Showing preview only (1,699K chars total). Download the full file or copy to clipboard to get everything.
Repository: sirocco-ventures/raggenie
Branch: main
Commit: 8a069ccc9cd9
Files: 351
Total size: 87.8 MB
Directory structure:
gitextract_rx9dudey/
├── .dockerignore
├── .flake8
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── bug_report.md
│ │ └── feature_request.md
│ └── workflows/
│ └── static.yml
├── .gitignore
├── .pre-commit-config.yaml
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE
├── Makefile
├── README.md
├── app/
│ ├── __init__.py
│ ├── api/
│ │ └── v1/
│ │ ├── auth.py
│ │ ├── commons.py
│ │ ├── connector.py
│ │ ├── llmchat.py
│ │ ├── main_router.py
│ │ └── provider.py
│ ├── base/
│ │ ├── abstract_handlers.py
│ │ ├── base_formatter.py
│ │ ├── base_llm.py
│ │ ├── base_plugin.py
│ │ ├── base_vectordb.py
│ │ ├── document_data_plugin.py
│ │ ├── loader_metadata_mixin.py
│ │ ├── messaging_plugin.py
│ │ ├── model_loader.py
│ │ ├── plugin_metadata_mixin.py
│ │ ├── query_plugin.py
│ │ └── remote_data_plugin.py
│ ├── chain/
│ │ ├── chains/
│ │ │ ├── capability_chain.py
│ │ │ ├── general_chain.py
│ │ │ ├── intent_chain.py
│ │ │ ├── metadata_chain.py
│ │ │ └── query_chain.py
│ │ ├── formatter/
│ │ │ └── general_response.py
│ │ └── modules/
│ │ ├── cache_checker.py
│ │ ├── cache_updater.py
│ │ ├── context_retreiver.py
│ │ ├── context_storage.py
│ │ ├── document_retriever.py
│ │ ├── executer.py
│ │ ├── follow_up_handler.py
│ │ ├── followup_interpreter.py
│ │ ├── general_answer_generator.py
│ │ ├── generator.py
│ │ ├── input_formatter.py
│ │ ├── intent_extracter.py
│ │ ├── metadata_generator.py
│ │ ├── metadata_ragfilter.py
│ │ ├── ouput_formatter.py
│ │ ├── post_processor.py
│ │ ├── prompt_generator.py
│ │ ├── router.py
│ │ ├── schema_retriever.py
│ │ └── validator.py
│ ├── embeddings/
│ │ ├── cohere/
│ │ │ ├── __init__.py
│ │ │ └── handler.py
│ │ ├── default/
│ │ │ ├── chroma_default.py
│ │ │ ├── default.py
│ │ │ └── onnx.py
│ │ ├── google/
│ │ │ ├── __init__.py
│ │ │ └── handler.py
│ │ ├── loader.py
│ │ └── openai/
│ │ ├── __init__.py
│ │ └── handler.py
│ ├── loaders/
│ │ ├── ai71/
│ │ │ ├── __init__.py
│ │ │ └── loader.py
│ │ ├── base_loader.py
│ │ ├── ollama/
│ │ │ ├── __init__.py
│ │ │ └── loader.py
│ │ ├── openai/
│ │ │ ├── __init__.py
│ │ │ └── loader.py
│ │ └── togethor/
│ │ ├── __init__.py
│ │ └── loader.py
│ ├── main.py
│ ├── models/
│ │ ├── connector.py
│ │ ├── db.py
│ │ ├── environment.py
│ │ ├── llmchat.py
│ │ ├── prompt.py
│ │ ├── provider.py
│ │ ├── request.py
│ │ └── user.py
│ ├── plugins/
│ │ ├── airtable/
│ │ │ ├── __init__.py
│ │ │ ├── formatter.py
│ │ │ └── handler.py
│ │ ├── bigquery/
│ │ │ ├── __init__.py
│ │ │ ├── formatter.py
│ │ │ └── handler.py
│ │ ├── csv/
│ │ │ ├── __init__.py
│ │ │ ├── formatter.py
│ │ │ └── handler.py
│ │ ├── document/
│ │ │ ├── __init__.py
│ │ │ ├── formatter.py
│ │ │ └── handler.py
│ │ ├── loader.py
│ │ ├── maria/
│ │ │ ├── __init__.py
│ │ │ ├── formatter.py
│ │ │ └── handler.py
│ │ ├── mssql/
│ │ │ ├── __init__.py
│ │ │ ├── formatter.py
│ │ │ └── handler.py
│ │ ├── mysql/
│ │ │ ├── __init__.py
│ │ │ ├── formatter.py
│ │ │ └── handler.py
│ │ ├── postgresql/
│ │ │ ├── __init__.py
│ │ │ ├── formatter.py
│ │ │ └── handler.py
│ │ ├── sqlite/
│ │ │ ├── __init__.py
│ │ │ ├── formatter.py
│ │ │ └── handler.py
│ │ └── website/
│ │ ├── __init__.py
│ │ ├── formatter.py
│ │ └── handler.py
│ ├── providers/
│ │ ├── cache_manager.py
│ │ ├── clustering.py
│ │ ├── config.py
│ │ ├── container.py
│ │ ├── context_storage.py
│ │ ├── data_preperation.py
│ │ ├── middleware.py
│ │ ├── reranker.py
│ │ └── zitadel.py
│ ├── readers/
│ │ ├── base_reader.py
│ │ ├── docs_reader.py
│ │ ├── docx_reader.py
│ │ ├── pdf_reader.py
│ │ ├── text_reader.py
│ │ ├── url_reader.py
│ │ └── yaml_reader.py
│ ├── repository/
│ │ ├── connector.py
│ │ ├── environment.py
│ │ ├── llmchat.py
│ │ ├── provider.py
│ │ └── user.py
│ ├── schemas/
│ │ ├── common.py
│ │ ├── connector.py
│ │ ├── environment.py
│ │ ├── llmchat.py
│ │ ├── provider.py
│ │ └── user.py
│ ├── services/
│ │ ├── connector.py
│ │ ├── connector_details.py
│ │ ├── llmchat.py
│ │ ├── provider.py
│ │ └── user.py
│ ├── utils/
│ │ ├── database.py
│ │ ├── jwt.py
│ │ ├── module_reader.py
│ │ ├── parser.py
│ │ └── read_config.py
│ └── vectordb/
│ ├── loader.py
│ └── mongodb/
│ ├── __init__.py
│ └── handler.py
├── commands/
│ ├── cli.py
│ └── llm.py
├── config.yaml
├── docker-compose.yml
├── documents/
│ ├── .gitignore
│ ├── README.md
│ ├── babel.config.js
│ ├── docs/
│ │ ├── Configuring agents.md
│ │ ├── Connectors/
│ │ │ ├── Airtable.md
│ │ │ ├── Bigquery.md
│ │ │ ├── Connectors.md
│ │ │ ├── PDFs.md
│ │ │ ├── Postgressql.md
│ │ │ └── Websites.md
│ │ ├── Examples.md
│ │ ├── How to configure raggenie/
│ │ │ ├── Configuration.md
│ │ │ ├── Deploy.md
│ │ │ ├── Plugins.md
│ │ │ ├── Preview.md
│ │ │ ├── Samples.md
│ │ │ └── _category_.json
│ │ ├── How to run raggenie/
│ │ │ ├── To run raggenie backend Server.md
│ │ │ ├── To run raggenie ui server.md
│ │ │ ├── Using Docker.md
│ │ │ └── _category_.json
│ │ ├── LLM Inferences.md
│ │ └── Prerequesites.md
│ ├── docusaurus.config.js
│ ├── package.json
│ ├── sidebars.js
│ ├── src/
│ │ ├── css/
│ │ │ └── custom.css
│ │ └── pages/
│ │ ├── index.md
│ │ └── index.module.css
│ └── static/
│ └── .nojekyll
├── embeddings/
│ └── onnx/
│ ├── model.onnx
│ └── tokenizer.json
├── main.py
├── nginx.conf
├── pyproject.toml
├── requirements.txt
├── setup.py
├── tests/
│ ├── README.md
│ ├── __init__.py
│ ├── conftest.py
│ ├── functional/
│ │ ├── test_commons.py
│ │ ├── test_connectors.py
│ │ ├── test_llmchat.py
│ │ └── test_provider.py
│ ├── integration/
│ │ └── test_integration_connector.py
│ └── unittest/
│ └── test_svc/
│ └── test_svc_provider.py
├── ui/
│ ├── .dockerignore
│ ├── Dockerfile
│ ├── README.md
│ ├── eslint.config.js
│ ├── index.html
│ ├── jsconfig.json
│ ├── nginx.conf
│ ├── package.json
│ ├── src/
│ │ ├── App.jsx
│ │ ├── components/
│ │ │ ├── Breadcrumbs/
│ │ │ │ ├── Breadcrumbs.jsx
│ │ │ │ └── Breadcrumbs.module.css
│ │ │ ├── Button/
│ │ │ │ ├── Button.jsx
│ │ │ │ ├── Button.module.css
│ │ │ │ └── Button.test.jsx
│ │ │ ├── Chart/
│ │ │ │ ├── AreaChart/
│ │ │ │ │ └── AreaChart.jsx
│ │ │ │ ├── BarChart/
│ │ │ │ │ └── BarChart.jsx
│ │ │ │ ├── LineChart/
│ │ │ │ │ └── LineChart.jsx
│ │ │ │ ├── PieChart/
│ │ │ │ │ └── PieChart.jsx
│ │ │ │ ├── Table/
│ │ │ │ │ └── Table.jsx
│ │ │ │ └── style.module.css
│ │ │ ├── ChatBox/
│ │ │ │ ├── ChatBox.jsx
│ │ │ │ ├── ChatBox.module.css
│ │ │ │ ├── ChatDropdownMenu/
│ │ │ │ │ ├── ChatDropdownMenu.jsx
│ │ │ │ │ └── ChatDropdownMenu.module.css
│ │ │ │ ├── ChatHistoryButton.jsx
│ │ │ │ ├── ChatHistorySideBar.jsx
│ │ │ │ ├── ErrorMessage.jsx
│ │ │ │ ├── Feedback.jsx
│ │ │ │ ├── Loader.jsx
│ │ │ │ ├── Message.jsx
│ │ │ │ ├── Summary.jsx
│ │ │ │ └── Time.jsx
│ │ │ ├── CodeBlock/
│ │ │ │ ├── CodeBlock.jsx
│ │ │ │ └── CodeBlock.module.css
│ │ │ ├── FileUpload/
│ │ │ │ ├── FileUpload.jsx
│ │ │ │ └── FileUpload.module.css
│ │ │ ├── Input/
│ │ │ │ ├── Input.jsx
│ │ │ │ └── Input.module.css
│ │ │ ├── Modal/
│ │ │ │ ├── Modal.jsx
│ │ │ │ └── Modal.module.css
│ │ │ ├── NotificationPanel/
│ │ │ │ ├── NotificationPanel.jsx
│ │ │ │ └── NotificationPanel.module.css
│ │ │ ├── RouteTab/
│ │ │ │ ├── RouteTab.jsx
│ │ │ │ └── RouteTab.module.css
│ │ │ ├── SearchInput/
│ │ │ │ ├── SearchInput.jsx
│ │ │ │ └── SearchInput.module.css
│ │ │ ├── Select/
│ │ │ │ ├── Select.jsx
│ │ │ │ └── Select.module.css
│ │ │ ├── Tab/
│ │ │ │ ├── Tab.jsx
│ │ │ │ ├── Tab.module.css
│ │ │ │ └── Tabs.jsx
│ │ │ ├── Table/
│ │ │ │ ├── DatatableCustomTheme.css
│ │ │ │ ├── Pagination.jsx
│ │ │ │ ├── Table.jsx
│ │ │ │ └── Table.module.css
│ │ │ ├── Tag/
│ │ │ │ ├── Tag.jsx
│ │ │ │ └── Tag.module.css
│ │ │ ├── Textarea/
│ │ │ │ ├── Textarea.jsx
│ │ │ │ └── Textarea.module.css
│ │ │ └── TitleDescription/
│ │ │ ├── TitleDescription.jsx
│ │ │ ├── TitleDescription.module.css
│ │ │ └── TitleDescriptionContainer.jsx
│ │ ├── config/
│ │ │ ├── const.js
│ │ │ └── routes.jsx
│ │ ├── embedbot/
│ │ │ ├── ChatBot.css
│ │ │ ├── ChatBot.jsx
│ │ │ ├── ChatBotAPI.js
│ │ │ └── index.jsx
│ │ ├── global.css
│ │ ├── layouts/
│ │ │ ├── auth/
│ │ │ │ ├── AuthLogin.jsx
│ │ │ │ ├── UserAuth.module.css
│ │ │ │ ├── UserLogin.jsx
│ │ │ │ └── UserSignUp.jsx
│ │ │ ├── dashboard/
│ │ │ │ ├── DashboadBody.jsx
│ │ │ │ ├── Dashboard.jsx
│ │ │ │ ├── Dashboard.module.css
│ │ │ │ ├── SideMenu.jsx
│ │ │ │ └── SideMenuRoutes.js
│ │ │ ├── errorPage/
│ │ │ │ ├── 404.jsx
│ │ │ │ ├── 500.jsx
│ │ │ │ └── error.module.css
│ │ │ └── general/
│ │ │ ├── GeneralLayout.jsx
│ │ │ └── GeneralLayout.module.css
│ │ ├── main.jsx
│ │ ├── pages/
│ │ │ ├── Chat/
│ │ │ │ ├── Chat.jsx
│ │ │ │ └── Chat.module.css
│ │ │ ├── ChatConfiguration/
│ │ │ │ ├── Capability/
│ │ │ │ │ ├── Capability.jsx
│ │ │ │ │ └── Capability.module.css
│ │ │ │ ├── ChatConfiguration.jsx
│ │ │ │ ├── ChatConfiguration.module.css
│ │ │ │ ├── ChatConfigurationForm.jsx
│ │ │ │ ├── Configuration.module.css
│ │ │ │ ├── ConfigurationList.jsx
│ │ │ │ └── EmptyConfiguration.jsx
│ │ │ ├── Configuration/
│ │ │ │ ├── Configuration.jsx
│ │ │ │ ├── Configuration.module.css
│ │ │ │ ├── ConfigurationList.jsx
│ │ │ │ ├── EmptyConfiguration.jsx
│ │ │ │ ├── ProviderForm/
│ │ │ │ │ ├── DatabaseTable.css
│ │ │ │ │ ├── ProviderForm.jsx
│ │ │ │ │ └── ProviderForm.module.css
│ │ │ │ └── SchemaTable/
│ │ │ │ ├── SchemaTable.jsx
│ │ │ │ └── SchemaTable.module.css
│ │ │ ├── Deploy/
│ │ │ │ ├── Deploy.jsx
│ │ │ │ ├── Deploy.module.css
│ │ │ │ ├── DeployTabs/
│ │ │ │ │ ├── CopyEmbedCode.jsx
│ │ │ │ │ ├── CopyURL.jsx
│ │ │ │ │ ├── DeployTabs.module.css
│ │ │ │ │ ├── MaximizedLayout.jsx
│ │ │ │ │ └── MinimizedLayout.jsx
│ │ │ │ └── deployTabRoutes.jsx
│ │ │ ├── Preview/
│ │ │ │ ├── ChatBox.jsx
│ │ │ │ ├── EmptyPreview.jsx
│ │ │ │ ├── Preview.jsx
│ │ │ │ └── Preview.module.css
│ │ │ ├── Samples/
│ │ │ │ ├── EmptySample.jsx
│ │ │ │ ├── SampleForm.jsx
│ │ │ │ ├── SampleList.jsx
│ │ │ │ ├── Samples.jsx
│ │ │ │ └── Samples.module.css
│ │ │ └── Sources/
│ │ │ ├── Connetor.jsx
│ │ │ ├── Sources.jsx
│ │ │ └── Sources.module.css
│ │ ├── routes/
│ │ │ ├── DashboardRoute.jsx
│ │ │ └── MainRoute.jsx
│ │ ├── services/
│ │ │ ├── Auth.js
│ │ │ ├── BotConfifuration.js
│ │ │ ├── Capability.js
│ │ │ ├── Connectors.js
│ │ │ ├── Plugins.js
│ │ │ └── Sample.js
│ │ ├── store/
│ │ │ └── authStore.js
│ │ ├── test/
│ │ │ └── setup.js
│ │ └── utils/
│ │ ├── ConfirmDialog.jsx
│ │ ├── form/
│ │ │ └── GenerateConfigs.jsx
│ │ ├── http/
│ │ │ ├── DeleteService.js
│ │ │ ├── GetService.js
│ │ │ ├── PostService.js
│ │ │ ├── Request.js
│ │ │ └── UploadFile.js
│ │ └── utils.js
│ ├── vite.config.js
│ └── vite.library.config.js
└── zitadel-docker-compose.yaml
================================================
FILE CONTENTS
================================================
================================================
FILE: .dockerignore
================================================
./github
.gitignore
poetry.lock
README.md
CODE_OF_CONDUCT.md
pyproject.toml
CONTRIBUTING.md
.flake8
LICENSE
setup.py
Makefile
.pre-commit-config.yaml
.env.example
ui/node_modules
pgdata
================================================
FILE: .flake8
================================================
[flake8]
max-line-length = 88
enable-extensions = N, F, C, W, E # Enable naming checks
select = E201, E202, E204, E999, N801, N802, N803, N806, F401, F405, F811, F821, F823, F841, C901, W503, W504, E741, T001
exclude = .git, __pycache__, build, dist, venv
# Naming and Style Checks
#N801: Class names should use CamelCase
#N802: Function names should be snake_case
#N803: Argument names should be snake_case
#N806: Variable in function should be snake_case
# Functionality Checks
#F405: Name may be undefined, or defined from star imports: module
#F401: Module imported but unused
#F811: Redefinition of unused name from line n
#F823: Local variable name ... referenced before assignment
#F841: Local variable name is assigned to but never used
#F821: Undefined name
# Performance & Efficiency
# E741: Do not use ambiguous variable names like 'l', 'O', or 'I'
# Code Complexity
#C901: Function is too complex (cyclomatic complexity)
# Line Breaks
#W503: Line break before binary operator
#W504: Line break after binary operator
#T001: Print statements found
#E201: Whitespace after '('
#E202: Whitespace before ')'
#E203: Whitespace before ':'
#E211: Whitespace before '('
================================================
FILE: .github/ISSUE_TEMPLATE/bug_report.md
================================================
---
name: Bug report
about: Create a report to help us improve
title: ''
labels: ''
assignees: ''
---
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Desktop (please complete the following information):**
- OS: [e.g. iOS]
- Browser [e.g. chrome, safari]
- Version [e.g. 22]
**Additional context**
Add any other context about the problem here.
================================================
FILE: .github/ISSUE_TEMPLATE/feature_request.md
================================================
---
name: Feature request
about: Suggest an idea for this project
title: ''
labels: ''
assignees: ''
---
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
================================================
FILE: .github/workflows/static.yml
================================================
# Simple workflow for deploying static content to GitHub Pages
name: Deploy static content to Pages
on:
# Runs on pushes targeting the default branch
push:
branches: ["main"]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# Sets permissions of the GITHUB_TOKEN to allow deployment to GitHub Pages
permissions:
contents: read
pages: write
id-token: write
# Allow only one concurrent deployment, skipping runs queued between the run in-progress and latest queued.
# However, do NOT cancel in-progress runs as we want to allow these production deployments to complete.
concurrency:
group: "pages"
cancel-in-progress: false
jobs:
buid_and_deploy:
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }}
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
with:
sparse-checkout: 'documents'
sparse-checkout-cone-mode: false
- name: Setup Pages
uses: actions/configure-pages@v5
# Set up Node.js and install dependencies with npm
- name: Set up Node.js
uses: actions/setup-node@v3
with:
node-version: 18.0.x
- name: Install docusaurus
run: npm install
working-directory: documents
- name: Build documents
run: npm run build
working-directory: documents
- name: Upload artifact
uses: actions/upload-pages-artifact@v3
with:
path: documents/build
- name: Deploy to GitHub Pages
id: deployment
uses: actions/deploy-pages@v4
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
__pycache__
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
.DS_STORE
# Default vector db path
vector_db
chromadb
#assets files
assets/datasource
# Default log file
.cache
# Default databases
context_store.db
raggenie.db
test_db.db
csv_db.sqlite
# node_modules folder
ui/node_modules
ui/dist-library
#zitadel
pgdata
machinekey
================================================
FILE: .pre-commit-config.yaml
================================================
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.6.0 # Use the latest version
hooks:
- id: check-yaml
- id: check-added-large-files
- id: check-case-conflict
- id: check-docstring-first
- id: check-merge-conflict
- id: trailing-whitespace
================================================
FILE: CODE_OF_CONDUCT.md
================================================
# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or
advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email
address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
slack : https://join.slack.com/t/theailounge/shared_invite/zt-2ogkrruyf-FPOHuPr5hdqXl34bDWjHjw.
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.0, available at
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
Community Impact Guidelines were inspired by [Mozilla's code of conduct
enforcement ladder](https://github.com/mozilla/diversity).
[homepage]: https://www.contributor-covenant.org
For answers to common questions about this code of conduct, see the FAQ at
https://www.contributor-covenant.org/faq. Translations are available at
https://www.contributor-covenant.org/translations.
================================================
FILE: CONTRIBUTING.md
================================================
# Contributing Guidelines for RAGGENIE
## 🪜 Steps to Contribute
To contribute to this project, please follow these steps:
1. Fork and clone this repository
2. Make your changes on your fork.
3. If you modify the code (for a new feature or bug fix), please add corresponding tests.
4. Check for linting issues [see below](https://github.com/sirocco-ventures/raggenie/blob/main/CONTRIBUTING.md#-Linting)
5. Ensure all tests pass [see below](https://github.com/sirocco-ventures/raggenie/blob/main/CONTRIBUTING.md#-Testing)
6. Submit a pull request
For more detailed information about pull requests, please refer to [GitHub's guides](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request).
## 📦 Package manager
At the moment we are using pip as our package manager. Please make sure to include all the required libraries in `requirements.txt` at the time of build.
## 📌 Pre-commit
To ensure our standards, make sure to install pre-commit before starting to contribute.
```bash
pre-commit install
```
## 🧹 Linting
We use `Flake8` for linting our code. You can use the linter by running the following code.
```bash
make linting
```
## 📝 Code formatting
We use `Flake8` as our code formatter. You can format the code using the following code.
```bash
make formatting
```
## 🗒 Spellcheck
We use `codespell` for spell checking our code. For running the spellchecker run the following code.
```bash
make spellcheck
```
## 🧪 Testing
we use `pytest` for integration testing the RAGGENIE. and `unittest` for unit testing individual components.
for unit testing run the following code
```bash
make unit-test
```
for integration testing run the following code
```bash
make integration-test
```
================================================
FILE: Dockerfile
================================================
# Stage 1: UI Build
FROM node:20-alpine AS ui-build
ARG BACKEND_URL
WORKDIR /app/ui
# Copy package files first for better caching
COPY ./ui/package.json ./ui/package-lock.json ./
# Install dependencies
RUN npm install
# Copy the rest of the UI source code
COPY ./ui/ .
# Set environment variable and build
ENV VITE_BACKEND_URL=$BACKEND_URL
RUN npm run build
# Stage 2: Python Builder
FROM python:3.11 AS python-builder
# Improve performance and prevent generation of .pyc files
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Create and activate a virtual environment, then install the dependencies
RUN pip install virtualenv && \
virtualenv /opt/venv && \
. /opt/venv/bin/activate && \
pip install -r requirements.txt
# Stage 3: Final Deployer
FROM python:3.11 AS deployer
# Copy the virtual environment from the builder stage
COPY --from=python-builder /opt/venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
# Install system dependencies
RUN apt-get update && \
apt-get install -y unixodbc-dev libgl1 && \
rm -rf /var/lib/apt/lists/*
# Set the working directory
WORKDIR /app
# Copy the rest of the application code
COPY . .
# Copy the built UI files from the UI build stage
COPY --from=ui-build /app/ui/dist ./ui/dist
COPY --from=ui-build /app/ui/dist-library ./ui/dist-library
EXPOSE 8001
CMD ["python3", "main.py", "--config", "./config.yaml", "llm"]
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2024 sirocco ventures
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: Makefile
================================================
# Define variables
POETRY = poetry
PYTHON = $(POETRY) run python
POETRY_VENV = .venv
PROJECT_DIR=./app
# Specify the directories or files to spell check
SPELLCHECK_FILES := **/*.py
# Default target
.PHONY: help
help:
@echo "Available commands:"
@echo " make install Install dependencies"
# Install dependencies
.PHONY: install
install:
$(POETRY) install
# Spellcheck target
.PHONY: spellcheck
spellcheck:
- codespell $(shell find ./app -name "*.py")
# lint check
.PHONY: lint
lint:
@echo "Running flake8..."
flake8 $(PROJECT_DIR)
================================================
FILE: README.md
================================================
<p align="center">
<a href="https://www.raggenie.com/">
<img src="https://cdn.prod.website-files.com/664e485574efd184749b7301/6658314c55210573e334ac1b_Group%2042.png" width="150" alt="RAGGENIE Logo">
</a>
</p>
<h1 align="center">
RAGGENIE
</h1>
## What is RAGGENIE
RAGGENIE is a low-code RAG builder designed to make it easy to build your own conversational AI applications. RAGGENIE out of the box pluggins where you can connect to multiple data sources and create a conversational AI on top of that, along with integrating it with pre-built agents for actions.
The project is in its early stages, and we are working on adding more capabilities soon.
• Open-source tool: Since there is some community interest in this project and we can't build all the plugins ourselves, we decided to release it under the MIT license, giving the community full freedom.
• Current focus: We are currently focused on making it easy to build RAG Application. Going forward we will be focusing on maintaince and monitoring of the RAG system as well cosidering how to help these applications to take from pilots to production.
### RAGGENIE Demo
1. Demo with database - [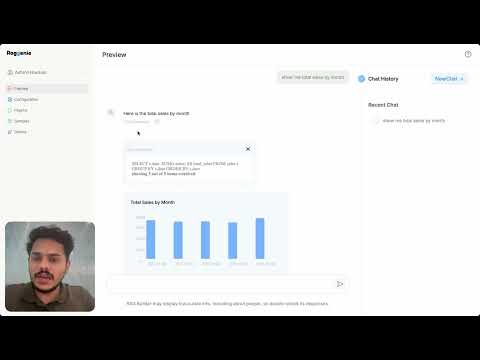](https://www.youtube.com/watch?v=7wBO6g4rj3U)
2. Demo with website data - [](https://www.youtube.com/watch?v=8h4bqqs5S3U)
## 🌎 Communities
Join our communities for product updates, support, and to stay connected with the latest from RAGGENIE!
* Join our [Slack community](https://join.slack.com/t/theailounge/shared_invite/zt-2ogkrruyf-FPOHuPr5hdqXl34bDWjHjw) <img src="https://cdn.prod.website-files.com/634fa785d369cb60d80b6dd1/6375e1774613600a91630a78_Slack_icon_2019.svg.png" width="15" alt="RAGGENIE Logo">
* Leave a star on our [GitHub](https://github.com/sirocco-ventures/raggenie) 🌟
* Report bugs with [GitHub Issues](https://github.com/sirocco-ventures/raggenie/issues) 🐞
## 📐 Architecture
![picture of Architecture flow]()
### 🔮 Supported LLM Inferences
Raggenie supports inference APIs to different LLM providers to run your model. The are the inference APIs currently supported by us:
* [OpenAI](https://openai.com/index/openai-api/)
* [Together.ai](https://www.together.ai/)
* [Ollama] (https://ollama.com/)
* [AI71] (https://ai71.ai/)
### 🗃️ Data Sources
These connectors will help you connect your data to RAG. It can handle structured or unstructured data, enabling the RAG to answer questions from these sources.
* Structured Datasources(airtable):<br />
You can use raggenie to connect to your data sources to analyse it or to intergrate it to your application. Raggenie generates queries to execute on your data sources and provides the results. Current integrations are:
* [MySQL](https://www.mysql.com/)
* [PostgreSQL](https://www.postgresql.org/)
* [Bigquery](https://cloud.google.com/bigquery)
* [Airtable] (https://www.airtable.com/)
* [MariaDB](https://mariadb.org/)
* [MSSQL] (https://www.microsoft.com/en-in/sql-server)
* [SQLite] (https://www.sqlite.org/)
* Document based sources(default):<br />
These sources allows you to load documents such as text documents or Word documents to create an AI chat application that can interact with this data. Current integrations are:
* Document loader
* CSV loader
* Website loader
### 💡Capabilities
you can have more functionalities from RAGGENIE than just as a chatbot by defining its capabilities. They can be used to do tasks such as booking a meeting, checking a calendar, or completing a form from the chat.
Capabilities of the chatbot are defined by the user at the time of configuration. You can setup parameters required for each capability.
* RAGGENIE can make sure that all the parameters are obtained for executing the capability.
* RAGGENIE uses intent extraction to decide which of its defined capabilities should be used.
* Capabilities can be used to trigger different actions.
### 🤖 Agents/Actions
RAGGENIE can do actions to accomplish tasks with user queries. These can be setup along with capabilities to make RAGGENIE more than just a coversation bot. Currently supported actions are.
* Fetch data from a database
* Insert data into database
### 🖼️ UI Plugin
This component will help you embed the chat widget into your UI with JavaScript. So that you can embeed this as a chat bot to your website or portal
## 🛠️ Getting Started
You can use RAGGENIE to create your own conversational chat feature for your application either by integrating it as a chatbot or by embedding it into your application. You can also use it to create different chatbots for different internal teams by tuning each chatbot for different tasks and using different knowledge base for different usecases.
### How to run Video
[](https://www.youtube.com/watch?v=LfCqiToOCvI)
### 📄 Documentation
Comprehensive documentation is available to help you get the most out of RAGGENIE. The full documentation for RAGGENIE can be found [here]()
### 📦 Installation and running
#### Raggenie Backend
* Installing dependencies
* **Using `requirements.txt`**
To install the required dependencies with `pip`, run:
```bash
pip install -r requirements.txt
```
* **Using Poetry**
First, install Poetry:
```bash
curl -sSL https://install.python-poetry.org | python3 -
```
Then, to install the dependencies, run:
```bash
poetry install
```
* Running Zitadel Container and Initial Setup
* **Prerequisities**
* **Docker** installed on your system.
* **Docker Compose** installed on your system.
1. Start the Zitadel container using Docker Compose:
```bash
docker-compose -f zitadel-docker-compose.yaml up -d
```
2. Once the container is running, open your browser and go to: http://localhost:8080
3. Log in using the default credentials:
- **Username:** `zitadel-admin@zitadel.localhost`
- **Password:** `Password1!`
4. Creating a Service User and downloading key file
1. Navigate to the **Users** tab.
2. Select **Service Users** and create a new service user.
3. Provide a username and name of your choice.
4. Set the **Access Token Type** to **JWT**.
5. Go to the **Keys** section and create a new key:
- Click **New**, then **Add**, and finally **Download** the key file.
5. Go to the Organization tab, click **Add a Manager** (top right), select the service user you just created, set **Org Owner** permission, and click **Add**.
6. Follow this [guide](https://zitadel.com/docs/guides/integrate/identity-providers/google) to add Google as an identity provider. Use http://localhost:8080/idps/callback as the redirect URI.
* #### Configuring Environment Variables
After downloading the key file, create an `.env` file and set the following variables:
```env
CLIENT_PRIVATE_KEY_FILE_PATH="./path/to/downloaded/key.json"
ZITADEL_TOKEN_URL="http://localhost:8080/oauth/v2/token"
ZITADEL_DOMAIN="http://localhost:8080"
```
* Running RAGGENIE backend
To run **RAGGENIE** in API mode, specify the config file to use by running the following command:
```bash
python main.py --config ./config.yaml llm
```
Below is a sample configuration for the vector database setup in `config.yaml`:
```yaml
vector_db:
name: "chroma"
params:
path: "./vector_db"
embeddings:
provider: "chroma_default"
```
This configuration ensures that the RAGGENIE system connects to the `chroma` vector database and uses the default embeddings provided by Chroma.
#### Raggenie Frontend
* Move into the ui folder
```
cd ./ui
```
* Install dependencies
```bash
npm install
```
* Running RAGGENIE Frontend
* To run **RAGGENIE** frontend, create a .env file and add the URL to backend as env variables
```env
VITE_BACKEND_URL=${BACKEND_URL}
```
* To start the server, run
```bash
npm run dev
```
* Running RAGGENIE Frontend using fast api
* Update .env file inside `./ui` folder
```env
VITE_BACKEND_URL=""
```
* To serve UI using python server first build the UI
```bash
npm run build
```
* Stop and start python server
```bash
python main.py --config ./config.yaml llm
```
for more details visit [frontend readme](./ui/README.md)
## ⛔️ Troubleshooting
If you encounter an error while running Python, please check the following
- `Your system has an unsupported version of sqlite3. Chroma requires sqlite3 >= 3.35.0`
This issue arises when the system is running a version of SQLite that is below 3.35. Chroma requires SQLite version 3.35 or higher.
Please use the following links for suggested solutions
- https://docs.trychroma.com/troubleshooting#sqlite
- https://discuss.streamlit.io/t/issues-with-chroma-and-sqlite/47950/4
- https://gist.github.com/defulmere/8b9695e415a44271061cc8e272f3c300
## 🚧 Feature Pipeline
These are the planned features and improvements that are in the pipeline for future releases.
* REST API Requests for actions
* Web hooks for actions
## 📜 License
RagGenie is licensed under the [MIT License](https://opensource.org/license/mit), which is a permissive open-source license that allows you to freely use, modify, and distribute the software with very few restrictions.
## 🤝 Contributing
Contributions are welcome! Please check the outstanding issues and feel free to open a pull request. For more information, please check out the [contribution guidelines](https://github.com/sirocco-ventures/raggenie/blob/main/CONTRIBUTING.md).
================================================
FILE: app/__init__.py
================================================
================================================
FILE: app/api/v1/auth.py
================================================
import json
import requests
from app.schemas.common import LoginData
from fastapi import APIRouter, Depends, Response, Request, HTTPException, status
from fastapi.responses import RedirectResponse, JSONResponse
from app.providers.config import configs
from app.providers.zitadel import Zitadel
from app.schemas.common import CommonResponse
from app.providers.middleware import verify_token
import app.services.user as svc
import app.schemas.user as schemas
from app.utils.database import get_db
from sqlalchemy.orm import Session
import app.api.v1.commons as commons
login = APIRouter()
if configs.auth_enabled:
zitadel = Zitadel()
@login.post("/login")
def login_user(response: Response, user: LoginData, db: Session = Depends(get_db)):
login_response = zitadel.login_with_username_password(user.username, user.password)
# Extract user_id from the respons e
if login_response.status_code == 201:
response_data = login_response.body.decode("utf-8")
response_json = json.loads(response_data)
user_id = response_json.get("user_id")
username = response_json.get("username")
user, error = svc.get_or_create_user(schemas.UserCreate(id=int(user_id), username=username), db)
if error:
return commons.is_error_response("DB Error", error, {"user": {}})
return login_response
# will redirect to idp when called with ipdId
# need to set successurl and failureUrl dynamically *****
@login.get("/login/idp/{idp_id}")
def idp_login(response: Response, idp_id : int):
return zitadel.redirect_to_idp(idp_id)
# if idp login is success then is redirected to this endpoint with which we get the user
# details from the idp (currently only tested with google)
@login.get("/idp/success")
def idp_success(request: Request,db: Session = Depends(get_db)):
query_params = request.query_params
idp_intent_id = query_params.get("id")
idp_token = query_params.get("token")
if not idp_intent_id or not idp_token:
return commons.is_error_response("Missing required parameters", {}, {"user": {}})
user_id = query_params.get("user")
try:
response = zitadel.get_idp_intent_data(idp_intent_id, idp_token)
user_data = response.json()
username = user_data.get("idpInformation", {}).get("rawInformation", {}).get("User", {}).get("name", "")
if(user_id):
user, error = svc.get_or_create_user(schemas.UserCreate(id=int(user_id), username=username), db)
session_response = zitadel.create_user_session(user_id, idp_intent_id, idp_token)
else:
session_response = zitadel.create_user(user_data, idp_intent_id, idp_token)
if session_response.status_code != 201:
return commons.is_error_response("Failed to create Zitadel user", session_response.body.decode("utf-8"), {"user": {}})
response_data = json.loads(session_response.body.decode("utf-8"))
zitadel_user_id = response_data.get("user_id")
new_user = schemas.UserCreate(
id=int(zitadel_user_id),
username=username,
)
result, error = svc.get_or_create_user(new_user, db)
if error:
return commons.is_error_response("DB Error", error, {"user": {}})
if not result:
return commons.is_none_reponse("User Not Created", {"user": {}})
if session_response.status_code == 201:
redirect_response = RedirectResponse(url="/ui", status_code=303)
# Copy cookies from session_response to redirect_response
for cookie in session_response.headers.getlist("set-cookie"):
redirect_response.headers.append("set-cookie", cookie)
return redirect_response
return session_response
except (requests.exceptions.RequestException, json.JSONDecodeError, AttributeError) as e:
return {"error": "Failed to create session", "details": str(e)}, 500
# endpoint to retreive all the available idp providers that is setup in Zitadel
@login.get("/idp/list")
def list_idp(response: Response):
return zitadel.list_idp_providers()
@login.get("/user_info", dependencies=[Depends(verify_token)])
def get_user_info(request: Request, db: Session = Depends(get_db), user_data: dict = Depends(verify_token)):
if user_data.get("username") == 'Admin':
new_user = schemas.UserCreate(
id=int(user_data.get("user_id")),
username=user_data.get("username"),
)
result, error = svc.get_or_create_user(new_user, db)
if error:
return commons.is_error_response("DB Error", error, {"user": {}})
if not result:
return commons.is_none_reponse("User Not Created", {"user": {}})
env_id, error = svc.get_users_active_env(user_data.get("user_id"), db)
if error:
return commons.is_error_response("DB Error", error, {"env": {}})
return CommonResponse(
status=True,
status_code=200,
message="User info retrieved successfully",
data={ "username": user_data['username'], "auth_enabled": configs.auth_enabled, "env_id": env_id },
error=None
)
session_id = user_data["session_id"]
user_info = zitadel.get_user_info(session_id)
username = user_info.get("session").get("factors").get("user").get("displayName")
user_id = user_info.get("session").get("factors").get("user").get("id")
env_id, error = svc.get_users_active_env(user_id, db)
if error:
return commons.is_error_response("DB Error", error, {"env": {}})
return CommonResponse(
status=True,
status_code=200,
message="User info retrieved successfully",
data={ "username": username, "auth_enabled": configs.auth_enabled, "env_id": env_id },
error=None
)
# change to get user info from raggenie.db
@login.post("/logout",dependencies=[Depends(verify_token)])
def logout_user(response: Response, user_data: dict = Depends(verify_token)):
session_id = user_data["session_id"]
res = zitadel.logout_user(session_id)
if res.status_code == 200:
response.delete_cookie("session_data")
return res
================================================
FILE: app/api/v1/commons.py
================================================
import app.schemas.common as resp_schemas
def is_error_response(message:str, err:str, data:dict):
return resp_schemas.CommonResponse(
status= False,
status_code=422,
message=message,
data=data,
error=err
)
def is_none_reponse(message:str, data:dict):
return resp_schemas.CommonResponse(
status= True,
status_code=200,
message=message,
data=data,
error="Not Found"
)
================================================
FILE: app/api/v1/connector.py
================================================
from typing import List, Optional
from app.providers.cache_manager import cache_manager
from fastapi import APIRouter, Depends
from sqlalchemy.orm import Session
import app.schemas.connector as schemas
import app.schemas.common as resp_schemas
from app.utils.database import get_db
import app.services.connector as svc
import app.services.provider as provider_svc
from starlette.requests import Request
from fastapi import APIRouter, UploadFile, File
from app.chain.chains.capability_chain import CapabilityChain
from app.chain.chains.metadata_chain import MetadataChain
from app.chain.chains.query_chain import QueryChain
from app.chain.chains.intent_chain import IntentChain
from app.chain.chains.general_chain import GeneralChain
import app.api.v1.commons as commons
from loguru import logger
from app.providers.config import configs
from app.providers.middleware import verify_token
import copy
router = APIRouter()
cap_router = APIRouter()
inference_router = APIRouter()
actions = APIRouter()
@router.get("/list", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def list_connectors(db: Session = Depends(get_db), provider_category_ids: Optional[List[int]] = None, user_data: dict = Depends(verify_token)):
"""
Retrieves a list of all connectors from the database. If a provider category ID is provided, only connectors from that category are returned.
Args:
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing either the list of connectors or an error message.
"""
user_id = user_data["user_id"]
if provider_category_ids:
result, error = svc.list_connectors_by_provider_category(provider_category_ids, db, user_id)
else:
result, error = svc.list_connectors(db, user_id)
if error:
return commons.is_error_response("DB Error", result, {"connectors": []})
if not result:
return commons.is_none_reponse("Connector Not Found", {"connectors": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"connectors": result},
message="Connectors Found",
error=None
)
@router.get("/get/{connector_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_connector(connector_id: int, db: Session = Depends(get_db)):
"""
Retrieves a specific connector by its ID from the database.
Args:
connector_id (int): The ID of the connector.
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing either the connector details or an error message.
"""
result, error = svc.get_connector(connector_id, db)
if error:
return commons.is_error_response("DB Error", result, {"connector": {}})
if not result:
return commons.is_none_reponse("Connector Not Found", {"connector": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"connector": result},
message="Connector Found",
error=None
)
@router.post("/upload/datasource", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
async def upload_document_datsource(
file: UploadFile = File(...)
):
"""
Uploads an document data source file to the server.
Args:
file (UploadFile): The uploaded document file. Accepted formats are .pdf, .txt, .yaml, and .docx.
Returns:
CommonResponse: A response containing the file upload status, file details, or an error message.
"""
error, size = await svc.fileValidation(file)
if error:
return commons.is_error_response("Invalid File", error, {"file_path": None})
result, error = await svc.upload_pdf(file)
if error:
return commons.is_error_response("document not uploaded", error, {"file_path": None})
return resp_schemas.CommonResponse(
status=True,
status_code=201,
data={"file": {"file_path": result["file_path"],"file_name": file.filename, "file_size":f"{round(size / (1024 * 1024), 2)}MB", "file_id": result["file_id"]}},
message="File Uploaded Success",
error=None
)
@router.post("/create", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def create_connector(connector: schemas.ConnectorBase, db: Session = Depends(get_db), user_data: dict = Depends(verify_token)):
"""
Creates a new connector in the database.
Args:
connector (ConnectorBase): The data for the new connector.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating success or failure of the connector creation process.
"""
user_id = user_data["user_id"]
result, error = svc.create_connector(connector, db, user_id)
if error:
return commons.is_error_response("Connector Not Created", error, {"connector": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=201,
data={"connector": result},
message="Connector Created",
error=None
)
@router.post("/update/{connector_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def update_connector(connector_id: int, connector: schemas.ConnectorUpdate, db: Session = Depends(get_db)):
"""
Updates an existing connector based on its ID.
Args:
connector_id (int): The ID of the connector to update.
connector (ConnectorUpdate): The updated data for the connector.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating success or failure of the update process.
"""
result, error = svc.update_connector(connector_id, connector, db)
if error:
return commons.is_error_response("DB Error", result, {"connector": {}})
if not result:
return commons.is_none_reponse("Connector Not Found", {"connector": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"connector": result},
message="Connector Updated",
error=None
)
@router.post("/delete/{connector_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def delete_connector(connector_id: int, db: Session = Depends(get_db)):
"""
Deletes a connector from the database based on its ID.
Args:
connector_id (int): The ID of the connector to delete.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating success or failure of the deletion process.
"""
result, error = svc.delete_connector(connector_id, db)
if error:
return commons.is_error_response("DB Error", result, {"connector": {}})
if not result:
return commons.is_none_reponse("Connector Not Found", {"connector": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"connector": result},
message="Connector Deleted",
error=None
)
@router.post("/schema/update/{connector_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def updateschemas(connector_id: int, connector: schemas.SchemaUpdate, db: Session = Depends(get_db)):
"""
Updates the schema details of a connector based on its ID.
Args:
connector_id (int): The ID of the connector whose schema is being updated.
connector (SchemaUpdate): The schema update data for the connector.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating success or failure of the schema update.
"""
result, error = svc.updateschemas(connector_id, connector, db)
if error:
return commons.is_error_response("DB Error", result, {"schemas": {}})
if not result:
return commons.is_none_reponse("Connector Not Found", {"schemas": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"schemas": result},
message="Schema Updated",
error=None
)
@router.get("/configuration/list", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def list_configurations(db: Session = Depends(get_db), user_data: dict = Depends(verify_token)):
"""
Lists all available configurations from the database.
Args:
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing the list of configurations or an error message.
"""
user_id = user_data["user_id"]
result, error = svc.list_configurations(db, user_id)
if error:
return commons.is_error_response("DB error", result, {"configurations": []})
if not result:
return commons.is_none_reponse("Configurations Not Found", {"configurations": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Configurations retrieved successfully",
error=None,
data={"configurations": result}
)
@router.get("/configuration/{config_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_configuration(config_id: int, db: Session = Depends(get_db)):
"""
Retrieves a configuration by its ID.
Args:
config_id (int): ID of the configuration to retrieve.
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing the configuration or an error message.
"""
result, error = svc.get_configuration(db, config_id)
if error == "DB Error":
return commons.is_error_response("DB error", result, {"configuration": None})
if error == "Configuration not found":
return commons.is_none_reponse("Configuration Not Found", {"configuration": None})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Configuration retrieved successfully",
error=None,
data={"configuration": result}
)
@router.delete("/configuration/{config_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_configuration(config_id: int, db: Session = Depends(get_db)):
"""
Retrieves a configuration by its ID.
Args:
config_id (int): ID of the configuration to retrieve.
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing the configuration or an error message.
"""
result, error = svc.delete_configuration(db, config_id)
if error == "DB Error":
return commons.is_error_response("DB error", result, {"configuration": None})
if error == "Configuration not found":
return commons.is_none_reponse("Configuration Not Found", {"configuration": None})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Configuration deleted successfully",
error=None,
data={"configuration": result}
)
@router.post("/configuration/create", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def create_configuration(configuration: schemas.ConfigurationCreation, db: Session = Depends(get_db), user_data: dict = Depends(verify_token)):
"""
Creates a new configuration and stores it in the database.
Args:
configuration (ConfigurationCreation): The new configuration details.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the configuration creation.
"""
user_id = user_data["user_id"]
result, error = svc.create_configuration(configuration, db, user_id)
if error:
return commons.is_error_response("DB error", result, {"configuration": []})
if not result:
return commons.is_none_reponse("Configuration Not Found", {"configuration": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=201,
message="Configuration created successfully",
error=None,
data={"configuration": result}
)
@router.post("/configuration/update/{config_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def update_configuration(config_id: int, configuration: schemas.ConfigurationUpdate, db: Session = Depends(get_db)):
"""
Updates an existing configuration in the database.
Args:
config_id (int): The ID of the configuration to update.
configuration (ConfigurationUpdate): The updated configuration details.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the configuration update.
"""
result, error = svc.update_configuration(config_id, configuration, db)
if error:
return commons.is_error_response("DB error", result, {"configuration": []})
if not result:
return commons.is_none_reponse("Configuration Not Found", {"configuration": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Configuration updated successfully",
error=None,
data={"configuration": result}
)
@cap_router.post("/create", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def create_capability(capability: schemas.CapabilitiesBase, db: Session = Depends(get_db)):
"""
Creates a new capability in the database.
Args:
capability (CapabilitiesBase): The new capability details.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the capability creation.
"""
result, error = svc.create_capabilities(capability, db)
if error:
return commons.is_error_response("DB error", result, {"capability": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=201,
message="Capabilities created successfully",
error=None,
data={"capability": result}
)
@cap_router.get("/all", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_all_capabilities(db: Session = Depends(get_db)):
"""
Retrieves all capabilities from the database.
Args:
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing the list of capabilities or an error message.
"""
result, error = svc.get_all_capabilities(db)
if error:
return commons.is_error_response("DB error", result, {"capabilities": []})
if not result:
return commons.is_none_reponse("Capabilities Not Found", {"capabilities": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Capabilities retrieved successfully",
error=None,
data={"capabilities": result}
)
@cap_router.post("/update/{cap_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def update_capability(cap_id: int, capability: schemas.CapabilitiesUpdateBase, db: Session = Depends(get_db)):
"""
Updates an existing capability in the database.
Args:
cap_id (int): The ID of the capability to update.
capability (CapabilitiesUpdateBase): The updated capability details.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the capability update.
"""
result, error = svc.update_capability(cap_id, capability, db)
if error:
return commons.is_error_response("DB error", result, {"capability": {}})
if not result:
return commons.is_none_reponse("Capability Not Found", {"capability": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Capability updated successfully",
error=None,
data={"capability": result}
)
@cap_router.delete("/delete/{cap_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def delete_capability(cap_id: int, db: Session = Depends(get_db)):
"""
Deletes an existing capability from the database.
Args:
cap_id (int): The ID of the capability to delete.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the capability deletion.
"""
result, error = svc.delete_capability(cap_id, db)
if error:
return commons.is_error_response("DB error", result, {"capability": {}})
if not result:
return commons.is_none_reponse("Capability Not Found", {"capability": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Capability deleted successfully",
error=None,
data={"capability": {}}
)
@router.post("/createyaml/{config_id}", dependencies=[Depends(verify_token)])
def create_yaml(request: Request, config_id: int, db: Session = Depends(get_db), index: Optional[bool] = True):
"""
Creates a YAML configuration file and initializes processing chains for the specified configuration.
Args:
request (Request): The request object containing the data for YAML creation.
config_id (int): The ID of the configuration to use.
db (Session): The database session dependency.
Returns:
dict: A dictionary with success status and error message, if any.
"""
documentations, use_case, is_error = svc.create_yaml_file(request,config_id, db)
if is_error:
return {
"success":False,
"error":is_error
}
inference_config, is_error = svc.create_inference_yaml(config_id,db)
if is_error and not inference_config:
return {
"success":False,
"error":is_error
}
combined_yaml_content = {
'datasources': documentations if documentations != None else [],
'use_case': use_case
}
configs.inference_llm_model=inference_config[0]["unique_name"]
config = copy.deepcopy(request.app.config)
vector_store, is_error = provider_svc.create_vectorstore_instance(db, config_id)
if vector_store:
vector_store.connect()
context_storage = request.app.context_storage
data_sources = combined_yaml_content["datasources"]
use_case = combined_yaml_content["use_case"]
config["use_case"] = use_case
config["datasources"] = data_sources
config["models"] = inference_config
confyaml = svc.get_inference_and_plugin_configurations(db, config_id)
request.app.container.config.from_dict(confyaml)
datasources = request.app.container.datasources()
mappings = confyaml.get("mappings",{})
datasources, err = svc.update_datasource_documentations(db, vector_store, datasources, mappings, config_id, index)
if err:
logger.error("Error updating")
query_chain = QueryChain(config, vector_store, datasources, context_storage)
general_chain = GeneralChain(config, vector_store, datasources, context_storage)
capability_chain = CapabilityChain(config, context_storage, query_chain)
metedata_chain = MetadataChain(config, vector_store, datasources, context_storage)
chain = IntentChain(config, vector_store, datasources, context_storage, query_chain, general_chain, capability_chain, metedata_chain)
cache_manager.set(config_id, {
"chain": chain,
"config": config,
"vector_store": vector_store,
"datasources": datasources,
"context_storage": context_storage
})
return {
"success": True,
"error":None
}
@inference_router.post("/get/models", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_llm_provider_models(llm_provider: schemas.LLMProviderBase):
"""
Retrieves the models associated with the specified LLM provider.
Args:
llm_provider (schemas.LLMProviderBase): The details of the LLM provider.
db (Session): The database session dependency.
Returns:
CommonResponse: A response containing the list of LLM provider models or an error message.
"""
data, is_error = svc.get_llm_provider_models(llm_provider)
if is_error:
return commons.is_error_response("LLM Provider Models Not Found", data, {"provider_models": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="LLM Provider Models Found",
error=None,
data={"provider_models": [data]}
)
@inference_router.get("/get/{inference_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_inference(inference_id: int, db: Session = Depends(get_db)):
"""
Retrieves an inference record from the database using the given inference ID.
Args:
inference_id (int): The ID of the inference record to retrieve.
db (Session): The database session dependency.
Returns:
dict: A dictionary with the inference details or error message, if any.
"""
result, error = svc.get_inference(inference_id, db)
if error:
return commons.is_error_response("DB error", result, {"inference": {}})
if not result:
return commons.is_none_reponse("Inference Not Found", {"inference": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Inference Found",
error=None,
data={"inference": result}
)
@inference_router.post("/create", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def create_inference(inference: schemas.InferenceBase, db: Session = Depends(get_db)):
"""
Creates a new inference record in the database.
Args:
inference (schemas.InferenceBase): The details of the inference to be created.
db (Session): The database session dependency.
Returns:
dict: A dictionary indicating the success of the operation and the created inference details or error message.
"""
success, message = provider_svc.test_inference_credentials(inference)
if not success:
return commons.is_error_response("Test Credentials Failed", message, {"inference": {}})
result, error = svc.create_inference(inference, db)
if error:
return commons.is_error_response("DB error", result, {"inference": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=201,
message="Inference Created Successfully",
error=None,
data={"inference": result}
)
@inference_router.post("/update/{inference_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def update_inference(inference_id: int, inference: schemas.InferenceBaseUpdate, db: Session = Depends(get_db)):
"""
Updates an existing inference record in the database.
Args:
inference_id (int): The ID of the inference record to update.
inference (schemas.InferenceBaseUpdate): The updated details of the inference.
db (Session): The database session dependency.
Returns:
dict: A dictionary with the status of the update operation and the updated inference details or error message, if any.
"""
success, message = provider_svc.test_inference_credentials(inference)
if not success:
return commons.is_error_response("Test Credentials Failed", message, {"inference": {}})
result, error = svc.update_inference(inference_id, inference, db)
if error:
return commons.is_error_response("DB error", result, {"inference": {}})
if not result:
return commons.is_none_reponse("Inference Not Found", {"inference": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Inference Updated Successfully",
error=None,
data={"inference": result}
)
@actions.get("/list", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def list_actions(db: Session = Depends(get_db)):
"""
Retrieves all actions from the database.
Args:
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing the list of actions or an error message.
"""
result, error = svc.list_actions(db)
if error:
return commons.is_error_response("DB error", result, {"actions": []})
if not result:
return commons.is_none_reponse("Actions Not Found", {"actions": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"actions": result},
message="Actions Found",
error=None
)
@actions.get("/get/{action_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_action(action_id:int, db: Session = Depends(get_db)):
"""
Retrieves a specific action by its ID.
Args:
action_id (int): The unique identifier of the action to retrieve.
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing the action details or an error message.
"""
result, error = svc.get_actions(action_id,db)
if error:
return commons.is_error_response("DB error", result, {"action": {}})
if not result:
return commons.is_none_reponse("Action Not Found", {"action": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"action": result},
message="Action Found",
error=None
)
@actions.get("/{connector_id}/list", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_actions_by_connector(connector_id:int, db: Session = Depends(get_db)):
"""
Retrieves all actions related to a specific connector by its ID.
Args:
connector_id (int): The unique identifier of the connector.
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing the list of actions or an error message.
"""
result, error = svc.get_actions_by_connector(connector_id,db)
if error:
return commons.is_error_response("DB error", result, {"actions": []})
if not result:
return commons.is_none_reponse("Actions Not Found", {"actions": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"actions": result},
message="Action Found",
error=None
)
@actions.post("/create", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def create_action(action: schemas.Actions, db: Session = Depends(get_db)):
"""
Creates a new action in the database.
Args:
action (Actions): The schema containing action details to create.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the action creation.
"""
result, error = svc.create_action(action, db)
if error:
return commons.is_error_response("Action Not Created", result, {"action": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=201,
data={"action": result},
message="Action Created",
error=None
)
@actions.post("/update/{action_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def update_action(action_id: int, action: schemas.ActionsUpdate, db: Session = Depends(get_db)):
"""
Updates an existing action in the database by its ID.
Args:
action_id (int): The unique identifier of the action to update.
action (ActionsUpdate): The schema containing updated action details.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the action update.
"""
result, error = svc.update_action(action_id, action, db)
if error:
return commons.is_error_response("DB error", result, {"action": {}})
if not result:
return commons.is_none_reponse("Action Not Found", {"action": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"action": result},
message="Action Updated",
error=None
)
@actions.post("/{action_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def delete_action(action_id: int, db: Session = Depends(get_db)):
"""
Deletes an action by its ID from the database.
Args:
action_id (int): The unique identifier of the action to delete.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the action deletion.
"""
result, error = svc.delete_action(action_id, db)
if error:
return commons.is_error_response("DB error", result, {"action": {}})
if not result:
return commons.is_none_reponse("Action Not Found", {"action": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"action": result},
message="Action Deleted",
error=None
)
================================================
FILE: app/api/v1/llmchat.py
================================================
# src/endpoints/chat.py
from fastapi import APIRouter, Depends
from sqlalchemy.orm import Session
import app.schemas.common as resp_schemas
from app.schemas import llmchat as schemas
from app.utils.database import get_db
from app.services import llmchat as svc
import app.api.v1.commons as commons
chat_router = APIRouter()
# Create a new chat
@chat_router.post("/create", response_model=resp_schemas.CommonResponse)
def create_chat(chat: schemas.ChatHistoryCreate, db: Session = Depends(get_db)):
"""
Creates a new chat record in the database.
Args:
chat (ChatHistoryCreate): The data for the new chat entry.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating success or failure of the chat creation process.
"""
result, error = svc.create_chat(chat, db)
if error:
return commons.is_error_response("DB Error", result, {"chat": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=201,
data={"chat": result},
message="Chat created successfully",
error=None
)
# Create feedback for a chat
@chat_router.post("/feedback/create", response_model=resp_schemas.CommonResponse)
def create_feedback(feedback: schemas.FeedbackCreate, db: Session = Depends(get_db)):
"""
Creates feedback for an existing chat record.
Args:
feedback (FeedbackCreate): The feedback data to be added to the chat.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating success or failure of the feedback creation process.
"""
result, error = svc.create_feedback(feedback, db)
if error:
return commons.is_error_response("DB Error", result, {"chat": {}})
if not result:
return commons.is_none_reponse("Chat Not Found", {"chat": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"chat": result},
message="Feedback updated successfully",
error=None
)
# List the primary chat based on context
@chat_router.get("/list/context/all/{env_id}", response_model=resp_schemas.CommonResponse)
def list_chat_by_context(env_id: int, db: Session = Depends(get_db)):
"""
Retrieves all the primary chats based on context from the database.
Args:
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing either the list of primary chats or an error message.
"""
result, error = svc.list_chats_by_context(env_id, db)
if error:
return commons.is_error_response("DB Error", error, {"chats": []})
if not result:
return commons.is_none_reponse("Context Not found", {"chats": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"chats": result},
message="Primary chats found",
error=None
)
# Get a specific chat by context ID
@chat_router.get("/get/{context_id}", response_model=resp_schemas.CommonResponse)
def get_chat_by_context(context_id: str, db: Session = Depends(get_db)):
"""
Retrieves a specific chat by context ID from the database.
Args:
context_id (str): The ID of the context to retrieve the chat for.
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing either the chat data or an error message.
"""
result, error = svc.list_all_chats_by_context_id(context_id, db)
if error:
return commons.is_error_response("DB Error", error, {"chats": []})
if not result:
return commons.is_none_reponse("Chat not found", {"chats": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"chats": result},
message="Chat found",
error=None
)
================================================
FILE: app/api/v1/main_router.py
================================================
from app.providers.cache_manager import cache_manager
from fastapi import APIRouter, Depends, status, Query
from fastapi.encoders import jsonable_encoder
from app.models.request import Chat, FeedbackCorrectionRequest
from starlette.requests import Request
from loguru import logger
from app.schemas import llmchat as schemas
from app.api.v1 import llmchat
from app.api.v1 import connector
from sqlalchemy.orm import Session
from app.utils.database import get_db
MainRouter = APIRouter()
@MainRouter.post("/query", status_code=status.HTTP_201_CREATED)
async def qna(
query: Chat,
request: Request,
context_id: str = Query(..., alias="contextId"),
config_id: str = Query(..., alias="configId"),
env_id: str = Query(..., alias="envId"),
db: Session = Depends(get_db)
):
"""
Handles user queries and invokes the chain to get an answer from the LLM.
Args:
query (Chat): User query as a Chat model.
request (Request): FastAPI request object containing context and app-level dependencies.
background_tasks (BackgroundTasks): Background task for asynchronous logging.
db (Session): Database session dependency.
Returns:
dict: Response containing the answer to the user's query and the original query text.
"""
logger.info(f"{context_id} - {config_id} - query: {query.content}")
cached_data = cache_manager.get(int(config_id))
if not cached_data:
logger.info("configuration was not found in the cache")
response = connector.create_yaml(request, int(config_id), db, False)
if response['success'] == True:
cached_data = cache_manager.get(int(config_id))
else:
return
chain = cached_data["chain"]
vector_store = cached_data['vector_store']
request.app.chain = chain
request.app.vector_store = vector_store
out = await chain.invoke({
"question": query.content,
"context_id": context_id,
})
resp = llmchat.create_chat(
schemas.ChatHistoryCreate(
chat_context_id=context_id,
chat_query=query.content,
chat_answer= jsonable_encoder(out),
chat_summary=out.get("summary", query.content),
configuration_id=config_id,
environment_id=env_id
),
db
)
if resp.status:
out["chat_id"] = resp.data["chat"].chat_id
return {
"response": out,
"query": query.content,
}
#! This api is not in use right now, instead we are using a scheduler for the feedback_correction job
@MainRouter.post("/feedback_correction", status_code=status.HTTP_201_CREATED)
def feedback_correction(request: Request, body: FeedbackCorrectionRequest):
"""
Processes feedback from LLM responses and updates the vector store accordingly.
Args:
request (Request): FastAPI request object containing the app's vector store.
body (FeedbackCorrectionRequest): Request body containing user feedback to be processed.
Returns:
str: Success message indicating the feedback processing outcome.
"""
store = request.app.vector_store
if body.responses:
for response in body.responses:
similar_sample = store.find_similar_samples(response.description)
if len(similar_sample) > 0 and similar_sample[0]['distances'] < 0.3:
store.update_store(similar_sample[0]['id'],response.metadata,response.description)
else:
store.update_store(metadatas = response.metadata,documents = response.description)
return "Success: Feedback received and processed."
else:
return "Success: No Feedback received and processed."
================================================
FILE: app/api/v1/provider.py
================================================
from fastapi import APIRouter, Depends
from sqlalchemy.orm import Session
import app.schemas.common as resp_schemas
import app.schemas.provider as schemas
from app.utils.database import get_db
import app.services.provider as svc
import app.api.v1.commons as commons
import app.schemas.connector as conn_schemas
from fastapi import Request
from app.providers.middleware import verify_token
router = APIRouter()
sample = APIRouter()
vectordb = APIRouter()
@router.get("/list", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def list_providers(db: Session = Depends(get_db)):
"""
Retrieves a list of providers (plugins) from the database.
Args:
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing either the list of providers or an error message.
"""
result, error = svc.list_providers(db)
if error:
return commons.is_error_response("DB error", result, {"providers": []})
if not result:
return commons.is_none_reponse("Providers Not Found", {"providers": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"providers": result},
message="Providers Found",
error=None
)
@router.get("/get/{provider_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_provider(provider_id: int, db: Session = Depends(get_db)):
"""
Retrieves a specific provider (plugin) by its ID.
Args:
provider_id (int): The ID of the provider to retrieve.
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing either the provider details or an error message.
"""
result, error=svc.get_provider(provider_id, db)
if error:
return commons.is_error_response("DB error", result, {"provider": {}})
if not result:
return commons.is_none_reponse("Providers Not Found", {"provider": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"provider": result},
message="Provider Found",
error=None
)
@router.post("/{provider_id}/test-credentials", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def test_connections(provider_id: int, config: schemas.TestCredentials, db: Session = Depends(get_db)):
"""
Tests the credentials for a specific provider (plugin) by its ID.
Args:
provider_id (int): The ID of the provider for which to test credentials.
config (TestCredentials): The credentials to test.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the credential test.
"""
success, message = svc.test_credentials(provider_id, config, db)
if not success:
return resp_schemas.CommonResponse(
status=False,
status_code=422,
message=message,
error=message,
)
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message=message,
error=None,
)
@vectordb.post("/test_credentials", response_model=resp_schemas.CommonResponse)
def test_vectordb_credentials(config: schemas.TestVectorDBCredentials, db: Session = Depends(get_db)):
"""
Tests the credentials for a VectorDB provider.
Args:
config (TestVectorDBCredentials): The credentials to test.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the credential test.
"""
message, is_error = svc.test_vectordb_credentials(config, db)
if is_error:
return resp_schemas.CommonResponse(
status=False,
status_code=422,
message="Test credentials Failed",
error=message,
)
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message=message,
error=None,
)
@vectordb.get("/list/all",response_model= resp_schemas.CommonResponse)
def getvectordbs(db: Session = Depends(get_db)):
"""
Retrieves a list of available VectorDB providers.
Args:
request (Request): The HTTP request object.
Returns:
CommonResponse: A response containing either the list of VectorDB providers or an error message.
"""
result, is_error = svc.getvectordbs(db)
if is_error:
return commons.is_error_response("DB error", result, {"vectordbs": []})
if not result:
return commons.is_none_reponse("Sample SQL Not Found", {"vectordbs": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="VectorDB providers found",
data={"vectordbs":result},
error=None,
)
@router.get("/llmproviders", response_model=resp_schemas.CommonResponse)
def getllmproviders(request: Request):
"""
Retrieves a list of available LLM (Large Language Model) providers.
Args:
request (Request): The HTTP request object.
Returns:
CommonResponse: A response containing either the list of LLM providers or an error message.
"""
result, is_error = svc.getllmproviders(request)
if is_error:
return resp_schemas.CommonResponse(
status=False,
status_code=422,
message="LLM providers not found",
error=None,
)
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="LLM providers found",
data=result,
error=None,
)
@router.post("/test-inference-credentials", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def test_inference_connections(inference: conn_schemas.InferenceBase):
"""
Tests the inference connections by validating the credentials for a specific LLM provider.
Args:
inference (conn_schemas.InferenceBase):
Configuration object containing the provider details, including model name, API key, and endpoint, for testing the connections.
Returns:
resp_schemas.CommonResponse:
- Response object containing:
- status (bool): Indicates whether the credentials validation was successful.
- status_code (int): HTTP status code (200 for success, 422 for failure).
- message (str): A message providing the outcome of the credentials test.
- error (Optional[str]): Error message if the credentials test failed, otherwise None.
"""
success, message = svc.test_inference_credentials(inference)
if not success:
return resp_schemas.CommonResponse(
status=False,
status_code=422,
message="Test Credentials Failed",
error=message,
)
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message=message,
error=None,
)
@sample.get("/list", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def list_sql(db: Session = Depends(get_db), user_data: dict = Depends(verify_token)):
"""
Retrieves a list of sample SQL records from the database.
Args:
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing either the list of sample SQL records or an error message.
"""
user_id = user_data["user_id"]
result, error = svc.listsql(db, user_id)
if error:
return commons.is_error_response("DB error", result, {"sql": []})
if not result:
return commons.is_none_reponse("Sample SQL Not Found", {"sql": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"sql": result},
message="Sample SQL Found",
error=None
)
@sample.get("/{id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_sql(id: int, db: Session = Depends(get_db)):
"""
Retrieves a specific sample SQL record by its ID.
Args:
id (int): The ID of the sample SQL record to retrieve.
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing either the SQL record or an error message.
"""
result, error = svc.getsql(id, db)
if error:
return commons.is_error_response("DB error", result, {"sql": {}})
if not result:
return commons.is_none_reponse("Sample SQL Not Found", {"sql": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
data={"sql": result},
message="Sample SQL Found",
error=None
)
@sample.post("/create", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def create_sql(request:Request,sql: schemas.SampleSQLBase, db: Session = Depends(get_db), user_data: dict = Depends(verify_token)):
"""
Creates a new sample SQL record in the database.
Args:
request (Request): The HTTP request object.
sql (SampleSQLBase): The data for the new SQL record.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the SQL creation process.
"""
user_id = user_data["user_id"]
result, error = svc.create_sql(request, sql, db, user_id)
if error:
return commons.is_error_response("DB error", result, {"sql": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=201,
message="Sample SQL Created Successfully",
error=None,
data={"SQL": result}
)
@sample.post("/update/{id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def update_sql(id: int, request: Request, sql: schemas.SampleSQLUpdate, db: Session = Depends(get_db)):
"""
Updates an existing sample SQL record by its ID.
Args:
id (int): The ID of the SQL record to update.
request (Request): The HTTP request object.
sql (SampleSQLUpdate): The updated SQL data.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the SQL update process.
"""
result, error = svc.update_sql(request, id, sql, db)
if error:
return commons.is_error_response("DB error", result, {"sql": {}})
if not result:
return commons.is_none_reponse("Sample SQL Not Found", {"sql": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Sample SQL Updated Successfully",
error=None,
data={"sql": result}
)
@sample.post("delete/{id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def delete_sql(id: int, db: Session = Depends(get_db)):
"""
Deletes a sample SQL record by its ID.
Args:
id (int): The ID of the SQL record to delete.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the SQL deletion process.
"""
result, error = svc.delete_sql(id, db)
if error:
return commons.is_error_response("DB error", result, {"sql": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Sample SQL Deleted Successfully",
error=None,
)
@vectordb.post("/create", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def create_vectordb_instance(vectordb: schemas.VectorDBBase, db: Session = Depends(get_db)):
"""
Creates a new VectorDB instance in the database.
Args:
request (Request): The HTTP request object.
sql (VectorDBBase): The data for the new VectorDB instance.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the VectorDB instance creation process.
"""
result, error = svc.create_vectordb_and_embedding("create",0,vectordb, db)
if error:
return commons.is_error_response("DB error", result, {"vectordb": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=201,
message="VectorDB Instance Created Successfully",
error=None,
data={"VectorDB": result}
)
@vectordb.post("/update/{id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def update_vectordb_instance(id:int,vectordb: schemas.VectorDBUpdateBase, db: Session = Depends(get_db)):
"""
Updates VectorDB instance in the database.
Args:
request (Request): The HTTP request object.
sql (VectorDBBase): The data for the new VectorDB instance.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the VectorDB instance creation process.
"""
result, error = svc.create_vectordb_and_embedding(key="update",id=id,vectordb=vectordb, db=db)
if error:
return commons.is_error_response("DB error", result, {"vectordb": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=201,
message="VectorDB Instance Updated Successfully",
error=None,
data={"VectorDB": result}
)
@vectordb.get("/get/{config_id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_vectordb_instance(id: int, db: Session = Depends(get_db)):
"""
Retrieves a VectorDB instance by its ID.
Args:
id (int): The ID of the VectorDB instance.
db (Session): Database session dependency.
Returns:
CommonResponse: A response containing the VectorDB instance or an error message.
"""
result, error = svc.get_vectordb_instance(id, db)
if error:
return commons.is_error_response("DB error", result, {"vectordb": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="VectorDB Instance Retrieved Successfully",
error=None,
data={"VectorDB": result}
)
@vectordb.delete("/delete/{id}", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def delete_vectordb_instance(id: int, db: Session = Depends(get_db)):
"""
Deletes a VectorDB instance by its ID, along with its associated config mapping.
Args:
id (int): The ID of the VectorDB instance to delete.
db (Session): Database session dependency.
Returns:
CommonResponse: A response indicating the success or failure of the deletion process.
"""
result, error = svc.delete_vectordb_instance(id, db)
if error:
return commons.is_error_response("DB error or VectorDB not found", result, {"vectordb": {}})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="VectorDB Instance Deleted Successfully",
error=None,
data={"VectorDB": result}
)
@vectordb.get("/embedding/all", response_model=resp_schemas.CommonResponse, dependencies=[Depends(verify_token)])
def get_all_embeddings():
"""
Retrieves all embeddings from module.
Returns:
CommonResponse: A response containing the embeddings or an error message.
"""
result, error = svc.get_all_embeddings()
if error:
return commons.is_error_response("Fetching Error", result, {"embeddings": []})
return resp_schemas.CommonResponse(
status=True,
status_code=200,
message="Embeddings Retrieved Successfully",
error=None,
data={"embeddings": result}
)
================================================
FILE: app/base/abstract_handlers.py
================================================
from __future__ import annotations
from abc import ABC, abstractmethod
from typing import Any, Optional
class Handler(ABC):
"""
The Handler interface declares a method for building the chain of handlers.
It also declares a method for executing a request.
"""
@abstractmethod
def set_next(self, handler: Handler) -> Handler:
pass
@abstractmethod
async def handle(self, request) -> Optional[str]:
pass
class AbstractHandler(Handler):
"""
The default chaining behavior can be implemented inside a base handler
class.
"""
_next_handler: Handler = None
def set_next(self, handler: Handler) -> Handler:
self._next_handler = handler
# Returning a handler from here will let us link handlers in a
# convenient way like this:
# monkey.set_next(squirrel).set_next(dog)
return handler
@abstractmethod
async def handle(self, request: Any) -> str:
if self._next_handler:
return await self._next_handler.handle(request)
return None
================================================
FILE: app/base/base_formatter.py
================================================
from abc import ABC, abstractmethod
class BaseFormatter(ABC):
@abstractmethod
def format(self)-> (dict):
"""
Abstract method to format data.
This method should be implemented by subclasses to define
specific formatting logic.
Returns:
dict: A dictionary containing the formatted data.
"""
pass
================================================
FILE: app/base/base_llm.py
================================================
# SPDX-FileCopyrightText: Copyright (c) 2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import List, Optional, Any
import requests
import json
from langchain.callbacks.manager import (
AsyncCallbackManagerForLLMRun,
CallbackManagerForLLMRun,
)
from langchain.llms.base import LLM
from loguru import logger
class BaseLLM(LLM):
temperature: Optional[float] = 0.5
url: Any = ""
headers : Optional[Any] = {}
body : Optional[Any] = {}
def _call(
self,
prompt: Optional[str]="",
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
) -> str:
if prompt != "":
self.body["prompt"] = prompt
try:
r = requests.post(self.url, json=self.body,headers=self.headers)
model_out = json.loads(r.content)
except Exception as e:
logger.error(e)
model_out = {}
return model_out
async def _acall(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[AsyncCallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
return "hi"
@property
def _llm_type(self) -> str:
return "rest llm"
@property
def _identifying_params(self) -> dict:
return {
"url": self.url,
}
================================================
FILE: app/base/base_plugin.py
================================================
from abc import ABC, abstractmethod
class BasePlugin(ABC):
@abstractmethod
def connect(self):
pass
@abstractmethod
def healthcheck(self):
pass
================================================
FILE: app/base/base_vectordb.py
================================================
from app.embeddings.loader import EmLoader
class BaseVectorDB():
def load_embeddings_function(self):
return EmLoader(self.embeddings).load_embclass().load_emb()
================================================
FILE: app/base/document_data_plugin.py
================================================
from abc import ABC, abstractmethod
from typing import Dict, Any, Optional
class DocumentDataPlugin(ABC):
@abstractmethod
def fetch_data(self, params: Optional[Dict[str, Any]] = None) -> list:
"""
Fetches data based on the provided parameters.
:param params: Optional query parameters.
:return: a list of strings
"""
pass
================================================
FILE: app/base/loader_metadata_mixin.py
================================================
import importlib
from loguru import logger
class LoaderMetadataMixin:
# plugin default variables
__unique_name__ = ""
__display_name__ = ""
__icon__ = ""
def __init__(self, name):
logger.info("Initializing mixin class")
self._load_metadata(name.removesuffix('.loader'))
@classmethod
def _load_metadata(self, class_path):
module = importlib.import_module(class_path)
try:
self.__unique_name__ = getattr(module, '__unique_name__')
self.__display_name__ = getattr(module, '__display_name__')
self.__icon__ = getattr(module, '__icon__')
except Exception as e:
raise Exception(e)
================================================
FILE: app/base/messaging_plugin.py
================================================
from abc import ABC, abstractmethod
class MessagePlugin(ABC):
@abstractmethod
def send(self):
pass
================================================
FILE: app/base/model_loader.py
================================================
class ModelLoader:
def __init__(self, model_config):
self.model_config = model_config
def load_model(self):
raise NotImplementedError("load_model method must be implemented in subclass")
def get_response(self) -> dict:
raise NotImplementedError("load_model method must be implemented in subclass")
def get_usage(self, prompt, response, out) -> dict:
raise NotImplementedError("load_model method must be implemented in subclass")
def get_models(self):
raise NotImplementedError("load_model method must be implemented in subclass")
================================================
FILE: app/base/plugin_metadata_mixin.py
================================================
import importlib
from loguru import logger
class PluginMetadataMixin:
# plugin default variables
__version__ = ""
__plugin_name__ = ""
__description__ = ""
__icon__ = ""
__connection_args__= ""
__category__ = ""
__prompt__ = ""
def __init__(self, name):
logger.info("Initializing mixin class")
self._load_metadata(name.removesuffix('.handler'))
@classmethod
def _load_metadata(self, class_path):
module = importlib.import_module(class_path)
try:
self.__version__ = getattr(module, '__version__')
self.__plugin_name__ = getattr(module, '__plugin_name__')
self.__description__ = getattr(module, '__description__')
self.__icon__ = getattr(module, '__icon__')
self.__connection_args__ = getattr(module, '__connection_args__')
self.__category__ = getattr(module, '__category__')
self.__prompt__ = getattr(module, '__prompt__')
except Exception as e:
raise Exception(e)
================================================
FILE: app/base/query_plugin.py
================================================
from abc import ABC, abstractmethod
from typing import Dict, Any, Optional, Tuple
class QueryPlugin(ABC):
@abstractmethod
def fetch_data(self, query: str, params: Optional[Dict[str, Any]] = None) -> Tuple[Any, Optional[str]]:
"""
Fetches data based on the provided query.
:param query: The query.
:param params: Optional query parameters.
:return: A tuple containing the fetched data and an optional error message.
"""
pass
@abstractmethod
def fetch_schema_details(self) -> Tuple[list, list]:
"""
Fetches schema details from Airtable.
:return: A tuple containing schema DDL as a list of strings and table metadata.
"""
pass
@abstractmethod
def create_ddl_from_metadata(self, table_metadata: list) -> list:
"""
Creates DDL from table metadata.
:param table_metadata: List of table metadata dictionaries.
:return: List of schema DDL strings.
"""
pass
@abstractmethod
def validate(self, formatted_sql: str) -> None:
"""
Validates the provided SQL.
:param formatted_sql: SQL string to validate.
"""
pass
================================================
FILE: app/base/remote_data_plugin.py
================================================
from abc import ABC, abstractmethod
from typing import Dict, Any, Optional
class RemoteDataPlugin(ABC):
@abstractmethod
def fetch_data(self, params: Optional[Dict[str, Any]] = None) -> list:
"""
Fetches data based on the provided parameters.
:param params: Optional query parameters.
:return: a list of strings
"""
pass
================================================
FILE: app/chain/chains/capability_chain.py
================================================
from app.chain.modules.input_formatter import InputFormatter
from app.chain.modules.post_processor import PostProcessor
from app.chain.modules.follow_up_handler import FollowupHandler
from app.chain.modules.context_retreiver import ContextRetreiver
from app.chain.modules.followup_interpreter import FollowupInterpreter
from loguru import logger
class CapabilityChain:
"""
CapabilityChain class represents the processing chain for handling capability-related requests.
This class orchestrates various modules to process user input, handle follow-ups,
interpret follow-up requests, and manage context across interactions.
Attributes:
common_context (dict): A shared context dictionary used across modules.
input_formatter (InputFormatter): Module for formatting user input.
context_retriver (ContextRetreiver): Module for retrieving context.
followup_handler (FollowupHandler): Module for handling follow-up requests.
followup_interpreter (FollowupInterpreter): Module for interpreting follow-up requests.
post_processor (PostProcessor): Module for post-processing responses.
handler: The first module in the processing chain.
The CapabilityChain class follows a modular design, where each module is responsible
for a specific part of the processing pipeline. This allows for flexibility
and easy extension of functionality.
"""
def __init__(self, model_configs, context_storage, general_chain):
logger.info("loading modules into capability chain")
self.common_context = {}
self.input_formatter = InputFormatter()
self.context_retriver = ContextRetreiver(self.common_context, context_storage)
self.followup_handler = FollowupHandler(self.common_context, model_configs)
self.followup_interpreter = FollowupInterpreter(self.common_context, general_chain)
self.post_processor = PostProcessor()
logger.info("initializing chain")
self.input_formatter.set_next(self.context_retriver).set_next(self.followup_handler).set_next(self.followup_interpreter).set_next(self.post_processor)
self.handler = self.input_formatter
def invoke(self, user_request):
logger.info("Processing user request")
return self.handler.handle(user_request)
================================================
FILE: app/chain/chains/general_chain.py
================================================
from app.chain.modules.input_formatter import InputFormatter
# from app.chain.modules.guard_rail import GuardRail
from app.chain.modules.prompt_generator import PromptGenerator
from app.chain.modules.general_answer_generator import GeneralAnswerGenerator
from app.chain.modules.ouput_formatter import OutputFormatter
from app.chain.modules.post_processor import PostProcessor
from app.chain.modules.context_retreiver import ContextRetreiver
from loguru import logger
class GeneralChain:
"""
Chain class represents the main processing chain for handling user requests.
This class orchestrates various modules to process user input, retrieve context,
generate prompts, execute actions, and format output.
Attributes:
vector_store: A storage system for vector embeddings.
data_sources: A list of data sources to be used in processing.
context_store: A storage system for maintaining context across interactions.
common_context (dict): A shared context dictionary used across modules.
configs (dict): Configuration settings for the models.
input_formatter (InputFormatter): Module for formatting user input.
rag_module (RagModule): Module for Retrieval-Augmented Generation.
prompt_generator (PromptGenerator): Module for generating prompts.
generator (Generator): Module for generating responses.
validator (Validator): Module for validating responses.
context_retriver (ContextRetreiver): Module for retrieving context.
context_storage (ContextStorage): Module for storing context.
executer (Executer): Module for executing actions.
cache_checker (Cachechecker): Module for checking and managing cache.
output_formatter (OutputFormatter): Module for formatting output.
The Chain class follows a modular design, where each module is responsible
for a specific part of the processing pipeline. This allows for flexibility
and easy extension of functionality.
"""
def __init__(self, model_configs, store, datasource, context_store):
logger.info("loading modules into chain")
self.vector_store = store
self.data_sources = datasource if datasource is not None else []
self.context_store = context_store
self.common_context = {
"chain_retries" : 0,
"rag": {
"context": [],
"schema" : [],
},
}
self.configs = model_configs
self.input_formatter = InputFormatter()
self.prompt_generator = PromptGenerator(self.common_context, model_configs, self.data_sources)
self.generator = GeneralAnswerGenerator(self.common_context, model_configs)
self.context_retriver = ContextRetreiver(self.common_context, context_store)
self.output_formatter = OutputFormatter(self.common_context,self.data_sources)
self.post_processor = PostProcessor()
logger.info("initializing chain")
self.input_formatter.set_next(self.context_retriver) \
.set_next(self.prompt_generator).set_next(self.generator).set_next(self.output_formatter).set_next(self.post_processor)
self.handler = self.input_formatter
def invoke(self, user_request):
self.common_context["chain_retries"] = 0
self.common_context["intent"] = user_request["intent_extractor"]["intent"]
self.common_context["context_id"] = user_request["context_id"]
self.common_context["rag"].update({
"context": [],
"schema" : [],
})
return self.handler.handle(user_request)
================================================
FILE: app/chain/chains/intent_chain.py
================================================
from app.chain.modules.document_retriever import DocumentRetriever
from app.chain.modules.input_formatter import InputFormatter
from app.chain.modules.intent_extracter import IntentExtracter
from app.chain.modules.router import Router
from app.chain.modules.post_processor import PostProcessor
from app.chain.formatter.general_response import Formatter
from app.chain.modules.context_retreiver import ContextRetreiver
from loguru import logger
class IntentChain:
"""
IntentChain class represents the main processing chain for handling user intents.
This class orchestrates various modules to process user input, extract intents,
route requests, and manage context across interactions.
Attributes:
vector_store: A storage system for vector embeddings.
data_source: A data source to be used in processing.
context_store: A storage system for maintaining context across interactions.
common_context (dict): A shared context dictionary used across modules.
configs (dict): Configuration settings for the models.
input_formatter (InputFormatter): Module for formatting user input.
context_retriver (ContextRetreiver): Module for retrieving context.
intent_extractor (IntentExtracter): Module for extracting intents from user input.
post_processor (PostProcessor): Module for post-processing responses.
router (Router): Module for routing requests to appropriate chains.
handler: The first module in the processing chain.
The IntentChain class follows a modular design, where each module is responsible
for a specific part of the processing pipeline. This allows for flexibility
and easy extension of functionality.
"""
def __init__(self, model_configs, store, datasource, context_store, intent_chain, general_chain, capability_chain, metadata_chain):
logger.info("loading modules into chain")
self.vector_store = store
self.context_store = context_store
self.data_sources = datasource if datasource is not None else {}
self.common_context = {
"chain_retries" : 0,
}
self.configs = model_configs
self.input_formatter = InputFormatter()
self.context_retriver = ContextRetreiver(self.common_context, context_store)
self.intent_extractor = IntentExtracter(self.common_context, model_configs, self.data_sources)
self.document_retriever = DocumentRetriever(self.vector_store, self.data_sources)
self.post_processor = PostProcessor()
self.router = Router(self.common_context, self.post_processor, intent_chain, general_chain, capability_chain, metadata_chain)
self.input_formatter.set_next(self.context_retriver).set_next(self.document_retriever).set_next(self.intent_extractor).set_next(self.router).set_next(self.post_processor)
self.handler = self.input_formatter
def invoke(self, user_request):
try:
self.common_context["chain_retries"] = 0
self.common_context["context_id"] = user_request["context_id"]
return self.handler.handle(user_request)
except Exception as error:
logger.error(f"An error occurred: {error}")
return Formatter.format("Oops! Something went wrong. Try Again!",error)
================================================
FILE: app/chain/chains/metadata_chain.py
================================================
from app.chain.modules.input_formatter import InputFormatter
from app.chain.modules.post_processor import PostProcessor
from app.chain.modules.metadata_generator import MetadataGenerator
from app.chain.modules.context_retreiver import ContextRetreiver
from app.chain.modules.ouput_formatter import OutputFormatter
from app.chain.modules.metadata_ragfilter import MetadataRagFilter
from app.chain.modules.document_retriever import DocumentRetriever
from loguru import logger
class MetadataChain:
"""
MetadataChain class represents the processing chain for handling metadata-related requests.
This class orchestrates various modules to process user input, retrieve context,
generate metadata, and format output for metadata-related operations.
Attributes:
vector_store: A storage system for vector embeddings.
data_sources: A list of data sources to be used in processing.
context_store: A storage system for maintaining context across interactions.
common_context (dict): A shared context dictionary used across modules.
input_formatter (InputFormatter): Module for formatting user input.
context_retriver (ContextRetreiver): Module for retrieving context.
document_retriever (DocumentRetriever): Module for retrieving relevant documents.
metadata_generator (MetadataGenerator): Module for generating metadata.
post_processor (PostProcessor): Module for post-processing responses.
metadata_ragfilter (MetadataRagFilter): Module for filtering metadata using RAG.
output_formatter (OutputFormatter): Module for formatting output.
handler: The first module in the processing chain.
The MetadataChain class follows a modular design, where each module is responsible
for a specific part of the processing pipeline. This allows for flexibility
and easy extension of functionality in metadata processing and generation.
"""
def __init__(self, model_configs, store, datasource, context_store):
logger.info("loading modules into metadata chain")
self.vector_store = store
self.data_sources = datasource if datasource is not None else []
self.context_store = context_store
self.common_context = {
"chain_retries" : 0,
}
self.input_formatter = InputFormatter()
self.context_retriver = ContextRetreiver(self.common_context, context_store)
self.document_retriever = DocumentRetriever(self.vector_store, self.data_sources)
self.metadata_generator = MetadataGenerator(self.common_context, model_configs, self.data_sources)
self.post_processor = PostProcessor()
self.metadata_ragfilter = MetadataRagFilter()
self.output_formatter = OutputFormatter(self.common_context,self.data_sources)
self.input_formatter.set_next(self.context_retriver).set_next(self.metadata_ragfilter).set_next(self.document_retriever).set_next(self.metadata_generator).set_next(self.output_formatter).set_next(self.post_processor)
self.handler = self.input_formatter
def invoke(self, user_request):
self.common_context["chain_retries"] = 0
return self.handler.handle(user_request)
================================================
FILE: app/chain/chains/query_chain.py
================================================
from app.chain.modules.document_retriever import DocumentRetriever
from app.chain.modules.input_formatter import InputFormatter
# from app.chain.modules.guard_rail import GuardRail
from app.chain.modules.prompt_generator import PromptGenerator
from app.chain.modules.generator import Generator
from app.chain.modules.schema_retriever import SchemaRetriever
from app.chain.modules.validator import Validator
from app.chain.modules.executer import Executer
from app.chain.modules.ouput_formatter import OutputFormatter
from app.chain.modules.post_processor import PostProcessor
from app.chain.formatter.general_response import Formatter
from app.chain.modules.cache_checker import Cachechecker
from app.chain.modules.context_retreiver import ContextRetreiver
from app.chain.modules.context_storage import ContextStorage
from loguru import logger
class QueryChain:
"""
Chain class represents the main processing chain for handling user requests.
This class orchestrates various modules to process user input, retrieve context,
generate prompts, execute actions, and format output.
Attributes:
vector_store: A storage system for vector embeddings.
data_sources: A list of data sources to be used in processing.
context_store: A storage system for maintaining context across interactions.
common_context (dict): A shared context dictionary used across modules.
configs (dict): Configuration settings for the models.
input_formatter (InputFormatter): Module for formatting user input.
rag_module (RagModule): Module for Retrieval-Augmented Generation.
prompt_generator (PromptGenerator): Module for generating prompts.
generator (Generator): Module for generating responses.
validator (Validator): Module for validating responses.
context_retriver (ContextRetreiver): Module for retrieving context.
context_storage (ContextStorage): Module for storing context.
executer (Executer): Module for executing actions.
cache_checker (Cachechecker): Module for checking and managing cache.
output_formatter (OutputFormatter): Module for formatting output.
The Chain class follows a modular design, where each module is responsible
for a specific part of the processing pipeline. This allows for flexibility
and easy extension of functionality.
"""
def __init__(self, model_configs, store, datasource, context_store):
logger.info("loading modules into chain")
self.vector_store = store
self.data_sources = datasource if datasource is not None else []
self.context_store = context_store
self.common_context = {
"chain_retries" : 0,
"llm": {
"input_tokens" : 0,
"output_tokens": 0,
"total_cost": 0,
"latency": 0,
"response": {
"input_tokens" : 0,
"output_tokens": 0,
"total_cost": 0,
"latency": 0,
"logprob_percentage": 0,
"name": "default"
},
},
"execution_logs": [],
"general_response": Formatter,
"prompt_mode" : "manual",
"inference_raw" : "",
"prompt": "",
"rag": {
"context": [],
"schema" : [],
},
}
self.configs = model_configs
self.input_formatter = InputFormatter()
self.prompt_generator = PromptGenerator(self.common_context, model_configs, self.data_sources)
self.generator = Generator(self.common_context, model_configs)
self.validator = Validator(self.common_context,self.data_sources)
self.context_retriver = ContextRetreiver(self.common_context, context_store)
self.context_storage = ContextStorage(self.common_context, context_store)
self.schema_retriever = SchemaRetriever(self.vector_store, self.data_sources)
self.executer = Executer(self.common_context,self.data_sources, self.prompt_generator)
self.cache_checker = Cachechecker(self.common_context, self.vector_store,self.executer)
self.output_formatter = OutputFormatter(self.common_context,self.data_sources)
self.post_processor = PostProcessor()
logger.info("initializing chain")
self.input_formatter.set_next(self.cache_checker) \
.set_next(self.context_retriver) \
.set_next(self.prompt_generator).set_next(self.generator).set_next(self.validator).set_next(self.executer) \
.set_next(self.output_formatter).set_next(self.post_processor)
self.handler = self.input_formatter
def invoke(self, user_request):
self.common_context["chain_retries"] = 0
self.common_context["intent"] = user_request["intent_extractor"]["intent"]
self.common_context["context_id"] = user_request["context_id"]
self.common_context["llm"].update({
"input_tokens" : 0,
"output_tokens": 0,
"total_cost": 0,
"latency": 0,
"response": {
"input_tokens" : 0,
"output_tokens": 0,
"total_cost": 0,
"latency": 0,
"logprob_percentage": 0,
"name": "default"
},
})
self.common_context["prompt_mode"] = "manual"
self.common_context["rag"].update({
"context": [],
"schema" : [],
})
return self.handler.handle(user_request)
================================================
FILE: app/chain/formatter/general_response.py
================================================
class Formatter:
def format(data: any, error: any) -> (dict):
response = {}
response["main_entity"] = "none"
response["main_format"] = "general_chat"
response["role"] = "assistant"
response["content"] = data
response["summary"] = data
response["error"] = error
return response
================================================
FILE: app/chain/modules/cache_checker.py
================================================
from typing import Any
from loguru import logger
from app.base.abstract_handlers import AbstractHandler
class Cachechecker(AbstractHandler):
"""
A handler class for checking and managing cache operations.
This class extends AbstractHandler and provides functionality to check
if a query exists in the cache and handle the response accordingly.
"""
def __init__(self,common_context, cachestore, forward_handler, forward: bool = True) -> None:
"""
Initialize the Cachechecker.
Args:
common_context: The common context shared across handlers.
Cachestore: The cache storage mechanism.
forward_handler: The next handler in the chain.
forward (bool): Whether to forward the request to the next handler.
"""
self.cache = cachestore
self.forward_handler = forward_handler
self.forward = forward
self.common_context = common_context
async def handle(self, request: Any) -> str:
"""
Handle the incoming request by checking the cache
Args:
request (Any): The incoming request to be processed.
Returns:
str: The response after processing the request.
"""
logger.info("passing through => cache_checker")
response = request
question = request.get("question", "")
rag_filters = response["rag_filters"]["datasources"]
output = await self.cache.find_similar_cache(rag_filters, question)
if "rag" not in response:
response["rag"] = {
"suggestions": output
}
else:
response["rag"]["suggestions"] = output
if self.forward and len(output) > 0:
if output[0]["distances"] < -10:
result = output[0]["metadatas"]
logger.info("query retrieved from cache")
return await self.forward_handler.handle({"inference":result})
logger.info("query not retrieved from cache")
return await super().handle(response)
================================================
FILE: app/chain/modules/cache_updater.py
================================================
from typing import Any
from loguru import logger
from app.base.abstract_handlers import AbstractHandler
class Cacheupdater(AbstractHandler):
"""
A handler class for updating the cache with new query responses.
This class extends AbstractHandler and provides functionality to update
the cache with new question-inference pairs when appropriate.
"""
def __init__(self,cachestore) -> None:
"""
Initialize the Cacheupdater.
Args:
Cachestore (Any): The cache storage mechanism.
"""
self.cache = cachestore
async def handle(self, response: Any) -> str:
"""
Handle the incoming response by updating the cache if necessary.
Args:
response (Dict[str, Any]): The response to be processed.
Returns:
str: The response after processing.
"""
logger.info("passing through => cache_updater")
data = response["query_response"]
# question would not be in response if retrieved from cache
if ("question" in response) and not(data is None or len(data) == 0):
logger.info("cache updated")
inference = response["inference"]
question = response["question"]
self.cache.update_cache(
document = question,
metadata = inference,
)
return await super().handle(response)
================================================
FILE: app/chain/modules/context_retreiver.py
================================================
from typing import Any
from loguru import logger
from app.base.abstract_handlers import AbstractHandler
from app.models.llmchat import ChatHistory
class ContextRetreiver(AbstractHandler):
"""
A handler class for retrieving context information for a chat.
This class extends AbstractHandler and provides functionality to fetch
relevant context based on the context_id provided in the request.
"""
def __init__(self,common_context, context_store) -> None:
"""
Initialize the ContextRetriever.
Args:
common_context (Any): The common context shared across handlers.
context_store (Any): The storage mechanism for context data.
"""
self.context_store = context_store
self.common_context = context_store
async def handle(self, request: Any) -> str:
"""
Handle the incoming request by retrieving relevant context.
Args:
request (Dict[str, Any]): The incoming request to be processed.
Returns:
str: The response after processing the request.
"""
logger.info("retrieving context into chain")
response = request
context = []
if "context_id" in request:
records = self.context_store.query_data(model = ChatHistory, filters= {"chat_context_id": request["context_id"]})
context.extend(records)
response["context"] = context
return await super().handle(response)
================================================
FILE: app/chain/modules/context_storage.py
================================================
from typing import Any
from loguru import logger
from app.base.abstract_handlers import AbstractHandler
from app.models.db import Chat
import datetime
class ContextStorage(AbstractHandler):
"""
A handler class for storing chat interactions in the context.
This class extends AbstractHandler and provides functionality to store
chat interactions, including questions, answers, and summaries, in the context store.
"""
def __init__(self,common_context, context_store) -> None:
"""
Initialize the ContextStorage.
Args:
common_context (Any): The common context shared across handlers.
context_store (Any): The storage mechanism for context data.
"""
self.context_store = context_store
self.common_context = context_store
async def handle(self, request: Any) -> str:
"""
Handle the incoming request by storing the interaction in the context.
Args:
request (Dict[str, Any]): The incoming request to be processed.
Returns:
str: The response after processing the request.
"""
logger.info("Storing interaction into context")
response = request
summary = ''
if "summary" in request:
summary = request['summary']
if "context_id" in request:
self.context_store.insert_data(Chat(context_id = request["context_id"], question = request["question"], created_at = datetime.datetime.now(), answer = request["content"], summary = summary))
return await super().handle(response)
================================================
FILE: app/chain/modules/document_retriever.py
================================================
from app.base.abstract_handlers import AbstractHandler
from loguru import logger
from typing import Any
from app.providers.container import Container
import asyncio
class DocumentRetriever(AbstractHandler):
"""
A handler class for retrieving relevant documents based on the input question.
This class extends AbstractHandler and provides functionality to find and
process similar documents from a vector store based on the input question.
"""
def __init__(self,store, datasources):
"""
Initialize the DocumentRetriever.
Args:
store (Any): The vector store for document retrieval.
"""
self.store =store
self.context_relevance_threshold = 4
self.datasources = datasources
async def handle(self, request: Any) -> str:
"""
Handle the incoming request by retrieving relevant documents.
Args:
request (Dict[str, Any]): The incoming request to be processed.
Returns:
str: The response after processing the request.
"""
logger.info("passing through => document_retriever")
response = request
tasks = [
self.store.find_similar_documentation(datasource, request['question'], 10)
for datasource in self.datasources
]
results = await asyncio.gather(*tasks)
logger.info("sorting retrieved documents")
for index, out in enumerate(results):
opt_doc = []
if out and len(out) > 0 and out[0]['distances'] < self.context_relevance_threshold:
distances = [doc['distances'] for doc in out]
if len(out) > 5:
clusters = Container.clustering().kmeans(distances, 2)
shortest_cluster = clusters[0]
for doc in out:
if doc['distances'] in shortest_cluster:
opt_doc.append(doc)
else:
opt_doc = out
if "rag" not in response:
response["rag"]= {"context" : {}}
response["rag"]["context"][list(self.datasources.keys())[index]] = opt_doc
return await super().handle(response)
================================================
FILE: app/chain/modules/executer.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
from app.providers.config import configs
class Executer(AbstractHandler):
"""
A handler class for executing queries based on the inference.
This class extends AbstractHandler and provides functionality to execute
queries using the appropriate datasource and handle any errors that occur.
"""
def __init__(self, common_context, datasource, fallback_handler) -> None:
"""
Initialize the Executer.
Args:
common_context (Dict[str, Any]): The common context shared across handlers.
datasource (Dict[str, Any]): A dictionary of datasources keyed by intent.
fallback_handler (AbstractHandler): The handler to call in case of errors.
"""
self.fall_back_handler = fallback_handler
self.common_context = common_context
self.datasource = datasource
async def handle(self, request: Any) -> str:
"""
Handle the incoming request by executing the query.
Args:
request (Dict[str, Any]): The incoming request to be processed.
Returns:
str: The response after processing the request.
"""
logger.info("passing through => executor")
inference = request.get("inference", {})
formated_sql = inference.get("query", "")
logger.debug(f"executing query:{formated_sql}")
out, err = self.datasource[self.common_context["intent"]].fetch_data(formated_sql)
if err is not None:
logger.error(f"error in executing query:{err}")
if self.common_context["chain_retries"] < configs.retry_limit :
logger.info("going back for resolving error")
self.common_context["chain_retries"] =self.common_context["chain_retries"] + 1
self.common_context["execution_logs"].append({"query": formated_sql, "error": str(err)})
return await self.fall_back_handler.handle(request)
response = {**dict(request), **{
"query_response": out,
"query_error": err,
}}
return await super().handle(response)
================================================
FILE: app/chain/modules/follow_up_handler.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
from app.providers.config import configs
from app.loaders.base_loader import BaseLoader
from string import Template
from app.utils.parser import parse_llm_response
from app.chain.formatter.general_response import Formatter
class FollowupHandler(AbstractHandler):
"""
A handler class for processing follow-up queries and extracting required parameters.
This class extends AbstractHandler and provides functionality to process
follow-up queries, extract intent-specific parameters, and generate appropriate responses.
"""
def __init__(self, common_context , model_configs) -> None:
"""
Initialize the FollowupHandler.
Args:
common_context (Dict[str, Any]): The common context shared across handlers.
model_configs (Dict[str, Any]): Configuration for the models used in processing.
"""
self.model_configs = model_configs
self.common_context = common_context
async def handle(self, request: Any) -> str:
"""
Handle the incoming request by processing follow-up queries and extracting parameters.
Args:
request (Dict[str, Any]): The incoming request to be processed.
Returns:
str: The response after processing the request.
"""
response = request
logger.info("passing through => Intent extractor")
use_case = self.model_configs.get("use_case", {})
capabilities = use_case.get("capabilities", [])
intent_extracted = request.get("intent_extractor")
intent = intent_extracted.get("intent", "")
filtered_capabilities = [capability for capability in capabilities if capability["name"]== intent]
capability = filtered_capabilities[0]
long_description = use_case["long_description"]
capability_description = capability["description"]
parameter_description = ""
parameters = capability["requirements"]
for parameter in parameters:
parameter_description= parameter_description + parameter["parameter_name"]+ " : "+ parameter["parameter_description"]+"\n"
prompt = """
You are part of a Form automations system where your duty is to: $capability_description
You will be given inputs that need to be captured. Your task is to ask and capture this information from the user and get it confirmed.
-- Form system context ---
$long_description
-- Form system context ---
Required parameters
-- Parameter section ---
$parameter_description
--- Parameter section ---
Instructions:
Carefully review all previous messages to establish context.
Only extract values that are explicitly provided in previous messages.
Do not assume or fill in any values that are not present in previous messages.
Do not hallucinate or claim that required values are present when they are not.
Generate a JSON response in the following format for the query '$question':
{
"explanation": "Describe which required values were found in previous messages and how they were extracted. If no values were found, state this clearly.",
"params": {},dont extract values for the params which is not mentioned in previous messages
"completed": "true|false, if all the required values are captured",
"message": "Ask for specific required parameters that have not been provided yet. If all parameters are captured, provide a success message for the booking.",
"summary" : "summarise question and answer in one sentence"
}
"""
contexts = request.get("context", [])
contexts = contexts[-5:] if len(contexts) >= 5 else contexts
prompt = Template(prompt).safe_substitute(
question = request["question"],
long_description= long_description,
capability_description= capability_description,
parameter_description=parameter_description
)
loader = BaseLoader(model_configs=self.model_configs["models"])
infernce_model = loader.load_model(configs.inference_llm_model)
output, response_metadata = infernce_model.do_inference(
prompt, contexts
)
if output["error"] is not None:
return await Formatter.format("Oops! Something went wrong. Try Again!",output['error'])
response["inference"] = parse_llm_response(output['content'])
response["capability"] = capability
return await super().handle(response)
================================================
FILE: app/chain/modules/followup_interpreter.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
from app.chain.formatter.general_response import Formatter
class FollowupInterpreter(AbstractHandler):
"""
A handler class for interpreting follow-up responses and formatting them.
This class extends AbstractHandler and provides functionality to interpret
the inference results from follow-up queries and format the response accordingly.
"""
def __init__(self, common_context, general_chain) -> None:
"""
Initialize the FollowupInterpreter.
Args:
common_context (Dict[str, Any]): The common context shared across handlers.
general_chain (Any): The general processing chain for fallback scenarios.
"""
self.common_context = common_context
self.general_chain = general_chain
async def handle(self, request: Any) -> str:
"""
Handle the incoming request by interpreting the inference results and formatting the response.
Args:
request (Dict[str, Any]): The incoming request to be processed.
Returns:
str: The formatted response after processing the request.
"""
logger.info("passing through => interpreter")
response = request
if "inference" in request:
inference = request["inference"]
if inference["completed"] == True or inference["completed"] == "true":
logger.info("Intent completed, trigger the action")
response = Formatter.format(inference["message"],"")
response["summary"] = request["inference"]["summary"]
response["question"] = request["question"]
response["context_id"] = request["context_id"]
else:
logger.info("No intents detected")
response = Formatter.format("Sorry, I didn't get that","")
return await super().handle(response)
================================================
FILE: app/chain/modules/general_answer_generator.py
================================================
from app.base.abstract_handlers import AbstractHandler
from app.providers.config import configs
from app.loaders.base_loader import BaseLoader
from app.utils.parser import markdown_parse_llm_response
from app.chain.formatter.general_response import Formatter
from loguru import logger
class GeneralAnswerGenerator(AbstractHandler):
"""
A handler class for generating inferences based on prompts and contexts.
This class extends AbstractHandler and provides functionality to generate
inferences using a specified language model based on given prompts and contexts.
"""
def __init__(self, common_context, model_configs) -> None:
"""
Initialize the Generator.
Args:
common_context (Dict[str, Any]): The common context shared across handlers.
model_configs (Dict[str, Any]): Configuration for the models used in processing.
"""
self.model_configs = model_configs
self.common_context = common_context
async def handle(self, request: dict) -> str:
"""
Handle the incoming request by generating an inference based on the prompt and context.
This method extracts the prompt and context from the request, uses an inference model
to generate a response, and adds the parsed inference to the response.
Args:
request (Dict[str, Any]): The incoming request to be processed.
Returns:
str: The response after processing the request, including the generated inference.
"""
logger.info("passing through => generator")
response = request
prompt = response["prompt"]
contexts = request.get("context",[])
contexts = contexts[-5:] if len(contexts) >= 5 else contexts
loader = BaseLoader(model_configs=self.model_configs["models"])
infernce_model = loader.load_model(configs.inference_llm_model)
output, response_metadata = infernce_model.do_inference(
prompt, contexts
)
if output["error"] is not None:
return Formatter.format("Oops! Something went wrong. Try Again!",output['error'])
response["inference"] = markdown_parse_llm_response(output['content'])
if not response["inference"]:
return Formatter.format("Oops! Something went wrong. Try Again!","")
return await super().handle(response)
================================================
FILE: app/chain/modules/generator.py
================================================
from app.base.abstract_handlers import AbstractHandler
from app.providers.config import configs
from app.loaders.base_loader import BaseLoader
from app.utils.parser import parse_llm_response
from app.chain.formatter.general_response import Formatter
from loguru import logger
class Generator(AbstractHandler):
"""
A handler class for generating inferences based on prompts and contexts.
This class extends AbstractHandler and provides functionality to generate
inferences using a specified language model based on given prompts and contexts.
"""
def __init__(self, common_context, model_configs) -> None:
"""
Initialize the Generator.
Args:
common_context (Dict[str, Any]): The common context shared across handlers.
model_configs (Dict[str, Any]): Configuration for the models used in processing.
"""
self.model_configs = model_configs
self.common_context = common_context
async def handle(self, request: dict) -> str:
"""
Handle the incoming request by generating an inference based on the prompt and context.
This method extracts the prompt and context from the request, uses an inference model
to generate a response, and adds the parsed inference to the response.
Args:
request (Dict[str, Any]): The incoming request to be processed.
Returns:
str: The response after processing the request, including the generated inference.
"""
logger.info("passing through => generator")
response = request
prompt = response["prompt"]
loader = BaseLoader(model_configs=self.model_configs["models"])
infernce_model = loader.load_model(configs.inference_llm_model)
output, response_metadata = infernce_model.do_inference(
prompt, []
)
if output["error"] is not None:
return Formatter.format("Oops! Something went wrong. Try Again!",output['error'])
response["inference"] = parse_llm_response(output['content'])
if not response["inference"]:
return Formatter.format("Oops! Something went wrong. Try Again!","")
return await super().handle(response)
================================================
FILE: app/chain/modules/input_formatter.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
class InputFormatter(AbstractHandler):
async def handle(self, request: Any) -> str:
logger.info("passing through => input_formatter")
response = request
return await super().handle(response)
================================================
FILE: app/chain/modules/intent_extracter.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
from app.providers.config import configs
from app.loaders.base_loader import BaseLoader
from string import Template
from app.chain.formatter.general_response import Formatter
from app.utils.parser import parse_llm_response
class IntentExtracter(AbstractHandler):
"""
A handler for extracting user intents from chat queries based on a provided use case configuration.
This class processes chat requests to determine the intent behind user queries using a language model.
It generates a prompt with the chat context, available intents, and instructions to guide the model in
intent extraction.
Attributes:
common_context (Any): Shared context information used across handlers.
model_configs (dict): Configuration settings for the model, including use case details and model paths.
"""
def __init__(self, common_context , model_configs, datasources) -> None:
"""
Initializes the IntentExtractor with common context and model configurations.
Args:
common_context (Any): Shared context information used across handlers.
model_configs (dict): Configuration settings for the model.
"""
self.model_configs = model_configs
self.common_context = common_context
self.datasources = datasources
async def handle(self, request: Any) -> str:
"""
Processes the request to extract the intent from the user's query.
Args:
request (Any): The incoming request containing the user query and context.
Returns:
str: The result of the superclass's handle method with updated response information.
"""
response = request
logger.info("passing through => Intent extractor")
use_case = self.model_configs.get("use_case", {})
long_description = use_case.get("long_description", "")
short_description = use_case.get("short_description", "")
capabilities = use_case.get("capabilities", [])
rag = request.get("rag", {})
context = rag.get("context", {})
capability_description = ""
capability_names = ["out_of_context"]
for capability in capabilities:
name = capability["name"]
description = capability["description"]
capability_names.append(name)
capability_description += f"{name} : {description}\n"
datasources = self.model_configs.get("datasources", [])
datasource_names = []
for datasource in datasources:
if datasource["name"] in self.datasources:
if self.datasources[datasource["name"]].__category__ in [2,5] and "metadata_inquiry" not in capability_names:
capability_names.append("metadata_inquiry")
name = datasource["name"]
description = datasource["description"]
capability_names.append(name)
datasource_names.append(name)
capability_description += f"\n{name} : {description}\n"
datasource_context = context[name]
for index,cont in enumerate(datasource_context[:2]):
if index == 0:
capability_description += f"{cont.get('document','')}\n"
else:
capability_description += f"{cont.get('document','')}\n"
response["available_datasources"] = datasource_names
if "metadata_inquiry" in capability_names:
capability_description += "\n\nmetadata_inquiry : queries about overview of available data, the structure of a database (including tables and columns), the meaning behind specific columns, and the purpose within a database context, eg: what kind of data you have? or list questions which can be asked?\n"
chat_contexts = request.get("context", [])
previous_intent = chat_contexts[-1].chat_answer.get("intent","") if len(chat_contexts) > 0 else "None"
prompt = """
You are part of a chatbot system where you have to extract intent from users chats and match it with given intents.
-- chatbot context ---
$long_description
Also provide data structure information and overview of available data.
-- chatbot context ---
Available intents are:
-- Intent section ---
$capabilities
out_of_context: If chat is irrelevant to chatbot context and its capabilities
--- Intent section ---
Previous last message Intent : $previous_intent
Instructions:
1.Only one intent must be identified.Multiple intents are prohibited.
2.Pay special attention to whether the previous intent has been completed.
3.Strictly only if the current user query doesn't clearly match an intent, consider the previous messages to identify the most appropriate intent.
4.When asked to list possible questions, provide general examples without mentioning "specific" word
Generate a response for the user query '$question' in the following JSON format:
{
"explanation": "Explain how you finalized the intent based on user context and instructions. Include your reasoning for determining whether the previous intent was completed or if the current query relates to a new intent.",
"intent": "Detected intent, strictly one from the $capability_list"
}
"""
capability_list = "|".join(capability_names)
prompt = Template(prompt).safe_substitute(
question = request["question"],
long_description = long_description,
short_description =short_description,
capability_list = capability_list,
capabilities= capability_description,
previous_intent = previous_intent
)
logger.debug(f"intent prompt:{prompt}")
loader = BaseLoader(model_configs=self.model_configs["models"])
infernce_model = loader.load_model(configs.inference_llm_model)
output, response_metadata = infernce_model.do_inference(
prompt, chat_contexts
)
if output["error"] is not None:
return Formatter.format("Oops! Something went wrong. Try Again!",output['error'])
response["available_intents"] = capability_names
response["intent_extractor"] = parse_llm_response(output['content'])
response["rag_filters"] = {
"datasources" : response.get('intent_extractor', {}).get('intent', ''),
"document_count" : 5,
"schema_count" : 5
}
return await super().handle(response)
================================================
FILE: app/chain/modules/metadata_generator.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
from app.providers.config import configs
from app.loaders.base_loader import BaseLoader
from string import Template
from app.utils.parser import markdown_parse_llm_response
from app.chain.formatter.general_response import Formatter
class MetadataGenerator(AbstractHandler):
def __init__(self, common_context , model_configs, datasources) -> None:
self.model_configs = model_configs
self.common_context = common_context
self.datasources = datasources
async def handle(self, request: Any) -> str:
response = request
logger.info("passing through => Metadata description generator")
rag = request["rag"]
contexts = ""
for datasource_name, handler in self.datasources.items():
if handler.__category__ in [2,5]:
rag_contexts = rag.get("context", {}).get(datasource_name,"")
for index,cont in enumerate(rag_contexts):
if index==0:
contexts += "\n\n" + "Plugin/Database Name: "+ datasource_name + "\n" + cont["document"]
else:
contexts += "\n" + cont["document"]
prompt = """
You are part of a chatbot system where you need to answer user questions based on the given database schema and context.
Please review the following information carefully:
A brief description about the schema is given below:
-- start db schema context section--
$context
-- end db schema context section--
Make sure to follow these:
1. Use the provided schema and context to inform your answer.
2. while listing tables and its columns strictly mention under which plugin name it is.
3. Provide accurate information based on the available data.
4. Keep the answer concise and with minimal explanation
5. If the question cannot be fully answered with the given information, explain what can be answered and what additional information might be needed.
6. Present the answer in a human-readable Markdown format
7. Give only what user wants, don't hallucinate to give long answers
Your task is to go through the chat history carefully to understand the user's context and instructions. Then, generate a response to the user query '$question' using the provided schema and metadata information. Format your response in the following JSON structure:
{
"general_message": "Provide a concise human-readable answer in Markdown format to the user's question using the available information",
}
"""
prompt = Template(prompt).safe_substitute(question = request["question"], context =contexts)
response["prompt"] = prompt
logger.info(f"prompt:{prompt}")
chat_history = []
if "context" in request and len(request["context"]) > 0:
chat_history = request["context"]
chat_history = chat_history[-7:] if len(chat_history) >= 7 else chat_history
loader = BaseLoader(model_configs=self.model_configs["models"])
infernce_model = loader.load_model(configs.inference_llm_model)
output, response_metadata = infernce_model.do_inference(
prompt, chat_history
)
if output["error"] is not None:
return Formatter.format("Oops! Something went wrong. Try Again!",output['error'])
response["inference"] = markdown_parse_llm_response(output['content'])
response["summary"] = ""
return await super().handle(response)
================================================
FILE: app/chain/modules/metadata_ragfilter.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
class MetadataRagFilter(AbstractHandler):
"""
A handler for applying RAG (retrieval-augmented generation) filters based on metadata.
This class modifies the request's response to include RAG filters, setting the number of documents and schemas
to be considered in retrieval operations. It also includes tracing for monitoring and debugging purposes.
Inherits from:
AbstractHandler: A base class for handling requests in the application.
Methods:
handle(request: Any) -> str:
Processes the request to apply RAG filters and forwards it to the next handler.
"""
async def handle(self, request: Any) -> str:
"""
Applies RAG filters to the request's response and forwards it to the next handler.
Args:
request (Any): The incoming request containing the necessary information for filtering.
Returns:
str: The result of the superclass's handle method with updated response information.
"""
logger.info("passing through => metadata_ragfilter")
response = request
response["rag_filters"] = {
"datasources": response.get("available_datasources", []),
"document_count": 50,
"schema_count": 10
}
return await super().handle(response)
================================================
FILE: app/chain/modules/ouput_formatter.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
class OutputFormatter(AbstractHandler):
"""
A handler for formatting the output based on the provided inference and query responses.
This class processes the response from a query, formats it based on the available data and inference results,
and prepares it for further handling. It manages content, context, and additional metadata.
Attributes:
common_context (dict): Shared context information used across handlers.
datasource (dict): A dictionary for data formatting based on the intent.
"""
def __init__(self,common_context, datasource):
"""
Initializes the OutputFormatter with common context and datasource.
Args:
common_context (dict): Shared context information used across handlers.
datasource (dict): A dictionary for data formatting based on the intent.
"""
self.datasource = datasource
self.common_context = common_context
async def handle(self, request: Any) -> str:
"""
Formats the response based on the inference and query response.
Args:
request (Any): The incoming request containing inference results and query response.
Returns:
str: The result of the superclass's handle method with updated response information.
"""
logger.info("passing through => output_formatter")
input_data = request.get("inference", {})
response = {}
if "main_entity" in input_data and "operation_kind" in input_data :
intent_key = self.common_context.get("intent")
if intent_key in self.datasource:
response = self.datasource[intent_key].format(request.get("query_response"), input_data)
elif "general_message" in input_data:
response["content"] = str(input_data.get('general_message'))
if "data" in response and isinstance(response["data"], list) and len(response["data"]) == 0:
if "empty_message" in input_data:
response["content"] = input_data["empty_message"]
else:
response["content"] = "I didn't find any data matching the query"
response["main_format"] = "general_chat"
elif "kind" in response and response["kind"] == "none":
response["content"] = input_data.get("empty_message", "I didn't find any relevant data regarding this, please reframe your query")
response["main_format"] = "general_chat"
response["next_questions"] = input_data.get("next_questions", [])
if "context_id" in request:
response["context_id"] = request["context_id"]
response["question"] = request["question"]
response["query"] = input_data.get("query", '')
response["intent"] = request.get("intent_extractor", {}).get("intent","")
response["summary"] = request.get("summary", '')
logger.debug(f"content: {response.get('content')}")
return await super().handle(response)
================================================
FILE: app/chain/modules/post_processor.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
class PostProcessor(AbstractHandler):
async def handle(self, request: Any) -> str:
logger.info("passing through => post_processor")
response = request
return response
================================================
FILE: app/chain/modules/prompt_generator.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
from string import Template
class PromptGenerator(AbstractHandler):
"""
A handler for generating prompts based on the provided context, model configurations, and data sources.
This class creates a formatted prompt for the model by combining various elements such as system prompts,
user prompts, and context information. It supports both manual and automatic prompt injection modes.
Attributes:
common_context (dict): Shared context information used across handlers.
model_configs (dict): Configuration settings for the model, including prompt injection settings.
datasources (dict): Data sources for generating prompt contexts based on intent.
"""
def __init__(self, common_context , model_configs, datasources) -> None:
"""
Initializes the PromptGenerator with common context, model configurations, and data sources.
Args:
common_context (dict): Shared context information used across handlers.
model_configs (dict): Configuration settings for the model.
datasources (dict): Data sources for generating prompt contexts based on intent.
"""
self.model_configs = model_configs
self.common_context = common_context
self.datasources = datasources
async def handle(self, request: Any) -> str:
"""
Generates a prompt based on the incoming request and provided configurations.
Args:
request (Any): The incoming request containing data for prompt generation.
Returns:
str: The result of the superclass's handle method with the generated prompt included in the response.
"""
logger.info("passing through => prompt_generator")
response = request
intent = response["intent_extractor"]['intent']
contexts = request.get("context",[])
previous_messages = contexts[-5:] if len(contexts) >= 5 else contexts
recal_history = ""
for message in previous_messages:
recal_history += f"USER: {message.chat_query}\n"
answer = message.chat_answer
recal_history += f"ASSITANT: {answer.get('query','')}\n\n"
# Few shot prompting
samples_retrieved = ""
rag = request.get("rag", {})
suggestions = rag.get("suggestions", [])
for doc in suggestions:
samples_retrieved += f"question: {doc.get('document', '')}\n"
samples_retrieved += f"query: {doc.get('metadatas', {}).get('query', '')}\n\n"
prompt_injection = self.model_configs.get("prompt_injection", {"mode": "auto"})
data_source = self.datasources.get(self.common_context.get("intent", "default"))
context = data_source.__prompt__
prompt = context.base_prompt
system_prompt = ""
if prompt_injection["mode"] == "manual" :
system_prompt_context = context.system_prompt
system_prompt = system_prompt_context.template.format(
**{**system_prompt_context["prompt_variables"]}
)
else:
auto_context = "\n\n".join(cont["document"] for cont in rag.get("context", {}).get(intent,[]))
auto_schema = "\n\n".join(schema["document"] for schema in rag.get("schema", []))
system_prompt_context = context.system_prompt
system_prompt = system_prompt_context.template.format(
schema=auto_schema,
context=auto_context,
question=request.get("question", ""),
suggestions="",
recal_history=recal_history
)
user_prompt = ""
if self.common_context["chain_retries"] == 0:
user_prompt = context.user_prompt.template
else:
logger.info("regenerating prompt using available context")
regeneration_promt_context = context.regeneration_prompt
user_prompt = Template(regeneration_promt_context.template).safe_substitute(
exception_log =self.common_context["execution_logs"][0]["error"] if len(self.common_context["execution_logs"])>0 else "",
query_generated =self.common_context["execution_logs"][0]["query"] if len(self.common_context["execution_logs"])>0 else ""
)
final_prompt = prompt.format(user_prompt=user_prompt, system_prompt=system_prompt)
final_prompt = Template(final_prompt).safe_substitute(
question=request.get("question", ""),
suggestions=samples_retrieved,
**self.model_configs.get("use_case", {})
)
response["prompt"] = final_prompt
logger.debug(f"final_prompt:{final_prompt}")
return await super().handle(response)
================================================
FILE: app/chain/modules/router.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
from app.chain.formatter.general_response import Formatter
class Router(AbstractHandler):
"""
A handler that routes requests to appropriate handlers based on the detected intent.
The Router class determines the correct handler to process the request based on the intent extracted
from the request. It forwards the request to the appropriate handler or returns a fallback response
if no suitable handler is found.
Attributes:
fallback_handler (AbstractHandler): Handler to process requests that do not match any specific intent.
general_handler (AbstractHandler): Handler for general intent processing.
capability_handler (AbstractHandler): Handler for capability-related intents.
metadata_handler (AbstractHandler): Handler for metadata-related intents.
"""
def __init__(self, common_context, fallback_handler, intent_handler, general_handler, capability_handler, metadata_handler) -> None:
"""
Initializes the Router with the provided handlers.
Args:
common_context (dict): Shared context information used across handlers.
fallback_handler (AbstractHandler): Handler for fallback responses.
general_handler (AbstractHandler): Handler for general intent processing.
capability_handler (AbstractHandler): Handler for capability-related intents.
metadata_handler (AbstractHandler): Handler for metadata-related intents.
"""
self.fallback_handler = fallback_handler
self.forwared_handler = intent_handler
self.general_handler = general_handler
self.capability_handler = capability_handler
self.metadata_handler = metadata_handler
async def handle(self, request: Any) -> str:
"""
Routes the request to the appropriate handler based on the detected intent.
Args:
request (Any): The incoming request containing intent information.
Returns:
str: The result of the handled request.
"""
logger.info("passing through => Router")
response = request
intent_extractor = request.get("intent_extractor", {})
intent = intent_extractor.get("intent", "")
if intent:
if intent in self.forwared_handler.data_sources:
datasource = self.forwared_handler.data_sources[intent]
if datasource.__category__ == 2 or datasource.__category__ == 5:
logger.info("entered database workflow")
return await self.forwared_handler.invoke(request)
else:
logger.info("entered default workflow")
return await self.general_handler.invoke(request)
elif intent == "metadata_inquiry":
return await self.metadata_handler.invoke(request)
elif intent in request.get("available_intents", []) and intent != "out_of_context":
return await self.capability_handler.invoke(request)
else:
response = Formatter.format("Sorry, I can't help you with that. Is there anything i can help you with ?","")
return await self.fallback_handler.handle(response)
else:
logger.info("No intents detected")
response = Formatter.format("Sorry, I can't help you with that. Is there anything i can help you with ?","")
return await self.fallback_handler.handle(response)
================================================
FILE: app/chain/modules/schema_retriever.py
================================================
from app.base.abstract_handlers import AbstractHandler
from loguru import logger
from typing import Any
from app.providers.container import Container
class SchemaRetriever(AbstractHandler):
"""
A handler for retrieving similar schemas based on a given question and context.
This class queries the store for schemas similar to the input question and context. It processes the
retrieved schemas to potentially cluster them and select the most relevant schemas based on certain criteria.
Attributes:
store (object): The data store used to find similar schemas.
"""
def __init__(self,store,datasources):
"""
Initializes the SchemaRetriever with the provided store.
Args:
store (object): The data store used for schema retrieval.
"""
self.store = store
self.datasources = datasources
async def handle(self, request: Any) -> str:
"""
Retrieves similar schemas from the store and updates the response with the results.
Args:
request (Any): The incoming request containing the question, context, and filtering criteria.
Returns:
Dict[str, Any]: The updated response dictionary with retrieved schemas.
"""
logger.info("passing through => schema_retriever")
response = request
schema_count = request.get('rag_filters', {}).get("schema_count", 0)
auto_context = "\n\n".join(cont.get("document", "") for cont in request.get("rag", {}).get("context", []))
intent = request.get("intent_extracter",{}).get("intent","")
datasource = self.datasources[intent]
out = await self.store.find_similar_schema(datasource, request["question"] + "\n" + auto_context, schema_count)
if out and len(out) > 0:
distances = [doc['distances'] for doc in out]
if len(out) > 2:
clusters = Container.clustering().kmeans(distances, 2)
shortest_cluster = clusters[0]
opt_doc = [doc for doc in out if doc.get('distances') in shortest_cluster]
else:
opt_doc = out
response["rag"].update({
"schema": opt_doc,
})
else:
response["rag"].update({
"schema": [],
})
return await super().handle(response)
================================================
FILE: app/chain/modules/validator.py
================================================
from app.base.abstract_handlers import AbstractHandler
from typing import Any
from loguru import logger
from app.chain.formatter.general_response import Formatter
class Validator(AbstractHandler):
"""
A handler for validating queries generated by the system.
This class validates the generated SQL queries against the data source and returns an appropriate response
if there are validation issues.
Attributes:
common_context (dict): Shared context information used for formatting responses and accessing intent-specific data.
datasource (dict): Data source used to validate the generated SQL queries.
"""
def __init__(self,common_context,datasource) -> None:
"""
Initializes the Validator with the provided context and datasource.
Args:
common_context (dict): Shared context information used for validation and response formatting.
datasource (dict): Data source used for query validation.
"""
super().__init__()
self.common_context = common_context
self.datasource = datasource
async def handle(self, request: Any) -> str:
"""
Validates the generated SQL query and updates the response if there are validation issues.
Args:
request (Any): The incoming request containing the generated query and other relevant information.
Returns:
str: The result of the handled request or an error message if validation fails.
"""
logger.info("passing through => query_validator")
response = request
inference = request.get("inference", {})
formated_sql = inference.get("query", "")
if formated_sql:
intent = self.common_context.get("intent", "")
validator = self.datasource.get(intent, None)
if validator:
result = validator.validate(formated_sql)
if result:
logger.critical(f"Generated Query Validation Issue: {result}")
return Formatter.format(result,"")
return await super().handle(response)
================================================
FILE: app/embeddings/cohere/__init__.py
================================================
from collections import OrderedDict
from app.models.request import ConnectionArgument
__provider_name__ = "cohere"
__vectordb_name__ = ["chroma"]
__icon__ = '/assets/embeddings/logos/cohere.svg'
__connection_args__ = [
{
"config": ["api_key"],
"models": [
"large"
]
}
]
__all__ = [
__vectordb_name__, __connection_args__, __provider_name__, __icon__
]
================================================
FILE: app/embeddings/cohere/handler.py
================================================
import chromadb.utils.embedding_functions as embedding_functions
from loguru import logger
class CohereEm:
def __init__(self,model_name:str = "",api_key:str = ""):
logger.info("Initialising embedding providers")
self.ef = embedding_functions.CohereEmbeddingFunction(api_key=api_key, model_name= model_name)
def load_emb(self):
return self.ef
def health_check(self) -> None:
pass
================================================
FILE: app/embeddings/default/chroma_default.py
================================================
import chromadb.utils.embedding_functions as embedding_functions
from loguru import logger
class ChromaDefaultEmbedding:
def __init__(self):
logger.info("Initialising embedding providers")
self.ef = embedding_functions.DefaultEmbeddingFunction()
def load_emb(self):
return self.ef
================================================
FILE: app/embeddings/default/default.py
================================================
from .onnx import DefaultEmbeddingModel
from .chroma_default import ChromaDefaultEmbedding
from loguru import logger
class DefaultEmbedding:
def __init__(self, vectordb_key: str = "chroma"):
logger.info("Initializing embedding providers")
self.vectordb = vectordb_key
def load_emb(self):
match self.vectordb:
case "chroma":
return ChromaDefaultEmbedding().load_emb()
case "mongodb":
return DefaultEmbeddingModel()
case _:
logger.error(f"Unsupported vectordb_key: {self.key}")
return None
def health_check(self) -> None:
pass
================================================
FILE: app/embeddings/default/onnx.py
================================================
import os
import requests
import numpy as np
from tokenizers import Tokenizer
import onnxruntime as ort
from typing import List
from loguru import logger
MODEL_ID = "sentence-transformers/all-MiniLM-L6-v2"
TOKENIZER_URL = "https://raw.githubusercontent.com/chroma-core/onnx-embedding/main/onnx/tokenizer.json"
MODEL_URL = "https://github.com/chroma-core/onnx-embedding/raw/main/onnx/model.onnx?download="
# Function to download files from a URL and save them locally
def download_file(url: str, local_path: str):
response = requests.get(url)
response.raise_for_status() # Check if the download is successful
with open(local_path, 'wb') as f:
f.write(response.content)
# Ensure that the directory exists
def ensure_dir(path):
if not os.path.exists(path):
os.makedirs(path)
# Use PyTorch's default epsilon for division by zero
def normalize(v):
norm = np.linalg.norm(v, axis=1)
norm[norm == 0] = 1e-12
return v / norm[:, np.newaxis]
# Sample implementation of the default sentence-transformers model using ONNX
class DefaultEmbeddingModel():
def __init__(self):
# Define paths to save the tokenizer and model
embedding_dir = os.path.join(os.getcwd(), "embeddings", "onnx")
ensure_dir(embedding_dir)
tokenizer_path = os.path.join(embedding_dir, "tokenizer.json")
model_path = os.path.join(embedding_dir, "model.onnx")
# Download the tokenizer and model from GitHub if they don't exist locally
if not os.path.isfile(tokenizer_path):
logger.info("Downloading tokenizer...")
download_file(TOKENIZER_URL, tokenizer_path)
if not os.path.isfile(model_path):
logger.info("Downloading ONNX model...")
download_file(MODEL_URL, model_path)
# Load the tokenizer
self.tokenizer = Tokenizer.from_file(tokenizer_path)
self.tokenizer.enable_truncation(max_length=256)
self.tokenizer.enable_padding(pad_id=0, pad_token="[PAD]", length=256)
# Load the ONNX model
self.model = ort.InferenceSession(model_path)
def __call__(self, documents: List[str], batch_size: int = 32):
all_embeddings = []
for i in range(0, len(documents), batch_size):
batch = documents[i:i + batch_size]
encoded = [self.tokenizer.encode(d) for d in batch]
input_ids = np.array([e.ids for e in encoded])
attention_mask = np.array([e.attention_mask for e in encoded])
onnx_input = {
"input_ids": np.array(input_ids, dtype=np.int64),
"attention_mask": np.array(attention_mask, dtype=np.int64),
"token_type_ids": np.array([np.zeros(len(e), dtype=np.int64) for e in input_ids], dtype=np.int64),
}
model_output = self.model.run(None, onnx_input)
last_hidden_state = model_output[0]
# Perform mean pooling with attention weighting
input_mask_expanded = np.broadcast_to(np.expand_dims(attention_mask, -1), last_hidden_state.shape)
embeddings = np.sum(last_hidden_state * input_mask_expanded, 1) / np.clip(input_mask_expanded.sum(1), a_min=1e-9, a_max=None)
embeddings = normalize(embeddings).astype(np.float32)
all_embeddings.append(embeddings)
return np.concatenate(all_embeddings)
================================================
FILE: app/embeddings/google/__init__.py
================================================
from collections import OrderedDict
from app.models.request import ConnectionArgument
__provider_name__ = "google"
__vectordb_name__ = ["chroma"]
__icon__ = '/assets/embeddings/logos/google.svg'
__connection_args__ = [
{
"config": ["api_key"],
"models": []
}
]
__all__ = [
__vectordb_name__, __connection_args__, __provider_name__, __icon__
]
================================================
FILE: app/embeddings/google/handler.py
================================================
import chromadb.utils.embedding_functions as embedding_functions
from loguru import logger
class GoogleEm:
def __init__(self,api_key:str = ""):
logger.info("Initialising embedding providers")
self.ef = embedding_functions.GoogleGenerativeAiEmbeddingFunction(api_key=api_key)
def load_emb(self):
return self.ef
def health_check(self) -> None:
pass
================================================
FILE: app/embeddings/loader.py
================================================
from app.embeddings.google. handler import GoogleEm
from app.embeddings.default.default import DefaultEmbedding
from app.embeddings.openai.handler import OpenAIEm
from app.embeddings.cohere.handler import CohereEm
from loguru import logger
class EmLoader:
def __init__(self, configs):
self.config = configs
def load_embclass(self):
emb_classes = {
"google": GoogleEm,
"openai": OpenAIEm,
"cohere": CohereEm,
# "default": DefaultEmbedding,
}
emb_provider = self.config.get("provider")
connection_params = self.config.get("params")
emb_class = emb_classes.get(emb_provider)
logger.info(f"embedding class: {emb_provider}")
if emb_class:
return emb_class(**connection_params if connection_params else {})
else:
logger.info("No specified embedding providers")
return DefaultEmbedding(self.config.get("vectordb"))
================================================
FILE: app/embeddings/openai/__init__.py
================================================
from collections import OrderedDict
from app.models.request import ConnectionArgument
__provider_name__ = "openai"
__vectordb_name__ = ["chroma"]
__icon__ = '/assets/embeddings/logos/openai.svg'
__connection_args__ = [
{
"config": ["api_key"],
"models": [
"text-embedding-ada-002",
"text-embedding-3-small",
"text-embedding-3-large"
]
}
]
__all__ = [
__vectordb_name__, __connection_args__, __provider_name__, __icon__
]
================================================
FILE: app/embeddings/openai/handler.py
================================================
import chromadb.utils.embedding_functions as embedding_functions
from loguru import logger
class OpenAIEm:
def __init__(self,model_name:str = "",api_key:str = ""):
logger.info("Initialising embedding providers")
self.ef = embedding_functions.OpenAIEmbeddingFunction(api_key=api_key, model_name= model_name)
def load_emb(self):
return self.ef
def health_check(self) -> None:
pass
================================================
FILE: app/loaders/ai71/__init__.py
================================================
__unique_name__ = "ai71"
__display_name__ = "AI71"
__icon__ = "/assets/providers/logos/ai71.png"
__all__ = ['__unique_name__', '__display_name__', '__icon__']
================================================
FILE: app/loaders/ai71/loader.py
================================================
from app.base.model_loader import ModelLoader
from app.base.loader_metadata_mixin import LoaderMetadataMixin
from app.base.base_llm import BaseLLM
from typing import Any
import json
import requests
class Ai71ModelLoader(ModelLoader, LoaderMetadataMixin):
model: Any = None
model_config : Any = {}
def do_inference(self, prompt, previous_messages) -> dict:
messages = self.messages_format(prompt, previous_messages)
self.model = BaseLLM(
url = self.model_config["endpoint"],
headers = {
"Authorization": "Bearer "+self.model_config["api_key"],
},
body = {
"temperature" : 0.5,
"model": self.model_config["name"],
"messages": messages
}
)
out = self.model._call("")
response = self.get_response(out)
usage = self.get_response_metadata(prompt, response, out)
return response, usage
def get_response(self, message) -> dict:
if "choices" in message and len(message["choices"]) > 0:
choice = message["choices"][0]
if "message" in choice:
return {"content" : choice["message"]["content"], "error" : None}
elif "error" in message:
error = message["error"]
if "message" in error:
return {"content" : "", "error" : error["message"]}
elif "detail" in message:
return {"content" : "", "error" : message["detail"]}
return {"content" : "", "error" : "Empty Response from LLM Provider"}
def get_response_metadata(self, prompt, response, out) -> dict:
return{
"input_tokens" : 0,
"output_tokens" : 0,
"logprobs" : [],
}
def messages_format(self, prompt, previous_messages) -> list:
chat_history = []
for prev_message in previous_messages:
chat_history.append({"role": "user", "content": prev_message.chat_query})
if prev_message.chat_answer is not None:
temp = prev_message.chat_answer
temp.pop("data", None)
chat_history.append({"role": "assistant", "content": json.dumps(temp)})
messages = []
if len(chat_history) > 0:
messages.extend(chat_history)
messages.append({"role": "user", "content": prompt})
return messages
def get_models(self):
"""
Retrieve models from the AI71 API and reformat the response.
Args:
llm_provider: The LLM provider object with API key.
Returns:
List of reformatted model information or an error message.
"""
url = "https://api.ai71.ai/v1/models"
try:
response = requests.get(url)
if response.status_code == 200:
data = response.json()
models = [{"display_name": model["name"], "id": model["id"]} for model in data.get("data", [])]
return models, False
else:
return f"Failed to retrieve AI71 models: {response.status_code} {response.text}", True
except requests.RequestException as e:
return f"Error occurred: {str(e)}", True
================================================
FILE: app/loaders/base_loader.py
================================================
from app.loaders.ollama.loader import OllamaModelLoader
from app.loaders.togethor.loader import TogethorModelLoader
from app.loaders.openai.loader import OpenAiModelLoader
from app.loaders.ai71.loader import Ai71ModelLoader
class BaseLoader:
def __init__(self, model_configs):
self.model_configs = model_configs
def load_model(self, unique_name):
for model in self.model_configs:
if model['unique_name'] == unique_name:
match model['kind']:
case "togethor":
loader = TogethorModelLoader(model_config=model)
case "openai":
loader = OpenAiModelLoader(model_config = model)
case "ai71":
loader = Ai71ModelLoader(model_config = model)
case "ollama":
loader = OllamaModelLoader(model_config = model)
case _ :
raise ValueError(f"Model with the inference provider '{model['kind']}' with the unique name '{unique_name}' was not found")
return loader
raise ValueError(f"Model with unique name '{unique_name}' not found")
def load_model_config(self, unique_name):
for model in self.model_configs:
if model['unique_name'] == unique_name:
return model
================================================
FILE: app/loaders/ollama/__init__.py
================================================
__unique_name__ = "ollama"
__display_name__ = "Ollama"
__icon__ = "/assets/providers/logos/ollama.png"
__all__ = ['__unique_name__', '__display_name__', '__icon__']
================================================
FILE: app/loaders/ollama/loader.py
================================================
from app.base.model_loader import ModelLoader
from app.base.base_llm import BaseLLM
from typing import Any
from loguru import logger
from app.base.loader_metadata_mixin import LoaderMetadataMixin
import json
import requests
class OllamaModelLoader(ModelLoader, LoaderMetadataMixin):
model: Any = None
model_config : Any = {}
def do_inference(self, prompt, previous_messages) -> dict:
messages = self.messages_format(prompt, previous_messages)
self.model = BaseLLM(
url = self.model_config["endpoint"],
body = {
"model": self.model_config["name"],
"messages": messages,
"stream" : False
}
)
out = self.model._call("")
logger.info(f"response:{out}")
response = self.get_response(out)
usage = self.get_response_metadata(prompt, response, out)
return response, usage
def get_response(self, message) -> dict:
if "message" in message:
message = message["message"]
if "content" in message:
return {"content" : message["content"], "error" : None}
elif "error" in message:
error = message["error"]
return {"content" : "", "error" : error}
return {"content" : "", "error" : "Empty Response from LLM Provider"}
def get_response_metadata(self, prompt, response, out) -> dict:
response_metadata = {}
if "usage" in out:
usage = out["usage"]
response_metadata.update({
"input_tokens" : usage["prompt_tokens"],
"output_tokens" : usage["completion_tokens"],
})
else:
response_metadata.update({
"input_tokens" : len(prompt),
"output_tokens" : len(out),
})
if "choices" in out and len(out["choices"]) > 0:
choice = out["choices"][0]
if "logprobs" in choice and choice["message"]["content"] != '' and choice['logprobs'] is not None:
response_metadata.update({
"logprobs" : [logprob['logprob'] for logprob in choice['logprobs']['content']]
})
return response_metadata
response_metadata.update({
"logprobs" : []
})
return response_metadata
def messages_format(self, prompt, previous_messages) -> list:
chat_history = []
for prev_message in previous_messages:
chat_history.append({"role": "user", "content": prev_message.chat_query})
if prev_message.chat_answer is not None:
temp = prev_message.chat_answer
temp.pop("data", None)
chat_history.append({"role": "assistant", "content": json.dumps(temp)})
messages = []
if len(chat_history) > 0:
messages.extend(chat_history)
messages.append({"role": "user", "content": prompt})
logger.info(f"messages:{messages}")
return messages
def get_models(self):
"""
Retrieve models from the Ollama API.
Returns:
List of Ollama model names or an error message.
"""
url = "curl http://localhost:11434/api/tags"
try:
response = requests.get(url)
if response.status_code == 200:
data = response.json()
models = [{"display_name": model["id"], "id": model["id"]} for model in data.get("data", [])]
return models, False
else:
return f"Failed to retrieve Ollama models: {response.status_code} {response.text}", True
except requests.RequestException as e:
return f"Error occurred: {str(e)}", True
================================================
FILE: app/loaders/openai/__init__.py
================================================
__unique_name__ = "openai"
__display_name__ = "Open AI"
__icon__ = "/assets/providers/logos/openai.png"
__all__ = ['__unique_name__', '__display_name__', '__icon__']
================================================
FILE: app/loaders/openai/loader.py
================================================
from app.base.model_loader import ModelLoader
from app.base.base_llm import BaseLLM
from typing import Any
from loguru import logger
from app.base.loader_metadata_mixin import LoaderMetadataMixin
import json
import requests
class OpenAiModelLoader(ModelLoader, LoaderMetadataMixin):
model: Any = None
model_config : Any = {}
def do_inference(self, prompt, previous_messages) -> dict:
messages = self.messages_format(prompt, previous_messages)
self.model = BaseLLM(
url = self.model_config["endpoint"],
headers = {
"Authorization": "Bearer "+self.model_config["api_key"],
},
body = {
"temperature" : 0.5,
"model": self.model_config["name"],
"messages": messages,
"logprobs": False,
}
)
out = self.model._call("")
response = self.get_response(out)
logger.info(f"response: {response}")
usage = self.get_response_metadata(prompt, response, out)
return response, usage
def get_response(self, message) -> dict:
if "choices" in message and len(message["choices"]) > 0:
choice = message["choices"][0]
if "message" in choice:
return {"content" : choice["message"]["content"], "error" : None}
elif "error" in message:
error = message["error"]
if "message" in error:
return {"content" : "", "error" : error["message"]}
return {"content" : "", "error" : "Empty Response from LLM Provider"}
def get_response_metadata(self, prompt, response, out) -> dict:
response_metadata = {}
if "usage" in out:
usage = out["usage"]
response_metadata.update({
"input_tokens" : usage["prompt_tokens"],
"output_tokens" : usage["completion_tokens"],
})
else:
response_metadata.update({
"input_tokens" : len(prompt),
"output_tokens" : len(out),
})
if "choices" in out and len(out["choices"]) > 0:
choice = out["choices"][0]
if "logprobs" in choice and choice["message"]["content"] != '' and choice['logprobs'] is not None:
response_metadata.update({
"logprobs" : [logprob['logprob'] for logprob in choice['logprobs']['content']]
})
return response_metadata
response_metadata.update({
"logprobs" : []
})
return response_metadata
def messages_format(self, prompt, previous_messages) -> list:
chat_history = []
for prev_message in previous_messages:
chat_history.append({"role": "user", "content": prev_message.chat_query})
if prev_message.chat_answer is not None:
temp = prev_message.chat_answer
temp.pop("data", None)
chat_history.append({"role": "assistant", "content": json.dumps(temp)})
messages = []
if len(chat_history) > 0:
messages.extend(chat_history)
messages.append({"role": "user", "content": prompt})
return messages
def get_models(self):
"""
Retrieve models from the OpenAI API.
Returns:
List of OpenAI model names or an error message.
"""
url = "https://api.openai.com/v1/models"
headers = {
"Authorization": f"Bearer {self.model_config.get('api_key', '')}",
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
models = [{"display_name": model["id"], "id": model["id"]} for model in data.get("data", [])]
return models, False
else:
return f"Failed to retrieve OpenAI models: {response.status_code} {response.text}", True
except requests.RequestException as e:
return f"Error occurred: {str(e)}", True
================================================
FILE: app/loaders/togethor/__init__.py
================================================
__unique_name__ = "togethor"
__display_name__ = "Togethor AI"
__icon__ = "/assets/providers/logos/togetherai.png"
__all__ = ['__unique_name__', '__display_name__', '__icon__']
================================================
FILE: app/loaders/togethor/loader.py
================================================
from app.base.model_loader import ModelLoader
from app.base.base_llm import BaseLLM
from typing import Any
from loguru import logger
from app.base.loader_metadata_mixin import LoaderMetadataMixin
import json
import requests
class TogethorModelLoader(ModelLoader, LoaderMetadataMixin):
model: Any = None
model_config : Any = {}
def do_inference(self, prompt, previous_messages) -> dict:
messages = self.messages_format(prompt, previous_messages)
self.model = BaseLLM(
url = self.model_config["endpoint"],
headers = {
"Authorization": "Bearer "+self.model_config["api_key"],
},
body = {
"temperature" : 0.5,
"model": self.model_config["name"],
"messages": messages,
"logprobs": 1,
}
)
out = self.model._call("")
logger.debug(out)
response = self.get_response(out)
respone_metadata = self.get_response_metadata(prompt, response, out)
return response, respone_metadata
def get_response(self, message) -> dict:
if "choices" in message and len(message["choices"]) > 0:
choice = message["choices"][0]
if "message" in choice:
return {"content" : choice["message"]["content"], "error" : None}
elif "error" in message:
error = message["error"]
if "message" in error:
return {"content" : "", "error" : error["message"]}
return {"content" : "", "error" : "Empty Response from LLM Provider"}
def get_response_metadata(self, prompt, response, out) -> dict:
response_metadata = {}
if "usage" in out:
usage = out["usage"]
response_metadata.update({
"input_tokens" : usage["prompt_tokens"],
"output_tokens" : usage["completion_tokens"],
})
else:
response_metadata.update({
"input_tokens" : len(prompt),
"output_tokens" : len(out),
})
if "choices" in out and len(out["choices"]) > 0:
choice = out["choices"][0]
if "message" in choice:
if "logprobs" in choice and choice["message"]["content"] != '':
response_metadata.update({
"logprobs" : choice['logprobs']['token_logprobs']
})
return response_metadata
response_metadata.update({
"logprobs" : []
})
return response_metadata
def messages_format(self, prompt, previous_messages) -> list:
chat_history = []
for prev_message in previous_messages:
chat_history.append({"role": "user", "content": prev_message.chat_query})
if prev_message.chat_answer is not None:
temp = prev_message.chat_answer
temp.pop("data", None)
chat_history.append({"role": "assistant", "content": json.dumps(temp)})
messages
gitextract_rx9dudey/ ├── .dockerignore ├── .flake8 ├── .github/ │ ├── ISSUE_TEMPLATE/ │ │ ├── bug_report.md │ │ └── feature_request.md │ └── workflows/ │ └── static.yml ├── .gitignore ├── .pre-commit-config.yaml ├── CODE_OF_CONDUCT.md ├── CONTRIBUTING.md ├── Dockerfile ├── LICENSE ├── Makefile ├── README.md ├── app/ │ ├── __init__.py │ ├── api/ │ │ └── v1/ │ │ ├── auth.py │ │ ├── commons.py │ │ ├── connector.py │ │ ├── llmchat.py │ │ ├── main_router.py │ │ └── provider.py │ ├── base/ │ │ ├── abstract_handlers.py │ │ ├── base_formatter.py │ │ ├── base_llm.py │ │ ├── base_plugin.py │ │ ├── base_vectordb.py │ │ ├── document_data_plugin.py │ │ ├── loader_metadata_mixin.py │ │ ├── messaging_plugin.py │ │ ├── model_loader.py │ │ ├── plugin_metadata_mixin.py │ │ ├── query_plugin.py │ │ └── remote_data_plugin.py │ ├── chain/ │ │ ├── chains/ │ │ │ ├── capability_chain.py │ │ │ ├── general_chain.py │ │ │ ├── intent_chain.py │ │ │ ├── metadata_chain.py │ │ │ └── query_chain.py │ │ ├── formatter/ │ │ │ └── general_response.py │ │ └── modules/ │ │ ├── cache_checker.py │ │ ├── cache_updater.py │ │ ├── context_retreiver.py │ │ ├── context_storage.py │ │ ├── document_retriever.py │ │ ├── executer.py │ │ ├── follow_up_handler.py │ │ ├── followup_interpreter.py │ │ ├── general_answer_generator.py │ │ ├── generator.py │ │ ├── input_formatter.py │ │ ├── intent_extracter.py │ │ ├── metadata_generator.py │ │ ├── metadata_ragfilter.py │ │ ├── ouput_formatter.py │ │ ├── post_processor.py │ │ ├── prompt_generator.py │ │ ├── router.py │ │ ├── schema_retriever.py │ │ └── validator.py │ ├── embeddings/ │ │ ├── cohere/ │ │ │ ├── __init__.py │ │ │ └── handler.py │ │ ├── default/ │ │ │ ├── chroma_default.py │ │ │ ├── default.py │ │ │ └── onnx.py │ │ ├── google/ │ │ │ ├── __init__.py │ │ │ └── handler.py │ │ ├── loader.py │ │ └── openai/ │ │ ├── __init__.py │ │ └── handler.py │ ├── loaders/ │ │ ├── ai71/ │ │ │ ├── __init__.py │ │ │ └── loader.py │ │ ├── base_loader.py │ │ ├── ollama/ │ │ │ ├── __init__.py │ │ │ └── loader.py │ │ ├── openai/ │ │ │ ├── __init__.py │ │ │ └── loader.py │ │ └── togethor/ │ │ ├── __init__.py │ │ └── loader.py │ ├── main.py │ ├── models/ │ │ ├── connector.py │ │ ├── db.py │ │ ├── environment.py │ │ ├── llmchat.py │ │ ├── prompt.py │ │ ├── provider.py │ │ ├── request.py │ │ └── user.py │ ├── plugins/ │ │ ├── airtable/ │ │ │ ├── __init__.py │ │ │ ├── formatter.py │ │ │ └── handler.py │ │ ├── bigquery/ │ │ │ ├── __init__.py │ │ │ ├── formatter.py │ │ │ └── handler.py │ │ ├── csv/ │ │ │ ├── __init__.py │ │ │ ├── formatter.py │ │ │ └── handler.py │ │ ├── document/ │ │ │ ├── __init__.py │ │ │ ├── formatter.py │ │ │ └── handler.py │ │ ├── loader.py │ │ ├── maria/ │ │ │ ├── __init__.py │ │ │ ├── formatter.py │ │ │ └── handler.py │ │ ├── mssql/ │ │ │ ├── __init__.py │ │ │ ├── formatter.py │ │ │ └── handler.py │ │ ├── mysql/ │ │ │ ├── __init__.py │ │ │ ├── formatter.py │ │ │ └── handler.py │ │ ├── postgresql/ │ │ │ ├── __init__.py │ │ │ ├── formatter.py │ │ │ └── handler.py │ │ ├── sqlite/ │ │ │ ├── __init__.py │ │ │ ├── formatter.py │ │ │ └── handler.py │ │ └── website/ │ │ ├── __init__.py │ │ ├── formatter.py │ │ └── handler.py │ ├── providers/ │ │ ├── cache_manager.py │ │ ├── clustering.py │ │ ├── config.py │ │ ├── container.py │ │ ├── context_storage.py │ │ ├── data_preperation.py │ │ ├── middleware.py │ │ ├── reranker.py │ │ └── zitadel.py │ ├── readers/ │ │ ├── base_reader.py │ │ ├── docs_reader.py │ │ ├── docx_reader.py │ │ ├── pdf_reader.py │ │ ├── text_reader.py │ │ ├── url_reader.py │ │ └── yaml_reader.py │ ├── repository/ │ │ ├── connector.py │ │ ├── environment.py │ │ ├── llmchat.py │ │ ├── provider.py │ │ └── user.py │ ├── schemas/ │ │ ├── common.py │ │ ├── connector.py │ │ ├── environment.py │ │ ├── llmchat.py │ │ ├── provider.py │ │ └── user.py │ ├── services/ │ │ ├── connector.py │ │ ├── connector_details.py │ │ ├── llmchat.py │ │ ├── provider.py │ │ └── user.py │ ├── utils/ │ │ ├── database.py │ │ ├── jwt.py │ │ ├── module_reader.py │ │ ├── parser.py │ │ └── read_config.py │ └── vectordb/ │ ├── loader.py │ └── mongodb/ │ ├── __init__.py │ └── handler.py ├── commands/ │ ├── cli.py │ └── llm.py ├── config.yaml ├── docker-compose.yml ├── documents/ │ ├── .gitignore │ ├── README.md │ ├── babel.config.js │ ├── docs/ │ │ ├── Configuring agents.md │ │ ├── Connectors/ │ │ │ ├── Airtable.md │ │ │ ├── Bigquery.md │ │ │ ├── Connectors.md │ │ │ ├── PDFs.md │ │ │ ├── Postgressql.md │ │ │ └── Websites.md │ │ ├── Examples.md │ │ ├── How to configure raggenie/ │ │ │ ├── Configuration.md │ │ │ ├── Deploy.md │ │ │ ├── Plugins.md │ │ │ ├── Preview.md │ │ │ ├── Samples.md │ │ │ └── _category_.json │ │ ├── How to run raggenie/ │ │ │ ├── To run raggenie backend Server.md │ │ │ ├── To run raggenie ui server.md │ │ │ ├── Using Docker.md │ │ │ └── _category_.json │ │ ├── LLM Inferences.md │ │ └── Prerequesites.md │ ├── docusaurus.config.js │ ├── package.json │ ├── sidebars.js │ ├── src/ │ │ ├── css/ │ │ │ └── custom.css │ │ └── pages/ │ │ ├── index.md │ │ └── index.module.css │ └── static/ │ └── .nojekyll ├── embeddings/ │ └── onnx/ │ ├── model.onnx │ └── tokenizer.json ├── main.py ├── nginx.conf ├── pyproject.toml ├── requirements.txt ├── setup.py ├── tests/ │ ├── README.md │ ├── __init__.py │ ├── conftest.py │ ├── functional/ │ │ ├── test_commons.py │ │ ├── test_connectors.py │ │ ├── test_llmchat.py │ │ └── test_provider.py │ ├── integration/ │ │ └── test_integration_connector.py │ └── unittest/ │ └── test_svc/ │ └── test_svc_provider.py ├── ui/ │ ├── .dockerignore │ ├── Dockerfile │ ├── README.md │ ├── eslint.config.js │ ├── index.html │ ├── jsconfig.json │ ├── nginx.conf │ ├── package.json │ ├── src/ │ │ ├── App.jsx │ │ ├── components/ │ │ │ ├── Breadcrumbs/ │ │ │ │ ├── Breadcrumbs.jsx │ │ │ │ └── Breadcrumbs.module.css │ │ │ ├── Button/ │ │ │ │ ├── Button.jsx │ │ │ │ ├── Button.module.css │ │ │ │ └── Button.test.jsx │ │ │ ├── Chart/ │ │ │ │ ├── AreaChart/ │ │ │ │ │ └── AreaChart.jsx │ │ │ │ ├── BarChart/ │ │ │ │ │ └── BarChart.jsx │ │ │ │ ├── LineChart/ │ │ │ │ │ └── LineChart.jsx │ │ │ │ ├── PieChart/ │ │ │ │ │ └── PieChart.jsx │ │ │ │ ├── Table/ │ │ │ │ │ └── Table.jsx │ │ │ │ └── style.module.css │ │ │ ├── ChatBox/ │ │ │ │ ├── ChatBox.jsx │ │ │ │ ├── ChatBox.module.css │ │ │ │ ├── ChatDropdownMenu/ │ │ │ │ │ ├── ChatDropdownMenu.jsx │ │ │ │ │ └── ChatDropdownMenu.module.css │ │ │ │ ├── ChatHistoryButton.jsx │ │ │ │ ├── ChatHistorySideBar.jsx │ │ │ │ ├── ErrorMessage.jsx │ │ │ │ ├── Feedback.jsx │ │ │ │ ├── Loader.jsx │ │ │ │ ├── Message.jsx │ │ │ │ ├── Summary.jsx │ │ │ │ └── Time.jsx │ │ │ ├── CodeBlock/ │ │ │ │ ├── CodeBlock.jsx │ │ │ │ └── CodeBlock.module.css │ │ │ ├── FileUpload/ │ │ │ │ ├── FileUpload.jsx │ │ │ │ └── FileUpload.module.css │ │ │ ├── Input/ │ │ │ │ ├── Input.jsx │ │ │ │ └── Input.module.css │ │ │ ├── Modal/ │ │ │ │ ├── Modal.jsx │ │ │ │ └── Modal.module.css │ │ │ ├── NotificationPanel/ │ │ │ │ ├── NotificationPanel.jsx │ │ │ │ └── NotificationPanel.module.css │ │ │ ├── RouteTab/ │ │ │ │ ├── RouteTab.jsx │ │ │ │ └── RouteTab.module.css │ │ │ ├── SearchInput/ │ │ │ │ ├── SearchInput.jsx │ │ │ │ └── SearchInput.module.css │ │ │ ├── Select/ │ │ │ │ ├── Select.jsx │ │ │ │ └── Select.module.css │ │ │ ├── Tab/ │ │ │ │ ├── Tab.jsx │ │ │ │ ├── Tab.module.css │ │ │ │ └── Tabs.jsx │ │ │ ├── Table/ │ │ │ │ ├── DatatableCustomTheme.css │ │ │ │ ├── Pagination.jsx │ │ │ │ ├── Table.jsx │ │ │ │ └── Table.module.css │ │ │ ├── Tag/ │ │ │ │ ├── Tag.jsx │ │ │ │ └── Tag.module.css │ │ │ ├── Textarea/ │ │ │ │ ├── Textarea.jsx │ │ │ │ └── Textarea.module.css │ │ │ └── TitleDescription/ │ │ │ ├── TitleDescription.jsx │ │ │ ├── TitleDescription.module.css │ │ │ └── TitleDescriptionContainer.jsx │ │ ├── config/ │ │ │ ├── const.js │ │ │ └── routes.jsx │ │ ├── embedbot/ │ │ │ ├── ChatBot.css │ │ │ ├── ChatBot.jsx │ │ │ ├── ChatBotAPI.js │ │ │ └── index.jsx │ │ ├── global.css │ │ ├── layouts/ │ │ │ ├── auth/ │ │ │ │ ├── AuthLogin.jsx │ │ │ │ ├── UserAuth.module.css │ │ │ │ ├── UserLogin.jsx │ │ │ │ └── UserSignUp.jsx │ │ │ ├── dashboard/ │ │ │ │ ├── DashboadBody.jsx │ │ │ │ ├── Dashboard.jsx │ │ │ │ ├── Dashboard.module.css │ │ │ │ ├── SideMenu.jsx │ │ │ │ └── SideMenuRoutes.js │ │ │ ├── errorPage/ │ │ │ │ ├── 404.jsx │ │ │ │ ├── 500.jsx │ │ │ │ └── error.module.css │ │ │ └── general/ │ │ │ ├── GeneralLayout.jsx │ │ │ └── GeneralLayout.module.css │ │ ├── main.jsx │ │ ├── pages/ │ │ │ ├── Chat/ │ │ │ │ ├── Chat.jsx │ │ │ │ └── Chat.module.css │ │ │ ├── ChatConfiguration/ │ │ │ │ ├── Capability/ │ │ │ │ │ ├── Capability.jsx │ │ │ │ │ └── Capability.module.css │ │ │ │ ├── ChatConfiguration.jsx │ │ │ │ ├── ChatConfiguration.module.css │ │ │ │ ├── ChatConfigurationForm.jsx │ │ │ │ ├── Configuration.module.css │ │ │ │ ├── ConfigurationList.jsx │ │ │ │ └── EmptyConfiguration.jsx │ │ │ ├── Configuration/ │ │ │ │ ├── Configuration.jsx │ │ │ │ ├── Configuration.module.css │ │ │ │ ├── ConfigurationList.jsx │ │ │ │ ├── EmptyConfiguration.jsx │ │ │ │ ├── ProviderForm/ │ │ │ │ │ ├── DatabaseTable.css │ │ │ │ │ ├── ProviderForm.jsx │ │ │ │ │ └── ProviderForm.module.css │ │ │ │ └── SchemaTable/ │ │ │ │ ├── SchemaTable.jsx │ │ │ │ └── SchemaTable.module.css │ │ │ ├── Deploy/ │ │ │ │ ├── Deploy.jsx │ │ │ │ ├── Deploy.module.css │ │ │ │ ├── DeployTabs/ │ │ │ │ │ ├── CopyEmbedCode.jsx │ │ │ │ │ ├── CopyURL.jsx │ │ │ │ │ ├── DeployTabs.module.css │ │ │ │ │ ├── MaximizedLayout.jsx │ │ │ │ │ └── MinimizedLayout.jsx │ │ │ │ └── deployTabRoutes.jsx │ │ │ ├── Preview/ │ │ │ │ ├── ChatBox.jsx │ │ │ │ ├── EmptyPreview.jsx │ │ │ │ ├── Preview.jsx │ │ │ │ └── Preview.module.css │ │ │ ├── Samples/ │ │ │ │ ├── EmptySample.jsx │ │ │ │ ├── SampleForm.jsx │ │ │ │ ├── SampleList.jsx │ │ │ │ ├── Samples.jsx │ │ │ │ └── Samples.module.css │ │ │ └── Sources/ │ │ │ ├── Connetor.jsx │ │ │ ├── Sources.jsx │ │ │ └── Sources.module.css │ │ ├── routes/ │ │ │ ├── DashboardRoute.jsx │ │ │ └── MainRoute.jsx │ │ ├── services/ │ │ │ ├── Auth.js │ │ │ ├── BotConfifuration.js │ │ │ ├── Capability.js │ │ │ ├── Connectors.js │ │ │ ├── Plugins.js │ │ │ └── Sample.js │ │ ├── store/ │ │ │ └── authStore.js │ │ ├── test/ │ │ │ └── setup.js │ │ └── utils/ │ │ ├── ConfirmDialog.jsx │ │ ├── form/ │ │ │ └── GenerateConfigs.jsx │ │ ├── http/ │ │ │ ├── DeleteService.js │ │ │ ├── GetService.js │ │ │ ├── PostService.js │ │ │ ├── Request.js │ │ │ └── UploadFile.js │ │ └── utils.js │ ├── vite.config.js │ └── vite.library.config.js └── zitadel-docker-compose.yaml
SYMBOL INDEX (745 symbols across 151 files)
FILE: app/api/v1/auth.py
function login_user (line 21) | def login_user(response: Response, user: LoginData, db: Session = Depend...
function idp_login (line 39) | def idp_login(response: Response, idp_id : int):
function idp_success (line 45) | def idp_success(request: Request,db: Session = Depends(get_db)):
function list_idp (line 93) | def list_idp(response: Response):
function get_user_info (line 98) | def get_user_info(request: Request, db: Session = Depends(get_db), user_...
function logout_user (line 139) | def logout_user(response: Response, user_data: dict = Depends(verify_tok...
FILE: app/api/v1/commons.py
function is_error_response (line 3) | def is_error_response(message:str, err:str, data:dict):
function is_none_reponse (line 12) | def is_none_reponse(message:str, data:dict):
FILE: app/api/v1/connector.py
function list_connectors (line 32) | def list_connectors(db: Session = Depends(get_db), provider_category_ids...
function get_connector (line 64) | def get_connector(connector_id: int, db: Session = Depends(get_db)):
function upload_document_datsource (line 94) | async def upload_document_datsource(
function create_connector (line 127) | def create_connector(connector: schemas.ConnectorBase, db: Session = Dep...
function update_connector (line 153) | def update_connector(connector_id: int, connector: schemas.ConnectorUpda...
function delete_connector (line 184) | def delete_connector(connector_id: int, db: Session = Depends(get_db)):
function updateschemas (line 214) | def updateschemas(connector_id: int, connector: schemas.SchemaUpdate, db...
function list_configurations (line 247) | def list_configurations(db: Session = Depends(get_db), user_data: dict =...
function get_configuration (line 276) | def get_configuration(config_id: int, db: Session = Depends(get_db)):
function get_configuration (line 304) | def get_configuration(config_id: int, db: Session = Depends(get_db)):
function create_configuration (line 333) | def create_configuration(configuration: schemas.ConfigurationCreation, d...
function update_configuration (line 365) | def update_configuration(config_id: int, configuration: schemas.Configur...
function create_capability (line 401) | def create_capability(capability: schemas.CapabilitiesBase, db: Session ...
function get_all_capabilities (line 429) | def get_all_capabilities(db: Session = Depends(get_db)):
function update_capability (line 461) | def update_capability(cap_id: int, capability: schemas.CapabilitiesUpdat...
function delete_capability (line 494) | def delete_capability(cap_id: int, db: Session = Depends(get_db)):
function create_yaml (line 528) | def create_yaml(request: Request, config_id: int, db: Session = Depends(...
function get_llm_provider_models (line 611) | def get_llm_provider_models(llm_provider: schemas.LLMProviderBase):
function get_inference (line 632) | def get_inference(inference_id: int, db: Session = Depends(get_db)):
function create_inference (line 664) | def create_inference(inference: schemas.InferenceBase, db: Session = Dep...
function update_inference (line 695) | def update_inference(inference_id: int, inference: schemas.InferenceBase...
function list_actions (line 733) | def list_actions(db: Session = Depends(get_db)):
function get_action (line 763) | def get_action(action_id:int, db: Session = Depends(get_db)):
function get_actions_by_connector (line 794) | def get_actions_by_connector(connector_id:int, db: Session = Depends(get...
function create_action (line 825) | def create_action(action: schemas.Actions, db: Session = Depends(get_db)):
function update_action (line 852) | def update_action(action_id: int, action: schemas.ActionsUpdate, db: Ses...
function delete_action (line 884) | def delete_action(action_id: int, db: Session = Depends(get_db)):
FILE: app/api/v1/llmchat.py
function create_chat (line 15) | def create_chat(chat: schemas.ChatHistoryCreate, db: Session = Depends(g...
function create_feedback (line 43) | def create_feedback(feedback: schemas.FeedbackCreate, db: Session = Depe...
function list_chat_by_context (line 74) | def list_chat_by_context(env_id: int, db: Session = Depends(get_db)):
function get_chat_by_context (line 105) | def get_chat_by_context(context_id: str, db: Session = Depends(get_db)):
FILE: app/api/v1/main_router.py
function qna (line 19) | async def qna(
function feedback_correction (line 85) | def feedback_correction(request: Request, body: FeedbackCorrectionRequest):
FILE: app/api/v1/provider.py
function list_providers (line 19) | def list_providers(db: Session = Depends(get_db)):
function get_provider (line 49) | def get_provider(provider_id: int, db: Session = Depends(get_db)):
function test_connections (line 80) | def test_connections(provider_id: int, config: schemas.TestCredentials, ...
function test_vectordb_credentials (line 112) | def test_vectordb_credentials(config: schemas.TestVectorDBCredentials, d...
function getvectordbs (line 142) | def getvectordbs(db: Session = Depends(get_db)):
function getllmproviders (line 171) | def getllmproviders(request: Request):
function test_inference_connections (line 202) | def test_inference_connections(inference: conn_schemas.InferenceBase):
function list_sql (line 235) | def list_sql(db: Session = Depends(get_db), user_data: dict = Depends(ve...
function get_sql (line 266) | def get_sql(id: int, db: Session = Depends(get_db)):
function create_sql (line 299) | def create_sql(request:Request,sql: schemas.SampleSQLBase, db: Session =...
function update_sql (line 329) | def update_sql(id: int, request: Request, sql: schemas.SampleSQLUpdate, ...
function delete_sql (line 362) | def delete_sql(id: int, db: Session = Depends(get_db)):
function create_vectordb_instance (line 390) | def create_vectordb_instance(vectordb: schemas.VectorDBBase, db: Session...
function update_vectordb_instance (line 419) | def update_vectordb_instance(id:int,vectordb: schemas.VectorDBUpdateBase...
function get_vectordb_instance (line 448) | def get_vectordb_instance(id: int, db: Session = Depends(get_db)):
function delete_vectordb_instance (line 474) | def delete_vectordb_instance(id: int, db: Session = Depends(get_db)):
function get_all_embeddings (line 500) | def get_all_embeddings():
FILE: app/base/abstract_handlers.py
class Handler (line 6) | class Handler(ABC):
method set_next (line 13) | def set_next(self, handler: Handler) -> Handler:
method handle (line 17) | async def handle(self, request) -> Optional[str]:
class AbstractHandler (line 20) | class AbstractHandler(Handler):
method set_next (line 28) | def set_next(self, handler: Handler) -> Handler:
method handle (line 36) | async def handle(self, request: Any) -> str:
FILE: app/base/base_formatter.py
class BaseFormatter (line 4) | class BaseFormatter(ABC):
method format (line 7) | def format(self)-> (dict):
FILE: app/base/base_llm.py
class BaseLLM (line 28) | class BaseLLM(LLM):
method _call (line 36) | def _call(
method _acall (line 56) | async def _acall(
method _llm_type (line 67) | def _llm_type(self) -> str:
method _identifying_params (line 71) | def _identifying_params(self) -> dict:
FILE: app/base/base_plugin.py
class BasePlugin (line 3) | class BasePlugin(ABC):
method connect (line 6) | def connect(self):
method healthcheck (line 10) | def healthcheck(self):
FILE: app/base/base_vectordb.py
class BaseVectorDB (line 3) | class BaseVectorDB():
method load_embeddings_function (line 5) | def load_embeddings_function(self):
FILE: app/base/document_data_plugin.py
class DocumentDataPlugin (line 4) | class DocumentDataPlugin(ABC):
method fetch_data (line 7) | def fetch_data(self, params: Optional[Dict[str, Any]] = None) -> list:
FILE: app/base/loader_metadata_mixin.py
class LoaderMetadataMixin (line 4) | class LoaderMetadataMixin:
method __init__ (line 12) | def __init__(self, name):
method _load_metadata (line 18) | def _load_metadata(self, class_path):
FILE: app/base/messaging_plugin.py
class MessagePlugin (line 3) | class MessagePlugin(ABC):
method send (line 6) | def send(self):
FILE: app/base/model_loader.py
class ModelLoader (line 1) | class ModelLoader:
method __init__ (line 4) | def __init__(self, model_config):
method load_model (line 7) | def load_model(self):
method get_response (line 10) | def get_response(self) -> dict:
method get_usage (line 13) | def get_usage(self, prompt, response, out) -> dict:
method get_models (line 16) | def get_models(self):
FILE: app/base/plugin_metadata_mixin.py
class PluginMetadataMixin (line 4) | class PluginMetadataMixin:
method __init__ (line 17) | def __init__(self, name):
method _load_metadata (line 23) | def _load_metadata(self, class_path):
FILE: app/base/query_plugin.py
class QueryPlugin (line 4) | class QueryPlugin(ABC):
method fetch_data (line 7) | def fetch_data(self, query: str, params: Optional[Dict[str, Any]] = No...
method fetch_schema_details (line 18) | def fetch_schema_details(self) -> Tuple[list, list]:
method create_ddl_from_metadata (line 27) | def create_ddl_from_metadata(self, table_metadata: list) -> list:
method validate (line 37) | def validate(self, formatted_sql: str) -> None:
FILE: app/base/remote_data_plugin.py
class RemoteDataPlugin (line 4) | class RemoteDataPlugin(ABC):
method fetch_data (line 7) | def fetch_data(self, params: Optional[Dict[str, Any]] = None) -> list:
FILE: app/chain/chains/capability_chain.py
class CapabilityChain (line 10) | class CapabilityChain:
method __init__ (line 30) | def __init__(self, model_configs, context_storage, general_chain):
method invoke (line 50) | def invoke(self, user_request):
FILE: app/chain/chains/general_chain.py
class GeneralChain (line 15) | class GeneralChain:
method __init__ (line 43) | def __init__(self, model_configs, store, datasource, context_store):
method invoke (line 77) | def invoke(self, user_request):
FILE: app/chain/chains/intent_chain.py
class IntentChain (line 13) | class IntentChain:
method __init__ (line 37) | def __init__(self, model_configs, store, datasource, context_store, in...
method invoke (line 61) | def invoke(self, user_request):
FILE: app/chain/chains/metadata_chain.py
class MetadataChain (line 11) | class MetadataChain:
method __init__ (line 36) | def __init__(self, model_configs, store, datasource, context_store):
method invoke (line 59) | def invoke(self, user_request):
FILE: app/chain/chains/query_chain.py
class QueryChain (line 22) | class QueryChain:
method __init__ (line 50) | def __init__(self, model_configs, store, datasource, context_store):
method invoke (line 110) | def invoke(self, user_request):
FILE: app/chain/formatter/general_response.py
class Formatter (line 1) | class Formatter:
method format (line 3) | def format(data: any, error: any) -> (dict):
FILE: app/chain/modules/cache_checker.py
class Cachechecker (line 6) | class Cachechecker(AbstractHandler):
method __init__ (line 14) | def __init__(self,common_context, cachestore, forward_handler, forward...
method handle (line 30) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/cache_updater.py
class Cacheupdater (line 5) | class Cacheupdater(AbstractHandler):
method __init__ (line 13) | def __init__(self,cachestore) -> None:
method handle (line 22) | async def handle(self, response: Any) -> str:
FILE: app/chain/modules/context_retreiver.py
class ContextRetreiver (line 6) | class ContextRetreiver(AbstractHandler):
method __init__ (line 14) | def __init__(self,common_context, context_store) -> None:
method handle (line 25) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/context_storage.py
class ContextStorage (line 7) | class ContextStorage(AbstractHandler):
method __init__ (line 15) | def __init__(self,common_context, context_store) -> None:
method handle (line 26) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/document_retriever.py
class DocumentRetriever (line 9) | class DocumentRetriever(AbstractHandler):
method __init__ (line 17) | def __init__(self,store, datasources):
method handle (line 30) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/executer.py
class Executer (line 7) | class Executer(AbstractHandler):
method __init__ (line 15) | def __init__(self, common_context, datasource, fallback_handler) -> None:
method handle (line 29) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/follow_up_handler.py
class FollowupHandler (line 10) | class FollowupHandler(AbstractHandler):
method __init__ (line 18) | def __init__(self, common_context , model_configs) -> None:
method handle (line 30) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/followup_interpreter.py
class FollowupInterpreter (line 6) | class FollowupInterpreter(AbstractHandler):
method __init__ (line 15) | def __init__(self, common_context, general_chain) -> None:
method handle (line 27) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/general_answer_generator.py
class GeneralAnswerGenerator (line 8) | class GeneralAnswerGenerator(AbstractHandler):
method __init__ (line 16) | def __init__(self, common_context, model_configs) -> None:
method handle (line 27) | async def handle(self, request: dict) -> str:
FILE: app/chain/modules/generator.py
class Generator (line 8) | class Generator(AbstractHandler):
method __init__ (line 16) | def __init__(self, common_context, model_configs) -> None:
method handle (line 27) | async def handle(self, request: dict) -> str:
FILE: app/chain/modules/input_formatter.py
class InputFormatter (line 6) | class InputFormatter(AbstractHandler):
method handle (line 8) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/intent_extracter.py
class IntentExtracter (line 11) | class IntentExtracter(AbstractHandler):
method __init__ (line 24) | def __init__(self, common_context , model_configs, datasources) -> None:
method handle (line 36) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/metadata_generator.py
class MetadataGenerator (line 12) | class MetadataGenerator(AbstractHandler):
method __init__ (line 14) | def __init__(self, common_context , model_configs, datasources) -> None:
method handle (line 19) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/metadata_ragfilter.py
class MetadataRagFilter (line 6) | class MetadataRagFilter(AbstractHandler):
method handle (line 21) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/ouput_formatter.py
class OutputFormatter (line 6) | class OutputFormatter(AbstractHandler):
method __init__ (line 18) | def __init__(self,common_context, datasource):
method handle (line 30) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/post_processor.py
class PostProcessor (line 5) | class PostProcessor(AbstractHandler):
method handle (line 7) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/prompt_generator.py
class PromptGenerator (line 6) | class PromptGenerator(AbstractHandler):
method __init__ (line 20) | def __init__(self, common_context , model_configs, datasources) -> None:
method handle (line 34) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/router.py
class Router (line 7) | class Router(AbstractHandler):
method __init__ (line 23) | def __init__(self, common_context, fallback_handler, intent_handler, g...
method handle (line 42) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/schema_retriever.py
class SchemaRetriever (line 8) | class SchemaRetriever(AbstractHandler):
method __init__ (line 19) | def __init__(self,store,datasources):
method handle (line 30) | async def handle(self, request: Any) -> str:
FILE: app/chain/modules/validator.py
class Validator (line 6) | class Validator(AbstractHandler):
method __init__ (line 18) | def __init__(self,common_context,datasource) -> None:
method handle (line 31) | async def handle(self, request: Any) -> str:
FILE: app/embeddings/cohere/handler.py
class CohereEm (line 6) | class CohereEm:
method __init__ (line 7) | def __init__(self,model_name:str = "",api_key:str = ""):
method load_emb (line 11) | def load_emb(self):
method health_check (line 14) | def health_check(self) -> None:
FILE: app/embeddings/default/chroma_default.py
class ChromaDefaultEmbedding (line 5) | class ChromaDefaultEmbedding:
method __init__ (line 6) | def __init__(self):
method load_emb (line 10) | def load_emb(self):
FILE: app/embeddings/default/default.py
class DefaultEmbedding (line 5) | class DefaultEmbedding:
method __init__ (line 6) | def __init__(self, vectordb_key: str = "chroma"):
method load_emb (line 10) | def load_emb(self):
method health_check (line 20) | def health_check(self) -> None:
FILE: app/embeddings/default/onnx.py
function download_file (line 14) | def download_file(url: str, local_path: str):
function ensure_dir (line 21) | def ensure_dir(path):
function normalize (line 26) | def normalize(v):
class DefaultEmbeddingModel (line 32) | class DefaultEmbeddingModel():
method __init__ (line 34) | def __init__(self):
method __call__ (line 59) | def __call__(self, documents: List[str], batch_size: int = 32):
FILE: app/embeddings/google/handler.py
class GoogleEm (line 5) | class GoogleEm:
method __init__ (line 7) | def __init__(self,api_key:str = ""):
method load_emb (line 11) | def load_emb(self):
method health_check (line 14) | def health_check(self) -> None:
FILE: app/embeddings/loader.py
class EmLoader (line 13) | class EmLoader:
method __init__ (line 14) | def __init__(self, configs):
method load_embclass (line 17) | def load_embclass(self):
FILE: app/embeddings/openai/handler.py
class OpenAIEm (line 6) | class OpenAIEm:
method __init__ (line 8) | def __init__(self,model_name:str = "",api_key:str = ""):
method load_emb (line 12) | def load_emb(self):
method health_check (line 15) | def health_check(self) -> None:
FILE: app/loaders/ai71/loader.py
class Ai71ModelLoader (line 8) | class Ai71ModelLoader(ModelLoader, LoaderMetadataMixin):
method do_inference (line 13) | def do_inference(self, prompt, previous_messages) -> dict:
method get_response (line 35) | def get_response(self, message) -> dict:
method get_response_metadata (line 48) | def get_response_metadata(self, prompt, response, out) -> dict:
method messages_format (line 57) | def messages_format(self, prompt, previous_messages) -> list:
method get_models (line 74) | def get_models(self):
FILE: app/loaders/base_loader.py
class BaseLoader (line 9) | class BaseLoader:
method __init__ (line 10) | def __init__(self, model_configs):
method load_model (line 13) | def load_model(self, unique_name):
method load_model_config (line 31) | def load_model_config(self, unique_name):
FILE: app/loaders/ollama/loader.py
class OllamaModelLoader (line 10) | class OllamaModelLoader(ModelLoader, LoaderMetadataMixin):
method do_inference (line 15) | def do_inference(self, prompt, previous_messages) -> dict:
method get_response (line 33) | def get_response(self, message) -> dict:
method get_response_metadata (line 43) | def get_response_metadata(self, prompt, response, out) -> dict:
method messages_format (line 71) | def messages_format(self, prompt, previous_messages) -> list:
method get_models (line 88) | def get_models(self):
FILE: app/loaders/openai/loader.py
class OpenAiModelLoader (line 9) | class OpenAiModelLoader(ModelLoader, LoaderMetadataMixin):
method do_inference (line 14) | def do_inference(self, prompt, previous_messages) -> dict:
method get_response (line 36) | def get_response(self, message) -> dict:
method get_response_metadata (line 47) | def get_response_metadata(self, prompt, response, out) -> dict:
method messages_format (line 75) | def messages_format(self, prompt, previous_messages) -> list:
method get_models (line 91) | def get_models(self):
FILE: app/loaders/togethor/loader.py
class TogethorModelLoader (line 9) | class TogethorModelLoader(ModelLoader, LoaderMetadataMixin):
method do_inference (line 16) | def do_inference(self, prompt, previous_messages) -> dict:
method get_response (line 38) | def get_response(self, message) -> dict:
method get_response_metadata (line 49) | def get_response_metadata(self, prompt, response, out) -> dict:
method messages_format (line 77) | def messages_format(self, prompt, previous_messages) -> list:
method get_models (line 95) | def get_models(self):
FILE: app/main.py
function create_app (line 42) | def create_app(config):
FILE: app/models/connector.py
class Connector (line 6) | class Connector(Base):
class Configuration (line 31) | class Configuration(Base):
class ConfigurationConnectorMapping (line 57) | class ConfigurationConnectorMapping(Base):
class Capabilities (line 71) | class Capabilities(Base):
class Inference (line 87) | class Inference(Base):
class Inferenceconfigmapping (line 104) | class Inferenceconfigmapping(Base):
class Actions (line 119) | class Actions(Base):
class CapActionsMapping (line 138) | class CapActionsMapping(Base):
FILE: app/models/db.py
class Chat (line 6) | class Chat(Base):
FILE: app/models/environment.py
class Environment (line 6) | class Environment(Base):
class UserEnvironmentMapping (line 17) | class UserEnvironmentMapping(Base):
FILE: app/models/llmchat.py
class ChatHistory (line 6) | class ChatHistory(Base):
FILE: app/models/prompt.py
class SystemPrompt (line 2) | class SystemPrompt(BaseModel):
class UserPrompt (line 8) | class UserPrompt(BaseModel):
class RegenerationPrompt (line 14) | class RegenerationPrompt(BaseModel):
class Prompt (line 20) | class Prompt(BaseModel):
FILE: app/models/provider.py
class Category (line 6) | class Category(Base):
class Provider (line 19) | class Provider(Base):
class ProviderConfig (line 37) | class ProviderConfig(Base):
class VectorDBConfig (line 57) | class VectorDBConfig(Base):
class SampleSQL (line 71) | class SampleSQL(Base):
class VectorDB (line 87) | class VectorDB(Base):
class VectorDBConfigMapping (line 102) | class VectorDBConfigMapping(Base):
class Embeddings (line 116) | class Embeddings(Base):
class VectorEmbeddingMapping (line 129) | class VectorEmbeddingMapping(Base):
FILE: app/models/request.py
class Chat (line 6) | class Chat(BaseModel):
class FlowItem (line 11) | class FlowItem(BaseModel):
class PostBody (line 15) | class PostBody(BaseModel):
class ResponseItem (line 19) | class ResponseItem(BaseModel):
class FeedbackCorrectionRequest (line 23) | class FeedbackCorrectionRequest(BaseModel):
class ConnectionArgument (line 27) | class ConnectionArgument(BaseModel):
FILE: app/models/user.py
class User (line 4) | class User(Base):
FILE: app/plugins/airtable/formatter.py
class Formatter (line 4) | class Formatter:
method format (line 10) | def format(self, data: Dict[str, Any], inference: Dict[str, Any]) -> d...
FILE: app/plugins/airtable/handler.py
class Airtable (line 12) | class Airtable(BasePlugin, QueryPlugin, PluginMetadataMixin, Formatter):
method __init__ (line 17) | def __init__(self, connector_name : str, token:str, workspace:str):
method connect (line 31) | def connect(self):
method healthcheck (line 40) | def healthcheck(self)-> Tuple[bool, Optional[str]]:
method configure_datasource (line 68) | def configure_datasource(self, init_config):
method fetch_data (line 77) | def fetch_data(self, query, params=None):
method fetch_schema_details (line 126) | def fetch_schema_details(self):
method create_ddl_from_metadata (line 174) | def create_ddl_from_metadata(self,table_metadata):
method validate (line 189) | def validate(self, formatted_sql: str) -> None:
method close_connection (line 197) | def close_connection(self) -> None:
FILE: app/plugins/bigquery/formatter.py
class Formatter (line 5) | class Formatter:
method format (line 6) | def format(self, data: Any,input) -> (dict):
method basic_formatter (line 42) | def basic_formatter(self, data: Any, input:Any) -> dict :
method aggregation_formatter (line 61) | def aggregation_formatter(self, data:Any, input:Any) -> dict :
FILE: app/plugins/bigquery/handler.py
class Bigquery (line 14) | class Bigquery(Formatter, BasePlugin, QueryPlugin, PluginMetadataMixin):
method __init__ (line 16) | def __init__(self, connector_name : str, project_id: str, service_acco...
method connect (line 29) | def connect(self):
method healthcheck (line 43) | def healthcheck(self):
method configure_datasource (line 70) | def configure_datasource(self, init_config):
method fetch_data (line 74) | def fetch_data(self,query: str):
method fetch_schema_details (line 89) | def fetch_schema_details(self):
method create_ddl_from_metadata (line 154) | def create_ddl_from_metadata(self, table_metadata: List[dict]):
method validate (line 175) | def validate(self, formatted_query: str) -> None:
FILE: app/plugins/csv/formatter.py
class Formatter (line 5) | class Formatter:
method format (line 6) | def format(self, data: Any,input) -> (dict):
method basic_formatter (line 42) | def basic_formatter(self, data: Any, input:Any) -> dict :
method aggregation_formatter (line 61) | def aggregation_formatter(self, data:Any, input:Any) -> dict :
FILE: app/plugins/csv/handler.py
class CSVPlugin (line 14) | class CSVPlugin(BasePlugin, PluginMetadataMixin, Formatter):
method __init__ (line 19) | def __init__(self, connector_name : str, document_files: List[str]):
method _dict_factory (line 30) | def _dict_factory(self, cursor, row):
method connect (line 36) | def connect(self) -> Tuple[bool, Optional[str]]:
method healthcheck (line 80) | def healthcheck(self):
method _insert_csv_to_db (line 91) | def _insert_csv_to_db(self, csv_file: str, table_name: str):
method configure_datasource (line 109) | def configure_datasource(self, init_config):
method fetch_data (line 112) | def fetch_data(self, query, params=None):
method fetch_schema_details (line 125) | def fetch_schema_details(self):
method create_ddl_from_metadata (line 162) | def create_ddl_from_metadata(self,table_metadata):
method _fetch_table_schema (line 171) | def _fetch_table_schema(self):
method fetch_feedback (line 186) | def fetch_feedback(self):
method validate (line 190) | def validate(self,formated_sql):
method close_conection (line 214) | def close_conection(self):
FILE: app/plugins/document/formatter.py
class Formatter (line 4) | class Formatter:
method format (line 10) | def format(self, data: Dict[str, Any], inference: Dict[str, Any]) -> d...
FILE: app/plugins/document/handler.py
class Document (line 13) | class Document(BasePlugin, PluginMetadataMixin,DocumentDataPlugin, Form...
method __init__ (line 18) | def __init__(self, connector_name : str, document_files:str):
method connect (line 31) | def connect(self):
method healthcheck (line 40) | def healthcheck(self)-> Tuple[bool, Optional[str]]:
method fetch_data (line 79) | def fetch_data(self, params=None):
FILE: app/plugins/loader.py
class DSLoader (line 14) | class DSLoader:
method __init__ (line 15) | def __init__(self, configs):
method load_ds (line 18) | def load_ds(self):
FILE: app/plugins/maria/formatter.py
class Formatter (line 5) | class Formatter:
method format (line 6) | def format(self, data: Any,input) -> (dict):
method basic_formatter (line 42) | def basic_formatter(self, data: Any, input:Any) -> dict :
method aggregation_formatter (line 61) | def aggregation_formatter(self, data:Any, input:Any) -> dict :
FILE: app/plugins/maria/handler.py
class Maria (line 13) | class Maria(Formatter, BasePlugin, QueryPlugin, PluginMetadataMixin):
method __init__ (line 15) | def __init__(self,connector_name : str, db_name:str, db_user:str="root...
method connect (line 39) | def connect(self):
method healthcheck (line 49) | def healthcheck(self):
method configure_datasource (line 64) | def configure_datasource(self, init_config):
method fetch_data (line 75) | def fetch_data(self, query, params=None):
method fetch_schema_details (line 87) | def fetch_schema_details(self):
method create_ddl_from_metadata (line 125) | def create_ddl_from_metadata(self,table_metadata):
method _fetch_table_schema (line 135) | def _fetch_table_schema(self):
method fetch_feedback (line 153) | def fetch_feedback(self):
method validate (line 159) | def validate(self,formated_sql):
method close_connection (line 181) | def close_connection(self):
FILE: app/plugins/mssql/formatter.py
class Formatter (line 5) | class Formatter:
method format (line 6) | def format(self, data: Any,input) -> (dict):
method basic_formatter (line 42) | def basic_formatter(self, data: Any, input:Any) -> dict :
method aggregation_formatter (line 61) | def aggregation_formatter(self, data:Any, input:Any) -> dict :
FILE: app/plugins/mssql/handler.py
class Mssql (line 13) | class Mssql(Formatter, BasePlugin, QueryPlugin, PluginMetadataMixin):
method __init__ (line 16) | def __init__(self, connector_name : str, db_name:str, db_user:str, db_...
method connect (line 35) | def connect(self):
method healthcheck (line 54) | def healthcheck(self):
method configure_datasource (line 69) | def configure_datasource(self, init_config):
method fetch_data (line 72) | def fetch_data(self, query, reconnect_attempt = True, params=None):
method fetch_schema_details (line 98) | def fetch_schema_details(self):
method create_ddl_from_metadata (line 176) | def create_ddl_from_metadata(self,table_metadata):
method fetch_feedback (line 186) | def fetch_feedback(self):
method validate (line 189) | def validate(self,formated_sql):
method close_connection (line 211) | def close_connection(self):
FILE: app/plugins/mysql/formatter.py
class Formatter (line 5) | class Formatter:
method format (line 6) | def format(self, data: Any,input) -> (dict):
method basic_formatter (line 42) | def basic_formatter(self, data: Any, input:Any) -> dict :
method aggregation_formatter (line 61) | def aggregation_formatter(self, data:Any, input:Any) -> dict :
FILE: app/plugins/mysql/handler.py
class Mysql (line 14) | class Mysql(Formatter, BasePlugin, QueryPlugin, PluginMetadataMixin):
method __init__ (line 16) | def __init__(self, connector_name : str, db_name:str, db_user:str="roo...
method connect (line 37) | def connect(self):
method healthcheck (line 47) | def healthcheck(self):
method configure_datasource (line 62) | def configure_datasource(self, init_config):
method fetch_data (line 73) | def fetch_data(self, query, params=None):
method fetch_schema_details (line 85) | def fetch_schema_details(self):
method create_ddl_from_metadata (line 123) | def create_ddl_from_metadata(self,table_metadata):
method _fetch_table_schema (line 133) | def _fetch_table_schema(self):
method fetch_feedback (line 151) | def fetch_feedback(self):
method validate (line 157) | def validate(self,formated_sql):
method close_connection (line 179) | def close_connection(self):
FILE: app/plugins/postgresql/formatter.py
class Formatter (line 5) | class Formatter:
method format (line 6) | def format(self, data: Any,input) -> (dict):
method basic_formatter (line 42) | def basic_formatter(self, data: Any, input:Any) -> dict :
method aggregation_formatter (line 61) | def aggregation_formatter(self, data:Any, input:Any) -> dict :
FILE: app/plugins/postgresql/handler.py
class Postresql (line 14) | class Postresql(Formatter, BasePlugin, QueryPlugin, PluginMetadataMixin):
method __init__ (line 16) | def __init__(self, connector_name : str, db_name:str, db_user:str="pos...
method connect (line 38) | def connect(self):
method healthcheck (line 48) | def healthcheck(self):
method configure_datasource (line 61) | def configure_datasource(self, init_config):
method fetch_data (line 72) | def fetch_data(self, query, params=None):
method fetch_schema_details (line 84) | def fetch_schema_details(self):
method create_ddl_from_metadata (line 124) | def create_ddl_from_metadata(self,table_metadata):
method select_all_from_table (line 133) | def select_all_from_table(self, table_name):
method _fetch_table_schema (line 137) | def _fetch_table_schema(self):
method fetch_feedback (line 155) | def fetch_feedback(self):
method validate (line 161) | def validate(self,formated_sql):
method close_connection (line 183) | def close_connection(self):
FILE: app/plugins/sqlite/formatter.py
class Formatter (line 5) | class Formatter:
method format (line 6) | def format(self, data: Any,input) -> (dict):
method basic_formatter (line 42) | def basic_formatter(self, data: Any, input:Any) -> dict :
method aggregation_formatter (line 61) | def aggregation_formatter(self, data:Any, input:Any) -> dict :
FILE: app/plugins/sqlite/handler.py
class Sqlite (line 14) | class Sqlite(Formatter, BasePlugin, QueryPlugin, PluginMetadataMixin):
method __init__ (line 15) | def __init__(self, connector_name : str, db_name:str, db_parent_path:s...
method _dict_factory (line 30) | def _dict_factory(self, cursor, row):
method _path_to_uri (line 36) | def _path_to_uri(self, path):
method connect (line 42) | def connect(self):
method healthcheck (line 56) | def healthcheck(self):
method configure_datasource (line 67) | def configure_datasource(self, init_config):
method fetch_data (line 78) | def fetch_data(self, query, params=None):
method fetch_schema_details (line 91) | def fetch_schema_details(self):
method create_ddl_from_metadata (line 131) | def create_ddl_from_metadata(self,table_metadata):
method _fetch_table_schema (line 140) | def _fetch_table_schema(self):
method fetch_feedback (line 158) | def fetch_feedback(self):
method validate (line 161) | def validate(self,formated_sql):
method close_conection (line 183) | def close_conection(self):
FILE: app/plugins/website/formatter.py
class Formatter (line 4) | class Formatter:
method format (line 10) | def format(self, data: Dict[str, Any], inference: Dict[str, Any]) -> d...
FILE: app/plugins/website/handler.py
class Website (line 12) | class Website(BasePlugin, PluginMetadataMixin,RemoteDataPlugin, Formatt...
method __init__ (line 17) | def __init__(self, connector_name : str, website_url:str, depth : int ...
method connect (line 30) | def connect(self):
method healthcheck (line 39) | def healthcheck(self)-> Tuple[bool, Optional[str]]:
method fetch_data (line 68) | def fetch_data(self, params=None):
FILE: app/providers/cache_manager.py
class CacheManager (line 4) | class CacheManager(object):
method __init__ (line 9) | def __init__(self):
method get_instance (line 13) | def get_instance(cls):
method set (line 18) | def set(self, key, value):
method get (line 26) | def get(self, key):
method clear (line 29) | def clear(self, key):
FILE: app/providers/clustering.py
class Clustering (line 4) | class Clustering:
method _initialize_centroids (line 6) | def _initialize_centroids(self,data, k):
method _assign_clusters (line 9) | def _assign_clusters(self, data, centroids):
method _recalculate_centroids (line 16) | def _recalculate_centroids(self, data, clusters, k):
method _get_clustered_values (line 26) | def _get_clustered_values(self, data, clusters, k):
method kmeans (line 32) | def kmeans(self, data, k, max_iterations=100):
FILE: app/providers/config.py
class Configs (line 10) | class Configs(BaseSettings):
FILE: app/providers/container.py
class Container (line 10) | class Container(containers.DeclarativeContainer):
FILE: app/providers/context_storage.py
class ContextStorage (line 7) | class ContextStorage:
method __init__ (line 8) | def __init__(self,db: Session=Depends(get_db)):
method create_table (line 13) | def create_table(self):
method insert_data (line 16) | def insert_data(self, data):
method update_data (line 20) | def update_data(self, model, filters, updates):
method query_data (line 24) | def query_data(self, model, filters=None, limit=None):
FILE: app/providers/data_preperation.py
class SourceDocuments (line 4) | class SourceDocuments:
method __init__ (line 5) | def __init__(self,schema_details, schema_configs, documentation):
method get_source_documents (line 22) | def get_source_documents(self):
FILE: app/providers/middleware.py
function verify_token (line 12) | async def verify_token(request: Request, session_data: Optional[str] = C...
FILE: app/providers/reranker.py
class Reranker (line 8) | class Reranker:
method __init__ (line 10) | def __init__(self,model_name):
method predict (line 14) | def predict(self,pairs):
FILE: app/providers/zitadel.py
class Zitadel (line 10) | class Zitadel:
method __init__ (line 12) | def __init__(self):
method _generate_jwt (line 28) | def _generate_jwt(self):
method _refresh_token (line 40) | def _refresh_token(self):
method _ensure_valid_token (line 57) | def _ensure_valid_token(self):
method create_user_session (line 64) | def create_user_session(self , user_id: str, idp_intent_id: str, token...
method create_user (line 122) | def create_user(self, user_data: dict, idp_intent_id: str, token: str):
method redirect_to_idp (line 170) | def redirect_to_idp(self, idp_id: int):
method get_user_info (line 199) | def get_user_info(self, session_id: int):
method get_idp_intent_data (line 221) | def get_idp_intent_data(self,idp_intent_id: int, idp_token: str):
method list_idp_providers (line 237) | def list_idp_providers(self):
method login_with_username_password (line 262) | def login_with_username_password(self, username: str, password: str):
method logout_user (line 330) | def logout_user(self, session_id: str):
FILE: app/readers/base_reader.py
class BaseReader (line 9) | class BaseReader:
method __init__ (line 10) | def __init__(self, source):
method load_data (line 14) | def load_data(self):
FILE: app/readers/docs_reader.py
class DocsReader (line 1) | class DocsReader:
method __init__ (line 3) | def __init__(self, source):
method load (line 6) | def load(self):
FILE: app/readers/docx_reader.py
class DocxReader (line 5) | class DocxReader(DocsReader):
method load (line 6) | def load(self):
FILE: app/readers/pdf_reader.py
class PDFLoader (line 21) | class PDFLoader(DocsReader):
method load (line 22) | def load(self):
FILE: app/readers/text_reader.py
class TxtLoader (line 4) | class TxtLoader(DocsReader):
method load (line 5) | def load(self):
FILE: app/readers/url_reader.py
class UrlReader (line 10) | class UrlReader(DocsReader):
method __init__ (line 12) | def __init__(self, source):
method load (line 18) | def load(self):
FILE: app/readers/yaml_reader.py
class YamlLoader (line 5) | class YamlLoader(DocsReader):
method load (line 6) | def load(self):
FILE: app/repository/connector.py
function get_connectors_by_configuration_id (line 11) | def get_connectors_by_configuration_id(configuration_id: int, db: Session):
function get_all_connectors (line 24) | def get_all_connectors(db: Session, user_id: str):
function get_connector_by_id (line 40) | def get_connector_by_id(connector_id: int, db: Session):
function create_new_connector (line 46) | def create_new_connector(connector: schemas.ConnectorBase, db: Session, ...
function update_existing_connector (line 60) | def update_existing_connector(connector_id: int, connector: schemas.Conn...
function update_schemas (line 73) | def update_schemas(connector_id: int, connector: schemas.ConnectorUpdate...
function delete_connector_by_id (line 88) | def delete_connector_by_id(connector_id: int, db: Session):
function get_all_configurations (line 99) | def get_all_configurations(db: Session, user_id: str):
function get_inference_by_config (line 120) | def get_inference_by_config(config_id: int, db: Session):
function getbotconfiguration (line 143) | def getbotconfiguration(db:Session):
function create_new_configuration (line 153) | def create_new_configuration(configuration: schemas.ConfigurationCreatio...
function link_configuration_to_connectors (line 186) | def link_configuration_to_connectors(config_id: int, connector_ids: list...
function update_existing_configuration (line 207) | def update_existing_configuration(config_id: int, configuration: schemas...
function get_configuration_by_id (line 263) | def get_configuration_by_id(config_id: int, db: Session):
function delete_configuration_by_id (line 280) | def delete_configuration_by_id(configuration_id: int, db: Session):
function update_configuration_status (line 291) | def update_configuration_status(config_id: int,status: int, db: Session):
function default_configuration_status (line 308) | def default_configuration_status(db: Session):
function create_capability (line 324) | def create_capability(capability: schemas.CapabilitiesBase, db: Session):
function create_capability_action_mappings (line 341) | def create_capability_action_mappings(capability_id: int, action_ids: Li...
function get_all_capabilities (line 357) | def get_all_capabilities(db: Session):
function update_capability (line 368) | def update_capability(cap_id: int, capability: schemas.CapabilitiesUpdat...
function delete_capability (line 399) | def delete_capability(cap_id: int, db: Session):
function get_inference_by_id (line 417) | def get_inference_by_id(inference_id: int, db: Session):
function create_inference (line 424) | def create_inference(inference: schemas.InferenceBase, db: Session):
function update_inference (line 453) | def update_inference(inference_id: int, inference: schemas.InferenceBase...
function get_inferences_by_config_id (line 489) | def get_inferences_by_config_id(config_id: int, db: Session):
function list_actions (line 495) | def list_actions(db:Session):
function get_action_by_id (line 501) | def get_action_by_id(action_id:int, db:Session):
function get_actions_by_connector (line 507) | def get_actions_by_connector(connector_id:int, db:Session):
function create_action (line 513) | def create_action(action:schemas.Actions, db:Session):
function update_action (line 534) | def update_action(action_id: int, action: schemas.ActionsUpdate, db: Ses...
function delete_action_by_id (line 559) | def delete_action_by_id(action_id: int, db: Session):
FILE: app/repository/environment.py
function create_environment (line 6) | def create_environment(name: str, db: Session):
function get_or_create_default_environment (line 14) | def get_or_create_default_environment(db: Session):
function assign_user_to_environment (line 25) | def assign_user_to_environment(user_id: int, environment_id: int, db: Se...
function get_current_env_id (line 37) | def get_current_env_id(user_id: int, db: Session):
FILE: app/repository/llmchat.py
function get_chat_by_context_and_id (line 8) | def get_chat_by_context_and_id(chat_context_id: str, chat_id: int, db: S...
function create_new_chat (line 15) | def create_new_chat(chat: schemas.ChatHistoryCreate, db: Session):
function update_chat_feedback (line 35) | def update_chat_feedback(feedback: schemas.FeedbackCreate, db: Session):
function get_primary_chat (line 54) | def get_primary_chat(env_id: int, db: Session):
function get_all_chats_by_context_id (line 63) | def get_all_chats_by_context_id(context_id: str, db: Session):
FILE: app/repository/provider.py
function insert_or_update_data (line 12) | def insert_or_update_data(db: Session, model: Any, filters: Dict[str, An...
function get_all_providers (line 37) | def get_all_providers(db: Session):
function get_provider_by_id (line 43) | def get_provider_by_id(provider_id: int, db: Session):
function get_vector_db_config (line 49) | def get_vector_db_config(db: Session, key: str):
function get_vectordb_providers (line 55) | def get_vectordb_providers(db:Session):
function get_config_types (line 61) | def get_config_types(provider_id: int, db:Session):
function get_sql_by_connector (line 67) | def get_sql_by_connector(id:int, db:Session):
function list_sql (line 73) | def list_sql(db:Session, user_id: str):
function get_sql (line 87) | def get_sql(id:int,db:Session):
function create_sql (line 93) | def create_sql(sql:schemas.SampleSQLBase, db:Session, user_id: str):
function update_sql (line 114) | def update_sql(sql_id:int, sql:schemas.SampleSQLUpdate, db:Session):
function delete_sql (line 132) | def delete_sql(sql_id:int, db: Session):
function get_sql_by_key (line 145) | def get_sql_by_key(key: str, db: Session):
function revoke_existing_vectordb_confg (line 152) | def revoke_existing_vectordb_confg(id: int, db: Session):
function create_vectordb_with_embedding (line 180) | def create_vectordb_with_embedding(key,id, vectordb, db: Session):
function get_vectordb_instance (line 235) | def get_vectordb_instance(id: int, db: Session):
function get_mapped_vector_store (line 265) | def get_mapped_vector_store(db: Session, config_id: int):
FILE: app/repository/user.py
function create_user (line 6) | def create_user(user: schemas.UserCreate, db: Session):
function get_user_by_id (line 17) | def get_user_by_id(user_id: int, db: Session):
FILE: app/schemas/common.py
class DBConfig (line 4) | class DBConfig(BaseModel):
class CommonResponse (line 11) | class CommonResponse(BaseModel):
class LoginData (line 18) | class LoginData(BaseModel):
FILE: app/schemas/connector.py
class ConnectorBase (line 4) | class ConnectorBase(BaseModel):
class ConnectorResponse (line 13) | class ConnectorResponse(ConnectorBase):
class ConnectorUpdate (line 19) | class ConnectorUpdate(BaseModel):
class SchemaUpdate (line 27) | class SchemaUpdate(BaseModel):
class CapabilitiesBase (line 30) | class CapabilitiesBase(BaseModel):
class CapabilitiesArray (line 39) | class CapabilitiesArray(BaseModel):
class CapabilitiesUpdateBase (line 42) | class CapabilitiesUpdateBase(BaseModel):
class ConfigurationBase (line 50) | class ConfigurationBase(BaseModel):
class ConfigurationCreation (line 56) | class ConfigurationCreation(ConfigurationBase):
class ConfigurationUpdate (line 62) | class ConfigurationUpdate(BaseModel):
class InferenceBase (line 71) | class InferenceBase(BaseModel):
class InferenceBaseUpdate (line 79) | class InferenceBaseUpdate(BaseModel):
class InferenceResponse (line 87) | class InferenceResponse(InferenceBase):
class ConfigurationResponse (line 90) | class ConfigurationResponse(ConfigurationBase):
class Actions (line 97) | class Actions(BaseModel):
class ActionsResponse (line 107) | class ActionsResponse(Actions):
class ActionsUpdate (line 111) | class ActionsUpdate(BaseModel):
class LLMProviderBase (line 120) | class LLMProviderBase(BaseModel):
FILE: app/schemas/environment.py
class EnvironmentBase (line 5) | class EnvironmentBase(BaseModel):
class EnvironmentResponse (line 8) | class EnvironmentResponse(EnvironmentBase):
class UserEnvironmentMappingBase (line 12) | class UserEnvironmentMappingBase(BaseModel):
class UserEnvironmentMappingResponse (line 16) | class UserEnvironmentMappingResponse(UserEnvironmentMappingBase):
FILE: app/schemas/llmchat.py
class ChatHistoryBase (line 6) | class ChatHistoryBase(BaseModel):
class ChatHistoryCreate (line 19) | class ChatHistoryCreate(ChatHistoryBase):
class ChatHistory (line 23) | class ChatHistory(ChatHistoryBase):
class ChatResponse (line 27) | class ChatResponse(ChatHistory):
class FeedbackCreate (line 31) | class FeedbackCreate(BaseModel):
class ListPrimaryContext (line 37) | class ListPrimaryContext(BaseModel):
FILE: app/schemas/provider.py
class ProviderConfigBase (line 6) | class ProviderConfigBase(BaseModel):
class ProviderConfigResponse (line 17) | class ProviderConfigResponse(ProviderConfigBase):
class ProviderBase (line 20) | class ProviderBase(BaseModel):
class ProviderResp (line 27) | class ProviderResp(ProviderBase):
class ProviderCreate (line 32) | class ProviderCreate(ProviderBase):
class ProviderUpdate (line 35) | class ProviderUpdate(ProviderBase):
class ProviderInDBBase (line 38) | class ProviderInDBBase(ProviderBase):
class Provider (line 45) | class Provider(ProviderInDBBase):
class ProviderList (line 48) | class ProviderList(BaseModel):
class CategoryBase (line 52) | class CategoryBase(BaseModel):
class CategoryResponse (line 57) | class CategoryResponse(CategoryBase):
class CategoryCreate (line 61) | class CategoryCreate(CategoryBase):
class CategoryList (line 64) | class CategoryList(BaseModel):
class ProviderConfigBase (line 68) | class ProviderConfigBase(BaseModel):
class ProviderConfigResponse (line 76) | class ProviderConfigResponse(ProviderConfigBase):
class ProviderConfigList (line 79) | class ProviderConfigList(BaseModel):
class TestCredentials (line 84) | class TestCredentials(BaseModel):
class TestVectorDBCredentials (line 88) | class TestVectorDBCredentials(BaseModel):
class SampleSQLBase (line 92) | class SampleSQLBase(BaseModel):
class SampleSQLUpdate (line 97) | class SampleSQLUpdate(BaseModel):
class SampleSQLResponse (line 102) | class SampleSQLResponse(SampleSQLBase):
class CredentialsHelper (line 105) | class CredentialsHelper(BaseModel):
class VectorDBConfigBase (line 109) | class VectorDBConfigBase(BaseModel):
class VectorDBConfigResponse (line 116) | class VectorDBConfigResponse(VectorDBConfigBase):
class VectorDBUpdateBase (line 119) | class VectorDBUpdateBase(BaseModel):
class VectorDBBase (line 125) | class VectorDBBase(BaseModel):
class VectorDBResponse (line 132) | class VectorDBResponse(VectorDBBase):
FILE: app/schemas/user.py
class UserBase (line 5) | class UserBase(BaseModel):
class UserResponse (line 9) | class UserResponse(UserBase):
class UserCreate (line 14) | class UserCreate(UserBase): # Used when creating a new user
FILE: app/services/connector.py
function list_connectors (line 20) | def list_connectors(db: Session, user_id: str):
function list_connectors_by_provider_category (line 56) | def list_connectors_by_provider_category(category_ids: int, db: Session,...
function get_connector (line 80) | def get_connector(connector_id: int, db: Session):
function download_and_save_pdf (line 118) | def download_and_save_pdf(connector_name: str, url: str) -> str:
function fileValidation (line 140) | async def fileValidation(file):
function upload_pdf (line 167) | async def upload_pdf(file):
function create_connector (line 191) | def create_connector(connector: schemas.ConnectorBase, db: Session, user...
function update_connector (line 248) | def update_connector(connector_id: int, connector: schemas.ConnectorUpda...
function delete_connector (line 283) | def delete_connector(connector_id: int, db: Session):
function updateschemas (line 319) | def updateschemas(connector_id: int, connector: schemas.SchemaUpdate, db...
function get_inference_by_config_id (line 348) | def get_inference_by_config_id(config_id:int , db:Session):
function list_configurations (line 379) | def list_configurations(db: Session, user_id: str):
function get_configuration (line 431) | def get_configuration(db: Session, config_id: int):
function delete_configuration (line 500) | def delete_configuration(db: Session, config_id: int):
function create_configuration (line 539) | def create_configuration(configuration: schemas.ConfigurationCreation, d...
function update_configuration (line 578) | def update_configuration(config_id: int, configuration: schemas.Configur...
function create_capabilities (line 618) | def create_capabilities(capabilities: schemas.CapabilitiesBase, db: Sess...
function get_all_capabilities (line 664) | def get_all_capabilities(db: Session):
function update_capability (line 707) | def update_capability(cap_id: int, capability: schemas.CapabilitiesUpdat...
function delete_capability (line 747) | def delete_capability(cap_id: int, db: Session):
function update_datasource_documentations (line 771) | def update_datasource_documentations(db: Session, vector_store, datasour...
function get_inference_and_plugin_configurations (line 818) | def get_inference_and_plugin_configurations(db: Session, config_id: int):
function create_inference_yaml (line 862) | def create_inference_yaml(config_id:int, db:Session):
function get_all_connector_samples (line 894) | def get_all_connector_samples(connector_id: int, db: Session):
function create_yaml_file (line 910) | def create_yaml_file(request:Request, config_id: int, db: Session):
function formatting_datasource (line 967) | def formatting_datasource(connector, provider):
function get_llm_provider_models (line 1000) | def get_llm_provider_models(llm_provider: schemas.LLMProviderBase):
function get_inference (line 1015) | def get_inference(inference_id: int, db: Session):
function create_inference (line 1047) | def create_inference(inference: schemas.InferenceBase, db: Session):
function update_inference (line 1076) | def update_inference(inference_id: int, inference: schemas.InferenceBase...
function list_actions (line 1109) | def list_actions(db:Session):
function get_actions (line 1142) | def get_actions(action_id:int, db:Session):
function get_actions_by_connector (line 1175) | def get_actions_by_connector(connector_id:int, db:Session):
function create_action (line 1208) | def create_action(action: schemas.Actions, db:Session):
function update_action (line 1239) | def update_action(action_id: int, action: schemas.ActionsUpdate, db: Ses...
function delete_action (line 1274) | def delete_action(action_id: int, db: Session):
function get_use_cases (line 1295) | def get_use_cases(db: Session):
FILE: app/services/connector_details.py
function test_plugin_connection (line 10) | def test_plugin_connection(db_configs, config, provider_class):
function get_plugin_metadata (line 36) | def get_plugin_metadata(db_configs, config, connector_name, provider_cla...
function check_configurations_availability (line 72) | def check_configurations_availability(db: Session)-> Any:
function test_vector_db_credentials (line 89) | def test_vector_db_credentials(db_config, config, key):
FILE: app/services/llmchat.py
function create_chat (line 6) | def create_chat(chat: schemas.ChatHistoryCreate, db: Session):
function create_feedback (line 40) | def create_feedback(feedback: schemas.FeedbackCreate, db: Session):
function list_chats_by_context (line 77) | def list_chats_by_context(env_id: int, db: Session):
function list_all_chats_by_context_id (line 118) | def list_all_chats_by_context_id(context_id: str, db: Session):
FILE: app/services/provider.py
function test_inference_credentials (line 16) | def test_inference_credentials(inference: conn_schemas.InferenceBase):
function initialize_vectordb_provider (line 51) | def initialize_vectordb_provider(db:Session):
function initialize_embeddings (line 74) | def initialize_embeddings(db:Session):
function initialize_plugin_providers (line 78) | def initialize_plugin_providers(db:Session):
function list_providers (line 121) | def list_providers(db: Session):
function get_provider (line 171) | def get_provider(provider_id: int,db: Session):
function test_vectordb_credentials (line 221) | def test_vectordb_credentials(config:schemas.TestVectorDBCredentials, db...
function vector_embedding_connector (line 243) | def vector_embedding_connector(config, db_config):
function test_credentials (line 259) | def test_credentials(provider_id: int, config: schemas.TestCredentials, ...
function getvectordbs (line 293) | def getvectordbs(db: Session):
function getllmproviders (line 325) | def getllmproviders(request: Request):
function getsqlbyconnector (line 341) | def getsqlbyconnector(id:int, db:Session):
function listsql (line 374) | def listsql(db:Session, user_id: str):
function getsql (line 406) | def getsql(id:int, db:Session):
function create_sql (line 438) | def create_sql(request: Request,sql:schemas.SampleSQLBase,db:Session, us...
function update_sql (line 468) | def update_sql(request: Request, sql_id: int, sql: schemas.SampleSQLUpda...
function delete_sql (line 500) | def delete_sql(sql_id: int, db: Session):
function get_quries_by_key (line 528) | def get_quries_by_key(key:str, db: Session):
function insert_vector_store (line 555) | def insert_vector_store(request, sql, db: Session):
function create_vector_db_default_config (line 585) | def create_vector_db_default_config(vectordb):
function attach_vector_config_if_missing (line 595) | def attach_vector_config_if_missing(vectordb, db):
function create_vectordb_and_embedding (line 608) | def create_vectordb_and_embedding(key,id,vectordb, db):
function get_vectordb_instance (line 643) | def get_vectordb_instance(id: int, db: Session):
function delete_vectordb_instance (line 669) | def delete_vectordb_instance(id: int, db: Session):
function create_vectorstore_instance (line 688) | def create_vectorstore_instance(db:Session, config_id: int):
function get_all_embeddings (line 734) | def get_all_embeddings():
FILE: app/services/user.py
function get_or_create_user (line 6) | def get_or_create_user(user: schemas.UserCreate, db: Session):
function get_users_active_env (line 40) | def get_users_active_env(user_id: int, db: Session):
FILE: app/utils/database.py
function get_db (line 13) | def get_db():
FILE: app/utils/jwt.py
class JWTUtils (line 5) | class JWTUtils:
method __init__ (line 6) | def __init__(self, secret_key, algorithm="HS256"):
method create_jwt_token (line 10) | def create_jwt_token(self, data: dict, expires_delta: timedelta = time...
method decode_jwt_token (line 17) | def decode_jwt_token(self, token: str):
FILE: app/utils/module_reader.py
function get_vectordb_providers (line 6) | def get_vectordb_providers():
function get_plugin_providers (line 26) | def get_plugin_providers():
function get_llm_providers (line 49) | def get_llm_providers():
function get_all_embedding (line 68) | def get_all_embedding():
FILE: app/utils/parser.py
function parse_llm_response (line 4) | def parse_llm_response(body):
function markdown_parse_llm_response (line 22) | def markdown_parse_llm_response(body):
FILE: app/utils/read_config.py
function read_yaml_file (line 6) | def read_yaml_file(config_file) -> dict:
FILE: app/vectordb/loader.py
class VectorDBLoader (line 8) | class VectorDBLoader:
method __init__ (line 9) | def __init__(self, config):
method load_class (line 12) | def load_class(self):
FILE: app/vectordb/mongodb/handler.py
class AltasMongoDB (line 7) | class AltasMongoDB(BaseVectorDB):
method __init__ (line 8) | def __init__(self, uri: str , embeddings: dict={"provider": "default",...
method connect (line 14) | def connect(self):
method health_check (line 31) | def health_check(self):
method clear_collection (line 60) | def clear_collection(self, config_id):
method generate_embedding (line 69) | def generate_embedding(self, context: str) -> list[float]:
method prepare_data (line 73) | def prepare_data(self, datasource_name, chunked_document, chunked_sche...
method _create_index (line 117) | def _create_index(self, collection, index_name):
method create_knn_index (line 142) | def create_knn_index(self):
method _find_similar (line 147) | async def _find_similar(self, datasource, collection, query, count, in...
method find_similar_schema (line 185) | async def find_similar_schema(self, datasource, query,count):
method find_similar_documentation (line 188) | async def find_similar_documentation(self, datasource, query, count):
method find_similar_cache (line 191) | async def find_similar_cache(self, datasource, query,count = 3):
FILE: commands/cli.py
function cli (line 10) | def cli(ctx, debug, config):
FILE: commands/llm.py
function llm (line 13) | def llm(ctx) -> None:
FILE: setup.py
function read (line 7) | def read(fname):
function parse_requirements (line 14) | def parse_requirements(filename):
FILE: tests/conftest.py
function start_application (line 21) | def start_application() -> FastAPI:
function app (line 42) | def app() -> Generator[FastAPI, None, None]:
function db_session (line 53) | def db_session(app: FastAPI) -> Generator[Session, None, None]:
function client (line 65) | def client(app: FastAPI, db_session: Session) -> Generator[TestClient, N...
function provider_fixture (line 84) | def provider_fixture(db_session: Session) -> Provider:
FILE: tests/functional/test_connectors.py
class TestConnectorAPI (line 7) | class TestConnectorAPI:
method test_list_connectors (line 40) | def test_list_connectors(self, mock_list_connectors, client: TestClien...
method test_get_connector (line 82) | def test_get_connector(self, mock_get_connector, client: TestClient, m...
method test_create_connector (line 116) | def test_create_connector(self, mock_create_connector, client: TestCli...
method test_update_connector (line 163) | def test_update_connector(self, mock_update_connector, client: TestCli...
method test_delete_connector (line 205) | def test_delete_connector(self, mock_delete_connector, client: TestCli...
method test_update_schemas (line 247) | def test_update_schemas(self, mock_updateschemas, client: TestClient, ...
method test_list_configurations (line 290) | def test_list_configurations(self, mock_list_configurations, client: T...
method test_create_configuration (line 323) | def test_create_configuration(self, mock_create_configuration, client:...
method test_update_configuration (line 362) | def test_update_configuration(self, mock_update_configuration, client:...
method test_create_capability (line 399) | def test_create_capability(self, mock_create_capabilities, client: Tes...
method test_list_capabilities (line 444) | def test_list_capabilities(self, mock_get_all_capabilities, client: Te...
method test_update_capability (line 485) | def test_update_capability(self, mock_update_capability, client: TestC...
method test_delete_capability (line 530) | def test_delete_capability(self, mock_delete_capability, client: TestC...
FILE: tests/functional/test_llmchat.py
class TestLLMChat (line 6) | class TestLLMChat:
method chat_payload (line 10) | def chat_payload(self):
method feedback_payload (line 22) | def feedback_payload(self):
method test_create_chat (line 51) | def test_create_chat(self, mock_create_chat, client: TestClient, chat_...
method test_create_feedback (line 88) | def test_create_feedback(self, mock_create_feedback, client: TestClien...
method test_list_chats_by_context (line 125) | def test_list_chats_by_context(self, mock_list_chats_by_context, clien...
method test_get_chat_by_context (line 162) | def test_get_chat_by_context(self, mock_list_all_chats_by_context_id, ...
FILE: tests/functional/test_provider.py
class TestProviderAPI (line 8) | class TestProviderAPI:
method test_list_providers (line 40) | def test_list_providers(self, mock_list_providers, client: TestClient,...
method test_get_provider (line 81) | def test_get_provider(self, mock_get_provider, client: TestClient, moc...
method test_test_connections (line 146) | def test_test_connections(self, mock_test_credentials, client: TestCli...
method test_getllmproviders (line 181) | def test_getllmproviders(self, mock_getllmproviders, client: TestClien...
FILE: tests/integration/test_integration_connector.py
class TestConnectorAPI (line 10) | class TestConnectorAPI:
method test_create_connector_type_2 (line 14) | def test_create_connector_type_2(self, mock_get_config_types, client: ...
FILE: tests/unittest/test_svc/test_svc_provider.py
class TestProviderAPI (line 12) | class TestProviderAPI:
method test_get_provider_success (line 16) | def test_get_provider_success(self, mock_repo, db_session: Session):
method test_get_provider_db_error (line 43) | def test_get_provider_db_error(self, mock_repo, db_session: Session):
method test_get_provider_not_found (line 56) | def test_get_provider_not_found(self, mock_repo, db_session: Session):
FILE: ui/src/App.jsx
function App (line 3) | function App() {
FILE: ui/src/components/Button/Button.jsx
constant BUTTON_TYPE (line 18) | const BUTTON_TYPE = {
constant BUTTON_VARIANT (line 24) | const BUTTON_VARIANT = {
FILE: ui/src/components/Chart/AreaChart/AreaChart.jsx
function AreaChart (line 4) | function AreaChart({ title = "Area Chart", data = [], xAxis = "name", yA...
FILE: ui/src/components/Chart/PieChart/PieChart.jsx
constant COLORS (line 5) | const COLORS = ['#3893FF', '#84BCFF', '#CDE5FF', '#FF8042'];
FILE: ui/src/components/ChatBox/ChatDropdownMenu/ChatDropdownMenu.jsx
function ChatDropdownMenu (line 6) | function ChatDropdownMenu({ handleNavigateChatContext = () => {}, data =...
FILE: ui/src/components/ChatBox/ChatHistoryButton.jsx
function ChatHistoryButton (line 3) | function ChatHistoryButton({icon,text, onClick = ()=>{}}) {
FILE: ui/src/components/ChatBox/ChatHistorySideBar.jsx
function ChatHistorySideBar (line 10) | function ChatHistorySideBar({handleNavigateChatContext=()=>{}, onCreateN...
FILE: ui/src/components/ChatBox/Feedback.jsx
function Feedback (line 5) | function Feedback({ onSubmit=()=>{}, message={}, onFeedBackClose = ()=>{...
FILE: ui/src/components/ChatBox/Summary.jsx
function Summary (line 7) | function Summary({message={}}) {
FILE: ui/src/components/ChatBox/Time.jsx
function Time (line 3) | function Time({message={}, time= "", onLike = ()=>{}, onDisLike = ()=>{}...
FILE: ui/src/components/RouteTab/RouteTab.jsx
function RouteTab (line 4) | function RouteTab({className, TabName="", Deployroutes, TabStyle, Contai...
FILE: ui/src/config/const.js
constant API_URL (line 2) | const API_URL = (import.meta.env.VITE_BACKEND_URL ?? defaultBackednURL)...
constant BACKEND_SERVER_URL (line 3) | const BACKEND_SERVER_URL = import.meta.env.VITE_BACKEND_URL ?? defaultB...
constant SLACK_URL (line 4) | const SLACK_URL = "https://theailounge.slack.com"
FILE: ui/src/embedbot/ChatBot.jsx
function ChatBot (line 15) | function ChatBot({ apiURL, configID, uiSize }) {
function scrollToLastMessage (line 169) | function scrollToLastMessage(delay) {
FILE: ui/src/layouts/auth/UserLogin.jsx
function capitalizeFirstLetter (line 33) | function capitalizeFirstLetter(str) {
FILE: ui/src/layouts/dashboard/DashboadBody.jsx
function generateContextUUID (line 18) | function generateContextUUID() {
FILE: ui/src/pages/Configuration/SchemaTable/SchemaTable.jsx
function SchemaTable (line 11) | function SchemaTable({ data, itemsPerPage = 8 }) {
FILE: ui/src/pages/Preview/ChatBox.jsx
function generateContextUUID (line 144) | function generateContextUUID() {
Condensed preview — 351 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (1,787K chars).
[
{
"path": ".dockerignore",
"chars": 199,
"preview": "./github\r\n.gitignore\r\npoetry.lock\r\nREADME.md\r\nCODE_OF_CONDUCT.md\r\npyproject.toml\r\nCONTRIBUTING.md\r\n.flake8\r\nLICENSE\r\nset"
},
{
"path": ".flake8",
"chars": 1180,
"preview": "[flake8]\nmax-line-length = 88\nenable-extensions = N, F, C, W, E # Enable naming checks\nselect = E201, E202, E204, E999, "
},
{
"path": ".github/ISSUE_TEMPLATE/bug_report.md",
"chars": 665,
"preview": "---\nname: Bug report\nabout: Create a report to help us improve\ntitle: ''\nlabels: ''\nassignees: ''\n\n---\n\n**Describe the b"
},
{
"path": ".github/ISSUE_TEMPLATE/feature_request.md",
"chars": 595,
"preview": "---\nname: Feature request\nabout: Suggest an idea for this project\ntitle: ''\nlabels: ''\nassignees: ''\n\n---\n\n**Is your fea"
},
{
"path": ".github/workflows/static.yml",
"chars": 1647,
"preview": "# Simple workflow for deploying static content to GitHub Pages\nname: Deploy static content to Pages\n\non:\n # Runs on pus"
},
{
"path": ".gitignore",
"chars": 837,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n__pycache__\n\n# C extensions\n*.so\n\n# Distribution / packaging\n.Pytho"
},
{
"path": ".pre-commit-config.yaml",
"chars": 306,
"preview": "repos:\n - repo: https://github.com/pre-commit/pre-commit-hooks\n rev: v4.6.0 # Use the latest version\n hooks:\n "
},
{
"path": "CODE_OF_CONDUCT.md",
"chars": 5296,
"preview": "# Contributor Covenant Code of Conduct\n\n## Our Pledge\n\nWe as members, contributors, and leaders pledge to make participa"
},
{
"path": "CONTRIBUTING.md",
"chars": 1843,
"preview": "# Contributing Guidelines for RAGGENIE\r\n\r\n## 🪜 Steps to Contribute\r\n\r\nTo contribute to this project, please follow these"
},
{
"path": "Dockerfile",
"chars": 1591,
"preview": "# Stage 1: UI Build\r\nFROM node:20-alpine AS ui-build\r\n\r\nARG BACKEND_URL\r\n\r\nWORKDIR /app/ui\r\n\r\n# Copy package files first"
},
{
"path": "LICENSE",
"chars": 1073,
"preview": "MIT License\n\nCopyright (c) 2024 sirocco ventures\n\nPermission is hereby granted, free of charge, to any person obtaining "
},
{
"path": "Makefile",
"chars": 549,
"preview": "# Define variables\nPOETRY = poetry\nPYTHON = $(POETRY) run python\nPOETRY_VENV = .venv\nPROJECT_DIR=./app\n\n# Specify the di"
},
{
"path": "README.md",
"chars": 10178,
"preview": "<p align=\"center\">\r\n <a href=\"https://www.raggenie.com/\">\r\n <img src=\"https://cdn.prod.website-files.com/664e485574e"
},
{
"path": "app/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "app/api/v1/auth.py",
"chars": 6377,
"preview": "import json\nimport requests\nfrom app.schemas.common import LoginData\nfrom fastapi import APIRouter, Depends, Response, R"
},
{
"path": "app/api/v1/commons.py",
"chars": 511,
"preview": "import app.schemas.common as resp_schemas\n\ndef is_error_response(message:str, err:str, data:dict):\n return resp_schem"
},
{
"path": "app/api/v1/connector.py",
"chars": 29768,
"preview": "from typing import List, Optional\nfrom app.providers.cache_manager import cache_manager\nfrom fastapi import APIRouter, D"
},
{
"path": "app/api/v1/llmchat.py",
"chars": 3906,
"preview": "# src/endpoints/chat.py\n\nfrom fastapi import APIRouter, Depends\nfrom sqlalchemy.orm import Session\nimport app.schemas.co"
},
{
"path": "app/api/v1/main_router.py",
"chars": 3753,
"preview": "from app.providers.cache_manager import cache_manager\nfrom fastapi import APIRouter, Depends, status, Query\nfrom fastapi"
},
{
"path": "app/api/v1/provider.py",
"chars": 15981,
"preview": "from fastapi import APIRouter, Depends\nfrom sqlalchemy.orm import Session\nimport app.schemas.common as resp_schemas\nimpo"
},
{
"path": "app/base/abstract_handlers.py",
"chars": 1074,
"preview": "from __future__ import annotations\nfrom abc import ABC, abstractmethod\nfrom typing import Any, Optional\n\n\nclass Handler("
},
{
"path": "app/base/base_formatter.py",
"chars": 374,
"preview": "from abc import ABC, abstractmethod\n\n\nclass BaseFormatter(ABC):\n\n @abstractmethod\n def format(self)-> (dict):\n "
},
{
"path": "app/base/base_llm.py",
"chars": 1982,
"preview": "# SPDX-FileCopyrightText: Copyright (c) 2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.\n# SPDX-License-Identi"
},
{
"path": "app/base/base_plugin.py",
"chars": 177,
"preview": "from abc import ABC, abstractmethod\n\nclass BasePlugin(ABC):\n\n @abstractmethod\n def connect(self):\n pass\n\n "
},
{
"path": "app/base/base_vectordb.py",
"chars": 174,
"preview": "from app.embeddings.loader import EmLoader\n\nclass BaseVectorDB():\n\n def load_embeddings_function(self):\n retur"
},
{
"path": "app/base/document_data_plugin.py",
"chars": 381,
"preview": "from abc import ABC, abstractmethod\nfrom typing import Dict, Any, Optional\n\nclass DocumentDataPlugin(ABC):\n\n @abstrac"
},
{
"path": "app/base/loader_metadata_mixin.py",
"chars": 697,
"preview": "import importlib\nfrom loguru import logger\n\nclass LoaderMetadataMixin:\n\n # plugin default variables\n __unique_name"
},
{
"path": "app/base/messaging_plugin.py",
"chars": 117,
"preview": "from abc import ABC, abstractmethod\n\nclass MessagePlugin(ABC):\n\n @abstractmethod\n def send(self):\n pass\n"
},
{
"path": "app/base/model_loader.py",
"chars": 595,
"preview": "class ModelLoader:\n\n\n def __init__(self, model_config):\n self.model_config = model_config\n\n def load_model("
},
{
"path": "app/base/plugin_metadata_mixin.py",
"chars": 1051,
"preview": "import importlib\nfrom loguru import logger\n\nclass PluginMetadataMixin:\n\n # plugin default variables\n __version__ ="
},
{
"path": "app/base/query_plugin.py",
"chars": 1224,
"preview": "from abc import ABC, abstractmethod\nfrom typing import Dict, Any, Optional, Tuple\n\nclass QueryPlugin(ABC):\n\n @abstrac"
},
{
"path": "app/base/remote_data_plugin.py",
"chars": 379,
"preview": "from abc import ABC, abstractmethod\nfrom typing import Dict, Any, Optional\n\nclass RemoteDataPlugin(ABC):\n\n @abstractm"
},
{
"path": "app/chain/chains/capability_chain.py",
"chars": 2335,
"preview": "from app.chain.modules.input_formatter import InputFormatter\nfrom app.chain.modules.post_processor import PostProcessor\n"
},
{
"path": "app/chain/chains/general_chain.py",
"chars": 3646,
"preview": "from app.chain.modules.input_formatter import InputFormatter\n# from app.chain.modules.guard_rail import GuardRail\nfrom a"
},
{
"path": "app/chain/chains/intent_chain.py",
"chars": 3335,
"preview": "from app.chain.modules.document_retriever import DocumentRetriever\nfrom app.chain.modules.input_formatter import InputFo"
},
{
"path": "app/chain/chains/metadata_chain.py",
"chars": 3238,
"preview": "from app.chain.modules.input_formatter import InputFormatter\nfrom app.chain.modules.post_processor import PostProcessor\n"
},
{
"path": "app/chain/chains/query_chain.py",
"chars": 5657,
"preview": "from app.chain.modules.document_retriever import DocumentRetriever\nfrom app.chain.modules.input_formatter import InputFo"
},
{
"path": "app/chain/formatter/general_response.py",
"chars": 347,
"preview": "class Formatter:\n\n def format(data: any, error: any) -> (dict):\n response = {}\n\n response[\"main_entity\""
},
{
"path": "app/chain/modules/cache_checker.py",
"chars": 2087,
"preview": "from typing import Any\nfrom loguru import logger\nfrom app.base.abstract_handlers import AbstractHandler\n\n\nclass Cacheche"
},
{
"path": "app/chain/modules/cache_updater.py",
"chars": 1425,
"preview": "from typing import Any\nfrom loguru import logger\nfrom app.base.abstract_handlers import AbstractHandler\n\nclass Cacheupda"
},
{
"path": "app/chain/modules/context_retreiver.py",
"chars": 1497,
"preview": "from typing import Any\nfrom loguru import logger\nfrom app.base.abstract_handlers import AbstractHandler\nfrom app.models."
},
{
"path": "app/chain/modules/context_storage.py",
"chars": 1605,
"preview": "from typing import Any\nfrom loguru import logger\nfrom app.base.abstract_handlers import AbstractHandler\nfrom app.models."
},
{
"path": "app/chain/modules/document_retriever.py",
"chars": 2267,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom loguru import logger\nfrom typing import Any\nfrom app.provide"
},
{
"path": "app/chain/modules/executer.py",
"chars": 2229,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\nfrom app.provide"
},
{
"path": "app/chain/modules/follow_up_handler.py",
"chars": 4927,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\nfrom app.provide"
},
{
"path": "app/chain/modules/followup_interpreter.py",
"chars": 1974,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\nfrom app.chain.f"
},
{
"path": "app/chain/modules/general_answer_generator.py",
"chars": 2694,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom app.providers.config import configs\nfrom app.loaders.base_lo"
},
{
"path": "app/chain/modules/generator.py",
"chars": 2527,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom app.providers.config import configs\nfrom app.loaders.base_lo"
},
{
"path": "app/chain/modules/input_formatter.py",
"chars": 327,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\n\n\nclass InputFor"
},
{
"path": "app/chain/modules/intent_extracter.py",
"chars": 6835,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\nfrom app.provide"
},
{
"path": "app/chain/modules/metadata_generator.py",
"chars": 3807,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\nfrom app.provide"
},
{
"path": "app/chain/modules/metadata_ragfilter.py",
"chars": 1448,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\n\n\nclass Metadata"
},
{
"path": "app/chain/modules/ouput_formatter.py",
"chars": 3135,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\n\n\nclass OutputFo"
},
{
"path": "app/chain/modules/post_processor.py",
"chars": 301,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\n\nclass PostProce"
},
{
"path": "app/chain/modules/prompt_generator.py",
"chars": 4872,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\nfrom string impo"
},
{
"path": "app/chain/modules/router.py",
"chars": 3611,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\nfrom app.chain.f"
},
{
"path": "app/chain/modules/schema_retriever.py",
"chars": 2408,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom loguru import logger\nfrom typing import Any\nfrom app.provide"
},
{
"path": "app/chain/modules/validator.py",
"chars": 2143,
"preview": "from app.base.abstract_handlers import AbstractHandler\nfrom typing import Any\nfrom loguru import logger\nfrom app.chain.f"
},
{
"path": "app/embeddings/cohere/__init__.py",
"chars": 410,
"preview": "from collections import OrderedDict\nfrom app.models.request import ConnectionArgument\n\n\n__provider_name__ = \"cohere\"\n__v"
},
{
"path": "app/embeddings/cohere/handler.py",
"chars": 433,
"preview": "\nimport chromadb.utils.embedding_functions as embedding_functions\nfrom loguru import logger\n\n\nclass CohereEm:\n def __"
},
{
"path": "app/embeddings/default/chroma_default.py",
"chars": 322,
"preview": "import chromadb.utils.embedding_functions as embedding_functions\n\nfrom loguru import logger\n\nclass ChromaDefaultEmbeddin"
},
{
"path": "app/embeddings/default/default.py",
"chars": 672,
"preview": "from .onnx import DefaultEmbeddingModel\nfrom .chroma_default import ChromaDefaultEmbedding\n\nfrom loguru import logger\ncl"
},
{
"path": "app/embeddings/default/onnx.py",
"chars": 3382,
"preview": "import os\nimport requests\nimport numpy as np\nfrom tokenizers import Tokenizer\nimport onnxruntime as ort\nfrom typing impo"
},
{
"path": "app/embeddings/google/__init__.py",
"chars": 368,
"preview": "from collections import OrderedDict\nfrom app.models.request import ConnectionArgument\n\n__provider_name__ = \"google\"\n__ve"
},
{
"path": "app/embeddings/google/handler.py",
"chars": 397,
"preview": "import chromadb.utils.embedding_functions as embedding_functions\nfrom loguru import logger\n\n\nclass GoogleEm:\n\n def __"
},
{
"path": "app/embeddings/loader.py",
"chars": 982,
"preview": "from app.embeddings.google. handler import GoogleEm\nfrom app.embeddings.default.default import DefaultEmbedding\nfrom app"
},
{
"path": "app/embeddings/openai/__init__.py",
"chars": 511,
"preview": "from collections import OrderedDict\nfrom app.models.request import ConnectionArgument\n\n\n__provider_name__ = \"openai\"\n__v"
},
{
"path": "app/embeddings/openai/handler.py",
"chars": 429,
"preview": "\nimport chromadb.utils.embedding_functions as embedding_functions\nfrom loguru import logger\n\n\nclass OpenAIEm:\n\n def _"
},
{
"path": "app/loaders/ai71/__init__.py",
"chars": 159,
"preview": "__unique_name__ = \"ai71\"\n__display_name__ = \"AI71\"\n__icon__ = \"/assets/providers/logos/ai71.png\"\n\n__all__ = ['__unique_n"
},
{
"path": "app/loaders/ai71/loader.py",
"chars": 3282,
"preview": "from app.base.model_loader import ModelLoader\nfrom app.base.loader_metadata_mixin import LoaderMetadataMixin\nfrom app.ba"
},
{
"path": "app/loaders/base_loader.py",
"chars": 1383,
"preview": "\nfrom app.loaders.ollama.loader import OllamaModelLoader\nfrom app.loaders.togethor.loader import TogethorModelLoader\nfro"
},
{
"path": "app/loaders/ollama/__init__.py",
"chars": 165,
"preview": "__unique_name__ = \"ollama\"\n__display_name__ = \"Ollama\"\n__icon__ = \"/assets/providers/logos/ollama.png\"\n\n__all__ = ['__un"
},
{
"path": "app/loaders/ollama/loader.py",
"chars": 3888,
"preview": "from app.base.model_loader import ModelLoader\nfrom app.base.base_llm import BaseLLM\nfrom typing import Any\nfrom loguru i"
},
{
"path": "app/loaders/openai/__init__.py",
"chars": 166,
"preview": "__unique_name__ = \"openai\"\n__display_name__ = \"Open AI\"\n__icon__ = \"/assets/providers/logos/openai.png\"\n\n__all__ = ['__u"
},
{
"path": "app/loaders/openai/loader.py",
"chars": 4157,
"preview": "from app.base.model_loader import ModelLoader\nfrom app.base.base_llm import BaseLLM\nfrom typing import Any\nfrom loguru i"
},
{
"path": "app/loaders/togethor/__init__.py",
"chars": 176,
"preview": "__unique_name__ = \"togethor\"\n__display_name__ = \"Togethor AI\"\n__icon__ = \"/assets/providers/logos/togetherai.png\"\n\n__all"
},
{
"path": "app/loaders/togethor/loader.py",
"chars": 4198,
"preview": "from app.base.model_loader import ModelLoader\nfrom app.base.base_llm import BaseLLM\nfrom typing import Any\nfrom loguru i"
},
{
"path": "app/main.py",
"chars": 4803,
"preview": "from fastapi import FastAPI\nfrom app.providers.container import Container\nfrom app.api.v1.main_router import MainRouter\n"
},
{
"path": "app/models/connector.py",
"chars": 7064,
"preview": "from sqlalchemy import Column, String, Integer, ForeignKey, DateTime, Boolean, JSON, Text\nfrom sqlalchemy.sql import fun"
},
{
"path": "app/models/db.py",
"chars": 469,
"preview": "from sqlalchemy import Column, Integer, String, DATETIME\nfrom sqlalchemy.orm import declarative_base\n\nBase = declarati"
},
{
"path": "app/models/environment.py",
"chars": 951,
"preview": "from sqlalchemy import Column, Integer, String, ForeignKey, Boolean\nfrom app.utils.database import Base\nfrom sqlalchemy."
},
{
"path": "app/models/llmchat.py",
"chars": 1341,
"preview": "from sqlalchemy import Column, String, Integer, DateTime, Boolean, JSON, ForeignKey\nfrom sqlalchemy.sql import func\nfrom"
},
{
"path": "app/models/prompt.py",
"chars": 999,
"preview": "from pydantic import BaseModel, Field\nclass SystemPrompt(BaseModel):\n template: str = Field(\n ...,\n des"
},
{
"path": "app/models/provider.py",
"chars": 6786,
"preview": "from sqlalchemy import Column, String, Integer, DateTime, Boolean, ForeignKey, JSON\nfrom sqlalchemy.sql import func\nfrom"
},
{
"path": "app/models/request.py",
"chars": 622,
"preview": "from pydantic import BaseModel\nfrom typing import Dict,List, Literal\nfrom typing import Any\n\n\nclass Chat(BaseModel):\n "
},
{
"path": "app/models/user.py",
"chars": 229,
"preview": "from sqlalchemy import Column, Integer, String, Boolean\nfrom app.utils.database import Base\n\nclass User(Base):\n __tab"
},
{
"path": "app/plugins/airtable/__init__.py",
"chars": 3593,
"preview": "from app.models.prompt import Prompt\nfrom collections import OrderedDict\nfrom app.models.request import ConnectionArgume"
},
{
"path": "app/plugins/airtable/formatter.py",
"chars": 1401,
"preview": "from typing import Any, Dict\nfrom loguru import logger\n\nclass Formatter:\n \"\"\"\n Formatter class to format the respo"
},
{
"path": "app/plugins/airtable/handler.py",
"chars": 6630,
"preview": "from .formatter import Formatter\nfrom loguru import logger\nimport requests\nimport uuid\nfrom urllib.parse import urlsplit"
},
{
"path": "app/plugins/bigquery/__init__.py",
"chars": 5190,
"preview": "from app.models.prompt import Prompt\nfrom collections import OrderedDict\nfrom app.models.request import ConnectionArgume"
},
{
"path": "app/plugins/bigquery/formatter.py",
"chars": 3450,
"preview": "from typing import Any\nfrom loguru import logger\n\n\nclass Formatter:\n def format(self, data: Any,input) -> (dict):\n "
},
{
"path": "app/plugins/bigquery/handler.py",
"chars": 6435,
"preview": "from google.cloud import bigquery\nfrom google.oauth2 import service_account\nfrom .formatter import Formatter\nfrom loguru"
},
{
"path": "app/plugins/csv/__init__.py",
"chars": 7389,
"preview": "from app.models.prompt import Prompt\nfrom collections import OrderedDict\nfrom app.models.request import ConnectionArgume"
},
{
"path": "app/plugins/csv/formatter.py",
"chars": 3471,
"preview": "from typing import Any\nfrom loguru import logger\n\n\nclass Formatter:\n def format(self, data: Any,input) -> (dict):\n "
},
{
"path": "app/plugins/csv/handler.py",
"chars": 7713,
"preview": "from .formatter import Formatter\nfrom loguru import logger\nimport sqlite3\nimport pandas as pd\nfrom app.base.base_plugin "
},
{
"path": "app/plugins/document/__init__.py",
"chars": 2599,
"preview": "from app.models.prompt import Prompt\nfrom collections import OrderedDict\nfrom app.models.request import ConnectionArgume"
},
{
"path": "app/plugins/document/formatter.py",
"chars": 1064,
"preview": "from typing import Any, Dict\nfrom loguru import logger\n\nclass Formatter:\n \"\"\"\n Formatter class to format the respo"
},
{
"path": "app/plugins/document/handler.py",
"chars": 3654,
"preview": "from .formatter import Formatter\nfrom loguru import logger\nimport requests\nfrom app.base.base_plugin import BasePlugin\nf"
},
{
"path": "app/plugins/loader.py",
"chars": 1540,
"preview": "from app.plugins.csv.handler import CSVPlugin\nfrom app.plugins.postgresql.handler import Postresql\nfrom app.plugins.mysq"
},
{
"path": "app/plugins/maria/__init__.py",
"chars": 8057,
"preview": "from app.models.prompt import Prompt\nfrom collections import OrderedDict\nfrom app.models.request import ConnectionArgume"
},
{
"path": "app/plugins/maria/formatter.py",
"chars": 3448,
"preview": "from typing import Any\nfrom loguru import logger\n\n\nclass Formatter:\n def format(self, data: Any,input) -> (dict):\n "
},
{
"path": "app/plugins/maria/handler.py",
"chars": 6199,
"preview": "import mariadb\nfrom loguru import logger\nimport sqlvalidator\nimport sqlparse\nfrom .formatter import Formatter\nimport uui"
},
{
"path": "app/plugins/mssql/__init__.py",
"chars": 8259,
"preview": "from app.models.prompt import Prompt\nfrom collections import OrderedDict\nfrom app.models.request import ConnectionArgume"
},
{
"path": "app/plugins/mssql/formatter.py",
"chars": 3446,
"preview": "from typing import Any\nfrom loguru import logger\n\n\nclass Formatter:\n def format(self, data: Any,input) -> (dict):\n "
},
{
"path": "app/plugins/mssql/handler.py",
"chars": 7389,
"preview": "import pyodbc\nfrom loguru import logger\nimport sqlvalidator\nimport sqlparse\nfrom .formatter import Formatter\nimport uuid"
},
{
"path": "app/plugins/mysql/__init__.py",
"chars": 8034,
"preview": "from app.models.prompt import Prompt\nfrom collections import OrderedDict\nfrom app.models.request import ConnectionArgume"
},
{
"path": "app/plugins/mysql/formatter.py",
"chars": 3446,
"preview": "from typing import Any\nfrom loguru import logger\n\n\nclass Formatter:\n def format(self, data: Any,input) -> (dict):\n "
},
{
"path": "app/plugins/mysql/handler.py",
"chars": 6186,
"preview": "import pymysql\nimport mysql.connector\nfrom loguru import logger\nimport sqlvalidator\nimport sqlparse\nfrom .formatter impo"
},
{
"path": "app/plugins/postgresql/__init__.py",
"chars": 8385,
"preview": "from app.models.prompt import Prompt\nfrom collections import OrderedDict\nfrom app.models.request import ConnectionArgume"
},
{
"path": "app/plugins/postgresql/formatter.py",
"chars": 3451,
"preview": "from typing import Any\nfrom loguru import logger\n\n\nclass Formatter:\n def format(self, data: Any,input) -> (dict):\n "
},
{
"path": "app/plugins/postgresql/handler.py",
"chars": 6486,
"preview": "import psycopg2\nfrom psycopg2 import sql, extras\nfrom loguru import logger\nimport sqlvalidator\nimport sqlparse\nfrom .for"
},
{
"path": "app/plugins/sqlite/__init__.py",
"chars": 7118,
"preview": "from app.models.prompt import Prompt\nfrom collections import OrderedDict\nfrom app.models.request import ConnectionArgume"
},
{
"path": "app/plugins/sqlite/formatter.py",
"chars": 3443,
"preview": "from typing import Any\nfrom loguru import logger\n\n\nclass Formatter:\n def format(self, data: Any,input) -> (dict):\n "
},
{
"path": "app/plugins/sqlite/handler.py",
"chars": 6224,
"preview": "import sqlite3\nimport pathlib\nimport urllib\nfrom loguru import logger\nimport sqlvalidator\nimport sqlparse\nfrom .formatte"
},
{
"path": "app/plugins/website/__init__.py",
"chars": 3072,
"preview": "from app.models.prompt import Prompt\nfrom collections import OrderedDict\nfrom app.models.request import ConnectionArgume"
},
{
"path": "app/plugins/website/formatter.py",
"chars": 1064,
"preview": "from typing import Any, Dict\nfrom loguru import logger\n\nclass Formatter:\n \"\"\"\n Formatter class to format the respo"
},
{
"path": "app/plugins/website/handler.py",
"chars": 2676,
"preview": "from .formatter import Formatter\nfrom loguru import logger\nimport requests\nimport json\nfrom app.base.base_plugin import "
},
{
"path": "app/providers/cache_manager.py",
"chars": 939,
"preview": "from collections import OrderedDict\nfrom app.providers.config import configs\n\nclass CacheManager(object):\n _instance "
},
{
"path": "app/providers/clustering.py",
"chars": 1776,
"preview": "import random\n\n\nclass Clustering:\n\n def _initialize_centroids(self,data, k):\n return random.sample(data, k)\n\n "
},
{
"path": "app/providers/config.py",
"chars": 1352,
"preview": "import os\nfrom typing import List\n\nfrom dotenv import load_dotenv\nfrom pydantic_settings import BaseSettings\n\n\nload_dote"
},
{
"path": "app/providers/container.py",
"chars": 618,
"preview": "from dependency_injector import containers, providers\nfrom app.plugins.loader import DSLoader\nfrom app.providers.cluster"
},
{
"path": "app/providers/context_storage.py",
"chars": 887,
"preview": "from app.models.db import Base\nfrom app.utils.database import get_db\nfrom fastapi import Depends\nfrom sqlalchemy.orm imp"
},
{
"path": "app/providers/data_preperation.py",
"chars": 1895,
"preview": "from loguru import logger\nfrom langchain.text_splitter import RecursiveCharacterTextSplitter\n\nclass SourceDocuments:\n "
},
{
"path": "app/providers/middleware.py",
"chars": 1985,
"preview": "from datetime import datetime, timezone\nimport json\nfrom app.providers.zitadel import Zitadel\nimport requests\nfrom app.u"
},
{
"path": "app/providers/reranker.py",
"chars": 238,
"preview": "\n\n\nfrom sentence_transformers import CrossEncoder\n\n\n\nclass Reranker:\n\n def __init__(self,model_name):\n self.cr"
},
{
"path": "app/providers/zitadel.py",
"chars": 13127,
"preview": "import json\nimport requests\nimport time\nfrom app.providers.config import configs\nfrom app.schemas.common import CommonRe"
},
{
"path": "app/readers/base_reader.py",
"chars": 1041,
"preview": "from app.readers.text_reader import TxtLoader\nfrom app.readers.docx_reader import DocxReader\nfrom app.readers.yaml_reade"
},
{
"path": "app/readers/docs_reader.py",
"chars": 183,
"preview": "class DocsReader:\n\n def __init__(self, source):\n self.source = source\n\n def load(self):\n raise NotIm"
},
{
"path": "app/readers/docx_reader.py",
"chars": 639,
"preview": "from app.readers.docs_reader import DocsReader\nfrom loguru import logger\n# import textract\n\nclass DocxReader(DocsReader)"
},
{
"path": "app/readers/pdf_reader.py",
"chars": 1408,
"preview": "from app.readers.docs_reader import DocsReader\nfrom loguru import logger\nfrom docling.document_converter import Document"
},
{
"path": "app/readers/text_reader.py",
"chars": 981,
"preview": "from app.readers.docs_reader import DocsReader\nfrom loguru import logger\n\nclass TxtLoader(DocsReader):\n def load(self"
},
{
"path": "app/readers/url_reader.py",
"chars": 2424,
"preview": "from app.readers.docs_reader import DocsReader\nfrom loguru import logger\nimport requests\nfrom bs4 import BeautifulSoup\nf"
},
{
"path": "app/readers/yaml_reader.py",
"chars": 751,
"preview": "from app.readers.docs_reader import DocsReader\nfrom loguru import logger\nimport yaml\n\nclass YamlLoader(DocsReader):\n "
},
{
"path": "app/repository/connector.py",
"chars": 21363,
"preview": "from sqlalchemy.orm import Session, joinedload\nimport app.models.connector as models\nimport app.models.provider as prov_"
},
{
"path": "app/repository/environment.py",
"chars": 1510,
"preview": "from sqlalchemy.orm import Session\nimport app.models.environment as models\nimport app.schemas.environment as schemas\nfro"
},
{
"path": "app/repository/llmchat.py",
"chars": 2050,
"preview": "from sqlalchemy.orm import Session\nfrom app.models.llmchat import ChatHistory\nfrom app.schemas import llmchat as schemas"
},
{
"path": "app/repository/provider.py",
"chars": 9554,
"preview": "from sqlalchemy.orm import Session\nimport app.models.provider as models\nimport app.models.connector as conn_model\nfrom s"
},
{
"path": "app/repository/user.py",
"chars": 652,
"preview": "from sqlalchemy.orm import Session\nimport app.models.user as models\nimport app.schemas.user as schemas\nfrom sqlalchemy.e"
},
{
"path": "app/schemas/common.py",
"chars": 405,
"preview": "from pydantic import BaseModel\nfrom typing import Optional, Any\n\nclass DBConfig(BaseModel):\n host: str\n port: int\n"
},
{
"path": "app/schemas/connector.py",
"chars": 3396,
"preview": "from pydantic import BaseModel\nfrom typing import List, Dict, Optional, Union\nfrom app.schemas.provider import VectorDBR"
},
{
"path": "app/schemas/environment.py",
"chars": 381,
"preview": "from pydantic import BaseModel\nfrom datetime import datetime\nfrom typing import Optional\n\nclass EnvironmentBase(BaseMode"
},
{
"path": "app/schemas/llmchat.py",
"chars": 984,
"preview": "from pydantic import BaseModel\nfrom typing import Optional, Dict\nfrom datetime import datetime\n\n\nclass ChatHistoryBase(B"
},
{
"path": "app/schemas/provider.py",
"chars": 2807,
"preview": "from pydantic import BaseModel\nfrom typing import List, Optional, Any, Dict\nfrom datetime import datetime\n\n\nclass Provid"
},
{
"path": "app/schemas/user.py",
"chars": 366,
"preview": "from datetime import datetime\nfrom typing import Optional\nfrom pydantic import BaseModel\n\nclass UserBase(BaseModel):\n "
},
{
"path": "app/services/connector.py",
"chars": 41588,
"preview": "from sqlalchemy.orm import Session\nimport app.repository.connector as repo\nimport app.repository.provider as config_repo"
},
{
"path": "app/services/connector_details.py",
"chars": 3584,
"preview": "from typing import Any\nfrom app.plugins.loader import DSLoader\nfrom loguru import logger\n\nfrom app.repository import co"
},
{
"path": "app/services/llmchat.py",
"chars": 4276,
"preview": "from sqlalchemy.orm import Session\nfrom app.repository import llmchat as repo\nfrom app.schemas import llmchat as schemas"
},
{
"path": "app/services/provider.py",
"chars": 21502,
"preview": "from sqlalchemy.orm import Session\nimport app.repository.provider as repo\nimport app.schemas.provider as schemas\nimport "
},
{
"path": "app/services/user.py",
"chars": 1398,
"preview": "from sqlalchemy.orm import Session\nimport app.repository.user as repo\nimport app.repository.environment as env_repo\nimpo"
},
{
"path": "app/utils/database.py",
"chars": 437,
"preview": "from sqlalchemy import create_engine\nfrom sqlalchemy.orm import sessionmaker\nfrom sqlalchemy.orm import declarative_base"
},
{
"path": "app/utils/jwt.py",
"chars": 779,
"preview": "import jwt\nfrom jwt import PyJWTError\nfrom datetime import datetime, timedelta\n\nclass JWTUtils:\n def __init__(self, s"
},
{
"path": "app/utils/module_reader.py",
"chars": 3240,
"preview": "from loguru import logger\nimport importlib\nimport pkgutil\n\n\ndef get_vectordb_providers():\n vectordb = importlib.impor"
},
{
"path": "app/utils/parser.py",
"chars": 1192,
"preview": "import json\nfrom loguru import logger\n\ndef parse_llm_response(body):\n text = body.replace(\"\\\\n\",\"\")\n text "
},
{
"path": "app/utils/read_config.py",
"chars": 506,
"preview": "import yaml\nfrom loguru import logger\n\n\n\ndef read_yaml_file(config_file) -> dict:\n \"\"\"\n Reads a YAML file and retu"
},
{
"path": "app/vectordb/loader.py",
"chars": 861,
"preview": "from app.vectordb.chromadb.handler import ChromaDataBase\nfrom app.vectordb.mongodb.handler import AltasMongoDB\n\nfrom log"
},
{
"path": "app/vectordb/mongodb/__init__.py",
"chars": 733,
"preview": "from collections import OrderedDict\nfrom app.models.request import ConnectionArgument\n\n# Plugin Metadata\n__version__ = '"
},
{
"path": "app/vectordb/mongodb/handler.py",
"chars": 7770,
"preview": "import pymongo\nfrom loguru import logger\nfrom app.base.base_vectordb import BaseVectorDB\nimport certifi\n\n\nclass AltasMon"
},
{
"path": "commands/cli.py",
"chars": 891,
"preview": "import click\nfrom loguru import logger\nfrom app.utils.read_config import read_yaml_file\nimport sys\n\n@click.group()\n@clic"
},
{
"path": "commands/llm.py",
"chars": 851,
"preview": "import click\nfrom commands.cli import cli\nfrom loguru import logger\nfrom app.providers.config import configs\nfrom app.ma"
},
{
"path": "config.yaml",
"chars": 111,
"preview": "vector_db:\n name: \"chroma\"\n params:\n path: \"./vector_db\"\n embeddings:\n provider: \"chroma_default\"\n"
},
{
"path": "docker-compose.yml",
"chars": 2580,
"preview": "services:\r\n nginx:\r\n image: nginx:latest\r\n container_name: nginx\r\n ports:\r\n - \"80:80\"\r\n - \"82:82\"\r\n "
},
{
"path": "documents/.gitignore",
"chars": 233,
"preview": "# Dependencies\n/node_modules\n\n# Production\n/build\n\n# Generated files\n.docusaurus\n.cache-loader\n\n# Misc\n.DS_Store\n.env.lo"
},
{
"path": "documents/README.md",
"chars": 768,
"preview": "# Website\n\nThis website is built using [Docusaurus](https://docusaurus.io/), a modern static website generator.\n\n### Ins"
},
{
"path": "documents/babel.config.js",
"chars": 89,
"preview": "module.exports = {\n presets: [require.resolve('@docusaurus/core/lib/babel/preset')],\n};\n"
},
{
"path": "documents/docs/Configuring agents.md",
"chars": 49,
"preview": "---\nsidebar_position: 7\n---\n\n# Configuring agents"
},
{
"path": "documents/docs/Connectors/Airtable.md",
"chars": 946,
"preview": "---\nsidebar_position: 2\n---\n\n# Airtable Plugin\n\n### Plugin name\nThe name of the plugin is used to differentiare between "
},
{
"path": "documents/docs/Connectors/Bigquery.md",
"chars": 951,
"preview": "---\nsidebar_position: 3\n---\n\n# Bigquery Plugin\n\n### Plugin name\nThe name of the plugin is used to differentiare between "
},
{
"path": "documents/docs/Connectors/Connectors.md",
"chars": 391,
"preview": "---\nsidebar_position: 4\n---\n\n# Connectors/pluggins\nDifferent components in your LLM app can be inserted using plugins.\n\n"
},
{
"path": "documents/docs/Connectors/PDFs.md",
"chars": 691,
"preview": "---\nsidebar_position: 4\n---\n\n# PDFs Plugin\n\n### Plugin name\nThe name of the plugin is used to differentiare between diff"
},
{
"path": "documents/docs/Connectors/Postgressql.md",
"chars": 2278,
"preview": "---\nsidebar_position: 1\n---\n\n# Postgressql Plugin\n\nYou can connect to an instance of postgress using the postgressql plu"
},
{
"path": "documents/docs/Connectors/Websites.md",
"chars": 671,
"preview": "---\nsidebar_position: 5\n---\n\n# Websites Plugin\n\n### Plugin name\nThe name of the plugin is used to differentiare between "
},
{
"path": "documents/docs/Examples.md",
"chars": 39,
"preview": "---\nsidebar_position: 4\n---\n\n# Examples"
},
{
"path": "documents/docs/How to configure raggenie/Configuration.md",
"chars": 1646,
"preview": "---\nsidebar_position: 2\n---\n\n# Configuration\n\n## Configuration details\nYou should provide a bot name, a short discriptio"
},
{
"path": "documents/docs/How to configure raggenie/Deploy.md",
"chars": 271,
"preview": "---\nsidebar_position: 4\n---\n\n# Deploy\n\n`Restart Chatbot` to apply all the changes that have been made to the chat bot. T"
},
{
"path": "documents/docs/How to configure raggenie/Plugins.md",
"chars": 1749,
"preview": "---\nsidebar_position: 1\n---\n\n# Plugins\n\n## Configuration\nPlugin configuration is used to specify the metadata of differe"
},
{
"path": "documents/docs/How to configure raggenie/Preview.md",
"chars": 215,
"preview": "---\nsidebar_position: 5\n---\n\n# Preview\n\nYou can see the live preview of your chatbot to interact with and run tests. It "
},
{
"path": "documents/docs/How to configure raggenie/Samples.md",
"chars": 726,
"preview": "---\nsidebar_position: 3\n---\n\n# Samples\n\nYou can give example questions and their responses to improve the models accurac"
},
{
"path": "documents/docs/How to configure raggenie/_category_.json",
"chars": 157,
"preview": "{\n \"label\": \"How to configure raggenie\",\n \"position\": 3,\n \"link\": {\n \"type\": \"generated-index\",\n \"description\":"
},
{
"path": "documents/docs/How to run raggenie/To run raggenie backend Server.md",
"chars": 1300,
"preview": "---\nsidebar_position: 1\n---\n\n# To run raggenie backend Server\n\n### Clone the project\nThe first step is to clone the RAGG"
},
{
"path": "documents/docs/How to run raggenie/To run raggenie ui server.md",
"chars": 836,
"preview": "---\nsidebar_position: 2\n---\n\n# To run raggenie ui server\n\n### Go to the project ui directory\nThe raggenie UI is located "
},
{
"path": "documents/docs/How to run raggenie/Using Docker.md",
"chars": 519,
"preview": "---\nsidebar_position: 3\n---\n\n# Using Docker\nThe raggenie project includes both a Dockerfile and a Docker Compose file, l"
},
{
"path": "documents/docs/How to run raggenie/_category_.json",
"chars": 145,
"preview": "{\n \"label\": \"How to run raggenie\",\n \"position\": 2,\n \"link\": {\n \"type\": \"generated-index\",\n \"description\": \"Step"
},
{
"path": "documents/docs/LLM Inferences.md",
"chars": 189,
"preview": "---\nsidebar_position: 6\n---\n\n# LLM Inferences\n\nWe currently support these LLM Inference endpoints.\n* [OpenAI](https://op"
},
{
"path": "documents/docs/Prerequesites.md",
"chars": 1482,
"preview": "---\nsidebar_position: 1\n---\n\n# Prerequesites\n\n## Backend\n\n### Python\nRaggenie uses python to run its backend server. Cur"
},
{
"path": "documents/docusaurus.config.js",
"chars": 3503,
"preview": "// @ts-check\n// `@type` JSDoc annotations allow editor autocompletion and type checking\n// (when paired with `@ts-check`"
},
{
"path": "documents/package.json",
"chars": 1060,
"preview": "{\n \"name\": \"documents\",\n \"version\": \"0.0.0\",\n \"private\": true,\n \"scripts\": {\n \"docusaurus\": \"docusaurus\",\n \"st"
},
{
"path": "documents/sidebars.js",
"chars": 779,
"preview": "/**\n * Creating a sidebar enables you to:\n - create an ordered group of docs\n - render a sidebar for each doc of that gr"
},
{
"path": "documents/src/css/custom.css",
"chars": 1042,
"preview": "/**\n * Any CSS included here will be global. The classic template\n * bundles Infima by default. Infima is a CSS framewor"
},
{
"path": "documents/src/pages/index.md",
"chars": 2580,
"preview": "<p align=\"center\">\n <a href=\"https://www.raggenie.com/\">\n <img src=\"https://cdn.prod.website-files.com/664e485574efd"
},
{
"path": "documents/src/pages/index.module.css",
"chars": 365,
"preview": "/**\n * CSS files with the .module.css suffix will be treated as CSS modules\n * and scoped locally.\n */\n\n.heroBanner {\n "
},
{
"path": "documents/static/.nojekyll",
"chars": 0,
"preview": ""
},
{
"path": "embeddings/onnx/tokenizer.json",
"chars": 708362,
"preview": "{\n \"version\": \"1.0\",\n \"truncation\": {\n \"direction\": \"Right\",\n \"max_length\": 128,\n \"strategy\": \"LongestFirst\","
},
{
"path": "main.py",
"chars": 100,
"preview": "from commands.cli import cli\nfrom commands.llm import llm\n\nif __name__ == '__main__':\n cli()\n "
},
{
"path": "nginx.conf",
"chars": 4009,
"preview": "# Define the user and worker processes\nuser nginx;\nworker_processes auto;\n\n# Set the error log and pid file locations\n"
},
{
"path": "pyproject.toml",
"chars": 3795,
"preview": "[tool.poetry]\nname = \"raggenie\"\nversion = \"0.0.1\"\ndescription = \"Raggenie is a platform for easy RAG building and integr"
},
{
"path": "requirements.txt",
"chars": 3061,
"preview": "aiofiles==23.2.1\naiohappyeyeballs==2.4.0\naiohttp==3.10.5\naiosignal==1.3.1\nannotated-types==0.7.0\nanyio==4.4.0\nAPSchedule"
},
{
"path": "setup.py",
"chars": 827,
"preview": "import os\nfrom setuptools import setup, find_packages\n\n\n\n\ndef read(fname):\n return open(os.path.join(os.path.dirname("
},
{
"path": "tests/README.md",
"chars": 1124,
"preview": "## Getting Started\n\nThis project includes functional, integration, and unit testing using pytest. Tests are organized in"
},
{
"path": "tests/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tests/conftest.py",
"chars": 4308,
"preview": "from typing import Generator, Any\nimport pytest\nfrom fastapi import FastAPI\nfrom fastapi.testclient import TestClient\nfr"
}
]
// ... and 151 more files (download for full content)
About this extraction
This page contains the full source code of the sirocco-ventures/raggenie GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 351 files (87.8 MB), approximately 486.0k tokens, and a symbol index with 745 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.