNsjdu3Ij09HQ0a9YMjx8rqtpk5c8//xQj7549e2ZaP3HiRGzZsgUnTpzAJ598gnnz5uHzzz/Psa/z58+HmZmZqpH1gGEYhtEsZQ10RbIYMqP7PIzE6I2Xxfo+jSqjgklGadiSjJaUnbtfERESEoKKFSvi/Pnz8PDwUK0nQT116hQuXLjw1mOkpKTAxcUF/fr1w3fffffadmdnZ7Rv3x7Lli1743Ho5oAEnUb7BgYG2Y7IqSl58uSJEPPg4GBUqlQpF1fLMAzDFBYHb4WqRJyc4E5OfQ+VyxvJ+gWnASpZnt+mMxodkVtaWkJHR0eYv9WhZZqzzg16enrCNO7vr5gTUefMmTPw8/PDxx9//NbjkLc8mdYDAwOz3U7iTk52ykajfIZhGKZ40Km2Dca8qmzWu0El2Yt4XtCokOvr66Nhw4Y4duyYah2ZymlZfYT+Jsg0f/PmTdja2r627Y8//hDHJ0/4t3Ht2jUxP29lZZXHq2AYhmGKA593dMKe8S3wbfdaKE3oaroDFHo2ZMgQNGrUCO7u7li6dCni4uKEFzsxePBgYX6nOWplyFjTpk3h6OiIqKgo4aRG4WdZR93kkLZt2zYsWrTotXOSIx2Z7cmTnUbWtDx58mQMHDgQ5ubmRXTlDMMwTEE7v9WpZFbqXlSNC3nfvn0RHh6OWbNmCQe3evXq4eDBgyoHuKCgIDFSVvLixQsRrkb7kujSiJvm2LM6n5EjG03/09x5dmZy2j5nzhwx712tWjUh5HRTwTAMwzByQqPObqXBCYFhGIZhSqyzG8MwDMMw7wYLOcMwDMPIGBZyhmEYhpExGnd2kysUJkdQsRWGYRiGKWiU+qLUm5xgIc8nyiQ2FDLHMAzDMIWpN/b2OddUZ6/1fEJZ4K5evSrC5NTD4/IKFV+h0Lk7d+5wtjiGYRiZE1OAv+k0EicRp+yluro5j7tZyDUMJa6hIizR0dEi9SvDMAwjX15q4Dednd0YhmEYRsawkDMMwzCMjGEh1zCULnb27NnZlk5lGIZh5IWBBn7TeY6cYRiGYWQMj8gZhmEYRsawkDMMwzCMjGEhZxiGYRgZw0KuYZYvX46qVavC0NAQTZo0gY+Pj6a7xDAMw+SR06dPo2vXrrCzs4OWlhZ27dqFooKFXINs3boVU6ZMER6OV65cgZubGzp27IiwsDBNdothGIbJI3FxceI3nAZnRQ17rWsQGoE3btwYv/76qyodHxWRnzBhAr744gtNdo1hGIbJJzQi37lzJ7p3746igEfkGiI5ORmXL1+Gp6dnxpuhrS2Wvby8NNUthmEYRmawkGuIiIgIpKWliaIr6tByaGioprrFMAzDyAwWcoZhGIaRMSzkGsLS0hI6OjqquuZKaNnGxkZT3WIYhmFkBgu5htDX10fDhg1x7Ngx1TpydqNlDw8PTXWLYRiGkRk5VypnCh0KPRsyZAgaNWoEd3d3LF26VIQwDBs2jF99hmEYGREbGwt/f3/V8sOHD3Ht2jWUL18e9vb2hXpuDj/TMBR6tmDBAuHgVq9ePfzyyy8iLI1hGIaRDydPnkSbNm1eW0+DtfXr1xfquVnIGYZhGEbG8Bw5wzAMw8gYFnKGYRiGkTEs5AzDMAwjY1jIGYZhGEbGsJAzDMMwjIxhIWcYhmEYGcNCzjAMwzAyhoWcYRiGYWQMCznDMMUKLS0t7Nq1S9PdYBjZwELOMIyKoUOHCiHN2jp16sSvEsMUU7hoCsMwmSDRXrduXaZ1BgYG/CoxTDGFR+QMw7wm2jY2Npmaubm52Eaj85UrV+L9999HmTJl4ODggO3bt2d6/s2bN9G2bVux3cLCAqNGjRKVodRZu3YtatWqJc5la2uL8ePHZ9oeERGBHj16wMjICDVq1MDu3btV2168eIEBAwagQoUK4hy0PeuNB8OUJljIGYbJE19//TV69eqF69evC0H93//+B19fX7GNyvB27NhRCP/Fixexbds2HD16NJNQ043AuHHjhMCT6JNIOzo6ZjrHN998gz59+uDGjRvo3LmzOE9kZKTq/Hfu3MGBAwfEeel4lpaW/C4ypReJYRjmFUOGDJF0dHSksmXLZmpz584V2+knY/To0ZleryZNmkhjxowRj1evXi2Zm5tLsbGxqu379u2TtLW1pdDQULFsZ2cnzZw5M8fXnM7x1VdfqZbpWLTuwIEDYrlr167SsGHD+D1jmFfwHDnDMJmgmso0ylWnfPnyqsceHh6ZttHytWvXxGMaIbu5uaFs2bKq7c2bN0d6ejr8/PyEaT4kJATt2rV746tet25d1WM6lqmpKcLCwsTymDFjhEXgypUr6NChA7p3745mzZrxu8iUWljIGYbJBAlnVlN3QUFz2rlBT08v0zLdANDNAEHz848ePcL+/ftx5MgRcVNApvqFCxcWSp8ZprjDc+QMw+QJb2/v15ZdXFzEY/pPc+c0V67k3Llz0NbWhpOTE0xMTFC1alUcO3bsnV51cnQbMmQINm7ciKVLl2L16tX8LjKlFh6RMwyTiaSkJISGhmb+odDVVTmUkQNbo0aN0KJFC2zatAk+Pj74448/xDZySps9e7YQ2Tlz5iA8PBwTJkzAoEGDYG1tLfah9aNHj4aVlZUYXcfExAixp/1yw6xZs9CwYUPh9U593bt3r+pGgmFKIyzkDMNk4uDBgyIkTB0aTd+9e1flUb5lyxaMHTtW7Pf333/D1dVVbKNwsUOHDmHSpElo3LixWKb57MWLF6uORSKfmJiIJUuWYOrUqeIGoXfv3rl+F/T19TFjxgwEBgYKU33Lli1FfximtKJFHm+a7gTDMPKA5qp37twpHMwYhike8Bw5wzAMw8gYFnKGYRiGkTE8R84wTK7hmTiGKX7wiJxhGIZhZAwLOcMwDMPIGBZyhmEYhpExLOQMwzAMI2NYyBmGYRhGxrCQMwzDMIyMYSFnGIZhGBnDQs4wDMMwMoaFnGEYhmEgX/4PWxMBimGdkCkAAAAASUVORK5CYII=\",\n \"text/plain\": [\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dd7491b5-f619-4501-ad39-2942de57c115\",\n \"metadata\": {\n \"id\": \"dd7491b5-f619-4501-ad39-2942de57c115\"\n },\n \"source\": [\n \"- In the equation above,\\n\",\n \" - \\\"expected value\\\" $\\\\mathbb{E}$ is statistics jargon and stands for the average or mean value of the random variable (the expression inside the brackets); optimizing $-\\\\mathbb{E}$ aligns the model better with user preferences\\n\",\n \" - The $\\\\pi_{\\\\theta}$ variable is the so-called policy (a term borrowed from reinforcement learning) and represents the LLM we want to optimize; $\\\\pi_{ref}$ is a reference LLM, which is typically the original LLM before optimization (at the beginning of the training, $\\\\pi_{\\\\theta}$ and $\\\\pi_{ref}$ are typically the same)\\n\",\n \" - $\\\\beta$ is a hyperparameter to control the divergence between the $\\\\pi_{\\\\theta}$ and the reference model; increasing $\\\\beta$ reduces the impact of the difference between\\n\",\n \"$\\\\pi_{\\\\theta}$ and $\\\\pi_{ref}$ in terms of their log probabilities on the overall loss function, thereby decreasing the divergence between the two models\\n\",\n \" - the logistic sigmoid function, $\\\\sigma(\\\\centerdot)$ transforms the log-odds of the preferred and rejected responses (the terms inside the logistic sigmoid function) into a probability score \\n\",\n \"- To avoid bloating the code notebook with a more detailed discussion, I may write a separate standalone article with more details on these concepts in the future\\n\",\n \"- In the meantime, if you are interested in comparing RLHF and DPO, please see the section [2.2. RLHF vs Direct Preference Optimization (DPO)](https://magazine.sebastianraschka.com/i/142924793/rlhf-vs-direct-preference-optimization-dpo) in my article [Tips for LLM Pretraining and Evaluating Reward Models](https://magazine.sebastianraschka.com/p/tips-for-llm-pretraining-and-evaluating-rms)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"xqVAgsyQ6LuG\",\n \"metadata\": {\n \"id\": \"xqVAgsyQ6LuG\",\n \"tags\": []\n },\n \"source\": [\n \" \\n\",\n \"# 2) Preparing a preference dataset for DPO\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"60b2195d-8734-469b-a52e-5031ca7ea6b1\",\n \"metadata\": {\n \"id\": \"60b2195d-8734-469b-a52e-5031ca7ea6b1\"\n },\n \"source\": [\n \"- Let's begin by loading and preparing the dataset, which may already answer a lot of the questions you might have before we revisit the DPO loss equation\\n\",\n \"- Here, we work with a dataset that contains more polite and less polite responses to instruction prompts (concrete examples are shown in the next section)\\n\",\n \"- The dataset was generated via the [create-preference-data-ollama.ipynb](create-preference-data-ollama.ipynb) notebook\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"wHLB62Nj7haD\",\n \"metadata\": {\n \"id\": \"wHLB62Nj7haD\"\n },\n \"source\": [\n \" \\n\",\n \"## 2.1) Loading a preference dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"13e09f99-1b18-4923-ba36-af46d8e3075f\",\n \"metadata\": {\n \"id\": \"13e09f99-1b18-4923-ba36-af46d8e3075f\"\n },\n \"source\": [\n \"- The dataset is a json file with 1100 entries:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"5266e66c-5ec0-45e6-a654-148971f6aee7\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"5266e66c-5ec0-45e6-a654-148971f6aee7\",\n \"outputId\": \"04e8ee70-3076-441d-d2bf-7641da3d0c1d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Number of entries: 1100\\n\"\n ]\n }\n ],\n \"source\": [\n \"import json\\n\",\n \"import os\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"\\n\",\n \"def download_and_load_file(file_path, url):\\n\",\n \" if not os.path.exists(file_path):\\n\",\n \" response = requests.get(url, timeout=30)\\n\",\n \" response.raise_for_status()\\n\",\n \" text_data = response.text\\n\",\n \" with open(file_path, \\\"w\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" file.write(text_data)\\n\",\n \" else:\\n\",\n \" with open(file_path, \\\"r\\\", encoding=\\\"utf-8\\\") as file:\\n\",\n \" text_data = file.read()\\n\",\n \"\\n\",\n \" data = json.loads(text_data)\\n\",\n \" return data\\n\",\n \"\\n\",\n \"\\n\",\n \"file_path = \\\"instruction-data-with-preference.json\\\"\\n\",\n \"url = (\\n\",\n \" \\\"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch\\\"\\n\",\n \" \\\"/main/ch07/04_preference-tuning-with-dpo/instruction-data-with-preference.json\\\"\\n\",\n \")\\n\",\n \"\\n\",\n \"data = download_and_load_file(file_path, url)\\n\",\n \"print(\\\"Number of entries:\\\", len(data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"725d2b9a-d6d2-46e2-89f8-5ab87e040e3b\",\n \"metadata\": {\n \"id\": \"725d2b9a-d6d2-46e2-89f8-5ab87e040e3b\"\n },\n \"source\": [\n \"- Let's take a look at two example entries:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"5c11916f-9a26-4367-a16e-7b0c121a20a6\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"5c11916f-9a26-4367-a16e-7b0c121a20a6\",\n \"outputId\": \"00a432cc-19b1-484f-80e2-e897ee5e4024\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"{'instruction': 'Identify the correct spelling of the following word.',\\n\",\n \" 'input': 'Ocassion',\\n\",\n \" 'output': \\\"The correct spelling is 'Occasion.'\\\",\\n\",\n \" 'rejected': \\\"The correct spelling is obviously 'Occasion.'\\\",\\n\",\n \" 'chosen': \\\"The correct spelling is 'Occasion.'\\\"}\\n\"\n ]\n }\n ],\n \"source\": [\n \"import pprint\\n\",\n \"\\n\",\n \"pprint.pp(data[50])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"01ef804a-8c13-4a0b-9b2e-b65a4d0a870d\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"01ef804a-8c13-4a0b-9b2e-b65a4d0a870d\",\n \"outputId\": \"078cd643-83fb-4b42-ecf9-3256e8c9d239\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"{'instruction': \\\"What is an antonym of 'complicated'?\\\",\\n\",\n \" 'input': '',\\n\",\n \" 'output': \\\"An antonym of 'complicated' is 'simple'.\\\",\\n\",\n \" 'chosen': \\\"A suitable antonym for 'complicated' would be 'simple'.\\\",\\n\",\n \" 'rejected': \\\"An antonym of 'complicated' is 'simple'.\\\"}\\n\"\n ]\n }\n ],\n \"source\": [\n \"pprint.pp(data[999])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"56db5697-a089-4b40-a1f3-e928e8018220\",\n \"metadata\": {\n \"id\": \"56db5697-a089-4b40-a1f3-e928e8018220\"\n },\n \"source\": [\n \"\\n\",\n \"\\n\",\n \"```\\n\",\n \"# This is formatted as code\\n\",\n \"```\\n\",\n \"\\n\",\n \"- As we can see above, the dataset consists of 5 keys:\\n\",\n \" - The `'instruction'` and `'input'` that are used as LLM inputs\\n\",\n \" - The `'output'` contains the response the model was trained on via the instruction finetuning step in chapter 7\\n\",\n \" - the `'chosen'` and `'rejected'` entries are the entries we use for DPO; here `'chosen'` is the preferred response, and `'rejected'` is the dispreferred response\\n\",\n \"- The goal is to get the model to follow the style of the chosen over the rejected responses\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"86257468-a6ab-4ba3-9c9f-2fdc2c0cc284\",\n \"metadata\": {\n \"id\": \"86257468-a6ab-4ba3-9c9f-2fdc2c0cc284\"\n },\n \"source\": [\n \"- Below is a utility function that formats the model input by applying the Alpaca prompt style similar to chapter 7 ([../01_main-chapter-code/ch07.ipynb](../01_main-chapter-code/ch07.ipynb)):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"4564d55c-1c5d-46a6-b5e8-46ab568ad627\",\n \"metadata\": {\n \"id\": \"4564d55c-1c5d-46a6-b5e8-46ab568ad627\"\n },\n \"outputs\": [],\n \"source\": [\n \"def format_input(entry):\\n\",\n \" instruction_text = (\\n\",\n \" f\\\"Below is an instruction that describes a task. \\\"\\n\",\n \" f\\\"Write a response that appropriately completes the request.\\\"\\n\",\n \" f\\\"\\\\n\\\\n### Instruction:\\\\n{entry['instruction']}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" input_text = f\\\"\\\\n\\\\n### Input:\\\\n{entry['input']}\\\" if entry[\\\"input\\\"] else \\\"\\\"\\n\",\n \"\\n\",\n \" return instruction_text + input_text\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"3f38b49f-63fd-48c5-bde8-a4717b7923ea\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"3f38b49f-63fd-48c5-bde8-a4717b7923ea\",\n \"outputId\": \"9ad07c59-05b3-42ae-c5bc-68780aaf6780\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Identify the correct spelling of the following word.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"Ocassion\\n\"\n ]\n }\n ],\n \"source\": [\n \"model_input = format_input(data[50])\\n\",\n \"print(model_input)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7dd9e4c9-88a3-463a-8c16-c60ed7e6b51e\",\n \"metadata\": {\n \"id\": \"7dd9e4c9-88a3-463a-8c16-c60ed7e6b51e\"\n },\n \"source\": [\n \"- Similarly, we can format the chosen and rejected responses using the Alpaca prompt style:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"8ad5831a-e936-44e5-a5cf-02953fe7d848\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"8ad5831a-e936-44e5-a5cf-02953fe7d848\",\n \"outputId\": \"2c0a0cbf-c13d-43cf-fcc1-a4585c21e66f\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"### Response:\\n\",\n \"The correct spelling is 'Occasion.'\\n\"\n ]\n }\n ],\n \"source\": [\n \"desired_response = f\\\"### Response:\\\\n{data[50]['chosen']}\\\"\\n\",\n \"print(desired_response)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"fc0991f6-fef7-48ab-8dee-fbd2863f784c\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"fc0991f6-fef7-48ab-8dee-fbd2863f784c\",\n \"outputId\": \"cd85406c-3470-48f8-9792-63f91affd50a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"### Response:\\n\",\n \"The correct spelling is obviously 'Occasion.'\\n\"\n ]\n }\n ],\n \"source\": [\n \"possible_response = f\\\"### Response:\\\\n{data[50]['rejected']}\\\"\\n\",\n \"print(possible_response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6G3j2Q987t_g\",\n \"metadata\": {\n \"id\": \"6G3j2Q987t_g\"\n },\n \"source\": [\n \" \\n\",\n \"## 2.2) Creating training, validation, and test splits\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"53ce2b1e-32d7-414c-8e6b-01f21a2488c2\",\n \"metadata\": {\n \"id\": \"53ce2b1e-32d7-414c-8e6b-01f21a2488c2\"\n },\n \"source\": [\n \"- Next, we divide the dataset into 3 subsets, 85% training data, 5% validation data, and 10% test data:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 10,\n \"id\": \"36c7b919-8531-4e33-aebf-aaf8e6dbcfbd\",\n \"metadata\": {\n \"id\": \"36c7b919-8531-4e33-aebf-aaf8e6dbcfbd\"\n },\n \"outputs\": [],\n \"source\": [\n \"train_portion = int(len(data) * 0.85) # 85% for training\\n\",\n \"test_portion = int(len(data) * 0.1) # 10% for testing\\n\",\n \"val_portion = len(data) - train_portion - test_portion # Remaining 5% for validation\\n\",\n \"\\n\",\n \"train_data = data[:train_portion]\\n\",\n \"test_data = data[train_portion:train_portion + test_portion]\\n\",\n \"val_data = data[train_portion + test_portion:]\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 11,\n \"id\": \"831a6c1b-119b-4622-9862-87f1db36e066\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"831a6c1b-119b-4622-9862-87f1db36e066\",\n \"outputId\": \"8e017483-1a75-4336-9540-ac6a69104e27\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training set length: 935\\n\",\n \"Validation set length: 55\\n\",\n \"Test set length: 110\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Training set length:\\\", len(train_data))\\n\",\n \"print(\\\"Validation set length:\\\", len(val_data))\\n\",\n \"print(\\\"Test set length:\\\", len(test_data))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"c07d09f7-66af-49ed-8b9e-484f46e6a68d\",\n \"metadata\": {\n \"id\": \"c07d09f7-66af-49ed-8b9e-484f46e6a68d\"\n },\n \"source\": [\n \" \\n\",\n \"## 2.3) Developing a `PreferenceDataset` class and batch processing function\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"86101174-00c8-485d-8273-d086d5311926\",\n \"metadata\": {\n \"id\": \"86101174-00c8-485d-8273-d086d5311926\"\n },\n \"source\": [\n \"- In this section, we rewrite the `InstructionDataset` class from chapter 7 ([../01_main-chapter-code/ch07.ipynb](../01_main-chapter-code/ch07.ipynb)) for DPO\\n\",\n \"- This means that instead of focusing on single output sequences (responses), we modify the dataset class to return pairs of responses where one is preferred (\\\"chosen\\\") over the other (\\\"rejected\\\")\\n\",\n \"- Overall, the `PreferenceDataset` is almost identical to the `InstructionDataset` used in chapter 7:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"id\": \"db08ad74-6dd4-4e40-b1e5-bc5f037d3d27\",\n \"metadata\": {\n \"id\": \"db08ad74-6dd4-4e40-b1e5-bc5f037d3d27\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch\\n\",\n \"from torch.utils.data import Dataset\\n\",\n \"\\n\",\n \"\\n\",\n \"class PreferenceDataset(Dataset):\\n\",\n \" def __init__(self, data, tokenizer):\\n\",\n \" self.data = data\\n\",\n \"\\n\",\n \" # Pre-tokenize texts\\n\",\n \" self.encoded_texts = []\\n\",\n \" for entry in data:\\n\",\n \" prompt = format_input(entry)\\n\",\n \" rejected_response = entry[\\\"rejected\\\"]\\n\",\n \" chosen_response = entry[\\\"chosen\\\"]\\n\",\n \"\\n\",\n \" prompt_tokens = tokenizer.encode(prompt)\\n\",\n \" chosen_full_text = f\\\"{prompt}\\\\n\\\\n### Response:\\\\n{chosen_response}\\\"\\n\",\n \" rejected_full_text = f\\\"{prompt}\\\\n\\\\n### Response:\\\\n{rejected_response}\\\"\\n\",\n \" chosen_full_tokens = tokenizer.encode(chosen_full_text)\\n\",\n \" rejected_full_tokens = tokenizer.encode(rejected_full_text)\\n\",\n \"\\n\",\n \" self.encoded_texts.append({\\n\",\n \" \\\"prompt\\\": prompt_tokens,\\n\",\n \" \\\"chosen\\\": chosen_full_tokens,\\n\",\n \" \\\"rejected\\\": rejected_full_tokens,\\n\",\n \" })\\n\",\n \"\\n\",\n \" def __getitem__(self, index):\\n\",\n \" return self.encoded_texts[index]\\n\",\n \"\\n\",\n \" def __len__(self):\\n\",\n \" return len(self.data)\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2325d183-75b9-400a-80ac-0b8d2f526561\",\n \"metadata\": {\n \"id\": \"2325d183-75b9-400a-80ac-0b8d2f526561\"\n },\n \"source\": [\n \"- Along with an updated `PreferenceDataset` class, we also need an updated batch collation function that we use to pad the sequences in each batch to an equal length so that we can assemble them in batches\\n\",\n \"- I added comments to the code below to illustrate the process; however, it might be easiest to understand how it works by looking at the example inputs and outputs further below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 13,\n \"id\": \"8d3a43a6-7704-4bff-9bbc-a38632374f30\",\n \"metadata\": {\n \"id\": \"8d3a43a6-7704-4bff-9bbc-a38632374f30\"\n },\n \"outputs\": [],\n \"source\": [\n \"def custom_collate_fn(\\n\",\n \" batch,\\n\",\n \" pad_token_id=50256,\\n\",\n \" allowed_max_length=None,\\n\",\n \" mask_prompt_tokens=True,\\n\",\n \" device=\\\"cpu\\\"\\n\",\n \"):\\n\",\n \" # Initialize lists to hold batch data\\n\",\n \" batch_data = {\\n\",\n \" \\\"prompt\\\": [],\\n\",\n \" \\\"chosen\\\": [],\\n\",\n \" \\\"rejected\\\": [],\\n\",\n \" \\\"rejected_mask\\\": [],\\n\",\n \" \\\"chosen_mask\\\": []\\n\",\n \"\\n\",\n \" }\\n\",\n \"\\n\",\n \" # Determine the longest sequence to set a common padding length\\n\",\n \" max_length_common = 0\\n\",\n \" if batch:\\n\",\n \" for key in [\\\"chosen\\\", \\\"rejected\\\"]:\\n\",\n \" current_max = max(len(item[key])+1 for item in batch)\\n\",\n \" max_length_common = max(max_length_common, current_max)\\n\",\n \"\\n\",\n \" # Process each item in the batch\\n\",\n \" for item in batch:\\n\",\n \" prompt = torch.tensor(item[\\\"prompt\\\"])\\n\",\n \" batch_data[\\\"prompt\\\"].append(prompt)\\n\",\n \"\\n\",\n \" for key in [\\\"chosen\\\", \\\"rejected\\\"]:\\n\",\n \" # Adjust padding according to the common maximum length\\n\",\n \" sequence = item[key]\\n\",\n \" padded = sequence + [pad_token_id] * (max_length_common - len(sequence))\\n\",\n \" mask = torch.ones(len(padded)).bool()\\n\",\n \"\\n\",\n \" # Set mask for all padding tokens to False\\n\",\n \" mask[len(sequence):] = False\\n\",\n \"\\n\",\n \" # Set mask for all input tokens to False\\n\",\n \" # +2 sets the 2 newline (\\\"\\\\n\\\") tokens before \\\"### Response\\\" to False\\n\",\n \" if mask_prompt_tokens:\\n\",\n \" mask[:prompt.shape[0]+2] = False\\n\",\n \"\\n\",\n \" batch_data[key].append(torch.tensor(padded))\\n\",\n \" batch_data[f\\\"{key}_mask\\\"].append(mask)\\n\",\n \"\\n\",\n \" # Final processing\\n\",\n \" for key in [\\\"chosen\\\", \\\"rejected\\\", \\\"chosen_mask\\\", \\\"rejected_mask\\\"]:\\n\",\n \" # Stack all sequences into a tensor for the given key\\n\",\n \" tensor_stack = torch.stack(batch_data[key])\\n\",\n \"\\n\",\n \" # Optionally truncate to maximum sequence length\\n\",\n \" if allowed_max_length is not None:\\n\",\n \" tensor_stack = tensor_stack[:, :allowed_max_length]\\n\",\n \"\\n\",\n \" # Move to the specified device\\n\",\n \" batch_data[key] = tensor_stack.to(device)\\n\",\n \"\\n\",\n \" return batch_data\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"76f3744b-9bb0-4f1e-b66b-cff35ad8fd9f\",\n \"metadata\": {\n \"id\": \"76f3744b-9bb0-4f1e-b66b-cff35ad8fd9f\"\n },\n \"source\": [\n \"- Before we start using the custom collate function, let's make version of it with some of its function arguments prefilled:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 14,\n \"id\": \"d3cc137c-7ed7-4758-a518-cc4071b2817a\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"d3cc137c-7ed7-4758-a518-cc4071b2817a\",\n \"outputId\": \"598e9def-9768-441a-f886-01f6ba6e250b\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Device: mps\\n\"\n ]\n }\n ],\n \"source\": [\n \"from functools import partial\\n\",\n \"\\n\",\n \"if torch.cuda.is_available():\\n\",\n \" device = torch.device(\\\"cuda\\\")\\n\",\n \"elif torch.backends.mps.is_available():\\n\",\n \" # Use PyTorch 2.9 or newer for stable mps results\\n\",\n \" major, minor = map(int, torch.__version__.split(\\\".\\\")[:2])\\n\",\n \" if (major, minor) >= (2, 9):\\n\",\n \" device = torch.device(\\\"mps\\\")\\n\",\n \" else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"else:\\n\",\n \" device = torch.device(\\\"cpu\\\")\\n\",\n \"\\n\",\n \"print(\\\"Device:\\\", device)\\n\",\n \"\\n\",\n \"customized_collate_fn = partial(\\n\",\n \" custom_collate_fn,\\n\",\n \" device=device, # Put the data directly on a GPU if available\\n\",\n \" mask_prompt_tokens=True, # This is optional\\n\",\n \" allowed_max_length=1024 # The supported context length of the model\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5d29e996-e267-4348-bc1d-4ac6b725cf6a\",\n \"metadata\": {\n \"id\": \"5d29e996-e267-4348-bc1d-4ac6b725cf6a\"\n },\n \"source\": [\n \"- Now, let's see the `customized_collate_fn` in action and apply it to some sample data from our preference dataset; for this, we take the first two entries:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 15,\n \"id\": \"1171057d-2a0f-48ff-bad6-4917a072f0f5\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"1171057d-2a0f-48ff-bad6-4917a072f0f5\",\n \"outputId\": \"3db3eee8-db29-4ff6-8078-6577a05d953a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"\\n\",\n \"{'instruction': 'Evaluate the following phrase by transforming it into the '\\n\",\n \" 'spelling given.',\\n\",\n \" 'input': 'freind --> friend',\\n\",\n \" 'output': 'The spelling of the given phrase \\\"freind\\\" is incorrect, the '\\n\",\n \" 'correct spelling is \\\"friend\\\".',\\n\",\n \" 'rejected': 'The spelling of the given phrase \\\"freind\\\" is flat out wrong, get '\\n\",\n \" 'it together, the correct spelling is \\\"friend\\\".',\\n\",\n \" 'chosen': 'The spelling of the given phrase \\\"freind\\\" is incorrect, the '\\n\",\n \" 'correct spelling is \\\"friend\\\".'}\\n\",\n \"\\n\",\n \"{'instruction': 'Edit the following sentence for grammar.',\\n\",\n \" 'input': 'He go to the park every day.',\\n\",\n \" 'output': 'He goes to the park every day.',\\n\",\n \" 'rejected': 'He goes to the stupid park every single day.',\\n\",\n \" 'chosen': 'He goes to the park every day.'}\\n\"\n ]\n }\n ],\n \"source\": [\n \"example_data = data[:2]\\n\",\n \"\\n\",\n \"for i in example_data:\\n\",\n \" print()\\n\",\n \" pprint.pp(i)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8f1436cc-fbe5-4581-89d8-1992b5f04042\",\n \"metadata\": {\n \"id\": \"8f1436cc-fbe5-4581-89d8-1992b5f04042\"\n },\n \"source\": [\n \"- Next, let's instantiate an `example_dataset` and use a PyTorch `DataLoader` to create an `example_dataloader` that mimics the data loader we will use for the model training later:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 16,\n \"id\": \"db327575-c34b-4fea-b3c7-e30569c9be78\",\n \"metadata\": {\n \"id\": \"db327575-c34b-4fea-b3c7-e30569c9be78\"\n },\n \"outputs\": [],\n \"source\": [\n \"import tiktoken\\n\",\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"\\n\",\n \"tokenizer = tiktoken.get_encoding(\\\"gpt2\\\")\\n\",\n \"\\n\",\n \"example_dataset = PreferenceDataset(example_data, tokenizer)\\n\",\n \"\\n\",\n \"example_dataloader = DataLoader(\\n\",\n \" example_dataset,\\n\",\n \" batch_size=2,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=False\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"43a446b7-7037-4d9a-9f14-b4ee0f6f37af\",\n \"metadata\": {\n \"id\": \"43a446b7-7037-4d9a-9f14-b4ee0f6f37af\"\n },\n \"source\": [\n \"- The dataset has the following keys:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 17,\n \"id\": \"87ed4cf9-d70a-4bc7-b676-67e76ed3ee10\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"87ed4cf9-d70a-4bc7-b676-67e76ed3ee10\",\n \"outputId\": \"fa724d65-b0e1-4239-8090-9263135ad199\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"batch.keys: dict_keys(['prompt', 'chosen', 'rejected', 'rejected_mask', 'chosen_mask'])\\n\"\n ]\n }\n ],\n \"source\": [\n \"for batch in example_dataloader:\\n\",\n \" break\\n\",\n \"\\n\",\n \"print(\\\"batch.keys:\\\", batch.keys())\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5bda3193-8c68-478c-98d8-0d9d880e7077\",\n \"metadata\": {\n \"id\": \"5bda3193-8c68-478c-98d8-0d9d880e7077\"\n },\n \"source\": [\n \"- The prompts are a list of tensors, where each tensor contains the token IDs for a given example; since we selected a batch size of 2, we have two lists of token ID tensors here:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 18,\n \"id\": \"468995ce-2906-498f-ac99-0a3f80d13d12\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"468995ce-2906-498f-ac99-0a3f80d13d12\",\n \"outputId\": \"7f3df961-fcb5-4e49-9b0c-c99447c67cc1\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"[tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 36, 2100, 4985, 262, 1708, 9546,\\n\",\n \" 416, 25449, 340, 656, 262, 24993, 1813, 13, 198, 198,\\n\",\n \" 21017, 23412, 25, 198, 19503, 521, 14610, 1545]),\\n\",\n \" tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 18378, 262, 1708, 6827, 329, 23491,\\n\",\n \" 13, 198, 198, 21017, 23412, 25, 198, 1544, 467, 284,\\n\",\n \" 262, 3952, 790, 1110, 13])]\"\n ]\n },\n \"execution_count\": 18,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"batch[\\\"prompt\\\"]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"89cadebe-2516-4ae0-a71f-a8a623f2e1da\",\n \"metadata\": {\n \"id\": \"89cadebe-2516-4ae0-a71f-a8a623f2e1da\"\n },\n \"source\": [\n \"- We don't really need the responses for training; what we need to feed to the model during training are the `\\\"chosen\\\"` and `\\\"rejected\\\"` entries\\n\",\n \"- The `\\\"chosen\\\"` and `\\\"rejected\\\"` response entries are padded so that we can stack them as tensors; similar to the prompts, these response texts are encoded into token IDs:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 19,\n \"id\": \"e8f49c56-3989-4fe9-81ac-6bb3cce1a5b8\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"e8f49c56-3989-4fe9-81ac-6bb3cce1a5b8\",\n \"outputId\": \"ccc0bd06-6e85-4ee9-893b-d985f26a835d\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 36, 2100, 4985, 262, 1708, 9546,\\n\",\n \" 416, 25449, 340, 656, 262, 24993, 1813, 13, 198, 198,\\n\",\n \" 21017, 23412, 25, 198, 19503, 521, 14610, 1545, 198, 198,\\n\",\n \" 21017, 18261, 25, 198, 464, 24993, 286, 262, 1813, 9546,\\n\",\n \" 366, 19503, 521, 1, 318, 11491, 11, 262, 3376, 24993,\\n\",\n \" 318, 366, 6726, 1911, 50256, 50256, 50256, 50256, 50256, 50256,\\n\",\n \" 50256],\\n\",\n \" [21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,\\n\",\n \" 257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,\\n\",\n \" 21017, 46486, 25, 198, 18378, 262, 1708, 6827, 329, 23491,\\n\",\n \" 13, 198, 198, 21017, 23412, 25, 198, 1544, 467, 284,\\n\",\n \" 262, 3952, 790, 1110, 13, 198, 198, 21017, 18261, 25,\\n\",\n \" 198, 1544, 2925, 284, 262, 3952, 790, 1110, 13, 50256,\\n\",\n \" 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,\\n\",\n \" 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,\\n\",\n \" 50256]], device='mps:0')\"\n ]\n },\n \"execution_count\": 19,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"batch[\\\"chosen\\\"]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"35a4cd6d-b2ad-45a6-b00a-ba5b720be4ea\",\n \"metadata\": {\n \"id\": \"35a4cd6d-b2ad-45a6-b00a-ba5b720be4ea\"\n },\n \"source\": [\n \"- The token IDs above represent the model inputs, but in this format, they are hard to interpret for us humans\\n\",\n \"- So, let's implement a small utility function to convert them back into text so that we can inspect and interpret them more easily:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 20,\n \"id\": \"52ea54ba-32cb-4ecb-b38b-923f42fd4615\",\n \"metadata\": {\n \"id\": \"52ea54ba-32cb-4ecb-b38b-923f42fd4615\"\n },\n \"outputs\": [],\n \"source\": [\n \"def decode_tokens_from_batch(token_ids, tokenizer):\\n\",\n \" ids_in_python_list = token_ids.flatten().tolist()\\n\",\n \" return tokenizer.decode(ids_in_python_list)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"bc9dd0ce-1fd4-419c-833f-ea5a1f8d800d\",\n \"metadata\": {\n \"id\": \"bc9dd0ce-1fd4-419c-833f-ea5a1f8d800d\"\n },\n \"source\": [\n \"- Let's apply the `decode_tokens_from_batch` utility function to the first prompt entry in the batch:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 21,\n \"id\": \"55ee481e-3e2c-4ff6-b614-8cb18eb16a41\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"55ee481e-3e2c-4ff6-b614-8cb18eb16a41\",\n \"outputId\": \"17ddec15-a09d-45b5-b1e8-600cd59a9600\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Evaluate the following phrase by transforming it into the spelling given.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"freind --> friend\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = decode_tokens_from_batch(\\n\",\n \" token_ids=batch[\\\"prompt\\\"][0], # [0] for the first entry in the batch\\n\",\n \" tokenizer=tokenizer,\\n\",\n \")\\n\",\n \"print(text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"637b95c4-d5c2-4492-9d19-a45b090eee7e\",\n \"metadata\": {\n \"id\": \"637b95c4-d5c2-4492-9d19-a45b090eee7e\"\n },\n \"source\": [\n \"- As we can see above, the prompt was correctly formatted; let's now do the same for the `\\\"chosen\\\"` response:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 22,\n \"id\": \"33a24f20-5ec3-4a89-b57a-52e997163d07\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"33a24f20-5ec3-4a89-b57a-52e997163d07\",\n \"outputId\": \"e04366ee-3719-4b07-fcef-6e9dddc06310\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Evaluate the following phrase by transforming it into the spelling given.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"freind --> friend\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"The spelling of the given phrase \\\"freind\\\" is incorrect, the correct spelling is \\\"friend\\\".<|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|>\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = decode_tokens_from_batch(\\n\",\n \" token_ids=batch[\\\"chosen\\\"][0],\\n\",\n \" tokenizer=tokenizer,\\n\",\n \")\\n\",\n \"print(text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ac9fbdbd-1cff-401f-8e6c-cd98c134c0f2\",\n \"metadata\": {\n \"id\": \"ac9fbdbd-1cff-401f-8e6c-cd98c134c0f2\"\n },\n \"source\": [\n \"- As we can see above, similar to instruction finetuning, the response that is passed to the model during training also contains the input prompt\\n\",\n \"- Also note that we included `<|endoftext|>` tokens as padding tokens, which are necessary so that we can extend the responses to a similar length to stack them as a batch\\n\",\n \"- Don't worry; the `<|endoftext|>` tokens will be ignored in the loss later so that they won't affect the training outcome\\n\",\n \"- Let's now also inspect the corresponding rejected response:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 23,\n \"id\": \"db382be5-c727-4299-8597-c05424ba9308\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"db382be5-c727-4299-8597-c05424ba9308\",\n \"outputId\": \"edbd8c4a-0528-4361-aeba-9b3c3bbde33b\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Evaluate the following phrase by transforming it into the spelling given.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"freind --> friend\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"The spelling of the given phrase \\\"freind\\\" is flat out wrong, get it together, the correct spelling is \\\"friend\\\".<|endoftext|>\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = decode_tokens_from_batch(\\n\",\n \" token_ids=batch[\\\"rejected\\\"][0],\\n\",\n \" tokenizer=tokenizer,\\n\",\n \")\\n\",\n \"print(text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"715dc968-aa64-4388-b577-7c295831bdcf\",\n \"metadata\": {\n \"id\": \"715dc968-aa64-4388-b577-7c295831bdcf\"\n },\n \"source\": [\n \"- In this case, as we can see above, the rejected response is a more impolite version of the chosen response (we don't want the model to generate impolite responses)\\n\",\n \"- Lastly, let's talk about the data masks: if you took a closer look at our custom collate function we implemented above, we created a `\\\"chosen_mask\\\"` and a `\\\"rejected_mask\\\"` for each dataset entry\\n\",\n \"- The masks have the same shape as the response entries, as shown below for the `\\\"chosen\\\"` entry:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 24,\n \"id\": \"5c324eab-cf1d-4071-b3ba-797d8ec4d1da\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"5c324eab-cf1d-4071-b3ba-797d8ec4d1da\",\n \"outputId\": \"742a5742-1bc0-4f74-9eb9-cbf81f936ecb\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"chosen inputs: torch.Size([81])\\n\",\n \"chosen mask: torch.Size([81])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"chosen inputs:\\\", batch[\\\"chosen\\\"][0].shape)\\n\",\n \"print(\\\"chosen mask: \\\", batch[\\\"chosen_mask\\\"][0].shape)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"880e95f7-cfc3-4f5f-be5e-c279fba5f674\",\n \"metadata\": {\n \"id\": \"880e95f7-cfc3-4f5f-be5e-c279fba5f674\"\n },\n \"source\": [\n \"- The contents of these masks are boolean (`True` and `False`) values:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 25,\n \"id\": \"da75b550-5da4-4292-9a7e-a05b842bdcb7\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"da75b550-5da4-4292-9a7e-a05b842bdcb7\",\n \"outputId\": \"e5f012c3-33ba-4e6b-aa55-3e331865218f\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([False, False, False, False, False, False, False, False, False, False,\\n\",\n \" False, False, False, False, False, False, False, False, False, False,\\n\",\n \" False, False, False, False, False, False, False, False, False, False,\\n\",\n \" False, False, False, False, False, False, False, False, False, False,\\n\",\n \" False, False, False, False, False, False, False, False, False, False,\\n\",\n \" True, True, True, True, True, True, True, True, True, True,\\n\",\n \" True, True, True, True, True, True, True, True, True, True,\\n\",\n \" True, True, True, True, False, False, False, False, False, False,\\n\",\n \" False], device='mps:0')\"\n ]\n },\n \"execution_count\": 25,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"batch[\\\"chosen_mask\\\"][0]\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0e67b862-4430-4c99-9157-90955dde29b6\",\n \"metadata\": {\n \"id\": \"0e67b862-4430-4c99-9157-90955dde29b6\"\n },\n \"source\": [\n \"- The `True` values denote token IDs that correspond to the actual response\\n\",\n \"- the `False` tokens correspond to token IDs that correspond to either prompt tokens (if we set `mask_prompt_tokens=True` in the `customized_collate_fn` function, which we previously did) or padding tokens\\n\",\n \"- Hence, we can use the mask as a selection mask to select only the token IDs that correspond to the response, that is, stripping all prompt and padding tokens, as we can see below:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 26,\n \"id\": \"1114c6fe-524b-401c-b9fe-02260e6f0541\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"1114c6fe-524b-401c-b9fe-02260e6f0541\",\n \"outputId\": \"6d99af1d-940a-4012-c5d9-21d463a66e40\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"### Response:\\n\",\n \"The spelling of the given phrase \\\"freind\\\" is incorrect, the correct spelling is \\\"friend\\\".\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = decode_tokens_from_batch(\\n\",\n \" token_ids=batch[\\\"chosen\\\"][0][batch[\\\"chosen_mask\\\"][0]],\\n\",\n \" tokenizer=tokenizer,\\n\",\n \")\\n\",\n \"print(text)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 27,\n \"id\": \"a89f83a4-d16e-40d2-ba43-bd410affd967\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"a89f83a4-d16e-40d2-ba43-bd410affd967\",\n \"outputId\": \"1d439c7e-c079-4594-d02a-fa83a3cb275d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"### Response:\\n\",\n \"The spelling of the given phrase \\\"freind\\\" is flat out wrong, get it together, the correct spelling is \\\"friend\\\".\\n\"\n ]\n }\n ],\n \"source\": [\n \"text = decode_tokens_from_batch(\\n\",\n \" token_ids=batch[\\\"rejected\\\"][0][batch[\\\"rejected_mask\\\"][0]],\\n\",\n \" tokenizer=tokenizer,\\n\",\n \")\\n\",\n \"print(text)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"e525287f-137c-4d71-94ae-cfd6db7b057c\",\n \"metadata\": {\n \"id\": \"e525287f-137c-4d71-94ae-cfd6db7b057c\"\n },\n \"source\": [\n \"- We will make use of this mask to ignore prompt and padding tokens when computing the DPO loss later\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"jbafhM_R8z5q\",\n \"metadata\": {\n \"id\": \"jbafhM_R8z5q\"\n },\n \"source\": [\n \" \\n\",\n \"## 2.4 Creating training, validation, and test set data loaders\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b3c29eb8-d1b9-4abe-a155-52b3270d759a\",\n \"metadata\": {\n \"id\": \"b3c29eb8-d1b9-4abe-a155-52b3270d759a\"\n },\n \"source\": [\n \"- Above, we worked with a small example subsets from the preference dataset for illustration purposes\\n\",\n \"- Let's now create the actual training, validation, and test set data loaders\\n\",\n \"- This process is identical to creating the data loaders in the pretraining and instruction finetuning chapters and thus should be self-explanatory\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 28,\n \"id\": \"5c0068bf-bda0-4d9e-9f79-2fc4b94cbd1c\",\n \"metadata\": {\n \"id\": \"5c0068bf-bda0-4d9e-9f79-2fc4b94cbd1c\"\n },\n \"outputs\": [],\n \"source\": [\n \"from torch.utils.data import DataLoader\\n\",\n \"\\n\",\n \"\\n\",\n \"num_workers = 0\\n\",\n \"batch_size = 8\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"train_dataset = PreferenceDataset(train_data, tokenizer)\\n\",\n \"train_loader = DataLoader(\\n\",\n \" train_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=True,\\n\",\n \" drop_last=True,\\n\",\n \" num_workers=num_workers\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 29,\n \"id\": \"2f4a257b-6835-4194-abe2-5831d6a44885\",\n \"metadata\": {\n \"id\": \"2f4a257b-6835-4194-abe2-5831d6a44885\"\n },\n \"outputs\": [],\n \"source\": [\n \"val_dataset = PreferenceDataset(val_data, tokenizer)\\n\",\n \"val_loader = DataLoader(\\n\",\n \" val_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=False,\\n\",\n \" drop_last=False,\\n\",\n \" num_workers=num_workers\\n\",\n \")\\n\",\n \"\\n\",\n \"test_dataset = PreferenceDataset(test_data, tokenizer)\\n\",\n \"test_loader = DataLoader(\\n\",\n \" test_dataset,\\n\",\n \" batch_size=batch_size,\\n\",\n \" collate_fn=customized_collate_fn,\\n\",\n \" shuffle=False,\\n\",\n \" drop_last=False,\\n\",\n \" num_workers=num_workers\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"1fe1ba19-a6d5-4a77-8283-7a17d7ec06e2\",\n \"metadata\": {\n \"id\": \"1fe1ba19-a6d5-4a77-8283-7a17d7ec06e2\"\n },\n \"source\": [\n \"- Let's iterate through the data loader and take a look at the dataset shapes:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 30,\n \"id\": \"80d61f15-facb-4eb8-a9be-6427887d24b2\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"80d61f15-facb-4eb8-a9be-6427887d24b2\",\n \"outputId\": \"dacd3bdf-f069-4b36-da2c-d6c1c6cc5405\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Train loader:\\n\",\n \"torch.Size([8, 77]) torch.Size([8, 77])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 94]) torch.Size([8, 94])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 99]) torch.Size([8, 99])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 88]) torch.Size([8, 88])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 97]) torch.Size([8, 97])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 89]) torch.Size([8, 89])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 84]) torch.Size([8, 84])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 101]) torch.Size([8, 101])\\n\",\n \"torch.Size([8, 87]) torch.Size([8, 87])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 91]) torch.Size([8, 91])\\n\",\n \"torch.Size([8, 78]) torch.Size([8, 78])\\n\",\n \"torch.Size([8, 78]) torch.Size([8, 78])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 84]) torch.Size([8, 84])\\n\",\n \"torch.Size([8, 92]) torch.Size([8, 92])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 78]) torch.Size([8, 78])\\n\",\n \"torch.Size([8, 66]) torch.Size([8, 66])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 100]) torch.Size([8, 100])\\n\",\n \"torch.Size([8, 77]) torch.Size([8, 77])\\n\",\n \"torch.Size([8, 92]) torch.Size([8, 92])\\n\",\n \"torch.Size([8, 93]) torch.Size([8, 93])\\n\",\n \"torch.Size([8, 115]) torch.Size([8, 115])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 95]) torch.Size([8, 95])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 94]) torch.Size([8, 94])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\",\n \"torch.Size([8, 89]) torch.Size([8, 89])\\n\",\n \"torch.Size([8, 90]) torch.Size([8, 90])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\",\n \"torch.Size([8, 85]) torch.Size([8, 85])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 84]) torch.Size([8, 84])\\n\",\n \"torch.Size([8, 84]) torch.Size([8, 84])\\n\",\n \"torch.Size([8, 65]) torch.Size([8, 65])\\n\",\n \"torch.Size([8, 63]) torch.Size([8, 63])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 93]) torch.Size([8, 93])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 99]) torch.Size([8, 99])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 77]) torch.Size([8, 77])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 73]) torch.Size([8, 73])\\n\",\n \"torch.Size([8, 87]) torch.Size([8, 87])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 75]) torch.Size([8, 75])\\n\",\n \"torch.Size([8, 81]) torch.Size([8, 81])\\n\",\n \"torch.Size([8, 86]) torch.Size([8, 86])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 63]) torch.Size([8, 63])\\n\",\n \"torch.Size([8, 82]) torch.Size([8, 82])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 68]) torch.Size([8, 68])\\n\",\n \"torch.Size([8, 97]) torch.Size([8, 97])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 85]) torch.Size([8, 85])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 85]) torch.Size([8, 85])\\n\",\n \"torch.Size([8, 87]) torch.Size([8, 87])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 74]) torch.Size([8, 74])\\n\",\n \"torch.Size([8, 92]) torch.Size([8, 92])\\n\",\n \"torch.Size([8, 85]) torch.Size([8, 85])\\n\",\n \"torch.Size([8, 72]) torch.Size([8, 72])\\n\",\n \"torch.Size([8, 93]) torch.Size([8, 93])\\n\",\n \"torch.Size([8, 82]) torch.Size([8, 82])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 93]) torch.Size([8, 93])\\n\",\n \"torch.Size([8, 80]) torch.Size([8, 80])\\n\",\n \"torch.Size([8, 87]) torch.Size([8, 87])\\n\",\n \"torch.Size([8, 69]) torch.Size([8, 69])\\n\",\n \"torch.Size([8, 90]) torch.Size([8, 90])\\n\",\n \"torch.Size([8, 99]) torch.Size([8, 99])\\n\",\n \"torch.Size([8, 104]) torch.Size([8, 104])\\n\",\n \"torch.Size([8, 101]) torch.Size([8, 101])\\n\",\n \"torch.Size([8, 98]) torch.Size([8, 98])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 71]) torch.Size([8, 71])\\n\",\n \"torch.Size([8, 76]) torch.Size([8, 76])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 79]) torch.Size([8, 79])\\n\",\n \"torch.Size([8, 67]) torch.Size([8, 67])\\n\",\n \"torch.Size([8, 84]) torch.Size([8, 84])\\n\",\n \"torch.Size([8, 78]) torch.Size([8, 78])\\n\",\n \"torch.Size([8, 85]) torch.Size([8, 85])\\n\",\n \"torch.Size([8, 70]) torch.Size([8, 70])\\n\"\n ]\n }\n ],\n \"source\": [\n \"print(\\\"Train loader:\\\")\\n\",\n \"for batch in train_loader:\\n\",\n \" print(\\n\",\n \" batch[\\\"chosen\\\"].shape,\\n\",\n \" batch[\\\"rejected\\\"].shape,\\n\",\n \" )\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"7ff958a6-5e61-49f5-9a97-360aa34e3758\",\n \"metadata\": {\n \"id\": \"7ff958a6-5e61-49f5-9a97-360aa34e3758\"\n },\n \"source\": [\n \"- Each row shows the shape of the `\\\"chosen\\\"` and `\\\"rejected\\\"` entries in each batch\\n\",\n \"- Since we applied padding on a batch-by-batch basis, each row has a different shape\\n\",\n \"- This is for efficiency reasons because it would be inefficient to pad all samples to the longest sample in the whole dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"29cb0543-1142-4374-8825-3384e20c6ac0\",\n \"metadata\": {\n \"id\": \"29cb0543-1142-4374-8825-3384e20c6ac0\"\n },\n \"source\": [\n \" \\n\",\n \"# 3) Loading a finetuned LLM for DPO alignment\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"22b08881-b769-4b26-8153-5ec0e8573ed2\",\n \"metadata\": {\n \"id\": \"22b08881-b769-4b26-8153-5ec0e8573ed2\"\n },\n \"source\": [\n \"- LLM alignment steps, such as RLHF or DPO, assume that we already have an instruction-finetuned model\\n\",\n \"- This section contains minimal code to load the model that was instruction finetuned and saved in chapter 7 (via [../01_main-chapter-code/ch07.ipynb](../01_main-chapter-code/ch07.ipynb))\\n\",\n \"- Make sure you run the chapter 7 code first to create the instruction-finetuned model before you proceed\\n\",\n \"- The code below will copy the instruction-finetuned model into the current directory:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"id\": \"b3c6d82b-63f7-459a-b901-7125ab225e56\",\n \"metadata\": {\n \"id\": \"b3c6d82b-63f7-459a-b901-7125ab225e56\"\n },\n \"outputs\": [],\n \"source\": [\n \"from pathlib import Path\\n\",\n \"import shutil\\n\",\n \"\\n\",\n \"\\n\",\n \"finetuned_model_path = Path(\\\"gpt2-medium355M-sft.pth\\\")\\n\",\n \"if not finetuned_model_path.exists():\\n\",\n \"\\n\",\n \" # Try finding the model checkpoint locally:\\n\",\n \" relative_path = Path(\\\"..\\\") / \\\"01_main-chapter-code\\\" / finetuned_model_path\\n\",\n \" if relative_path.exists():\\n\",\n \" shutil.copy(relative_path, \\\".\\\")\\n\",\n \"\\n\",\n \" # If this notebook is run on Google Colab, get it from a Google Drive folder\\n\",\n \" elif \\\"COLAB_GPU\\\" in os.environ or \\\"COLAB_TPU_ADDR\\\" in os.environ:\\n\",\n \" from google.colab import drive\\n\",\n \" drive.mount(\\\"/content/drive\\\")\\n\",\n \" google_drive_path = \\\"/content/drive/My Drive/Books/LLMs-From-Scratch/ch07/colab/gpt2-medium355M-sft.pth\\\" # Readers need to adjust this path\\n\",\n \" shutil.copy(google_drive_path, \\\".\\\")\\n\",\n \"\\n\",\n \" else:\\n\",\n \" print(\\n\",\n \" f\\\"Could not find '{finetuned_model_path}'.\\\\n\\\"\\n\",\n \" \\\"Run the `ch07.ipynb` notebook to finetune and save the finetuned model.\\\"\\n\",\n \" )\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"71c8585e-4569-4033-84a7-3903d0e8aaf8\",\n \"metadata\": {\n \"id\": \"71c8585e-4569-4033-84a7-3903d0e8aaf8\"\n },\n \"source\": [\n \"- Next, we reuse the basic configuration from previous chapters to load the model weights:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 32,\n \"id\": \"a8333fee-e7fe-4f8c-9411-8c1db6252d98\",\n \"metadata\": {\n \"id\": \"a8333fee-e7fe-4f8c-9411-8c1db6252d98\"\n },\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import GPTModel\\n\",\n \"# If the `previous_chapters.py` file is not available locally,\\n\",\n \"# you can import it from the `llms-from-scratch` PyPI package.\\n\",\n \"# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg\\n\",\n \"# E.g.,\\n\",\n \"# from llms_from_scratch.ch04 import GPTModel\\n\",\n \"\\n\",\n \"\\n\",\n \"BASE_CONFIG = {\\n\",\n \" \\\"vocab_size\\\": 50257, # Vocabulary size\\n\",\n \" \\\"context_length\\\": 1024, # Context length\\n\",\n \" \\\"drop_rate\\\": 0.0, # Dropout rate\\n\",\n \" \\\"qkv_bias\\\": True # Query-key-value bias\\n\",\n \"}\\n\",\n \"\\n\",\n \"model_configs = {\\n\",\n \" \\\"gpt2-small (124M)\\\": {\\\"emb_dim\\\": 768, \\\"n_layers\\\": 12, \\\"n_heads\\\": 12},\\n\",\n \" \\\"gpt2-medium (355M)\\\": {\\\"emb_dim\\\": 1024, \\\"n_layers\\\": 24, \\\"n_heads\\\": 16},\\n\",\n \" \\\"gpt2-large (774M)\\\": {\\\"emb_dim\\\": 1280, \\\"n_layers\\\": 36, \\\"n_heads\\\": 20},\\n\",\n \" \\\"gpt2-xl (1558M)\\\": {\\\"emb_dim\\\": 1600, \\\"n_layers\\\": 48, \\\"n_heads\\\": 25},\\n\",\n \"}\\n\",\n \"\\n\",\n \"CHOOSE_MODEL = \\\"gpt2-medium (355M)\\\"\\n\",\n \"\\n\",\n \"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\\n\",\n \"\\n\",\n \"model = GPTModel(BASE_CONFIG)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 33,\n \"id\": \"c2821403-605c-4071-a4ff-e23f4c9a11fd\",\n \"metadata\": {\n \"id\": \"c2821403-605c-4071-a4ff-e23f4c9a11fd\"\n },\n \"outputs\": [],\n \"source\": [\n \"model.load_state_dict(\\n\",\n \" torch.load(\\n\",\n \" \\\"gpt2-medium355M-sft.pth\\\",\\n\",\n \" map_location=torch.device(\\\"cpu\\\"),\\n\",\n \" weights_only=True\\n\",\n \" )\\n\",\n \")\\n\",\n \"model.eval();\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"61863bec-bd42-4194-b994-645bfe2df8be\",\n \"metadata\": {\n \"id\": \"61863bec-bd42-4194-b994-645bfe2df8be\"\n },\n \"source\": [\n \"- Before training the loaded model with DPO, let's make sure that the finetuned model was saved and loaded correctly by trying it out on some sample data:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 34,\n \"id\": \"4357aec5-0db2-4d73-b37b-539cd8fa80a3\",\n \"metadata\": {\n \"id\": \"4357aec5-0db2-4d73-b37b-539cd8fa80a3\"\n },\n \"outputs\": [],\n \"source\": [\n \"prompt = \\\"\\\"\\\"Below is an instruction that describes a task. Write a response\\n\",\n \"that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Convert the active sentence to passive: 'The chef cooks the meal every day.'\\n\",\n \"\\\"\\\"\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 35,\n \"id\": \"541e7988-38d3-47f6-bd52-9da6564479fa\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"541e7988-38d3-47f6-bd52-9da6564479fa\",\n \"outputId\": \"278f7ddf-37c2-4c3a-d069-c510ef6f8d7a\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response\\n\",\n \"that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Convert the active sentence to passive: 'The chef cooks the meal every day.'\\n\",\n \"\\n\",\n \"### Response:\\n\",\n \"The meal is cooked every day by the chef.\\n\"\n ]\n }\n ],\n \"source\": [\n \"from previous_chapters import (\\n\",\n \" generate,\\n\",\n \" text_to_token_ids,\\n\",\n \" token_ids_to_text\\n\",\n \")\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch05 (\\n\",\n \"# generate,\\n\",\n \"# text_to_token_ids,\\n\",\n \"# token_ids_to_text\\n\",\n \"# )\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(prompt, tokenizer),\\n\",\n \" max_new_tokens=35,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"],\\n\",\n \" eos_id=50256\\n\",\n \")\\n\",\n \"\\n\",\n \"response = token_ids_to_text(token_ids, tokenizer)\\n\",\n \"print(response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"be87ed19-fded-4e56-8585-6c7c0367b354\",\n \"metadata\": {\n \"id\": \"be87ed19-fded-4e56-8585-6c7c0367b354\"\n },\n \"source\": [\n \"- As we can see above, the model gives a reasonable and correct response\\n\",\n \"- As explained in chapter 7, in practice, we would clean up the response to only return the response text with the prompt and prompt style removed (similar to what you are familiar with from ChatGPT, for example):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 36,\n \"id\": \"0c30c4e2-af84-4ab4-95d0-9641e32c1e7f\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"0c30c4e2-af84-4ab4-95d0-9641e32c1e7f\",\n \"outputId\": \"70192bbe-fdf6-43eb-c673-f573f8c70156\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"The meal is cooked every day by the chef.\\n\"\n ]\n }\n ],\n \"source\": [\n \"def extract_response(response_text, input_text):\\n\",\n \" return response_text[len(input_text):].replace(\\\"### Response:\\\", \\\"\\\").strip()\\n\",\n \"\\n\",\n \"response = extract_response(response, prompt)\\n\",\n \"print(response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"80442cb9-83b1-46b8-bad0-7d44297ca52d\",\n \"metadata\": {\n \"id\": \"80442cb9-83b1-46b8-bad0-7d44297ca52d\"\n },\n \"source\": [\n \"- Now, we are almost ready to get to the DPO part\\n\",\n \"- As mentioned at the beginning of this notebook, DPO works with two LLMs: a policy model (the LLM that we want to optimize) and a reference model (the original model that we keep unchanged)\\n\",\n \"- Below, we rename the `model` as `policy_model` and instantiate a second instance of the model we refer to as the `reference_model`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 37,\n \"id\": \"5d88cc3a-312e-4b29-bc6d-de8354c1eb9f\",\n \"metadata\": {\n \"id\": \"5d88cc3a-312e-4b29-bc6d-de8354c1eb9f\"\n },\n \"outputs\": [],\n \"source\": [\n \"policy_model = model\\n\",\n \"\\n\",\n \"reference_model = GPTModel(BASE_CONFIG)\\n\",\n \"reference_model.load_state_dict(\\n\",\n \" torch.load(\\n\",\n \" \\\"gpt2-medium355M-sft.pth\\\",\\n\",\n \" map_location=torch.device(\\\"cpu\\\"),\\n\",\n \" weights_only=True\\n\",\n \" )\\n\",\n \")\\n\",\n \"reference_model.eval()\\n\",\n \"\\n\",\n \"policy_model.to(device)\\n\",\n \"reference_model.to(device);\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"9c6c1469-0038-4914-8aa5-15b1f81877cc\",\n \"metadata\": {\n \"id\": \"9c6c1469-0038-4914-8aa5-15b1f81877cc\"\n },\n \"source\": [\n \" \\n\",\n \"# 4) Coding the DPO Loss Function\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"75dbe60c-e4ce-413e-beec-22eff0237d11\",\n \"metadata\": {\n \"id\": \"75dbe60c-e4ce-413e-beec-22eff0237d11\"\n },\n \"source\": [\n \"- After we took care of the model loading and dataset preparation in the previous sections, we can now get to the fun part and code the DPO loss\\n\",\n \"- Note that the DPO loss code below is based on the method proposed in the [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://arxiv.org/abs/2305.18290) paper\\n\",\n \"- For reference, the core DPO equation is shown again below:\\n\",\n \"\\n\",\n \"\\n\",\n \"\\n\",\n \"- In the equation above,\\n\",\n \" - \\\"expected value\\\" $\\\\mathbb{E}$ is statistics jargon and stands for the average or mean value of the random variable (the expression inside the brackets); optimizing $-\\\\mathbb{E}$ aligns the model better with user preferences\\n\",\n \" - The $\\\\pi_{\\\\theta}$ variable is the so-called policy (a term borrowed from reinforcement learning) and represents the LLM we want to optimize; $\\\\pi_{ref}$ is a reference LLM, which is typically the original LLM before optimization (at the beginning of the training, $\\\\pi_{\\\\theta}$ and $\\\\pi_{ref}$ are typically the same)\\n\",\n \" - $\\\\beta$ is a hyperparameter to control the divergence between the $\\\\pi_{\\\\theta}$ and the reference model; increasing $\\\\beta$ increases the impact of the difference between\\n\",\n \"$\\\\pi_{\\\\theta}$ and $\\\\pi_{ref}$ in terms of their log probabilities on the overall loss function, thereby increasing the divergence between the two models\\n\",\n \" - the logistic sigmoid function, $\\\\sigma(\\\\centerdot)$ transforms the log-odds of the preferred and rejected responses (the terms inside the logistic sigmoid function) into a probability score \\n\",\n \"- In code, we can implement the DPO loss as follows:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 38,\n \"id\": \"38CsrrwJIZiV\",\n \"metadata\": {\n \"id\": \"38CsrrwJIZiV\"\n },\n \"outputs\": [],\n \"source\": [\n \"import torch.nn.functional as F\\n\",\n \"\\n\",\n \"def compute_dpo_loss(\\n\",\n \" model_chosen_logprobs,\\n\",\n \" model_rejected_logprobs,\\n\",\n \" reference_chosen_logprobs,\\n\",\n \" reference_rejected_logprobs,\\n\",\n \" beta=0.1,\\n\",\n \" ):\\n\",\n \" \\\"\\\"\\\"Compute the DPO loss for a batch of policy and reference model log probabilities.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" model_chosen_logprobs: Log probabilities of the policy model for the chosen responses. Shape: (batch_size,)\\n\",\n \" model_rejected_logprobs: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)\\n\",\n \" reference_chosen_logprobs: Log probabilities of the reference model for the chosen responses. Shape: (batch_size,)\\n\",\n \" reference_rejected_logprobs: Log probabilities of the reference model for the rejected responses. Shape: (batch_size,)\\n\",\n \" beta: Temperature parameter for the DPO loss; typically something in the range of 0.1 to 0.5. We ignore the reference model as beta -> 0.\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" A tuple of three tensors: (loss, chosen_rewards, rejected_rewards).\\n\",\n \" \\\"\\\"\\\"\\n\",\n \"\\n\",\n \" model_logratios = model_chosen_logprobs - model_rejected_logprobs\\n\",\n \" reference_logratios = reference_chosen_logprobs - reference_rejected_logprobs\\n\",\n \" logits = model_logratios - reference_logratios\\n\",\n \"\\n\",\n \" # DPO (Eq. 7 of https://arxiv.org/pdf/2305.18290.pdf)\\n\",\n \" losses = -F.logsigmoid(beta * logits)\\n\",\n \"\\n\",\n \" # Optional values to track progress during training\\n\",\n \" chosen_rewards = (model_chosen_logprobs - reference_chosen_logprobs).detach()\\n\",\n \" rejected_rewards = (model_rejected_logprobs - reference_rejected_logprobs).detach()\\n\",\n \"\\n\",\n \" # .mean() to average over the samples in the batch\\n\",\n \" return losses.mean(), chosen_rewards.mean(), rejected_rewards.mean()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"693be65b-38fc-4d18-bf53-a260a15436e1\",\n \"metadata\": {\n \"id\": \"693be65b-38fc-4d18-bf53-a260a15436e1\"\n },\n \"source\": [\n \"- If you are familiar with logarithms, note that we have the general relationship $\\\\log\\\\left(\\\\frac{a}{b}\\\\right) = \\\\log a - \\\\log b$, which we applied in the code above\\n\",\n \"- Keeping this in mind, let's go through some of the steps (we will calculate the `logprobs` using a separate function later)\\n\",\n \"- Let's start with the lines\\n\",\n \"\\n\",\n \" ```python\\n\",\n \" model_logratios = model_chosen_logprobs - model_rejected_logprobs\\n\",\n \" reference_logratios = reference_chosen_logprobs - reference_rejected_logprobs\\n\",\n \" ```\\n\",\n \"\\n\",\n \"- These lines above calculate the difference in log probabilities (logits) for the chosen and rejected samples for both the policy model and the reference model (this is due to $\\\\log\\\\left(\\\\frac{a}{b}\\\\right) = \\\\log a - \\\\log b$):\\n\",\n \"\\n\",\n \"$$\\\\log \\\\left( \\\\frac{\\\\pi_\\\\theta (y_w \\\\mid x)}{\\\\pi_\\\\theta (y_l \\\\mid x)} \\\\right) \\\\quad \\\\text{and} \\\\quad \\\\log \\\\left( \\\\frac{\\\\pi_{\\\\text{ref}}(y_w \\\\mid x)}{\\\\pi_{\\\\text{ref}}(y_l \\\\mid x)} \\\\right)$$\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"5458d217-e0ad-40a5-925c-507a8fcf5795\",\n \"metadata\": {\n \"id\": \"5458d217-e0ad-40a5-925c-507a8fcf5795\"\n },\n \"source\": [\n \"- Next, the code `logits = model_logratios - reference_logratios` computes the difference between the model's log ratios and the reference model's log ratios, i.e., \\n\",\n \"\\n\",\n \"$$\\\\beta \\\\log \\\\left( \\\\frac{\\\\pi_\\\\theta (y_w \\\\mid x)}{\\\\pi_{\\\\text{ref}} (y_w \\\\mid x)} \\\\right)\\n\",\n \"- \\\\beta \\\\log \\\\left( \\\\frac{\\\\pi_\\\\theta (y_l \\\\mid x)}{\\\\pi_{\\\\text{ref}} (y_l \\\\mid x)} \\\\right)$$\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f18e3e36-f5f1-407f-b662-4c20a0ac0354\",\n \"metadata\": {\n \"id\": \"f18e3e36-f5f1-407f-b662-4c20a0ac0354\"\n },\n \"source\": [\n \"- Finally, `losses = -F.logsigmoid(beta * logits)` calculates the loss using the log-sigmoid function; in the original equation, the term inside the expectation is \\n\",\n \"\\n\",\n \"$$\\\\log \\\\sigma \\\\left( \\\\beta \\\\log \\\\left( \\\\frac{\\\\pi_\\\\theta (y_w \\\\mid x)}{\\\\pi_{\\\\text{ref}} (y_w \\\\mid x)} \\\\right)\\n\",\n \"- \\\\beta \\\\log \\\\left( \\\\frac{\\\\pi_\\\\theta (y_l \\\\mid x)}{\\\\pi_{\\\\text{ref}} (y_l \\\\mid x)} \\\\right) \\\\right)$$\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"00a6f92d-7d64-41fe-bcaa-2bddd46027e1\",\n \"metadata\": {\n \"id\": \"00a6f92d-7d64-41fe-bcaa-2bddd46027e1\"\n },\n \"source\": [\n \"- Above, we assumed that the log probabilities were already computed; let's now define a `compute_logprobs` function that we can use to compute these log probabilities that were passed into the `compute_dpo_loss` function above, that is, the values $\\\\pi_\\\\theta (y_w \\\\mid x)$, ${\\\\pi_\\\\theta (y_l \\\\mid x)}$, and so forth:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 39,\n \"id\": \"71e6507b-d2e2-4469-86b9-f057b08b5df9\",\n \"metadata\": {\n \"id\": \"71e6507b-d2e2-4469-86b9-f057b08b5df9\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_logprobs(logits, labels, selection_mask=None):\\n\",\n \" \\\"\\\"\\\"\\n\",\n \" Compute log probabilities.\\n\",\n \"\\n\",\n \" Args:\\n\",\n \" logits: Tensor of shape (batch_size, num_tokens, vocab_size)\\n\",\n \" labels: Tensor of shape (batch_size, num_tokens)\\n\",\n \" selection_mask: Tensor for shape (batch_size, num_tokens)\\n\",\n \"\\n\",\n \" Returns:\\n\",\n \" mean_log_prob: Mean log probability excluding padding tokens.\\n\",\n \" \\\"\\\"\\\"\\n\",\n \"\\n\",\n \" # Labels are the inputs shifted by one\\n\",\n \" labels = labels[:, 1:].clone()\\n\",\n \"\\n\",\n \" # Truncate logits to match the labels num_tokens\\n\",\n \" logits = logits[:, :-1, :]\\n\",\n \"\\n\",\n \" log_probs = F.log_softmax(logits, dim=-1)\\n\",\n \"\\n\",\n \" # Gather the log probabilities for the actual labels\\n\",\n \" selected_log_probs = torch.gather(\\n\",\n \" input=log_probs,\\n\",\n \" dim=-1,\\n\",\n \" index=labels.unsqueeze(-1)\\n\",\n \" ).squeeze(-1)\\n\",\n \"\\n\",\n \" if selection_mask is not None:\\n\",\n \" mask = selection_mask[:, 1:].clone()\\n\",\n \"\\n\",\n \" # Apply the mask to filter out padding tokens\\n\",\n \" selected_log_probs = selected_log_probs * mask\\n\",\n \"\\n\",\n \" # Calculate the average log probability excluding padding tokens\\n\",\n \" # This averages over the tokens, so the shape is (batch_size,)\\n\",\n \" avg_log_prob = selected_log_probs.sum(-1) / mask.sum(-1)\\n\",\n \"\\n\",\n \" return avg_log_prob\\n\",\n \"\\n\",\n \" else:\\n\",\n \" return selected_log_probs.mean(-1)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cf6a71ac-3fcc-44a4-befc-1c56bbd378d7\",\n \"metadata\": {\n \"id\": \"cf6a71ac-3fcc-44a4-befc-1c56bbd378d7\"\n },\n \"source\": [\n \"- Note that this function above might look a bit intimidating at first due to the `torch.gather` function, but it's pretty similar to what happens under the hood in PyTorch's `cross_entropy` function\\n\",\n \"- For example, consider the following example:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 40,\n \"id\": \"59873470-464d-4be2-860f-cbb7ac2d80ba\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"59873470-464d-4be2-860f-cbb7ac2d80ba\",\n \"outputId\": \"8f7b47d4-73fe-4605-c17d-ad6cfd909a9b\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"tensor(1.4185) tensor(1.4185)\\n\"\n ]\n }\n ],\n \"source\": [\n \"# Sample data\\n\",\n \"logits = torch.tensor(\\n\",\n \" [[2.0, 1.0, 0.1],\\n\",\n \" [0.5, 2.5, 0.3]]) # Shape: (2, 3)\\n\",\n \"targets = torch.tensor([0, 2]) # Shape: (2,)\\n\",\n \"\\n\",\n \"\\n\",\n \"# Manual loss using torch.gather\\n\",\n \"log_softmax_logits = F.log_softmax(logits, dim=1) # Shape: (2, 3)\\n\",\n \"selected_log_probs = torch.gather(\\n\",\n \" input=log_softmax_logits,\\n\",\n \" dim=1,\\n\",\n \" index=targets.unsqueeze(1), # Shape 2, 1\\n\",\n \").squeeze(1) # Shape: (2,)\\n\",\n \"manual_loss = -selected_log_probs.mean() # Averaging over the batch\\n\",\n \"\\n\",\n \"\\n\",\n \"# PyTorch loss\\n\",\n \"cross_entropy_loss = F.cross_entropy(logits, targets)\\n\",\n \"\\n\",\n \"print(manual_loss, cross_entropy_loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"f86d7add-f7ff-4a87-9193-7878c42bf0e7\",\n \"metadata\": {\n \"id\": \"f86d7add-f7ff-4a87-9193-7878c42bf0e7\"\n },\n \"source\": [\n \"- So, above, we can see that the two implementations are equivalent, but let's narrow down a bit further to the `torch.gather` mechanics\\n\",\n \"- Consider the following two tensors:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 41,\n \"id\": \"508db6ba-cc40-479f-a996-2250cf862388\",\n \"metadata\": {\n \"id\": \"508db6ba-cc40-479f-a996-2250cf862388\"\n },\n \"outputs\": [],\n \"source\": [\n \"t = torch.tensor(\\n\",\n \" [[1., 2.,],\\n\",\n \" [3., 4.]]\\n\",\n \")\\n\",\n \"\\n\",\n \"m = torch.tensor(\\n\",\n \" [[1, 1],\\n\",\n \" [0, 1]]\\n\",\n \")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"821cbf45-8fbb-47b7-bae8-6c3271e36979\",\n \"metadata\": {\n \"id\": \"821cbf45-8fbb-47b7-bae8-6c3271e36979\"\n },\n \"source\": [\n \"- Above, `t` is a tensor we want to select from, and `m` is a mask to specify how we want to select\\n\",\n \" - For instance, since `m` contains `[1, 1]` n the first row, it will select two times the value of `t` in index position `1`, which is the value 2.\\n\",\n \" - The second row of `m`, `[0, 1]`, selects index positions 0 and 1 in the second row or `t`, which are `3.` and `4.`\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 42,\n \"id\": \"4fdN5q1YPAbM\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"4fdN5q1YPAbM\",\n \"outputId\": \"e935e8ad-1519-4c4b-dbff-65adae0a15a4\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"tensor([[2., 2.],\\n\",\n \" [3., 4.]])\"\n ]\n },\n \"execution_count\": 42,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"torch.gather(input=t, dim=-1, index=m)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d10eeaf4-f24b-4e79-916a-abedf74fe4a3\",\n \"metadata\": {\n \"id\": \"d10eeaf4-f24b-4e79-916a-abedf74fe4a3\"\n },\n \"source\": [\n \"- In other words, `torch.gather` is a selection function\\n\",\n \"- When we computed the loss earlier, we used it to retrieve the log probabilities corresponding to the correct token in the 50,257-token vocabulary\\n\",\n \"- The \\\"correct\\\" tokens are the tokens given in the response entry\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"d5d10a43-ee5b-47ed-9d55-ddd96e66cf0b\",\n \"metadata\": {\n \"id\": \"d5d10a43-ee5b-47ed-9d55-ddd96e66cf0b\"\n },\n \"source\": [\n \"- Regarding the `compute_logprobs` function above, we use `torch.gather` here because it gives us a bit more control than `cross_entropy`, but is, in essence, a similar idea\\n\",\n \"- The `selection_mask` we use there is to optionally ignore prompt and padding tokens\\n\",\n \"- We can then use the `compute_logprobs` function as follows to compute the inputs for the `compute_dpo_loss` loss function\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 43,\n \"id\": \"dfa7a4db-eba0-47d8-ad6d-7b5e7676e318\",\n \"metadata\": {\n \"id\": \"dfa7a4db-eba0-47d8-ad6d-7b5e7676e318\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_dpo_loss_batch(batch, policy_model, reference_model, beta):\\n\",\n \" \\\"\\\"\\\"Compute the DPO loss on an input batch\\\"\\\"\\\"\\n\",\n \"\\n\",\n \" # where policy_model(batch[\\\"chosen\\\"]) are the logits\\n\",\n \" policy_chosen_log_probas = compute_logprobs(\\n\",\n \" logits=policy_model(batch[\\\"chosen\\\"]),\\n\",\n \" labels=batch[\\\"chosen\\\"],\\n\",\n \" selection_mask=batch[\\\"chosen_mask\\\"]\\n\",\n \" )\\n\",\n \" policy_rejected_log_probas = compute_logprobs(\\n\",\n \" logits=policy_model(batch[\\\"rejected\\\"]),\\n\",\n \" labels=batch[\\\"rejected\\\"],\\n\",\n \" selection_mask=batch[\\\"rejected_mask\\\"]\\n\",\n \" )\\n\",\n \" \\n\",\n \" with torch.no_grad():\\n\",\n \" ref_chosen_log_probas = compute_logprobs(\\n\",\n \" logits=reference_model(batch[\\\"chosen\\\"]),\\n\",\n \" labels=batch[\\\"chosen\\\"],\\n\",\n \" selection_mask=batch[\\\"chosen_mask\\\"]\\n\",\n \" )\\n\",\n \" ref_rejected_log_probas = compute_logprobs(\\n\",\n \" logits=reference_model(batch[\\\"rejected\\\"]),\\n\",\n \" labels=batch[\\\"rejected\\\"],\\n\",\n \" selection_mask=batch[\\\"rejected_mask\\\"]\\n\",\n \" )\\n\",\n \" loss, chosen_rewards, rejected_rewards = compute_dpo_loss(\\n\",\n \" model_chosen_logprobs=policy_chosen_log_probas,\\n\",\n \" model_rejected_logprobs=policy_rejected_log_probas,\\n\",\n \" reference_chosen_logprobs=ref_chosen_log_probas,\\n\",\n \" reference_rejected_logprobs=ref_rejected_log_probas,\\n\",\n \" beta=beta\\n\",\n \" )\\n\",\n \" return loss, chosen_rewards, rejected_rewards\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b28caafb-f378-4332-a142-3e0f9ef67fbb\",\n \"metadata\": {\n \"id\": \"b28caafb-f378-4332-a142-3e0f9ef67fbb\"\n },\n \"source\": [\n \"- The above function works for a single batch, for example:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"id\": \"dd74fcc4-4280-41e9-9a22-838e85c84ee4\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"dd74fcc4-4280-41e9-9a22-838e85c84ee4\",\n \"outputId\": \"65a70828-7dd2-4f72-ffec-45aeaf8afad0\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"(tensor(0.6931, device='mps:0'), tensor(0., device='mps:0'), tensor(0., device='mps:0'))\\n\"\n ]\n }\n ],\n \"source\": [\n \"with torch.no_grad():\\n\",\n \" loss = compute_dpo_loss_batch(batch, policy_model, reference_model, beta=0.1)\\n\",\n \"print(loss)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b17429cd-2a00-41c8-9f16-38b1c9a5179f\",\n \"metadata\": {\n \"id\": \"b17429cd-2a00-41c8-9f16-38b1c9a5179f\"\n },\n \"source\": [\n \"- Below, we extend this function to work for a specified `num_batches` in a data loader:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"id\": \"682e9ad5-c5de-4d1b-9e93-3918bf5d5302\",\n \"metadata\": {\n \"id\": \"682e9ad5-c5de-4d1b-9e93-3918bf5d5302\"\n },\n \"outputs\": [],\n \"source\": [\n \"def compute_dpo_loss_loader(data_loader, policy_model, reference_model, beta, num_batches=None):\\n\",\n \" \\\"\\\"\\\"Apply compute_dpo_loss_batch to a whole data loader\\\"\\\"\\\"\\n\",\n \"\\n\",\n \" total_loss, total_chosen_rewards, total_rejected_rewards = 0., 0., 0.\\n\",\n \" if len(data_loader) == 0:\\n\",\n \" return float(\\\"nan\\\")\\n\",\n \"\\n\",\n \" elif num_batches is None:\\n\",\n \" num_batches = len(data_loader)\\n\",\n \" else:\\n\",\n \" # Reduce the number of batches to match the total number of batches in the data loader\\n\",\n \" # if num_batches exceeds the number of batches in the data loader\\n\",\n \" num_batches = min(num_batches, len(data_loader))\\n\",\n \" for i, batch in enumerate(data_loader):\\n\",\n \" if i < num_batches:\\n\",\n \" loss, chosen_rewards, rejected_rewards = compute_dpo_loss_batch(\\n\",\n \" batch=batch,\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" beta=beta\\n\",\n \" )\\n\",\n \" total_loss += loss.item()\\n\",\n \" total_chosen_rewards += chosen_rewards.item()\\n\",\n \" total_rejected_rewards += rejected_rewards.item()\\n\",\n \"\\n\",\n \" else:\\n\",\n \" break\\n\",\n \"\\n\",\n \" # calculate average\\n\",\n \" total_loss /= num_batches\\n\",\n \" total_chosen_rewards /= num_batches\\n\",\n \" total_rejected_rewards /= num_batches\\n\",\n \" return total_loss, total_chosen_rewards, total_rejected_rewards\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"852e4c09-d285-44d5-be12-d29769950cb6\",\n \"metadata\": {\n \"id\": \"852e4c09-d285-44d5-be12-d29769950cb6\"\n },\n \"source\": [\n \"- Why a specified `num_batches`? That's purely for efficiency reasons (because calculating the loss on the whole dataset each time would slow down the training significantly)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2cca95b7-18fe-4076-9138-f70f21607b8c\",\n \"metadata\": {\n \"id\": \"2cca95b7-18fe-4076-9138-f70f21607b8c\"\n },\n \"source\": [\n \"- Lastly, we define a convenience function for our training function later; this `evaluate_dpo_loss_loader` function computes the DPO loss and rewards for both the training and validation loader for logging purposes:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 46,\n \"id\": \"c3d214ec-49ba-4bf0-ac80-f90fa0d832e9\",\n \"metadata\": {\n \"id\": \"c3d214ec-49ba-4bf0-ac80-f90fa0d832e9\"\n },\n \"outputs\": [],\n \"source\": [\n \"def evaluate_dpo_loss_loader(policy_model, reference_model, train_loader, val_loader, beta, eval_iter):\\n\",\n \" \\\"\\\"\\\"Compute the DPO loss for the training and validation dataset\\\"\\\"\\\"\\n\",\n \"\\n\",\n \" policy_model.eval()\\n\",\n \" with torch.no_grad():\\n\",\n \" train_loss, train_chosen_rewards, train_rejected_rewards = compute_dpo_loss_loader(\\n\",\n \" data_loader=train_loader,\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" beta=beta,\\n\",\n \" num_batches=eval_iter\\n\",\n \" )\\n\",\n \"\\n\",\n \" val_loss, val_chosen_rewards, val_rejected_rewards = compute_dpo_loss_loader(\\n\",\n \" data_loader=val_loader,\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" beta=beta,\\n\",\n \" num_batches=eval_iter\\n\",\n \" )\\n\",\n \"\\n\",\n \" res = {\\n\",\n \" \\\"train_loss\\\": train_loss,\\n\",\n \" \\\"train_chosen_reward\\\": train_chosen_rewards,\\n\",\n \" \\\"train_rejected_reward\\\": train_rejected_rewards,\\n\",\n \" \\\"val_loss\\\": val_loss,\\n\",\n \" \\\"val_chosen_reward\\\": val_chosen_rewards,\\n\",\n \" \\\"val_rejected_reward\\\": val_rejected_rewards\\n\",\n \" }\\n\",\n \"\\n\",\n \" policy_model.train()\\n\",\n \" return res\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"6e95ed92-6743-4f13-8b91-0fbf2e540de1\",\n \"metadata\": {\n \"id\": \"6e95ed92-6743-4f13-8b91-0fbf2e540de1\"\n },\n \"source\": [\n \"- In this section, we covered a lot of ground as a brief recap:\\n\",\n \" - The flow is: compute `logits` via the models $\\\\rightarrow$ `compute_logprobs` from logits $\\\\rightarrow$ compute `compute_dpo_loss` from log probabilities\\n\",\n \" - we have the `compute_dpo_loss_batch` function that facilitates the process above\\n\",\n \" - the `compute_dpo_loss_loader` utility function applies the `compute_dpo_loss_batch` function to a data loader\\n\",\n \" - the `evaluate_dpo_loss_loader` function applies the `compute_dpo_loss_batch` to both the training and validation set data loaders for logging purposes\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"cb8a8f18-536e-4d83-a0d0-ac518a85f157\",\n \"metadata\": {\n \"id\": \"cb8a8f18-536e-4d83-a0d0-ac518a85f157\"\n },\n \"source\": [\n \" \\n\",\n \"# 5) Training the model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4b11d63d-3ddc-4070-9b2b-5ca0edb08d0c\",\n \"metadata\": {\n \"id\": \"4b11d63d-3ddc-4070-9b2b-5ca0edb08d0c\"\n },\n \"source\": [\n \"- After setting up the DPO loss functions in the previous section, we can now finally train the model\\n\",\n \"- Note that this training function is the same one we used for pretraining and instruction finetuning, with minor differences:\\n\",\n \" - we swap the cross-entropy loss with our new DPO loss function\\n\",\n \" - we also track the rewards and reward margins, which are commonly used in RLHF and DPO contexts to track the training progress\\n\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"820d4904-f819-4d62-bfb4-85cf28863683\",\n \"metadata\": {\n \"id\": \"820d4904-f819-4d62-bfb4-85cf28863683\"\n },\n \"source\": [\n \"- Before we start the training, let's print the initial losses and rewards:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 47,\n \"id\": \"f90d9325-77b2-417f-88ff-0a5174889413\",\n \"metadata\": {\n \"id\": \"f90d9325-77b2-417f-88ff-0a5174889413\"\n },\n \"outputs\": [],\n \"source\": [\n \"from previous_chapters import generate_and_print_sample\\n\",\n \"# Alternatively:\\n\",\n \"# from llms_from_scratch.ch04 import generate_text_simple\\n\",\n \"\\n\",\n \"\\n\",\n \"def train_model_dpo_simple(\\n\",\n \" policy_model, reference_model, train_loader, val_loader,\\n\",\n \" optimizer, num_epochs, beta,\\n\",\n \" eval_freq, eval_iter, start_context, tokenizer\\n\",\n \"):\\n\",\n \"\\n\",\n \" # Initialize lists to track losses and tokens seen\\n\",\n \" tracking = {\\n\",\n \" \\\"train_losses\\\": [],\\n\",\n \" \\\"train_chosen_rewards\\\": [],\\n\",\n \" \\\"train_rejected_rewards\\\": [],\\n\",\n \" \\\"val_losses\\\": [],\\n\",\n \" \\\"val_chosen_rewards\\\": [],\\n\",\n \" \\\"val_rejected_rewards\\\": [],\\n\",\n \" \\\"tokens_seen\\\": []\\n\",\n \" }\\n\",\n \" tokens_seen, global_step = 0, -1\\n\",\n \"\\n\",\n \" # Main training loop\\n\",\n \" for epoch in range(num_epochs):\\n\",\n \" policy_model.train() # Set model to training mode\\n\",\n \"\\n\",\n \" for batch in train_loader:\\n\",\n \"\\n\",\n \" optimizer.zero_grad() # Reset loss gradients from previous batch iteration\\n\",\n \"\\n\",\n \" loss, chosen_rewards, rejected_rewards = compute_dpo_loss_batch(\\n\",\n \" batch=batch,\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" beta=beta\\n\",\n \" )\\n\",\n \"\\n\",\n \" loss.backward() # Calculate loss gradients\\n\",\n \" optimizer.step() # Update model weights using loss gradients\\n\",\n \"\\n\",\n \" tokens_seen += batch[\\\"chosen\\\"].numel()\\n\",\n \" global_step += 1\\n\",\n \"\\n\",\n \" # Optional evaluation step\\n\",\n \" if global_step % eval_freq == 0:\\n\",\n \" res = evaluate_dpo_loss_loader(\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" train_loader=train_loader,\\n\",\n \" val_loader=val_loader,\\n\",\n \" beta=beta,\\n\",\n \" eval_iter=eval_iter\\n\",\n \" )\\n\",\n \" tracking[\\\"train_losses\\\"].append(res[\\\"train_loss\\\"])\\n\",\n \" tracking[\\\"train_chosen_rewards\\\"].append(res[\\\"train_chosen_reward\\\"])\\n\",\n \" tracking[\\\"train_rejected_rewards\\\"].append(res[\\\"train_rejected_reward\\\"])\\n\",\n \" tracking[\\\"val_losses\\\"].append(res[\\\"val_loss\\\"])\\n\",\n \" tracking[\\\"val_chosen_rewards\\\"].append(res[\\\"val_chosen_reward\\\"])\\n\",\n \" tracking[\\\"val_rejected_rewards\\\"].append(res[\\\"val_rejected_reward\\\"])\\n\",\n \" tracking[\\\"tokens_seen\\\"].append(tokens_seen)\\n\",\n \" train_reward_margin = res[\\\"train_chosen_reward\\\"] - res[\\\"train_rejected_reward\\\"]\\n\",\n \" val_reward_margin = res[\\\"val_chosen_reward\\\"] - res[\\\"val_rejected_reward\\\"]\\n\",\n \"\\n\",\n \" print(\\n\",\n \" f\\\"Ep {epoch+1} (Step {global_step:06d}): \\\"\\n\",\n \" f\\\"Train loss {res['train_loss']:.3f}, Val loss {res['val_loss']:.3f}, \\\"\\n\",\n \" f\\\"Train reward margins {train_reward_margin:.3f}, \\\"\\n\",\n \" f\\\"Val reward margins {val_reward_margin:.3f}\\\"\\n\",\n \" )\\n\",\n \"\\n\",\n \" # Print a sample text after each epoch\\n\",\n \" generate_and_print_sample(\\n\",\n \" model=model,\\n\",\n \" tokenizer=tokenizer,\\n\",\n \" device=loss.device,\\n\",\n \" start_context=start_context\\n\",\n \" )\\n\",\n \"\\n\",\n \" return tracking\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 48,\n \"id\": \"d53210c5-6d9c-46b0-af22-ee875c2806c5\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"d53210c5-6d9c-46b0-af22-ee875c2806c5\",\n \"outputId\": \"8b1d2b39-16c5-4b99-e920-5b33d3c0f34d\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Training loss: 0.6931471824645996\\n\",\n \"Validation loss: 0.6931471824645996\\n\",\n \"Train reward margin: 0.0\\n\",\n \"Val reward margin: 0.0\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123) # For reproducibility due to the shuffling in the data loader\\n\",\n \"\\n\",\n \"res = evaluate_dpo_loss_loader(\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" train_loader=train_loader,\\n\",\n \" val_loader=val_loader,\\n\",\n \" beta=0.1,\\n\",\n \" eval_iter=5\\n\",\n \")\\n\",\n \"\\n\",\n \"print(\\\"Training loss:\\\", res[\\\"train_loss\\\"])\\n\",\n \"print(\\\"Validation loss:\\\", res[\\\"val_loss\\\"])\\n\",\n \"\\n\",\n \"print(\\\"Train reward margin:\\\", res[\\\"train_chosen_reward\\\"] - res[\\\"train_rejected_reward\\\"])\\n\",\n \"print(\\\"Val reward margin:\\\", res[\\\"val_chosen_reward\\\"] - res[\\\"val_rejected_reward\\\"])\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"4a006e91-df94-43ca-8025-1ba791e37bc4\",\n \"metadata\": {\n \"id\": \"4a006e91-df94-43ca-8025-1ba791e37bc4\"\n },\n \"source\": [\n \"- Also, let's take a look at some of the initial model responses (the first 3 examples in the validation set):\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 49,\n \"id\": \"q4Ro9DrBa7zH\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"q4Ro9DrBa7zH\",\n \"outputId\": \"b974d4bd-b92a-4a2a-bb7a-5a2a0d1eca11\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Convert the active sentence to passive: 'The chef cooks the meal every day.'\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> The meal is cooked by the chef every day.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The meal is cooked everyday by the chef.\\n\",\n \"\\n\",\n \"-------------------------------------\\n\",\n \"\\n\",\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Classify an input string as either a noun or a verb.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"Dance\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> 'Dance' can be classified as a verb.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> Dance is a verb.\\n\",\n \"\\n\",\n \"-------------------------------------\\n\",\n \"\\n\",\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\",\n \"\\n\",\n \"### Instruction:\\n\",\n \"Rewrite the sentence using a metaphor.\\n\",\n \"\\n\",\n \"### Input:\\n\",\n \"The book is very interesting.\\n\",\n \"\\n\",\n \"Correct response:\\n\",\n \">> The book is a page-turner.\\n\",\n \"\\n\",\n \"Model response:\\n\",\n \">> The book is a book.\\n\",\n \"\\n\",\n \"-------------------------------------\\n\",\n \"\\n\"\n ]\n }\n ],\n \"source\": [\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"\\n\",\n \"for entry in val_data[:3]:\\n\",\n \"\\n\",\n \" input_text = format_input(entry)\\n\",\n \"\\n\",\n \" token_ids = generate(\\n\",\n \" model=model,\\n\",\n \" idx=text_to_token_ids(input_text, tokenizer).to(device),\\n\",\n \" max_new_tokens=256,\\n\",\n \" context_size=BASE_CONFIG[\\\"context_length\\\"],\\n\",\n \" eos_id=50256\\n\",\n \" )\\n\",\n \" generated_text = token_ids_to_text(token_ids, tokenizer)\\n\",\n \" response_text = (\\n\",\n \" generated_text[len(input_text):]\\n\",\n \" .replace(\\\"### Response:\\\", \\\"\\\")\\n\",\n \" .strip()\\n\",\n \")\\n\",\n \"\\n\",\n \" print(input_text)\\n\",\n \" print(f\\\"\\\\nCorrect response:\\\\n>> {entry['output']}\\\")\\n\",\n \" print(f\\\"\\\\nModel response:\\\\n>> {response_text.strip()}\\\")\\n\",\n \" print(\\\"\\\\n-------------------------------------\\\\n\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"ac2386ae-5c4c-448e-bfbf-4ec0604b171e\",\n \"metadata\": {\n \"id\": \"ac2386ae-5c4c-448e-bfbf-4ec0604b171e\"\n },\n \"source\": [\n \"- Above, we see the original model responses\\n\",\n \"- Note that the goal of DPO is to induce slight style changes; this means we want the model to generate similar but slightly more polite responses\\n\",\n \"- Before we execute the following code cell that starts the training, here are a few notes about some of the settings:\\n\",\n \" - we are only passing the parameters of the policy model into the `AdamW` optimizer; that's the model we want to optimize (we don't want to modify the reference model)\\n\",\n \" - we only train for 1 epoch; that's because DPO is very prone to collapse (the loss might improve, but the model will start generating nonsensical texts)\\n\",\n \" - in DPO, it's best to use a very small learning rate\\n\",\n \" - the beta value can be increased from 0.1 to 0.5 to reduce the effect of DPO (we use 0.1 here to make the results more noticeable)\\n\",\n \" - The training takes about 2 minutes on an A100 GPU, but it can also be trained in 4 minutes on a smaller L4 GPU; training on a M3 MacBook Air takes about 30 minutes\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 50,\n \"id\": \"54b739be-871e-4c97-bf14-ffd2c58e1311\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n },\n \"id\": \"54b739be-871e-4c97-bf14-ffd2c58e1311\",\n \"outputId\": \"d98b08b0-c325-411e-a1a4-05e7403f0345\"\n },\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Ep 1 (Step 000000): Train loss 0.692, Val loss 0.693, Train reward margins 0.014, Val reward margins 0.006\\n\",\n \"Ep 1 (Step 000005): Train loss 0.691, Val loss 0.692, Train reward margins 0.040, Val reward margins 0.030\\n\",\n \"Ep 1 (Step 000010): Train loss 0.688, Val loss 0.690, Train reward margins 0.108, Val reward margins 0.060\\n\",\n \"Ep 1 (Step 000015): Train loss 0.682, Val loss 0.688, Train reward margins 0.228, Val reward margins 0.100\\n\",\n \"Ep 1 (Step 000020): Train loss 0.682, Val loss 0.685, Train reward margins 0.235, Val reward margins 0.155\\n\",\n \"Ep 1 (Step 000025): Train loss 0.674, Val loss 0.682, Train reward margins 0.396, Val reward margins 0.234\\n\",\n \"Ep 1 (Step 000030): Train loss 0.677, Val loss 0.677, Train reward margins 0.328, Val reward margins 0.341\\n\",\n \"Ep 1 (Step 000035): Train loss 0.668, Val loss 0.672, Train reward margins 0.529, Val reward margins 0.435\\n\",\n \"Ep 1 (Step 000040): Train loss 0.675, Val loss 0.667, Train reward margins 0.405, Val reward margins 0.544\\n\",\n \"Ep 1 (Step 000045): Train loss 0.651, Val loss 0.662, Train reward margins 0.904, Val reward margins 0.675\\n\",\n \"Ep 1 (Step 000050): Train loss 0.657, Val loss 0.657, Train reward margins 0.809, Val reward margins 0.800\\n\",\n \"Ep 1 (Step 000055): Train loss 0.645, Val loss 0.653, Train reward margins 1.064, Val reward margins 0.885\\n\",\n \"Ep 1 (Step 000060): Train loss 0.655, Val loss 0.649, Train reward margins 0.845, Val reward margins 0.981\\n\",\n \"Ep 1 (Step 000065): Train loss 0.629, Val loss 0.645, Train reward margins 1.452, Val reward margins 1.070\\n\",\n \"Ep 1 (Step 000070): Train loss 0.616, Val loss 0.641, Train reward margins 1.798, Val reward margins 1.179\\n\",\n \"Ep 1 (Step 000075): Train loss 0.612, Val loss 0.637, Train reward margins 1.886, Val reward margins 1.287\\n\",\n \"Ep 1 (Step 000080): Train loss 0.585, Val loss 0.633, Train reward margins 2.550, Val reward margins 1.373\\n\",\n \"Ep 1 (Step 000085): Train loss 0.605, Val loss 0.629, Train reward margins 2.059, Val reward margins 1.466\\n\",\n \"Ep 1 (Step 000090): Train loss 0.649, Val loss 0.625, Train reward margins 1.029, Val reward margins 1.576\\n\",\n \"Ep 1 (Step 000095): Train loss 0.593, Val loss 0.622, Train reward margins 2.331, Val reward margins 1.661\\n\",\n \"Ep 1 (Step 000100): Train loss 0.588, Val loss 0.619, Train reward margins 2.477, Val reward margins 1.735\\n\",\n \"Ep 1 (Step 000105): Train loss 0.574, Val loss 0.617, Train reward margins 2.938, Val reward margins 1.798\\n\",\n \"Ep 1 (Step 000110): Train loss 0.598, Val loss 0.613, Train reward margins 2.273, Val reward margins 1.896\\n\",\n \"Ep 1 (Step 000115): Train loss 0.606, Val loss 0.610, Train reward margins 2.008, Val reward margins 1.975\\n\",\n \"Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Rewrite the sentence using a metaphor. ### Input: The book is very interesting. ### Response: The book would be of great interest.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What is the chemical symbol for iron? \\n\",\n \"Training completed in 5.23 minutes.\\n\"\n ]\n }\n ],\n \"source\": [\n \"import time\\n\",\n \"\\n\",\n \"start_time = time.time()\\n\",\n \"\\n\",\n \"torch.manual_seed(123)\\n\",\n \"\\n\",\n \"\\n\",\n \"optimizer = torch.optim.AdamW(policy_model.parameters(), lr=5e-6, weight_decay=0.01)\\n\",\n \"\\n\",\n \"num_epochs = 1\\n\",\n \"tracking = train_model_dpo_simple(\\n\",\n \" policy_model=policy_model,\\n\",\n \" reference_model=reference_model,\\n\",\n \" train_loader=train_loader,\\n\",\n \" val_loader=val_loader,\\n\",\n \" optimizer=optimizer,\\n\",\n \" num_epochs=num_epochs,\\n\",\n \" beta=0.1, # value between 0.1 and 0.5\\n\",\n \" eval_freq=5,\\n\",\n \" eval_iter=5,\\n\",\n \" start_context=format_input(val_data[2]),\\n\",\n \" tokenizer=tokenizer\\n\",\n \")\\n\",\n \"\\n\",\n \"end_time = time.time()\\n\",\n \"execution_time_minutes = (end_time - start_time) / 60\\n\",\n \"print(f\\\"Training completed in {execution_time_minutes:.2f} minutes.\\\")\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"eba8ea88-8771-4eb9-855d-2fe1ca2dc2fa\",\n \"metadata\": {\n \"id\": \"eba8ea88-8771-4eb9-855d-2fe1ca2dc2fa\"\n },\n \"source\": [\n \"- As we can see based on the tracked results above, the loss improves\\n\",\n \"- Also, the reward margins, which is the difference between the rewards of the chosen and the rejected responses, improve, which is a good sign\\n\",\n \"- Let's take a more concrete look at these results in the next section\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"11e23989-92bd-4ac2-a4bc-65d4c7ac334e\",\n \"metadata\": {\n \"id\": \"11e23989-92bd-4ac2-a4bc-65d4c7ac334e\"\n },\n \"source\": [\n \" \\n\",\n \"# 6) Analyzing the results\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"66d7d5fe-c617-45cb-8ea9-ddc7baa22654\",\n \"metadata\": {\n \"id\": \"66d7d5fe-c617-45cb-8ea9-ddc7baa22654\"\n },\n \"source\": [\n \"- Let's begin analyzing the results by plotting the DPO loss:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 51,\n \"id\": \"8ddcc66f-cd7c-4f46-96ea-af919ea1a199\",\n \"metadata\": {\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\",\n \"height\": 307\n },\n \"id\": \"8ddcc66f-cd7c-4f46-96ea-af919ea1a199\",\n \"outputId\": \"c7164b26-8d32-41d1-8c6a-ab835d58d4c5\"\n },\n \"outputs\": [\n {\n \"data\": {\n \"image/png\": \"iVBORw0KGgoAAAANSUhEUgAAAfIAAAEiCAYAAAACr1D/AAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjcsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvTLEjVAAAAAlwSFlzAAAPYQAAD2EBqD+naQAAZPNJREFUeJztnQd8Tecbx3/ZERkikYUgQoYRM8QsYpSqWf72KrWVUlUtOtDWbNUoLVqjFKX23iRizwgJkRCRRCSy5/l/nve6NzeRkESSm5M838/nTe4Z95z33PU77/M+Q0uSJAkMwzAMw8gSbU13gGEYhmGY/MNCzjAMwzAyhoWcYRiGYWQMCznDMAzDyBgWcoZhGIaRMSzkDMMwDCNjWMgZhmEYRsawkDMMwzCMjGEhZxiGYRgZw0LOMKWcwMBAaGlp4dq1a5ruCsMw+YCFnGFKACTEb2pz5szRdBcZhikkdAvrwAzDFB1Pnz5VPd66dStmzZoFPz8/1TpjY2N+OximhMIjcoYpAdjY2KiamZmZGIUrl62srLB48WJUqlQJBgYGqFevHg4ePJjjsdLS0jB8+HA4OzsjKChIrPvvv//QoEEDGBoawsHBAd988w1SU1NVz6Hz/f777+jRoweMjIxQo0YN7N69W7X9xYsXGDBgACpUqIAyZcqI7evWrcuxD9u3b0edOnXEvhYWFvD09ERcXJxqO53LxcVF9If6uWLFikzPDw4ORp8+fVCuXDmUL18e3bp1E1MISoYOHYru3btj4cKFsLW1FecYN24cUlJS8vHqM4yGoepnDMOUHNatWyeZmZmplhcvXiyZmppKf//9t3T37l3p888/l/T09KR79+6J7Q8fPqQKiNLVq1elxMREqUePHlL9+vWlsLAwsf306dPi+evXr5cCAgKkw4cPS1WrVpXmzJmjOgc9v1KlStLmzZul+/fvSxMnTpSMjY2l58+fi+3jxo2T6tWrJ128eFGc78iRI9Lu3buz7X9ISIikq6sr+k373rhxQ1q+fLkUExMjtm/cuFGytbWVduzYIT148ED8L1++vOgfkZycLLm4uEjDhw8Xz71z547Uv39/ycnJSUpKShL7DBkyRFzT6NGjJV9fX2nPnj2SkZGRtHr16kJ7XximsGAhZ5gSLuR2dnbS3LlzM+3TuHFjaezYsZmE/MyZM1K7du2kFi1aSFFRUap9ad28efMyPX/Dhg1CTJXQ87/66ivVcmxsrFh34MABsdy1a1dp2LBhuer/5cuXxXMDAwOz3V69enVxw6DOd999J3l4eKj6RqKdnp6u2k4CXqZMGenQoUMqIa9SpYqUmpqq2uejjz6S+vbtm6s+MkxxgufIGaYE8/LlS4SEhKB58+aZ1tPy9evXM63r16+fML8fP35cmLSV0H7nzp3D3LlzM5nfExMTER8fL0zpRN26dVXby5YtC1NTU4SFhYnlMWPGoFevXrhy5Qo6dOggzNrNmjXLts9ubm5o166dMK137NhR7N+7d2+Ym5sL83pAQABGjBiBkSNHqp5DZn6aUlD219/fHyYmJpmOS/2l5yqpVasWdHR0VMtkYr9582auX1uGKS6wkDMMI+jcuTM2btwILy8vtG3bVvWqxMbGijnxnj17vvZK0Ry1Ej09vUzbaN48PT1dPH7//ffx6NEj7N+/H0eOHBFCTXPSNEedFRJX2uf8+fM4fPgwli1bhpkzZ+LChQuqm4Y1a9agSZMmrz1P2d+GDRti06ZNrx2b5uhz01+GkRMs5AxTgqFRsZ2dnRhRt27dWrWelt3d3TPtS6Pm2rVr48MPP8S+fftU+5OTG3nAOzo6vlNfSESHDBkiWsuWLTFt2rRshVwpqmQ1oEYe+FWqVMHOnTsxZcoUcT0PHjwQznPZQf0lz31y8qPrZ5iSDgs5w5RwSDBnz56N6tWrC4918han5C/ZjVgnTJggzOYffPABDhw4gBYtWgghpWV7e3th4tbW1hbm61u3buH777/PVR/oGDRKJnN2UlIS9u7dK7zOs4NG3seOHRMmdRJjWg4PD1ftT9aBiRMnClN6p06dxPEuXbokPONJ6EngFyxYIDzVv/32WzFdQNaAf//9F59//rlYZpiSBAs5w5RwSPSio6Px2WefiTlrV1dXERpGIWDZ8emnnwoTM5naKUyN5qlJeEkUf/zxR2GSppCvjz/+ONd90NfXx4wZM0QIGM2/04h8y5Yt2e5Lo+jTp09j6dKlYo6fRuOLFi0S5nmCzksmdhJrukmh+XiaT6d+E7SNnj99+nQxHRATE4OKFSsKcz6P0JmSiBZ5vGm6EwzDMAzD5A9OCMMwDMMwMoaFnGEYhmFkDAs5wzAMw8gYFnKGYRiGkTEs5AzDMAwjY1jIGYZhGEbGsJBrgOXLl6Nq1aoivSWlmfTx8Smyc1N8bdeuXUV2LMqetWvXrkzbKRqRkndQ3mmK96Xykffv38+0T2RkpEi6QTG5VCaS8l5TWkx1bty4IWKF6RorV66Mn3766bW+bNu2TcQj0z4UB0zpO3PL/Pnz0bhxY5FPm5KGUO5u9frbytzalAaUSlRSPW7K9f3s2bNM+1CZzi5duojYYzoOxSWrl+ckTp48KbKFUQlQym62fv36An1PV65cKfKU0+tJzcPDQyRjkdt1ZOWHH34QnzFlfLecrmXOnDmi7+qNPqtyuw7iyZMnGDhwoOgrfafpu0YJdOT0nafrz/p+UKP3QG7vR6Gg6aotpY0tW7ZI+vr60tq1a6Xbt29LI0eOlMqVKyc9e/asSM6/f/9+aebMmdK///4rKkzt3Lkz0/YffvhBVM7atWuXdP36denDDz+UqlWrJiUkJKj26dSpk+Tm5iZ5e3uLilmOjo5Sv379VNujo6Mla2tracCAAdKtW7dE+UyqPPXbb7+p9jl37pyko6Mj/fTTT6LMJFXOotKaN2/ezNV1dOzYUVT5ouNfu3ZN6ty5s2Rvby+qbimhEpWVK1eWjh07Jl26dElq2rSp1KxZM9V2qnxVu3ZtydPTU5TwpNfG0tJSmjFjhmofKpNJ5S2nTJki+rls2TLR74MHDxbYe0rlPPft2yfKivr5+UlffvmleC3o2uR0Her4+PiIUqd169aVJk2aJLv3ZPbs2VKtWrWkp0+fqlp4eLjsriMyMlJUeRs6dKh04cIFcU6qAOfv7y+r7zyV1FV/L6gMLv1+nThxQlbvR2HBQl7EuLu7i9rMStLS0kSZyfnz5xd1V14Tcir7aGNjIy1YsEC1jspZGhgYiC8mQR9weh7VlVZCpSq1tLSkJ0+eiOUVK1ZI5ubmqtrPxPTp00VpSSV9+vSRunTpkqk/TZo0kT755JN8XQt90alfp06dUvWbfiS2bdum2ofqTtM+Xl5eYpm+zNra2lJoaKhqn5UrV4o61cq+U+1u+kFXh0pd0o1EYb6n9Pr9/vvvsrwOqhteo0YN8WPbunVrlZDL6VpIyEm4skNO10HfOypLmxNy/c7TZ4rK2VL/o2T0fhQWbFovQpKTk3H58mVhulJCeatpmSpOaZqHDx8iNDQ0U/8onzWZj5T9o/9kWmvUqJFqH9qfroNyYiv3adWqlUjLqYTSfJLpm/JhK/dRP49yn/y+DpSClChfvrz4T69zSkpKpnOQSY/yhatfC5n3rK2tM/WB0oLevn07V/0s6PeU8pxT6lIq10kmdjleB5k4yYSZ9XxyuxYyL9MUlIODgzArk2lWbtdBqXjpu/rRRx8Jc3L9+vVF5Tg5f+fpdaEqfcOHDxfm9csyej8KCxbyIiQiIkL8UKt/mAhapi+TplH24U39o//0g6COrq6uEFD1fbI7hvo5ctonP68D5QWneViqlEXVu5THpx8V+gF607Xkt5/0A5CQkFBg7ynVwaa5PZqbGz16tKj0RTnR5XYddBNCNcfJhyErcroWEjKaH6Vc8+TDQIJH87+Ut11O10FV4qj/lFf/0KFDosId5d7/888/ZfudJ7+eqKgoDB06VHVcfZm8H4UFF01hZA+NAKkS19mzZyFXnJycREUysixs375dlPo8deoU5ERwcDAmTZokaomr1ymXI8oCLQQ5IpKwU/GWf/75RziEyQW6yaWR9Lx588Qyjcjpu7Jq1SrxGZMjf/zxh3h/yFrCKOAReRFiaWkJHR2d17wpadnGxgaaRtmHN/WP/lMFLXXI85O8WtX3ye4Y6ufIaZ+8vg7jx48XlblOnDiRqTwlHYdMYXTn/qZryW8/yXuXftAL6j2lEQV5yVKpTxrNurm54eeff5bVdZDZkT4b5PVLIzZqdDPyyy+/iMc0cpHLtWSFRns1a9aEv7+/rN4T8kQny446VA5WOU0gt+88laM9evRopsp7NjJ6PwoLFvIihH6s6Yeaai2r3zHTMs2Happq1aqJD6R6/8isRPNgyv7Rf/rC0I+2kuPHj4vroFGLch8Kc6N5KyU0SqNRp7m5uWof9fMo98nt60C+eiTiZIKm81Pf1aHXmcptqp+D5uvoB0z9Wsikrf4jRX2gL67yx+9t/Sys95SOQXW25XQdVCaU+kGWBWWj0SDNLysfy+VaskKhVgEBAUIY5fSe0HRT1rDMe/fuCeuC3L7zxLp164SZn3wwlDSU0ftRaGjU1a4UQuEL5BG6fv164Q06atQoEb6g7k1ZmJBHMYVfUKO3f/HixeLxo0ePVKEo1J///vtPunHjhtStW7dsQ1Hq168vwlnOnj0rPJTVQ1HIi5RCUQYNGiRCUeiaKawjayiKrq6utHDhQuFhSl7CeQk/GzNmjAiZOXnyZKawlPj4eNU+FJJCIWnHjx8XISkeHh6iZQ1J6dChgwhhozCTChUqZBuSMm3aNNHP5cuXZxuS8i7v6RdffCG87R8+fChec1omj+DDhw/L6jqyQ91rXU7X8tlnn4nPFr0n9FmlsCUKV6LoCDldB4UB0vds7ty50v3796VNmzaJc27cuFG1j1y+8+QhTq85ecNnZbRM3o/CgoVcA1B8In3oKB6RwhkoNrOooLhLEvCsbciQIWI7hXN8/fXX4ktJH9h27dqJ2GZ1nj9/Lr7ExsbGInxj2LBh4gZBHYpHpbAXOkbFihXFj0VW/vnnH6lmzZridaCwD4qlzi3ZXQM1ii1XQj9EY8eOFWEx9AXt0aOHEHt1AgMDpffff1/EvNIPNf2Ap6SkvPaa1atXT/TTwcEh0zkK4j0dPny4iPWl59KPC73mShGX03XkRsjlci0UdmRrayueS59fWlaPvZbLdRB79uwRIkbfRWdnZ2n16tWZtsvlO0/x7/Qdz9o3ub0fhYEW/dGsTYBhGIZhmPzCc+QMwzAMI2NYyBmGYRhGxrCQMwzDMIyMYSFnGIZhGBnDQs4wDMMwMoaFnGEYhmFkDAu5BqCMXXPmzBH/5U5JuZaSch0l6Vr4Ooof/J4UTziOXANQCkQqFUgFMihFoJwpKddSUq6jJF0LX0fxg9+T4gmPyBmGYRhGxrCQMwzDMIyM4Xrk+YTK+F29elWUZtTWztv9UExMjPj/5MkTYaqSMyXlWkrKdZSka+HrKH7we1K0UHU1KpNKdeSpFHBO8Bx5Prl48SLc3d3z+3SGYRiGyRU+Pj5o3Lhxjtt5RJ5PaCSufIGpRjHDMAzDFCRPnz4VA0al3uQEC3k+UZrTScQrVaqU38MwDMMwzBt52/QtO7sxDMMwjIxhIWcYhmEYGcNCzjAMwzAyhufIGYZh8khaWhpSUlL4dWPeCT09Pejo6LzbQVjIiwmRD4HkWMDEDjAqD2hpabpHDMNkgyRJCA0NRVRUFL8+TIFQrlw52NjYQOsdfvd5RK5hlp/wR7WL36Jz/H9iOU1bH8llrCGZ2ELXvBL0ylWElqkdYGoLmFYETGwBExtAR0/TXWeYUodSxK2srGBkZPROP75M6UaSJMTHxyMsLEwsv0sYMwu5hrkdEg39lyl4rmMCC60Y6KQno0xcMEAt1Cfb50jQwnP7joj5cC1szQxhqKcD+KwBjK0AR09Av2yRXwfDlAZzulLELSwsNN0dpgRQpkwZ8Z/EnD5X+TWzs5BrmPFtasC/9iJsi0pAWGQ04p8/QXr0Y2jHhsI4ORy2WpGw1oqEjdYL2NBjvICeVhpOPYzDZwtPimPYlQXOpk2DNiSEj7mNCtavhNxrORDkDZhXBcyrAOXof1WgXGVA10CzF84wMkM5J04jcYYpKJSfJ/p8sZDLFFc7U9EyaKB6lJCchqfRCQiJSsSD6ASci0rE0xdxiHkRirDoeBjF6CA+OQ1xcbHYo+cBK0Sh35JrqFMxEG2crTAi+CTMgg5nc1YtgMz15aooBJ7E3cIRsHIBLGoAuvpFcu0MI0fYnM4Ut88Tj8iLMWX0deBQwVi0nOZYXiakIiAiFqfv1cfau2HA42jcfKJo3lpN0LhMRTQpFwsng+ewTA2FTtQjICUOePlE0YLOZz5o7d5A7z8Uj9PTAN/dQAUXwLImpRcqgqtmGIZh8gILuczv5MyM9NDA3ly0Tz1rIiwmESf9wnHibhjO3NeFT7wLlscr9tfV1kLjKuboXF0PbWwSUFF6Bi0SdvKaj7gHhN0FrJwzTvAiENg2FNA1BL4MyVjvu0fxnwS+fDVA+93DJxiGkQ9Vq1bFp59+KlpuOHnyJNq0aYMXL14IL+3CYv369aJPpS2qgIW8hGFlYog+jSqLlpyajkuBkTh+N0y0BxFx8HoYCa+Hin2rWFigjZML2rpYoamDBfR1tIA0tdhYComr2FAh5OpiffIH4NktxWPaZlkDsHED7JsCVZoB5R04hI5hZGC2nT17NubMmZOv6o9ly+beqbZZs2aiAIiZmVmez8W8HRbyEoy+rjaaOVqK9tUHrgiMiBOCfsIvDBceROLR83isPx8omp2ZISa0q4HeDStBFdhm6waMPP76gUnctXWBcD8gNQEIvalo1zYqthtbA/YeClGn/9a1eNTOMBqAxFPJ1q1bMWvWLPj5+anWGRsbZ5qqI8/8N9W9VlKhQoU89UNfX1/ESjOFA096liKqWpbF8BbVsGFEE1yZ1R6rBjZE30aVYWmsj5DoRMz49ybaLTqFHZcfIy1dyvlAH/4CfHIK+PIJMPEq8L/NQIspCtHW0QdinwF3dgEHPgd+awn8WBXwO1iUl8owDCDEU9loNEwjdOXy3bt3YWJiggMHDqBhw4YwMDDA2bNnERAQgG7duonSmST0VAf76NGjr5nWly5dqlqm4/7+++/o0aOH8MKuUaMGdu/encm0TvsoTd5kAicT+6FDh+Di4iLO06lTp0w3HqmpqZg4caLYj8L9pk+fjiFDhqB79+55em9XrlyJ6tWri5sJJycnbNiwIdPNC1kk7O3txfXb2dmJcypZsWKFuBZDQ0PxevTu3btYfq54RF5KMTbQRafaNqIlpqRh84UgrDjpj6DIeHy27bp4THPuXerYQls7B/McmdvJjE7NuYtiXUoiEHIFeHRe0YJ9gKSXCu94JVc3Alc3AfUHAvUHFM0FM0wBQyKQkJKmkde1jJ5OgXnPf/HFF1i4cCEcHBxgbm6O4OBgdO7cGXPnzhXi9tdff6Fr165iJE+ClxPffPMNfvrpJyxYsADLli3DgAED8OjRI5QvXz7b/SkZCp2XhJXKdA4cOBBTp07Fpk2bxPYff/xRPF63bp0Q+59//hm7du0Sc+25ZefOnZg0aZK46fD09MTevXsxbNgwUXqajrNjxw4sWbIEW7ZsQa1atUTCn+vXr4vnXrp0SYg69Y+mBiIjI3HmzBkUR1jIGZFQhkbq/3OvjD/PP8JvpwMQEB6HCX9fFZnnprSvifau1rn74dAzVJjUqRFpqYr5dEunjH0enFR4yzu0zliXHAdc+A1w7QZYVOd3hSn2kIi7zjqkkXPf+bYjjPQL5uf722+/Rfv27VXLJLxubm6q5e+++04IIo2wx48fn+Nxhg4din79+onH8+bNwy+//AIfHx8x0s4OiptetWqVGC0TdGzqixK6GZgxY4YY5RO//vor9u/fn6drW7hwoejX2LFjxfKUKVPg7e0t1pOQBwUFCesEiTzlPacbFXd3d7EvbSM/gA8++EBYLqpUqYL69eujOMKmdUYF/TCMea86znzeBpM9a8LEQBd3Q2MwasNldFt+Dif9wsQoJE/o6AJ29TKHrrX5EvhwGeDyYca6+4eBY98AyxoAK1sApxcAEf787jBMIdOoUaNMy7GxsWJkTKNgMmuT2dvX11cI25uoW7eu6jEJoKmpqSr9aHaQCV4p4soUpcr9o6Oj8ezZM5WoEpQshaYA8oKvry+aN2+eaR0t03rio48+QkJCgrBGjBw5UtywkEmfoJsbEm/aNmjQIGEdICtCcYRH5MxrmBjqYZJnDQxpVgVrzjzAunOBuPE4GkPXXUSjKub4rIMTPKq/Q4pKpTlenTLmgEMb4OFp4NlNRTv+PWBdG3DtrhipV6jJ7xZTbCDzNo2MNXXugiKr9zmJ+JEjR8So1dHRUaQRpbnh5OTkNx6HRrTqkAUvPT09T/vneaDwjlSuXFlMGZAPAF0zjdxpauDUqVNiFH7lyhUxv3/48GHhKEjz6eSxX5ghdPmBR+RMjpQz0se0js44/XkbfNyiGgx0tXHp0Qv0W+ON/mu8cflRZMG9eg7vAYN3AdP8FaP16u0UnvFklj/xPbC8MbDCAzj5o8JbnmE0DAkPWbE00Qozu9y5c+eEOZpM2nXq1BGm58DAQBQl5JhHzmUkmkrIo56ENS+4uLiI61GHll1dXVXLdKNCPgA0FUCi7eXlhZs3b4pt5MFPZnea+79x44Z4HY4fzyaSR8PwiJx5K5bGBiJ8bWQrBzFn/rdPEM4HPMf5lV5o41QBU9o7oU6lAooPpTKuDQYrWnwkcHefwgOe5tXD7ijayXlABWeg5VSg7kf8DjJMAUJe2v/++68QN7ph+Prrr984si4sJkyYgPnz5wurgLOzs5gzp4QyebmJmTZtGvr06SPmtkmQ9+zZI65N6YVP3vN0g9CkSRNh6t+4caMQdjKpk2PcgwcP0KpVK+EESPPz9DqQ53txg4WcyTXWpob4tlttjGrlgF+P+2Pb5cc4QVnk/MLhYmuKsvo6InZdT0db/KdmoPZYX/3xq2WDV48rljNCc0eLzF9SIeqDFC3hBXB3v0LUA04A4XeBFLX5quR4xT5mFfkdZZh3YPHixRg+fLjw1La0tBRhXy9fvizy15TOS17kgwcPFvPjo0aNQseOHfNUWKR79+7C252mCch7vVq1asIL/r333hPbyUT+ww8/CCc4EnSyQJDYU7gbbSPRJ3N6YmKiuMH5+++/hXd7cUNLKupJiRLC48ePxfwKhWpQKENphBLM/HzsPnZde4KC+BTR6H5+z7qwMTN8844k2H4HgBodgbKv5uqpjOvBL4BmEwDPvGeqYpi3QT/mDx8+FGJAccVM0UKjYTKV0wibPOlLw+fqcS51hkfkzDslmFnStx4+9awB/7BYkRI2OS098//UzMtJWbalpKWLOPZzAc/FyL79klOY3bUWejWomLMJjRzj6vXPvC7kGpCeCpjYZayj0DctbS72wjAyhGLQycmsdevWSEpKEuFnJHj9+2f57jMs5My7U8WirGjvwv1nMZi67TquP44W/w/cfIp5PesIc36u6L4ccB+pKMeq5MYW4MxioOkYhfDrv1sfGYYpOihJDM1hkxc9GY5r164t5rZpVM5khr3WmWJBDWsT7BjTDJ93chJz58fuhqHDktPYefVx7kNSKF7dQK3kK2WPiwwA9k8FFrsCR78BXmakgGQYpvhCJmXyMKeYcpqjP3/+vHA8Y16HhZwpNujqaGPse47YM6EF6lQ0Q3RCCiZvvS4S0lB51jwzYBvw/gLAvBqQGAWcXQwsrQP8+wnwVJGGkWEYRu6wkDPFDicbE/w7thmmdqgJPR0tHLnzTIzO/xNOdXnwqqPReZNRwITLQN9NgH0zID1FYXL/rRWw/gNRzOV5TAKO+T7Dy0S1Eq4MwzAyQeNCvnz5clFJh7z1KJaPcvO+CaqeM27cOJHOjxL616xZM1P+XToWOUllbfQcJRR6kHX76NGjC/U6mbxBIWzj29bA7vEtUMvOFFHxKZi05RpGb7yM8JikvB2Miru4fAAMPyDKskq1e0PS0gECzwB/90X0gvo4vvEH9PnlCPxCY/itYhhGVmhUyKk+LsXvUXF7ythDifopTjCn/LyUIpDy31J2ne3bt4vUemvWrEHFihmxw5QJiErhKRul3VPm1FWH8uqq70eZe5jiB8Wn7xrXXOR+19XWwqHbNDo/hT3XQ/I0Ok9KTcOpe+GYdckALfwHoFnCUqxK/QAvJSM4aD/FXL21WBM7ET1WnMXBWzyPzjCMfNDVdOIBElQqK0dQJZx9+/Zh7dq1orReVmg9lZIjpwdlnl4agb+p4D0F+1NifgphUIey+HChe/mMzin3u6erFaZuuwHfpy9FZbb9N5/iu+61Rea57KCR+wm/MGE2P3M/AvHJGSUnDXQrwMfxU5RznIn3U4/B+Ppa3E6pi/iIdIzeeAUT2jhgctnD0K7VDTDP/BljGIYpTmgsIQyNrklMaWStXiieCseT+fy///577TlUI5dK7NHzaDuJNsUUUgag7LL90DmoUDyN+r/88stMpvXbt2+LER2JOaUipDSEdNycoDhGakqePHki8vWW5oQwmoBizylNLLXUdAnly+rju2610aWurXg/fZ/GCOEmr/frj6MyJaqxMjFAOxcrtHO2RnNHS5TRV/vMSBJSk+Lww9Eg/H72IZpq38EW/e8hGZhCa1oAoKtfqNd1LTgKhnracLYxLdTzMPmHE8IwhYGsE8JERESIlHiUGF8dWr579262z6G8t5SwngrW07y4v7+/qFZDdW3JPJ8VKkJPNwVUAEAdEn/KpUsiT4nw6UaAzPSUji8nKOfvN998k+/rZQoGSuc6+VV9dIo3pzKr4zZfwQbv8gh6Ho+Q6Mze7eT9rhRvmmvX1s4hyYyWFnQNjUVO+VoVTbF1x32cTquDqHQ7uEYmw9FKX4g9js4GHNsDVZoXSKIZip+ft99XJMOhdLXHp76HiuXKvPNxGaYgocFPvXr1sHTpUpUl9NNPPxUtJ8j3iMqCqg/U8kNBHedNUBpW0otr165BjujKLUWflZUVVq9erapNSyNjKjuXnZD/8ccfeP/994Vgq0M5e5VQbl1ynGvXrh0CAgIy1cdVhwrc08g+64ic0Qy1K5oJR7hlx+9jxckAeD9QVGKjUW0LxwpCvNs6W+U+oYwaPepXgmOFYRi1oQ5Co+NRdvk5LO1bD56mj4FzPytaOXvArT9Qr1++TO8RsUlYevQe/vYJRlq6wmxAWe9+OxUg8tkzTEFA1kYa6Bw8ePC1bWfOnBFx2devX89USzw3kC9S1vKnhSWm5MNERUuYYijklIyfxJiKx6tDyznNXZPg0ty4uhmdsvxQYn0yo+vr62dK70dZgN40ylZC3vIEjfBzEnLykKemRBNFBJjXR+dUG71jLRuc9AuDq50pmlW3hGEB1Gqmam50ozBu0xX4BEbi478u4dvmBhjUYAi0bu8EooKAUz8oWpUWisxxVDNdPSFNNlA6WqrvTlMDsUmpYl0HV2tx4zF9x01suRiM8W0cYZWPGxCGycqIESPQq1cvYaLNapql4iGNGjXKs4hn54tUmLAvUzH2WifRpRH1sWPHMo24adnDwyPb5zRv3lyIrXpJvXv37gmBVxdx5YeURu9dunR5a1+Ud4B0HEaeo3MKVWvrbF0gIq6kgokBNn7cBIM9qojlWeeSMCZ6CGIn3AZ6/g44tCHDH/DoLPDfWEX2uIMzgOcBrx2L5u93Xw9Bu0Wn8OPBu0LEa1c0xZZRTbF6cCP0aVQZjaqYCx+A304/KLBrYEo3H3zwgRBdSnWqTmxsLLZt2yaE/vnz5+jXr5+I/iE/IbJSUpWvN0GmdaWZnbh//74Y3dMcL1kqldFC6tAUJoUL0zkcHByEXxJZCwjqH01dknVAGRKs7DM9ppG6EqoV3rZtW1FulKqUjRo1SlyPEppKJTM8VTyj33Tah8KPlefKDaQx3377rbj5oQEcTSuoWzVo4Dh+/HhxfLpmmqql6Vfld52sC/b29uK5ZBGeOHEiSqxpnUzV5NxGd4Xu7u7igxEXF6fyYqfydfThUr5AY8aMEYnzqRwd1aqlD8+8efNee5HoTSAhp2NTYXh1yHy+efNm4ThHbzDNkU+ePFl8CPNzZ8qU/FE/mbpdbU0x67/bOHg7FA8iYrF6UGdUpVro0Y+B61uAa5QO9gHgvQLwXgnUaA80+QRwaIvLwdH4ft8dXA2KEse0MTUUqWi716uomrOnH6uJ7Wpg8FofbLrwCGPeq56jNz5TzEiOy/tzdAwAHd2M4j5pSYoCP3pl3n7cPNQMoN8/+h0lUZw5c6aqEBGJOPkokYCTCNKgioTW1NRURA4NGjRIWCfpd/lt0O9tz549hX/ThQsXRErV7ObOTUxMRD9I2EiMKWKJ1n3++efo27cvbt26JcRSWSvczMzstWOQPlCIMg32yLxPocoff/yxEFX1m5UTJ04IkaX/NPij45MY0zlzA5U+XbRoEX777TdRy5wipj788EPhJE3lTH/55Rfs3r0b//zzjxBsckajRuzYsQNLlizBli1bRMlTshjTDUqhImmYZcuWSfb29pK+vr7k7u4ueXt7q7a1bt1aGjJkSKb9z58/LzVp0kQyMDCQHBwcpLlz50qpqamZ9jl06BBNOkp+fn6vnS8oKEhq1aqVVL58eXEMR0dHadq0aVJ0dHSe+h0cHCzOQf+Z0sGlwEip8fdHpCrT90p1Zh+UTvqFZWxMS5Oke0ckaUMvSZptqmq7f5kk9qfm8vUB6eej96T4pMyfVyXp6enSh7+eFfvO23+n6C6MyRUJCQnSnTt3xP9MqL3fuW63/s14Pj2mdWs7Zz7uj9Wyf24e8fX1Fb9VJ06cUK1r2bKlNHDgwByf06VLF+mzzz7L9Fs8adIk1XKVKlWkJUuWqH5vdXV1pSdPnqi2HzhwQJxz586dOZ5jwYIFUsOGDVXLs2fPltzc3F7bT/04q1evlszNzaXY2FjV9n379kna2tpSaGioWCbNoP6p68JHH30k9e3bN8e+ZD23nZ2d0BZ1GjduLI0dO1Y8njBhgtS2bVvxnc3KokWLpJo1a0rJycnSO32u8qAzGnd2ozspatlx8uTJ19bRnZi3t/cbj9mhQ4cck4WQK/+pU6fy2VumNNOwirnIA0/Z5Wh0PWydDz7v5IxPWjlAizzYa3iKFhviC9//FsMpdC8WhtQhh3j0aVgZnzfShoWJNqAe9qaGGJW3dcSIPy9hg9cjfNKqugivY5h3wdnZGc2aNROjSvI+pxEqObqR6ZigkTlZNml0SU68ZDamUNs3heOq4+vrK35X1Z2Ks5sepQRgNJIlqyhZAVJTU4UFIC/QuShxmLqjXfPmzYVVgCKPlFFQNBJW96Wi0TlZAXID+T+FhISI46pDy8qRNZnvKTmZk5MTOnXqJKYwSHeUycfIukzTB7SNrL/kdJjVOlyQaFzIGUZOkBc8zWt/vesW/rn0GD8cuItbT6LxU++6omrb3z5BWHL0MSLjusMAndHI0RYrO7sKRzxsHQj47gE6/Qg0zT4lMHnaU5jc7ZCXWHv2IaZ2dCrya2TyyJch+TOtK3HuqjgGmdbV+TR3wpMbaC6cpiMpJTZNO6onyaKoHzIlk/jQ/DiJJJnGSdALCi8vLxE2TPPgZBonszmZnsl8XRjovUoYpn6TrO5b9a40aNBAxH4fOHBATAX06dMHnp6eIi8K3dTQTQWtJ18BCpGm15gGkFn7VVCwkDNMHjHQ1cGPveqKGPVv9tzB3htP4R8WKxLU0H+ieoWymNmlEdo4WSnmJdPTaDJR4RznoJZlkMqq0pynoWJkQvtOaFtDjPr/PB+Ika0cYFamcL78TAHxrnXuaa5cOV9ekMdVg4SGfIvIP+ivv/4S/kbK+XIqFdqtWzcMHDhQLJPgkRNxbsNrKXKI5ocpTEzpMJzVakrZOMkhjObp1SOL1CGHZbIOvO1cNBdOc+XKUfm5c+dE7XIaHRcEZCUg6wIdVz0jKC2r+wzQfjT3Tq13795i9E2ZRylpGTni0SicGjnakVWELAJ0A1AYsJAzTD6gH8FBHlVR09oEYzddEYlpCDKFT/asgf+524vUspkKt/TbDLwMAUzV8hpQgpm7+wC3fkCT0YClowhHc7I2gd+zGKw/FyjS0zLMu2BsbCwEh/JhkOlYPUkWOW/RSJLEluK1KXU2hQHnVshpJEre6ORcTCNPOr66YCvPERQUJEbhjRs3Fg51lOQlqyc8jXIpioi8xckRTj3kl6BRPeUMoXORZ3h4eLiwNJBzXtbkYu/CtGnTxHnIckFOcmTFoH5t2rRJbKfXiG5ayBGObiLIeZDC5MqVKyduNOiGhMKaaXpi48aNQtjpRqbEVj9jGDnTxMFCzJtTitix71XHianvCYHPJOLqqIs4eSuH3QGSY4GLa4DljYEdI6H9/D7Gt3UUu/xx9gFiuLwqU0Dm9RcvXgjTtvp89ldffSVGirSe5tBJkPKSRY2EjEQ5ISFBjFjJi3zu3LmZ9iGPb4oOIn8oEka6aaDwM3Uo3p1GtW3atBEhc9mFwJEwHjp0SIx86YaARsLt2rUT0UwFCUVCUVTVZ599JqYbyJuevNTphoSgmwwqtEURV9QPKuRF2UbptSAxp2JeNKdOkVBkYt+zZ4+IkipxudblTm5z4DLMG6Gv34OTwIVVwL1Xcapa2kiv3RvDHrTGqefmmNbRCePaKISd0Ryca50prrnWeUTOMJqE5imrtwH6bwU+OQ04dQGkdGjf/Afr4yZgid5yHD1zFnGvssAxDMNkhYWcYYoLtm6KefRXgq6FdPTQOYftaZ8iZO0gIOK+pnvIMEwxhIWcYYqroI86hSfWbaGjJaHGs/2QlrsDpxdquncMwxQzWMgZprhiVw9Wo3ZgmP5CHElrCC0pHbCrn7Gd3VsYhmEhZ5jiDXm/e7brgJEpn+F/ekuRaK8Wg356AfDvqGyLtDAMU3rgETnDFHN6N6wEWzNDeMdYYduVJ4qVyfHA+V+BG1uB0ILLAMa8nYLMEMYw6QXweeKEMAwjg0xylM99zp47WHUyAH0bVYa+vhEw5D/g2mbA5cOMnSkFrIkdUKmhJrtcIqHMYxQnTHm4Kc6ZlpXZ0Rgmr1DkN6XBpaQ29LnKWoo7L7CQM4wMoExxy08G4ElUAnZefYy+je0V8+Xqc+YpicDeyUBcOFClOdB8EuDYnjJ2aLLrJQb6saVYX0pFSmLOMAUBJbmhUqj0+covLOQMIwMM9RSj8u/3+WL5iQD0alAJulmzx1H96hodgBv/AI/OKVoFZ6DZRKDOR4AuV1J7V2jURD+6VLnrbXnBGeZtUIU2qor2rpYdzuyWTzizG1PUxCenosWPJxAZl4xFH7mhV8McMj1RPnfvlcDl9UDSS8U6E1ug6Rig4VDA0KxI+80wTP7gzG4MU8Iw0tfFyJYO4vHyE/5IS5dyzufe4Ttg8i2g/bcKEY95ChyZBSyuBRz+Coh+5TTHMIzs4ckzhpERgzyqoJyRHh5ExGHvjbfM09LIm+bJJ90Auq0AKrgAyTHA+WXAz27AzjFA2N2i6jrDMIUECznDyAhjA10Mb15NNSpPz2lUrg7NjdcfAIw5D/T/B6jSAkhPAa5vBgKO4WViChYfuYc+q7xwNehF4V8EwzAFCgs5w8iMIc2qwsRAF/eexeLQ7dDcP5G8Ymt2BIbtA0YeR1qdvliX0BKtfjqBX47dR5mgEzi6djYeBPgVZvcZhilgWMgZRmaYldHDsOZVxeNfjvuLeNS8kJqWjr+fVEBzv7745nAwouJTUN3SCLPL/INp+BP/bP4dwZHxip3TUjgVLMMUc1jIGUaGDG9RDWX1deD79CWO+obl6jlkht9zPQTtl5zGjH9vIvRlIiqWK4OfetfFoYkesGk9Atd06uDfODcM+uMCwmOSFJ7vS+sA+z8HHpxSCHshcDskGu//fAY/HOA5e4bJKxxHzjAypJyRPgZ5VMWqUwFYdvw+PF2scoxFpRH7yXvhWHjID7dDFOFoFmX1Ma6NIwY0tReZ4wjdVhNg4zYS+qvOI/B5PIau88Eu84PQiw4GfH5TNMNyQM1OgHNnoHo7wMD4na/FK+A5Rv11CTFJqfALfSkc+ugGg2GY3MEjcoaRKR+3rAZDPW3ceByNU/fCs93nUmAk+v7mjWHrLgoRJ2e5yZ41cerzNmJUrxRxJTZmhtgwogksjfXF/sPiJiD5o81A/YGAkQWQGAXc2AL8Mxj4yQHY3Be48hcQm/3538b+m08xZK2PEHEdbS2Q794Gr0f5OhbDlFZYyBlGplgaG2BgkyriMTmrqc+Vk8l9xPqL6L3KCz6BkdDX1cbIltVw+vM2mORZQwh6TlSzLIv1w9yFQ93ZwDiMu2yN1A+WAVPvA8MOAB7jAfOqQFoScO8gsHsCsLAG8EdHwGsFEJs7U/8G70cYt/kKktPS0amWDZb2rSfWb7kYhMQUzprGMLIR8uXLl6Nq1aowNDREkyZN4OPj88b9o6KiMG7cONja2sLAwAA1a9bE/v37VdvnzJkjTIzqzdnZOdMxEhMTxTEsLCxgbGyMXr164dmzZ4V2jQxTWIxq5SBE+kpQFM4HPMej53GYtOUqOv9yBsfuholRbj/3yjg17T3M7OKK8mVzl6a1dkUzrBnSSBz7yJ1n+OLfm5C0tIEqzYCOc4GJ14AxXkCbrwBbEmAJCPYGDs0Agi9kHCgbRzy64aBwt6933RKb+zexx/IBDdC5ji0qmZcRznf/XeOENQwjCyHfunUrpkyZgtmzZ+PKlStwc3NDx44dERaW/R09VYpp3749AgMDsX37dvj5+WHNmjWoWLFipv1q1aolChso29mzZzNtnzx5Mvbs2YNt27bh1KlTogBCz549C/VaGaYwsDI1RL/GlcXjKf9cQ7tFp/DftRAhkB/UtcWRya0wv2dd2Jrlfc65qYMFlvdvIG4Gtl9+jHn7fTNG/TQfb+0KtJ4GfHIKmHwb6PQj4PCeolCLes30v7oDASfEImWjm7nrlrAgEJ961sDc7rXFOagN9lBYGNadC8yzNz7DlFY0mmudRuCNGzfGr7/+qqrLWrlyZUyYMAFffPHFa/uvWrUKCxYswN27d6Gnp5ftMWlEvmvXLly7di3b7dHR0aIE4ebNm9G7d2+xjo7n4uICLy8vNG3aNFd951zrTHHhaXQCWv90UpioidY1K2BaRycxqi4ISMSnbrsuHk/v5Iwx71XP3RPpp+XXRsBzf6DnGiS69MKnW67h3O0HkLS08EW3xhjYVCHcSqLjU9B0/jEkpKRh66imaOJgUSDXwDBypNjnWqfR9eXLl+Hp6ZnRGW1tsUyCmh27d++Gh4eHMItbW1ujdu3amDdv3mtViO7fvw87Ozs4ODhgwIABCAoKUm2jc6akpGQ6L5neqaJRTudlmOIMjba/6VYLnevYCPH7c7h7gYk40bthJczs7CIe/3jwLrb4ZHyf3giN2imTXNuvEW3vicFrfXDwdigG6x3D9TJjMfDRTOD2TiA5PiNG3kgPPRooLGzrzwcW2DUwTElGY+FnERERQoBJkNWhZRohZ8eDBw9w/PhxIc40L+7v74+xY8cKYSbzvHKUv379ejg5OQmz+jfffIOWLVvi1q1bMDExQWhoqChFWK5cudfOS9tyIikpSTQlMTEx7/gKMEzB0c/dXrTCYmQrB0TGJ2PlyQB8ufOmyPfeqbbt259oUR3P6o0Xnul3Q2OEA93wKpHQCUoCfPcoml5ZwOl9oHZPwNETQzyqYvOFIJG1juqvcygawxRzZ7e8QKZ3KysrrF69Gg0bNkTfvn0xc+ZMYXJX8v777+Ojjz5C3bp1xXw7CT45yP3zzz/vdO758+fDzMxM1VxdXQvgihhGPnze0Qn/a1xZhIhN/PsazvtHvPU5D8Jj0WvleSHiFUwMsPUTD1gM2wp8cgZoMRkoZw+kxAG3tgNb+gM/VYfT2UmYbHcbhlIiNnpzKFpR8rdPELZezKXFhSk2aEzILS0tRVH1rN7itGxjY5Ptc8hTnbzU6XlKaG6bRtJkqs8OGnnTc2j0TtCxaV8S99yel5gxY4aYX1e2O3fu5Ol6GUbuUATI3B51RKgYzceP/OsSbjzO/D1S53pwlAh/e/wiAVUtjPDvmGZwtTNVmNxt6wKecxSV2T4+DjQdB5jYKaqz3dqBSZFzcdXgE7h7j0Py5Y1AQs7nYQoGsn5Qxr/pO24qsvoxskFjQk7mbRpVHzt2LNOIm5ZpHjw7mjdvLgSZ9lNy7949IfB0vOyIjY1FQECA2Iegc5KjnPp5yfud5tFzOi9BoW6mpqaqRmZ6hiltkGf5z/3qoVl1C8Qlp2HouovwD4t9bb/T98LRb403IuOSUbeSGbaPaYbK5Y1ePyCJeqWGQKd5Cs/3j4+J0quSeTUYaKWgDS5Bf884IPRmxnPUvv9MwaFuYbn5hG+c5IRGTesUekbhY3/++Sd8fX0xZswYxMXFYdiwYWL74MGDxUhYCW2PjIzEpEmThIDv27dPOLuR85uSqVOnipAyClE7f/48evToIUbw/fr1E9vJLD5ixAhx7hMnTgjnNzofiXhuPdYZpjRD2eBWD24kBJqEevAfFxASlaDaTjHgw9dfRHxyGlrWsMTmkU1F8ppcVWer1Aho/y20Jl7FNvetWJLSCzd0a0OyV/tuHvoS+KMD4H+0kK6wdEKpcpVQtkBGPmg01zrNcYeHh2PWrFnCPF6vXj0cPHhQ5QBHo2TyZFdCbviHDh0SceA0B07x4yTq06dPz+SuT6L9/PlzEWbWokULeHt7i8dKlixZIo5LiWDIgY3m0lesWFHEV88w8oUyw60b2hgf/eaFB+FxosjKttHNsPPqE3y3VzHt9KGbHRZ+5CaSyuQZLS10eK8dmnoBP8emYeujl4pQNAppIwe5l4+BtNSM/aMfA0mxQAUnxSifyRMUhXwuQG1EzkIuKzQaRy5nOI6cYRTzqr1XnsfT6ERYmRgg7NXcKpVZ/bqLK7S1301Uac6WHLDer22DlQMbKla+DAHu7gPqDwL0DBXrjn4DnF0MVHABGgwG3P4HGJXntyiXBITHimRCSsiCcnFmuxwL8TBFQ7GPI2cYRv5QaNiGEe4wN9JTiTgljZn1wbuLODG0maLu+uE7z8RNg8DUDnAfmSHiRFIMoKMPhPsq0sQucgZ2fAw8PMP11HMBpfcl6lUuJ/wgImKTRJlbRh6wkDMM8044WpmIJDStalYQhU8o81tBjeScbEyEYx2ldn1jKFqXhcA0f6DLYsCmrqKgy81twJ8fAMsaAmeX5rtCW2lydGvnbIWa1gpHXp4nlw8s5AzDvDN1K5XDX8Pd0b1+5roHBcGQV6NyMrG/sSqaoRnQeAQw+gww6iTQcBigbwxEBgBHZwOLXRTlV/2Psee7GunpErweKEbkzRwtUPdVVsA3hRYyxQsWcoZhijWeLtbChE9V0XZfC8ndk+zqA12XAp/5AR8uAyo2AtJTgDv/ARt7Ar/UA14+LeyuywLf0JfitS2rryNuyOpUUgo5e67LBRZyhmGKNTRnO6TZq6po5/NYFc3AWOH8NvIYMPoc4D4KMDADdA0AE7UEUGF3gfTSWQP9vL9iNO5erTz0dLThVkmRvvrmk2iuQCcTWMgZhin29GlUGYZ62vB9+hI+DyPzdxCb2kDnBcBnd4E+GzLC1KhoC8WlL60DvCh9hVrOvwo7a1bdUvyvaWMMfR1tMUoPjszID8CUMCEnV3hyi1fi4+ODTz/9VORAZxiGKWjKGemjR31F+M2fXu8otvpGgJVzxnL4XUBbB9DWBczUCs+E3gJSS3aq0pS0dNWNkUd1C1XCH2fbVw5vnOGt5Ap5//79RVY0ghK5tG/fXog5FTD59ttvC7qPDMMwqlC0Q7fVQtEKgooNFKP0AdsU2eWI1GTgrw8VDnKHZipM7yUQcmijVLtUzc7V1lS1vs4rhzdODFOChZxKgrq7u4vHVFWM6oJTOtRNmzaJEqIMwzAFDYWieTjkIhQtP9CcOWWFU0Ke7hSXHv8c8PoVWNFEYX6/skGRQa6EzY/T66oe96+cJ2eHtxIs5FT/m4qIEEePHsWHH34oHjs7O4sa4AzDMIXB0OaKUfmWt4WivStWLsCnt4B+WwGnLoCWDhB8Adg9HljkBOyeCDy+LPtkM8pEMBSrr47Sc/3Wk2gRnsaUQCGvVauWqAF+5swZHDlyBJ06dRLrQ0JCYGGR+QPBMAxT0KFoL/ISipZfdHQBp05Av83AlDuKsqvlHYDkWODKn8DvbYGVzQHvlUB8Ph3wNAjdCF0OeiEeN3NUOLopqWFlLJwLY5JS8fB5nIZ6yBSqkP/444/47bff8N5774kCJW5ubmL97t27VSZ3hmGYwghFG+yRz1C0d4FC1VpMBiZcAYbuA+r2BXQNgbDbwMEvFKP0499DTlx+9ALJqemwNjWAg2XZTNt0dbRRy47nyUu0kJOAR0REiLZ27VrV+lGjRomROsMwTGHRt3FGKNrFQMWIssigkLWqLYCeqxXJZjovBGzqAGnJQFmrjP1ohH7vULH2elcPO8supa7S4e06Z3grmUKekJAgyn+am5uL5UePHmHp0qXw8/ODlZXah5lhGKZQQtEUqWDXn3+oude3TDlF8ZbRZ4FRp4C6fTK2+e4GNvcBNvREceWcf/bz40qo3jzBnuslVMi7deuGv/76SzyOiopCkyZNsGjRInTv3h0rV64s6D4yDMNkm3+dQtFCCjIULb/Y1VMIuxLKEmdiCzi2zViXGA383U/h+R6nEFFN8TIxRZVLXRk/nhVK10rcDnmJ1LT0Iu0fUwRCfuXKFbRs2VI83r59O6ytrcWonMT9l19+yc8hGYZhco2zjWnhhaIVBFS8ZfIdoOm4jHX3jwB++xWe7wsdgfUfAN6rgKjgIu/exYeRIGf0KhZGqGRulO0+NG9O+dcTUtLgH15yQu5KIvkS8vj4eJiYKDL/HD58GD179oS2tjaaNm0qBJ1hGKawyXVVNE1ByWXUa6ZXagS0+UpRZlVKBwLPAAenA0trA6vfA04vBML9itisntlbXR2KK6+tqoTGBVRKnJA7Ojpi165dIlXroUOH0KFDB7E+LCwMpqYZ2YEYhmEKC08Xq6ILRSsIzKsCracpyqxOugF0nA/YNyMPOiDkKnD8O2C5O/CrO3BiHvDsdqHFqWc4ur05XNit8qsCKizkJU/IZ82ahalTp6Jq1aoi3MzDw0M1Oq9fv35B95FhGOY1KERKGYq2vihD0QoC8yqAx1hg+AFg6n2g6y+AY3tAWw+I8ANO/QisbAbsmVTgp34em4S7oTFvnB/P6rnOtclLoJD37t0bQUFBuHTpkhiRK2nXrh2WLFlSkP1jGIZ5ayjaHU2EohUUxhWAhkOAgduBzwOAnmsA5w8AHQPAvmnGflFBwJFZwJMr73Q6rwcKs7qzjQksjRUZOnNC6bnu+zRGxJwzxRPd/D7RxsZGNGUVtEqVKnEyGIZhNBKK9rdPsAhFo5rassbQTBHGRi0pRlGRTcmd/4BzPyuEfOjejPVkicgmDvxtaVnfNhon7MsbwayMHqITUnDvWYxqzpwpASPy9PR0UeXMzMwMVapUEa1cuXL47rvvxDaGYZhSG4pWUBiYAHplMpZt3YBaPRVZ5ZTEhgFLagP7PwcCzynC3t6CV8DbHd2UUKIY5aicE8OUsBE5lSv9448/8MMPP6B58+Zi3dmzZzFnzhwkJiZi7ty5Bd1PhmGYHEPRmjqUh/eDSBGK9nkntVrjJYlqrRRNnbt7gZePAZ/fFI2yy9XqAdTrrxD+LCN1utF5GBEHKnTWxCF31guaJz9zP0Lh8NakIC+I0aiQ//nnn/j9999VVc+IunXromLFihg7diwLOcMwRcrQZtWEkG+6EIQBTasIb/ZSQb0BgImdwuzutw+IC8sQdStXhaDX6QOYWGcyq9epVA6mhnq5OoVyRM4haCXMtB4ZGSlKlmaF1tE2hmGYoqS9qzVcbE3FXO7wdRdF5rJSAdVRpwptPVYCU/2B/v8oRuTkKBd2Bzj8FbDYBdjUB7i9Ez73n+Qq7Cy7DG80R14s4/WZ/Ak5VTv79ddfX1tP62hknheWL18uwtgMDQ1FqlcfH5837k8pYceNGwdbW1tRE71mzZrYv3+/avv8+fPRuHFjkbCG8r5T2ljKAZ+16AvN/ai30aNH56nfDMMUr6povw9pBCsTA/g9i8HYjVeQUtrSiurqAzU7Ah+tB6b6AV0WA5UaA1IacP8QsG0ovrrbA311TqB5LubHldiaGcLSWB+p6ZKIDmBKiJD/9NNPouqZq6srRowYIRo9Xr9+PRYuXJjr42zduhVTpkzB7NmzRdpXukHo2LGjSCyTHcnJyWjfvj0CAwNFalgS6DVr1giTvpJTp04Joff29ha10lNSUkTCmri4zDV1R44ciadPn6oaXRPDMPKFzOlrhzaGkb4OzvpHYObOm/KKLS9Iypgr0sR+fBQYfwloMQWpxrYwRRyitczQsIqi4BViw4GXb06mQwMdZTw5J4YpQULeunVr3Lt3Dz169BAjZGqUpvX27dvYsGFDro+zePFiIajDhg0TNwJUAtXIyChTaVR1aD2Z7imrHDnZ0Uie+qKsh04cPHgQQ4cORa1atcR6urmgmPfLly9nOhadRxlCR40z0jGM/KHwqF/71xfOXP9ceoxfj/trukuax7IG4DkbW5vvx4DkGXhZ6T2U0ddRbKO59MWub62lrjSv8zx5CRJyws7OTji17dixQ7Tvv/8eL168EN7suYFG1ySunp6eGZ3R1hbLXl5e2T5n9+7dIoscjbipUEvt2rUxb948pKXlPG8THa3IEVy+fGYPzU2bNsHS0lIcY8aMGSJ//Jugsq0vX75UtZgYRWYkhmGKF22drfFNt9ri8aIj97DzqiLXRWnn/IMonEuvg6Y1bDJWvgikQHSggnPmdbd3AgmK6miZHd4y1jElICHMuxIRESEEmARZHVq+e/duts958OABjh8/jgEDBoh5cX9/f+ElT+ZzMs9nhWLaP/30UzF6J8FW0r9/fxH7TjcjN27cwPTp04WZ/t9//82xvzT3/s0337zTNTMMUzQMaloFjyPj8dvpB/h8+w3YmpVBU4fcO3iVNNLTpezzq/f6HWgzU1FyVcmtHcCxbwEtHUVmuRrtUc+2tRB8qoIWl5SKsgYakw4mG2T1bpAwkwPb6tWroaOjg4YNG+LJkydYsGBBtkJOI/dbt26JGHd1Ro0apXpcp04d4ThH6WUDAgJQvXr1bM9No3aaz1dC56XpAIZhiifTOzkj+EU89t8Mxai/LuHfsc3gaKWo2ljaoNzqVFyG/AeUZnIV5au9nl3O0kmR8/3ROdFI+i8YWuBYqhueeMegZtMuioQ1TOkWcjJrkxg/e/Ys03papjnr7CDB1dPTE89T4uLigtDQUGGq19fXV60fP3489u7di9OnT4v0sW+CvOUJGuHnJOTkIU9NCZnXGYYpvlAZzsV96iE02htXgqIwdN1F7BzbHBVM3pxfvCSiHI03rloe+rpvmVFt/LGikYmdaqhTe3ga1qnP0V/3OHDiOHBKD6jSDKjRQdFoHj4PaWIZDQo5ObS9CXJ6yy0kujSiPnbsmAgRU464aZlEODvIRL5582axH82nE+R0RwKvFHHyUp0wYQJ27tyJkydPolq1LHeb2XDt2jXxn47DMEzJwVBPB2sGN0LPlefx6Hk8Pv7rEraMbJrh7FVKUCaCae5okbeyq+4jFS0lAbv/24bn1/bigzI3USElBHh4StEOz1TUWacSrUzxd3aj3OpvajTvPHjw4Fwfj0zVFD5GmeJ8fX0xZswYESZGXuwEHYtM2kpoO3mtT5o0SQj4vn37hLMbmdCV0OONGzcKwadYchqtU0tIUORgJvM55YQnRzsKYyMHOjpPq1at8hwDzzBM8cfC2ADrhjZGOSM9XA+OwqQtV5GWXnrC0iie/sKD3OdXzxa9MjCr+z6+SR2CPgYrgQlXgE4/ANXbvl6lze8g8Lsn4LWigK6AKdAR+bp161CQ9O3bF+Hh4aK+OYltvXr1RPiY0gGOwsaUI2+icuXKomzq5MmTVSlhSdTJWU3JypUrVUlfsvadwtJo5H706FEsXbpU3DTQMXv16oWvvvqqQK+NYZjig0MFYzEyH7DmAg7feYa5+3wxq2vp8HG5+SQacclpoooZZb/LL3VfxZJTrvZoI3uYNR0DUEuOU4i5ksAzwOOLgHWGgzFSk4H9nwGV3BWib+HIpvgCREsqtRkT3g0q30o3AcHBwW+dg2cYpniw+3oIJv59VTye3dUVw5q/fepN7vx6/D4WHr6HTrVssGpQw3c6VsufjiM4MgGbPm6C5o45jO6jghVOcuWrA5UbK9YFXwT+yAg1hpEFULmpQtSp2dZTZKZj8qUzsvJaZxiGeRc+dLPD4xfx+OmgH77de0dkg+tQK3vn2pI2P94sL/PjOVC3Yjkh5JQYJkchL1cZKPe/zOvKWgAtJgNBF4Anl4H454oiL9QIXUPArkGGsNNj4wrv3N/SAgs5wzClijGtqyM4Mh5/+wRj4par2DrKA26Vs4RklRCoyMmlRy/yXCglJygxzL6bT/OeGKa8A+A5R/E4NQl4eh0I8lIIe7C3QtiDziuaEosawPiLGSZ4eh4ViWFeg4WcYZhSBeUO/7ZbbTyJSsTpe+EY8ecl7BzbDJXLG6GkceXRCySnpotiMtUrGL/z8eoURElTEuPK7orWXIQaAc/9gSBvRXvsA0TcB8qUyzyPvqYtkBIP9PoDqNhAsY6eq8VhbyzkDMOUOvR0tLFiQAN8tMoLvk9fYtj6i9gxpplwCCuRZvXqFuIGpiBy2RNPohLwPDZJRAS8M9QvikOn1mCQYl3iSyAuPGOflAQgzFdRyc1EbSrkzELg5g7Arr5C3Ok/OdnpGaI0ke9c6wzDMHLG2EAXa4c2go2pIfzDYjF6w2Uxei1JZKRlzWfYWRZMDfXgUKGsyhu+0DA0BSzUknPplQGm+QODdmVOJ/v4EhDuC1zfDOyfCvzeDphfEVj/AeC9EnjxCKUBFnKGYUotlIOdSp+W1deB14Pn+GzbdYRGJ6IkEJOYguuvTOAF4eiWNQytyCuhGZUHqrfJbErv+gvQbyvQeroiw5yRJZCeqgiBO/gF8HNdYGVz4PhcIOSqwhRfAmHTOsMwpRpXO1MsH9BAzJXvuR4iGjl1ebpYo72rNZxtTArELF3UXAyMFIlv7MsboZJ5wc3/16lUDruuhRSPkqYm1oBTJ0UjSKgjHwD3DgJ39yuc557dUrTTPwEmdkCn+UAtRTbRkgILOcMwpZ73nKywckADrDwVgGvBUUKkqC0+cg+VzMsIQW/vYo3G1cqL+XU5cN4/Y368IFGWNL35pBiWNNXSUpjkPcYpWnwkcO+QIszN/zgQE6IY2SsJvQWE3REV3lDGHHKFhZxhGAYQ8eTUwmIScdw3DEfuPMNZ/wg8fpGAdecCRTM11EVbZyu0d7VBq5qWMDEsvs5x51Tx4wUzP66klp0ptLWAZy+T8OxlIqxNi7FjmVF5oF4/RUtJFMVfYO+Rsf3KX4DPb0D9gUC35ZArLOQMwzBqWJkY4n/u9qLFJ6fizP0IIerH74YhMi5ZmJWp6etoo2l1C9Vo3cas+Aga9ZO88QmPAq7DbqSvixpWJvB7FiOsFu1di891vxHyZK/Z4fUSrlaugFOXjHWPLwM7PwGqtQSqvmrFPDkNCznDMMwbRKtjLRvRaL75StALIerUKOc4xaFT+3rXLdSpaIYudW3xcYtq0NWw+d37VZGUmtbGhVK2leLJSchvPo4SNzKypemrfPHqTnB++4Hn9xXt0lrFugouQNUWCnGv0kKRqa4YwULOMAyTC3S0tUQ9b2oz3ndGQHjcK1EPxdXgKBGORY1C2Ca2q1Giws6y4lbJDNsvP1Z5xcseLTVnxmbjFfHo5Pn+8AwQdlsR4kbt4hrFPhSrTsIuRuzNNT6/zkLOMAyTR8iL3dHKWLQx71VHeEwS/vIKxLLj/tjo/Uis06RTXGE5uql7rhN040J1t+To1Z8jJMouHygaEfcceHRWIeok7uF3MzzhL6yiT8OrOfZfoSlYyBmGYd4RMl9PaFtD5G8Pi0nC4dvPhJldEzyNTsCDiDjhkNakgOfHlVBInq62lpiLpyxvBRneVuwoawG4dlM0IjZMIeiBr8SdTPDqSWoSXigy05lXKbIuyiOOgmEYppijr6uNfu6VxeMN3oEa64fXK291mrMvrJSzhno6cLY1EY+LRTx5UWJsBdTuBXywBJhwCZhyF2j8ccb25wFAOfsi7RILOcMwTAHRz91ejIS9H0Ti3rMYjbyu516Z1T0KaX5cSZ2K5UqnkGfF1FaRmEYJzZ8X8VQDCznDMEwBYVdOkTyG2OBV9Hm+ab7aS+XoVrie1cU6MYwm0UDBFhZyhmGYAmSwR1Xx/98rj0W+86Lk0fN4hEQnQk9H4WFfFEJOI/L09JKZw1wusJAzDMMUIDQSrl6hLOKS07Dz6pMifW3PvRqN17c3Rxl9nUI9V01rE+EXEJOYikeR8YV6LjlxPTgKh26HFuk5WcgZhmEKEArFGtRU4bH8l9cjYe7WRP3xwobC61xtTcXjG4/ZvC5JkghB7L3qPCZvvQb/sKLzkWAhZxiGKWB6NqwEI30dUeecHN+KAjJve6uEvHAd3V6bJy/lDm+xSamYuOUaZv13GylpElrVqACrIsxBz0LOMAxTwJga6qF7/YpFGop2/XEUnsclo4yeDupVVniUFzZ1XyWGKc2e6/eexeDDX8+K8rcUW/9VFxesHNhAfAaKChZyhmGYQmCwh8K8fuj2M4RGJxa6WfeHA3fF4061bcTcdVGOyG+FRItc9KWNnVcfo9uv5/AgPA42pobYMqopPm7pUOSZ7ljIGYZhCgFnG1O4Vy0vBG6zT1ChvsZ0s3DhYSQMdLUxtaMTiorqFYzFFEJ8choehMeitJCYkoYvd97E5K3XkZCShpY1LLFvYgs0KuRIgWIr5MuXL0fVqlVhaGiIJk2awMfH5437R0VFYdy4cbC1tYWBgQFq1qyJ/fv35+mYiYmJ4hgWFhYwNjZGr1698OzZs0K5PoZhSi+DXo3K//YJEsVUCoOk1DTMP+ArHo9q5YCK5cqgKAvJ1LZTjMpLTAGVtxD0PF44tG2+ECTyvkxqVwPrh7nDwrjgq8zJQsi3bt2KKVOmYPbs2bhy5Qrc3NzQsWNHhIWFZbt/cnIy2rdvj8DAQGzfvh1+fn5Ys2YNKlasmKdjTp48GXv27MG2bdtw6tQphISEoGfPnkVyzQzDlB6o/CnlYaeiKoUVkvTn+UARP25lYoDRraujqKGSpgSVNC3pHLnzDF2WncGtJy9hbqQnBHxy+5rihkajSBrE3d1dGjdunGo5LS1NsrOzk+bPn5/t/itXrpQcHByk5OTkfB8zKipK0tPTk7Zt26bax9fXlyZ3JC8vr1z3PTg4WDyH/jMMw+TEosN+UpXpe6WPVp0v8BcpIiZRqj3roDj+PxeDNPIm7Lr6WJy/+/KzUkklJTVNmrf/jrhO5bU+eRFf6OfNrc5obEROo+vLly/D09NTtU5bW1sse3l5Zfuc3bt3w8PDQ5jFra2tUbt2bcybNw9paWm5PiZtT0lJybSPs7Mz7O3tczwvwzBMfunvbi9GbD4PI3E39GWBvpCLj9xDTFIqalc0Ra8GlaAJlJ7rd0JeIiWtcKYPNEnYy0T0X3MBv516IJaHN6+GraM8RDre4oLGhDwiIkIIMAmyOrQcGpq9CerBgwfCpE7Po3nxr7/+GosWLcL333+f62PSf319fZQrVy7X5yWSkpLw8uVLVYuJ0UxBBIZh5IWNmSE6FEL+db/QGDH3TnzdxRXaGjLvVilvBBNDXSSlpmusUExhcT4gAp1/OQufwEgYG+hixYAGmNXVtciiAnJL8erNW0hPT4eVlRVWr16Nhg0bom/fvpg5cyZWraLi7oXL/PnzYWZmpmqurq6Ffk6GYUqW0xulbH1ZAPnXKdzs+313QBFf79e2KbS647mBbiCoZGpJSgyTni5h+Ql/DPz9AiJik0T99d3jm6NzHc3UmC+2Qm5paQkdHZ3XvMVp2cbGJtvnkKc6eanT85S4uLiIkTSZ1XNzTPpP+5L3e27PS8yYMQPR0dGqdufOnXxdN8MwpQ8PBwvUsDIWYVr/Xn78zsc74ReGM/cjoK+jjRnvu0DTKM3rJcFz/UVcMkb8eRELDvmJG6XeDSth59jmcKhgjOKKxoSczNs0qj527FimETct0zx4djRv3hz+/v5iPyX37t0TAk/Hy80xabuenl6mfcj7PSgoKMfzEhTqZmpqqmomJibv/BowDFOK8q+/GpVv8H63/Os0D/39PkW42bAWVWFvYQRNU1JKmj6PTULXX8/ihF+4iMn/qVddLPzIrdAL0MjatE5hYhQ+9ueff8LX1xdjxoxBXFwchg0bJrYPHjxYjISV0PbIyEhMmjRJCPi+ffuEsxs5v+X2mGQWHzFihNjvxIkTwvmNtpGIN23aVAOvAsMwpYEe9SuirL4OAsLj4PUqJ3p+2Oj9SGQSszTWx/g2jigOKE3rNG9PyVLkypozD/H4RQIqmZfBv2OboU/jypADupo8Oc1xh4eHY9asWcI8Xq9ePRw8eFDlrEajZPI6V1K5cmUcOnRIxIHXrVtXxI+TqE+fPj3XxySWLFkijkuJYMiJjeLMV6xYUcRXzzBMacLEUA89GlTERu8gURWtmWPeC5tExSdj6dH74vGU9k7imMUBEj6Kq34Rn4K7oTFFluu9IIlOSBE3ScTsrrVQ61WiGzmgRTFomu6EHHn8+LG4sQgODkalSpoJ+2AYRl6QV3eHJadFONrZ6W1ga5a3EKY5u29j/flA4Xy1b2JLzSciUWPIWh+cuheO77rVwiCPqpAbvx6/j4WH78HJ2gQHJrXUWBRAfnRGVl7rDMMwcqamtQmaVHuVf/1C3vKvU0lUml8nvv7AtViJuPo8uRwroSUkp2HtOUWVurFtqhcLEc8LLOQMwzBFyOBXo9W/fYLzlH993n5fcQPg6WKN5vkwyxfVPLkchXzLxSBExiXDvrwRuhTTELM3wULOMAxThHSoZS3yolN88sFc5l8/fS8cx++GiXrXX3Z2RnHE7dW8+P2wGMQUQKx8UZGcmo7VpxVZ2z5p7QBdHfnJovx6zDAMI2P0dLTRz91ePN7gpTDnvolUEW6myFsxpFnVYhvPbG1qCGtTAxF73WbhSSw67FfoddgLgl3XnuBpdKIobqOpNLfvCgs5wzBMEdO/ib0YXV8MfAHfp2/Ov/73xWDcexYrvMIntq2B4sxXXVxhY2qIiNhkLDvuj+Y/Hse4TVdEnvni6Fedli5h1ckA8Xhky2ow1Cve8eI5wULOMAyjgdErlTglKBTtTSFRS47cE4+pXKaZUfEIN8uJrm52ODO9jchJ7v7KqW/fzafo85uXyFm+9WJQsYozP3Q7FA8i4mBWRg/9mygS9sgRFnKGYRgNoMz0tuvqEyHYOYVEkROWo5WxqKIml6kDykn+zyce2D+xJf7XuDIM9bSF5WH6jptoOv8Y5u/3RXBkvEb7KUmKfOrKKQsqiiJXWMgZhmE0AIWh1bQ2RkJKGnZkk389MCJOxIwTX3VxkaUTlqudKX7oVRfeM9oJJz1KHBMVn4LfTj9A6wUnMPKvSzjnH6ERs/upe+G4HfISRvo6GNZMfnHv6sjvk8EwDFNi8q8rBIQyimUVMwo3S0mT0LpmBbznZAU5U85IH6NaVcepaW2wZnAjtHC0FE5xR+48w4DfL6D9ktPC8S8uKbXI+rTi1dw4OR6al9WHnGEhZxiG0WD+dTLp0jztOf/nmepgH77zTCR9odF4SYGup72rNTZ+3ARHp7TCYI8qIv88Jbv5+r/baDrvGL7bewexhSzolwIjhQOeno4WRrZ0gNxhIWcYhtEQJOI9G1QUj/96FYpGDmLf7VVUNxvQxB41rEtmpUVHKxN82602vL5sh9ldXVHNsixiklLxx9mH+HTLNVETvLBH470aVIKNmSHkDgs5wzCMBhnUVOH0dtT3GZ5EJWD75WDhGGZqqItPPWuW+PfG1FAPw5pXw7EprbF6UEPo62qL12LlKYXYFjS3Q6JFch3KwvpJ6+ooCbCQMwzDaBAacXs4WIg54zWnH2DBIUW42cR2NVBe5nO3eYHym3eoZSOKrhALD/uJjHYFzcpXo/Eude2EFaAkwELOMAyjYWiumCAvdUrdSgKjzMle2ujb2F6ErJHv36QtV/H4RcGFqT2MiMP+m0/F4zElZDROsJAzDMNoGHIAo/SmSr7s7CJMzKWVOR/WEtXUqL752E1XCiyJzG+nAoTlo62zlQiNKymU3k8KwzBMMYFixJVz5c0dLeDpIu9ws3eFUqVSdjhKS0vV1KgO+7sSGp2IHVcU8fpj3ys5o3GChZxhGKYYMLp1dfz8v3pY0b+hiDEv7VQyN8Iv/eqDXootF4OxxSdv9duzsubMAxGXT6ljG1Utj5IECznDMEwxGZV3q1ex2OdTL0pa1qiAqR2cxONZu2/jxuOofB0nMi4Zmy8ElcjROMFCzjAMwxRbyCnN08Va1A0fs/GKEOW8sv58oEiFW8vOVGTKK2mwkDMMwzDFOixtUR83VLUwEnH25MlOSXNyS2xSKtafeygej2vjWCKnLVjIGYZhmGINlRldNaghyujp4Mz9CCw9qoi1zw2bLzzCy8RUOFiWVZWOLWmwkDMMwzDFHmcbqqRWRzxedtxfFFx5G4kpaVhzRjEaH/1edZHrvSTCQs4wDMPIAnIGHPqq5OiUrddEgpc3sf3yY4THJMHWzBDd6yly2pdEWMgZhmEY2UDJchpVMRcFVsZsvIz45OwrpaWmpeO304p0rKNaOZToBDsl98oYhmGYEgcJ8vIBDWBpbIC7oTGY8e/N12q5E3tvPEVwZILIV/+/xvYoyRQLIV++fDmqVq0KQ0NDNGnSBD4+Pjnuu379euF1qN7oeepk3a5sCxYsUO1D58u6/YcffijU62QYhmHeHWtTQyzvX1/Mef93LQR/eT3KtJ1KoCqLowxvXhVl9HVK9MuucSHfunUrpkyZgtmzZ+PKlStwc3NDx44dERYWluNzTE1N8fTpU1V79Cjzm6i+jdratWuFUPfq1SvTft9++22m/SZMmFBo18kwDMMUHE0cLDDjfWfx+Lu9d3ApMFK17djdMPg9ixH13geVguIzGhfyxYsXY+TIkRg2bBhcXV2xatUqGBkZCfHNCRJlGxsbVbO2ts60XX0btf/++w9t2rSBg4NDpv1MTEwy7Ve2bMkoaccwDFMaGNGiGj6oa4vUdEkUVwmLSRRm9uUn/MX2gU2riNC1ko5GhTw5ORmXL1+Gp6dnRoe0tcWyl5dXjs+LjY1FlSpVULlyZXTr1g23b+ecUP/Zs2fYt28fRowY8do2MqVbWFigfv36wuyempq90wSRlJSEly9fqlpMTEyerpVhGIYpWGhQ92OvuqhhZYywmCSM33xVxJlfC46Cga62EPrSgEaFPCIiAmlpaa+NqGk5NDQ02+c4OTmJ0TqNsjdu3Ij09HQ0a9YMjx8rqtpk5c8//xQj7549e2ZaP3HiRGzZsgUnTpzAJ598gnnz5uHzzz/Psa/z58+HmZmZqpH1gGEYhtEsZQ10RbIYMqP7PIzE6I2Xxfo+jSqjgklGadiSjJaUnbtfERESEoKKFSvi/Pnz8PDwUK0nQT116hQuXLjw1mOkpKTAxcUF/fr1w3fffffadmdnZ7Rv3x7Lli1743Ho5oAEnUb7BgYG2Y7IqSl58uSJEPPg4GBUqlQpF1fLMAzDFBYHb4WqRJyc4E5OfQ+VyxvJ+gWnASpZnt+mMxodkVtaWkJHR0eYv9WhZZqzzg16enrCNO7vr5gTUefMmTPw8/PDxx9//NbjkLc8mdYDAwOz3U7iTk52ykajfIZhGKZ40Km2Dca8qmzWu0El2Yt4XtCokOvr66Nhw4Y4duyYah2ZymlZfYT+Jsg0f/PmTdja2r627Y8//hDHJ0/4t3Ht2jUxP29lZZXHq2AYhmGKA593dMKe8S3wbfdaKE3oaroDFHo2ZMgQNGrUCO7u7li6dCni4uKEFzsxePBgYX6nOWplyFjTpk3h6OiIqKgo4aRG4WdZR93kkLZt2zYsWrTotXOSIx2Z7cmTnUbWtDx58mQMHDgQ5ubmRXTlDMMwTEE7v9WpZFbqXlSNC3nfvn0RHh6OWbNmCQe3evXq4eDBgyoHuKCgIDFSVvLixQsRrkb7kujSiJvm2LM6n5EjG03/09x5dmZy2j5nzhwx712tWjUh5HRTwTAMwzByQqPObqXBCYFhGIZhSqyzG8MwDMMw7wYLOcMwDMPIGBZyhmEYhpExGnd2kysUJkdQsRWGYRiGKWiU+qLUm5xgIc8nyiQ2FDLHMAzDMIWpN/b2OddUZ6/1fEJZ4K5evSrC5NTD4/IKFV+h0Lk7d+5wtjiGYRiZE1OAv+k0EicRp+yluro5j7tZyDUMJa6hIizR0dEi9SvDMAwjX15q4Dednd0YhmEYRsawkDMMwzCMjGEh1zCULnb27NnZlk5lGIZh5IWBBn7TeY6cYRiGYWQMj8gZhmEYRsawkDMMwzCMjGEhZxiGYRgZw0KuYZYvX46qVavC0NAQTZo0gY+Pj6a7xDAMw+SR06dPo2vXrrCzs4OWlhZ27dqFooKFXINs3boVU6ZMER6OV65cgZubGzp27IiwsDBNdothGIbJI3FxceI3nAZnRQ17rWsQGoE3btwYv/76qyodHxWRnzBhAr744gtNdo1hGIbJJzQi37lzJ7p3746igEfkGiI5ORmXL1+Gp6dnxpuhrS2Wvby8NNUthmEYRmawkGuIiIgIpKWliaIr6tByaGioprrFMAzDyAwWcoZhGIaRMSzkGsLS0hI6OjqquuZKaNnGxkZT3WIYhmFkBgu5htDX10fDhg1x7Ngx1TpydqNlDw8PTXWLYRiGkRk5VypnCh0KPRsyZAgaNWoEd3d3LF26VIQwDBs2jF99hmEYGREbGwt/f3/V8sOHD3Ht2jWUL18e9vb2hXpuDj/TMBR6tmDBAuHgVq9ePfzyyy8iLI1hGIaRDydPnkSbNm1eW0+DtfXr1xfquVnIGYZhGEbG8Bw5wzAMw8gYFnKGYRiGkTEs5AzDMAwjY1jIGYZhGEbGsJAzDMMwjIxhIWcYhmEYGcNCzjAMwzAyhoWcYRiGYWQMCznDMMUKLS0t7Nq1S9PdYBjZwELOMIyKoUOHCiHN2jp16sSvEsMUU7hoCsMwmSDRXrduXaZ1BgYG/CoxTDGFR+QMw7wm2jY2Npmaubm52Eaj85UrV+L9999HmTJl4ODggO3bt2d6/s2bN9G2bVux3cLCAqNGjRKVodRZu3YtatWqJc5la2uL8ePHZ9oeERGBHj16wMjICDVq1MDu3btV2168eIEBAwagQoUK4hy0PeuNB8OUJljIGYbJE19//TV69eqF69evC0H93//+B19fX7GNyvB27NhRCP/Fixexbds2HD16NJNQ043AuHHjhMCT6JNIOzo6ZjrHN998gz59+uDGjRvo3LmzOE9kZKTq/Hfu3MGBAwfEeel4lpaW/C4ypReJYRjmFUOGDJF0dHSksmXLZmpz584V2+knY/To0ZleryZNmkhjxowRj1evXi2Zm5tLsbGxqu379u2TtLW1pdDQULFsZ2cnzZw5M8fXnM7x1VdfqZbpWLTuwIEDYrlr167SsGHD+D1jmFfwHDnDMJmgmso0ylWnfPnyqsceHh6ZttHytWvXxGMaIbu5uaFs2bKq7c2bN0d6ejr8/PyEaT4kJATt2rV746tet25d1WM6lqmpKcLCwsTymDFjhEXgypUr6NChA7p3745mzZrxu8iUWljIGYbJBAlnVlN3QUFz2rlBT08v0zLdANDNAEHz848ePcL+/ftx5MgRcVNApvqFCxcWSp8ZprjDc+QMw+QJb2/v15ZdXFzEY/pPc+c0V67k3Llz0NbWhpOTE0xMTFC1alUcO3bsnV51cnQbMmQINm7ciKVLl2L16tX8LjKlFh6RMwyTiaSkJISGhmb+odDVVTmUkQNbo0aN0KJFC2zatAk+Pj74448/xDZySps9e7YQ2Tlz5iA8PBwTJkzAoEGDYG1tLfah9aNHj4aVlZUYXcfExAixp/1yw6xZs9CwYUPh9U593bt3r+pGgmFKIyzkDMNk4uDBgyIkTB0aTd+9e1flUb5lyxaMHTtW7Pf333/D1dVVbKNwsUOHDmHSpElo3LixWKb57MWLF6uORSKfmJiIJUuWYOrUqeIGoXfv3rl+F/T19TFjxgwEBgYKU33Lli1FfximtKJFHm+a7gTDMPKA5qp37twpHMwYhike8Bw5wzAMw8gYFnKGYRiGkTE8R84wTK7hmTiGKX7wiJxhGIZhZAwLOcMwDMPIGBZyhmEYhpExLOQMwzAMI2NYyBmGYRhGxrCQMwzDMIyMYSFnGIZhGBnDQs4wDMMwMoaFnGEYhmEgX/4PWxMBimGdkCkAAAAASUVORK5CYII=\",\n \"text/plain\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
\\n\",\n \"\\n\",\n \"\\n\",\n \"- With the ollama application or `ollama serve` running, in a different terminal, on the command line, execute the following command to try out the 8-billion-parameter Llama 3 model (the model, which takes up 4.7 GB of storage space, will be automatically downloaded the first time you execute this command)\\n\",\n \"\\n\",\n \"```bash\\n\",\n \"# 8B model\\n\",\n \"ollama run llama3\\n\",\n \"```\\n\",\n \"\\n\",\n \"\\n\",\n \"The output looks like as follows:\\n\",\n \"\\n\",\n \"```\\n\",\n \"$ ollama run llama3\\n\",\n \"pulling manifest \\n\",\n \"pulling 6a0746a1ec1a... 100% ▕████████████████▏ 4.7 GB \\n\",\n \"pulling 4fa551d4f938... 100% ▕████████████████▏ 12 KB \\n\",\n \"pulling 8ab4849b038c... 100% ▕████████████████▏ 254 B \\n\",\n \"pulling 577073ffcc6c... 100% ▕████████████████▏ 110 B \\n\",\n \"pulling 3f8eb4da87fa... 100% ▕████████████████▏ 485 B \\n\",\n \"verifying sha256 digest \\n\",\n \"writing manifest \\n\",\n \"removing any unused layers \\n\",\n \"success \\n\",\n \"```\\n\",\n \"\\n\",\n \"- Note that `llama3` refers to the instruction finetuned 8-billion-parameter Llama 3 model\\n\",\n \"\\n\",\n \"- Alternatively, you can also use the larger 70-billion-parameter Llama 3 model, if your machine supports it, by replacing `llama3` with `llama3:70b`\\n\",\n \"\\n\",\n \"- After the download has been completed, you will see a command line prompt that allows you to chat with the model\\n\",\n \"\\n\",\n \"- Try a prompt like \\\"What do llamas eat?\\\", which should return an output similar to the following:\\n\",\n \"\\n\",\n \"```\\n\",\n \">>> What do llamas eat?\\n\",\n \"Llamas are ruminant animals, which means they have a four-chambered \\n\",\n \"stomach and eat plants that are high in fiber. In the wild, llamas \\n\",\n \"typically feed on:\\n\",\n \"1. Grasses: They love to graze on various types of grasses, including tall \\n\",\n \"grasses, wheat, oats, and barley.\\n\",\n \"```\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"0b5addcb-fc7d-455d-bee9-6cc7a0d684c7\",\n \"metadata\": {},\n \"source\": [\n \"- You can end this session using the input `/bye`\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"dda155ee-cf36-44d3-b634-20ba8e1ca38a\",\n \"metadata\": {},\n \"source\": [\n \"## Using Ollama's REST API\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"89343a84-0ddc-42fc-bf50-298a342b93c0\",\n \"metadata\": {},\n \"source\": [\n \"- Now, an alternative way to interact with the model is via its REST API in Python via the following function\\n\",\n \"- Before you run the next cells in this notebook, make sure that ollama is still running, as described above, via\\n\",\n \" - `ollama serve` in a terminal\\n\",\n \" - the ollama application\\n\",\n \"- Next, run the following code cell to query the model\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"16642a48-1cab-40d2-af08-ab8c2fbf5876\",\n \"metadata\": {},\n \"source\": [\n \"- First, let's try the API with a simple example to make sure it works as intended:\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"65b0ba76-1fb1-4306-a7c2-8f3bb637ccdb\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import json\\n\",\n \"import requests\\n\",\n \"\\n\",\n \"def query_model(prompt, model=\\\"llama3\\\", url=\\\"http://localhost:11434/api/chat\\\", role=\\\"user\\\"):\\n\",\n \" # Create the data payload as a dictionary\\n\",\n \" data = {\\n\",\n \" \\\"model\\\": model,\\n\",\n \" \\\"seed\\\": 123, # for deterministic responses\\n\",\n \" \\\"temperature\\\": 1., # for deterministic responses\\n\",\n \" \\\"top_p\\\": 1, \\n\",\n \" \\\"messages\\\": [\\n\",\n \" {\\\"role\\\": role, \\\"content\\\": prompt}\\n\",\n \" ]\\n\",\n \" }\\n\",\n \"\\n\",\n \" # Send the POST request\\n\",\n \" with requests.post(url, json=data, stream=True, timeout=30) as r:\\n\",\n \" r.raise_for_status()\\n\",\n \" response_data = \\\"\\\"\\n\",\n \" for line in r.iter_lines(decode_unicode=True):\\n\",\n \" if not line:\\n\",\n \" continue\\n\",\n \" response_json = json.loads(line)\\n\",\n \" if \\\"message\\\" in response_json:\\n\",\n \" response_data += response_json[\\\"message\\\"][\\\"content\\\"]\\n\",\n \"\\n\",\n \" return response_data\\n\",\n \"\\n\",\n \"result = query_model(\\\"What do Llamas eat?\\\")\\n\",\n \"print(result)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 3,\n \"id\": \"4fb61a4e-2706-431a-835e-7e472b42989e\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"Llamas are herbivores, which means they primarily eat plants and plant-based foods. Their diet typically consists of:\\n\",\n \"\\n\",\n \"1. Grasses: Llamas love to graze on various types of grasses, including tall grasses, short grasses, and even weeds.\\n\",\n \"2. Hay: They enjoy eating hay, such as alfalfa or timothy hay, which provides them with fiber, protein, and other essential nutrients.\\n\",\n \"3. Grains: Llamas may eat grains like oats, barley, or corn as a supplement to their diet.\\n\",\n \"4. Leaves: They will also munch on leaves from trees and shrubs, including clover, alfalfa, and various types of leaves.\\n\",\n \"5. Fruits and vegetables: In the wild, llamas might eat fruits and vegetables that grow in their natural habitat, such as apples, carrots, or potatoes.\\n\",\n \"\\n\",\n \"In general, a llama's diet should consist of:\\n\",\n \"\\n\",\n \"* 50% grasses and hay\\n\",\n \"* 20% grains (like oats or corn)\\n\",\n \"* 10% leaves and other plant material\\n\",\n \"* 5% fruits and vegetables (as treats)\\n\",\n \"\\n\",\n \"It's essential to provide llamas with a balanced diet that meets their nutritional needs, as they can be prone to health issues if they don't receive the right combination of nutrients.\\n\"\n ]\n }\n ],\n \"source\": [\n \"result = query_model(\\\"What do Llamas eat?\\\")\\n\",\n \"print(result)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"8c079c6c-5845-4b31-a648-060d0273cd1d\",\n \"metadata\": {},\n \"source\": [\n \"## Extract Instructions\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"92b09132-4a92-4492-9b67-24a644767498\",\n \"metadata\": {},\n \"source\": [\n \"- Now, let's use the \\\"hack\\\" proposed in the paper: we provide the empty prompt template `\\\"<|begin_of_text|><|start_header_id|>user<|end_header_id|>\\\"` prompt, which will cause the instruction-finetuned Llama 3 model to generate an instruction\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 4,\n \"id\": \"d7320a41-ed86-49e9-8eb1-5d609a82ad74\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"def extract_instruction(text):\\n\",\n \" for content in text.split(\\\"\\\\n\\\"):\\n\",\n \" if content:\\n\",\n \" return content.strip()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 5,\n \"id\": \"bc41b72f-a8cf-4367-b0ca-0bf8c1f094fd\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"I am trying to find a way to make my child's birthday party more special and unique. What are some creative ideas you have?\\n\"\n ]\n }\n ],\n \"source\": [\n \"query = \\\"<|begin_of_text|><|start_header_id|>user<|end_header_id|>\\\"\\n\",\n \"\\n\",\n \"result = query_model(query, role=\\\"assistant\\\")\\n\",\n \"instruction = extract_instruction(result)\\n\",\n \"print(instruction)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"04d04ba7-bffc-47f0-87dc-d60fc676b14a\",\n \"metadata\": {},\n \"source\": [\n \"- As we can see above, surprisingly, the model indeed generated an instruction\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"162a4739-6f03-4092-a5c2-f57a0b6a4c4d\",\n \"metadata\": {},\n \"source\": [\n \"## Generate Responses\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"2542f8d3-2db2-4a89-ae50-8825eb19d3b6\",\n \"metadata\": {},\n \"source\": [\n \"- Now, the next step is to create the corresponding response, which can be done by simply passing the instruction as input\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 6,\n \"id\": \"2349eb06-710f-4459-8a03-1a3b2e1e8905\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"What an exciting question! I'd be delighted to help you come up with some creative and unique ideas to make your child's birthday party truly special!\\n\",\n \"\\n\",\n \"Here are a few ideas to get you started:\\n\",\n \"\\n\",\n \"1. **Themed Scavenger Hunt**: Plan a scavenger hunt based on the birthday child's favorite theme (e.g., superheroes, animals, or princesses). Hide clues and challenges throughout the party area, leading up to a final surprise.\\n\",\n \"2. **DIY Crafts Station**: Set up a craft station where kids can create their own party favors, such as customized t-shirts, crowns, or jewelry. This activity encourages creativity and makes for a memorable keepsake.\\n\",\n \"3. **Mystery Box Challenge**: Fill mystery boxes with different textures, smells, and sounds. Have the kids guess what's inside each box without looking. This game promotes problem-solving and teamwork.\\n\",\n \"4. **Indoor Camping Adventure**: Set up a cozy indoor \\\"camping\\\" area with sleeping bags, flashlights, and s'mores-making stations. Kids can enjoy a camping experience without leaving the party location.\\n\",\n \"5. **Personalized Photo Booth**: Create a customized photo booth with props and backdrops that match the birthday child's theme. This activity allows kids to take home special memories and share them on social media.\\n\",\n \"6. **Foodie Fun**: Plan a cooking or baking station where kids can make their own treats, such as cupcakes, pizzas, or trail mix. This activity teaches valuable skills and lets kids enjoy their creations.\\n\",\n \"7. **Outdoor Movie Night**: Set up an outdoor movie screen (or projector) with cozy seating and snacks. Screen the birthday child's favorite film or a classic kid-friendly movie.\\n\",\n \"8. **Science Experiments**: Host a science-themed party where kids can conduct fun experiments, such as making slime, creating lava lamps, or growing crystals.\\n\",\n \"9. **Karaoke Contest**: Set up a karaoke machine with popular kids' songs and have a singing competition. Offer prizes for the best performances, and provide fun props like microphones and costumes.\\n\",\n \"10. **Time Capsule Ceremony**: Have each guest bring a small item that represents their favorite memory or something they're looking forward to in the future. Bury the time capsule together as a group, with instructions to open it on a specific date (e.g., next year's birthday party).\\n\",\n \"11. **Special Guest Appearance**: Arrange for a special guest, such as a superhero, princess, or even a real-life animal (if feasible), to make an appearance at the party.\\n\",\n \"12. **Customized Games**: Design custom games and activities that fit the birthday child's interests and personality. This could include a customized version of a favorite game or a new game altogether.\\n\",\n \"\\n\",\n \"Remember, the key to making your child's birthday party unique is to incorporate elements that reflect their personality and interests. Mix and match these ideas or come up with something entirely new – the possibilities are endless!\\n\",\n \"\\n\",\n \"What do you think? Is there anything in particular that resonates with you, or would you like more suggestions?\\n\"\n ]\n }\n ],\n \"source\": [\n \"response = query_model(instruction, role=\\\"user\\\")\\n\",\n \"print(response)\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"b12cf92c-3272-4b36-ae30-d1135af56328\",\n \"metadata\": {},\n \"source\": [\n \"## Generate Dataset\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"id\": \"470037f3-64f4-4465-9f00-55b69e883a04\",\n \"metadata\": {},\n \"source\": [\n \"- We can scale up this approach to an arbitrary number of data samples (you may want to apply some optional filtering length or quality (e.g., using another LLM to rate the generated data)\\n\",\n \"- Below, we generate 5 synthetic instruction-response pairs, which takes about 3 minutes on an M3 MacBook Air\\n\",\n \"- (To generate a dataset suitable for instruction finetuning, we want to increase this to at least 1k to 50k and perhaps run it on a GPU to generate the examples in a more timely fashion)\\n\",\n \"\\n\",\n \"**Tip**\\n\",\n \"\\n\",\n \"- You can generate even higher-quality responses by changing `model=\\\"llama3\\\"` to `model=\\\"llama3:70b\\\"`, however, this will require more computational resources\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 7,\n \"id\": \"3b9e94ab-02ef-4372-91cd-60128159fd83\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stderr\",\n \"output_type\": \"stream\",\n \"text\": [\n \"100%|█████████████████████████████████████████████| 5/5 [02:37<00:00, 31.41s/it]\\n\"\n ]\n }\n ],\n \"source\": [\n \"from tqdm import tqdm\\n\",\n \"\\n\",\n \"dataset_size = 5\\n\",\n \"dataset = []\\n\",\n \"\\n\",\n \"for i in tqdm(range(dataset_size)):\\n\",\n \"\\n\",\n \" result = query_model(query, role=\\\"assistant\\\")\\n\",\n \" instruction = extract_instruction(result)\\n\",\n \" response = query_model(instruction, role=\\\"user\\\")\\n\",\n \" entry = {\\n\",\n \" \\\"instruction\\\": instruction,\\n\",\n \" \\\"output\\\": response\\n\",\n \" }\\n\",\n \" dataset.append(entry)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 8,\n \"id\": \"5fdbc194-c12a-4138-96d1-51bf66ca1574\",\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"with open(\\\"instruction-data-llama3-7b.json\\\", \\\"w\\\") as file:\\n\",\n \" json.dump(dataset, file, indent=4)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 9,\n \"id\": \"b4027ead-bba4-49b7-9965-47532c3fdeee\",\n \"metadata\": {},\n \"outputs\": [\n {\n \"name\": \"stdout\",\n \"output_type\": \"stream\",\n \"text\": [\n \"[\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": \\\"What is the significance of the number 7 in various cultures and religions?\\\",\\n\",\n \" \\\"output\\\": \\\"The number 7 has been a significant and recurring theme across many cultures and religions, often imbuing it with special meaning and symbolism. Here are some examples:\\\\n\\\\n1. **Numerology**: In numerology, the number 7 is considered sacred and mystical, associated with spiritual awakening, introspection, and enlightenment.\\\\n2. **Judaism**: The Torah has seven days of creation, seven weeks in the wilderness, and seven years of rest (Sabbatical year). Seven is also a symbol of completion or perfection.\\\\n3. **Christianity**: In Christianity, there are seven deadly sins, seven virtues, and seven sacraments. Jesus was said to have spoken seven sermons, and the number 7 appears in various biblical accounts, such as the seven days of creation and the seven angels who appear before God.\\\\n4. **Islam**: In Islamic tradition, there are seven heavens, seven earths, and seven veils that separate the physical world from the divine realm. The Quran mentions seven verses (Ayats) that were revealed to Muhammad in a single revelation.\\\\n5. **Hinduism**: In Hindu mythology, there are seven chakras (energy centers) in the human body, seven colors of the rainbow, and seven planets (including the sun and moon). The number 7 is also associated with the seven aspects of the divine feminine (Saptamatrikas).\\\\n6. **Buddhism**: In Buddhist cosmology, there are seven levels of existence (dhatus) and seven stages of enlightenment (bodhisattva path). The seven days of meditation retreats in Tibetan Buddhism are also a nod to this number.\\\\n7. **Ancient Greek and Roman cultures**: The number 7 was considered perfect or complete, with seven being the number of planets known at the time (including Earth, Sun, Moon, Mars, Mercury, Jupiter, and Venus). Seven days were also the typical duration of a week in these cultures.\\\\n8. **Chinese culture**: In Chinese astrology, there are seven celestial stems and 12 earthly branches, creating a system of cyclical time reckoning. The number 7 is also associated with good luck and prosperity.\\\\n9. **African cultures**: In some African traditions, the number 7 is associated with spiritual powers, such as divination and healing. Seven is also considered a sacred number in Yoruba culture, representing the seven orishas (deities).\\\\n10. **Esoteric traditions**: Many esoteric traditions, including Hermeticism, Gnosticism, and Theosophy, have employed the number 7 to represent spiritual principles, such as the seven planes of existence, seven chakras, or seven sacred seals.\\\\n\\\\nThese examples illustrate the widespread significance of the number 7 across various cultures and religions. While the specific meanings may vary, the number 7 often represents completion, perfection, spiritual growth, and mystical connections.\\\"\\n\",\n \" },\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": \\\"I've been wondering, what is the most important thing you can learn from a child?\\\",\\n\",\n \" \\\"output\\\": \\\"What a great question!\\\\n\\\\nChildren have so much to teach us, and I think one of the most important things we can learn from them is the power of simplicity, curiosity, and joy. Children are often unencumbered by the complexities and worries that come with adulthood, and they approach life with a fresh perspective.\\\\n\\\\nHere are some specific things children can teach us:\\\\n\\\\n1. **Simplicity**: Children are masters of simplifying things. They don't get bogged down in details or worry about what others think. They just enjoy the moment and find joy in simple things like playing outside, drawing, or reading.\\\\n2. **Curiosity**: Kids are naturally curious and love to explore their world. They ask questions, investigate, and learn from experience. This curiosity can be a powerful reminder to us adults to stay open-minded and seek new knowledge and experiences.\\\\n3. **Joy and playfulness**: Children have an amazing capacity for joy and playfulness. They find happiness in the simplest things, like playing with blocks or having a water balloon fight. We could all benefit from embracing our inner child and finding more joy in life's simple pleasures.\\\\n4. **Unconditional love**: Children are capable of loving unconditionally, without judgment or expectation. This can be a powerful reminder to us adults to practice self-love, self-acceptance, and kindness towards others.\\\\n5. **Creativity and imagination**: Kids are incredibly creative and imaginative, often thinking outside the box and coming up with innovative solutions. This creativity can inspire us adults to think differently, try new things, and approach problems from unique angles.\\\\n6. **Resilience**: Children are surprisingly resilient in the face of challenges and setbacks. They learn to adapt, cope, and move forward, teaching us valuable lessons about perseverance and bouncing back from adversity.\\\\n\\\\nIn summary, learning from children can help us regain a sense of simplicity, curiosity, joy, and playfulness, while also reminding us of the importance of unconditional love, creativity, and resilience.\\\"\\n\",\n \" },\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": null,\\n\",\n \" \\\"output\\\": \\\"\\\"\\n\",\n \" },\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": \\\"What is the best way to deal with a difficult person?\\\",\\n\",\n \" \\\"output\\\": \\\"Dealing with a difficult person can be challenging, but there are strategies that can help you navigate the situation effectively. Here are some tips:\\\\n\\\\n1. **Stay calm**: Take a deep breath and try not to take their behavior personally. A calm demeanor can help de-escalate tensions and prevent misunderstandings.\\\\n2. **Listen actively**: Sometimes, people act out because they feel unheard or misunderstood. Make an effort to listen carefully to what they're saying, and respond thoughtfully.\\\\n3. **Set boundaries**: Establish clear limits on what you are and aren't willing to engage in. Be firm but respectful when communicating your needs.\\\\n4. **Avoid taking the bait**: Don't let their provocations get under your skin. Stay focused on the issue at hand and avoid getting drawn into an argument or debate.\\\\n5. **Use \\\\\\\"I\\\\\\\" statements**: When expressing yourself, use \\\\\\\"I\\\\\\\" statements instead of \\\\\\\"you\\\\\\\" statements, which can come across as accusatory. This helps to reduce defensiveness and promotes a more constructive conversation.\\\\n6. **Practice empathy**: Try to understand where the other person is coming from, even if you don't agree with their perspective. Showing that you care about their feelings can help diffuse tension.\\\\n7. **Don't take it personally**: Remember that the difficult person's behavior is often a reflection of themselves, not you. Keep your self-worth and confidence intact.\\\\n8. **Seek common ground**: Look for areas of agreement or shared interests. This can help to build bridges and create a more positive atmosphere.\\\\n9. **Use humor (carefully)**: A well-timed, lighthearted joke or witty remark can help diffuse tension and lighten the mood. However, be cautious not to offend or make light of serious issues.\\\\n10. **Know when to disengage**: If the situation becomes too heated or toxic, it may be necessary to take a step back and re-engage at a later time when emotions have cooled down.\\\\n11. **Seek support**: Don't be afraid to ask for help from friends, family, or a professional if you're struggling to manage your interactions with a difficult person.\\\\n12. **Practice self-care**: Take care of yourself physically, emotionally, and mentally. Engage in activities that bring you joy and help you maintain your energy and resilience.\\\\n\\\\nRemember, dealing with a difficult person is not about winning an argument or changing their behavior; it's about maintaining your own emotional well-being and responding constructively to the situation.\\\"\\n\",\n \" },\\n\",\n \" {\\n\",\n \" \\\"instruction\\\": \\\"I'm looking for a way to get my cat's attention when they're hiding under the bed or in a closet.\\\",\\n\",\n \" \\\"output\\\": \\\"The classic \\\\\\\"where'd my cat go?\\\\\\\" conundrum! Don't worry, I've got some tips to help you coax your kitty out from their hiding spots:\\\\n\\\\n1. **Use their favorite treats**: Cats love food, and familiar treats can be a powerful lure. Try calling your cat's name and saying \\\\\\\"treat time\\\\\\\" in a playful tone. This might encourage them to emerge and investigate.\\\\n2. **Make some noise**: Cats have poor eyesight but excellent hearing. Gently knock on the bed frame or closet door with your knuckles, making a soft, rhythmic sound. This can help your cat pinpoint where you are and entice them to come out.\\\\n3. **Speak softly and calmly**: When speaking to your cat, use a gentle, soothing tone. Avoid loud or harsh voices, as these might scare them even further into hiding.\\\\n4. **Use verbal cues**: Establish a consistent verbal cue, like \\\\\\\"come on out\\\\\\\" or \\\\\\\"let's play,\\\\\\\" which can become associated with the idea of leaving their hiding spot.\\\\n5. **Create a \\\\\\\"safe zone\\\\\\\"**: If your cat is hiding due to fear or anxiety (e.g., from loud noises or other pets), try creating a safe, comfortable space for them to emerge into. This could be a cozy blanket or a familiar toy.\\\\n6. **Patiently wait it out**: Sometimes, cats just need time and space to feel secure enough to come out. Give your cat the opportunity to leave their hiding spot at their own pace.\\\\n7. **Use a flashlight (carefully)**: If your cat is hiding in a dark space, try using a flashlight to create a gentle beam of light. Be cautious not to shine it directly into their eyes, as this could startle them further.\\\\n8. **Offer a familiar object**: Place a familiar toy or blanket near the entrance to the hiding spot, which can help your cat feel more comfortable coming out.\\\\n9. **Make the space inviting**: If your cat is hiding under the bed, try moving any clutter or dust bunnies away from the area. Make the space underneath the bed a pleasant place for them to emerge into.\\\\n10. **Be patient and don't force it**: Respect your cat's boundaries and allow them to come out when they're ready. Forcing them to leave their hiding spot can create negative associations and make them more likely to hide in the future.\\\\n\\\\nRemember, every cat is different, so try a combination of these methods to see what works best for your feline friend.\\\"\\n\",\n \" }\\n\",\n \"]\"\n ]\n }\n ],\n \"source\": [\n \"!cat instruction-data-llama3-7b.json\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3 (ipykernel)\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.10.16\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 5\n}\n"
},
{
"path": "ch07/05_dataset-generation/reflection-gpt4.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"136a4efe-fb99-4311-8679-e0a5b6282755\",\n \"metadata\": {},\n \"source\": [\n \"| \\n\",\n \"\\n\",\n \"Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \\n\",\n \" Code repository: https://github.com/rasbt/LLMs-from-scratch\\n\",\n \"\\n\",\n \" | \\n\",\n \"\\n\",\n \"\\n\",\n \" | \\n\",\n \"
 \n\n
\n\n \n\n
\n\n \n\nOptionally, you can deactivate the environment it by executing the command `deactivate`.\n\n
\n\nOptionally, you can deactivate the environment it by executing the command `deactivate`.\n\n \n\n \n## 3. Install packages\n\nAfter activating your virtual environment, you can install Python packages using `uv`. For example:\n\n```bash\nuv pip install packaging\n```\n\nTo install all required packages from a `requirements.txt` file (such as the one located at the top level of this GitHub repository) run the following command, assuming the file is in the same directory as your terminal session:\n\n```bash\nuv pip install -r requirements.txt\n```\n\n\nAlternatively, install the latest dependencies directly from the repository:\n\n```bash\nuv pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt\n```\n\n\n
\n\n \n## 3. Install packages\n\nAfter activating your virtual environment, you can install Python packages using `uv`. For example:\n\n```bash\nuv pip install packaging\n```\n\nTo install all required packages from a `requirements.txt` file (such as the one located at the top level of this GitHub repository) run the following command, assuming the file is in the same directory as your terminal session:\n\n```bash\nuv pip install -r requirements.txt\n```\n\n\nAlternatively, install the latest dependencies directly from the repository:\n\n```bash\nuv pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt\n```\n\n\n \n\n \n\n> **Note:**\n> If you have problems with the following commands above due to certain dependencies (for example, if you are using Windows), you can always fall back to using regular pip:\n> `pip install -r requirements.txt`\n> or\n> `pip install -U -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt`\n\n \n\n> **Optional dependencies for bonus materials:**\n> To include the optional dependencies used throughout the bonus materials, install the `bonus` dependency group from the project root:\n> `uv pip install --group bonus`\n> This is useful if you don't want to install them separately as you check out the optional bonus materials later on.\n\n
\n\n \n\n> **Note:**\n> If you have problems with the following commands above due to certain dependencies (for example, if you are using Windows), you can always fall back to using regular pip:\n> `pip install -r requirements.txt`\n> or\n> `pip install -U -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt`\n\n \n\n> **Optional dependencies for bonus materials:**\n> To include the optional dependencies used throughout the bonus materials, install the `bonus` dependency group from the project root:\n> `uv pip install --group bonus`\n> This is useful if you don't want to install them separately as you check out the optional bonus materials later on.\n\n \n\nIf you encounter any issues with specific packages, try reinstalling them using:\n\n```bash\nuv pip install packagename\n```\n\n(Here, `packagename` is a placeholder name that needs to be replaced with the package name you are having problems with.)\n\nIf problems persist, consider [opening a discussion](https://github.com/rasbt/LLMs-from-scratch/discussions) on GitHub or working through the *Option 2: Using Conda* section below.\n\n
\n\nIf you encounter any issues with specific packages, try reinstalling them using:\n\n```bash\nuv pip install packagename\n```\n\n(Here, `packagename` is a placeholder name that needs to be replaced with the package name you are having problems with.)\n\nIf problems persist, consider [opening a discussion](https://github.com/rasbt/LLMs-from-scratch/discussions) on GitHub or working through the *Option 2: Using Conda* section below.\n\n \n\n \n
\n\n \n \n\nDepending on your operating system, this should download either an `.sh` (macOS, Linux) or `.exe` file (Windows).\n\nFor the `.sh` file, open your command line terminal and execute the following command\n\n```bash\nsh ~/Desktop/Miniforge3-MacOSX-arm64.sh\n```\n\nwhere `Desktop/` is the folder where the Miniforge installer was downloaded to. On your computer, you may have to replace it with `Downloads/`.\n\n
\n\nDepending on your operating system, this should download either an `.sh` (macOS, Linux) or `.exe` file (Windows).\n\nFor the `.sh` file, open your command line terminal and execute the following command\n\n```bash\nsh ~/Desktop/Miniforge3-MacOSX-arm64.sh\n```\n\nwhere `Desktop/` is the folder where the Miniforge installer was downloaded to. On your computer, you may have to replace it with `Downloads/`.\n\n \n\nNext, step through the download instructions, confirming with \"Enter\".\n\n\n \n## 2. Create a new virtual environment\n\nAfter the installation was successfully completed, I recommend creating a new virtual environment called `LLMs`, which you can do by executing\n\n```bash\nconda create -n LLMs python=3.10\n```\n\n
\n\nNext, step through the download instructions, confirming with \"Enter\".\n\n\n \n## 2. Create a new virtual environment\n\nAfter the installation was successfully completed, I recommend creating a new virtual environment called `LLMs`, which you can do by executing\n\n```bash\nconda create -n LLMs python=3.10\n```\n\n \n\n> Many scientific computing libraries do not immediately support the newest version of Python. Therefore, when installing PyTorch, it's advisable to use a version of Python that is one or two releases older. For instance, if the latest version of Python is 3.13, using Python 3.10 or 3.11 is recommended.\n\nNext, activate your new virtual environment (you have to do it every time you open a new terminal window or tab):\n\n```bash\nconda activate LLMs\n```\n\n
\n\n> Many scientific computing libraries do not immediately support the newest version of Python. Therefore, when installing PyTorch, it's advisable to use a version of Python that is one or two releases older. For instance, if the latest version of Python is 3.13, using Python 3.10 or 3.11 is recommended.\n\nNext, activate your new virtual environment (you have to do it every time you open a new terminal window or tab):\n\n```bash\nconda activate LLMs\n```\n\n \n\n\n \n## Optional: styling your terminal\n\nIf you want to style your terminal similar to mine so that you can see which virtual environment is active, check out the [Oh My Zsh](https://github.com/ohmyzsh/ohmyzsh) project.\n\n \n## 3. Install new Python libraries\n\n\n\nTo install new Python libraries, you can now use the `conda` package installer. For example, you can install [JupyterLab](https://jupyter.org/install) and [watermark](https://github.com/rasbt/watermark) as follows:\n\n```bash\nconda install jupyterlab watermark\n```\n\n
\n\n\n \n## Optional: styling your terminal\n\nIf you want to style your terminal similar to mine so that you can see which virtual environment is active, check out the [Oh My Zsh](https://github.com/ohmyzsh/ohmyzsh) project.\n\n \n## 3. Install new Python libraries\n\n\n\nTo install new Python libraries, you can now use the `conda` package installer. For example, you can install [JupyterLab](https://jupyter.org/install) and [watermark](https://github.com/rasbt/watermark) as follows:\n\n```bash\nconda install jupyterlab watermark\n```\n\n \n\n\n\nYou can also still use `pip` to install libraries. By default, `pip` should be linked to your new `LLms` conda environment:\n\n
\n\n\n\nYou can also still use `pip` to install libraries. By default, `pip` should be linked to your new `LLms` conda environment:\n\n \n\n \n## 4. Install PyTorch\n\nPyTorch can be installed just like any other Python library or package using pip. For example:\n\n```bash\npip install torch\n```\n\nHowever, since PyTorch is a comprehensive library featuring CPU- and GPU-compatible codes, the installation may require additional settings and explanation (see the *A.1.3 Installing PyTorch in the book for more information*).\n\nIt's also highly recommended to consult the installation guide menu on the official PyTorch website at [https://pytorch.org](https://pytorch.org).\n\n
\n\n \n## 4. Install PyTorch\n\nPyTorch can be installed just like any other Python library or package using pip. For example:\n\n```bash\npip install torch\n```\n\nHowever, since PyTorch is a comprehensive library featuring CPU- and GPU-compatible codes, the installation may require additional settings and explanation (see the *A.1.3 Installing PyTorch in the book for more information*).\n\nIt's also highly recommended to consult the installation guide menu on the official PyTorch website at [https://pytorch.org](https://pytorch.org).\n\n \n\n \n## 5. Installing Python packages and libraries used in this book\n\nPlease refer to the [Installing Python packages and libraries used in this book](../02_installing-python-libraries/README.md) document for instructions on how to install the required libraries.\n\n
\n\n \n## 5. Installing Python packages and libraries used in this book\n\nPlease refer to the [Installing Python packages and libraries used in this book](../02_installing-python-libraries/README.md) document for instructions on how to install the required libraries.\n\n \n\n\n
\n\n\n \n\nIt's also recommended to check the versions in JupyterLab by running the `python_environment_check.ipynb` in this directory, which should ideally give you the same results as above.\n\n
\n\nIt's also recommended to check the versions in JupyterLab by running the `python_environment_check.ipynb` in this directory, which should ideally give you the same results as above.\n\n \n\nIf you see the following issues, it's likely that your JupyterLab instance is connected to wrong conda environment:\n\n
\n\nIf you see the following issues, it's likely that your JupyterLab instance is connected to wrong conda environment:\n\n \n\nIn this case, you may want to use `watermark` to check if you opened the JupyterLab instance in the right conda environment using the `--conda` flag:\n\n
\n\nIn this case, you may want to use `watermark` to check if you opened the JupyterLab instance in the right conda environment using the `--conda` flag:\n\n \n\n\n \n## Installing PyTorch\n\nPyTorch can be installed just like any other Python library or package using pip. For example:\n\n```bash\npip install torch\n```\n\nHowever, since PyTorch is a comprehensive library featuring CPU- and GPU-compatible codes, the installation may require additional settings and explanation (see the *A.1.3 Installing PyTorch in the book for more information*).\n\nIt's also highly recommended to consult the installation guide menu on the official PyTorch website at [https://pytorch.org](https://pytorch.org).\n\n
\n\n\n \n## Installing PyTorch\n\nPyTorch can be installed just like any other Python library or package using pip. For example:\n\n```bash\npip install torch\n```\n\nHowever, since PyTorch is a comprehensive library featuring CPU- and GPU-compatible codes, the installation may require additional settings and explanation (see the *A.1.3 Installing PyTorch in the book for more information*).\n\nIt's also highly recommended to consult the installation guide menu on the official PyTorch website at [https://pytorch.org](https://pytorch.org).\n\n \n\n
\n\n \n\nAlternatively, you can move the `.vscode` extension folder into the root directory of this GitHub repository:\n\n```bash\nmv setup/.vscode ./\n```\n\nThen, VSCode automatically checks if the recommended extensions are already installed on your system every time you open the `LLMs-from-scratch` main folder.\n\n \n\n# Cloud Resources\n\nThis section describes cloud alternatives for running the code presented in this book.\n\nWhile the code can run on conventional laptops and desktop computers without a dedicated GPU, cloud platforms with NVIDIA GPUs can substantially improve the runtime of the code, especially in chapters 5 to 7.\n\n \n\n## Using Lightning Studio\n\nFor a smooth development experience in the cloud, I recommend the [Lightning AI Studio](https://lightning.ai/) platform, which allows users to set up a persistent environment and use both VSCode and Jupyter Lab on cloud CPUs and GPUs.\n\nOnce you start a new Studio, you can open the terminal and execute the following setup steps to clone the repository and install the dependencies:\n\n```bash\ngit clone https://github.com/rasbt/LLMs-from-scratch.git\ncd LLMs-from-scratch\npip install -r requirements.txt\n```\n\n(In contrast to Google Colab, these only need to be executed once since the Lightning AI Studio environments are persistent, even if you switch between CPU and GPU machines.)\n\nThen, navigate to the Python script or Jupyter Notebook you want to run. Optionally, you can also easily connect a GPU to accelerate the code's runtime, for example, when you are pretraining the LLM in chapter 5 or finetuning it in chapters 6 and 7.\n\n
\n\nAlternatively, you can move the `.vscode` extension folder into the root directory of this GitHub repository:\n\n```bash\nmv setup/.vscode ./\n```\n\nThen, VSCode automatically checks if the recommended extensions are already installed on your system every time you open the `LLMs-from-scratch` main folder.\n\n \n\n# Cloud Resources\n\nThis section describes cloud alternatives for running the code presented in this book.\n\nWhile the code can run on conventional laptops and desktop computers without a dedicated GPU, cloud platforms with NVIDIA GPUs can substantially improve the runtime of the code, especially in chapters 5 to 7.\n\n \n\n## Using Lightning Studio\n\nFor a smooth development experience in the cloud, I recommend the [Lightning AI Studio](https://lightning.ai/) platform, which allows users to set up a persistent environment and use both VSCode and Jupyter Lab on cloud CPUs and GPUs.\n\nOnce you start a new Studio, you can open the terminal and execute the following setup steps to clone the repository and install the dependencies:\n\n```bash\ngit clone https://github.com/rasbt/LLMs-from-scratch.git\ncd LLMs-from-scratch\npip install -r requirements.txt\n```\n\n(In contrast to Google Colab, these only need to be executed once since the Lightning AI Studio environments are persistent, even if you switch between CPU and GPU machines.)\n\nThen, navigate to the Python script or Jupyter Notebook you want to run. Optionally, you can also easily connect a GPU to accelerate the code's runtime, for example, when you are pretraining the LLM in chapter 5 or finetuning it in chapters 6 and 7.\n\n \n\n \n\n## Using Google Colab\n\nTo use a Google Colab environment in the cloud, head over to [https://colab.research.google.com/](https://colab.research.google.com/) and open the respective chapter notebook from the GitHub menu or by dragging the notebook into the *Upload* field as shown in the figure below.\n\n
\n\n \n\n## Using Google Colab\n\nTo use a Google Colab environment in the cloud, head over to [https://colab.research.google.com/](https://colab.research.google.com/) and open the respective chapter notebook from the GitHub menu or by dragging the notebook into the *Upload* field as shown in the figure below.\n\n \n\n\nAlso make sure you upload the relevant files (dataset files and .py files the notebook is importing from) to the Colab environment as well, as shown below.\n\n
\n\n\nAlso make sure you upload the relevant files (dataset files and .py files the notebook is importing from) to the Colab environment as well, as shown below.\n\n \n\n\nYou can optionally run the code on a GPU by changing the *Runtime* as illustrated in the figure below.\n\n
\n\n\nYou can optionally run the code on a GPU by changing the *Runtime* as illustrated in the figure below.\n\n \n\n\n \n\n# Questions?\n\nIf you have any questions, please don't hesitate to reach out via the [Discussions](https://github.com/rasbt/LLMs-from-scratch/discussions) forum in this GitHub repository.\n"
}
]
\n\n\n \n\n# Questions?\n\nIf you have any questions, please don't hesitate to reach out via the [Discussions](https://github.com/rasbt/LLMs-from-scratch/discussions) forum in this GitHub repository.\n"
}
]