Repository: richzhang/splitbrainauto
Branch: master
Commit: 79c1349907b7
Files: 6
Total size: 12.3 KB
Directory structure:
gitextract_b_vhnvgh/
├── LICENSE
├── README.md
├── models/
│ ├── deploy.prototxt
│ └── deploy_lab.prototxt
└── resources/
├── fetch_caffe.sh
└── fetch_models.sh
================================================
FILE CONTENTS
================================================
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2016 Richard Zhang
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
## Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction [[Project Page]](http://richzhang.github.io/splitbrainauto/) ##
[Richard Zhang](https://richzhang.github.io/), [Phillip Isola](http://web.mit.edu/phillipi/), [Alexei A. Efros](http://www.eecs.berkeley.edu/~efros/). In CVPR, 2017. (hosted on [ArXiv](https://arxiv.org/abs/1611.09842))
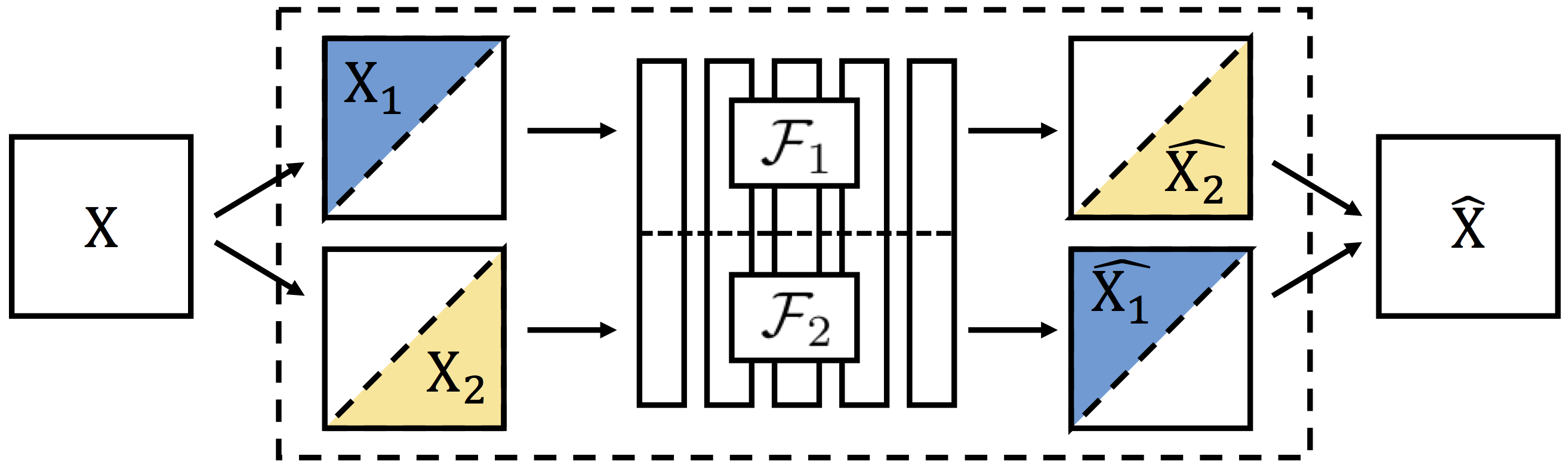 ### Overview ###
This repository contains a pre-trained Split-Brain Autoencoder network. The network achieves state-of-the-art results on several large-scale unsupervised representation learning benchmarks.
### Clone this repository ###
Clone the master branch of the respository using `git clone -b master --single-branch https://github.com/richzhang/splitbrainauto.git`
### Dependencies ###
This code requires a working installation of [Caffe](http://caffe.berkeleyvision.org/). For guidelines and help with installation of Caffe, consult the [installation guide](http://caffe.berkeleyvision.org/) and [Caffe users group](https://groups.google.com/forum/#!forum/caffe-users).
### Test-Time Usage ###
**(1)** Run `./resources/fetch_models.sh`. This will load model `model_splitbrainauto_clcl.caffemodel`. It will also load model `model_splitbrainauto_clcl_rs.caffemodel`, which is the model with the rescaling method from [Krähenbühl et al. ICLR 2016](https://github.com/philkr/magic_init) applied. The rescaling method has been shown to improve fine-tuning performance in some models, and we use it for the PASCAL tests in Table 4 in the paper. Alternatively, download the models from [here](https://people.eecs.berkeley.edu/~rich.zhang/projects/2017_splitbrain/files/models/) and put them in the `models` directory.
**(2)** To extract features, you can (a) use the main branch of Caffe and do color conversion outside of the network or (b) download and install a modified Caffe and not worry about color conversion.
**(a)** **Color conversion outside of prototxt** To extract features with the main branch of [Caffe](http://caffe.berkeleyvision.org/):
### Overview ###
This repository contains a pre-trained Split-Brain Autoencoder network. The network achieves state-of-the-art results on several large-scale unsupervised representation learning benchmarks.
### Clone this repository ###
Clone the master branch of the respository using `git clone -b master --single-branch https://github.com/richzhang/splitbrainauto.git`
### Dependencies ###
This code requires a working installation of [Caffe](http://caffe.berkeleyvision.org/). For guidelines and help with installation of Caffe, consult the [installation guide](http://caffe.berkeleyvision.org/) and [Caffe users group](https://groups.google.com/forum/#!forum/caffe-users).
### Test-Time Usage ###
**(1)** Run `./resources/fetch_models.sh`. This will load model `model_splitbrainauto_clcl.caffemodel`. It will also load model `model_splitbrainauto_clcl_rs.caffemodel`, which is the model with the rescaling method from [Krähenbühl et al. ICLR 2016](https://github.com/philkr/magic_init) applied. The rescaling method has been shown to improve fine-tuning performance in some models, and we use it for the PASCAL tests in Table 4 in the paper. Alternatively, download the models from [here](https://people.eecs.berkeley.edu/~rich.zhang/projects/2017_splitbrain/files/models/) and put them in the `models` directory.
**(2)** To extract features, you can (a) use the main branch of Caffe and do color conversion outside of the network or (b) download and install a modified Caffe and not worry about color conversion.
**(a)** **Color conversion outside of prototxt** To extract features with the main branch of [Caffe](http://caffe.berkeleyvision.org/):
**(i)** Load the downloaded weights with model definition file `deploy_lab.prototxt` in the `models` directory. The input is blob `data_lab`, which is an ***image in Lab colorspace***. You will have to do the Lab color conversion pre-processing outside of the network.
**(b)** **Color conversion in prototxt** You can also extract features with in-prototxt color version with a modified Caffe.
**(i)** Run `./resources/fetch_caffe.sh`. This will load a modified Caffe into directory `./caffe-colorization`.
**(ii)** Install the modified Caffe. For guidelines and help with installation of Caffe, consult the [installation guide](http://caffe.berkeleyvision.org/) and [Caffe users group](https://groups.google.com/forum/#!forum/caffe-users).
**(iii)** Load the downloaded weights with model definition file `deploy.prototxt` in the `models` directory. The input is blob `data`, which is a ***non mean-centered BGR image***.
### Citation ###
If you find this model useful for your resesarch, please use this [bibtex](http://richzhang.github.io/index_files/bibtex_cvpr2017_splitbrain.txt) to cite.
================================================
FILE: models/deploy.prototxt
================================================
layer {
name: "input"
type: "Input"
top: "data" # BGR image from [0,255] ***NOT MEAN CENTERED***
input_param { shape { dim: 1 dim: 3 dim: 227 dim: 227 } }
}
layer { # Convert to lab
name: "img_lab"
type: "ColorConv"
bottom: "data"
top: "img_lab"
propagate_down: false
color_conv_param {
input: 0 # BGR
output: 3 # Lab
}
}
layer { # 0-center lightness channel
name: "data_lab"
type: "Convolution"
bottom: "img_lab"
top: "data_lab" # [-50,50]
propagate_down: false
param {lr_mult: 0 decay_mult: 0}
param {lr_mult: 0 decay_mult: 0}
convolution_param {
kernel_size: 1
num_output: 3
group: 3
}
}
layer {
name: "conv1"
type: "Convolution"
# bottom: "img"
bottom: "data_lab"
# bottom: "img_bn"
top: "conv1"
param {lr_mult: 0 decay_mult: 0}
param {lr_mult: 0 decay_mult: 0}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
# bottom: "conv2"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
# pad: 1
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
# propagate_down: false
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "Convolution"
bottom: "pool5"
top: "fc6"
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
kernel_size: 6
dilation: 2
pad: 5
stride: 1
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "Convolution"
bottom: "fc6"
top: "fc7"
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
kernel_size: 1
stride: 1
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
================================================
FILE: models/deploy_lab.prototxt
================================================
layer {
name: "input"
type: "Input"
top: "img_lab" # image in Lab color space
input_param { shape { dim: 1 dim: 3 dim: 227 dim: 227 } }
}
layer { # 0-center lightness channel
name: "data_lab"
type: "Convolution"
bottom: "img_lab"
top: "data_lab" # [-50,50]
propagate_down: false
param {lr_mult: 0 decay_mult: 0}
param {lr_mult: 0 decay_mult: 0}
convolution_param {
kernel_size: 1
num_output: 3
group: 3
}
}
layer {
name: "conv1"
type: "Convolution"
# bottom: "img"
bottom: "data_lab"
# bottom: "img_bn"
top: "conv1"
param {lr_mult: 0 decay_mult: 0}
param {lr_mult: 0 decay_mult: 0}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
# bottom: "conv2"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
# pad: 1
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
# propagate_down: false
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "Convolution"
bottom: "pool5"
top: "fc6"
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
kernel_size: 6
dilation: 2
pad: 5
stride: 1
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "Convolution"
bottom: "fc6"
top: "fc7"
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
kernel_size: 1
stride: 1
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
================================================
FILE: resources/fetch_caffe.sh
================================================
wget eecs.berkeley.edu/~rich.zhang/projects/2016_colorization/files/train/caffe-colorization.tar.gz -O ./caffe-colorization.tar.gz
tar -xvf ./caffe-colorization.tar.gz
================================================
FILE: resources/fetch_models.sh
================================================
wget eecs.berkeley.edu/~rich.zhang/projects/2017_splitbrain/files/models/model_splitbrainauto_clcl.caffemodel -O ./models/model_splitbrainauto_clcl.caffemodel
wget eecs.berkeley.edu/~rich.zhang/projects/2017_splitbrain/files/models/model_splitbrainauto_clcl_rs.caffemodel -O ./models/model_splitbrainauto_clcl_rs.caffemodel