Showing preview only (2,861K chars total). Download the full file or copy to clipboard to get everything.
Repository: reasonml/reason
Branch: master
Commit: 1013ec710a49
Files: 419
Total size: 2.7 MB
Directory structure:
gitextract_cg_wrl9f/
├── .github/
│ └── workflows/
│ ├── esy-ci.yml
│ ├── nix-build.yml
│ ├── opam-ci.yml
│ └── print-esy-cache.js
├── .gitignore
├── .npmignore
├── .ocamlformat
├── .ocamlformat-ignore
├── CHANGES.md
├── CODE_OF_CONDUCT.md
├── LICENSE.txt
├── Makefile
├── ORIGINS.md
├── PLAN
├── README.md
├── docs/
│ ├── GETTING_STARTED_CONTRIBUTING.md
│ ├── README.md
│ ├── RELEASING.md
│ ├── TYPE_PARAMETERS_PARSING.md
│ ├── USING_PARSER_PROGRAMMATICALLY.md
│ └── site/
│ ├── Bookmark.js
│ ├── ORIGINS.md
│ └── theme-white/
│ ├── theme.js
│ └── theme.styl.html
├── dune
├── dune-project
├── esy.json
├── esy.lock.json
├── flake.nix
├── js/
│ ├── dune
│ ├── refmt.ml
│ └── testRefmtJs.js
├── nix/
│ ├── ci.nix
│ ├── default.nix
│ └── shell.nix
├── package.json
├── reason.json
├── reason.opam
├── reason.opam.template
├── rtop/
│ ├── dune
│ ├── reason_toploop.cppo.ml
│ ├── reason_util.ml
│ ├── reason_utop.cppo.ml
│ └── rtop.ml
├── rtop.json
├── rtop.opam
├── scripts/
│ └── esy-prepublish.js
├── src/
│ ├── menhir-error-processor/
│ │ ├── dune
│ │ └── menhir_error_processor.ml
│ ├── menhir-recover/
│ │ ├── attributes.ml
│ │ ├── attributes.mli
│ │ ├── cost.ml
│ │ ├── cost.mli
│ │ ├── dune
│ │ ├── emitter.ml
│ │ ├── emitter.mli
│ │ ├── menhir_recover.ml
│ │ ├── recovery_custom.ml
│ │ ├── recovery_custom.mli
│ │ ├── recovery_intf.ml
│ │ ├── synthesis.ml
│ │ └── synthesis.mli
│ ├── reason-merlin/
│ │ ├── dune
│ │ └── ocamlmerlin_reason.ml
│ ├── reason-parser/
│ │ ├── TODO
│ │ ├── dune
│ │ ├── error-handling.md
│ │ ├── merlin_recovery.ml
│ │ ├── merlin_recovery.mli
│ │ ├── merlin_recovery_intf.ml
│ │ ├── ocaml_util.cppo.ml
│ │ ├── ocaml_util.cppo.mli
│ │ ├── reason_attributes.ml
│ │ ├── reason_attributes.mli
│ │ ├── reason_comment.ml
│ │ ├── reason_comment.mli
│ │ ├── reason_config.ml
│ │ ├── reason_config.mli
│ │ ├── reason_declarative_lexer.mli
│ │ ├── reason_declarative_lexer.mll
│ │ ├── reason_errors.ml
│ │ ├── reason_errors.mli
│ │ ├── reason_heuristics.ml
│ │ ├── reason_heuristics.mli
│ │ ├── reason_layout.ml
│ │ ├── reason_layout.mli
│ │ ├── reason_lexer.ml
│ │ ├── reason_lexer.mli
│ │ ├── reason_location.ml
│ │ ├── reason_location.mli
│ │ ├── reason_multi_parser.ml
│ │ ├── reason_multi_parser.mli
│ │ ├── reason_oprint.ml
│ │ ├── reason_oprint.mli
│ │ ├── reason_parser.mly
│ │ ├── reason_parser_def.ml
│ │ ├── reason_parser_def.mli
│ │ ├── reason_parser_explain.ml
│ │ ├── reason_parser_explain.mli
│ │ ├── reason_pprint_ast.ml
│ │ ├── reason_pprint_ast.mli
│ │ ├── reason_recover_parser.ml
│ │ ├── reason_recover_parser.mli
│ │ ├── reason_single_parser.ml
│ │ ├── reason_single_parser.mli
│ │ ├── reason_syntax_util.ml
│ │ ├── reason_syntax_util.mli
│ │ ├── reason_toolchain.ml
│ │ ├── reason_toolchain.mli
│ │ ├── reason_toolchain_conf.ml
│ │ ├── reason_toolchain_conf.mli
│ │ ├── reason_toolchain_ocaml.ml
│ │ ├── reason_toolchain_ocaml.mli
│ │ ├── reason_toolchain_reason.ml
│ │ ├── reason_toolchain_reason.mli
│ │ └── vendor/
│ │ └── easy_format/
│ │ ├── VERSION
│ │ ├── dune
│ │ ├── reason_easy_format.ml
│ │ └── reason_easy_format.mli
│ ├── refmt/
│ │ ├── .gitignore
│ │ ├── README.md
│ │ ├── dune
│ │ ├── end_of_line.ml
│ │ ├── end_of_line.mli
│ │ ├── git_commit.mli
│ │ ├── package.ml
│ │ ├── package.mli
│ │ ├── printer_maker.ml
│ │ ├── printer_maker.mli
│ │ ├── reason_implementation_printer.ml
│ │ ├── reason_implementation_printer.mli
│ │ ├── reason_interface_printer.ml
│ │ ├── reason_interface_printer.mli
│ │ ├── refmt.ml
│ │ └── refmt_args.ml
│ └── vendored-omp/
│ ├── LICENSE.md
│ ├── MANUAL.md
│ ├── Makefile
│ ├── README.md
│ ├── src/
│ │ ├── ast_408.ml
│ │ ├── ast_409.ml
│ │ ├── ast_410.ml
│ │ ├── ast_411.ml
│ │ ├── ast_412.ml
│ │ ├── ast_413.ml
│ │ ├── ast_414.ml
│ │ ├── ast_500.ml
│ │ ├── ast_51.ml
│ │ ├── ast_52.ml
│ │ ├── ast_53.ml
│ │ ├── ast_54.ml
│ │ ├── ast_55.ml
│ │ ├── caml_format_doc.cppo.ml
│ │ ├── cinaps_helpers
│ │ ├── compiler-functions/
│ │ │ ├── ge_406_and_lt_408.ml
│ │ │ ├── ge_408_and_lt_410.ml
│ │ │ ├── ge_410_and_lt_412.ml
│ │ │ ├── ge_412.ml
│ │ │ ├── ge_50.ml
│ │ │ ├── ge_52.ml
│ │ │ └── lt_406.ml
│ │ ├── config/
│ │ │ └── gen.ml
│ │ ├── dune
│ │ ├── locations.ml
│ │ ├── migrate_parsetree_408_409.ml
│ │ ├── migrate_parsetree_408_409_migrate.ml
│ │ ├── migrate_parsetree_409_408.ml
│ │ ├── migrate_parsetree_409_408_migrate.ml
│ │ ├── migrate_parsetree_409_410.ml
│ │ ├── migrate_parsetree_409_410_migrate.ml
│ │ ├── migrate_parsetree_410_409.ml
│ │ ├── migrate_parsetree_410_409_migrate.ml
│ │ ├── migrate_parsetree_410_411.ml
│ │ ├── migrate_parsetree_410_411_migrate.ml
│ │ ├── migrate_parsetree_411_410.ml
│ │ ├── migrate_parsetree_411_410_migrate.ml
│ │ ├── migrate_parsetree_411_412.ml
│ │ ├── migrate_parsetree_411_412_migrate.ml
│ │ ├── migrate_parsetree_412_411.ml
│ │ ├── migrate_parsetree_412_411_migrate.ml
│ │ ├── migrate_parsetree_412_413.ml
│ │ ├── migrate_parsetree_412_413_migrate.ml
│ │ ├── migrate_parsetree_413_412.ml
│ │ ├── migrate_parsetree_413_412_migrate.ml
│ │ ├── migrate_parsetree_413_414.ml
│ │ ├── migrate_parsetree_413_414_migrate.ml
│ │ ├── migrate_parsetree_414_413.ml
│ │ ├── migrate_parsetree_414_413_migrate.ml
│ │ ├── migrate_parsetree_414_500.ml
│ │ ├── migrate_parsetree_414_500_migrate.ml
│ │ ├── migrate_parsetree_500_414.ml
│ │ ├── migrate_parsetree_500_414_migrate.ml
│ │ ├── migrate_parsetree_500_51.ml
│ │ ├── migrate_parsetree_500_51_migrate.ml
│ │ ├── migrate_parsetree_51_500.ml
│ │ ├── migrate_parsetree_51_500_migrate.ml
│ │ ├── migrate_parsetree_51_52.ml
│ │ ├── migrate_parsetree_51_52_migrate.ml
│ │ ├── migrate_parsetree_52_51.ml
│ │ ├── migrate_parsetree_52_51_migrate.ml
│ │ ├── migrate_parsetree_52_53.ml
│ │ ├── migrate_parsetree_52_53_migrate.ml
│ │ ├── migrate_parsetree_53_52.ml
│ │ ├── migrate_parsetree_53_52_migrate.ml
│ │ ├── migrate_parsetree_53_54.ml
│ │ ├── migrate_parsetree_53_54_migrate.ml
│ │ ├── migrate_parsetree_54_53.ml
│ │ ├── migrate_parsetree_54_53_migrate.ml
│ │ ├── migrate_parsetree_54_55.ml
│ │ ├── migrate_parsetree_54_55_migrate.ml
│ │ ├── migrate_parsetree_55_54.ml
│ │ ├── migrate_parsetree_55_54_migrate.ml
│ │ ├── migrate_parsetree_def.ml
│ │ ├── migrate_parsetree_def.mli
│ │ ├── migrate_parsetree_driver_main.ml
│ │ ├── migrate_parsetree_versions.ml
│ │ ├── migrate_parsetree_versions.mli
│ │ ├── reason_omp.ml
│ │ └── stdlib0.ml
│ └── tools/
│ ├── add_special_comments.ml
│ ├── add_special_comments.mli
│ ├── dune
│ ├── gencopy.ml
│ ├── pp.ml
│ ├── pp.mli
│ ├── pp_rewrite.mli
│ └── pp_rewrite.mll
└── test/
├── 4.08/
│ ├── dune
│ ├── error-comments.t
│ ├── error-lowercase_module.t
│ ├── error-lowercase_module_rec.t
│ ├── error-reservedField.t
│ ├── error-reservedRecord.t
│ ├── error-reservedRecordPunned.t
│ ├── error-reservedRecordType.t
│ ├── error-reservedRecordTypePunned.t
│ ├── error-syntaxError.t
│ ├── mlSyntax.t/
│ │ ├── input.ml
│ │ └── run.t
│ ├── type-jsx.t/
│ │ ├── input.re
│ │ └── run.t
│ └── typecheck-features.t
├── 4.10/
│ ├── attributes-re.t/
│ │ ├── input.re
│ │ └── run.t
│ ├── dune
│ ├── local-openings.t/
│ │ ├── input.ml
│ │ └── run.t
│ ├── reasonComments-re.t/
│ │ ├── input.re
│ │ └── run.t
│ ├── type-jsx.t/
│ │ ├── input.re
│ │ └── run.t
│ └── typecheck-let-ops.t
├── 4.12/
│ ├── attributes-re.t/
│ │ ├── input.re
│ │ └── run.t
│ ├── dune
│ ├── local-openings.t/
│ │ ├── input.ml
│ │ └── run.t
│ ├── reasonComments-re.t/
│ │ ├── input.re
│ │ └── run.t
│ ├── type-jsx.t/
│ │ ├── input.re
│ │ └── run.t
│ └── typecheck-let-ops.t
├── README.md
├── arityConversion.t/
│ ├── arity.txt
│ ├── input.ml
│ └── run.t
├── assert.t/
│ ├── input.re
│ └── run.t
├── attributes-rei.t/
│ ├── input.rei
│ └── run.t
├── backportSyntax.t/
│ ├── input.re
│ └── run.t
├── basic.t/
│ ├── input.re
│ └── run.t
├── basicStructures.t/
│ ├── input.re
│ └── run.t
├── basics.t/
│ ├── input.re
│ └── run.t
├── basics_no_semi.t/
│ ├── input.re
│ └── run.t
├── bigarray.t/
│ ├── input.re
│ └── run.t
├── bigarraySyntax.t/
│ ├── input.re
│ └── run.t
├── class.t/
│ ├── input.re
│ └── run.t
├── class_types.t/
│ ├── input.re
│ └── run.t
├── comments-ml.t/
│ ├── input.ml
│ └── run.t
├── comments-mli.t/
│ ├── input.mli
│ └── run.t
├── dune
├── emptyFileComment.t/
│ ├── input.re
│ └── run.t
├── escapesInStrings.t/
│ ├── input.re
│ └── run.t
├── expr-constraint-with-vbct.t/
│ ├── input.re
│ └── run.t
├── extension-exprs.t/
│ ├── input.re
│ └── run.t
├── extension-str-in-module.t
├── extensions.t/
│ ├── input.re
│ └── run.t
├── externals.t/
│ ├── input.re
│ └── run.t
├── fdLeak.t/
│ ├── input.re
│ └── run.t
├── firstClassModules.t/
│ ├── input.re
│ └── run.t
├── fixme.t/
│ ├── input.re
│ └── run.t
├── functionInfix.t/
│ ├── input.re
│ └── run.t
├── general-syntax-re.t/
│ ├── input.re
│ └── run.t
├── general-syntax-rei.t/
│ ├── input.rei
│ └── run.t
├── generics.t/
│ ├── input.re
│ └── run.t
├── if.t/
│ ├── input.re
│ └── run.t
├── imperative.t/
│ ├── input.re
│ └── run.t
├── infix.t/
│ ├── input.re
│ └── run.t
├── inlineRecord.t/
│ ├── input.re
│ └── run.t
├── jsx.t/
│ ├── input.re
│ └── run.t
├── jsx_functor.t/
│ ├── input.re
│ └── run.t
├── keyword-operators.t/
│ ├── input.re
│ └── run.t
├── knownMlIssues.t/
│ ├── input.ml
│ └── run.t
├── knownReIssues.t/
│ ├── input.re
│ └── run.t
├── lazy.t/
│ ├── input.re
│ └── run.t
├── letop.t/
│ ├── input.re
│ └── run.t
├── lib/
│ ├── dune
│ ├── fdLeak.ml
│ └── outcometreePrinter.cppo.ml
├── lineComments.t/
│ ├── input.re
│ └── run.t
├── melange-support.t/
│ ├── input.re
│ └── run.t
├── mlFunctions.t/
│ ├── input.ml
│ └── run.t
├── mlVariants.t/
│ ├── input.ml
│ └── run.t
├── modules.t/
│ ├── input.re
│ └── run.t
├── modules_no_semi.t/
│ ├── input.re
│ └── run.t
├── mutation.t/
│ ├── input.re
│ └── run.t
├── object.t/
│ ├── input.re
│ └── run.t
├── ocaml_identifiers.t/
│ ├── input.ml
│ └── run.t
├── oo.t/
│ ├── input.re
│ └── run.t
├── patternMatching.t/
│ ├── input.re
│ └── run.t
├── pervasive.t/
│ ├── input.mli
│ └── run.t
├── pexpFun.t/
│ ├── input.re
│ └── run.t
├── pipeFirst.t/
│ ├── input.re
│ └── run.t
├── polymorphism.t/
│ ├── input.re
│ └── run.t
├── print-width-env.t
├── raw-identifiers.t/
│ ├── input.re
│ └── run.t
├── reasonComments-rei.t/
│ ├── input.rei
│ └── run.t
├── rtopIntegration.t
├── sequences.t/
│ ├── input.re
│ └── run.t
├── sharpop.t/
│ ├── input.re
│ └── run.t
├── singleLineCommentEof.t/
│ ├── input.re
│ └── run.t
├── testUtils.t/
│ ├── input.re
│ └── run.t
├── trailing.t/
│ ├── input.re
│ └── run.t
├── trailingSpaces.t/
│ ├── input.re
│ └── run.t
├── type-constraint-in-body.t/
│ ├── input.ml
│ └── run.t
├── type-pipeFirst.t/
│ ├── input.re
│ └── run.t
├── typeDeclarations.t/
│ ├── input.re
│ └── run.t
├── typeParameters.t/
│ ├── input.re
│ └── run.t
├── uchar-esc.t/
│ ├── input.re
│ └── run.t
├── uncurried.t/
│ ├── input.re
│ └── run.t
├── unicodeIdentifiers.t/
│ ├── input.re
│ └── run.t
├── value-constraint-alias-pattern.t/
│ ├── input.re
│ └── run.t
├── variants.t/
│ ├── input.re
│ └── run.t
├── whitespace-re.t/
│ ├── input.re
│ └── run.t
├── whitespace-rei.t/
│ ├── input.rei
│ └── run.t
├── wrapping-re.t/
│ ├── input.re
│ └── run.t
└── wrapping-rei.t/
├── input.rei
└── run.t
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/workflows/esy-ci.yml
================================================
name: esy CI
on:
pull_request:
push:
branches:
- master
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: true
defaults:
run:
shell: bash
jobs:
build:
name: Build
strategy:
fail-fast: false
matrix:
os:
- ubuntu-latest
- macos-15-intel
- windows-latest
ocaml-compiler:
- 4.14.x
runs-on: ${{ matrix.os }}
steps:
- uses: actions/checkout@v6
- uses: actions/setup-node@v6
with:
node-version: 24
- name: Set up MinGW (Windows)
if: runner.os == 'Windows'
shell: pwsh
run: |
choco upgrade mingw -y --no-progress
echo "C:\ProgramData\mingw64\mingw64\bin" | Out-File -FilePath $env:GITHUB_PATH -Encoding utf8 -Append
- name: Install esy
run: npm install -g esy@0.9.0-beta.1
- name: Restore global cache (~/.esy/source)
id: global-cache
uses: actions/cache/restore@v5
with:
path: ~/.esy/source
key: v0.0.2-esy-source-${{ matrix.os }}-${{ matrix.ocaml-compiler }}-${{ hashFiles('esy.lock.json') }}
- name: Print esy cache
id: print_esy_cache
run: echo "ESY_CACHE=$(node .github/workflows/print-esy-cache.js)" >> $GITHUB_OUTPUT;
- name: Load dependencies cache
id: deps-cache
uses: actions/cache/restore@v5
with:
path: |
${{ steps.print_esy_cache.outputs.ESY_CACHE }}
_export
key: v0.0.2-esy-build-${{ matrix.os }}-${{ matrix.ocaml-compiler }}-${{ hashFiles('esy.lock.json') }}
restore-keys: v0.0.2-esy-build-${{ matrix.os }}-
- name: Install dependencies
run: esy install
- name: Import dependencies
if: steps.deps-cache.outputs.cache-hit == 'true'
# Don't crash the run if esy cache import fails - mostly happens on Windows
continue-on-error: true
run: |
esy import-dependencies _export
rm -rf _export
- name: Build dependencies
run: esy build-dependencies
- name: Build
run: esy build
- name: Test when not Windows
if: runner.os != 'Windows'
run: esy dune runtest
- name: Test when Windows
if: runner.os == 'Windows'
run: esy b dune runtest -p "reason,rtop"
- name: Export dependencies
if: steps.deps-cache.outputs.cache-hit != 'true'
run: esy export-dependencies
- name: Save global cache
uses: actions/cache/save@v5
if: steps.global-cache.outputs.cache-hit != 'true'
with:
path: ~/.esy/source
key: v0.0.2-esy-source-${{ matrix.os }}-${{ matrix.ocaml-compiler }}-${{ hashFiles('esy.lock.json') }}
- name: Save dependencies cache
if: steps.deps-cache.outputs.cache-hit != 'true'
uses: actions/cache/save@v5
with:
path: |
${{ steps.print_esy_cache.outputs.ESY_CACHE }}
_export
key: v0.0.2-esy-build-${{ matrix.os }}-${{ matrix.ocaml-compiler }}-${{ hashFiles('esy.lock.json') }}
# Cleanup build cache in case dependencies have changed
- name: Cleanup
if: steps.deps-cache.outputs.cache-hit != 'true'
run: esy cleanup .
================================================
FILE: .github/workflows/nix-build.yml
================================================
name: Nix Pipeline
on:
pull_request:
push:
branches:
- master
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: true
jobs:
ubuntu-tests:
name: Build and test (Ubuntu) (${{ matrix.ocaml-version }})
strategy:
matrix:
ocaml-version:
- 4_14
- 5_0
- 5_1
- 5_2
- 5_3
- 5_4
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
with:
submodules: 'recursive'
- uses: cachix/install-nix-action@v31
with:
extra_nix_config: |
extra-substituters = https://anmonteiro.nix-cache.workers.dev
extra-trusted-public-keys = ocaml.nix-cache.com-1:/xI2h2+56rwFfKyyFVbkJSeGqSIYMC/Je+7XXqGKDIY=
- name: "Run nix-build"
run: nix-build ./nix/ci.nix --argstr ocamlVersion ${{ matrix.ocaml-version }}
macos-tests:
name: Build and test (${{ matrix.setup.os }}) (${{ matrix.setup.ocaml-version }})
strategy:
matrix:
setup:
- {ocaml-version: '5_3', os: macos-15-intel}
- {ocaml-version: '4_14', os: macos-latest}
- {ocaml-version: '5_3', os: macos-latest}
- {ocaml-version: '5_4', os: macos-latest}
runs-on: ${{ matrix.setup.os }}
steps:
- uses: actions/checkout@v6
with:
submodules: 'recursive'
- uses: cachix/install-nix-action@v31
with:
extra_nix_config: |
extra-substituters = https://anmonteiro.nix-cache.workers.dev
extra-trusted-public-keys = ocaml.nix-cache.com-1:/xI2h2+56rwFfKyyFVbkJSeGqSIYMC/Je+7XXqGKDIY=
- name: "Run nix-build"
run: nix-build ./nix/ci.nix --argstr ocamlVersion ${{ matrix.setup.ocaml-version }}
================================================
FILE: .github/workflows/opam-ci.yml
================================================
name: opam CI
on:
pull_request:
push:
branches:
- master
tags:
- '*'
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: true
jobs:
build:
name: Build
strategy:
fail-fast: false
matrix:
setup:
- {ocaml-compiler: '4.08.x', os: ubuntu-latest}
- {ocaml-compiler: '4.10.x', os: ubuntu-latest}
- {ocaml-compiler: '4.12.x', os: ubuntu-latest}
- {ocaml-compiler: '4.13.x', os: ubuntu-latest}
- {ocaml-compiler: '4.14.x', os: ubuntu-latest}
- {ocaml-compiler: 'ocaml-base-compiler.5.3.0', os: ubuntu-latest}
- {ocaml-compiler: 'ocaml-base-compiler.5.4.0', os: ubuntu-latest}
- {ocaml-compiler: 'ocaml-base-compiler.5.5.0~alpha1', os: ubuntu-latest}
- {ocaml-compiler: 'ocaml-base-compiler.5.4.0', os: macos-15-intel}
- {ocaml-compiler: 'ocaml-base-compiler.5.4.0', os: macos-latest}
- {ocaml-compiler: 'ocaml-base-compiler.5.5.0~alpha1', os: macos-latest}
# looks like setup-ocaml@v3 can only run actions on windows for
# OCaml >= 4.13
# https://github.com/ocaml/setup-ocaml/issues/822#issuecomment-2215525942
- {ocaml-compiler: '4.14.x', os: windows-latest}
- {ocaml-compiler: 'ocaml-base-compiler.5.4.0', os: windows-latest}
runs-on: ${{ matrix.setup.os }}
steps:
- name: Checkout code
uses: actions/checkout@v6
- name: Use OCaml ${{ matrix.setup.ocaml-compiler }}
uses: ocaml/setup-ocaml@v3
with:
ocaml-compiler: ${{ matrix.setup.ocaml-compiler }}
opam-pin: true
- name: Load opam cache when not Windows
if: runner.os != 'Windows'
id: opam-cache
uses: actions/cache/restore@v5
with:
path: ~/.opam
key: v0.0.1-opam-${{ matrix.setup.os }}-${{ matrix.setup.ocaml-compiler }}-${{ hashFiles('*.opam') }}
- name: Load opam cache when Windows
if: runner.os == 'Windows'
id: opam-cache-windows
uses: actions/cache/restore@v5
with:
path: _opam
key: v0.0.1-opam-${{ matrix.setup.os }}-${{ matrix.setup.ocaml-compiler }}-${{ hashFiles('**.opam') }}
- name: Pin utop for OCaml 5.5
if: ${{ matrix.setup.ocaml-compiler == 'ocaml-base-compiler.5.5.0~alpha1' }}
run: opam pin add utop --dev-repo
- name: Install dependencies
run: opam install . --deps-only
- name: Build reason and rtop
run: opam exec -- dune build -p reason,rtop
- name: Test
run: opam exec -- dune runtest -p reason,rtop
- name: Install dune-release
if: startsWith(github.ref, 'refs/tags/') && matrix.setup.os == 'ubuntu-latest' && matrix.setup.ocaml-compiler == 'ocaml-base-compiler.5.4.0'
run: opam install dune-release -y
- name: Release to opam
uses: davesnx/dune-release-action@v0.2.14
if: startsWith(github.ref, 'refs/tags/') && matrix.setup.os == 'ubuntu-latest' && matrix.setup.ocaml-compiler == 'ocaml-base-compiler.5.4.0'
with:
packages: 'reason,rtop'
changelog: './CHANGES.md'
github-token: ${{ secrets.GH_TOKEN }}
- name: Save cache when not Windows
uses: actions/cache/save@v5
if: steps.opam-cache.outputs.cache-hit != 'true' && runner.os != 'Windows'
with:
path: ~/.opam
key: v0.0.1-opam-${{ matrix.setup.os }}-${{ matrix.setup.ocaml-compiler }}-${{ hashFiles('**.opam') }}
- name: Save cache when Windows
uses: actions/cache/save@v5
if: steps.opam-cache-windows.outputs.cache-hit != 'true' && runner.os == 'Windows'
with:
path: _opam
key: v0.0.1-opam-${{ matrix.setup.os }}-${{ matrix.setup.ocaml-compiler }}-${{ hashFiles('**.opam') }}
================================================
FILE: .github/workflows/print-esy-cache.js
================================================
const fs = require("fs");
const os = require("os");
const path = require("path");
const ESY_FOLDER = process.env.ESY__PREFIX
? process.env.ESY__PREFIX
: path.join(os.homedir(), ".esy");
const someEsy3 = fs
.readdirSync(ESY_FOLDER)
.filter((name) => name.length > 0 && name[0] === "3");
const esy3 = someEsy3
.sort()
.pop();
console.log(path.join(ESY_FOLDER, esy3, "i"));
================================================
FILE: .gitignore
================================================
_build
.DS_Store
*.log
# gitignored, but not npmignored. Published by `npm run prepublish`
refmt.js
refmt.map
# Esy
_esy
_esybuild
_esyinstall
_release
_export/
# opam
_opam/
================================================
FILE: .npmignore
================================================
_esy
node_modules
_build
.git
refmt.js
refmt.map
================================================
FILE: .ocamlformat
================================================
break-infix = fit-or-vertical
break-infix-before-func = false
break-fun-decl = fit-or-vertical
break-separators = before
break-sequences = true
cases-exp-indent = 2
dock-collection-brackets = false
field-space = loose
if-then-else = keyword-first
indicate-multiline-delimiters = no
infix-precedence = parens
leading-nested-match-parens = true
let-and = sparse
let-module = sparse
ocp-indent-compat = true
parens-tuple = multi-line-only
parse-docstrings = true
sequence-blank-line = preserve-one
sequence-style = terminator
single-case = sparse
space-around-arrays= true
space-around-lists= true
space-around-records= true
space-around-variants= true
type-decl = sparse
wrap-comments = true
wrap-fun-args = false
================================================
FILE: .ocamlformat-ignore
================================================
src/vendored-omp/**
src/reason-parser/vendor/**
test/**.cppo.ml
src/**.cppo.ml
src/**.cppo.mli
rtop/**.cppo.ml
================================================
FILE: CHANGES.md
================================================
## 3.17.3
- fix: Stack overflow on Pconstraint (@davesnx, [#2906](https://github.com/reasonml/reason/pull/2906))
- ci: Run 4.08 in CI (@davesnx, [#2910](https://github.com/reasonml/reason/pull/2910))
- test: Remove 4.06 cram tests (@davesnx, [#2910](https://github.com/reasonml/reason/pull/2910))
## 3.17.2
- fix: make `End_of_line.Convert.lf_to_crlf` compatible with OCaml 4.08
(@anmonteiro, [#2898](https://github.com/reasonml/reason/pull/2898))
## 3.17.1
- printer: don't escape infix keywords (@syaiful6,
[#2872](https://github.com/reasonml/reason/pull/2874))
- fix(printer): wrap `Ppat_constraint` in parentheses (@anmonteiro,
[#2874](https://github.com/reasonml/reason/pull/2874))
## 3.17.0
- Support OCaml 5.4 (@anmonteiro,
[#2844](https://github.com/reasonml/reason/pull/2844))
- build: use `(wrapped true)` for internal libraries (@anmonteiro,
[#2842](https://github.com/reasonml/reason/pull/2842))
- BREAKING: remove `refmttype` binary (@anmonteiro,
[#2855](https://github.com/reasonml/reason/pull/2855))
- printer: pad record braces with spaces (@anmonteiro,
[#2859](https://github.com/reasonml/reason/pull/2859))
## 3.16.0
- require OCaml >= 4.08 (@anmonteiro,
[#2840](https://github.com/reasonml/reason/pull/2840))
- support ppxlib with OCaml 5.2 AST (and require ppxlib >= 0.36) (@anmonteiro,
[#2835](https://github.com/reasonml/reason/pull/2835))
## 3.15.0
- rtop: read `~/.config/rtop/init.re` configuration file (@anmonteiro,
[#2813](https://github.com/reasonml/reason/pull/2813))
- the `-init FILE` flag works as before
- rtop: ignore `~/.ocamlinit.ml` or `~/.config/utop/init.ml` config files
(@anmonteiro, [#2813](https://github.com/reasonml/reason/pull/2813))
- Add support for raw identifier syntax (@anmonteiro,
[#2796](https://github.com/reasonml/reason/pull/2796))
- Fix: display attributes in record field and JSX props under punning
(@pedrobslisboa, [#2824](https://github.com/reasonml/reason/pull/2824))
- Support modest Unicode letters in identifiers
(@anmonteiro, [#2828](https://github.com/reasonml/reason/pull/2828))
- refmt: fix file descriptor leak
(@anmonteiro, [#2830](https://github.com/reasonml/reason/pull/2830))
## 3.14.0
- Support OCaml 5.3 (@anmonteiro,
[#2800](https://github.com/reasonml/reason/pull/2800))
- Fix: don't print all extension strings as quoted extensions (@anmonteiro,
[#2809](https://github.com/reasonml/reason/pull/2809))
- Fix: unify printing of extensions across structure items / expressions
(@anmonteiro, [#2814](https://github.com/reasonml/reason/pull/2814))
## 3.13.0
- Support `module%ppx` syntax (@anmonteiro,
[#2771](https://github.com/reasonml/reason/pull/2771))
- Extend open to arbitrary module expression (@anmonteiro,
[#2773](https://github.com/reasonml/reason/pull/2773))
- Wrap `let lazy patterns = ..` in parentheses (`let lazy(patterns) = ..`)
(@anmonteiro, [#2774](https://github.com/reasonml/reason/pull/2774))
- Print poly variants as normal variants (@Sander Spies,
[#2708](https://github.com/reasonml/reason/pull/2708))
- Improve printing of anonymous function return type (@Sander Spies,
[#2686](https://github.com/reasonml/reason/pull/2686))
- Improve printing of destructuring with local open (@Sander Spies,
[#2684](https://github.com/reasonml/reason/pull/2684)).
- Parse and print attributes in binding `let` ops (@anmonteiro,
[#2777](https://github.com/reasonml/reason/pull/2777)).
- Parse polymorphic variants starting with `[|` (@anmonteiro,
[#2781](https://github.com/reasonml/reason/pull/2781))
- Always add a line break in records with 2 or more fields (@anmonteiro,
[#2779](https://github.com/reasonml/reason/pull/2779))
- Always break nonempty doc comments after `*/` (@anmonteiro,
[#2780](https://github.com/reasonml/reason/pull/2780))
- Improve printing of arrows with labelled arguments (@anmonteiro,
[#2778](https://github.com/reasonml/reason/pull/2778))
- Parse and print extensions in `open%foo` expressions and structure items
(@anmonteiro, [#2784](https://github.com/reasonml/reason/pull/2784))
- Add support for module type substitutions
(@anmonteiro, [#2785](https://github.com/reasonml/reason/pull/2785))
- Support `type%foo` extension sugar syntax (@anmonteiro,
[#2790](https://github.com/reasonml/reason/pull/2790))
- Support quoted extensions (@anmonteiro,
[#2794](https://github.com/reasonml/reason/pull/2794))
- Parse universal type variables in signature items (@anmonteiro,
[#2797](https://github.com/reasonml/reason/pull/2797))
- Fix formatting of callbacks with sequence expressions (@anmonteiro,
[#2799](https://github.com/reasonml/reason/pull/2799))
- Fix printing of attributes on module expressions (@anmonteiro,
[#2803](https://github.com/reasonml/reason/pull/2803))
## 3.12.0
- Add `\u{hex-escape}` syntax (@anmonteiro,
[#2738](https://github.com/reasonml/reason/pull/2738))
- Support local open and let bindings (@SanderSpies) [#2716](https://github.com/reasonml/reason/pull/2716)
- outcome printer: change the printing of `@bs.*` to `@mel.*` (@anmonteiro, [#2755](https://github.com/reasonml/reason/pull/2755))
- Fix outcome printing of optional arguments on OCaml 5.2 (@anmonteiro, [#2753](https://github.com/reasonml/reason/pull/2753))
- support parsing and printing of `external%extension` (@anmonteiro, [#2750](https://github.com/reasonml/reason/pull/2750), [#2766](https://github.com/reasonml/reason/pull/2766), [#2767](https://github.com/reasonml/reason/pull/2767))
- install `refmt` manpage (@anmonteiro, [#2760](https://github.com/reasonml/reason/pull/2760))
- add support for parsing / printing of refutation clause in `switch` (@anmonteiro, [#2765](https://github.com/reasonml/reason/pull/2765))
- support `let%ppx` in signatures (@anmonteiro, [#2770](https://github.com/reasonml/reason/pull/2770))
## 3.11.0
- Print structure items extension nodes correctly inside modules (@anmonteiro,
[#2723](https://github.com/reasonml/reason/pull/2723))
- Print wrapped type constraint on record patterns (@anmonteiro,
[#2725](https://github.com/reasonml/reason/pull/2725))
- Support OCaml 5.2 (@anmonteiro, [#2734](https://github.com/reasonml/reason/pull/2734))
## 3.10.0
- Support `@mel.*` attributes in addition to `@bs.*` (@anmonteiro,
[#2721](https://github.com/reasonml/reason/pull/2721))
## 3.9.0
- Reduce the amount of parentheses around functor usage (@SanderSpies, [#2683](https://github.com/reasonml/reason/pull/2683))
- Print module type body on separate line (@SanderSpies, [#2709](https://github.com/reasonml/reason/pull/2709))
- Fix missing patterns around contraint pattern (a pattern with a type annotation).
- Fix top level extension printing
- Remove the dependency on the `result` package, which isn't needed for OCaml
4.03 and above (@anmonteiro) [#2703](https://github.com/reasonml/reason/pull/2703)
- Fix the binary parser by converting to the internal AST version used by
Reason (@anmonteiro) [#2713](https://github.com/reasonml/reason/pull/2713)
- Port Reason to `ppxlib` (@anmonteiro, [#2711](https://github.com/reasonml/reason/pull/2711))
- Support OCaml 5.1 (@anmonteiro, [#2714](https://github.com/reasonml/reason/pull/2714))
## 3.8.2
- Fix magic numbers for OCaml 5.0 (@anmonteiro) [#2671](https://github.com/reasonml/reason/pull/2671)
## 3.8.1
- (Internal) Rename: Reason_migrate_parsetree -> Reason_omp (@ManasJayanth) [#2666](https://github.com/reasonml/reason/pull/2666)
- Add support for OCaml 5.0 (@EduardoRFS and @anmonteiro) [#2667](https://github.com/reasonml/reason/pull/2667)
## 3.8.0
- Add support for OCaml 4.13 (@EduardoRFS and @anmonteiro) [#2657](https://github.com/reasonml/reason/pull/2657)
- Add support for OCaml 4.14 (@EduardoRFS and @anmonteiro) [#2662](https://github.com/reasonml/reason/pull/2662)
## 3.7.0
- Add support for (limited) interop between letop + OCaml upstream (@anmonteiro) [#2624](https://github.com/facebook/reason/pull/2624)
- Add support for OCaml 4.12 (@kit-ty-kate) [#2635](https://github.com/facebook/reason/pull/2635)
- Remove support for OCaml 4.02.3 (@anmonteiro) [#2638](https://github.com/facebook/reason/pull/2638)
## 3.6.2
**New Feature, Non Breaking:**
- Reason Syntax v4 [NEW-FEATURE-NON-BREAKING]: Angle Brackets Type Parameters (PARSING) (@jordwalke)[#2604][https://github.com/facebook/reason/pull/2604]
**Bug Fixes:**
- Fix printing of externals that happen to have newlines/quotes in them (@jordwalke)[#2593](https://github.com/facebook/reason/pull/2593)
- Fix parsing/printing of attributes on patterns (@jordwalke)[#2592](https://github.com/facebook/reason/pull/2592)
- Fix Windows CI (@ManasJayanth) [#2611](https://github.com/facebook/reason/pull/2611)
- Fix uncurry attribute on function application(@anmonteiro) [#2566](https://github.com/facebook/reason/pull/2566)
- Support OCaml 4.11 (@anmonteiro) [#2582](https://github.com/facebook/reason/pull/2582)
- Vendor ocaml-migrate-parsetree for greater compatibility (@jordwalke) [#2623](https://github.com/facebook/reason/pull/2623)
**Docs:**
- README Reason logo (@iamdarshshah)[#2609][https://github.com/facebook/reason/pull/2609]
## 3.6.0
**New Feature, Non Breaking:**
- External syntax: make the `external ... = ""` part optional (@romanschejbal)[#2464](https://github.com/facebook/reason/pull/2464)
- `external myFn: (string) => unit;` is now equivalent to `external myFn: (string) => unit = "";`
**Bug Fixes:**
- Fixes issues where `method` and similar keywords will be transformed to `method_` (@cristianoc) [#2530](https://github.com/facebook/reason/pull/2530)
## 3.5.4
Fixes:
- Fix regression where keywords were not renamed correctly (@cristianoc) [#2520](https://github.com/facebook/reason/pull/2520)
- Fix regression where quoted object attributes / labeled arguments weren't renamed correctly (@anmonteiro) [#2509](https://github.com/facebook/reason/pull/2509)
- Fix issue where JSX braces break into multiple lines (@anmonteiro) [#2503](https://github.com/facebook/reason/pull/2503)
Others:
- Improve bspacks process for 4.06 and add esy workflow for building refmt.js
## 3.5.3
- 🎉 MUCH better parsing error locations - more reliable autocomplete 🎉 (@let-def)[https://github.com/let-def] ([#2439](https://github.com/facebook/reason/pull/2439))
- Rebased the better error recovery diff onto 4.09 OCaml [@anmonteiro](https://github.com/anmonteiro) ([#2480](https://github.com/facebook/reason/pull/2480))
- Fix printing of fragments inside JSX props [@anmonteiro](https://github.com/anmonteiro) ([#2463](https://github.com/facebook/reason/pull/2463))
- Modernize CI based on latest hello-reason CI [@jordwalke](https://github.com/jordwalke) ([#2479](https://github.com/facebook/reason/pull/2479))
- Fix bug that caused necessary braces to be removed [@anmonteiro](https://github.com/anmonteiro) ([#2481](https://github.com/facebook/reason/pull/2481))
- Make prepublish script auto-generate opam files [@jordwalke](https://github.com/jordwalke) ([#2468](https://github.com/facebook/reason/pull/2468))
- Fix brace removal with pipe-first in JSX attributes [@bloodyowl](https://github.com/bloodyowl) ([#2474](https://github.com/facebook/reason/pull/2474))
- CI Improvements [@ulrikstrid](https://github.com/ulrikstrid) ([#2459](https://github.com/facebook/reason/pull/2459))
- Make sure you can still include rtop from inside utop [@sync ](https://github.com/sync ) ([#2466](https://github.com/facebook/reason/pull/2466))
## 3.5.2
- Support OCaml 4.09 ([2450](https://github.com/facebook/reason/pull/2450)).
- Improve opam packaging config ([2431](https://github.com/facebook/reason/pull/2431)).
- Improve repo to support esy resolutions to master branch ([31225fc0](https://github.co(https://github.com/facebook/reason/commit/31225fc066731075b6fa695e555f65ffcc172bcf))
## 3.5.0
Improvements:
- Support OCaml 4.08 ([2426](https://github.com/facebook/reason/pull/2426)).
Fixes:
- Print attributes in class fields [2414](https://github.com/facebook/reason/pull/2414).
- Preserve function body braces when Pexp_fun is an argument to a function [commit](https://github.com/facebook/reason/commit/f8eb7b1c1f3bc93883b663bb6b7fc0552e7b1791)
- Prettify try to hug braces [2378](https://github.com/facebook/reason/pull/2378)
- Fix operator swap for type declarations [commit](https://github.com/facebook/reason/commit/d4516beaceb1fa1fa53b9d1c30565c7e7cacd39b)
- Fix JSX removing semicolons [commit](https://github.com/facebook/reason/commit/ab4bf53ab1a76d7ead7e634489a2a1fcbb7cf817)
- Better formatting of Pexp_lazy [commit](https://github.com/facebook/reason/commit/46bffd1590a4f19a72a9c6e8d754bb47fb63fa4b)
## 3.4.2
Not released to @esy-ocaml/reason - would have required a major version bump.
These features will be released in 3.5.0.
Improvements:
- Parse and print parentheses around inline record declarations ([2363](https://github.com/facebook/reason/pull/2363))
- Proper outcome printing (for editor and build) of inline records ([2336](https://github.com/facebook/reason/pull/2336))
- Proper outcome printing of types with inline records (parentheses) ([2370](https://github.com/facebook/reason/pull/2370))
## 3.4.1
Fixes:
- Don't remove semis in blocks inside ternary expressions as jsx children ([2352](https://github.com/facebook/reason/pull/2352)).
- Handle single line comments ending with end-of-file ([2353](https://github.com/facebook/reason/pull/2353)).
## 3.4.0
Fixes:
- Don't pun record types if they contain attributes ([2316](https://github.com/facebook/reason/pull/2316)).
Improvements:
- `// line comments`! ([2268](https://github.com/facebook/reason/pull/2146)). Make sure that your constraints on `refmt` versions for native projects. Specify a version >= `3.4.0` if you use `//` comments in your Reason code. Specifiy ranges like `3.4.0-3.5.0`.
- Better whitespace interleaving ([1990](https://github.com/facebook/reason/pull/1990)).
- Allow Reason to be used with Merlin Natively on Windows ([2256](https://github.com/facebook/reason/pull/2256)).
- Improved Ternary Formatting ([2294](https://github.com/facebook/reason/pull/2294)).
## 3.3.4
Fixes:
- Pipe first braces ([2133](https://github.com/facebook/reason/pull/2133), [2148](https://github.com/facebook/reason/pull/2148)).
- Better rtop `use` directives ([2146](https://github.com/facebook/reason/pull/2146), [2147](https://github.com/facebook/reason/pull/2147)).
- `foo(~Foo.a)` becoming `foo(~Fooa=Foo.a)` ([2136](https://github.com/facebook/reason/pull/2136)).
- Parse `<div> ...c</div>` correctly ([2137](https://github.com/facebook/reason/pull/2137)).
- Invalid formatting of first-class module with type constraint ([2151](https://github.com/facebook/reason/pull/2151)).
- Precedence printing of pipe first with underscore sugar as JSX child ([2159](https://github.com/facebook/reason/pull/2159)).
- Correct location for JSX name & extension expression ([2166](https://github.com/facebook/reason/pull/2166), [2162](https://github.com/facebook/reason/pull/2162)).
- Lack of space after `module type of` ([2175](https://github.com/facebook/reason/pull/2175)).
- Outcome printer (editor & interface generator) function signature ([2185](https://github.com/facebook/reason/pull/2185)).
- Precedence issue with unary operators and labeled arguments ([2201](https://github.com/facebook/reason/pull/2201)).
- Type printing of polymorphic variants row fields ([2191](https://github.com/facebook/reason/pull/2191)).
- Pattern parsing inside ternary expressions ([2188](https://github.com/facebook/reason/pull/2188)).
Improvements:
- Preserve empty lines in records and bs objects ([2152](https://github.com/facebook/reason/pull/2152)).
- Make `let not = blabla` work (not is a keyword) ([2197](https://github.com/facebook/reason/pull/2197)).
- Format doc comments on variant leafs with consistency ([2194](https://github.com/facebook/reason/pull/2194))
- Single pipe first printing layout ([2193](https://github.com/facebook/reason/pull/2193)).
- Performance. One case where the printer took exponential time ([2195](https://github.com/facebook/reason/pull/2195)).
## 3.3.3
- More fixes for pipe first ([2120](https://github.com/facebook/reason/pull/2120), [2119](https://github.com/facebook/reason/pull/2119), [2111](https://github.com/facebook/reason/pull/2111)).
- Fix regressed printing of first-class module ([2124](https://github.com/facebook/reason/pull/2124)).
- Fix local open printing for `bs.obj` ([2123](https://github.com/facebook/reason/pull/2123)).
- fix printing of `foo[(bar + 1)]` to `foo[bar + 1]` ([2110](https://github.com/facebook/reason/pull/2110)).
- Only wrap `fun` in parentheses when necessary ([2033](https://github.com/facebook/reason/pull/2033)).
- Change all precedence printing to braces for consistency inside JSX ([2106](https://github.com/facebook/reason/pull/2106)).
- Format docblock comments above std attrs on record rows ([2105](https://github.com/facebook/reason/pull/2105)).
## 3.3.2
Big release! No breaking change. Big shout out to [@anmonteiro](https://twitter.com/anmonteiro90) and [@iwanKaramazow](https://twitter.com/_iwan_refmt)!
Major:
- Pipe first `|.` now got a Reason sugar, `->`, with better precedence support than the former ([1999](https://github.com/facebook/reason/pull/1999), [2078](https://github.com/facebook/reason/pull/2078), [2092](https://github.com/facebook/reason/pull/2092), [2082](https://github.com/facebook/reason/pull/2082), [2087](https://github.com/facebook/reason/pull/2087), [2055](https://github.com/facebook/reason/pull/2055)).
- ReasonReact JSX PPX DOM children spread ([2095](https://github.com/facebook/reason/pull/2095)).
- ReasonReact JSX PPX fragment ([2091](https://github.com/facebook/reason/pull/2091)).
- Other ReasonReact JSX PPX fixes ([2088](https://github.com/facebook/reason/pull/2088), [2060](https://github.com/facebook/reason/pull/2060), [2027](https://github.com/facebook/reason/pull/2027), [2024](https://github.com/facebook/reason/pull/2024), [2007](https://github.com/facebook/reason/pull/2007), [2021](https://github.com/facebook/reason/pull/2021), [1963](https://github.com/facebook/reason/pull/1963)).
- Semicolon relaxation & reporting improvements ([2040](https://github.com/facebook/reason/pull/2040), [2012](https://github.com/facebook/reason/pull/2012), [1968](https://github.com/facebook/reason/pull/1968)).
- Module parsing & formatting improvements ([2061](https://github.com/facebook/reason/pull/2061), [2059](https://github.com/facebook/reason/pull/2059), [1984](https://github.com/facebook/reason/pull/1984), [1949](https://github.com/facebook/reason/pull/1949), [1946](https://github.com/facebook/reason/pull/1946), [2062](https://github.com/facebook/reason/pull/2062)).
- Remove extra space in some places after formatting ([2047](https://github.com/facebook/reason/pull/2047), [2041](https://github.com/facebook/reason/pull/2041), [1969](https://github.com/facebook/reason/pull/1969), [1966](https://github.com/facebook/reason/pull/1966), [2097](https://github.com/facebook/reason/pull/2097)).
- Much better `...` spread errors for everything ([1973](https://github.com/facebook/reason/pull/1973)).
- Fix `foo##bar[baz]`, `foo->bar^##baz` and other precedences ([2050](https://github.com/facebook/reason/pull/2050), [2055](https://github.com/facebook/reason/pull/2055), [2044](https://github.com/facebook/reason/pull/2044), [2044](https://github.com/facebook/reason/pull/2044)).
- Milder "unknown syntax error" message ([1962](https://github.com/facebook/reason/pull/1962)).
Others:
- Parentheses hugging for multi-line `Js.t({foo: bar})` ([2074](https://github.com/facebook/reason/pull/2074)).
- Correctly parse prefix ops in labeled parameters ([2071](https://github.com/facebook/reason/pull/2071)).
- Attach doc attributes before extension sugar ([2069](https://github.com/facebook/reason/pull/2069)).
- Support non-parenthesized label colon type equal optional in type declarations ([2058](https://github.com/facebook/reason/pull/2058)).
- Printf uncurried application when last argument is a callback ([2064](https://github.com/facebook/reason/pull/2064)).
- OCaml rtop syntax printing( [2031](https://github.com/facebook/reason/pull/2031)).
- Fix Bigarray syntax ([2045](https://github.com/facebook/reason/pull/2045)).
- Parse `M.[]` ([2043](https://github.com/facebook/reason/pull/2043)).
- Fix printing of polymorphic variant with annotation ([2019](https://github.com/facebook/reason/pull/2019)).
- Format GADT type variants better ([2016](https://github.com/facebook/reason/pull/2016)).
- Better autocomplete for Merlin ([1998](https://github.com/facebook/reason/pull/1998)).
- Print newline after doc comments before attributes ([1869](https://github.com/facebook/reason/pull/1869)).
- Fix inconsistent printing of opening extension expressions ([1979](https://github.com/facebook/reason/pull/1979)).
- Fix error when parsing `let x=-.1;` and others ([1945](https://github.com/facebook/reason/pull/1945)).
- Arguments no longer accidentally punned when they carry attributes ([1955](https://github.com/facebook/reason/pull/1955)).
## 3.2.0
See the blog post [here](https://reasonml.github.io/blog/2018/05/25/reason-3.2.0.html).
- **WHITESPACES IMPROVEMENTS ARE HERE**: empty lines between most things will now be preserved when you format your code! Multiple lines still collapse to one line in most cases ([1921](https://github.com/facebook/reason/pull/1921), [1919](https://github.com/facebook/reason/pull/1919), [1876](https://github.com/facebook/reason/pull/1876)).
- **Semicolon relaxation**: see blog post ([1887](https://github.com/facebook/reason/pull/1887)).
- Fix parsing & printing of es6 function syntax inside attributes ([1943](https://github.com/facebook/reason/pull/1943)).
- List spread now has better error ([1925](https://github.com/facebook/reason/pull/1925)).
- Functor in JSX tags ([1927](https://github.com/facebook/reason/pull/1927)).
- Better comment printing ([1940](https://github.com/facebook/reason/pull/1940), [1934](https://github.com/facebook/reason/pull/1934)).
- Various other printer improvements.
## 3.1.0
- **New pipe sugar for function call argument in arbitrary position**: `foo |> map(_, addOne) |> filter(_, isEven)` ([1804](https://github.com/facebook/reason/pull/1804)).
- **BuckleScript [@bs] uncurry sugar**: `[@bs] foo(bar, baz)` is now `foo(. bar, baz)`. Same for declaration ([1803](https://github.com/facebook/reason/pull/1803), [1832](https://github.com/facebook/reason/pull/1832)).
- **Trailing commas** for record, list, array, and everything else ([1775](https://github.com/facebook/reason/pull/1775), [1821](https://github.com/facebook/reason/pull/1821))!
- Better comments interleaving ([1769](https://github.com/facebook/reason/pull/1769), [1770](https://github.com/facebook/reason/pull/1770), [1817](https://github.com/facebook/reason/pull/1817))
- Better JSX printing: `<Foo bar=<Baz />>`, `<div><span></span></div>` ([1745](https://github.com/facebook/reason/pull/1745), [1762](https://github.com/facebook/reason/pull/1762)).
- **switch** now mandates parentheses around the value. Non-breaking, as we currently support parentheses-less syntax but print parens ([1720](https://github.com/facebook/reason/pull/1720), [1733](https://github.com/facebook/reason/pull/1733)).
- Attributes on open expressions ([1833](https://github.com/facebook/reason/pull/1833)).
- Better OCaml 4.06 support ([1709](https://github.com/facebook/reason/pull/1709)).
- Extension points sugar: `let%foo a = 1` ([1703](https://github.com/facebook/reason/pull/1703))!
- Final expression in a function body now also has semicolon. Easier to add new expressions afterward now ([1693](https://github.com/facebook/reason/pull/1693))!
- Better editor printing (outcome printer) of Js.t object types, @bs types, unary variants and infix operators ([1688](https://github.com/facebook/reason/pull/1688), [1784](https://github.com/facebook/reason/pull/1784), [1831](https://github.com/facebook/reason/pull/1831)).
- Parser doesn't throw Location.Error anymore; easier exception handling when refmt is used programmatically ([1695](https://github.com/facebook/reason/pull/1695)).
## 3.0.4
- **Default print width is now changed from 100 to 80** ([1675](https://github.com/facebook/reason/pull/1675)).
- Much better callback formatting ([1664](https://github.com/facebook/reason/pull/1664))!
- Single argument function doesn't require wrapping the argument with parentheses anymore ([1692](https://github.com/facebook/reason/pull/1692)).
- Printer more lenient when user writes `[%bs.obj {"foo": bar}]`. Probably a confusion with just `{"foo": bar}` ([1659](https://github.com/facebook/reason/pull/1659)).
- Better formatting for variants constructors with attributes ([1668](https://github.com/facebook/reason/pull/1668), [1677](https://github.com/facebook/reason/pull/1677)).
- Fix exponentiation operator printing associativity ([1678](https://github.com/facebook/reason/pull/1678)).
## 3.0.2
- **JSX**: fix most of the parsing errors (#856 #904 [1181](https://github.com/facebook/reason/pull/1181) [1263](https://github.com/facebook/reason/pull/1263) [1292](https://github.com/facebook/reason/pull/1292))!! Thanks @IwanKaramazow!
- In-editor syntax error messages are now fixed! They should be as good as the terminal ones ([1654](https://github.com/facebook/reason/pull/1654)).
- Polymorphic variants can now parse and print \`foo(()) as \`foo() ([1560](https://github.com/facebook/reason/pull/1560)).
- Variant values with annotations like `Some((x: string))` can now be `Some(x: string)` ([1576](https://github.com/facebook/reason/pull/1576)).
- Remove few places remaining that accidentally print `fun` for functions ([1588](https://github.com/facebook/reason/pull/1588)).
- Better record & object printing ([1593](https://github.com/facebook/reason/pull/1593), [1596](https://github.com/facebook/reason/pull/1596)).
- Fewer unnecessary wrappings in type declarations and negative constants ([1616](https://github.com/facebook/reason/pull/1616), [1634](https://github.com/facebook/reason/pull/1634)).
- Parse and print attributes on object type rows ([1637](https://github.com/facebook/reason/pull/1637)).
- Better printing of externals with attributes ([1640](https://github.com/facebook/reason/pull/1640)).
- Better printing for multiple type equations in a module type in a function argument ([1641](https://github.com/facebook/reason/pull/1641)).
- Better printing for unary -. in labeled argument ([1642](https://github.com/facebook/reason/pull/1642)).
## 3.0.0
Our biggest release! **Please see our blog post** on https://reasonml.github.io/blog/2017/10/27/reason3.html.
Summary: this is, practically speaking, a **non-breaking** change. You can mix and match two projects with different syntax versions in BuckleScript 2 (which just got release too! Go check), and they'll Just Work (tm).
To upgrade your own project, we've released a script, https://github.com/reasonml/upgradeSyntaxFrom2To3
Improvements:
- Much better printing for most common idioms.
- Even better infix operators formatting for `==`, `&&`, `>` and the rest ([1380](https://github.com/facebook/reason/pull/1380), [1386](https://github.com/facebook/reason/pull/1386), etc.).
- More predictable keyword swapping behavior ([1539](https://github.com/facebook/reason/pull/1539)).
- BuckleScript's `Js.t {. foo: bar}` now formats to `{. "foo": bar}`, just like its value counterpart (`[%bs.obj {foo: 1}]` to `{"foo": bar}`.
- `[@foo]`, `[@@foo]` and `[@@@foo]` are now unified into `[@foo]` and placed in front instead of at the back.
- `!` is now the logical negation. It was `not` previously.
- Dereference was `!`. Now it's a postfix `^`.
- Labeled argument with type now has punning!
- String concat is now `++` instead of the old `^`.
- For native, Reason now works on OCaml 4.05 and the latest topkg ([1438](https://github.com/facebook/reason/pull/1438)).
- Record field punning for module field prefix now prints well too: `{M.x, y}` is `{M.x: x, y: y}`.
- JSX needs `{}` like in JS.
- Fix reason-specific keywords printing in interface files (e.g. `==`, `match`, `method`).
- Record punning with renaming ([1517](https://github.com/facebook/reason/pull/1517)).
- The combination of function label renaming + type annotation + punning is now supported!
- Label is now changed from `::foo` back to `~foo`, just like for OCaml.
- Fix LOTS of bugs regarding parsing & formatting (closing around 100 improvement-related issues!).
- Official `refmt.js`, with public API. See `README.md`.
- Official `refmt` native public API too.
- **New JS application/abstraction syntax**. Yes yes, we know. Despite the 100+ fixes, this one's all you cared about. Modern software engineering ¯\\\_(ツ)\_/¯. Please do read the blog post though.
Breaking Changes:
- Remove `--use-stdin` and `--is-interface-pp` option from refmt; they've been deprecated for a long time now
- Remove unused binaries: `reup`, etc.
- Remove the old `reactjs_jsx_ppx.ml`. You've all been on `reactjs_jsx_ppx_2.ml` for a long time now.
- Reserved keywords can no longer be used as an `external` declaration's labels.
Deprecated:
- Deprecate `--add-printers` option from refmt; we'll have a better strategy soon.
## 1.13.7
- Much better infix operators (e.g. |>) formatting! ([1259](https://github.com/facebook/reason/pull/1259))
- Official `refmt.js`, with public API. See `README.md`. We've back-ported this into the 1.13.7 release =)
## 1.13.6
- Changelog got sent into a black hole
================================================
FILE: CODE_OF_CONDUCT.md
================================================
# Code of Conduct
Facebook has adopted a Code of Conduct that we expect project participants to adhere to. Please [read the full text](https://code.facebook.com/codeofconduct) so that you can understand what actions will and will not be tolerated.
================================================
FILE: LICENSE.txt
================================================
MIT License
Copyright (c) 2015-present, Facebook, Inc.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: Makefile
================================================
# Portions Copyright (c) 2015-present, Facebook, Inc. All rights reserved.
SHELL=bash -o pipefail
default: build
build:
dune build
install:
opam pin add reason . -y
# CI uses opam. Regular workflow needn't.
test-ci: install test-once-installed
test-once-installed: test
test:
esy dune runtest
test-watch:
esy dune runtest --watch
.PHONY: coverage
coverage:
find -iname "bisect*.out" -exec rm {} \;
make test-once-installed
bisect-ppx-report -ignore-missing-files -I _build/ -html coverage-after/ bisect*.out ./*/*/*/bisect*.out
find -iname "bisect*.out" -exec rm {} \;
testFormat: build test-once-installed
all_errors:
@ echo "Regenerate all the possible error states for Menhir."
@ echo "Warning: This will take a while and use a lot of CPU and memory."
@ echo "---"
menhir --explain --strict --unused-tokens src/reason-parser/reason_parser.mly --list-errors > src/reason-parser/reason_parser.messages.checked-in
clean:
dune clean
clean-for-ci:
rm -rf ./_build
.PHONY: build clean
# For publishing esy releases to npm
esy-prepublish: build
node ./scripts/esy-prepublish.js
all-supported-ocaml-versions:
# the --dev flag has been omitted here but should be re-introduced eventually
dune build @install @runtest --root .
.PHONY: all-supported-ocaml-versions
doc:
esy dune build @doc
.PHONY: doc
================================================
FILE: ORIGINS.md
================================================
This repo was forked from [m17n](https://github.com/whitequark/ocaml-m17n), which is licensed under MIT.
Copyright (c) 2014 Peter Zotov <whitequark@whitequark.org>
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
---
`./formatTest/` is entirely original content (by @jordwalke/Facebook)
---
Copyright (c) 2015 The Rust Project Developers
Permission is hereby granted, free of charge, to any
person obtaining a copy of this software and associated
documentation files (the "Software"), to deal in the
Software without restriction, including without
limitation the rights to use, copy, modify, merge,
publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software
is furnished to do so, subject to the following
conditions:
The above copyright notice and this permission notice
shall be included in all copies or substantial portions
of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF
ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED
TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT
SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR
IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
DEALINGS IN THE SOFTWARE.
================================================
FILE: PLAN
================================================
Fix error recovery & error reporting
Step 1: remove existing implementation
OK * Put reason parser in its own file
OK * Remove menhir error management:
OK - remove "error" token
OK - remove error messages infrastructure
OK Now message defaults to "Syntax error"
* Fix reported error location (when recovering or not)
Step 2: reintroduce recovery
* Preprocess grammar:
- check exhaustivity of recovery
- produce a mapping of automaton states to automaton-items suitable for
recovery
* Instrument parser:
- first, always complete the AST and drop user input (":'(")
- second, introduce an heuristic for recovering based on location
Step 3: reintroduce error messages
* Ask the crowd:
What should messages look like?
Which situations are tricky or counter-intuitive?
* Make a testsuite representative of common syntax errors
* ... Design an analysis sufficient to produce the messages automatically
:P
================================================
FILE: README.md
================================================
<p align="center"><img src="https://reasonml.github.io/img/reason.svg" alt="logo" width="316" /></p>
<h1 align="center">Reason</h1>
<p align="center">Simple, fast & type safe code that leverages the JavaScript & OCaml ecosystems.</p>
<p align="center">
<a href="https://dev.azure.com/reasonml/reason/_build/latest?definitionId=2?branchName=master">
<img src="https://dev.azure.com/reasonml/reason/_apis/build/status/reasonml.reason?branchName=master" alt="Build Status" />
</a>
<a href="https://circleci.com/gh/reasonml/reason/tree/master">
<img src="https://circleci.com/gh/reasonml/reason/tree/master.svg?style=svg" alt="CircleCI" />
</a>
<a href="https://discord.gg/reasonml">
<img src="https://img.shields.io/discord/235176658175262720.svg?logo=discord&colorb=blue" alt="Chat" />
</a>
</p>
## Latest Releases:
[![native esy package on npm][reason-badge]](https://www.npmjs.com/package/@esy-ocaml/reason)
## User Documentation
**The Reason user docs live online at [https://reasonml.github.io](https://reasonml.github.io)**.
The repo for those Reason docs lives at [github.com/reasonml/reasonml.github.io](https://github.com/reasonml/reasonml.github.io)
Docs links for new users:
- [Getting Started](https://reasonml.github.io/docs/en/installation)
- [Community](https://reasonml.github.io/docs/en/community.html)
### Contributing:
```sh
npm install -g esy@next
git clone https://github.com/facebook/reason.git
cd reason
esy
esy test # Run the tests
```
### Contributor Documentation:
The [`docs/`](./docs/) directory in this repo contains documentation for
contributors to Reason itself (this repo).
## License
See Reason license in [LICENSE.txt](LICENSE.txt).
Works that are forked from other projects are under their original licenses.
## Credit
The general structure of `refmt` repo was copied from [whitequark's m17n project](https://github.com/whitequark/ocaml-m17n), including parts of the `README` that instruct how to use this with the OPAM toolchain. Thank you OCaml!
[reason]: https://www.npmjs.com/package/@reason-native/console
[reason-badge]: https://img.shields.io/npm/v/@esy-ocaml/reason/latest.svg?color=blue&label=@esy-ocaml/reason&style=flat&logo=data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHZpZXdCb3g9IjAgMCAzOTcgNDE3IiB3aWR0aD0iMzk3IiBoZWlnaHQ9IjQxNyI+PGcgZmlsbD0iI0ZDRkFGQSI+PHBhdGggZD0iTTI2Ny42NDYgMTQyLjk4MmwzOS42MTYtMjIuOTQ2TDI2Ny41ODMgOTcuMmwtMzkuNjE2IDIyLjk0NiAzOS42NzkgMjIuODM2em0tNjkuMzI4IDQwLjEyOWwzOS42MTYtMjIuOTQ1LTM5LjY3OS0yMi44MzYtMzkuNjE2IDIyLjk0NiAzOS42NzkgMjIuODM1em0tNjkuNDM5LTQwLjEzbDM5LjYxNi0yMi45NDVMMTI4LjgxNiA5Ny4yIDg5LjIgMTIwLjE0NmwzOS42NzkgMjIuODM1em02OS4zMjgtMzkuOThsMzkuNjE2LTIyLjk0NS0zOS42NzktMjIuODM2LTM5LjYxNiAyMi45NDYgMzkuNjc5IDIyLjgzNXoiLz48cGF0aCBkPSJNMTkuODU2IDEzNy41OTFsMTY4LjYzOCA5Ny4wNTEuMjA2IDE0OC43ODlMMjAuMDYzIDI4Ni4zOGwtLjIwNy0xNDguNzg5ek0xOTguMTEyIDIyLjg5bDE2OC42MzcgOTcuMDUyLTE2OC4zNjcgOTcuNTE5TDI5Ljc0NCAxMjAuNDFsMTY4LjM2OC05Ny41MnptMTc4LjU3MyAxMTQuMjA2bC4yMDcgMTQ4Ljc4OS0xNjguMzY4IDk3LjUxOS0uMjA2LTE0OC43ODkgMTY4LjM2Ny05Ny41MTl6TTE5OC4wOCAwTDAgMTE0LjcyOGwuMjU1IDE4My4xMjUgMTk4LjM5NyAxMTQuMTc4IDE5OC4wOC0xMTQuNzI4LS4yNTUtMTgzLjEyNUwxOTguMDggMHoiLz48L2c+PC9zdmc+Cg== "esy package on npm"
================================================
FILE: docs/GETTING_STARTED_CONTRIBUTING.md
================================================
# Core Reason
## Contributor Setup
### With esy
```sh
# Make sure you have the latest esy
npm install -g esy@next
git clone https://github.com/facebook/reason.git
cd reason
esy
```
#### Testing:
**Test Suite:**
```sh
esy test # Run tests
```
**One Off Tests:**
Start up the `rtop` top level with your changes:
```sh
esy x rtop
```
Pipe some text to `refmt` with your changes:
```sh
echo "let a = 1" | esy x refmt
```
> **`esy` tips:**
> - `esy x your command` will run one command `your command` in an environment
> where the projects are built/installed. `esy x which refmt` will build the
> packages and install them for the duration of one command - `which refmt`.
> This will print the location of the built `refmt` binary.
> - For more, see the [esy documentation](https://github.com/esy-ocaml/esy).
> All the built binaries are in `esy echo '#{self.target_dir}/install/default/bin'`.
### With opam
```sh
# On OSX, install opam via Homebrew:
brew update
brew install opam
# On Linux, see here (you will need opam >= 1.2.2): http://opam.ocaml.org/doc/Install.html
opam init
# Add this to your ~/.bashrc (or ~/.zshrc), then do `source ~/.bashrc`
# eval $(opam config env)
opam update
opam switch 4.04.2
eval $(opam config env)
git clone https://github.com/facebook/reason.git
cd reason
opam pin add -y reason .
opam pin add -y rtop .
```
> **Opam Troubleshooting:**
> - Is the previous pinning unsuccessful? We might have updated a dependency;
> try `opam update` then `opam upgrade`.
> - During the last `opam pin` step, make sure your local repo is clean. In
> particular, remove artifacts and `node_modules`. Otherwise the pinning
> might go stale or stall due to the big `node_modules`.
## Repo Walkthrough
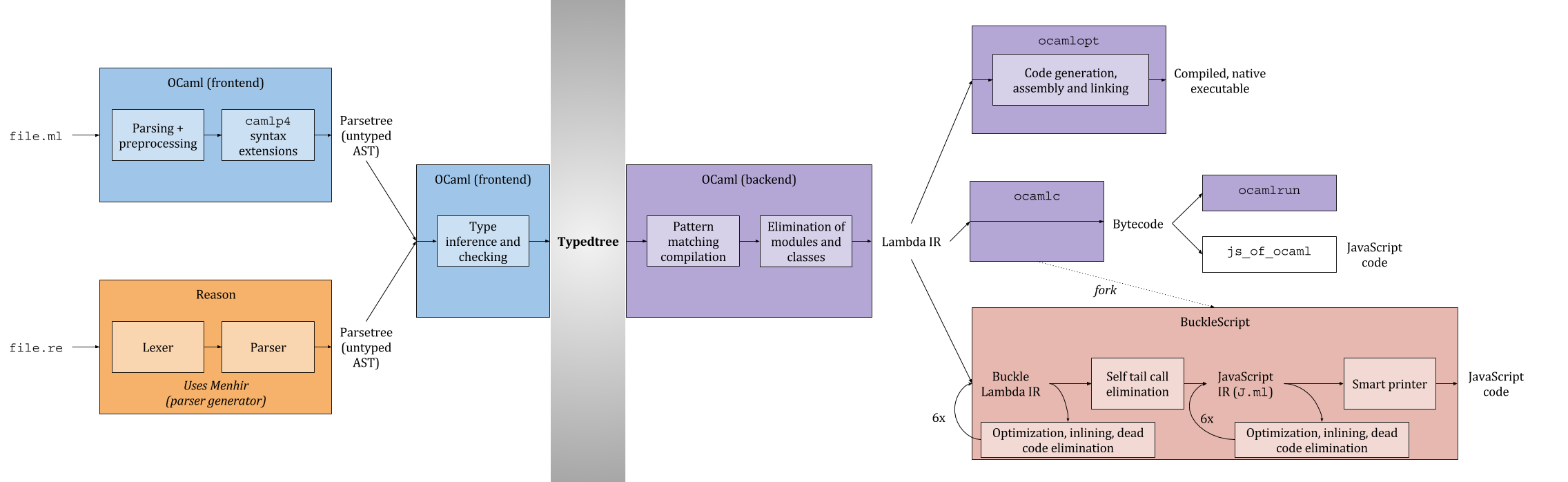
(_Click to see a larger version_)
Reason is the orange part. The core of the codebase is a parser + a printer, plus other miscellaneous utilities we expose.
Throughout the codebase, you might see mentions of "migrate-parsetree", `Ast_404`, etc. These refer to https://github.com/let-def/ocaml-migrate-parsetree. It's a library that allows you to convert between different versions of the OCaml AST. This way, the Reason repo can be written in OCaml 4.04's AST data structures, while being usable on OCaml 4.02's libraries (BuckleScript's on 4.02 too).
The Reason lexer & parser use [Menhir](http://gallium.inria.fr/~fpottier/menhir/), a library that generates parsers. You can read more about Menhir [here](https://realworldocaml.org/v1/en/html/parsing-with-ocamllex-and-menhir.html).
### Core Files
- `src/reason-parser/reason_lexer.mll`: the lexer that chunks a raw string into tokens. See the file for more comments.
- `src/reason-parser/reason_parser.mly`: the parser that takes the lexer's result and turns it into a proper AST (abstract syntax tree). See the file for more comments.
- `src/reason-parser/reason_pprint_ast.ml`: the pretty-printer! This is the reverse of parsing: it takes in the AST (abstract syntax tree) and prints out the nicely formatted code text.
- `src/reason-parser/reason_parser.messages.checked-in`: this is the huge table of mostly generated, sometimes hand-written, syntax error messages. When the parser ends up at an invalid parsing state (aka ends up with a syntax error), it'd refer to that file's content and see if that case has a specific error message assigned to it. For an example fix, see [this PR](https://github.com/facebook/reason/pull/1018) and the [follow-up](https://github.com/facebook/reason/pull/1033). To add a syntax error message see the "Add a Menhir Error Message" section below.
- When running `esy`, and a new `reason_parser.messages` file is generated, do a `mv reason_parser.messages reason_parser.messages.checked-in` to persist the updated messages.
- `src/reason-parser/reason_oprint.ml`: the "outcome printer" used by Merlin, rtop and terminal, that prints the errors in Reason syntax. More info in the file itself.
- `src/reason-parser/menhir_error_processor.ml, reason_parser_explain.ml`: two files that allows us to batch assign a better syntax error message for a category of errors, like accidentally using a reserved token. More info in the comments of these files.
### Miscellaneous Files
- `ocamlmerlin_reason.ml`: produces the `ocamlmerlin-reason` binary, used in conjunction with [Merlin-extend](https://github.com/let-def/merlin-extend). This is an extension to [Merlin](https://github.com/ocaml/merlin), which picks up this binary from your environment to analyze Reason files when your editor calls Merlin.
- `*.mllib`: related: see the [OCaml extensions list](https://reasonml.github.io/docs/en/faq.html#i-m-seeing-a-weird-cmi-cmx-cmj-cma-file-referenced-in-a-compiler-error-where-do-these-files-come-from-). These are generated file from `pkg/build.ml`, which describes the package we distribute. No need to worry about them.
- `src/reason-parser/reason_config.ml`: global configuration that says whether the parser should run in "recoverable" mode. Merlin has a neat feature which lets it continue diagnosing e.g. type errors even when the file is syntactically invalid (at the expense of the accuracy of those type error reports' quality). Searching `reason_config` in the codebase will show you how this is used.
- `src/reason-parser/reason_parser.messages`: auto-generated from parser changes. Menhir generates parsing code that assigns each syntax error to a code, and lets us customize these errors. Syntax errors can be very precisely pinpointed and explained this way.
- `src/reason-parser/reason_toolchain.ml`, `src/reason-parser/refmt_impl.ml`: the entry point that calls the parsing logic.
- `src/rtop/reason_utop.ml`, `src/rtop/reason_toploop.ml`, `src/rtop/rtop_init.ml`: Reason's [Utop](https://github.com/diml/utop) integration. Utop's the terminal-based REPL you see when executing `utop` (in Reason's case, the wrapper `rtop`).
- `*.sh`: some of the binaries' entries.
- `src/rtop/reason_util.ml`, `reason_syntax_util.ml`: utils.
- `src/reason-parser/reactjs_jsx_ppx_v2.ml`: the ReactJS interop that translates [Reason JSX](https://reasonml.github.io/docs/en/jsx.html) into something that ReactJS understands. See the comments in the file and the description in [ReasonReact](https://reasonml.github.io/reason-react/#reason-react-jsx).
- `src/reason-parser-tests/testOprint.ml`: unit tests for the outcome printer mentioned above. See the file for more info on how outcome printing is tested.
## Working With Parser
Here's a recommended workflow:
- First put your code in the current master syntax in a file `test.re`
- `esy x refmt --print ast test.re`
- look closely at the ast, spot the thing you need
- Search for your item in `reason_parser.mly`
- Change the logic
- `esy test`
Lexer helpers doc: http://caml.inria.fr/pub/docs/manual-ocaml/libref/Lexing.html
Parser helper docs: http://caml.inria.fr/pub/docs/manual-ocaml/libref/Parsetree.html
Menhir manual: http://gallium.inria.fr/~fpottier/menhir/manual.pdf
Small Menhir example: https://github.com/derdon/menhir-example
Random Stack Overflow answer: https://stackoverflow.com/questions/9897358/ocaml-menhir-compiling-writing
(Ok seriously, we need some more Menhir examples. But hey, nobody said it was easy... for now!)
**Want some example pull requests**? Here are a few:
- [Fix outcome printer object printing](https://github.com/facebook/reason/pull/1357)
- [Add more spacing when printing Ptyp_package](https://github.com/facebook/reason/pull/1430)
- [Implement spread for jsx3](https://github.com/facebook/reason/pull/1429)
- [Make deref be a prefix operator](https://github.com/facebook/reason/pull/1463)
- [Print MyConstructor(()) as MyConstructor()](https://github.com/facebook/reason/pull/1465)
- [Ensure valid parsing of constraint expressions after printing](https://github.com/facebook/reason/pull/1464)
- [Record punning for value & pattern for fields with module prefix](https://github.com/facebook/reason/pull/1456)
- [Rage implement everything](https://github.com/facebook/reason/pull/1448)
- [Print functions as javascript](https://github.com/facebook/reason/pull/1469)
- [Transform ocaml pervasives interfaces to reason correctly](https://github.com/facebook/reason/pull/1474)
- [Special case printing of foo(bar)##value](https://github.com/facebook/reason/pull/1481)
- [Use ~ for named args](https://github.com/facebook/reason/pull/1483/)
- [Bring back parentheses-less `switch foo`](https://github.com/facebook/reason/pull/1476)
- [Remove extra parens printed in `type a = Foo((unit => unit))`](https://github.com/facebook/reason/pull/1491)
- [Don't apply sugar to Js.t({.}) and Js.t({..})](https://github.com/facebook/reason/pull/1502)
- [Pun record destructuring with renaming](https://github.com/facebook/reason/pull/1517)
- [Add support for simple pattern direct argument with array, list & record](https://github.com/facebook/reason/pull/1528)
- [Fix outcome printer record value printing](https://github.com/facebook/reason/pull/1529)
- [Print`foo(()) as `foo() + update parser](https://github.com/facebook/reason/pull/1560)
- [Allow parsing of constraint expressions without parens inside constructor expr](https://github.com/facebook/reason/pull/1576)
- [Don't print fun in record expressions with Pexp_fun values](https://github.com/facebook/reason/pull/1588)
- [Force breaks for nested records](https://github.com/facebook/reason/pull/1593)
- [Always break object def with two or more rows](https://github.com/facebook/reason/pull/1596)
- [Make exponentiation operator print with right associativity](https://github.com/facebook/reason/pull/1678)
### Debugging Grammar Conflicts
Run the main parser through Menhir with the `--explain` flag to have it print
out details about the conflict. `esy menhir --explain src/reason-parser/reason_parser.mly`.
The debug information can be found at `src/reason-parser/reason_parser.conflicts`.
Use the `--dump` flag to have Menhir print the state transitions for debugging the parser rules
that are applied `esy menhir --dump src/reason-parser/reason_parser.mly`
It will generate `src/reason-parser/reason_parser.automaton` which you can inspect. It will also
drop a `reason_parser.ml` and `reason_parser.mli` in that directory which you need to remove before
building again.
### Debugging the Lexer/Parser State at Runtime
Add the `--trace` flag to the _end_ of the `menhir` `(flags..)` section in the
`dune` file for the `reason-parser`, and it will print out tokens that are
lexed along with parser state transitions.
### Add a Menhir Error Message
To add a Menhir error message, you first need to know the error code. To find the error code, you can run the following commands from the Reason project root:
```
esy x refmt --parse re foo.re
```
Where `foo.re` contains a syntax error. This will result in an error message like:
```
File "test2.re", line 4, characters 2-6:
Error: 2665: <syntax error>
```
Here, the error code is 2665. We then search for this code in `src/reason-parser/reason_parser.messages`.
- If you find it, you can add a better error message instead of the not so descriptive `<syntax error>`.
To test the new error message you can run the following commands again:
```
esy x refmt --parse re foo.re
```
Then submit a PR!
### Improve Error Message Locations
In some situations, Reason might report errors in a different place than where it occurs. This is caused by the AST not having a correct location for a node. When the error reports a location that's simply at the top of the file, that means we likely didn't attach the location in the parser correctly, altogether.
Before digging into Reason parser, make sure this isn't actually caused by some PPX. Otherwise, run:
```
esy x refmt --parse re --print ast test.re
```
Where `test.re` has the code that produces the error message at the wrong location.
In the printed AST, you can see nodes such as `Ptyp_constr "int" (test.re[1,0+15]..[1,0+18])` where the part between parentheses is the location of the node.
The error message's own location will look like `([0,0+-1]..[0,0+-1])` too.
To fix this, we need to find the AST node in `src/reason-parser/reason_parser.mly`. It's a big file, but if you search for the AST node, you should be able to find the location (if not, bug us on Discord). It will probably involve a `mkexp` or `mkpat` without a proper `~loc` attached to it.
As you can see from other parts in the parser, many do have a `~loc` assigned to it. For example
```
| LIDENT jsx_arguments
{
(* a (punning) *)
let loc_lident = mklocation $startpos($1) $endpos($1) in
[($1, mkexp (Pexp_ident {txt = Lident $1; loc = loc_lident}) ~loc:loc_lident)] @ $2
}
```
## Testing Two Different Syntax Versions
If you'd like to convert from an old Reason syntax version to the one in master (whether to debug things, or if you're interested in trying out some syntax changes from master and then explaining to us why your perspective on the Reason syntax is the best, lol):
- Revert the repo to the old commit you want
- Build, through `esy`
- Move the built refmt binary `esy x which refmt` somewhere else
- Revert back to master
- `esy x which refmt` again to get the master binary.
Then do:
```
esy x refmt --parse my_old_syntax_file.re --print binary_reason | ./refmt_impl --parse binary_reason --print re
```
Basically, turn your old syntax into an AST (which is resilient to syntax changes), then turn it back into the new, textual code. If you're reverting to an old enough version, the old binary's flags and/or the old build instructions might be different. In that case, see `esy x refmt --help` and/or the old README.
================================================
FILE: docs/README.md
================================================
### Documentation
> This directory is not the Reason _User_ documentation. This directory is for
> Reason contributor documentation. **The Reason user docs live online at
> [https://reasonml.github.io](https://reasonml.github.io)**. The repo for
> those Reason docs lives at
> [github.com/reasonml/reasonml.github.io](https://github.com/reasonml/reasonml.github.io)
**Inside of this directory:**
**Getting Started Contributing:**
[`GETTING_STARTED_CONTRIBUTING.md`](./GETTING_STARTED_CONTRIBUTING.md).
**Releasing:**
[`RELEASING.md`](./RELEASING.md)
**Programmatically Using Reason Parser From JavaScript:**
[`USING_PARSER_PROGRAMMATICALLY.md`](./USING_PARSER_PROGRAMMATICALLY.md)
================================================
FILE: docs/RELEASING.md
================================================
## Releasing Native Packages To Npm:
There's a few native `esy` packages included which are released to npm.
- `@esy-ocaml/reason`
- `@esy-ocaml/rtop`
## Releasing
The Reason repo is a "monorepo" `esy` project. To actually created individual
packages from the monorepo that should be published, there is a script
`./scripts/esy-prepublish.js` which accepts the relative paths to various
`.json` files you wish to publish as individual packages. To release packages
`@esy-ocaml/reason` and `@esy-ocaml/rtop` which have json files `reason.json`
and `rtop.json` respectively in the repo root, you would run that script after
committing/bumping some versions:
```sh
git checkout -b MYRELEASE origin/master
git rebase origin/master
vim -O esy.json reason.json
# Then edit the version number accordingly on BOTH files. With that same VERSION do:
version=3.5.0 make pre_release
git commit -m "Bump version"
git push origin HEAD:PullRequestForVersion # Commit these version bumps
node ./scripts/esy-prepublish.js ./reason.json ./rtop.json
# Then publish. For example:
# cd _release/reason.json/package/
# npm publish --access=public
# cd _release/refmt.json/package/
# npm publish --access=public
```
Then follow the printed instructions for pushing any of the packages to npm.
They will show up under `@esy-ocaml/reason` etc.
## Releasing Native Packages To Opam:
*note: it is recommended to install opam-publish via* `opam-depext -i opam-publish`
*Also, the commands below are examples based on specific Reason and rtop versions, the version numbers and possibly source urls will need to be changed to match the relevant release.
1. `cd` into a directory that you don't mind having stuff downloaded into
2. `opam-publish prepare reason.3.2.0 "https://registry.npmjs.org/@esy-ocaml/reason/-/reason-3.2.0.tgz"`
3. `opam-publish submit reason.3.2.0`
4. `opam-publish prepare rtop.3.2.0 "https://registry.npmjs.org/@esy-ocaml/rtop/-/rtop-3.2.0.tgz"`
5. `opam-publish rtop.3.2.0`
## [Depracated] reason-cli
Those two Reason packages are combined together into a separate npm package
`reason-cli` which prebuilds those as well as merlin. They can also be used
individually from `esy` projects without prebuilding, but they are more or less
just npm hosted versions of the Opam packages. `reason-cli` is now no longer
necessary, as projects can/should declare `@esy-ocaml` and `@opam/merlin` as
`devDependencies` in their project's `package.json`/`esy.json`. We may revive
a separate project just for prebuilt binaries of `rtop` without merlin.
================================================
FILE: docs/TYPE_PARAMETERS_PARSING.md
================================================
Contributors: Lexing and Parsing Type Parameters:
===================================================
Lexing and Parsing type parameters with angle brackets such as the following:
```reason
type t<'x> = list<'x>;
```
is difficult because type parameter angle brackets can "stack" at the end of a
nested parameterized type, resulting in something that looks a lot like an
infix operator beginning with greater-than symbol `>`.
```reason
type t<'x> = something<list<'x>>;
```
In the original implementation of the Reason lexer
`reason_declarative_lexer.mll`, it would tokenize what appears to be infix
operators as a single token so in that case will tokenize `>>` at the end of
the type definition. But in order to correctly parse parameterized types, we
nee to be able to "balance" the opening and closing angle brackets.
Another potential lexing conflict with infix operators is in the parsing of
default values in named arguments with type annotations.
```reason
let f = (~name: list<thing>=[myThing]) => {..};
```
In that example, the `>=` could be parsed as an infix operator if we are not
careful.
Any workable solution will need to maintain multiple `GREATER` tokens when
lexing `>>>` so they can be used for balancing type parameters. There are a few
options:
**Solution:**
In `Reason_single_parser.ml`, we use the same token splitting technique, where
upon a failure to parse on a token, we examine the token and determine if we
can split it into several tokens. We already did this for when we lexed the
token `=?` and failed to parse with it (we split it into `=`, `?'`). When we
fail to parse with a lexed token beginning with `>`, we split all of the
leading `>` characters into a stream of `GREATER` tokens, and split the
remaining as best as possible.
================================================
FILE: docs/USING_PARSER_PROGRAMMATICALLY.md
================================================
## Using Reason Parser Programmatically
This document describes how to integrate the Reason parser into other custom toolchains that need to get an AST tree of Reason source code.
### JavaScript API
We expose a `refmt.js` for you to use on the web. Again, for local development, please use the native `refmt` that comes with the installation [here](https://reasonml.github.io/docs/en/installation.html). It's an order of magnitude faster than the JS version. Don't use the JS version unless you know what you're doing. Let's keep our ecosystem fast please.
Aaaanyways, to install `refmt.js`: `npm install reason`.
Here's the API, with pseudo type annotations:
- `parseRE(code: string): astAndComments`: parse Reason code
- `parseREI(code: string): astAndComments`: parse Reason interface code
- `printRE(data: astAndComments): string`: print Reason code
- `printREI(data: astAndComments): string`: print Reason interface code
- `parseML(code)`, `parseMLI(code)`, `printML(data)`, `printMLI(data)`: same as above, but for the OCaml syntax
The type `string` is self-descriptive. The type `astAndComments` returned by the `parse*` functions is an opaque data structure; you will only use it as input to the `print*` functions. For example:
```js
const refmt = require('reason');
// convert the ocaml syntax to reason syntax
const ast = refmt.parseML('let f a = 1');
const result = refmt.printRE(ast);
console.log(result); // prints `let f = (a) => 1`
```
The `parse*` functions potentially throw an error of this shape:
```js
{
message: string,
// location can be undefined
location: {
// all 1-indexed
startLine: number, // inclusive
startLineStartChar: number, // inclusive
endLine: number, // inclusive
endLineEndChar: number, // **exclusive**
}
}
```
**NOTE**: `refmt.js` requires the node module `fs`, which of course isn't available on the web. If using webpack, to avoid the missing module error, put `node: { fs: 'empty' }` into `webpack.config.js`. See https://webpack.js.org/configuration/node/#other-node-core-libraries for more information.
`refmt.js` is minified for you through Closure Compiler, with an accompanying `refmt.map`. The size is 2.3MB **but don't get fooled; it gzips down to just 345KB**. This way, you can carry it around in your own blog and use it to create an interactive refmt playground, without worrying about imposing bandwidth overhead to your readers. Again, keep our ecosystem fast and lean.
### Native API
We're spoiled with more APIs on the native side. To use Reason from OPAM as a native library, you have [these functions](https://github.com/facebook/reason/blob/5a253048e8077c4597a8935adbed7aa22bfff647/src/reason_toolchain.ml#L141-L157). So:
- `Reason_toolchain.RE.implementation_with_comments`
- `Reason_toolchain.RE.interface_with_comments`
- `Reason_toolchain.RE.print_interface_with_comments`
- `Reason_toolchain.ML.implementation_with_comments`
- etc.
The `ML` parsing functions might throw [`Syntaxerr.Error error`](https://caml.inria.fr/pub/docs/manual-ocaml/compilerlibref/Syntaxerr.html). The `RE` parsing functions might throw:
- [`Reason_syntax_util.Error`](https://github.com/facebook/reason/blob/6e99ea5aae3791359b1e356060691f7b5b596365/src/reason-parser/reason_syntax_util.ml#L456) (docs on `Location.t` [here](https://caml.inria.fr/pub/docs/manual-ocaml/libref/Location.html))
- [`Syntaxerr.Error`](https://caml.inria.fr/pub/docs/manual-ocaml/compilerlibref/Syntaxerr.html).
- [`Reason_lexer.Error`](https://github.com/facebook/reason/blob/6e99ea5aae3791359b1e356060691f7b5b596365/src/reason-parser/reason_lexer.mll#L84).
Example usage:
```ocaml
let ast_and_comments =
Lexing.from_string "let f a => 1"
|> Reason_toolchain.RE.implementation_with_comments
(* Convert Reason back to OCaml syntax. That'll show these Reason users! *)
let ocaml_syntax =
Reason_toolchain.ML.print_implementation_with_comments
Format.str_formatter
ast_and_comments;
Format.flush_str_formatter ()
```
================================================
FILE: docs/site/Bookmark.js
================================================
/*!
* Flatdoc - (c) 2013, 2014 Rico Sta. Cruz
* http://ricostacruz.com/flatdoc
* @license MIT
*/
// Keep this in sync with $header-height in style.
var headerHeight = 52;
/**
* The default searchCrumbContext function. Clears out any h1 context if there
* is an h2. TODO: only clear out h1 if there is an h2 and there is only *one*
* h1.
*/
var defaultSearchBreadcrumbContext = function(ctx) {
return ctx;
// If there *is* an h2+, don't show h1
// if(ctx.h2 || ctx.h3 || ctx.h4) {
// return {...ctx, h1: null};
// } else {
// // Else show the h1
// return ctx;
// }
};
/**
* Pass the window.location.href
*/
var urlBasename = function(s) {
return s.split('/').pop().split('#')[0].split('?')[0];
};
var urlExtensionlessBasename = function(s) {
return s.split('/').pop().split('#')[0].split('?')[0].replace(".html", "");
};
var slugPrefix = function(hash) {
if (hash === '' || hash[0] !== '#') {
return ''
} else {
hash = hash.substr(1);
return (hash.split('-').length ? hash.split('-')[0] : '').toLowerCase();
}
};
var pageKeyForUrl = function(windowLocation, pageConfig) {
var urlBasenameRoot = urlBasename(windowLocation.pathname).replace(".html", "").replace(".htm", "").toLowerCase().toLowerCase();
for(var pageKey in pageConfig) {
if(urlBasenameRoot.toLowerCase() === pageKey) {
return pageKey.toLowerCase();
}
}
return null;
};
var getEffectivePageKeyAndHashFromPageifiedId = function(id) {
if(hash.lastIndexOf('#') === -1) {
console.error('cannot parse pageified id', id);
return {
pageKey: null,
hashContents: id
};
} else {
var effectivePageKey =
hash.substr(0, hash.lastIndexOf('#') - 1).replace(".html", "").replace(".htm", "").toLowerCase();
return {
pageKey: effectivePageKey,
hashContents: hash.substr(hash.lastIndexOf('#') + 1)
}
}
};
/**
* Urls like blah.html#foo/bar#another-hash
* Are interpreted as being another way to reference the page
* foo/bar.html#another-hash (Currently everything relative from the
* timeTemplate)
*/
var getEffectivePageAndHashFromLocation = function(windowLocation) {
var urlBasenameRootLowerCase =
urlBasename(windowLocation.pathname).replace(".html", "").replace(".htm", "").toLowerCase().toLowerCase();
var hash = windowLocation.hash;
if(hash[0] !== '#' || (hash[0] === '#' && hash.lastIndexOf('#') === 0)) {
return {
loadingFromPageKey: urlBasenameRootLowerCase,
pageKey: urlBasenameRootLowerCase,
hashContents: hash.substr(1)
};
} else {
var effectivePageKey =
hash.substr(1, hash.lastIndexOf('#') - 1).replace(".html", "").replace(".htm", "").toLowerCase();
return {
loadingFromPageKey: urlBasenameRootLowerCase,
pageKey: effectivePageKey,
hashContents: hash.substr(hash.lastIndexOf('#') + 1)
}
}
};
var isNodeSearchHit = function(node) {
return (
node.tagName === 'TR' || node.tagName === 'tr' ||
node.tagName === 'H0' || node.tagName === 'h0' ||
node.tagName === 'H1' || node.tagName === 'h1' ||
node.tagName === 'H2' || node.tagName === 'h2' ||
node.tagName === 'H3' || node.tagName === 'h3' ||
node.tagName === 'H4' || node.tagName === 'h4' ||
node.tagName === 'H5' || node.tagName === 'h5' ||
node.tagName === 'H6' || node.tagName === 'h6' ||
node.tagName === 'codetabbutton' || node.tagName === 'CODETABBUTTON' ||
node.tagName === 'P' || node.tagName === 'p' ||
node.tagName === 'LI' || node.tagName === 'li' ||
node.tagName === 'UL' || node.tagName === 'ul' ||
node.tagName === 'CODE' || node.tagName === 'code' ||
node.tagName === 'PRE' || node.tagName === 'pre' ||
node.nodeType === Node.TEXT_NODE
);
};
var pageDataForUrl = function(windowLocation, pageConfig) {
var effectivePageKeyAndHash = getEffectivePageAndHashFromLocation(windowLocation, pageConfig);
if(!pageConfig[effectivePageKeyAndHash.pageKey]) {
console.error(
"Current effective page basename ",
effectivePageKeyAndHash.pageKey,
"is not in pageConfig",
pageConfig
);
return null;
}
return pageConfig[effectivePageKeyAndHash.pageKey];
};
var SUPPORTS_SEARCH_TABBING = false;
/**
* We can't have the ids of elements be the exact same as the hashes in the URL
* because that will cause the browser to scroll. But we want to have full
* control over scroll for things like better back button support and deep
* linking / custom animation.
* So the element to scroll to would have id="--bookmark-linkified--foo", but
* the anchor links that jump to it would have href="#foo".
*
* This allows deep linking to page#section-header?text=this%20text Which will
* animate a scroll to a specific text portion of that section with an
* animation. If we don't have full control over the animation, then our own
* animation might fight the browser's.
*/
var BOOKMARK_LINK_ID_PREFIX = '--bookmark-linkified--';
/**
* Prepends the linkified prefix.
*/
function linkifidIdForHash(s) {
return BOOKMARK_LINK_ID_PREFIX + s;
}
function pageifiedIdForHash(slug, pageKey) {
return pageKey + '#' + slug;
}
/**
* Strips the linkified prefix.
*/
function hashForLinkifiedId(s) {
return s.indexOf(BOOKMARK_LINK_ID_PREFIX) === 0 ?
s.substring(BOOKMARK_LINK_ID_PREFIX.length) : s;
}
var queryContentsViaIframe = function(url, onDoneCell, onFailCell) {
var timeout = window.setTimeout(function() {
onFailCell.contents && onFailCell.contents(
"Timed out loading " + url +
". Maybe it doesn't exist? Alternatively, perhaps you were paused " +
"in the debugger so it timed out?"
);
}, 900);
var listenerID = window.addEventListener('message', function(e) {
if(e.data.messageType === 'docPageContent' && e.data.iframeName === url) {
window.removeEventListener('message', listenerID);
if(onDoneCell.contents) {
window.clearTimeout(timeout);
onDoneCell.contents(e.data.content);
}
}
});
var iframe = document.createElement('iframe');
iframe.name = url;
// Themes may opt to handle offline/pre rendering, and this is convenient
// to mark these iframes as not-essential once rendered so they may be
// removed from the DOM after rendering, and won't take up space in the
// bundle.
// TODO: Consider this for merging many html pages into one book https://github.com/fidian/metalsmith-bookify-html
iframe.className = 'removeFromRenderedPage';
iframe.src=url + '?bookmarkContentQuery=true';
iframe.style="display:none !important";
iframe.type="text/plain";
iframe.onerror = function(e) {
if(onFailCell.contents) {
onFailCell.contents(e);
}
};
// iframe.onload = function(e) {
// };
document.body.appendChild(iframe);
};
function anchorJump(href) {
var queryParamLoc = href.indexOf('?');
if(queryParamLoc !== -1) {
href = href.substring(0, queryParamLoc);
}
if (href != '#') {
var $area = $(href);
console.log('href area', href, $area);
// Find the parent
if (!$area.length) { return; }
customScrollIntoView({
smooth: true,
container: 'page',
element: $area[0],
mode: 'top',
topMargin: 2 * headerHeight,
bottomMargin: 0
});
$.highlightNode($area[0]);
$('body').trigger('anchor', href);
}
};
// https://stackoverflow.com/a/8342709
var customScrollIntoView = function(props) {
var smooth = props.smooth || false;
var container = props.container;
var containerElement = props.container === 'page' ?
document.documentElement : props.container;
var scrollerElement = props.container === 'page' ? window : containerElement;
var element = props.element;
// closest-if-needed | top | bottom
var mode = props.mode || 'closest-if-needed';
var topMargin = props.topMargin || 0;
var bottomMargin = props.bottomMargin || 0;
var containerRect = containerElement.getBoundingClientRect();
var elementRect = element.getBoundingClientRect();
var containerOffset = $(containerElement).offset();
var elementOffset = $(element).offset();
// TODO: For "whole document" scrolling,
// use Math.max(window.pageYOffset, document.documentElement.scrollTop, document.body.scrollTop)
// When loading the page from entrypoint mode, the document.documentElement scrollTop is zero!!
// But not when loading form an index.dev.html. Something about the way loading from entrypoint
// rewrites the entire document with document.write screws up the scroll measurement.
if(mode !== 'top' && mode !== 'closest-if-needed' && mode !== 'bottom') {
console.error('Invalid mode to scrollIntoView', mode);
}
var containerScrollTop =
container === 'page' ? Math.max(window.pageYOffset, document.documentElement.scrollTop, document.body.scrollTop) : containerElement.scrollTop;
var elementOffsetInContainer = elementOffset.top - containerOffset.top +
// Relative to the document element does not need to account for document scrollTop
(container === 'page' ? 0 : containerScrollTop);
if(mode === 'bottom' || mode === 'closest-if-needed' && elementOffsetInContainer + elementRect.height > containerScrollTop + containerRect.height - bottomMargin) {
var newTop = elementOffsetInContainer - containerRect.height + elementRect.height + bottomMargin;
scrollerElement.scrollTo({left:0, top: newTop, behavior:smooth ? 'smooth' : 'auto'});
} else if (mode === 'top' || mode === 'closest-if-needed' && elementOffsetInContainer < containerScrollTop) {
var newTop = elementOffsetInContainer - topMargin;
scrollerElement.scrollTo({left:0, top: newTop, behavior: smooth ? 'smooth' : 'auto'});
}
};
var defaultSlugifyConfig = {
shorter: false,
h0: false,
h1: true,
h2: true,
h3: true,
h4: true,
h5: false,
h6: false
};
var defaultSidenavifyConfig = {
h1: true,
h2: true,
h3: true,
h4: false,
h5: false,
h6: false
};
var defaultSlugContributions = {
h1: true,
h2: true,
h3: true,
h4: true,
h5: true,
h6: true
};
// Thank you David Walsh:
// https://davidwalsh.name/query-string-javascript
function queryParam(name) {
var res = (
new RegExp('[\\?&]' + (name.replace(/[\[]/, '\\[').replace(/[\]]/, '\\]'))+ '=([^&#]*)')
).exec(location.search);
return res === null
? ''
: decodeURIComponent(res[1].replace(/\+/g, ' '));
}
function parseYamlHeader(markdown, locationPathname) {
if(markdown.indexOf('---\n') === 0) {
var withoutFirstDashes = markdown.substr(4);
var nextDashesIndex = withoutFirstDashes.indexOf('\n---\n');
if(nextDashesIndex !== -1) {
var potentialYamlContent = withoutFirstDashes.substr(0, nextDashesIndex);
var lines = potentialYamlContent.split('\n');
var props = {};
for(var i = 0; i < lines.length; i++) {
var colonIndex = lines[i].indexOf(':');
if(colonIndex === -1) {
return {markdown: markdown, headerProps: {}};
} else {
var field = lines[i].substr(0, colonIndex);
// Todo: escape strings
var content = lines[i].substr(colonIndex+1).trim();
if(content[0] === '"' && content[content.length -1 ] === '"') {
var strContent = content.substr(1, content.length -2);
content = content.replace(new RegExp('\\\\"', 'g'), '"');
}
props[field] = content;
}
}
if(!props.id) {
var filename = locationPathname.substring(locationPathname.lastIndexOf('/') + 1);
props.id = filename.indexOf('.') !== -1 ? filename.substring(0, filename.lastIndexOf('.')) : filename;
}
return {
markdown: withoutFirstDashes.substr(nextDashesIndex + 4),
headerProps: props
};
} else {
return {markdown: markdown, headerProps: {}};
}
} else {
return {markdown: markdown, headerProps: {}};
}
}
/**
* Strips out a special case of markdown "comments" which is supported in all
* markdown parsers, will not be rendered in Github previews, but can be used
* to convey yaml header information.
*
* Include this in your doc to have Bookmark interpret the yaml headers without
* it appearing in the Github preview. This allows using one source of truth
* markdown file for Github READMEs as well as using to generate your site
* (when you don't want metadata showing up in your Github previews).
*
* [//]: # (---)
* [//]: # (something: hey)
* [//]: # (title: me)
* [//]: # (description: "Hi there here is an escaped quote \" inside of quotes")
* [//]: # (---)
*/
function normalizeYamlMarkdownComments(markdown) {
markdown = markdown.trim();
if(markdown.indexOf('[//]: # (---)\n') === 0) {
var withoutFirstDashes = markdown.substr(14);
var nextDashesIndex = withoutFirstDashes.indexOf('\n[//]: # (---)\n');
if(nextDashesIndex !== -1) {
var potentialYamlContent = withoutFirstDashes.substr(0, nextDashesIndex);
var lines = potentialYamlContent.split('\n');
var yamlLines = ['---'];
for(var i = 0; i < lines.length; i++) {
var line = lines[i];
var commentStartIndex = line.indexOf('[//]: # (');
if(commentStartIndex !== 0 || line[line.length - 1] !== ')') {
return markdown;
} else {
var commentContent = line.substr(9, line.length - 9 - 1); /*Minus one to trim last paren*/
yamlLines.push(commentContent);
}
}
yamlLines.push('---');
return yamlLines.join('\n') + withoutFirstDashes.substr(nextDashesIndex + 15);
} else {
return markdown;
}
} else {
return markdown;
}
}
/**
* The user can put this in their html file to:
* 1. Get vim syntax highlighting to work.
* 2. Get github to treat their html/htm file as a markdown file for rendering.
* 3. Load the script tag only when rendered with ReFresh.
*
* [ vim:syntax=Markdown ]: # (<script src="flatdoc.js"></script>)
*
* Only downside is that it leaves a dangling ) in the text returned to
* us which we can easily normalize.
*/
function normalizeMarkdownResponse(markdown) {
if(markdown[0] === ')' && markdown[1] === '\n') {
markdown = markdown.substring(2);
}
return markdown;
}
/**
* [^] means don't match "no" characters - which is all characters including
* newlines. The ? makes it not greddy.
*/
var docusaurusTabsRegionRegex = new RegExp(
"^" + escapeRegExpSearchString("<!--DOCUSAURUS_CODE_TABS-->") +
"$([^]*?)" +
escapeRegExpSearchString("<!--END_DOCUSAURUS_CODE_TABS-->"),
'gm'
);
var nonDocusaurusTabsRegionRegex = new RegExp(
"^" + escapeRegExpSearchString("<!--CODE_TABS-->") +
"$([^]*?)" +
escapeRegExpSearchString("<!--END_CODE_TABS-->"),
'gm'
);
var anyHtmlCommentRegex = new RegExp(
"(^(" + escapeRegExpSearchString("<!--") +
"([^]*?)" +
escapeRegExpSearchString("-->") + ")[\n\r])?^```(.+)[\n\r]([^]*?)[\n\r]```",
'gm'
);
function normalizeDocusaurusCodeTabs(markdown) {
// Used to look it up later in the DOM and move things around to a more
// convenient structure targetable by css.
var onReplace = function(matchedStr, matchedCommentContents) {
var tabs = [];
var maxLengthOfCode = 0;
var getMaxLengthOfCode = function(matchedStr, _, _, commentContent, syntax, codeContents) {
var split = codeContents.split('\n');
maxLengthOfCode =
codeContents && split.length > maxLengthOfCode ? split.length : maxLengthOfCode;
return matchedStr;
};
var onIndividualReplace = function(_, _, _, commentContent, syntax, codeContents) {
var className = tabs.length === 0 ? 'active' : '';
var split = codeContents.split('\n');
var splitLen = split.length;
// For some reason - 1 is needed when adding empty strings, instead of
// non-empty spacers.
while(splitLen - 1 < maxLengthOfCode) {
split.push(" ");
splitLen++;
}
tabs.push({
syntax: syntax,
codeContents: split.join("\n"),
tabMarkup: "<codetabbutton class='" + className + "'" +
" data-index=" + (tabs.length + 1) + ">" +
escapeHtml(commentContent || syntax) + "</codetabbutton>"
});
return "\n```" + syntax + "\n" + split.join("\n") + "\n```";
};
tabs = [];
maxLengthOfCode = 0;
matchedCommentContents.replace(anyHtmlCommentRegex, getMaxLengthOfCode);
var ret = matchedCommentContents.replace(anyHtmlCommentRegex, onIndividualReplace);
return "<codetabscontainer data-num-codes=" +
tabs.length +
" class='bookmark-codetabs-active1 bookmark-codetabs-length" +
tabs.length +
"'>" +
tabs.map(function(t){return t.tabMarkup;}).join("") +
"</codetabscontainer>" +
ret;
};
var ret = markdown.replace(docusaurusTabsRegionRegex, onReplace);
return ret;
}
var emptyHTML = "";
/**
* Scrolling into view:
* https://www.bram.us/2020/03/01/prevent-content-from-being-hidden-underneath-a-fixed-header-by-using-scroll-margin-top/
*/
function escapePlatformStringLoop(html, lastIndex, index, s, len) {
var html__0 = html;
var lastIndex__0 = lastIndex;
var index__0 = index;
for (; ; ) {
if (index__0 === len) {
var match = 0 === lastIndex__0 ? 1 : 0;
if (0 === match) {
var match__0 = lastIndex__0 !== index__0 ? 1 : 0;
return 0 === match__0 ?
html__0 :
html__0+s.substring(lastIndex__0, len);
}
return s;
}
var code = s.charCodeAt(index__0);
if (40 <= code) {
var switcher = code + -60 | 0;
if (! (2 < switcher >>> 0)) {
switch (switcher) {
case 0:
var html__1 = html__0+s.substring(lastIndex__0, index__0);
var lastIndex__1 = index__0 + 1 | 0;
var html__2 = html__1+"<";
var index__2 = index__0 + 1 | 0;
var html__0 = html__2;
var lastIndex__0 = lastIndex__1;
var index__0 = index__2;
continue;
case 1:break;
default:
var html__3 = html__0+s.substring(lastIndex__0, index__0);
var lastIndex__2 = index__0 + 1 | 0;
var html__4 = html__3+">";
var index__3 = index__0 + 1 | 0;
var html__0 = html__4;
var lastIndex__0 = lastIndex__2;
var index__0 = index__3;
continue
}
}
}
else if (34 <= code) {
var switcher__0 = code + -34 | 0;
switch (switcher__0) {
case 0:
var su = s.substring(lastIndex__0, index__0);
var html__5 = html__0+su;
var lastIndex__3 = index__0 + 1 | 0;
var html__6 = html__5+""";
var index__4 = index__0 + 1 | 0;
var html__0 = html__6;
var lastIndex__0 = lastIndex__3;
var index__0 = index__4;
continue;
case 4:
var su__0 = s.substring(lastIndex__0, index__0);
var html__7 = html__0+su__0;
var lastIndex__4 = index__0 + 1 | 0;
var html__8 = html__7+"&";
var index__5 = index__0 + 1 | 0;
var html__0 = html__8;
var lastIndex__0 = lastIndex__4;
var index__0 = index__5;
continue;
case 5:
var su__1 = s.substring(lastIndex__0, index__0);
var html__9 = html__0+su__1;
var lastIndex__5 = index__0 + 1 | 0;
var html__10 = html__9+"'";
var index__6 = index__0 + 1 | 0;
var html__0 = html__10;
var lastIndex__0 = lastIndex__5;
var index__0 = index__6;
continue
}
}
var index__1 = index__0 + 1 | 0;
var index__0 = index__1;
continue;
}
}
function escapeHtml(s) {
return (
escapePlatformStringLoop(
emptyHTML,
0,
0,
s,
s.length
)
);
}
var updateContextFromTreeNode = function(context, treeNode) {
if(treeNode.level === 0) {
return {...context, h0: treeNode, h1: null, h2: null, h3: null, h4: null, h5: null, h6: null};
}
if(treeNode.level === 1) {
return {...context, h1: treeNode, h2: null, h3: null, h4: null, h5: null, h6: null};
}
if(treeNode.level === 2) {
return {...context, h2: treeNode, h3: null, h4: null, h5: null, h6: null};
}
if(treeNode.level === 3) {
return {...context, h3: treeNode, h4: null, h5: null, h6: null};
}
if(treeNode.level === 4) {
return {...context, h4: treeNode, h5: null, h6: null};
}
if(treeNode.level === 5) {
return {...context, h5: treeNode, h6: null};
}
if(treeNode.level === 6) {
return {...context, h6: treeNode};
}
// LEAF_LEVEL
return context;
};
/**
* Turn a search string into a regex portion.
* https://stackoverflow.com/a/1144788
*/
function escapeRegExpSearchString(string) {
return string.replace(/[.*+\-?^${}()|[\]\\]/g, '\\$&');
}
function replaceAllStringsCaseInsensitive(str, find, replace) {
return str.replace(new RegExp(escapeRegExp(find), 'gi'), replace);
}
function escapeRegExpSplitString(string) {
return string.replace(/[.*+\-?^${}()|[\]\\]/g, '\\$&');
}
function splitStringCaseInsensitiveImpl(regexes, str, find) {
return str.split(regexes.caseInsensitive.anywhere);
}
function splitStringCaseInsensitive(str, find) {
return str.split(new RegExp('(' + escapeRegExpSplitString(find) + ')', 'gi'));
}
/**
* Only trust for markdown that came from trusted source (your own page).
* I do not know exactly what portions are unsafe - perhaps none.
*/
var trustedTraverseAndHighlightImpl = function traverseAndHighlightImpl(regex, text, node) {
var tagName = node.nodeType === Node.TEXT_NODE ? 'p' : node.tagName.toLowerCase();
var className = node.nodeType === Node.TEXT_NODE ? '' : node.getAttributeNode("class");
var childNodes = node.nodeType === Node.TEXT_NODE ? [node] : node.childNodes;
var childNode = childNodes.length > 0 ? childNodes[0] : null;
var i = 0;
var newInnerHtml = '';
while(childNode && i < 2000) {
if(childNode.nodeType === Node.TEXT_NODE) {
if(regex) {
var splitOnMatch = splitStringCaseInsensitiveImpl(regex, childNode.textContent, text);
splitOnMatch.forEach(function(seg) {
if(seg !== '') {
if(seg.toLowerCase() === text.toLowerCase()) {
newInnerHtml +=
('<search-highlight>' + escapeHtml(seg) + '</search-highlight>');
} else {
newInnerHtml += escapeHtml(seg);
}
}
});
} else {
newInnerHtml += escapeHtml(childNode.textContent);
}
} else {
newInnerHtml += trustedTraverseAndHighlightImpl(regex, text, childNode);
}
i++;
childNode = childNodes[i];
}
var openTag = '';
var closeTag = '';
classAttr = className ? ' class="' + escapeHtml(className.value.replace('bookmark-in-doc-highlight', '')) + '"' : '';
switch(tagName) {
case 'a':
var href = node.getAttributeNode("href");
openTag = href ? '<a onclick="false" tabindex=-1 ' + classAttr + '>' : '<a>';
closeTag = '</a>'
break;
case 'code':
var className = node.getAttributeNode("class");
openTag = className ? '<code class="' + escapeHtml(className.value) + '"' + classAttr + '>' : '<code>';
closeTag = '</code>'
break;
default:
openTag = '<' + tagName + classAttr + '>';
closeTag = '</' + tagName + '>';
}
return openTag + newInnerHtml + closeTag;
}
var trustedTraverseAndHighlight = function(searchRegex, text, node) {
return trustedTraverseAndHighlightImpl(searchRegex, text, node);
};
/**
* Leaf nodes will be considered level 999 (something absurdly high).
*/
var LEAF_LEVEL = 999;
var PAGE_LEVEL = -1;
var getDomNodeStructureLevel = function getStructureLevel(node) {
if(node.tagName === 'h0' || node.tagName === 'H0') {
return 0;
}
if(node.tagName === 'h1' || node.tagName === 'H1') {
return 1;
}
if(node.tagName === 'h2' || node.tagName === 'H2') {
return 2;
}
if(node.tagName === 'h3' || node.tagName === 'H3') {
return 3;
}
if(node.tagName === 'h4' || node.tagName === 'H4') {
return 4;
}
if(node.tagName === 'h5' || node.tagName === 'H5') {
return 5;
}
if(node.tagName === 'h6' || node.tagName === 'H6') {
return 6;
}
return LEAF_LEVEL;
};
var deepensContext = function(treeNode) {
return treeNode.level >= 0 && treeNode.level < 7;
};
/**
* Searches up in the context for the correct place for this level to be
* inserted.
*/
function recontext(context, nextTreeNode) {
// Root document level is level zero.
while(context.length > 1 && context[context.length - 1].level >= nextTreeNode.level) {
context.pop();
}
};
function hierarchicalIndexForSearch(pageState) {
for(var pageKey in pageState) {
if(!pageState[pageKey].hierarchicalIndex) {
var containerNode = pageState[pageKey].contentContainerNode;
pageState[pageKey].hierarchicalIndex = hierarchicalIndexFromHierarchicalDoc(pageState[pageKey].hierarchicalDoc);
}
}
}
function mapHierarchyOne(f, treeNode) {
return {
levelContent: f(treeNode.levelContent),
level: treeNode.level,
subtreeNodes: mapHierarchy(f, treeNode.subtreeNodes)
};
}
function mapHierarchy(f, treeNodes) {
return treeNodes.map(mapHierarchyOne.bind(null, f));
}
function forEachHierarchyOne(f, context, treeNode) {
var newContext = updateContextFromTreeNode(context, treeNode);
f(treeNode.levelContent, treeNode.level, treeNode.subtreeNodes, newContext);
forEachHierarchyImpl(f, newContext, treeNode.subtreeNodes);
}
function forEachHierarchyImpl(f, context, treeNodes) {
return treeNodes.forEach(forEachHierarchyOne.bind(null, f, context));
}
function forEachHierarchy(f, treeNodes) {
var context = startContext;
return treeNodes.forEach(forEachHierarchyOne.bind(null, f, context));
}
/**
* Returns a hierarchy tree where level contents are the individual items that
* may be searchable. The original structured hierarchy tree has the
* levelContent of each subtreeNode being the root node of every element that
* appears directly under that heading. The hierarchicalIndex expands a single
* tree node (such as one for a ul element) into several tree nodes (one for
* each li in the ul for example). So it's a pretty simple mapping of the tree,
* where each levelContent is expanded out into an array of content.
*/
function hierarchicalIndexFromHierarchicalDoc(treeNodes) {
function expandTreeNodeContentToSearchables(domNode) {
if(isNodeSearchHit(domNode)) {
return [domNode];
} else {
var more = [];
var childDomNode = domNode.firstChild;
while(childDomNode) {
more = more.concat(expandTreeNodeContentToSearchables(childDomNode));
childDomNode = childDomNode.nextSibling;
}
return more;
}
};
return treeNodes.map(mapHierarchyOne.bind(null, expandTreeNodeContentToSearchables));
}
/**
* Forms a hierarchy of content from structure forming nodes (such as headers)
* from what would otherwise be a flat document.
* The subtreeNodes are not dom Subtree nodes but the hierarchy subtree (level
* heading content etc).
*
* The subtreeNodes are either the list of Dom nodes immediately under that
* level, else another "tree" node. (Type check it at runtime by looking for
* .tagName property).
*
* page:
*
* H1Text
* text
* H2Text
* textB
* textC
*
* Would be of the shape:
* {
* level: 0, // page
* levelContent: null,
* subtreeNodes: [
* {
* level: 1,
* levelContent: <h1>H1Text</h1>, // h1 dom node
* subtreeNodes: [
* {level: LEAF_LEVEL, levelContent: <p>text</p>}, // p DOM node
* {
* level: 2,
* levelContent: <h2>H2Text</h2>,
* subtreeNodes: [
* {level: LEAF_LEVEL, levelContent: <p>textB</p>},
* {level: LEAF_LEVEL, levelContent: <p>textC</p>}
* ]
* }
* ]
*
* }
*
* ]
* }
*/
function hierarchize(containerNode) {
// Mutable reference.
var dummyNode = {
// Such as the h2 node that forms the new level etc.
levelContent: null,
level: PAGE_LEVEL,
subtreeNodes: []
};
var context = [dummyNode];
function hierarchicalIndexChildrenImpl(domNode) {
var childDomNode = domNode.firstChild;
while(childDomNode) {
hierarchicalIndexImpl(childDomNode);
childDomNode = childDomNode.nextSibling;
}
};
function hierarchicalIndexImpl(domNode) {
var domNodeLevel = getDomNodeStructureLevel(domNode);
var treeNode = {
levelContent: domNode,
level: domNodeLevel,
subtreeNodes: []
};
recontext(context, treeNode);
context[context.length - 1].subtreeNodes.push(treeNode);
if(deepensContext(treeNode)) {
context.push(treeNode)
}
};
hierarchicalIndexChildrenImpl(containerNode);
return dummyNode.subtreeNodes;
};
var filterHierarchicalSearchablesLowerCaseImpl = function(searchRegex, txt, pageState, renderTopRow) {
var totalResultsLen = function() {
return smartCaseWordBoundaryResults.length +
smartCaseAnywhereNotWordBoundaryResults.length +
caseInsensitiveWordBoundaryResults.length +
caseInsensitiveAnywhereNotWordBoundaryResults.length;
};
var smartCaseWordBoundaryResults = [];
var smartCaseAnywhereNotWordBoundaryResults = [];
var caseInsensitiveWordBoundaryResults = [];
var caseInsensitiveAnywhereNotWordBoundaryResults = [];
// On the first keystroke, it will return far too many results, almost all of
// them useless since it matches anything with that character. In that case, limit to
// 20 results. Then on the next keystroke allow more.
var maxResultsLen = txt.length === 1 ? 20 : 999;
Flatdoc.forEachPage(pageState, (pageData, pageKey) => {
forEachSearchableInHierarchy(function(searchable) {
if(totalResultsLen() < maxResultsLen) {
var node = searchable.node;
var context = searchable.context;
var nodeText = node.nodeType === Node.TEXT_NODE ? node.textContent : node.innerText;
var test = findBestMatch(nodeText, searchRegex);
var resultsToPush =
test === -1 ? null :
test & (SMARTCASE | WORDBOUNDARY) ? smartCaseWordBoundaryResults :
test & (SMARTCASE) ? smartCaseAnywhereNotWordBoundaryResults :
test & (WORDBOUNDARY) ? caseInsensitiveAnywhereNotWordBoundaryResults :
caseInsensitiveAnywhereNotWordBoundaryResults;
if(resultsToPush !== null) {
// TODO: Show multiple matches per searchable.
resultsToPush.push({
searchable: searchable,
highlightedInnerText: trustedTraverseAndHighlight(searchRegex, txt, node),
topRow: renderTopRow(searchable.context, node)
})
}
}
}, pageData.hierarchicalIndex);
});
return smartCaseWordBoundaryResults.concat(
smartCaseAnywhereNotWordBoundaryResults
).concat(
caseInsensitiveWordBoundaryResults)
.concat(
caseInsensitiveAnywhereNotWordBoundaryResults
)
};
/**
* Invokes the callback for each searchable tree node (which has expanded array
* of levelContent), will not invoke callback for subtree of that searchable
* node, even if they are searchable.
*/
function forEachSearchableInHierarchyImpl(cb, treeNode, context) {
for(var j = 0; j < treeNode.levelContent.length; j++) {
var searchable = {node: treeNode.levelContent[j], context: context};
cb(searchable);
}
context = updateContextFromTreeNode(context, treeNode);
forEachSearchableInHierarchy(cb, treeNode.subtreeNodes, context);
}
function forEachSearchableInHierarchy(cb, treeNodes, context) {
var context = typeof context === 'undefined' ? startContext : context;
for(var i = 0; i < treeNodes.length; i++) {
forEachSearchableInHierarchyImpl(cb, treeNodes[i], context);
}
}
/**
* Useful for converting unfiltered results into a "filtered" "highlighted" results set.
*/
var noopHierarchicalFilter = function(pageState, renderTopRow) {
var results = [];
// TODO: Here is where you would categorize the results by page.
Flatdoc.forEachPage(pageState, (pageData, pageKey) => {
forEachSearchableInHierarchy(function(searchable) {
results.push({
searchable: searchable,
highlightedInnerText: trustedTraverseAndHighlight(null, "", searchable.node),
topRow: renderTopRow(searchable.context, searchable.node)
});
}, pageData.hierarchicalIndex);
});
return results;
};
var SMARTCASE = 0b10;
var WORDBOUNDARY = 0b01;
var regexesFor = function(str) {
var hasUpper = str.toLowerCase() !== str;
return {
// TODO: Add checks that remove symbols like hyphen, dot, parens
smartCase: {
// Priority 1
wordBoundary: !hasUpper ? null : new RegExp('\\b(' + escapeRegExpSplitString(str) + ')', 'g' + (hasUpper ? '' : 'i')),
// Priority 2
anywhere: !hasUpper ? null : new RegExp('(' + escapeRegExpSplitString(str) + ')', 'g' + (hasUpper ? '' : 'i'))
},
caseInsensitive: {
// Priority 3
wordBoundary: new RegExp('\\b(' + escapeRegExpSplitString(str) + ')', 'gi'),
// Priority 4
anywhere: new RegExp('(' + escapeRegExpSplitString(str) + ')', 'gi')
}
}
};
var findBestMatch = function(stringToTest, regexes) {
if(regexes.smartCase.wordBoundary && regexes.smartCase.wordBoundary.test(stringToTest)) {
return SMARTCASE | WORDBOUNDARY;
} else if(regexes.smartCase.anywhere && regexes.smartCase.anywhere.test(stringToTest)) {
return SMARTCASE;
} else if(regexes.caseInsensitive.wordBoundary.test(stringToTest)) {
return WORDBOUNDARY;
} else if (regexes.caseInsensitive.anywhere.test(stringToTest)) {
return 0
} else {
return -1;
}
};
var filterHierarchicalSearchables = function(query, pageState, renderTopRow) {
var txt = query.trim();
var searchRegex = regexesFor(txt);new RegExp('(' + escapeRegExpSplitString(txt) + ')', 'gi');
return filterHierarchicalSearchablesLowerCaseImpl(searchRegex, txt, pageState, renderTopRow);
};
var matchedSearchableToHit = function(matchedSearchable) {
return {
category:
matchedSearchable.searchable.context.h3 ? matchedSearchable.searchable.context.h3.innerText :
matchedSearchable.searchable.context.h2 ? matchedSearchable.searchable.context.h2.innerText :
matchedSearchable.searchable.context.h1 ? matchedSearchable.searchable.context.h1.innerText : "",
content: matchedSearchable.searchable.node.innerText,
matchedSearchable: matchedSearchable
}
};
/* Matches found in the header itself will be considered in that context */
var startContext = {
h0: null,
h1: null,
h2: null,
h3: null,
h4: null,
h5: null,
h6: null
};
var contextToSlug = function(context, slugContributions) {
var slug = '';
if(context.h0 && slugContributions.h0) {
slug += ' ' + Flatdoc.slugify(context.h0.levelContent.innerText);
}
if(context.h1 && slugContributions.h1) {
slug += ' ' + Flatdoc.slugify(context.h1.levelContent.innerText);
}
if(context.h2 && slugContributions.h2) {
slug += ' ' + Flatdoc.slugify(context.h2.levelContent.innerText);
}
if(context.h3 && slugContributions.h3) {
slug += ' ' + Flatdoc.slugify(context.h3.levelContent.innerText);
}
if(context.h4 && slugContributions.h4) {
slug += ' ' + Flatdoc.slugify(context.h4.levelContent.innerText);
}
if(context.h5 && slugContributions.h5) {
slug += ' ' + Flatdoc.slugify(context.h5.levelContent.innerText);
}
if(context.h6 && slugContributions.h6) {
slug += ' ' + Flatdoc.slugify(context.h6.levelContent.innerText);
}
return Flatdoc.slugify(slug.length > 0 ? slug.substring(1) : '');
};
/**
* Bookmark is just a paired down version of Flatdoc with some additional
* features, and many features removed.
*
* This version of flatdoc can run in three modes:
*
* Main entrypoint script include (when included from an index.html or
* foo.html).
*
* <script start src="pathto/Bookmark.js"></script>
*
* Included in a name.md.html markdown document or name.styl.html Stylus
* document at the start of file
*
* <script src="pathto/Bookmark.js"></script>
* # Rest of markdown here
* - regular markdown
* - regular markdown
*
* or:
*
* <script src="pathto/Bookmark.js"></script>
* Rest of .styl document here:
*
* As a node script which will bundle your page into a single file assuming you've run npm install.
*/
/**
* Since we use one simple script for everything, we need to detect how it's
* being used. If not a node script, it could be included form the main html
* page, or from a docs/stylus page. The main script tag in the main page will
* be run at a point where there's no body in the document. For doc pages
* (markdown/stylus) it will have a script tag at the top which implicitly
* defines a body.
*/
function detectDocOrStyleIfNotNodeScript() {
var hasParentFrame = window.parent !== window;
var hasBody = document.body !== null;
return hasParentFrame || hasBody;
};
/**
* Assuming you are a doc or a style file (in an html extension), is this
* trying to be loaded as an async doc/style content fetch from another HTML
* page, or is this file attempting to be loaded as the main entrypoint (wihout
* going through an index.html or something?) All requests for doc content go
* through the Bookmark loader, and will ensure there is a query param
* indicating this.
*/
function detectMode() {
if(typeof process !== 'undefined') {
return 'bookmarkNodeMode';
}
if(detectDocOrStyleIfNotNodeScript()) {
var isHostPageQueryingContent = queryParam('bookmarkContentQuery');
if (isHostPageQueryingContent) {
return 'bookmarkContentQuery';
} else {
return 'bookmarkEntrypoint';
}
}
// Either loading from a non template index.dev.html, or we are running a
// template that includes the Bookmark.js script. We are loading from a
// previous bookmarkEntrypoint flow, which has been turned into
// bookmarkLoadFromHostPage after injecting the template.
return 'bookmarkLoadFromHostPage';
};
var MODE = detectMode();
/**
* Here's the order of events that occur when using the local file system at least:
* 1. body DOMContentLoaded
* 2. body onload event
* 3. settimeout 0 handler.
*/
if(MODE === 'bookmarkNodeMode') {
if(process.argv && process.argv.length > 2 && process.argv[2] === 'bundle') {
var fs = require('fs');
var path = require('path');
var Inliner = require('inliner');
var siteDir = __dirname;
var pathToChrome =
process.platform === 'win32' ?
path.join(require('process').env['LOCALAPPDATA'], 'Google', 'Chrome', 'Application', 'chrome.exe') :
'/Applications/Google\\ Chrome.app/Contents/MacOS/Google\\ Chrome';
var cmd = pathToChrome + " " + path.join(siteDir, "..", "README.html") + ' --headless --dump-dom --virtual-time-budget=400';
var rendered = require('child_process').execSync(cmd).toString();
var renderedHtmlPath = path.join(siteDir, "..", 'index.rendered.html');
var indexHtmlPath = path.join(siteDir, "..", 'index.html');
fs.writeFileSync(renderedHtmlPath, rendered);
console.log("INLINING PAGE: ", indexHtmlPath);
var options = {
/* Make sure you have this set to true to avoid flickering jumps */
images: true,
compressCSS: true,
compressJS: true,
// If true, will mess with hljs.
collapseWhitespace: false,
nosvg: true, // by default, DO compress SVG with SVGO
skipAbsoluteUrls: false,
preserveComments: false,
iesafe: false
};
new Inliner(renderedHtmlPath, options, function (error, html) {
// compressed and inlined HTML page
// console.log(html);
if(error) {
console.error(e);
process.exit(1);
}
fs.writeFileSync(indexHtmlPath, html)
process.exit(0);
});
}
}
else if(MODE === 'bookmarkContentQuery') {
// We are being asked about the document content from some host page (like an index.html that
// manually calls out to docs).
document.write('<plaintext style="display:none">');
document.addEventListener("DOMContentLoaded", function() {
var plaintexts = document.querySelectorAll('plaintext');
if(plaintexts.length === 1) {
window.parent.postMessage({
messageType: 'docPageContent' ,
iframeName: window.name,
// innerHtml escapes markup in plaintext in Safari, but not Chrome.
// innerText behaves correctly for both.
content: plaintexts[0].innerText
}, "*");
} else {
window.parent.postMessage({
messageType: "docPageError",
iframeName: window.name,
error: "There isn't exactly one plaintext tag inside of " + window.name +
". Something went wrong and we didn't inject the plaintext tag."
}, "*");
}
});
} else if(MODE === 'bookmarkEntrypoint') {
// This is the a workflow where the md html page itself wants to be loadable without
// needing to be included via some index.html. In this mode it can specify a page template
// in its markdown header.
// Remove the typical leading content before the script: This just helps
// minimize the flash of that text. To completely eliminate it during
// development mode, you can put this at the top of your md.
// [ vim: set filetype=Markdown: ]: # (<style type="text/css">body {visibility: hidden} </style>)
// while(document.body.hasChildNodes) {
while(document.body.childNodes[0].nodeType === document.TEXT_NODE) {
document.body.removeChild(document.body.childNodes[0]);
}
// Try to hide the plain text that comes before the important script include.
// Minimize flash.
document.write('<plaintext style="display:none">');
// I find page reloads much less reliable if you document.close()
// document.close();
// However, I think this caused html contents inside of the markdown to be executed as html?
window.onbeforeunload = function() {
};
document.addEventListener("DOMContentLoaded", function() {
var plaintexts = document.querySelectorAll('plaintext');
if(plaintexts.length === 1) {
// innerHtml escapes markup in plaintext in Safari, but not Chrome.
// innerText behaves correctly for both.
// Parse out the yaml header just so we can get the siteTemplate, then
// forward along the original markdown. Might as well leave the yaml
// lines normalized.
var markdown = normalizeMarkdownResponse(plaintexts[0].innerText);
var markdownNormalizedYaml = normalizeYamlMarkdownComments(markdown);
var markdownAndHeader = parseYamlHeader(markdownNormalizedYaml, window.location.pathname);
if(typeof window.BookmarkTemplate === 'undefined') {
window.BookmarkTemplate = {};
}
window.BookmarkTemplate.prefetchedCurrentPageBasename = urlBasename(window.location.href);
window.BookmarkTemplate.prefetchedCurrentPageMarkdownAndHeader = markdownNormalizedYaml;
// Set the variables for templates to read from.
// https://www.geeksforgeeks.org/how-to-replace-the-entire-html-node-using-javascript/
if(markdownAndHeader.headerProps.siteTemplate) {
var templateFetchStart = Date.now();
/**
* The iframe's onDone will fire before the document's readystatechange 'complete' event.
*/
var onDone = function(siteTemplate) {
var templateFetchEnd = Date.now();
console.log("fetching SITE TEMPLATE took", templateFetchEnd - templateFetchStart);
var yetAnotherHtml = document.open("text/html", "replace");
// If you want to listen for another readystatechange 'complete'
// after images have loaded you have to create yetAnotherHtml This
// isn't really needed since we don't listen to this. Make sure to
// hide the content while it is loading, since .write replaces.
// flatdoc:ready will reveal it after images load.
siteTemplate =
siteTemplate.replace(
new RegExp("(" +
escapeRegExpSearchString( "<template>") +
"|" + escapeRegExpSearchString( "</template>") +
"|" + escapeRegExpSearchString( "<plaintext>") +
")", "g"),
function(_) {return "";}
);
siteTemplate =
siteTemplate.replace(
new RegExp("\\$\\{Bookmark\\.Header\\.([^:\\}]*)}", 'g'),
function(matchString, field) {
if(field !== 'siteTemplate' && field in markdownAndHeader.headerProps) {
return escapeHtml(markdownAndHeader.headerProps[field]);
}
}
);
siteTemplate =
siteTemplate.replace(
new RegExp("\\$\\{Bookmark\\.Active\\.([^\\}]*)}", 'g'),
function(matchString, field) {
return markdownAndHeader.headerProps.id === field ? 'active' : 'inactive';
}
);
// The site template should also have
// <script>
// document.body.style="visibility:hidden"
// </script>
// So that when pre-rendered it is also correctly hidden
yetAnotherHtml.write(siteTemplate);
yetAnotherHtml.close();
};
var onDoneCell = {contents: onDone};
var onFailCell = {contents: (err) => {console.error(err);}};
queryContentsViaIframe(markdownAndHeader.headerProps.siteTemplate, onDoneCell, onFailCell);
} else {
console.error(
'You are loading a Bookmark doc from a markdown file, but that ' +
'markdown doc does not specify a siteTemplate: in its yaml header.'
);
}
} else {
console.error(
"There isn't exactly one plaintext tag inside of " + window.name +
". Something went wrong and we didn't inject the plaintext tag."
);
}
});
} else {
// Must be 'bookmarkLoadFromHostPage' mode. At least populate this empty
// dictionary so that when
// BookmarkTemplate.prefetchedCurrentPageMarkdownAndHeader is accessed in
// the rehydration workflow it doesn't fail (it will bail out) when it
// realizes the page is already rendered though.
if(typeof window.BookmarkTemplate === 'undefined') {
window.BookmarkTemplate = {};
}
(function($) {
var exports = this;
$.highlightNode = function(node) {
$('.bookmark-in-doc-highlight').each(function() {
var $el = $(this);
$el.removeClass('bookmark-in-doc-highlight');
});
$(node).addClass('bookmark-in-doc-highlight');
};
var marked;
/**
* Basic Flatdoc module.
*
* The main entry point is Flatdoc.run(), which invokes the [Runner].
*
* Flatdoc.run({
* fetcher: Flatdoc.github('rstacruz/backbone-patterns');
* });
*
* These fetcher functions are available:
*
* Flatdoc.github('owner/repo')
* Flatdoc.github('owner/repo', 'API.md')
* Flatdoc.github('owner/repo', 'API.md', 'branch')
* Flatdoc.bitbucket('owner/repo')
* Flatdoc.bitbucket('owner/repo', 'API.md')
* Flatdoc.bitbucket('owner/repo', 'API.md', 'branch')
* Flatdoc.file('http://path/to/url')
* Flatdoc.file([ 'http://path/to/url', ... ])
*/
var Flatdoc = exports.Flatdoc = {};
exports.Bookmark = exports.Flatdoc;
/**
* Creates a runner.
* See [Flatdoc].
*/
Flatdoc.run = function(options) {
var runner = new Flatdoc.runner(options)
runner.run();
return runner;
};
Flatdoc.mapPages = function(dict, onPage) {
var result = {};
for(var pageKey in dict) {
result[pageKey] = onPage(dict[pageKey], pageKey);
}
return result;
};
Flatdoc.forEachPage = function(dict, onPage) {
var _throwAway = Flatdoc.mapPages(
dict,
(pageData, pageKey) =>
(onPage(pageData, pageKey), pageData)
);
};
Flatdoc.keepOnly = function(dict, f) {
var result = {};
for(var pageKey in dict) {
if(f(dict[pageKey]), pageKey) {
result[pageKey] = dict[pageKey];
}
}
return result;
};
Flatdoc.setFetcher = function(keyLowerCase, obj) {
if(BookmarkTemplate.prefetchedCurrentPageBasename &&
urlExtensionlessBasename(BookmarkTemplate.prefetchedCurrentPageBasename).toLowerCase() === keyLowerCase) {
obj.fetcher = Bookmark.docPageContent(BookmarkTemplate.prefetchedCurrentPageMarkdownAndHeader);
} else {
obj.fetcher = Bookmark.docPage(keyLowerCase + ".html");
}
};
/**
* Simplified easy to use API that calls the underlying API.
*/
Flatdoc.go = function(options) {
var pageState = {};
var actualOptions = {
searchFormId: options.searchFormId,
searchHitsId: options.searchHitsId,
versionButtonId: options.versionButtonId,
versionPageIs: options.versionPageIs ? options.versionPageIs.toLowerCase() : null,
searchBreadcrumbContext: options.searchBreadcrumbContext,
slugify: options.slugify || defaultSlugifyConfig,
slugContributions: options.slugContributions || defaultSlugContributions,
sidenavify: options.sidenavify || defaultSidenavifyConfig,
pageState: pageState,
effectiveHref: ''
};
if(options.stylus) {
actualOptions.stylusFetcher = Flatdoc.docPage(options.stylus);
}
if(!options.pages) {
alert("Error, no pages provided in Bookmark options");
console.error("Error, no pages provided in Bookmark options");
} else {
var pages = options.pages;
for(var pageKey in pages) {
var pageKeyLowerCase = pageKey.toLowerCase();
var page = pages[pageKey];
pageState[pageKeyLowerCase] = {
fetcher: null,
markdownAndHeader: null,
contentContainerNode: null,
menuContainerNode: null,
hierarchicalDoc: null,
hierarchicalIndex: null
};
Flatdoc.setFetcher(pageKeyLowerCase, pageState[pageKeyLowerCase]);
}
if(options.highlight) {
actualOptions.highlight = options.highlight;
}
var runner = Flatdoc.run(actualOptions);
}
};
/**
* File fetcher function.
*
* Fetches a given url via AJAX.
* See [Runner#run()] for a description of fetcher functions.
*/
Flatdoc.file = function(url) {
function loadData(locations, response, callback) {
if (locations.length === 0) callback(null, response);
else $.get(locations.shift())
.fail(function(e) {
callback(e, null);
})
.done(function (data) {
if (response.length > 0) response += '\n\n';
response += data;
loadData(locations, response, callback);
});
}
return function(callback) {
loadData(url instanceof Array ?
url : [url], '', callback);
};
};
/**
* Runs with the already loaded string contents representing a doc.
* This is used for "entrypoint mode".
* TODO: Instead just maintain a cache, warm it up and use the regular
* fetcher. This also allows reuse as a "style pre-fetch" property in the
* yaml header.
*/
Flatdoc.docPageContent = function(url) {
if (!Flatdoc.errorHandler) {
var listenerID = window.addEventListener('message', function(e) {
if (e.data.messageType === 'docPageError') {
console.error(e.data.error);
}
});
Flatdoc.docPageErrorHandler = listenerID;
}
var fetchdocPage = function(content) {
var onDone = null;
var onFail = null;
var returns = {
fail: function(cb) {
onFail = cb;
return returns;
},
done: function(cb) {
onDone = cb;
onDone(content);
return returns;
}
};
return returns;
};
function loadData(locations, response, callback) {
if (locations.length === 0) callback(null, response);
else fetchdocPage(locations.shift())
.fail(function(e) {
callback(e, null);
})
.done(function (data) {
if (response.length > 0) response += '\n\n';
response += data;
loadData(locations, response, callback);
});
}
var url = url instanceof Array ? url : [url];
var ret = function(callback) {
loadData(url, '', callback);
};
// Tag the fetcher with the url in case you want it.
ret.url = url;
return ret;
};
/**
* Local docPage doc fetcher function.
*
* Fetches a given url via iframe inclusion, expecting the file to be of
* the "docPage" form of markdown which can be loaded offline.
* See [Runner#run()] for a description of fetcher functions.
*
* Tags the url argument on the fetcher itself so it can be used for other
* debugging/relativization.
*/
Flatdoc.docPageErrorHandler = null;
Flatdoc.docPage = function(url) {
if (!Flatdoc.errorHandler) {
var listenerID = window.addEventListener('message', function(e) {
if (e.data.messageType === 'docPageError') {
console.error(e.data.error);
}
});
Flatdoc.docPageErrorHandler = listenerID;
}
var fetchdocPage = function(url) {
var onDoneCell = {contents: null};
var onFailCell = {contents: null};
var returns = {
fail: function(cb) {
onFailCell.contents = cb;
return returns;
},
done: function(cb) {
onDoneCell.contents = cb;
return returns;
}
};
queryContentsViaIframe(url, onDoneCell, onFailCell);
// Even if using the local file system, this will immediately resume
// after appending without waiting or blocking. There is no way to tell
// that an iframe has loaded successfully without some kind of a timeout.
// Even bad src locations will fire the onload event. An onerror event is
// a solid signal that the page failed, but abscense of an onerror on the
// iframe is not a confirmation of success or that it hasn't failed.
return returns;
};
function loadData(locations, response, callback) {
if (locations.length === 0) callback(null, response);
else fetchdocPage(locations.shift())
.fail(function(e) {
callback(e, null);
})
.done(function (data) {
if (response.length > 0) response += '\n\n';
response += data;
loadData(locations, response, callback);
});
}
var url = url instanceof Array ? url : [url];
var ret = function(callback) {
loadData(url, '', callback);
};
// Tag the fetcher with the url in case you want it.
ret.url = url;
return ret;
};
/**
* Github fetcher.
* Fetches from repo repo (in format 'user/repo').
*
* If the parameter filepath` is supplied, it fetches the contents of that
* given file in the repo's default branch. To fetch the contents of
* `filepath` from a different branch, the parameter `ref` should be
* supplied with the target branch name.
*
* See [Runner#run()] for a description of fetcher functions.
*
* See: http://developer.github.com/v3/repos/contents/
*/
Flatdoc.github = function(opts) {
if (typeof opts === 'string') {
opts = {
repo: arguments[0],
filepath: arguments[1]
};
}
var url;
if (opts.filepath) {
url = 'https://api.github.com/repos/'+opts.repo+'/contents/'+opts.filepath;
} else {
url = 'https://api.github.com/repos/'+opts.repo+'/readme';
}
var data = {};
if (opts.token) {
data.access_token = opts.token;
}
if (opts.ref) {
data.ref = opts.ref;
}
return function(callback) {
$.get(url, data)
.fail(function(e) { callback(e, null); })
.done(function(data) {
var markdown = exports.Base64.decode(data.content);
callback(null, markdown);
});
};
};
/**
* Bitbucket fetcher.
* Fetches from repo `repo` (in format 'user/repo').
*
* If the parameter `filepath` is supplied, it fetches the contents of that
* given file in the repo.
*
* See [Runner#run()] for a description of fetcher functions.
*
* See: https://confluence.atlassian.com/display/BITBUCKET/src+Resources#srcResources-GETrawcontentofanindividualfile
* See: http://ben.onfabrik.com/posts/embed-bitbucket-source-code-on-your-website
* Bitbucket appears to have stricter restrictions on
* Access-Control-Allow-Origin, and so the method here is a bit
* more complicated than for Github
*
* If you don't pass a branch name, then 'default' for Hg repos is assumed
* For git, you should pass 'master'. In both cases, you should also be able
* to pass in a revision number here -- in Mercurial, this also includes
* things like 'tip' or the repo-local integer revision number
* Default to Mercurial because Git users historically tend to use GitHub
*/
Flatdoc.bitbucket = function(opts) {
if (typeof opts === 'string') {
opts = {
repo: arguments[0],
filepath: arguments[1],
branch: arguments[2]
};
}
if (!opts.filepath) opts.filepath = 'readme.md';
if (!opts.branch) opts.branch = 'default';
var url = 'https://bitbucket.org/api/1.0/repositories/'+opts.repo+'/src/'+opts.branch+'/'+opts.filepath;
return function(callback) {
$.ajax({
url: url,
dataType: 'jsonp',
error: function(xhr, status, error) {
alert(error);
},
success: function(response) {
var markdown = response.data;
callback(null, markdown);
}
});
};
};
/**
* Parser module.
* Parses a given Markdown document and returns a JSON object with data
* on the Markdown document.
*
* var data = Flatdoc.parser.parse('markdown source here');
* console.log(data);
*
* data == {
* title: 'My Project',
* content: '<p>This project is a...',
* menu: {...}
* }
*/
var Parser = Flatdoc.parser = {};
/**
* Parses a given Markdown document.
* See `Parser` for more info.
*/
Parser.parse = function(doc, markdownAndHeader, highlight, pageState, pageKey) {
marked = exports.marked;
Parser.setMarkedOptions(highlight);
var html = $("<div>" + marked(markdownAndHeader.markdown));
var title = markdownAndHeader.headerProps.title;
if(!title) {
title = html.find('h1').eq(0).text();
}
// Mangle content
Transformer.mangle(doc, html, pageState, pageKey);
var menu = Transformer.getMenu(doc, html);
return {content: html, menu: menu};
};
Parser.setMarkedOptions = function(highlight) {
marked.setOptions({
highlight: function(code, lang) {
if (lang) {
return highlight(code, lang);
}
return code;
}
});
marked.Renderer.prototype.paragraph = (text) => {
if (text.startsWith("<codetabscontainer")) {
return text + "\n";
}
return "<p>" + text + "</p>";
};
};
/**
* Transformer module.
* This takes care of any HTML mangling needed. The main entry point is
* `.mangle()` which applies all transformations needed.
*
* var $content = $("<p>Hello there, this is a docu...");
* Flatdoc.transformer.mangle($content);
*
* If you would like to change any of the transformations, decorate any of
* the functions in `Flatdoc.transformer`.
*/
var Transformer = Flatdoc.transformer = {};
/**
* Takes a given HTML `$content` and improves the markup of it by executing
* the transformations.
*
* > See: [Transformer](#transformer)
*/
Transformer.mangle = function(runner, pageKey, hierarchicalDoc) {
};
/**
* Adds IDs to headings. What's nice about this approach is that it is
* agnostic to how the markup is rendered.
* TODO: These (better) links won't always work in markdown on github because
* github doesn't encode subsections into the links. To address this, we can allow
* Github links in the markdown and then transform them into the better ones
* on the rendered page. This produces more stable linked slugs.
*/
Transformer.addIDsToHierarchicalDoc = function(runner, hierarchicalDoc, pageKey) {
var seenSlugs = {};
// Requesting side-nav requires linkifying
var headers = 'h0 h1 h2 h3 h4 h5 h6 H0 H1 H2 H3 H4 H5 H6';
forEachHierarchy(function(levelContent, level, subtreeNodes, inclusiveContext) {
if(headers.indexOf(levelContent.tagName) !== -1) {
var slugCandidate = contextToSlug(inclusiveContext, runner.slugContributions);
var slug = seenSlugs[slugCandidate] ? (slugCandidate + '--' + (seenSlugs[slugCandidate] + 1)) : slugCandidate;
seenSlugs[slugCandidate] = seenSlugs[slugCandidate] ? seenSlugs[slugCandidate] + 1 : 1;
levelContent.id = linkifidIdForHash(pageifiedIdForHash(slug, pageKey));
}
}, hierarchicalDoc);
};
/**
* Returns menu data for a given HTML.
*
* menu = Flatdoc.transformer.getMenu($content);
* menu == {
* level: 0,
* items: [{
* section: "Getting started",
* level: 1,
* items: [...]}, ...]}
*/
Transformer.getMenu = function(runner, $content) {
var root = {items: [], id: '', level: 0};
var cache = [root];
function mkdir_p(level) {
cache.length = level + 1;
var obj = cache[level];
if (!obj) {
var parent = (level > 1) ? mkdir_p(level-1) : root;
obj = { items: [], level: level };
cache = cache.concat([obj, obj]);
parent.items.push(obj);
}
return obj;
}
var query = [];
if(runner.sidenavify.h1) {
query.push('h1');
}
if(runner.sidenavify.h2) {
query.push('h2');
}
if(runner.sidenavify.h3) {
query.push('h3');
}
if(runner.sidenavify.h4) {
query.push('h4');
}
if(runner.sidenavify.h5) {
query.push('h5');
}
if(runner.sidenavify.h6) {
query.push('h6');
}
$content.find(query.join(',')).each(function() {
var $el = $(this);
var level = +(this.nodeName.substr(1));
var parent = mkdir_p(level-1);
var text = $el.text();
var el = $el[0];
if(el.childNodes.length === 1 && el.childNodes[0].tagName === 'code' || el.childNodes[0].tagName === 'CODE') {
text = '<code>' + text + '</code>';
}
var obj = { section: text, items: [], level: level, id: $el.attr('id') };
parent.items.push(obj);
cache[level] = obj;
});
return root;
};
/**
* Changes "button >" text to buttons.
*/
Transformer.buttonize = function(content) {
$(content).find('a').each(function() {
var $a = $(this);
var m = $a.text().match(/^(.*) >$/);
if (m) $a.text(m[1]).addClass('button');
});
};
/**
* Applies smart quotes to a given element.
* It leaves `code` and `pre` blocks alone.
*/
Transformer.smartquotes = function (content) {
var nodes = getTextNodesIn($(content)), len = nodes.length;
for (var i=0; i<len; i++) {
var node = nodes[i];
node.nodeValue = quotify(node.nodeValue);
}
};
/**
* Syntax highlighters.
*
* You may add or change more highlighters via the `Flatdoc.highlighters`
* object.
*
* Flatdoc.highlighters.js = function(code) {
* };
*
* Each of these functions
*/
var Highlighters = Flatdoc.highlighters = {};
/**
* JavaScript syntax highlighter.
*
* Thanks @visionmedia!
*/
Highlighters.js = Highlighters.javascript = function(code) {
return code
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/("[^\"]*?")/g, '<span class="string">$1</span>')
.replace(/('[^\']*?')/g, '<span class="string">$1</span>')
.replace(/\/\/(.*)/gm, '<span class="comment">//$1</span>')
.replace(/\/\*(.*)\*\//gm, '<span class="comment">/*$1*/</span>')
.replace(/(\d+\.\d+)/gm, '<span class="number">$1</span>')
.replace(/(\d+)/gm, '<span class="number">$1</span>')
.replace(/\bnew *(\w+)/gm, '<span class="keyword">new</span> <span class="init">$1</span>')
.replace(/\b(function|new|throw|return|var|if|else)\b/gm, '<span class="keyword">$1</span>');
};
Highlighters.html = function(code) {
return code
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/("[^\"]*?")/g, '<span class="string">$1</span>')
.replace(/('[^\']*?')/g, '<span class="string">$1</span>')
.replace(/<!--(.*)-->/g, '<span class="comment"><!--$1--></span>')
.replace(/<([^!][^\s&]*)/g, '<<span class="keyword">$1</span>');
};
Highlighters.generic = function(code) {
return code
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/("[^\"]*?")/g, '<span class="string">$1</span>')
.replace(/('[^\']*?')/g, '<span class="string">$1</span>')
.replace(/(\/\/|#)(.*)/gm, '<span class="comment">$1$2</span>')
.replace(/(\d+\.\d+)/gm, '<span class="number">$1</span>')
.replace(/(\d+)/gm, '<span class="number">$1</span>');
};
/**
* Menu view. Renders menus
*/
var MenuView = Flatdoc.menuView = function(menu) {
var $el = $("<ul>");
function process(node, $parent) {
var id = node.id || 'root';
var nodeHashToChangeTo = hashForLinkifiedId(id);
var $li = $('<li>')
.attr('id', id + '-item')
.addClass('level-' + node.level)
.appendTo($parent);
if (node.section) {
var $a = $('<a>')
.html(node.section)
.attr('id', id + '-link')
.attr('href', '#' + nodeHashToChangeTo)
.addClass('level-' + node.level)
.appendTo($li);
$a.on('click', function() {
var foundNode = $('#' + node.id);
foundNode && $.highlightNode(foundNode);
});
}
if (node.items.length > 0) {
var $ul = $('<ul>')
.addClass('level-' + (node.level+1))
.attr('id', id + '-list')
.appendTo($li);
node.items.forEach(function(item) {
process(item, $ul);
});
}
}
process(menu, $el);
return $el;
};
/**
* A runner module that fetches via a `fetcher` function.
*
* var runner = new Flatdoc.runner({
* fetcher: Flatdoc.url('readme.txt')
* });
* runner.run();
*
* The following options are available:
*
* - `fetcher` - a function that takes a callback as an argument and
* executes that callback when data is returned.
*
* See: [Flatdoc.run()]
*/
var Runner = Flatdoc.runner = function(options) {
this.initialize(options);
};
Runner.prototype.pageRootSelector = 'body';
/**
* Really, is used to model internal *component* state based on entered
* control value. Like if a text input is empty, the text input component
* sets the search component to QueryStates.NONE_AND_HIDE.
* If the user hits enter on a dropdown selector, it toggles it between NONE
* and ALL.
*
* There's three bits of information per control that determine visibility:
*
* 1. Which component is "active" (like focused). This is currently modeled
* by activeSearchComponent (but that is almost redundant with document focus). It's not
* exactly the same as focused DOM element because we also want a component
* to be able to keep the popup open even if the user tabs to other parts of
* the document. That doesn't always make sense for every kind of component,
* but it's a feature. So activeSearchComponent recreates _another_ notion of active
* element apart from the document's.
* 2. Whether or not the internal state of the component warrants showing any
* popup. (QueryStates). Like a search input could have empty text which
* warrants showing no results. Or a dropdown component (which always has
* "empty text"), could be focused but it's not supposed to show any results
* until you click or press enter/space. That internal component state helps
* determine whether or not a popup should be shown. In the case of text
* input this is redundant or derivable from its input text (but not the case
* for other component types).
* 3. Whether or not the user requested that a popup for the currently active
* component be supressed. Even if 1 and 2 would otherwise result in showing
* a popup, the user could press escape.
* An autocomplete text input with non-empty input, that is currently focused
* (or "active") could press ctrl-c closing the popup window.
* A dropdown component could be "active", could have been clicked on, but
* the user could click a second time closing it (or pressing escape).
*/
var QueryStates = {
NONE: 'NONE',
ALL: 'ALL',
FILTER: 'FILTER'
};
function SearchComponentBase(root, pages) {
this.root = root;
this.pages = pages;
this.queryState = QueryStates.ALL;
this.results = [];
/**
* This state is managed both internally and externally. Internally,
* components know when they need to reset the user requested cursor. But
* externally search lists know when to reach out and mutate this.
*/
this.userRequestedCursor = null;
};
SearchComponentBase.effectiveCursorPosition = function() {
return this.userRequestedCursor === null
? 0
: this.userRequestedCursor;
}
function TextDocSearch(props) {
SearchComponentBase.call(this, props.root, props.pages);
this.queryState = QueryStates.FILTER;
var placeholder = this.getPlaceholder();
if(this.root.tagName.toUpperCase() !== 'FORM') {
console.error('You provided a searchFormId that does not exist');
return;
}
var theSearchInput;
var theSearchClear;
if(this.root.className.indexOf('bookmark-search-form-already-setup') !== -1) {
theSearchInput = this.root.childNodes[0];
theSearchClear = this.root.childNodes[1];
} else {
this.root.className += ' bookmark-search-form bookmark-search-form-already-setup';
this.root.onsubmit="";
var theSearchInput = document.createElement('input');
theSearchInput.name = 'focus';
theSearchInput.className = 'bookmark-search-input';
theSearchInput.placeholder = placeholder;
theSearchInput.required = true;
theSearchClear = document.createElement('button');
theSearchClear.tabindex=1;
theSearchClear.className='bookmark-search-input-right-reset-icon';
theSearchClear.type='reset';
theSearchClear.tabIndex=-1;
this.root.prepend(theSearchClear);
this.root.prepend(theSearchInput);
}
this.theSearchInput = theSearchInput;
theSearchInput.addEventListener('focus', function(e) {
var focusedPlaceholder = this.getFocusedPlaceholder(this.root);
theSearchInput.placeholder = focusedPlaceholder;
if(this.userRequestedCursor === -1) {
this.userRequestedCursor = null;
}
if(this.valueWarrantsHiding()) {
props.onDoesntWantActiveStatus && props.onDoesntWantActiveStatus(this);
} else {
props.onWantsToHaveActiveStatus && props.onWantsToHaveActiveStatus(this);
}
props.onFocus && props.onFocus(e);
}.bind(this));
theSearchInput.addEventListener('keydown', function(e) {
props.onKeydown && props.onKeydown(e);
}.bind(this));
theSearchInput.addEventListener('input', function(e) {
this.userRequestedCursor = null;
if(this.valueWarrantsHiding()) {
props.onDoesntWantActiveStatus && props.onDoesntWantActiveStatus(this);
} else {
props.onWantsToHaveActiveStatus && props.onWantsToHaveActiveStatus(this);
}
props.onInput && props.onInput(e);
}.bind(this));
theSearchInput.addEventListener('blur', function(e) {
var focusedPlaceholder = this.getPlaceholder();
theSearchInput.placeholder = focusedPlaceholder;
props.onBlur && props.onBlur(e);
}.bind(this));
// This one goes on the form itself
this.root.addEventListener('reset', function() {
this.setValue('');
this.focus();
this.userRequestedCursor = null;
props.onDoesntWantActiveStatus && props.onDoesntWantActiveStatus(this);
if(props.onReset) {
props.onReset
}
}.bind(this));
this.root.addEventListener('submit', function(e) {
e.preventDefault();
}.bind(this));
};
TextDocSearch.prototype.getQuery = function() {
return this.getValue().trim();
};
TextDocSearch.prototype.valueWarrantsHiding = function() {
return this.getValue().trim() === '';
};
TextDocSearch.prototype.effectiveCursorPosition = SearchComponentBase.effectiveCursorPosition;
TextDocSearch.prototype.getFocusedPlaceholder = function() {
var defaultTxt = "Search (Esc close)";
return this.root ?
(this.root.dataset.focusedPlaceholder || defaultTxt) :
defaultTxt;
};
TextDocSearch.prototype.getPlaceholder = function(root) {
var defaultTxt = "Press '/' to focus" ;
return this.root ?
(this.root.dataset.placeholder || defaultTxt) :
defaultTxt;
};
TextDocSearch.prototype.focus = function() {
return this.theSearchInput.focus();
};
TextDocSearch.prototype.selectAll = function() {
return this.theSearchInput.select();
};
TextDocSearch.prototype.isFocused = function() {
return document.activeElement === this.theSearchInput;
};
TextDocSearch.prototype.blur = function() {
return this.theSearchInput.blur();
};
TextDocSearch.prototype.getValue = function() {
return this.theSearchInput.value;
};
TextDocSearch.prototype.setValue = function(v) {
this.theSearchInput.value = v;
};
TextDocSearch.prototype.setPlaceholder = function(ph) {
this.theSearchInput.placeholder = ph;
};
TextDocSearch.prototype.isSearchable = isNodeSearchHit;
TextDocSearch.prototype.onLostActiveSearchComponent = function() {
// this.queryState = QueryStates.NONE_AND_HIDE;
};
TextDocSearch.prototype.onGainedActiveSearchComponent = function() {
// this.queryState = QueryStates.ALL;
};
/**
* An "input selector" style component that uses the navigation autocomplete window.
*/
function TextDocSelector(props) {
SearchComponentBase.call(this, props.root, props.pages);
this.queryState = QueryStates.ALL;
this.root.addEventListener('focus', function(e) {
if(this.userRequestedCursor === -1) {
this.userRequestedCursor = null;
}
props.onFocus && props.onFocus(e);
});
this.root.addEventListener('keydown', function(e) {
props.onKeydown && props.onKeydown(e);
});
this.root.addEventListener('click', function(e) {
if(props.isActiveComponent()) {
props.onDoesntWantActiveStatus && props.onDoesntWantActiveStatus(this);
} else {
props.onWantsToHaveActiveStatus && props.onWantsToHaveActiveStatus(this);
}
}.bind(this));
this.root.addEventListener('blur', function() {
props.onDoesntWantActiveStatus && props.onDoesntWantActiveStatus(this);
}.bind(this));
};
TextDocSelector.prototype.isSearchable = isNodeSearchHit;
TextDocSelector.prototype.getQuery = function() {
return '';
};
TextDocSelector.prototype.onLostActiveSearchComponent = function() {
};
TextDocSelector.prototype.onGainedActiveSearchComponent = function() {
};
TextDocSelector.prototype.effectiveCursorPosition = SearchComponentBase.effectiveCursorPosition;
/**
* Custom methods (extends base API for search components).
*/
Runner.prototype.initialize = function(options) {
this.pageState = {};
this.searchState = {
/**
* "global" state - across all searches.
*/
activeSearchComponent: null,
/**
* Typically until the next event that switches the active component.
*/
userRequestedCloseEvenIfActive: true,
VERSIONS: null,
CONTENT: null
}
this.nodes = {
theSearchHits: null,
theHitsScrollContainer: null,
versionMenuButton: null,
versionsContainer: null
}
$.extend(this, options);
};
/**
* Syntax highlighting.
*
* You may define a custom highlight function such as `highlight` from
* the highlight.js library.
*
* Flatdoc.run({
* highlight: function (code, value) {
* return hljs.highlight(lang, code).value;
* },
* ...
* });
*
*/
/**
* There is only one active search component. It is the one that will be
* responsible for providing search results. The moment a different component
* becomes the new active component, the new active component determines
* which results will be shown, and helps decide whether or not to show the
* popup menu at all.
*/
Runner.prototype.setActiveSearchComponent = function(newComp) {
if(newComp !== this.searchState.activeSearchComponent) {
if(this.searchState.activeSearchComponent) {
this.searchState.activeSearchComponent.onLostActiveSearchComponent();
}
this.searchState.activeSearchComponent = newComp;
this.searchState.userRequestedCloseEvenIfActive = false;
if(this.searchState.activeSearchComponent) {
this.searchState.activeSearchComponent.onGainedActiveSearchComponent();
}
}
};
Runner.prototype.highlight = function(code, lang) {
var fn = Flatdoc.highlighters[lang] || Flatdoc.highlighters.generic;
return fn(code);
};
Runner.prototype.noResultsNode = function(query) {
var d = document.createElement('div');
d.className = "bookmark-hits-noresults-list";
d.innerText = 'No results for "' + query + '"';
return d;
};
Runner.prototype.getHitsScrollContainer = function() {
return this.nodes.theHitsScrollContainer;
};
Runner.prototype.effectiveCursorPosition = function(searchComponent) {
return searchComponent.userRequestedCursor === null
? 0
: searchComponent.userRequestedCursor;
}
Runner.prototype.updateSearchResultsList = function(searchComponent, query, results, clickHandler) {
var doc = this;
// var isNowVisible = doc.updateSearchHitsVisibility(searchComponent);
// // If toggling to invisible, do not change the rendered list. The reason is
// // that we want existing contents to always fade out instead of changing the list contents
// // while fading out.
// if(!isNowVisible) {
// return;
// }
var hitsScrollContainer = this.getHitsScrollContainer();
var firstItem = null;
var lastItem = null;
var effectiveCursorPosition = this.effectiveCursorPosition(searchComponent);
if(!results.length) {
var len = hitsScrollContainer.childNodes.length;
for(var i = 0; i < len; i++) {
hitsScrollContainer.removeChild(hitsScrollContainer.childNodes[i]);
}
hitsScrollContainer.appendChild(this.noResultsNode(query));
} else {
var existingHitsList;
var hitsList;
if(hitsScrollContainer.childNodes[0] && hitsScrollContainer.childNodes[0].className === 'bookmark-hits-noresults-list') {
existingHitsList = null;
hitsScrollContainer.removeChild(hitsScrollContainer.childNodes[0]);
} else {
existingHitsList = hitsScrollContainer.childNodes[0];
}
if(!existingHitsList) {
hitsList = document.createElement('div');
hitsList.className = 'bookmark-hits-list';
hitsScrollContainer.appendChild(hitsList);
} else {
hitsList = existingHitsList;
}
var numExistingHitsListItems = existingHitsList ? existingHitsList.childNodes.length : 0;
for(var i = results.length; i < numExistingHitsListItems; i++) {
existingHitsList.removeChild(existingHitsList.childNodes[existingHitsList.childNodes.length - 1]);
}
for(var i = 0; i < results.length; i++) {
var category = results[i].category;
var textContent = results[i].content;
var _highlightResultContentValue = results[i].matchedSearchable.highlightedInnerText;
var topRow = results[i].matchedSearchable.topRow;
var hitsItem;
var cursor = null;
// Reuse dom nodes to avoid flickering of css classes/animation.
if(existingHitsList && existingHitsList.childNodes[i]) {
hitsItem = existingHitsList.childNodes[i];
$(hitsItem).off('click');
hitsItem.removeChild(hitsItem.childNodes[0]);
} else {
hitsItem = document.createElement('div');
hitsItem.tabIndex = -1;
hitsItem.className = 'bookmark-hits-item';
hitsList.appendChild(hitsItem);
}
if(effectiveCursorPosition === i) {
cursor = $(hitsItem)[0];
$(hitsItem).addClass('cursor');
} else {
$(hitsItem).removeClass('cursor');
}
$(hitsItem).on('click', function(i, e) {
clickHandler(searchComponent, query, results, i, e);
}.bind(null, i));
var buttonContents = document.createElement('div');
buttonContents.className='bookmark-hits-item-button-contents';
buttonContents.innerHTML = _highlightResultContentValue;
topRow && buttonContents.insertBefore(topRow, buttonContents.firstChild);
hitsItem.appendChild(buttonContents);
if(cursor) {
customScrollIntoView({
smooth: true,
container: hitsScrollContainer,
element: cursor,
mode: 'closest-if-needed',
topMargin: 10,
bottomMargin: 10
});
}
}
}
};
Runner.prototype._createTopRow = function(row, context, level) {
row = document.createElement('div');
row.className = 'bookmark-hits-item-button-contents-top-row';
var crumb = document.createElement('div');
crumb.className = 'bookmark-hits-item-contents-top-row-crumb';
var tags = document.createElement('div');
tags.className = 'bookmark-hits-item-contents-top-row-tags';
row.appendChild(crumb);
row.appendChild(tags);
return row;
};
Runner.prototype._appendContextCrumb = function(row, context, level) {
if(!row) {
row = this._createTopRow();
}
if(context[level]) {
if(row.childNodes[0].childNodes.length > 0) {
var chevron = document.createElement('span');
chevron.className = 'bookmark-hits-item-button-contents-crumb-sep';
chevron.innerText = '›';
// Append to the crumb child
row.childNodes[0].appendChild(chevron);
}
var seg = document.createElement('span');
seg.className = 'bookmark-hits-item-button-contents-crumb-row-first';
seg.innerText = context[level].levelContent[0].innerText;
row.childNodes[0].appendChild(seg);
}
return row;
};
Runner.prototype.topRowForDocSearch = function(context, node) {
var searchBreadcrumbContext =
this.searchBreadcrumbContext ? this.searchBreadcrumbContext :
defaultSearchBreadcrumbContext;
var context = searchBreadcrumbContext(context);
var row = this._appendContextCrumb(null, context, 'h1');
row = this._appendContextCrumb(row, context, 'h2');
row = this._appendContextCrumb(row, context, 'h3');
row = this._appendContextCrumb(row, context, 'h4');
row = this._appendContextCrumb(row, context, 'h5');
row = this._appendContextCrumb(row, context, 'h6');
return row;
};
Runner.prototype.setupHitsScrollContainer = function() {
var theSearchHitsId = this.searchHitsId;
var theSearchHits = document.getElementById(theSearchHitsId);
var hitsScrollContainer = theSearchHits.childNodes[0];
var hitsScrollContainerAppearsSetup =
hitsScrollContainer &&
hitsScrollContainer.className.indexOf('bookmark-hits-scroll') !== -1;
// After this then this.getHitsScrollContainer() will work:
// We are probably reviving a prerendered page
if(theSearchHits && hitsScrollContainerAppearsSetup) {
this.nodes.theSearchHits = theSearchHits;
this.nodes.theHitsScrollContainer = hitsScrollContainer;
} else if(theSearchHits && !hitsScrollContainer) {
hitsScrollContainer = document.createElement('div');
var hiddenClass = 'bookmark-hits-scroll bookmark-hits-scroll-hidden';
hitsScrollContainer.className = hiddenClass;
theSearchHits.appendChild(hitsScrollContainer);
this.nodes.theSearchHits = theSearchHits;
this.nodes.theHitsScrollContainer = hitsScrollContainer;
} else if(theSearchHitsId) {
console.error(
'You supplied options searchHitsId but we could not find one of the elements ' + theSearchHitsId +
'. Either that or something is wrong with the pre-rendering of the page'
);
}
/**
* Prevent blur from any existing controls that already have focus by
* preventDefault on mouseDown event.
* You can still style the mouse down state by using the css :active
* pseudo-class.
*/
hitsScrollContainer.addEventListener('mousedown', function(e) {e.preventDefault();});
};
Runner.prototype.getItemForCursor = function(i) {
var hitsScrollContainer = this.getHitsScrollContainer();
var maybeHitsList = hitsScrollContainer.childNodes[0];
return maybeHitsList.className.indexOf('bookmark-hits-list') === -1 ? null :
maybeHitsList.childNodes[i];
}
// alert('TODO: When clicking on document, set the active mode to null - let compeonts decide what they want to do when they are no longer the active mode. Dropdowns can reset their querystate to NONE. Autocompletes would not. Then make it so that all components get a notification for any active state transition away from them (or maybe even to them).');
Runner.prototype.shouldSearchBeVisible = function(activeSearchComponent) {
if(!activeSearchComponent) {
return false;
}
if(this.searchState.userRequestedCloseEvenIfActive) {
return false;
} else {
return true;
// return activeSearchComponent.queryState !== QueryStates.NONE_AND_HIDE;
}
};
Runner.prototype.setupSearchInput = function() {
var doc = this;
var theSearchFormId = doc.searchFormId;
if(theSearchFormId) {
var theSearchForm = document.getElementById(theSearchFormId);
doc.searchState.CONTENT = new TextDocSearch({
root: theSearchForm,
pages: doc.pageState,
/**
* When input is blurred we do not set the active component to null.
*/
onBlur: function inputBlur(e) {
console.log('blur input');
},
// TODO: Rembember last focused element so that escape can jump back to it.
// Ctrl-c can toggle open, and Esc can toggle open + focus.
// When hitting enter it can reset the "last focused" memory.
onFocus: function doInputFocus(e) {
if(window['bookmark-header']) {
window['bookmark-header'].scrollIntoView({behavior: 'smooth'});
}
},
onDoesntWantActiveStatus: function(comp) {
console.log('search input doesnt want');
if(doc.searchState.activeSearchComponent === comp) {
doc.setActiveSearchComponent(null);
doc.updateSearchHitsVisibility(doc.searchState.activeSearchComponent);
}
},
/**
* When the component wants the popup menu to be shown for it, and it
* has a useful (or new) .getQuery() that can be polled.
*/
onWantsToHaveActiveStatus: function(comp) {
doc.setActiveSearchComponent(comp);
// Upon focus, reselect the first result cursor, otherwise keep old one
console.log("text input wants to have active status");
doc.runSearchWithInputValue();
},
onKeydown: function(e) {return doc.handleSearchComponentKeydown(doc.searchState.CONTENT, e)},
/**
* Allow components to test if they are the active component.
*/
isActiveComponent: function() {
return doc.searchState.activeSearchComponent === doc.searchState.CONTENT;
}
});
}
};
Runner.prototype.searchDocsWithActiveSearchComponent = function(query, renderTopRow, contentRoot) {
var doc = this;
var searchComponent = doc.searchState.activeSearchComponent;
hierarchicalIndexForSearch(doc.pageState)
var hits = [];
console.log(searchComponent.queryState);
if(searchComponent.queryState === QueryStates.ALL) {
console.log('noop filter', doc.pageState);
return noopHierarchicalFilter(doc.pageState, renderTopRow).map(matchedSearchableToHit);
} else if(searchComponent.queryState === QueryStates.FILTER) {
var filteredHierarchicalSearchables = filterHierarchicalSearchables(query, doc.pageState, renderTopRow);
hits = filteredHierarchicalSearchables.map(matchedSearchableToHit);
return hits;
} else {
console.error('Unknown query state', searchComponent.queryState, 'for component', searchComponent);
}
};
Runner.prototype.runSearchWithInputValue = function () {
var doc = this;
var theTextDocSearch = doc.searchState.CONTENT;
if(doc.searchState.activeSearchComponent === theTextDocSearch) {
var query = theTextDocSearch.getQuery();
var results = doc.searchDocsWithActiveSearchComponent(
query,
doc.topRowForDocSearch.bind(doc)
);
doc.searchState.activeSearchComponent.results = results;
doc.updateSearchResultsList(doc.searchState.activeSearchComponent, query, results, doc.standardResultsClickHandler.bind(doc));
doc.updateSearchHitsVisibility(doc.searchState.activeSearchComponent);
}
};
Runner.prototype.setupVersionButton = function () {
var doc = this;
if(this.versionButtonId && this.versionPageIs) {
var versionMenuButton = document.getElementById(this.versionButtonId);
var versionContentsContainer =
this.pageState[this.versionPageIs].contentContainerNode;
if(!versionMenuButton) {
console.error('Version menu selector/content with id ', this.versionButtonId, ' doesnt exist');
}
if(!versionContentsContainer) {
console.error(
'Page for config option "versionPageIs" does not exist: ',
this.versionButtonId,
'. There should be a page key in your "pages" config with that name'
);
}
this.searchState.VERSIONS = new TextDocSelector({
root: versionMenuButton,
pages: Flatdoc.keepOnly(doc.pageState, (pageData, pageKey) => this.versionPageIs.toLowerCase() === pageKey),
onKeydown: function(e) {return this.handleSearchComponentKeydown(doc.searchState.VERSIONS, e)}.bind(this),
onWantsToHaveActiveStatus: function(comp) {
doc.setActiveSearchComponent(comp);
// Upon focus, reselect the first result cursor, otherwise keep old one
console.log("version selector wants to have active status");
doc.runVersionsSearch();
},
/**
* Allow components to test if they are the active component.
*/
isActiveComponent: function() {
return doc.searchState.activeSearchComponent === doc.searchState.VERSIONS;
},
onDoesntWantActiveStatus: function(comp) {
console.log('vversion doesnt want');
if(doc.searchState.activeSearchComponent === comp) {
doc.setActiveSearchComponent(null);
doc.updateSearchHitsVisibility(doc.searchState.activeSearchComponent);
}
},
onBlur: function inputBlur(e) {
console.log('blur input');
},
// TODO: Rembember last focused element so that escape can jump back to it.
// Ctrl-c can toggle open, and Esc can toggle open + focus.
// When hitting enter it can reset the "last focused" memory.
onFocus: function doInputFocus(e) {
if(window['bookmark-header']) {
window['bookmark-header'].scrollIntoView({behavior: 'smooth'});
}
},
});
}
};
Runner.prototype.updateSearchHitsVisibility = function(searchComponent) {
console.log('updateSearchHitsVisibility');
var hitsScrollContainer = this.nodes.theHitsScrollContainer;
if(!this.shouldSearchBeVisible(searchComponent)) {
hitsScrollContainer.className = 'bookmark-hits-scroll bookmark-hits-scroll-hidden';
return false;
} else {
hitsScrollContainer.className = 'bookmark-hits-scroll';
return true;
}
};
Runner.prototype.handleSearchComponentKeydown = function(searchComponent, evt) {
var doc = this;
// alert('need to make sure the active component is set here');
var effectiveCursorPosition = doc.effectiveCursorPosition(searchComponent);
var isVisible = doc.shouldSearchBeVisible(searchComponent);
var nextIndex;
if (evt.keyCode === 40 /* down */) {
if(!isVisible && searchComponent.getQuery() !== "") {
// Promote to zero on first down if neg one
nextIndex = Math.max(searchComponent.userRequestedCursor, 0);
doc.searchState.userRequestedCloseEvenIfActive = false;
} else {
nextIndex = (effectiveCursorPosition < searchComponent.results.length - 1)
? effectiveCursorPosition + 1
: searchComponent.userRequestedCursor;
}
}
if (evt.keyCode === 38 /* up */) {
if(effectiveCursorPosition !== -1) {
nextIndex = effectiveCursorPosition - 1;
} else {
nextIndex = searchComponent.userRequestedCursor;
}
}
if (evt.keyCode === 38 || evt.keyCode === 40) {
searchComponent.userRequestedCursor = nextIndex;
}
if(isVisible && evt.keyCode === 13) { // enter
var itemForCursor = doc.getItemForCursor(effectiveCursorPosition);
$(itemForCursor).trigger('click');
} else if(!isVisible && evt.keyCode === 13) {
doc.searchState.userRequestedCloseEvenIfActive = false;
} else if(evt.keyCode === 27) {
// console.log('local escape');
// // Let's make escape close and blur
// $(theSearchInput).blur();
// doc.searchState.userRequestedCloseEvenIfActive = !doc.searchState.userRequestedCloseEvenIfActive;
// doc.updateSearchHitsVisibility(searchComponent);
} else if(evt.keyCode === 67 && evt.ctrlKey) { // esc or ctrl-c
// But ctrl-c can toggle without losing focus
// doc.searchState.userRequestedCloseEvenIfActive = !doc.searchState.userRequestedCloseEvenIfActive;
// doc.updateSearchHitsVisibility(searchComponent);
}
// Either way, visible or not - if enter is pressed, prevent default.
// Because a "required" form field that is empty will submit on enter and
// then make an ugly Chrome popup saying "this is required".
if (evt.keyCode === 38 || evt.keyCode === 40 || evt.keyCode === 13) {
evt.preventDefault();
doc.updateSearchResultsList(
searchComponent,
searchComponent.getQuery(),
searchComponent.results,
doc.standardResultsClickHandler.bind(doc)
);
}
};
Runner.prototype.deepestContextWithSlug = function(context) {
return context.h6 && context.h6.id ? context.h6 :
context.h5 && context.h5.id ? context.h5 :
context.h4 && context.h4.id ? context.h4 :
context.h3 && context.h3.id ? context.h3 :
context.h2 && context.h2.id ? context.h2 :
context.h1 && context.h1.id ? context.h1 : null;
};
Runner.prototype.standardResultsClickHandler = function(searchComponent, query, results, i, e) {
var doc = this;
searchComponent.userRequestedCursor = i;
// doc.searchState.userRequestedCloseEvenIfActive = true;
// doc.updateSearchHitsVisibility();
doc.updateSearchResultsList(searchComponent, query, results, doc.standardResultsClickHandler.bind(doc));
var node = results[i].matchedSearchable.searchable.node;
$.highlightNode(node);
customScrollIntoView({
smooth: true,
container: 'page',
element: node,
mode: 'top',
topMargin: 2 * headerHeight,
bottomMargin: 0
});
};
Runner.prototype.setupSearch = function() {
var doc = this;
doc.setupSearchInput();
doc.setupVersionButton();
doc.setupHitsScrollContainer();
var theTextDocSearch = doc.searchState.CONTENT;
var theSearchHits = doc.nodes.theSearchHits;
if(!theTextDocSearch || !theSearchHits) {
return;
}
var hitsScrollContainer = doc.nodes.theHitsScrollContainer;
doc.nodes.theSearchHits.style.cssText += "position: sticky; top: " + (headerHeight - 1) + "px; z-index: 100;"
function setupGlobalKeybindings() {
window.document.body.addEventListener('keypress', e => {
if(!theTextDocSearch.isFocused() && e.key === "/") {
theTextDocSearch.focus()
theTextDocSearch.selectAll()
e.preventDefault();
}
});
}
document.addEventListener('keydown', function (evt) {
if(evt.keyCode === 27) {
console.log('global escape');
// Let's make escape close and blur
if(theTextDocSearch.isFocused()) {
theTextDocSearch.blur();
}
if(!doc.searchState.userRequestedCloseEvenIfActive) {
doc.searchState.userRequestedCloseEvenIfActive = true;
}
doc.setActiveSearchComponent(null);
// Maybe updateSearchHitsVisibility should happen in setActiveSearchComponent.
doc.updateSearchHitsVisibility(doc.searchState.activeSearchComponent);
} else if(evt.keyCode === 67 && evt.ctrlKey) { // esc or ctrl-c
// But ctrl-c can toggle without losing focus
doc.searchState.userRequestedCloseEvenIfActive = !doc.searchState.userRequestedCloseEvenIfActive;
doc.updateSearchHitsVisibility(doc.searchState.activeSearchComponent);
}
// alert('todo have ctrl-c keep the current active component, but tell that component to go to QueryMode.NONE_AND_HIDE');
});
setupGlobalKeybindings();
function onGlobalClickOff(e) {
doc.setActiveSearchComponent(null);
// We'll consider all other search modes to be "ephemeral".
doc.updateSearchHitsVisibility(null);
// e.stopPropagation();
}
document.querySelectorAll('.bookmark-content-root')[0].addEventListener('click', onGlobalClickOff);
};
Runner.prototype.topRowForVersionSearch = function(context, node) {
var topRow = this.topRowForDocSearch(context, node);
var tagsDiv = topRow.childNodes[1];
var tag = document.createElement('div');
tag.className = 'bookmark-hits-item-contents-top-row-tags-tag';
tag.innerText = "Latest";
tagsDiv.appendChild(tag);
return topRow;
};
Runner.prototype.runVersionsSearch = function runVersionsSearch() {
var doc = this;
var searchComponent = doc.searchState.VERSIONS;
if(window['bookmark-header']) {
window['bookmark-header'].scrollIntoView({behavior: 'smooth'});
}
doc.setActiveSearchComponent(searchComponent);
console.log('running version search');
// TODO: Reset this to NONE on blur/selection etc.
doc.updateSearchHitsVisibility(doc.searchState.VERSIONS);
var results = doc.searchDocsWithActiveSearchComponent(
searchComponent.getQuery(),
doc.topRowForVersionSearch.bind(doc)
);
searchComponent.results = results;
doc.updateSearchResultsList(searchComponent, searchComponent.getQuery(), results, doc.standardResultsClickHandler.bind(doc));
};
Runner.prototype.makeCodeTabsInteractive = function() {
$('codetabbutton').each(function(i, e) {
var forTabContainerId = e.dataset.forContainerId;
var index = e.dataset.index;
$(e).on('click', function(evt) {
var tabContainer = e.parentNode;
console.log('searching this query what: $("' + '#' + forTabContainerId + ' codetabbutton")');
$(e).addClass('bookmark-codetabs-active');
$(tabContainer).removeClass('bookmark-codetabs-active1');
$(tabContainer).removeClass('bookmark-codetabs-active2');
$(tabContainer).removeClass('bookmark-codetabs-active3');
$(tabContainer).removeClass('bookmark-codetabs-active4');
$(tabContainer).removeClass('bookmark-codetabs-active5');
$(tabContainer).addClass('bookmark-codetabs-active' + index);
});
});
};
/**
* Remove any nodes that are not needed once rendered. This way when
* generating a pre-rendered `.rendered.html`, they won't become part of the
* bundle, when that rendered page is turned into a `.html` bundle. They have
* served their purpose. Add `class='removeFromRenderedPage'` to anything you
* want removed once used to render the page. (Don't use for script tags that
* are needed for interactivity).
*/
Runner.prototype.removeFromRenderedPage = function() {
$('.removeFromRenderedPage').each(function(i, e) {
e.parentNode.removeChild(e);
});
};
/**
* See documentation for `continueRight` css class in style.styl.
*/
Runner.prototype.fixupAlignment = function() {
document.querySelectorAll(
// TODO: Add the tabs container here too.
'.bookmark-content > img + pre,' +
'.bookmark-content > img + blockquote,' +
'.bookmark-content > p + pre,' +
'.bookmark-content > p + blockquote,' +
'.bookmark-content > ul + pre,' +
'.bookmark-content > ul + blockquote,' +
'.bookmark-content > ol + pre,' +
'.bookmark-content > ol + blockquote,' +
'.bookmark-content > h0 + pre,' +
'.bookmark-content > h0 + blockquote,' +
'.bookmark-content > h1 + pre,' +
'.bookmark-content > h1 + blockquote,' +
'.bookmark-content > h2 + pre,' +
'.bookmark-content > h2 + blockquote,' +
'.bookmark-content > h3 + pre,' +
'.bookmark-content > h3 + blockquote,' +
'.bookmark-content > h4 + pre,' +
'.bookmark-content > h4 + blockquote,' +
'.bookmark-content > h5 + pre,' +
'.bookmark-content > h5 + blockquote,' +
'.bookmark-content > h6 + pre,' +
'.bookmark-content > h6 + blockquote,' +
'.bookmark-content > table + pre,' +
'.bookmark-content > table + blockquote'
).forEach(function(e) {
// Annotate classes for the left and right items that are "resynced".
// This allows styling them differently. Maybe more top margins. TODO:
// I don't think that bookmark-synced-up-left is needed. continueRight
// seems to do the trick and the css for bookmark-synced-up-left seems to
// just ruin it actually.
e.className += 'bookmark-synced-up-right';
if(e.previousSibling) {
e.previousSibling.className += 'bookmark-synced-up-left';
}
})
};
Runner.prototype.setupLeftNavScrollHighlighting = function() {
var majorHeaders = $("h2, h3");
majorHeaders.length && majorHeaders.scrollagent(function(cid, pid, currentElement, previousElement) {
console.log('setting up scroll watchers for pid', pid);
if (pid) {
$("[href='#"+hashForLinkifiedId(pid)+"']").removeClass('active');
}
if (cid) {
$("[href='#"+hashForLinkifiedId(cid)+"']").addClass('active');
}
});
};
Runner.prototype.handleHashChange = function(hash) {
if (hash !== ''){
console.log('hash changed', hash);
if(hash[0] === '#') {
hash = hash.substring(1);
anchorJump('#' + linkifidIdForHash(hash));
}
}
};
Runner.prototype.waitForImages = function() {
var onAllImagesLoaded = function() {
// Has to be done after images are loaded for correct detection of position.
this.setupLeftNavScrollHighlighting();
window.addEventListener('hashchange', function(e) {
this.handleHashChange(location.hash);
}.bind(this));
// Rejump after images have loaded
this.handleHashChange(location.hash);
/**
* If you add a style="visibility:hidden" to your document body, we will clear
* the style after the styles have been injected. This avoids a flash of
* unstyled content.
* Only after scrolling and loading a stable page with all styles, do we
* reenable visibility.
* TODO: This is only needed if there is a hash in the URL. Otherwise,
* we can show the page immediately, non-blocking since we don't need to scroll
* to the current anchor. (We don't need to wait for images to load which are
* likely below the fold). This assumes we can implement a header that is scalable
* entirely in css. As soon as styles are loaded, the visibility can be shown.
*/
console.log('all images loaded at', Date.now());
if(window.location.hash) {
document.body.style="visibility: visible";
} else {
console.log('Lack of hash in URL saved time in display:', Date.now() - window._bookmarkTimingStyleReady);
}
}.bind(this);
var imageCount = $('img').length;
var nImagesLoaded = 0;
// Wait for all images to be loaded by cloning and checking:
// https://cobwwweb.com/wait-until-all-images-loaded
// Thankfully browsers cache images.
function onOneImageLoaded(loadedEl) {
nImagesLoaded++;
if (nImagesLoaded == imageCount) {
onAllImagesLoaded();
}
}
if(imageCount === 0) {
onAllImagesLoaded();
} else {
$('img').each(function(_i, imgEl) {
$('<img>').on('load', onOneImageLoaded).attr('src', $(imgEl).attr('src'));
$('<img>').on('error', onOneImageLoaded).attr('src', $(imgEl).attr('src'));
});
}
};
Runner.prototype.run = function(
onCurrentRenderPageDone, onAllRenderPagesDone, onNextIndexPageDone, onAllIndexPagesDone) {
};
/**
* Loads the Markdown document (via the fetcher), parses it, and applies it
* to the elements.
*/
Runner.prototype.run = function(
onCurrentRenderPageDone, onAllRenderPagesDone, onNextIndexPageDone, onAllIndexPagesDone) {
var start = Date.now();
var doc = this;
$(doc.pageRootSelector).trigger('flatdoc:loading');
$(doc.pageRootSelector).on('flatdoc:ready', this.makeCodeTabsInteractive);
$(doc.pageRootSelector).on('flatdoc:ready', this.removeFromRenderedPage.bind(this));
$(doc.pageRootSelector).on('flatdoc:ready', this.fixupAlignment.bind(this));
$(doc.pageRootSelector).on('flatdoc:ready', this.waitForImages.bind(this));
// If this *is* an already rendered snapshot, then no need to render
// anything. Just fire off the ready events so that hacky jquery code can
// perform resizing etc.
$(doc.pageRootSelector).on('flatdoc:ready', function(e) {
doc.makeCodeTabsInteractive();
doc.setupSearch();
// Need to focus the window so global keyboard shortcuts are heard.
$(window).focus()
});
if(document.body.className.indexOf('bookmark-already-rendered') !== -1) {
$(doc.pageRootSelector).trigger('flatdoc:style-ready');
$(doc.pageRootSelector).trigger('flatdoc:ready');
return;
}
document.body.className += ' bookmark-already-rendered';
var stylusFetchedYet = !doc.stylusFetcher;
var allDocsFetchedYet = false;
var everythingFetchedYet = false;
var stylusResult = null;
function handleDones() {
var foundUnfetchedDoc = false;
Flatdoc.forEachPage(
doc.pageState,
function(chapData, _) {
foundUnfetchedDoc = foundUnfetchedDoc || chapData.markdownAndHeader === null;
}
);
var wasEverythingFetchedYetBefore = allDocsFetchedYet && stylusFetchedYet;
if(!allDocsFetchedYet && !foundUnfetchedDoc) {
allDocsFetchedYet = true;
doc.handleDocsFetched();
}
if(!stylusFetchedYet && !!stylusResult) {
stylusFetchedYet = true;
$(doc.pageRootSelector).trigger('flatdoc:style-ready');
}
everythingFetchedYet = allDocsFetchedYet && stylusFetchedYet;
if(everythingFetchedYet && !wasEverythingFetchedYetBefore) {
$(doc.pageRootSelector).trigger('flatdoc:ready');
}
};
var fetchOne = function(fetcher, cb) {
fetcher(function(err, md) {
if(err) {
cb(err, null);
return;
}
var markdown = normalizeMarkdownResponse(md);
var markdownNormalizedCodeTabs = normalizeDocusaurusCodeTabs(markdown);
var markdownNormalizedYaml = normalizeYamlMarkdownComments(markdownNormalizedCodeTabs);
var markdownAndHeader = parseYamlHeader(markdownNormalizedYaml, window.location.pathname);
// Parse out the YAML header if present.
var data = markdownAndHeader;
/* Flatdoc.parser.parse(
doc,
markdownAndHeader,
doc.highlight,
pageState,
pageKey
); */
// About 258
cb(err, data);
});
};
Flatdoc.forEachPage(
doc.pageState,
function(pageData, pageKey) {
fetchOne(pageData.fetcher, function(err, data) {
doc.pageState[pageKey].markdownAndHeader = data;
err && console.error(
'[Flatdoc] fetching Markdown data failed for page:' + pageKey + '.',
err
);
handleDones();
})
},
);
if(doc.stylusFetcher) {
var templateFetchStart = Date.now();
doc.stylusFetcher(function(err, stylusTxt) { // Will run sync
doc.renderAndInjectStylus(err, stylusTxt, function(res) {
stylusResult = res;
handleDones();
});
});
}
};
Runner.prototype.renderAndInjectStylus = function(err, stylusTxt, cb) {
if(err) {
console.error('[Flatdoc] fetching Stylus data failed.', err);
cb('');
} else {
window.stylus.render(stylusTxt, function(err, result) {
if(err) {
console.error('Stylus error:' + err.message);
cb('');
} else {
var style = document.createElement('style');
style.type = 'text/css';
style.name = 'style generated from .styl.html file';
style.innerHTML = result;
document.getElementsByTagName('head')[0].appendChild(style);
cb(stylusTxt);
}
});
}
};
Runner.prototype.handleDocsFetched = function() {
var runner = this;
function appendExperience(pageKey, pageData) {
var markdownAndHeader = pageData.markdownAndHeader;
marked = exports.marked;
Parser.setMarkedOptions(runner.highlight);
var premangledContent = $("<div>" + marked(markdownAndHeader.markdown));
var title = markdownAndHeader.headerProps.title;
if(!title) {
title = premangledContent.find('h1').eq(0).text();
}
var pageClassName = 'page-' + pageKey;
var containerForPageContent = document.createElement('div');
containerForPageContent.className = 'bookmark-content ' + pageClassName;
if(markdownAndHeader.headerProps.title) {
var titleForPage = document.createElement('h0');
titleForPage.className = 'bookmark-content-title ' + pageClassName;
// Prepend the title to the main content section so it matches the style
// of content (indentation etc).
titleForPage.innerText = markdownAndHeader.headerProps.title;
containerForPageContent.appendChild(titleForPage);
if(markdownAndHeader.headerProps.subtitle) {
var subtitleForPage = document.createElement('p');
subtitleForPage.className = 'bookmark-content-subtitle';
containerForPageContent.appendChild(subtitleForPage);
subtitleForPage.innerText = markdownAndHeader.headerProps.subtitle;
}
}
containerForPageContent.appendChild(premangledContent[0]);
var menuBarForPage = document.createElement('div');
menuBarForPage.className = 'bookmark-menubar ' + pageClassName;
var premangledMenuForPage = document.createElement('div');
premangledMenuForPage.className = 'bookmark-menu section ' + pageClassName;
menuBarForPage.appendChild(premangledMenuForPage);
var nonBlankContent = $(premangledContent).find('>*');
var menu = Transformer.getMenu(runner, premangledContent)
Array.prototype.forEach.call(nonBlankContent, (itm) => containerForPageContent.appendChild(itm));
Array.prototype.forEach.call(MenuView(menu), (itm) => premangledMenuForPage.appendChild(itm));
Transformer.buttonize(containerForPageContent);
Transformer.smartquotes(containerForPageContent);
var hierarchicalDoc = hierarchize(containerForPageContent);
// Mangle content
Transformer.addIDsToHierarchicalDoc(runner, hierarchicalDoc, pageKey);
Transformer.mangle(runner, pageKey, hierarchicalDoc);
// It's mutated.
var mangledContentForPage = containerForPageContent;
return {
...pageData,
contentContainerNode: mangledContentForPage,
menuContainerNode: menuBarForPage,
hierarchicalDoc: hierarchicalDoc
};
}
runner.pageState = Flatdoc.mapPages(
runner.pageState,
function(data, pageKey) {
return appendExperience(pageKey, data);
}
);
runner.appendDocNodesToDom(runner.pageState);
runner.activatePageForCurrentUrl(runner.pageState);
};
Runner.prototype.appendDocNodesToDom = function(data) {
var contentRootNode = $('.bookmark-content-root')[0];
var append = function(data, _) {
contentRootNode.appendChild(data.contentContainerNode)
contentRootNode.appendChild(data.menuContainerNode)
};
Flatdoc.forEachPage(data, append, append);
};
Runner.prototype.activatePageForCurrentUrl = function(data) {
var dataForUrl = pageDataForUrl(window.location, data);
var toggleClasses = function(data, _) {
dataForUrl === data ?
data.contentContainerNode.classList.add("current") :
data.contentContainerNode.classList.remove("current");
dataForUrl === data ?
data.menuContainerNode.classList.add("current") :
data.menuContainerNode.classList.remove("current");
};
Flatdoc.forEachPage(data, toggleClasses, toggleClasses);
};
/**
* Fetches a given element from the DOM.
*
* Returns a jQuery object.
* @api private
*/
Runner.prototype.el = function(aspect) {
return $(this[aspect], document.body);
};
/*
* Helpers
*/
// http://stackoverflow.com/questions/298750/how-do-i-select-text-nodes-with-jquery
function getTextNodesIn(el) {
var exclude = 'iframe,pre,code';
return $(el).find(':not('+exclude+')').andSelf().contents().filter(function() {
return this.nodeType == 3 && $(this).closest(exclude).length === 0;
});
}
// http://www.leancrew.com/all-this/2010/11/smart-quotes-in-javascript/
function quotify(a) {
a = a.replace(/(^|[\-\u2014\s(\["])'/g, "$1\u2018"); // opening singles
a = a.replace(/'/g, "\u2019"); // closing singles & apostrophes
a = a.replace(/(^|[\-\u2014\/\[(\u2018\s])"/g, "$1\u201c"); // opening doubles
a = a.replace(/"/g, "\u201d"); // closing doubles
a = a.replace(/\.\.\./g, "\u2026"); // ellipses
a = a.replace(/--/g, "\u2014"); // em-dashes
return a;
}
})(jQuery);
/* jshint ignore:start */
/*!
* base64.js
* http://github.com/dankogai/js-base64
* THERE's A PROBLEM LOADING THIS in entrypoint mode.
*/
/**
* marked - a markdown parser
* Copyright (c) 2011-2020, Christopher Jeffrey. (MIT Licensed)
* https://github.com/markedjs/marked
*/
/*!
* node-parameterize 0.0.7
* https://github.com/fyalavuz/node-parameterize
* Exported as `Flatdoc.slugify`
*/
/* jshint ignore:end */
// This } is for the initial if() statement that bails out early.
}
================================================
FILE: docs/site/ORIGINS.md
================================================
Bookmark:
(A simple tool for editing and rendering Reason documentation)
Here's a list of all of the technologies that are used and included in Bookmark.
Each of these projects should include a LICENSE file from their original
project, but even if they do not, they still retain the license/copyright of
their original project (even though they are copied/"vendored" in
## Flatdoc:
This project is just a fork of flatdoc, so of course
[https://github.com/rstacruz/flatdoc](flatdoc) should be mentioned. Flatdoc is
excellent.
# jquery:
jquery is licensed under the MIT license, and is vendored in vendor/jquery.js
See its license [here](https://jquery.org/license/)
#medium-zoom
[Medium-zoom](https://github.com/francoischalifour/medium-zoom) is vendored as
well.
#Fira Mono Font
Is also vendored as the default source code font. See its LICENSE included in the vendor directory.
#Roboto Font
Is also vendored and is the default font for text. See its LICENSE included in the vendor directory.
# Stylus
The vendored stylus in `support/vendor/stylus.min.js` is gotten from
https://github.com/stylus/stylus/tree/client and is under MIT license (see the
repo).
# hljs
HLJS is vendored in support/vendor/ along with all of its out of the box css
styles. hljs is licensed under BSD 3-Clause License and the license can be
found in its repo [here](https://github.com/highlightjs/highlight.js).
# marked
Flatdoc vendors marked (markdown parsing library) inside of flatdoc.js
https://github.com/markedjs/marked
It is licensed under MIT (see the repo for license).
# Beach Images:
Credit Lance Aspser:
https://unsplash.com/photos/W785zpEXZZo
https://unsplash.com/photos/woDxDNvpmdk
================================================
FILE: docs/site/theme-white/theme.js
================================================
/*!
* Flatdoc - (c) 2013, 2014 Rico Sta. Cruz
* http://ricostacruz.com/flatdoc
* @license MIT
*/
(function($) {
var $window = $(window);
var $document = $(document);
/*
* If the hash is empty, we don't need to scroll to anything, and therefore
* we don't need to wait until images load to reveal the body (for size
* issues).
*/
$document.on('flatdoc:style-ready', function() {
window._bookmarkTimingStyleReady = Date.now();
if(!window.location.hash) {
document.body.style="visibility: visible";
}
});
/*
* Scrollspy.
*/
$document.on('flatdoc:ready', function() {
if (typeof mediumZoom !== 'undefined') {
mediumZoom(document.querySelectorAll('.bookmark-content img'), {
scrollOffset: 20,
container: document.body,
margin: 24,
background: '#ffffff',
});
document.querySelectorAll('.bookmark-content img').forEach(function(img) {
var parent = img.parentElement;
if (parent && parent.tagName.toUpperCase() === 'P') {
// Allows targeting css for containers of images
// since has() selector is not yet supported in css
parent.className += ' imageContainer';
}
});
}
});
})(jQuery);
/*! jQuery.scrollagent (c) 2012, Rico Sta. Cruz. MIT License.
* https://github.com/rstacruz/jquery-stuff/tree/master/scrollagent */
// Call $(...).scrollagent() with a callback function.
//
// The callback will be called everytime the focus changes.
//
// Example:
//
// $("h2").scrollagent(function(cid, pid, currentElement, previousElement) {
// if (pid) {
// $("[href='#"+pid+"']").removeClass('active');
// }
// if (cid) {
// $("[href='#"+cid+"']").addClass('active');
// }
// });
(function($) {
$.fn.scrollagent = function(options, callback) {
// Account for $.scrollspy(function)
if (typeof callback === 'undefined') {
callback = options;
options = {};
}
var $sections = $(this);
var $parent = options.parent || $(window);
// Find the top offsets of each section
var offsets = [];
$sections.each(function(i) {
var offset = $(this).attr('data-anchor-offset') ?
parseInt($(this).attr('data-anchor-offset'), 10) :
(options.offset || 0);
offsets.push({
id: $(this).attr('id'),
index: i,
el: this,
offset: offset
});
});
// State
var current = null;
var height = null;
var range = null;
// Save the height. Do this only whenever the window is resized so we don't
// recalculate often.
$(window).on('resize', function() {
height = $parent.height();
range = $(document).height();
});
// Find the current active section every scroll tick.
$parent.on('scroll', function() {
var y = $parent.scrollTop();
// y += height * (0.3 + 0.7 * Math.pow(y/range, 2));
var latest = null;
for (var i in offsets) {
if (offsets.hasOwnProperty(i)) {
var offset = offsets[i];
var el = offset.el;
var relToViewport = offset.el.getBoundingClientRect().top;
if(relToViewport > 0 && relToViewport < height / 2) {
latest = offset;
break;
}
}
}
if (latest && (!current || (latest.index !== current.index))) {
callback.call($sections,
latest ? latest.id : null,
current ? current.id : null,
latest ? latest.el : null,
current ? current.el : null);
current = latest;
}
});
$(window).trigger('resize');
$parent.trigger('scroll');
return this;
};
})(jQuery);
================================================
FILE: docs/site/theme-white/theme.styl.html
================================================
<meta charset="utf-8" vim: set filetype=Stylus: >
<script src="../Bookmark.js"> </script>
support-for-ie = true
$prim = #5674FF
$lowlight = #3f3e4d
$prim-1 = rgb(blend(rgba(#000000,.40) $prim))
$prim-2 = rgb(blend(rgba(#000000,.30) $prim))
$prim-3 = rgb(blend(rgba(#000000,.20) $prim))
$prim-4 = rgb(blend(rgba(#000000,.10) $prim))
$prim-5 = $prim
$prim-6 = rgb(blend(rgba(#FFFFFF,.10) $prim))
$prim-7 = rgb(blend(rgba(#FFFFFF,.20) $prim))
$prim-8 = rgb(blend(rgba(#FFFFFF,.30) $prim))
$prim-9 = rgb(blend(rgba(#FFFFFF,.40) $prim))
$prim-10 = rgb(blend(rgba(#FFFFFF,.50) $prim))
$prim-11 = rgb(blend(rgba(#FFFFFF,.60) $prim))
$prim-12 = rgb(blend(rgba(#FFFFFF,.68) $prim))
$prim-13 = rgb(blend(rgba(#FFFFFF,.78) $prim))
$prim-14 = rgb(blend(rgba(#FFFFFF,.86) $prim))
$prim-15 = rgb(blend(rgba(#FFFFFF,.91) $prim))
$prim-16 = rgb(blend(rgba(#FFFFFF,.95) $prim))
$prim-17 = rgb(blend(rgba(#FFFFFF,.98) $prim))
$prim-desat-1 = rgb(desaturate($prim-1, 50%))
$prim-desat-2 = rgb(desaturate($prim-2, 50%))
$prim-desat-3 = rgb(desaturate($prim-3, 50%))
$prim-desat-4 = rgb(desaturate($prim-4, 50%))
$prim-desat-5 = rgb(desaturate($prim-5, 50%))
$prim-desat = $prim-desat-5
$prim-desat-6 = rgb(desaturate($prim-6, 50%))
$prim-desat-7 = rgb(desaturate($prim-7, 50%))
$prim-desat-8 = rgb(desaturate($prim-8, 50%))
$prim-desat-9 = rgb(desaturate($prim-9, 50%))
$prim-desat-10 = rgb(desaturate($prim-10, 50%))
$prim-desat-11 = rgb(desaturate($prim-11, 50%))
$prim-desat-12 = rgb(desaturate($prim-12, 50%))
$prim-desat-13 = rgb(desaturate($prim-13, 50%))
$prim-desat-14 = rgb(desaturate($prim-14, 50%))
$prim-desat-15 = rgb(desaturate($prim-15, 50%))
$prim-desat-16 = rgb(desaturate($prim-16, 50%))
$prim-desat-17 = rgb(desaturate($prim-17, 50%))
$lowlight-1 = rgb(blend(rgba(#000000,.40) $lowlight))
$lowlight-2 = rgb(blend(rgba(#000000,.30) $lowlight))
$lowlight-3 = rgb(blend(rgba(#000000,.20) $lowlight))
$lowlight-4 = rgb(blend(rgba(#000000,.10) $lowlight))
$lowlight-5 = $lowlight
$lowlight-6 = rgb(blend(rgba(#FFFFFF,.10) $lowlight))
$lowlight-7 = rgb(blend(rgba(#FFFFFF,.20) $lowlight))
$lowlight-8 = rgb(blend(rgba(#FFFFFF,.30) $lowlight))
$lowlight-9 = rgb(blend(rgba(#FFFFFF,.40) $lowlight))
$lowlight-10 = rgb(blend(rgba(#FFFFFF,.50) $lowlight))
$lowlight-11 = rgb(blend(rgba(#FFFFFF,.60) $lowlight))
$lowlight-12 = rgb(blend(rgba(#FFFFFF,.68) $lowlight))
$lowlight-13 = rgb(blend(rgba(#FFFFFF,.78) $lowlight))
$lowlight-14 = rgb(blend(rgba(#FFFFFF,.86) $lowlight))
$lowlight-15 = rgb(blend(rgba(#FFFFFF,.91) $lowlight))
$lowlight-16 = rgb(blend(rgba(#FFFFFF,.95) $lowlight))
$lowlight-17 = rgb(blend(rgba(#FFFFFF,.98) $lowlight))
$lowlight-desat-1 = rgb(desaturate($lowlight-1, 50%))
$lowlight-desat-2 = rgb(desaturate($lowlight-2, 50%))
$lowlight-desat-3 = rgb(desaturate($lowlight-3, 50%))
$lowlight-desat-4 = rgb(desaturate($lowlight-4, 50%))
$lowlight-desat
gitextract_cg_wrl9f/
├── .github/
│ └── workflows/
│ ├── esy-ci.yml
│ ├── nix-build.yml
│ ├── opam-ci.yml
│ └── print-esy-cache.js
├── .gitignore
├── .npmignore
├── .ocamlformat
├── .ocamlformat-ignore
├── CHANGES.md
├── CODE_OF_CONDUCT.md
├── LICENSE.txt
├── Makefile
├── ORIGINS.md
├── PLAN
├── README.md
├── docs/
│ ├── GETTING_STARTED_CONTRIBUTING.md
│ ├── README.md
│ ├── RELEASING.md
│ ├── TYPE_PARAMETERS_PARSING.md
│ ├── USING_PARSER_PROGRAMMATICALLY.md
│ └── site/
│ ├── Bookmark.js
│ ├── ORIGINS.md
│ └── theme-white/
│ ├── theme.js
│ └── theme.styl.html
├── dune
├── dune-project
├── esy.json
├── esy.lock.json
├── flake.nix
├── js/
│ ├── dune
│ ├── refmt.ml
│ └── testRefmtJs.js
├── nix/
│ ├── ci.nix
│ ├── default.nix
│ └── shell.nix
├── package.json
├── reason.json
├── reason.opam
├── reason.opam.template
├── rtop/
│ ├── dune
│ ├── reason_toploop.cppo.ml
│ ├── reason_util.ml
│ ├── reason_utop.cppo.ml
│ └── rtop.ml
├── rtop.json
├── rtop.opam
├── scripts/
│ └── esy-prepublish.js
├── src/
│ ├── menhir-error-processor/
│ │ ├── dune
│ │ └── menhir_error_processor.ml
│ ├── menhir-recover/
│ │ ├── attributes.ml
│ │ ├── attributes.mli
│ │ ├── cost.ml
│ │ ├── cost.mli
│ │ ├── dune
│ │ ├── emitter.ml
│ │ ├── emitter.mli
│ │ ├── menhir_recover.ml
│ │ ├── recovery_custom.ml
│ │ ├── recovery_custom.mli
│ │ ├── recovery_intf.ml
│ │ ├── synthesis.ml
│ │ └── synthesis.mli
│ ├── reason-merlin/
│ │ ├── dune
│ │ └── ocamlmerlin_reason.ml
│ ├── reason-parser/
│ │ ├── TODO
│ │ ├── dune
│ │ ├── error-handling.md
│ │ ├── merlin_recovery.ml
│ │ ├── merlin_recovery.mli
│ │ ├── merlin_recovery_intf.ml
│ │ ├── ocaml_util.cppo.ml
│ │ ├── ocaml_util.cppo.mli
│ │ ├── reason_attributes.ml
│ │ ├── reason_attributes.mli
│ │ ├── reason_comment.ml
│ │ ├── reason_comment.mli
│ │ ├── reason_config.ml
│ │ ├── reason_config.mli
│ │ ├── reason_declarative_lexer.mli
│ │ ├── reason_declarative_lexer.mll
│ │ ├── reason_errors.ml
│ │ ├── reason_errors.mli
│ │ ├── reason_heuristics.ml
│ │ ├── reason_heuristics.mli
│ │ ├── reason_layout.ml
│ │ ├── reason_layout.mli
│ │ ├── reason_lexer.ml
│ │ ├── reason_lexer.mli
│ │ ├── reason_location.ml
│ │ ├── reason_location.mli
│ │ ├── reason_multi_parser.ml
│ │ ├── reason_multi_parser.mli
│ │ ├── reason_oprint.ml
│ │ ├── reason_oprint.mli
│ │ ├── reason_parser.mly
│ │ ├── reason_parser_def.ml
│ │ ├── reason_parser_def.mli
│ │ ├── reason_parser_explain.ml
│ │ ├── reason_parser_explain.mli
│ │ ├── reason_pprint_ast.ml
│ │ ├── reason_pprint_ast.mli
│ │ ├── reason_recover_parser.ml
│ │ ├── reason_recover_parser.mli
│ │ ├── reason_single_parser.ml
│ │ ├── reason_single_parser.mli
│ │ ├── reason_syntax_util.ml
│ │ ├── reason_syntax_util.mli
│ │ ├── reason_toolchain.ml
│ │ ├── reason_toolchain.mli
│ │ ├── reason_toolchain_conf.ml
│ │ ├── reason_toolchain_conf.mli
│ │ ├── reason_toolchain_ocaml.ml
│ │ ├── reason_toolchain_ocaml.mli
│ │ ├── reason_toolchain_reason.ml
│ │ ├── reason_toolchain_reason.mli
│ │ └── vendor/
│ │ └── easy_format/
│ │ ├── VERSION
│ │ ├── dune
│ │ ├── reason_easy_format.ml
│ │ └── reason_easy_format.mli
│ ├── refmt/
│ │ ├── .gitignore
│ │ ├── README.md
│ │ ├── dune
│ │ ├── end_of_line.ml
│ │ ├── end_of_line.mli
│ │ ├── git_commit.mli
│ │ ├── package.ml
│ │ ├── package.mli
│ │ ├── printer_maker.ml
│ │ ├── printer_maker.mli
│ │ ├── reason_implementation_printer.ml
│ │ ├── reason_implementation_printer.mli
│ │ ├── reason_interface_printer.ml
│ │ ├── reason_interface_printer.mli
│ │ ├── refmt.ml
│ │ └── refmt_args.ml
│ └── vendored-omp/
│ ├── LICENSE.md
│ ├── MANUAL.md
│ ├── Makefile
│ ├── README.md
│ ├── src/
│ │ ├── ast_408.ml
│ │ ├── ast_409.ml
│ │ ├── ast_410.ml
│ │ ├── ast_411.ml
│ │ ├── ast_412.ml
│ │ ├── ast_413.ml
│ │ ├── ast_414.ml
│ │ ├── ast_500.ml
│ │ ├── ast_51.ml
│ │ ├── ast_52.ml
│ │ ├── ast_53.ml
│ │ ├── ast_54.ml
│ │ ├── ast_55.ml
│ │ ├── caml_format_doc.cppo.ml
│ │ ├── cinaps_helpers
│ │ ├── compiler-functions/
│ │ │ ├── ge_406_and_lt_408.ml
│ │ │ ├── ge_408_and_lt_410.ml
│ │ │ ├── ge_410_and_lt_412.ml
│ │ │ ├── ge_412.ml
│ │ │ ├── ge_50.ml
│ │ │ ├── ge_52.ml
│ │ │ └── lt_406.ml
│ │ ├── config/
│ │ │ └── gen.ml
│ │ ├── dune
│ │ ├── locations.ml
│ │ ├── migrate_parsetree_408_409.ml
│ │ ├── migrate_parsetree_408_409_migrate.ml
│ │ ├── migrate_parsetree_409_408.ml
│ │ ├── migrate_parsetree_409_408_migrate.ml
│ │ ├── migrate_parsetree_409_410.ml
│ │ ├── migrate_parsetree_409_410_migrate.ml
│ │ ├── migrate_parsetree_410_409.ml
│ │ ├── migrate_parsetree_410_409_migrate.ml
│ │ ├── migrate_parsetree_410_411.ml
│ │ ├── migrate_parsetree_410_411_migrate.ml
│ │ ├── migrate_parsetree_411_410.ml
│ │ ├── migrate_parsetree_411_410_migrate.ml
│ │ ├── migrate_parsetree_411_412.ml
│ │ ├── migrate_parsetree_411_412_migrate.ml
│ │ ├── migrate_parsetree_412_411.ml
│ │ ├── migrate_parsetree_412_411_migrate.ml
│ │ ├── migrate_parsetree_412_413.ml
│ │ ├── migrate_parsetree_412_413_migrate.ml
│ │ ├── migrate_parsetree_413_412.ml
│ │ ├── migrate_parsetree_413_412_migrate.ml
│ │ ├── migrate_parsetree_413_414.ml
│ │ ├── migrate_parsetree_413_414_migrate.ml
│ │ ├── migrate_parsetree_414_413.ml
│ │ ├── migrate_parsetree_414_413_migrate.ml
│ │ ├── migrate_parsetree_414_500.ml
│ │ ├── migrate_parsetree_414_500_migrate.ml
│ │ ├── migrate_parsetree_500_414.ml
│ │ ├── migrate_parsetree_500_414_migrate.ml
│ │ ├── migrate_parsetree_500_51.ml
│ │ ├── migrate_parsetree_500_51_migrate.ml
│ │ ├── migrate_parsetree_51_500.ml
│ │ ├── migrate_parsetree_51_500_migrate.ml
│ │ ├── migrate_parsetree_51_52.ml
│ │ ├── migrate_parsetree_51_52_migrate.ml
│ │ ├── migrate_parsetree_52_51.ml
│ │ ├── migrate_parsetree_52_51_migrate.ml
│ │ ├── migrate_parsetree_52_53.ml
│ │ ├── migrate_parsetree_52_53_migrate.ml
│ │ ├── migrate_parsetree_53_52.ml
│ │ ├── migrate_parsetree_53_52_migrate.ml
│ │ ├── migrate_parsetree_53_54.ml
│ │ ├── migrate_parsetree_53_54_migrate.ml
│ │ ├── migrate_parsetree_54_53.ml
│ │ ├── migrate_parsetree_54_53_migrate.ml
│ │ ├── migrate_parsetree_54_55.ml
│ │ ├── migrate_parsetree_54_55_migrate.ml
│ │ ├── migrate_parsetree_55_54.ml
│ │ ├── migrate_parsetree_55_54_migrate.ml
│ │ ├── migrate_parsetree_def.ml
│ │ ├── migrate_parsetree_def.mli
│ │ ├── migrate_parsetree_driver_main.ml
│ │ ├── migrate_parsetree_versions.ml
│ │ ├── migrate_parsetree_versions.mli
│ │ ├── reason_omp.ml
│ │ └── stdlib0.ml
│ └── tools/
│ ├── add_special_comments.ml
│ ├── add_special_comments.mli
│ ├── dune
│ ├── gencopy.ml
│ ├── pp.ml
│ ├── pp.mli
│ ├── pp_rewrite.mli
│ └── pp_rewrite.mll
└── test/
├── 4.08/
│ ├── dune
│ ├── error-comments.t
│ ├── error-lowercase_module.t
│ ├── error-lowercase_module_rec.t
│ ├── error-reservedField.t
│ ├── error-reservedRecord.t
│ ├── error-reservedRecordPunned.t
│ ├── error-reservedRecordType.t
│ ├── error-reservedRecordTypePunned.t
│ ├── error-syntaxError.t
│ ├── mlSyntax.t/
│ │ ├── input.ml
│ │ └── run.t
│ ├── type-jsx.t/
│ │ ├── input.re
│ │ └── run.t
│ └── typecheck-features.t
├── 4.10/
│ ├── attributes-re.t/
│ │ ├── input.re
│ │ └── run.t
│ ├── dune
│ ├── local-openings.t/
│ │ ├── input.ml
│ │ └── run.t
│ ├── reasonComments-re.t/
│ │ ├── input.re
│ │ └── run.t
│ ├── type-jsx.t/
│ │ ├── input.re
│ │ └── run.t
│ └── typecheck-let-ops.t
├── 4.12/
│ ├── attributes-re.t/
│ │ ├── input.re
│ │ └── run.t
│ ├── dune
│ ├── local-openings.t/
│ │ ├── input.ml
│ │ └── run.t
│ ├── reasonComments-re.t/
│ │ ├── input.re
│ │ └── run.t
│ ├── type-jsx.t/
│ │ ├── input.re
│ │ └── run.t
│ └── typecheck-let-ops.t
├── README.md
├── arityConversion.t/
│ ├── arity.txt
│ ├── input.ml
│ └── run.t
├── assert.t/
│ ├── input.re
│ └── run.t
├── attributes-rei.t/
│ ├── input.rei
│ └── run.t
├── backportSyntax.t/
│ ├── input.re
│ └── run.t
├── basic.t/
│ ├── input.re
│ └── run.t
├── basicStructures.t/
│ ├── input.re
│ └── run.t
├── basics.t/
│ ├── input.re
│ └── run.t
├── basics_no_semi.t/
│ ├── input.re
│ └── run.t
├── bigarray.t/
│ ├── input.re
│ └── run.t
├── bigarraySyntax.t/
│ ├── input.re
│ └── run.t
├── class.t/
│ ├── input.re
│ └── run.t
├── class_types.t/
│ ├── input.re
│ └── run.t
├── comments-ml.t/
│ ├── input.ml
│ └── run.t
├── comments-mli.t/
│ ├── input.mli
│ └── run.t
├── dune
├── emptyFileComment.t/
│ ├── input.re
│ └── run.t
├── escapesInStrings.t/
│ ├── input.re
│ └── run.t
├── expr-constraint-with-vbct.t/
│ ├── input.re
│ └── run.t
├── extension-exprs.t/
│ ├── input.re
│ └── run.t
├── extension-str-in-module.t
├── extensions.t/
│ ├── input.re
│ └── run.t
├── externals.t/
│ ├── input.re
│ └── run.t
├── fdLeak.t/
│ ├── input.re
│ └── run.t
├── firstClassModules.t/
│ ├── input.re
│ └── run.t
├── fixme.t/
│ ├── input.re
│ └── run.t
├── functionInfix.t/
│ ├── input.re
│ └── run.t
├── general-syntax-re.t/
│ ├── input.re
│ └── run.t
├── general-syntax-rei.t/
│ ├── input.rei
│ └── run.t
├── generics.t/
│ ├── input.re
│ └── run.t
├── if.t/
│ ├── input.re
│ └── run.t
├── imperative.t/
│ ├── input.re
│ └── run.t
├── infix.t/
│ ├── input.re
│ └── run.t
├── inlineRecord.t/
│ ├── input.re
│ └── run.t
├── jsx.t/
│ ├── input.re
│ └── run.t
├── jsx_functor.t/
│ ├── input.re
│ └── run.t
├── keyword-operators.t/
│ ├── input.re
│ └── run.t
├── knownMlIssues.t/
│ ├── input.ml
│ └── run.t
├── knownReIssues.t/
│ ├── input.re
│ └── run.t
├── lazy.t/
│ ├── input.re
│ └── run.t
├── letop.t/
│ ├── input.re
│ └── run.t
├── lib/
│ ├── dune
│ ├── fdLeak.ml
│ └── outcometreePrinter.cppo.ml
├── lineComments.t/
│ ├── input.re
│ └── run.t
├── melange-support.t/
│ ├── input.re
│ └── run.t
├── mlFunctions.t/
│ ├── input.ml
│ └── run.t
├── mlVariants.t/
│ ├── input.ml
│ └── run.t
├── modules.t/
│ ├── input.re
│ └── run.t
├── modules_no_semi.t/
│ ├── input.re
│ └── run.t
├── mutation.t/
│ ├── input.re
│ └── run.t
├── object.t/
│ ├── input.re
│ └── run.t
├── ocaml_identifiers.t/
│ ├── input.ml
│ └── run.t
├── oo.t/
│ ├── input.re
│ └── run.t
├── patternMatching.t/
│ ├── input.re
│ └── run.t
├── pervasive.t/
│ ├── input.mli
│ └── run.t
├── pexpFun.t/
│ ├── input.re
│ └── run.t
├── pipeFirst.t/
│ ├── input.re
│ └── run.t
├── polymorphism.t/
│ ├── input.re
│ └── run.t
├── print-width-env.t
├── raw-identifiers.t/
│ ├── input.re
│ └── run.t
├── reasonComments-rei.t/
│ ├── input.rei
│ └── run.t
├── rtopIntegration.t
├── sequences.t/
│ ├── input.re
│ └── run.t
├── sharpop.t/
│ ├── input.re
│ └── run.t
├── singleLineCommentEof.t/
│ ├── input.re
│ └── run.t
├── testUtils.t/
│ ├── input.re
│ └── run.t
├── trailing.t/
│ ├── input.re
│ └── run.t
├── trailingSpaces.t/
│ ├── input.re
│ └── run.t
├── type-constraint-in-body.t/
│ ├── input.ml
│ └── run.t
├── type-pipeFirst.t/
│ ├── input.re
│ └── run.t
├── typeDeclarations.t/
│ ├── input.re
│ └── run.t
├── typeParameters.t/
│ ├── input.re
│ └── run.t
├── uchar-esc.t/
│ ├── input.re
│ └── run.t
├── uncurried.t/
│ ├── input.re
│ └── run.t
├── unicodeIdentifiers.t/
│ ├── input.re
│ └── run.t
├── value-constraint-alias-pattern.t/
│ ├── input.re
│ └── run.t
├── variants.t/
│ ├── input.re
│ └── run.t
├── whitespace-re.t/
│ ├── input.re
│ └── run.t
├── whitespace-rei.t/
│ ├── input.rei
│ └── run.t
├── wrapping-re.t/
│ ├── input.re
│ └── run.t
└── wrapping-rei.t/
├── input.rei
└── run.t
SYMBOL INDEX (45 symbols across 2 files)
FILE: .github/workflows/print-esy-cache.js
constant ESY_FOLDER (line 5) | const ESY_FOLDER = process.env.ESY__PREFIX
FILE: docs/site/Bookmark.js
function linkifidIdForHash (line 158) | function linkifidIdForHash(s) {
function pageifiedIdForHash (line 162) | function pageifiedIdForHash(slug, pageKey) {
function hashForLinkifiedId (line 170) | function hashForLinkifiedId(s) {
function anchorJump (line 214) | function anchorJump(href) {
function queryParam (line 307) | function queryParam(name) {
function parseYamlHeader (line 316) | function parseYamlHeader(markdown, locationPathname) {
function normalizeYamlMarkdownComments (line 371) | function normalizeYamlMarkdownComments(markdown) {
function normalizeMarkdownResponse (line 411) | function normalizeMarkdownResponse(markdown) {
function normalizeDocusaurusCodeTabs (line 440) | function normalizeDocusaurusCodeTabs(markdown) {
function escapePlatformStringLoop (line 495) | function escapePlatformStringLoop(html, lastIndex, index, s, len) {
function escapeHtml (line 578) | function escapeHtml(s) {
function escapeRegExpSearchString (line 621) | function escapeRegExpSearchString(string) {
function replaceAllStringsCaseInsensitive (line 625) | function replaceAllStringsCaseInsensitive(str, find, replace) {
function escapeRegExpSplitString (line 629) | function escapeRegExpSplitString(string) {
function splitStringCaseInsensitiveImpl (line 633) | function splitStringCaseInsensitiveImpl(regexes, str, find) {
function splitStringCaseInsensitive (line 636) | function splitStringCaseInsensitive(str, find) {
function recontext (line 737) | function recontext(context, nextTreeNode) {
function hierarchicalIndexForSearch (line 744) | function hierarchicalIndexForSearch(pageState) {
function mapHierarchyOne (line 752) | function mapHierarchyOne(f, treeNode) {
function mapHierarchy (line 759) | function mapHierarchy(f, treeNodes) {
function forEachHierarchyOne (line 763) | function forEachHierarchyOne(f, context, treeNode) {
function forEachHierarchyImpl (line 768) | function forEachHierarchyImpl(f, context, treeNodes) {
function forEachHierarchy (line 771) | function forEachHierarchy(f, treeNodes) {
function hierarchicalIndexFromHierarchicalDoc (line 785) | function hierarchicalIndexFromHierarchicalDoc(treeNodes) {
function hierarchize (line 846) | function hierarchize(containerNode) {
function forEachSearchableInHierarchyImpl (line 934) | function forEachSearchableInHierarchyImpl(cb, treeNode, context) {
function forEachSearchableInHierarchy (line 942) | function forEachSearchableInHierarchy(cb, treeNodes, context) {
function detectDocOrStyleIfNotNodeScript (line 1095) | function detectDocOrStyleIfNotNodeScript() {
function detectMode (line 1109) | function detectMode() {
function loadData (line 1457) | function loadData(locations, response, callback) {
function loadData (line 1509) | function loadData(locations, response, callback) {
function loadData (line 1575) | function loadData(locations, response, callback) {
function mkdir_p (line 1807) | function mkdir_p(level) {
function process (line 1944) | function process(node, $parent) {
function SearchComponentBase (line 2042) | function SearchComponentBase(root, pages) {
function TextDocSearch (line 2061) | function TextDocSearch(props) {
function TextDocSelector (line 2189) | function TextDocSelector(props) {
function setupGlobalKeybindings (line 2730) | function setupGlobalKeybindings() {
function onGlobalClickOff (line 2761) | function onGlobalClickOff(e) {
function onOneImageLoaded (line 2930) | function onOneImageLoaded(loadedEl) {
function handleDones (line 2982) | function handleDones() {
function appendExperience (line 3076) | function appendExperience(pageKey, pageData) {
function getTextNodesIn (line 3185) | function getTextNodesIn(el) {
function quotify (line 3193) | function quotify(a) {
Condensed preview — 419 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (2,923K chars).
[
{
"path": ".github/workflows/esy-ci.yml",
"chars": 3338,
"preview": "name: esy CI\n\non:\n pull_request:\n push:\n branches:\n - master\n\nconcurrency:\n group: ${{ github.workflow }}-${{ g"
},
{
"path": ".github/workflows/nix-build.yml",
"chars": 1750,
"preview": "name: Nix Pipeline\n\non:\n pull_request:\n push:\n branches:\n - master\n\nconcurrency:\n group: ${{ github.workflow }}"
},
{
"path": ".github/workflows/opam-ci.yml",
"chars": 3896,
"preview": "name: opam CI\n\non:\n pull_request:\n push:\n branches:\n - master\n tags:\n - '*'\n\nconcurrency:\n group: ${{"
},
{
"path": ".github/workflows/print-esy-cache.js",
"chars": 387,
"preview": "const fs = require(\"fs\");\nconst os = require(\"os\");\nconst path = require(\"path\");\n\nconst ESY_FOLDER = process.env.ESY__P"
},
{
"path": ".gitignore",
"chars": 178,
"preview": "_build\n.DS_Store\n*.log\n\n# gitignored, but not npmignored. Published by `npm run prepublish`\nrefmt.js\nrefmt.map\n\n# Esy\n_e"
},
{
"path": ".npmignore",
"chars": 49,
"preview": "_esy\nnode_modules\n_build\n.git\nrefmt.js\nrefmt.map\n"
},
{
"path": ".ocamlformat",
"chars": 712,
"preview": "break-infix = fit-or-vertical\nbreak-infix-before-func = false\nbreak-fun-decl = fit-or-vertical\nbreak-separators = before"
},
{
"path": ".ocamlformat-ignore",
"chars": 111,
"preview": "src/vendored-omp/**\nsrc/reason-parser/vendor/**\ntest/**.cppo.ml\nsrc/**.cppo.ml\nsrc/**.cppo.mli\nrtop/**.cppo.ml\n"
},
{
"path": "CHANGES.md",
"chars": 29504,
"preview": "## 3.17.3\n\n- fix: Stack overflow on Pconstraint (@davesnx, [#2906](https://github.com/reasonml/reason/pull/2906))\n- ci: "
},
{
"path": "CODE_OF_CONDUCT.md",
"chars": 249,
"preview": "# Code of Conduct\n\nFacebook has adopted a Code of Conduct that we expect project participants to adhere to. Please [read"
},
{
"path": "LICENSE.txt",
"chars": 1080,
"preview": "MIT License\n\nCopyright (c) 2015-present, Facebook, Inc.\n\nPermission is hereby granted, free of charge, to any person obt"
},
{
"path": "Makefile",
"chars": 1330,
"preview": "# Portions Copyright (c) 2015-present, Facebook, Inc. All rights reserved.\n\nSHELL=bash -o pipefail\n\ndefault: build\n\nbuil"
},
{
"path": "ORIGINS.md",
"chars": 2343,
"preview": "This repo was forked from [m17n](https://github.com/whitequark/ocaml-m17n), which is licensed under MIT.\n\nCopyright (c) "
},
{
"path": "PLAN",
"chars": 1000,
"preview": "Fix error recovery & error reporting\n\nStep 1: remove existing implementation\n\nOK * Put reason parser in its own file\nOK"
},
{
"path": "README.md",
"chars": 3232,
"preview": "<p align=\"center\"><img src=\"https://reasonml.github.io/img/reason.svg\" alt=\"logo\" width=\"316\" /></p>\n<h1 align=\"center\">"
},
{
"path": "docs/GETTING_STARTED_CONTRIBUTING.md",
"chars": 13825,
"preview": "# Core Reason\n\n## Contributor Setup\n\n\n### With esy\n\n```sh\n# Make sure you have the latest esy\nnpm install -g esy@next\ngi"
},
{
"path": "docs/README.md",
"chars": 689,
"preview": "### Documentation\n\n> This directory is not the Reason _User_ documentation. This directory is for\n> Reason contributor d"
},
{
"path": "docs/RELEASING.md",
"chars": 2548,
"preview": "## Releasing Native Packages To Npm:\n\nThere's a few native `esy` packages included which are released to npm.\n\n- `@esy-o"
},
{
"path": "docs/TYPE_PARAMETERS_PARSING.md",
"chars": 1779,
"preview": "Contributors: Lexing and Parsing Type Parameters:\n===================================================\n\nLexing and Parsin"
},
{
"path": "docs/USING_PARSER_PROGRAMMATICALLY.md",
"chars": 4001,
"preview": "## Using Reason Parser Programmatically\n\nThis document describes how to integrate the Reason parser into other custom to"
},
{
"path": "docs/site/Bookmark.js",
"chars": 116654,
"preview": "/*!\n * Flatdoc - (c) 2013, 2014 Rico Sta. Cruz\n * http://ricostacruz.com/flatdoc\n * @license MIT\n */\n\n\n// Keep this in s"
},
{
"path": "docs/site/ORIGINS.md",
"chars": 1687,
"preview": "Bookmark:\n(A simple tool for editing and rendering Reason documentation)\n\nHere's a list of all of the technologies that "
},
{
"path": "docs/site/theme-white/theme.js",
"chars": 3736,
"preview": "/*!\n * Flatdoc - (c) 2013, 2014 Rico Sta. Cruz\n * http://ricostacruz.com/flatdoc\n * @license MIT\n */\n\n(function($) {\n\n "
},
{
"path": "docs/site/theme-white/theme.styl.html",
"chars": 59696,
"preview": "<meta charset=\"utf-8\" vim: set filetype=Stylus: >\n<script src=\"../Bookmark.js\"> </script>\nsupport-for-ie = true\n\n\n$prim "
},
{
"path": "dune",
"chars": 112,
"preview": "(dirs :standard \\ node_modules js)\n\n; (install\n; (package reason)\n; (section bin)\n; (files src/refmt/refmt.bc))\n"
},
{
"path": "dune-project",
"chars": 1248,
"preview": "(lang dune 3.18)\n\n(maintenance_intent \"(latest)\")\n\n(name reason)\n\n(using menhir 2.0)\n\n(cram enable)\n\n(version 3.17.3)\n\n("
},
{
"path": "esy.json",
"chars": 2520,
"preview": "{\n \"name\": \"reason-cli\",\n \"notes\": \"This is just the dev package config (also built as globally installable reason-cli"
},
{
"path": "esy.lock.json",
"chars": 89969,
"preview": "{\n \"hash\": \"af23e4b097dab9418dd65b8da739c788\",\n \"root\": \"root@path:./esy.json\",\n \"node\": {\n \"root@path:./esy.json\""
},
{
"path": "flake.nix",
"chars": 1102,
"preview": "{\n description = \"Nix Flake for ReasonML\";\n\n inputs.nixpkgs.url = \"github:nix-ocaml/nix-overlays\";\n\n outputs =\n { "
},
{
"path": "js/dune",
"chars": 253,
"preview": "(executable\n (name refmt)\n (modes js)\n (js_of_ocaml\n (flags\n --source-map\n --debug-info\n --pretty\n --linkall\n "
},
{
"path": "js/refmt.ml",
"chars": 3771,
"preview": "(*\n * Note: This file is currently broken, since Reason removed\n * Reason_syntax_util.Error in favor of Reerror's `Print"
},
{
"path": "js/testRefmtJs.js",
"chars": 629,
"preview": "const refmt = require('../refmt')\nconsole.log(refmt)\n\nconsole.log(refmt.printRE(refmt.parseRE(`let f = (a) => a + 1; pri"
},
{
"path": "nix/ci.nix",
"chars": 366,
"preview": "{ ocamlVersion }:\n\nlet\n lock = builtins.fromJSON (builtins.readFile ./../flake.lock);\n pkgs =\n let\n src = fetc"
},
{
"path": "nix/default.nix",
"chars": 1223,
"preview": "{\n lib,\n ocamlPackages,\n doCheck ? false,\n}:\n\nrec {\n reason = ocamlPackages.buildDunePackage {\n pname = \"reason\";"
},
{
"path": "nix/shell.nix",
"chars": 420,
"preview": "{\n mkShell,\n ocamlPackages,\n reason,\n cacert,\n curl,\n git,\n release-mode ? false,\n}:\n\nmkShell {\n inputsFrom = [ "
},
{
"path": "package.json",
"chars": 410,
"preview": "{\n \"name\": \"reason\",\n \"version\": \"3.6.2\",\n \"description\": \"Simple, fast & type safe code that leverages the JavaScrip"
},
{
"path": "reason.json",
"chars": 817,
"preview": "{\n \"name\": \"@esy-ocaml/reason\",\n \"version\": \"3.8.2\",\n \"license\": \"MIT\",\n \"description\": \"Native Compiler Support for"
},
{
"path": "reason.opam",
"chars": 1250,
"preview": "# This file is generated by dune, edit dune-project instead\nopam-version: \"2.0\"\nversion: \"3.17.3\"\nsynopsis: \"Reason: Syn"
},
{
"path": "reason.opam.template",
"chars": 131,
"preview": "pin-depends: [\n [ \"ppxlib.dev\" \"https://github.com/NathanReb/ppxlib/archive/547c6cfd69671e147767e0937d069c5b9eb2aa4a.ta"
},
{
"path": "rtop/dune",
"chars": 681,
"preview": "(library\n (name rtoplib)\n (public_name rtop)\n (modules reason_util reason_utop reason_toploop)\n (modes byte)\n (flags :st"
},
{
"path": "rtop/reason_toploop.cppo.ml",
"chars": 1875,
"preview": "(*\n * Copyright (c) 2015-present, Facebook, Inc.\n *\n * This source code is licensed under the MIT license found in the\n "
},
{
"path": "rtop/reason_util.ml",
"chars": 1371,
"preview": "(**\n * Some of this was coppied from @whitequark's m17n project.\n *)\n(*\n * Portions Copyright (c) 2015-present, Facebook"
},
{
"path": "rtop/reason_utop.cppo.ml",
"chars": 5417,
"preview": "(** * Some of this was coppied from \\@whitequark's m17n project. *)\n(*\n * Portions Copyright (c) 2015-present, Facebook,"
},
{
"path": "rtop/rtop.ml",
"chars": 1671,
"preview": "let print_init_message () =\n print_string\n \"\\n\\\n \\ ___ _______ ________ _ __\\n\\\n \\ "
},
{
"path": "rtop.json",
"chars": 540,
"preview": "{\n \"name\": \"@esy-ocaml/rtop\",\n \"version\": \"3.8.2\",\n \"license\": \"MIT\",\n \"repository\": {\n \"type\": \"git\",\n \"url\":"
},
{
"path": "rtop.opam",
"chars": 898,
"preview": "# This file is generated by dune, edit dune-project instead\nopam-version: \"2.0\"\nversion: \"3.17.3\"\nsynopsis: \"Reason topl"
},
{
"path": "scripts/esy-prepublish.js",
"chars": 11047,
"preview": "/**\n * Copyright 2004-present Facebook. All Rights Reserved.\n *\n * This source code is licensed under the MIT license fo"
},
{
"path": "src/menhir-error-processor/dune",
"chars": 107,
"preview": "(executable\n (name menhir_error_processor)\n (flags :standard -open StdLabels)\n (libraries unix menhirSdk))\n"
},
{
"path": "src/menhir-error-processor/menhir_error_processor.ml",
"chars": 2748,
"preview": "(* This file is an executable run at build time to generate a file called\n _build/default/src/reason-parser/reason_par"
},
{
"path": "src/menhir-recover/attributes.ml",
"chars": 10125,
"preview": "(* Attributes guide the recovery .\n\n Some information can be passed to Menhir-recover via attributes. These are\n pie"
},
{
"path": "src/menhir-recover/attributes.mli",
"chars": 5581,
"preview": "(* Attributes guide the recovery .\n\n Some information can be passed to Menhir-recover via attributes. These are\n pie"
},
{
"path": "src/menhir-recover/cost.ml",
"chars": 403,
"preview": "type t = int\n\nlet zero = 0\nlet infinite = max_int\nlet compare : t -> t -> int = compare\n\nlet add t1 t2 =\n let result = "
},
{
"path": "src/menhir-recover/cost.mli",
"chars": 241,
"preview": "type t\n\nval zero : t\nval infinite : t\nval compare : t -> t -> int\nval add : t -> t -> t\nval of_int : int -> t\nval to_int"
},
{
"path": "src/menhir-recover/dune",
"chars": 108,
"preview": "(executable\n (name menhir_recover)\n (flags :standard -open StdLabels)\n (libraries fix menhirLib menhirSdk))\n"
},
{
"path": "src/menhir-recover/emitter.ml",
"chars": 10535,
"preview": "open Recovery_intf\n\nlet menhir = \"MenhirInterpreter\"\n\n(* Generation scheme doing checks and failing at runtime, or not ."
},
{
"path": "src/menhir-recover/emitter.mli",
"chars": 272,
"preview": "open MenhirSdk.Cmly_api\nopen Attributes\nopen Synthesis\nopen Recovery_intf\n\nmodule Make\n (G : GRAMMAR)\n (_ : ATTRIB"
},
{
"path": "src/menhir-recover/menhir_recover.ml",
"chars": 1706,
"preview": "open MenhirSdk\nopen Recovery_custom\n\nlet name = ref \"\"\nlet verbose = ref false\n\nlet usage () =\n Printf.eprintf \"Usage: "
},
{
"path": "src/menhir-recover/recovery_custom.ml",
"chars": 8261,
"preview": "module type RECOVERY = sig\n module G : MenhirSdk.Cmly_api.GRAMMAR\n\n type item = G.lr1 * G.production * int\n\n type rec"
},
{
"path": "src/menhir-recover/recovery_custom.mli",
"chars": 1005,
"preview": "module type RECOVERY = sig\n module G : MenhirSdk.Cmly_api.GRAMMAR\n\n type item = G.lr1 * G.production * int\n\n type rec"
},
{
"path": "src/menhir-recover/recovery_intf.ml",
"chars": 831,
"preview": "module type RECOVERY = sig\n module G : MenhirSdk.Cmly_api.GRAMMAR\n\n type item = G.lr1 * G.production * int\n\n type rec"
},
{
"path": "src/menhir-recover/synthesis.ml",
"chars": 10577,
"preview": "open MenhirSdk.Cmly_api\nopen Attributes\n\nlet group_assoc l =\n let cons k v acc = (k, List.rev v) :: acc in\n let rec au"
},
{
"path": "src/menhir-recover/synthesis.mli",
"chars": 2665,
"preview": "open MenhirSdk.Cmly_api\nopen Attributes\n\nval group_assoc : ('a * 'b) list -> ('a * 'b list) list\n\nval pp_list :\n f:(Fo"
},
{
"path": "src/reason-merlin/dune",
"chars": 182,
"preview": "(executable\n (name ocamlmerlin_reason)\n (public_name ocamlmerlin-reason)\n (package reason)\n (flags :standard -open StdLa"
},
{
"path": "src/reason-merlin/ocamlmerlin_reason.ml",
"chars": 3806,
"preview": "open Reason\n\nlet () = Reason_config.recoverable := true\n\nmodule Reason_reader = struct\n open Extend_protocol.Reader\n\n "
},
{
"path": "src/reason-parser/TODO",
"chars": 704,
"preview": "Recovery (Urgent):\n* Not clear what the pipeline for errors should be\n* Find better names for the many modules\n* If nece"
},
{
"path": "src/reason-parser/dune",
"chars": 1418,
"preview": "(ocamllex\n (modules reason_declarative_lexer))\n\n(rule\n (targets ocaml_util.ml)\n (deps ocaml_util.cppo.ml)\n (action\n (ru"
},
{
"path": "src/reason-parser/error-handling.md",
"chars": 172,
"preview": "Categories of error:\n\n- Lexer errors, produced by `Reason_lexer` and stored in exception\n `Reason_lexer.Error`\n- Concre"
},
{
"path": "src/reason-parser/merlin_recovery.ml",
"chars": 6719,
"preview": "let split_pos { Lexing.pos_lnum; pos_bol; pos_cnum; _ } =\n pos_lnum, pos_cnum - pos_bol\n\nlet rev_filter ~f xs =\n let r"
},
{
"path": "src/reason-parser/merlin_recovery.mli",
"chars": 606,
"preview": "module Make\n (Parser : MenhirLib.IncrementalEngine.EVERYTHING)\n (_ : Merlin_recovery_intf.RECOVERY with module Par"
},
{
"path": "src/reason-parser/merlin_recovery_intf.ml",
"chars": 559,
"preview": "module type RECOVERY = sig\n module Parser : MenhirLib.IncrementalEngine.EVERYTHING\n\n val default_value : Location.t ->"
},
{
"path": "src/reason-parser/ocaml_util.cppo.ml",
"chars": 16305,
"preview": "let print_error ~loc ~f ppf x =\n#if OCAML_VERSION >= (5,3,0)\n let error =\n let f = Format_doc.deprecated f in\n Lo"
},
{
"path": "src/reason-parser/ocaml_util.cppo.mli",
"chars": 645,
"preview": "val print_error :\n loc:Location.t\n -> f:(Format.formatter -> 'a -> unit)\n -> Format.formatter\n -> 'a\n -> unit\n\n#if"
},
{
"path": "src/reason-parser/reason_attributes.ml",
"chars": 4847,
"preview": "open Ppxlib\n\ntype attributesPartition =\n { arityAttrs : attributes\n ; docAttrs : attributes\n ; stdAttrs : attributes\n"
},
{
"path": "src/reason-parser/reason_attributes.mli",
"chars": 883,
"preview": "open Ppxlib\n\ntype attributesPartition =\n { arityAttrs : attributes\n ; docAttrs : attributes\n ; stdAttrs : attributes\n"
},
{
"path": "src/reason-parser/reason_comment.ml",
"chars": 1131,
"preview": "type category =\n | EndOfLine\n | SingleLine\n | Regular\n\ntype t =\n { location : Location.t\n ; category : category\n ;"
},
{
"path": "src/reason-parser/reason_comment.mli",
"chars": 311,
"preview": "type category =\n | EndOfLine\n | SingleLine\n | Regular\n\ntype t =\n { location : Location.t\n ; category : category\n ;"
},
{
"path": "src/reason-parser/reason_config.ml",
"chars": 263,
"preview": "(** * Copyright (c) 2015-present, Facebook, Inc. * * This source code is\n licensed under the MIT license found in the"
},
{
"path": "src/reason-parser/reason_config.mli",
"chars": 255,
"preview": "(** * Copyright (c) 2015-present, Facebook, Inc. * * This source code is\n licensed under the MIT license found in the"
},
{
"path": "src/reason-parser/reason_declarative_lexer.mli",
"chars": 155,
"preview": "type state\n\nval keyword_table : (string, Reason_parser.token) Hashtbl.t\nval make : unit -> state\nval token : state -> Le"
},
{
"path": "src/reason-parser/reason_declarative_lexer.mll",
"chars": 34300,
"preview": "(*\n * Copyright (c) 2015-present, Facebook, Inc.\n *\n * This source code is licensed under the MIT license found in the\n "
},
{
"path": "src/reason-parser/reason_errors.ml",
"chars": 5790,
"preview": "open Ppxlib\n\ntype lexing_error =\n | Illegal_character of char\n | Illegal_escape of string\n | Unterminated_comment of "
},
{
"path": "src/reason-parser/reason_errors.mli",
"chars": 1924,
"preview": "(** There are three main categories of error:\n - _lexer errors_, thrown by Reason_lexer when the source **text is\n "
},
{
"path": "src/reason-parser/reason_heuristics.ml",
"chars": 5248,
"preview": "open Ppxlib\n\nlet is_punned_labelled_expression e lbl =\n match e.pexp_desc with\n | Pexp_ident { txt; _ }\n | Pexp_const"
},
{
"path": "src/reason-parser/reason_heuristics.mli",
"chars": 498,
"preview": "open Ppxlib\n\nval is_punned_labelled_expression : expression -> string -> bool\nval isUnderscoreIdent : expression -> bool"
},
{
"path": "src/reason-parser/reason_layout.ml",
"chars": 6487,
"preview": "module Easy_format = Reason_easy_format\n\ntype break_criterion =\n | Never\n | IfNeed\n | Always\n (* Always_rec not only"
},
{
"path": "src/reason-parser/reason_layout.mli",
"chars": 3578,
"preview": "module Easy_format = Reason_easy_format\n\ntype break_criterion =\n | Never\n | IfNeed\n | Always\n (* Always_rec not only"
},
{
"path": "src/reason-parser/reason_lexer.ml",
"chars": 7067,
"preview": "open Reason_parser\n\ntype 'a positioned = 'a * Lexing.position * Lexing.position\n\ntype t =\n { declarative_lexer_state : "
},
{
"path": "src/reason-parser/reason_lexer.mli",
"chars": 608,
"preview": "open Reason_parser\n\ntype t\ntype 'a positioned = 'a * Lexing.position * Lexing.position\n\nval init : ?insert_completion_id"
},
{
"path": "src/reason-parser/reason_location.ml",
"chars": 1997,
"preview": "module Range = struct\n type t =\n { lnum_start : int\n ; lnum_end : int\n }\n (** [t] represents an interval, inc"
},
{
"path": "src/reason-parser/reason_location.mli",
"chars": 519,
"preview": "module Range : sig\n type t =\n { lnum_start : int\n ; lnum_end : int\n }\n (** [t] represents an interval, includ"
},
{
"path": "src/reason-parser/reason_multi_parser.ml",
"chars": 1673,
"preview": "module S = Reason_single_parser\n\ntype 'a parser = 'a S.parser list\n\nlet initial entry_point position = [ S.initial entry"
},
{
"path": "src/reason-parser/reason_multi_parser.mli",
"chars": 581,
"preview": "type 'a parser\n\nval initial :\n (Lexing.position -> 'a Reason_parser.MenhirInterpreter.checkpoint)\n -> Lexing.position"
},
{
"path": "src/reason-parser/reason_oprint.ml",
"chars": 33595,
"preview": "(*\n * Copyright (c) 2015-present, Facebook, Inc.\n *\n * This source code is licensed under the MIT license found in the\n "
},
{
"path": "src/reason-parser/reason_oprint.mli",
"chars": 749,
"preview": "open Format\nopen Reason_omp.Ast_414.Outcometree\n\nval print_ident : formatter -> out_ident -> unit\nval print_out_value : "
},
{
"path": "src/reason-parser/reason_parser.mly",
"chars": 185302,
"preview": "(*\n * Copyright (c) 2015-present, Facebook, Inc.\n *\n * This source code is licensed under the MIT license found in the\n "
},
{
"path": "src/reason-parser/reason_parser_def.ml",
"chars": 341,
"preview": "open Ppxlib\n\ntype labelled_parameter =\n | Term of Asttypes.arg_label * Parsetree.expression option * Parsetree.pattern\n"
},
{
"path": "src/reason-parser/reason_parser_def.mli",
"chars": 341,
"preview": "open Ppxlib\n\ntype labelled_parameter =\n | Term of Asttypes.arg_label * Parsetree.expression option * Parsetree.pattern\n"
},
{
"path": "src/reason-parser/reason_parser_explain.ml",
"chars": 4805,
"preview": "(* See the comments in menhir_error_processor.ml *)\n\nmodule Parser = Reason_parser\nmodule Interp = Parser.MenhirInterpre"
},
{
"path": "src/reason-parser/reason_parser_explain.mli",
"chars": 156,
"preview": "(* See the comments in menhir_error_processor.ml *)\n\nval message :\n 'a Reason_parser.MenhirInterpreter.env\n -> Reason"
},
{
"path": "src/reason-parser/reason_pprint_ast.ml",
"chars": 418271,
"preview": "(* Copyright (c) 2015-present, Facebook, Inc. * * This source code is licensed\n under the MIT license found in the * L"
},
{
"path": "src/reason-parser/reason_pprint_ast.mli",
"chars": 750,
"preview": "open Ppxlib\n\nval configure :\n width:int\n -> assumeExplicitArity:bool\n -> constructorLists:string list\n -> unit\n\nval"
},
{
"path": "src/reason-parser/reason_recover_parser.ml",
"chars": 1763,
"preview": "module M = Reason_multi_parser\n\nmodule R =\n Merlin_recovery.Make\n (Reason_parser.MenhirInterpreter)\n (struct\n "
},
{
"path": "src/reason-parser/reason_recover_parser.mli",
"chars": 324,
"preview": "type 'a parser\n\nval initial :\n (Lexing.position -> 'a Reason_parser.MenhirInterpreter.checkpoint)\n -> Lexing.position"
},
{
"path": "src/reason-parser/reason_single_parser.ml",
"chars": 9298,
"preview": "module I = Reason_parser.MenhirInterpreter\n\ntype token = Reason_parser.token\ntype invalid_docstrings = Reason_lexer.inva"
},
{
"path": "src/reason-parser/reason_single_parser.mli",
"chars": 581,
"preview": "type 'a parser\n\nval initial :\n (Lexing.position -> 'a Reason_parser.MenhirInterpreter.checkpoint)\n -> Lexing.position"
},
{
"path": "src/reason-parser/reason_syntax_util.ml",
"chars": 24275,
"preview": "open Ppxlib\n\n(* Rename labels in function definition/application and records *)\nlet rename_labels = ref false\n\n(** Check"
},
{
"path": "src/reason-parser/reason_syntax_util.mli",
"chars": 2361,
"preview": "open Ppxlib\n\nval ml_to_reason_swap : string -> string\nval escape_string : string -> string\nval reason_to_ml_swap : strin"
},
{
"path": "src/reason-parser/reason_toolchain.ml",
"chars": 14654,
"preview": "(***********************************************************************)\n(* "
},
{
"path": "src/reason-parser/reason_toolchain.mli",
"chars": 832,
"preview": "(***********************************************************************)\n(* "
},
{
"path": "src/reason-parser/reason_toolchain_conf.ml",
"chars": 2344,
"preview": "open Ppxlib\n\nmodule From_current = struct\n include Selected_ast.Of_ocaml\n include Reason_omp.Convert (Reason_omp.OCaml"
},
{
"path": "src/reason-parser/reason_toolchain_conf.mli",
"chars": 5400,
"preview": "open Ppxlib\n\nmodule type Toolchain = sig\n (* Parsing *)\n val core_type_with_comments :\n Lexing.lexbuf\n -> Parse"
},
{
"path": "src/reason-parser/reason_toolchain_ocaml.ml",
"chars": 5524,
"preview": "open Ppxlib\n\n(* The OCaml parser keep doc strings in the comment list. To avoid duplicating\n comments, we need to filt"
},
{
"path": "src/reason-parser/reason_toolchain_ocaml.mli",
"chars": 45,
"preview": "include Reason_toolchain_conf.Toolchain_spec\n"
},
{
"path": "src/reason-parser/reason_toolchain_reason.ml",
"chars": 3016,
"preview": "module P = Reason_recover_parser\nmodule Lexer = Reason_lexer\n\n(* From Reason source text to OCaml AST\n *\n * 1. Make a le"
},
{
"path": "src/reason-parser/reason_toolchain_reason.mli",
"chars": 45,
"preview": "include Reason_toolchain_conf.Toolchain_spec\n"
},
{
"path": "src/reason-parser/vendor/easy_format/VERSION",
"chars": 5,
"preview": "1.2.0"
},
{
"path": "src/reason-parser/vendor/easy_format/dune",
"chars": 195,
"preview": "(library\n (name reason_easy_format)\n (public_name reason.easy_format)\n (preprocess\n (action\n (run %{bin:cppo} -V OCAM"
},
{
"path": "src/reason-parser/vendor/easy_format/reason_easy_format.ml",
"chars": 19998,
"preview": "open Format\n\n(** Shadow map and split with tailrecursive variants. *)\nmodule List = struct\n include List\n (** Tail rec"
},
{
"path": "src/reason-parser/vendor/easy_format/reason_easy_format.mli",
"chars": 7853,
"preview": "(**\n Easy_format: indentation made easy.\n*)\n\n(**\n This module provides a functional, simplified layer over\n the Form"
},
{
"path": "src/refmt/.gitignore",
"chars": 15,
"preview": "git_version.ml\n"
},
{
"path": "src/refmt/README.md",
"chars": 1098,
"preview": "# Reason (For Native Compilers)\n\nSimple, fast & type safe code that leverages the JavaScript & OCaml ecosystems.\n\nThis p"
},
{
"path": "src/refmt/dune",
"chars": 643,
"preview": "(executable\n (public_name refmt)\n (package reason)\n (modes exe byte)\n (modules refmt)\n (flags :standard -open StdLabels)"
},
{
"path": "src/refmt/end_of_line.ml",
"chars": 2062,
"preview": "type t =\n | LF\n | CRLF\n\nmodule Detect = struct\n let default = match Sys.win32 with true -> CRLF | _ -> LF\n\n let get_"
},
{
"path": "src/refmt/end_of_line.mli",
"chars": 190,
"preview": "type t =\n | LF\n | CRLF\n\nmodule Detect : sig\n val default : t\n val get_eol_for_file : string -> t\nend\n\nmodule Convert"
},
{
"path": "src/refmt/git_commit.mli",
"chars": 123,
"preview": "(* Interface file to ensure git_commit is generated properly with dune *)\n\nval version : string\nval short_version : stri"
},
{
"path": "src/refmt/package.ml",
"chars": 205,
"preview": "let version =\n match Build_info.V1.version () with\n | None -> \"n/a\"\n | Some v -> Build_info.V1.Version.to_string v\n\nl"
},
{
"path": "src/refmt/package.mli",
"chars": 77,
"preview": "val version : string\nval git_version : string\nval git_short_version : string\n"
},
{
"path": "src/refmt/printer_maker.ml",
"chars": 1840,
"preview": "open Reason\n\ntype 'a parser_result =\n { ast : 'a\n ; comments : Reason_comment.t list\n ; parsed_as_ml : bool\n ; parse"
},
{
"path": "src/refmt/printer_maker.mli",
"chars": 909,
"preview": "open Reason\n\ntype 'a parser_result =\n { ast : 'a\n ; comments : Reason_comment.t list\n ; parsed_as_ml : bool\n ; parse"
},
{
"path": "src/refmt/reason_implementation_printer.ml",
"chars": 3418,
"preview": "open Reason\nopen Ppxlib\n\ntype t = Parsetree.structure\n\nlet err = Printer_maker.err\n\n(* Note: filename should only be use"
},
{
"path": "src/refmt/reason_implementation_printer.mli",
"chars": 30,
"preview": "include Printer_maker.PRINTER\n"
},
{
"path": "src/refmt/reason_interface_printer.ml",
"chars": 3362,
"preview": "open Reason\nopen Ppxlib\n\ntype t = Parsetree.signature\n\nlet err = Printer_maker.err\n\n(* Note: filename should only be use"
},
{
"path": "src/refmt/reason_interface_printer.mli",
"chars": 30,
"preview": "include Printer_maker.PRINTER\n"
},
{
"path": "src/refmt/refmt.ml",
"chars": 6367,
"preview": "(* Copyright (c) 2015-present, Facebook, Inc.\n *\n * This source code is licensed under the MIT license found in the\n * L"
},
{
"path": "src/refmt/refmt_args.ml",
"chars": 2289,
"preview": "open Cmdliner\n\nlet interface =\n let doc = \"parse AST as an interface\" in\n Arg.(value & opt bool false & info [ \"i\"; \"i"
},
{
"path": "src/vendored-omp/LICENSE.md",
"chars": 27152,
"preview": "In the following, \"this library\" refers to all files marked\n\"Copyright INRIA\" in this distribution.\n\nThe OCaml Core Syst"
},
{
"path": "src/vendored-omp/MANUAL.md",
"chars": 16411,
"preview": "Title: Guide to OCaml Migrate Parsetree\nAuthor: Frédéric Bour, @let-def\nDate: March 9, 2017\n\n\n**Table of Contents**\n\n"
},
{
"path": "src/vendored-omp/Makefile",
"chars": 904,
"preview": "# This file is part of the migrate-parsetree package. It is released under the\n# terms of the LGPL 2.1 license (see LICE"
},
{
"path": "src/vendored-omp/README.md",
"chars": 6701,
"preview": "# OCaml-migrate-parsetree\nConvert OCaml parsetrees between different major versions\n\nThis library converts between parse"
},
{
"path": "src/vendored-omp/src/ast_408.ml",
"chars": 8482,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/ast_409.ml",
"chars": 8128,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/ast_410.ml",
"chars": 8298,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/ast_411.ml",
"chars": 8315,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/ast_412.ml",
"chars": 8383,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/ast_413.ml",
"chars": 8167,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/ast_414.ml",
"chars": 8509,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/ast_500.ml",
"chars": 8509,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/ast_51.ml",
"chars": 7147,
"preview": "module Asttypes = struct\n type constant (*IF_CURRENT = Asttypes.constant *) =\n Const_int of int\n | Const_char o"
},
{
"path": "src/vendored-omp/src/ast_52.ml",
"chars": 7306,
"preview": "module Asttypes = struct\n type constant (*IF_CURRENT = Asttypes.constant *) =\n Const_int of int\n | Const_char o"
},
{
"path": "src/vendored-omp/src/ast_53.ml",
"chars": 7448,
"preview": "module Asttypes = struct\n type constant (*IF_CURRENT = Asttypes.constant *) =\n Const_int of int\n | Const_char o"
},
{
"path": "src/vendored-omp/src/ast_54.ml",
"chars": 7793,
"preview": "module Asttypes = struct\n type constant (*IF_CURRENT = Asttypes.constant *) =\n Const_int of int\n | Const_char o"
},
{
"path": "src/vendored-omp/src/ast_55.ml",
"chars": 8212,
"preview": "module Asttypes = struct\n (** Auxiliary AST types used by parsetree and typedtree.\n\n {b Warning:} this module is uns"
},
{
"path": "src/vendored-omp/src/caml_format_doc.cppo.ml",
"chars": 17093,
"preview": "#if OCAML_VERSION >= (5,3,0)\ninclude Format_doc\n\n#else\n(****************************************************************"
},
{
"path": "src/vendored-omp/src/cinaps_helpers",
"chars": 1265,
"preview": "(* -*- tuareg -*- *)\n\nopen StdLabels\nopen Printf\n\nlet nl () = printf \"\\n\"\n\nlet supported_versions = [\n (\"402\", \"4.02\");"
},
{
"path": "src/vendored-omp/src/compiler-functions/ge_406_and_lt_408.ml",
"chars": 424,
"preview": "let error_of_exn exn =\n match Location.error_of_exn exn with\n | Some (`Ok exn) -> Some exn\n | Some `Already_displayed"
},
{
"path": "src/vendored-omp/src/compiler-functions/ge_408_and_lt_410.ml",
"chars": 424,
"preview": "let error_of_exn exn =\n match Location.error_of_exn exn with\n | Some (`Ok exn) -> Some exn\n | Some `Already_displayed"
},
{
"path": "src/vendored-omp/src/compiler-functions/ge_410_and_lt_412.ml",
"chars": 422,
"preview": "let error_of_exn exn =\n match Location.error_of_exn exn with\n | Some (`Ok exn) -> Some exn\n | Some `Already_displayed"
},
{
"path": "src/vendored-omp/src/compiler-functions/ge_412.ml",
"chars": 429,
"preview": "let error_of_exn exn =\n match Location.error_of_exn exn with\n | Some (`Ok exn) -> Some exn\n | Some `Already_displayed"
},
{
"path": "src/vendored-omp/src/compiler-functions/ge_50.ml",
"chars": 660,
"preview": "let error_of_exn exn =\n match Location.error_of_exn exn with\n | Some (`Ok exn) -> Some exn\n | Some `Already_displayed"
},
{
"path": "src/vendored-omp/src/compiler-functions/ge_52.ml",
"chars": 680,
"preview": "let error_of_exn exn =\n match Location.error_of_exn exn with\n | Some (`Ok exn) -> Some exn\n | Some `Already_displayed"
},
{
"path": "src/vendored-omp/src/compiler-functions/lt_406.ml",
"chars": 279,
"preview": "let error_of_exn = Location.error_of_exn\n\nlet get_load_paths () =\n !Config.load_path\n\nlet load_path_init l =\n Config.l"
},
{
"path": "src/vendored-omp/src/config/gen.ml",
"chars": 1277,
"preview": "let write fn s =\n let oc = open_out fn in\n output_string oc s;\n close_out oc\n\nlet () =\n let ocaml_version_str = Sys."
},
{
"path": "src/vendored-omp/src/dune",
"chars": 1041,
"preview": "(library\n (name reason_omp)\n (public_name reason.ocaml-migrate-parsetree)\n (wrapped true)\n (libraries ppxlib.astlib)\n (m"
},
{
"path": "src/vendored-omp/src/locations.ml",
"chars": 5958,
"preview": "type old_location_error (*IF_NOT_AT_LEAST 408 = Location.error *) = {\n loc: Location.t;\n msg: string;\n sub: old"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_408_409.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_408_409_migrate.ml",
"chars": 14081,
"preview": "open Stdlib0\nmodule From = Ast_408\nmodule To = Ast_409\nlet rec copy_out_type_extension :\n Ast_408.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_409_408.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_409_408_migrate.ml",
"chars": 14081,
"preview": "open Stdlib0\nmodule From = Ast_409\nmodule To = Ast_408\nlet rec copy_out_type_extension :\n Ast_409.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_409_410.ml",
"chars": 1121,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_409_410_migrate.ml",
"chars": 14328,
"preview": "open Stdlib0\nmodule From = Ast_409\nmodule To = Ast_410\nlet rec copy_out_type_extension :\n Ast_409.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_410_409.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_410_409_migrate.ml",
"chars": 14664,
"preview": "open Stdlib0\nmodule From = Ast_410\nmodule To = Ast_409\n\n\nmodule Def = Migrate_parsetree_def\n\nlet migration_error locatio"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_410_411.ml",
"chars": 1121,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_410_411_migrate.ml",
"chars": 14550,
"preview": "open Stdlib0\nmodule From = Ast_410\nmodule To = Ast_411\nlet rec copy_out_type_extension :\n Ast_410.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_411_410.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_411_410_migrate.ml",
"chars": 14550,
"preview": "open Stdlib0\nmodule From = Ast_411\nmodule To = Ast_410\nlet rec copy_out_type_extension :\n Ast_411.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_411_412.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_411_412_migrate.ml",
"chars": 14684,
"preview": "open Stdlib0\nmodule From = Ast_411\nmodule To = Ast_412\nlet rec copy_out_type_extension :\n Ast_411.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_412_411.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_412_411_migrate.ml",
"chars": 15083,
"preview": "open Stdlib0\nmodule From = Ast_412\nmodule To = Ast_411\nlet rec copy_out_type_extension :\n Ast_412.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_412_413.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_412_413_migrate.ml",
"chars": 14998,
"preview": "open Stdlib0\nmodule From = Ast_412\nmodule To = Ast_413\nlet rec copy_out_type_extension :\n Ast_412.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_413_412.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_413_412_migrate.ml",
"chars": 15029,
"preview": "open Stdlib0\nmodule From = Ast_413\nmodule To = Ast_412\nlet rec copy_out_type_extension :\n Ast_413.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_413_414.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_413_414_migrate.ml",
"chars": 15281,
"preview": "open Stdlib0\nmodule From = Ast_413\nmodule To = Ast_414\nlet rec copy_out_type_extension :\n Ast_413.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_414_413.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_414_413_migrate.ml",
"chars": 15171,
"preview": "open Stdlib0\nmodule From = Ast_414\nmodule To = Ast_413\nlet rec copy_out_type_extension :\n Ast_414.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_414_500.ml",
"chars": 1122,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_414_500_migrate.ml",
"chars": 15288,
"preview": "open Stdlib0\nmodule From = Ast_414\nmodule To = Ast_500\nlet rec copy_out_type_extension :\n Ast_414.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_500_414.ml",
"chars": 1121,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_500_414_migrate.ml",
"chars": 15288,
"preview": "open Stdlib0\nmodule From = Ast_500\nmodule To = Ast_414\nlet rec copy_out_type_extension :\n Ast_500.Outcometree.out_type_"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_500_51.ml",
"chars": 1121,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_500_51_migrate.ml",
"chars": 15198,
"preview": "open Stdlib0\nmodule From = Ast_500\nmodule To = Ast_51\nlet rec copy_out_type_extension :\n Ast_500.Outcometree.out_type_e"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_51_500.ml",
"chars": 1120,
"preview": "(**************************************************************************)\n(* "
},
{
"path": "src/vendored-omp/src/migrate_parsetree_51_500_migrate.ml",
"chars": 15167,
"preview": "open Stdlib0\nmodule From = Ast_51\nmodule To = Ast_500\nlet rec copy_out_type_extension :\n Ast_51.Outcometree.out_type_ex"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_51_52.ml",
"chars": 41,
"preview": "\ninclude Migrate_parsetree_51_52_migrate\n"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_51_52_migrate.ml",
"chars": 15309,
"preview": "open Stdlib0\nmodule From = Ast_51\nmodule To = Ast_52\n\nlet get_label lbl =\n if lbl = \"\" then Ast_52.Asttypes.Nolabel\n e"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_52_51.ml",
"chars": 41,
"preview": "\ninclude Migrate_parsetree_52_51_migrate\n"
},
{
"path": "src/vendored-omp/src/migrate_parsetree_52_51_migrate.ml",
"chars": 15745,
"preview": "open Stdlib0\nmodule From = Ast_52\nmodule To = Ast_51\nlet rec copy_out_type_extension :\n Ast_52.Outcometree.out_type_ext"
}
]
// ... and 219 more files (download for full content)
About this extraction
This page contains the full source code of the reasonml/reason GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 419 files (2.7 MB), approximately 717.3k tokens, and a symbol index with 45 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.