Repository: scottrogowski/code2flow
Branch: master
Commit: c2c22afe5e12
Files: 174
Total size: 658.0 KB
Directory structure:
gitextract_mss9r7uy/
├── .github/
│ └── FUNDING.yml
├── .gitignore
├── CHANGELOG.md
├── LICENSE
├── MANIFEST.in
├── Makefile
├── README.md
├── c2f
├── code2flow/
│ ├── __init__.py
│ ├── engine.py
│ ├── get_ast.js
│ ├── get_ast.php
│ ├── javascript.py
│ ├── model.py
│ ├── package.json
│ ├── php.py
│ ├── python.py
│ └── ruby.py
├── make_expected.py
├── requirements_dev.txt
├── setup.py
└── tests/
├── __init__.py
├── test_code/
│ ├── js/
│ │ ├── ambiguous_names/
│ │ │ └── ambiguous_names.js
│ │ ├── bad_parse/
│ │ │ ├── file_a_good.js
│ │ │ └── file_b_bad.js
│ │ ├── chained/
│ │ │ └── chained.js
│ │ ├── class_in_function/
│ │ │ └── class_in_function.js
│ │ ├── classes/
│ │ │ └── classes.js
│ │ ├── complex_ownership/
│ │ │ └── complex_ownership.js
│ │ ├── exclude_modules/
│ │ │ └── exclude_modules.js
│ │ ├── exclude_modules_es6/
│ │ │ └── exclude_modules_es6.js
│ │ ├── globals/
│ │ │ └── globals.js
│ │ ├── inheritance/
│ │ │ └── inheritance.js
│ │ ├── inheritance_attr/
│ │ │ └── inheritance_attr.js
│ │ ├── moment/
│ │ │ └── moment.js
│ │ ├── scoping/
│ │ │ └── scoping.js
│ │ ├── simple_a_js/
│ │ │ └── simple_a.js
│ │ ├── simple_b_js/
│ │ │ └── simple_b.js
│ │ ├── ternary_new/
│ │ │ └── ternary_new.js
│ │ ├── two_file_imports/
│ │ │ ├── imported.js
│ │ │ └── importer.js
│ │ ├── two_file_simple/
│ │ │ ├── file_a.js
│ │ │ ├── file_b.js
│ │ │ └── shouldntberead
│ │ └── weird_assignments/
│ │ └── weird_assignments.js
│ ├── mjs/
│ │ └── two_file_imports_es6/
│ │ ├── imported_es6.mjs
│ │ └── importer_es6.mjs
│ ├── php/
│ │ ├── ambiguous_resolution/
│ │ │ └── ambiguous_resolution.php
│ │ ├── anon/
│ │ │ └── anonymous_function.php
│ │ ├── anon2/
│ │ │ └── anonymous_function2.php
│ │ ├── bad_php/
│ │ │ ├── bad_php_a.php
│ │ │ └── bad_php_b.php
│ │ ├── branch/
│ │ │ └── branch.php
│ │ ├── chains/
│ │ │ └── chains.php
│ │ ├── factory/
│ │ │ ├── currency.php
│ │ │ └── factory.php
│ │ ├── inheritance/
│ │ │ └── inheritance.php
│ │ ├── inheritance2/
│ │ │ └── inheritance2.php
│ │ ├── instance_methods/
│ │ │ └── instance_methods.php
│ │ ├── money/
│ │ │ ├── Calculator/
│ │ │ │ ├── BcMathCalculator.php
│ │ │ │ └── GmpCalculator.php
│ │ │ ├── Calculator.php
│ │ │ ├── Converter.php
│ │ │ ├── Currencies/
│ │ │ │ ├── AggregateCurrencies.php
│ │ │ │ ├── BitcoinCurrencies.php
│ │ │ │ ├── CachedCurrencies.php
│ │ │ │ ├── CurrencyList.php
│ │ │ │ └── ISOCurrencies.php
│ │ │ ├── Currencies.php
│ │ │ ├── Currency.php
│ │ │ ├── CurrencyPair.php
│ │ │ ├── Exception/
│ │ │ │ ├── FormatterException.php
│ │ │ │ ├── InvalidArgumentException.php
│ │ │ │ ├── ParserException.php
│ │ │ │ ├── UnknownCurrencyException.php
│ │ │ │ └── UnresolvableCurrencyPairException.php
│ │ │ ├── Exception.php
│ │ │ ├── Exchange/
│ │ │ │ ├── ExchangerExchange.php
│ │ │ │ ├── FixedExchange.php
│ │ │ │ ├── IndirectExchange.php
│ │ │ │ ├── IndirectExchangeQueuedItem.php
│ │ │ │ ├── ReversedCurrenciesExchange.php
│ │ │ │ └── SwapExchange.php
│ │ │ ├── Exchange.php
│ │ │ ├── Formatter/
│ │ │ │ ├── AggregateMoneyFormatter.php
│ │ │ │ ├── BitcoinMoneyFormatter.php
│ │ │ │ ├── DecimalMoneyFormatter.php
│ │ │ │ ├── IntlLocalizedDecimalFormatter.php
│ │ │ │ └── IntlMoneyFormatter.php
│ │ │ ├── Money.php
│ │ │ ├── MoneyFactory.php
│ │ │ ├── MoneyFormatter.php
│ │ │ ├── MoneyParser.php
│ │ │ ├── Number.php
│ │ │ ├── PHPUnit/
│ │ │ │ └── Comparator.php
│ │ │ └── Parser/
│ │ │ ├── AggregateMoneyParser.php
│ │ │ ├── BitcoinMoneyParser.php
│ │ │ ├── DecimalMoneyParser.php
│ │ │ ├── IntlLocalizedDecimalParser.php
│ │ │ └── IntlMoneyParser.php
│ │ ├── namespace_a/
│ │ │ └── namespace_a.php
│ │ ├── namespace_b/
│ │ │ ├── namespace_b1.php
│ │ │ └── namespace_b2.php
│ │ ├── namespace_c/
│ │ │ ├── namespace_c1.php
│ │ │ └── namespace_c2.php
│ │ ├── nested/
│ │ │ └── nested.php
│ │ ├── nested_calls/
│ │ │ └── nested_calls.php
│ │ ├── publicprivateprotected/
│ │ │ └── publicprivateprotected.php
│ │ ├── resolve_correct_class/
│ │ │ └── rcc.php
│ │ ├── simple_a/
│ │ │ └── simple_a.php
│ │ ├── simple_b/
│ │ │ └── simple_b.php
│ │ ├── static/
│ │ │ └── static.php
│ │ ├── traits/
│ │ │ └── traits.php
│ │ ├── two_file_simple/
│ │ │ ├── file_a.php
│ │ │ └── file_b.php
│ │ └── weird_assign/
│ │ └── weird_assign.php
│ ├── py/
│ │ ├── ambiguous_resolution/
│ │ │ └── ambiguous_resolution.py
│ │ ├── async_basic/
│ │ │ └── async_basic.py
│ │ ├── chained/
│ │ │ └── chained.py
│ │ ├── exclude_modules/
│ │ │ └── exclude_modules.py
│ │ ├── exclude_modules_two_files/
│ │ │ ├── exclude_modules_a.py
│ │ │ └── exclude_modules_b.py
│ │ ├── import_paths/
│ │ │ ├── abra.py
│ │ │ ├── cadabra.py
│ │ │ └── import_paths.py
│ │ ├── inherits/
│ │ │ ├── inherits.py
│ │ │ └── inherits_import.py
│ │ ├── init/
│ │ │ ├── init.py
│ │ │ └── the_import.py
│ │ ├── nested_calls/
│ │ │ └── nested_calls.py
│ │ ├── nested_class/
│ │ │ └── nested_class.py
│ │ ├── pytz/
│ │ │ ├── __init__.py
│ │ │ ├── exceptions.py
│ │ │ ├── lazy.py
│ │ │ ├── reference.py
│ │ │ ├── tzfile.py
│ │ │ └── tzinfo.py
│ │ ├── resolve_correct_class/
│ │ │ └── rcc.py
│ │ ├── simple_a/
│ │ │ └── simple_a.py
│ │ ├── simple_b/
│ │ │ └── simple_b.py
│ │ ├── subset_find_exception/
│ │ │ ├── two.py
│ │ │ └── zero.py
│ │ ├── two_file_simple/
│ │ │ ├── file_a.py
│ │ │ ├── file_b.py
│ │ │ └── shouldntberead
│ │ ├── weird_calls/
│ │ │ └── weird_calls.py
│ │ ├── weird_encoding/
│ │ │ └── weird_encoding.py
│ │ └── weird_imports/
│ │ └── weird_imports.py
│ └── rb/
│ ├── ambiguous_resolution/
│ │ └── ambiguous_resolution.rb
│ ├── chains/
│ │ └── chains.rb
│ ├── doublecolon/
│ │ └── doublecolon.rb
│ ├── inheritance_2/
│ │ └── inheritance_2.rb
│ ├── instance_methods/
│ │ └── instance_methods.rb
│ ├── modules/
│ │ └── modules.rb
│ ├── nested/
│ │ └── nested.rb
│ ├── nested_classes/
│ │ └── nested_classes.rb
│ ├── onelinefile/
│ │ └── onelinefile.rb
│ ├── public_suffix/
│ │ ├── public_suffix/
│ │ │ ├── domain.rb
│ │ │ ├── errors.rb
│ │ │ ├── list.rb
│ │ │ ├── rule.rb
│ │ │ └── version.rb
│ │ └── public_suffix.rb
│ ├── resolve_correct_class/
│ │ └── rcc.rb
│ ├── simple_a/
│ │ └── simple_a.rb
│ ├── simple_b/
│ │ └── simple_b.rb
│ ├── split_modules/
│ │ ├── split_modules_a.rb
│ │ └── split_modules_b.rb
│ ├── two_file_simple/
│ │ ├── file_a.rb
│ │ └── file_b.rb
│ └── weird_chains/
│ └── weird_chains.rb
├── test_graphs.py
├── test_interface.py
└── testdata.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/FUNDING.yml
================================================
github: scottrogowski
================================================
FILE: .gitignore
================================================
.DS_Store
__pycache__
out.*
.coverage*
htmlcov
build/
*.egg-info
dist
composer.json
composer.lock
vendor
================================================
FILE: CHANGELOG.md
================================================
# Code2flow CHANGELOG
## [2.5.1] - 2023-01-08
- Minor fix for installing code2flow in windows environments
- Minor README updates and typo corrections
## [2.5.0] - 2022-03-25
- Add async/await functionality to Python
- Add --include-only-* CLI options
- Minor README updates
- Minor logging updates
## [2.4.0] - 2021-12-26
- Implement subsets
## [2.3.1] - 2021-12-13
- Colored edges
- Improve dependency robustness
- Fixes for two Python bugs
- Small textual improvements
## [2.3.0] - 2021-10-11
Fix a few rare javascript bugs. Fix non-UTF8 encoding issue for Python. Better debugging.
## [2.2.0] - 2021-06-21
Ruby + PHP support
## [2.1.1] - 2021-06-15
Updates to the CLI that allow code2flow to hypothetically run in Windows
## [2.1.0] - 2021-06-15
Javascript support
## [2.0.1] - 2021-05-30
Add support for constructors to Python
## [2.0.0] - 2021-04-28
Almost complete rewrite / refactor. Update to Python3. Use ASTs
## [0.2] - 2013-06-08
Cleaned up code. Remove comments runs much faster. Test scripts. Template.py implementation file. More to come!
## [0.1] - 2013-05-23
Initial release
================================================
FILE: LICENSE
================================================
Copyright 2021 Scott Rogowski
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
================================================
FILE: MANIFEST.in
================================================
include LICENSE, CHANGELOG.md
include code2flow/get_ast.js
include code2flow/get_ast.php
================================================
FILE: Makefile
================================================
build:
rm -rf dist
python3 setup.py sdist
test:
pytest -n=4 --cov-report=html --cov-report=term --cov=code2flow -x
clean:
rm -rf build
rm -rf dist
rm -f out.*
rm -rf *.egg-info
rm -rf htmlcov
================================================
FILE: README.md
================================================
   
Code2flow generates [call graphs](https://en.wikipedia.org/wiki/Call_graph) for dynamic programming language. Code2flow supports Python, JavaScript, Ruby, and PHP.
The basic algorithm is simple:
1. Translate your source files into ASTs.
1. Find all function definitions.
1. Determine where those functions are called.
1. Connect the dots.
Code2flow is useful for:
- Untangling spaghetti code.
- Identifying orphaned functions.
- Getting new developers up to speed.
Code2flow provides a *pretty good estimate* of your project's structure. No algorithm can generate a perfect call graph for a [dynamic language](https://en.wikipedia.org/wiki/Dynamic_programming_language) – even less so if that language is [duck-typed](https://en.wikipedia.org/wiki/Duck_typing). See the known limitations in the section below.
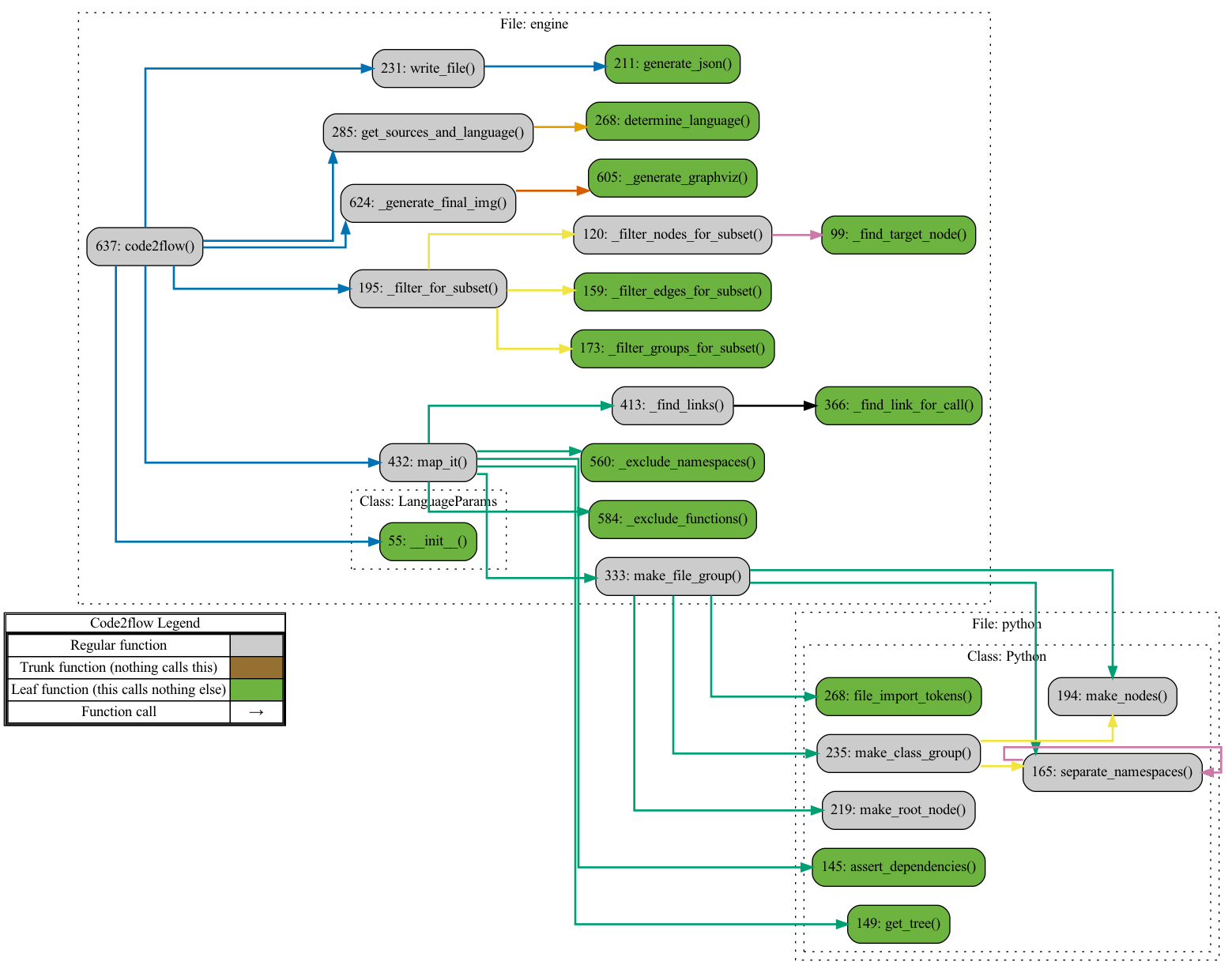
*(Below: Code2flow running against a subset of itself `code2flow code2flow/engine.py code2flow/python.py --target-function=code2flow --downstream-depth=3`)*
Installation
------------
```bash
pip3 install code2flow
```
If you don't have it already, you will also need to install graphviz. Installation instructions can be found [here](https://graphviz.org/download/).
Additionally, depending on the language you want to parse, you may need to install additional dependencies:
- JavaScript: [Acorn](https://www.npmjs.com/package/acorn)
- Ruby: [Parser](https://github.com/whitequark/parser)
- PHP: [PHP-Parser](https://github.com/nikic/PHP-Parser)
- Python: No extra dependencies needed
Usage
-----
To generate a DOT file, run something like:
```bash
code2flow mypythonfile.py
```
Or, for Javascript:
```bash
code2flow myjavascriptfile.js
```
You can specify multiple files or import directories:
```bash
code2flow project/directory/source_a.js project/directory/source_b.js
```
```bash
code2flow project/directory/*.js
```
```bash
code2flow project/directory --language js
```
To pull out a subset of the graph, try something like:
```bash
code2flow mypythonfile.py --target-function my_func --upstream-depth=1 --downstream-depth=1
```
There are a ton of command line options, to see them all, run:
```bash
code2flow --help
```
How code2flow works
------------
Code2flow approximates the structure of projects in dynamic languages. It is *not possible* to generate a perfect callgraph for a dynamic language.
Detailed algorithm:
1. Generate an AST of the source code
2. Recursively separate groups and nodes. Groups are files, modules, or classes. More precisely, groups are namespaces where functions live. Nodes are the functions themselves.
3. For all nodes, identify function calls in those nodes.
4. For all nodes, identify in-scope variables. Attempt to connect those variables to specific nodes and groups. This is where there is some ambiguity in the algorithm because it is impossible to know the types of variables in dynamic languages. So, instead, heuristics must be used.
5. For all calls in all nodes, attempt to find a match from the in-scope variables. This will be an edge.
6. If a definitive match from in-scope variables cannot be found, attempt to find a single match from all other groups and nodes.
7. Trim orphaned nodes and groups.
8. Output results.
Why is it impossible to generate a perfect call graph?
----------------
Consider this toy example in Python
```python
def func_factory(param):
if param < .5:
return func_a
else:
return func_b
func = func_factory(important_variable)
func()
```
We have no way of knowing whether `func` will point to `func_a` or `func_b` until runtime. In practice, ambiguity like this is common and is present in most non-trivial applications.
Known limitations
-----------------
Code2flow is internally powered by ASTs. Most limitations stem from a token not being named what code2flow expects it to be named.
* All functions without definitions are skipped. This most often happens when a file is not included.
* Functions with identical names in different namespaces are (loudly) skipped. E.g. If you have two classes with identically named methods, code2flow cannot distinguish between these and skips them.
* Imported functions from outside your project directory (including from standard libraries) which share names with your defined functions may not be handled correctly. Instead, when you call the imported function, code2flow will link to your local functions. For example, if you have a function `search()` and call, `import searcher; searcher.search()`, code2flow may link (incorrectly) to your defined function.
* Anonymous or generated functions are skipped. This includes lambdas and factories.
* If a function is renamed, either explicitly or by being passed around as a parameter, it will be skipped.
As an imported library
-----------------
You can work with code2flow as an imported Python library in much the same way as you work with it
from the CLI.
```python
import code2flow
code2flow.code2flow(['path/to/filea', 'path/to/fileb'], 'path/to/outputfile')
```
The keyword arguments to `code2flow.code2flow` are roughly the same as the CLI
parameters. To see all available parameters, refer to the code2flow function in [engine.py](https://github.com/scottrogowski/code2flow/blob/master/code2flow/engine.py).
How to contribute
-----------------------
1. **Open an issue**: Code2flow is not perfect and there is a lot that can be improved. If you find a problem parsing your source that you can identify with a simplified example, please open an issue.
2. **Create a PR**: Even better, if you have a fix for the issue you identified that passes unit tests, please open a PR.
3. **Add a language**: While dense, each language implementation is between 250-400 lines of code including comments. If you want to implement another language, the existing implementations can be your guide.
Unit tests
------------------
Test coverage is 100%. To run:
```bash
pip install -r requirements_dev.txt
make test
```
License
-----------------------------
Code2flow is licensed under the MIT license.
Prior to the rewrite in April 2021, code2flow was licensed under LGPL. The last commit under that license was 24b2cb854c6a872ba6e17409fbddb6659bf64d4c.
The April 2021 rewrite was substantial, so it's probably reasonable to treat code2flow as completely MIT-licensed.
Acknowledgements
-----------------------------
* In mid 2021, Code2flow was rewritten, and two new languages were added. This was prompted and financially supported by the [Sider Corporation](https://siderlabs.com/).
* The code2flow pip name was graciously transferred to this project from [Dheeraj Nair](https://github.com/Dheeraj1998). He was using it for his own (unrelated) [code2flow](https://github.com/Dheeraj1998/code2flow) project.
* Many others have contributed through bug fixes, cleanups, and identifying issues. Thank you!!!
Unrelated projects
-----------------------
The name, "code2flow", has been used for several unrelated projects. Specifically, the domain, code2flow.com, has no association with this project. I've never heard anything from them and it doesn't appear like they use anything from here.
Feedback / Issues / Contact
-----------------------------
If you have an issue using code2flow or a feature request, please post it in the issues tab. In general, I don't provide help over email. Answering a question publicly helps way more people. For everything else, please do email! scottmrogowski@gmail.com
Feature Requests
----------------
Email me. Usually, I'm spread thin across a lot of projects, so I will, unfortunately, turn down most requests. However, I am open to paid development for compelling features.
================================================
FILE: c2f
================================================
#!/usr/bin/env python3
import sys
from code2flow.engine import main
if __name__ == "__main__":
main(sys.argv[1:])
================================================
FILE: code2flow/__init__.py
================================================
from .engine import code2flow, VERSION
code2flow = code2flow
VERSION = VERSION
================================================
FILE: code2flow/engine.py
================================================
import argparse
import collections
import json
import logging
import os
import subprocess
import sys
import time
from .python import Python
from .javascript import Javascript
from .ruby import Ruby
from .php import PHP
from .model import (TRUNK_COLOR, LEAF_COLOR, NODE_COLOR, GROUP_TYPE, OWNER_CONST,
Edge, Group, Node, Variable, is_installed, flatten)
VERSION = '2.5.1'
IMAGE_EXTENSIONS = ('png', 'svg')
TEXT_EXTENSIONS = ('dot', 'gv', 'json')
VALID_EXTENSIONS = IMAGE_EXTENSIONS + TEXT_EXTENSIONS
DESCRIPTION = "Generate flow charts from your source code. " \
"See the README at https://github.com/scottrogowski/code2flow."
LEGEND = """subgraph legend{
rank = min;
label = "legend";
Legend [shape=none, margin=0, label = <
Code2flow Legend
Regular function
Trunk function (nothing calls this)
Leaf function (this calls nothing else)
Function call
→
>];
}""" % (NODE_COLOR, TRUNK_COLOR, LEAF_COLOR)
LANGUAGES = {
'py': Python,
'js': Javascript,
'mjs': Javascript,
'rb': Ruby,
'php': PHP,
}
class LanguageParams():
"""
Shallow structure to make storing language-specific parameters cleaner
"""
def __init__(self, source_type='script', ruby_version='27'):
self.source_type = source_type
self.ruby_version = ruby_version
class SubsetParams():
"""
Shallow structure to make storing subset-specific parameters cleaner.
"""
def __init__(self, target_function, upstream_depth, downstream_depth):
self.target_function = target_function
self.upstream_depth = upstream_depth
self.downstream_depth = downstream_depth
@staticmethod
def generate(target_function, upstream_depth, downstream_depth):
"""
:param target_function str:
:param upstream_depth int:
:param downstream_depth int:
:rtype: SubsetParams|Nonetype
"""
if upstream_depth and not target_function:
raise AssertionError("--upstream-depth requires --target-function")
if downstream_depth and not target_function:
raise AssertionError("--downstream-depth requires --target-function")
if not target_function:
return None
if not (upstream_depth or downstream_depth):
raise AssertionError("--target-function requires --upstream-depth or --downstream-depth")
if upstream_depth < 0:
raise AssertionError("--upstream-depth must be >= 0. Exclude argument for complete depth.")
if downstream_depth < 0:
raise AssertionError("--downstream-depth must be >= 0. Exclude argument for complete depth.")
return SubsetParams(target_function, upstream_depth, downstream_depth)
def _find_target_node(subset_params, all_nodes):
"""
Find the node referenced by subset_params.target_function
:param subset_params SubsetParams:
:param all_nodes list[Node]:
:rtype: Node
"""
target_nodes = []
for node in all_nodes:
if node.token == subset_params.target_function or \
node.token_with_ownership() == subset_params.target_function or \
node.name() == subset_params.target_function:
target_nodes.append(node)
if not target_nodes:
raise AssertionError("Could not find node %r to build a subset." % subset_params.target_function)
if len(target_nodes) > 1:
raise AssertionError("Found multiple nodes for %r: %r. Try either a `class.func` or "
"`filename::class.func`." % (subset_params.target_function, target_nodes))
return target_nodes[0]
def _filter_nodes_for_subset(subset_params, all_nodes, edges):
"""
Given subset_params, return a set of all nodes upstream and downstream of the target node.
:param subset_params SubsetParams:
:param all_nodes list[Node]:
:param edges list[Edge]:
:rtype: set[Node]
"""
target_node = _find_target_node(subset_params, all_nodes)
downstream_dict = collections.defaultdict(set)
upstream_dict = collections.defaultdict(set)
for edge in edges:
upstream_dict[edge.node1].add(edge.node0)
downstream_dict[edge.node0].add(edge.node1)
include_nodes = {target_node}
step_nodes = {target_node}
next_step_nodes = set()
for _ in range(subset_params.downstream_depth):
for node in step_nodes:
next_step_nodes.update(downstream_dict[node])
include_nodes.update(next_step_nodes)
step_nodes = next_step_nodes
next_step_nodes = set()
step_nodes = {target_node}
next_step_nodes = set()
for _ in range(subset_params.upstream_depth):
for node in step_nodes:
next_step_nodes.update(upstream_dict[node])
include_nodes.update(next_step_nodes)
step_nodes = next_step_nodes
next_step_nodes = set()
return include_nodes
def _filter_edges_for_subset(new_nodes, edges):
"""
Given the subset of nodes, filter for edges within this subset
:param new_nodes set[Node]:
:param edges list[Edge]:
:rtype: list[Edge]
"""
new_edges = []
for edge in edges:
if edge.node0 in new_nodes and edge.node1 in new_nodes:
new_edges.append(edge)
return new_edges
def _filter_groups_for_subset(new_nodes, file_groups):
"""
Given the subset of nodes, do housekeeping and filter out for groups within this subset
:param new_nodes set[Node]:
:param file_groups list[Group]:
:rtype: list[Group]
"""
for file_group in file_groups:
for node in file_group.all_nodes():
if node not in new_nodes:
node.remove_from_parent()
new_file_groups = [g for g in file_groups if g.all_nodes()]
for file_group in new_file_groups:
for group in file_group.all_groups():
if not group.all_nodes():
group.remove_from_parent()
return new_file_groups
def _filter_for_subset(subset_params, all_nodes, edges, file_groups):
"""
Given subset_params, return the subset of nodes, edges, and groups
upstream and downstream of the target node.
:param subset_params SubsetParams:
:param all_nodes list[Node]:
:param edges list[Edge]:
:param file_groups list[Group]:
:rtype: list[Group], list[Node], list[Edge]
"""
new_nodes = _filter_nodes_for_subset(subset_params, all_nodes, edges)
new_edges = _filter_edges_for_subset(new_nodes, edges)
new_file_groups = _filter_groups_for_subset(new_nodes, file_groups)
return new_file_groups, list(new_nodes), new_edges
def generate_json(nodes, edges):
'''
Generate a json string from nodes and edges
See https://github.com/jsongraph/json-graph-specification
:param nodes list[Node]: functions
:param edges list[Edge]: function calls
:rtype: str
'''
nodes = [n.to_dict() for n in nodes]
nodes = {n['uid']: n for n in nodes}
edges = [e.to_dict() for e in edges]
return json.dumps({"graph": {
"directed": True,
"nodes": nodes,
"edges": edges,
}})
def write_file(outfile, nodes, edges, groups, hide_legend=False,
no_grouping=False, as_json=False):
'''
Write a dot file that can be read by graphviz
:param outfile File:
:param nodes list[Node]: functions
:param edges list[Edge]: function calls
:param groups list[Group]: classes and files
:param hide_legend bool:
:rtype: None
'''
if as_json:
content = generate_json(nodes, edges)
outfile.write(content)
return
splines = "polyline" if len(edges) >= 500 else "ortho"
content = "digraph G {\n"
content += "concentrate=true;\n"
content += f'splines="{splines}";\n'
content += 'rankdir="LR";\n'
if not hide_legend:
content += LEGEND
for node in nodes:
content += node.to_dot() + ';\n'
for edge in edges:
content += edge.to_dot() + ';\n'
if not no_grouping:
for group in groups:
content += group.to_dot()
content += '}\n'
outfile.write(content)
def determine_language(individual_files):
"""
Given a list of filepaths, determine the language from the first
valid extension
:param list[str] individual_files:
:rtype: str
"""
for source, _ in individual_files:
suffix = source.rsplit('.', 1)[-1]
if suffix in LANGUAGES:
logging.info("Implicitly detected language as %r.", suffix)
return suffix
raise AssertionError(f"Language could not be detected from input {individual_files}. ",
"Try explicitly passing the language flag.")
def get_sources_and_language(raw_source_paths, language):
"""
Given a list of files and directories, return just files.
If we are not passed a language, determine it.
Filter out files that are not of that language
:param list[str] raw_source_paths: file or directory paths
:param str|None language: Input language
:rtype: (list, str)
"""
individual_files = []
for source in sorted(raw_source_paths):
if os.path.isfile(source):
individual_files.append((source, True))
continue
for root, _, files in os.walk(source):
for f in files:
individual_files.append((os.path.join(root, f), False))
if not individual_files:
raise AssertionError("No source files found from %r" % raw_source_paths)
logging.info("Found %d files from sources argument.", len(individual_files))
if not language:
language = determine_language(individual_files)
sources = set()
for source, explicity_added in individual_files:
if explicity_added or source.endswith('.' + language):
sources.add(source)
else:
logging.info("Skipping %r which is not a %s file. "
"If this is incorrect, include it explicitly.",
source, language)
if not sources:
raise AssertionError("Could not find any source files given {raw_source_paths} "
"and language {language}.")
sources = sorted(list(sources))
logging.info("Processing %d source file(s)." % (len(sources)))
for source in sources:
logging.info(" " + source)
return sources, language
def make_file_group(tree, filename, extension):
"""
Given an AST for the entire file, generate a file group complete with
subgroups, nodes, etc.
:param tree ast:
:param filename str:
:param extension str:
:rtype: Group
"""
language = LANGUAGES[extension]
subgroup_trees, node_trees, body_trees = language.separate_namespaces(tree)
group_type = GROUP_TYPE.FILE
token = os.path.split(filename)[-1].rsplit('.' + extension, 1)[0]
line_number = 0
display_name = 'File'
import_tokens = language.file_import_tokens(filename)
file_group = Group(token, group_type, display_name, import_tokens,
line_number, parent=None)
for node_tree in node_trees:
for new_node in language.make_nodes(node_tree, parent=file_group):
file_group.add_node(new_node)
file_group.add_node(language.make_root_node(body_trees, parent=file_group), is_root=True)
for subgroup_tree in subgroup_trees:
file_group.add_subgroup(language.make_class_group(subgroup_tree, parent=file_group))
return file_group
def _find_link_for_call(call, node_a, all_nodes):
"""
Given a call that happened on a node (node_a), return the node
that the call links to and the call itself if >1 node matched.
:param call Call:
:param node_a Node:
:param all_nodes list[Node]:
:returns: The node it links to and the call if >1 node matched.
:rtype: (Node|None, Call|None)
"""
all_vars = node_a.get_variables(call.line_number)
for var in all_vars:
var_match = call.matches_variable(var)
if var_match:
# Unknown modules (e.g. third party) we don't want to match)
if var_match == OWNER_CONST.UNKNOWN_MODULE:
return None, None
assert isinstance(var_match, Node)
return var_match, None
possible_nodes = []
if call.is_attr():
for node in all_nodes:
# checking node.parent != node_a.file_group() prevents self linkage in cases like
# function a() {b = Obj(); b.a()}
if call.token == node.token and node.parent != node_a.file_group():
possible_nodes.append(node)
else:
for node in all_nodes:
if call.token == node.token \
and isinstance(node.parent, Group) \
and node.parent.group_type == GROUP_TYPE.FILE:
possible_nodes.append(node)
elif call.token == node.parent.token and node.is_constructor:
possible_nodes.append(node)
if len(possible_nodes) == 1:
return possible_nodes[0], None
if len(possible_nodes) > 1:
return None, call
return None, None
def _find_links(node_a, all_nodes):
"""
Iterate through the calls on node_a to find everything the node links to.
This will return a list of tuples of nodes and calls that were ambiguous.
:param Node node_a:
:param list[Node] all_nodes:
:param BaseLanguage language:
:rtype: list[(Node, Call)]
"""
links = []
for call in node_a.calls:
lfc = _find_link_for_call(call, node_a, all_nodes)
assert not isinstance(lfc, Group)
links.append(lfc)
return list(filter(None, links))
def map_it(sources, extension, no_trimming, exclude_namespaces, exclude_functions,
include_only_namespaces, include_only_functions,
skip_parse_errors, lang_params):
'''
Given a language implementation and a list of filenames, do these things:
1. Read/parse source ASTs
2. Find all groups (classes/modules) and nodes (functions) (a lot happens here)
3. Trim namespaces / functions that we don't want
4. Consolidate groups / nodes given all we know so far
5. Attempt to resolve the variables (point them to a node or group)
6. Find all calls between all nodes
7. Loudly complain about duplicate edges that were skipped
8. Trim nodes that didn't connect to anything
:param list[str] sources:
:param str extension:
:param bool no_trimming:
:param list exclude_namespaces:
:param list exclude_functions:
:param list include_only_namespaces:
:param list include_only_functions:
:param bool skip_parse_errors:
:param LanguageParams lang_params:
:rtype: (list[Group], list[Node], list[Edge])
'''
language = LANGUAGES[extension]
# 0. Assert dependencies
language.assert_dependencies()
# 1. Read/parse source ASTs
file_ast_trees = []
for source in sources:
try:
file_ast_trees.append((source, language.get_tree(source, lang_params)))
except Exception as ex:
if skip_parse_errors:
logging.warning("Could not parse %r. (%r) Skipping...", source, ex)
else:
raise ex
# 2. Find all groups (classes/modules) and nodes (functions) (a lot happens here)
file_groups = []
for source, file_ast_tree in file_ast_trees:
file_group = make_file_group(file_ast_tree, source, extension)
file_groups.append(file_group)
# 3. Trim namespaces / functions to exactly what we want
if exclude_namespaces or include_only_namespaces:
file_groups = _limit_namespaces(file_groups, exclude_namespaces, include_only_namespaces)
if exclude_functions or include_only_functions:
file_groups = _limit_functions(file_groups, exclude_functions, include_only_functions)
# 4. Consolidate structures
all_subgroups = flatten(g.all_groups() for g in file_groups)
all_nodes = flatten(g.all_nodes() for g in file_groups)
nodes_by_subgroup_token = collections.defaultdict(list)
for subgroup in all_subgroups:
if subgroup.token in nodes_by_subgroup_token:
logging.warning("Duplicate group name %r. Naming collision possible.",
subgroup.token)
nodes_by_subgroup_token[subgroup.token] += subgroup.nodes
for group in file_groups:
for subgroup in group.all_groups():
subgroup.inherits = [nodes_by_subgroup_token.get(g) for g in subgroup.inherits]
subgroup.inherits = list(filter(None, subgroup.inherits))
for inherit_nodes in subgroup.inherits:
for node in subgroup.nodes:
node.variables += [Variable(n.token, n, n.line_number) for n in inherit_nodes]
# 5. Attempt to resolve the variables (point them to a node or group)
for node in all_nodes:
node.resolve_variables(file_groups)
# Not a step. Just log what we know so far
logging.info("Found groups %r." % [g.label() for g in all_subgroups])
logging.info("Found nodes %r." % sorted(n.token_with_ownership() for n in all_nodes))
logging.info("Found calls %r." % sorted(list(set(c.to_string() for c in
flatten(n.calls for n in all_nodes)))))
logging.info("Found variables %r." % sorted(list(set(v.to_string() for v in
flatten(n.variables for n in all_nodes)))))
# 6. Find all calls between all nodes
bad_calls = []
edges = []
for node_a in list(all_nodes):
links = _find_links(node_a, all_nodes)
for node_b, bad_call in links:
if bad_call:
bad_calls.append(bad_call)
if not node_b:
continue
edges.append(Edge(node_a, node_b))
# 7. Loudly complain about duplicate edges that were skipped
bad_calls_strings = set()
for bad_call in bad_calls:
bad_calls_strings.add(bad_call.to_string())
bad_calls_strings = list(sorted(list(bad_calls_strings)))
if bad_calls_strings:
logging.info("Skipped processing these calls because the algorithm "
"linked them to multiple function definitions: %r." % bad_calls_strings)
if no_trimming:
return file_groups, all_nodes, edges
# 8. Trim nodes that didn't connect to anything
nodes_with_edges = set()
for edge in edges:
nodes_with_edges.add(edge.node0)
nodes_with_edges.add(edge.node1)
for node in all_nodes:
if node not in nodes_with_edges:
node.remove_from_parent()
for file_group in file_groups:
for group in file_group.all_groups():
if not group.all_nodes():
group.remove_from_parent()
file_groups = [g for g in file_groups if g.all_nodes()]
all_nodes = list(nodes_with_edges)
if not all_nodes:
logging.warning("No functions found! Most likely, your file(s) do not have "
"functions that call each other. Note that to generate a flowchart, "
"you need to have both the function calls and the function "
"definitions. Or, you might be excluding too many "
"with --exclude-* / --include-* / --target-function arguments. ")
logging.warning("Code2flow will generate an empty output file.")
return file_groups, all_nodes, edges
def _limit_namespaces(file_groups, exclude_namespaces, include_only_namespaces):
"""
Exclude namespaces (classes/modules) which match any of the exclude_namespaces
:param list[Group] file_groups:
:param list exclude_namespaces:
:param list include_only_namespaces:
:rtype: list[Group]
"""
removed_namespaces = set()
for group in list(file_groups):
if group.token in exclude_namespaces:
for node in group.all_nodes():
node.remove_from_parent()
removed_namespaces.add(group.token)
if include_only_namespaces and group.token not in include_only_namespaces:
for node in group.nodes:
node.remove_from_parent()
removed_namespaces.add(group.token)
for subgroup in group.all_groups():
print(subgroup, subgroup.all_parents())
if subgroup.token in exclude_namespaces:
for node in subgroup.all_nodes():
node.remove_from_parent()
removed_namespaces.add(subgroup.token)
if include_only_namespaces and \
subgroup.token not in include_only_namespaces and \
all(p.token not in include_only_namespaces for p in subgroup.all_parents()):
for node in subgroup.nodes:
node.remove_from_parent()
removed_namespaces.add(group.token)
for namespace in exclude_namespaces:
if namespace not in removed_namespaces:
logging.warning(f"Could not exclude namespace '{namespace}' "
"because it was not found.")
return file_groups
def _limit_functions(file_groups, exclude_functions, include_only_functions):
"""
Exclude nodes (functions) which match any of the exclude_functions
:param list[Group] file_groups:
:param list exclude_functions:
:param list include_only_functions:
:rtype: list[Group]
"""
removed_functions = set()
for group in list(file_groups):
for node in group.all_nodes():
if node.token in exclude_functions or \
(include_only_functions and node.token not in include_only_functions):
node.remove_from_parent()
removed_functions.add(node.token)
for function_name in exclude_functions:
if function_name not in removed_functions:
logging.warning(f"Could not exclude function '{function_name}' "
"because it was not found.")
return file_groups
def _generate_graphviz(output_file, extension, final_img_filename):
"""
Write the graphviz file
:param str output_file:
:param str extension:
:param str final_img_filename:
"""
start_time = time.time()
logging.info("Running graphviz to make the image...")
command = ["dot", "-T" + extension, output_file]
with open(final_img_filename, 'w') as f:
try:
subprocess.run(command, stdout=f, check=True)
logging.info("Graphviz finished in %.2f seconds." % (time.time() - start_time))
except subprocess.CalledProcessError:
logging.warning("*** Graphviz returned non-zero exit code! "
"Try running %r for more detail ***", ' '.join(command + ['-v', '-O']))
def _generate_final_img(output_file, extension, final_img_filename, num_edges):
"""
Write the graphviz file
:param str output_file:
:param str extension:
:param str final_img_filename:
:param int num_edges:
"""
_generate_graphviz(output_file, extension, final_img_filename)
logging.info("Completed your flowchart! To see it, open %r.",
final_img_filename)
def code2flow(raw_source_paths, output_file, language=None, hide_legend=True,
exclude_namespaces=None, exclude_functions=None,
include_only_namespaces=None, include_only_functions=None,
no_grouping=False, no_trimming=False, skip_parse_errors=False,
lang_params=None, subset_params=None, level=logging.INFO):
"""
Top-level function. Generate a diagram based on source code.
Can generate either a dotfile or an image.
:param list[str] raw_source_paths: file or directory paths
:param str|file output_file: path to the output file. SVG/PNG will generate an image.
:param str language: input language extension
:param bool hide_legend: Omit the legend from the output
:param list exclude_namespaces: List of namespaces to exclude
:param list exclude_functions: List of functions to exclude
:param list include_only_namespaces: List of namespaces to include
:param list include_only_functions: List of functions to include
:param bool no_grouping: Don't group functions into namespaces in the final output
:param bool no_trimming: Don't trim orphaned functions / namespaces
:param bool skip_parse_errors: If a language parser fails to parse a file, skip it
:param lang_params LanguageParams: Object to store lang-specific params
:param subset_params SubsetParams: Object to store subset-specific params
:param int level: logging level
:rtype: None
"""
start_time = time.time()
if not isinstance(raw_source_paths, list):
raw_source_paths = [raw_source_paths]
lang_params = lang_params or LanguageParams()
exclude_namespaces = exclude_namespaces or []
assert isinstance(exclude_namespaces, list)
exclude_functions = exclude_functions or []
assert isinstance(exclude_functions, list)
include_only_namespaces = include_only_namespaces or []
assert isinstance(include_only_namespaces, list)
include_only_functions = include_only_functions or []
assert isinstance(include_only_functions, list)
logging.basicConfig(format="Code2Flow: %(message)s", level=level)
sources, language = get_sources_and_language(raw_source_paths, language)
output_ext = None
if isinstance(output_file, str):
assert '.' in output_file, "Output filename must end in one of: %r." % set(VALID_EXTENSIONS)
output_ext = output_file.rsplit('.', 1)[1] or ''
assert output_ext in VALID_EXTENSIONS, "Output filename must end in one of: %r." % \
set(VALID_EXTENSIONS)
final_img_filename = None
if output_ext and output_ext in IMAGE_EXTENSIONS:
if not is_installed('dot') and not is_installed('dot.exe'):
raise AssertionError(
"Can't generate a flowchart image because neither `dot` nor "
"`dot.exe` was found. Either install graphviz (see the README) "
"or, if you just want an intermediate text file, set your --output "
"file to use a supported text extension: %r" % set(TEXT_EXTENSIONS))
final_img_filename = output_file
output_file, extension = output_file.rsplit('.', 1)
output_file += '.gv'
file_groups, all_nodes, edges = map_it(sources, language, no_trimming,
exclude_namespaces, exclude_functions,
include_only_namespaces, include_only_functions,
skip_parse_errors, lang_params)
if subset_params:
logging.info("Filtering into subset...")
file_groups, all_nodes, edges = _filter_for_subset(subset_params, all_nodes, edges, file_groups)
file_groups.sort()
all_nodes.sort()
edges.sort()
logging.info("Generating output file...")
if isinstance(output_file, str):
with open(output_file, 'w') as fh:
as_json = output_ext == 'json'
write_file(fh, nodes=all_nodes, edges=edges,
groups=file_groups, hide_legend=hide_legend,
no_grouping=no_grouping, as_json=as_json)
else:
write_file(output_file, nodes=all_nodes, edges=edges,
groups=file_groups, hide_legend=hide_legend,
no_grouping=no_grouping)
logging.info("Wrote output file %r with %d nodes and %d edges.",
output_file, len(all_nodes), len(edges))
if not output_ext == 'json':
logging.info("For better machine readability, you can also try outputting in a json format.")
logging.info("Code2flow finished processing in %.2f seconds." % (time.time() - start_time))
# translate to an image if that was requested
if final_img_filename:
_generate_final_img(output_file, extension, final_img_filename, len(edges))
def main(sys_argv=None):
"""
CLI interface. Sys_argv is a parameter for the sake of unittest coverage.
:param sys_argv list:
:rtype: None
"""
parser = argparse.ArgumentParser(
description=DESCRIPTION,
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
'sources', metavar='sources', nargs='+',
help='source code file/directory paths.')
parser.add_argument(
'--output', '-o', default='out.png',
help=f'output file path. Supported types are {VALID_EXTENSIONS}.')
parser.add_argument(
'--language', choices=['py', 'js', 'rb', 'php'],
help='process this language and ignore all other files.'
'If omitted, use the suffix of the first source file.')
parser.add_argument(
'--target-function',
help='output a subset of the graph centered on this function. '
'Valid formats include `func`, `class.func`, and `file::class.func`. '
'Requires --upstream-depth and/or --downstream-depth. ')
parser.add_argument(
'--upstream-depth', type=int, default=0,
help='include n nodes upstream of --target-function.')
parser.add_argument(
'--downstream-depth', type=int, default=0,
help='include n nodes downstream of --target-function.')
parser.add_argument(
'--exclude-functions',
help='exclude functions from the output. Comma delimited.')
parser.add_argument(
'--exclude-namespaces',
help='exclude namespaces (Classes, modules, etc) from the output. Comma delimited.')
parser.add_argument(
'--include-only-functions',
help='include only functions in the output. Comma delimited.')
parser.add_argument(
'--include-only-namespaces',
help='include only namespaces (Classes, modules, etc) in the output. Comma delimited.')
parser.add_argument(
'--no-grouping', action='store_true',
help='instead of grouping functions into namespaces, let functions float.')
parser.add_argument(
'--no-trimming', action='store_true',
help='show all functions/namespaces whether or not they connect to anything.')
parser.add_argument(
'--hide-legend', action='store_true',
help='by default, Code2flow generates a small legend. This flag hides it.')
parser.add_argument(
'--skip-parse-errors', action='store_true',
help='skip files that the language parser fails on.')
parser.add_argument(
'--source-type', choices=['script', 'module'], default='script',
help='js only. Parse the source as scripts (commonJS) or modules (es6)')
parser.add_argument(
'--ruby-version', default='27',
help='ruby only. Which ruby version to parse? This is passed directly into ruby-parse. '
'Use numbers like 25, 27, or 31.')
parser.add_argument(
'--quiet', '-q', action='store_true',
help='suppress most logging')
parser.add_argument(
'--verbose', '-v', action='store_true',
help='add more logging')
parser.add_argument(
'--version', action='version', version='%(prog)s ' + VERSION)
sys_argv = sys_argv or sys.argv[1:]
args = parser.parse_args(sys_argv)
level = logging.INFO
if args.verbose and args.quiet:
raise AssertionError("Passed both --verbose and --quiet flags")
if args.verbose:
level = logging.DEBUG
if args.quiet:
level = logging.WARNING
exclude_namespaces = list(filter(None, (args.exclude_namespaces or "").split(',')))
exclude_functions = list(filter(None, (args.exclude_functions or "").split(',')))
include_only_namespaces = list(filter(None, (args.include_only_namespaces or "").split(',')))
include_only_functions = list(filter(None, (args.include_only_functions or "").split(',')))
lang_params = LanguageParams(args.source_type, args.ruby_version)
subset_params = SubsetParams.generate(args.target_function, args.upstream_depth,
args.downstream_depth)
code2flow(
raw_source_paths=args.sources,
output_file=args.output,
language=args.language,
hide_legend=args.hide_legend,
exclude_namespaces=exclude_namespaces,
exclude_functions=exclude_functions,
include_only_namespaces=include_only_namespaces,
include_only_functions=include_only_functions,
no_grouping=args.no_grouping,
no_trimming=args.no_trimming,
skip_parse_errors=args.skip_parse_errors,
lang_params=lang_params,
subset_params=subset_params,
level=level,
)
================================================
FILE: code2flow/get_ast.js
================================================
const fs = require('fs');
const {Parser} = require("acorn")
const sourceType = process.argv[2]
const src = fs.readFileSync(process.argv[3], 'utf8')
const tree = Parser.parse(src, {'locations': true, 'sourceType': sourceType,
'ecmaVersion': '2020'})
process.stdout.write(JSON.stringify(tree))
================================================
FILE: code2flow/get_ast.php
================================================
create(ParserFactory::PREFER_PHP7);
try {
$stmts = $parser->parse($code);
echo json_encode($stmts, JSON_PRETTY_PRINT), "\n";
} catch (PhpParser\Error $e) {
echo 'Parse Error: ', $e->getMessage();
exit(1);
}
?>
================================================
FILE: code2flow/javascript.py
================================================
import logging
import os
import json
import subprocess
from .model import (Group, Node, Call, Variable, BaseLanguage,
OWNER_CONST, GROUP_TYPE, is_installed, djoin, flatten)
def lineno(el):
"""
Get the first line number of ast element
:param ast el:
:rtype: int
"""
if isinstance(el, list):
el = el[0]
ret = el['loc']['start']['line']
assert type(ret) == int
return ret
def walk(tree):
"""
Walk through the ast tree and return all nodes
:param ast tree:
:rtype: list[ast]
"""
ret = []
if type(tree) == list:
for el in tree:
if el.get('type'):
ret.append(el)
ret += walk(el)
elif type(tree) == dict:
for k, v in tree.items():
if type(v) == dict and v.get('type'):
ret.append(v)
ret += walk(v)
if type(v) == list:
ret += walk(v)
return ret
def resolve_owner(callee):
"""
Resolve who owns the call object.
So if the expression is i_ate.pie(). And i_ate is a Person, the callee is Person.
This is returned as a string and eventually set to the owner_token in the call
:param ast callee:
:rtype: str
"""
if callee['object']['type'] == 'ThisExpression':
return 'this'
if callee['object']['type'] == 'Identifier':
return callee['object']['name']
if callee['object']['type'] == 'MemberExpression':
if 'object' in callee['object'] and 'name' in callee['object']['property']:
return djoin((resolve_owner(callee['object']) or ''),
callee['object']['property']['name'])
return OWNER_CONST.UNKNOWN_VAR
if callee['object']['type'] == 'CallExpression':
return OWNER_CONST.UNKNOWN_VAR
if callee['object']['type'] == 'NewExpression':
if 'name' in callee['object']['callee']:
return callee['object']['callee']['name']
return djoin(callee['object']['callee']['object']['name'],
callee['object']['callee']['property']['name'])
return OWNER_CONST.UNKNOWN_VAR
def get_call_from_func_element(func):
"""
Given a javascript ast that represents a function call, clear and create our
generic Call object. Some calls have no chance at resolution (e.g. array[2](param))
so we return nothing instead.
:param func dict:
:rtype: Call|None
"""
callee = func['callee']
if callee['type'] == 'MemberExpression' and 'name' in callee['property']:
owner_token = resolve_owner(callee)
return Call(token=callee['property']['name'],
line_number=lineno(callee),
owner_token=owner_token)
if callee['type'] == 'Identifier':
return Call(token=callee['name'], line_number=lineno(callee))
return None
def make_calls(body):
"""
Given a list of lines, find all calls in this list.
:param list|dict body:
:rtype: list[Call]
"""
calls = []
for element in walk(body):
if element['type'] == 'CallExpression':
call = get_call_from_func_element(element)
if call:
calls.append(call)
elif element['type'] == 'NewExpression' and element['callee']['type'] == 'Identifier':
calls.append(Call(token=element['callee']['name'],
line_number=lineno(element)))
return calls
def process_assign(element):
"""
Given an element from the ast which is an assignment statement, return a
Variable that points_to the type of object being assigned. The
points_to is often a string but that is resolved later.
:param element ast:
:rtype: Variable
"""
if len(element['declarations']) > 1:
return []
target = element['declarations'][0]
assert target['type'] == 'VariableDeclarator'
if target['init'] is None:
return []
if target['init']['type'] == 'NewExpression':
token = target['id']['name']
call = get_call_from_func_element(target['init'])
if call:
return [Variable(token, call, lineno(element))]
# this block is for require (as in: import) expressions
if target['init']['type'] == 'CallExpression' \
and target['init']['callee'].get('name') == 'require':
import_src_str = target['init']['arguments'][0]['value']
if 'name' in target['id']:
imported_name = target['id']['name']
points_to_str = djoin(import_src_str, imported_name)
return [Variable(imported_name, points_to_str, lineno(element))]
ret = []
for prop in target['id'].get('properties', []):
imported_name = prop['key']['name']
points_to_str = djoin(import_src_str, imported_name)
ret.append(Variable(imported_name, points_to_str, lineno(element)))
return ret
# For the other type of import expressions
if target['init']['type'] == 'ImportExpression':
import_src_str = target['init']['source']['raw']
imported_name = target['id']['name']
points_to_str = djoin(import_src_str, imported_name)
return [Variable(imported_name, points_to_str, lineno(element))]
if target['init']['type'] == 'CallExpression':
if 'name' not in target['id']:
return []
call = get_call_from_func_element(target['init'])
if call:
return [Variable(target['id']['name'], call, lineno(element))]
if target['init']['type'] == 'ThisExpression':
assert set(target['init'].keys()) == {'start', 'end', 'loc', 'type'}
return []
return []
def make_local_variables(tree, parent):
"""
Given an ast of all the lines in a function, generate a list of
variables in that function. Variables are tokens and what they link to.
In this case, what it links to is just a string. However, that is resolved
later.
Also return variables for the outer scope parent
:param tree list|dict:
:param parent Group:
:rtype: list[Variable]
"""
if not tree:
return []
variables = []
for element in walk(tree):
if element['type'] == 'VariableDeclaration':
variables += process_assign(element)
# Make a 'this' variable for use anywhere we need it that points to the class
if isinstance(parent, Group) and parent.group_type == GROUP_TYPE.CLASS:
variables.append(Variable('this', parent, lineno(tree)))
variables = list(filter(None, variables))
return variables
def children(tree):
"""
The acorn AST is tricky. This returns all the children of an element
:param ast tree:
:rtype: list[ast]
"""
assert type(tree) == dict
ret = []
for k, v in tree.items():
if type(v) == dict and v.get('type'):
ret.append(v)
if type(v) == list:
ret += filter(None, v)
return ret
def get_inherits(tree):
"""
Gets the superclass of the class. In js, this will be max 1 element
:param ast tree:
:rtype: list[str]
"""
if tree['superClass']:
if 'name' in tree['superClass']:
return [tree['superClass']['name']]
return [djoin(tree['superClass']['object']['name'], tree['superClass']['property']['name'])]
return []
def get_acorn_version():
"""
Get the version of installed acorn
:rtype: str
"""
proc = subprocess.Popen(['node', '-p', 'require(\'acorn/package.json\').version'],
stdout=subprocess.PIPE, stderr=subprocess.PIPE,
cwd=os.path.dirname(os.path.realpath(__file__)))
assert proc.wait() == 0, "Acorn is required to parse javascript files. " \
"It was found on the path but could not be imported " \
"in node.\n" + proc.stderr.read().decode()
return proc.stdout.read().decode().strip()
class Javascript(BaseLanguage):
@staticmethod
def assert_dependencies():
"""Assert that acorn is installed and the correct version"""
assert is_installed('acorn'), "Acorn is required to parse javascript files " \
"but was not found on the path. Install it " \
"from npm and try again."
version = get_acorn_version()
if not version.startswith('8.'):
logging.warning("Acorn is required to parse javascript files. "
"Version %r was found but code2flow has only been "
"tested on 8.*", version)
logging.info("Using Acorn %s" % version)
@staticmethod
def get_tree(filename, lang_params):
"""
Get the entire AST for this file
:param filename str:
:param lang_params LanguageParams:
:rtype: ast
"""
script_loc = os.path.join(os.path.dirname(os.path.realpath(__file__)),
"get_ast.js")
cmd = ["node", script_loc, lang_params.source_type, filename]
try:
output = subprocess.check_output(cmd, stderr=subprocess.PIPE)
except subprocess.CalledProcessError:
raise AssertionError(
"Acorn could not parse file %r. You may have a JS syntax error or "
"if this is an es6-style source, you may need to run code2flow "
"with --source-type=module. "
"For more detail, try running the command "
"\n acorn %s\n"
"Warning: Acorn CANNOT parse all javascript files. See their docs. " %
(filename, filename)) from None
tree = json.loads(output)
assert isinstance(tree, dict)
assert tree['type'] == 'Program'
return tree
@staticmethod
def separate_namespaces(tree):
"""
Given an AST, recursively separate that AST into lists of ASTs for the
subgroups, nodes, and body. This is an intermediate step to allow for
cleaner processing downstream
:param tree ast:
:returns: tuple of group, node, and body trees. These are processed
downstream into real Groups and Nodes.
:rtype: (list[ast], list[ast], list[ast])
"""
groups = []
nodes = []
body = []
for el in children(tree):
if el['type'] in ('MethodDefinition', 'FunctionDeclaration'):
nodes.append(el)
elif el['type'] == 'ClassDeclaration':
groups.append(el)
else:
tup = Javascript.separate_namespaces(el)
if tup[0] or tup[1]:
groups += tup[0]
nodes += tup[1]
body += tup[2]
else:
body.append(el)
return groups, nodes, body
@staticmethod
def make_nodes(tree, parent):
"""
Given an ast of all the lines in a function, create the node along with the
calls and variables internal to it.
Also make the nested subnodes
:param tree ast:
:param parent Group:
:rtype: list[Node]
"""
is_constructor = False
if tree.get('kind') == 'constructor':
token = '(constructor)'
is_constructor = True
elif tree['type'] == 'FunctionDeclaration':
token = tree['id']['name']
elif tree['type'] == 'MethodDefinition':
token = tree['key']['name']
if tree['type'] == 'FunctionDeclaration':
full_node_body = tree['body']
else:
full_node_body = tree['value']
subgroup_trees, subnode_trees, this_scope_body = Javascript.separate_namespaces(full_node_body)
if subgroup_trees:
# TODO - this is when a class is defined within a function
# It's unusual but should probably be handled in the future.
# Handling this use case would require some code reorganziation.
# Take a look at class_in_function.js to better understand.
logging.warning("Skipping class defined within a function!")
line_number = lineno(tree)
calls = make_calls(this_scope_body)
variables = make_local_variables(this_scope_body, parent)
node = Node(token, calls, variables, parent=parent, line_number=line_number,
is_constructor=is_constructor)
subnodes = flatten([Javascript.make_nodes(t, node) for t in subnode_trees])
return [node] + subnodes
@staticmethod
def make_root_node(lines, parent):
"""
The "root_node" is an implict node of lines which are executed in the global
scope on the file itself and not otherwise part of any function.
:param lines list[ast]:
:param parent Group:
:rtype: Node
"""
token = "(global)"
calls = make_calls(lines)
variables = make_local_variables(lines, parent)
root_node = Node(token, calls, variables,
line_number=0, parent=parent)
return root_node
@staticmethod
def make_class_group(tree, parent):
"""
Given an AST for the subgroup (a class), generate that subgroup.
In this function, we will also need to generate all of the nodes internal
to the group.
:param tree ast:
:param parent Group:
:rtype: Group
"""
assert tree['type'] == 'ClassDeclaration'
subgroup_trees, node_trees, body_trees = Javascript.separate_namespaces(tree)
assert not subgroup_trees
group_type = GROUP_TYPE.CLASS
token = tree['id']['name']
display_name = 'Class'
line_number = lineno(tree)
inherits = get_inherits(tree)
class_group = Group(token, group_type, display_name,
inherits=inherits, line_number=line_number, parent=parent)
for node_tree in node_trees:
for new_node in Javascript.make_nodes(node_tree, parent=class_group):
class_group.add_node(new_node)
return class_group
@staticmethod
def file_import_tokens(filename):
"""
Returns the token(s) we would use if importing this file from another.
:param filename str:
:rtype: list[str]
"""
return []
================================================
FILE: code2flow/model.py
================================================
import abc
import os
TRUNK_COLOR = '#966F33'
LEAF_COLOR = '#6db33f'
EDGE_COLORS = ["#000000", "#E69F00", "#56B4E9", "#009E73",
"#F0E442", "#0072B2", "#D55E00", "#CC79A7"]
NODE_COLOR = "#cccccc"
class Namespace(dict):
"""
Abstract constants class
Constants can be accessed via .attribute or [key] and can be iterated over.
"""
def __init__(self, *args, **kwargs):
d = {k: k for k in args}
d.update(dict(kwargs.items()))
super().__init__(d)
def __getattr__(self, item):
return self[item]
OWNER_CONST = Namespace("UNKNOWN_VAR", "UNKNOWN_MODULE")
GROUP_TYPE = Namespace("FILE", "CLASS", "NAMESPACE")
def is_installed(executable_cmd):
"""
Determine whether a command can be run or not
:param list[str] individual_files:
:rtype: str
"""
for path in os.environ["PATH"].split(os.pathsep):
path = path.strip('"')
exe_file = os.path.join(path, executable_cmd)
if os.path.isfile(exe_file) and os.access(exe_file, os.X_OK):
return True
return False
def djoin(*tup):
"""
Convenience method to join strings with dots
:rtype: str
"""
if len(tup) == 1 and isinstance(tup[0], list):
return '.'.join(tup[0])
return '.'.join(tup)
def flatten(list_of_lists):
"""
Return a list from a list of lists
:param list[list[Value]] list_of_lists:
:rtype: list[Value]
"""
return [el for sublist in list_of_lists for el in sublist]
def _resolve_str_variable(variable, file_groups):
"""
String variables are when variable.points_to is a string
This happens ONLY when we have imports that we delayed processing for
This function looks through all files to see if any particular node matches
the variable.points_to string
:param Variable variable:
:param list[Group] file_groups:
:rtype: Node|Group|str
"""
for file_group in file_groups:
for node in file_group.all_nodes():
if any(ot == variable.points_to for ot in node.import_tokens):
return node
for group in file_group.all_groups():
if any(ot == variable.points_to for ot in group.import_tokens):
return group
return OWNER_CONST.UNKNOWN_MODULE
class BaseLanguage(abc.ABC):
"""
Languages are individual implementations for different dynamic languages.
This is the superclass of Python, Javascript, PHP, and Ruby.
Every implementation must implement all of these methods.
For more detail, see the individual implementations.
Note that the 'Tree' type is generic and will be a different
type for different languages. In Python, it is an ast.AST.
"""
@staticmethod
@abc.abstractmethod
def assert_dependencies():
"""
:rtype: None
"""
@staticmethod
@abc.abstractmethod
def get_tree(filename, lang_params):
"""
:param filename str:
:rtype: Tree
"""
@staticmethod
@abc.abstractmethod
def separate_namespaces(tree):
"""
:param tree Tree:
:rtype: (list[tree], list[tree], list[tree])
"""
@staticmethod
@abc.abstractmethod
def make_nodes(tree, parent):
"""
:param tree Tree:
:param parent Group:
:rtype: list[Node]
"""
@staticmethod
@abc.abstractmethod
def make_root_node(lines, parent):
"""
:param lines list[Tree]:
:param parent Group:
:rtype: Node
"""
@staticmethod
@abc.abstractmethod
def make_class_group(tree, parent):
"""
:param tree Tree:
:param parent Group:
:rtype: Group
"""
class Variable():
"""
Variables represent named tokens that are accessible to their scope.
They may either point to a string or, once resolved, a Group/Node.
Not all variables can be resolved
"""
def __init__(self, token, points_to, line_number=None):
"""
:param str token:
:param str|Call|Node|Group points_to: (str/Call is eventually resolved to Nodes|Groups)
:param int|None line_number:
"""
assert token
assert points_to
self.token = token
self.points_to = points_to
self.line_number = line_number
def __repr__(self):
return f"{self.points_to.token}'
return f'{self.token}->{self.points_to}'
class Call():
"""
Calls represent function call expressions.
They can be an attribute call like
object.do_something()
Or a "naked" call like
do_something()
"""
def __init__(self, token, line_number=None, owner_token=None, definite_constructor=False):
self.token = token
self.owner_token = owner_token
self.line_number = line_number
self.definite_constructor = definite_constructor
def __repr__(self):
return f""
def to_string(self):
"""
Returns a representation of this call to be printed by the engine
in logging.
:rtype: str
"""
if self.owner_token:
return f"{self.owner_token}.{self.token}()"
return f"{self.token}()"
def is_attr(self):
"""
Attribute calls are like `a.do_something()` rather than `do_something()`
:rtype: bool
"""
return self.owner_token is not None
def matches_variable(self, variable):
"""
Check whether this variable is what the call is acting on.
For example, if we had 'obj' from
obj = Obj()
as a variable and a call of
obj.do_something()
Those would match and we would return the "do_something" node from obj.
:param variable Variable:
:rtype: Node
"""
if self.is_attr():
if self.owner_token == variable.token:
for node in getattr(variable.points_to, 'nodes', []):
if self.token == node.token:
return node
for inherit_nodes in getattr(variable.points_to, 'inherits', []):
for node in inherit_nodes:
if self.token == node.token:
return node
if variable.points_to in OWNER_CONST:
return variable.points_to
# This section is specifically for resolving namespace variables
if isinstance(variable.points_to, Group) \
and variable.points_to.group_type == GROUP_TYPE.NAMESPACE:
parts = self.owner_token.split('.')
if len(parts) != 2:
return None
if parts[0] != variable.token:
return None
for node in variable.points_to.all_nodes():
if parts[1] == node.namespace_ownership() \
and self.token == node.token:
return node
return None
if self.token == variable.token:
if isinstance(variable.points_to, Node):
return variable.points_to
if isinstance(variable.points_to, Group) \
and variable.points_to.group_type == GROUP_TYPE.CLASS \
and variable.points_to.get_constructor():
return variable.points_to.get_constructor()
return None
class Node():
def __init__(self, token, calls, variables, parent, import_tokens=None,
line_number=None, is_constructor=False):
self.token = token
self.line_number = line_number
self.calls = calls
self.variables = variables
self.import_tokens = import_tokens or []
self.parent = parent
self.is_constructor = is_constructor
self.uid = "node_" + os.urandom(4).hex()
# Assume it is a leaf and a trunk. These are modified later
self.is_leaf = True # it calls nothing else
self.is_trunk = True # nothing calls it
def __repr__(self):
return f""
def __lt__(self, other):
return self.name() < other.name()
def name(self):
"""
Names exist largely for unit tests and deterministic node sorting
:rtype: str
"""
return f"{self.first_group().filename()}::{self.token_with_ownership()}"
def first_group(self):
"""
The first group that contains this node.
:rtype: Group
"""
parent = self.parent
while not isinstance(parent, Group):
parent = parent.parent
return parent
def file_group(self):
"""
Get the file group that this node is in.
:rtype: Group
"""
parent = self.parent
while parent.parent:
parent = parent.parent
return parent
def is_attr(self):
"""
Whether this node is attached to something besides the file
:rtype: bool
"""
return (self.parent
and isinstance(self.parent, Group)
and self.parent.group_type in (GROUP_TYPE.CLASS, GROUP_TYPE.NAMESPACE))
def token_with_ownership(self):
"""
Token which includes what group this is a part of
:rtype: str
"""
if self.is_attr():
return djoin(self.parent.token, self.token)
return self.token
def namespace_ownership(self):
"""
Get the ownership excluding namespace
:rtype: str
"""
parent = self.parent
ret = []
while parent and parent.group_type == GROUP_TYPE.CLASS:
ret = [parent.token] + ret
parent = parent.parent
return djoin(ret)
def label(self):
"""
Labels are what you see on the graph
:rtype: str
"""
if self.line_number is not None:
return f"{self.line_number}: {self.token}()"
return f"{self.token}()"
def remove_from_parent(self):
"""
Remove this node from it's parent. This effectively deletes the node.
:rtype: None
"""
self.first_group().nodes = [n for n in self.first_group().nodes if n != self]
def get_variables(self, line_number=None):
"""
Get variables in-scope on the line number.
This includes all local variables as-well-as outer-scope variables
:rtype: list[Variable]
"""
if line_number is None:
ret = list(self.variables)
else:
# TODO variables should be sorted by scope before line_number
ret = list([v for v in self.variables if v.line_number <= line_number])
if any(v.line_number for v in ret):
ret.sort(key=lambda v: v.line_number, reverse=True)
parent = self.parent
while parent:
ret += parent.get_variables()
parent = parent.parent
return ret
def resolve_variables(self, file_groups):
"""
For all variables, attempt to resolve the Node/Group on points_to.
There is a good chance this will be unsuccessful.
:param list[Group] file_groups:
:rtype: None
"""
for variable in self.variables:
if isinstance(variable.points_to, str):
variable.points_to = _resolve_str_variable(variable, file_groups)
elif isinstance(variable.points_to, Call):
# else, this is a call variable
call = variable.points_to
# Only process Class(); Not a.Class()
if call.is_attr() and not call.definite_constructor:
continue
# Else, assume the call is a constructor.
# iterate through to find the right group
for file_group in file_groups:
for group in file_group.all_groups():
if group.token == call.token:
variable.points_to = group
else:
assert isinstance(variable.points_to, (Node, Group))
def to_dot(self):
"""
Output for graphviz (.dot) files
:rtype: str
"""
attributes = {
'label': self.label(),
'name': self.name(),
'shape': "rect",
'style': 'rounded,filled',
'fillcolor': NODE_COLOR,
}
if self.is_trunk:
attributes['fillcolor'] = TRUNK_COLOR
elif self.is_leaf:
attributes['fillcolor'] = LEAF_COLOR
ret = self.uid + ' ['
for k, v in attributes.items():
ret += f'{k}="{v}" '
ret += ']'
return ret
def to_dict(self):
"""
Output for json files (json graph specification)
:rtype: dict
"""
return {
'uid': self.uid,
'label': self.label(),
'name': self.name(),
}
def _wrap_as_variables(sequence):
"""
Given a list of either Nodes or Groups, wrap them in variables.
This is used in the get_variables method to allow all defined
functions and classes to be defined as variables
:param list[Group|Node] sequence:
:rtype: list[Variable]
"""
return [Variable(el.token, el, el.line_number) for el in sequence]
class Edge():
def __init__(self, node0, node1):
self.node0 = node0
self.node1 = node1
# When we draw the edge, we know the calling function is definitely not a leaf...
# and the called function is definitely not a trunk
node0.is_leaf = False
node1.is_trunk = False
def __repr__(self):
return f" {self.node1}"
def __lt__(self, other):
if self.node0 == other.node0:
return self.node1 < other.node1
return self.node0 < other.node0
def to_dot(self):
'''
Returns string format for embedding in a dotfile. Example output:
node_uid_a -> node_uid_b [color='#aaa' penwidth='2']
:rtype: str
'''
ret = self.node0.uid + ' -> ' + self.node1.uid
source_color = int(self.node0.uid.split("_")[-1], 16) % len(EDGE_COLORS)
ret += f' [color="{EDGE_COLORS[source_color]}" penwidth="2"]'
return ret
def to_dict(self):
"""
:rtype: dict
"""
return {
'source': self.node0.uid,
'target': self.node1.uid,
'directed': True,
}
class Group():
"""
Groups represent namespaces (classes and modules/files)
"""
def __init__(self, token, group_type, display_type, import_tokens=None,
line_number=None, parent=None, inherits=None):
self.token = token
self.line_number = line_number
self.nodes = []
self.root_node = None
self.subgroups = []
self.parent = parent
self.group_type = group_type
self.display_type = display_type
self.import_tokens = import_tokens or []
self.inherits = inherits or []
assert group_type in GROUP_TYPE
self.uid = "cluster_" + os.urandom(4).hex() # group doesn't work by syntax rules
def __repr__(self):
return f""
def __lt__(self, other):
return self.label() < other.label()
def label(self):
"""
Labels are what you see on the graph
:rtype: str
"""
return f"{self.display_type}: {self.token}"
def filename(self):
"""
The ultimate filename of this group.
:rtype: str
"""
if self.group_type == GROUP_TYPE.FILE:
return self.token
return self.parent.filename()
def add_subgroup(self, sg):
"""
Subgroups are found after initialization. This is how they are added.
:param sg Group:
"""
self.subgroups.append(sg)
def add_node(self, node, is_root=False):
"""
Nodes are found after initialization. This is how they are added.
:param node Node:
:param is_root bool:
"""
self.nodes.append(node)
if is_root:
self.root_node = node
def all_nodes(self):
"""
List of nodes that are part of this group + all subgroups
:rtype: list[Node]
"""
ret = list(self.nodes)
for subgroup in self.subgroups:
ret += subgroup.all_nodes()
return ret
def get_constructor(self):
"""
Return the first constructor for this group - if any
TODO, this excludes the possibility of multiple constructors like
__init__ vs __new__
:rtype: Node|None
"""
assert self.group_type == GROUP_TYPE.CLASS
constructors = [n for n in self.nodes if n.is_constructor]
if constructors:
return constructors[0]
def all_groups(self):
"""
List of groups that are part of this group + all subgroups
:rtype: list[Group]
"""
ret = [self]
for subgroup in self.subgroups:
ret += subgroup.all_groups()
return ret
def get_variables(self, line_number=None):
"""
Get in-scope variables from this group.
This assumes every variable will be in-scope in nested functions
line_number is included for compatibility with Node.get_variables but is not used
:param int line_number:
:rtype: list[Variable]
"""
if self.root_node:
variables = (self.root_node.variables
+ _wrap_as_variables(self.subgroups)
+ _wrap_as_variables(n for n in self.nodes if n != self.root_node))
if any(v.line_number for v in variables):
return sorted(variables, key=lambda v: v.line_number, reverse=True)
return variables
else:
return []
def remove_from_parent(self):
"""
Remove this group from it's parent. This is effectively a deletion
:rtype: None
"""
if self.parent:
self.parent.subgroups = [g for g in self.parent.subgroups if g != self]
def all_parents(self):
"""
Recursively get the entire inheritance tree of this group
:rtype: list[Group]
"""
if self.parent:
return [self.parent] + self.parent.all_parents()
return []
def to_dot(self):
"""
Returns string format for embedding in a dotfile. Example output:
subgraph group_uid_a {
node_uid_b node_uid_c;
label='class_name';
...
subgraph group_uid_z {
...
}
...
}
:rtype: str
"""
ret = 'subgraph ' + self.uid + ' {\n'
if self.nodes:
ret += ' '
ret += ' '.join(node.uid for node in self.nodes)
ret += ';\n'
attributes = {
'label': self.label(),
'name': self.token,
'style': 'filled',
}
for k, v in attributes.items():
ret += f' {k}="{v}";\n'
ret += ' graph[style=dotted];\n'
for subgroup in self.subgroups:
ret += ' ' + ('\n'.join(' ' + ln for ln in
subgroup.to_dot().split('\n'))).strip() + '\n'
ret += '};\n'
return ret
================================================
FILE: code2flow/package.json
================================================
{
"dependencies": {
"acorn": "^8.6.0"
}
}
================================================
FILE: code2flow/php.py
================================================
import json
import os
import subprocess
from .model import (Group, Node, Call, Variable, BaseLanguage,
OWNER_CONST, GROUP_TYPE, is_installed, flatten, djoin)
def lineno(tree):
"""
Return the line number of the AST
:param tree ast:
:rtype: int
"""
return tree['attributes']['startLine']
def get_name(tree, from_='name'):
"""
Get the name (token) of the AST node.
:param tree ast:
:rtype: str|None
"""
# return tree['name']['name']
if 'name' in tree and isinstance(tree['name'], str):
return tree['name']
if 'parts' in tree:
return djoin(tree['parts'])
if from_ in tree:
return get_name(tree[from_])
return None
def get_call_from_expr(func_expr):
"""
Given an ast that represents a send call, clear and create our
generic Call object. Some calls have no chance at resolution (e.g. array[2](param))
so we return nothing instead.
:param func_expr ast:
:rtype: Call|None
"""
if func_expr['nodeType'] == 'Expr_FuncCall':
token = get_name(func_expr)
owner_token = None
elif func_expr['nodeType'] == 'Expr_New' and func_expr['class'].get('parts'):
token = '__construct'
owner_token = get_name(func_expr['class'])
elif func_expr['nodeType'] == 'Expr_MethodCall':
# token = func_expr['name']['name']
token = get_name(func_expr)
if 'var' in func_expr['var']:
owner_token = OWNER_CONST.UNKNOWN_VAR
else:
owner_token = get_name(func_expr['var'])
elif func_expr['nodeType'] == 'Expr_BinaryOp_Concat' and func_expr['right']['nodeType'] == 'Expr_FuncCall':
token = get_name(func_expr['right'])
if 'class' in func_expr['left']:
owner_token = get_name(func_expr['left']['class'])
else:
owner_token = get_name(func_expr['left'])
elif func_expr['nodeType'] == 'Expr_StaticCall':
token = get_name(func_expr)
owner_token = get_name(func_expr['class'])
else:
return None
if owner_token and token == '__construct':
# Taking out owner_token for constructors as a little hack to make it work
return Call(token=owner_token,
line_number=lineno(func_expr))
ret = Call(token=token,
owner_token=owner_token,
line_number=lineno(func_expr))
return ret
def walk(tree):
"""
Given an ast tree walk it to get every node. For PHP, the exception
is that we return Expr_BinaryOp_Concat which has internal nodes but
is important to process as a whole.
:param tree_el ast:
:rtype: list[ast]
"""
if isinstance(tree, list):
ret = []
for el in tree:
if isinstance(el, dict) and el.get('nodeType'):
ret += walk(el)
return ret
assert isinstance(tree, dict)
assert tree['nodeType']
ret = [tree]
if tree['nodeType'] == 'Expr_BinaryOp_Concat':
return ret
for v in tree.values():
if isinstance(v, list) or (isinstance(v, dict) and v.get('nodeType')):
ret += walk(v)
return ret
def children(tree):
"""
Given an ast tree get all children. For PHP, children are anything
with a nodeType.
:param tree_el ast:
:rtype: list[ast]
"""
assert isinstance(tree, dict)
ret = []
for v in tree.values():
if isinstance(v, list):
for el in v:
if isinstance(el, dict) and el.get('nodeType'):
ret.append(el)
elif isinstance(v, dict) and v.get('nodeType'):
ret.append(v)
return ret
def make_calls(body_el):
"""
Given a list of lines, find all calls in this list.
:param body_el ast:
:rtype: list[Call]
"""
calls = []
for expr in walk(body_el):
call = get_call_from_expr(expr)
calls.append(call)
ret = list(filter(None, calls))
return ret
def process_assign(assignment_el):
"""
Given an assignment statement, return a
Variable that points_to the type of object being assigned.
:param assignment_el ast:
:rtype: Variable
"""
assert assignment_el['nodeType'] == 'Expr_Assign'
if 'name' not in assignment_el['var']:
return None
varname = assignment_el['var']['name']
call = get_call_from_expr(assignment_el['expr'])
if call:
return Variable(varname, call, line_number=lineno(assignment_el))
# else is something like `varname = num`
return None
def make_local_variables(tree_el, parent):
"""
Given an ast of all the lines in a function, generate a list of
variables in that function. Variables are tokens and what they link to.
:param tree_el ast:
:param parent Group:
:rtype: list[Variable]
"""
variables = []
for el in walk(tree_el):
if el['nodeType'] == 'Expr_Assign':
variables.append(process_assign(el))
if el['nodeType'] == 'Stmt_Use':
for use in el['uses']:
owner_token = djoin(use['name']['parts'])
token = use['alias']['name'] if use['alias'] else owner_token
variables.append(Variable(token, points_to=owner_token,
line_number=lineno(el)))
# Make a 'this'/'self' variable for use anywhere we need it that points to the class
if isinstance(parent, Group) and parent.group_type in GROUP_TYPE.CLASS:
variables.append(Variable('this', parent, line_number=parent.line_number))
variables.append(Variable('self', parent, line_number=parent.line_number))
return list(filter(None, variables))
def get_inherits(tree):
"""
Get the various types of inheritances this class/namespace/trait can have
:param tree ast:
:rtype: list[str]
"""
ret = []
if tree.get('extends', {}):
ret.append(djoin(tree['extends']['parts']))
for stmt in tree.get('stmts', []):
if stmt['nodeType'] == 'Stmt_TraitUse':
for trait in stmt['traits']:
ret.append(djoin(trait['parts']))
return ret
def run_ast_parser(filename):
"""
Parse the php file and return the output + the returncode
Separate function b/c unittesting and asserting php-parser installation.
:param filename str:
:type: str, int
"""
script_loc = os.path.join(os.path.dirname(os.path.realpath(__file__)),
"get_ast.php")
cmd = ["php", script_loc, filename]
proc = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
return proc.communicate()[0], proc.returncode
class PHP(BaseLanguage):
@staticmethod
def assert_dependencies():
"""Assert that php and php-parser are installed"""
assert is_installed('php'), "No php installation could be found"
self_ref = os.path.join(os.path.dirname(os.path.realpath(__file__)),
"get_ast.php")
outp, returncode = run_ast_parser(self_ref)
path = os.path.dirname(os.path.realpath(__file__))
assert_msg = 'Error running the PHP parser. From the `%s` directory, run ' \
'`composer require nikic/php-parser "^4.10"`.' % path
assert not returncode, assert_msg
return outp
@staticmethod
def get_tree(filename, lang_params):
"""
Get the entire AST for this file
:param filename str:
:param lang_params LanguageParams:
:rtype: ast
"""
outp, returncode = run_ast_parser(filename)
if returncode:
raise AssertionError(
"Could not parse file %r. You may have a syntax error. "
"For more detail, try running with `php %s`. " %
(filename, filename))
tree = json.loads(outp)
assert isinstance(tree, list)
if len(tree) == 1 and tree[0]['nodeType'] == 'Stmt_InlineHTML':
raise AssertionError("Tried to parse a file that is not likely PHP")
return tree
@staticmethod
def separate_namespaces(tree):
"""
Given a tree element, recursively separate that AST into lists of ASTs for the
subgroups, nodes, and body. This is an intermediate step to allow for
cleaner processing downstream
:param tree ast:
:returns: tuple of group, node, and body trees. These are processed
downstream into real Groups and Nodes.
:rtype: (list[ast], list[ast], list[ast])
"""
tree = tree or [] # if its abstract, it comes in with no body
groups = []
nodes = []
body = []
for el in tree:
if el['nodeType'] in ('Stmt_Function', 'Stmt_ClassMethod', 'Expr_Closure'):
nodes.append(el)
elif el['nodeType'] in ('Stmt_Class', 'Stmt_Namespace', 'Stmt_Trait'):
groups.append(el)
else:
tup = PHP.separate_namespaces(children(el))
if tup[0] or tup[1]:
groups += tup[0]
nodes += tup[1]
body += tup[2]
else:
body.append(el)
return groups, nodes, body
@staticmethod
def make_nodes(tree, parent):
"""
Given a tree element of all the lines in a function, create the node along
with the calls and variables internal to it.
Also make the nested subnodes
:param tree ast:
:param parent Group:
:rtype: list[Node]
"""
assert tree['nodeType'] in ('Stmt_Function', 'Stmt_ClassMethod', 'Expr_Closure')
if tree['nodeType'] == 'Expr_Closure':
token = '(Closure)'
else:
token = tree['name']['name']
is_constructor = token == '__construct' and parent.group_type == GROUP_TYPE.CLASS
tree_body = tree['stmts']
subgroup_trees, subnode_trees, this_scope_body = PHP.separate_namespaces(tree_body)
assert not subgroup_trees
calls = make_calls(this_scope_body)
variables = make_local_variables(this_scope_body, parent)
if parent.group_type == GROUP_TYPE.CLASS and parent.parent.group_type == GROUP_TYPE.NAMESPACE:
import_tokens = [djoin(parent.parent.token, parent.token, token)]
if parent.group_type in (GROUP_TYPE.NAMESPACE, GROUP_TYPE.CLASS):
import_tokens = [djoin(parent.token, token)]
else:
import_tokens = [token]
node = Node(token, calls, variables, parent, import_tokens=import_tokens,
is_constructor=is_constructor, line_number=lineno(tree))
subnodes = flatten([PHP.make_nodes(t, parent) for t in subnode_trees])
return [node] + subnodes
@staticmethod
def make_root_node(lines, parent):
"""
The "root_node" is an implict node of lines which are executed in the global
scope on the file itself and not otherwise part of any function.
:param lines list[ast]:
:param parent Group:
:rtype: Node
"""
token = "(global)"
line_number = lineno(lines[0]) if lines else 0
calls = make_calls(lines)
variables = make_local_variables(lines, parent)
root_node = Node(token, calls, variables, parent,
line_number=line_number)
return root_node
@staticmethod
def make_class_group(tree, parent):
"""
Given an AST for the subgroup (a class), generate that subgroup.
In this function, we will also need to generate all of the nodes internal
to the group.
Specific to PHP, this can also be a namespace or class.
:param tree ast:
:param parent Group:
:rtype: Group
"""
assert tree['nodeType'] in ('Stmt_Class', 'Stmt_Namespace', 'Stmt_Trait')
subgroup_trees, node_trees, body_trees = PHP.separate_namespaces(tree['stmts'])
token = get_name(tree['name'])
display_type = tree['nodeType'][5:]
inherits = get_inherits(tree)
group_type = GROUP_TYPE.CLASS
if display_type == 'Namespace':
group_type = GROUP_TYPE.NAMESPACE
import_tokens = [token]
if display_type == 'Class' and parent.group_type == GROUP_TYPE.NAMESPACE:
import_tokens = [djoin(parent.token, token)]
class_group = Group(token, group_type, display_type, import_tokens=import_tokens,
parent=parent, inherits=inherits, line_number=lineno(tree))
for subgroup_tree in subgroup_trees:
class_group.add_subgroup(PHP.make_class_group(subgroup_tree, class_group))
for node_tree in node_trees:
for new_node in PHP.make_nodes(node_tree, parent=class_group):
class_group.add_node(new_node)
if group_type == GROUP_TYPE.NAMESPACE:
class_group.add_node(PHP.make_root_node(body_trees, class_group))
for node in class_group.nodes:
node.variables += [Variable(n.token, n, line_number=n.line_number)
for n in class_group.nodes]
return class_group
@staticmethod
def file_import_tokens(filename):
"""
Returns the token(s) we would use if importing this file from another.
:param filename str:
:rtype: list[str]
"""
return []
================================================
FILE: code2flow/python.py
================================================
import ast
import logging
import os
from .model import (OWNER_CONST, GROUP_TYPE, Group, Node, Call, Variable,
BaseLanguage, djoin)
def get_call_from_func_element(func):
"""
Given a python ast that represents a function call, clear and create our
generic Call object. Some calls have no chance at resolution (e.g. array[2](param))
so we return nothing instead.
:param func ast:
:rtype: Call|None
"""
assert type(func) in (ast.Attribute, ast.Name, ast.Subscript, ast.Call)
if type(func) == ast.Attribute:
owner_token = []
val = func.value
while True:
try:
owner_token.append(getattr(val, 'attr', val.id))
except AttributeError:
pass
val = getattr(val, 'value', None)
if not val:
break
if owner_token:
owner_token = djoin(*reversed(owner_token))
else:
owner_token = OWNER_CONST.UNKNOWN_VAR
return Call(token=func.attr, line_number=func.lineno, owner_token=owner_token)
if type(func) == ast.Name:
return Call(token=func.id, line_number=func.lineno)
if type(func) in (ast.Subscript, ast.Call):
return None
def make_calls(lines):
"""
Given a list of lines, find all calls in this list.
:param lines list[ast]:
:rtype: list[Call]
"""
calls = []
for tree in lines:
for element in ast.walk(tree):
if type(element) != ast.Call:
continue
call = get_call_from_func_element(element.func)
if call:
calls.append(call)
return calls
def process_assign(element):
"""
Given an element from the ast which is an assignment statement, return a
Variable that points_to the type of object being assigned. For now, the
points_to is a string but that is resolved later.
:param element ast:
:rtype: Variable
"""
if type(element.value) != ast.Call:
return []
call = get_call_from_func_element(element.value.func)
if not call:
return []
ret = []
for target in element.targets:
if type(target) != ast.Name:
continue
token = target.id
ret.append(Variable(token, call, element.lineno))
return ret
def process_import(element):
"""
Given an element from the ast which is an import statement, return a
Variable that points_to the module being imported. For now, the
points_to is a string but that is resolved later.
:param element ast:
:rtype: Variable
"""
ret = []
for single_import in element.names:
assert isinstance(single_import, ast.alias)
token = single_import.asname or single_import.name
rhs = single_import.name
if hasattr(element, 'module') and element.module:
rhs = djoin(element.module, rhs)
ret.append(Variable(token, points_to=rhs, line_number=element.lineno))
return ret
def make_local_variables(lines, parent):
"""
Given an ast of all the lines in a function, generate a list of
variables in that function. Variables are tokens and what they link to.
In this case, what it links to is just a string. However, that is resolved
later.
:param lines list[ast]:
:param parent Group:
:rtype: list[Variable]
"""
variables = []
for tree in lines:
for element in ast.walk(tree):
if type(element) == ast.Assign:
variables += process_assign(element)
if type(element) in (ast.Import, ast.ImportFrom):
variables += process_import(element)
if parent.group_type == GROUP_TYPE.CLASS:
variables.append(Variable('self', parent, lines[0].lineno))
variables = list(filter(None, variables))
return variables
def get_inherits(tree):
"""
Get what superclasses this class inherits
This handles exact names like 'MyClass' but skips things like 'cls' and 'mod.MyClass'
Resolving those would be difficult
:param tree ast:
:rtype: list[str]
"""
return [base.id for base in tree.bases if type(base) == ast.Name]
class Python(BaseLanguage):
@staticmethod
def assert_dependencies():
pass
@staticmethod
def get_tree(filename, _):
"""
Get the entire AST for this file
:param filename str:
:rtype: ast
"""
try:
with open(filename) as f:
raw = f.read()
except ValueError:
with open(filename, encoding='UTF-8') as f:
raw = f.read()
return ast.parse(raw)
@staticmethod
def separate_namespaces(tree):
"""
Given an AST, recursively separate that AST into lists of ASTs for the
subgroups, nodes, and body. This is an intermediate step to allow for
cleaner processing downstream
:param tree ast:
:returns: tuple of group, node, and body trees. These are processed
downstream into real Groups and Nodes.
:rtype: (list[ast], list[ast], list[ast])
"""
groups = []
nodes = []
body = []
for el in tree.body:
if type(el) in (ast.FunctionDef, ast.AsyncFunctionDef):
nodes.append(el)
elif type(el) == ast.ClassDef:
groups.append(el)
elif getattr(el, 'body', None):
tup = Python.separate_namespaces(el)
groups += tup[0]
nodes += tup[1]
body += tup[2]
else:
body.append(el)
return groups, nodes, body
@staticmethod
def make_nodes(tree, parent):
"""
Given an ast of all the lines in a function, create the node along with the
calls and variables internal to it.
:param tree ast:
:param parent Group:
:rtype: list[Node]
"""
token = tree.name
line_number = tree.lineno
calls = make_calls(tree.body)
variables = make_local_variables(tree.body, parent)
is_constructor = False
if parent.group_type == GROUP_TYPE.CLASS and token in ['__init__', '__new__']:
is_constructor = True
import_tokens = []
if parent.group_type == GROUP_TYPE.FILE:
import_tokens = [djoin(parent.token, token)]
return [Node(token, calls, variables, parent, import_tokens=import_tokens,
line_number=line_number, is_constructor=is_constructor)]
@staticmethod
def make_root_node(lines, parent):
"""
The "root_node" is an implict node of lines which are executed in the global
scope on the file itself and not otherwise part of any function.
:param lines list[ast]:
:param parent Group:
:rtype: Node
"""
token = "(global)"
line_number = 0
calls = make_calls(lines)
variables = make_local_variables(lines, parent)
return Node(token, calls, variables, line_number=line_number, parent=parent)
@staticmethod
def make_class_group(tree, parent):
"""
Given an AST for the subgroup (a class), generate that subgroup.
In this function, we will also need to generate all of the nodes internal
to the group.
:param tree ast:
:param parent Group:
:rtype: Group
"""
assert type(tree) == ast.ClassDef
subgroup_trees, node_trees, body_trees = Python.separate_namespaces(tree)
group_type = GROUP_TYPE.CLASS
token = tree.name
display_name = 'Class'
line_number = tree.lineno
import_tokens = [djoin(parent.token, token)]
inherits = get_inherits(tree)
class_group = Group(token, group_type, display_name, import_tokens=import_tokens,
inherits=inherits, line_number=line_number, parent=parent)
for node_tree in node_trees:
class_group.add_node(Python.make_nodes(node_tree, parent=class_group)[0])
for subgroup_tree in subgroup_trees:
logging.warning("Code2flow does not support nested classes. Skipping %r in %r.",
subgroup_tree.name, parent.token)
return class_group
@staticmethod
def file_import_tokens(filename):
"""
Returns the token(s) we would use if importing this file from another.
:param filename str:
:rtype: list[str]
"""
return [os.path.split(filename)[-1].rsplit('.py', 1)[0]]
================================================
FILE: code2flow/ruby.py
================================================
import json
import subprocess
from .model import (Group, Node, Call, Variable, BaseLanguage,
OWNER_CONST, GROUP_TYPE, is_installed, flatten)
def resolve_owner(owner_el):
"""
Resolve who owns the call, if anyone.
So if the expression is i_ate.pie(). And i_ate is a Person, the callee is Person.
This is returned as a string and eventually set to the owner_token in the call
:param owner_el ast:
:rtype: str|None
"""
if not owner_el or not isinstance(owner_el, list):
return None
if owner_el[0] == 'begin':
# skip complex ownership
return OWNER_CONST.UNKNOWN_VAR
if owner_el[0] == 'send':
# sends are complex too
return OWNER_CONST.UNKNOWN_VAR
if owner_el[0] == 'lvar':
# var.func()
return owner_el[1]
if owner_el[0] == 'ivar':
# @var.func()
return owner_el[1]
if owner_el[0] == 'self':
return 'self'
if owner_el[0] == 'const':
return owner_el[2]
return OWNER_CONST.UNKNOWN_VAR
def get_call_from_send_el(func_el):
"""
Given an ast that represents a send call, clear and create our
generic Call object. Some calls have no chance at resolution (e.g. array[2](param))
so we return nothing instead.
:param func_el ast:
:rtype: Call|None
"""
owner_el = func_el[1]
token = func_el[2]
owner = resolve_owner(owner_el)
if owner and token == 'new':
# Taking out owner_token for constructors as a little hack to make it work
return Call(token=owner)
return Call(token=token,
owner_token=owner)
def walk(tree_el):
"""
Given an ast element (list), walk it in a dfs to get every el (list) out of it
:param tree_el ast:
:rtype: list[ast]
"""
if not tree_el:
return []
ret = [tree_el]
for el in tree_el:
if isinstance(el, list):
ret += walk(el)
return ret
def make_calls(body_el):
"""
Given a list of lines, find all calls in this list.
:param body_el ast:
:rtype: list[Call]
"""
calls = []
for el in walk(body_el):
if el[0] == 'send':
calls.append(get_call_from_send_el(el))
return calls
def process_assign(assignment_el):
"""
Given an assignment statement, return a
Variable that points_to the type of object being assigned. The
points_to is often a string but that is resolved later.
:param assignment_el ast:
:rtype: Variable
"""
assert assignment_el[0] == 'lvasgn'
varname = assignment_el[1]
if assignment_el[2][0] == 'send':
call = get_call_from_send_el(assignment_el[2])
return Variable(varname, call)
# else is something like `varname = num`
return None
def make_local_variables(tree_el, parent):
"""
Given an ast of all the lines in a function, generate a list of
variables in that function. Variables are tokens and what they link to.
In this case, what it links to is just a string. However, that is resolved
later.
Also return variables for the outer scope parent
:param tree_el ast:
:param parent Group:
:rtype: list[Variable]
"""
variables = []
for el in tree_el:
if el[0] == 'lvasgn':
variables.append(process_assign(el))
# Make a 'self' variable for use anywhere we need it that points to the class
if isinstance(parent, Group) and parent.group_type == GROUP_TYPE.CLASS:
variables.append(Variable('self', parent))
variables = list(filter(None, variables))
return variables
def as_lines(tree_el):
"""
Ruby ast bodies are structured differently depending on circumstances.
This ensures that they are structured as a list of statements
:param tree_el ast:
:rtype: list[tree_el]
"""
if not tree_el:
return []
if isinstance(tree_el[0], list):
return tree_el
if tree_el[0] == 'begin':
return tree_el
return [tree_el]
def get_tree_body(tree_el):
"""
Depending on the type of element, get the body of that element
:param tree_el ast:
:rtype: list[tree_el]
"""
if tree_el[0] == 'module':
body_struct = tree_el[2]
elif tree_el[0] == 'defs':
body_struct = tree_el[4]
else:
body_struct = tree_el[3]
return as_lines(body_struct)
def get_inherits(tree, body_tree):
"""
Get the various types of inheritances this class/module can have
:param tree ast:
:param body_tree list[ast]
:rtype: list[str]
"""
inherits = []
# extends
if tree[0] == 'class' and tree[2]:
inherits.append(tree[2][2])
# module automatically extends same-named modules
if tree[0] == 'module':
inherits.append(tree[1][2])
# mixins
for el in body_tree:
if el[0] == 'send' and el[2] == 'include':
inherits.append(el[3][2])
return inherits
class Ruby(BaseLanguage):
@staticmethod
def assert_dependencies():
"""Assert that ruby-parse is installed"""
assert is_installed('ruby-parse'), "The 'parser' gem is requred to " \
"parse ruby files but was not found " \
"on the path. Install it from gem " \
"and try again."
@staticmethod
def get_tree(filename, lang_params):
"""
Get the entire AST for this file
:param filename str:
:param lang_params LanguageParams:
:rtype: ast
"""
version_flag = "--" + lang_params.ruby_version
cmd = ["ruby-parse", "--emit-json", version_flag, filename]
output = subprocess.check_output(cmd, stderr=subprocess.PIPE)
try:
tree = json.loads(output)
except json.decoder.JSONDecodeError:
raise AssertionError(
"Ruby-parse could not parse file %r. You may have a syntax error. "
"For more detail, try running the command `ruby-parse %s`. " %
(filename, filename)) from None
assert isinstance(tree, list)
if tree[0] not in ('module', 'begin'):
# one-line files
tree = [tree]
return tree
@staticmethod
def separate_namespaces(tree):
"""
Given a tree element, recursively separate that AST into lists of ASTs for the
subgroups, nodes, and body. This is an intermediate step to allow for
cleaner processing downstream
:param tree ast:
:returns: tuple of group, node, and body trees. These are processed
downstream into real Groups and Nodes.
:rtype: (list[ast], list[ast], list[ast])
"""
groups = []
nodes = []
body = []
for el in as_lines(tree):
if el[0] in ('def', 'defs'):
nodes.append(el)
elif el[0] in ('class', 'module'):
groups.append(el)
else:
body.append(el)
return groups, nodes, body
@staticmethod
def make_nodes(tree, parent):
"""
Given a tree element of all the lines in a function, create the node along
with the calls and variables internal to it.
Also make the nested subnodes
:param tree ast:
:param parent Group:
:rtype: list[Node]
"""
if tree[0] == 'defs':
token = tree[2] # def self.func
else:
token = tree[1] # def func
is_constructor = token == 'initialize' and parent.group_type == GROUP_TYPE.CLASS
tree_body = get_tree_body(tree)
subgroup_trees, subnode_trees, this_scope_body = Ruby.separate_namespaces(tree_body)
assert not subgroup_trees
calls = make_calls(this_scope_body)
variables = make_local_variables(this_scope_body, parent)
node = Node(token, calls, variables,
parent=parent, is_constructor=is_constructor)
# This is a little different from the other languages in that
# the node is now on the parent
subnodes = flatten([Ruby.make_nodes(t, parent) for t in subnode_trees])
return [node] + subnodes
@staticmethod
def make_root_node(lines, parent):
"""
The "root_node" is an implict node of lines which are executed in the global
scope on the file itself and not otherwise part of any function.
:param lines list[ast]:
:param parent Group:
:rtype: Node
"""
token = "(global)"
calls = make_calls(lines)
variables = make_local_variables(lines, parent)
root_node = Node(token, calls, variables, parent=parent)
return root_node
@staticmethod
def make_class_group(tree, parent):
"""
Given an AST for the subgroup (a class), generate that subgroup.
In this function, we will also need to generate all of the nodes internal
to the group.
:param tree ast:
:param parent Group:
:rtype: Group
"""
assert tree[0] in ('class', 'module')
tree_body = get_tree_body(tree)
subgroup_trees, node_trees, body_trees = Ruby.separate_namespaces(tree_body)
group_type = GROUP_TYPE.CLASS
if tree[0] == 'module':
group_type = GROUP_TYPE.NAMESPACE
display_type = tree[0].capitalize()
assert tree[1][0] == 'const'
token = tree[1][2]
inherits = get_inherits(tree, body_trees)
class_group = Group(token, group_type, display_type,
inherits=inherits, parent=parent)
for subgroup_tree in subgroup_trees:
class_group.add_subgroup(Ruby.make_class_group(subgroup_tree, class_group))
for node_tree in node_trees:
for new_node in Ruby.make_nodes(node_tree, parent=class_group):
class_group.add_node(new_node)
for node in class_group.nodes:
node.variables += [Variable(n.token, n) for n in class_group.nodes]
return class_group
@staticmethod
def file_import_tokens(filename):
"""
Returns the token(s) we would use if importing this file from another.
:param filename str:
:rtype: list[str]
"""
return []
================================================
FILE: make_expected.py
================================================
#!/usr/bin/env python3
import os
import pprint
import sys
import tempfile
from code2flow.engine import main
from tests.test_graphs import get_edges_set_from_file, get_nodes_set_from_file
DESCRIPTION = """
This file is a tool to generate test cases given a directory
"""
if __name__ == '__main__':
output_filename = tempfile.NamedTemporaryFile(suffix='.gv').name
args = sys.argv[1:] + ['--output', output_filename]
main(args)
output_file = open(output_filename, 'r')
generated_edges = get_edges_set_from_file(output_file)
generated_nodes = get_nodes_set_from_file(output_file)
directory = os.path.split(sys.argv[1])[-1]
ret = {
'test_name': directory,
'directory': directory,
'kwargs': sys.argv[2:],
'expected_edges': list(map(list, generated_edges)),
'expected_nodes': list(generated_nodes),
}
ret = pprint.pformat(ret, sort_dicts=False)
ret = " " + ret.replace("'", '"')[1:-1]
print('\n'.join(" " + l for l in ret.split('\n')))
================================================
FILE: requirements_dev.txt
================================================
# Testing
pytest>=6.2.5,<7.0
pygraphviz>=1.7,<2.0
pytest-cov>=2.10.1,<3.0
pytest-mock>=3.6.1,<4.0
pytest-xdist>=2.5.0,<3.0
# Development
ipdb>=0.13.9,<1.0
icecream>=2.1.1,<3.0
================================================
FILE: setup.py
================================================
from setuptools import setup
from code2flow.engine import VERSION
url_base = 'https://github.com/scottrogowski/code2flow'
download_url = '%s/archive/code2flow-%s.tar.gz' % (url_base, VERSION)
setup(
name='code2flow',
version=VERSION,
description='Visualize your source code as DOT flowcharts',
long_description=open('README.md', encoding='utf-8').read(),
long_description_content_type="text/markdown",
entry_points={
'console_scripts': ['code2flow=code2flow.engine:main'],
},
license='MIT',
author='Scott Rogowski',
author_email='scottmrogowski@gmail.com',
url=url_base,
download_url=download_url,
packages=['code2flow'],
python_requires='>=3.6',
include_package_data=True,
classifiers=[
'Natural Language :: English',
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
]
)
================================================
FILE: tests/__init__.py
================================================
================================================
FILE: tests/test_code/js/ambiguous_names/ambiguous_names.js
================================================
class Abra {
constructor() {
this.abra_it();
}
magic() {
console.log('magic 1');
}
abra_it() {
}
}
class Cadabra {
magic() {
console.log('magic 2');
}
cadabra_it(a) {
let b = a.abra_it()
let c = "d"
}
}
function main(cls) {
obj = cls()
obj.magic()
obj.cadabra_it()
}
main()
================================================
FILE: tests/test_code/js/bad_parse/file_a_good.js
================================================
function a() {}
a()
================================================
FILE: tests/test_code/js/bad_parse/file_b_bad.js
================================================
function a() {
a)
================================================
FILE: tests/test_code/js/chained/chained.js
================================================
class Chain {
constructor(val) {
this.val = val;
}
add(b) {
this.val += b
return this;
}
sub(b) {
this.val -= b;
return this;
}
mul(b) {
this.val *= b;
return this;
}
}
console.log((new Chain(5)).add(5).sub(2).mul(10));
================================================
FILE: tests/test_code/js/class_in_function/class_in_function.js
================================================
function rectangleClassFactory() {
class Rectangle {
constructor(height, width) {
this.height = height;
this.width = width;
}
}
return Rectangle
}
rectangleClassFactory()
================================================
FILE: tests/test_code/js/classes/classes.js
================================================
function print_hi() {
console.log("HI")
}
class Rectangle {
constructor(height, width) {
this.height = height;
this.width = width;
this.i = 0;
print_hi();
this.calcArea()
}
calcArea() {
this.incr();
return this.height * this.width
}
incr() {
this.i++;
}
}
function do_calc() {
const the_area = square.calcArea()
calcit()
const square = new Rectangle(10, 10);
}
const do_calc_wrapper = function() {
console.log("BANANAS")
do_calc();
}
const square = new Rectangle(10, 10);
square.calcArea()
do_calc_wrapper()
================================================
FILE: tests/test_code/js/complex_ownership/complex_ownership.js
================================================
class ABC {
constructor() {
this.b = 5;
}
doit() {
let _this = this;
return _this.b;
}
apply() {
return 5;
}
ret_def() {
return DEF
}
}
class DEF {
toABC() {
calls = 5;
return new ABC();
}
}
class GHI {
doit2(varname) {
return varname.apply()
}
doit3() {
console.log("");
}
}
var empty_var;
var double_decl = [], empty_var;
calls = 5;
let abc = new DEF();
abc.toABC().doit(calls);
new GHI().doit2()
var inp = AbsentClass()
inp.a.b.c.apply(null, arguments);
var jsism = (function() {
return "no other language does this crazy nonsense";
})()
var jsism_2 = (function() {
return "no other language does this crazy nonsense";
}).anything()
var obj_calls = {
'abc': ABC,
'def': DEF,
'ghi': GHI,
}
obj_calls['ghi'].doit3();
// This below shouldn't match anything because it's too complex of a constructor
var def = new abc.ret_def()
================================================
FILE: tests/test_code/js/exclude_modules/exclude_modules.js
================================================
//Node/CommonJS
const fs = require('fs')
const {readFile, chmod} = require('fs')
function readFileSync() {
console.log("This is the local readFileSync");
}
function beta() {
print("this still connects")
readFileSync()
b = Nothing()
b.beta()
chmod();
}
function alpha() {
fs.readFileSync("exclude_modules.js");
beta()
match()
alpha()
}
alpha()
module.exports = {alpha}
================================================
FILE: tests/test_code/js/exclude_modules_es6/exclude_modules_es6.js
================================================
//Node/CommonJS
const fs = import('fs');
import {readFile, chmod} from 'fs';
function readFileSync() {
console.log("This is the local readFileSync");
}
function beta() {
print("this still connects")
readFileSync()
b = Nothing()
b.beta()
chmod();
}
function alpha() {
fs.readFileSync("exclude_modules.js");
beta()
match()
alpha()
}
alpha()
module.exports = {alpha}
================================================
FILE: tests/test_code/js/globals/globals.js
================================================
var g = (function() {
function a() {
function c() {
function d() {
console.log('d');
}
d()
}
b();
c();
}
function b() {
console.log("c");
}
return {
'a': a,
'b': b
}
})()
================================================
FILE: tests/test_code/js/inheritance/inheritance.js
================================================
// from https://ruby-doc.com/docs/ProgrammingRuby/html/tut_modules.html
function majorNum() {}
function pentaNum() {}
class MajorScales {
majorNum() {
this.numNotes = 7;
return this.numNotes;
}
}
class FakeMajorScales {
majorNum() {
console.log("Not this one")
}
}
class ScaleDemo extends MajorScales {
constructor() {
console.log(this.majorNum())
}
}
let sd = new ScaleDemo();
pentaNum()
================================================
FILE: tests/test_code/js/inheritance_attr/inheritance_attr.js
================================================
class ClsA {
bark() {
console.log("woof");
}
}
class ClsB {
meow() {
console.log("meow");
}
}
ClsA.B = ClsB;
class ClsC extends ClsA.B {}
let c = new ClsC();
c.meow();
================================================
FILE: tests/test_code/js/moment/moment.js
================================================
//! moment.js
//! version : 2.29.1
//! authors : Tim Wood, Iskren Chernev, Moment.js contributors
//! license : MIT
//! momentjs.com
;(function (global, factory) {
typeof exports === 'object' && typeof module !== 'undefined' ? module.exports = factory() :
typeof define === 'function' && define.amd ? define(factory) :
global.moment = factory()
}(this, (function () { 'use strict';
var hookCallback;
function hooks() {
return hookCallback.apply(null, arguments);
}
// This is done to register the method called with moment()
// without creating circular dependencies.
function setHookCallback(callback) {
hookCallback = callback;
}
function isArray(input) {
return (
input instanceof Array ||
Object.prototype.toString.call(input) === '[object Array]'
);
}
function isObject(input) {
// IE8 will treat undefined and null as object if it wasn't for
// input != null
return (
input != null &&
Object.prototype.toString.call(input) === '[object Object]'
);
}
function hasOwnProp(a, b) {
return Object.prototype.hasOwnProperty.call(a, b);
}
function isObjectEmpty(obj) {
if (Object.getOwnPropertyNames) {
return Object.getOwnPropertyNames(obj).length === 0;
} else {
var k;
for (k in obj) {
if (hasOwnProp(obj, k)) {
return false;
}
}
return true;
}
}
function isUndefined(input) {
return input === void 0;
}
function isNumber(input) {
return (
typeof input === 'number' ||
Object.prototype.toString.call(input) === '[object Number]'
);
}
function isDate(input) {
return (
input instanceof Date ||
Object.prototype.toString.call(input) === '[object Date]'
);
}
function map(arr, fn) {
var res = [],
i;
for (i = 0; i < arr.length; ++i) {
res.push(fn(arr[i], i));
}
return res;
}
function extend(a, b) {
for (var i in b) {
if (hasOwnProp(b, i)) {
a[i] = b[i];
}
}
if (hasOwnProp(b, 'toString')) {
a.toString = b.toString;
}
if (hasOwnProp(b, 'valueOf')) {
a.valueOf = b.valueOf;
}
return a;
}
function createUTC(input, format, locale, strict) {
return createLocalOrUTC(input, format, locale, strict, true).utc();
}
function defaultParsingFlags() {
// We need to deep clone this object.
return {
empty: false,
unusedTokens: [],
unusedInput: [],
overflow: -2,
charsLeftOver: 0,
nullInput: false,
invalidEra: null,
invalidMonth: null,
invalidFormat: false,
userInvalidated: false,
iso: false,
parsedDateParts: [],
era: null,
meridiem: null,
rfc2822: false,
weekdayMismatch: false,
};
}
function getParsingFlags(m) {
if (m._pf == null) {
m._pf = defaultParsingFlags();
}
return m._pf;
}
var some;
if (Array.prototype.some) {
some = Array.prototype.some;
} else {
some = function (fun) {
var t = Object(this),
len = t.length >>> 0,
i;
for (i = 0; i < len; i++) {
if (i in t && fun.call(this, t[i], i, t)) {
return true;
}
}
return false;
};
}
function isValid(m) {
if (m._isValid == null) {
var flags = getParsingFlags(m),
parsedParts = some.call(flags.parsedDateParts, function (i) {
return i != null;
}),
isNowValid =
!isNaN(m._d.getTime()) &&
flags.overflow < 0 &&
!flags.empty &&
!flags.invalidEra &&
!flags.invalidMonth &&
!flags.invalidWeekday &&
!flags.weekdayMismatch &&
!flags.nullInput &&
!flags.invalidFormat &&
!flags.userInvalidated &&
(!flags.meridiem || (flags.meridiem && parsedParts));
if (m._strict) {
isNowValid =
isNowValid &&
flags.charsLeftOver === 0 &&
flags.unusedTokens.length === 0 &&
flags.bigHour === undefined;
}
if (Object.isFrozen == null || !Object.isFrozen(m)) {
m._isValid = isNowValid;
} else {
return isNowValid;
}
}
return m._isValid;
}
function createInvalid(flags) {
var m = createUTC(NaN);
if (flags != null) {
extend(getParsingFlags(m), flags);
} else {
getParsingFlags(m).userInvalidated = true;
}
return m;
}
// Plugins that add properties should also add the key here (null value),
// so we can properly clone ourselves.
var momentProperties = (hooks.momentProperties = []),
updateInProgress = false;
function copyConfig(to, from) {
var i, prop, val;
if (!isUndefined(from._isAMomentObject)) {
to._isAMomentObject = from._isAMomentObject;
}
if (!isUndefined(from._i)) {
to._i = from._i;
}
if (!isUndefined(from._f)) {
to._f = from._f;
}
if (!isUndefined(from._l)) {
to._l = from._l;
}
if (!isUndefined(from._strict)) {
to._strict = from._strict;
}
if (!isUndefined(from._tzm)) {
to._tzm = from._tzm;
}
if (!isUndefined(from._isUTC)) {
to._isUTC = from._isUTC;
}
if (!isUndefined(from._offset)) {
to._offset = from._offset;
}
if (!isUndefined(from._pf)) {
to._pf = getParsingFlags(from);
}
if (!isUndefined(from._locale)) {
to._locale = from._locale;
}
if (momentProperties.length > 0) {
for (i = 0; i < momentProperties.length; i++) {
prop = momentProperties[i];
val = from[prop];
if (!isUndefined(val)) {
to[prop] = val;
}
}
}
return to;
}
// Moment prototype object
function Moment(config) {
copyConfig(this, config);
this._d = new Date(config._d != null ? config._d.getTime() : NaN);
if (!this.isValid()) {
this._d = new Date(NaN);
}
// Prevent infinite loop in case updateOffset creates new moment
// objects.
if (updateInProgress === false) {
updateInProgress = true;
hooks.updateOffset(this);
updateInProgress = false;
}
}
function isMoment(obj) {
return (
obj instanceof Moment || (obj != null && obj._isAMomentObject != null)
);
}
function warn(msg) {
if (
hooks.suppressDeprecationWarnings === false &&
typeof console !== 'undefined' &&
console.warn
) {
console.warn('Deprecation warning: ' + msg);
}
}
function deprecate(msg, fn) {
var firstTime = true;
return extend(function () {
if (hooks.deprecationHandler != null) {
hooks.deprecationHandler(null, msg);
}
if (firstTime) {
var args = [],
arg,
i,
key;
for (i = 0; i < arguments.length; i++) {
arg = '';
if (typeof arguments[i] === 'object') {
arg += '\n[' + i + '] ';
for (key in arguments[0]) {
if (hasOwnProp(arguments[0], key)) {
arg += key + ': ' + arguments[0][key] + ', ';
}
}
arg = arg.slice(0, -2); // Remove trailing comma and space
} else {
arg = arguments[i];
}
args.push(arg);
}
warn(
msg +
'\nArguments: ' +
Array.prototype.slice.call(args).join('') +
'\n' +
new Error().stack
);
firstTime = false;
}
return fn.apply(this, arguments);
}, fn);
}
var deprecations = {};
function deprecateSimple(name, msg) {
if (hooks.deprecationHandler != null) {
hooks.deprecationHandler(name, msg);
}
if (!deprecations[name]) {
warn(msg);
deprecations[name] = true;
}
}
hooks.suppressDeprecationWarnings = false;
hooks.deprecationHandler = null;
function isFunction(input) {
return (
(typeof Function !== 'undefined' && input instanceof Function) ||
Object.prototype.toString.call(input) === '[object Function]'
);
}
function set(config) {
var prop, i;
for (i in config) {
if (hasOwnProp(config, i)) {
prop = config[i];
if (isFunction(prop)) {
this[i] = prop;
} else {
this['_' + i] = prop;
}
}
}
this._config = config;
// Lenient ordinal parsing accepts just a number in addition to
// number + (possibly) stuff coming from _dayOfMonthOrdinalParse.
// TODO: Remove "ordinalParse" fallback in next major release.
this._dayOfMonthOrdinalParseLenient = new RegExp(
(this._dayOfMonthOrdinalParse.source || this._ordinalParse.source) +
'|' +
/\d{1,2}/.source
);
}
function mergeConfigs(parentConfig, childConfig) {
var res = extend({}, parentConfig),
prop;
for (prop in childConfig) {
if (hasOwnProp(childConfig, prop)) {
if (isObject(parentConfig[prop]) && isObject(childConfig[prop])) {
res[prop] = {};
extend(res[prop], parentConfig[prop]);
extend(res[prop], childConfig[prop]);
} else if (childConfig[prop] != null) {
res[prop] = childConfig[prop];
} else {
delete res[prop];
}
}
}
for (prop in parentConfig) {
if (
hasOwnProp(parentConfig, prop) &&
!hasOwnProp(childConfig, prop) &&
isObject(parentConfig[prop])
) {
// make sure changes to properties don't modify parent config
res[prop] = extend({}, res[prop]);
}
}
return res;
}
function Locale(config) {
if (config != null) {
this.set(config);
}
}
var keys;
if (Object.keys) {
keys = Object.keys;
} else {
keys = function (obj) {
var i,
res = [];
for (i in obj) {
if (hasOwnProp(obj, i)) {
res.push(i);
}
}
return res;
};
}
var defaultCalendar = {
sameDay: '[Today at] LT',
nextDay: '[Tomorrow at] LT',
nextWeek: 'dddd [at] LT',
lastDay: '[Yesterday at] LT',
lastWeek: '[Last] dddd [at] LT',
sameElse: 'L',
};
function calendar(key, mom, now) {
var output = this._calendar[key] || this._calendar['sameElse'];
return isFunction(output) ? output.call(mom, now) : output;
}
function zeroFill(number, targetLength, forceSign) {
var absNumber = '' + Math.abs(number),
zerosToFill = targetLength - absNumber.length,
sign = number >= 0;
return (
(sign ? (forceSign ? '+' : '') : '-') +
Math.pow(10, Math.max(0, zerosToFill)).toString().substr(1) +
absNumber
);
}
var formattingTokens = /(\[[^\[]*\])|(\\)?([Hh]mm(ss)?|Mo|MM?M?M?|Do|DDDo|DD?D?D?|ddd?d?|do?|w[o|w]?|W[o|W]?|Qo?|N{1,5}|YYYYYY|YYYYY|YYYY|YY|y{2,4}|yo?|gg(ggg?)?|GG(GGG?)?|e|E|a|A|hh?|HH?|kk?|mm?|ss?|S{1,9}|x|X|zz?|ZZ?|.)/g,
localFormattingTokens = /(\[[^\[]*\])|(\\)?(LTS|LT|LL?L?L?|l{1,4})/g,
formatFunctions = {},
formatTokenFunctions = {};
// token: 'M'
// padded: ['MM', 2]
// ordinal: 'Mo'
// callback: function () { this.month() + 1 }
function addFormatToken(token, padded, ordinal, callback) {
var func = callback;
if (typeof callback === 'string') {
func = function () {
return this[callback]();
};
}
if (token) {
formatTokenFunctions[token] = func;
}
if (padded) {
formatTokenFunctions[padded[0]] = function () {
return zeroFill(func.apply(this, arguments), padded[1], padded[2]);
};
}
if (ordinal) {
formatTokenFunctions[ordinal] = function () {
return this.localeData().ordinal(
func.apply(this, arguments),
token
);
};
}
}
function removeFormattingTokens(input) {
if (input.match(/\[[\s\S]/)) {
return input.replace(/^\[|\]$/g, '');
}
return input.replace(/\\/g, '');
}
function makeFormatFunction(format) {
var array = format.match(formattingTokens),
i,
length;
for (i = 0, length = array.length; i < length; i++) {
if (formatTokenFunctions[array[i]]) {
array[i] = formatTokenFunctions[array[i]];
} else {
array[i] = removeFormattingTokens(array[i]);
}
}
return function (mom) {
var output = '',
i;
for (i = 0; i < length; i++) {
output += isFunction(array[i])
? array[i].call(mom, format)
: array[i];
}
return output;
};
}
// format date using native date object
function formatMoment(m, format) {
if (!m.isValid()) {
return m.localeData().invalidDate();
}
format = expandFormat(format, m.localeData());
formatFunctions[format] =
formatFunctions[format] || makeFormatFunction(format);
return formatFunctions[format](m);
}
function expandFormat(format, locale) {
var i = 5;
function replaceLongDateFormatTokens(input) {
return locale.longDateFormat(input) || input;
}
localFormattingTokens.lastIndex = 0;
while (i >= 0 && localFormattingTokens.test(format)) {
format = format.replace(
localFormattingTokens,
replaceLongDateFormatTokens
);
localFormattingTokens.lastIndex = 0;
i -= 1;
}
return format;
}
var defaultLongDateFormat = {
LTS: 'h:mm:ss A',
LT: 'h:mm A',
L: 'MM/DD/YYYY',
LL: 'MMMM D, YYYY',
LLL: 'MMMM D, YYYY h:mm A',
LLLL: 'dddd, MMMM D, YYYY h:mm A',
};
function longDateFormat(key) {
var format = this._longDateFormat[key],
formatUpper = this._longDateFormat[key.toUpperCase()];
if (format || !formatUpper) {
return format;
}
this._longDateFormat[key] = formatUpper
.match(formattingTokens)
.map(function (tok) {
if (
tok === 'MMMM' ||
tok === 'MM' ||
tok === 'DD' ||
tok === 'dddd'
) {
return tok.slice(1);
}
return tok;
})
.join('');
return this._longDateFormat[key];
}
var defaultInvalidDate = 'Invalid date';
function invalidDate() {
return this._invalidDate;
}
var defaultOrdinal = '%d',
defaultDayOfMonthOrdinalParse = /\d{1,2}/;
function ordinal(number) {
return this._ordinal.replace('%d', number);
}
var defaultRelativeTime = {
future: 'in %s',
past: '%s ago',
s: 'a few seconds',
ss: '%d seconds',
m: 'a minute',
mm: '%d minutes',
h: 'an hour',
hh: '%d hours',
d: 'a day',
dd: '%d days',
w: 'a week',
ww: '%d weeks',
M: 'a month',
MM: '%d months',
y: 'a year',
yy: '%d years',
};
function relativeTime(number, withoutSuffix, string, isFuture) {
var output = this._relativeTime[string];
return isFunction(output)
? output(number, withoutSuffix, string, isFuture)
: output.replace(/%d/i, number);
}
function pastFuture(diff, output) {
var format = this._relativeTime[diff > 0 ? 'future' : 'past'];
return isFunction(format) ? format(output) : format.replace(/%s/i, output);
}
var aliases = {};
function addUnitAlias(unit, shorthand) {
var lowerCase = unit.toLowerCase();
aliases[lowerCase] = aliases[lowerCase + 's'] = aliases[shorthand] = unit;
}
function normalizeUnits(units) {
return typeof units === 'string'
? aliases[units] || aliases[units.toLowerCase()]
: undefined;
}
function normalizeObjectUnits(inputObject) {
var normalizedInput = {},
normalizedProp,
prop;
for (prop in inputObject) {
if (hasOwnProp(inputObject, prop)) {
normalizedProp = normalizeUnits(prop);
if (normalizedProp) {
normalizedInput[normalizedProp] = inputObject[prop];
}
}
}
return normalizedInput;
}
var priorities = {};
function addUnitPriority(unit, priority) {
priorities[unit] = priority;
}
function getPrioritizedUnits(unitsObj) {
var units = [],
u;
for (u in unitsObj) {
if (hasOwnProp(unitsObj, u)) {
units.push({ unit: u, priority: priorities[u] });
}
}
units.sort(function (a, b) {
return a.priority - b.priority;
});
return units;
}
function isLeapYear(year) {
return (year % 4 === 0 && year % 100 !== 0) || year % 400 === 0;
}
function absFloor(number) {
if (number < 0) {
// -0 -> 0
return Math.ceil(number) || 0;
} else {
return Math.floor(number);
}
}
function toInt(argumentForCoercion) {
var coercedNumber = +argumentForCoercion,
value = 0;
if (coercedNumber !== 0 && isFinite(coercedNumber)) {
value = absFloor(coercedNumber);
}
return value;
}
function makeGetSet(unit, keepTime) {
return function (value) {
if (value != null) {
set$1(this, unit, value);
hooks.updateOffset(this, keepTime);
return this;
} else {
return get(this, unit);
}
};
}
function get(mom, unit) {
return mom.isValid()
? mom._d['get' + (mom._isUTC ? 'UTC' : '') + unit]()
: NaN;
}
function set$1(mom, unit, value) {
if (mom.isValid() && !isNaN(value)) {
if (
unit === 'FullYear' &&
isLeapYear(mom.year()) &&
mom.month() === 1 &&
mom.date() === 29
) {
value = toInt(value);
mom._d['set' + (mom._isUTC ? 'UTC' : '') + unit](
value,
mom.month(),
daysInMonth(value, mom.month())
);
} else {
mom._d['set' + (mom._isUTC ? 'UTC' : '') + unit](value);
}
}
}
// MOMENTS
function stringGet(units) {
units = normalizeUnits(units);
if (isFunction(this[units])) {
return this[units]();
}
return this;
}
function stringSet(units, value) {
if (typeof units === 'object') {
units = normalizeObjectUnits(units);
var prioritized = getPrioritizedUnits(units),
i;
for (i = 0; i < prioritized.length; i++) {
this[prioritized[i].unit](units[prioritized[i].unit]);
}
} else {
units = normalizeUnits(units);
if (isFunction(this[units])) {
return this[units](value);
}
}
return this;
}
var match1 = /\d/, // 0 - 9
match2 = /\d\d/, // 00 - 99
match3 = /\d{3}/, // 000 - 999
match4 = /\d{4}/, // 0000 - 9999
match6 = /[+-]?\d{6}/, // -999999 - 999999
match1to2 = /\d\d?/, // 0 - 99
match3to4 = /\d\d\d\d?/, // 999 - 9999
match5to6 = /\d\d\d\d\d\d?/, // 99999 - 999999
match1to3 = /\d{1,3}/, // 0 - 999
match1to4 = /\d{1,4}/, // 0 - 9999
match1to6 = /[+-]?\d{1,6}/, // -999999 - 999999
matchUnsigned = /\d+/, // 0 - inf
matchSigned = /[+-]?\d+/, // -inf - inf
matchOffset = /Z|[+-]\d\d:?\d\d/gi, // +00:00 -00:00 +0000 -0000 or Z
matchShortOffset = /Z|[+-]\d\d(?::?\d\d)?/gi, // +00 -00 +00:00 -00:00 +0000 -0000 or Z
matchTimestamp = /[+-]?\d+(\.\d{1,3})?/, // 123456789 123456789.123
// any word (or two) characters or numbers including two/three word month in arabic.
// includes scottish gaelic two word and hyphenated months
matchWord = /[0-9]{0,256}['a-z\u00A0-\u05FF\u0700-\uD7FF\uF900-\uFDCF\uFDF0-\uFF07\uFF10-\uFFEF]{1,256}|[\u0600-\u06FF\/]{1,256}(\s*?[\u0600-\u06FF]{1,256}){1,2}/i,
regexes;
regexes = {};
function addRegexToken(token, regex, strictRegex) {
regexes[token] = isFunction(regex)
? regex
: function (isStrict, localeData) {
return isStrict && strictRegex ? strictRegex : regex;
};
}
function getParseRegexForToken(token, config) {
if (!hasOwnProp(regexes, token)) {
return new RegExp(unescapeFormat(token));
}
return regexes[token](config._strict, config._locale);
}
// Code from http://stackoverflow.com/questions/3561493/is-there-a-regexp-escape-function-in-javascript
function unescapeFormat(s) {
return regexEscape(
s
.replace('\\', '')
.replace(/\\(\[)|\\(\])|\[([^\]\[]*)\]|\\(.)/g, function (
matched,
p1,
p2,
p3,
p4
) {
return p1 || p2 || p3 || p4;
})
);
}
function regexEscape(s) {
return s.replace(/[-\/\\^$*+?.()|[\]{}]/g, '\\$&');
}
var tokens = {};
function addParseToken(token, callback) {
var i,
func = callback;
if (typeof token === 'string') {
token = [token];
}
if (isNumber(callback)) {
func = function (input, array) {
array[callback] = toInt(input);
};
}
for (i = 0; i < token.length; i++) {
tokens[token[i]] = func;
}
}
function addWeekParseToken(token, callback) {
addParseToken(token, function (input, array, config, token) {
config._w = config._w || {};
callback(input, config._w, config, token);
});
}
function addTimeToArrayFromToken(token, input, config) {
if (input != null && hasOwnProp(tokens, token)) {
tokens[token](input, config._a, config, token);
}
}
var YEAR = 0,
MONTH = 1,
DATE = 2,
HOUR = 3,
MINUTE = 4,
SECOND = 5,
MILLISECOND = 6,
WEEK = 7,
WEEKDAY = 8;
function mod(n, x) {
return ((n % x) + x) % x;
}
var indexOf;
if (Array.prototype.indexOf) {
indexOf = Array.prototype.indexOf;
} else {
indexOf = function (o) {
// I know
var i;
for (i = 0; i < this.length; ++i) {
if (this[i] === o) {
return i;
}
}
return -1;
};
}
function daysInMonth(year, month) {
if (isNaN(year) || isNaN(month)) {
return NaN;
}
var modMonth = mod(month, 12);
year += (month - modMonth) / 12;
return modMonth === 1
? isLeapYear(year)
? 29
: 28
: 31 - ((modMonth % 7) % 2);
}
// FORMATTING
addFormatToken('M', ['MM', 2], 'Mo', function () {
return this.month() + 1;
});
addFormatToken('MMM', 0, 0, function (format) {
return this.localeData().monthsShort(this, format);
});
addFormatToken('MMMM', 0, 0, function (format) {
return this.localeData().months(this, format);
});
// ALIASES
addUnitAlias('month', 'M');
// PRIORITY
addUnitPriority('month', 8);
// PARSING
addRegexToken('M', match1to2);
addRegexToken('MM', match1to2, match2);
addRegexToken('MMM', function (isStrict, locale) {
return locale.monthsShortRegex(isStrict);
});
addRegexToken('MMMM', function (isStrict, locale) {
return locale.monthsRegex(isStrict);
});
addParseToken(['M', 'MM'], function (input, array) {
array[MONTH] = toInt(input) - 1;
});
addParseToken(['MMM', 'MMMM'], function (input, array, config, token) {
var month = config._locale.monthsParse(input, token, config._strict);
// if we didn't find a month name, mark the date as invalid.
if (month != null) {
array[MONTH] = month;
} else {
getParsingFlags(config).invalidMonth = input;
}
});
// LOCALES
var defaultLocaleMonths = 'January_February_March_April_May_June_July_August_September_October_November_December'.split(
'_'
),
defaultLocaleMonthsShort = 'Jan_Feb_Mar_Apr_May_Jun_Jul_Aug_Sep_Oct_Nov_Dec'.split(
'_'
),
MONTHS_IN_FORMAT = /D[oD]?(\[[^\[\]]*\]|\s)+MMMM?/,
defaultMonthsShortRegex = matchWord,
defaultMonthsRegex = matchWord;
function localeMonths(m, format) {
if (!m) {
return isArray(this._months)
? this._months
: this._months['standalone'];
}
return isArray(this._months)
? this._months[m.month()]
: this._months[
(this._months.isFormat || MONTHS_IN_FORMAT).test(format)
? 'format'
: 'standalone'
][m.month()];
}
function localeMonthsShort(m, format) {
if (!m) {
return isArray(this._monthsShort)
? this._monthsShort
: this._monthsShort['standalone'];
}
return isArray(this._monthsShort)
? this._monthsShort[m.month()]
: this._monthsShort[
MONTHS_IN_FORMAT.test(format) ? 'format' : 'standalone'
][m.month()];
}
function handleStrictParse(monthName, format, strict) {
var i,
ii,
mom,
llc = monthName.toLocaleLowerCase();
if (!this._monthsParse) {
// this is not used
this._monthsParse = [];
this._longMonthsParse = [];
this._shortMonthsParse = [];
for (i = 0; i < 12; ++i) {
mom = createUTC([2000, i]);
this._shortMonthsParse[i] = this.monthsShort(
mom,
''
).toLocaleLowerCase();
this._longMonthsParse[i] = this.months(mom, '').toLocaleLowerCase();
}
}
if (strict) {
if (format === 'MMM') {
ii = indexOf.call(this._shortMonthsParse, llc);
return ii !== -1 ? ii : null;
} else {
ii = indexOf.call(this._longMonthsParse, llc);
return ii !== -1 ? ii : null;
}
} else {
if (format === 'MMM') {
ii = indexOf.call(this._shortMonthsParse, llc);
if (ii !== -1) {
return ii;
}
ii = indexOf.call(this._longMonthsParse, llc);
return ii !== -1 ? ii : null;
} else {
ii = indexOf.call(this._longMonthsParse, llc);
if (ii !== -1) {
return ii;
}
ii = indexOf.call(this._shortMonthsParse, llc);
return ii !== -1 ? ii : null;
}
}
}
function localeMonthsParse(monthName, format, strict) {
var i, mom, regex;
if (this._monthsParseExact) {
return handleStrictParse.call(this, monthName, format, strict);
}
if (!this._monthsParse) {
this._monthsParse = [];
this._longMonthsParse = [];
this._shortMonthsParse = [];
}
// TODO: add sorting
// Sorting makes sure if one month (or abbr) is a prefix of another
// see sorting in computeMonthsParse
for (i = 0; i < 12; i++) {
// make the regex if we don't have it already
mom = createUTC([2000, i]);
if (strict && !this._longMonthsParse[i]) {
this._longMonthsParse[i] = new RegExp(
'^' + this.months(mom, '').replace('.', '') + '$',
'i'
);
this._shortMonthsParse[i] = new RegExp(
'^' + this.monthsShort(mom, '').replace('.', '') + '$',
'i'
);
}
if (!strict && !this._monthsParse[i]) {
regex =
'^' + this.months(mom, '') + '|^' + this.monthsShort(mom, '');
this._monthsParse[i] = new RegExp(regex.replace('.', ''), 'i');
}
// test the regex
if (
strict &&
format === 'MMMM' &&
this._longMonthsParse[i].test(monthName)
) {
return i;
} else if (
strict &&
format === 'MMM' &&
this._shortMonthsParse[i].test(monthName)
) {
return i;
} else if (!strict && this._monthsParse[i].test(monthName)) {
return i;
}
}
}
// MOMENTS
function setMonth(mom, value) {
var dayOfMonth;
if (!mom.isValid()) {
// No op
return mom;
}
if (typeof value === 'string') {
if (/^\d+$/.test(value)) {
value = toInt(value);
} else {
value = mom.localeData().monthsParse(value);
// TODO: Another silent failure?
if (!isNumber(value)) {
return mom;
}
}
}
dayOfMonth = Math.min(mom.date(), daysInMonth(mom.year(), value));
mom._d['set' + (mom._isUTC ? 'UTC' : '') + 'Month'](value, dayOfMonth);
return mom;
}
function getSetMonth(value) {
if (value != null) {
setMonth(this, value);
hooks.updateOffset(this, true);
return this;
} else {
return get(this, 'Month');
}
}
function getDaysInMonth() {
return daysInMonth(this.year(), this.month());
}
function monthsShortRegex(isStrict) {
if (this._monthsParseExact) {
if (!hasOwnProp(this, '_monthsRegex')) {
computeMonthsParse.call(this);
}
if (isStrict) {
return this._monthsShortStrictRegex;
} else {
return this._monthsShortRegex;
}
} else {
if (!hasOwnProp(this, '_monthsShortRegex')) {
this._monthsShortRegex = defaultMonthsShortRegex;
}
return this._monthsShortStrictRegex && isStrict
? this._monthsShortStrictRegex
: this._monthsShortRegex;
}
}
function monthsRegex(isStrict) {
if (this._monthsParseExact) {
if (!hasOwnProp(this, '_monthsRegex')) {
computeMonthsParse.call(this);
}
if (isStrict) {
return this._monthsStrictRegex;
} else {
return this._monthsRegex;
}
} else {
if (!hasOwnProp(this, '_monthsRegex')) {
this._monthsRegex = defaultMonthsRegex;
}
return this._monthsStrictRegex && isStrict
? this._monthsStrictRegex
: this._monthsRegex;
}
}
function computeMonthsParse() {
function cmpLenRev(a, b) {
return b.length - a.length;
}
var shortPieces = [],
longPieces = [],
mixedPieces = [],
i,
mom;
for (i = 0; i < 12; i++) {
// make the regex if we don't have it already
mom = createUTC([2000, i]);
shortPieces.push(this.monthsShort(mom, ''));
longPieces.push(this.months(mom, ''));
mixedPieces.push(this.months(mom, ''));
mixedPieces.push(this.monthsShort(mom, ''));
}
// Sorting makes sure if one month (or abbr) is a prefix of another it
// will match the longer piece.
shortPieces.sort(cmpLenRev);
longPieces.sort(cmpLenRev);
mixedPieces.sort(cmpLenRev);
for (i = 0; i < 12; i++) {
shortPieces[i] = regexEscape(shortPieces[i]);
longPieces[i] = regexEscape(longPieces[i]);
}
for (i = 0; i < 24; i++) {
mixedPieces[i] = regexEscape(mixedPieces[i]);
}
this._monthsRegex = new RegExp('^(' + mixedPieces.join('|') + ')', 'i');
this._monthsShortRegex = this._monthsRegex;
this._monthsStrictRegex = new RegExp(
'^(' + longPieces.join('|') + ')',
'i'
);
this._monthsShortStrictRegex = new RegExp(
'^(' + shortPieces.join('|') + ')',
'i'
);
}
// FORMATTING
addFormatToken('Y', 0, 0, function () {
var y = this.year();
return y <= 9999 ? zeroFill(y, 4) : '+' + y;
});
addFormatToken(0, ['YY', 2], 0, function () {
return this.year() % 100;
});
addFormatToken(0, ['YYYY', 4], 0, 'year');
addFormatToken(0, ['YYYYY', 5], 0, 'year');
addFormatToken(0, ['YYYYYY', 6, true], 0, 'year');
// ALIASES
addUnitAlias('year', 'y');
// PRIORITIES
addUnitPriority('year', 1);
// PARSING
addRegexToken('Y', matchSigned);
addRegexToken('YY', match1to2, match2);
addRegexToken('YYYY', match1to4, match4);
addRegexToken('YYYYY', match1to6, match6);
addRegexToken('YYYYYY', match1to6, match6);
addParseToken(['YYYYY', 'YYYYYY'], YEAR);
addParseToken('YYYY', function (input, array) {
array[YEAR] =
input.length === 2 ? hooks.parseTwoDigitYear(input) : toInt(input);
});
addParseToken('YY', function (input, array) {
array[YEAR] = hooks.parseTwoDigitYear(input);
});
addParseToken('Y', function (input, array) {
array[YEAR] = parseInt(input, 10);
});
// HELPERS
function daysInYear(year) {
return isLeapYear(year) ? 366 : 365;
}
// HOOKS
hooks.parseTwoDigitYear = function (input) {
return toInt(input) + (toInt(input) > 68 ? 1900 : 2000);
};
// MOMENTS
var getSetYear = makeGetSet('FullYear', true);
function getIsLeapYear() {
return isLeapYear(this.year());
}
function createDate(y, m, d, h, M, s, ms) {
// can't just apply() to create a date:
// https://stackoverflow.com/q/181348
var date;
// the date constructor remaps years 0-99 to 1900-1999
if (y < 100 && y >= 0) {
// preserve leap years using a full 400 year cycle, then reset
date = new Date(y + 400, m, d, h, M, s, ms);
if (isFinite(date.getFullYear())) {
date.setFullYear(y);
}
} else {
date = new Date(y, m, d, h, M, s, ms);
}
return date;
}
function createUTCDate(y) {
var date, args;
// the Date.UTC function remaps years 0-99 to 1900-1999
if (y < 100 && y >= 0) {
args = Array.prototype.slice.call(arguments);
// preserve leap years using a full 400 year cycle, then reset
args[0] = y + 400;
date = new Date(Date.UTC.apply(null, args));
if (isFinite(date.getUTCFullYear())) {
date.setUTCFullYear(y);
}
} else {
date = new Date(Date.UTC.apply(null, arguments));
}
return date;
}
// start-of-first-week - start-of-year
function firstWeekOffset(year, dow, doy) {
var // first-week day -- which january is always in the first week (4 for iso, 1 for other)
fwd = 7 + dow - doy,
// first-week day local weekday -- which local weekday is fwd
fwdlw = (7 + createUTCDate(year, 0, fwd).getUTCDay() - dow) % 7;
return -fwdlw + fwd - 1;
}
// https://en.wikipedia.org/wiki/ISO_week_date#Calculating_a_date_given_the_year.2C_week_number_and_weekday
function dayOfYearFromWeeks(year, week, weekday, dow, doy) {
var localWeekday = (7 + weekday - dow) % 7,
weekOffset = firstWeekOffset(year, dow, doy),
dayOfYear = 1 + 7 * (week - 1) + localWeekday + weekOffset,
resYear,
resDayOfYear;
if (dayOfYear <= 0) {
resYear = year - 1;
resDayOfYear = daysInYear(resYear) + dayOfYear;
} else if (dayOfYear > daysInYear(year)) {
resYear = year + 1;
resDayOfYear = dayOfYear - daysInYear(year);
} else {
resYear = year;
resDayOfYear = dayOfYear;
}
return {
year: resYear,
dayOfYear: resDayOfYear,
};
}
function weekOfYear(mom, dow, doy) {
var weekOffset = firstWeekOffset(mom.year(), dow, doy),
week = Math.floor((mom.dayOfYear() - weekOffset - 1) / 7) + 1,
resWeek,
resYear;
if (week < 1) {
resYear = mom.year() - 1;
resWeek = week + weeksInYear(resYear, dow, doy);
} else if (week > weeksInYear(mom.year(), dow, doy)) {
resWeek = week - weeksInYear(mom.year(), dow, doy);
resYear = mom.year() + 1;
} else {
resYear = mom.year();
resWeek = week;
}
return {
week: resWeek,
year: resYear,
};
}
function weeksInYear(year, dow, doy) {
var weekOffset = firstWeekOffset(year, dow, doy),
weekOffsetNext = firstWeekOffset(year + 1, dow, doy);
return (daysInYear(year) - weekOffset + weekOffsetNext) / 7;
}
// FORMATTING
addFormatToken('w', ['ww', 2], 'wo', 'week');
addFormatToken('W', ['WW', 2], 'Wo', 'isoWeek');
// ALIASES
addUnitAlias('week', 'w');
addUnitAlias('isoWeek', 'W');
// PRIORITIES
addUnitPriority('week', 5);
addUnitPriority('isoWeek', 5);
// PARSING
addRegexToken('w', match1to2);
addRegexToken('ww', match1to2, match2);
addRegexToken('W', match1to2);
addRegexToken('WW', match1to2, match2);
addWeekParseToken(['w', 'ww', 'W', 'WW'], function (
input,
week,
config,
token
) {
week[token.substr(0, 1)] = toInt(input);
});
// HELPERS
// LOCALES
function localeWeek(mom) {
return weekOfYear(mom, this._week.dow, this._week.doy).week;
}
var defaultLocaleWeek = {
dow: 0, // Sunday is the first day of the week.
doy: 6, // The week that contains Jan 6th is the first week of the year.
};
function localeFirstDayOfWeek() {
return this._week.dow;
}
function localeFirstDayOfYear() {
return this._week.doy;
}
// MOMENTS
function getSetWeek(input) {
var week = this.localeData().week(this);
return input == null ? week : this.add((input - week) * 7, 'd');
}
function getSetISOWeek(input) {
var week = weekOfYear(this, 1, 4).week;
return input == null ? week : this.add((input - week) * 7, 'd');
}
// FORMATTING
addFormatToken('d', 0, 'do', 'day');
addFormatToken('dd', 0, 0, function (format) {
return this.localeData().weekdaysMin(this, format);
});
addFormatToken('ddd', 0, 0, function (format) {
return this.localeData().weekdaysShort(this, format);
});
addFormatToken('dddd', 0, 0, function (format) {
return this.localeData().weekdays(this, format);
});
addFormatToken('e', 0, 0, 'weekday');
addFormatToken('E', 0, 0, 'isoWeekday');
// ALIASES
addUnitAlias('day', 'd');
addUnitAlias('weekday', 'e');
addUnitAlias('isoWeekday', 'E');
// PRIORITY
addUnitPriority('day', 11);
addUnitPriority('weekday', 11);
addUnitPriority('isoWeekday', 11);
// PARSING
addRegexToken('d', match1to2);
addRegexToken('e', match1to2);
addRegexToken('E', match1to2);
addRegexToken('dd', function (isStrict, locale) {
return locale.weekdaysMinRegex(isStrict);
});
addRegexToken('ddd', function (isStrict, locale) {
return locale.weekdaysShortRegex(isStrict);
});
addRegexToken('dddd', function (isStrict, locale) {
return locale.weekdaysRegex(isStrict);
});
addWeekParseToken(['dd', 'ddd', 'dddd'], function (input, week, config, token) {
var weekday = config._locale.weekdaysParse(input, token, config._strict);
// if we didn't get a weekday name, mark the date as invalid
if (weekday != null) {
week.d = weekday;
} else {
getParsingFlags(config).invalidWeekday = input;
}
});
addWeekParseToken(['d', 'e', 'E'], function (input, week, config, token) {
week[token] = toInt(input);
});
// HELPERS
function parseWeekday(input, locale) {
if (typeof input !== 'string') {
return input;
}
if (!isNaN(input)) {
return parseInt(input, 10);
}
input = locale.weekdaysParse(input);
if (typeof input === 'number') {
return input;
}
return null;
}
function parseIsoWeekday(input, locale) {
if (typeof input === 'string') {
return locale.weekdaysParse(input) % 7 || 7;
}
return isNaN(input) ? null : input;
}
// LOCALES
function shiftWeekdays(ws, n) {
return ws.slice(n, 7).concat(ws.slice(0, n));
}
var defaultLocaleWeekdays = 'Sunday_Monday_Tuesday_Wednesday_Thursday_Friday_Saturday'.split(
'_'
),
defaultLocaleWeekdaysShort = 'Sun_Mon_Tue_Wed_Thu_Fri_Sat'.split('_'),
defaultLocaleWeekdaysMin = 'Su_Mo_Tu_We_Th_Fr_Sa'.split('_'),
defaultWeekdaysRegex = matchWord,
defaultWeekdaysShortRegex = matchWord,
defaultWeekdaysMinRegex = matchWord;
function localeWeekdays(m, format) {
var weekdays = isArray(this._weekdays)
? this._weekdays
: this._weekdays[
m && m !== true && this._weekdays.isFormat.test(format)
? 'format'
: 'standalone'
];
return m === true
? shiftWeekdays(weekdays, this._week.dow)
: m
? weekdays[m.day()]
: weekdays;
}
function localeWeekdaysShort(m) {
return m === true
? shiftWeekdays(this._weekdaysShort, this._week.dow)
: m
? this._weekdaysShort[m.day()]
: this._weekdaysShort;
}
function localeWeekdaysMin(m) {
return m === true
? shiftWeekdays(this._weekdaysMin, this._week.dow)
: m
? this._weekdaysMin[m.day()]
: this._weekdaysMin;
}
function handleStrictParse$1(weekdayName, format, strict) {
var i,
ii,
mom,
llc = weekdayName.toLocaleLowerCase();
if (!this._weekdaysParse) {
this._weekdaysParse = [];
this._shortWeekdaysParse = [];
this._minWeekdaysParse = [];
for (i = 0; i < 7; ++i) {
mom = createUTC([2000, 1]).day(i);
this._minWeekdaysParse[i] = this.weekdaysMin(
mom,
''
).toLocaleLowerCase();
this._shortWeekdaysParse[i] = this.weekdaysShort(
mom,
''
).toLocaleLowerCase();
this._weekdaysParse[i] = this.weekdays(mom, '').toLocaleLowerCase();
}
}
if (strict) {
if (format === 'dddd') {
ii = indexOf.call(this._weekdaysParse, llc);
return ii !== -1 ? ii : null;
} else if (format === 'ddd') {
ii = indexOf.call(this._shortWeekdaysParse, llc);
return ii !== -1 ? ii : null;
} else {
ii = indexOf.call(this._minWeekdaysParse, llc);
return ii !== -1 ? ii : null;
}
} else {
if (format === 'dddd') {
ii = indexOf.call(this._weekdaysParse, llc);
if (ii !== -1) {
return ii;
}
ii = indexOf.call(this._shortWeekdaysParse, llc);
if (ii !== -1) {
return ii;
}
ii = indexOf.call(this._minWeekdaysParse, llc);
return ii !== -1 ? ii : null;
} else if (format === 'ddd') {
ii = indexOf.call(this._shortWeekdaysParse, llc);
if (ii !== -1) {
return ii;
}
ii = indexOf.call(this._weekdaysParse, llc);
if (ii !== -1) {
return ii;
}
ii = indexOf.call(this._minWeekdaysParse, llc);
return ii !== -1 ? ii : null;
} else {
ii = indexOf.call(this._minWeekdaysParse, llc);
if (ii !== -1) {
return ii;
}
ii = indexOf.call(this._weekdaysParse, llc);
if (ii !== -1) {
return ii;
}
ii = indexOf.call(this._shortWeekdaysParse, llc);
return ii !== -1 ? ii : null;
}
}
}
function localeWeekdaysParse(weekdayName, format, strict) {
var i, mom, regex;
if (this._weekdaysParseExact) {
return handleStrictParse$1.call(this, weekdayName, format, strict);
}
if (!this._weekdaysParse) {
this._weekdaysParse = [];
this._minWeekdaysParse = [];
this._shortWeekdaysParse = [];
this._fullWeekdaysParse = [];
}
for (i = 0; i < 7; i++) {
// make the regex if we don't have it already
mom = createUTC([2000, 1]).day(i);
if (strict && !this._fullWeekdaysParse[i]) {
this._fullWeekdaysParse[i] = new RegExp(
'^' + this.weekdays(mom, '').replace('.', '\\.?') + '$',
'i'
);
this._shortWeekdaysParse[i] = new RegExp(
'^' + this.weekdaysShort(mom, '').replace('.', '\\.?') + '$',
'i'
);
this._minWeekdaysParse[i] = new RegExp(
'^' + this.weekdaysMin(mom, '').replace('.', '\\.?') + '$',
'i'
);
}
if (!this._weekdaysParse[i]) {
regex =
'^' +
this.weekdays(mom, '') +
'|^' +
this.weekdaysShort(mom, '') +
'|^' +
this.weekdaysMin(mom, '');
this._weekdaysParse[i] = new RegExp(regex.replace('.', ''), 'i');
}
// test the regex
if (
strict &&
format === 'dddd' &&
this._fullWeekdaysParse[i].test(weekdayName)
) {
return i;
} else if (
strict &&
format === 'ddd' &&
this._shortWeekdaysParse[i].test(weekdayName)
) {
return i;
} else if (
strict &&
format === 'dd' &&
this._minWeekdaysParse[i].test(weekdayName)
) {
return i;
} else if (!strict && this._weekdaysParse[i].test(weekdayName)) {
return i;
}
}
}
// MOMENTS
function getSetDayOfWeek(input) {
if (!this.isValid()) {
return input != null ? this : NaN;
}
var day = this._isUTC ? this._d.getUTCDay() : this._d.getDay();
if (input != null) {
input = parseWeekday(input, this.localeData());
return this.add(input - day, 'd');
} else {
return day;
}
}
function getSetLocaleDayOfWeek(input) {
if (!this.isValid()) {
return input != null ? this : NaN;
}
var weekday = (this.day() + 7 - this.localeData()._week.dow) % 7;
return input == null ? weekday : this.add(input - weekday, 'd');
}
function getSetISODayOfWeek(input) {
if (!this.isValid()) {
return input != null ? this : NaN;
}
// behaves the same as moment#day except
// as a getter, returns 7 instead of 0 (1-7 range instead of 0-6)
// as a setter, sunday should belong to the previous week.
if (input != null) {
var weekday = parseIsoWeekday(input, this.localeData());
return this.day(this.day() % 7 ? weekday : weekday - 7);
} else {
return this.day() || 7;
}
}
function weekdaysRegex(isStrict) {
if (this._weekdaysParseExact) {
if (!hasOwnProp(this, '_weekdaysRegex')) {
computeWeekdaysParse.call(this);
}
if (isStrict) {
return this._weekdaysStrictRegex;
} else {
return this._weekdaysRegex;
}
} else {
if (!hasOwnProp(this, '_weekdaysRegex')) {
this._weekdaysRegex = defaultWeekdaysRegex;
}
return this._weekdaysStrictRegex && isStrict
? this._weekdaysStrictRegex
: this._weekdaysRegex;
}
}
function weekdaysShortRegex(isStrict) {
if (this._weekdaysParseExact) {
if (!hasOwnProp(this, '_weekdaysRegex')) {
computeWeekdaysParse.call(this);
}
if (isStrict) {
return this._weekdaysShortStrictRegex;
} else {
return this._weekdaysShortRegex;
}
} else {
if (!hasOwnProp(this, '_weekdaysShortRegex')) {
this._weekdaysShortRegex = defaultWeekdaysShortRegex;
}
return this._weekdaysShortStrictRegex && isStrict
? this._weekdaysShortStrictRegex
: this._weekdaysShortRegex;
}
}
function weekdaysMinRegex(isStrict) {
if (this._weekdaysParseExact) {
if (!hasOwnProp(this, '_weekdaysRegex')) {
computeWeekdaysParse.call(this);
}
if (isStrict) {
return this._weekdaysMinStrictRegex;
} else {
return this._weekdaysMinRegex;
}
} else {
if (!hasOwnProp(this, '_weekdaysMinRegex')) {
this._weekdaysMinRegex = defaultWeekdaysMinRegex;
}
return this._weekdaysMinStrictRegex && isStrict
? this._weekdaysMinStrictRegex
: this._weekdaysMinRegex;
}
}
function computeWeekdaysParse() {
function cmpLenRev(a, b) {
return b.length - a.length;
}
var minPieces = [],
shortPieces = [],
longPieces = [],
mixedPieces = [],
i,
mom,
minp,
shortp,
longp;
for (i = 0; i < 7; i++) {
// make the regex if we don't have it already
mom = createUTC([2000, 1]).day(i);
minp = regexEscape(this.weekdaysMin(mom, ''));
shortp = regexEscape(this.weekdaysShort(mom, ''));
longp = regexEscape(this.weekdays(mom, ''));
minPieces.push(minp);
shortPieces.push(shortp);
longPieces.push(longp);
mixedPieces.push(minp);
mixedPieces.push(shortp);
mixedPieces.push(longp);
}
// Sorting makes sure if one weekday (or abbr) is a prefix of another it
// will match the longer piece.
minPieces.sort(cmpLenRev);
shortPieces.sort(cmpLenRev);
longPieces.sort(cmpLenRev);
mixedPieces.sort(cmpLenRev);
this._weekdaysRegex = new RegExp('^(' + mixedPieces.join('|') + ')', 'i');
this._weekdaysShortRegex = this._weekdaysRegex;
this._weekdaysMinRegex = this._weekdaysRegex;
this._weekdaysStrictRegex = new RegExp(
'^(' + longPieces.join('|') + ')',
'i'
);
this._weekdaysShortStrictRegex = new RegExp(
'^(' + shortPieces.join('|') + ')',
'i'
);
this._weekdaysMinStrictRegex = new RegExp(
'^(' + minPieces.join('|') + ')',
'i'
);
}
// FORMATTING
function hFormat() {
return this.hours() % 12 || 12;
}
function kFormat() {
return this.hours() || 24;
}
addFormatToken('H', ['HH', 2], 0, 'hour');
addFormatToken('h', ['hh', 2], 0, hFormat);
addFormatToken('k', ['kk', 2], 0, kFormat);
addFormatToken('hmm', 0, 0, function () {
return '' + hFormat.apply(this) + zeroFill(this.minutes(), 2);
});
addFormatToken('hmmss', 0, 0, function () {
return (
'' +
hFormat.apply(this) +
zeroFill(this.minutes(), 2) +
zeroFill(this.seconds(), 2)
);
});
addFormatToken('Hmm', 0, 0, function () {
return '' + this.hours() + zeroFill(this.minutes(), 2);
});
addFormatToken('Hmmss', 0, 0, function () {
return (
'' +
this.hours() +
zeroFill(this.minutes(), 2) +
zeroFill(this.seconds(), 2)
);
});
function meridiem(token, lowercase) {
addFormatToken(token, 0, 0, function () {
return this.localeData().meridiem(
this.hours(),
this.minutes(),
lowercase
);
});
}
meridiem('a', true);
meridiem('A', false);
// ALIASES
addUnitAlias('hour', 'h');
// PRIORITY
addUnitPriority('hour', 13);
// PARSING
function matchMeridiem(isStrict, locale) {
return locale._meridiemParse;
}
addRegexToken('a', matchMeridiem);
addRegexToken('A', matchMeridiem);
addRegexToken('H', match1to2);
addRegexToken('h', match1to2);
addRegexToken('k', match1to2);
addRegexToken('HH', match1to2, match2);
addRegexToken('hh', match1to2, match2);
addRegexToken('kk', match1to2, match2);
addRegexToken('hmm', match3to4);
addRegexToken('hmmss', match5to6);
addRegexToken('Hmm', match3to4);
addRegexToken('Hmmss', match5to6);
addParseToken(['H', 'HH'], HOUR);
addParseToken(['k', 'kk'], function (input, array, config) {
var kInput = toInt(input);
array[HOUR] = kInput === 24 ? 0 : kInput;
});
addParseToken(['a', 'A'], function (input, array, config) {
config._isPm = config._locale.isPM(input);
config._meridiem = input;
});
addParseToken(['h', 'hh'], function (input, array, config) {
array[HOUR] = toInt(input);
getParsingFlags(config).bigHour = true;
});
addParseToken('hmm', function (input, array, config) {
var pos = input.length - 2;
array[HOUR] = toInt(input.substr(0, pos));
array[MINUTE] = toInt(input.substr(pos));
getParsingFlags(config).bigHour = true;
});
addParseToken('hmmss', function (input, array, config) {
var pos1 = input.length - 4,
pos2 = input.length - 2;
array[HOUR] = toInt(input.substr(0, pos1));
array[MINUTE] = toInt(input.substr(pos1, 2));
array[SECOND] = toInt(input.substr(pos2));
getParsingFlags(config).bigHour = true;
});
addParseToken('Hmm', function (input, array, config) {
var pos = input.length - 2;
array[HOUR] = toInt(input.substr(0, pos));
array[MINUTE] = toInt(input.substr(pos));
});
addParseToken('Hmmss', function (input, array, config) {
var pos1 = input.length - 4,
pos2 = input.length - 2;
array[HOUR] = toInt(input.substr(0, pos1));
array[MINUTE] = toInt(input.substr(pos1, 2));
array[SECOND] = toInt(input.substr(pos2));
});
// LOCALES
function localeIsPM(input) {
// IE8 Quirks Mode & IE7 Standards Mode do not allow accessing strings like arrays
// Using charAt should be more compatible.
return (input + '').toLowerCase().charAt(0) === 'p';
}
var defaultLocaleMeridiemParse = /[ap]\.?m?\.?/i,
// Setting the hour should keep the time, because the user explicitly
// specified which hour they want. So trying to maintain the same hour (in
// a new timezone) makes sense. Adding/subtracting hours does not follow
// this rule.
getSetHour = makeGetSet('Hours', true);
function localeMeridiem(hours, minutes, isLower) {
if (hours > 11) {
return isLower ? 'pm' : 'PM';
} else {
return isLower ? 'am' : 'AM';
}
}
var baseConfig = {
calendar: defaultCalendar,
longDateFormat: defaultLongDateFormat,
invalidDate: defaultInvalidDate,
ordinal: defaultOrdinal,
dayOfMonthOrdinalParse: defaultDayOfMonthOrdinalParse,
relativeTime: defaultRelativeTime,
months: defaultLocaleMonths,
monthsShort: defaultLocaleMonthsShort,
week: defaultLocaleWeek,
weekdays: defaultLocaleWeekdays,
weekdaysMin: defaultLocaleWeekdaysMin,
weekdaysShort: defaultLocaleWeekdaysShort,
meridiemParse: defaultLocaleMeridiemParse,
};
// internal storage for locale config files
var locales = {},
localeFamilies = {},
globalLocale;
function commonPrefix(arr1, arr2) {
var i,
minl = Math.min(arr1.length, arr2.length);
for (i = 0; i < minl; i += 1) {
if (arr1[i] !== arr2[i]) {
return i;
}
}
return minl;
}
function normalizeLocale(key) {
return key ? key.toLowerCase().replace('_', '-') : key;
}
// pick the locale from the array
// try ['en-au', 'en-gb'] as 'en-au', 'en-gb', 'en', as in move through the list trying each
// substring from most specific to least, but move to the next array item if it's a more specific variant than the current root
function chooseLocale(names) {
var i = 0,
j,
next,
locale,
split;
while (i < names.length) {
split = normalizeLocale(names[i]).split('-');
j = split.length;
next = normalizeLocale(names[i + 1]);
next = next ? next.split('-') : null;
while (j > 0) {
locale = loadLocale(split.slice(0, j).join('-'));
if (locale) {
return locale;
}
if (
next &&
next.length >= j &&
commonPrefix(split, next) >= j - 1
) {
//the next array item is better than a shallower substring of this one
break;
}
j--;
}
i++;
}
return globalLocale;
}
function loadLocale(name) {
var oldLocale = null,
aliasedRequire;
// TODO: Find a better way to register and load all the locales in Node
if (
locales[name] === undefined &&
typeof module !== 'undefined' &&
module &&
module.exports
) {
try {
oldLocale = globalLocale._abbr;
aliasedRequire = require;
aliasedRequire('./locale/' + name);
getSetGlobalLocale(oldLocale);
} catch (e) {
// mark as not found to avoid repeating expensive file require call causing high CPU
// when trying to find en-US, en_US, en-us for every format call
locales[name] = null; // null means not found
}
}
return locales[name];
}
// This function will load locale and then set the global locale. If
// no arguments are passed in, it will simply return the current global
// locale key.
function getSetGlobalLocale(key, values) {
var data;
if (key) {
if (isUndefined(values)) {
data = getLocale(key);
} else {
data = defineLocale(key, values);
}
if (data) {
// moment.duration._locale = moment._locale = data;
globalLocale = data;
} else {
if (typeof console !== 'undefined' && console.warn) {
//warn user if arguments are passed but the locale could not be set
console.warn(
'Locale ' + key + ' not found. Did you forget to load it?'
);
}
}
}
return globalLocale._abbr;
}
function defineLocale(name, config) {
if (config !== null) {
var locale,
parentConfig = baseConfig;
config.abbr = name;
if (locales[name] != null) {
deprecateSimple(
'defineLocaleOverride',
'use moment.updateLocale(localeName, config) to change ' +
'an existing locale. moment.defineLocale(localeName, ' +
'config) should only be used for creating a new locale ' +
'See http://momentjs.com/guides/#/warnings/define-locale/ for more info.'
);
parentConfig = locales[name]._config;
} else if (config.parentLocale != null) {
if (locales[config.parentLocale] != null) {
parentConfig = locales[config.parentLocale]._config;
} else {
locale = loadLocale(config.parentLocale);
if (locale != null) {
parentConfig = locale._config;
} else {
if (!localeFamilies[config.parentLocale]) {
localeFamilies[config.parentLocale] = [];
}
localeFamilies[config.parentLocale].push({
name: name,
config: config,
});
return null;
}
}
}
locales[name] = new Locale(mergeConfigs(parentConfig, config));
if (localeFamilies[name]) {
localeFamilies[name].forEach(function (x) {
defineLocale(x.name, x.config);
});
}
// backwards compat for now: also set the locale
// make sure we set the locale AFTER all child locales have been
// created, so we won't end up with the child locale set.
getSetGlobalLocale(name);
return locales[name];
} else {
// useful for testing
delete locales[name];
return null;
}
}
function updateLocale(name, config) {
if (config != null) {
var locale,
tmpLocale,
parentConfig = baseConfig;
if (locales[name] != null && locales[name].parentLocale != null) {
// Update existing child locale in-place to avoid memory-leaks
locales[name].set(mergeConfigs(locales[name]._config, config));
} else {
// MERGE
tmpLocale = loadLocale(name);
if (tmpLocale != null) {
parentConfig = tmpLocale._config;
}
config = mergeConfigs(parentConfig, config);
if (tmpLocale == null) {
// updateLocale is called for creating a new locale
// Set abbr so it will have a name (getters return
// undefined otherwise).
config.abbr = name;
}
locale = new Locale(config);
locale.parentLocale = locales[name];
locales[name] = locale;
}
// backwards compat for now: also set the locale
getSetGlobalLocale(name);
} else {
// pass null for config to unupdate, useful for tests
if (locales[name] != null) {
if (locales[name].parentLocale != null) {
locales[name] = locales[name].parentLocale;
if (name === getSetGlobalLocale()) {
getSetGlobalLocale(name);
}
} else if (locales[name] != null) {
delete locales[name];
}
}
}
return locales[name];
}
// returns locale data
function getLocale(key) {
var locale;
if (key && key._locale && key._locale._abbr) {
key = key._locale._abbr;
}
if (!key) {
return globalLocale;
}
if (!isArray(key)) {
//short-circuit everything else
locale = loadLocale(key);
if (locale) {
return locale;
}
key = [key];
}
return chooseLocale(key);
}
function listLocales() {
return keys(locales);
}
function checkOverflow(m) {
var overflow,
a = m._a;
if (a && getParsingFlags(m).overflow === -2) {
overflow =
a[MONTH] < 0 || a[MONTH] > 11
? MONTH
: a[DATE] < 1 || a[DATE] > daysInMonth(a[YEAR], a[MONTH])
? DATE
: a[HOUR] < 0 ||
a[HOUR] > 24 ||
(a[HOUR] === 24 &&
(a[MINUTE] !== 0 ||
a[SECOND] !== 0 ||
a[MILLISECOND] !== 0))
? HOUR
: a[MINUTE] < 0 || a[MINUTE] > 59
? MINUTE
: a[SECOND] < 0 || a[SECOND] > 59
? SECOND
: a[MILLISECOND] < 0 || a[MILLISECOND] > 999
? MILLISECOND
: -1;
if (
getParsingFlags(m)._overflowDayOfYear &&
(overflow < YEAR || overflow > DATE)
) {
overflow = DATE;
}
if (getParsingFlags(m)._overflowWeeks && overflow === -1) {
overflow = WEEK;
}
if (getParsingFlags(m)._overflowWeekday && overflow === -1) {
overflow = WEEKDAY;
}
getParsingFlags(m).overflow = overflow;
}
return m;
}
// iso 8601 regex
// 0000-00-00 0000-W00 or 0000-W00-0 + T + 00 or 00:00 or 00:00:00 or 00:00:00.000 + +00:00 or +0000 or +00)
var extendedIsoRegex = /^\s*((?:[+-]\d{6}|\d{4})-(?:\d\d-\d\d|W\d\d-\d|W\d\d|\d\d\d|\d\d))(?:(T| )(\d\d(?::\d\d(?::\d\d(?:[.,]\d+)?)?)?)([+-]\d\d(?::?\d\d)?|\s*Z)?)?$/,
basicIsoRegex = /^\s*((?:[+-]\d{6}|\d{4})(?:\d\d\d\d|W\d\d\d|W\d\d|\d\d\d|\d\d|))(?:(T| )(\d\d(?:\d\d(?:\d\d(?:[.,]\d+)?)?)?)([+-]\d\d(?::?\d\d)?|\s*Z)?)?$/,
tzRegex = /Z|[+-]\d\d(?::?\d\d)?/,
isoDates = [
['YYYYYY-MM-DD', /[+-]\d{6}-\d\d-\d\d/],
['YYYY-MM-DD', /\d{4}-\d\d-\d\d/],
['GGGG-[W]WW-E', /\d{4}-W\d\d-\d/],
['GGGG-[W]WW', /\d{4}-W\d\d/, false],
['YYYY-DDD', /\d{4}-\d{3}/],
['YYYY-MM', /\d{4}-\d\d/, false],
['YYYYYYMMDD', /[+-]\d{10}/],
['YYYYMMDD', /\d{8}/],
['GGGG[W]WWE', /\d{4}W\d{3}/],
['GGGG[W]WW', /\d{4}W\d{2}/, false],
['YYYYDDD', /\d{7}/],
['YYYYMM', /\d{6}/, false],
['YYYY', /\d{4}/, false],
],
// iso time formats and regexes
isoTimes = [
['HH:mm:ss.SSSS', /\d\d:\d\d:\d\d\.\d+/],
['HH:mm:ss,SSSS', /\d\d:\d\d:\d\d,\d+/],
['HH:mm:ss', /\d\d:\d\d:\d\d/],
['HH:mm', /\d\d:\d\d/],
['HHmmss.SSSS', /\d\d\d\d\d\d\.\d+/],
['HHmmss,SSSS', /\d\d\d\d\d\d,\d+/],
['HHmmss', /\d\d\d\d\d\d/],
['HHmm', /\d\d\d\d/],
['HH', /\d\d/],
],
aspNetJsonRegex = /^\/?Date\((-?\d+)/i,
// RFC 2822 regex: For details see https://tools.ietf.org/html/rfc2822#section-3.3
rfc2822 = /^(?:(Mon|Tue|Wed|Thu|Fri|Sat|Sun),?\s)?(\d{1,2})\s(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)\s(\d{2,4})\s(\d\d):(\d\d)(?::(\d\d))?\s(?:(UT|GMT|[ECMP][SD]T)|([Zz])|([+-]\d{4}))$/,
obsOffsets = {
UT: 0,
GMT: 0,
EDT: -4 * 60,
EST: -5 * 60,
CDT: -5 * 60,
CST: -6 * 60,
MDT: -6 * 60,
MST: -7 * 60,
PDT: -7 * 60,
PST: -8 * 60,
};
// date from iso format
function configFromISO(config) {
var i,
l,
string = config._i,
match = extendedIsoRegex.exec(string) || basicIsoRegex.exec(string),
allowTime,
dateFormat,
timeFormat,
tzFormat;
if (match) {
getParsingFlags(config).iso = true;
for (i = 0, l = isoDates.length; i < l; i++) {
if (isoDates[i][1].exec(match[1])) {
dateFormat = isoDates[i][0];
allowTime = isoDates[i][2] !== false;
break;
}
}
if (dateFormat == null) {
config._isValid = false;
return;
}
if (match[3]) {
for (i = 0, l = isoTimes.length; i < l; i++) {
if (isoTimes[i][1].exec(match[3])) {
// match[2] should be 'T' or space
timeFormat = (match[2] || ' ') + isoTimes[i][0];
break;
}
}
if (timeFormat == null) {
config._isValid = false;
return;
}
}
if (!allowTime && timeFormat != null) {
config._isValid = false;
return;
}
if (match[4]) {
if (tzRegex.exec(match[4])) {
tzFormat = 'Z';
} else {
config._isValid = false;
return;
}
}
config._f = dateFormat + (timeFormat || '') + (tzFormat || '');
configFromStringAndFormat(config);
} else {
config._isValid = false;
}
}
function extractFromRFC2822Strings(
yearStr,
monthStr,
dayStr,
hourStr,
minuteStr,
secondStr
) {
var result = [
untruncateYear(yearStr),
defaultLocaleMonthsShort.indexOf(monthStr),
parseInt(dayStr, 10),
parseInt(hourStr, 10),
parseInt(minuteStr, 10),
];
if (secondStr) {
result.push(parseInt(secondStr, 10));
}
return result;
}
function untruncateYear(yearStr) {
var year = parseInt(yearStr, 10);
if (year <= 49) {
return 2000 + year;
} else if (year <= 999) {
return 1900 + year;
}
return year;
}
function preprocessRFC2822(s) {
// Remove comments and folding whitespace and replace multiple-spaces with a single space
return s
.replace(/\([^)]*\)|[\n\t]/g, ' ')
.replace(/(\s\s+)/g, ' ')
.replace(/^\s\s*/, '')
.replace(/\s\s*$/, '');
}
function checkWeekday(weekdayStr, parsedInput, config) {
if (weekdayStr) {
// TODO: Replace the vanilla JS Date object with an independent day-of-week check.
var weekdayProvided = defaultLocaleWeekdaysShort.indexOf(weekdayStr),
weekdayActual = new Date(
parsedInput[0],
parsedInput[1],
parsedInput[2]
).getDay();
if (weekdayProvided !== weekdayActual) {
getParsingFlags(config).weekdayMismatch = true;
config._isValid = false;
return false;
}
}
return true;
}
function calculateOffset(obsOffset, militaryOffset, numOffset) {
if (obsOffset) {
return obsOffsets[obsOffset];
} else if (militaryOffset) {
// the only allowed military tz is Z
return 0;
} else {
var hm = parseInt(numOffset, 10),
m = hm % 100,
h = (hm - m) / 100;
return h * 60 + m;
}
}
// date and time from ref 2822 format
function configFromRFC2822(config) {
var match = rfc2822.exec(preprocessRFC2822(config._i)),
parsedArray;
if (match) {
parsedArray = extractFromRFC2822Strings(
match[4],
match[3],
match[2],
match[5],
match[6],
match[7]
);
if (!checkWeekday(match[1], parsedArray, config)) {
return;
}
config._a = parsedArray;
config._tzm = calculateOffset(match[8], match[9], match[10]);
config._d = createUTCDate.apply(null, config._a);
config._d.setUTCMinutes(config._d.getUTCMinutes() - config._tzm);
getParsingFlags(config).rfc2822 = true;
} else {
config._isValid = false;
}
}
// date from 1) ASP.NET, 2) ISO, 3) RFC 2822 formats, or 4) optional fallback if parsing isn't strict
function configFromString(config) {
var matched = aspNetJsonRegex.exec(config._i);
if (matched !== null) {
config._d = new Date(+matched[1]);
return;
}
configFromISO(config);
if (config._isValid === false) {
delete config._isValid;
} else {
return;
}
configFromRFC2822(config);
if (config._isValid === false) {
delete config._isValid;
} else {
return;
}
if (config._strict) {
config._isValid = false;
} else {
// Final attempt, use Input Fallback
hooks.createFromInputFallback(config);
}
}
hooks.createFromInputFallback = deprecate(
'value provided is not in a recognized RFC2822 or ISO format. moment construction falls back to js Date(), ' +
'which is not reliable across all browsers and versions. Non RFC2822/ISO date formats are ' +
'discouraged. Please refer to http://momentjs.com/guides/#/warnings/js-date/ for more info.',
function (config) {
config._d = new Date(config._i + (config._useUTC ? ' UTC' : ''));
}
);
// Pick the first defined of two or three arguments.
function defaults(a, b, c) {
if (a != null) {
return a;
}
if (b != null) {
return b;
}
return c;
}
function currentDateArray(config) {
// hooks is actually the exported moment object
var nowValue = new Date(hooks.now());
if (config._useUTC) {
return [
nowValue.getUTCFullYear(),
nowValue.getUTCMonth(),
nowValue.getUTCDate(),
];
}
return [nowValue.getFullYear(), nowValue.getMonth(), nowValue.getDate()];
}
// convert an array to a date.
// the array should mirror the parameters below
// note: all values past the year are optional and will default to the lowest possible value.
// [year, month, day , hour, minute, second, millisecond]
function configFromArray(config) {
var i,
date,
input = [],
currentDate,
expectedWeekday,
yearToUse;
if (config._d) {
return;
}
currentDate = currentDateArray(config);
//compute day of the year from weeks and weekdays
if (config._w && config._a[DATE] == null && config._a[MONTH] == null) {
dayOfYearFromWeekInfo(config);
}
//if the day of the year is set, figure out what it is
if (config._dayOfYear != null) {
yearToUse = defaults(config._a[YEAR], currentDate[YEAR]);
if (
config._dayOfYear > daysInYear(yearToUse) ||
config._dayOfYear === 0
) {
getParsingFlags(config)._overflowDayOfYear = true;
}
date = createUTCDate(yearToUse, 0, config._dayOfYear);
config._a[MONTH] = date.getUTCMonth();
config._a[DATE] = date.getUTCDate();
}
// Default to current date.
// * if no year, month, day of month are given, default to today
// * if day of month is given, default month and year
// * if month is given, default only year
// * if year is given, don't default anything
for (i = 0; i < 3 && config._a[i] == null; ++i) {
config._a[i] = input[i] = currentDate[i];
}
// Zero out whatever was not defaulted, including time
for (; i < 7; i++) {
config._a[i] = input[i] =
config._a[i] == null ? (i === 2 ? 1 : 0) : config._a[i];
}
// Check for 24:00:00.000
if (
config._a[HOUR] === 24 &&
config._a[MINUTE] === 0 &&
config._a[SECOND] === 0 &&
config._a[MILLISECOND] === 0
) {
config._nextDay = true;
config._a[HOUR] = 0;
}
config._d = (config._useUTC ? createUTCDate : createDate).apply(
null,
input
);
expectedWeekday = config._useUTC
? config._d.getUTCDay()
: config._d.getDay();
// Apply timezone offset from input. The actual utcOffset can be changed
// with parseZone.
if (config._tzm != null) {
config._d.setUTCMinutes(config._d.getUTCMinutes() - config._tzm);
}
if (config._nextDay) {
config._a[HOUR] = 24;
}
// check for mismatching day of week
if (
config._w &&
typeof config._w.d !== 'undefined' &&
config._w.d !== expectedWeekday
) {
getParsingFlags(config).weekdayMismatch = true;
}
}
function dayOfYearFromWeekInfo(config) {
var w, weekYear, week, weekday, dow, doy, temp, weekdayOverflow, curWeek;
w = config._w;
if (w.GG != null || w.W != null || w.E != null) {
dow = 1;
doy = 4;
// TODO: We need to take the current isoWeekYear, but that depends on
// how we interpret now (local, utc, fixed offset). So create
// a now version of current config (take local/utc/offset flags, and
// create now).
weekYear = defaults(
w.GG,
config._a[YEAR],
weekOfYear(createLocal(), 1, 4).year
);
week = defaults(w.W, 1);
weekday = defaults(w.E, 1);
if (weekday < 1 || weekday > 7) {
weekdayOverflow = true;
}
} else {
dow = config._locale._week.dow;
doy = config._locale._week.doy;
curWeek = weekOfYear(createLocal(), dow, doy);
weekYear = defaults(w.gg, config._a[YEAR], curWeek.year);
// Default to current week.
week = defaults(w.w, curWeek.week);
if (w.d != null) {
// weekday -- low day numbers are considered next week
weekday = w.d;
if (weekday < 0 || weekday > 6) {
weekdayOverflow = true;
}
} else if (w.e != null) {
// local weekday -- counting starts from beginning of week
weekday = w.e + dow;
if (w.e < 0 || w.e > 6) {
weekdayOverflow = true;
}
} else {
// default to beginning of week
weekday = dow;
}
}
if (week < 1 || week > weeksInYear(weekYear, dow, doy)) {
getParsingFlags(config)._overflowWeeks = true;
} else if (weekdayOverflow != null) {
getParsingFlags(config)._overflowWeekday = true;
} else {
temp = dayOfYearFromWeeks(weekYear, week, weekday, dow, doy);
config._a[YEAR] = temp.year;
config._dayOfYear = temp.dayOfYear;
}
}
// constant that refers to the ISO standard
hooks.ISO_8601 = function () {};
// constant that refers to the RFC 2822 form
hooks.RFC_2822 = function () {};
// date from string and format string
function configFromStringAndFormat(config) {
// TODO: Move this to another part of the creation flow to prevent circular deps
if (config._f === hooks.ISO_8601) {
configFromISO(config);
return;
}
if (config._f === hooks.RFC_2822) {
configFromRFC2822(config);
return;
}
config._a = [];
getParsingFlags(config).empty = true;
// This array is used to make a Date, either with `new Date` or `Date.UTC`
var string = '' + config._i,
i,
parsedInput,
tokens,
token,
skipped,
stringLength = string.length,
totalParsedInputLength = 0,
era;
tokens =
expandFormat(config._f, config._locale).match(formattingTokens) || [];
for (i = 0; i < tokens.length; i++) {
token = tokens[i];
parsedInput = (string.match(getParseRegexForToken(token, config)) ||
[])[0];
if (parsedInput) {
skipped = string.substr(0, string.indexOf(parsedInput));
if (skipped.length > 0) {
getParsingFlags(config).unusedInput.push(skipped);
}
string = string.slice(
string.indexOf(parsedInput) + parsedInput.length
);
totalParsedInputLength += parsedInput.length;
}
// don't parse if it's not a known token
if (formatTokenFunctions[token]) {
if (parsedInput) {
getParsingFlags(config).empty = false;
} else {
getParsingFlags(config).unusedTokens.push(token);
}
addTimeToArrayFromToken(token, parsedInput, config);
} else if (config._strict && !parsedInput) {
getParsingFlags(config).unusedTokens.push(token);
}
}
// add remaining unparsed input length to the string
getParsingFlags(config).charsLeftOver =
stringLength - totalParsedInputLength;
if (string.length > 0) {
getParsingFlags(config).unusedInput.push(string);
}
// clear _12h flag if hour is <= 12
if (
config._a[HOUR] <= 12 &&
getParsingFlags(config).bigHour === true &&
config._a[HOUR] > 0
) {
getParsingFlags(config).bigHour = undefined;
}
getParsingFlags(config).parsedDateParts = config._a.slice(0);
getParsingFlags(config).meridiem = config._meridiem;
// handle meridiem
config._a[HOUR] = meridiemFixWrap(
config._locale,
config._a[HOUR],
config._meridiem
);
// handle era
era = getParsingFlags(config).era;
if (era !== null) {
config._a[YEAR] = config._locale.erasConvertYear(era, config._a[YEAR]);
}
configFromArray(config);
checkOverflow(config);
}
function meridiemFixWrap(locale, hour, meridiem) {
var isPm;
if (meridiem == null) {
// nothing to do
return hour;
}
if (locale.meridiemHour != null) {
return locale.meridiemHour(hour, meridiem);
} else if (locale.isPM != null) {
// Fallback
isPm = locale.isPM(meridiem);
if (isPm && hour < 12) {
hour += 12;
}
if (!isPm && hour === 12) {
hour = 0;
}
return hour;
} else {
// this is not supposed to happen
return hour;
}
}
// date from string and array of format strings
function configFromStringAndArray(config) {
var tempConfig,
bestMoment,
scoreToBeat,
i,
currentScore,
validFormatFound,
bestFormatIsValid = false;
if (config._f.length === 0) {
getParsingFlags(config).invalidFormat = true;
config._d = new Date(NaN);
return;
}
for (i = 0; i < config._f.length; i++) {
currentScore = 0;
validFormatFound = false;
tempConfig = copyConfig({}, config);
if (config._useUTC != null) {
tempConfig._useUTC = config._useUTC;
}
tempConfig._f = config._f[i];
configFromStringAndFormat(tempConfig);
if (isValid(tempConfig)) {
validFormatFound = true;
}
// if there is any input that was not parsed add a penalty for that format
currentScore += getParsingFlags(tempConfig).charsLeftOver;
//or tokens
currentScore += getParsingFlags(tempConfig).unusedTokens.length * 10;
getParsingFlags(tempConfig).score = currentScore;
if (!bestFormatIsValid) {
if (
scoreToBeat == null ||
currentScore < scoreToBeat ||
validFormatFound
) {
scoreToBeat = currentScore;
bestMoment = tempConfig;
if (validFormatFound) {
bestFormatIsValid = true;
}
}
} else {
if (currentScore < scoreToBeat) {
scoreToBeat = currentScore;
bestMoment = tempConfig;
}
}
}
extend(config, bestMoment || tempConfig);
}
function configFromObject(config) {
if (config._d) {
return;
}
var i = normalizeObjectUnits(config._i),
dayOrDate = i.day === undefined ? i.date : i.day;
config._a = map(
[i.year, i.month, dayOrDate, i.hour, i.minute, i.second, i.millisecond],
function (obj) {
return obj && parseInt(obj, 10);
}
);
configFromArray(config);
}
function createFromConfig(config) {
var res = new Moment(checkOverflow(prepareConfig(config)));
if (res._nextDay) {
// Adding is smart enough around DST
res.add(1, 'd');
res._nextDay = undefined;
}
return res;
}
function prepareConfig(config) {
var input = config._i,
format = config._f;
config._locale = config._locale || getLocale(config._l);
if (input === null || (format === undefined && input === '')) {
return createInvalid({ nullInput: true });
}
if (typeof input === 'string') {
config._i = input = config._locale.preparse(input);
}
if (isMoment(input)) {
return new Moment(checkOverflow(input));
} else if (isDate(input)) {
config._d = input;
} else if (isArray(format)) {
configFromStringAndArray(config);
} else if (format) {
configFromStringAndFormat(config);
} else {
configFromInput(config);
}
if (!isValid(config)) {
config._d = null;
}
return config;
}
function configFromInput(config) {
var input = config._i;
if (isUndefined(input)) {
config._d = new Date(hooks.now());
} else if (isDate(input)) {
config._d = new Date(input.valueOf());
} else if (typeof input === 'string') {
configFromString(config);
} else if (isArray(input)) {
config._a = map(input.slice(0), function (obj) {
return parseInt(obj, 10);
});
configFromArray(config);
} else if (isObject(input)) {
configFromObject(config);
} else if (isNumber(input)) {
// from milliseconds
config._d = new Date(input);
} else {
hooks.createFromInputFallback(config);
}
}
function createLocalOrUTC(input, format, locale, strict, isUTC) {
var c = {};
if (format === true || format === false) {
strict = format;
format = undefined;
}
if (locale === true || locale === false) {
strict = locale;
locale = undefined;
}
if (
(isObject(input) && isObjectEmpty(input)) ||
(isArray(input) && input.length === 0)
) {
input = undefined;
}
// object construction must be done this way.
// https://github.com/moment/moment/issues/1423
c._isAMomentObject = true;
c._useUTC = c._isUTC = isUTC;
c._l = locale;
c._i = input;
c._f = format;
c._strict = strict;
return createFromConfig(c);
}
function createLocal(input, format, locale, strict) {
return createLocalOrUTC(input, format, locale, strict, false);
}
var prototypeMin = deprecate(
'moment().min is deprecated, use moment.max instead. http://momentjs.com/guides/#/warnings/min-max/',
function () {
var other = createLocal.apply(null, arguments);
if (this.isValid() && other.isValid()) {
return other < this ? this : other;
} else {
return createInvalid();
}
}
),
prototypeMax = deprecate(
'moment().max is deprecated, use moment.min instead. http://momentjs.com/guides/#/warnings/min-max/',
function () {
var other = createLocal.apply(null, arguments);
if (this.isValid() && other.isValid()) {
return other > this ? this : other;
} else {
return createInvalid();
}
}
);
// Pick a moment m from moments so that m[fn](other) is true for all
// other. This relies on the function fn to be transitive.
//
// moments should either be an array of moment objects or an array, whose
// first element is an array of moment objects.
function pickBy(fn, moments) {
var res, i;
if (moments.length === 1 && isArray(moments[0])) {
moments = moments[0];
}
if (!moments.length) {
return createLocal();
}
res = moments[0];
for (i = 1; i < moments.length; ++i) {
if (!moments[i].isValid() || moments[i][fn](res)) {
res = moments[i];
}
}
return res;
}
// TODO: Use [].sort instead?
function min() {
var args = [].slice.call(arguments, 0);
return pickBy('isBefore', args);
}
function max() {
var args = [].slice.call(arguments, 0);
return pickBy('isAfter', args);
}
var now = function () {
return Date.now ? Date.now() : +new Date();
};
var ordering = [
'year',
'quarter',
'month',
'week',
'day',
'hour',
'minute',
'second',
'millisecond',
];
function isDurationValid(m) {
var key,
unitHasDecimal = false,
i;
for (key in m) {
if (
hasOwnProp(m, key) &&
!(
indexOf.call(ordering, key) !== -1 &&
(m[key] == null || !isNaN(m[key]))
)
) {
return false;
}
}
for (i = 0; i < ordering.length; ++i) {
if (m[ordering[i]]) {
if (unitHasDecimal) {
return false; // only allow non-integers for smallest unit
}
if (parseFloat(m[ordering[i]]) !== toInt(m[ordering[i]])) {
unitHasDecimal = true;
}
}
}
return true;
}
function isValid$1() {
return this._isValid;
}
function createInvalid$1() {
return createDuration(NaN);
}
function Duration(duration) {
var normalizedInput = normalizeObjectUnits(duration),
years = normalizedInput.year || 0,
quarters = normalizedInput.quarter || 0,
months = normalizedInput.month || 0,
weeks = normalizedInput.week || normalizedInput.isoWeek || 0,
days = normalizedInput.day || 0,
hours = normalizedInput.hour || 0,
minutes = normalizedInput.minute || 0,
seconds = normalizedInput.second || 0,
milliseconds = normalizedInput.millisecond || 0;
this._isValid = isDurationValid(normalizedInput);
// representation for dateAddRemove
this._milliseconds =
+milliseconds +
seconds * 1e3 + // 1000
minutes * 6e4 + // 1000 * 60
hours * 1000 * 60 * 60; //using 1000 * 60 * 60 instead of 36e5 to avoid floating point rounding errors https://github.com/moment/moment/issues/2978
// Because of dateAddRemove treats 24 hours as different from a
// day when working around DST, we need to store them separately
this._days = +days + weeks * 7;
// It is impossible to translate months into days without knowing
// which months you are are talking about, so we have to store
// it separately.
this._months = +months + quarters * 3 + years * 12;
this._data = {};
this._locale = getLocale();
this._bubble();
}
function isDuration(obj) {
return obj instanceof Duration;
}
function absRound(number) {
if (number < 0) {
return Math.round(-1 * number) * -1;
} else {
return Math.round(number);
}
}
// compare two arrays, return the number of differences
function compareArrays(array1, array2, dontConvert) {
var len = Math.min(array1.length, array2.length),
lengthDiff = Math.abs(array1.length - array2.length),
diffs = 0,
i;
for (i = 0; i < len; i++) {
if (
(dontConvert && array1[i] !== array2[i]) ||
(!dontConvert && toInt(array1[i]) !== toInt(array2[i]))
) {
diffs++;
}
}
return diffs + lengthDiff;
}
// FORMATTING
function offset(token, separator) {
addFormatToken(token, 0, 0, function () {
var offset = this.utcOffset(),
sign = '+';
if (offset < 0) {
offset = -offset;
sign = '-';
}
return (
sign +
zeroFill(~~(offset / 60), 2) +
separator +
zeroFill(~~offset % 60, 2)
);
});
}
offset('Z', ':');
offset('ZZ', '');
// PARSING
addRegexToken('Z', matchShortOffset);
addRegexToken('ZZ', matchShortOffset);
addParseToken(['Z', 'ZZ'], function (input, array, config) {
config._useUTC = true;
config._tzm = offsetFromString(matchShortOffset, input);
});
// HELPERS
// timezone chunker
// '+10:00' > ['10', '00']
// '-1530' > ['-15', '30']
var chunkOffset = /([\+\-]|\d\d)/gi;
function offsetFromString(matcher, string) {
var matches = (string || '').match(matcher),
chunk,
parts,
minutes;
if (matches === null) {
return null;
}
chunk = matches[matches.length - 1] || [];
parts = (chunk + '').match(chunkOffset) || ['-', 0, 0];
minutes = +(parts[1] * 60) + toInt(parts[2]);
return minutes === 0 ? 0 : parts[0] === '+' ? minutes : -minutes;
}
// Return a moment from input, that is local/utc/zone equivalent to model.
function cloneWithOffset(input, model) {
var res, diff;
if (model._isUTC) {
res = model.clone();
diff =
(isMoment(input) || isDate(input)
? input.valueOf()
: createLocal(input).valueOf()) - res.valueOf();
// Use low-level api, because this fn is low-level api.
res._d.setTime(res._d.valueOf() + diff);
hooks.updateOffset(res, false);
return res;
} else {
return createLocal(input).local();
}
}
function getDateOffset(m) {
// On Firefox.24 Date#getTimezoneOffset returns a floating point.
// https://github.com/moment/moment/pull/1871
return -Math.round(m._d.getTimezoneOffset());
}
// HOOKS
// This function will be called whenever a moment is mutated.
// It is intended to keep the offset in sync with the timezone.
hooks.updateOffset = function () {};
// MOMENTS
// keepLocalTime = true means only change the timezone, without
// affecting the local hour. So 5:31:26 +0300 --[utcOffset(2, true)]-->
// 5:31:26 +0200 It is possible that 5:31:26 doesn't exist with offset
// +0200, so we adjust the time as needed, to be valid.
//
// Keeping the time actually adds/subtracts (one hour)
// from the actual represented time. That is why we call updateOffset
// a second time. In case it wants us to change the offset again
// _changeInProgress == true case, then we have to adjust, because
// there is no such time in the given timezone.
function getSetOffset(input, keepLocalTime, keepMinutes) {
var offset = this._offset || 0,
localAdjust;
if (!this.isValid()) {
return input != null ? this : NaN;
}
if (input != null) {
if (typeof input === 'string') {
input = offsetFromString(matchShortOffset, input);
if (input === null) {
return this;
}
} else if (Math.abs(input) < 16 && !keepMinutes) {
input = input * 60;
}
if (!this._isUTC && keepLocalTime) {
localAdjust = getDateOffset(this);
}
this._offset = input;
this._isUTC = true;
if (localAdjust != null) {
this.add(localAdjust, 'm');
}
if (offset !== input) {
if (!keepLocalTime || this._changeInProgress) {
addSubtract(
this,
createDuration(input - offset, 'm'),
1,
false
);
} else if (!this._changeInProgress) {
this._changeInProgress = true;
hooks.updateOffset(this, true);
this._changeInProgress = null;
}
}
return this;
} else {
return this._isUTC ? offset : getDateOffset(this);
}
}
function getSetZone(input, keepLocalTime) {
if (input != null) {
if (typeof input !== 'string') {
input = -input;
}
this.utcOffset(input, keepLocalTime);
return this;
} else {
return -this.utcOffset();
}
}
function setOffsetToUTC(keepLocalTime) {
return this.utcOffset(0, keepLocalTime);
}
function setOffsetToLocal(keepLocalTime) {
if (this._isUTC) {
this.utcOffset(0, keepLocalTime);
this._isUTC = false;
if (keepLocalTime) {
this.subtract(getDateOffset(this), 'm');
}
}
return this;
}
function setOffsetToParsedOffset() {
if (this._tzm != null) {
this.utcOffset(this._tzm, false, true);
} else if (typeof this._i === 'string') {
var tZone = offsetFromString(matchOffset, this._i);
if (tZone != null) {
this.utcOffset(tZone);
} else {
this.utcOffset(0, true);
}
}
return this;
}
function hasAlignedHourOffset(input) {
if (!this.isValid()) {
return false;
}
input = input ? createLocal(input).utcOffset() : 0;
return (this.utcOffset() - input) % 60 === 0;
}
function isDaylightSavingTime() {
return (
this.utcOffset() > this.clone().month(0).utcOffset() ||
this.utcOffset() > this.clone().month(5).utcOffset()
);
}
function isDaylightSavingTimeShifted() {
if (!isUndefined(this._isDSTShifted)) {
return this._isDSTShifted;
}
var c = {},
other;
copyConfig(c, this);
c = prepareConfig(c);
if (c._a) {
other = c._isUTC ? createUTC(c._a) : createLocal(c._a);
this._isDSTShifted =
this.isValid() && compareArrays(c._a, other.toArray()) > 0;
} else {
this._isDSTShifted = false;
}
return this._isDSTShifted;
}
function isLocal() {
return this.isValid() ? !this._isUTC : false;
}
function isUtcOffset() {
return this.isValid() ? this._isUTC : false;
}
function isUtc() {
return this.isValid() ? this._isUTC && this._offset === 0 : false;
}
// ASP.NET json date format regex
var aspNetRegex = /^(-|\+)?(?:(\d*)[. ])?(\d+):(\d+)(?::(\d+)(\.\d*)?)?$/,
// from http://docs.closure-library.googlecode.com/git/closure_goog_date_date.js.source.html
// somewhat more in line with 4.4.3.2 2004 spec, but allows decimal anywhere
// and further modified to allow for strings containing both week and day
isoRegex = /^(-|\+)?P(?:([-+]?[0-9,.]*)Y)?(?:([-+]?[0-9,.]*)M)?(?:([-+]?[0-9,.]*)W)?(?:([-+]?[0-9,.]*)D)?(?:T(?:([-+]?[0-9,.]*)H)?(?:([-+]?[0-9,.]*)M)?(?:([-+]?[0-9,.]*)S)?)?$/;
function createDuration(input, key) {
var duration = input,
// matching against regexp is expensive, do it on demand
match = null,
sign,
ret,
diffRes;
if (isDuration(input)) {
duration = {
ms: input._milliseconds,
d: input._days,
M: input._months,
};
} else if (isNumber(input) || !isNaN(+input)) {
duration = {};
if (key) {
duration[key] = +input;
} else {
duration.milliseconds = +input;
}
} else if ((match = aspNetRegex.exec(input))) {
sign = match[1] === '-' ? -1 : 1;
duration = {
y: 0,
d: toInt(match[DATE]) * sign,
h: toInt(match[HOUR]) * sign,
m: toInt(match[MINUTE]) * sign,
s: toInt(match[SECOND]) * sign,
ms: toInt(absRound(match[MILLISECOND] * 1000)) * sign, // the millisecond decimal point is included in the match
};
} else if ((match = isoRegex.exec(input))) {
sign = match[1] === '-' ? -1 : 1;
duration = {
y: parseIso(match[2], sign),
M: parseIso(match[3], sign),
w: parseIso(match[4], sign),
d: parseIso(match[5], sign),
h: parseIso(match[6], sign),
m: parseIso(match[7], sign),
s: parseIso(match[8], sign),
};
} else if (duration == null) {
// checks for null or undefined
duration = {};
} else if (
typeof duration === 'object' &&
('from' in duration || 'to' in duration)
) {
diffRes = momentsDifference(
createLocal(duration.from),
createLocal(duration.to)
);
duration = {};
duration.ms = diffRes.milliseconds;
duration.M = diffRes.months;
}
ret = new Duration(duration);
if (isDuration(input) && hasOwnProp(input, '_locale')) {
ret._locale = input._locale;
}
if (isDuration(input) && hasOwnProp(input, '_isValid')) {
ret._isValid = input._isValid;
}
return ret;
}
createDuration.fn = Duration.prototype;
createDuration.invalid = createInvalid$1;
function parseIso(inp, sign) {
// We'd normally use ~~inp for this, but unfortunately it also
// converts floats to ints.
// inp may be undefined, so careful calling replace on it.
var res = inp && parseFloat(inp.replace(',', '.'));
// apply sign while we're at it
return (isNaN(res) ? 0 : res) * sign;
}
function positiveMomentsDifference(base, other) {
var res = {};
res.months =
other.month() - base.month() + (other.year() - base.year()) * 12;
if (base.clone().add(res.months, 'M').isAfter(other)) {
--res.months;
}
res.milliseconds = +other - +base.clone().add(res.months, 'M');
return res;
}
function momentsDifference(base, other) {
var res;
if (!(base.isValid() && other.isValid())) {
return { milliseconds: 0, months: 0 };
}
other = cloneWithOffset(other, base);
if (base.isBefore(other)) {
res = positiveMomentsDifference(base, other);
} else {
res = positiveMomentsDifference(other, base);
res.milliseconds = -res.milliseconds;
res.months = -res.months;
}
return res;
}
// TODO: remove 'name' arg after deprecation is removed
function createAdder(direction, name) {
return function (val, period) {
var dur, tmp;
//invert the arguments, but complain about it
if (period !== null && !isNaN(+period)) {
deprecateSimple(
name,
'moment().' +
name +
'(period, number) is deprecated. Please use moment().' +
name +
'(number, period). ' +
'See http://momentjs.com/guides/#/warnings/add-inverted-param/ for more info.'
);
tmp = val;
val = period;
period = tmp;
}
dur = createDuration(val, period);
addSubtract(this, dur, direction);
return this;
};
}
function addSubtract(mom, duration, isAdding, updateOffset) {
var milliseconds = duration._milliseconds,
days = absRound(duration._days),
months = absRound(duration._months);
if (!mom.isValid()) {
// No op
return;
}
updateOffset = updateOffset == null ? true : updateOffset;
if (months) {
setMonth(mom, get(mom, 'Month') + months * isAdding);
}
if (days) {
set$1(mom, 'Date', get(mom, 'Date') + days * isAdding);
}
if (milliseconds) {
mom._d.setTime(mom._d.valueOf() + milliseconds * isAdding);
}
if (updateOffset) {
hooks.updateOffset(mom, days || months);
}
}
var add = createAdder(1, 'add'),
subtract = createAdder(-1, 'subtract');
function isString(input) {
return typeof input === 'string' || input instanceof String;
}
// type MomentInput = Moment | Date | string | number | (number | string)[] | MomentInputObject | void; // null | undefined
function isMomentInput(input) {
return (
isMoment(input) ||
isDate(input) ||
isString(input) ||
isNumber(input) ||
isNumberOrStringArray(input) ||
isMomentInputObject(input) ||
input === null ||
input === undefined
);
}
function isMomentInputObject(input) {
var objectTest = isObject(input) && !isObjectEmpty(input),
propertyTest = false,
properties = [
'years',
'year',
'y',
'months',
'month',
'M',
'days',
'day',
'd',
'dates',
'date',
'D',
'hours',
'hour',
'h',
'minutes',
'minute',
'm',
'seconds',
'second',
's',
'milliseconds',
'millisecond',
'ms',
],
i,
property;
for (i = 0; i < properties.length; i += 1) {
property = properties[i];
propertyTest = propertyTest || hasOwnProp(input, property);
}
return objectTest && propertyTest;
}
function isNumberOrStringArray(input) {
var arrayTest = isArray(input),
dataTypeTest = false;
if (arrayTest) {
dataTypeTest =
input.filter(function (item) {
return !isNumber(item) && isString(input);
}).length === 0;
}
return arrayTest && dataTypeTest;
}
function isCalendarSpec(input) {
var objectTest = isObject(input) && !isObjectEmpty(input),
propertyTest = false,
properties = [
'sameDay',
'nextDay',
'lastDay',
'nextWeek',
'lastWeek',
'sameElse',
],
i,
property;
for (i = 0; i < properties.length; i += 1) {
property = properties[i];
propertyTest = propertyTest || hasOwnProp(input, property);
}
return objectTest && propertyTest;
}
function getCalendarFormat(myMoment, now) {
var diff = myMoment.diff(now, 'days', true);
return diff < -6
? 'sameElse'
: diff < -1
? 'lastWeek'
: diff < 0
? 'lastDay'
: diff < 1
? 'sameDay'
: diff < 2
? 'nextDay'
: diff < 7
? 'nextWeek'
: 'sameElse';
}
function calendar$1(time, formats) {
// Support for single parameter, formats only overload to the calendar function
if (arguments.length === 1) {
if (!arguments[0]) {
time = undefined;
formats = undefined;
} else if (isMomentInput(arguments[0])) {
time = arguments[0];
formats = undefined;
} else if (isCalendarSpec(arguments[0])) {
formats = arguments[0];
time = undefined;
}
}
// We want to compare the start of today, vs this.
// Getting start-of-today depends on whether we're local/utc/offset or not.
var now = time || createLocal(),
sod = cloneWithOffset(now, this).startOf('day'),
format = hooks.calendarFormat(this, sod) || 'sameElse',
output =
formats &&
(isFunction(formats[format])
? formats[format].call(this, now)
: formats[format]);
return this.format(
output || this.localeData().calendar(format, this, createLocal(now))
);
}
function clone() {
return new Moment(this);
}
function isAfter(input, units) {
var localInput = isMoment(input) ? input : createLocal(input);
if (!(this.isValid() && localInput.isValid())) {
return false;
}
units = normalizeUnits(units) || 'millisecond';
if (units === 'millisecond') {
return this.valueOf() > localInput.valueOf();
} else {
return localInput.valueOf() < this.clone().startOf(units).valueOf();
}
}
function isBefore(input, units) {
var localInput = isMoment(input) ? input : createLocal(input);
if (!(this.isValid() && localInput.isValid())) {
return false;
}
units = normalizeUnits(units) || 'millisecond';
if (units === 'millisecond') {
return this.valueOf() < localInput.valueOf();
} else {
return this.clone().endOf(units).valueOf() < localInput.valueOf();
}
}
function isBetween(from, to, units, inclusivity) {
var localFrom = isMoment(from) ? from : createLocal(from),
localTo = isMoment(to) ? to : createLocal(to);
if (!(this.isValid() && localFrom.isValid() && localTo.isValid())) {
return false;
}
inclusivity = inclusivity || '()';
return (
(inclusivity[0] === '('
? this.isAfter(localFrom, units)
: !this.isBefore(localFrom, units)) &&
(inclusivity[1] === ')'
? this.isBefore(localTo, units)
: !this.isAfter(localTo, units))
);
}
function isSame(input, units) {
var localInput = isMoment(input) ? input : createLocal(input),
inputMs;
if (!(this.isValid() && localInput.isValid())) {
return false;
}
units = normalizeUnits(units) || 'millisecond';
if (units === 'millisecond') {
return this.valueOf() === localInput.valueOf();
} else {
inputMs = localInput.valueOf();
return (
this.clone().startOf(units).valueOf() <= inputMs &&
inputMs <= this.clone().endOf(units).valueOf()
);
}
}
function isSameOrAfter(input, units) {
return this.isSame(input, units) || this.isAfter(input, units);
}
function isSameOrBefore(input, units) {
return this.isSame(input, units) || this.isBefore(input, units);
}
function diff(input, units, asFloat) {
var that, zoneDelta, output;
if (!this.isValid()) {
return NaN;
}
that = cloneWithOffset(input, this);
if (!that.isValid()) {
return NaN;
}
zoneDelta = (that.utcOffset() - this.utcOffset()) * 6e4;
units = normalizeUnits(units);
switch (units) {
case 'year':
output = monthDiff(this, that) / 12;
break;
case 'month':
output = monthDiff(this, that);
break;
case 'quarter':
output = monthDiff(this, that) / 3;
break;
case 'second':
output = (this - that) / 1e3;
break; // 1000
case 'minute':
output = (this - that) / 6e4;
break; // 1000 * 60
case 'hour':
output = (this - that) / 36e5;
break; // 1000 * 60 * 60
case 'day':
output = (this - that - zoneDelta) / 864e5;
break; // 1000 * 60 * 60 * 24, negate dst
case 'week':
output = (this - that - zoneDelta) / 6048e5;
break; // 1000 * 60 * 60 * 24 * 7, negate dst
default:
output = this - that;
}
return asFloat ? output : absFloor(output);
}
function monthDiff(a, b) {
if (a.date() < b.date()) {
// end-of-month calculations work correct when the start month has more
// days than the end month.
return -monthDiff(b, a);
}
// difference in months
var wholeMonthDiff = (b.year() - a.year()) * 12 + (b.month() - a.month()),
// b is in (anchor - 1 month, anchor + 1 month)
anchor = a.clone().add(wholeMonthDiff, 'months'),
anchor2,
adjust;
if (b - anchor < 0) {
anchor2 = a.clone().add(wholeMonthDiff - 1, 'months');
// linear across the month
adjust = (b - anchor) / (anchor - anchor2);
} else {
anchor2 = a.clone().add(wholeMonthDiff + 1, 'months');
// linear across the month
adjust = (b - anchor) / (anchor2 - anchor);
}
//check for negative zero, return zero if negative zero
return -(wholeMonthDiff + adjust) || 0;
}
hooks.defaultFormat = 'YYYY-MM-DDTHH:mm:ssZ';
hooks.defaultFormatUtc = 'YYYY-MM-DDTHH:mm:ss[Z]';
function toString() {
return this.clone().locale('en').format('ddd MMM DD YYYY HH:mm:ss [GMT]ZZ');
}
function toISOString(keepOffset) {
if (!this.isValid()) {
return null;
}
var utc = keepOffset !== true,
m = utc ? this.clone().utc() : this;
if (m.year() < 0 || m.year() > 9999) {
return formatMoment(
m,
utc
? 'YYYYYY-MM-DD[T]HH:mm:ss.SSS[Z]'
: 'YYYYYY-MM-DD[T]HH:mm:ss.SSSZ'
);
}
if (isFunction(Date.prototype.toISOString)) {
// native implementation is ~50x faster, use it when we can
if (utc) {
return this.toDate().toISOString();
} else {
return new Date(this.valueOf() + this.utcOffset() * 60 * 1000)
.toISOString()
.replace('Z', formatMoment(m, 'Z'));
}
}
return formatMoment(
m,
utc ? 'YYYY-MM-DD[T]HH:mm:ss.SSS[Z]' : 'YYYY-MM-DD[T]HH:mm:ss.SSSZ'
);
}
/**
* Return a human readable representation of a moment that can
* also be evaluated to get a new moment which is the same
*
* @link https://nodejs.org/dist/latest/docs/api/util.html#util_custom_inspect_function_on_objects
*/
function inspect() {
if (!this.isValid()) {
return 'moment.invalid(/* ' + this._i + ' */)';
}
var func = 'moment',
zone = '',
prefix,
year,
datetime,
suffix;
if (!this.isLocal()) {
func = this.utcOffset() === 0 ? 'moment.utc' : 'moment.parseZone';
zone = 'Z';
}
prefix = '[' + func + '("]';
year = 0 <= this.year() && this.year() <= 9999 ? 'YYYY' : 'YYYYYY';
datetime = '-MM-DD[T]HH:mm:ss.SSS';
suffix = zone + '[")]';
return this.format(prefix + year + datetime + suffix);
}
function format(inputString) {
if (!inputString) {
inputString = this.isUtc()
? hooks.defaultFormatUtc
: hooks.defaultFormat;
}
var output = formatMoment(this, inputString);
return this.localeData().postformat(output);
}
function from(time, withoutSuffix) {
if (
this.isValid() &&
((isMoment(time) && time.isValid()) || createLocal(time).isValid())
) {
return createDuration({ to: this, from: time })
.locale(this.locale())
.humanize(!withoutSuffix);
} else {
return this.localeData().invalidDate();
}
}
function fromNow(withoutSuffix) {
return this.from(createLocal(), withoutSuffix);
}
function to(time, withoutSuffix) {
if (
this.isValid() &&
((isMoment(time) && time.isValid()) || createLocal(time).isValid())
) {
return createDuration({ from: this, to: time })
.locale(this.locale())
.humanize(!withoutSuffix);
} else {
return this.localeData().invalidDate();
}
}
function toNow(withoutSuffix) {
return this.to(createLocal(), withoutSuffix);
}
// If passed a locale key, it will set the locale for this
// instance. Otherwise, it will return the locale configuration
// variables for this instance.
function locale(key) {
var newLocaleData;
if (key === undefined) {
return this._locale._abbr;
} else {
newLocaleData = getLocale(key);
if (newLocaleData != null) {
this._locale = newLocaleData;
}
return this;
}
}
var lang = deprecate(
'moment().lang() is deprecated. Instead, use moment().localeData() to get the language configuration. Use moment().locale() to change languages.',
function (key) {
if (key === undefined) {
return this.localeData();
} else {
return this.locale(key);
}
}
);
function localeData() {
return this._locale;
}
var MS_PER_SECOND = 1000,
MS_PER_MINUTE = 60 * MS_PER_SECOND,
MS_PER_HOUR = 60 * MS_PER_MINUTE,
MS_PER_400_YEARS = (365 * 400 + 97) * 24 * MS_PER_HOUR;
// actual modulo - handles negative numbers (for dates before 1970):
function mod$1(dividend, divisor) {
return ((dividend % divisor) + divisor) % divisor;
}
function localStartOfDate(y, m, d) {
// the date constructor remaps years 0-99 to 1900-1999
if (y < 100 && y >= 0) {
// preserve leap years using a full 400 year cycle, then reset
return new Date(y + 400, m, d) - MS_PER_400_YEARS;
} else {
return new Date(y, m, d).valueOf();
}
}
function utcStartOfDate(y, m, d) {
// Date.UTC remaps years 0-99 to 1900-1999
if (y < 100 && y >= 0) {
// preserve leap years using a full 400 year cycle, then reset
return Date.UTC(y + 400, m, d) - MS_PER_400_YEARS;
} else {
return Date.UTC(y, m, d);
}
}
function startOf(units) {
var time, startOfDate;
units = normalizeUnits(units);
if (units === undefined || units === 'millisecond' || !this.isValid()) {
return this;
}
startOfDate = this._isUTC ? utcStartOfDate : localStartOfDate;
switch (units) {
case 'year':
time = startOfDate(this.year(), 0, 1);
break;
case 'quarter':
time = startOfDate(
this.year(),
this.month() - (this.month() % 3),
1
);
break;
case 'month':
time = startOfDate(this.year(), this.month(), 1);
break;
case 'week':
time = startOfDate(
this.year(),
this.month(),
this.date() - this.weekday()
);
break;
case 'isoWeek':
time = startOfDate(
this.year(),
this.month(),
this.date() - (this.isoWeekday() - 1)
);
break;
case 'day':
case 'date':
time = startOfDate(this.year(), this.month(), this.date());
break;
case 'hour':
time = this._d.valueOf();
time -= mod$1(
time + (this._isUTC ? 0 : this.utcOffset() * MS_PER_MINUTE),
MS_PER_HOUR
);
break;
case 'minute':
time = this._d.valueOf();
time -= mod$1(time, MS_PER_MINUTE);
break;
case 'second':
time = this._d.valueOf();
time -= mod$1(time, MS_PER_SECOND);
break;
}
this._d.setTime(time);
hooks.updateOffset(this, true);
return this;
}
function endOf(units) {
var time, startOfDate;
units = normalizeUnits(units);
if (units === undefined || units === 'millisecond' || !this.isValid()) {
return this;
}
startOfDate = this._isUTC ? utcStartOfDate : localStartOfDate;
switch (units) {
case 'year':
time = startOfDate(this.year() + 1, 0, 1) - 1;
break;
case 'quarter':
time =
startOfDate(
this.year(),
this.month() - (this.month() % 3) + 3,
1
) - 1;
break;
case 'month':
time = startOfDate(this.year(), this.month() + 1, 1) - 1;
break;
case 'week':
time =
startOfDate(
this.year(),
this.month(),
this.date() - this.weekday() + 7
) - 1;
break;
case 'isoWeek':
time =
startOfDate(
this.year(),
this.month(),
this.date() - (this.isoWeekday() - 1) + 7
) - 1;
break;
case 'day':
case 'date':
time = startOfDate(this.year(), this.month(), this.date() + 1) - 1;
break;
case 'hour':
time = this._d.valueOf();
time +=
MS_PER_HOUR -
mod$1(
time + (this._isUTC ? 0 : this.utcOffset() * MS_PER_MINUTE),
MS_PER_HOUR
) -
1;
break;
case 'minute':
time = this._d.valueOf();
time += MS_PER_MINUTE - mod$1(time, MS_PER_MINUTE) - 1;
break;
case 'second':
time = this._d.valueOf();
time += MS_PER_SECOND - mod$1(time, MS_PER_SECOND) - 1;
break;
}
this._d.setTime(time);
hooks.updateOffset(this, true);
return this;
}
function valueOf() {
return this._d.valueOf() - (this._offset || 0) * 60000;
}
function unix() {
return Math.floor(this.valueOf() / 1000);
}
function toDate() {
return new Date(this.valueOf());
}
function toArray() {
var m = this;
return [
m.year(),
m.month(),
m.date(),
m.hour(),
m.minute(),
m.second(),
m.millisecond(),
];
}
function toObject() {
var m = this;
return {
years: m.year(),
months: m.month(),
date: m.date(),
hours: m.hours(),
minutes: m.minutes(),
seconds: m.seconds(),
milliseconds: m.milliseconds(),
};
}
function toJSON() {
// new Date(NaN).toJSON() === null
return this.isValid() ? this.toISOString() : null;
}
function isValid$2() {
return isValid(this);
}
function parsingFlags() {
return extend({}, getParsingFlags(this));
}
function invalidAt() {
return getParsingFlags(this).overflow;
}
function creationData() {
return {
input: this._i,
format: this._f,
locale: this._locale,
isUTC: this._isUTC,
strict: this._strict,
};
}
addFormatToken('N', 0, 0, 'eraAbbr');
addFormatToken('NN', 0, 0, 'eraAbbr');
addFormatToken('NNN', 0, 0, 'eraAbbr');
addFormatToken('NNNN', 0, 0, 'eraName');
addFormatToken('NNNNN', 0, 0, 'eraNarrow');
addFormatToken('y', ['y', 1], 'yo', 'eraYear');
addFormatToken('y', ['yy', 2], 0, 'eraYear');
addFormatToken('y', ['yyy', 3], 0, 'eraYear');
addFormatToken('y', ['yyyy', 4], 0, 'eraYear');
addRegexToken('N', matchEraAbbr);
addRegexToken('NN', matchEraAbbr);
addRegexToken('NNN', matchEraAbbr);
addRegexToken('NNNN', matchEraName);
addRegexToken('NNNNN', matchEraNarrow);
addParseToken(['N', 'NN', 'NNN', 'NNNN', 'NNNNN'], function (
input,
array,
config,
token
) {
var era = config._locale.erasParse(input, token, config._strict);
if (era) {
getParsingFlags(config).era = era;
} else {
getParsingFlags(config).invalidEra = input;
}
});
addRegexToken('y', matchUnsigned);
addRegexToken('yy', matchUnsigned);
addRegexToken('yyy', matchUnsigned);
addRegexToken('yyyy', matchUnsigned);
addRegexToken('yo', matchEraYearOrdinal);
addParseToken(['y', 'yy', 'yyy', 'yyyy'], YEAR);
addParseToken(['yo'], function (input, array, config, token) {
var match;
if (config._locale._eraYearOrdinalRegex) {
match = input.match(config._locale._eraYearOrdinalRegex);
}
if (config._locale.eraYearOrdinalParse) {
array[YEAR] = config._locale.eraYearOrdinalParse(input, match);
} else {
array[YEAR] = parseInt(input, 10);
}
});
function localeEras(m, format) {
var i,
l,
date,
eras = this._eras || getLocale('en')._eras;
for (i = 0, l = eras.length; i < l; ++i) {
switch (typeof eras[i].since) {
case 'string':
// truncate time
date = hooks(eras[i].since).startOf('day');
eras[i].since = date.valueOf();
break;
}
switch (typeof eras[i].until) {
case 'undefined':
eras[i].until = +Infinity;
break;
case 'string':
// truncate time
date = hooks(eras[i].until).startOf('day').valueOf();
eras[i].until = date.valueOf();
break;
}
}
return eras;
}
function localeErasParse(eraName, format, strict) {
var i,
l,
eras = this.eras(),
name,
abbr,
narrow;
eraName = eraName.toUpperCase();
for (i = 0, l = eras.length; i < l; ++i) {
name = eras[i].name.toUpperCase();
abbr = eras[i].abbr.toUpperCase();
narrow = eras[i].narrow.toUpperCase();
if (strict) {
switch (format) {
case 'N':
case 'NN':
case 'NNN':
if (abbr === eraName) {
return eras[i];
}
break;
case 'NNNN':
if (name === eraName) {
return eras[i];
}
break;
case 'NNNNN':
if (narrow === eraName) {
return eras[i];
}
break;
}
} else if ([name, abbr, narrow].indexOf(eraName) >= 0) {
return eras[i];
}
}
}
function localeErasConvertYear(era, year) {
var dir = era.since <= era.until ? +1 : -1;
if (year === undefined) {
return hooks(era.since).year();
} else {
return hooks(era.since).year() + (year - era.offset) * dir;
}
}
function getEraName() {
var i,
l,
val,
eras = this.localeData().eras();
for (i = 0, l = eras.length; i < l; ++i) {
// truncate time
val = this.clone().startOf('day').valueOf();
if (eras[i].since <= val && val <= eras[i].until) {
return eras[i].name;
}
if (eras[i].until <= val && val <= eras[i].since) {
return eras[i].name;
}
}
return '';
}
function getEraNarrow() {
var i,
l,
val,
eras = this.localeData().eras();
for (i = 0, l = eras.length; i < l; ++i) {
// truncate time
val = this.clone().startOf('day').valueOf();
if (eras[i].since <= val && val <= eras[i].until) {
return eras[i].narrow;
}
if (eras[i].until <= val && val <= eras[i].since) {
return eras[i].narrow;
}
}
return '';
}
function getEraAbbr() {
var i,
l,
val,
eras = this.localeData().eras();
for (i = 0, l = eras.length; i < l; ++i) {
// truncate time
val = this.clone().startOf('day').valueOf();
if (eras[i].since <= val && val <= eras[i].until) {
return eras[i].abbr;
}
if (eras[i].until <= val && val <= eras[i].since) {
return eras[i].abbr;
}
}
return '';
}
function getEraYear() {
var i,
l,
dir,
val,
eras = this.localeData().eras();
for (i = 0, l = eras.length; i < l; ++i) {
dir = eras[i].since <= eras[i].until ? +1 : -1;
// truncate time
val = this.clone().startOf('day').valueOf();
if (
(eras[i].since <= val && val <= eras[i].until) ||
(eras[i].until <= val && val <= eras[i].since)
) {
return (
(this.year() - hooks(eras[i].since).year()) * dir +
eras[i].offset
);
}
}
return this.year();
}
function erasNameRegex(isStrict) {
if (!hasOwnProp(this, '_erasNameRegex')) {
computeErasParse.call(this);
}
return isStrict ? this._erasNameRegex : this._erasRegex;
}
function erasAbbrRegex(isStrict) {
if (!hasOwnProp(this, '_erasAbbrRegex')) {
computeErasParse.call(this);
}
return isStrict ? this._erasAbbrRegex : this._erasRegex;
}
function erasNarrowRegex(isStrict) {
if (!hasOwnProp(this, '_erasNarrowRegex')) {
computeErasParse.call(this);
}
return isStrict ? this._erasNarrowRegex : this._erasRegex;
}
function matchEraAbbr(isStrict, locale) {
return locale.erasAbbrRegex(isStrict);
}
function matchEraName(isStrict, locale) {
return locale.erasNameRegex(isStrict);
}
function matchEraNarrow(isStrict, locale) {
return locale.erasNarrowRegex(isStrict);
}
function matchEraYearOrdinal(isStrict, locale) {
return locale._eraYearOrdinalRegex || matchUnsigned;
}
function computeErasParse() {
var abbrPieces = [],
namePieces = [],
narrowPieces = [],
mixedPieces = [],
i,
l,
eras = this.eras();
for (i = 0, l = eras.length; i < l; ++i) {
namePieces.push(regexEscape(eras[i].name));
abbrPieces.push(regexEscape(eras[i].abbr));
narrowPieces.push(regexEscape(eras[i].narrow));
mixedPieces.push(regexEscape(eras[i].name));
mixedPieces.push(regexEscape(eras[i].abbr));
mixedPieces.push(regexEscape(eras[i].narrow));
}
this._erasRegex = new RegExp('^(' + mixedPieces.join('|') + ')', 'i');
this._erasNameRegex = new RegExp('^(' + namePieces.join('|') + ')', 'i');
this._erasAbbrRegex = new RegExp('^(' + abbrPieces.join('|') + ')', 'i');
this._erasNarrowRegex = new RegExp(
'^(' + narrowPieces.join('|') + ')',
'i'
);
}
// FORMATTING
addFormatToken(0, ['gg', 2], 0, function () {
return this.weekYear() % 100;
});
addFormatToken(0, ['GG', 2], 0, function () {
return this.isoWeekYear() % 100;
});
function addWeekYearFormatToken(token, getter) {
addFormatToken(0, [token, token.length], 0, getter);
}
addWeekYearFormatToken('gggg', 'weekYear');
addWeekYearFormatToken('ggggg', 'weekYear');
addWeekYearFormatToken('GGGG', 'isoWeekYear');
addWeekYearFormatToken('GGGGG', 'isoWeekYear');
// ALIASES
addUnitAlias('weekYear', 'gg');
addUnitAlias('isoWeekYear', 'GG');
// PRIORITY
addUnitPriority('weekYear', 1);
addUnitPriority('isoWeekYear', 1);
// PARSING
addRegexToken('G', matchSigned);
addRegexToken('g', matchSigned);
addRegexToken('GG', match1to2, match2);
addRegexToken('gg', match1to2, match2);
addRegexToken('GGGG', match1to4, match4);
addRegexToken('gggg', match1to4, match4);
addRegexToken('GGGGG', match1to6, match6);
addRegexToken('ggggg', match1to6, match6);
addWeekParseToken(['gggg', 'ggggg', 'GGGG', 'GGGGG'], function (
input,
week,
config,
token
) {
week[token.substr(0, 2)] = toInt(input);
});
addWeekParseToken(['gg', 'GG'], function (input, week, config, token) {
week[token] = hooks.parseTwoDigitYear(input);
});
// MOMENTS
function getSetWeekYear(input) {
return getSetWeekYearHelper.call(
this,
input,
this.week(),
this.weekday(),
this.localeData()._week.dow,
this.localeData()._week.doy
);
}
function getSetISOWeekYear(input) {
return getSetWeekYearHelper.call(
this,
input,
this.isoWeek(),
this.isoWeekday(),
1,
4
);
}
function getISOWeeksInYear() {
return weeksInYear(this.year(), 1, 4);
}
function getISOWeeksInISOWeekYear() {
return weeksInYear(this.isoWeekYear(), 1, 4);
}
function getWeeksInYear() {
var weekInfo = this.localeData()._week;
return weeksInYear(this.year(), weekInfo.dow, weekInfo.doy);
}
function getWeeksInWeekYear() {
var weekInfo = this.localeData()._week;
return weeksInYear(this.weekYear(), weekInfo.dow, weekInfo.doy);
}
function getSetWeekYearHelper(input, week, weekday, dow, doy) {
var weeksTarget;
if (input == null) {
return weekOfYear(this, dow, doy).year;
} else {
weeksTarget = weeksInYear(input, dow, doy);
if (week > weeksTarget) {
week = weeksTarget;
}
return setWeekAll.call(this, input, week, weekday, dow, doy);
}
}
function setWeekAll(weekYear, week, weekday, dow, doy) {
var dayOfYearData = dayOfYearFromWeeks(weekYear, week, weekday, dow, doy),
date = createUTCDate(dayOfYearData.year, 0, dayOfYearData.dayOfYear);
this.year(date.getUTCFullYear());
this.month(date.getUTCMonth());
this.date(date.getUTCDate());
return this;
}
// FORMATTING
addFormatToken('Q', 0, 'Qo', 'quarter');
// ALIASES
addUnitAlias('quarter', 'Q');
// PRIORITY
addUnitPriority('quarter', 7);
// PARSING
addRegexToken('Q', match1);
addParseToken('Q', function (input, array) {
array[MONTH] = (toInt(input) - 1) * 3;
});
// MOMENTS
function getSetQuarter(input) {
return input == null
? Math.ceil((this.month() + 1) / 3)
: this.month((input - 1) * 3 + (this.month() % 3));
}
// FORMATTING
addFormatToken('D', ['DD', 2], 'Do', 'date');
// ALIASES
addUnitAlias('date', 'D');
// PRIORITY
addUnitPriority('date', 9);
// PARSING
addRegexToken('D', match1to2);
addRegexToken('DD', match1to2, match2);
addRegexToken('Do', function (isStrict, locale) {
// TODO: Remove "ordinalParse" fallback in next major release.
return isStrict
? locale._dayOfMonthOrdinalParse || locale._ordinalParse
: locale._dayOfMonthOrdinalParseLenient;
});
addParseToken(['D', 'DD'], DATE);
addParseToken('Do', function (input, array) {
array[DATE] = toInt(input.match(match1to2)[0]);
});
// MOMENTS
var getSetDayOfMonth = makeGetSet('Date', true);
// FORMATTING
addFormatToken('DDD', ['DDDD', 3], 'DDDo', 'dayOfYear');
// ALIASES
addUnitAlias('dayOfYear', 'DDD');
// PRIORITY
addUnitPriority('dayOfYear', 4);
// PARSING
addRegexToken('DDD', match1to3);
addRegexToken('DDDD', match3);
addParseToken(['DDD', 'DDDD'], function (input, array, config) {
config._dayOfYear = toInt(input);
});
// HELPERS
// MOMENTS
function getSetDayOfYear(input) {
var dayOfYear =
Math.round(
(this.clone().startOf('day') - this.clone().startOf('year')) / 864e5
) + 1;
return input == null ? dayOfYear : this.add(input - dayOfYear, 'd');
}
// FORMATTING
addFormatToken('m', ['mm', 2], 0, 'minute');
// ALIASES
addUnitAlias('minute', 'm');
// PRIORITY
addUnitPriority('minute', 14);
// PARSING
addRegexToken('m', match1to2);
addRegexToken('mm', match1to2, match2);
addParseToken(['m', 'mm'], MINUTE);
// MOMENTS
var getSetMinute = makeGetSet('Minutes', false);
// FORMATTING
addFormatToken('s', ['ss', 2], 0, 'second');
// ALIASES
addUnitAlias('second', 's');
// PRIORITY
addUnitPriority('second', 15);
// PARSING
addRegexToken('s', match1to2);
addRegexToken('ss', match1to2, match2);
addParseToken(['s', 'ss'], SECOND);
// MOMENTS
var getSetSecond = makeGetSet('Seconds', false);
// FORMATTING
addFormatToken('S', 0, 0, function () {
return ~~(this.millisecond() / 100);
});
addFormatToken(0, ['SS', 2], 0, function () {
return ~~(this.millisecond() / 10);
});
addFormatToken(0, ['SSS', 3], 0, 'millisecond');
addFormatToken(0, ['SSSS', 4], 0, function () {
return this.millisecond() * 10;
});
addFormatToken(0, ['SSSSS', 5], 0, function () {
return this.millisecond() * 100;
});
addFormatToken(0, ['SSSSSS', 6], 0, function () {
return this.millisecond() * 1000;
});
addFormatToken(0, ['SSSSSSS', 7], 0, function () {
return this.millisecond() * 10000;
});
addFormatToken(0, ['SSSSSSSS', 8], 0, function () {
return this.millisecond() * 100000;
});
addFormatToken(0, ['SSSSSSSSS', 9], 0, function () {
return this.millisecond() * 1000000;
});
// ALIASES
addUnitAlias('millisecond', 'ms');
// PRIORITY
addUnitPriority('millisecond', 16);
// PARSING
addRegexToken('S', match1to3, match1);
addRegexToken('SS', match1to3, match2);
addRegexToken('SSS', match1to3, match3);
var token, getSetMillisecond;
for (token = 'SSSS'; token.length <= 9; token += 'S') {
addRegexToken(token, matchUnsigned);
}
function parseMs(input, array) {
array[MILLISECOND] = toInt(('0.' + input) * 1000);
}
for (token = 'S'; token.length <= 9; token += 'S') {
addParseToken(token, parseMs);
}
getSetMillisecond = makeGetSet('Milliseconds', false);
// FORMATTING
addFormatToken('z', 0, 0, 'zoneAbbr');
addFormatToken('zz', 0, 0, 'zoneName');
// MOMENTS
function getZoneAbbr() {
return this._isUTC ? 'UTC' : '';
}
function getZoneName() {
return this._isUTC ? 'Coordinated Universal Time' : '';
}
var proto = Moment.prototype;
proto.add = add;
proto.calendar = calendar$1;
proto.clone = clone;
proto.diff = diff;
proto.endOf = endOf;
proto.format = format;
proto.from = from;
proto.fromNow = fromNow;
proto.to = to;
proto.toNow = toNow;
proto.get = stringGet;
proto.invalidAt = invalidAt;
proto.isAfter = isAfter;
proto.isBefore = isBefore;
proto.isBetween = isBetween;
proto.isSame = isSame;
proto.isSameOrAfter = isSameOrAfter;
proto.isSameOrBefore = isSameOrBefore;
proto.isValid = isValid$2;
proto.lang = lang;
proto.locale = locale;
proto.localeData = localeData;
proto.max = prototypeMax;
proto.min = prototypeMin;
proto.parsingFlags = parsingFlags;
proto.set = stringSet;
proto.startOf = startOf;
proto.subtract = subtract;
proto.toArray = toArray;
proto.toObject = toObject;
proto.toDate = toDate;
proto.toISOString = toISOString;
proto.inspect = inspect;
if (typeof Symbol !== 'undefined' && Symbol.for != null) {
proto[Symbol.for('nodejs.util.inspect.custom')] = function () {
return 'Moment<' + this.format() + '>';
};
}
proto.toJSON = toJSON;
proto.toString = toString;
proto.unix = unix;
proto.valueOf = valueOf;
proto.creationData = creationData;
proto.eraName = getEraName;
proto.eraNarrow = getEraNarrow;
proto.eraAbbr = getEraAbbr;
proto.eraYear = getEraYear;
proto.year = getSetYear;
proto.isLeapYear = getIsLeapYear;
proto.weekYear = getSetWeekYear;
proto.isoWeekYear = getSetISOWeekYear;
proto.quarter = proto.quarters = getSetQuarter;
proto.month = getSetMonth;
proto.daysInMonth = getDaysInMonth;
proto.week = proto.weeks = getSetWeek;
proto.isoWeek = proto.isoWeeks = getSetISOWeek;
proto.weeksInYear = getWeeksInYear;
proto.weeksInWeekYear = getWeeksInWeekYear;
proto.isoWeeksInYear = getISOWeeksInYear;
proto.isoWeeksInISOWeekYear = getISOWeeksInISOWeekYear;
proto.date = getSetDayOfMonth;
proto.day = proto.days = getSetDayOfWeek;
proto.weekday = getSetLocaleDayOfWeek;
proto.isoWeekday = getSetISODayOfWeek;
proto.dayOfYear = getSetDayOfYear;
proto.hour = proto.hours = getSetHour;
proto.minute = proto.minutes = getSetMinute;
proto.second = proto.seconds = getSetSecond;
proto.millisecond = proto.milliseconds = getSetMillisecond;
proto.utcOffset = getSetOffset;
proto.utc = setOffsetToUTC;
proto.local = setOffsetToLocal;
proto.parseZone = setOffsetToParsedOffset;
proto.hasAlignedHourOffset = hasAlignedHourOffset;
proto.isDST = isDaylightSavingTime;
proto.isLocal = isLocal;
proto.isUtcOffset = isUtcOffset;
proto.isUtc = isUtc;
proto.isUTC = isUtc;
proto.zoneAbbr = getZoneAbbr;
proto.zoneName = getZoneName;
proto.dates = deprecate(
'dates accessor is deprecated. Use date instead.',
getSetDayOfMonth
);
proto.months = deprecate(
'months accessor is deprecated. Use month instead',
getSetMonth
);
proto.years = deprecate(
'years accessor is deprecated. Use year instead',
getSetYear
);
proto.zone = deprecate(
'moment().zone is deprecated, use moment().utcOffset instead. http://momentjs.com/guides/#/warnings/zone/',
getSetZone
);
proto.isDSTShifted = deprecate(
'isDSTShifted is deprecated. See http://momentjs.com/guides/#/warnings/dst-shifted/ for more information',
isDaylightSavingTimeShifted
);
function createUnix(input) {
return createLocal(input * 1000);
}
function createInZone() {
return createLocal.apply(null, arguments).parseZone();
}
function preParsePostFormat(string) {
return string;
}
var proto$1 = Locale.prototype;
proto$1.calendar = calendar;
proto$1.longDateFormat = longDateFormat;
proto$1.invalidDate = invalidDate;
proto$1.ordinal = ordinal;
proto$1.preparse = preParsePostFormat;
proto$1.postformat = preParsePostFormat;
proto$1.relativeTime = relativeTime;
proto$1.pastFuture = pastFuture;
proto$1.set = set;
proto$1.eras = localeEras;
proto$1.erasParse = localeErasParse;
proto$1.erasConvertYear = localeErasConvertYear;
proto$1.erasAbbrRegex = erasAbbrRegex;
proto$1.erasNameRegex = erasNameRegex;
proto$1.erasNarrowRegex = erasNarrowRegex;
proto$1.months = localeMonths;
proto$1.monthsShort = localeMonthsShort;
proto$1.monthsParse = localeMonthsParse;
proto$1.monthsRegex = monthsRegex;
proto$1.monthsShortRegex = monthsShortRegex;
proto$1.week = localeWeek;
proto$1.firstDayOfYear = localeFirstDayOfYear;
proto$1.firstDayOfWeek = localeFirstDayOfWeek;
proto$1.weekdays = localeWeekdays;
proto$1.weekdaysMin = localeWeekdaysMin;
proto$1.weekdaysShort = localeWeekdaysShort;
proto$1.weekdaysParse = localeWeekdaysParse;
proto$1.weekdaysRegex = weekdaysRegex;
proto$1.weekdaysShortRegex = weekdaysShortRegex;
proto$1.weekdaysMinRegex = weekdaysMinRegex;
proto$1.isPM = localeIsPM;
proto$1.meridiem = localeMeridiem;
function get$1(format, index, field, setter) {
var locale = getLocale(),
utc = createUTC().set(setter, index);
return locale[field](utc, format);
}
function listMonthsImpl(format, index, field) {
if (isNumber(format)) {
index = format;
format = undefined;
}
format = format || '';
if (index != null) {
return get$1(format, index, field, 'month');
}
var i,
out = [];
for (i = 0; i < 12; i++) {
out[i] = get$1(format, i, field, 'month');
}
return out;
}
// ()
// (5)
// (fmt, 5)
// (fmt)
// (true)
// (true, 5)
// (true, fmt, 5)
// (true, fmt)
function listWeekdaysImpl(localeSorted, format, index, field) {
if (typeof localeSorted === 'boolean') {
if (isNumber(format)) {
index = format;
format = undefined;
}
format = format || '';
} else {
format = localeSorted;
index = format;
localeSorted = false;
if (isNumber(format)) {
index = format;
format = undefined;
}
format = format || '';
}
var locale = getLocale(),
shift = localeSorted ? locale._week.dow : 0,
i,
out = [];
if (index != null) {
return get$1(format, (index + shift) % 7, field, 'day');
}
for (i = 0; i < 7; i++) {
out[i] = get$1(format, (i + shift) % 7, field, 'day');
}
return out;
}
function listMonths(format, index) {
return listMonthsImpl(format, index, 'months');
}
function listMonthsShort(format, index) {
return listMonthsImpl(format, index, 'monthsShort');
}
function listWeekdays(localeSorted, format, index) {
return listWeekdaysImpl(localeSorted, format, index, 'weekdays');
}
function listWeekdaysShort(localeSorted, format, index) {
return listWeekdaysImpl(localeSorted, format, index, 'weekdaysShort');
}
function listWeekdaysMin(localeSorted, format, index) {
return listWeekdaysImpl(localeSorted, format, index, 'weekdaysMin');
}
getSetGlobalLocale('en', {
eras: [
{
since: '0001-01-01',
until: +Infinity,
offset: 1,
name: 'Anno Domini',
narrow: 'AD',
abbr: 'AD',
},
{
since: '0000-12-31',
until: -Infinity,
offset: 1,
name: 'Before Christ',
narrow: 'BC',
abbr: 'BC',
},
],
dayOfMonthOrdinalParse: /\d{1,2}(th|st|nd|rd)/,
ordinal: function (number) {
var b = number % 10,
output =
toInt((number % 100) / 10) === 1
? 'th'
: b === 1
? 'st'
: b === 2
? 'nd'
: b === 3
? 'rd'
: 'th';
return number + output;
},
});
// Side effect imports
hooks.lang = deprecate(
'moment.lang is deprecated. Use moment.locale instead.',
getSetGlobalLocale
);
hooks.langData = deprecate(
'moment.langData is deprecated. Use moment.localeData instead.',
getLocale
);
var mathAbs = Math.abs;
function abs() {
var data = this._data;
this._milliseconds = mathAbs(this._milliseconds);
this._days = mathAbs(this._days);
this._months = mathAbs(this._months);
data.milliseconds = mathAbs(data.milliseconds);
data.seconds = mathAbs(data.seconds);
data.minutes = mathAbs(data.minutes);
data.hours = mathAbs(data.hours);
data.months = mathAbs(data.months);
data.years = mathAbs(data.years);
return this;
}
function addSubtract$1(duration, input, value, direction) {
var other = createDuration(input, value);
duration._milliseconds += direction * other._milliseconds;
duration._days += direction * other._days;
duration._months += direction * other._months;
return duration._bubble();
}
// supports only 2.0-style add(1, 's') or add(duration)
function add$1(input, value) {
return addSubtract$1(this, input, value, 1);
}
// supports only 2.0-style subtract(1, 's') or subtract(duration)
function subtract$1(input, value) {
return addSubtract$1(this, input, value, -1);
}
function absCeil(number) {
if (number < 0) {
return Math.floor(number);
} else {
return Math.ceil(number);
}
}
function bubble() {
var milliseconds = this._milliseconds,
days = this._days,
months = this._months,
data = this._data,
seconds,
minutes,
hours,
years,
monthsFromDays;
// if we have a mix of positive and negative values, bubble down first
// check: https://github.com/moment/moment/issues/2166
if (
!(
(milliseconds >= 0 && days >= 0 && months >= 0) ||
(milliseconds <= 0 && days <= 0 && months <= 0)
)
) {
milliseconds += absCeil(monthsToDays(months) + days) * 864e5;
days = 0;
months = 0;
}
// The following code bubbles up values, see the tests for
// examples of what that means.
data.milliseconds = milliseconds % 1000;
seconds = absFloor(milliseconds / 1000);
data.seconds = seconds % 60;
minutes = absFloor(seconds / 60);
data.minutes = minutes % 60;
hours = absFloor(minutes / 60);
data.hours = hours % 24;
days += absFloor(hours / 24);
// convert days to months
monthsFromDays = absFloor(daysToMonths(days));
months += monthsFromDays;
days -= absCeil(monthsToDays(monthsFromDays));
// 12 months -> 1 year
years = absFloor(months / 12);
months %= 12;
data.days = days;
data.months = months;
data.years = years;
return this;
}
function daysToMonths(days) {
// 400 years have 146097 days (taking into account leap year rules)
// 400 years have 12 months === 4800
return (days * 4800) / 146097;
}
function monthsToDays(months) {
// the reverse of daysToMonths
return (months * 146097) / 4800;
}
function as(units) {
if (!this.isValid()) {
return NaN;
}
var days,
months,
milliseconds = this._milliseconds;
units = normalizeUnits(units);
if (units === 'month' || units === 'quarter' || units === 'year') {
days = this._days + milliseconds / 864e5;
months = this._months + daysToMonths(days);
switch (units) {
case 'month':
return months;
case 'quarter':
return months / 3;
case 'year':
return months / 12;
}
} else {
// handle milliseconds separately because of floating point math errors (issue #1867)
days = this._days + Math.round(monthsToDays(this._months));
switch (units) {
case 'week':
return days / 7 + milliseconds / 6048e5;
case 'day':
return days + milliseconds / 864e5;
case 'hour':
return days * 24 + milliseconds / 36e5;
case 'minute':
return days * 1440 + milliseconds / 6e4;
case 'second':
return days * 86400 + milliseconds / 1000;
// Math.floor prevents floating point math errors here
case 'millisecond':
return Math.floor(days * 864e5) + milliseconds;
default:
throw new Error('Unknown unit ' + units);
}
}
}
// TODO: Use this.as('ms')?
function valueOf$1() {
if (!this.isValid()) {
return NaN;
}
return (
this._milliseconds +
this._days * 864e5 +
(this._months % 12) * 2592e6 +
toInt(this._months / 12) * 31536e6
);
}
function makeAs(alias) {
return function () {
return this.as(alias);
};
}
var asMilliseconds = makeAs('ms'),
asSeconds = makeAs('s'),
asMinutes = makeAs('m'),
asHours = makeAs('h'),
asDays = makeAs('d'),
asWeeks = makeAs('w'),
asMonths = makeAs('M'),
asQuarters = makeAs('Q'),
asYears = makeAs('y');
function clone$1() {
return createDuration(this);
}
function get$2(units) {
units = normalizeUnits(units);
return this.isValid() ? this[units + 's']() : NaN;
}
function makeGetter(name) {
return function () {
return this.isValid() ? this._data[name] : NaN;
};
}
var milliseconds = makeGetter('milliseconds'),
seconds = makeGetter('seconds'),
minutes = makeGetter('minutes'),
hours = makeGetter('hours'),
days = makeGetter('days'),
months = makeGetter('months'),
years = makeGetter('years');
function weeks() {
return absFloor(this.days() / 7);
}
var round = Math.round,
thresholds = {
ss: 44, // a few seconds to seconds
s: 45, // seconds to minute
m: 45, // minutes to hour
h: 22, // hours to day
d: 26, // days to month/week
w: null, // weeks to month
M: 11, // months to year
};
// helper function for moment.fn.from, moment.fn.fromNow, and moment.duration.fn.humanize
function substituteTimeAgo(string, number, withoutSuffix, isFuture, locale) {
return locale.relativeTime(number || 1, !!withoutSuffix, string, isFuture);
}
function relativeTime$1(posNegDuration, withoutSuffix, thresholds, locale) {
var duration = createDuration(posNegDuration).abs(),
seconds = round(duration.as('s')),
minutes = round(duration.as('m')),
hours = round(duration.as('h')),
days = round(duration.as('d')),
months = round(duration.as('M')),
weeks = round(duration.as('w')),
years = round(duration.as('y')),
a =
(seconds <= thresholds.ss && ['s', seconds]) ||
(seconds < thresholds.s && ['ss', seconds]) ||
(minutes <= 1 && ['m']) ||
(minutes < thresholds.m && ['mm', minutes]) ||
(hours <= 1 && ['h']) ||
(hours < thresholds.h && ['hh', hours]) ||
(days <= 1 && ['d']) ||
(days < thresholds.d && ['dd', days]);
if (thresholds.w != null) {
a =
a ||
(weeks <= 1 && ['w']) ||
(weeks < thresholds.w && ['ww', weeks]);
}
a = a ||
(months <= 1 && ['M']) ||
(months < thresholds.M && ['MM', months]) ||
(years <= 1 && ['y']) || ['yy', years];
a[2] = withoutSuffix;
a[3] = +posNegDuration > 0;
a[4] = locale;
return substituteTimeAgo.apply(null, a);
}
// This function allows you to set the rounding function for relative time strings
function getSetRelativeTimeRounding(roundingFunction) {
if (roundingFunction === undefined) {
return round;
}
if (typeof roundingFunction === 'function') {
round = roundingFunction;
return true;
}
return false;
}
// This function allows you to set a threshold for relative time strings
function getSetRelativeTimeThreshold(threshold, limit) {
if (thresholds[threshold] === undefined) {
return false;
}
if (limit === undefined) {
return thresholds[threshold];
}
thresholds[threshold] = limit;
if (threshold === 's') {
thresholds.ss = limit - 1;
}
return true;
}
function humanize(argWithSuffix, argThresholds) {
if (!this.isValid()) {
return this.localeData().invalidDate();
}
var withSuffix = false,
th = thresholds,
locale,
output;
if (typeof argWithSuffix === 'object') {
argThresholds = argWithSuffix;
argWithSuffix = false;
}
if (typeof argWithSuffix === 'boolean') {
withSuffix = argWithSuffix;
}
if (typeof argThresholds === 'object') {
th = Object.assign({}, thresholds, argThresholds);
if (argThresholds.s != null && argThresholds.ss == null) {
th.ss = argThresholds.s - 1;
}
}
locale = this.localeData();
output = relativeTime$1(this, !withSuffix, th, locale);
if (withSuffix) {
output = locale.pastFuture(+this, output);
}
return locale.postformat(output);
}
var abs$1 = Math.abs;
function sign(x) {
return (x > 0) - (x < 0) || +x;
}
function toISOString$1() {
// for ISO strings we do not use the normal bubbling rules:
// * milliseconds bubble up until they become hours
// * days do not bubble at all
// * months bubble up until they become years
// This is because there is no context-free conversion between hours and days
// (think of clock changes)
// and also not between days and months (28-31 days per month)
if (!this.isValid()) {
return this.localeData().invalidDate();
}
var seconds = abs$1(this._milliseconds) / 1000,
days = abs$1(this._days),
months = abs$1(this._months),
minutes,
hours,
years,
s,
total = this.asSeconds(),
totalSign,
ymSign,
daysSign,
hmsSign;
if (!total) {
// this is the same as C#'s (Noda) and python (isodate)...
// but not other JS (goog.date)
return 'P0D';
}
// 3600 seconds -> 60 minutes -> 1 hour
minutes = absFloor(seconds / 60);
hours = absFloor(minutes / 60);
seconds %= 60;
minutes %= 60;
// 12 months -> 1 year
years = absFloor(months / 12);
months %= 12;
// inspired by https://github.com/dordille/moment-isoduration/blob/master/moment.isoduration.js
s = seconds ? seconds.toFixed(3).replace(/\.?0+$/, '') : '';
totalSign = total < 0 ? '-' : '';
ymSign = sign(this._months) !== sign(total) ? '-' : '';
daysSign = sign(this._days) !== sign(total) ? '-' : '';
hmsSign = sign(this._milliseconds) !== sign(total) ? '-' : '';
return (
totalSign +
'P' +
(years ? ymSign + years + 'Y' : '') +
(months ? ymSign + months + 'M' : '') +
(days ? daysSign + days + 'D' : '') +
(hours || minutes || seconds ? 'T' : '') +
(hours ? hmsSign + hours + 'H' : '') +
(minutes ? hmsSign + minutes + 'M' : '') +
(seconds ? hmsSign + s + 'S' : '')
);
}
var proto$2 = Duration.prototype;
proto$2.isValid = isValid$1;
proto$2.abs = abs;
proto$2.add = add$1;
proto$2.subtract = subtract$1;
proto$2.as = as;
proto$2.asMilliseconds = asMilliseconds;
proto$2.asSeconds = asSeconds;
proto$2.asMinutes = asMinutes;
proto$2.asHours = asHours;
proto$2.asDays = asDays;
proto$2.asWeeks = asWeeks;
proto$2.asMonths = asMonths;
proto$2.asQuarters = asQuarters;
proto$2.asYears = asYears;
proto$2.valueOf = valueOf$1;
proto$2._bubble = bubble;
proto$2.clone = clone$1;
proto$2.get = get$2;
proto$2.milliseconds = milliseconds;
proto$2.seconds = seconds;
proto$2.minutes = minutes;
proto$2.hours = hours;
proto$2.days = days;
proto$2.weeks = weeks;
proto$2.months = months;
proto$2.years = years;
proto$2.humanize = humanize;
proto$2.toISOString = toISOString$1;
proto$2.toString = toISOString$1;
proto$2.toJSON = toISOString$1;
proto$2.locale = locale;
proto$2.localeData = localeData;
proto$2.toIsoString = deprecate(
'toIsoString() is deprecated. Please use toISOString() instead (notice the capitals)',
toISOString$1
);
proto$2.lang = lang;
// FORMATTING
addFormatToken('X', 0, 0, 'unix');
addFormatToken('x', 0, 0, 'valueOf');
// PARSING
addRegexToken('x', matchSigned);
addRegexToken('X', matchTimestamp);
addParseToken('X', function (input, array, config) {
config._d = new Date(parseFloat(input) * 1000);
});
addParseToken('x', function (input, array, config) {
config._d = new Date(toInt(input));
});
//! moment.js
hooks.version = '2.29.1';
setHookCallback(createLocal);
hooks.fn = proto;
hooks.min = min;
hooks.max = max;
hooks.now = now;
hooks.utc = createUTC;
hooks.unix = createUnix;
hooks.months = listMonths;
hooks.isDate = isDate;
hooks.locale = getSetGlobalLocale;
hooks.invalid = createInvalid;
hooks.duration = createDuration;
hooks.isMoment = isMoment;
hooks.weekdays = listWeekdays;
hooks.parseZone = createInZone;
hooks.localeData = getLocale;
hooks.isDuration = isDuration;
hooks.monthsShort = listMonthsShort;
hooks.weekdaysMin = listWeekdaysMin;
hooks.defineLocale = defineLocale;
hooks.updateLocale = updateLocale;
hooks.locales = listLocales;
hooks.weekdaysShort = listWeekdaysShort;
hooks.normalizeUnits = normalizeUnits;
hooks.relativeTimeRounding = getSetRelativeTimeRounding;
hooks.relativeTimeThreshold = getSetRelativeTimeThreshold;
hooks.calendarFormat = getCalendarFormat;
hooks.prototype = proto;
// currently HTML5 input type only supports 24-hour formats
hooks.HTML5_FMT = {
DATETIME_LOCAL: 'YYYY-MM-DDTHH:mm', //
DATETIME_LOCAL_SECONDS: 'YYYY-MM-DDTHH:mm:ss', //
DATETIME_LOCAL_MS: 'YYYY-MM-DDTHH:mm:ss.SSS', //
DATE: 'YYYY-MM-DD', //
TIME: 'HH:mm', //
TIME_SECONDS: 'HH:mm:ss', //
TIME_MS: 'HH:mm:ss.SSS', //
WEEK: 'GGGG-[W]WW', //
MONTH: 'YYYY-MM', //
};
return hooks;
})));
================================================
FILE: tests/test_code/js/scoping/scoping.js
================================================
function scope_confusion() {
console.log('scope_confusion');
}
class MyClass {
scope_confusion() {
console.log('scope_confusion');
}
a() {
this.scope_confusion();
}
b() {
scope_confusion();
}
}
let obj = new myClass();
obj.a();
obj.b();
================================================
FILE: tests/test_code/js/simple_a_js/simple_a.js
================================================
function func_b() {}
function func_a() {
func_b();
}
================================================
FILE: tests/test_code/js/simple_b_js/simple_b.js
================================================
function a() {
b();
}
function b() {
a("STRC #");
}
class C {
d(param) {
a("AnotherSTR");
}
}
const c = new C()
c.d()
================================================
FILE: tests/test_code/js/ternary_new/ternary_new.js
================================================
class Abra {
init() {
return this.init()
}
}
class Cadabra {
init() {
return this.init()
}
}
function abra_fact() {
return Abra;
}
function cadabra_fact() {
return Cadabra;
}
class ClassMap {
fact(which) {
return which == "abra" ? abra_fact : cadabra_fact;
}
}
obj = true ? new ClassMap.fact("abra").init(n) : new ClassMap.fact("cadabra").init(n)
obj = true ? new ClassMap.fact("abra").fact().init(n) : new ClassMap.fact("cadabra").fact().init(n)
================================================
FILE: tests/test_code/js/two_file_imports/imported.js
================================================
class myClass {
constructor() {
this.doit()
}
get doit() {
this.doit2()
}
doit2() {
console.log('at the end')
}
}
function inner() {
console.log("inner")
}
function bye() {
}
module.exports = {myClass, inner, 'hi': bye};
================================================
FILE: tests/test_code/js/two_file_imports/importer.js
================================================
const {myClass, inner, hi} = require("imported");
function outer() {
let cls = new myClass();
inner();
hi();
}
outer();
================================================
FILE: tests/test_code/js/two_file_simple/file_a.js
================================================
function a() {
b()
}
a();
================================================
FILE: tests/test_code/js/two_file_simple/file_b.js
================================================
function b() {
console.log("here")
}
function c() {}
================================================
FILE: tests/test_code/js/two_file_simple/shouldntberead
================================================
function d() {
e();
}
================================================
FILE: tests/test_code/js/weird_assignments/weird_assignments.js
================================================
function get_ab() {
return {a: 1, b: 2};
}
let {a, b} = get_ab()
================================================
FILE: tests/test_code/mjs/two_file_imports_es6/imported_es6.mjs
================================================
class myClass {
constructor() {
this.doit();
}
doit() {
this.doit2();
}
doit2() {
console.log('at the end')
}
}
function inner() {
console.log("inner")
}
export {myClass, inner};
================================================
FILE: tests/test_code/mjs/two_file_imports_es6/importer_es6.mjs
================================================
import {myClass, inner} from "./imported_es6.mjs";
function outer() {
let cls = new myClass();
inner();
}
outer();
================================================
FILE: tests/test_code/php/ambiguous_resolution/ambiguous_resolution.php
================================================
abra_it();
$a->magic();
}
}
function main($cls) {
echo "main";
$obj = new $cls;
$obj->magic();
$obj->cadabra_it(new Abra());
}
main(Cadabra::class);
?>
================================================
FILE: tests/test_code/php/anon/anonymous_function.php
================================================
================================================
FILE: tests/test_code/php/anon2/anonymous_function2.php
================================================
================================================
FILE: tests/test_code/php/bad_php/bad_php_a.php
================================================
================================================
FILE: tests/test_code/php/bad_php/bad_php_b.php
================================================
Hello World
================================================
FILE: tests/test_code/php/branch/branch.php
================================================
================================================
FILE: tests/test_code/php/chains/chains.php
================================================
a()->b()->a();
}
a();
b();
c();
?>
================================================
FILE: tests/test_code/php/factory/currency.php
================================================
code */
$this->code = strtoupper($code);
}
/**
* Returns the currency code.
*
* @psalm-return non-empty-string
*/
public function getCode(): string
{
return $this->code;
}
/**
* Checks whether this currency is the same as an other.
*/
public function equals(Currency $other): bool
{
return $this->code === $other->code;
}
public function __toString(): string
{
return $this->code;
}
/**
* {@inheritdoc}
*
* @return string
*/
public function jsonSerialize()
{
return $this->code;
}
}
/**
* Implement this to provide a list of currencies.
*/
interface Currencies extends IteratorAggregate
{
/**
* Checks whether a currency is available in the current context.
*/
public function contains(Currency $currency): bool;
/**
* Returns the subunit for a currency.
*
* @throws UnknownCurrencyException If currency is not available in the current context.
*/
public function subunitFor(Currency $currency): int;
/**
* @psalm-return Traversable
*/
public function getIterator(): Traversable;
}
================================================
FILE: tests/test_code/php/factory/factory.php
================================================
strcmp($a->getCode(), $b->getCode()));
/** @var Currency[] $currencies */
foreach ($currencies as $currency) {
$methodBuffer .= sprintf(" * @method static Money %s(numeric-string|int \$amount)\n", $currency->getCode());
echo $currency.contains($bitcoin);
}
$buffer = str_replace('PHPDOC', rtrim($methodBuffer), $buffer);
file_put_contents('content.php', $buffer);
})();
================================================
FILE: tests/test_code/php/inheritance/inheritance.php
================================================
name = $name;
$this->color = $color;
}
public function __construct() {
echo "__construct";
}
public function intro() {
echo "The fruit is {$this->name} and the color is {$this->color}.";
}
}
class Fruit {
public $name;
public $color;
public function __construct($name, $color) {
$this->name = $name;
$this->color = $color;
}
public function intro() {
echo "The fruit is {$this->name} and the color is {$this->color}.";
}
public function getColor() {
return $this->color;
}
}
class PhantomFruit {
public $name;
public $color;
public function __construct($name, $color) {
$this->name = $name;
$this->color = $color;
}
public function __construct() {
echo "__construct";
}
public function intro() {
echo "The fruit is {$this->name} and the color is {$this->color}.";
}
}
// Strawberry is inherited from Fruit
class Strawberry extends Fruit {
public function message() {
echo "Am I a fruit or a berry? ";
$this.getColor();
}
}
$strawberry = new Strawberry("Strawberry", "red");
$strawberry->message();
$strawberry->intro();
?>
================================================
FILE: tests/test_code/php/inheritance2/inheritance2.php
================================================
name = $name;
}
abstract public function intro() : string;
}
// Interface
interface Noisy {
public function makeSound();
}
// Child classes
class Audi extends Car implements Noisy {
public function intro() : string {
return "Choose German quality! I'm an $this->name!";
}
public function makeSound(): string {
return "HONK!";
}
}
class Volvo extends Car implements Noisy {
public function intro() : string {
return "Proud to be Swedish! I'm a $this->name!";
}
public function makeSound(): string {
return "HONK!";
}
}
class Citroen extends Car implements Noisy {
public function intro() : string {
return "French extravagance! I'm a $this->name!";
}
}
// Create objects from the child classes
$audi = new Audi("Audi");
echo $audi->intro();
echo $audi->makeSound();
echo " ";
$volvo = new Volvo("Volvo");
echo $volvo->intro();
echo " ";
$citroen = new Citroen("Citroen");
echo $citroen->intro();
?>
================================================
FILE: tests/test_code/php/instance_methods/instance_methods.php
================================================
nested();
}
function main2() {
echo "Abra.main2";
function nested2() {
echo "Abra.nested2";
$this.main();
}
}
}
echo "A";
$a = new Abra();
echo "B";
$a.main();
echo "C";
$a.nested();
$a.main2();
$a.nested2();
?>
================================================
FILE: tests/test_code/php/money/Calculator/BcMathCalculator.php
================================================
isInteger()) {
return $number->__toString();
}
if ($number->isNegative()) {
return bcadd($number->__toString(), '0', 0);
}
return bcadd($number->__toString(), '1', 0);
}
/** @psalm-pure */
public static function floor(string $number): string
{
$number = Number::fromString($number);
if ($number->isInteger()) {
return $number->__toString();
}
if ($number->isNegative()) {
return bcadd($number->__toString(), '-1', 0);
}
return bcadd($number->__toString(), '0', 0);
}
/**
* @psalm-suppress MoreSpecificReturnType we know that trimming `-` produces a positive numeric-string here
* @psalm-suppress LessSpecificReturnStatement we know that trimming `-` produces a positive numeric-string here
* @psalm-pure
*/
public static function absolute(string $number): string
{
return ltrim($number, '-');
}
/**
* @psalm-param Money::ROUND_* $roundingMode
*
* @psalm-return numeric-string
*
* @psalm-pure
*/
public static function round(string $number, int $roundingMode): string
{
$number = Number::fromString($number);
if ($number->isInteger()) {
return $number->__toString();
}
if ($number->isHalf() === false) {
return self::roundDigit($number);
}
if ($roundingMode === Money::ROUND_HALF_UP) {
return bcadd(
$number->__toString(),
$number->getIntegerRoundingMultiplier(),
0
);
}
if ($roundingMode === Money::ROUND_HALF_DOWN) {
return bcadd($number->__toString(), '0', 0);
}
if ($roundingMode === Money::ROUND_HALF_EVEN) {
if ($number->isCurrentEven()) {
return bcadd($number->__toString(), '0', 0);
}
return bcadd(
$number->__toString(),
$number->getIntegerRoundingMultiplier(),
0
);
}
if ($roundingMode === Money::ROUND_HALF_ODD) {
if ($number->isCurrentEven()) {
return bcadd(
$number->__toString(),
$number->getIntegerRoundingMultiplier(),
0
);
}
return bcadd($number->__toString(), '0', 0);
}
if ($roundingMode === Money::ROUND_HALF_POSITIVE_INFINITY) {
if ($number->isNegative()) {
return bcadd($number->__toString(), '0', 0);
}
return bcadd(
$number->__toString(),
$number->getIntegerRoundingMultiplier(),
0
);
}
if ($roundingMode === Money::ROUND_HALF_NEGATIVE_INFINITY) {
if ($number->isNegative()) {
return bcadd(
$number->__toString(),
$number->getIntegerRoundingMultiplier(),
0
);
}
return bcadd(
$number->__toString(),
'0',
0
);
}
throw new CoreInvalidArgumentException('Unknown rounding mode');
}
/**
* @psalm-return numeric-string
*
* @psalm-pure
*/
private static function roundDigit(Number $number): string
{
if ($number->isCloserToNext()) {
return bcadd(
$number->__toString(),
$number->getIntegerRoundingMultiplier(),
0
);
}
return bcadd($number->__toString(), '0', 0);
}
/** @psalm-pure */
public static function share(string $amount, string $ratio, string $total): string
{
return self::floor(bcdiv(bcmul($amount, $ratio, self::SCALE), $total, self::SCALE));
}
/** @psalm-pure */
public static function mod(string $amount, string $divisor): string
{
if (bccomp($divisor, '0') === 0) {
throw InvalidArgumentException::moduloByZero();
}
return bcmod($amount, $divisor) ?? '0';
}
}
================================================
FILE: tests/test_code/php/money/Calculator/GmpCalculator.php
================================================
isDecimal() || $bNum->isDecimal()) {
$integersCompared = gmp_cmp($aNum->getIntegerPart(), $bNum->getIntegerPart());
if ($integersCompared !== 0) {
return $integersCompared;
}
$aNumFractional = $aNum->getFractionalPart() === '' ? '0' : $aNum->getFractionalPart();
$bNumFractional = $bNum->getFractionalPart() === '' ? '0' : $bNum->getFractionalPart();
return gmp_cmp($aNumFractional, $bNumFractional);
}
return gmp_cmp($a, $b);
}
/** @psalm-pure */
public static function add(string $amount, string $addend): string
{
return gmp_strval(gmp_add($amount, $addend));
}
/** @psalm-pure */
public static function subtract(string $amount, string $subtrahend): string
{
return gmp_strval(gmp_sub($amount, $subtrahend));
}
/** @psalm-pure */
public static function multiply(string $amount, string $multiplier): string
{
$multiplier = Number::fromString($multiplier);
if ($multiplier->isDecimal()) {
$decimalPlaces = strlen($multiplier->getFractionalPart());
$multiplierBase = $multiplier->getIntegerPart();
$negativeZero = $multiplierBase === '-0';
if ($negativeZero) {
$multiplierBase = '-';
}
if ($multiplierBase) {
$multiplierBase .= $multiplier->getFractionalPart();
} else {
$multiplierBase = ltrim($multiplier->getFractionalPart(), '0');
}
$resultBase = gmp_strval(gmp_mul(gmp_init($amount), gmp_init($multiplierBase)));
if ($resultBase === '0') {
return '0';
}
$result = substr($resultBase, $decimalPlaces * -1);
$resultLength = strlen($result);
if ($decimalPlaces > $resultLength) {
/** @psalm-var numeric-string $finalResult */
$finalResult = '0.' . str_pad('', $decimalPlaces - $resultLength, '0') . $result;
return $finalResult;
}
/** @psalm-var numeric-string $finalResult */
$finalResult = substr($resultBase, 0, $decimalPlaces * -1) . '.' . $result;
if ($negativeZero) {
/** @psalm-var numeric-string $finalResult */
$finalResult = str_replace('-.', '-0.', $finalResult);
}
return $finalResult;
}
return gmp_strval(gmp_mul(gmp_init($amount), gmp_init((string) $multiplier)));
}
/** @psalm-pure */
public static function divide(string $amount, string $divisor): string
{
if (self::compare($divisor, '0') === 0) {
throw InvalidArgumentException::divisionByZero();
}
$divisor = Number::fromString($divisor);
if ($divisor->isDecimal()) {
$decimalPlaces = strlen($divisor->getFractionalPart());
$divisorBase = $divisor->getIntegerPart();
$negativeZero = $divisorBase === '-0';
if ($negativeZero) {
$divisorBase = '-';
}
if ($divisor->getIntegerPart()) {
$divisor = new Number($divisorBase . $divisor->getFractionalPart());
} else {
$divisor = new Number(ltrim($divisor->getFractionalPart(), '0'));
}
$amount = gmp_strval(gmp_mul(gmp_init($amount), gmp_init('1' . str_pad('', $decimalPlaces, '0'))));
}
[$integer, $remainder] = gmp_div_qr(gmp_init($amount), gmp_init((string) $divisor));
if (gmp_cmp($remainder, '0') === 0) {
return gmp_strval($integer);
}
$divisionOfRemainder = gmp_strval(
gmp_div_q(
gmp_mul($remainder, gmp_init('1' . str_pad('', self::SCALE, '0'))),
gmp_init((string) $divisor),
GMP_ROUND_MINUSINF
)
);
if ($divisionOfRemainder[0] === '-') {
$divisionOfRemainder = substr($divisionOfRemainder, 1);
}
/** @psalm-var numeric-string $finalResult */
$finalResult = gmp_strval($integer) . '.' . str_pad($divisionOfRemainder, self::SCALE, '0', STR_PAD_LEFT);
return $finalResult;
}
/** @psalm-pure */
public static function ceil(string $number): string
{
$number = Number::fromString($number);
if ($number->isInteger()) {
return $number->__toString();
}
if ($number->isNegative()) {
return self::add($number->getIntegerPart(), '0');
}
return self::add($number->getIntegerPart(), '1');
}
/** @psalm-pure */
public static function floor(string $number): string
{
$number = Number::fromString($number);
if ($number->isInteger()) {
return $number->__toString();
}
if ($number->isNegative()) {
return self::add($number->getIntegerPart(), '-1');
}
return self::add($number->getIntegerPart(), '0');
}
/**
* @psalm-suppress MoreSpecificReturnType we know that trimming `-` produces a positive numeric-string here
* @psalm-suppress LessSpecificReturnStatement we know that trimming `-` produces a positive numeric-string here
* @psalm-pure
*/
public static function absolute(string $number): string
{
return ltrim($number, '-');
}
/**
* @psalm-param Money::ROUND_* $roundingMode
*
* @psalm-return numeric-string
*
* @psalm-pure
*/
public static function round(string $number, int $roundingMode): string
{
$number = Number::fromString($number);
if ($number->isInteger()) {
return $number->__toString();
}
if ($number->isHalf() === false) {
return self::roundDigit($number);
}
if ($roundingMode === Money::ROUND_HALF_UP) {
return self::add(
$number->getIntegerPart(),
$number->getIntegerRoundingMultiplier()
);
}
if ($roundingMode === Money::ROUND_HALF_DOWN) {
return self::add($number->getIntegerPart(), '0');
}
if ($roundingMode === Money::ROUND_HALF_EVEN) {
if ($number->isCurrentEven()) {
return self::add($number->getIntegerPart(), '0');
}
return self::add(
$number->getIntegerPart(),
$number->getIntegerRoundingMultiplier()
);
}
if ($roundingMode === Money::ROUND_HALF_ODD) {
if ($number->isCurrentEven()) {
return self::add(
$number->getIntegerPart(),
$number->getIntegerRoundingMultiplier()
);
}
return self::add($number->getIntegerPart(), '0');
}
if ($roundingMode === Money::ROUND_HALF_POSITIVE_INFINITY) {
if ($number->isNegative()) {
return self::add(
$number->getIntegerPart(),
'0'
);
}
return self::add(
$number->getIntegerPart(),
$number->getIntegerRoundingMultiplier()
);
}
if ($roundingMode === Money::ROUND_HALF_NEGATIVE_INFINITY) {
if ($number->isNegative()) {
return self::add(
$number->getIntegerPart(),
$number->getIntegerRoundingMultiplier()
);
}
return self::add(
$number->getIntegerPart(),
'0'
);
}
throw new CoreInvalidArgumentException('Unknown rounding mode');
}
/**
* @psalm-return numeric-string
*
* @psalm-pure
*/
private static function roundDigit(Number $number): string
{
if ($number->isCloserToNext()) {
return self::add(
$number->getIntegerPart(),
$number->getIntegerRoundingMultiplier()
);
}
return self::add($number->getIntegerPart(), '0');
}
/** @psalm-pure */
public static function share(string $amount, string $ratio, string $total): string
{
return self::floor(self::divide(self::multiply($amount, $ratio), $total));
}
/** @psalm-pure */
public static function mod(string $amount, string $divisor): string
{
if (self::compare($divisor, '0') === 0) {
throw InvalidArgumentException::moduloByZero();
}
// gmp_mod() only calculates non-negative integers, so we use absolutes
$remainder = gmp_mod(self::absolute($amount), self::absolute($divisor));
// If the amount was negative, we negate the result of the modulus operation
$amount = Number::fromString($amount);
if ($amount->isNegative()) {
$remainder = gmp_neg($remainder);
}
return gmp_strval($remainder);
}
}
================================================
FILE: tests/test_code/php/money/Calculator.php
================================================
$b.
* Retrieves zero if $a == $b
*
* @psalm-param numeric-string $a
* @psalm-param numeric-string $b
*
* @psalm-pure
*/
public static function compare(string $a, string $b): int;
/**
* Add added to amount.
*
* @psalm-param numeric-string $amount
* @psalm-param numeric-string $addend
*
* @psalm-return numeric-string
*
* @psalm-pure
*/
public static function add(string $amount, string $addend): string;
/**
* Subtract subtrahend from amount.
*
* @psalm-param numeric-string $amount
* @psalm-param numeric-string $subtrahend
*
* @psalm-return numeric-string
*
* @psalm-pure
*/
public static function subtract(string $amount, string $subtrahend): string;
/**
* Multiply amount with multiplier.
*
* @psalm-param numeric-string $amount
* @psalm-param numeric-string $multiplier
*
* @psalm-return numeric-string
*
* @psalm-pure
*/
public static function multiply(string $amount, string $multiplier): string;
/**
* Divide amount with divisor.
*
* @psalm-param numeric-string $amount
* @psalm-param numeric-string $divisor
*
* @psalm-return numeric-string
*
* @throws InvalidArgumentException when $divisor is zero.
*
* @psalm-pure
*/
public static function divide(string $amount, string $divisor): string;
/**
* Round number to following integer.
*
* @psalm-param numeric-string $number
*
* @psalm-return numeric-string
*
* @psalm-pure
*/
public static function ceil(string $number): string;
/**
* Round number to preceding integer.
*
* @psalm-param numeric-string $number
*
* @psalm-return numeric-string
*
* @psalm-pure
*/
public static function floor(string $number): string;
/**
* Returns the absolute value of the number.
*
* @psalm-param numeric-string $number
*
* @psalm-return numeric-string
*
* @psalm-pure
*/
public static function absolute(string $number): string;
/**
* Round number, use rounding mode for tie-breaker.
*
* @psalm-param numeric-string $number
* @psalm-param Money::ROUND_* $roundingMode
*
* @psalm-return numeric-string
*
* @psalm-pure
*/
public static function round(string $number, int $roundingMode): string;
/**
* Share amount among ratio / total portions.
*
* @psalm-param numeric-string $amount
* @psalm-param numeric-string $ratio
* @psalm-param numeric-string $total
*
* @psalm-return numeric-string
*
* @psalm-pure
*/
public static function share(string $amount, string $ratio, string $total): string;
/**
* Get the modulus of an amount.
*
* @psalm-param numeric-string $amount
* @psalm-param numeric-string $divisor
*
* @psalm-return numeric-string
*
* @throws InvalidArgumentException when $divisor is zero.
*
* @psalm-pure
*/
public static function mod(string $amount, string $divisor): string;
}
================================================
FILE: tests/test_code/php/money/Converter.php
================================================
currencies = $currencies;
$this->exchange = $exchange;
}
public function convert(Money $money, Currency $counterCurrency, int $roundingMode = Money::ROUND_HALF_UP): Money
{
return $this->convertAgainstCurrencyPair(
$money,
$this->exchange->quote(
$money->getCurrency(),
$counterCurrency
),
$roundingMode
);
}
/** @return array{0: Money, 1: CurrencyPair} */
public function convertAndReturnWithCurrencyPair(Money $money, Currency $counterCurrency, int $roundingMode = Money::ROUND_HALF_UP): array
{
$pair = $this->exchange->quote(
$money->getCurrency(),
$counterCurrency
);
return [$this->convertAgainstCurrencyPair($money, $pair, $roundingMode), $pair];
}
public function convertAgainstCurrencyPair(Money $money, CurrencyPair $currencyPair, int $roundingMode = Money::ROUND_HALF_UP): Money
{
if (! $money->getCurrency()->equals($currencyPair->getBaseCurrency())) {
throw new InvalidArgumentException(
sprintf(
'Expecting to convert against base currency %s, but got %s instead',
$money->getCurrency()->getCode(),
$currencyPair->getBaseCurrency()->getCode()
)
);
}
$ratio = $currencyPair->getConversionRatio();
$baseCurrencySubunit = $this->currencies->subunitFor($currencyPair->getBaseCurrency());
$counterCurrencySubunit = $this->currencies->subunitFor($currencyPair->getCounterCurrency());
$subunitDifference = $baseCurrencySubunit - $counterCurrencySubunit;
$ratio = Number::fromString($ratio)
->base10($subunitDifference)
->__toString();
$counterValue = $money->multiply($ratio, $roundingMode);
return new Money($counterValue->getAmount(), $currencyPair->getCounterCurrency());
}
}
================================================
FILE: tests/test_code/php/money/Currencies/AggregateCurrencies.php
================================================
currencies = $currencies;
}
public function contains(Currency $currency): bool
{
foreach ($this->currencies as $currencies) {
if ($currencies->contains($currency)) {
return true;
}
}
return false;
}
public function subunitFor(Currency $currency): int
{
foreach ($this->currencies as $currencies) {
if ($currencies->contains($currency)) {
return $currencies->subunitFor($currency);
}
}
throw new UnknownCurrencyException('Cannot find currency ' . $currency->getCode());
}
/** {@inheritDoc} */
public function getIterator(): Traversable
{
/** @psalm-var AppendIterator&Traversable $iterator */
$iterator = new AppendIterator();
foreach ($this->currencies as $currencies) {
$iterator->append($currencies->getIterator());
}
return $iterator;
}
}
================================================
FILE: tests/test_code/php/money/Currencies/BitcoinCurrencies.php
================================================
getCode() === self::CODE;
}
public function subunitFor(Currency $currency): int
{
if ($currency->getCode() !== self::CODE) {
throw new UnknownCurrencyException($currency->getCode() . ' is not bitcoin and is not supported by this currency repository');
}
return 8;
}
/** {@inheritDoc} */
public function getIterator(): Traversable
{
return new ArrayIterator([new Currency(self::CODE)]);
}
}
================================================
FILE: tests/test_code/php/money/Currencies/CachedCurrencies.php
================================================
currencies = $currencies;
$this->pool = $pool;
}
public function contains(Currency $currency): bool
{
$item = $this->pool->getItem('currency|availability|' . $currency->getCode());
if ($item->isHit() === false) {
$item->set($this->currencies->contains($currency));
if ($item instanceof TaggableCacheItemInterface) {
$item->setTags(['currency.availability']);
}
$this->pool->save($item);
}
return (bool) $item->get();
}
public function subunitFor(Currency $currency): int
{
$item = $this->pool->getItem('currency|subunit|' . $currency->getCode());
if ($item->isHit() === false) {
$item->set($this->currencies->subunitFor($currency));
if ($item instanceof TaggableCacheItemInterface) {
$item->setTags(['currency.subunit']);
}
$this->pool->save($item);
}
return (int) $item->get();
}
/** {@inheritDoc} */
public function getIterator(): Traversable
{
return new CallbackFilterIterator(
new ArrayIterator(iterator_to_array($this->currencies->getIterator())),
function (Currency $currency): bool {
$item = $this->pool->getItem('currency|availability|' . $currency->getCode());
$item->set(true);
if ($item instanceof TaggableCacheItemInterface) {
$item->setTags(['currency.availability']);
}
$this->pool->save($item);
return true;
}
);
}
}
================================================
FILE: tests/test_code/php/money/Currencies/CurrencyList.php
================================================
*/
private array $currencies;
/** @psalm-param array $currencies */
public function __construct(array $currencies)
{
$this->currencies = $currencies;
}
public function contains(Currency $currency): bool
{
return isset($this->currencies[$currency->getCode()]);
}
public function subunitFor(Currency $currency): int
{
if (! $this->contains($currency)) {
throw new UnknownCurrencyException('Cannot find currency ' . $currency->getCode());
}
return $this->currencies[$currency->getCode()];
}
/** {@inheritDoc} */
public function getIterator(): Traversable
{
return new ArrayIterator(
array_map(
static function ($code) {
return new Currency($code);
},
array_keys($this->currencies)
)
);
}
}
================================================
FILE: tests/test_code/php/money/Currencies/ISOCurrencies.php
================================================
|null
*/
private static ?array $currencies = null;
public function contains(Currency $currency): bool
{
return isset($this->getCurrencies()[$currency->getCode()]);
}
public function subunitFor(Currency $currency): int
{
if (! $this->contains($currency)) {
throw new UnknownCurrencyException('Cannot find ISO currency ' . $currency->getCode());
}
return $this->getCurrencies()[$currency->getCode()]['minorUnit'];
}
/**
* Returns the numeric code for a currency.
*
* @throws UnknownCurrencyException If currency is not available in the current context.
*/
public function numericCodeFor(Currency $currency): int
{
if (! $this->contains($currency)) {
throw new UnknownCurrencyException('Cannot find ISO currency ' . $currency->getCode());
}
return $this->getCurrencies()[$currency->getCode()]['numericCode'];
}
/**
* @psalm-return Traversable
*/
public function getIterator(): Traversable
{
return new ArrayIterator(
array_map(
static function ($code) {
return new Currency($code);
},
array_keys($this->getCurrencies())
)
);
}
/**
* Returns a map of known currencies indexed by code.
*
* @psalm-return non-empty-array
*/
private function getCurrencies(): array
{
if (self::$currencies === null) {
self::$currencies = $this->loadCurrencies();
}
return self::$currencies;
}
/**
* @psalm-return non-empty-array
*
* @psalm-suppress MixedInferredReturnType `include` cannot be inferred here
* @psalm-suppress MixedReturnStatement `include` cannot be inferred here
*/
private function loadCurrencies(): array
{
$file = __DIR__ . '/../../resources/currency.php';
if (is_file($file)) {
return require $file;
}
throw new RuntimeException('Failed to load currency ISO codes.');
}
}
================================================
FILE: tests/test_code/php/money/Currencies.php
================================================
*/
public function getIterator(): Traversable;
}
================================================
FILE: tests/test_code/php/money/Currency.php
================================================
code */
$this->code = strtoupper($code);
}
/**
* Returns the currency code.
*
* @psalm-return non-empty-string
*/
public function getCode(): string
{
return $this->code;
}
/**
* Checks whether this currency is the same as an other.
*/
public function equals(Currency $other): bool
{
return $this->code === $other->code;
}
public function __toString(): string
{
return $this->code;
}
/**
* {@inheritdoc}
*
* @return string
*/
public function jsonSerialize()
{
return $this->code;
}
}
================================================
FILE: tests/test_code/php/money/CurrencyPair.php
================================================
counterCurrency = $counterCurrency;
$this->baseCurrency = $baseCurrency;
$this->conversionRatio = $conversionRatio;
}
/**
* Creates a new Currency Pair based on "EUR/USD 1.2500" form representation.
*
* @param string $iso String representation of the form "EUR/USD 1.2500"
*
* @throws InvalidArgumentException Format of $iso is invalid.
*/
public static function createFromIso(string $iso): CurrencyPair
{
$currency = '([A-Z]{2,3})';
$ratio = '([0-9]*\.?[0-9]+)'; // @see http://www.regular-expressions.info/floatingpoint.html
$pattern = '#' . $currency . '/' . $currency . ' ' . $ratio . '#';
$matches = [];
if (! preg_match($pattern, $iso, $matches)) {
throw new InvalidArgumentException(sprintf('Cannot create currency pair from ISO string "%s", format of string is invalid', $iso));
}
assert(! empty($matches[1]));
assert(is_numeric($matches[2]));
assert(is_numeric($matches[3]));
return new self(new Currency($matches[1]), new Currency($matches[2]), $matches[3]);
}
/**
* Returns the counter currency.
*/
public function getCounterCurrency(): Currency
{
return $this->counterCurrency;
}
/**
* Returns the base currency.
*/
public function getBaseCurrency(): Currency
{
return $this->baseCurrency;
}
/**
* Returns the conversion ratio.
*
* @psalm-return numeric-string
*/
public function getConversionRatio(): string
{
return $this->conversionRatio;
}
/**
* Checks if an other CurrencyPair has the same parameters as this.
*/
public function equals(CurrencyPair $other): bool
{
return $this->baseCurrency->equals($other->baseCurrency)
&& $this->counterCurrency->equals($other->counterCurrency)
&& $this->conversionRatio === $other->conversionRatio;
}
/**
* {@inheritdoc}
*
* @return array
*/
public function jsonSerialize()
{
return [
'baseCurrency' => $this->baseCurrency,
'counterCurrency' => $this->counterCurrency,
'ratio' => $this->conversionRatio,
];
}
}
================================================
FILE: tests/test_code/php/money/Exception/FormatterException.php
================================================
getCode(),
$counterCurrency->getCode()
);
return new self($message);
}
}
================================================
FILE: tests/test_code/php/money/Exception.php
================================================
exchanger = $exchanger;
}
public function quote(Currency $baseCurrency, Currency $counterCurrency): CurrencyPair
{
try {
$query = new ExchangeRateQuery(
new ExchangerCurrencyPair($baseCurrency->getCode(), $counterCurrency->getCode())
);
$rate = $this->exchanger->getExchangeRate($query);
} catch (ExchangerException) {
throw UnresolvableCurrencyPairException::createFromCurrencies($baseCurrency, $counterCurrency);
}
$rateValue = sprintf('%.14F', $rate->getValue());
assert(is_numeric($rateValue));
return new CurrencyPair($baseCurrency, $counterCurrency, $rateValue);
}
}
================================================
FILE: tests/test_code/php/money/Exchange/FixedExchange.php
================================================
> */
private array $list;
/** @psalm-param array> $list */
public function __construct(array $list)
{
$this->list = $list;
}
public function quote(Currency $baseCurrency, Currency $counterCurrency): CurrencyPair
{
if (isset($this->list[$baseCurrency->getCode()][$counterCurrency->getCode()])) {
return new CurrencyPair(
$baseCurrency,
$counterCurrency,
$this->list[$baseCurrency->getCode()][$counterCurrency->getCode()]
);
}
throw UnresolvableCurrencyPairException::createFromCurrencies($baseCurrency, $counterCurrency);
}
}
================================================
FILE: tests/test_code/php/money/Exchange/IndirectExchange.php
================================================
exchange = $exchange;
$this->currencies = $currencies;
}
public function quote(Currency $baseCurrency, Currency $counterCurrency): CurrencyPair
{
try {
return $this->exchange->quote($baseCurrency, $counterCurrency);
} catch (UnresolvableCurrencyPairException) {
$rate = array_reduce(
$this->getConversions($baseCurrency, $counterCurrency),
/**
* @psalm-param numeric-string $carry
*
* @psalm-return numeric-string
*/
static function (string $carry, CurrencyPair $pair) {
$calculator = Money::getCalculator();
return $calculator::multiply($carry, $pair->getConversionRatio());
},
'1.0'
);
return new CurrencyPair($baseCurrency, $counterCurrency, $rate);
}
}
/**
* @return CurrencyPair[]
*
* @throws UnresolvableCurrencyPairException
*/
private function getConversions(Currency $baseCurrency, Currency $counterCurrency): array
{
$startNode = new IndirectExchangeQueuedItem($baseCurrency);
$startNode->discovered = true;
/** @psalm-var array $nodes */
$nodes = [$baseCurrency->getCode() => $startNode];
/** @psam-var SplQueue $frontier */
$frontier = new SplQueue();
$frontier->enqueue($startNode);
while ($frontier->count()) {
/** @psalm-var IndirectExchangeQueuedItem $currentNode */
$currentNode = $frontier->dequeue();
$currentCurrency = $currentNode->currency;
if ($currentCurrency->equals($counterCurrency)) {
return $this->reconstructConversionChain($nodes, $currentNode);
}
foreach ($this->currencies as $candidateCurrency) {
if (! isset($nodes[$candidateCurrency->getCode()])) {
$nodes[$candidateCurrency->getCode()] = new IndirectExchangeQueuedItem($candidateCurrency);
}
$node = $nodes[$candidateCurrency->getCode()];
if ($node->discovered) {
continue;
}
try {
// Check if the candidate is a neighbor. This will throw an exception if it isn't.
$this->exchange->quote($currentCurrency, $candidateCurrency);
$node->discovered = true;
$node->parent = $currentNode;
$frontier->enqueue($node);
} catch (UnresolvableCurrencyPairException $exception) {
// Not a neighbor. Move on.
}
}
}
throw UnresolvableCurrencyPairException::createFromCurrencies($baseCurrency, $counterCurrency);
}
/**
* @psalm-param array $currencies
*
* @return CurrencyPair[]
* @psalm-return list
*/
private function reconstructConversionChain(array $currencies, IndirectExchangeQueuedItem $goalNode): array
{
$current = $goalNode;
$conversions = [];
while ($current->parent) {
$previous = $currencies[$current->parent->currency->getCode()];
$conversions[] = $this->exchange->quote($previous->currency, $current->currency);
$current = $previous;
}
return array_reverse($conversions);
}
}
================================================
FILE: tests/test_code/php/money/Exchange/IndirectExchangeQueuedItem.php
================================================
currency = $currency;
}
}
================================================
FILE: tests/test_code/php/money/Exchange/ReversedCurrenciesExchange.php
================================================
exchange = $exchange;
}
public function quote(Currency $baseCurrency, Currency $counterCurrency): CurrencyPair
{
try {
return $this->exchange->quote($baseCurrency, $counterCurrency);
} catch (UnresolvableCurrencyPairException $exception) {
$calculator = Money::getCalculator();
try {
$currencyPair = $this->exchange->quote($counterCurrency, $baseCurrency);
return new CurrencyPair(
$baseCurrency,
$counterCurrency,
$calculator::divide('1', $currencyPair->getConversionRatio())
);
} catch (UnresolvableCurrencyPairException) {
throw $exception;
}
}
}
}
================================================
FILE: tests/test_code/php/money/Exchange/SwapExchange.php
================================================
swap = $swap;
}
public function quote(Currency $baseCurrency, Currency $counterCurrency): CurrencyPair
{
try {
$rate = $this->swap->latest($baseCurrency->getCode() . '/' . $counterCurrency->getCode());
} catch (ExchangerException) {
throw UnresolvableCurrencyPairException::createFromCurrencies($baseCurrency, $counterCurrency);
}
return new CurrencyPair($baseCurrency, $counterCurrency, (string) $rate->getValue());
}
}
================================================
FILE: tests/test_code/php/money/Exchange.php
================================================
indexed by currency code
*/
private array $formatters;
/**
* @param MoneyFormatter[] $formatters indexed by currency code
* @psalm-param non-empty-array $formatters indexed by currency code
*/
public function __construct(array $formatters)
{
$this->formatters = $formatters;
}
public function format(Money $money): string
{
$currencyCode = $money->getCurrency()->getCode();
if (isset($this->formatters[$currencyCode])) {
return $this->formatters[$currencyCode]->format($money);
}
if (isset($this->formatters['*'])) {
return $this->formatters['*']->format($money);
}
throw new FormatterException('No formatter found for currency ' . $currencyCode);
}
}
================================================
FILE: tests/test_code/php/money/Formatter/BitcoinMoneyFormatter.php
================================================
fractionDigits = $fractionDigits;
$this->currencies = $currencies;
}
public function format(Money $money): string
{
if ($money->getCurrency()->getCode() !== BitcoinCurrencies::CODE) {
throw new FormatterException('Bitcoin Formatter can only format Bitcoin currency');
}
$valueBase = $money->getAmount();
$negative = false;
if ($valueBase[0] === '-') {
$negative = true;
$valueBase = substr($valueBase, 1);
}
$subunit = $this->currencies->subunitFor($money->getCurrency());
$valueBase = Number::roundMoneyValue($valueBase, $this->fractionDigits, $subunit);
$valueLength = strlen($valueBase);
if ($valueLength > $subunit) {
$formatted = substr($valueBase, 0, $valueLength - $subunit);
if ($subunit) {
$formatted .= '.';
$formatted .= substr($valueBase, $valueLength - $subunit);
}
} else {
$formatted = '0.' . str_pad('', $subunit - $valueLength, '0') . $valueBase;
}
if ($this->fractionDigits === 0) {
$formatted = substr($formatted, 0, (int) strpos($formatted, '.'));
} elseif ($this->fractionDigits > $subunit) {
$formatted .= str_pad('', $this->fractionDigits - $subunit, '0');
} elseif ($this->fractionDigits < $subunit) {
$lastDigit = (int) strpos($formatted, '.') + $this->fractionDigits + 1;
$formatted = substr($formatted, 0, $lastDigit);
}
$formatted = BitcoinCurrencies::SYMBOL . $formatted;
if ($negative) {
$formatted = '-' . $formatted;
}
return $formatted;
}
}
================================================
FILE: tests/test_code/php/money/Formatter/DecimalMoneyFormatter.php
================================================
currencies = $currencies;
}
public function format(Money $money): string
{
$valueBase = $money->getAmount();
$negative = $valueBase[0] === '-';
if ($negative) {
$valueBase = substr($valueBase, 1);
}
$subunit = $this->currencies->subunitFor($money->getCurrency());
$valueLength = strlen($valueBase);
if ($valueLength > $subunit) {
$formatted = substr($valueBase, 0, $valueLength - $subunit);
$decimalDigits = substr($valueBase, $valueLength - $subunit);
if (strlen($decimalDigits) > 0) {
$formatted .= '.' . $decimalDigits;
}
} else {
$formatted = '0.' . str_pad('', $subunit - $valueLength, '0') . $valueBase;
}
if ($negative) {
return '-' . $formatted;
}
assert(! empty($formatted));
return $formatted;
}
}
================================================
FILE: tests/test_code/php/money/Formatter/IntlLocalizedDecimalFormatter.php
================================================
formatter = $formatter;
$this->currencies = $currencies;
}
public function format(Money $money): string
{
$valueBase = $money->getAmount();
$negative = $valueBase[0] === '-';
if ($negative) {
$valueBase = substr($valueBase, 1);
}
$subunit = $this->currencies->subunitFor($money->getCurrency());
$valueLength = strlen($valueBase);
if ($valueLength > $subunit) {
$formatted = substr($valueBase, 0, $valueLength - $subunit);
$decimalDigits = substr($valueBase, $valueLength - $subunit);
if (strlen($decimalDigits) > 0) {
$formatted .= '.' . $decimalDigits;
}
} else {
$formatted = '0.' . str_pad('', $subunit - $valueLength, '0') . $valueBase;
}
if ($negative) {
$formatted = '-' . $formatted;
}
$formatted = $this->formatter->format((float) $formatted);
assert(is_string($formatted) && ! empty($formatted));
return $formatted;
}
}
================================================
FILE: tests/test_code/php/money/Formatter/IntlMoneyFormatter.php
================================================
formatter = $formatter;
$this->currencies = $currencies;
}
public function format(Money $money): string
{
$valueBase = $money->getAmount();
$negative = $valueBase[0] === '-';
if ($negative) {
$valueBase = substr($valueBase, 1);
}
$subunit = $this->currencies->subunitFor($money->getCurrency());
$valueLength = strlen($valueBase);
if ($valueLength > $subunit) {
$formatted = substr($valueBase, 0, $valueLength - $subunit);
$decimalDigits = substr($valueBase, $valueLength - $subunit);
if (strlen($decimalDigits) > 0) {
$formatted .= '.' . $decimalDigits;
}
} else {
$formatted = '0.' . str_pad('', $subunit - $valueLength, '0') . $valueBase;
}
if ($negative) {
$formatted = '-' . $formatted;
}
$formatted = $this->formatter->formatCurrency((float) $formatted, $money->getCurrency()->getCode());
assert(! empty($formatted));
return $formatted;
}
}
================================================
FILE: tests/test_code/php/money/Money.php
================================================
*/
private static string $calculator = BcMathCalculator::class;
/**
* @param int|string $amount Amount, expressed in the smallest units of $currency (eg cents)
* @psalm-param int|numeric-string $amount
*
* @throws InvalidArgumentException If amount is not integer.
*/
public function __construct(int|string $amount, Currency $currency)
{
$this->currency = $currency;
if (filter_var($amount, FILTER_VALIDATE_INT) === false) {
$numberFromString = Number::fromString((string) $amount);
if (! $numberFromString->isInteger()) {
throw new InvalidArgumentException('Amount must be an integer(ish) value');
}
$this->amount = $numberFromString->getIntegerPart();
return;
}
$this->amount = (string) $amount;
}
/**
* Checks whether a Money has the same Currency as this.
*/
public function isSameCurrency(Money ...$others): bool
{
foreach ($others as $other) {
// Note: non-strict equality is intentional here, since `Currency` is `final` and reliable.
if ($this->currency != $other->currency) {
return false;
}
}
return true;
}
/**
* Checks whether the value represented by this object equals to the other.
*/
public function equals(Money $other): bool
{
// Note: non-strict equality is intentional here, since `Currency` is `final` and reliable.
if ($this->currency != $other->currency) {
return false;
}
if ($this->amount === $other->amount) {
return true;
}
// @TODO do we want Money instance to be byte-equivalent when trailing zeroes exist? Very expensive!
// Assumption: Money#equals() is called **less** than other number-based comparisons, and probably
// only within test suites. Therefore, using complex normalization here is acceptable waste of performance.
return $this->compare($other) === 0;
}
/**
* Returns an integer less than, equal to, or greater than zero
* if the value of this object is considered to be respectively
* less than, equal to, or greater than the other.
*/
public function compare(Money $other): int
{
// Note: non-strict equality is intentional here, since `Currency` is `final` and reliable.
if ($this->currency != $other->currency) {
throw new InvalidArgumentException('Currencies must be identical');
}
return self::$calculator::compare($this->amount, $other->amount);
}
/**
* Checks whether the value represented by this object is greater than the other.
*/
public function greaterThan(Money $other): bool
{
return $this->compare($other) > 0;
}
public function greaterThanOrEqual(Money $other): bool
{
return $this->compare($other) >= 0;
}
/**
* Checks whether the value represented by this object is less than the other.
*/
public function lessThan(Money $other): bool
{
return $this->compare($other) < 0;
}
public function lessThanOrEqual(Money $other): bool
{
return $this->compare($other) <= 0;
}
/**
* Returns the value represented by this object.
*
* @psalm-return numeric-string
*/
public function getAmount(): string
{
return $this->amount;
}
/**
* Returns the currency of this object.
*/
public function getCurrency(): Currency
{
return $this->currency;
}
/**
* Returns a new Money object that represents
* the sum of this and an other Money object.
*
* @param Money[] $addends
*/
public function add(Money ...$addends): Money
{
$amount = $this->amount;
foreach ($addends as $addend) {
// Note: non-strict equality is intentional here, since `Currency` is `final` and reliable.
if ($this->currency != $addend->currency) {
throw new InvalidArgumentException('Currencies must be identical');
}
$amount = self::$calculator::add($amount, $addend->amount);
}
return new self($amount, $this->currency);
}
/**
* Returns a new Money object that represents
* the difference of this and an other Money object.
*
* @param Money[] $subtrahends
*
* @psalm-pure
*/
public function subtract(Money ...$subtrahends): Money
{
$amount = $this->amount;
foreach ($subtrahends as $subtrahend) {
// Note: non-strict equality is intentional here, since `Currency` is `final` and reliable.
if ($this->currency != $subtrahend->currency) {
throw new InvalidArgumentException('Currencies must be identical');
}
$amount = self::$calculator::subtract($amount, $subtrahend->amount);
}
return new self($amount, $this->currency);
}
/**
* Returns a new Money object that represents
* the multiplied value by the given factor.
*
* @psalm-param int|numeric-string $multiplier
* @psalm-param self::ROUND_* $roundingMode
*/
public function multiply(int|string $multiplier, int $roundingMode = self::ROUND_HALF_UP): Money
{
if (is_int($multiplier)) {
$multiplier = (string) $multiplier;
}
$product = $this->round(self::$calculator::multiply($this->amount, $multiplier), $roundingMode);
return new self($product, $this->currency);
}
/**
* Returns a new Money object that represents
* the divided value by the given factor.
*
* @psalm-param int|numeric-string $divisor
* @psalm-param self::ROUND_* $roundingMode
*/
public function divide(int|string $divisor, int $roundingMode = self::ROUND_HALF_UP): Money
{
if (is_int($divisor)) {
$divisor = (string) $divisor;
}
$quotient = $this->round(self::$calculator::divide($this->amount, $divisor), $roundingMode);
return new self($quotient, $this->currency);
}
/**
* Returns a new Money object that represents
* the remainder after dividing the value by
* the given factor.
*/
public function mod(Money $divisor): Money
{
// Note: non-strict equality is intentional here, since `Currency` is `final` and reliable.
if ($this->currency != $divisor->currency) {
throw new InvalidArgumentException('Currencies must be identical');
}
return new self(self::$calculator::mod($this->amount, $divisor->amount), $this->currency);
}
/**
* Allocate the money according to a list of ratios.
*
* @psalm-param TRatios $ratios
*
* @return Money[]
* @psalm-return (
* TRatios is list
* ? non-empty-list
* : non-empty-array
* )
*
* @template TRatios as non-empty-array
*/
public function allocate(array $ratios): array
{
$remainder = $this->amount;
$results = [];
$total = array_sum($ratios);
if ($total <= 0) {
throw new InvalidArgumentException('Cannot allocate to none, sum of ratios must be greater than zero');
}
foreach ($ratios as $key => $ratio) {
if ($ratio < 0) {
throw new InvalidArgumentException('Cannot allocate to none, ratio must be zero or positive');
}
$share = self::$calculator::share($this->amount, (string) $ratio, (string) $total);
$results[$key] = new self($share, $this->currency);
$remainder = self::$calculator::subtract($remainder, $share);
}
if (self::$calculator::compare($remainder, '0') === 0) {
return $results;
}
$amount = $this->amount;
$fractions = array_map(static function (float|int $ratio) use ($total, $amount) {
$share = (float) $ratio / $total * (float) $amount;
return $share - floor($share);
}, $ratios);
while (self::$calculator::compare($remainder, '0') > 0) {
$index = ! empty($fractions) ? array_keys($fractions, max($fractions))[0] : 0;
$results[$index] = new self(self::$calculator::add($results[$index]->amount, '1'), $results[$index]->currency);
$remainder = self::$calculator::subtract($remainder, '1');
unset($fractions[$index]);
}
return $results;
}
/**
* Allocate the money among N targets.
*
* @psalm-param positive-int $n
*
* @return Money[]
* @psalm-return non-empty-list
*
* @throws InvalidArgumentException If number of targets is not an integer.
*/
public function allocateTo(int $n): array
{
return $this->allocate(array_fill(0, $n, 1));
}
/**
* @throws InvalidArgumentException if the given $money is zero.
*/
public function ratioOf(Money $money): string
{
if ($money->isZero()) {
throw new InvalidArgumentException('Cannot calculate a ratio of zero');
}
return self::$calculator::divide($this->amount, $money->amount);
}
/**
* @psalm-param numeric-string $amount
* @psalm-param self::ROUND_* $roundingMode
*
* @psalm-return numeric-string
*/
private function round(string $amount, int $roundingMode): string
{
if ($roundingMode === self::ROUND_UP) {
return self::$calculator::ceil($amount);
}
if ($roundingMode === self::ROUND_DOWN) {
return self::$calculator::floor($amount);
}
return self::$calculator::round($amount, $roundingMode);
}
/**
* Round to a specific unit.
*
* @psalm-param positive-int|0 $unit
* @psalm-param self::ROUND_* $roundingMode
*/
public function roundToUnit(int $unit, int $roundingMode = self::ROUND_HALF_UP): self
{
if ($unit === 0) {
return $this;
}
$abs = self::$calculator::absolute($this->amount);
if (strlen($abs) < $unit) {
return new self('0', $this->currency);
}
/** @psalm-var numeric-string $toBeRounded */
$toBeRounded = substr($this->amount, 0, strlen($this->amount) - $unit) . '.' . substr($this->amount, $unit * -1);
/** @psalm-var numeric-string $result */
$result = self::$calculator::round($toBeRounded, $roundingMode) . str_pad('', $unit, '0');
return new self($result, $this->currency);
}
public function absolute(): Money
{
return new self(
self::$calculator::absolute($this->amount),
$this->currency
);
}
public function negative(): Money
{
return (new self(0, $this->currency))
->subtract($this);
}
/**
* Checks if the value represented by this object is zero.
*/
public function isZero(): bool
{
return self::$calculator::compare($this->amount, '0') === 0;
}
/**
* Checks if the value represented by this object is positive.
*/
public function isPositive(): bool
{
return self::$calculator::compare($this->amount, '0') > 0;
}
/**
* Checks if the value represented by this object is negative.
*/
public function isNegative(): bool
{
return self::$calculator::compare($this->amount, '0') < 0;
}
/**
* {@inheritdoc}
*
* @return array
*/
public function jsonSerialize()
{
return [
'amount' => $this->amount,
'currency' => $this->currency->jsonSerialize(),
];
}
/**
* @param Money $first
* @param Money ...$collection
*
* @psalm-pure
*/
public static function min(self $first, self ...$collection): Money
{
$min = $first;
foreach ($collection as $money) {
if (! $money->lessThan($min)) {
continue;
}
$min = $money;
}
return $min;
}
/**
* @param Money $first
* @param Money ...$collection
*
* @psalm-pure
*/
public static function max(self $first, self ...$collection): Money
{
$max = $first;
foreach ($collection as $money) {
if (! $money->greaterThan($max)) {
continue;
}
$max = $money;
}
return $max;
}
/** @psalm-pure */
public static function sum(self $first, self ...$collection): Money
{
return $first->add(...$collection);
}
/** @psalm-pure */
public static function avg(self $first, self ...$collection): Money
{
return $first->add(...$collection)->divide((string) (count($collection) + 1));
}
/** @psalm-param class-string $calculator */
public static function registerCalculator(string $calculator): void
{
self::$calculator = $calculator;
}
/** @psalm-return class-string */
public static function getCalculator(): string
{
return self::$calculator;
}
}
================================================
FILE: tests/test_code/php/money/MoneyFactory.php
================================================
* $fiveDollar = Money::USD(500);
*
*
* @param array $arguments
* @psalm-param non-empty-string $method
* @psalm-param array{numeric-string|int} $arguments
*
* @throws InvalidArgumentException If amount is not integer(ish).
*
* @psalm-pure
*/
public static function __callStatic(string $method, array $arguments): Money
{
return new Money($arguments[0], new Currency($method));
}
}
================================================
FILE: tests/test_code/php/money/MoneyFormatter.php
================================================
1, 1 => 1, 2 => 1, 3 => 1, 4 => 1, 5 => 1, 6 => 1, 7 => 1, 8 => 1, 9 => 1];
public function __construct(string $integerPart, string $fractionalPart = '')
{
if ($integerPart === '' && $fractionalPart === '') {
throw new InvalidArgumentException('Empty number is invalid');
}
$this->integerPart = self::parseIntegerPart($integerPart);
$this->fractionalPart = self::parseFractionalPart($fractionalPart);
}
/** @psalm-pure */
public static function fromString(string $number): self
{
$portions = explode('.', $number, 2);
return new self(
$portions[0],
rtrim($portions[1] ?? '', '0')
);
}
/** @psalm-pure */
public static function fromFloat(float $number): self
{
return self::fromString(sprintf('%.14F', $number));
}
/** @psalm-pure */
public static function fromNumber(int|string $number): self
{
if (is_int($number)) {
return new self((string) $number);
}
return self::fromString($number);
}
public function isDecimal(): bool
{
return $this->fractionalPart !== '';
}
public function isInteger(): bool
{
return $this->fractionalPart === '';
}
public function isHalf(): bool
{
return $this->fractionalPart === '5';
}
public function isCurrentEven(): bool
{
$lastIntegerPartNumber = (int) $this->integerPart[strlen($this->integerPart) - 1];
return $lastIntegerPartNumber % 2 === 0;
}
public function isCloserToNext(): bool
{
if ($this->fractionalPart === '') {
return false;
}
return $this->fractionalPart[0] >= 5;
}
/** @psalm-return numeric-string */
public function __toString(): string
{
if ($this->fractionalPart === '') {
return $this->integerPart;
}
/** @psalm-suppress LessSpecificReturnStatement this operation is guaranteed to pruduce a numeric-string, but inference can't understand it */
return $this->integerPart . '.' . $this->fractionalPart;
}
public function isNegative(): bool
{
return $this->integerPart[0] === '-';
}
/** @psalm-return numeric-string */
public function getIntegerPart(): string
{
return $this->integerPart;
}
/** @psalm-return numeric-string|'' */
public function getFractionalPart(): string
{
return $this->fractionalPart;
}
/** @psalm-return numeric-string */
public function getIntegerRoundingMultiplier(): string
{
if ($this->integerPart[0] === '-') {
return '-1';
}
return '1';
}
public function base10(int $number): self
{
if ($this->integerPart === '0' && ! $this->fractionalPart) {
return $this;
}
$sign = '';
$integerPart = $this->integerPart;
if ($integerPart[0] === '-') {
$sign = '-';
$integerPart = substr($integerPart, 1);
}
if ($number >= 0) {
$integerPart = ltrim($integerPart, '0');
$lengthIntegerPart = strlen($integerPart);
$integers = $lengthIntegerPart - min($number, $lengthIntegerPart);
$zeroPad = $number - min($number, $lengthIntegerPart);
return new self(
$sign . substr($integerPart, 0, $integers),
rtrim(str_pad('', $zeroPad, '0') . substr($integerPart, $integers) . $this->fractionalPart, '0')
);
}
$number = abs($number);
$lengthFractionalPart = strlen($this->fractionalPart);
$fractions = $lengthFractionalPart - min($number, $lengthFractionalPart);
$zeroPad = $number - min($number, $lengthFractionalPart);
return new self(
$sign . ltrim($integerPart . substr($this->fractionalPart, 0, $lengthFractionalPart - $fractions) . str_pad('', $zeroPad, '0'), '0'),
substr($this->fractionalPart, $lengthFractionalPart - $fractions)
);
}
/**
* @psalm-return numeric-string
*
* @psalm-pure
*
* @psalm-suppress MoreSpecificReturnType this operation is guaranteed to pruduce a numeric-string, but inference can't understand it
* @psalm-suppress LessSpecificReturnStatement this operation is guaranteed to pruduce a numeric-string, but inference can't understand it
*/
private static function parseIntegerPart(string $number): string
{
if ($number === '' || $number === '0') {
return '0';
}
if ($number === '-') {
return '-0';
}
// Happy path performance optimization: number can be used as-is if it is within
// the platform's integer capabilities.
if ($number === (string) (int) $number) {
return $number;
}
$nonZero = false;
for ($position = 0, $characters = strlen($number); $position < $characters; ++$position) {
$digit = $number[$position];
/** @psalm-suppress InvalidArrayOffset we are, on purpose, checking if the digit is valid against a fixed structure */
if (! isset(self::NUMBERS[$digit]) && ! ($position === 0 && $digit === '-')) {
throw new InvalidArgumentException(sprintf('Invalid integer part %1$s. Invalid digit %2$s found', $number, $digit));
}
if ($nonZero === false && $digit === '0') {
throw new InvalidArgumentException('Leading zeros are not allowed');
}
$nonZero = true;
}
return $number;
}
/**
* @psalm-return numeric-string|''
*
* @psalm-pure
*/
private static function parseFractionalPart(string $number): string
{
if ($number === '') {
return $number;
}
$intFraction = (int) $number;
// Happy path performance optimization: number can be used as-is if it is within
// the platform's integer capabilities, and it starts with zeroes only.
if ($intFraction > 0 && ltrim($number, '0') === (string) $intFraction) {
return $number;
}
for ($position = 0, $characters = strlen($number); $position < $characters; ++$position) {
$digit = $number[$position];
/** @psalm-suppress InvalidArrayOffset we are, on purpose, checking if the digit is valid against a fixed structure */
if (! isset(self::NUMBERS[$digit])) {
throw new InvalidArgumentException(sprintf('Invalid fractional part %1$s. Invalid digit %2$s found', $number, $digit));
}
}
return $number;
}
/**
* @psalm-pure
* @psalm-suppress InvalidOperand string and integers get concatenated here - that is by design, as we're computing remainders
*/
public static function roundMoneyValue(string $moneyValue, int $targetDigits, int $havingDigits): string
{
$valueLength = strlen($moneyValue);
$shouldRound = $targetDigits < $havingDigits && $valueLength - $havingDigits + $targetDigits > 0;
if ($shouldRound && $moneyValue[$valueLength - $havingDigits + $targetDigits] >= 5) {
$position = $valueLength - $havingDigits + $targetDigits;
/** @psalm-var positive-int|0 $addend */
$addend = 1;
while ($position > 0) {
$newValue = (string) ((int) $moneyValue[$position - 1] + $addend);
if ($newValue >= 10) {
$moneyValue[$position - 1] = $newValue[1];
/** @psalm-var numeric-string $addend */
$addend = $newValue[0];
--$position;
if ($position === 0) {
$moneyValue = $addend . $moneyValue;
}
} else {
if ($moneyValue[$position - 1] === '-') {
$moneyValue[$position - 1] = $newValue[0];
$moneyValue = '-' . $moneyValue;
} else {
$moneyValue[$position - 1] = $newValue[0];
}
break;
}
}
}
return $moneyValue;
}
}
================================================
FILE: tests/test_code/php/money/PHPUnit/Comparator.php
================================================
register(new \Money\PHPUnit\Comparator());
*
* @internal do not use within your sources: this comparator is only to be used within the test suite of this library
*
* @psalm-suppress PropertyNotSetInConstructor the parent implementation includes factories that cannot be initialized here
*/
final class Comparator extends \SebastianBergmann\Comparator\Comparator
{
private IntlMoneyFormatter $formatter;
public function __construct()
{
parent::__construct();
$currencies = new AggregateCurrencies([
new ISOCurrencies(),
new BitcoinCurrencies(),
]);
$numberFormatter = new NumberFormatter('en_US', NumberFormatter::CURRENCY);
$this->formatter = new IntlMoneyFormatter($numberFormatter, $currencies);
}
/** {@inheritDoc} */
public function accepts($expected, $actual)
{
return $expected instanceof Money && $actual instanceof Money;
}
/** {@inheritDoc} */
public function assertEquals(
$expected,
$actual,
$delta = 0.0,
$canonicalize = false,
$ignoreCase = false
): void {
assert($expected instanceof Money);
assert($actual instanceof Money);
if (! $expected->equals($actual)) {
throw new ComparisonFailure($expected, $actual, $this->formatter->format($expected), $this->formatter->format($actual), false, 'Failed asserting that two Money objects are equal.');
}
}
}
================================================
FILE: tests/test_code/php/money/Parser/AggregateMoneyParser.php
================================================
*/
private array $parsers;
/**
* @param MoneyParser[] $parsers
* @psalm-param non-empty-array $parsers
*/
public function __construct(array $parsers)
{
$this->parsers = $parsers;
}
public function parse(string $money, Currency|null $fallbackCurrency = null): Money
{
foreach ($this->parsers as $parser) {
try {
return $parser->parse($money, $fallbackCurrency);
} catch (Exception\ParserException $e) {
}
}
throw new Exception\ParserException(sprintf('Unable to parse %s', $money));
}
}
================================================
FILE: tests/test_code/php/money/Parser/BitcoinMoneyParser.php
================================================
fractionDigits = $fractionDigits;
}
public function parse(string $money, Currency|null $fallbackCurrency = null): Money
{
if (strpos($money, BitcoinCurrencies::SYMBOL) === false) {
throw new ParserException('Value cannot be parsed as Bitcoin');
}
$currency = $fallbackCurrency ?? new Currency(BitcoinCurrencies::CODE);
$decimal = str_replace(BitcoinCurrencies::SYMBOL, '', $money);
$decimalSeparator = strpos($decimal, '.');
if ($decimalSeparator !== false) {
$decimal = rtrim($decimal, '0');
$lengthDecimal = strlen($decimal);
$decimal = str_replace('.', '', $decimal);
$decimal .= str_pad('', ($lengthDecimal - $decimalSeparator - $this->fractionDigits - 1) * -1, '0');
} else {
$decimal .= str_pad('', $this->fractionDigits, '0');
}
if (substr($decimal, 0, 1) === '-') {
$decimal = '-' . ltrim(substr($decimal, 1), '0');
} else {
$decimal = ltrim($decimal, '0');
}
if ($decimal === '') {
$decimal = '0';
}
/** @psalm-var numeric-string $decimal */
return new Money($decimal, $currency);
}
}
================================================
FILE: tests/test_code/php/money/Parser/DecimalMoneyParser.php
================================================
-)?(?P0|[1-9]\d*)?\.?(?P\d+)?$/';
private Currencies $currencies;
public function __construct(Currencies $currencies)
{
$this->currencies = $currencies;
}
public function parse(string $money, Currency|null $fallbackCurrency = null): Money
{
if ($fallbackCurrency === null) {
throw new ParserException('DecimalMoneyParser cannot parse currency symbols. Use forceCurrency argument');
}
$decimal = trim($money);
if ($decimal === '') {
return new Money(0, $fallbackCurrency);
}
if (! preg_match(self::DECIMAL_PATTERN, $decimal, $matches) || ! isset($matches['digits'])) {
throw new ParserException(sprintf('Cannot parse "%s" to Money.', $decimal));
}
$negative = isset($matches['sign']) && $matches['sign'] === '-';
$decimal = $matches['digits'];
if ($negative) {
$decimal = '-' . $decimal;
}
$subunit = $this->currencies->subunitFor($fallbackCurrency);
if (isset($matches['fraction'])) {
$fractionDigits = strlen($matches['fraction']);
$decimal .= $matches['fraction'];
$decimal = Number::roundMoneyValue($decimal, $subunit, $fractionDigits);
if ($fractionDigits > $subunit) {
$decimal = substr($decimal, 0, $subunit - $fractionDigits);
} elseif ($fractionDigits < $subunit) {
$decimal .= str_pad('', $subunit - $fractionDigits, '0');
}
} else {
$decimal .= str_pad('', $subunit, '0');
}
if ($negative) {
$decimal = '-' . ltrim(substr($decimal, 1), '0');
} else {
$decimal = ltrim($decimal, '0');
}
if ($decimal === '' || $decimal === '-') {
$decimal = '0';
}
/** @psalm-var numeric-string $decimal */
return new Money($decimal, $fallbackCurrency);
}
}
================================================
FILE: tests/test_code/php/money/Parser/IntlLocalizedDecimalParser.php
================================================
formatter = $formatter;
$this->currencies = $currencies;
}
public function parse(string $money, Currency|null $fallbackCurrency = null): Money
{
if ($fallbackCurrency === null) {
throw new ParserException('IntlLocalizedDecimalParser cannot parse currency symbols. Use forceCurrency argument');
}
$decimal = $this->formatter->parse($money);
if ($decimal === false) {
throw new ParserException('Cannot parse ' . $money . ' to Money. ' . $this->formatter->getErrorMessage());
}
$decimal = (string) $decimal;
$subunit = $this->currencies->subunitFor($fallbackCurrency);
$decimalPosition = strpos($decimal, '.');
if ($decimalPosition !== false) {
$decimalLength = strlen($decimal);
$fractionDigits = $decimalLength - $decimalPosition - 1;
$decimal = str_replace('.', '', $decimal);
$decimal = Number::roundMoneyValue($decimal, $subunit, $fractionDigits);
if ($fractionDigits > $subunit) {
$decimal = substr($decimal, 0, $decimalPosition + $subunit);
} elseif ($fractionDigits < $subunit) {
$decimal .= str_pad('', $subunit - $fractionDigits, '0');
}
} else {
$decimal .= str_pad('', $subunit, '0');
}
if ($decimal[0] === '-') {
$decimal = '-' . ltrim(substr($decimal, 1), '0');
} else {
$decimal = ltrim($decimal, '0');
}
if ($decimal === '') {
$decimal = '0';
}
/** @psalm-var numeric-string $decimal */
return new Money($decimal, $fallbackCurrency);
}
}
================================================
FILE: tests/test_code/php/money/Parser/IntlMoneyParser.php
================================================
formatter = $formatter;
$this->currencies = $currencies;
}
public function parse(string $money, Currency|null $fallbackCurrency = null): Money
{
$currency = null;
$decimal = $this->formatter->parseCurrency($money, $currency);
if ($decimal === false) {
throw new ParserException('Cannot parse ' . $money . ' to Money. ' . $this->formatter->getErrorMessage());
}
if ($fallbackCurrency === null) {
assert(! empty($currency));
$fallbackCurrency = new Currency($currency);
}
$decimal = (string) $decimal;
$subunit = $this->currencies->subunitFor($fallbackCurrency);
$decimalPosition = strpos($decimal, '.');
if ($decimalPosition !== false) {
$decimalLength = strlen($decimal);
$fractionDigits = $decimalLength - $decimalPosition - 1;
$decimal = str_replace('.', '', $decimal);
$decimal = Number::roundMoneyValue($decimal, $subunit, $fractionDigits);
if ($fractionDigits > $subunit) {
$decimal = substr($decimal, 0, $decimalPosition + $subunit);
} elseif ($fractionDigits < $subunit) {
$decimal .= str_pad('', $subunit - $fractionDigits, '0');
}
} else {
$decimal .= str_pad('', $subunit, '0');
}
if ($decimal[0] === '-') {
$decimal = '-' . ltrim(substr($decimal, 1), '0');
} else {
$decimal = ltrim($decimal, '0');
}
if ($decimal === '') {
$decimal = '0';
}
/** @psalm-var numeric-string $decimal */
return new Money($decimal, $fallbackCurrency);
}
}
================================================
FILE: tests/test_code/php/namespace_a/namespace_a.php
================================================
instance_method();
?>
================================================
FILE: tests/test_code/php/namespace_b/namespace_b1.php
================================================
instance_method();
echo \foo\Cat::meows(), " \n";
echo \feline\Cat::says(), " \n";
use animate;
echo \animate\Animal::meows(), " \n";
?>
================================================
FILE: tests/test_code/php/namespace_b/namespace_b2.php
================================================
================================================
FILE: tests/test_code/php/namespace_c/namespace_c1.php
================================================
================================================
FILE: tests/test_code/php/namespace_c/namespace_c2.php
================================================
================================================
FILE: tests/test_code/php/nested/nested.php
================================================
================================================
FILE: tests/test_code/php/nested_calls/nested_calls.php
================================================
================================================
FILE: tests/test_code/php/publicprivateprotected/publicprivateprotected.php
================================================
name = $n;
}
protected function set_color($n) { // a protected function
$this->color = $n;
}
private function set_weight($n) { // a private function
$this->weight = $n;
}
}
function set_color_weight($fruit) {
$fruit.set_color('blue');
$fruit.set_weight(5);
}
$fruit = new Fruit();
$fruit.set_name('blueberry');
set_color_weight();
?>
================================================
FILE: tests/test_code/php/resolve_correct_class/rcc.php
================================================
func_2();
}
function func_2() {
echo "alpha func_2";
}
}
class Beta {
function func_1() {
echo "beta func_1";
$al = new Alpha();
$al->func_2();
}
function func_2() {
echo "beta func_2";
}
}
?>
================================================
FILE: tests/test_code/php/simple_a/simple_a.php
================================================
================================================
FILE: tests/test_code/php/simple_b/simple_b.php
================================================
d();
?>
================================================
FILE: tests/test_code/php/static/static.php
================================================
name;
}
function __construct($name) {
$this->name = $name;
echo self::welcome() + ' ' + $this->say_name();
}
}
function welcome() {}
// Call static method
Greeting::welcome();
$greet = new Greeting("Scott");
?>
================================================
FILE: tests/test_code/php/traits/traits.php
================================================
msg1();
echo " ";
}
function welcome2() {
$obj2 = new Welcome2();
$obj2->msg1();
$obj2->msg2();
}
?>
================================================
FILE: tests/test_code/php/two_file_simple/file_a.php
================================================
================================================
FILE: tests/test_code/php/two_file_simple/file_b.php
================================================
================================================
FILE: tests/test_code/php/weird_assign/weird_assign.php
================================================
================================================
FILE: tests/test_code/py/ambiguous_resolution/ambiguous_resolution.py
================================================
class Abra():
def magic():
pass
def abra_it():
pass
class Cadabra():
def magic():
pass
def cadabra_it(a=None):
a.abra_it()
def main(cls):
obj = cls()
obj.magic()
obj.cadabra_it()
main()
================================================
FILE: tests/test_code/py/async_basic/async_basic.py
================================================
import asyncio
class A:
def __init__(self):
pass
async def test(self):
print("hello world")
async def main():
a = A()
await a.test()
asyncio.run(main())
================================================
FILE: tests/test_code/py/chained/chained.py
================================================
class Chain():
def __init__(self, val):
self.val = val
def add(self, b):
self.val += b
return self
def sub(self, b):
self.val -= b
return self
def mul(self, b):
self.val *= b
return self
print(Chain(5).add(5).sub(2).mul(10))
================================================
FILE: tests/test_code/py/exclude_modules/exclude_modules.py
================================================
import re
from re import match
def search():
print("This is the wrong search")
def beta():
print("this still connects")
search()
b = Nothing()
b.beta()
def alpha():
re.search("hello world")
beta()
match()
# ret = str('')
# ret()
if __name__ == '__main__':
alpha()
================================================
FILE: tests/test_code/py/exclude_modules_two_files/exclude_modules_a.py
================================================
import re
from exclude_modules_b import match
def a():
re.match()
def b():
match()
a()
b()
================================================
FILE: tests/test_code/py/exclude_modules_two_files/exclude_modules_b.py
================================================
def match():
print("match")
================================================
FILE: tests/test_code/py/import_paths/abra.py
================================================
def abra2():
pass
================================================
FILE: tests/test_code/py/import_paths/cadabra.py
================================================
def cadabra2():
pass
================================================
FILE: tests/test_code/py/import_paths/import_paths.py
================================================
import abra
from . import cadabra
from abra import abra2 as abra3
def main():
abra3()
cadabra.cadabra2()
main2()
def main2():
abra.abra2()
main()
================================================
FILE: tests/test_code/py/inherits/inherits.py
================================================
# from https://ruby-doc.com/docs/ProgrammingRuby/html/tut_modules.html
from inherits_import import MajorScales, PentatonicScales
def majorNum():
pass
def pentaNum():
pass
class FakePentatonicScales():
def pentaNum(self):
if self.numNotes is None:
self.numNotes = 5
return self.numNotes
class ScaleDemo(MajorScales, PentatonicScales):
def __init__(self):
self.numNotes = None
print(self.majorNum())
print(self.pentaNum())
def nothing(self):
pass
class ScaleDemoLimited(MajorScales):
def __init__(self):
self.numNotes = None
print(self.majorNum())
sd = ScaleDemo()
majorNum()
================================================
FILE: tests/test_code/py/inherits/inherits_import.py
================================================
# from https://ruby-doc.com/docs/ProgrammingRuby/html/tut_modules.html
class MajorScales():
def majorNum(self):
if self.numNotes is None:
self.numNotes = 7
return self.numNotes
class PentatonicScales():
def pentaNum(self):
if self.numNotes is None:
self.numNotes = 5
return self.numNotes
================================================
FILE: tests/test_code/py/init/init.py
================================================
from the_import import ProvincialClass as pc, imported_func
class Abra():
def __init__(self):
self.cadabra()
def cadabra(self):
print("cadabra")
def b():
Abra()
b()
pc()
HiddenClass() # this is probably too defensive
imported_func()
================================================
FILE: tests/test_code/py/init/the_import.py
================================================
class ProvincialClass():
def __init__(self):
print("here")
class HiddenClass():
def __init__(self):
print("here")
def imported_func():
print("here")
================================================
FILE: tests/test_code/py/nested_calls/nested_calls.py
================================================
from typing import Callable
def trace(fn: Callable) -> Callable:
def wrapper(*args, **kwargs):
print('traced call')
return fn(*args, **kwargs)
return wrapper
def do_something(msg):
return msg + ' world'
message = 'hello'
new_message = trace(do_something)(message)
================================================
FILE: tests/test_code/py/nested_class/nested_class.py
================================================
class Outer():
class Inner():
def inner_func():
Outer().outer_func()
def outer_func(a):
print("Outer_func")
a.inner_func()
def __init__(self):
self.inner = self.Inner()
print("do something")
new_obj = Outer()
new_obj.outer_func()
================================================
FILE: tests/test_code/py/pytz/__init__.py
================================================
'''
datetime.tzinfo timezone definitions generated from the
Olson timezone database:
ftp://elsie.nci.nih.gov/pub/tz*.tar.gz
See the datetime section of the Python Library Reference for information
on how to use these modules.
'''
import sys
import datetime
import os.path
from pytz.exceptions import AmbiguousTimeError
from pytz.exceptions import InvalidTimeError
from pytz.exceptions import NonExistentTimeError
from pytz.exceptions import UnknownTimeZoneError
from pytz.lazy import LazyDict, LazyList, LazySet # noqa
from pytz.tzinfo import unpickler, BaseTzInfo
from pytz.tzfile import build_tzinfo
# The IANA (nee Olson) database is updated several times a year.
OLSON_VERSION = '2021a'
VERSION = '2021.1' # pip compatible version number.
__version__ = VERSION
OLSEN_VERSION = OLSON_VERSION # Old releases had this misspelling
__all__ = [
'timezone', 'utc', 'country_timezones', 'country_names',
'AmbiguousTimeError', 'InvalidTimeError',
'NonExistentTimeError', 'UnknownTimeZoneError',
'all_timezones', 'all_timezones_set',
'common_timezones', 'common_timezones_set',
'BaseTzInfo', 'FixedOffset',
]
if sys.version_info[0] > 2: # Python 3.x
# Python 3.x doesn't have unicode(), making writing code
# for Python 2.3 and Python 3.x a pain.
unicode = str
def ascii(s):
r"""
>>> ascii('Hello')
'Hello'
>>> ascii('\N{TRADE MARK SIGN}') #doctest: +IGNORE_EXCEPTION_DETAIL
Traceback (most recent call last):
...
UnicodeEncodeError: ...
"""
if type(s) == bytes:
s = s.decode('ASCII')
else:
s.encode('ASCII') # Raise an exception if not ASCII
return s # But the string - not a byte string.
else: # Python 2.x
def ascii(s):
r"""
>>> ascii('Hello')
'Hello'
>>> ascii(u'Hello')
'Hello'
>>> ascii(u'\N{TRADE MARK SIGN}') #doctest: +IGNORE_EXCEPTION_DETAIL
Traceback (most recent call last):
...
UnicodeEncodeError: ...
"""
return s.encode('ASCII')
def open_resource(name):
"""Open a resource from the zoneinfo subdir for reading.
Uses the pkg_resources module if available and no standard file
found at the calculated location.
It is possible to specify different location for zoneinfo
subdir by using the PYTZ_TZDATADIR environment variable.
"""
name_parts = name.lstrip('/').split('/')
for part in name_parts:
if part == os.path.pardir or os.path.sep in part:
raise ValueError('Bad path segment: %r' % part)
zoneinfo_dir = os.environ.get('PYTZ_TZDATADIR', None)
if zoneinfo_dir is not None:
filename = os.path.join(zoneinfo_dir, *name_parts)
else:
filename = os.path.join(os.path.dirname(__file__),
'zoneinfo', *name_parts)
if not os.path.exists(filename):
# http://bugs.launchpad.net/bugs/383171 - we avoid using this
# unless absolutely necessary to help when a broken version of
# pkg_resources is installed.
try:
from pkg_resources import resource_stream
except ImportError:
resource_stream = None
if resource_stream is not None:
return resource_stream(__name__, 'zoneinfo/' + name)
return open(filename, 'rb')
def resource_exists(name):
"""Return true if the given resource exists"""
try:
if os.environ.get('PYTZ_SKIPEXISTSCHECK', ''):
# In "standard" distributions, we can assume that
# all the listed timezones are present. As an
# import-speed optimization, you can set the
# PYTZ_SKIPEXISTSCHECK flag to skip checking
# for the presence of the resource file on disk.
return True
open_resource(name).close()
return True
except IOError:
return False
_tzinfo_cache = {}
def timezone(zone):
r''' Return a datetime.tzinfo implementation for the given timezone
>>> from datetime import datetime, timedelta
>>> utc = timezone('UTC')
>>> eastern = timezone('US/Eastern')
>>> eastern.zone
'US/Eastern'
>>> timezone(unicode('US/Eastern')) is eastern
True
>>> utc_dt = datetime(2002, 10, 27, 6, 0, 0, tzinfo=utc)
>>> loc_dt = utc_dt.astimezone(eastern)
>>> fmt = '%Y-%m-%d %H:%M:%S %Z (%z)'
>>> loc_dt.strftime(fmt)
'2002-10-27 01:00:00 EST (-0500)'
>>> (loc_dt - timedelta(minutes=10)).strftime(fmt)
'2002-10-27 00:50:00 EST (-0500)'
>>> eastern.normalize(loc_dt - timedelta(minutes=10)).strftime(fmt)
'2002-10-27 01:50:00 EDT (-0400)'
>>> (loc_dt + timedelta(minutes=10)).strftime(fmt)
'2002-10-27 01:10:00 EST (-0500)'
Raises UnknownTimeZoneError if passed an unknown zone.
>>> try:
... timezone('Asia/Shangri-La')
... except UnknownTimeZoneError:
... print('Unknown')
Unknown
>>> try:
... timezone(unicode('\N{TRADE MARK SIGN}'))
... except UnknownTimeZoneError:
... print('Unknown')
Unknown
'''
if zone is None:
raise UnknownTimeZoneError(None)
if zone.upper() == 'UTC':
return utc
try:
zone = ascii(zone)
except UnicodeEncodeError:
# All valid timezones are ASCII
raise UnknownTimeZoneError(zone)
zone = _case_insensitive_zone_lookup(_unmunge_zone(zone))
if zone not in _tzinfo_cache:
if zone in all_timezones_set: # noqa
fp = open_resource(zone)
try:
_tzinfo_cache[zone] = build_tzinfo(zone, fp)
finally:
fp.close()
else:
raise UnknownTimeZoneError(zone)
return _tzinfo_cache[zone]
def _unmunge_zone(zone):
"""Undo the time zone name munging done by older versions of pytz."""
return zone.replace('_plus_', '+').replace('_minus_', '-')
_all_timezones_lower_to_standard = None
def _case_insensitive_zone_lookup(zone):
"""case-insensitively matching timezone, else return zone unchanged"""
global _all_timezones_lower_to_standard
if _all_timezones_lower_to_standard is None:
_all_timezones_lower_to_standard = dict((tz.lower(), tz) for tz in all_timezones) # noqa
return _all_timezones_lower_to_standard.get(zone.lower()) or zone # noqa
ZERO = datetime.timedelta(0)
HOUR = datetime.timedelta(hours=1)
class UTC(BaseTzInfo):
"""UTC
Optimized UTC implementation. It unpickles using the single module global
instance defined beneath this class declaration.
"""
zone = "UTC"
_utcoffset = ZERO
_dst = ZERO
_tzname = zone
def fromutc(self, dt):
if dt.tzinfo is None:
return self.localize(dt)
return super(utc.__class__, self).fromutc(dt)
def utcoffset(self, dt):
return ZERO
def tzname(self, dt):
return "UTC"
def dst(self, dt):
return ZERO
def __reduce__(self):
return _UTC, ()
def localize(self, dt, is_dst=False):
'''Convert naive time to local time'''
if dt.tzinfo is not None:
raise ValueError('Not naive datetime (tzinfo is already set)')
return dt.replace(tzinfo=self)
def normalize(self, dt, is_dst=False):
'''Correct the timezone information on the given datetime'''
if dt.tzinfo is self:
return dt
if dt.tzinfo is None:
raise ValueError('Naive time - no tzinfo set')
return dt.astimezone(self)
def __repr__(self):
return ""
def __str__(self):
return "UTC"
UTC = utc = UTC() # UTC is a singleton
def _UTC():
"""Factory function for utc unpickling.
Makes sure that unpickling a utc instance always returns the same
module global.
These examples belong in the UTC class above, but it is obscured; or in
the README.rst, but we are not depending on Python 2.4 so integrating
the README.rst examples with the unit tests is not trivial.
>>> import datetime, pickle
>>> dt = datetime.datetime(2005, 3, 1, 14, 13, 21, tzinfo=utc)
>>> naive = dt.replace(tzinfo=None)
>>> p = pickle.dumps(dt, 1)
>>> naive_p = pickle.dumps(naive, 1)
>>> len(p) - len(naive_p)
17
>>> new = pickle.loads(p)
>>> new == dt
True
>>> new is dt
False
>>> new.tzinfo is dt.tzinfo
True
>>> utc is UTC is timezone('UTC')
True
>>> utc is timezone('GMT')
False
"""
return utc
_UTC.__safe_for_unpickling__ = True
def _p(*args):
"""Factory function for unpickling pytz tzinfo instances.
Just a wrapper around tzinfo.unpickler to save a few bytes in each pickle
by shortening the path.
"""
return unpickler(*args)
_p.__safe_for_unpickling__ = True
class _CountryTimezoneDict(LazyDict):
"""Map ISO 3166 country code to a list of timezone names commonly used
in that country.
iso3166_code is the two letter code used to identify the country.
>>> def print_list(list_of_strings):
... 'We use a helper so doctests work under Python 2.3 -> 3.x'
... for s in list_of_strings:
... print(s)
>>> print_list(country_timezones['nz'])
Pacific/Auckland
Pacific/Chatham
>>> print_list(country_timezones['ch'])
Europe/Zurich
>>> print_list(country_timezones['CH'])
Europe/Zurich
>>> print_list(country_timezones[unicode('ch')])
Europe/Zurich
>>> print_list(country_timezones['XXX'])
Traceback (most recent call last):
...
KeyError: 'XXX'
Previously, this information was exposed as a function rather than a
dictionary. This is still supported::
>>> print_list(country_timezones('nz'))
Pacific/Auckland
Pacific/Chatham
"""
def __call__(self, iso3166_code):
"""Backwards compatibility."""
return self[iso3166_code]
def _fill(self):
data = {}
zone_tab = open_resource('zone.tab')
try:
for line in zone_tab:
line = line.decode('UTF-8')
if line.startswith('#'):
continue
code, coordinates, zone = line.split(None, 4)[:3]
if zone not in all_timezones_set: # noqa
continue
try:
data[code].append(zone)
except KeyError:
data[code] = [zone]
self.data = data
finally:
zone_tab.close()
country_timezones = _CountryTimezoneDict()
class _CountryNameDict(LazyDict):
'''Dictionary proving ISO3166 code -> English name.
>>> print(country_names['au'])
Australia
'''
def _fill(self):
data = {}
zone_tab = open_resource('iso3166.tab')
try:
for line in zone_tab.readlines():
line = line.decode('UTF-8')
if line.startswith('#'):
continue
code, name = line.split(None, 1)
data[code] = name.strip()
self.data = data
finally:
zone_tab.close()
country_names = _CountryNameDict()
# Time-zone info based solely on fixed offsets
class _FixedOffset(datetime.tzinfo):
zone = None # to match the standard pytz API
def __init__(self, minutes):
if abs(minutes) >= 1440:
raise ValueError("absolute offset is too large", minutes)
self._minutes = minutes
self._offset = datetime.timedelta(minutes=minutes)
def utcoffset(self, dt):
return self._offset
def __reduce__(self):
return FixedOffset, (self._minutes, )
def dst(self, dt):
return ZERO
def tzname(self, dt):
return None
def __repr__(self):
return 'pytz.FixedOffset(%d)' % self._minutes
def localize(self, dt, is_dst=False):
'''Convert naive time to local time'''
if dt.tzinfo is not None:
raise ValueError('Not naive datetime (tzinfo is already set)')
return dt.replace(tzinfo=self)
def normalize(self, dt, is_dst=False):
'''Correct the timezone information on the given datetime'''
if dt.tzinfo is self:
return dt
if dt.tzinfo is None:
raise ValueError('Naive time - no tzinfo set')
return dt.astimezone(self)
def FixedOffset(offset, _tzinfos={}):
"""return a fixed-offset timezone based off a number of minutes.
>>> one = FixedOffset(-330)
>>> one
pytz.FixedOffset(-330)
>>> str(one.utcoffset(datetime.datetime.now()))
'-1 day, 18:30:00'
>>> str(one.dst(datetime.datetime.now()))
'0:00:00'
>>> two = FixedOffset(1380)
>>> two
pytz.FixedOffset(1380)
>>> str(two.utcoffset(datetime.datetime.now()))
'23:00:00'
>>> str(two.dst(datetime.datetime.now()))
'0:00:00'
The datetime.timedelta must be between the range of -1 and 1 day,
non-inclusive.
>>> FixedOffset(1440)
Traceback (most recent call last):
...
ValueError: ('absolute offset is too large', 1440)
>>> FixedOffset(-1440)
Traceback (most recent call last):
...
ValueError: ('absolute offset is too large', -1440)
An offset of 0 is special-cased to return UTC.
>>> FixedOffset(0) is UTC
True
There should always be only one instance of a FixedOffset per timedelta.
This should be true for multiple creation calls.
>>> FixedOffset(-330) is one
True
>>> FixedOffset(1380) is two
True
It should also be true for pickling.
>>> import pickle
>>> pickle.loads(pickle.dumps(one)) is one
True
>>> pickle.loads(pickle.dumps(two)) is two
True
"""
if offset == 0:
return UTC
info = _tzinfos.get(offset)
if info is None:
# We haven't seen this one before. we need to save it.
# Use setdefault to avoid a race condition and make sure we have
# only one
info = _tzinfos.setdefault(offset, _FixedOffset(offset))
return info
FixedOffset.__safe_for_unpickling__ = True
def _test():
import doctest
sys.path.insert(0, os.pardir)
import pytz
return doctest.testmod(pytz)
if __name__ == '__main__':
_test()
================================================
FILE: tests/test_code/py/pytz/exceptions.py
================================================
'''
Custom exceptions raised by pytz.
'''
__all__ = [
'UnknownTimeZoneError', 'InvalidTimeError', 'AmbiguousTimeError',
'NonExistentTimeError',
]
class Error(Exception):
'''Base class for all exceptions raised by the pytz library'''
class UnknownTimeZoneError(KeyError, Error):
'''Exception raised when pytz is passed an unknown timezone.
>>> isinstance(UnknownTimeZoneError(), LookupError)
True
This class is actually a subclass of KeyError to provide backwards
compatibility with code relying on the undocumented behavior of earlier
pytz releases.
>>> isinstance(UnknownTimeZoneError(), KeyError)
True
And also a subclass of pytz.exceptions.Error, as are other pytz
exceptions.
>>> isinstance(UnknownTimeZoneError(), Error)
True
'''
pass
class InvalidTimeError(Error):
'''Base class for invalid time exceptions.'''
class AmbiguousTimeError(InvalidTimeError):
'''Exception raised when attempting to create an ambiguous wallclock time.
At the end of a DST transition period, a particular wallclock time will
occur twice (once before the clocks are set back, once after). Both
possibilities may be correct, unless further information is supplied.
See DstTzInfo.normalize() for more info
'''
class NonExistentTimeError(InvalidTimeError):
'''Exception raised when attempting to create a wallclock time that
cannot exist.
At the start of a DST transition period, the wallclock time jumps forward.
The instants jumped over never occur.
'''
================================================
FILE: tests/test_code/py/pytz/lazy.py
================================================
from threading import RLock
try:
from collections.abc import Mapping as DictMixin
except ImportError: # Python < 3.3
try:
from UserDict import DictMixin # Python 2
except ImportError: # Python 3.0-3.3
from collections import Mapping as DictMixin
# With lazy loading, we might end up with multiple threads triggering
# it at the same time. We need a lock.
_fill_lock = RLock()
class LazyDict(DictMixin):
"""Dictionary populated on first use."""
data = None
def __getitem__(self, key):
if self.data is None:
_fill_lock.acquire()
try:
if self.data is None:
self._fill()
finally:
_fill_lock.release()
return self.data[key.upper()]
def __contains__(self, key):
if self.data is None:
_fill_lock.acquire()
try:
if self.data is None:
self._fill()
finally:
_fill_lock.release()
return key in self.data
def __iter__(self):
if self.data is None:
_fill_lock.acquire()
try:
if self.data is None:
self._fill()
finally:
_fill_lock.release()
return iter(self.data)
def __len__(self):
if self.data is None:
_fill_lock.acquire()
try:
if self.data is None:
self._fill()
finally:
_fill_lock.release()
return len(self.data)
def keys(self):
if self.data is None:
_fill_lock.acquire()
try:
if self.data is None:
self._fill()
finally:
_fill_lock.release()
return self.data.keys()
class LazyList(list):
"""List populated on first use."""
_props = [
'__str__', '__repr__', '__unicode__',
'__hash__', '__sizeof__', '__cmp__',
'__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__',
'append', 'count', 'index', 'extend', 'insert', 'pop', 'remove',
'reverse', 'sort', '__add__', '__radd__', '__iadd__', '__mul__',
'__rmul__', '__imul__', '__contains__', '__len__', '__nonzero__',
'__getitem__', '__setitem__', '__delitem__', '__iter__',
'__reversed__', '__getslice__', '__setslice__', '__delslice__']
def __new__(cls, fill_iter=None):
if fill_iter is None:
return list()
# We need a new class as we will be dynamically messing with its
# methods.
class LazyList(list):
pass
fill_iter = [fill_iter]
def lazy(name):
def _lazy(self, *args, **kw):
_fill_lock.acquire()
try:
if len(fill_iter) > 0:
list.extend(self, fill_iter.pop())
for method_name in cls._props:
delattr(LazyList, method_name)
finally:
_fill_lock.release()
return getattr(list, name)(self, *args, **kw)
return _lazy
for name in cls._props:
setattr(LazyList, name, lazy(name))
new_list = LazyList()
return new_list
# Not all versions of Python declare the same magic methods.
# Filter out properties that don't exist in this version of Python
# from the list.
LazyList._props = [prop for prop in LazyList._props if hasattr(list, prop)]
class LazySet(set):
"""Set populated on first use."""
_props = (
'__str__', '__repr__', '__unicode__',
'__hash__', '__sizeof__', '__cmp__',
'__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__',
'__contains__', '__len__', '__nonzero__',
'__getitem__', '__setitem__', '__delitem__', '__iter__',
'__sub__', '__and__', '__xor__', '__or__',
'__rsub__', '__rand__', '__rxor__', '__ror__',
'__isub__', '__iand__', '__ixor__', '__ior__',
'add', 'clear', 'copy', 'difference', 'difference_update',
'discard', 'intersection', 'intersection_update', 'isdisjoint',
'issubset', 'issuperset', 'pop', 'remove',
'symmetric_difference', 'symmetric_difference_update',
'union', 'update')
def __new__(cls, fill_iter=None):
if fill_iter is None:
return set()
class LazySet(set):
pass
fill_iter = [fill_iter]
def lazy(name):
def _lazy(self, *args, **kw):
_fill_lock.acquire()
try:
if len(fill_iter) > 0:
for i in fill_iter.pop():
set.add(self, i)
for method_name in cls._props:
delattr(LazySet, method_name)
finally:
_fill_lock.release()
return getattr(set, name)(self, *args, **kw)
return _lazy
for name in cls._props:
setattr(LazySet, name, lazy(name))
new_set = LazySet()
return new_set
# Not all versions of Python declare the same magic methods.
# Filter out properties that don't exist in this version of Python
# from the list.
LazySet._props = [prop for prop in LazySet._props if hasattr(set, prop)]
================================================
FILE: tests/test_code/py/pytz/reference.py
================================================
'''
Reference tzinfo implementations from the Python docs.
Used for testing against as they are only correct for the years
1987 to 2006. Do not use these for real code.
'''
from datetime import tzinfo, timedelta, datetime
from pytz import HOUR, ZERO, UTC
__all__ = [
'FixedOffset',
'LocalTimezone',
'USTimeZone',
'Eastern',
'Central',
'Mountain',
'Pacific',
'UTC'
]
# A class building tzinfo objects for fixed-offset time zones.
# Note that FixedOffset(0, "UTC") is a different way to build a
# UTC tzinfo object.
class FixedOffset(tzinfo):
"""Fixed offset in minutes east from UTC."""
def __init__(self, offset, name):
self.__offset = timedelta(minutes=offset)
self.__name = name
def utcoffset(self, dt):
return self.__offset
def tzname(self, dt):
return self.__name
def dst(self, dt):
return ZERO
import time as _time
STDOFFSET = timedelta(seconds=-_time.timezone)
if _time.daylight:
DSTOFFSET = timedelta(seconds=-_time.altzone)
else:
DSTOFFSET = STDOFFSET
DSTDIFF = DSTOFFSET - STDOFFSET
# A class capturing the platform's idea of local time.
class LocalTimezone(tzinfo):
def utcoffset(self, dt):
if self._isdst(dt):
return DSTOFFSET
else:
return STDOFFSET
def dst(self, dt):
if self._isdst(dt):
return DSTDIFF
else:
return ZERO
def tzname(self, dt):
return _time.tzname[self._isdst(dt)]
def _isdst(self, dt):
tt = (dt.year, dt.month, dt.day,
dt.hour, dt.minute, dt.second,
dt.weekday(), 0, -1)
stamp = _time.mktime(tt)
tt = _time.localtime(stamp)
return tt.tm_isdst > 0
Local = LocalTimezone()
def first_sunday_on_or_after(dt):
days_to_go = 6 - dt.weekday()
if days_to_go:
dt += timedelta(days_to_go)
return dt
# In the US, DST starts at 2am (standard time) on the first Sunday in April.
DSTSTART = datetime(1, 4, 1, 2)
# and ends at 2am (DST time; 1am standard time) on the last Sunday of Oct.
# which is the first Sunday on or after Oct 25.
DSTEND = datetime(1, 10, 25, 1)
# A complete implementation of current DST rules for major US time zones.
class USTimeZone(tzinfo):
def __init__(self, hours, reprname, stdname, dstname):
self.stdoffset = timedelta(hours=hours)
self.reprname = reprname
self.stdname = stdname
self.dstname = dstname
def __repr__(self):
return self.reprname
def tzname(self, dt):
if self.dst(dt):
return self.dstname
else:
return self.stdname
def utcoffset(self, dt):
return self.stdoffset + self.dst(dt)
def dst(self, dt):
if dt is None or dt.tzinfo is None:
# An exception may be sensible here, in one or both cases.
# It depends on how you want to treat them. The default
# fromutc() implementation (called by the default astimezone()
# implementation) passes a datetime with dt.tzinfo is self.
return ZERO
assert dt.tzinfo is self
# Find first Sunday in April & the last in October.
start = first_sunday_on_or_after(DSTSTART.replace(year=dt.year))
end = first_sunday_on_or_after(DSTEND.replace(year=dt.year))
# Can't compare naive to aware objects, so strip the timezone from
# dt first.
if start <= dt.replace(tzinfo=None) < end:
return HOUR
else:
return ZERO
Eastern = USTimeZone(-5, "Eastern", "EST", "EDT")
Central = USTimeZone(-6, "Central", "CST", "CDT")
Mountain = USTimeZone(-7, "Mountain", "MST", "MDT")
Pacific = USTimeZone(-8, "Pacific", "PST", "PDT")
================================================
FILE: tests/test_code/py/pytz/tzfile.py
================================================
'''
$Id: tzfile.py,v 1.8 2004/06/03 00:15:24 zenzen Exp $
'''
from datetime import datetime
from struct import unpack, calcsize
from pytz.tzinfo import StaticTzInfo, DstTzInfo, memorized_ttinfo
from pytz.tzinfo import memorized_datetime, memorized_timedelta
def _byte_string(s):
"""Cast a string or byte string to an ASCII byte string."""
return s.encode('ASCII')
_NULL = _byte_string('\0')
def _std_string(s):
"""Cast a string or byte string to an ASCII string."""
return str(s.decode('ASCII'))
def build_tzinfo(zone, fp):
head_fmt = '>4s c 15x 6l'
head_size = calcsize(head_fmt)
(magic, format, ttisgmtcnt, ttisstdcnt, leapcnt, timecnt,
typecnt, charcnt) = unpack(head_fmt, fp.read(head_size))
# Make sure it is a tzfile(5) file
assert magic == _byte_string('TZif'), 'Got magic %s' % repr(magic)
# Read out the transition times, localtime indices and ttinfo structures.
data_fmt = '>%(timecnt)dl %(timecnt)dB %(ttinfo)s %(charcnt)ds' % dict(
timecnt=timecnt, ttinfo='lBB' * typecnt, charcnt=charcnt)
data_size = calcsize(data_fmt)
data = unpack(data_fmt, fp.read(data_size))
# make sure we unpacked the right number of values
assert len(data) == 2 * timecnt + 3 * typecnt + 1
transitions = [memorized_datetime(trans)
for trans in data[:timecnt]]
lindexes = list(data[timecnt:2 * timecnt])
ttinfo_raw = data[2 * timecnt:-1]
tznames_raw = data[-1]
del data
# Process ttinfo into separate structs
ttinfo = []
tznames = {}
i = 0
while i < len(ttinfo_raw):
# have we looked up this timezone name yet?
tzname_offset = ttinfo_raw[i + 2]
if tzname_offset not in tznames:
nul = tznames_raw.find(_NULL, tzname_offset)
if nul < 0:
nul = len(tznames_raw)
tznames[tzname_offset] = _std_string(
tznames_raw[tzname_offset:nul])
ttinfo.append((ttinfo_raw[i],
bool(ttinfo_raw[i + 1]),
tznames[tzname_offset]))
i += 3
# Now build the timezone object
if len(ttinfo) == 1 or len(transitions) == 0:
ttinfo[0][0], ttinfo[0][2]
cls = type(zone, (StaticTzInfo,), dict(
zone=zone,
_utcoffset=memorized_timedelta(ttinfo[0][0]),
_tzname=ttinfo[0][2]))
else:
# Early dates use the first standard time ttinfo
i = 0
while ttinfo[i][1]:
i += 1
if ttinfo[i] == ttinfo[lindexes[0]]:
transitions[0] = datetime.min
else:
transitions.insert(0, datetime.min)
lindexes.insert(0, i)
# calculate transition info
transition_info = []
for i in range(len(transitions)):
inf = ttinfo[lindexes[i]]
utcoffset = inf[0]
if not inf[1]:
dst = 0
else:
for j in range(i - 1, -1, -1):
prev_inf = ttinfo[lindexes[j]]
if not prev_inf[1]:
break
dst = inf[0] - prev_inf[0] # dst offset
# Bad dst? Look further. DST > 24 hours happens when
# a timzone has moved across the international dateline.
if dst <= 0 or dst > 3600 * 3:
for j in range(i + 1, len(transitions)):
stdinf = ttinfo[lindexes[j]]
if not stdinf[1]:
dst = inf[0] - stdinf[0]
if dst > 0:
break # Found a useful std time.
tzname = inf[2]
# Round utcoffset and dst to the nearest minute or the
# datetime library will complain. Conversions to these timezones
# might be up to plus or minus 30 seconds out, but it is
# the best we can do.
utcoffset = int((utcoffset + 30) // 60) * 60
dst = int((dst + 30) // 60) * 60
transition_info.append(memorized_ttinfo(utcoffset, dst, tzname))
cls = type(zone, (DstTzInfo,), dict(
zone=zone,
_utc_transition_times=transitions,
_transition_info=transition_info))
return cls()
if __name__ == '__main__':
import os.path
from pprint import pprint
base = os.path.join(os.path.dirname(__file__), 'zoneinfo')
tz = build_tzinfo('Australia/Melbourne',
open(os.path.join(base, 'Australia', 'Melbourne'), 'rb'))
tz = build_tzinfo('US/Eastern',
open(os.path.join(base, 'US', 'Eastern'), 'rb'))
pprint(tz._utc_transition_times)
================================================
FILE: tests/test_code/py/pytz/tzinfo.py
================================================
'''Base classes and helpers for building zone specific tzinfo classes'''
from datetime import datetime, timedelta, tzinfo
from bisect import bisect_right
try:
set
except NameError:
from sets import Set as set
import pytz
from pytz.exceptions import AmbiguousTimeError, NonExistentTimeError
__all__ = []
_timedelta_cache = {}
def memorized_timedelta(seconds):
'''Create only one instance of each distinct timedelta'''
try:
return _timedelta_cache[seconds]
except KeyError:
delta = timedelta(seconds=seconds)
_timedelta_cache[seconds] = delta
return delta
_epoch = datetime.utcfromtimestamp(0)
_datetime_cache = {0: _epoch}
def memorized_datetime(seconds):
'''Create only one instance of each distinct datetime'''
try:
return _datetime_cache[seconds]
except KeyError:
# NB. We can't just do datetime.utcfromtimestamp(seconds) as this
# fails with negative values under Windows (Bug #90096)
dt = _epoch + timedelta(seconds=seconds)
_datetime_cache[seconds] = dt
return dt
_ttinfo_cache = {}
def memorized_ttinfo(*args):
'''Create only one instance of each distinct tuple'''
try:
return _ttinfo_cache[args]
except KeyError:
ttinfo = (
memorized_timedelta(args[0]),
memorized_timedelta(args[1]),
args[2]
)
_ttinfo_cache[args] = ttinfo
return ttinfo
_notime = memorized_timedelta(0)
def _to_seconds(td):
'''Convert a timedelta to seconds'''
return td.seconds + td.days * 24 * 60 * 60
class BaseTzInfo(tzinfo):
# Overridden in subclass
_utcoffset = None
_tzname = None
zone = None
def __str__(self):
return self.zone
class StaticTzInfo(BaseTzInfo):
'''A timezone that has a constant offset from UTC
These timezones are rare, as most locations have changed their
offset at some point in their history
'''
def fromutc(self, dt):
'''See datetime.tzinfo.fromutc'''
if dt.tzinfo is not None and dt.tzinfo is not self:
raise ValueError('fromutc: dt.tzinfo is not self')
return (dt + self._utcoffset).replace(tzinfo=self)
def utcoffset(self, dt, is_dst=None):
'''See datetime.tzinfo.utcoffset
is_dst is ignored for StaticTzInfo, and exists only to
retain compatibility with DstTzInfo.
'''
return self._utcoffset
def dst(self, dt, is_dst=None):
'''See datetime.tzinfo.dst
is_dst is ignored for StaticTzInfo, and exists only to
retain compatibility with DstTzInfo.
'''
return _notime
def tzname(self, dt, is_dst=None):
'''See datetime.tzinfo.tzname
is_dst is ignored for StaticTzInfo, and exists only to
retain compatibility with DstTzInfo.
'''
return self._tzname
def localize(self, dt, is_dst=False):
'''Convert naive time to local time'''
if dt.tzinfo is not None:
raise ValueError('Not naive datetime (tzinfo is already set)')
return dt.replace(tzinfo=self)
def normalize(self, dt, is_dst=False):
'''Correct the timezone information on the given datetime.
This is normally a no-op, as StaticTzInfo timezones never have
ambiguous cases to correct:
>>> from pytz import timezone
>>> gmt = timezone('GMT')
>>> isinstance(gmt, StaticTzInfo)
True
>>> dt = datetime(2011, 5, 8, 1, 2, 3, tzinfo=gmt)
>>> gmt.normalize(dt) is dt
True
The supported method of converting between timezones is to use
datetime.astimezone(). Currently normalize() also works:
>>> la = timezone('America/Los_Angeles')
>>> dt = la.localize(datetime(2011, 5, 7, 1, 2, 3))
>>> fmt = '%Y-%m-%d %H:%M:%S %Z (%z)'
>>> gmt.normalize(dt).strftime(fmt)
'2011-05-07 08:02:03 GMT (+0000)'
'''
if dt.tzinfo is self:
return dt
if dt.tzinfo is None:
raise ValueError('Naive time - no tzinfo set')
return dt.astimezone(self)
def __repr__(self):
return '' % (self.zone,)
def __reduce__(self):
# Special pickle to zone remains a singleton and to cope with
# database changes.
return pytz._p, (self.zone,)
class DstTzInfo(BaseTzInfo):
'''A timezone that has a variable offset from UTC
The offset might change if daylight saving time comes into effect,
or at a point in history when the region decides to change their
timezone definition.
'''
# Overridden in subclass
# Sorted list of DST transition times, UTC
_utc_transition_times = None
# [(utcoffset, dstoffset, tzname)] corresponding to
# _utc_transition_times entries
_transition_info = None
zone = None
# Set in __init__
_tzinfos = None
_dst = None # DST offset
def __init__(self, _inf=None, _tzinfos=None):
if _inf:
self._tzinfos = _tzinfos
self._utcoffset, self._dst, self._tzname = _inf
else:
_tzinfos = {}
self._tzinfos = _tzinfos
self._utcoffset, self._dst, self._tzname = (
self._transition_info[0])
_tzinfos[self._transition_info[0]] = self
for inf in self._transition_info[1:]:
if inf not in _tzinfos:
_tzinfos[inf] = self.__class__(inf, _tzinfos)
def fromutc(self, dt):
'''See datetime.tzinfo.fromutc'''
if (dt.tzinfo is not None and
getattr(dt.tzinfo, '_tzinfos', None) is not self._tzinfos):
raise ValueError('fromutc: dt.tzinfo is not self')
dt = dt.replace(tzinfo=None)
idx = max(0, bisect_right(self._utc_transition_times, dt) - 1)
inf = self._transition_info[idx]
return (dt + inf[0]).replace(tzinfo=self._tzinfos[inf])
def normalize(self, dt):
'''Correct the timezone information on the given datetime
If date arithmetic crosses DST boundaries, the tzinfo
is not magically adjusted. This method normalizes the
tzinfo to the correct one.
To test, first we need to do some setup
>>> from pytz import timezone
>>> utc = timezone('UTC')
>>> eastern = timezone('US/Eastern')
>>> fmt = '%Y-%m-%d %H:%M:%S %Z (%z)'
We next create a datetime right on an end-of-DST transition point,
the instant when the wallclocks are wound back one hour.
>>> utc_dt = datetime(2002, 10, 27, 6, 0, 0, tzinfo=utc)
>>> loc_dt = utc_dt.astimezone(eastern)
>>> loc_dt.strftime(fmt)
'2002-10-27 01:00:00 EST (-0500)'
Now, if we subtract a few minutes from it, note that the timezone
information has not changed.
>>> before = loc_dt - timedelta(minutes=10)
>>> before.strftime(fmt)
'2002-10-27 00:50:00 EST (-0500)'
But we can fix that by calling the normalize method
>>> before = eastern.normalize(before)
>>> before.strftime(fmt)
'2002-10-27 01:50:00 EDT (-0400)'
The supported method of converting between timezones is to use
datetime.astimezone(). Currently, normalize() also works:
>>> th = timezone('Asia/Bangkok')
>>> am = timezone('Europe/Amsterdam')
>>> dt = th.localize(datetime(2011, 5, 7, 1, 2, 3))
>>> fmt = '%Y-%m-%d %H:%M:%S %Z (%z)'
>>> am.normalize(dt).strftime(fmt)
'2011-05-06 20:02:03 CEST (+0200)'
'''
if dt.tzinfo is None:
raise ValueError('Naive time - no tzinfo set')
# Convert dt in localtime to UTC
offset = dt.tzinfo._utcoffset
dt = dt.replace(tzinfo=None)
dt = dt - offset
# convert it back, and return it
return self.fromutc(dt)
def localize(self, dt, is_dst=False):
'''Convert naive time to local time.
This method should be used to construct localtimes, rather
than passing a tzinfo argument to a datetime constructor.
is_dst is used to determine the correct timezone in the ambiguous
period at the end of daylight saving time.
>>> from pytz import timezone
>>> fmt = '%Y-%m-%d %H:%M:%S %Z (%z)'
>>> amdam = timezone('Europe/Amsterdam')
>>> dt = datetime(2004, 10, 31, 2, 0, 0)
>>> loc_dt1 = amdam.localize(dt, is_dst=True)
>>> loc_dt2 = amdam.localize(dt, is_dst=False)
>>> loc_dt1.strftime(fmt)
'2004-10-31 02:00:00 CEST (+0200)'
>>> loc_dt2.strftime(fmt)
'2004-10-31 02:00:00 CET (+0100)'
>>> str(loc_dt2 - loc_dt1)
'1:00:00'
Use is_dst=None to raise an AmbiguousTimeError for ambiguous
times at the end of daylight saving time
>>> try:
... loc_dt1 = amdam.localize(dt, is_dst=None)
... except AmbiguousTimeError:
... print('Ambiguous')
Ambiguous
is_dst defaults to False
>>> amdam.localize(dt) == amdam.localize(dt, False)
True
is_dst is also used to determine the correct timezone in the
wallclock times jumped over at the start of daylight saving time.
>>> pacific = timezone('US/Pacific')
>>> dt = datetime(2008, 3, 9, 2, 0, 0)
>>> ploc_dt1 = pacific.localize(dt, is_dst=True)
>>> ploc_dt2 = pacific.localize(dt, is_dst=False)
>>> ploc_dt1.strftime(fmt)
'2008-03-09 02:00:00 PDT (-0700)'
>>> ploc_dt2.strftime(fmt)
'2008-03-09 02:00:00 PST (-0800)'
>>> str(ploc_dt2 - ploc_dt1)
'1:00:00'
Use is_dst=None to raise a NonExistentTimeError for these skipped
times.
>>> try:
... loc_dt1 = pacific.localize(dt, is_dst=None)
... except NonExistentTimeError:
... print('Non-existent')
Non-existent
'''
if dt.tzinfo is not None:
raise ValueError('Not naive datetime (tzinfo is already set)')
# Find the two best possibilities.
possible_loc_dt = set()
for delta in [timedelta(days=-1), timedelta(days=1)]:
loc_dt = dt + delta
idx = max(0, bisect_right(
self._utc_transition_times, loc_dt) - 1)
inf = self._transition_info[idx]
tzinfo = self._tzinfos[inf]
loc_dt = tzinfo.normalize(dt.replace(tzinfo=tzinfo))
if loc_dt.replace(tzinfo=None) == dt:
possible_loc_dt.add(loc_dt)
if len(possible_loc_dt) == 1:
return possible_loc_dt.pop()
# If there are no possibly correct timezones, we are attempting
# to convert a time that never happened - the time period jumped
# during the start-of-DST transition period.
if len(possible_loc_dt) == 0:
# If we refuse to guess, raise an exception.
if is_dst is None:
raise NonExistentTimeError(dt)
# If we are forcing the pre-DST side of the DST transition, we
# obtain the correct timezone by winding the clock forward a few
# hours.
elif is_dst:
return self.localize(
dt + timedelta(hours=6), is_dst=True) - timedelta(hours=6)
# If we are forcing the post-DST side of the DST transition, we
# obtain the correct timezone by winding the clock back.
else:
return self.localize(
dt - timedelta(hours=6),
is_dst=False) + timedelta(hours=6)
# If we get this far, we have multiple possible timezones - this
# is an ambiguous case occuring during the end-of-DST transition.
# If told to be strict, raise an exception since we have an
# ambiguous case
if is_dst is None:
raise AmbiguousTimeError(dt)
# Filter out the possiblilities that don't match the requested
# is_dst
filtered_possible_loc_dt = [
p for p in possible_loc_dt if bool(p.tzinfo._dst) == is_dst
]
# Hopefully we only have one possibility left. Return it.
if len(filtered_possible_loc_dt) == 1:
return filtered_possible_loc_dt[0]
if len(filtered_possible_loc_dt) == 0:
filtered_possible_loc_dt = list(possible_loc_dt)
# If we get this far, we have in a wierd timezone transition
# where the clocks have been wound back but is_dst is the same
# in both (eg. Europe/Warsaw 1915 when they switched to CET).
# At this point, we just have to guess unless we allow more
# hints to be passed in (such as the UTC offset or abbreviation),
# but that is just getting silly.
#
# Choose the earliest (by UTC) applicable timezone if is_dst=True
# Choose the latest (by UTC) applicable timezone if is_dst=False
# i.e., behave like end-of-DST transition
dates = {} # utc -> local
for local_dt in filtered_possible_loc_dt:
utc_time = (
local_dt.replace(tzinfo=None) - local_dt.tzinfo._utcoffset)
assert utc_time not in dates
dates[utc_time] = local_dt
return dates[[min, max][not is_dst](dates)]
def utcoffset(self, dt, is_dst=None):
'''See datetime.tzinfo.utcoffset
The is_dst parameter may be used to remove ambiguity during DST
transitions.
>>> from pytz import timezone
>>> tz = timezone('America/St_Johns')
>>> ambiguous = datetime(2009, 10, 31, 23, 30)
>>> str(tz.utcoffset(ambiguous, is_dst=False))
'-1 day, 20:30:00'
>>> str(tz.utcoffset(ambiguous, is_dst=True))
'-1 day, 21:30:00'
>>> try:
... tz.utcoffset(ambiguous)
... except AmbiguousTimeError:
... print('Ambiguous')
Ambiguous
'''
if dt is None:
return None
elif dt.tzinfo is not self:
dt = self.localize(dt, is_dst)
return dt.tzinfo._utcoffset
else:
return self._utcoffset
def dst(self, dt, is_dst=None):
'''See datetime.tzinfo.dst
The is_dst parameter may be used to remove ambiguity during DST
transitions.
>>> from pytz import timezone
>>> tz = timezone('America/St_Johns')
>>> normal = datetime(2009, 9, 1)
>>> str(tz.dst(normal))
'1:00:00'
>>> str(tz.dst(normal, is_dst=False))
'1:00:00'
>>> str(tz.dst(normal, is_dst=True))
'1:00:00'
>>> ambiguous = datetime(2009, 10, 31, 23, 30)
>>> str(tz.dst(ambiguous, is_dst=False))
'0:00:00'
>>> str(tz.dst(ambiguous, is_dst=True))
'1:00:00'
>>> try:
... tz.dst(ambiguous)
... except AmbiguousTimeError:
... print('Ambiguous')
Ambiguous
'''
if dt is None:
return None
elif dt.tzinfo is not self:
dt = self.localize(dt, is_dst)
return dt.tzinfo._dst
else:
return self._dst
def tzname(self, dt, is_dst=None):
'''See datetime.tzinfo.tzname
The is_dst parameter may be used to remove ambiguity during DST
transitions.
>>> from pytz import timezone
>>> tz = timezone('America/St_Johns')
>>> normal = datetime(2009, 9, 1)
>>> tz.tzname(normal)
'NDT'
>>> tz.tzname(normal, is_dst=False)
'NDT'
>>> tz.tzname(normal, is_dst=True)
'NDT'
>>> ambiguous = datetime(2009, 10, 31, 23, 30)
>>> tz.tzname(ambiguous, is_dst=False)
'NST'
>>> tz.tzname(ambiguous, is_dst=True)
'NDT'
>>> try:
... tz.tzname(ambiguous)
... except AmbiguousTimeError:
... print('Ambiguous')
Ambiguous
'''
if dt is None:
return self.zone
elif dt.tzinfo is not self:
dt = self.localize(dt, is_dst)
return dt.tzinfo._tzname
else:
return self._tzname
def __repr__(self):
if self._dst:
dst = 'DST'
else:
dst = 'STD'
if self._utcoffset > _notime:
return '' % (
self.zone, self._tzname, self._utcoffset, dst
)
else:
return '' % (
self.zone, self._tzname, self._utcoffset, dst
)
def __reduce__(self):
# Special pickle to zone remains a singleton and to cope with
# database changes.
return pytz._p, (
self.zone,
_to_seconds(self._utcoffset),
_to_seconds(self._dst),
self._tzname
)
def unpickler(zone, utcoffset=None, dstoffset=None, tzname=None):
"""Factory function for unpickling pytz tzinfo instances.
This is shared for both StaticTzInfo and DstTzInfo instances, because
database changes could cause a zones implementation to switch between
these two base classes and we can't break pickles on a pytz version
upgrade.
"""
# Raises a KeyError if zone no longer exists, which should never happen
# and would be a bug.
tz = pytz.timezone(zone)
# A StaticTzInfo - just return it
if utcoffset is None:
return tz
# This pickle was created from a DstTzInfo. We need to
# determine which of the list of tzinfo instances for this zone
# to use in order to restore the state of any datetime instances using
# it correctly.
utcoffset = memorized_timedelta(utcoffset)
dstoffset = memorized_timedelta(dstoffset)
try:
return tz._tzinfos[(utcoffset, dstoffset, tzname)]
except KeyError:
# The particular state requested in this timezone no longer exists.
# This indicates a corrupt pickle, or the timezone database has been
# corrected violently enough to make this particular
# (utcoffset,dstoffset) no longer exist in the zone, or the
# abbreviation has been changed.
pass
# See if we can find an entry differing only by tzname. Abbreviations
# get changed from the initial guess by the database maintainers to
# match reality when this information is discovered.
for localized_tz in tz._tzinfos.values():
if (localized_tz._utcoffset == utcoffset and
localized_tz._dst == dstoffset):
return localized_tz
# This (utcoffset, dstoffset) information has been removed from the
# zone. Add it back. This might occur when the database maintainers have
# corrected incorrect information. datetime instances using this
# incorrect information will continue to do so, exactly as they were
# before being pickled. This is purely an overly paranoid safety net - I
# doubt this will ever been needed in real life.
inf = (utcoffset, dstoffset, tzname)
tz._tzinfos[inf] = tz.__class__(inf, tz._tzinfos)
return tz._tzinfos[inf]
================================================
FILE: tests/test_code/py/resolve_correct_class/rcc.py
================================================
def func_1():
print("global func_1")
class Alpha():
def func_1(self):
print("alpha func_1")
self.func_1()
func_1()
b = Beta()
b.func_2()
def func_2(self):
print("alpha func_2")
class Beta():
def func_1(self):
print("beta func_1")
al = Alpha()
al.func_2()
def func_2(self):
print("beta func_2")
================================================
FILE: tests/test_code/py/simple_a/simple_a.py
================================================
def func_b():
pass
def func_a():
func_b()
================================================
FILE: tests/test_code/py/simple_b/simple_b.py
================================================
"""
Comments
"""
def a():
b()
# comments
def b():
a("""STRC #""")
class c():
def d(a="String"):
a("AnotherSTR")
c.d()
================================================
FILE: tests/test_code/py/subset_find_exception/two.py
================================================
def private():
pass
class Abra:
def func():
private()
class Cadabra:
def func():
private()
================================================
FILE: tests/test_code/py/subset_find_exception/zero.py
================================================
def private():
pass
class Abra:
def other():
private()
================================================
FILE: tests/test_code/py/two_file_simple/file_a.py
================================================
from file_b import b
def a():
b()
if __name__ == '__main__':
a()
================================================
FILE: tests/test_code/py/two_file_simple/file_b.py
================================================
def b():
print("here")
def c():
pass
================================================
FILE: tests/test_code/py/two_file_simple/shouldntberead
================================================
def d():
e()
================================================
FILE: tests/test_code/py/weird_calls/weird_calls.py
================================================
def print_it(string):
print(string)
def func_a():
print_it("func_a")
def func_b():
print_it("func_a")
def func_c():
print_it("func_a")
func_dict = {
'func_a': func_a,
'func_b': func_b,
'func_c': func_c,
}
func_dict['func_a']()
func_b()
def factory():
return lambda x: x**x
factory()(5)
================================================
FILE: tests/test_code/py/weird_encoding/weird_encoding.py
================================================
def a():
print("😅😂😘")
a()
================================================
FILE: tests/test_code/py/weird_imports/weird_imports.py
================================================
from re import (search, match)
import re.match as mitch
def main():
a = b = search("abc", "def")
c = mitch("abc", "def")
return a, b, c
match("abc", "def")
main()
================================================
FILE: tests/test_code/rb/ambiguous_resolution/ambiguous_resolution.rb
================================================
class Abra
def magic()
end
def abra_it()
end
end
class Cadabra
def magic()
end
def cadabra_it(a: nil)
a.abra_it()
end
end
def main(cls)
obj = cls.new()
obj.magic()
obj.cadabra_it()
end
main(Cadabra)
================================================
FILE: tests/test_code/rb/chains/chains.rb
================================================
def a
puts "A"
b
end
def b
puts "B"
a
end
class Cls
def initialize
puts "init"
end
def a
puts "a"
self
end
def b
puts "b"
return self
end
end
def c
obj = Cls.new()
obj.a.b.a.c
end
a
b
c
================================================
FILE: tests/test_code/rb/doublecolon/doublecolon.rb
================================================
# def func_a
# puts "global func_a"
# end
# def func_b
# puts "global func_b"
# end
class Class1
def self.func_a
Class2::func_b()
puts "Class1::func_a"
end
def self.func_b
func_a()
puts "Class1::func_b"
end
end
class Class2
def self.func_a
Class1::func_b()
puts "Class2::func_a"
end
def self.func_b
func_a()
puts "Class2::func_b"
end
end
a = 5
Class2::func_b
================================================
FILE: tests/test_code/rb/inheritance_2/inheritance_2.rb
================================================
# from https://launchschool.com/books/oo_ruby/read/inheritance
def speak
puts "WOOF"
end
class Animal
def speak
puts "Hello!"
end
end
class GoodDog < Animal
end
class Cat < Animal
def meow
speak
end
end
sparky = GoodDog.new
paws = Cat.new
puts sparky.speak
puts paws.meow
================================================
FILE: tests/test_code/rb/instance_methods/instance_methods.rb
================================================
def main
puts("This is not called")
end
class Abra
def main
def nested
puts("This will reference the main on Abra")
main
end
nested
puts("Hello from main")
end
def main2
def nested2
main()
end
end
end
a = Abra.new()
a.main()
a.nested()
a.main2()
a.nested2()
================================================
FILE: tests/test_code/rb/modules/modules.rb
================================================
# from https://ruby-doc.com/docs/ProgrammingRuby/html/tut_modules.html
def majorNum
end
def pentaNum
end
module MajorScales
def majorNum
@numNotes = 7 if @numNotes.nil?
@numNotes # Return 7
end
end
module PentatonicScales
def pentaNum
@numNotes = 5 if @numNotes.nil?
@numNotes # Return 5?
end
end
class ScaleDemo
include MajorScales
include PentatonicScales
def initialize
puts majorNum # Should be 7
puts pentaNum # Should be 5
end
end
class ScaleDemoLimited
include MajorScales
def initialize
puts majorNum # Should be 7
end
end
sd = ScaleDemo.new()
majorNum
================================================
FILE: tests/test_code/rb/nested/nested.rb
================================================
module Mod
def func_1
puts("func_1 outer")
end
def func_2
puts("func_2 outer")
end
class Nested
def initialize
puts("hello world")
func_1
end
def func_1
puts("func_1")
Mod::func_1
end
def func_2
puts("func_2")
func_1()
Mod::func_2
end
end
end
def func_1
puts("func_1 top_level")
func_2
end
def func_2
puts("func_2 top_level")
func_1
end
obj = Mod::Nested.new()
obj.func_2()
Mod::func_1()
================================================
FILE: tests/test_code/rb/nested_classes/nested_classes.rb
================================================
class Mod
def func_1
puts("func_1 outer")
end
def func_2
puts("func_2 outer")
end
class Nested
def initialize
puts("hello world")
func_1
end
def func_1
puts("func_1")
Mod::func_1
end
def func_2
puts("func_2")
func_1()
Mod::func_2
end
end
end
def func_1
puts("func_1 top_level")
func_2
end
def func_2
puts("func_2 top_level")
func_1
end
obj = Mod::Nested.new()
obj.func_2()
outer_obj = Mod.new()
outer_obj.func_1()
================================================
FILE: tests/test_code/rb/onelinefile/onelinefile.rb
================================================
adder = lambda { |a, b| a + b}
================================================
FILE: tests/test_code/rb/public_suffix/public_suffix/domain.rb
================================================
# frozen_string_literal: true
# = Public Suffix
#
# Domain name parser based on the Public Suffix List.
#
# Copyright (c) 2009-2020 Simone Carletti
module PublicSuffix
# Domain represents a domain name, composed by a TLD, SLD and TRD.
class Domain
# Splits a string into the labels, that is the dot-separated parts.
#
# The input is not validated, but it is assumed to be a valid domain name.
#
# @example
#
# name_to_labels('example.com')
# # => ['example', 'com']
#
# name_to_labels('example.co.uk')
# # => ['example', 'co', 'uk']
#
# @param name [String, #to_s] The domain name to split.
# @return [Array]
def self.name_to_labels(name)
name.to_s.split(DOT)
end
attr_reader :tld, :sld, :trd
# Creates and returns a new {PublicSuffix::Domain} instance.
#
# @overload initialize(tld)
# Initializes with a +tld+.
# @param [String] tld The TLD (extension)
# @overload initialize(tld, sld)
# Initializes with a +tld+ and +sld+.
# @param [String] tld The TLD (extension)
# @param [String] sld The TRD (domain)
# @overload initialize(tld, sld, trd)
# Initializes with a +tld+, +sld+ and +trd+.
# @param [String] tld The TLD (extension)
# @param [String] sld The SLD (domain)
# @param [String] trd The TRD (subdomain)
#
# @yield [self] Yields on self.
# @yieldparam [PublicSuffix::Domain] self The newly creates instance
#
# @example Initialize with a TLD
# PublicSuffix::Domain.new("com")
# # => #
#
# @example Initialize with a TLD and SLD
# PublicSuffix::Domain.new("com", "example")
# # => #
#
# @example Initialize with a TLD, SLD and TRD
# PublicSuffix::Domain.new("com", "example", "wwww")
# # => #
#
def initialize(*args)
@tld, @sld, @trd = args
yield(self) if block_given?
end
# Returns a string representation of this object.
#
# @return [String]
def to_s
name
end
# Returns an array containing the domain parts.
#
# @return [Array]
#
# @example
#
# PublicSuffix::Domain.new("google.com").to_a
# # => [nil, "google", "com"]
#
# PublicSuffix::Domain.new("www.google.com").to_a
# # => [nil, "google", "com"]
#
def to_a
[@trd, @sld, @tld]
end
# Returns the full domain name.
#
# @return [String]
#
# @example Gets the domain name of a domain
# PublicSuffix::Domain.new("com", "google").name
# # => "google.com"
#
# @example Gets the domain name of a subdomain
# PublicSuffix::Domain.new("com", "google", "www").name
# # => "www.google.com"
#
def name
[@trd, @sld, @tld].compact.join(DOT)
end
# Returns a domain-like representation of this object
# if the object is a {#domain?}, nil otherwise.
#
# PublicSuffix::Domain.new("com").domain
# # => nil
#
# PublicSuffix::Domain.new("com", "google").domain
# # => "google.com"
#
# PublicSuffix::Domain.new("com", "google", "www").domain
# # => "www.google.com"
#
# This method doesn't validate the input. It handles the domain
# as a valid domain name and simply applies the necessary transformations.
#
# This method returns a FQD, not just the domain part.
# To get the domain part, use #sld (aka second level domain).
#
# PublicSuffix::Domain.new("com", "google", "www").domain
# # => "google.com"
#
# PublicSuffix::Domain.new("com", "google", "www").sld
# # => "google"
#
# @see #domain?
# @see #subdomain
#
# @return [String]
def domain
[@sld, @tld].join(DOT) if domain?
end
# Returns a subdomain-like representation of this object
# if the object is a {#subdomain?}, nil otherwise.
#
# PublicSuffix::Domain.new("com").subdomain
# # => nil
#
# PublicSuffix::Domain.new("com", "google").subdomain
# # => nil
#
# PublicSuffix::Domain.new("com", "google", "www").subdomain
# # => "www.google.com"
#
# This method doesn't validate the input. It handles the domain
# as a valid domain name and simply applies the necessary transformations.
#
# This method returns a FQD, not just the subdomain part.
# To get the subdomain part, use #trd (aka third level domain).
#
# PublicSuffix::Domain.new("com", "google", "www").subdomain
# # => "www.google.com"
#
# PublicSuffix::Domain.new("com", "google", "www").trd
# # => "www"
#
# @see #subdomain?
# @see #domain
#
# @return [String]
def subdomain
[@trd, @sld, @tld].join(DOT) if subdomain?
end
# Checks whether self looks like a domain.
#
# This method doesn't actually validate the domain.
# It only checks whether the instance contains
# a value for the {#tld} and {#sld} attributes.
#
# @example
#
# PublicSuffix::Domain.new("com").domain?
# # => false
#
# PublicSuffix::Domain.new("com", "google").domain?
# # => true
#
# PublicSuffix::Domain.new("com", "google", "www").domain?
# # => true
#
# # This is an invalid domain, but returns true
# # because this method doesn't validate the content.
# PublicSuffix::Domain.new("com", nil).domain?
# # => true
#
# @see #subdomain?
#
# @return [Boolean]
def domain?
!(@tld.nil? || @sld.nil?)
end
# Checks whether self looks like a subdomain.
#
# This method doesn't actually validate the subdomain.
# It only checks whether the instance contains
# a value for the {#tld}, {#sld} and {#trd} attributes.
# If you also want to validate the domain,
# use {#valid_subdomain?} instead.
#
# @example
#
# PublicSuffix::Domain.new("com").subdomain?
# # => false
#
# PublicSuffix::Domain.new("com", "google").subdomain?
# # => false
#
# PublicSuffix::Domain.new("com", "google", "www").subdomain?
# # => true
#
# # This is an invalid domain, but returns true
# # because this method doesn't validate the content.
# PublicSuffix::Domain.new("com", "example", nil).subdomain?
# # => true
#
# @see #domain?
#
# @return [Boolean]
def subdomain?
!(@tld.nil? || @sld.nil? || @trd.nil?)
end
end
end
================================================
FILE: tests/test_code/rb/public_suffix/public_suffix/errors.rb
================================================
# frozen_string_literal: true
# = Public Suffix
#
# Domain name parser based on the Public Suffix List.
#
# Copyright (c) 2009-2020 Simone Carletti
module PublicSuffix
class Error < StandardError
end
# Raised when trying to parse an invalid name.
# A name is considered invalid when no rule is found in the definition list.
#
# @example
#
# PublicSuffix.parse("nic.test")
# # => PublicSuffix::DomainInvalid
#
# PublicSuffix.parse("http://www.nic.it")
# # => PublicSuffix::DomainInvalid
#
class DomainInvalid < Error
end
# Raised when trying to parse a name that matches a suffix.
#
# @example
#
# PublicSuffix.parse("nic.do")
# # => PublicSuffix::DomainNotAllowed
#
# PublicSuffix.parse("www.nic.do")
# # => PublicSuffix::Domain
#
class DomainNotAllowed < DomainInvalid
end
end
================================================
FILE: tests/test_code/rb/public_suffix/public_suffix/list.rb
================================================
# frozen_string_literal: true
# = Public Suffix
#
# Domain name parser based on the Public Suffix List.
#
# Copyright (c) 2009-2020 Simone Carletti
module PublicSuffix
# A {PublicSuffix::List} is a collection of one
# or more {PublicSuffix::Rule}.
#
# Given a {PublicSuffix::List},
# you can add or remove {PublicSuffix::Rule},
# iterate all items in the list or search for the first rule
# which matches a specific domain name.
#
# # Create a new list
# list = PublicSuffix::List.new
#
# # Push two rules to the list
# list << PublicSuffix::Rule.factory("it")
# list << PublicSuffix::Rule.factory("com")
#
# # Get the size of the list
# list.size
# # => 2
#
# # Search for the rule matching given domain
# list.find("example.com")
# # => #
# list.find("example.org")
# # => nil
#
# You can create as many {PublicSuffix::List} you want.
# The {PublicSuffix::List.default} rule list is used
# to tokenize and validate a domain.
#
class List
DEFAULT_LIST_PATH = File.expand_path("../../data/list.txt", __dir__)
# Gets the default rule list.
#
# Initializes a new {PublicSuffix::List} parsing the content
# of {PublicSuffix::List.default_list_content}, if required.
#
# @return [PublicSuffix::List]
def self.default(**options)
@default ||= parse(File.read(DEFAULT_LIST_PATH), **options)
end
# Sets the default rule list to +value+.
#
# @param value [PublicSuffix::List] the new list
# @return [PublicSuffix::List]
def self.default=(value)
@default = value
end
# Parse given +input+ treating the content as Public Suffix List.
#
# See http://publicsuffix.org/format/ for more details about input format.
#
# @param string [#each_line] the list to parse
# @param private_domains [Boolean] whether to ignore the private domains section
# @return [PublicSuffix::List]
def self.parse(input, private_domains: true)
comment_token = "//"
private_token = "===BEGIN PRIVATE DOMAINS==="
section = nil # 1 == ICANN, 2 == PRIVATE
new do |list|
input.each_line do |line|
line.strip!
case # rubocop:disable Style/EmptyCaseCondition
# skip blank lines
when line.empty?
next
# include private domains or stop scanner
when line.include?(private_token)
break if !private_domains
section = 2
# skip comments
when line.start_with?(comment_token)
next
else
list.add(Rule.factory(line, private: section == 2))
end
end
end
end
# Initializes an empty {PublicSuffix::List}.
#
# @yield [self] Yields on self.
# @yieldparam [PublicSuffix::List] self The newly created instance.
def initialize
@rules = {}
yield(self) if block_given?
end
# Checks whether two lists are equal.
#
# List one is equal to two, if two is an instance of
# {PublicSuffix::List} and each +PublicSuffix::Rule::*+
# in list one is available in list two, in the same order.
#
# @param other [PublicSuffix::List] the List to compare
# @return [Boolean]
def ==(other)
return false unless other.is_a?(List)
equal?(other) || @rules == other.rules
end
alias eql? ==
# Iterates each rule in the list.
def each(&block)
Enumerator.new do |y|
@rules.each do |key, node|
y << entry_to_rule(node, key)
end
end.each(&block)
end
# Adds the given object to the list and optionally refreshes the rule index.
#
# @param rule [PublicSuffix::Rule::*] the rule to add to the list
# @return [self]
def add(rule)
@rules[rule.value] = rule_to_entry(rule)
self
end
alias << add
# Gets the number of rules in the list.
#
# @return [Integer]
def size
@rules.size
end
# Checks whether the list is empty.
#
# @return [Boolean]
def empty?
@rules.empty?
end
# Removes all rules.
#
# @return [self]
def clear
@rules.clear
self
end
# Finds and returns the rule corresponding to the longest public suffix for the hostname.
#
# @param name [#to_s] the hostname
# @param default [PublicSuffix::Rule::*] the default rule to return in case no rule matches
# @return [PublicSuffix::Rule::*]
def find(name, default: default_rule, **options)
rule = select(name, **options).inject do |l, r|
return r if r.class == Rule::Exception
l.length > r.length ? l : r
end
rule || default
end
# Selects all the rules matching given hostame.
#
# If `ignore_private` is set to true, the algorithm will skip the rules that are flagged as
# private domain. Note that the rules will still be part of the loop.
# If you frequently need to access lists ignoring the private domains,
# you should create a list that doesn't include these domains setting the
# `private_domains: false` option when calling {.parse}.
#
# Note that this method is currently private, as you should not rely on it. Instead,
# the public interface is {#find}. The current internal algorithm allows to return all
# matching rules, but different data structures may not be able to do it, and instead would
# return only the match. For this reason, you should rely on {#find}.
#
# @param name [#to_s] the hostname
# @param ignore_private [Boolean]
# @return [Array]
def select(name, ignore_private: false)
name = name.to_s
parts = name.split(DOT).reverse!
index = 0
query = parts[index]
rules = []
loop do
match = @rules[query]
rules << entry_to_rule(match, query) if !match.nil? && (ignore_private == false || match.private == false)
index += 1
break if index >= parts.size
query = parts[index] + DOT + query
end
rules
end
private :select
# Gets the default rule.
#
# @see PublicSuffix::Rule.default_rule
#
# @return [PublicSuffix::Rule::*]
def default_rule
PublicSuffix::Rule.default
end
protected
attr_reader :rules
private
def entry_to_rule(entry, value)
entry.type.new(value: value, length: entry.length, private: entry.private)
end
def rule_to_entry(rule)
Rule::Entry.new(rule.class, rule.length, rule.private)
end
end
end
================================================
FILE: tests/test_code/rb/public_suffix/public_suffix/rule.rb
================================================
# frozen_string_literal: true
# = Public Suffix
#
# Domain name parser based on the Public Suffix List.
#
# Copyright (c) 2009-2020 Simone Carletti
module PublicSuffix
# A Rule is a special object which holds a single definition
# of the Public Suffix List.
#
# There are 3 types of rules, each one represented by a specific
# subclass within the +PublicSuffix::Rule+ namespace.
#
# To create a new Rule, use the {PublicSuffix::Rule#factory} method.
#
# PublicSuffix::Rule.factory("ar")
# # => #
#
module Rule
# @api internal
Entry = Struct.new(:type, :length, :private) # rubocop:disable Lint/StructNewOverride
# = Abstract rule class
#
# This represent the base class for a Rule definition
# in the {Public Suffix List}[https://publicsuffix.org].
#
# This is intended to be an Abstract class
# and you shouldn't create a direct instance. The only purpose
# of this class is to expose a common interface
# for all the available subclasses.
#
# * {PublicSuffix::Rule::Normal}
# * {PublicSuffix::Rule::Exception}
# * {PublicSuffix::Rule::Wildcard}
#
# ## Properties
#
# A rule is composed by 4 properties:
#
# value - A normalized version of the rule name.
# The normalization process depends on rule tpe.
#
# Here's an example
#
# PublicSuffix::Rule.factory("*.google.com")
# #
#
# ## Rule Creation
#
# The best way to create a new rule is passing the rule name
# to the PublicSuffix::Rule.factory method.
#
# PublicSuffix::Rule.factory("com")
# # => PublicSuffix::Rule::Normal
#
# PublicSuffix::Rule.factory("*.com")
# # => PublicSuffix::Rule::Wildcard
#
# This method will detect the rule type and create an instance
# from the proper rule class.
#
# ## Rule Usage
#
# A rule describes the composition of a domain name and explains how to tokenize
# the name into tld, sld and trd.
#
# To use a rule, you first need to be sure the name you want to tokenize
# can be handled by the current rule.
# You can use the #match? method.
#
# rule = PublicSuffix::Rule.factory("com")
#
# rule.match?("google.com")
# # => true
#
# rule.match?("google.com")
# # => false
#
# Rule order is significant. A name can match more than one rule.
# See the {Public Suffix Documentation}[http://publicsuffix.org/format/]
# to learn more about rule priority.
#
# When you have the right rule, you can use it to tokenize the domain name.
#
# rule = PublicSuffix::Rule.factory("com")
#
# rule.decompose("google.com")
# # => ["google", "com"]
#
# rule.decompose("www.google.com")
# # => ["www.google", "com"]
#
# @abstract
#
class Base
# @return [String] the rule definition
attr_reader :value
# @return [String] the length of the rule
attr_reader :length
# @return [Boolean] true if the rule is a private domain
attr_reader :private
# Initializes a new rule from the content.
#
# @param content [String] the content of the rule
# @param private [Boolean]
def self.build(content, private: false)
new(value: content, private: private)
end
# Initializes a new rule.
#
# @param value [String]
# @param private [Boolean]
def initialize(value:, length: nil, private: false)
@value = value.to_s
@length = length || @value.count(DOT) + 1
@private = private
end
# Checks whether this rule is equal to other.
#
# @param [PublicSuffix::Rule::*] other The rule to compare
# @return [Boolean]
# Returns true if this rule and other are instances of the same class
# and has the same value, false otherwise.
def ==(other)
equal?(other) || (self.class == other.class && value == other.value)
end
alias eql? ==
# Checks if this rule matches +name+.
#
# A domain name is said to match a rule if and only if
# all of the following conditions are met:
#
# - When the domain and rule are split into corresponding labels,
# that the domain contains as many or more labels than the rule.
# - Beginning with the right-most labels of both the domain and the rule,
# and continuing for all labels in the rule, one finds that for every pair,
# either they are identical, or that the label from the rule is "*".
#
# @see https://publicsuffix.org/list/
#
# @example
# PublicSuffix::Rule.factory("com").match?("example.com")
# # => true
# PublicSuffix::Rule.factory("com").match?("example.net")
# # => false
#
# @param name [String] the domain name to check
# @return [Boolean]
def match?(name)
# Note: it works because of the assumption there are no
# rules like foo.*.com. If the assumption is incorrect,
# we need to properly walk the input and skip parts according
# to wildcard component.
diff = name.chomp(value)
diff.empty? || diff.end_with?(DOT)
end
# @abstract
def parts
raise NotImplementedError
end
# @abstract
# @param [String, #to_s] name The domain name to decompose
# @return [Array]
def decompose(*)
raise NotImplementedError
end
end
# Normal represents a standard rule (e.g. com).
class Normal < Base
# Gets the original rule definition.
#
# @return [String] The rule definition.
def rule
value
end
# Decomposes the domain name according to rule properties.
#
# @param [String, #to_s] name The domain name to decompose
# @return [Array] The array with [trd + sld, tld].
def decompose(domain)
suffix = parts.join('\.')
matches = domain.to_s.match(/^(.*)\.(#{suffix})$/)
matches ? matches[1..2] : [nil, nil]
end
# dot-split rule value and returns all rule parts
# in the order they appear in the value.
#
# @return [Array]
def parts
@value.split(DOT)
end
end
# Wildcard represents a wildcard rule (e.g. *.co.uk).
class Wildcard < Base
# Initializes a new rule from the content.
#
# @param content [String] the content of the rule
# @param private [Boolean]
def self.build(content, private: false)
new(value: content.to_s[2..-1], private: private)
end
# Initializes a new rule.
#
# @param value [String]
# @param private [Boolean]
def initialize(value:, length: nil, private: false)
super(value: value, length: length, private: private)
length or @length += 1 # * counts as 1
end
# Gets the original rule definition.
#
# @return [String] The rule definition.
def rule
value == "" ? STAR : STAR + DOT + value
end
# Decomposes the domain name according to rule properties.
#
# @param [String, #to_s] name The domain name to decompose
# @return [Array] The array with [trd + sld, tld].
def decompose(domain)
suffix = ([".*?"] + parts).join('\.')
matches = domain.to_s.match(/^(.*)\.(#{suffix})$/)
matches ? matches[1..2] : [nil, nil]
end
# dot-split rule value and returns all rule parts
# in the order they appear in the value.
#
# @return [Array]
def parts
@value.split(DOT)
end
end
# Exception represents an exception rule (e.g. !parliament.uk).
class Exception < Base
# Initializes a new rule from the content.
#
# @param content [String] the content of the rule
# @param private [Boolean]
def self.build(content, private: false)
new(value: content.to_s[1..-1], private: private)
end
# Gets the original rule definition.
#
# @return [String] The rule definition.
def rule
BANG + value
end
# Decomposes the domain name according to rule properties.
#
# @param [String, #to_s] name The domain name to decompose
# @return [Array] The array with [trd + sld, tld].
def decompose(domain)
suffix = parts.join('\.')
matches = domain.to_s.match(/^(.*)\.(#{suffix})$/)
matches ? matches[1..2] : [nil, nil]
end
# dot-split rule value and returns all rule parts
# in the order they appear in the value.
# The leftmost label is not considered a label.
#
# See http://publicsuffix.org/format/:
# If the prevailing rule is a exception rule,
# modify it by removing the leftmost label.
#
# @return [Array]
def parts
@value.split(DOT)[1..-1]
end
end
# Takes the +name+ of the rule, detects the specific rule class
# and creates a new instance of that class.
# The +name+ becomes the rule +value+.
#
# @example Creates a Normal rule
# PublicSuffix::Rule.factory("ar")
# # => #
#
# @example Creates a Wildcard rule
# PublicSuffix::Rule.factory("*.ar")
# # => #
#
# @example Creates an Exception rule
# PublicSuffix::Rule.factory("!congresodelalengua3.ar")
# # => #
#
# @param [String] content The rule content.
# @return [PublicSuffix::Rule::*] A rule instance.
def self.factory(content, private: false)
case content.to_s[0, 1]
when STAR
Wildcard
when BANG
Exception
else
Normal
end.build(content, private: private)
end
# The default rule to use if no rule match.
#
# The default rule is "*". From https://publicsuffix.org/list/:
#
# > If no rules match, the prevailing rule is "*".
#
# @return [PublicSuffix::Rule::Wildcard] The default rule.
def self.default
factory(STAR)
end
end
end
================================================
FILE: tests/test_code/rb/public_suffix/public_suffix/version.rb
================================================
# frozen_string_literal: true
#
# = Public Suffix
#
# Domain name parser based on the Public Suffix List.
#
# Copyright (c) 2009-2020 Simone Carletti
module PublicSuffix
# The current library version.
VERSION = "4.0.6"
end
================================================
FILE: tests/test_code/rb/public_suffix/public_suffix.rb
================================================
# frozen_string_literal: true
# = Public Suffix
#
# Domain name parser based on the Public Suffix List.
#
# Copyright (c) 2009-2020 Simone Carletti
require_relative "public_suffix/domain"
require_relative "public_suffix/version"
require_relative "public_suffix/errors"
require_relative "public_suffix/rule"
require_relative "public_suffix/list"
# PublicSuffix is a Ruby domain name parser based on the Public Suffix List.
#
# The [Public Suffix List](https://publicsuffix.org) is a cross-vendor initiative
# to provide an accurate list of domain name suffixes.
#
# The Public Suffix List is an initiative of the Mozilla Project,
# but is maintained as a community resource. It is available for use in any software,
# but was originally created to meet the needs of browser manufacturers.
module PublicSuffix
DOT = "."
BANG = "!"
STAR = "*"
# Parses +name+ and returns the {PublicSuffix::Domain} instance.
#
# @example Parse a valid domain
# PublicSuffix.parse("google.com")
# # => #
#
# @example Parse a valid subdomain
# PublicSuffix.parse("www.google.com")
# # => #
#
# @example Parse a fully qualified domain
# PublicSuffix.parse("google.com.")
# # => #
#
# @example Parse a fully qualified domain (subdomain)
# PublicSuffix.parse("www.google.com.")
# # => #
#
# @example Parse an invalid (unlisted) domain
# PublicSuffix.parse("x.yz")
# # => #
#
# @example Parse an invalid (unlisted) domain with strict checking (without applying the default * rule)
# PublicSuffix.parse("x.yz", default_rule: nil)
# # => PublicSuffix::DomainInvalid: `x.yz` is not a valid domain
#
# @example Parse an URL (not supported, only domains)
# PublicSuffix.parse("http://www.google.com")
# # => PublicSuffix::DomainInvalid: http://www.google.com is not expected to contain a scheme
#
#
# @param [String, #to_s] name The domain name or fully qualified domain name to parse.
# @param [PublicSuffix::List] list The rule list to search, defaults to the default {PublicSuffix::List}
# @param [Boolean] ignore_private
# @return [PublicSuffix::Domain]
#
# @raise [PublicSuffix::DomainInvalid]
# If domain is not a valid domain.
# @raise [PublicSuffix::DomainNotAllowed]
# If a rule for +domain+ is found, but the rule doesn't allow +domain+.
def self.parse(name, list: List.default, default_rule: list.default_rule, ignore_private: false)
what = normalize(name)
raise what if what.is_a?(DomainInvalid)
rule = list.find(what, default: default_rule, ignore_private: ignore_private)
# rubocop:disable Style/IfUnlessModifier
if rule.nil?
raise DomainInvalid, "`#{what}` is not a valid domain"
end
if rule.decompose(what).last.nil?
raise DomainNotAllowed, "`#{what}` is not allowed according to Registry policy"
end
# rubocop:enable Style/IfUnlessModifier
decompose(what, rule)
end
# Checks whether +domain+ is assigned and allowed, without actually parsing it.
#
# This method doesn't care whether domain is a domain or subdomain.
# The validation is performed using the default {PublicSuffix::List}.
#
# @example Validate a valid domain
# PublicSuffix.valid?("example.com")
# # => true
#
# @example Validate a valid subdomain
# PublicSuffix.valid?("www.example.com")
# # => true
#
# @example Validate a not-listed domain
# PublicSuffix.valid?("example.tldnotlisted")
# # => true
#
# @example Validate a not-listed domain with strict checking (without applying the default * rule)
# PublicSuffix.valid?("example.tldnotlisted")
# # => true
# PublicSuffix.valid?("example.tldnotlisted", default_rule: nil)
# # => false
#
# @example Validate a fully qualified domain
# PublicSuffix.valid?("google.com.")
# # => true
# PublicSuffix.valid?("www.google.com.")
# # => true
#
# @example Check an URL (which is not a valid domain)
# PublicSuffix.valid?("http://www.example.com")
# # => false
#
#
# @param [String, #to_s] name The domain name or fully qualified domain name to validate.
# @param [Boolean] ignore_private
# @return [Boolean]
def self.valid?(name, list: List.default, default_rule: list.default_rule, ignore_private: false)
what = normalize(name)
return false if what.is_a?(DomainInvalid)
rule = list.find(what, default: default_rule, ignore_private: ignore_private)
!rule.nil? && !rule.decompose(what).last.nil?
end
# Attempt to parse the name and returns the domain, if valid.
#
# This method doesn't raise. Instead, it returns nil if the domain is not valid for whatever reason.
#
# @param [String, #to_s] name The domain name or fully qualified domain name to parse.
# @param [PublicSuffix::List] list The rule list to search, defaults to the default {PublicSuffix::List}
# @param [Boolean] ignore_private
# @return [String]
def self.domain(name, **options)
parse(name, **options).domain
rescue PublicSuffix::Error
nil
end
# private
def self.decompose(name, rule)
left, right = rule.decompose(name)
parts = left.split(DOT)
# If we have 0 parts left, there is just a tld and no domain or subdomain
# If we have 1 part left, there is just a tld, domain and not subdomain
# If we have 2 parts left, the last part is the domain, the other parts (combined) are the subdomain
tld = right
sld = parts.empty? ? nil : parts.pop
trd = parts.empty? ? nil : parts.join(DOT)
Domain.new(tld, sld, trd)
end
# Pretend we know how to deal with user input.
def self.normalize(name)
name = name.to_s.dup
name.strip!
name.chomp!(DOT)
name.downcase!
return DomainInvalid.new("Name is blank") if name.empty?
return DomainInvalid.new("Name starts with a dot") if name.start_with?(DOT)
return DomainInvalid.new("%s is not expected to contain a scheme" % name) if name.include?("://")
name
end
end
================================================
FILE: tests/test_code/rb/resolve_correct_class/rcc.rb
================================================
def func_1
puts "this should never get called"
end
class Alpha
def func_1()
puts "alpha func_1"
self.func_1()
func_1()
b = Beta.new()
b.func_2()
end
def func_2()
puts "alpha func_2"
end
end
class Beta
def func_1()
puts "beta func_1"
al = Alpha.new()
al.func_2()
end
def func_2()
puts "beta func_2"
end
end
================================================
FILE: tests/test_code/rb/simple_a/simple_a.rb
================================================
def func_b(var)
puts "hello world"
end
def func_a()
func_b()
end
func_a()
================================================
FILE: tests/test_code/rb/simple_b/simple_b.rb
================================================
"""
Comments
"""
def a()
b()
end
# comments
def b()
a("""STRC #""")
end
class Cls
def initialize(val)
@val = val
end
def d(a="String")
a("AnotherSTR")
end
end
c = Cls.new()
c.d()
================================================
FILE: tests/test_code/rb/split_modules/split_modules_a.rb
================================================
require_relative("split_modules_b")
def say_hi
end
def say_bye
end
module Split
def self.say_hi
puts "hi"
say_bye
end
end
obj = Split::MyClass.new()
obj.doit()
================================================
FILE: tests/test_code/rb/split_modules/split_modules_b.rb
================================================
module Split
class MyClass
def initialize
puts "initialize"
end
def doit
puts "doit"
Split::say_hi
end
end
def self.say_bye
puts "bye"
end
end
================================================
FILE: tests/test_code/rb/two_file_simple/file_a.rb
================================================
require_relative 'file_b.rb'
def abra()
babra()
end
if true
abra()
end
================================================
FILE: tests/test_code/rb/two_file_simple/file_b.rb
================================================
def babra()
print("here")
end
def cadabra()
end
================================================
FILE: tests/test_code/rb/weird_chains/weird_chains.rb
================================================
class DivByTwo
def initialize(val: 0)
@val = val
end
def +(val)
@val += (val / 2)
self
end
def -(val)
@val -= (val / 2)
self
end
def *(val)
@val *= (val / 2)
self
end
def result()
@val
end
end
num = DivByTwo.new(val: 5)
puts ((num + 5 - 5) * 5).result
puts 5 + 6 + 3
================================================
FILE: tests/test_graphs.py
================================================
import io
import os
import sys
import pygraphviz
import pytest
sys.path.append(os.getcwd().split('/tests')[0])
from code2flow.engine import code2flow, LanguageParams, SubsetParams
from tests.testdata import testdata
LANGUAGES = (
'py',
'js',
'mjs',
'rb',
'php',
)
flattened_tests = {}
for lang, tests in testdata.items():
if lang not in LANGUAGES:
continue
for test_dict in tests:
flattened_tests[lang + ': ' + test_dict['test_name']] = (lang, test_dict)
def _edge(tup):
return f"{tup[0]}->{tup[1]}"
def assert_eq(seq_a, seq_b):
try:
assert seq_a == seq_b
except AssertionError:
print("generated", file=sys.stderr)
for el in seq_a:
print(_edge(el), file=sys.stderr)
print("expected", file=sys.stderr)
for el in seq_b:
print(_edge(el), file=sys.stderr)
extra = seq_a - seq_b
missing = seq_b - seq_a
if extra:
print("extra", file=sys.stderr)
for el in extra:
print(_edge(el), file=sys.stderr)
if missing:
print("missing", file=sys.stderr)
for el in missing:
print(_edge(el), file=sys.stderr)
sys.stderr.flush()
raise AssertionError()
@pytest.mark.parametrize("test_tup", flattened_tests)
def test_all(test_tup):
os.chdir(os.path.dirname(os.path.abspath(__file__)))
(language, test_dict) = flattened_tests[test_tup]
print("Running test %r..." % test_dict['test_name'])
directory_path = os.path.join('test_code', language, test_dict['directory'])
kwargs = test_dict.get('kwargs', {})
kwargs['lang_params'] = LanguageParams(kwargs.pop('source_type', 'script'),
kwargs.pop('ruby_version', '27'))
kwargs['subset_params'] = SubsetParams.generate(kwargs.pop('target_function', ''),
int(kwargs.pop('upstream_depth', 0)),
int(kwargs.pop('downstream_depth', 0)))
output_file = io.StringIO()
code2flow([directory_path], output_file, language, **kwargs)
generated_edges = get_edges_set_from_file(output_file)
print("generated_edges eq", file=sys.stderr)
assert_eq(generated_edges, set(map(tuple, test_dict['expected_edges'])))
generated_nodes = get_nodes_set_from_file(output_file)
print("generated_nodes eq", file=sys.stderr)
assert_eq(generated_nodes, set(test_dict['expected_nodes']))
def get_nodes_set_from_file(dot_file):
dot_file.seek(0)
ag = pygraphviz.AGraph(dot_file.read())
generated_nodes = []
for node in ag.nodes():
if not node.attr['name']:
# skip the first which is a legend
continue
generated_nodes.append(node.attr['name'])
ret = set(generated_nodes)
assert_eq(set(list(ret)), set(generated_nodes)) # assert no dupes
return ret
def get_edges_set_from_file(dot_file):
dot_file.seek(0)
ag = pygraphviz.AGraph(dot_file.read())
generated_edges = []
for edge in ag.edges():
to_add = (edge[0].attr['name'],
edge[1].attr['name'])
generated_edges.append(to_add)
ret = set(generated_edges)
assert_eq(set(list(ret)), set(generated_edges)) # assert no dupes
return ret
================================================
FILE: tests/test_interface.py
================================================
import json
import locale
import logging
import os
import shutil
import sys
import pytest
sys.path.append(os.getcwd().split('/tests')[0])
from code2flow.engine import code2flow, main, _generate_graphviz, SubsetParams
from code2flow import model
IMG_PATH = '/tmp/code2flow/output.png'
if os.path.exists("/tmp/code2flow"):
try:
shutil.rmtree('/tmp/code2flow')
except FileNotFoundError:
os.remove('/tmp/code2flow')
os.mkdir('/tmp/code2flow')
os.chdir(os.path.dirname(os.path.abspath(__file__)))
def test_generate_image():
if os.path.exists(IMG_PATH):
os.remove(IMG_PATH)
code2flow(os.path.abspath(__file__),
output_file=IMG_PATH,
hide_legend=True)
assert os.path.exists(IMG_PATH)
os.remove(IMG_PATH)
code2flow(os.path.abspath(__file__),
output_file=IMG_PATH,
hide_legend=False)
assert os.path.exists(IMG_PATH)
def test_not_installed():
if os.path.exists(IMG_PATH):
os.remove(IMG_PATH)
tmp_path = os.environ['PATH']
os.environ['PATH'] = ''
with pytest.raises(AssertionError):
code2flow(os.path.abspath(__file__),
output_file=IMG_PATH)
os.environ['PATH'] = tmp_path
def test_invalid_extension():
with pytest.raises(AssertionError):
code2flow(os.path.abspath(__file__),
output_file='out.pdf')
def test_no_files():
with pytest.raises(AssertionError):
code2flow(os.path.abspath(__file__) + "fakefile",
output_file=IMG_PATH)
def test_graphviz_error(caplog):
caplog.set_level(logging.DEBUG)
_generate_graphviz("/tmp/code2flow/nothing", "/tmp/code2flow/nothing",
"/tmp/code2flow/nothing")
assert "non-zero exit" in caplog.text
def test_no_files_2():
if not os.path.exists('/tmp/code2flow/no_source_dir'):
os.mkdir('/tmp/code2flow/no_source_dir')
if not os.path.exists('/tmp/code2flow/no_source_dir/fakefile'):
with open('/tmp/code2flow/no_source_dir/fakefile', 'w') as f:
f.write("hello world")
with pytest.raises(AssertionError):
code2flow('/tmp/code2flow/no_source_dir',
output_file=IMG_PATH)
with pytest.raises(AssertionError):
code2flow('/tmp/code2flow/no_source_dir',
language='py',
output_file=IMG_PATH)
def test_json():
code2flow('test_code/py/simple_b',
output_file='/tmp/code2flow/out.json',
hide_legend=False)
with open('/tmp/code2flow/out.json') as f:
jobj = json.loads(f.read())
assert set(jobj.keys()) == {'graph'}
assert set(jobj['graph'].keys()) == {'nodes', 'edges', 'directed'}
assert jobj['graph']['directed'] is True
assert isinstance(jobj['graph']['nodes'], dict)
assert len(jobj['graph']['nodes']) == 4
assert set(n['name'] for n in jobj['graph']['nodes'].values()) == {'simple_b::a', 'simple_b::(global)', 'simple_b::c.d', 'simple_b::b'}
assert isinstance(jobj['graph']['edges'], list)
assert len(jobj['graph']['edges']) == 4
assert len(set(n['source'] for n in jobj['graph']['edges'])) == 4
assert len(set(n['target'] for n in jobj['graph']['edges'])) == 3
def test_weird_encoding():
"""
To address https://github.com/scottrogowski/code2flow/issues/28
The windows user had an error b/c their default encoding was cp1252
and they were trying to read a unicode file with emojis
I don't have that installed but was able to reproduce by changing to
US-ASCII which I assume is a little more universal anyway.
"""
locale.setlocale(locale.LC_ALL, 'en_US.US-ASCII')
code2flow('test_code/py/weird_encoding',
output_file='/tmp/code2flow/out.json',
hide_legend=False)
with open('/tmp/code2flow/out.json') as f:
jobj = json.loads(f.read())
assert set(jobj.keys()) == {'graph'}
def test_repr():
module = model.Group('my_file', model.GROUP_TYPE.FILE, [], 0)
group = model.Group('Obj', model.GROUP_TYPE.CLASS, [], 0)
call = model.Call('tostring', 'obj', 42)
variable = model.Variable('the_string', call, 42)
node_a = model.Node('tostring', [], [], [], 13, group)
node_b = model.Node('main', [call], [], [], 59, module)
edge = model.Edge(node_b, node_a)
print(module)
print(group)
print(call)
print(variable)
print(node_a)
print(node_b)
print(edge)
def test_bad_acorn(mocker, caplog):
caplog.set_level(logging.DEBUG)
mocker.patch('code2flow.javascript.get_acorn_version', return_value='7.6.9')
code2flow("test_code/js/simple_a_js", "/tmp/code2flow/out.json")
assert "Acorn" in caplog.text and "8.*" in caplog.text
def test_bad_ruby_parse(mocker):
mocker.patch('subprocess.check_output', return_value=b'blah blah')
with pytest.raises(AssertionError) as ex:
code2flow("test_code/rb/simple_b", "/tmp/code2flow/out.json")
assert "ruby-parse" in ex and "syntax" in ex
def test_bad_php_parse_a():
with pytest.raises(AssertionError) as ex:
code2flow("test_code/php/bad_php/bad_php_a.php", "/tmp/code2flow/out.json")
assert "parse" in ex and "syntax" in ex
def test_bad_php_parse_b():
with pytest.raises(AssertionError) as ex:
code2flow("test_code/php/bad_php/bad_php_b.php", "/tmp/code2flow/out.json")
assert "parse" in ex and "php" in ex.lower()
def test_no_source_type():
with pytest.raises(AssertionError):
code2flow('test_code/js/exclude_modules_es6',
output_file='/tmp/code2flow/out.json',
hide_legend=False)
def test_cli_no_args(capsys):
with pytest.raises(SystemExit):
main([])
assert 'the following arguments are required' in capsys.readouterr().err
def test_cli_verbose_quiet(capsys):
with pytest.raises(AssertionError):
main(['test_code/py/simple_a', '--verbose', '--quiet'])
def test_cli_log_default(mocker):
logging.basicConfig = mocker.MagicMock()
main(['test_code/py/simple_a'])
logging.basicConfig.assert_called_once_with(format="Code2Flow: %(message)s",
level=logging.INFO)
def test_cli_log_verbose(mocker):
logging.basicConfig = mocker.MagicMock()
main(['test_code/py/simple_a', '--verbose'])
logging.basicConfig.assert_called_once_with(format="Code2Flow: %(message)s",
level=logging.DEBUG)
def test_cli_log_quiet(mocker):
logging.basicConfig = mocker.MagicMock()
main(['test_code/py/simple_a', '--quiet'])
logging.basicConfig.assert_called_once_with(format="Code2Flow: %(message)s",
level=logging.WARNING)
def test_subset_cli(mocker):
with pytest.raises(AssertionError):
SubsetParams.generate(target_function='', upstream_depth=1, downstream_depth=0)
with pytest.raises(AssertionError):
SubsetParams.generate(target_function='', upstream_depth=0, downstream_depth=1)
with pytest.raises(AssertionError):
SubsetParams.generate(target_function='test', upstream_depth=0, downstream_depth=0)
with pytest.raises(AssertionError):
SubsetParams.generate(target_function='test', upstream_depth=-1, downstream_depth=0)
with pytest.raises(AssertionError):
SubsetParams.generate(target_function='test', upstream_depth=0, downstream_depth=-1)
with pytest.raises(AssertionError):
main(['test_code/py/subset_find_exception/zero.py', '--target-function', 'func', '--upstream-depth', '1'])
with pytest.raises(AssertionError):
main(['test_code/py/subset_find_exception/two.py', '--target-function', 'func', '--upstream-depth', '1'])
================================================
FILE: tests/testdata.py
================================================
testdata = {
"py": [
{
"test_name": "simple_a",
"directory": "simple_a",
"expected_edges": [["simple_a::func_a", "simple_a::func_b"]],
"expected_nodes": ["simple_a::func_a", "simple_a::func_b"]
},
{
"test_name": "simple_b",
"directory": "simple_b",
"expected_edges": [
["simple_b::c.d", "simple_b::a"],
["simple_b::a", "simple_b::b"],
["simple_b::(global)", "simple_b::c.d"],
["simple_b::b", "simple_b::a"]],
"expected_nodes": ["simple_b::c.d", "simple_b::a", "simple_b::b",
"simple_b::(global)"]
},
{
"test_name": "simple_b --exclude-functions",
"comment": "We don't have a function c so nothing should happen",
"directory": "simple_b",
"kwargs": {"exclude_functions": ["c"]},
"expected_edges": [
["simple_b::c.d", "simple_b::a"],
["simple_b::a", "simple_b::b"],
["simple_b::(global)", "simple_b::c.d"],
["simple_b::b", "simple_b::a"]
],
"expected_nodes": ["simple_b::c.d", "simple_b::a", "simple_b::b",
"simple_b::(global)"]
},
{
"test_name": "simple_b --exclude-functions2",
"comment": "Exclude all edges with function a",
"directory": "simple_b",
"kwargs": {"exclude_functions": ["a"]},
"expected_edges": [
["simple_b::(global)", "simple_b::c.d"]
],
"expected_nodes": ["simple_b::c.d", "simple_b::(global)"]
},
{
"test_name": "simple_b --exclude-functions2 no_trimming",
"comment": "Exclude all edges with function a. No trimming keeps nodes except a",
"directory": "simple_b",
"kwargs": {"exclude_functions": ["a"], "no_trimming": True},
"expected_edges": [
["simple_b::(global)", "simple_b::c.d"]
],
"expected_nodes": ["simple_b::c.d", "simple_b::b", "simple_b::(global)"]
},
{
"test_name": "simple_b --exclude-functions2",
"comment": "Exclude all edges with function d (d is in a class)",
"directory": "simple_b",
"kwargs": {"exclude_functions": ["d"]},
"expected_edges": [
["simple_b::a", "simple_b::b"],
["simple_b::b", "simple_b::a"]
],
"expected_nodes": ["simple_b::a", "simple_b::b"]
},
{
"test_name": "simple_b --exclude-namespaces",
"comment": "Exclude the file itself",
"directory": "simple_b",
"kwargs": {"exclude_namespaces": ["simple_b"]},
"expected_edges": [],
"expected_nodes": []
},
{
"test_name": "simple_b --exclude-namespaces 2",
"comment": "Exclude a class in the file",
"directory": "simple_b",
"kwargs": {"exclude_namespaces": ["c"]},
"expected_edges": [
["simple_b::a", "simple_b::b"],
["simple_b::b", "simple_b::a"]
],
"expected_nodes": ["simple_b::a", "simple_b::b"]
},
{
"test_name": "simple_b --include-only-functions",
"comment": "Include one a and b",
"directory": "simple_b",
"kwargs": {"include_only_functions": ["a", "b"]},
"expected_edges": [
["simple_b::a", "simple_b::b"],
["simple_b::b", "simple_b::a"]
],
"expected_nodes": ["simple_b::a", "simple_b::b"]
},
{
"test_name": "pytz --include-only-functions",
"comment": "Include only two functions",
"directory": "pytz",
"kwargs": {"include_only_functions": ["_fill", "open_resource"]},
"expected_edges": [
["__init__::_CountryTimezoneDict._fill", "__init__::open_resource"],
["__init__::_CountryNameDict._fill", "__init__::open_resource"]
],
"expected_nodes": ["__init__::_CountryTimezoneDict._fill", "__init__::_CountryNameDict._fill", "__init__::open_resource"]
},
{
"test_name": "--include-only-namespaces=reference",
"directory": "pytz",
"kwargs":{"include_only_namespaces": ["reference"]},
"expected_edges": [["reference::USTimeZone.utcoffset",
"reference::USTimeZone.dst"],
["reference::LocalTimezone.utcoffset",
"reference::LocalTimezone._isdst"],
["reference::(global)", "reference::USTimeZone.__init__"],
["reference::USTimeZone.tzname",
"reference::USTimeZone.dst"],
["reference::LocalTimezone.dst",
"reference::LocalTimezone._isdst"],
["reference::LocalTimezone.tzname",
"reference::LocalTimezone._isdst"],
["reference::USTimeZone.dst",
"reference::first_sunday_on_or_after"]],
"expected_nodes": ["reference::USTimeZone.utcoffset",
"reference::LocalTimezone.dst",
"reference::LocalTimezone.tzname",
"reference::USTimeZone.__init__",
"reference::USTimeZone.tzname",
"reference::USTimeZone.dst",
"reference::(global)",
"reference::LocalTimezone._isdst",
"reference::LocalTimezone.utcoffset",
"reference::first_sunday_on_or_after"]
},
{
"test_name": "--include-only-namespaces=USTimeZone",
"directory": "pytz",
"kwargs":{"include_only_namespaces": ["USTimeZone"]},
"expected_edges": [["reference::USTimeZone.utcoffset",
"reference::USTimeZone.dst"],
["reference::USTimeZone.tzname",
"reference::USTimeZone.dst"]],
"expected_nodes": ["reference::USTimeZone.dst",
"reference::USTimeZone.utcoffset",
"reference::USTimeZone.tzname"]
},
{
"test_name": "include_exclude_namespaces",
"comment": "Complex including/excluding namespaces",
"directory": "pytz",
"kwargs": {"include_only_namespaces": ["tzfile","tzinfo"],
"exclude_namespaces": ["DstTzInfo"]},
"expected_edges": [["tzinfo::(global)", "tzinfo::memorized_timedelta"],
["tzfile::build_tzinfo", "tzfile::_std_string"],
["tzfile::(global)", "tzfile::build_tzinfo"],
["tzfile::build_tzinfo", "tzinfo::memorized_ttinfo"],
["tzfile::build_tzinfo", "tzinfo::memorized_timedelta"],
["tzfile::(global)", "tzfile::_byte_string"],
["tzinfo::unpickler", "tzinfo::memorized_timedelta"],
["tzfile::build_tzinfo", "tzfile::_byte_string"],
["tzfile::build_tzinfo", "tzinfo::memorized_datetime"],
["tzinfo::memorized_ttinfo",
"tzinfo::memorized_timedelta"]],
"expected_nodes": ["tzinfo::unpickler",
"tzfile::build_tzinfo",
"tzinfo::(global)",
"tzfile::_std_string",
"tzinfo::memorized_timedelta",
"tzfile::(global)",
"tzinfo::memorized_datetime",
"tzfile::_byte_string",
"tzinfo::memorized_ttinfo"]
},
{
"test_name": "include_exclude_namespaces_exclude_functions",
"comment": "Very complex including/excluding namespaces and excluding functions",
"directory": "pytz",
"kwargs": {"include_only_namespaces": ["tzfile","tzinfo"],
"exclude_namespaces": ["DstTzInfo"],
"exclude_functions": ["(global)"]},
"expected_edges": [["tzfile::build_tzinfo", "tzinfo::memorized_ttinfo"],
["tzfile::build_tzinfo", "tzinfo::memorized_timedelta"],
["tzfile::build_tzinfo", "tzinfo::memorized_datetime"],
["tzinfo::memorized_ttinfo", "tzinfo::memorized_timedelta"],
["tzfile::build_tzinfo", "tzfile::_std_string"],
["tzfile::build_tzinfo", "tzfile::_byte_string"],
["tzinfo::unpickler", "tzinfo::memorized_timedelta"]],
"expected_nodes": ["tzinfo::unpickler",
"tzinfo::memorized_datetime",
"tzinfo::memorized_ttinfo",
"tzfile::build_tzinfo",
"tzfile::_std_string",
"tzinfo::memorized_timedelta",
"tzfile::_byte_string"]
},
{
"test_name": "simple_b --exclude-namespaces not found",
"comment": "Exclude something not there",
"directory": "simple_b",
"kwargs": {"exclude_namespaces": ["notreal"]},
"expected_edges": [
["simple_b::c.d", "simple_b::a"],
["simple_b::a", "simple_b::b"],
["simple_b::(global)", "simple_b::c.d"],
["simple_b::b", "simple_b::a"]
],
"expected_nodes": ["simple_b::c.d", "simple_b::a", "simple_b::b",
"simple_b::(global)"]
},
{
"test_name": "two_file_simple",
"directory": "two_file_simple",
"expected_edges": [["file_a::(global)", "file_a::a"],
["file_a::a", "file_b::b"]],
"expected_nodes": ["file_a::(global)", "file_a::a", "file_b::b"]
},
{
"test_name": "two_file_simple --exclude_functions",
"comment": "Function a is in both files so should be removed from both",
"directory": "two_file_simple",
"kwargs": {"exclude_functions": ["a"]},
"expected_edges": [],
"expected_nodes": []
},
{
"test_name": "two_file_simple --exclude_functions no-trim",
"comment": "Function a is in both files but don't trim so leave file_b nodes",
"directory": "two_file_simple",
"kwargs": {"exclude_functions": ["a"], "no_trimming": True},
"expected_edges": [],
"expected_nodes": ["file_a::(global)", "file_b::(global)", "file_b::b", "file_b::c"]
},
{
"test_name": "two_file_simple --exclude_namespaces no-trim",
"comment": "Trim one file and leave the other intact",
"directory": "two_file_simple",
"kwargs": {"exclude_namespaces": ["file_a"], "no_trimming": True},
"expected_edges": [],
"expected_nodes": ["file_b::(global)", "file_b::b", "file_b::c"]
},
{
"test_name": "async_basic",
"directory": "async_basic",
"kwargs": {},
"expected_edges": [["async_basic::main", "async_basic::A.__init__"],
["async_basic::(global)", "async_basic::main"],
["async_basic::main", "async_basic::A.test"]],
"expected_nodes": ["async_basic::(global)",
"async_basic::A.__init__",
"async_basic::A.test",
"async_basic::main"]
},
{
"test_name": "exclude_modules",
"comment": "Correct name resolution when third-party modules are involved",
"directory": "exclude_modules",
"kwargs": {},
"expected_edges": [["exclude_modules::(global)", "exclude_modules::alpha"],
["exclude_modules::alpha", "exclude_modules::beta"],
["exclude_modules::beta", "exclude_modules::search"]],
"expected_nodes": ["exclude_modules::(global)", "exclude_modules::alpha",
"exclude_modules::beta", "exclude_modules::search"]
},
{
"test_name": "exclude_modules_two_files",
"comment": "Correct name resolution when third-party modules are involved with two files",
"directory": "exclude_modules_two_files",
"expected_edges": [["exclude_modules_a::b", "exclude_modules_b::match"],
["exclude_modules_a::(global)", "exclude_modules_a::b"],
["exclude_modules_a::(global)", "exclude_modules_a::a"]],
"expected_nodes": ["exclude_modules_a::a",
"exclude_modules_a::b",
"exclude_modules_b::match",
"exclude_modules_a::(global)"]
},
{
"test_name": "resolve_correct_class",
"comment": "Correct name resolution with multiple classes",
"directory": "resolve_correct_class",
"kwargs": {},
"expected_edges": [["rcc::Alpha.func_1", "rcc::Alpha.func_1"],
["rcc::Alpha.func_1", "rcc::func_1"],
["rcc::Alpha.func_1", "rcc::Beta.func_2"],
["rcc::Beta.func_1", "rcc::Alpha.func_2"],
],
"expected_nodes": ["rcc::Alpha.func_1", "rcc::Alpha.func_2",
"rcc::func_1", "rcc::Beta.func_2",
"rcc::Beta.func_1"]
},
{
"test_name": "ambibuous resolution",
"comment": "If we can't resolve, do not inlude node.",
"directory": "ambiguous_resolution",
"expected_edges": [["ambiguous_resolution::(global)",
"ambiguous_resolution::main"],
["ambiguous_resolution::main",
"ambiguous_resolution::Cadabra.cadabra_it"],
["ambiguous_resolution::Cadabra.cadabra_it",
"ambiguous_resolution::Abra.abra_it"]],
"expected_nodes": ["ambiguous_resolution::(global)",
"ambiguous_resolution::main",
"ambiguous_resolution::Cadabra.cadabra_it",
"ambiguous_resolution::Abra.abra_it"]
},
{
"test_name": "weird_imports",
"directory": "weird_imports",
"expected_edges": [["weird_imports::(global)", "weird_imports::main"]],
"expected_nodes": ["weird_imports::main", "weird_imports::(global)"]
},
{
"test_name": "nested classes",
"directory": "nested_class",
"expected_edges": [["nested_class::(global)",
"nested_class::Outer.outer_func"],
["nested_class::(global)", "nested_class::Outer.__init__"]],
"expected_nodes": ["nested_class::Outer.outer_func",
"nested_class::Outer.__init__",
"nested_class::(global)"]
},
{
"test_name": "init",
"comment": "working with constructors",
"directory": "init",
"expected_edges": [["init::Abra.__init__", "init::Abra.cadabra"],
["init::(global)", "the_import::imported_func"],
["init::(global)", "init::b"],
["init::b", "init::Abra.__init__"],
["init::(global)", "the_import::HiddenClass.__init__"],
["init::(global)", "the_import::ProvincialClass.__init__"]],
"expected_nodes": ["init::(global)",
"the_import::ProvincialClass.__init__",
"init::Abra.__init__",
"init::Abra.cadabra",
"the_import::HiddenClass.__init__",
"the_import::imported_func",
"init::b"]
},
{
"test_name": "weird_calls",
"directory": "weird_calls",
"comment": "Subscript calls",
"expected_edges": [["weird_calls::func_c", "weird_calls::print_it"],
["weird_calls::func_b", "weird_calls::print_it"],
["weird_calls::(global)", "weird_calls::func_b"],
["weird_calls::func_a", "weird_calls::print_it"],
["weird_calls::(global)", "weird_calls::factory"]],
"expected_nodes": ["weird_calls::func_b",
"weird_calls::print_it",
"weird_calls::(global)",
"weird_calls::func_c",
"weird_calls::func_a",
"weird_calls::factory"]
},
{
"test_name": "chained",
"directory": "chained",
"expected_edges": [["chained::(global)", "chained::Chain.sub"],
["chained::(global)", "chained::Chain.__init__"],
["chained::(global)", "chained::Chain.add"],
["chained::(global)", "chained::Chain.mul"]],
"expected_nodes": ["chained::Chain.__init__",
"chained::(global)",
"chained::Chain.sub",
"chained::Chain.add",
"chained::Chain.mul"]
},
{
"test_name": "inherits",
"directory": "inherits",
"expected_edges": [["inherits::(global)", "inherits::ScaleDemo.__init__"],
["inherits::ScaleDemoLimited.__init__",
"inherits_import::MajorScales.majorNum"],
["inherits::ScaleDemo.__init__",
"inherits_import::MajorScales.majorNum"],
["inherits::(global)", "inherits::majorNum"],
["inherits::ScaleDemo.__init__",
"inherits_import::PentatonicScales.pentaNum"]],
"expected_nodes": ["inherits_import::MajorScales.majorNum",
"inherits::(global)",
"inherits::ScaleDemoLimited.__init__",
"inherits_import::PentatonicScales.pentaNum",
"inherits::majorNum",
"inherits::ScaleDemo.__init__"]
},
{
"test_name": "import_paths",
"directory": "import_paths",
"comment": "relative and absolute imports",
"expected_edges": [["import_paths::main", "abra::abra2"],
["import_paths::main", "cadabra::cadabra2"],
["import_paths::main2", "abra::abra2"],
["import_paths::main", "import_paths::main2"],
["import_paths::(global)", "import_paths::main"]],
"expected_nodes": ["abra::abra2",
"import_paths::main2",
"import_paths::main",
"cadabra::cadabra2",
"import_paths::(global)"]
},
{
"test_name": "nested_calls",
"directory": "nested_calls",
"comment": "Something like func(a)(b)",
"expected_edges": [["nested_calls::(global)", "nested_calls::trace"]],
"expected_nodes": ["nested_calls::trace", "nested_calls::(global)"]
},
{
"test_name": "pytz",
"directory": "pytz",
"kwargs": {"exclude_namespaces": ["test_tzinfo"]},
"expected_edges": [["tzinfo::(global)", "tzinfo::memorized_timedelta"],
["tzfile::(global)", "tzfile::_byte_string"],
["__init__::timezone", "tzfile::build_tzinfo"],
["tzfile::build_tzinfo", "tzinfo::memorized_datetime"],
["__init__::timezone",
"__init__::_case_insensitive_zone_lookup"],
["tzinfo::DstTzInfo.utcoffset",
"tzinfo::DstTzInfo.localize"],
["tzinfo::memorized_ttinfo", "tzinfo::memorized_timedelta"],
["reference::USTimeZone.tzname",
"reference::USTimeZone.dst"],
["tzfile::build_tzinfo", "tzfile::_std_string"],
["__init__::_CountryTimezoneDict._fill",
"__init__::open_resource"],
["tzfile::build_tzinfo", "tzinfo::memorized_timedelta"],
["tzinfo::DstTzInfo.dst", "tzinfo::DstTzInfo.localize"],
["reference::LocalTimezone.tzname",
"reference::LocalTimezone._isdst"],
["reference::LocalTimezone.utcoffset",
"reference::LocalTimezone._isdst"],
["__init__::(global)", "__init__::_test"],
["tzinfo::DstTzInfo.__reduce__", "tzinfo::_to_seconds"],
["__init__::_p", "tzinfo::unpickler"],
["reference::USTimeZone.utcoffset",
"reference::USTimeZone.dst"],
["__init__::_CountryNameDict._fill",
"__init__::open_resource"],
["reference::(global)", "reference::USTimeZone.__init__"],
["__init__::timezone", "__init__::open_resource"],
["__init__::timezone", "__init__::_unmunge_zone"],
["__init__::timezone", "__init__::ascii"],
["__init__::UTC.fromutc", "__init__::UTC.localize"],
["lazy::LazyList.__new__", "lazy::LazyList.__new__"],
["lazy::LazySet.__new__", "lazy::LazySet.__new__"],
["tzinfo::DstTzInfo.tzname", "tzinfo::DstTzInfo.localize"],
["tzfile::(global)", "tzfile::build_tzinfo"],
["tzinfo::DstTzInfo.localize",
"tzinfo::DstTzInfo.localize"],
["reference::USTimeZone.dst",
"reference::first_sunday_on_or_after"],
["tzfile::build_tzinfo", "tzinfo::memorized_ttinfo"],
["tzinfo::unpickler", "tzinfo::memorized_timedelta"],
["tzinfo::DstTzInfo.normalize",
"tzinfo::DstTzInfo.fromutc"],
["lazy::LazyDict.keys", "lazy::LazyDict.keys"],
["__init__::resource_exists", "__init__::open_resource"],
["tzfile::build_tzinfo", "tzfile::_byte_string"],
["__init__::FixedOffset",
"__init__::_FixedOffset.__init__"],
["reference::LocalTimezone.dst",
"reference::LocalTimezone._isdst"]],
"expected_nodes": ["reference::USTimeZone.__init__",
"tzinfo::_to_seconds",
"__init__::_p",
"lazy::LazyDict.keys",
"tzinfo::memorized_ttinfo",
"lazy::LazySet.__new__",
"__init__::_CountryTimezoneDict._fill",
"__init__::FixedOffset",
"tzinfo::DstTzInfo.tzname",
"tzfile::build_tzinfo",
"lazy::LazyList.__new__",
"reference::first_sunday_on_or_after",
"tzinfo::DstTzInfo.__reduce__",
"tzfile::(global)",
"reference::LocalTimezone.dst",
"reference::USTimeZone.dst",
"__init__::timezone",
"reference::USTimeZone.tzname",
"tzinfo::DstTzInfo.dst",
"reference::USTimeZone.utcoffset",
"reference::LocalTimezone._isdst",
"tzfile::_std_string",
"__init__::open_resource",
"tzinfo::DstTzInfo.localize",
"__init__::_case_insensitive_zone_lookup",
"__init__::UTC.localize",
"reference::LocalTimezone.tzname",
"tzinfo::DstTzInfo.normalize",
"tzfile::_byte_string",
"__init__::UTC.fromutc",
"tzinfo::DstTzInfo.fromutc",
"__init__::_unmunge_zone",
"__init__::ascii",
"__init__::_FixedOffset.__init__",
"tzinfo::memorized_datetime",
"tzinfo::memorized_timedelta",
"__init__::_test",
"reference::(global)",
"tzinfo::DstTzInfo.utcoffset",
"reference::LocalTimezone.utcoffset",
"__init__::_CountryNameDict._fill",
"__init__::(global)",
"__init__::resource_exists",
"tzinfo::(global)",
"tzinfo::unpickler"]
},
{
"test_name": "pytz_basic_upstream_downstream",
"directory": "pytz",
"kwargs": {"target_function": "build_tzinfo",
"upstream_depth": "1",
"downstream_depth": "1"},
"expected_edges": [["__init__::timezone", "tzfile::build_tzinfo"],
["tzfile::(global)", "tzfile::build_tzinfo"],
["tzinfo::memorized_ttinfo", "tzinfo::memorized_timedelta"],
["tzfile::build_tzinfo", "tzfile::_std_string"],
["tzfile::build_tzinfo", "tzinfo::memorized_timedelta"],
["tzfile::build_tzinfo", "tzfile::_byte_string"],
["tzfile::(global)", "tzfile::_byte_string"],
["tzfile::build_tzinfo", "tzinfo::memorized_ttinfo"],
["tzfile::build_tzinfo", "tzinfo::memorized_datetime"]],
"expected_nodes": ["__init__::timezone",
"tzfile::(global)",
"tzfile::_std_string",
"tzinfo::memorized_ttinfo",
"tzfile::_byte_string",
"tzinfo::memorized_datetime",
"tzfile::build_tzinfo",
"tzinfo::memorized_timedelta"]
},
{
"test_name": "pytz_no_upstream_file_handle",
"directory": "pytz",
"kwargs": {"target_function": "tzfile::(global)",
"downstream_depth": "2"},
"expected_edges": [["tzfile::(global)", "tzfile::build_tzinfo"],
["tzfile::(global)", "tzfile::_byte_string"],
["tzinfo::memorized_ttinfo", "tzinfo::memorized_timedelta"],
["tzfile::build_tzinfo", "tzfile::_std_string"],
["tzfile::build_tzinfo", "tzinfo::memorized_timedelta"],
["tzfile::build_tzinfo", "tzinfo::memorized_ttinfo"],
["tzfile::build_tzinfo", "tzinfo::memorized_datetime"],
["tzfile::build_tzinfo", "tzfile::_byte_string"]],
"expected_nodes": ["tzinfo::memorized_datetime",
"tzfile::_byte_string",
"tzinfo::memorized_ttinfo",
"tzfile::_std_string",
"tzfile::build_tzinfo",
"tzfile::(global)",
"tzinfo::memorized_timedelta"]
},
],
"js": [
{
"test_name": "simple_a_js",
"directory": "simple_a_js",
"expected_edges": [["simple_a::func_a", "simple_a::func_b"]],
"expected_nodes": ["simple_a::func_a", "simple_a::func_b"]
},
{
"test_name": "simple_b_js",
"directory": "simple_b_js",
"expected_edges": [
["simple_b::C.d", "simple_b::a"],
["simple_b::a", "simple_b::b"],
["simple_b::(global)", "simple_b::C.d"],
["simple_b::b", "simple_b::a"]],
"expected_nodes": ["simple_b::C.d", "simple_b::a", "simple_b::b",
"simple_b::(global)"]
},
{
"test_name": "two_file_simple",
"directory": "two_file_simple",
"expected_edges": [["file_a::(global)", "file_a::a"],
["file_a::a", "file_b::b"]],
"expected_nodes": ["file_a::(global)", "file_a::a", "file_b::b"]
},
{
"test_name": "two_file_simple exclude entire file",
"directory": "two_file_simple",
"kwargs": {"exclude_namespaces": ["file_b", "file_c"]},
"expected_edges": [["file_a::(global)", "file_a::a"]],
"expected_nodes": ["file_a::(global)", "file_a::a"]
},
{
"test_name": "exclude modules",
"directory": "exclude_modules",
"expected_edges": [["exclude_modules::(global)", "exclude_modules::alpha"],
["exclude_modules::alpha", "exclude_modules::alpha"],
["exclude_modules::alpha", "exclude_modules::beta"],
["exclude_modules::beta", "exclude_modules::readFileSync"]],
"expected_nodes": ["exclude_modules::alpha",
"exclude_modules::beta",
"exclude_modules::(global)",
"exclude_modules::readFileSync"]
},
{
"test_name": "exclude modules exclude_functions no_trimming",
"comment": "makes sense to test in js as well. Include a function that's not there for more coverage",
"directory": "exclude_modules",
"kwargs": {"exclude_functions": ["beta", "gamma"], "no_trimming": True},
"expected_edges": [["exclude_modules::(global)", "exclude_modules::alpha"],
["exclude_modules::alpha", "exclude_modules::alpha"]],
"expected_nodes": ["exclude_modules::alpha",
"exclude_modules::(global)",
"exclude_modules::readFileSync"],
},
{
"test_name": "exclude modules es6",
"directory": "exclude_modules_es6",
"kwargs": {'source_type': 'module'},
"expected_edges": [["exclude_modules_es6::(global)", "exclude_modules_es6::alpha"],
["exclude_modules_es6::alpha", "exclude_modules_es6::alpha"],
["exclude_modules_es6::alpha", "exclude_modules_es6::beta"],
["exclude_modules_es6::beta", "exclude_modules_es6::readFileSync"]],
"expected_nodes": ["exclude_modules_es6::alpha",
"exclude_modules_es6::beta",
"exclude_modules_es6::(global)",
"exclude_modules_es6::readFileSync"]
},
{
"test_name": "ambiguous_names",
"directory": "ambiguous_names",
"expected_edges": [["ambiguous_names::Cadabra.cadabra_it",
"ambiguous_names::Abra.abra_it"],
["ambiguous_names::main",
"ambiguous_names::Cadabra.cadabra_it"],
["ambiguous_names::(global)",
"ambiguous_names::main"],
["ambiguous_names::Abra.(constructor)",
"ambiguous_names::Abra.abra_it"]],
"expected_nodes": ["ambiguous_names::Cadabra.cadabra_it",
"ambiguous_names::main",
"ambiguous_names::(global)",
"ambiguous_names::Abra.abra_it",
"ambiguous_names::Abra.(constructor)"]
},
{
"test_name": "ambiguous_names",
"directory": "ambiguous_names",
"kwargs": {"no_trimming": True},
"expected_edges": [["ambiguous_names::Cadabra.cadabra_it",
"ambiguous_names::Abra.abra_it"],
["ambiguous_names::main",
"ambiguous_names::Cadabra.cadabra_it"],
["ambiguous_names::(global)",
"ambiguous_names::main"],
["ambiguous_names::Abra.(constructor)",
"ambiguous_names::Abra.abra_it"]],
"expected_nodes": ["ambiguous_names::Cadabra.cadabra_it",
"ambiguous_names::main",
"ambiguous_names::(global)",
"ambiguous_names::Abra.abra_it",
"ambiguous_names::Abra.(constructor)",
"ambiguous_names::Abra.magic",
"ambiguous_names::Cadabra.magic",
]
},
{
"test_name": "ambiguous_names exclude_namespaces",
"directory": "ambiguous_names",
"comment": "Also tests an important thing. .magic is in two classes in the first test. This eliminates a class and magic is resolved.",
"kwargs": {"exclude_namespaces": ['Abra']},
"expected_edges": [["ambiguous_names::main",
"ambiguous_names::Cadabra.cadabra_it"],
["ambiguous_names::(global)",
"ambiguous_names::main"],
["ambiguous_names::main",
"ambiguous_names::Cadabra.magic"]],
"expected_nodes": ["ambiguous_names::Cadabra.cadabra_it",
"ambiguous_names::Cadabra.magic",
"ambiguous_names::main",
"ambiguous_names::(global)"]
},
{
"test_name": "weird_assignments",
"directory": "weird_assignments",
"expected_edges": [["weird_assignments::(global)",
"weird_assignments::get_ab"]],
"expected_nodes": ["weird_assignments::(global)", "weird_assignments::get_ab"]
},
{
"test_name": "complex_ownership",
"directory": "complex_ownership",
"expected_edges": [["complex_ownership::(global)",
"complex_ownership::DEF.toABC"],
["complex_ownership::DEF.toABC",
"complex_ownership::ABC.(constructor)"],
["complex_ownership::(global)",
"complex_ownership::ABC.apply"],
["complex_ownership::GHI.doit2",
"complex_ownership::ABC.apply"],
["complex_ownership::(global)",
"complex_ownership::GHI.doit2"],
["complex_ownership::(global)",
"complex_ownership::ABC.doit"],
["complex_ownership::(global)",
"complex_ownership::GHI.doit3"]],
"expected_nodes": ["complex_ownership::(global)",
"complex_ownership::ABC.apply",
"complex_ownership::ABC.doit",
"complex_ownership::ABC.(constructor)",
"complex_ownership::DEF.toABC",
"complex_ownership::GHI.doit2",
"complex_ownership::GHI.doit3"]
},
{
"test_name": "two_file_imports",
"directory": "two_file_imports",
"expected_edges": [["importer::outer", "imported::myClass.(constructor)"],
["importer::outer", "imported::inner"],
["importer::(global)", "importer::outer"],
["imported::myClass.(constructor)",
"imported::myClass.doit"],
["imported::myClass.doit", "imported::myClass.doit2"]],
"expected_nodes": ["imported::myClass.doit2",
"imported::myClass.(constructor)",
"imported::myClass.doit",
"imported::inner",
"importer::(global)",
"importer::outer"]
},
{
"test_name": "globals",
"comment": "ensure that nested functions behave correctly",
"directory": "globals",
"expected_edges": [["globals::a", "globals::b"],
["globals::a", "globals::c"],
["globals::c", "globals::d"]],
"expected_nodes": ["globals::d", "globals::a", "globals::c", "globals::b"]
},
{
"test_name": "scope confusion",
"comment": "Be sure that 'this' is used correctly",
"directory": "scoping",
"expected_edges": [["scoping::(global)", "scoping::MyClass.a"],
["scoping::MyClass.a", "scoping::MyClass.scope_confusion"],
["scoping::(global)", "scoping::MyClass.b"],
["scoping::MyClass.b", "scoping::scope_confusion"]],
"expected_nodes": ["scoping::MyClass.scope_confusion",
"scoping::MyClass.b",
"scoping::scope_confusion",
"scoping::MyClass.a",
"scoping::(global)"]
},
{
"test_name": "chained",
"directory": "chained",
"expected_edges": [["chained::(global)", "chained::Chain.(constructor)"],
["chained::(global)", "chained::Chain.mul"],
["chained::(global)", "chained::Chain.add"],
["chained::(global)", "chained::Chain.sub"]],
"expected_nodes": ["chained::Chain.sub",
"chained::(global)",
"chained::Chain.(constructor)",
"chained::Chain.add",
"chained::Chain.mul"]
},
{
"test_name": "inheritance",
"directory": "inheritance",
"expected_edges": [["inheritance::(global)",
"inheritance::ScaleDemo.(constructor)"],
["inheritance::(global)", "inheritance::pentaNum"],
["inheritance::ScaleDemo.(constructor)",
"inheritance::MajorScales.majorNum"]],
"expected_nodes": ["inheritance::MajorScales.majorNum",
"inheritance::ScaleDemo.(constructor)",
"inheritance::pentaNum",
"inheritance::(global)"]
},
{
"test_name": "inheritance_attr",
"directory": "inheritance_attr",
"comment": "This is rare but it happened while testing chart.js. Extends was done on an attr.",
"expected_edges": [["inheritance_attr::(global)",
"inheritance_attr::ClsB.meow"]],
"expected_nodes": ["inheritance_attr::(global)",
"inheritance_attr::ClsB.meow"]
},
{
"test_name": "bad_parse",
"directory": "bad_parse",
"comments": "One file is bad. Test bad parse line",
"kwargs": {"skip_parse_errors": True},
"expected_edges": [["file_a_good::(global)", "file_a_good::a"]],
"expected_nodes": ["file_a_good::(global)", "file_a_good::a"]
},
{
"test_name": "class_in_function",
"directory": "class_in_function",
"comments": "when a function defines a class within it",
"expected_edges": [["class_in_function::(global)",
"class_in_function::rectangleClassFactory"]],
"expected_nodes": ["class_in_function::rectangleClassFactory",
"class_in_function::(global)"]
},
{
"test_name": "ternary_new",
"directory": "ternary_new",
"comments": "Ignore the name. This is for complex multi-layered object instantiation.",
"expected_edges": [["ternary_new::Cadabra.init", "ternary_new::Cadabra.init"],
["ternary_new::Abra.init", "ternary_new::Abra.init"],
["ternary_new::(global)", "ternary_new::ClassMap.fact"]],
"expected_nodes": ["ternary_new::Cadabra.init",
"ternary_new::ClassMap.fact",
"ternary_new::(global)",
"ternary_new::Abra.init"]
},
{
"test_name": "moment.js",
"directory": "moment",
"expected_edges": [["moment::getWeeksInWeekYear", "moment::weeksInYear"],
["moment::configFromRFC2822", "moment::preprocessRFC2822"],
["moment::isNumberOrStringArray", "moment::isString"],
["moment::prepareConfig", "moment::isDate"],
["moment::handleStrictParse$1", "moment::createUTC"],
["moment::addSubtract", "moment::setMonth"],
["moment::makeGetSet", "moment::set$1"],
["moment::dayOfYearFromWeeks", "moment::firstWeekOffset"],
["moment::createDuration", "moment::Duration"],
["moment::prepareConfig", "moment::Moment"],
["moment::isNumberOrStringArray", "moment::isNumber"],
["moment::configFromInput", "moment::configFromString"],
["moment::createAdder", "moment::addSubtract"],
["moment::pastFuture", "moment::isFunction"],
["moment::configFromArray", "moment::daysInYear"],
["moment::isSame", "moment::normalizeUnits"],
["moment::getParsingFlags", "moment::defaultParsingFlags"],
["moment::makeFormatFunction",
"moment::removeFormattingTokens"],
["moment::relativeTime$1", "moment::createDuration"],
["moment::defineLocale", "moment::deprecateSimple"],
["moment::localeMonthsParse", "moment::createUTC"],
["moment::getPrioritizedUnits", "moment::hasOwnProp"],
["moment::(global)", "moment::setHookCallback"],
["moment::deprecate", "moment::hasOwnProp"],
["moment::listWeekdaysImpl", "moment::isNumber"],
["moment::parseMs", "moment::toInt"],
["moment::createLocalOrUTC", "moment::isArray"],
["moment::relativeTime", "moment::isFunction"],
["moment::(global)", "moment::toInt"],
["moment::weekdaysShortRegex", "moment::hasOwnProp"],
["moment::isSame", "moment::isMoment"],
["moment::formatMoment", "moment::expandFormat"],
["moment::getSetWeekYearHelper", "moment::weekOfYear"],
["moment::max", "moment::pickBy"],
["moment::createDuration", "moment::momentsDifference"],
["moment::startOf", "moment::normalizeUnits"],
["moment::prepareConfig", "moment::isArray"],
["moment::bubble", "moment::monthsToDays"],
["moment::configFromInput", "moment::configFromObject"],
["moment::createLocal", "moment::createLocalOrUTC"],
["moment::defineLocale", "moment::mergeConfigs"],
["moment::addSubtract$1", "moment::createDuration"],
["moment::configFromStringAndArray", "moment::extend"],
["moment::parsingFlags", "moment::extend"],
["moment::as", "moment::daysToMonths"],
["moment::normalizeObjectUnits", "moment::normalizeUnits"],
["moment::weekdaysMinRegex", "moment::hasOwnProp"],
["moment::mergeConfigs", "moment::isObject"],
["moment::localeEras", "moment::getLocale"],
["moment::checkOverflow", "moment::getParsingFlags"],
["moment::configFromStringAndFormat",
"moment::getParseRegexForToken"],
["moment::listMonthsShort", "moment::listMonthsImpl"],
["moment::extractFromRFC2822Strings",
"moment::untruncateYear"],
["moment::(global)", "moment::addWeekParseToken"],
["moment::getSetWeekYearHelper", "moment::weeksInYear"],
["moment::configFromObject", "moment::configFromArray"],
["moment::isBetween", "moment::createLocal"],
["moment::addTimeToArrayFromToken", "moment::hasOwnProp"],
["moment::configFromStringAndArray", "moment::copyConfig"],
["moment::valueOf$1", "moment::toInt"],
["moment::to", "moment::createLocal"],
["moment::getSetMonth", "moment::setMonth"],
["moment::getSetGlobalLocale", "moment::getLocale"],
["moment::(global)", "moment::offset"],
["moment::copyConfig", "moment::getParsingFlags"],
["moment::offset", "moment::zeroFill"],
["moment::isCalendarSpec", "moment::isObject"],
["moment::isSame", "moment::createLocal"],
["moment::addSubtract", "moment::set$1"],
["moment::listWeekdaysImpl", "moment::getLocale"],
["moment::isDaylightSavingTimeShifted",
"moment::prepareConfig"],
["moment::diff", "moment::absFloor"],
["moment::(global)", "moment::zeroFill"],
["moment::createDuration", "moment::toInt"],
["moment::setOffsetToLocal", "moment::getDateOffset"],
["moment::subtract$1", "moment::addSubtract$1"],
["moment::toISOString", "moment::isFunction"],
["moment::normalizeObjectUnits", "moment::hasOwnProp"],
["moment::mergeConfigs", "moment::extend"],
["moment::prepareConfig",
"moment::configFromStringAndArray"],
["moment::locale", "moment::getLocale"],
["moment::listMonthsImpl", "moment::get$1"],
["moment::updateLocale", "moment::loadLocale"],
["moment::configFromObject", "moment::map"],
["moment::meridiem", "moment::addFormatToken"],
["moment::calendar$1", "moment::createLocal"],
["moment::configFromArray", "moment::defaults"],
["moment::toISOString$1", "moment::sign"],
["moment::configFromStringAndFormat",
"moment::getParsingFlags"],
["moment::configFromRFC2822", "moment::getParsingFlags"],
["moment::getIsLeapYear", "moment::isLeapYear"],
["moment::isMomentInputObject", "moment::hasOwnProp"],
["moment::stringSet", "moment::normalizeObjectUnits"],
["moment::cloneWithOffset", "moment::createLocal"],
["moment::isValid$2", "moment::isValid"],
["moment::(global)", "moment::hasOwnProp"],
["moment::(global)", "moment::makeGetSet"],
["moment::configFromInput", "moment::configFromArray"],
["moment::configFromRFC2822",
"moment::extractFromRFC2822Strings"],
["moment::(global)", "moment::getSetGlobalLocale"],
["moment::getSetISOWeek", "moment::weekOfYear"],
["moment::isNumberOrStringArray", "moment::isArray"],
["moment::monthsShortRegex", "moment::hasOwnProp"],
["moment::set", "moment::hasOwnProp"],
["moment::from", "moment::createLocal"],
["moment::deprecate", "moment::warn"],
["moment::configFromArray", "moment::currentDateArray"],
["moment::addSubtract", "moment::absRound"],
["moment::configFromInput", "moment::isNumber"],
["moment::(global)", "moment::getParsingFlags"],
["moment::defineLocale", "moment::loadLocale"],
["moment::getSetOffset", "moment::getDateOffset"],
["moment::Duration", "moment::normalizeObjectUnits"],
["moment::createInvalid", "moment::extend"],
["moment::getSetISODayOfWeek", "moment::parseIsoWeekday"],
["moment::configFromStringAndArray",
"moment::getParsingFlags"],
["moment::parsingFlags", "moment::getParsingFlags"],
["moment::endOf", "moment::normalizeUnits"],
["moment::erasNameRegex", "moment::hasOwnProp"],
["moment::diff", "moment::monthDiff"],
["moment::getSetOffset", "moment::offsetFromString"],
["moment::dayOfYearFromWeekInfo", "moment::createLocal"],
["moment::calendar", "moment::isFunction"],
["moment::configFromRFC2822", "moment::checkWeekday"],
["moment::getSetOffset", "moment::createDuration"],
["moment::configFromString", "moment::configFromISO"],
["moment::getWeeksInYear", "moment::weeksInYear"],
["moment::set", "moment::isFunction"],
["moment::(global)", "moment::createInvalid"],
["moment::daysInMonth", "moment::isLeapYear"],
["moment::stringSet", "moment::isFunction"],
["moment::getISOWeeksInYear", "moment::weeksInYear"],
["moment::dayOfYearFromWeekInfo",
"moment::dayOfYearFromWeeks"],
["moment::isAfter", "moment::normalizeUnits"],
["moment::calendar$1", "moment::isMomentInput"],
["moment::getLocale", "moment::chooseLocale"],
["moment::toNow", "moment::createLocal"],
["moment::prepareConfig", "moment::createInvalid"],
["moment::weekdaysRegex", "moment::hasOwnProp"],
["moment::loadLocale", "moment::getSetGlobalLocale"],
["moment::pickBy", "moment::createLocal"],
["moment::fromNow", "moment::createLocal"],
["moment::setWeekAll", "moment::dayOfYearFromWeeks"],
["moment::configFromStringAndFormat",
"moment::addTimeToArrayFromToken"],
["moment::isAfter", "moment::isMoment"],
["moment::formatMoment", "moment::makeFormatFunction"],
["moment::createAdder", "moment::deprecateSimple"],
["moment::updateLocale", "moment::mergeConfigs"],
["moment::stringSet", "moment::getPrioritizedUnits"],
["moment::localeWeek", "moment::weekOfYear"],
["moment::as", "moment::monthsToDays"],
["moment::setMonth", "moment::isNumber"],
["moment::isMomentInput", "moment::isMomentInputObject"],
["moment::chooseLocale", "moment::commonPrefix"],
["moment::monthsRegex", "moment::hasOwnProp"],
["moment::computeWeekdaysParse", "moment::createUTC"],
["moment::configFromInput", "moment::isDate"],
["moment::prepareConfig", "moment::configFromInput"],
["moment::localeMonthsShort", "moment::isArray"],
["moment::get$1", "moment::getLocale"],
["moment::as", "moment::normalizeUnits"],
["moment::isMomentInputObject", "moment::isObjectEmpty"],
["moment::to", "moment::createDuration"],
["moment::configFromInput", "moment::isUndefined"],
["moment::dayOfYearFromWeeks", "moment::daysInYear"],
["moment::listMonthsImpl", "moment::isNumber"],
["moment::getLocale", "moment::loadLocale"],
["moment::configFromStringAndFormat",
"moment::configFromRFC2822"],
["moment::isMomentInput", "moment::isMoment"],
["moment::isDaylightSavingTimeShifted",
"moment::createLocal"],
["moment::erasAbbrRegex", "moment::hasOwnProp"],
["moment::computeMonthsParse", "moment::createUTC"],
["moment::stringGet", "moment::isFunction"],
["moment::isObjectEmpty", "moment::hasOwnProp"],
["moment::listMonths", "moment::listMonthsImpl"],
["moment::compareArrays", "moment::toInt"],
["moment::createUnix", "moment::createLocal"],
["moment::addFormatToken", "moment::zeroFill"],
["moment::isAfter", "moment::createLocal"],
["moment::createInvalid$1", "moment::createDuration"],
["moment::createAdder", "moment::createDuration"],
["moment::isDaylightSavingTimeShifted",
"moment::isUndefined"],
["moment::configFromRFC2822", "moment::calculateOffset"],
["moment::pickBy", "moment::isArray"],
["moment::localeWeekdaysMin", "moment::shiftWeekdays"],
["moment::configFromInput", "moment::isObject"],
["moment::getLocale", "moment::isArray"],
["moment::createDuration", "moment::absRound"],
["moment::configFromInput", "moment::isArray"],
["moment::deprecateSimple", "moment::warn"],
["moment::extend", "moment::hasOwnProp"],
["moment::(global)", "moment::addParseToken"],
["moment::(global)", "moment::makeAs"],
["moment::from", "moment::createDuration"],
["moment::addParseToken", "moment::isNumber"],
["moment::chooseLocale", "moment::normalizeLocale"],
["moment::Moment", "moment::copyConfig"],
["moment::localeMonths", "moment::isArray"],
["moment::clone$1", "moment::createDuration"],
["moment::getSetGlobalLocale", "moment::isUndefined"],
["moment::stringSet", "moment::normalizeUnits"],
["moment::isBefore", "moment::isMoment"],
["moment::makeFormatFunction", "moment::isFunction"],
["moment::defineLocale", "moment::getSetGlobalLocale"],
["moment::min", "moment::pickBy"],
["moment::createUTC", "moment::createLocalOrUTC"],
["moment::add$1", "moment::addSubtract$1"],
["moment::get$1", "moment::createUTC"],
["moment::weeksInYear", "moment::daysInYear"],
["moment::configFromObject",
"moment::normalizeObjectUnits"],
["moment::dayOfYearFromWeekInfo", "moment::weekOfYear"],
["moment::prepareConfig", "moment::isMoment"],
["moment::offsetFromString", "moment::toInt"],
["moment::calendar$1", "moment::isFunction"],
["moment::(global)", "moment::createAdder"],
["moment::getParseRegexForToken", "moment::hasOwnProp"],
["moment::cloneWithOffset", "moment::isDate"],
["moment::configFromArray", "moment::getParsingFlags"],
["moment::localeWeekdays", "moment::isArray"],
["moment::dayOfYearFromWeekInfo", "moment::defaults"],
["moment::configFromStringAndArray",
"moment::configFromStringAndFormat"],
["moment::getEraYear", "moment::hooks"],
["moment::setOffsetToParsedOffset",
"moment::offsetFromString"],
["moment::bubble", "moment::absFloor"],
["moment::createInvalid", "moment::createUTC"],
["moment::addSubtract", "moment::get"],
["moment::weekOfYear", "moment::weeksInYear"],
["moment::prepareConfig",
"moment::configFromStringAndFormat"],
["moment::(global)", "moment::addWeekYearFormatToken"],
["moment::setMonth", "moment::toInt"],
["moment::configFromInput", "moment::map"],
["moment::offset", "moment::addFormatToken"],
["moment::(global)", "moment::deprecate"],
["moment::listWeekdays", "moment::listWeekdaysImpl"],
["moment::endOf", "moment::mod$1"],
["moment::isValid", "moment::getParsingFlags"],
["moment::isMomentInput", "moment::isNumberOrStringArray"],
["moment::defineLocale", "moment::Locale"],
["moment::localeWeekdays", "moment::shiftWeekdays"],
["moment::calendar$1", "moment::isCalendarSpec"],
["moment::pastFuture", "moment::format"],
["moment::configFromStringAndArray", "moment::isValid"],
["moment::isDaylightSavingTimeShifted",
"moment::copyConfig"],
["moment::mergeConfigs", "moment::hasOwnProp"],
["moment::setMonth", "moment::daysInMonth"],
["moment::stringGet", "moment::normalizeUnits"],
["moment::humanize", "moment::relativeTime$1"],
["moment::toISOString", "moment::formatMoment"],
["moment::createFromConfig", "moment::prepareConfig"],
["moment::listWeekdaysMin", "moment::listWeekdaysImpl"],
["moment::addWeekYearFormatToken",
"moment::addFormatToken"],
["moment::prepareConfig", "moment::isValid"],
["moment::handleStrictParse", "moment::createUTC"],
["moment::createDuration", "moment::hasOwnProp"],
["moment::isCalendarSpec", "moment::hasOwnProp"],
["moment::erasNarrowRegex", "moment::hasOwnProp"],
["moment::localeEras", "moment::hooks"],
["moment::weekOfYear", "moment::firstWeekOffset"],
["moment::Duration", "moment::getLocale"],
["moment::isMomentInput", "moment::isString"],
["moment::getSetGlobalLocale", "moment::defineLocale"],
["moment::createDuration", "moment::parseIso"],
["moment::configFromStringAndFormat",
"moment::meridiemFixWrap"],
["moment::diff", "moment::normalizeUnits"],
["moment::configFromStringAndFormat",
"moment::checkOverflow"],
["moment::daysInMonth", "moment::mod"],
["moment::createFromConfig", "moment::checkOverflow"],
["moment::get$2", "moment::normalizeUnits"],
["moment::(global)", "moment::addRegexToken"],
["moment::isMomentInputObject", "moment::isObject"],
["moment::isBetween", "moment::isMoment"],
["moment::createDuration", "moment::createLocal"],
["moment::(global)", "moment::addUnitAlias"],
["moment::createLocalOrUTC", "moment::isObjectEmpty"],
["moment::isMomentInput", "moment::isNumber"],
["moment::addParseToken", "moment::toInt"],
["moment::startOf", "moment::mod$1"],
["moment::makeGetSet", "moment::get"],
["moment::createLocalOrUTC", "moment::isObject"],
["moment::to", "moment::isMoment"],
["moment::checkWeekday", "moment::getParsingFlags"],
["moment::defineLocale", "moment::defineLocale"],
["moment::localeErasConvertYear", "moment::hooks"],
["moment::getSetMonth", "moment::get"],
["moment::createInvalid", "moment::getParsingFlags"],
["moment::momentsDifference", "moment::cloneWithOffset"],
["moment::configFromISO",
"moment::configFromStringAndFormat"],
["moment::configFromStringAndFormat",
"moment::configFromArray"],
["moment::updateLocale", "moment::getSetGlobalLocale"],
["moment::unescapeFormat", "moment::regexEscape"],
["moment::configFromISO", "moment::getParsingFlags"],
["moment::configFromStringAndFormat",
"moment::configFromISO"],
["moment::getDaysInMonth", "moment::daysInMonth"],
["moment::daysInYear", "moment::isLeapYear"],
["moment::diff", "moment::cloneWithOffset"],
["moment::configFromArray",
"moment::dayOfYearFromWeekInfo"],
["moment::prepareConfig", "moment::checkOverflow"],
["moment::addRegexToken", "moment::isFunction"],
["moment::isBefore", "moment::normalizeUnits"],
["moment::bubble", "moment::absCeil"],
["moment::isDurationValid", "moment::toInt"],
["moment::computeWeekdaysParse", "moment::regexEscape"],
["moment::momentsDifference",
"moment::positiveMomentsDifference"],
["moment::cloneWithOffset", "moment::isMoment"],
["moment::getParseRegexForToken", "moment::unescapeFormat"],
["moment::configFromArray", "moment::createUTCDate"],
["moment::toISOString$1", "moment::absFloor"],
["moment::isDaylightSavingTimeShifted",
"moment::compareArrays"],
["moment::monthDiff", "moment::monthDiff"],
["moment::from", "moment::isMoment"],
["moment::isCalendarSpec", "moment::isObjectEmpty"],
["moment::bubble", "moment::daysToMonths"],
["moment::chooseLocale", "moment::loadLocale"],
["moment::weeksInYear", "moment::firstWeekOffset"],
["moment::listWeekdaysImpl", "moment::get$1"],
["moment::calendar$1", "moment::cloneWithOffset"],
["moment::isMomentInput", "moment::isDate"],
["moment::(global)", "moment::offsetFromString"],
["moment::addWeekParseToken", "moment::addParseToken"],
["moment::getISOWeeksInISOWeekYear", "moment::weeksInYear"],
["moment::invalidAt", "moment::getParsingFlags"],
["moment::computeMonthsParse", "moment::regexEscape"],
["moment::localeWeekdaysShort", "moment::shiftWeekdays"],
["moment::getSetOffset", "moment::addSubtract"],
["moment::firstWeekOffset", "moment::createUTCDate"],
["moment::weeks", "moment::absFloor"],
["moment::updateLocale", "moment::Locale"],
["moment::copyConfig", "moment::isUndefined"],
["moment::createDuration", "moment::isDuration"],
["moment::hasAlignedHourOffset", "moment::createLocal"],
["moment::clone", "moment::Moment"],
["moment::set$1", "moment::toInt"],
["moment::getSetDayOfWeek", "moment::parseWeekday"],
["moment::setWeekAll", "moment::createUTCDate"],
["moment::(global)", "moment::meridiem"],
["moment::isDaylightSavingTimeShifted",
"moment::createUTC"],
["moment::set$1", "moment::isLeapYear"],
["moment::configFromStringAndFormat",
"moment::expandFormat"],
["moment::set$1", "moment::daysInMonth"],
["moment::format", "moment::formatMoment"],
["moment::localeWeekdaysParse", "moment::createUTC"],
["moment::deprecate", "moment::extend"],
["moment::computeErasParse", "moment::regexEscape"],
["moment::(global)", "moment::makeGetter"],
["moment::isBefore", "moment::createLocal"],
["moment::configFromString", "moment::configFromRFC2822"],
["moment::dayOfYearFromWeekInfo",
"moment::getParsingFlags"],
["moment::dayOfYearFromWeekInfo", "moment::weeksInYear"],
["moment::(global)", "moment::addFormatToken"],
["moment::createDuration", "moment::isNumber"],
["moment::createLocalOrUTC", "moment::createFromConfig"],
["moment::(global)", "moment::addUnitPriority"],
["moment::createFromConfig", "moment::Moment"],
["moment::checkOverflow", "moment::daysInMonth"],
["moment::listWeekdaysShort", "moment::listWeekdaysImpl"],
["moment::Duration", "moment::isDurationValid"],
["moment::toInt", "moment::absFloor"],
["moment::isDurationValid", "moment::hasOwnProp"],
["moment::prepareConfig", "moment::getLocale"]],
"expected_nodes": ["moment::weeksInYear",
"moment::toISOString$1",
"moment::createFromConfig",
"moment::mod$1",
"moment::checkOverflow",
"moment::configFromISO",
"moment::getSetISODayOfWeek",
"moment::regexEscape",
"moment::isCalendarSpec",
"moment::from",
"moment::setOffsetToLocal",
"moment::setHookCallback",
"moment::deprecateSimple",
"moment::checkWeekday",
"moment::Locale",
"moment::daysToMonths",
"moment::getIsLeapYear",
"moment::isFunction",
"moment::defineLocale",
"moment::loadLocale",
"moment::configFromObject",
"moment::listWeekdaysShort",
"moment::addFormatToken",
"moment::getEraYear",
"moment::startOf",
"moment::makeGetSet",
"moment::fromNow",
"moment::currentDateArray",
"moment::makeAs",
"moment::stringGet",
"moment::createAdder",
"moment::copyConfig",
"moment::hasAlignedHourOffset",
"moment::getSetDayOfWeek",
"moment::isValid",
"moment::isMomentInputObject",
"moment::localeWeek",
"moment::getWeeksInYear",
"moment::getDaysInMonth",
"moment::sign",
"moment::dayOfYearFromWeeks",
"moment::addSubtract$1",
"moment::getLocale",
"moment::setMonth",
"moment::addTimeToArrayFromToken",
"moment::getWeeksInWeekYear",
"moment::configFromStringAndFormat",
"moment::meridiem",
"moment::handleStrictParse$1",
"moment::set",
"moment::parseIso",
"moment::chooseLocale",
"moment::daysInYear",
"moment::localeErasConvertYear",
"moment::createInvalid",
"moment::isBefore",
"moment::erasNameRegex",
"moment::handleStrictParse",
"moment::subtract$1",
"moment::defaultParsingFlags",
"moment::meridiemFixWrap",
"moment::parseMs",
"moment::isNumber",
"moment::createInvalid$1",
"moment::createUnix",
"moment::isSame",
"moment::relativeTime$1",
"moment::addUnitAlias",
"moment::createDuration",
"moment::expandFormat",
"moment::deprecate",
"moment::to",
"moment::offset",
"moment::getParsingFlags",
"moment::absRound",
"moment::firstWeekOffset",
"moment::monthsToDays",
"moment::isAfter",
"moment::localeMonths",
"moment::toInt",
"moment::normalizeLocale",
"moment::isUndefined",
"moment::weeks",
"moment::createLocal",
"moment::addRegexToken",
"moment::add$1",
"moment::makeGetter",
"moment::createUTCDate",
"moment::computeWeekdaysParse",
"moment::configFromStringAndArray",
"moment::absCeil",
"moment::normalizeUnits",
"moment::max",
"moment::pickBy",
"moment::endOf",
"moment::configFromRFC2822",
"moment::isDaylightSavingTimeShifted",
"moment::bubble",
"moment::createUTC",
"moment::getPrioritizedUnits",
"moment::isObjectEmpty",
"moment::isObject",
"moment::zeroFill",
"moment::addParseToken",
"moment::calendar",
"moment::momentsDifference",
"moment::unescapeFormat",
"moment::monthsRegex",
"moment::compareArrays",
"moment::setOffsetToParsedOffset",
"moment::prepareConfig",
"moment::toISOString",
"moment::isValid$2",
"moment::weekOfYear",
"moment::format",
"moment::localeWeekdays",
"moment::getISOWeeksInISOWeekYear",
"moment::isMoment",
"moment::hooks",
"moment::shiftWeekdays",
"moment::(global)",
"moment::preprocessRFC2822",
"moment::clone$1",
"moment::isNumberOrStringArray",
"moment::warn",
"moment::weekdaysRegex",
"moment::formatMoment",
"moment::getSetISOWeek",
"moment::weekdaysMinRegex",
"moment::listMonths",
"moment::isDuration",
"moment::extractFromRFC2822Strings",
"moment::weekdaysShortRegex",
"moment::configFromArray",
"moment::untruncateYear",
"moment::min",
"moment::Duration",
"moment::getParseRegexForToken",
"moment::erasNarrowRegex",
"moment::removeFormattingTokens",
"moment::updateLocale",
"moment::listWeekdays",
"moment::mergeConfigs",
"moment::isString",
"moment::getSetOffset",
"moment::hasOwnProp",
"moment::configFromString",
"moment::isDate",
"moment::parsingFlags",
"moment::calculateOffset",
"moment::stringSet",
"moment::listMonthsImpl",
"moment::dayOfYearFromWeekInfo",
"moment::isDurationValid",
"moment::positiveMomentsDifference",
"moment::clone",
"moment::map",
"moment::get$1",
"moment::makeFormatFunction",
"moment::erasAbbrRegex",
"moment::computeMonthsParse",
"moment::daysInMonth",
"moment::listWeekdaysImpl",
"moment::computeErasParse",
"moment::getSetWeekYearHelper",
"moment::pastFuture",
"moment::isBetween",
"moment::listWeekdaysMin",
"moment::normalizeObjectUnits",
"moment::isMomentInput",
"moment::getSetMonth",
"moment::parseWeekday",
"moment::offsetFromString",
"moment::addWeekParseToken",
"moment::set$1",
"moment::localeMonthsShort",
"moment::addUnitPriority",
"moment::localeWeekdaysMin",
"moment::createLocalOrUTC",
"moment::commonPrefix",
"moment::getSetGlobalLocale",
"moment::valueOf$1",
"moment::localeMonthsParse",
"moment::addWeekYearFormatToken",
"moment::as",
"moment::mod",
"moment::get",
"moment::configFromInput",
"moment::humanize",
"moment::addSubtract",
"moment::listMonthsShort",
"moment::absFloor",
"moment::relativeTime",
"moment::monthDiff",
"moment::getISOWeeksInYear",
"moment::isArray",
"moment::setWeekAll",
"moment::monthsShortRegex",
"moment::Moment",
"moment::extend",
"moment::locale",
"moment::cloneWithOffset",
"moment::localeWeekdaysParse",
"moment::toNow",
"moment::localeEras",
"moment::localeWeekdaysShort",
"moment::get$2",
"moment::parseIsoWeekday",
"moment::diff",
"moment::getDateOffset",
"moment::calendar$1",
"moment::invalidAt",
"moment::defaults",
"moment::isLeapYear"]
},
{
"test_name": "moment_depth_1",
"directory": "moment",
"kwargs": {"target_function": "createDuration",
"upstream_depth": "1",
"downstream_depth": "1"},
"expected_edges": [["moment::clone$1", "moment::createDuration"],
["moment::createInvalid$1", "moment::createDuration"],
["moment::createDuration", "moment::isDuration"],
["moment::relativeTime$1", "moment::createDuration"],
["moment::createDuration", "moment::Duration"],
["moment::createDuration", "moment::isNumber"],
["moment::createDuration", "moment::absRound"],
["moment::createAdder", "moment::createDuration"],
["moment::createDuration", "moment::hasOwnProp"],
["moment::addSubtract$1", "moment::createDuration"],
["moment::createDuration", "moment::parseIso"],
["moment::from", "moment::createLocal"],
["moment::to", "moment::createLocal"],
["moment::createDuration", "moment::momentsDifference"],
["moment::to", "moment::createDuration"],
["moment::from", "moment::createDuration"],
["moment::getSetOffset", "moment::createDuration"],
["moment::createDuration", "moment::toInt"],
["moment::createDuration", "moment::createLocal"]],
"expected_nodes": ["moment::toInt",
"moment::Duration",
"moment::createAdder",
"moment::createDuration",
"moment::absRound",
"moment::from",
"moment::addSubtract$1",
"moment::isDuration",
"moment::isNumber",
"moment::hasOwnProp",
"moment::createLocal",
"moment::parseIso",
"moment::getSetOffset",
"moment::relativeTime$1",
"moment::createInvalid$1",
"moment::clone$1",
"moment::to",
"moment::momentsDifference"]
},
{
"test_name": "moment_only_down",
"directory": "moment",
"kwargs": {"target_function": "createDuration", "downstream_depth": "1"},
"expected_edges": [["moment::createDuration", "moment::hasOwnProp"],
["moment::createDuration", "moment::isDuration"],
["moment::createDuration", "moment::momentsDifference"],
["moment::createDuration", "moment::absRound"],
["moment::createDuration", "moment::isNumber"],
["moment::createDuration", "moment::parseIso"],
["moment::createDuration", "moment::toInt"],
["moment::createDuration", "moment::Duration"],
["moment::createDuration", "moment::createLocal"]],
"expected_nodes": ["moment::parseIso",
"moment::createDuration",
"moment::isNumber",
"moment::hasOwnProp",
"moment::toInt",
"moment::isDuration",
"moment::createLocal",
"moment::momentsDifference",
"moment::absRound",
"moment::Duration"]
},
{
"test_name": "moment_only_up",
"directory": "moment",
"kwargs": {"target_function": "createDuration", "upstream_depth": "1"},
"expected_edges": [["moment::createInvalid$1", "moment::createDuration"],
["moment::to", "moment::createDuration"],
["moment::from", "moment::createDuration"],
["moment::createAdder", "moment::createDuration"],
["moment::getSetOffset", "moment::createDuration"],
["moment::clone$1", "moment::createDuration"],
["moment::addSubtract$1", "moment::createDuration"],
["moment::relativeTime$1", "moment::createDuration"]],
"expected_nodes": ["moment::relativeTime$1",
"moment::createDuration",
"moment::createInvalid$1",
"moment::to",
"moment::createAdder",
"moment::from",
"moment::getSetOffset",
"moment::clone$1",
"moment::addSubtract$1"]
},
{
"test_name": "moment_double_depth",
"directory": "moment",
"kwargs": {"target_function": "createDuration",
"upstream_depth": "2",
"downstream_depth": "2"},
"expected_edges": [["moment::(global)", "moment::toInt"],
["moment::isDurationValid", "moment::hasOwnProp"],
["moment::to", "moment::createLocal"],
["moment::cloneWithOffset", "moment::createLocal"],
["moment::createDuration", "moment::absRound"],
["moment::createLocal", "moment::createLocalOrUTC"],
["moment::isDurationValid", "moment::toInt"],
["moment::clone$1", "moment::createDuration"],
["moment::momentsDifference", "moment::cloneWithOffset"],
["moment::subtract$1", "moment::addSubtract$1"],
["moment::momentsDifference",
"moment::positiveMomentsDifference"],
["moment::normalizeObjectUnits", "moment::hasOwnProp"],
["moment::createDuration", "moment::createLocal"],
["moment::from", "moment::createDuration"],
["moment::add$1", "moment::addSubtract$1"],
["moment::Duration", "moment::isDurationValid"],
["moment::relativeTime$1", "moment::createDuration"],
["moment::createDuration", "moment::Duration"],
["moment::getSetOffset", "moment::createDuration"],
["moment::humanize", "moment::relativeTime$1"],
["moment::Duration", "moment::getLocale"],
["moment::addSubtract$1", "moment::createDuration"],
["moment::to", "moment::createDuration"],
["moment::Duration", "moment::normalizeObjectUnits"],
["moment::toInt", "moment::absFloor"],
["moment::createDuration", "moment::hasOwnProp"],
["moment::from", "moment::createLocal"],
["moment::createAdder", "moment::createDuration"],
["moment::(global)", "moment::hasOwnProp"],
["moment::createDuration", "moment::isDuration"],
["moment::(global)", "moment::createAdder"],
["moment::createDuration", "moment::momentsDifference"],
["moment::createDuration", "moment::toInt"],
["moment::createDuration", "moment::isNumber"],
["moment::createDuration", "moment::parseIso"],
["moment::createInvalid$1", "moment::createDuration"]],
"expected_nodes": ["moment::normalizeObjectUnits",
"moment::cloneWithOffset",
"moment::createInvalid$1",
"moment::to",
"moment::isDuration",
"moment::hasOwnProp",
"moment::isNumber",
"moment::momentsDifference",
"moment::createLocalOrUTC",
"moment::(global)",
"moment::absFloor",
"moment::relativeTime$1",
"moment::Duration",
"moment::from",
"moment::absRound",
"moment::addSubtract$1",
"moment::getSetOffset",
"moment::isDurationValid",
"moment::positiveMomentsDifference",
"moment::createDuration",
"moment::getLocale",
"moment::parseIso",
"moment::add$1",
"moment::createAdder",
"moment::clone$1",
"moment::createLocal",
"moment::toInt",
"moment::subtract$1",
"moment::humanize"]
}
],
'mjs': [
{
"test_name": "two_file_imports_es6",
"directory": "two_file_imports_es6",
"comment": "mjs files should be detected and this separately tests es6 imports",
"kwargs": {'source_type': 'module'},
"expected_edges": [["imported_es6::myClass.(constructor)",
"imported_es6::myClass.doit"],
["importer_es6::outer", "imported_es6::inner"],
["imported_es6::myClass.doit",
"imported_es6::myClass.doit2"],
["importer_es6::outer",
"imported_es6::myClass.(constructor)"],
["importer_es6::(global)", "importer_es6::outer"]],
"expected_nodes": ["imported_es6::myClass.doit",
"imported_es6::inner",
"imported_es6::myClass.doit2",
"imported_es6::myClass.(constructor)",
"importer_es6::(global)",
"importer_es6::outer"]
},
],
'rb': [
{
"test_name": "simple_a",
"directory": "simple_a",
"expected_edges": [["simple_a::func_a", "simple_a::func_b"],
["simple_a::(global)", "simple_a::func_a"]],
"expected_nodes": ["simple_a::(global)",
"simple_a::func_a",
"simple_a::func_b"]
},
{
"test_name": "simple_b",
"directory": "simple_b",
"expected_edges": [["simple_b::b", "simple_b::a"],
["simple_b::a", "simple_b::b"],
["simple_b::Cls.d", "simple_b::a"],
["simple_b::(global)", "simple_b::Cls.initialize"],
["simple_b::(global)", "simple_b::Cls.d"]],
"expected_nodes": ["simple_b::(global)",
"simple_b::a",
"simple_b::b",
"simple_b::Cls.d",
"simple_b::Cls.initialize"]
},
{
"test_name": "two_file_simple",
"directory": "two_file_simple",
"expected_edges": [["file_a::(global)", "file_a::abra"],
["file_a::abra", "file_b::babra"]],
"expected_nodes": ["file_a::(global)", "file_a::abra", "file_b::babra"]
},
{
"test_name": "resolve_correct_class",
"directory": "resolve_correct_class",
"expected_edges": [["rcc::Beta.func_1", "rcc::Alpha.func_2"],
["rcc::Alpha.func_1", "rcc::Beta.func_2"],
["rcc::Alpha.func_1", "rcc::Alpha.func_1"]],
"expected_nodes": ["rcc::Beta.func_1",
"rcc::Alpha.func_1",
"rcc::Alpha.func_2",
"rcc::Beta.func_2"]
},
{
"test_name": "ambiguous_resolution",
"directory": "ambiguous_resolution",
"expected_edges": [["ambiguous_resolution::Cadabra.cadabra_it",
"ambiguous_resolution::Abra.abra_it"],
["ambiguous_resolution::(global)",
"ambiguous_resolution::main"],
["ambiguous_resolution::main",
"ambiguous_resolution::Cadabra.cadabra_it"]],
"expected_nodes": ["ambiguous_resolution::Abra.abra_it",
"ambiguous_resolution::main",
"ambiguous_resolution::(global)",
"ambiguous_resolution::Cadabra.cadabra_it"]
},
{
"test_name": "instance_methods",
"directory": "instance_methods",
"expected_edges": [["instance_methods::Abra.nested2",
"instance_methods::Abra.main"],
["instance_methods::(global)",
"instance_methods::Abra.nested2"],
["instance_methods::Abra.nested",
"instance_methods::Abra.main"],
["instance_methods::(global)",
"instance_methods::Abra.nested"],
["instance_methods::(global)",
"instance_methods::Abra.main2"],
["instance_methods::Abra.main",
"instance_methods::Abra.nested"],
["instance_methods::(global)",
"instance_methods::Abra.main"]],
"expected_nodes": ["instance_methods::Abra.nested2",
"instance_methods::Abra.main2",
"instance_methods::Abra.nested",
"instance_methods::Abra.main",
"instance_methods::(global)"]
},
{
"test_name": "chains",
"directory": "chains",
"expected_edges": [["chains::a", "chains::b"],
["chains::(global)", "chains::c"],
["chains::b", "chains::a"],
["chains::c", "chains::Cls.initialize"],
["chains::c", "chains::Cls.b"],
["chains::(global)", "chains::b"],
["chains::(global)", "chains::a"],
["chains::c", "chains::Cls.a"]],
"expected_nodes": ["chains::a",
"chains::Cls.initialize",
"chains::Cls.a",
"chains::c",
"chains::(global)",
"chains::Cls.b",
"chains::b"]
},
{
"test_name": "modules",
"directory": "modules",
"expected_edges": [["modules::(global)", "modules::ScaleDemo.initialize"],
["modules::(global)", "modules::majorNum"],
["modules::ScaleDemoLimited.initialize",
"modules::MajorScales.majorNum"],
["modules::ScaleDemo.initialize",
"modules::MajorScales.majorNum"],
["modules::ScaleDemo.initialize",
"modules::PentatonicScales.pentaNum"]],
"expected_nodes": ["modules::PentatonicScales.pentaNum",
"modules::ScaleDemo.initialize",
"modules::(global)",
"modules::MajorScales.majorNum",
"modules::ScaleDemoLimited.initialize",
"modules::majorNum"]
},
{
"test_name": "doublecolon",
"directory": "doublecolon",
"expected_edges": [["doublecolon::Class1.func_a",
"doublecolon::Class2.func_b"],
["doublecolon::Class1.func_b",
"doublecolon::Class1.func_a"],
["doublecolon::Class2.func_b",
"doublecolon::Class2.func_a"],
["doublecolon::Class2.func_a",
"doublecolon::Class1.func_b"],
["doublecolon::(global)", "doublecolon::Class2.func_b"]],
"expected_nodes": ["doublecolon::Class2.func_a",
"doublecolon::(global)",
"doublecolon::Class1.func_b",
"doublecolon::Class1.func_a",
"doublecolon::Class2.func_b"]
},
{
"test_name": "weird_chains",
"directory": "weird_chains",
"expected_edges": [["weird_chains::(global)", "weird_chains::DivByTwo.result"],
["weird_chains::(global)", "weird_chains::DivByTwo.-"],
["weird_chains::(global)",
"weird_chains::DivByTwo.initialize"],
["weird_chains::(global)", "weird_chains::DivByTwo.*"],
["weird_chains::(global)", "weird_chains::DivByTwo.+"]],
"expected_nodes": ["weird_chains::DivByTwo.+",
"weird_chains::DivByTwo.*",
"weird_chains::DivByTwo.-",
"weird_chains::DivByTwo.result",
"weird_chains::DivByTwo.initialize",
"weird_chains::(global)"]
},
{
"test_name": "onelinefile",
"directory": "onelinefile",
"comment": "Including this because the ruby ast treats single line stuff different from multiline. Also there is a lambda",
"expected_edges": [],
"expected_nodes": []
},
{
"test_name": "nested",
"directory": "nested",
"expected_edges": [["nested::Nested.initialize", "nested::Nested.func_1"],
["nested::(global)", "nested::Nested.func_2"],
["nested::(global)", "nested::Mod.func_1"],
["nested::Nested.func_2", "nested::Mod.func_2"],
["nested::func_1", "nested::func_2"],
["nested::(global)", "nested::Nested.initialize"],
["nested::Nested.func_2", "nested::Nested.func_1"],
["nested::func_2", "nested::func_1"],
["nested::Nested.func_1", "nested::Mod.func_1"]],
"expected_nodes": ["nested::Mod.func_1",
"nested::func_2",
"nested::Nested.func_1",
"nested::func_1",
"nested::Nested.initialize",
"nested::(global)",
"nested::Mod.func_2",
"nested::Nested.func_2"]
},
{
"test_name": "nested_classes",
"directory": "nested_classes",
"comment": "like the last nested test but with classes instead of modules",
"expected_edges": [["nested_classes::(global)", "nested_classes::Mod.func_1"],
["nested_classes::Nested.func_1",
"nested_classes::Mod.func_1"],
["nested_classes::Nested.func_2",
"nested_classes::Mod.func_2"],
["nested_classes::(global)",
"nested_classes::Nested.initialize"],
["nested_classes::func_1", "nested_classes::func_2"],
["nested_classes::Nested.func_2",
"nested_classes::Nested.func_1"],
["nested_classes::func_2", "nested_classes::func_1"],
["nested_classes::Nested.initialize",
"nested_classes::Nested.func_1"],
["nested_classes::(global)",
"nested_classes::Nested.func_2"]],
"expected_nodes": ["nested_classes::Mod.func_1",
"nested_classes::func_1",
"nested_classes::func_2",
"nested_classes::Nested.func_2",
"nested_classes::Nested.initialize",
"nested_classes::Mod.func_2",
"nested_classes::(global)",
"nested_classes::Nested.func_1"]
},
{
"test_name": "inheritance_2",
"directory": "inheritance_2",
"comment": "The '<' style of inheritance",
"expected_edges": [["inheritance_2::Cat.meow", "inheritance_2::Animal.speak"],
["inheritance_2::(global)", "inheritance_2::Animal.speak"],
["inheritance_2::(global)", "inheritance_2::Cat.meow"]],
"expected_nodes": ["inheritance_2::Cat.meow",
"inheritance_2::Animal.speak",
"inheritance_2::(global)"]
},
{
"test_name": "split_modules",
"directory": "split_modules",
"expected_edges": [["split_modules_a::(global)",
"split_modules_b::MyClass.doit"],
["split_modules_b::MyClass.doit",
"split_modules_a::Split.say_hi"],
["split_modules_a::(global)",
"split_modules_b::MyClass.initialize"],
["split_modules_a::Split.say_hi",
"split_modules_b::Split.say_bye"]],
"expected_nodes": ["split_modules_b::MyClass.doit",
"split_modules_b::Split.say_bye",
"split_modules_b::MyClass.initialize",
"split_modules_a::(global)",
"split_modules_a::Split.say_hi"]
},
{
"test_name": "public_suffix",
"directory": "public_suffix",
"expected_edges": [["domain::Domain.to_s", "domain::Domain.name"],
["list::List.select", "list::List.size"],
["public_suffix::PublicSuffix.normalize",
"list::List.empty?"],
["domain::Domain.subdomain", "domain::Domain.subdomain?"],
["rule::Exception.decompose", "rule::Exception.parts"],
["domain::Domain.name_to_labels", "domain::Domain.to_s"],
["list::List.select", "domain::Domain.to_s"],
["public_suffix::PublicSuffix.decompose",
"domain::Domain.initialize"],
["rule::Normal.decompose", "domain::Domain.to_s"],
["list::List.clear", "list::List.clear"],
["list::List.empty?", "list::List.empty?"],
["list::List.select", "list::List.entry_to_rule"],
["rule::Base.initialize", "domain::Domain.to_s"],
["list::List.each", "list::List.entry_to_rule"],
["domain::Domain.domain", "domain::Domain.domain?"],
["list::List.find", "list::List.select"],
["public_suffix::PublicSuffix.parse",
"public_suffix::PublicSuffix.decompose"],
["public_suffix::PublicSuffix.normalize",
"domain::Domain.to_s"],
["public_suffix::PublicSuffix.valid?",
"public_suffix::PublicSuffix.normalize"],
["rule::Wildcard.decompose", "domain::Domain.to_s"],
["rule::Rule.default", "rule::Rule.factory"],
["list::List.size", "list::List.size"],
["rule::Wildcard.decompose", "rule::Wildcard.parts"],
["rule::Base.match?", "list::List.empty?"],
["list::List.parse", "list::List.add"],
["public_suffix::PublicSuffix.decompose",
"list::List.empty?"],
["public_suffix::PublicSuffix.valid?", "list::List.find"],
["public_suffix::PublicSuffix.domain",
"public_suffix::PublicSuffix.parse"],
["rule::Exception.build", "domain::Domain.to_s"],
["list::List.each", "list::List.each"],
["public_suffix::PublicSuffix.parse",
"public_suffix::PublicSuffix.normalize"],
["rule::Normal.decompose", "rule::Normal.parts"],
["rule::Exception.decompose", "domain::Domain.to_s"],
["rule::Wildcard.build", "domain::Domain.to_s"],
["list::List.parse", "list::List.empty?"],
["list::List.parse", "rule::Rule.factory"],
["public_suffix::PublicSuffix.parse", "list::List.find"],
["list::List.default", "list::List.parse"],
["rule::Rule.factory", "domain::Domain.to_s"],
["list::List.add", "list::List.rule_to_entry"]],
"expected_nodes": ["rule::Base.initialize",
"list::List.empty?",
"domain::Domain.initialize",
"domain::Domain.name",
"rule::Normal.parts",
"list::List.clear",
"list::List.select",
"list::List.default",
"rule::Wildcard.decompose",
"list::List.rule_to_entry",
"rule::Normal.decompose",
"public_suffix::PublicSuffix.domain",
"list::List.parse",
"list::List.add",
"domain::Domain.name_to_labels",
"list::List.entry_to_rule",
"list::List.each",
"rule::Wildcard.parts",
"public_suffix::PublicSuffix.valid?",
"rule::Base.match?",
"rule::Exception.decompose",
"rule::Rule.default",
"domain::Domain.domain",
"rule::Exception.build",
"domain::Domain.subdomain",
"public_suffix::PublicSuffix.parse",
"list::List.find",
"list::List.size",
"domain::Domain.to_s",
"domain::Domain.subdomain?",
"domain::Domain.domain?",
"rule::Rule.factory",
"public_suffix::PublicSuffix.decompose",
"rule::Exception.parts",
"rule::Wildcard.build",
"public_suffix::PublicSuffix.normalize"]
}
],
'php': [
{
"test_name": "simple_a",
"directory": "simple_a",
"expected_edges": [["simple_a::func_a", "simple_a::func_b"],
["simple_a::(global)", "simple_a::func_a"]],
"expected_nodes": ["simple_a::func_a",
"simple_a::func_b",
"simple_a::(global)"]
},
{
"test_name": "simple_b",
"directory": "simple_b",
"expected_edges": [["simple_b::(global)", "simple_b::C.d"],
["simple_b::a", "simple_b::b"],
["simple_b::C.d", "simple_b::a"],
["simple_b::b", "simple_b::a"]],
"expected_nodes": ["simple_b::b",
"simple_b::(global)",
"simple_b::a",
"simple_b::C.d"]
},
{
"test_name": "two_file_simple",
"directory": "two_file_simple",
"expected_edges": [["file_a::(global)", "file_a::a"],
["file_a::a", "file_b::b"]],
"expected_nodes": ["file_a::a", "file_b::b", "file_a::(global)"]
},
{
"test_name": "resolve_correct_class",
"directory": "resolve_correct_class",
"expected_edges": [["rcc::Alpha.func_1", "rcc::Alpha.func_1"],
["rcc::Alpha.func_1", "rcc::Beta.func_2"],
["rcc::Beta.func_1", "rcc::Alpha.func_2"]],
"expected_nodes": ["rcc::Beta.func_1",
"rcc::Beta.func_2",
"rcc::Alpha.func_2",
"rcc::Alpha.func_1"]
},
{
"test_name": "ambiguous_resolution",
"directory": "ambiguous_resolution",
"expected_edges": [["ambiguous_resolution::main",
"ambiguous_resolution::Cadabra.cadabra_it"],
["ambiguous_resolution::Cadabra.cadabra_it",
"ambiguous_resolution::Abra.abra_it"],
["ambiguous_resolution::(global)",
"ambiguous_resolution::main"]],
"expected_nodes": ["ambiguous_resolution::main",
"ambiguous_resolution::(global)",
"ambiguous_resolution::Abra.abra_it",
"ambiguous_resolution::Cadabra.cadabra_it"]
},
{
"test_name": "chains",
"directory": "chains",
"expected_edges": [["chains::c", "chains::Cls.__construct"],
["chains::a", "chains::b"],
["chains::b", "chains::a"],
["chains::c", "chains::Cls.a"],
["chains::c", "chains::Cls.b"],
["chains::(global)", "chains::c"],
["chains::(global)", "chains::b"],
["chains::(global)", "chains::a"]],
"expected_nodes": ["chains::c",
"chains::Cls.b",
"chains::(global)",
"chains::a",
"chains::Cls.__construct",
"chains::b",
"chains::Cls.a"]
},
{
"test_name": "publicprivateprotected",
"directory": "publicprivateprotected",
"comment": "Just ensuring that access modifiers don't confuse code2flow",
"expected_edges": [["publicprivateprotected::set_color_weight",
"publicprivateprotected::Fruit.set_weight"],
["publicprivateprotected::(global)",
"publicprivateprotected::set_color_weight"],
["publicprivateprotected::(global)",
"publicprivateprotected::Fruit.set_name"],
["publicprivateprotected::set_color_weight",
"publicprivateprotected::Fruit.set_color"]],
"expected_nodes": ["publicprivateprotected::Fruit.set_color",
"publicprivateprotected::set_color_weight",
"publicprivateprotected::Fruit.set_weight",
"publicprivateprotected::Fruit.set_name",
"publicprivateprotected::(global)"]
},
{
"test_name": "inheritance",
"directory": "inheritance",
"expected_edges": [["inheritance::Strawberry.message",
"inheritance::Fruit.getColor"],
["inheritance::(global)",
"inheritance::Strawberry.message"],
["inheritance::(global)", "inheritance::Fruit.intro"]],
"expected_nodes": ["inheritance::Fruit.intro",
"inheritance::(global)",
"inheritance::Fruit.getColor",
"inheritance::Strawberry.message"]
},
{
"test_name": "inheritance2",
"directory": "inheritance2",
"expected_edges": [["inheritance2::(global)", "inheritance2::Audi.intro"],
["inheritance2::(global)", "inheritance2::Volvo.intro"],
["inheritance2::(global)", "inheritance2::Audi.makeSound"],
["inheritance2::(global)", "inheritance2::Citroen.intro"]],
"expected_nodes": ["inheritance2::Audi.makeSound",
"inheritance2::Citroen.intro",
"inheritance2::Audi.intro",
"inheritance2::Volvo.intro",
"inheritance2::(global)"]
},
{
"test_name": "traits",
"directory": "traits",
"expected_edges": [["traits::welcome2", "traits::message1.msg1"],
["traits::welcome1", "traits::Welcome.__construct"],
["traits::welcome2", "traits::message2.msg2"],
["traits::welcome1", "traits::message1.msg1"]],
"expected_nodes": ["traits::message1.msg1",
"traits::Welcome.__construct",
"traits::message2.msg2",
"traits::welcome2",
"traits::welcome1"]
},
{
"test_name": "static",
"directory": "static",
"expected_edges": [["static::(global)", "static::Greeting.__construct"],
["static::(global)", "static::Greeting.welcome"],
["static::Greeting.__construct",
"static::Greeting.say_name"],
["static::Greeting.__construct",
"static::Greeting.welcome"]],
"expected_nodes": ["static::Greeting.__construct",
"static::(global)",
"static::Greeting.welcome",
"static::Greeting.say_name"]
},
{
"test_name": "anon",
"directory": "anon",
"comment": "skip closure methods",
"expected_edges": [["anonymous_function::(global)", "anonymous_function::a"]],
"expected_nodes": ["anonymous_function::(global)", "anonymous_function::a"]
},
{
"test_name": "anon2",
"directory": "anon2",
"expected_edges": [["anonymous_function2::(Closure)",
"anonymous_function2::func_a"]],
"expected_nodes": ["anonymous_function2::(Closure)",
"anonymous_function2::func_a"]
},
{
"test_name": "branch",
"directory": "branch",
"comment": "just a simple sub-block",
"expected_edges": [["branch::(global)", "branch::a"]],
"expected_nodes": ["branch::a", "branch::(global)"]
},
{
"test_name": "factory",
"directory": "factory",
"expected_edges": [["factory::(Closure)", "currency::Currency.__construct"],
["factory::(Closure)", "currency::Currency.getCode"],
["factory::(Closure)", "currency::Money.contains"]],
"expected_nodes": ["currency::Currency.getCode",
"currency::Money.contains",
"factory::(Closure)",
"currency::Currency.__construct"]
},
{
"test_name": "nested",
"directory": "nested",
"expected_edges": [["nested::(global)", "nested::outer"],
["nested::(global)", "nested::inner"]],
"expected_nodes": ["nested::outer", "nested::inner", "nested::(global)"]
},
{
"test_name": "namespace_a",
"directory": "namespace_a",
"expected_edges": [["namespace_a::NS.(global)",
"namespace_a::Namespaced_cls.__construct"],
["namespace_a::NS.(global)",
"namespace_a::NS.namespaced_func"],
["namespace_a::NS.(global)",
"namespace_a::Namespaced_cls.instance_method"]],
"expected_nodes": ["namespace_a::NS.namespaced_func",
"namespace_a::Namespaced_cls.__construct",
"namespace_a::Namespaced_cls.instance_method",
"namespace_a::NS.(global)"]
},
{
"test_name": "namespace_b",
"directory": "namespace_b",
"expected_edges": [["namespace_b1::(global)", "namespace_b2::Cat.says"],
["namespace_b1::(global)", "namespace_b2::Animal.meows"],
["namespace_b1::(global)", "namespace_b2::Cat.meows"]],
"expected_nodes": ["namespace_b2::Cat.says",
"namespace_b1::(global)",
"namespace_b2::Animal.meows",
"namespace_b2::Cat.meows"]
},
{
"test_name": "namespace_c",
"directory": "namespace_c",
"expected_edges": [["namespace_c1::(global)",
"namespace_c2::Outer.Inner.speak"],
["namespace_c1::(global)", "namespace_c2::Cat.meow"]],
"expected_nodes": ["namespace_c2::Outer.Inner.speak",
"namespace_c2::Cat.meow",
"namespace_c1::(global)"]
},
{
"test_name": "nested_calls",
"directory": "nested_calls",
"test_name": "nested_calls",
"directory": "nested_calls",
"expected_edges": [["nested_calls::(global)", "nested_calls::Cls.func"],
["nested_calls::x_", "nested_calls::Cls.func2"],
["nested_calls::Cls.func", "nested_calls::Cls.a"],
["nested_calls::Cls.func2", "nested_calls::z_"],
["nested_calls::Cls.func2", "nested_calls::y_"],
["nested_calls::Cls.func2", "nested_calls::x_"],
["nested_calls::Cls.func", "nested_calls::Cls.c"],
["nested_calls::Cls.func", "nested_calls::Cls.b"],
["nested_calls::(global)", "nested_calls::func2"]],
"expected_nodes": ["nested_calls::z_",
"nested_calls::Cls.a",
"nested_calls::x_",
"nested_calls::Cls.c",
"nested_calls::Cls.func2",
"nested_calls::func2",
"nested_calls::Cls.b",
"nested_calls::(global)",
"nested_calls::Cls.func",
"nested_calls::y_"]
},
{
"test_name": "weird_assign",
"directory": "weird_assign",
"comment": "Not a complicated test but an unusual usecase",
"expected_edges": [["weird_assign::c", "weird_assign::b"],
["weird_assign::c", "weird_assign::a"]],
"expected_nodes": ["weird_assign::c", "weird_assign::a", "weird_assign::b"]
},
{
"test_name": "money",
"directory": "money",
"expected_edges": [["GmpCalculator::GmpCalculator.round",
"Number::Number.isCurrentEven"],
["BcMathCalculator::BcMathCalculator.round",
"Number::Number.isHalf"],
["Money::Money.greaterThan", "Money::Money.compare"],
["IntlLocalizedDecimalFormatter::IntlLocalizedDecimalFormatter.format",
"Money::Money.getAmount"],
["Number::Number.fromNumber", "Number::Number.__construct"],
["IntlLocalizedDecimalParser::IntlLocalizedDecimalParser.parse",
"Money::Money.__construct"],
["GmpCalculator::GmpCalculator.divide",
"InvalidArgumentException::InvalidArgumentException.divisionByZero"],
["GmpCalculator::GmpCalculator.round",
"Number::Number.isInteger"],
["CurrencyPair::CurrencyPair.createFromIso",
"Currency::Currency.__construct"],
["BitcoinMoneyFormatter::BitcoinMoneyFormatter.format",
"Number::Number.roundMoneyValue"],
["GmpCalculator::GmpCalculator.divide",
"Number::Number.getFractionalPart"],
["IndirectExchange::IndirectExchange.getConversions",
"UnresolvableCurrencyPairException::UnresolvableCurrencyPairException.createFromCurrencies"],
["GmpCalculator::GmpCalculator.round",
"Number::Number.fromString"],
["BitcoinMoneyFormatter::BitcoinMoneyFormatter.format",
"Money::Money.getCurrency"],
["DecimalMoneyParser::DecimalMoneyParser.parse",
"Money::Money.__construct"],
["BcMathCalculator::BcMathCalculator.round",
"Number::Number.getIntegerRoundingMultiplier"],
["GmpCalculator::GmpCalculator.compare",
"Number::Number.fromString"],
["ReversedCurrenciesExchange::ReversedCurrenciesExchange.quote",
"CurrencyPair::CurrencyPair.getConversionRatio"],
["Converter::Converter.convertAgainstCurrencyPair",
"Money::Money.getCurrency"],
["BitcoinMoneyFormatter::BitcoinMoneyFormatter.format",
"Currency::Currency.getCode"],
["FixedExchange::FixedExchange.quote",
"UnresolvableCurrencyPairException::UnresolvableCurrencyPairException.createFromCurrencies"],
["Money::Money.allocate", "Money::Money.__construct"],
["IntlMoneyParser::IntlMoneyParser.parse",
"Number::Number.roundMoneyValue"],
["CurrencyList::CurrencyList.contains",
"Currency::Currency.getCode"],
["Money::Money.min", "Money::Money.lessThan"],
["Number::Number.fromNumber", "Number::Number.fromString"],
["Converter::Converter.convertAgainstCurrencyPair",
"Currency::Currency.getCode"],
["Money::Money.absolute", "Money::Money.__construct"],
["GmpCalculator::GmpCalculator.share",
"GmpCalculator::GmpCalculator.multiply"],
["ISOCurrencies::ISOCurrencies.subunitFor",
"ISOCurrencies::ISOCurrencies.contains"],
["GmpCalculator::GmpCalculator.divide",
"Number::Number.isDecimal"],
["SwapExchange::SwapExchange.quote",
"CurrencyPair::CurrencyPair.__construct"],
["GmpCalculator::GmpCalculator.roundDigit",
"Number::Number.getIntegerPart"],
["IntlMoneyFormatter::IntlMoneyFormatter.format",
"Money::Money.getCurrency"],
["ISOCurrencies::ISOCurrencies.subunitFor",
"Currency::Currency.getCode"],
["GmpCalculator::GmpCalculator.floor",
"Number::Number.getIntegerPart"],
["BcMathCalculator::BcMathCalculator.floor",
"Number::Number.isInteger"],
["IntlLocalizedDecimalParser::IntlLocalizedDecimalParser.parse",
"Number::Number.roundMoneyValue"],
["Money::Money.divide", "Money::Money.__construct"],
["Money::Money.max", "Money::Money.greaterThan"],
["GmpCalculator::GmpCalculator.share",
"GmpCalculator::GmpCalculator.floor"],
["Converter::Converter.convertAgainstCurrencyPair",
"CurrencyPair::CurrencyPair.getCounterCurrency"],
["BitcoinMoneyParser::BitcoinMoneyParser.parse",
"Currency::Currency.__construct"],
["BitcoinMoneyFormatter::BitcoinMoneyFormatter.format",
"Money::Money.getAmount"],
["BcMathCalculator::BcMathCalculator.floor",
"Number::Number.fromString"],
["DecimalMoneyParser::DecimalMoneyParser.parse",
"Number::Number.roundMoneyValue"],
["Converter::Converter.convertAgainstCurrencyPair",
"Number::Number.fromString"],
["Comparator::Comparator.__construct",
"IntlMoneyFormatter::IntlMoneyFormatter.__construct"],
["Number::Number.base10", "Number::Number.__construct"],
["GmpCalculator::GmpCalculator.round",
"Number::Number.getIntegerPart"],
["BitcoinCurrencies::BitcoinCurrencies.contains",
"Currency::Currency.getCode"],
["GmpCalculator::GmpCalculator.roundDigit",
"Number::Number.getIntegerRoundingMultiplier"],
["GmpCalculator::GmpCalculator.compare",
"Number::Number.getIntegerPart"],
["DecimalMoneyFormatter::DecimalMoneyFormatter.format",
"Money::Money.getCurrency"],
["ISOCurrencies::ISOCurrencies.subunitFor",
"ISOCurrencies::ISOCurrencies.getCurrencies"],
["GmpCalculator::GmpCalculator.roundDigit",
"Number::Number.isCloserToNext"],
["GmpCalculator::GmpCalculator.compare",
"Number::Number.isDecimal"],
["ISOCurrencies::ISOCurrencies.(Closure)",
"Currency::Currency.__construct"],
["GmpCalculator::GmpCalculator.round",
"Number::Number.isHalf"],
["ISOCurrencies::ISOCurrencies.contains",
"Currency::Currency.getCode"],
["ReversedCurrenciesExchange::ReversedCurrenciesExchange.quote",
"Money::Money.getCalculator"],
["GmpCalculator::GmpCalculator.ceil",
"Number::Number.isInteger"],
["Number::Number.fromFloat", "Number::Number.fromString"],
["Money::Money.roundToUnit", "Money::Money.__construct"],
["Money::Money.negative", "Money::Money.__construct"],
["GmpCalculator::GmpCalculator.round",
"GmpCalculator::GmpCalculator.roundDigit"],
["UnresolvableCurrencyPairException::UnresolvableCurrencyPairException.createFromCurrencies",
"Currency::Currency.getCode"],
["Money::Money.multiply", "Money::Money.__construct"],
["FixedExchange::FixedExchange.quote",
"CurrencyPair::CurrencyPair.__construct"],
["Converter::Converter.convert",
"Money::Money.getCurrency"],
["GmpCalculator::GmpCalculator.roundDigit",
"GmpCalculator::GmpCalculator.add"],
["IndirectExchange::IndirectExchange.getConversions",
"Currency::Currency.getCode"],
["GmpCalculator::GmpCalculator.ceil",
"Number::Number.fromString"],
["Money::Money.lessThan", "Money::Money.compare"],
["GmpCalculator::GmpCalculator.floor",
"GmpCalculator::GmpCalculator.add"],
["Money::Money.allocateTo", "Money::Money.allocate"],
["CurrencyList::CurrencyList.(Closure)",
"Currency::Currency.__construct"],
["Converter::Converter.convertAndReturnWithCurrencyPair",
"Money::Money.getCurrency"],
["GmpCalculator::GmpCalculator.round",
"Number::Number.getIntegerRoundingMultiplier"],
["BcMathCalculator::BcMathCalculator.roundDigit",
"Number::Number.getIntegerRoundingMultiplier"],
["CurrencyList::CurrencyList.subunitFor",
"Currency::Currency.getCode"],
["BcMathCalculator::BcMathCalculator.round",
"Number::Number.isInteger"],
["ISOCurrencies::ISOCurrencies.numericCodeFor",
"ISOCurrencies::ISOCurrencies.contains"],
["Number::Number.__construct",
"Number::Number.parseIntegerPart"],
["ISOCurrencies::ISOCurrencies.numericCodeFor",
"Currency::Currency.getCode"],
["BcMathCalculator::BcMathCalculator.roundDigit",
"Number::Number.isCloserToNext"],
["BcMathCalculator::BcMathCalculator.share",
"BcMathCalculator::BcMathCalculator.floor"],
["GmpCalculator::GmpCalculator.multiply",
"Number::Number.fromString"],
["FixedExchange::FixedExchange.quote",
"Currency::Currency.getCode"],
["GmpCalculator::GmpCalculator.share",
"GmpCalculator::GmpCalculator.divide"],
["BcMathCalculator::BcMathCalculator.mod",
"InvalidArgumentException::InvalidArgumentException.moduloByZero"],
["Money::Money.subtract", "Money::Money.__construct"],
["IntlMoneyFormatter::IntlMoneyFormatter.format",
"Currency::Currency.getCode"],
["Converter::Converter.convertAndReturnWithCurrencyPair",
"Converter::Converter.convertAgainstCurrencyPair"],
["GmpCalculator::GmpCalculator.compare",
"Number::Number.getFractionalPart"],
["IntlMoneyParser::IntlMoneyParser.parse",
"Currency::Currency.__construct"],
["ISOCurrencies::ISOCurrencies.contains",
"ISOCurrencies::ISOCurrencies.getCurrencies"],
["IndirectExchange::IndirectExchange.quote",
"IndirectExchange::IndirectExchange.getConversions"],
["GmpCalculator::GmpCalculator.divide",
"GmpCalculator::GmpCalculator.compare"],
["ISOCurrencies::ISOCurrencies.getIterator",
"ISOCurrencies::ISOCurrencies.getCurrencies"],
["Converter::Converter.convertAgainstCurrencyPair",
"Money::Money.getAmount"],
["GmpCalculator::GmpCalculator.round",
"GmpCalculator::GmpCalculator.add"],
["GmpCalculator::GmpCalculator.mod",
"GmpCalculator::GmpCalculator.compare"],
["Money::Money.equals", "Money::Money.compare"],
["GmpCalculator::GmpCalculator.divide",
"Number::Number.__construct"],
["IndirectExchange::IndirectExchange.(Closure)",
"CurrencyPair::CurrencyPair.getConversionRatio"],
["Money::Money.__construct", "Number::Number.isInteger"],
["IntlMoneyFormatter::IntlMoneyFormatter.format",
"Money::Money.getAmount"],
["Converter::Converter.convertAgainstCurrencyPair",
"CurrencyPair::CurrencyPair.getConversionRatio"],
["ISOCurrencies::ISOCurrencies.numericCodeFor",
"ISOCurrencies::ISOCurrencies.getCurrencies"],
["CurrencyList::CurrencyList.subunitFor",
"CurrencyList::CurrencyList.contains"],
["ExchangerExchange::ExchangerExchange.quote",
"UnresolvableCurrencyPairException::UnresolvableCurrencyPairException.createFromCurrencies"],
["Converter::Converter.convertAgainstCurrencyPair",
"Number::Number.base10"],
["IntlLocalizedDecimalFormatter::IntlLocalizedDecimalFormatter.format",
"Money::Money.getCurrency"],
["Money::Money.__construct", "Number::Number.fromString"],
["Number::Number.__construct",
"Number::Number.parseFractionalPart"],
["GmpCalculator::GmpCalculator.ceil",
"Number::Number.getIntegerPart"],
["Money::Money.add", "Money::Money.__construct"],
["GmpCalculator::GmpCalculator.mod",
"GmpCalculator::GmpCalculator.absolute"],
["BcMathCalculator::BcMathCalculator.round",
"Number::Number.isCurrentEven"],
["GmpCalculator::GmpCalculator.multiply",
"Number::Number.getIntegerPart"],
["IndirectExchange::IndirectExchange.getConversions",
"IndirectExchangeQueuedItem::IndirectExchangeQueuedItem.__construct"],
["GmpCalculator::GmpCalculator.mod",
"InvalidArgumentException::InvalidArgumentException.moduloByZero"],
["GmpCalculator::GmpCalculator.divide",
"Number::Number.fromString"],
["GmpCalculator::GmpCalculator.multiply",
"Number::Number.isDecimal"],
["MoneyFactory::MoneyFactory.__callStatic",
"Currency::Currency.__construct"],
["BitcoinMoneyParser::BitcoinMoneyParser.parse",
"Money::Money.__construct"],
["GmpCalculator::GmpCalculator.mod",
"Number::Number.fromString"],
["Money::Money.divide", "Money::Money.round"],
["BcMathCalculator::BcMathCalculator.divide",
"InvalidArgumentException::InvalidArgumentException.divisionByZero"],
["DecimalMoneyFormatter::DecimalMoneyFormatter.format",
"Money::Money.getAmount"],
["BitcoinCurrencies::BitcoinCurrencies.subunitFor",
"Currency::Currency.getCode"],
["Number::Number.fromString", "Number::Number.__construct"],
["BcMathCalculator::BcMathCalculator.ceil",
"Number::Number.isInteger"],
["Converter::Converter.convert",
"Converter::Converter.convertAgainstCurrencyPair"],
["IndirectExchange::IndirectExchange.getConversions",
"IndirectExchange::IndirectExchange.reconstructConversionChain"],
["Comparator::Comparator.__construct",
"AggregateCurrencies::AggregateCurrencies.__construct"],
["BcMathCalculator::BcMathCalculator.round",
"Number::Number.fromString"],
["BcMathCalculator::BcMathCalculator.round",
"BcMathCalculator::BcMathCalculator.roundDigit"],
["BcMathCalculator::BcMathCalculator.ceil",
"Number::Number.fromString"],
["IndirectExchange::IndirectExchange.reconstructConversionChain",
"Currency::Currency.getCode"],
["Money::Money.lessThanOrEqual", "Money::Money.compare"],
["IndirectExchange::IndirectExchange.quote",
"CurrencyPair::CurrencyPair.__construct"],
["IndirectExchange::IndirectExchange.(Closure)",
"Money::Money.getCalculator"],
["Money::Money.greaterThanOrEqual", "Money::Money.compare"],
["Money::Money.__construct",
"Number::Number.getIntegerPart"],
["GmpCalculator::GmpCalculator.multiply",
"Number::Number.getFractionalPart"],
["AggregateMoneyFormatter::AggregateMoneyFormatter.format",
"Money::Money.getCurrency"],
["GmpCalculator::GmpCalculator.ceil",
"GmpCalculator::GmpCalculator.add"],
["ExchangerExchange::ExchangerExchange.quote",
"CurrencyPair::CurrencyPair.__construct"],
["ReversedCurrenciesExchange::ReversedCurrenciesExchange.quote",
"CurrencyPair::CurrencyPair.__construct"],
["AggregateMoneyFormatter::AggregateMoneyFormatter.format",
"Currency::Currency.getCode"],
["GmpCalculator::GmpCalculator.divide",
"Number::Number.getIntegerPart"],
["MoneyFactory::MoneyFactory.__callStatic",
"Money::Money.__construct"],
["Money::Money.multiply", "Money::Money.round"],
["SwapExchange::SwapExchange.quote",
"UnresolvableCurrencyPairException::UnresolvableCurrencyPairException.createFromCurrencies"],
["Money::Money.mod", "Money::Money.__construct"],
["Converter::Converter.convertAgainstCurrencyPair",
"Money::Money.__construct"],
["GmpCalculator::GmpCalculator.floor",
"Number::Number.isInteger"],
["ExchangerExchange::ExchangerExchange.quote",
"Currency::Currency.getCode"],
["BitcoinCurrencies::BitcoinCurrencies.getIterator",
"Currency::Currency.__construct"],
["Converter::Converter.convertAgainstCurrencyPair",
"CurrencyPair::CurrencyPair.getBaseCurrency"],
["CurrencyPair::CurrencyPair.createFromIso",
"CurrencyPair::CurrencyPair.__construct"],
["ISOCurrencies::ISOCurrencies.getCurrencies",
"ISOCurrencies::ISOCurrencies.loadCurrencies"],
["Money::Money.ratioOf", "Money::Money.isZero"],
["IntlMoneyParser::IntlMoneyParser.parse",
"Money::Money.__construct"],
["GmpCalculator::GmpCalculator.floor",
"Number::Number.fromString"]],
"expected_nodes": ["GmpCalculator::GmpCalculator.add",
"FixedExchange::FixedExchange.quote",
"Number::Number.roundMoneyValue",
"CurrencyPair::CurrencyPair.getBaseCurrency",
"ISOCurrencies::ISOCurrencies.loadCurrencies",
"Number::Number.isCloserToNext",
"GmpCalculator::GmpCalculator.roundDigit",
"Money::Money.greaterThan",
"Money::Money.subtract",
"Money::Money.lessThanOrEqual",
"CurrencyList::CurrencyList.subunitFor",
"BcMathCalculator::BcMathCalculator.ceil",
"Money::Money.equals",
"Number::Number.isHalf",
"Comparator::Comparator.__construct",
"IndirectExchange::IndirectExchange.reconstructConversionChain",
"Number::Number.__construct",
"GmpCalculator::GmpCalculator.share",
"Number::Number.getIntegerRoundingMultiplier",
"Number::Number.isDecimal",
"InvalidArgumentException::InvalidArgumentException.moduloByZero",
"Money::Money.mod",
"Converter::Converter.convertAgainstCurrencyPair",
"BitcoinCurrencies::BitcoinCurrencies.getIterator",
"GmpCalculator::GmpCalculator.compare",
"IntlLocalizedDecimalParser::IntlLocalizedDecimalParser.parse",
"Money::Money.multiply",
"Money::Money.divide",
"Money::Money.isZero",
"Number::Number.fromNumber",
"BcMathCalculator::BcMathCalculator.roundDigit",
"IntlMoneyFormatter::IntlMoneyFormatter.format",
"BcMathCalculator::BcMathCalculator.mod",
"ISOCurrencies::ISOCurrencies.(Closure)",
"BitcoinCurrencies::BitcoinCurrencies.contains",
"Money::Money.getCurrency",
"IndirectExchange::IndirectExchange.(Closure)",
"Money::Money.__construct",
"Number::Number.fromFloat",
"Money::Money.allocate",
"BitcoinMoneyFormatter::BitcoinMoneyFormatter.format",
"Money::Money.lessThan",
"ISOCurrencies::ISOCurrencies.contains",
"Money::Money.add",
"ReversedCurrenciesExchange::ReversedCurrenciesExchange.quote",
"Number::Number.parseFractionalPart",
"Currency::Currency.__construct",
"ISOCurrencies::ISOCurrencies.subunitFor",
"Money::Money.ratioOf",
"Number::Number.isInteger",
"SwapExchange::SwapExchange.quote",
"BitcoinMoneyParser::BitcoinMoneyParser.parse",
"IndirectExchange::IndirectExchange.quote",
"Number::Number.base10",
"CurrencyPair::CurrencyPair.createFromIso",
"Number::Number.isCurrentEven",
"DecimalMoneyParser::DecimalMoneyParser.parse",
"GmpCalculator::GmpCalculator.divide",
"ISOCurrencies::ISOCurrencies.numericCodeFor",
"AggregateCurrencies::AggregateCurrencies.__construct",
"GmpCalculator::GmpCalculator.floor",
"Money::Money.negative",
"Number::Number.getFractionalPart",
"Money::Money.roundToUnit",
"CurrencyList::CurrencyList.(Closure)",
"ISOCurrencies::ISOCurrencies.getIterator",
"IndirectExchange::IndirectExchange.getConversions",
"InvalidArgumentException::InvalidArgumentException.divisionByZero",
"Money::Money.compare",
"CurrencyPair::CurrencyPair.__construct",
"AggregateMoneyFormatter::AggregateMoneyFormatter.format",
"DecimalMoneyFormatter::DecimalMoneyFormatter.format",
"BcMathCalculator::BcMathCalculator.floor",
"Money::Money.getCalculator",
"BcMathCalculator::BcMathCalculator.divide",
"IndirectExchangeQueuedItem::IndirectExchangeQueuedItem.__construct",
"MoneyFactory::MoneyFactory.__callStatic",
"Money::Money.greaterThanOrEqual",
"Money::Money.min",
"Converter::Converter.convert",
"ISOCurrencies::ISOCurrencies.getCurrencies",
"GmpCalculator::GmpCalculator.absolute",
"Money::Money.absolute",
"IntlMoneyParser::IntlMoneyParser.parse",
"Number::Number.fromString",
"Money::Money.max",
"GmpCalculator::GmpCalculator.mod",
"UnresolvableCurrencyPairException::UnresolvableCurrencyPairException.createFromCurrencies",
"CurrencyPair::CurrencyPair.getConversionRatio",
"Money::Money.getAmount",
"IntlMoneyFormatter::IntlMoneyFormatter.__construct",
"GmpCalculator::GmpCalculator.ceil",
"ExchangerExchange::ExchangerExchange.quote",
"Money::Money.round",
"GmpCalculator::GmpCalculator.multiply",
"GmpCalculator::GmpCalculator.round",
"BcMathCalculator::BcMathCalculator.share",
"IntlLocalizedDecimalFormatter::IntlLocalizedDecimalFormatter.format",
"Converter::Converter.convertAndReturnWithCurrencyPair",
"BcMathCalculator::BcMathCalculator.round",
"CurrencyList::CurrencyList.contains",
"Number::Number.parseIntegerPart",
"Currency::Currency.getCode",
"CurrencyPair::CurrencyPair.getCounterCurrency",
"Money::Money.allocateTo",
"BitcoinCurrencies::BitcoinCurrencies.subunitFor",
"Number::Number.getIntegerPart"]
}
]
}