![]()
dots.ocr
[](https://huggingface.co/rednote-hilab/dots.ocr-1.5) [](https://arxiv.org/abs/2512.02498)| models | olmOCR-Bench | OmniDocBench (v1.5) | XDocParse |
|---|---|---|---|
| GLM-OCR | 859.9 | 937.5 | 742.1 |
| PaddleOCR-VL-1.5 | 873.6 | 965.6 | 797.6 |
| HuanyuanOCR | 978.9 | 974.4 | 895.9 |
| dots.ocr | 1027.4 | 994.7 | 1133.4 |
| dots.ocr-1.5 | 1089.0 | 1025.8 | 1157.1 |
| Gemini 3 Pro | 1171.2 | 1102.1 | 1273.9 |
| Model | ArXiv | Old scans math | Tables | Old scans | Headers & footers | Multi column | Long tiny text | Base | Overall |
|---|---|---|---|---|---|---|---|---|---|
| Mistral OCR API | 77.2 | 67.5 | 60.6 | 29.3 | 93.6 | 71.3 | 77.1 | 99.4 | 72.0±1.1 |
| Marker 1.10.1 | 83.8 | 66.8 | 72.9 | 33.5 | 86.6 | 80.0 | 85.7 | 99.3 | 76.1±1.1 |
| MinerU 2.5.4* | 76.6 | 54.6 | 84.9 | 33.7 | 96.6 | 78.2 | 83.5 | 93.7 | 75.2±1.1 |
| DeepSeek-OCR | 77.2 | 73.6 | 80.2 | 33.3 | 96.1 | 66.4 | 79.4 | 99.8 | 75.7±1.0 |
| Nanonets-OCR2-3B | 75.4 | 46.1 | 86.8 | 40.9 | 32.1 | 81.9 | 93.0 | 99.6 | 69.5±1.1 |
| PaddleOCR-VL* | 85.7 | 71.0 | 84.1 | 37.8 | 97.0 | 79.9 | 85.7 | 98.5 | 80.0±1.0 |
| Infinity-Parser 7B* | 84.4 | 83.8 | 85.0 | 47.9 | 88.7 | 84.2 | 86.4 | 99.8 | 82.5±? |
| olmOCR v0.4.0 | 83.0 | 82.3 | 84.9 | 47.7 | 96.1 | 83.7 | 81.9 | 99.7 | 82.4±1.1 |
| Chandra OCR 0.1.0* | 82.2 | 80.3 | 88.0 | 50.4 | 90.8 | 81.2 | 92.3 | 99.9 | 83.1±0.9 |
| dots.ocr | 82.1 | 64.2 | 88.3 | 40.9 | 94.1 | 82.4 | 81.2 | 99.5 | 79.1±1.0 |
| dots.ocr-1.5 | 85.9 | 85.5 | 90.7 | 48.2 | 94.0 | 85.3 | 81.6 | 99.7 | 83.9±0.9 |
| Model Type | Methods | Size | OmniDocBench(v1.5) TextEdit↓ |
OmniDocBench(v1.5) Read OrderEdit↓ |
pdf-parse-bench |
|---|---|---|---|---|---|
| GeneralVLMs | Gemini-2.5 Pro | - | 0.075 | 0.097 | 9.06 |
| Qwen3-VL-235B-A22B-Instruct | 235B | 0.069 | 0.068 | 9.71 | |
| gemini3pro | - | 0.066 | 0.079 | 9.68 | |
| SpecializedVLMs | Mistral OCR | - | 0.164 | 0.144 | 8.84 |
| Deepseek-OCR | 3B | 0.073 | 0.086 | 8.26 | |
| MonkeyOCR-3B | 3B | 0.075 | 0.129 | 9.27 | |
| OCRVerse | 4B | 0.058 | 0.071 | -- | |
| MonkeyOCR-pro-3B | 3B | 0.075 | 0.128 | - | |
| MinerU2.5 | 1.2B | 0.047 | 0.044 | - | |
| PaddleOCR-VL | 0.9B | 0.035 | 0.043 | 9.51 | |
| HunyuanOCR | 0.9B | 0.042 | - | - | |
| PaddleOCR-VL1.5 | 0.9B | 0.035 | 0.042 | - | |
| GLMOCR | 0.9B | 0.04 | 0.043 | - | |
| dots.ocr | 3B | 0.048 | 0.053 | 9.29 | |
| dots.ocr-1.5 | 3B | 0.031 | 0.029 | 9.54 |
| Methods | Unisvg | Chartmimic | Design2Code | Genexam | SciGen | ChemDraw | ||
|---|---|---|---|---|---|---|---|---|
| Low-Level | High-Level | Score | ||||||
| OCRVerse | 0.632 | 0.852 | 0.763 | 0.799 | - | - | - | 0.881 |
| Gemini 3 Pro | 0.563 | 0.850 | 0.735 | 0.788 | 0.760 | 0.756 | 0.783 | 0.839 |
| dots.ocr-1.5 | 0.850 | 0.923 | 0.894 | 0.772 | 0.801 | 0.664 | 0.660 | 0.790 |
| dots.ocr-1.5-svg | 0.860 | 0.931 | 0.902 | 0.905 | 0.834 | 0.8 | 0.797 | 0.901 |
| Model | CharXiv_descriptive | CharXiv_reasoning | OCR_Reasoning | infovqa | docvqa | ChartQA | OCRBench | AI2D | CountBenchQA | refcoco |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3vl-2b-instruct | 62.3 | 26.8 | - | 72.4 | 93.3 | - | 85.8 | 76.9 | 88.4 | - |
| dots.ocr-1.5 | 77.4 | 55.3 | 22.85 | 73.76 | 91.85 | 83.2 | 86.0 | 82.16 | 94.46 | 80.03 |
Hugginface inference details
```python import torch from transformers import AutoModelForCausalLM, AutoProcessor, AutoTokenizer from qwen_vl_utils import process_vision_info from dots_ocr.utils import dict_promptmode_to_prompt model_path = "./weights/DotsOCR_1_5" model = AutoModelForCausalLM.from_pretrained( model_path, attn_implementation="flash_attention_2", torch_dtype=torch.bfloat16, device_map="auto", trust_remote_code=True ) processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True) image_path = "demo/demo_image1.jpg" prompt = """Please output the layout information from the PDF image, including each layout element's bbox, its category, and the corresponding text content within the bbox. 1. Bbox format: [x1, y1, x2, y2] 2. Layout Categories: The possible categories are ['Caption', 'Footnote', 'Formula', 'List-item', 'Page-footer', 'Page-header', 'Picture', 'Section-header', 'Table', 'Text', 'Title']. 3. Text Extraction & Formatting Rules: - Picture: For the 'Picture' category, the text field should be omitted. - Formula: Format its text as LaTeX. - Table: Format its text as HTML. - All Others (Text, Title, etc.): Format their text as Markdown. 4. Constraints: - The output text must be the original text from the image, with no translation. - All layout elements must be sorted according to human reading order. 5. Final Output: The entire output must be a single JSON object. """ messages = [ { "role": "user", "content": [ { "type": "image", "image": image_path }, {"type": "text", "text": prompt} ] } ] # Preparation for inference text = processor.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) image_inputs, video_inputs = process_vision_info(messages) inputs = processor( text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt", ) inputs = inputs.to("cuda") # Inference: Generation of the output generated_ids = model.generate(**inputs, max_new_tokens=24000) generated_ids_trimmed = [ out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids) ] output_text = processor.batch_decode( generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False ) print(output_text) ```Output Results
1. **Structured Layout Data** (`demo_image1.json`): A JSON file containing the detected layout elements, including their bounding boxes, categories, and extracted text. 2. **Processed Markdown File** (`demo_image1.md`): A Markdown file generated from the concatenated text of all detected cells. * An additional version, `demo_image1_nohf.md`, is also provided, which excludes page headers and footers for compatibility with benchmarks like Omnidocbench and olmOCR-bench. 3. **Layout Visualization** (`demo_image1.jpg`): The original image with the detected layout bounding boxes drawn on it.
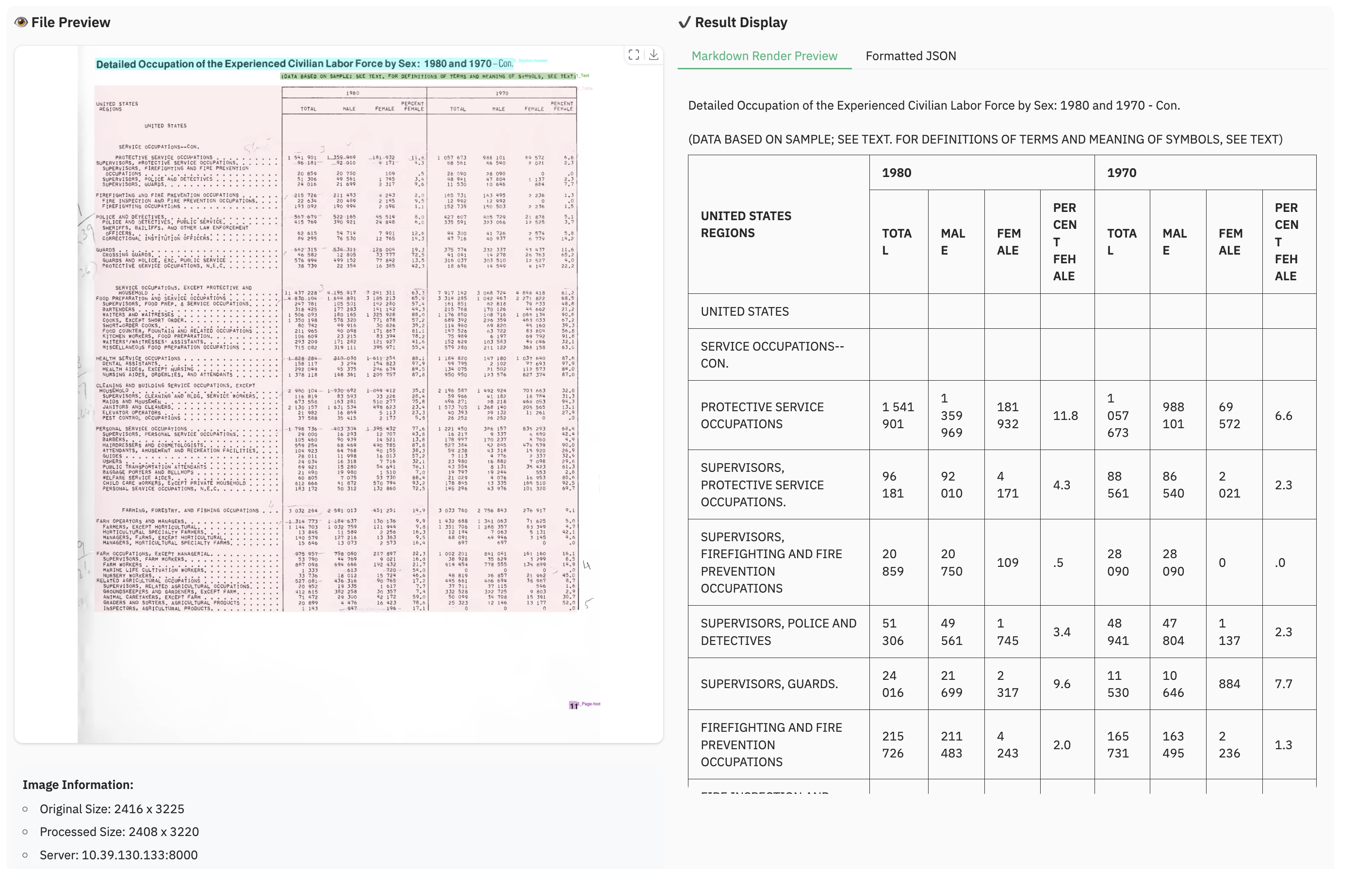




 ### Examples for image parsing
### Examples for image parsing
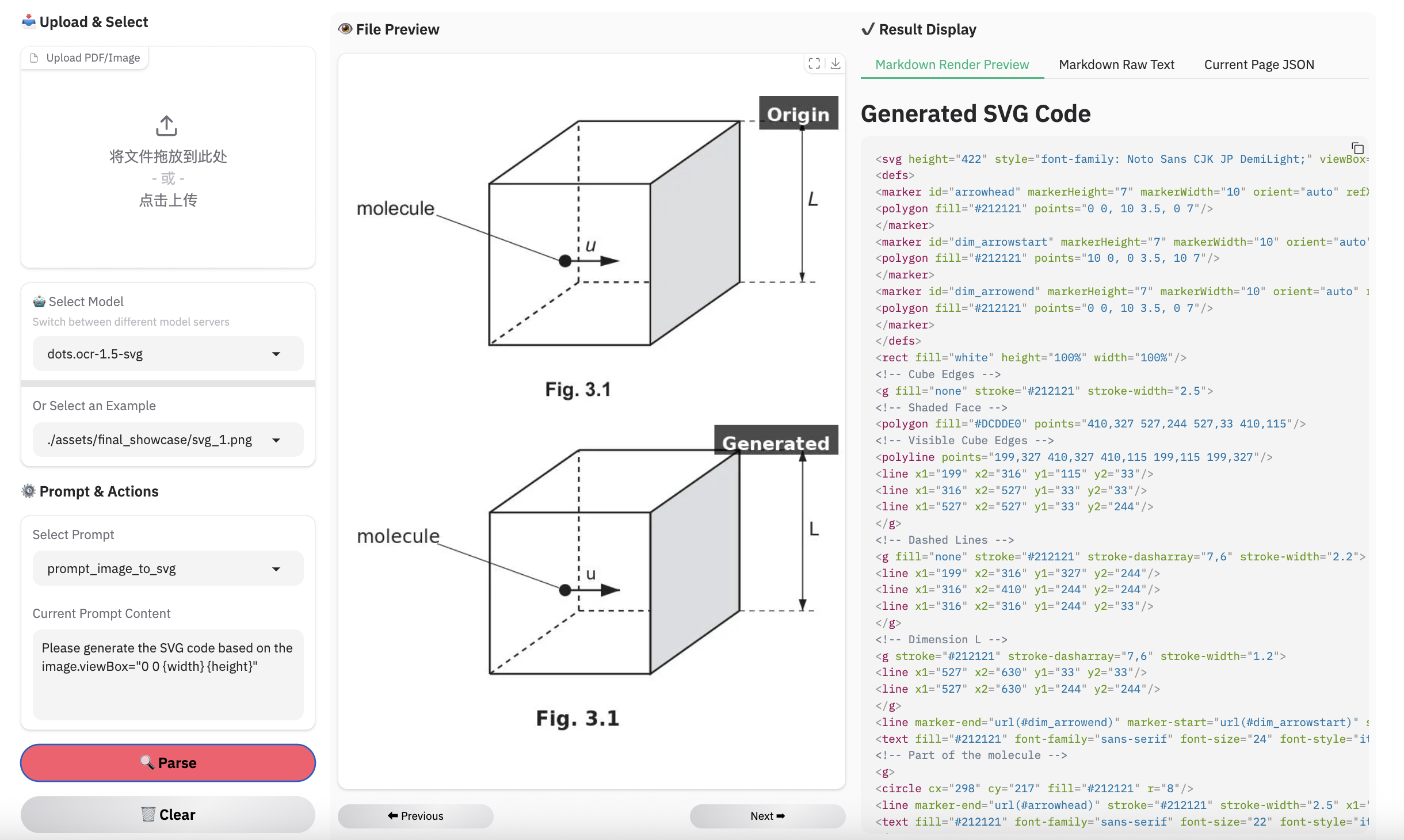
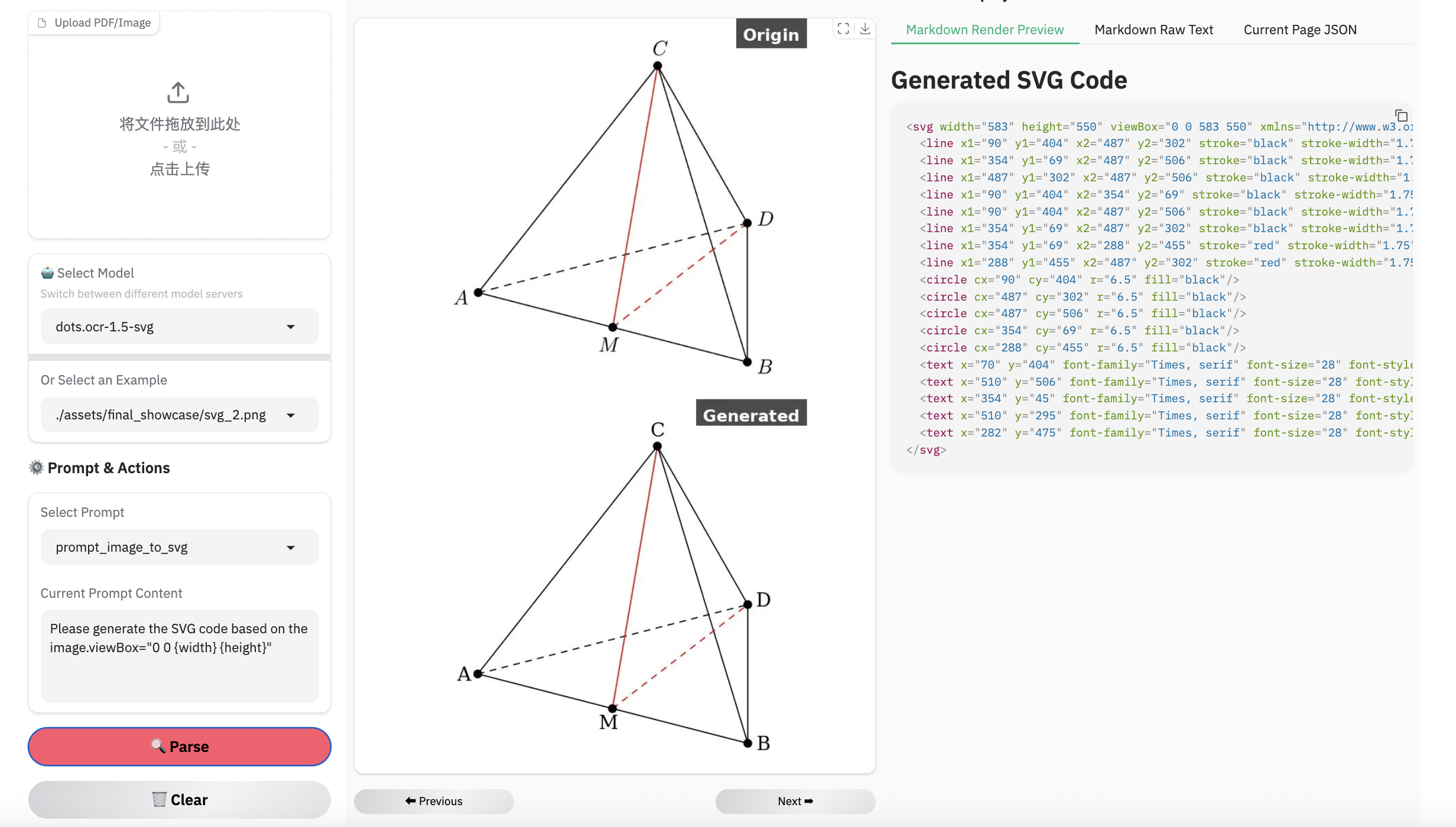
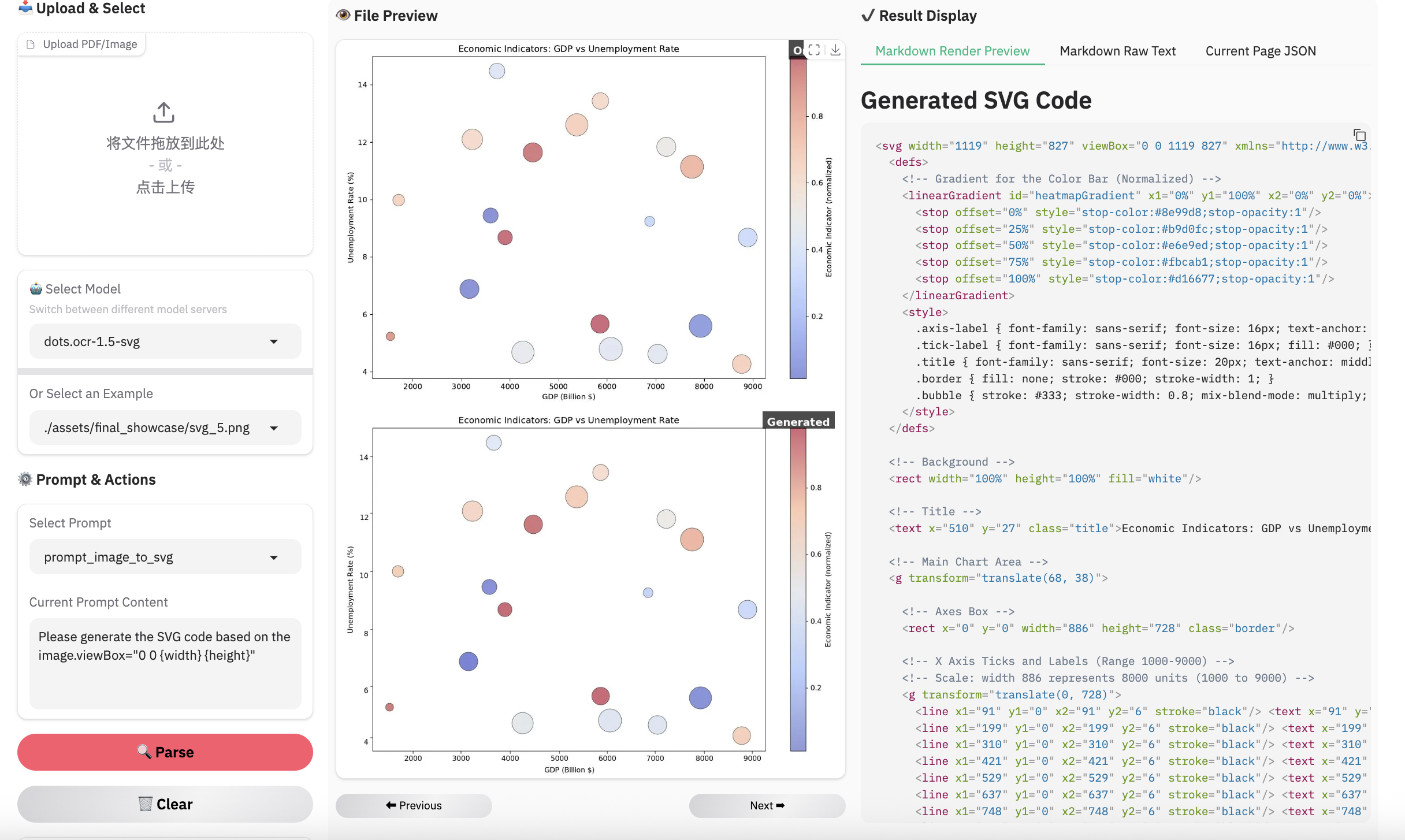
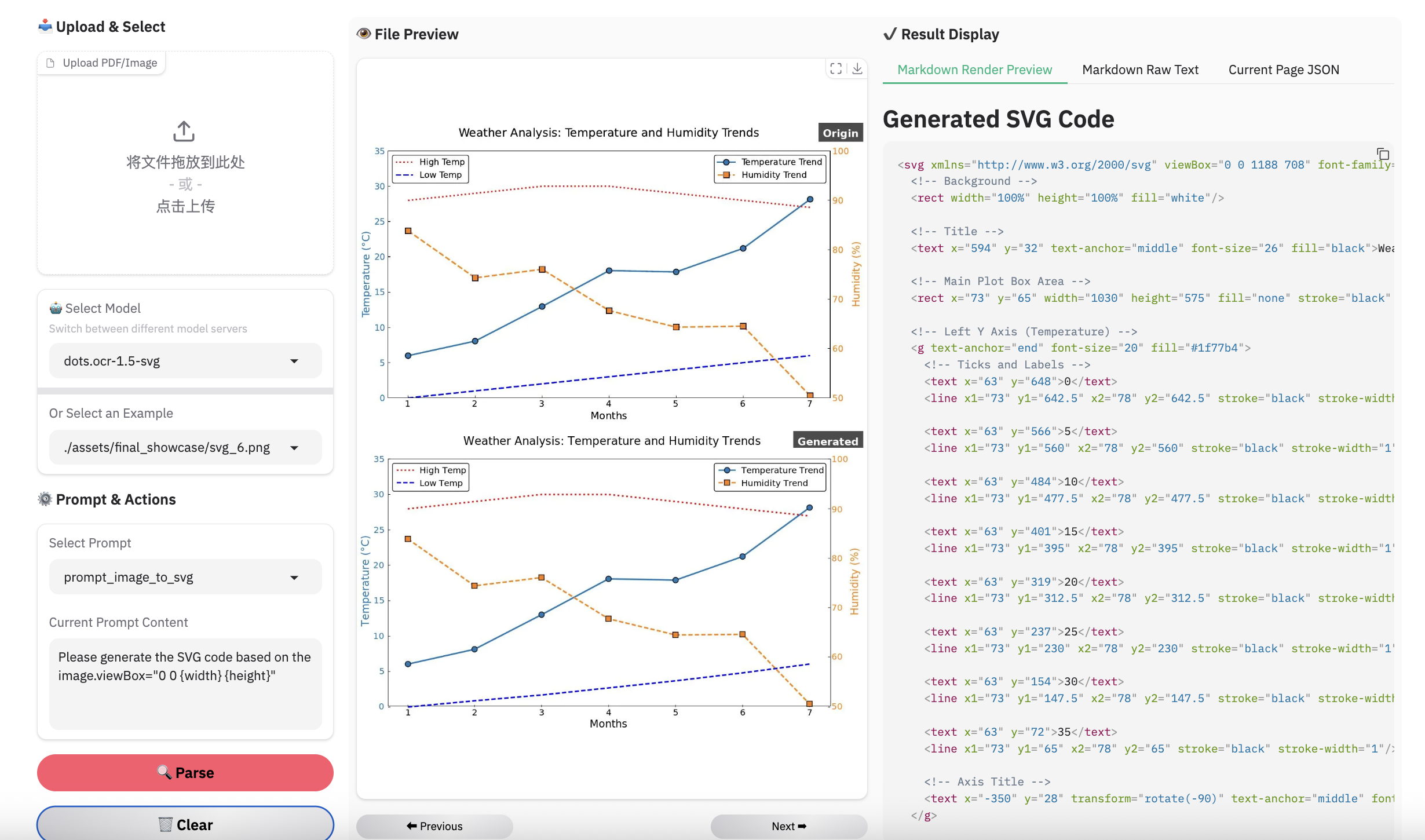 > **Note:**
> - Inferenced by dots.ocr-1.5-svg
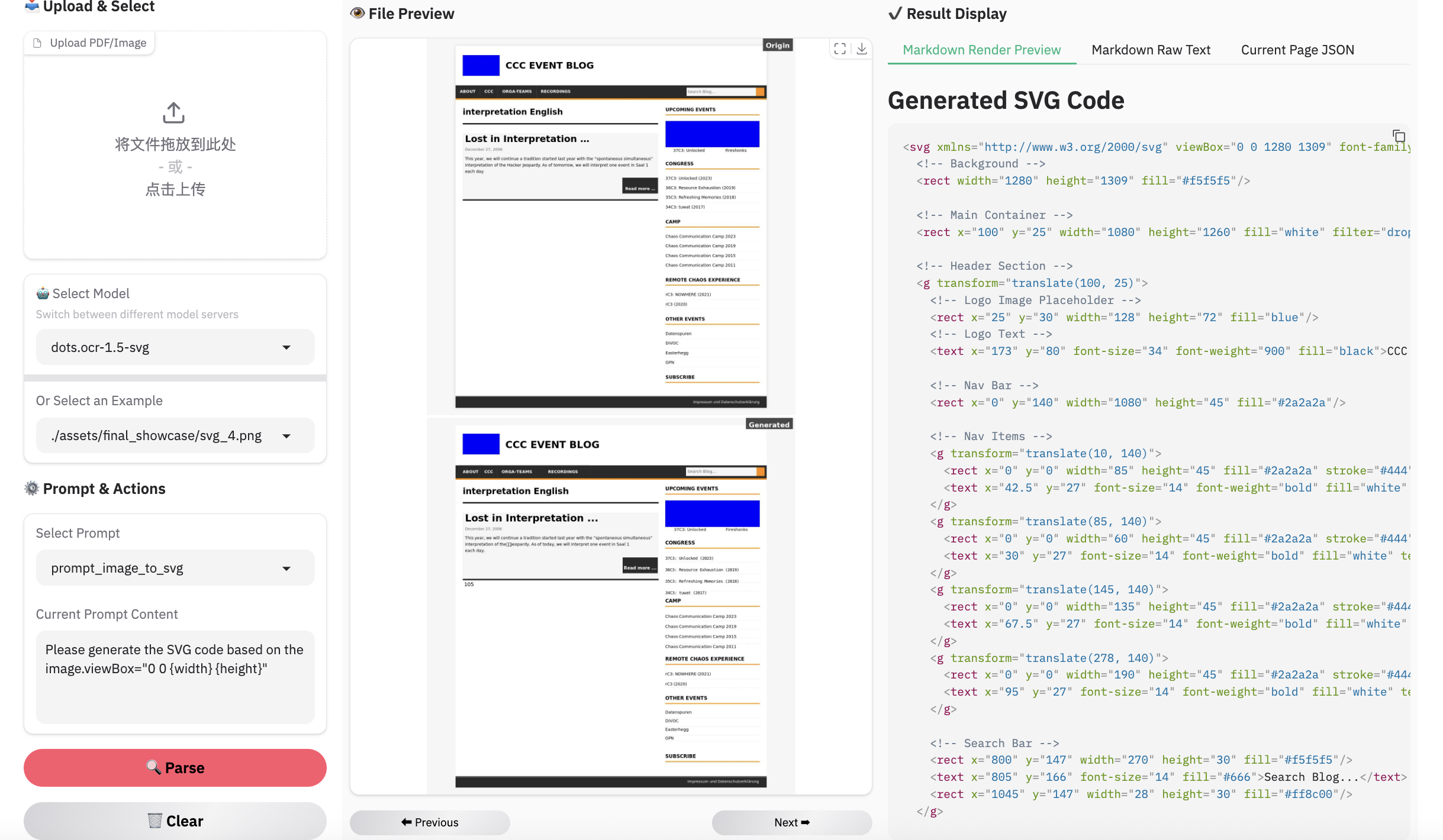
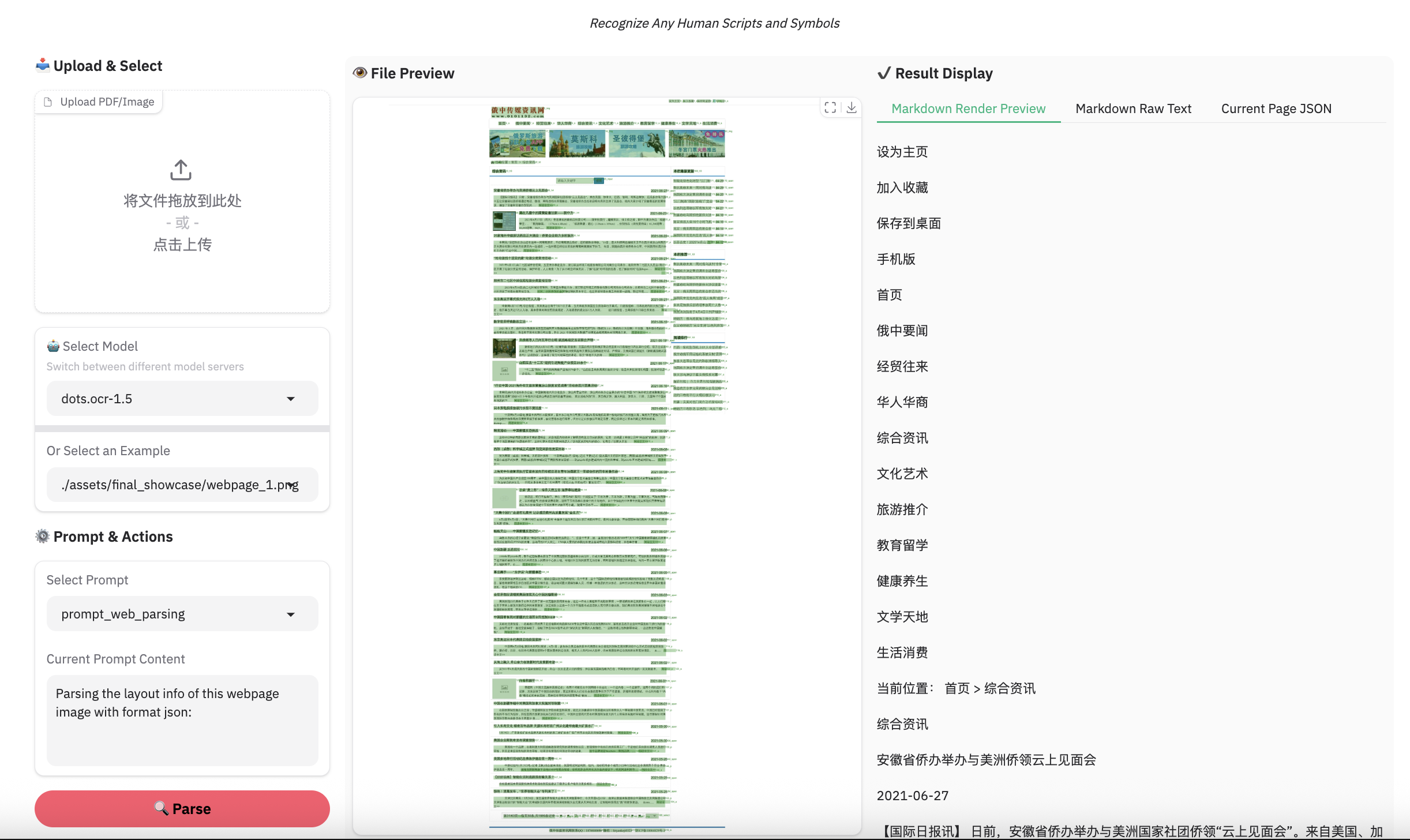
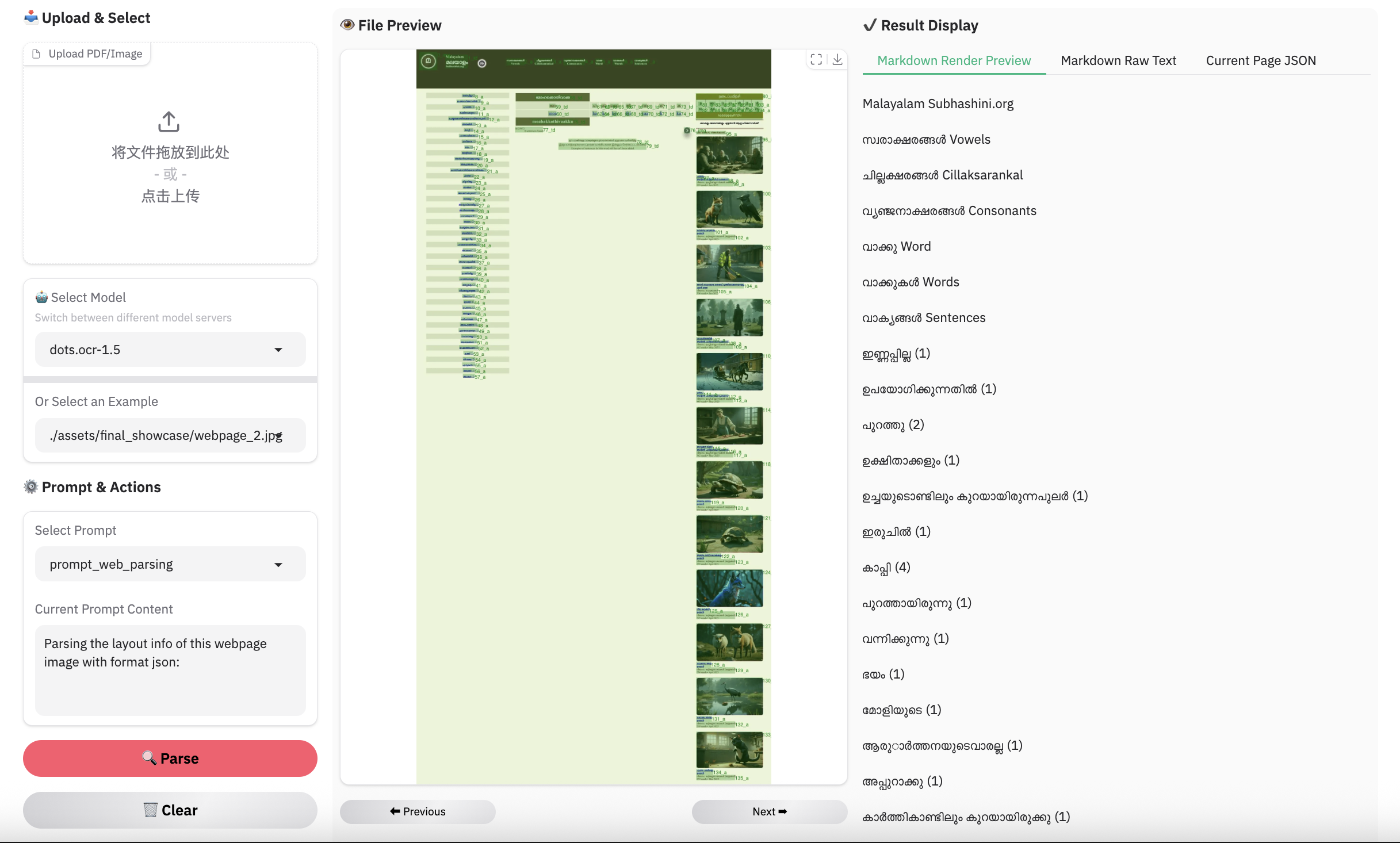
### Example for web parsing
> **Note:**
> - Inferenced by dots.ocr-1.5-svg
### Example for web parsing
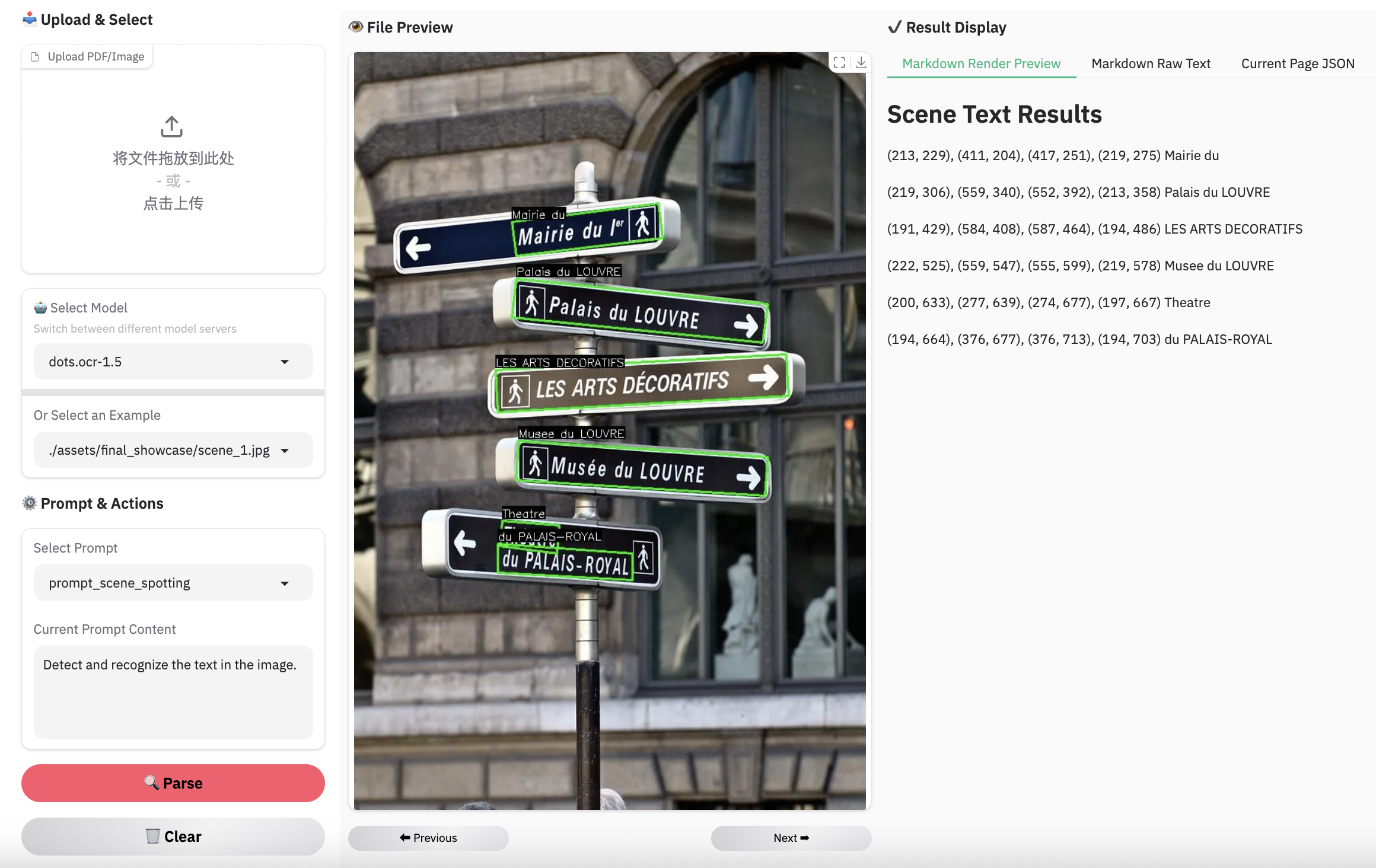
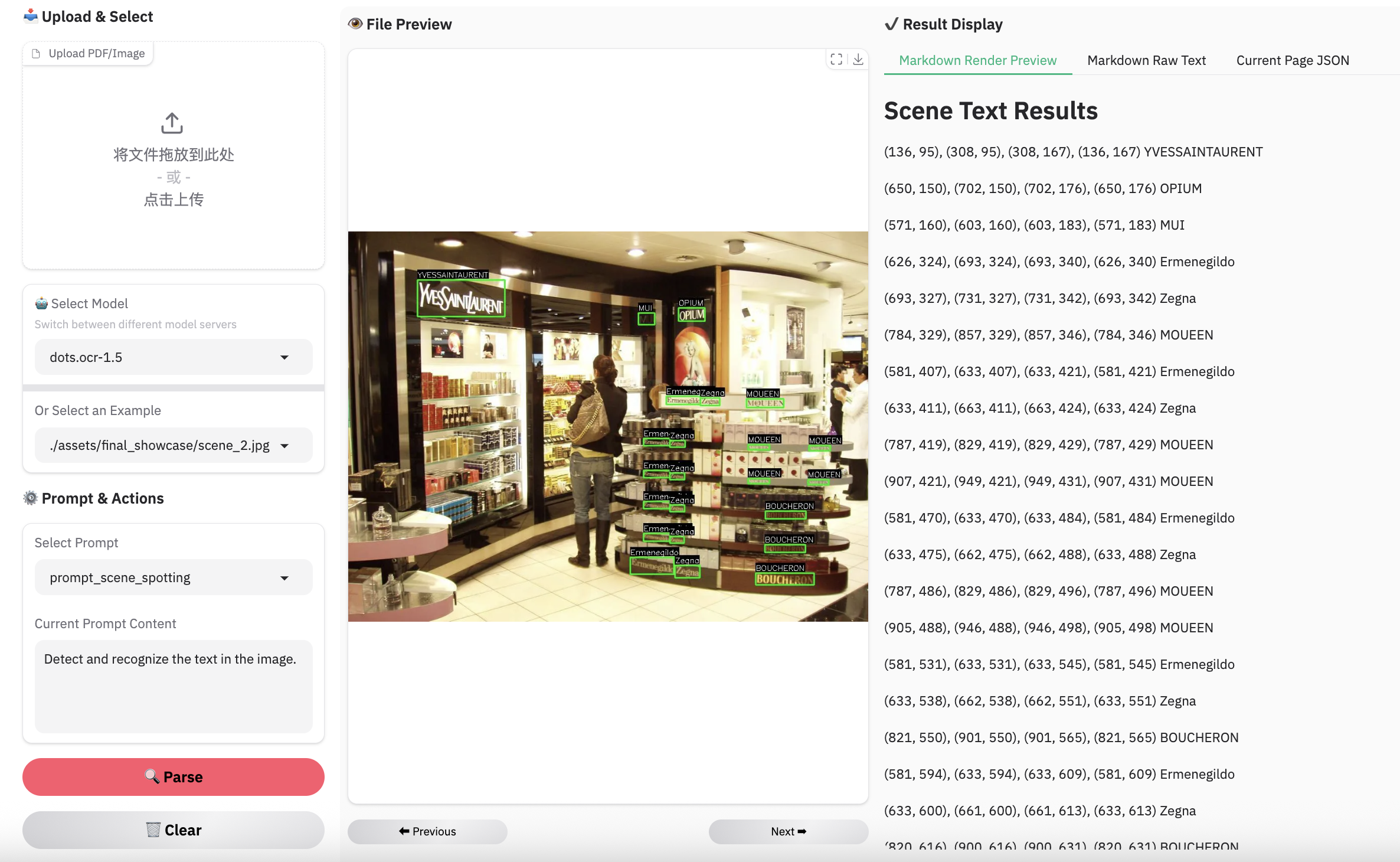
 ### Examples for scene spotting
### Examples for scene spotting
 # Limitation & Future Work
- **Complex Document Elements:**
- **Table&Formula**: The extraction of complex tables and mathematical formulas persists as a difficult task given the model's compact architecture.
- **Picture**: We have adopted an SVG code representation for parsing structured graphics; however, the performance has yet to achieve the desired level of robustness.
- **Parsing Failures:** While we have reduced the rate of parsing failures compared to the previous version, these issues may still occur occasionally. We remain committed to further resolving these edge cases in future updates.
# Citation
```BibTeX
@misc{li2025dotsocrmultilingualdocumentlayout,
title={dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model},
author={Yumeng Li and Guang Yang and Hao Liu and Bowen Wang and Colin Zhang},
year={2025},
eprint={2512.02498},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.02498},
}
```
================================================
FILE: assets/blog.md
================================================
# Limitation & Future Work
- **Complex Document Elements:**
- **Table&Formula**: The extraction of complex tables and mathematical formulas persists as a difficult task given the model's compact architecture.
- **Picture**: We have adopted an SVG code representation for parsing structured graphics; however, the performance has yet to achieve the desired level of robustness.
- **Parsing Failures:** While we have reduced the rate of parsing failures compared to the previous version, these issues may still occur occasionally. We remain committed to further resolving these edge cases in future updates.
# Citation
```BibTeX
@misc{li2025dotsocrmultilingualdocumentlayout,
title={dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model},
author={Yumeng Li and Guang Yang and Hao Liu and Bowen Wang and Colin Zhang},
year={2025},
eprint={2512.02498},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.02498},
}
```
================================================
FILE: assets/blog.md
================================================
dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model
## Introduction **dots.ocr** is a powerful, multilingual document parser that unifies layout detection and content recognition within a single vision-language model while maintaining good reading order. Despite its compact 1.7B-parameter LLM foundation, it achieves state-of-the-art(SOTA) performance. 1. **Powerful Performance:** **dots.ocr** achieves SOTA performance for text, tables, and reading order on [OmniDocBench](https://github.com/opendatalab/OmniDocBench), while delivering formula recognition results comparable to much larger models like Doubao-1.5 and gemini2.5-pro. 2. **Multilingual Support:** **dots.ocr** demonstrates robust parsing capabilities for low-resource languages, achieving decisive advantages across both layout detection and content recognition on our in-house multilingual documents benchmark. 3. **Unified and Simple Architecture:** By leveraging a single vision-language model, **dots.ocr** offers a significantly more streamlined architecture than conventional methods that rely on complex, multi-model pipelines. Switching between tasks is accomplished simply by altering the input prompt, proving that a VLM can achieve competitive detection results compared to traditional detection models like DocLayout-YOLO. 4. **Efficient and Fast Performance:** Built upon a compact 1.7B LLM, **dots.ocr** provides faster inference speeds than many other high-performing models based on larger foundations. ### Performance Comparison on Document Parsing Benchmarks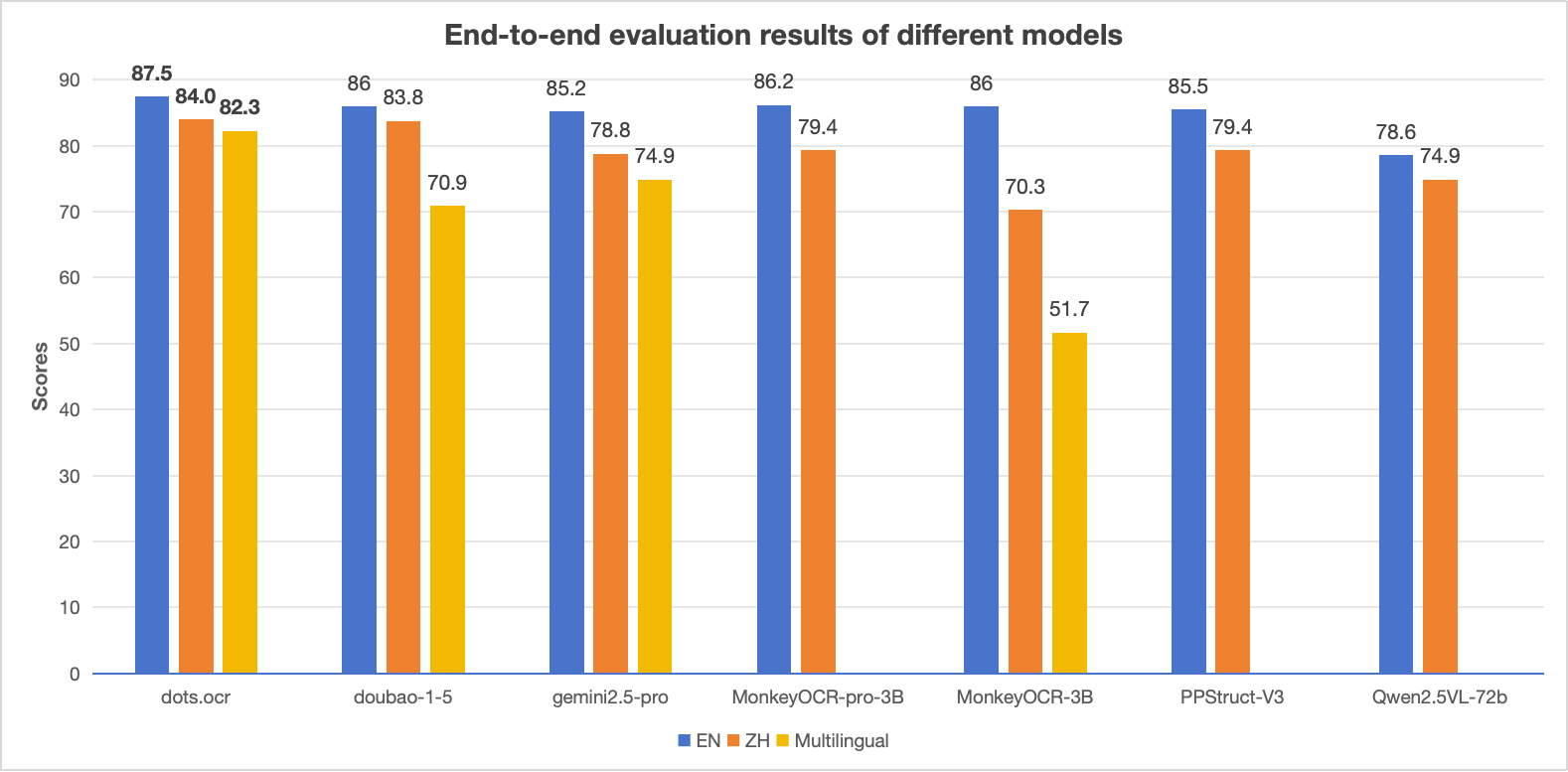 > **Notes:**
> - The EN, ZH metrics are the end2end evaluation results of [OmniDocBench](https://github.com/opendatalab/OmniDocBench), and Multilingual metric is the end2end evaluation results of dots.ocr-bench.
## Show Case
### Example for formula document
> **Notes:**
> - The EN, ZH metrics are the end2end evaluation results of [OmniDocBench](https://github.com/opendatalab/OmniDocBench), and Multilingual metric is the end2end evaluation results of dots.ocr-bench.
## Show Case
### Example for formula document
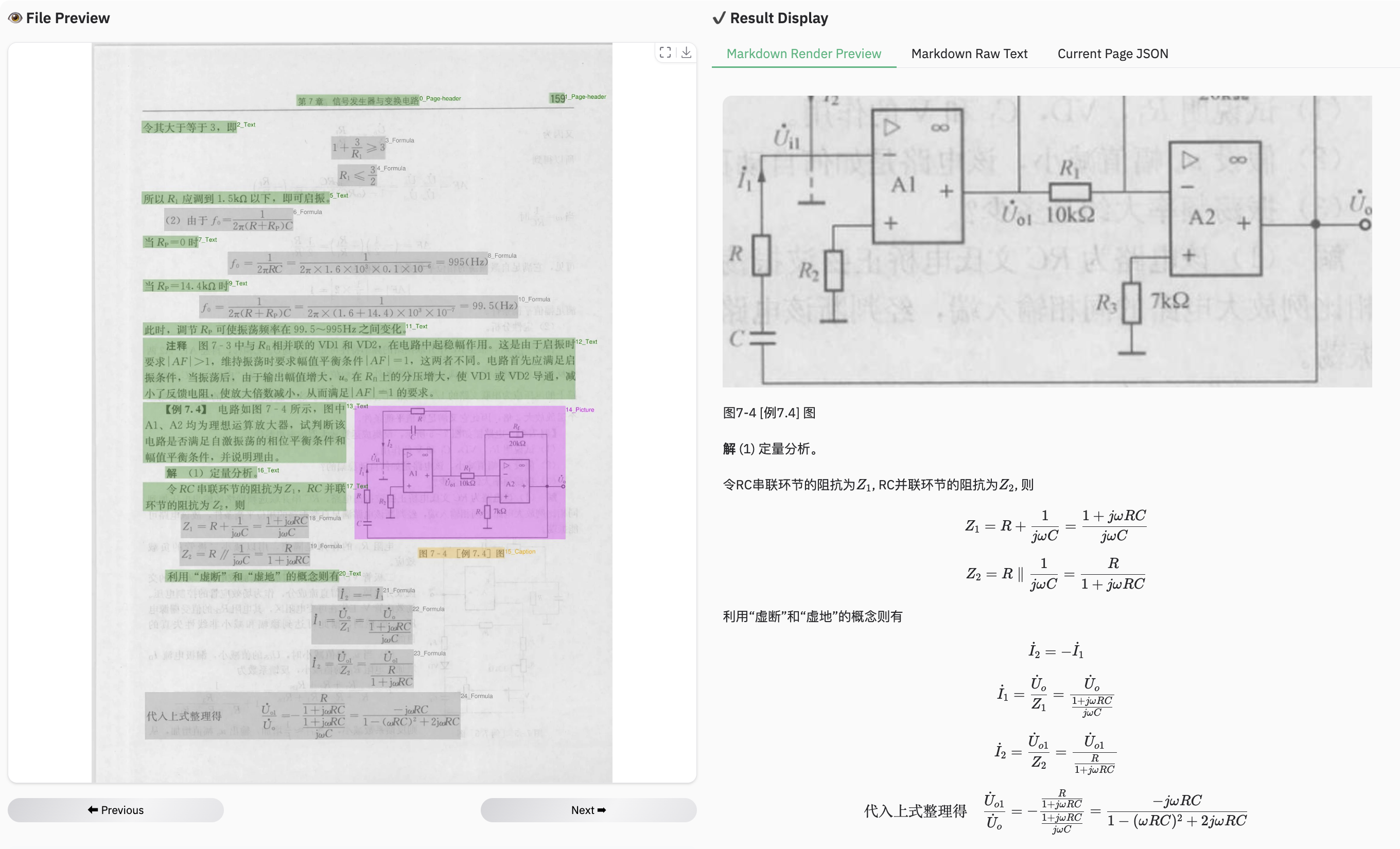
 ### Example for table document
### Example for table document
 ### Example for multilingual document
### Example for reading order
### Example for multilingual document
### Example for reading order
 ### Example for grounding ocr
### Example for grounding ocr
 ## Benchmark Results
### 1. OmniDocBench
#### The end-to-end evaluation results of different tasks.
## Benchmark Results
### 1. OmniDocBench
#### The end-to-end evaluation results of different tasks.
| Model Type |
Methods | OverallEdit↓ | TextEdit↓ | FormulaEdit↓ | TableTEDS↑ | TableEdit↓ | Read OrderEdit↓ | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | ||
| Pipeline Tools |
MinerU | 0.150 | 0.357 | 0.061 | 0.215 | 0.278 | 0.577 | 78.6 | 62.1 | 0.180 | 0.344 | 0.079 | 0.292 |
| Marker | 0.336 | 0.556 | 0.080 | 0.315 | 0.530 | 0.883 | 67.6 | 49.2 | 0.619 | 0.685 | 0.114 | 0.340 | |
| Mathpix | 0.191 | 0.365 | 0.105 | 0.384 | 0.306 | 0.454 | 77.0 | 67.1 | 0.243 | 0.320 | 0.108 | 0.304 | |
| Docling | 0.589 | 0.909 | 0.416 | 0.987 | 0.999 | 1 | 61.3 | 25.0 | 0.627 | 0.810 | 0.313 | 0.837 | |
| Pix2Text | 0.320 | 0.528 | 0.138 | 0.356 | 0.276 | 0.611 | 73.6 | 66.2 | 0.584 | 0.645 | 0.281 | 0.499 | |
| Unstructured | 0.586 | 0.716 | 0.198 | 0.481 | 0.999 | 1 | 0 | 0.06 | 1 | 0.998 | 0.145 | 0.387 | |
| OpenParse | 0.646 | 0.814 | 0.681 | 0.974 | 0.996 | 1 | 64.8 | 27.5 | 0.284 | 0.639 | 0.595 | 0.641 | |
| PPStruct-V3 | 0.145 | 0.206 | 0.058 | 0.088 | 0.295 | 0.535 | - | - | 0.159 | 0.109 | 0.069 | 0.091 | |
| Expert VLMs |
GOT-OCR | 0.287 | 0.411 | 0.189 | 0.315 | 0.360 | 0.528 | 53.2 | 47.2 | 0.459 | 0.520 | 0.141 | 0.280 |
| Nougat | 0.452 | 0.973 | 0.365 | 0.998 | 0.488 | 0.941 | 39.9 | 0 | 0.572 | 1.000 | 0.382 | 0.954 | |
| Mistral OCR | 0.268 | 0.439 | 0.072 | 0.325 | 0.318 | 0.495 | 75.8 | 63.6 | 0.600 | 0.650 | 0.083 | 0.284 | |
| OLMOCR-sglang | 0.326 | 0.469 | 0.097 | 0.293 | 0.455 | 0.655 | 68.1 | 61.3 | 0.608 | 0.652 | 0.145 | 0.277 | |
| SmolDocling-256M | 0.493 | 0.816 | 0.262 | 0.838 | 0.753 | 0.997 | 44.9 | 16.5 | 0.729 | 0.907 | 0.227 | 0.522 | |
| Dolphin | 0.206 | 0.306 | 0.107 | 0.197 | 0.447 | 0.580 | 77.3 | 67.2 | 0.180 | 0.285 | 0.091 | 0.162 | |
| MinerU 2 | 0.139 | 0.240 | 0.047 | 0.109 | 0.297 | 0.536 | 82.5 | 79.0 | 0.141 | 0.195 | 0.069< | 0.118 | |
| OCRFlux | 0.195 | 0.281 | 0.064 | 0.183 | 0.379 | 0.613 | 71.6 | 81.3 | 0.253 | 0.139 | 0.086 | 0.187 | |
| MonkeyOCR-pro-3B | 0.138 | 0.206 | 0.067 | 0.107 | 0.246 | 0.421 | 81.5 | 87.5 | 0.139 | 0.111 | 0.100 | 0.185 | |
| General VLMs |
GPT4o | 0.233 | 0.399 | 0.144 | 0.409 | 0.425 | 0.606 | 72.0 | 62.9 | 0.234 | 0.329 | 0.128 | 0.251 |
| Qwen2-VL-72B | 0.252 | 0.327 | 0.096 | 0.218 | 0.404 | 0.487 | 76.8 | 76.4 | 0.387 | 0.408 | 0.119 | 0.193 | |
| Qwen2.5-VL-72B | 0.214 | 0.261 | 0.092 | 0.18 | 0.315 | 0.434 | 82.9 | 83.9 | 0.341 | 0.262 | 0.106 | 0.168 | |
| Gemini2.5-Pro | 0.148 | 0.212 | 0.055 | 0.168 | 0.356 | 0.439 | 85.8 | 86.4 | 0.13 | 0.119 | 0.049 | 0.121 | |
| doubao-1-5-thinking-vision-pro-250428 | 0.140 | 0.162 | 0.043 | 0.085 | 0.295 | 0.384 | 83.3 | 89.3 | 0.165 | 0.085 | 0.058 | 0.094 | |
| Expert VLMs | dots.ocr | 0.125 | 0.160 | 0.032 | 0.066 | 0.329 | 0.416 | 88.6 | 89.0 | 0.099 | 0.092 | 0.040 | 0.067 |
| Model Type |
Models | Book | Slides | Financial Report |
Textbook | Exam Paper |
Magazine | Academic Papers |
Notes | Newspaper | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pipeline Tools |
MinerU | 0.055 | 0.124 | 0.033 | 0.102 | 0.159 | 0.072 | 0.025 | 0.984 | 0.171 | 0.206 |
| Marker | 0.074 | 0.340 | 0.089 | 0.319 | 0.452 | 0.153 | 0.059 | 0.651 | 0.192 | 0.274 | |
| Mathpix | 0.131 | 0.220 | 0.202 | 0.216 | 0.278 | 0.147 | 0.091 | 0.634 | 0.690 | 0.300 | |
| Expert VLMs |
GOT-OCR | 0.111 | 0.222 | 0.067 | 0.132 | 0.204 | 0.198 | 0.179 | 0.388 | 0.771 | 0.267 |
| Nougat | 0.734 | 0.958 | 1.000 | 0.820 | 0.930 | 0.830 | 0.214 | 0.991 | 0.871 | 0.806 | |
| Dolphin | 0.091 | 0.131 | 0.057 | 0.146 | 0.231 | 0.121 | 0.074 | 0.363 | 0.307 | 0.177 | |
| OCRFlux | 0.068 | 0.125 | 0.092 | 0.102 | 0.119 | 0.083 | 0.047 | 0.223 | 0.536 | 0.149 | |
| MonkeyOCR-pro-3B | 0.084 | 0.129 | 0.060 | 0.090 | 0.107 | 0.073 | 0.050 | 0.171 | 0.107 | 0.100 | |
| General VLMs |
GPT4o | 0.157 | 0.163 | 0.348 | 0.187 | 0.281 | 0.173 | 0.146 | 0.607 | 0.751 | 0.316 |
| Qwen2.5-VL-7B | 0.148 | 0.053 | 0.111 | 0.137 | 0.189 | 0.117 | 0.134 | 0.204 | 0.706 | 0.205 | |
| InternVL3-8B | 0.163 | 0.056 | 0.107 | 0.109 | 0.129 | 0.100 | 0.159 | 0.150 | 0.681 | 0.188 | |
| doubao-1-5-thinking-vision-pro-250428 | 0.048 | 0.048 | 0.024 | 0.062 | 0.085 | 0.051 | 0.039 | 0.096 | 0.181 | 0.073 | |
| Expert VLMs | dots.ocr | 0.031 | 0.047 | 0.011 | 0.082 | 0.079 | 0.028 | 0.029 | 0.109 | 0.056 | 0.055 |
| Methods | OverallEdit↓ | TextEdit↓ | FormulaEdit↓ | TableTEDS↑ | TableEdit↓ | Read OrderEdit↓ | MonkeyOCR-3B | 0.483 | 0.445 | 0.627 | 50.93 | 0.452 | 0.409 |
|---|---|---|---|---|---|---|
| doubao-1-5-thinking-vision-pro-250428 | 0.291 | 0.226 | 0.440 | 71.2 | 0.260 | 0.238 |
| doubao-1-6 | 0.299 | 0.270 | 0.417 | 71.0 | 0.258 | 0.253 |
| Gemini2.5-Pro | 0.251 | 0.163 | 0.402 | 77.1 | 0.236 | 0.202 |
| dots.ocr | 0.177 | 0.075 | 0.297 | 79.2 | 0.186 | 0.152 |
| Method | F1@IoU=.50:.05:.95↑ | F1@IoU=.50↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Overall | Text | Formula | Table | Picture | Overall | Text | Formula | Table | Picture | DocLayout-YOLO-DocStructBench | 0.733 | 0.694 | 0.480 | 0.803 | 0.619 | 0.806 | 0.779 | 0.620 | 0.858 | 0.678 |
| dots.ocr-parse all | 0.831 | 0.801 | 0.654 | 0.838 | 0.748 | 0.922 | 0.909 | 0.770 | 0.888 | 0.831 |
| dots.ocr-detection only | 0.845 | 0.816 | 0.716 | 0.875 | 0.765 | 0.930 | 0.917 | 0.832 | 0.918 | 0.843 |
| Model | ArXiv | Old Scans Math |
Tables | Old Scans | Headers and Footers |
Multi column |
Long Tiny Text |
Base | Overall |
|---|---|---|---|---|---|---|---|---|---|
| GOT OCR | 52.7 | 52.0 | 0.2 | 22.1 | 93.6 | 42.0 | 29.9 | 94.0 | 48.3 ± 1.1 |
| Marker | 76.0 | 57.9 | 57.6 | 27.8 | 84.9 | 72.9 | 84.6 | 99.1 | 70.1 ± 1.1 |
| MinerU | 75.4 | 47.4 | 60.9 | 17.3 | 96.6 | 59.0 | 39.1 | 96.6 | 61.5 ± 1.1 |
| Mistral OCR | 77.2 | 67.5 | 60.6 | 29.3 | 93.6 | 71.3 | 77.1 | 99.4 | 72.0 ± 1.1 |
| Nanonets OCR | 67.0 | 68.6 | 77.7 | 39.5 | 40.7 | 69.9 | 53.4 | 99.3 | 64.5 ± 1.1 |
| GPT-4o (No Anchor) |
51.5 | 75.5 | 69.1 | 40.9 | 94.2 | 68.9 | 54.1 | 96.7 | 68.9 ± 1.1 |
| GPT-4o (Anchored) |
53.5 | 74.5 | 70.0 | 40.7 | 93.8 | 69.3 | 60.6 | 96.8 | 69.9 ± 1.1 |
| Gemini Flash 2 (No Anchor) |
32.1 | 56.3 | 61.4 | 27.8 | 48.0 | 58.7 | 84.4 | 94.0 | 57.8 ± 1.1 |
| Gemini Flash 2 (Anchored) |
54.5 | 56.1 | 72.1 | 34.2 | 64.7 | 61.5 | 71.5 | 95.6 | 63.8 ± 1.2 |
| Qwen 2 VL (No Anchor) |
19.7 | 31.7 | 24.2 | 17.1 | 88.9 | 8.3 | 6.8 | 55.5 | 31.5 ± 0.9 |
| Qwen 2.5 VL (No Anchor) |
63.1 | 65.7 | 67.3 | 38.6 | 73.6 | 68.3 | 49.1 | 98.3 | 65.5 ± 1.2 |
| olmOCR v0.1.75 (No Anchor) |
71.5 | 71.4 | 71.4 | 42.8 | 94.1 | 77.7 | 71.0 | 97.8 | 74.7 ± 1.1 |
| olmOCR v0.1.75 (Anchored) |
74.9 | 71.2 | 71.0 | 42.2 | 94.5 | 78.3 | 73.3 | 98.3 | 75.5 ± 1.0 |
| MonkeyOCR-pro-3B | 83.8 | 68.8 | 74.6 | 36.1 | 91.2 | 76.6 | 80.1 | 95.3 | 75.8 ± 1.0 |
| dots.ocr | 82.1 | 64.2 | 88.3 | 40.9 | 94.1 | 82.4 | 81.2 | 99.5 | 79.1 ± 1.0 |
0 / 0
", session_state
file_ext = os.path.splitext(file_path)[1].lower()
try:
if file_ext == '.pdf':
pages = load_images_from_pdf(file_path)
pdf_cache["file_type"] = "pdf"
elif file_ext in ['.jpg', '.jpeg', '.png']:
image = Image.open(file_path)
pages = [image]
pdf_cache["file_type"] = "image"
else:
return None, "Unsupported file format
", session_state
except Exception as e:
return None, f"PDF loading failed: {str(e)}
", session_state
pdf_cache["images"] = pages
pdf_cache["current_page"] = 0
pdf_cache["total_pages"] = len(pages)
pdf_cache["is_parsed"] = False
pdf_cache["results"] = []
return pages[0], f"1 / {len(pages)}
", session_state
def turn_page(direction, session_state):
"""Page turning function"""
pdf_cache = session_state['pdf_cache']
if not pdf_cache["images"]:
return None, "0 / 0
", "", session_state
if direction == "prev":
pdf_cache["current_page"] = max(0, pdf_cache["current_page"] - 1)
elif direction == "next":
pdf_cache["current_page"] = min(pdf_cache["total_pages"] - 1, pdf_cache["current_page"] + 1)
index = pdf_cache["current_page"]
current_image = pdf_cache["images"][index] # Use the original image by default
page_info = f"{index + 1} / {pdf_cache['total_pages']}
"
current_json = ""
if pdf_cache["is_parsed"] and index < len(pdf_cache["results"]):
result = pdf_cache["results"][index]
if 'cells_data' in result and result['cells_data']:
try:
current_json = json.dumps(result['cells_data'], ensure_ascii=False, indent=2)
except:
current_json = str(result.get('cells_data', ''))
if 'layout_image' in result and result['layout_image']:
current_image = result['layout_image']
return current_image, page_info, current_json, session_state
def get_test_images():
"""Gets the list of test images"""
test_images = []
test_dir = current_config['test_images_dir']
if os.path.exists(test_dir):
test_images = [os.path.join(test_dir, name) for name in os.listdir(test_dir)
if name.lower().endswith(('.png', '.jpg', '.jpeg', '.pdf'))]
return test_images
def create_temp_session_dir():
"""Creates a unique temporary directory for each processing request"""
session_id = uuid.uuid4().hex[:8]
temp_dir = os.path.join(tempfile.gettempdir(), f"dots_ocr_demo_{session_id}")
os.makedirs(temp_dir, exist_ok=True)
return temp_dir, session_id
def parse_image_with_high_level_api(parser, image, prompt_mode, fitz_preprocess=False):
"""
Processes using the high-level API parse_image from DotsOCRParser
"""
# Create a temporary session directory
temp_dir, session_id = create_temp_session_dir()
try:
# Save the PIL Image as a temporary file
temp_image_path = os.path.join(temp_dir, f"input_{session_id}.png")
image.save(temp_image_path, "PNG")
# Use the high-level API parse_image
filename = f"demo_{session_id}"
results = parser.parse_image(
input_path=image,
filename=filename,
prompt_mode=prompt_mode,
save_dir=temp_dir,
fitz_preprocess=fitz_preprocess
)
# Parse the results
if not results:
raise ValueError("No results returned from parser")
result = results[0] # parse_image returns a list with a single result
layout_image = None
if 'layout_image_path' in result and os.path.exists(result['layout_image_path']):
layout_image = Image.open(result['layout_image_path'])
cells_data = None
if 'layout_info_path' in result and os.path.exists(result['layout_info_path']):
with open(result['layout_info_path'], 'r', encoding='utf-8') as f:
cells_data = json.load(f)
md_content = None
if 'md_content_path' in result and os.path.exists(result['md_content_path']):
with open(result['md_content_path'], 'r', encoding='utf-8') as f:
md_content = f.read()
return {
'layout_image': layout_image,
'cells_data': cells_data,
'md_content': md_content,
'filtered': result.get('filtered', False),
'temp_dir': temp_dir,
'session_id': session_id,
'result_paths': result,
'input_width': result.get('input_width', 0),
'input_height': result.get('input_height', 0),
}
except Exception as e:
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir, ignore_errors=True)
raise e
def parse_pdf_with_high_level_api(parser, pdf_path, prompt_mode):
"""
Processes using the high-level API parse_pdf from DotsOCRParser
"""
# Create a temporary session directory
temp_dir, session_id = create_temp_session_dir()
try:
# Use the high-level API parse_pdf
filename = f"demo_{session_id}"
results = parser.parse_pdf(
input_path=pdf_path,
filename=filename,
prompt_mode=prompt_mode,
save_dir=temp_dir
)
# Parse the results
if not results:
raise ValueError("No results returned from parser")
# Handle multi-page results
parsed_results = []
all_md_content = []
all_cells_data = []
for i, result in enumerate(results):
page_result = {
'page_no': result.get('page_no', i),
'layout_image': None,
'cells_data': None,
'md_content': None,
'filtered': False
}
# Read the layout image
if 'layout_image_path' in result and os.path.exists(result['layout_image_path']):
page_result['layout_image'] = Image.open(result['layout_image_path'])
# Read the JSON data
if 'layout_info_path' in result and os.path.exists(result['layout_info_path']):
with open(result['layout_info_path'], 'r', encoding='utf-8') as f:
page_result['cells_data'] = json.load(f)
all_cells_data.extend(page_result['cells_data'])
# Read the Markdown content
if 'md_content_path' in result and os.path.exists(result['md_content_path']):
with open(result['md_content_path'], 'r', encoding='utf-8') as f:
page_content = f.read()
page_result['md_content'] = page_content
all_md_content.append(page_content)
page_result['filtered'] = result.get('filtered', False)
parsed_results.append(page_result)
combined_md = "\n\n---\n\n".join(all_md_content) if all_md_content else ""
return {
'parsed_results': parsed_results,
'combined_md_content': combined_md,
'combined_cells_data': all_cells_data,
'temp_dir': temp_dir,
'session_id': session_id,
'total_pages': len(results)
}
except Exception as e:
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir, ignore_errors=True)
raise e
# ==================== Core Processing Function ====================
def process_image_inference(session_state, test_image_input, file_input,
prompt_mode, server_ip, server_port, min_pixels, max_pixels,
fitz_preprocess=False
):
"""Core function to handle image/PDF inference"""
# Use session_state instead of global variables
processing_results = session_state['processing_results']
pdf_cache = session_state['pdf_cache']
if processing_results.get('temp_dir') and os.path.exists(processing_results['temp_dir']):
try:
shutil.rmtree(processing_results['temp_dir'], ignore_errors=True)
except Exception as e:
print(f"Failed to clean up previous temporary directory: {e}")
# Reset processing results for the current session
session_state['processing_results'] = get_initial_session_state()['processing_results']
processing_results = session_state['processing_results']
current_config.update({
'ip': server_ip,
'port_vllm': server_port,
'min_pixels': min_pixels,
'max_pixels': max_pixels
})
# Update parser configuration
dots_parser.ip = server_ip
dots_parser.port = server_port
dots_parser.min_pixels = min_pixels
dots_parser.max_pixels = max_pixels
input_file_path = file_input if file_input else test_image_input
if not input_file_path:
return None, "Please upload image/PDF file or select test image", "", "", gr.update(value=None), None, "", session_state
file_ext = os.path.splitext(input_file_path)[1].lower()
try:
if file_ext == '.pdf':
# MINIMAL CHANGE: The `process_pdf_file` function is now inlined and uses session_state.
preview_image, page_info, session_state = load_file_for_preview(input_file_path, session_state)
pdf_result = parse_pdf_with_high_level_api(dots_parser, input_file_path, prompt_mode)
session_state['pdf_cache']["is_parsed"] = True
session_state['pdf_cache']["results"] = pdf_result['parsed_results']
processing_results.update({
'markdown_content': pdf_result['combined_md_content'],
'cells_data': pdf_result['combined_cells_data'],
'temp_dir': pdf_result['temp_dir'],
'session_id': pdf_result['session_id'],
'pdf_results': pdf_result['parsed_results']
})
total_elements = len(pdf_result['combined_cells_data'])
info_text = f"**PDF Information:**\n- Total Pages: {pdf_result['total_pages']}\n- Server: {current_config['ip']}:{current_config['port_vllm']}\n- Total Detected Elements: {total_elements}\n- Session ID: {pdf_result['session_id']}"
current_page_layout_image = preview_image
current_page_json = ""
if session_state['pdf_cache']["results"]:
first_result = session_state['pdf_cache']["results"][0]
if 'layout_image' in first_result and first_result['layout_image']:
current_page_layout_image = first_result['layout_image']
if first_result.get('cells_data'):
try:
current_page_json = json.dumps(first_result['cells_data'], ensure_ascii=False, indent=2)
except:
current_page_json = str(first_result['cells_data'])
download_zip_path = None
if pdf_result['temp_dir']:
download_zip_path = os.path.join(pdf_result['temp_dir'], f"layout_results_{pdf_result['session_id']}.zip")
with zipfile.ZipFile(download_zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, _, files in os.walk(pdf_result['temp_dir']):
for file in files:
if not file.endswith('.zip'): zipf.write(os.path.join(root, file), os.path.relpath(os.path.join(root, file), pdf_result['temp_dir']))
return (
current_page_layout_image, info_text, pdf_result['combined_md_content'] or "No markdown content generated",
pdf_result['combined_md_content'] or "No markdown content generated",
gr.update(value=download_zip_path, visible=bool(download_zip_path)), page_info, current_page_json, session_state
)
else: # Image processing
image = read_image_v2(input_file_path)
session_state['pdf_cache'] = get_initial_session_state()['pdf_cache']
original_image = image
parse_result = parse_image_with_high_level_api(dots_parser, image, prompt_mode, fitz_preprocess)
if parse_result['filtered']:
info_text = f"**Image Information:**\n- Original Size: {original_image.width} x {original_image.height}\n- Processing: JSON parsing failed, using cleaned text output\n- Server: {current_config['ip']}:{current_config['port_vllm']}\n- Session ID: {parse_result['session_id']}"
processing_results.update({
'original_image': original_image, 'markdown_content': parse_result['md_content'],
'temp_dir': parse_result['temp_dir'], 'session_id': parse_result['session_id'],
'result_paths': parse_result['result_paths']
})
return original_image, info_text, parse_result['md_content'], parse_result['md_content'], gr.update(visible=False), None, "", session_state
md_content_raw = parse_result['md_content'] or "No markdown content generated"
processing_results.update({
'original_image': original_image, 'layout_result': parse_result['layout_image'],
'markdown_content': parse_result['md_content'], 'cells_data': parse_result['cells_data'],
'temp_dir': parse_result['temp_dir'], 'session_id': parse_result['session_id'],
'result_paths': parse_result['result_paths']
})
num_elements = len(parse_result['cells_data']) if parse_result['cells_data'] else 0
info_text = f"**Image Information:**\n- Original Size: {original_image.width} x {original_image.height}\n- Model Input Size: {parse_result['input_width']} x {parse_result['input_height']}\n- Server: {current_config['ip']}:{current_config['port_vllm']}\n- Detected {num_elements} layout elements\n- Session ID: {parse_result['session_id']}"
current_json = json.dumps(parse_result['cells_data'], ensure_ascii=False, indent=2) if parse_result['cells_data'] else ""
download_zip_path = None
if parse_result['temp_dir']:
download_zip_path = os.path.join(parse_result['temp_dir'], f"layout_results_{parse_result['session_id']}.zip")
with zipfile.ZipFile(download_zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, _, files in os.walk(parse_result['temp_dir']):
for file in files:
if not file.endswith('.zip'): zipf.write(os.path.join(root, file), os.path.relpath(os.path.join(root, file), parse_result['temp_dir']))
return (
parse_result['layout_image'], info_text, parse_result['md_content'] or "No markdown content generated",
md_content_raw, gr.update(value=download_zip_path, visible=bool(download_zip_path)),
None, current_json, session_state
)
except Exception as e:
import traceback
traceback.print_exc()
return None, f"Error during processing: {e}", "", "", gr.update(value=None), None, "", session_state
# MINIMAL CHANGE: Functions now take `session_state` as an argument.
def clear_all_data(session_state):
"""Clears all data"""
processing_results = session_state['processing_results']
if processing_results.get('temp_dir') and os.path.exists(processing_results['temp_dir']):
try:
shutil.rmtree(processing_results['temp_dir'], ignore_errors=True)
except Exception as e:
print(f"Failed to clean up temporary directory: {e}")
# Reset the session state by returning a new initial state
new_session_state = get_initial_session_state()
return (
None, # Clear file input
"", # Clear test image selection
None, # Clear result image
"Waiting for processing results...", # Reset info display
"## Waiting for processing results...", # Reset Markdown display
"🕐 Waiting for parsing result...", # Clear raw Markdown text
gr.update(visible=False), # Hide download button
"0 / 0
", # Reset page info
"🕐 Waiting for parsing result...", # Clear current page JSON
new_session_state
)
def update_prompt_display(prompt_mode):
"""Updates the prompt display content"""
return dict_promptmode_to_prompt[prompt_mode]
# ==================== Gradio Interface ====================
def create_gradio_interface():
"""Creates the Gradio interface"""
# CSS styles, matching the reference style
css = """
#parse_button {
background: #FF576D !important; /* !important 确保覆盖主题默认样式 */
border-color: #FF576D !important;
}
/* 鼠标悬停时的颜色 */
#parse_button:hover {
background: #F72C49 !important;
border-color: #F72C49 !important;
}
#page_info_html {
display: flex;
align-items: center;
justify-content: center;
height: 100%;
margin: 0 12px;
}
#page_info_box {
padding: 8px 20px;
font-size: 16px;
border: 1px solid #bbb;
border-radius: 8px;
background-color: #f8f8f8;
text-align: center;
min-width: 80px;
box-shadow: 0 1px 3px rgba(0,0,0,0.1);
}
#markdown_output {
min-height: 800px;
overflow: auto;
}
footer {
visibility: hidden;
}
#info_box {
padding: 10px;
background-color: #f8f9fa;
border-radius: 8px;
border: 1px solid #dee2e6;
margin: 10px 0;
font-size: 14px;
}
#result_image {
border-radius: 8px;
}
#markdown_tabs {
height: 100%;
}
"""
with gr.Blocks(theme="ocean", css=css, title='dots.ocr') as demo:
session_state = gr.State(value=get_initial_session_state())
# Title
gr.HTML("""
🔍 dots.ocr
Supports image/PDF layout analysis and structured output
""")
with gr.Row():
# Left side: Input and Configuration
with gr.Column(scale=1, elem_id="left-panel"):
gr.Markdown("### 📥 Upload & Select")
file_input = gr.File(
label="Upload PDF/Image",
type="filepath",
file_types=[".pdf", ".jpg", ".jpeg", ".png"],
)
test_images = get_test_images()
test_image_input = gr.Dropdown(
label="Or Select an Example",
choices=[""] + test_images,
value="",
)
gr.Markdown("### ⚙️ Prompt & Actions")
prompt_mode = gr.Dropdown(
label="Select Prompt",
choices=["prompt_layout_all_en", "prompt_layout_only_en", "prompt_ocr"],
value="prompt_layout_all_en",
)
# Display current prompt content
prompt_display = gr.Textbox(
label="Current Prompt Content",
value=dict_promptmode_to_prompt[list(dict_promptmode_to_prompt.keys())[0]],
lines=4,
max_lines=8,
interactive=False,
show_copy_button=True
)
with gr.Row():
process_btn = gr.Button("🔍 Parse", variant="primary", scale=2, elem_id="parse_button")
clear_btn = gr.Button("🗑️ Clear", variant="secondary", scale=1)
with gr.Accordion("🛠️ Advanced Configuration", open=False):
fitz_preprocess = gr.Checkbox(
label="Enable fitz_preprocess for images",
value=True,
info="Processes image via a PDF-like pipeline (image->pdf->200dpi image). Recommended if your image DPI is low."
)
with gr.Row():
server_ip = gr.Textbox(label="Server IP", value=DEFAULT_CONFIG['ip'])
server_port = gr.Number(label="Port", value=DEFAULT_CONFIG['port_vllm'], precision=0)
with gr.Row():
min_pixels = gr.Number(label="Min Pixels", value=DEFAULT_CONFIG['min_pixels'], precision=0)
max_pixels = gr.Number(label="Max Pixels", value=DEFAULT_CONFIG['max_pixels'], precision=0)
# Right side: Result Display
with gr.Column(scale=6, variant="compact"):
with gr.Row():
# Result Image
with gr.Column(scale=3):
gr.Markdown("### 👁️ File Preview")
result_image = gr.Image(
label="Layout Preview",
visible=True,
height=800,
show_label=False
)
# Page navigation (shown during PDF preview)
with gr.Row():
prev_btn = gr.Button("⬅ Previous", size="sm")
page_info = gr.HTML(
value="0 / 0
",
elem_id="page_info_html"
)
next_btn = gr.Button("Next ➡", size="sm")
# Info Display
info_display = gr.Markdown(
"Waiting for processing results...",
elem_id="info_box"
)
# Markdown Result
with gr.Column(scale=3):
gr.Markdown("### ✔️ Result Display")
with gr.Tabs(elem_id="markdown_tabs"):
with gr.TabItem("Markdown Render Preview"):
md_output = gr.Markdown(
"## Please click the parse button to parse or select for single-task recognition...",
max_height=600,
latex_delimiters=[
{"left": "$$", "right": "$$", "display": True},
{"left": "$", "right": "$", "display": False}
],
show_copy_button=False,
elem_id="markdown_output"
)
with gr.TabItem("Markdown Raw Text"):
md_raw_output = gr.Textbox(
value="🕐 Waiting for parsing result...",
label="Markdown Raw Text",
max_lines=100,
lines=38,
show_copy_button=True,
elem_id="markdown_output",
show_label=False
)
with gr.TabItem("Current Page JSON"):
current_page_json = gr.Textbox(
value="🕐 Waiting for parsing result...",
label="Current Page JSON",
max_lines=100,
lines=38,
show_copy_button=True,
elem_id="markdown_output",
show_label=False
)
# Download Button
with gr.Row():
download_btn = gr.DownloadButton(
"⬇️ Download Results",
visible=False
)
# When the prompt mode changes, update the display content
prompt_mode.change(
fn=update_prompt_display,
inputs=prompt_mode,
outputs=prompt_display,
)
# Show preview on file upload
file_input.upload(
# fn=lambda file_data, state: load_file_for_preview(file_data, state),
fn=load_file_for_preview,
inputs=[file_input, session_state],
outputs=[result_image, page_info, session_state]
)
# Also handle test image selection
test_image_input.change(
# fn=lambda path, state: load_file_for_preview(path, state),
fn=load_file_for_preview,
inputs=[test_image_input, session_state],
outputs=[result_image, page_info, session_state]
)
prev_btn.click(
fn=lambda s: turn_page("prev", s),
inputs=[session_state],
outputs=[result_image, page_info, current_page_json, session_state]
)
next_btn.click(
fn=lambda s: turn_page("next", s),
inputs=[session_state],
outputs=[result_image, page_info, current_page_json, session_state]
)
process_btn.click(
fn=process_image_inference,
inputs=[
session_state, test_image_input, file_input,
prompt_mode, server_ip, server_port, min_pixels, max_pixels,
fitz_preprocess
],
outputs=[
result_image, info_display, md_output, md_raw_output,
download_btn, page_info, current_page_json, session_state
]
)
clear_btn.click(
fn=clear_all_data,
inputs=[session_state],
outputs=[
file_input, test_image_input,
result_image, info_display, md_output, md_raw_output,
download_btn, page_info, current_page_json, session_state
]
)
return demo
# ==================== Main Program ====================
if __name__ == "__main__":
import sys
port = int(sys.argv[1])
demo = create_gradio_interface()
demo.queue().launch(
server_name="0.0.0.0",
server_port=port,
debug=True
)
================================================
FILE: demo/demo_gradio_annotion.py
================================================
"""
Layout Inference Web Application with Gradio - Annotation Version
A Gradio-based layout inference tool that supports image uploads and multiple backend inference engines.
This version adds an image annotation feature, allowing users to draw bounding boxes on an image and send both the image and the boxes to the model.
"""
import gradio as gr
import json
import os
import io
import tempfile
import base64
import zipfile
import uuid
import re
from pathlib import Path
from PIL import Image
import requests
from gradio_image_annotation import image_annotator
# Local utility imports
from dots_ocr.utils import dict_promptmode_to_prompt
from dots_ocr.utils.consts import MIN_PIXELS, MAX_PIXELS
from dots_ocr.utils.demo_utils.display import read_image
from dots_ocr.utils.doc_utils import load_images_from_pdf
# Add DotsOCRParser import
from dots_ocr.parser import DotsOCRParser
# ==================== Configuration ====================
DEFAULT_CONFIG = {
'ip': "127.0.0.1",
'port_vllm': 8000,
'min_pixels': MIN_PIXELS,
'max_pixels': MAX_PIXELS,
'test_images_dir': "./assets/showcase_origin",
}
# ==================== Global Variables ====================
# Store the current configuration
current_config = DEFAULT_CONFIG.copy()
# Create a DotsOCRParser instance
dots_parser = DotsOCRParser(
ip=DEFAULT_CONFIG['ip'],
port=DEFAULT_CONFIG['port_vllm'],
dpi=200,
min_pixels=DEFAULT_CONFIG['min_pixels'],
max_pixels=DEFAULT_CONFIG['max_pixels']
)
# Store processing results
processing_results = {
'original_image': None,
'processed_image': None,
'layout_result': None,
'markdown_content': None,
'cells_data': None,
'temp_dir': None,
'session_id': None,
'result_paths': None,
'annotation_data': None # Store annotation data
}
# ==================== Utility Functions ====================
def read_image_v2(img):
"""Reads an image, supporting URLs and local paths."""
if isinstance(img, str) and img.startswith(("http://", "https://")):
with requests.get(img, stream=True) as response:
response.raise_for_status()
img = Image.open(io.BytesIO(response.content))
elif isinstance(img, str):
img, _, _ = read_image(img, use_native=True)
elif isinstance(img, Image.Image):
pass
else:
raise ValueError(f"Invalid image type: {type(img)}")
return img
def get_test_images():
"""Gets the list of test images."""
test_images = []
test_dir = current_config['test_images_dir']
if os.path.exists(test_dir):
test_images = [os.path.join(test_dir, name) for name in os.listdir(test_dir)
if name.lower().endswith(('.png', '.jpg', '.jpeg'))]
return test_images
def create_temp_session_dir():
"""Creates a unique temporary directory for each processing request."""
session_id = uuid.uuid4().hex[:8]
temp_dir = os.path.join(tempfile.gettempdir(), f"dots_ocr_demo_{session_id}")
os.makedirs(temp_dir, exist_ok=True)
return temp_dir, session_id
def parse_image_with_bbox(parser, image, prompt_mode, bbox=None, fitz_preprocess=False):
"""
Processes an image using DotsOCRParser, with support for the bbox parameter.
"""
# Create a temporary session directory
temp_dir, session_id = create_temp_session_dir()
try:
# Save the PIL Image to a temporary file
temp_image_path = os.path.join(temp_dir, f"input_{session_id}.png")
image.save(temp_image_path, "PNG")
# Use the high-level parse_image interface, passing the bbox parameter
filename = f"demo_{session_id}"
results = parser.parse_image(
input_path=temp_image_path,
filename=filename,
prompt_mode=prompt_mode,
save_dir=temp_dir,
bbox=bbox,
fitz_preprocess=fitz_preprocess
)
# Parse the results
if not results:
raise ValueError("No results returned from parser")
result = results[0] # parse_image returns a list with a single result
# Read the result files
layout_image = None
cells_data = None
md_content = None
filtered = False
# Read the layout image
if 'layout_image_path' in result and os.path.exists(result['layout_image_path']):
layout_image = Image.open(result['layout_image_path'])
# Read the JSON data
if 'layout_info_path' in result and os.path.exists(result['layout_info_path']):
with open(result['layout_info_path'], 'r', encoding='utf-8') as f:
cells_data = json.load(f)
# Read the Markdown content
if 'md_content_path' in result and os.path.exists(result['md_content_path']):
with open(result['md_content_path'], 'r', encoding='utf-8') as f:
md_content = f.read()
# Check for the original response file (if JSON parsing fails)
if 'filtered' in result:
filtered = result['filtered']
return {
'layout_image': layout_image,
'cells_data': cells_data,
'md_content': md_content,
'filtered': filtered,
'temp_dir': temp_dir,
'session_id': session_id,
'result_paths': result
}
except Exception as e:
# Clean up the temporary directory on error
import shutil
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir, ignore_errors=True)
raise e
def process_annotation_data(annotation_data):
"""Processes annotation data, converting it to the format required by the model."""
if not annotation_data or not annotation_data.get('boxes'):
return None, None
# Get image and box data
image = annotation_data.get('image')
boxes = annotation_data.get('boxes', [])
if not boxes:
return image, None
# Ensure the image is in PIL Image format
if image is not None:
import numpy as np
if isinstance(image, np.ndarray):
image = Image.fromarray(image)
elif not isinstance(image, Image.Image):
# If it's another format, try to convert it
try:
image = Image.open(image) if isinstance(image, str) else Image.fromarray(image)
except Exception as e:
print(f"Image format conversion failed: {e}")
return None, None
# Get the coordinate information of the box (only one box)
box = boxes[0]
bbox = [box['xmin'], box['ymin'], box['xmax'], box['ymax']]
return image, bbox
# ==================== Core Processing Function ====================
def process_image_inference_with_annotation(annotation_data, test_image_input,
prompt_mode, server_ip, server_port, min_pixels, max_pixels,
fitz_preprocess=False
):
"""Core function for image inference, supporting annotation data."""
global current_config, processing_results, dots_parser
# First, clean up previous processing results
if processing_results.get('temp_dir') and os.path.exists(processing_results['temp_dir']):
import shutil
try:
shutil.rmtree(processing_results['temp_dir'], ignore_errors=True)
except Exception as e:
print(f"Failed to clean up previous temporary directory: {e}")
# Reset processing results
processing_results = {
'original_image': None,
'processed_image': None,
'layout_result': None,
'markdown_content': None,
'cells_data': None,
'temp_dir': None,
'session_id': None,
'result_paths': None,
'annotation_data': annotation_data
}
# Update configuration
current_config.update({
'ip': server_ip,
'port_vllm': server_port,
'min_pixels': min_pixels,
'max_pixels': max_pixels
})
# Update parser configuration
dots_parser.ip = server_ip
dots_parser.port = server_port
dots_parser.min_pixels = min_pixels
dots_parser.max_pixels = max_pixels
# Determine the input source and process annotation data
image = None
bbox = None
# Prioritize processing annotation data
if annotation_data and annotation_data.get('image') is not None:
image, bbox = process_annotation_data(annotation_data)
if image is not None:
# If there's a bbox, force the use of 'prompt_grounding_ocr' mode
assert bbox is not None
prompt_mode = "prompt_grounding_ocr"
# If there's no annotation data, check the test image input
if image is None and test_image_input and test_image_input != "":
try:
image = read_image_v2(test_image_input)
except Exception as e:
return None, f"Failed to read test image: {e}", "", "", gr.update(value=None), ""
if image is None:
return None, "Please select a test image or add an image in the annotation component", "", "", gr.update(value=None), ""
if bbox is None:
return None, "Please select a bounding box by mouse", "Please select a bounding box by mouse", "", "", gr.update(value=None)
try:
# Process using DotsOCRParser, passing the bbox parameter
original_image = image
parse_result = parse_image_with_bbox(dots_parser, image, prompt_mode, bbox, fitz_preprocess)
# Extract parsing results
layout_image = parse_result['layout_image']
cells_data = parse_result['cells_data']
md_content = parse_result['md_content']
filtered = parse_result['filtered']
# Store the results
processing_results.update({
'original_image': original_image,
'processed_image': None,
'layout_result': layout_image,
'markdown_content': md_content,
'cells_data': cells_data,
'temp_dir': parse_result['temp_dir'],
'session_id': parse_result['session_id'],
'result_paths': parse_result['result_paths'],
'annotation_data': annotation_data
})
# Handle the case where parsing fails
if filtered:
info_text = f"""
**Image Information:**
- Original Dimensions: {original_image.width} x {original_image.height}
- Processing Mode: {'Region OCR' if bbox else 'Full Image OCR'}
- Processing Status: JSON parsing failed, using cleaned text output
- Server: {current_config['ip']}:{current_config['port_vllm']}
- Session ID: {parse_result['session_id']}
- Box Coordinates: {bbox if bbox else 'None'}
"""
return (
md_content or "No markdown content generated",
info_text,
md_content or "No markdown content generated",
md_content or "No markdown content generated",
gr.update(visible=False),
""
)
# Handle the case where JSON parsing succeeds
num_elements = len(cells_data) if cells_data else 0
info_text = f"""
**Image Information:**
- Original Dimensions: {original_image.width} x {original_image.height}
- Processing Mode: {'Region OCR' if bbox else 'Full Image OCR'}
- Server: {current_config['ip']}:{current_config['port_vllm']}
- Detected {num_elements} layout elements
- Session ID: {parse_result['session_id']}
- Box Coordinates: {bbox if bbox else 'None'}
"""
# Current page JSON output
current_json = ""
if cells_data:
try:
current_json = json.dumps(cells_data, ensure_ascii=False, indent=2)
except:
current_json = str(cells_data)
# Create a downloadable ZIP file
download_zip_path = None
if parse_result['temp_dir']:
download_zip_path = os.path.join(parse_result['temp_dir'], f"layout_results_{parse_result['session_id']}.zip")
try:
with zipfile.ZipFile(download_zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, dirs, files in os.walk(parse_result['temp_dir']):
for file in files:
if file.endswith('.zip'):
continue
file_path = os.path.join(root, file)
arcname = os.path.relpath(file_path, parse_result['temp_dir'])
zipf.write(file_path, arcname)
except Exception as e:
print(f"Failed to create download ZIP: {e}")
download_zip_path = None
return (
md_content or "No markdown content generated",
info_text,
md_content or "No markdown content generated",
md_content or "No markdown content generated",
gr.update(value=download_zip_path, visible=True) if download_zip_path else gr.update(visible=False),
current_json
)
except Exception as e:
return f"An error occurred during processing: {e}", f"An error occurred during processing: {e}", "", "", gr.update(value=None), ""
def load_image_to_annotator(test_image_input):
"""Loads an image into the annotation component."""
image = None
# Check the test image input
if test_image_input and test_image_input != "":
try:
image = read_image_v2(test_image_input)
except Exception as e:
return None
if image is None:
return None
# Return the format required by the annotation component
return {
"image": image,
"boxes": []
}
def clear_all_data():
"""Clears all data."""
global processing_results
# Clean up the temporary directory
if processing_results.get('temp_dir') and os.path.exists(processing_results['temp_dir']):
import shutil
try:
shutil.rmtree(processing_results['temp_dir'], ignore_errors=True)
except Exception as e:
print(f"Failed to clean up temporary directory: {e}")
# Reset processing results
processing_results = {
'original_image': None,
'processed_image': None,
'layout_result': None,
'markdown_content': None,
'cells_data': None,
'temp_dir': None,
'session_id': None,
'result_paths': None,
'annotation_data': None
}
return (
"", # Clear test image selection
None, # Clear annotation component
"Waiting for processing results...", # Reset info display
"## Waiting for processing results...", # Reset Markdown display
"🕐 Waiting for parsing results...", # Clear raw Markdown text
gr.update(visible=False), # Hide download button
"🕐 Waiting for parsing results..." # Clear JSON
)
def update_prompt_display(prompt_mode):
"""Updates the displayed prompt content."""
return dict_promptmode_to_prompt[prompt_mode]
# ==================== Gradio Interface ====================
def create_gradio_interface():
"""Creates the Gradio interface."""
# CSS styling to match the reference style
css = """
footer {
visibility: hidden;
}
#info_box {
padding: 10px;
background-color: #f8f9fa;
border-radius: 8px;
border: 1px solid #dee2e6;
margin: 10px 0;
font-size: 14px;
}
#markdown_tabs {
height: 100%;
}
#annotation_component {
border-radius: 8px;
}
"""
with gr.Blocks(theme="ocean", css=css, title='dots.ocr - Annotation') as demo:
# Title
gr.HTML("""
🔍 dots.ocr - Annotation Version
Supports image annotation, drawing boxes, and sending box information to the model for OCR.
""")
with gr.Row():
# Left side: Input and Configuration
with gr.Column(scale=1, variant="compact"):
gr.Markdown("### 📁 Select Example")
test_images = get_test_images()
test_image_input = gr.Dropdown(
label="Select Example",
choices=[""] + test_images,
value="",
show_label=True
)
# Button to load image into the annotation component
load_btn = gr.Button("📷 Load Image to Annotation Area", variant="secondary")
prompt_mode = gr.Dropdown(
label="Select Prompt",
# choices=["prompt_layout_all_en", "prompt_layout_only_en", "prompt_ocr", "prompt_grounding_ocr"],
choices=["prompt_grounding_ocr"],
value="prompt_grounding_ocr",
show_label=True,
info="If a box is drawn, 'prompt_grounding_ocr' mode will be used automatically."
)
# Display the current prompt content
prompt_display = gr.Textbox(
label="Current Prompt Content",
# value=dict_promptmode_to_prompt[list(dict_promptmode_to_prompt.keys())[0]],
value=dict_promptmode_to_prompt["prompt_grounding_ocr"],
lines=4,
max_lines=8,
interactive=False,
show_copy_button=True
)
gr.Markdown("### ⚙️ Actions")
process_btn = gr.Button("🔍 Parse", variant="primary")
clear_btn = gr.Button("🗑️ Clear", variant="secondary")
gr.Markdown("### 🛠️ Configuration")
fitz_preprocess = gr.Checkbox(
label="Enable fitz_preprocess",
value=False,
info="Performs fitz preprocessing on the image input, converting the image to a PDF and then to a 200dpi image."
)
with gr.Row():
server_ip = gr.Textbox(
label="Server IP",
value=DEFAULT_CONFIG['ip']
)
server_port = gr.Number(
label="Port",
value=DEFAULT_CONFIG['port_vllm'],
precision=0
)
with gr.Row():
min_pixels = gr.Number(
label="Min Pixels",
value=DEFAULT_CONFIG['min_pixels'],
precision=0
)
max_pixels = gr.Number(
label="Max Pixels",
value=DEFAULT_CONFIG['max_pixels'],
precision=0
)
# Right side: Result Display
with gr.Column(scale=6, variant="compact"):
with gr.Row():
# Image Annotation Area
with gr.Column(scale=3):
gr.Markdown("### 🎯 Image Annotation Area")
gr.Markdown("""
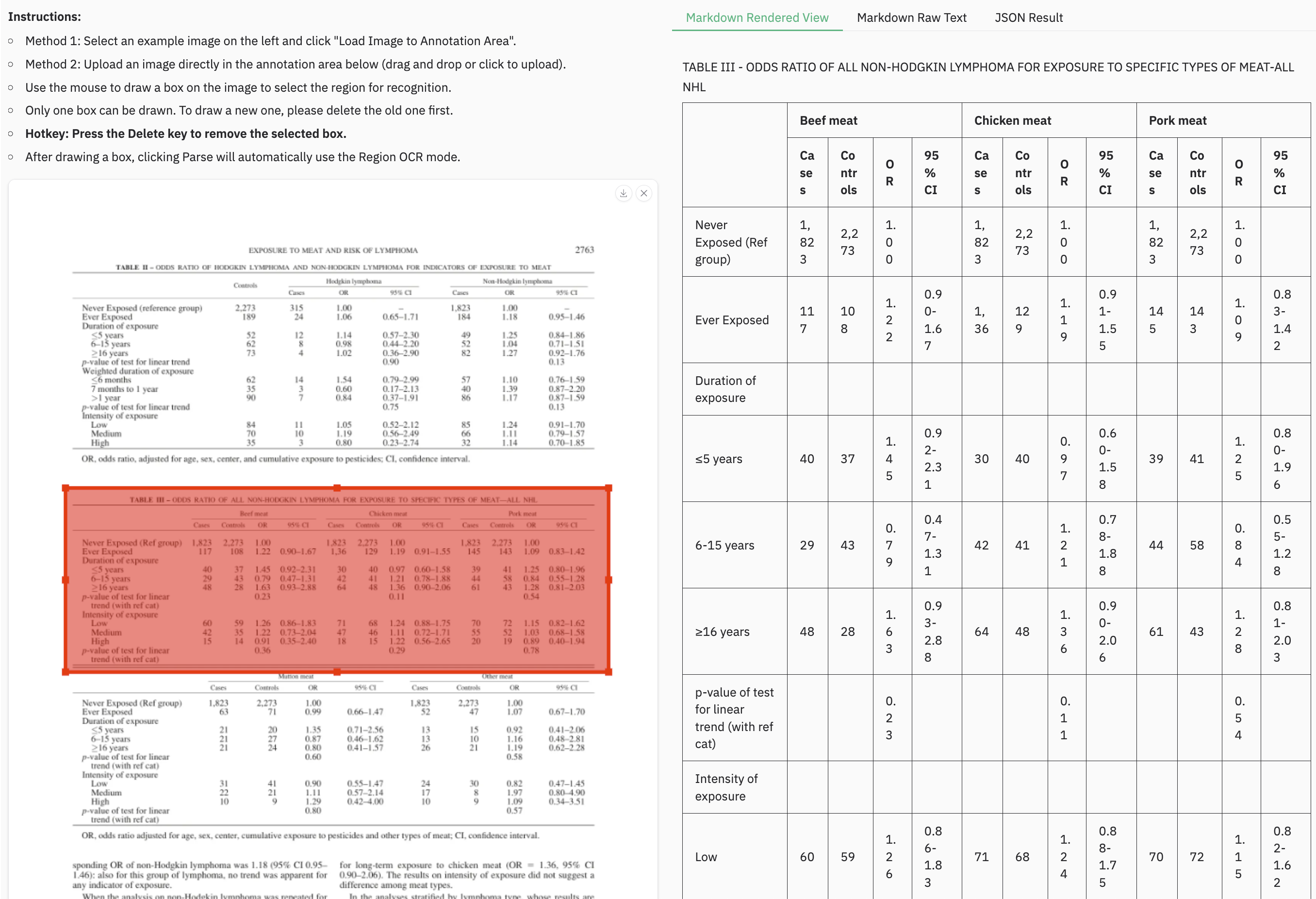
**Instructions:**
- Method 1: Select an example image on the left and click "Load Image to Annotation Area".
- Method 2: Upload an image directly in the annotation area below (drag and drop or click to upload).
- Use the mouse to draw a box on the image to select the region for recognition.
- Only one box can be drawn. To draw a new one, please delete the old one first.
- **Hotkey: Press the Delete key to remove the selected box.**
- After drawing a box, clicking Parse will automatically use the Region OCR mode.
""")
annotator = image_annotator(
value=None,
label="Image Annotation",
height=600,
show_label=False,
elem_id="annotation_component",
single_box=True, # Only allow one box; a new box will replace the old one
box_min_size=10,
interactive=True,
disable_edit_boxes=True, # Disable the edit dialog
label_list=["OCR Region"], # Set the default label
label_colors=[(255, 0, 0)], # Set color to red
use_default_label=True, # Use the default label
image_type="pil" # Ensure it returns a PIL Image format
)
# Information Display
info_display = gr.Markdown(
"Waiting for processing results...",
elem_id="info_box"
)
# Result Display Area
with gr.Column(scale=3):
gr.Markdown("### ✅ Results")
with gr.Tabs(elem_id="markdown_tabs"):
with gr.TabItem("Markdown Rendered View"):
md_output = gr.Markdown(
"## Please upload an image and click the Parse button for recognition...",
label="Markdown Preview",
max_height=1000,
latex_delimiters=[
{"left": "$$", "right": "$$", "display": True},
{"left": "$", "right": "$", "display": False},
],
show_copy_button=False,
elem_id="markdown_output"
)
with gr.TabItem("Markdown Raw Text"):
md_raw_output = gr.Textbox(
value="🕐 Waiting for parsing results...",
label="Markdown Raw Text",
max_lines=100,
lines=38,
show_copy_button=True,
elem_id="markdown_output",
show_label=False
)
with gr.TabItem("JSON Result"):
json_output = gr.Textbox(
value="🕐 Waiting for parsing results...",
label="JSON Result",
max_lines=100,
lines=38,
show_copy_button=True,
elem_id="markdown_output",
show_label=False
)
# Download Button
with gr.Row():
download_btn = gr.DownloadButton(
"⬇️ Download Results",
visible=False
)
# Event Binding
# When the prompt mode changes, update the displayed content
prompt_mode.change(
fn=update_prompt_display,
inputs=prompt_mode,
outputs=prompt_display,
show_progress=False
)
# Load image into the annotation component
load_btn.click(
fn=load_image_to_annotator,
inputs=[test_image_input],
outputs=annotator,
show_progress=False
)
# Process Inference
process_btn.click(
fn=process_image_inference_with_annotation,
inputs=[
annotator, test_image_input,
prompt_mode, server_ip, server_port, min_pixels, max_pixels,
fitz_preprocess
],
outputs=[
md_output, info_display, md_raw_output, md_raw_output,
download_btn, json_output
],
show_progress=True
)
# Clear Data
clear_btn.click(
fn=clear_all_data,
outputs=[
test_image_input, annotator,
info_display, md_output, md_raw_output,
download_btn, json_output
],
show_progress=False
)
return demo
# ==================== Main Program ====================
if __name__ == "__main__":
demo = create_gradio_interface()
demo.queue().launch(
server_name="0.0.0.0",
server_port=7861, # Use a different port to avoid conflicts
debug=True
)
================================================
FILE: demo/demo_gradio_batch.py
================================================
import os
import io
import uuid
import json
import zipfile
import tempfile
import threading
import queue
import shutil
from pathlib import Path
from PIL import Image
import requests
import gradio as gr
import re
import math
import datetime
# Local project imports (assumed available)
from dots_ocr.utils import dict_promptmode_to_prompt
from dots_ocr.utils.consts import MIN_PIXELS, MAX_PIXELS
from dots_ocr.utils.demo_utils.display import read_image
from dots_ocr.parser import DotsOCRParser
# ---------------- Config & globals ----------------
DEFAULT_CONFIG = {
"ip": "127.0.0.1",
"port_vllm": 8000,
"min_pixels": MIN_PIXELS,
"max_pixels": MAX_PIXELS,
}
# Absolute constraints discovered from runtime:
ABS_MIN_PIXELS = 3136
ABS_MAX_PIXELS = 11289600
current_config = DEFAULT_CONFIG.copy()
# default parser instance (can be overridden per-task)
dots_parser = DotsOCRParser(
ip=DEFAULT_CONFIG["ip"],
port=DEFAULT_CONFIG["port_vllm"],
dpi=200,
min_pixels=DEFAULT_CONFIG["min_pixels"],
max_pixels=DEFAULT_CONFIG["max_pixels"],
)
RESULTS_CACHE = {} # rid -> result dict or placeholder
TASK_QUEUE = queue.Queue()
# Worker pool for background processing (adjustable via UI)
WORKER_THREADS = []
MAX_CONCURRENCY = 6
THREAD_LOCK = threading.Lock()
RETRY_COUNTS = {} # rid -> attempts
MAX_AUTO_RETRIES = 5
RETRY_BACKOFF_BASE = 1.7
DEFAULT_SCRIPT_TEMPLATE = """# 高级脚本使用说明
# 提供对象: api
# 日志: 使用 print(...) 或 debug(...) 输出到下方“脚本日志”实时区域。
# api.get_ids() -> [rid,...] 按当前 UI 顺序返回
# api.get_status(rid) -> {'status','ui': {'tab','nohf','source'}, 'filtered': bool, 'input_width': int, 'input_height': int}
# api.get_texts(rid) -> {
# 'md': 原始 Markdown, 'md_nohf': 原始 NOHF Markdown, 'json': 原始 JSON,
# 'md_edit': 编辑版 Markdown 或 None, 'md_nohf_edit': 编辑版 NOHF Markdown 或 None, 'json_edit': 编辑版 JSON 或 None
# }
# api.choose_texts(rid, prefer_ui=True, prefer_edit=True, prefer_nohf=None) -> {'md','json'}
# - prefer_ui: True 时根据当前 UI 的 NOHF/来源选择内容
# - prefer_edit: True 时优先用编辑内容(若存在)
# - prefer_nohf: 显式指定是否使用 NOHF(覆盖 UI),None 表示跟随 UI
# api.list_paths(rid) -> {
# 'temp_dir': str, 'session_id': str,
# 'result': {'md':path,'md_nohf':path,'json':path,'layout':path or None,'image':path or None},
# 'edited': {'md':path or None,'md_nohf':path or None,'json':path or None}
# }
# api.path_exists(path) -> bool 判断路径是否存在
# api.build_export(name='custom') -> ExportBuilder
# ExportBuilder:
# .add_text('dir/file.md', '...') 写入文本
# .add_bytes('bin/data.bin', b'...') 写入二进制
# .add_file('/abs/path/file.md', 'dir/file.md') 拷贝已有文件
# .mkdir('subdir/') 创建目录
# .finalize() -> zip_path 打包为 zip 并返回路径
#
# 约定: 定义 main(api) 并返回以下之一:
# - ExportBuilder 实例(将自动 finalize)
# - 目录路径或文件路径(目录将被打包为 zip)
# - None(若存在变量 export=ExportBuilder,将自动 finalize)
#
# 示例:按 UI 所见优先使用“编辑源码”与 NOHF,导出每个结果的 md/json,同时附带原始与编辑文件
def main(api):
ids = api.get_ids()
eb = api.build_export('custom_export')
for i, rid in enumerate(ids, start=1):
st = api.get_status(rid)
if st['status'] != 'done':
continue
choice = api.choose_texts(rid, prefer_ui=True, prefer_edit=True)
eb.add_text(f'result_{i}_{rid}/content.md', choice['md'] or '')
eb.add_text(f'result_{i}_{rid}/data.json', choice['json'] or '{}')
paths = api.list_paths(rid)
# 附带原始文件
for p in (paths.get('result') or {}).values():
if p and api.path_exists(p):
name = Path(p).name
eb.add_file(p, f'result_{i}_{rid}/raw/{name}')
# 附带编辑文件
for p in (paths.get('edited') or {}).values():
if p and api.path_exists(p):
name = Path(p).name
eb.add_file(p, f'result_{i}_{rid}/edited/{name}')
return eb
"""
# ---------------- Helpers ----------------
def read_image_v2(img):
"""Read image from URL or local path / PIL.Image. Supports file paths and URLs."""
if isinstance(img, Image.Image):
return img
if isinstance(img, str) and img.startswith(("http://", "https://")):
with requests.get(img, stream=True) as r:
r.raise_for_status()
return Image.open(io.BytesIO(r.content)).convert("RGB")
if isinstance(img, str) and os.path.exists(img):
return Image.open(img).convert("RGB")
try:
img_res = read_image(img, use_native=True)
if isinstance(img_res, tuple) and isinstance(img_res[0], Image.Image):
return img_res[0]
except Exception:
pass
raise ValueError(f"Unsupported image input: {type(img)} / {repr(img)[:200]}")
def create_temp_session_dir():
session_id = uuid.uuid4().hex[:8]
temp_dir = os.path.join(tempfile.gettempdir(), f"dots_ocr_demo_{session_id}")
os.makedirs(temp_dir, exist_ok=True)
return temp_dir, session_id
def classify_parse_failure(exc, min_p, max_p):
"""Return a user-friendly error message for known failure causes."""
msg = str(exc)
reasons = []
# Absolute & semantic constraints
if min_p < ABS_MIN_PIXELS:
reasons.append(
f"Min Pixels 过小:{min_p},必须 >= {ABS_MIN_PIXELS}。建议提高 Min Pixels。"
)
if max_p > ABS_MAX_PIXELS:
reasons.append(
f"Max Pixels 过大:{max_p},必须 <= {ABS_MAX_PIXELS}。建议降低 Max Pixels。"
)
if min_p >= max_p:
reasons.append(
f"像素参数不合法:Min Pixels({min_p}) >= Max Pixels({max_p}),必须满足 Min Pixels < Max Pixels。"
)
lower = msg.lower()
if "no results returned from parser" in lower or "no results returned" in lower:
reasons.append(
"解析未返回结果。可能原因:图像过小、Min Pixels 设置过小或过滤过强。"
f"建议:Min Pixels >= {ABS_MIN_PIXELS} 且 Max Pixels <= {ABS_MAX_PIXELS}。"
)
if "failed to read input" in lower or "cannot identify image file" in lower:
reasons.append("无法读取输入文件,请确认文件是否为有效图片或PDF。")
if ("connection" in lower and "refused" in lower) or ("connectionerror" in lower):
reasons.append("无法连接后端推理服务,请检查 Server IP/Port 与服务状态。")
if not reasons:
reasons.append(f"未知错误:{msg}")
detail = "\n".join(f"- {r}" for r in reasons)
cfg = f"(当前参数:min_pixels={min_p}, max_pixels={max_p})"
return f"解析失败:\n{detail}\n{cfg}"
def _is_transient_backend_error(exc: Exception):
lower = str(exc).lower()
# Common signals: connection refused/reset, timeout, gateway, service unavailable
keywords = [
"connection refused",
"connectionerror",
"timeout",
"timed out",
"gateway",
"service unavailable",
"failed to establish a new connection",
"max retries exceeded",
"read timeout",
"connect timeout",
]
return any(k in lower for k in keywords)
def parse_image_with_high_level_api(parser, image, prompt_mode, fitz_preprocess=False):
"""
Calls parser.parse_image with a PIL image (or accepts image path if parser expects path).
Returns dictionary with artifacts. Keeps a temp PNG of the input for traceability.
"""
temp_dir, session_id = create_temp_session_dir()
if not isinstance(image, Image.Image):
image = read_image_v2(image)
temp_image_path = os.path.join(temp_dir, f"input_{session_id}.png")
image.save(temp_image_path, "PNG")
filename = f"demo_{session_id}"
results = parser.parse_image(
input_path=image,
filename=filename,
prompt_mode=prompt_mode,
save_dir=temp_dir,
fitz_preprocess=fitz_preprocess,
)
if not results:
raise RuntimeError("No results returned from parser")
result = results[0]
layout_image = None
if result.get("layout_image_path") and os.path.exists(result["layout_image_path"]):
try:
layout_image = Image.open(result["layout_image_path"]).convert("RGB")
except Exception:
layout_image = None
cells_data = None
if result.get("layout_info_path") and os.path.exists(result["layout_info_path"]):
with open(result["layout_info_path"], "r", encoding="utf-8") as f:
cells_data = json.load(f)
md_content = None
if result.get("md_content_path") and os.path.exists(result["md_content_path"]):
with open(result["md_content_path"], "r", encoding="utf-8") as f:
md_content = f.read()
md_content_nohf = None
if result.get("md_content_nohf_path") and os.path.exists(
result["md_content_nohf_path"]
):
with open(result["md_content_nohf_path"], "r", encoding="utf-8") as f:
md_content_nohf = f.read()
json_code = ""
if cells_data is not None:
try:
json_code = json.dumps(cells_data, ensure_ascii=False, indent=2)
except Exception:
json_code = str(cells_data)
return {
"original_image": image,
"layout_image": layout_image,
"cells_data": cells_data,
"md_content": md_content,
"md_content_nohf": md_content_nohf,
"json_code": json_code,
"filtered": result.get("filtered", False),
"temp_dir": temp_dir,
"session_id": session_id,
"result_paths": result,
"input_width": result.get("input_width", 0),
"input_height": result.get("input_height", 0),
"input_temp_path": temp_image_path,
}
def _validate_pixels(min_p, max_p):
"""Coerce pixel parameters. Do NOT auto-swap; semantic errors are handled by pre-validation."""
try:
min_p = int(min_p)
except Exception:
min_p = DEFAULT_CONFIG["min_pixels"]
try:
max_p = int(max_p)
except Exception:
max_p = DEFAULT_CONFIG["max_pixels"]
if min_p <= 0:
min_p = DEFAULT_CONFIG["min_pixels"]
if max_p <= 0:
max_p = DEFAULT_CONFIG["max_pixels"]
return min_p, max_p
def _set_parser_config(server_ip, server_port, min_pixels, max_pixels):
min_pixels, max_pixels = _validate_pixels(min_pixels, max_pixels)
current_config.update(
{
"ip": server_ip,
"port_vllm": int(server_port),
"min_pixels": min_pixels,
"max_pixels": max_pixels,
}
)
dots_parser.ip = server_ip
dots_parser.port = int(server_port)
dots_parser.min_pixels = min_pixels
dots_parser.max_pixels = max_pixels
def purge_queue(rid):
"""Best-effort remove tasks matching rid from queue."""
pending = []
try:
while True:
task = TASK_QUEUE.get_nowait()
if task and isinstance(task, tuple):
if task[0] != rid:
pending.append(task)
TASK_QUEUE.task_done()
except queue.Empty:
pass
for t in pending:
TASK_QUEUE.put(t)
# ---------------- Export helpers ----------------
def export_one_rid(rid):
st = RESULTS_CACHE.get(rid)
if not st:
return None
temp_dir = st.get("temp_dir")
if not temp_dir or not os.path.isdir(temp_dir):
return None
out_dir, _sess = create_temp_session_dir()
zip_path = os.path.join(out_dir, f"export_{rid}.zip")
with zipfile.ZipFile(zip_path, "w", zipfile.ZIP_DEFLATED) as zf:
for rt, _, files in os.walk(temp_dir):
for f in files:
src = os.path.join(rt, f)
rel = os.path.relpath(src, temp_dir)
zf.write(src, os.path.join(f"result_{rid}", rel))
return zip_path
def ensure_export_ready(rid):
"""Create and cache export zip path if not present."""
st = RESULTS_CACHE.get(rid) or {}
if not st or st.get("status") != "done":
return None
path = st.get("export_path")
if path and os.path.exists(path):
return path
path = export_one_rid(rid)
if path:
st["export_path"] = path
RESULTS_CACHE[rid] = st
return path
# ---------------- Script API & execution ----------------
class ExportBuilder:
def __init__(self, name=None):
root, sid = create_temp_session_dir()
sub = f"script_export_{sid}"
if name:
sub = f"{name}_{sid}"
self.root_dir = os.path.join(root, sub)
os.makedirs(self.root_dir, exist_ok=True)
self._final_zip = None
def _abspath(self, rel_path: str):
rel_path = rel_path.lstrip("/\\")
return os.path.join(self.root_dir, rel_path)
def mkdir(self, rel_dir: str):
p = self._abspath(rel_dir)
os.makedirs(p, exist_ok=True)
return p
def add_text(self, rel_path: str, content: str, encoding: str = "utf-8"):
p = self._abspath(rel_path)
os.makedirs(os.path.dirname(p), exist_ok=True)
with open(p, "w", encoding=encoding) as f:
f.write("" if content is None else str(content))
return p
def add_bytes(self, rel_path: str, data: bytes):
p = self._abspath(rel_path)
os.makedirs(os.path.dirname(p), exist_ok=True)
with open(p, "wb") as f:
f.write(data or b"")
return p
def add_file(self, src_path: str, dest_rel_path: str = None):
if not src_path or not os.path.exists(src_path):
return None
dest_rel_path = dest_rel_path or os.path.basename(src_path)
p = self._abspath(dest_rel_path)
os.makedirs(os.path.dirname(p), exist_ok=True)
shutil.copy2(src_path, p)
return p
def finalize(self, zip_name: str = None):
if self._final_zip and os.path.exists(self._final_zip):
return self._final_zip
out_dir, sid = create_temp_session_dir()
zip_name = zip_name or f"script_export_{sid}.zip"
zip_path = os.path.join(out_dir, zip_name)
with zipfile.ZipFile(zip_path, "w", zipfile.ZIP_DEFLATED) as zf:
for rt, _, files in os.walk(self.root_dir):
for f in files:
src = os.path.join(rt, f)
rel = os.path.relpath(src, self.root_dir)
zf.write(src, rel)
self._final_zip = zip_path
return zip_path
class ScriptAPI:
def __init__(self, ids_snapshot):
self._ids = list(ids_snapshot or [])
def get_ids(self):
return list(self._ids)
def get_status(self, rid: str):
st = dict(RESULTS_CACHE.get(rid) or {})
ui = dict(st.get("ui") or {})
return {
"status": st.get("status", "pending"),
"ui": {
"tab": ui.get("tab", "md"),
"nohf": bool(ui.get("nohf", False)),
"source": ui.get("source", "源码"),
},
"filtered": bool(st.get("filtered", False)),
"input_width": int(st.get("input_width", 0) or 0),
"input_height": int(st.get("input_height", 0) or 0),
}
def get_texts(self, rid: str):
st = dict(RESULTS_CACHE.get(rid) or {})
edits = dict(st.get("edits") or {})
return {
"md": st.get("md_content") or "",
"md_nohf": st.get("md_content_nohf") or "",
"json": st.get("json_code") or "",
"md_edit": edits.get("md"),
"md_nohf_edit": edits.get("nohf"),
"json_edit": edits.get("json"),
}
def choose_texts(
self,
rid: str,
prefer_ui: bool = True,
prefer_edit: bool = True,
prefer_nohf: bool | None = None,
):
st = dict(RESULTS_CACHE.get(rid) or {})
ui = dict(st.get("ui") or {})
# UI 指示
ui_nohf = bool(ui.get("nohf", False))
ui_source_is_edit = str(ui.get("source", "源码")) == "编辑源码"
# 选择 nohf
use_nohf = ui_nohf if prefer_nohf is None else bool(prefer_nohf)
# 选择是否优先编辑
prefer_edit_final = bool(prefer_edit or (prefer_ui and ui_source_is_edit))
t = self.get_texts(rid)
# Markdown
md_orig = t["md_nohf"] if use_nohf else t["md"]
md_edit = t["md_nohf_edit"] if use_nohf else t["md_edit"]
md = (md_edit if (prefer_edit_final and md_edit is not None) else md_orig) or ""
# JSON
json_text = (
t["json_edit"]
if (prefer_edit_final and t.get("json_edit") is not None)
else t["json"]
) or ""
return {"md": md, "json": json_text}
def list_paths(self, rid: str):
st = dict(RESULTS_CACHE.get(rid) or {})
rp = dict(st.get("result_paths") or {})
md_p = rp.get("md_content_path")
nohf_p = rp.get("md_content_nohf_path")
json_p = rp.get("layout_info_path") or rp.get("json_path")
image_p = rp.get("layout_image_path") or None
# 编辑路径(若存在)
edited_md = None
edited_nohf = None
edited_json = None
try:
edited_md = _edited_filepath(st, "md")
if not os.path.exists(edited_md):
edited_md = None
except Exception:
edited_md = None
try:
edited_nohf = _edited_filepath(st, "nohf")
if not os.path.exists(edited_nohf):
edited_nohf = None
except Exception:
edited_nohf = None
try:
edited_json = _edited_filepath(st, "json")
if not os.path.exists(edited_json):
edited_json = None
except Exception:
edited_json = None
return {
"temp_dir": st.get("temp_dir"),
"session_id": st.get("session_id"),
"result": {
"md": md_p if (md_p and os.path.exists(md_p)) else None,
"md_nohf": nohf_p if (nohf_p and os.path.exists(nohf_p)) else None,
"json": json_p if (json_p and os.path.exists(json_p)) else None,
"layout": image_p if (image_p and os.path.exists(image_p)) else None,
"input_image": (
st.get("input_temp_path")
if (
st.get("input_temp_path")
and os.path.exists(st.get("input_temp_path"))
)
else None
),
},
"edited": {
"md": edited_md,
"md_nohf": edited_nohf,
"json": edited_json,
},
}
def path_exists(self, p: str) -> bool:
try:
return bool(p) and os.path.exists(p)
except Exception:
return False
def build_export(self, name: str | None = None):
return ExportBuilder(name=name)
def _safe_builtins():
base = (
__builtins__
if isinstance(__builtins__, dict)
else getattr(__builtins__, "__dict__", {})
)
allow = [
"abs",
"min",
"max",
"sum",
"len",
"range",
"enumerate",
"map",
"filter",
"zip",
"list",
"dict",
"set",
"tuple",
"str",
"int",
"float",
"bool",
"print",
"any",
"all",
"sorted",
]
return {k: base[k] for k in allow if k in base}
def run_user_script(script_code: str, ids_snapshot):
"""
非流式执行用户脚本,捕获标准输出并返回(zip_path, logs)。
"""
api = ScriptAPI(ids_snapshot)
ns = {
"__builtins__": _safe_builtins(),
"api": api,
"json": json,
"re": re,
"math": math,
"datetime": datetime,
"Path": Path,
"io": io,
"ExportBuilder": ExportBuilder,
}
import contextlib
from io import StringIO
buf = StringIO()
zip_path = None
try:
code = script_code or ""
with contextlib.redirect_stdout(buf):
exec(code, ns, ns)
result = None
main_fn = ns.get("main")
if callable(main_fn):
result = main_fn(api)
else:
result = ns.get("RESULT") or ns.get("OUTPUT_PATH")
if isinstance(result, ExportBuilder):
zip_path = result.finalize()
elif isinstance(result, str) and result:
if os.path.isdir(result):
eb = ExportBuilder("script_dir_export")
for rt, _, files in os.walk(result):
for f in files:
src = os.path.join(rt, f)
rel = os.path.relpath(src, result)
eb.add_file(src, rel)
zip_path = eb.finalize()
elif os.path.exists(result):
zip_path = result
if not zip_path:
exp = ns.get("export")
if isinstance(exp, ExportBuilder):
zip_path = exp.finalize()
except Exception as e:
err = f"[Script Error] {type(e).__name__}: {e}"
return None, (buf.getvalue() + "\n" + err)
return (
zip_path if (zip_path and os.path.exists(zip_path)) else None
), buf.getvalue()
def run_user_script_stream(script_code: str, ids_snapshot):
"""生成器:实时输出日志,并在结束时返回下载地址与完成状态。"""
# 日志队列
log_q = queue.Queue()
def _emit(kind, payload=None):
log_q.put((kind, payload))
def debug(*args, **kwargs):
text = " ".join(str(a) for a in args)
if text:
_emit("log", text)
# 准备脚本命名空间(与非流式版本一致,但覆盖 print/debug)
api = ScriptAPI(ids_snapshot)
ns = {
"__builtins__": _safe_builtins(),
"api": api,
"json": json,
"re": re,
"math": math,
"datetime": datetime,
"Path": Path,
"io": io,
"ExportBuilder": ExportBuilder,
# 专用日志函数
"debug": debug,
"print": debug,
}
result_holder = {"zip_path": None, "error": None}
def _worker():
try:
code = script_code or ""
exec(code, ns, ns)
res = None
main_fn = ns.get("main")
if callable(main_fn):
res = main_fn(api)
else:
res = ns.get("RESULT") or ns.get("OUTPUT_PATH")
zip_path = None
if isinstance(res, ExportBuilder):
zip_path = res.finalize()
elif isinstance(res, str) and res:
if os.path.isdir(res):
eb = ExportBuilder("script_dir_export")
for rt, _, files in os.walk(res):
for f in files:
src = os.path.join(rt, f)
rel = os.path.relpath(src, res)
eb.add_file(src, rel)
zip_path = eb.finalize()
elif os.path.exists(res):
zip_path = res
if not zip_path:
exp = ns.get("export")
if isinstance(exp, ExportBuilder):
zip_path = exp.finalize()
result_holder["zip_path"] = (
zip_path if (zip_path and os.path.exists(zip_path)) else None
)
except Exception as e:
result_holder["error"] = f"[Script Error] {type(e).__name__}: {e}"
finally:
_emit("done", None)
# 启动脚本线程
t = threading.Thread(target=_worker, daemon=True)
t.start()
# 初始状态显示
spinner_html = (
""
""
""
"脚本运行中…
"
)
log_buf_lines = []
# 初始仅显示运行中动画,日志区域留空
yield None, spinner_html, ""
# 实时拉取日志并渲染
while True:
try:
kind, payload = log_q.get(timeout=0.2)
except queue.Empty:
if not t.is_alive():
# 线程已结束但没有新的事件,跳到收尾
break
else:
continue
if kind == "log":
# 追加日志并推送更新
if isinstance(payload, str):
for line in payload.splitlines() or [payload]:
if line.strip() == "":
continue
log_buf_lines.append(line)
yield None, spinner_html, "```\n" + "\n".join(
log_buf_lines[-200:]
) + "\n```" # 限制最后200行
elif kind == "done":
break
# 收尾:根据结果/错误输出最终状态
if result_holder.get("error"):
log_buf_lines.append(result_holder["error"])
status_html = (
""
"❌ 脚本执行失败
"
)
yield None, status_html, "```\n" + "\n".join(log_buf_lines[-500:]) + "\n```"
else:
status_html = (
""
"✅ 脚本执行完成
"
)
if result_holder.get("zip_path"):
yield result_holder["zip_path"], status_html, "```\n" + "\n".join(
log_buf_lines[-500:]
) + "\n```"
else:
log_buf_lines.append(
"(无可下载文件返回,若需导出请返回 ExportBuilder 或目录/文件路径)"
)
yield None, status_html, "```\n" + "\n".join(log_buf_lines[-500:]) + "\n```"
"""
执行用户脚本,返回 (zip_path or None, log_text)
"""
api = ScriptAPI(ids_snapshot)
ns = {
"__builtins__": _safe_builtins(),
"api": api,
# 常用库(只读注入)
"json": json,
"re": re,
"math": math,
"datetime": datetime,
"Path": Path,
"io": io,
# 导出构建器类型(如需构造)
"ExportBuilder": ExportBuilder,
}
import contextlib
from io import StringIO
buf = StringIO()
zip_path = None
try:
code = script_code or ""
with contextlib.redirect_stdout(buf):
exec(code, ns, ns)
result = None
main_fn = ns.get("main")
if callable(main_fn):
result = main_fn(api)
else:
result = ns.get("RESULT") or ns.get("OUTPUT_PATH")
# 结果归档处理
if isinstance(result, ExportBuilder):
zip_path = result.finalize()
elif isinstance(result, str) and result:
if os.path.isdir(result):
eb = ExportBuilder("script_dir_export")
for rt, _, files in os.walk(result):
for f in files:
src = os.path.join(rt, f)
rel = os.path.relpath(src, result)
eb.add_file(src, rel)
zip_path = eb.finalize()
elif os.path.exists(result):
zip_path = result
if not zip_path:
exp = ns.get("export")
if isinstance(exp, ExportBuilder):
zip_path = exp.finalize()
except Exception as e:
err = f"[Script Error] {type(e).__name__}: {e}"
return None, (buf.getvalue() + "\n" + err)
return (
zip_path if (zip_path and os.path.exists(zip_path)) else None
), buf.getvalue()
def export_selected_rids(ids, selected_labels):
"""
Build a combined zip for multiple selected results based on their current images (no reupload).
Only includes items with status == 'done'.
"""
if not ids or not selected_labels:
return None
# Map labels "Result N" -> indices
sel_indices = []
for label in selected_labels:
try:
idx = int(str(label).split()[-1]) - 1
if 0 <= idx < len(ids):
sel_indices.append(idx)
except Exception:
continue
if not sel_indices:
return None
out_dir, session_id = create_temp_session_dir()
zip_path = os.path.join(out_dir, f"export_selected_{session_id}.zip")
with zipfile.ZipFile(zip_path, "w", zipfile.ZIP_DEFLATED) as zf:
for i in sel_indices:
rid = ids[i]
st = RESULTS_CACHE.get(rid) or {}
if st.get("status") != "done":
continue
temp_dir = st.get("temp_dir")
if not temp_dir or not os.path.isdir(temp_dir):
# fallback: ensure individual export then include that zip
single_zip = ensure_export_ready(rid)
if single_zip and os.path.exists(single_zip):
zf.write(single_zip, os.path.join(f"result_{i+1}_{rid}.zip"))
continue
base_dir = f"result_{i+1}_{rid}"
for rt, _, files in os.walk(temp_dir):
for f in files:
src = os.path.join(rt, f)
rel = os.path.relpath(src, temp_dir)
zf.write(src, os.path.join(base_dir, rel))
return zip_path if os.path.exists(zip_path) else None
# --------- Edited sources helpers ----------
def _get_base_name_from_result(st: dict):
"""Infer base filename like 'demo_xxx' from result paths or session id."""
rp = st.get("result_paths") or {}
for key in ("md_content_path", "md_content_nohf_path", "layout_info_path"):
p = rp.get(key)
if p and isinstance(p, str):
base = os.path.splitext(os.path.basename(p))[0]
if key == "md_content_nohf_path" and base.endswith("_nohf"):
base = base[: -len("_nohf")]
return base
sid = st.get("session_id")
if sid:
return f"demo_{sid}"
return f"demo_{uuid.uuid4().hex[:8]}"
def _edited_dir_for(st: dict):
temp_dir = st.get("temp_dir")
if not temp_dir:
temp_dir, _ = create_temp_session_dir()
st["temp_dir"] = temp_dir
d = os.path.join(temp_dir, "edited")
os.makedirs(d, exist_ok=True)
return d
def _edited_filepath(st: dict, which: str):
"""
which in {'md','nohf','json'}
"""
base = _get_base_name_from_result(st)
if which == "md":
name = f"{base}.md"
elif which == "nohf":
name = f"{base}_nohf.md"
elif which == "json":
name = f"{base}.json"
else:
raise ValueError(f"unknown edited type: {which}")
return os.path.join(_edited_dir_for(st), name)
def _save_edited_to_disk(st: dict, which: str, content: str):
path = _edited_filepath(st, which)
with open(path, "w", encoding="utf-8") as f:
f.write(content if content is not None else "")
return path
def _delete_edited_from_disk(st: dict, which: str):
try:
path = _edited_filepath(st, which)
if os.path.exists(path):
os.remove(path)
except Exception:
pass
def _invalidate_export_zip(rid: str):
st = RESULTS_CACHE.get(rid) or {}
old = st.get("export_path")
if old and isinstance(old, str) and os.path.exists(old):
try:
os.remove(old)
except Exception:
pass
if "export_path" in st:
st["export_path"] = None
RESULTS_CACHE[rid] = st
# ---------------- UI state helpers (per-card) ----------------
def _default_ui_state():
# 增加 source: '源码' 或 '编辑源码'
return {"preview": True, "nohf": False, "tab": "md", "source": "源码"}
def _ensure_ui_state(rid):
st = RESULTS_CACHE.get(rid) or {}
ui = st.get("ui")
if not isinstance(ui, dict):
ui = _default_ui_state()
st["ui"] = ui
RESULTS_CACHE[rid] = st
else:
# 兼容旧状态缺少新字段
if "source" not in ui:
ui["source"] = "源码"
if "tab" not in ui:
ui["tab"] = "md"
if "preview" not in ui:
ui["preview"] = True
if "nohf" not in ui:
ui["nohf"] = False
RESULTS_CACHE[rid] = st
return ui
# ---------------- Background worker ----------------
def background_processor():
while True:
try:
task = TASK_QUEUE.get(timeout=1)
except queue.Empty:
continue
if task is None:
# Important: mark done for sentinel to keep queue counters balanced
try:
TASK_QUEUE.task_done()
finally:
pass
break
rid, filepath, prompt_mode, server_ip, server_port, min_p, max_p, fitz_flag = (
task
)
image = None
try:
# Build parser instance for this task
local_parser = DotsOCRParser(
ip=server_ip,
port=int(server_port),
dpi=200,
min_pixels=min_p,
max_pixels=max_p,
)
# Read image
try:
fp_lower = str(filepath).lower() if isinstance(filepath, str) else ""
if fitz_flag or fp_lower.endswith(".pdf"):
try:
import fitz as _fitz
doc = _fitz.open(filepath)
page = doc.load_page(0)
pix = page.get_pixmap()
mode = "RGBA" if pix.alpha else "RGB"
image = Image.frombytes(
mode, (pix.width, pix.height), pix.samples
)
doc.close()
except Exception:
image = read_image_v2(filepath)
else:
image = read_image_v2(filepath)
except Exception as e:
raise RuntimeError(f"Failed to read input {filepath}: {e}")
# Parse
result = parse_image_with_high_level_api(
local_parser, image, prompt_mode, fitz_preprocess=fitz_flag
)
result["status"] = "done"
# Preserve source/input path but prefer prev.source_path if available
prev = RESULTS_CACHE.get(rid) or {}
# Preserve UI state across re-parses/results
prev_ui = prev.get("ui") if isinstance(prev, dict) else None
result["ui"] = prev_ui if isinstance(prev_ui, dict) else _default_ui_state()
if isinstance(prev, dict) and isinstance(prev.get("edits"), dict):
result["edits"] = dict(prev.get("edits"))
if isinstance(prev, dict) and prev.get("source_path"):
result["source_path"] = prev.get("source_path")
else:
if isinstance(filepath, str) and os.path.exists(filepath):
result["source_path"] = filepath
else:
result["source_path"] = result.get("input_temp_path")
if isinstance(prev, dict) and prev.get("input_path"):
result["input_path"] = prev.get("input_path")
# Commit result
RESULTS_CACHE[rid] = result
# Pre-build export zip for first-click download
try:
zip_path = ensure_export_ready(rid)
if zip_path:
result = RESULTS_CACHE.get(rid, result)
result["export_path"] = zip_path
RESULTS_CACHE[rid] = result
except Exception:
pass
except Exception as e:
# Auto-retry for transient backend errors (e.g., server down temporarily)
if _is_transient_backend_error(e):
attempts = RETRY_COUNTS.get(rid, 0)
if attempts < MAX_AUTO_RETRIES:
RETRY_COUNTS[rid] = attempts + 1
delay = min(10.0, (RETRY_BACKOFF_BASE**attempts))
# keep state pending, annotate attempts
prev = RESULTS_CACHE.get(rid, {}) or {}
pend_state = dict(prev)
pend_state.update(
{
"status": "pending",
"retry_attempts": attempts + 1,
}
)
RESULTS_CACHE[rid] = pend_state
# Re-enqueue after delay on a timer to avoid blocking worker
def _requeue_later():
TASK_QUEUE.put(
(
rid,
filepath,
prompt_mode,
server_ip,
int(server_port),
min_p,
max_p,
fitz_flag,
)
)
threading.Timer(delay, _requeue_later).start()
# Do not mark error; move on
continue
# Build a rich error state that preserves re-parse materials
prev = RESULTS_CACHE.get(rid, {}) or {}
err_state = dict(prev) # preserve input_path etc.
err_state["status"] = "error"
err_state["md_content"] = classify_parse_failure(e, min_p, max_p)
# Save a temporary PNG for re-parse if we have an image in memory
if isinstance(image, Image.Image):
try:
tmp_dir, _sid = create_temp_session_dir()
tmp_path = os.path.join(tmp_dir, f"error_input_{rid}.png")
image.save(tmp_path, "PNG")
err_state["original_image"] = image
err_state["input_temp_path"] = tmp_path
err_state["temp_dir"] = tmp_dir
except Exception:
err_state["original_image"] = image
if isinstance(filepath, str) and filepath:
err_state.setdefault("source_path", filepath)
# Preserve UI state if missing
if not isinstance(err_state.get("ui"), dict):
err_state["ui"] = _default_ui_state()
RESULTS_CACHE[rid] = err_state
finally:
# Mark the non-sentinel task as done
try:
# If previous branch already marked sentinel done, skip double mark
if task is not None:
TASK_QUEUE.task_done()
except Exception:
pass
def _stop_all_workers():
"""Stop all worker threads gracefully by sending sentinels and joining."""
global WORKER_THREADS
with THREAD_LOCK:
n = len(WORKER_THREADS)
if n == 0:
return
# Send one sentinel per worker
for _ in range(n):
TASK_QUEUE.put(None)
# Join all workers
for t in WORKER_THREADS:
try:
t.join(timeout=5.0)
except Exception:
pass
WORKER_THREADS = []
def _start_workers(count: int):
"""Start exactly `count` worker threads if not already running."""
global WORKER_THREADS
with THREAD_LOCK:
running = len(WORKER_THREADS)
need = max(0, int(count) - running)
for _ in range(need):
t = threading.Thread(target=background_processor, daemon=True)
t.start()
WORKER_THREADS.append(t)
def start_background_processor():
"""Ensure at least one worker is running (used by legacy calls)."""
_start_workers(max(1, MAX_CONCURRENCY))
def set_max_concurrency(n: int):
"""Restart worker pool to match desired concurrency."""
global MAX_CONCURRENCY
n = int(n) if isinstance(n, (int, float)) else 1
if n <= 0:
n = 1
MAX_CONCURRENCY = n
# Restart workers to apply new concurrency
_stop_all_workers()
_start_workers(MAX_CONCURRENCY)
# ---------------- Queueing / task helpers ----------------
def _pixel_reasons(min_p, max_p):
reasons = []
if min_p < ABS_MIN_PIXELS:
reasons.append(f"Min Pixels 过小:{min_p},必须 >= {ABS_MIN_PIXELS}。")
if max_p > ABS_MAX_PIXELS:
reasons.append(f"Max Pixels 过大:{max_p},必须 <= {ABS_MAX_PIXELS}。")
if min_p >= max_p:
reasons.append(
f"像素参数不合法:Min Pixels({min_p}) >= Max Pixels({max_p}),必须满足 Min Pixels < Max Pixels。"
)
return reasons
def add_tasks_to_queue(
file_list, prompt_mode, server_ip, server_port, min_p, max_p, fitz, cur_ids
):
"""Queue uploaded file paths (expects file_list of local file paths or tuples (parse_path, source_path))."""
if not file_list:
return cur_ids, "No images uploaded."
min_p, max_p = _validate_pixels(min_p, max_p)
start_background_processor()
ids = list(cur_ids or [])
skipped = 0
queued = 0
for fp in file_list:
# Normalize: support tuple (parse_path, source_path)
parse_fp = None
source_fp = None
if isinstance(fp, (list, tuple)) and len(fp) >= 1:
parse_fp = fp[0]
# If tuple contains original source as second element, use it
source_fp = fp[1] if len(fp) >= 2 else fp[0]
else:
parse_fp = fp
source_fp = fp
if isinstance(parse_fp, (list, tuple)):
parse_fp = parse_fp[0] if len(parse_fp) > 0 else None
rid = uuid.uuid4().hex[:8]
ids.append(rid)
# placeholder with input_path so re-parse works even before parse
RESULTS_CACHE[rid] = {
"status": "pending",
"input_path": parse_fp,
"source_path": source_fp,
"ui": _default_ui_state(), # 初始化每项的独立 UI 状态
}
reason = _pixel_reasons(min_p, max_p)
if reason:
RESULTS_CACHE[rid] = {
"status": "error",
"md_content": "参数越界,未开始解析:\n"
+ "\n".join(f"- {r}" for r in reason)
+ f"\n(当前参数:min_pixels={min_p}, max_pixels={max_p})",
"input_path": parse_fp,
"source_path": source_fp,
"ui": _default_ui_state(),
}
skipped += 1
continue
TASK_QUEUE.put(
(
rid,
parse_fp,
prompt_mode,
server_ip,
int(server_port),
min_p,
max_p,
fitz,
)
)
queued += 1
info = f"Queued {queued} item(s)."
if skipped:
info += f" Skipped {skipped} due to invalid pixel limits."
return ids, info
def enqueue_single_reparse(
rid, reupload_path, prompt_mode, server_ip, server_port, min_p, max_p, fitz
):
"""
Enqueue a reparse for single result id.
Path selection priority:
reupload_path -> result.source_path -> result.input_temp_path -> result.input_path -> result.original_image (dump to temp PNG)
"""
min_p, max_p = _validate_pixels(min_p, max_p)
start_background_processor()
st = RESULTS_CACHE.get(rid, {}) or {}
# Pixel constraints: if invalid, set error state and return (do not enqueue)
reason = _pixel_reasons(min_p, max_p)
if reason:
new_state = st.copy()
new_state.update(
{
"status": "error",
"md_content": "参数越界,未开始解析:\n"
+ "\n".join(f"- {r}" for r in reason)
+ f"\n(当前参数:min_pixels={min_p}, max_pixels={max_p})",
}
)
# 保留 UI 状态
if "ui" not in new_state:
new_state["ui"] = _default_ui_state()
RESULTS_CACHE[rid] = new_state
return
if isinstance(reupload_path, (tuple, list)):
reupload_path = reupload_path[0] if len(reupload_path) > 0 else None
filepath = None
if reupload_path:
filepath = reupload_path
elif st.get("source_path"):
filepath = st.get("source_path")
elif st.get("input_temp_path"):
filepath = st.get("input_temp_path")
elif st.get("input_path"):
filepath = st.get("input_path")
else:
img = st.get("original_image")
if isinstance(img, Image.Image):
tmp_dir, _ = create_temp_session_dir()
tmp_path = os.path.join(tmp_dir, f"reparse_{rid}.png")
try:
img.save(tmp_path, "PNG")
filepath = tmp_path
except Exception:
filepath = None
if not filepath:
new_state = st.copy()
new_state.update(
{
"status": "error",
"md_content": "重解析失败:未找到可用的图片来源。请重新上传图片或检查缓存目录。",
}
)
if "ui" not in new_state:
new_state["ui"] = _default_ui_state()
RESULTS_CACHE[rid] = new_state
return
new_state = st.copy()
new_state.update(
{
"status": "pending",
"input_path": filepath,
"last_used_config": {
"ip": server_ip,
"port": int(server_port),
"min_pixels": min_p,
"max_pixels": max_p,
"prompt_mode": prompt_mode,
},
}
)
# 保留 UI 状态
if "ui" not in new_state:
new_state["ui"] = _default_ui_state()
RESULTS_CACHE[rid] = new_state
TASK_QUEUE.put(
(rid, filepath, prompt_mode, server_ip, int(server_port), min_p, max_p, fitz)
)
def delete_one(ids, rid, tick):
new_ids = [x for x in (ids or []) if x != rid]
st = RESULTS_CACHE.get(rid)
temp_dir = st.get("temp_dir") if st else None
if rid in RESULTS_CACHE:
del RESULTS_CACHE[rid]
if rid in RETRY_COUNTS:
del RETRY_COUNTS[rid]
purge_queue(rid)
if temp_dir and os.path.exists(temp_dir):
threading.Thread(
target=lambda: shutil.rmtree(temp_dir, ignore_errors=True), daemon=True
).start()
return new_ids, int(tick or 0) + 1
# ---------------- Gradio UI ----------------
def create_gradio_interface():
css = """
/* basic theme */
:root { --bg:#0b1220; --card:#111827; --muted:#9ca3af; --accent:#FF576D; --text:#e5e7eb; }
body, .gradio-container { background: var(--bg) !important; color: var(--text) !important; }
.result-card { background: var(--card); border:1px solid #1f2937; border-radius:8px; padding:10px; margin-bottom:12px; }
.muted { color: var(--muted); font-size:0.9em; }
/* skeleton shimmer */
.skeleton { position:relative; overflow:hidden; background:#0f172a; border-radius:6px; }
.skeleton::after {
content:""; position:absolute; inset:0; transform:translateX(-100%);
background:linear-gradient(90deg, rgba(255,255,255,0), rgba(255,255,255,0.06), rgba(255,255,255,0));
animation:shimmer 1.2s infinite;
}
@keyframes shimmer { 100% { transform:translateX(100%);} }
/* Hide unwanted footer/buttons (robust selectors) */
footer, .footer, #footer, footer[role="contentinfo"] { display:none !important; }
[aria-label="Use via API"], [aria-label*="API"], [title*="API"], a[href*="/api"], a[href*="api_docs"], a[href*="gradio.app"] { display:none !important; }
button[aria-label="Settings"], button[aria-label*="设置"], [aria-label="Built with Gradio"] { display:none !important; }
/* Script log area: single inner scrollbar on , outer container hidden overflow */
.script-log { max-height: 260px; overflow: hidden; border:1px solid #1f2937; border-radius:6px; padding:0; }
.script-log pre {
max-height: 260px;
overflow: auto;
margin: 0;
padding: 6px;
background: transparent;
scrollbar-width: thin; /* Firefox */
scrollbar-color: rgba(255,255,255,0.2) transparent;
}
.script-log pre::-webkit-scrollbar { width: 6px; height: 6px; }
.script-log pre::-webkit-scrollbar-track { background: transparent; }
.script-log pre::-webkit-scrollbar-thumb { background: rgba(255,255,255,0.12); border-radius: 4px; }
.script-log pre:hover::-webkit-scrollbar-thumb { background: rgba(255,255,255,0.25); }
"""
with gr.Blocks(css=css, title="dots.ocr") as demo:
# Left column controls
with gr.Row():
with gr.Column(scale=1):
file_input = gr.File(
label="Upload Multiple Images",
type="filepath",
file_count="multiple",
file_types=[".jpg", ".jpeg", ".png", ".pdf"],
)
# Filter out the unwanted 'prompt_grounding_ocr' mode
allowed_modes = [
m
for m in dict_promptmode_to_prompt.keys()
if m != "prompt_grounding_ocr"
]
if not allowed_modes:
allowed_modes = list(dict_promptmode_to_prompt.keys())
prompt_mode = gr.Dropdown(
label="Prompt Mode",
choices=allowed_modes,
value=allowed_modes[0],
)
prompt_display = gr.Textbox(
label="Prompt Preview",
value=dict_promptmode_to_prompt[allowed_modes[0]],
interactive=False,
lines=4,
)
with gr.Row():
parse_btn = gr.Button("🔍 Parse", variant="primary")
clear_btn = gr.Button("🗑️ Clear")
with gr.Accordion("Advanced Config", open=False):
fitz_preprocess = gr.Checkbox(label="fitz_preprocess", value=True)
server_ip = gr.Textbox(
label="Server IP", value=DEFAULT_CONFIG["ip"]
)
server_port = gr.Number(
label="Port", value=DEFAULT_CONFIG["port_vllm"], precision=0
)
min_pixels = gr.Number(
label="Min Pixels", value=DEFAULT_CONFIG["min_pixels"]
)
max_pixels = gr.Number(
label="Max Pixels", value=DEFAULT_CONFIG["max_pixels"]
)
concurrency = gr.Number(
label="Max Concurrency",
value=MAX_CONCURRENCY, # 与实际生效的后台并发保持一致(支持刷新后保持)
precision=0,
interactive=True,
)
confirm_delete = gr.Checkbox(
label="删除前确认(推荐)", value=True, interactive=True
)
# Right column: results & actions
with gr.Column(scale=5):
info_display = gr.Markdown("Waiting...", elem_id="info_box")
ids_state = gr.State(value=[])
store_tick = gr.State(value=0)
render_bump = gr.State(value=0) # 仅用于在状态变化时触发结果重渲染
confirm_delete_state = gr.State(value=True)
confirm_delete.change(
lambda v: v, inputs=[confirm_delete], outputs=[confirm_delete_state]
)
progress_timer = gr.Timer(1.0)
# Actions 面板(多选)
with gr.Accordion("Actions", open=False):
selected_group = gr.CheckboxGroup(
label="Select Items", choices=[], value=[], interactive=True
)
with gr.Row():
select_all_btn = gr.Button("全选")
clear_sel_btn = gr.Button("清空选择")
with gr.Row():
bulk_reparse_btn = gr.Button("🔁 重解析所选")
delete_selected_btn = gr.Button("🗑️ 删除所选", variant="stop")
export_selected_btn = gr.DownloadButton("📦 导出所选")
# 高级脚本导出
with gr.Accordion("高级脚本", open=False):
gr.Markdown(
"在下方编辑并运行自定义 Python 脚本以自由处理当前解析结果并导出为任意目录/文件结构。"
"
脚本将在受限环境中执行,可通过 api 对象访问只读数据与构建导出压缩包。",
elem_classes=["muted"],
)
script_code = gr.Code(
label="Python 脚本",
language="python",
value=DEFAULT_SCRIPT_TEMPLATE,
lines=24,
interactive=True,
)
with gr.Row():
run_script_btn = gr.Button("▶ 运行脚本", variant="primary")
script_download_btn = gr.DownloadButton("📦 下载脚本输出")
script_status = gr.HTML("")
script_log = gr.Markdown(
"", elem_id="script_log", elem_classes=["script-log"]
)
# 流式执行脚本:实时打印日志与运行状态,并在完成后绑定下载按钮
run_script_btn.click(
run_user_script_stream,
inputs=[script_code, ids_state],
outputs=[script_download_btn, script_status, script_log],
show_progress="hidden",
)
# 批量删除确认面板
with gr.Row(visible=False) as bulk_delete_confirm_panel:
gr.Markdown(
"确认删除所选结果?该操作不可恢复。",
elem_classes=["muted"],
)
bulk_confirm_delete_btn = gr.Button("确认删除", variant="stop")
bulk_cancel_delete_btn = gr.Button("取消")
# Render results dynamically
@gr.render(inputs=[ids_state, render_bump])
def render_results(ids, _bump):
if not ids:
return gr.Markdown("No results yet.")
with gr.Column():
for idx, rid in enumerate(ids):
data = RESULTS_CACHE.get(rid, {}) or {}
status = data.get("status", "pending")
# 确保每张卡都有独立 UI 状态(并写回缓存,保证后续使用)
ui = _ensure_ui_state(rid)
preview_on = bool(ui.get("preview", True))
nohf_on = bool(ui.get("nohf", False))
active_tab = ui.get("tab", "md")
if active_tab not in ("md", "json"):
active_tab = "md"
source_sel = ui.get("source", "源码")
if source_sel not in ("源码", "编辑源码"):
source_sel = "源码"
with gr.Column(
elem_classes=["result-card"], elem_id=f"card-{rid}"
):
with gr.Row():
gr.Markdown(
f"### Result {idx+1} RID: {rid}"
)
if status == "error":
gr.Markdown(
f"⚠️ 解析失败:\n\n{data.get('md_content','Unknown error')}",
elem_classes=["muted"],
)
if status == "done":
orig_img = data.get("original_image")
layout_img = data.get("layout_image")
with gr.Row():
gr.Image(
value=orig_img, label="Original", height=300
)
gr.Image(
value=layout_img, label="Layout", height=300
)
elif status == "pending":
with gr.Row():
gr.HTML(
""
)
gr.HTML(
""
)
# badges
with gr.Row():
badge_md = gr.HTML(
f"MD: {'Preview' if preview_on else 'Source'}"
)
badge_nohf = gr.HTML(
f"NOHF: {'On' if nohf_on else 'Off'}"
)
# controls
with gr.Row():
rid_box = gr.Textbox(value=rid, visible=False)
preview_cb = gr.Checkbox(
label="Preview Markdown",
value=preview_on,
)
nohf_cb = gr.Checkbox(label="NOHF", value=nohf_on)
# 视图切换
selected_label = (
"Markdown" if active_tab == "md" else "JSON"
)
with gr.Row():
view_radio = gr.Radio(
label="视图",
choices=["Markdown", "JSON"],
value=selected_label,
)
# 内容来源(仅完成状态可用)
with gr.Row():
source_radio = gr.Radio(
label="内容来源",
choices=["源码", "编辑源码"],
value=source_sel,
interactive=True,
visible=(status == "done"),
)
# 内容获取助手
def _get_texts(rid_value, nohf_flag):
st = RESULTS_CACHE.get(rid_value, {}) or {}
md_orig = st.get("md_content") or ""
md_nohf_orig = st.get("md_content_nohf") or ""
md_current_orig = (
md_nohf_orig if nohf_flag else md_orig
)
edits = st.get("edits") or {}
md_edit = (
edits.get("nohf")
if nohf_flag
else edits.get("md")
)
if md_edit is None:
md_edit = md_current_orig
json_orig = st.get("json_code") or ""
json_edit = edits.get("json")
if json_edit is None:
json_edit = json_orig
return (
md_current_orig,
md_edit,
json_orig,
json_edit,
)
(
md_orig_val,
md_edit_val,
json_orig_val,
json_edit_val,
) = _get_texts(rid, nohf_on)
is_md_init = selected_label == "Markdown"
use_edit_init = source_sel == "编辑源码"
# 单一预览组件(Markdown 用)
md_preview = gr.Markdown(
value=(
md_edit_val if use_edit_init else md_orig_val
),
visible=(
status == "done" and is_md_init and preview_on
),
)
# 原始源码(只读)
md_code_orig = gr.Code(
language="markdown",
value=md_orig_val,
interactive=False,
visible=(
status == "done"
and is_md_init
and (not preview_on)
and (not use_edit_init)
),
)
# 编辑源码(可编辑、自动保存)
md_code_edit = gr.Code(
language="markdown",
value=md_edit_val,
interactive=True,
visible=(
status == "done"
and is_md_init
and (not preview_on)
and use_edit_init
),
)
# JSON(原始与编辑)
json_code_orig = gr.Code(
language="json",
value=json_orig_val,
interactive=False,
visible=(
status == "done"
and (not is_md_init)
and (not use_edit_init)
),
)
json_code_edit = gr.Code(
language="json",
value=json_edit_val,
interactive=True,
visible=(
status == "done"
and (not is_md_init)
and use_edit_init
),
)
# 仅编辑模式显示
restore_btn = gr.Button(
"还原当前内容",
visible=(status == "done" and use_edit_init),
)
# 统一可见性/内容更新
def _apply_all(
preview, use_nohf, view_label, src_label, rid_value
):
preview = bool(preview)
use_nohf = bool(use_nohf)
is_md = str(view_label) == "Markdown"
use_edit = str(src_label) == "编辑源码"
# 写回 UI 状态
st = RESULTS_CACHE.get(rid_value, {}) or {}
ui0 = dict(st.get("ui") or _default_ui_state())
ui0["preview"] = preview
ui0["nohf"] = use_nohf
ui0["tab"] = "md" if is_md else "json"
ui0["source"] = "编辑源码" if use_edit else "源码"
st["ui"] = ui0
RESULTS_CACHE[rid_value] = st
md_o, md_e, j_o, j_e = _get_texts(
rid_value, use_nohf
)
return (
gr.update(
value=f"MD: {'Preview' if preview else 'Source'}"
),
gr.update(
value=f"NOHF: {'On' if use_nohf else 'Off'}"
),
gr.update(
value=(md_e if use_edit else md_o),
visible=(is_md and preview),
),
gr.update(
value=md_o,
visible=(
is_md
and (not preview)
and (not use_edit)
),
),
gr.update(
value=md_e,
visible=(
is_md and (not preview) and use_edit
),
),
gr.update(
value=j_o,
visible=(not is_md and (not use_edit)),
),
gr.update(
value=j_e, visible=(not is_md and use_edit)
),
gr.update(visible=use_edit),
)
# 绑定控制项变化:预览、NOHF、视图、来源
preview_cb.change(
_apply_all,
inputs=[
preview_cb,
nohf_cb,
view_radio,
source_radio,
rid_box,
],
outputs=[
badge_md,
badge_nohf,
md_preview,
md_code_orig,
md_code_edit,
json_code_orig,
json_code_edit,
restore_btn,
],
show_progress="hidden",
)
nohf_cb.change(
_apply_all,
inputs=[
preview_cb,
nohf_cb,
view_radio,
source_radio,
rid_box,
],
outputs=[
badge_md,
badge_nohf,
md_preview,
md_code_orig,
md_code_edit,
json_code_orig,
json_code_edit,
restore_btn,
],
show_progress="hidden",
)
def _on_view_change(
view_label,
rid_value,
preview_flag,
nohf_flag,
src_label,
):
st = RESULTS_CACHE.get(rid_value, {}) or {}
ui0 = dict(st.get("ui") or _default_ui_state())
ui0["tab"] = (
"md"
if str(view_label) == "Markdown"
else "json"
)
st["ui"] = ui0
RESULTS_CACHE[rid_value] = st
return _apply_all(
preview_flag,
nohf_flag,
view_label,
src_label,
rid_value,
)
view_radio.change(
_on_view_change,
inputs=[
view_radio,
rid_box,
preview_cb,
nohf_cb,
source_radio,
],
outputs=[
badge_md,
badge_nohf,
md_preview,
md_code_orig,
md_code_edit,
json_code_orig,
json_code_edit,
restore_btn,
],
show_progress="hidden",
)
def _on_source_change(
src_label,
rid_value,
preview_flag,
nohf_flag,
view_label,
):
st = RESULTS_CACHE.get(rid_value, {}) or {}
ui0 = dict(st.get("ui") or _default_ui_state())
ui0["source"] = (
"编辑源码"
if str(src_label) == "编辑源码"
else "源码"
)
st["ui"] = ui0
RESULTS_CACHE[rid_value] = st
return _apply_all(
preview_flag,
nohf_flag,
view_label,
src_label,
rid_value,
)
source_radio.change(
_on_source_change,
inputs=[
source_radio,
rid_box,
preview_cb,
nohf_cb,
view_radio,
],
outputs=[
badge_md,
badge_nohf,
md_preview,
md_code_orig,
md_code_edit,
json_code_orig,
json_code_edit,
restore_btn,
],
show_progress="hidden",
)
# Action buttons per-card
with gr.Row():
reparse_btn = gr.Button(
"🔁 重新解析",
interactive=(status in ("done", "error")),
)
export_btn = gr.DownloadButton(
"📦 导出",
interactive=(status == "done"),
value=(
data.get("export_path")
if status == "done"
else None
),
)
delete_btn = gr.Button("🗑️ 删除", variant="stop")
# 自动保存(编辑器变更即写盘 + 刷新导出 + 可能的 Markdown 预览)
def _save_md_edit(
val,
rid_value,
nohf_flag,
preview_flag,
view_label,
src_label,
ids,
selected_labels,
):
st = RESULTS_CACHE.get(rid_value, {}) or {}
if st.get("status") != "done":
# 同步“导出所选”以防其它项在编辑(极少见)
path_sel = export_selected_rids(
ids, selected_labels
)
return (
gr.update(),
gr.update(),
gr.update(value=path_sel),
)
which = "nohf" if bool(nohf_flag) else "md"
edits = dict(st.get("edits") or {})
edits[which] = val or ""
st["edits"] = edits
RESULTS_CACHE[rid_value] = st
try:
_save_edited_to_disk(st, which, val or "")
except Exception:
pass
_invalidate_export_zip(rid_value)
new_zip = ensure_export_ready(rid_value)
# 刷新“导出所选”
path_sel = export_selected_rids(
ids, selected_labels
)
# 若当前正处于 Markdown/预览/编辑模式,则更新预览内容
is_md = str(view_label) == "Markdown"
use_edit = str(src_label) == "编辑源码"
if is_md and use_edit and bool(preview_flag):
return (
gr.update(value=val or ""),
gr.update(value=new_zip),
gr.update(value=path_sel),
)
return (
gr.update(),
gr.update(value=new_zip),
gr.update(value=path_sel),
)
md_code_edit.change(
_save_md_edit,
inputs=[
md_code_edit,
rid_box,
nohf_cb,
preview_cb,
view_radio,
source_radio,
ids_state,
selected_group,
],
outputs=[
md_preview,
export_btn,
export_selected_btn,
],
show_progress="hidden",
)
def _save_json_edit(
val, rid_value, ids, selected_labels
):
st = RESULTS_CACHE.get(rid_value, {}) or {}
if st.get("status") != "done":
path_sel = export_selected_rids(
ids, selected_labels
)
return gr.update(), gr.update(value=path_sel)
edits = dict(st.get("edits") or {})
edits["json"] = val or ""
st["edits"] = edits
RESULTS_CACHE[rid_value] = st
try:
_save_edited_to_disk(st, "json", val or "")
except Exception:
pass
_invalidate_export_zip(rid_value)
new_zip = ensure_export_ready(rid_value)
path_sel = export_selected_rids(
ids, selected_labels
)
return gr.update(value=new_zip), gr.update(
value=path_sel
)
json_code_edit.change(
_save_json_edit,
inputs=[
json_code_edit,
rid_box,
ids_state,
selected_group,
],
outputs=[export_btn, export_selected_btn],
show_progress="hidden",
)
# 还原当前内容
def _restore_current(
src_label,
rid_value,
nohf_flag,
preview_flag,
view_label,
ids,
selected_labels,
):
st = RESULTS_CACHE.get(rid_value, {}) or {}
which = (
"json"
if str(view_label) == "JSON"
else ("nohf" if bool(nohf_flag) else "md")
)
# 删除编辑版
edits = dict(st.get("edits") or {})
if which in edits:
edits.pop(which, None)
st["edits"] = edits
RESULTS_CACHE[rid_value] = st
try:
_delete_edited_from_disk(st, which)
except Exception:
pass
# 重新取原始内容
md_o, md_e, j_o, j_e = _get_texts(
rid_value, bool(nohf_flag)
)
# 刷新导出
_invalidate_export_zip(rid_value)
new_zip = ensure_export_ready(rid_value)
path_sel = export_selected_rids(
ids, selected_labels
)
# 更新编辑器与预览
up_md_editor = (
gr.update(value=md_o)
if which in ("md", "nohf")
else gr.update()
)
up_json_editor = (
gr.update(value=j_o)
if which == "json"
else gr.update()
)
is_md = str(view_label) == "Markdown"
use_edit = str(src_label) == "编辑源码"
up_preview = (
gr.update(value=(md_e if use_edit else md_o))
if is_md and bool(preview_flag)
else gr.update()
)
return (
up_md_editor,
up_json_editor,
up_preview,
gr.update(value=new_zip),
gr.update(value=path_sel),
)
restore_btn.click(
_restore_current,
inputs=[
source_radio,
rid_box,
nohf_cb,
preview_cb,
view_radio,
ids_state,
selected_group,
],
outputs=[
md_code_edit,
json_code_edit,
md_preview,
export_btn,
export_selected_btn,
],
show_progress="hidden",
)
# Reparse panel (collapsed)
with gr.Column(visible=False) as reparse_panel:
gr.Markdown("**重解析**")
with gr.Row():
reparse_current_btn = gr.Button(
"基于当前图片直接重解析", variant="primary"
)
# Delete confirm panel (collapsed)
with gr.Row(visible=False) as delete_confirm_panel:
gr.Markdown(
"确认删除该结果?该操作不可恢复。",
elem_classes=["muted"],
)
confirm_delete_btn = gr.Button(
"确认删除", variant="stop"
)
cancel_delete_btn = gr.Button("取消")
# 绑定其他交互
reparse_btn.click(
lambda: gr.update(visible=True),
outputs=[reparse_panel],
show_progress="hidden",
)
def _start_reparse_current(
rid_value,
p_mode,
ip_addr,
port_val,
minp,
maxp,
fitz_flag,
tick,
ids,
selected_labels,
):
try:
enqueue_single_reparse(
rid_value,
None,
p_mode,
ip_addr,
int(port_val),
int(minp),
int(maxp),
fitz_flag,
)
# 重建“导出所选”
path_sel = export_selected_rids(
ids, selected_labels
)
return (
int(tick or 0) + 1,
gr.update(visible=False),
gr.update(value=path_sel),
)
except Exception as e:
RESULTS_CACHE[rid_value] = {
"status": "error",
"md_content": f"Reparse error: {e}",
# 保留 UI 状态
"ui": _ensure_ui_state(rid_value),
}
path_sel = export_selected_rids(
ids, selected_labels
)
return (
int(tick or 0) + 1,
gr.update(visible=False),
gr.update(value=path_sel),
)
reparse_current_btn.click(
_start_reparse_current,
inputs=[
rid_box,
prompt_mode,
server_ip,
server_port,
min_pixels,
max_pixels,
fitz_preprocess,
store_tick,
ids_state,
selected_group,
],
outputs=[
store_tick,
reparse_panel,
export_selected_btn,
],
show_progress="hidden",
)
def _on_delete_click(
rid_value, ids, need_confirm, tick
):
# 如果需要确认,仅展开确认面板,不修改选择框/导出按钮
if need_confirm:
return (
gr.update(visible=True),
ids,
tick,
gr.update(), # selected_group 不变
gr.update(), # export button 不变
)
# 直接删除:更新 ids/tick,并同步 Actions 的选择项与导出按钮
new_ids, new_tick = delete_one(ids, rid_value, tick)
choices = [
f"Result {i+1}"
for i in range(len(new_ids or []))
]
return (
gr.update(visible=False),
new_ids,
new_tick,
gr.update(choices=choices, value=[]),
gr.update(value=None), # 清空导出
)
# 单卡删除输出同步 selected_group 与 export_selected_btn
delete_btn.click(
_on_delete_click,
inputs=[
rid_box,
ids_state,
confirm_delete_state,
store_tick,
],
outputs=[
delete_confirm_panel,
ids_state,
store_tick,
selected_group,
export_selected_btn,
],
show_progress="hidden",
)
def _confirm_delete(rid_value, ids, tick):
new_ids, new_tick = delete_one(ids, rid_value, tick)
choices = [
f"Result {i+1}"
for i in range(len(new_ids or []))
]
return (
new_ids,
new_tick,
gr.update(visible=False),
gr.update(choices=choices, value=[]),
gr.update(value=None),
)
# 确认删除后同步 selected_group 与 export_selected_btn
confirm_delete_btn.click(
_confirm_delete,
inputs=[rid_box, ids_state, store_tick],
outputs=[
ids_state,
store_tick,
delete_confirm_panel,
selected_group,
export_selected_btn,
],
show_progress="hidden",
)
cancel_delete_btn.click(
lambda: gr.update(visible=False),
outputs=[delete_confirm_panel],
show_progress="hidden",
)
# Top-level events
def _on_prompt_mode_change(m):
return dict_promptmode_to_prompt.get(m, "")
prompt_mode.change(
fn=_on_prompt_mode_change,
inputs=[prompt_mode],
outputs=[prompt_display],
show_progress="hidden",
)
def process_images_simple(
file_list,
p_mode,
server_ip_val,
server_port_val,
min_p_val,
max_p_val,
fitz_val,
cur_ids,
tick,
):
"""
Process images with selected prompt mode. Grounding mode is removed; all files go through normal path.
"""
minp, maxp = _validate_pixels(min_p_val, max_p_val)
_set_parser_config(server_ip_val, server_port_val, minp, maxp)
# normalize file_list (gradio file element may pass nested lists)
files = []
if not file_list:
return (
gr.update(value=None),
gr.update(value="No files uploaded."),
cur_ids,
tick,
gr.update(choices=[], value=[]),
gr.update(value=None), # 清空导出
)
# build normalized list
for f in file_list:
if isinstance(f, (list, tuple)):
files.append(f[0] if len(f) > 0 else None)
else:
files.append(f)
# Normal path: queue originals
new_ids, info = add_tasks_to_queue(
files,
p_mode,
server_ip_val,
server_port_val,
minp,
maxp,
fitz_val,
cur_ids,
)
# Update checkbox group choices
choices = [f"Result {i+1}" for i in range(len(new_ids or []))]
return (
gr.update(value=None),
gr.update(value=info),
new_ids,
int(tick or 0) + 1,
gr.update(choices=choices, value=[]),
gr.update(value=None), # 清空导出
)
parse_btn.click(
fn=process_images_simple,
inputs=[
file_input,
prompt_mode,
server_ip,
server_port,
min_pixels,
max_pixels,
fitz_preprocess,
ids_state,
store_tick,
],
outputs=[
file_input,
info_display,
ids_state,
store_tick,
selected_group,
export_selected_btn,
],
show_progress="hidden",
)
# Concurrency change handler: apply immediately
def _on_concurrency_change(n):
try:
set_max_concurrency(int(n))
return gr.update(value=f"并发已设置为 {int(n)}。")
except Exception as e:
return gr.update(value=f"设置并发失败:{e}")
concurrency.change(
_on_concurrency_change,
inputs=[concurrency],
outputs=[info_display],
show_progress="hidden",
)
# 会话加载时同步 UI 与当前真实并发(解决刷新后 UI 值与实际不一致)
def _sync_concurrency_on_session_load():
try:
# 如有需要,补齐 worker 到目标并发数(不会减少已有线程)
_start_workers(max(1, MAX_CONCURRENCY))
return (
gr.update(value=int(MAX_CONCURRENCY)),
gr.update(
value=f"已同步当前并发为 {int(MAX_CONCURRENCY)}。"
),
)
except Exception as e:
return (
gr.update(value=int(MAX_CONCURRENCY)),
gr.update(value=f"同步并发时发生异常:{e}"),
)
demo.load(
_sync_concurrency_on_session_load,
inputs=None,
outputs=[concurrency, info_display],
)
# 生成导出 ZIP(基于当前选择),用于首次点击即可下载
def _update_export_for_selection(ids, selected_labels):
path = export_selected_rids(ids, selected_labels)
return gr.update(
value=path if path and os.path.exists(path) else None
)
# Actions: 全选/清空
def _select_all(ids):
choices = [f"Result {i+1}" for i in range(len(ids or []))]
# 预生成 zip
path = export_selected_rids(ids, choices)
return (
gr.update(choices=choices, value=choices),
gr.update(
value=path if path and os.path.exists(path) else None
),
)
def _clear_selection(ids):
choices = [f"Result {i+1}" for i in range(len(ids or []))]
return (
gr.update(choices=choices, value=[]),
gr.update(value=None),
)
select_all_btn.click(
_select_all,
inputs=[ids_state],
outputs=[selected_group, export_selected_btn],
show_progress="hidden",
)
clear_sel_btn.click(
_clear_selection,
inputs=[ids_state],
outputs=[selected_group, export_selected_btn],
show_progress="hidden",
)
# 当用户手动变更选择时,预构建导出 zip 并绑定到按钮
selected_group.change(
_update_export_for_selection,
inputs=[ids_state, selected_group],
outputs=[export_selected_btn],
show_progress="hidden",
)
# Actions: 批量重解析(基于当前图片)
def bulk_reparse(
selected_labels, ids, p_mode, ip, port, minp, maxp, fitz, tick
):
if not ids or not selected_labels:
path_sel = export_selected_rids(ids, selected_labels)
return (
gr.update(value="未选择任何结果。"),
int(tick or 0),
gr.update(value=path_sel),
)
# Map labels -> rids
count = 0
for label in selected_labels:
try:
idx = int(str(label).split()[-1]) - 1
rid = ids[idx]
enqueue_single_reparse(
rid,
None,
p_mode,
ip,
int(port),
int(minp),
int(maxp),
fitz,
)
count += 1
except Exception:
continue
path_sel = export_selected_rids(ids, selected_labels)
return (
gr.update(value=f"已触发 {count} 个重解析任务。"),
int(tick or 0) + 1,
gr.update(value=path_sel),
)
bulk_reparse_btn.click(
bulk_reparse,
inputs=[
selected_group,
ids_state,
prompt_mode,
server_ip,
server_port,
min_pixels,
max_pixels,
fitz_preprocess,
store_tick,
],
outputs=[info_display, store_tick, export_selected_btn],
show_progress="hidden",
)
# Actions: 删除所选(尊重“删除前确认”)
def delete_selected_action(ids, selected_labels, tick):
# 先从“原始 ids 列表”解析出要删除的 rid 列表,避免索引随删除而错位
if not ids or not selected_labels:
choices = [f"Result {i+1}" for i in range(len(ids or []))]
return (
ids,
int(tick or 0),
gr.update(choices=choices, value=[]),
gr.update(value=None),
)
# 解析 label -> index(去重、过滤非法)
sel_indices = []
for label in selected_labels:
try:
idx = int(str(label).split()[-1]) - 1
if 0 <= idx < len(ids):
sel_indices.append(idx)
except Exception:
continue
if not sel_indices:
choices = [f"Result {i+1}" for i in range(len(ids or []))]
return (
ids,
int(tick or 0),
gr.update(choices=choices, value=[]),
gr.update(value=None),
)
sel_indices = sorted(set(sel_indices))
rids_to_delete = [ids[i] for i in sel_indices]
new_ids = list(ids)
new_tick = int(tick or 0)
# 基于 rid 删除,避免受索引变化影响
for rid in rids_to_delete:
new_ids, new_tick = delete_one(new_ids, rid, new_tick)
choices = [f"Result {i+1}" for i in range(len(new_ids or []))]
return (
new_ids,
new_tick,
gr.update(choices=choices, value=[]),
gr.update(value=None),
)
def _on_bulk_delete_click(ids, selected_labels, need_confirm, tick):
if need_confirm:
# 展示确认面板,不改动任何选择与导出
return (
gr.update(visible=True),
ids,
tick,
gr.update(),
gr.update(),
)
# 直接删除并隐藏确认面板
new_ids, new_tick, sel_update, export_update = (
delete_selected_action(ids, selected_labels, tick)
)
return (
gr.update(visible=False),
new_ids,
new_tick,
sel_update,
export_update,
)
delete_selected_btn.click(
_on_bulk_delete_click,
inputs=[
ids_state,
selected_group,
confirm_delete_state,
store_tick,
],
outputs=[
bulk_delete_confirm_panel,
ids_state,
store_tick,
selected_group,
export_selected_btn,
],
show_progress="hidden",
)
def _bulk_confirm_delete(ids, selected_labels, tick):
new_ids, new_tick, sel_update, export_update = (
delete_selected_action(ids, selected_labels, tick)
)
return (
new_ids,
new_tick,
sel_update,
export_update,
gr.update(visible=False),
)
bulk_confirm_delete_btn.click(
_bulk_confirm_delete,
inputs=[ids_state, selected_group, store_tick],
outputs=[
ids_state,
store_tick,
selected_group,
export_selected_btn,
bulk_delete_confirm_panel,
],
show_progress="hidden",
)
bulk_cancel_delete_btn.click(
lambda: gr.update(visible=False),
outputs=[bulk_delete_confirm_panel],
show_progress="hidden",
)
# 进度信息
def update_progress_info(ids, tick, bump):
if not ids:
return (
gr.update(value="Waiting..."),
tick,
int(bump or 0),
)
pending = 0
done = 0
errors = 0
status_signature = []
for rid in ids:
st = RESULTS_CACHE.get(rid, {})
status = st.get("status", "pending")
status_signature.append((rid, status))
if status == "done":
done += 1
elif status == "error":
errors += 1
else:
pending += 1
qsize = TASK_QUEUE.qsize()
running = max(0, pending - qsize)
# Info text
if pending == 0:
info = (
f"进度:完成 {done}"
+ ("" if errors == 0 else f",错误 {errors}")
+ "。"
)
else:
info = f"进度:完成 {done},错误 {errors},正在解析 {running},排队 {qsize},待处理合计 {pending}。"
# Only bump render when any item's status changed
sig_tuple = tuple(status_signature)
last_sig = getattr(update_progress_info, "_last_status_sig", None)
bump_out = int(bump or 0)
if last_sig != sig_tuple:
setattr(update_progress_info, "_last_status_sig", sig_tuple)
bump_out = bump_out + 1
# Only tick when coarse counts change (avoid unnecessary churn)
key = f"{done}_{errors}_{pending}"
last_key = getattr(update_progress_info, "_last_counts_key", None)
new_tick = int(tick or 0)
if last_key != key:
setattr(update_progress_info, "_last_counts_key", key)
new_tick = new_tick + 1
return (
gr.update(value=info),
new_tick,
bump_out,
)
# 计时器不再触达 selected_group,杜绝与用户交互竞争导致选择重置/计时停止
progress_timer.tick(
fn=update_progress_info,
inputs=[ids_state, store_tick, render_bump],
outputs=[info_display, store_tick, render_bump],
show_progress="hidden",
)
# Clear all
def clear_all():
global RESULTS_CACHE
while not TASK_QUEUE.empty():
try:
TASK_QUEUE.get_nowait()
TASK_QUEUE.task_done()
except queue.Empty:
break
RESULTS_CACHE = {}
RETRY_COUNTS.clear()
# Do not stop workers; keep them alive
return (
[],
0,
gr.update(value="Waiting..."),
0,
gr.update(choices=[], value=[]),
gr.update(value=None),
)
clear_btn.click(
clear_all,
inputs=None,
outputs=[
ids_state,
store_tick,
info_display,
render_bump,
selected_group,
export_selected_btn,
],
show_progress="hidden",
)
return demo
# ---------------- main ----------------
def _queue_compat(blocks: gr.Blocks):
"""
Gradio version compatibility layer for Blocks.queue:
- Try Gradio 4.x: default_concurrency_limit + status_update_rate
- Fallback to Gradio 3.x: concurrency_count + status_update_rate
- Final fallback: no-arg queue()
"""
try:
# Gradio 4.x path
return blocks.queue(default_concurrency_limit=20, status_update_rate=0.2)
except TypeError:
try:
# Gradio 3.x path
return blocks.queue(concurrency_count=16, status_update_rate=0.2)
except TypeError:
# Minimal fallback
return blocks.queue()
def _launch_compat(app: gr.Blocks, port: int):
"""
Gradio version compatibility for launch parameters.
"""
try:
app.launch(
server_name="0.0.0.0",
server_port=port,
debug=True,
show_api=False, # 3.x/部分4.x可用
)
except TypeError:
# Fallback without show_api
app.launch(
server_name="0.0.0.0",
server_port=port,
debug=True,
)
if __name__ == "__main__":
import sys
port = int(sys.argv[1]) if len(sys.argv) > 1 else 7860
demo = create_gradio_interface()
app = _queue_compat(demo)
_launch_compat(app, port)
================================================
FILE: demo/demo_hf.py
================================================
import os
if "LOCAL_RANK" not in os.environ:
os.environ["LOCAL_RANK"] = "0"
import torch
from transformers import AutoModelForCausalLM, AutoProcessor, AutoTokenizer
from qwen_vl_utils import process_vision_info
from dots_ocr.utils import dict_promptmode_to_prompt
def inference(image_path, prompt, model, processor):
# image_path = "demo/demo_image1.jpg"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image_path
},
{"type": "text", "text": prompt}
]
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=24000)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
if __name__ == "__main__":
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
model_path = "./weights/DotsOCR"
model = AutoModelForCausalLM.from_pretrained(
model_path,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
image_path = "demo/demo_image1.jpg"
for prompt_mode, prompt in dict_promptmode_to_prompt.items():
print(f"prompt: {prompt}")
inference(image_path, prompt, model, processor)
================================================
FILE: demo/demo_streamlit.py
================================================
"""
Layout Inference Web Application
A Streamlit-based layout inference tool that supports image uploads and multiple backend inference engines.
"""
import streamlit as st
import json
import os
import io
import tempfile
from PIL import Image
import requests
# Local utility imports
# from utils import infer
from dots_ocr.utils import dict_promptmode_to_prompt
from dots_ocr.utils.format_transformer import layoutjson2md
from dots_ocr.utils.layout_utils import draw_layout_on_image, post_process_cells
from dots_ocr.utils.image_utils import get_input_dimensions, get_image_by_fitz_doc
from dots_ocr.model.inference import inference_with_vllm
from dots_ocr.utils.consts import MIN_PIXELS, MAX_PIXELS
import os
from PIL import Image
from dots_ocr.utils.demo_utils.display import read_image
# ==================== Configuration ====================
DEFAULT_CONFIG = {
'ip': "127.0.0.1",
'port_vllm': 8000,
'min_pixels': MIN_PIXELS,
'max_pixels': MAX_PIXELS,
'test_images_dir': "./assets/showcase_origin",
}
# ==================== Utility Functions ====================
@st.cache_resource
def read_image_v2(img: str):
if img.startswith(("http://", "https://")):
with requests.get(img, stream=True) as response:
response.raise_for_status()
img = Image.open(io.BytesIO(response.content))
if isinstance(img, str):
# img = transform_image_path(img)
img, _, _ = read_image(img, use_native=True)
elif isinstance(img, Image.Image):
pass
else:
raise ValueError(f"Invalid image type: {type(img)}")
return img
# ==================== UI Components ====================
def create_config_sidebar():
"""Create configuration sidebar"""
st.sidebar.header("Configuration Parameters")
config = {}
config['prompt_key'] = st.sidebar.selectbox("Prompt Mode", list(dict_promptmode_to_prompt.keys()))
config['ip'] = st.sidebar.text_input("Server IP", DEFAULT_CONFIG['ip'])
config['port'] = st.sidebar.number_input("Port", min_value=1000, max_value=9999, value=DEFAULT_CONFIG['port_vllm'])
# config['eos_word'] = st.sidebar.text_input("EOS Word", DEFAULT_CONFIG['eos_word'])
# Image configuration
st.sidebar.subheader("Image Configuration")
config['min_pixels'] = st.sidebar.number_input("Min Pixels", value=DEFAULT_CONFIG['min_pixels'])
config['max_pixels'] = st.sidebar.number_input("Max Pixels", value=DEFAULT_CONFIG['max_pixels'])
return config
def get_image_input():
"""Get image input"""
st.markdown("#### Image Input")
input_mode = st.pills(label="Select input method", options=["Upload Image", "Enter Image URL/Path", "Select Test Image"], key="input_mode", label_visibility="collapsed")
if input_mode == "Upload Image":
# File uploader
uploaded_file = st.file_uploader("Upload Image", type=["png", "jpg", "jpeg"])
if uploaded_file is not None:
with tempfile.NamedTemporaryFile(delete=False, suffix='.png') as tmp_file:
tmp_file.write(uploaded_file.getvalue())
return tmp_file.name
elif input_mode == 'Enter Image URL/Path':
# URL input
img_url_input = st.text_input("Enter Image URL/Path")
return img_url_input
elif input_mode == 'Select Test Image':
# Test image selection
test_images = []
test_dir = DEFAULT_CONFIG['test_images_dir']
if os.path.exists(test_dir):
test_images = [os.path.join(test_dir, name) for name in os.listdir(test_dir)]
img_url_test = st.selectbox("Select Test Image", [""] + test_images)
return img_url_test
else:
raise ValueError(f"Invalid input mode: {input_mode}")
return None
def process_and_display_results(output: str, image: Image.Image, config: dict):
"""Process and display inference results"""
prompt, response = output['prompt'], output['response']
try:
col1, col2 = st.columns(2)
# st.markdown('---')
cells = json.loads(response)
# image = Image.open(img_url)
# Post-processing
cells = post_process_cells(
image, cells,
image.width, image.height,
min_pixels=config['min_pixels'],
max_pixels=config['max_pixels']
)
# Calculate input dimensions
input_width, input_height = get_input_dimensions(
image,
min_pixels=config['min_pixels'],
max_pixels=config['max_pixels']
)
st.markdown('---')
st.write(f'Input Dimensions: {input_width} x {input_height}')
# st.write(f'Prompt: {prompt}')
# st.markdown(f'模型原始输出: {result}', unsafe_allow_html=True)
# st.write('模型原始输出:')
# st.write(response)
# st.write('后处理结果:', str(cells))
st.text_area('Original Model Output', response, height=200)
st.text_area('Post-processed Result', str(cells), height=200)
# 显示结果
# st.title("Layout推理结果")
with col1:
# st.markdown("##### 可视化结果")
new_image = draw_layout_on_image(
image, cells,
resized_height=None, resized_width=None,
# text_key='text',
fill_bbox=True, draw_bbox=True
)
st.markdown('##### Visualization Result')
st.image(new_image, width=new_image.width)
# st.write(f"尺寸: {new_image.width} x {new_image.height}")
with col2:
# st.markdown("##### Markdown格式")
md_code = layoutjson2md(image, cells, text_key='text')
# md_code = fix_streamlit_formula(md_code)
st.markdown('##### Markdown Format')
st.markdown(md_code, unsafe_allow_html=True)
except json.JSONDecodeError:
st.error("Model output is not a valid JSON format")
except Exception as e:
st.error(f"Error processing results: {e}")
# ==================== Main Application ====================
def main():
"""Main application function"""
st.set_page_config(page_title="Layout Inference Tool", layout="wide")
st.title("🔍 Layout Inference Tool")
# Configuration
config = create_config_sidebar()
prompt = dict_promptmode_to_prompt[config['prompt_key']]
st.sidebar.info(f"Current Prompt: {prompt}")
# Image input
img_url = get_image_input()
start_button = st.button('🚀 Start Inference', type="primary")
if img_url is not None and img_url.strip() != "":
try:
# processed_image = read_image_v2(img_url)
origin_image = read_image_v2(img_url)
st.write(f"Original Dimensions: {origin_image.width} x {origin_image.height}")
# processed_image = get_image_by_fitz_doc(origin_image, target_dpi=200)
processed_image = origin_image
except Exception as e:
st.error(f"Failed to read image: {e}")
return
else:
st.info("Please enter an image URL/path or upload an image")
return
output = None
# Inference button
if start_button:
with st.spinner(f"Inferring... Server: {config['ip']}:{config['port']}"):
response = inference_with_vllm(
processed_image, prompt, config['ip'], config['port'],
# config['min_pixels'], config['max_pixels']
)
output = {
'prompt': prompt,
'response': response,
}
else:
st.image(processed_image, width=500)
# Process results
if output:
process_and_display_results(output, processed_image, config)
if __name__ == "__main__":
main()
================================================
FILE: demo/demo_vllm.py
================================================
import argparse
from openai import OpenAI
from transformers.utils.versions import require_version
from PIL import Image
from dots_ocr.utils import dict_promptmode_to_prompt
from dots_ocr.model.inference import inference_with_vllm
parser = argparse.ArgumentParser()
parser.add_argument("--ip", type=str, default="localhost")
parser.add_argument("--port", type=str, default="8000")
parser.add_argument("--model_name", type=str, default="rednote-hilab/dots.ocr-1.5")
parser.add_argument("--image_path", type=str, default="demo/demo_image1.jpg")
parser.add_argument("--prompt_mode", type=str, default="prompt_layout_all_en",help=(
"Choose a task prompt: "
"prompt_layout_all_en=full document layout+OCR to JSON/MD; "
"prompt_layout_only_en=layout detection only; "
"prompt_grounding_ocr=OCR within a given bbox; "
"prompt_web_parsing=parse webpage screenshot layout into JSON; "
"prompt_scene_spotting=detect+recognize scene text (OCR boxes+texts); "
"prompt_image_to_svg=generate SVG code to reconstruct the image.")
)
args = parser.parse_args()
require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")
def main():
addr = f"http://{args.ip}:{args.port}/v1"
image_path = args.image_path
prompt = dict_promptmode_to_prompt[args.prompt_mode]
image = Image.open(image_path)
response = inference_with_vllm(
image,
prompt,
ip=args.ip,
port=args.port,
temperature=0.1,
top_p=0.9,
model_name=args.model_name,
)
print(f"response: {response}")
if __name__ == "__main__":
main()
================================================
FILE: demo/demo_vllm_general.py
================================================
import argparse
from openai import OpenAI
from transformers.utils.versions import require_version
from PIL import Image
from dots_ocr.utils import dict_promptmode_to_prompt
from dots_ocr.model.inference import inference_with_vllm
parser = argparse.ArgumentParser()
parser.add_argument("--ip", type=str, default="localhost")
parser.add_argument("--port", type=str, default="8000")
parser.add_argument("--model_name", type=str, default="rednote-hilab/dots.ocr-1.5")
parser.add_argument("--custom_prompt", type=str, default="Please describe the content of this image.")
args = parser.parse_args()
require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")
def main():
addr = f"http://{args.ip}:{args.port}/v1"
image_path = "demo/demo_image3.jpg"
prompt = args.custom_prompt
image = Image.open(image_path)
response = inference_with_vllm(
image,
prompt,
ip=args.ip,
port=args.port,
temperature=0.1,
top_p=0.9,
model_name=args.model_name,
system_prompt="You are a helpful assistant.", #general tasks need system_prompt
)
print(f"response: {response}")
if __name__ == "__main__":
main()
================================================
FILE: demo/demo_vllm_svg.py
================================================
import argparse
from openai import OpenAI
from transformers.utils.versions import require_version
from PIL import Image
from dots_ocr.utils import dict_promptmode_to_prompt
from dots_ocr.model.inference import inference_with_vllm
parser = argparse.ArgumentParser()
parser.add_argument("--ip", type=str, default="localhost")
parser.add_argument("--port", type=str, default="8000")
parser.add_argument("--model_name", type=str, default="rednote-hilab/dots.ocr-1.5-svg")
parser.add_argument("--prompt_mode", type=str, default="prompt_image_to_svg")
args = parser.parse_args()
require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")
def main():
addr = f"http://{args.ip}:{args.port}/v1"
image_path = "demo/demo_image2.png"
image = Image.open(image_path)
prompt = dict_promptmode_to_prompt[args.prompt_mode]
#prompt = Please generate the SVG code based on the image.viewBox="0 0 {img_width} {img_height}"
prompt = prompt.replace("{width}", str(image.width)).replace("{height}", str(image.height))
response = inference_with_vllm(
image,
prompt,
ip=args.ip,
port=args.port,
temperature=0.9, # SVG: low temperature often causes repetitive/looping output
top_p=1.0,
model_name=args.model_name,
)
print(f"response: {response}")
if __name__ == "__main__":
main()
================================================
FILE: demo/launch_model_vllm.sh
================================================
# download model to /path/to/model
if [ -z "$NODOWNLOAD" ]; then
python3 tools/download_model.py
fi
# register model to vllm
hf_model_path=./weights/DotsOCR # Path to your downloaded model weights
export PYTHONPATH=$(dirname "$hf_model_path"):$PYTHONPATH
sed -i '/^from vllm\.entrypoints\.cli\.main import main$/a\
from DotsOCR import modeling_dots_ocr_vllm' `which vllm`
# launch vllm server
model_name=model
CUDA_VISIBLE_DEVICES=0 vllm serve ${hf_model_path} --tensor-parallel-size 1 --gpu-memory-utilization 0.95 --chat-template-content-format string --served-model-name ${model_name} --trust-remote-code
# # run python demo after launch vllm server
# python demo/demo_vllm.py
================================================
FILE: docker/Dockerfile
================================================
# Dots OCR has been officially integrated into vLLM since v0.11.0
# Below is the dockerfile for out-of-tree model registration support based on v0.9.1
from vllm/vllm-openai:v0.9.1
RUN pip3 install flash_attn==2.8.0.post2
RUN pip3 install transformers==4.51.3
================================================
FILE: docker/docker-compose.yml
================================================
version: '3.8'
services:
dots-ocr-server:
image: dots-ocr:latest
container_name: dots-ocr-container
ports:
- "8000:8000"
volumes:
#download model to local,model url:https://www.modelscope.cn/models/rednote-hilab/dots.ocr
- ./model/dots.ocr:/workspace/weights/DotsOCR
environment:
- PYTHONPATH=/workspace/weights:$PYTHONPATH
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
device_ids: ['0']
entrypoint: /bin/bash
command:
- -c
- |
set -ex;
echo '--- Starting setup and server ---';
echo 'Modifying vllm entrypoint...';
# This sed command patches the vllm entrypoint script to import the custom modeling code.
sed -i '/^from vllm\.entrypoints\.cli\.main import main/a from DotsOCR import modeling_dots_ocr_vllm' $(which vllm) && \
echo 'vllm script after patch:';
# Show the patched part of the vllm script for verification.
grep -A 1 'from vllm.entrypoints.cli.main import main' $(which vllm) && \
echo 'Starting server...';
# Use 'exec' to replace the current shell process with the vllm server,
# ensuring logs are properly forwarded to Docker's standard output.
exec vllm serve /workspace/weights/DotsOCR \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.8 \
--chat-template-content-format string \
--served-model-name dotsocr-model \
--trust-remote-code
================================================
FILE: dots.ocr LICENSE AGREEMENT
================================================
dots.ocr LICENSE AGREEMENT
Effective Date: [ August 8, 2025]
Copyright Holder: [Xingyin Information Technology (Shanghai) Co., Ltd]
This License Agreement (“Agreement”) governs Your use, reproduction, modification, and distribution of dots.ocr (the "Model Materials"). This Agreement is designed to maximize the openness and use of the Model Materials while addressing the unique legal, ethical, and technical challenges posed by large language models.
WHEREAS, Licensor has developed the dots.ocr document parsing model and intends to distribute the Model Materials under an open‑source framework;
WHEREAS, traditional open-source licenses (e.g., the MIT License) may not fully address the complexity inherent complexities of document parsing models, namely their multiple components (code, weights, training data), potential ethical risks, data‑governance issues, and intellectual‑property and liability questions regarding AI‑generated content;
WHEREAS, Licensor seeks to provide a legal framework that ensures maximum access to and use of the Model Materials while clearly defining the rights, obligations, and liabilities of Licensee;
THEREFORE, the parties agree that, subject to the MIT License, they shall be bound by the following terms and conditions:
1. Definitions and Interpretation
Purpose: To define key terms used in this Agreement, particularly "Model Materials," ensuring clarity of the license scope beyond traditional software code. To clarify the order of precedence between this Agreement and the MIT License to avoid conflict.
1.1 “Licensor” shall mean the entity providing the Model Materials under this Agreement, namely [Xingyin Information Technology (Shanghai) Co., Ltd].
1.2 “Licensee” or "You" shall mean any individual or entity exercising permissions granted by this Agreement.
1.3 “Model Materials” shall mean all materials provided by Licensor under this Agreement, including but not limited to:
(a) one or more machine‑learning models, including architecture and trained parameters (i.e., model weights);
(b) all associated preprocessing, training, inference, and fine‑tuning code;
(c) training datasets and evaluation scripts (or their detailed descriptions and access mechanisms); and
(d) any accompanying documentation, metadata, and tools.
The above Model Materials shall be subject to the content published on the Licensor’s website or GitHub repository at https://github.com/rednote-hilab/dots.ocr.
1.4 “Outputs” shall mean any content generated through the use of the Model Materials, such as text, tables, code,layout information, and formulas extracted from documents.
1.5 “MIT License” shall mean The MIT Open Source License published by the Massachusetts Institute of Technology.
1.6 Priority of Agreement. In the event of any conflict or inconsistency between this Agreement and the MIT License, the terms of the MIT License shall prevail. However, if the terms of the MIT License are ambiguous or silent on a particular matter, the provisions of this Agreement shall apply and supplement the MIT License.
2. Grant of Rights and Scope of Use
Purpose: To grant broad, permissive rights to the Licensee for the Model Materials—including code, weights, data, and documentation—to ensure maximum openness and flexibility while clarifying the free use of model-generated content. Additionally, it clarifies the feasibility of transitioning from open-source to commercial‑use and the use of OpenAPI interfaces.
2.1 Grant of Copyright License. Subject to Licensee's compliance with this Agreement, Licensor hereby grants Licensee a perpetual, worldwide, non‑exclusive, no-charge, royalty‑free copyright license to use (run or test), reproduce, modify, create derivative works of, merge, publish, distribute the Model Materials; sublicense and/or sell copies of the Model Materials or any derivative works thereof; and incorporate the unmodified or modified Model Materials into proprietary products or services, including for commercial purposes, software‑as‑a‑service (SaaS) offerings, or via OpenAPI or other interfaces.
2.2 Fundamental Capabilities. The Model Materials only provide the fundamental model’s capabilities. Licensees may develop derivative AI applications or undertake task‑specific training thereon.
2.3 From Open Source to Commercial Use. The open-source release does not preclude Licensor’s commercial exploitation of the Model Materials, in whole or in part. Any such commercial use shall, at that time, be subject to license agreements between Licensor and applicable users.
2.4 API‑Service Exception. Licensees who access the Model Materials through API calls or provide model services via API interfaces(without directly distributing model weights )shall not be subject to this Agreement unless otherwise expressly agreed. Instead, such use shall be governed by the API terms of use published by Licensor (if any).
3. Acceptable Use Policy and Prohibited Uses
3.1 Responsible Use. Licensee must use the Model Materials in a responsible, ethical, and lawful manner, in compliance with all applicable laws, regulations, industry standards, and best practices.
3.2 Enterprise On‑Premises Deployment. The Licensee may deploy the Model Materials in closed‑source, on‑premises enterprise environments.
3.3 Prohibited Uses. Any breach of the prohibitions below will result in the automatic termination of all licenses granted under this Agreement. Licensee agrees not to use the Model Materials or any derivative works thereof, in connection with:
(a) Identification and Utilization of Illegal/Harmful Content:Includes identifying graphic/text materials used for counterfeiting certificates/invoices, perpetrating fraud, or launching cyberattacks; or processing images containing illegal content such as violence, criminal activities, disinformation, or child exploitation.
(b) Privacy Infringement and Discriminatory Practices:Extracting personal sensitive information (e.g., ID numbers, medical records, biometric data) or protected characteristics (e.g., race, gender) from images without legal authorization or consent, for purposes of privacy violation, automated discriminatory decision-making, or harassment.
(c) Copyright Restrictions:Licensees shall not use the tool for unauthorized digitization of publications/document scanning or bulk scraping of content. Any use involving publications or other copyright-protected materials must first obtain relevant permissions.
4. Intellectual Property Ownership and Contributions
4.1 Licensor's Copyright Reservation. Licensor reserves all right, title, and interest in and to the Model Materials (including the model architecture, parameters, code, and original training data), except as expressly licensed herein. The original copyright of the Model Materials belongs to the Licensor.
4.2 Patent License. Subject to the terms and conditions of this Agreement, Licensor hereby grants Licensee a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Model Materials, where such license applies only to those patent claims licensable by the Lisensor that are necessarily infringed by its contribution(s).
If Licensee institutes patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Model Materials constitute direct or contributory patent infringement, then any patent licenses granted under this License for the Model Materials shall terminate as of the date such litigation is asserted or filed.
4.3 Outputs: The Outputs generated through the use of the Model Materials generally refer to text, tables, layouts, and other content extracted from documents or images. The extracted content itself does not generate new intellectual property rights, and all intellectual property remains with the original authors or copyright holders. The Licensee is responsible for due diligence regarding the legality of the Outputs, particularly where the content extracted by the OCR model may be substantially similar to existing copyrighted works, which could present intellectual property infringement risks. The Licensor assumes no liability for such infringements.
4.4 Trademarks. Nothing in this License permits Licensee to make use of Licensor’s trademarks, trade names, logos (e.g., “rednote,” “Xiaohongshu,” “dots.ocr”) or to otherwise suggest endorsement or misrepresent the relationship between the parties, unless Licensor’s prior written approval is granted.
5. Data Governance, Privacy, and Security
5.1 Data Quality and Bias. Licensee shall use training data from lawful sources and is encouraged to conduct due diligence before deploying the Model Materials and to take reasonable steps to mitigate any known biases in its training data or applications.
5.2 Privacy Protection.
(a) Sensitive‑Data Restrictions. It is prohibited to use the Model Materials to process,or extract infer sensitive personal data protected under specific laws (such as GDPR or HIPAA), particularly when dealing with documents containing personally identifiable information (such as ID numbers, health data, financial information, etc.), unless Licensee has obtained all necessary consents, lawful basis, or authorizations, and has implemented adequate anonymization, pseudonymization, or other privacy-enhancing technologies.
(b) Data Minimization and Purpose Limitation. The Licensee shall follow the principle of data minimization when using the OCR Model, processing only the user data necessary for specific, explicit, and lawful purposes. Specifically, the OCR Model should avoid processing unnecessary sensitive data and ensure compliance with applicable privacy protection laws during data handling.
(c) Transparency. Licensee shall provide clear and transparent privacy policies and terms of use when processing user data, particularly during document scanning and information extraction. .
5.3 Security Measures. Licensee shall implement appropriate technical and administrative safeguards to protect the Model Materials and any associated data against unauthorized access, disclosure, alteration, or destruction. Such measures may include, but are not limited to, encryption, access controls, logging, and audit trails.
5.4 Further Training. Licensee may only use user‑provided input or Outputs for training, fine-tuning, or improving other AI models if it has obtained the specific and informed consent of data subjects.
6. Disclaimer of Warranty and Limitation of Liability
6.1 “AS IS” Basis. Unless required by applicable law, the Model Materials are provided on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. Licensee is solely responsible for determining the appropriateness of using or redistributing the Model Materials and assume any risks associated with the exercise of permissions under this License. Licensor does not provide any warranty of non-infringement but represents that no infringing code has been knowingly included.
6.2 Outputs Disclaimer. As a neutral technology, Licensor disclaims all liability for the accuracy, completeness, reliability, safety, legality, or suitability of any Outputs. The Licensee is solely responsible for verifying the accuracy and appropriateness of AI-generated content and shall provide appropriate disclosures when publishing or relying upon such content.
6.3 Limitation of Liability and Recourse. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, shall Licensor or contributors be liable for any claims, damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Model Materials (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Licensor has been advised of the possibility of such damages. If such losses are incurred, recourse may be sought against the Licensee responsible for causing the loss.
6.4 Content‑Filtering Disclaimer. Although the Model Materials may include content‑filtering mechanisms, Licensor makes no warranties of any kind regarding the stability, quality, accuracy, completeness, or any specific outcome of Outputs. Licensee is solely responsible for reviewing, verifying, and performing quality control on Outputs and assumes all associated risks and liabilities.
7. Attribution and License Reservation
7.1 License. When distributing or redistributing the Model Materials, Licensee must give any other recipients of the Model Materials a copy of this Agreement.
7.2 Copyright and Notices. When distributing any part of the Model Materials, Licensee must retain all copyright, patent, trademark, and attribution notices included in the Model Materials.
7.3 Attribution. Licensee is encouraged to prominently display the name of Licensor and the Model Materials in any public statements, products, or services that contain the Model Materials (or any derivative works thereof), to promote transparency and community trust. If Licensee distributes modified weights or fine‑tuned models based on the Model Materials, Licensee must prominently display the following statement in the related website or documentation: “Built with dots.ocr.”
8. Governing Law and Dispute Resolution
8.1 Governing Law. This Agreement shall be governed by and construed in accordance with the laws of the People’s Republic of China, without regard to its conflict of laws principles.
8.2 Dispute Resolution. Any dispute claim, or disagreement arising out of or relating to this Agreement shall first be resolved through amicable consultation. If such consultation fails, the dispute shall be submitted to the Hangzhou Arbitration Commission for arbitration. The arbitration shall be conducted in accordance with the laws of China, and the place of arbitration shall be [Hangzhou, China]. The arbitral award shall be final and binding upon both parties.
9. Regulatory Compliance Amendments
In the event that any part of this Agreement becomes invalid or requires adjustment due to changes in applicable laws or regulations, Licensor reserves the right to issue a revised version of this Agreement. Licensee shall migrate to the new version within [e.g., ninety (90)] days of its release; otherwise, all rights granted under this Agreement shall automatically terminate.
10. Security Reporting
Licensee discovering any security vulnerability in the Model Materials may report it to Licensor via: dots-feedback@xiaohongshu.com. Licensee shall not disclose vulnerability details until Licensor issues an official remediation, unless otherwise required by law.
================================================
FILE: dots_ocr/__init__.py
================================================
from .parser import DotsOCRParser
================================================
FILE: dots_ocr/model/inference.py
================================================
import requests
from dots_ocr.utils.image_utils import PILimage_to_base64
from openai import OpenAI
import os
def inference_with_vllm(
image,
prompt,
protocol="http",
ip="localhost",
port=8000,
temperature=0.1,
top_p=0.9,
max_completion_tokens=32768,
model_name='rednote-hilab/dots.ocr',
system_prompt=None,
):
addr = f"{protocol}://{ip}:{port}/v1"
client = OpenAI(api_key="{}".format(os.environ.get("API_KEY", "0")), base_url=addr)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append(
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": PILimage_to_base64(image)},
},
{"type": "text", "text": f"<|img|><|imgpad|><|endofimg|>{prompt}"} # if no "<|img|><|imgpad|><|endofimg|>" here,vllm v1 will add "\n" here
],
}
)
try:
response = client.chat.completions.create(
messages=messages,
model=model_name,
max_completion_tokens=max_completion_tokens,
temperature=temperature,
top_p=top_p)
response = response.choices[0].message.content
return response
except requests.exceptions.RequestException as e:
print(f"request error: {e}")
return None
================================================
FILE: dots_ocr/parser.py
================================================
import os
import json
from tqdm import tqdm
from multiprocessing.pool import ThreadPool, Pool
import argparse
from dots_ocr.model.inference import inference_with_vllm
from dots_ocr.utils.consts import image_extensions, MIN_PIXELS, MAX_PIXELS
from dots_ocr.utils.image_utils import get_image_by_fitz_doc, fetch_image, smart_resize
from dots_ocr.utils.doc_utils import fitz_doc_to_image, load_images_from_pdf
from dots_ocr.utils.prompts import dict_promptmode_to_prompt
from dots_ocr.utils.layout_utils import post_process_output, draw_layout_on_image, pre_process_bboxes
from dots_ocr.utils.format_transformer import layoutjson2md
class DotsOCRParser:
"""
parse image or pdf file
"""
def __init__(self,
protocol='http',
ip='localhost',
port=8000,
model_name='model',
temperature=0.1,
top_p=1.0,
max_completion_tokens=16384,
num_thread=64,
dpi = 200,
output_dir="./output",
min_pixels=None,
max_pixels=None,
use_hf=False,
):
self.dpi = dpi
# default args for vllm server
self.protocol = protocol
self.ip = ip
self.port = port
self.model_name = model_name
# default args for inference
self.temperature = temperature
self.top_p = top_p
self.max_completion_tokens = max_completion_tokens
self.num_thread = num_thread
self.output_dir = output_dir
self.min_pixels = min_pixels
self.max_pixels = max_pixels
self.use_hf = use_hf
if self.use_hf:
self._load_hf_model()
print(f"use hf model, num_thread will be set to 1")
else:
print(f"use vllm model, num_thread will be set to {self.num_thread}")
assert self.min_pixels is None or self.min_pixels >= MIN_PIXELS
assert self.max_pixels is None or self.max_pixels <= MAX_PIXELS
def _load_hf_model(self):
import torch
from transformers import AutoModelForCausalLM, AutoProcessor, AutoTokenizer
from qwen_vl_utils import process_vision_info
model_path = "./weights/DotsOCR"
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
self.processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True,use_fast=True)
self.process_vision_info = process_vision_info
def _inference_with_hf(self, image, prompt):
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image
},
{"type": "text", "text": prompt}
]
}
]
# Preparation for inference
text = self.processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
image_inputs, video_inputs = self.process_vision_info(messages)
inputs = self.processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = self.model.generate(**inputs, max_new_tokens=24000)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
response = self.processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
return response
def _inference_with_vllm(self, image, prompt):
response = inference_with_vllm(
image,
prompt,
model_name=self.model_name,
protocol=self.protocol,
ip=self.ip,
port=self.port,
temperature=self.temperature,
top_p=self.top_p,
max_completion_tokens=self.max_completion_tokens,
)
return response
def get_prompt(self, prompt_mode, bbox=None, origin_image=None, image=None, min_pixels=None, max_pixels=None):
prompt = dict_promptmode_to_prompt[prompt_mode]
if prompt_mode == 'prompt_grounding_ocr':
assert bbox is not None
bboxes = [bbox]
bbox = pre_process_bboxes(origin_image, bboxes, input_width=image.width, input_height=image.height, min_pixels=min_pixels, max_pixels=max_pixels)[0]
prompt = prompt + str(bbox)
return prompt
# def post_process_results(self, response, prompt_mode, save_dir, save_name, origin_image, image, min_pixels, max_pixels)
def _parse_single_image(
self,
origin_image,
prompt_mode,
save_dir,
save_name,
source="image",
page_idx=0,
bbox=None,
fitz_preprocess=False,
):
min_pixels, max_pixels = self.min_pixels, self.max_pixels
if prompt_mode == "prompt_grounding_ocr":
min_pixels = min_pixels or MIN_PIXELS # preprocess image to the final input
max_pixels = max_pixels or MAX_PIXELS
if min_pixels is not None: assert min_pixels >= MIN_PIXELS, f"min_pixels should >= {MIN_PIXELS}"
if max_pixels is not None: assert max_pixels <= MAX_PIXELS, f"max_pixels should <= {MAX_PIXELS}"
if source == 'image' and fitz_preprocess:
image = get_image_by_fitz_doc(origin_image, target_dpi=self.dpi)
image = fetch_image(image, min_pixels=min_pixels, max_pixels=max_pixels)
else:
image = fetch_image(origin_image, min_pixels=min_pixels, max_pixels=max_pixels)
input_height, input_width = smart_resize(image.height, image.width)
prompt = self.get_prompt(prompt_mode, bbox, origin_image, image, min_pixels=min_pixels, max_pixels=max_pixels)
if self.use_hf:
response = self._inference_with_hf(image, prompt)
else:
response = self._inference_with_vllm(image, prompt)
result = {'page_no': page_idx,
"input_height": input_height,
"input_width": input_width
}
if source == 'pdf':
save_name = f"{save_name}_page_{page_idx}"
if prompt_mode in ['prompt_layout_all_en', 'prompt_layout_only_en', 'prompt_grounding_ocr']:
cells, filtered = post_process_output(
response,
prompt_mode,
origin_image,
image,
min_pixels=min_pixels,
max_pixels=max_pixels,
)
if filtered and prompt_mode != 'prompt_layout_only_en': # model output json failed, use filtered process
json_file_path = os.path.join(save_dir, f"{save_name}.json")
with open(json_file_path, 'w', encoding="utf-8") as w:
json.dump(response, w, ensure_ascii=False)
image_layout_path = os.path.join(save_dir, f"{save_name}.jpg")
origin_image.save(image_layout_path)
result.update({
'layout_info_path': json_file_path,
'layout_image_path': image_layout_path,
})
md_file_path = os.path.join(save_dir, f"{save_name}.md")
with open(md_file_path, "w", encoding="utf-8") as md_file:
md_file.write(cells)
result.update({
'md_content_path': md_file_path
})
result.update({
'filtered': True
})
else:
try:
image_with_layout = draw_layout_on_image(origin_image, cells)
except Exception as e:
print(f"Error drawing layout on image: {e}")
image_with_layout = origin_image
json_file_path = os.path.join(save_dir, f"{save_name}.json")
with open(json_file_path, 'w', encoding="utf-8") as w:
json.dump(cells, w, ensure_ascii=False)
image_layout_path = os.path.join(save_dir, f"{save_name}.jpg")
image_with_layout.save(image_layout_path)
result.update({
'layout_info_path': json_file_path,
'layout_image_path': image_layout_path,
})
if prompt_mode != "prompt_layout_only_en": # no text md when detection only
md_content = layoutjson2md(origin_image, cells, text_key='text')
md_content_no_hf = layoutjson2md(origin_image, cells, text_key='text', no_page_hf=True) # used for clean output or metric of omnidocbench、olmbench
md_file_path = os.path.join(save_dir, f"{save_name}.md")
with open(md_file_path, "w", encoding="utf-8") as md_file:
md_file.write(md_content)
md_nohf_file_path = os.path.join(save_dir, f"{save_name}_nohf.md")
with open(md_nohf_file_path, "w", encoding="utf-8") as md_file:
md_file.write(md_content_no_hf)
result.update({
'md_content_path': md_file_path,
'md_content_nohf_path': md_nohf_file_path,
})
else:
image_layout_path = os.path.join(save_dir, f"{save_name}.jpg")
origin_image.save(image_layout_path)
result.update({
'layout_image_path': image_layout_path,
})
md_content = response
md_file_path = os.path.join(save_dir, f"{save_name}.md")
with open(md_file_path, "w", encoding="utf-8") as md_file:
md_file.write(md_content)
result.update({
'md_content_path': md_file_path,
})
return result
def parse_image(self, input_path, filename, prompt_mode, save_dir, bbox=None, fitz_preprocess=False):
origin_image = fetch_image(input_path)
result = self._parse_single_image(origin_image, prompt_mode, save_dir, filename, source="image", bbox=bbox, fitz_preprocess=fitz_preprocess)
result['file_path'] = input_path
return [result]
def parse_pdf(self, input_path, filename, prompt_mode, save_dir):
print(f"loading pdf: {input_path}")
images_origin = load_images_from_pdf(input_path, dpi=self.dpi)
total_pages = len(images_origin)
tasks = [
{
"origin_image": image,
"prompt_mode": prompt_mode,
"save_dir": save_dir,
"save_name": filename,
"source":"pdf",
"page_idx": i,
} for i, image in enumerate(images_origin)
]
def _execute_task(task_args):
return self._parse_single_image(**task_args)
if self.use_hf:
num_thread = 1
else:
num_thread = min(total_pages, self.num_thread)
print(f"Parsing PDF with {total_pages} pages using {num_thread} threads...")
results = []
with ThreadPool(num_thread) as pool:
with tqdm(total=total_pages, desc="Processing PDF pages") as pbar:
for result in pool.imap_unordered(_execute_task, tasks):
results.append(result)
pbar.update(1)
results.sort(key=lambda x: x["page_no"])
for i in range(len(results)):
results[i]['file_path'] = input_path
return results
def parse_file(self,
input_path,
output_dir="",
prompt_mode="prompt_layout_all_en",
bbox=None,
fitz_preprocess=False
):
output_dir = output_dir or self.output_dir
output_dir = os.path.abspath(output_dir)
filename, file_ext = os.path.splitext(os.path.basename(input_path))
save_dir = os.path.join(output_dir, filename)
os.makedirs(save_dir, exist_ok=True)
if file_ext == '.pdf':
results = self.parse_pdf(input_path, filename, prompt_mode, save_dir)
elif file_ext in image_extensions:
results = self.parse_image(input_path, filename, prompt_mode, save_dir, bbox=bbox, fitz_preprocess=fitz_preprocess)
else:
raise ValueError(f"file extension {file_ext} not supported, supported extensions are {image_extensions} and pdf")
print(f"Parsing finished, results saving to {save_dir}")
with open(os.path.join(output_dir, os.path.basename(filename)+'.jsonl'), 'w', encoding="utf-8") as w:
for result in results:
w.write(json.dumps(result, ensure_ascii=False) + '\n')
return results
def main():
prompts = list(dict_promptmode_to_prompt.keys())
parser = argparse.ArgumentParser(
description="dots.ocr Multilingual Document Layout Parser",
)
parser.add_argument(
"input_path", type=str,
help="Input PDF/image file path"
)
parser.add_argument(
"--output", type=str, default="./output",
help="Output directory (default: ./output)"
)
parser.add_argument(
"--prompt", choices=prompts, type=str, default="prompt_layout_all_en",
help="prompt to query the model, different prompts for different tasks"
)
parser.add_argument(
'--bbox',
type=int,
nargs=4,
metavar=('x1', 'y1', 'x2', 'y2'),
help='should give this argument if you want to prompt_grounding_ocr'
)
parser.add_argument(
"--protocol", type=str, choices=['http', 'https'], default="http",
help=""
)
parser.add_argument(
"--ip", type=str, default="localhost",
help=""
)
parser.add_argument(
"--port", type=int, default=8000,
help=""
)
parser.add_argument(
"--model_name", type=str, default="model",
help=""
)
parser.add_argument(
"--temperature", type=float, default=0.1,
help=""
)
parser.add_argument(
"--top_p", type=float, default=1.0,
help=""
)
parser.add_argument(
"--dpi", type=int, default=200,
help=""
)
parser.add_argument(
"--max_completion_tokens", type=int, default=16384,
help=""
)
parser.add_argument(
"--num_thread", type=int, default=16,
help=""
)
parser.add_argument(
"--no_fitz_preprocess", action='store_true',
help="False will use tikz dpi upsample pipeline, good for images which has been render with low dpi, but maybe result in higher computational costs"
)
parser.add_argument(
"--min_pixels", type=int, default=None,
help=""
)
parser.add_argument(
"--max_pixels", type=int, default=None,
help=""
)
parser.add_argument(
"--use_hf", type=bool, default=False,
help=""
)
args = parser.parse_args()
dots_ocr_parser = DotsOCRParser(
protocol=args.protocol,
ip=args.ip,
port=args.port,
model_name=args.model_name,
temperature=args.temperature,
top_p=args.top_p,
max_completion_tokens=args.max_completion_tokens,
num_thread=args.num_thread,
dpi=args.dpi,
output_dir=args.output,
min_pixels=args.min_pixels,
max_pixels=args.max_pixels,
use_hf=args.use_hf,
)
fitz_preprocess = not args.no_fitz_preprocess
if fitz_preprocess:
print(f"Using fitz preprocess for image input, check the change of the image pixels")
result = dots_ocr_parser.parse_file(
args.input_path,
prompt_mode=args.prompt,
bbox=args.bbox,
fitz_preprocess=fitz_preprocess,
)
if __name__ == "__main__":
main()
================================================
FILE: dots_ocr/utils/__init__.py
================================================
from .prompts import dict_promptmode_to_prompt
================================================
FILE: dots_ocr/utils/consts.py
================================================
MIN_PIXELS=3136
MAX_PIXELS=11289600
IMAGE_FACTOR=28
image_extensions = {'.jpg', '.jpeg', '.png'}
================================================
FILE: dots_ocr/utils/demo_utils/display.py
================================================
import os
from PIL import Image
def is_valid_image_path(image_path):
"""
Checks if the image path is valid.
Args:
image_path: The path to the image.
Returns:
bool: True if the path is valid, False otherwise.
"""
if not os.path.exists(image_path):
return False
# Check if the file extension is one of the common image formats.
image_extensions = ['.jpg', '.jpeg', '.png', '.gif', '.bmp']
_, extension = os.path.splitext(image_path)
if extension.lower() in image_extensions:
return True
else:
return False
def read_image(image_path, use_native=False):
"""
Reads an image and resizes it while maintaining aspect ratio.
Args:
image_path: The path to the image.
use_native: If True, the max dimension of the original image is used as the max size.
If False, max size is set to 1024.
Returns:
tuple: (resized_image, original_width, original_height)
"""
# Create a default 512x512 blue image as a fallback.
image = Image.new('RGB', (512, 512), color=(0, 0, 255))
if is_valid_image_path(image_path):
image = Image.open(image_path)
else:
raise FileNotFoundError(f"{image_path}: Image path does not exist")
w, h = image.size
if use_native:
max_size = max(w, h)
else:
max_size = 1024
if w > h:
new_w = max_size
new_h = int(h * max_size / w)
else:
new_h = max_size
new_w = int(w * max_size / h)
image = image.resize((new_w, new_h))
return image, w, h
================================================
FILE: dots_ocr/utils/doc_utils.py
================================================
import fitz
import numpy as np
import enum
from pydantic import BaseModel, Field
from PIL import Image
class SupportedPdfParseMethod(enum.Enum):
OCR = 'ocr'
TXT = 'txt'
class PageInfo(BaseModel):
"""The width and height of page
"""
w: float = Field(description='the width of page')
h: float = Field(description='the height of page')
def fitz_doc_to_image(doc, target_dpi=200, origin_dpi=None) -> dict:
"""Convert fitz.Document to image, Then convert the image to numpy array.
Args:
doc (_type_): pymudoc page
dpi (int, optional): reset the dpi of dpi. Defaults to 200.
Returns:
dict: {'img': numpy array, 'width': width, 'height': height }
"""
from PIL import Image
mat = fitz.Matrix(target_dpi / 72, target_dpi / 72)
pm = doc.get_pixmap(matrix=mat, alpha=False)
if pm.width > 4500 or pm.height > 4500:
mat = fitz.Matrix(72 / 72, 72 / 72) # use fitz default dpi
pm = doc.get_pixmap(matrix=mat, alpha=False)
image = Image.frombytes('RGB', (pm.width, pm.height), pm.samples)
return image
def load_images_from_pdf(pdf_file, dpi=200, start_page_id=0, end_page_id=None) -> list:
images = []
with fitz.open(pdf_file) as doc:
pdf_page_num = doc.page_count
end_page_id = (
end_page_id
if end_page_id is not None and end_page_id >= 0
else pdf_page_num - 1
)
if end_page_id > pdf_page_num - 1:
print('end_page_id is out of range, use images length')
end_page_id = pdf_page_num - 1
for index in range(0, doc.page_count):
if start_page_id <= index <= end_page_id:
page = doc[index]
img = fitz_doc_to_image(page, target_dpi=dpi)
images.append(img)
return images
================================================
FILE: dots_ocr/utils/format_transformer.py
================================================
import os
import sys
import json
import re
from PIL import Image
from dots_ocr.utils.image_utils import PILimage_to_base64
def has_latex_markdown(text: str) -> bool:
"""
Checks if a string contains LaTeX markdown patterns.
Args:
text (str): The string to check.
Returns:
bool: True if LaTeX markdown is found, otherwise False.
"""
if not isinstance(text, str):
return False
# Define regular expression patterns for LaTeX markdown
latex_patterns = [
r'\$\$.*?\$\$', # Block-level math formula $$...$$
r'\$[^$\n]+?\$', # Inline math formula $...$
r'\\begin\{.*?\}.*?\\end\{.*?\}', # LaTeX environment \begin{...}...\end{...}
r'\\[a-zA-Z]+\{.*?\}', # LaTeX command \command{...}
r'\\[a-zA-Z]+', # Simple LaTeX command \command
r'\\\[.*?\\\]', # Display math formula \[...\]
r'\\\(.*?\\\)', # Inline math formula \(...\)
]
# Check if any of the patterns match
for pattern in latex_patterns:
if re.search(pattern, text, re.DOTALL):
return True
return False
def clean_latex_preamble(latex_text: str) -> str:
"""
Removes LaTeX preamble commands like document class and package imports.
Args:
latex_text (str): The original LaTeX text.
Returns:
str: The cleaned LaTeX text without preamble commands.
"""
# Define patterns to be removed
patterns = [
r'\\documentclass\{[^}]+\}', # \documentclass{...}
r'\\usepackage\{[^}]+\}', # \usepackage{...}
r'\\usepackage\[[^\]]*\]\{[^}]+\}', # \usepackage[options]{...}
r'\\begin\{document\}', # \begin{document}
r'\\end\{document\}', # \end{document}
]
# Apply each pattern to clean the text
cleaned_text = latex_text
for pattern in patterns:
cleaned_text = re.sub(pattern, '', cleaned_text, flags=re.IGNORECASE)
return cleaned_text
def get_formula_in_markdown(text: str) -> str:
"""
Formats a string containing a formula into a standard Markdown block.
Args:
text (str): The input string, potentially containing a formula.
Returns:
str: The formatted string, ready for Markdown rendering.
"""
# Remove leading/trailing whitespace
text = text.strip()
# Check if it's already enclosed in $$
if text.startswith('$$') and text.endswith('$$'):
text_new = text[2:-2].strip()
if not '$' in text_new:
return f"$$\n{text_new}\n$$"
else:
return text
# Handle \[...\] format, convert to $$...$$
if text.startswith('\\[') and text.endswith('\\]'):
inner_content = text[2:-2].strip()
return f"$$\n{inner_content}\n$$"
# Check if it's enclosed in \[ \]
if len(re.findall(r'.*\\\[.*\\\].*', text)) > 0:
return text
# Handle inline formulas ($...$)
pattern = r'\$([^$]+)\$'
matches = re.findall(pattern, text)
if len(matches) > 0:
# It's an inline formula, return it as is
return text
# If no LaTeX markdown syntax is present, return directly
if not has_latex_markdown(text):
return text
# Handle unnecessary LaTeX formatting like \usepackage
if 'usepackage' in text:
text = clean_latex_preamble(text)
if text[0] == '`' and text[-1] == '`':
text = text[1:-1]
# Enclose the final text in a $$ block with newlines
text = f"$$\n{text}\n$$"
return text
def clean_text(text: str) -> str:
"""
Cleans text by removing extra whitespace.
Args:
text: The original text.
Returns:
str: The cleaned text.
"""
if not text:
return ""
# Remove leading and trailing whitespace
text = text.strip()
# Replace multiple consecutive whitespace characters with a single space
if text[:2] == '`$' and text[-2:] == '$`':
text = text[1:-1]
return text
def layoutjson2md(image: Image.Image, cells: list, text_key: str = 'text', no_page_hf: bool = False) -> str:
"""
Converts a layout JSON format to Markdown.
In the layout JSON, formulas are LaTeX, tables are HTML, and text is Markdown.
Args:
image: A PIL Image object.
cells: A list of dictionaries, each representing a layout cell.
text_key: The key for the text field in the cell dictionary.
no_page_header_footer: If True, skips page headers and footers.
Returns:
str: The text in Markdown format.
"""
text_items = []
for i, cell in enumerate(cells):
x1, y1, x2, y2 = [int(coord) for coord in cell['bbox']]
text = cell.get(text_key, "")
if no_page_hf and cell['category'] in ['Page-header', 'Page-footer']:
continue
if cell['category'] == 'Picture':
image_crop = image.crop((x1, y1, x2, y2))
image_base64 = PILimage_to_base64(image_crop)
text_items.append(f"")
elif cell['category'] == 'Formula':
text_items.append(get_formula_in_markdown(text))
else:
text = clean_text(text)
text_items.append(f"{text}")
markdown_text = '\n\n'.join(text_items)
return markdown_text
def fix_streamlit_formulas(md: str) -> str:
"""
Fixes the format of formulas in Markdown to ensure they display correctly in Streamlit.
It adds a newline after the opening $$ and before the closing $$ if they don't already exist.
Args:
md_text (str): The Markdown text to fix.
Returns:
str: The fixed Markdown text.
"""
# This inner function will be used by re.sub to perform the replacement
def replace_formula(match):
content = match.group(1)
# If the content already has surrounding newlines, don't add more.
if content.startswith('\n'):
content = content[1:]
if content.endswith('\n'):
content = content[:-1]
return f'$$\n{content}\n$$'
# Use regex to find all $$....$$ patterns and replace them using the helper function.
return re.sub(r'\$\$(.*?)\$\$', replace_formula, md, flags=re.DOTALL)
================================================
FILE: dots_ocr/utils/image_utils.py
================================================
import math
import base64
from PIL import Image
from typing import Tuple
import os
from dots_ocr.utils.consts import IMAGE_FACTOR, MIN_PIXELS, MAX_PIXELS
from dots_ocr.utils.doc_utils import fitz_doc_to_image
from io import BytesIO
import fitz
import requests
import copy
def round_by_factor(number: int, factor: int) -> int:
"""Returns the closest integer to 'number' that is divisible by 'factor'."""
return round(number / factor) * factor
def ceil_by_factor(number: int, factor: int) -> int:
"""Returns the smallest integer greater than or equal to 'number' that is divisible by 'factor'."""
return math.ceil(number / factor) * factor
def floor_by_factor(number: int, factor: int) -> int:
"""Returns the largest integer less than or equal to 'number' that is divisible by 'factor'."""
return math.floor(number / factor) * factor
def smart_resize(
height: int,
width: int,
factor: int = 28,
min_pixels: int = 3136,
max_pixels: int = 11289600,
):
"""Rescales the image so that the following conditions are met:
1. Both dimensions (height and width) are divisible by 'factor'.
2. The total number of pixels is within the range ['min_pixels', 'max_pixels'].
3. The aspect ratio of the image is maintained as closely as possible.
"""
if max(height, width) / min(height, width) > 200:
raise ValueError(
f"absolute aspect ratio must be smaller than 200, got {max(height, width) / min(height, width)}"
)
h_bar = max(factor, round_by_factor(height, factor))
w_bar = max(factor, round_by_factor(width, factor))
if h_bar * w_bar > max_pixels:
beta = math.sqrt((height * width) / max_pixels)
h_bar = max(factor, floor_by_factor(height / beta, factor))
w_bar = max(factor, floor_by_factor(width / beta, factor))
elif h_bar * w_bar < min_pixels:
beta = math.sqrt(min_pixels / (height * width))
h_bar = ceil_by_factor(height * beta, factor)
w_bar = ceil_by_factor(width * beta, factor)
if h_bar * w_bar > max_pixels: # max_pixels first to control the token length
beta = math.sqrt((h_bar * w_bar) / max_pixels)
h_bar = max(factor, floor_by_factor(h_bar / beta, factor))
w_bar = max(factor, floor_by_factor(w_bar / beta, factor))
return h_bar, w_bar
def PILimage_to_base64(image, format='PNG'):
buffered = BytesIO()
image.save(buffered, format=format)
base64_str = base64.b64encode(buffered.getvalue()).decode('utf-8')
return f"data:image/{format.lower()};base64,{base64_str}"
def to_rgb(pil_image: Image.Image) -> Image.Image:
if pil_image.mode == 'RGBA':
white_background = Image.new("RGB", pil_image.size, (255, 255, 255))
white_background.paste(pil_image, mask=pil_image.split()[3]) # Use alpha channel as mask
return white_background
else:
return pil_image.convert("RGB")
# copy from https://github.com/QwenLM/Qwen2.5-VL/blob/main/qwen-vl-utils/src/qwen_vl_utils/vision_process.py
def fetch_image(
image,
min_pixels=None,
max_pixels=None,
resized_height=None,
resized_width=None,
) -> Image.Image:
assert image is not None, f"image not found, maybe input format error: {image}"
image_obj = None
if isinstance(image, Image.Image):
image_obj = image
elif image.startswith("http://") or image.startswith("https://"):
# fix memory leak issue while using BytesIO
with requests.get(image, stream=True) as response:
response.raise_for_status()
with BytesIO(response.content) as bio:
image_obj = copy.deepcopy(Image.open(bio))
elif image.startswith("file://"):
image_obj = Image.open(image[7:])
elif image.startswith("data:image"):
if "base64," in image:
_, base64_data = image.split("base64,", 1)
data = base64.b64decode(base64_data)
# fix memory leak issue while using BytesIO
with BytesIO(data) as bio:
image_obj = copy.deepcopy(Image.open(bio))
else:
image_obj = Image.open(image)
if image_obj is None:
raise ValueError(f"Unrecognized image input, support local path, http url, base64 and PIL.Image, got {image}")
image = to_rgb(image_obj)
## resize
if resized_height and resized_width:
resized_height, resized_width = smart_resize(
resized_height,
resized_width,
factor=IMAGE_FACTOR,
)
assert resized_height>0 and resized_width>0, f"resized_height: {resized_height}, resized_width: {resized_width}, min_pixels: {min_pixels}, max_pixels:{max_pixels}, width: {width}, height:{height}, "
image = image.resize((resized_width, resized_height))
elif min_pixels or max_pixels:
width, height = image.size
if not min_pixels:
min_pixels = MIN_PIXELS
if not max_pixels:
max_pixels = MAX_PIXELS
resized_height, resized_width = smart_resize(
height,
width,
factor=IMAGE_FACTOR,
min_pixels=min_pixels,
max_pixels=max_pixels,
)
assert resized_height>0 and resized_width>0, f"resized_height: {resized_height}, resized_width: {resized_width}, min_pixels: {min_pixels}, max_pixels:{max_pixels}, width: {width}, height:{height}, "
image = image.resize((resized_width, resized_height))
return image
def get_input_dimensions(
image: Image.Image,
min_pixels: int,
max_pixels: int,
factor: int = 28
) -> Tuple[int, int]:
"""
Gets the resized dimensions of the input image.
Args:
image: The original image.
min_pixels: The minimum number of pixels.
max_pixels: The maximum number of pixels.
factor: The resizing factor.
Returns:
The resized (width, height).
"""
input_height, input_width = smart_resize(
image.height,
image.width,
factor=factor,
min_pixels=min_pixels,
max_pixels=max_pixels
)
return input_width, input_height
def get_image_by_fitz_doc(image, target_dpi=200):
# get image through fitz, to get target dpi image, mainly for higher image
if not isinstance(image, Image.Image):
assert isinstance(image, str)
_, file_ext = os.path.splitext(image)
assert file_ext in {'.jpg', '.jpeg', '.png'}
if image.startswith("http://") or image.startswith("https://"):
with requests.get(image, stream=True) as response:
response.raise_for_status()
data_bytes = response.content
else:
with open(image, 'rb') as f:
data_bytes = f.read()
image = Image.open(BytesIO(data_bytes))
else:
data_bytes = BytesIO()
image.save(data_bytes, format='PNG')
origin_dpi = image.info.get('dpi', None)
pdf_bytes = fitz.open(stream=data_bytes).convert_to_pdf()
doc = fitz.open('pdf', pdf_bytes)
page = doc[0]
image_fitz = fitz_doc_to_image(page, target_dpi=target_dpi, origin_dpi=origin_dpi)
return image_fitz
================================================
FILE: dots_ocr/utils/layout_utils.py
================================================
from PIL import Image
from typing import Dict, List
import fitz
from io import BytesIO
import json
from dots_ocr.utils.image_utils import smart_resize
from dots_ocr.utils.consts import MIN_PIXELS, MAX_PIXELS
from dots_ocr.utils.output_cleaner import OutputCleaner
# Define a color map (using RGBA format)
dict_layout_type_to_color = {
"Text": (0, 128, 0, 256), # Green, translucent
"Picture": (255, 0, 255, 256), # Magenta, translucent
"Caption": (255, 165, 0, 256), # Orange, translucent
"Section-header": (0, 255, 255, 256), # Cyan, translucent
"Footnote": (0, 128, 0, 256), # Green, translucent
"Formula": (128, 128, 128, 256), # Gray, translucent
"Table": (255, 192, 203, 256), # Pink, translucent
"Title": (255, 0, 0, 256), # Red, translucent
"List-item": (0, 0, 255, 256), # Blue, translucent
"Page-header": (0, 128, 0, 256), # Green, translucent
"Page-footer": (128, 0, 128, 256), # Purple, translucent
"Other": (165, 42, 42, 256), # Brown, translucent
"Unknown": (0, 0, 0, 0),
}
def draw_layout_on_image(image, cells, resized_height=None, resized_width=None, fill_bbox=True, draw_bbox=True):
"""
Draw transparent boxes on an image.
Args:
image: The source PIL Image.
cells: A list of cells containing bounding box information.
resized_height: The resized height.
resized_width: The resized width.
fill_bbox: Whether to fill the bounding box.
draw_bbox: Whether to draw the bounding box.
Returns:
PIL.Image: The image with drawings.
"""
# origin_image = Image.open(image_path)
original_width, original_height = image.size
# Create a new PDF document
doc = fitz.open()
# Get image information
img_bytes = BytesIO()
image.save(img_bytes, format='PNG')
# pix = fitz.Pixmap(image_path)
pix = fitz.Pixmap(img_bytes)
# Create a page
page = doc.new_page(width=pix.width, height=pix.height)
page.insert_image(
fitz.Rect(0, 0, pix.width, pix.height),
# filename=image_path
pixmap=pix
)
for i, cell in enumerate(cells):
bbox = cell['bbox']
layout_type = cell['category']
order = i
top_left = (bbox[0], bbox[1])
down_right = (bbox[2], bbox[3])
if resized_height and resized_width:
scale_x = resized_width / original_width
scale_y = resized_height / original_height
top_left = (int(bbox[0] / scale_x), int(bbox[1] / scale_y))
down_right = (int(bbox[2] / scale_x), int(bbox[3] / scale_y))
color = dict_layout_type_to_color.get(layout_type, (0, 128, 0, 256))
color = [col/255 for col in color[:3]]
x0, y0, x1, y1 = top_left[0], top_left[1], down_right[0], down_right[1]
rect_coords = fitz.Rect(x0, y0, x1, y1)
if draw_bbox:
if fill_bbox:
page.draw_rect(
rect_coords,
color=None,
fill=color,
fill_opacity=0.3,
width=0.5,
overlay=True,
) # Draw the rectangle
else:
page.draw_rect(
rect_coords,
color=color,
fill=None,
fill_opacity=1,
width=0.5,
overlay=True,
) # Draw the rectangle
order_cate = f"{order}_{layout_type}"
page.insert_text(
(x1, y0 + 20), order_cate, fontsize=20, color=color
) # Insert the index in the top left corner of the rectangle
# Convert to a Pixmap (maintaining original dimensions)
mat = fitz.Matrix(1.0, 1.0)
pix = page.get_pixmap(matrix=mat)
return Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
def pre_process_bboxes(
origin_image,
bboxes,
input_width,
input_height,
factor: int = 28,
min_pixels: int = 3136,
max_pixels: int = 11289600
):
assert isinstance(bboxes, list) and len(bboxes) > 0 and isinstance(bboxes[0], list)
min_pixels = min_pixels or MIN_PIXELS
max_pixels = max_pixels or MAX_PIXELS
original_width, original_height = origin_image.size
input_height, input_width = smart_resize(input_height, input_width, min_pixels=min_pixels, max_pixels=max_pixels)
scale_x = original_width / input_width
scale_y = original_height / input_height
bboxes_out = []
for bbox in bboxes:
bbox_resized = [
int(float(bbox[0]) / scale_x),
int(float(bbox[1]) / scale_y),
int(float(bbox[2]) / scale_x),
int(float(bbox[3]) / scale_y)
]
bboxes_out.append(bbox_resized)
return bboxes_out
def post_process_cells(
origin_image: Image.Image,
cells: List[Dict],
input_width, # server input width, also has smart_resize in server
input_height,
factor: int = 28,
min_pixels: int = 3136,
max_pixels: int = 11289600
) -> List[Dict]:
"""
Post-processes cell bounding boxes, converting coordinates from the resized dimensions back to the original dimensions.
Args:
origin_image: The original PIL Image.
cells: A list of cells containing bounding box information.
input_width: The width of the input image sent to the server.
input_height: The height of the input image sent to the server.
factor: Resizing factor.
min_pixels: Minimum number of pixels.
max_pixels: Maximum number of pixels.
Returns:
A list of post-processed cells.
"""
assert isinstance(cells, list) and len(cells) > 0 and isinstance(cells[0], dict)
min_pixels = min_pixels or MIN_PIXELS
max_pixels = max_pixels or MAX_PIXELS
original_width, original_height = origin_image.size
input_height, input_width = smart_resize(input_height, input_width, min_pixels=min_pixels, max_pixels=max_pixels)
scale_x = input_width / original_width
scale_y = input_height / original_height
cells_out = []
for cell in cells:
bbox = cell['bbox']
bbox_resized = [
int(float(bbox[0]) / scale_x),
int(float(bbox[1]) / scale_y),
int(float(bbox[2]) / scale_x),
int(float(bbox[3]) / scale_y)
]
cell_copy = cell.copy()
cell_copy['bbox'] = bbox_resized
cells_out.append(cell_copy)
return cells_out
def is_legal_bbox(cells):
for cell in cells:
bbox = cell['bbox']
if bbox[2] <= bbox[0] or bbox[3] <= bbox[1]:
return False
return True
def post_process_output(response, prompt_mode, origin_image, input_image, min_pixels=None, max_pixels=None):
if prompt_mode in ["prompt_ocr", "prompt_table_html", "prompt_table_latex", "prompt_formula_latex"]:
return response
json_load_failed = False
cells = response
try:
cells = json.loads(cells)
cells = post_process_cells(
origin_image,
cells,
input_image.width,
input_image.height,
min_pixels=min_pixels,
max_pixels=max_pixels
)
return cells, False
except Exception as e:
print(f"cells post process error: {e}, when using {prompt_mode}")
json_load_failed = True
if json_load_failed:
cleaner = OutputCleaner()
response_clean = cleaner.clean_model_output(cells)
if isinstance(response_clean, list):
response_clean = "\n\n".join([cell['text'] for cell in response_clean if 'text' in cell])
return response_clean, True
================================================
FILE: dots_ocr/utils/output_cleaner.py
================================================
#!/usr/bin/env python3
"""
Data Cleaning Script - Cleans all data using a simplified regex method and saves the results
Features:
1. Cleans all cases using a simplified regex method.
2. Saves the cleaned data for each case.
3. Ensures the relative order of dicts remains unchanged.
4. Generates a before-and-after cleaning report.
"""
import json
import re
import os
from typing import Dict, List, Tuple, Optional, Any
from dataclasses import dataclass
from collections import Counter
import traceback
@dataclass
class CleanedData:
"""Data structure for cleaned data"""
case_id: int
original_type: str # 'list' or 'str'
original_length: int
cleaned_data: List[Dict]
cleaning_operations: Dict[str, Any] # Records the cleaning operations performed
success: bool
class OutputCleaner:
"""Data Cleaner - Based on a simplified regex method"""
def __init__(self):
# Simplified regular expression patterns
self.dict_pattern = re.compile(r'\{[^{}]*?"bbox"\s*:\s*\[[^\]]*?\][^{}]*?\}', re.DOTALL)
self.bbox_pattern = re.compile(r'"bbox"\s*:\s*\[([^\]]+)\]')
self.missing_delimiter_pattern = re.compile(r'\}\s*\{(?!")')
self.cleaned_results: List[CleanedData] = []
def clean_list_data(self, data: List[Dict], case_id: int) -> CleanedData:
"""Cleans list-type data"""
print(f"🔧 Cleaning List data - Case {case_id}")
print(f" Original items: {len(data)}")
cleaned_data = []
operations = {
'type': 'list',
'bbox_fixes': 0,
'removed_items': 0,
'original_count': len(data)
}
for i, item in enumerate(data):
if not isinstance(item, dict):
operations['removed_items'] += 1
continue
# Check the bbox field
if 'bbox' in item:
bbox = item['bbox']
# Check bbox length - core logic
if isinstance(bbox, list) and len(bbox) == 3:
print(f" ⚠️ Item {i}: bbox has only 3 coordinates. Removing bbox, keeping category and text.")
# Keep only category and text, ensuring order is preserved
new_item = {}
if 'category' in item:
new_item['category'] = item['category']
if 'text' in item:
new_item['text'] = item['text']
if new_item: # Add only if there is valid content
cleaned_data.append(new_item)
operations['bbox_fixes'] += 1
else:
operations['removed_items'] += 1
continue
elif isinstance(bbox, list) and len(bbox) == 4:
# bbox is normal, add directly, preserving original order
cleaned_data.append(item.copy())
continue
else:
print(f" ❌ Item {i}: Abnormal bbox format, skipping.")
operations['removed_items'] += 1
continue
else:
# No bbox field, keep if category exists
if 'category' in item:
cleaned_data.append(item.copy())
continue
else:
operations['removed_items'] += 1
operations['final_count'] = len(cleaned_data)
print(f" ✅ Cleaning complete: {len(cleaned_data)} items, {operations['bbox_fixes']} bbox fixes, {operations['removed_items']} items removed")
return CleanedData(
case_id=case_id,
original_type='list',
original_length=len(data),
cleaned_data=cleaned_data,
cleaning_operations=operations,
success=True
)
def clean_string_data(self, data_str: str, case_id: int) -> CleanedData:
"""Cleans string-type data"""
print(f"🔧 Cleaning String data - Case {case_id}")
print(f" Original length: {len(data_str):,}")
operations = {
'type': 'str',
'original_length': len(data_str),
'delimiter_fixes': 0,
'tail_truncated': False,
'truncated_length': 0,
'duplicate_dicts_removed': 0,
'final_objects': 0
}
try:
# Step 1: Detect and fix missing delimiters
data_str, delimiter_fixes = self._fix_missing_delimiters(data_str)
operations['delimiter_fixes'] = delimiter_fixes
# Step 2: Truncate the last incomplete element
data_str, tail_truncated = self._truncate_last_incomplete_element(data_str)
operations['tail_truncated'] = tail_truncated
operations['truncated_length'] = len(data_str)
# Step 3: Remove duplicate complete dict objects, preserving order
data_str, duplicate_removes = self._remove_duplicate_complete_dicts_preserve_order(data_str)
operations['duplicate_dicts_removed'] = duplicate_removes
# Step 4: Ensure correct JSON format
data_str = self._ensure_json_format(data_str)
# Step 5: Try to parse the final result
final_data = self._parse_final_json(data_str)
if final_data is not None:
operations['final_objects'] = len(final_data)
print(f" ✅ Cleaning complete: {len(final_data)} objects")
return CleanedData(
case_id=case_id,
original_type='str',
original_length=operations['original_length'],
cleaned_data=final_data,
cleaning_operations=operations,
success=True
)
else:
raise Exception("Could not parse the cleaned data")
except Exception as e:
print(f" ❌ Cleaning failed: {e}")
return CleanedData(
case_id=case_id,
original_type='str',
original_length=operations['original_length'],
cleaned_data=[],
cleaning_operations=operations,
success=False
)
def _fix_missing_delimiters(self, text: str) -> Tuple[str, int]:
"""Fixes missing delimiters"""
fixes = 0
def replace_delimiter(match):
nonlocal fixes
fixes += 1
return '},{'
text = self.missing_delimiter_pattern.sub(replace_delimiter, text)
if fixes > 0:
print(f" ✅ Fixed {fixes} missing delimiters")
return text, fixes
def _truncate_last_incomplete_element(self, text: str) -> Tuple[str, bool]:
"""Truncates the last incomplete element"""
# For very long text (>50k) or text not ending with ']', directly truncate the last '{"bbox":'
needs_truncation = (
len(text) > 50000 or
not text.strip().endswith(']')
)
if needs_truncation:
# Check how many dict objects there are
bbox_count = text.count('{"bbox":')
# If there is only one dict object, do not truncate to avoid deleting the only object
if bbox_count <= 1:
print(f" ⚠️ Only {bbox_count} dict objects found, skipping truncation to avoid deleting all content")
return text, False
# Find the position of the last '{"bbox":'
last_bbox_pos = text.rfind('{"bbox":')
if last_bbox_pos > 0:
# Truncate before this position
truncated_text = text[:last_bbox_pos].rstrip()
# Remove trailing comma
if truncated_text.endswith(','):
truncated_text = truncated_text[:-1]
print(f" ✂️ Truncated the last incomplete element, length reduced from {len(text):,} to {len(truncated_text):,}")
return truncated_text, True
return text, False
def _remove_duplicate_complete_dicts_preserve_order(self, text: str) -> Tuple[str, int]:
"""Removes duplicate complete dict objects, preserving original order"""
# Extract all dict objects, preserving order
dict_matches = list(self.dict_pattern.finditer(text))
if not dict_matches:
return text, 0
print(f" 📊 Found {len(dict_matches)} dict objects")
# Deduplication while preserving order: only keep the first occurrence of a dict
unique_dicts = []
seen_dict_strings = set()
total_duplicates = 0
for match in dict_matches:
dict_str = match.group()
if dict_str not in seen_dict_strings:
unique_dicts.append(dict_str)
seen_dict_strings.add(dict_str)
else:
total_duplicates += 1
if total_duplicates > 0:
# Reconstruct the JSON array, preserving the original order
new_text = '[' + ', '.join(unique_dicts) + ']'
print(f" ✅ Removed {total_duplicates} duplicate dicts, keeping {len(unique_dicts)} unique dicts (order preserved)")
return new_text, total_duplicates
else:
print(f" ✅ No duplicate dict objects found")
return text, 0
def _ensure_json_format(self, text: str) -> str:
"""Ensures correct JSON format"""
text = text.strip()
if not text.startswith('['):
text = '[' + text
if not text.endswith(']'):
# Remove trailing comma
text = text.rstrip(',').rstrip()
text += ']'
return text
def _parse_final_json(self, text: str) -> Optional[List[Dict]]:
"""Tries to parse the final JSON"""
try:
data = json.loads(text)
if isinstance(data, list):
return data
except json.JSONDecodeError as e:
print(f" ❌ JSON parsing failed: {e}")
# fallback1: Extract valid dict objects
valid_dicts = []
for match in self.dict_pattern.finditer(text):
dict_str = match.group()
try:
dict_obj = json.loads(dict_str)
valid_dicts.append(dict_obj)
except:
continue
if valid_dicts:
print(f" ✅ Extracted {len(valid_dicts)} valid dicts")
return valid_dicts
# fallback2: Special handling for a single incomplete dict
return self._handle_single_incomplete_dict(text)
return None
def _handle_single_incomplete_dict(self, text: str) -> Optional[List[Dict]]:
"""Handles the special case of a single incomplete dict"""
# Check if it's a single incomplete dict case
if not text.strip().startswith('[{"bbox":'):
return None
try:
# Try to extract bbox coordinates
bbox_match = re.search(r'"bbox"\s*:\s*\[([^\]]+)\]', text)
if not bbox_match:
return None
bbox_str = bbox_match.group(1)
bbox_coords = [int(x.strip()) for x in bbox_str.split(',')]
if len(bbox_coords) != 4:
return None
# Try to extract category
category_match = re.search(r'"category"\s*:\s*"([^"]+)"', text)
category = category_match.group(1) if category_match else "Text"
# Try to extract the beginning of the text (first 10000 characters)
text_match = re.search(r'"text"\s*:\s*"([^"]{0,10000})', text)
if text_match:
text_content = text_match.group(1)
else:
text_content = ""
# Construct the fixed dict
fixed_dict = {
"bbox": bbox_coords,
"category": category
}
if text_content:
fixed_dict["text"] = text_content
print(f" 🔧 Special fix: single incomplete dict → {fixed_dict}")
return [fixed_dict]
except Exception as e:
print(f" ❌ Special fix failed: {e}")
return None
def remove_duplicate_category_text_pairs_and_bbox(self, data_list: List[dict], case_id: int) -> List[dict]:
"""Removes duplicate category-text pairs and duplicate bboxes"""
if not data_list or len(data_list) <= 1:
print(f" 📊 Data length {len(data_list)} <= 1, skipping deduplication check")
return data_list
print(f" 📊 Original data length: {len(data_list)}")
# 1. Count occurrences and positions of each category-text pair
category_text_pairs = {}
for i, item in enumerate(data_list):
if isinstance(item, dict) and 'category' in item and 'text' in item:
pair_key = (item.get('category', ''), item.get('text', ''))
if pair_key not in category_text_pairs:
category_text_pairs[pair_key] = []
category_text_pairs[pair_key].append(i)
# 2. Count occurrences and positions of each bbox
bbox_pairs = {}
for i, item in enumerate(data_list):
if isinstance(item, dict) and 'bbox' in item:
bbox = item.get('bbox')
if isinstance(bbox, list) and len(bbox) > 0:
bbox_key = tuple(bbox) # Convert to tuple to use as a dictionary key
if bbox_key not in bbox_pairs:
bbox_pairs[bbox_key] = []
bbox_pairs[bbox_key].append(i)
# 3. Identify items to be removed
duplicates_to_remove = set()
# 3a. Process category-text pairs that appear 5 or more times
for pair_key, positions in category_text_pairs.items():
if len(positions) >= 5:
category, text = pair_key
# Keep the first occurrence, remove subsequent duplicates
positions_to_remove = positions[1:]
duplicates_to_remove.update(positions_to_remove)
print(f" 🔍 Found duplicate category-text pair: category='{category}', first 50 chars of text='{text[:50]}...'")
print(f" Count: {len(positions)}, removing at positions: {positions_to_remove}")
# 3b. Process bboxes that appear 2 or more times
for bbox_key, positions in bbox_pairs.items():
if len(positions) >= 2:
# Keep the first occurrence, remove subsequent duplicates
positions_to_remove = positions[1:]
duplicates_to_remove.update(positions_to_remove)
print(f" 🔍 Found duplicate bbox: {list(bbox_key)}")
print(f" Count: {len(positions)}, removing at positions: {positions_to_remove}")
if not duplicates_to_remove:
print(f" ✅ No category-text pairs or bboxes found exceeding the duplication threshold")
return data_list
# 4. Remove duplicate items from the original data (preserving order)
cleaned_data = []
removed_count = 0
for i, item in enumerate(data_list):
if i not in duplicates_to_remove:
cleaned_data.append(item)
else:
removed_count += 1
print(f" ✅ Deduplication complete: Removed {removed_count} duplicate items")
print(f" 📊 Cleaned data length: {len(cleaned_data)}")
return cleaned_data
def clean_model_output(self, model_output: str):
try:
# Select cleaning method based on data type
if isinstance(model_output, list):
result = self.clean_list_data(model_output, case_id=0)
else:
result = self.clean_string_data(str(model_output), case_id=0)
# Add deduplication step: remove duplicate category-text pairs and bboxes
if result and hasattr(result, 'success') and result.success and result.cleaned_data:
original_data = result.cleaned_data
deduplicated_data = self.remove_duplicate_category_text_pairs_and_bbox(original_data, case_id=0)
# Update the cleaned_data in the CleanedData object
result.cleaned_data = deduplicated_data
return result.cleaned_data
except Exception as e:
print(f"❌ Case cleaning failed: {e}")
return model_output
def clean_all_data(self, jsonl_path: str) -> List[CleanedData]:
"""Cleans all data from a JSONL file"""
print(f"🚀 Starting to clean JSONL file: {jsonl_path}")
with open(jsonl_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
datas = []
for i, line in enumerate(lines):
if line.strip():
try:
data = json.loads(line)
predict_field = data.get('predict')
case_id = i + 1
print(f"\n{'='*50}")
print(f"🎯 Cleaning Case {case_id}")
print(f"{'='*50}")
# Select cleaning method based on data type
if isinstance(predict_field, list):
print("📊 Data type: List")
result = self.clean_list_data(predict_field, case_id)
else:
print("📊 Data type: String")
result = self.clean_string_data(str(predict_field), case_id)
# Add deduplication step: remove duplicate category-text pairs and bboxes
if result and hasattr(result, 'success') and result.success and result.cleaned_data:
print("🔄 Checking for and removing duplicate category-text pairs and bboxes...")
original_data = result.cleaned_data
deduplicated_data = self.remove_duplicate_category_text_pairs_and_bbox(original_data, case_id)
# Update the cleaned_data in the CleanedData object
result.cleaned_data = deduplicated_data
data['predict_resized'] = result.cleaned_data
datas.append(data)
self.cleaned_results.append(result)
except Exception as e:
print(f"❌ Case {i+1} cleaning failed: {e}")
traceback.print_exc()
save_path = jsonl_path.replace('.jsonl', '_filtered.jsonl')
with open(save_path, 'w') as w:
for data in datas:
w.write(json.dumps(data, ensure_ascii=False) + '\n')
print(f"✅ Saved cleaned data to: {save_path}")
return self.cleaned_results
def save_cleaned_data(self, output_dir: str):
"""Saves the cleaned data"""
print(f"\n💾 Saving cleaned data to: {output_dir}")
os.makedirs(output_dir, exist_ok=True)
# 1. Save cleaned data for each case
for result in self.cleaned_results:
case_filename = f"cleaned_case_{result.case_id:02d}.json"
case_filepath = os.path.join(output_dir, case_filename)
# Save the cleaned data
with open(case_filepath, 'w', encoding='utf-8') as f:
json.dump(result.cleaned_data, f, ensure_ascii=False, indent=2)
print(f" ✅ Case {result.case_id}: {len(result.cleaned_data)} objects → {case_filename}")
# 2. Save all cleaned data to a single file
all_cleaned_data = []
for result in self.cleaned_results:
all_cleaned_data.append({
'case_id': result.case_id,
'original_type': result.original_type,
'original_length': result.original_length,
'cleaned_objects_count': len(result.cleaned_data),
'success': result.success,
'cleaning_operations': result.cleaning_operations,
'cleaned_data': result.cleaned_data
})
all_data_filepath = os.path.join(output_dir, "all_cleaned_data.json")
with open(all_data_filepath, 'w', encoding='utf-8') as f:
json.dump(all_cleaned_data, f, ensure_ascii=False, indent=2)
print(f" 📁 All data: {len(all_cleaned_data)} cases → all_cleaned_data.json")
# 3. Generate a cleaning report
self._generate_cleaning_report(output_dir)
def _generate_cleaning_report(self, output_dir: str):
"""Generates a cleaning report"""
report = []
report.append("📊 Data Cleaning Report")
report.append("=" * 60)
import datetime
report.append(f"Processing Time: {datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
report.append("")
# Overall statistics
total_cases = len(self.cleaned_results)
successful_cases = sum(1 for r in self.cleaned_results if r.success)
total_objects = sum(len(r.cleaned_data) for r in self.cleaned_results)
report.append("📈 Overall Statistics:")
report.append(f" Total Cases: {total_cases}")
report.append(f" Successfully Cleaned: {successful_cases}")
report.append(f" Success Rate: {successful_cases/total_cases*100:.1f}%")
report.append(f" Total Recovered Objects: {total_objects}")
report.append("")
# Detailed statistics
list_results = [r for r in self.cleaned_results if r.original_type == 'list']
str_results = [r for r in self.cleaned_results if r.original_type == 'str']
if list_results:
report.append("📋 List Type Cleaning Statistics:")
for r in list_results:
ops = r.cleaning_operations
report.append(f" Case {r.case_id}: {ops['original_count']} → {ops['final_count']} objects")
if ops['bbox_fixes'] > 0:
report.append(f" - bbox fixes: {ops['bbox_fixes']}")
if ops['removed_items'] > 0:
report.append(f" - invalid items removed: {ops['removed_items']}")
report.append("")
if str_results:
report.append("📝 String Type Cleaning Statistics:")
for r in str_results:
ops = r.cleaning_operations
status = "✅" if r.success else "❌"
report.append(f" Case {r.case_id} {status}: {ops['original_length']:,} chars → {ops['final_objects']} objects")
details = []
if ops['delimiter_fixes'] > 0:
details.append(f"Delimiter fixes: {ops['delimiter_fixes']}")
if ops['tail_truncated']:
reduction = ops['original_length'] - ops['truncated_length']
details.append(f"Tail truncation: -{reduction:,} chars")
if ops['duplicate_dicts_removed'] > 0:
details.append(f"Duplicates removed: {ops['duplicate_dicts_removed']}")
if details:
report.append(f" - {', '.join(details)}")
report.append("")
# Note on data order
report.append("🔄 Data Order Guarantee:")
report.append(" ✅ The relative order of all dict objects is preserved during cleaning.")
report.append(" ✅ When deduplicating, the first occurrence of a dict is kept, and subsequent duplicates are removed.")
report.append(" ✅ The order of items in List-type data is fully preserved.")
# Save the report
report_filepath = os.path.join(output_dir, "cleaning_report.txt")
with open(report_filepath, 'w', encoding='utf-8') as f:
f.write('\n'.join(report))
print(f" 📋 Cleaning report: cleaning_report.txt")
# Also print to console
print(f"\n{chr(10).join(report)}")
def main():
"""Main function"""
# Create a data cleaner instance
cleaner = OutputCleaner()
# Input file
jsonl_path = "output_with_failcase.jsonl"
# Output directory
output_dir = "output_with_failcase_cleaned"
# Clean all data
results = cleaner.clean_all_data(jsonl_path)
# Save the cleaned data
cleaner.save_cleaned_data(output_dir)
print(f"\n🎉 Data cleaning complete!")
print(f"📁 Cleaned data saved in: {output_dir}")
if __name__ == "__main__":
main()
================================================
FILE: dots_ocr/utils/prompts.py
================================================
dict_promptmode_to_prompt = {
# prompt_layout_all_en: parse all layout info in json format.
"prompt_layout_all_en": """Please output the layout information from the PDF image, including each layout element's bbox, its category, and the corresponding text content within the bbox.
1. Bbox format: [x1, y1, x2, y2]
2. Layout Categories: The possible categories are ['Caption', 'Footnote', 'Formula', 'List-item', 'Page-footer', 'Page-header', 'Picture', 'Section-header', 'Table', 'Text', 'Title'].
3. Text Extraction & Formatting Rules:
- Picture: For the 'Picture' category, the text field should be omitted.
- Formula: Format its text as LaTeX.
- Table: Format its text as HTML.
- All Others (Text, Title, etc.): Format their text as Markdown.
4. Constraints:
- The output text must be the original text from the image, with no translation.
- All layout elements must be sorted according to human reading order.
5. Final Output: The entire output must be a single JSON object.
""",
# prompt_layout_only_en: layout detection
"prompt_layout_only_en": """Please output the layout information from this PDF image, including each layout's bbox and its category. The bbox should be in the format [x1, y1, x2, y2]. The layout categories for the PDF document include ['Caption', 'Footnote', 'Formula', 'List-item', 'Page-footer', 'Page-header', 'Picture', 'Section-header', 'Table', 'Text', 'Title']. Do not output the corresponding text. The layout result should be in JSON format.""",
# prompt_ocr: parse ocr text except the Page-header and Page-footer
"prompt_ocr": """Extract the text content from this image.""",
# prompt_grounding_ocr: extract text content in the given bounding box
"prompt_grounding_ocr": """Extract text from the given bounding box on the image (format: [x1, y1, x2, y2]).\nBounding Box:\n""",
# prompt_web_parsing: parse all webpage layout info in json format.
"prompt_web_parsing": """Parsing the layout info of this webpage image with format json:\n""",
# prompt_scene_spotting: scene spotting
"prompt_scene_spotting": """Detect and recognize the text in the image.""",
# prompt_img2svg: generate the SVG code of the image
"prompt_image_to_svg": """Please generate the SVG code based on the image.viewBox="0 0 {width} {height}\"""",
# prompt_free_qa: general prompt
"prompt_general": """ """,
# "prompt_table_html": """Convert the table in this image to HTML.""",
# "prompt_table_latex": """Convert the table in this image to LaTeX.""",
# "prompt_formula_latex": """Convert the formula in this image to LaTeX.""",
}
================================================
FILE: requirements.txt
================================================
# streamlit
gradio
gradio_image_annotation
PyMuPDF
openai
qwen_vl_utils
transformers==4.56.1
huggingface_hub
modelscope
# flash-attn==2.8.0.post2 # to speed up inference need flash-attn
accelerate
cairosvg
================================================
FILE: setup.py
================================================
from setuptools import setup, find_packages
# 从requirements.txt文件读取依赖
def parse_requirements(filename):
with open(filename, 'r', encoding='utf-8') as f:
return f.read().splitlines()
setup(
name='dots_ocr',
version='1.0',
packages=find_packages(),
include_package_data=True,
install_requires=parse_requirements('requirements.txt'),
description='dots.ocr: Multilingual Document Layout Parsing in one Vision-Language Model',
url="https://github.com/rednote-hilab/dots.ocr",
python_requires=">=3.10",
)
================================================
FILE: tools/download_model.py
================================================
from argparse import ArgumentParser
import os
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--type', '-t', type=str, default="huggingface")
parser.add_argument('--name', '-n', type=str, default="rednote-hilab/dots.ocr-1.5")
args = parser.parse_args()
script_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
print(f"Attention: The model save dir dots.ocr should be replace by a name without `.` like DotsOCR, util we merge our code to transformers.")
model_dir = os.path.join(script_dir, "weights/DotsOCR_1_5")
if not os.path.exists(model_dir):
os.makedirs(model_dir)
if args.type == "huggingface":
from huggingface_hub import snapshot_download
snapshot_download(repo_id=args.name, local_dir=model_dir, local_dir_use_symlinks=False, resume_download=True)
elif args.type == "modelscope":
from modelscope import snapshot_download
snapshot_download(repo_id=args.name, local_dir=model_dir)
else:
raise ValueError(f"Invalid type: {args.type}")
print(f"model downloaded to {model_dir}")
================================================
FILE: tools/elo_score_prompt.py
================================================
def construct_prompt(c1_text, c2_text):
"""
Constructs the complete Prompt sent to Gemini (English Version).
c1_text: Markdown text from Model 1
c2_text: Markdown text from Model 2
"""
prompt = f"""You are an expert in evaluating OCR content accuracy. Please compare the model outputs with the original image, focusing heavily on **content accuracy** while ignoring formatting and layout differences.
【Evaluation Focus - Focus ONLY on Content Accuracy】
1. **Text Accuracy**:
- Typos: Character recognition errors (e.g., "test" recognized as "tost").
- Omissions: Missing characters or words present in the original text.
- Hallucinations: Adding characters that do not exist in the original text.
2. **Table Accuracy**:
- Correctness of data and text within the table.
- Completeness of cell content.
- Correct row/column alignment.
3. **Formula Accuracy** (Evaluate based on):
- **Correctness**: Are mathematical symbols, variables, and operators preserved accurately?
- **Completeness**: Are all parts of the formula present without omission?
- **Semantic Equivalence**: Does the extracted formula convey the exact same mathematical meaning?
【Tie Judgment Criteria - Important】
You must judge as a **tie** in the following cases:
- Text content is identical, differing only in Markdown formatting.
- Table data is identical, differing only in Markdown table syntax.
- Formula content is semantically equivalent, differing only in LaTeX representation.
- Both models correctly identified the core content; minor differences do not affect information retrieval.
- Both models share the same minor errors or are both perfect.
- **Image/Figure processing differs** (one extracts text, one gives bbox, one ignores it), but the main text is accurate.
【Items to Ignore - Do NOT factor into scoring】
- Markdown formatting differences (e.g., `# Header` vs `## Header`, `*` vs `-` for lists).
- Layout and typesetting differences (newlines, indentation, alignment).
- Recognition differences in non-body text like Headers, Footers, and Page Numbers.
- Text wrapping and paragraph segmentation nuances.
- Table border styles (e.g., `|---|---|` vs `|:--|--:|`).
- Different but equivalent LaTeX representations for formulas.
- **Image/Figure Processing Differences (ABSOLUTELY IGNORE)**:
- How the model parses image/figure regions is **completely excluded** from the scoring standard.
- Whether it parses as a `figure` field, outputs bbox coordinates, extracts text inside the image, provides a caption, describes the image content, or **completely ignores/skips the image**, these are all considered equivalent.
- Do NOT declare a winner based on image handling.
【Model 1 Output】:
```markdown
{c1_text}
```
【Model 2 Output】:
```markdown
{c2_text}
```
【Evaluation Process】
1. Carefully compare the text content against the original image.
2. Identify errors, omissions, or additions in text recognition for both models.
3. Check the accuracy of table data.
4. Evaluate the correctness, completeness, and semantic equivalence of mathematical formulas.
5. **Ignore image regions**: Confirm that differences in image/figure parsing are not used for scoring.
6. Important: If the substance is the same and only the format differs, judge as a tie.
7. Only declare a winner if there is a significant difference in **content accuracy**.
【Examples of Ties】
- Model 1: "# Title", Model 2: "## Title" (Same content, different level).
- Model 1: "* Item", Model 2: "- Item" (Same content, different bullet).
- Formula: Model 1 "$x^2$", Model 2 "$x*x$" (Different LaTeX, same meaning).
- Table data is identical, but column alignment syntax differs.
- Identification is identical, but one model parsed the footer while the other didn't (Judge as Tie).
- **Image handling**: Model 1 outputs an image bbox, Model 2 outputs an image description, Model 3 ignores the image. As long as the main text is accurate, this is a **Tie**.
【Output Requirement】 Please strictly return the result in the following JSON format:
{{"winner": "tie", "reason": "Detailed explanation of the judgment, specifically noting the logic for a tie"}}
The value of "winner" must be one of:
- "1": Model 1 is clearly better in content accuracy.
- "2": Model 2 is clearly better in content accuracy.
- "tie": Both models perform equally in content accuracy (including cases of identical content but different formatting/image handling).
In the "reason" field, specifically explain:
- If a tie: Explain the consistency of the content and explicitly mention which formatting or image handling differences were ignored.
- If a winner: Specifically point out the accuracy differences (typos, missing words, table/formula errors).
- **Note**: It is better to judge a tie than to incorrectly determine a winner based on minor formatting or image parsing differences. **Content accuracy of the main text is the ONLY standard.**
"""
return prompt
================================================
FILE: tools/eval_omnidocbench.md
================================================
Here is the step-by-step doc to reproduce OmniDocBench benchmark results.
## 1. Model Env
Here, we use [Docker Image](https://hub.docker.com/r/rednotehilab/dots.ocr) for setup.
## 2. Model Launch
```shell
# dots.ocr parser env
git clone https://github.com/rednote-hilab/dots.ocr.git
cd dots.ocr
pip install -e .
# model setup and register
python3 tools/download_model.py
export hf_model_path=./weights/DotsOCR # Path to your downloaded model weights, Please use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`) for the model save path. This is a temporary workaround pending our integration with Transformers.
export PYTHONPATH=$(dirname "$hf_model_path"):$PYTHONPATH
sed -i '/^from vllm\.entrypoints\.cli\.main import main$/a\
from DotsOCR import modeling_dots_ocr_vllm' `which vllm` # If you downloaded model weights by yourself, please replace `DotsOCR` by your model saved directory name, and remember to use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`)
# launch vllm server
CUDA_VISIBLE_DEVICES=0 vllm serve ${hf_model_path} --tensor-parallel-size 1 --gpu-memory-utilization 0.95 --chat-template-content-format string --served-model-name model --trust-remote-code
```
## 3. Model Inference
```python
from tqdm import tqdm
import json
import argparse
from multiprocessing.pool import ThreadPool, Pool
import shutil
import os
if __name__=="__main__":
from dots_ocr import DotsOCRParser
parser = argparse.ArgumentParser(
description="dots.ocr Multilingual Document Layout Parser",
)
parser.add_argument(
'--bbox',
type=int,
nargs=4,
metavar=('x1', 'y1', 'x2', 'y2'),
help='should give this argument if you want to prompt_grounding_ocr'
)
parser.add_argument(
"--ip", type=str, default="localhost",
help=""
)
parser.add_argument(
"--port", type=int, default=8000,
help=""
)
parser.add_argument(
"--model_name", type=str, default="model",
help=""
)
parser.add_argument(
"--temperature", type=float, default=0.1,
help=""
)
parser.add_argument(
"--top_p", type=float, default=1.0,
help=""
)
parser.add_argument(
"--dpi", type=int, default=200,
help=""
)
parser.add_argument(
"--max_completion_tokens", type=int, default=16384,
help=""
)
parser.add_argument(
"--num_thread", type=int, default=128,
help=""
)
# parser.add_argument(
# "--fitz_preprocess", type=bool, default=False,
# help="False will use tikz dpi upsample pipeline, good for images which has been render with low dpi, but maybe result in higher computational costs"
# )
parser.add_argument(
"--min_pixels", type=int, default=None,
help=""
)
parser.add_argument(
"--max_pixels", type=int, default=None,
help=""
)
args = parser.parse_args()
dots_ocr_parser = DotsOCRParser(
ip=args.ip,
port=args.port,
model_name=args.model_name,
temperature=args.temperature,
top_p=args.top_p,
max_completion_tokens=args.max_completion_tokens,
num_thread=args.num_thread,
dpi=args.dpi,
# output_dir=args.output,
min_pixels=args.min_pixels,
max_pixels=args.max_pixels,
)
filepath = "/path/to/OmniDocBench.jsonl" # download OmniDocBench datasets from https://huggingface.co/datasets/opendatalab/OmniDocBench, reformat it to input the images into model
with open(filepath, 'r') as f:
list_items = [json.loads(line) for line in f]
results = []
output_path = "./output_omni.jsonl"
f_out = open(output_path, 'w')
tasks = [[item['file_path'], f_out] for item in list_items]
def _excute(task):
image_path, f_out = task
result = dots_ocr_parser.parse_file(
image_path,
prompt_mode="prompt_layout_all_en",
# prompt_mode="prompt_ocr",
fitz_preprocess=True,
)
results.append(result)
f_out.write(f"{json.dumps(result, ensure_ascii=False)}\n")
f_out.flush()
with ThreadPool(128) as pool:
with tqdm(total=len(tasks)) as pbar:
for result in pool.imap(_excute, tasks):
pbar.update(1)
pool.close()
pool.join()
f_out.close()
eval_result_save_dir = "./output_omni/"
os.makedirs(eval_result_save_dir, exist_ok=True)
with open(output_path, "r") as f:
for line in f.readlines():
item = json.loads(line)[0]
if 'md_content_nohf_path' in item:
file_name = os.path.basename(item['md_content_nohf_path']).replace("_nohf", "")
shutil.copy2(item['md_content_nohf_path'], os.path.join(eval_result_save_dir, file_name))
else:
shutil.copy2(item['md_content_path'], eval_result_save_dir)
print(f"md results saved to {eval_result_save_dir}")
```
## 4. Evaluation
We use [OmniDocBench](https://github.com/opendatalab/OmniDocBench) to evaluate the performance. Prepare the omnidocbench env by yourself, follow the official steps.
```shell
git clone https://github.com/opendatalab/OmniDocBench.git
cd /OmniDocBench
# Follow https://github.com/opendatalab/OmniDocBench?tab=readme-ov-file#environment-setup-and-running
conda create -n omnidocbench python=3.10
conda activate omnidocbench
pip install -r requirements.txt
# Eval. Change the gt&pred path in end2end.yaml to your own, here by our inference steps, prediction data_path set as: /path/to/dots.ocr/output_omni/
python pdf_validation.py --config ./end2end.yaml > evaluation_output.log
cat evaluation_output.log
```
./end2end.yaml like:
```yaml
end2end_eval:
metrics:
text_block:
metric:
- Edit_dist
display_formula:
metric:
- Edit_dist
- CDM
table:
metric:
- TEDS
- Edit_dist
reading_order:
metric:
- Edit_dist
dataset:
dataset_name: end2end_dataset
ground_truth:
data_path: ./OmniDocBench.json # change to omnidocbench official gt
prediction:
data_path: /path/to/dots.ocr/output_omni/ # change to your own output dir
match_method: quick_match
```
Eval results as follow:
```shell
DATASET_REGISTRY: ['recogition_text_dataset', 'omnidocbench_single_module_dataset', 'recogition_formula_dataset', 'recogition_table_dataset', 'end2end_dataset', 'recogition_end2end_base_dataset', 'recogition_end2end_table_dataset', 'detection_dataset', 'detection_dataset_simple_format', 'md2md_dataset']
METRIC_REGISTRY: ['TEDS', 'BLEU', 'METEOR', 'Edit_dist', 'CDM']
EVAL_TASK_REGISTRY: ['detection_eval', 'end2end_eval', 'recogition_eval']
###### Process: _quick_match
【Overall】
display_formula CDM is not found
display_formula CDM is not found
---------------------------- --------------------
text_block_Edit_dist_EN 0.031039851583834904
text_block_Edit_dist_CH 0.0643426705744435
display_formula_Edit_dist_EN 0.32843522681423176
display_formula_Edit_dist_CH 0.42557920974720154
display_formula_CDM_EN -
display_formula_CDM_CH -
table_TEDS_EN 88.91012727754615
table_TEDS_CH 89.0531009325606
table_Edit_dist_EN 0.0943878061222165
table_Edit_dist_CH 0.09173810770062703
reading_order_Edit_dist_EN 0.04079293927450415
reading_order_Edit_dist_CH 0.06625588944827145
overall_EN 0.12366395594869685
overall_CH 0.16197896936763587
---------------------------- --------------------
【PDF types】
-------------------------------- ---------
data_source: book 0.0183191
data_source: PPT2PDF 0.0470068
data_source: research_report 0.0107441
data_source: colorful_textbook 0.0710044
data_source: exam_paper 0.0763102
data_source: magazine 0.0278807
data_source: academic_literature 0.0279
data_source: note 0.112103
data_source: newspaper 0.0787516
ALL 0.055183
-------------------------------- ---------
【Layout】
Layout Mean Var
--------------------- --------- ----------
layout: single_column 0.0267498 0.0187775
layout: double_column 0.0789817 0.0283393
layout: three_column 0.0738766 0.00154036
layout: other_layout 0.115941 0.0336075
【Text Attribute】
-------------------------------------- ---------
text_language: text_english 0.0296053
text_language: text_simplified_chinese 0.106577
text_language: text_en_ch_mixed 0.0888106
text_background: white 0.0880222
text_background: single_colored 0.0752833
text_background: multi_colored 0.0723353
-------------------------------------- ---------
【Table Attribute】
---------------------------------- --------
language: table_en 0.876843
language: table_simplified_chinese 0.872133
language: table_en_ch_mixed 0.941139
line: full_line 0.895071
line: less_line 0.897401
line: fewer_line 0.842987
line: wireless_line 0.847398
with_span: True 0.865542
with_span: False 0.881582
include_equation: True 0.839543
include_equation: False 0.884461
include_background: True 0.886555
include_background: False 0.8707
table_layout: vertical 0.884036
table_layout: horizontal 0.875826
---------------------------------- --------
```
> **Notes:**
> - The metrics reported in the README.md are the average of 5 runs. Each run may show a variance of ±0.005 for the overall_EN and overall_ZH scores.