Repository: sml2h3/ddddocr
Branch: master
Commit: c40f56f95412
Files: 52
Total size: 84.2 MB
Directory structure:
gitextract_nf9m0pr2/
├── .dockerignore
├── .idea/
│ ├── .gitignore
│ ├── ddddocr.iml
│ ├── inspectionProfiles/
│ │ └── profiles_settings.xml
│ ├── misc.xml
│ ├── modules.xml
│ └── vcs.xml
├── Dockerfile
├── LICENSE
├── MANIFEST.in
├── README.md
├── ddddocr/
│ ├── README.md
│ ├── __init__.py
│ ├── __main__.py
│ ├── api/
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── app.py
│ │ ├── mcp.py
│ │ ├── models.py
│ │ ├── routes.py
│ │ └── server.py
│ ├── charsets.py
│ ├── common.onnx
│ ├── common_det.onnx
│ ├── common_old.onnx
│ ├── compat/
│ │ ├── __init__.py
│ │ └── v1.py
│ ├── core/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── detection_engine.py
│ │ ├── ocr_engine.py
│ │ └── slide_engine.py
│ ├── models/
│ │ ├── __init__.py
│ │ ├── charset_manager.py
│ │ └── model_loader.py
│ ├── preprocessing/
│ │ ├── __init__.py
│ │ ├── color_filter.py
│ │ └── image_processor.py
│ ├── requirements.txt
│ └── utils/
│ ├── __init__.py
│ ├── compat.py
│ ├── exceptions.py
│ ├── image_io.py
│ └── validators.py
├── docker-compose.yml
├── examples/
│ ├── README.md
│ ├── api_client.py
│ ├── basic_ocr.py
│ ├── detector.py
│ └── ocr.py
├── pyproject.toml
└── requirements.txt
================================================
FILE CONTENTS
================================================
================================================
FILE: .dockerignore
================================================
# Git相关
.git
.gitignore
.github
# Python缓存文件
__pycache__/
*.py[cod]
*$py.class
*.so
.Python
.pytest_cache/
.coverage
htmlcov/
.tox/
.nox/
.hypothesis/
.egg-info/
.eggs/
*.egg
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
# IDE相关
.idea/
.vscode/
*.sublime-project
*.sublime-workspace
.project
.spyderproject
.spyproject
.ropeproject
# 环境相关
env/
venv/
ENV/
env.bak/
venv.bak/
.env
.venv
# 日志文件
logs/
*.log
# 数据文件夹(可能包含测试数据)
data/
test_images/
# Docker相关
Dockerfile
docker-compose.yml
.dockerignore
# 文档
docs/
*.md
# 特定排除(自定义模型或测试数据)
custom_models/
*.zip
*.tar.gz
*.csv
*.json
*.txt
!requirements.txt
================================================
FILE: .idea/.gitignore
================================================
# Default ignored files
/shelf/
/workspace.xml
# Editor-based HTTP Client requests
/httpRequests/
# Datasource local storage ignored files
/dataSources/
/dataSources.local.xml
================================================
FILE: .idea/ddddocr.iml
================================================
================================================
FILE: .idea/inspectionProfiles/profiles_settings.xml
================================================
================================================
FILE: .idea/misc.xml
================================================
================================================
FILE: .idea/modules.xml
================================================
================================================
FILE: .idea/vcs.xml
================================================
================================================
FILE: Dockerfile
================================================
# 基础镜像使用 Python 3.10 (slim 版本可以减小镜像体积)
FROM python:3.10-slim
# 镜像作者信息
LABEL maintainer="sml2h3"
LABEL description="DdddOcr - 通用验证码识别API服务"
# 设置工作目录
WORKDIR /app
# 安装系统依赖 (apt-get 非交互式安装并在安装后清理缓存以减小镜像大小)
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
curl \
libgl1-mesa-glx \
libglib2.0-0 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# 复制项目依赖文件
COPY requirements.txt .
# 安装 Python 依赖
# --no-cache-dir: 不缓存下载的包,减小镜像大小
# -r requirements.txt: 从文件安装依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制项目文件到工作目录
COPY . .
# 设置 Python 路径
ENV PYTHONPATH=/app
# 设置 DdddOcr API 服务的默认环境变量
# 这些环境变量可以在 docker run 或 docker-compose 中覆盖
# API 服务器配置
ENV DDDDOCR_HOST=0.0.0.0 # 监听所有网络接口
ENV DDDDOCR_PORT=8000 # 服务运行端口
ENV DDDDOCR_WORKERS=1 # API 服务工作进程数
# OCR 引擎配置
ENV DDDDOCR_OCR=true # 是否启用 OCR 功能
ENV DDDDOCR_DET=false # 是否启用目标检测功能
ENV DDDDOCR_OLD=false # 是否使用旧版 OCR 模型
ENV DDDDOCR_BETA=false # 是否使用 Beta 版 OCR 模型
ENV DDDDOCR_USE_GPU=false # 是否使用 GPU 加速
ENV DDDDOCR_DEVICE_ID=0 # GPU 设备 ID
ENV DDDDOCR_SHOW_AD=true # 是否显示广告
# 自定义模型配置(需要挂载卷才能访问)
ENV DDDDOCR_IMPORT_ONNX_PATH="" # 自定义模型路径
ENV DDDDOCR_CHARSETS_PATH="" # 自定义字符集路径
# 暴露端口(与 DDDDOCR_PORT 环境变量保持一致)
EXPOSE 8000
# 容器启动时执行的命令,使用 python -m ddddocr api 启动 API 服务
# 参数从环境变量读取
CMD python -m ddddocr api \
--host=${DDDDOCR_HOST} \
--port=${DDDDOCR_PORT} \
--workers=${DDDDOCR_WORKERS} \
--ocr=${DDDDOCR_OCR} \
--det=${DDDDOCR_DET} \
--old=${DDDDOCR_OLD} \
--beta=${DDDDOCR_BETA} \
--use-gpu=${DDDDOCR_USE_GPU} \
--device-id=${DDDDOCR_DEVICE_ID} \
--show-ad=${DDDDOCR_SHOW_AD} \
--import-onnx-path=${DDDDOCR_IMPORT_ONNX_PATH} \
--charsets-path=${DDDDOCR_CHARSETS_PATH}
# 健康检查,确保容器正常运行
HEALTHCHECK --interval=30s --timeout=10s --retries=3 \
CMD curl -f http://localhost:${DDDDOCR_PORT}/health || exit 1
================================================
FILE: LICENSE
================================================
The MIT License (MIT)
Copyright © 2022
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
================================================
FILE: MANIFEST.in
================================================
recursive-include ddddocr common.onnx
recursive-include ddddocr common_old.onnx
recursive-include ddddocr common_det.onnx
================================================
FILE: README.md
================================================
# DdddOcr - 通用验证码识别SDK

一个简单易用的通用验证码识别Python库
## 目录
- [赞助合作商](#赞助合作商)
- [项目介绍](#项目介绍)
- [环境支持](#环境支持)
- [安装方法](#安装方法)
- [功能概览](#功能概览)
- [初始化参数详解](#初始化参数详解)
- [参数详细说明](#参数详细说明)
- [功能组合与冲突](#功能组合与冲突)
- [模型选择指南](#模型选择指南)
- [性能优化参数](#性能优化参数)
- [详细使用说明](#详细使用说明)
- [文字识别功能](#文字识别功能)
- [基础OCR识别](#基础ocr识别)
- [OCR概率输出](#ocr概率输出)
- [自定义字符范围](#自定义字符范围)
- [颜色过滤功能](#颜色过滤功能)
- [目标检测功能](#目标检测功能)
- [滑块验证码处理](#滑块验证码处理)
- [算法1:边缘匹配](#算法1边缘匹配)
- [算法2:图像差异比较](#算法2图像差异比较)
- [自定义模型导入](#自定义模型导入)
- [高级用法](#高级用法)
- [批量处理](#批量处理)
- [多线程优化](#多线程优化)
- [验证码预处理](#验证码预处理)
- [常见问题](#常见问题)
- [初始化速度慢](#初始化速度慢)
- [识别准确率不高](#识别准确率不高)
- [GPU加速](#gpu加速)
- [处理复杂验证码](#如何处理复杂验证码)
- [内存占用过高](#内存占用过高)
- [参数冲突问题](#参数冲突问题)
- [支持的图片格式](#支持的图片格式)
- [多线程并发问题](#多线程并发问题)
- [项目技术支持](#项目技术支持)
- [使用示例](#使用示例)
- [许可证](#许可证)
## 赞助合作商
| | 赞助合作商 | 推荐理由 |
|------------------------------------------------------------|------------|--------------------------------------------------------------------------------------------------|
|  | [YesCaptcha](https://yescaptcha.com/i/NSwk7i) | 谷歌reCaptcha验证码 / hCaptcha验证码 / funCaptcha验证码商业级识别接口 [点我](https://yescaptcha.com/i/NSwk7i) 直达VIP4 |
|  | [超级鹰](https://www.chaojiying.com/) | 全球领先的智能图片分类及识别商家,安全、准确、高效、稳定、开放,强大的技术及校验团队,支持大并发。7*24h作业进度管理 |
|  | [Malenia](https://malenia.iinti.cn/malenia-doc/) | Malenia企业级代理IP网关平台/代理IP分销软件 |
| 雨云VPS | [注册首月5折](https://www.rainyun.com/ddddocr_) | 浙江节点低价大带宽,100M每月30元 |
## 项目介绍
DdddOcr 是一个通用验证码离线本地识别SDK,由 [sml2h3](https://github.com/sml2h3) 与 [kerlomz](https://github.com/kerlomz) 共同开发完成。该项目通过大批量生成随机数据进行深度网络训练,可以识别各种类型的验证码,包括:
- 常见的数字字母组合验证码
- 中文验证码
- 滑块验证码
- 各种特殊字符验证码
项目设计理念是"最简依赖",尽量减少用户的配置和使用成本,提供简单易用的API接口。
## 环境支持
| 系统 | CPU | GPU | 最大支持Python版本 | 备注 |
|-----|-----|-----|--------------|-----|
| Windows 64位 | ✓ | ✓ | 3.12 | 部分版本Windows需要安装[vc运行库](https://www.ghxi.com/yxkhj.html) |
| Linux 64 / ARM64 | ✓ | ✓ | 3.12 | |
| macOS X64 | ✓ | ✓ | 3.12 | M1/M2/M3芯片用户请参考[相关说明](https://github.com/sml2h3/ddddocr/issues/67) |
不支持的环境:
- Windows 32位
- Linux 32位
## 安装方法
### 从PyPI安装(推荐)
```bash
pip install ddddocr
```
### 从源码安装
```bash
git clone https://github.com/sml2h3/ddddocr.git
cd ddddocr
pip install .
```
### 安装 API 依赖(可选)
```bash
pip install ".[api]"
```
> **注意**:请勿直接在ddddocr项目的根目录内直接import ddddocr,请确保你的开发项目目录名称不为ddddocr。
## 功能概览
DdddOcr提供以下核心功能:
| 功能 | 描述 | 初始化参数 |
|-----|-----|----------|
| 文字识别 | 识别图片中的文字内容 | `ocr=True`(默认) |
| 目标检测 | 检测图片中的目标位置 | `det=True` |
| 滑块验证码识别 | 识别滑块验证码的缺口位置 | `ocr=False` |
| 自定义模型导入 | 导入自定义训练的模型 | `import_onnx_path="模型路径"` |
## 初始化参数详解
`DdddOcr` 类初始化时支持多种参数配置,以适应不同的使用场景:
```python
ddddocr.DdddOcr(
ocr=True, # 是否启用OCR功能
det=False, # 是否启用目标检测功能
old=False, # 是否使用旧版OCR模型
beta=False, # 是否使用Beta版OCR模型(新模型)
use_gpu=False, # 是否使用GPU加速
device_id=0, # 使用的GPU设备ID
show_ad=True, # 是否显示广告信息
import_onnx_path="", # 自定义模型路径
charsets_path="", # 自定义字符集路径
max_image_bytes=None, # 单图最大字节数(默认 8MB)
max_image_side=None # 单图最长边限制(默认 4096px)
)
```
### 参数详细说明
| 参数 | 类型 | 默认值 | 说明 |
|-----|-----|-----|-----|
| `ocr` | bool | True | 是否启用OCR功能,用于识别图片中的文字。**互斥性**:当`det=True`时会强制关闭OCR |
| `det` | bool | False | 是否启用目标检测功能,用于检测图片中的目标位置。**互斥性**:`det=True`会覆盖`ocr=True` |
| `old` | bool | False | 兼容参数,当前不会改变模型选择(默认即使用旧版模型) |
| `beta` | bool | False | 是否使用Beta版OCR模型(新模型),对某些验证码识别效果更好。**互斥性**:与`old=True`参数互斥(但`old`当前不生效) |
| `use_gpu` | bool | False | 是否使用GPU加速。**依赖关系**:需要安装CUDA和相应的onnxruntime-gpu版本,否则会初始化失败 |
| `device_id` | int | 0 | 使用的GPU设备ID。**依赖关系**:仅在`use_gpu=True`时生效,指定使用哪个GPU设备 |
| `show_ad` | bool | True | 是否在初始化时显示广告信息 |
| `import_onnx_path` | str | "" | 自定义模型的onnx文件路径。**依赖关系**:设置此参数时,`charsets_path`参数必须同时提供;此时`ocr/det`设置会被忽略 |
| `charsets_path` | str | "" | 自定义字符集的json文件路径。**依赖关系**:必须与`import_onnx_path`一起使用,否则无效 |
| `max_image_bytes` | int/str | 8MB | 单图最大字节数上限(入参可为 int 或数字字符串) |
| `max_image_side` | int/str | 4096 | 单图最长边像素上限(入参可为 int 或数字字符串) |
### 功能组合与冲突
根据参数组合,ddddocr具有不同的工作模式:
1. **标准OCR模式**:
- 参数设置:`ocr=True, det=False`(默认)
- 功能:识别图片中的文字
2. **目标检测模式**:
- 参数设置:`ocr=False, det=True`
- 功能:检测图片中的目标位置
- 注意:同时设置`ocr=True, det=True`时,会进入目标检测模式(`det`优先)
3. **滑块识别模式**:
- 参数设置:`ocr=False, det=False`
- 功能:使用滑块匹配算法(需调用`slide_match`或`slide_comparison`方法)
4. **自定义模型模式**:
- 参数设置:`import_onnx_path="模型路径", charsets_path="字符集路径"`
- 功能:使用自定义训练的模型进行识别
- 注意:设置此模式时,`ocr`和`det`参数会被忽略,且自定义字符集文件需包含 `charset/word/image/channel` 字段
5. **OCR模型选择**:
- 默认模型:不设置特殊参数(当前使用 `common_old.onnx`)
- Beta模型:`beta=True`(使用 `common.onnx`)
- 旧版模型参数:`old=True`(当前不改变模型,仅为兼容保留)
- 注意:`beta`和`old`参数互斥,但`old`当前不生效
### 模型选择指南
- **默认模型**:当前默认使用 `common_old.onnx`,适用于多数简单验证码场景
- **Beta模型**:`beta=True` 使用 `common.onnx`,对部分复杂验证码效果更好
- **自定义模型**:当默认模型无法满足需求时,可以通过[dddd_trainer](https://github.com/sml2h3/dddd_trainer)训练自己的模型
### 性能优化参数
- **GPU加速**:对于处理大量图片时,开启GPU加速可显著提升性能
```python
ocr = ddddocr.DdddOcr(use_gpu=True, device_id=0)
```
- **GPU设备选择**:在多GPU环境中,可通过`device_id`指定使用的GPU
```python
# 使用第二张GPU卡
ocr = ddddocr.DdddOcr(use_gpu=True, device_id=1)
```
- **关闭广告显示**:在生产环境中可关闭广告提示
```python
ocr = ddddocr.DdddOcr(show_ad=False)
```
## 详细使用说明
### 文字识别功能
#### 基础OCR识别
主要用于识别单行文字,如常见的英数验证码等。支持中文、英文、数字以及部分特殊字符的识别。
```python
import ddddocr
# 初始化OCR对象
ocr = ddddocr.DdddOcr()
# 读取图片
with open("验证码图片.jpg", "rb") as f:
image = f.read()
# 识别图片
result = ocr.classification(image)
print(result) # 输出识别结果
```
**OCR识别示例图片**
**参考例图**
包括且不限于以下图片




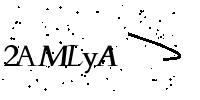




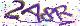

 **OCR模型选择**
DdddOcr内置两套OCR模型,可以通过`beta`参数切换:
```python
# 使用第二套OCR模型
ocr = ddddocr.DdddOcr(beta=True)
```
**透明PNG图片处理**
对于透明黑色PNG图片,可以使用`png_fix`参数(对所有 OCR 模式生效):
```python
result = ocr.classification(image, png_fix=True)
```
> **注意**:`png_fix` 仅对带透明通道的图片生效;初始化DdddOcr对象只需要一次,不要在每次识别时都重新初始化,这会导致速度变慢。
#### OCR概率输出
可以获取OCR识别结果的概率分布,便于进行更灵活的结果处理:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 获取识别结果的概率分布
result = ocr.classification(image, probability=True)
# 处理概率结果
s = ""
for i in result['probability']:
s += result['charsets'][i.index(max(i))]
print(s)
```
**概率输出示例**(仅对内置模型生效,自定义模型会忽略`probability=True`并直接返回字符串):
```python
# 概率输出结果示例
{
'charsets': ['', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', ...],
'probability': [
[0.01, 0.02, 0.01, 0.03, 0.02, 0.01, 0.02, 0.75, 0.03, 0.05, 0.01, ...], # 第一个字符的概率分布
[0.01, 0.01, 0.02, 0.01, 0.03, 0.02, 0.01, 0.02, 0.01, 0.80, 0.01, ...], # 第二个字符的概率分布
...
]
}
```
#### 自定义字符范围
可以通过`set_ranges`方法限定OCR识别的字符范围:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 设置识别范围为数字
ocr.set_ranges(0) # 等同于 ocr.set_ranges("0123456789")
# 或自定义字符范围
ocr.set_ranges("0123456789+-x/=")
result = ocr.classification(image)
print(result)
```
**内置字符范围参数**:
| 参数值 | 含义 |
|-----|-----|
| 0 | 纯数字 0-9 |
| 1 | 纯小写英文 a-z |
| 2 | 纯大写英文 A-Z |
| 3 | 小写英文 + 大写英文 |
| 4 | 小写英文 + 数字 |
| 5 | 大写英文 + 数字 |
| 6 | 小写英文 + 大写英文 + 数字 |
| 7 | 默认字符库 - 小写英文 - 大写英文 - 数字 |
#### 颜色过滤功能
对于一些特殊的验证码,可以通过颜色过滤来提高识别准确率:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 只保留红色和蓝色部分
result = ocr.classification(image, colors=["red", "blue"])
print(result)
```
**支持的颜色**:
- red (红色)
- green (绿色)
- blue (蓝色)
- yellow (黄色)
- orange (橙色)
- purple (紫色)
- pink (粉色)
- brown (棕色)
也可以自定义颜色范围:
```python
# 自定义颜色范围
custom_ranges = {
'light_blue': [(90, 30, 30), (110, 255, 255)] # HSV颜色空间
}
result = ocr.classification(image, colors=["light_blue"], custom_color_ranges=custom_ranges)
```
> **提示**:`custom_color_ranges` 只有在 `colors` 列表包含对应键名时才会生效。
### 目标检测功能
用于检测图像中可能的目标主体位置,返回目标的边界框坐标:
```python
import ddddocr
import cv2
# 初始化检测对象
det = ddddocr.DdddOcr(det=True, ocr=False)
# 读取图片
with open("test.jpg", 'rb') as f:
image = f.read()
# 检测目标
bboxes = det.detection(image)
print(bboxes) # 输出格式:[[x1, y1, x2, y2], ...]
# 可视化检测结果
im = cv2.imread("test.jpg")
for bbox in bboxes:
x1, y1, x2, y2 = bbox
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
cv2.imwrite("result.jpg", im)
```
**目标检测示例**:
**参考例图**
包括且不限于以下图片
**OCR模型选择**
DdddOcr内置两套OCR模型,可以通过`beta`参数切换:
```python
# 使用第二套OCR模型
ocr = ddddocr.DdddOcr(beta=True)
```
**透明PNG图片处理**
对于透明黑色PNG图片,可以使用`png_fix`参数(对所有 OCR 模式生效):
```python
result = ocr.classification(image, png_fix=True)
```
> **注意**:`png_fix` 仅对带透明通道的图片生效;初始化DdddOcr对象只需要一次,不要在每次识别时都重新初始化,这会导致速度变慢。
#### OCR概率输出
可以获取OCR识别结果的概率分布,便于进行更灵活的结果处理:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 获取识别结果的概率分布
result = ocr.classification(image, probability=True)
# 处理概率结果
s = ""
for i in result['probability']:
s += result['charsets'][i.index(max(i))]
print(s)
```
**概率输出示例**(仅对内置模型生效,自定义模型会忽略`probability=True`并直接返回字符串):
```python
# 概率输出结果示例
{
'charsets': ['', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', ...],
'probability': [
[0.01, 0.02, 0.01, 0.03, 0.02, 0.01, 0.02, 0.75, 0.03, 0.05, 0.01, ...], # 第一个字符的概率分布
[0.01, 0.01, 0.02, 0.01, 0.03, 0.02, 0.01, 0.02, 0.01, 0.80, 0.01, ...], # 第二个字符的概率分布
...
]
}
```
#### 自定义字符范围
可以通过`set_ranges`方法限定OCR识别的字符范围:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 设置识别范围为数字
ocr.set_ranges(0) # 等同于 ocr.set_ranges("0123456789")
# 或自定义字符范围
ocr.set_ranges("0123456789+-x/=")
result = ocr.classification(image)
print(result)
```
**内置字符范围参数**:
| 参数值 | 含义 |
|-----|-----|
| 0 | 纯数字 0-9 |
| 1 | 纯小写英文 a-z |
| 2 | 纯大写英文 A-Z |
| 3 | 小写英文 + 大写英文 |
| 4 | 小写英文 + 数字 |
| 5 | 大写英文 + 数字 |
| 6 | 小写英文 + 大写英文 + 数字 |
| 7 | 默认字符库 - 小写英文 - 大写英文 - 数字 |
#### 颜色过滤功能
对于一些特殊的验证码,可以通过颜色过滤来提高识别准确率:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 只保留红色和蓝色部分
result = ocr.classification(image, colors=["red", "blue"])
print(result)
```
**支持的颜色**:
- red (红色)
- green (绿色)
- blue (蓝色)
- yellow (黄色)
- orange (橙色)
- purple (紫色)
- pink (粉色)
- brown (棕色)
也可以自定义颜色范围:
```python
# 自定义颜色范围
custom_ranges = {
'light_blue': [(90, 30, 30), (110, 255, 255)] # HSV颜色空间
}
result = ocr.classification(image, colors=["light_blue"], custom_color_ranges=custom_ranges)
```
> **提示**:`custom_color_ranges` 只有在 `colors` 列表包含对应键名时才会生效。
### 目标检测功能
用于检测图像中可能的目标主体位置,返回目标的边界框坐标:
```python
import ddddocr
import cv2
# 初始化检测对象
det = ddddocr.DdddOcr(det=True, ocr=False)
# 读取图片
with open("test.jpg", 'rb') as f:
image = f.read()
# 检测目标
bboxes = det.detection(image)
print(bboxes) # 输出格式:[[x1, y1, x2, y2], ...]
# 可视化检测结果
im = cv2.imread("test.jpg")
for bbox in bboxes:
x1, y1, x2, y2 = bbox
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
cv2.imwrite("result.jpg", im)
```
**目标检测示例**:
**参考例图**
包括且不限于以下图片



 ### 滑块验证码处理
DdddOcr提供两种滑块验证码处理算法:
#### 算法1:边缘匹配
适用于有透明背景的滑块图片,通过边缘检测找到滑块在背景图中的位置:
```python
import ddddocr
# 初始化滑块检测对象
slide = ddddocr.DdddOcr(det=False, ocr=False)
# 读取滑块图和背景图
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
# 匹配位置
res = slide.slide_match(target_bytes, background_bytes)
print(f"滑块位置: {res}")
# 可视化结果
background = cv2.imdecode(np.frombuffer(background_bytes, np.uint8), cv2.IMREAD_COLOR)
x1, y1, x2, y2 = res["target"]
# 在背景图上绘制匹配位置
cv2.rectangle(background, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 显示结果
plt.figure(figsize=(10, 6))
plt.imshow(cv2.cvtColor(background, cv2.COLOR_BGR2RGB))
plt.title("滑块匹配结果")
plt.axis('off')
plt.savefig("slide_result.jpg")
plt.show()
```
**滑块匹配示例**:
### 滑块验证码处理
DdddOcr提供两种滑块验证码处理算法:
#### 算法1:边缘匹配
适用于有透明背景的滑块图片,通过边缘检测找到滑块在背景图中的位置:
```python
import ddddocr
# 初始化滑块检测对象
slide = ddddocr.DdddOcr(det=False, ocr=False)
# 读取滑块图和背景图
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
# 匹配位置
res = slide.slide_match(target_bytes, background_bytes)
print(f"滑块位置: {res}")
# 可视化结果
background = cv2.imdecode(np.frombuffer(background_bytes, np.uint8), cv2.IMREAD_COLOR)
x1, y1, x2, y2 = res["target"]
# 在背景图上绘制匹配位置
cv2.rectangle(background, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 显示结果
plt.figure(figsize=(10, 6))
plt.imshow(cv2.cvtColor(background, cv2.COLOR_BGR2RGB))
plt.title("滑块匹配结果")
plt.axis('off')
plt.savefig("slide_result.jpg")
plt.show()
```
**滑块匹配示例**:

滑块图
|

背景图
|
对于没有透明背景的滑块图,可以使用`simple_target`参数:
```python
res = slide.slide_match(target_bytes, background_bytes, simple_target=True)
```
#### 算法2:图像差异比较
适用于比较两张图片的不同之处,找出滑块缺口位置:
```python
import ddddocr
slide = ddddocr.DdddOcr(det=False, ocr=False)
# 读取带有缺口阴影的图片和完整图片
with open('bg.jpg', 'rb') as f:
target_bytes = f.read()
with open('fullpage.jpg', 'rb') as f:
background_bytes = f.read()
# 比较差异
res = slide.slide_comparison(target_bytes, background_bytes)
print(res) # 输出格式:{"target": [x, y]}
```
**图像差异比较示例**:

带缺口阴影的图片
|

完整图片
|
### 自定义模型导入
DdddOcr支持导入通过[dddd_trainer](https://github.com/sml2h3/dddd_trainer)训练的自定义模型:
```python
import ddddocr
# 导入自定义模型
ocr = ddddocr.DdddOcr(
det=False,
ocr=False,
import_onnx_path="mymodel.onnx",
charsets_path="charsets.json"
)
with open('test.jpg', 'rb') as f:
image_bytes = f.read()
res = ocr.classification(image_bytes)
print(res)
```
## 高级用法
### 批量处理
对大量验证码进行批量处理时,保持OCR实例的复用可以显著提高效率:
```python
import ddddocr
import os
import time
# 初始化OCR对象(只需一次)
ocr = ddddocr.DdddOcr()
# 批量处理目录中的所有图片
def batch_process(directory):
results = {}
start_time = time.time()
for filename in os.listdir(directory):
if filename.endswith(('.png', '.jpg', '.jpeg', '.bmp')):
file_path = os.path.join(directory, filename)
with open(file_path, 'rb') as f:
image = f.read()
# 使用同一个OCR实例处理所有图片
result = ocr.classification(image)
results[filename] = result
end_time = time.time()
print(f"处理 {len(results)} 张图片耗时: {end_time - start_time:.2f} 秒")
return results
# 使用示例
results = batch_process("./captchas/")
for filename, text in results.items():
print(f"{filename}: {text}")
```
### 多线程优化
在多线程环境下使用时,应当为每个线程创建独立的OCR实例:
```python
import ddddocr
import concurrent.futures
import os
def process_image(file_path):
# 每个线程创建自己的OCR实例
ocr = ddddocr.DdddOcr()
with open(file_path, 'rb') as f:
image = f.read()
result = ocr.classification(image)
return os.path.basename(file_path), result
def parallel_process(directory, max_workers=4):
file_paths = [os.path.join(directory, f) for f in os.listdir(directory)
if f.endswith(('.png', '.jpg', '.jpeg', '.bmp'))]
results = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_file = {executor.submit(process_image, file_path): file_path for file_path in file_paths}
for future in concurrent.futures.as_completed(future_to_file):
filename, result = future.result()
results[filename] = result
return results
# 使用示例
results = parallel_process("./captchas/", max_workers=8)
```
### 验证码预处理
对于干扰较多的验证码,可以先进行预处理再识别:
```python
import ddddocr
import cv2
import numpy as np
from PIL import Image
import io
def preprocess_captcha(image_bytes):
# 转换为OpenCV格式
nparr = np.frombuffer(image_bytes, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY_INV)
# 去除小噪点
kernel = np.ones((2, 2), np.uint8)
opening = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel)
# 转回字节流
is_success, buffer = cv2.imencode(".jpg", opening)
processed_bytes = io.BytesIO(buffer).getvalue()
return processed_bytes
# 使用示例
ocr = ddddocr.DdddOcr()
with open("noisy_captcha.jpg", "rb") as f:
image_bytes = f.read()
# 预处理验证码
processed_bytes = preprocess_captcha(image_bytes)
# 识别处理后的图片
result = ocr.classification(processed_bytes)
print(f"验证码识别结果: {result}")
```
## 常见问题
1. **初始化速度慢**
首次初始化DdddOcr对象时会加载模型,可能会比较慢,但只需要初始化一次即可。避免在循环中反复初始化。
```python
# 错误的用法
for img in images:
ocr = ddddocr.DdddOcr() # 每次都初始化,严重影响性能
result = ocr.classification(img)
# 正确的用法
ocr = ddddocr.DdddOcr() # 只初始化一次
for img in images:
result = ocr.classification(img)
```
2. **识别准确率不高**
- 尝试使用另一个OCR模型(设置`beta=True`)
- 对于特殊验证码,尝试使用颜色过滤功能
- 限定识别字符范围(使用`set_ranges`方法)
- 对于透明PNG图片,使用`png_fix=True`参数
3. **GPU加速**
可以通过设置`use_gpu=True`和`device_id`参数来启用GPU加速:
```python
ocr = ddddocr.DdddOcr(use_gpu=True, device_id=0)
```
使用GPU需确保已安装对应的CUDA版本和onnxruntime-gpu库。
4. **如何处理复杂验证码**
对于复杂的验证码,可以尝试以下步骤:
- 先使用目标检测功能定位验证码位置
- 对检测到的区域进行裁剪
- 应用颜色过滤去除干扰
- 使用OCR识别处理后的图片
5. **内存占用过高**
如果在同一程序中需要使用多个功能,建议不要同时初始化多个不同功能的实例,而是根据需要初始化:
```python
# 根据需要初始化不同的对象
if need_ocr:
processor = ddddocr.DdddOcr(ocr=True, det=False)
elif need_detection:
processor = ddddocr.DdddOcr(ocr=False, det=True)
```
6. **参数冲突问题**
当同时设置多个模式参数时,需注意优先级:
- `ocr=True`和`det=True`同时设置时,优先使用目标检测模式
- `beta=True`和`old=True`同时设置时,使用Beta模型(`old`当前不生效)
- 设置`import_onnx_path`时,`ocr`和`det`参数会被忽略
7. **支持的图片格式**
ddddocr支持多种图片格式:
- JPG/JPEG
- PNG (带透明通道时可配合`png_fix=True`)
- BMP
- GIF (仅识别第一帧)
对于不常见格式或Base64编码的图片,可以先转换为bytes:
```python
# Base64编码图片处理
import base64
image_bytes = base64.b64decode(base64_str)
result = ocr.classification(image_bytes)
```
8. **多线程并发问题**
在多线程环境下使用时,每个线程应当创建独立的OCR实例,否则可能导致识别结果错乱。
## 项目技术支持
本项目基于[dddd_trainer](https://github.com/sml2h3/dddd_trainer)训练所得,训练底层框架为PyTorch,推理底层依赖于[onnxruntime](https://pypi.org/project/onnxruntime/)。
## 使用示例
### 完整的验证码识别流程
```python
import ddddocr
import cv2
import numpy as np
from PIL import Image
import io
# 初始化OCR对象
ocr = ddddocr.DdddOcr()
# 读取验证码图片
with open("captcha.jpg", "rb") as f:
image_bytes = f.read()
# 转换为OpenCV格式进行预处理
# img = cv2.imdecode(np.frombuffer(image_bytes, np.uint8), cv2.IMREAD_COLOR)
# 预处理:灰度化、二值化等
# gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# _, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY_INV)
# 转回字节流
# is_success, buffer = cv2.imencode(".jpg", binary)
# processed_bytes = io.BytesIO(buffer).getvalue()
# 识别处理后的图片
result = ocr.classification(image_bytes)
print(f"验证码识别结果: {result}")
```
### 滑块验证码完整示例
```python
import ddddocr
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 初始化滑块检测对象
slide = ddddocr.DdddOcr(det=False, ocr=False)
# 读取滑块图和背景图
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
# 匹配位置
res = slide.slide_match(target_bytes, background_bytes)
print(f"滑块位置: {res}")
# 可视化结果
background = cv2.imdecode(np.frombuffer(background_bytes, np.uint8), cv2.IMREAD_COLOR)
x1, y1, x2, y2 = res["target"]
# 在背景图上绘制匹配位置
cv2.rectangle(background, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 显示结果
plt.figure(figsize=(10, 6))
plt.imshow(cv2.cvtColor(background, cv2.COLOR_BGR2RGB))
plt.title("滑块匹配结果")
plt.axis('off')
plt.savefig("slide_result.jpg")
plt.show()
```
## API 服务
DdddOcr 提供了一键启动 API 服务的功能,可以通过 RESTful API 的方式访问 DdddOcr 的所有功能。
### 命令行启动 API 服务
```bash
# 使用默认配置启动 API 服务
python -m ddddocr api
# 指定 API 服务配置
python -m ddddocr api --host 0.0.0.0 --port 8000 --workers 4
# 配置 OCR 功能
python -m ddddocr api --ocr true --beta true
# 配置目标检测功能
python -m ddddocr api --ocr false --det true
```
> **提示**:如果直接运行 `python -m ddddocr.api`,默认会绑定在 `127.0.0.1`,可通过环境变量 `DDDDOCR_HOST` 覆盖。
### API 命令行参数说明
| 参数名 | 类型 | 默认值 | 说明 |
|-------|------|-------|------|
| `--host` | 字符串 | 0.0.0.0 | API 服务主机地址(`python -m ddddocr api` 默认) |
| `--port` | 整数 | 8000 | API 服务端口 |
| `--workers` | 整数 | 1 | API 服务工作进程数 |
| `--ocr` | 布尔值 | true | 是否启用 OCR 功能 |
| `--det` | 布尔值 | false | 是否启用目标检测功能 |
| `--old` | 布尔值 | false | 是否使用旧版 OCR 模型 |
| `--beta` | 布尔值 | false | 是否使用 Beta 版 OCR 模型 |
| `--use-gpu` | 布尔值 | false | 是否使用 GPU 加速 |
| `--device-id` | 整数 | 0 | GPU 设备 ID |
| `--show-ad` | 布尔值 | true | 是否显示广告 |
| `--import-onnx-path` | 字符串 | "" | 自定义模型路径 |
| `--charsets-path` | 字符串 | "" | 自定义字符集路径 |
### 使用 Docker 运行 API 服务
#### 构建并运行 Docker 镜像
```bash
# 构建 Docker 镜像
docker build -t ddddocr-api .
# 运行 Docker 容器
docker run -d --name ddddocr-api -p 8000:8000 ddddocr-api
# 使用自定义配置运行
docker run -d --name ddddocr-api \
-p 8000:8000 \
-e DDDDOCR_OCR=true \
-e DDDDOCR_BETA=true \
-e DDDDOCR_WORKERS=4 \
ddddocr-api
```
#### 使用 Docker Compose 运行 API 服务
```bash
# 使用默认配置启动
docker-compose up -d
# 使用自定义配置启动
DDDDOCR_OCR=true DDDDOCR_BETA=true DDDDOCR_WORKERS=4 docker-compose up -d
```
### API 接口说明
API 服务提供了以下接口:
#### 1. 文字识别接口 (OCR)
```
POST /ocr
```
请求体:
```json
{
"image": "图片的Base64编码字符串",
"probability": false,
"colors": [],
"custom_color_ranges": null
}
```
响应:
```json
{
"result": "识别到的文字",
"processing_time": 0.123
}
```
> **注意**:当 `probability=true` 时,API 会返回 `result` 为一个字典,包含 `charsets` 与 `probability` 字段,结构与本地 `classification(probability=True)` 一致。
#### 2. 目标检测接口
```
POST /det
```
请求体:
```json
{
"image": "图片的Base64编码字符串"
}
```
响应:
```json
{
"result": [
[x1, y1, x2, y2],
...
],
"processing_time": 0.123
}
```
#### 3. 滑块匹配接口
```
POST /slide_match
```
请求体:
```json
{
"target_image": "目标图片的Base64编码字符串",
"background_image": "背景图片的Base64编码字符串",
"simple_target": false,
"flag": false
}
```
响应:
```json
{
"result": {
"target_x": 0,
"target_y": 0,
"target": [x1, y1, x2, y2]
},
"processing_time": 0.123
}
```
#### 4. 滑块比较接口
```
POST /slide_comparison
```
请求体:
```json
{
"target_image": "目标图片的Base64编码字符串",
"background_image": "背景图片的Base64编码字符串"
}
```
响应:
```json
{
"result": {
"target": [x, y]
},
"processing_time": 0.123
}
```
#### 5. 设置字符范围接口
```
POST /set_charset_range
```
请求体:
```json
{
"charset_range": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
}
```
响应:
```json
{
"result": "字符范围设置成功",
"charset_range": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"],
"processing_time": 0.123
}
```
#### 6. 健康检查接口
```
GET /health
```
响应:
```json
{
"status": "ok",
"timestamp": 1628765432.1234
}
```
#### 文件上传接口
所有上述接口都支持通过表单上传文件的方式提交请求。例如:
```
POST /ocr/file
```
可以通过表单字段上传图片文件。
### API 客户端示例
#### Python 示例 (Base64编码方式)
```python
import requests
import base64
# 读取图片文件并Base64编码
with open("captcha.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
# 发送OCR请求
url = "http://localhost:8000/ocr"
response = requests.post(url, json={"image": img_base64})
# 处理响应
result = response.json()
print(f"识别结果: {result['result']}")
```
#### Python 示例 (文件上传方式)
```python
import requests
# 准备文件
files = {"file": open("captcha.png", "rb")}
# 发送OCR请求
url = "http://localhost:8000/ocr/file"
response = requests.post(url, files=files)
# 处理响应
result = response.json()
print(f"识别结果: {result['result']}")
```
### Docker 环境变量配置参考
| 环境变量名 | 默认值 | 说明 |
|-----------|-------|------|
| `DDDDOCR_HOST` | 0.0.0.0(CLI 默认)/ 127.0.0.1(直接运行 `python -m ddddocr.api` 默认) | API 服务主机地址 |
| `DDDDOCR_PORT` | 8000 | API 服务端口 |
| `DDDDOCR_WORKERS` | 1 | API 服务工作进程数 |
| `DDDDOCR_OCR` | true | 是否启用 OCR 功能 |
| `DDDDOCR_DET` | false | 是否启用目标检测功能 |
| `DDDDOCR_OLD` | false | 是否使用旧版 OCR 模型 |
| `DDDDOCR_BETA` | false | 是否使用 Beta 版 OCR 模型 |
| `DDDDOCR_USE_GPU` | false | 是否使用 GPU 加速 |
| `DDDDOCR_DEVICE_ID` | 0 | GPU 设备 ID |
| `DDDDOCR_SHOW_AD` | true | 是否显示广告 |
| `DDDDOCR_IMPORT_ONNX_PATH` | "" | 自定义模型路径 |
| `DDDDOCR_CHARSETS_PATH` | "" | 自定义字符集路径 |
## 许可证
本项目采用MIT许可证,详情请参阅[LICENSE](https://github.com/sml2h3/ddddocr/blob/master/LICENSE)文件。
## 输入与输出校验说明
- **图片合法性**:所有 Base64 与文件上传都会做尺寸、格式与大小校验(默认上限 8192 KB、最长边 4096px,可在实例化 `DdddOcr(max_image_bytes=..., max_image_side=...)` 时自定义),异常时返回 400。
- **允许格式**:PNG / JPEG / JPG / WEBP / BMP / GIF / TIFF。
- **输入类型**:本地调用支持 `bytes/bytearray`、Base64 字符串、文件路径或 `PIL.Image`。
- **类型约束**:`DdddOcr` 的公开方法会校验布尔/整数参数,`FastAPI` 层也通过 Pydantic 验证请求体,错误会带具体字段。
- **统一异常**:核心库新增 `DdddOcrInputError` / `InvalidImageError`,API 会把这些异常映射为 400,方便调用方处理。
- **响应结构**:HTTP 接口现有明确的 `response_model`,文档 (`/docs`) 中可直接查看字段含义。
- **模式提示**:在 `det=True` 模式下调用 `classification` 会抛出 “当前识别类型为目标检测”。
## 示例库
仓库新增 `examples/` 目录,覆盖本地调用、目标检测和 HTTP 客户端等典型场景:
- `basic_ocr.py`:最小 OCR 示例,可演示概率输出与颜色过滤。
- `detector.py`:演示如何用 `det=True` 模式返回所有检测框。
- `api_client.py`:演示如何向 `python -m ddddocr api` 服务发送 JSON 请求。
- `generate_basic_ocr_cases.py`:生成基础 OCR 测试用例图片。
详细说明见 `examples/README.md`,可结合 README 其他章节快速起步。
================================================
FILE: ddddocr/README.md
================================================
# DdddOcr - 通用验证码识别SDK
一个简单易用的通用验证码识别Python库
## 目录
- [赞助合作商](#赞助合作商)
- [项目介绍](#项目介绍)
- [环境支持](#环境支持)
- [安装方法](#安装方法)
- [功能概览](#功能概览)
- [初始化参数详解](#初始化参数详解)
- [参数详细说明](#参数详细说明)
- [功能组合与冲突](#功能组合与冲突)
- [模型选择指南](#模型选择指南)
- [性能优化参数](#性能优化参数)
- [详细使用说明](#详细使用说明)
- [文字识别功能](#文字识别功能)
- [基础OCR识别](#基础ocr识别)
- [OCR概率输出](#ocr概率输出)
- [自定义字符范围](#自定义字符范围)
- [颜色过滤功能](#颜色过滤功能)
- [目标检测功能](#目标检测功能)
- [滑块验证码处理](#滑块验证码处理)
- [算法1:边缘匹配](#算法1边缘匹配)
- [算法2:图像差异比较](#算法2图像差异比较)
- [自定义模型导入](#自定义模型导入)
- [高级用法](#高级用法)
- [批量处理](#批量处理)
- [多线程优化](#多线程优化)
- [验证码预处理](#验证码预处理)
- [常见问题](#常见问题)
- [初始化速度慢](#初始化速度慢)
- [识别准确率不高](#识别准确率不高)
- [GPU加速](#gpu加速)
- [处理复杂验证码](#如何处理复杂验证码)
- [内存占用过高](#内存占用过高)
- [参数冲突问题](#参数冲突问题)
- [支持的图片格式](#支持的图片格式)
- [多线程并发问题](#多线程并发问题)
- [项目技术支持](#项目技术支持)
- [使用示例](#使用示例)
- [许可证](#许可证)
## 赞助合作商
| | 赞助合作商 | 推荐理由 |
|------------------------------------------------------------|------------|--------------------------------------------------------------------------------------------------|
|  | [YesCaptcha](https://yescaptcha.com/i/NSwk7i) | 谷歌reCaptcha验证码 / hCaptcha验证码 / funCaptcha验证码商业级识别接口 [点我](https://yescaptcha.com/i/NSwk7i) 直达VIP4 |
|  | [超级鹰](https://www.chaojiying.com/) | 全球领先的智能图片分类及识别商家,安全、准确、高效、稳定、开放,强大的技术及校验团队,支持大并发。7*24h作业进度管理 |
|  | [Malenia](https://malenia.iinti.cn/malenia-doc/) | Malenia企业级代理IP网关平台/代理IP分销软件 |
| 雨云VPS | [注册首月5折](https://www.rainyun.com/ddddocr_) | 浙江节点低价大带宽,100M每月30元 |
## 项目介绍
DdddOcr 是一个通用验证码离线本地识别SDK,由 [sml2h3](https://github.com/sml2h3) 与 [kerlomz](https://github.com/kerlomz) 共同开发完成。该项目通过大批量生成随机数据进行深度网络训练,可以识别各种类型的验证码,包括:
- 常见的数字字母组合验证码
- 中文验证码
- 滑块验证码
- 各种特殊字符验证码
项目设计理念是"最简依赖",尽量减少用户的配置和使用成本,提供简单易用的API接口。
## 环境支持
| 系统 | CPU | GPU | 最大支持Python版本 | 备注 |
|-----|-----|-----|--------------|-----|
| Windows 64位 | ✓ | ✓ | 3.12 | 部分版本Windows需要安装[vc运行库](https://www.ghxi.com/yxkhj.html) |
| Linux 64 / ARM64 | ✓ | ✓ | 3.12 | |
| macOS X64 | ✓ | ✓ | 3.12 | M1/M2/M3芯片用户请参考[相关说明](https://github.com/sml2h3/ddddocr/issues/67) |
不支持的环境:
- Windows 32位
- Linux 32位
## 安装方法
### 从PyPI安装(推荐)
```bash
pip install ddddocr
```
### 从源码安装
```bash
git clone https://github.com/sml2h3/ddddocr.git
cd ddddocr
pip install .
```
### 安装 API 依赖(可选)
```bash
pip install ".[api]"
```
> **注意**:请勿直接在ddddocr项目的根目录内直接import ddddocr,请确保你的开发项目目录名称不为ddddocr。
## 功能概览
DdddOcr提供以下核心功能:
| 功能 | 描述 | 初始化参数 |
|-----|-----|----------|
| 文字识别 | 识别图片中的文字内容 | `ocr=True`(默认) |
| 目标检测 | 检测图片中的目标位置 | `det=True` |
| 滑块验证码识别 | 识别滑块验证码的缺口位置 | `ocr=False` |
| 自定义模型导入 | 导入自定义训练的模型 | `import_onnx_path="模型路径"` |
## 初始化参数详解
`DdddOcr` 类初始化时支持多种参数配置,以适应不同的使用场景:
```python
ddddocr.DdddOcr(
ocr=True, # 是否启用OCR功能
det=False, # 是否启用目标检测功能
old=False, # 是否使用旧版OCR模型
beta=False, # 是否使用Beta版OCR模型(新模型)
use_gpu=False, # 是否使用GPU加速
device_id=0, # 使用的GPU设备ID
show_ad=True, # 是否显示广告信息
import_onnx_path="", # 自定义模型路径
charsets_path="", # 自定义字符集路径
max_image_bytes=None, # 单图最大字节数(默认 8MB)
max_image_side=None # 单图最长边限制(默认 4096px)
)
```
### 参数详细说明
| 参数 | 类型 | 默认值 | 说明 |
|-----|-----|-----|-----|
| `ocr` | bool | True | 是否启用OCR功能,用于识别图片中的文字。**互斥性**:当`det=True`时会强制关闭OCR |
| `det` | bool | False | 是否启用目标检测功能,用于检测图片中的目标位置。**互斥性**:`det=True`会覆盖`ocr=True` |
| `old` | bool | False | 兼容参数,当前不会改变模型选择(默认即使用旧版模型) |
| `beta` | bool | False | 是否使用Beta版OCR模型(新模型),对某些验证码识别效果更好。**互斥性**:与`old=True`参数互斥(但`old`当前不生效) |
| `use_gpu` | bool | False | 是否使用GPU加速。**依赖关系**:需要安装CUDA和相应的onnxruntime-gpu版本,否则会初始化失败 |
| `device_id` | int | 0 | 使用的GPU设备ID。**依赖关系**:仅在`use_gpu=True`时生效,指定使用哪个GPU设备 |
| `show_ad` | bool | True | 是否在初始化时显示广告信息 |
| `import_onnx_path` | str | "" | 自定义模型的onnx文件路径。**依赖关系**:设置此参数时,`charsets_path`参数必须同时提供;此时`ocr/det`设置会被忽略 |
| `charsets_path` | str | "" | 自定义字符集的json文件路径。**依赖关系**:必须与`import_onnx_path`一起使用,否则无效 |
| `max_image_bytes` | int/str | 8MB | 单图最大字节数上限(入参可为 int 或数字字符串) |
| `max_image_side` | int/str | 4096 | 单图最长边像素上限(入参可为 int 或数字字符串) |
### 功能组合与冲突
根据参数组合,ddddocr具有不同的工作模式:
1. **标准OCR模式**:
- 参数设置:`ocr=True, det=False`(默认)
- 功能:识别图片中的文字
2. **目标检测模式**:
- 参数设置:`ocr=False, det=True`
- 功能:检测图片中的目标位置
- 注意:同时设置`ocr=True, det=True`时,会进入目标检测模式(`det`优先)
3. **滑块识别模式**:
- 参数设置:`ocr=False, det=False`
- 功能:使用滑块匹配算法(需调用`slide_match`或`slide_comparison`方法)
4. **自定义模型模式**:
- 参数设置:`import_onnx_path="模型路径", charsets_path="字符集路径"`
- 功能:使用自定义训练的模型进行识别
- 注意:设置此模式时,`ocr`和`det`参数会被忽略,且自定义字符集文件需包含 `charset/word/image/channel` 字段
5. **OCR模型选择**:
- 默认模型:不设置特殊参数(当前使用 `common_old.onnx`)
- Beta模型:`beta=True`(使用 `common.onnx`)
- 旧版模型参数:`old=True`(当前不改变模型,仅为兼容保留)
- 注意:`beta`和`old`参数互斥,但`old`当前不生效
### 模型选择指南
- **默认模型**:当前默认使用 `common_old.onnx`,适用于多数简单验证码场景
- **Beta模型**:`beta=True` 使用 `common.onnx`,对部分复杂验证码效果更好
- **自定义模型**:当默认模型无法满足需求时,可以通过[dddd_trainer](https://github.com/sml2h3/dddd_trainer)训练自己的模型
### 性能优化参数
- **GPU加速**:对于处理大量图片时,开启GPU加速可显著提升性能
```python
ocr = ddddocr.DdddOcr(use_gpu=True, device_id=0)
```
- **GPU设备选择**:在多GPU环境中,可通过`device_id`指定使用的GPU
```python
# 使用第二张GPU卡
ocr = ddddocr.DdddOcr(use_gpu=True, device_id=1)
```
- **关闭广告显示**:在生产环境中可关闭广告提示
```python
ocr = ddddocr.DdddOcr(show_ad=False)
```
## 详细使用说明
### 文字识别功能
#### 基础OCR识别
主要用于识别单行文字,如常见的英数验证码等。支持中文、英文、数字以及部分特殊字符的识别。
```python
import ddddocr
# 初始化OCR对象
ocr = ddddocr.DdddOcr()
# 读取图片
with open("验证码图片.jpg", "rb") as f:
image = f.read()
# 识别图片
result = ocr.classification(image)
print(result) # 输出识别结果
```
**OCR识别示例图片**
**参考例图**
包括且不限于以下图片
**OCR模型选择**
DdddOcr内置两套OCR模型,可以通过`beta`参数切换:
```python
# 使用第二套OCR模型
ocr = ddddocr.DdddOcr(beta=True)
```
**透明PNG图片处理**
对于透明黑色PNG图片,可以使用`png_fix`参数(对所有 OCR 模式生效):
```python
result = ocr.classification(image, png_fix=True)
```
> **注意**:`png_fix` 仅对带透明通道的图片生效;初始化DdddOcr对象只需要一次,不要在每次识别时都重新初始化,这会导致速度变慢。
#### OCR概率输出
可以获取OCR识别结果的概率分布,便于进行更灵活的结果处理:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 获取识别结果的概率分布
result = ocr.classification(image, probability=True)
# 处理概率结果
s = ""
for i in result['probability']:
s += result['charsets'][i.index(max(i))]
print(s)
```
**概率输出示例**(仅对内置模型生效,自定义模型会忽略`probability=True`并直接返回字符串):
```python
# 概率输出结果示例
{
'charsets': ['', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', ...],
'probability': [
[0.01, 0.02, 0.01, 0.03, 0.02, 0.01, 0.02, 0.75, 0.03, 0.05, 0.01, ...], # 第一个字符的概率分布
[0.01, 0.01, 0.02, 0.01, 0.03, 0.02, 0.01, 0.02, 0.01, 0.80, 0.01, ...], # 第二个字符的概率分布
...
]
}
```
#### 自定义字符范围
可以通过`set_ranges`方法限定OCR识别的字符范围:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 设置识别范围为数字
ocr.set_ranges(0) # 等同于 ocr.set_ranges("0123456789")
# 或自定义字符范围
ocr.set_ranges("0123456789+-x/=")
result = ocr.classification(image)
print(result)
```
**内置字符范围参数**:
| 参数值 | 含义 |
|-----|-----|
| 0 | 纯数字 0-9 |
| 1 | 纯小写英文 a-z |
| 2 | 纯大写英文 A-Z |
| 3 | 小写英文 + 大写英文 |
| 4 | 小写英文 + 数字 |
| 5 | 大写英文 + 数字 |
| 6 | 小写英文 + 大写英文 + 数字 |
| 7 | 默认字符库 - 小写英文 - 大写英文 - 数字 |
#### 颜色过滤功能
对于一些特殊的验证码,可以通过颜色过滤来提高识别准确率:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 只保留红色和蓝色部分
result = ocr.classification(image, colors=["red", "blue"])
print(result)
```
**支持的颜色**:
- red (红色)
- green (绿色)
- blue (蓝色)
- yellow (黄色)
- orange (橙色)
- purple (紫色)
- pink (粉色)
- brown (棕色)
也可以自定义颜色范围:
```python
# 自定义颜色范围
custom_ranges = {
'light_blue': [(90, 30, 30), (110, 255, 255)] # HSV颜色空间
}
result = ocr.classification(image, colors=["light_blue"], custom_color_ranges=custom_ranges)
```
> **提示**:`custom_color_ranges` 只有在 `colors` 列表包含对应键名时才会生效。
### 目标检测功能
用于检测图像中可能的目标主体位置,返回目标的边界框坐标:
```python
import ddddocr
import cv2
# 初始化检测对象
det = ddddocr.DdddOcr(det=True, ocr=False)
# 读取图片
with open("test.jpg", 'rb') as f:
image = f.read()
# 检测目标
bboxes = det.detection(image)
print(bboxes) # 输出格式:[[x1, y1, x2, y2], ...]
# 可视化检测结果
im = cv2.imread("test.jpg")
for bbox in bboxes:
x1, y1, x2, y2 = bbox
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
cv2.imwrite("result.jpg", im)
```
**目标检测示例**:
**参考例图**
包括且不限于以下图片
### 滑块验证码处理
DdddOcr提供两种滑块验证码处理算法:
#### 算法1:边缘匹配
适用于有透明背景的滑块图片,通过边缘检测找到滑块在背景图中的位置:
```python
import ddddocr
# 初始化滑块检测对象
slide = ddddocr.DdddOcr(det=False, ocr=False)
# 读取滑块图和背景图
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
# 匹配位置
res = slide.slide_match(target_bytes, background_bytes)
print(f"滑块位置: {res}")
# 可视化结果
background = cv2.imdecode(np.frombuffer(background_bytes, np.uint8), cv2.IMREAD_COLOR)
x1, y1, x2, y2 = res["target"]
# 在背景图上绘制匹配位置
cv2.rectangle(background, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 显示结果
plt.figure(figsize=(10, 6))
plt.imshow(cv2.cvtColor(background, cv2.COLOR_BGR2RGB))
plt.title("滑块匹配结果")
plt.axis('off')
plt.savefig("slide_result.jpg")
plt.show()
```
**滑块匹配示例**:
滑块图
|
背景图
|
对于没有透明背景的滑块图,可以使用`simple_target`参数:
```python
res = slide.slide_match(target_bytes, background_bytes, simple_target=True)
```
#### 算法2:图像差异比较
适用于比较两张图片的不同之处,找出滑块缺口位置:
```python
import ddddocr
slide = ddddocr.DdddOcr(det=False, ocr=False)
# 读取带有缺口阴影的图片和完整图片
with open('bg.jpg', 'rb') as f:
target_bytes = f.read()
with open('fullpage.jpg', 'rb') as f:
background_bytes = f.read()
# 比较差异
res = slide.slide_comparison(target_bytes, background_bytes)
print(res) # 输出格式:{"target": [x, y]}
```
**图像差异比较示例**:
带缺口阴影的图片
|
完整图片
|
### 自定义模型导入
DdddOcr支持导入通过[dddd_trainer](https://github.com/sml2h3/dddd_trainer)训练的自定义模型:
```python
import ddddocr
# 导入自定义模型
ocr = ddddocr.DdddOcr(
det=False,
ocr=False,
import_onnx_path="mymodel.onnx",
charsets_path="charsets.json"
)
with open('test.jpg', 'rb') as f:
image_bytes = f.read()
res = ocr.classification(image_bytes)
print(res)
```
## 高级用法
### 批量处理
对大量验证码进行批量处理时,保持OCR实例的复用可以显著提高效率:
```python
import ddddocr
import os
import time
# 初始化OCR对象(只需一次)
ocr = ddddocr.DdddOcr()
# 批量处理目录中的所有图片
def batch_process(directory):
results = {}
start_time = time.time()
for filename in os.listdir(directory):
if filename.endswith(('.png', '.jpg', '.jpeg', '.bmp')):
file_path = os.path.join(directory, filename)
with open(file_path, 'rb') as f:
image = f.read()
# 使用同一个OCR实例处理所有图片
result = ocr.classification(image)
results[filename] = result
end_time = time.time()
print(f"处理 {len(results)} 张图片耗时: {end_time - start_time:.2f} 秒")
return results
# 使用示例
results = batch_process("./captchas/")
for filename, text in results.items():
print(f"{filename}: {text}")
```
### 多线程优化
在多线程环境下使用时,应当为每个线程创建独立的OCR实例:
```python
import ddddocr
import concurrent.futures
import os
def process_image(file_path):
# 每个线程创建自己的OCR实例
ocr = ddddocr.DdddOcr()
with open(file_path, 'rb') as f:
image = f.read()
result = ocr.classification(image)
return os.path.basename(file_path), result
def parallel_process(directory, max_workers=4):
file_paths = [os.path.join(directory, f) for f in os.listdir(directory)
if f.endswith(('.png', '.jpg', '.jpeg', '.bmp'))]
results = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_file = {executor.submit(process_image, file_path): file_path for file_path in file_paths}
for future in concurrent.futures.as_completed(future_to_file):
filename, result = future.result()
results[filename] = result
return results
# 使用示例
results = parallel_process("./captchas/", max_workers=8)
```
### 验证码预处理
对于干扰较多的验证码,可以先进行预处理再识别:
```python
import ddddocr
import cv2
import numpy as np
from PIL import Image
import io
def preprocess_captcha(image_bytes):
# 转换为OpenCV格式
nparr = np.frombuffer(image_bytes, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY_INV)
# 去除小噪点
kernel = np.ones((2, 2), np.uint8)
opening = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel)
# 转回字节流
is_success, buffer = cv2.imencode(".jpg", opening)
processed_bytes = io.BytesIO(buffer).getvalue()
return processed_bytes
# 使用示例
ocr = ddddocr.DdddOcr()
with open("noisy_captcha.jpg", "rb") as f:
image_bytes = f.read()
# 预处理验证码
processed_bytes = preprocess_captcha(image_bytes)
# 识别处理后的图片
result = ocr.classification(processed_bytes)
print(f"验证码识别结果: {result}")
```
## 常见问题
1. **初始化速度慢**
首次初始化DdddOcr对象时会加载模型,可能会比较慢,但只需要初始化一次即可。避免在循环中反复初始化。
```python
# 错误的用法
for img in images:
ocr = ddddocr.DdddOcr() # 每次都初始化,严重影响性能
result = ocr.classification(img)
# 正确的用法
ocr = ddddocr.DdddOcr() # 只初始化一次
for img in images:
result = ocr.classification(img)
```
2. **识别准确率不高**
- 尝试使用另一个OCR模型(设置`beta=True`)
- 对于特殊验证码,尝试使用颜色过滤功能
- 限定识别字符范围(使用`set_ranges`方法)
- 对于透明PNG图片,使用`png_fix=True`参数
3. **GPU加速**
可以通过设置`use_gpu=True`和`device_id`参数来启用GPU加速:
```python
ocr = ddddocr.DdddOcr(use_gpu=True, device_id=0)
```
使用GPU需确保已安装对应的CUDA版本和onnxruntime-gpu库。
4. **如何处理复杂验证码**
对于复杂的验证码,可以尝试以下步骤:
- 先使用目标检测功能定位验证码位置
- 对检测到的区域进行裁剪
- 应用颜色过滤去除干扰
- 使用OCR识别处理后的图片
5. **内存占用过高**
如果在同一程序中需要使用多个功能,建议不要同时初始化多个不同功能的实例,而是根据需要初始化:
```python
# 根据需要初始化不同的对象
if need_ocr:
processor = ddddocr.DdddOcr(ocr=True, det=False)
elif need_detection:
processor = ddddocr.DdddOcr(ocr=False, det=True)
```
6. **参数冲突问题**
当同时设置多个模式参数时,需注意优先级:
- `ocr=True`和`det=True`同时设置时,优先使用目标检测模式
- `beta=True`和`old=True`同时设置时,使用Beta模型(`old`当前不生效)
- 设置`import_onnx_path`时,`ocr`和`det`参数会被忽略
7. **支持的图片格式**
ddddocr支持多种图片格式:
- JPG/JPEG
- PNG (带透明通道时可配合`png_fix=True`)
- BMP
- GIF (仅识别第一帧)
对于不常见格式或Base64编码的图片,可以先转换为bytes:
```python
# Base64编码图片处理
import base64
image_bytes = base64.b64decode(base64_str)
result = ocr.classification(image_bytes)
```
8. **多线程并发问题**
在多线程环境下使用时,每个线程应当创建独立的OCR实例,否则可能导致识别结果错乱。
## 项目技术支持
本项目基于[dddd_trainer](https://github.com/sml2h3/dddd_trainer)训练所得,训练底层框架为PyTorch,推理底层依赖于[onnxruntime](https://pypi.org/project/onnxruntime/)。
## 使用示例
### 完整的验证码识别流程
```python
import ddddocr
import cv2
import numpy as np
from PIL import Image
import io
# 初始化OCR对象
ocr = ddddocr.DdddOcr()
# 读取验证码图片
with open("captcha.jpg", "rb") as f:
image_bytes = f.read()
# 转换为OpenCV格式进行预处理
# img = cv2.imdecode(np.frombuffer(image_bytes, np.uint8), cv2.IMREAD_COLOR)
# 预处理:灰度化、二值化等
# gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# _, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY_INV)
# 转回字节流
# is_success, buffer = cv2.imencode(".jpg", binary)
# processed_bytes = io.BytesIO(buffer).getvalue()
# 识别处理后的图片
result = ocr.classification(image_bytes)
print(f"验证码识别结果: {result}")
```
### 滑块验证码完整示例
```python
import ddddocr
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 初始化滑块检测对象
slide = ddddocr.DdddOcr(det=False, ocr=False)
# 读取滑块图和背景图
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
# 匹配位置
res = slide.slide_match(target_bytes, background_bytes)
print(f"滑块位置: {res}")
# 可视化结果
background = cv2.imdecode(np.frombuffer(background_bytes, np.uint8), cv2.IMREAD_COLOR)
x1, y1, x2, y2 = res["target"]
# 在背景图上绘制匹配位置
cv2.rectangle(background, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 显示结果
plt.figure(figsize=(10, 6))
plt.imshow(cv2.cvtColor(background, cv2.COLOR_BGR2RGB))
plt.title("滑块匹配结果")
plt.axis('off')
plt.savefig("slide_result.jpg")
plt.show()
```
## API 服务
DdddOcr 提供了一键启动 API 服务的功能,可以通过 RESTful API 的方式访问 DdddOcr 的所有功能。
### 命令行启动 API 服务
```bash
# 使用默认配置启动 API 服务
python -m ddddocr api
# 指定 API 服务配置
python -m ddddocr api --host 0.0.0.0 --port 8000 --workers 4
# 配置 OCR 功能
python -m ddddocr api --ocr true --beta true
# 配置目标检测功能
python -m ddddocr api --ocr false --det true
```
> **提示**:如果直接运行 `python -m ddddocr.api`,默认会绑定在 `127.0.0.1`,可通过环境变量 `DDDDOCR_HOST` 覆盖。
### API 命令行参数说明
| 参数名 | 类型 | 默认值 | 说明 |
|-------|------|-------|------|
| `--host` | 字符串 | 0.0.0.0 | API 服务主机地址(`python -m ddddocr api` 默认) |
| `--port` | 整数 | 8000 | API 服务端口 |
| `--workers` | 整数 | 1 | API 服务工作进程数 |
| `--ocr` | 布尔值 | true | 是否启用 OCR 功能 |
| `--det` | 布尔值 | false | 是否启用目标检测功能 |
| `--old` | 布尔值 | false | 是否使用旧版 OCR 模型 |
| `--beta` | 布尔值 | false | 是否使用 Beta 版 OCR 模型 |
| `--use-gpu` | 布尔值 | false | 是否使用 GPU 加速 |
| `--device-id` | 整数 | 0 | GPU 设备 ID |
| `--show-ad` | 布尔值 | true | 是否显示广告 |
| `--import-onnx-path` | 字符串 | "" | 自定义模型路径 |
| `--charsets-path` | 字符串 | "" | 自定义字符集路径 |
### 使用 Docker 运行 API 服务
#### 构建并运行 Docker 镜像
```bash
# 构建 Docker 镜像
docker build -t ddddocr-api .
# 运行 Docker 容器
docker run -d --name ddddocr-api -p 8000:8000 ddddocr-api
# 使用自定义配置运行
docker run -d --name ddddocr-api \
-p 8000:8000 \
-e DDDDOCR_OCR=true \
-e DDDDOCR_BETA=true \
-e DDDDOCR_WORKERS=4 \
ddddocr-api
```
#### 使用 Docker Compose 运行 API 服务
```bash
# 使用默认配置启动
docker-compose up -d
# 使用自定义配置启动
DDDDOCR_OCR=true DDDDOCR_BETA=true DDDDOCR_WORKERS=4 docker-compose up -d
```
### API 接口说明
API 服务提供了以下接口:
#### 1. 文字识别接口 (OCR)
```
POST /ocr
```
请求体:
```json
{
"image": "图片的Base64编码字符串",
"probability": false,
"colors": [],
"custom_color_ranges": null
}
```
响应:
```json
{
"result": "识别到的文字",
"processing_time": 0.123
}
```
> **注意**:当 `probability=true` 时,API 会返回 `result` 为一个字典,包含 `charsets` 与 `probability` 字段,结构与本地 `classification(probability=True)` 一致。
#### 2. 目标检测接口
```
POST /det
```
请求体:
```json
{
"image": "图片的Base64编码字符串"
}
```
响应:
```json
{
"result": [
[x1, y1, x2, y2],
...
],
"processing_time": 0.123
}
```
#### 3. 滑块匹配接口
```
POST /slide_match
```
请求体:
```json
{
"target_image": "目标图片的Base64编码字符串",
"background_image": "背景图片的Base64编码字符串",
"simple_target": false,
"flag": false
}
```
响应:
```json
{
"result": {
"target_x": 0,
"target_y": 0,
"target": [x1, y1, x2, y2]
},
"processing_time": 0.123
}
```
#### 4. 滑块比较接口
```
POST /slide_comparison
```
请求体:
```json
{
"target_image": "目标图片的Base64编码字符串",
"background_image": "背景图片的Base64编码字符串"
}
```
响应:
```json
{
"result": {
"target": [x, y]
},
"processing_time": 0.123
}
```
#### 5. 设置字符范围接口
```
POST /set_charset_range
```
请求体:
```json
{
"charset_range": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
}
```
响应:
```json
{
"result": "字符范围设置成功",
"charset_range": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"],
"processing_time": 0.123
}
```
#### 6. 健康检查接口
```
GET /health
```
响应:
```json
{
"status": "ok",
"timestamp": 1628765432.1234
}
```
#### 文件上传接口
所有上述接口都支持通过表单上传文件的方式提交请求。例如:
```
POST /ocr/file
```
可以通过表单字段上传图片文件。
### API 客户端示例
#### Python 示例 (Base64编码方式)
```python
import requests
import base64
# 读取图片文件并Base64编码
with open("captcha.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
# 发送OCR请求
url = "http://localhost:8000/ocr"
response = requests.post(url, json={"image": img_base64})
# 处理响应
result = response.json()
print(f"识别结果: {result['result']}")
```
#### Python 示例 (文件上传方式)
```python
import requests
# 准备文件
files = {"file": open("captcha.png", "rb")}
# 发送OCR请求
url = "http://localhost:8000/ocr/file"
response = requests.post(url, files=files)
# 处理响应
result = response.json()
print(f"识别结果: {result['result']}")
```
### Docker 环境变量配置参考
| 环境变量名 | 默认值 | 说明 |
|-----------|-------|------|
| `DDDDOCR_HOST` | 0.0.0.0(CLI 默认)/ 127.0.0.1(直接运行 `python -m ddddocr.api` 默认) | API 服务主机地址 |
| `DDDDOCR_PORT` | 8000 | API 服务端口 |
| `DDDDOCR_WORKERS` | 1 | API 服务工作进程数 |
| `DDDDOCR_OCR` | true | 是否启用 OCR 功能 |
| `DDDDOCR_DET` | false | 是否启用目标检测功能 |
| `DDDDOCR_OLD` | false | 是否使用旧版 OCR 模型 |
| `DDDDOCR_BETA` | false | 是否使用 Beta 版 OCR 模型 |
| `DDDDOCR_USE_GPU` | false | 是否使用 GPU 加速 |
| `DDDDOCR_DEVICE_ID` | 0 | GPU 设备 ID |
| `DDDDOCR_SHOW_AD` | true | 是否显示广告 |
| `DDDDOCR_IMPORT_ONNX_PATH` | "" | 自定义模型路径 |
| `DDDDOCR_CHARSETS_PATH` | "" | 自定义字符集路径 |
## 许可证
本项目采用MIT许可证,详情请参阅[LICENSE](https://github.com/sml2h3/ddddocr/blob/master/LICENSE)文件。
## 输入与输出校验说明
- **图片合法性**:所有 Base64 与文件上传都会做尺寸、格式与大小校验(默认上限 8192 KB、最长边 4096px,可在实例化 `DdddOcr(max_image_bytes=..., max_image_side=...)` 时自定义),异常时返回 400。
- **允许格式**:PNG / JPEG / JPG / WEBP / BMP / GIF / TIFF。
- **输入类型**:本地调用支持 `bytes/bytearray`、Base64 字符串、文件路径或 `PIL.Image`。
- **类型约束**:`DdddOcr` 的公开方法会校验布尔/整数参数,`FastAPI` 层也通过 Pydantic 验证请求体,错误会带具体字段。
- **统一异常**:核心库新增 `DdddOcrInputError` / `InvalidImageError`,API 会把这些异常映射为 400,方便调用方处理。
- **响应结构**:HTTP 接口现有明确的 `response_model`,文档 (`/docs`) 中可直接查看字段含义。
- **模式提示**:在 `det=True` 模式下调用 `classification` 会抛出 “当前识别类型为目标检测”。
## 示例库
仓库新增 `examples/` 目录,覆盖本地调用、目标检测和 HTTP 客户端等典型场景:
- `basic_ocr.py`:最小 OCR 示例,可演示概率输出与颜色过滤。
- `detector.py`:演示如何用 `det=True` 模式返回所有检测框。
- `api_client.py`:演示如何向 `python -m ddddocr api` 服务发送 JSON 请求。
- `generate_basic_ocr_cases.py`:生成基础 OCR 测试用例图片。
详细说明见 `examples/README.md`,可结合 README 其他章节快速起步。
================================================
FILE: ddddocr/__init__.py
================================================
# coding=utf-8
# 从兼容层导入主类(新的模块化结构)
from .compat.v1 import DdddOcr
from .utils import (
ALLOWED_IMAGE_FORMATS,
MAX_IMAGE_BYTES,
MAX_IMAGE_SIDE,
DdddOcrInputError,
InvalidImageError,
TypeError,
base64_to_image,
get_img_base64,
)
__all__ = [
"ALLOWED_IMAGE_FORMATS",
"MAX_IMAGE_BYTES",
"MAX_IMAGE_SIDE",
"DdddOcr",
"DdddOcrInputError",
"InvalidImageError",
"TypeError",
"base64_to_image",
"get_img_base64",
]
================================================
FILE: ddddocr/__main__.py
================================================
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import argparse
import sys
import os
def main():
"""
ddddocr 命令行入口点
"""
parser = argparse.ArgumentParser(description='DdddOcr 通用验证码识别工具')
# API 子命令
subparsers = parser.add_subparsers(dest='command', help='子命令')
# API 服务子命令
api_parser = subparsers.add_parser('api', help='启动 API 服务')
# API 服务配置
api_parser.add_argument('--host', type=str, default='0.0.0.0',
help='API 服务主机地址,默认 0.0.0.0')
api_parser.add_argument('--port', type=int, default=8000,
help='API 服务端口,默认 8000')
api_parser.add_argument('--workers', type=int, default=1,
help='API 服务工作进程数,默认为 1')
# OCR 引擎配置
api_parser.add_argument('--ocr', type=lambda x: x.lower() == 'true', default=True,
help='是否启用 OCR 功能(true/false)')
api_parser.add_argument('--det', type=lambda x: x.lower() == 'true', default=False,
help='是否启用目标检测功能(true/false)')
api_parser.add_argument('--old', type=lambda x: x.lower() == 'true', default=False,
help='是否使用旧版 OCR 模型(true/false)')
api_parser.add_argument('--beta', type=lambda x: x.lower() == 'true', default=False,
help='是否使用 Beta 版 OCR 模型(true/false)')
api_parser.add_argument('--use-gpu', type=lambda x: x.lower() == 'true', default=False,
help='是否使用 GPU 加速(true/false)')
api_parser.add_argument('--device-id', type=int, default=0,
help='GPU 设备 ID,默认 0')
api_parser.add_argument('--show-ad', type=lambda x: x.lower() == 'true', default=True,
help='是否显示广告(true/false)')
api_parser.add_argument('--import-onnx-path', type=str, default='',
help='自定义模型路径')
api_parser.add_argument('--charsets-path', type=str, default='',
help='自定义字符集路径')
# 解析命令行参数
args = parser.parse_args()
# 处理命令
if args.command == 'api':
# 设置环境变量
os.environ['DDDDOCR_HOST'] = args.host
os.environ['DDDDOCR_PORT'] = str(args.port)
os.environ['DDDDOCR_WORKERS'] = str(args.workers)
os.environ['DDDDOCR_OCR'] = str(args.ocr).lower()
os.environ['DDDDOCR_DET'] = str(args.det).lower()
os.environ['DDDDOCR_OLD'] = str(args.old).lower()
os.environ['DDDDOCR_BETA'] = str(args.beta).lower()
os.environ['DDDDOCR_USE_GPU'] = str(args.use_gpu).lower()
os.environ['DDDDOCR_DEVICE_ID'] = str(args.device_id)
os.environ['DDDDOCR_SHOW_AD'] = str(args.show_ad).lower()
os.environ['DDDDOCR_IMPORT_ONNX_PATH'] = args.import_onnx_path
os.environ['DDDDOCR_CHARSETS_PATH'] = args.charsets_path
# 导入 API 模块并启动服务
from ddddocr.api import main as api_main
api_main()
else:
# 没有提供子命令,显示帮助
parser.print_help()
return 1
return 0
if __name__ == '__main__':
sys.exit(main())
================================================
FILE: ddddocr/api/__init__.py
================================================
# coding=utf-8
"""
ddddocr HTTP API服务模块
提供RESTful API接口和MCP协议支持
"""
__version__ = "1.6.1"
__author__ = "sml2h3"
from .server import create_app, run_server
from .models import *
from .app import app, main
__all__ = ['create_app', 'run_server', 'app', 'main']
================================================
FILE: ddddocr/api/__main__.py
================================================
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
允许通过 `python -m ddddocr.api` 启动 API 服务(向后兼容)。
"""
from .app import main
if __name__ == "__main__":
main()
================================================
FILE: ddddocr/api/app.py
================================================
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from fastapi import FastAPI, UploadFile, File, Form, HTTPException, Query, BackgroundTasks
from fastapi.middleware.cors import CORSMiddleware
try:
from pydantic import BaseModel, Field, field_validator
except ImportError: # pragma: no cover - fallback for older pydantic
from pydantic import BaseModel, Field, validator as field_validator
import uvicorn
import base64
import io
import os
import binascii
from typing import Optional, List, Union, Dict, Any
import time
from PIL import Image
import logging
import sys
import json
# 设置日志配置
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[logging.StreamHandler(sys.stdout)]
)
logger = logging.getLogger("ddddocr-api")
# 导入 ddddocr
try:
from . import DdddOcr, DdddOcrInputError, InvalidImageError, MAX_IMAGE_BYTES as CORE_MAX_IMAGE_BYTES
except ImportError:
import ddddocr
DdddOcr = ddddocr.DdddOcr
DdddOcrInputError = getattr(ddddocr, 'DdddOcrInputError', Exception)
InvalidImageError = getattr(ddddocr, 'InvalidImageError', Exception)
CORE_MAX_IMAGE_BYTES = getattr(ddddocr, 'MAX_IMAGE_BYTES', 8 * 1024 * 1024)
# 全局变量存储OCR实例
ocr_instances: Dict[str, Dict[str, Any]] = {}
def _validate_base64_payload(value: str, field_name: str) -> str:
if not isinstance(value, str) or not value.strip():
raise ValueError(f"{field_name} 不能为空")
try:
decoded = base64.b64decode(value, validate=True)
except binascii.Error as exc:
raise ValueError(f"{field_name} 不是合法的Base64字符串") from exc
if len(decoded) == 0:
raise ValueError(f"{field_name} 内容为空")
if len(decoded) > CORE_MAX_IMAGE_BYTES:
raise ValueError(f"{field_name} 大小超过 {CORE_MAX_IMAGE_BYTES // 1024}KB 限制")
return value
def _decode_base64_bytes(value: str) -> bytes:
try:
return base64.b64decode(value, validate=True)
except binascii.Error as exc:
raise HTTPException(status_code=400, detail="Base64 内容错误") from exc
def _ensure_colors_list(data: List[Any]) -> List[str]:
if not isinstance(data, list):
raise HTTPException(status_code=400, detail="colors 必须是字符串列表")
normalized = []
for item in data:
if not isinstance(item, str):
raise HTTPException(status_code=400, detail="colors 列表中必须是字符串")
stripped = item.strip()
if stripped:
normalized.append(stripped)
return normalized
def _validate_custom_range_dict(parsed: Dict[str, List[List[int]]]) -> Dict[str, List[List[int]]]:
if not isinstance(parsed, dict):
raise ValueError("custom_color_ranges 必须是字典")
for key, ranges in parsed.items():
if not isinstance(key, str):
raise ValueError("custom_color_ranges 的键必须为字符串")
if not isinstance(ranges, list):
raise ValueError("custom_color_ranges 的值必须为列表")
for segment in ranges:
if not isinstance(segment, list) or len(segment) != 3:
raise ValueError("颜色区间必须是长度为3的列表")
for value in segment:
if not isinstance(value, int):
raise ValueError("颜色区间中的值需要为整数")
if not 0 <= value <= 255:
raise ValueError("颜色区间的值需位于0-255之间")
return parsed
def _ensure_custom_ranges(data: Any) -> Optional[Dict[str, List[List[int]]]]:
if data in (None, "null", ""):
return None
if isinstance(data, str):
try:
parsed = json.loads(data)
except json.JSONDecodeError as exc:
raise HTTPException(status_code=400, detail="custom_color_ranges JSON 解析失败") from exc
else:
parsed = data
if parsed is None:
return None
try:
return _validate_custom_range_dict(parsed)
except ValueError as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
def _coerce_bool_param(value: Union[bool, str], field_name: str) -> bool:
if isinstance(value, bool):
return value
if isinstance(value, str):
lowered = value.strip().lower()
if lowered in {'true', '1', 'yes', 'y'}:
return True
if lowered in {'false', '0', 'no', 'n'}:
return False
raise HTTPException(status_code=400, detail=f"{field_name} 只能是布尔值")
# 定义请求模型
class Base64Image(BaseModel):
image: str = Field(..., description="Base64编码的图片数据")
@field_validator('image')
def validate_image(cls, value):
return _validate_base64_payload(value, 'image')
class OCRRequest(Base64Image):
probability: bool = Field(False, description="是否返回识别概率")
colors: List[str] = Field(default_factory=list, description="颜色过滤列表")
custom_color_ranges: Optional[Dict[str, List[List[int]]]] = Field(None, description="自定义颜色范围")
@field_validator('colors')
def validate_colors(cls, value):
if value is None:
return []
if not isinstance(value, list):
raise ValueError('colors 必须是字符串列表')
normalized = []
for item in value:
if not isinstance(item, str):
raise ValueError('colors 中的元素必须是字符串')
stripped = item.strip()
if not stripped:
raise ValueError('colors 不允许包含空字符串')
normalized.append(stripped)
return normalized
@field_validator('custom_color_ranges')
def validate_custom_ranges(cls, value):
if value is None:
return value
return _validate_custom_range_dict(value)
class SlideMatchRequest(BaseModel):
target_image: str = Field(..., description="目标图片的Base64编码")
background_image: str = Field(..., description="背景图片的Base64编码")
simple_target: bool = Field(False, description="是否使用简化目标")
flag: bool = Field(False, description="标记选项")
@field_validator('target_image')
def validate_target_image(cls, value):
return _validate_base64_payload(value, 'target_image')
@field_validator('background_image')
def validate_background_image(cls, value):
return _validate_base64_payload(value, 'background_image')
class SlideComparisonRequest(BaseModel):
target_image: str = Field(..., description="目标图片的Base64编码")
background_image: str = Field(..., description="背景图片的Base64编码")
@field_validator('target_image')
def validate_target_image(cls, value):
return _validate_base64_payload(value, 'target_image')
@field_validator('background_image')
def validate_background_image(cls, value):
return _validate_base64_payload(value, 'background_image')
class CharsetRangeRequest(BaseModel):
charset_range: List[str] = Field(..., description="字符范围")
@field_validator('charset_range')
def validate_charset(cls, value):
if not isinstance(value, list):
raise ValueError('charset_range 需要为字符串列表')
normalized = []
for item in value:
if not isinstance(item, str) or not item:
raise ValueError('charset_range 需要为非空字符串')
normalized.append(item)
return normalized
class ModelConfig(BaseModel):
ocr: bool = Field(True, description="是否启用OCR功能")
det: bool = Field(False, description="是否启用目标检测功能")
old: bool = Field(False, description="是否使用旧版OCR模型")
beta: bool = Field(False, description="是否使用Beta版OCR模型")
use_gpu: bool = Field(False, description="是否使用GPU加速")
device_id: int = Field(0, description="GPU设备ID")
show_ad: bool = Field(True, description="是否显示广告")
import_onnx_path: str = Field("", description="自定义模型路径")
charsets_path: str = Field("", description="自定义字符集路径")
class OCRResponse(BaseModel):
result: Union[str, Dict[str, Any]]
probability: Optional[Any] = None
processing_time: float
class DetectionResponse(BaseModel):
result: List[List[int]]
processing_time: float
class SlideMatchResult(BaseModel):
target_x: int
target_y: int
target: List[int]
class SlideMatchResponse(BaseModel):
result: SlideMatchResult
processing_time: float
class SlideComparisonResponse(BaseModel):
result: Dict[str, List[int]]
processing_time: float
# 函数:获取OCR实例
def get_ocr_instance(
config_key: str,
ocr: bool = True,
det: bool = False,
old: bool = False,
beta: bool = False,
use_gpu: bool = False,
device_id: int = 0,
show_ad: bool = True,
import_onnx_path: str = "",
charsets_path: str = ""
):
"""
获取或创建OCR实例
"""
if config_key in ocr_instances:
ocr_instances[config_key]["last_used"] = time.time()
return ocr_instances[config_key]["instance"]
logger.info(f"创建新的OCR实例,配置: {config_key}")
try:
instance = DdddOcr(
ocr=ocr,
det=det,
old=old,
beta=beta,
use_gpu=use_gpu,
device_id=device_id,
show_ad=show_ad,
import_onnx_path=import_onnx_path,
charsets_path=charsets_path
)
ocr_instances[config_key] = {
"instance": instance,
"last_used": time.time()
}
return instance
except (DdddOcrInputError, InvalidImageError) as e:
logger.error(f"创建OCR实例失败: {str(e)}")
raise HTTPException(status_code=400, detail=str(e)) from e
except Exception as e:
logger.error(f"创建OCR实例失败: {str(e)}")
raise HTTPException(status_code=500, detail=f"初始化OCR失败: {str(e)}") from e
# 清理不活跃的OCR实例
def cleanup_inactive_instances(max_idle_time: int = 3600):
"""
清理长时间不活跃的OCR实例以释放内存
"""
global ocr_instances
current_time = time.time()
instances_to_remove = []
for key, instance_data in ocr_instances.items():
if current_time - instance_data["last_used"] > max_idle_time:
instances_to_remove.append(key)
for key in instances_to_remove:
del ocr_instances[key]
logger.info(f"已清理不活跃的OCR实例: {key}")
# 创建FastAPI应用
app = FastAPI(
title="DdddOcr API",
description="DdddOcr通用验证码识别API服务",
version="1.6.1",
docs_url="/docs",
redoc_url="/redoc"
)
# 添加CORS中间件
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 定义API默认参数
default_ocr = os.environ.get("DDDDOCR_OCR", "true").lower() == "true"
default_det = os.environ.get("DDDDOCR_DET", "false").lower() == "true"
default_old = os.environ.get("DDDDOCR_OLD", "false").lower() == "true"
default_beta = os.environ.get("DDDDOCR_BETA", "false").lower() == "true"
default_use_gpu = os.environ.get("DDDDOCR_USE_GPU", "false").lower() == "true"
default_device_id = int(os.environ.get("DDDDOCR_DEVICE_ID", "0"))
default_show_ad = os.environ.get("DDDDOCR_SHOW_AD", "true").lower() == "true"
default_import_onnx_path = os.environ.get("DDDDOCR_IMPORT_ONNX_PATH", "")
default_charsets_path = os.environ.get("DDDDOCR_CHARSETS_PATH", "")
# 健康检查端点
@app.get("/health")
async def health_check():
return {"status": "ok", "timestamp": time.time()}
# OCR识别端点 - JSON请求
@app.post("/ocr", response_model=OCRResponse)
async def ocr_recognition(
request: OCRRequest,
background_tasks: BackgroundTasks,
ocr: bool = Query(default_ocr, description="是否启用OCR功能"),
det: bool = Query(default_det, description="是否启用目标检测功能"),
old: bool = Query(default_old, description="是否使用旧版OCR模型"),
beta: bool = Query(default_beta, description="是否使用Beta版OCR模型"),
use_gpu: bool = Query(default_use_gpu, description="是否使用GPU加速"),
device_id: int = Query(default_device_id, description="GPU设备ID"),
show_ad: bool = Query(default_show_ad, description="是否显示广告")
):
"""
OCR文字识别 - 接收Base64编码的图片
"""
image = None
try:
img_data = _decode_base64_bytes(request.image)
image = Image.open(io.BytesIO(img_data))
except HTTPException:
raise
except Exception as exc:
logger.error(f"OCR请求图片解析失败: {str(exc)}")
raise HTTPException(status_code=400, detail="无法读取图片") from exc
config_key = f"ocr={ocr}-det={det}-old={old}-beta={beta}-gpu={use_gpu}-dev={device_id}"
ocr_instance = get_ocr_instance(
config_key, ocr, det, old, beta, use_gpu, device_id, show_ad,
default_import_onnx_path, default_charsets_path
)
start_time = time.time()
try:
if request.probability:
result = ocr_instance.classification(
image,
probability=True,
colors=request.colors,
custom_color_ranges=request.custom_color_ranges
)
response_data = {
"result": result,
"processing_time": time.time() - start_time
}
else:
result = ocr_instance.classification(
image,
colors=request.colors,
custom_color_ranges=request.custom_color_ranges
)
response_data = {
"result": result,
"processing_time": time.time() - start_time
}
except (DdddOcrInputError, InvalidImageError) as exc:
logger.warning(f"OCR识别参数错误: {str(exc)}")
raise HTTPException(status_code=400, detail=str(exc)) from exc
except Exception as exc:
logger.error(f"OCR识别失败: {str(exc)}")
raise HTTPException(status_code=500, detail=f"OCR识别失败: {str(exc)}") from exc
finally:
if image is not None:
try:
image.close()
except Exception:
pass
background_tasks.add_task(cleanup_inactive_instances)
return response_data
# OCR识别端点 - 文件上传
# OCR识别端点 - 文件上传
@app.post("/ocr/file", response_model=OCRResponse)
async def ocr_recognition_file(
background_tasks: BackgroundTasks,
file: UploadFile = File(...),
probability: Union[bool, str] = Form(False),
colors: str = Form("[]"),
custom_color_ranges: str = Form("null"),
ocr: bool = Query(default_ocr, description="是否启用OCR功能"),
det: bool = Query(default_det, description="是否启用目标检测功能"),
old: bool = Query(default_old, description="是否使用旧版OCR模型"),
beta: bool = Query(default_beta, description="是否使用Beta版OCR模型"),
use_gpu: bool = Query(default_use_gpu, description="是否使用GPU加速"),
device_id: int = Query(default_device_id, description="GPU设备ID"),
show_ad: bool = Query(default_show_ad, description="是否显示广告")
):
"""
OCR文字识别 - 接收上传的图片文件
"""
image = None
try:
contents = await file.read()
except Exception as exc:
raise HTTPException(status_code=400, detail="无法读取上传文件") from exc
if not contents:
raise HTTPException(status_code=400, detail="上传文件为空")
if len(contents) > CORE_MAX_IMAGE_BYTES:
raise HTTPException(
status_code=400,
detail=f"图片大小超过 {CORE_MAX_IMAGE_BYTES // 1024}KB 限制"
)
try:
image = Image.open(io.BytesIO(contents))
except Exception as exc:
raise HTTPException(status_code=400, detail="无法解析上传的图片") from exc
try:
colors_data = json.loads(colors) if colors else []
except json.JSONDecodeError as exc:
raise HTTPException(status_code=400, detail="colors JSON 解析失败") from exc
colors_list = _ensure_colors_list(colors_data)
custom_ranges = _ensure_custom_ranges(custom_color_ranges)
probability_flag = _coerce_bool_param(probability, 'probability')
config_key = f"ocr={ocr}-det={det}-old={old}-beta={beta}-gpu={use_gpu}-dev={device_id}"
ocr_instance = get_ocr_instance(
config_key, ocr, det, old, beta, use_gpu, device_id, show_ad,
default_import_onnx_path, default_charsets_path
)
start_time = time.time()
try:
if probability_flag:
result = ocr_instance.classification(
image,
probability=True,
colors=colors_list,
custom_color_ranges=custom_ranges
)
response_data = {
"result": result,
"processing_time": time.time() - start_time
}
else:
result = ocr_instance.classification(
image,
colors=colors_list,
custom_color_ranges=custom_ranges
)
response_data = {
"result": result,
"processing_time": time.time() - start_time
}
except (DdddOcrInputError, InvalidImageError) as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
except Exception as exc:
logger.error(f"OCR文件识别失败: {str(exc)}")
raise HTTPException(status_code=500, detail=f"OCR识别失败: {str(exc)}") from exc
finally:
if image is not None:
try:
image.close()
except Exception:
pass
background_tasks.add_task(cleanup_inactive_instances)
return response_data
# 目标检测端点
# 目标检测端点
# 目标检测端点
@app.post("/det", response_model=DetectionResponse)
async def object_detection(
request: Base64Image,
background_tasks: BackgroundTasks,
ocr: bool = Query(False, description="是否启用OCR功能"),
det: bool = Query(True, description="是否启用目标检测功能"),
use_gpu: bool = Query(default_use_gpu, description="是否使用GPU加速"),
device_id: int = Query(default_device_id, description="GPU设备ID"),
show_ad: bool = Query(default_show_ad, description="是否显示广告")
):
"""
目标检测功能 - 接收Base64编码的图片
"""
try:
img_data = _decode_base64_bytes(request.image)
except HTTPException:
raise
config_key = f"ocr={ocr}-det={det}-gpu={use_gpu}-dev={device_id}"
ocr_instance = get_ocr_instance(
config_key, ocr, det, False, False, use_gpu, device_id, show_ad,
default_import_onnx_path, default_charsets_path
)
start_time = time.time()
try:
result = ocr_instance.detection(img_bytes=img_data)
except (DdddOcrInputError, InvalidImageError) as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
except Exception as exc:
logger.error(f"目标检测失败: {str(exc)}")
raise HTTPException(status_code=500, detail=f"目标检测失败: {str(exc)}") from exc
background_tasks.add_task(cleanup_inactive_instances)
return {
"result": result,
"processing_time": time.time() - start_time
}
# 目标检测端点 - 文件上传
@app.post("/det/file", response_model=DetectionResponse)
async def object_detection_file(
background_tasks: BackgroundTasks,
file: UploadFile = File(...),
ocr: bool = Query(False, description="是否启用OCR功能"),
det: bool = Query(True, description="是否启用目标检测功能"),
use_gpu: bool = Query(default_use_gpu, description="是否使用GPU加速"),
device_id: int = Query(default_device_id, description="GPU设备ID"),
show_ad: bool = Query(default_show_ad, description="是否显示广告")
):
"""
目标检测功能 - 接收上传的图片文件
"""
try:
contents = await file.read()
except Exception as exc:
raise HTTPException(status_code=400, detail="无法读取上传文件") from exc
if not contents:
raise HTTPException(status_code=400, detail="上传文件为空")
if len(contents) > CORE_MAX_IMAGE_BYTES:
raise HTTPException(
status_code=400,
detail=f"图片大小超过 {CORE_MAX_IMAGE_BYTES // 1024}KB 限制"
)
config_key = f"ocr={ocr}-det={det}-gpu={use_gpu}-dev={device_id}"
ocr_instance = get_ocr_instance(
config_key, ocr, det, False, False, use_gpu, device_id, show_ad,
default_import_onnx_path, default_charsets_path
)
start_time = time.time()
try:
result = ocr_instance.detection(img_bytes=contents)
except (DdddOcrInputError, InvalidImageError) as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
except Exception as exc:
logger.error(f"目标检测文件识别失败: {str(exc)}")
raise HTTPException(status_code=500, detail=f"目标检测失败: {str(exc)}") from exc
background_tasks.add_task(cleanup_inactive_instances)
return {
"result": result,
"processing_time": time.time() - start_time
}
# 滑块匹配端点
@app.post("/slide_match", response_model=SlideMatchResponse)
async def slide_match_recognition(
request: SlideMatchRequest,
background_tasks: BackgroundTasks,
ocr: bool = Query(False, description="是否启用OCR功能"),
det: bool = Query(False, description="是否启用目标检测功能"),
use_gpu: bool = Query(default_use_gpu, description="是否使用GPU加速"),
device_id: int = Query(default_device_id, description="GPU设备ID"),
show_ad: bool = Query(default_show_ad, description="是否显示广告")
):
"""
滑块验证码匹配 - 接收Base64编码的目标图和背景图
"""
target_data = _decode_base64_bytes(request.target_image)
background_data = _decode_base64_bytes(request.background_image)
config_key = f"ocr={ocr}-det={det}-gpu={use_gpu}-dev={device_id}"
ocr_instance = get_ocr_instance(
config_key, ocr, det, False, False, use_gpu, device_id, show_ad,
default_import_onnx_path, default_charsets_path
)
start_time = time.time()
try:
result = ocr_instance.slide_match(
target_bytes=target_data,
background_bytes=background_data,
simple_target=request.simple_target,
flag=request.flag
)
except (DdddOcrInputError, InvalidImageError) as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
except Exception as exc:
logger.error(f"滑块匹配失败: {str(exc)}")
raise HTTPException(status_code=500, detail=f"滑块匹配失败: {str(exc)}") from exc
background_tasks.add_task(cleanup_inactive_instances)
return {
"result": result,
"processing_time": time.time() - start_time
}
# 滑块比较端点
@app.post("/slide_comparison", response_model=SlideComparisonResponse)
async def slide_comparison_recognition(
request: SlideComparisonRequest,
background_tasks: BackgroundTasks,
ocr: bool = Query(False, description="是否启用OCR功能"),
det: bool = Query(False, description="是否启用目标检测功能"),
use_gpu: bool = Query(default_use_gpu, description="是否使用GPU加速"),
device_id: int = Query(default_device_id, description="GPU设备ID"),
show_ad: bool = Query(default_show_ad, description="是否显示广告")
):
"""
滑块验证码图像差异比较 - 接收Base64编码的目标图和背景图
"""
target_data = _decode_base64_bytes(request.target_image)
background_data = _decode_base64_bytes(request.background_image)
config_key = f"ocr={ocr}-det={det}-gpu={use_gpu}-dev={device_id}"
ocr_instance = get_ocr_instance(
config_key, ocr, det, False, False, use_gpu, device_id, show_ad,
default_import_onnx_path, default_charsets_path
)
start_time = time.time()
try:
result = ocr_instance.slide_comparison(
target_bytes=target_data,
background_bytes=background_data
)
except (DdddOcrInputError, InvalidImageError) as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
except Exception as exc:
logger.error(f"滑块比较失败: {str(exc)}")
raise HTTPException(status_code=500, detail=f"滑块比较失败: {str(exc)}") from exc
background_tasks.add_task(cleanup_inactive_instances)
return {
"result": result,
"processing_time": time.time() - start_time
}
# 设置字符范围端点
# 设置字符范围端点
@app.post("/set_charset_range")
async def set_charset_range(
request: CharsetRangeRequest,
background_tasks: BackgroundTasks,
ocr: bool = Query(True, description="是否启用OCR功能"),
det: bool = Query(False, description="是否启用目标检测功能"),
old: bool = Query(default_old, description="是否使用旧版OCR模型"),
beta: bool = Query(default_beta, description="是否使用Beta版OCR模型"),
use_gpu: bool = Query(default_use_gpu, description="是否使用GPU加速"),
device_id: int = Query(default_device_id, description="GPU设备ID"),
show_ad: bool = Query(default_show_ad, description="是否显示广告")
):
"""
设置OCR识别的字符范围
"""
try:
config_key = f"ocr={ocr}-det={det}-old={old}-beta={beta}-gpu={use_gpu}-dev={device_id}"
ocr_instance = get_ocr_instance(
config_key, ocr, det, old, beta, use_gpu, device_id, show_ad,
default_import_onnx_path, default_charsets_path
)
start_time = time.time()
ocr_instance.set_ranges(request.charset_range)
background_tasks.add_task(cleanup_inactive_instances)
return {
"result": "字符范围设置成功",
"charset_range": request.charset_range,
"processing_time": time.time() - start_time
}
except (DdddOcrInputError, InvalidImageError, TypeError) as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
except Exception as e:
logger.error(f"设置字符范围失败: {str(e)}")
raise HTTPException(status_code=500, detail=f"设置字符范围失败: {str(e)}") from e
# 获取当前配置信息
@app.get("/config")
async def get_current_config():
return {
"default_config": {
"ocr": default_ocr,
"det": default_det,
"old": default_old,
"beta": default_beta,
"use_gpu": default_use_gpu,
"device_id": default_device_id,
"show_ad": default_show_ad,
"import_onnx_path": default_import_onnx_path,
"charsets_path": default_charsets_path
},
"active_instances": len(ocr_instances),
"environment": {
"python_version": sys.version,
"time": time.strftime("%Y-%m-%d %H:%M:%S")
}
}
# 主函数,用于直接运行此文件时启动服务
def main():
# 获取环境变量或使用默认值
host = os.environ.get("DDDDOCR_HOST", "127.0.0.1")
port = int(os.environ.get("DDDDOCR_PORT", "8000"))
workers = int(os.environ.get("DDDDOCR_WORKERS", "1"))
# 启动服务
print(f"启动DdddOcr API服务在 {host}:{port},工作进程数: {workers}")
uvicorn.run("ddddocr.api:app", host=host, port=port, workers=workers)
if __name__ == "__main__":
main()
================================================
FILE: ddddocr/api/mcp.py
================================================
# coding=utf-8
"""
MCP (Model Context Protocol) 协议支持
使AI Agent能够调用ddddocr服务
"""
import json
import base64
from typing import Dict, Any, List
from fastapi import APIRouter, HTTPException, Request
from fastapi.responses import JSONResponse
from .models import MCPRequest, MCPResponse, MCPCapabilities
class MCPHandler:
"""MCP协议处理器"""
def __init__(self, service):
self.service = service
self.router = APIRouter()
self._setup_routes()
def _setup_routes(self):
"""设置MCP路由"""
@self.router.get("/capabilities")
async def get_capabilities():
"""获取MCP能力声明"""
capabilities = MCPCapabilities(
tools=[
{
"name": "ddddocr_initialize",
"description": "初始化DDDDOCR服务,选择加载的模型类型",
"inputSchema": {
"type": "object",
"properties": {
"ocr": {"type": "boolean", "description": "是否启用OCR功能"},
"det": {"type": "boolean", "description": "是否启用目标检测功能"},
"old": {"type": "boolean", "description": "是否使用旧版OCR模型"},
"beta": {"type": "boolean", "description": "是否使用beta版OCR模型"},
"use_gpu": {"type": "boolean", "description": "是否使用GPU"}
}
}
},
{
"name": "ddddocr_ocr",
"description": "执行OCR文字识别",
"inputSchema": {
"type": "object",
"properties": {
"image": {"type": "string", "description": "图片数据(base64编码)"},
"png_fix": {"type": "boolean", "description": "是否修复PNG透明背景问题"},
"probability": {"type": "boolean", "description": "是否返回概率信息"},
"color_filter_colors": {
"type": "array",
"items": {"type": "string"},
"description": "颜色过滤预设颜色列表,如 ['red', 'blue']"
},
"charset_range": {
"oneOf": [
{"type": "integer"},
{"type": "string"}
],
"description": "字符集范围限制"
}
},
"required": ["image"]
}
},
{
"name": "ddddocr_detection",
"description": "执行目标检测",
"inputSchema": {
"type": "object",
"properties": {
"image": {"type": "string", "description": "图片数据(base64编码)"}
},
"required": ["image"]
}
},
{
"name": "ddddocr_slide_match",
"description": "滑块匹配算法",
"inputSchema": {
"type": "object",
"properties": {
"target_image": {"type": "string", "description": "滑块图片(base64编码)"},
"background_image": {"type": "string", "description": "背景图片(base64编码)"},
"simple_target": {"type": "boolean", "description": "是否为简单滑块"}
},
"required": ["target_image", "background_image"]
}
},
{
"name": "ddddocr_slide_comparison",
"description": "滑块比较算法",
"inputSchema": {
"type": "object",
"properties": {
"target_image": {"type": "string", "description": "带坑位的图片(base64编码)"},
"background_image": {"type": "string", "description": "完整背景图片(base64编码)"}
},
"required": ["target_image", "background_image"]
}
},
{
"name": "ddddocr_status",
"description": "获取服务状态信息",
"inputSchema": {
"type": "object",
"properties": {}
}
}
]
)
return capabilities
@self.router.post("/call")
async def call_tool(request: MCPRequest):
"""调用MCP工具"""
try:
method = request.method
params = request.params
if method == "ddddocr_initialize":
from .models import InitializeRequest
init_request = InitializeRequest(**params)
result = self.service.initialize(init_request)
elif method == "ddddocr_ocr":
from .models import OCRRequest
ocr_request = OCRRequest(**params)
if not self.service.ocr_instance:
raise HTTPException(status_code=400, detail="OCR功能未初始化")
# 解码base64图片
image_data = base64.b64decode(ocr_request.image)
# 设置字符集范围
if ocr_request.charset_range is not None:
self.service.ocr_instance.set_ranges(ocr_request.charset_range)
# 执行OCR识别
result = self.service.ocr_instance.classification(
image_data,
png_fix=ocr_request.png_fix,
probability=ocr_request.probability,
color_filter_colors=ocr_request.color_filter_colors,
color_filter_custom_ranges=ocr_request.color_filter_custom_ranges
)
elif method == "ddddocr_detection":
from .models import DetectionRequest
det_request = DetectionRequest(**params)
if not self.service.det_instance:
raise HTTPException(status_code=400, detail="目标检测功能未初始化")
# 解码base64图片
image_data = base64.b64decode(det_request.image)
# 执行目标检测
result = self.service.det_instance.detection(image_data)
elif method == "ddddocr_slide_match":
from .models import SlideMatchRequest
slide_request = SlideMatchRequest(**params)
if not self.service.slide_instance:
raise HTTPException(status_code=500, detail="滑块功能未初始化")
# 解码base64图片
target_data = base64.b64decode(slide_request.target_image)
background_data = base64.b64decode(slide_request.background_image)
# 执行滑块匹配
result = self.service.slide_instance.slide_match(
target_data, background_data, simple_target=slide_request.simple_target
)
elif method == "ddddocr_slide_comparison":
from .models import SlideComparisonRequest
slide_request = SlideComparisonRequest(**params)
if not self.service.slide_instance:
raise HTTPException(status_code=500, detail="滑块功能未初始化")
# 解码base64图片
target_data = base64.b64decode(slide_request.target_image)
background_data = base64.b64decode(slide_request.background_image)
# 执行滑块比较
result = self.service.slide_instance.slide_comparison(target_data, background_data)
elif method == "ddddocr_status":
result = self.service.get_status().dict()
else:
raise HTTPException(status_code=400, detail=f"不支持的方法: {method}")
return MCPResponse(result=result, id=request.id)
except Exception as e:
return MCPResponse(
error={
"code": -1,
"message": str(e),
"data": None
},
id=request.id
)
@self.router.get("/")
async def mcp_info():
"""MCP协议信息"""
return {
"protocol": "MCP",
"version": "1.6.1",
"description": "DDDDOCR MCP协议支持",
"endpoints": {
"capabilities": "/mcp/capabilities",
"call": "/mcp/call"
}
}
================================================
FILE: ddddocr/api/models.py
================================================
# coding=utf-8
"""
API数据模型定义
"""
from typing import List, Optional, Union, Dict, Any
from pydantic import BaseModel, Field
class InitializeRequest(BaseModel):
"""初始化请求模型"""
ocr: bool = Field(True, description="是否启用OCR功能")
det: bool = Field(False, description="是否启用目标检测功能")
old: bool = Field(False, description="是否使用旧版OCR模型")
beta: bool = Field(False, description="是否使用beta版OCR模型")
use_gpu: bool = Field(False, description="是否使用GPU")
device_id: int = Field(0, description="GPU设备ID")
import_onnx_path: str = Field("", description="自定义ONNX模型路径")
charsets_path: str = Field("", description="自定义字符集路径")
class SwitchModelRequest(BaseModel):
"""切换模型请求模型"""
model_type: str = Field(..., description="模型类型: 'ocr', 'det', 'ocr_old', 'ocr_beta'")
use_gpu: bool = Field(False, description="是否使用GPU")
device_id: int = Field(0, description="GPU设备ID")
class ToggleFeatureRequest(BaseModel):
"""开启/关闭功能请求模型"""
feature: str = Field(..., description="功能名称: 'ocr', 'detection', 'color_filter'")
enabled: bool = Field(..., description="是否启用")
class OCRRequest(BaseModel):
"""OCR识别请求模型"""
image: str = Field(..., description="图片数据(base64编码)")
png_fix: bool = Field(False, description="是否修复PNG透明背景问题")
probability: bool = Field(False, description="是否返回概率信息")
color_filter_colors: Optional[List[str]] = Field(None, description="颜色过滤预设颜色列表")
color_filter_custom_ranges: Optional[List[List[List[int]]]] = Field(None, description="自定义HSV颜色范围")
charset_range: Optional[Union[int, str]] = Field(None, description="字符集范围限制")
class DetectionRequest(BaseModel):
"""目标检测请求模型"""
image: str = Field(..., description="图片数据(base64编码)")
class SlideMatchRequest(BaseModel):
"""滑块匹配请求模型"""
target_image: str = Field(..., description="滑块图片(base64编码)")
background_image: str = Field(..., description="背景图片(base64编码)")
simple_target: bool = Field(False, description="是否为简单滑块")
class SlideComparisonRequest(BaseModel):
"""滑块比较请求模型"""
target_image: str = Field(..., description="带坑位的图片(base64编码)")
background_image: str = Field(..., description="完整背景图片(base64编码)")
class APIResponse(BaseModel):
"""API响应基础模型"""
success: bool = Field(..., description="请求是否成功")
message: str = Field("", description="响应消息")
data: Optional[Any] = Field(None, description="响应数据")
class StatusResponse(BaseModel):
"""状态响应模型"""
service_status: str = Field(..., description="服务状态")
loaded_models: List[str] = Field(..., description="已加载的模型列表")
enabled_features: List[str] = Field(..., description="已启用的功能列表")
version: str = Field(..., description="版本信息")
uptime: float = Field(..., description="运行时间(秒)")
class OCRResponse(BaseModel):
"""OCR识别响应模型"""
text: Optional[str] = Field(None, description="识别的文本")
probability: Optional[Dict[str, Any]] = Field(None, description="概率信息")
class DetectionResponse(BaseModel):
"""目标检测响应模型"""
bboxes: List[List[int]] = Field(..., description="检测到的边界框列表")
class SlideResponse(BaseModel):
"""滑块响应模型"""
target: List[int] = Field(..., description="目标位置坐标")
target_x: Optional[int] = Field(None, description="滑块X偏移")
target_y: Optional[int] = Field(None, description="滑块Y偏移")
# MCP协议相关模型
class MCPRequest(BaseModel):
"""MCP请求模型"""
method: str = Field(..., description="方法名")
params: Dict[str, Any] = Field({}, description="参数")
id: Optional[Union[str, int]] = Field(None, description="请求ID")
class MCPResponse(BaseModel):
"""MCP响应模型"""
result: Optional[Any] = Field(None, description="结果")
error: Optional[Dict[str, Any]] = Field(None, description="错误信息")
id: Optional[Union[str, int]] = Field(None, description="请求ID")
class MCPCapabilities(BaseModel):
"""MCP能力声明模型"""
tools: List[Dict[str, Any]] = Field(..., description="可用工具列表")
resources: List[Dict[str, Any]] = Field([], description="可用资源列表")
prompts: List[Dict[str, Any]] = Field([], description="可用提示列表")
================================================
FILE: ddddocr/api/routes.py
================================================
# coding=utf-8
"""
API路由定义
"""
import base64
import time
import traceback
from typing import Dict, Any
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import JSONResponse, HTMLResponse
from .models import *
def create_routes(app: FastAPI, service):
"""创建API路由"""
@app.get("/", response_class=HTMLResponse)
async def root():
"""根路径,返回API文档链接"""
return """
DDDDOCR API
"""
@app.post("/initialize", response_model=APIResponse)
async def initialize(request: InitializeRequest):
"""初始化并选择加载的模型类型"""
try:
result = service.initialize(request)
return APIResponse(success=True, message=result["message"], data=result)
except Exception as e:
return APIResponse(success=False, message=str(e))
@app.post("/switch-model", response_model=APIResponse)
async def switch_model(request: SwitchModelRequest):
"""运行时切换模型配置"""
try:
result = service.switch_model(request)
return APIResponse(success=True, message=result["message"], data=result)
except Exception as e:
return APIResponse(success=False, message=str(e))
@app.post("/toggle-feature", response_model=APIResponse)
async def toggle_feature(request: ToggleFeatureRequest):
"""开启/关闭特定功能"""
try:
result = service.toggle_feature(request)
return APIResponse(success=True, message=result["message"], data=result)
except Exception as e:
return APIResponse(success=False, message=str(e))
@app.post("/ocr", response_model=APIResponse)
async def ocr_recognition(request: OCRRequest):
"""执行OCR识别"""
try:
if not service.ocr_instance:
raise HTTPException(status_code=400, detail="OCR功能未初始化,请先调用 /initialize 接口")
if "ocr" not in service.enabled_features:
raise HTTPException(status_code=400, detail="OCR功能已禁用")
# 解码base64图片
try:
image_data = base64.b64decode(request.image)
except Exception:
raise HTTPException(status_code=400, detail="图片base64解码失败")
# 设置字符集范围
if request.charset_range is not None:
service.ocr_instance.set_ranges(request.charset_range)
# 执行OCR识别
result = service.ocr_instance.classification(
image_data,
png_fix=request.png_fix,
probability=request.probability,
color_filter_colors=request.color_filter_colors,
color_filter_custom_ranges=request.color_filter_custom_ranges
)
if request.probability:
response_data = OCRResponse(text=None, probability=result)
else:
response_data = OCRResponse(text=result, probability=None)
return APIResponse(success=True, message="OCR识别成功", data=response_data.dict())
except HTTPException:
raise
except Exception as e:
return APIResponse(success=False, message=f"OCR识别失败: {str(e)}")
@app.post("/detect", response_model=APIResponse)
async def object_detection(request: DetectionRequest):
"""执行目标检测"""
try:
if not service.det_instance:
raise HTTPException(status_code=400, detail="目标检测功能未初始化,请先调用 /initialize 接口")
if "detection" not in service.enabled_features:
raise HTTPException(status_code=400, detail="目标检测功能已禁用")
# 解码base64图片
try:
image_data = base64.b64decode(request.image)
except Exception:
raise HTTPException(status_code=400, detail="图片base64解码失败")
# 执行目标检测
bboxes = service.det_instance.detection(image_data)
response_data = DetectionResponse(bboxes=bboxes)
return APIResponse(success=True, message="目标检测成功", data=response_data.dict())
except HTTPException:
raise
except Exception as e:
return APIResponse(success=False, message=f"目标检测失败: {str(e)}")
@app.post("/slide-match", response_model=APIResponse)
async def slide_match(request: SlideMatchRequest):
"""滑块匹配"""
try:
if not service.slide_instance:
raise HTTPException(status_code=500, detail="滑块功能未初始化")
# 解码base64图片
try:
target_data = base64.b64decode(request.target_image)
background_data = base64.b64decode(request.background_image)
except Exception:
raise HTTPException(status_code=400, detail="图片base64解码失败")
# 执行滑块匹配
result = service.slide_instance.slide_match(
target_data, background_data, simple_target=request.simple_target
)
response_data = SlideResponse(**result)
return APIResponse(success=True, message="滑块匹配成功", data=response_data.dict())
except HTTPException:
raise
except Exception as e:
return APIResponse(success=False, message=f"滑块匹配失败: {str(e)}")
@app.post("/slide-comparison", response_model=APIResponse)
async def slide_comparison(request: SlideComparisonRequest):
"""滑块比较"""
try:
if not service.slide_instance:
raise HTTPException(status_code=500, detail="滑块功能未初始化")
# 解码base64图片
try:
target_data = base64.b64decode(request.target_image)
background_data = base64.b64decode(request.background_image)
except Exception:
raise HTTPException(status_code=400, detail="图片base64解码失败")
# 执行滑块比较
result = service.slide_instance.slide_comparison(target_data, background_data)
response_data = SlideResponse(**result)
return APIResponse(success=True, message="滑块比较成功", data=response_data.dict())
except HTTPException:
raise
except Exception as e:
return APIResponse(success=False, message=f"滑块比较失败: {str(e)}")
@app.get("/status", response_model=StatusResponse)
async def get_status():
"""获取当前服务状态和已加载的模型信息"""
return service.get_status()
@app.get("/health")
async def health_check():
"""健康检查"""
return {"status": "healthy", "timestamp": time.time()}
@app.exception_handler(Exception)
async def global_exception_handler(request: Request, exc: Exception):
"""全局异常处理"""
return JSONResponse(
status_code=500,
content={
"success": False,
"message": f"服务器内部错误: {str(exc)}",
"detail": traceback.format_exc() if app.debug else None
}
)
================================================
FILE: ddddocr/api/server.py
================================================
# coding=utf-8
"""
FastAPI服务器实现
"""
import time
import base64
import traceback
from typing import Optional, Dict, Any
from contextlib import asynccontextmanager
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import JSONResponse, HTMLResponse
from fastapi.middleware.cors import CORSMiddleware
import uvicorn
from .models import *
from .routes import create_routes
from .mcp import MCPHandler
class DDDDOCRService:
"""DDDDOCR服务管理类"""
def __init__(self):
self.ocr_instance = None
self.det_instance = None
self.slide_instance = None
self.enabled_features = set()
self.start_time = time.time()
self.version = "1.6.1"
def initialize(self, config: InitializeRequest) -> Dict[str, Any]:
"""初始化服务"""
try:
# 动态导入ddddocr以避免循环导入
import ddddocr
# 清理现有实例
self.ocr_instance = None
self.det_instance = None
self.slide_instance = None
self.enabled_features.clear()
# 根据配置初始化实例
if config.ocr:
self.ocr_instance = ddddocr.DdddOcr(
ocr=True,
det=False,
old=config.old,
beta=config.beta,
use_gpu=config.use_gpu,
device_id=config.device_id,
show_ad=False,
import_onnx_path=config.import_onnx_path,
charsets_path=config.charsets_path
)
self.enabled_features.add("ocr")
if config.det:
self.det_instance = ddddocr.DdddOcr(
ocr=False,
det=True,
use_gpu=config.use_gpu,
device_id=config.device_id,
show_ad=False
)
self.enabled_features.add("detection")
# 滑块功能总是可用
self.slide_instance = ddddocr.DdddOcr(ocr=False, det=False, show_ad=False)
self.enabled_features.add("slide")
return {
"loaded_models": list(self.enabled_features),
"message": "服务初始化成功"
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"初始化失败: {str(e)}")
def switch_model(self, config: SwitchModelRequest) -> Dict[str, Any]:
"""切换模型"""
try:
import ddddocr
if config.model_type == "ocr":
self.ocr_instance = ddddocr.DdddOcr(
ocr=True, det=False, old=False, beta=False,
use_gpu=config.use_gpu, device_id=config.device_id, show_ad=False
)
self.enabled_features.add("ocr")
elif config.model_type == "ocr_old":
self.ocr_instance = ddddocr.DdddOcr(
ocr=True, det=False, old=True, beta=False,
use_gpu=config.use_gpu, device_id=config.device_id, show_ad=False
)
self.enabled_features.add("ocr")
elif config.model_type == "ocr_beta":
self.ocr_instance = ddddocr.DdddOcr(
ocr=True, det=False, old=False, beta=True,
use_gpu=config.use_gpu, device_id=config.device_id, show_ad=False
)
self.enabled_features.add("ocr")
elif config.model_type == "det":
self.det_instance = ddddocr.DdddOcr(
ocr=False, det=True,
use_gpu=config.use_gpu, device_id=config.device_id, show_ad=False
)
self.enabled_features.add("detection")
else:
raise ValueError(f"不支持的模型类型: {config.model_type}")
return {
"model_type": config.model_type,
"message": f"模型 {config.model_type} 切换成功"
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"模型切换失败: {str(e)}")
def toggle_feature(self, config: ToggleFeatureRequest) -> Dict[str, Any]:
"""开启/关闭功能"""
if config.enabled:
self.enabled_features.add(config.feature)
message = f"功能 {config.feature} 已启用"
else:
self.enabled_features.discard(config.feature)
message = f"功能 {config.feature} 已禁用"
return {
"feature": config.feature,
"enabled": config.enabled,
"message": message
}
def get_status(self) -> StatusResponse:
"""获取服务状态"""
loaded_models = []
if self.ocr_instance:
loaded_models.append("ocr")
if self.det_instance:
loaded_models.append("detection")
if self.slide_instance:
loaded_models.append("slide")
return StatusResponse(
service_status="running",
loaded_models=loaded_models,
enabled_features=list(self.enabled_features),
version=self.version,
uptime=time.time() - self.start_time
)
# 全局服务实例
service = DDDDOCRService()
@asynccontextmanager
async def lifespan(app: FastAPI):
"""应用生命周期管理"""
# 启动时初始化
print("DDDDOCR API服务启动中...")
yield
# 关闭时清理
print("DDDDOCR API服务关闭中...")
def create_app() -> FastAPI:
"""创建FastAPI应用"""
app = FastAPI(
title="DDDDOCR API",
description="带带弟弟OCR通用验证码识别API服务",
version="1.6.1",
docs_url="/docs",
redoc_url="/redoc",
lifespan=lifespan
)
# 添加CORS中间件
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 添加路由
create_routes(app, service)
# 添加MCP处理器
mcp_handler = MCPHandler(service)
app.include_router(mcp_handler.router, prefix="/mcp", tags=["MCP"])
return app
def run_server(host: str = "0.0.0.0", port: int = 8000, **kwargs):
"""运行服务器"""
app = create_app()
print(f"DDDDOCR API服务启动在 http://{host}:{port}")
print(f"API文档地址: http://{host}:{port}/docs")
print(f"MCP协议地址: http://{host}:{port}/mcp")
uvicorn.run(app, host=host, port=port, **kwargs)
================================================
FILE: ddddocr/charsets.py
================================================
# coding=utf-8
CHARSET_OLD = ['',
'掀',
'袜',
'顧',
'徕',
'榱',
'荪',
'浡',
'其',
'炎',
'玉',
'恩',
'劣',
'徽',
'廉',
'桂',
'拂',
'鳊',
'撤',
'赏',
'哮',
'侄',
'蓮',
'И',
'进',
'饭',
'饱',
'优',
'楸',
'礻',
'蜉',
'營',
'伙',
'杌',
'修',
'榜',
'准',
'铒',
'戏',
'赭',
'襟',
'彘',
'彩',
'雁',
'闽',
'坎',
'聂',
'氡',
'辜',
'苁',
'潆',
'摁',
'月',
'稇',
'而',
'醴',
'簉',
'卑',
'妖',
'埽',
'嘡',
'醛',
'見',
'煎',
'汪',
'秽',
'迄',
'噭',
'焉',
'钌',
'瑕',
'玻',
'仙',
'蹑',
'钀',
'翦',
'丰',
'矗',
'2',
'胚',
'镊',
'镡',
'鍊',
'帖',
'僰',
'淀',
'吒',
'冲',
'挡',
'粼',
'螈',
'缵',
'孺',
'侦',
'曷',
'渐',
'敷',
'投',
'宸',
'祉',
'柳',
'尖',
'梃',
'淘',
'臁',
'躇',
'撖',
'惭',
'狄',
'聢',
'官',
'狴',
'诬',
'骄',
'跻',
'場',
'姻',
'钎',
'藥',
'綉',
'驾',
'舻',
'黢',
'鲦',
'蜣',
'渖',
'绹',
'佰',
'怜',
'三',
'痪',
'眍',
'养',
'角',
'薜',
'濑',
'劳',
'戟',
'傎',
'纫',
'徉',
'收',
'稍',
'虫',
'螋',
'鬲',
'捌',
'陡',
'蓟',
'邳',
'蹢',
'涉',
'煋',
'端',
'懷',
'椤',
'埶',
'廊',
'免',
'秫',
'猢',
'睐',
'臺',
'擀',
'布',
'麃',
'彗',
'汊',
'芄',
'遣',
'胙',
'另',
'癯',
'徭',
'疢',
'茆',
'忡',
''',
'烃',
'笕',
'薤',
'肆',
'熛',
'過',
'盖',
'跷',
'呷',
'痿',
'沖',
'魍',
'讣',
'庤',
'弑',
'诩',
'庵',
'履',
'暮',
'始',
'滟',
'矅',
'蛹',
'鸿',
'啃',
'铋',
'沿',
'鐾',
'酆',
'團',
'恙',
'閥',
'聒',
'讵',
'颠',
'沾',
'堅',
'踣',
'陴',
'覃',
'滙',
'浐',
'钇',
'脆',
'炙',
'亮',
'觌',
'産',
'汩',
'鸭',
'斄',
'堆',
'掭',
'揞',
'鹂',
'郫',
'瘅',
'蚂',
'揩',
'学',
'组',
'浸',
'腙',
'耀',
'嗛',
'局',
'蠓',
'肠',
'昏',
'I',
'岑',
'镯',
'憧',
'油',
'泸',
'鸟',
'潇',
'蕻',
'褒',
'瞧',
'旸',
'昭',
'庐',
'鞒',
'内',
'痈',
'己',
'曙',
'怠',
'锟',
'晞',
'耢',
'鲢',
'醦',
'糕',
'療',
'寇',
'梵',
'黾',
'呻',
'苒',
'ü',
'校',
'嘏',
'昃',
'Ⅰ',
'蕰',
'凖',
'嵛',
'裨',
'筏',
'匜',
'咋',
'乏',
'婵',
'镂',
'珰',
'感',
'蔗',
'蚵',
'庞',
'弢',
'槟',
'口',
'漉',
'﹒',
'咂',
'俩',
'增',
'硐',
'襙',
'绉',
'卿',
'距',
'璱',
'猖',
'铚',
'郚',
'嬖',
'缒',
'阃',
'扞',
'V',
'望',
'最',
'浔',
'骜',
'赃',
'闻',
'砍',
'奸',
'灶',
'以',
'获',
'鳎',
'浦',
'罐',
'孓',
'纭',
'瘀',
'普',
'氰',
'塮',
'症',
'顷',
'们',
'螓',
'蛸',
'鵰',
'册',
'美',
'萨',
'沘',
'犰',
'嫌',
'名',
')',
'懦',
'滇',
'F',
'垡',
'声',
'毅',
'隅',
'鲎',
'煨',
'萦',
'宜',
'唇',
'鯨',
'邛',
'杲',
'赜',
'长',
'魂',
'桠',
'锇',
'搓',
'俘',
'仰',
'膘',
'宦',
'歹',
'遁',
'猃',
'噉',
'幂',
'糜',
'嗤',
'周',
'剂',
'曦',
'暧',
'焖',
'髻',
'釐',
'泰',
'窟',
'檎',
'旧',
'犀',
'镄',
'百',
'取',
'岍',
'逗',
'叽',
'呃',
'鲪',
'萬',
'陈',
'7',
'習',
'区',
'逄',
'宏',
'罡',
'漭',
'盗',
'郿',
'般',
'谢',
'倪',
'纵',
'婶',
'砧',
'揖',
'扪',
'濒',
'愤',
'茓',
'浞',
'子',
'揄',
'旌',
'趄',
'樊',
'醑',
'遄',
'婚',
'汶',
'矩',
'裈',
'弊',
'呱',
'铳',
'勿',
'蚴',
'忿',
'褓',
'缚',
'酱',
'璞',
'庆',
'除',
'礌',
'珩',
'榨',
'鼢',
'逞',
'容',
'圯',
'猛',
'陌',
'-',
'嚯',
'镘',
'鱾',
'睚',
'猬',
'杜',
'鳓',
'燈',
'計',
'咣',
'炜',
'睁',
'箱',
'邮',
'略',
'馇',
'逐',
'雀',
'僬',
'髯',
'奖',
'俱',
'-',
'绗',
'犏',
'辱',
'忑',
'挽',
'康',
'蝼',
'栏',
'模',
'辒',
'•',
'儋',
'罱',
'墈',
'会',
'秀',
'栈',
'缔',
'醜',
'蚣',
'阮',
'鼗',
'眼',
'湧',
'沁',
'夥',
'毕',
'媚',
'瘳',
'痣',
'搴',
'闿',
'遍',
'焰',
'岣',
'舱',
'埌',
'麿',
'嘿',
'靽',
'体',
'想',
'霓',
'钛',
'摽',
'苑',
'芳',
'技',
'綮',
'钅',
'燠',
'栾',
'年',
'悱',
'腹',
'员',
'呕',
'闇',
'嗫',
'檩',
'荒',
'溱',
'舨',
'峙',
'卒',
'洑',
'预',
'弯',
'蔷',
'叵',
'锯',
'慈',
'牧',
'患',
'贇',
'偷',
'鲜',
'锓',
'躔',
'嚬',
'烈',
'娌',
'嘲',
'详',
'麺',
'舒',
'厨',
'徵',
'葹',
'只',
'篦',
'鹀',
'剕',
'驳',
'聍',
'黧',
'砾',
'暅',
'褫',
'呈',
'森',
'结',
'龛',
'钲',
'轧',
'扔',
'蕹',
'赵',
'涒',
'冯',
'渲',
'缭',
'坚',
'趼',
'鲑',
'倫',
'门',
'班',
'垚',
'鞍',
'菘',
'畐',
'僇',
'侉',
'禢',
'轳',
'饦',
'兽',
'呯',
'捂',
'樨',
'卧',
'栝',
'豭',
'冶',
'鉰',
'申',
'蜈',
'印',
'缨',
'镫',
'蕾',
'圜',
'扑',
'娉',
'烦',
'缳',
'广',
'峄',
'獒',
'铔',
'奁',
'醚',
'倥',
'蹇',
'阚',
'镆',
'煺',
'德',
'颉',
'嗅',
'绷',
'蒯',
'祺',
'崧',
'往',
'枨',
'涡',
'鲲',
'瓅',
'岌',
'肘',
'飔',
'缘',
'千',
'棱',
'溶',
'窣',
'篼',
'代',
'捡',
'送',
'咡',
'术',
'滑',
'茜',
'晾',
'挤',
'曳',
'糈',
'G',
'翊',
'殴',
'妹',
'溥',
'璆',
'烩',
'拙',
'襄',
'几',
'嘴',
'D',
'驮',
'淙',
'蹐',
'合',
'環',
'剑',
'怪',
'褂',
'畑',
'燏',
'订',
'珪',
'≥',
'瘟',
'耷',
'槑',
'衷',
'猕',
'迁',
'霎',
'槜',
'﹖',
'鋈',
'苹',
'嫣',
'祜',
'李',
'鄒',
'噢',
'萄',
'仝',
'纨',
'直',
'悛',
'拣',
'远',
'诏',
'圧',
'躬',
'蝟',
'總',
'眆',
'筻',
'硇',
'鳁',
'眠',
'钆',
'泞',
'猱',
'宾',
'酞',
'募',
'螳',
'腴',
'念',
'宠',
'唯',
'怊',
'勃',
'M',
'兿',
'蟑',
'妁',
'掸',
'拌',
'铸',
'讼',
'诟',
'锺',
'Ω',
'竟',
'羚',
'剽',
'C',
'苦',
'煳',
'罢',
'跨',
'~',
'豸',
'±',
'俬',
'捺',
'彦',
'钣',
'鋆',
'用',
'缤',
'搁',
'徼',
'谦',
'筘',
'嗨',
'扮',
'旇',
'折',
'咯',
'昆',
'叟',
'垂',
'箐',
'捻',
'燕',
'島',
'瞀',
'鮮',
'屡',
'點',
'瘭',
'恚',
'旚',
'丟',
'捽',
'菁',
'瀑',
'炕',
'蹩',
'芒',
'r',
'是',
'媾',
'鹝',
'囵',
'萤',
'拷',
'频',
'埴',
'课',
'癍',
'袱',
'螯',
'谘',
'榛',
'Y',
'缣',
'裔',
'憩',
'相',
'觀',
'晗',
'坳',
'炔',
'勉',
'汆',
'钡',
'舐',
'衫',
'疫',
'鲙',
'蘩',
'穈',
'殁',
'九',
'泻',
'咤',
'構',
'谆',
'陕',
'装',
'蔡',
'画',
'介',
'苋',
'務',
'敝',
'俟',
'帇',
'鸺',
'贸',
'茗',
'肃',
'滪',
'输',
'瘗',
'菽',
'饹',
'诉',
'遐',
'浑',
'扎',
'卟',
'铀',
'邗',
'觋',
'嘎',
'塑',
'潏',
'金',
'姘',
'潋',
'逵',
'鲻',
'逯',
'炮',
'甄',
'髡',
'剩',
'嗬',
'芴',
'屋',
'改',
'骣',
'芪',
'邠',
'痋',
'珑',
'帆',
'狙',
'八',
'奔',
'族',
'轵',
'氖',
'雕',
'痧',
'眊',
'胛',
'酉',
'鲼',
'砣',
'猸',
'餮',
'郇',
'沫',
'跖',
'蝉',
'屑',
'辘',
'閣',
'涑',
'邡',
'篃',
'交',
'笼',
'颇',
'贻',
'魄',
'黡',
'劂',
'糠',
'炅',
'帨',
'苍',
'瓴',
'粤',
'莎',
'朿',
'埔',
'绸',
'齁',
'鱿',
'惨',
'腢',
'郡',
'棠',
'猫',
'脑',
'風',
'蚱',
'捐',
'嵌',
'胱',
'馗',
'竽',
'泥',
'辍',
'怖',
'雾',
'絮',
'淼',
'筝',
'碲',
'悼',
'龀',
'の',
'珥',
'忐',
'溲',
'昕',
'荔',
'掂',
'瘦',
'僭',
'蔌',
'抺',
'椅',
'誉',
'扯',
'僜',
'停',
'衉',
'汇',
'赔',
'眄',
'呙',
'咙',
'剿',
'次',
'蛟',
'嗓',
'』',
'汕',
'詈',
'帘',
'踧',
'姁',
'血',
'堪',
'喜',
'滩',
'璎',
'胄',
'俨',
'眚',
'凌',
'拽',
'滔',
'⑿',
'嬃',
'―',
'汐',
'潭',
'阡',
'呓',
'婷',
'执',
'妊',
'恂',
'妥',
'鳘',
'蔫',
'设',
'睒',
'笪',
'謇',
'鞋',
'谍',
'黯',
'虍',
'馬',
'蚧',
'骑',
'峤',
'舾',
'儀',
'駡',
'β',
'蓑',
'柏',
'痒',
'蒇',
'痕',
'妍',
'熠',
'僻',
'爬',
'迭',
'畫',
'绰',
'湯',
'凭',
'菼',
'懈',
'顒',
'午',
'箪',
'糙',
'址',
'钼',
'堵',
'佘',
'侍',
'卤',
'(',
'榚',
'泽',
'溘',
'蟹',
'b',
'燁',
'颂',
'菠',
'榉',
'鲡',
'埸',
'荛',
'歘',
'断',
'邸',
'贡',
'礞',
'蔼',
'脸',
'爪',
'帜',
'翡',
'仟',
'皎',
'辆',
'滫',
'昔',
'™',
'柬',
'弓',
'遇',
'杪',
'侨',
'娓',
'镪',
'觑',
'一',
'踌',
'牟',
'褡',
'厩',
'晌',
'每',
'娘',
'渤',
'c',
'咫',
'成',
'颏',
'孩',
'鼓',
'瞌',
'槁',
'捒',
'阉',
'伉',
'癣',
'胞',
'鲟',
'瓤',
'杅',
'紡',
'喂',
'掠',
'镜',
'镧',
'侞',
'赦',
'貝',
'丕',
'臧',
'L',
'池',
'彷',
'棓',
'锽',
'渊',
'食',
'饨',
'堡',
'玥',
'氣',
'讽',
'敬',
'闺',
'帡',
'携',
'哫',
'珈',
'魆',
'哄',
'旁',
'喻',
'泄',
'畎',
'郁',
'唅',
'葜',
'繪',
'飐',
'谶',
'聆',
'斝',
'谥',
'辉',
'髅',
'進',
'吧',
'蹀',
'铛',
'笛',
'睥',
'楼',
'凝',
'況',
'鸷',
'苠',
'饺',
'沙',
'缴',
'块',
'梢',
'慝',
'珐',
'鄏',
'霰',
'迸',
'氆',
'趵',
'棣',
'鳔',
'祆',
'☆',
'苯',
'恁',
'螨',
'庭',
'缠',
'槠',
'津',
'髋',
'诔',
'葶',
'蜾',
'坻',
'蒹',
'摔',
'向',
'垩',
'蹭',
'淇',
'筛',
'滬',
'玡',
'铺',
'逼',
'劵',
'绲',
'团',
'鳀',
'常',
'玖',
'擢',
'株',
'铵',
'樽',
'弭',
'醇',
'糨',
'璈',
'曩',
'潔',
'祘',
'磨',
'希',
'鲅',
'擂',
'谗',
'唳',
'欷',
'欧',
'绋',
'庙',
'琬',
'稳',
'糊',
'拥',
'霪',
'浼',
'翎',
'俜',
'摸',
'筚',
'巯',
'墼',
'苫',
'缩',
'镚',
'婪',
'圹',
'咚',
'儿',
'蒽',
'婆',
'鲐',
'雹',
'霞',
'嶪',
'濠',
'琉',
'澌',
'媢',
'禤',
'摺',
'掏',
'矢',
'艄',
'围',
'呸',
'寺',
'拤',
'氐',
'柝',
'跎',
'僖',
'挢',
'茨',
'涮',
'缫',
'撸',
'荨',
'嶷',
'廋',
'魋',
'付',
'喋',
'蜗',
'邙',
'棹',
'璪',
'倡',
'鞭',
'游',
'錦',
'眬',
'抒',
'眈',
'培',
'夏',
'黔',
'獐',
'皋',
'戛',
'鲀',
'垒',
'耽',
'纤',
'漩',
'铈',
'握',
'窝',
'芋',
'濞',
'截',
'零',
'敖',
'眸',
'怦',
'噎',
'簋',
'掳',
'妣',
'湃',
'璠',
'殄',
'觞',
'桅',
'笋',
'鲞',
'踯',
'傀',
'犨',
'抵',
'疰',
'暌',
'耖',
'供',
'枳',
'怂',
'娶',
'鸩',
'捣',
'庸',
'逡',
'懋',
'颃',
'長',
'鼫',
'姮',
'蹈',
'耵',
'乂',
'骐',
'殇',
'膏',
'仳',
'冥',
'梭',
'洵',
'碣',
'昝',
'仉',
'軒',
'隍',
'更',
'な',
'嵕',
'拜',
'粑',
'鲴',
'吇',
'秃',
'尕',
'魃',
'狨',
'臛',
'蟥',
'胨',
'注',
'谁',
'张',
'才',
'尸',
'派',
'矮',
'洳',
'舟',
'溺',
'锴',
'寓',
'籴',
'夕',
'叭',
'荠',
'澼',
'劃',
'久',
'私',
'炉',
'娟',
'麤',
'稂',
'河',
'纴',
'夺',
'亏',
'焙',
'。',
'塗',
'蜩',
'栌',
'渡',
'薰',
'崋',
'揿',
'漤',
'啾',
'郏',
'舣',
'卉',
'爱',
'牚',
'撵',
'钺',
'再',
'企',
'笺',
'疾',
'承',
'俾',
'瞈',
'邰',
'汾',
'瘛',
'檫',
'蒎',
'觅',
'绀',
'掎',
'U',
'赓',
'匳',
'聘',
'蛤',
'跤',
'嗜',
'洼',
'歔',
'弟',
'飕',
'莼',
'嫉',
'那',
'滈',
'践',
'僦',
'偎',
'扢',
'绚',
'乕',
'旳',
'招',
'饯',
'®',
'攸',
'鞁',
'囫',
'铨',
'陒',
'鷄',
'畀',
'韨',
'經',
'纾',
'萸',
'肴',
'→',
'宗',
'迳',
'鳞',
'亚',
'搂',
'喀',
'狮',
'坦',
'瞥',
'采',
'姝',
'钳',
'□',
'剌',
'維',
'葸',
'鼩',
'公',
'刀',
'沩',
'喔',
'泺',
'哉',
'徨',
'篝',
'掊',
'沕',
'运',
'偆',
'浒',
'语',
'乇',
'仪',
'萝',
'疍',
'踽',
'碡',
'熰',
'荞',
'嚓',
'天',
'饰',
'泵',
'械',
'孑',
'蛰',
'荟',
'源',
'峡',
'矜',
'睬',
'噬',
'腆',
'婉',
'‘',
'等',
'誓',
'辀',
'岖',
'琖',
'碜',
'霍',
'怼',
'唛',
'弈',
'淑',
'疆',
'晴',
'镴',
'鸡',
'埚',
'焕',
'芦',
'唻',
'踅',
'吴',
'殡',
'唏',
'吨',
'寡',
'鹉',
'絲',
'坉',
'會',
'埭',
'Ⅲ',
'捏',
'墅',
'卓',
'叙',
'徇',
'柜',
'各',
'荭',
'J',
'恝',
'囐',
'蓉',
'犋',
'叡',
'莺',
'颌',
'蒸',
'饸',
'疋',
'玊',
'兢',
'鱽',
'藍',
'杳',
'辂',
'獘',
'拔',
'侪',
'湍',
'膂',
'渔',
'瘊',
'雉',
'稁',
'職',
'僤',
'鄳',
'祁',
'稱',
'I',
'裴',
'锉',
'曹',
'鲶',
'挨',
'哑',
'鷪',
'鏠',
'煞',
'师',
'蛲',
'牁',
'琅',
'告',
'媒',
'祭',
'确',
'荚',
'亰',
'蝗',
'阗',
'歩',
'疲',
'f',
'唣',
'愛',
'郾',
'棍',
'山',
'狲',
'纽',
'蚡',
'栂',
'馓',
'诊',
'猴',
'喤',
'来',
'继',
'桎',
'嬛',
'骞',
'邴',
'暄',
'贼',
'昴',
'廿',
'克',
'耔',
'彤',
'鹭',
'葓',
'骢',
'龁',
'鏡',
'瀚',
'赅',
'韩',
'譄',
'榷',
'殚',
'膛',
'须',
'、',
'砖',
'唶',
'番',
'蛘',
'畴',
'铠',
'亢',
'氓',
'铰',
'炻',
'筫',
'迢',
'兰',
'玺',
'砻',
'积',
'莜',
'吸',
'监',
'膦',
'迪',
'迷',
'冷',
'哀',
'贳',
'瞄',
'器',
'鹡',
'惺',
'徐',
'酢',
'寒',
'Ⓡ',
'倾',
'飞',
'楽',
'涢',
'队',
'舆',
'赤',
'璩',
'戳',
'殳',
'掮',
'舴',
'蜷',
'宄',
'拴',
'癌',
'舛',
'婀',
'抟',
'靡',
'骍',
'揸',
'思',
'慧',
'平',
'橘',
'臭',
'硖',
'卬',
'畈',
'兠',
'茸',
'脂',
'魚',
'晩',
'御',
'龋',
'涣',
'罨',
'爍',
'糌',
'汧',
'缐',
'贽',
'要',
'祀',
'鲊',
'爼',
'獯',
'瀣',
'棋',
'肈',
'佣',
'娣',
'柩',
'枸',
'偃',
'v',
'唷',
'劍',
'榴',
'槐',
'漫',
'洽',
'蒡',
'籼',
'魔',
'峋',
'第',
'歙',
'萧',
'谮',
'埯',
'撮',
'马',
'绡',
'裘',
'鹋',
'蓬',
'显',
'噶',
'倒',
'镳',
'艽',
'窬',
'拳',
'樯',
'跋',
'詹',
'钥',
'心',
'嶽',
'嚋',
'戎',
'吕',
'涂',
'悃',
'麦',
'骋',
'推',
'箩',
'硚',
'匆',
'村',
'五',
'杨',
'凑',
'鞫',
'镰',
'伥',
'诒',
'纣',
'崃',
'鸻',
'翰',
'辌',
'廛',
'證',
'舢',
'盼',
'腿',
'圳',
'贱',
'皿',
'隆',
'屈',
'龏',
'瓒',
'顏',
'↓',
'赈',
'煙',
'窍',
'韧',
'壁',
'莰',
'箬',
'蹋',
'褰',
'峥',
'悚',
'坜',
'环',
'回',
'疼',
'渍',
'蝄',
'东',
'臂',
'坩',
'走',
'痍',
'或',
'蜀',
'熳',
'蜻',
'佐',
'懿',
'嚅',
'紗',
'螭',
'忖',
'顶',
'狡',
'吲',
'洣',
'帛',
'呶',
'柞',
'柫',
'酿',
'粥',
'琢',
'呵',
'踝',
'榀',
'呲',
'價',
'鼋',
'欺',
'此',
'背',
'猎',
'昱',
'濡',
'稚',
'欠',
'暇',
'茬',
'牙',
'迹',
'尼',
'氛',
'膠',
'缯',
'娼',
'骚',
'姒',
'鬟',
'霁',
'鲔',
'者',
'驰',
'倩',
'馉',
'工',
'芬',
'烙',
'卦',
'C',
'裂',
'垲',
'摆',
'珮',
'缏',
'杞',
'绘',
'司',
'如',
'姞',
'荆',
'挖',
'跗',
'伍',
'氚',
'钘',
'郢',
'轱',
'篆',
'吭',
'夡',
'鹫',
'讷',
'轺',
'!',
'匈',
'待',
'聱',
'黏',
'海',
'蹶',
'趋',
'鎮',
'觊',
'江',
'咸',
'富',
'艴',
'稗',
'钜',
'搏',
'壶',
'鲮',
'薪',
'猞',
'轰',
'踪',
'赣',
'循',
'序',
'噻',
'若',
'裾',
'许',
'癞',
'吓',
'判',
'踔',
'查',
'蚀',
'[',
'樓',
'坌',
'岳',
'榄',
'役',
'倜',
'⒂',
'旭',
'溆',
'惯',
'咀',
'跫',
'选',
'囱',
'污',
'镶',
'⒁',
'淠',
'氮',
'酯',
'寅',
'芼',
'炊',
'夯',
'郪',
'农',
'褲',
'嘬',
'蹻',
'烔',
'罄',
'开',
'靴',
'镇',
'杯',
'羰',
'硪',
'籍',
'摘',
'馀',
'餐',
'眯',
'⑴',
'呗',
'巫',
'幤',
'蒤',
'蒗',
'镥',
'檵',
'盛',
'純',
'娃',
'●',
'耿',
'巡',
'婴',
'槔',
'i',
'颊',
'Ⅳ',
'栅',
'绅',
'邘',
'冉',
'碧',
'使',
'熨',
'羞',
'扼',
'漳',
'觯',
'楊',
'励',
'逑',
'咄',
'之',
'斤',
'嘣',
'鹰',
'媸',
'鲂',
'褚',
'磚',
'琨',
'聪',
'牖',
'太',
'蓍',
'涫',
'≤',
'虽',
'鸽',
'燧',
'褊',
'聿',
'壬',
'然',
'疚',
'莲',
'悴',
'簃',
'颓',
'坠',
'瞬',
'汳',
'l',
'登',
'瘼',
'窳',
'桤',
'縯',
'匣',
'坡',
'↑',
'愦',
'攘',
'渭',
'嬢',
'鲰',
'性',
'楚',
'澈',
'赪',
'達',
'鄯',
'罅',
'帽',
'茠',
'底',
'嫜',
'奏',
'浅',
'荽',
'楹',
'鼍',
'枵',
'嗔',
'滍',
'椴',
'嵩',
'氤',
'搠',
'两',
'榔',
'树',
'吝',
'基',
'峂',
'栎',
'侮',
'舸',
'遂',
'颡',
'锷',
'杼',
'酔',
'幄',
'哽',
'睢',
'陔',
'※',
'嚆',
'宬',
'宽',
'髦',
'笾',
'保',
'蹊',
'榕',
'咏',
'椋',
'丧',
'裤',
'骛',
'逧',
'弇',
'崆',
'樘',
'疤',
'鸤',
'伞',
'抚',
'诎',
'诵',
'豢',
'佳',
'差',
'埝',
'极',
'黍',
'煜',
'曰',
'阱',
'悞',
'叹',
'垤',
'藁',
'嗵',
'崔',
'卫',
'珂',
'憯',
'蔬',
'菜',
'碑',
'扈',
'铆',
'夹',
'衡',
'弱',
'挈',
'徜',
'疠',
'丶',
'遠',
'提',
'斧',
'炟',
'肺',
'B',
'她',
'晟',
'谎',
'邱',
'粳',
'酽',
'爨',
'鬼',
'伧',
'兹',
'嶓',
'谤',
'饕',
'揶',
'谱',
'歡',
'髪',
'餍',
'泳',
'郞',
'谣',
'汉',
'褐',
'非',
'刽',
'缅',
'饴',
'齐',
'兴',
'涯',
'芫',
'凡',
'褶',
'晡',
'努',
'蚶',
'彥',
'皤',
'砌',
'黼',
'吹',
'指',
'㙟',
'蓁',
'鹜',
'話',
'拊',
'辨',
'盎',
'肌',
'旘',
'软',
'颍',
'甏',
'滚',
'旦',
'滨',
'间',
'尴',
'对',
'鄘',
'称',
'镗',
'咅',
'璐',
'怔',
'垛',
'洎',
'瓮',
'绨',
'脚',
'遒',
'吊',
'纸',
'蹅',
'经',
'泉',
'武',
'汀',
'歪',
'败',
'拾',
'铪',
'吼',
'邹',
'磊',
'论',
'岛',
'厍',
'锛',
'芎',
'芭',
'音',
'澧',
'镕',
'锒',
'宙',
'牵',
'忱',
'嫔',
'麯',
'澉',
'擐',
'砥',
'撞',
'痴',
'盹',
'畿',
'厾',
'酸',
'俑',
'脽',
'鸈',
'枷',
'咨',
'蔹',
'诂',
'胰',
'董',
'脶',
'黩',
'髓',
'鉵',
'澎',
'鲽',
'梧',
'樱',
'诜',
'鲯',
'跂',
'盂',
'浴',
'苻',
'锅',
'實',
'碁',
'嘛',
'氕',
'艮',
'涟',
'绢',
'姿',
'茝',
'砘',
'簿',
'穷',
'镃',
'∈',
'抽',
'事',
'誜',
'窅',
'瀘',
'鲹',
'兖',
'嵎',
'陧',
'榍',
'轶',
'柿',
'藤',
'薏',
'娆',
'骷',
'梅',
'摒',
'睪',
'剪',
'羸',
'忧',
'邝',
'跺',
'旆',
'堕',
'伫',
'绍',
'疵',
'樟',
'–',
'绾',
'蜴',
'靸',
'侃',
'瘘',
'珧',
'遨',
'縠',
'信',
'充',
'桔',
'黇',
'劬',
'脒',
'良',
'俵',
'颙',
'轹',
'犿',
'屐',
'牾',
'4',
'兮',
'澝',
'汗',
'沼',
'铲',
'濋',
'鹬',
'丝',
'妫',
'重',
'蒺',
'磲',
'曚',
'尔',
'国',
'桐',
'俣',
'剐',
'哼',
'恹',
'哧',
'藔',
'谓',
'轨',
'眩',
'痞',
'添',
'鬯',
'库',
'梱',
'婕',
'蜢',
'贿',
'敕',
'泯',
'羟',
'龇',
'垸',
'左',
'肖',
'辎',
'鞣',
'谄',
'可',
'腺',
'末',
'狞',
'贷',
'嗌',
'仕',
'楞',
'膻',
'臻',
'欻',
'洲',
'所',
'檀',
'抔',
'罹',
'牒',
'仫',
'芨',
'柄',
'嫩',
'酒',
'祙',
'渠',
'的',
'笨',
'鳐',
'楡',
'过',
'苡',
'核',
'拖',
'阢',
'莒',
'凤',
'锋',
'`',
'硎',
'弁',
'鬶',
'朐',
'忏',
'於',
'昊',
'剟',
'咳',
'湘',
'日',
'满',
'哨',
'螵',
'餪',
'放',
'佶',
'葵',
'硷',
'c',
'抱',
'锥',
'芮',
'啻',
'惊',
'峁',
'琊',
'嶲',
'撺',
'煅',
'屏',
'袗',
'鄞',
'梓',
'鹌',
'宅',
'赂',
'鱼',
'洱',
'騳',
'E',
'物',
'觏',
'雙',
'瑀',
'上',
'淩',
'愀',
'❋',
'鄙',
'憝',
'沛',
'硫',
'产',
'垯',
'亁',
'枭',
'堰',
'赑',
'趾',
'庹',
'腭',
'迨',
'拚',
'晒',
'蜇',
'扣',
'纰',
'闵',
'窭',
'椽',
'菏',
'嘁',
'伛',
'郸',
'素',
'殷',
'表',
'躞',
'笸',
'耻',
'荧',
'辛',
'篑',
'馈',
'壮',
'耩',
'宛',
'慰',
'盡',
'塆',
'铯',
'苏',
'王',
'桕',
'⑧',
'°',
'浚',
'栉',
'朘',
'虚',
'骆',
'坂',
'秤',
'鲋',
'蕊',
'渝',
'呦',
'潼',
'驱',
'诼',
'峇',
'盤',
'趴',
'肄',
'笑',
'讹',
'貋',
'穂',
'啼',
'趟',
'暽',
'傣',
'蜎',
'挎',
'陳',
'勖',
'戴',
'旃',
'瞎',
'舌',
'幻',
'喾',
'赁',
'E',
'播',
'诀',
'蟛',
'鹛',
'骶',
'輸',
'連',
'醳',
'逅',
'奉',
'崖',
'娩',
'幔',
'佃',
'扅',
'阔',
'生',
'贬',
'疯',
'珀',
'苶',
'屯',
'裣',
'蹯',
'蝮',
'解',
'陂',
'疝',
'茈',
'帑',
'议',
'仲',
'埙',
'竺',
'峰',
'遮',
'涎',
'穸',
'阂',
'潵',
'镱',
'例',
'荑',
'u',
'脎',
'衍',
'轲',
'⑵',
'虾',
'颚',
'钞',
'²',
'伴',
'根',
'沣',
'腌',
'户',
'~',
'辙',
'愧',
'噤',
'觥',
'波',
'铗',
'纂',
'鲺',
'僚',
'毐',
'〇',
'桼',
'祗',
'慢',
'啵',
'坏',
'吗',
'嗞',
'甬',
'曈',
'徹',
'灏',
'混',
'渌',
'括',
'脖',
'汝',
'現',
'訇',
'紅',
'飘',
'虢',
'腱',
'旄',
'嬴',
'昨',
'孀',
'蚁',
'呛',
'讳',
'病',
',',
'喈',
'蒋',
'镭',
'葩',
'耲',
'鳈',
'锄',
'喘',
'返',
'傕',
'咆',
'享',
'枥',
'瓠',
'茳',
'铱',
'脘',
'暹',
'廒',
'爝',
'橹',
'瞑',
'铎',
'岢',
'叁',
'翏',
'捭',
'賀',
'悉',
'帝',
'芥',
'牀',
'闌',
'毯',
'亍',
'弧',
'锆',
'币',
'祊',
'纔',
'齑',
'肟',
'绤',
'獨',
'翚',
'颢',
'係',
'鍪',
'粉',
'统',
'诗',
'娜',
'褥',
'鈺',
'湔',
'呤',
'犸',
'湨',
'泣',
'蟾',
'犾',
'烛',
'斐',
'朦',
'室',
'诨',
'榭',
'煦',
'醺',
'敞',
'燮',
'糅',
'衽',
'孔',
'猄',
'疭',
'辰',
'钽',
'胁',
'釆',
'钉',
'胤',
'涧',
'弼',
'濯',
'汨',
'颖',
'茫',
'皑',
'遏',
'捃',
'坭',
'燴',
'肩',
'滞',
'玢',
'巽',
'砺',
'蜿',
'毁',
'億',
'骥',
'本',
'忽',
'肚',
'搽',
'靰',
'郴',
'跆',
'客',
'酣',
'α',
'屎',
'辩',
'殂',
'垝',
'紫',
'秦',
'喇',
'凶',
'傧',
'铐',
'蘊',
'補',
'贤',
'竿',
'途',
'慗',
'榖',
'券',
'莠',
'逆',
'鳇',
'误',
'崟',
'妇',
'磷',
'捧',
'莸',
'⇋',
'绺',
'稻',
'填',
'逋',
'侈',
'隶',
'侵',
'翥',
'惘',
'惧',
'鸥',
'赠',
'壳',
'芯',
'巩',
'獗',
'硅',
'搎',
'鲛',
'9',
'夸',
'穆',
'缜',
'诓',
'观',
'薛',
'咎',
'杧',
'页',
'饫',
'瑟',
'率',
'礤',
'悭',
'畔',
'匯',
'匮',
'鼠',
'犒',
'芡',
'傍',
'嫂',
'啸',
'鄉',
'哭',
'鄱',
'捷',
'靺',
'嚒',
'嘀',
'哒',
'#',
'拼',
'钚',
'魁',
'霣',
'眶',
'郊',
'死',
'愁',
'箭',
'鼙',
'签',
'害',
'斛',
'睑',
'蟜',
'余',
'墨',
'様',
'读',
'養',
'貉',
'较',
'浆',
'翩',
'徂',
'冕',
'铧',
'列',
'诈',
'穝',
'缑',
'纲',
'志',
'舀',
'甾',
'举',
'馁',
'ä',
'畹',
'榼',
'垢',
'襁',
'麟',
'灭',
'佴',
'镩',
'酝',
'柒',
'梯',
'傈',
'萭',
'悫',
'莨',
'搞',
'+',
'兄',
'偲',
'攀',
'曝',
'嵝',
'喳',
'从',
'遶',
'撴',
'.',
'鄄',
'欲',
'挺',
'娡',
'发',
'速',
'胲',
'褀',
'态',
'行',
'蚓',
'坼',
'适',
'厦',
'寐',
'带',
'緃',
'醤',
'珽',
'‧',
'溍',
'斋',
'鐀',
'朝',
'欢',
'传',
'築',
'咪',
'据',
'蹜',
'医',
'妄',
'肇',
'囝',
'怡',
'镎',
'桩',
'轩',
'岔',
'腐',
'矽',
'媵',
'搒',
'菔',
'拘',
'D',
'欃',
'唧',
'瞒',
'郈',
'绦',
'吟',
'撝',
'醉',
'镣',
'匝',
'拎',
'砒',
'顸',
'袁',
'驼',
'愔',
'实',
'國',
'奧',
'胩',
'府',
'逾',
'愕',
'廷',
'碌',
'锖',
'狩',
'褴',
'镢',
'芷',
'娥',
'唤',
'┌',
'云',
'О',
'檔',
'驴',
'躯',
'驺',
'洃',
'檑',
'窴',
'(',
'腕',
'立',
'楯',
'齮',
'〔',
'漆',
'k',
'芍',
'蹽',
'鬓',
'概',
'楣',
'唐',
'闲',
'糗',
'旱',
'幸',
'腽',
'嗄',
'迂',
'镠',
'顿',
'扥',
'圃',
'烜',
'馍',
'佝',
'岷',
'童',
'悦',
'┐',
'铌',
'袈',
'靓',
'骸',
'和',
'乔',
'灸',
'泓',
'临',
'睿',
'掖',
'偿',
'鐘',
'犁',
'祓',
'鈴',
'搌',
'授',
'鹳',
'赢',
'怅',
'絪',
'硬',
'芙',
'螅',
'”',
'傢',
'避',
'裕',
'歁',
'全',
'衰',
'仃',
'媛',
'鬻',
'跽',
'沌',
'急',
'猷',
'激',
'巉',
'哝',
'渣',
'笫',
'跳',
'螫',
'熜',
'Z',
'筷',
'佩',
'啶',
'萃',
'頫',
'荙',
'出',
'孽',
'钟',
'戡',
'釉',
'咬',
'滦',
'鹇',
'贯',
'鹮',
'具',
'翁',
'机',
'濱',
'谳',
'釣',
'懑',
'葛',
'袯',
'谭',
'质',
'胴',
'誊',
'侗',
'⑩',
'静',
'蚜',
'溋',
'嫪',
'嗲',
'瑭',
'座',
'舫',
'靶',
'棘',
'泊',
'嵖',
'摧',
'勋',
'僡',
'藉',
'疖',
'巂',
'随',
'罾',
'崚',
'猹',
'憨',
'苘',
'斓',
'鼷',
'利',
'谲',
'剔',
'艺',
'箓',
'蛀',
'鲚',
'搐',
'裟',
'捶',
'绌',
'揪',
'帮',
'缥',
'匍',
'冀',
'杻',
'逛',
'邑',
'禾',
'郰',
'黜',
'丘',
'樂',
'滌',
'緣',
'胃',
'苄',
'巾',
'瑜',
'元',
'蝶',
'层',
'烧',
'级',
'岭',
'蘭',
'繇',
'蝓',
'洞',
'奢',
'则',
'政',
'矾',
'啭',
'瘠',
'碴',
'忤',
'身',
'匠',
'警',
'饩',
'犬',
'皲',
'箔',
'豕',
'虑',
'草',
'喟',
'芤',
'逭',
'艳',
'幡',
'姚',
'賓',
'饪',
'卯',
'敌',
'烽',
'嫚',
'黝',
'豺',
'㭗',
'教',
'偕',
'板',
'茹',
'孤',
'人',
'狻',
'寰',
'厕',
'玲',
'璨',
'锵',
'搛',
'勍',
'匾',
'聃',
'奘',
'垃',
'焓',
'喽',
'嫫',
'貌',
'瘐',
'嚰',
'孟',
'衔',
'郎',
'账',
'础',
'电',
'黑',
'骁',
'拨',
'濆',
'圉',
'刮',
'闭',
'竣',
'铅',
'羔',
'硌',
'筑',
'难',
'管',
'苕',
'眺',
'嫄',
'竖',
'榟',
'崴',
'摭',
'狐',
'娑',
'②',
'罽',
'谊',
'←',
'狳',
'铫',
'凯',
'狉',
'9',
'肪',
'崤',
'莊',
'妨',
'缶',
'滃',
'瀦',
'揉',
'肫',
'恧',
'糯',
'嵬',
'5',
'裆',
'嚷',
'稣',
'隐',
'仂',
'て',
'驹',
'籽',
'肢',
'尘',
'苈',
'撷',
'镲',
'趹',
'晤',
'唱',
'鉏',
'篌',
'驩',
'雍',
'闳',
'拄',
'藜',
'朴',
'伺',
'诳',
'房',
'吱',
'Й',
'鳄',
'罿',
'祧',
'酩',
'郅',
'耎',
'尜',
'绝',
'禅',
'揠',
'鎏',
'慕',
'麥',
'呜',
'鸫',
'党',
'尝',
'砑',
'牌',
'踉',
'刨',
'襻',
'㾄',
'螽',
'谌',
'止',
'抑',
'爻',
'磬',
'铄',
'蓠',
'委',
'汲',
'鹑',
'╱',
'嚣',
'彝',
'穄',
'穹',
'態',
'醋',
'⒀',
'叼',
'婳',
'簌',
'渥',
'很',
'甸',
'帅',
'锏',
'与',
'樾',
'泷',
'棼',
'湲',
'越',
'祥',
'短',
'顼',
'阘',
'宋',
'馘',
'鈉',
'未',
'囍',
'浏',
'叻',
'箜',
'鑽',
'法',
'曲',
'淤',
'僮',
'做',
'强',
'析',
'磕',
'谠',
'染',
'促',
'朊',
'隼',
'铉',
'莆',
'蝣',
'孛',
'薮',
's',
'惴',
'秘',
'妩',
'訄',
'蔓',
'喷',
'诡',
'犷',
'酐',
'酇',
'刹',
'壅',
'甫',
'史',
'孃',
'髌',
'螬',
'擤',
'漏',
'寞',
'奡',
'悢',
'颔',
'岁',
'耄',
';',
'又',
'锭',
'鲤',
'癔',
'杰',
'孥',
'酲',
'蓐',
'耋',
'捆',
'庖',
'面',
'鹈',
'殊',
'剡',
'峪',
'识',
'锨',
'归',
'茴',
'—',
'菤',
'汁',
'攝',
'液',
'鼐',
'示',
'讠',
'男',
'凍',
'ò',
'明',
'莓',
'砜',
'崎',
'蜂',
'斡',
'榫',
'娅',
'钪',
'昙',
'胜',
'欣',
'怨',
'◆',
'粗',
'秷',
'节',
'市',
'贩',
'祟',
'弍',
'蒟',
'烁',
'糧',
'蠃',
'編',
'黙',
'壕',
'戚',
'犊',
'桥',
'仺',
'孳',
'怯',
'皓',
'倆',
'垮',
'扩',
'诮',
'钝',
'脯',
'晏',
'帔',
'葫',
'瑾',
'運',
'孬',
'跄',
'掣',
'癜',
'掌',
'墀',
'禇',
'耸',
'蜓',
'鹆',
'鄢',
'攰',
'瘢',
'暝',
'鸣',
'峧',
'遵',
'笃',
'畚',
'帧',
'晨',
'镔',
'搜',
'靠',
'咐',
'韓',
'绮',
'觉',
'拦',
'斲',
'疽',
'掐',
'尽',
'許',
'矶',
'镉',
'豹',
'粞',
'袋',
'酵',
'蛙',
'戕',
'劉',
'髀',
'彭',
'玎',
'囿',
'郐',
'善',
'睃',
'結',
'拧',
'邯',
'讧',
'召',
'椭',
'瑪',
'痼',
'庼',
'反',
'疱',
'屠',
'荣',
'君',
'胍',
'乙',
'臬',
'头',
'诰',
'讪',
'席',
'晁',
':',
'理',
'槿',
'璘',
'禧',
'呢',
'蹙',
'擒',
'鸲',
'丐',
'苓',
'壑',
'滥',
'⑾',
'炗',
'礴',
'耕',
'卅',
'唿',
'苛',
'寵',
'窖',
'麻',
'蕨',
'沤',
'氢',
'虔',
'癃',
'及',
'崛',
'爽',
'蛔',
'颤',
'膲',
'桢',
'坐',
'蟞',
'儇',
'葚',
'骤',
'誤',
'寝',
'嘭',
'灰',
'汹',
'韂',
'铮',
'慒',
'寶',
'肽',
'摅',
'紧',
'亞',
'潸',
'悯',
'橛',
'檗',
'闹',
'愿',
'担',
'袄',
'棚',
'垟',
'塄',
'婞',
'麈',
'麸',
'暗',
'咦',
'跞',
'谡',
'盈',
'磐',
'慎',
'瘰',
'掼',
'憔',
'研',
'被',
'贮',
'莛',
'至',
'呀',
'庑',
'矫',
'摛',
'怃',
'缙',
'磺',
'即',
'驻',
'瘤',
'偏',
'℃',
'嫘',
'癫',
'汈',
'鹟',
'搅',
'辅',
'璀',
'阊',
'绻',
'瑙',
'蓂',
'棺',
'孢',
'铊',
'鼒',
'果',
'砮',
'飾',
'凰',
'Я',
'遗',
'祛',
'纮',
'劲',
'霹',
'骃',
'绔',
'薅',
'瀵',
'垅',
'?',
'轻',
'惇',
'怕',
'啥',
'哙',
'燎',
'缆',
'匡',
'怫',
'卞',
'朋',
'酏',
'阑',
'爾',
'伏',
'敏',
'埼',
'罩',
'菹',
'艋',
'肭',
'鯭',
'杋',
'裀',
'撬',
'蕺',
'惠',
'大',
'爇',
'笈',
'絷',
'琳',
'谫',
'诛',
'糇',
'袢',
'倓',
'髃',
'觽',
'埏',
'寖',
'個',
'筴',
'外',
'漯',
'樭',
'喁',
'杀',
'臑',
'缇',
'裸',
'巅',
'毹',
'茅',
'忆',
'琼',
'唑',
'烷',
'项',
'隋',
'约',
'排',
'吮',
'谂',
'宝',
'牲',
'瘫',
'娄',
'沂',
'醫',
'拭',
'纺',
'蹰',
'哞',
'风',
'霆',
'值',
'酺',
'侠',
'螾',
'埂',
'育',
'夷',
'鮼',
'怍',
'鸠',
'Θ',
'瞳',
'阇',
'耥',
'羝',
'伽',
'洴',
'記',
'楔',
'颼',
'沪',
'邢',
'冰',
'昀',
'阙',
'洌',
'嫦',
'杂',
'仔',
'芑',
'潴',
'痄',
'桨',
'连',
'碓',
'塈',
'F',
'昇',
'何',
'桦',
'晥',
'驵',
'旋',
'药',
'银',
'奋',
'灣',
'俐',
'絡',
'嫁',
'浮',
'为',
'鞅',
'科',
'颦',
'潽',
'镍',
'鸨',
'粵',
'骂',
'拱',
'韫',
'盆',
'赎',
'尿',
'钿',
'坍',
'唁',
'秧',
'昌',
'曆',
'颋',
'遭',
'秭',
'褔',
'腋',
'〉',
'吉',
'漓',
'臆',
'焘',
'已',
'制',
'钹',
'鴨',
'咖',
'莘',
'P',
'碥',
'互',
'治',
'标',
'膝',
'伪',
'浿',
'纛',
'郗',
'看',
'佧',
'糖',
'篓',
'亡',
'´',
'骙',
'澡',
'影',
'窂',
'紬',
'镅',
'慌',
'框',
'晋',
'説',
'丢',
'凹',
'卖',
'巧',
'蹉',
'乾',
'莫',
'Z',
'谔',
'矧',
'铑',
'暴',
'庄',
'湿',
'活',
'穿',
'腩',
'筣',
'水',
'6',
'琦',
'迈',
'伯',
'洄',
'抡',
'▪',
'酋',
'荤',
'雒',
'粕',
'簠',
'菰',
'髁',
'枇',
'陲',
'多',
'仗',
'央',
'滁',
'胸',
'梏',
'痉',
'姑',
'襞',
'﹑',
'齿',
'弩',
'花',
'吆',
'赫',
'岵',
'佪',
'谑',
'锤',
'轴',
'盐',
'馄',
'臜',
'戢',
'涠',
'鸸',
'糟',
'孪',
'禁',
'蒲',
'化',
'疏',
'痰',
'脾',
'刈',
'應',
'珍',
'膺',
'扌',
'廙',
'汜',
'牍',
'虐',
'婿',
'啕',
'彻',
'赝',
'陶',
'蠲',
'>',
'位',
'屁',
'醍',
'粢',
'挪',
'臌',
'滹',
'遴',
'馨',
'n',
'稼',
'徊',
'酌',
'轸',
'债',
'朰',
'程',
'辞',
'痊',
'插',
'鹩',
'郄',
'铝',
'狱',
'叱',
'同',
'寄',
'搪',
'蚯',
'魭',
'舍',
'旷',
'闰',
'涝',
'民',
'嗡',
'苌',
'馕',
'姥',
'屉',
'啧',
'枢',
'❤',
'窕',
'钊',
'矬',
'菂',
'佑',
'≠',
'獬',
'桁',
'墟',
'皖',
'鼻',
'它',
'歇',
'独',
'好',
'晕',
'蚝',
'锞',
'颈',
'豚',
'聖',
'裉',
'扫',
'岿',
'悒',
'佥',
'苗',
'妞',
'晚',
'圭',
'茼',
'脲',
'摊',
'窠',
'狸',
'抻',
'场',
'呼',
'囟',
'噗',
'狺',
'困',
'瀹',
'削',
'衬',
'谰',
'蛆',
'訓',
'鉄',
'痃',
'炱',
'蝻',
'我',
'暨',
'骓',
'馋',
'埤',
'脞',
'晃',
'螟',
'洮',
'泛',
'掾',
'穑',
'米',
'蕲',
'玦',
'讙',
'逢',
'劐',
'袭',
'凫',
'僳',
'畛',
'晷',
'鳕',
'Ë',
'愬',
'坫',
'鳡',
'鞯',
'叔',
'胂',
'囚',
'筋',
'青',
'度',
'涕',
'琰',
'﹔',
'径',
'陇',
'睛',
'链',
'状',
'逶',
'蘅',
'“',
'庇',
'邽',
'纥',
'踶',
'爺',
'狭',
'钫',
'桃',
'弛',
'淳',
'办',
'茕',
'砸',
'喱',
'仅',
'潞',
'杈',
'得',
'咕',
'俞',
'检',
'借',
'恋',
'驿',
'倌',
'钢',
'琐',
'哆',
'撙',
'箫',
'川',
'猥',
'牢',
'蹁',
'城',
'馏',
'锡',
'楝',
'蛱',
'奈',
'瑶',
'桺',
'耆',
'翟',
'阒',
'稲',
'橐',
'萱',
'惹',
'蘼',
'主',
'擦',
'蟒',
'台',
'佬',
'荫',
'廖',
'笏',
'铕',
'衣',
'洇',
'炒',
'瀍',
'崭',
'圻',
'洚',
'契',
'嫱',
'倏',
'晶',
'了',
'堠',
'勰',
'椎',
'询',
'梗',
'飒',
'锰',
'览',
'溇',
'寻',
'蓅',
'【',
'碇',
'井',
'露',
'顔',
'堌',
'庳',
'踩',
'i',
'饷',
'俊',
'楫',
'條',
'搭',
'奍',
'羽',
'憋',
'岘',
'毡',
'曜',
'乃',
'′',
'针',
'羲',
'菓',
'吩',
'咩',
'鞘',
'尊',
'宫',
'舜',
'啖',
'惗',
'北',
'懊',
'骇',
'阄',
'躅',
'权',
'缲',
'肥',
'铜',
'《',
'录',
'也',
'棬',
'煮',
'舄',
'厮',
"'",
'順',
'受',
'霜',
'新',
'售',
'牞',
'圣',
'妗',
'犴',
'宥',
'哦',
'陀',
'卺',
'冚',
'蹒',
'亸',
'禮',
'骰',
'瑢',
'弒',
'抛',
'谷',
'嫰',
'動',
'嘌',
'惩',
'枣',
'忌',
'茡',
'爵',
'嘚',
'郧',
'丨',
'敲',
'帚',
'沭',
'槊',
'⑶',
'專',
'毶',
'圄',
'磅',
'蛭',
'由',
'蠹',
'剜',
'诫',
'秆',
'愠',
'藓',
'母',
'请',
'衩',
'忸',
'蜕',
'饽',
'晦',
'倔',
'腠',
'痛',
'品',
'簧',
'父',
'锐',
'描',
'蓰',
'蛴',
'箍',
'兕',
'苜',
'饼',
'奚',
'泗',
'裥',
'皂',
'嵚',
',',
'澶',
'蠖',
'沅',
'馎',
'籀',
'菝',
'眵',
'糥',
'铽',
'痤',
'颟',
'淄',
'作',
'抉',
'俄',
'么',
'郑',
'耒',
'佛',
'1',
'纡',
'鸢',
'④',
'鎚',
'壖',
'遢',
'鬈',
'拢',
'托',
'哈',
'節',
'橦',
'冼',
'六',
'耗',
'樵',
'涔',
'舳',
'龌',
'衿',
'婧',
'栓',
'椹',
'嘘',
'膊',
'茁',
'丹',
'螃',
'剖',
'洧',
'珞',
'潺',
'孱',
'呐',
'萩',
'刷',
'引',
'说',
'熟',
'/',
'靖',
'酷',
'耠',
'饬',
'菌',
'洙',
'荃',
'饲',
'酾',
'阁',
'陬',
'铿',
'倻',
'牮',
'鞡',
'撕',
'倘',
'盒',
'曺',
'襦',
'辄',
'算',
'塬',
'潢',
'羖',
'湾',
'续',
'△',
'疙',
'谖',
'嘅',
'遑',
'篚',
'筮',
'氍',
'递',
'尧',
'G',
'{',
'分',
'埒',
'@',
'蜍',
'荼',
'襆',
'槭',
'檠',
'縢',
'濉',
'梆',
'隔',
'镛',
'倞',
'润',
'瓯',
'瓢',
'蟊',
'沐',
'啷',
'砚',
'皱',
'剅',
'儙',
'错',
'幌',
'滓',
'砗',
'郤',
'喧',
'峣',
'簸',
'毖',
'踏',
'锕',
'…',
'悖',
'谧',
'醵',
'加',
'镐',
'泐',
'傫',
'胪',
'缄',
'卩',
'蓼',
'丸',
'垌',
'汞',
'宴',
'膙',
'圊',
'矻',
'嚏',
'漾',
'幕',
'駕',
'葒',
'绪',
'袪',
'镋',
'杭',
'澴',
'鬃',
'粟',
'偻',
'饳',
'抨',
'亟',
'温',
'韶',
'轿',
'罟',
'际',
'诖',
'复',
'坯',
'骗',
'*',
'副',
'裢',
'憬',
'邾',
'崇',
'蕈',
'疮',
'粽',
'炝',
'珲',
'莅',
'衾',
'爲',
'枯',
'汛',
'仁',
'熏',
'馥',
'㎡',
'檐',
'锦',
'竭',
'颁',
'遽',
'瘙',
'样',
'遛',
'殍',
'湄',
'消',
'鳌',
'痫',
'鳏',
'瓶',
'窈',
'谚',
'麒',
'鸹',
'蟋',
'横',
'唠',
'瘪',
'媪',
'侔',
'鐵',
'系',
'杖',
'm',
'叉',
'沟',
'衢',
'寘',
'■',
'弗',
'建',
'疣',
'珣',
'綦',
'劈',
'道',
'嘈',
'先',
'芝',
'降',
'滕',
'邵',
'邺',
'給',
')',
'廨',
'郛',
'势',
'氇',
'坤',
'昂',
'焼',
'奕',
'闱',
'朓',
'毽',
'还',
'坨',
'銭',
'龂',
'銎',
'壽',
'矸',
'窒',
'①',
'玷',
'蝽',
'泃',
'烀',
'魈',
'★',
'慶',
'K',
'嘶',
'酶',
'呖',
'殿',
'乡',
'䄂',
'阳',
'轪',
'碱',
'譬',
'摩',
'鳖',
'刳',
'地',
'包',
'貊',
'悝',
'圩',
'今',
'嚭',
'凳',
'谕',
'馃',
'捎',
'佯',
'侬',
'愆',
'微',
'涤',
'舔',
'蛇',
'筲',
'助',
'锾',
'剧',
'缧',
'簪',
'惚',
'柢',
'庾',
'虹',
'雪',
'猡',
'脔',
'亶',
'烨',
'T',
'锗',
'芈',
'女',
'动',
'偬',
'琥',
'县',
'诣',
'精',
'嬗',
'栀',
'艨',
'智',
'冗',
'闼',
'嗝',
'z',
'夢',
'拿',
'鹲',
'尤',
'啮',
'﹐',
'ɔ',
'钓',
'施',
'萼',
'邻',
'竞',
'碶',
'艰',
'》',
'翻',
'馆',
'橪',
'逝',
'臀',
'淫',
'枉',
'羿',
'拇',
'溷',
'徒',
'涓',
'關',
'聋',
'嵊',
'殖',
'叛',
'敫',
'舵',
'亊',
'诽',
'菱',
'苎',
'破',
'腚',
'A',
'嵋',
'扊',
'挂',
'篷',
'棂',
'碟',
'復',
'劾',
'韪',
'疔',
'粒',
'鲵',
'毙',
'店',
'锻',
'衮',
'寳',
'◎',
'斯',
'倦',
'醢',
'曾',
'茚',
'荐',
'隗',
'芊',
'豪',
'亻',
'哂',
'堃',
'宇',
'桑',
'匋',
'植',
'亥',
'撂',
'棒',
'蟠',
'W',
'迟',
'蚋',
'溊',
'缌',
'鞚',
'蚤',
'適',
'赌',
'卣',
'厚',
'鲾',
'匙',
'槃',
'郎',
'鬏',
'玳',
'龄',
'丈',
'圮',
'冑',
'院',
'葬',
'嵐',
'瓦',
'孵',
'漶',
'星',
'吐',
'獍',
'藠',
'萍',
'振',
'潜',
'龉',
'匦',
'粹',
'諾',
'畵',
'峦',
'&',
'埕',
'朵',
'戒',
'炳',
'酪',
'绂',
'篁',
'测',
'殆',
'涌',
'业',
'盏',
'醊',
'笆',
'孰',
'骊',
'湛',
'踰',
'汎',
'哲',
'澙',
'鲷',
'√',
'鄣',
'亿',
'螺',
'吠',
'伟',
'凛',
'骡',
'恻',
'巨',
'扶',
'泡',
'峯',
'韵',
'腎',
'睦',
'栖',
'}',
'笙',
'疌',
'绶',
'忒',
'哥',
'价',
'纻',
'薨',
'漂',
'濮',
'缮',
'勐',
'妮',
'傩',
'陛',
'陷',
'柆',
'瞭',
'鲳',
'烬',
'喉',
'固',
'桡',
'聊',
'逦',
'猊',
'梻',
'涵',
'栒',
'逍',
'饥',
'凼',
'早',
'姣',
'蕤',
'塌',
'桀',
'亳',
'虻',
'鹨',
'典',
'情',
'怄',
'商',
'钍',
'赚',
'塥',
'煽',
'垱',
'蝴',
'乓',
'籁',
'帷',
'锢',
'圪',
'快',
'赘',
'杵',
'漠',
'滴',
'斩',
'拈',
'蚕',
'陽',
'篡',
'郦',
'瞻',
'郯',
'鳍',
'幽',
'旅',
'乖',
'鹖',
'斫',
'痂',
'肸',
'右',
'锂',
'永',
'泾',
'茎',
'觱',
'彼',
'擎',
'䨱',
'翱',
'徝',
'醅',
'求',
'湫',
'転',
'溴',
'師',
'瓣',
'蝠',
'铭',
'社',
'苞',
'仇',
'噌',
'你',
'嗾',
'雳',
'榧',
'駹',
'雯',
'叨',
'遫',
'氏',
'航',
'辗',
'溢',
'历',
'楷',
'诱',
'雏',
'梳',
'藕',
'屺',
'槎',
'钐',
'燘',
'棽',
'驸',
'褪',
'清',
'十',
'廰',
'移',
'筌',
'揾',
'瞠',
'姽',
'馑',
'恢',
'逸',
'p',
'瑚',
'茄',
'鹧',
'俗',
'璟',
'栊',
'买',
'瀛',
'镒',
'球',
'氲',
'缛',
'講',
'胀',
'焒',
'悲',
'翕',
'拗',
'T',
'桌',
'脓',
'闪',
'稀',
'狎',
'火',
'柁',
'琴',
'澍',
'嗟',
'龚',
'楮',
'噼',
'隽',
'栩',
'焻',
'哩',
'藻',
'瘸',
'含',
'偶',
'界',
'嘃',
'昶',
'澄',
'頤',
'绒',
'鲁',
'麝',
'决',
'撒',
'岙',
'季',
'刿',
'肝',
'蒉',
'蓇',
'财',
'完',
'蠔',
'脉',
'肱',
'谙',
'蜮',
'郭',
'慨',
'晔',
'髂',
'蛏',
'眨',
'钗',
'葺',
'惆',
'娈',
'瞵',
'踞',
'棁',
'蝢',
'嚎',
'猝',
'必',
'剞',
'关',
'咛',
'劫',
'闸',
'肯',
'№',
'莩',
'哇',
'蛑',
'镬',
'羡',
'驊',
'茂',
'塍',
'沓',
'筱',
'杉',
'战',
'茧',
'耙',
'击',
'需',
'腊',
'酎',
'畦',
'葙',
'鹘',
'韭',
'嚚',
'争',
'域',
'伢',
'鞲',
'哳',
'栲',
'某',
'翌',
'哗',
'焚',
'螗',
'懲',
'躲',
'約',
'镖',
'凿',
'饶',
'够',
'剁',
'铥',
'应',
'署',
'杮',
'蒂',
' ',
'坷',
'礅',
'款',
'梁',
'鄜',
'髹',
'選',
'伤',
'路',
'З',
'亲',
'野',
'啦',
'捯',
'憷',
'鲩',
'札',
'怏',
'塘',
'绊',
'愍',
'簦',
'牦',
'黥',
'鳜',
'唉',
'W',
'沱',
'蚺',
'甪',
'摉',
'协',
'耨',
'娱',
'桄',
'仆',
'类',
'搡',
'滤',
'岗',
'休',
'坶',
'谒',
'忭',
'飨',
'闷',
'菟',
'鲣',
'驷',
'湜',
'疡',
'蚩',
'萊',
'䝉',
'硒',
'贺',
'弃',
'徘',
'陨',
'否',
'遥',
'妒',
'X',
'間',
'觜',
'跬',
'夬',
'羮',
'喙',
'赇',
'鹗',
'『',
'砀',
'残',
'绿',
'小',
'勘',
'瀌',
'扉',
'耧',
'衅',
'挟',
'乐',
'鹏',
'墁',
'澜',
'噍',
'坊',
'術',
'嗖',
'知',
'盉',
'圆',
'嗈',
'蘖',
'资',
'爭',
'=',
'刑',
'裒',
'〈',
'淸',
'定',
'袒',
'戗',
'钤',
'吵',
'旯',
'蓝',
'裎',
'溅',
'贰',
'荏',
'甥',
'悌',
'勤',
'炽',
'换',
'躜',
'!',
'薄',
'痱',
'双',
'匕',
'肷',
'挥',
'茑',
'船',
'砝',
'煤',
'荜',
'弘',
'▏',
'陆',
'稔',
'朽',
'冤',
'頉',
'遊',
'砰',
'迎',
'碎',
'唪',
'醪',
'稆',
'练',
'锸',
'阵',
'皇',
'香',
'镀',
'嫡',
'持',
'桶',
'垄',
'阍',
'戥',
'臣',
'琛',
'涘',
'惶',
'赙',
'葆',
'住',
'舊',
'枝',
'媲',
'蓣',
'龅',
'搦',
'_',
'图',
'力',
'纪',
'悍',
'麗',
'戽',
'腧',
'绣',
'跟',
'哕',
'打',
'蝰',
'Φ',
'吞',
'功',
'夀',
'劓',
'沇',
'熔',
'占',
'隰',
'命',
'佻',
'豁',
'苣',
'楦',
'掇',
'蛛',
'唢',
'郜',
'霉',
'鲏',
'予',
'沸',
'殻',
'俯',
'探',
'篪',
'荇',
'邈',
'烯',
'忮',
'伸',
'岬',
'×',
'锧',
'窸',
'毪',
'纩',
'蛋',
'讯',
'骼',
'叶',
'楂',
'犟',
'站',
'盘',
'隈',
'喝',
'儣',
'兵',
'尚',
'孙',
'爿',
'芜',
'羁',
'旖',
'溽',
'迩',
'京',
'7',
'龃',
'狝',
'缦',
'缁',
'鲃',
'怒',
'故',
'據',
'枫',
'髙',
'亭',
'耳',
'飚',
'O',
'编',
'箸',
'幼',
'氘',
'鞮',
'匐',
'祯',
'臃',
'辫',
'磋',
'溝',
'墙',
'诚',
'阻',
'档',
'歆',
'璃',
'悻',
'婤',
'映',
'瑞',
'牂',
'话',
'忠',
'潘',
'惋',
'冬',
'氦',
'腔',
'胬',
'盔',
'"',
'饮',
'贶',
'嚄',
'儆',
'溜',
'砷',
'樇',
'跏',
'泩',
'馌',
'埃',
'莙',
'革',
'珙',
'乌',
'鍋',
'穴',
'石',
'珺',
'熹',
'诞',
'<',
'腉',
'姊',
'钧',
'罪',
'拆',
'赊',
'殒',
'堇',
'仑',
'掺',
'塃',
'獴',
'迥',
'盦',
'檬',
'益',
'居',
'鼑',
'异',
'嘻',
'悔',
'旮',
'况',
'時',
'阋',
'洛',
'線',
'#',
'型',
'迕',
'睇',
'橱',
'笊',
'蛞',
'愚',
'茉',
'镈',
'镞',
'垭',
'扁',
'泫',
'搬',
'古',
'书',
'疸',
'痨',
'黟',
'墉',
'料',
'并',
'ㆍ',
'裳',
'鞑',
'湮',
'柠',
'颐',
'形',
'━',
'逹',
'硁',
'置',
'韦',
'瓞',
'象',
'殽',
'均',
'浓',
'瞓',
'椐',
'洨',
'乱',
'襜',
'终',
'優',
'睹',
'敦',
'鼬',
'唆',
'佼',
'財',
'瘃',
'H',
'痳',
'勺',
'依',
'虎',
'蕖',
'玄',
'缓',
'滢',
'^',
'骅',
'诘',
'弋',
':',
'∩',
'廪',
'缈',
'造',
'蕉',
'孖',
'嫒',
'寨',
'意',
'岽',
'庶',
'罗',
'瞢',
'酹',
'蔟',
'赴',
'烂',
'栋',
'格',
'矛',
'驯',
'词',
'嗦',
'剀',
'蓓',
'期',
'鏢',
'羑',
'奴',
'椱',
'A',
'狗',
'烟',
'蹬',
'案',
'记',
'讴',
'鳑',
'侯',
'霏',
'焜',
'沬',
'份',
'酦',
'芗',
'庚',
'瑗',
'鹎',
'穗',
'鲠',
'肛',
'厄',
'蜔',
'學',
'伊',
'⑥',
'琪',
'邒',
'少',
'霖',
'蓖',
'猜',
'塾',
'肾',
'罃',
'伐',
'钩',
'骈',
'溟',
'饵',
'莉',
'é',
'刖',
'洯',
'堉',
'锝',
'趔',
'七',
'萁',
'竹',
'憾',
'蚨',
'离',
'柔',
'替',
'侑',
'飙',
'气',
'震',
'厥',
'备',
'刻',
'顽',
'瞽',
'腄',
'雄',
'燃',
'旬',
'简',
'翠',
'熥',
'◇',
'吃',
'囡',
'玙',
'铷',
'暖',
'配',
'傻',
'窄',
'皈',
'夼',
'舂',
'乜',
'苩',
'攉',
'雠',
'茇',
'锈',
'酰',
'粮',
'祝',
'考',
'堍',
'鳅',
'彬',
'▲',
'孝',
'蠊',
'顇',
'娲',
'腥',
'$',
'珠',
'厂',
'诠',
'蹓',
'轼',
'嵫',
'捩',
'硗',
'胺',
'证',
'膀',
'」',
'胯',
'钷',
'毂',
'柙',
'深',
'沄',
'匹',
'8',
'爷',
'礳',
'秏',
'窜',
'魑',
'd',
'转',
'烆',
'屿',
'眙',
'極',
'袤',
'護',
'V',
'狂',
'柑',
'玠',
'氩',
'’',
'馊',
'玛',
'坢',
'%',
'燔',
'颗',
'舅',
'暂',
'艾',
'芹',
'溏',
'晰',
'件',
'琚',
'仿',
'祾',
'酤',
'騠',
'揳',
'鲫',
'蜥',
'仨',
'牺',
'步',
'讓',
'港',
'煲',
'铴',
'腦',
'鳝',
'危',
'鋪',
'冠',
'正',
'柽',
'抍',
'掘',
'控',
'娴',
'娀',
'離',
'手',
'臾',
'酗',
'筼',
'煸',
'弹',
'照',
'哎',
'毒',
'颀',
'诙',
'刚',
'搢',
'䧳',
'峒',
'滋',
'\\',
'匀',
'黉',
'毓',
'娠',
'床',
'浪',
'祐',
'铟',
'4',
'?',
'凄',
'飗',
'蚍',
'葑',
'抗',
'鹞',
'糸',
'红',
'英',
'违',
'橡',
'眷',
'防',
'缬',
'龠',
'察',
'仍',
'辇',
'减',
'闫',
'箴',
'龍',
'館',
'屙',
'翙',
'媽',
'涴',
'到',
'旻',
'删',
'瞾',
'鏖',
'咭',
'豨',
'荘',
'炭',
'畼',
'构',
'锘',
'鉫',
'候',
'扇',
'繄',
'猩',
'瘵',
'恺',
'贵',
'榦',
'息',
'恽',
'胎',
'狰',
'雜',
'辋',
'璜',
'硈',
'泠',
'呔',
'蹿',
'踹',
'摄',
'炀',
'坞',
'蹄',
'裝',
'赛',
'蝥',
'塔',
'靳',
'荬',
'找',
'仡',
'淮',
'比',
'淆',
'义',
'淝',
'卢',
'辟',
'寂',
'庒',
'鳯',
'暲',
'景',
'邪',
'腻',
'赍',
'甍',
'讲',
'哌',
'嶝',
'鎌',
'总',
'缱',
'问',
'磛',
'谅',
'拉',
'靈',
'奭',
'沆',
'茔',
'羅',
'鄠',
'網',
'吏',
'懵',
'鑫',
'歌',
'黹',
'嵘',
'涞',
'碳',
'崂',
'婥',
'赞',
'镑',
'購',
'幺',
'鸰',
'饟',
'蝌',
'忝',
'懒',
'禺',
'梽',
'齉',
'恳',
'拯',
'弥',
'荡',
'芾',
'幪',
'厌',
'馒',
'蜘',
'欸',
'吣',
'1',
'却',
'榻',
'碾',
'袂',
'錎',
'钬',
'無',
'嬉',
'笞',
'蹴',
'视',
'雇',
'创',
'椟',
'6',
'瘁',
'斜',
'傥',
'喃',
'炷',
'秾',
'嘱',
'茀',
'犄',
'窑',
'庀',
'潍',
'伦',
'䀲',
'凉',
'Р',
'撻',
'萜',
'二',
'倨',
'蔑',
'捕',
'勚',
'士',
'鈇',
'踺',
'啤',
'彧',
'缪',
'述',
'傅',
'颅',
'畸',
'畜',
'滗',
'慭',
'琎',
'斌',
'参',
'胳',
'骖',
'稠',
'汰',
'铻',
'闯',
'留',
'蘘',
'沏',
'亦',
'择',
'華',
'禽',
'砟',
'祼',
'狃',
'噫',
'狼',
'寤',
'跪',
'浠',
'·',
'费',
'瓘',
'鼹',
'锪',
'箢',
'垣',
'慊',
'虏',
'秩',
'偉',
'镏',
'钯',
'恐',
'鹃',
'菇',
'炸',
'潮',
'蟀',
'硂',
'偌',
'哏',
'验',
'桉',
'阴',
'初',
'掴',
'鹺',
'峨',
'赋',
'舉',
'裹',
'赶',
'土',
'淋',
'瘌',
'沔',
'r',
'赀',
'淖',
'茯',
'怛',
'谜',
'洗',
'似',
'舡',
'纳',
'晓',
'R',
'诐',
'痹',
'漪',
'顺',
'挛',
'阎',
'贝',
'钰',
'惬',
'疬',
'菀',
'埘',
'怙',
'部',
'译',
'鲭',
'窋',
'敢',
'夜',
'撰',
'珅',
'特',
'襕',
'癖',
'胡',
'⒃',
'附',
'擘',
'痢',
'尬',
'鉴',
'瞋',
'膨',
'阽',
'挲',
'⒄',
'骎',
'帕',
'缕',
'计',
'障',
'鳆',
'隹',
'朔',
'碹',
'当',
'迦',
'氙',
'蘑',
'妓',
'炬',
'苊',
'萎',
'浈',
'沥',
'绯',
'壤',
'噱',
'蹾',
'驶',
'葱',
'孕',
'羹',
'钻',
'農',
'勝',
'膈',
'灿',
'赆',
'靿',
'耱',
'陪',
'忙',
'缰',
'奶',
'儒',
'个',
'朱',
'燹',
'琮',
'轷',
'錾',
'箅',
'澳',
'嗥',
'攥',
'没',
'匿',
'鲆',
'|',
'矣',
'他',
'鸶',
'芸',
'B',
'髑',
'街',
'巿',
'廣',
'盯',
'監',
'鲸',
'胭',
'凬',
'寿',
'挝',
'绽',
'+',
'劝',
'究',
'眢',
'集',
'衙',
'卷',
'j',
'跶',
'牡',
'畯',
'貅',
'销',
'發',
'咱',
'蓊',
'揣',
'咝',
'琶',
'荦',
'阌',
'盅',
'嘹',
'苟',
'醮',
'洪',
'鲧',
'钒',
'柱',
'氨',
'旰',
'冽',
'茭',
'嵇',
'粲',
'蛾',
'訾',
'辔',
'N',
'尹',
'趿',
'蹲',
'疟',
'祠',
'段',
'車',
'网',
'⒉',
'舷',
'廐',
'侣',
'棵',
'粜',
'觐',
'铼',
'锁',
'兒',
'舁',
'时',
'垦',
'版',
'摈',
'扳',
'见',
'腮',
'嫖',
'痭',
'呆',
'簖',
'伋',
'鳙',
'珊',
'麂',
'既',
'谴',
'热',
'超',
'蠕',
'铞',
'e',
'殓',
'因',
'锿',
'文',
'禊',
'皙',
'鑙',
'爹',
'鋼',
'忻',
'秣',
'镁',
'奠',
'橉',
'畺',
'笮',
'疹',
'湝',
'龟',
'殃',
'毵',
'溃',
'勢',
'索',
'砉',
'阼',
'堞',
'酥',
'冁',
'喊',
'¥',
'幛',
'娇',
'锲',
'蕃',
'铘',
'铍',
'鴿',
'响',
'傲',
'脏',
'杓',
'罕',
'笥',
'弦',
'但',
'缃',
'扬',
'盲',
'碚',
'幢',
'鎖',
'缺',
'钋',
'麽',
'禳',
'浃',
'啄',
'昧',
'蒴',
'帙',
'琏',
'咧',
'舰',
'亵',
'浊',
'豳',
'衲',
'俏',
'镵',
'浩',
'勾',
'槛',
'榈',
'徙',
'鹤',
'洹',
'铂',
'揎',
'棕',
'挦',
'挫',
'阆',
'衹',
'甚',
'近',
'】',
'簏',
'汽',
'踮',
'淌',
'檇',
'痔',
'谝',
'钙',
'蕞',
'蔯',
'兆',
'蔽',
'后',
'蚬',
'谸',
'芟',
'枞',
'叫',
'栗',
'餘',
'营',
'郝',
'氯',
'㺃',
'狍',
'冏',
'庛',
'纱',
'泼',
'碍',
'认',
'邓',
'茵',
'饧',
'闟',
'惝',
'裙',
'噙',
'忘',
'虬',
'群',
'S',
'佗',
'恼',
'坟',
'肮',
'皮',
'玃',
'在',
'赧',
'孚',
'偾',
'镨',
'恨',
'葡',
'西',
'缞',
'挠',
'逃',
'吾',
'膪',
'焦',
'翘',
'桧',
'变',
'渗',
'繁',
'際',
'痘',
'撼',
'筅',
'坑',
'前',
'玑',
'数',
'融',
'鲌',
'讦',
'窃',
'鄌',
'伾',
'众',
'攻',
'彪',
'锎',
'焐',
'殛',
'锊',
'嗉',
'枓',
'抢',
'鞠',
'掩',
'贾',
'搔',
'皁',
'拶',
'朗',
'渺',
'跛',
'㛃',
'鏾',
'慥',
'杆',
'沈',
'戍',
'豫',
'楠',
'爆',
'汤',
'昉',
'耘',
'缡',
'.',
'允',
'揜',
'责',
'艟',
'裁',
'喬',
'砹',
'鹣',
'裼',
'啉',
'蛳',
'酮',
'听',
'维',
'阪',
'獾',
'浣',
'訂',
'瘿',
'蜡',
'泖',
'蔚',
'貔',
'致',
'禨',
'尓',
'糺',
'绐',
'遯',
'笄',
'邦',
'圈',
'洟',
'缟',
'槲',
'桹',
'镓',
'骒',
'髫',
'暾',
'像',
'縻',
'戊',
'飧',
'驽',
'干',
'万',
'绕',
'披',
'雅',
'桊',
'卡',
'贲',
'吡',
'沧',
'鳟',
'堂',
'扺',
'岱',
'封',
'鄭',
'螣',
'瞩',
'幞',
'邕',
'睫',
'涩',
'自',
'趱',
'愣',
'威',
'酊',
'罂',
'慑',
'袴',
'架',
'烘',
'现',
'灞',
'钔',
'股',
'興',
'乍',
'噜',
'济',
'碛',
'兀',
'诅',
'柴',
'瓿',
'[',
'怿',
'竦',
'白',
'黄',
'阶',
'务',
'榮',
'澹',
'谏',
'垓',
'跸',
'繻',
'窿',
'紊',
'陟',
'劁',
'嗑',
'牯',
'厉',
'敛',
'鮕',
'嘉',
'蔻',
'鼎',
'恒',
'硝',
'溉',
'骘',
'窘',
'任',
'裱',
'处',
'旨',
'舶',
'缸',
'囹',
'笠',
'讥',
'泜',
'脊',
'煊',
'淦',
'牝',
'硕',
'胧',
'泚',
'溪',
'贪',
'牛',
'答',
'瘴',
'Q',
'炯',
'⑤',
'篾',
'銀',
'乩',
'杶',
'垆',
'蛐',
'苔',
'啪',
'y',
'玮',
'琫',
'寮',
'邂',
'後',
'僵',
'贴',
'硭',
'枚',
'姆',
'乎',
'讶',
'醭',
'橥',
'脱',
'蒈',
'擞',
'忪',
'顾',
'柚',
'褿',
'忲',
'辖',
'铡',
'螠',
'殉',
'喆',
'爡',
'轮',
'棰',
'鲉',
'跃',
'韬',
'睡',
'嘧',
'袅',
'圗',
'檄',
'踊',
'阀',
'题',
'桫',
'林',
'沉',
'禚',
'散',
'麇',
'沦',
'秋',
'导',
'斑',
'宰',
'嘞',
'暑',
'笱',
'搋',
'擅',
'镤',
'锶',
'L',
'厣',
'有',
'猗',
'袆',
'绞',
'甭',
'歧',
'跣',
'潦',
'専',
'绑',
'飱',
'廓',
'磔',
'接',
'腓',
'窎',
'瑁',
'飓',
'蟪',
'俎',
'П',
'缉',
'䘵',
'夙',
'潟',
'桷',
'淡',
'虺',
'恶',
'|',
'驭',
'怀',
'邋',
'辢',
'逻',
'晖',
'蜃',
'蜊',
'溻',
'冢',
'尻',
'礼',
'厝',
'亘',
'酴',
'饔',
'悸',
'戆',
'什',
'玚',
'馔',
'哔',
'沃',
'竑',
'葭',
'垞',
'鏂',
'抃',
'弄',
'去',
'焊',
'焌',
'x',
'苇',
'與',
'炼',
'蛄',
'莴',
'阏',
'薷',
'禀',
'鸯',
'栽',
'冒',
'姓',
'0',
'尃',
'蜞',
'毗',
'骟',
'秸',
'荸',
'柈',
'恬',
'赡',
'侏',
'兑',
'蝤',
'荷',
'徳',
'押',
'挣',
'腰',
'宣',
'鸵',
'葳',
'遘',
'讨',
'狒',
'涿',
'囤',
'邃',
'蒜',
'疑',
'脍',
'嘟',
'鹠',
'吻',
'鄹',
'耦',
'华',
'霸',
'侥',
'勒',
'挞',
'臊',
'尺',
'让',
'榆',
'阝',
'鳚',
'灾',
'鲬',
'艿',
'Ⅱ',
'锩',
'攮',
'蚊',
'蔁',
'唝',
'涅',
'挹',
'淏',
'鏊',
'氵',
'鹕',
'律',
'對',
'粱',
'恫',
'挻',
'滏',
'叮',
'‰',
'鼯',
'绫',
'秉',
'怩',
'質',
'岐',
'菊',
'佤',
'帏',
'骺',
'爰',
'珉',
'耪',
'乞',
'郕',
'鲱',
'雷',
'蒿',
'不',
'啐',
'侓',
'郓',
'歼',
'拒',
'胗',
'寕',
'旒',
'勁',
'婢',
'诌',
'蹂',
'姐',
'媳',
'歃',
'拐',
'辐',
'拟',
'醯',
'雌',
'点',
'玟',
'您',
'鲨',
'载',
'藩',
'罔',
'噀',
'抹',
'萏',
'补',
'蝎',
'辈',
'劢',
'乚',
'唔',
'瓜',
'恿',
'蟭',
'涸',
'纬',
'睽',
'樣',
'帻',
'蓥',
'谯',
'柯',
'渴',
'脁',
'诲',
'福',
'③',
'熊',
'羌',
'疴',
'袖',
'虿',
'杏',
'覌',
'易',
'醾',
'筒',
'肤',
'苷',
'柃',
'榇',
'酬',
'癸',
'啰',
'眛',
'稷',
'展',
'鸾',
'祢',
'蝾',
'敵',
'毛',
'痦',
'老',
'赐',
'单',
'淹',
'畋',
'符',
'奎',
'绥',
'轾',
'鄺',
'濩',
'眦',
'觎',
'忾',
'璋',
'刘',
'翳',
'菪',
'簟',
'胼',
'孫',
'機',
'獻',
'低',
'o',
'捅',
'鳥',
'⑨',
'卸',
'废',
'启',
'呋',
'窥',
'巢',
'揭',
'咴',
'趺',
'鲥',
'空',
'膄',
'崮',
'锜',
'络',
'納',
'恤',
'刭',
'批',
'霭',
'氧',
'钮',
'甑',
'祲',
'粘',
'辏',
'∶',
'臨',
'│',
'粪',
'惰',
'肼',
'浉',
'橄',
'5',
'東',
'8',
'漁',
'浜',
'忍',
'奂',
'遹',
'扃',
'扦',
'入',
'欤',
'豆',
'悠',
'蕴',
'萑',
'媄',
'龈',
'÷',
'磙',
'鸬',
'缎',
'嗯',
'浕',
'木',
'陋',
'柰',
'瘩',
'箨',
'松',
'躁',
'鲇',
'彰',
'恕',
'楗',
'姨',
'撅',
'诹',
'戮',
'桓',
'棉',
'束',
'嗍',
'庋',
'瞿',
'郂',
'哪',
'町',
'a',
'铁',
'洫',
'失',
'栳',
'篇',
'鳗',
'眇',
'椿',
'義',
'就',
'都',
'镌',
'阖',
'夭',
'拃',
'跚',
'業',
'圬',
'演',
'篥',
'3',
'昼',
'從',
'瞍',
'蓦',
'鼾',
'坪',
'觫',
'鲍',
'馿',
'妾',
'密',
'奥',
'耰',
'佟',
'嘤',
'貘',
'薯',
'稽',
'届',
'褛',
'钠',
'猿',
'佈',
'倍',
'铩',
'铙',
'踵',
'o',
'捱',
'鹐',
'當',
'狷',
'写',
'遆',
'钱',
'姗',
'寸',
'综',
'挑',
'礶',
'靼',
'溯',
'湟',
'漱',
'碰',
'职',
'味',
'Λ',
'璁',
'壴',
'给',
'碘',
'恭',
'苴',
'酚',
'套',
'宕',
'辽',
'窀',
'催',
'踢',
'惟',
'璧',
'翔',
'稿',
'癀',
'霈',
'光',
'膑',
'妆',
'庡',
'圾',
'躺',
'惮',
'切',
'目',
'梦',
'岫',
'飑',
'叠',
'累',
'鴻',
'透',
'量',
'妻',
'沨',
'俪',
'屣',
'挚',
'w',
'厅',
'货',
'箧',
'漦',
'隙',
'瘥',
'妃',
'門',
'鹦',
'隳',
'龆',
'瞪',
'跑',
'帼',
'刺',
'起',
'鞴',
'岸',
'渫',
'莽',
'髭',
'耜',
'瑛',
'葉',
'宵',
'绠',
'眭',
'畅',
'茱',
'卜',
'濂',
'浍',
'冈',
'脬',
'厘',
'夔',
'纟',
'槚',
'哐',
'萋',
'曼',
'膳',
'潲',
'啜',
'啊',
'猾',
'捉',
'箕',
'㐂',
'藝',
'艘',
'園',
'妲',
'灵',
'蚌',
'范',
'&',
'疥',
'陑',
'洒',
'唾',
'a',
'婄',
'谋',
't',
'唬',
'宓',
'瓷',
'︰',
'焗',
'默',
'噔',
'菡',
'恃',
'亩',
'边',
'啟',
'颞',
'啬',
'盟',
'墩',
'汭',
'缝',
'魇',
'酡',
'疗',
'梾',
'尾',
'鹿',
'锔',
'溦',
'酃',
'囊',
'掉',
'罥',
'报',
'诤',
'喹',
'蕙',
'割',
'蠢',
'兼',
'俺',
'升',
'屦',
'獠',
'辣',
'跹',
'颧',
'宪',
'抬',
'咿',
'沲',
'旗',
'荩',
'傒',
'鳳',
'變',
'偈',
'薹',
'钭',
'垧',
'谪',
'躐',
'谀',
'R',
'字',
'怆',
'陵',
'追',
'迓',
'舞',
'卲',
'捲',
'麾',
'税',
'方',
'竴',
'壹',
'射',
'轫',
'塞',
'僧',
'椠',
'突',
'阕',
'惫',
'U',
'佞',
'秒',
'友',
'視',
'莹',
'攒',
'荻',
'俅',
'筐',
'能',
'刓',
'拍',
'浥',
'揽',
'谨',
'军',
'巷',
'怵',
'额',
'恪',
'荀',
'糍',
'湎',
'褙',
'觇',
'效',
'估',
'噩',
'恍',
'聚',
'涛',
'式',
'兜',
'汔',
'祃',
'銘',
'烺',
'瑄',
'枘',
'丁',
'樗',
'堙',
'窗',
'號',
'鬣',
'阈',
'乳',
'簇',
'绳',
'淞',
']',
'征',
'聩',
'凸',
'礓',
'柘',
'懂',
'㧎',
'纷',
'里',
'爸',
'靥',
'莞',
'馅',
'仞',
'芏',
'莳',
'殪',
'煌',
'落',
'佚',
'帱',
'诶',
'家',
'将',
'浯',
'抿',
'讫',
'趸',
'筢',
'绩',
'原',
'专',
'滂',
'嗳',
'踬',
'泱',
'體',
'蜱',
'绵',
'伻',
'埗',
'妤',
'蔺',
'赳',
'嘢',
'梨',
'鹪',
'烤',
'镦',
'赉',
'崞',
'蚰',
'骝',
'幅',
'汴',
'丽',
'访',
'叩',
'羼',
'亓',
'恸',
'燥',
'笤',
'丑',
'枰',
'守',
'蜚',
'戈',
'高',
'q',
'瓻',
'隘',
'H',
'南',
'剎',
'扭',
'骠',
'孜',
'园',
'锬',
'审',
'¥',
'罚',
'购',
'裰',
'泔',
'醌',
'醒',
'绎',
'莪',
'掬',
'睾',
'鹁',
'蛊',
'票',
'剃',
'释',
'调',
'黛',
'撩',
'篱',
'茌',
'敓',
'蜜',
'魉',
'鳤',
'昽',
'俳',
'辁',
'键',
'犯',
'嶙',
'狈',
'邬',
'枋',
'婊',
'憎',
'督',
'救',
'措',
'足',
'码',
'栟',
'虼',
'棻',
'阅',
'肊',
'坛',
'鸱',
'侩',
'烫',
'湉',
'脐',
'戾',
'旎',
'膚',
'椒',
'境',
'绛',
'濛',
'蓄',
'章',
'压',
'窦',
'彖',
'阜',
'咻',
'神',
'存',
'诺',
'課',
'覺',
'鲈',
'渚',
'「',
'缢',
'仓',
'氅',
'筇',
'桴',
'荥',
'些',
'纯',
'肋',
'退',
'妪',
'别',
'書',
'租',
'嚼',
'芘',
'笳',
'涰',
'馐',
'熵',
'犹',
'朕',
'猪',
'蔸',
'參',
'觳',
'舖',
'蝙',
'骏',
'织',
'躏',
'纹',
'锹',
'蛉',
'撑',
'氽',
'茶',
'俛',
'誠',
'胖',
'崽',
'炫',
'乘',
'把',
'趑',
'谵',
'骧',
'犍',
'鸮',
'灌',
'焯',
'倭',
'狁',
'盱',
'踱',
'滠',
'儡',
'诸',
'芽',
'駆',
'蹼',
'虱',
'祇',
'\u3000',
'蠡',
'衄',
'谬',
'蒍',
'婺',
'蘧',
'博',
'捍',
'磁',
'慷',
'釂',
'蛩',
'钕',
'祎',
'呑',
'贫',
'斗',
'菅',
'操',
'规',
'硼',
'惕',
'丫',
'俭',
'肿',
'骀',
'砼',
'句',
'茛',
'闶',
'钏',
'饻',
'圠',
'萌',
'魏',
'铃',
'摞',
'┅',
'伎',
'獭',
'田',
'钴',
'峭',
'魅',
'捋',
'唼',
'鹅',
'祚',
'嬷',
'圖',
'抄',
'嶂',
'鸳',
'溧',
'钵',
'嗽',
'墠',
'锌',
'愈',
'併',
'踟',
'羯',
'翅',
'纠',
'勻',
'岚',
'菖',
'便',
'祈',
'毳',
'屹',
'掰',
'倬',
'扛',
'巴',
'拮',
'绁',
'跌',
'飯',
'嵯',
'翮',
'堤',
'诃',
'腑',
'皆',
'鄂',
'胾',
'片',
'这',
'浙',
'雨',
'鼱',
'袼',
'鹊',
'厢',
'蛣',
'摇',
'蛮',
'揍',
'⒅',
'啱',
'薇',
'岈',
'兔',
'谇',
'纶',
'肉',
'崩',
'甩',
'涪',
'馼',
'铣',
'锚',
'丙',
'雲',
'烹',
'钦',
'撄',
'铬',
'令',
'虮',
'湊',
'禹',
'抖',
'喏',
'旺',
'畲',
'戬',
'嗷',
'釜',
'车',
'缀',
'玕',
'谐',
'啁',
'怎',
'下',
'惑',
'恅',
'藿',
'筰',
'帐',
'祸',
'镝',
'喵',
'刁',
'习',
'藏',
'墓',
'护',
'聲',
'箦',
'严',
'按',
'谛',
'睨',
'艚',
'歉',
'蟮',
'胶',
'盍',
'鳃',
'狯',
'垫',
'杠',
'线',
'3',
'葖',
't',
'熬',
'虞',
'嶶',
'篮',
'黻',
'墒',
'氟',
'嫠',
'漕',
'腾',
'哟',
'玫',
'撇',
'垍',
'靛',
'翼',
'淅',
'省',
'斥',
'稞',
'蠼',
'谩',
'埠',
'蘸',
'刊',
'烝',
'宁',
'鹚',
'龊',
'苪',
'袷',
'诧',
'细',
'蒌',
'焅',
'2',
'筹',
'扒',
'卮',
'捞',
'净',
'菲',
'逮',
'槍',
'蛎',
'莱',
'黠',
'逖',
'辚',
'剥',
'啴',
'诿',
'楱',
'氪',
'领',
'嗒',
'藐',
'惜',
'甘',
'佾',
'嵴',
'胫',
';',
'晳',
'锣',
'瞅',
'缷',
'耶',
'搤',
'策',
'咽',
'邀',
'霾',
'悟',
'属',
'鸪',
'牴',
'贞',
'趁',
'丞',
'瘆',
'豌',
'著',
'饿',
'筠',
'划',
'璇',
'损',
'卵',
'腒',
'畏',
'盥',
'耐',
'圏',
'拓',
'蒙',
'鋫',
'劙',
'蹦',
'熘',
'烊',
'匏',
'咔',
'轘',
'沽',
'菩',
'罴',
'磉',
'炖',
'假',
'枪',
'龙',
'俸',
'焱',
'四',
'─',
'毫',
'涨',
'浇',
'椰',
'賣',
'蘇',
'真',
'安',
'坝',
'枕',
'鸼',
'昵',
'亨',
'苤',
'祷',
'枧',
'赟',
'菑',
'鳂',
'戌',
'悄',
'種',
'鳢',
'嗣',
'電',
'颥',
'妯',
'谟',
'蜒',
'训',
'泍',
'洁',
'勇',
'哿',
'扰',
'蟆',
'螂',
'刃',
'絜',
'曪',
'乒',
'湖',
'鞨',
'懜',
'夤',
'哓',
'胥',
'桞',
'俇',
'肣',
'半',
'于',
'橼',
'锑',
'熙',
'甜',
'槌',
'盾',
'屃',
'缗',
'共',
'碗',
'凇',
'笔',
'阿',
'擗',
'袍',
'敉',
'钾',
'俶',
'蚪',
'琤',
'凱',
'辕',
'à',
'恣',
'皴',
'創',
'寥',
'妳',
'腈',
'畤',
'迤',
'垠',
'触',
'趙',
'铤',
'逊',
'羊',
'碉',
'锱',
'骨',
'仄',
'斟',
'俚',
'啡',
'芩',
'迫',
'杷',
'种',
'鹄',
'牗',
'耑',
'艇',
'芰',
'整',
'慙',
'飛',
'甓',
'岩',
'鸦',
'黎',
'僊',
'糁',
'谈',
'洋',
'椑',
'健',
'〕',
'內',
'言',
'掷',
'倚',
'姬',
'矿',
'灯',
'阐',
'凋',
'銮',
'豇',
'瑰',
'抓',
'噪',
'堋',
'吁',
'妈',
'庥',
'彳',
'鄗',
'闩',
'夫',
'0',
'庠',
'悬',
'妙',
'琵',
'着',
'首',
'熣',
'瞰',
'揆',
'燚',
'条',
'姜',
'滘',
'麓',
'鳉',
'椀',
'蓿',
'廠',
'泌',
'蝈',
'倕',
'丛',
'耍',
'且',
'蝇',
'凉',
'豐',
'泪',
'臼',
'服',
'刍',
'織',
'渎',
'尥',
'甙',
'埋',
'珏',
'援',
'祖',
'彊',
'臱',
'惦',
'葴',
'礁',
'达',
'橋',
'钨',
'崦',
'醐',
'巳',
'中',
'颜',
'溠',
'铹',
'负',
'抠',
'愎',
'罘',
'雩',
'胝',
'冱',
'筵',
'篙',
'材',
'肓',
'○',
'迅',
'腼',
'橙',
'仵',
'茏',
'慵',
'齌',
'琯',
'疃',
'貢',
'豉',
'瞟',
'忉',
'禄',
'通',
'咒',
'愫',
'秕',
'筜',
'觖',
'州',
'渑',
'胆',
'喑',
'張',
'衖',
'洺',
'眉',
'榞',
'色',
'邶',
'攫',
'堑',
'淬',
'嗪',
'肐',
'殣',
'辊',
'隧',
'献',
'潤',
'蓺',
'函',
'鹱',
'轭',
'劭',
'椁',
'膜',
'亹',
'侧',
'貂',
'哚',
'磴',
'蠋',
'囔',
'险',
'伶',
'世',
'菥',
'莶',
'瘾',
'燫',
'延',
'∵',
'毋',
'羧',
'无',
'雎',
'曛',
'沚',
'巍',
'g',
'熄',
'恰',
'伷',
'開',
'冻',
'颛',
'支',
'⑦',
'鞥',
'赖',
'试',
'泮',
'联',
'沮',
'穰',
'è',
'峻',
'滿',
'豊',
'刎',
'鴈',
'覆',
'串',
'锃',
'春',
'储',
'矍',
'哺',
'评',
'猁',
'愉',
'疳',
'閃',
'奄',
'甲',
'墦',
'頭',
'锫',
'俦',
'玩',
'搀',
'砭',
'流',
'橇',
'泅',
'琇',
'趣',
'∧',
'辑',
'灊',
'貴',
'迮',
'摹',
'霄',
'濟',
'限',
'彀',
'匪',
'缂',
'觚',
'奇',
'诋',
'灼',
'萘',
'狠',
'澥',
'岂',
'悺',
'闾',
'麋',
'号',
'槽',
'姹',
'陉',
'瑯',
'尉',
'h',
'绖',
'宿',
'戋',
'粝',
'砂',
'该',
'鞧',
'翯',
'釘',
'铢',
'窨',
'設',
'⒆']
CHARSET_BETA = ['',
'笤',
'谴',
'膀',
'荔',
'佰',
'电',
'臁',
'矍',
'同',
'奇',
'芄',
'吠',
'6',
'曛',
'荇',
'砥',
'蹅',
'晃',
'厄',
'殣',
'c',
'辱',
'钋',
'杻',
'價',
'眙',
'鴿',
'⒄',
'裙',
'训',
'涛',
'酉',
'挞',
'忙',
'怍',
'︰',
'镍',
'檐',
'眯',
'茓',
'辖',
'淩',
'啟',
'蜀',
'芟',
'裟',
'楝',
'彘',
'嶪',
'费',
'亞',
'滁',
'榉',
'朝',
'f',
'倻',
'裎',
'谧',
'崂',
'卑',
'助',
'触',
'氐',
'锟',
'铢',
'膪',
'脐',
'渲',
'荫',
'佾',
'琯',
'钣',
'珰',
'翦',
'膻',
'娥',
'浥',
'淄',
'猸',
'内',
'消',
'粞',
'反',
'苪',
'冽',
'酵',
'玩',
'父',
'存',
'屯',
'殷',
'俐',
'篱',
'俛',
'塮',
'苕',
'耲',
'输',
'壖',
'溶',
'琤',
'氏',
'真',
'黩',
'瑄',
'阶',
'茔',
'眩',
'浙',
'痄',
'噔',
'烤',
'楯',
'²',
'铆',
'裈',
'偬',
'盏',
'祐',
'伯',
'庙',
'獯',
'榀',
'裒',
'综',
'蒸',
'架',
'蜱',
'鹖',
'涴',
'肌',
'廖',
'祾',
'蔗',
'破',
'!',
'鑫',
'瓷',
'H',
'宛',
'倪',
'贝',
'酝',
'倞',
'榼',
'菊',
'帕',
'胍',
'淌',
'抨',
'倕',
'味',
'独',
'à',
'庐',
'蹲',
'肸',
'洹',
'騳',
'绖',
'觉',
'蝙',
'铜',
'選',
'郚',
'奄',
'手',
'篦',
'忮',
'潺',
'歁',
'湖',
'貔',
'缚',
'癫',
'捣',
'翎',
'勇',
'徒',
'杪',
'捃',
'纴',
'郞',
'蛱',
'浓',
'講',
'薇',
'汊',
'彻',
'琖',
'觇',
'驩',
'野',
'闺',
'彩',
'膊',
'簸',
'瑭',
'龏',
'栓',
'攸',
'堕',
'鹿',
'檠',
'锽',
'晟',
'煊',
'衖',
'p',
'L',
'侞',
'吹',
'岵',
'捡',
'邃',
'曩',
'泼',
'娌',
'磙',
'鞮',
'號',
'苤',
'骁',
'感',
'氙',
'榜',
'菟',
'蠲',
'∶',
'焌',
'漯',
'胪',
'以',
'剜',
'=',
'衰',
'剔',
'疏',
'韩',
'邋',
'探',
'搌',
'握',
'舵',
'腰',
'咐',
'郎',
'鈺',
'赴',
'斩',
'铥',
'棂',
'褫',
'秾',
'城',
'葬',
'缺',
'甓',
'沙',
'鴨',
'恧',
'吩',
'膈',
'俗',
'引',
'濑',
'坛',
'蛘',
'谍',
'飘',
'鎚',
'貋',
'袅',
'圃',
'肽',
'祖',
'瑢',
'鄣',
'卡',
'恸',
'饷',
'撖',
'阖',
'碌',
'墉',
'⇋',
'抗',
'僇',
'撩',
'狷',
'静',
'荽',
'憯',
'虻',
'滹',
'簧',
'Y',
'汾',
'嫁',
'蚴',
'岈',
'榔',
'邶',
'挛',
'火',
'w',
'旌',
'線',
'3',
'跏',
'F',
'楸',
'瞬',
'證',
'現',
'符',
'鲀',
'窸',
'朗',
'm',
'劉',
'襄',
'鸻',
'敖',
'憩',
'濛',
'胶',
'雏',
'禽',
'缜',
'鐀',
'澄',
'泉',
'懈',
'鹟',
'牙',
'叟',
'镖',
'膨',
'硷',
'钏',
'嵌',
'冲',
'橪',
'厨',
'溘',
'妻',
'贺',
'耀',
'潲',
'瞳',
'惺',
'涑',
'鄄',
'舡',
'战',
'钹',
'盍',
'窀',
'凳',
'锋',
'(',
'绤',
'翻',
'》',
'嶷',
'戛',
'照',
'设',
'两',
'霹',
'風',
'格',
'栖',
'椹',
'№',
'蔌',
'达',
'悠',
'旒',
'函',
'抔',
'逆',
'疙',
'玫',
'箢',
'恩',
'樘',
'远',
'考',
'荭',
'殒',
'靡',
'蝾',
'舅',
'䀲',
'偾',
'灿',
'埴',
'瀍',
'特',
'诸',
'搦',
'恒',
'妊',
'课',
'劂',
'殊',
'艋',
'柚',
'硕',
'捅',
'钍',
'芘',
'脖',
'襁',
'募',
'卅',
'疆',
'嫖',
'黹',
'臀',
'豇',
'瘗',
'憎',
'嗯',
'Θ',
'跺',
'喧',
'捺',
'爪',
'鲠',
'縠',
'屋',
'撑',
'者',
'娶',
'喝',
'墼',
'丶',
'茚',
'髅',
'瓢',
'农',
'橼',
'攰',
'折',
'诋',
'镒',
'赂',
'捲',
'耑',
'沐',
'窜',
'亰',
'煌',
'阕',
'羯',
'纤',
'滇',
'值',
'琥',
'渴',
'祗',
'鳌',
'蛞',
'庄',
'鹇',
'訄',
'犷',
'弋',
'琐',
'佗',
'氛',
'揄',
'旺',
'聱',
'榨',
'湿',
'蟥',
'湎',
'敕',
'轷',
'耿',
'三',
'運',
'瑶',
'困',
'勁',
'蚱',
'泸',
'螫',
'斜',
'蟠',
'轨',
'镞',
'霆',
'嶙',
'烷',
'瘩',
'敦',
'塾',
'僚',
'澙',
'關',
'酩',
'殴',
'—',
'例',
'筷',
'乘',
'颗',
'核',
'孬',
'舣',
'糇',
'劾',
'黧',
'镌',
'罅',
'X',
'仅',
'哐',
'蟊',
'呻',
'呕',
'粟',
'配',
'伊',
'槊',
'昌',
'宰',
'盘',
'肫',
'鳥',
'圾',
'恬',
'辘',
'绿',
'時',
'丐',
'扃',
'敓',
'摄',
'陕',
'滿',
'鹆',
'嗬',
'龅',
'渣',
'釣',
'萦',
'督',
'孑',
'∧',
'疥',
'噱',
'蝎',
'君',
'笮',
'泌',
'镔',
'称',
'柘',
'鬣',
'罨',
'潍',
'垣',
'顔',
'褶',
'礓',
'△',
'骐',
'湍',
'獾',
'羖',
'戾',
'预',
'祭',
'鹨',
'凤',
'茕',
'珏',
'蛊',
'毛',
'枰',
'鄭',
'娲',
'丕',
'蜜',
'纟',
'蛹',
'粮',
'嚰',
'嚓',
'螨',
'裰',
'G',
'集',
'删',
'郜',
'舻',
'嵛',
'鵰',
'腊',
'峄',
'脸',
'鲺',
'坢',
'寞',
'撰',
'顸',
'枋',
'荠',
'夡',
'豆',
'馆',
'赭',
'傎',
'淼',
'镪',
'許',
'礌',
'带',
'訂',
'饧',
'锜',
'及',
'漾',
'編',
'究',
'仍',
'糜',
'喳',
'嗝',
'醦',
'堅',
'企',
'烔',
'图',
'垲',
'枥',
'畿',
'踱',
'槟',
'◆',
'酽',
'溢',
'酥',
'谚',
'缨',
'死',
'镑',
'干',
'用',
'紊',
'坑',
'副',
'枭',
'琮',
'鸨',
'獻',
'弈',
'伺',
'醍',
'氓',
'宁',
'臻',
'贾',
'啐',
'玉',
'咀',
'孀',
'烆',
'嘱',
'频',
'蜥',
'楡',
'瞩',
'委',
'锺',
'赀',
'睬',
'旅',
'刿',
'韪',
'抹',
'鞘',
'x',
'钝',
'倌',
'奖',
'蟭',
'灌',
'肼',
'曰',
'啊',
'属',
'唐',
'彦',
'煦',
'鄘',
'坦',
'鬻',
'告',
'单',
'菽',
'匏',
'浚',
'仺',
'怜',
'拦',
'鸡',
'拄',
'乍',
'燠',
'暧',
'竭',
'⒂',
'济',
'Ⓡ',
'趑',
'舴',
'体',
'拒',
'罂',
'说',
'猎',
'闫',
'鄗',
'妲',
'鑙',
'葶',
'匍',
'等',
'略',
'盲',
'唔',
'钰',
'渠',
'镦',
'葫',
'蹒',
'姘',
'婵',
'夯',
'实',
'何',
'株',
'锌',
'礁',
'桺',
'捉',
'鮕',
'莓',
'轶',
'辉',
'溋',
'视',
'嗒',
'猞',
'猁',
'杓',
'怡',
'咴',
'巷',
'仂',
'婉',
'睛',
'?',
'淡',
'/',
'郛',
'绨',
'较',
'毁',
'沓',
'瞎',
'馏',
'蕙',
'戏',
'i',
'董',
'臣',
'鹫',
'栳',
'锹',
'裕',
'蜷',
'唣',
'9',
'缂',
'螬',
'笥',
'惶',
'蚰',
'徨',
'忭',
'传',
'绛',
'离',
'锑',
'候',
'拓',
'德',
'损',
'附',
'紡',
'徕',
'錾',
'蕻',
'⑧',
'構',
'镊',
'脘',
'靸',
'涒',
'镡',
'光',
'廒',
'尴',
'荥',
'佳',
'弼',
'暮',
'榆',
'鼑',
'辅',
'钆',
'湝',
'佤',
'瘌',
'炽',
'筰',
'嗈',
'電',
'飙',
'坶',
'椿',
'俾',
'灊',
'泵',
'像',
'咅',
'樓',
'苒',
'烨',
'溺',
'棽',
'戒',
'箅',
'愔',
'缢',
'楞',
'庤',
'塑',
'湮',
'沽',
'蝌',
'赌',
'薨',
'锾',
'圜',
'骥',
'秉',
'瞌',
'惇',
'诊',
'圣',
'睢',
'我',
'廰',
'苠',
'襻',
'鲚',
'酮',
'厮',
'评',
'沈',
'愀',
'垞',
'习',
'敷',
'比',
'欢',
'尚',
'钪',
'卣',
'她',
',',
'伴',
'赃',
'蚬',
'喇',
'醇',
'嚅',
'T',
'姝',
'鍊',
'悯',
'N',
'抚',
'颡',
'獐',
'趟',
'洑',
'缝',
'喁',
'帷',
'憷',
'获',
'阉',
'镫',
'臨',
'炮',
'奴',
'揩',
'叩',
'恺',
'粱',
'胁',
'憬',
'痿',
'´',
'沘',
'彀',
'饩',
'滋',
'竑',
'嗑',
'鸟',
'T',
'璠',
'快',
'銀',
'舶',
'羞',
'桞',
'飛',
'茹',
'師',
'偌',
'節',
'冁',
'叡',
'臑',
'踔',
'酔',
'養',
'溦',
'岐',
'豉',
'杌',
'胩',
'仳',
'沾',
'窑',
'曳',
'闷',
'垢',
'垆',
'磨',
'髹',
'態',
'丽',
'見',
'洃',
'遣',
'场',
'铭',
'溉',
'衬',
'橦',
'详',
'馊',
'濂',
'瑾',
'鲫',
'贞',
'搴',
'胺',
' ',
'景',
'执',
'袴',
'炖',
'箭',
'楂',
'婚',
'镧',
'厩',
'宣',
'缣',
'跃',
'痘',
'亓',
'宦',
'豪',
'侣',
'郧',
'與',
'痳',
'挚',
'殻',
'嘢',
'洽',
'蹉',
'孽',
'森',
'俚',
'八',
'砹',
'凹',
'訇',
'屹',
'啰',
'宴',
'廨',
'沇',
'麇',
'泅',
'绡',
'辛',
'鹲',
'鋆',
'旮',
'婀',
'幔',
'赞',
':',
'永',
'活',
'萸',
'霉',
'←',
'媲',
'阚',
'鲮',
'佝',
'獒',
'圹',
'隋',
'征',
'蚶',
'龊',
'搀',
'嫫',
'鬏',
'幞',
'學',
'然',
'沧',
'萑',
'襜',
'撻',
'苯',
'狳',
'鞠',
'咋',
'壹',
'栅',
'款',
'镘',
'阳',
'蚜',
'荬',
'糊',
'疳',
'糕',
'镵',
'寐',
'褴',
'v',
'醋',
'诀',
'汰',
'啸',
'备',
'娘',
'氚',
'镓',
'室',
'簟',
'硝',
'嘌',
'釐',
'争',
'男',
'疬',
'鹄',
'艳',
'倒',
'忸',
'庶',
'葒',
'岖',
'涨',
'羝',
'诼',
'纨',
'纰',
'扉',
'酎',
'藉',
'疮',
'枞',
'黜',
'戮',
'芽',
'鳑',
'末',
'蒿',
'茈',
'透',
'渊',
'秷',
'〈',
'试',
'络',
'羼',
'滪',
'奋',
'虏',
'脁',
'沫',
'蓰',
'襆',
'披',
'鲌',
'艚',
'逹',
'炳',
'泔',
'叹',
'轳',
'锵',
'嫜',
'佥',
'严',
'迅',
'筠',
'逵',
'铿',
'钇',
'拇',
'诏',
'绯',
'吊',
'纠',
'蟾',
'c',
'涝',
'汩',
'盐',
'跋',
'拤',
'邹',
'镨',
'羚',
'龆',
'脊',
'攉',
'傕',
'短',
'團',
'蹬',
'嘤',
'奎',
'熨',
'芪',
'鸢',
'濉',
"''",
'莴',
'義',
'赜',
'踺',
'皂',
'努',
'偏',
'狡',
'遭',
'吞',
'嘿',
'婊',
'媸',
'增',
'殿',
'刮',
'燘',
'劫',
'娜',
'瞄',
'寡',
'优',
'捋',
'佴',
'菰',
'蓠',
'笙',
'镃',
'樇',
'瘫',
'B',
'橇',
'逯',
'堍',
'О',
'磐',
'腼',
'て',
'送',
'狭',
'皓',
'亡',
'嗉',
'菠',
'顺',
'連',
'嶶',
'瑪',
'辟',
'婷',
'牛',
'笫',
'窅',
'萁',
'戟',
'覃',
'馍',
'建',
'謇',
'旘',
'镣',
'燏',
'葉',
'轺',
'倏',
'堪',
'见',
'葛',
'钕',
'键',
'押',
'僊',
'槐',
'戎',
'窨',
'洙',
'鲢',
'鞒',
'慒',
'雁',
'圭',
'D',
'陌',
'肱',
'蜿',
'洧',
'惑',
'祛',
'樟',
'矧',
'呵',
'峻',
'凝',
'蕨',
'拯',
'珮',
'塥',
'展',
'贻',
'囐',
'弱',
'庳',
'嫔',
'緣',
'呈',
'策',
'漉',
'瑗',
'鲂',
'鹂',
'吾',
'灶',
'并',
'挲',
'重',
'奭',
'皙',
'侪',
'埗',
'烬',
'纾',
'椒',
'技',
'ɔ',
'擀',
'恍',
'遨',
'订',
'雨',
'卵',
'锏',
'猗',
'癸',
')',
'谡',
'稷',
'枨',
'蹽',
'荑',
'沅',
'稽',
'間',
'冉',
'颇',
'酺',
'份',
'瞾',
'毯',
'藥',
'蕞',
'狲',
'吡',
'慷',
'卯',
'摽',
'肿',
'嗛',
'悒',
'丨',
'横',
'鳡',
'仫',
'狎',
'砗',
'聿',
'腥',
'酡',
'飱',
'柳',
'遽',
'汇',
'湔',
'麋',
'垃',
'粽',
'坷',
'鳗',
'迫',
'丢',
'"',
'⒀',
'嗲',
'肐',
'結',
'署',
'飨',
'蠡',
'涩',
'挈',
'浿',
'鐾',
'姞',
'隧',
'铘',
'呜',
'蜕',
'鷄',
'逼',
'哌',
'病',
'係',
'偿',
'Ⅲ',
'埋',
'妤',
'赘',
'悉',
'陷',
'沸',
'呲',
'誓',
'舆',
'髀',
'挫',
'羑',
'据',
'顿',
'淝',
'抟',
'珧',
'郑',
'仗',
'怛',
'掠',
'稳',
'尥',
'祙',
'找',
'郐',
'锔',
'轹',
'钓',
'黙',
'饸',
'谌',
'斐',
'龙',
'噫',
'駆',
'浼',
'峒',
'育',
'纣',
'溠',
'铊',
'亨',
'杮',
'呓',
'钌',
'业',
'繻',
'溪',
'戌',
'蓿',
'椱',
'悱',
'仉',
'阮',
'芈',
'濋',
'搔',
'纽',
'琛',
'趄',
'双',
'镯',
'☆',
'敉',
'啬',
'讦',
'娱',
'爾',
'遶',
'漱',
'郗',
'锪',
'颃',
'靰',
'醊',
'驊',
'呢',
'術',
'妙',
'蚣',
'溽',
'酇',
'巾',
'舐',
'却',
'废',
'邾',
'砣',
'乙',
'鲜',
'蒤',
'囍',
'璈',
'稔',
'蘘',
'匐',
'業',
'碟',
'渺',
'贤',
'绋',
'畑',
'颞',
'侥',
'盟',
'鼍',
'阊',
'蔽',
'标',
'吮',
'淬',
'鏾',
'圗',
'夜',
'乕',
'娇',
'瞿',
'循',
'讲',
'懒',
'熘',
'禚',
'观',
'钷',
'万',
'n',
'未',
'藝',
'愿',
'圈',
'浩',
'伦',
'扛',
'暄',
'饶',
'梧',
'欣',
'咿',
'檔',
'吼',
'妮',
'覆',
'辰',
'誤',
'允',
'危',
'硗',
'惫',
'瘪',
'李',
'焱',
'沣',
'坯',
'穄',
'归',
'画',
'营',
':',
'色',
'哔',
'矢',
'巯',
'祆',
'傍',
'享',
'悻',
'取',
'凫',
'铒',
'唅',
'眈',
'疹',
'败',
'晴',
'顼',
'绶',
'剃',
'斗',
'禾',
'4',
'誜',
'俨',
'2',
'患',
'结',
'可',
'帇',
'抍',
'筝',
'衢',
'鹛',
'跸',
'颢',
'钾',
'渡',
'棒',
'丛',
'皱',
'梓',
'将',
'压',
'#',
'岛',
'?',
'砺',
'过',
'党',
'挣',
'瞋',
'谶',
'妯',
'羡',
'化',
'淫',
'歪',
'鼗',
'阄',
'蔓',
'烩',
'餘',
'猊',
'.',
'畯',
'祧',
'狒',
'碁',
'咛',
'鲈',
'叨',
'哞',
'5',
'娈',
'半',
'免',
'拿',
'畎',
'媾',
'棚',
'丈',
'周',
'匋',
'酯',
'奚',
'爇',
'摇',
'搭',
'蓇',
'陽',
'岢',
'禤',
'藠',
'雅',
'哲',
'弹',
'按',
'↑',
'蹀',
'察',
'螾',
'渎',
'褂',
'觳',
'耍',
'皲',
'骗',
'箫',
'蕺',
'亚',
'保',
'棵',
'放',
'踪',
'了',
'熣',
'亦',
'痛',
'币',
'馐',
'夢',
'诱',
'梱',
'鲰',
'郕',
'璜',
'祯',
'颦',
'走',
'踣',
'嫚',
'旯',
'雲',
'湟',
'墨',
'笃',
'肇',
'撝',
'腦',
'账',
'舞',
'⑨',
'噻',
'幂',
'僵',
'崦',
'’',
'牢',
'号',
'嫡',
'囱',
'肥',
'代',
'锶',
'掏',
'随',
'棓',
'殉',
'嘅',
'掰',
'功',
'垛',
'踶',
'娠',
'霜',
'碣',
'鲼',
'伉',
'凄',
'骋',
'鹞',
'洺',
'乌',
'赧',
'瑛',
'黎',
'曚',
'鲴',
'髫',
'瘴',
'藏',
'雍',
'畐',
'蔻',
'爼',
'蹴',
'巨',
'贱',
'汜',
'胡',
'虬',
'椎',
'逸',
'魇',
'亶',
'Φ',
'忆',
'赉',
'塞',
'潢',
'垌',
'简',
'鼹',
'發',
'枢',
'麝',
'虹',
'惭',
'唛',
'春',
'瑟',
'郰',
'桡',
'捩',
'堙',
'嗨',
'驳',
'F',
'荪',
'忑',
'贪',
'躅',
'步',
'揜',
'闪',
'垟',
'晶',
'分',
'韭',
'戴',
'泪',
'啧',
'機',
'峙',
'和',
'鸱',
'绎',
'屠',
'阋',
'黍',
'淸',
'萩',
'汉',
'吐',
'匙',
'铗',
'蠔',
'簠',
'鲵',
'须',
'蛣',
'躏',
'完',
'咻',
'釜',
'馼',
'崤',
'欻',
'珐',
'于',
'郅',
'焓',
'轴',
'递',
'堰',
'嗷',
'儇',
'壕',
'嘟',
'酸',
'庾',
'龂',
'妍',
'锅',
'雳',
'桦',
'抬',
'谄',
'气',
'六',
'诎',
'绀',
'张',
'復',
'客',
'荞',
'鳚',
'衔',
'亁',
'昂',
'漤',
'鞚',
'筘',
'绫',
'彝',
'枪',
'苊',
'榟',
'饺',
'苦',
'顶',
'衷',
'聚',
'寮',
'揆',
'轪',
'栋',
'臂',
'葖',
'颋',
'镐',
'愕',
'贸',
'Q',
'琼',
'糥',
'世',
'莪',
'龁',
'禁',
'绲',
'陶',
'弑',
'黢',
'铵',
'睐',
'沄',
'紬',
'防',
'癣',
'曾',
'钉',
'纶',
'膘',
'句',
'莸',
'踝',
'躐',
'酤',
'腑',
'雄',
'堤',
'喀',
'姣',
'孢',
'阡',
'褐',
'胂',
'髙',
';',
'骖',
'膺',
'糙',
'辢',
'⒃',
'险',
'砻',
'缫',
'骎',
'低',
'蚵',
'箐',
'苞',
'劭',
'峪',
'工',
'盈',
'腹',
'袄',
'祉',
'癔',
'笨',
'R',
'乚',
'畏',
'虍',
'臾',
'泛',
'噙',
'杷',
'麗',
'蹋',
'逍',
'迓',
'摅',
'页',
'戥',
'胞',
'艄',
'壅',
'啶',
'趼',
'牟',
'翙',
'蓝',
'府',
'轿',
'砼',
'荜',
'杆',
'惊',
'起',
'瘅',
'墈',
'氖',
'匀',
'麃',
'阘',
'虮',
'蘇',
'蚤',
'汗',
'鳞',
'籁',
'缲',
'畈',
'亟',
'劬',
'課',
'蓄',
'缅',
'楮',
'湜',
'珩',
'斋',
'塬',
'殁',
'魃',
'脞',
'H',
'澼',
'钚',
'饕',
'缕',
'Ⅱ',
'攮',
'卿',
'莅',
'镆',
'熹',
'藩',
'汁',
'順',
'趿',
'拆',
'蟹',
'砒',
'惴',
'㎡',
'忖',
'寝',
'戕',
'螭',
'酿',
'™',
'柬',
'枧',
'凶',
'蚁',
'島',
'殄',
'鲊',
'忠',
'肉',
'辕',
'叫',
'徙',
'漆',
'缞',
'夀',
'楦',
'佪',
'兴',
'粉',
'裳',
'蘧',
'國',
'旬',
'看',
'Ⅰ',
'剑',
'痭',
'襟',
'恐',
'遹',
'◎',
'窃',
'穰',
'澎',
'敬',
'旱',
'燚',
'坩',
'彤',
'尜',
'猃',
'夏',
'穈',
'媒',
'柑',
'駡',
'孛',
'脉',
'车',
'零',
'菩',
'痊',
'卉',
'桔',
'距',
'吧',
'漦',
'启',
'仁',
'滬',
'馋',
'帅',
'鳈',
'鄌',
'超',
'芡',
'窘',
'刽',
'掌',
'氤',
'梽',
'拎',
'踏',
'勋',
'甍',
'玑',
'稱',
'鞍',
'浍',
'翅',
'饟',
'鼎',
'罩',
'加',
'虚',
'蕰',
'簉',
'堇',
'巢',
'疲',
'蟑',
'狝',
'瓮',
'潋',
'行',
'饥',
'散',
'糌',
'牵',
'貢',
'偉',
'咄',
'痕',
'沃',
'苓',
'锂',
'狻',
'褿',
'畸',
'姿',
'煎',
'胜',
'觅',
'烊',
'質',
'疵',
'擢',
'椤',
'米',
'累',
'诳',
'斡',
'K',
'恻',
'匦',
'烫',
'湾',
'鹎',
'吟',
'摘',
'涞',
'恿',
'嫉',
'炎',
'婧',
'朽',
'铑',
'ㆍ',
'讧',
'曜',
'挑',
'〇',
'搅',
'鹐',
'丁',
'彼',
'棠',
'饪',
'箬',
'祎',
'魄',
'囿',
'犬',
'市',
'髃',
'勚',
'桶',
'辎',
'瓞',
'财',
'缄',
'園',
'睒',
'护',
'尿',
'融',
'围',
'水',
'糍',
'虢',
'呦',
'越',
'棺',
'砮',
'邓',
'鹦',
'稣',
'呃',
'柙',
'鎌',
'转',
'袋',
'湉',
'亘',
'俩',
'腆',
'谣',
'飔',
'撂',
'鄳',
'爲',
'盦',
'谳',
'卸',
'W',
'嚆',
'婕',
'卫',
'拚',
'呀',
'汽',
'洣',
'冻',
'鳝',
'录',
'毋',
'閥',
'熬',
'谜',
'齐',
'匳',
'慧',
'猴',
'撬',
'妳',
'諾',
'蠼',
'瘟',
'伐',
'颤',
'奶',
'陧',
'麾',
'岌',
'浇',
'邸',
'「',
'不',
'哼',
'热',
'旳',
'慙',
'&',
'苔',
'郿',
'钗',
'氡',
'纹',
'侬',
'霓',
'靈',
'扁',
'聢',
'疼',
'岣',
'甥',
'恭',
'喷',
'芫',
'骂',
'肪',
'熥',
'揠',
'鲷',
'遁',
'霎',
'娆',
'圩',
'爬',
'傲',
'贽',
'紫',
'觑',
'琇',
'蟆',
'怙',
'玙',
'庼',
'筮',
'慗',
'层',
'娓',
'蚨',
'糟',
'璩',
'隼',
'锧',
'疱',
'铎',
'祠',
'绁',
'速',
'湛',
'蝮',
'立',
'媵',
'禇',
'撸',
'禳',
'>',
'恋',
'⑥',
'鹡',
'蓑',
'樱',
'奸',
'蝣',
'埭',
'聪',
'慭',
'睑',
'肢',
'焗',
'骃',
'毵',
'潼',
'塘',
'烧',
'劓',
'栾',
'牯',
'〉',
'毓',
'釉',
'庞',
'宕',
'磚',
'夺',
'畜',
'俏',
'筼',
'虱',
'釆',
'计',
'陀',
'诧',
'臱',
'牌',
'固',
'鹉',
'凰',
'擞',
'■',
'㛃',
'词',
'店',
'當',
'许',
'妣',
'耋',
'硼',
'根',
'焅',
'砸',
'霈',
'锃',
'巳',
'誉',
'咕',
'锊',
'P',
'云',
'乞',
'为',
'姆',
'桕',
'丞',
'鳤',
'楷',
'醒',
'趔',
'怔',
'砉',
'潏',
'肝',
'拷',
'也',
'璐',
'厘',
'致',
'昇',
'绥',
'抃',
'佩',
'斥',
'⑶',
'断',
'纵',
'翁',
'耄',
'沭',
'洄',
'别',
'吻',
'渍',
'r',
'愦',
'替',
'骓',
'攻',
'旦',
'来',
'案',
'坫',
'辞',
'班',
'锝',
'拜',
'掎',
'穸',
'笛',
'痂',
'笈',
'鲶',
'僻',
'依',
'碎',
'蕤',
'炕',
'寥',
'拔',
'髑',
'慨',
'眺',
'⑿',
'珞',
'歧',
'湲',
'錦',
'拮',
'哭',
'爰',
'验',
'寸',
'%',
'口',
'阔',
'积',
'篝',
'狴',
'殂',
'痧',
'绽',
'搪',
'祸',
'缘',
'遯',
'祜',
'种',
'缓',
'冒',
'庵',
'窥',
'颂',
'哕',
'谘',
'蜗',
'掖',
'驮',
'郎',
'跂',
'蝓',
'贲',
'馔',
'琰',
'大',
'芊',
'粝',
'啻',
'蒉',
'谒',
'羔',
'蘑',
'菑',
'布',
'徂',
'l',
'炬',
'蘩',
'弭',
'嵎',
'補',
'岑',
'佯',
'棍',
'没',
'志',
'裣',
'咸',
'权',
'豺',
'韦',
'優',
'紧',
'嚚',
'牴',
'酚',
'沤',
'睥',
'葆',
'乓',
'划',
'犒',
'惚',
'埕',
'锴',
'就',
'滓',
'汕',
'冏',
'缵',
'囟',
'旸',
'麂',
'接',
'餮',
'瓤',
'偕',
'灏',
'溻',
'揶',
'钯',
'荸',
'宪',
'泠',
'槠',
'抺',
'威',
'燴',
'井',
'骣',
'耜',
'磔',
'懜',
'淇',
'瘘',
'蹼',
'觏',
'圬',
'纔',
'恤',
'铝',
'薏',
'鞫',
'衉',
'E',
'球',
'姽',
'毹',
'嵘',
'睦',
'蛉',
'伽',
'橥',
'痤',
'卞',
'警',
'则',
'芬',
'磉',
'悢',
'逾',
'吆',
'朿',
'锒',
'卧',
'E',
'焉',
'纥',
'髦',
'鞯',
'牞',
'蹿',
'琪',
'洌',
'幛',
'淳',
'菲',
'涔',
'噗',
'勺',
'势',
'哓',
'毪',
'刖',
'雜',
'浪',
'懵',
'棁',
'秋',
'◇',
'玡',
'埯',
'谥',
'芑',
'拌',
'Z',
'埂',
'寻',
'虼',
'豫',
'蛄',
'蜞',
'椟',
'〔',
'哩',
'絷',
'咱',
'郈',
'湫',
'抡',
'矮',
'庖',
'锰',
'鎖',
'葸',
'棣',
'砑',
'题',
'棋',
'晕',
'兠',
'蓣',
'貂',
'裤',
'昊',
'扳',
'讴',
'弩',
'蚀',
'尓',
'暗',
'莘',
'黏',
'寖',
'蛔',
'И',
'痪',
'饳',
'妈',
'Z',
'秏',
'矽',
'蘭',
'艴',
'菖',
'寿',
'撅',
'秤',
'颓',
'廪',
'醪',
'耢',
'螣',
'椰',
'麈',
'听',
'敞',
'铠',
'润',
'穑',
'涟',
'澹',
'茨',
'昨',
'嚯',
'钟',
'護',
'榇',
'曦',
'蜎',
'呷',
'邦',
'瘵',
'鲬',
'谖',
'概',
'九',
'飞',
'潇',
'高',
'锫',
'钐',
'徘',
'诟',
'缧',
'剞',
'【',
'簋',
'噍',
'痋',
'关',
'糁',
'鹊',
'潤',
'邬',
'赔',
'序',
'盤',
'拙',
'盾',
'鸫',
'迟',
'氇',
'塄',
'庀',
'噩',
'臃',
'绔',
'岔',
'珠',
'癀',
'骡',
'隶',
'堋',
'笆',
'影',
'昶',
'飗',
'α',
'薄',
'碜',
'瞅',
'奠',
'鲽',
'牂',
'裆',
'刀',
'遑',
'隙',
'沔',
'訾',
'旇',
's',
'诮',
'炱',
'榚',
'些',
'縯',
'提',
'甚',
'埏',
'峣',
'意',
'出',
'郡',
'摊',
'哦',
'轼',
'嚒',
'杈',
'痢',
'裥',
'袖',
'陔',
'溷',
'裀',
'迄',
'枇',
'筑',
'貊',
'鲃',
'鸪',
'V',
'鞭',
'粳',
'菥',
'盒',
'毙',
'风',
'壽',
'胝',
'章',
'泄',
'浜',
'菇',
'釘',
'揖',
'蝰',
'榧',
'掊',
'瘿',
'亍',
'欤',
'髻',
'歃',
'朱',
'撇',
'铁',
'兜',
'喋',
'趵',
'瘼',
'芤',
'邳',
'除',
'滌',
'么',
'践',
'矜',
'曆',
'炒',
'咔',
'促',
'姐',
'酦',
'货',
'箔',
'锡',
'吝',
'医',
'汀',
'精',
'馘',
'骶',
'碉',
'啷',
'缉',
'褪',
'阙',
'滕',
'蓐',
'搏',
'俅',
'癌',
'股',
'圪',
'孕',
'鳕',
'话',
'鳳',
'妩',
'馬',
'鞣',
'璁',
'测',
'螠',
'圆',
'颥',
'卒',
'钲',
'䨱',
'骢',
'批',
'陨',
'婶',
'熵',
'鸣',
'梁',
'怅',
'滑',
'驵',
'帑',
'鑽',
'痈',
'鲑',
'犍',
'茑',
'糧',
'谫',
'咒',
'绘',
'塆',
'耖',
'铮',
'殳',
'角',
'齮',
'挻',
'捎',
'2',
'З',
'廋',
'泻',
'犊',
'儋',
'椋',
'聍',
'鼬',
'鳏',
'收',
'跞',
'盥',
'信',
'嘴',
'眉',
'黠',
'纡',
'Ω',
'愆',
'桹',
'昽',
'讠',
'蚧',
'龀',
'鳓',
'麓',
'括',
'蘊',
'鈇',
'写',
'焕',
'哒',
'忌',
'咳',
'蜮',
'衄',
'氰',
'邘',
'缇',
'缮',
'表',
'续',
'篇',
'旄',
'闻',
'門',
'偃',
'茳',
'晗',
'鋪',
'讶',
'衙',
'闭',
'管',
'傒',
'藔',
'鳯',
'萼',
'泥',
'汔',
'浆',
'姚',
'几',
'含',
'沆',
'繇',
'灾',
'嗦',
'饬',
'系',
'熠',
'漶',
'潭',
'牲',
'湘',
'稁',
'宄',
'亳',
'杏',
'豳',
'監',
'印',
'旁',
'辙',
'播',
'让',
'乳',
'镚',
'腒',
'衅',
'铅',
'殛',
'形',
'颚',
'茸',
'绚',
'铲',
'贬',
'溆',
'寘',
'傫',
'解',
'事',
'旻',
'差',
'竣',
'篃',
'渥',
'嵩',
'@',
'鹀',
'哈',
'痍',
'绪',
'囔',
'渗',
'帐',
'叙',
'⑦',
'跖',
'貝',
'盅',
'碶',
'哗',
'裼',
'窝',
'滙',
'郸',
'延',
'炼',
'芹',
'簃',
'谭',
'莱',
'佞',
'猝',
'褥',
'陆',
'王',
'碴',
'粑',
'怃',
'倭',
'貉',
'硈',
'裴',
'溍',
'坂',
'勐',
'踬',
'敌',
'改',
'膠',
'罘',
'罚',
'繁',
'幢',
'煸',
'扩',
'黑',
'氮',
'孓',
'饔',
'姹',
'蠖',
'倬',
'慝',
'沩',
'嚏',
'雌',
'琏',
'莹',
'觊',
'颟',
'坤',
'筅',
'桉',
'肈',
'幻',
'”',
'烽',
'蓅',
'噌',
'桎',
'矻',
'指',
'瀚',
'羊',
'邒',
'筒',
'匣',
'旨',
'葑',
'团',
'偻',
'镛',
'忉',
'帱',
'往',
'刎',
'害',
'母',
'串',
'酢',
'舟',
'栝',
'娣',
'⒉',
'装',
'笊',
'篑',
'垄',
'镳',
'牝',
'煲',
'氵',
'遂',
'骜',
'钜',
'屡',
'宇',
'z',
'惨',
'潆',
'鹃',
'豌',
'浞',
'幄',
'麺',
'暽',
'弁',
'菤',
'酲',
'虑',
'样',
'访',
'睁',
'黼',
'悞',
'禧',
'涠',
'舂',
'駕',
'屈',
'噀',
'邽',
'炅',
'欸',
'隆',
'描',
'绦',
'派',
'溲',
'颙',
'忐',
'鹺',
'只',
'诈',
'腭',
'亵',
'这',
'炀',
'趣',
'喙',
'跨',
'場',
'全',
'搢',
'舨',
'踢',
'巿',
'糸',
'乐',
'澈',
'羰',
'匯',
'D',
'濒',
'莛',
'癯',
'娴',
'姒',
'祥',
'渖',
'庭',
'渑',
'挹',
'狉',
'萍',
'鹚',
'焻',
'自',
'舸',
'岫',
'飑',
'戍',
'淙',
'愠',
'导',
'賣',
'进',
'赳',
'鱿',
'硂',
'僤',
'O',
'拟',
'钨',
'笳',
'汴',
'挤',
'稞',
'柏',
'阐',
'弥',
'艽',
'爻',
'魭',
'俶',
'聂',
'鲎',
'齌',
'菀',
'僜',
'煅',
'满',
'兀',
'辔',
'舊',
'胥',
'卢',
'额',
'膝',
'嵬',
'昼',
'唏',
'璨',
'苷',
'舫',
'倨',
'耵',
'碳',
'鄺',
'橘',
'裔',
'裸',
'宋',
'窋',
'悚',
'昱',
'错',
'咣',
'檄',
'硁',
'莆',
'肃',
'曼',
'垍',
'绵',
'役',
'內',
'館',
'规',
'犋',
'毅',
'锨',
'瓘',
'丘',
'疝',
'杀',
'袗',
'屏',
'阎',
'衹',
'嚣',
'冼',
'铪',
'熏',
't',
'储',
'傧',
'髁',
'邙',
'窴',
'泾',
'止',
'晾',
'涵',
'庸',
'庠',
'靿',
'睚',
'减',
'衲',
'思',
'簖',
'耘',
'之',
'斑',
'扬',
'袼',
'缗',
'菏',
'滍',
'研',
'垚',
'艘',
'黇',
'蜘',
'汨',
'侦',
'疃',
'再',
'沂',
'榛',
'励',
'嚼',
'拴',
'钴',
'珑',
'撕',
'鸯',
'共',
'醐',
'揿',
'醴',
'凭',
'菹',
'鹬',
'捷',
'掼',
'芝',
'缪',
'咏',
'挺',
'蒗',
'疖',
'伸',
'索',
'黉',
'髋',
'習',
'姜',
'蔺',
'扶',
'忽',
'锉',
'戚',
'珲',
'摸',
'黛',
'跌',
'螈',
'冚',
'洱',
'鼯',
'庡',
'痒',
'哆',
'品',
'歆',
'登',
'呔',
'追',
'鉫',
'碾',
'祚',
'总',
'帚',
'薹',
'趴',
'容',
'滘',
'❋',
'迷',
'拾',
'炯',
'析',
'佼',
'嗾',
'-',
'针',
'滩',
'禅',
'讯',
'織',
'饱',
'哟',
'蹓',
'侧',
'蹯',
'踽',
'趙',
'漫',
'卷',
'朴',
'卺',
'狈',
'绉',
'浉',
'玳',
'榕',
'畛',
'蛾',
'帔',
'欠',
'劙',
'矾',
'進',
'蚺',
'骨',
'捂',
'疾',
'璱',
'圠',
'坚',
'弯',
'秩',
'逧',
'烟',
'佛',
'嫱',
'鳢',
'裹',
'耥',
'潮',
'巽',
'嶝',
'廷',
'鳆',
'五',
'西',
'壤',
'慌',
'鴈',
'爡',
'‧',
'儆',
'萘',
'愁',
'昔',
'咩',
'侃',
'炫',
'迳',
'构',
'缶',
'皴',
'捱',
'菜',
'秀',
'粢',
'畵',
'辊',
'伟',
'榄',
'嗪',
'已',
'聖',
'枕',
'恢',
'厍',
'涅',
'鄢',
'饨',
'鲨',
'谪',
'礤',
'搁',
'疔',
'雎',
'羿',
'犁',
'硐',
'盹',
'若',
'操',
'昀',
'亩',
'凑',
'睃',
'贰',
'穷',
'荆',
'葹',
'嘃',
'廓',
'憔',
'制',
'胧',
'染',
'麿',
'镴',
'砀',
'组',
'茎',
'畫',
'哑',
'坨',
'罱',
'刳',
'嘲',
'瞰',
'缏',
'侩',
'谝',
'谮',
'还',
'惋',
'佈',
'谏',
'酗',
'怩',
'i',
'秽',
'抻',
'蟪',
'狠',
'辑',
'羟',
'娉',
'肯',
'毕',
'枸',
'啮',
'鳙',
'要',
'娑',
'蜈',
'忍',
'侗',
'Р',
'凛',
'巉',
'拽',
'该',
'俎',
'惠',
'薅',
'猬',
'忲',
'●',
'哏',
'柔',
'沉',
'磁',
'脾',
'龃',
'鲩',
'钞',
'厂',
'鱽',
'濞',
'群',
'唱',
'攝',
'刃',
'蹻',
'剕',
'朊',
'啜',
'语',
'蜻',
'遠',
'呖',
'都',
'嫄',
'戢',
'丫',
'酞',
'修',
'户',
'膏',
'侈',
'浣',
'捍',
'馒',
'谱',
'點',
'滏',
'跟',
'鹁',
'书',
'愉',
'扭',
'票',
'耒',
'燁',
'魚',
'拨',
'鞑',
'匆',
'最',
'憨',
'晨',
'癍',
'邻',
'醅',
'骘',
'骇',
'蔫',
'。',
'珪',
'安',
'歉',
'邑',
'淦',
'胱',
'漏',
'咂',
'叮',
'瘛',
'钺',
'聘',
'玎',
'荻',
'涰',
'淏',
'烈',
'囚',
'㙟',
'矫',
'嗵',
'澶',
'磛',
'肖',
'蹑',
'支',
'哪',
'久',
'嗅',
'稍',
'抠',
'具',
'裨',
'韨',
'虿',
'漪',
'外',
'埸',
'ä',
'葡',
'鲇',
'廛',
'蝥',
'广',
'兒',
'涧',
'阌',
'谊',
'嵴',
'拂',
'悸',
'哳',
'4',
'佘',
'篁',
'基',
'赪',
'掬',
'演',
'谋',
'酣',
'植',
'波',
'恅',
'杼',
'胀',
'纯',
'缩',
'盆',
'芷',
'绺',
'施',
'礞',
'莳',
'稻',
'狐',
'馌',
'椑',
'恃',
'镩',
'骼',
'孱',
'硭',
'曈',
'焼',
'秕',
'觥',
'茛',
'射',
'肣',
'蟞',
'′',
'彰',
'罔',
'麻',
'逋',
'谓',
'革',
'藤',
'堆',
'忿',
'茂',
'屦',
'炟',
'碹',
'啤',
'垤',
'文',
'佐',
'叼',
'蹭',
'踉',
'眍',
'龟',
'黾',
'崋',
'氘',
'尼',
'瞢',
'悦',
'罢',
'瑀',
'睇',
'贴',
'涿',
'拍',
'庥',
'粪',
'陳',
'闌',
'蓍',
'元',
'磊',
'忻',
'葴',
'买',
'诺',
'㐂',
'沦',
'苏',
'岂',
'浊',
'脍',
'誠',
'嚬',
'蔬',
'黄',
'銘',
'钩',
'劃',
'嫘',
'嵖',
'笄',
'鸰',
'熳',
'堑',
'河',
'遮',
'尝',
'灭',
'愬',
'娅',
'鸽',
'锢',
'狂',
'弓',
'侨',
'滚',
'释',
'晏',
'徵',
'苡',
'佚',
'切',
'惰',
'降',
'槎',
'脑',
'磺',
'谟',
'裉',
'弘',
'醺',
'眇',
'顒',
'兰',
'忧',
'础',
'-',
'茫',
'袒',
'喤',
'慶',
'話',
'跽',
'堵',
'能',
'武',
'壳',
'汤',
'橐',
'圧',
'嗡',
'簌',
'斧',
'林',
'楊',
'净',
'嫌',
'猛',
'炸',
'冠',
'弦',
'洵',
'°',
'創',
'葜',
'苁',
'顏',
'薛',
'平',
'舜',
'崧',
'撼',
'哮',
'窣',
'殖',
'象',
'飒',
'瞥',
'玥',
'斝',
'胭',
'葱',
'擎',
'踰',
'盛',
'稇',
'斫',
'滴',
'硫',
'胬',
'唁',
'拐',
'殍',
'冱',
'陪',
'鋈',
'烦',
'辋',
'妇',
'轸',
'潴',
'荤',
'碡',
'徭',
'膜',
'秧',
'淀',
'缤',
'琶',
'^',
'肋',
'违',
'轭',
'$',
'箕',
'墩',
'罗',
'摆',
'槛',
'笠',
'塃',
'畚',
'嘛',
'秸',
'≥',
'剪',
'羅',
'帜',
'庇',
'骙',
'酾',
'康',
'陬',
'蝶',
'闇',
'圏',
'琴',
'鬈',
'苶',
'黡',
'瓠',
'酋',
'琎',
'奏',
'科',
'搒',
'億',
'翡',
'熊',
'性',
'痞',
'篾',
'邴',
'篥',
'饵',
'揸',
'狙',
'鳂',
'否',
'煺',
'畦',
'凖',
'鹧',
'宵',
'庛',
'鬯',
'袂',
'昴',
'徽',
'奧',
'鸥',
'锸',
'庚',
'彪',
'槿',
'趱',
'铡',
'讹',
'莎',
'約',
'璞',
'┌',
'铫',
'鸈',
'瞀',
'鼙',
'廙',
'估',
'屺',
'锘',
'渝',
'汶',
'囵',
'跻',
'酏',
'扎',
'孜',
'腔',
'吗',
'块',
'潽',
'“',
'焚',
'倘',
'靥',
'默',
'笺',
'遍',
'剅',
'桠',
'极',
'夷',
'眸',
'泳',
'谢',
'懦',
')',
'泜',
'物',
'开',
'淮',
'邵',
'卟',
'徜',
'轧',
'苍',
'酶',
'捌',
'耨',
'膄',
'琦',
'痦',
'涪',
'舰',
'迥',
'涘',
'季',
'悫',
'初',
'贩',
'碍',
'沼',
'腮',
'勻',
'恣',
'他',
'院',
'7',
'蜒',
'叉',
'昉',
'瞽',
'疢',
'蓼',
'相',
'臜',
'ü',
'秘',
'蚌',
'摉',
'莞',
'番',
'盼',
'冀',
'缠',
'学',
'馗',
'搞',
'苛',
'羹',
'潟',
'嬴',
'杶',
'妖',
'↓',
'銭',
'斄',
'猢',
'搂',
'芦',
'埶',
'癜',
'铴',
'從',
'留',
'硎',
'簇',
'臬',
'侮',
'鳎',
'頉',
'所',
'邝',
'哂',
'弛',
'垂',
'暑',
'仿',
'療',
'轾',
'熜',
'悃',
'勘',
'鋫',
'泞',
'閃',
'+',
'士',
'虐',
'盡',
'溯',
'劣',
'1',
'锇',
'蜇',
'碛',
'婴',
'8',
'捶',
'藻',
'嫰',
'跹',
'芋',
'淠',
'疯',
'Й',
'诨',
'醢',
'痨',
'栌',
'摧',
'噤',
'灸',
'馉',
'蒇',
'洲',
'孪',
'孵',
'亿',
'枝',
'涕',
'孟',
'缎',
'攒',
'湧',
'褛',
'铺',
'廣',
'诃',
'蕈',
'维',
'珣',
'逖',
'瓯',
'苘',
'榫',
'寰',
'供',
'铽',
'暲',
'义',
'兖',
'喆',
'祇',
'蝽',
'膛',
'髭',
'尹',
'乒',
'柈',
'抓',
'镋',
'脏',
'乩',
'挎',
'酬',
'靳',
'躔',
'霞',
'離',
'桌',
'o',
'\u3000',
'滨',
'懷',
'萭',
'望',
'仆',
'怂',
'麸',
'槁',
'洨',
'俬',
'孚',
'匕',
'栩',
't',
'被',
'邗',
'纺',
'狄',
'国',
'苋',
'眢',
'秣',
'畤',
'∵',
'创',
'嵫',
'胖',
'垮',
'镁',
'壑',
'A',
'趾',
'荟',
'汝',
'嗥',
'驰',
'向',
'磴',
'讪',
'溅',
'箍',
'驾',
'讙',
'蛐',
'眨',
'醯',
'筣',
'鼫',
'叠',
'沥',
'恕',
'埽',
'甩',
'煜',
'端',
'蜃',
'帏',
'丙',
'荏',
'圻',
'夥',
'暖',
'抛',
'岸',
'头',
'恝',
'船',
'鞲',
'の',
'七',
'怪',
'诅',
'茧',
'北',
'搓',
'皖',
'綉',
'坪',
'簪',
'贵',
'阍',
'刑',
'偶',
'雷',
'體',
'髡',
'岚',
'剂',
'妾',
'茬',
'鹣',
'鲳',
'蜊',
'假',
'认',
'嗍',
'傈',
'焘',
'驷',
'賀',
'氆',
'炝',
'聋',
'嘡',
'悺',
'﹐',
'僭',
'证',
'侉',
'屐',
'吃',
'十',
'〕',
'瀦',
'骤',
'俳',
'舁',
'驸',
'竿',
'坍',
'|',
'普',
'軒',
'瘃',
'现',
'醾',
'铈',
'榭',
'蓁',
'唷',
'睫',
'绰',
'叶',
'頤',
'锤',
'浸',
'杂',
'汹',
'璟',
'蓖',
'迦',
'截',
'錎',
'年',
'達',
'劁',
'码',
'乃',
'捯',
'髪',
'埚',
'呯',
'頭',
'镈',
'汆',
'β',
'舷',
'菂',
'纸',
'造',
'晁',
'卦',
'蛎',
'枉',
'脯',
'诛',
'生',
'令',
'桄',
'恶',
'鬟',
'怯',
'囡',
'充',
'省',
'控',
'螂',
'笕',
'邺',
'扅',
'斲',
'骏',
'鹋',
'队',
'套',
'镢',
'牖',
'I',
'援',
'封',
'泚',
'艿',
'沮',
'铙',
'揳',
'抄',
'帨',
'近',
'唾',
'珥',
'销',
'非',
'啱',
'驼',
'瓅',
'遢',
'筱',
'奥',
'善',
'氩',
'盉',
'帖',
'杜',
'鈉',
'蕉',
'鳄',
'江',
'鄂',
'矩',
'排',
'诠',
'准',
'菼',
'刻',
'足',
'峦',
'灰',
'僳',
'蝢',
'孫',
'據',
'璆',
'孳',
'徹',
'妆',
'坭',
'渌',
'喏',
'钦',
'朔',
'机',
'徼',
'掾',
'其',
'愧',
'刹',
'迹',
'惹',
'闿',
'鹘',
'窗',
'贳',
'箓',
'奡',
'鸮',
'翟',
'滠',
'辄',
'夸',
'袱',
'】',
'阿',
'摁',
'觽',
'垠',
'棼',
'杉',
'甏',
'旖',
'阜',
'猩',
'埤',
'醛',
'馥',
'哫',
'囝',
'晖',
'骸',
'椭',
'军',
'哺',
'束',
'犄',
'遛',
'涡',
'罄',
'赇',
'幌',
'曙',
'契',
'饹',
'圳',
'仝',
'爝',
'示',
'敝',
'漓',
'马',
'铐',
'掳',
'鲱',
'蟀',
'阵',
'栒',
'b',
'轮',
'俯',
'嬉',
'漩',
'佟',
'捆',
'迩',
'液',
'炊',
'抒',
'迭',
'换',
'菘',
'请',
'柩',
'腓',
'妥',
'怖',
'穆',
'骝',
'胛',
'幺',
'燥',
'棹',
'孖',
'洁',
'边',
'彥',
'睨',
'桁',
'淆',
'醤',
'奘',
'伙',
'刘',
'o',
'過',
'鏖',
'怄',
'镗',
'蘖',
'卩',
'龈',
'枣',
'联',
'圊',
'贫',
'郭',
'梗',
'赡',
'輸',
'拼',
'冰',
'Ë',
'姓',
'办',
'拉',
'富',
'对',
'肩',
'缬',
'逻',
'瞠',
'な',
'荚',
'宝',
'緃',
'峋',
'鞁',
'坉',
'译',
'银',
'猹',
'榞',
'借',
'楠',
'殽',
'片',
'谸',
'雩',
'琨',
'颏',
'晷',
';',
'莠',
'楽',
'嬗',
'啉',
'爍',
'視',
'岽',
'荙',
'冗',
'『',
'鯭',
'觌',
'喹',
'药',
'腈',
'蹰',
'–',
'泷',
'榷',
'卮',
'缥',
'各',
'瘙',
'凡',
'悍',
'劢',
'6',
'镰',
'四',
'摈',
'驹',
'陵',
'沟',
'麟',
'骊',
'椀',
'★',
'滦',
'菌',
'彊',
'疽',
'辫',
'璎',
'郁',
'资',
'粼',
'萄',
'鳁',
'鸤',
'漁',
'痃',
'绌',
'蒴',
'尊',
'哙',
'守',
'坠',
'胯',
'泽',
'持',
'隅',
'耧',
'逛',
'鄯',
'瑜',
'召',
'眷',
'逄',
'垦',
'窄',
'板',
'赵',
'源',
'绹',
'總',
'适',
'轰',
'钛',
'停',
'唝',
'燎',
'栽',
'燃',
'搬',
'夬',
'掐',
'簦',
'旃',
'更',
'蹊',
'熙',
'埃',
'偲',
'蒙',
'舍',
'杭',
'朋',
'霍',
'谙',
'蓥',
'赫',
'鲏',
'純',
'缃',
'蓓',
'è',
'萧',
'锆',
'诉',
'恚',
'u',
'旷',
'⑵',
'褲',
'鲟',
'互',
'峂',
'绝',
'陒',
'议',
'脽',
'态',
'岙',
'僮',
'突',
'濯',
'犹',
'阆',
'溧',
'宜',
'霣',
'呆',
'鄉',
'觖',
'濠',
'耐',
'橱',
'敛',
'踮',
'怦',
'鸠',
'授',
'滫',
'叭',
'镤',
'仵',
'圖',
'救',
'变',
'寕',
'洋',
'泃',
'晥',
'檎',
'缦',
'鏠',
'悬',
'彧',
'韓',
'籽',
'磷',
'歙',
'÷',
'杨',
'闯',
'罴',
'鼠',
'陋',
'瀣',
'揾',
'匪',
'晚',
'丧',
'彷',
'梏',
'诽',
'尻',
'蹢',
'拊',
'氕',
'芳',
'凸',
'懊',
'型',
'媄',
'憝',
'骆',
'纭',
'刺',
'悼',
'藍',
'欧',
'葳',
'艺',
'±',
'紗',
'钡',
'钭',
'首',
'栈',
'闩',
'勃',
'喑',
'栉',
'栟',
'焊',
'哀',
'竖',
'肘',
'悲',
'鳜',
'迨',
'怿',
'裘',
'綮',
'蕹',
'冕',
'无',
'鼢',
'戽',
'鲣',
'蜍',
'插',
'扯',
'俣',
'袪',
'级',
'理',
'茵',
'矣',
'障',
'禊',
'惯',
'䄂',
'宏',
'韫',
'栗',
'编',
'座',
'跫',
'、',
'捞',
'谠',
'車',
'袆',
'舖',
'暝',
'9',
'混',
'蓊',
'韂',
'拳',
'j',
'伶',
'啦',
'0',
'诰',
'缑',
'郴',
'蕲',
'谛',
'皋',
'兢',
'件',
'隈',
'溊',
'窈',
'檀',
'洪',
'揭',
'油',
'颐',
'剎',
'侠',
'或',
'腻',
'迪',
'舔',
'牺',
'倦',
'夭',
'蠋',
'鹑',
'倜',
'喱',
'豨',
'谨',
'翥',
'馄',
'蔚',
'类',
'鳍',
'泯',
'岷',
'張',
'紅',
'情',
'婪',
'睡',
'诒',
'旋',
'舱',
'列',
'求',
'姥',
'翯',
'锲',
'適',
'蒡',
'㭗',
'韵',
'撄',
'律',
'湊',
'鲪',
'碓',
'馓',
'汛',
'尤',
'℃',
'泫',
'竹',
'溃',
'诵',
'乡',
'楹',
'肷',
'戋',
'獭',
'撴',
'晤',
'嘎',
'裢',
'轱',
'歘',
'鼱',
'舀',
'潵',
'腩',
'挽',
'至',
'骞',
'佻',
'蕊',
'轫',
'岘',
'斌',
'《',
'雇',
'枘',
'贶',
'履',
'亭',
'绍',
'空',
'泡',
'擒',
'蠓',
'桼',
'舢',
'踵',
'柢',
'躺',
'罥',
'蔁',
'幪',
'蒯',
'≤',
'齉',
'況',
'锕',
'徇',
'儿',
'帽',
'谕',
'抽',
'獍',
'揪',
'膳',
'酴',
'姊',
'作',
'弍',
'郦',
'翮',
'髌',
'勝',
'孔',
'颁',
'泩',
'衾',
'翊',
'噉',
'∩',
'先',
'的',
'財',
'绢',
'崇',
'饲',
'賓',
'绾',
'陡',
'砾',
'纷',
'酱',
'窎',
'浕',
'琫',
'补',
'嗽',
'呛',
'蚓',
'伪',
'艨',
'搡',
'粗',
'阱',
'商',
'郫',
'喵',
'缯',
'炻',
'州',
'珽',
'芒',
'脶',
'蕖',
'拘',
'\\',
'蕃',
'伏',
'蛏',
'璘',
'缡',
'伞',
'吸',
'煞',
'嗫',
'餪',
'━',
'8',
'漠',
'衮',
'峭',
'筌',
'阀',
'乇',
'杞',
'镕',
'鹈',
'觚',
'疋',
'猥',
'肚',
'阃',
'地',
'鸾',
'玚',
'镀',
'诬',
'凇',
'惬',
'劝',
'堠',
'睪',
'瞪',
'涓',
'專',
'琢',
'蠹',
'裂',
'芎',
'轲',
'谯',
'畋',
'长',
'攘',
'缁',
'吵',
'汈',
'稂',
'咤',
'甸',
'瀑',
'讣',
'翠',
'綦',
'笑',
'掺',
'宫',
'唆',
'旗',
'帘',
'遵',
'唪',
'连',
'必',
'姬',
'枵',
'渫',
'神',
'凱',
'虞',
'闵',
'爭',
'迢',
'飓',
'桴',
'冑',
'招',
'鬶',
'赊',
'朦',
'薜',
'逗',
'铩',
'焖',
'狱',
'昕',
'犀',
'捏',
'侓',
'爆',
'箧',
'怠',
'缐',
'苄',
'踯',
'暹',
'絮',
'裁',
'嘶',
'诙',
'攥',
'¥',
'痫',
'摹',
'朕',
'薰',
'闼',
'樨',
'需',
'蕾',
'扔',
'服',
'蚩',
'漳',
'瞻',
'陟',
'诐',
'爽',
'耩',
'坏',
'寶',
'瞧',
'蘅',
'爺',
'仇',
'瞈',
'揉',
'隰',
'阏',
'皤',
'鉏',
'郇',
'啵',
'僧',
'渐',
'骠',
'厾',
'谦',
'榱',
'蓮',
'乂',
'伷',
'觐',
'遫',
'畀',
'污',
'眭',
'蝗',
'亢',
'腾',
'遇',
'欺',
'狸',
'籼',
'锯',
'赚',
'槔',
'域',
'老',
'掩',
'锎',
'邪',
'沬',
'袯',
'映',
'肤',
'舒',
'箦',
'涎',
'缔',
'孃',
'萎',
'推',
'峧',
'嫒',
'嵐',
'怒',
'闾',
'阅',
'扢',
'絡',
'剩',
'腢',
'晌',
'铟',
'铚',
'燔',
'鄜',
'墠',
'擤',
'芸',
'鼩',
'食',
'朰',
'啥',
'贿',
'券',
'垩',
'典',
'逭',
'成',
'帧',
'侯',
'妒',
'顷',
'晩',
'浦',
'汳',
'㾄',
'坊',
'②',
'蝼',
'倩',
'挦',
'騠',
'蓂',
'兹',
'渤',
'茴',
'矶',
'煤',
'伛',
'逃',
'堞',
'漭',
'闽',
'埠',
'妗',
'烙',
'傀',
'滢',
'堂',
'骅',
'崮',
'兿',
'螟',
'榴',
'蒈',
'蟛',
'员',
'嗟',
'毗',
'鹭',
'毖',
'籍',
'傣',
'偈',
'澴',
'耆',
'黔',
'薷',
'俘',
'箸',
'蒺',
'记',
'铣',
'拥',
'瑰',
'抉',
'史',
'急',
'什',
'川',
'曪',
'剖',
'罪',
'扥',
'鱼',
'羌',
'复',
'昵',
'朓',
'氪',
'矅',
'ò',
'摒',
'催',
'{',
'懂',
'莉',
'屃',
'症',
'遒',
'璋',
'鄒',
'玄',
'氦',
'舳',
'納',
'锷',
'鲥',
'羸',
'怵',
'嬖',
'飚',
'倔',
'辨',
'篌',
'娄',
'洎',
'弟',
'悝',
'婥',
'待',
'梃',
'棕',
'撞',
'肊',
'婺',
'桥',
'慕',
'5',
'尖',
'监',
'囊',
'腎',
'瘁',
'⑴',
'伢',
'邈',
'炷',
'籴',
'月',
'终',
'龠',
'蹇',
'柯',
'噜',
'多',
'玮',
'踹',
'泣',
'圮',
'辈',
'鄙',
'赆',
'蠃',
'珈',
'鬃',
'识',
'甑',
'藓',
'宥',
'韧',
'隗',
'跚',
'峁',
'晒',
'戳',
'環',
'葓',
'筐',
'瑚',
'稆',
'巩',
'葵',
'网',
'铨',
'仡',
'呶',
'休',
'村',
'傩',
'浡',
'祝',
'幅',
'晳',
'岿',
'[',
'尃',
'响',
'咽',
'讵',
'淹',
'糠',
'驴',
'烹',
'甪',
'焯',
'整',
'瘆',
'茀',
'瑞',
'嘁',
'赅',
'芼',
'震',
'怼',
'膑',
'蒟',
'钊',
'缷',
'獨',
'俄',
'噪',
'亏',
'芍',
'鲲',
'黟',
'酃',
'铻',
'→',
'鲡',
'仑',
'有',
'扌',
'治',
'聆',
'腙',
'冬',
'剥',
'诓',
'祃',
'棘',
'孥',
'濆',
'鞋',
'赣',
'卜',
'谆',
'投',
'琊',
'塍',
'洗',
'津',
'肴',
'奕',
'掴',
'螗',
'胸',
'惦',
'赠',
'耶',
'蛸',
'曷',
'名',
'栏',
'崖',
'始',
'孤',
'篆',
'椴',
'模',
'儙',
'袁',
'颌',
'卤',
'寂',
'呸',
'蓺',
'噶',
'钔',
'粹',
'潸',
'郾',
'娡',
'啖',
'芜',
'䧳',
'缟',
'鞅',
'哇',
'嚄',
'熛',
'私',
'住',
'鉄',
'U',
'失',
'蜾',
'㺃',
'莨',
'擂',
'沕',
'铄',
'耰',
'炔',
'藐',
'锈',
'苇',
'芯',
'檇',
'龍',
'珀',
'筻',
'褚',
'缀',
'棬',
'仲',
'杧',
'铛',
'挖',
'缸',
'嵇',
'剟',
'觋',
'鬼',
'天',
'鹪',
'豭',
'腴',
'驿',
'粵',
'馈',
'迸',
'夕',
'蜚',
'禺',
'迎',
'狞',
'嶽',
'躯',
'暅',
'蹾',
'甾',
'柆',
'e',
'欃',
'無',
'羽',
'蛛',
'僖',
'碲',
'遴',
'厝',
'滂',
'眦',
'鹅',
'咖',
'潜',
'媽',
'啴',
'寨',
'琬',
'判',
'塌',
'与',
'剧',
'掮',
'读',
'庆',
'愚',
'氲',
'梾',
'稗',
'很',
'饯',
'淘',
'灞',
'A',
'!',
'飾',
'醚',
'壁',
'芮',
'蔼',
'知',
'郯',
'瞒',
'术',
'法',
'匠',
'┅',
'尕',
'脂',
'琅',
'孝',
'埙',
'濟',
'袷',
'方',
'芾',
'驽',
'线',
'咡',
'睿',
'滥',
'鞨',
'駹',
'馎',
'蛲',
'申',
'涣',
'牗',
'跄',
'鲐',
'泐',
'铍',
'肓',
'é',
'司',
'辣',
'慑',
'崞',
'魏',
'髯',
'涯',
'滃',
'薪',
'~',
'鐵',
'町',
'芥',
'匿',
'癞',
'嘚',
'□',
'啪',
'俇',
'橛',
'巅',
'鄞',
'痱',
'回',
'着',
'魂',
'瘀',
'埒',
'措',
'蚪',
'锁',
'巴',
'芏',
'另',
'忏',
'洇',
'⑾',
'箱',
'劳',
'榈',
'B',
'毒',
'泰',
'巍',
'寇',
'斛',
'赖',
'酒',
'密',
'左',
'莜',
'茯',
'脆',
'饴',
'洳',
'舉',
'酪',
'鼒',
'職',
'桫',
'螋',
'砌',
'戬',
'前',
'豁',
'膲',
'鲯',
'憋',
'珺',
'蹂',
'亥',
'冷',
'蜔',
'俦',
'碇',
'慰',
'扒',
'亮',
'弒',
'胫',
'肠',
'弇',
'拣',
'丸',
'涫',
'勉',
'帝',
'玠',
'应',
'砜',
'鬓',
'泮',
'鳖',
'峇',
'辗',
'吴',
'僡',
'玊',
'钘',
'惘',
'奁',
'翰',
'爨',
'罽',
'莶',
'纻',
'菪',
'興',
'钧',
'鄹',
'缌',
'嘉',
'玲',
'蛋',
'倚',
'镬',
'彳',
'氯',
'谐',
'疗',
'魉',
'扈',
'鏡',
'涤',
'佑',
'勾',
'饽',
'R',
'局',
'醉',
'燫',
'驱',
'崽',
'榮',
'锄',
'脎',
'枓',
'敲',
'俑',
'镶',
'当',
'逦',
'寅',
'捽',
'宗',
'茼',
'稿',
'躇',
'晋',
'东',
'渭',
'闶',
'潦',
'慊',
'蔟',
'疑',
'蜡',
'嬛',
'荒',
'扪',
'拈',
'受',
'沱',
'螽',
'嗣',
'瘰',
'颖',
'百',
'楱',
'崛',
'窿',
'蓬',
'禨',
'螵',
'捕',
'鳀',
'霰',
'瘸',
'圄',
'陂',
'敢',
'矗',
'炉',
'篪',
'注',
'凉',
'摔',
'衿',
'g',
'遘',
'鳟',
'腚',
'泱',
'荣',
'池',
'杰',
'阻',
'里',
'峥',
'葺',
'翔',
'柁',
'飐',
'载',
'刨',
'瘊',
'溏',
'嚭',
'穝',
'站',
'笞',
'厌',
'门',
'汞',
'雠',
'靖',
'怨',
'葙',
'厅',
'凉',
'荨',
'底',
'坼',
'海',
'轩',
'秃',
'醭',
'莒',
'坎',
'驺',
'瀛',
'嵝',
'溥',
'嚋',
'寤',
'k',
'築',
'耔',
'跎',
'小',
'弊',
'疭',
'√',
'洞',
'利',
'次',
'迕',
'鸿',
'刁',
'媳',
'酹',
'磋',
'勒',
'伎',
'浔',
'斤',
'珊',
'鸳',
'颊',
'塗',
'刈',
'龛',
'縻',
'楚',
'脓',
'南',
'伧',
'桨',
'尸',
'退',
'亊',
'侔',
'蓟',
'削',
'诲',
'瑯',
'挝',
'绩',
'嶂',
'耷',
'太',
'著',
'讥',
'烂',
'哥',
'菔',
'唳',
'筫',
'嚷',
'斯',
'蔡',
'碧',
'慵',
'搐',
'琵',
'逶',
'菡',
'篙',
'驭',
'莲',
'毫',
'犯',
'坌',
'啕',
'疴',
'傻',
'牧',
'肺',
'既',
'悟',
'讳',
'练',
'钠',
'胨',
'G',
'迁',
'帙',
'嫦',
'哿',
'柝',
'迤',
'庑',
'踟',
'粤',
'乜',
'悭',
'霁',
'在',
'虔',
'蓦',
'暾',
'鲅',
'様',
'徐',
'诫',
'料',
'蒂',
'揎',
'溜',
'崎',
'玦',
'隐',
'绳',
'幼',
'钼',
'腧',
'槌',
'镅',
'锿',
'蹁',
'猱',
'狁',
'蹈',
'S',
'傢',
'}',
'珉',
'浴',
'龚',
'吇',
'肆',
'⑩',
'臌',
'鏢',
'―',
'定',
'哧',
'螳',
'爹',
'摞',
'榍',
'苩',
'丑',
'犴',
'璀',
'偎',
'燹',
'洯',
'啁',
'鱾',
'計',
'镂',
'字',
'琉',
'壴',
'霖',
'蟜',
'做',
'松',
'扣',
'徊',
'叱',
'桑',
'≠',
'寓',
'崔',
'茌',
'`',
'殓',
'猖',
'慎',
'坻',
'皮',
'喔',
'耕',
'拧',
'织',
'桂',
'垝',
'约',
'飯',
'皿',
'移',
'微',
'桅',
'钬',
'赑',
'宓',
'颉',
'掂',
'希',
'沁',
'翳',
'澝',
'崭',
'聃',
'蔸',
'磕',
'崚',
'奉',
'槍',
'颠',
'任',
'飕',
'蛴',
'歼',
'蛭',
'¥',
'鉵',
'刷',
'泓',
'頫',
'诤',
'阈',
'诖',
'漂',
'冯',
'柠',
'本',
'狼',
'芗',
'丹',
'柒',
'饫',
'衫',
'摩',
'桃',
'啼',
'譄',
'醌',
'帡',
'少',
'螃',
'祷',
'幸',
'喘',
'噼',
'甲',
'刭',
'泊',
'那',
'舄',
'畲',
'遊',
'記',
'绠',
'蝈',
'忒',
'耙',
'鹌',
'搽',
'绕',
'镠',
'凼',
'扫',
'鸵',
'匡',
'缈',
'铼',
'挢',
'踊',
'噭',
'苴',
'貌',
'啾',
'蒜',
'茱',
'⒅',
'邛',
'棉',
'怀',
'筵',
'笾',
'邢',
'濱',
'蒲',
'嫠',
'儡',
'益',
'萊',
'歩',
'日',
'婢',
'楔',
'嚎',
'髂',
'禄',
'巫',
'懿',
'砍',
'惆',
'袭',
'~',
'欲',
'鳅',
'書',
'撷',
'库',
'绻',
'⒁',
'蒹',
'辜',
'屉',
'奂',
'龇',
'诡',
'醑',
'儀',
'讷',
'聒',
'盖',
'浅',
'長',
'蛑',
'念',
'辒',
'蚊',
'勖',
'揣',
'岬',
'糅',
'刊',
'蛆',
'硌',
'柜',
'惗',
'激',
'颈',
'閣',
'唬',
'捧',
'蒽',
'爸',
'侏',
'氧',
'蛤',
'牡',
'瘦',
'铉',
'撒',
'屿',
'谔',
'钀',
'瓦',
'恂',
'钻',
'声',
'馨',
'贷',
'藁',
'闰',
'人',
'瀹',
'间',
'炜',
'煨',
'畴',
'鞡',
'悔',
'量',
'原',
'屁',
'杯',
'趋',
'愎',
'瓶',
'烘',
'韬',
'姮',
'勰',
'眛',
'饮',
'瘐',
'决',
'版',
'際',
'俸',
'此',
'辽',
'愫',
'爷',
'隘',
'螯',
'腕',
'闟',
'厣',
'齁',
'矿',
'女',
'扇',
'郄',
'诚',
'焜',
'<',
'檵',
'赙',
'郢',
'酌',
'恳',
'侵',
'劍',
'徳',
'脔',
'岍',
'倍',
'隹',
'镲',
'僬',
'○',
'啭',
'坳',
'谰',
'璪',
'昆',
'⒆',
'惧',
'虺',
'篡',
'锐',
'邮',
'嵊',
'恹',
'茄',
'黯',
'對',
'魑',
'禀',
'添',
'汎',
'廉',
'戈',
'∈',
'陈',
'肟',
'螅',
'缰',
'啃',
'瘾',
'辁',
'茜',
'曝',
'C',
'餍',
'蜴',
'咦',
'臺',
'扺',
'隽',
'崴',
'遐',
'胃',
'铕',
'楗',
'墀',
'魈',
'淑',
'邰',
'飧',
'勤',
'糨',
'你',
'铂',
'蛰',
'锻',
'塈',
'予',
'怏',
'鷪',
'暂',
'诞',
'會',
'鼐',
'辏',
'矬',
'筜',
'蟒',
'柫',
'靴',
'垒',
'樵',
'狨',
'魋',
'查',
'掸',
''',
'每',
'浮',
'绞',
'疍',
'於',
'饦',
'辐',
'墟',
'窳',
'养',
'墦',
'鲔',
'黝',
'迈',
'砟',
'伥',
'藜',
'墅',
'喬',
'卬',
'赶',
'眼',
'龌',
'主',
'嗞',
'転',
'襕',
',',
'杲',
'儒',
'政',
'蹩',
'付',
'Я',
'厢',
'点',
'如',
'茗',
'奍',
'嗌',
'蕴',
'问',
'膚',
'硒',
'佃',
'居',
'赍',
'鯨',
'槜',
'衡',
'廐',
'鲾',
'慈',
'莫',
'篮',
'铱',
'园',
'范',
'靠',
'叻',
'绸',
'众',
'抑',
'浃',
'極',
'辀',
'千',
'蔯',
'r',
'碱',
'應',
'夼',
'祺',
'绣',
'澉',
'愛',
'譬',
'刚',
'扼',
'檫',
'时',
'荼',
'部',
'耽',
'稀',
'琳',
'鎮',
'鳃',
'疌',
'挠',
'京',
'筴',
'胳',
'橡',
'裱',
'栊',
'蛩',
'流',
'猄',
'葭',
'邯',
'伤',
'秦',
'孺',
'郓',
'筏',
'茉',
'谈',
'黥',
'鳇',
'魅',
'秫',
'敫',
'肄',
'俪',
'尺',
'度',
'廊',
'昏',
'怎',
'钎',
'愤',
'腿',
'Λ',
'碘',
'囤',
'婆',
'煋',
'桀',
'阪',
'焒',
'砘',
'澡',
'阒',
'臼',
'茭',
'纛',
'唻',
'胗',
'歌',
'吱',
'铸',
'種',
'礳',
'舾',
'砰',
'即',
'慥',
'缆',
'躞',
'卖',
'眆',
'搎',
'鲁',
'稠',
'惝',
'毶',
'耎',
'挡',
'异',
'咨',
'歔',
'垫',
'素',
'鳊',
'打',
'镏',
'耗',
'锭',
'剀',
'讓',
'鍋',
'歇',
'拗',
'齿',
'聊',
'惕',
'塔',
'况',
'汐',
'采',
'灣',
'菁',
'峰',
'呋',
'阴',
'衽',
'鹏',
'挂',
'鲞',
'第',
'浑',
'秭',
'铯',
'胎',
'滔',
'雕',
'渔',
'骍',
'鴻',
'眚',
'易',
'枫',
'麥',
'罹',
'劈',
'苣',
'蹄',
'是',
'锛',
'饼',
'铳',
'器',
'秒',
'開',
'舛',
'纳',
'庒',
'饰',
'发',
'虎',
'乏',
'届',
'浯',
'目',
'霪',
'氢',
'华',
'澧',
'陴',
'誊',
'欷',
'瀌',
'梵',
'嗖',
'惩',
'妞',
'螓',
'溇',
'嬃',
'笼',
'嬢',
'獠',
'辩',
'骛',
'挪',
'礅',
'銎',
'趺',
'狍',
'阑',
'擦',
'咙',
'+',
'鼻',
'戆',
'宿',
'霏',
'牁',
'耦',
'枳',
'鲸',
'阽',
'峯',
'瘭',
'祁',
'镜',
'绮',
'道',
'摭',
'﹒',
'耠',
'限',
'轻',
'莽',
'帛',
'唯',
'墒',
'W',
'荦',
'矸',
'崃',
'洫',
'杳',
'舌',
'涌',
'朵',
'苑',
'瓻',
'辂',
'凬',
'畺',
'莩',
'奔',
'荐',
'撵',
'嶲',
'憧',
'沖',
'邱',
'瞑',
'瘢',
'腺',
'嵯',
'诗',
'經',
'胚',
'谎',
'央',
'稼',
'3',
'冈',
'痣',
'故',
'皎',
'珅',
'踅',
'硇',
'通',
'鹱',
'草',
'粕',
'而',
'梨',
'萜',
'搛',
'鸺',
'托',
'倡',
'匾',
'骷',
'桐',
'阇',
'璃',
'抖',
'显',
'镝',
'I',
'锣',
'辆',
'茝',
'虫',
'谀',
'萤',
'帼',
'滈',
'鮼',
'乔',
'会',
'产',
'縢',
'纱',
'跆',
'铤',
'圯',
'旚',
'墓',
'棰',
'苜',
'聩',
'蚍',
'筢',
'殇',
'槚',
'阂',
'豊',
'翚',
'犰',
'疚',
'浠',
'礴',
'界',
'蛙',
'吁',
'忪',
'讫',
'辇',
'汧',
'澥',
'纮',
'糺',
'拭',
'镉',
'鄠',
'讼',
'鎏',
'逐',
'烝',
'扊',
'筹',
'仪',
'段',
'杵',
'卲',
'钤',
'曹',
'潘',
'浏',
'陑',
'答',
'期',
'橋',
'位',
'梅',
'榻',
'芨',
'汭',
'贇',
'杅',
'伋',
'馁',
'皈',
'躁',
'鲦',
'良',
'幤',
'曺',
'榖',
'便',
'氍',
'窍',
'槃',
'設',
'襦',
'菓',
'猡',
'槲',
'觱',
'邠',
'岩',
'骈',
'鬲',
'睽',
'残',
'碗',
'凯',
'览',
'伾',
'吣',
'峡',
'箨',
'忡',
'岁',
'醵',
'霸',
'焐',
'谁',
'疟',
'樾',
'竺',
'果',
'阝',
'花',
'•',
'耱',
'嗜',
'骰',
'萋',
'甄',
'侍',
'厦',
'辌',
'给',
'健',
'垧',
'娩',
'校',
'又',
'临',
'揽',
'犟',
'蠢',
'包',
'檬',
'穹',
'燮',
'札',
'翏',
'领',
'深',
'诶',
'窒',
'鸷',
'统',
'肾',
'澍',
'畹',
'职',
'蝟',
'眬',
'旎',
'朘',
'眠',
'篚',
'贼',
'貴',
'#',
'茆',
'磬',
'①',
'祀',
'坞',
'盯',
'苹',
'痼',
'耪',
'狺',
'妓',
'湨',
'動',
'渚',
'售',
'鸶',
'霄',
'某',
'×',
'铀',
'桓',
'脲',
'心',
'节',
'[',
'蜩',
'剐',
'猜',
'盂',
'穿',
'洮',
'坜',
'掷',
'坐',
'烜',
'冶',
'袍',
'穴',
'偷',
'槽',
'面',
'媛',
'撙',
'孩',
'询',
'苈',
'橙',
'恙',
'吉',
'燈',
'暇',
'杋',
'後',
'璇',
'喟',
'妪',
'湄',
'贡',
'兮',
'楫',
'锗',
'肮',
'圉',
'参',
'烃',
'葩',
'骀',
'锖',
'犿',
'恼',
'麯',
'牮',
'溱',
'俵',
'祢',
'割',
'羲',
'中',
'博',
'膦',
'7',
'钙',
'耸',
'蚋',
'嘬',
'逝',
'瓿',
'且',
'苗',
'屑',
'華',
'糯',
'吓',
'陇',
'.',
'魆',
'd',
'拶',
'箜',
'澳',
'蘼',
'垸',
'钅',
'樯',
'侑',
'娼',
'赛',
'恪',
'击',
'濮',
'隔',
'似',
'惜',
'滤',
'培',
'谩',
'坝',
'煙',
'馕',
'茡',
'颼',
'啡',
'强',
'巡',
'糗',
'芙',
'骒',
'常',
'鳔',
'楣',
'嫩',
'师',
'攀',
'旭',
'茠',
'吏',
'剌',
'露',
'把',
'携',
'忘',
'软',
'荩',
'弧',
'锩',
'僦',
'掘',
'仓',
'嵚',
'沲',
'傅',
'蝴',
'爵',
'纪',
'薮',
'參',
'荀',
'珙',
'逞',
'蹙',
'徉',
'佶',
'庹',
'弢',
'锞',
'想',
'窕',
'躬',
'蚡',
'闸',
'难',
'妃',
'唶',
'V',
'蚂',
'酐',
']',
'羁',
'土',
'敏',
'蝻',
'赎',
'闹',
'铷',
'脬',
'攫',
'椐',
'橹',
'(',
'暨',
'剁',
'灵',
'咫',
'苻',
'赈',
'萝',
'鹮',
'颛',
'勿',
'臆',
'福',
'蝠',
'烺',
'跤',
'垓',
'庋',
'鏊',
'彭',
'碚',
'膂',
'鐘',
'鸹',
'择',
'疫',
'暌',
'胙',
'翘',
'仞',
'實',
'猫',
'嘹',
'坟',
'泺',
'靽',
'仟',
'鲋',
'畅',
'箪',
'箩',
'星',
'辍',
'餐',
'伍',
'狃',
'蹐',
'芴',
'龋',
'仨',
'狩',
'诌',
'媚',
'琚',
'❤',
'鉰',
'仔',
'忝',
'垅',
'嗤',
'氅',
'填',
'詹',
'诿',
'皑',
'椅',
'鲭',
'繪',
'碑',
'选',
'廠',
'嶓',
'迮',
'唠',
'赏',
'│',
'泍',
'姑',
'晦',
'直',
'艾',
'邂',
'裝',
'郊',
'疡',
'」',
'鸲',
'兕',
'县',
'邡',
'麤',
'旧',
'壶',
'礼',
'梭',
'铔',
'玕',
'硬',
'后',
'馅',
'窠',
'俊',
'犾',
'槭',
'姨',
'妨',
'幡',
'沿',
'帮',
'爿',
'褊',
'淅',
'册',
'诔',
'使',
'唢',
'族',
'逮',
'蟋',
'掣',
'红',
'颔',
'闲',
'咧',
'衍',
'矛',
'蹜',
'抱',
'雀',
'箴',
'雙',
'茁',
'聲',
'芰',
'瘤',
'落',
'峨',
'秆',
'献',
'霭',
'胰',
'墁',
'柽',
'跛',
'阼',
'菝',
'谗',
'蠊',
'懋',
'蔷',
'拃',
'岱',
'戡',
'逡',
'背',
'克',
'棱',
'栲',
'乖',
'橄',
'炭',
'萱',
'胲',
'摺',
'殆',
'魍',
'宾',
'拢',
'姁',
'祲',
'·',
'歹',
'胆',
'爱',
'旰',
'抢',
'匜',
'硚',
'愈',
'跳',
'▲',
'跪',
'網',
'糈',
'維',
'痹',
'娃',
'疸',
'痔',
'褙',
'芭',
'鹜',
'猷',
'檩',
'吨',
'淖',
'竟',
'呱',
'瘠',
'奢',
'呐',
'扞',
'灼',
'家',
'饿',
'玻',
'倾',
'锚',
'遗',
'赝',
'去',
'跣',
'纬',
'玢',
'梆',
'陉',
'屎',
'上',
'酆',
'搤',
'併',
'腌',
'避',
'禹',
'绅',
'帆',
'英',
'区',
'交',
'▪',
'巧',
'豹',
'游',
'清',
'荧',
'娀',
'訓',
'尾',
'觫',
'梢',
'均',
'忤',
'继',
'變',
'喽',
'尉',
'骚',
'趸',
'馃',
'石',
'置',
'毡',
'竴',
'龄',
'掭',
'骟',
'堡',
'确',
'街',
'沌',
'恨',
'壮',
'弄',
'鞴',
'剿',
'貅',
'路',
'杠',
'豚',
'澜',
'靼',
'擐',
'租',
'媪',
'彖',
'逢',
'撺',
'盗',
'呑',
'锥',
'栎',
'唧',
'翩',
'倥',
'虽',
'郏',
'钒',
'雉',
'捒',
'官',
'酷',
'樽',
'房',
'屣',
'堌',
'蒍',
'悌',
'④',
'蛳',
'俱',
'慢',
'筇',
'框',
'椽',
'债',
'吭',
'柱',
'夤',
'嘈',
'骺',
'趹',
'刓',
'豕',
'噢',
'J',
'论',
'俞',
'仙',
'碰',
'经',
'铋',
'⑤',
'顽',
'曲',
'得',
'汪',
'浒',
'际',
'嘏',
'扮',
'祊',
'嵋',
'‘',
'牒',
'禮',
'粒',
'籀',
'闱',
'刍',
'邕',
'美',
'苫',
'靺',
'铹',
'莰',
'蔑',
'敵',
'逑',
'锬',
'宸',
'鞥',
'匝',
'褀',
'菅',
'逊',
'脱',
'晔',
'罾',
'郝',
'恰',
'丟',
'芩',
'枷',
'鹩',
'a',
'夙',
'述',
'钢',
'瀵',
'铧',
'翱',
'尧',
'醮',
'&',
'鳐',
'懲',
'濩',
'树',
'劵',
'虾',
'砚',
'腄',
'罟',
'硖',
'崩',
'埘',
'╱',
'血',
'觯',
'巂',
'栀',
'萏',
'雪',
'眵',
'白',
'新',
'靶',
'猪',
'亻',
'窬',
'Ⅳ',
'麽',
'遄',
'沏',
'茅',
'笋',
'甬',
'潔',
'悛',
'幕',
'鹤',
'悴',
'耻',
'觜',
'滞',
'己',
'鏂',
'肛',
'婤',
'嘞',
'蘸',
'胴',
'柿',
'穗',
'咯',
'嵕',
'蜣',
'僰',
'玃',
'细',
'▏',
'戗',
'尘',
'仄',
'子',
'历',
'翌',
'烀',
'晞',
'桷',
'藕',
'啄',
'腐',
'瘥',
'诣',
'彗',
'捭',
'懑',
'陛',
'傥',
'沚',
'贯',
'﹑',
'雒',
'航',
'跬',
'晓',
'赢',
'鸭',
'臊',
'闳',
'稲',
'阁',
'鼋',
'‰',
'个',
'農',
'匮',
'辚',
'滗',
'桢',
'詈',
'绗',
'馇',
'蜓',
'专',
'余',
'鳉',
'稚',
'午',
'珍',
'癃',
'钵',
'档',
'颍',
'厕',
'岭',
'祓',
'诂',
'襙',
'炙',
'枯',
'锦',
'袤',
'桊',
'嗓',
'䘵',
'嫂',
'丰',
'苎',
'梦',
'早',
'菱',
'钱',
'灯',
'钮',
'锓',
'豐',
'蝤',
'协',
'h',
'鼓',
'燕',
'覺',
'涮',
'呗',
'専',
'篓',
'玷',
'褓',
'从',
'鲍',
'羧',
'俭',
'萌',
'樣',
'颜',
'谷',
'夹',
'囫',
'』',
'缙',
'鹰',
'条',
'状',
'沨',
'因',
'莺',
'楼',
'扰',
'禢',
'砧',
'埔',
'纩',
'臭',
'茶',
'妹',
'莼',
'境',
'山',
'诘',
'蒌',
'唤',
'仃',
'眄',
'田',
'畼',
'缱',
'祘',
'痴',
'揍',
'猾',
'甙',
'躲',
'返',
'砝',
'叽',
'苟',
'肭',
'悖',
'嫣',
'凋',
'踞',
'勢',
'弃',
'般',
'赤',
'佣',
'嘘',
'智',
'寒',
'旆',
'咎',
'戊',
'温',
'昙',
'蝄',
'掉',
'冤',
'凍',
'一',
'鋼',
'茏',
'兼',
'昃',
'峤',
'挟',
'0',
'顾',
'颅',
'*',
'遆',
'硅',
'烯',
'眊',
'鳘',
'下',
'雾',
'癖',
'贮',
'缴',
'升',
'劲',
'婞',
'掇',
'梯',
'壬',
'撮',
'绑',
'氣',
'薤',
'兔',
'赟',
'漕',
'签',
'顇',
'砭',
'鸼',
'明',
'佧',
'鹗',
'哉',
'席',
'趁',
'砖',
'澌',
'撤',
'萨',
'熔',
'蚝',
'狮',
'夔',
'介',
'青',
'喈',
'郂',
'埝',
'狗',
'哚',
'咪',
'材',
'跑',
'炗',
'龉',
'髓',
'衣',
'觀',
'淋',
'寄',
'羮',
'抵',
'恁',
'藿',
'蜢',
'甜',
'兽',
'洒',
'眶',
'薯',
'绷',
'颀',
'骑',
'鲻',
'|',
'q',
'繄',
'丝',
'焙',
'瑕',
'童',
'豸',
'讨',
'钿',
'艮',
'踧',
'幽',
'焰',
'宽',
'址',
'鸩',
'堉',
'音',
'擅',
'铞',
'埌',
'宙',
'_',
'钥',
'承',
'率',
'噬',
'凌',
'程',
'蚕',
'嘣',
'饭',
'橉',
'径',
'1',
'鄏',
'袜',
'孙',
'樊',
'窦',
'牦',
'歡',
'罕',
'蓉',
'诩',
'㧎',
'责',
'豢',
'逅',
'甘',
'礶',
'镥',
'穂',
'到',
'檑',
'皇',
'泖',
'腱',
'郤',
'竞',
'竽',
'溴',
'木',
'蛀',
'蛟',
'燧',
'鹳',
'谵',
'钳',
'魔',
'链',
'咆',
'荡',
'婳',
'冢',
'鲧',
'昝',
'※',
'倫',
'才',
'簿',
'醫',
'吕',
'姗',
'L',
'俺',
'隳',
'鮮',
'衩',
'鲆',
'崟',
'鲹',
'岗',
'镇',
'嗄',
'硪',
'盎',
'氟',
'笪',
'今',
'公',
'尽',
'佬',
'骧',
'驻',
'翼',
'咚',
'盱',
'镎',
'浈',
'谅',
'洟',
'嘭',
'跶',
'蔹',
'咭',
'妁',
'殚',
'砷',
'购',
'犸',
'哄',
'笸',
'喂',
'赋',
'倓',
'项',
'臧',
'梳',
'笏',
'鹝',
'昭',
'罿',
'镄',
'П',
'湯',
'U',
'绐',
'绂',
'鸬',
'毐',
'台',
'鈴',
'憾',
'痰',
'缭',
'绒',
'赁',
'效',
'哝',
'─',
'偆',
'泗',
'谇',
'貘',
'搜',
'阗',
'個',
'艟',
'嗔',
'正',
'筛',
'鼷',
'摛',
'馀',
'坡',
'卓',
'厥',
'睾',
'雯',
'篷',
'狰',
'掀',
'夫',
'靛',
'伻',
'茇',
'顧',
'猕',
'占',
'俟',
'兄',
'垡',
'兆',
'铃',
'屙',
'轵',
'銮',
'磲',
'桤',
'跷',
'缳',
'粘',
'袢',
'尬',
'獘',
'社',
'彬',
'哨',
'煳',
'莊',
'教',
'鸸',
'窖',
'晰',
'捻',
'环',
'廿',
'驶',
'椠',
'熟',
'赓',
'挥',
'兵',
'洚',
'桧',
'埼',
'嘀',
'哎',
'柞',
'悄',
'调',
'洼',
'蛇',
'铬',
'蝇',
'倆',
'谂',
'姻',
'怕',
'瑙',
'算',
'惮',
'遥',
'惟',
'甫',
'玺',
'袈',
'税',
'玟',
'械',
'擗',
'淤',
'溟',
'揞',
'纲',
'谤',
'條',
'翕',
'荛',
'忾',
'馿',
'糖',
'檗',
'垱',
'┐',
'躜',
'缒',
'您',
'蹶',
'合',
'数',
'斟',
'粲',
'玖',
'淞',
'孰',
'觎',
'M',
'嫪',
'毽',
'桩',
'蹦',
'亹',
'胾',
'亲',
'痉',
'莙',
'捐',
'烁',
'瓣',
'邀',
'但',
'误',
'饻',
'妄',
'镱',
'民',
'嗳',
'竦',
'柰',
'脒',
'斓',
'瞟',
'拱',
'霾',
'粜',
'腽',
'咬',
'唿',
'礻',
'y',
'褒',
'郪',
'熰',
'梻',
'甭',
'处',
'拖',
'蜉',
'鄱',
'絲',
'宠',
'瞵',
'荷',
'靓',
'喻',
'阢',
'伫',
'担',
'朐',
'墙',
'儣',
'胄',
'簏',
'皆',
'踌',
'萃',
'命',
'滟',
'睹',
'叁',
'蟮',
'東',
'﹖',
'式',
'營',
'疠',
'醳',
'尔',
'購',
'吒',
'柴',
'途',
'力',
'疰',
'寳',
'萬',
'挨',
'碥',
'牍',
'嘻',
'柃',
'剡',
'徝',
'杖',
'螺',
'祈',
'産',
'煽',
'讽',
'瞭',
'由',
'牀',
'涉',
'暴',
'枚',
'仰',
'它',
'胤',
'驯',
'港',
'寵',
'熄',
'蛮',
'务',
'殃',
'亸',
'涢',
'妫',
'粥',
'扦',
'寺',
'抿',
'湃',
'C',
'脚',
'涸',
'动',
'務',
'镭',
'检',
'釂',
'耳',
'榦',
'怆',
'氨',
'瘳',
'钽',
'牚',
'负',
'纂',
'獬',
'息',
'婄',
'襞',
'囹',
'酰',
'扑',
'臛',
'价',
'褡',
'篼',
'媢',
'酊',
'腋',
'愣',
'垯',
'喃',
'牾',
'犨',
'蜂',
'诹',
'迂',
'槑',
'好',
'褰',
'咝',
'③',
'劐',
'骄',
'腉',
'仕',
'叵',
'磅',
'金',
'皁',
'勍',
'煮',
'鍪',
'筚',
'吲',
'艰',
'床',
'叛',
'﹔',
'喜',
'齑',
'昧',
'乎',
'谲',
'匈',
'麒',
'身',
'唑',
'鲤',
'栂',
'垭',
'殪',
'沪',
'苌',
'濡',
'蒎',
'遏',
'®',
'质',
'纫',
'罐',
'瞍',
'柄',
'呼',
'锱',
'盔',
'搋',
'烛',
'喉',
'奈',
'赦',
'轘',
'鉴',
'瓒',
'铰',
'恽',
'腠',
'韶',
'胼',
'侄',
'珂',
'鹕',
'䝉',
'呤',
'椁',
'岳',
'汲',
'疤',
'绊',
'涂',
'乾',
'噎',
'兑',
'絜',
'嘧',
'蚯',
'们',
'蝉',
'玛',
'魁',
'黻',
'振',
'冥',
'报',
'窟',
'笱',
'喊',
'瓴',
'喾',
'説',
'雹',
'恫',
'a',
'颧',
'給',
'宅',
'鞧',
'嬷',
'鼾',
'笔',
'鲉',
'匹',
'蠕',
'愍',
'氽',
'赐',
'畔',
'絪',
'洴',
'审',
'窂',
'褔',
'狯',
'谑',
'毳',
'右',
'疣',
'鲙',
'堃',
'瓜',
'…',
'崆',
'钫',
'樭',
'鲛',
'砂',
'筋',
'犏',
'乱',
'入',
'浐',
'膙',
'厚',
'獗',
'覌',
'焦',
'罃',
'宬',
'隍',
'荃',
'醜',
'厉',
'艇',
'娟',
'樂',
'筲',
'洛',
'唼',
'诜',
'馑',
'香',
'缛',
'运',
'祟',
'踩',
'陲',
'叔',
'潞',
'二',
'搠',
'祼',
'瀘',
'蒋',
'樗',
'麦',
'鸦',
'棻',
'古',
'鹠',
'怊',
'裾',
'够',
'璧',
'晡',
'擘',
'毂',
'御',
'葚',
'忱',
'觞',
'瑁',
'唇',
'罡',
'剽',
'殡',
'沛',
'帻',
'举',
'瞓',
'谬',
'溝',
'言',
'哽',
'婿',
'猿',
'跗',
'獴',
'俜',
'呙',
'弗',
'凿',
'窭',
'铌',
'友',
'唉',
'怫',
'荘']
================================================
FILE: ddddocr/common.onnx
================================================
[File too large to display: 51.6 MB]
================================================
FILE: ddddocr/common_det.onnx
================================================
[File too large to display: 19.2 MB]
================================================
FILE: ddddocr/common_old.onnx
================================================
[File too large to display: 13.0 MB]
================================================
FILE: ddddocr/compat/__init__.py
================================================
# coding=utf-8
"""
兼容性模块
提供向后兼容性支持,确保现有代码无需修改即可使用
"""
from .v1 import DdddOcr
__all__ = ['DdddOcr']
================================================
FILE: ddddocr/compat/v1.py
================================================
# coding=utf-8
"""
向后兼容性支持模块
提供与原始DdddOcr类完全兼容的接口
"""
from typing import Union, List, Optional, Dict, Any, Tuple
import pathlib
from PIL import Image
from ..core.ocr_engine import OCREngine
from ..core.detection_engine import DetectionEngine
from ..core.slide_engine import SlideEngine
from ..utils.exceptions import DDDDOCRError
from ..utils.validators import validate_model_config
class DdddOcr:
"""
DDDDOCR主类 - 向后兼容版本
这个类保持与原始DdddOcr类完全相同的接口,
但内部使用新的模块化架构实现
"""
def __init__(self, ocr: bool = True, det: bool = False, old: bool = False, beta: bool = False,
use_gpu: bool = False, device_id: int = 0, show_ad: bool = True,
import_onnx_path: str = "", charsets_path: str = ""):
"""
初始化DDDDOCR
Args:
ocr: 是否启用OCR功能
det: 是否启用目标检测功能
old: 是否使用旧版OCR模型
beta: 是否使用beta版OCR模型
use_gpu: 是否使用GPU
device_id: GPU设备ID
show_ad: 是否显示广告信息
import_onnx_path: 自定义ONNX模型路径
charsets_path: 自定义字符集路径
"""
# 显示广告信息(保持原有行为)
if show_ad:
print("欢迎使用ddddocr,本项目专注带动行业内卷,个人博客:wenanzhe.com")
print("训练数据支持来源于:http://146.56.204.113:19199/preview")
print("爬虫框架feapder可快速一键接入,快速开启爬虫之旅:https://github.com/Boris-code/feapder")
print("谷歌reCaptcha验证码 / hCaptcha验证码 / funCaptcha验证码商业级识别接口:https://yescaptcha.com/i/NSwk7i")
# 兼容性处理:确保PIL有ANTIALIAS属性
if not hasattr(Image, 'ANTIALIAS'):
setattr(Image, 'ANTIALIAS', Image.LANCZOS)
# 验证配置参数
validate_model_config(ocr, det, old, beta, use_gpu, device_id)
# 保存配置
self.ocr_enabled = ocr
self.det_enabled = det
self.old = old
self.beta = beta
self.use_gpu = use_gpu
self.device_id = device_id
self.import_onnx_path = import_onnx_path
self.charsets_path = charsets_path
# 初始化引擎
self.ocr_engine: Optional[OCREngine] = None
self.detection_engine: Optional[DetectionEngine] = None
self.slide_engine: Optional[SlideEngine] = None
# 根据配置初始化相应的引擎
if det:
# 目标检测模式
self.det = True
self.detection_engine = DetectionEngine(use_gpu, device_id)
elif ocr or import_onnx_path:
# OCR模式
self.det = False
self.ocr_engine = OCREngine(
use_gpu=use_gpu,
device_id=device_id,
old=old,
beta=beta,
import_onnx_path=import_onnx_path,
charsets_path=charsets_path
)
else:
# 滑块模式
self.det = False
# 滑块引擎总是可用
self.slide_engine = SlideEngine()
def classification(self, img: Union[bytes, str, pathlib.PurePath, Image.Image],
png_fix: bool = False, probability: bool = False,
color_filter_colors: Optional[List[str]] = None,
color_filter_custom_ranges: Optional[List[Tuple[Tuple[int, int, int], Tuple[int, int, int]]]] = None) -> Union[str, Dict[str, Any]]:
"""
OCR识别方法
Args:
img: 图片数据(bytes、str、pathlib.PurePath或PIL.Image)
png_fix: 是否修复PNG透明背景问题
probability: 是否返回概率信息
color_filter_colors: 颜色过滤预设颜色列表,如 ['red', 'blue']
color_filter_custom_ranges: 自定义HSV颜色范围列表,如 [((0,50,50), (10,255,255))]
Returns:
识别结果文本或包含概率信息的字典
Raises:
DDDDOCRError: 当功能未启用或识别失败时
"""
if self.det:
raise DDDDOCRError("当前识别类型为目标检测")
if not self.ocr_engine:
raise DDDDOCRError("OCR功能未初始化")
return self.ocr_engine.predict(
image=img,
png_fix=png_fix,
probability=probability,
color_filter_colors=color_filter_colors,
color_filter_custom_ranges=color_filter_custom_ranges
)
def detection(self, img: Union[bytes, str, pathlib.PurePath, Image.Image]) -> List[List[int]]:
"""
目标检测方法
Args:
img: 图片数据
Returns:
检测到的边界框列表
Raises:
DDDDOCRError: 当功能未启用或检测失败时
"""
if not self.det:
raise DDDDOCRError("当前识别类型为OCR")
if not self.detection_engine:
raise DDDDOCRError("目标检测功能未初始化")
return self.detection_engine.predict(img)
def slide_match(self, target_img: Union[bytes, str, pathlib.PurePath, Image.Image],
background_img: Union[bytes, str, pathlib.PurePath, Image.Image],
simple_target: bool = False) -> Dict[str, Any]:
"""
滑块匹配方法
Args:
target_img: 滑块图片
background_img: 背景图片
simple_target: 是否为简单滑块
Returns:
匹配结果字典
Raises:
DDDDOCRError: 当匹配失败时
"""
if not self.slide_engine:
raise DDDDOCRError("滑块功能未初始化")
return self.slide_engine.slide_match(target_img, background_img, simple_target)
def slide_comparison(self, target_img: Union[bytes, str, pathlib.PurePath, Image.Image],
background_img: Union[bytes, str, pathlib.PurePath, Image.Image]) -> Dict[str, Any]:
"""
滑块比较方法
Args:
target_img: 带坑位的图片
background_img: 完整背景图片
Returns:
比较结果字典
Raises:
DDDDOCRError: 当比较失败时
"""
if not self.slide_engine:
raise DDDDOCRError("滑块功能未初始化")
return self.slide_engine.slide_comparison(target_img, background_img)
def set_ranges(self, charset_range: Union[int, str, List[str]]) -> None:
"""
设置字符集范围
Args:
charset_range: 字符集范围参数
Raises:
DDDDOCRError: 当OCR功能未启用时
"""
if self.det:
raise DDDDOCRError("目标检测模式不支持字符集设置")
if not self.ocr_engine:
raise DDDDOCRError("OCR功能未初始化")
self.ocr_engine.set_charset_range(charset_range)
def get_charset(self) -> List[str]:
"""
获取字符集
Returns:
字符集列表
Raises:
DDDDOCRError: 当OCR功能未启用时
"""
if self.det:
raise DDDDOCRError("目标检测模式不支持字符集获取")
if not self.ocr_engine:
raise DDDDOCRError("OCR功能未初始化")
return self.ocr_engine.get_charset()
def switch_device(self, use_gpu: bool, device_id: int = 0) -> None:
"""
切换计算设备
Args:
use_gpu: 是否使用GPU
device_id: GPU设备ID
"""
self.use_gpu = use_gpu
self.device_id = device_id
# 更新所有已初始化的引擎
if self.ocr_engine:
self.ocr_engine.switch_device(use_gpu, device_id)
if self.detection_engine:
self.detection_engine.switch_device(use_gpu, device_id)
def get_model_info(self) -> Dict[str, Any]:
"""
获取模型信息
Returns:
模型信息字典
"""
info = {
'ocr_enabled': self.ocr_enabled,
'det_enabled': self.det_enabled,
'use_gpu': self.use_gpu,
'device_id': self.device_id
}
if self.ocr_engine:
info['ocr_model'] = self.ocr_engine.get_model_info()
if self.detection_engine:
info['detection_model'] = self.detection_engine.get_model_info()
return info
def cleanup(self) -> None:
"""清理所有资源"""
if self.ocr_engine:
self.ocr_engine.cleanup()
if self.detection_engine:
self.detection_engine.cleanup()
if self.slide_engine:
self.slide_engine.cleanup()
def __del__(self):
"""析构函数"""
self.cleanup()
def __repr__(self) -> str:
return f"DdddOcr(ocr={self.ocr_enabled}, det={self.det_enabled}, use_gpu={self.use_gpu})"
================================================
FILE: ddddocr/core/__init__.py
================================================
# coding=utf-8
"""
核心功能模块
提供OCR识别、目标检测、滑块匹配等核心功能
"""
from .base import BaseEngine
from .ocr_engine import OCREngine
from .detection_engine import DetectionEngine
from .slide_engine import SlideEngine
__all__ = [
'BaseEngine',
'OCREngine',
'DetectionEngine',
'SlideEngine',
'DdddOcr'
]
def __getattr__(name: str):
# 延迟导入,避免 compat.v1 -> core -> compat.v1 的循环依赖
if name == 'DdddOcr':
from ..compat.v1 import DdddOcr as _DdddOcr
return _DdddOcr
raise AttributeError(f"module {__name__!r} has no attribute {name!r}")
================================================
FILE: ddddocr/core/base.py
================================================
# coding=utf-8
"""
基础引擎类
定义所有引擎的基础接口和通用功能
"""
from abc import ABC, abstractmethod
from typing import Any, Dict, Optional
import onnxruntime
from ..models.model_loader import ModelLoader
from ..utils.exceptions import ModelLoadError
class BaseEngine(ABC):
"""基础引擎抽象类"""
def __init__(self, use_gpu: bool = False, device_id: int = 0):
"""
初始化基础引擎
Args:
use_gpu: 是否使用GPU
device_id: GPU设备ID
"""
self.use_gpu = use_gpu
self.device_id = device_id
self.model_loader = ModelLoader(use_gpu, device_id)
self.session: Optional[onnxruntime.InferenceSession] = None
self.is_initialized = False
@abstractmethod
def initialize(self, **kwargs) -> None:
"""
初始化引擎
Args:
**kwargs: 初始化参数
Raises:
ModelLoadError: 当初始化失败时
"""
pass
@abstractmethod
def predict(self, *args, **kwargs) -> Any:
"""
执行预测
Args:
*args: 位置参数
**kwargs: 关键字参数
Returns:
预测结果
"""
pass
def get_model_info(self) -> Dict[str, Any]:
"""
获取模型信息
Returns:
模型信息字典
"""
if self.session:
return self.model_loader.get_model_info(self.session)
return {'error': '模型未加载'}
def is_ready(self) -> bool:
"""
检查引擎是否就绪
Returns:
是否就绪
"""
return self.is_initialized and self.session is not None
def switch_device(self, use_gpu: bool, device_id: int = 0) -> None:
"""
切换计算设备
Args:
use_gpu: 是否使用GPU
device_id: GPU设备ID
"""
if self.use_gpu != use_gpu or self.device_id != device_id:
self.use_gpu = use_gpu
self.device_id = device_id
self.model_loader.switch_provider(use_gpu, device_id)
# 如果已经初始化,需要重新加载模型
if self.is_initialized:
self._reload_model()
def _reload_model(self) -> None:
"""重新加载模型(子类可重写)"""
pass
def cleanup(self) -> None:
"""清理资源"""
if self.session:
del self.session
self.session = None
self.is_initialized = False
def __del__(self):
"""析构函数"""
self.cleanup()
def __repr__(self) -> str:
return f"{self.__class__.__name__}(use_gpu={self.use_gpu}, device_id={self.device_id}, ready={self.is_ready()})"
================================================
FILE: ddddocr/core/detection_engine.py
================================================
# coding=utf-8
"""
目标检测引擎
提供目标检测功能
"""
from typing import Union, List, Tuple
import numpy as np
from PIL import Image
from .base import BaseEngine
from ..utils.image_io import load_image_from_input, image_to_numpy
from ..utils.exceptions import ModelLoadError, ImageProcessError, safe_import_opencv
from ..utils.validators import validate_image_input
# 安全导入OpenCV
cv2 = safe_import_opencv()
class DetectionEngine(BaseEngine):
"""目标检测引擎"""
def __init__(self, use_gpu: bool = False, device_id: int = 0):
"""
初始化检测引擎
Args:
use_gpu: 是否使用GPU
device_id: GPU设备ID
"""
super().__init__(use_gpu, device_id)
self.initialize()
def initialize(self, **kwargs) -> None:
"""
初始化检测引擎
Raises:
ModelLoadError: 当初始化失败时
"""
try:
# 加载检测模型
self.session = self.model_loader.load_detection_model()
self.is_initialized = True
except Exception as e:
raise ModelLoadError(f"检测引擎初始化失败: {str(e)}") from e
def predict(self, image: Union[bytes, str, Image.Image]) -> List[List[int]]:
"""
执行目标检测
Args:
image: 输入图像
Returns:
检测到的边界框列表,每个边界框格式为[x1, y1, x2, y2]
Raises:
ImageProcessError: 当图像处理失败时
ModelLoadError: 当模型未初始化时
"""
if not self.is_ready():
raise ModelLoadError("检测引擎未初始化")
# 验证输入
validate_image_input(image)
try:
# 直接使用原始的get_bbox方法
if isinstance(image, bytes):
return self.get_bbox(image)
elif isinstance(image, Image.Image):
import io
img_bytes = io.BytesIO()
image.save(img_bytes, format='PNG')
return self.get_bbox(img_bytes.getvalue())
else:
# 其他类型先转换为PIL Image再处理
pil_image = load_image_from_input(image)
import io
img_bytes = io.BytesIO()
pil_image.save(img_bytes, format='PNG')
return self.get_bbox(img_bytes.getvalue())
except Exception as e:
raise ImageProcessError(f"目标检测失败: {str(e)}") from e
def preproc(self, img, input_size, swap=(2, 0, 1)):
"""预处理函数(来自原始代码)"""
if len(img.shape) == 3:
padded_img = np.ones((input_size[0], input_size[1], 3), dtype=np.uint8) * 114
else:
padded_img = np.ones(input_size, dtype=np.uint8) * 114
r = min(input_size[0] / img.shape[0], input_size[1] / img.shape[1])
resized_img = cv2.resize(
img,
(int(img.shape[1] * r), int(img.shape[0] * r)),
interpolation=cv2.INTER_LINEAR,
).astype(np.uint8)
padded_img[: int(img.shape[0] * r), : int(img.shape[1] * r)] = resized_img
padded_img = padded_img.transpose(swap)
padded_img = np.ascontiguousarray(padded_img, dtype=np.float32)
return padded_img, r
def demo_postprocess(self, outputs, img_size, p6=False):
"""后处理函数(来自原始代码)"""
grids = []
expanded_strides = []
if not p6:
strides = [8, 16, 32]
else:
strides = [8, 16, 32, 64]
hsizes = [img_size[0] // stride for stride in strides]
wsizes = [img_size[1] // stride for stride in strides]
for hsize, wsize, stride in zip(hsizes, wsizes, strides):
xv, yv = np.meshgrid(np.arange(wsize), np.arange(hsize))
grid = np.stack((xv, yv), 2).reshape(1, -1, 2)
grids.append(grid)
shape = grid.shape[:2]
expanded_strides.append(np.full((*shape, 1), stride))
grids = np.concatenate(grids, 1)
expanded_strides = np.concatenate(expanded_strides, 1)
outputs[..., :2] = (outputs[..., :2] + grids) * expanded_strides
outputs[..., 2:4] = np.exp(outputs[..., 2:4]) * expanded_strides
return outputs
def nms(self, boxes, scores, nms_thr):
"""Single class NMS implemented in Numpy."""
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= nms_thr)[0]
order = order[inds + 1]
return keep
def multiclass_nms_class_agnostic(self, boxes, scores, nms_thr, score_thr):
"""Multiclass NMS implemented in Numpy. Class-agnostic version."""
cls_inds = scores.argmax(1)
cls_scores = scores[np.arange(len(cls_inds)), cls_inds]
valid_score_mask = cls_scores > score_thr
if valid_score_mask.sum() == 0:
return None
valid_scores = cls_scores[valid_score_mask]
valid_boxes = boxes[valid_score_mask]
valid_cls_inds = cls_inds[valid_score_mask]
keep = self.nms(valid_boxes, valid_scores, nms_thr)
if keep:
dets = np.concatenate(
[valid_boxes[keep], valid_scores[keep, None], valid_cls_inds[keep, None]], 1
)
return dets
def multiclass_nms(self, boxes, scores, nms_thr, score_thr):
"""Multiclass NMS implemented in Numpy"""
return self.multiclass_nms_class_agnostic(boxes, scores, nms_thr, score_thr)
def get_bbox(self, image_bytes):
"""原始的目标检测方法"""
img = cv2.imdecode(np.frombuffer(image_bytes, np.uint8), cv2.IMREAD_COLOR)
im, ratio = self.preproc(img, (416, 416))
ort_inputs = {self.session.get_inputs()[0].name: im[None, :, :, :]}
output = self.session.run(None, ort_inputs)
predictions = self.demo_postprocess(output[0], (416, 416))[0]
boxes = predictions[:, :4]
scores = predictions[:, 4:5] * predictions[:, 5:]
boxes_xyxy = np.ones_like(boxes)
boxes_xyxy[:, 0] = boxes[:, 0] - boxes[:, 2] / 2.
boxes_xyxy[:, 1] = boxes[:, 1] - boxes[:, 3] / 2.
boxes_xyxy[:, 2] = boxes[:, 0] + boxes[:, 2] / 2.
boxes_xyxy[:, 3] = boxes[:, 1] + boxes[:, 3] / 2.
boxes_xyxy /= ratio
pred = self.multiclass_nms(boxes_xyxy, scores, nms_thr=0.45, score_thr=0.1)
try:
final_boxes = pred[:, :4].tolist()
result = []
for b in final_boxes:
if b[0] < 0:
x_min = 0
else:
x_min = int(b[0])
if b[1] < 0:
y_min = 0
else:
y_min = int(b[1])
if b[2] > img.shape[1]:
x_max = int(img.shape[1])
else:
x_max = int(b[2])
if b[3] > img.shape[0]:
y_max = int(img.shape[0])
else:
y_max = int(b[3])
result.append([x_min, y_min, x_max, y_max])
except Exception as e:
return []
return result
================================================
FILE: ddddocr/core/ocr_engine.py
================================================
# coding=utf-8
"""
OCR识别引擎
提供文字识别功能
"""
from typing import Union, List, Optional, Dict, Any, Tuple
import numpy as np
from PIL import Image
from .base import BaseEngine
from ..models.charset_manager import CharsetManager
from ..preprocessing.color_filter import ColorFilter
from ..preprocessing.image_processor import ImageProcessor
from ..utils.image_io import load_image_from_input, png_rgba_black_preprocess
from ..utils.exceptions import ModelLoadError, ImageProcessError
from ..utils.validators import validate_image_input
class OCREngine(BaseEngine):
"""OCR识别引擎"""
def __init__(self, use_gpu: bool = False, device_id: int = 0,
old: bool = False, beta: bool = False,
import_onnx_path: str = "", charsets_path: str = ""):
"""
初始化OCR引擎
Args:
use_gpu: 是否使用GPU
device_id: GPU设备ID
old: 是否使用旧版模型
beta: 是否使用beta版模型
import_onnx_path: 自定义模型路径
charsets_path: 自定义字符集路径
"""
super().__init__(use_gpu, device_id)
self.old = old
self.beta = beta
self.import_onnx_path = import_onnx_path
self.charsets_path = charsets_path
self.use_import_onnx = bool(import_onnx_path)
# 字符集管理器
self.charset_manager = CharsetManager()
# 模型配置
self.word = False
self.resize = []
self.channel = 1
# 初始化引擎
self.initialize()
def initialize(self, **kwargs) -> None:
"""
初始化OCR引擎
Raises:
ModelLoadError: 当初始化失败时
"""
try:
if self.use_import_onnx:
# 加载自定义模型
self.session, charset_info = self.model_loader.load_custom_model(
self.import_onnx_path, self.charsets_path
)
# 设置模型配置
self.charset_manager.charset = charset_info['charset']
# 初始化有效字符索引(使用完整字符集)
self.charset_manager._update_valid_indices()
self.word = charset_info['word']
self.resize = charset_info['image']
self.channel = charset_info['channel']
else:
# 加载默认模型
self.session = self.model_loader.load_ocr_model(self.old, self.beta)
# 加载默认字符集
self.charset_manager.load_default_charset(self.old, self.beta)
# 初始化有效字符索引(使用完整字符集)
self.charset_manager._update_valid_indices()
# 设置默认配置
self.word = False
self.resize = [64, 64] # 默认尺寸
self.channel = 1
self.is_initialized = True
except Exception as e:
raise ModelLoadError(f"OCR引擎初始化失败: {str(e)}") from e
def predict(self, image: Union[bytes, str, Image.Image],
png_fix: bool = False, probability: bool = False,
color_filter_colors: Optional[List[str]] = None,
color_filter_custom_ranges: Optional[List[Tuple[Tuple[int, int, int], Tuple[int, int, int]]]] = None,
charset_range: Optional[Union[int, str, List[str]]] = None) -> Union[str, Dict[str, Any]]:
"""
执行OCR识别
Args:
image: 输入图像
png_fix: 是否修复PNG透明背景
probability: 是否返回概率信息
color_filter_colors: 颜色过滤预设颜色列表
color_filter_custom_ranges: 自定义HSV颜色范围列表
charset_range: 字符集范围限制
Returns:
识别结果文本或包含概率信息的字典
Raises:
ImageProcessError: 当图像处理失败时
ModelLoadError: 当模型未初始化时
"""
if not self.is_ready():
raise ModelLoadError("OCR引擎未初始化")
# 验证输入
validate_image_input(image)
try:
# 加载图像
pil_image = load_image_from_input(image)
# 应用颜色过滤
if color_filter_colors or color_filter_custom_ranges:
try:
color_filter = ColorFilter(colors=color_filter_colors,
custom_ranges=color_filter_custom_ranges)
pil_image = color_filter.filter_image(pil_image)
except Exception as e:
print(f"颜色过滤警告: {str(e)},将跳过颜色过滤步骤")
# 设置字符集范围
if charset_range is not None:
self.charset_manager.set_ranges(charset_range)
else:
# 确保在没有设置字符集范围时,有效索引被正确初始化
self.charset_manager._update_valid_indices()
# 预处理图像
processed_image = self._preprocess_image(pil_image, png_fix)
# 执行推理
result = self._inference(processed_image, probability)
return result
except Exception as e:
raise ImageProcessError(f"OCR识别失败: {str(e)}") from e
def _preprocess_image(self, image: Image.Image, png_fix: bool) -> np.ndarray:
"""
预处理图像
Args:
image: 输入图像
png_fix: 是否修复PNG透明背景
Returns:
预处理后的numpy数组
"""
try:
# 处理PNG透明背景
if png_fix and image.mode == 'RGBA':
image = png_rgba_black_preprocess(image)
# 调整图像尺寸
if not self.use_import_onnx:
# 默认模型的预处理
target_height = 64
target_width = int(image.size[0] * (target_height / image.size[1]))
image = ImageProcessor.resize_image(image, (target_width, target_height))
image = ImageProcessor.convert_to_grayscale(image)
else:
# 自定义模型的预处理
if self.resize[0] == -1:
if self.word:
image = ImageProcessor.resize_image(image, (self.resize[1], self.resize[1]))
else:
target_height = self.resize[1]
target_width = int(image.size[0] * (target_height / image.size[1]))
image = ImageProcessor.resize_image(image, (target_width, target_height))
else:
image = ImageProcessor.resize_image(image, (self.resize[0], self.resize[1]))
# 根据通道数转换
if self.channel == 1:
image = ImageProcessor.convert_to_grayscale(image)
# 转换为numpy数组并标准化
img_array = np.array(image).astype(np.float32)
# 标准化到[0,1]
img_array = img_array / 255.0
# 调整维度
if len(img_array.shape) == 2:
img_array = np.expand_dims(img_array, axis=0) # 添加通道维度
elif len(img_array.shape) == 3:
img_array = img_array.transpose(2, 0, 1) # HWC -> CHW
img_array = np.expand_dims(img_array, axis=0) # 添加batch维度
return img_array
except Exception as e:
raise ImageProcessError(f"图像预处理失败: {str(e)}") from e
def _inference(self, image_array: np.ndarray, probability: bool) -> Union[str, Dict[str, Any]]:
"""
执行模型推理
Args:
image_array: 预处理后的图像数组
probability: 是否返回概率信息
Returns:
识别结果
"""
try:
# 获取输入名称
input_name = self.session.get_inputs()[0].name
# 执行推理
outputs = self.session.run(None, {input_name: image_array})
# 处理输出
if probability:
return self._process_probability_output(outputs[0])
else:
return self._process_text_output(outputs[0])
except Exception as e:
raise ModelLoadError(f"模型推理失败: {str(e)}") from e
def _process_text_output(self, output: np.ndarray) -> str:
"""
处理文本输出
Args:
output: 模型输出
Returns:
识别的文本
"""
try:
# 获取预测结果
if len(output.shape) == 3:
# 序列输出 (sequence_length, batch_size, num_classes) 或 (batch_size, sequence_length, num_classes)
# 需要判断哪个维度是batch_size=1
if output.shape[1] == 1:
# 形状为 (sequence_length, 1, num_classes)
predicted_indices = np.argmax(output[:, 0, :], axis=1)
elif output.shape[0] == 1:
# 形状为 (1, sequence_length, num_classes)
predicted_indices = np.argmax(output[0, :, :], axis=1)
else:
# 默认取第一个batch
predicted_indices = np.argmax(output[0, :, :], axis=1)
else:
# 单字符输出或2D序列输出
predicted_indices = np.argmax(output, axis=-1)
# 确保结果是数组形式,即使是单个值
if predicted_indices.ndim == 0:
predicted_indices = np.array([predicted_indices])
# 正确的CTC解码:在索引级别进行去重
charset = self.charset_manager.get_charset()
valid_indices = self.charset_manager.get_valid_indices()
# 步骤1:CTC解码 - 在索引级别去除连续重复
decoded_indices = self._ctc_decode_indices(predicted_indices)
# 步骤2:转换为字符并应用字符集范围限制
result_chars = []
for idx in decoded_indices:
# 检查字符集范围限制
if valid_indices and idx not in valid_indices:
continue
# 检查索引有效性并转换为字符
if 0 <= idx < len(charset):
char = charset[idx]
# 注意:这里不跳过空字符,因为CTC解码已经处理了blank
result_chars.append(char)
return ''.join(result_chars)
except Exception as e:
raise ModelLoadError(f"文本输出处理失败: {str(e)}") from e
def _ctc_decode_indices(self, predicted_indices: np.ndarray) -> List[int]:
"""
CTC解码:在索引级别去除连续重复和blank字符
Args:
predicted_indices: 预测的索引数组
Returns:
解码后的索引列表
"""
if len(predicted_indices) == 0:
return []
decoded_indices = []
prev_idx = None
for idx in predicted_indices:
# 转换为Python int类型以确保一致性
idx = int(idx)
# CTC解码规则:
# 1. 跳过连续重复的索引
# 2. 跳过blank字符(索引0,对应空字符)
if idx != prev_idx: # 不是连续重复
if idx != 0: # 不是blank字符(假设索引0是blank)
decoded_indices.append(idx)
prev_idx = idx
return decoded_indices
def _process_probability_output(self, output: np.ndarray) -> Dict[str, Any]:
"""
处理概率输出
Args:
output: 模型输出
Returns:
包含概率信息的字典
"""
try:
# 应用softmax
if len(output.shape) == 3:
probabilities = self._softmax(output, axis=2)
else:
probabilities = self._softmax(output, axis=1)
# 获取文本结果
text_result = self._process_text_output(output)
# 构建概率信息
charset = self.charset_manager.get_charset()
prob_info = {
'text': text_result,
'probabilities': probabilities.tolist(),
'charset': charset,
'confidence': float(np.mean(np.max(probabilities, axis=-1)))
}
return prob_info
except Exception as e:
raise ModelLoadError(f"概率输出处理失败: {str(e)}") from e
def _softmax(self, x: np.ndarray, axis: int = -1) -> np.ndarray:
"""
计算softmax
Args:
x: 输入数组
axis: 计算轴
Returns:
softmax结果
"""
exp_x = np.exp(x - np.max(x, axis=axis, keepdims=True))
return exp_x / np.sum(exp_x, axis=axis, keepdims=True)
def set_charset_range(self, charset_range: Union[int, str, List[str]]) -> None:
"""
设置字符集范围
Args:
charset_range: 字符集范围参数
"""
self.charset_manager.set_ranges(charset_range)
def get_charset(self) -> List[str]:
"""
获取字符集
Returns:
字符集列表
"""
return self.charset_manager.get_charset()
def _reload_model(self) -> None:
"""重新加载模型"""
self.initialize()
================================================
FILE: ddddocr/core/slide_engine.py
================================================
# coding=utf-8
"""
滑块匹配引擎
提供滑块验证码的匹配和比较功能
"""
from typing import Union, Dict, Any, Tuple
import numpy as np
from PIL import Image
from .base import BaseEngine
from ..utils.image_io import load_image_from_input, image_to_numpy
from ..utils.exceptions import ImageProcessError, safe_import_opencv
from ..utils.validators import validate_image_input
# 安全导入OpenCV
cv2 = safe_import_opencv()
class SlideEngine(BaseEngine):
"""滑块匹配引擎"""
def __init__(self):
"""
初始化滑块引擎
注意:滑块引擎不需要GPU和模型加载
"""
# 不调用父类的__init__,因为不需要模型加载器
self.is_initialized = True
def initialize(self, **kwargs) -> None:
"""
初始化滑块引擎
滑块引擎不需要特殊初始化
"""
self.is_initialized = True
def predict(self, *args, **kwargs) -> Any:
"""
预测方法的通用接口
具体功能通过slide_match和slide_comparison方法实现
"""
raise NotImplementedError("请使用slide_match或slide_comparison方法")
def slide_match(self, target_image: Union[bytes, str, Image.Image],
background_image: Union[bytes, str, Image.Image],
simple_target: bool = False) -> Dict[str, Any]:
"""
滑块匹配算法
Args:
target_image: 滑块图片
background_image: 背景图片
simple_target: 是否为简单滑块
Returns:
匹配结果字典,包含target坐标
Raises:
ImageProcessError: 当图像处理失败时
"""
# 验证输入
validate_image_input(target_image)
validate_image_input(background_image)
try:
# 加载图像
target_pil = load_image_from_input(target_image)
background_pil = load_image_from_input(background_image)
# 转换为numpy数组
target_array = image_to_numpy(target_pil, 'RGB')
background_array = image_to_numpy(background_pil, 'RGB')
# 执行匹配
result = self._perform_slide_match(target_array, background_array, simple_target)
return result
except Exception as e:
raise ImageProcessError(f"滑块匹配失败: {str(e)}") from e
def slide_comparison(self, target_image: Union[bytes, str, Image.Image],
background_image: Union[bytes, str, Image.Image]) -> Dict[str, Any]:
"""
滑块比较算法(用于带坑位的图片)
Args:
target_image: 带坑位的图片
background_image: 完整背景图片
Returns:
比较结果字典,包含target坐标
Raises:
ImageProcessError: 当图像处理失败时
"""
# 验证输入
validate_image_input(target_image)
validate_image_input(background_image)
try:
# 加载图像
target_pil = load_image_from_input(target_image)
background_pil = load_image_from_input(background_image)
# 转换为numpy数组
target_array = image_to_numpy(target_pil, 'RGB')
background_array = image_to_numpy(background_pil, 'RGB')
# 执行比较
result = self._perform_slide_comparison(target_array, background_array)
return result
except Exception as e:
raise ImageProcessError(f"滑块比较失败: {str(e)}") from e
def _perform_slide_match(self, target: np.ndarray, background: np.ndarray,
simple_target: bool) -> Dict[str, Any]:
"""
执行滑块匹配
Args:
target: 滑块图像数组
background: 背景图像数组
simple_target: 是否为简单滑块
Returns:
匹配结果
"""
try:
# 转换为灰度图
target_gray = cv2.cvtColor(target, cv2.COLOR_RGB2GRAY)
background_gray = cv2.cvtColor(background, cv2.COLOR_RGB2GRAY)
if simple_target:
# 简单滑块匹配
result = self._simple_template_match(target_gray, background_gray)
else:
# 复杂滑块匹配(边缘检测)
result = self._edge_based_match(target_gray, background_gray)
return result
except Exception as e:
raise ImageProcessError(f"滑块匹配执行失败: {str(e)}") from e
def _perform_slide_comparison(self, target: np.ndarray, background: np.ndarray) -> Dict[str, Any]:
"""
执行滑块比较
Args:
target: 带坑位的图像数组
background: 完整背景图像数组
Returns:
比较结果
"""
try:
# 计算图像差异
diff = cv2.absdiff(target, background)
# 转换为灰度图
diff_gray = cv2.cvtColor(diff, cv2.COLOR_RGB2GRAY)
# 二值化
_, binary = cv2.threshold(diff_gray, 30, 255, cv2.THRESH_BINARY)
# 形态学操作去噪
kernel = np.ones((3, 3), np.uint8)
binary = cv2.morphologyEx(binary, cv2.MORPH_CLOSE, kernel)
binary = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel)
# 查找轮廓
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if not contours:
return {'target': [0, 0]}
# 找到最大的轮廓(假设是缺口)
largest_contour = max(contours, key=cv2.contourArea)
# 获取边界框
x, y, w, h = cv2.boundingRect(largest_contour)
# 计算中心点
center_x = x + w // 2
center_y = y + h // 2
return {
'target': [center_x, center_y],
'target_x': center_x,
'target_y': center_y
}
except Exception as e:
raise ImageProcessError(f"滑块比较执行失败: {str(e)}") from e
def _simple_template_match(self, target: np.ndarray, background: np.ndarray) -> Dict[str, Any]:
"""
简单模板匹配
Args:
target: 滑块模板
background: 背景图像
Returns:
匹配结果
"""
try:
# 模板匹配
result = cv2.matchTemplate(background, target, cv2.TM_CCOEFF_NORMED)
# 找到最佳匹配位置
_, max_val, _, max_loc = cv2.minMaxLoc(result)
# 计算滑块中心位置
if len(target.shape) == 3:
target_h, target_w, _ = target.shape
else:
target_h, target_w = target.shape
center_x = max_loc[0] + target_w // 2
center_y = max_loc[1] + target_h // 2
return {
'target': [center_x, center_y],
'target_x': center_x,
'target_y': center_y,
'confidence': float(max_val)
}
except Exception as e:
raise ImageProcessError(f"简单模板匹配失败: {str(e)}") from e
def _edge_based_match(self, target: np.ndarray, background: np.ndarray) -> Dict[str, Any]:
"""
基于边缘检测的滑块匹配
Args:
target: 滑块图像
background: 背景图像
Returns:
匹配结果
"""
try:
# 边缘检测
target_edges = cv2.Canny(target, 50, 150)
background_edges = cv2.Canny(background, 50, 150)
# 模板匹配
result = cv2.matchTemplate(background_edges, target_edges, cv2.TM_CCOEFF_NORMED)
# 找到最佳匹配位置
_, max_val, _, max_loc = cv2.minMaxLoc(result)
# 计算滑块中心位置
if len(target.shape) == 3:
target_h, target_w, _ = target.shape
else:
target_h, target_w = target.shape
center_x = max_loc[0] + target_w // 2
center_y = max_loc[1] + target_h // 2
return {
'target': [center_x, center_y],
'target_x': center_x,
'target_y': center_y,
'confidence': float(max_val)
}
except Exception as e:
raise ImageProcessError(f"边缘匹配失败: {str(e)}") from e
def is_ready(self) -> bool:
"""
检查引擎是否就绪
滑块引擎总是就绪的
Returns:
总是返回True
"""
return True
def cleanup(self) -> None:
"""清理资源(滑块引擎无需清理)"""
pass
def __repr__(self) -> str:
return "SlideEngine(ready=True)"
================================================
FILE: ddddocr/models/__init__.py
================================================
# coding=utf-8
"""
模型管理模块
提供ONNX模型加载、字符集管理等功能
"""
from .model_loader import ModelLoader
from .charset_manager import CharsetManager
__all__ = [
'ModelLoader',
'CharsetManager'
]
================================================
FILE: ddddocr/models/charset_manager.py
================================================
# coding=utf-8
"""
字符集管理模块
负责字符集的加载、管理和范围限制
"""
from typing import List, Union, Optional, Set
import json
import os
from ..utils.exceptions import ModelLoadError
from ..utils.validators import validate_charset_range
class CharsetManager:
"""字符集管理器"""
def __init__(self, charset: Optional[List[str]] = None):
"""
初始化字符集管理器
Args:
charset: 字符集列表
"""
self.charset = charset or []
self.charset_range = []
self.valid_charset_range_index = []
def load_default_charset(self, old: bool = False, beta: bool = False) -> None:
"""
加载默认字符集
Args:
old: 是否使用旧版字符集
beta: 是否使用beta版字符集
"""
if old:
self.charset = self._get_old_charset()
elif beta:
self.charset = self._get_beta_charset()
else:
self.charset = self._get_old_charset() # 默认使用旧版
# 加载字符集后,初始化有效索引(使用完整字符集)
self._update_valid_indices()
def load_custom_charset(self, charset_path: str) -> dict:
"""
从文件加载自定义字符集
Args:
charset_path: 字符集文件路径
Returns:
字符集信息字典
Raises:
ModelLoadError: 当加载失败时
"""
try:
if not os.path.exists(charset_path):
raise ModelLoadError(f"字符集文件不存在: {charset_path}")
with open(charset_path, 'r', encoding="utf-8") as f:
charset_info = json.loads(f.read())
# 验证字符集信息格式
required_keys = ['charset', 'word', 'image', 'channel']
for key in required_keys:
if key not in charset_info:
raise ModelLoadError(f"字符集文件缺少必需字段: {key}")
self.charset = charset_info['charset']
# 加载字符集后,初始化有效索引(使用完整字符集)
self._update_valid_indices()
return charset_info
except Exception as e:
raise ModelLoadError(f"字符集加载失败: {str(e)}") from e
def set_ranges(self, charset_range: Union[int, str, List[str]]) -> None:
"""
设置字符集范围限制
Args:
charset_range: 字符集范围参数
"""
validate_charset_range(charset_range)
self.charset_range.clear()
if isinstance(charset_range, int):
# 按索引范围限制
if 0 <= charset_range < len(self.charset):
self.charset_range = self.charset[:charset_range + 1]
elif isinstance(charset_range, str):
# 按字符串限制
for char in charset_range:
if char not in self.charset_range:
self.charset_range.append(char)
elif isinstance(charset_range, list):
# 按字符列表限制
self.charset_range = charset_range.copy()
# 去重并添加空字符
self.charset_range = list(set(self.charset_range)) + [""]
# 计算有效索引
self._update_valid_indices()
def _update_valid_indices(self) -> None:
"""更新有效字符索引"""
self.valid_charset_range_index.clear()
if len(self.charset_range) > 0:
for item in self.charset_range:
if item in self.charset:
self.valid_charset_range_index.append(self.charset.index(item))
# 未知字符没有索引,直接忽略
else:
# 当没有设置字符集范围时,使用完整字符集的所有索引
self.valid_charset_range_index = list(range(len(self.charset)))
def get_valid_indices(self) -> List[int]:
"""
获取有效字符索引列表
Returns:
有效字符索引列表
"""
return self.valid_charset_range_index.copy()
def get_charset(self) -> List[str]:
"""
获取完整字符集
Returns:
字符集列表
"""
return self.charset.copy()
def get_charset_range(self) -> List[str]:
"""
获取字符集范围
Returns:
字符集范围列表
"""
return self.charset_range.copy()
def char_to_index(self, char: str) -> int:
"""
将字符转换为索引
Args:
char: 字符
Returns:
字符索引,如果不存在返回-1
"""
try:
return self.charset.index(char)
except ValueError:
return -1
def index_to_char(self, index: int) -> str:
"""
将索引转换为字符
Args:
index: 字符索引
Returns:
字符,如果索引无效返回空字符串
"""
if 0 <= index < len(self.charset):
return self.charset[index]
return ""
def is_valid_char(self, char: str) -> bool:
"""
检查字符是否在字符集中
Args:
char: 字符
Returns:
是否有效
"""
return char in self.charset
def filter_text(self, text: str) -> str:
"""
过滤文本,只保留字符集中的字符
Args:
text: 输入文本
Returns:
过滤后的文本
"""
if not self.charset_range:
return text
filtered_chars = []
for char in text:
if char in self.charset_range:
filtered_chars.append(char)
return ''.join(filtered_chars)
def get_charset_size(self) -> int:
"""
获取字符集大小
Returns:
字符集大小
"""
return len(self.charset)
def get_range_size(self) -> int:
"""
获取字符集范围大小
Returns:
字符集范围大小
"""
return len(self.charset_range)
def clear_ranges(self) -> None:
"""清空字符集范围限制"""
self.charset_range.clear()
self.valid_charset_range_index.clear()
def _get_old_charset(self) -> List[str]:
"""获取旧版字符集"""
return ["", "掀", "袜", "顧", "徕", "榱", "荪", "浡", "其", "炎", "玉", "恩", "劣", "徽",
"廉", "桂", "拂",
"鳊", "撤",
"赏", "哮", "侄", "蓮", "И", "进", "饭", "饱", "优", "楸", "礻", "蜉", "營", "伙",
"杌", "修", "榜",
"准", "铒",
"戏", "赭", "襟", "彘", "彩", "雁", "闽", "坎", "聂", "氡", "辜", "苁", "潆", "摁",
"月", "稇", "而",
"醴", "簉",
"卑", "妖", "埽", "嘡", "醛", "見", "煎", "汪", "秽", "迄", "噭", "焉", "钌", "瑕",
"玻", "仙", "蹑",
"钀", "翦",
"丰", "矗", "2", "胚", "镊", "镡", "鍊", "帖", "僰", "淀", "吒", "冲", "挡", "粼",
"螈", "缵", "孺",
"侦", "曷",
"渐", "敷", "投", "宸", "祉", "柳", "尖", "梃", "淘", "臁", "躇", "撖", "惭", "狄",
"聢", "官", "狴",
"诬", "骄",
"跻", "場", "姻", "钎", "藥", "綉", "驾", "舻", "黢", "鲦", "蜣", "渖", "绹", "佰",
"怜", "三", "痪",
"眍", "养",
"角", "薜", "濑", "劳", "戟", "傎", "纫", "徉", "收", "稍", "虫", "螋", "鬲", "捌",
"陡", "蓟", "邳",
"蹢", "涉",
"煋", "端", "懷", "椤", "埶", "廊", "免", "秫", "猢", "睐", "臺", "擀", "布", "麃",
"彗", "汊", "芄",
"遣", "胙",
"另", "癯", "徭", "疢", "茆", "忡", "'", "烃", "笕", "薤", "肆", "熛", "過", "盖",
"跷", "呷", "痿",
"沖", "魍",
"讣", "庤", "弑", "诩", "庵", "履", "暮", "始", "滟", "矅", "蛹", "鸿", "啃", "铋",
"沿", "鐾", "酆",
"團", "恙",
"閥", "聒", "讵", "颠", "沾", "堅", "踣", "陴", "覃", "滙", "浐", "钇", "脆", "炙",
"亮", "觌", "産",
"汩", "鸭",
"斄", "堆", "掭", "揞", "鹂", "郫", "瘅", "蚂", "揩", "学", "组", "浸", "腙", "耀",
"嗛", "局", "蠓",
"肠", "昏",
"I", "岑", "镯", "憧", "油", "泸", "鸟", "潇", "蕻", "褒", "瞧", "旸", "昭", "庐",
"鞒", "内", "痈",
"己", "曙",
"怠", "锟", "晞", "耢", "鲢", "醦", "糕", "療", "寇", "梵", "黾", "呻", "苒", "ü",
"校", "嘏", "昃",
"Ⅰ", "蕰",
"凖", "嵛", "裨", "筏", "匜", "咋", "乏", "婵", "镂", "珰", "感", "蔗", "蚵", "庞",
"弢", "槟", "口",
"漉", "﹒",
"咂", "俩", "增", "硐", "襙", "绉", "卿", "距", "璱", "猖", "铚", "郚", "嬖", "缒",
"阃", "扞", "V",
"望", "最",
"浔", "骜", "赃", "闻", "砍", "奸", "灶", "以", "获", "鳎", "浦", "罐", "孓", "纭",
"瘀", "普", "氰",
"塮", "症",
"顷", "们", "螓", "蛸", "鵰", "册", "美", "萨", "沘", "犰", "嫌", "名", ")", "懦",
"滇", "F", "垡",
"声", "毅",
"隅", "鲎", "煨", "萦", "宜", "唇", "鯨", "邛", "杲", "赜", "长", "魂", "桠", "锇",
"搓", "俘", "仰",
"膘", "宦",
"歹", "遁", "猃", "噉", "幂", "糜", "嗤", "周", "剂", "曦", "暧", "焖", "髻", "釐",
"泰", "窟", "檎",
"旧", "犀",
"镄", "百", "取", "岍", "逗", "叽", "呃", "鲪", "萬", "陈", "7", "習", "区", "逄",
"宏", "罡", "漭",
"盗", "郿",
"般", "谢", "倪", "纵", "婶", "砧", "揖", "扪", "濒", "愤", "茓", "浞", "子", "揄",
"旌", "趄", "樊",
"醑", "遄",
"婚", "汶", "矩", "裈", "弊", "呱", "铳", "勿", "蚴", "忿", "褓", "缚", "酱", "璞",
"庆", "除", "礌",
"珩", "榨",
"鼢", "逞", "容", "圯", "猛", "陌", "-", "嚯", "镘", "鱾", "睚", "猬", "杜", "鳓",
"燈", "計", "咣",
"炜", "睁",
"箱", "邮", "略", "馇", "逐", "雀", "僬", "髯", "奖", "俱", "-", "绗", "犏", "辱",
"忑", "挽", "康",
"蝼", "栏",
"模", "辒", "•", "儋", "罱", "墈", "会", "秀", "栈", "缔", "醜", "蚣", "阮", "鼗",
"眼", "湧", "沁",
"夥", "毕",
"媚", "瘳", "痣", "搴", "闿", "遍", "焰", "岣", "舱", "埌", "麿", "嘿", "靽", "体",
"想", "霓", "钛",
"摽", "苑",
"芳", "技", "綮", "钅", "燠", "栾", "年", "悱", "腹", "员", "呕", "闇", "嗫", "檩",
"荒", "溱", "舨",
"峙", "卒",
"洑", "预", "弯", "蔷", "叵", "锯", "慈", "牧", "患", "贇", "偷", "鲜", "锓", "躔",
"嚬", "烈", "娌",
"嘲", "详",
"麺", "舒", "厨", "徵", "葹", "只", "篦", "鹀", "剕", "驳", "聍", "黧", "砾", "暅",
"褫", "呈", "森",
"结", "龛",
"钲", "轧", "扔", "蕹", "赵", "涒", "冯", "渲", "缭", "坚", "趼", "鲑", "倫", "门",
"班", "垚", "鞍",
"菘", "畐",
"僇", "侉", "禢", "轳", "饦", "兽", "呯", "捂", "樨", "卧", "栝", "豭", "冶", "鉰",
"申", "蜈", "印",
"缨", "镫",
"蕾", "圜", "扑", "娉", "烦", "缳", "广", "峄", "獒", "铔", "奁", "醚", "倥", "蹇",
"阚", "镆", "煺",
"德", "颉",
"嗅", "绷", "蒯", "祺", "崧", "往", "枨", "涡", "鲲", "瓅", "岌", "肘", "飔", "缘",
"千", "棱", "溶",
"窣", "篼",
"代", "捡", "送", "咡", "术", "滑", "茜", "晾", "挤", "曳", "糈", "G", "翊", "殴",
"妹", "溥", "璆",
"烩", "拙",
"襄", "几", "嘴", "D", "驮", "淙", "蹐", "合", "環", "剑", "怪", "褂", "畑", "燏",
"订", "珪", "≥",
"瘟", "耷",
"槑", "衷", "猕", "迁", "霎", "槜", "﹖", "鋈", "苹", "嫣", "祜", "李", "鄒", "噢",
"萄", "仝", "纨",
"直", "悛",
"拣", "远", "诏", "圧", "躬", "蝟", "總", "眆", "筻", "硇", "鳁", "眠", "钆", "泞",
"猱", "宾", "酞",
"募", "螳",
"腴", "念", "宠", "唯", "怊", "勃", "M", "兿", "蟑", "妁", "掸", "拌", "铸", "讼",
"诟", "锺", "Ω",
"竟", "羚",
"剽", "C", "苦", "煳", "罢", "跨", "~", "豸", "±", "俬", "捺", "彦", "钣", "鋆", "用",
"缤", "搁",
"徼", "谦",
"筘", "嗨", "扮", "旇", "折", "咯", "昆", "叟", "垂", "箐", "捻", "燕", "島", "瞀",
"鮮", "屡", "點",
"瘭", "恚",
"旚", "丟", "捽", "菁", "瀑", "炕", "蹩", "芒", "r", "是", "媾", "鹝", "囵", "萤",
"拷", "频", "埴",
"课", "癍",
"袱", "螯", "谘", "榛", "Y", "缣", "裔", "憩", "相", "觀", "晗", "坳", "炔", "勉",
"汆", "钡", "舐",
"衫", "疫",
"鲙", "蘩", "穈", "殁", "九", "泻", "咤", "構", "谆", "陕", "装", "蔡", "画", "介",
"苋", "務", "敝",
"俟", "帇",
"鸺", "贸", "茗", "肃", "滪", "输", "瘗", "菽", "饹", "诉", "遐", "浑", "扎", "卟",
"铀", "邗", "觋",
"嘎", "塑",
"潏", "金", "姘", "潋", "逵", "鲻", "逯", "炮", "甄", "髡", "剩", "嗬", "芴", "屋",
"改", "骣", "芪",
"邠", "痋",
"珑", "帆", "狙", "八", "奔", "族", "轵", "氖", "雕", "痧", "眊", "胛", "酉", "鲼",
"砣", "猸", "餮",
"郇", "沫",
"跖", "蝉", "屑", "辘", "閣", "涑", "邡", "篃", "交", "笼", "颇", "贻", "魄", "黡",
"劂", "糠", "炅",
"帨", "苍",
"瓴", "粤", "莎", "朿", "埔", "绸", "齁", "鱿", "惨", "腢", "郡", "棠", "猫", "脑",
"風", "蚱", "捐",
"嵌", "胱",
"馗", "竽", "泥", "辍", "怖", "雾", "絮", "淼", "筝", "碲", "悼", "龀", "の", "珥",
"忐", "溲", "昕",
"荔", "掂",
"瘦", "僭", "蔌", "抺", "椅", "誉", "扯", "僜", "停", "衉", "汇", "赔", "眄", "呙",
"咙", "剿", "次",
"蛟", "嗓",
"』", "汕", "詈", "帘", "踧", "姁", "血", "堪", "喜", "滩", "璎", "胄", "俨", "眚",
"凌", "拽", "滔",
"⑿", "嬃",
"―", "汐", "潭", "阡", "呓", "婷", "执", "妊", "恂", "妥", "鳘", "蔫", "设", "睒",
"笪", "謇", "鞋",
"谍", "黯",
"虍", "馬", "蚧", "骑", "峤", "舾", "儀", "駡", "β", "蓑", "柏", "痒", "蒇", "痕",
"妍", "熠", "僻",
"爬", "迭",
"畫", "绰", "湯", "凭", "菼", "懈", "顒", "午", "箪", "糙", "址", "钼", "堵", "佘",
"侍", "卤", "(",
"榚", "泽",
"溘", "蟹", "b", "燁", "颂", "菠", "榉", "鲡", "埸", "荛", "歘", "断", "邸", "贡",
"礞", "蔼", "脸",
"爪", "帜",
"翡", "仟", "皎", "辆", "滫", "昔", "™", "柬", "弓", "遇", "杪", "侨", "娓", "镪",
"觑", "一", "踌",
"牟", "褡",
"厩", "晌", "每", "娘", "渤", "c", "咫", "成", "颏", "孩", "鼓", "瞌", "槁", "捒",
"阉", "伉", "癣",
"胞", "鲟",
"瓤", "杅", "紡", "喂", "掠", "镜", "镧", "侞", "赦", "貝", "丕", "臧", "L", "池",
"彷", "棓", "锽",
"渊", "食",
"饨", "堡", "玥", "氣", "讽", "敬", "闺", "帡", "携", "哫", "珈", "魆", "哄", "旁",
"喻", "泄", "畎",
"郁", "唅",
"葜", "繪", "飐", "谶", "聆", "斝", "谥", "辉", "髅", "進", "吧", "蹀", "铛", "笛",
"睥", "楼", "凝",
"況", "鸷",
"苠", "饺", "沙", "缴", "块", "梢", "慝", "珐", "鄏", "霰", "迸", "氆", "趵", "棣",
"鳔", "祆", "☆",
"苯", "恁",
"螨", "庭", "缠", "槠", "津", "髋", "诔", "葶", "蜾", "坻", "蒹", "摔", "向", "垩",
"蹭", "淇", "筛",
"滬", "玡",
"铺", "逼", "劵", "绲", "团", "鳀", "常", "玖", "擢", "株", "铵", "樽", "弭", "醇",
"糨", "璈", "曩",
"潔", "祘",
"磨", "希", "鲅", "擂", "谗", "唳", "欷", "欧", "绋", "庙", "琬", "稳", "糊", "拥",
"霪", "浼", "翎",
"俜", "摸",
"筚", "巯", "墼", "苫", "缩", "镚", "婪", "圹", "咚", "儿", "蒽", "婆", "鲐", "雹",
"霞", "嶪", "濠",
"琉", "澌",
"媢", "禤", "摺", "掏", "矢", "艄", "围", "呸", "寺", "拤", "氐", "柝", "跎", "僖",
"挢", "茨", "涮",
"缫", "撸",
"荨", "嶷", "廋", "魋", "付", "喋", "蜗", "邙", "棹", "璪", "倡", "鞭", "游", "錦",
"眬", "抒", "眈",
"培", "夏",
"黔", "獐", "皋", "戛", "鲀", "垒", "耽", "纤", "漩", "铈", "握", "窝", "芋", "濞",
"截", "零", "敖",
"眸", "怦",
"噎", "簋", "掳", "妣", "湃", "璠", "殄", "觞", "桅", "笋", "鲞", "踯", "傀", "犨",
"抵", "疰", "暌",
"耖", "供",
"枳", "怂", "娶", "鸩", "捣", "庸", "逡", "懋", "颃", "長", "鼫", "姮", "蹈", "耵",
"乂", "骐", "殇",
"膏", "仳",
"冥", "梭", "洵", "碣", "昝", "仉", "軒", "隍", "更", "な", "嵕", "拜", "粑", "鲴",
"吇", "秃", "尕",
"魃", "狨",
"臛", "蟥", "胨", "注", "谁", "张", "才", "尸", "派", "矮", "洳", "舟", "溺", "锴",
"寓", "籴", "夕",
"叭", "荠",
"澼", "劃", "久", "私", "炉", "娟", "麤", "稂", "河", "纴", "夺", "亏", "焙", "。",
"塗", "蜩", "栌",
"渡", "薰",
"崋", "揿", "漤", "啾", "郏", "舣", "卉", "爱", "牚", "撵", "钺", "再", "企", "笺",
"疾", "承", "俾",
"瞈", "邰",
"汾", "瘛", "檫", "蒎", "觅", "绀", "掎", "U", "赓", "匳", "聘", "蛤", "跤", "嗜",
"洼", "歔", "弟",
"飕", "莼",
"嫉", "那", "滈", "践", "僦", "偎", "扢", "绚", "乕", "旳", "招", "饯", "®", "攸",
"鞁", "囫", "铨",
"陒", "鷄",
"畀", "韨", "經", "纾", "萸", "肴", "→", "宗", "迳", "鳞", "亚", "搂", "喀", "狮",
"坦", "瞥", "采",
"姝", "钳",
"□", "剌", "維", "葸", "鼩", "公", "刀", "沩", "喔", "泺", "哉", "徨", "篝", "掊",
"沕", "运", "偆",
"浒", "语",
"乇", "仪", "萝", "疍", "踽", "碡", "熰", "荞", "嚓", "天", "饰", "泵", "械", "孑",
"蛰", "荟", "源",
"峡", "矜",
"睬", "噬", "腆", "婉", "‘", "等", "誓", "辀", "岖", "琖", "碜", "霍", "怼", "唛",
"弈", "淑", "疆",
"晴", "镴",
"鸡", "埚", "焕", "芦", "唻", "踅", "吴", "殡", "唏", "吨", "寡", "鹉", "絲", "坉",
"會", "埭", "Ⅲ",
"捏", "墅",
"卓", "叙", "徇", "柜", "各", "荭", "J", "恝", "囐", "蓉", "犋", "叡", "莺", "颌",
"蒸", "饸", "疋",
"玊", "兢",
"鱽", "藍", "杳", "辂", "獘", "拔", "侪", "湍", "膂", "渔", "瘊", "雉", "稁", "職",
"僤", "鄳", "祁",
"稱", "I",
"裴", "锉", "曹", "鲶", "挨", "哑", "鷪", "鏠", "煞", "师", "蛲", "牁", "琅", "告",
"媒", "祭", "确",
"荚", "亰",
"蝗", "阗", "歩", "疲", "f", "唣", "愛", "郾", "棍", "山", "狲", "纽", "蚡", "栂",
"馓", "诊", "猴",
"喤", "来",
"继", "桎", "嬛", "骞", "邴", "暄", "贼", "昴", "廿", "克", "耔", "彤", "鹭", "葓",
"骢", "龁", "鏡",
"瀚", "赅",
"韩", "譄", "榷", "殚", "膛", "须", "、", "砖", "唶", "番", "蛘", "畴", "铠", "亢",
"氓", "铰", "炻",
"筫", "迢",
"兰", "玺", "砻", "积", "莜", "吸", "监", "膦", "迪", "迷", "冷", "哀", "贳", "瞄",
"器", "鹡", "惺",
"徐", "酢",
"寒", "Ⓡ", "倾", "飞", "楽", "涢", "队", "舆", "赤", "璩", "戳", "殳", "掮", "舴",
"蜷", "宄", "拴",
"癌", "舛",
"婀", "抟", "靡", "骍", "揸", "思", "慧", "平", "橘", "臭", "硖", "卬", "畈", "兠",
"茸", "脂", "魚",
"晩", "御",
"龋", "涣", "罨", "爍", "糌", "汧", "缐", "贽", "要", "祀", "鲊", "爼", "獯", "瀣",
"棋", "肈", "佣",
"娣", "柩",
"枸", "偃", "v", "唷", "劍", "榴", "槐", "漫", "洽", "蒡", "籼", "魔", "峋", "第",
"歙", "萧", "谮",
"埯", "撮",
"马", "绡", "裘", "鹋", "蓬", "显", "噶", "倒", "镳", "艽", "窬", "拳", "樯", "跋",
"詹", "钥", "心",
"嶽", "嚋",
"戎", "吕", "涂", "悃", "麦", "骋", "推", "箩", "硚", "匆", "村", "五", "杨", "凑",
"鞫", "镰", "伥",
"诒", "纣",
"崃", "鸻", "翰", "辌", "廛", "證", "舢", "盼", "腿", "圳", "贱", "皿", "隆", "屈",
"龏", "瓒", "顏",
"↓", "赈",
"煙", "窍", "韧", "壁", "莰", "箬", "蹋", "褰", "峥", "悚", "坜", "环", "回", "疼",
"渍", "蝄", "东",
"臂", "坩",
"走", "痍", "或", "蜀", "熳", "蜻", "佐", "懿", "嚅", "紗", "螭", "忖", "顶", "狡",
"吲", "洣", "帛",
"呶", "柞",
"柫", "酿", "粥", "琢", "呵", "踝", "榀", "呲", "價", "鼋", "欺", "此", "背", "猎",
"昱", "濡", "稚",
"欠", "暇",
"茬", "牙", "迹", "尼", "氛", "膠", "缯", "娼", "骚", "姒", "鬟", "霁", "鲔", "者",
"驰", "倩", "馉",
"工", "芬",
"烙", "卦", "C", "裂", "垲", "摆", "珮", "缏", "杞", "绘", "司", "如", "姞", "荆",
"挖", "跗", "伍",
"氚", "钘",
"郢", "轱", "篆", "吭", "夡", "鹫", "讷", "轺", "!", "匈", "待", "聱", "黏", "海",
"蹶", "趋", "鎮",
"觊", "江",
"咸", "富", "艴", "稗", "钜", "搏", "壶", "鲮", "薪", "猞", "轰", "踪", "赣", "循",
"序", "噻", "若",
"裾", "许",
"癞", "吓", "判", "踔", "查", "蚀", "[", "樓", "坌", "岳", "榄", "役", "倜", "⒂",
"旭", "溆", "惯",
"咀", "跫",
"选", "囱", "污", "镶", "⒁", "淠", "氮", "酯", "寅", "芼", "炊", "夯", "郪", "农",
"褲", "嘬", "蹻",
"烔", "罄",
"开", "靴", "镇", "杯", "羰", "硪", "籍", "摘", "馀", "餐", "眯", "⑴", "呗", "巫",
"幤", "蒤", "蒗",
"镥", "檵",
"盛", "純", "娃", "●", "耿", "巡", "婴", "槔", "i", "颊", "Ⅳ", "栅", "绅", "邘", "冉",
"碧", "使",
"熨", "羞",
"扼", "漳", "觯", "楊", "励", "逑", "咄", "之", "斤", "嘣", "鹰", "媸", "鲂", "褚",
"磚", "琨", "聪",
"牖", "太",
"蓍", "涫", "≤", "虽", "鸽", "燧", "褊", "聿", "壬", "然", "疚", "莲", "悴", "簃",
"颓", "坠", "瞬",
"汳", "l",
"登", "瘼", "窳", "桤", "縯", "匣", "坡", "↑", "愦", "攘", "渭", "嬢", "鲰", "性",
"楚", "澈", "赪",
"達", "鄯",
"罅", "帽", "茠", "底", "嫜", "奏", "浅", "荽", "楹", "鼍", "枵", "嗔", "滍", "椴",
"嵩", "氤", "搠",
"两", "榔",
"树", "吝", "基", "峂", "栎", "侮", "舸", "遂", "颡", "锷", "杼", "酔", "幄", "哽",
"睢", "陔", "※",
"嚆", "宬",
"宽", "髦", "笾", "保", "蹊", "榕", "咏", "椋", "丧", "裤", "骛", "逧", "弇", "崆",
"樘", "疤", "鸤",
"伞", "抚",
"诎", "诵", "豢", "佳", "差", "埝", "极", "黍", "煜", "曰", "阱", "悞", "叹", "垤",
"藁", "嗵", "崔",
"卫", "珂",
"憯", "蔬", "菜", "碑", "扈", "铆", "夹", "衡", "弱", "挈", "徜", "疠", "丶", "遠",
"提", "斧", "炟",
"肺", "B",
"她", "晟", "谎", "邱", "粳", "酽", "爨", "鬼", "伧", "兹", "嶓", "谤", "饕", "揶",
"谱", "歡", "髪",
"餍", "泳",
"郞", "谣", "汉", "褐", "非", "刽", "缅", "饴", "齐", "兴", "涯", "芫", "凡", "褶",
"晡", "努", "蚶",
"彥", "皤",
"砌", "黼", "吹", "指", "㙟", "蓁", "鹜", "話", "拊", "辨", "盎", "肌", "旘", "软",
"颍", "甏", "滚",
"旦", "滨",
"间", "尴", "对", "鄘", "称", "镗", "咅", "璐", "怔", "垛", "洎", "瓮", "绨", "脚",
"遒", "吊", "纸",
"蹅", "经",
"泉", "武", "汀", "歪", "败", "拾", "铪", "吼", "邹", "磊", "论", "岛", "厍", "锛",
"芎", "芭", "音",
"澧", "镕",
"锒", "宙", "牵", "忱", "嫔", "麯", "澉", "擐", "砥", "撞", "痴", "盹", "畿", "厾",
"酸", "俑", "脽",
"鸈", "枷",
"咨", "蔹", "诂", "胰", "董", "脶", "黩", "髓", "鉵", "澎", "鲽", "梧", "樱", "诜",
"鲯", "跂", "盂",
"浴", "苻",
"锅", "實", "碁", "嘛", "氕", "艮", "涟", "绢", "姿", "茝", "砘", "簿", "穷", "镃",
"∈", "抽", "事",
"誜", "窅",
"瀘", "鲹", "兖", "嵎", "陧", "榍", "轶", "柿", "藤", "薏", "娆", "骷", "梅", "摒",
"睪", "剪", "羸",
"忧", "邝",
"跺", "旆", "堕", "伫", "绍", "疵", "樟", "–", "绾", "蜴", "靸", "侃", "瘘", "珧",
"遨", "縠", "信",
"充", "桔",
"黇", "劬", "脒", "良", "俵", "颙", "轹", "犿", "屐", "牾", "4", "兮", "澝", "汗",
"沼", "铲", "濋",
"鹬", "丝",
"妫", "重", "蒺", "磲", "曚", "尔", "国", "桐", "俣", "剐", "哼", "恹", "哧", "藔",
"谓", "轨", "眩",
"痞", "添",
"鬯", "库", "梱", "婕", "蜢", "贿", "敕", "泯", "羟", "龇", "垸", "左", "肖", "辎",
"鞣", "谄", "可",
"腺", "末",
"狞", "贷", "嗌", "仕", "楞", "膻", "臻", "欻", "洲", "所", "檀", "抔", "罹", "牒",
"仫", "芨", "柄",
"嫩", "酒",
"祙", "渠", "的", "笨", "鳐", "楡", "过", "苡", "核", "拖", "阢", "莒", "凤", "锋",
"`", "硎", "弁",
"鬶", "朐",
"忏", "於", "昊", "剟", "咳", "湘", "日", "满", "哨", "螵", "餪", "放", "佶", "葵",
"硷", "c", "抱",
"锥", "芮",
"啻", "惊", "峁", "琊", "嶲", "撺", "煅", "屏", "袗", "鄞", "梓", "鹌", "宅", "赂",
"鱼", "洱", "騳",
"E", "物",
"觏", "雙", "瑀", "上", "淩", "愀", "❋", "鄙", "憝", "沛", "硫", "产", "垯", "亁",
"枭", "堰", "赑",
"趾", "庹",
"腭", "迨", "拚", "晒", "蜇", "扣", "纰", "闵", "窭", "椽", "菏", "嘁", "伛", "郸",
"素", "殷", "表",
"躞", "笸",
"耻", "荧", "辛", "篑", "馈", "壮", "耩", "宛", "慰", "盡", "塆", "铯", "苏", "王",
"桕", "⑧", "°",
"浚", "栉",
"朘", "虚", "骆", "坂", "秤", "鲋", "蕊", "渝", "呦", "潼", "驱", "诼", "峇", "盤",
"趴", "肄", "笑",
"讹", "貋",
"穂", "啼", "趟", "暽", "傣", "蜎", "挎", "陳", "勖", "戴", "旃", "瞎", "舌", "幻",
"喾", "赁", "E",
"播", "诀",
"蟛", "鹛", "骶", "輸", "連", "醳", "逅", "奉", "崖", "娩", "幔", "佃", "扅", "阔",
"生", "贬", "疯",
"珀", "苶",
"屯", "裣", "蹯", "蝮", "解", "陂", "疝", "茈", "帑", "议", "仲", "埙", "竺", "峰",
"遮", "涎", "穸",
"阂", "潵",
"镱", "例", "荑", "u", "脎", "衍", "轲", "⑵", "虾", "颚", "钞", "²", "伴", "根", "沣",
"腌", "户",
"~", "辙",
"愧", "噤", "觥", "波", "铗", "纂", "鲺", "僚", "毐", "〇", "桼", "祗", "慢", "啵",
"坏", "吗", "嗞",
"甬", "曈",
"徹", "灏", "混", "渌", "括", "脖", "汝", "現", "訇", "紅", "飘", "虢", "腱", "旄",
"嬴", "昨", "孀",
"蚁", "呛",
"讳", "病", ",", "喈", "蒋", "镭", "葩", "耲", "鳈", "锄", "喘", "返", "傕", "咆",
"享", "枥", "瓠",
"茳", "铱",
"脘", "暹", "廒", "爝", "橹", "瞑", "铎", "岢", "叁", "翏", "捭", "賀", "悉", "帝",
"芥", "牀", "闌",
"毯", "亍",
"弧", "锆", "币", "祊", "纔", "齑", "肟", "绤", "獨", "翚", "颢", "係", "鍪", "粉",
"统", "诗", "娜",
"褥", "鈺",
"湔", "呤", "犸", "湨", "泣", "蟾", "犾", "烛", "斐", "朦", "室", "诨", "榭", "煦",
"醺", "敞", "燮",
"糅", "衽",
"孔", "猄", "疭", "辰", "钽", "胁", "釆", "钉", "胤", "涧", "弼", "濯", "汨", "颖",
"茫", "皑", "遏",
"捃", "坭",
"燴", "肩", "滞", "玢", "巽", "砺", "蜿", "毁", "億", "骥", "本", "忽", "肚", "搽",
"靰", "郴", "跆",
"客", "酣",
"α", "屎", "辩", "殂", "垝", "紫", "秦", "喇", "凶", "傧", "铐", "蘊", "補", "贤",
"竿", "途", "慗",
"榖", "券",
"莠", "逆", "鳇", "误", "崟", "妇", "磷", "捧", "莸", "⇋", "绺", "稻", "填", "逋",
"侈", "隶", "侵",
"翥", "惘",
"惧", "鸥", "赠", "壳", "芯", "巩", "獗", "硅", "搎", "鲛", "9", "夸", "穆", "缜",
"诓", "观", "薛",
"咎", "杧",
"页", "饫", "瑟", "率", "礤", "悭", "畔", "匯", "匮", "鼠", "犒", "芡", "傍", "嫂",
"啸", "鄉", "哭",
"鄱", "捷",
"靺", "嚒", "嘀", "哒", "#", "拼", "钚", "魁", "霣", "眶", "郊", "死", "愁", "箭",
"鼙", "签", "害",
"斛", "睑",
"蟜", "余", "墨", "様", "读", "養", "貉", "较", "浆", "翩", "徂", "冕", "铧", "列",
"诈", "穝", "缑",
"纲", "志",
"舀", "甾", "举", "馁", "ä", "畹", "榼", "垢", "襁", "麟", "灭", "佴", "镩", "酝",
"柒", "梯", "傈",
"萭", "悫",
"莨", "搞", "+", "兄", "偲", "攀", "曝", "嵝", "喳", "从", "遶", "撴", ".", "鄄",
"欲", "挺", "娡",
"发", "速",
"胲", "褀", "态", "行", "蚓", "坼", "适", "厦", "寐", "带", "緃", "醤", "珽", "‧",
"溍", "斋", "鐀",
"朝", "欢",
"传", "築", "咪", "据", "蹜", "医", "妄", "肇", "囝", "怡", "镎", "桩", "轩", "岔",
"腐", "矽", "媵",
"搒", "菔",
"拘", "D", "欃", "唧", "瞒", "郈", "绦", "吟", "撝", "醉", "镣", "匝", "拎", "砒",
"顸", "袁", "驼",
"愔", "实",
"國", "奧", "胩", "府", "逾", "愕", "廷", "碌", "锖", "狩", "褴", "镢", "芷", "娥",
"唤", "┌", "云",
"О", "檔",
"驴", "躯", "驺", "洃", "檑", "窴", "(", "腕", "立", "楯", "齮", "〔", "漆", "k", "芍",
"蹽", "鬓",
"概", "楣",
"唐", "闲", "糗", "旱", "幸", "腽", "嗄", "迂", "镠", "顿", "扥", "圃", "烜", "馍",
"佝", "岷", "童",
"悦", "┐",
"铌", "袈", "靓", "骸", "和", "乔", "灸", "泓", "临", "睿", "掖", "偿", "鐘", "犁",
"祓", "鈴", "搌",
"授", "鹳",
"赢", "怅", "絪", "硬", "芙", "螅", "”", "傢", "避", "裕", "歁", "全", "衰", "仃",
"媛", "鬻", "跽",
"沌", "急",
"猷", "激", "巉", "哝", "渣", "笫", "跳", "螫", "熜", "Z", "筷", "佩", "啶", "萃",
"頫", "荙", "出",
"孽", "钟",
"戡", "釉", "咬", "滦", "鹇", "贯", "鹮", "具", "翁", "机", "濱", "谳", "釣", "懑",
"葛", "袯", "谭",
"质", "胴",
"誊", "侗", "⑩", "静", "蚜", "溋", "嫪", "嗲", "瑭", "座", "舫", "靶", "棘", "泊",
"嵖", "摧", "勋",
"僡", "藉",
"疖", "巂", "随", "罾", "崚", "猹", "憨", "苘", "斓", "鼷", "利", "谲", "剔", "艺",
"箓", "蛀", "鲚",
"搐", "裟",
"捶", "绌", "揪", "帮", "缥", "匍", "冀", "杻", "逛", "邑", "禾", "郰", "黜", "丘",
"樂", "滌", "緣",
"胃", "苄",
"巾", "瑜", "元", "蝶", "层", "烧", "级", "岭", "蘭", "繇", "蝓", "洞", "奢", "则",
"政", "矾", "啭",
"瘠", "碴",
"忤", "身", "匠", "警", "饩", "犬", "皲", "箔", "豕", "虑", "草", "喟", "芤", "逭",
"艳", "幡", "姚",
"賓", "饪",
"卯", "敌", "烽", "嫚", "黝", "豺", "㭗", "教", "偕", "板", "茹", "孤", "人", "狻",
"寰", "厕", "玲",
"璨", "锵",
"搛", "勍", "匾", "聃", "奘", "垃", "焓", "喽", "嫫", "貌", "瘐", "嚰", "孟", "衔",
"郎", "账", "础",
"电", "黑",
"骁", "拨", "濆", "圉", "刮", "闭", "竣", "铅", "羔", "硌", "筑", "难", "管", "苕",
"眺", "嫄", "竖",
"榟", "崴",
"摭", "狐", "娑", "②", "罽", "谊", "←", "狳", "铫", "凯", "狉", "9", "肪", "崤", "莊",
"妨", "缶",
"滃", "瀦",
"揉", "肫", "恧", "糯", "嵬", "5", "裆", "嚷", "稣", "隐", "仂", "て", "驹", "籽",
"肢", "尘", "苈",
"撷", "镲",
"趹", "晤", "唱", "鉏", "篌", "驩", "雍", "闳", "拄", "藜", "朴", "伺", "诳", "房",
"吱", "Й", "鳄",
"罿", "祧",
"酩", "郅", "耎", "尜", "绝", "禅", "揠", "鎏", "慕", "麥", "呜", "鸫", "党", "尝",
"砑", "牌", "踉",
"刨", "襻",
"㾄", "螽", "谌", "止", "抑", "爻", "磬", "铄", "蓠", "委", "汲", "鹑", "╱", "嚣",
"彝", "穄", "穹",
"態", "醋",
"⒀", "叼", "婳", "簌", "渥", "很", "甸", "帅", "锏", "与", "樾", "泷", "棼", "湲",
"越", "祥", "短",
"顼", "阘",
"宋", "馘", "鈉", "未", "囍", "浏", "叻", "箜", "鑽", "法", "曲", "淤", "僮", "做",
"强", "析", "磕",
"谠", "染",
"促", "朊", "隼", "铉", "莆", "蝣", "孛", "薮", "s", "惴", "秘", "妩", "訄", "蔓",
"喷", "诡", "犷",
"酐", "酇",
"刹", "壅", "甫", "史", "孃", "髌", "螬", "擤", "漏", "寞", "奡", "悢", "颔", "岁",
"耄", ";", "又",
"锭", "鲤",
"癔", "杰", "孥", "酲", "蓐", "耋", "捆", "庖", "面", "鹈", "殊", "剡", "峪", "识",
"锨", "归", "茴",
"—", "菤",
"汁", "攝", "液", "鼐", "示", "讠", "男", "凍", "ò", "明", "莓", "砜", "崎", "蜂",
"斡", "榫", "娅",
"钪", "昙",
"胜", "欣", "怨", "◆", "粗", "秷", "节", "市", "贩", "祟", "弍", "蒟", "烁", "糧",
"蠃", "編", "黙",
"壕", "戚",
"犊", "桥", "仺", "孳", "怯", "皓", "倆", "垮", "扩", "诮", "钝", "脯", "晏", "帔",
"葫", "瑾", "運",
"孬", "跄",
"掣", "癜", "掌", "墀", "禇", "耸", "蜓", "鹆", "鄢", "攰", "瘢", "暝", "鸣", "峧",
"遵", "笃", "畚",
"帧", "晨",
"镔", "搜", "靠", "咐", "韓", "绮", "觉", "拦", "斲", "疽", "掐", "尽", "許", "矶",
"镉", "豹", "粞",
"袋", "酵",
"蛙", "戕", "劉", "髀", "彭", "玎", "囿", "郐", "善", "睃", "結", "拧", "邯", "讧",
"召", "椭", "瑪",
"痼", "庼",
"反", "疱", "屠", "荣", "君", "胍", "乙", "臬", "头", "诰", "讪", "席", "晁", ":",
"理", "槿", "璘",
"禧", "呢",
"蹙", "擒", "鸲", "丐", "苓", "壑", "滥", "⑾", "炗", "礴", "耕", "卅", "唿", "苛",
"寵", "窖", "麻",
"蕨", "沤",
"氢", "虔", "癃", "及", "崛", "爽", "蛔", "颤", "膲", "桢", "坐", "蟞", "儇", "葚",
"骤", "誤", "寝",
"嘭", "灰",
"汹", "韂", "铮", "慒", "寶", "肽", "摅", "紧", "亞", "潸", "悯", "橛", "檗", "闹",
"愿", "担", "袄",
"棚", "垟",
"塄", "婞", "麈", "麸", "暗", "咦", "跞", "谡", "盈", "磐", "慎", "瘰", "掼", "憔",
"研", "被", "贮",
"莛", "至",
"呀", "庑", "矫", "摛", "怃", "缙", "磺", "即", "驻", "瘤", "偏", "℃", "嫘", "癫",
"汈", "鹟", "搅",
"辅", "璀",
"阊", "绻", "瑙", "蓂", "棺", "孢", "铊", "鼒", "果", "砮", "飾", "凰", "Я", "遗",
"祛", "纮", "劲",
"霹", "骃",
"绔", "薅", "瀵", "垅", "?", "轻", "惇", "怕", "啥", "哙", "燎", "缆", "匡", "怫",
"卞", "朋", "酏",
"阑", "爾",
"伏", "敏", "埼", "罩", "菹", "艋", "肭", "鯭", "杋", "裀", "撬", "蕺", "惠", "大",
"爇", "笈", "絷",
"琳", "谫",
"诛", "糇", "袢", "倓", "髃", "觽", "埏", "寖", "個", "筴", "外", "漯", "樭", "喁",
"杀", "臑", "缇",
"裸", "巅",
"毹", "茅", "忆", "琼", "唑", "烷", "项", "隋", "约", "排", "吮", "谂", "宝", "牲",
"瘫", "娄", "沂",
"醫", "拭",
"纺", "蹰", "哞", "风", "霆", "值", "酺", "侠", "螾", "埂", "育", "夷", "鮼", "怍",
"鸠", "Θ", "瞳",
"阇", "耥",
"羝", "伽", "洴", "記", "楔", "颼", "沪", "邢", "冰", "昀", "阙", "洌", "嫦", "杂",
"仔", "芑", "潴",
"痄", "桨",
"连", "碓", "塈", "F", "昇", "何", "桦", "晥", "驵", "旋", "药", "银", "奋", "灣",
"俐", "絡", "嫁",
"浮", "为",
"鞅", "科", "颦", "潽", "镍", "鸨", "粵", "骂", "拱", "韫", "盆", "赎", "尿", "钿",
"坍", "唁", "秧",
"昌", "曆",
"颋", "遭", "秭", "褔", "腋", "〉", "吉", "漓", "臆", "焘", "已", "制", "钹", "鴨",
"咖", "莘", "P",
"碥", "互",
"治", "标", "膝", "伪", "浿", "纛", "郗", "看", "佧", "糖", "篓", "亡", "´", "骙",
"澡", "影", "窂",
"紬", "镅",
"慌", "框", "晋", "説", "丢", "凹", "卖", "巧", "蹉", "乾", "莫", "Z", "谔", "矧",
"铑", "暴", "庄",
"湿", "活",
"穿", "腩", "筣", "水", "6", "琦", "迈", "伯", "洄", "抡", "▪", "酋", "荤", "雒",
"粕", "簠", "菰",
"髁", "枇",
"陲", "多", "仗", "央", "滁", "胸", "梏", "痉", "姑", "襞", "﹑", "齿", "弩", "花",
"吆", "赫", "岵",
"佪", "谑",
"锤", "轴", "盐", "馄", "臜", "戢", "涠", "鸸", "糟", "孪", "禁", "蒲", "化", "疏",
"痰", "脾", "刈",
"應", "珍",
"膺", "扌", "廙", "汜", "牍", "虐", "婿", "啕", "彻", "赝", "陶", "蠲", ">", "位",
"屁", "醍", "粢",
"挪", "臌",
"滹", "遴", "馨", "n", "稼", "徊", "酌", "轸", "债", "朰", "程", "辞", "痊", "插",
"鹩", "郄", "铝",
"狱", "叱",
"同", "寄", "搪", "蚯", "魭", "舍", "旷", "闰", "涝", "民", "嗡", "苌", "馕", "姥",
"屉", "啧", "枢",
"❤", "窕",
"钊", "矬", "菂", "佑", "≠", "獬", "桁", "墟", "皖", "鼻", "它", "歇", "独", "好",
"晕", "蚝", "锞",
"颈", "豚",
"聖", "裉", "扫", "岿", "悒", "佥", "苗", "妞", "晚", "圭", "茼", "脲", "摊", "窠",
"狸", "抻", "场",
"呼", "囟",
"噗", "狺", "困", "瀹", "削", "衬", "谰", "蛆", "訓", "鉄", "痃", "炱", "蝻", "我",
"暨", "骓", "馋",
"埤", "脞",
"晃", "螟", "洮", "泛", "掾", "穑", "米", "蕲", "玦", "讙", "逢", "劐", "袭", "凫",
"僳", "畛", "晷",
"鳕", "Ë",
"愬", "坫", "鳡", "鞯", "叔", "胂", "囚", "筋", "青", "度", "涕", "琰", "﹔", "径",
"陇", "睛", "链",
"状", "逶",
"蘅", "“", "庇", "邽", "纥", "踶", "爺", "狭", "钫", "桃", "弛", "淳", "办", "茕",
"砸", "喱", "仅",
"潞", "杈",
"得", "咕", "俞", "检", "借", "恋", "驿", "倌", "钢", "琐", "哆", "撙", "箫", "川",
"猥", "牢", "蹁",
"城", "馏",
"锡", "楝", "蛱", "奈", "瑶", "桺", "耆", "翟", "阒", "稲", "橐", "萱", "惹", "蘼",
"主", "擦", "蟒",
"台", "佬",
"荫", "廖", "笏", "铕", "衣", "洇", "炒", "瀍", "崭", "圻", "洚", "契", "嫱", "倏",
"晶", "了", "堠",
"勰", "椎",
"询", "梗", "飒", "锰", "览", "溇", "寻", "蓅", "【", "碇", "井", "露", "顔", "堌",
"庳", "踩", "i",
"饷", "俊",
"楫", "條", "搭", "奍", "羽", "憋", "岘", "毡", "曜", "乃", "′", "针", "羲", "菓",
"吩", "咩", "鞘",
"尊", "宫",
"舜", "啖", "惗", "北", "懊", "骇", "阄", "躅", "权", "缲", "肥", "铜", "《", "录",
"也", "棬", "煮",
"舄", "厮",
"'", "順", "受", "霜", "新", "售", "牞", "圣", "妗", "犴", "宥", "哦", "陀", "卺",
"冚", "蹒", "亸",
"禮", "骰",
"瑢", "弒", "抛", "谷", "嫰", "動", "嘌", "惩", "枣", "忌", "茡", "爵", "嘚", "郧",
"丨", "敲", "帚",
"沭", "槊",
"⑶", "專", "毶", "圄", "磅", "蛭", "由", "蠹", "剜", "诫", "秆", "愠", "藓", "母",
"请", "衩", "忸",
"蜕", "饽",
"晦", "倔", "腠", "痛", "品", "簧", "父", "锐", "描", "蓰", "蛴", "箍", "兕", "苜",
"饼", "奚", "泗",
"裥", "皂",
"嵚", ",", "澶", "蠖", "沅", "馎", "籀", "菝", "眵", "糥", "铽", "痤", "颟", "淄",
"作", "抉", "俄",
"么", "郑",
"耒", "佛", "1", "纡", "鸢", "④", "鎚", "壖", "遢", "鬈", "拢", "托", "哈", "節",
"橦", "冼", "六",
"耗", "樵",
"涔", "舳", "龌", "衿", "婧", "栓", "椹", "嘘", "膊", "茁", "丹", "螃", "剖", "洧",
"珞", "潺", "孱",
"呐", "萩",
"刷", "引", "说", "熟", "/", "靖", "酷", "耠", "饬", "菌", "洙", "荃", "饲", "酾",
"阁", "陬", "铿",
"倻", "牮",
"鞡", "撕", "倘", "盒", "曺", "襦", "辄", "算", "塬", "潢", "羖", "湾", "续", "△",
"疙", "谖", "嘅",
"遑", "篚",
"筮", "氍", "递", "尧", "G", "{", "分", "埒", "@", "蜍", "荼", "襆", "槭", "檠", "縢",
"濉", "梆",
"隔", "镛",
"倞", "润", "瓯", "瓢", "蟊", "沐", "啷", "砚", "皱", "剅", "儙", "错", "幌", "滓",
"砗", "郤", "喧",
"峣", "簸",
"毖", "踏", "锕", "…", "悖", "谧", "醵", "加", "镐", "泐", "傫", "胪", "缄", "卩",
"蓼", "丸", "垌",
"汞", "宴",
"膙", "圊", "矻", "嚏", "漾", "幕", "駕", "葒", "绪", "袪", "镋", "杭", "澴", "鬃",
"粟", "偻", "饳",
"抨", "亟",
"温", "韶", "轿", "罟", "际", "诖", "复", "坯", "骗", "*", "副", "裢", "憬", "邾",
"崇", "蕈", "疮",
"粽", "炝",
"珲", "莅", "衾", "爲", "枯", "汛", "仁", "熏", "馥", "㎡", "檐", "锦", "竭", "颁",
"遽", "瘙", "样",
"遛", "殍",
"湄", "消", "鳌", "痫", "鳏", "瓶", "窈", "谚", "麒", "鸹", "蟋", "横", "唠", "瘪",
"媪", "侔", "鐵",
"系", "杖",
"m", "叉", "沟", "衢", "寘", "■", "弗", "建", "疣", "珣", "綦", "劈", "道", "嘈",
"先", "芝", "降",
"滕", "邵",
"邺", "給", ")", "廨", "郛", "势", "氇", "坤", "昂", "焼", "奕", "闱", "朓", "毽",
"还", "坨", "銭",
"龂", "銎",
"壽", "矸", "窒", "①", "玷", "蝽", "泃", "烀", "魈", "★", "慶", "K", "嘶", "酶", "呖",
"殿", "乡",
"䄂", "阳",
"轪", "碱", "譬", "摩", "鳖", "刳", "地", "包", "貊", "悝", "圩", "今", "嚭", "凳",
"谕", "馃", "捎",
"佯", "侬",
"愆", "微", "涤", "舔", "蛇", "筲", "助", "锾", "剧", "缧", "簪", "惚", "柢", "庾",
"虹", "雪", "猡",
"脔", "亶",
"烨", "T", "锗", "芈", "女", "动", "偬", "琥", "县", "诣", "精", "嬗", "栀", "艨",
"智", "冗", "闼",
"嗝", "z",
"夢", "拿", "鹲", "尤", "啮", "﹐", "ɔ", "钓", "施", "萼", "邻", "竞", "碶", "艰", "》",
"翻", "馆",
"橪", "逝",
"臀", "淫", "枉", "羿", "拇", "溷", "徒", "涓", "關", "聋", "嵊", "殖", "叛", "敫",
"舵", "亊", "诽",
"菱", "苎",
"破", "腚", "A", "嵋", "扊", "挂", "篷", "棂", "碟", "復", "劾", "韪", "疔", "粒",
"鲵", "毙", "店",
"锻", "衮",
"寳", "◎", "斯", "倦", "醢", "曾", "茚", "荐", "隗", "芊", "豪", "亻", "哂", "堃",
"宇", "桑", "匋",
"植", "亥",
"撂", "棒", "蟠", "W", "迟", "蚋", "溊", "缌", "鞚", "蚤", "適", "赌", "卣", "厚",
"鲾", "匙", "槃",
"郎", "鬏",
"玳", "龄", "丈", "圮", "冑", "院", "葬", "嵐", "瓦", "孵", "漶", "星", "吐", "獍",
"藠", "萍", "振",
"潜", "龉",
"匦", "粹", "諾", "畵", "峦", "&", "埕", "朵", "戒", "炳", "酪", "绂", "篁", "测",
"殆", "涌", "业",
"盏", "醊",
"笆", "孰", "骊", "湛", "踰", "汎", "哲", "澙", "鲷", "√", "鄣", "亿", "螺", "吠",
"伟", "凛", "骡",
"恻", "巨",
"扶", "泡", "峯", "韵", "腎", "睦", "栖", "}", "笙", "疌", "绶", "忒", "哥", "价",
"纻", "薨", "漂",
"濮", "缮",
"勐", "妮", "傩", "陛", "陷", "柆", "瞭", "鲳", "烬", "喉", "固", "桡", "聊", "逦",
"猊", "梻", "涵",
"栒", "逍",
"饥", "凼", "早", "姣", "蕤", "塌", "桀", "亳", "虻", "鹨", "典", "情", "怄", "商",
"钍", "赚", "塥",
"煽", "垱",
"蝴", "乓", "籁", "帷", "锢", "圪", "快", "赘", "杵", "漠", "滴", "斩", "拈", "蚕",
"陽", "篡", "郦",
"瞻", "郯",
"鳍", "幽", "旅", "乖", "鹖", "斫", "痂", "肸", "右", "锂", "永", "泾", "茎", "觱",
"彼", "擎", "䨱",
"翱", "徝",
"醅", "求", "湫", "転", "溴", "師", "瓣", "蝠", "铭", "社", "苞", "仇", "噌", "你",
"嗾", "雳", "榧",
"駹", "雯",
"叨", "遫", "氏", "航", "辗", "溢", "历", "楷", "诱", "雏", "梳", "藕", "屺", "槎",
"钐", "燘", "棽",
"驸", "褪",
"清", "十", "廰", "移", "筌", "揾", "瞠", "姽", "馑", "恢", "逸", "p", "瑚", "茄",
"鹧", "俗", "璟",
"栊", "买",
"瀛", "镒", "球", "氲", "缛", "講", "胀", "焒", "悲", "翕", "拗", "T", "桌", "脓",
"闪", "稀", "狎",
"火", "柁",
"琴", "澍", "嗟", "龚", "楮", "噼", "隽", "栩", "焻", "哩", "藻", "瘸", "含", "偶",
"界", "嘃", "昶",
"澄", "頤",
"绒", "鲁", "麝", "决", "撒", "岙", "季", "刿", "肝", "蒉", "蓇", "财", "完", "蠔",
"脉", "肱", "谙",
"蜮", "郭",
"慨", "晔", "髂", "蛏", "眨", "钗", "葺", "惆", "娈", "瞵", "踞", "棁", "蝢", "嚎",
"猝", "必", "剞",
"关", "咛",
"劫", "闸", "肯", "№", "莩", "哇", "蛑", "镬", "羡", "驊", "茂", "塍", "沓", "筱",
"杉", "战", "茧",
"耙", "击",
"需", "腊", "酎", "畦", "葙", "鹘", "韭", "嚚", "争", "域", "伢", "鞲", "哳", "栲",
"某", "翌", "哗",
"焚", "螗",
"懲", "躲", "約", "镖", "凿", "饶", "够", "剁", "铥", "应", "署", "杮", "蒂", " ",
"坷", "礅", "款",
"梁", "鄜",
"髹", "選", "伤", "路", "З", "亲", "野", "啦", "捯", "憷", "鲩", "札", "怏", "塘",
"绊", "愍", "簦",
"牦", "黥",
"鳜", "唉", "W", "沱", "蚺", "甪", "摉", "协", "耨", "娱", "桄", "仆", "类", "搡",
"滤", "岗", "休",
"坶", "谒",
"忭", "飨", "闷", "菟", "鲣", "驷", "湜", "疡", "蚩", "萊", "䝉", "硒", "贺", "弃",
"徘", "陨", "否",
"遥", "妒",
"X", "間", "觜", "跬", "夬", "羮", "喙", "赇", "鹗", "『", "砀", "残", "绿", "小",
"勘", "瀌", "扉",
"耧", "衅",
"挟", "乐", "鹏", "墁", "澜", "噍", "坊", "術", "嗖", "知", "盉", "圆", "嗈", "蘖",
"资", "爭", "=",
"刑", "裒",
"〈", "淸", "定", "袒", "戗", "钤", "吵", "旯", "蓝", "裎", "溅", "贰", "荏", "甥",
"悌", "勤", "炽",
"换", "躜",
"!", "薄", "痱", "双", "匕", "肷", "挥", "茑", "船", "砝", "煤", "荜", "弘", "▏",
"陆", "稔", "朽",
"冤", "頉",
"遊", "砰", "迎", "碎", "唪", "醪", "稆", "练", "锸", "阵", "皇", "香", "镀", "嫡",
"持", "桶", "垄",
"阍", "戥",
"臣", "琛", "涘", "惶", "赙", "葆", "住", "舊", "枝", "媲", "蓣", "龅", "搦", "_",
"图", "力", "纪",
"悍", "麗",
"戽", "腧", "绣", "跟", "哕", "打", "蝰", "Φ", "吞", "功", "夀", "劓", "沇", "熔",
"占", "隰", "命",
"佻", "豁",
"苣", "楦", "掇", "蛛", "唢", "郜", "霉", "鲏", "予", "沸", "殻", "俯", "探", "篪",
"荇", "邈", "烯",
"忮", "伸",
"岬", "×", "锧", "窸", "毪", "纩", "蛋", "讯", "骼", "叶", "楂", "犟", "站", "盘",
"隈", "喝", "儣",
"兵", "尚",
"孙", "爿", "芜", "羁", "旖", "溽", "迩", "京", "7", "龃", "狝", "缦", "缁", "鲃",
"怒", "故", "據",
"枫", "髙",
"亭", "耳", "飚", "O", "编", "箸", "幼", "氘", "鞮", "匐", "祯", "臃", "辫", "磋",
"溝", "墙", "诚",
"阻", "档",
"歆", "璃", "悻", "婤", "映", "瑞", "牂", "话", "忠", "潘", "惋", "冬", "氦", "腔",
"胬", "盔", "\"",
"饮", "贶",
"嚄", "儆", "溜", "砷", "樇", "跏", "泩", "馌", "埃", "莙", "革", "珙", "乌", "鍋",
"穴", "石", "珺",
"熹", "诞",
"<", "腉", "姊", "钧", "罪", "拆", "赊", "殒", "堇", "仑", "掺", "塃", "獴", "迥",
"盦", "檬", "益",
"居", "鼑",
"异", "嘻", "悔", "旮", "况", "時", "阋", "洛", "線", "#", "型", "迕", "睇", "橱",
"笊", "蛞", "愚",
"茉", "镈",
"镞", "垭", "扁", "泫", "搬", "古", "书", "疸", "痨", "黟", "墉", "料", "并", "ㆍ",
"裳", "鞑", "湮",
"柠", "颐",
"形", "━", "逹", "硁", "置", "韦", "瓞", "象", "殽", "均", "浓", "瞓", "椐", "洨",
"乱", "襜", "终",
"優", "睹",
"敦", "鼬", "唆", "佼", "財", "瘃", "H", "痳", "勺", "依", "虎", "蕖", "玄", "缓",
"滢", "^", "骅",
"诘", "弋",
":", "∩", "廪", "缈", "造", "蕉", "孖", "嫒", "寨", "意", "岽", "庶", "罗", "瞢",
"酹", "蔟", "赴",
"烂", "栋",
"格", "矛", "驯", "词", "嗦", "剀", "蓓", "期", "鏢", "羑", "奴", "椱", "A", "狗",
"烟", "蹬", "案",
"记", "讴",
"鳑", "侯", "霏", "焜", "沬", "份", "酦", "芗", "庚", "瑗", "鹎", "穗", "鲠", "肛",
"厄", "蜔", "學",
"伊", "⑥",
"琪", "邒", "少", "霖", "蓖", "猜", "塾", "肾", "罃", "伐", "钩", "骈", "溟", "饵",
"莉", "é", "刖",
"洯", "堉",
"锝", "趔", "七", "萁", "竹", "憾", "蚨", "离", "柔", "替", "侑", "飙", "气", "震",
"厥", "备", "刻",
"顽", "瞽",
"腄", "雄", "燃", "旬", "简", "翠", "熥", "◇", "吃", "囡", "玙", "铷", "暖", "配",
"傻", "窄", "皈",
"夼", "舂",
"乜", "苩", "攉", "雠", "茇", "锈", "酰", "粮", "祝", "考", "堍", "鳅", "彬", "▲",
"孝", "蠊", "顇",
"娲", "腥",
"$", "珠", "厂", "诠", "蹓", "轼", "嵫", "捩", "硗", "胺", "证", "膀", "」", "胯",
"钷", "毂", "柙",
"深", "沄",
"匹", "8", "爷", "礳", "秏", "窜", "魑", "d", "转", "烆", "屿", "眙", "極", "袤",
"護", "V", "狂",
"柑", "玠",
"氩", "’", "馊", "玛", "坢", "%", "燔", "颗", "舅", "暂", "艾", "芹", "溏", "晰",
"件", "琚", "仿",
"祾", "酤",
"騠", "揳", "鲫", "蜥", "仨", "牺", "步", "讓", "港", "煲", "铴", "腦", "鳝", "危",
"鋪", "冠", "正",
"柽", "抍",
"掘", "控", "娴", "娀", "離", "手", "臾", "酗", "筼", "煸", "弹", "照", "哎", "毒",
"颀", "诙", "刚",
"搢", "䧳",
"峒", "滋", "\\", "匀", "黉", "毓", "娠", "床", "浪", "祐", "铟", "4", "?", "凄",
"飗", "蚍", "葑",
"抗", "鹞",
"糸", "红", "英", "违", "橡", "眷", "防", "缬", "龠", "察", "仍", "辇", "减", "闫",
"箴", "龍", "館",
"屙", "翙",
"媽", "涴", "到", "旻", "删", "瞾", "鏖", "咭", "豨", "荘", "炭", "畼", "构", "锘",
"鉫", "候", "扇",
"繄", "猩",
"瘵", "恺", "贵", "榦", "息", "恽", "胎", "狰", "雜", "辋", "璜", "硈", "泠", "呔",
"蹿", "踹", "摄",
"炀", "坞",
"蹄", "裝", "赛", "蝥", "塔", "靳", "荬", "找", "仡", "淮", "比", "淆", "义", "淝",
"卢", "辟", "寂",
"庒", "鳯",
"暲", "景", "邪", "腻", "赍", "甍", "讲", "哌", "嶝", "鎌", "总", "缱", "问", "磛",
"谅", "拉", "靈",
"奭", "沆",
"茔", "羅", "鄠", "網", "吏", "懵", "鑫", "歌", "黹", "嵘", "涞", "碳", "崂", "婥",
"赞", "镑", "購",
"幺", "鸰",
"饟", "蝌", "忝", "懒", "禺", "梽", "齉", "恳", "拯", "弥", "荡", "芾", "幪", "厌",
"馒", "蜘", "欸",
"吣", "1",
"却", "榻", "碾", "袂", "錎", "钬", "無", "嬉", "笞", "蹴", "视", "雇", "创", "椟",
"6", "瘁", "斜",
"傥", "喃",
"炷", "秾", "嘱", "茀", "犄", "窑", "庀", "潍", "伦", "䀲", "凉", "Р", "撻", "萜",
"二", "倨", "蔑",
"捕", "勚",
"士", "鈇", "踺", "啤", "彧", "缪", "述", "傅", "颅", "畸", "畜", "滗", "慭", "琎",
"斌", "参", "胳",
"骖", "稠",
"汰", "铻", "闯", "留", "蘘", "沏", "亦", "择", "華", "禽", "砟", "祼", "狃", "噫",
"狼", "寤", "跪",
"浠", "·",
"费", "瓘", "鼹", "锪", "箢", "垣", "慊", "虏", "秩", "偉", "镏", "钯", "恐", "鹃",
"菇", "炸", "潮",
"蟀", "硂",
"偌", "哏", "验", "桉", "阴", "初", "掴", "鹺", "峨", "赋", "舉", "裹", "赶", "土",
"淋", "瘌", "沔",
"r", "赀",
"淖", "茯", "怛", "谜", "洗", "似", "舡", "纳", "晓", "R", "诐", "痹", "漪", "顺",
"挛", "阎", "贝",
"钰", "惬",
"疬", "菀", "埘", "怙", "部", "译", "鲭", "窋", "敢", "夜", "撰", "珅", "特", "襕",
"癖", "胡", "⒃",
"附", "擘",
"痢", "尬", "鉴", "瞋", "膨", "阽", "挲", "⒄", "骎", "帕", "缕", "计", "障", "鳆",
"隹", "朔", "碹",
"当", "迦",
"氙", "蘑", "妓", "炬", "苊", "萎", "浈", "沥", "绯", "壤", "噱", "蹾", "驶", "葱",
"孕", "羹", "钻",
"農", "勝",
"膈", "灿", "赆", "靿", "耱", "陪", "忙", "缰", "奶", "儒", "个", "朱", "燹", "琮",
"轷", "錾", "箅",
"澳", "嗥",
"攥", "没", "匿", "鲆", "|", "矣", "他", "鸶", "芸", "B", "髑", "街", "巿", "廣",
"盯", "監", "鲸",
"胭", "凬",
"寿", "挝", "绽", "+", "劝", "究", "眢", "集", "衙", "卷", "j", "跶", "牡", "畯",
"貅", "销", "發",
"咱", "蓊",
"揣", "咝", "琶", "荦", "阌", "盅", "嘹", "苟", "醮", "洪", "鲧", "钒", "柱", "氨",
"旰", "冽", "茭",
"嵇", "粲",
"蛾", "訾", "辔", "N", "尹", "趿", "蹲", "疟", "祠", "段", "車", "网", "⒉", "舷",
"廐", "侣", "棵",
"粜", "觐",
"铼", "锁", "兒", "舁", "时", "垦", "版", "摈", "扳", "见", "腮", "嫖", "痭", "呆",
"簖", "伋", "鳙",
"珊", "麂",
"既", "谴", "热", "超", "蠕", "铞", "e", "殓", "因", "锿", "文", "禊", "皙", "鑙",
"爹", "鋼", "忻",
"秣", "镁",
"奠", "橉", "畺", "笮", "疹", "湝", "龟", "殃", "毵", "溃", "勢", "索", "砉", "阼",
"堞", "酥", "冁",
"喊", "¥",
"幛", "娇", "锲", "蕃", "铘", "铍", "鴿", "响", "傲", "脏", "杓", "罕", "笥", "弦",
"但", "缃", "扬",
"盲", "碚",
"幢", "鎖", "缺", "钋", "麽", "禳", "浃", "啄", "昧", "蒴", "帙", "琏", "咧", "舰",
"亵", "浊", "豳",
"衲", "俏",
"镵", "浩", "勾", "槛", "榈", "徙", "鹤", "洹", "铂", "揎", "棕", "挦", "挫", "阆",
"衹", "甚", "近",
"】", "簏",
"汽", "踮", "淌", "檇", "痔", "谝", "钙", "蕞", "蔯", "兆", "蔽", "后", "蚬", "谸",
"芟", "枞", "叫",
"栗", "餘",
"营", "郝", "氯", "㺃", "狍", "冏", "庛", "纱", "泼", "碍", "认", "邓", "茵", "饧",
"闟", "惝", "裙",
"噙", "忘",
"虬", "群", "S", "佗", "恼", "坟", "肮", "皮", "玃", "在", "赧", "孚", "偾", "镨",
"恨", "葡", "西",
"缞", "挠",
"逃", "吾", "膪", "焦", "翘", "桧", "变", "渗", "繁", "際", "痘", "撼", "筅", "坑",
"前", "玑", "数",
"融", "鲌",
"讦", "窃", "鄌", "伾", "众", "攻", "彪", "锎", "焐", "殛", "锊", "嗉", "枓", "抢",
"鞠", "掩", "贾",
"搔", "皁",
"拶", "朗", "渺", "跛", "㛃", "鏾", "慥", "杆", "沈", "戍", "豫", "楠", "爆", "汤",
"昉", "耘", "缡",
".", "允",
"揜", "责", "艟", "裁", "喬", "砹", "鹣", "裼", "啉", "蛳", "酮", "听", "维", "阪",
"獾", "浣", "訂",
"瘿", "蜡",
"泖", "蔚", "貔", "致", "禨", "尓", "糺", "绐", "遯", "笄", "邦", "圈", "洟", "缟",
"槲", "桹", "镓",
"骒", "髫",
"暾", "像", "縻", "戊", "飧", "驽", "干", "万", "绕", "披", "雅", "桊", "卡", "贲",
"吡", "沧", "鳟",
"堂", "扺",
"岱", "封", "鄭", "螣", "瞩", "幞", "邕", "睫", "涩", "自", "趱", "愣", "威", "酊",
"罂", "慑", "袴",
"架", "烘",
"现", "灞", "钔", "股", "興", "乍", "噜", "济", "碛", "兀", "诅", "柴", "瓿", "[",
"怿", "竦", "白",
"黄", "阶",
"务", "榮", "澹", "谏", "垓", "跸", "繻", "窿", "紊", "陟", "劁", "嗑", "牯", "厉",
"敛", "鮕", "嘉",
"蔻", "鼎",
"恒", "硝", "溉", "骘", "窘", "任", "裱", "处", "旨", "舶", "缸", "囹", "笠", "讥",
"泜", "脊", "煊",
"淦", "牝",
"硕", "胧", "泚", "溪", "贪", "牛", "答", "瘴", "Q", "炯", "⑤", "篾", "銀", "乩",
"杶", "垆", "蛐",
"苔", "啪",
"y", "玮", "琫", "寮", "邂", "後", "僵", "贴", "硭", "枚", "姆", "乎", "讶", "醭",
"橥", "脱", "蒈",
"擞", "忪",
"顾", "柚", "褿", "忲", "辖", "铡", "螠", "殉", "喆", "爡", "轮", "棰", "鲉", "跃",
"韬", "睡", "嘧",
"袅", "圗",
"檄", "踊", "阀", "题", "桫", "林", "沉", "禚", "散", "麇", "沦", "秋", "导", "斑",
"宰", "嘞", "暑",
"笱", "搋",
"擅", "镤", "锶", "L", "厣", "有", "猗", "袆", "绞", "甭", "歧", "跣", "潦", "専",
"绑", "飱", "廓",
"磔", "接",
"腓", "窎", "瑁", "飓", "蟪", "俎", "П", "缉", "䘵", "夙", "潟", "桷", "淡", "虺",
"恶", "|", "驭",
"怀", "邋",
"辢", "逻", "晖", "蜃", "蜊", "溻", "冢", "尻", "礼", "厝", "亘", "酴", "饔", "悸",
"戆", "什", "玚",
"馔", "哔",
"沃", "竑", "葭", "垞", "鏂", "抃", "弄", "去", "焊", "焌", "x", "苇", "與", "炼",
"蛄", "莴", "阏",
"薷", "禀",
"鸯", "栽", "冒", "姓", "0", "尃", "蜞", "毗", "骟", "秸", "荸", "柈", "恬", "赡",
"侏", "兑", "蝤",
"荷", "徳",
"押", "挣", "腰", "宣", "鸵", "葳", "遘", "讨", "狒", "涿", "囤", "邃", "蒜", "疑",
"脍", "嘟", "鹠",
"吻", "鄹",
"耦", "华", "霸", "侥", "勒", "挞", "臊", "尺", "让", "榆", "阝", "鳚", "灾", "鲬",
"艿", "Ⅱ", "锩",
"攮", "蚊",
"蔁", "唝", "涅", "挹", "淏", "鏊", "氵", "鹕", "律", "對", "粱", "恫", "挻", "滏",
"叮", "‰", "鼯",
"绫", "秉",
"怩", "質", "岐", "菊", "佤", "帏", "骺", "爰", "珉", "耪", "乞", "郕", "鲱", "雷",
"蒿", "不", "啐",
"侓", "郓",
"歼", "拒", "胗", "寕", "旒", "勁", "婢", "诌", "蹂", "姐", "媳", "歃", "拐", "辐",
"拟", "醯", "雌",
"点", "玟",
"您", "鲨", "载", "藩", "罔", "噀", "抹", "萏", "补", "蝎", "辈", "劢", "乚", "唔",
"瓜", "恿", "蟭",
"涸", "纬",
"睽", "樣", "帻", "蓥", "谯", "柯", "渴", "脁", "诲", "福", "③", "熊", "羌", "疴",
"袖", "虿", "杏",
"覌", "易",
"醾", "筒", "肤", "苷", "柃", "榇", "酬", "癸", "啰", "眛", "稷", "展", "鸾", "祢",
"蝾", "敵", "毛",
"痦", "老",
"赐", "单", "淹", "畋", "符", "奎", "绥", "轾", "鄺", "濩", "眦", "觎", "忾", "璋",
"刘", "翳", "菪",
"簟", "胼",
"孫", "機", "獻", "低", "o", "捅", "鳥", "⑨", "卸", "废", "启", "呋", "窥", "巢",
"揭", "咴", "趺",
"鲥", "空",
"膄", "崮", "锜", "络", "納", "恤", "刭", "批", "霭", "氧", "钮", "甑", "祲", "粘",
"辏", "∶", "臨",
"│", "粪",
"惰", "肼", "浉", "橄", "5", "東", "8", "漁", "浜", "忍", "奂", "遹", "扃", "扦",
"入", "欤", "豆",
"悠", "蕴",
"萑", "媄", "龈", "÷", "磙", "鸬", "缎", "嗯", "浕", "木", "陋", "柰", "瘩", "箨",
"松", "躁", "鲇",
"彰", "恕",
"楗", "姨", "撅", "诹", "戮", "桓", "棉", "束", "嗍", "庋", "瞿", "郂", "哪", "町",
"a", "铁", "洫",
"失", "栳",
"篇", "鳗", "眇", "椿", "義", "就", "都", "镌", "阖", "夭", "拃", "跚", "業", "圬",
"演", "篥", "3",
"昼", "從",
"瞍", "蓦", "鼾", "坪", "觫", "鲍", "馿", "妾", "密", "奥", "耰", "佟", "嘤", "貘",
"薯", "稽", "届",
"褛", "钠",
"猿", "佈", "倍", "铩", "铙", "踵", "o", "捱", "鹐", "當", "狷", "写", "遆", "钱",
"姗", "寸", "综",
"挑", "礶",
"靼", "溯", "湟", "漱", "碰", "职", "味", "Λ", "璁", "壴", "给", "碘", "恭", "苴",
"酚", "套", "宕",
"辽", "窀",
"催", "踢", "惟", "璧", "翔", "稿", "癀", "霈", "光", "膑", "妆", "庡", "圾", "躺",
"惮", "切", "目",
"梦", "岫",
"飑", "叠", "累", "鴻", "透", "量", "妻", "沨", "俪", "屣", "挚", "w", "厅", "货",
"箧", "漦", "隙",
"瘥", "妃",
"門", "鹦", "隳", "龆", "瞪", "跑", "帼", "刺", "起", "鞴", "岸", "渫", "莽", "髭",
"耜", "瑛", "葉",
"宵", "绠",
"眭", "畅", "茱", "卜", "濂", "浍", "冈", "脬", "厘", "夔", "纟", "槚", "哐", "萋",
"曼", "膳", "潲",
"啜", "啊",
"猾", "捉", "箕", "㐂", "藝", "艘", "園", "妲", "灵", "蚌", "范", "&", "疥", "陑",
"洒", "唾", "a",
"婄", "谋",
"t", "唬", "宓", "瓷", "︰", "焗", "默", "噔", "菡", "恃", "亩", "边", "啟", "颞",
"啬", "盟", "墩",
"汭", "缝",
"魇", "酡", "疗", "梾", "尾", "鹿", "锔", "溦", "酃", "囊", "掉", "罥", "报", "诤",
"喹", "蕙", "割",
"蠢", "兼",
"俺", "升", "屦", "獠", "辣", "跹", "颧", "宪", "抬", "咿", "沲", "旗", "荩", "傒",
"鳳", "變", "偈",
"薹", "钭",
"垧", "谪", "躐", "谀", "R", "字", "怆", "陵", "追", "迓", "舞", "卲", "捲", "麾",
"税", "方", "竴",
"壹", "射",
"轫", "塞", "僧", "椠", "突", "阕", "惫", "U", "佞", "秒", "友", "視", "莹", "攒",
"荻", "俅", "筐",
"能", "刓",
"拍", "浥", "揽", "谨", "军", "巷", "怵", "额", "恪", "荀", "糍", "湎", "褙", "觇",
"效", "估", "噩",
"恍", "聚",
"涛", "式", "兜", "汔", "祃", "銘", "烺", "瑄", "枘", "丁", "樗", "堙", "窗", "號",
"鬣", "阈", "乳",
"簇", "绳",
"淞", "]", "征", "聩", "凸", "礓", "柘", "懂", "㧎", "纷", "里", "爸", "靥", "莞",
"馅", "仞", "芏",
"莳", "殪",
"煌", "落", "佚", "帱", "诶", "家", "将", "浯", "抿", "讫", "趸", "筢", "绩", "原",
"专", "滂", "嗳",
"踬", "泱",
"體", "蜱", "绵", "伻", "埗", "妤", "蔺", "赳", "嘢", "梨", "鹪", "烤", "镦", "赉",
"崞", "蚰", "骝",
"幅", "汴",
"丽", "访", "叩", "羼", "亓", "恸", "燥", "笤", "丑", "枰", "守", "蜚", "戈", "高",
"q", "瓻", "隘",
"H", "南",
"剎", "扭", "骠", "孜", "园", "锬", "审", "¥", "罚", "购", "裰", "泔", "醌", "醒",
"绎", "莪", "掬",
"睾", "鹁",
"蛊", "票", "剃", "释", "调", "黛", "撩", "篱", "茌", "敓", "蜜", "魉", "鳤", "昽",
"俳", "辁", "键",
"犯", "嶙",
"狈", "邬", "枋", "婊", "憎", "督", "救", "措", "足", "码", "栟", "虼", "棻", "阅",
"肊", "坛", "鸱",
"侩", "烫",
"湉", "脐", "戾", "旎", "膚", "椒", "境", "绛", "濛", "蓄", "章", "压", "窦", "彖",
"阜", "咻", "神",
"存", "诺",
"課", "覺", "鲈", "渚", "「", "缢", "仓", "氅", "筇", "桴", "荥", "些", "纯", "肋",
"退", "妪", "别",
"書", "租",
"嚼", "芘", "笳", "涰", "馐", "熵", "犹", "朕", "猪", "蔸", "參", "觳", "舖", "蝙",
"骏", "织", "躏",
"纹", "锹",
"蛉", "撑", "氽", "茶", "俛", "誠", "胖", "崽", "炫", "乘", "把", "趑", "谵", "骧",
"犍", "鸮", "灌",
"焯", "倭",
"狁", "盱", "踱", "滠", "儡", "诸", "芽", "駆", "蹼", "虱", "祇", " ", "蠡", "衄",
"谬", "蒍", "婺",
"蘧", "博",
"捍", "磁", "慷", "釂", "蛩", "钕", "祎", "呑", "贫", "斗", "菅", "操", "规", "硼",
"惕", "丫", "俭",
"肿", "骀",
"砼", "句", "茛", "闶", "钏", "饻", "圠", "萌", "魏", "铃", "摞", "┅", "伎", "獭",
"田", "钴", "峭",
"魅", "捋",
"唼", "鹅", "祚", "嬷", "圖", "抄", "嶂", "鸳", "溧", "钵", "嗽", "墠", "锌", "愈",
"併", "踟", "羯",
"翅", "纠",
"勻", "岚", "菖", "便", "祈", "毳", "屹", "掰", "倬", "扛", "巴", "拮", "绁", "跌",
"飯", "嵯", "翮",
"堤", "诃",
"腑", "皆", "鄂", "胾", "片", "这", "浙", "雨", "鼱", "袼", "鹊", "厢", "蛣", "摇",
"蛮", "揍", "⒅",
"啱", "薇",
"岈", "兔", "谇", "纶", "肉", "崩", "甩", "涪", "馼", "铣", "锚", "丙", "雲", "烹",
"钦", "撄", "铬",
"令", "虮",
"湊", "禹", "抖", "喏", "旺", "畲", "戬", "嗷", "釜", "车", "缀", "玕", "谐", "啁",
"怎", "下", "惑",
"恅", "藿",
"筰", "帐", "祸", "镝", "喵", "刁", "习", "藏", "墓", "护", "聲", "箦", "严", "按",
"谛", "睨", "艚",
"歉", "蟮",
"胶", "盍", "鳃", "狯", "垫", "杠", "线", "3", "葖", "t", "熬", "虞", "嶶", "篮",
"黻", "墒", "氟",
"嫠", "漕",
"腾", "哟", "玫", "撇", "垍", "靛", "翼", "淅", "省", "斥", "稞", "蠼", "谩", "埠",
"蘸", "刊", "烝",
"宁", "鹚",
"龊", "苪", "袷", "诧", "细", "蒌", "焅", "2", "筹", "扒", "卮", "捞", "净", "菲",
"逮", "槍", "蛎",
"莱", "黠",
"逖", "辚", "剥", "啴", "诿", "楱", "氪", "领", "嗒", "藐", "惜", "甘", "佾", "嵴",
"胫", ";", "晳",
"锣", "瞅",
"缷", "耶", "搤", "策", "咽", "邀", "霾", "悟", "属", "鸪", "牴", "贞", "趁", "丞",
"瘆", "豌", "著",
"饿", "筠",
"划", "璇", "损", "卵", "腒", "畏", "盥", "耐", "圏", "拓", "蒙", "鋫", "劙", "蹦",
"熘", "烊", "匏",
"咔", "轘",
"沽", "菩", "罴", "磉", "炖", "假", "枪", "龙", "俸", "焱", "四", "─", "毫", "涨",
"浇", "椰", "賣",
"蘇", "真",
"安", "坝", "枕", "鸼", "昵", "亨", "苤", "祷", "枧", "赟", "菑", "鳂", "戌", "悄",
"種", "鳢", "嗣",
"電", "颥",
"妯", "谟", "蜒", "训", "泍", "洁", "勇", "哿", "扰", "蟆", "螂", "刃", "絜", "曪",
"乒", "湖", "鞨",
"懜", "夤",
"哓", "胥", "桞", "俇", "肣", "半", "于", "橼", "锑", "熙", "甜", "槌", "盾", "屃",
"缗", "共", "碗",
"凇", "笔",
"阿", "擗", "袍", "敉", "钾", "俶", "蚪", "琤", "凱", "辕", "à", "恣", "皴", "創",
"寥", "妳", "腈",
"畤", "迤",
"垠", "触", "趙", "铤", "逊", "羊", "碉", "锱", "骨", "仄", "斟", "俚", "啡", "芩",
"迫", "杷", "种",
"鹄", "牗",
"耑", "艇", "芰", "整", "慙", "飛", "甓", "岩", "鸦", "黎", "僊", "糁", "谈", "洋",
"椑", "健", "〕",
"內", "言",
"掷", "倚", "姬", "矿", "灯", "阐", "凋", "銮", "豇", "瑰", "抓", "噪", "堋", "吁",
"妈", "庥", "彳",
"鄗", "闩",
"夫", "0", "庠", "悬", "妙", "琵", "着", "首", "熣", "瞰", "揆", "燚", "条", "姜",
"滘", "麓", "鳉",
"椀", "蓿",
"廠", "泌", "蝈", "倕", "丛", "耍", "且", "蝇", "凉", "豐", "泪", "臼", "服", "刍",
"織", "渎", "尥",
"甙", "埋",
"珏", "援", "祖", "彊", "臱", "惦", "葴", "礁", "达", "橋", "钨", "崦", "醐", "巳",
"中", "颜", "溠",
"铹", "负",
"抠", "愎", "罘", "雩", "胝", "冱", "筵", "篙", "材", "肓", "○", "迅", "腼", "橙",
"仵", "茏", "慵",
"齌", "琯",
"疃", "貢", "豉", "瞟", "忉", "禄", "通", "咒", "愫", "秕", "筜", "觖", "州", "渑",
"胆", "喑", "張",
"衖", "洺",
"眉", "榞", "色", "邶", "攫", "堑", "淬", "嗪", "肐", "殣", "辊", "隧", "献", "潤",
"蓺", "函", "鹱",
"轭", "劭",
"椁", "膜", "亹", "侧", "貂", "哚", "磴", "蠋", "囔", "险", "伶", "世", "菥", "莶",
"瘾", "燫", "延",
"∵", "毋",
"羧", "无", "雎", "曛", "沚", "巍", "g", "熄", "恰", "伷", "開", "冻", "颛", "支",
"⑦", "鞥", "赖",
"试", "泮",
"联", "沮", "穰", "è", "峻", "滿", "豊", "刎", "鴈", "覆", "串", "锃", "春", "储",
"矍", "哺", "评",
"猁", "愉",
"疳", "閃", "奄", "甲", "墦", "頭", "锫", "俦", "玩", "搀", "砭", "流", "橇", "泅",
"琇", "趣", "∧",
"辑", "灊",
"貴", "迮", "摹", "霄", "濟", "限", "彀", "匪", "缂", "觚", "奇", "诋", "灼", "萘",
"狠", "澥", "岂",
"悺", "闾",
"麋", "号", "槽", "姹", "陉", "瑯", "尉", "h", "绖", "宿", "戋", "粝", "砂", "该",
"鞧", "翯", "釘",
"铢", "窨",
"設", "⒆"]
def _get_beta_charset(self) -> List[str]:
"""获取beta版字符集"""
# 这里是beta版的字符集
return ["", "笤", "谴", "膀", "荔", "佰", "电", "臁", "矍", "同", "奇", "芄", "吠", "6",
"曛", "荇", "砥", "蹅", "晃", "厄", "殣", "c", "辱", "钋", "杻", "價", "眙", "鴿",
"⒄", "裙",
"训", "涛", "酉", "挞", "忙", "怍", "︰", "镍", "檐", "眯", "茓", "辖", "淩", "啟",
"蜀", "芟",
"裟", "楝", "彘", "嶪", "费", "亞", "滁", "榉", "朝", "f", "倻", "裎", "谧", "崂",
"卑", "助",
"触", "氐", "锟", "铢", "膪", "脐", "渲", "荫", "佾", "琯", "钣", "珰", "翦", "膻",
"娥", "浥",
"淄", "猸", "内", "消", "粞", "反", "苪", "冽", "酵", "玩", "父", "存", "屯", "殷",
"俐", "篱",
"俛", "塮", "苕", "耲", "输", "壖", "溶", "琤", "氏", "真", "黩", "瑄", "阶", "茔",
"眩", "浙",
"痄", "噔", "烤", "楯", "²", "铆", "裈", "偬", "盏", "祐", "伯", "庙", "獯", "榀",
"裒", "综",
"蒸", "架", "蜱", "鹖", "涴", "肌", "廖", "祾", "蔗", "破", "!", "鑫", "瓷", "H",
"宛", "倪",
"贝", "酝", "倞", "榼", "菊", "帕", "胍", "淌", "抨", "倕", "味", "独", "à", "庐",
"蹲", "肸",
"洹", "騳", "绖", "觉", "蝙", "铜", "選", "郚", "奄", "手", "篦", "忮", "潺", "歁",
"湖", "貔",
"缚", "癫", "捣", "翎", "勇", "徒", "杪", "捃", "纴", "郞", "蛱", "浓", "講", "薇",
"汊", "彻",
"琖", "觇", "驩", "野", "闺", "彩", "膊", "簸", "瑭", "龏", "栓", "攸", "堕", "鹿",
"檠", "锽",
"晟", "煊", "衖", "p", "L", "侞", "吹", "岵", "捡", "邃", "曩", "泼", "娌", "磙",
"鞮", "號",
"苤", "骁", "感", "氙", "榜", "菟", "蠲", "∶", "焌", "漯", "胪", "以", "剜", "=",
"衰", "剔",
"疏", "韩", "邋", "探", "搌", "握", "舵", "腰", "咐", "郎", "鈺", "赴", "斩", "铥",
"棂", "褫",
"秾", "城", "葬", "缺", "甓", "沙", "鴨", "恧", "吩", "膈", "俗", "引", "濑", "坛",
"蛘", "谍",
"飘", "鎚", "貋", "袅", "圃", "肽", "祖", "瑢", "鄣", "卡", "恸", "饷", "撖", "阖",
"碌", "墉",
"⇋", "抗", "僇", "撩", "狷", "静", "荽", "憯", "虻", "滹", "簧", "Y", "汾", "嫁",
"蚴", "岈",
"榔", "邶", "挛", "火", "w", "旌", "線", "3", "跏", "F", "楸", "瞬", "證", "現", "符",
"鲀",
"窸", "朗", "m", "劉", "襄", "鸻", "敖", "憩", "濛", "胶", "雏", "禽", "缜", "鐀",
"澄", "泉",
"懈", "鹟", "牙", "叟", "镖", "膨", "硷", "钏", "嵌", "冲", "橪", "厨", "溘", "妻",
"贺", "耀",
"潲", "瞳", "惺", "涑", "鄄", "舡", "战", "钹", "盍", "窀", "凳", "锋", "(", "绤",
"翻", "》",
"嶷", "戛", "照", "设", "两", "霹", "風", "格", "栖", "椹", "№", "蔌", "达", "悠",
"旒", "函",
"抔", "逆", "疙", "玫", "箢", "恩", "樘", "远", "考", "荭", "殒", "靡", "蝾", "舅",
"䀲", "偾",
"灿", "埴", "瀍", "特", "诸", "搦", "恒", "妊", "课", "劂", "殊", "艋", "柚", "硕",
"捅", "钍",
"芘", "脖", "襁", "募", "卅", "疆", "嫖", "黹", "臀", "豇", "瘗", "憎", "嗯", "Θ",
"跺", "喧",
"捺", "爪", "鲠", "縠", "屋", "撑", "者", "娶", "喝", "墼", "丶", "茚", "髅", "瓢",
"农", "橼",
"攰", "折", "诋", "镒", "赂", "捲", "耑", "沐", "窜", "亰", "煌", "阕", "羯", "纤",
"滇", "值",
"琥", "渴", "祗", "鳌", "蛞", "庄", "鹇", "訄", "犷", "弋", "琐", "佗", "氛", "揄",
"旺", "聱",
"榨", "湿", "蟥", "湎", "敕", "轷", "耿", "三", "運", "瑶", "困", "勁", "蚱", "泸",
"螫", "斜",
"蟠", "轨", "镞", "霆", "嶙", "烷", "瘩", "敦", "塾", "僚", "澙", "關", "酩", "殴",
"—", "例",
"筷", "乘", "颗", "核", "孬", "舣", "糇", "劾", "黧", "镌", "罅", "X", "仅", "哐",
"蟊", "呻",
"呕", "粟", "配", "伊", "槊", "昌", "宰", "盘", "肫", "鳥", "圾", "恬", "辘", "绿",
"時", "丐",
"扃", "敓", "摄", "陕", "滿", "鹆", "嗬", "龅", "渣", "釣", "萦", "督", "孑", "∧",
"疥", "噱",
"蝎", "君", "笮", "泌", "镔", "称", "柘", "鬣", "罨", "潍", "垣", "顔", "褶", "礓",
"△", "骐",
"湍", "獾", "羖", "戾", "预", "祭", "鹨", "凤", "茕", "珏", "蛊", "毛", "枰", "鄭",
"娲", "丕",
"蜜", "纟", "蛹", "粮", "嚰", "嚓", "螨", "裰", "G", "集", "删", "郜", "舻", "嵛",
"鵰", "腊",
"峄", "脸", "鲺", "坢", "寞", "撰", "顸", "枋", "荠", "夡", "豆", "馆", "赭", "傎",
"淼", "镪",
"許", "礌", "带", "訂", "饧", "锜", "及", "漾", "編", "究", "仍", "糜", "喳", "嗝",
"醦", "堅",
"企", "烔", "图", "垲", "枥", "畿", "踱", "槟", "◆", "酽", "溢", "酥", "谚", "缨",
"死", "镑",
"干", "用", "紊", "坑", "副", "枭", "琮", "鸨", "獻", "弈", "伺", "醍", "氓", "宁",
"臻", "贾",
"啐", "玉", "咀", "孀", "烆", "嘱", "频", "蜥", "楡", "瞩", "委", "锺", "赀", "睬",
"旅", "刿",
"韪", "抹", "鞘", "x", "钝", "倌", "奖", "蟭", "灌", "肼", "曰", "啊", "属", "唐",
"彦", "煦",
"鄘", "坦", "鬻", "告", "单", "菽", "匏", "浚", "仺", "怜", "拦", "鸡", "拄", "乍",
"燠", "暧",
"竭", "⒂", "济", "Ⓡ", "趑", "舴", "体", "拒", "罂", "说", "猎", "闫", "鄗", "妲",
"鑙", "葶",
"匍", "等", "略", "盲", "唔", "钰", "渠", "镦", "葫", "蹒", "姘", "婵", "夯", "实",
"何", "株",
"锌", "礁", "桺", "捉", "鮕", "莓", "轶", "辉", "溋", "视", "嗒", "猞", "猁", "杓",
"怡", "咴",
"巷", "仂", "婉", "睛", "?", "淡", "/", "郛", "绨", "较", "毁", "沓", "瞎", "馏",
"蕙", "戏",
"i", "董", "臣", "鹫", "栳", "锹", "裕", "蜷", "唣", "9", "缂", "螬", "笥", "惶",
"蚰", "徨",
"忭", "传", "绛", "离", "锑", "候", "拓", "德", "损", "附", "紡", "徕", "錾", "蕻",
"⑧", "構",
"镊", "脘", "靸", "涒", "镡", "光", "廒", "尴", "荥", "佳", "弼", "暮", "榆", "鼑",
"辅", "钆",
"湝", "佤", "瘌", "炽", "筰", "嗈", "電", "飙", "坶", "椿", "俾", "灊", "泵", "像",
"咅", "樓",
"苒", "烨", "溺", "棽", "戒", "箅", "愔", "缢", "楞", "庤", "塑", "湮", "沽", "蝌",
"赌", "薨",
"锾", "圜", "骥", "秉", "瞌", "惇", "诊", "圣", "睢", "我", "廰", "苠", "襻", "鲚",
"酮", "厮",
"评", "沈", "愀", "垞", "习", "敷", "比", "欢", "尚", "钪", "卣", "她", ",", "伴",
"赃", "蚬",
"喇", "醇", "嚅", "T", "姝", "鍊", "悯", "N", "抚", "颡", "獐", "趟", "洑", "缝",
"喁", "帷",
"憷", "获", "阉", "镫", "臨", "炮", "奴", "揩", "叩", "恺", "粱", "胁", "憬", "痿",
"´", "沘",
"彀", "饩", "滋", "竑", "嗑", "鸟", "T", "璠", "快", "銀", "舶", "羞", "桞", "飛",
"茹", "師",
"偌", "節", "冁", "叡", "臑", "踔", "酔", "養", "溦", "岐", "豉", "杌", "胩", "仳",
"沾", "窑",
"曳", "闷", "垢", "垆", "磨", "髹", "態", "丽", "見", "洃", "遣", "场", "铭", "溉",
"衬", "橦",
"详", "馊", "濂", "瑾", "鲫", "贞", "搴", "胺", " ", "景", "执", "袴", "炖", "箭",
"楂", "婚",
"镧", "厩", "宣", "缣", "跃", "痘", "亓", "宦", "豪", "侣", "郧", "與", "痳", "挚",
"殻", "嘢",
"洽", "蹉", "孽", "森", "俚", "八", "砹", "凹", "訇", "屹", "啰", "宴", "廨", "沇",
"麇", "泅",
"绡", "辛", "鹲", "鋆", "旮", "婀", "幔", "赞", ":", "永", "活", "萸", "霉", "←",
"媲", "阚",
"鲮", "佝", "獒", "圹", "隋", "征", "蚶", "龊", "搀", "嫫", "鬏", "幞", "學", "然",
"沧", "萑",
"襜", "撻", "苯", "狳", "鞠", "咋", "壹", "栅", "款", "镘", "阳", "蚜", "荬", "糊",
"疳", "糕",
"镵", "寐", "褴", "v", "醋", "诀", "汰", "啸", "备", "娘", "氚", "镓", "室", "簟",
"硝", "嘌",
"釐", "争", "男", "疬", "鹄", "艳", "倒", "忸", "庶", "葒", "岖", "涨", "羝", "诼",
"纨", "纰",
"扉", "酎", "藉", "疮", "枞", "黜", "戮", "芽", "鳑", "末", "蒿", "茈", "透", "渊",
"秷", "〈",
"试", "络", "羼", "滪", "奋", "虏", "脁", "沫", "蓰", "襆", "披", "鲌", "艚", "逹",
"炳", "泔",
"叹", "轳", "锵", "嫜", "佥", "严", "迅", "筠", "逵", "铿", "钇", "拇", "诏", "绯",
"吊", "纠",
"蟾", "c", "涝", "汩", "盐", "跋", "拤", "邹", "镨", "羚", "龆", "脊", "攉", "傕",
"短", "團",
"蹬", "嘤", "奎", "熨", "芪", "鸢", "濉", "''", "莴", "義", "赜", "踺", "皂", "努",
"偏", "狡",
"遭", "吞", "嘿", "婊", "媸", "增", "殿", "刮", "燘", "劫", "娜", "瞄", "寡", "优",
"捋", "佴",
"菰", "蓠", "笙", "镃", "樇", "瘫", "B", "橇", "逯", "堍", "О", "磐", "腼", "て",
"送", "狭",
"皓", "亡", "嗉", "菠", "顺", "連", "嶶", "瑪", "辟", "婷", "牛", "笫", "窅", "萁",
"戟", "覃",
"馍", "建", "謇", "旘", "镣", "燏", "葉", "轺", "倏", "堪", "见", "葛", "钕", "键",
"押", "僊",
"槐", "戎", "窨", "洙", "鲢", "鞒", "慒", "雁", "圭", "D", "陌", "肱", "蜿", "洧",
"惑", "祛",
"樟", "矧", "呵", "峻", "凝", "蕨", "拯", "珮", "塥", "展", "贻", "囐", "弱", "庳",
"嫔", "緣",
"呈", "策", "漉", "瑗", "鲂", "鹂", "吾", "灶", "并", "挲", "重", "奭", "皙", "侪",
"埗", "烬",
"纾", "椒", "技", "ɔ", "擀", "恍", "遨", "订", "雨", "卵", "锏", "猗", "癸", ")",
"谡", "稷",
"枨", "蹽", "荑", "沅", "稽", "間", "冉", "颇", "酺", "份", "瞾", "毯", "藥", "蕞",
"狲", "吡",
"慷", "卯", "摽", "肿", "嗛", "悒", "丨", "横", "鳡", "仫", "狎", "砗", "聿", "腥",
"酡", "飱",
"柳", "遽", "汇", "湔", "麋", "垃", "粽", "坷", "鳗", "迫", "丢", "\"", "⒀", "嗲",
"肐", "結",
"署", "飨", "蠡", "涩", "挈", "浿", "鐾", "姞", "隧", "铘", "呜", "蜕", "鷄", "逼",
"哌", "病",
"係", "偿", "Ⅲ", "埋", "妤", "赘", "悉", "陷", "沸", "呲", "誓", "舆", "髀", "挫",
"羑", "据",
"顿", "淝", "抟", "珧", "郑", "仗", "怛", "掠", "稳", "尥", "祙", "找", "郐", "锔",
"轹", "钓",
"黙", "饸", "谌", "斐", "龙", "噫", "駆", "浼", "峒", "育", "纣", "溠", "铊", "亨",
"杮", "呓",
"钌", "业", "繻", "溪", "戌", "蓿", "椱", "悱", "仉", "阮", "芈", "濋", "搔", "纽",
"琛", "趄",
"双", "镯", "☆", "敉", "啬", "讦", "娱", "爾", "遶", "漱", "郗", "锪", "颃", "靰",
"醊", "驊",
"呢", "術", "妙", "蚣", "溽", "酇", "巾", "舐", "却", "废", "邾", "砣", "乙", "鲜",
"蒤", "囍",
"璈", "稔", "蘘", "匐", "業", "碟", "渺", "贤", "绋", "畑", "颞", "侥", "盟", "鼍",
"阊", "蔽",
"标", "吮", "淬", "鏾", "圗", "夜", "乕", "娇", "瞿", "循", "讲", "懒", "熘", "禚",
"观", "钷",
"万", "n", "未", "藝", "愿", "圈", "浩", "伦", "扛", "暄", "饶", "梧", "欣", "咿",
"檔", "吼",
"妮", "覆", "辰", "誤", "允", "危", "硗", "惫", "瘪", "李", "焱", "沣", "坯", "穄",
"归", "画",
"营", ":", "色", "哔", "矢", "巯", "祆", "傍", "享", "悻", "取", "凫", "铒", "唅",
"眈", "疹",
"败", "晴", "顼", "绶", "剃", "斗", "禾", "4", "誜", "俨", "2", "患", "结", "可",
"帇", "抍",
"筝", "衢", "鹛", "跸", "颢", "钾", "渡", "棒", "丛", "皱", "梓", "将", "压", "#",
"岛", "?",
"砺", "过", "党", "挣", "瞋", "谶", "妯", "羡", "化", "淫", "歪", "鼗", "阄", "蔓",
"烩", "餘",
"猊", ".", "畯", "祧", "狒", "碁", "咛", "鲈", "叨", "哞", "5", "娈", "半", "免",
"拿", "畎",
"媾", "棚", "丈", "周", "匋", "酯", "奚", "爇", "摇", "搭", "蓇", "陽", "岢", "禤",
"藠", "雅",
"哲", "弹", "按", "↑", "蹀", "察", "螾", "渎", "褂", "觳", "耍", "皲", "骗", "箫",
"蕺", "亚",
"保", "棵", "放", "踪", "了", "熣", "亦", "痛", "币", "馐", "夢", "诱", "梱", "鲰",
"郕", "璜",
"祯", "颦", "走", "踣", "嫚", "旯", "雲", "湟", "墨", "笃", "肇", "撝", "腦", "账",
"舞", "⑨",
"噻", "幂", "僵", "崦", "’", "牢", "号", "嫡", "囱", "肥", "代", "锶", "掏", "随",
"棓", "殉",
"嘅", "掰", "功", "垛", "踶", "娠", "霜", "碣", "鲼", "伉", "凄", "骋", "鹞", "洺",
"乌", "赧",
"瑛", "黎", "曚", "鲴", "髫", "瘴", "藏", "雍", "畐", "蔻", "爼", "蹴", "巨", "贱",
"汜", "胡",
"虬", "椎", "逸", "魇", "亶", "Φ", "忆", "赉", "塞", "潢", "垌", "简", "鼹", "發",
"枢", "麝",
"虹", "惭", "唛", "春", "瑟", "郰", "桡", "捩", "堙", "嗨", "驳", "F", "荪", "忑",
"贪", "躅",
"步", "揜", "闪", "垟", "晶", "分", "韭", "戴", "泪", "啧", "機", "峙", "和", "鸱",
"绎", "屠",
"阋", "黍", "淸", "萩", "汉", "吐", "匙", "铗", "蠔", "簠", "鲵", "须", "蛣", "躏",
"完", "咻",
"釜", "馼", "崤", "欻", "珐", "于", "郅", "焓", "轴", "递", "堰", "嗷", "儇", "壕",
"嘟", "酸",
"庾", "龂", "妍", "锅", "雳", "桦", "抬", "谄", "气", "六", "诎", "绀", "张", "復",
"客", "荞",
"鳚", "衔", "亁", "昂", "漤", "鞚", "筘", "绫", "彝", "枪", "苊", "榟", "饺", "苦",
"顶", "衷",
"聚", "寮", "揆", "轪", "栋", "臂", "葖", "颋", "镐", "愕", "贸", "Q", "琼", "糥",
"世", "莪",
"龁", "禁", "绲", "陶", "弑", "黢", "铵", "睐", "沄", "紬", "防", "癣", "曾", "钉",
"纶", "膘",
"句", "莸", "踝", "躐", "酤", "腑", "雄", "堤", "喀", "姣", "孢", "阡", "褐", "胂",
"髙", ";",
"骖", "膺", "糙", "辢", "⒃", "险", "砻", "缫", "骎", "低", "蚵", "箐", "苞", "劭",
"峪", "工",
"盈", "腹", "袄", "祉", "癔", "笨", "R", "乚", "畏", "虍", "臾", "泛", "噙", "杷",
"麗", "蹋",
"逍", "迓", "摅", "页", "戥", "胞", "艄", "壅", "啶", "趼", "牟", "翙", "蓝", "府",
"轿", "砼",
"荜", "杆", "惊", "起", "瘅", "墈", "氖", "匀", "麃", "阘", "虮", "蘇", "蚤", "汗",
"鳞", "籁",
"缲", "畈", "亟", "劬", "課", "蓄", "缅", "楮", "湜", "珩", "斋", "塬", "殁", "魃",
"脞", "H",
"澼", "钚", "饕", "缕", "Ⅱ", "攮", "卿", "莅", "镆", "熹", "藩", "汁", "順", "趿",
"拆", "蟹",
"砒", "惴", "㎡", "忖", "寝", "戕", "螭", "酿", "™", "柬", "枧", "凶", "蚁", "島",
"殄", "鲊",
"忠", "肉", "辕", "叫", "徙", "漆", "缞", "夀", "楦", "佪", "兴", "粉", "裳", "蘧",
"國", "旬",
"看", "Ⅰ", "剑", "痭", "襟", "恐", "遹", "◎", "窃", "穰", "澎", "敬", "旱", "燚",
"坩", "彤",
"尜", "猃", "夏", "穈", "媒", "柑", "駡", "孛", "脉", "车", "零", "菩", "痊", "卉",
"桔", "距",
"吧", "漦", "启", "仁", "滬", "馋", "帅", "鳈", "鄌", "超", "芡", "窘", "刽", "掌",
"氤", "梽",
"拎", "踏", "勋", "甍", "玑", "稱", "鞍", "浍", "翅", "饟", "鼎", "罩", "加", "虚",
"蕰", "簉",
"堇", "巢", "疲", "蟑", "狝", "瓮", "潋", "行", "饥", "散", "糌", "牵", "貢", "偉",
"咄", "痕",
"沃", "苓", "锂", "狻", "褿", "畸", "姿", "煎", "胜", "觅", "烊", "質", "疵", "擢",
"椤", "米",
"累", "诳", "斡", "K", "恻", "匦", "烫", "湾", "鹎", "吟", "摘", "涞", "恿", "嫉",
"炎", "婧",
"朽", "铑", "ㆍ", "讧", "曜", "挑", "〇", "搅", "鹐", "丁", "彼", "棠", "饪", "箬",
"祎", "魄",
"囿", "犬", "市", "髃", "勚", "桶", "辎", "瓞", "财", "缄", "園", "睒", "护", "尿",
"融", "围",
"水", "糍", "虢", "呦", "越", "棺", "砮", "邓", "鹦", "稣", "呃", "柙", "鎌", "转",
"袋", "湉",
"亘", "俩", "腆", "谣", "飔", "撂", "鄳", "爲", "盦", "谳", "卸", "W", "嚆", "婕",
"卫", "拚",
"呀", "汽", "洣", "冻", "鳝", "录", "毋", "閥", "熬", "谜", "齐", "匳", "慧", "猴",
"撬", "妳",
"諾", "蠼", "瘟", "伐", "颤", "奶", "陧", "麾", "岌", "浇", "邸", "「", "不", "哼",
"热", "旳",
"慙", "&", "苔", "郿", "钗", "氡", "纹", "侬", "霓", "靈", "扁", "聢", "疼", "岣",
"甥", "恭",
"喷", "芫", "骂", "肪", "熥", "揠", "鲷", "遁", "霎", "娆", "圩", "爬", "傲", "贽",
"紫", "觑",
"琇", "蟆", "怙", "玙", "庼", "筮", "慗", "层", "娓", "蚨", "糟", "璩", "隼", "锧",
"疱", "铎",
"祠", "绁", "速", "湛", "蝮", "立", "媵", "禇", "撸", "禳", ">", "恋", "⑥", "鹡",
"蓑", "樱",
"奸", "蝣", "埭", "聪", "慭", "睑", "肢", "焗", "骃", "毵", "潼", "塘", "烧", "劓",
"栾", "牯",
"〉", "毓", "釉", "庞", "宕", "磚", "夺", "畜", "俏", "筼", "虱", "釆", "计", "陀",
"诧", "臱",
"牌", "固", "鹉", "凰", "擞", "■", "㛃", "词", "店", "當", "许", "妣", "耋", "硼",
"根", "焅",
"砸", "霈", "锃", "巳", "誉", "咕", "锊", "P", "云", "乞", "为", "姆", "桕", "丞",
"鳤", "楷",
"醒", "趔", "怔", "砉", "潏", "肝", "拷", "也", "璐", "厘", "致", "昇", "绥", "抃",
"佩", "斥",
"⑶", "断", "纵", "翁", "耄", "沭", "洄", "别", "吻", "渍", "r", "愦", "替", "骓",
"攻", "旦",
"来", "案", "坫", "辞", "班", "锝", "拜", "掎", "穸", "笛", "痂", "笈", "鲶", "僻",
"依", "碎",
"蕤", "炕", "寥", "拔", "髑", "慨", "眺", "⑿", "珞", "歧", "湲", "錦", "拮", "哭",
"爰", "验",
"寸", "%", "口", "阔", "积", "篝", "狴", "殂", "痧", "绽", "搪", "祸", "缘", "遯",
"祜", "种",
"缓", "冒", "庵", "窥", "颂", "哕", "谘", "蜗", "掖", "驮", "郎", "跂", "蝓", "贲",
"馔", "琰",
"大", "芊", "粝", "啻", "蒉", "谒", "羔", "蘑", "菑", "布", "徂", "l", "炬", "蘩",
"弭", "嵎",
"補", "岑", "佯", "棍", "没", "志", "裣", "咸", "权", "豺", "韦", "優", "紧", "嚚",
"牴", "酚",
"沤", "睥", "葆", "乓", "划", "犒", "惚", "埕", "锴", "就", "滓", "汕", "冏", "缵",
"囟", "旸",
"麂", "接", "餮", "瓤", "偕", "灏", "溻", "揶", "钯", "荸", "宪", "泠", "槠", "抺",
"威", "燴",
"井", "骣", "耜", "磔", "懜", "淇", "瘘", "蹼", "觏", "圬", "纔", "恤", "铝", "薏",
"鞫", "衉",
"E", "球", "姽", "毹", "嵘", "睦", "蛉", "伽", "橥", "痤", "卞", "警", "则", "芬",
"磉", "悢",
"逾", "吆", "朿", "锒", "卧", "E", "焉", "纥", "髦", "鞯", "牞", "蹿", "琪", "洌",
"幛", "淳",
"菲", "涔", "噗", "勺", "势", "哓", "毪", "刖", "雜", "浪", "懵", "棁", "秋", "◇",
"玡", "埯",
"谥", "芑", "拌", "Z", "埂", "寻", "虼", "豫", "蛄", "蜞", "椟", "〔", "哩", "絷",
"咱", "郈",
"湫", "抡", "矮", "庖", "锰", "鎖", "葸", "棣", "砑", "题", "棋", "晕", "兠", "蓣",
"貂", "裤",
"昊", "扳", "讴", "弩", "蚀", "尓", "暗", "莘", "黏", "寖", "蛔", "И", "痪", "饳",
"妈", "Z",
"秏", "矽", "蘭", "艴", "菖", "寿", "撅", "秤", "颓", "廪", "醪", "耢", "螣", "椰",
"麈", "听",
"敞", "铠", "润", "穑", "涟", "澹", "茨", "昨", "嚯", "钟", "護", "榇", "曦", "蜎",
"呷", "邦",
"瘵", "鲬", "谖", "概", "九", "飞", "潇", "高", "锫", "钐", "徘", "诟", "缧", "剞",
"【", "簋",
"噍", "痋", "关", "糁", "鹊", "潤", "邬", "赔", "序", "盤", "拙", "盾", "鸫", "迟",
"氇", "塄",
"庀", "噩", "臃", "绔", "岔", "珠", "癀", "骡", "隶", "堋", "笆", "影", "昶", "飗",
"α", "薄",
"碜", "瞅", "奠", "鲽", "牂", "裆", "刀", "遑", "隙", "沔", "訾", "旇", "s", "诮",
"炱", "榚",
"些", "縯", "提", "甚", "埏", "峣", "意", "出", "郡", "摊", "哦", "轼", "嚒", "杈",
"痢", "裥",
"袖", "陔", "溷", "裀", "迄", "枇", "筑", "貊", "鲃", "鸪", "V", "鞭", "粳", "菥",
"盒", "毙",
"风", "壽", "胝", "章", "泄", "浜", "菇", "釘", "揖", "蝰", "榧", "掊", "瘿", "亍",
"欤", "髻",
"歃", "朱", "撇", "铁", "兜", "喋", "趵", "瘼", "芤", "邳", "除", "滌", "么", "践",
"矜", "曆",
"炒", "咔", "促", "姐", "酦", "货", "箔", "锡", "吝", "医", "汀", "精", "馘", "骶",
"碉", "啷",
"缉", "褪", "阙", "滕", "蓐", "搏", "俅", "癌", "股", "圪", "孕", "鳕", "话", "鳳",
"妩", "馬",
"鞣", "璁", "测", "螠", "圆", "颥", "卒", "钲", "䨱", "骢", "批", "陨", "婶", "熵",
"鸣", "梁",
"怅", "滑", "驵", "帑", "鑽", "痈", "鲑", "犍", "茑", "糧", "谫", "咒", "绘", "塆",
"耖", "铮",
"殳", "角", "齮", "挻", "捎", "2", "З", "廋", "泻", "犊", "儋", "椋", "聍", "鼬",
"鳏", "收",
"跞", "盥", "信", "嘴", "眉", "黠", "纡", "Ω", "愆", "桹", "昽", "讠", "蚧", "龀",
"鳓", "麓",
"括", "蘊", "鈇", "写", "焕", "哒", "忌", "咳", "蜮", "衄", "氰", "邘", "缇", "缮",
"表", "续",
"篇", "旄", "闻", "門", "偃", "茳", "晗", "鋪", "讶", "衙", "闭", "管", "傒", "藔",
"鳯", "萼",
"泥", "汔", "浆", "姚", "几", "含", "沆", "繇", "灾", "嗦", "饬", "系", "熠", "漶",
"潭", "牲",
"湘", "稁", "宄", "亳", "杏", "豳", "監", "印", "旁", "辙", "播", "让", "乳", "镚",
"腒", "衅",
"铅", "殛", "形", "颚", "茸", "绚", "铲", "贬", "溆", "寘", "傫", "解", "事", "旻",
"差", "竣",
"篃", "渥", "嵩", "@", "鹀", "哈", "痍", "绪", "囔", "渗", "帐", "叙", "⑦", "跖",
"貝", "盅",
"碶", "哗", "裼", "窝", "滙", "郸", "延", "炼", "芹", "簃", "谭", "莱", "佞", "猝",
"褥", "陆",
"王", "碴", "粑", "怃", "倭", "貉", "硈", "裴", "溍", "坂", "勐", "踬", "敌", "改",
"膠", "罘",
"罚", "繁", "幢", "煸", "扩", "黑", "氮", "孓", "饔", "姹", "蠖", "倬", "慝", "沩",
"嚏", "雌",
"琏", "莹", "觊", "颟", "坤", "筅", "桉", "肈", "幻", "”", "烽", "蓅", "噌", "桎",
"矻", "指",
"瀚", "羊", "邒", "筒", "匣", "旨", "葑", "团", "偻", "镛", "忉", "帱", "往", "刎",
"害", "母",
"串", "酢", "舟", "栝", "娣", "⒉", "装", "笊", "篑", "垄", "镳", "牝", "煲", "氵",
"遂", "骜",
"钜", "屡", "宇", "z", "惨", "潆", "鹃", "豌", "浞", "幄", "麺", "暽", "弁", "菤",
"酲", "虑",
"样", "访", "睁", "黼", "悞", "禧", "涠", "舂", "駕", "屈", "噀", "邽", "炅", "欸",
"隆", "描",
"绦", "派", "溲", "颙", "忐", "鹺", "只", "诈", "腭", "亵", "这", "炀", "趣", "喙",
"跨", "場",
"全", "搢", "舨", "踢", "巿", "糸", "乐", "澈", "羰", "匯", "D", "濒", "莛", "癯",
"娴", "姒",
"祥", "渖", "庭", "渑", "挹", "狉", "萍", "鹚", "焻", "自", "舸", "岫", "飑", "戍",
"淙", "愠",
"导", "賣", "进", "赳", "鱿", "硂", "僤", "O", "拟", "钨", "笳", "汴", "挤", "稞",
"柏", "阐",
"弥", "艽", "爻", "魭", "俶", "聂", "鲎", "齌", "菀", "僜", "煅", "满", "兀", "辔",
"舊", "胥",
"卢", "额", "膝", "嵬", "昼", "唏", "璨", "苷", "舫", "倨", "耵", "碳", "鄺", "橘",
"裔", "裸",
"宋", "窋", "悚", "昱", "错", "咣", "檄", "硁", "莆", "肃", "曼", "垍", "绵", "役",
"內", "館",
"规", "犋", "毅", "锨", "瓘", "丘", "疝", "杀", "袗", "屏", "阎", "衹", "嚣", "冼",
"铪", "熏",
"t", "储", "傧", "髁", "邙", "窴", "泾", "止", "晾", "涵", "庸", "庠", "靿", "睚",
"减", "衲",
"思", "簖", "耘", "之", "斑", "扬", "袼", "缗", "菏", "滍", "研", "垚", "艘", "黇",
"蜘", "汨",
"侦", "疃", "再", "沂", "榛", "励", "嚼", "拴", "钴", "珑", "撕", "鸯", "共", "醐",
"揿", "醴",
"凭", "菹", "鹬", "捷", "掼", "芝", "缪", "咏", "挺", "蒗", "疖", "伸", "索", "黉",
"髋", "習",
"姜", "蔺", "扶", "忽", "锉", "戚", "珲", "摸", "黛", "跌", "螈", "冚", "洱", "鼯",
"庡", "痒",
"哆", "品", "歆", "登", "呔", "追", "鉫", "碾", "祚", "总", "帚", "薹", "趴", "容",
"滘", "❋",
"迷", "拾", "炯", "析", "佼", "嗾", "-", "针", "滩", "禅", "讯", "織", "饱", "哟",
"蹓", "侧",
"蹯", "踽", "趙", "漫", "卷", "朴", "卺", "狈", "绉", "浉", "玳", "榕", "畛", "蛾",
"帔", "欠",
"劙", "矾", "進", "蚺", "骨", "捂", "疾", "璱", "圠", "坚", "弯", "秩", "逧", "烟",
"佛", "嫱",
"鳢", "裹", "耥", "潮", "巽", "嶝", "廷", "鳆", "五", "西", "壤", "慌", "鴈", "爡",
"‧", "儆",
"萘", "愁", "昔", "咩", "侃", "炫", "迳", "构", "缶", "皴", "捱", "菜", "秀", "粢",
"畵", "辊",
"伟", "榄", "嗪", "已", "聖", "枕", "恢", "厍", "涅", "鄢", "饨", "鲨", "谪", "礤",
"搁", "疔",
"雎", "羿", "犁", "硐", "盹", "若", "操", "昀", "亩", "凑", "睃", "贰", "穷", "荆",
"葹", "嘃",
"廓", "憔", "制", "胧", "染", "麿", "镴", "砀", "组", "茎", "畫", "哑", "坨", "罱",
"刳", "嘲",
"瞰", "缏", "侩", "谝", "谮", "还", "惋", "佈", "谏", "酗", "怩", "i", "秽", "抻",
"蟪", "狠",
"辑", "羟", "娉", "肯", "毕", "枸", "啮", "鳙", "要", "娑", "蜈", "忍", "侗", "Р",
"凛", "巉",
"拽", "该", "俎", "惠", "薅", "猬", "忲", "●", "哏", "柔", "沉", "磁", "脾", "龃",
"鲩", "钞",
"厂", "鱽", "濞", "群", "唱", "攝", "刃", "蹻", "剕", "朊", "啜", "语", "蜻", "遠",
"呖", "都",
"嫄", "戢", "丫", "酞", "修", "户", "膏", "侈", "浣", "捍", "馒", "谱", "點", "滏",
"跟", "鹁",
"书", "愉", "扭", "票", "耒", "燁", "魚", "拨", "鞑", "匆", "最", "憨", "晨", "癍",
"邻", "醅",
"骘", "骇", "蔫", "。", "珪", "安", "歉", "邑", "淦", "胱", "漏", "咂", "叮", "瘛",
"钺", "聘",
"玎", "荻", "涰", "淏", "烈", "囚", "㙟", "矫", "嗵", "澶", "磛", "肖", "蹑", "支",
"哪", "久",
"嗅", "稍", "抠", "具", "裨", "韨", "虿", "漪", "外", "埸", "ä", "葡", "鲇", "廛",
"蝥", "广",
"兒", "涧", "阌", "谊", "嵴", "拂", "悸", "哳", "4", "佘", "篁", "基", "赪", "掬",
"演", "谋",
"酣", "植", "波", "恅", "杼", "胀", "纯", "缩", "盆", "芷", "绺", "施", "礞", "莳",
"稻", "狐",
"馌", "椑", "恃", "镩", "骼", "孱", "硭", "曈", "焼", "秕", "觥", "茛", "射", "肣",
"蟞", "′",
"彰", "罔", "麻", "逋", "谓", "革", "藤", "堆", "忿", "茂", "屦", "炟", "碹", "啤",
"垤", "文",
"佐", "叼", "蹭", "踉", "眍", "龟", "黾", "崋", "氘", "尼", "瞢", "悦", "罢", "瑀",
"睇", "贴",
"涿", "拍", "庥", "粪", "陳", "闌", "蓍", "元", "磊", "忻", "葴", "买", "诺", "㐂",
"沦", "苏",
"岂", "浊", "脍", "誠", "嚬", "蔬", "黄", "銘", "钩", "劃", "嫘", "嵖", "笄", "鸰",
"熳", "堑",
"河", "遮", "尝", "灭", "愬", "娅", "鸽", "锢", "狂", "弓", "侨", "滚", "释", "晏",
"徵", "苡",
"佚", "切", "惰", "降", "槎", "脑", "磺", "谟", "裉", "弘", "醺", "眇", "顒", "兰",
"忧", "础",
"-", "茫", "袒", "喤", "慶", "話", "跽", "堵", "能", "武", "壳", "汤", "橐", "圧",
"嗡", "簌",
"斧", "林", "楊", "净", "嫌", "猛", "炸", "冠", "弦", "洵", "°", "創", "葜", "苁",
"顏", "薛",
"平", "舜", "崧", "撼", "哮", "窣", "殖", "象", "飒", "瞥", "玥", "斝", "胭", "葱",
"擎", "踰",
"盛", "稇", "斫", "滴", "硫", "胬", "唁", "拐", "殍", "冱", "陪", "鋈", "烦", "辋",
"妇", "轸",
"潴", "荤", "碡", "徭", "膜", "秧", "淀", "缤", "琶", "^", "肋", "违", "轭", "$",
"箕", "墩",
"罗", "摆", "槛", "笠", "塃", "畚", "嘛", "秸", "≥", "剪", "羅", "帜", "庇", "骙",
"酾", "康",
"陬", "蝶", "闇", "圏", "琴", "鬈", "苶", "黡", "瓠", "酋", "琎", "奏", "科", "搒",
"億", "翡",
"熊", "性", "痞", "篾", "邴", "篥", "饵", "揸", "狙", "鳂", "否", "煺", "畦", "凖",
"鹧", "宵",
"庛", "鬯", "袂", "昴", "徽", "奧", "鸥", "锸", "庚", "彪", "槿", "趱", "铡", "讹",
"莎", "約",
"璞", "┌", "铫", "鸈", "瞀", "鼙", "廙", "估", "屺", "锘", "渝", "汶", "囵", "跻",
"酏", "扎",
"孜", "腔", "吗", "块", "潽", "“", "焚", "倘", "靥", "默", "笺", "遍", "剅", "桠",
"极", "夷",
"眸", "泳", "谢", "懦", ")", "泜", "物", "开", "淮", "邵", "卟", "徜", "轧", "苍",
"酶", "捌",
"耨", "膄", "琦", "痦", "涪", "舰", "迥", "涘", "季", "悫", "初", "贩", "碍", "沼",
"腮", "勻",
"恣", "他", "院", "7", "蜒", "叉", "昉", "瞽", "疢", "蓼", "相", "臜", "ü", "秘",
"蚌", "摉",
"莞", "番", "盼", "冀", "缠", "学", "馗", "搞", "苛", "羹", "潟", "嬴", "杶", "妖",
"↓", "銭",
"斄", "猢", "搂", "芦", "埶", "癜", "铴", "從", "留", "硎", "簇", "臬", "侮", "鳎",
"頉", "所",
"邝", "哂", "弛", "垂", "暑", "仿", "療", "轾", "熜", "悃", "勘", "鋫", "泞", "閃",
"+", "士",
"虐", "盡", "溯", "劣", "1", "锇", "蜇", "碛", "婴", "8", "捶", "藻", "嫰", "跹",
"芋", "淠",
"疯", "Й", "诨", "醢", "痨", "栌", "摧", "噤", "灸", "馉", "蒇", "洲", "孪", "孵",
"亿", "枝",
"涕", "孟", "缎", "攒", "湧", "褛", "铺", "廣", "诃", "蕈", "维", "珣", "逖", "瓯",
"苘", "榫",
"寰", "供", "铽", "暲", "义", "兖", "喆", "祇", "蝽", "膛", "髭", "尹", "乒", "柈",
"抓", "镋",
"脏", "乩", "挎", "酬", "靳", "躔", "霞", "離", "桌", "o", " ", "滨", "懷", "萭",
"望", "仆",
"怂", "麸", "槁", "洨", "俬", "孚", "匕", "栩", "t", "被", "邗", "纺", "狄", "国",
"苋", "眢",
"秣", "畤", "∵", "创", "嵫", "胖", "垮", "镁", "壑", "A", "趾", "荟", "汝", "嗥",
"驰", "向",
"磴", "讪", "溅", "箍", "驾", "讙", "蛐", "眨", "醯", "筣", "鼫", "叠", "沥", "恕",
"埽", "甩",
"煜", "端", "蜃", "帏", "丙", "荏", "圻", "夥", "暖", "抛", "岸", "头", "恝", "船",
"鞲", "の",
"七", "怪", "诅", "茧", "北", "搓", "皖", "綉", "坪", "簪", "贵", "阍", "刑", "偶",
"雷", "體",
"髡", "岚", "剂", "妾", "茬", "鹣", "鲳", "蜊", "假", "认", "嗍", "傈", "焘", "驷",
"賀", "氆",
"炝", "聋", "嘡", "悺", "﹐", "僭", "证", "侉", "屐", "吃", "十", "〕", "瀦", "骤",
"俳", "舁",
"驸", "竿", "坍", "|", "普", "軒", "瘃", "现", "醾", "铈", "榭", "蓁", "唷", "睫",
"绰", "叶",
"頤", "锤", "浸", "杂", "汹", "璟", "蓖", "迦", "截", "錎", "年", "達", "劁", "码",
"乃", "捯",
"髪", "埚", "呯", "頭", "镈", "汆", "β", "舷", "菂", "纸", "造", "晁", "卦", "蛎",
"枉", "脯",
"诛", "生", "令", "桄", "恶", "鬟", "怯", "囡", "充", "省", "控", "螂", "笕", "邺",
"扅", "斲",
"骏", "鹋", "队", "套", "镢", "牖", "I", "援", "封", "泚", "艿", "沮", "铙", "揳",
"抄", "帨",
"近", "唾", "珥", "销", "非", "啱", "驼", "瓅", "遢", "筱", "奥", "善", "氩", "盉",
"帖", "杜",
"鈉", "蕉", "鳄", "江", "鄂", "矩", "排", "诠", "准", "菼", "刻", "足", "峦", "灰",
"僳", "蝢",
"孫", "據", "璆", "孳", "徹", "妆", "坭", "渌", "喏", "钦", "朔", "机", "徼", "掾",
"其", "愧",
"刹", "迹", "惹", "闿", "鹘", "窗", "贳", "箓", "奡", "鸮", "翟", "滠", "辄", "夸",
"袱", "】",
"阿", "摁", "觽", "垠", "棼", "杉", "甏", "旖", "阜", "猩", "埤", "醛", "馥", "哫",
"囝", "晖",
"骸", "椭", "军", "哺", "束", "犄", "遛", "涡", "罄", "赇", "幌", "曙", "契", "饹",
"圳", "仝",
"爝", "示", "敝", "漓", "马", "铐", "掳", "鲱", "蟀", "阵", "栒", "b", "轮", "俯",
"嬉", "漩",
"佟", "捆", "迩", "液", "炊", "抒", "迭", "换", "菘", "请", "柩", "腓", "妥", "怖",
"穆", "骝",
"胛", "幺", "燥", "棹", "孖", "洁", "边", "彥", "睨", "桁", "淆", "醤", "奘", "伙",
"刘", "o",
"過", "鏖", "怄", "镗", "蘖", "卩", "龈", "枣", "联", "圊", "贫", "郭", "梗", "赡",
"輸", "拼",
"冰", "Ë", "姓", "办", "拉", "富", "对", "肩", "缬", "逻", "瞠", "な", "荚", "宝",
"緃", "峋",
"鞁", "坉", "译", "银", "猹", "榞", "借", "楠", "殽", "片", "谸", "雩", "琨", "颏",
"晷", ";",
"莠", "楽", "嬗", "啉", "爍", "視", "岽", "荙", "冗", "『", "鯭", "觌", "喹", "药",
"腈", "蹰",
"–", "泷", "榷", "卮", "缥", "各", "瘙", "凡", "悍", "劢", "6", "镰", "四", "摈",
"驹", "陵",
"沟", "麟", "骊", "椀", "★", "滦", "菌", "彊", "疽", "辫", "璎", "郁", "资", "粼",
"萄", "鳁",
"鸤", "漁", "痃", "绌", "蒴", "尊", "哙", "守", "坠", "胯", "泽", "持", "隅", "耧",
"逛", "鄯",
"瑜", "召", "眷", "逄", "垦", "窄", "板", "赵", "源", "绹", "總", "适", "轰", "钛",
"停", "唝",
"燎", "栽", "燃", "搬", "夬", "掐", "簦", "旃", "更", "蹊", "熙", "埃", "偲", "蒙",
"舍", "杭",
"朋", "霍", "谙", "蓥", "赫", "鲏", "純", "缃", "蓓", "è", "萧", "锆", "诉", "恚",
"u", "旷",
"⑵", "褲", "鲟", "互", "峂", "绝", "陒", "议", "脽", "态", "岙", "僮", "突", "濯",
"犹", "阆",
"溧", "宜", "霣", "呆", "鄉", "觖", "濠", "耐", "橱", "敛", "踮", "怦", "鸠", "授",
"滫", "叭",
"镤", "仵", "圖", "救", "变", "寕", "洋", "泃", "晥", "檎", "缦", "鏠", "悬", "彧",
"韓", "籽",
"磷", "歙", "÷", "杨", "闯", "罴", "鼠", "陋", "瀣", "揾", "匪", "晚", "丧", "彷",
"梏", "诽",
"尻", "蹢", "拊", "氕", "芳", "凸", "懊", "型", "媄", "憝", "骆", "纭", "刺", "悼",
"藍", "欧",
"葳", "艺", "±", "紗", "钡", "钭", "首", "栈", "闩", "勃", "喑", "栉", "栟", "焊",
"哀", "竖",
"肘", "悲", "鳜", "迨", "怿", "裘", "綮", "蕹", "冕", "无", "鼢", "戽", "鲣", "蜍",
"插", "扯",
"俣", "袪", "级", "理", "茵", "矣", "障", "禊", "惯", "䄂", "宏", "韫", "栗", "编",
"座", "跫",
"、", "捞", "谠", "車", "袆", "舖", "暝", "9", "混", "蓊", "韂", "拳", "j", "伶", "啦",
"0",
"诰", "缑", "郴", "蕲", "谛", "皋", "兢", "件", "隈", "溊", "窈", "檀", "洪", "揭",
"油", "颐",
"剎", "侠", "或", "腻", "迪", "舔", "牺", "倦", "夭", "蠋", "鹑", "倜", "喱", "豨",
"谨", "翥",
"馄", "蔚", "类", "鳍", "泯", "岷", "張", "紅", "情", "婪", "睡", "诒", "旋", "舱",
"列", "求",
"姥", "翯", "锲", "適", "蒡", "㭗", "韵", "撄", "律", "湊", "鲪", "碓", "馓", "汛",
"尤", "℃",
"泫", "竹", "溃", "诵", "乡", "楹", "肷", "戋", "獭", "撴", "晤", "嘎", "裢", "轱",
"歘", "鼱",
"舀", "潵", "腩", "挽", "至", "骞", "佻", "蕊", "轫", "岘", "斌", "《", "雇", "枘",
"贶", "履",
"亭", "绍", "空", "泡", "擒", "蠓", "桼", "舢", "踵", "柢", "躺", "罥", "蔁", "幪",
"蒯", "≤",
"齉", "況", "锕", "徇", "儿", "帽", "谕", "抽", "獍", "揪", "膳", "酴", "姊", "作",
"弍", "郦",
"翮", "髌", "勝", "孔", "颁", "泩", "衾", "翊", "噉", "∩", "先", "的", "財", "绢",
"崇", "饲",
"賓", "绾", "陡", "砾", "纷", "酱", "窎", "浕", "琫", "补", "嗽", "呛", "蚓", "伪",
"艨", "搡",
"粗", "阱", "商", "郫", "喵", "缯", "炻", "州", "珽", "芒", "脶", "蕖", "拘", "\\",
"蕃", "伏",
"蛏", "璘", "缡", "伞", "吸", "煞", "嗫", "餪", "━", "8", "漠", "衮", "峭", "筌",
"阀", "乇",
"杞", "镕", "鹈", "觚", "疋", "猥", "肚", "阃", "地", "鸾", "玚", "镀", "诬", "凇",
"惬", "劝",
"堠", "睪", "瞪", "涓", "專", "琢", "蠹", "裂", "芎", "轲", "谯", "畋", "长", "攘",
"缁", "吵",
"汈", "稂", "咤", "甸", "瀑", "讣", "翠", "綦", "笑", "掺", "宫", "唆", "旗", "帘",
"遵", "唪",
"连", "必", "姬", "枵", "渫", "神", "凱", "虞", "闵", "爭", "迢", "飓", "桴", "冑",
"招", "鬶",
"赊", "朦", "薜", "逗", "铩", "焖", "狱", "昕", "犀", "捏", "侓", "爆", "箧", "怠",
"缐", "苄",
"踯", "暹", "絮", "裁", "嘶", "诙", "攥", "¥", "痫", "摹", "朕", "薰", "闼", "樨",
"需", "蕾",
"扔", "服", "蚩", "漳", "瞻", "陟", "诐", "爽", "耩", "坏", "寶", "瞧", "蘅", "爺",
"仇", "瞈",
"揉", "隰", "阏", "皤", "鉏", "郇", "啵", "僧", "渐", "骠", "厾", "谦", "榱", "蓮",
"乂", "伷",
"觐", "遫", "畀", "污", "眭", "蝗", "亢", "腾", "遇", "欺", "狸", "籼", "锯", "赚",
"槔", "域",
"老", "掩", "锎", "邪", "沬", "袯", "映", "肤", "舒", "箦", "涎", "缔", "孃", "萎",
"推", "峧",
"嫒", "嵐", "怒", "闾", "阅", "扢", "絡", "剩", "腢", "晌", "铟", "铚", "燔", "鄜",
"墠", "擤",
"芸", "鼩", "食", "朰", "啥", "贿", "券", "垩", "典", "逭", "成", "帧", "侯", "妒",
"顷", "晩",
"浦", "汳", "㾄", "坊", "②", "蝼", "倩", "挦", "騠", "蓂", "兹", "渤", "茴", "矶",
"煤", "伛",
"逃", "堞", "漭", "闽", "埠", "妗", "烙", "傀", "滢", "堂", "骅", "崮", "兿", "螟",
"榴", "蒈",
"蟛", "员", "嗟", "毗", "鹭", "毖", "籍", "傣", "偈", "澴", "耆", "黔", "薷", "俘",
"箸", "蒺",
"记", "铣", "拥", "瑰", "抉", "史", "急", "什", "川", "曪", "剖", "罪", "扥", "鱼",
"羌", "复",
"昵", "朓", "氪", "矅", "ò", "摒", "催", "{", "懂", "莉", "屃", "症", "遒", "璋",
"鄒", "玄",
"氦", "舳", "納", "锷", "鲥", "羸", "怵", "嬖", "飚", "倔", "辨", "篌", "娄", "洎",
"弟", "悝",
"婥", "待", "梃", "棕", "撞", "肊", "婺", "桥", "慕", "5", "尖", "监", "囊", "腎",
"瘁", "⑴",
"伢", "邈", "炷", "籴", "月", "终", "龠", "蹇", "柯", "噜", "多", "玮", "踹", "泣",
"圮", "辈",
"鄙", "赆", "蠃", "珈", "鬃", "识", "甑", "藓", "宥", "韧", "隗", "跚", "峁", "晒",
"戳", "環",
"葓", "筐", "瑚", "稆", "巩", "葵", "网", "铨", "仡", "呶", "休", "村", "傩", "浡",
"祝", "幅",
"晳", "岿", "[", "尃", "响", "咽", "讵", "淹", "糠", "驴", "烹", "甪", "焯", "整",
"瘆", "茀",
"瑞", "嘁", "赅", "芼", "震", "怼", "膑", "蒟", "钊", "缷", "獨", "俄", "噪", "亏",
"芍", "鲲",
"黟", "酃", "铻", "→", "鲡", "仑", "有", "扌", "治", "聆", "腙", "冬", "剥", "诓",
"祃", "棘",
"孥", "濆", "鞋", "赣", "卜", "谆", "投", "琊", "塍", "洗", "津", "肴", "奕", "掴",
"螗", "胸",
"惦", "赠", "耶", "蛸", "曷", "名", "栏", "崖", "始", "孤", "篆", "椴", "模", "儙",
"袁", "颌",
"卤", "寂", "呸", "蓺", "噶", "钔", "粹", "潸", "郾", "娡", "啖", "芜", "䧳", "缟",
"鞅", "哇",
"嚄", "熛", "私", "住", "鉄", "U", "失", "蜾", "㺃", "莨", "擂", "沕", "铄", "耰",
"炔", "藐",
"锈", "苇", "芯", "檇", "龍", "珀", "筻", "褚", "缀", "棬", "仲", "杧", "铛", "挖",
"缸", "嵇",
"剟", "觋", "鬼", "天", "鹪", "豭", "腴", "驿", "粵", "馈", "迸", "夕", "蜚", "禺",
"迎", "狞",
"嶽", "躯", "暅", "蹾", "甾", "柆", "e", "欃", "無", "羽", "蛛", "僖", "碲", "遴",
"厝", "滂",
"眦", "鹅", "咖", "潜", "媽", "啴", "寨", "琬", "判", "塌", "与", "剧", "掮", "读",
"庆", "愚",
"氲", "梾", "稗", "很", "饯", "淘", "灞", "A", "!", "飾", "醚", "壁", "芮", "蔼",
"知", "郯",
"瞒", "术", "法", "匠", "┅", "尕", "脂", "琅", "孝", "埙", "濟", "袷", "方", "芾",
"驽", "线",
"咡", "睿", "滥", "鞨", "駹", "馎", "蛲", "申", "涣", "牗", "跄", "鲐", "泐", "铍",
"肓", "é",
"司", "辣", "慑", "崞", "魏", "髯", "涯", "滃", "薪", "~", "鐵", "町", "芥", "匿",
"癞", "嘚",
"□", "啪", "俇", "橛", "巅", "鄞", "痱", "回", "着", "魂", "瘀", "埒", "措", "蚪",
"锁", "巴",
"芏", "另", "忏", "洇", "⑾", "箱", "劳", "榈", "B", "毒", "泰", "巍", "寇", "斛",
"赖", "酒",
"密", "左", "莜", "茯", "脆", "饴", "洳", "舉", "酪", "鼒", "職", "桫", "螋", "砌",
"戬", "前",
"豁", "膲", "鲯", "憋", "珺", "蹂", "亥", "冷", "蜔", "俦", "碇", "慰", "扒", "亮",
"弒", "胫",
"肠", "弇", "拣", "丸", "涫", "勉", "帝", "玠", "应", "砜", "鬓", "泮", "鳖", "峇",
"辗", "吴",
"僡", "玊", "钘", "惘", "奁", "翰", "爨", "罽", "莶", "纻", "菪", "興", "钧", "鄹",
"缌", "嘉",
"玲", "蛋", "倚", "镬", "彳", "氯", "谐", "疗", "魉", "扈", "鏡", "涤", "佑", "勾",
"饽", "R",
"局", "醉", "燫", "驱", "崽", "榮", "锄", "脎", "枓", "敲", "俑", "镶", "当", "逦",
"寅", "捽",
"宗", "茼", "稿", "躇", "晋", "东", "渭", "闶", "潦", "慊", "蔟", "疑", "蜡", "嬛",
"荒", "扪",
"拈", "受", "沱", "螽", "嗣", "瘰", "颖", "百", "楱", "崛", "窿", "蓬", "禨", "螵",
"捕", "鳀",
"霰", "瘸", "圄", "陂", "敢", "矗", "炉", "篪", "注", "凉", "摔", "衿", "g", "遘",
"鳟", "腚",
"泱", "荣", "池", "杰", "阻", "里", "峥", "葺", "翔", "柁", "飐", "载", "刨", "瘊",
"溏", "嚭",
"穝", "站", "笞", "厌", "门", "汞", "雠", "靖", "怨", "葙", "厅", "凉", "荨", "底",
"坼", "海",
"轩", "秃", "醭", "莒", "坎", "驺", "瀛", "嵝", "溥", "嚋", "寤", "k", "築", "耔",
"跎", "小",
"弊", "疭", "√", "洞", "利", "次", "迕", "鸿", "刁", "媳", "酹", "磋", "勒", "伎",
"浔", "斤",
"珊", "鸳", "颊", "塗", "刈", "龛", "縻", "楚", "脓", "南", "伧", "桨", "尸", "退",
"亊", "侔",
"蓟", "削", "诲", "瑯", "挝", "绩", "嶂", "耷", "太", "著", "讥", "烂", "哥", "菔",
"唳", "筫",
"嚷", "斯", "蔡", "碧", "慵", "搐", "琵", "逶", "菡", "篙", "驭", "莲", "毫", "犯",
"坌", "啕",
"疴", "傻", "牧", "肺", "既", "悟", "讳", "练", "钠", "胨", "G", "迁", "帙", "嫦",
"哿", "柝",
"迤", "庑", "踟", "粤", "乜", "悭", "霁", "在", "虔", "蓦", "暾", "鲅", "様", "徐",
"诫", "料",
"蒂", "揎", "溜", "崎", "玦", "隐", "绳", "幼", "钼", "腧", "槌", "镅", "锿", "蹁",
"猱", "狁",
"蹈", "S", "傢", "}", "珉", "浴", "龚", "吇", "肆", "⑩", "臌", "鏢", "―", "定", "哧",
"螳",
"爹", "摞", "榍", "苩", "丑", "犴", "璀", "偎", "燹", "洯", "啁", "鱾", "計", "镂",
"字", "琉",
"壴", "霖", "蟜", "做", "松", "扣", "徊", "叱", "桑", "≠", "寓", "崔", "茌", "`",
"殓", "猖",
"慎", "坻", "皮", "喔", "耕", "拧", "织", "桂", "垝", "约", "飯", "皿", "移", "微",
"桅", "钬",
"赑", "宓", "颉", "掂", "希", "沁", "翳", "澝", "崭", "聃", "蔸", "磕", "崚", "奉",
"槍", "颠",
"任", "飕", "蛴", "歼", "蛭", "¥", "鉵", "刷", "泓", "頫", "诤", "阈", "诖", "漂",
"冯", "柠",
"本", "狼", "芗", "丹", "柒", "饫", "衫", "摩", "桃", "啼", "譄", "醌", "帡", "少",
"螃", "祷",
"幸", "喘", "噼", "甲", "刭", "泊", "那", "舄", "畲", "遊", "記", "绠", "蝈", "忒",
"耙", "鹌",
"搽", "绕", "镠", "凼", "扫", "鸵", "匡", "缈", "铼", "挢", "踊", "噭", "苴", "貌",
"啾", "蒜",
"茱", "⒅", "邛", "棉", "怀", "筵", "笾", "邢", "濱", "蒲", "嫠", "儡", "益", "萊",
"歩", "日",
"婢", "楔", "嚎", "髂", "禄", "巫", "懿", "砍", "惆", "袭", "~", "欲", "鳅", "書",
"撷", "库",
"绻", "⒁", "蒹", "辜", "屉", "奂", "龇", "诡", "醑", "儀", "讷", "聒", "盖", "浅",
"長", "蛑",
"念", "辒", "蚊", "勖", "揣", "岬", "糅", "刊", "蛆", "硌", "柜", "惗", "激", "颈",
"閣", "唬",
"捧", "蒽", "爸", "侏", "氧", "蛤", "牡", "瘦", "铉", "撒", "屿", "谔", "钀", "瓦",
"恂", "钻",
"声", "馨", "贷", "藁", "闰", "人", "瀹", "间", "炜", "煨", "畴", "鞡", "悔", "量",
"原", "屁",
"杯", "趋", "愎", "瓶", "烘", "韬", "姮", "勰", "眛", "饮", "瘐", "决", "版", "際",
"俸", "此",
"辽", "愫", "爷", "隘", "螯", "腕", "闟", "厣", "齁", "矿", "女", "扇", "郄", "诚",
"焜", "<",
"檵", "赙", "郢", "酌", "恳", "侵", "劍", "徳", "脔", "岍", "倍", "隹", "镲", "僬",
"○", "啭",
"坳", "谰", "璪", "昆", "⒆", "惧", "虺", "篡", "锐", "邮", "嵊", "恹", "茄", "黯",
"對", "魑",
"禀", "添", "汎", "廉", "戈", "∈", "陈", "肟", "螅", "缰", "啃", "瘾", "辁", "茜",
"曝", "C",
"餍", "蜴", "咦", "臺", "扺", "隽", "崴", "遐", "胃", "铕", "楗", "墀", "魈", "淑",
"邰", "飧",
"勤", "糨", "你", "铂", "蛰", "锻", "塈", "予", "怏", "鷪", "暂", "诞", "會", "鼐",
"辏", "矬",
"筜", "蟒", "柫", "靴", "垒", "樵", "狨", "魋", "查", "掸", "'", "每", "浮", "绞",
"疍", "於",
"饦", "辐", "墟", "窳", "养", "墦", "鲔", "黝", "迈", "砟", "伥", "藜", "墅", "喬",
"卬", "赶",
"眼", "龌", "主", "嗞", "転", "襕", ",", "杲", "儒", "政", "蹩", "付", "Я", "厢",
"点", "如",
"茗", "奍", "嗌", "蕴", "问", "膚", "硒", "佃", "居", "赍", "鯨", "槜", "衡", "廐",
"鲾", "慈",
"莫", "篮", "铱", "园", "范", "靠", "叻", "绸", "众", "抑", "浃", "極", "辀", "千",
"蔯", "r",
"碱", "應", "夼", "祺", "绣", "澉", "愛", "譬", "刚", "扼", "檫", "时", "荼", "部",
"耽", "稀",
"琳", "鎮", "鳃", "疌", "挠", "京", "筴", "胳", "橡", "裱", "栊", "蛩", "流", "猄",
"葭", "邯",
"伤", "秦", "孺", "郓", "筏", "茉", "谈", "黥", "鳇", "魅", "秫", "敫", "肄", "俪",
"尺", "度",
"廊", "昏", "怎", "钎", "愤", "腿", "Λ", "碘", "囤", "婆", "煋", "桀", "阪", "焒",
"砘", "澡",
"阒", "臼", "茭", "纛", "唻", "胗", "歌", "吱", "铸", "種", "礳", "舾", "砰", "即",
"慥", "缆",
"躞", "卖", "眆", "搎", "鲁", "稠", "惝", "毶", "耎", "挡", "异", "咨", "歔", "垫",
"素", "鳊",
"打", "镏", "耗", "锭", "剀", "讓", "鍋", "歇", "拗", "齿", "聊", "惕", "塔", "况",
"汐", "采",
"灣", "菁", "峰", "呋", "阴", "衽", "鹏", "挂", "鲞", "第", "浑", "秭", "铯", "胎",
"滔", "雕",
"渔", "骍", "鴻", "眚", "易", "枫", "麥", "罹", "劈", "苣", "蹄", "是", "锛", "饼",
"铳", "器",
"秒", "開", "舛", "纳", "庒", "饰", "发", "虎", "乏", "届", "浯", "目", "霪", "氢",
"华", "澧",
"陴", "誊", "欷", "瀌", "梵", "嗖", "惩", "妞", "螓", "溇", "嬃", "笼", "嬢", "獠",
"辩", "骛",
"挪", "礅", "銎", "趺", "狍", "阑", "擦", "咙", "+", "鼻", "戆", "宿", "霏", "牁",
"耦", "枳",
"鲸", "阽", "峯", "瘭", "祁", "镜", "绮", "道", "摭", "﹒", "耠", "限", "轻", "莽",
"帛", "唯",
"墒", "W", "荦", "矸", "崃", "洫", "杳", "舌", "涌", "朵", "苑", "瓻", "辂", "凬",
"畺", "莩",
"奔", "荐", "撵", "嶲", "憧", "沖", "邱", "瞑", "瘢", "腺", "嵯", "诗", "經", "胚",
"谎", "央",
"稼", "3", "冈", "痣", "故", "皎", "珅", "踅", "硇", "通", "鹱", "草", "粕", "而",
"梨", "萜",
"搛", "鸺", "托", "倡", "匾", "骷", "桐", "阇", "璃", "抖", "显", "镝", "I", "锣",
"辆", "茝",
"虫", "谀", "萤", "帼", "滈", "鮼", "乔", "会", "产", "縢", "纱", "跆", "铤", "圯",
"旚", "墓",
"棰", "苜", "聩", "蚍", "筢", "殇", "槚", "阂", "豊", "翚", "犰", "疚", "浠", "礴",
"界", "蛙",
"吁", "忪", "讫", "辇", "汧", "澥", "纮", "糺", "拭", "镉", "鄠", "讼", "鎏", "逐",
"烝", "扊",
"筹", "仪", "段", "杵", "卲", "钤", "曹", "潘", "浏", "陑", "答", "期", "橋", "位",
"梅", "榻",
"芨", "汭", "贇", "杅", "伋", "馁", "皈", "躁", "鲦", "良", "幤", "曺", "榖", "便",
"氍", "窍",
"槃", "設", "襦", "菓", "猡", "槲", "觱", "邠", "岩", "骈", "鬲", "睽", "残", "碗",
"凯", "览",
"伾", "吣", "峡", "箨", "忡", "岁", "醵", "霸", "焐", "谁", "疟", "樾", "竺", "果",
"阝", "花",
"•", "耱", "嗜", "骰", "萋", "甄", "侍", "厦", "辌", "给", "健", "垧", "娩", "校",
"又", "临",
"揽", "犟", "蠢", "包", "檬", "穹", "燮", "札", "翏", "领", "深", "诶", "窒", "鸷",
"统", "肾",
"澍", "畹", "职", "蝟", "眬", "旎", "朘", "眠", "篚", "贼", "貴", "#", "茆", "磬",
"①", "祀",
"坞", "盯", "苹", "痼", "耪", "狺", "妓", "湨", "動", "渚", "售", "鸶", "霄", "某",
"×", "铀",
"桓", "脲", "心", "节", "[", "蜩", "剐", "猜", "盂", "穿", "洮", "坜", "掷", "坐",
"烜", "冶",
"袍", "穴", "偷", "槽", "面", "媛", "撙", "孩", "询", "苈", "橙", "恙", "吉", "燈",
"暇", "杋",
"後", "璇", "喟", "妪", "湄", "贡", "兮", "楫", "锗", "肮", "圉", "参", "烃", "葩",
"骀", "锖",
"犿", "恼", "麯", "牮", "溱", "俵", "祢", "割", "羲", "中", "博", "膦", "7", "钙",
"耸", "蚋",
"嘬", "逝", "瓿", "且", "苗", "屑", "華", "糯", "吓", "陇", ".", "魆", "d", "拶",
"箜", "澳",
"蘼", "垸", "钅", "樯", "侑", "娼", "赛", "恪", "击", "濮", "隔", "似", "惜", "滤",
"培", "谩",
"坝", "煙", "馕", "茡", "颼", "啡", "强", "巡", "糗", "芙", "骒", "常", "鳔", "楣",
"嫩", "师",
"攀", "旭", "茠", "吏", "剌", "露", "把", "携", "忘", "软", "荩", "弧", "锩", "僦",
"掘", "仓",
"嵚", "沲", "傅", "蝴", "爵", "纪", "薮", "參", "荀", "珙", "逞", "蹙", "徉", "佶",
"庹", "弢",
"锞", "想", "窕", "躬", "蚡", "闸", "难", "妃", "唶", "V", "蚂", "酐", "]", "羁",
"土", "敏",
"蝻", "赎", "闹", "铷", "脬", "攫", "椐", "橹", "(", "暨", "剁", "灵", "咫", "苻",
"赈", "萝",
"鹮", "颛", "勿", "臆", "福", "蝠", "烺", "跤", "垓", "庋", "鏊", "彭", "碚", "膂",
"鐘", "鸹",
"择", "疫", "暌", "胙", "翘", "仞", "實", "猫", "嘹", "坟", "泺", "靽", "仟", "鲋",
"畅", "箪",
"箩", "星", "辍", "餐", "伍", "狃", "蹐", "芴", "龋", "仨", "狩", "诌", "媚", "琚",
"❤", "鉰",
"仔", "忝", "垅", "嗤", "氅", "填", "詹", "诿", "皑", "椅", "鲭", "繪", "碑", "选",
"廠", "嶓",
"迮", "唠", "赏", "│", "泍", "姑", "晦", "直", "艾", "邂", "裝", "郊", "疡", "」",
"鸲", "兕",
"县", "邡", "麤", "旧", "壶", "礼", "梭", "铔", "玕", "硬", "后", "馅", "窠", "俊",
"犾", "槭",
"姨", "妨", "幡", "沿", "帮", "爿", "褊", "淅", "册", "诔", "使", "唢", "族", "逮",
"蟋", "掣",
"红", "颔", "闲", "咧", "衍", "矛", "蹜", "抱", "雀", "箴", "雙", "茁", "聲", "芰",
"瘤", "落",
"峨", "秆", "献", "霭", "胰", "墁", "柽", "跛", "阼", "菝", "谗", "蠊", "懋", "蔷",
"拃", "岱",
"戡", "逡", "背", "克", "棱", "栲", "乖", "橄", "炭", "萱", "胲", "摺", "殆", "魍",
"宾", "拢",
"姁", "祲", "·", "歹", "胆", "爱", "旰", "抢", "匜", "硚", "愈", "跳", "▲", "跪",
"網", "糈",
"維", "痹", "娃", "疸", "痔", "褙", "芭", "鹜", "猷", "檩", "吨", "淖", "竟", "呱",
"瘠", "奢",
"呐", "扞", "灼", "家", "饿", "玻", "倾", "锚", "遗", "赝", "去", "跣", "纬", "玢",
"梆", "陉",
"屎", "上", "酆", "搤", "併", "腌", "避", "禹", "绅", "帆", "英", "区", "交", "▪",
"巧", "豹",
"游", "清", "荧", "娀", "訓", "尾", "觫", "梢", "均", "忤", "继", "變", "喽", "尉",
"骚", "趸",
"馃", "石", "置", "毡", "竴", "龄", "掭", "骟", "堡", "确", "街", "沌", "恨", "壮",
"弄", "鞴",
"剿", "貅", "路", "杠", "豚", "澜", "靼", "擐", "租", "媪", "彖", "逢", "撺", "盗",
"呑", "锥",
"栎", "唧", "翩", "倥", "虽", "郏", "钒", "雉", "捒", "官", "酷", "樽", "房", "屣",
"堌", "蒍",
"悌", "④", "蛳", "俱", "慢", "筇", "框", "椽", "债", "吭", "柱", "夤", "嘈", "骺",
"趹", "刓",
"豕", "噢", "J", "论", "俞", "仙", "碰", "经", "铋", "⑤", "顽", "曲", "得", "汪",
"浒", "际",
"嘏", "扮", "祊", "嵋", "‘", "牒", "禮", "粒", "籀", "闱", "刍", "邕", "美", "苫",
"靺", "铹",
"莰", "蔑", "敵", "逑", "锬", "宸", "鞥", "匝", "褀", "菅", "逊", "脱", "晔", "罾",
"郝", "恰",
"丟", "芩", "枷", "鹩", "a", "夙", "述", "钢", "瀵", "铧", "翱", "尧", "醮", "&",
"鳐", "懲",
"濩", "树", "劵", "虾", "砚", "腄", "罟", "硖", "崩", "埘", "╱", "血", "觯", "巂",
"栀", "萏",
"雪", "眵", "白", "新", "靶", "猪", "亻", "窬", "Ⅳ", "麽", "遄", "沏", "茅", "笋",
"甬", "潔",
"悛", "幕", "鹤", "悴", "耻", "觜", "滞", "己", "鏂", "肛", "婤", "嘞", "蘸", "胴",
"柿", "穗",
"咯", "嵕", "蜣", "僰", "玃", "细", "▏", "戗", "尘", "仄", "子", "历", "翌", "烀",
"晞", "桷",
"藕", "啄", "腐", "瘥", "诣", "彗", "捭", "懑", "陛", "傥", "沚", "贯", "﹑", "雒",
"航", "跬",
"晓", "赢", "鸭", "臊", "闳", "稲", "阁", "鼋", "‰", "个", "農", "匮", "辚", "滗",
"桢", "詈",
"绗", "馇", "蜓", "专", "余", "鳉", "稚", "午", "珍", "癃", "钵", "档", "颍", "厕",
"岭", "祓",
"诂", "襙", "炙", "枯", "锦", "袤", "桊", "嗓", "䘵", "嫂", "丰", "苎", "梦", "早",
"菱", "钱",
"灯", "钮", "锓", "豐", "蝤", "协", "h", "鼓", "燕", "覺", "涮", "呗", "専", "篓",
"玷", "褓",
"从", "鲍", "羧", "俭", "萌", "樣", "颜", "谷", "夹", "囫", "』", "缙", "鹰", "条",
"状", "沨",
"因", "莺", "楼", "扰", "禢", "砧", "埔", "纩", "臭", "茶", "妹", "莼", "境", "山",
"诘", "蒌",
"唤", "仃", "眄", "田", "畼", "缱", "祘", "痴", "揍", "猾", "甙", "躲", "返", "砝",
"叽", "苟",
"肭", "悖", "嫣", "凋", "踞", "勢", "弃", "般", "赤", "佣", "嘘", "智", "寒", "旆",
"咎", "戊",
"温", "昙", "蝄", "掉", "冤", "凍", "一", "鋼", "茏", "兼", "昃", "峤", "挟", "0",
"顾", "颅",
"*", "遆", "硅", "烯", "眊", "鳘", "下", "雾", "癖", "贮", "缴", "升", "劲", "婞",
"掇", "梯",
"壬", "撮", "绑", "氣", "薤", "兔", "赟", "漕", "签", "顇", "砭", "鸼", "明", "佧",
"鹗", "哉",
"席", "趁", "砖", "澌", "撤", "萨", "熔", "蚝", "狮", "夔", "介", "青", "喈", "郂",
"埝", "狗",
"哚", "咪", "材", "跑", "炗", "龉", "髓", "衣", "觀", "淋", "寄", "羮", "抵", "恁",
"藿", "蜢",
"甜", "兽", "洒", "眶", "薯", "绷", "颀", "骑", "鲻", "|", "q", "繄", "丝", "焙",
"瑕", "童",
"豸", "讨", "钿", "艮", "踧", "幽", "焰", "宽", "址", "鸩", "堉", "音", "擅", "铞",
"埌", "宙",
"_", "钥", "承", "率", "噬", "凌", "程", "蚕", "嘣", "饭", "橉", "径", "1", "鄏",
"袜", "孙",
"樊", "窦", "牦", "歡", "罕", "蓉", "诩", "㧎", "责", "豢", "逅", "甘", "礶", "镥",
"穂", "到",
"檑", "皇", "泖", "腱", "郤", "竞", "竽", "溴", "木", "蛀", "蛟", "燧", "鹳", "谵",
"钳", "魔",
"链", "咆", "荡", "婳", "冢", "鲧", "昝", "※", "倫", "才", "簿", "醫", "吕", "姗",
"L", "俺",
"隳", "鮮", "衩", "鲆", "崟", "鲹", "岗", "镇", "嗄", "硪", "盎", "氟", "笪", "今",
"公", "尽",
"佬", "骧", "驻", "翼", "咚", "盱", "镎", "浈", "谅", "洟", "嘭", "跶", "蔹", "咭",
"妁", "殚",
"砷", "购", "犸", "哄", "笸", "喂", "赋", "倓", "项", "臧", "梳", "笏", "鹝", "昭",
"罿", "镄",
"П", "湯", "U", "绐", "绂", "鸬", "毐", "台", "鈴", "憾", "痰", "缭", "绒", "赁",
"效", "哝",
"─", "偆", "泗", "谇", "貘", "搜", "阗", "個", "艟", "嗔", "正", "筛", "鼷", "摛",
"馀", "坡",
"卓", "厥", "睾", "雯", "篷", "狰", "掀", "夫", "靛", "伻", "茇", "顧", "猕", "占",
"俟", "兄",
"垡", "兆", "铃", "屙", "轵", "銮", "磲", "桤", "跷", "缳", "粘", "袢", "尬", "獘",
"社", "彬",
"哨", "煳", "莊", "教", "鸸", "窖", "晰", "捻", "环", "廿", "驶", "椠", "熟", "赓",
"挥", "兵",
"洚", "桧", "埼", "嘀", "哎", "柞", "悄", "调", "洼", "蛇", "铬", "蝇", "倆", "谂",
"姻", "怕",
"瑙", "算", "惮", "遥", "惟", "甫", "玺", "袈", "税", "玟", "械", "擗", "淤", "溟",
"揞", "纲",
"谤", "條", "翕", "荛", "忾", "馿", "糖", "檗", "垱", "┐", "躜", "缒", "您", "蹶",
"合", "数",
"斟", "粲", "玖", "淞", "孰", "觎", "M", "嫪", "毽", "桩", "蹦", "亹", "胾", "亲",
"痉", "莙",
"捐", "烁", "瓣", "邀", "但", "误", "饻", "妄", "镱", "民", "嗳", "竦", "柰", "脒",
"斓", "瞟",
"拱", "霾", "粜", "腽", "咬", "唿", "礻", "y", "褒", "郪", "熰", "梻", "甭", "处",
"拖", "蜉",
"鄱", "絲", "宠", "瞵", "荷", "靓", "喻", "阢", "伫", "担", "朐", "墙", "儣", "胄",
"簏", "皆",
"踌", "萃", "命", "滟", "睹", "叁", "蟮", "東", "﹖", "式", "營", "疠", "醳", "尔",
"購", "吒",
"柴", "途", "力", "疰", "寳", "萬", "挨", "碥", "牍", "嘻", "柃", "剡", "徝", "杖",
"螺", "祈",
"産", "煽", "讽", "瞭", "由", "牀", "涉", "暴", "枚", "仰", "它", "胤", "驯", "港",
"寵", "熄",
"蛮", "务", "殃", "亸", "涢", "妫", "粥", "扦", "寺", "抿", "湃", "C", "脚", "涸",
"动", "務",
"镭", "检", "釂", "耳", "榦", "怆", "氨", "瘳", "钽", "牚", "负", "纂", "獬", "息",
"婄", "襞",
"囹", "酰", "扑", "臛", "价", "褡", "篼", "媢", "酊", "腋", "愣", "垯", "喃", "牾",
"犨", "蜂",
"诹", "迂", "槑", "好", "褰", "咝", "③", "劐", "骄", "腉", "仕", "叵", "磅", "金",
"皁", "勍",
"煮", "鍪", "筚", "吲", "艰", "床", "叛", "﹔", "喜", "齑", "昧", "乎", "谲", "匈",
"麒", "身",
"唑", "鲤", "栂", "垭", "殪", "沪", "苌", "濡", "蒎", "遏", "®", "质", "纫", "罐",
"瞍", "柄",
"呼", "锱", "盔", "搋", "烛", "喉", "奈", "赦", "轘", "鉴", "瓒", "铰", "恽", "腠",
"韶", "胼",
"侄", "珂", "鹕", "䝉", "呤", "椁", "岳", "汲", "疤", "绊", "涂", "乾", "噎", "兑",
"絜", "嘧",
"蚯", "们", "蝉", "玛", "魁", "黻", "振", "冥", "报", "窟", "笱", "喊", "瓴", "喾",
"説", "雹",
"恫", "a", "颧", "給", "宅", "鞧", "嬷", "鼾", "笔", "鲉", "匹", "蠕", "愍", "氽",
"赐", "畔",
"絪", "洴", "审", "窂", "褔", "狯", "谑", "毳", "右", "疣", "鲙", "堃", "瓜", "…",
"崆", "钫",
"樭", "鲛", "砂", "筋", "犏", "乱", "入", "浐", "膙", "厚", "獗", "覌", "焦", "罃",
"宬", "隍",
"荃", "醜", "厉", "艇", "娟", "樂", "筲", "洛", "唼", "诜", "馑", "香", "缛", "运",
"祟", "踩",
"陲", "叔", "潞", "二", "搠", "祼", "瀘", "蒋", "樗", "麦", "鸦", "棻", "古", "鹠",
"怊", "裾",
"够", "璧", "晡", "擘", "毂", "御", "葚", "忱", "觞", "瑁", "唇", "罡", "剽", "殡",
"沛", "帻",
"举", "瞓", "谬", "溝", "言", "哽", "婿", "猿", "跗", "獴", "俜", "呙", "弗", "凿",
"窭", "铌",
"友", "唉", "怫", "荘"]
def __repr__(self) -> str:
return f"CharsetManager(size={len(self.charset)}, range_size={len(self.charset_range)})"
def __str__(self) -> str:
return f"CharsetManager with {len(self.charset)} characters, {len(self.charset_range)} in range"
================================================
FILE: ddddocr/models/model_loader.py
================================================
# coding=utf-8
"""
模型加载器模块
负责ONNX模型的加载和管理
"""
import os
import json
from typing import List, Optional, Dict, Any
import onnxruntime
from ..utils.exceptions import ModelLoadError
from ..utils.validators import validate_model_config
class ModelLoader:
"""ONNX模型加载器"""
def __init__(self, use_gpu: bool = False, device_id: int = 0):
"""
初始化模型加载器
Args:
use_gpu: 是否使用GPU
device_id: GPU设备ID
"""
self.use_gpu = use_gpu
self.device_id = device_id
self._setup_providers()
def _setup_providers(self) -> None:
"""设置ONNX运行时提供者"""
try:
if self.use_gpu:
# GPU提供者
self.providers = [
('CUDAExecutionProvider', {
'device_id': self.device_id,
'arena_extend_strategy': 'kNextPowerOfTwo',
'gpu_mem_limit': 2 * 1024 * 1024 * 1024, # 2GB
'cudnn_conv_algo_search': 'EXHAUSTIVE',
'do_copy_in_default_stream': True,
}),
'CPUExecutionProvider'
]
else:
# CPU提供者
self.providers = ['CPUExecutionProvider']
except Exception as e:
# 如果GPU设置失败,回退到CPU
self.providers = ['CPUExecutionProvider']
if self.use_gpu:
print(f"GPU设置失败,回退到CPU模式: {str(e)}")
def load_model(self, model_path: str) -> onnxruntime.InferenceSession:
"""
加载ONNX模型
Args:
model_path: 模型文件路径
Returns:
ONNX推理会话对象
Raises:
ModelLoadError: 当模型加载失败时
"""
try:
if not os.path.exists(model_path):
raise ModelLoadError(f"模型文件不存在: {model_path}")
# 设置ONNX运行时日志级别
onnxruntime.set_default_logger_severity(3)
# 创建推理会话
session = onnxruntime.InferenceSession(model_path, providers=self.providers)
return session
except Exception as e:
raise ModelLoadError(f"模型加载失败: {str(e)}") from e
def get_model_info(self, session: onnxruntime.InferenceSession) -> Dict[str, Any]:
"""
获取模型信息
Args:
session: ONNX推理会话
Returns:
模型信息字典
"""
try:
input_info = []
for input_meta in session.get_inputs():
input_info.append({
'name': input_meta.name,
'shape': input_meta.shape,
'type': input_meta.type
})
output_info = []
for output_meta in session.get_outputs():
output_info.append({
'name': output_meta.name,
'shape': output_meta.shape,
'type': output_meta.type
})
return {
'inputs': input_info,
'outputs': output_info,
'providers': session.get_providers()
}
except Exception as e:
return {'error': str(e)}
def load_ocr_model(self, old: bool = False, beta: bool = False,
import_onnx_path: str = "") -> onnxruntime.InferenceSession:
"""
加载OCR模型
Args:
old: 是否使用旧版模型
beta: 是否使用beta版模型
import_onnx_path: 自定义模型路径
Returns:
ONNX推理会话对象
Raises:
ModelLoadError: 当模型加载失败时
"""
try:
if import_onnx_path:
model_path = import_onnx_path
else:
base_dir = os.path.dirname(os.path.dirname(__file__))
if old:
model_path = os.path.join(base_dir, 'common_old.onnx')
elif beta:
model_path = os.path.join(base_dir, 'common.onnx')
else:
model_path = os.path.join(base_dir, 'common_old.onnx')
return self.load_model(model_path)
except Exception as e:
raise ModelLoadError(f"OCR模型加载失败: {str(e)}") from e
def load_detection_model(self) -> onnxruntime.InferenceSession:
"""
加载目标检测模型
Returns:
ONNX推理会话对象
Raises:
ModelLoadError: 当模型加载失败时
"""
try:
base_dir = os.path.dirname(os.path.dirname(__file__))
model_path = os.path.join(base_dir, 'common_det.onnx')
return self.load_model(model_path)
except Exception as e:
raise ModelLoadError(f"检测模型加载失败: {str(e)}") from e
def load_custom_model(self, model_path: str, charset_path: str) -> tuple:
"""
加载自定义模型和字符集
Args:
model_path: 模型文件路径
charset_path: 字符集文件路径
Returns:
(推理会话, 字符集信息)
Raises:
ModelLoadError: 当加载失败时
"""
try:
# 加载模型
session = self.load_model(model_path)
# 加载字符集信息
if not os.path.exists(charset_path):
raise ModelLoadError(f"字符集文件不存在: {charset_path}")
with open(charset_path, 'r', encoding="utf-8") as f:
charset_info = json.loads(f.read())
# 验证字符集信息格式
required_keys = ['charset', 'word', 'image', 'channel']
for key in required_keys:
if key not in charset_info:
raise ModelLoadError(f"字符集文件缺少必需字段: {key}")
return session, charset_info
except Exception as e:
raise ModelLoadError(f"自定义模型加载失败: {str(e)}") from e
def validate_model_compatibility(self, session: onnxruntime.InferenceSession,
expected_input_shape: Optional[List[int]] = None) -> bool:
"""
验证模型兼容性
Args:
session: ONNX推理会话
expected_input_shape: 期望的输入形状
Returns:
是否兼容
"""
try:
inputs = session.get_inputs()
if len(inputs) == 0:
return False
if expected_input_shape:
input_shape = inputs[0].shape
# 检查形状兼容性(忽略batch维度)
if len(input_shape) != len(expected_input_shape):
return False
for i, (actual, expected) in enumerate(zip(input_shape[1:], expected_input_shape[1:])):
if expected != -1 and actual != expected:
return False
return True
except Exception:
return False
def get_available_providers(self) -> List[str]:
"""
获取可用的执行提供者
Returns:
可用提供者列表
"""
return onnxruntime.get_available_providers()
def switch_provider(self, use_gpu: bool, device_id: int = 0) -> None:
"""
切换执行提供者
Args:
use_gpu: 是否使用GPU
device_id: GPU设备ID
"""
self.use_gpu = use_gpu
self.device_id = device_id
self._setup_providers()
def __repr__(self) -> str:
return f"ModelLoader(use_gpu={self.use_gpu}, device_id={self.device_id})"
================================================
FILE: ddddocr/preprocessing/__init__.py
================================================
# coding=utf-8
"""
图像预处理模块
提供颜色过滤、图像增强等预处理功能
"""
from .color_filter import ColorFilter
from .image_processor import ImageProcessor
__all__ = [
'ColorFilter',
'ImageProcessor'
]
================================================
FILE: ddddocr/preprocessing/color_filter.py
================================================
# coding=utf-8
"""
颜色过滤模块
提供基于HSV颜色空间的图像颜色过滤功能
"""
from typing import List, Tuple, Optional, Union
import numpy as np
from PIL import Image
from ..utils.exceptions import safe_import_opencv, ImageProcessError
from ..utils.validators import validate_color_filter_params
from ..utils.image_io import image_to_numpy, numpy_to_image
# 安全导入OpenCV
cv2 = safe_import_opencv()
class ColorFilter:
"""图片颜色过滤器类,支持HSV颜色空间的颜色范围过滤"""
# 内置常见颜色预设的HSV范围值
COLOR_PRESETS = {
'red': [((0, 50, 50), (10, 255, 255)), ((170, 50, 50), (180, 255, 255))], # 红色需要两个范围
'blue': [((100, 50, 50), (130, 255, 255))],
'green': [((40, 50, 50), (80, 255, 255))],
'yellow': [((20, 50, 50), (40, 255, 255))],
'orange': [((10, 50, 50), (20, 255, 255))],
'purple': [((130, 50, 50), (170, 255, 255))],
'cyan': [((80, 50, 50), (100, 255, 255))],
'black': [((0, 0, 0), (180, 255, 50))],
'white': [((0, 0, 200), (180, 30, 255))],
'gray': [((0, 0, 50), (180, 30, 200))]
}
def __init__(self, colors: Optional[List[str]] = None,
custom_ranges: Optional[List[Tuple[Tuple[int, int, int], Tuple[int, int, int]]]] = None):
"""
初始化颜色过滤器
Args:
colors: 预设颜色名称列表,如 ['red', 'blue']
custom_ranges: 自定义HSV范围列表,如 [((0,50,50), (10,255,255))]
Raises:
ValueError: 当参数无效时
"""
# 验证输入参数
validate_color_filter_params(colors, custom_ranges)
self.hsv_ranges = []
if colors:
for color in colors:
color_lower = color.lower()
if color_lower in self.COLOR_PRESETS:
self.hsv_ranges.extend(self.COLOR_PRESETS[color_lower])
else:
available_colors = ', '.join(self.COLOR_PRESETS.keys())
raise ValueError(f"不支持的颜色预设: {color}。可用颜色: {available_colors}")
if custom_ranges:
self.hsv_ranges.extend(custom_ranges)
if not self.hsv_ranges:
raise ValueError("必须指定colors或custom_ranges参数")
def filter_image(self, image: Union[Image.Image, np.ndarray]) -> Image.Image:
"""
对图片进行颜色过滤
Args:
image: 输入图片(PIL.Image或numpy.ndarray)
Returns:
过滤后的PIL Image对象
Raises:
ImageProcessError: 当图片处理失败时
"""
try:
# 转换为numpy数组
if isinstance(image, Image.Image):
img_array = cv2.cvtColor(image_to_numpy(image, 'RGB'), cv2.COLOR_RGB2BGR)
else:
img_array = image.copy()
# 转换到HSV颜色空间
hsv = cv2.cvtColor(img_array, cv2.COLOR_BGR2HSV)
# 创建掩码
mask = np.zeros(hsv.shape[:2], dtype=np.uint8)
for lower, upper in self.hsv_ranges:
# 创建当前颜色范围的掩码
range_mask = cv2.inRange(hsv, np.array(lower), np.array(upper))
# 合并到总掩码
mask = cv2.bitwise_or(mask, range_mask)
# 应用掩码
result = cv2.bitwise_and(img_array, img_array, mask=mask)
# 将背景设为白色
result[mask == 0] = [255, 255, 255]
# 转换回PIL Image
result_rgb = cv2.cvtColor(result, cv2.COLOR_BGR2RGB)
return numpy_to_image(result_rgb, 'RGB')
except Exception as e:
raise ImageProcessError(f"颜色过滤处理失败: {str(e)}") from e
def get_mask(self, image: Union[Image.Image, np.ndarray]) -> np.ndarray:
"""
获取颜色过滤的掩码
Args:
image: 输入图片
Returns:
二值掩码数组
Raises:
ImageProcessError: 当处理失败时
"""
try:
# 转换为numpy数组
if isinstance(image, Image.Image):
img_array = cv2.cvtColor(image_to_numpy(image, 'RGB'), cv2.COLOR_RGB2BGR)
else:
img_array = image.copy()
# 转换到HSV颜色空间
hsv = cv2.cvtColor(img_array, cv2.COLOR_BGR2HSV)
# 创建掩码
mask = np.zeros(hsv.shape[:2], dtype=np.uint8)
for lower, upper in self.hsv_ranges:
# 创建当前颜色范围的掩码
range_mask = cv2.inRange(hsv, np.array(lower), np.array(upper))
# 合并到总掩码
mask = cv2.bitwise_or(mask, range_mask)
return mask
except Exception as e:
raise ImageProcessError(f"掩码生成失败: {str(e)}") from e
def add_color_range(self, lower: Tuple[int, int, int], upper: Tuple[int, int, int]) -> None:
"""
添加自定义颜色范围
Args:
lower: HSV下界
upper: HSV上界
"""
validate_color_filter_params(None, [(lower, upper)])
self.hsv_ranges.append((lower, upper))
def add_preset_color(self, color: str) -> None:
"""
添加预设颜色
Args:
color: 预设颜色名称
Raises:
ValueError: 当颜色名称不存在时
"""
color_lower = color.lower()
if color_lower in self.COLOR_PRESETS:
self.hsv_ranges.extend(self.COLOR_PRESETS[color_lower])
else:
available_colors = ', '.join(self.COLOR_PRESETS.keys())
raise ValueError(f"不支持的颜色预设: {color}。可用颜色: {available_colors}")
def clear_ranges(self) -> None:
"""清空所有颜色范围"""
self.hsv_ranges.clear()
def get_ranges(self) -> List[Tuple[Tuple[int, int, int], Tuple[int, int, int]]]:
"""
获取当前所有颜色范围
Returns:
颜色范围列表
"""
return self.hsv_ranges.copy()
@classmethod
def get_available_colors(cls) -> List[str]:
"""
获取所有可用的预设颜色名称
Returns:
可用颜色名称列表
"""
return list(cls.COLOR_PRESETS.keys())
@classmethod
def get_color_range(cls, color: str) -> List[Tuple[Tuple[int, int, int], Tuple[int, int, int]]]:
"""
获取指定颜色的HSV范围
Args:
color: 颜色名称
Returns:
颜色的HSV范围列表
Raises:
ValueError: 当颜色名称不存在时
"""
color_lower = color.lower()
if color_lower in cls.COLOR_PRESETS:
return cls.COLOR_PRESETS[color_lower].copy()
else:
available_colors = ', '.join(cls.COLOR_PRESETS.keys())
raise ValueError(f"不支持的颜色预设: {color}。可用颜色: {available_colors}")
def __repr__(self) -> str:
return f"ColorFilter(ranges={len(self.hsv_ranges)})"
def __str__(self) -> str:
return f"ColorFilter with {len(self.hsv_ranges)} color ranges"
================================================
FILE: ddddocr/preprocessing/image_processor.py
================================================
# coding=utf-8
"""
图像处理模块
提供图像预处理、增强、变换等功能
"""
from typing import Tuple, Union, Optional
import numpy as np
from PIL import Image
from ..utils.exceptions import safe_import_opencv, ImageProcessError
from ..utils.image_io import image_to_numpy, numpy_to_image, png_rgba_black_preprocess
# 安全导入OpenCV
cv2 = safe_import_opencv()
class ImageProcessor:
"""图像处理器类,提供各种图像预处理功能"""
@staticmethod
def resize_image(image: Image.Image, target_size: Tuple[int, int],
keep_aspect_ratio: bool = False,
resample: int = Image.LANCZOS) -> Image.Image:
"""
调整图像尺寸
Args:
image: 输入图像
target_size: 目标尺寸 (width, height)
keep_aspect_ratio: 是否保持宽高比
resample: 重采样方法
Returns:
调整尺寸后的图像
Raises:
ImageProcessError: 当处理失败时
"""
try:
if keep_aspect_ratio:
# 计算保持宽高比的尺寸
original_width, original_height = image.size
target_width, target_height = target_size
# 计算缩放比例
width_ratio = target_width / original_width
height_ratio = target_height / original_height
scale_ratio = min(width_ratio, height_ratio)
# 计算新尺寸
new_width = int(original_width * scale_ratio)
new_height = int(original_height * scale_ratio)
return image.resize((new_width, new_height), resample)
else:
return image.resize(target_size, resample)
except Exception as e:
raise ImageProcessError(f"图像尺寸调整失败: {str(e)}") from e
@staticmethod
def convert_to_grayscale(image: Image.Image) -> Image.Image:
"""
将图像转换为灰度图
Args:
image: 输入图像
Returns:
灰度图像
Raises:
ImageProcessError: 当转换失败时
"""
try:
return image.convert('L')
except Exception as e:
raise ImageProcessError(f"灰度转换失败: {str(e)}") from e
@staticmethod
def normalize_image(image: Union[Image.Image, np.ndarray],
target_mean: float = 0.0, target_std: float = 1.0) -> np.ndarray:
"""
标准化图像像素值
Args:
image: 输入图像
target_mean: 目标均值
target_std: 目标标准差
Returns:
标准化后的numpy数组
Raises:
ImageProcessError: 当处理失败时
"""
try:
if isinstance(image, Image.Image):
img_array = image_to_numpy(image)
else:
img_array = image.copy()
# 转换为float32并归一化到[0,1]
img_array = img_array.astype(np.float32) / 255.0
# 计算当前均值和标准差
current_mean = np.mean(img_array)
current_std = np.std(img_array)
# 避免除零
if current_std == 0:
current_std = 1.0
# 标准化
normalized = (img_array - current_mean) / current_std
normalized = normalized * target_std + target_mean
return normalized
except Exception as e:
raise ImageProcessError(f"图像标准化失败: {str(e)}") from e
@staticmethod
def enhance_contrast(image: Image.Image, factor: float = 1.5) -> Image.Image:
"""
增强图像对比度
Args:
image: 输入图像
factor: 对比度增强因子
Returns:
对比度增强后的图像
Raises:
ImageProcessError: 当处理失败时
"""
try:
from PIL import ImageEnhance
enhancer = ImageEnhance.Contrast(image)
return enhancer.enhance(factor)
except Exception as e:
raise ImageProcessError(f"对比度增强失败: {str(e)}") from e
@staticmethod
def enhance_sharpness(image: Image.Image, factor: float = 1.5) -> Image.Image:
"""
增强图像锐度
Args:
image: 输入图像
factor: 锐度增强因子
Returns:
锐度增强后的图像
Raises:
ImageProcessError: 当处理失败时
"""
try:
from PIL import ImageEnhance
enhancer = ImageEnhance.Sharpness(image)
return enhancer.enhance(factor)
except Exception as e:
raise ImageProcessError(f"锐度增强失败: {str(e)}") from e
@staticmethod
def remove_noise(image: Image.Image, kernel_size: int = 3) -> Image.Image:
"""
去除图像噪声
Args:
image: 输入图像
kernel_size: 滤波核大小
Returns:
去噪后的图像
Raises:
ImageProcessError: 当处理失败时
"""
try:
img_array = image_to_numpy(image)
# 使用中值滤波去噪
if len(img_array.shape) == 3:
# 彩色图像
denoised = cv2.medianBlur(img_array, kernel_size)
else:
# 灰度图像
denoised = cv2.medianBlur(img_array, kernel_size)
return numpy_to_image(denoised, image.mode)
except Exception as e:
raise ImageProcessError(f"图像去噪失败: {str(e)}") from e
@staticmethod
def binarize_image(image: Image.Image, threshold: int = 128,
method: str = 'simple') -> Image.Image:
"""
图像二值化
Args:
image: 输入图像
threshold: 二值化阈值
method: 二值化方法 ('simple', 'otsu', 'adaptive')
Returns:
二值化后的图像
Raises:
ImageProcessError: 当处理失败时
"""
try:
# 转换为灰度图
if image.mode != 'L':
gray_image = image.convert('L')
else:
gray_image = image
img_array = image_to_numpy(gray_image)
if method == 'simple':
_, binary = cv2.threshold(img_array, threshold, 255, cv2.THRESH_BINARY)
elif method == 'otsu':
_, binary = cv2.threshold(img_array, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
elif method == 'adaptive':
binary = cv2.adaptiveThreshold(img_array, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2)
else:
raise ValueError(f"不支持的二值化方法: {method}")
return numpy_to_image(binary, 'L')
except Exception as e:
raise ImageProcessError(f"图像二值化失败: {str(e)}") from e
@staticmethod
def preprocess_for_ocr(image: Image.Image, target_height: int = 64,
enhance_contrast: bool = True,
remove_noise: bool = True) -> Image.Image:
"""
OCR预处理流水线
Args:
image: 输入图像
target_height: 目标高度
enhance_contrast: 是否增强对比度
remove_noise: 是否去噪
Returns:
预处理后的图像
Raises:
ImageProcessError: 当处理失败时
"""
try:
processed_image = image.copy()
# 处理PNG透明背景
if processed_image.mode == 'RGBA':
processed_image = png_rgba_black_preprocess(processed_image)
# 调整尺寸(保持宽高比)
original_width, original_height = processed_image.size
target_width = int(original_width * (target_height / original_height))
processed_image = ImageProcessor.resize_image(
processed_image, (target_width, target_height), keep_aspect_ratio=False
)
# 增强对比度
if enhance_contrast:
processed_image = ImageProcessor.enhance_contrast(processed_image, factor=1.2)
# 去噪
if remove_noise:
processed_image = ImageProcessor.remove_noise(processed_image, kernel_size=3)
# 转换为灰度图
processed_image = ImageProcessor.convert_to_grayscale(processed_image)
return processed_image
except Exception as e:
raise ImageProcessError(f"OCR预处理失败: {str(e)}") from e
================================================
FILE: ddddocr/requirements.txt
================================================
numpy
onnxruntime
Pillow
opencv-python; sys_platform == "win32" or sys_platform == "darwin"
opencv-python-headless; sys_platform == "linux"
fastapi>=0.68.0
uvicorn>=0.15.0
python-multipart>=0.0.5
pydantic>=1.8.0,<3
requests>=2.25.0
================================================
FILE: ddddocr/utils/__init__.py
================================================
# coding=utf-8
"""
工具函数模块
提供图像处理、异常处理、输入验证等工具函数
"""
# 从新的模块化结构导入
from .image_io import png_rgba_black_preprocess
from .exceptions import DDDDOCRError, ModelLoadError, ImageProcessError
from .validators import validate_image_input, validate_model_config
# 从兼容模块导入(保持向后兼容)
from .compat import (
ALLOWED_IMAGE_FORMATS,
MAX_IMAGE_BYTES,
MAX_IMAGE_SIDE,
DdddOcrInputError,
InvalidImageError,
TypeError,
base64_to_image,
get_img_base64,
)
__all__ = [
# 新模块化结构的导出
'png_rgba_black_preprocess',
'DDDDOCRError',
'ModelLoadError',
'ImageProcessError',
'validate_image_input',
'validate_model_config',
# 从 compat.py 导入的兼容性导出
'ALLOWED_IMAGE_FORMATS',
'MAX_IMAGE_BYTES',
'MAX_IMAGE_SIDE',
'DdddOcrInputError',
'InvalidImageError',
'TypeError',
'base64_to_image',
'get_img_base64',
]
================================================
FILE: ddddocr/utils/compat.py
================================================
# coding=utf-8
import base64
import binascii
import io
import os
from typing import Union
from PIL import Image
MAX_IMAGE_BYTES = 8 * 1024 * 1024
MAX_IMAGE_SIDE = 4096
ALLOWED_IMAGE_FORMATS = {
'PNG', 'JPEG', 'JPG', 'WEBP', 'BMP', 'GIF', 'TIFF'
}
class TypeError(Exception):
pass
class DdddOcrInputError(TypeError):
"""向下兼容的输入异常基类"""
class InvalidImageError(DdddOcrInputError):
"""图片格式或大小非法时抛出"""
def base64_to_image(img_base64: str) -> Image.Image:
if not isinstance(img_base64, str):
raise DdddOcrInputError("base64 输入必须是字符串")
try:
img_data = base64.b64decode(img_base64, validate=True)
except binascii.Error as exc:
raise DdddOcrInputError("base64 内容非法") from exc
if len(img_data) == 0:
raise InvalidImageError("base64 内容为空")
if len(img_data) > MAX_IMAGE_BYTES:
raise InvalidImageError("图片容量超过允许上限")
try:
image = Image.open(io.BytesIO(img_data))
except Exception as exc:
raise InvalidImageError("无法从 base64 中解析图片") from exc
return image
def get_img_base64(single_image_path):
with open(single_image_path, 'rb') as fp:
img_base64 = base64.b64encode(fp.read())
return img_base64.decode()
def _coerce_bool(value: Union[bool, str], field_name: str) -> bool:
if isinstance(value, bool):
return value
if isinstance(value, str):
lowered = value.strip().lower()
if lowered in {'true', '1', 'yes', 'y'}:
return True
if lowered in {'false', '0', 'no', 'n'}:
return False
raise DdddOcrInputError(f"字段 {field_name} 只能是 bool 或 true/false 字符串,当前值: {value!r}")
def _coerce_int(value: Union[int, str], field_name: str) -> int:
if isinstance(value, int):
return value
if isinstance(value, str):
try:
return int(value.strip())
except ValueError:
pass
raise DdddOcrInputError(f"字段 {field_name} 只能是整数,当前值: {value!r}")
def _coerce_positive_int(value: Union[int, str], field_name: str) -> int:
result = _coerce_int(value, field_name)
if result <= 0:
raise DdddOcrInputError(f"字段 {field_name} 必须是正整数")
return result
def _ensure_file_exists(path: str, description: str) -> None:
if path and not os.path.exists(path):
raise DdddOcrInputError(f"{description} {path} 不存在")
def png_rgba_black_preprocess(img: Image):
width = img.width
height = img.height
image = Image.new('RGB', size=(width, height), color=(255, 255, 255))
image.paste(img, (0, 0), mask=img)
return image
================================================
FILE: ddddocr/utils/exceptions.py
================================================
# coding=utf-8
"""
异常处理模块
定义项目中使用的自定义异常类
"""
import sys
import platform
class DDDDOCRError(Exception):
"""DDDDOCR基础异常类"""
pass
class ModelLoadError(DDDDOCRError):
"""模型加载异常"""
pass
class ImageProcessError(DDDDOCRError):
"""图像处理异常"""
pass
class TypeError(Exception):
"""类型错误异常(保持向后兼容)"""
pass
def handle_opencv_import_error(error: ImportError) -> None:
"""
处理OpenCV导入错误,提供详细的解决方案
Args:
error: ImportError异常对象
"""
error_msg = f"""
OpenCV导入失败: {str(error)}
常见解决方案:
1. 重新安装opencv-python:
pip uninstall opencv-python opencv-python-headless
pip install opencv-python-headless
2. 系统特定解决方案:
"""
system = platform.system().lower()
if system == "linux":
error_msg += """
Linux系统:
- Ubuntu/Debian: sudo apt-get install build-essential libglib2.0-0 libsm6 libxext6 libxrender-dev libgl1-mesa-glx
- CentOS/RHEL: sudo yum install gcc gcc-c++ make glib2-devel libSM libXext libXrender mesa-libGL
- 或尝试: sudo apt-get install python3-opencv
"""
elif system == "windows":
error_msg += """
Windows系统:
- 安装Visual C++运行库: https://www.ghxi.com/yxkhj.html
- 确保使用64位Python版本
- 尝试: pip install opencv-python --force-reinstall
"""
elif system == "darwin": # macOS
error_msg += """
macOS系统:
- 使用Homebrew: brew install opencv
- 或使用conda: conda install opencv
- M1/M2芯片参考: https://github.com/sml2h3/ddddocr/issues/67
"""
error_msg += """
3. 如果问题持续存在,请访问项目Issues页面寻求帮助:
https://github.com/sml2h3/ddddocr/issues
注意:请不要自动安装依赖,按照上述指导手动安装。
"""
print(error_msg)
raise ImportError("OpenCV导入失败,请参考上述解决方案") from error
def safe_import_opencv():
"""
安全导入OpenCV,如果失败则提供详细错误信息
Returns:
cv2模块对象
Raises:
ImportError: 当OpenCV导入失败时
"""
try:
import cv2
return cv2
except ImportError as e:
handle_opencv_import_error(e)
================================================
FILE: ddddocr/utils/image_io.py
================================================
# coding=utf-8
"""
图像输入输出工具模块
提供图像格式转换、读取、保存等功能
"""
import io
import os
import base64
import pathlib
from typing import Union, BinaryIO
from PIL import Image
import numpy as np
from .exceptions import ImageProcessError
def base64_to_image(img_base64: str) -> Image.Image:
"""
将base64编码的图片转换为PIL Image对象
Args:
img_base64: base64编码的图片字符串
Returns:
PIL Image对象
Raises:
ImageProcessError: 当base64解码或图片加载失败时
"""
try:
img_data = base64.b64decode(img_base64)
return Image.open(io.BytesIO(img_data))
except Exception as e:
raise ImageProcessError(f"base64图片解码失败: {str(e)}") from e
def get_img_base64(image_path: Union[str, pathlib.Path]) -> str:
"""
读取图片文件并转换为base64编码字符串
Args:
image_path: 图片文件路径
Returns:
base64编码的图片字符串
Raises:
ImageProcessError: 当文件读取失败时
"""
try:
with open(image_path, 'rb') as fp:
img_base64 = base64.b64encode(fp.read())
return img_base64.decode()
except Exception as e:
raise ImageProcessError(f"图片文件读取失败: {str(e)}") from e
def png_rgba_black_preprocess(img: Image.Image) -> Image.Image:
"""
处理PNG图片的RGBA透明背景,将透明部分设置为白色背景
Args:
img: PIL Image对象
Returns:
处理后的PIL Image对象
Raises:
ImageProcessError: 当图片处理失败时
"""
try:
width = img.width
height = img.height
image = Image.new('RGB', size=(width, height), color=(255, 255, 255))
image.paste(img, (0, 0), mask=img)
return image
except Exception as e:
raise ImageProcessError(f"PNG透明背景处理失败: {str(e)}") from e
def load_image_from_input(img_input: Union[bytes, str, pathlib.PurePath, Image.Image, np.ndarray]) -> Image.Image:
"""
从多种输入格式加载图片
Args:
img_input: 图片输入,支持bytes、base64字符串、文件路径、PIL Image对象或numpy数组
Returns:
PIL Image对象
Raises:
ImageProcessError: 当图片加载失败时
"""
try:
if isinstance(img_input, bytes):
return Image.open(io.BytesIO(img_input))
elif isinstance(img_input, Image.Image):
return img_input.copy()
elif isinstance(img_input, np.ndarray):
return _numpy_to_pil_image(img_input)
elif isinstance(img_input, str):
# 先尝试作为文件路径,如果失败则作为base64
if os.path.exists(img_input):
return Image.open(img_input)
else:
return base64_to_image(img_input)
elif isinstance(img_input, pathlib.PurePath):
return Image.open(img_input)
else:
supported_types = (bytes, str, pathlib.PurePath, Image.Image, np.ndarray)
raise ImageProcessError(
f"不支持的图片输入类型: {type(img_input)}。"
f"支持的类型: {supported_types}"
)
except ImageProcessError:
raise
except Exception as e:
raise ImageProcessError(f"图片加载失败: {str(e)}") from e
def _numpy_to_pil_image(array: np.ndarray) -> Image.Image:
"""
将numpy数组转换为PIL Image对象
Args:
array: numpy数组
Returns:
PIL Image对象
Raises:
ImageProcessError: 当转换失败时
"""
try:
# 确保数组是正确的数据类型
if array.dtype != np.uint8:
# 如果是浮点数,假设范围是0-1,转换为0-255
if array.dtype in [np.float32, np.float64]:
if array.max() <= 1.0:
array = (array * 255).astype(np.uint8)
else:
array = array.astype(np.uint8)
else:
array = array.astype(np.uint8)
# 处理不同的数组形状
if len(array.shape) == 2:
# 灰度图像 (H, W)
return Image.fromarray(array, mode='L')
elif len(array.shape) == 3:
if array.shape[2] == 1:
# 单通道图像 (H, W, 1) -> (H, W)
return Image.fromarray(array.squeeze(axis=2), mode='L')
elif array.shape[2] == 3:
# RGB图像 (H, W, 3)
return Image.fromarray(array, mode='RGB')
elif array.shape[2] == 4:
# RGBA图像 (H, W, 4)
return Image.fromarray(array, mode='RGBA')
else:
raise ImageProcessError(f"不支持的通道数: {array.shape[2]},支持1、3、4通道")
else:
raise ImageProcessError(f"不支持的数组维度: {len(array.shape)},支持2D或3D数组")
except Exception as e:
raise ImageProcessError(f"numpy数组转PIL图像失败: {str(e)}") from e
def image_to_numpy(image: Image.Image, target_mode: str = 'RGB') -> np.ndarray:
"""
将PIL Image转换为numpy数组
Args:
image: PIL Image对象
target_mode: 目标颜色模式,默认为'RGB'
Returns:
numpy数组
Raises:
ImageProcessError: 当转换失败时
"""
try:
if image.mode != target_mode:
image = image.convert(target_mode)
return np.array(image)
except Exception as e:
raise ImageProcessError(f"图片转numpy数组失败: {str(e)}") from e
def numpy_to_image(array: np.ndarray, mode: str = 'RGB') -> Image.Image:
"""
将numpy数组转换为PIL Image
Args:
array: numpy数组
mode: 图片模式,默认为'RGB'
Returns:
PIL Image对象
Raises:
ImageProcessError: 当转换失败时
"""
try:
return Image.fromarray(array, mode=mode)
except Exception as e:
raise ImageProcessError(f"numpy数组转图片失败: {str(e)}") from e
================================================
FILE: ddddocr/utils/validators.py
================================================
# coding=utf-8
"""
输入验证模块
提供各种输入参数的验证功能
"""
import pathlib
from typing import Union, List, Tuple, Any
from PIL import Image
import numpy as np
from .exceptions import DDDDOCRError
def validate_image_input(img_input: Any) -> bool:
"""
验证图片输入是否为支持的类型
Args:
img_input: 图片输入
Returns:
bool: 是否为有效的图片输入
Raises:
DDDDOCRError: 当输入类型不支持时
"""
valid_types = (bytes, str, pathlib.PurePath, Image.Image, np.ndarray)
if not isinstance(img_input, valid_types):
raise DDDDOCRError(f"不支持的图片输入类型: {type(img_input)}。支持的类型: {valid_types}")
return True
def validate_model_config(ocr: bool = True, det: bool = False, old: bool = False,
beta: bool = False, use_gpu: bool = False, device_id: int = 0) -> bool:
"""
验证模型配置参数
Args:
ocr: 是否启用OCR功能
det: 是否启用目标检测功能
old: 是否使用旧版OCR模型
beta: 是否使用beta版OCR模型
use_gpu: 是否使用GPU
device_id: GPU设备ID
Returns:
bool: 配置是否有效
Raises:
DDDDOCRError: 当配置无效时
"""
# 检查基本参数类型
if not isinstance(ocr, bool):
raise DDDDOCRError("ocr参数必须为布尔值")
if not isinstance(det, bool):
raise DDDDOCRError("det参数必须为布尔值")
if not isinstance(old, bool):
raise DDDDOCRError("old参数必须为布尔值")
if not isinstance(beta, bool):
raise DDDDOCRError("beta参数必须为布尔值")
if not isinstance(use_gpu, bool):
raise DDDDOCRError("use_gpu参数必须为布尔值")
if not isinstance(device_id, int) or device_id < 0:
raise DDDDOCRError("device_id参数必须为非负整数")
# 检查功能组合的有效性
if not ocr and not det:
# 允许两者都为False,这种情况下只能使用滑块功能
pass
# 检查模型版本冲突
if old and beta:
raise DDDDOCRError("old和beta参数不能同时为True")
# 检查GPU配置
if use_gpu and device_id < 0:
raise DDDDOCRError("使用GPU时device_id必须为非负整数")
return True
def validate_color_filter_params(colors: List[str] = None,
custom_ranges: List[Tuple[Tuple[int, int, int], Tuple[int, int, int]]] = None) -> bool:
"""
验证颜色过滤参数
Args:
colors: 预设颜色名称列表
custom_ranges: 自定义HSV范围列表
Returns:
bool: 参数是否有效
Raises:
DDDDOCRError: 当参数无效时
"""
if colors is not None:
if not isinstance(colors, list):
raise DDDDOCRError("colors参数必须为列表")
for color in colors:
if not isinstance(color, str):
raise DDDDOCRError("colors列表中的元素必须为字符串")
if custom_ranges is not None:
if not isinstance(custom_ranges, list):
raise DDDDOCRError("custom_ranges参数必须为列表")
for range_item in custom_ranges:
if not isinstance(range_item, (list, tuple)) or len(range_item) != 2:
raise DDDDOCRError("custom_ranges中的每个元素必须为包含两个元素的列表或元组")
lower, upper = range_item
if not isinstance(lower, (list, tuple)) or len(lower) != 3:
raise DDDDOCRError("HSV范围的下界必须为包含3个元素的列表或元组")
if not isinstance(upper, (list, tuple)) or len(upper) != 3:
raise DDDDOCRError("HSV范围的上界必须为包含3个元素的列表或元组")
# 验证HSV值范围
for i, (l, u) in enumerate(zip(lower, upper)):
if not isinstance(l, int) or not isinstance(u, int):
raise DDDDOCRError("HSV值必须为整数")
if i == 0: # H通道
if not (0 <= l <= 180) or not (0 <= u <= 180):
raise DDDDOCRError("H通道值必须在0-180范围内")
else: # S和V通道
if not (0 <= l <= 255) or not (0 <= u <= 255):
raise DDDDOCRError("S和V通道值必须在0-255范围内")
if l > u:
raise DDDDOCRError(f"HSV范围下界不能大于上界: {l} > {u}")
if colors is None and custom_ranges is None:
raise DDDDOCRError("必须指定colors或custom_ranges参数")
return True
def validate_charset_range(charset_range: Union[int, str, List[str]]) -> bool:
"""
验证字符集范围参数
Args:
charset_range: 字符集范围参数
Returns:
bool: 参数是否有效
Raises:
DDDDOCRError: 当参数无效时
"""
if charset_range is None:
return True
if isinstance(charset_range, int):
if charset_range < 0:
raise DDDDOCRError("字符集范围索引必须为非负整数")
elif isinstance(charset_range, str):
if len(charset_range) == 0:
raise DDDDOCRError("字符集范围字符串不能为空")
elif isinstance(charset_range, list):
if len(charset_range) == 0:
raise DDDDOCRError("字符集范围列表不能为空")
for char in charset_range:
if not isinstance(char, str):
raise DDDDOCRError("字符集范围列表中的元素必须为字符串")
else:
raise DDDDOCRError(f"不支持的字符集范围类型: {type(charset_range)}")
return True
================================================
FILE: docker-compose.yml
================================================
version: '3.8'
# DdddOcr API 服务的 Docker Compose 配置文件
# 本文件定义了运行 DdddOcr API 服务所需的所有服务和配置
services:
# DdddOcr API 服务
ddddocr-api:
# 使用当前目录的 Dockerfile 构建镜像
build:
context: .
dockerfile: Dockerfile
# 容器名称
container_name: ddddocr-api
# 端口映射: 宿主机端口:容器内部端口 (可通过环境变量覆盖宿主机端口)
ports:
- "${DDDDOCR_PORT:-8000}:8000"
# 环境变量配置 (可通过宿主机上的环境变量覆盖)
# 这些环境变量将传递给 DdddOcr API 服务
environment:
# API 服务器配置
- DDDDOCR_HOST=0.0.0.0 # 服务绑定地址,0.0.0.0 表示监听所有网络接口
- DDDDOCR_PORT=8000 # 服务监听端口
- DDDDOCR_WORKERS=${DDDDOCR_WORKERS:-1} # API 服务工作进程数,默认 1
# OCR 引擎配置
- DDDDOCR_OCR=${DDDDOCR_OCR:-true} # 是否启用 OCR 功能,默认启用
- DDDDOCR_DET=${DDDDOCR_DET:-false} # 是否启用目标检测功能,默认不启用
- DDDDOCR_OLD=${DDDDOCR_OLD:-false} # 是否使用旧版 OCR 模型,默认不使用
- DDDDOCR_BETA=${DDDDOCR_BETA:-false} # 是否使用 Beta 版 OCR 模型,默认不使用
- DDDDOCR_USE_GPU=${DDDDOCR_USE_GPU:-false} # 是否使用 GPU 加速,默认不使用
- DDDDOCR_DEVICE_ID=${DDDDOCR_DEVICE_ID:-0} # GPU 设备 ID,默认 0
- DDDDOCR_SHOW_AD=${DDDDOCR_SHOW_AD:-true} # 是否显示广告,默认显示
# 自定义模型配置
- DDDDOCR_IMPORT_ONNX_PATH=${DDDDOCR_IMPORT_ONNX_PATH:-""} # 自定义模型路径
- DDDDOCR_CHARSETS_PATH=${DDDDOCR_CHARSETS_PATH:-""} # 自定义字符集路径
# 卷挂载配置,用于持久化数据或提供自定义模型
volumes:
# 可选:挂载自定义模型目录
# - ./custom_models:/app/custom_models
# 可选:如果需要日志持久化,取消下面的注释
# - ./logs:/app/logs
# 容器重启策略
restart: unless-stopped
# 资源限制配置
# deploy:
# resources:
# limits:
# cpus: '2' # 限制 CPU 使用,例如 '2' 表示使用最多 2 个核心
# memory: 2G # 限制内存使用,例如 2G
# GPU 支持配置(仅在需要 GPU 加速且宿主机有 NVIDIA GPU 时启用)
# 如果需要使用 GPU,取消注释以下 deploy 配置,同时将 DDDDOCR_USE_GPU 设置为 true
# deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# count: 1
# capabilities: [gpu]
# 健康检查配置
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 10s
# 可选:使用卷来持久化数据
# volumes:
# logs:
# driver: local
================================================
FILE: examples/README.md
================================================
# DdddOcr - 通用验证码识别SDK
一个简单易用的通用验证码识别Python库
## 目录
- [赞助合作商](#赞助合作商)
- [项目介绍](#项目介绍)
- [环境支持](#环境支持)
- [安装方法](#安装方法)
- [功能概览](#功能概览)
- [初始化参数详解](#初始化参数详解)
- [参数详细说明](#参数详细说明)
- [功能组合与冲突](#功能组合与冲突)
- [模型选择指南](#模型选择指南)
- [性能优化参数](#性能优化参数)
- [详细使用说明](#详细使用说明)
- [文字识别功能](#文字识别功能)
- [基础OCR识别](#基础ocr识别)
- [OCR概率输出](#ocr概率输出)
- [自定义字符范围](#自定义字符范围)
- [颜色过滤功能](#颜色过滤功能)
- [目标检测功能](#目标检测功能)
- [滑块验证码处理](#滑块验证码处理)
- [算法1:边缘匹配](#算法1边缘匹配)
- [算法2:图像差异比较](#算法2图像差异比较)
- [自定义模型导入](#自定义模型导入)
- [高级用法](#高级用法)
- [批量处理](#批量处理)
- [多线程优化](#多线程优化)
- [验证码预处理](#验证码预处理)
- [常见问题](#常见问题)
- [初始化速度慢](#初始化速度慢)
- [识别准确率不高](#识别准确率不高)
- [GPU加速](#gpu加速)
- [处理复杂验证码](#如何处理复杂验证码)
- [内存占用过高](#内存占用过高)
- [参数冲突问题](#参数冲突问题)
- [支持的图片格式](#支持的图片格式)
- [多线程并发问题](#多线程并发问题)
- [项目技术支持](#项目技术支持)
- [使用示例](#使用示例)
- [许可证](#许可证)
## 赞助合作商
| | 赞助合作商 | 推荐理由 |
|------------------------------------------------------------|------------|--------------------------------------------------------------------------------------------------|
|  | [YesCaptcha](https://yescaptcha.com/i/NSwk7i) | 谷歌reCaptcha验证码 / hCaptcha验证码 / funCaptcha验证码商业级识别接口 [点我](https://yescaptcha.com/i/NSwk7i) 直达VIP4 |
|  | [超级鹰](https://www.chaojiying.com/) | 全球领先的智能图片分类及识别商家,安全、准确、高效、稳定、开放,强大的技术及校验团队,支持大并发。7*24h作业进度管理 |
|  | [Malenia](https://malenia.iinti.cn/malenia-doc/) | Malenia企业级代理IP网关平台/代理IP分销软件 |
| 雨云VPS | [注册首月5折](https://www.rainyun.com/ddddocr_) | 浙江节点低价大带宽,100M每月30元 |
## 项目介绍
DdddOcr 是一个通用验证码离线本地识别SDK,由 [sml2h3](https://github.com/sml2h3) 与 [kerlomz](https://github.com/kerlomz) 共同开发完成。该项目通过大批量生成随机数据进行深度网络训练,可以识别各种类型的验证码,包括:
- 常见的数字字母组合验证码
- 中文验证码
- 滑块验证码
- 各种特殊字符验证码
项目设计理念是"最简依赖",尽量减少用户的配置和使用成本,提供简单易用的API接口。
## 环境支持
| 系统 | CPU | GPU | 最大支持Python版本 | 备注 |
|-----|-----|-----|--------------|-----|
| Windows 64位 | ✓ | ✓ | 3.12 | 部分版本Windows需要安装[vc运行库](https://www.ghxi.com/yxkhj.html) |
| Linux 64 / ARM64 | ✓ | ✓ | 3.12 | |
| macOS X64 | ✓ | ✓ | 3.12 | M1/M2/M3芯片用户请参考[相关说明](https://github.com/sml2h3/ddddocr/issues/67) |
不支持的环境:
- Windows 32位
- Linux 32位
## 安装方法
### 从PyPI安装(推荐)
```bash
pip install ddddocr
```
### 从源码安装
```bash
git clone https://github.com/sml2h3/ddddocr.git
cd ddddocr
pip install .
```
### 安装 API 依赖(可选)
```bash
pip install ".[api]"
```
> **注意**:请勿直接在ddddocr项目的根目录内直接import ddddocr,请确保你的开发项目目录名称不为ddddocr。
## 功能概览
DdddOcr提供以下核心功能:
| 功能 | 描述 | 初始化参数 |
|-----|-----|----------|
| 文字识别 | 识别图片中的文字内容 | `ocr=True`(默认) |
| 目标检测 | 检测图片中的目标位置 | `det=True` |
| 滑块验证码识别 | 识别滑块验证码的缺口位置 | `ocr=False` |
| 自定义模型导入 | 导入自定义训练的模型 | `import_onnx_path="模型路径"` |
## 初始化参数详解
`DdddOcr` 类初始化时支持多种参数配置,以适应不同的使用场景:
```python
ddddocr.DdddOcr(
ocr=True, # 是否启用OCR功能
det=False, # 是否启用目标检测功能
old=False, # 是否使用旧版OCR模型
beta=False, # 是否使用Beta版OCR模型(新模型)
use_gpu=False, # 是否使用GPU加速
device_id=0, # 使用的GPU设备ID
show_ad=True, # 是否显示广告信息
import_onnx_path="", # 自定义模型路径
charsets_path="", # 自定义字符集路径
max_image_bytes=None, # 单图最大字节数(默认 8MB)
max_image_side=None # 单图最长边限制(默认 4096px)
)
```
### 参数详细说明
| 参数 | 类型 | 默认值 | 说明 |
|-----|-----|-----|-----|
| `ocr` | bool | True | 是否启用OCR功能,用于识别图片中的文字。**互斥性**:当`det=True`时会强制关闭OCR |
| `det` | bool | False | 是否启用目标检测功能,用于检测图片中的目标位置。**互斥性**:`det=True`会覆盖`ocr=True` |
| `old` | bool | False | 兼容参数,当前不会改变模型选择(默认即使用旧版模型) |
| `beta` | bool | False | 是否使用Beta版OCR模型(新模型),对某些验证码识别效果更好。**互斥性**:与`old=True`参数互斥(但`old`当前不生效) |
| `use_gpu` | bool | False | 是否使用GPU加速。**依赖关系**:需要安装CUDA和相应的onnxruntime-gpu版本,否则会初始化失败 |
| `device_id` | int | 0 | 使用的GPU设备ID。**依赖关系**:仅在`use_gpu=True`时生效,指定使用哪个GPU设备 |
| `show_ad` | bool | True | 是否在初始化时显示广告信息 |
| `import_onnx_path` | str | "" | 自定义模型的onnx文件路径。**依赖关系**:设置此参数时,`charsets_path`参数必须同时提供;此时`ocr/det`设置会被忽略 |
| `charsets_path` | str | "" | 自定义字符集的json文件路径。**依赖关系**:必须与`import_onnx_path`一起使用,否则无效 |
| `max_image_bytes` | int/str | 8MB | 单图最大字节数上限(入参可为 int 或数字字符串) |
| `max_image_side` | int/str | 4096 | 单图最长边像素上限(入参可为 int 或数字字符串) |
### 功能组合与冲突
根据参数组合,ddddocr具有不同的工作模式:
1. **标准OCR模式**:
- 参数设置:`ocr=True, det=False`(默认)
- 功能:识别图片中的文字
2. **目标检测模式**:
- 参数设置:`ocr=False, det=True`
- 功能:检测图片中的目标位置
- 注意:同时设置`ocr=True, det=True`时,会进入目标检测模式(`det`优先)
3. **滑块识别模式**:
- 参数设置:`ocr=False, det=False`
- 功能:使用滑块匹配算法(需调用`slide_match`或`slide_comparison`方法)
4. **自定义模型模式**:
- 参数设置:`import_onnx_path="模型路径", charsets_path="字符集路径"`
- 功能:使用自定义训练的模型进行识别
- 注意:设置此模式时,`ocr`和`det`参数会被忽略,且自定义字符集文件需包含 `charset/word/image/channel` 字段
5. **OCR模型选择**:
- 默认模型:不设置特殊参数(当前使用 `common_old.onnx`)
- Beta模型:`beta=True`(使用 `common.onnx`)
- 旧版模型参数:`old=True`(当前不改变模型,仅为兼容保留)
- 注意:`beta`和`old`参数互斥,但`old`当前不生效
### 模型选择指南
- **默认模型**:当前默认使用 `common_old.onnx`,适用于多数简单验证码场景
- **Beta模型**:`beta=True` 使用 `common.onnx`,对部分复杂验证码效果更好
- **自定义模型**:当默认模型无法满足需求时,可以通过[dddd_trainer](https://github.com/sml2h3/dddd_trainer)训练自己的模型
### 性能优化参数
- **GPU加速**:对于处理大量图片时,开启GPU加速可显著提升性能
```python
ocr = ddddocr.DdddOcr(use_gpu=True, device_id=0)
```
- **GPU设备选择**:在多GPU环境中,可通过`device_id`指定使用的GPU
```python
# 使用第二张GPU卡
ocr = ddddocr.DdddOcr(use_gpu=True, device_id=1)
```
- **关闭广告显示**:在生产环境中可关闭广告提示
```python
ocr = ddddocr.DdddOcr(show_ad=False)
```
## 详细使用说明
### 文字识别功能
#### 基础OCR识别
主要用于识别单行文字,如常见的英数验证码等。支持中文、英文、数字以及部分特殊字符的识别。
```python
import ddddocr
# 初始化OCR对象
ocr = ddddocr.DdddOcr()
# 读取图片
with open("验证码图片.jpg", "rb") as f:
image = f.read()
# 识别图片
result = ocr.classification(image)
print(result) # 输出识别结果
```
**OCR识别示例图片**
**参考例图**
包括且不限于以下图片
**OCR模型选择**
DdddOcr内置两套OCR模型,可以通过`beta`参数切换:
```python
# 使用第二套OCR模型
ocr = ddddocr.DdddOcr(beta=True)
```
**透明PNG图片处理**
对于透明黑色PNG图片,可以使用`png_fix`参数(对所有 OCR 模式生效):
```python
result = ocr.classification(image, png_fix=True)
```
> **注意**:`png_fix` 仅对带透明通道的图片生效;初始化DdddOcr对象只需要一次,不要在每次识别时都重新初始化,这会导致速度变慢。
#### OCR概率输出
可以获取OCR识别结果的概率分布,便于进行更灵活的结果处理:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 获取识别结果的概率分布
result = ocr.classification(image, probability=True)
# 处理概率结果
s = ""
for i in result['probability']:
s += result['charsets'][i.index(max(i))]
print(s)
```
**概率输出示例**(仅对内置模型生效,自定义模型会忽略`probability=True`并直接返回字符串):
```python
# 概率输出结果示例
{
'charsets': ['', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', ...],
'probability': [
[0.01, 0.02, 0.01, 0.03, 0.02, 0.01, 0.02, 0.75, 0.03, 0.05, 0.01, ...], # 第一个字符的概率分布
[0.01, 0.01, 0.02, 0.01, 0.03, 0.02, 0.01, 0.02, 0.01, 0.80, 0.01, ...], # 第二个字符的概率分布
...
]
}
```
#### 自定义字符范围
可以通过`set_ranges`方法限定OCR识别的字符范围:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 设置识别范围为数字
ocr.set_ranges(0) # 等同于 ocr.set_ranges("0123456789")
# 或自定义字符范围
ocr.set_ranges("0123456789+-x/=")
result = ocr.classification(image)
print(result)
```
**内置字符范围参数**:
| 参数值 | 含义 |
|-----|-----|
| 0 | 纯数字 0-9 |
| 1 | 纯小写英文 a-z |
| 2 | 纯大写英文 A-Z |
| 3 | 小写英文 + 大写英文 |
| 4 | 小写英文 + 数字 |
| 5 | 大写英文 + 数字 |
| 6 | 小写英文 + 大写英文 + 数字 |
| 7 | 默认字符库 - 小写英文 - 大写英文 - 数字 |
#### 颜色过滤功能
对于一些特殊的验证码,可以通过颜色过滤来提高识别准确率:
```python
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("test.jpg", "rb").read()
# 只保留红色和蓝色部分
result = ocr.classification(image, colors=["red", "blue"])
print(result)
```
**支持的颜色**:
- red (红色)
- green (绿色)
- blue (蓝色)
- yellow (黄色)
- orange (橙色)
- purple (紫色)
- pink (粉色)
- brown (棕色)
也可以自定义颜色范围:
```python
# 自定义颜色范围
custom_ranges = {
'light_blue': [(90, 30, 30), (110, 255, 255)] # HSV颜色空间
}
result = ocr.classification(image, colors=["light_blue"], custom_color_ranges=custom_ranges)
```
> **提示**:`custom_color_ranges` 只有在 `colors` 列表包含对应键名时才会生效。
### 目标检测功能
用于检测图像中可能的目标主体位置,返回目标的边界框坐标:
```python
import ddddocr
import cv2
# 初始化检测对象
det = ddddocr.DdddOcr(det=True, ocr=False)
# 读取图片
with open("test.jpg", 'rb') as f:
image = f.read()
# 检测目标
bboxes = det.detection(image)
print(bboxes) # 输出格式:[[x1, y1, x2, y2], ...]
# 可视化检测结果
im = cv2.imread("test.jpg")
for bbox in bboxes:
x1, y1, x2, y2 = bbox
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
cv2.imwrite("result.jpg", im)
```
**目标检测示例**:
**参考例图**
包括且不限于以下图片
### 滑块验证码处理
DdddOcr提供两种滑块验证码处理算法:
#### 算法1:边缘匹配
适用于有透明背景的滑块图片,通过边缘检测找到滑块在背景图中的位置:
```python
import ddddocr
# 初始化滑块检测对象
slide = ddddocr.DdddOcr(det=False, ocr=False)
# 读取滑块图和背景图
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
# 匹配位置
res = slide.slide_match(target_bytes, background_bytes)
print(f"滑块位置: {res}")
# 可视化结果
background = cv2.imdecode(np.frombuffer(background_bytes, np.uint8), cv2.IMREAD_COLOR)
x1, y1, x2, y2 = res["target"]
# 在背景图上绘制匹配位置
cv2.rectangle(background, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 显示结果
plt.figure(figsize=(10, 6))
plt.imshow(cv2.cvtColor(background, cv2.COLOR_BGR2RGB))
plt.title("滑块匹配结果")
plt.axis('off')
plt.savefig("slide_result.jpg")
plt.show()
```
**滑块匹配示例**:
滑块图
|
背景图
|
对于没有透明背景的滑块图,可以使用`simple_target`参数:
```python
res = slide.slide_match(target_bytes, background_bytes, simple_target=True)
```
#### 算法2:图像差异比较
适用于比较两张图片的不同之处,找出滑块缺口位置:
```python
import ddddocr
slide = ddddocr.DdddOcr(det=False, ocr=False)
# 读取带有缺口阴影的图片和完整图片
with open('bg.jpg', 'rb') as f:
target_bytes = f.read()
with open('fullpage.jpg', 'rb') as f:
background_bytes = f.read()
# 比较差异
res = slide.slide_comparison(target_bytes, background_bytes)
print(res) # 输出格式:{"target": [x, y]}
```
**图像差异比较示例**:
带缺口阴影的图片
|
完整图片
|
### 自定义模型导入
DdddOcr支持导入通过[dddd_trainer](https://github.com/sml2h3/dddd_trainer)训练的自定义模型:
```python
import ddddocr
# 导入自定义模型
ocr = ddddocr.DdddOcr(
det=False,
ocr=False,
import_onnx_path="mymodel.onnx",
charsets_path="charsets.json"
)
with open('test.jpg', 'rb') as f:
image_bytes = f.read()
res = ocr.classification(image_bytes)
print(res)
```
## 高级用法
### 批量处理
对大量验证码进行批量处理时,保持OCR实例的复用可以显著提高效率:
```python
import ddddocr
import os
import time
# 初始化OCR对象(只需一次)
ocr = ddddocr.DdddOcr()
# 批量处理目录中的所有图片
def batch_process(directory):
results = {}
start_time = time.time()
for filename in os.listdir(directory):
if filename.endswith(('.png', '.jpg', '.jpeg', '.bmp')):
file_path = os.path.join(directory, filename)
with open(file_path, 'rb') as f:
image = f.read()
# 使用同一个OCR实例处理所有图片
result = ocr.classification(image)
results[filename] = result
end_time = time.time()
print(f"处理 {len(results)} 张图片耗时: {end_time - start_time:.2f} 秒")
return results
# 使用示例
results = batch_process("./captchas/")
for filename, text in results.items():
print(f"{filename}: {text}")
```
### 多线程优化
在多线程环境下使用时,应当为每个线程创建独立的OCR实例:
```python
import ddddocr
import concurrent.futures
import os
def process_image(file_path):
# 每个线程创建自己的OCR实例
ocr = ddddocr.DdddOcr()
with open(file_path, 'rb') as f:
image = f.read()
result = ocr.classification(image)
return os.path.basename(file_path), result
def parallel_process(directory, max_workers=4):
file_paths = [os.path.join(directory, f) for f in os.listdir(directory)
if f.endswith(('.png', '.jpg', '.jpeg', '.bmp'))]
results = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_file = {executor.submit(process_image, file_path): file_path for file_path in file_paths}
for future in concurrent.futures.as_completed(future_to_file):
filename, result = future.result()
results[filename] = result
return results
# 使用示例
results = parallel_process("./captchas/", max_workers=8)
```
### 验证码预处理
对于干扰较多的验证码,可以先进行预处理再识别:
```python
import ddddocr
import cv2
import numpy as np
from PIL import Image
import io
def preprocess_captcha(image_bytes):
# 转换为OpenCV格式
nparr = np.frombuffer(image_bytes, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY_INV)
# 去除小噪点
kernel = np.ones((2, 2), np.uint8)
opening = cv2.morphologyEx(binary, cv2.MORPH_OPEN, kernel)
# 转回字节流
is_success, buffer = cv2.imencode(".jpg", opening)
processed_bytes = io.BytesIO(buffer).getvalue()
return processed_bytes
# 使用示例
ocr = ddddocr.DdddOcr()
with open("noisy_captcha.jpg", "rb") as f:
image_bytes = f.read()
# 预处理验证码
processed_bytes = preprocess_captcha(image_bytes)
# 识别处理后的图片
result = ocr.classification(processed_bytes)
print(f"验证码识别结果: {result}")
```
## 常见问题
1. **初始化速度慢**
首次初始化DdddOcr对象时会加载模型,可能会比较慢,但只需要初始化一次即可。避免在循环中反复初始化。
```python
# 错误的用法
for img in images:
ocr = ddddocr.DdddOcr() # 每次都初始化,严重影响性能
result = ocr.classification(img)
# 正确的用法
ocr = ddddocr.DdddOcr() # 只初始化一次
for img in images:
result = ocr.classification(img)
```
2. **识别准确率不高**
- 尝试使用另一个OCR模型(设置`beta=True`)
- 对于特殊验证码,尝试使用颜色过滤功能
- 限定识别字符范围(使用`set_ranges`方法)
- 对于透明PNG图片,使用`png_fix=True`参数
3. **GPU加速**
可以通过设置`use_gpu=True`和`device_id`参数来启用GPU加速:
```python
ocr = ddddocr.DdddOcr(use_gpu=True, device_id=0)
```
使用GPU需确保已安装对应的CUDA版本和onnxruntime-gpu库。
4. **如何处理复杂验证码**
对于复杂的验证码,可以尝试以下步骤:
- 先使用目标检测功能定位验证码位置
- 对检测到的区域进行裁剪
- 应用颜色过滤去除干扰
- 使用OCR识别处理后的图片
5. **内存占用过高**
如果在同一程序中需要使用多个功能,建议不要同时初始化多个不同功能的实例,而是根据需要初始化:
```python
# 根据需要初始化不同的对象
if need_ocr:
processor = ddddocr.DdddOcr(ocr=True, det=False)
elif need_detection:
processor = ddddocr.DdddOcr(ocr=False, det=True)
```
6. **参数冲突问题**
当同时设置多个模式参数时,需注意优先级:
- `ocr=True`和`det=True`同时设置时,优先使用目标检测模式
- `beta=True`和`old=True`同时设置时,使用Beta模型(`old`当前不生效)
- 设置`import_onnx_path`时,`ocr`和`det`参数会被忽略
7. **支持的图片格式**
ddddocr支持多种图片格式:
- JPG/JPEG
- PNG (带透明通道时可配合`png_fix=True`)
- BMP
- GIF (仅识别第一帧)
对于不常见格式或Base64编码的图片,可以先转换为bytes:
```python
# Base64编码图片处理
import base64
image_bytes = base64.b64decode(base64_str)
result = ocr.classification(image_bytes)
```
8. **多线程并发问题**
在多线程环境下使用时,每个线程应当创建独立的OCR实例,否则可能导致识别结果错乱。
## 项目技术支持
本项目基于[dddd_trainer](https://github.com/sml2h3/dddd_trainer)训练所得,训练底层框架为PyTorch,推理底层依赖于[onnxruntime](https://pypi.org/project/onnxruntime/)。
## 使用示例
### 完整的验证码识别流程
```python
import ddddocr
import cv2
import numpy as np
from PIL import Image
import io
# 初始化OCR对象
ocr = ddddocr.DdddOcr()
# 读取验证码图片
with open("captcha.jpg", "rb") as f:
image_bytes = f.read()
# 转换为OpenCV格式进行预处理
# img = cv2.imdecode(np.frombuffer(image_bytes, np.uint8), cv2.IMREAD_COLOR)
# 预处理:灰度化、二值化等
# gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# _, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY_INV)
# 转回字节流
# is_success, buffer = cv2.imencode(".jpg", binary)
# processed_bytes = io.BytesIO(buffer).getvalue()
# 识别处理后的图片
result = ocr.classification(image_bytes)
print(f"验证码识别结果: {result}")
```
### 滑块验证码完整示例
```python
import ddddocr
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 初始化滑块检测对象
slide = ddddocr.DdddOcr(det=False, ocr=False)
# 读取滑块图和背景图
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
# 匹配位置
res = slide.slide_match(target_bytes, background_bytes)
print(f"滑块位置: {res}")
# 可视化结果
background = cv2.imdecode(np.frombuffer(background_bytes, np.uint8), cv2.IMREAD_COLOR)
x1, y1, x2, y2 = res["target"]
# 在背景图上绘制匹配位置
cv2.rectangle(background, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 显示结果
plt.figure(figsize=(10, 6))
plt.imshow(cv2.cvtColor(background, cv2.COLOR_BGR2RGB))
plt.title("滑块匹配结果")
plt.axis('off')
plt.savefig("slide_result.jpg")
plt.show()
```
## API 服务
DdddOcr 提供了一键启动 API 服务的功能,可以通过 RESTful API 的方式访问 DdddOcr 的所有功能。
### 命令行启动 API 服务
```bash
# 使用默认配置启动 API 服务
python -m ddddocr api
# 指定 API 服务配置
python -m ddddocr api --host 0.0.0.0 --port 8000 --workers 4
# 配置 OCR 功能
python -m ddddocr api --ocr true --beta true
# 配置目标检测功能
python -m ddddocr api --ocr false --det true
```
> **提示**:如果直接运行 `python -m ddddocr.api`,默认会绑定在 `127.0.0.1`,可通过环境变量 `DDDDOCR_HOST` 覆盖。
### API 命令行参数说明
| 参数名 | 类型 | 默认值 | 说明 |
|-------|------|-------|------|
| `--host` | 字符串 | 0.0.0.0 | API 服务主机地址(`python -m ddddocr api` 默认) |
| `--port` | 整数 | 8000 | API 服务端口 |
| `--workers` | 整数 | 1 | API 服务工作进程数 |
| `--ocr` | 布尔值 | true | 是否启用 OCR 功能 |
| `--det` | 布尔值 | false | 是否启用目标检测功能 |
| `--old` | 布尔值 | false | 是否使用旧版 OCR 模型 |
| `--beta` | 布尔值 | false | 是否使用 Beta 版 OCR 模型 |
| `--use-gpu` | 布尔值 | false | 是否使用 GPU 加速 |
| `--device-id` | 整数 | 0 | GPU 设备 ID |
| `--show-ad` | 布尔值 | true | 是否显示广告 |
| `--import-onnx-path` | 字符串 | "" | 自定义模型路径 |
| `--charsets-path` | 字符串 | "" | 自定义字符集路径 |
### 使用 Docker 运行 API 服务
#### 构建并运行 Docker 镜像
```bash
# 构建 Docker 镜像
docker build -t ddddocr-api .
# 运行 Docker 容器
docker run -d --name ddddocr-api -p 8000:8000 ddddocr-api
# 使用自定义配置运行
docker run -d --name ddddocr-api \
-p 8000:8000 \
-e DDDDOCR_OCR=true \
-e DDDDOCR_BETA=true \
-e DDDDOCR_WORKERS=4 \
ddddocr-api
```
#### 使用 Docker Compose 运行 API 服务
```bash
# 使用默认配置启动
docker-compose up -d
# 使用自定义配置启动
DDDDOCR_OCR=true DDDDOCR_BETA=true DDDDOCR_WORKERS=4 docker-compose up -d
```
### API 接口说明
API 服务提供了以下接口:
#### 1. 文字识别接口 (OCR)
```
POST /ocr
```
请求体:
```json
{
"image": "图片的Base64编码字符串",
"probability": false,
"colors": [],
"custom_color_ranges": null
}
```
响应:
```json
{
"result": "识别到的文字",
"processing_time": 0.123
}
```
> **注意**:当 `probability=true` 时,API 会返回 `result` 为一个字典,包含 `charsets` 与 `probability` 字段,结构与本地 `classification(probability=True)` 一致。
#### 2. 目标检测接口
```
POST /det
```
请求体:
```json
{
"image": "图片的Base64编码字符串"
}
```
响应:
```json
{
"result": [
[x1, y1, x2, y2],
...
],
"processing_time": 0.123
}
```
#### 3. 滑块匹配接口
```
POST /slide_match
```
请求体:
```json
{
"target_image": "目标图片的Base64编码字符串",
"background_image": "背景图片的Base64编码字符串",
"simple_target": false,
"flag": false
}
```
响应:
```json
{
"result": {
"target_x": 0,
"target_y": 0,
"target": [x1, y1, x2, y2]
},
"processing_time": 0.123
}
```
#### 4. 滑块比较接口
```
POST /slide_comparison
```
请求体:
```json
{
"target_image": "目标图片的Base64编码字符串",
"background_image": "背景图片的Base64编码字符串"
}
```
响应:
```json
{
"result": {
"target": [x, y]
},
"processing_time": 0.123
}
```
#### 5. 设置字符范围接口
```
POST /set_charset_range
```
请求体:
```json
{
"charset_range": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
}
```
响应:
```json
{
"result": "字符范围设置成功",
"charset_range": ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"],
"processing_time": 0.123
}
```
#### 6. 健康检查接口
```
GET /health
```
响应:
```json
{
"status": "ok",
"timestamp": 1628765432.1234
}
```
#### 文件上传接口
所有上述接口都支持通过表单上传文件的方式提交请求。例如:
```
POST /ocr/file
```
可以通过表单字段上传图片文件。
### API 客户端示例
#### Python 示例 (Base64编码方式)
```python
import requests
import base64
# 读取图片文件并Base64编码
with open("captcha.png", "rb") as f:
img_base64 = base64.b64encode(f.read()).decode()
# 发送OCR请求
url = "http://localhost:8000/ocr"
response = requests.post(url, json={"image": img_base64})
# 处理响应
result = response.json()
print(f"识别结果: {result['result']}")
```
#### Python 示例 (文件上传方式)
```python
import requests
# 准备文件
files = {"file": open("captcha.png", "rb")}
# 发送OCR请求
url = "http://localhost:8000/ocr/file"
response = requests.post(url, files=files)
# 处理响应
result = response.json()
print(f"识别结果: {result['result']}")
```
### Docker 环境变量配置参考
| 环境变量名 | 默认值 | 说明 |
|-----------|-------|------|
| `DDDDOCR_HOST` | 0.0.0.0(CLI 默认)/ 127.0.0.1(直接运行 `python -m ddddocr.api` 默认) | API 服务主机地址 |
| `DDDDOCR_PORT` | 8000 | API 服务端口 |
| `DDDDOCR_WORKERS` | 1 | API 服务工作进程数 |
| `DDDDOCR_OCR` | true | 是否启用 OCR 功能 |
| `DDDDOCR_DET` | false | 是否启用目标检测功能 |
| `DDDDOCR_OLD` | false | 是否使用旧版 OCR 模型 |
| `DDDDOCR_BETA` | false | 是否使用 Beta 版 OCR 模型 |
| `DDDDOCR_USE_GPU` | false | 是否使用 GPU 加速 |
| `DDDDOCR_DEVICE_ID` | 0 | GPU 设备 ID |
| `DDDDOCR_SHOW_AD` | true | 是否显示广告 |
| `DDDDOCR_IMPORT_ONNX_PATH` | "" | 自定义模型路径 |
| `DDDDOCR_CHARSETS_PATH` | "" | 自定义字符集路径 |
## 许可证
本项目采用MIT许可证,详情请参阅[LICENSE](https://github.com/sml2h3/ddddocr/blob/master/LICENSE)文件。
## 输入与输出校验说明
- **图片合法性**:所有 Base64 与文件上传都会做尺寸、格式与大小校验(默认上限 8192 KB、最长边 4096px,可在实例化 `DdddOcr(max_image_bytes=..., max_image_side=...)` 时自定义),异常时返回 400。
- **允许格式**:PNG / JPEG / JPG / WEBP / BMP / GIF / TIFF。
- **输入类型**:本地调用支持 `bytes/bytearray`、Base64 字符串、文件路径或 `PIL.Image`。
- **类型约束**:`DdddOcr` 的公开方法会校验布尔/整数参数,`FastAPI` 层也通过 Pydantic 验证请求体,错误会带具体字段。
- **统一异常**:核心库新增 `DdddOcrInputError` / `InvalidImageError`,API 会把这些异常映射为 400,方便调用方处理。
- **响应结构**:HTTP 接口现有明确的 `response_model`,文档 (`/docs`) 中可直接查看字段含义。
- **模式提示**:在 `det=True` 模式下调用 `classification` 会抛出 “当前识别类型为目标检测”。
## 示例库
仓库新增 `examples/` 目录,覆盖本地调用、目标检测和 HTTP 客户端等典型场景:
- `basic_ocr.py`:最小 OCR 示例,可演示概率输出与颜色过滤。
- `detector.py`:演示如何用 `det=True` 模式返回所有检测框。
- `api_client.py`:演示如何向 `python -m ddddocr api` 服务发送 JSON 请求。
- `generate_basic_ocr_cases.py`:生成基础 OCR 测试用例图片。
详细说明见 `examples/README.md`,可结合 README 其他章节快速起步。
================================================
FILE: examples/api_client.py
================================================
#!/usr/bin/env python3
"""
调用 API 服务的示例(需要先启动 ddddocr api)
用法:
python -m ddddocr api
python examples/api_client.py <图片路径>
python examples/api_client.py <图片路径> --endpoint http://127.0.0.1:8000/ocr
python examples/api_client.py <图片路径> --probability
"""
from __future__ import annotations
import argparse
import base64
import json
import sys
from pathlib import Path
from typing import Any, Dict
sys.path.insert(0, str(Path(__file__).resolve().parents[1]))
import requests
def build_parser() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(description="DdddOcr API 示例客户端")
parser.add_argument("image", type=Path, help="待识别图片路径")
parser.add_argument(
"--endpoint",
default="http://127.0.0.1:8000/ocr",
help="API 接口地址,默认 http://127.0.0.1:8000/ocr",
)
parser.add_argument(
"--probability",
action="store_true",
help="是否请求概率输出",
)
return parser
def payload_from_image(path: Path, probability: bool) -> Dict[str, Any]:
data = base64.b64encode(path.read_bytes()).decode()
return {
"image": data,
"probability": probability,
}
def main() -> int:
parser = build_parser()
args = parser.parse_args()
if not args.image.exists():
parser.error(f"文件 {args.image} 不存在")
payload = payload_from_image(args.image, args.probability)
try:
response = requests.post(args.endpoint, json=payload, timeout=15)
except requests.RequestException as exc:
parser.error(f"请求 API 失败: {exc}")
return 1
if response.status_code != 200:
parser.error(f"API 返回错误: {response.status_code} {response.text}")
return 1
print("API 返回结果:")
print(json.dumps(response.json(), indent=2, ensure_ascii=False))
return 0
if __name__ == "__main__":
raise SystemExit(main())
================================================
FILE: examples/basic_ocr.py
================================================
#!/usr/bin/env python3
"""
基本 OCR 识别示例(本地离线)
用法:
python examples/basic_ocr.py <图片路径>
python examples/basic_ocr.py <图片路径> --probability
python examples/basic_ocr.py <图片路径> --colors red green
python examples/basic_ocr.py <图片路径> --beta
python examples/basic_ocr.py <图片路径> --old
"""
from __future__ import annotations
import argparse
import sys
from pathlib import Path
sys.path.insert(0, str(Path(__file__).resolve().parents[1]))
from ddddocr import DdddOcr, DdddOcrInputError, InvalidImageError
def build_parser() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(description="DdddOcr 本地识别示例")
parser.add_argument("image", type=Path, help="待识别图片路径")
parser.add_argument(
"--probability",
action="store_true",
help="输出每一列的概率分布",
)
parser.add_argument(
"--colors",
nargs="*",
default=(),
help="可选:指定需要保留的颜色,例如 red green",
)
parser.add_argument(
"--beta",
action="store_true",
help="使用新版 beta OCR 模型",
)
parser.add_argument(
"--old",
action="store_true",
help="使用旧版 OCR 模型 (beta=False 时有效)",
)
return parser
def main() -> int:
parser = build_parser()
args = parser.parse_args()
if not args.image.exists():
parser.error(f"文件 {args.image} 不存在")
ocr = DdddOcr(ocr=True, det=False, beta=args.beta, old=args.old, show_ad=False)
try:
data = args.image.read_bytes()
if args.probability:
result = ocr.classification(
data,
probability=True,
colors=list(args.colors),
)
else:
result = ocr.classification(
data,
probability=False,
colors=list(args.colors),
)
except (DdddOcrInputError, InvalidImageError) as exc:
parser.error(str(exc))
return 1
print("识别结果:")
print(result)
return 0
if __name__ == "__main__":
raise SystemExit(main())
================================================
FILE: examples/detector.py
================================================
#!/usr/bin/env python3
"""
目标检测示例(det=True)
用法:
python examples/detector.py <图片路径>
python examples/detector.py <图片路径> --use-gpu
"""
from __future__ import annotations
import argparse
import sys
from pathlib import Path
from typing import List
sys.path.insert(0, str(Path(__file__).resolve().parents[1]))
from ddddocr import DdddOcr, DdddOcrInputError, InvalidImageError
def build_parser() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(description="DdddOcr 目标检测示例")
parser.add_argument("image", type=Path, help="待检测图片路径")
parser.add_argument(
"--use-gpu",
action="store_true",
help="如果环境支持,启用 GPU 推理",
)
return parser
def format_boxes(boxes: List[List[int]]) -> str:
if not boxes:
return "未检测到目标"
lines = ["检测到的矩形框 (x_min, y_min, x_max, y_max):"]
for idx, (x_min, y_min, x_max, y_max) in enumerate(boxes, 1):
lines.append(f" #{idx}: ({x_min}, {y_min}, {x_max}, {y_max})")
return "\n".join(lines)
def main() -> int:
parser = build_parser()
args = parser.parse_args()
if not args.image.exists():
parser.error(f"文件 {args.image} 不存在")
detector = DdddOcr(ocr=False, det=True, use_gpu=args.use_gpu, show_ad=False)
try:
data = args.image.read_bytes()
boxes = detector.detection(img_bytes=data)
except (DdddOcrInputError, InvalidImageError) as exc:
parser.error(str(exc))
return 1
print(format_boxes(boxes))
return 0
if __name__ == "__main__":
raise SystemExit(main())
================================================
FILE: examples/ocr.py
================================================
import ddddocr
with open("../samples/yzm2.jpeg", "rb") as f:
data = f.read()
ocr = ddddocr.DdddOcr(det=True, ocr=False)
result = ocr.detection(data)
print(result)
================================================
FILE: pyproject.toml
================================================
[build-system]
requires = ["setuptools>=64", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "ddddocr"
version = "1.6.1"
description = "带带弟弟OCR"
readme = "README.md"
requires-python = ">=3.10"
license = { file = "LICENSE" }
authors = [{ name = "sml2h3" }]
classifiers = [
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
]
dependencies = [
"numpy",
"onnxruntime",
"Pillow",
"opencv-python; sys_platform == 'win32' or sys_platform == 'darwin'",
"opencv-python-headless; sys_platform == 'linux'",
]
[project.urls]
Homepage = "https://github.com/sml2h3/ddddocr"
[project.optional-dependencies]
api = [
"fastapi>=0.68.0",
"uvicorn>=0.15.0",
"python-multipart>=0.0.5",
"pydantic>=1.8.0,<3",
]
[project.scripts]
ddddocr = "ddddocr.__main__:main"
[tool.setuptools]
include-package-data = true
[tool.setuptools.packages.find]
where = ["."]
include = ["ddddocr*"]
[tool.setuptools.package-data]
ddddocr = ["*.onnx", "logo.png", "README.md"]
================================================
FILE: requirements.txt
================================================
numpy>=1.19.0
Pillow>=8.0.0
onnxruntime>=1.8.0
opencv-python>=4.5.0; sys_platform == "win32" or sys_platform == "darwin"
opencv-python-headless>=4.5.0; sys_platform == "linux"
fastapi>=0.68.0
uvicorn>=0.15.0
python-multipart>=0.0.5
pydantic>=1.8.0,<3
requests>=2.25.0