[
{
"path": ".classpath",
"content": "\n\n\t\n\t\t\n\t\t\t\n\t\t\t\n\t\t\n\t\n\t\n\t\n\t\t\n\t\t\t\n\t\t\t\n\t\t\n\t\n\t\n\t\n\t\n\t\t\n\t\t\t\n\t\t\n\t\n\t\n\n"
},
{
"path": ".project",
"content": "\n\n\tspark-elastic\n\t\n\t\n\t\n\t\n\t\t\n\t\t\torg.eclipse.m2e.core.maven2Builder\n\t\t\t\n\t\t\t\n\t\t\n\t\t\n\t\t\torg.scala-ide.sdt.core.scalabuilder\n\t\t\t\n\t\t\t\n\t\t\n\t\n\t\n\t\torg.scala-ide.sdt.core.scalanature\n\t\torg.eclipse.jdt.core.javanature\n\t\torg.eclipse.m2e.core.maven2Nature\n\t\n\n"
},
{
"path": "README.md",
"content": "\n\n## Integration of Elasticsearch with Spark\n\nThis project shows how to easily integrate [Apache Spark](http://spark.apache.org), a fast and general purpose engine for \nlarge-scale data processing, with [Elasticsearch](http://elasticsearch.org), a real-time distributed search and analytics \nengine.\n\nSpark is an in-memory processing framework and outperforms Hadoop up to a factor of 100. Spark is accompanied by \n\n* [MLlib](https://spark.apache.org/mllib/), a scalable machine learning library,\n* [Spark SQL](https://spark.apache.org/sql/), a unified access platform for structured big data,\n* [Spark Streaming](https://spark.apache.org/streaming/), a library to build scalable fault-tolerant streaming applications.\n\nIf you are more interested in an Elasticsearch plugin-in that brings the power of [Predictiveworks.](http://predictiveworks.eu) to Elasticsearch,\nthen please refer to [Elasticinsight.](http://elasticinsight.eu)\n\n\n\n[Predictiveworks.](http://predictiveworks.eu) is an ensemble of dedicated predictive engines that covers a wide range of today's analytics requirements from Association Analysis,\nto Context-Aware Recommendations up to Text Analysis. Elasticinsight. empowers Elasticsearch to seamlessly uses these multiple engines.\n\n---\n\n### Machine Learning with Elasticsearch\n\nBesides linguistic and semantic enrichment, for data in a search index there is an increasing demand to apply knowledge discovery and\ndata mining techniques, and even predictive analytics to gain deeper insights into the data and further increase their business value.\n\nOne of the key prerequisites is to easily connect existing data sources to state-of-the art machine learning and predictive analytics \nframeworks.\n\nIn this project, we give advice how to connect Elasticsearch, a powerful distributed search engine, to Apache Spark and profit from the increasing number of existing machine learning algorithms.\n\nThe figure shows the integration pattern for Elasticsearch and Spark from an architectural persepctive and also indicates how to proceed with the enriched content (i.e. the way back to the search index).\n\n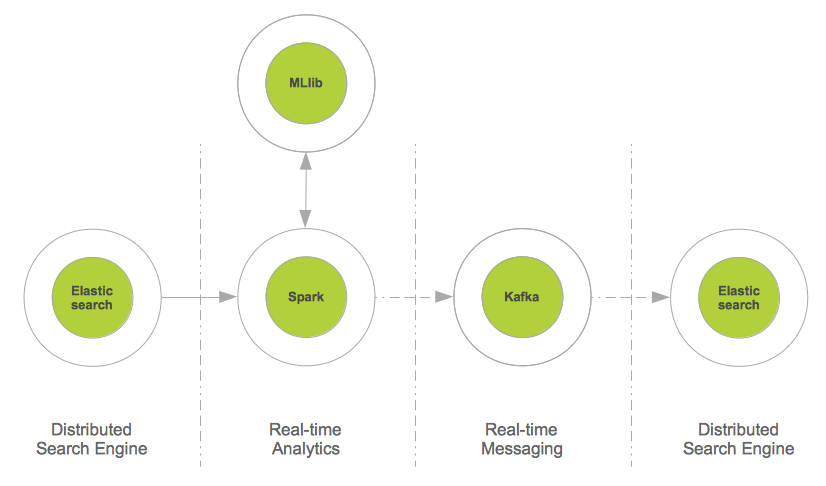\n\nThe source code below describes a few lines of Scala, that are sufficient to read from Elasticsearch and provide data for further mining \nand prediction tasks:\n\n```\nval source = sc.newAPIHadoopRDD(conf, classOf[EsInputFormat[Text, MapWritable]], classOf[Text], classOf[MapWritable])\nval docs = source.map(hit => {\n new EsDocument(hit._1.toString,toMap(hit._2))\n})\n```\n\n#### Document Segmentation with KMeans\n\nFrom the data format extracted from Elasticsearch `RDD[EsDocument]` it is just a few lines of Scala to segment these documents with respect to their geo location (latitude,longitude). \n\nFrom these data a heatmap can be drawn to visualize from which region of world most of the documents come from. The image below shows a multi-colored heatmap, where the colors red, yellow, green and blue indicate different heat ranges.\n\n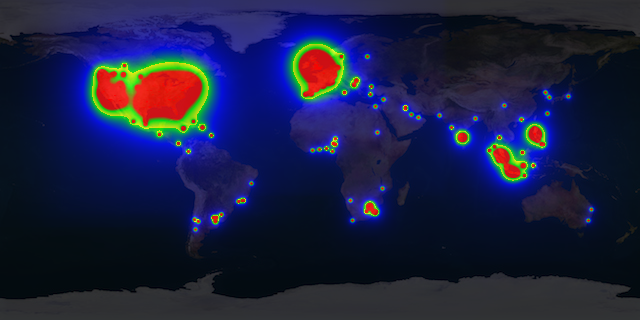\n\nSegmenting documents into specific target groups is not restricted their geo location. Time of the day, product or service categories, total revenue, and other parameters may be used.\n\nFor segmentation, the [K-Means clustering](http://http://en.wikipedia.org/wiki/K-means_clustering) implementation \nof [MLlib](https://spark.apache.org/mllib/) is used:\n\n```\ndef cluster(documents:RDD[EsDocument],esConf:Configuration):RDD[(Int,EsDocument)] = {\n \n val fields = esConf.get(\"es.fields\").split(\",\")\n val vectors = documents.map(doc => toVector(doc.data,fields)) \n\n val clusters = esConf.get(\"es.clusters\").toInt\n val iterations = esConf.get(\"es.iterations\").toInt\n \n /* Train model */\n val model = KMeans.train(vectors, clusters, iterations)\n \n /* Apply model */\n documents.map(doc => (model.predict(toVector(doc.data,fields)),doc))\n \n}\n```\n\nClustering Elasticsearch data with K-Means is a first and simple example of how to immediately benefit from the integration with Spark. Other business cases may cover recommendations:\n\nSuppose Elasticsearch is used to index e-commerce transactions on a per user basis, then it is also straightforward to build a recommendation system in just two steps:\n\n* **First**, implicit user-item ratings have to be derived from the e-commerce transactions, and \n* **Second**, from this item similarities are calculated to provide a recommendation model.\n\nFor more information, please read [here](https://github.com/skrusche63/spark-elastic/wiki/Item-Similarity-with-Spark).\n\n\n#### Insights from Elasticsearch with SQL\n\n[Spark SQL](https://spark.apache.org/sql/) allows relational queries expressed in SQL to be executed using Spark. This enables to apply queries to Spark data structures and also to Spark data streams (see below).\n\nAs SQL queries generate Spark data structures, a mixture of SQL and native Spark operations is also possible, thus providing a sophisticated mechanism to compute valuable insight from data in real-time.\n\nThe code example below illustrates how to apply SQL queries on a Spark data structure (RDD) and provide further insight by mixing with native Spark operations.\n\n```\n/*\n * Elasticsearch specific configuration\n */\nval esConf = new Configuration() \n\nesConf.set(\"es.nodes\",\"localhost\")\nesConf.set(\"es.port\",\"9200\")\n \nesConf.set(\"es.resource\", \"enron/mails\") \nesConf.set(\"es.query\", \"?q=*:*\") \n\nesConf.set(\"es.table\", \"docs\")\nesConf.set(\"es.sql\", \"select subject from docs\")\n\n...\n\n/*\n * Read from ES and provide some insight with Spark & SparkSQL,\n * thereby mixing SQL and other Spark operations\n */\nval documents = es.documentsAsJson(esConf)\nval subjects = es.query(documents, esConf).filter(row => row.getString(0).contains(\"Re\")) \n\n...\n\ndef query(documents:RDD[String], esConfig:Configuration):SchemaRDD = {\n\n val query = esConfig.get(\"es.sql\")\n val name = esConfig.get(\"es.table\")\n \n val table = sqlc.jsonRDD(documents)\n table.registerAsTable(name)\n\n sqlc.sql(query) \n\n}\n```\n\n---\n\n### Real-Time Stream Processing and Elasticsearch\n\nReal-time analytics is a very popular topic with a wide range of application areas:\n\n* High frequency trading (finance), \n* Real-time bidding (adtech), \n* Real-time social activity (social networks),\n* Real-time sensoring (Internet of things),\n* Real-time user behavior,\n\nand more, gain tremendous business value from real-time analytics. There exist a lot of popular frameworks to aggregate data in real-time, such as Apache Storm, \nApache S4, Apache Samza, Akka Streams, SQLStream to name just a few.\n\nSpark Streaming, which is capable to process about 400,000 records per node per second for simple aggregations on small records, significantly outperforms other popular \nstreaming systems. This is mainly because Spark Streaming groups messages in small batches which are then processed together. \n\nMoreover in case of failure, Spark Streaming batches are only processed once which greatly simplifies the logic (e.g. to make sure some values are not counted multiple times).\n\nSpark Streaming is a layer on top of Spark and transforms and batches data streams from various sources, such as Kafka, Twitter or ZeroMQ into a sequence of \nSpark RDDs (Resilient Distributed DataSets) using a sliding window. These RDDs can then be manipulated using normal Spark operations.\n\nThis project provides a real-time data integration pattern based on Apache Kafka, Spark Streaming and Elasticsearch: \n\n[Apache Kafka](http://kafka.apache.org/) is a distributed publish-subscribe messaging system, that may also be seen as a real-time integration system. For example, Web tracking events are easily sent to Kafka, \nand may then be consumed by a set of different consumers.\n\nIn this project, we use Spark Streaming as a consumer and aggregator of e.g. such tracking data streams, and perform a live indexing. As Spark Streaming is also able to directly \ncompute new insights from data streams, this data integration pattern may be used as a starting point for real-time data analytics and enrichment before search indexing.\n\nThe figure below illustrates the architecture of this pattern. For completeness reasons, [Spray](http://spray.io/) has been introduced. Spray is an open-source toolkit for \nbuilding REST/HTTP-based integration layers on top of Scala and Akka. As it is asynchronous, actor-based, fast, lightweight, and modular, it is an easy way to connect Scala \napplications to the Web.\n\n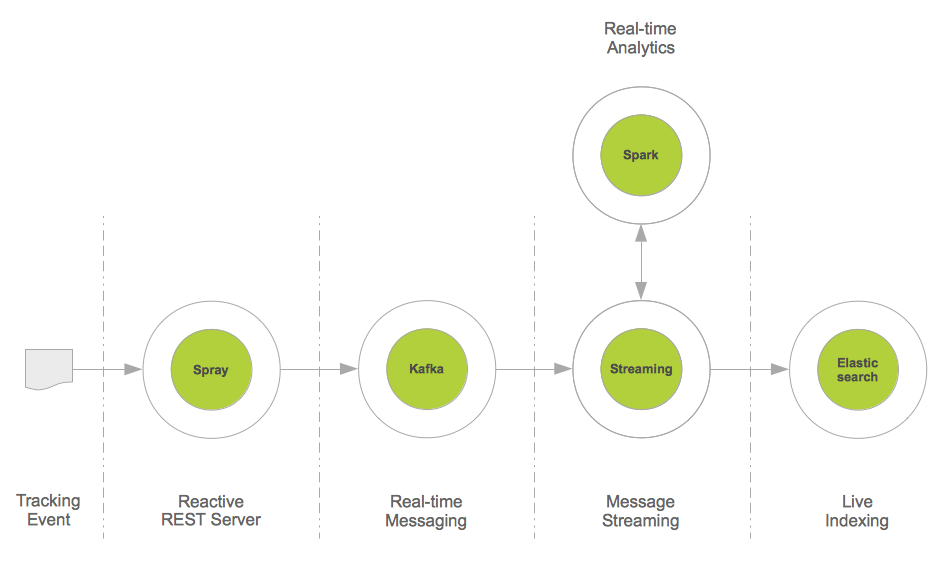\n\nThe code example below illustrates that such an integration pattern may be implemented with just a few lines of Scala code:\n\n```\nval stream = KafkaUtils.createStream[String,Message,StringDecoder,MessageDecoder](ssc, kafkaConfig, kafkaTopics, StorageLevel.MEMORY_AND_DISK).map(_._2)\nstream.foreachRDD(messageRDD => {\n /**\n * Live indexing of Kafka messages; note, that this is also\n * an appropriate place to integrate further message analysis\n */\n val messages = messageRDD.map(prepare)\n messages.saveAsNewAPIHadoopFile(\"-\",classOf[NullWritable],classOf[MapWritable],classOf[EsOutputFormat],esConfig) \n \n})\n\n```\n\n#### Most Frequent Items from Streams\n\nUsing the architecture as illustrated above not only enables to apply Spark to data streams. It also opens real-time streams to other data processing libraries such as [Algebird](https://github.com/twitter/algebird) from \nTwitter. \n\nAlgebird brings, as the name indicates, algebraic algorithms to streaming data. An important representative is [Count-Min Sketch](http://en.wikipedia.org/wiki/Count%E2%80%93min_sketch) which enables to compute the most \nfrequent items from streams in a certain time window. The code example below describes how to apply the CountMinSketchMonoid (Algebird) to compute the most frequent messages from a Kafka Stream with respect to the messages' classification: \n\n```\n\nobject EsCountMinSktech {\n \n def findTopK(stream:DStream[Message]):Seq[(Long,Long)] = {\n \n val DELTA = 1E-3\n val EPS = 0.01\n \n val SEED = 1\n val PERC = 0.001\n \n val k = 5\n \n var globalCMS = new CountMinSketchMonoid(DELTA, EPS, SEED, PERC).zero\n \n val clases = stream.map(message => message.clas)\n val approxTopClases = clases.mapPartitions(clases => {\n \n val localCMS = new CountMinSketchMonoid(DELTA, EPS, SEED, PERC)\n clases.map(clas => localCMS.create(clas))\n \n }).reduce(_ ++ _)\n\n approxTopClases.foreach(rdd => {\n if (rdd.count() != 0) globalCMS ++= rdd.first()\n })\n \n /**\n * Retrieve approximate TopK classifiers from the provided messages\n */\n val globalTopK = globalCMS.heavyHitters.map(clas => (clas, globalCMS.frequency(clas).estimate))\n /*\n * Retrieve the top k message classifiers: it may also be interesting to \n * return the classifier frequency from this method, ignoring the line below\n */\n .toSeq.sortBy(_._2).reverse.slice(0, k)\n \n globalTopK\n \n }\n}\n\n```\n\n***\n\n### Technology Stack\n\n* [Scala](http://scala-lang.org)\n* [Apache Kafka](http://kafka.apache.org/)\n* [Apache Spark](http://spark.apache.org)\n* [Spark SQL](https://spark.apache.org/sql/)\n* [Spark Streaming](https://spark.apache.org/streaming/)\n* [Twitter Algebird](https://github.com/twitter/algebird)\n* [Elasticsearch](http://elasticsearch.org)\n* [Elasticsearch Hadoop](http://elasticsearch.org/overview/hadoop/)\n* [Spray](http://spray.io/)\n"
},
{
"path": "pom.xml",
"content": "\n 4.0.0\n spark-elastic\n spark-elastic\n 0.0.1-SNAPSHOT\n Spark-ELASTIC\n This project combines Apache Spark and Elasticsearch to enable mining & prediction for Elasticsearch.\n 2010\n \n \n GPL v3\n http://....\n repo\n \n \n\n \n 1.6\n 1.6\n UTF-8\n 2.10\n 2.10.0\n \n\n \n \n org.scala-lang\n scala-library\n ${scala.version}\n \n\n \n \n junit\n junit\n 4.11\n test\n \n \n org.specs2\n specs2_${scala.tools.version}\n 1.13\n test\n \n\n \n org.scalatest\n scalatest_${scala.tools.version}\n 2.0.M6-SNAP8\n test\n \n\n \n \n\t org.apache.spark\n\t spark-core_2.10\n\t 1.0.2\n\t \n\t \n \n org.codehaus.jackson\n jackson-mapper-asl\n \n\t \n \n \n \n \n\t org.apache.spark\n\t spark-mllib_2.10\n\t 1.0.2\n \n\n \n \n\t org.apache.spark\n\t spark-sql_2.10\n\t 1.0.2\n \n \n \n \n\t org.apache.spark\n\t spark-streaming_2.10\n\t 1.0.2\n \n\n \n \n\t org.apache.spark\n\t spark-streaming-twitter_2.10\n\t 1.0.2\n \n \n \n \n\t org.apache.spark\n\t spark-streaming-kafka_2.10\n\t 1.0.2\n \n\n \n \n\t com.twitter\n\t algebird-core_2.10\n\t 0.7.0\n \n \n \n \n org.elasticsearch\n elasticsearch-hadoop\n 2.0.0\n \n\n \n \n org.elasticsearch\n elasticsearch\n 1.3.0 \n \n \n \n \n\t org.json4s\n\t json4s-native_2.10\n\t 3.2.10\n \n \n \n \n io.spray\n spray-client\n 1.2.0\n \n\n \n io.spray\n spray-httpx\n 1.2.0\n \n\n \n \n com.typesafe.akka\n akka-actor_2.10\n 2.2.3\n \n \n \n\t com.typesafe.akka\n\t akka-contrib_2.10\n\t 2.2.3\n \n \n \n\t com.typesafe.akka\n\t akka-remote_2.10\n\t 2.2.3\n \n\n \n \n\t org.apache.kafka\n\t kafka_2.10\n\t 0.8.1.1\n\t \n \n com.sun.jmx\n jmxri\n \n \n com.sun.jdmk\n jmxtools\n \n \n javax.jms\n jms\n \n \n \n\n \n com.twitter\n twitter-text\n 1.9.9\n \n\n \n\n \n \n spray repo\n Spray Repository\n http://repo.spray.io/\n \n \n conjars.org\n http://conjars.org/repo\n \n \n \n \n src/main/scala\n src/test/scala\n \n \n \n net.alchim31.maven\n scala-maven-plugin\n 3.1.3\n \n \n \n compile\n testCompile\n \n \n \n -make:transitive\n -dependencyfile\n ${project.build.directory}/.scala_dependencies\n \n \n \n \n \n \n org.apache.maven.plugins\n maven-surefire-plugin\n 2.13\n \n false\n true\n \n \n \n **/*Test.*\n **/*Suite.*\n \n \n \n \n \n \n \tDr. Krusche & Partner PartG\n \thttp://dr-kruscheundpartner.de\n \n\n"
},
{
"path": "src/main/resources/goals.xml",
"content": "\n\t/shoppingCart,/checkOut,/signin,/signup,/billing,/confirmShipping,/placeOrder\n"
},
{
"path": "src/main/resources/pageview.xml",
"content": "\n\tsessionid\n\ttimestamp\n\tuserid\n pageurl\t\n visittime\t\n referrer\n"
},
{
"path": "src/main/resources/server.conf",
"content": "akka {\n actor {\n provider = \"akka.remote.RemoteActorRefProvider\"\n }\n remote {\n enabled-transports = [\"akka.remote.netty.tcp\"]\n netty.tcp {\n hostname = \"127.0.0.1\"\n port = 2600\n }\n log-sent-messages = on\n log-received-messages = on\n }\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/Configuration.scala",
"content": "package de.kp.spark.elastic\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\nimport com.typesafe.config.ConfigFactory\nimport java.util.Properties\n\nobject Configuration {\n\n /* Load configuration for router */\n val path = \"application.conf\"\n val config = ConfigFactory.load(path)\n\n def elastic():(String,String,String,String) = {\n \n val cfg = config.getConfig(\"elastic\")\n\n val host = cfg.getString(\"host\")\n val port = cfg.getString(\"port\")\n\n val index = cfg.getString(\"index\")\n val mapping = cfg.getString(\"mapping\")\n\n (host,port,index,mapping) \n \n }\n\n def kafka():Properties = {\n \n val cfg = config.getConfig(\"kafka\")\n\n val host = cfg.getString(\"zk.connect.host\")\n val port = cfg.getString(\"zk.connect.port\")\n \n val gid = config.getString(\"consumer.groupid\")\n\n val ctimeout = cfg.getString(\"consumer.timeout.ms\")\n val stimeout = cfg.getString(\"consumer.socket.timeout.ms\")\n\n val ccommit = cfg.getString(\"consumer.commit.ms\")\n val aoffset = cfg.getString(\"auto.offset.reset\")\n \n val params = Map(\n \"zookeeper.connect\" -> (host + \":\" + port),\n\n \"group.id\" -> gid,\n\n \"socket.timeout.ms\" -> stimeout,\n \"consumer.timeout.ms\" -> ctimeout,\n\n \"autocommit.interval.ms\" -> ccommit,\n \"auto.offset.reset\" -> aoffset\n \n )\n\n val props = new Properties()\n params.map(kv => {\n props.put(kv._1,kv._2)\n })\n\n props\n\n }\n \n def router():(Int,Int,Int) = {\n \n val cfg = config.getConfig(\"router\")\n \n val time = cfg.getInt(\"time\")\n val retries = cfg.getInt(\"retries\") \n val workers = cfg.getInt(\"workers\")\n \n (time,retries,workers)\n\n }\n\n def topic() = config.getString(\"topic\")\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/EsClient.scala",
"content": "package de.kp.spark.elastic\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n \nimport akka.actor.ActorSystem\n\nimport spray.http.{HttpRequest,HttpResponse}\nimport spray.client.pipelining.{Get,Post,sendReceive }\n\nimport org.elasticsearch.client.transport.TransportClient\nimport org.elasticsearch.common.transport.InetSocketTransportAddress\n\nimport org.elasticsearch.transport.ConnectTransportException\n\nimport scala.concurrent.Future\nimport scala.util.{Success,Failure}\n\ncase class EsConfig(\n hosts:Seq[String],ports:Seq[Int]\n)\n\n/**\n * A Http client implementation based on Akka & Spray\n */\nclass EsHttpClient {\n \n import concurrent.ExecutionContext.Implicits._\n \n implicit val system = ActorSystem(\"EsClient\")\n \n val pipeline: HttpRequest => Future[HttpResponse] = sendReceive\n\n def get(url:String):Future[HttpResponse] = pipeline(Get(url))\n\n def post(url:String,payload:String):Future[HttpResponse] = pipeline(Post(url, payload))\n \n def shutdown = system.shutdown\n \n}\n\nobject EsTransportClient {\n\n def apply(config:EsConfig):TransportClient = {\n \n val client = try {\n \n val transportClient = new TransportClient()\n \n (config.hosts zip config.ports) foreach { hp =>\n transportClient.addTransportAddress(\n new InetSocketTransportAddress(hp._1, hp._2))\n }\n \n transportClient\n \n } catch {\n case e: ConnectTransportException =>\n throw new Exception(e.getMessage)\n }\n\n client\n \n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/EsContext.scala",
"content": "package de.kp.spark.elastic\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.apache.spark.SparkContext\nimport org.apache.spark.SparkContext._\n\nimport org.apache.spark.rdd.RDD\n\nimport org.apache.spark.sql.{SchemaRDD,SQLContext}\n\nimport org.apache.spark.mllib.clustering.KMeans\nimport org.apache.spark.mllib.linalg.{Vector,Vectors}\n\nimport org.apache.hadoop.conf.{Configuration => HadoopConfig}\nimport org.apache.hadoop.io.{ArrayWritable,MapWritable,NullWritable,Text}\n\nimport org.elasticsearch.hadoop.mr.EsInputFormat\n\nimport org.json4s.native.Serialization.write\nimport org.json4s.DefaultFormats\n\nimport scala.collection.JavaConversions._\n\ncase class EsDocument(id:String,data:Map[String,String])\n\n/**\n * ElasticContext supports access to Elasticsearch from Apache Spark using the library\n * from org.elasticsearch.hadoop. For read requests, the [Text] specifies the _id field\n * from Elasticsearch, and [MapWritable] specifies a (field,value) map\n * \n */\nclass EsContext(sparkConf:HadoopConfig) extends SparkBase {\n \n private val sc = createSCLocal(\"ElasticContext\",sparkConf)\n private val sqlc = new SQLContext(sc)\n\n /**\n * EsDocument is the common format to be used if machine learning algorithms\n * have to be applied to the extracted content of an Elasticseach index\n */\n def documents(esConf:HadoopConfig):RDD[EsDocument] = {\n \n val source = sc.newAPIHadoopRDD(esConf, classOf[EsInputFormat[Text, MapWritable]], classOf[Text], classOf[MapWritable])\n source.map(hit => new EsDocument(hit._1.toString,toMap(hit._2)))\n \n }\n /**\n * Json format is the common format to be used if SQL queries have to be applied\n * to the extracted content of an Elasticsearch index\n */\n def documentsAsJson(esConf:HadoopConfig):RDD[String] = {\n \n implicit val formats = DefaultFormats \n \n val source = sc.newAPIHadoopRDD(esConf, classOf[EsInputFormat[Text, MapWritable]], classOf[Text], classOf[MapWritable])\n val docs = source.map(hit => {\n val doc = Map(\"ident\" -> hit._1.toString()) ++ toMap(hit._2)\n write(doc) \n })\n \n docs\n \n }\n\n def documentsFromSpec(conf:HadoopConfig):RDD[EsDocument] = {\n \n val fields = sc.broadcast(conf.get(\"es.fields\").split(\",\"))\n\n val source = sc.newAPIHadoopRDD(conf, classOf[EsInputFormat[Text, MapWritable]], classOf[Text], classOf[MapWritable])\n source.map(hit => new EsDocument(hit._1.toString,toMap(hit._2,fields.value)))\n \n }\n\n /**\n * Cluster extracted content from an Elasticsearch index by applying KMeans \n * clustering algorithm from MLLib\n */\n def cluster(documents:RDD[EsDocument],conf:HadoopConfig):RDD[(Int,EsDocument)] = {\n \n val fields = sc.broadcast(conf.get(\"es.fields\").split(\",\"))\n \n val vectors = documents.map(doc => toVector(doc.data,fields.value)) \n\n val clusters = conf.get(\"es.clusters\").toInt\n val iterations = conf.get(\"es.iterations\").toInt\n \n /* Train model */\n val model = KMeans.train(vectors, clusters, iterations)\n \n /* Apply model */\n documents.map(doc => (model.predict(toVector(doc.data,fields.value)),doc))\n \n }\n\n /**\n * Apply SQL statement to extracted content from an Elasticsearch index\n */\n def query(documents:RDD[String], esConfig:HadoopConfig):SchemaRDD = {\n\n val query = esConfig.get(\"es.sql\")\n val name = esConfig.get(\"es.table\")\n \n val table = sqlc.jsonRDD(documents)\n table.registerAsTable(name)\n\n sqlc.sql(query) \n\n }\n\n /**\n * Wrapper to stop SparkContext\n */\n def shutdown = sc.stop\n /**\n * Wrapper to get SparkContext from ElasticContext\n */\n def sparkContext = sc\n \n /**\n * A helper method to convert a MapWritable into a Map\n */\n private def toMap(mw:MapWritable):Map[String,String] = {\n \n val m = mw.map(e => {\n \n val k = e._1.toString \n val v = (if (e._2.isInstanceOf[Text]) e._2.toString()\n else if (e._2.isInstanceOf[ArrayWritable]) {\n \n val array = e._2.asInstanceOf[ArrayWritable].get()\n array.map(item => {\n \n (if (item.isInstanceOf[NullWritable]) \"\" else item.asInstanceOf[Text].toString)}).mkString(\",\")\n \n }\n else \"\")\n \n \n k -> v\n \n })\n \n m.toMap\n \n }\n \n /**\n * A helper method to convert a MapWritable into a Map\n * thereby selecting predefined fields\n */\n private def toMap(mw:MapWritable,fields:Array[String]):Map[String,String] = {\n \n val m = mw.map(e => {\n \n val k = e._1.toString \n val v = (if (e._2.isInstanceOf[Text]) e._2.toString()\n else if (e._2.isInstanceOf[ArrayWritable]) {\n \n val array = e._2.asInstanceOf[ArrayWritable].get()\n array.map(item => {\n \n (if (item.isInstanceOf[NullWritable]) \"\" else item.asInstanceOf[Text].toString)}).mkString(\",\")\n \n }\n else \"\")\n \n \n k -> v\n \n })\n \n m.filter(kv => fields.contains(kv._1)).toMap\n \n }\n\n private def toVector(data:Map[String,String], fields:Array[String]):Vector = {\n \n val features = data.filter(kv => fields.contains(kv._1)).map(_._2.toDouble) \n Vectors.dense(features.toArray)\n \n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/EsEvents.scala",
"content": "package de.kp.spark.elastic\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.elasticsearch.client.Client\n\nimport org.elasticsearch.action.index.IndexResponse\nimport org.elasticsearch.action.ActionListener\n\nimport scala.concurrent.{ExecutionContext,Future,Promise}\n\n/**\n * EsEvents indexes trackable events retrieved from Apache Kafka\n */\nclass EsEvents(client:Client,index:String,mapping:String) {\n\n def insert(event:String)(implicit ec:ExecutionContext): Future[Either[String,String]] = {\n \n val response = Promise[IndexResponse]\n\n /* index/mapping = enron/mails */\n client.prepareIndex(index,mapping).setSource(event)\n .execute(new EsActionListener(response))\n\n response.future\n .map(r => Right(r.getId()))\n .recover {\n case e: Exception => Left(e.toString)\n }\n \n }\n\n}\n\nclass EsActionListener[T](val p: Promise[T]) extends ActionListener[T]{\n \n override def onResponse(r: T) = {\n p.success(r)\n }\n \n override def onFailure(e: Throwable) = {\n p.failure(e)\n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/EsService.scala",
"content": "package de.kp.spark.elastic\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport akka.actor.{ActorSystem,Props}\nimport com.typesafe.config.ConfigFactory\n\nimport de.kp.spark.elastic.actor.EsMaster\n\nobject EsService {\n\n def main(args: Array[String]) {\n \n val name:String = \"elastic-server\"\n val conf:String = \"server.conf\"\n\n val server = new EsService(conf, name)\n while (true) {}\n \n server.shutdown\n \n }\n\n}\n\nclass EsService(conf:String, name:String) {\n\n val system = ActorSystem(name, ConfigFactory.load(conf))\n sys.addShutdownHook(system.shutdown)\n\n val master = system.actorOf(Props[EsMaster], name=\"elastic-master\")\n\n def shutdown = system.shutdown()\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/KafkaReader.scala",
"content": "package de.kp.spark.elastic\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport akka.actor.ActorRef\n\nimport kafka.consumer.{Consumer,ConsumerConfig,Whitelist}\nimport kafka.serializer.DefaultDecoder\n\nclass KafkaReader(topic:String,actor:ActorRef) {\n\n private val props = Configuration.kafka\n private val connector = Consumer.create(new ConsumerConfig(props))\n\n private val stream = connector.createMessageStreamsByFilter(new Whitelist(topic),1,new DefaultDecoder(),new DefaultDecoder())(0)\n\n def shutdown {\n connector.shutdown()\n }\n\n def read {\n\tconsume(execute)\n }\n\n private def consume(write:(Array[Byte]) => Unit) = {\n\n for (compose <- stream) {\n try { \n write(compose.message)\n } catch {\n \n case e: Throwable =>\n if (true) { //this is objective even how to conditionalize on it\n //error(\"Error processing message, skipping this message: \", e)\n } else {\n throw e\n }\n }\n } \n }\n\n private def execute(bytes:Array[Byte]) {\n actor ! new String(bytes) \n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/KafkaService.scala",
"content": "package de.kp.spark.elastic\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport akka.actor.{ActorSystem,Props}\nimport de.kp.spark.elastic.actor.KafkaMaster\n\nobject KafkaService {\n\n val topic = Configuration.topic\n \n val system = ActorSystem(\"elastic-kafka\") \n sys.addShutdownHook(system.shutdown)\n \n def main(args: Array[String]) {\n \n val master = system.actorOf(Props(new KafkaMaster()))\n val reader = new KafkaReader(topic, master)\n \n while (true) reader.read\n \n reader.shutdown\n system.shutdown\n\n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/SparkBase.scala",
"content": "package de.kp.spark.elastic\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.apache.spark.{SparkConf,SparkContext}\nimport org.apache.spark.serializer.KryoSerializer\n\nimport org.apache.spark.streaming.{Seconds,StreamingContext}\n\nimport org.apache.hadoop.conf.{Configuration => HadoopConfig}\nimport scala.collection.JavaConversions._\n\ntrait SparkBase {\n \n protected def createSSCLocal(name:String,config:HadoopConfig):StreamingContext = {\n\n val sc = createSCLocal(name,config)\n \n /*\n * Batch duration is the time duration spark streaming uses to \n * collect spark RDDs; with a duration of 5 seconds, for example\n * spark streaming collects RDDs every 5 seconds, which then are\n * gathered int RDDs \n */\n val batch = config.get(\"spark.batch.duration\").toInt \n new StreamingContext(sc, Seconds(batch))\n\n }\n \n protected def createSCLocal(name:String,config:HadoopConfig):SparkContext = {\n\n /* Extract Spark related properties from the Hadoop configuration */\n val iterator = config.iterator()\n for (prop <- iterator) {\n\n val k = prop.getKey()\n val v = prop.getValue()\n \n if (k.startsWith(\"spark.\"))System.setProperty(k,v) \n \n }\n\n val runtime = Runtime.getRuntime()\n\truntime.gc()\n\t\t\n\tval cores = runtime.availableProcessors()\n\t\t\n\tval conf = new SparkConf()\n\tconf.setMaster(\"local[\"+cores+\"]\")\n\t\t\n\tconf.setAppName(name);\n conf.set(\"spark.serializer\", classOf[KryoSerializer].getName)\t\t\n \n /* Set the Jetty port to 0 to find a random port */\n conf.set(\"spark.ui.port\", \"0\") \n \n\tnew SparkContext(conf)\n\t\t\n }\n\n protected def createSSCRemote(name:String,config:HadoopConfig):SparkContext = {\n /* Not implemented yet */\n null\n }\n\n protected def createSCRemote(name:String,config:HadoopConfig):SparkContext = {\n /* Not implemented yet */\n null\n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/actor/EsMaster.scala",
"content": "package de.kp.spark.elastic.actor\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport akka.actor.{Actor,ActorLogging,ActorRef,Props}\n\nimport akka.pattern.ask\nimport akka.util.Timeout\n\nimport akka.actor.{OneForOneStrategy, SupervisorStrategy}\nimport akka.routing.RoundRobinRouter\n\nimport com.typesafe.config.ConfigFactory\n\nimport scala.concurrent.duration.DurationInt\n\n/**\n * EsMaster handles remote search requests based on Akka Remoting\n * feature; also see: EsService (remote service) \n */\nclass EsMaster extends Actor with ActorLogging {\n \n def receive = {\n \n case _ => log.info(\"Unknown request\")\n \n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/actor/KafkaMaster.scala",
"content": "package de.kp.spark.elastic.actor\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport akka.actor.{Actor,ActorLogging,ActorRef,Props}\nimport akka.actor.{OneForOneStrategy, SupervisorStrategy}\n\nimport akka.routing.RoundRobinRouter\n\nimport de.kp.spark.elastic.{Configuration,EsConfig,EsEvents,EsTransportClient}\n\nimport scala.concurrent.duration._\nimport scala.concurrent.duration.Duration._\n\nimport scala.concurrent.duration.DurationInt\n\nclass KafkaMaster extends Actor with ActorLogging {\n \n private val (esHost,esPort,esIndex,esType) = Configuration.elastic \n private val esClient = EsTransportClient(EsConfig(Seq(esHost),Seq(esPort.toInt)))\n \n private val esEvents = new EsEvents(esClient,esIndex,esType)\n \n import concurrent.ExecutionContext.Implicits._\n \n /* Load configuration for routers */\n val (time,retries,workers) = Configuration.router \n\n override val supervisorStrategy = OneForOneStrategy(maxNrOfRetries=retries,withinTimeRange = DurationInt(time).minutes) {\n case _ : Exception => SupervisorStrategy.Restart\n }\n \n def receive = {\n\n case req:String => {\n \n val response = esEvents.insert(req)\n \n }\n \n case _ => {}\n \n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/apps/GoalApp.scala",
"content": "package de.kp.spark.elastic.apps\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.apache.spark.rdd.RDD\nimport org.apache.hadoop.conf.Configuration\n\nimport de.kp.spark.elastic.{EsContext,EsDocument}\n\nimport de.kp.spark.elastic.bayes.{ClickModel,ClickTrainer}\nimport de.kp.spark.elastic.specs.{GoalSpec,PageViewSpec}\n\nobject GoalApp {\n\n def run(clicks:Int,goal:String) {\n\n val start = System.currentTimeMillis()\n \n /* Configure Apache Spark */\n val sparkConf = new Configuration()\n\n sparkConf.set(\"spark.executor.memory\",\"1g\")\n\tsparkConf.set(\"spark.kryoserializer.buffer.mb\",\"256\")\n\n\tval es = new EsContext(sparkConf)\n\n /* Configure Elasticsearch */\n val esConf = new Configuration() \n\n esConf.set(\"es.nodes\",\"localhost\")\n esConf.set(\"es.port\",\"9200\")\n \n esConf.set(\"es.resource\", \"visits/pageview\") \n esConf.set(\"es.query\", \"?q=*:*\") \n\n val fields = PageViewSpec.get.map(_._2._1).mkString(\",\")\n esConf.set(\"es.fields\", fields)\n \n /*\n * Read from Elasticsearch and restrict to those document fields\n * specified by PageViewSpec \n */\n val documents = es.documentsFromSpec(esConf)\n\n /*\n * Extract dataset: (sessionid,timestamp,userid,pageurl,visittime,referrer)\n */\n val extracted = extract(documents,PageViewSpec.get)\n /*\n * Evaluate extracted dataset and determine whether the conversion goal provided matches the \n * page urls within a session\n * \n * Evaluated dataset: (sessid,userid,total,starttime,timespent,referrer,exitpage,flowstatus)\n */\n val evaluated = evaluate(extracted,goal)\n /*\n * Train a Bayes model from the evaluated dataset\n */\n val model = ClickTrainer.train(evaluated)\n println(\"Conversion Probability: \" + model.predict(clicks))\n \n val end = System.currentTimeMillis()\n println(\"Total time: \" + (end-start) + \" ms\")\n \n es.shutdown\n \n }\n \n def evaluate(source:RDD[(String,Long,String,String,String,String)],goal:String):RDD[(String,String,Int,Long,Long,String,String,Int)] = {\n \n /* Group source by sessionid */\n val dataset = source.groupBy(group => group._1)\n dataset.map(valu => {\n \n /* Sort single session data by timestamp */\n val data = valu._2.toList.sortBy(_._2)\n\n val pages = data.map(_._4)\n \n /* Total number of page clicks */\n val total = pages.size\n \n val (sessid,starttime,userid,pageurl,visittime,referrer) = data.head\n val endtime = data.last._2\n \n /* Total time spent for session */\n val timespent = (if (total > 1) (endtime - starttime) / 1000 else 0)\n val exitpage = pages(total - 1)\n \n /*\n * This is a simple session evaluation to determine whether the sequence of\n * pages per session matches with a predefined page flow\n */\n val flowstatus = GoalSpec.checkFlow(goal,pages) \n (sessid,userid,total,starttime,timespent,referrer,exitpage,flowstatus)\n \n })\n \n }\n\n private def extract(documents:RDD[EsDocument],spec:Map[String,(String,String)]):RDD[(String,Long,String,String,String,String)] = {\n\n val sc = documents.context\n val bspec = sc.broadcast(spec)\n \n documents.map(document => {\n \n /* sessionid */\n val sessionid = document.data(bspec.value(\"sessionid\")._1)\n \n /* timestamp */\n val timestamp = document.data(bspec.value(\"timestamp\")._1).toLong\n\n /* userid */\n val userid = document.data(bspec.value(\"userid\")._1)\n \n /* pageurl */\n val pageurl = document.data(bspec.value(\"pageurl\")._1)\n \n /* visittime */\n val visittime = document.data(bspec.value(\"visittime\")._1)\n \n /* referrer */\n val referrer = document.data(bspec.value(\"referrer\")._1)\n \n /* Format: (sessionid,timestamp,userid,pageurl,visittime,referrer) */\n (sessionid,timestamp,userid,pageurl,visittime,referrer)\n \n })\n \n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/apps/InsightApp.scala",
"content": "package de.kp.spark.elastic.apps\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.apache.hadoop.conf.Configuration\nimport de.kp.spark.elastic.EsContext\n\n/**\n * An example of how to extract documents from Elasticsearch\n * and apply a simple SQL statement to the documents\n */\nobject InsightApp {\n\n def run() {\n\n val start = System.currentTimeMillis()\n \n /*\n * Spark specific configuration\n */\n val sparkConf = new Configuration()\n\n sparkConf.set(\"spark.executor.memory\",\"1g\")\n\tsparkConf.set(\"spark.kryoserializer.buffer.mb\",\"256\")\n\n\tval es = new EsContext(sparkConf)\n\n /*\n * Elasticsearch specific configuration\n */\n val esConf = new Configuration() \n\n esConf.set(\"es.nodes\",\"localhost\")\n esConf.set(\"es.port\",\"9200\")\n \n esConf.set(\"es.resource\", \"enron/mails\") \n esConf.set(\"es.query\", \"?q=*:*\") \n\n esConf.set(\"es.table\", \"docs\")\n esConf.set(\"es.sql\", \"select subject from docs\")\n \n /*\n * Read from ES and provide some insight with Spark & SparkSQL,\n * thereby mixing SQL and other Spark operations\n */\n val documents = es.documentsAsJson(esConf)\n val subjects = es.query(documents, esConf).filter(row => row.getString(0).contains(\"Re\")) \n\n subjects.foreach(subject => println(subject))\n\n val end = System.currentTimeMillis()\n println(\"Total time: \" + (end-start) + \" ms\")\n \n es.shutdown\n \n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/apps/SegmentApp.scala",
"content": "package de.kp.spark.elastic.apps\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.apache.hadoop.conf.Configuration\nimport de.kp.spark.elastic.EsContext\n\n/**\n * An example of how to extract documents from Elasticsearch\n * and apply KMeans clustering algorithm to group documents\n * by similar features\n */\nobject SegmentApp {\n\n def run() {\n\n val start = System.currentTimeMillis()\n \n /*\n * Spark specific configuration\n */\n val sparkConf = new Configuration()\n\n sparkConf.set(\"spark.executor.memory\",\"1g\")\n\tsparkConf.set(\"spark.kryoserializer.buffer.mb\",\"256\")\n\n\tval es = new EsContext(sparkConf)\n\n /*\n * Elasticsearch specific configuration\n */\n val esConf = new Configuration() \n\n esConf.set(\"es.nodes\",\"localhost\")\n esConf.set(\"es.port\",\"9200\")\n \n esConf.set(\"es.resource\", \"visits/pageview\") \n esConf.set(\"es.query\", \"?q=*:*\") \n\n esConf.set(\"es.fields\", \"lat,lon\")\n \n esConf.set(\"es.clusters\", \"10\")\n esConf.set(\"es.iterations\", \"100\")\n \n /*\n * Read from Elasticsearch and apply KMeans clustering\n * to the extracted documents\n */\n val documents = es.documents(esConf)\n val clustered = es.cluster(documents, esConf) \n\n val end = System.currentTimeMillis()\n println(\"Total time: \" + (end-start) + \" ms\")\n \n es.shutdown\n \n }\n\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/bayes/ClickPredictor.scala",
"content": "package de.kp.spark.elastic.bayes\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.apache.spark.SparkContext._\nimport org.apache.spark.rdd.RDD\n\nimport de.kp.spark.elastic.specs.GoalSpec\n\nclass ClickModel(probabilities:Map[Int,Double]) {\n \n def predict(clicks:Int):Double = {\n \n val nearest = probabilities.map(valu => {\n \n val k = valu._1\n val d = Math.abs(k - clicks)\n\n (k,d)\n \n }).toList.sortBy(_._2).take(1)(0)._1\n \n probabilities(nearest)\n \n }\n}\n\n/**\n * This Predictor is backed by the Bayesian Discriminant method \n * to determine the conversion probability given a number of clicks \n * within a certain web session; in this context, a web session is \n * considered to be converted, if a certain sequence of page views \n * appeared\n */\nobject ClickTrainer {\n \n /**\n * Input = (sessid,userid,total,starttime,timespent,referrer,exiturl,flowstatus)\n */\n def train(dataset:RDD[(String,String,Int,Long,Long,String,String,Int)]):ClickModel = {\n \n val histo = histogram(dataset)\n \n /*\n * p(c|v=1): probability of clicks per session, given the visitor converted in the session\n */\n val prob1 = histo.filter(valu => {valu._1._2 == 1}).map(valu => {\n \n val (clicks,converted) = valu._1\n val support = valu._2\n \n val prop = 1.toDouble / support\n (clicks,prop)\n \n }).collect().toMap\n \n /*\n * (p(c|v=0): probability of clicks per session, given the visitor did not convert in the session\n */\n val prob2 = histo.filter(valu => {valu._1._2 == 0}).map(valu => {\n \n val (clicks,converted) = valu._1\n val support = valu._2\n \n val prop = 1.toDouble / support\n (clicks,prop)\n \n }).collect().toMap\n \n val counts = conversions(dataset)\n \n /*\n * p(v=1): unconditional probability of visitor converted in a session\n */\n val prob3 = 1.toDouble / counts.filter(valu => valu._1 == 1).map(valu => valu._2).collect()(0)\n \n /*\n * p(v=0): unconditional probability of visitor did not convert in a session\n */\n val prob4 = 1.toDouble / counts.filter(valu => valu._1 == 0).map(valu => valu._2).collect()(0)\n\n /*\n * p(v=1|c) = p(c|v=1) * p(v=1) / (p(c|v=0) * p(v=0) + p(c|v=1) * p(v=1))\n */\n val clickProbs = prob1.map(valu => {\n \n val (clicks,prop) = valu\n \n val numerator = prop * prob3\n val denominator = numerator + prob4 * prob2(clicks)\n \n val res = (if (denominator > 0) numerator / denominator else 0)\n \n (clicks,res)\n \n })\n \n new ClickModel(clickProbs)\n \n }\n\n /**\n * Input = (sessid,userid,total,starttime,timespent,referrer,exiturl,flowstatus)\n * \n */\n private def conversions(dataset:RDD[(String,String,Int,Long,Long,String,String,Int)]):RDD[(Int,Int)] = {\n \n val counts = dataset.map(valu => {\n \n val userConvertedPerSession = if (valu._8 == GoalSpec.FLOW_COMPLETED) 1 else 0\n \n val k = userConvertedPerSession\n val v = 1\n \n (k,v)\n \n }).reduceByKey(_ + _)\n \n /* \n * The output shows the session counts \n * for conversion and no conversion\n */\n counts\n \n }\n\n /**\n * Input = (sessid,userid,total,starttime,timespent,referrer,exiturl,flowstatus)\n * \n */\n private def histogram(dataset:RDD[(String,String,Int,Long,Long,String,String,Int)]):RDD[((Int,Int),Int)] = {\n /*\n * The input contains one row per session. Each row contains the number of clicks \n * in the session, time spent in the session and a boolean indicating whether the \n * user converted during the session.\n */\n val histogram = dataset.map(valu => {\n \n val clicksPerSession = valu._3\n val userConvertedPerSession = if (valu._8 == GoalSpec.FLOW_COMPLETED) 1 else 0\n \n val k = (clicksPerSession,userConvertedPerSession)\n val v = 1\n \n (k,v)\n \n }).reduceByKey(_ + _)\n \n /*\n * Each row of the output contains the conversion flag, click count \n * per session and the number of sessions with those click counts. \n */ \n histogram\n \n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/enron/EnronApp.scala",
"content": "package de.kp.spark.elastic.enron\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\n/**\n * EnronApp is a helper to prepare and index data in ES\n */\nobject EnronApp {\n \n def main(args : Array[String]) {\n \n val settings = Map(\n \n \"dir\" -> \"/Work/tmp/enron/20110402/mails/allen-p\",\n \n \"index\" -> \"enron\",\n \"mapping\" -> \"mails\",\n \n \"server\" -> \"http://localhost:9200\"\n \n )\n\n val action = \"index\" // or prepare\n EnronEngine.execute(action, settings)\n \n }\n}\n"
},
{
"path": "src/main/scala/de/kp/spark/elastic/enron/EnronEngine.scala",
"content": "package de.kp.spark.elastic.enron\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n \nimport java.io.File\n\nimport scala.io.Source\nimport scala.concurrent.Future\n\nimport spray.http.HttpResponse\nimport org.json4s._\n\nimport org.json4s.native.Serialization\nimport org.json4s.native.Serialization.{read,write}\n\nimport de.kp.spark.elastic.EsHttpClient\n\n/**\n * Please note, that part of the functionality below is taken from\n * the code base assigned to this blog entry:\n * \n * http://sujitpal.blogspot.de/2012/11/indexing-into-elasticsearch-with-akka.html\n */\n\nobject EnronEngine {\n \n import concurrent.ExecutionContext.Implicits._\n \n private val client = new EsHttpClient()\n\n private val shards:Int = 1\n private val replicas:Int = 1\n \n private val es_CreateIndex:String = \"\"\"\n {\"settings\": {\"index\": {\"number_of_shards\": %s, \"number_of_replicas\": %s}}}\"\"\".format(shards, replicas)\n \n private val es_CreateSchema:String = \"\"\"{ \"%s\" : { \"properties\" : %s } }\"\"\"\n\n private val parser = new EnronParser()\n private val schema = new EnronSchema()\n\n def execute(action:String,settings:Map[String,String]) {\n \n action match {\n \n case \"index\" => \n \n index(settings)\n client.shutdown\n \n case \"prepare\" =>\n \n prepare(settings)\n client.shutdown\n \n case _ => {}\n \n }\n \n }\n \n private def prepare(settings:Map[String,String]) {\n \n /**\n * Create new index\n */\n val server0 = List(settings(\"server\"), settings(\"index\")).foldRight(\"\")(_ + \"/\" + _)\n client.post(server0, es_CreateIndex)\n \n /**\n * Create new schema\n */ \n val server1 = List(settings(\"server\"), settings(\"index\"), settings(\"mapping\")).foldRight(\"\")(_ + \"/\" + _)\n client.post(server1 + \"_mapping\", es_CreateSchema.format(\"enron\", schema.mappings))\n\n }\n \n private def index(settings:Map[String,String]) {\n\n val dir = settings.get(\"dir\").get\n \n val filefilter = new EnronFilter()\n val files = walk(new File(dir)).filter(f => filefilter.accept(f))\n\n val server1 = List(settings(\"server\"), settings(\"index\"), settings(\"mapping\")).foldRight(\"\")(_ + \"/\" + _)\n\n for (file <- files) {\n \n val path = file.getAbsolutePath()\n val doc = parser.parse(Source.fromFile(path))\n\n val response = addDocument(doc,server1)\n response.map(result => println(\"RESPONSE: \" + result.entity.asString))\n\n }\n \n }\n \n private def getProps(path:String): Map[String,String] = {\n \n val file:File = new File(path)\n \n Map() ++ Source.fromFile(file).getLines().toList.\n filter(line => (! (line.isEmpty || line.startsWith(\"#\")))).\n map(line => (line.split(\"=\")(0) -> line.split(\"=\")(1)))\n \n } \n\n private def walk(root: File): Stream[File] = {\n \n if (root.isDirectory) { \n root #:: root.listFiles.toStream.flatMap(walk(_))\n \n } else root #:: Stream.empty\n \n }\n\n private def addDocument(doc:EnronDoc, server:String):Future[HttpResponse] = {\n\n implicit val formats = Serialization.formats(NoTypeHints)\n val json = write(doc)\n \n client.post(server, json)\n\n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/enron/EnronUtils.scala",
"content": "package de.kp.spark.elastic.enron\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport scala.io.Source\nimport scala.collection.immutable.HashMap\n\nimport java.io.{File,FileFilter}\nimport java.util.Locale\n\nimport java.text.SimpleDateFormat\n\n/**\n * Please note, that part of the functionality below is taken from\n * the code base assigned to this blog entry:\n * \n * http://sujitpal.blogspot.de/2012/11/indexing-into-elasticsearch-with-akka.html\n */\n\ncase class EnronDoc ( \n message_id: String,\n from: String,\n to: Seq[String],\n x_cc: Seq[String],\n x_bcc: Seq[String],\n date: String,\n subject: String,\n body:String\n)\n\nclass EnronSchema {\n \n def mappings(): String = \"\"\"{\n \"message_id\": {\"type\": \"string\", \"index\": \"not_analyzed\", \"store\": \"yes\"},\n \"from\": {\"type\": \"string\", \"index\": \"not_analyzed\", \"store\": \"yes\"},\n \"to\": {\"type\": \"string\", \"index\": \"not_analyzed\", \"store\": \"yes\", \"multi_field\": \"yes\"},\n \"x_cc\": {\"type\": \"string\", \"index\": \"not_analyzed\", \"store\": \"yes\", \"multi_field\": \"yes\"},\n \"x_bcc\": {\"type\": \"string\", \"index\": \"not_analyzed\", \"store\": \"yes\", \"multi_field\": \"yes\"},\n \"date\": {\"type\": \"date\", \"index\": \"not_analyzed\", \"store\": \"yes\"},\n \"subject\": {\"type\": \"string\", \"index\": \"analyzed\", \"store\": \"yes\"},\n \"body\": {\"type\": \"string\", \"index\": \"analyzed\", \"store\": \"yes\"}\n }\"\"\"\n \n}\n\nclass EnronParser {\n\n def parse(source: Source):EnronDoc = {\n \n val map = parse(source.getLines(), HashMap[String,String](), false)\n /**\n * Convert map into case class\n */\n val message_id = map.get(\"message_id\").get\n val from = map.get(\"from\").get\n \n val to = map.get(\"to\") match {\n case None => Seq()\n case Some(to) => to.split(\",\").toSeq\n }\n \n val x_cc = map.get(\"x_cc\").get.split(\",\").toSeq\n\n val x_bcc = map.get(\"x_bcc\").get.split(\",\").toSeq\n val date = map.get(\"date\").get\n\n val subject = map.get(\"subject\").get\n val body = map.get(\"body\").get\n \n new EnronDoc(message_id,from,to,x_cc,x_bcc,date,subject,body)\n\n }\n \n private def parse(lines: Iterator[String], map: Map[String,String], startBody: Boolean): Map[String,String] = {\n \n if (lines.isEmpty) map\n else {\n \n val head = lines.next()\n \n if (head.trim.length == 0) parse(lines, map, true)\n else if (startBody) {\n \n val body = map.getOrElse(\"body\", \"\") + \"\\n\" + head\n parse(lines, map + (\"body\" -> body), startBody)\n \n } else {\n \n val split = head.indexOf(':')\n if (split > 0) {\n val kv = (head.substring(0, split), head.substring(split + 1))\n val key = kv._1.map(c => if (c == '-') '_' else c).trim.toLowerCase\n val value = kv._1 match {\n case \"Date\" => formatDate(kv._2.trim)\n case _ => kv._2.trim\n }\n parse(lines, map + (key -> value), startBody)\n } else parse(lines, map, startBody)\n }\n }\n }\n \n private def formatDate(date: String): String = {\n\n lazy val parser = new SimpleDateFormat(\"EEE, dd MMM yyyy HH:mm:ss\", Locale.US)\n lazy val formatter = new SimpleDateFormat(\"yyyy-MM-dd'T'HH:mm:ss\")\n \n formatter.format(parser.parse(date.substring(0, date.lastIndexOf('-') - 1)))\n \n }\n\n}\n/**\n * We restrict to the /sent/ folders of the Enron dataset\n */\nclass EnronFilter extends FileFilter {\n \n override def accept(file: File): Boolean = {\n file.getAbsolutePath().contains(\"/sent/\")\n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/ml/EsKMeans.scala",
"content": "package de.kp.spark.elastic.ml\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.apache.spark.rdd.RDD\n\nimport org.apache.spark.mllib.clustering.KMeans\nimport org.apache.spark.mllib.linalg.{Vector,Vectors}\n\nobject EsKMeans {\n\n /**\n * This method segments an RDD of documents clustering the assigned (lat,lon) geo coordinates.\n * The field parameter specifies the names of the lat & lon coordinate fields \n */\n def segmentByLocation(docs:RDD[(String,Map[String,String])],fields:Array[String],clusters:Int,iterations:Int):RDD[(Int,String,Map[String,String])] = {\n /**\n * Train model\n */\n val vectors = docs.map(doc => toVector(doc._2,fields)) \n val model = KMeans.train(vectors, clusters, iterations)\n /**\n * Apply model\n */\n docs.map(doc => {\n \n val vector = toVector(doc._2,fields)\n (model.predict(vector),doc._1,doc._2)\n \n })\n \n }\n\n private def toVector(data:Map[String,String], fields:Array[String]):Vector = {\n \n val lat = data(fields(0)).toDouble\n val lon = data(fields(1)).toDouble\n \n Vectors.dense(Array(lat,lon))\n \n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/ml/EsNPref.scala",
"content": "package de.kp.spark.cf\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.apache.spark.rdd.RDD\nimport org.apache.spark.SparkContext._\n\nobject EsNPref {\n\n def build(docs:RDD[(String,Map[String,String])],fields:Array[String]):RDD[(String,String,Int)] = {\n\n val transactions = docs.map(doc => {\n /**\n * Each document (doc) represents an ecommerce transaction per user\n */\n val user = doc._2(fields(0))\n val line = doc._2(fields(1))\n \n (user,line)\n \n })\n \n build(transactions)\n \n }\n \n def build(transactions:RDD[(String,String)]):RDD[(String,String,Int)] = {\n /**\n * STEP #1\n * \n * Compute the total number of transactions per user. The transactions are\n * grouped by user (_._1) and then mapped onto number of transactions\n * per user\n */\n val total = transactions.groupBy(_._1).map(grouped => (grouped._1, grouped._2.size)) \n /**\n * STEP #2\n * \n * Computer the item support per user. Each transaction (text line) is split\n * into an Array[String] and all items are made unique. The result is mapped\n * into (user,item,support) tuples\n */\n val userItemSupport = transactions.flatMap(valu => List.fromArray(valu._2.split(\" \")).distinct.map(item => (valu._1,item)))\n .groupBy(valu => (valu._1,valu._2))\n .map(grouped => (grouped._1,grouped._2.size)).map(valu => (valu._1._1,valu._1._2,valu._2)) \n /**\n * STEP #3\n * \n * Compute item preference per user. Item support and total transactions per user\n * are used to compute the respective item preference:\n * \n * pref = Math.log(1 + supp.toDouble / total.toDouble)\n */\n val userItemPref = userItemSupport.keyBy(value => value._1).join(total)\n .map(valu => {\n \n val user = valu._1 \n val data = valu._2 // ((user,item,support),total)\n \n val item = data._1._2\n val supp = data._1._3\n \n val total = data._2\n\n /**\n * Math.log means natural logarithm in Scala\n */\n val pref = Math.log(1 + supp.toDouble / total.toDouble)\n (user, item, pref)\n \n })\n \n /**\n * The user-item preferences are solely based on the purchase data of a \n * particluar user; the respective value, however, is far from representing\n * a real-life value, as it only takes the purchase frequency into account.\n * \n * The frequency is quite different depending on the item price, item lifetime, \n * and the like. For example, since expensive items or items with long lifespan,\n * such as jewelry or electronic home appliances, are purchased infrequently.\n * \n * So the preferences of users form them cannot be higher that cheap items or\n * those with a short lifespan such as hand creams or tissues. Also, when a \n * user u purchase item i four times out of ten transactions, we may think that\n * he does not prefer item i if other users purchased the same item eight times\n * out of ten transactions.\n * \n * It is therefore necessary to define a relative preference so it is comparable \n * among all users. We therefore proceed to compute the maximum item preference\n * for all users and use this value to normalize the user-item preference derived\n * above. \n */\n\n /**\n * STEP #4\n * \n * Compute the maximum preference per item (independent of the user)\n */\n val itemMaxPref = userItemPref.map(valu => (valu._2,valu._3)).groupBy(valu => valu._1)\n .map(grouped => {\n \n def max(pref1:Double, pref2:Double):Double = if (pref1 > pref2) pref1 else pref2\n \n val item = grouped._1\n val mpref = grouped._2.map(valu => valu._2).reduceLeft(max)\n \n (item,mpref)\n\n })\n /**\n * STEP #5\n * \n * Finally compute the user-item rating with scores from 1..5\n */\n\n val userItemRating = userItemPref.keyBy(valu => valu._2).join(itemMaxPref)\n .map(valu => {\n \n val item = valu._1\n val data = valu._2\n \n val uid = data._1._1\n val pref = data._1._3\n \n val mpref = data._2\n val npref = Math.round( 5* (pref.toDouble / mpref.toDouble) ).toInt\n \n (uid,item,npref)\n \n })\n \n userItemRating\n \n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/ml/EsSimilarity.scala",
"content": "package de.kp.spark.elastic.ml\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.apache.spark.rdd.RDD\nimport org.apache.spark.SparkContext._\n\nclass EsSimilarity(ratings:RDD[(String,String,Int)]) {\n /**\n * Parameters to regularize correlation.\n */\n val PRIOR_COUNT = 10\n val PRIOR_CORRELATION = 0\n\n val model = build()\n \n def recommend(item:String, k:Int):Array[(String,Double,Double,Double,Double)] = {\n \n /**\n * Retrieve all similarities where the first item\n * is equal to the provided one\n */\n val similarities = model.filter(valu => {\n \n val pair = valu._1\n pair._1 == item\n \n })\n\n val result = similarities.map(valu => {\n \n val (item1,item2) = valu._1\n val (corr,rcorr,cos,jac) = valu._2\n \n (item2, corr, rcorr, cos, jac)\n\n }).collect().filter(valu => (valu._3 equals Double.NaN) == false)\n .sortBy(valu => valu._4).take(k)\n \n result\n \n }\n \n private def build():RDD[((String,String),(Double,Double,Double,Double))] = {\n \n /**\n * Compute the number of raters per item\n */ \n val itemSupport = ratings.groupBy(valu => valu._2)\n .map(grouped => (grouped._1, grouped._2.size))\n /**\n * Join rating with item support: the result contains\n * the following data (user,item,rating,support)\n */\n val ratingsSupport = ratings.groupBy(valu => valu._2).join(itemSupport)\n .flatMap(joined => joined._2._1.map(valu => (valu._1, valu._2, valu._3, joined._2._2)))\n /**\n * Clone data, join on user and filter pairs to make sure\n * that we do not double count and exclude self pairs \n */\n val ratingsSupportClone = ratingsSupport.keyBy(valu => valu._1)\n val ratingsPairs = ratingsSupportClone.join(ratingsSupportClone).filter(valu => valu._2._1._2 < valu._2._2._2)\n\n /** \n * Compute raw inputs to similarity metrics\n */\n val vectorCalcs = ratingsPairs.map(valu => {\n \n val (user1,item1,rating1,support1) = valu._2._1\n val (user2,item2,rating2,support2) = valu._2._2\n \n val key = (item1, item2)\n val stats = (\n rating1 * rating2,\n rating1, \n rating2, \n math.pow(rating1, 2), \n math.pow(rating2, 2), \n support1, \n support2\n ) \n \n (key, stats)\n \n }).groupByKey().map(valu => {\n \n val key = valu._1\n val stats = valu._2\n \n val size = stats.size\n val dotProduct = stats.map(f => f._1).sum\n \n val rating1Sum = stats.map(f => f._2).sum\n val rating2Sum = stats.map(f => f._3).sum\n \n val rating1Sq = stats.map(f => f._4).sum\n val rating2Sq = stats.map(f => f._5).sum\n \n val support1 = stats.map(f => f._6).max\n val support2 = stats.map(f => f._7).max\n \n (key, (size, dotProduct, rating1Sum, rating2Sum, rating1Sq, rating2Sq, support1, support2))\n \n })\n \n /** \n * Compute similarity metrics for each item pair\n */\n vectorCalcs.map(valu => {\n \n val key = valu._1\n val (size, dotProduct, ratingSum, rating2Sum, ratingNormSq, rating2NormSq, support, support2) = valu._2\n /*\n * Correlation\n */\n val corr = correlation(size, dotProduct, ratingSum, rating2Sum, ratingNormSq, rating2NormSq)\n val regCorr = regularizedCorrelation(size, dotProduct, ratingSum, rating2Sum, ratingNormSq, rating2NormSq, PRIOR_COUNT, PRIOR_CORRELATION)\n /*\n * Cosine similarity\n */ \n val cosSim = cosineSimilarity(dotProduct, scala.math.sqrt(ratingNormSq), scala.math.sqrt(rating2NormSq))\n /*\n * Jaccard Similarity\n */\n val jaccard = jaccardSimilarity(size, support, support2)\n\n (key, (corr, regCorr, cosSim, jaccard))\n \n })\n \n }\n\n /**\n * The correlation between two vectors A, B is cov(A, B) / (stdDev(A) * stdDev(B))\n *\n * This is equivalent to:\n * \n * [n * dotProduct(A, B) - sum(A) * sum(B)] / sqrt{ [n * norm(A)^2 - sum(A)^2] [n * norm(B)^2 - sum(B)^2] }\n */\n private def correlation (\n size:Double,\n dotProduct:Double,\n rating1Sum:Double,\n rating2Sum:Double,\n rating1NormSq:Double,\n rating2NormSq:Double) = {\n\n val numerator = size * dotProduct - rating1Sum * rating2Sum\n val denominator = scala.math.sqrt(size * rating1NormSq - rating1Sum * rating1Sum) * scala.math.sqrt(size * rating2NormSq - rating2Sum * rating2Sum)\n\n numerator / denominator\n \n }\n\n /**\n * Regularize correlation by adding virtual pseudocounts over a prior:\n * \n * RegularizedCorrelation = w * ActualCorrelation + (1 - w) * PriorCorrelation\n * where w = # actualPairs / (# actualPairs + # virtualPairs).\n */\n private def regularizedCorrelation (\n size:Double,\n dotProduct:Double,\n rating1Sum:Double,\n rating2Sum:Double,\n rating1NormSq:Double,\n rating2NormSq:Double,\n virtualCount:Double,\n priorCorrelation:Double) = {\n\n \n val unregularizedCorrelation = correlation(size,dotProduct,rating1Sum,rating2Sum,rating1NormSq,rating2NormSq)\n val w = size / (size + virtualCount)\n\n w * unregularizedCorrelation + (1 - w) * priorCorrelation\n \n }\n\n /**\n * The cosine similarity between two vectors A, B is dotProduct(A, B) / (norm(A) * norm(B))\n */\n private def cosineSimilarity (\n dotProduct:Double, \n rating1Norm:Double,\n rating2Norm:Double) = {\n \n dotProduct / (rating1Norm * rating2Norm)\n \n }\n\n /**\n * The Jaccard Similarity between two sets A, B is |Intersection(A, B)| / |Union(A, B)|\n */\n private def jaccardSimilarity (\n usersInCommon:Double, \n totalUsers1:Double, \n totalUsers2:Double) = {\n \n val union = totalUsers1 + totalUsers2 - usersInCommon\n usersInCommon / union\n \n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/samples/EsCountMinSktech.scala",
"content": "package de.kp.spark.elastic.samples\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport scala.util.parsing.json._\n\nimport com.twitter.algebird._\n\nimport org.apache.spark.streaming.dstream.DStream\n\n/**\n * Frequency Estimation\n */\nobject EsCountMinSktech {\n \n def findTopK(stream:DStream[Message]):Seq[(Long,Long)] = {\n \n val DELTA = 1E-3\n val EPS = 0.01\n \n val SEED = 1\n val PERC = 0.001\n \n val k = 5\n \n var globalCMS = new CountMinSketchMonoid(DELTA, EPS, SEED, PERC).zero\n \n val clases = stream.map(message => message.clas)\n val approxTopClases = clases.mapPartitions(clases => {\n \n val localCMS = new CountMinSketchMonoid(DELTA, EPS, SEED, PERC)\n clases.map(clas => localCMS.create(clas))\n \n }).reduce(_ ++ _)\n\n approxTopClases.foreach(rdd => {\n if (rdd.count() != 0) globalCMS ++= rdd.first()\n })\n \n /**\n * Retrieve approximate TopK classifiers from the provided messages\n */\n val globalTopK = globalCMS.heavyHitters.map(clas => (clas, globalCMS.frequency(clas).estimate))\n /*\n * Retrieve the top k message classifiers: it may also be interesting to \n * return the classifier frequency from this method, ignoring the line below\n */\n .toSeq.sortBy(_._2).reverse.slice(0, k)\n \n globalTopK\n \n }\n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/samples/EsHyperLogLog.scala",
"content": "package de.kp.spark.elastic.samples\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport com.twitter.algebird._\nimport org.apache.spark.streaming.dstream.DStream\nimport java.nio.ByteBuffer\n\nobject EsHyperLogLog {\n\n def estimateCardinality(stream:DStream[Message]):Double = {\n\n val BIT_SIZE = 12\n \n val clases = stream.map(message => message.clas)\n val approxClases = clases.mapPartitions(clases => {\n \n /* 12: Number of bits */\n val hll = new HyperLogLogMonoid(12)\n clases.map(clas => {\n \n val bytes = ByteBuffer.allocate(8).putLong(clas).array()\n hll(bytes)\n \n })\n \n }).reduce(_ + _)\n\n val hll = new HyperLogLogMonoid(BIT_SIZE)\n var globalHll = hll.zero\n \n approxClases.foreach(rdd => {\n if (rdd.count() != 0) {\n globalHll += rdd.first()\n }\n })\n \n /*\n * Approximate distinct clases in the observed messages\n */\n globalHll.estimatedSize\n\n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/samples/KafkaEngine.scala",
"content": "package de.kp.spark.elastic.samples\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport kafka.serializer.StringDecoder\n\nimport org.apache.spark.streaming._\nimport org.apache.spark.streaming.StreamingContext._\nimport org.apache.spark.streaming.{Seconds, StreamingContext}\n\nimport org.apache.spark.streaming.kafka._\n\nimport org.apache.spark.SparkContext._\nimport org.apache.spark.storage.StorageLevel\n\nimport org.apache.hadoop.io.{MapWritable,NullWritable,Text}\nimport org.apache.hadoop.conf.{Configuration => HConf}\n\nimport org.elasticsearch.hadoop.mr.EsOutputFormat\n\nimport de.kp.spark.elastic.SparkBase\n\nclass KafkaEngine(name:String,conf:HConf) extends SparkBase with Serializable {\n\n /* Elasticsearch configuration */\t\n val ec = getEsConf(conf) \n\n /* Kafka configuration */\n val (kc,topics) = getKafkaConf(conf)\n \n def run() {\n \n val ssc = createSSCLocal(name,conf)\n\n val stream = KafkaUtils.createStream[String,Message,StringDecoder,MessageDecoder](ssc,kc,topics, StorageLevel.MEMORY_AND_DISK).map(_._2)\n stream.foreachRDD(messageRDD => {\n /**\n * Live indexing of Kafka messages; note, that this is also\n * an appropriate place to integrate further message analysis\n */\n val messages = messageRDD.map(prepare)\n messages.saveAsNewAPIHadoopFile(\"-\",classOf[NullWritable],classOf[MapWritable],classOf[EsOutputFormat],ec) \n \n })\n \n ssc.start()\n ssc.awaitTermination() \n\n }\n \n private def prepare(msg:Message):(Object,Object) = {\n \n val m = MessageUtils.messageToMap(msg)\n\n /**\n * Prepare (Keywritable, ValueWritable)\n */\n val kw = NullWritable.get\n \n val vw = new MapWritable\n for ((k, v) <- m) vw.put(new Text(k), new Text(v))\n \n (kw, vw)\n \n }\n\n \n private def getEsConf(config:HConf):HConf = {\n \n val conf = new HConf() \n\n conf.set(\"es.nodes\", conf.get(\"es.nodes\"))\n conf.set(\"es.port\", conf.get(\"es.port\"))\n \n conf.set(\"es.resource\", conf.get(\"es.resource\")) \n \n conf\n \n }\n \n private def getKafkaConf(config:HConf):(Map[String,String],Map[String,Int]) = {\n\n val cfg = Map(\n \"group.id\" -> conf.get(\"kafka.group\"),\n \n \"zookeeper.connect\" -> conf.get(\"kafka.zklist\"),\n \"zookeeper.connection.timeout.ms\" -> conf.get(\"kafka.timeout\")\n \n )\n\n val topics = conf.get(\"kafka.topics\").split(\",\").map((_,conf.get(\"kafka.threads\").toInt)).toMap \n \n (cfg,topics)\n \n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/samples/KafkaSerializer.scala",
"content": "package de.kp.spark.elastic.samples\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport kafka.serializer.{Decoder, Encoder}\nimport kafka.utils.VerifiableProperties\n\nimport org.apache.commons.io.Charsets\n\nimport org.json4s._\n\nimport org.json4s.native.Serialization\nimport org.json4s.native.Serialization.{read,write}\n\n/**\n * Message refers to any Scala case class that is serializable or deserializable\n * with json4s\n */\nclass MessageDecoder(props: VerifiableProperties) extends Decoder[Message] {\n \n implicit val formats = Serialization.formats(NoTypeHints)\n \n def fromBytes(bytes: Array[Byte]): Message = {\n read[Message](new String(bytes, Charsets.UTF_8))\n }\n\n}\n\nclass MessageEncoder(props: VerifiableProperties) extends Encoder[Message] {\n \n implicit val formats = Serialization.formats(NoTypeHints)\n \n def toBytes(message: Message): Array[Byte] = {\n write[Message](message).getBytes(Charsets.UTF_8)\n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/samples/MessageApp.scala",
"content": "package de.kp.spark.elastic.samples\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport java.util.UUID\nimport org.apache.hadoop.conf.{Configuration => HConf}\n\nobject MessageApp {\n\n val task = \"index\" // prepare\n \n def main(args:Array[String]) {\n \n val conf = new HConf()\n \n conf.set(\"es.nodes\",\"localhost\")\n conf.set(\"es.port\",\"9200\")\n \n conf.set(\"es.resource\",\"kafka/messages\") \n\n conf.set(\"es.index\",\"kafka\")\n conf.set(\"es.mapping\",\"messages\")\n \n conf.set(\"es.server\",\"http://localhost:9200\")\n\n conf.set(\"spark.master\",\"local\")\n conf.set(\"spark.batch.duration\",\"15\")\n \n conf.set(\"kafka.topics\",\"publisher\")\n conf.set(\"kafka.threads\",\"1\")\n \n conf.set(\"kafka.group\",UUID.randomUUID().toString)\n conf.set(\"kafka.zklist\",\"127.0.0.1:2181\")\n \n // in milliseconds\n conf.set(\"kafka.timeout\",\"10000\")\n \n task match {\n \n case \"prepare\" => \n \n val action = \"prepare\"\n MessageEngine.execute(action,conf)\n \n case \"index\" => \n \n val engine = new KafkaEngine(\"KafkaEngine\",conf)\n engine.run\n\n case _ => {}\n \n } \n \n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/samples/MessageGenerator.scala",
"content": "package de.kp.spark.elastic.samples\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport kafka.producer.{KeyedMessage,Producer,ProducerConfig}\nimport kafka.message.DefaultCompressionCodec\n\nimport java.lang.Thread\n\nimport java.util.{Properties, Random, UUID}\n\n/**\n * A helper to generate random messages and\n * send to Apache Kafka\n */\nobject MessageGenerator {\n\n def main(args:Array[String]) {\n \n val topic = \"publisher\"\n /** \n * This is for bootstrapping and the producer will only use it for getting metadata \n * (topics, partitions and replicas). The socket connections for sending the actual \n * data will be established based on the broker information returned in the metadata. \n * \n * The format is host1:port1,host2:port2, and the list can be a subset of brokers or \n * a VIP pointing to a subset of brokers.\n */ \n val broker = \"127.0.0.1:9092\" \n /**\n * This parameter allows you to specify the compression codec for all data generated by \n * this producer. When set to true gzip is used. To override and use snappy you need to \n * implement that as the default codec for compression using SnappyCompressionCodec.codec \n * instead of DefaultCompressionCodec.codec below.\n */\n val codec = DefaultCompressionCodec.codec\n /**\n * This parameter specifies whether the messages are sent asynchronously in a background \n * thread. Valid values are false for asynchronous send and true for synchronous send.\n * \n * By setting the producer to async we allow batching together of requests (which is great \n * for throughput) but open the possibility of a failure of the client machine dropping \n * unsent data.\n */\n val synchronously = true \n /**\n * The client id is a user-specified string sent in each request to help trace calls. \n * It should logically identify the application making the request.\n */ \n val clientId = UUID.randomUUID().toString\n /**\n * The number of messages to send in one batch when using async mode. \n * The producer will wait until either this number of messages are ready \n * to send or queue.buffer.max.ms is reached.\n */\n val batchSize = 200\n /** messageSendMaxRetries\n * This property will cause the producer to automatically retry a failed send request. \n * This property specifies the number of retries when such failures occur. Note that \n * setting a non-zero value here can lead to duplicates in the case of network errors \n * that cause a message to be sent but the acknowledgement to be lost.\n */\n val messageSendMaxRetries = 3\n /** \n * 0) which means that the producer never waits for an acknowledgement from the broker (the same behavior as 0.7). \n * This option provides the lowest latency but the weakest durability guarantees (some data will be lost when a server fails).\n * 1) which means that the producer gets an acknowledgement after the leader replica has received the data. This option provides \n * better durability as the client waits until the server acknowledges the request as successful (only messages that were \n * written to the now-dead leader but not yet replicated will be lost).\n * -1) which means that the producer gets an acknowledgement after all in-sync replicas have received the data. This option \n * provides the best durability, we guarantee that no messages will be lost as long as at least one in sync replica remains.\n */\n val requestRequiredAcks = -1\n \n val props = new Properties()\n \n props.put(\"compression.codec\", codec.toString) \n props.put(\"producer.type\", \"sync\")\n \n props.put(\"metadata.broker.list\", broker)\n props.put(\"batch.num.messages\", batchSize.toString)\n \n props.put(\"message.send.max.retries\", messageSendMaxRetries.toString)\n props.put(\"require.requred.acks\",requestRequiredAcks.toString)\n \n props.put(\"client.id\",clientId.toString)\n props.put(\"serializer.class\", \"de.kp.spark.elastic.samples.MessageEncoder\")\n\n val producer = new Producer[String, Message](new ProducerConfig(props))\n\n var i = 0 \n while(true) {\n \n val text = \"This is message, no=%s\".format(i)\n \n val mid = UUID.randomUUID().toString()\n val timestamp = System.currentTimeMillis()\n \n val clas = new Random().nextInt(10).toLong\n \n val message = new Message(mid,clas,text,timestamp)\n producer.send(new KeyedMessage[String, Message](topic, message))\n\n i += 1\n Thread.sleep(1000)\n\n }\n \n }\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/samples/MessageUtils.scala",
"content": "package de.kp.spark.elastic.samples\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport org.apache.hadoop.conf.{Configuration => HConf}\nimport de.kp.spark.elastic.EsHttpClient\n\n/**\n * Please note, that part of the functionality below is taken from\n * the code base assigned to this blog entry:\n * \n * http://sujitpal.blogspot.de/2012/11/indexing-into-elasticsearch-with-akka.html\n */\n\nobject MessageEngine {\n \n import concurrent.ExecutionContext.Implicits._\n \n private val client = new EsHttpClient()\n\n private val shards:Int = 1\n private val replicas:Int = 1\n \n private val es_CreateIndex:String = \"\"\"\n {\"settings\": {\"index\": {\"number_of_shards\": %s, \"number_of_replicas\": %s}}}\"\"\".format(shards, replicas)\n \n private val es_CreateSchema:String = \"\"\"{ \"%s\" : { \"properties\" : %s } }\"\"\"\n\n private val schema = new MessageSchema()\n\n def execute(action:String,conf:HConf) {\n \n action match {\n \n case \"prepare\" => prepare(conf)\n \n case _ => {}\n \n }\n \n }\n \n private def prepare(conf:HConf) {\n \n val index = conf.get(\"es.index\")\n val server = conf.get(\"es.server\")\n \n /**\n * Create new index\n */\n val server0 = List(server, index).foldRight(\"\")(_ + \"/\" + _)\n client.post(server0, es_CreateIndex)\n \n /**\n * Create new schema\n */ \n val server1 = List(server, index, conf.get(\"es.mapping\")).foldRight(\"\")(_ + \"/\" + _)\n client.post(server1 + \"_mapping\", es_CreateSchema.format(index, schema.mappings))\n\n }\n \n}\n\nobject MessageUtils {\n \n def messageToMap(message:Message):Map[String,String] = {\n \n Map(\n \"mid\" -> message.mid,\n \"text\" -> message.text, \n \"timestamp\" -> message.timestamp.toString\n )\n\n }\n \n}\n\n/**\n * Specification of sample data structures; the classifier\n * is introduced to support the CountMinSketch algorithm\n */\n\ncase class Message(\n mid:String,\n clas:Long,\n text:String,\n timestamp:Long\n)\n\nclass MessageSchema {\n \n def mappings(): String = \"\"\"{\n \"mid\": {\"type\": \"string\", \"index\": \"not_analyzed\", \"store\": \"yes\"},\n \"text\": {\"type\": \"string\", \"index\": \"analyzed\", \"store\": \"yes\"},\n \"timestamp\": {\"type\": \"string\", \"index\": \"not_analyzed\", \"store\": \"yes\"}\n }\"\"\"\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/specs/FieldSpec.scala",
"content": "package de.kp.spark.elastic.specs\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport scala.xml._\n\nclass FieldSpec(path:String) {\n \n val root:Elem = XML.load(getClass.getClassLoader.getResource(path)) \n\n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/specs/GoalSpec.scala",
"content": "package de.kp.spark.elastic.specs\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport scala.xml._\n\nimport scala.collection.mutable.{ArrayBuffer,HashMap}\nimport scala.util.control.Breaks._\n\nobject GoalSpec extends Serializable {\n \n private val spec = new FieldSpec(\"goals.xml\")\n private val flows = HashMap.empty[String,Array[String]]\n \n val FLOW_NOT_ENTERED:Int = 0\n val FLOW_ENTERED:Int = 1\n val FLOW_COMPLETED:Int = 2\n \n load()\n \n private def load() {\n\n for (goal <- spec.root \\ \"goal\") {\n \n val fid = (goal \\ \"@id\").toString\n val flow = goal.text.split(\",\")\n \n flows += fid -> flow\n \n }\n\n }\n\n def getFlow(fid:String):Option[Array[String]] = {\n flows.get(fid)\n }\n \n def getFlows():Array[(String,Array[String])] = {\n flows.toArray\n }\n \n def checkFlow(goal:String,pages:List[String]):Int = {\n \n getFlow(goal) match {\n \n case None => 0\n case Some(flow) => checkFlow(flow,pages)\n \n }\n \n }\n \n /**\n * A helper method to evaluate whether the pages clicked in a certain \n * session match, partially match or do not match a predefined sequence\n * of pages (flow)\n */\n def checkFlow(flow:Array[String],pages:List[String]):Int = { \t\t\t\n \t\t\n var j = 0\n var\tflowStat = FLOW_NOT_ENTERED\n \t\t\n var matched = false;\n \t\t\n for (i <- 0 until flow.length) {\n \t\t\t\n breakable {while (j < pages.size) {\n \t\t\t\t\n matched = false\n /*\n * We expect that a certain page url has to start with the \n * configured url part of the flow\n */\n \tif (pages(j).startsWith(flow(i))) {\n \t flowStat = (if (i == flow.length - 1) FLOW_COMPLETED else FLOW_ENTERED)\n \t matched = true\n \t\t\t\t\n \t}\n \tj += 1\n \tif (matched) break\n \t\t\t\n }}\n \n }\n\n flowStat\n \n }\n \n /**\n * A helper method to evaluate whether the pages clicked in a certain \n * session match, partially match or do not match a predefined sequences\n * of page flows\n */\n def checkFlows(pages:List[String]):Array[(String,Int)] = { \t\t\t\n \n val flows = getFlows\n flows.map(v => (v._1, checkFlow(v._2,pages)))\n \n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/specs/PageViewSpec.scala",
"content": "package de.kp.spark.elastic.specs\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport scala.xml._\nimport scala.collection.mutable.HashMap\n\nobject PageViewSpec {\n\n private val spec = new FieldSpec(\"pageview.xml\")\n private val fields = HashMap.empty[String,(String,String)]\n \n load()\n \n private def load() {\n\n for (field <- spec.root \\ \"field\") {\n \n val _name = (field \\ \"@name\").toString\n val _type = (field \\ \"@type\").toString\n\n val _mapping = field.text\n fields += _name -> (_mapping,_type) \n \n }\n\n }\n\n def get = fields.toMap\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/stream/EsHistogram.scala",
"content": "package de.kp.spark.elastic.stream\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport scala.util.parsing.json._\n\nimport org.json4s.DefaultFormats\nimport org.json4s.native.Serialization.write\n\nimport org.apache.hadoop.conf.{Configuration => HConf}\n\nimport org.apache.spark.streaming.StreamingContext._\nimport org.apache.spark.streaming.dstream.DStream\n\nimport com.twitter.algebird._\n\nclass EsHistogram(field:String,conf:HConf) extends EsStream(\"EsHistogram\",conf) {\n \n override def transform(stream:DStream[String]):DStream[String] = {\n histogram(stream,field)\n }\n \n private def histogram(stream:DStream[String],field:String):DStream[String] = {\n \n implicit val formats = DefaultFormats \n \n /* Mapify stream */\n val mapified = stream.map(json => {\n \n JSON.parseFull(json) match {\n \n case Some(map) => map.asInstanceOf[Map[String,String]]\n case None => Map.empty[String,String]\n \n }\n \n })\n\n /* Extract field values and compute support for each field value */\n val values = mapified.map(m => m(field))\n val support = values.map(v => (v, 1)).reduceByKey((a, b) => a + b)\n\n /* The data type of the field value is a String */\n var global = Map[String,Int]()\n val monoid = new MapMonoid[String, Int]() \n \n /* Determine Top K */\n support.foreachRDD(rdd => {\n \n if (rdd.count() != 0) {\n val partial = rdd.collect().toMap\n global = monoid.plus(global.toMap, partial)\n }\n \n })\n \n mapified.transform(rdd => {\n \n rdd.map(m => {\n \n val v = m(field)\n val s = global(v)\n \n write(m ++ Map(\"_field\" -> field, \"_valu\" -> v, \"_supp\" -> s.toString))\n \n })\n \n })\n \n }\n \n}"
},
{
"path": "src/main/scala/de/kp/spark/elastic/stream/EsStream.scala",
"content": "package de.kp.spark.elastic.stream\n/* Copyright (c) 2014 Dr. Krusche & Partner PartG\n* \n* This file is part of the Spark-ELASTIC project\n* (https://github.com/skrusche63/spark-elastic).\n* \n* Spark-ELASTIC is free software: you can redistribute it and/or modify it under the\n* terms of the GNU General Public License as published by the Free Software\n* Foundation, either version 3 of the License, or (at your option) any later\n* version.\n* \n* Spark-ELASTIC is distributed in the hope that it will be useful, but WITHOUT ANY\n* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR\n* A PARTICULAR PURPOSE. See the GNU General Public License for more details.\n* You should have received a copy of the GNU General Public License along with\n* Spark-ELASTIC. \n* \n* If not, see .\n*/\n\nimport scala.util.parsing.json._\n\nimport kafka.serializer.StringDecoder\n\nimport org.apache.spark.SparkContext._\n\nimport org.apache.spark.streaming._\nimport org.apache.spark.streaming.StreamingContext._\n\nimport org.apache.spark.streaming.{Seconds, StreamingContext}\nimport org.apache.spark.streaming.dstream.DStream\n\nimport org.apache.spark.rdd.RDD\nimport org.apache.spark.storage.StorageLevel\n\nimport org.apache.spark.streaming.kafka._\n\nimport org.apache.hadoop.conf.{Configuration => HConf}\nimport org.apache.hadoop.io.{MapWritable,NullWritable,Text}\n\nimport org.elasticsearch.hadoop.mr.EsOutputFormat\n\nimport de.kp.spark.elastic.SparkBase\n\n/**\n * EsStream provides base functionality for indexing transformed live streams \n * from Apache Kafka with Elasticsearch; to appy a customized transformation,\n * the method 'transform' must be overwritten\n */\nclass EsStream(name:String,conf:HConf) extends SparkBase with Serializable {\n\n /* Elasticsearch configuration */\t\n val ec = getEsConf(conf) \n\n /* Kafka configuration */\n val (kc,topics) = getKafkaConf(conf)\n \n def run() {\n \n val ssc = createSSCLocal(name,conf)\n\n /*\n * The KafkaInputDStream returns a Tuple where only the second component\n * holds the respective message; we therefore reduce to a DStream[String]\n */\n val stream = KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](ssc,kc,topics,StorageLevel.MEMORY_AND_DISK).map(_._2)\n /*\n * Inline transformation of the incoming stream by any function that maps \n * a DStream[String] onto a DStream[String]\n */\n val transformed = transform(stream)\n /*\n * Write transformed stream to Elasticsearch index\n */\n transformed.foreachRDD(rdd => {\n val messages = rdd.map(prepare)\n messages.saveAsNewAPIHadoopFile(\"-\",classOf[NullWritable],classOf[MapWritable],classOf[EsOutputFormat],ec) \n })\n \n ssc.start()\n ssc.awaitTermination() \n\n }\n \n def transform(stream:DStream[String]) = stream\n \n private def getEsConf(config:HConf):HConf = {\n \n val conf = new HConf() \n\n conf.set(\"es.nodes\", conf.get(\"es.nodes\"))\n conf.set(\"es.port\", conf.get(\"es.port\"))\n \n conf.set(\"es.resource\", conf.get(\"es.resource\")) \n \n conf\n \n }\n \n private def getKafkaConf(config:HConf):(Map[String,String],Map[String,Int]) = {\n\n val cfg = Map(\n \"group.id\" -> conf.get(\"kafka.group\"),\n \n \"zookeeper.connect\" -> conf.get(\"kafka.zklist\"),\n \"zookeeper.connection.timeout.ms\" -> conf.get(\"kafka.timeout\")\n \n )\n\n val topics = conf.get(\"kafka.topics\").split(\",\").map((_,conf.get(\"kafka.threads\").toInt)).toMap \n \n (cfg,topics)\n \n }\n \n private def prepare(message:String):(Object,Object) = {\n \n val m = JSON.parseFull(message) match {\n case Some(map) => map.asInstanceOf[Map[String,String]]\n case None => Map.empty[String,String]\n }\n\n val kw = NullWritable.get\n \n val vw = new MapWritable\n for ((k, v) <- m) vw.put(new Text(k), new Text(v))\n \n (kw, vw)\n \n }\n\n}"
}
]