"]
edition = "2021"
description = "Robyn is a Super Fast Async Python Web Framework with a Rust runtime."
license = "BSD License (BSD)"
homepage = "https://github.com/sparckles/robyn"
readme = "README.md"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[lib]
name = "robyn"
crate-type = ["cdylib", "rlib"]
[dependencies]
pyo3 = { version = "0.27.2", features = ["extension-module", "py-clone"]}
pyo3-async-runtimes = { version = "0.27", features = ["tokio-runtime"] }
pyo3-async-runtimes-macros = { version = "0.27" }
pyo3-log = "0.13.2"
tokio = { version = "1.40", features = ["full"] }
dashmap = "5.4.3"
anyhow = "1.0.69"
actix = "0.13.4"
actix-web-actors = "4.3.0"
actix-web = "4.4.2"
actix-http = "3.3.1"
actix-files = "0.6.2"
futures = "0.3.27"
futures-util = "0.3.27"
matchit = "0.7.3"
socket2 = { version = "0.5.1", features = ["all"] }
uuid = { version = "1.3.0", features = ["serde", "v4"] }
log = "0.4.17"
pythonize = "0.27"
serde = "1.0.187"
serde_json = "1.0.109"
once_cell = "1.8.0"
actix-multipart = "0.6.1"
parking_lot = "0.12.3"
crossbeam-channel = "0.5"
[features]
io-uring = ["actix-web/experimental-io-uring"]
[profile.release]
codegen-units = 1
lto = "fat"
panic = "abort"
strip = true
opt-level = 3
[profile.release.build-override]
opt-level = 3
[package.metadata.maturin]
name = "robyn"
================================================
FILE: LICENSE
================================================
BSD 2-Clause License
Copyright (c) 2021, Sanskar Jethi
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
================================================
FILE: README.md
================================================

# Robyn
[](https://twitter.com/Robyn_oss)
[](https://pepy.tech/project/Robyn)
[](https://github.com/sparckles/Robyn/releases/)
[](https://github.com/sparckles/Robyn/blob/main/LICENSE)

[](https://deepwiki.com/sparckles/Robyn)
[](https://robyn.tech/documentation)
[](https://discord.gg/rkERZ5eNU8)
[](https://gurubase.io/g/robyn)
Robyn is a High-Performance, Community-Driven, and Innovator Friendly Web Framework with a Rust runtime. You can learn more by checking our [community resources](https://robyn.tech/documentation/en/community-resources#talks)!
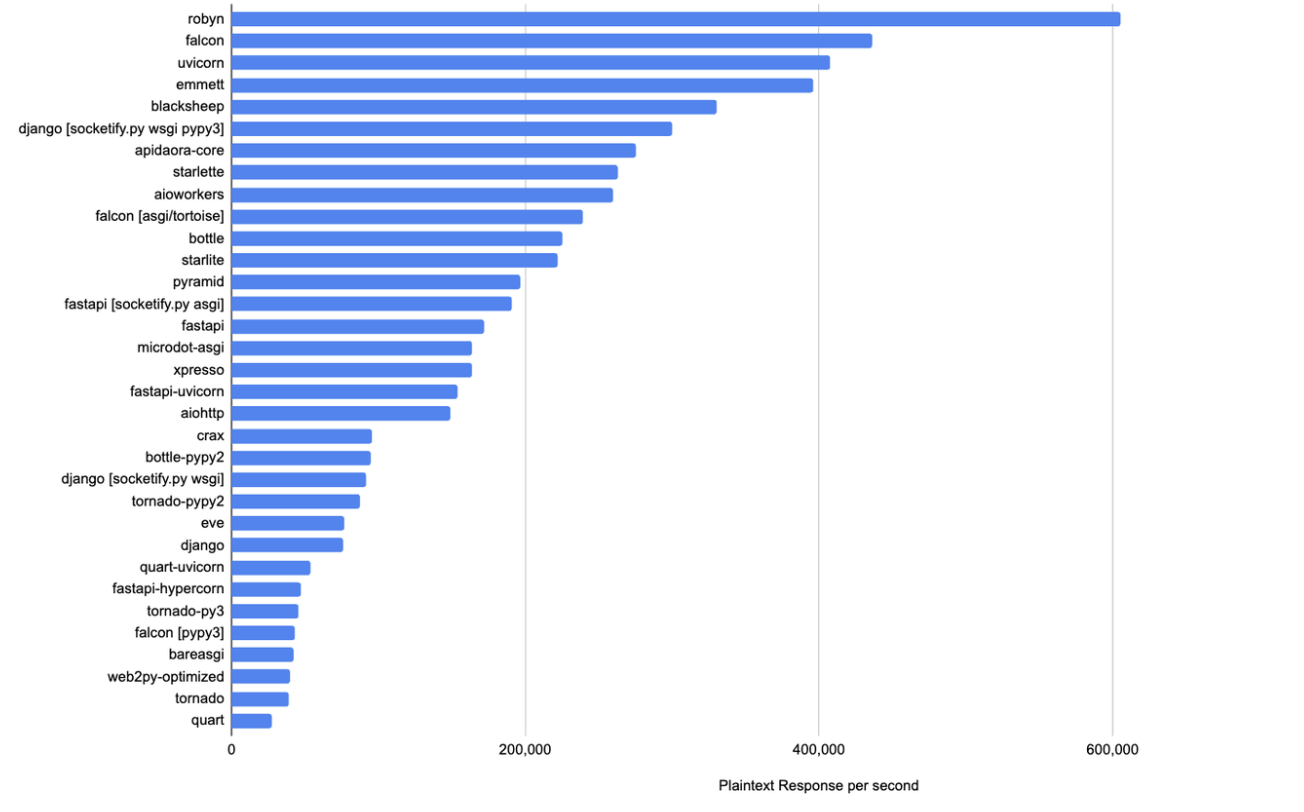 Source: [TechEmpower Round 22](https://www.techempower.com/benchmarks/#section=data-r22&test=plaintext)
## 📦 Installation
You can simply use Pip for installation.
```bash
pip install robyn
```
Or, with [conda-forge](https://conda-forge.org/)
```bash
conda install -c conda-forge robyn
```
To install with all optional features (Pydantic validation, Jinja2 templating):
```bash
pip install "robyn[all]"
```
## 🤔 Usage
### 🚀 Define your API
To define your API, you can add the following code in an `app.py` file.
```python
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
async def h(request):
return "Hello, world!"
app.start(port=8080)
```
### 🏃 Run your code
Simply run the app.py file you created. You will then have access to a server on the `localhost:8080`, that you can request from an other program. Robyn provides several options to customize your web server.
```
$ python3 app.py
```
To see the usage
```
usage: app.py [-h] [--processes PROCESSES] [--workers WORKERS] [--dev] [--log-level LOG_LEVEL]
Robyn, a fast async web framework with a rust runtime.
options:
-h, --help show this help message and exit
--processes PROCESSES
Choose the number of processes. [Default: 1]
--workers WORKERS Choose the number of workers. [Default: 1]
--dev Development mode. It restarts the server based on file changes.
--log-level LOG_LEVEL
Set the log level name
--create Create a new project template.
--docs Open the Robyn documentation.
--open-browser Open the browser on successful start.
--version Show the Robyn version.
--compile-rust-path COMPILE_RUST_PATH
Compile rust files in the given path.
--create-rust-file CREATE_RUST_FILE
Create a rust file with the given name.
--disable-openapi Disable the OpenAPI documentation.
--fast Enable the fast mode.
```
Log level can be `DEBUG`, `INFO`, `WARNING`, or `ERROR`.
When running the app using `--open-browser` a new browser window will open at the app location, e.g:
```
$ python3 app.py --open-browser
```
### 💻 Add more routes
You can add more routes to your API. Check out the routes in [this file](https://github.com/sparckles/Robyn/blob/main/integration_tests/base_routes.py) as examples.
### 🐍 Python Version Support
Robyn is compatible with the following Python versions:
> Python >= 3.10
It is recommended to use the latest version of Python for the best performances.
Please make sure you have the correct version of Python installed before starting to use
this project. You can check your Python version by running the following command in your
terminal:
```bash
python --version
```
## 💡 Features
- Under active development!
- A multithreaded Runtime
- Extensible
- A simple API
- Sync and Async Function Support
- Dynamic URL Routing
- Multi Core Scaling
- WebSockets
- Middlewares (before and after request hooks)
- Built in form data handling
- Dependency Injection
- Hot Reloading
- Direct Rust Integration
- Automatic OpenAPI generation
- Jinja2 Templating
- Static File Serving
- File Responses and Downloads
- Authentication Support
- CORS Configuration
- Streaming / SSE Responses
- Startup and Shutdown Events
- Exception Handling
- SubRouters
- Project Scaffolding via CLI
- Experimental io-uring Support
- **🤖 AI Agent Support** - Built-in agent routing and execution
- **🔌 MCP (Model Context Protocol)** - Connect to AI applications as a server
- Community First and truly FOSS!
## 🗒️ How to contribute
### 🏁 Get started
Please read the [code of conduct](https://github.com/sparckles/Robyn/blob/main/CODE_OF_CONDUCT.md) and go through [CONTRIBUTING.md](https://github.com/sparckles/Robyn/blob/main/CONTRIBUTING.md) before contributing to Robyn.
Feel free to open an issue for any clarifications or suggestions.
If you're feeling curious. You can take a look at a more detailed architecture [here](https://robyn.tech/documentation/architecture).
If you still need help to get started, feel free to reach out on our [community discord](https://discord.gg/rkERZ5eNU8).
### ⚙️ To Develop Locally
#### Prerequisites
Before starting, ensure you have the following installed:
- Python >= 3.10, <= 3.14
- Rust (latest stable)
- C compiler (gcc/clang)
#### Setup
- Clone the repository:
```
git clone https://github.com/sparckles/Robyn.git
```
- Setup a virtual environment:
```
python3 -m venv .venv
source .venv/bin/activate
```
- Install required packages
```
pip install pre-commit poetry maturin
```
- Install development dependencies
```
poetry install --with dev --with test
```
- Install pre-commit git hooks
```
pre-commit install
```
- Build & install Robyn Rust package
```
maturin develop
```
- Build & install Robyn Rust package (**experimental**)
```
maturin develop --cargo-extra-args="--features=io-uring"
```
- Run!
```
poetry run test_server
```
- Run all tests
```
pytest
```
- Run only the integration tests
```
pytest integration_tests
```
- Run only the unit tests (you don't need to be running the test_server for these)
```
pytest unit_tests
```
- Test (refer to `integration_tests/base_routes.py` for more endpoints)
```
curl http://localhost:8080/sync/str
```
- **tip:** One liners for testing changes!
```
maturin develop && poetry run test_server
maturin develop && pytest
```
- **tip:** For IO-uring support, you can use the following command:
```
maturin develop --cargo-extra-args="--features=io-uring"
```
- **tip:** To use your local Robyn version in other projects, you can install it using pip:
```
pip install -e path/to/robyn/target/wheels/robyn---.whl
```
e.g.
```
pip install -e /repos/Robyn/target/wheels/robyn-0.63.0-cp312-cp312-macosx_10_15_universal2.whl
```
#### Troubleshooting
If you face any issues, here are some common fixes:
- install `patchelf` with `pip install patchelf` if you face `patchelf` not found issue during `maturin develop` (esp. on Arch Linux)
- If you get Rust compilation errors, ensure you have a C compiler installed:
- Ubuntu/Debian: `sudo apt install build-essential`
- Fedora: `sudo dnf install gcc`
- macOS: Install Xcode Command Line Tools
- Windows: Install Visual Studio Build Tools
## ✨ Special thanks
### ✨ Contributors/Supporters
Thanks to all the contributors of the project. Robyn will not be what it is without all your support :heart:.
Source: [TechEmpower Round 22](https://www.techempower.com/benchmarks/#section=data-r22&test=plaintext)
## 📦 Installation
You can simply use Pip for installation.
```bash
pip install robyn
```
Or, with [conda-forge](https://conda-forge.org/)
```bash
conda install -c conda-forge robyn
```
To install with all optional features (Pydantic validation, Jinja2 templating):
```bash
pip install "robyn[all]"
```
## 🤔 Usage
### 🚀 Define your API
To define your API, you can add the following code in an `app.py` file.
```python
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
async def h(request):
return "Hello, world!"
app.start(port=8080)
```
### 🏃 Run your code
Simply run the app.py file you created. You will then have access to a server on the `localhost:8080`, that you can request from an other program. Robyn provides several options to customize your web server.
```
$ python3 app.py
```
To see the usage
```
usage: app.py [-h] [--processes PROCESSES] [--workers WORKERS] [--dev] [--log-level LOG_LEVEL]
Robyn, a fast async web framework with a rust runtime.
options:
-h, --help show this help message and exit
--processes PROCESSES
Choose the number of processes. [Default: 1]
--workers WORKERS Choose the number of workers. [Default: 1]
--dev Development mode. It restarts the server based on file changes.
--log-level LOG_LEVEL
Set the log level name
--create Create a new project template.
--docs Open the Robyn documentation.
--open-browser Open the browser on successful start.
--version Show the Robyn version.
--compile-rust-path COMPILE_RUST_PATH
Compile rust files in the given path.
--create-rust-file CREATE_RUST_FILE
Create a rust file with the given name.
--disable-openapi Disable the OpenAPI documentation.
--fast Enable the fast mode.
```
Log level can be `DEBUG`, `INFO`, `WARNING`, or `ERROR`.
When running the app using `--open-browser` a new browser window will open at the app location, e.g:
```
$ python3 app.py --open-browser
```
### 💻 Add more routes
You can add more routes to your API. Check out the routes in [this file](https://github.com/sparckles/Robyn/blob/main/integration_tests/base_routes.py) as examples.
### 🐍 Python Version Support
Robyn is compatible with the following Python versions:
> Python >= 3.10
It is recommended to use the latest version of Python for the best performances.
Please make sure you have the correct version of Python installed before starting to use
this project. You can check your Python version by running the following command in your
terminal:
```bash
python --version
```
## 💡 Features
- Under active development!
- A multithreaded Runtime
- Extensible
- A simple API
- Sync and Async Function Support
- Dynamic URL Routing
- Multi Core Scaling
- WebSockets
- Middlewares (before and after request hooks)
- Built in form data handling
- Dependency Injection
- Hot Reloading
- Direct Rust Integration
- Automatic OpenAPI generation
- Jinja2 Templating
- Static File Serving
- File Responses and Downloads
- Authentication Support
- CORS Configuration
- Streaming / SSE Responses
- Startup and Shutdown Events
- Exception Handling
- SubRouters
- Project Scaffolding via CLI
- Experimental io-uring Support
- **🤖 AI Agent Support** - Built-in agent routing and execution
- **🔌 MCP (Model Context Protocol)** - Connect to AI applications as a server
- Community First and truly FOSS!
## 🗒️ How to contribute
### 🏁 Get started
Please read the [code of conduct](https://github.com/sparckles/Robyn/blob/main/CODE_OF_CONDUCT.md) and go through [CONTRIBUTING.md](https://github.com/sparckles/Robyn/blob/main/CONTRIBUTING.md) before contributing to Robyn.
Feel free to open an issue for any clarifications or suggestions.
If you're feeling curious. You can take a look at a more detailed architecture [here](https://robyn.tech/documentation/architecture).
If you still need help to get started, feel free to reach out on our [community discord](https://discord.gg/rkERZ5eNU8).
### ⚙️ To Develop Locally
#### Prerequisites
Before starting, ensure you have the following installed:
- Python >= 3.10, <= 3.14
- Rust (latest stable)
- C compiler (gcc/clang)
#### Setup
- Clone the repository:
```
git clone https://github.com/sparckles/Robyn.git
```
- Setup a virtual environment:
```
python3 -m venv .venv
source .venv/bin/activate
```
- Install required packages
```
pip install pre-commit poetry maturin
```
- Install development dependencies
```
poetry install --with dev --with test
```
- Install pre-commit git hooks
```
pre-commit install
```
- Build & install Robyn Rust package
```
maturin develop
```
- Build & install Robyn Rust package (**experimental**)
```
maturin develop --cargo-extra-args="--features=io-uring"
```
- Run!
```
poetry run test_server
```
- Run all tests
```
pytest
```
- Run only the integration tests
```
pytest integration_tests
```
- Run only the unit tests (you don't need to be running the test_server for these)
```
pytest unit_tests
```
- Test (refer to `integration_tests/base_routes.py` for more endpoints)
```
curl http://localhost:8080/sync/str
```
- **tip:** One liners for testing changes!
```
maturin develop && poetry run test_server
maturin develop && pytest
```
- **tip:** For IO-uring support, you can use the following command:
```
maturin develop --cargo-extra-args="--features=io-uring"
```
- **tip:** To use your local Robyn version in other projects, you can install it using pip:
```
pip install -e path/to/robyn/target/wheels/robyn---.whl
```
e.g.
```
pip install -e /repos/Robyn/target/wheels/robyn-0.63.0-cp312-cp312-macosx_10_15_universal2.whl
```
#### Troubleshooting
If you face any issues, here are some common fixes:
- install `patchelf` with `pip install patchelf` if you face `patchelf` not found issue during `maturin develop` (esp. on Arch Linux)
- If you get Rust compilation errors, ensure you have a C compiler installed:
- Ubuntu/Debian: `sudo apt install build-essential`
- Fedora: `sudo dnf install gcc`
- macOS: Install Xcode Command Line Tools
- Windows: Install Visual Studio Build Tools
## ✨ Special thanks
### ✨ Contributors/Supporters
Thanks to all the contributors of the project. Robyn will not be what it is without all your support :heart:.
 Special thanks to the [PyO3](https://pyo3.rs/v0.13.2/) community and [Andrew from PyO3-asyncio](https://github.com/awestlake87/pyo3-asyncio) for their amazing libraries and their support for my queries. 💖
### ✨ Sponsors
These sponsors help us make the magic happen!
[](https://www.digitalocean.com/?refcode=3f2b9fd4968d&utm_campaign=Referral_Invite&utm_medium=Referral_Program&utm_source=badge)
[](https://github.com/appwrite)
## Star History
[](https://star-history.com/#sparckles/Robyn&Date)
================================================
FILE: benchmark.sh
================================================
#!/bin/sh
# Benchmark script to get info about Robyn's performances
# You can use this benchmark when developing on Robyn to test if your changes had a huge
# impact on performances. You cannot compare benchmarks from different machine and even
# several runs on the same machine can give very different results sometimes.
# Be aware of this when using this script!
Help() {
echo "Benchmark script to get info about Robyn's performances."
echo
echo "USAGE:"
echo " benchmark [-h|m|n|y]"
echo
echo "OPTIONS:"
echo " -h Print this help."
echo " -m Run 'maturin develop' to compile the Rust part of Robyn."
echo " -n Set the number of requests that oha sends."
echo " -y Skip prompt"
exit 0
}
yes_flag=false
run_maturin=false
number=100000
while getopts hymn: opt; do
case $opt in
h)
Help
;;
y)
yes_flag=true
;;
m)
run_maturin=true
;;
n)
number=$OPTARG
;;
?)
echo 'Error in command line parsing' >&2
Help
exit 1
;;
esac
done
# Prompt user to check if he installed the requirements for running the benchmark
if [ "$yes_flag" = false ]; then
echo "Make sure you are running this in your venv and you installed 'oha' using 'cargo install oha'"
echo "Do you want to proceed?"
while true; do
read -p "" yn
case $yn in
[Yy]* ) break;;
[Nn]* ) exit;;
* ) echo "Please answer yes or no.";;
esac
done
fi
# Compile Rust
if $run_maturin; then
maturin develop
fi
# Run the server in the background
python3 ./integration_tests/base_routes.py &
sleep 1
# oha will display benchmark results
oha -n "$number" http://localhost:8080/sync
# Kill subprocesses after exiting the script (python + robyn server)
# (see https://stackoverflow.com/questions/360201/how-do-i-kill-background-processes-jobs-when-my-shell-script-exits)
trap "trap - TERM && kill 0" INT TERM EXIT
================================================
FILE: ci-local.sh
================================================
#!/usr/bin/env bash
set -euo pipefail
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
CYAN='\033[0;36m'
NC='\033[0m'
FAILED=()
PASSED=()
SKIPPED=()
run_step() {
local name="$1"
shift
echo -e "\n${CYAN}── $name ──${NC}"
echo -e "${YELLOW}$ $*${NC}"
if "$@"; then
PASSED+=("$name")
echo -e "${GREEN}✓ $name${NC}"
else
FAILED+=("$name")
echo -e "${RED}✗ $name${NC}"
fi
}
skip_step() {
local name="$1"
local reason="$2"
SKIPPED+=("$name ($reason)")
echo -e "\n${YELLOW}── $name [SKIPPED: $reason] ──${NC}"
}
usage() {
echo "Usage: $0 [rust|lint|python|all|fix]"
echo ""
echo "Mirrors the GitHub Actions CI workflows locally."
echo ""
echo " rust Rust CI: cargo check, test, fmt --check, clippy"
echo " lint Lint PR: ruff check, isort --check-only"
echo " python Python CI: nox test suite (current Python version)"
echo " all Everything (default)"
echo " fix Auto-fix: cargo fmt, ruff --fix, isort"
exit 0
}
# ── rust-CI.yml ───────────────────────────────────────────────────────────────
run_rust() {
echo -e "\n${CYAN}═══ Rust CI (.github/workflows/rust-CI.yml) ═══${NC}"
run_step "cargo check" cargo check
run_step "cargo test" cargo test
run_step "cargo fmt" cargo fmt --check
run_step "cargo clippy" cargo clippy
}
# ── lint-pr.yml ───────────────────────────────────────────────────────────────
run_lint() {
echo -e "\n${CYAN}═══ Lint PR (.github/workflows/lint-pr.yml) ═══${NC}"
if command -v ruff &>/dev/null; then
run_step "ruff check" ruff check .
else
skip_step "ruff check" "ruff not installed (pip install ruff)"
fi
if command -v isort &>/dev/null; then
run_step "isort check" isort --check-only --diff .
else
skip_step "isort check" "isort not installed (pip install isort)"
fi
}
# ── python-CI.yml ─────────────────────────────────────────────────────────────
run_python() {
echo -e "\n${CYAN}═══ Python CI (.github/workflows/python-CI.yml) ═══${NC}"
local pyver
pyver=$(python3 -c "import sys; print(f'{sys.version_info.major}.{sys.version_info.minor}')")
if command -v nox &>/dev/null; then
run_step "nox (python $pyver)" nox --non-interactive --error-on-missing-interpreter -p "$pyver"
else
skip_step "nox tests" "nox not installed (pip install nox)"
fi
}
# ── fix mode ──────────────────────────────────────────────────────────────────
run_fix() {
echo -e "\n${CYAN}═══ Auto-fix ═══${NC}"
run_step "cargo fmt" cargo fmt
command -v ruff &>/dev/null && run_step "ruff fix" ruff check --fix . || skip_step "ruff fix" "not installed"
command -v isort &>/dev/null && run_step "isort fix" isort . || skip_step "isort fix" "not installed"
}
# ── main ──────────────────────────────────────────────────────────────────────
MODE="${1:-all}"
case "$MODE" in
rust) run_rust ;;
lint) run_lint ;;
python) run_python ;;
fix) run_fix ;;
all) run_rust; run_lint; run_python ;;
-h|--help|help) usage ;;
*) echo "Unknown mode: $MODE"; usage ;;
esac
# ── summary ───────────────────────────────────────────────────────────────────
echo -e "\n${CYAN}═══ Summary ═══${NC}"
for s in "${PASSED[@]+"${PASSED[@]}"}"; do echo -e " ${GREEN}✓${NC} $s"; done
for s in "${SKIPPED[@]+"${SKIPPED[@]}"}"; do echo -e " ${YELLOW}⊘${NC} $s"; done
for s in "${FAILED[@]+"${FAILED[@]}"}"; do echo -e " ${RED}✗${NC} $s"; done
if [ ${#FAILED[@]} -gt 0 ]; then
echo -e "\n${RED}CI would fail: ${#FAILED[@]} check(s) failed.${NC}"
exit 1
else
echo -e "\n${GREEN}All checks passed. Safe to push.${NC}"
exit 0
fi
================================================
FILE: docs_src/.eslintrc.json
================================================
{
"extends": ["next","next/core-web-vitals"],
"rules": {
"react/no-unescaped-entities": "off"
}
}
================================================
FILE: docs_src/.gitignore
================================================
# See https://help.github.com/articles/ignoring-files/ for more about ignoring files.
# dependencies
/node_modules
/.pnp
.pnp.js
# testing
/coverage
# next.js
/.next/
/out/
# production
/build
# misc
.DS_Store
*.pem
# debug
npm-debug.log*
yarn-debug.log*
yarn-error.log*
.pnpm-debug.log*
# local env files
.env*.local
# vercel
.vercel
# generated files
/public/rss/
================================================
FILE: docs_src/README.md
================================================
## Docs Base
This is the documentation website that will be used as a base for Robyn and Starfyre docs.
## Setup
1. Clone this repo
2. Run `npm install`
3. Run `npm run dev`
4. Open `http://localhost:3000` in your browser
================================================
FILE: docs_src/jsconfig.json
================================================
{
"compilerOptions": {
"baseUrl": ".",
"paths": {
"@/*": ["src/*"]
}
}
}
================================================
FILE: docs_src/mdx/recma.mjs
================================================
import { mdxAnnotations } from 'mdx-annotations'
import recmaNextjsStaticProps from 'recma-nextjs-static-props'
import { recmaImportImages } from 'recma-import-images'
function recmaRemoveNamedExports() {
return (tree) => {
tree.body = tree.body.map((node) => {
if (node.type === 'ExportNamedDeclaration') {
return node.declaration
}
return node
})
}
}
export const recmaPlugins = [
mdxAnnotations.recma,
recmaRemoveNamedExports,
recmaNextjsStaticProps,
recmaImportImages,
]
================================================
FILE: docs_src/mdx/rehype.mjs
================================================
import { mdxAnnotations } from 'mdx-annotations'
import { visit } from 'unist-util-visit'
import rehypeMdxTitle from 'rehype-mdx-title'
import shiki from 'shiki'
import { toString } from 'mdast-util-to-string'
import * as acorn from 'acorn'
import { slugifyWithCounter } from '@sindresorhus/slugify'
import rehypeSlug from 'rehype-slug'
import { remarkRehypeWrap } from 'remark-rehype-wrap'
import rehypeAutolinkHeadings from 'rehype-autolink-headings'
function rehypeParseCodeBlocks() {
return (tree) => {
visit(tree, 'element', (node, _nodeIndex, parentNode) => {
if (node.tagName === 'code' && node.properties.className) {
parentNode.properties.language = node.properties.className[0]?.replace(
/^language-/,
''
)
}
})
}
}
let highlighter
function rehypeShiki() {
return async (tree) => {
highlighter =
highlighter ?? (await shiki.getHighlighter({ theme: 'css-variables' }))
visit(tree, 'element', (node) => {
if (node.tagName === 'pre' && node.children[0]?.tagName === 'code') {
let codeNode = node.children[0]
let textNode = codeNode.children[0]
node.properties.code = textNode.value
if (node.properties.language) {
let tokens = highlighter.codeToThemedTokens(
textNode.value,
node.properties.language
)
textNode.value = shiki.renderToHtml(tokens, {
elements: {
pre: ({ children }) => children,
code: ({ children }) => children,
line: ({ children }) => `${children}`,
},
})
}
}
})
}
}
function rehypeSlugify() {
return (tree) => {
let slugify = slugifyWithCounter()
visit(tree, 'element', (node) => {
if (node.tagName === 'h2' && !node.properties.id) {
node.properties.id = slugify(toString(node))
}
})
}
}
function rehypeAddMDXExports(getExports) {
return (tree) => {
let exports = Object.entries(getExports(tree))
for (let [name, value] of exports) {
for (let node of tree.children) {
if (
node.type === 'mdxjsEsm' &&
new RegExp(`export\\s+const\\s+${name}\\s*=`).test(node.value)
) {
return
}
}
let exportStr = `export const ${name} = ${value}`
tree.children.push({
type: 'mdxjsEsm',
value: exportStr,
data: {
estree: acorn.parse(exportStr, {
sourceType: 'module',
ecmaVersion: 'latest',
}),
},
})
}
}
}
function getSections(node) {
let sections = []
for (let child of node.children ?? []) {
if (child.type === 'element' && child.tagName === 'h2') {
sections.push(`{
title: ${JSON.stringify(toString(child))},
id: ${JSON.stringify(child.properties.id)},
...${child.properties.annotation}
}`)
} else if (child.children) {
sections.push(...getSections(child))
}
}
return sections
}
export const rehypePlugins = [
rehypeSlug,
[rehypeAutolinkHeadings, { behavior: 'wrap', test: ['h2'] }],
[
remarkRehypeWrap,
{
node: { type: 'element', tagName: 'article' },
start: 'element[tagName=hr]',
transform: (article) => {
article.children.splice(0, 1)
let heading = article.children.find((n) => n.tagName === 'h2')
if (heading) {
article.properties = { ...heading.properties, title: toString(heading) }
heading.properties = {}
} else {
article.properties = {}
}
return article
},
},
],
mdxAnnotations.rehype,
rehypeParseCodeBlocks,
rehypeShiki,
rehypeSlugify,
rehypeMdxTitle,
[
rehypeAddMDXExports,
(tree) => ({
sections: `[${getSections(tree).join()}]`,
}),
],
]
================================================
FILE: docs_src/mdx/remark.mjs
================================================
import { mdxAnnotations } from 'mdx-annotations'
import remarkGfm from 'remark-gfm'
import remarkUnwrapImages from 'remark-unwrap-images'
export const remarkPlugins = [
mdxAnnotations.remark,
remarkGfm,
remarkUnwrapImages,
]
================================================
FILE: docs_src/next.config.mjs
================================================
import nextMDX from '@next/mdx'
import { remarkPlugins } from './mdx/remark.mjs'
import { rehypePlugins } from './mdx/rehype.mjs'
import { recmaPlugins } from './mdx/recma.mjs'
const withMDX = nextMDX({
options: {
remarkPlugins,
rehypePlugins,
recmaPlugins,
providerImportSource: '@mdx-js/react',
},
})
/** @type {import('next').NextConfig} */
const nextConfig = {
reactStrictMode: true,
pageExtensions: ['js', 'jsx', 'ts', 'tsx', 'mdx'],
experimental: {
scrollRestoration: true,
},
i18n: {
locales: ['en', 'zh'],
defaultLocale: 'en',
localeDetection: false,
},
async redirects() {
return [
{
source: '/documentation',
destination: '/documentation/en',
permanent: false,
},
]
},
}
export default withMDX(nextConfig)
================================================
FILE: docs_src/package.json
================================================
{
"name": "tailwindui-template",
"version": "0.1.0",
"private": true,
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "next lint"
},
"browserslist": "defaults, not ie <= 11",
"dependencies": {
"@algolia/autocomplete-core": "^1.9.3",
"@algolia/autocomplete-preset-algolia": "^1.9.3",
"@headlessui/react": "^1.7.15",
"@heroicons/react": "^2.0.18",
"@mapbox/rehype-prism": "^0.8.0",
"@mdx-js/loader": "^2.1.5",
"@mdx-js/react": "^2.1.5",
"@next/mdx": "^13.0.2",
"@sindresorhus/slugify": "^2.2.1",
"@tailwindcss/typography": "^0.5.4",
"@vercel/analytics": "^1.0.2",
"algoliasearch": "^4.17.2",
"autoprefixer": "^10.4.12",
"axios": "^1.4.0",
"clsx": "^1.2.1",
"fast-glob": "^3.2.11",
"feed": "^4.2.2",
"focus-visible": "^5.2.0",
"framer-motion": "^10.12.16",
"highlight.js": "^11.8.0",
"mdx-annotations": "^0.1.3",
"meilisearch": "^0.33.0",
"next": "13.4.2",
"next-mdx-remote": "^6.0.0",
"next-router-mock": "^0.9.3",
"postcss-focus-visible": "^6.0.4",
"prism-themes": "^1.9.0",
"prismjs": "^1.29.0",
"react": "18.2.0",
"react-dom": "18.2.0",
"react-markdown": "^8.0.7",
"recma-import-images": "^0.0.3",
"recma-nextjs-static-props": "^1.0.0",
"rehype-autolink-headings": "^6.1.1",
"rehype-mdx-title": "^2.0.0",
"rehype-slug": "^5.1.0",
"remark-gfm": "^3.0.1",
"remark-rehype-wrap": "^0.0.2",
"remark-unwrap-images": "^3.0.1",
"shiki": "^0.14.2",
"tailwindcss": "^3.3.0",
"zustand": "^4.3.8"
},
"devDependencies": {
"eslint": "8.26.0",
"eslint-config-next": "13.0.2",
"prettier": "^2.8.7",
"prettier-plugin-tailwindcss": "^0.2.6"
}
}
================================================
FILE: docs_src/postcss.config.js
================================================
module.exports = {
plugins: {
tailwindcss: {},
'postcss-focus-visible': {
replaceWith: '[data-focus-visible-added]',
},
autoprefixer: {},
},
}
================================================
FILE: docs_src/prettier.config.js
================================================
module.exports = {
singleQuote: true,
semi: false,
plugins: [require('prettier-plugin-tailwindcss')],
}
================================================
FILE: docs_src/public/funding.json
================================================
{
"version": "v1.0.0",
"entity": {
"type": "individual",
"role": "owner",
"name": "Sanskar Jethi",
"email": "sansyrox@gmail.com",
"phone": "",
"description": "Sanskar is a FOSS engineer who created Robyn and Starfyre. Sanskar has created software for over half his life and used it for almost all of his.",
"webpageUrl": {
"url": "https://robyn.tech/"
}
},
"projects": [
{
"guid": "robyn",
"name": "robyn",
"description": "Robyn is one of the fastest Python web frameworks, which comes with a built in web server and a Rust runtime.",
"webpageUrl": {
"url": "https://robyn.tech/"
},
"repositoryUrl": {
"url": "https://github.com/sparckles/Robyn",
"wellKnown": "https://github.com/sparckles/Robyn/blob/main/.well-known/funding-manifest-urls"
},
"licenses": ["BSD 2-Clause \"Simplified\" License"],
"tags": ["programming", "python", "rust", "web", "backend", "async"]
}
],
"funding": {
"channels": [
{
"guid": "mybank",
"type": "bank",
"address": "",
"description": "Send me an email to get my bank details"
}
],
"plans": [
{
"guid": "mybank",
"status": "active",
"name": "Support Maintainer Part Time",
"description": "Support the maintainer for his work on Robyn part time.",
"amount": 500,
"currency": "GBP",
"frequency": "monthly",
"channels": ["mybank"]
},
{
"guid": "mybank",
"status": "active",
"name": "Support Maintainer Full Time",
"description": "Support the maintainer for his work on Robyn full time.",
"amount": 3000,
"currency": "GBP",
"frequency": "monthly",
"channels": ["mybank"]
},
{
"guid": "150",
"status": "active",
"name": " Support Contributor Part Time",
"description": "Support for one contributor per month",
"amount": 150,
"currency": "GBP",
"frequency": "monthly",
"channels": ["mybank"]
},
{
"guid": "500",
"status": "active",
"name": " Support Contributor Full Time",
"description": "Support for one contributor per month",
"amount": 500,
"currency": "GBP",
"frequency": "monthly",
"channels": ["mybank"]
}
],
"history": []
}
}
================================================
FILE: docs_src/public/llms.txt
================================================
# Robyn
> Robyn is a high-performance, community-driven, and innovator-friendly async web framework for Python with a Rust runtime. It combines Python's ease of use with Rust's performance.
## Quick Facts
- Version: 0.79.0
- Python: >= 3.10
- License: BSD 2.0
- Repository: https://github.com/sparckles/robyn
- Documentation: https://robyn.tech/documentation
- Discord: https://discord.gg/rkERZ5eNU8
## Installation
```bash
pip install robyn
```
## Basic Usage
```python
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
async def index(request):
return "Hello, World!"
app.start(port=8080)
```
## Key Features
- **Rust Runtime**: Core server written in Rust using actix-web for high performance
- **Async/Sync Support**: Both async and sync route handlers supported
- **Multi-Process Scaling**: Built-in multiprocess execution via `--processes` and `--workers`
- **WebSockets**: Native WebSocket support
- **Middlewares**: Before/after request middlewares
- **Dependency Injection**: Built-in DI system
- **OpenAPI/Swagger**: Automatic OpenAPI documentation generation
- **Hot Reloading**: Development mode with `--dev` flag
- **AI Agents**: Built-in AI agent routing via `robyn.ai`
- **MCP Support**: Model Context Protocol server capabilities via `app.mcp`
- **Templating**: Jinja2 templating support (optional)
- **CORS**: Built-in CORS helper via `ALLOW_CORS()`
- **Authentication**: AuthenticationHandler base class for custom auth
- **Static Files**: Directory serving via `app.serve_directory()`
- **SSE**: Server-Sent Events support via `SSEResponse`
- **Easy Access Parameters**: Typed path/query params with automatic coercion in handler signatures
- **Direct Rust Integration**: Embed Rust code directly in routes
## Project Structure
```
robyn/
├── src/ # Rust source code
│ ├── lib.rs # PyO3 module entry point
│ ├── server.rs # Main HTTP server implementation
│ ├── types/ # Request, Response, Headers, Cookie types
│ ├── routers/ # HTTP, WebSocket, middleware routers
│ ├── executors/ # Route execution handlers
│ └── websockets/ # WebSocket implementation
├── robyn/ # Python package
│ ├── __init__.py # Main Robyn and SubRouter classes
│ ├── router.py # Python router implementation
│ ├── authentication.py # AuthenticationHandler
│ ├── dependency_injection.py
│ ├── openapi.py # OpenAPI generation
│ ├── mcp.py # MCP protocol support
│ ├── ai.py # AI agent support
│ ├── responses.py # Response helpers (serve_file, html, SSE)
│ ├── ws.py # WebSocket class
│ └── robyn.pyi # Type stubs
├── integration_tests/ # Integration test suite
├── unit_tests/ # Unit test suite
├── docs_src/ # Documentation (Next.js)
├── granian/ # Bundled Granian server (fork)
└── examples/ # Example applications
```
## Core Classes
### Robyn / SubRouter
Main application class and sub-router for modular routes.
```python
from robyn import Robyn, SubRouter
app = Robyn(__file__)
api = SubRouter(__file__, prefix="/api")
@api.get("/users")
def get_users(request):
return {"users": []}
app.include_router(api)
```
### Request Object
```python
request.method # HTTP method
request.url # Url object (scheme, host, path)
request.headers # Headers dict-like
request.query_params # QueryParams
request.path_params # Dict of URL params
request.body # Raw bytes
request.json() # Parse JSON body
request.form_data # Multipart form data
request.ip_addr # Client IP
request.identity # Identity (if authenticated)
```
### Response Object
```python
from robyn import Response
Response(
status_code=200,
headers={"Content-Type": "application/json"},
description="body content" # or body bytes
)
```
### Decorators
```python
@app.get("/path")
@app.post("/path")
@app.put("/path")
@app.delete("/path")
@app.patch("/path")
@app.head("/path")
@app.options("/path")
@app.before_request("/path") # Middleware before
@app.after_request("/path") # Middleware after
@app.startup_handler # Server startup
@app.shutdown_handler # Server shutdown
```
### WebSockets
```python
from robyn import WebSocketDisconnect
@app.websocket("/ws")
async def handler(websocket):
try:
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
except WebSocketDisconnect:
pass
@handler.on_connect
def on_connect(websocket):
return "Connected"
@handler.on_close
def on_close(websocket):
return "Closed"
```
### Easy Access Parameters
Declare typed path and query parameters directly in handler signatures. Works for both HTTP and WebSocket handlers.
```python
from typing import List, Optional
# HTTP: path params + query params with type coercion
@app.get("/items/:id")
async def get_item(id: int, q: str, page: int = 1):
return {"id": id, "q": q, "page": page}
# Optional, List, and bool params
@app.get("/search")
def search(name: str, tags: List[str], active: bool = False, age: Optional[int] = None):
return {"name": name, "tags": tags, "active": active, "age": age}
# WebSocket: typed query params on handler and callbacks
@app.websocket("/ws")
async def handler(websocket, room: str = "default", page: int = 1):
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"room={room} page={page} msg={msg}")
@handler.on_connect
def on_connect(websocket, room: str = "default"):
return f"connected to {room}"
```
### MCP (Model Context Protocol)
```python
@app.mcp.resource("time://current")
def get_time():
return datetime.now().isoformat()
@app.mcp.tool(name="calc", description="Calculate", input_schema={...})
def calculate(args):
return eval(args["expression"])
@app.mcp.prompt(name="explain", description="Explain code", arguments=[...])
def explain_prompt(args):
return f"Please explain: {args['code']}"
```
## CLI Commands
```bash
python app.py # Start server
python app.py --dev # Development mode (hot reload)
python app.py --processes 4 # Multi-process
python app.py --workers 2 # Workers per process
python app.py --log-level DEBUG # Log level
python app.py --open-browser # Open browser on start
python app.py --create # Create new project scaffold
python app.py --docs # Open documentation
```
## Development Setup
```bash
# Clone
git clone https://github.com/sparckles/robyn.git
cd robyn
# Virtual environment
python3 -m venv .venv && source .venv/bin/activate
# Install tools
pip install pre-commit poetry maturin
# Install dependencies
poetry install --with dev --with test
# Build Rust extension
maturin develop
# Run tests
pytest
```
## Key Dependencies
- **PyO3**: Rust-Python bindings
- **actix-web**: Rust HTTP server (via cookie crate)
- **orjson**: Fast JSON serialization
- **multiprocess**: Multi-process support
- **uvloop**: Fast event loop (non-Windows)
- **watchdog**: File watching for hot reload
## Configuration
Environment variables:
- `ROBYN_HOST`: Server host (default: 127.0.0.1)
- `ROBYN_PORT`: Server port (default: 8080)
- `ROBYN_DEV_MODE`: Enable dev mode
- `ROBYN_BROWSER_OPEN`: Open browser on start
- `ROBYN_CLIENT_TIMEOUT`: Client timeout seconds
- `ROBYN_KEEP_ALIVE_TIMEOUT`: Keep-alive timeout
## Documentation Structure
Main docs at `docs_src/src/pages/documentation/`:
- `api_reference/getting_started.mdx` - Quick start guide
- `api_reference/request_object.mdx` - Request handling
- `api_reference/middlewares.mdx` - Middleware usage
- `api_reference/websockets.mdx` - WebSocket guide
- `api_reference/authentication.mdx` - Auth patterns
- `api_reference/openapi.mdx` - OpenAPI docs
- `api_reference/agents.mdx` - AI agent integration
- `api_reference/mcps.mdx` - MCP server guide
- `example_app/` - Full example application tutorial
================================================
FILE: docs_src/src/components/Button.jsx
================================================
import Link from 'next/link'
import clsx from 'clsx'
const variantStyles = {
primary:
'font-semibold text-zinc-100 bg-zinc-700 hover:bg-zinc-600 active:bg-zinc-700 active:text-zinc-100/70',
secondary:
'font-medium bg-zinc-800/50 text-zinc-300 hover:bg-zinc-800 hover:text-zinc-50 active:bg-zinc-800/50 active:text-zinc-50/70',
}
export function Button({ variant = 'primary', className, href, ...props }) {
className = clsx(
'inline-flex items-center gap-2 justify-center rounded-md py-2 px-3 text-sm outline-offset-2 transition active:transition-none',
variantStyles[variant],
className
)
return href ? (
) : (
)
}
================================================
FILE: docs_src/src/components/Card.jsx
================================================
import Link from 'next/link'
import clsx from 'clsx'
function ChevronRightIcon(props) {
return (
)
}
export function Card({ as: Component = 'div', className, children }) {
return (
{children}
)
}
Card.Link = function CardLink({ children, ...props }) {
return (
<>
{children}
)
}
Card.Title = function CardTitle({ as: Component = 'h2', href, children }) {
return (
{href ? {children} : children}
)
}
Card.Description = function CardDescription({ children }) {
return
Special thanks to the [PyO3](https://pyo3.rs/v0.13.2/) community and [Andrew from PyO3-asyncio](https://github.com/awestlake87/pyo3-asyncio) for their amazing libraries and their support for my queries. 💖
### ✨ Sponsors
These sponsors help us make the magic happen!
[](https://www.digitalocean.com/?refcode=3f2b9fd4968d&utm_campaign=Referral_Invite&utm_medium=Referral_Program&utm_source=badge)
[](https://github.com/appwrite)
## Star History
[](https://star-history.com/#sparckles/Robyn&Date)
================================================
FILE: benchmark.sh
================================================
#!/bin/sh
# Benchmark script to get info about Robyn's performances
# You can use this benchmark when developing on Robyn to test if your changes had a huge
# impact on performances. You cannot compare benchmarks from different machine and even
# several runs on the same machine can give very different results sometimes.
# Be aware of this when using this script!
Help() {
echo "Benchmark script to get info about Robyn's performances."
echo
echo "USAGE:"
echo " benchmark [-h|m|n|y]"
echo
echo "OPTIONS:"
echo " -h Print this help."
echo " -m Run 'maturin develop' to compile the Rust part of Robyn."
echo " -n Set the number of requests that oha sends."
echo " -y Skip prompt"
exit 0
}
yes_flag=false
run_maturin=false
number=100000
while getopts hymn: opt; do
case $opt in
h)
Help
;;
y)
yes_flag=true
;;
m)
run_maturin=true
;;
n)
number=$OPTARG
;;
?)
echo 'Error in command line parsing' >&2
Help
exit 1
;;
esac
done
# Prompt user to check if he installed the requirements for running the benchmark
if [ "$yes_flag" = false ]; then
echo "Make sure you are running this in your venv and you installed 'oha' using 'cargo install oha'"
echo "Do you want to proceed?"
while true; do
read -p "" yn
case $yn in
[Yy]* ) break;;
[Nn]* ) exit;;
* ) echo "Please answer yes or no.";;
esac
done
fi
# Compile Rust
if $run_maturin; then
maturin develop
fi
# Run the server in the background
python3 ./integration_tests/base_routes.py &
sleep 1
# oha will display benchmark results
oha -n "$number" http://localhost:8080/sync
# Kill subprocesses after exiting the script (python + robyn server)
# (see https://stackoverflow.com/questions/360201/how-do-i-kill-background-processes-jobs-when-my-shell-script-exits)
trap "trap - TERM && kill 0" INT TERM EXIT
================================================
FILE: ci-local.sh
================================================
#!/usr/bin/env bash
set -euo pipefail
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
CYAN='\033[0;36m'
NC='\033[0m'
FAILED=()
PASSED=()
SKIPPED=()
run_step() {
local name="$1"
shift
echo -e "\n${CYAN}── $name ──${NC}"
echo -e "${YELLOW}$ $*${NC}"
if "$@"; then
PASSED+=("$name")
echo -e "${GREEN}✓ $name${NC}"
else
FAILED+=("$name")
echo -e "${RED}✗ $name${NC}"
fi
}
skip_step() {
local name="$1"
local reason="$2"
SKIPPED+=("$name ($reason)")
echo -e "\n${YELLOW}── $name [SKIPPED: $reason] ──${NC}"
}
usage() {
echo "Usage: $0 [rust|lint|python|all|fix]"
echo ""
echo "Mirrors the GitHub Actions CI workflows locally."
echo ""
echo " rust Rust CI: cargo check, test, fmt --check, clippy"
echo " lint Lint PR: ruff check, isort --check-only"
echo " python Python CI: nox test suite (current Python version)"
echo " all Everything (default)"
echo " fix Auto-fix: cargo fmt, ruff --fix, isort"
exit 0
}
# ── rust-CI.yml ───────────────────────────────────────────────────────────────
run_rust() {
echo -e "\n${CYAN}═══ Rust CI (.github/workflows/rust-CI.yml) ═══${NC}"
run_step "cargo check" cargo check
run_step "cargo test" cargo test
run_step "cargo fmt" cargo fmt --check
run_step "cargo clippy" cargo clippy
}
# ── lint-pr.yml ───────────────────────────────────────────────────────────────
run_lint() {
echo -e "\n${CYAN}═══ Lint PR (.github/workflows/lint-pr.yml) ═══${NC}"
if command -v ruff &>/dev/null; then
run_step "ruff check" ruff check .
else
skip_step "ruff check" "ruff not installed (pip install ruff)"
fi
if command -v isort &>/dev/null; then
run_step "isort check" isort --check-only --diff .
else
skip_step "isort check" "isort not installed (pip install isort)"
fi
}
# ── python-CI.yml ─────────────────────────────────────────────────────────────
run_python() {
echo -e "\n${CYAN}═══ Python CI (.github/workflows/python-CI.yml) ═══${NC}"
local pyver
pyver=$(python3 -c "import sys; print(f'{sys.version_info.major}.{sys.version_info.minor}')")
if command -v nox &>/dev/null; then
run_step "nox (python $pyver)" nox --non-interactive --error-on-missing-interpreter -p "$pyver"
else
skip_step "nox tests" "nox not installed (pip install nox)"
fi
}
# ── fix mode ──────────────────────────────────────────────────────────────────
run_fix() {
echo -e "\n${CYAN}═══ Auto-fix ═══${NC}"
run_step "cargo fmt" cargo fmt
command -v ruff &>/dev/null && run_step "ruff fix" ruff check --fix . || skip_step "ruff fix" "not installed"
command -v isort &>/dev/null && run_step "isort fix" isort . || skip_step "isort fix" "not installed"
}
# ── main ──────────────────────────────────────────────────────────────────────
MODE="${1:-all}"
case "$MODE" in
rust) run_rust ;;
lint) run_lint ;;
python) run_python ;;
fix) run_fix ;;
all) run_rust; run_lint; run_python ;;
-h|--help|help) usage ;;
*) echo "Unknown mode: $MODE"; usage ;;
esac
# ── summary ───────────────────────────────────────────────────────────────────
echo -e "\n${CYAN}═══ Summary ═══${NC}"
for s in "${PASSED[@]+"${PASSED[@]}"}"; do echo -e " ${GREEN}✓${NC} $s"; done
for s in "${SKIPPED[@]+"${SKIPPED[@]}"}"; do echo -e " ${YELLOW}⊘${NC} $s"; done
for s in "${FAILED[@]+"${FAILED[@]}"}"; do echo -e " ${RED}✗${NC} $s"; done
if [ ${#FAILED[@]} -gt 0 ]; then
echo -e "\n${RED}CI would fail: ${#FAILED[@]} check(s) failed.${NC}"
exit 1
else
echo -e "\n${GREEN}All checks passed. Safe to push.${NC}"
exit 0
fi
================================================
FILE: docs_src/.eslintrc.json
================================================
{
"extends": ["next","next/core-web-vitals"],
"rules": {
"react/no-unescaped-entities": "off"
}
}
================================================
FILE: docs_src/.gitignore
================================================
# See https://help.github.com/articles/ignoring-files/ for more about ignoring files.
# dependencies
/node_modules
/.pnp
.pnp.js
# testing
/coverage
# next.js
/.next/
/out/
# production
/build
# misc
.DS_Store
*.pem
# debug
npm-debug.log*
yarn-debug.log*
yarn-error.log*
.pnpm-debug.log*
# local env files
.env*.local
# vercel
.vercel
# generated files
/public/rss/
================================================
FILE: docs_src/README.md
================================================
## Docs Base
This is the documentation website that will be used as a base for Robyn and Starfyre docs.
## Setup
1. Clone this repo
2. Run `npm install`
3. Run `npm run dev`
4. Open `http://localhost:3000` in your browser
================================================
FILE: docs_src/jsconfig.json
================================================
{
"compilerOptions": {
"baseUrl": ".",
"paths": {
"@/*": ["src/*"]
}
}
}
================================================
FILE: docs_src/mdx/recma.mjs
================================================
import { mdxAnnotations } from 'mdx-annotations'
import recmaNextjsStaticProps from 'recma-nextjs-static-props'
import { recmaImportImages } from 'recma-import-images'
function recmaRemoveNamedExports() {
return (tree) => {
tree.body = tree.body.map((node) => {
if (node.type === 'ExportNamedDeclaration') {
return node.declaration
}
return node
})
}
}
export const recmaPlugins = [
mdxAnnotations.recma,
recmaRemoveNamedExports,
recmaNextjsStaticProps,
recmaImportImages,
]
================================================
FILE: docs_src/mdx/rehype.mjs
================================================
import { mdxAnnotations } from 'mdx-annotations'
import { visit } from 'unist-util-visit'
import rehypeMdxTitle from 'rehype-mdx-title'
import shiki from 'shiki'
import { toString } from 'mdast-util-to-string'
import * as acorn from 'acorn'
import { slugifyWithCounter } from '@sindresorhus/slugify'
import rehypeSlug from 'rehype-slug'
import { remarkRehypeWrap } from 'remark-rehype-wrap'
import rehypeAutolinkHeadings from 'rehype-autolink-headings'
function rehypeParseCodeBlocks() {
return (tree) => {
visit(tree, 'element', (node, _nodeIndex, parentNode) => {
if (node.tagName === 'code' && node.properties.className) {
parentNode.properties.language = node.properties.className[0]?.replace(
/^language-/,
''
)
}
})
}
}
let highlighter
function rehypeShiki() {
return async (tree) => {
highlighter =
highlighter ?? (await shiki.getHighlighter({ theme: 'css-variables' }))
visit(tree, 'element', (node) => {
if (node.tagName === 'pre' && node.children[0]?.tagName === 'code') {
let codeNode = node.children[0]
let textNode = codeNode.children[0]
node.properties.code = textNode.value
if (node.properties.language) {
let tokens = highlighter.codeToThemedTokens(
textNode.value,
node.properties.language
)
textNode.value = shiki.renderToHtml(tokens, {
elements: {
pre: ({ children }) => children,
code: ({ children }) => children,
line: ({ children }) => `${children}`,
},
})
}
}
})
}
}
function rehypeSlugify() {
return (tree) => {
let slugify = slugifyWithCounter()
visit(tree, 'element', (node) => {
if (node.tagName === 'h2' && !node.properties.id) {
node.properties.id = slugify(toString(node))
}
})
}
}
function rehypeAddMDXExports(getExports) {
return (tree) => {
let exports = Object.entries(getExports(tree))
for (let [name, value] of exports) {
for (let node of tree.children) {
if (
node.type === 'mdxjsEsm' &&
new RegExp(`export\\s+const\\s+${name}\\s*=`).test(node.value)
) {
return
}
}
let exportStr = `export const ${name} = ${value}`
tree.children.push({
type: 'mdxjsEsm',
value: exportStr,
data: {
estree: acorn.parse(exportStr, {
sourceType: 'module',
ecmaVersion: 'latest',
}),
},
})
}
}
}
function getSections(node) {
let sections = []
for (let child of node.children ?? []) {
if (child.type === 'element' && child.tagName === 'h2') {
sections.push(`{
title: ${JSON.stringify(toString(child))},
id: ${JSON.stringify(child.properties.id)},
...${child.properties.annotation}
}`)
} else if (child.children) {
sections.push(...getSections(child))
}
}
return sections
}
export const rehypePlugins = [
rehypeSlug,
[rehypeAutolinkHeadings, { behavior: 'wrap', test: ['h2'] }],
[
remarkRehypeWrap,
{
node: { type: 'element', tagName: 'article' },
start: 'element[tagName=hr]',
transform: (article) => {
article.children.splice(0, 1)
let heading = article.children.find((n) => n.tagName === 'h2')
if (heading) {
article.properties = { ...heading.properties, title: toString(heading) }
heading.properties = {}
} else {
article.properties = {}
}
return article
},
},
],
mdxAnnotations.rehype,
rehypeParseCodeBlocks,
rehypeShiki,
rehypeSlugify,
rehypeMdxTitle,
[
rehypeAddMDXExports,
(tree) => ({
sections: `[${getSections(tree).join()}]`,
}),
],
]
================================================
FILE: docs_src/mdx/remark.mjs
================================================
import { mdxAnnotations } from 'mdx-annotations'
import remarkGfm from 'remark-gfm'
import remarkUnwrapImages from 'remark-unwrap-images'
export const remarkPlugins = [
mdxAnnotations.remark,
remarkGfm,
remarkUnwrapImages,
]
================================================
FILE: docs_src/next.config.mjs
================================================
import nextMDX from '@next/mdx'
import { remarkPlugins } from './mdx/remark.mjs'
import { rehypePlugins } from './mdx/rehype.mjs'
import { recmaPlugins } from './mdx/recma.mjs'
const withMDX = nextMDX({
options: {
remarkPlugins,
rehypePlugins,
recmaPlugins,
providerImportSource: '@mdx-js/react',
},
})
/** @type {import('next').NextConfig} */
const nextConfig = {
reactStrictMode: true,
pageExtensions: ['js', 'jsx', 'ts', 'tsx', 'mdx'],
experimental: {
scrollRestoration: true,
},
i18n: {
locales: ['en', 'zh'],
defaultLocale: 'en',
localeDetection: false,
},
async redirects() {
return [
{
source: '/documentation',
destination: '/documentation/en',
permanent: false,
},
]
},
}
export default withMDX(nextConfig)
================================================
FILE: docs_src/package.json
================================================
{
"name": "tailwindui-template",
"version": "0.1.0",
"private": true,
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "next lint"
},
"browserslist": "defaults, not ie <= 11",
"dependencies": {
"@algolia/autocomplete-core": "^1.9.3",
"@algolia/autocomplete-preset-algolia": "^1.9.3",
"@headlessui/react": "^1.7.15",
"@heroicons/react": "^2.0.18",
"@mapbox/rehype-prism": "^0.8.0",
"@mdx-js/loader": "^2.1.5",
"@mdx-js/react": "^2.1.5",
"@next/mdx": "^13.0.2",
"@sindresorhus/slugify": "^2.2.1",
"@tailwindcss/typography": "^0.5.4",
"@vercel/analytics": "^1.0.2",
"algoliasearch": "^4.17.2",
"autoprefixer": "^10.4.12",
"axios": "^1.4.0",
"clsx": "^1.2.1",
"fast-glob": "^3.2.11",
"feed": "^4.2.2",
"focus-visible": "^5.2.0",
"framer-motion": "^10.12.16",
"highlight.js": "^11.8.0",
"mdx-annotations": "^0.1.3",
"meilisearch": "^0.33.0",
"next": "13.4.2",
"next-mdx-remote": "^6.0.0",
"next-router-mock": "^0.9.3",
"postcss-focus-visible": "^6.0.4",
"prism-themes": "^1.9.0",
"prismjs": "^1.29.0",
"react": "18.2.0",
"react-dom": "18.2.0",
"react-markdown": "^8.0.7",
"recma-import-images": "^0.0.3",
"recma-nextjs-static-props": "^1.0.0",
"rehype-autolink-headings": "^6.1.1",
"rehype-mdx-title": "^2.0.0",
"rehype-slug": "^5.1.0",
"remark-gfm": "^3.0.1",
"remark-rehype-wrap": "^0.0.2",
"remark-unwrap-images": "^3.0.1",
"shiki": "^0.14.2",
"tailwindcss": "^3.3.0",
"zustand": "^4.3.8"
},
"devDependencies": {
"eslint": "8.26.0",
"eslint-config-next": "13.0.2",
"prettier": "^2.8.7",
"prettier-plugin-tailwindcss": "^0.2.6"
}
}
================================================
FILE: docs_src/postcss.config.js
================================================
module.exports = {
plugins: {
tailwindcss: {},
'postcss-focus-visible': {
replaceWith: '[data-focus-visible-added]',
},
autoprefixer: {},
},
}
================================================
FILE: docs_src/prettier.config.js
================================================
module.exports = {
singleQuote: true,
semi: false,
plugins: [require('prettier-plugin-tailwindcss')],
}
================================================
FILE: docs_src/public/funding.json
================================================
{
"version": "v1.0.0",
"entity": {
"type": "individual",
"role": "owner",
"name": "Sanskar Jethi",
"email": "sansyrox@gmail.com",
"phone": "",
"description": "Sanskar is a FOSS engineer who created Robyn and Starfyre. Sanskar has created software for over half his life and used it for almost all of his.",
"webpageUrl": {
"url": "https://robyn.tech/"
}
},
"projects": [
{
"guid": "robyn",
"name": "robyn",
"description": "Robyn is one of the fastest Python web frameworks, which comes with a built in web server and a Rust runtime.",
"webpageUrl": {
"url": "https://robyn.tech/"
},
"repositoryUrl": {
"url": "https://github.com/sparckles/Robyn",
"wellKnown": "https://github.com/sparckles/Robyn/blob/main/.well-known/funding-manifest-urls"
},
"licenses": ["BSD 2-Clause \"Simplified\" License"],
"tags": ["programming", "python", "rust", "web", "backend", "async"]
}
],
"funding": {
"channels": [
{
"guid": "mybank",
"type": "bank",
"address": "",
"description": "Send me an email to get my bank details"
}
],
"plans": [
{
"guid": "mybank",
"status": "active",
"name": "Support Maintainer Part Time",
"description": "Support the maintainer for his work on Robyn part time.",
"amount": 500,
"currency": "GBP",
"frequency": "monthly",
"channels": ["mybank"]
},
{
"guid": "mybank",
"status": "active",
"name": "Support Maintainer Full Time",
"description": "Support the maintainer for his work on Robyn full time.",
"amount": 3000,
"currency": "GBP",
"frequency": "monthly",
"channels": ["mybank"]
},
{
"guid": "150",
"status": "active",
"name": " Support Contributor Part Time",
"description": "Support for one contributor per month",
"amount": 150,
"currency": "GBP",
"frequency": "monthly",
"channels": ["mybank"]
},
{
"guid": "500",
"status": "active",
"name": " Support Contributor Full Time",
"description": "Support for one contributor per month",
"amount": 500,
"currency": "GBP",
"frequency": "monthly",
"channels": ["mybank"]
}
],
"history": []
}
}
================================================
FILE: docs_src/public/llms.txt
================================================
# Robyn
> Robyn is a high-performance, community-driven, and innovator-friendly async web framework for Python with a Rust runtime. It combines Python's ease of use with Rust's performance.
## Quick Facts
- Version: 0.79.0
- Python: >= 3.10
- License: BSD 2.0
- Repository: https://github.com/sparckles/robyn
- Documentation: https://robyn.tech/documentation
- Discord: https://discord.gg/rkERZ5eNU8
## Installation
```bash
pip install robyn
```
## Basic Usage
```python
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
async def index(request):
return "Hello, World!"
app.start(port=8080)
```
## Key Features
- **Rust Runtime**: Core server written in Rust using actix-web for high performance
- **Async/Sync Support**: Both async and sync route handlers supported
- **Multi-Process Scaling**: Built-in multiprocess execution via `--processes` and `--workers`
- **WebSockets**: Native WebSocket support
- **Middlewares**: Before/after request middlewares
- **Dependency Injection**: Built-in DI system
- **OpenAPI/Swagger**: Automatic OpenAPI documentation generation
- **Hot Reloading**: Development mode with `--dev` flag
- **AI Agents**: Built-in AI agent routing via `robyn.ai`
- **MCP Support**: Model Context Protocol server capabilities via `app.mcp`
- **Templating**: Jinja2 templating support (optional)
- **CORS**: Built-in CORS helper via `ALLOW_CORS()`
- **Authentication**: AuthenticationHandler base class for custom auth
- **Static Files**: Directory serving via `app.serve_directory()`
- **SSE**: Server-Sent Events support via `SSEResponse`
- **Easy Access Parameters**: Typed path/query params with automatic coercion in handler signatures
- **Direct Rust Integration**: Embed Rust code directly in routes
## Project Structure
```
robyn/
├── src/ # Rust source code
│ ├── lib.rs # PyO3 module entry point
│ ├── server.rs # Main HTTP server implementation
│ ├── types/ # Request, Response, Headers, Cookie types
│ ├── routers/ # HTTP, WebSocket, middleware routers
│ ├── executors/ # Route execution handlers
│ └── websockets/ # WebSocket implementation
├── robyn/ # Python package
│ ├── __init__.py # Main Robyn and SubRouter classes
│ ├── router.py # Python router implementation
│ ├── authentication.py # AuthenticationHandler
│ ├── dependency_injection.py
│ ├── openapi.py # OpenAPI generation
│ ├── mcp.py # MCP protocol support
│ ├── ai.py # AI agent support
│ ├── responses.py # Response helpers (serve_file, html, SSE)
│ ├── ws.py # WebSocket class
│ └── robyn.pyi # Type stubs
├── integration_tests/ # Integration test suite
├── unit_tests/ # Unit test suite
├── docs_src/ # Documentation (Next.js)
├── granian/ # Bundled Granian server (fork)
└── examples/ # Example applications
```
## Core Classes
### Robyn / SubRouter
Main application class and sub-router for modular routes.
```python
from robyn import Robyn, SubRouter
app = Robyn(__file__)
api = SubRouter(__file__, prefix="/api")
@api.get("/users")
def get_users(request):
return {"users": []}
app.include_router(api)
```
### Request Object
```python
request.method # HTTP method
request.url # Url object (scheme, host, path)
request.headers # Headers dict-like
request.query_params # QueryParams
request.path_params # Dict of URL params
request.body # Raw bytes
request.json() # Parse JSON body
request.form_data # Multipart form data
request.ip_addr # Client IP
request.identity # Identity (if authenticated)
```
### Response Object
```python
from robyn import Response
Response(
status_code=200,
headers={"Content-Type": "application/json"},
description="body content" # or body bytes
)
```
### Decorators
```python
@app.get("/path")
@app.post("/path")
@app.put("/path")
@app.delete("/path")
@app.patch("/path")
@app.head("/path")
@app.options("/path")
@app.before_request("/path") # Middleware before
@app.after_request("/path") # Middleware after
@app.startup_handler # Server startup
@app.shutdown_handler # Server shutdown
```
### WebSockets
```python
from robyn import WebSocketDisconnect
@app.websocket("/ws")
async def handler(websocket):
try:
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
except WebSocketDisconnect:
pass
@handler.on_connect
def on_connect(websocket):
return "Connected"
@handler.on_close
def on_close(websocket):
return "Closed"
```
### Easy Access Parameters
Declare typed path and query parameters directly in handler signatures. Works for both HTTP and WebSocket handlers.
```python
from typing import List, Optional
# HTTP: path params + query params with type coercion
@app.get("/items/:id")
async def get_item(id: int, q: str, page: int = 1):
return {"id": id, "q": q, "page": page}
# Optional, List, and bool params
@app.get("/search")
def search(name: str, tags: List[str], active: bool = False, age: Optional[int] = None):
return {"name": name, "tags": tags, "active": active, "age": age}
# WebSocket: typed query params on handler and callbacks
@app.websocket("/ws")
async def handler(websocket, room: str = "default", page: int = 1):
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"room={room} page={page} msg={msg}")
@handler.on_connect
def on_connect(websocket, room: str = "default"):
return f"connected to {room}"
```
### MCP (Model Context Protocol)
```python
@app.mcp.resource("time://current")
def get_time():
return datetime.now().isoformat()
@app.mcp.tool(name="calc", description="Calculate", input_schema={...})
def calculate(args):
return eval(args["expression"])
@app.mcp.prompt(name="explain", description="Explain code", arguments=[...])
def explain_prompt(args):
return f"Please explain: {args['code']}"
```
## CLI Commands
```bash
python app.py # Start server
python app.py --dev # Development mode (hot reload)
python app.py --processes 4 # Multi-process
python app.py --workers 2 # Workers per process
python app.py --log-level DEBUG # Log level
python app.py --open-browser # Open browser on start
python app.py --create # Create new project scaffold
python app.py --docs # Open documentation
```
## Development Setup
```bash
# Clone
git clone https://github.com/sparckles/robyn.git
cd robyn
# Virtual environment
python3 -m venv .venv && source .venv/bin/activate
# Install tools
pip install pre-commit poetry maturin
# Install dependencies
poetry install --with dev --with test
# Build Rust extension
maturin develop
# Run tests
pytest
```
## Key Dependencies
- **PyO3**: Rust-Python bindings
- **actix-web**: Rust HTTP server (via cookie crate)
- **orjson**: Fast JSON serialization
- **multiprocess**: Multi-process support
- **uvloop**: Fast event loop (non-Windows)
- **watchdog**: File watching for hot reload
## Configuration
Environment variables:
- `ROBYN_HOST`: Server host (default: 127.0.0.1)
- `ROBYN_PORT`: Server port (default: 8080)
- `ROBYN_DEV_MODE`: Enable dev mode
- `ROBYN_BROWSER_OPEN`: Open browser on start
- `ROBYN_CLIENT_TIMEOUT`: Client timeout seconds
- `ROBYN_KEEP_ALIVE_TIMEOUT`: Keep-alive timeout
## Documentation Structure
Main docs at `docs_src/src/pages/documentation/`:
- `api_reference/getting_started.mdx` - Quick start guide
- `api_reference/request_object.mdx` - Request handling
- `api_reference/middlewares.mdx` - Middleware usage
- `api_reference/websockets.mdx` - WebSocket guide
- `api_reference/authentication.mdx` - Auth patterns
- `api_reference/openapi.mdx` - OpenAPI docs
- `api_reference/agents.mdx` - AI agent integration
- `api_reference/mcps.mdx` - MCP server guide
- `example_app/` - Full example application tutorial
================================================
FILE: docs_src/src/components/Button.jsx
================================================
import Link from 'next/link'
import clsx from 'clsx'
const variantStyles = {
primary:
'font-semibold text-zinc-100 bg-zinc-700 hover:bg-zinc-600 active:bg-zinc-700 active:text-zinc-100/70',
secondary:
'font-medium bg-zinc-800/50 text-zinc-300 hover:bg-zinc-800 hover:text-zinc-50 active:bg-zinc-800/50 active:text-zinc-50/70',
}
export function Button({ variant = 'primary', className, href, ...props }) {
className = clsx(
'inline-flex items-center gap-2 justify-center rounded-md py-2 px-3 text-sm outline-offset-2 transition active:transition-none',
variantStyles[variant],
className
)
return href ? (
) : (
)
}
================================================
FILE: docs_src/src/components/Card.jsx
================================================
import Link from 'next/link'
import clsx from 'clsx'
function ChevronRightIcon(props) {
return (
)
}
export function Card({ as: Component = 'div', className, children }) {
return (
{children}
)
}
Card.Link = function CardLink({ children, ...props }) {
return (
<>
{children}
)
}
Card.Title = function CardTitle({ as: Component = 'h2', href, children }) {
return (
{href ? {children} : children}
)
}
Card.Description = function CardDescription({ children }) {
return {children}
}
Card.Cta = function CardCta({ children }) {
return (
{children}
)
}
Card.Eyebrow = function CardEyebrow({
as: Component = 'p',
decorate = false,
className,
children,
...props
}) {
return (
{decorate && (
)}
{children}
)
}
================================================
FILE: docs_src/src/components/Container.jsx
================================================
import { forwardRef } from 'react'
import clsx from 'clsx'
const OuterContainer = forwardRef(function OuterContainer(
{ className, children, ...props },
ref
) {
return (
)
})
const InnerContainer = forwardRef(function InnerContainer(
{ className, children, ...props },
ref
) {
return (
)
})
export const Container = forwardRef(function Container(
{ children, ...props },
ref
) {
return (
{children}
)
})
Container.Outer = OuterContainer
Container.Inner = InnerContainer
================================================
FILE: docs_src/src/components/Footer.jsx
================================================
import Link from 'next/link'
import { Container } from '@/components/Container'
import { GitHubIcon } from './SocialIcons'
function NavLink({ href, children, ...props }) {
return (
{children}
)
}
export function GithubButton() {
return (
)
}
export function Footer() {
return (
<>
)
}
================================================
FILE: docs_src/src/components/Header.jsx
================================================
import { Fragment, useEffect, useRef, useState } from 'react'
import Image from 'next/image'
import Link from 'next/link'
import { useRouter } from 'next/router'
import { Popover, Transition } from '@headlessui/react'
import clsx from 'clsx'
import { Container } from '@/components/Container'
import robynLogo from '@/images/robyn_logo.jpg'
import { MobileSearch, Search } from '@/components/documentation/Search'
function CloseIcon(props) {
return (
)
}
function ChevronDownIcon(props) {
return (
)
}
function MobileNavItem({ href, children }) {
return (
{children}
)
}
function MobileNavigation(props) {
return (
Menu
)
}
function NavItem({ href, children, ...props }) {
let isActive = useRouter().pathname === href
return (
{children}
{isActive && (
)}
)
}
function DesktopNavigation(props) {
return (
)
}
function GitHubStars() {
const [stars, setStars] = useState('6.1k')
const [loading, setLoading] = useState(false)
const fetchStars = async () => {
if (loading) return
setLoading(true)
try {
const response = await fetch('https://api.github.com/repos/sparckles/robyn')
const data = await response.json()
if (data.stargazers_count) {
const count = data.stargazers_count
const formatted = count >= 1000
? `${(count / 1000).toFixed(1)}k`
: count.toString()
setStars(formatted)
}
} catch (error) {
console.error('Failed to fetch GitHub stars:', error)
} finally {
setLoading(false)
}
}
useEffect(() => {
fetchStars()
const interval = setInterval(fetchStars, 300000)
return () => clearInterval(interval)
}, [])
return (
{stars}
)
}
function clamp(number, a, b) {
let min = Math.min(a, b)
let max = Math.max(a, b)
return Math.min(Math.max(number, min), max)
}
function Avatar({ large = false, className, ...props }) {
return (
)
}
export function Header() {
let isHomePage = useRouter().pathname === '/'
let headerRef = useRef()
let avatarRef = useRef()
let isInitial = useRef(true)
useEffect(() => {
let downDelay = avatarRef.current?.offsetTop ?? 0
let upDelay = 64
function setProperty(property, value) {
document.documentElement.style.setProperty(property, value)
}
function removeProperty(property) {
document.documentElement.style.removeProperty(property)
}
function updateHeaderStyles() {
let { top, height } = headerRef.current.getBoundingClientRect()
let scrollY = clamp(
window.scrollY,
0,
document.body.scrollHeight - window.innerHeight
)
if (isInitial.current) {
setProperty('--header-position', 'sticky')
}
setProperty('--content-offset', `${downDelay}px`)
if (isInitial.current || scrollY < downDelay) {
setProperty('--header-height', `${downDelay + height}px`)
setProperty('--header-mb', `${-downDelay}px`)
} else if (top + height < -upDelay) {
let offset = Math.max(height, scrollY - upDelay)
setProperty('--header-height', `${offset}px`)
setProperty('--header-mb', `${height - offset}px`)
} else if (top === 0) {
setProperty('--header-height', `${scrollY + height}px`)
setProperty('--header-mb', `${-scrollY}px`)
}
if (top === 0 && scrollY > 0 && scrollY >= downDelay) {
setProperty('--header-inner-position', 'fixed')
removeProperty('--header-top')
removeProperty('--avatar-top')
} else {
removeProperty('--header-inner-position')
setProperty('--header-top', '0px')
setProperty('--avatar-top', '0px')
}
}
function updateStyles() {
updateHeaderStyles()
isInitial.current = false
}
updateStyles()
window.addEventListener('scroll', updateStyles, { passive: true })
window.addEventListener('resize', updateStyles)
return () => {
window.removeEventListener('scroll', updateStyles)
window.removeEventListener('resize', updateStyles)
}
}, [isHomePage])
return (
<>
{isHomePage && }
)
}
================================================
FILE: docs_src/src/components/Prose.jsx
================================================
import clsx from 'clsx'
export function Prose({ children, className }) {
return {children}
}
================================================
FILE: docs_src/src/components/Section.jsx
================================================
import { useId } from 'react'
export function Section({ title, children }) {
let id = useId()
return (
)
}
================================================
FILE: docs_src/src/components/SimpleLayout.jsx
================================================
import { Container } from '@/components/Container'
export function SimpleLayout({ title, intro, children }) {
return (
{children}
)
}
================================================
FILE: docs_src/src/components/SocialIcons.jsx
================================================
export function TwitterIcon(props) {
return (
)
}
export function InstagramIcon(props) {
return (
)
}
export function GitHubIcon(props) {
return (
)
}
export function LinkedInIcon(props) {
return (
)
}
export function DiscordIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/Testimonials.jsx
================================================
import { useEffect } from 'react'
let testimonials = [
{
body: "Robyn has revolutionized the way I develop web solutions. Its seamless integration of Python's async capabilities with a Rust runtime not only ensures reliability and scalability but also provides quick project setup, a delightful user experience, and robust plugin support. With its exceptional speed and multithreaded efficiency, Robyn's real-time communication through WebSockets and dynamic URL routing has empowered me to create highly performant and interactive applications while maintaining full control over navigation and workflows. A game-changer for modern web development!",
author: {
name: 'Kunal Kushwaha',
handle: 'kunalstwt',
imageUrl: '/testimonials/kunalstwt.jpg',
title: 'DevRel manager at Civo',
},
},
{
body: "Having worked with a company building a Rust based open source search engine for over a year, I strongly believe in the notion that rewriting software with Rust can significantly improve software performance. Sanskar's idea to recreate Flask with Rust, was just incredible. Having used Robyn myself, it is refreshing to see such a performant Python framework and just the amazing developer ecosystem around it. Yes it still new and being developed, but I can say this with confidence that given the underlying Rust-based multithreaded run time will provide immense performance for running high throughout applications. I am glad to be one of the early sponsors and adopters for Robyn!",
author: {
name: 'Shivay Lamba',
handle: 'howdevelop',
imageUrl: '/testimonials/howdevelop.jpg',
title: 'Developer Experience Engineer at MeiliSearch',
},
},
{
body: "I'm impressed with Robyn. It's a fast asynchronous web framework for the Python ecosystem that's built on top of Rust. The syntax is similar to other popular web frameworks, so it's easy to learn and be productive with. I've been using it to build web applications and services, and I'm really happy with the results. I'm also impressed with the Robyn community. They are very supportive and the developers are very responsive to feedback",
author: {
name: 'Carlos A. Marcano Vargas',
handle: 'carlos_marcv',
imageUrl: '/testimonials/carlos_marcv.jpg',
title: 'Technical Writer',
},
},
// More testimonials...
{
body: 'Great to see a Community Driven Open Source project, achieve new heights! Robyn is built by the community for the community',
author: {
name: 'Eddie Jaoude',
handle: 'eddiejaoude',
imageUrl: '/testimonials/eddiejaoude.jpg',
title: 'Creator of EddieHub',
},
},
// More testimonials...
{
body: 'I used to be a Batman fan, but having met Robyn I now think the sidekick has become the hero. Free, OSS, straight forward and powerful, what is not to love?',
author: {
name: 'GrahamTheDev',
handle: 'GrahamTheDev',
imageUrl: '/testimonials/GrahamTheDev.jpg',
title: 'The Accessibility First DevRel ',
},
},
{
body: 'Having used both, Flask and Django for writing web applications in Python in the past, Robyn looks like their combined successor in terms of ergonomics and features available. Its reliance on a Rust runtime for performance and security is the cherry on the cake!',
author: {
name: 'Daniel Bodky',
handle: 'd_bodky',
imageUrl: '/testimonials/d_bodky.jpg',
title: 'Consultant, Trainer, Speaker @NETWAYS',
},
},
// More testimonials...
{
body: 'Robyn has made a big difference in my projects. Its flexible structure allows my work to adapt smoothly to my needs, even when I face complex challenges. The community-driven and open-source nature of Robyn makes it a welcoming place for developers like me. Plus, its simple yet powerful API has greatly streamlined my development process, reducing my wor oad. I highly recommend it!',
author: {
name: 'Julia Furst Morgado',
handle: 'juliafmorgado',
imageUrl: '/testimonials/juliafmorgado.jpg',
title: 'Global technologist @Veeam',
},
},
// More testimonials...
{
body: 'Robyn opens a new chapter in the Python web frameworks scene: the Rust powered one, where performance and safety are not the sole protagonists.',
author: {
name: 'Giovanni Barillari',
handle: 'gi0baro',
imageUrl: '/testimonials/gi0baro.jpeg',
title: 'Author of Granian and Emmett',
},
},
// More testimonials...
{
body: "I collaborate with Robyn's team and I must say, Sanskar does an excellent job maintaining the community. The project as a whole is immensely beneficial, both for collaboration and its practical uses. The tool is impressive, easy to use and the entire community is very welcoming to first-time contributors",
author: {
name: 'Jyoti Bisht',
handle: 'joeyousss',
imageUrl: '/testimonials/joeyousss.jpg',
title: 'Open Source Developer',
},
},
// More testimonials...
{
body: "Robyn is a breath of fresh air in web development. Merging Python's simplicity with Rust's speed, it offers a seamless experience for developers. Its features are precisely what today's web projects need. I'm particularly impressed with its community focus; it's evident that everyone's voice matters in shaping Robyn's journey. In a sea of web frameworks, Robyn stands out not just for its tech but also for its heart.",
author: {
name: 'Francesco Ciulla',
handle: 'FrancescoCiull4',
imageUrl: '/testimonials/FrancescoCiull4.jpg',
title: 'DevRel at daily.dev',
},
},
// More testimonials...
]
//shuflle testimonials
function classNames(...classes) {
return classes.filter(Boolean).join(' ')
}
const chunk = (arr, size) =>
Array.from({ length: Math.ceil(arr.length / size) }, (v, i) =>
arr.slice(i * size, i * size + size)
)
export default function Testimonials() {
let chunkedTestimonials = [];
// Separate testimonials into groups of 3, 4, and 3
const firstGroup = chunk(testimonials.slice(0, 3), 3);
const secondGroup = chunk(testimonials.slice(3, 7), 4);
const thirdGroup = chunk(testimonials.slice(7), 3);
// Concatenate the groups in the desired order
chunkedTestimonials = firstGroup.concat(secondGroup, thirdGroup);
return (
Testimonials
Some amazing people have said nice things about us.
{chunkedTestimonials.map((columnGroup, columnGroupIdx) => (
{columnGroup.map((testimonial) => (
{`"${testimonial.body}"`}

{testimonial.author.name}
{`@${testimonial.author.handle}`}
{testimonial.author.title}
))}
))}
)
}
================================================
FILE: docs_src/src/components/documentation/ApiDocs.jsx
================================================
import { Button } from '@/components/documentation/Button'
import { Heading } from '@/components/documentation/Heading'
const guides = [
{
href: '/documentation/en/api_reference',
name: 'Installation',
description: 'Start using Robyn in your project.',
},
{
href: '/documentation/en/api_reference/getting_started',
name: 'Getting Started',
description: 'Start with creating basic routes in Robyn.',
},
{
href: '/documentation/en/api_reference/request_object',
name: 'The Request Object',
description: 'Learn about the Request Object in Robyn.',
},
{
href: '/documentation/en/api_reference/robyn_env',
name: 'The Robyn Env file',
description: 'Learn about the Robyn variables',
},
{
href: '/documentation/en/api_reference/middlewares',
name: 'Middlewares, Events and Websockets',
description: 'Learn about Middlewares, Events and Websockets in Robyn.',
},
{
href: '/documentation/en/api_reference/authentication',
name: 'Authentication',
description: 'Learn about Authentication in Robyn.',
},
{
href: '/documentation/en/api_reference/const_requests',
name: 'Const Requests and Multi Core Scaling',
description: 'Learn about Const Requests and Multi Core Scaling in Robyn.',
},
{
href: '/documentation/en/api_reference/cors',
name: 'CORS',
description: 'CORS',
},
{
href: '/documentation/en/api_reference/templating',
name: 'Templating',
description: 'Learn about Templating in Robyn.',
},
{
href: '/documentation/en/api_reference/redirection',
name: 'Redirection',
description: 'Learn how to redirect requests to different endpoints.',
},
{
href: '/documentation/en/api_reference/file-uploads',
name: 'File Uploads',
description:
'Learn how to upload and download files to your server using Robyn.',
},
{
href: '/documentation/en/api_reference/form_data',
name: 'Form Data and Multi Part Form Data',
description: 'Learn how to handle form data.',
},
{
href: '/documentation/en/api_reference/websockets',
name: 'Websockets',
description: 'Learn how to use Websockets in Robyn.',
},
{
href: '/documentation/en/api_reference/server_sent_events',
name: 'Server-Sent Events',
description: 'Learn how to implement Server-Sent Events for real-time communication.',
},
{
href: '/documentation/en/api_reference/exceptions',
name: 'Exceptions',
description: 'Learn how to handle exceptions in Robyn.',
},
{
href: '/documentation/en/api_reference/scaling',
name: 'Scaling the Application',
description: 'Learn how to scaled Robyn across multiple cores.',
},
{
href: '/documentation/en/api_reference/advanced_features',
name: 'Advanced Features',
description: 'Learn about advanced features in Robyn.',
},
{
href: '/documentation/en/api_reference/multiprocess_execution',
name: 'Multiprocess Execution',
description: 'Learn about the behaviour or variables during multithreading',
},
{
href: '/documentation/en/api_reference/using_rust_directly',
name: 'Direct Rust Usage',
description: 'Learn about directly using Rust in Robyn.',
},
{
href: '/documentation/en/api_reference/graphql-support',
name: 'GraphQL Support',
description: 'Learn about GraphQL Support in Robyn.',
},
{
href: '/documentation/en/api_reference/openapi',
name: 'OpenAPI Documentation',
description: 'Learn how to generate OpenAPI docs for your applications.',
},
{
href: '/documentation/en/api_reference/dependency_injection',
name: 'Dependency Injection',
description: 'Learn about Dependency Injection in Robyn.',
},
]
export function ApiDocs() {
return (
Api Docs
{guides.map((guide) => (
{guide.name}
{guide.description}
))}
)
}
================================================
FILE: docs_src/src/components/documentation/BottomNavbar.jsx
================================================
import { forwardRef } from 'react'
import Link from 'next/link'
import clsx from 'clsx'
import { motion, useScroll, useTransform } from 'framer-motion'
import { MobileNavigation } from '@/components/documentation/MobileNavigation'
import { useMobileNavigationStore } from '@/components/documentation/MobileNavigation'
import { MobileSearch, Search } from '@/components/documentation/Search'
export const BottomNavbar = forwardRef(function Header({ className }, ref) {
let { scrollY } = useScroll()
let bgOpacityLight = useTransform(scrollY, [0, 72], [0.5, 0.9])
let bgOpacityDark = useTransform(scrollY, [0, 72], [0.2, 0.8])
return (
<>
)
})
================================================
FILE: docs_src/src/components/documentation/Button.jsx
================================================
import Link from 'next/link'
import clsx from 'clsx'
function ArrowIcon(props) {
return (
)
}
const variantStyles = {
primary:
'rounded-full py-1 px-3 bg-orange-400/10 text-orange-400 ring-1 ring-inset ring-orange-400/20 hover:bg-orange-400/10 hover:text-orange-300 hover:ring-orange-300',
secondary:
'rounded-full py-1 px-3 bg-zinc-800/40 text-zinc-400 ring-1 ring-inset ring-zinc-800 hover:bg-zinc-800 hover:text-zinc-300',
filled: 'rounded-full py-1 px-3 bg-orange-500 text-white hover:bg-orange-400',
outline:
'rounded-full py-1 px-3 ring-1 ring-inset text-zinc-400 ring-white/10 hover:bg-white/5 hover:text-white',
text: 'text-orange-400 hover:text-orange-500',
}
export function Button({
variant = 'primary',
className,
children,
arrow,
...props
}) {
let Component = props.href ? Link : 'button'
className = clsx(
'inline-flex gap-0.5 justify-center overflow-hidden text-sm font-medium transition',
variantStyles[variant],
className
)
let arrowIcon = (
)
return (
{arrow === 'left' && arrowIcon}
{children}
{arrow === 'right' && arrowIcon}
)
}
================================================
FILE: docs_src/src/components/documentation/Code.jsx
================================================
import {
Children,
createContext,
useContext,
useEffect,
useRef,
useState,
} from 'react'
import { Tab } from '@headlessui/react'
import clsx from 'clsx'
import { create } from 'zustand'
import { Tag } from '@/components/documentation/Tag'
const languageNames = {
js: 'JavaScript',
ts: 'TypeScript',
javascript: 'JavaScript',
typescript: 'TypeScript',
php: 'PHP',
python: 'Python',
ruby: 'Ruby',
go: 'Go',
}
function getPanelTitle({ title, language }) {
return title ?? languageNames[language] ?? 'Code'
}
function ClipboardIcon(props) {
return (
)
}
function CopyButton({ code }) {
let [copyCount, setCopyCount] = useState(0)
let copied = copyCount > 0
useEffect(() => {
if (copyCount > 0) {
let timeout = setTimeout(() => setCopyCount(0), 1000)
return () => {
clearTimeout(timeout)
}
}
}, [copyCount])
return (
)
}
function CodePanelHeader({ tag, label }) {
if (!tag && !label) {
return null
}
return (
{tag && (
{tag}
)}
{tag && label && (
)}
{label && (
{label}
)}
{title && (
{title}
)}
{hasTabs && (
{Children.map(children, (child, childIndex) => (
{getPanelTitle(child.props)}
))}
)}
)
}
function CodeGroupPanels({ children, ...props }) {
let hasTabs = Children.count(children) > 1
if (hasTabs) {
return (
{Children.map(children, (child) => (
{child}
))}
)
}
return {children}
}
function usePreventLayoutShift() {
let positionRef = useRef()
let rafRef = useRef()
useEffect(() => {
return () => {
window.cancelAnimationFrame(rafRef.current)
}
}, [])
return {
positionRef,
preventLayoutShift(callback) {
let initialTop = positionRef.current.getBoundingClientRect().top
callback()
rafRef.current = window.requestAnimationFrame(() => {
let newTop = positionRef.current.getBoundingClientRect().top
window.scrollBy(0, newTop - initialTop)
})
},
}
}
const usePreferredLanguageStore = create((set) => ({
preferredLanguages: [],
addPreferredLanguage: (language) =>
set((state) => ({
preferredLanguages: [
...state.preferredLanguages.filter(
(preferredLanguage) => preferredLanguage !== language
),
language,
],
})),
}))
function useTabGroupProps(availableLanguages) {
let { preferredLanguages, addPreferredLanguage } = usePreferredLanguageStore()
let [selectedIndex, setSelectedIndex] = useState(0)
let activeLanguage = [...availableLanguages].sort(
(a, z) => preferredLanguages.indexOf(z) - preferredLanguages.indexOf(a)
)[0]
let languageIndex = availableLanguages.indexOf(activeLanguage)
let newSelectedIndex = languageIndex === -1 ? selectedIndex : languageIndex
if (newSelectedIndex !== selectedIndex) {
setSelectedIndex(newSelectedIndex)
}
let { positionRef, preventLayoutShift } = usePreventLayoutShift()
return {
as: 'div',
ref: positionRef,
selectedIndex,
onChange: (newSelectedIndex) => {
preventLayoutShift(() =>
addPreferredLanguage(availableLanguages[newSelectedIndex])
)
},
}
}
const CodeGroupContext = createContext(false)
export function CodeGroup({ children, title, ...props }) {
let languages = Children.map(children, (child) => getPanelTitle(child.props))
let tabGroupProps = useTabGroupProps(languages)
let hasTabs = Children.count(children) > 1
let Container = hasTabs ? Tab.Group : 'div'
let containerProps = hasTabs ? tabGroupProps : {}
let headerProps = hasTabs
? { selectedIndex: tabGroupProps.selectedIndex }
: {}
return (
{children}
{children}
)
}
export function Code({ children, ...props }) {
let isGrouped = useContext(CodeGroupContext)
if (isGrouped) {
return (
{children}
)
}
export function Pre({ children, ...props }) {
let isGrouped = useContext(CodeGroupContext)
if (isGrouped) {
return children
}
return {children}
}
================================================
FILE: docs_src/src/components/documentation/Guides.jsx
================================================
import { Button } from '@/components/documentation/Button'
import { Heading } from '@/components/documentation/Heading'
const guides = [
{
href: '/documentation/en/example_app',
name: 'Getting Started',
description: 'Learn how to authenticate your API requests.',
},
{
href: '/documentation/en/example_app/authentication',
name: 'Authentication and Authorization',
description: 'Understand how to use authentication and authorization.',
},
{
href: '/documentation/en/example_app/authentication-middlewares',
name: 'Middlewares',
description:
'Read about different kinds of Middlewares and how to use them.',
},
{
href: '/documentation/en/example_app/monitoring_and_logging',
name: 'Monitoring and Logging',
description: 'Learn how to have montoring and logging in Robyn.',
},
{
href: '/documentation/en/example_app/real_time_notifications',
name: 'Real Time Notifications',
description: 'Learn how to have real time notification in Robyn.',
},
{
href: '/documentation/en/example_app/deployment',
name: 'Deployments',
description:
'Learn how to deploy your app to production and manage your deployments.',
},
{
href: '/documentation/en/example_app/openapi',
name: 'OpenAPI Documentation',
description: 'Learn how OpenAPI docs are generate for your applications.',
},
]
export function Guides() {
return (
Example Application
{guides.map((guide) => (
{guide.name}
{guide.description}
))}
)
}
================================================
FILE: docs_src/src/components/documentation/Heading.jsx
================================================
import { useEffect, useRef } from 'react'
import Link from 'next/link'
import { useInView } from 'framer-motion'
import { useSectionStore } from '@/components/documentation/SectionProvider'
import { Tag } from '@/components/documentation/Tag'
import { remToPx } from '@/lib/remToPx'
function AnchorIcon(props) {
return (
)
}
function Eyebrow({ tag, label }) {
if (!tag && !label) {
return null
}
return (
{tag && {tag}}
{tag && label && (
)}
{label && (
{label}
)}
)
}
function Anchor({ id, inView, children }) {
return (
{inView && (
)}
{children}
)
}
export function Heading({
level = 2,
children,
id,
tag,
label,
anchor = true,
...props
}) {
let Component = `h${level}`
let ref = useRef()
let registerHeading = useSectionStore((s) => s.registerHeading)
let inView = useInView(ref, {
margin: `${remToPx(-3.5)}px 0px 0px 0px`,
amount: 'all',
})
useEffect(() => {
if (level === 2) {
registerHeading({ id, ref, offsetRem: tag || label ? 8 : 6 })
}
})
return (
<>
{anchor ? (
{children}
) : (
children
)}
)
}
================================================
FILE: docs_src/src/components/documentation/HeroPattern.jsx
================================================
export function HeroPattern() {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/LanguageSelector.jsx
================================================
import { useRouter } from 'next/router'
import { Menu } from '@headlessui/react'
import { motion } from 'framer-motion'
const languages = [
{ code: 'en', name: 'English' },
{ code: 'zh', name: '中文' },
]
function LanguageSelector() {
const router = useRouter()
const { pathname, asPath, query } = router
const currentLanguage = asPath.includes('/zh') ? 'zh' : 'en'
const changeLanguage = (locale) => {
const currentPath = asPath.split('?')[0]
if (currentPath === '/documentation' || currentPath === '/documentation/') {
router.push(`/documentation/${locale}`)
return
}
const newPath = currentPath.replace(
/\/documentation\/(en|zh)/,
`/documentation/${locale}`
)
router.push(newPath)
}
return (
)
}
export default LanguageSelector
================================================
FILE: docs_src/src/components/documentation/Layout.jsx
================================================
import { motion } from 'framer-motion'
import { Footer } from '@/components/Footer'
import { BottomNavbar } from '@/components/documentation/BottomNavbar'
import { Navigation } from '@/components/documentation/Navigation'
import { Prose } from '@/components/documentation/Prose'
import { SectionProvider } from '@/components/documentation/SectionProvider'
export function Layout({ children, sections = [] }) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/Libraries.jsx
================================================
import Image from 'next/image'
import { Button } from '@/components/documentation/Button'
import { Heading } from '@/components/documentation/Heading'
const libraries = [
{
href: '#',
name: 'PHP',
description:
'A popular general-purpose scripting language that is especially suited to web development.',
},
{
href: '#',
name: 'Ruby',
description:
'A dynamic, open source programming language with a focus on simplicity and productivity.',
},
{
href: '#',
name: 'Node.js',
description:
'Node.js® is an open-source, cross-platform JavaScript runtime environment.',
},
{
href: '#',
name: 'Python',
description:
'Python is a programming language that lets you work quickly and integrate systems more effectively.',
},
{
href: '#',
name: 'Go',
description:
'An open-source programming language supported by Google with built-in concurrency.',
},
]
export function Libraries() {
return (
Official libraries
{libraries.map((library) => (
{library.name}
{library.description}
))}
)
}
================================================
FILE: docs_src/src/components/documentation/MobileNavigation.jsx
================================================
import { createContext, Fragment, useContext } from 'react'
import { Dialog, Transition } from '@headlessui/react'
import { motion } from 'framer-motion'
import { create } from 'zustand'
import { BottomNavbar } from '@/components/documentation/BottomNavbar'
import { Navigation } from '@/components/documentation/Navigation'
function MenuIcon(props) {
return (
)
}
function XIcon(props) {
return (
)
}
const IsInsideMobileNavigationContext = createContext(false)
export function useIsInsideMobileNavigation() {
return useContext(IsInsideMobileNavigationContext)
}
export const useMobileNavigationStore = create((set) => ({
isOpen: false,
open: () => set({ isOpen: true }),
close: () => set({ isOpen: false }),
toggle: () => set((state) => ({ isOpen: !state.isOpen })),
}))
export function MobileNavigation() {
let isInsideMobileNavigation = useIsInsideMobileNavigation()
let { isOpen, toggle, close } = useMobileNavigationStore()
let ToggleIcon = isOpen ? XIcon : MenuIcon
return (
{!isInsideMobileNavigation && (
)}
)
}
================================================
FILE: docs_src/src/components/documentation/ModeToggle.jsx
================================================
function SunIcon(props) {
return (
)
}
function MoonIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/Navigation.jsx
================================================
import { useRef } from 'react'
import Link from 'next/link'
import { useRouter } from 'next/router'
import clsx from 'clsx'
import { AnimatePresence, motion, useIsPresent } from 'framer-motion'
import { useIsInsideMobileNavigation } from '@/components/documentation/MobileNavigation'
import { useSectionStore } from '@/components/documentation/SectionProvider'
import { Tag } from '@/components/documentation/Tag'
import LanguageSelector from '@/components/documentation/LanguageSelector'
import { remToPx } from '@/lib/remToPx'
function useInitialValue(value, condition = true) {
let initialValue = useRef(value).current
return condition ? initialValue : value
}
function TopLevelNavItem({ href, children }) {
return (
{children}
)
}
function NavLink({ href, tag, active, isAnchorLink = false, children }) {
return (
{children}
{tag && (
{tag}
)}
)
}
function VisibleSectionHighlight({ group, pathname }) {
let [sections, visibleSections] = useInitialValue(
[
useSectionStore((s) => s.sections),
useSectionStore((s) => s.visibleSections),
],
useIsInsideMobileNavigation()
)
let isPresent = useIsPresent()
let firstVisibleSectionIndex = Math.max(
0,
[{ id: '_top' }, ...sections].findIndex(
(section) => section.id === visibleSections[0]
)
)
let itemHeight = remToPx(2)
let height = isPresent
? Math.max(1, visibleSections.length) * itemHeight
: itemHeight
let top =
group.links.findIndex((link) => link.href === pathname) * itemHeight +
firstVisibleSectionIndex * itemHeight
return (
)
}
function ActivePageMarker({ group, pathname }) {
let itemHeight = remToPx(2)
let offset = remToPx(0.25)
let activePageIndex = group.links.findIndex((link) => link.href === pathname)
let top = offset + activePageIndex * itemHeight
return (
)
}
function NavigationGroup({ group, className }) {
// If this is the mobile navigation then we always render the initial
// state, so that the state does not change during the close animation.
// The state will still update when we re-open (re-render) the navigation.
let isInsideMobileNavigation = useIsInsideMobileNavigation()
let [router, sections] = useInitialValue(
[useRouter(), useSectionStore((s) => s.sections)],
isInsideMobileNavigation
)
let isActiveGroup =
group.links.findIndex((link) => link.href === router.pathname) !== -1
return (
{group.title}
{isActiveGroup && (
)}
{isActiveGroup && (
)}
{group.links.map((link) => (
{link.title}
{link.href === router.pathname && sections.length > 0 && (
{sections.map((section) => (
-
{section.title}
))}
)}
))}
)
}
export const navigation = [
{
title: 'Documentation',
links: [{ title: 'Introduction', href: '/documentation' }],
},
{
title: 'Example Application',
links: [
{ title: 'Getting Started', href: '/documentation/en/example_app' },
{
title: 'Modeling Routes',
href: '/documentation/en/example_app/modeling_routes',
},
{
title: 'Authentication and Authorization',
href: '/documentation/en/example_app/authentication',
},
{
title: 'Middlewares',
href: '/documentation/en/example_app/authentication-middlewares',
},
{
title: 'Real Time Notifications',
href: '/documentation/en/example_app/real_time_notifications',
},
{
title: 'Monitoring and Logging',
href: '/documentation/en/example_app/monitoring_and_logging',
},
{ title: 'Deployment', href: '/documentation/en/example_app/deployment' },
{
title: 'OpenAPI Documentation',
href: '/documentation/en/example_app/openapi',
},
{ title: 'Templates', href: '/documentation/en/example_app/templates' },
{
title: 'SubRouters',
href: '/documentation/en/example_app/subrouters',
},
],
},
{
title: 'API Reference',
links: [
{
href: '/documentation/en/api_reference/',
title: 'Installation',
},
{
href: '/documentation/en/api_reference/getting_started',
title: 'Getting Started',
},
{
href: '/documentation/en/api_reference/request_object',
title: 'The Request Object',
},
{
href: '/documentation/en/api_reference/robyn_env',
title: 'The Robyn Env file',
},
{
href: '/documentation/en/api_reference/middlewares',
title: 'Middlewares, Events and Websockets',
},
{
href: '/documentation/en/api_reference/authentication',
title: 'Authentication',
},
{
href: '/documentation/en/api_reference/const_requests',
title: 'Const Requests and Multi Core Scaling',
},
{
href: '/documentation/en/api_reference/cors',
title: 'CORS',
},
{
href: '/documentation/en/api_reference/templating',
title: 'Templating',
},
{
title: 'Redirection',
href: '/documentation/en/api_reference/redirection',
},
{
href: '/documentation/en/api_reference/file-uploads',
title: 'File Uploads',
},
{
href: '/documentation/en/api_reference/form_data',
title: 'Form Data',
},
{
href: '/documentation/en/api_reference/websockets',
title: 'Websockets',
},
{
href: '/documentation/en/api_reference/server_sent_events',
title: 'Server-Sent Events',
},
{
href: '/documentation/en/api_reference/exceptions',
title: 'Exceptions',
},
{
href: '/documentation/en/api_reference/scaling',
title: 'Scaling the Application',
},
{
href: '/documentation/en/api_reference/timeout_configuration',
title: 'Timeout Configuration',
},
{
href: '/documentation/en/api_reference/advanced_features',
title: 'Advanced Features',
},
{
href: '/documentation/en/api_reference/advanced_routing',
title: 'Advanced Routing',
},
{
href: '/documentation/en/api_reference/architecture_deep_dive',
title: 'Architecture Deep Dive',
},
{
href: '/documentation/en/api_reference/multiprocess_execution',
title: 'Multiprocess Execution',
},
{
href: '/documentation/en/api_reference/using_rust_directly',
title: 'Direct Rust Usage',
},
{
href: '/documentation/en/api_reference/graphql-support',
title: 'GraphQL Support',
},
{
href: '/documentation/en/api_reference/openapi',
title: 'OpenAPI Documentation',
},
{
href: '/documentation/en/api_reference/pydantic',
title: 'Pydantic Integration',
},
{
href: '/documentation/en/api_reference/dependency_injection',
title: 'Dependency Injection',
},
{
href: '/documentation/en/api_reference/mcps',
title: 'MCPs',
},
{
href: '/documentation/en/api_reference/ai',
title: 'AI',
},
{
href: '/documentation/en/api_reference/agents',
title: 'AI Agents',
},
],
},
{
title: 'Community Resources',
links: [
{
href: '/documentation/en/community-resources#talks',
title: 'Talks',
},
{
href: '/documentation/en/community-resources#blogs',
title: 'Blogs',
},
],
},
{
title: 'Architecture',
links: [
{
href: '/documentation/en/architecture',
title: 'Architecture',
},
],
},
{
title: 'Framework Comparison',
links: [
{
href: '/documentation/en/framework_performance_comparison',
title: 'Performance Comparison',
},
],
},
{
title: 'Hosting',
links: [
{
href: '/documentation/en/hosting#railway',
title: 'Railway',
},
{
href: '/documentation/en/hosting#exposing-ports',
title: 'Exposing Ports',
},
],
},
{
title: 'Plugins',
links: [
{
href: '/documentation/en/plugins',
title: 'Plugins',
},
],
},
{
title: 'Future Roadmap',
links: [
{
href: '/documentation/en/api_reference/future-roadmap',
title: 'Upcoming Features',
},
],
},
]
// Add translations for navigation titles
const navigationTitles = {
en: {
Documentation: 'Documentation',
'Example Application': 'Example Application',
'API Reference': 'API Reference',
'Community Resources': 'Community Resources',
Architecture: 'Architecture',
'Framework Comparison': 'Framework Comparison',
Hosting: 'Hosting',
Plugins: 'Plugins',
'Future Roadmap': 'Future Roadmap',
},
zh: {
'Documentation': '文档',
'Example Application': '应用示例',
'API Reference': 'API 参考',
'Community Resources': '社区资源',
'Architecture': '架构',
'Framework Comparison': '性能对比',
'Hosting': '托管',
'Plugins': '插件',
'Future Roadmap': '未来发展路线图'
}
}
// Add translations for navigation titles and link titles
const translations = {
en: {
titles: navigationTitles.en,
links: {
'Getting Started': 'Getting Started',
'Modeling Routes': 'Modeling Routes',
'Authentication and Authorization': 'Authentication and Authorization',
Middlewares: 'Middlewares',
'Real Time Notifications': 'Real Time Notifications',
'Monitoring and Logging': 'Monitoring and Logging',
Deployment: 'Deployment',
'OpenAPI Documentation': 'OpenAPI Documentation',
Templates: 'Templates',
SubRouters: 'SubRouters',
Installation: 'Installation',
'The Request Object': 'The Request Object',
'The Robyn Env file': 'The Robyn Env file',
'Middlewares, Events and Websockets':
'Middlewares, Events and Websockets',
Authentication: 'Authentication',
'Const Requests and Multi Core Scaling':
'Const Requests and Multi Core Scaling',
CORS: 'CORS',
Templating: 'Templating',
Redirection: 'Redirection',
'File Uploads': 'File Uploads',
'Form Data': 'Form Data',
Websockets: 'Websockets',
Exceptions: 'Exceptions',
'Scaling the Application': 'Scaling the Application',
'Timeout Configuration': 'Timeout Configuration',
'Advanced Features': 'Advanced Features',
'Advanced Routing': 'Advanced Routing',
'Architecture Deep Dive': 'Architecture Deep Dive',
'Multiprocess Execution': 'Multiprocess Execution',
'Direct Rust Usage': 'Direct Rust Usage',
'GraphQL Support': 'GraphQL Support',
'Dependency Injection': 'Dependency Injection',
'Pydantic Integration': 'Pydantic Integration',
'AI': 'AI',
'AI Agents': 'AI Agents',
Talks: 'Talks',
Blogs: 'Blogs',
Introduction: 'Introduction',
'Upcoming Features': 'Upcoming Features',
Railway: 'Railway',
'Exposing Ports': 'Exposing Ports',
},
},
zh: {
titles: navigationTitles.zh,
links: {
'Getting Started': '开始',
'Modeling Routes': '路由建模',
'Authentication and Authorization': '身份验证',
'Middlewares': '身份验证中间件',
'Real Time Notifications': '即时通讯',
'Monitoring and Logging': '监控和日志',
Deployment: '部署',
'OpenAPI Documentation': 'OpenAPI 文档',
Templates: '模板',
SubRouters: '子路由',
Installation: '安装',
'The Request Object': '请求对象',
'The Robyn Env file': 'Robyn 环境文件',
'Middlewares, Events and Websockets': '中间件、事件和 WebSocket',
Authentication: '身份验证',
'Const Requests and Multi Core Scaling': '常量请求和多核心扩展',
CORS: '跨域资源共享',
Templating: '模板系统',
Redirection: '重定向',
'File Uploads': '文件上传',
'Form Data': '表单数据',
'Websockets': 'WebSocket',
'Server-Sent Events': '服务器发送事件',
'Exceptions': '异常处理',
'Scaling the Application': '多核扩展',
'Timeout Configuration': '超时配置',
'Advanced Features': '高级特性',
'Advanced Routing': '高级路由',
'Architecture Deep Dive': '架构深度剖析',
'Multiprocess Execution': '多进程执行',
'Direct Rust Usage': '直接使用 Rust',
'GraphQL Support': 'GraphQL 支持',
'Dependency Injection': '依赖注入',
'Pydantic Integration': 'Pydantic 集成',
'AI': 'AI',
'AI Agents': 'AI 代理',
'Talks': '演讲',
'Blogs': '博客',
'Introduction': '引入',
'Upcoming Features': '即将推出的功能',
'Railway': 'Railway',
'Exposing Ports': '开放端口'
}
}
}
export function Navigation(props) {
const router = useRouter()
const currentLanguage = router.asPath.includes('/zh') ? 'zh' : 'en'
const getLocalizedHref = (href) => {
if (href === '/documentation') {
return `/documentation/${currentLanguage}`
}
return href.replace(
'/documentation/en/',
`/documentation/${currentLanguage}/`
)
}
// Create localized navigation with translated titles and link titles
const localizedNavigation = navigation.map((group) => ({
...group,
title: translations[currentLanguage].titles[group.title] || group.title,
links: group.links.map((link) => ({
...link,
title: translations[currentLanguage].links[link.title] || link.title,
href: getLocalizedHref(link.href),
})),
}))
return (
)
}
================================================
FILE: docs_src/src/components/documentation/Prose.jsx
================================================
import clsx from 'clsx'
export function Prose({ className, ...props }) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/Search.jsx
================================================
import { forwardRef, Fragment, useEffect, useId, useRef, useState } from 'react'
import { useRouter } from 'next/router'
import { createAutocomplete } from '@algolia/autocomplete-core'
import { getAlgoliaResults } from '@algolia/autocomplete-preset-algolia'
import { Dialog, Transition } from '@headlessui/react'
import algoliasearch from 'algoliasearch/lite'
import clsx from 'clsx'
const searchClient = algoliasearch(
process.env.NEXT_PUBLIC_ALGOLIA_APP_ID,
process.env.NEXT_PUBLIC_ALGOLIA_API_KEY
)
function useAutocomplete() {
let id = useId()
let router = useRouter()
let [autocompleteState, setAutocompleteState] = useState({})
let [autocomplete] = useState(() =>
createAutocomplete({
id,
placeholder: 'Find something...',
defaultActiveItemId: 0,
onStateChange({ state }) {
setAutocompleteState(state)
},
shouldPanelOpen({ state }) {
return state.query !== ''
},
navigator: {
navigate({ itemUrl }) {
autocomplete.setIsOpen(true)
router.push(itemUrl)
},
},
getSources() {
return [
{
sourceId: 'documentation',
getItemInputValue({ item }) {
return item.query
},
getItemUrl({ item }) {
let url = new URL(item.url)
const pathname = url.pathname
// Get current language from router
const currentLanguage = router.asPath.includes('/zh') ? 'zh' : 'en'
// Check if the URL already has a language prefix
if (pathname.match(/\/documentation\/(en|zh)\//)) {
// If it does, ensure it matches the current language
const pathWithCorrectLang = pathname.replace(
/\/documentation\/(en|zh)\//,
`/documentation/${currentLanguage}/`
)
return `${pathWithCorrectLang}${url.hash}`
} else if (pathname.includes('/documentation/')) {
// If it doesn't have a language prefix but has /documentation/, add the language prefix
const pathWithLang = pathname.replace(
'/documentation/',
`/documentation/${currentLanguage}/`
)
return `${pathWithLang}${url.hash}`
}
// Return the original URL if it doesn't match any of the above patterns
return `${pathname}${url.hash}`
},
onSelect({ itemUrl }) {
router.push(itemUrl)
},
getItems({ query }) {
return getAlgoliaResults({
searchClient,
queries: [
{
query,
indexName: process.env.NEXT_PUBLIC_ALGOLIA_INDEX_NAME,
params: {
hitsPerPage: 5,
highlightPreTag:
'',
highlightPostTag: '',
},
},
],
})
},
},
]
},
})
)
return { autocomplete, autocompleteState }
}
function resolveResult(result) {
let allLevels = Object.keys(result.hierarchy)
let hierarchy = Object.entries(result._highlightResult.hierarchy).filter(
([, { value }]) => Boolean(value)
)
let levels = hierarchy.map(([level]) => level)
let level =
result.type === 'content'
? levels.pop()
: levels
.filter(
(level) =>
allLevels.indexOf(level) <= allLevels.indexOf(result.type)
)
.pop()
return {
titleHtml: result._highlightResult.hierarchy[level].value,
hierarchyHtml: hierarchy
.slice(0, levels.indexOf(level))
.map(([, { value }]) => value),
}
}
function SearchIcon(props) {
return (
)
}
function NoResultsIcon(props) {
return (
)
}
function LoadingIcon(props) {
let id = useId()
return (
)
}
function SearchResult({ result, resultIndex, autocomplete, collection }) {
let id = useId()
let { titleHtml, hierarchyHtml } = resolveResult(result)
return (
0 && 'border-t border-zinc-800'
)}
aria-labelledby={`${id}-hierarchy ${id}-title`}
{...autocomplete.getItemProps({
item: result,
source: collection.source,
})}
>
{hierarchyHtml.length > 0 && (
{hierarchyHtml.map((item, itemIndex, items) => (
/
))}
)}
)
}
function SearchResults({ autocomplete, query, collection }) {
if (collection.items.length === 0) {
return (
Nothing found for{' '}
‘{query}’
. Please try again.
)
}
return (
{collection.items.map((result, resultIndex) => (
))}
)
}
const SearchInput = forwardRef(function SearchInput(
{ autocomplete, autocompleteState, onClose },
inputRef
) {
let inputProps = autocomplete.getInputProps({})
return (
{
if (
event.key === 'Escape' &&
!autocompleteState.isOpen &&
autocompleteState.query === ''
) {
// In Safari, closing the dialog with the escape key can sometimes cause the scroll position to jump to the
// bottom of the page. This is a workaround for that until we can figure out a proper fix in Headless UI.
document.activeElement?.blur()
onClose()
} else {
inputProps.onKeyDown(event)
}
}}
/>
{autocompleteState.status === 'stalled' && (
)}
)
})
function AlgoliaLogo(props) {
return (
)
}
function SearchButton(props) {
let [modifierKey, setModifierKey] = useState()
useEffect(() => {
setModifierKey(
/(Mac|iPhone|iPod|iPad)/i.test(navigator.platform) ? '⌘' : 'Ctrl '
)
}, [])
return (
<>
)
}
function SearchDialog({ open, setOpen, className }) {
let router = useRouter()
let formRef = useRef()
let panelRef = useRef()
let inputRef = useRef()
let { autocomplete, autocompleteState } = useAutocomplete()
useEffect(() => {
if (!open) {
return
}
function onRouteChange() {
setOpen(false)
}
router.events.on('routeChangeStart', onRouteChange)
router.events.on('hashChangeStart', onRouteChange)
return () => {
router.events.off('routeChangeStart', onRouteChange)
router.events.off('hashChangeStart', onRouteChange)
}
}, [open, setOpen, router])
useEffect(() => {
if (open) {
return
}
function onKeyDown(event) {
if (event.key === 'k' && (event.metaKey || event.ctrlKey)) {
event.preventDefault()
setOpen(true)
}
}
window.addEventListener('keydown', onKeyDown)
return () => {
window.removeEventListener('keydown', onKeyDown)
}
}, [open, setOpen])
return (
autocomplete.setQuery('')}
>
)
}
function useSearchProps() {
let buttonRef = useRef()
let [open, setOpen] = useState(false)
return {
buttonProps: {
ref: buttonRef,
onClick() {
setOpen(true)
},
},
dialogProps: {
open,
setOpen(open) {
let { width, height } = buttonRef.current.getBoundingClientRect()
if (!open || (width !== 0 && height !== 0)) {
setOpen(open)
}
},
},
}
}
export function Search() {
let [modifierKey, setModifierKey] = useState()
let { buttonProps, dialogProps } = useSearchProps()
useEffect(() => {
setModifierKey(
/(Mac|iPhone|iPod|iPad)/i.test(navigator.platform) ? '⌘' : 'Ctrl '
)
}, [])
return (
)
}
export function MobileSearch() {
let { buttonProps, dialogProps } = useSearchProps()
return (
)
}
================================================
FILE: docs_src/src/components/documentation/SectionProvider.jsx
================================================
import {
createContext,
useContext,
useEffect,
useLayoutEffect,
useState,
} from 'react'
import { createStore, useStore } from 'zustand'
import { remToPx } from '@/lib/remToPx'
function createSectionStore(sections) {
return createStore((set) => ({
sections,
visibleSections: [],
setVisibleSections: (visibleSections) =>
set((state) =>
state.visibleSections.join() === visibleSections.join()
? {}
: { visibleSections }
),
registerHeading: ({ id, ref, offsetRem }) =>
set((state) => {
return {
sections: state.sections.map((section) => {
if (section.id === id) {
return {
...section,
headingRef: ref,
offsetRem,
}
}
return section
}),
}
}),
}))
}
function useVisibleSections(sectionStore) {
let setVisibleSections = useStore(sectionStore, (s) => s.setVisibleSections)
let sections = useStore(sectionStore, (s) => s.sections)
useEffect(() => {
function checkVisibleSections() {
let { innerHeight, scrollY } = window
let newVisibleSections = []
for (
let sectionIndex = 0;
sectionIndex < sections.length;
sectionIndex++
) {
let { id, headingRef, offsetRem } = sections[sectionIndex]
let offset = remToPx(offsetRem)
let top = headingRef.current.getBoundingClientRect().top + scrollY
if (sectionIndex === 0 && top - offset > scrollY) {
newVisibleSections.push('_top')
}
let nextSection = sections[sectionIndex + 1]
let bottom =
(nextSection?.headingRef.current.getBoundingClientRect().top ??
Infinity) +
scrollY -
remToPx(nextSection?.offsetRem ?? 0)
if (
(top > scrollY && top < scrollY + innerHeight) ||
(bottom > scrollY && bottom < scrollY + innerHeight) ||
(top <= scrollY && bottom >= scrollY + innerHeight)
) {
newVisibleSections.push(id)
}
}
setVisibleSections(newVisibleSections)
}
let raf = window.requestAnimationFrame(() => checkVisibleSections())
window.addEventListener('scroll', checkVisibleSections, { passive: true })
window.addEventListener('resize', checkVisibleSections)
return () => {
window.cancelAnimationFrame(raf)
window.removeEventListener('scroll', checkVisibleSections)
window.removeEventListener('resize', checkVisibleSections)
}
}, [setVisibleSections, sections])
}
const SectionStoreContext = createContext()
const useIsomorphicLayoutEffect =
typeof window === 'undefined' ? useEffect : useLayoutEffect
export function SectionProvider({ sections, children }) {
let [sectionStore] = useState(() => createSectionStore(sections))
useVisibleSections(sectionStore)
useIsomorphicLayoutEffect(() => {
sectionStore.setState({ sections })
}, [sectionStore, sections])
return (
{children}
)
}
export function useSectionStore(selector) {
let store = useContext(SectionStoreContext)
return useStore(store, selector)
}
================================================
FILE: docs_src/src/components/documentation/Tag.jsx
================================================
import clsx from 'clsx'
const variantStyles = {
medium: 'rounded-lg px-1.5 ring-1 ring-inset',
}
const colorStyles = {
orange: {
small: 'text-orange-400',
medium: 'ring-orange-400/30 bg-orange-400/10 text-orange-400',
},
sky: {
small: 'text-sky-500',
medium: 'ring-sky-400/30 bg-sky-400/10 text-sky-400',
},
amber: {
small: 'text-amber-500',
medium: 'ring-amber-400/30 bg-amber-400/10 text-amber-400',
},
rose: {
small: 'text-rose-500',
medium: 'ring-rose-500/20 bg-rose-400/10 text-rose-400',
},
zinc: {
small: 'text-zinc-500',
medium: 'ring-zinc-500/20 bg-zinc-400/10 text-zinc-400',
},
}
const valueColorMap = {
get: 'orange',
post: 'sky',
put: 'amber',
delete: 'rose',
}
export function Tag({
children,
variant = 'medium',
color = valueColorMap[children.toLowerCase()] ?? 'orange',
}) {
return (
{children}
)
}
================================================
FILE: docs_src/src/components/documentation/icons/BellIcon.jsx
================================================
export function BellIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/BoltIcon.jsx
================================================
export function BoltIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/BookIcon.jsx
================================================
export function BookIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/CalendarIcon.jsx
================================================
export function CalendarIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/CartIcon.jsx
================================================
export function CartIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/ChatBubbleIcon.jsx
================================================
export function ChatBubbleIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/CheckIcon.jsx
================================================
export function CheckIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/ChevronRightLeftIcon.jsx
================================================
export function ChevronRightLeftIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/ClipboardIcon.jsx
================================================
export function ClipboardIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/CogIcon.jsx
================================================
export function CogIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/CopyIcon.jsx
================================================
export function CopyIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/DocumentIcon.jsx
================================================
export function DocumentIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/EnvelopeIcon.jsx
================================================
export function EnvelopeIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/FaceSmileIcon.jsx
================================================
export function FaceSmileIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/FolderIcon.jsx
================================================
export function FolderIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/LinkIcon.jsx
================================================
export function LinkIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/ListIcon.jsx
================================================
export function ListIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/MagnifyingGlassIcon.jsx
================================================
export function MagnifyingGlassIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/MapPinIcon.jsx
================================================
export function MapPinIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/PackageIcon.jsx
================================================
export function PackageIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/PaperAirplaneIcon.jsx
================================================
export function PaperAirplaneIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/PaperClipIcon.jsx
================================================
export function PaperClipIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/ShapesIcon.jsx
================================================
export function ShapesIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/ShirtIcon.jsx
================================================
export function ShirtIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/SquaresPlusIcon.jsx
================================================
export function SquaresPlusIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/TagIcon.jsx
================================================
export function TagIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/UserIcon.jsx
================================================
export function UserIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/icons/UsersIcon.jsx
================================================
export function UsersIcon(props) {
return (
)
}
================================================
FILE: docs_src/src/components/documentation/mdx.jsx
================================================
import Link from 'next/link'
import clsx from 'clsx'
import { Heading } from '@/components/documentation/Heading'
export const a = Link
export { Button } from '@/components/documentation/Button'
export {
CodeGroup,
Code as code,
Pre as pre,
} from '@/components/documentation/Code'
export const h2 = function H2(props) {
return
}
export const h3 = function H3(props) {
return (
)
}
function InfoIcon(props) {
return (
)
}
export function Note({ children }) {
return (
)
}
export function Row({ children }) {
return (
{children}
)
}
export function Col({ children, sticky = false }) {
return (
:first-child]:mt-0 [&>:last-child]:mb-0',
sticky && 'xl:sticky xl:top-24'
)}
>
{children}
)
}
export function Properties({ children }) {
return (
)
}
export function Property({ name, type, children }) {
return (
- Name
-
{name}
- Type
- {type}
- Description
-
{children}
)
}
================================================
FILE: docs_src/src/components/releases/Button.jsx
================================================
import Link from 'next/link'
import clsx from 'clsx'
function ButtonInner({ arrow = false, children }) {
return (
<>
{children} {arrow ? → : null}
)
}
export function Button({ href, className, arrow, children, ...props }) {
className = clsx(
className,
'group relative isolate flex-none rounded-md py-1.5 text-[0.8125rem]/6 font-semibold text-white',
arrow ? 'pl-2.5 pr-[calc(9/16*1rem)]' : 'px-2.5'
)
return href ? (
{children}
) : (
)
}
================================================
FILE: docs_src/src/components/releases/FeedProvider.jsx
================================================
import { createContext, useContext } from 'react'
let FeedContext = createContext({ isFeed: false })
export function FeedProvider({ children }) {
return (
{children}
)
}
export function useFeed() {
return useContext(FeedContext)
}
================================================
FILE: docs_src/src/components/releases/FormattedDate.jsx
================================================
const dateFormatter = new Intl.DateTimeFormat('en-US', {
year: 'numeric',
month: 'short',
day: 'numeric',
timeZone: 'UTC',
})
export function FormattedDate({ date, ...props }) {
date = typeof date === 'string' ? new Date(date) : date
return (
)
}
================================================
FILE: docs_src/src/components/releases/IconLink.jsx
================================================
import Link from 'next/link'
import clsx from 'clsx'
export function IconLink({
children,
className,
compact = false,
large = false,
icon: Icon,
...props
}) {
return (
{children}
)
}
================================================
FILE: docs_src/src/components/releases/Intro.jsx
================================================
import { IconLink } from '@/components/releases/IconLink'
import { SignUpForm } from '@/components/releases/SignUpForm'
import {
InstagramIcon,
LinkedInIcon,
TwitterIcon,
} from '@/components/SocialIcons'
function BookIcon(props) {
return (
)
}
function GitHubIcon(props) {
return (
)
}
function FeedIcon(props) {
return (
)
}
export function Intro() {
return (
<>
All the latest Robyn releases,
right here.
Twitter
Release Page
)
}
================================================
FILE: docs_src/src/components/releases/Layout.jsx
================================================
import { useId } from 'react'
import { Intro } from '@/components/releases/Intro'
function Timeline() {
let id = useId()
return (
)
}
function FixedSidebar({ main }) {
return (
)
}
export function Layout({ children }) {
return (
<>
} />
{children}
)
}
================================================
FILE: docs_src/src/components/releases/SignUpForm.jsx
================================================
import { useId } from 'react'
import { Button } from '@/components/Button'
export function SignUpForm() {
let id = useId()
return (
)
}
================================================
FILE: docs_src/src/components/releases/mdx.jsx
================================================
import { useEffect, useRef, useState } from 'react'
import Image from 'next/image'
import Link from 'next/link'
import clsx from 'clsx'
import { useFeed } from '@/components/releases/FeedProvider'
import { FormattedDate } from '@/components/releases/FormattedDate'
export const a = Link
export const wrapper = function Wrapper({ children }) {
return children
}
export function H2(props) {
let { isFeed } = useFeed()
if (isFeed) {
return null
}
return (
)
}
export const p = function Paragraph({ children }) {
return {children}
}
export const img = function Img(props) {
return (
)
}
function ContentWrapper({ className, children }) {
return (
)
}
function ArticleHeader({ id, date }) {
return (
)
}
export function Article({ id, title, date, children }) {
let { isFeed } = useFeed()
let heightRef = useRef(null)
let [heightAdjustment, setHeightAdjustment] = useState(0)
useEffect(() => {
let observer = new window.ResizeObserver(() => {
let { height } = heightRef.current.getBoundingClientRect()
let nextMultipleOf8 = 8 * Math.ceil(height / 8)
setHeightAdjustment(nextMultipleOf8 - height)
})
observer.observe(heightRef.current)
return () => {
observer.disconnect()
}
}, [])
if (isFeed) {
return (
{children}
)
}
return (
)
}
export const article = Article
export const h2 = H2
export const ul = function UnorderedList({ children }) {
return
}
export const code = function Code({ highlightedCode, ...props }) {
if (highlightedCode) {
return (
{children}
}
================================================
FILE: docs_src/src/lib/formatDate.js
================================================
export function formatDate(dateString) {
return new Date(`${dateString}T00:00:00Z`).toLocaleDateString('en-US', {
day: 'numeric',
month: 'long',
year: 'numeric',
timeZone: 'UTC',
})
}
================================================
FILE: docs_src/src/lib/getAllArticles.js
================================================
import glob from 'fast-glob'
import * as path from 'path'
async function importArticle(articleFilename) {
let { meta, default: component } = await import(
`../pages/articles/${articleFilename}`
)
return {
slug: articleFilename.replace(/(\/index)?\.mdx$/, ''),
...meta,
component,
}
}
export async function getAllArticles() {
let articleFilenames = await glob(['*.mdx', '*/index.mdx'], {
cwd: path.join(process.cwd(), 'src/pages/articles'),
})
let articles = await Promise.all(articleFilenames.map(importArticle))
return articles.sort((a, z) => new Date(z.date) - new Date(a.date))
}
================================================
FILE: docs_src/src/lib/remToPx.js
================================================
export function remToPx(remValue) {
let rootFontSize =
typeof window === 'undefined'
? 16
: parseFloat(window.getComputedStyle(document.documentElement).fontSize)
return parseFloat(remValue) * rootFontSize
}
================================================
FILE: docs_src/src/pages/_app.jsx
================================================
import { useEffect, useRef } from 'react'
import { Footer, GithubButton } from '@/components/Footer'
import { Header } from '@/components/Header'
import '@/styles/tailwind.css'
import '@/styles/documentation.css'
import 'focus-visible'
import { Router, useRouter } from 'next/router'
import { MDXProvider } from '@mdx-js/react'
import { Layout } from '@/components/documentation/Layout'
import { Layout as ReleaseLayout } from '@/components/releases/Layout'
import * as mdxComponents from '@/components/documentation/mdx'
import { useMobileNavigationStore } from '@/components/documentation/MobileNavigation'
import { Analytics } from '@vercel/analytics/react'
function usePrevious(value) {
let ref = useRef()
useEffect(() => {
ref.current = value
}, [value])
return ref.current
}
function onRouteChange() {
useMobileNavigationStore.getState().close()
}
Router.events.on('routeChangeStart', onRouteChange)
Router.events.on('hashChangeStart', onRouteChange)
export default function App({ Component, pageProps, router }) {
let previousPathname = usePrevious(router.pathname)
let router_ = useRouter()
if (router_.pathname.includes('documentation')) {
return (
<>
)
} else if (router_.pathname.includes('release')) {
return (
<>
)
}
return (
<>
)
}
================================================
FILE: docs_src/src/pages/_document.jsx
================================================
import { Head, Html, Main, NextScript } from 'next/document'
import { Analytics } from '@vercel/analytics/react';
const modeScript = `
let darkModeMediaQuery = window.matchMedia('(prefers-color-scheme: dark)')
updateMode()
darkModeMediaQuery.addEventListener('change', updateModeWithoutTransitions)
window.addEventListener('storage', updateModeWithoutTransitions)
function updateMode() {
let isSystemDarkMode = darkModeMediaQuery.matches
let isDarkMode = window.localStorage.isDarkMode === 'true' || (!('isDarkMode' in window.localStorage) && isSystemDarkMode)
if (isDarkMode) {
document.documentElement.classList.add('dark')
} else {
document.documentElement.classList.remove('dark')
}
if (isDarkMode === isSystemDarkMode) {
delete window.localStorage.isDarkMode
}
}
function disableTransitionsTemporarily() {
document.documentElement.classList.add('[&_*]:!transition-none')
window.setTimeout(() => {
document.documentElement.classList.remove('[&_*]:!transition-none')
}, 0)
}
function updateModeWithoutTransitions() {
disableTransitionsTemporarily()
updateMode()
}
`
export default function Document() {
return (
)
}
================================================
FILE: docs_src/src/pages/community.jsx
================================================
import Head from 'next/head'
import Image from 'next/image'
import sparcklesLogo from '@/images/sparckles-logo.png'
import { useEffect, useState } from 'react'
function Contributors() {
const [contributors, setContributors] = useState([])
const [error, setError] = useState(null)
useEffect(() => {
const fetchContributors = async () => {
try {
const response = await fetch(
`https://api.github.com/repos/sparckles/robyn/contributors`
)
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`)
}
const data = await response.json()
setContributors(data)
} catch (error) {
setError(error.toString())
}
}
fetchContributors()
}, [])
if (error) {
return {error}
}
return (
{contributors.map((contributor) => (
))}
Robyn Community
Robyn is a community project and is housed under the sparckles
organisation.
{/* Content section */}
{/* Values section */}
Join us on our journey
Join us on our journey to spark new ideas, ignite the spirit of
open-source development, and break down the walls that limit
innovation and progress. Together, we can create a brighter future
for the Python ecosystem and the global software community.
{/* Team section */}
Our team
Robyn is housed under an open source organisation called
Sparckles. We are a group of developers passionate about the open
source community. Come join us and help us empower the Python web
ecosystem.
{/* CTA section */}
Sparckles
Sparckles is an innovative open-source organization dedicated
to enhancing the Python ecosystem by developing cutting-edge
tools, fostering a vibrant community, and providing robust
infrastructure solutions.
{/* sponsors */}
Sponsors
Thanks to our sponsors for supporting us!
-
{/* Community Contributors */}
-

)
}
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/advanced_features.mdx
================================================
export const description =
'On this page, we’ll dive into the different conversation endpoints you can use to manage conversations programmatically.'
## Keep a track of client's IP address
Now that the portal was up and ready, Batman realised that the Joker was using the Gotham Police Dashboard too. So, he wanted to keep a track of the IP address of the client who was accessing his application. He used the following code to do so:
Batman scaled his application across multiple cores for better performance. He used the following command:
```python
from robyn import Robyn, Request
app = Robyn(__file__)
@app.get("/")
async def h(request: Request):
return f"hello to you, {request.ip_addr}"
```
---
## What's next?
Batman wondered about how to help users explore the endpoints in his application.
Robyn showed him the OpenAPI Documentation!
[OpenAPI Documentation](/documentation/en/api_reference/openapi)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/advanced_routing.mdx
================================================
export const description =
'Master Robyn\'s advanced routing features including parameter injection, route optimization, and complex URL patterns.'
# Advanced Routing and Parameter Injection
Robyn's routing system goes far beyond simple URL matching. It includes sophisticated parameter injection, route optimization, and flexible pattern matching that makes building complex APIs effortless.
## Understanding Parameter Injection
Robyn automatically analyzes your function signatures and injects the appropriate request components. This eliminates boilerplate code and makes handlers cleaner.
### The Injection Engine
The parameter injection system works in two phases:
1. **Function Introspection**: Robyn analyzes your function signature at registration time
2. **Runtime Injection**: For each request, Robyn provides the exact parameters your function needs
**Type-Based Injection**: Uses type annotations to determine what to inject
```python
from robyn import Request, QueryParams, Headers
from robyn.types import PathParams, RequestBody, RequestMethod
@app.post("/users/:user_id/posts/:post_id")
async def update_post(
# Robyn automatically injects these based on type annotations
request: Request, # Complete request object
path_params: PathParams, # {"user_id": "123", "post_id": "456"}
query_params: QueryParams, # ?draft=true&tags=python,web
headers: Headers, # All request headers
body: RequestBody, # Raw request body
method: RequestMethod # "POST"
):
user_id = path_params["user_id"]
post_id = path_params["post_id"]
is_draft = query_params.get("draft") == "true"
content_type = headers.get("content-type")
return {
"user_id": user_id,
"post_id": post_id,
"is_draft": is_draft,
"body_size": len(body),
"method": method
}
```
**Name-Based Injection**: Uses parameter names to inject components when type annotations aren't available
```python
# Reserved parameter names that Robyn recognizes
@app.get("/search/:category")
def search_handler(
query_params, # Injected by name
path_params, # Injected by name
headers, # Injected by name
request # Injected by name (full request object)
):
category = path_params["category"]
search_term = query_params.get("q", "")
user_agent = headers.get("user-agent", "")
return {
"category": category,
"search": search_term,
"user_agent": user_agent
}
```
### Complete List of Injectable Types
| Type Annotation | Reserved Name | Description |
|-----------------|---------------|-------------|
| `Request` | `request`, `req`, `r` | Complete request object |
| `QueryParams` | `query_params` | URL query parameters |
| `Headers` | `headers` | Request headers |
| `PathParams` | `path_params` | URL path parameters |
| `RequestBody` | `body` | Raw request body |
| `RequestMethod` | `method` | HTTP method (GET, POST, etc.) |
| `RequestURL` | `url` | Request URL information |
| `FormData` | `form_data` | Form-encoded data |
| `RequestFiles` | `files` | Uploaded files |
| `RequestIP` | `ip_addr` | Client IP address |
| `RequestIdentity` | `identity` | Authentication identity |
## Advanced URL Patterns
### Dynamic Route Parameters
Robyn supports multiple types of path parameters with flexible matching patterns.
```python
# Simple parameter
@app.get("/users/:id")
def get_user(path_params):
return {"user_id": path_params["id"]}
# Multiple parameters
@app.get("/users/:user_id/posts/:post_id")
def get_user_post(path_params):
return {
"user_id": path_params["user_id"],
"post_id": path_params["post_id"]
}
# Optional parameters with defaults
@app.get("/posts/:id/:slug?")
def get_post(path_params):
post_id = path_params["id"]
slug = path_params.get("slug", f"post-{post_id}")
return {"id": post_id, "slug": slug}
# Wildcard matching
@app.get("/files/*filepath")
def serve_file(path_params):
filepath = path_params["filepath"]
return {"serving": filepath}
```
### Route Constraints and Validation
While Robyn doesn't have built-in parameter validation, you can implement it in your handlers for type safety.
```python
import re
from robyn import HTTPException
@app.get("/users/:user_id")
def get_user(path_params):
user_id = path_params["user_id"]
# Validate that user_id is numeric
if not user_id.isdigit():
raise HTTPException(400, "user_id must be numeric")
user_id = int(user_id)
if user_id <= 0:
raise HTTPException(400, "user_id must be positive")
return {"user_id": user_id}
@app.get("/posts/:slug")
def get_post_by_slug(path_params):
slug = path_params["slug"]
# Validate slug format
if not re.match(r'^[a-z0-9-]+$', slug):
raise HTTPException(400, "Invalid slug format")
return {"slug": slug}
```
## Route Optimization
### Const Routes for Static Responses
Use `const=True` for responses that never change. These are cached in Rust memory and the handler function is never re-executed after startup.
When no middleware is registered, const routes take a fast path served entirely from the Rust layer without entering Python at all. When middleware is registered (including global before-request and after-request handlers), const routes still serve the cached response but middleware executes normally for every request. This means const routes are always safe to use alongside middleware.
```python
# Perfect for health checks, static configuration
@app.get("/health", const=True)
def health_check():
return {"status": "healthy", "version": "1.0"}
# API metadata that rarely changes
@app.get("/api/info", const=True)
def api_info():
return {
"name": "My API",
"version": "2.1.0",
"documentation": "/docs"
}
# Static configuration endpoints
@app.get("/config/public", const=True)
def public_config():
return {
"max_upload_size": "10MB",
"allowed_origins": ["https://myapp.com"]
}
```
### Route Priority and Ordering
Routes are matched in the order they're registered. More specific routes should be registered before general ones.
```python
# GOOD: Specific routes first
@app.get("/users/profile")
def get_current_user_profile():
return {"profile": "current_user"}
@app.get("/users/settings")
def get_user_settings():
return {"settings": "user_settings"}
@app.get("/users/:id")
def get_user(path_params):
return {"user_id": path_params["id"]}
# BAD: This would never be reached
# @app.get("/users/:id") # Registered first
# @app.get("/users/profile") # Never matched!
```
## Advanced Query Parameter Handling
### Query Parameter Parsing
Robyn provides rich query parameter handling with automatic type conversion helpers.
```python
@app.get("/search")
def search(query_params):
# Basic parameter access
q = query_params.get("q", "")
# Parameters with defaults
page = int(query_params.get("page", "1"))
limit = int(query_params.get("limit", "10"))
# Boolean parameters
include_deleted = query_params.get("include_deleted", "false").lower() == "true"
# Array parameters (?tags=python&tags=web&tags=api)
tags = query_params.get_list("tags") or []
# Convert to dict for easier processing
all_params = query_params.to_dict()
return {
"query": q,
"page": page,
"limit": limit,
"include_deleted": include_deleted,
"tags": tags,
"all_params": all_params
}
```
### Complex Query String Patterns
Handle complex query patterns like filtering, sorting, and nested parameters.
```python
@app.get("/api/products")
def get_products(query_params):
# Filtering: ?filter[category]=electronics&filter[price_min]=100
filters = {}
for key, value in query_params.to_dict().items():
if key.startswith("filter[") and key.endswith("]"):
filter_key = key[7:-1] # Remove "filter[" and "]"
filters[filter_key] = value
# Sorting: ?sort=price&order=desc
sort_field = query_params.get("sort", "created_at")
sort_order = query_params.get("order", "asc")
# Pagination: ?page=2&per_page=20
page = int(query_params.get("page", "1"))
per_page = min(int(query_params.get("per_page", "10")), 100) # Cap at 100
# Field selection: ?fields=id,name,price
fields = query_params.get("fields", "").split(",") if query_params.get("fields") else None
return {
"filters": filters,
"sort": {"field": sort_field, "order": sort_order},
"pagination": {"page": page, "per_page": per_page},
"fields": fields
}
```
## SubRouters and Modular Routing
### Creating SubRouters
SubRouters help organize large applications by grouping related routes with common prefixes.
```python
from robyn import Robyn, SubRouter
app = Robyn(__file__)
# API v1 routes
api_v1 = SubRouter(__file__, prefix="/api/v1")
@api_v1.get("/users")
def list_users():
return {"users": []}
@api_v1.get("/users/:id")
def get_user(path_params):
return {"user_id": path_params["id"]}
@api_v1.post("/users")
def create_user(body):
return {"created": True, "data": body}
# Admin routes
admin = SubRouter(__file__, prefix="/admin")
@admin.get("/dashboard")
def admin_dashboard():
return {"dashboard": "admin"}
@admin.get("/users")
def admin_users():
return {"admin_users": []}
# Register subrouters
app.include_router(api_v1)
app.include_router(admin)
# Routes are now available at:
# /api/v1/users, /api/v1/users/:id, /admin/dashboard, etc.
```
### SubRouter Middleware
Configure authentication handlers on SubRouters and apply authentication to routes using `auth_required=True`.
```python
from robyn import SubRouter
from robyn.authentication import AuthenticationHandler
# Admin routes with authentication
admin = SubRouter(__file__, prefix="/admin")
class AdminAuth(AuthenticationHandler):
def authenticate(self, request):
auth_header = request.headers.get("authorization", "")
if not auth_header.startswith("Bearer "):
return None
token = auth_header[7:] # Remove "Bearer "
return self.validate_admin_token(token)
def validate_admin_token(self, token):
# Your token validation logic
if token == "admin-secret-token":
return {"user": "admin"} # Return identity object
return None
# Configure the authentication handler for this SubRouter
admin.configure_authentication(AdminAuth())
# Routes must explicitly require authentication with auth_required=True
@admin.get("/users", auth_required=True)
def admin_users():
return {"admin_users": ["user1", "user2"]}
@admin.delete("/users/:id", auth_required=True)
def delete_user(path_params):
return {"deleted": path_params["id"]}
```
## Route Testing and Debugging
### Route Inspection
Debug your routes by inspecting the registered route table.
```python
from robyn import Robyn
app = Robyn(__file__)
@app.get("/users/:id")
def get_user(path_params):
return {"user": path_params["id"]}
@app.post("/users")
def create_user(body):
return {"created": True}
# Debug: Print all registered routes
if __name__ == "__main__":
print("Registered routes:")
for route in app.get_routes():
print(f"{route.method} {route.path}")
app.start(port=8080)
```
### Route Performance Monitoring
Add timing middleware to monitor route performance.
```python
import time
from robyn import Robyn
app = Robyn(__file__)
@app.before_request
def timing_middleware(request):
request.start_time = time.time()
return request
@app.after_request
def timing_after_middleware(request, response):
duration = time.time() - request.start_time
print(f"{request.method} {request.url.path} - {duration:.3f}s")
response.headers["X-Response-Time"] = f"{duration:.3f}s"
return response
@app.get("/slow")
def slow_endpoint():
time.sleep(0.1) # Simulate work
return {"message": "slow response"}
```
## Best Practices
### 1. Parameter Injection Patterns
- **Use type annotations** for better IDE support and self-documenting code
- **Inject only what you need** to keep handlers focused
- **Validate parameters early** to provide clear error messages
### 2. Route Organization
- **Group related routes** using SubRouters
- **Order routes from specific to general** to avoid matching issues
- **Use consistent naming conventions** for path parameters
### 3. Performance Optimization
- **Use const routes** for static responses
- **Minimize parameter injection** in high-traffic endpoints
- **Cache expensive computations** rather than repeating them
### 4. Error Handling
- **Validate path parameters** early in handlers
- **Provide meaningful error messages** for invalid input
- **Use consistent error response formats** across your API
## What's Next?
Now that you've mastered advanced routing, explore other Robyn features:
- [Middleware Development Guide](/documentation/en/api_reference/middlewares_advanced)
- [Performance Optimization](/documentation/en/api_reference/performance_optimization)
- [WebSocket Advanced Features](/documentation/en/api_reference/websockets_advanced)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/agents.mdx
================================================
export const description =
'Robyn AI Agents provide intelligent functionality for building AI-powered applications using MCP (Model Context Protocol) implementation with file system access, task management, and context-aware capabilities.'
# Agents
This guide demonstrates how to build AI-powered agents using Robyn's MCP (Model Context Protocol) implementation.
## Overview
The agent system connects AI assistants like Claude Desktop to your development environment, providing seamless access to:
- File system operations (read, search, organize)
- Task and note management
- System monitoring and git integration
- Web content fetching and analysis
- Context-aware code analysis
## Quick Start
1. Run the MCP server:
```bash
python examples/agents.py
```
2. Connect your AI assistant to `http://localhost:8080/mcp`
3. Start using natural language commands:
- "What files are in my projects directory?"
- "Show me my recent git commits"
- "Create a note about today's standup meeting"
- "What processes are using the most CPU?"
- "Add a task to review the quarterly report"
## Configuration
The assistant creates the following structure:
```
~/Documents/
├── notes/ # Markdown notes
└── tasks.json # Task list
~/projects/ # Development projects
├── project1/
└── project2/
```
## Security
- File access restricted to home directory
- Safe mathematical expression evaluation
- Path validation for all file operations
- Read-only git operations
## Available Resources
### File System
- `fs://{path}` - Read files in home directory
- `fs://dir/{path}` - List directory contents
### Git Integration
- `git://repo/{repo_name}` - Repository status and commits
### System Monitoring
- `system://processes` - Running processes
- `system://stats` - System statistics
## Available Tools
- `create_note(title, content, tags)` - Create markdown notes
- `add_task(task, priority, due_date)` - Add tasks
- `complete_task(task_id)` - Mark tasks complete
- `search_files(query, directory)` - Search file contents
- `fetch_url_content(url, max_length)` - Download web content
## Available Prompts
- `analyze_file_structure(directory)` - Generate project analysis
- `code_review_request(file_path, focus_area)` - Create code reviews
- `task_prioritization(context)` - Organize and prioritize work
## Dependencies
Optional enhanced functionality:
```bash
pip install psutil # Enhanced system monitoring
```
## Implementation Examples
### Development Workflow
"Analyze my projects directory and help prioritize work based on recent activity"
### Project Analysis
"Review my web-app project structure and suggest improvements"
### Meeting Notes
"Create a note about today's architecture review with key decisions"
### Code Search
"Find all files mentioning 'authentication' and summarize approaches"
### Task Management
"Add high-priority task to refactor user service, due Friday"
## Integration Benefits
Connecting AI assistants to your development environment enables:
- Native file system browsing
- Context-aware project conversations
- Personalized code suggestions
- Real-time task management
- Workspace-specific code reviews
## Advanced Features
The MCP implementation includes:
- URI templates with parameter extraction
- Auto-generated schemas from type hints
- Async/sync operation handlers
- MCP-compliant error handling
- Type-safe parameter passing
Extend easily with custom resources, tools, and prompts for your specific workflow.
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/ai.mdx
================================================
export const description =
'Robyn AI provides agent and memory functionality for building intelligent applications with conversation history, context awareness, and pluggable AI runners.'
# AI Agent and Memory
Robyn includes built-in AI capabilities that allow you to create intelligent applications with conversation memory, context awareness, and pluggable agent runners. The AI module provides abstractions for memory storage and agent execution that can be easily integrated into your Robyn applications.
## Installation
The AI features are included with the base Robyn installation:
```bash
pip install robyn
```
## Quick Start
Here's a simple example of using Robyn's AI features:
```python
from robyn import Robyn
from robyn.ai import agent, memory
app = Robyn(__file__)
# Create memory instance
mem = memory(provider="inmemory", user_id="user123")
# Create agent with memory
chat_agent = agent(runner="simple", memory=mem)
@app.get("/chat")
async def chat_endpoint(request):
query = request.query_params.get("q", [""])[0]
if not query:
return {"error": "Query required"}
# Run agent with conversation history
result = await chat_agent.run(query, history=True)
return result
```
## Memory System
The memory system provides persistent storage for conversation history and context. It supports multiple providers and offers a consistent interface for storing and retrieving conversation data.
### Memory Providers
#### InMemory Provider
The simplest provider that stores data in memory. Data is lost when the application restarts.
```python
from robyn.ai import memory
# Create in-memory storage
mem = memory(provider="inmemory", user_id="user123")
# Add messages
await mem.add("Hello, how are you?")
await mem.add("I'm doing great, thanks!")
# Retrieve all messages
messages = await mem.get()
# Clear memory
await mem.clear()
```
### Memory API
The Memory class provides these key methods:
- `add(message, metadata=None)` - Store a message with optional metadata
- `get(query=None)` - Retrieve messages, optionally filtered by query
- `clear()` - Clear all stored messages for the user
## Agent System
Agents provide the execution layer for AI functionality. They can use different runners and integrate with memory for context-aware responses.
### Agent Runners
#### Simple Runner
A runner with OpenAI integration that provides intelligent responses:
```python
from robyn.ai import agent
# Create simple agent with OpenAI
from robyn.ai import configure
config = configure(openai_api_key="your-openai-key")
simple_agent = agent(runner="simple", config=config)
# Use the agent
result = await simple_agent.run("What's the weather like?")
# Returns structured response with AI-generated content
```
### Agent API
The Agent class provides:
- `run(query, history=False, **kwargs)` - Execute the agent with optional history context
- Automatic memory integration when provided
- Support for custom runners and configuration
## Complete Example
Here's a comprehensive example showing all features:
```python
from robyn import Robyn
from robyn.ai import agent, memory
app = Robyn(__file__)
# Create memory with InMemory provider
mem = memory(
provider="inmemory",
user_id="guest"
)
# Create agent with memory
chat_agent = agent(runner="simple", memory=mem)
@app.get("/")
async def home():
return {"message": "Robyn AI Chat API"}
@app.post("/chat")
async def chat(request):
"""Chat with AI agent"""
data = request.json()
query = data.get("query", "")
include_history = data.get("history", True)
if not query:
return {"error": "Query is required"}
try:
result = await chat_agent.run(query, history=include_history)
return {
"query": query,
"response": result.get("response"),
"history_included": include_history
}
except Exception as e:
return {"error": str(e)}
@app.get("/memory")
async def get_memory():
"""Retrieve conversation history"""
try:
memories = await mem.get()
return {"memories": memories, "count": len(memories)}
except Exception as e:
return {"error": str(e)}
@app.delete("/memory")
async def clear_memory():
"""Clear conversation history"""
try:
await mem.clear()
return {"message": "Memory cleared"}
except Exception as e:
return {"error": str(e)}
@app.post("/memory")
async def add_memory(request):
"""Add message to memory"""
data = request.json()
message = data.get("message", "")
metadata = data.get("metadata", {})
if not message:
return {"error": "Message is required"}
try:
await mem.add(message, metadata)
return {"message": "Added to memory"}
except Exception as e:
return {"error": str(e)}
if __name__ == "__main__":
app.start(host="127.0.0.1", port=8080)
```
## Advanced Usage
### Custom Memory Providers
You can create custom memory providers by extending the `MemoryProvider` abstract base class:
```python
from robyn.ai import MemoryProvider
from typing import Dict, List, Any, Optional
class CustomMemoryProvider(MemoryProvider):
async def store(self, user_id: str, data: Dict[str, Any]) -> None:
# Implement custom storage logic
pass
async def retrieve(self, user_id: str, query: Optional[str] = None) -> List[Dict[str, Any]]:
# Implement custom retrieval logic
return []
async def clear(self, user_id: str) -> None:
# Implement custom clearing logic
pass
# Use custom provider
from robyn.ai import Memory
custom_mem = Memory(provider=CustomMemoryProvider(), user_id="user123")
```
### Custom Agent Runners
Similarly, you can create custom agent runners:
```python
from robyn.ai import AgentRunner
from typing import Dict, Any
class CustomAgentRunner(AgentRunner):
async def run(self, query: str, **kwargs) -> Dict[str, Any]:
# Implement custom agent logic
return {
"response": f"Custom response to: {query}",
"processed": True
}
# Use custom runner
from robyn.ai import Agent
custom_agent = Agent(runner=CustomAgentRunner())
```
## Best Practices
1. **User Isolation**: Always use unique user IDs to isolate memory between different users
2. **Error Handling**: Wrap AI operations in try-catch blocks as external services may fail
3. **Memory Management**: Regularly clear or archive old memories to prevent unbounded growth
4. **Configuration**: Store sensitive configuration (API keys, etc.) in environment variables
5. **Testing**: Use the simple runner for development and testing before deploying complex agents
## Troubleshooting
### Common Issues
**ImportError for openai**: Install the required package:
```bash
pip install openai
```
**Memory not persisting**: Note that the in-memory provider loses data when the application restarts. Consider implementing a custom persistent provider for production use.
**Agent timeouts**: Complex operations may take time. Consider implementing timeout handling in your endpoints.
**Memory growing too large**: Implement periodic cleanup or use providers with built-in retention policies.
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/architecture_deep_dive.mdx
================================================
export const description =
'Deep dive into Robyn\'s unique hybrid Python-Rust architecture and how it delivers exceptional performance while maintaining Python\'s ease of use.'
# Architecture Deep Dive
Robyn's architecture is unique in the Python web framework landscape. It combines Python's expressiveness with Rust's performance through a carefully designed hybrid system. This deep dive explains how Robyn works under the hood and why it's so fast.
## The Hybrid Python-Rust Design
### Two-Layer Architecture
Robyn operates on two distinct but interconnected layers:
1. **Python Layer**: Provides the developer-facing API, routing configuration, and business logic
2. **Rust Layer**: Handles HTTP parsing, request routing, response generation, and I/O operations
The Python layer is where you write your application code. It handles:
- Route definitions and decorators
- Request parameter injection
- Middleware configuration
- Business logic execution
- Response formatting
```python
from robyn import Robyn, Request
app = Robyn(__file__)
@app.get("/users/:id")
async def get_user(request: Request, user_id: str):
# Business logic runs in Python
user = await fetch_user_from_db(user_id)
return {"user": user.to_dict()}
```
The Rust layer handles all performance-critical operations:
- HTTP request parsing
- URL routing and matching
- WebSocket connections
- Static file serving
- Response serialization
```rust
// This happens internally in Robyn's Rust core
impl HttpRouter {
pub fn route_request(&self, method: &str, path: &str) -> Option {
// High-performance routing using matchit crate
self.router.at(path).ok().map(|matched| {
RouteInfo {
handler: matched.value.clone(),
params: matched.params.clone(),
}
})
}
}
```
### PyO3 Bridge: Connecting Python and Rust
The magic happens through PyO3, which enables seamless communication between Python and Rust:
**Function Registration**: When you define a route handler in Python, Robyn registers it with the Rust runtime through PyO3 bindings.
```python
# Python side - route registration
@app.get("/api/data")
def handler(request):
return {"data": "example"}
# Internally, this creates a FunctionInfo object
# that's passed to the Rust runtime
```
**Request Execution Flow**: When a request arrives, the Rust layer routes it and then calls back into Python to execute your handler.
```
1. HTTP Request arrives → Rust HTTP parser
2. Route matching → Rust router (matchit crate)
3. Parameter extraction → Rust
4. Handler execution → Python (via PyO3)
5. Response processing → Rust
6. HTTP Response → Client
```
## Performance Optimizations
### Fast Path for Static Responses
Robyn includes a "const routes" optimization for static responses:
When you mark a route as `const`, Robyn caches the response in Rust memory and never re-executes the Python handler. If no middleware is registered, const routes are served entirely from the Rust layer without entering Python at all. When middleware is present, the cached response is still used but before-request and after-request middleware execute normally.
```python
# This response is cached in Rust memory
@app.get("/health", const=True)
def health_check():
return {"status": "healthy"}
# Without middleware: served directly from Rust, bypassing Python entirely
# With middleware: cached response is used, but middleware still runs
```
### Zero-Copy Request Handling
The Rust layer uses zero-copy techniques wherever possible:
- Request bodies are parsed once and shared between layers
- String data is referenced rather than copied
- Response buffers are reused across requests
### Async Runtime Integration
Robyn integrates with Python's asyncio while maintaining Rust's async runtime:
**Sync Handlers**: Executed in a thread pool to avoid blocking the async runtime
```python
@app.get("/sync")
def sync_handler(request):
# Runs in thread pool
time.sleep(1) # Won't block other requests
return "Done"
```
**Async Handlers**: Executed directly in the async runtime for maximum performance
```python
@app.get("/async")
async def async_handler(request):
# Runs in main async runtime
await asyncio.sleep(1)
return "Done"
```
## Advanced Parameter Injection
One of Robyn's most sophisticated features is its parameter injection system:
### Type-Based Injection
Robyn analyzes your function signatures and automatically injects the appropriate request components based on type annotations.
```python
from robyn import Request, QueryParams, Headers
from robyn.types import PathParams, RequestBody
@app.post("/complex/:id")
async def complex_handler(
request: Request, # Full request object
query_params: QueryParams, # ?param=value
headers: Headers, # Request headers
path_params: PathParams, # :id from URL
body: RequestBody # Request body
):
return {
"id": path_params["id"],
"query": query_params.to_dict(),
"user_agent": headers.get("user-agent"),
"body_length": len(body)
}
```
### Name-Based Injection
You can also use reserved parameter names without type annotations.
```python
@app.get("/simple/:id")
def simple_handler(query_params, path_params, headers):
# Parameters injected based on names
return {
"id": path_params["id"],
"search": query_params.get("q", ""),
"auth": headers.get("authorization")
}
```
## Memory Management
### Python Object Lifecycle
Robyn carefully manages Python objects across the Python-Rust boundary:
1. **Request Objects**: Created once per request and reused
2. **Response Objects**: Efficiently serialized and passed to Rust
3. **Handler References**: Stored in Rust and called via PyO3
### Rust Memory Safety
The Rust layer benefits from Rust's ownership system:
- No memory leaks from HTTP parsing
- Safe concurrent access to shared data
- Automatic cleanup of connection resources
## Scaling Architecture
### Multi-Process Mode
Robyn can spawn multiple processes to utilize all CPU cores.
```bash
# Spawn 4 worker processes
python app.py --processes 4 --workers 2
# Each process runs independently with shared-nothing architecture
```
### Multi-Worker Mode
Within each process, multiple worker threads handle requests concurrently.
```python
# Workers share the same Python interpreter
# but handle requests concurrently
app.start(port=8080, workers=4)
```
## WebSocket Architecture
### Persistent Connections
Robyn's WebSocket implementation maintains persistent connections in the Rust layer while allowing Python handlers to process messages:
**Connection Management**: Handled entirely in Rust for efficiency
**Message Processing**: Python handlers process individual messages
**Broadcasting**: Rust-based message distribution for high throughput
```python
from robyn import WebSocketDisconnect
@app.websocket("/chat")
async def websocket_handler(websocket):
try:
while True:
message = await websocket.receive_text()
response = process_chat_message(message)
await websocket.send_text(response)
except WebSocketDisconnect:
pass
```
## Why This Architecture Works
1. **Best of Both Worlds**: Python's productivity with Rust's performance
2. **Gradual Optimization**: Hot paths can be moved to Rust incrementally
3. **Memory Efficiency**: Minimal copying between layers
4. **Async Integration**: Seamless integration with Python's async/await
5. **Safety**: Rust's memory safety prevents common server vulnerabilities
This architecture allows Robyn to achieve performance comparable to pure Rust web frameworks while maintaining the ease of development that Python developers expect.
## What's Next?
Now that you understand Robyn's architecture, explore how to leverage its advanced features:
- [Advanced Routing and Parameter Injection](/documentation/en/api_reference/advanced_routing)
- [Performance Optimization Guide](/documentation/en/api_reference/performance_optimization)
- [WebSocket Deep Dive](/documentation/en/api_reference/websockets_advanced)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/authentication.mdx
================================================
export const description =
'On this page, we’ll dive into the different conversation endpoints you can use to manage conversations programmatically.'
After Creating a basic version of the app, Batman wanted to restrict the access to the Gotham Police Department. So, he enquired about the Authentication functionalities in Robyn.
## Authentication
As Batman found out, Robyn provides an easy way to add an authentication middleware to your application. You can then specify `auth_required=True` in your routes to make them accessible only to authenticated users.
```python
@app.get("/auth", auth_required=True)
async def auth(request: Request):
# This route method will only be executed if the user is authenticated
# Otherwise, a 401 response will be returned
return "Hello, world"
```
To add an authentication middleware, you can use the `configure_authentication` method. This method requires an `AuthenticationHandler` object as an argument. This object specifies how to authenticate a user, and uses a `TokenGetter` object to retrieve the token from the request. Robyn does currently provide a `BearerGetter` class that gets the token from the `Authorization` header, using the `Bearer` scheme. Here is an example of a basic authentication handler:
```python
class BasicAuthHandler(AuthenticationHandler):
def authenticate(self, request: Request) -> Optional[Identity]:
token = self.token_getter.get_token(request)
if token == "valid":
return Identity(claims={})
return None
app.configure_authentication(BasicAuthHandler(token_getter=BearerGetter()))
```
The authenticate method should return an `Identity` object if the user is authenticated, or `None` otherwise. The Identity object can contain any data you want, and will be accessible in the route methods using the `request.identity` attribute.
Note: that this authentication system is basically only using a `before request` middleware under the hood. This means you can overlook it and create your own authentication system using middlewares if you want to. However, Robyn still provides this easy to implement solution that should suit most use cases.
---
## What's next?
Now, that Batman has learned about authentication, he wanted to know about certain optimization techniques that he could use to make his application faster. He found out about the following features
- [Const Requests and Multi Core Scaling](/documentation/en/api_reference/const_requests)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/const_requests.mdx
================================================
export const description =
'On this page, we’ll dive into the different conversation endpoints you can use to manage conversations programmatically.'
After authentication, Batman was worried about the website traffic during the rush hours. He was worried about the server crashing when Joker would try to break all the criminals from the Arkham asylum one more time. So, Robyn told him about the `Const Requests` feature and the multi-core scaling potential.
## Const Requests
Robyn told Batman that you can pre-compute the response for each route. This will compute the response even before execution. This will improve the response time bypassing the need to access the router.
```python
@app.get("/", const=True)
async def h():
return "Hello, world"
```
## Muli-core scaling
Robyn told Batman that he can use the `--workers` flag to scale the application to multiple cores. This will create multiple instances of the application and will distribute the load among them. This will improve the performance of the application.
```python
python3 app.py --workers=N --process=M
```
The authenticate method should return an `Identity` object if the user is authenticated, or `None` otherwise. The Identity object can contain any data you want, and will be accessible in the route methods using the `request.identity` attribute.
Note: that this authentication system is basically only using a `before request` middleware under the hood. This means you can overlook it and create your own authentication system using middlewares if you want to. However, Robyn still provides this easy to implement solution that should suit most use cases.
---
## What's next?
After making the application faster, Batman was happy and wanted to make a request from his Frontend Dashboard.
But he was faced with CORS issues! He asked Robyn about how to solve this issue. Robyn told him about the following features
- [CORS](/documentation/en/api_reference/cors)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/cors.mdx
================================================
export const description =
'On this page, we’ll dive into the different conversation endpoints you can use to manage conversations programmatically.'
## CORS
Batman was annoyed on getting a CORS error whenever he tried to access the API.
## Scaling the Application
You can allow CORS for your application by adding the following code:
```python
from robyn import Robyn, ALLOW_CORS
app = Robyn(__file__)
ALLOW_CORS(app, origins = ["http://localhost:/"])
```
---
## What's next?
After fixing the CORS issues. Batman was satisfied but he wanted to learn about ways to have small frontend pages in the server itself.
Robyn told him about templates and how he can use them to render HTML pages.
- [Templating](/documentation/en/api_reference/templating)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/dependency_injection.mdx
================================================
export const description =
'On this page, we will learn about dependency injection in Robyn.'
## Dependency Injection
Batman wanted to learn about dependency injection in Robyn. Robyn introduced him to the concept of dependency injection and how it can be used in Robyn.
Robyn has two types of dependency injection:
One is for the application level and the other is for the router level.
### Application Level Dependency Injection
Application level dependency injection is used to inject dependencies into the application. These dependencies are available to all the requests.
```python
from robyn import Robyn, ALLOW_CORS
app = Robyn(__file__)
GLOBAL_DEPENDENCY = "GLOBAL DEPENDENCY"
app.inject_global(GLOBAL_DEPENDENCY=GLOBAL_DEPENDENCY)
@app.get("/sync/global_di")
def sync_global_di(request, global_dependencies):
return global_dependencies["GLOBAL_DEPENDENCY"]
```
### Router Level Dependency Injection
Router level dependency injection is used to inject dependencies into the router. These dependencies are available to all the requests of that router.
```python
from robyn import Robyn, ALLOW_CORS, Request
app = Robyn(__file__)
ROUTER_DEPENDENCY = "ROUTER DEPENDENCY"
app.inject(ROUTER_DEPENDENCY=ROUTER_DEPENDENCY)
@app.get("/sync/global_di")
def sync_global_di(r: Request, router_dependencies):
return router_dependencies["ROUTER_DEPENDENCY"]
```
Note: `router_dependencies`, `global_dependencies` are reserved parameters and **must** be named as such. The order of the parameters does not matter among them. However, the `router_dependencies` and `global_dependencies` must only come after the `request` parameter.
### WebSocket Dependency Injection
WebSockets support the same dependency injection system as HTTP routes. The `global_dependencies` and `router_dependencies` parameters work in the main handler, `on_connect`, and `on_close` callbacks.
```python {{ title: 'WebSocket DI' }}
from robyn import Robyn
import logging
app = Robyn(__file__)
app.inject_global(logger=logging.getLogger(__name__))
app.inject(cache=RedisCache())
@app.websocket("/chat")
async def chat(websocket, global_dependencies=None, router_dependencies=None):
logger = global_dependencies.get("logger")
cache = router_dependencies.get("cache")
logger.info(f"New connection: {websocket.id}")
while True:
message = await websocket.receive_text()
cache.set(f"ws_{websocket.id}", message)
await websocket.broadcast(f"User {websocket.id}: {message}")
@chat.on_connect
async def on_connect(websocket, global_dependencies=None):
logger = global_dependencies.get("logger")
logger.info(f"Client connected: {websocket.id}")
return "Connected"
```
---
## What's next?
Batman, being the familiar with the dark side wanted to know about Exceptions!
Robyn introduced him to the concept of exceptions and how he can use them to handle errors in his application.
- [Exceptions](/documentation/en/api_reference/exceptions)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/exceptions.mdx
================================================
## Custom Exception Handler
Batman learned how to create custom error handlers for different exception types in his application. He wrote the following code to handle exceptions and return a custom error response:
```python
@app.exception
def handle_exception(error: Exception):
return Response(status_code=500, description=f"error msg: {error}", headers={})
```
---
## What's next?
Now, Batman wanted to scale his application across multiple cores. Robyn led him to Scaling.
- [Scaling](/documentation/en/api_reference/scaling)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/file-uploads.mdx
================================================
export const description =
'On this page, we’ll dive into the different conversation endpoints you can use to manage conversations programmatically.'
## File Uploads
Batman learned how to handle file uploads using Robyn. He created an endpoint to handle file uploads using the following code:
## Sending a File without MultiPart Form Data
Batman scaled his application across multiple cores for better performance. He used the following command:
```python
@app.post("/upload")
async def upload():
body = request.body
file = bytearray(body)
# write whatever filename
with open('test.txt', 'wb') as f:
f.write(file)
return {'message': 'success'}
```
## Sending a File with MultiPart Form Data
Batman scaled his application across multiple cores for better performance. He used the following command:
```python
@app.post("/sync/multipart-file")
def sync_multipart_file(request: Request):
files = request.files
file_names = files.keys()
return {"file_names": list(file_names)}
```
---
## File Downloads
Batman now wanted to allow users to download files from his application. He created an endpoint to handle file downloads using the following code:
### Serving Simple HTML Files
Batman scaled his application across multiple cores for better performance. He used the following command:
```python
from robyn import Robyn, Request, serve_html
app = Robyn(__file__)
@app.get("/")
async def h(request: Request):
return serve_html("./index.html")
app.start(port=8080)
```
### Serving simple HTML strings
Speaking of HTML files, Batman wanted to serve simple HTML strings. He was suggested to use the following code:
```python
from robyn import Robyn, Request, html
app = Robyn(__file__)
@app.get("/")
async def h(request: Request):
html_string = "Hello World
"
return html(html_string)
app.start(port=8080)
```
### Serving Other Files
Now, that Batman was able to serve HTML files, he wanted to serve other files like CSS, JS, and images. He was suggested to use the following code:
```python
from robyn import Robyn, serve_file, Request
app = Robyn(__file__)
@app.get("/")
async def h(request: Request):
return serve_file("./index.html", file_name="index.html") # file_name is optional
app.start(port=8080)
```
### Serving Directories
After serving other files, Batman wanted to serve directories, e.g. to serve a React build directory or just a simple HTML/CSS/JS directory. He was suggested to use the following code:
```python
from robyn import Robyn, serve_file, Request
app = Robyn(__file__)
app.serve_directory(
route="/test_dir",
directory_path=os.path.join(current_file_path, "build"),
index_file="index.html",
)
app.start(port=8080)
```
## What's next?
Now, Batman was ready to learn about the advanced features of Robyn. He wanted to find a way to handle form data
- [Form Data](/documentation/en/api_reference/form_data)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/form_data.mdx
================================================
export const description =
'On this page, we’ll dive into using the form data.'
## Form Data and Multi Part Form Data
Batman learned how to handle file uploads using Robyn. Now, he wanted to handle the form data.
## Handling Multi Part Form Data
Batman uploaded some multipart form data and wanted to handle it using the following code:
```python
@app.post("/upload")
async def upload(request: Request):
form_data = request.form_data
return form_data
```
## What's next?
Now, Batman was ready to learn about the advanced features of Robyn. He wanted to find a way to get realtime updates in his dashboard.
- [WebSockets](/documentation/en/api_reference/websockets)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/future-roadmap.mdx
================================================
export const description =
'On this page, we`ll take a look at the future roadmap for Robyn.'
- Add performance optimizations
- Pydantic Integration
- Implement Auto Const Requests
- Add ORM support, especially Prisma integration
- Improve Plugin Ecosystem
- Better Documentation
- Improve the Websockets
- Template Support
- Graphql integration with Strawberry
- Invest more time in the community around Robyn.
## Next Steps
- [Advanced Features](/documentation/en/api_reference/advanced_features)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/getting_started.mdx
================================================
export const description =
'On this page, we’ll dive into the different fundamentals of building web applications with Robyn, including examples and best practices.'
## Building Your First Robyn Application
Robyn is the fastest Python web framework, combining Python's simplicity with Rust's performance. Whether you're building APIs, web services, or full-stack applications, Robyn makes it easy to get started and scale.
### Quick Start
Install Robyn and create your first application in minutes:
```bash
pip install robyn
```
## Understanding Handler Types
Robyn supports both synchronous and asynchronous request handlers, allowing you to choose the best approach for your use case:
- **Synchronous handlers**: Perfect for CPU-bound operations, simple logic, or when you don't need to wait for external resources
- **Asynchronous handlers**: Ideal for I/O-bound operations like database calls, HTTP requests, file operations, or any task that involves waiting
**Synchronous handlers** are perfect for simple operations, calculations, or when you don't need to wait for external resources:
```python
from robyn import Robyn, Request
app = Robyn(__file__)
@app.get("/")
def h(request: Request):
return "Hello, world"
app.start(port=8080, host="0.0.0.0") # host is optional, defaults to 127.0.0.1
```
**Asynchronous handlers** are ideal for database operations, HTTP requests, file I/O, or any operation that involves waiting:
```python
from robyn import Request
@app.get("/")
async def h(request: Request) -> str:
return "Hello, world"
```
### Complete Example: User Management API
Here's a comprehensive example that demonstrates both sync and async handlers, proper error handling, and real-world patterns:
```python
from robyn import Robyn, Request
import asyncio
import json
import time
from typing import Dict, Any
app = Robyn(__file__)
# In-memory storage for demo (use a real database in production)
users: Dict[str, Dict[str, Any]] = {
"1": {"id": "1", "name": "Alice", "email": "alice@example.com", "created_at": "2024-01-01"},
"2": {"id": "2", "name": "Bob", "email": "bob@example.com", "created_at": "2024-01-02"}
}
# Const route for health checks (cached in Rust for max performance)
@app.get("/health", const=True)
def health_check():
return {"status": "healthy", "version": "1.0.0"}
# Async handler for database-like operations
@app.get("/users/:id")
async def get_user(path_params):
user_id = path_params["id"]
# Simulate async database lookup
await asyncio.sleep(0.01) # Simulate DB query time
if user_id in users:
return {"success": True, "user": users[user_id]}
else:
return {"success": False, "error": "User not found"}, 404
# Get all users with pagination
@app.get("/users")
async def list_users(query_params):
page = int(query_params.get("page", "1"))
limit = int(query_params.get("limit", "10"))
# Simulate async operation
await asyncio.sleep(0.01)
user_list = list(users.values())
start = (page - 1) * limit
end = start + limit
return {
"users": user_list[start:end],
"total": len(user_list),
"page": page,
"limit": limit
}
# Create new user
@app.post("/users")
async def create_user(body):
try:
data = json.loads(body)
# Validate required fields
if not data.get("name") or not data.get("email"):
return {"success": False, "error": "Name and email are required"}, 400
# Generate new ID
new_id = str(len(users) + 1)
new_user = {
"id": new_id,
"name": data["name"],
"email": data["email"],
"created_at": time.strftime("%Y-%m-%d")
}
# Simulate async database save
await asyncio.sleep(0.02)
users[new_id] = new_user
return {"success": True, "user": new_user}, 201
except json.JSONDecodeError:
return {"success": False, "error": "Invalid JSON"}, 400
# Sync handler for CPU-intensive operations
@app.post("/calculate")
def calculate_fibonacci(body):
try:
data = json.loads(body)
n = data.get("number", 10)
if n < 0 or n > 35: # Prevent excessive computation
return {"error": "Number must be between 0 and 35"}, 400
# CPU-intensive calculation (runs in thread pool)
def fib(x):
if x <= 1:
return x
return fib(x-1) + fib(x-2)
start_time = time.time()
result = fib(n)
calc_time = time.time() - start_time
return {
"input": n,
"result": result,
"calculation_time": f"{calc_time:.4f}s"
}
except json.JSONDecodeError:
return {"error": "Invalid JSON"}, 400
if __name__ == "__main__":
app.start(port=8080)
```
### Testing Your API
Once your server is running, you can test these endpoints using curl or any HTTP client:
```bash
# Test health endpoint
curl http://localhost:8080/health
# Get a user
curl http://localhost:8080/users/1
# List users with pagination
curl "http://localhost:8080/users?page=1&limit=5"
# Create a new user
curl -X POST http://localhost:8080/users \
-H "Content-Type: application/json" \
-d '{"name": "Charlie", "email": "charlie@example.com"}'
# Calculate fibonacci
curl -X POST http://localhost:8080/calculate \
-H "Content-Type: application/json" \
-d '{"number": 20}'
```
---
## Running Your Application
Robyn applications can be run in several ways, each optimized for different scenarios. Here are the most common approaches:
**Direct execution** - Run your application file directly with various optimization flags:
- `--dev`: Development mode with auto-reload
- `--fast`: Optimized settings for production
- `--processes N`: Scale across multiple CPU cores
- `--workers N`: Multiple workers per process
```bash
usage: app.py [-h] [--processes PROCESSES] [--workers WORKERS] [--log-level LOG_LEVEL] [--create] [--docs] [--open-browser] [--version]
Robyn, a fast async web framework with a rust runtime.
options:
-h, --help show this help message and exit
--processes PROCESSES
Choose the number of processes. [Default: 1]
--workers WORKERS Choose the number of workers. [Default: 1]
--dev Development mode. It restarts the server based on file changes.
--log-level LOG_LEVEL
Set the log level name
--create Create a new project template.
--docs Open the Robyn documentation.
--open-browser Open the browser on successful start.
--version Show the Robyn version.
--compile-rust-path COMPILE_RUST_PATH
Compile rust files in the given path.
--create-rust-file CREATE_RUST_FILE
Create a rust file with the given name.
--disable-openapi Disable the OpenAPI documentation.
--fast Fast mode. It sets the optimal values for processes, workers and log level. However, you can override them.
```
### Common Run Configurations
**Development Mode**: Best for local development with automatic reloading when files change.
```bash
# Basic development mode
python app.py --dev
# Development with custom port
python app.py --dev --port 3000
# Development with debug logging
python app.py --dev --log-level DEBUG
```
**Production Mode**: Optimized for performance with multiple processes and workers.
```bash
# Fast mode (automatic optimization)
python app.py --fast
# Custom scaling configuration
python app.py --processes 4 --workers 2
# Production with specific log level
python app.py --fast --log-level INFO
```
|
**Module execution** - Use Robyn's CLI module for additional features and consistent behavior across environments:
```bash
usage: python -m robyn app.py [-h] [--processes PROCESSES] [--workers WORKERS] [--dev] [--log-level LOG_LEVEL] [--create] [--docs] [--open-browser] [--version]
Robyn, a fast async web framework with a rust runtime.
options:
-h, --help show this help message and exit
--processes PROCESSES
Choose the number of processes. [Default: 1]
--workers WORKERS Choose the number of workers. [Default: 1]
--dev Development mode. It restarts the server based on file changes.
--log-level LOG_LEVEL
Set the log level name
--create Create a new project template.
--docs Open the Robyn documentation.
--open-browser Open the browser on successful start.
--version Show the Robyn version.
--compile-rust-path COMPILE_RUST_PATH
Compile rust files in the given path.
--create-rust-file CREATE_RUST_FILE
Create a rust file with the given name.
--disable-openapi Disable the OpenAPI documentation.
--fast Fast mode. It sets the optimal values for processes, workers and log level. However, you can override them.
```
---
## Handling Different HTTP Methods
Robyn supports all standard HTTP methods. Here's how to create a complete RESTful API with proper request handling:
**Complete REST API Example**: Here's a practical example showing all HTTP methods for a blog post API:
```python
from robyn import Robyn, Request
app = Robyn(__file__)
# In-memory storage for demo
posts = {
"1": {"id": "1", "title": "First Post", "content": "Hello World"},
"2": {"id": "2", "title": "Second Post", "content": "Learning Robyn"}
}
# GET - Retrieve all posts
@app.get("/posts")
def get_posts(query_params):
limit = int(query_params.get("limit", "10"))
posts_list = list(posts.values())[:limit]
return {"posts": posts_list, "total": len(posts)}
# GET - Retrieve specific post
@app.get("/posts/:id")
def get_post(path_params):
post_id = path_params["id"]
if post_id in posts:
return {"post": posts[post_id]}
return {"error": "Post not found"}, 404
# POST - Create new post
@app.post("/posts")
def create_post(request: Request):
data = request.json()
post_id = str(len(posts) + 1)
new_post = {
"id": post_id,
"title": data.get("title", ""),
"content": data.get("content", "")
}
posts[post_id] = new_post
return {"message": "Post created", "post": new_post}, 201
# PUT - Update entire post
@app.put("/posts/:id")
def update_post(request: Request, path_params):
post_id = path_params["id"]
if post_id not in posts:
return {"error": "Post not found"}, 404
data = request.json()
posts[post_id] = {
"id": post_id,
"title": data.get("title", ""),
"content": data.get("content", "")
}
return {"message": "Post updated", "post": posts[post_id]}
# PATCH - Partial update
@app.patch("/posts/:id")
def patch_post(request: Request, path_params):
post_id = path_params["id"]
if post_id not in posts:
return {"error": "Post not found"}, 404
data = request.json()
post = posts[post_id]
# Update only provided fields
if "title" in data:
post["title"] = data["title"]
if "content" in data:
post["content"] = data["content"]
return {"message": "Post updated", "post": post}
# DELETE - Remove post
@app.delete("/posts/:id")
def delete_post(path_params):
post_id = path_params["id"]
if post_id not in posts:
return {"error": "Post not found"}, 404
deleted_post = posts.pop(post_id)
return {"message": "Post deleted", "post": deleted_post}
```
---
## Working with JSON and Response Formats
Robyn automatically handles JSON serialization, but also provides flexible response formatting options for different use cases.
**Automatic JSON Handling**: Robyn automatically converts Python dictionaries and lists to JSON responses with the correct Content-Type headers.
```python
from robyn import Robyn, Request
from datetime import datetime
app = Robyn(__file__)
# Simple JSON response - automatic serialization
@app.get("/api/status")
def get_status():
return {
"status": "active",
"timestamp": datetime.now().isoformat(),
"version": "1.0.0"
}
# Complex nested JSON
@app.get("/api/user/:id")
def get_user_profile(path_params):
user_id = path_params["id"]
return {
"user": {
"id": user_id,
"profile": {
"name": "John Doe",
"email": "john@example.com",
"preferences": {
"theme": "dark",
"notifications": True
}
},
"activity": [
{"action": "login", "timestamp": "2024-01-15T10:30:00Z"},
{"action": "view_post", "timestamp": "2024-01-15T10:35:00Z"}
]
}
}
# List/array responses
@app.get("/api/posts")
def get_posts():
return [
{"id": 1, "title": "First Post", "published": True},
{"id": 2, "title": "Draft Post", "published": False},
{"id": 3, "title": "Latest Post", "published": True}
]
# Custom status codes with JSON
@app.post("/api/posts")
def create_post(request: Request):
try:
data = request.json()
# Validate required fields
if not data.get("title"):
return {"error": "Title is required"}, 400
# Success response
return {
"message": "Post created successfully",
"post": {
"id": 123,
"title": data["title"],
"created_at": datetime.now().isoformat()
}
}, 201
except ValueError:
return {"error": "Invalid JSON format"}, 400
```
## Parameter Injection and Route Handling
Robyn provides powerful parameter injection that automatically extracts and injects request components into your handler functions. This eliminates boilerplate code and makes handlers cleaner and more focused.
**Path Parameters**: Extract dynamic segments from URLs using colon syntax (`:param`)
**Type-Safe Injection**: Use type annotations for automatic parameter injection with IDE support
```python {{ title: 'Type-based injection' }}
from robyn import Request
from robyn.types import PathParams
@app.get("/users/:id/posts/:post_id")
async def get_user_post(request: Request, path_params: PathParams):
user_id = path_params["id"]
post_id = path_params["post_id"]
# Validate parameters
if not user_id.isdigit():
return {"error": "Invalid user ID"}, 400
return {
"user_id": int(user_id),
"post_id": post_id,
"url": request.url.path
}
```
```python {{ title: 'Name-based injection' }}
@app.get("/users/:id/posts/:post_id")
async def get_user_post(request, path_params):
user_id = path_params["id"]
post_id = path_params["post_id"]
return {
"user_id": user_id,
"post_id": post_id,
"method": request.method
}
```
**Query Parameters**: Access URL query strings with automatic parsing and type conversion helpers
```python {{ title: 'Advanced query handling' }}
from robyn import Request
from robyn.robyn import QueryParams
@app.get("/search")
async def search_products(request: Request, query_params: QueryParams):
# Get search parameters with defaults
query = query_params.get("q", "")
page = int(query_params.get("page", "1"))
limit = min(int(query_params.get("limit", "10")), 100) # Cap at 100
# Boolean parameter
include_sold = query_params.get("include_sold", "false").lower() == "true"
# Array parameters (?tags=python&tags=web)
tags = query_params.get_list("tags") or []
# Build response
return {
"search_query": query,
"pagination": {"page": page, "limit": limit},
"filters": {"include_sold": include_sold, "tags": tags},
"total_params": len(query_params.to_dict())
}
```
```python {{ title: 'Simple query access' }}
@app.get("/search")
async def search_simple(query_params):
# Basic parameter access
query = query_params.get("q", "")
page = query_params.get("page", "1")
# Convert to dictionary for processing
all_params = query_params.to_dict()
return {
"query": query,
"page": page,
"all_params": all_params
}
```
Any request param can be used in the handler function either using type annotations or using the reserved names.
Do note that the type annotations will take precedence over the reserved names.
Robyn showed Batman example syntaxes of accessing the request params:
```python
from robyn.robyn import QueryParams, Headers
from robyn.types import PathParams, RequestMethod, RequestBody, RequestURL
@app.get("/untyped/query_params")
def untyped_basic(query_params):
return query_params.to_dict()
@app.get("/typed/query_params")
def typed_basic(query_data: QueryParams):
return query_data.to_dict()
@app.get("/untyped/path_params/:id")
def untyped_path_params(query_params: PathParams):
return query_params # contains the path params since the type annotations takes precedence over the reserved names
@app.post("/typed_untyped/combined")
def typed_untyped_combined(
query_params,
method_data: RequestMethod,
body_data: RequestBody,
url: RequestURL,
headers_item: Headers,
):
return {
"body": body_data,
"query_params": query_params.to_dict(),
"method": method_data,
"url": url.path,
"headers": headers_item.get("server"),
}
```
Type Aliases: `Request`, `QueryParams`, `Headers`, `PathParams`, `RequestBody`, `RequestMethod`, `RequestURL`, `FormData`, `RequestFiles`, `RequestIP`, `RequestIdentity`
Reserved Names: `r`, `req`, `request`, `query_params`, `headers`, `path_params`, `body`, `method`, `url`, `ip_addr`, `identity`, `form_data`, `files`
---
As Batman continued to develop his web application with Robyn, he explored more features and implemented them using code samples.
## Customizing Response Formats and Headers
After understanding the dynamic nature of Robyn, Batman, now wanted the ability to customize response formats and headers. Robyn showed him how to do this using dictionaries and Robyn's Response object.
### Using Dictionaries
Batman learned to customize response formats by returning dictionaries or using Robyn's Response object. He could also set status codes and headers for each response. For example, Batman created a response with a dictionary like this:
```python
from robyn import Request
@app.post("/dictionary")
async def dictionary(request: Request):
return {
"status_code": 200,
"description": "This is a regular response",
"type": "text",
"headers": {"Header": "header_value"},
}
```
### Using the Response object
To use the Response object, he wrote:
```python
from robyn.robyn import Response, Request
@app.get("/response")
async def response(request: Request):
return Response(status_code=200, headers=Headers({}), description="OK")
```
### Returning a Binary Output
Batman then wanted to return a binary output from his application. He could do this by setting the type of the response to "binary" and returning a bytes object. For example, he wrote:
```python
from robyn import Request, Response
@app.get("/binary_output_response_sync")
def binary_output_response_sync(request: Request):
return Response(
status_code=200,
headers={"Content-Type": "application/octet-stream"},
description="OK",
)
@app.get("/binary_output_async")
async def binary_output_async(request: Request):
return b"OK"
@app.get("/binary_output_response_async")
async def binary_output_response_async(request: Request):
return Response(
status_code=200,
headers={"Content-Type": "application/octet-stream"},
description="OK",
)
```
---
## Response Headers
Batman, being the world's greatest detective, spotted the `headers` field in the `Response` object. He, naturally wanted to know more about it. Robyn explained that he could use the `headers` field to set response headers. For example, he could set the `Content-Type` header to `application/json` by writing:
### Local Response Headers
Either, by using the `headers` field in the `Response` object:
```python
from robyn import Request
@app.get("/")
def binary_output_response_sync(request: Request):
return Response(
status_code=200,
headers={"Content-Type": "application/octet-stream"},
description="OK",
)
```
### Global Response Headers
Or setting the Headers globally *per* router.
```python
app.add_response_header("content-type", "application/json")
```
`add_response_header` appends the header to the list of headers, while `set_response_header` replaces the header if it exists.
```python
app.set_response_header("content-type", "application/json")
```
To prevent the headers from getting applied to certain endpoints, you can use the `exclude_response_headers_for` function.
```python
app.exclude_response_headers_for(["/login", "/signup"])
```
### Cookies
Robyn provides a complete cookie API following RFC 6265. Set cookies using the `set_cookie` method on the Response object.
```python
from robyn import Request, Response, Headers
@app.get("/")
def set_session(request: Request):
response = Response(200, Headers({}), "Welcome!")
response.set_cookie(key="session", value="abc123")
return response
```
#### Cookie Attributes
You can set additional cookie attributes for security and control:
- **path**: Cookie path (default: "/")
- **domain**: Cookie domain
- **max_age**: Cookie lifetime in seconds
- **secure**: Only send over HTTPS
- **http_only**: Not accessible via JavaScript
- **same_site**: CSRF protection ("Strict", "Lax", or "None" - case insensitive)
```python
from robyn import Request, Response, Headers
@app.get("/login")
def login(request: Request):
response = Response(200, Headers({}), "Logged in")
response.set_cookie(
key="auth_token",
value="secret123",
path="/",
max_age=3600, # 1 hour
secure=True, # HTTPS only
http_only=True, # No JavaScript access
same_site="Strict", # CSRF protection
)
return response
```
#### Deleting Cookies
To delete a cookie from the browser, use the `delete` method on the cookies collection. This sets `max_age=0` which tells the browser to remove the cookie.
```python
from robyn import Request, Response, Headers
@app.get("/logout")
def logout(request: Request):
response = Response(200, Headers({}), "Logged out")
response.cookies.delete("auth_token")
return response
```
#### Accessing Cookies
You can iterate over cookies or access them by name:
```python
from robyn import Request, Response, Headers
@app.get("/debug")
def debug_cookies(request: Request):
response = Response(200, Headers({}), "Cookies set")
response.set_cookie("a", "1")
response.set_cookie("b", "2")
# Get all cookie names
names = response.cookies.keys()
# Iterate over cookies
for name in response.cookies:
print(f"Cookie: {name}")
# Check if cookie exists
if "a" in response.cookies:
print("Cookie 'a' exists")
return response
```
## Request Headers
Batman, now wanted to know how to read request headers. Robyn explained that he could use the `request.headers` field to read request headers. For example, he could read the `Content-Type` header by writing:
### Local Request Headers
Either, by using the `headers` field in the `Request` object:
```python
from robyn import Request
@app.get("/")
def binary_output_response_sync(request: Request):
headers = request.headers
print("These are the request headers: ", headers)
existing_header = headers.get("exisiting_header")
existing_header = headers.get("exisiting_header", "default_value")
exisiting_header = headers["exisiting_header"] # This syntax is also valid
headers.set("modified", "modified_value")
headers["new_header"] = "new_value" # This syntax is also valid
print("These are the modified request headers: ", headers)
return ""
```
Or by using the global Request Headers:
```python
app.add_request_header("server", "robyn")
```
`add_request_header` appends the header to the list of headers, while `set_request_header` replaces the header if it exists.
```python
app.set_request_header("server", "robyn")
```
---
## Status Codes
After learning about response formats and headers, Batman learned to set status codes for his responses.
```python
from robyn import status_codes, Request
@app.get("/response")
async def response(request: Request):
return Response(status_code=status_codes.HTTP_200_OK, headers=Headers({}), description="OK")
```
---
## What's next?
Great, now Robyn, what is the `Request` Object that you keep talking about?, Batman said. "Next section", said Robyn.
- [The Request Object](/documentation/en/api_reference/request_object)
Batman was also interested to know about the architecture of Robyn. "Next section", said Robyn.
- [Architecture](/documentation/en/architecture)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/graphql-support.mdx
================================================
export const description =
'On this page, we`ll understand how GraphQL support is provided in the existing Robyn codebase to ensure faster data fetching in modern webapps .'
## GraphQL Support [(With Strawberry 🍓)](https://strawberry.rocks/)
This is in a very early stage right now. We will have a much more stable version when we have a stable API for Views and View Controllers.
## Step 1: Creating a virtualenv
To ensure that there are isolated dependencies, we will use virtual environments.
```bash {{ title: 'pip' }}
python3 -m venv venv
```
## Step 2: Activate the virtualenv and install Robyn
```bash {{ title: 'pip' }}
source venv/bin/activate
```
```bash {{ title: 'pip' }}
pip install robyn strawberry-graphql
```
## Step 3: Coding the App
```python {{ title: 'python' }}
from typing import List, Optional
from robyn import Robyn, jsonify
import json
import dataclasses
import strawberry
import strawberry.utils.graphiql
@strawberry.type
class User:
name: str
@strawberry.type
class Query:
@strawberry.field
def user(self) -> Optional[User]:
return User(name="Hello")
schema = strawberry.Schema(Query)
app = Robyn(__file__)
@app.get("/", const=True)
async def get():
return strawberry.utils.graphiql.get_graphiql_html()
@app.post("/")
async def post(request):
body = request.json()
query = body["query"]
variables = body.get("variables", None)
context_value = {"request": request}
root_value = body.get("root_value", None)
operation_name = body.get("operation_name", None)
data = await schema.execute(
query,
variables,
context_value,
root_value,
operation_name,
)
return jsonify(
{
"data": (data.data),
**({"errors": data.errors} if data.errors else {}),
**({"extensions": data.extensions} if data.extensions else {}),
}
)
if __name__ == "__main__":
app.start(port=8080, host="0.0.0.0")
```
Let us try to decipher the usage line by line.
These statements just import the dependencies.
```python {{ title: 'python' }}
from typing import List, Optional
from robyn import Robyn, jsonify
import json
import dataclasses
import strawberry
import strawberry.utils.graphiql
```
Here, we are creating a base `User` type with a `name` property.
We are then creating a GraphQl `Query` that returns the `User`.
```python {{ title: 'python' }}
@strawberry.type
class User:
name: str
@strawberry.type
class Query:
@strawberry.field
def user(self) -> Optional[User]:
return User(name="Hello")
schema = strawberry.Schema(Query)
```
Now, we are initializing a Robyn app. For us, to serve a GraphQl app, we need to have a `get` route to return the `GraphiQL(ide)` and then a post route to process the `GraphQl` request.
```python {{ title: 'python' }}
app = Robyn(__file__)
```
We are populating the html page with the GraphiQL IDE using `strawberry`. We are using `const=True` to precompute this population. Essentially, making it very fast and bypassing the execution overhead in this get request.
```python {{ title: 'python' }}
@app.get("/", const=True)
async def get():
return strawberry.utils.graphiql.get_graphiql_html()
```
Finally, we are getting params(body, query, variables, context_value, root_value, operation_name) from the `request` object.
```python {{ title: 'python' }}
@app.post("/")
async def post(request):
body = request.json()
query = body["query"]
variables = body.get("variables", None)
context_value = {"request": request}
root_value = body.get("root_value", None)
operation_name = body.get("operation_name", None)
data = await schema.execute(
query,
variables,
context_value,
root_value,
operation_name,
)
return jsonify(
{
"data": (data.data),
**({"errors": data.errors} if data.errors else {}),
**({"extensions": data.extensions} if data.extensions else {}),
}
)
```
The above is the example for just one route. You can do the same for as many as you like. :)
## What's next?
That's all folks. :D Keep an eye out for more updates on this page. We will be adding more examples and documentation as we go along.
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/index.mdx
================================================
export const description =
'On this page, we’ll dive into the different conversation endpoints you can use to manage conversations programmatically.'
Once upon a time in the city of Gotham, there was a powerful superhero named Robyn. Robyn had a unique set of abilities that allowed it to fetch information from the far corners of the internet. It could send requests and receive responses at lightning speed, and its prowess was admired by developers everywhere.
One day, Batman approached Robyn for help with building a web application. Batman had heard about Robyn's powerful features and wanted to harness them to create a remarkable application. Batman was looking for an ally and in Robyn, he found the best one!
## Installing Robyn
Robyn is a Python library that you can install using `pip` or `conda`
```bash {{ title: 'pip' }}
pip install robyn
```
```bash {{ title: 'conda' }}
conda install robyn -c conda-forge
```
While there are other more extensions of Robyn like
```bash {{ title: 'pip' }}
pip install "robyn[templating]"
```
```bash {{ title: 'conda' }}
conda install "robyn[templating]" -c conda-forge
```
It is recommended to install the base package first and then install the extensions as needed.
## What's next?
Now, we can start using Robyn to build our application.
- [Getting Started](/documentation/en/api_reference/getting_started)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/mcps.mdx
================================================
# Model Context Protocol (MCP)
> **⚠️ Experimental**: MCP support is experimental and may change.
Robyn supports MCP, allowing AI applications like Claude Desktop to connect to your application's resources and tools.
## Quick Start
```python
from robyn import Robyn
app = Robyn(__file__)
@app.mcp.resource("echo://{message}")
def echo_resource(message: str) -> str:
return f"Resource echo: {message}"
@app.mcp.tool()
def echo_tool(message: str) -> str:
return f"Tool echo: {message}"
@app.mcp.prompt()
def echo_prompt(message: str) -> str:
return f"Please process: {message}"
app.start()
```
## Features
- Auto-generated JSON schemas from function signatures
- URI templates with parameter extraction
- JSON-RPC 2.0 protocol compliance
- Type-aware parameter handling
## Decorator Reference
### `@app.mcp.resource(uri, name=None, description=None, mime_type=None)`
Register a resource that can be read by clients.
```python
@app.mcp.resource("user://{user_id}/profile")
def user_profile(user_id: str) -> str:
return f"Profile for user {user_id}"
```
### `@app.mcp.tool(name=None, description=None, input_schema=None)`
Register a tool that can be executed by AI models.
```python
@app.mcp.tool()
def greet(name: str, formal: bool = False) -> str:
if formal:
return f"Good day, {name}."
return f"Hi {name}!"
```
### `@app.mcp.prompt(name=None, description=None, arguments=None)`
Register a prompt template for AI workflows.
```python
@app.mcp.prompt()
def code_review(code: str, language: str = "python") -> str:
return f"Please review this {language} code: {code}"
```
## Type Support
Supported types: `str`, `int`, `float`, `bool`, `List`, `Dict`
## URI Templates
Extract parameters from URIs:
```python
@app.mcp.resource("user://{user_id}/posts/{post_id}")
def get_user_post(user_id: str, post_id: str) -> str:
return f"Post {post_id} from user {user_id}"
```
## Client Usage
Test with curl:
```bash
# List resources
curl -X POST http://localhost:8080/mcp \
-H "Content-Type: application/json" \
-d '{"jsonrpc": "2.0", "id": 1, "method": "resources/list", "params": {}}'
```
## Integration with Claude Desktop
To connect your Robyn MCP server to Claude Desktop:
1. Start your Robyn app with MCP endpoints
2. Configure Claude Desktop to connect to `http://localhost:8080/mcp`
3. Use the registered resources, tools, and prompts in your conversations
## Error Handling
```python
@app.mcp.tool()
def divide(a: float, b: float) -> str:
if b == 0:
raise ValueError("Division by zero")
return str(a / b)
```
## Testing
```bash
# Unit tests
python examples/mcp.py test-unit
# Live tests
python examples/mcp.py test-live
# All tests
python examples/mcp.py test-all
```
## Configuration
MCP runs at `/mcp` endpoint using JSON-RPC 2.0 over HTTP. No additional setup required.
## Claude Desktop Integration
1. Start your Robyn server
2. Configure Claude Desktop to connect to `http://localhost:8080/mcp`
3. Use resources, tools, and prompts in conversations
See `examples/mcp.py` for a complete example.
For more information: https://modelcontextprotocol.io/
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/middlewares.mdx
================================================
export const description =
'On this page, we’ll dive into the different conversation endpoints you can use to manage conversations programmatically.'
## Working with Middlewares and Events
As Batman's application grew more complex, Robyn taught him about middlewares, startup and shutdown events, and even working with WebSockets. Batman learned how to create functions that could execute before or after a request, manage the application's life cycle, and handle real-time communication with clients using WebSockets.
## Handling Events
Batman discovered that he could add startup and shutdown events to manage his application's life cycle. He added the following code to define these events:
Batman was excited to learn that he could add events as functions as well as decorators.
```python
async def startup_handler():
print("Starting up")
app.startup_handler(startup_handler)
@app.shutdown_handler
def shutdown_handler():
print("Shutting down")
```
For an asynchronous request, Batman used:
```python
from robyn import Request
@app.get("/")
async def h(request: Request) -> str:
return "Hello, world"
```
## Handling Middlewares {{ tag: 'POST', label: '/http_requests' }}
Batman learned to use both sync and async functions for middlewares. He wrote the following code to add a middleware that would execute before and after each request.
A before request middleware is a function that executes before each request. It can modify the request object or perform any other operation before the request is processed.
An after request middleware is a function that executes after each request. It can modify the response object or perform any other operation after the request is processed.
Every before request middleware should accept a request object and return a request object. Every after-request middleware should accept a response object and return a response object on happy case scenario. After-request middlewares can also optionally accept the request object as the first parameter to access request data.
The execution of the before request middleware is stopped if any of the before request middleware returns a response object. The response object is returned to the client without executing the after request middleware or the main entry point code.
```python
from robyn import Request, Response
@app.before_request("/")
async def hello_before_request(request: Request):
request.headers.set("before", "sync_before_request")
return request
@app.after_request("/")
def hello_after_request(response: Response):
response.headers.set("after", "sync_after_request")
return response
```
```python {{ title: 'after_request with request access' }}
from robyn import Request, Response
@app.after_request("/")
def hello_after_request(request: Request, response: Response):
# Access request data in after_request
response.headers.set("request_path", request.url.path)
response.headers.set("after", "sync_after_request")
return response
```
---
## What's next?
Robyn - Great, you're now familiar with the certain advanced concepts of Robyn.
Batman - "Authentication! I want to learn about authentication. I want to make sure that only the right people can access my application."
Robyn - Yes, Authentication!
- [Authentication](/documentation/en/api_reference/authentication)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/multiprocess_execution.mdx
================================================
export const description =
'On this page, we’ll dive into the different conversation endpoints you can use to manage conversations programmatically.'
## Multiprocess Execution
Batman wondered about the behaviour of variables in a Robyn multiprocessing environment.
Robyn reassured that it can indeed support them! i.e, handlers can be dispatched to multiple threads.
Any variable used in a multiprocessing environment is shared across multiple processes.
Whilst using multithreading in Robyn, the variables are not protected from multiple threads access by default.
If one needs a variable to be protected within a process, while accessing it from different threads, one can use `multiprocessing.Value` for achieving the required protection.
```python
import threading
import time
from multiprocessing import Value
from robyn import Robyn, Request
app = Robyn(__file__)
count: Value = Value("i", 0)
def counter():
while True:
count.value += 1
time.sleep(0.2)
print(count.value, "added 1")
@app.get("/")
def index(request: Request):
return f"{count.value}"
threading.Thread(target=counter, daemon=True).start()
app.start()
```
---
## What's next?
Batman wondered if it was possible to use Rust directly from Robyn's codebase.
Robyn showed him the path.
[Using Rust Directly](/documentation/en/api_reference/using_rust_directly)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/openapi.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
## OpenAPI Docs a.k.a Swagger
After deploying the application, Batman got multiple queries from the users on how to use the endpoints. Robyn showed him how to generate OpenAPI specifications for his application.
Out of the box, the following endpoints are setup for you:
- `/docs` The Swagger UI
- `/openapi.json` The JSON Specification
To use a custom openapi configuration, you can:
- Place the `openapi.json` config file in the root directory.
- Or, pass the file path to the `openapi_file_path` parameter in the `Robyn()` constructor. (the parameter gets priority over the file).
However, if you don't want to generate the OpenAPI docs, you can disable it by passing `--disable-openapi` flag while starting the application.
```bash
python app.py --disable-openapi
```
## How to use?
- Query Params: The typing for query params can be added as `def get(r: Request, query_params: GetRequestParams)` where `GetRequestParams` is a subclass of `QueryParams`
- Path Params are defaulted to string type (ref: https://en.wikipedia.org/wiki/Query_string)
```python
from robyn.robyn import QueryParams
from robyn import Robyn, Request
app = Robyn(
file_object=__file__,
openapi=OpenAPI(
info=OpenAPIInfo(
title="Sample App",
description="This is a sample server application.",
termsOfService="https://example.com/terms/",
version="1.0.0",
contact=Contact(
name="API Support",
url="https://www.example.com/support",
email="support@example.com",
),
license=License(
name="BSD2.0",
url="https://opensource.org/license/bsd-2-clause",
),
externalDocs=ExternalDocumentation(description="Find more info here", url="https://example.com/"),
components=Components(),
),
),
)
@app.get("/")
async def welcome():
"""welcome endpoint"""
return "hi"
class GetRequestParams(QueryParams):
appointment_id: str
year: int
@app.get("/api/v1/name", openapi_name="Name Route", openapi_tags=["Name"])
async def get(r: Request, query_params: GetRequestParams):
"""Get Name by ID"""
return r.query_params
@app.delete("/users/:name", openapi_tags=["Name"])
async def delete(r: Request):
"""Delete Name by ID"""
return r.path_params
if __name__ == "__main__":
app.start()
```
## How does it work with subrouters?
```python
from robyn.robyn import QueryParams
from robyn import Request, SubRouter
subrouter: SubRouter = SubRouter(__name__, prefix="/sub")
@subrouter.get("/")
async def subrouter_welcome():
"""welcome subrouter"""
return "hiiiiii subrouter"
class SubRouterGetRequestParams(QueryParams):
_id: int
value: str
@subrouter.get("/name")
async def subrouter_get(r: Request, query_params: SubRouterGetRequestParams):
"""Get Name by ID"""
return r.query_params
@subrouter.delete("/:name")
async def subrouter_delete(r: Request):
"""Delete Name by ID"""
return r.path_params
app.include_router(subrouter)
```
## Other Specification Params
We support all the params mentioned in the latest OpenAPI specifications (https://swagger.io/specification/). See an example using request & response bodies below:
```python
from robyn.types import JSONResponse, Body
class Initial(Body):
is_present: bool
letter: Optional[str]
class FullName(Body):
first: str
second: str
initial: Initial
class CreateItemBody(Body):
name: FullName
description: str
price: float
tax: float
class CreateResponse(JSONResponse):
success: bool
items_changed: int
@app.post("/")
def create_item(request: Request, body: CreateItemBody) -> CreateResponse:
return CreateResponse(success=True, items_changed=2)
```
With the reference documentation deployed and running smoothly, Batman had a powerful new tool at his disposal. The Robyn framework had provided him with the flexibility, scalability, and performance needed to create an effective crime-fighting application, giving him a technological edge in his ongoing battle to protect Gotham City.
## Using Pydantic Models
If you have Pydantic installed (`pip install "robyn[pydantic]"` or `pip install "robyn[all]"`), you can use Pydantic `BaseModel` classes directly as handler parameter annotations. Robyn will automatically validate the request body **and** generate a rich OpenAPI schema — including property types, required fields, defaults, and `$ref` for nested models.
```python
from pydantic import BaseModel
class UserCreate(BaseModel):
name: str
email: str
age: int
active: bool = True
@app.post("/users", openapi_tags=["Users"])
def create_user(user: UserCreate) -> dict:
"""Create a new user"""
return {"name": user.name}
```
For the full guide on Pydantic validation, nested models, error responses, and OpenAPI integration, see the dedicated [Pydantic Integration](/documentation/en/api_reference/pydantic) page.
## What's next?
Batman wondered about whether Robyn handlers can be dispatched to multiple processes.
Robyn showed him the way!
[Multiprocess Execution](/documentation/en/api_reference/multiprocess_execution)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/pydantic.mdx
================================================
export const description =
'Learn how to use Pydantic models with Robyn for automatic request body validation and OpenAPI schema generation.'
## Pydantic Integration
Robyn supports [Pydantic](https://docs.pydantic.dev/) v2 as an optional dependency for automatic request body validation and rich OpenAPI schema generation. Validation is **opt-in per handler** — it only activates when you annotate a parameter with a Pydantic `BaseModel`. Handlers without Pydantic annotations are completely unaffected: no parsing, no validation, no overhead. When Pydantic is not installed at all, Robyn never imports it.
## Installation
Install Robyn with Pydantic support using the optional extra:
```bash {{ title: 'Pydantic only' }}
pip install "robyn[pydantic]"
```
```bash {{ title: 'All extras' }}
pip install "robyn[all]"
```
```bash {{ title: 'conda' }}
conda install robyn pydantic -c conda-forge
```
`robyn[all]` includes Pydantic, Jinja2 templating, and any future optional features.
## Basic Usage
Define a Pydantic `BaseModel` and use it as a type annotation on your handler parameter. Robyn will automatically parse the incoming JSON body, validate it against the model, and inject the validated instance into your handler.
```python {{ title: 'Synchronous' }}
from pydantic import BaseModel
from robyn import Robyn
app = Robyn(__file__)
class UserCreate(BaseModel):
name: str
email: str
age: int
active: bool = True
@app.post("/users")
def create_user(user: UserCreate):
"""Create a new user"""
return {
"name": user.name,
"email": user.email,
"age": user.age,
"active": user.active,
}
if __name__ == "__main__":
app.start()
```
```python {{ title: 'Asynchronous' }}
from pydantic import BaseModel
from robyn import Robyn
app = Robyn(__file__)
class UserCreate(BaseModel):
name: str
email: str
age: int
active: bool = True
@app.post("/users")
async def create_user(user: UserCreate):
"""Create a new user"""
return {
"name": user.name,
"email": user.email,
"age": user.age,
"active": user.active,
}
if __name__ == "__main__":
app.start()
```
## Validation Errors
When the request body fails validation, Robyn automatically returns a **422 Unprocessable Entity** response with structured error details. You do not need to write any error handling code.
For example, sending `{"name": "Alice", "email": "alice@example.com", "age": "not_a_number"}` would produce:
```json
{
"error": "Validation Error",
"detail": [
{
"type": "int_parsing",
"loc": ["age"],
"msg": "Input should be a valid integer, unable to parse string as an integer",
"input": "not_a_number"
}
]
}
```
Missing required fields are also caught:
```json
{
"error": "Validation Error",
"detail": [
{
"type": "missing",
"loc": ["email"],
"msg": "Field required",
"input": {"name": "Alice", "age": 30}
}
]
}
```
## Nested Models
Pydantic models can reference other models. Robyn handles nested validation automatically.
```python
from pydantic import BaseModel
from robyn import Robyn
app = Robyn(__file__)
class Address(BaseModel):
street: str
city: str
zip_code: str
class UserWithAddress(BaseModel):
name: str
email: str
address: Address
@app.post("/users")
def create_user(data: UserWithAddress):
"""Create a user with an address"""
return {"name": data.name, "city": data.address.city}
```
If the nested `address` object is missing or malformed, Robyn returns a 422 with the full error path (e.g. `["address", "city"]`).
## Using with the Request Object
You can combine Pydantic parameters with the standard `Request` object in the same handler. This gives you access to headers, query params, and other request metadata alongside the validated body.
```python
from pydantic import BaseModel
from robyn import Robyn, Request
app = Robyn(__file__)
class UserCreate(BaseModel):
name: str
email: str
age: int
active: bool = True
@app.post("/users")
def create_user(request: Request, user: UserCreate):
"""Create a user — access both raw request and validated model"""
return {
"method": request.method,
"name": user.name,
"email": user.email,
}
```
## Returning Pydantic Models Directly
You can return a Pydantic model instance (or a list of them) directly from a handler. Robyn will automatically serialize it to JSON with the correct `Content-Type` header — no need to call `.model_dump()` manually.
```python {{ title: 'Single model' }}
@app.post("/users")
def create_user(user: UserCreate) -> UserCreate:
"""Validate and echo back the user"""
return user
```
```python {{ title: 'List of models' }}
@app.post("/users/batch")
def create_users(user: UserCreate) -> list[UserCreate]:
"""Return multiple model instances"""
return [user, user]
```
Both forms produce an `application/json` response. The single-model path uses Pydantic's Rust-based `model_dump_json()` for maximum throughput.
## How Validation Is Triggered
Pydantic validation is **annotation-driven, not method-driven**. The router inspects each handler's signature at registration time; any parameter annotated with a `BaseModel` subclass triggers automatic validation of `request.body` when that route is called. This works with every HTTP method — `POST`, `PUT`, `PATCH`, `DELETE`, or any other method that carries a body.
```python {{ title: 'PUT' }}
@app.put("/users/:id")
def update_user(user: UserCreate):
return {"updated": True, "name": user.name}
```
```python {{ title: 'PATCH' }}
@app.patch("/users/:id")
def patch_user(user: UserCreate):
return {"patched": True, "name": user.name}
```
## OpenAPI Integration
When you use Pydantic models, Robyn automatically generates rich JSON Schema in your OpenAPI specification at `/openapi.json`. This includes:
- **Property types** — `string`, `integer`, `boolean`, etc.
- **Required fields** — fields without defaults are listed in `required`
- **Default values** — shown in the schema
- **Nested models** — referenced via `$ref` and placed in `components/schemas`
```python
from pydantic import BaseModel
from robyn import Robyn, Request
app = Robyn(__file__)
class Address(BaseModel):
street: str
city: str
zip_code: str
class UserWithAddress(BaseModel):
name: str
email: str
address: Address
@app.post("/users", openapi_tags=["Users"])
def create_user(request: Request, data: UserWithAddress) -> dict:
"""Create a user with a nested address"""
return {"name": data.name, "city": data.address.city}
```
The generated `/openapi.json` will contain:
```json
{
"paths": {
"/users": {
"post": {
"requestBody": {
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"name": {"type": "string", "title": "Name"},
"email": {"type": "string", "title": "Email"},
"address": {"$ref": "#/components/schemas/Address"}
},
"required": ["name", "email", "address"],
"title": "UserWithAddress"
}
}
}
}
}
}
},
"components": {
"schemas": {
"Address": {
"type": "object",
"properties": {
"street": {"type": "string", "title": "Street"},
"city": {"type": "string", "title": "City"},
"zip_code": {"type": "string", "title": "Zip Code"}
},
"required": ["street", "city", "zip_code"],
"title": "Address"
}
}
}
}
```
## Pydantic vs Body
Robyn supports two approaches for typed request bodies. Choose the one that fits your needs:
| Feature | `Body` subclass | Pydantic `BaseModel` |
|---|---|---|
| Installation | Built-in | `pip install "robyn[pydantic]"` |
| Validation | No automatic validation | Full validation with detailed errors |
| Error responses | Manual | Automatic 422 with structured errors |
| Return serialization | Manual `dict()` | Auto-serialize model to JSON |
| OpenAPI schema | Basic type inference | Full JSON Schema (types, required, defaults, `$ref`) |
| Nested models | Supported (basic) | Supported (with `$ref` in OpenAPI) |
| Performance overhead | None | Only when Pydantic is installed and used |
Both approaches work with OpenAPI documentation. If you need validation, use Pydantic. If you just need OpenAPI schema hints without validation, `Body` is sufficient.
## Important Notes
- **Opt-in per handler** — Validation only runs on handlers where a parameter is annotated with a Pydantic `BaseModel`. All other handlers (using `Body`, `Request`, path params, etc.) behave exactly as before with zero additional overhead.
- **One Pydantic body per handler** — Each handler can have at most one parameter annotated with a Pydantic model. The entire request body is parsed into that single model. If you need multiple model inputs, compose them into a single parent model with nested fields.
- **Request validation only** — Robyn validates *incoming* request bodies against Pydantic models but does not validate *outgoing* responses. When you return a model instance, it is serialized as-is without re-validation. This is a deliberate design choice for performance — if you constructed the model, it's already valid.
## What's next?
Batman wondered about whether Robyn handlers can be dispatched to multiple processes.
Robyn showed him the way!
[Multiprocess Execution](/documentation/en/api_reference/multiprocess_execution)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/redirection.mdx
================================================
## Redirection
Batman wanted to redirect some endpoints to others. Robyn helped him do so by the following:
```python
from robyn import Robyn, Response
app = Robyn(__file__)
@app.get("/")
async def index():
return Response(
status_code=307,
description="",
headers={"Location": "landing"},
)
@app.get("/landing")
def landing():
return "hii!"
```
---
## What's next?
Now, Batman wanted to have the ability to upload files to the server if any new villain appeared. Robyn introduced him to the file upload and some of the form data features.
- [File Uploads](/documentation/en/api_reference/file-uploads)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/request_object.mdx
================================================
export const description =
'On this page, we’ll dive into the different conversation endpoints you can use to manage conversations programmatically.'
## Request Object
The request object is a dataclass that contains all the information about the request. It is available in the route handler as the first argument.
The request object is created in Rust side but is exposed to Python as a dataclass.
-
Attributes:
-
query_params (QueryParams): The query parameters of the request. `e.g. /user?id=123 -> {"id": [ "123" ]}`
-
headers (dict[str, str]): The headers of the request. `e.g. {"Content-Type": "application/json"}`
-
params (dict[str, str]): The parameters of the request. `e.g. /user/:id -> {"id": "123"}`
-
body (Union[str, bytes]): The raw body of the request. For JSON payloads, use the `json()` method to parse the body into a dict with proper type preservation.
-
method (str): The method of the request. `e.g. GET, POST, PUT, DELETE`
-
ip_addr (Optional[str]): The IP Address of the client
-
identity (Optional[Identity]): The identity of the client
```python
@dataclass
class Request:
"""
query_params: QueryParams
headers: Headers
path_params: dict[str, str]
body: Union[str, bytes]
method: str
url: Url
form_data: dict[str, str]
files: dict[str, bytes]
ip_addr: Optional[str]
identity: Optional[Identity]
"""
```
## Parsing JSON Body
The `request.json()` method parses the request body as JSON and returns a Python `dict` with full type preservation:
- JSON `null` becomes Python `None`
- JSON numbers become Python `int` or `float`
- JSON booleans become Python `bool`
- JSON strings become Python `str`
- JSON arrays become Python `list`
- JSON objects become Python `dict`
Nested structures are handled recursively up to a maximum depth of 128 levels.
```python
@app.post("/example")
async def handler(request: Request):
data = request.json() # Returns a dict with preserved types
# e.g. {"count": 42, "active": true, "tags": ["a", "b"]}
# -> {"count": 42, "active": True, "tags": ["a", "b"]}
return {"received": data}
```
If the body is not valid JSON or is not a JSON object, a `ValueError` will be raised.
## Extra Path Parameters
Robyn supports capturing extra path parameters using the `*extra` syntax in route definitions. This allows you to capture any additional segments in the URL path that come after the defined route.
For example, if you define a route like this:
```python
@app.get("/sync/extra/*extra")
def sync_param_extra(request: Request):
extra = request.path_params["extra"]
return extra
```
Any additional path segments after `/sync/extra/` will be captured in the `extra` parameter. For instance:
-
A request to `/sync/extra/foo/bar` would result in `extra = "foo/bar"`
-
A request to `/sync/extra/123/456/789` would result in `extra = "123/456/789"`
You can access the extra path parameters through `request.path_params["extra"]` in your route handler.
This feature is particularly useful when you need to handle dynamic, nested routes or when you want to capture an unknown number of path segments.
---
## Easy Access Parameters
Instead of manually extracting and converting query parameters and path parameters from the request object, you can declare them directly in your function signature with type annotations. Robyn will automatically resolve and coerce them for you.
Any handler parameter that doesn't match a known request component (`Request`, `QueryParams`, `Headers`, etc.) is treated as an individual path or query parameter.
**Basic usage** — path params and query params with type coercion and defaults.
```python {{ title: 'Typed Params' }}
@app.get("/items/:id")
async def get_item(id: int, q: str, page: int = 1):
# id is coerced from the path param string to int
# q is taken from ?q=...
# page defaults to 1 if not provided
return {"id": id, "q": q, "page": page}
```
```python {{ title: 'Mixed with Request' }}
@app.get("/items/:id")
async def get_item(request: Request, id: int, q: str = ""):
# request is still injected as usual
# id and q are resolved as individual params
return {"id": id, "q": q, "method": request.method}
```
**Optional, List, Bool, and Float params** — Robyn handles common Python types automatically.
- `Optional[T]` — resolves to `None` when not provided
- `List[T]` — collects repeated query params (e.g. `?tag=a&tag=b`)
- `bool` — accepts `true/false`, `1/0`, `yes/no`, `on/off`
- `float` — standard float coercion
```python {{ title: 'Optional' }}
@app.get("/search")
def search(name: str, age: Optional[int] = None):
return {"name": name, "age": age}
# GET /search?name=bob -> {"name": "bob", "age": null}
# GET /search?name=bob&age=30 -> {"name": "bob", "age": 30}
```
```python {{ title: 'List' }}
from typing import List
@app.get("/filter")
def filter_items(tag: List[str]):
return {"tags": tag}
# GET /filter?tag=python&tag=rust -> {"tags": ["python", "rust"]}
```
```python {{ title: 'Bool & Float' }}
@app.get("/settings")
def settings(active: bool = False, price: float = 0.0):
return {"active": active, "price": price}
# GET /settings?active=true&price=19.99
# -> {"active": true, "price": 19.99}
```
**Error handling** — if a required parameter is missing or a value cannot be coerced to the declared type, Robyn returns a `400 Bad Request` response automatically.
```python {{ title: 'Automatic 400' }}
@app.get("/items/:id")
def get_item(id: int, q: str):
return {"id": id, "q": q}
# GET /items/42 -> 400 (missing required 'q')
# GET /items/abc?q=test -> 400 (cannot coerce 'abc' to int)
```
---
## What's next?
Now, Batman wanted to understand the configuration of the Robyn server. He was then introduced to the concept of Robyn env files.
- [Robyn Env](/documentation/en/api_reference/robyn_env)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/robyn_env.mdx
================================================
export const description = 'In this section, we will learn how to configure the server through a configuration file.'
## Configuring the server through an environment file
Batman wanted to configure the server through an environment file. Changing code continuously induced the risk of error.
## Environment Variables
- `ROBYN_PORT`: Specifies the port on which the Robyn server will listen.
- Default: `8080`
- Example: `ROBYN_PORT=3000`
- `ROBYN_HOST`: Specifies the host address for the Robyn server.
- Default: `127.0.0.1`
- Example: `ROBYN_HOST=0.0.0.0`
- `ROBYN_BROWSER_OPEN`: Open the browser on successful start.
- Default: `False`
- Example: `ROBYN_BROWSER_OPEN=True`
- `ROBYN_DEV_MODE`: Configures the dev mode
- Default: `False`
- Example: `ROBYN_DEV_MODE=True`
- `ROBYN_MAX_PAYLOAD_SIZE`: Sets the maximum payload size for HTTP requests and WebSocket messages in bytes.
- Default: `1000000` bytes
- Example: `ROBYN_MAX_PAYLOAD_SIZE=1000000`
You can have a `robyn.env` file to load them automatically in your environment.
These environment variables are typically set in a `robyn.env` file located at the root of the project. The server parses this file at startup to configure itself accordingly.
For more details on the structure and usage of the `robyn.env` file, refer to the documentation snippet:
```bash {{title: 'Sample project directory'}}
--project/
--robyn.env
--index.py
...
```
Sample `robyn.env` file:
```bash {{ title: 'Sample Robyn.env' }}
ROBYN_PORT=8080
ROBYN_HOST=127.0.0.1
RANDOM_ENV=123
ROBYN_BROWSER_OPEN=True
ROBYN_DEV_MODE=True
ROBYN_MAX_PAYLOAD_SIZE=1000000
```
With the web application deployed and running smoothly, Batman had a powerful new tool at his disposal. The Robyn framework had provided him with the flexibility, scalability, and performance needed to create an effective crime-fighting application, giving him a technological edge in his ongoing battle to protect Gotham City.
## What's next?
Batman - Thanks, Robyn. Now tell me more.
Robyn - Let us learn about the Middlewares and events now!
- [Middlewares](/documentation/en/api_reference/middlewares)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/scaling.mdx
================================================
export const description =
'Comprehensive guide to scaling Robyn applications from development to production, including multi-process configuration, load balancing, and deployment strategies.'
# Scaling and Production Deployment
Robyn is designed to scale efficiently from development to production. This guide covers scaling strategies, production deployment patterns, and performance optimization techniques.
## Understanding Robyn's Scaling Model
### Multi-Process Architecture
Robyn uses a **shared-nothing multi-process model** optimized for modern multi-core systems. Each process:
- Runs independently with its own Python interpreter and memory space
- Has its own Global Interpreter Lock (GIL), eliminating GIL contention
- Can handle multiple concurrent requests via worker threads
- Scales linearly across CPU cores for true parallelism
- Provides fault isolation - one process crash doesn't affect others
### Worker Threads
Within each process, multiple worker threads provide concurrency:
- Share the same Python interpreter and memory space
- Are subject to the GIL for CPU-bound tasks (use more processes for CPU work)
- Excel at I/O-bound operations where threads can release the GIL
- Handle database calls, HTTP requests, file operations efficiently
- Provide request-level concurrency within the same process
## Scaling Configuration
### Basic Scaling
**Single Process Development**: Start simple during development with auto-reload enabled.
```bash
# Development mode (single process, single worker)
python app.py --dev
# Development with custom port
python app.py --dev --port 3000
```
**Multi-Core Production**: Scale across all available CPU cores for maximum performance.
```bash
# Automatic optimization (recommended)
python app.py --fast
# Manual configuration for 8-core system
python app.py --processes 8 --workers 2
# I/O heavy workloads
python app.py --processes 4 --workers 4
# CPU heavy workloads
python app.py --processes 8 --workers 1
```
### Advanced Configuration
**Hardware-Specific Tuning**: Optimize based on your specific hardware and application characteristics.
```bash
# High-traffic web API (4-core system)
python app.py --processes 4 --workers 3 --log-level INFO
# Data processing service (8-core system)
python app.py --processes 8 --workers 1 --log-level WARNING
# Mixed workload (balanced approach)
python app.py --processes 6 --workers 2 --log-level INFO
# Maximum concurrency (16-core system)
python app.py --processes 8 --workers 4
```
### Configuration Guidelines
**Choosing the Right Configuration**: Use these guidelines to optimize for your specific use case.
```python
# For CPU-intensive applications
# Rule: processes = CPU cores, workers = 1
# Example: 8-core machine
python app.py --processes 8 --workers 1
# For I/O-intensive applications
# Rule: processes = CPU cores / 2, workers = 2-4
# Example: 8-core machine
python app.py --processes 4 --workers 3
# For balanced applications
# Rule: processes = CPU cores / 2, workers = 2
# Example: 8-core machine
python app.py --processes 4 --workers 2
# Memory considerations
# Each process uses ~50-100MB base memory
# Monitor with: ps aux | grep python
```
## Production Deployment Strategies
### Container Deployment
**Docker Containerization**: Deploy Robyn applications using Docker for consistent environments and easy scaling.
```dockerfile
# Dockerfile
FROM python:3.11-slim
# Install system dependencies
RUN apt-get update && apt-get install -y \
build-essential \
&& rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /app
# Copy requirements and install dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy application code
COPY . .
# Expose port
EXPOSE 8080
# Health check
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/health || exit 1
# Run application with optimized settings
CMD ["python", "app.py", "--fast", "--host", "0.0.0.0", "--port", "8080"]
```
```yaml
# docker-compose.yml
version: '3.8'
services:
robyn-app:
build: .
ports:
- "8080:8080"
environment:
- ROBYN_HOST=0.0.0.0
- ROBYN_PORT=8080
- ROBYN_LOG_LEVEL=INFO
restart: unless-stopped
deploy:
resources:
limits:
cpus: '2.0'
memory: 1G
reservations:
cpus: '1.0'
memory: 512M
```
### Load Balancer Configuration
**Nginx Load Balancing**: Use Nginx as a reverse proxy and load balancer for multiple Robyn instances.
```nginx
# /etc/nginx/sites-available/robyn-app
upstream robyn_backend {
least_conn;
server 127.0.0.1:8080 max_fails=3 fail_timeout=30s;
server 127.0.0.1:8081 max_fails=3 fail_timeout=30s;
server 127.0.0.1:8082 max_fails=3 fail_timeout=30s;
server 127.0.0.1:8083 max_fails=3 fail_timeout=30s;
}
server {
listen 80;
server_name yourdomain.com;
# Security headers
add_header X-Frame-Options DENY;
add_header X-Content-Type-Options nosniff;
add_header X-XSS-Protection "1; mode=block";
# Gzip compression
gzip on;
gzip_types text/plain application/json application/javascript text/css;
# Static files (if any)
location /static/ {
alias /var/www/static/;
expires 1y;
add_header Cache-Control "public, immutable";
}
# API routes
location / {
proxy_pass http://robyn_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# Timeouts
proxy_connect_timeout 5s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
# Health checks
proxy_next_upstream error timeout http_500 http_502 http_503;
}
# Health check endpoint
location /health {
access_log off;
proxy_pass http://robyn_backend;
}
}
```
### Kubernetes Deployment
**Kubernetes Orchestration**: Deploy and scale Robyn applications in Kubernetes clusters.
```yaml
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: robyn-app
labels:
app: robyn-app
spec:
replicas: 3
selector:
matchLabels:
app: robyn-app
template:
metadata:
labels:
app: robyn-app
spec:
containers:
- name: robyn-app
image: your-registry/robyn-app:latest
ports:
- containerPort: 8080
env:
- name: ROBYN_HOST
value: "0.0.0.0"
- name: ROBYN_PORT
value: "8080"
- name: ROBYN_LOG_LEVEL
value: "INFO"
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: robyn-service
spec:
selector:
app: robyn-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: robyn-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: robyn-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
```
## Monitoring and Observability
### Application Metrics
**Built-in Monitoring**: Add comprehensive monitoring and metrics collection to your Robyn application for production observability.
```python
from robyn import Robyn
import time
import psutil
import logging
import threading
from collections import defaultdict, deque
app = Robyn(__file__)
# Configure structured logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(),
logging.FileHandler('app.log')
]
)
logger = logging.getLogger(__name__)
# Advanced metrics collection
class MetricsCollector:
def __init__(self):
self.request_count = 0
self.total_response_time = 0
self.status_codes = defaultdict(int)
self.endpoint_stats = defaultdict(lambda: {"count": 0, "total_time": 0})
self.response_times = deque(maxlen=1000) # Last 1000 requests
self.lock = threading.Lock()
def record_request(self, method, path, status_code, duration):
with self.lock:
self.request_count += 1
self.total_response_time += duration
self.status_codes[status_code] += 1
endpoint_key = f"{method} {path}"
self.endpoint_stats[endpoint_key]["count"] += 1
self.endpoint_stats[endpoint_key]["total_time"] += duration
self.response_times.append(duration)
def get_metrics(self):
with self.lock:
avg_response_time = self.total_response_time / max(self.request_count, 1)
p95_response_time = sorted(self.response_times)[int(len(self.response_times) * 0.95)] if self.response_times else 0
return {
"requests_total": self.request_count,
"avg_response_time": avg_response_time,
"p95_response_time": p95_response_time,
"status_codes": dict(self.status_codes),
"top_endpoints": dict(sorted(
self.endpoint_stats.items(),
key=lambda x: x[1]["count"],
reverse=True
)[:10])
}
metrics = MetricsCollector()
start_time = time.time()
@app.before_request
def monitor_request_start(request):
request.start_time = time.time()
return request
@app.after_request
def monitor_request_end(request, response):
duration = time.time() - request.start_time
status_code = getattr(response, 'status_code', 200)
# Record metrics
metrics.record_request(request.method, request.url.path, status_code, duration)
# Log slow requests
if duration > 1.0:
logger.warning(
f"Slow request: {request.method} {request.url.path} - "
f"{duration:.3f}s (status: {status_code})"
)
# Add response headers
response.headers["X-Response-Time"] = f"{duration:.3f}s"
response.headers["X-Request-ID"] = str(time.time_ns())
return response
# Health endpoint with detailed status
@app.get("/health", const=True)
def health_check():
return {
"status": "healthy",
"version": "1.0.0",
"uptime_seconds": time.time() - start_time
}
# Comprehensive metrics endpoint
@app.get("/metrics")
def get_metrics():
cpu_percent = psutil.cpu_percent(interval=1)
memory = psutil.virtual_memory()
disk = psutil.disk_usage('/')
app_metrics = metrics.get_metrics()
return {
"system": {
"cpu_usage_percent": cpu_percent,
"memory_usage_percent": memory.percent,
"memory_available_mb": memory.available / 1024 / 1024,
"disk_usage_percent": disk.percent,
"load_average": psutil.getloadavg()
},
"application": app_metrics,
"timestamp": time.time()
}
# Readiness endpoint for k8s
@app.get("/ready")
def readiness_check():
# Add your readiness checks here (DB connection, etc.)
return {"ready": True}
```
## Performance Optimization
### Scaling Best Practices
1. **Start Simple**: Begin with `--fast` mode and measure performance
2. **Profile Your Application**: Identify CPU vs I/O bound operations
3. **Test Different Configurations**: Benchmark various process/worker combinations
4. **Monitor Resource Usage**: Watch CPU, memory, and I/O utilization
5. **Scale Horizontally**: Use multiple instances behind a load balancer
### Performance Testing
**Load Testing**: Use tools like wrk, Apache Bench, or Locust to test different configurations and find optimal settings.
```bash
# Install wrk for load testing
# macOS: brew install wrk
# Ubuntu: sudo apt install wrk
# Test baseline performance
wrk -t4 -c100 -d30s http://localhost:8080/health
# Test with different configurations
# Configuration 1: Single process
python app.py --processes 1 --workers 1 &
wrk -t4 -c100 -d30s http://localhost:8080/api/endpoint
# Configuration 2: Multi-process
python app.py --processes 4 --workers 2 &
wrk -t4 -c100 -d30s http://localhost:8080/api/endpoint
# Configuration 3: Fast mode
python app.py --fast &
wrk -t4 -c100 -d30s http://localhost:8080/api/endpoint
# Compare results and choose the best configuration
```
```python
# Python script for automated testing
import subprocess
import time
import requests
def test_configuration(processes, workers, duration=30):
# Start server
cmd = f"python app.py --processes {processes} --workers {workers}"
server = subprocess.Popen(cmd.split())
time.sleep(2) # Wait for startup
try:
# Run load test
wrk_cmd = f"wrk -t4 -c100 -d{duration}s http://localhost:8080/health"
result = subprocess.run(wrk_cmd.split(), capture_output=True, text=True)
return result.stdout
finally:
server.terminate()
time.sleep(1)
# Test different configurations
configs = [(1, 1), (2, 2), (4, 1), (4, 2), (8, 1)]
for processes, workers in configs:
print(f"\nTesting: {processes} processes, {workers} workers")
result = test_configuration(processes, workers)
print(result)
```
### Environment Variables
**Configuration via Environment**: Use environment variables for deployment flexibility.
```bash
# Production environment variables
export ROBYN_HOST=0.0.0.0
export ROBYN_PORT=8080
export ROBYN_LOG_LEVEL=INFO
export ROBYN_PROCESSES=4
export ROBYN_WORKERS=2
# Database configuration
export DATABASE_URL=postgresql://user:pass@localhost/db
export REDIS_URL=redis://localhost:6379/0
# Application settings
export SECRET_KEY=your-secret-key
export DEBUG=false
export ENVIRONMENT=production
# Start application with environment config
python app.py
```
```python
# app.py - Using environment variables
import os
from robyn import Robyn
app = Robyn(__file__)
# Configuration from environment
HOST = os.getenv("ROBYN_HOST", "127.0.0.1")
PORT = int(os.getenv("ROBYN_PORT", "8080"))
PROCESSES = int(os.getenv("ROBYN_PROCESSES", "1"))
WORKERS = int(os.getenv("ROBYN_WORKERS", "1"))
LOG_LEVEL = os.getenv("ROBYN_LOG_LEVEL", "INFO")
if __name__ == "__main__":
app.start(
host=HOST,
port=PORT,
processes=PROCESSES,
workers=WORKERS,
log_level=LOG_LEVEL
)
```
---
## What's next?
Now, Batman wanted to extend Robyn. Robyn told him about the advanced features.
- [Advanced Features](/documentation/en/api_reference/advanced_features)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/server_sent_events.mdx
================================================
export const description =
'Learn how to implement Server-Sent Events (SSE) in Robyn for real-time server-to-client communication.'
# Server-Sent Events (SSE)
After learning about [form data handling](/documentation/en/api_reference/form_data), Batman realized he needed a way to push real-time updates to his crime monitoring dashboard. Criminals don't wait for Batman to refresh his browser!
He discovered Server-Sent Events (SSE) - a perfect solution for one-way communication from server to client over HTTP. SSE allows Batman to stream live data to his dashboard without the complexity of full bidirectional communication.
"This is exactly what I need for my crime alerts!" Batman exclaimed. "I can push updates to the dashboard instantly when new crimes are detected."
Server-Sent Events are ideal for:
- Real-time notifications
- Live data feeds
- Progress updates
- Chat applications (server-to-client only)
- Dashboard updates
- Log streaming
## How does it work?
Batman can create Server-Sent Events streams by using the `SSEResponse` and `SSEMessage` classes. He can use both regular generators and async generators depending on his needs:
- **Regular generators**: Perfect for simple data streams or when working with synchronous operations
- **Async generators**: Ideal when Batman needs to perform async operations like database queries or API calls within the stream
```python {{ title: 'Basic SSE Stream' }}
from robyn import Robyn, SSEResponse, SSEMessage
import time
app = Robyn(__file__)
@app.get("/events")
def stream_events(request):
def event_generator():
for i in range(10):
yield SSEMessage(f"Event {i}", id=str(i))
time.sleep(1)
return SSEResponse(event_generator())
```
```python {{ title: 'JSON Data Stream' }}
from robyn import Robyn, SSEResponse, SSEMessage
import json
import time
app = Robyn(__file__)
@app.get("/events/json")
def stream_json_events(request):
def json_event_generator():
for i in range(5):
data = {
"id": i,
"message": f"Update {i}",
"timestamp": time.time()
}
yield SSEMessage(
json.dumps(data),
event="update",
id=str(i)
)
time.sleep(2)
return SSEResponse(json_event_generator())
```
```python {{ title: 'Async Generator Stream' }}
from robyn import Robyn, SSEResponse, SSEMessage
import asyncio
import time
app = Robyn(__file__)
@app.get("/events/async")
async def stream_async_events(request):
async def async_event_generator():
for i in range(8):
# Simulate async work like database calls
await asyncio.sleep(0.5)
yield SSEMessage(
f"Async message {i} - {time.strftime('%H:%M:%S')}",
event="async",
id=str(i)
)
return SSEResponse(async_event_generator())
```
---
## Async Generators
When Batman needs to perform async operations during his SSE streams - like fetching data from databases or making API calls - he uses async generators with `async def` and `await`. This allows him to handle multiple streams concurrently without blocking other operations.
The key difference is using `async def` for the generator function and `await` for async operations inside the generator:
```python {{ title: 'Database Stream' }}
from robyn import Robyn, SSEResponse, SSEMessage
import asyncio
import json
import time
app = Robyn(__file__)
@app.get("/events/database")
async def stream_database_events(request):
async def database_event_generator():
for i in range(10):
# Simulate async database query
await asyncio.sleep(0.3)
# Simulate fetching data from database
data = {
"crime_id": i,
"location": f"Gotham District {i}",
"severity": "high" if i % 2 == 0 else "low",
"timestamp": time.time()
}
yield SSEMessage(
json.dumps(data),
event="crime_alert",
id=str(i)
)
return SSEResponse(database_event_generator())
```
```python {{ title: 'API Integration Stream' }}
from robyn import Robyn, SSEResponse, SSEMessage
import asyncio
import aiohttp
import json
app = Robyn(__file__)
@app.get("/events/api")
async def stream_api_events(request):
async def api_event_generator():
async with aiohttp.ClientSession() as session:
for i in range(5):
try:
# Make async API call
async with session.get(f"https://api.example.com/data/{i}") as response:
data = await response.json()
yield SSEMessage(
json.dumps(data),
event="api_update",
id=str(i)
)
except Exception as e:
yield SSEMessage(
f"Error fetching data: {str(e)}",
event="error",
id=f"error_{i}"
)
await asyncio.sleep(1)
return SSEResponse(api_event_generator())
```
---
## What's next?
Batman has mastered Server-Sent Events and can now stream real-time updates to his crime dashboard. While SSE is perfect for one-way communication from server to client, Batman realizes he needs bidirectional communication for more interactive features like real-time chat with his allies.
Next, he wants to explore how to handle bidirectional communication with [WebSockets](/documentation/en/api_reference/websockets) for more interactive features.
If Batman needs to handle unexpected situations, he'll learn about [Exception handling](/documentation/en/api_reference/exceptions) to make his applications more robust.
For scaling his crime monitoring system across multiple processes, Batman will explore [Scaling the Application](/documentation/en/api_reference/scaling).
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/templating.mdx
================================================
export const description =
'On this page, we’ll dive into the different conversation endpoints you can use to manage conversations programmatically.'
## Templating.
Batman wanted to quickly render html pages on the website. He wanted to use a templating engine to render the html pages. Robyn told him that he can use the Jinja2 templating engine to render the html pages. He can use the `JinjaTemplate` class to render the html pages.
Batman was excited to learn that he could add events as functions as well as decorators.
```python
from robyn.templating import JinjaTemplate
current_file_path = pathlib.Path(__file__).parent.resolve()
JINJA_TEMPLATE = JinjaTemplate(os.path.join(current_file_path, "templates"))
@app.get("/template_render")
def template_render():
context = {"framework": "Robyn", "templating_engine": "Jinja2"}
template = JINJA_TEMPLATE.render_template(template_name="test.html", **context)
return template
```
test.html file
```html
Results
Hello {{ framework }}! You're using {{ templating_engine }}.
```
## Supporting Custom Templating Engines
Batman was also super excited to know that Robyn allows the support of custom templating engines.
To do that, you need to import the `TemplateInterface` from `robyn.templating`
```python
from robyn.templating import TemplateInterface
```
Then You need to have a `render_template` method inside your implementation. So, an example would look like the following:
```python
class JinjaTemplate(TemplateInterface):
def __init__(self, directory, encoding="utf-8", followlinks=False):
self.env = Environment(
loader=FileSystemLoader(
searchpath=directory, encoding=encoding, followlinks=followlinks
)
)
def render_template(self, template_name: str, **kwargs):
return self.env.get_template(template_name).render(**kwargs)
```
## What's next?
Now, Batman wanted to have the ability to redirect the endpoints.
- [Redirection](/documentation/en/api_reference/redirection)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/timeout_configuration.mdx
================================================
export const description =
'Configure timeout settings to handle high-concurrency scenarios and prevent resource exhaustion.'
# Timeout Configuration
Robyn supports comprehensive timeout configuration to handle high-concurrency scenarios and prevent resource exhaustion like the "Too many open files" error. {{ className: 'lead' }}
## Configuration Options
### Method Parameters
Configure timeouts directly in the `app.start()` method:
```python
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
async def hello(request):
return "Hello, world!"
# Configure timeout settings
app.start(
host="0.0.0.0",
port=8080,
client_timeout=30, # Client connection timeout (seconds)
keep_alive_timeout=20 # Keep-alive timeout (seconds)
)
```
### Environment Variables
Override configuration using environment variables:
```bash
# Set timeout configurations
export ROBYN_CLIENT_TIMEOUT=45
export ROBYN_KEEP_ALIVE_TIMEOUT=30
# Start your application
python app.py
```
## Configuration Parameters
| Parameter | Default | Description | Environment Variable |
|-----------|---------|-------------|---------------------|
| `client_timeout` | 30 | Maximum time (seconds) for client request processing | `ROBYN_CLIENT_TIMEOUT` |
| `keep_alive_timeout` | 20 | Time (seconds) to keep idle connections alive | `ROBYN_KEEP_ALIVE_TIMEOUT` |
## Usage Examples
### Basic Configuration
```python
# Minimal timeout configuration
app.start(client_timeout=30)
```
### High-Traffic Production Setup
```python
# Optimized for high-traffic scenarios
app.start(
host="0.0.0.0",
port=8080,
client_timeout=60, # Allow longer processing time
keep_alive_timeout=15 # Shorter keep-alive for faster turnover
)
```
### Development Setup
```python
# Development-friendly settings
app.start(
client_timeout=300, # Long timeout for debugging
keep_alive_timeout=60 # Longer keep-alive for testing
)
```
### Load Testing Configuration
```python
# Optimized for load testing with tools like wrk
app.start(
client_timeout=10, # Quick timeouts
keep_alive_timeout=5 # Fast connection turnover
)
```
## Environment Variable Priority
Environment variables take precedence over method parameters:
```python
# This will use ROBYN_CLIENT_TIMEOUT=60 if set, otherwise 30
app.start(client_timeout=30)
```
## Troubleshooting
### "Too Many Open Files" Error
If you encounter file descriptor exhaustion:
1. **Increase system limits:**
```bash
ulimit -n 65536
```
2. **Optimize timeout settings:**
```python
app.start(
client_timeout=15, # Shorter timeouts
keep_alive_timeout=5 # Faster connection cleanup
)
```
3. **Use environment variables for deployment:**
```bash
export ROBYN_CLIENT_TIMEOUT=15
export ROBYN_KEEP_ALIVE_TIMEOUT=5
```
### Performance Tuning
**For high-throughput APIs:**
- Lower `keep_alive_timeout` (5-15s)
- Moderate `client_timeout` (15-30s)
**For long-running operations:**
- Higher `client_timeout` (60-300s)
- Standard `keep_alive_timeout` (20-30s)
## Best Practices
1. **Always set explicit timeouts** in production
2. **Use environment variables** for deployment-specific configuration
3. **Test timeout settings** with realistic load patterns
4. **Start with conservative values** and tune based on metrics
## Migration Guide
### From Previous Versions
If upgrading from earlier Robyn versions, the default behavior changes:
**Before (infinite timeout):**
```python
# Previously: no timeout (could cause resource exhaustion)
app.start(host="0.0.0.0", port=8080)
```
**After (sensible defaults):**
```python
# Now: automatic 30s client timeout, 20s keep-alive
app.start(host="0.0.0.0", port=8080)
# Equivalent to:
app.start(
host="0.0.0.0",
port=8080,
client_timeout=30,
keep_alive_timeout=20
)
```
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/using_rust_directly.mdx
================================================
## Using Rust to extend Robyn
There may be occasions where Batman may be working with a high computation task, or a task that requires a lot of memory. In such cases, he may want to use Rust to implement that task. Robyn introduces a special way to do this. Not only you can use Rust to extend Python code, you can do it while maintaining the hot reloading nature of your codebase. Making it *feel* like an interpreted version in many situations.
The first thing you need to is to create a Rust file. Let's call it `hello_world.rs`. You can do it using the cli:
```python
python -m robyn --create-rust-file hello_world
```
Then you can open the file and write your Rust code. For example, let's write a function that returns a string.
```rust
// hello_world.rs
// rustimport:pyo3
use pyo3::prelude::*;
#[pyfunction]
fn square(n: i32) -> i32 {
n * n
// this is another comment
}
```
Every Rust file that you create using the cli will have a special comment at the top of the file. This comment is used by Robyn to know which dependencies to import. In this case, we are importing the `pyo3` crate. You can import as many crates as you want. You can also import crates from crates.io. For example, if you want to use the `rusqlite` crate, you can do it like this:
```rust
// rustimport:pyo3
//:
//: [dependencies]
//: rusqlite = "0.19.0"
use pyo3::prelude::*;
#[pyfunction]
fn square(n: i32) -> i32 {
n * n * n
// this is another comment
}
```
Then you can import the function in your Python code and use it.
```python
from hello_world import square
print(square(5))
```
To run the code, you need to use the `--compile-rust-path` flag. This will compile the Rust code and run it. You can also use the `--dev` flag to watch for changes in the Rust code and recompile it on the fly.
```python
python -m robyn --compile-rust-path "." --dev
```
An example of a Robyn app with a Rust file that using the `rusqlite` crate to connect to a database and return the number of rows in a table: https://github.com/sansyrox/rusty-sql
## What's next?
Batman was curious to know what else he could do with Robyn.
Robyn told him to keep an eye on the GraphQl support.
[GraphQl Support](/documentation/en/api_reference/graphql_support)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/websockets.mdx
================================================
export const description =
'Learn how to use Robyn\'s WebSocket API for real-time, bidirectional communication — including message streaming, connect/close callbacks, broadcasting, and common patterns like live updates, presence tracking, and low-latency messaging.'
## WebSockets {{ tag: 'WebSockets', label: 'WebSockets' }}
After mastering [Server-Sent Events](/documentation/en/api_reference/server_sent_events) for one-way communication, Batman realized he needed something more powerful. When Commissioner Gordon wanted to chat with him in real-time during crisis situations, Batman needed bidirectional communication.
"SSE is great for pushing updates to my dashboard," Batman thought, "but I need two-way communication for coordinating with my allies!"
To handle real-time bidirectional communication, Batman learned how to work with WebSockets using Robyn's modern decorator-based API. Under the hood, messages flow through Rust channels for maximum performance — no Python GIL overhead during message dispatch.
```python {{ title: 'Basic Echo' }}
from robyn import Robyn
app = Robyn(__file__)
@app.websocket("/web_socket")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
app.start()
```
```python {{ title: 'With Callbacks' }}
from robyn import Robyn, WebSocketDisconnect
app = Robyn(__file__)
@app.websocket("/web_socket")
async def handler(websocket):
try:
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
except WebSocketDisconnect:
print(f"Client {websocket.id} disconnected")
@handler.on_connect
def on_connect(websocket):
return "Connected to ws"
@handler.on_close
def on_close(websocket):
return "Goodbye world, from ws"
app.start()
```
---
## Receiving Messages {{ tag: 'receive_text', label: 'receive_text' }}
The `receive_text()` method blocks until the next message arrives from the client. It is backed by a Rust `tokio::mpsc` channel, so the Python handler genuinely suspends without holding the GIL.
When the client disconnects, `receive_text()` raises `WebSocketDisconnect`. You can either catch it explicitly or let the internal wrapper handle it silently.
```python {{ title: 'Text Messages' }}
@app.websocket("/ws")
async def handler(websocket):
try:
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Got: {msg}")
except WebSocketDisconnect:
print(f"Client {websocket.id} disconnected")
```
```python {{ title: 'JSON Messages' }}
@app.websocket("/api")
async def handler(websocket):
while True:
data = await websocket.receive_json()
result = process(data)
await websocket.send_json({"status": "ok", "result": result})
```
---
## Sending Messages {{ tag: 'send_text', label: 'send_text' }}
To send a message to the current client, use `send_text()` or `send_json()`. All send methods are async.
```python {{ title: 'Send Text' }}
@app.websocket("/ws")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
```
```python {{ title: 'Send JSON' }}
@app.websocket("/ws")
async def handler(websocket):
while True:
data = await websocket.receive_json()
await websocket.send_json({"echo": data})
```
---
## Broadcasting {{ tag: 'broadcast', label: 'broadcast' }}
To send a message to all connected clients on the same WebSocket endpoint, use the `broadcast()` method.
```python {{ title: 'Broadcast' }}
@app.websocket("/chat")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
# Send to all connected clients
await websocket.broadcast(f"User {websocket.id}: {msg}")
# Also send a confirmation to this client only
await websocket.send_text("Your message was sent")
```
---
## Query Parameters {{ tag: 'query_params', label: 'query_params' }}
You can access query parameters from the WebSocket connection URL via `websocket.query_params`.
```python {{ title: 'Query Params' }}
@app.websocket("/ws")
async def handler(websocket):
name = websocket.query_params.get("name")
role = websocket.query_params.get("role")
if name == "gordon" and role == "commissioner":
await websocket.broadcast("Gordon authorized!")
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Hello {name}: {msg}")
```
---
## Easy Access Query Parameters {{ tag: 'easy_access', label: 'easy_access' }}
Instead of manually calling `websocket.query_params.get(...)`, you can declare typed query parameters directly in your handler, `on_connect`, and `on_close` signatures. Robyn will automatically resolve and coerce them — just like HTTP easy access parameters.
Parameters with defaults are optional. Parameters without defaults are required — if missing, the connection is rejected with an error message.
```python {{ title: 'Handler' }}
@app.websocket("/ws")
async def handler(websocket, room: str = "default", page: int = 1):
try:
while True:
msg = await websocket.receive_text()
await websocket.send_text(
f"room={room} page={page} msg={msg}"
)
except WebSocketDisconnect:
pass
```
```python {{ title: 'Callbacks' }}
@handler.on_connect
def on_connect(websocket, room: str = "default"):
return f"connected to {room}"
@handler.on_close
def on_close(websocket, room: str = "default"):
return f"left {room}"
```
---
## Closing Connections {{ tag: 'close', label: 'close' }}
To programmatically close a WebSocket connection from the server side, use `websocket.close()`. This will:
1. Close the WebSocket connection.
2. Remove the client from the WebSocket registry.
3. Cause any pending `receive_text()` to raise `WebSocketDisconnect`.
```python {{ title: 'Server Close' }}
@app.websocket("/ws")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
if msg == "quit":
await websocket.close()
break
await websocket.send_text(f"Got: {msg}")
```
---
## Connect and Close Callbacks {{ tag: 'Callbacks', label: 'Callbacks' }}
You can attach optional `on_connect` and `on_close` callbacks to your WebSocket handler. These are decorators on the handler function itself.
- `on_connect` is called when a new client connects. Its return value is sent to the client as the first message.
- `on_close` is called when the connection closes. Its return value is sent to the client as the final message.
Both callbacks receive a `websocket` object with access to `id` and `query_params`. Both are optional.
```python {{ title: 'Callbacks' }}
@app.websocket("/chat")
async def chat(websocket):
while True:
msg = await websocket.receive_text()
await websocket.broadcast(msg)
@chat.on_connect
def on_connect(websocket):
return f"Welcome, {websocket.id}!"
@chat.on_close
def on_close(websocket):
return "Goodbye!"
```
---
## WebSocket API Reference {{ tag: 'API', label: 'API' }}
The `websocket` object passed to handlers exposes the following methods and properties:
| Method / Property | Description |
|---|---|
| `await websocket.receive_text()` | Block until next message; raises `WebSocketDisconnect` on close |
| `await websocket.receive_bytes()` | Block until next binary message; raises `WebSocketDisconnect` on close |
| `await websocket.receive_json()` | Same as `receive_text()` but JSON-decoded |
| `await websocket.send_text(data)` | Send string to this client |
| `await websocket.send_bytes(data)` | Send binary data to this client |
| `await websocket.send_json(data)` | Send JSON to this client |
| `await websocket.broadcast(data)` | Send to all clients on this endpoint |
| `await websocket.close()` | Close the connection server-side |
| `websocket.id` | Connection UUID string |
| `websocket.query_params` | Query parameters from the connection URL |
---
## What's next?
As the codebase grew, Batman wanted to onboard the justice league to help him manage the application.
Robyn told him about the different ways he could scale his application, and how to use views and subrouters to make his code more readable.
- [Views and SubRouters](/documentation/en/api_reference/views)
================================================
FILE: docs_src/src/pages/documentation/en/api_reference/zh/getting_started.mdx
================================================
export const description =
'开始使用Robyn构建您的第一个应用程序。'
# 入门指南
## 创建您的第一个Robyn应用程序
让我们从创建一个简单的Robyn应用程序开始。首先,使用pip安装Robyn:
```bash
pip install robyn
```
然后,创建一个新的Python文件 `app.py`:
```python
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
async def hello_world():
return "Hello, World!"
if __name__ == "__main__":
app.start()
```
现在运行您的应用程序:
```bash
python app.py
```
访问 `http://localhost:8080`,您应该能看到 "Hello, World!" 消息。
## 命令行选项
Robyn提供了多个命令行选项来配置您的应用程序:
```bash
python app.py --help
```
输出将显示所有可用选项:
```text
options:
-h, --help 显示帮助信息
--processes PROCESSES
选择进程数量。[默认值: 1]
--workers WORKERS 选择工作线程数量。[默认值: 1]
--dev 开发模式。根据文件更改自动重启服务器。
--log-level LOG_LEVEL
设置日志级别
--create 创建新项目模板。
--docs 打开Robyn文档。
--open-browser 成功启动时打开浏览器。
--version 显示Robyn版本。
--compile-rust-path COMPILE_RUST_PATH
编译指定路径中的rust文件。
--create-rust-file CREATE_RUST_FILE
创建指定名称的rust文件。
--disable-openapi 禁用OpenAPI文档。
--fast 快速模式。设置最优的进程、工作线程和日志级别。但您可以覆盖这些设置。
```
## 路由装饰器
Robyn支持所有标准的HTTP方法:
```python
@app.get("/users")
async def get_users():
return {"users": ["user1", "user2"]}
@app.post("/users")
async def create_user(request):
return {"message": "用户已创建"}
@app.put("/users/:id")
async def update_user(request):
return {"message": "用户已更新"}
@app.delete("/users/:id")
async def delete_user(request):
return {"message": "用户已删除"}
```
## 请求参数
您可以通过多种方式访问请求数据:
```python
@app.post("/api/data")
async def handle_data(request):
# 访问JSON数据
json_data = request.json()
# 访问查询参数
query_params = request.query_params
# 访问路径参数
path_params = request.path_params
# 访问请求头
headers = request.headers
return {
"json": json_data,
"query": query_params,
"path": path_params,
"headers": headers
}
```
## 响应类型
Robyn支持多种响应类型:
```python
from robyn import Response, jsonify
@app.get("/text")
async def text_response():
return "纯文本响应"
@app.get("/json")
async def json_response():
return jsonify({"message": "JSON响应"})
@app.get("/custom")
async def custom_response():
return Response(
status_code=201,
description="自定义响应",
headers={"Content-Type": "text/plain"}
)
```
================================================
FILE: docs_src/src/pages/documentation/en/architecture.mdx
================================================
export const description = 'Robyn is a Python web server that employs the tokio runtime and leverages a blend of Python and Rust, enabling efficient request handling through a worker event cycle, multi-core scaling, and introducing "Const Requests" for optimized, cached responses in a multi-threaded environment.'
## Robyn Architecture Overview
Robyn's unique architecture combines Python's ease of development with Rust's performance. This hybrid design allows developers to write familiar Python code while benefiting from Rust's speed and memory safety.
## The Python-Rust Hybrid Design
### Two-Layer Architecture
Robyn operates on two interconnected but distinct layers:
**Python Layer (Developer Interface)**:
- Route definitions and decorators (`@app.get`, `@app.post`, etc.)
- Request parameter injection and validation
- Business logic execution
- Middleware configuration
- Response formatting
**Rust Layer (Performance Engine)**:
- HTTP request parsing and validation
- URL routing and pattern matching
- WebSocket connection management
- Static file serving
- Response serialization
- Memory management
### Communication Bridge
The layers communicate through **PyO3**, a Rust crate that enables seamless Python-Rust interoperability:
1. **Function Registration**: Python route handlers are registered with the Rust runtime at startup
2. **Request Flow**: Rust handles incoming HTTP requests and calls Python handlers via PyO3
3. **Response Processing**: Python responses are converted back to Rust for efficient HTTP serialization
### Why This Design Works
- **Best of Both Worlds**: Python's productivity with Rust's performance
- **Zero-Copy Operations**: Minimal data copying between layers
- **Memory Safety**: Rust prevents common server vulnerabilities
- **Async Integration**: Seamless integration with Python's asyncio
## Server Process Model
Robyn is built on a multi-process, multi-threaded model that maximizes hardware utilization:
## Master Process
The master process in Robyn is responsible for initializing the server, managing worker processes, and handling signals. It creates a socket and passes it to the worker processes, allowing them to accept connections. The master process is implemented in Python, providing a familiar interface for developers while leveraging Rust's performance for core operations.
```python
216:257:robyn/__init__.py
def start(self, host: str = "127.0.0.1", port: int = 8080, _check_port: bool = True):
"""
Starts the server
:param host str: represents the host at which the server is listening
:param port int: represents the port number at which the server is listening
:param _check_port bool: represents if the port should be checked if it is already in use
"""
host = os.getenv("ROBYN_HOST", host)
port = int(os.getenv("ROBYN_PORT", port))
open_browser = bool(os.getenv("ROBYN_BROWSER_OPEN", self.config.open_browser))
if _check_port:
while self.is_port_in_use(port):
logger.error("Port %s is already in use. Please use a different port.", port)
try:
port = int(input("Enter a different port: "))
except Exception:
logger.error("Invalid port number. Please enter a valid port number.")
continue
logger.info("Robyn version: %s", __version__)
logger.info("Starting server at http://%s:%s", host, port)
mp.allow_connection_pickling()
run_processes(
host,
port,
self.directories,
self.request_headers,
self.router.get_routes(),
self.middleware_router.get_global_middlewares(),
self.middleware_router.get_route_middlewares(),
self.web_socket_router.get_routes(),
self.event_handlers,
self.config.workers,
self.config.processes,
self.response_headers,
open_browser,
)
```
## Worker Processes
Robyn uses multiple worker processes to handle incoming requests. Each worker process is capable of managing multiple threads, allowing for efficient concurrent processing. The number of worker processes can be configured using the `--processes` flag, with a default of 1.
```python
66:116:robyn/processpool.py
def init_processpool(
directories: List[Directory],
request_headers: Headers,
routes: List[Route],
global_middlewares: List[GlobalMiddleware],
route_middlewares: List[RouteMiddleware],
web_sockets: Dict[str, WebSocket],
event_handlers: Dict[Events, FunctionInfo],
socket: SocketHeld,
workers: int,
processes: int,
response_headers: Headers,
) -> List[Process]:
process_pool = []
if sys.platform.startswith("win32") or processes == 1:
spawn_process(
directories,
request_headers,
routes,
global_middlewares,
route_middlewares,
web_sockets,
event_handlers,
socket,
workers,
response_headers,
)
return process_pool
for _ in range(processes):
copied_socket = socket.try_clone()
process = Process(
target=spawn_process,
args=(
directories,
request_headers,
routes,
global_middlewares,
route_middlewares,
web_sockets,
event_handlers,
copied_socket,
workers,
response_headers,
),
)
process.start()
process_pool.append(process)
return process_pool
```
## Worker Threads
Within each worker process, Robyn utilizes multiple threads to handle requests concurrently. The number of worker threads can be configured using the `--workers` flag. By default, Robyn uses a single worker thread per process.
## Request Processing Flow
Understanding how requests flow through Robyn's hybrid architecture:
### 1. Request Arrival
```
HTTP Request → Rust HTTP Parser → Fast Validation
```
### 2. Routing and Matching
```
Validated Request → Rust Router (matchit crate) → Route Resolution
```
### 3. Parameter Extraction
```
Matched Route → Rust Parameter Parser → Path/Query/Header Extraction
```
### 4. Python Handler Execution
```
Extracted Parameters → PyO3 Bridge → Python Handler → Response
```
### 5. Response Processing
```
Python Response → Rust Serializer → HTTP Response → Client
```
## Rust Integration Deep Dive
Robyn's Rust integration is powered by the **Tokio** async runtime and several high-performance crates:
### Core Components
- **Tokio Runtime**: Handles async I/O and task scheduling
- **Actix Web**: Provides HTTP server functionality
- **PyO3**: Enables Python-Rust communication
- **matchit**: Ultra-fast URL routing with radix tree implementation
- **Serde**: JSON serialization/deserialization
### Performance Benefits
1. **Zero-allocation routing** using compiled radix trees
2. **Memory-efficient HTTP parsing** with minimal allocations
3. **Async task scheduling** without GIL interference
4. **Direct memory access** for static file serving
```python
76:107:src/server.rs
pub fn start(
&mut self,
py: Python,
socket: &PyCell,
workers: usize,
) -> PyResult<()> {
pyo3_log::init();
if STARTED
.compare_exchange(false, true, SeqCst, Relaxed)
.is_err()
{
debug!("Robyn is already running...");
return Ok(());
}
let raw_socket = socket.try_borrow_mut()?.get_socket();
let router = self.router.clone();
let const_router = self.const_router.clone();
let middleware_router = self.middleware_router.clone();
let web_socket_router = self.websocket_router.clone();
let global_request_headers = self.global_request_headers.clone();
let global_response_headers = self.global_response_headers.clone();
let directories = self.directories.clone();
let asyncio = py.import("asyncio")?;
let event_loop = asyncio.call_method0("new_event_loop")?;
asyncio.call_method1("set_event_loop", (event_loop,))?;
let startup_handler = self.startup_handler.clone();
let shutdown_handler = self.shutdown_handler.clone();
```
## Const Requests Optimization
Robyn's "Const Requests" feature provides significant performance improvements for static endpoints:
### How Const Requests Work
1. **Route Registration**: Routes marked with `const=True` are identified at startup
2. **Response Caching**: The first response is cached in Rust memory
3. **Direct Serving**: Subsequent requests bypass Python entirely
4. **Zero Overhead**: Responses are served directly from Rust with minimal CPU usage
### Performance Impact
- **10x faster response times** compared to regular Python handlers
- **Minimal memory usage** with efficient caching
- **No Python GIL contention** for cached responses
- **Ideal for**: Health checks, API metadata, configuration endpoints
### Example Usage
```python
from robyn import Robyn
app = Robyn(__file__)
# Regular route - executes Python on every request
@app.get("/dynamic")
def dynamic_endpoint():
return {"timestamp": time.time()} # Changes every request
# Const route - cached in Rust after first request
@app.get("/health", const=True)
def health_check():
return {"status": "healthy", "version": "1.0.0"} # Static response
# Perfect for API metadata
@app.get("/api/info", const=True)
def api_info():
return {
"name": "My API",
"version": "2.1.0",
"endpoints": ["/users", "/posts", "/health"]
}
```
### When to Use Const Routes
- **Health/status endpoints** that return consistent data
- **API documentation** or metadata endpoints
- **Configuration endpoints** with static values
- **Version information** endpoints
## Scaling Configuration Guide
### Understanding Processes vs Workers
**Processes**:
- Independent Python interpreters
- Share no memory (shared-nothing architecture)
- Each process has its own GIL
- Best for CPU-bound applications
- Recommended: 1 process per CPU core
**Workers** (within each process):
- Threads sharing the same Python interpreter
- Affected by Python's GIL
- Better for I/O-bound operations
- Recommended: 2-4 workers per process
### Configuration Strategies
#### CPU-Intensive Applications
```bash
# Favor more processes, fewer workers
python app.py --processes=8 --workers=1
# Example: Image processing, data analysis, calculations
```
#### I/O-Intensive Applications
```bash
# Favor fewer processes, more workers
python app.py --processes=2 --workers=8
# Example: Database queries, API calls, file operations
```
#### Balanced Applications
```bash
# General-purpose configuration
python app.py --processes=4 --workers=2
# Most web applications fit this pattern
```
### Hardware-Based Recommendations
For a system with **N CPU cores**:
| Application Type | Processes | Workers | Total Concurrency |
|-----------------|-----------|---------|-------------------|
| CPU-bound | N | 1 | N |
| I/O-bound | N/2 | 4 | 2N |
| Balanced | N/2 | 2 | N |
| High-traffic | N | 2 | 2N |
### Performance Testing
Always benchmark your specific application:
```bash
# Test different configurations
python app.py --processes=1 --workers=1 # Baseline
python app.py --processes=2 --workers=2 # Moderate scaling
python app.py --processes=4 --workers=1 # CPU-focused
python app.py --processes=2 --workers=4 # I/O-focused
python app.py --fast # Auto-optimized
```
## Scaling Considerations
- Robyn's multi-process model allows it to scale across multiple CPU cores effectively.
- The combination of Python and Rust allows for both ease of development and high performance.
- Const Requests feature can significantly improve performance for routes with constant output.
- When scaling, consider both the number of processes and workers to find the optimal configuration for your hardware and application needs.
## Development Mode
Robyn provides a development mode that can be activated using the `--dev` flag. This mode is designed for ease of development and includes features like hot reloading. Note that in development mode, multi-process and multi-worker configurations are disabled to ensure consistent behavior during development.
```python
92:101:robyn/argument_parser.py
if self.dev and (self.processes != 1 or self.workers != 1):
raise Exception("--processes and --workers shouldn't be used with --dev")
if self.dev and args.log_level is None:
self.log_level = "DEBUG"
elif args.log_level is None:
self.log_level = "INFO"
else:
self.log_level = args.log_level
```
By understanding these design principles and adjusting the configuration accordingly, developers can leverage Robyn's unique architecture to build high-performance web applications that efficiently utilize system resources.
## Design Diagram
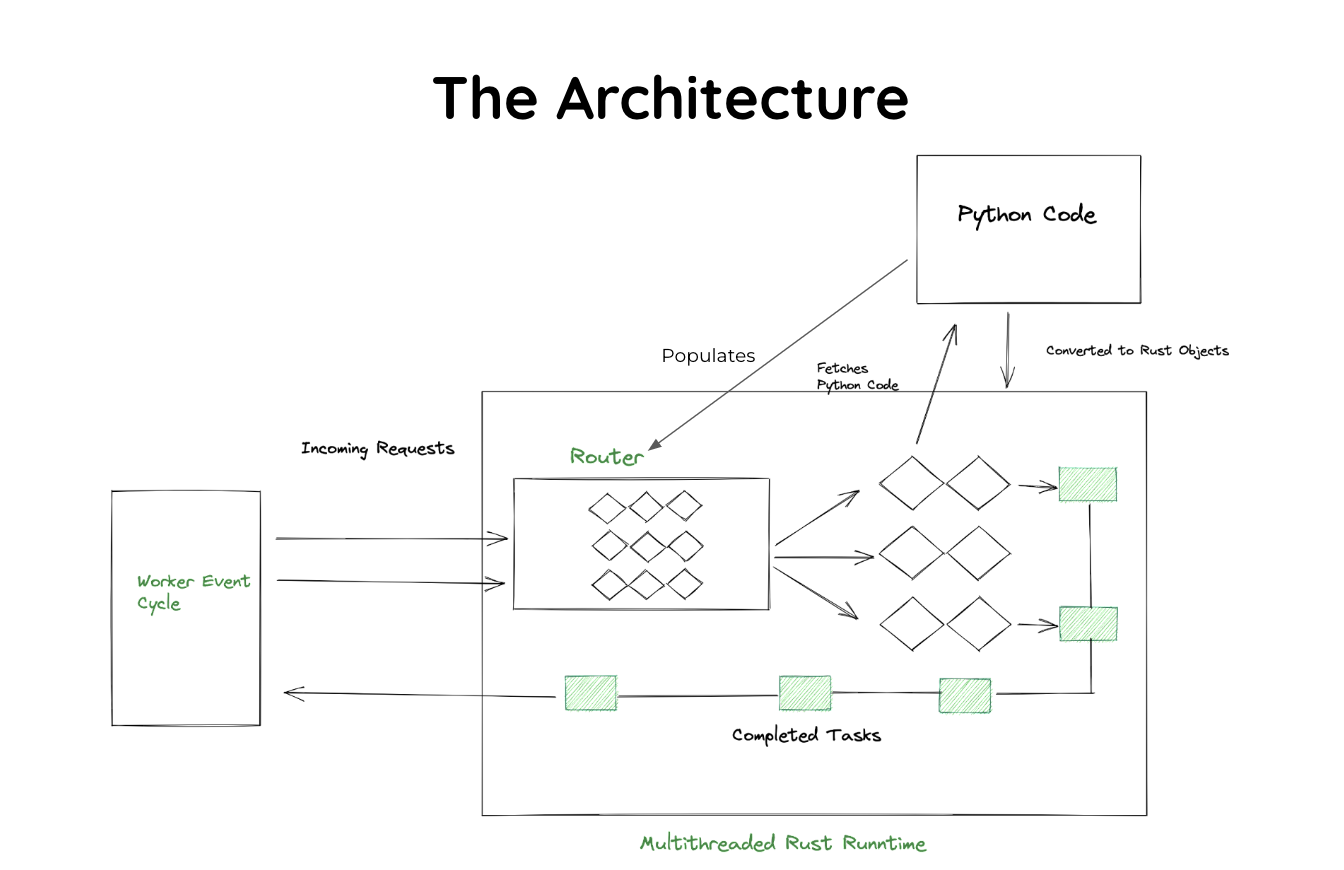 ================================================
FILE: docs_src/src/pages/documentation/en/community-resources.mdx
================================================
export const description =
'On this page, we`ll take a look at some community resources contributed by our amazing members to help developers get started with Robyn.'
## Talks
- [EuroPython 2022](https://www.youtube.com/watch?v=AutugvJNVkY&)
- [GeoPython 2022](https://www.youtube.com/watch?v=YCpbCQwbkd4)
- [PyCon US 2022](https://youtu.be/1IiL31tUEVk?t=2101)
- [PyCon Sweden 2021](https://www.youtube.com/watch?v=DK9teAs72Do)
## Blogs
- [Hello, Robyn!](https://www.sanskar.me/posts/hello-robyn)
## Next Steps
Batman was now interes
- [Hosting](/documentation/hosting)
================================================
FILE: docs_src/src/pages/documentation/en/example_app/authentication-middlewares.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
## Authentication and Authorization Middleware
Batman added middleware to the Robyn application to verify the JWT tokens and to restrict access to certain endpoints based on the user's role.
```python {{ title: 'Setting up Authentication Middlewares' }}
from robyn.authentication import AuthenticationHandler, BearerGetter, Identity
class BasicAuthHandler(AuthenticationHandler):
def authenticate(self, request: Request):
token = self.token_getter.get_token(request)
try:
payload = crud.decode_access_token(token)
username = payload["sub"]
except Exception:
return
with SessionLocal() as db:
user = crud.get_user_by_username(db, username=username)
return Identity(claims={"user": f"{ user }"})
app.configure_authentication(BasicAuthHandler(token_getter=BearerGetter()))
@app.get("/users/me", auth_required=True)
async def get_current_user(request):
user = request.identity.claims["user"]
return user
```
With the web application in place, the Gotham City Police Department could now efficiently manage crime data and track criminal activities in real-time. Batman had successfully used the Robyn web framework to build a real-world application to help fight crime in Gotham City.
================================================
FILE: docs_src/src/pages/documentation/en/community-resources.mdx
================================================
export const description =
'On this page, we`ll take a look at some community resources contributed by our amazing members to help developers get started with Robyn.'
## Talks
- [EuroPython 2022](https://www.youtube.com/watch?v=AutugvJNVkY&)
- [GeoPython 2022](https://www.youtube.com/watch?v=YCpbCQwbkd4)
- [PyCon US 2022](https://youtu.be/1IiL31tUEVk?t=2101)
- [PyCon Sweden 2021](https://www.youtube.com/watch?v=DK9teAs72Do)
## Blogs
- [Hello, Robyn!](https://www.sanskar.me/posts/hello-robyn)
## Next Steps
Batman was now interes
- [Hosting](/documentation/hosting)
================================================
FILE: docs_src/src/pages/documentation/en/example_app/authentication-middlewares.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
## Authentication and Authorization Middleware
Batman added middleware to the Robyn application to verify the JWT tokens and to restrict access to certain endpoints based on the user's role.
```python {{ title: 'Setting up Authentication Middlewares' }}
from robyn.authentication import AuthenticationHandler, BearerGetter, Identity
class BasicAuthHandler(AuthenticationHandler):
def authenticate(self, request: Request):
token = self.token_getter.get_token(request)
try:
payload = crud.decode_access_token(token)
username = payload["sub"]
except Exception:
return
with SessionLocal() as db:
user = crud.get_user_by_username(db, username=username)
return Identity(claims={"user": f"{ user }"})
app.configure_authentication(BasicAuthHandler(token_getter=BearerGetter()))
@app.get("/users/me", auth_required=True)
async def get_current_user(request):
user = request.identity.claims["user"]
return user
```
With the web application in place, the Gotham City Police Department could now efficiently manage crime data and track criminal activities in real-time. Batman had successfully used the Robyn web framework to build a real-world application to help fight crime in Gotham City.
================================================
FILE: docs_src/src/pages/documentation/en/example_app/authentication.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
## Authentication and Authorization
To restrict access to the crime data, Batman added authentication and authorization to the application. He decided to use JWT (JSON Web Token) for authentication. He created a new table for users and added an endpoint for user registration.
## User Model
Batman added a new User model to represent the users who can access the application.
```python {{ title: 'Example request with basic auth' }}
# models.py
from sqlalchemy import Column, Integer, String, Boolean
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
username = Column(String, unique=True, index=True)
hashed_password = Column(String)
def __repr__(self):
return "".format(
id=self.id,
username=self.username,
hashed_password=self.hashed_password,
)
```
Then in crud.py, he added a new method to create a user.
```python {{ title: 'Example request with basic auth' }}
# crud.py
# also need to do pip install passlib[bcrypt]
from sqlalchemy.orm import Session
from .models import User
from passlib.context import CryptContext
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
def get_password_hash(password: str) -> str:
return pwd_context.hash(password)
def get_user(db: Session, user_id: int):
return db.query(User).filter(User.id == user_id).first()
def create_user(db: Session, user: User):
hashed_password = get_password_hash(user.password)
db_user = User(username=user.username, hashed_password=hashed_password)
db.add(db_user)
db.commit()
db.refresh(db_user)
return db_user
```
## Authentication Utilities
Batman created utility functions to handle authentication, including hashing passwords and verifying passwords.
```python {{ title: 'Example request with bearer token' }}
# crud.py
# also need to do pip install passlib[bcrypt]
# pip install "python-jose[cryptography]"
from passlib.context import CryptContext
from jose import JWTError, jwt
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
ALGORITHM = "HS256"
SECRET_KEY = "your_secret_key"
def create_access_token(data: dict, expires_delta: timedelta = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
def decode_access_token(token: str):
return jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
def authenticate_user(db: Session, username: str, password: str):
user = get_user_by_username(db, username)
if user is None:
return False
if not verify_password(password, user.hashed_password):
return False
created_token = create_access_token(data={"sub": user.username})
return created_token
```
## User Registration Endpoint
Batman added a new endpoint to allow users to register.
```python {{ title: 'Setting up Routes' }}
from . import crud
@app.post("/users/register")
async def register_user(request):
user = request.json()
with SessionLocal() as db:
created_user = crud.create_user(db, user)
return created_user
@app.post("/users/login")
async def login_user(request):
user = request.json()
with SessionLocal() as db:
token = crud.authenticate_user(db, **user)
if token is None:
raise HTTPException(status_code=401, detail="Invalid credentials")
return {"access_token": token}
```
================================================
FILE: docs_src/src/pages/documentation/en/example_app/deployment.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
## Deploying the Application
After thoroughly testing the web application and ensuring that all features were working as expected, Batman decided it was time to deploy it to a production server. He chose to use a robust and scalable platform, ensuring that his application would be available and performant at all times.
```python {{ title: 'Deploying the Application' }}
python app.py --processes=n --workers=m
```
With the web application deployed and running smoothly, Batman had a powerful new tool at his disposal. The Robyn framework had provided him with the flexibility, scalability, and performance needed to create an effective crime-fighting application, giving him a technological edge in his ongoing battle to protect Gotham City.
================================================
FILE: docs_src/src/pages/documentation/en/example_app/index.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
# Real Life Web Apps with Robyn
Batman was tasked with building a web application to manage the crime data in Gotham City. The application would allow the Gotham police department to store and retrieve data on criminal activities, suspects, and their locations. He decided to use the Robyn web framework to build this application efficiently and quickly.
You can find the source code for this application [here](https://github.com/sparckles/example_robyn_app).
## Installing Robyn
The first step was to install Robyn. Batman created a virtual environment and installed Robyn using pip.
```bash
$ python3 -m venv venv
$ source venv/bin/activate
$ pip install robyn
```
## Creating a Robyn Application
Batman wanted to create a Robyn app and was about to create an `src/app.py` before he was told that Robyn comes with a CLI tool to create a new application. He ran the following command to create a new Robyn application.
```bash
$ python -m robyn --create
```
This, would result in the following output.
```bash
$ python3 -m robyn --create
? Directory Path: .
? Need Docker? (Y/N) Y
? Please select project type (Mongo/Postgres/Sqlalchemy/Prisma):
❯ No DB
Sqlite
Postgres
MongoDB
SqlAlchemy
Prisma
```
and the following directory structure.
Batman was asked a set of questions to configure the application. He chose to use the default values for most of the questions.
And he was done! The Robyn CLI created a new application with the following structure.
```bash
├── src
│ ├── app.py
├── Dockerfile
```
================================================
FILE: docs_src/src/pages/documentation/en/example_app/modeling_routes.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
## Crime Data Model and Database Connection
Batman designed a data model to represent crime data, including information about the crime, suspect, and location. He decided to use a SQLite database to store the data and used an ORM (Object Relational Mapping) library to interact with the database.
```python
# models.py
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Float
from sqlalchemy.orm import declarative_base, sessionmaker
DATABASE_URL = "sqlite:///./gotham_crime_data.db"
engine = create_engine(DATABASE_URL)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
class Crime(Base):
__tablename__ = "crimes"
id = Column(Integer, primary_key=True, index=True)
type = Column(String, index=True)
description = Column(String)
location = Column(String)
suspect_name = Column(String)
date_time = Column(DateTime)
latitude = Column(Float)
longitude = Column(Float)
```
## Setting up the Robyn Application
Batman set up a Robyn application and configured it to use the database session to access the SQLite database.
Based on the Database model, Batman created a few helper methods to interact with the database. These methods would be used by the endpoints to perform CRUD operations on the database.
```python {{ title: 'crud.py' }}
# crud.py
from sqlalchemy.orm import Session
from .models import Crime
def get_crime(db: Session, crime_id: int):
return db.query(Crime).filter(Crime.id == crime_id).first()
def get_crimes(db: Session, skip: int = 0, limit: int = 100):
return db.query(Crime).offset(skip).limit(limit).all()
def create_crime(db: Session, crime):
db_crime = Crime(**crime)
db.add(db_crime)
db.commit()
db.refresh(db_crime)
return db_crime
def update_crime(db: Session, crime_id: int, crime):
db_crime = get_crime(db, crime_id)
if db_crime is None:
return None
for key, value in crime.items():
setattr(db_crime, key, value)
db.commit()
db.refresh(db_crime)
return db_crime
def delete_crime(db: Session, crime_id: int):
db_crime = get_crime(db, crime_id)
if db_crime is None:
return False
db.delete(db_crime)
db.commit()
return True
```
## Crime Data Endpoints
Batman created various endpoints to manage crime data. These endpoints allowed the Gotham City Police Department to add, update, and retrieve crime data.
```python {{ title: 'Setting up Routes' }}
# __main__.py
from robyn import Robyn
from robyn.robyn import Request, Response
from sqlalchemy.orm import Session
app = Robyn(__file__)
@app.post("/crimes")
async def add_crime(request):
with SessionLocal() as db:
crime = request.json()
insertion = crud.create_crime(db, crime)
if insertion is None:
raise Exception("Crime not added")
return {
"description": "Crime added successfully",
"status_code": 200,
}
@app.get("/crimes")
async def get_crimes(request):
with SessionLocal() as db:
skip = request.query_params.get("skip", "0")
limit = request.query_params.get("limit", "100")
crimes = crud.get_crimes(db, skip=skip, limit=limit)
return crimes
@app.get("/crimes/:crime_id", auth_required=True)
async def get_crime(request):
crime_id = int(request.path_params.get("crime_id"))
with SessionLocal() as db:
crime = crud.get_crime(db, crime_id=crime_id)
if crime is None:
raise Exception("Crime not found")
return crime
@app.put("/crimes/:crime_id")
async def update_crime(request):
crime = request.json()
crime_id = int(request.path_params.get("crime_id"))
with SessionLocal() as db:
updated_crime = crud.update_crime(db, crime_id=crime_id, crime=crime)
if updated_crime is None:
raise Exception("Crime not found")
return updated_crime
@app.delete("/crimes/{crime_id}")
async def delete_crime(request):
crime_id = int(request.path_params.get("crime_id"))
with SessionLocal() as db:
success = crud.delete_crime(db, crime_id=crime_id)
if not success:
raise Exception("Crime not found")
return {"message": "Crime deleted successfully"}
```
================================================
FILE: docs_src/src/pages/documentation/en/example_app/monitoring_and_logging.mdx
================================================
## Monitoring and Logging
To keep an eye on the performance of his application and troubleshoot issues, Batman decided to implement monitoring and logging. He used a third-party library to integrate logging middleware, enabling him to track requests, errors, and performance metrics.
```python {{ title: 'Monitoring and Logging' }}
from robyn import Logger
logger = Logger(app)
@app.before_request()
async def log_request(request: Request):
logger.info(f"Received request: %s", request)
@app.after_request()
async def log_response(response: Response):
logger.info(f"Sending response: %s", response)
```
With monitoring and logging in place, Batman could now easily detect issues and analyze the performance of his web application, ensuring that it was always running optimally and ready to assist him in his fight against crime.
================================================
FILE: docs_src/src/pages/documentation/en/example_app/openapi.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
## OpenAPI Docs a.k.a Swagger
After deploying the application, Batman got multiple queries from the users on how to use the endpoints. Robyn showed him how to generate OpenAPI specifications for his application.
Out of the box, the following endpoints are setup for you:
- `/docs` The Swagger UI
- `/openapi.json` The JSON Specification
However, if you don't want to generate the OpenAPI docs, you can disable it by passing `--disable-openapi` flag while starting the application.
To use a custom openapi configuration, you can:
- Place the `openapi.json` config file in the root directory.
- Or, pass the file path to the `openapi_file_path` parameter in the `Robyn()` constructor. (the parameter gets priority over the file).
```bash
python app.py --disable-openapi
```
## How to use?
- Query Params: The typing for query params can be added as `def get(r: Request, query_params: GetRequestParams)` where `GetRequestParams` is a subclass of `QueryParams`
- Path Params are defaulted to string type (ref: https://en.wikipedia.org/wiki/Query_string)
```python
from robyn.robyn import QueryParams
from robyn import Robyn, Request
app = Robyn(
file_object=__file__,
openapi=OpenAPI(
info=OpenAPIInfo(
title="Sample App",
description="This is a sample server application.",
termsOfService="https://example.com/terms/",
version="1.0.0",
contact=Contact(
name="API Support",
url="https://www.example.com/support",
email="support@example.com",
),
license=License(
name="BSD2.0",
url="https://opensource.org/license/bsd-2-clause",
),
externalDocs=ExternalDocumentation(description="Find more info here", url="https://example.com/"),
components=Components(),
),
),
)
@app.get("/")
async def welcome():
"""welcome endpoint"""
return "hi"
class GetRequestParams(QueryParams):
appointment_id: str
year: int
@app.get("/api/v1/name", openapi_name="Name Route", openapi_tags=["Name"])
async def get(r: Request, query_params: GetRequestParams):
"""Get Name by ID"""
return r.query_params
@app.delete("/users/:name", openapi_tags=["Name"])
async def delete(r: Request):
"""Delete Name by ID"""
return r.path_params
if __name__ == "__main__":
app.start()
```
## How does it work with subrouters?
```python
from robyn.robyn import QueryParams
from robyn import Request, SubRouter
subrouter: SubRouter = SubRouter(__name__, prefix="/sub")
@subrouter.get("/")
async def subrouter_welcome():
"""welcome subrouter"""
return "hiiiiii subrouter"
class SubRouterGetRequestParams(QueryParams):
_id: int
value: str
@subrouter.get("/name")
async def subrouter_get(r: Request, query_params: SubRouterGetRequestParams):
"""Get Name by ID"""
return r.query_params
@subrouter.delete("/:name")
async def subrouter_delete(r: Request):
"""Delete Name by ID"""
return r.path_params
app.include_router(subrouter)
```
## Other Specification Params
We support all the params mentioned in the latest OpenAPI specifications (https://swagger.io/specification/). See an example using request & response bodies below:
```python
from robyn.types import JSONResponse, Body
class Initial(Body):
is_present: bool
letter: Optional[str]
class FullName(Body):
first: str
second: str
initial: Initial
class CreateItemBody(Body):
name: FullName
description: str
price: float
tax: float
class CreateResponse(JSONResponse):
success: bool
items_changed: int
@app.post("/")
def create_item(request: Request, body: CreateItemBody) -> CreateResponse:
return CreateResponse(success=True, items_changed=2)
```
With the reference documentation deployed and running smoothly, Batman had a powerful new tool at his disposal. The Robyn framework had provided him with the flexibility, scalability, and performance needed to create an effective crime-fighting application, giving him a technological edge in his ongoing battle to protect Gotham City.
================================================
FILE: docs_src/src/pages/documentation/en/example_app/real_time_notifications.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
## Real time notifications
Batman decided to implement real-time notifications for police officers using WebSockets. This would allow officers to receive instant updates on criminal activities, as well as alerts when a new crime is reported.
```python {{ title: 'Setting up Real-time Notifications' }}
from robyn import WebSocketDisconnect
@app.websocket("/notifications")
async def notify_handler(websocket):
try:
while True:
message = await websocket.receive_text()
await websocket.send_text(f"Received: {message}")
except WebSocketDisconnect:
pass
@notify_handler.on_connect
def notify_connect(websocket):
return "Connected to notifications"
@notify_handler.on_close
def notify_close(websocket):
return "Disconnected from notifications"
```
## Advanced Search and Filtering
To make it easier for the police officers to search for specific crimes or criminals, Batman added advanced search and filtering options to the application. He implemented a new endpoint that allows users to search based on various criteria like crime type, date, location, and status.
```python {{ title: 'Advanced Search and Filtering' }}
@app.get("/crimes/search")
async def search_crimes(request):
crime_type = request.query_params.get("crime_type")
date = request.query_params.get("date")
location = request.query_params.get("location")
status = request.query_params.get("status")
crimes = crud.search_crimes(db, crime_type=crime_type, date=date, location=location, status=status)
return crimes
```
With the new features in place, the Gotham City Police Department was able to use the web application more effectively to track criminal activities and deploy resources efficiently. Batman's work on the Robyn web framework had a significant impact on Gotham City's crime-fighting efforts, making it a safer place for its citizens.
Although Batman had achieved great success with the current implementation, he knew that there would always be room for improvement and new features to add. But for now, he could take a moment to appreciate his work and focus on his primary duty - protecting Gotham City as the Dark Knight.
================================================
FILE: docs_src/src/pages/documentation/en/example_app/subrouters.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
## Code Organization with SubRouters
As the application grew, Batman needed a way to organize his routes better. He decided to use Robyn's SubRouter feature to group related routes together.
```python
from robyn import SubRouter
# Create a subrouter for crime-related routes
crime_router = SubRouter(__file__, prefix="/crimes")
@crime_router.get("/list")
def list_crimes():
return {"crimes": get_all_crimes()}
@crime_router.post("/report")
def report_crime(request):
crime_data = request.json()
return {"id": create_crime_report(crime_data)}
# Create a subrouter for suspect-related routes
suspect_router = SubRouter(__file__, prefix="/suspects")
@suspect_router.get("/list")
def list_suspects():
return {"suspects": get_all_suspects()}
@suspect_router.get("/:id")
def get_suspect(request, path_params):
suspect_id = path_params.id
return {"suspect": get_suspect_by_id(suspect_id)}
# Include the subrouters in the main app
app.include_router(crime_router)
app.include_router(suspect_router)
```
SubRouters help organize related routes under a common prefix, making the code more maintainable and easier to understand. In this example:
- All crime-related routes are under `/crimes`
- All suspect-related routes are under `/suspects`
This organization makes it clear which routes handle what functionality and keeps related code together.
================================================
FILE: docs_src/src/pages/documentation/en/example_app/templates.mdx
================================================
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
## Templates
After implementing the backend, Batman decided to add a frontend to his application. He wanted to create a simple web page that would allow him to view the data he had collected. He also wanted to be able to add new data to the database and edit existing data.
This is when he was introduced to templates!
Templates are a powerful feature of the Robyn framework that allow you to create dynamic web pages using HTML and Python. They are a great way to add a frontend to your application without having to learn a new language or framework.
Robyn supports Jinja2 templates by default but provides an easy way to add other templating engines as well.
### Creating a Template
To create a template, you need to create a file with the `.html` extension in the a directory, usually it is convention to use the `templates` directory. For example, if you wanted to create a template called `index.html`, you would create a file called `index.html` in the `templates` directory.
So the folder structure would look like this:
```bash
├── app.py
├── templates
│ └── index.html
├── Dockerfile
└── requirements.txt
```
### Rendering a Template
Once you have created a template, you can render it by using the `render_template` function. This function takes the name of the template as its first argument and a dictionary of variables as its second argument.
For example, if you wanted to render the `index.html` template, you would use the following code:
```python {{ title: 'Rendering a Template' }}
import os
import pathlib
from robyn.templating import JinjaTemplate
current_file_path = pathlib.Path(__file__).parent.resolve()
jinja_template = JinjaTemplate(os.path.join(current_file_path, "templates"))
@app.get("/frontend")
async def get_frontend(request):
context = {"framework": "Robyn", "templating_engine": "Jinja2"}
return jinja_template.render_template("index.html", **context)
app.include_router(frontend)
```
Now Batman very happy that the application had come to completion. However, he was not satisfied with the current state of the application. He felt the code was all crammed in a single file and asked Robyn if there was a way to split the codebase in other parts.
This is Robyn introduced him to the concept of routers and views.
================================================
FILE: docs_src/src/pages/documentation/en/example_app/zh/index.mdx
================================================
export const description =
'欢迎来到Robyn API文档。您将找到全面的指南和文档,帮助您尽快开始使用Robyn,并在遇到困难时获得支持。'
# 使用Robyn构建实际应用
蝙蝠侠被委托开发一个Web应用程序来管理哥谭市的犯罪数据。该应用程序将允许哥谭警察局存储和检索有关犯罪活动、嫌疑人及其位置的数据。他决定使用Robyn Web框架来高效快速地构建这个应用程序。
您可以在[这里](https://github.com/sparckles/example_robyn_app)找到此应用程序的源代码。
## 安装Robyn
第一步是安装Robyn。蝙蝠侠创建了一个虚拟环境并使用pip安装了Robyn。
```bash
$ python3 -m venv venv
$ source venv/bin/activate
$ pip install robyn
```
## 创建Robyn应用程序
蝙蝠侠正准备创建一个`src/app.py`文件,这时他得知Robyn提供了一个CLI工具来创建新应用程序。他运行以下命令来创建一个新的Robyn应用程序:
```bash
$ python -m robyn --create
```
这个示例应用程序将展示如何:
- 设计和实现RESTful API
- 处理身份验证和授权
- 使用中间件进行请求处理
- 实现实时通知
- 设置监控和日志记录
- 部署应用程序
- 生成API文档
- 组织和构建可维护的代码
================================================
FILE: docs_src/src/pages/documentation/en/example_app/zh/subrouters.mdx
================================================
export const description =
'欢迎来到Robyn API文档。您将找到全面的指南和文档,帮助您尽快开始使用Robyn,并在遇到困难时获得支持。'
## 使用SubRouters组织代码
随着应用程序的增长,蝙蝠侠需要一种更好的方式来组织他的路由。他决定使用Robyn的SubRouter功能来对相关路由进行分组。
```python
from robyn import SubRouter
# 创建处理犯罪相关路由的子路由器
crime_router = SubRouter(__file__, prefix="/crimes")
@crime_router.get("/list")
def list_crimes():
return {"crimes": get_all_crimes()}
@crime_router.post("/report")
def report_crime(request):
crime_data = request.json()
return {"id": create_crime_report(crime_data)}
# 创建处理嫌疑人相关路由的子路由器
suspect_router = SubRouter(__file__, prefix="/suspects")
@suspect_router.get("/list")
def list_suspects():
return {"suspects": get_all_suspects()}
@suspect_router.get("/:id")
def get_suspect(request, path_params):
suspect_id = path_params.id
return {"suspect": get_suspect_by_id(suspect_id)}
# 将子路由器包含在主应用程序中
app.include_router(crime_router)
app.include_router(suspect_router)
```
SubRouters帮助在公共前缀下组织相关路由,使代码更易于维护和理解。在这个例子中:
- 所有与犯罪相关的路由都在 `/crimes` 下
- 所有与嫌疑人相关的路由都在 `/suspects` 下
这种组织方式清晰地表明了哪些路由处理什么功能,并将相关代码保持在一起。
================================================
FILE: docs_src/src/pages/documentation/en/framework_performance_comparison.mdx
================================================
export const description =
'On this page, we`ll understand the performance comparison across different frameworks.'
# Performance comparison across different frameworks
## Read this before you scroll down
Before delving into the details, it is imperative to note that this comparison doesn’t aim to discredit any developers or the frameworks listed below. Mentioning the names of the frameworks is solely for elucidating a clear comparison. My profound inclination towards the Python web ecosystem has been significantly influenced by all these frameworks, and my intention is not to cause offense to anyone by listing them here.
Moreover, these tests were conducted on my development machine, and thus, the figures portrayed below are not absolute. The numbers only serve to indicate the relative performance of these frameworks under the specific testing conditions.
The [oha](https://github.com/hatoo/oha) tool was utilized to test 10,000 requests on the following frameworks, yielding the subsequent results:
1. Flask(Gunicorn)
```
Total: 5.5254 secs
Slowest: 0.0784 secs
Fastest: 0.0028 secs
Average: 0.0275 secs
Requests/sec: 1809.8082
```
1. FastAPI(Uvicorn)
```
Total: 4.1314 secs
Slowest: 0.0733 secs
Fastest: 0.0027 secs
Average: 0.0206 secs
Requests/sec: 2420.4851
```
1. Django(Gunicorn)
```
Total: 13.5070 secs
Slowest: 0.3635 secs
Fastest: 0.0249 secs
Average: 0.0674 secs
Requests/sec: 740.3558
```
1. Robyn(Doesn't need a *SGI)
```
Total: 1.8324 secs
Slowest: 0.0269 secs
Fastest: 0.0024 secs
Average: 0.0091 secs
Requests/sec: 5457.2339
```
1. Robyn (5 workers)
```
Total: 1.5592 secs
Slowest: 0.0211 secs
Fastest: 0.0017 secs
Average: 0.0078 secs
Requests/sec: 6413.6480
```
Robyn is able to serve the 10k requests in 1.8 seconds followed by Flask and FastAPI, which take around 5 seconds(using 5 workers on a dual-core machine). Finally, Django takes around 13.5070 seconds.
## Verbose Logs
Flask(Gunicorn)
```
Summary:
Success rate: 1.0000
Total: 5.5254 secs
Slowest: 0.0784 secs
Fastest: 0.0028 secs
Average: 0.0275 secs
Requests/sec: 1809.8082
Total data: 126.95 KiB
Size/request: 13 B
Size/sec: 22.98 KiB
Response time histogram:
0.007 [55] |
0.014 [641] |■■■■■
0.021 [2413] |■■■■■■■■■■■■■■■■■■■■
0.027 [3771] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.034 [1999] |■■■■■■■■■■■■■■■■
0.041 [737] |■■■■■■
0.048 [236] |■■
0.055 [75] |
0.062 [46] |
0.069 [24] |
0.076 [3] |
Latency distribution:
10% in 0.0178 secs
25% in 0.0223 secs
50% in 0.0266 secs
75% in 0.0317 secs
90% in 0.0378 secs
95% in 0.0419 secs
99% in 0.0551 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0071 secs, 0.0001 secs, 0.0443 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0010 secs
Status code distribution:
[200] 10000 responses
```
FastAPI(Uvicorn)
```
Summary:
Success rate: 1.0000
Total: 4.1314 secs
Slowest: 0.0733 secs
Fastest: 0.0027 secs
Average: 0.0206 secs
Requests/sec: 2420.4851
Total data: 166.02 KiB
Size/request: 17 B
Size/sec: 40.18 KiB
Response time histogram:
0.005 [175] |■
0.011 [1541] |■■■■■■■■■■■■■■■■
0.016 [2942] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.021 [2770] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.027 [1479] |■■■■■■■■■■■■■■■■
0.032 [608] |■■■■■■
0.038 [217] |■■
0.043 [103] |■
0.048 [53] |
0.054 [54] |
0.059 [58] |
Latency distribution:
10% in 0.0120 secs
25% in 0.0151 secs
50% in 0.0194 secs
75% in 0.0243 secs
90% in 0.0300 secs
95% in 0.0348 secs
99% in 0.0522 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0088 secs, 0.0073 secs, 0.0103 secs
DNS-lookup: 0.0001 secs, 0.0000 secs, 0.0008 secs
Status code distribution:
[200] 10000 responses
```
Robyn
```
Summary:
Success rate: 1.0000
Total: 1.8324 secs
Slowest: 0.0269 secs
Fastest: 0.0024 secs
Average: 0.0091 secs
Requests/sec: 5457.2339
Total data: 117.19 KiB
Size/request: 12 B
Size/sec: 63.95 KiB
Response time histogram:
0.002 [183] |■
0.004 [1669] |■■■■■■■■■■■■■■
0.007 [3724] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.009 [2631] |■■■■■■■■■■■■■■■■■■■■■■
0.011 [1060] |■■■■■■■■■
0.013 [496] |■■■■
0.016 [188] |■
0.018 [34] |
0.020 [12] |
0.022 [2] |
0.025 [1] |
Latency distribution:
10% in 0.0061 secs
25% in 0.0073 secs
50% in 0.0087 secs
75% in 0.0105 secs
90% in 0.0129 secs
95% in 0.0143 secs
99% in 0.0171 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0049 secs, 0.0035 secs, 0.0065 secs
DNS-lookup: 0.0001 secs, 0.0000 secs, 0.0010 secs
Status code distribution:
[200] 10000 responses
```
Django(Gunicorn)
```
Summary:
Success rate: 1.0000
Total: 13.5070 secs
Slowest: 0.3635 secs
Fastest: 0.0249 secs
Average: 0.0674 secs
Requests/sec: 740.3558
Total data: 102.01 MiB
Size/request: 10.45 KiB
Size/sec: 7.55 MiB
Response time histogram:
0.016 [283] |■
0.032 [2616] |■■■■■■■■■■■■■■■■■■
0.048 [4587] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.064 [1829] |■■■■■■■■■■■■
0.081 [362] |■■
0.097 [98] |
0.113 [105] |
0.129 [20] |
0.145 [7] |
0.161 [28] |
0.177 [65] |
Latency distribution:
10% in 0.0493 secs
25% in 0.0559 secs
50% in 0.0638 secs
75% in 0.0733 secs
90% in 0.0840 secs
95% in 0.0948 secs
99% in 0.1543 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0097 secs, 0.0001 secs, 0.0444 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0007 secs
Status code distribution:
[200] 10000 responses
```
Robyn(with 5 workers)
```
Summary:
Success rate: 1.0000
Total: 1.5592 secs
Slowest: 0.0211 secs
Fastest: 0.0017 secs
Average: 0.0078 secs
Requests/sec: 6413.6480
Total data: 126.95 KiB
Size/request: 13 B
Size/sec: 81.42 KiB
Response time histogram:
0.002 [30] |
0.004 [599] |■■■■■
0.005 [3336] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.007 [3309] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.009 [1614] |■■■■■■■■■■■■■■■
0.011 [749] |■■■■■■■
0.012 [253] |■■
0.014 [94] |
0.016 [14] |
0.018 [1] |
0.019 [1] |
Latency distribution:
10% in 0.0055 secs
25% in 0.0063 secs
50% in 0.0074 secs
75% in 0.0089 secs
90% in 0.0107 secs
95% in 0.0117 secs
99% in 0.0142 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0022 secs, 0.0013 secs, 0.0028 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0001 secs
Status code distribution:
[200] 10000 responses
```
================================================
FILE: docs_src/src/pages/documentation/en/hosting.mdx
================================================
export const description =
'On this page, we`ll understand how Robyn can be deployed on various cloud providers .'
The process of hosting a Robyn app on various cloud providers.
## Railway
We will be deploying the app on `Railway`.
A GitHub account is needed as a mandatory prerequisite.
We will deploy a sample "Hello World," demonstrating a simple GET route and serving an HTML file.
Directory structure:
```bash
app folder/
main.py
requirements.txt
index.html
```
Note - Railway looks for a main.py as an entry point instead of app.py. The build process will fail if there is no main.py file.
```python {{ title: 'python' }}
from robyn import Robyn, serve_html
app = Robyn(__file__)
@app.get("/hello")
async def h(request):
print(request)
return "Hello, world!"
@app.get("/")
async def get_page(request):
return serve_html("./index.html")
if __name__ == "__main__":
app.start(url="0.0.0.0", port=PORT)
```
```python {{ title: 'python' }}
Hello World, this is Robyn framework!
```
## Exposing Ports
The Railway documentation says the following about the listening to ports:
> The easiest way to get up and running is to have your application listen on 0.0.0.0:$PORT, where PORT is a Railway-provided environment variable.
So, passing the host as `0.0.0.0` to `app.start()` as an argument is necessary.
We need to create a Railway account to deploy this app on Railway. We can do so by going on the `Railway HomePage`.
Press the "Login" button and select "login with a GitHub account."
 Then, we press the "New Project" button and select "Deploy from GitHub repo".
Then, we press the "New Project" button and select "Deploy from GitHub repo".
 Then we select the repo we want to deploy. And click "Deploy Now".
Then we select the repo we want to deploy. And click "Deploy Now".
 Now, we click on our project's card.
Select "Variables" and press the "New Variable" button to set the environments variables.
Now, we click on our project's card.
Select "Variables" and press the "New Variable" button to set the environments variables.
 Then, we go to the "Settings" tab and click on "Generate Domain."
We can generate a temporary domain under the "Domains" tab.
Then, we go to the "Settings" tab and click on "Generate Domain."
We can generate a temporary domain under the "Domains" tab.
 We can go to our domain `/hello` and confirm that the message "Hello World" is displayed.
## Next Steps
- [Future Roadmap](/documentation/en/api_reference/future-roadmap)
================================================
FILE: docs_src/src/pages/documentation/en/index.mdx
================================================
import { Guides } from '@/components/documentation/Guides'
import { ApiDocs } from '@/components/documentation/ApiDocs'
import { HeroPattern } from '@/components/documentation/HeroPattern'
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
export const sections = [
{ title: 'Example Application', id: 'guides' },
{ title: 'Api Reference', id: 'api_docs' },
]
We can go to our domain `/hello` and confirm that the message "Hello World" is displayed.
## Next Steps
- [Future Roadmap](/documentation/en/api_reference/future-roadmap)
================================================
FILE: docs_src/src/pages/documentation/en/index.mdx
================================================
import { Guides } from '@/components/documentation/Guides'
import { ApiDocs } from '@/components/documentation/ApiDocs'
import { HeroPattern } from '@/components/documentation/HeroPattern'
export const description =
'Welcome to the Robyn API documentation. You will find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.'
export const sections = [
{ title: 'Example Application', id: 'guides' },
{ title: 'Api Reference', id: 'api_docs' },
]
# API Documentation
Welcome to the Robyn API documentation. You'll find comprehensive guides and documentation to help you start working with Robyn as quickly as possible, as well as support if you get stuck.
We have divided the documentation into two parts: the [Example Application](#guides) and the [API Docs](#api_docs).
## Getting started {{ anchor: false }}
The Example Application is a simple web application that demonstrates how to use the Robyn API. It is a great place to start if you are new to Robyn.
The API Reference contains detailed information about the Robyn API. It is a great place to start if you are already familiar with Robyn and want to learn more about the API.
为了提升性能,他将应用程序扩展到了多个内核,并使用了以下命令:
```python
from robyn import Robyn, Request
app = Robyn(__file__)
@app.get("/")
async def h(request: Request):
return f"hello to you, {request.ip_addr}"
```
---
## 下一步
在成功实现 IP 跟踪功能后,蝙蝠侠开始思考如何帮助用户更好地理解和使用他的 API 接口。
为此,Robyn 向他介绍了 OpenAPI 文档功能。
[OpenAPI 文档](/documentation/zh/api_reference/openapi)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/authentication.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
创建应用程序的基本版本后,蝙蝠侠希望限制哥谭警察局的访问权限。因此,他询问了 Robyn 提供的身份验证功能。
## 身份验证
正如蝙蝠侠发现的那样,Robyn 提供了一种简便的方法,允许将身份验证中间件添加到应用程序中。通过在路由中指定 `auth_required=True`,可以确保该路由仅对已验证的用户开放。
```python
@app.get("/auth", auth_required=True)
async def auth(request: Request):
# This route method will only be executed if the user is authenticated
# Otherwise, a 401 response will be returned
return "Hello, world"
```
要添加身份验证中间件,您可以使用 `configure_authentication` 方法。此方法需要一个 `AuthenticationHandler` 对象作为参数。该对象定义了如何进行用户身份验证,并使用 `TokenGetter` 对象从请求中提取令牌。Robyn 目前提供了一个 `BearerGetter` 类,它使用 `Bearer` 认证方案从 `Authorization` 请求头中获取令牌。以下是一个基本身份验证处理程序的示例:
```python
class BasicAuthHandler(AuthenticationHandler):
def authenticate(self, request: Request) -> Optional[Identity]:
token = self.token_getter.get_token(request)
if token == "valid":
return Identity(claims={})
return None
app.configure_authentication(BasicAuthHandler(token_getter=BearerGetter()))
```
`authenticate` 方法应在用户通过身份验证时返回 `Identity` 对象,否则返回 `None`。`Identity` 对象可以包含任意数据,并可以通过 `request.identity` 属性在路由方法中访问。
注意:该身份验证系统在底层主要通过 `before request`
中间件实现。您可以忽略此机制,使用自定义中间件实现自己的身份验证系统。然而,Robyn
提供的这一简单易用的解决方案已能满足大多数应用场景的需求。
---
## 下一步
蝙蝠侠已经掌握了身份验证的基本知识,接下来他希望了解一些优化技术,以提升应用程序的性能。他发现了以下功能:
- [常量请求与多核扩展](/documentation/zh/api_reference/const_requests)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/const_requests.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
实现身份验证后,蝙蝠侠担心在高峰时段,尤其是小丑企图释放阿卡姆疯人院所有罪犯时,可能会引发大量请求,导致服务器崩溃。为此,Robyn 向他介绍了常量请求和多核扩展功能,以增强应用程序的性能。
## 常量请求
Robyn 告诉蝙蝠侠,可以为每个路由预处理响应,这样即使在路由处理之前,响应就已准备好。这样做可以减少访问路由器的次数,从而提高响应速度。
```python
@app.get("/", const=True)
async def h():
return "Hello, world"
```
## 多核扩展
Robyn 告诉蝙蝠侠,可以使用 `--workers` 参数将应用程序扩展到多个核心。这样,系统会创建多个应用实例并分配负载,从而提升性能。
```python
python3 app.py --workers=N --process=M
```
`authenticate` 方法应在用户通过身份验证时返回 `Identity` 对象,否则返回 `None`。`Identity` 对象可以包含任意数据,并可以通过 `request.identity` 属性在路由方法中访问。
注意:该身份验证系统在底层主要通过 `before request`
中间件实现。您可以忽略此机制,使用自定义中间件实现自己的身份验证系统。然而,Robyn
提供的这一简单易用的解决方案已能满足大多数应用场景的需求。
---
## 下一步
在提升了应用程序的性能后,蝙蝠侠非常高兴,并希望应用也可以接收从前端项目中发出请求。
然而,这是他却遇到了 CORS(跨源资源共享)问题!于是,他向 Robyn 咨询如何解决这个问题。Robyn 向他介绍了相关的功能:
- [跨域资源共享](/documentation/zh/api_reference/cors)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/cors.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
## CORS
每次蝙蝠侠尝试访问 API 时,都会遇到 CORS 错误,这让他苦不堪言。
## 扩展应用程序
You can allow CORS for your application by adding the following code:
```python
from robyn import Robyn, ALLOW_CORS
app = Robyn(__file__)
ALLOW_CORS(app, origins = ["http://localhost:/"])
```
---
## 下一步
修复了 CORS 问题后,蝙蝠侠感到非常满意,现在他希望了解如何在服务器中集成小型前端页面。
于是,Robyn 向他介绍了模板系统,以及如何使用模板来渲染 HTML 页面。
- [模板系统](/documentation/zh/api_reference/templating)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/dependency_injection.mdx
================================================
export const description = '在此页面中,我们将了解 Robyn 中的依赖注入。'
## 依赖注入
蝙蝠侠想要了解 Robyn 中的依赖注入机制。Robyn 向他介绍了依赖注入的概念以及如何在应用程序中使用它。
Robyn 提供了两种依赖注入方式:
全局依赖注入和局部依赖注入。
### 应用程序级依赖注入
全局依赖注入用于将依赖项注入到整个应用程序中,注入的依赖项对所有请求都可用。
```python
from robyn import Robyn, ALLOW_CORS
app = Robyn(__file__)
GLOBAL_DEPENDENCY = "GLOBAL DEPENDENCY"
app.inject_global(GLOBAL_DEPENDENCY=GLOBAL_DEPENDENCY)
@app.get("/sync/global_di")
def sync_global_di(request, global_dependencies):
return global_dependencies["GLOBAL_DEPENDENCY"]
```
### 路由器级依赖注入
局部依赖注入用于将依赖项注入到特定路由器中,注入的依赖项仅对该路由器的请求有效。
```python
from robyn import Robyn, ALLOW_CORS, Request
app = Robyn(__file__)
ROUTER_DEPENDENCY = "ROUTER DEPENDENCY"
app.inject(ROUTER_DEPENDENCY=ROUTER_DEPENDENCY)
@app.get("/sync/global_di")
def sync_global_di(r: Request, router_dependencies):
return router_dependencies["ROUTER_DEPENDENCY"]
```
注意:`router_dependencies` 和 `global_dependencies`
是保留参数名,必须按照这些名称使用。参数的顺序不重要,但这两个参数必须位于
`request` 参数之后。
### WebSocket 依赖注入
WebSocket 支持与 HTTP 路由相同的依赖注入系统。`global_dependencies` 和 `router_dependencies` 参数可以在主处理程序、`on_connect` 和 `on_close` 回调中使用。
```python {{ title: 'WebSocket 依赖注入' }}
from robyn import Robyn
import logging
app = Robyn(__file__)
app.inject_global(logger=logging.getLogger(__name__))
app.inject(cache=RedisCache())
@app.websocket("/chat")
async def chat(websocket, global_dependencies=None, router_dependencies=None):
logger = global_dependencies.get("logger")
cache = router_dependencies.get("cache")
logger.info(f"新连接: {websocket.id}")
while True:
message = await websocket.receive_text()
cache.set(f"ws_{websocket.id}", message)
await websocket.broadcast(f"用户 {websocket.id}: {message}")
@chat.on_connect
async def on_connect(websocket, global_dependencies=None):
logger = global_dependencies.get("logger")
logger.info(f"客户端已连接: {websocket.id}")
return "已连接"
```
---
## 下一步
由于蝙蝠侠对黑暗面非常熟悉,他对异常处理产生了兴趣。
Robyn 随即向他介绍了异常处理的概念,以及如何通过异常处理来应对应用程序中的各种错误情况。
- [异常处理](/documentation/zh/api_reference/exceptions)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/exceptions.mdx
================================================
## 自定义异常处理
蝙蝠侠学习了如何在应用程序中为不同类型的异常创建自定义处理程序。他实现了以下代码来捕获异常并返回自定义的错误响应:
```python
@app.exception
def handle_exception(error: Exception):
return Response(status_code=500, description=f"error msg: {error}", headers={})
```
---
## 下一步
现在,蝙蝠侠希望进一步提升 Web 应用的性能。Robyn 随即为他介绍了多核扩展的概念。
- [多核扩展](/documentation/zh/api_reference/scaling)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/file-uploads.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
## 文件上传
蝙蝠侠学会了如何使用 Robyn 实现文件上传功能,并创建了一个接口来处理文件上传。具体代码如下:
## 上传不带 MultiPart 表单数据的文件
为了提升性能,蝙蝠侠将应用程序扩展到了多个 CPU 核心。他使用以下代码处理文件上传:
```python
@app.post("/upload")
async def upload():
body = request.body
file = bytearray(body)
# write whatever filename
with open('test.txt', 'wb') as f:
f.write(file)
return {'message': 'success'}
```
## 上传带 MultiPart 表单数据的文件
为了进一步提升性能,蝙蝠侠继续扩展应用至多个内核,并使用以下代码处理带 MultiPart 表单数据的文件上传:
```python
@app.post("/sync/multipart-file")
def sync_multipart_file(request: Request):
files = request.files
file_names = files.keys()
return {"file_names": list(file_names)}
```
---
## 文件下载
蝙蝠侠希望让用户能够从 Web 应用中下载文件。他创建了一个接口来处理文件下载,具体代码如下:
### 返回简单的 HTML 文件
为提升应用性能,蝙蝠侠将应用扩展到多个核心,并使用以下命令提供简单的 HTML 文件:
```python
from robyn import Robyn, Request, serve_html
app = Robyn(__file__)
@app.get("/")
async def h(request: Request):
return serve_html("./index.html")
app.start(port=8080)
```
### 返回简单的 HTML 字符串
除了 HTML 文件,蝙蝠侠还希望提供简单的 HTML 字符串。为此,他使用了以下代码:
```python
from robyn import Robyn, Request, html
app = Robyn(__file__)
@app.get("/")
async def h(request: Request):
html_string = "Hello World
"
return html(html_string)
app.start(port=8080)
```
### 返回其他类型的文件
在成功提供 HTML 文件后,蝙蝠侠还希望能够提供其他类型的文件,如 CSS、JS 和图片。为此,他使用了以下代码:
```python
from robyn import Robyn, serve_file, Request
app = Robyn(__file__)
@app.get("/")
async def h(request: Request):
return serve_file("./index.html", file_name="index.html") # file_name is optional
app.start(port=8080)
```
### 返回文件目录
在能够提供其他类型的文件后,蝙蝠侠希望能够提供文件目录,例如用于提供 React 构建目录或简单的 HTML/CSS/JS 目录。为此,他使用了以下代码:
```python
from robyn import Robyn, serve_file, Request
app = Robyn(__file__)
app.serve_directory(
route="/test_dir",
directory_path=os.path.join(current_file_path, "build"),
index_file="index.html",
)
app.start(port=8080)
```
## 下一步
现在,蝙蝠侠准备好深入了解 Robyn 的高级功能。现在,他非常好奇如何处理表单数据。
- [表单处理](/documentation/zh/api_reference/form_data)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/form_data.mdx
================================================
export const description = '在此页面中,我们将深入了解如何处理表单数据。'
## 表单数据与 Multi-Part 表单数据
蝙蝠侠学会了如何使用 Robyn 处理文件上传。接下来,他希望能处理表单数据。
## 处理 Multi-Part 表单数据
蝙蝠侠上传了一些 Multi-Part 表单数据,并希望使用以下代码来处理这些数据:
```python
@app.post("/upload")
async def upload(request: Request):
form_data = request.form_data
return form_data
```
## 下一步
现在,蝙蝠侠准备深入了解 Robyn 的高级功能。他希望找到一种方法,在控制面板中实现实时更新。
- [WebSockets](/documentation/zh/api_reference/websockets)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/future-roadmap.mdx
================================================
export const description = '在此页面中,我们将查看 Robyn 的未来发展路线图。'
- 添加性能优化
- 集成 Pydantic
- 实现自动常量请求
- 添加 ORM 支持,特别是 Prisma 集成
- 改善插件生态系统
- 改善文档
- 改善 WebSocket 支持
- 添加模板支持
- 集成 GraphQL 与 Strawberry
- 更多地投入到 Robyn 社区建设中
## 下一步
- [高级特性](/documentation/zh/api_reference/advanced-features)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/getting_started.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
## 同步与异步请求
首先,Robyn 向蝙蝠侠介绍了它处理同步和异步请求的能力。蝙蝠侠很高兴了解这些功能,并开始在应用中实现它们。
对于一个简单的同步请求,蝙蝠侠使用以下代码:
```python
from robyn import Robyn, Request
app = Robyn(__file__)
@app.get("/")
def h(request: Request):
return "Hello, world"
app.start(port=8080, host="0.0.0.0") # host 是可选的,默认为 127.0.0.1
```
对于异步请求,蝙蝠侠使用了以下代码:
```python
from robyn import Request
@app.get("/")
async def h(request: Request) -> str:
return "Hello, world"
```
---
## 运行 Robyn
蝙蝠侠对如何运行该应用程序感到好奇。Robyn 解释说,他可以通过一个简单的命令 `python3 app.py` 来运行应用程序 `app.py`。
Robyn 公开如下命令。这些命令可用于运行应用程序或生成新项目。
```bash
usage: app.py [-h] [--processes PROCESSES] [--workers WORKERS] [--log-level LOG_LEVEL] [--create] [--docs] [--open-browser] [--version]
Robyn,一个快速的异步 web 框架,基于 Rust 运行。
选项:
-h, --help 显示帮助信息并退出
--processes PROCESSES
选择进程的数量。[默认值: 1]
--workers WORKERS 选择工作线程的数量。[默认值: 1]
--dev 开发者模式。它会根据文件更改重新启动服务器。
--log-level LOG_LEVEL
设置日志级别
--create 创建一个新的项目模板。
--docs 打开 Robyn 文档。
--open-browser 启动成功后打开浏览器。
--version 显示 Robyn 的版本。
--compile-rust-path COMPILE_RUST_PATH
编译指定路径下的 Rust 文件。
--create-rust-file CREATE_RUST_FILE
创建一个指定名称的 Rust 文件。
--disable-openapi 禁用 OpenAPI 文档。
--fast 快速模式。它设置进程、工作线程和日志级别的最佳值。不过,您可以覆盖这些设置。
```
|
另外,您还可以使用 Robyn 的 CLI 来运行应用程序,即 `python -m robyn app.py`。
```bash
usage: python -m robyn app.py [-h] [--processes PROCESSES] [--workers WORKERS] [--dev] [--log-level LOG_LEVEL] [--create] [--docs] [--open-browser] [--version]
Robyn,一个快速的异步 web 框架,基于 Rust 运行。
选项:
-h, --help 显示帮助信息并退出
--processes PROCESSES
选择进程的数量。[默认值: 1]
--workers WORKERS 选择工作线程的数量。[默认值: 1]
--dev 开发者模式。它会根据文件更改重新启动服务器。
--log-level LOG_LEVEL
设置日志级别
--create 创建一个新的项目模板。
--docs 打开 Robyn 文档。
--open-browser 启动成功后打开浏览器。
--version 显示 Robyn 的版本。
--compile-rust-path COMPILE_RUST_PATH
编译指定路径下的 Rust 文件。
--create-rust-file CREATE_RUST_FILE
创建一个指定名称的 Rust 文件。
--disable-openapi 禁用 OpenAPI 文档。
--fast 快速模式。它设置进程、工作线程和日志级别的最佳值。不过,您可以覆盖这些设置。
```
---
## 处理 HTTP 请求
然后,Robyn 教蝙蝠侠如何处理各种 HTTP 请求,如 GET、POST、PUT、PATCH 和 DELETE。在 Robyn 的指导下,蝙蝠侠可以为每种请求类型创建接口,从而使应用程序更加灵活和高效。
例如,蝙蝠侠学会了创建如下 POST 请求:
```python
from robyn import Request
@app.post("/")
async def h(request: Request):
return "Hello World"
```
---
## 响应 JSON 数据
蝙蝠侠对从应用程序返回 JSON 响应的能力感到好奇。Robyn 向他展示了如何使用 `jsonify` 函数来实现这一点。
现在,蝙蝠侠可以从应用程序返回 JSON 响应,从而方便前端解析数据。
```python
from robyn import jsonify, Request
@app.post("/jsonify")
async def json(request: Request):
return {"hello": "world"}
```
## 获取路径参数与查询参数
蝙蝠侠想了解如何从传入的请求中访问路径参数和查询参数,这样他就能创建动态路由,并从请求中提取特定信息。
Robyn 向蝙蝠侠展示了如何从请求中访问路径参数和查询参数。以下是相关的示例:
例如,蝙蝠侠可以创建带路径参数的路由,并通过以下代码访问该参数:
```python
from robyn import jsonify
from robyn.types import PathParams
@app.post("/jsonify/:id")
async def json(req_obj: Request, path_parameters: PathParams):
print(req_obj.path_params["id"])
print(path_parameters["id"])
assert req_obj.path_params["id"] == path_parameters["id"]
return {"hello": "world"}
```
要访问查询参数,蝙蝠侠可以使用以下代码:
```python
from robyn import Request
from robyn.robyn import QueryParams
@app.get("/query")
async def query_get(req_obj: Request, query_params: QueryParams):
query_data = query_params.to_dict()
assert query_data == req_obj.query_params.to_dict()
return jsonify(query_data)
```
任何请求参数都可以在处理程序函数中通过类型注释或使用保留名称进行访问。
{' '}
请注意,类型注释会优先于保留名称。
Robyn 向蝙蝠侠演示了访问请求参数的不同语法示例:
```python
from robyn.robyn import QueryParams, Headers
from robyn.types import PathParams, RequestMethod, RequestBody, RequestURL
@app.get("/untyped/query_params")
def untyped_basic(query_params):
return query_params.to_dict()
@app.get("/typed/query_params")
def typed_basic(query_data: QueryParams):
return query_data.to_dict()
@app.get("/untyped/path_params/:id")
def untyped_path_params(query_params: PathParams):
return query_params # 由于类型注释优先,PathParams 包含路径参数
@app.post("/typed_untyped/combined")
def typed_untyped_combined(
query_params,
method_data: RequestMethod,
body_data: RequestBody,
url: RequestURL,
headers_item: Headers,
):
return {
"body": body_data,
"query_params": query_params.to_dict(),
"method": method_data,
"url": url.path,
"headers": headers_item.get("server"),
}
```
类型别名: `Request`、`QueryParams`、`Headers`、`PathParams`、`RequestBody`、`RequestURL`、`FormData`、`RequestFiles`、`RequestIP`、`RequestIdentity`
保留名称: `r`、`req`、`request`、`query_params`、`headers`、`path_params`、`body、method`、`url`、`ip_addr`、`identity`、`form_data`、`files`
---
随着蝙蝠侠继续使用 Robyn 开发 Web 应用,他探索了更多功能,并通过代码示例实现它们。
## 自定义响应格式与响应头
在了解了 Robyn 的动态特性后,蝙蝠侠想要自定义响应格式和响应头。Robyn 向他展示了如何使用字典和 `Response` 对象来实现这一功能。
### 使用字典
蝙蝠侠学会了通过返回字典或使用 Robyn 的 `Response` 对象来定制响应格式,并为每个响应设置状态码和响应头。下面是一个使用字典创建响应的示例:
```python
from robyn import Request
@app.post("/dictionary")
async def dictionary(request: Request):
return {
"status_code": 200,
"description": "This is a regular response",
"type": "text",
"headers": {"Header": "header_value"},
}
```
### 使用 Response 对象
蝙蝠侠还学会了如何使用 `Response` 对象,示例如下:
```python
from robyn.robyn import Response, Request
@app.get("/response")
async def response(request: Request):
return Response(status_code=200, headers=Headers({}), description="OK")
```
### 返回二进制输出
蝙蝠侠还希望从应用程序返回二进制数据。他可以通过将响应类型设置为 binary 并返回一个字节对象来实现:
```python
from robyn import Request, Response
@app.get("/binary_output_response_sync")
def binary_output_response_sync(request: Request):
return Response(
status_code=200,
headers={"Content-Type": "application/octet-stream"},
description="OK",
)
@app.get("/binary_output_async")
async def binary_output_async(request: Request):
return b"OK"
@app.get("/binary_output_response_async")
async def binary_output_response_async(request: Request):
return Response(
status_code=200,
headers={"Content-Type": "application/octet-stream"},
description="OK",
)
```
---
## 响应头
作为世界上最伟大的侦探,蝙蝠侠在 `Response` 对象中发现了 `headers` 字段,他希望进一步了解如何使用它来设置响应头。例如,蝙蝠侠可以通过以下方式设置 `Content-Type` 响应头为 `application/json`:
### 局部响应头
通过使用 `Response` 对象中的 `headers` 字段:
```python
from robyn import Request
@app.get("/")
def binary_output_response_sync(request: Request):
return Response(
status_code=200,
headers={"Content-Type": "application/octet-stream"},
description="OK",
)
```
### 全局响应头
蝙蝠侠还可以为所有路由器设置全局响应头:
```python
app.add_response_header("content-type", "application/json")
```
`add_response_header` 会将响应头附加到响应头列表中,而 `set_response_header` 会替换现有响应头(如果有的话)。
```python
app.set_response_header("content-type", "application/json")
```
如果希望某些接口不使用响应头,可以使用 `exclude_response_headers_for` 函数。
```python
app.exclude_response_headers_for(["/login", "/signup"])
```
### Cookies
Robyn 提供了符合 RFC 6265 标准的完整 Cookie API。使用 Response 对象上的 `set_cookie` 方法来设置 Cookie。
```python
from robyn import Request, Response, Headers
@app.get("/")
def set_session(request: Request):
response = Response(200, Headers({}), "Welcome!")
response.set_cookie(key="session", value="abc123")
return response
```
#### Cookie 属性
您可以设置额外的 Cookie 属性以增强安全性和控制:
- **path**: Cookie 路径(默认:"/")
- **domain**: Cookie 域名
- **max_age**: Cookie 有效期(秒)
- **secure**: 仅通过 HTTPS 发送
- **http_only**: JavaScript 无法访问
- **same_site**: CSRF 保护("Strict"、"Lax" 或 "None" - 不区分大小写)
```python
from robyn import Request, Response, Headers
@app.get("/login")
def login(request: Request):
response = Response(200, Headers({}), "Logged in")
response.set_cookie(
key="auth_token",
value="secret123",
path="/",
max_age=3600, # 1 小时
secure=True, # 仅 HTTPS
http_only=True, # 禁止 JavaScript 访问
same_site="Strict", # CSRF 保护
)
return response
```
#### 删除 Cookie
要从浏览器删除 Cookie,请使用 cookies 集合上的 `delete` 方法。这会设置 `max_age=0`,告诉浏览器删除该 Cookie。
```python
from robyn import Request, Response, Headers
@app.get("/logout")
def logout(request: Request):
response = Response(200, Headers({}), "Logged out")
response.cookies.delete("auth_token")
return response
```
#### 访问 Cookie
您可以遍历 Cookie 或按名称访问它们:
```python
from robyn import Request, Response, Headers
@app.get("/debug")
def debug_cookies(request: Request):
response = Response(200, Headers({}), "Cookies set")
response.set_cookie("a", "1")
response.set_cookie("b", "2")
# 获取所有 Cookie 名称
names = response.cookies.keys()
# 遍历 Cookie
for name in response.cookies:
print(f"Cookie: {name}")
# 检查 Cookie 是否存在
if "a" in response.cookies:
print("Cookie 'a' exists")
return response
```
## 请求头
蝙蝠侠现在想了解如何读取请求头。Robyn 向他解释,他可以使用 `request.headers` 字段来读取响应头。例如,蝙蝠侠可以通过以下方式读取 `Content-Type` 请求头:
### 局部请求头
通过使用 `Request` 对象中的 `headers` 字段:
```python
from robyn import Request
@app.get("/")
def binary_output_response_sync(request: Request):
headers = request.headers
print("These are the request headers: ", headers)
existing_header = headers.get("exisiting_header")
existing_header = headers.get("exisiting_header", "default_value")
exisiting_header = headers["exisiting_header"] # This syntax is also valid
headers.set("modified", "modified_value")
headers["new_header"] = "new_value" # This syntax is also valid
print("These are the modified request headers: ", headers)
return ""
```
或者使用全局请求头:
```python
app.add_request_header("server", "robyn")
```
`add_request_header` 会将请求头附加到请求头列表中,而 `set_request_header` 会替换现有请求头(如果有的话)。
```python
app.set_request_header("server", "robyn")
```
---
## 响应状态码
了解了响应格式和响应头之后,蝙蝠侠学会了为他的响应设置状态码:
```python
from robyn import status_codes, Request
@app.get("/response")
async def response(request: Request):
return Response(status_code=status_codes.HTTP_200_OK, headers=Headers({}), description="OK")
```
---
## 下一步
接下来,蝙蝠侠想知道 Robyn 提到的 **`Request` 请求对象**是什么。Robyn 说:“下一部分。”
- [请求对象](/documentation/zh/api_reference/request_object)
蝙蝠侠也对 Robyn 的架构感兴趣。Robyn 继续说道:“下一部分。”
- [架构](/documentation/zh/architecture)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/graphql-support.mdx
================================================
export const description =
'在此页面中,我们将了解如何在现有的 Robyn 代码库中提供 GraphQL 支持,以更快速地获取数据。'
## GraphQL 支持 [(With Strawberry 🍓)](https://strawberry.rocks/)
目前,GraphQL 支持处于初步摸索阶段。当我们能为视图和视图控制器提供稳定的 API 时,将推出更加稳定的版本。
## 第 1 步:创建虚拟环境
为了确保依赖关系互相独立,我们将使用虚拟环境。
```bash {{ title: 'pip' }}
python3 -m venv venv
```
## 第 2 步:激活虚拟环境并安装 Robyn
```bash {{ title: 'pip' }}
source venv/bin/activate
```
```bash {{ title: 'pip' }}
pip install robyn strawberry-graphql
```
## 第 3 步:编写 Robyn 应用
```python {{ title: 'python' }}
from typing import List, Optional
from robyn import Robyn, jsonify
import json
import dataclasses
import strawberry
import strawberry.utils.graphiql
@strawberry.type
class User:
name: str
@strawberry.type
class Query:
@strawberry.field
def user(self) -> Optional[User]:
return User(name="Hello")
schema = strawberry.Schema(Query)
app = Robyn(__file__)
@app.get("/", const=True)
async def get():
return strawberry.utils.graphiql.get_graphiql_html()
@app.post("/")
async def post(request):
body = request.json()
query = body["query"]
variables = body.get("variables", None)
context_value = {"request": request}
root_value = body.get("root_value", None)
operation_name = body.get("operation_name", None)
data = await schema.execute(
query,
variables,
context_value,
root_value,
operation_name,
)
return jsonify(
{
"data": (data.data),
**({"errors": data.errors} if data.errors else {}),
**({"extensions": data.extensions} if data.extensions else {}),
}
)
if __name__ == "__main__":
app.start(port=8080, host="0.0.0.0")
```
接下来,让我们逐行解读以上代码。
这些语句导入了所需的依赖项。
```python {{ title: 'python' }}
from typing import List, Optional
from robyn import Robyn, jsonify
import json
import dataclasses
import strawberry
import strawberry.utils.graphiql
```
在这里,我们实现了一个基本的 `User` 类,并为其定义了 `name` 属性。
然后,我们创建了一个 GraphQl 查询类(`Query` 类型),该查询返回一个 `User` 实例。
```python {{ title: 'python' }}
@strawberry.type
class User:
name: str
@strawberry.type
class Query:
@strawberry.field
def user(self) -> Optional[User]:
return User(name="Hello")
schema = strawberry.Schema(Query)
```
接下来,我们初始化了一个 Robyn 应用。为了提供 GraphQl 应用,我们需要定义两个路由:一个 GET 路由用于返回 `GraphiQL(ide)`,另一个 POST 路由用于处理 `GraphQl` 请求。
```python {{ title: 'python' }}
app = Robyn(__file__)
```
我们通过 GraphiQL IDE 使用 `strawberry` 填充 HTML 页面,并设置 `const=True` 以预计算页面内容,从而加快返回速度,避免了 GET 请求的额外执行开销。
```python {{ title: 'python' }}
@app.get("/", const=True)
async def get():
return strawberry.utils.graphiql.get_graphiql_html()
```
最后,我们从 `request` 对象中获取参数(如 body、query、variables、context_value、root_value 和 operation_name)。
```python {{ title: 'python' }}
@app.post("/")
async def post(request):
body = request.json()
query = body["query"]
variables = body.get("variables", None)
context_value = {"request": request}
root_value = body.get("root_value", None)
operation_name = body.get("operation_name", None)
data = await schema.execute(
query,
variables,
context_value,
root_value,
operation_name,
)
return jsonify(
{
"data": (data.data),
**({"errors": data.errors} if data.errors else {}),
**({"extensions": data.extensions} if data.extensions else {}),
}
)
```
上述代码展示了如何为 Robyn 应用添加 GraphQL 支持。您可以为任意数量的路由执行类似操作。
## 下一步
这就是目前的所有内容。:D 请留意我们页面上的更新,我们将继续添加更多示例和文档。
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/index.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
很久以前,在哥谭市,有一位名叫 Robyn 的强大超级英雄。Robyn 拥有一种独特的能力,能够快速从互联网的各个角落获取信息。凭借其高效的请求发送和响应接收能力,Robyn 的技术实力在开发者社区中备受推崇。
有一天,蝙蝠侠向 Robyn 寻求帮助,计划构建一个 Web 应用程序。听闻 Robyn 的强大功能,蝙蝠侠希望借助其技术力量来打造一款卓越的应用。在寻找合作伙伴的过程中,蝙蝠侠最终选择了 Robyn,认为他是最合适的盟友。
## 安装 Robyn
Robyn 是一个 Python 库,您可以通过 `pip` 或 `conda` 来安装它:
```bash {{ title: 'pip' }}
pip install robyn
```
```bash {{ title: 'conda' }}
conda install robyn -c conda-forge
```
此外,Robyn 还提供了一些扩展功能,您可以根据需要进行安装:
```bash {{ title: 'pip' }}
pip install "robyn[templating]"
```
```bash {{ title: 'conda' }}
conda install "robyn[templating]" -c conda-forge
```
建议先安装基础包,然后根据实际需求安装扩展模块。
## 下一步
恭喜您成功安装了 Robyn!接下来,您可以开始使用它来构建您的 Web 应用程序。
- [开始](/documentation/zh/api_reference/getting_started)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/middlewares.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
## 使用中间件和事件
随着蝙蝠侠的应用程序逐渐变得更加复杂,Robyn 向他介绍了中间件、启动和关闭事件,甚至 WebSocket 的使用。蝙蝠侠学会了如何创建中间件(在请求之前或之后执行的函数),如何管理应用程序的生命周期,并通过 WebSocket 实现与客户端的实时通信。
## 处理事件
蝙蝠侠发现,通过添加启动和关闭事件,他能够有效地管理应用程序的生命周期。为此,他编写了以下代码来定义这些事件:
此外,蝙蝠侠也了解到,事件不仅可以通过函数来定义,还可以使用装饰器的方式来实现。
对于同步请求,蝙蝠侠使用如下代码:
```python
async def startup_handler():
print("Starting up")
app.startup_handler(startup_handler)
@app.shutdown_handler
def shutdown_handler():
print("Shutting down")
```
对于异步请求,蝙蝠侠则使用如下代码:
```python
from robyn import Request
@app.get("/")
async def h(request: Request) -> str:
return "Hello, world"
```
## 处理中间件 {{ tag: 'POST', label: '/http_requests' }}
蝙蝠侠学会了如何在中间件中同时使用同步和异步函数。他编写了以下代码,为每个请求添加了在请求之前和之后执行的中间件。
中间件可以分为两类:请求前中间件和请求后中间件。
该函数在每个请求处理之前执行,可以修改请求对象或执行其他操作。
请求后中间件:该函数在每个请求处理之后执行,可以修改响应对象或执行其他操作。
每个请求前中间件都应接收并返回一个请求对象;每个请求后中间件都应接收并返回一个响应对象。请求后中间件也可以选择性地接收请求对象作为第一个参数,以便访问请求数据。
如果某个请求前中间件返回了响应对象,执行将被中止,响应对象直接返回给客户端,后续的请求后中间件和主处理函数将不再执行。
```python
from robyn import Request, Response
@app.before_request("/")
async def hello_before_request(request: Request):
request.headers.set("before", "sync_before_request")
return request
@app.after_request("/")
def hello_after_request(response: Response):
response.headers.set("after", "sync_after_request")
return response
```
```python {{ title: '在 after_request 中访问请求对象' }}
from robyn import Request, Response
@app.after_request("/")
def hello_after_request(request: Request, response: Response):
# 在 after_request 中访问请求数据
response.headers.set("request_path", request.url.path)
response.headers.set("after", "sync_after_request")
return response
```
---
## 下一步
Robyn - 太好了,中间件是 Robyn 框架的重要组件之一,您现在已经掌握了 Robyn 的一些高级概念。
蝙蝠侠 - 身份验证!我想了解身份验证,确保只有经过身份验证的的人才能访问我的应用程序。
Robyn - 好的,接下来我将为您介绍身份验证!
- [身份验证](/documentation/zh/api_reference/authentication)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/multiprocess_execution.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
## 多进程
蝙蝠侠对 Robyn 多进程环境中变量的行为产生了好奇。
Robyn 向他保证,确实支持在多进程环境中共享变量。换句话说,处理程序可以分派到多个线程中。
在多进程环境中,任何使用的变量都会在多个进程之间共享。
然而,默认情况下,在 Robyn 中使用多线程时,变量并不受到多线程访问的保护。
如果需要在进程内保护某个变量,并希望多个线程能够访问该变量,可以使用 `multiprocessing.Value` 来实现所需的保护。
```python
import threading
import time
from multiprocessing import Value
from robyn import Robyn, Request
app = Robyn(__file__)
count: Value = Value("i", 0)
def counter():
while True:
count.value += 1
time.sleep(0.2)
print(count.value, "added 1")
@app.get("/")
def index(request: Request):
return f"{count.value}"
threading.Thread(target=counter, daemon=True).start()
app.start()
```
---
## 下一步
蝙蝠侠还想了解是否可以直接在 Robyn 的代码库中使用 Rust。
Robyn 随即向他介绍了如何在 Robyn 中使用 Rust。
[直接使用 Rust](/documentation/zh/api_reference/using_rust_directly)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/openapi.mdx
================================================
export const description =
'欢迎阅读 Robyn API 文档。本文档旨在提供全面的指南和参考,帮助您快速上手 Robyn,并在使用过程中解决可能遇到的问题。'
## OpenAPI 文档(Swagger)
部署应用程序后,蝙蝠侠收到了大量关于如何使用接口的问题。为了解决这一问题,Robyn 向他介绍了 OpenAPI 规范,该规范能够自动生成接口文档。
开箱即用,Robyn 为应用程序提供了以下默认接口:
- `/docs` Swagger UI 可视化界面
- `/openapi.json` JSON 格式的 OpenAPI 文档
若需要使用自定义的 OpenAPI 配置,您可以:
- 将 `openapi.json` 配置文件放在应用程序的根目录中。
- 或者,将文件路径作为参数传递给 `Robyn()` 构造函数中的 `openapi_file_path` 参数(参数的优先级高于文件)。
如果您不希望生成 OpenAPI 文档,可以在启动应用程序时传递 `--disable-openapi` 参数来禁用该功能。
```bash
python app.py --disable-openapi
```
## 如何使用?
- 查询参数:通过继承 `QueryParams` 类来定义参数类型。
- 路径参数默认为字符串类型(参考:[https://en.wikipedia.org/wiki/Query_string](https://en.wikipedia.org/wiki/Query_string))
```python
from robyn.robyn import QueryParams
from robyn import Robyn, Request
app = Robyn(
file_object=__file__,
openapi=OpenAPI(
info=OpenAPIInfo(
title="Sample App",
description="This is a sample server application.",
termsOfService="https://example.com/terms/",
version="1.0.0",
contact=Contact(
name="API Support",
url="https://www.example.com/support",
email="support@example.com",
),
license=License(
name="BSD2.0",
url="https://opensource.org/license/bsd-2-clause",
),
externalDocs=ExternalDocumentation(description="Find more info here", url="https://example.com/"),
components=Components(),
),
),
)
@app.get("/")
async def welcome():
"""welcome endpoint"""
return "hi"
class GetRequestParams(QueryParams):
appointment_id: str
year: int
@app.get("/api/v1/name", openapi_name="Name Route", openapi_tags=["Name"])
async def get(r: Request, query_params: GetRequestParams):
"""Get Name by ID"""
return r.query_params
@app.delete("/users/:name", openapi_tags=["Name"])
async def delete(r: Request):
"""Delete Name by ID"""
return r.path_params
if __name__ == "__main__":
app.start()
```
## 如何在子路由下使用?
```python
from robyn.robyn import QueryParams
from robyn import Request, SubRouter
subrouter: SubRouter = SubRouter(__name__, prefix="/sub")
@subrouter.get("/")
async def subrouter_welcome():
"""欢迎来到子路由"""
return "hiiiiii subrouter"
class SubRouterGetRequestParams(QueryParams):
_id: int
value: str
@subrouter.get("/name")
async def subrouter_get(r: Request, query_params: SubRouterGetRequestParams):
"""根据 ID 获取名称"""
return r.query_params
@subrouter.delete("/:name")
async def subrouter_delete(r: Request):
"""根据名称删除用户"""
return r.path_params
app.include_router(subrouter)
```
## 其他规范参数
We support all the params mentioned in the latest OpenAPI specifications (https://swagger.io/specification/). See an example using request & response bodies below:
```python
from robyn.types import JSONResponse, Body
class Initial(Body):
is_present: bool
letter: Optional[str]
class FullName(Body):
first: str
second: str
initial: Initial
class CreateItemBody(Body):
name: FullName
description: str
price: float
tax: float
class CreateResponse(JSONResponse):
success: bool
items_changed: int
@app.post("/")
def create_item(request: Request, body: CreateItemBody) -> CreateResponse:
return CreateResponse(success=True, items_changed=2)
```
随着参考文档的成功部署,蝙蝠侠拥有了一个强大的新工具。Robyn 框架为他提供了创建高效打击犯罪应用所需的灵活性、可扩展性和性能,使他在保护哥谭市的持续战斗中获得了技术优势。
## 使用 Pydantic 模型
如果您已安装 Pydantic(`pip install "robyn[pydantic]"` 或 `pip install "robyn[all]"`),可以直接使用 Pydantic `BaseModel` 类作为处理函数参数的类型注解。Robyn 将自动验证请求体,**并且**生成丰富的 OpenAPI Schema — 包括属性类型、必填字段、默认值,以及嵌套模型的 `$ref` 引用。
```python
from pydantic import BaseModel
class UserCreate(BaseModel):
name: str
email: str
age: int
active: bool = True
@app.post("/users", openapi_tags=["Users"])
def create_user(user: UserCreate) -> dict:
"""创建新用户"""
return {"name": user.name}
```
有关 Pydantic 验证、嵌套模型、错误响应和 OpenAPI 集成的完整指南,请参阅 [Pydantic 集成](/documentation/zh/api_reference/pydantic) 页面。
## 下一步
完成接口文档配置后,蝙蝠侠开始思考如何提升应用程序的并发处理能力。
Robyn 随即向他介绍了多进程执行的相关内容。
[多进程](/documentation/zh/api_reference/multiprocess_execution)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/pydantic.mdx
================================================
export const description =
'了解如何在 Robyn 中使用 Pydantic 模型实现自动请求体验证和 OpenAPI 文档生成。'
## Pydantic 集成
Robyn 支持 [Pydantic](https://docs.pydantic.dev/) v2 作为可选依赖,用于自动请求体验证和丰富的 OpenAPI 文档生成。验证是**按处理函数选择启用**的 — 只有当您使用 Pydantic `BaseModel` 注解参数时才会激活。未使用 Pydantic 注解的处理函数完全不受影响:不进行解析、不进行验证、无额外开销。当未安装 Pydantic 时,Robyn 不会导入它。
## 安装
使用可选扩展安装带 Pydantic 支持的 Robyn:
```bash {{ title: '仅 Pydantic' }}
pip install "robyn[pydantic]"
```
```bash {{ title: '所有扩展' }}
pip install "robyn[all]"
```
```bash {{ title: 'conda' }}
conda install robyn pydantic -c conda-forge
```
`robyn[all]` 包含 Pydantic、Jinja2 模板引擎以及未来的所有可选功能。
## 基本用法
定义一个 Pydantic `BaseModel`,并将其用作处理函数参数的类型注解。Robyn 将自动解析传入的 JSON 请求体,根据模型进行验证,并将验证后的实例注入到处理函数中。
```python {{ title: '同步' }}
from pydantic import BaseModel
from robyn import Robyn
app = Robyn(__file__)
class UserCreate(BaseModel):
name: str
email: str
age: int
active: bool = True
@app.post("/users")
def create_user(user: UserCreate):
"""创建新用户"""
return {
"name": user.name,
"email": user.email,
"age": user.age,
"active": user.active,
}
if __name__ == "__main__":
app.start()
```
```python {{ title: '异步' }}
from pydantic import BaseModel
from robyn import Robyn
app = Robyn(__file__)
class UserCreate(BaseModel):
name: str
email: str
age: int
active: bool = True
@app.post("/users")
async def create_user(user: UserCreate):
"""创建新用户"""
return {
"name": user.name,
"email": user.email,
"age": user.age,
"active": user.active,
}
if __name__ == "__main__":
app.start()
```
## 验证错误
当请求体验证失败时,Robyn 会自动返回 **422 Unprocessable Entity** 响应,并附带结构化的错误详情。您无需编写任何错误处理代码。
例如,发送 `{"name": "Alice", "email": "alice@example.com", "age": "not_a_number"}` 将产生:
```json
{
"error": "Validation Error",
"detail": [
{
"type": "int_parsing",
"loc": ["age"],
"msg": "Input should be a valid integer, unable to parse string as an integer",
"input": "not_a_number"
}
]
}
```
缺少必填字段也会被捕获:
```json
{
"error": "Validation Error",
"detail": [
{
"type": "missing",
"loc": ["email"],
"msg": "Field required",
"input": {"name": "Alice", "age": 30}
}
]
}
```
## 嵌套模型
Pydantic 模型可以引用其他模型。Robyn 会自动处理嵌套验证。
```python
from pydantic import BaseModel
from robyn import Robyn
app = Robyn(__file__)
class Address(BaseModel):
street: str
city: str
zip_code: str
class UserWithAddress(BaseModel):
name: str
email: str
address: Address
@app.post("/users")
def create_user(data: UserWithAddress):
"""创建带有地址的用户"""
return {"name": data.name, "city": data.address.city}
```
如果嵌套的 `address` 对象缺失或格式错误,Robyn 将返回 422 响应,并包含完整的错误路径(例如 `["address", "city"]`)。
## 与 Request 对象配合使用
您可以在同一个处理函数中同时使用 Pydantic 参数和标准的 `Request` 对象。这样您可以在获取验证后的请求体的同时,访问请求头、查询参数和其他请求元数据。
```python
from pydantic import BaseModel
from robyn import Robyn, Request
app = Robyn(__file__)
class UserCreate(BaseModel):
name: str
email: str
age: int
active: bool = True
@app.post("/users")
def create_user(request: Request, user: UserCreate):
"""创建用户 — 同时访问原始请求和验证后的模型"""
return {
"method": request.method,
"name": user.name,
"email": user.email,
}
```
## 直接返回 Pydantic 模型
您可以直接从处理函数返回 Pydantic 模型实例(或模型列表)。Robyn 会自动将其序列化为 JSON 并设置正确的 `Content-Type` 头 — 无需手动调用 `.model_dump()`。
```python {{ title: '单个模型' }}
@app.post("/users")
def create_user(user: UserCreate) -> UserCreate:
"""验证并直接返回用户"""
return user
```
```python {{ title: '模型列表' }}
@app.post("/users/batch")
def create_users(user: UserCreate) -> list[UserCreate]:
"""返回多个模型实例"""
return [user, user]
```
两种形式都会生成 `application/json` 响应。单个模型路径使用 Pydantic 基于 Rust 的 `model_dump_json()` 以获得最大吞吐量。
## 验证触发机制
Pydantic 验证是**基于注解驱动的,而非基于 HTTP 方法**。路由器在注册时检查每个处理函数的签名;任何使用 `BaseModel` 子类注解的参数都会在路由被调用时自动触发 `request.body` 的验证。这适用于所有 HTTP 方法 — `POST`、`PUT`、`PATCH`、`DELETE` 或任何携带请求体的方法。
```python {{ title: 'PUT' }}
@app.put("/users/:id")
def update_user(user: UserCreate):
return {"updated": True, "name": user.name}
```
```python {{ title: 'PATCH' }}
@app.patch("/users/:id")
def patch_user(user: UserCreate):
return {"patched": True, "name": user.name}
```
## OpenAPI 集成
当您使用 Pydantic 模型时,Robyn 会自动在 `/openapi.json` 的 OpenAPI 规范中生成丰富的 JSON Schema。包括:
- **属性类型** — `string`、`integer`、`boolean` 等
- **必填字段** — 没有默认值的字段会列在 `required` 中
- **默认值** — 在 Schema 中展示
- **嵌套模型** — 通过 `$ref` 引用,并放置在 `components/schemas` 中
```python
from pydantic import BaseModel
from robyn import Robyn, Request
app = Robyn(__file__)
class Address(BaseModel):
street: str
city: str
zip_code: str
class UserWithAddress(BaseModel):
name: str
email: str
address: Address
@app.post("/users", openapi_tags=["Users"])
def create_user(request: Request, data: UserWithAddress) -> dict:
"""创建带有嵌套地址的用户"""
return {"name": data.name, "city": data.address.city}
```
生成的 `/openapi.json` 将包含:
```json
{
"paths": {
"/users": {
"post": {
"requestBody": {
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"name": {"type": "string", "title": "Name"},
"email": {"type": "string", "title": "Email"},
"address": {"$ref": "#/components/schemas/Address"}
},
"required": ["name", "email", "address"],
"title": "UserWithAddress"
}
}
}
}
}
}
},
"components": {
"schemas": {
"Address": {
"type": "object",
"properties": {
"street": {"type": "string", "title": "Street"},
"city": {"type": "string", "title": "City"},
"zip_code": {"type": "string", "title": "Zip Code"}
},
"required": ["street", "city", "zip_code"],
"title": "Address"
}
}
}
}
```
## Pydantic 与 Body 对比
Robyn 支持两种类型化请求体的方式。根据您的需求选择合适的方式:
| 特性 | `Body` 子类 | Pydantic `BaseModel` |
|---|---|---|
| 安装 | 内置 | `pip install "robyn[pydantic]"` |
| 验证 | 无自动验证 | 完整验证,附带详细错误信息 |
| 错误响应 | 手动处理 | 自动返回 422 结构化错误 |
| 返回序列化 | 手动 `dict()` | 自动序列化模型为 JSON |
| OpenAPI Schema | 基本类型推断 | 完整 JSON Schema(类型、必填、默认值、`$ref`) |
| 嵌套模型 | 支持(基本) | 支持(OpenAPI 中使用 `$ref`) |
| 性能开销 | 无 | 仅在安装并使用 Pydantic 时 |
两种方式都支持 OpenAPI 文档。如果您需要验证功能,请使用 Pydantic。如果只需要 OpenAPI Schema 提示而不需要验证,`Body` 即可满足需求。
## 重要说明
- **按处理函数选择启用** — 验证仅在使用 Pydantic `BaseModel` 注解参数的处理函数上运行。所有其他处理函数(使用 `Body`、`Request`、路径参数等)行为完全不变,无任何额外开销。
- **每个处理函数只能有一个 Pydantic 请求体参数** — 每个处理函数最多只能有一个使用 Pydantic 模型注解的参数。整个请求体会被解析到这个模型中。如果需要多个模型输入,请将它们组合成一个包含嵌套字段的父模型。
- **仅验证请求** — Robyn 根据 Pydantic 模型验证*传入*的请求体,但不验证*传出*的响应。当您返回模型实例时,它会直接序列化而不进行重新验证。这是出于性能考虑的设计决策 — 如果您构造了模型,它已经是有效的。
## 下一步
蝙蝠侠想知道 Robyn 的处理函数是否可以分发到多个进程中执行。
Robyn 向他展示了方法!
[多进程执行](/documentation/zh/api_reference/multiprocess_execution)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/redirection.mdx
================================================
## 重定向
蝙蝠侠希望能够将一些路由重定向到其他路由。Robyn 帮助他实现了这一功能,具体操作如下:
```python
from robyn import Robyn, Response
app = Robyn(__file__)
@app.get("/")
async def index():
return Response(
status_code=307,
description="",
headers={"Location": "landing"},
)
@app.get("/landing")
def landing():
return "hii!"
```
---
## 下一步
实现路由重定向功能后,蝙蝠侠希望能够在出现新的反派时,将文件上传到服务器。Robyn 向他介绍了文件上传和表单处理的功能。
- [文件上传](/documentation/zh/api_reference/file-uploads)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/request_object.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
## 请求对象
请求对象是一个数据类,包含了与该次请求相关的所有信息。它会在路由处理程序中作为第一个参数传入。
该请求对象在 Rust 端创建,但会作为数据类暴露给 Python。
-
Attributes:
-
query_params (QueryParams):请求的查询参数。`例如:/user?id=123 -> {"id": ["123"]}`
-
headers (dict[str, str]):请求的标头。`例如:{"Content-Type": "application/json"}`
-
params (dict[str, str]):请求的路径参数。`例如:/user/:id -> {"id": "123"}`
-
body (Union[str, bytes]):请求的原始正文。对于 JSON 请求体,请使用 `json()` 方法将正文解析为具有正确类型保留的字典。
-
method (str):请求的方法。`例如:GET、POST、PUT、DELETE`
-
ip_addr (Optional[str]):客户端的 IP 地址
-
identity (Optional[Identity]):客户端的身份
```python
@dataclass
class Request:
"""
query_params: QueryParams
headers: Headers
path_params: dict[str, str]
body: Union[str, bytes]
method: str
url: Url
form_data: dict[str, str]
files: dict[str, bytes]
ip_addr: Optional[str]
identity: Optional[Identity]
"""
```
## 解析 JSON 请求体
`request.json()` 方法将请求体解析为 JSON,并返回一个保留完整类型的 Python `dict` 或 `list`(JSON 对象返回 `dict`,JSON 数组返回 `list`):
- JSON `null` 转换为 Python `None`
- JSON 数字转换为 Python `int` 或 `float`
- JSON 布尔值转换为 Python `bool`
- JSON 字符串转换为 Python `str`
- JSON 数组转换为 Python `list`
- JSON 对象转换为 Python `dict`
嵌套结构将被递归处理,最大深度为 128 层。
```python
@app.post("/example")
async def handler(request: Request):
data = request.json() # 返回一个保留类型的字典或列表
# 例如 {"count": 42, "active": true, "tags": ["a", "b"]}
# -> {"count": 42, "active": True, "tags": ["a", "b"]}
return {"received": data}
```
如果请求体不是有效的 JSON,将会抛出 `ValueError`。
## Extra Path Parameters
Robyn 支持通过 `*extra` 语法捕获额外的路径参数,这样可以捕获在定义的路由之后的所有额外的路径段。
例如,如果有这样一个路由:
```python
@app.get("/sync/extra/*extra") def sync_param_extra(request: Request):
extra = request.path_params["extra"]
return extra
```
在 `/sync/extra/` 后的任何路径段都会被捕获到 `extra` 参数中。例如:
- 请求 `/sync/extra/foo/bar` 将使得 `extra = "foo/bar`"
- 请求 `/sync/extra/123/456/789` 将使得 `extra = "123/456/789`"
你可以通过 `request.path_params["extra"]` 在路由处理程序中访问这些额外的路径参数。
在处理动态嵌套路由,或者捕获未知数量的路径段时,这个功能将有奇效。
---
## 便捷参数访问
你可以在函数签名中直接声明带类型注解的查询参数和路径参数,无需手动从请求对象中提取和转换。Robyn 会自动解析并进行类型转换。
任何不匹配已知请求组件(`Request`、`QueryParams`、`Headers` 等)的处理函数参数,都会被视为独立的路径参数或查询参数。
**基本用法** — 带类型转换和默认值的路径参数与查询参数。
```python {{ title: '类型化参数' }}
@app.get("/items/:id")
async def get_item(id: int, q: str, page: int = 1):
# id 从路径参数字符串自动转换为 int
# q 从 ?q=... 获取
# page 未提供时默认为 1
return {"id": id, "q": q, "page": page}
```
```python {{ title: '与 Request 混合使用' }}
@app.get("/items/:id")
async def get_item(request: Request, id: int, q: str = ""):
# request 仍然按原来的方式注入
# id 和 q 作为独立参数解析
return {"id": id, "q": q, "method": request.method}
```
**Optional、List、Bool 和 Float 参数** — Robyn 自动处理常见的 Python 类型。
- `Optional[T]` — 未提供时解析为 `None`
- `List[T]` — 收集重复的查询参数(例如 `?tag=a&tag=b`)
- `bool` — 接受 `true/false`、`1/0`、`yes/no`、`on/off`
- `float` — 标准浮点数转换
```python {{ title: 'Optional' }}
@app.get("/search")
def search(name: str, age: Optional[int] = None):
return {"name": name, "age": age}
# GET /search?name=bob -> {"name": "bob", "age": null}
# GET /search?name=bob&age=30 -> {"name": "bob", "age": 30}
```
```python {{ title: 'List' }}
from typing import List
@app.get("/filter")
def filter_items(tag: List[str]):
return {"tags": tag}
# GET /filter?tag=python&tag=rust -> {"tags": ["python", "rust"]}
```
```python {{ title: 'Bool 和 Float' }}
@app.get("/settings")
def settings(active: bool = False, price: float = 0.0):
return {"active": active, "price": price}
# GET /settings?active=true&price=19.99
# -> {"active": true, "price": 19.99}
```
**错误处理** — 如果缺少必需的参数或值无法转换为声明的类型,Robyn 会自动返回 `400 Bad Request` 响应。
```python {{ title: '自动返回 400' }}
@app.get("/items/:id")
def get_item(id: int, q: str):
return {"id": id, "q": q}
# GET /items/42 -> 400(缺少必需的 'q')
# GET /items/abc?q=test -> 400(无法将 'abc' 转换为 int)
```
---
## 下一步
接下来,蝙蝠侠希望了解 Robyn 服务器的配置。于是他开始了解 Robyn 环境配置文件的概念。
- [Robyn Env](/documentation/zh/api_reference/robyn_env)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/robyn_env.mdx
================================================
export const description = '在本节中,我们将学习如何通过配置文件配置服务器。'
## 通过环境文件配置服务器
因为频繁修改代码容易引起报错,蝙蝠侠想要通过使用环境文件来配置服务器。
## 环境变量
- `ROBYN_PORT`:设置 Robyn 服务器监听的端口。
- 默认值:`8080`
- 示例:`ROBYN_PORT=3000`
- `ROBYN_HOST`:设置 Robyn 服务器的主机地址。
- 默认值:`127.0.0.1`
- 示例:`ROBYN_HOST=0.0.0.0`
- `ROBYN_BROWSER_OPEN`:启动成功后是否自动打开浏览器。
- 默认值:`False`
- 示例:`ROBYN_BROWSER_OPEN=True`
- `ROBYN_DEV_MODE`:是否开启开发者模式。
- 默认值:`False`
- 示例:`ROBYN_DEV_MODE=True`
- `ROBYN_MAX_PAYLOAD_SIZE`:设置 HTTP 请求和 WebSocket 消息的最大负载大小(以字节为单位)。
- 默认值:1000000 bytes
- 示例:`ROBYN_MAX_PAYLOAD_SIZE=1000000`
您可以使用 `robyn.env` 文件自动加载这些环境变量。
这些环境变量通常存储在项目根目录下的 `robyn.env` 文件中。服务器在启动时会自动读取该文件,并据此进行配置。
更多关于项目结构和 `robyn.env` 的使用方法,请参考以下文档:
```bash {{title: '项目结构示例'}}
--project/
--robyn.env
--index.py
...
```
`robyn.env` 文件示例如下:
```bash {{ title: '简易 Robyn.env' }}
ROBYN_PORT=8080
ROBYN_HOST=127.0.0.1
RANDOM_ENV=123
ROBYN_BROWSER_OPEN=True
ROBYN_DEV_MODE=True
ROBYN_MAX_PAYLOAD_SIZE=1000000
```
随着 Web 应用程序的顺利部署和运行,蝙蝠侠拥有了一个强大的新工具。Robyn 框架为他提供了创建高效打击犯罪应用所需的灵活性、可扩展性和高性能,使他在保护哥谭市的战斗中获得了技术上的优势。
## 下一步
蝙蝠侠:罗宾。请告诉我更多。
Robyn:接下来我们来了解中间件和 `Events` 事件吧!
- [中间件](/documentation/zh/api_reference/middlewares)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/scaling.mdx
================================================
## 多核扩展
蝙蝠侠学习了如何利用多核资源来提升应用程序的性能。他使用了以下命令来启动多进程和多线程:
```python
python3 app.py --workers=N --process=M
```
---
## 下一步
掌握了多核扩展技术后,蝙蝠侠希望进一步探索 Robyn 框架的高级特性。Robyn 随即向他介绍了一些更为复杂和强大的功能。
- [高级特性](/documentation/zh/api_reference/advanced_features)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/server_sent_events.mdx
================================================
export const description =
'学习如何在 Robyn 中实现服务器发送事件 (SSE),用于实时的服务器到客户端通信。'
## 服务器发送事件 (SSE)
在学习了[表单数据处理](/documentation/zh/api_reference/form_data)之后,蝙蝠侠意识到他需要一种方法来向他的犯罪监控仪表板推送实时更新。犯罪分子不会等待蝙蝠侠刷新浏览器!
他发现了服务器发送事件 (SSE) - 一个完美的解决方案,用于通过 HTTP 进行服务器到客户端的单向通信。SSE 允许蝙蝠侠将实时数据流式传输到他的仪表板,而无需完整双向通信的复杂性。
"这正是我的犯罪警报系统所需要的!"蝙蝠侠惊呼道。"我可以在检测到新犯罪时立即向仪表板推送更新。"
服务器发送事件非常适合:
- 实时通知
- 实时数据源
- 进度更新
- 聊天应用程序(仅服务器到客户端)
- 仪表板更新
- 日志流式传输
## 如何工作?
蝙蝠侠可以使用 `SSEResponse` 和 `SSEMessage` 类创建服务器发送事件流。他可以根据需要使用常规生成器和异步生成器:
- **常规生成器**:非常适合简单的数据流或使用同步操作时
- **异步生成器**:当蝙蝠侠需要在流中执行异步操作(如数据库查询或 API 调用)时的理想选择
```python {{ title: '基本 SSE 流' }}
from robyn import Robyn, SSEResponse, SSEMessage
import time
app = Robyn(__file__)
@app.get("/events")
def stream_events(request):
def event_generator():
for i in range(10):
yield SSEMessage(f"事件 {i}", id=str(i))
time.sleep(1)
return SSEResponse(event_generator())
```
```python {{ title: 'JSON 数据流' }}
from robyn import Robyn, SSEResponse, SSEMessage
import json
import time
app = Robyn(__file__)
@app.get("/events/json")
def stream_json_events(request):
def json_event_generator():
for i in range(5):
data = {
"id": i,
"message": f"更新 {i}",
"timestamp": time.time()
}
yield SSEMessage(
json.dumps(data),
event="update",
id=str(i)
)
time.sleep(2)
return SSEResponse(json_event_generator())
```
```python {{ title: '异步生成器流' }}
from robyn import Robyn, SSEResponse, SSEMessage
import asyncio
import time
app = Robyn(__file__)
@app.get("/events/async")
async def stream_async_events(request):
async def async_event_generator():
for i in range(8):
# 模拟异步工作,如数据库调用
await asyncio.sleep(0.5)
yield SSEMessage(
f"异步消息 {i} - {time.strftime('%H:%M:%S')}",
event="async",
id=str(i)
)
return SSEResponse(async_event_generator())
```
---
## 异步生成器
当蝙蝠侠需要在他的 SSE 流中执行异步操作时(如从数据库获取数据或进行 API 调用),他使用带有 `async def` 和 `await` 的异步生成器。这使他能够并发处理多个流,而不会阻塞其他操作。
关键区别是为生成器函数使用 `async def`,并在生成器内部为异步操作使用 `await`:
```python {{ title: '数据库流' }}
from robyn import Robyn, SSEResponse, SSEMessage
import asyncio
import json
import time
app = Robyn(__file__)
@app.get("/events/database")
async def stream_database_events(request):
async def database_event_generator():
for i in range(10):
# 模拟异步数据库查询
await asyncio.sleep(0.3)
# 模拟从数据库获取数据
data = {
"crime_id": i,
"location": f"哥谭市第{i}区",
"severity": "高" if i % 2 == 0 else "低",
"timestamp": time.time()
}
yield SSEMessage(
json.dumps(data),
event="crime_alert",
id=str(i)
)
return SSEResponse(database_event_generator())
```
```python {{ title: 'API 集成流' }}
from robyn import Robyn, SSEResponse, SSEMessage
import asyncio
import aiohttp
import json
app = Robyn(__file__)
@app.get("/events/api")
async def stream_api_events(request):
async def api_event_generator():
async with aiohttp.ClientSession() as session:
for i in range(5):
try:
# 进行异步 API 调用
async with session.get(f"https://api.example.com/data/{i}") as response:
data = await response.json()
yield SSEMessage(
json.dumps(data),
event="api_update",
id=str(i)
)
except Exception as e:
yield SSEMessage(
f"获取数据错误: {str(e)}",
event="error",
id=f"error_{i}"
)
await asyncio.sleep(1)
return SSEResponse(api_event_generator())
```
---
## 接下来做什么?
蝙蝠侠已经掌握了服务器发送事件,现在可以向他的犯罪仪表板流式传输实时更新。虽然 SSE 非常适合服务器到客户端的单向通信,但蝙蝠侠意识到他需要双向通信来实现更多交互功能,比如与他的盟友进行实时聊天。
接下来,他想探索如何使用 [WebSocket](/documentation/zh/api_reference/websockets) 处理双向通信,以获得更多交互功能。
如果蝙蝠侠需要处理意外情况,他将学习[异常处理](/documentation/zh/api_reference/exceptions)以使他的应用程序更加健壮。
为了将他的犯罪监控系统扩展到多个进程,蝙蝠侠将探索[多核扩展](/documentation/zh/api_reference/scaling)。
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/templating.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
## 模板
蝙蝠侠希望能在网站上快速渲染 HTML 页面,并打算使用模板引擎来实现这一目标。Robyn 告诉他可以使用 Jinja2 模板引擎,并通过 JinjaTemplate 类来渲染 HTML 页面。
了解一番后,蝙蝠侠很高兴地发现,他还可以将事件作为函数和装饰器进行添加。
```python
from robyn.templating import JinjaTemplate
current_file_path = pathlib.Path(__file__).parent.resolve()
JINJA_TEMPLATE = JinjaTemplate(os.path.join(current_file_path, "templates"))
@app.get("/template_render")
def template_render():
context = {"framework": "Robyn", "templating_engine": "Jinja2"}
template = JINJA_TEMPLATE.render_template(template_name="test.html", **context)
return template
```
`test.html` 文件
```html
Results
Hello {{ framework }}! You're using {{ templating_engine }}.
```
## 自定义模板引擎
蝙蝠侠还发现,Robyn 允许支持自定义模板引擎。
为此,您需要从 `robyn.templating` 导入 `TemplateInterface`:
```python
from robyn.templating import TemplateInterface
```
然后,在您的项目中定义 `render_template` 方法。以下是一个自定义模板引擎的实现示例:
```python
class JinjaTemplate(TemplateInterface):
def __init__(self, directory, encoding="utf-8", followlinks=False):
self.env = Environment(
loader=FileSystemLoader(
searchpath=directory, encoding=encoding, followlinks=followlinks
)
)
def render_template(self, template_name: str, **kwargs):
return self.env.get_template(template_name).render(**kwargs)
```
## 下一步
在掌握了模板引擎的使用后,蝙蝠侠还希望能够在应用中实现路由重定向功能。
- [重定向](/documentation/zh/api_reference/redirection)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/timeout_configuration.mdx
================================================
export const description =
'配置超时设置以处理高并发场景并防止资源耗尽。'
# 超时配置
Robyn 支持全面的超时配置,以处理高并发场景并防止资源耗尽,如"打开文件过多"错误。 {{ className: 'lead' }}
## 配置选项
### 方法参数
直接在 `app.start()` 方法中配置超时:
```python
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
async def hello(request):
return "Hello, world!"
# 配置超时设置
app.start(
host="0.0.0.0",
port=8080,
client_timeout=30, # 客户端连接超时(秒)
keep_alive_timeout=20, # 保持连接超时(秒)
)
```
### 环境变量
使用环境变量覆盖配置:
```bash
# 设置超时配置
export ROBYN_CLIENT_TIMEOUT=45
export ROBYN_KEEP_ALIVE_TIMEOUT=30
# 启动应用程序
python app.py
```
## 配置参数
| 参数 | 默认值 | 描述 | 环境变量 |
|------|-------|------|---------|
| `client_timeout` | 30 | 客户端请求处理的最大时间(秒) | `ROBYN_CLIENT_TIMEOUT` |
| `keep_alive_timeout` | 20 | 保持空闲连接的时间(秒) | `ROBYN_KEEP_ALIVE_TIMEOUT` |
## 使用示例
### 基本配置
```python
# 最小超时配置
app.start(client_timeout=30)
```
### 高流量生产设置
```python
# 针对高流量场景优化
app.start(
host="0.0.0.0",
port=8080,
client_timeout=60, # 允许更长的处理时间
keep_alive_timeout=15, # 更短的保持连接以加快周转
)
```
### 开发设置
```python
# 开发友好设置
app.start(
client_timeout=300, # 调试的长超时
keep_alive_timeout=60, # 测试的长保持连接
)
```
### 负载测试配置
```python
# 针对 wrk 等工具的负载测试优化
app.start(
client_timeout=10, # 快速超时
keep_alive_timeout=5, # 快速连接周转
)
```
## 环境变量优先级
环境变量优先于方法参数:
```python
# 如果设置了 ROBYN_CLIENT_TIMEOUT=60,将使用 60,否则使用 30
app.start(client_timeout=30)
```
## 故障排除
### "打开文件过多"错误
如果遇到文件描述符耗尽:
1. **增加系统限制:**
```bash
ulimit -n 65536
```
2. **优化超时设置:**
```python
app.start(
client_timeout=15, # 更短的超时
keep_alive_timeout=5, # 更快的连接清理
)
```
3. **在部署中使用环境变量:**
```bash
export ROBYN_CLIENT_TIMEOUT=15
export ROBYN_KEEP_ALIVE_TIMEOUT=5
```
### 性能调优
**对于高吞吐量 API:**
- 较低的 `keep_alive_timeout` (5-15秒)
- 中等的 `client_timeout` (15-30秒)
**对于长时间运行的操作:**
- 较高的 `client_timeout` (60-300秒)
- 标准的 `keep_alive_timeout` (20-30秒)
## 与其他框架的比较
| 框架 | 默认客户端超时 | 默认保持连接 | 配置方式 |
|-----|--------------|-------------|----------|
| **Robyn** | 30秒 | 20秒 | 方法参数 + 环境变量 |
| Uvicorn | 无 | 20秒 | 构造函数参数 |
| Express.js | 120秒 | 5秒 | 方法链式调用 |
| Django/Gunicorn | 30秒 | 不适用 | 配置文件 |
| Flask/Gunicorn | 30秒 | 2秒 | 命令行选项 |
## 最佳实践
1. **在生产环境中始终设置明确的超时**
2. **使用环境变量进行特定部署的配置**
3. **在负载下监控文件描述符使用**
4. **用现实负载模式测试超时设置**
5. **从保守值开始,根据指标进行调优**
## 迁移指南
### 从早期版本
如果从早期 Robyn 版本升级,默认行为会改变:
**之前(无限超时):**
```python
# 以前:无超时(可能导致资源耗尽)
app.start(host="0.0.0.0", port=8080)
```
**之后(合理默认值):**
```python
# 现在:自动 30秒 客户端超时,20秒 保持连接
app.start(host="0.0.0.0", port=8080)
# 等价于:
app.start(
host="0.0.0.0",
port=8080,
client_timeout=30,
keep_alive_timeout=20,
)
```
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/using_rust_directly.mdx
================================================
## 使用 Rust 扩展 Robyn
有时,蝙蝠侠可能需要处理 CPU 密集型任务或需要大量内存的操作。在这种情况下,他可能希望使用 Rust 来实现这些任务。Robyn 提供了一种特殊的方式,允许通过 Rust 扩展 Python 代码,并且能够在保持代码热重载特性的同时进行扩展,使代码在许多情况下仍然表现得像解释型语言。
首先,您需要创建一个 Rust 文件,我们将其命名为 `hello_world.rs`。可以通过以下 CLI 命令创建该文件:
```python
python -m robyn --create-rust-file hello_world
```
然后,您可以打开该文件并开始编写 Rust 代码。例如,假设我们实现一个返回平方值的函数:
```rust
// hello_world.rs
// rustimport:pyo3
use pyo3::prelude::*;
#[pyfunction]
fn square(n: i32) -> i32 {
n * n
// 这是一个注释
}
```
每个通过 CLI 创建的 Rust 文件都会在文件顶部添加一个特殊注释,Robyn 会根据该注释确定需要导入的依赖项。在此例中,我们导入了 `pyo3` 包。您可以根据需要导入多个包,还可以从 `crates.io` 导入`crates`。例如,如果您希望使用 `rusqlite` 包,可以按如下方式导入:
```rust
// rustimport:pyo3
//:
//: [dependencies]
//: rusqlite = "0.19.0"
use pyo3::prelude::*;
#[pyfunction]
fn square(n: i32) -> i32 {
n * n * n
// 这是另一个注释
}
```
接下来,您可以在 Python 代码中导入并使用该 Rust 函数:
```python
from hello_world import square
print(square(5))
```
要运行此代码,您需要使用 `--compile-rust-path` 标志来编译 Rust 代码并执行。同时,您还可以使用 `--dev` 标志监控 Rust 代码的变化,并在变化时即时重新编译:
```python
python -m robyn --compile-rust-path "." --dev
```
以下是一个示例,展示了如何在 Robyn 应用中使用 Rust 文件,借助 `rusqlite` 包连接数据库并返回表中的行数:[rusty-sql 示例项目](https://github.com/sansyrox/rusty-sql)
## 下一步
蝙蝠侠很好奇 Robyn 还能做什么。
Robyn 向他透露,这个框架还可以支持 GraphQL。
[GraphQL 支持](/documentation/zh/api_reference/graphql-support)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/views.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
随着代码库的不断扩展,蝙蝠侠希望找到一种更好的方式来组织代码。Robyn 告诉他,他有能力以更清晰的方式组织代码,并向他介绍了视图和子路由器的概念。
## 视图 (Views)
为了更好地组织代码,无论是按照职责分组还是进行代码拆分,蝙蝠侠都可以选择使用视图。
简单来说,视图就是一个包含多个处理函数(闭包)的函数。例如:
```python
from robyn import Request
def sample_view():
def get():
return "Hello, world!"
def post(request: Request):
body = request.body
return Response({"status_code": 200, "description": body, "headers": {}})
```
上面的视图包含了处理 GET 和 POST 请求的两个闭包。
您可以通过以下两种方式来提供视图:
使用 `@app.view` 装饰器:
```python
from robyn import Request
@app.view("/sync/view/decorator")
def sync_decorator_view():
def get():
return "Hello, world!"
def post(request: Request):
body = request.body
return body
```
使用 `app.add_view` 方:
```python
from .views import sample_view
...
...
app.add_view("/", sample_view)
```
---
## 子路由器 (Subrouters)
蝙蝠侠可以在 Robyn 项目中创建子路由器,用于将多个相关的路由分组在一起,方便管理和使用。
子路由器不仅可以用来管理常规的 HTTP 路由,还可以用来管理 Web 套接字(web sockets)路由。换句话说,子路由器的功能与主路由器类似,它可以被视作是主路由器的一个简化版。
有一点需要注意的是,子路由器必须添加到主路由器中。
```python
from robyn import Robyn, SubRouter
app = Robyn(__file__)
sub_router = SubRouter("/sub_router")
@sub_router.get("/hello")
def hello():
return "Hello, world"
web_socket = SubRouter("/web_socket")
@web_socket.message()
async def hello():
return "Hello, world"
app.include_router(sub_router)
```
## 下一步
现在,蝙蝠侠已经了解了如何组织代码,接下来他希望学习如何向代码中添加依赖项。Robyn 告诉他,依赖项可以在全局级别、路由器级别和视图级别进行添加。
- [依赖注入](/documentation/zh/api_reference/dependency_injection)
================================================
FILE: docs_src/src/pages/documentation/zh/api_reference/websockets.mdx
================================================
export const description =
'在此页面中,我们将深入探讨如何通过不同的接口实现符合预期的交互。'
## WebSockets {{ tag: 'WebSockets', label: 'WebSockets' }}
在掌握了[服务器发送事件](/documentation/zh/api_reference/server_sent_events)的单向通信之后,蝙蝠侠意识到他需要更强大的功能。当戈登局长想要在危机情况下与他实时聊天时,蝙蝠侠需要双向通信。
"SSE 很适合向我的仪表板推送更新,"蝙蝠侠想道,"但我需要双向通信来与我的盟友协调!"
为了实现双向实时通信,蝙蝠侠学习了如何使用 Robyn 的现代装饰器 API 处理 WebSocket。底层消息通过 Rust 通道传递,实现最大性能——消息分发过程中无需 Python GIL。
```python {{ title: '基础回声' }}
from robyn import Robyn
app = Robyn(__file__)
@app.websocket("/web_socket")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
app.start()
```
```python {{ title: '带回调' }}
from robyn import Robyn
app = Robyn(__file__)
@app.websocket("/web_socket")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
@handler.on_connect
def on_connect(websocket):
return "已连接到 ws"
@handler.on_close
def on_close(websocket):
return "再见,来自 ws"
app.start()
```
---
## 接收消息 {{ tag: 'receive_text', label: 'receive_text' }}
`receive_text()` 方法会阻塞直到下一条消息到达。它由 Rust 的 `tokio::mpsc` 通道支持,因此 Python 处理程序在等待时不会持有 GIL。
当客户端断开连接时,`receive_text()` 会抛出 `WebSocketDisconnect` 异常。您可以显式捕获它,也可以让内部包装器静默处理。
```python {{ title: '文本消息' }}
@app.websocket("/ws")
async def handler(websocket):
try:
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"收到: {msg}")
except WebSocketDisconnect:
print(f"客户端 {websocket.id} 已断开")
```
```python {{ title: 'JSON 消息' }}
@app.websocket("/api")
async def handler(websocket):
while True:
data = await websocket.receive_json()
result = process(data)
await websocket.send_json({"status": "ok", "result": result})
```
---
## 发送消息 {{ tag: 'send_text', label: 'send_text' }}
使用 `send_text()` 或 `send_json()` 向当前客户端发送消息。所有发送方法都是异步的。
```python {{ title: '发送文本' }}
@app.websocket("/ws")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
```
```python {{ title: '发送 JSON' }}
@app.websocket("/ws")
async def handler(websocket):
while True:
data = await websocket.receive_json()
await websocket.send_json({"echo": data})
```
---
## 广播 {{ tag: 'broadcast', label: 'broadcast' }}
使用 `broadcast()` 方法向同一 WebSocket 端点上的所有已连接客户端发送消息。
```python {{ title: '广播' }}
@app.websocket("/chat")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
# 向所有已连接的客户端发送
await websocket.broadcast(f"用户 {websocket.id}: {msg}")
# 仅向当前客户端发送确认
await websocket.send_text("您的消息已发送")
```
---
## 查询参数 {{ tag: 'query_params', label: 'query_params' }}
通过 `websocket.query_params` 访问 WebSocket 连接 URL 中的查询参数。
```python {{ title: '查询参数' }}
@app.websocket("/ws")
async def handler(websocket):
name = websocket.query_params.get("name")
role = websocket.query_params.get("role")
if name == "gordon" and role == "commissioner":
await websocket.broadcast("戈登已授权!")
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"你好 {name}: {msg}")
```
---
## 便捷查询参数访问 {{ tag: 'easy_access', label: 'easy_access' }}
除了手动调用 `websocket.query_params.get(...)` 之外,你还可以在处理函数、`on_connect` 和 `on_close` 的签名中直接声明带类型注解的查询参数。Robyn 会自动解析并进行类型转换——与 HTTP 便捷参数访问的用法一致。
带默认值的参数是可选的。没有默认值的参数是必需的——如果缺少,连接将被拒绝并返回错误消息。
```python {{ title: '处理函数' }}
@app.websocket("/ws")
async def handler(websocket, room: str = "default", page: int = 1):
try:
while True:
msg = await websocket.receive_text()
await websocket.send_text(
f"room={room} page={page} msg={msg}"
)
except WebSocketDisconnect:
pass
```
```python {{ title: '回调' }}
@handler.on_connect
def on_connect(websocket, room: str = "default"):
return f"已连接到 {room}"
@handler.on_close
def on_close(websocket, room: str = "default"):
return f"已离开 {room}"
```
---
## 关闭连接 {{ tag: 'close', label: 'close' }}
使用 `websocket.close()` 从服务端关闭 WebSocket 连接。该方法将:
1. 关闭 WebSocket 连接。
2. 从 WebSocket 注册表中移除客户端。
3. 使任何挂起的 `receive_text()` 抛出 `WebSocketDisconnect` 异常。
```python {{ title: '服务端关闭' }}
@app.websocket("/ws")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
if msg == "quit":
await websocket.close()
break
await websocket.send_text(f"收到: {msg}")
```
---
## 连接和关闭回调 {{ tag: '回调', label: '回调' }}
您可以为 WebSocket 处理程序附加可选的 `on_connect` 和 `on_close` 回调。它们是处理函数本身的装饰器。
- `on_connect` 在新客户端连接时调用。其返回值作为第一条消息发送给客户端。
- `on_close` 在连接关闭时调用。其返回值作为最后一条消息发送给客户端。
两个回调都接收一个 `websocket` 对象,可以访问 `id` 和 `query_params`。两者都是可选的。
```python {{ title: '回调' }}
@app.websocket("/chat")
async def chat(websocket):
while True:
msg = await websocket.receive_text()
await websocket.broadcast(msg)
@chat.on_connect
def on_connect(websocket):
return f"欢迎,{websocket.id}!"
@chat.on_close
def on_close(websocket):
return "再见!"
```
---
## WebSocket API 参考 {{ tag: 'API', label: 'API' }}
传递给处理程序的 `websocket` 对象提供以下方法和属性:
| 方法 / 属性 | 描述 |
|---|---|
| `await websocket.receive_text()` | 阻塞直到下一条消息;连接关闭时抛出 `WebSocketDisconnect` |
| `await websocket.receive_bytes()` | 阻塞直到下一条二进制消息;连接关闭时抛出 `WebSocketDisconnect` |
| `await websocket.receive_json()` | 与 `receive_text()` 相同,但返回 JSON 解码后的数据 |
| `await websocket.send_text(data)` | 向当前客户端发送文本 |
| `await websocket.send_bytes(data)` | 向当前客户端发送二进制数据 |
| `await websocket.send_json(data)` | 向当前客户端发送 JSON |
| `await websocket.broadcast(data)` | 向此端点的所有客户端广播 |
| `await websocket.close()` | 从服务端关闭连接 |
| `websocket.id` | 连接 UUID 字符串 |
| `websocket.query_params` | 连接 URL 中的查询参数 |
---
## 下一步
随着代码库的扩展,蝙蝠侠希望正义联盟的成员能够参与管理应用程序。
Robyn 向他介绍了应用扩展的最佳实践,并展示了如何通过视图和子路由器来提升代码的可读性和可维护性。
- [视图和子路由器](/documentation/zh/api_reference/views)
================================================
FILE: docs_src/src/pages/documentation/zh/architecture.mdx
================================================
export const description = 'Robyn 是一个基于 Tokio 运行时的 Python Web 服务器,结合了 Python 和 Rust 的优势,利用工作者事件循环、高效的请求处理、多核扩展,以及引入了“常量请求”功能,在多线程环境中优化缓存响应。'
## Robyn 设计文档
## 服务器模型
Robyn 基于多进程、多线程模型构建,结合了 Python 和 Rust 的优势。它使用一个主进程来管理多个工作进程,每个工作进程可以处理多个线程。这种设计使 Robyn 能够高效利用系统资源并处理大量并发请求。
## 主进程
Robyn 的主进程负责初始化服务器、管理工作进程并处理信号。它创建一个套接字,并将其传递给工作进程,允许它们接受连接。主进程使用 Python 实现,为开发者提供熟悉的接口,同时利用 Rust 在核心操作中的高性能。
```python
216:257:robyn/__init__.py
def start(self, host: str = "127.0.0.1", port: int = 8080, _check_port: bool = True):
"""
启动服务器
:param host str: 服务器监听的主机地址
:param port int: 服务器监听的端口号
:param _check_port bool: 是否检查端口是否已被占用
"""
host = os.getenv("ROBYN_HOST", host)
port = int(os.getenv("ROBYN_PORT", port))
open_browser = bool(os.getenv("ROBYN_BROWSER_OPEN", self.config.open_browser))
if _check_port:
while self.is_port_in_use(port):
logger.error("端口 %s 已被占用,请使用其他端口。", port)
try:
port = int(input("Enter a different port: "))
except Exception:
logger.error("无效的端口号,请输入有效的端口号。")
continue
logger.info("Robyn 版本:%s", __version__)
logger.info("正在启动服务器,地址:http://%s:%s", host, port)
mp.allow_connection_pickling()
run_processes(
host,
port,
self.directories,
self.request_headers,
self.router.get_routes(),
self.middleware_router.get_global_middlewares(),
self.middleware_router.get_route_middlewares(),
self.web_socket_router.get_routes(),
self.event_handlers,
self.config.workers,
self.config.processes,
self.response_headers,
open_browser,
)
```
## 工作进程
Robyn 使用多个工作进程来处理传入的请求。每个工作进程能够管理多个线程,从而实现高效的并发处理。工作进程的数量可以通过 `--processes` 参数配置,默认值为 1。
```python
66:116:robyn/processpool.py
def init_processpool(
directories: List[Directory],
request_headers: Headers,
routes: List[Route],
global_middlewares: List[GlobalMiddleware],
route_middlewares: List[RouteMiddleware],
web_sockets: Dict[str, WebSocket],
event_handlers: Dict[Events, FunctionInfo],
socket: SocketHeld,
workers: int,
processes: int,
response_headers: Headers,
) -> List[Process]:
process_pool = []
if sys.platform.startswith("win32") or processes == 1:
spawn_process(
directories,
request_headers,
routes,
global_middlewares,
route_middlewares,
web_sockets,
event_handlers,
socket,
workers,
response_headers,
)
return process_pool
for _ in range(processes):
copied_socket = socket.try_clone()
process = Process(
target=spawn_process,
args=(
directories,
request_headers,
routes,
global_middlewares,
route_middlewares,
web_sockets,
event_handlers,
copied_socket,
workers,
response_headers,
),
)
process.start()
process_pool.append(process)
return process_pool
```
## 工作线程
在每个工作进程中,Robyn 使用多个线程并发处理请求。工作线程的数量可以通过 `--workers` 参数配置。默认情况下,Robyn 每个进程使用一个工作线程。
## Rust 集成
Robyn 的一个独特特性是与 Rust 的集成。核心的服务器功能,包括请求处理和路由,都是用 Rust 实现的。这使得 Robyn 在提供 Python 友好的 API 的同时,能够实现高性能。
```python
76:107:src/server.rs
pub fn start(
&mut self,
py: Python,
socket: &PyCell,
workers: usize,
) -> PyResult<()> {
pyo3_log::init();
if STARTED
.compare_exchange(false, true, SeqCst, Relaxed)
.is_err()
{
debug!("Robyn 已经启动...");
return Ok(());
}
let raw_socket = socket.try_borrow_mut()?.get_socket();
let router = self.router.clone();
let const_router = self.const_router.clone();
let middleware_router = self.middleware_router.clone();
let web_socket_router = self.websocket_router.clone();
let global_request_headers = self.global_request_headers.clone();
let global_response_headers = self.global_response_headers.clone();
let directories = self.directories.clone();
let asyncio = py.import("asyncio")?;
let event_loop = asyncio.call_method0("new_event_loop")?;
asyncio.call_method1("set_event_loop", (event_loop,))?;
let startup_handler = self.startup_handler.clone();
let shutdown_handler = self.shutdown_handler.clone();
```
## 常量请求(Const Requests)
Robyn 引入了一个优化功能,称为“常量请求”。这个功能允许某些路由在 Rust 层进行缓存,从而减少频繁访问的端点的开销,这些端点返回常量数据。
## 选择工作进程和进程配置
通过调整工作进程和进程的数量,Robyn 的性能可以根据系统资源和应用程序的性质进行优化。
1. 进程数量:
设置进程数量为 CPU 核心数(N)。这使得 Robyn 能够充分利用多核系统。
2. 工作线程数量:
使用公式 `2 * N + 1`,其中 N 是 CPU 核心数。这个配置有助于高效处理 I/O 密集型和 CPU 密集型任务。
例如,在一个 4 核的机器上:
```
python app.py --processes=4 --workers=9
```
请记住,最佳配置可能会因应用程序和服务器资源的不同而有所变化。建议进行负载测试,尝试不同的配置,以找到最适合您用例的平衡。
## 扩展考虑
- Robyn 的多进程模型使其能够有效地跨多个 CPU 核心扩展。
- Python 和 Rust 的结合既便于开发,又能提供高性能。
- 常量请求功能可以显著提高返回常量输出的路由的性能。
- 扩展时,考虑进程和工作线程的数量,以找到适合硬件和应用需求的最佳配置。
## 开发模式
Robyn 提供了一个开发模式,可以通过 `--dev` 参数启用。此模式旨在简化开发过程,包含热重载等功能。请注意,在开发者模式下,多进程和多工作线程配置被禁用,以确保开发过程中的一致性。
```python
92:101:robyn/argument_parser.py
if self.dev and (self.processes != 1 or self.workers != 1):
raise Exception("--processes and --workers shouldn't be used with --dev")
if self.dev and args.log_level is None:
self.log_level = "DEBUG"
elif args.log_level is None:
self.log_level = "INFO"
else:
self.log_level = args.log_level
```
通过理解这些设计原则并根据需要调整配置,开发者可以利用 Robyn 的独特架构构建高性能的 Web 应用程序,充分利用系统资源。
## 设计图
================================================
FILE: docs_src/src/pages/documentation/zh/community-resources.mdx
================================================
export const description =
'在此页面中,我们将看到一些由我们杰出的成员贡献的社区资源,以帮助开发者快速入门使用 Robyn。'
## 演讲
- [EuroPython 2022](https://www.youtube.com/watch?v=AutugvJNVkY&)
- [GeoPython 2022](https://www.youtube.com/watch?v=YCpbCQwbkd4)
- [PyCon US 2022](https://youtu.be/1IiL31tUEVk?t=2101)
- [PyCon Sweden 2021](https://www.youtube.com/watch?v=DK9teAs72Do)
## 博客
- [Hello, Robyn!](https://www.sanskar.me/posts/hello-robyn)
## 下一步
现在,蝙蝠侠对它充满兴趣
- [托管](/documentation/zh/hosting)
================================================
FILE: docs_src/src/pages/documentation/zh/example_app/authentication-middlewares.mdx
================================================
export const description =
'欢迎阅读 Robyn API 文档。本文档旨在提供全面的指南和参考,帮助您快速上手 Robyn,并在使用过程中解决可能遇到的问题。'
## 鉴权与授权中间件
为防止无关人员访问犯罪数据,蝙蝠侠为应用程序添加了基于 JWT(JSON Web Token)的身份验证和授权功能,并创建了用户表和用户注册接口。
```python {{ title: '设置鉴权中间件' }}
from robyn.authentication import AuthenticationHandler, BearerGetter, Identity
class BasicAuthHandler(AuthenticationHandler):
def authenticate(self, request: Request):
token = self.token_getter.get_token(request)
try:
payload = crud.decode_access_token(token)
username = payload["sub"]
except Exception:
return
with SessionLocal() as db:
user = crud.get_user_by_username(db, username=username)
return Identity(claims={"user": f"{ user }"})
app.configure_authentication(BasicAuthHandler(token_getter=BearerGetter()))
@app.get("/users/me", auth_required=True)
async def get_current_user(request):
user = request.identity.claims["user"]
return user
```
得益于 Robyn 框架,哥谭市警察局现在能高效管理犯罪数据并实时追踪犯罪动态。蝙蝠侠利用该框架成功实现能够实际运用的程序,助力哥谭市打击犯罪。
================================================
FILE: docs_src/src/pages/documentation/zh/example_app/authentication.mdx
================================================
export const description =
'欢迎阅读 Robyn API 文档。本文档旨在提供全面的指南和参考,帮助您快速上手 Robyn,并在使用过程中解决可能遇到的问题。'
## 身份验证
为防止无关人员访问犯罪数据,蝙蝠侠为应用程序添加了基于 JWT(JSON Web Token)的身份验证和授权功能,并创建了用户表和用户注册接口。
## 用户模型
蝙蝠侠设计了一个用户模型(User Model),用于表示可以访问该应用程序的用户。
```python {{ title: '基本身份验证请求示例' }}
# models.py
from sqlalchemy import Column, Integer, String, Boolean
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
username = Column(String, unique=True, index=True)
hashed_password = Column(String)
def __repr__(self):
return "".format(
id=self.id,
username=self.username,
hashed_password=self.hashed_password,
)
```
接着,他在 `crud.py` 文件中新增了一个方法,用于创建用户。
```python {{ title: '基本身份验证请求示例' }}
# crud.py
# also need to do pip install passlib[bcrypt]
from sqlalchemy.orm import Session
from .models import User
from passlib.context import CryptContext
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
def get_password_hash(password: str) -> str:
return pwd_context.hash(password)
def get_user(db: Session, user_id: int):
return db.query(User).filter(User.id == user_id).first()
def create_user(db: Session, user: User):
hashed_password = get_password_hash(user.password)
db_user = User(username=user.username, hashed_password=hashed_password)
db.add(db_user)
db.commit()
db.refresh(db_user)
return db_user
```
## 鉴权工具
同时,他还实现了一些工具函数,用于处理身份验证操作,包括密码加密与校验。
```python {{ title: '基本身份验证请求示例(bearer token)' }}
# crud.py
# also need to do pip install passlib[bcrypt]
# pip install "python-jose[cryptography]"
from passlib.context import CryptContext
from jose import JWTError, jwt
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
ALGORITHM = "HS256"
SECRET_KEY = "your_secret_key"
def create_access_token(data: dict, expires_delta: timedelta = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
def decode_access_token(token: str):
return jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
def authenticate_user(db: Session, username: str, password: str):
user = get_user_by_username(db, username)
if user is None:
return False
if not verify_password(password, user.hashed_password):
return False
created_token = create_access_token(data={"sub": user.username})
return created_token
```
## 用户注册接口
最后,蝙蝠侠新增了用户注册与登录接口,完成用户注册和登录验证功能。
```python {{ title: '设置路由' }}
from . import crud
@app.post("/users/register")
async def register_user(request):
user = request.json()
with SessionLocal() as db:
created_user = crud.create_user(db, user)
return created_user
@app.post("/users/login")
async def login_user(request):
user = request.json()
with SessionLocal() as db:
token = crud.authenticate_user(db, **user)
if token is None:
raise HTTPException(status_code=401, detail="Invalid credentials")
return {"access_token": token}
```
================================================
FILE: docs_src/src/pages/documentation/zh/example_app/deployment.mdx
================================================
export const description =
'欢迎阅读 Robyn API 文档。本文档旨在提供全面的指南和参考,帮助您快速上手 Robyn,并在使用过程中解决可能遇到的问题。'
## 部署
在对 Web 应用程序进行全面测试并确认所有功能正常后,蝙蝠侠决定将其部署到生产服务器。他选择了一个强大且可扩展的平台,确保应用程序始终保持高可用性和卓越性能。
```python {{ title: '部署' }}
python app.py --processes=n --workers=m
```
随着 Web 应用程序的成功部署,蝙蝠侠获得了一个强大的新工具。Robyn 框架为他提供了创建高效打击犯罪应用所需的灵活性、可扩展性和性能,使他在保护哥谭市的持续战斗中获得了显著的技术优势。
================================================
FILE: docs_src/src/pages/documentation/zh/example_app/index.mdx
================================================
export const description =
'欢迎阅读 Robyn API 文档。本文档旨在提供全面的指南和参考,帮助您快速上手 Robyn,并在使用过程中解决可能遇到的问题。'
# 基于 Robyn 创建真正的 Web 应用
蝙蝠侠的任务是开发一个 Web 应用,用于管理哥谭市的犯罪数据。该应用允许哥谭市警察局存储和检索有关犯罪活动、嫌疑人以及其位置的信息。为提高开发效率,蝙蝠侠决定使用 Robyn Web 框架来快速构建该应用。
您可以通过[此链接](https://github.com/sparckles/example_robyn_app)获取该应用的源代码。
## 安装 Robyn
首先,需要安装 Robyn。蝙蝠侠创建了一个虚拟环境,并通过 pip 安装了 Robyn。
```bash
$ python3 -m venv venv
$ source venv/bin/activate
$ pip install robyn
```
## 创建 Robyn 应用
蝙蝠侠决定使用 Robyn 框架创建应用,在他准备创建 `src/app.py` 文件时,有人提醒他,Robyn 自带了一个命令行工具 (CLI),可以帮助快速创建应用。于是他运行了以下命令来创建一个新的 Robyn 应用。
```bash
$ python -m robyn --create
```
运行命令后,终端显示如下提示:
```bash
$ python3 -m robyn --create
? Directory Path: .
? Need Docker? (Y/N) Y
? Please select project type (Mongo/Postgres/Sqlalchemy/Prisma):
❯ No DB
Sqlite
Postgres
MongoDB
SqlAlchemy
Prisma
```
接下来,他配置了应用的选项,大多数问题都选择了默认设置。
完成后,Robyn CLI 成功创建了一个应用,应用的目录结构如下:
```bash
├── src
│ ├── app.py
├── Dockerfile
```
================================================
FILE: docs_src/src/pages/documentation/zh/example_app/modeling_routes.mdx
================================================
export const description =
'欢迎阅读 Robyn API 文档。本文档旨在提供全面的指南和参考,帮助您快速上手 Robyn,并在使用过程中解决可能遇到的问题。'
## 数据模型和数据库连接
蝙蝠侠设计了一个数据模型,用于表示犯罪数据,包括罪行类型、嫌疑人及其位置等信息。他选择使用 SQLite 数据库来存储数据,并通过 ORM(对象关系映射)库与数据库进行交互。
```python
# models.py
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Float
from sqlalchemy.orm import declarative_base, sessionmaker
DATABASE_URL = "sqlite:///./gotham_crime_data.db"
engine = create_engine(DATABASE_URL)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
class Crime(Base):
__tablename__ = "crimes"
id = Column(Integer, primary_key=True, index=True)
type = Column(String, index=True)
description = Column(String)
location = Column(String)
suspect_name = Column(String)
date_time = Column(DateTime)
latitude = Column(Float)
longitude = Column(Float)
```
## 配置 Robyn 应用
蝙蝠侠成功创建了一个 Robyn 应用,并将其配置为使用数据库会话来访问 SQLite 数据库。
根据数据库模型,蝙蝠侠实现了一些辅助方法来与数据库进行交互。这些方法将用于在应用的 API 接口中执行 CRUD(增删改查)操作。
```python {{ title: 'crud.py' }}
# crud.py
from sqlalchemy.orm import Session
from .models import Crime
def get_crime(db: Session, crime_id: int):
return db.query(Crime).filter(Crime.id == crime_id).first()
def get_crimes(db: Session, skip: int = 0, limit: int = 100):
return db.query(Crime).offset(skip).limit(limit).all()
def create_crime(db: Session, crime):
db_crime = Crime(**crime)
db.add(db_crime)
db.commit()
db.refresh(db_crime)
return db_crime
def update_crime(db: Session, crime_id: int, crime):
db_crime = get_crime(db, crime_id)
if db_crime is None:
return None
for key, value in crime.items():
setattr(db_crime, key, value)
db.commit()
db.refresh(db_crime)
return db_crime
def delete_crime(db: Session, crime_id: int):
db_crime = get_crime(db, crime_id)
if db_crime is None:
return False
db.delete(db_crime)
db.commit()
return True
```
## 犯罪数据 API 接口
蝙蝠侠为管理犯罪数据创建了多个 API 接口。这些接口允许哥谭市警察局添加、更新和查询犯罪记录。
```python {{ title: 'Setting up Routes' }}
# __main__.py
from robyn import Robyn
from robyn.robyn import Request, Response
from sqlalchemy.orm import Session
app = Robyn(__file__)
@app.post("/crimes")
async def add_crime(request):
with SessionLocal() as db:
crime = request.json()
insertion = crud.create_crime(db, crime)
if insertion is None:
raise Exception("Crime not added")
return {
"description": "Crime added successfully",
"status_code": 200,
}
@app.get("/crimes")
async def get_crimes(request):
with SessionLocal() as db:
skip = request.query_params.get("skip", "0")
limit = request.query_params.get("limit", "100")
crimes = crud.get_crimes(db, skip=skip, limit=limit)
return crimes
@app.get("/crimes/:crime_id", auth_required=True)
async def get_crime(request):
crime_id = int(request.path_params.get("crime_id"))
with SessionLocal() as db:
crime = crud.get_crime(db, crime_id=crime_id)
if crime is None:
raise Exception("Crime not found")
return crime
@app.put("/crimes/:crime_id")
async def update_crime(request):
crime = request.json()
crime_id = int(request.path_params.get("crime_id"))
with SessionLocal() as db:
updated_crime = crud.update_crime(db, crime_id=crime_id, crime=crime)
if updated_crime is None:
raise Exception("Crime not found")
return updated_crime
@app.delete("/crimes/{crime_id}")
async def delete_crime(request):
crime_id = int(request.path_params.get("crime_id"))
with SessionLocal() as db:
success = crud.delete_crime(db, crime_id=crime_id)
if not success:
raise Exception("Crime not found")
return {"message": "Crime deleted successfully"}
```
================================================
FILE: docs_src/src/pages/documentation/zh/example_app/monitoring_and_logging.mdx
================================================
## 监控和日志记录
为了更好地监控应用程序的性能并及时解决潜在问题,蝙蝠侠决定实施全面的监控和日志记录机制。他通过集成第三方库来使用日志记录中间件,从而能够跟踪请求、错误和性能指标。
```python {{ title: '监控和日志记录' }}
from robyn import Logger
logger = Logger(app)
@app.before_request()
async def log_request(request: Request):
logger.info(f"Received request: %s", request)
@app.after_request()
async def log_response(response: Response):
logger.info(f"Sending response: %s", response)
```
借助监控和日志记录功能,蝙蝠侠现在能够轻松检测应用程序中的问题,分析其性能表现,确保系统始终保持最佳状态,随时准备协助他打击犯罪。
================================================
FILE: docs_src/src/pages/documentation/zh/example_app/openapi.mdx
================================================
export const description =
'欢迎阅读 Robyn API 文档。本文档旨在提供全面的指南和参考,帮助您快速上手 Robyn,并在使用过程中解决可能遇到的问题。'
## OpenAPI 文档 (Swagger)
应用程序部署后,蝙蝠侠收到许多用户询问如何使用接口。为了回应这些需求,Robyn 向他展示了如何生成 OpenAPI 规范。
开箱即用,Robyn 为应用程序提供了以下接口:
- `/docs` Swagger UI 可视化界面
- `/openapi.json` JSON 格式的 OpenAPI 文档
如果您不希望生成 OpenAPI 文档,可以在启动应用程序时传递 `--disable-openapi` 参数来禁用该功能。
若需要使用自定义的 OpenAPI 配置,您可以:
- 将 `openapi.json` 配置文件放在应用程序的根目录中。
- 或者,将文件路径作为参数传递给 `Robyn()` 构造函数中的 `openapi_file_path` 参数(参数的优先级高于文件)。
```bash
python app.py --disable-openapi
```
## 如何使用?
- 要使用查询参数类型,您可以通过定义 `def get(r: Request, query_params: GetRequestParams)` 的方式,其中 `GetRequestParams` 是 `QueryParams` 的子类。
- 路径参数默认为字符串类型(参考:[https://en.wikipedia.org/wiki/Query_string](https://en.wikipedia.org/wiki/Query_string))
```python
from robyn.robyn import QueryParams
from robyn import Robyn, Request
app = Robyn(
file_object=__file__,
openapi=OpenAPI(
info=OpenAPIInfo(
title="Sample App",
description="This is a sample server application.",
termsOfService="https://example.com/terms/",
version="1.0.0",
contact=Contact(
name="API Support",
url="https://www.example.com/support",
email="support@example.com",
),
license=License(
name="BSD2.0",
url="https://opensource.org/license/bsd-2-clause",
),
externalDocs=ExternalDocumentation(description="Find more info here", url="https://example.com/"),
components=Components(),
),
),
)
@app.get("/")
async def welcome():
"""欢迎"""
return "hi"
class GetRequestParams(QueryParams):
appointment_id: str
year: int
@app.get("/api/v1/name", openapi_name="Name Route", openapi_tags=["Name"])
async def get(r: Request, query_params: GetRequestParams):
"""根据 ID 获取名称"""
return r.query_params
@app.delete("/users/:name", openapi_tags=["Name"])
async def delete(r: Request):
"""根据名称删除用户"""
return r.path_params
if __name__ == "__main__":
app.start()
```
## 如何在子路由下使用?
```python
from robyn.robyn import QueryParams
from robyn import Request, SubRouter
subrouter: SubRouter = SubRouter(__name__, prefix="/sub")
@subrouter.get("/")
async def subrouter_welcome():
"""欢迎来到子路由"""
return "hiiiiii subrouter"
class SubRouterGetRequestParams(QueryParams):
_id: int
value: str
@subrouter.get("/name")
async def subrouter_get(r: Request, query_params: SubRouterGetRequestParams):
"""根据 ID 获取名称"""
return r.query_params
@subrouter.delete("/:name")
async def subrouter_delete(r: Request):
"""根据名称删除用户"""
return r.path_params
app.include_router(subrouter)
```
## 其他规范参数
Robyn 支持最新的 OpenAPI 规范([https://swagger.io/specification/](https://swagger.io/specification/))中提到的所有参数。下是请求和响应体的示例:
```python
from robyn.types import JSONResponse, Body
class Initial(Body):
is_present: bool
letter: Optional[str]
class FullName(Body):
first: str
second: str
initial: Initial
class CreateItemBody(Body):
name: FullName
description: str
price: float
tax: float
class CreateResponse(JSONResponse):
success: bool
items_changed: int
@app.post("/")
def create_item(request: Request, body: CreateItemBody) -> CreateResponse:
return CreateResponse(success=True, items_changed=2)
```
随着参考文档的成功部署,蝙蝠侠拥有了一个强大的新工具。Robyn 框架为他提供了创建高效打击犯罪应用所需的灵活性、可扩展性和性能,使他在保护哥谭市的持续战斗中获得了技术优势。
================================================
FILE: docs_src/src/pages/documentation/zh/example_app/real_time_notifications.mdx
================================================
export const description =
'欢迎阅读 Robyn API 文档。本文档旨在提供全面的指南和参考,帮助您快速上手 Robyn,并在使用过程中解决可能遇到的问题。'
## 即时通讯
蝙蝠侠决定使用 WebSockets 为哥谭市警察局的警官们实现实时通知功能,从而使他们能够即时接收关于犯罪活动的更新,并在发生新的犯罪报告时触发警报。
```python {{ title: '设置实时通知' }}
from robyn import WebSocketDisconnect
@app.websocket("/notifications")
async def notify_handler(websocket):
try:
while True:
message = await websocket.receive_text()
await websocket.send_text(f"Received: {message}")
except WebSocketDisconnect:
pass
@notify_handler.on_connect
def notify_connect(websocket):
return "Connected to notifications"
@notify_handler.on_close
def notify_close(websocket):
return "Disconnected from notifications"
```
## 高级搜索和过滤
为了提高警察在搜寻特定犯罪或嫌疑人时的效率,蝙蝠侠为应用程序增加了高级搜索和过滤选项。他设计了一个新的接口,允许用户根据多个标准(如犯罪类型、日期、地点和案件状态)进行精确搜索。
```python {{ title: '高级搜索和过滤' }}
@app.get("/crimes/search")
async def search_crimes(request):
crime_type = request.query_params.get("crime_type")
date = request.query_params.get("date")
location = request.query_params.get("location")
status = request.query_params.get("status")
crimes = crud.search_crimes(db, crime_type=crime_type, date=date, location=location, status=status)
return crimes
```
通过这些新功能,哥谭市警察局能够更高效地利用 Web 应用程序来跟踪犯罪活动,并合理调配资源。蝙蝠侠在 Robyn Web 框架上的努力显著提升了打击犯罪的能力,使哥谭市变得更加安全。
尽管蝙蝠侠在当前任务中取得了显著成效,他仍意识到系统有改进空间。因此,他将继续总结经验,不断完善系统,同时专注于履行黑暗骑士的核心使命——保护哥谭市的安全。
================================================
FILE: docs_src/src/pages/documentation/zh/example_app/subrouters_and_views.mdx
================================================
export const description =
'欢迎阅读 Robyn API 文档。本文档旨在提供全面的指南和参考,帮助您快速上手 Robyn,并在使用过程中解决可能遇到的问题。'
## 子路由器和视图
在实现了基本的应用程序功能后,蝙蝠侠希望将代码库拆分为多个文件,以提高可维护性和扩展性。
此时,Robyn 向他介绍了子路由器和视图的概念。
### 路由器 (Routers)
路由器用于将路由(URL 路径与请求处理函数的映射)组织到不同模块中,从而使应用更加模块化,便于管理和扩展。
例如,如果要为前端功能创建一个路由器,可以创建一个名为 `frontend.py` 的文件,该文件将包含所有与前端相关的路由。
`frontend.py` 文件中的代码示例如下:
```bash
├── app.py
├── frontend.py
├── Dockerfile
└── requirements.txt
```
`frontend.py` 文件中的代码示例如下:
```python {{ title: '创建路由器' }}
# frontend.py
from robyn.templating import JinjaTemplate
from robyn import SubRouter
import os
import pathlib
current_file_path = pathlib.Path(__file__).parent.resolve()
jinja_template = JinjaTemplate(os.path.join(current_file_path, "templates"))
frontend = SubRouter(__name__, prefix="/frontend")
@frontend.get("/")
async def get_frontend(request):
context = {"framework": "Robyn", "templating_engine": "Jinja2"}
return jinja_template.render_template("index.html", **context)
```
在 `app.py` 文件中,您可以通过以下方式引入并注册前端路由器:
```python {{ title: '嵌套路由' }}
# app.py
from .frontend import frontend
app.include_router(frontend)
```
### 视图 (Views)
视图用于组织和处理路由的具体功能,通常涉及同步或异步的请求处理。它侧重于定义路由的行为和处理请求与响应。
例如,如果要为前端创建视图,可以创建一个名为 `frontend.py` 的文件。此文件将包含所有与前端相关的路由。
代码示例如下:
```python {{ title: '创建装饰器下的视图' }}
from robyn import SyncView
@app.view("/sync/view/decorator")
def sync_decorator_view():
def get():
return "Hello, world!"
def post(request: Request):
body = request.body
return body
```
```python {{ title: '创建视图' }}
def sync_decorator_view():
def get():
return "Hello, world!"
def post(request: Request):
body = request.body
return body
app.add_view("/sync/view/decorator", sync_decorator_view)
```
================================================
FILE: docs_src/src/pages/documentation/zh/example_app/templates.mdx
================================================
export const description =
'欢迎阅读 Robyn API 文档。本文档旨在提供全面的指南和参考,帮助您快速上手 Robyn,并在使用过程中解决可能遇到的问题。'
## 模板
在完成后端开发后,蝙蝠侠决定为他的应用程序添加前端。他希望创建一个简单的网页来展示他收集的数据,同时也希望能够将新数据添加到数据库,并编辑现有的数据。
这时,他接触到了模板!
模板是 Robyn 框架中的一项强大功能,允许开发者使用 HTML 和 Python 创建动态网页。通过模板,您可以方便地为应用程序添加前端,而无需学习新的语言或框架。
Robyn 默认支持 Jinja2 模板引擎,并且提供了简单的方式来集成其他模板引擎。
### 创建模板
要创建模板,您需要在项目目录中创建一个扩展名为 `.html` 的文件。通常情况下,这些模板文件会存放在名为 `templates` 的目录下。例如,如果您想创建一个名为 `index.html` 的模板,您可以在 `templates` 目录中创建该文件。
因此,您的文件夹结构可能如下所示:
```bash
├── app.py
├── templates
│ └── index.html
├── Dockerfile
└── requirements.txt
```
### 模板渲染
创建好模板后,您可以使用 `render_template` 函数来渲染它。该函数的第一个参数是模板的名称,第二个参数是一个字典,其中包含要传递给模板的变量。
例如,要渲染 `index.html` 模板,可以使用如下代码:
```python {{ title: '模板渲染' }}
import os
import pathlib
from robyn.templating import JinjaTemplate
current_file_path = pathlib.Path(__file__).parent.resolve()
jinja_template = JinjaTemplate(os.path.join(current_file_path, "templates"))
@app.get("/frontend")
async def get_frontend(request):
context = {"framework": "Robyn", "templating_engine": "Jinja2"}
return jinja_template.render_template("index.html", **context)
app.include_router(frontend)
```
现在,蝙蝠侠的应用程序已经成功完成,前端页面也正常显示。然而,蝙蝠侠对当前的代码结构并不满意。他认为所有的代码都集中在一个文件中,难以维护。于是,他询问 Robyn 是否有办法将代码拆分成多个模块。
这时,Robyn 向蝙蝠侠介绍了路由器和视图的概念。
================================================
FILE: docs_src/src/pages/documentation/zh/framework_performance_comparison.mdx
================================================
export const description = '在此页面中,我们将了解不同框架之间的性能对比。'
# 不同框架之间的性能对比
## 请先阅读此内容
在深入之前,需要强调的是,本次性能对比的目的并非贬低任何开发者或下列所提及的框架。列出框架名称只是为了使对比更清晰。我对 Python-Web 生态系统的偏好很大程度上受到了这些框架的影响,在这里列出它们并不是为了冒犯任何人。
此外,这些测试是在我个人开发设备上进行的,因此,以下展示的数据并非绝对值。这些数据仅用于反映在特定测试条件下这些框架的相对性能。
使用 [oha](https://github.com/hatoo/oha) 工具对以下框架进行 10,000 个请求的测试,并得出了以下结果:
1. Flask(Gunicorn)
```bash
Total: 5.5254 secs
Slowest: 0.0784 secs
Fastest: 0.0028 secs
Average: 0.0275 secs
Requests/sec: 1809.8082
```
1. FastAPI(Uvicorn)
```bash
Total: 4.1314 secs
Slowest: 0.0733 secs
Fastest: 0.0027 secs
Average: 0.0206 secs
Requests/sec: 2420.4851
```
1. Django(Gunicorn)
```bash
Total: 13.5070 secs
Slowest: 0.3635 secs
Fastest: 0.0249 secs
Average: 0.0674 secs
Requests/sec: 740.3558
```
1. Robyn(Doesn't need a \*SGI)
```bash
Total: 1.8324 secs
Slowest: 0.0269 secs
Fastest: 0.0024 secs
Average: 0.0091 secs
Requests/sec: 5457.2339
```
1. Robyn (5 workers)
```bash
Total: 1.5592 secs
Slowest: 0.0211 secs
Fastest: 0.0017 secs
Average: 0.0078 secs
Requests/sec: 6413.6480
```
Robyn 需要 1.8 秒处理 10,000 个请求,其次是 Flask 和 FastAPI,它们大约需要 5 秒(在配备双核处理器的机器上使用 5 个工作进程)。相比之下,Django 大约需要 13.5070 秒。
## 详细日志
Flask(Gunicorn)
```bash
Summary:
Success rate: 1.0000
Total: 5.5254 secs
Slowest: 0.0784 secs
Fastest: 0.0028 secs
Average: 0.0275 secs
Requests/sec: 1809.8082
Total data: 126.95 KiB
Size/request: 13 B
Size/sec: 22.98 KiB
Response time histogram:
0.007 [55] |
0.014 [641] |■■■■■
0.021 [2413] |■■■■■■■■■■■■■■■■■■■■
0.027 [3771] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.034 [1999] |■■■■■■■■■■■■■■■■
0.041 [737] |■■■■■■
0.048 [236] |■■
0.055 [75] |
0.062 [46] |
0.069 [24] |
0.076 [3] |
Latency distribution:
10% in 0.0178 secs
25% in 0.0223 secs
50% in 0.0266 secs
75% in 0.0317 secs
90% in 0.0378 secs
95% in 0.0419 secs
99% in 0.0551 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0071 secs, 0.0001 secs, 0.0443 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0010 secs
Status code distribution:
[200] 10000 responses
```
FastAPI(Uvicorn)
```bash
Summary:
Success rate: 1.0000
Total: 4.1314 secs
Slowest: 0.0733 secs
Fastest: 0.0027 secs
Average: 0.0206 secs
Requests/sec: 2420.4851
Total data: 166.02 KiB
Size/request: 17 B
Size/sec: 40.18 KiB
Response time histogram:
0.005 [175] |■
0.011 [1541] |■■■■■■■■■■■■■■■■
0.016 [2942] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.021 [2770] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.027 [1479] |■■■■■■■■■■■■■■■■
0.032 [608] |■■■■■■
0.038 [217] |■■
0.043 [103] |■
0.048 [53] |
0.054 [54] |
0.059 [58] |
Latency distribution:
10% in 0.0120 secs
25% in 0.0151 secs
50% in 0.0194 secs
75% in 0.0243 secs
90% in 0.0300 secs
95% in 0.0348 secs
99% in 0.0522 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0088 secs, 0.0073 secs, 0.0103 secs
DNS-lookup: 0.0001 secs, 0.0000 secs, 0.0008 secs
Status code distribution:
[200] 10000 responses
```
Robyn
```bash
Summary:
Success rate: 1.0000
Total: 1.8324 secs
Slowest: 0.0269 secs
Fastest: 0.0024 secs
Average: 0.0091 secs
Requests/sec: 5457.2339
Total data: 117.19 KiB
Size/request: 12 B
Size/sec: 63.95 KiB
Response time histogram:
0.002 [183] |■
0.004 [1669] |■■■■■■■■■■■■■■
0.007 [3724] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.009 [2631] |■■■■■■■■■■■■■■■■■■■■■■
0.011 [1060] |■■■■■■■■■
0.013 [496] |■■■■
0.016 [188] |■
0.018 [34] |
0.020 [12] |
0.022 [2] |
0.025 [1] |
Latency distribution:
10% in 0.0061 secs
25% in 0.0073 secs
50% in 0.0087 secs
75% in 0.0105 secs
90% in 0.0129 secs
95% in 0.0143 secs
99% in 0.0171 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0049 secs, 0.0035 secs, 0.0065 secs
DNS-lookup: 0.0001 secs, 0.0000 secs, 0.0010 secs
Status code distribution:
[200] 10000 responses
```
Django(Gunicorn)
```bash
Summary:
Success rate: 1.0000
Total: 13.5070 secs
Slowest: 0.3635 secs
Fastest: 0.0249 secs
Average: 0.0674 secs
Requests/sec: 740.3558
Total data: 102.01 MiB
Size/request: 10.45 KiB
Size/sec: 7.55 MiB
Response time histogram:
0.016 [283] |■
0.032 [2616] |■■■■■■■■■■■■■■■■■■
0.048 [4587] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.064 [1829] |■■■■■■■■■■■■
0.081 [362] |■■
0.097 [98] |
0.113 [105] |
0.129 [20] |
0.145 [7] |
0.161 [28] |
0.177 [65] |
Latency distribution:
10% in 0.0493 secs
25% in 0.0559 secs
50% in 0.0638 secs
75% in 0.0733 secs
90% in 0.0840 secs
95% in 0.0948 secs
99% in 0.1543 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0097 secs, 0.0001 secs, 0.0444 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0007 secs
Status code distribution:
[200] 10000 responses
```
Robyn(with 5 workers)
```bash
Summary:
Success rate: 1.0000
Total: 1.5592 secs
Slowest: 0.0211 secs
Fastest: 0.0017 secs
Average: 0.0078 secs
Requests/sec: 6413.6480
Total data: 126.95 KiB
Size/request: 13 B
Size/sec: 81.42 KiB
Response time histogram:
0.002 [30] |
0.004 [599] |■■■■■
0.005 [3336] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.007 [3309] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.009 [1614] |■■■■■■■■■■■■■■■
0.011 [749] |■■■■■■■
0.012 [253] |■■
0.014 [94] |
0.016 [14] |
0.018 [1] |
0.019 [1] |
Latency distribution:
10% in 0.0055 secs
25% in 0.0063 secs
50% in 0.0074 secs
75% in 0.0089 secs
90% in 0.0107 secs
95% in 0.0117 secs
99% in 0.0142 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0022 secs, 0.0013 secs, 0.0028 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0001 secs
Status code distribution:
[200] 10000 responses
```
================================================
FILE: docs_src/src/pages/documentation/zh/hosting.mdx
================================================
export const description =
'在此页面中,我们将了解如何在不同的云提供商上部署 Robyn。'
在各种云提供商上托管 Robyn 应用程序的服务。
## Railway
这里,我们将在 `Railway` 上部署应用程序。
但是,在部署之前,我们需要一个 GitHub 账户作为必备条件。
我们将部署一个示例的 "Hello World",演示一个简单的 GET 路由并提供一个 HTML 文件。
Directory structure:
```bash
app folder/
main.py
requirements.txt
index.html
```
注意:Railway 会寻找 `main.py` 作为入口点,而不是 `app.py`。如果没有 `main.py` 文件,构建过程将失败。
```python {{ title: 'python' }}
from robyn import Robyn, serve_html
app = Robyn(__file__)
@app.get("/hello")
async def h(request):
print(request)
return "Hello, world!"
@app.get("/")
async def get_page(request):
return serve_html("./index.html")
if __name__ == "__main__":
app.start(url="0.0.0.0", port=PORT)
```
```python {{ title: 'python' }}
Hello World, this is Robyn framework!
```
## 开放端口
Railway 的文档中讲解了如何监听端口:
> 启动应用程序的最简单方法是让应用程序监听 `0.0.0.0:$PORT`,其中 `PORT` 是 Railway 提供的环境变量。
因此,必须将主机设置为 `0.0.0.0`,并将其作为参数传递给 `app.start()`。
我们需要创建一个 Railway 账户来在 Railway 上部署该应用。可以通过访问 `Railway 首页` 来完成。
点击 "登录" 按钮并选择 "使用 GitHub 账户登录"。
接下来,点击 "新项目" 按钮,并选择 "从 GitHub 仓库部署"。
然后选择我们想要部署的仓库,并点击 "立即部署"。
现在,点击我们项目。
选择 "变量" 并点击 "新变量" 按钮设置环境变量。
接着,进入 "设置" 标签页,点击 "生成域名"。
我们可以在 "域名" 标签页下生成一个临时域名。
我们可以访问 `/hello` 来确认 "Hello World" 消息是否正确显示。
## 下一步
- [未来发展路线图](/documentation/zh/api_reference/future-roadmap)
================================================
FILE: docs_src/src/pages/documentation/zh/index.mdx
================================================
import { Guides } from '@/components/documentation/Guides'
import { ApiDocs } from '@/components/documentation/ApiDocs'
import { HeroPattern } from '@/components/documentation/HeroPattern'
export const description =
'欢迎来到 Robyn API 文档。您将找到全面的指南和文档,帮助您尽快开始使用 Robyn,并在遇到困难时获得支持。'
export const sections = [
{ title: '应用示例', id: 'guides' },
{ title: 'API 参考', id: 'api_docs' },
]
# API文档
欢迎来到 Robyn API 文档。您将找到全面的指南和文档,帮助您尽快开始使用 Robyn,并在遇到困难时获得支持。
## 入门指南 {{ anchor: false }}
示例应用是一个简单的 Web 应用程序,展示了如何使用 Robyn API。如果您是 Robyn 的新手,这是一个很好的起点。
API 参考包含了有关 Robyn API 的详细信息。如果您已经熟悉 Robyn 并想了解更多关于 API 的信息,这是一个很好的起点。
)
}
export default function Home({ articles }) {
return (
<>
Robyn - A Fast, Innovator Friendly, and Community Driven Python Web
Framework.
{/*Twitter specific meta tags*/}
{/*LinkedIn specific meta tags*/}
Meet Robyn
A Fast, Innovator Friendly, and Community Driven Python Web
Framework
Robyn merges Python's async capabilities with a Rust runtime
for reliable, scalable web solutions. Experience quick project
scaffolding, enjoyable usage, and robust plugin support.
Our Philosophy
Fast. Innovator Friendly. Robust. Community Driven.
-
Fast.{' '}
-
Robyn, written in Rust, embodies speed and reliability. Our
multithreaded runtime creates a highly efficient and secure
environment optimized for peak performance.
-
Simple API.
-
With Robyn, complexity takes a backseat. Our API is simple yet
potent, built to streamline your development process and
minimize your workload.
-
Hacker Friendly.
-
While many focus on large-scale challenges that many of us might
never encounter, Robyn prioritizes the broader issues most
developers face. We foster innovation for all, ensuring both
common and complex challenges are met with expertise. At Robyn,
every developer feels at home.
-
Community First and Truly FOSS.
-
Rooted in a community-first ethos, Robyn is built with
collective effort and is a true representation of free and
open-source software.
Some of our stats
Robyn is going strong!
-
Robyn installs
{/*
-

*/}
-
3 million
-
Stars on Github
{/*
-

*/}
-
6k+
-
Community Contributors
{/*
-
*/}
-
70+
-
Community Members
-
500+
Ready to Dive In?
Start using Robyn today.
Go through a small tutorial or read the docs to get started.
)
}
================================================
FILE: docs_src/src/pages/releases/index.jsx
================================================
import axios from 'axios'
import { MDXProvider } from '@mdx-js/react'
import { serialize } from 'next-mdx-remote/serialize'
import { MDXRemote } from 'next-mdx-remote'
import {
a as A,
H2,
Article,
} from '@/components/releases/mdx'
import * as releaseMdxComponents from '@/components/releases/mdx'
const ChangelogPage = ({ releases }) => {
return (
<>
{releases.map((release) => (
{release.name}
))}
)
}
export async function getStaticProps() {
const response = await axios.get(
'https://api.github.com/repos/sparckles/robyn/releases'
)
const releases = await Promise.all(
response.data.map(async (release) => ({
id: release.id,
name: release.name,
body: await serialize(release.body),
publishedAt: release.published_at,
tag: release.tag_name,
}))
)
return {
props: {
releases,
},
}
}
export default ChangelogPage
================================================
FILE: docs_src/src/styles/documentation.css
================================================
:root {
--shiki-color-text: theme('colors.white');
--shiki-token-constant: theme('colors.orange.300');
--shiki-token-string: theme('colors.orange.300');
--shiki-token-comment: theme('colors.zinc.500');
--shiki-token-keyword: theme('colors.sky.300');
--shiki-token-parameter: theme('colors.pink.300');
--shiki-token-function: theme('colors.violet.300');
--shiki-token-string-expression: theme('colors.orange.300');
--shiki-token-punctuation: theme('colors.zinc.200');
}
@tailwind base;
@tailwind components;
@tailwind utilities;
================================================
FILE: docs_src/src/styles/prism.css
================================================
pre[class*='language-'] {
color: theme('colors.zinc.100');
}
.token.tag,
.token.class-name,
.token.selector,
.token.selector .class,
.token.selector.class,
.token.function {
color: theme('colors.pink.400');
}
.token.attr-name,
.token.keyword,
.token.rule,
.token.pseudo-class,
.token.important {
color: theme('colors.zinc.300');
}
.token.module {
color: theme('colors.pink.400');
}
.token.attr-value,
.token.class,
.token.string,
.token.property {
color: theme('colors.yellow.300');
}
.token.punctuation,
.token.attr-equals {
color: theme('colors.zinc.500');
}
.token.unit,
.language-css .token.function {
color: theme('colors.sky.200');
}
.token.comment,
.token.operator,
.token.combinator {
color: theme('colors.zinc.400');
}
================================================
FILE: docs_src/src/styles/releases/base.css
================================================
@font-face {
font-family: 'Inter';
font-weight: 100 900;
font-display: block;
font-style: normal;
font-named-instance: 'Regular';
src: url('/fonts/Inter-roman.var.woff2') format('woff2');
}
@font-face {
font-family: 'Inter';
font-weight: 100 900;
font-display: block;
font-style: italic;
font-named-instance: 'Italic';
src: url('/fonts/Inter-italic.var.woff2') format('woff2');
}
@font-face {
font-family: 'Mona Sans';
font-weight: 200 900;
font-display: block;
font-style: normal;
font-stretch: 75% 125%;
src: url('/fonts/Mona-Sans.var.woff2') format('woff2');
}
@tailwind base;
#__next {
flex: auto;
display: flex;
flex-direction: column;
}
================================================
FILE: docs_src/src/styles/releases/components.css
================================================
@import './typography.css';
@tailwind components;
================================================
FILE: docs_src/src/styles/releases/tailwind.css
================================================
@import './base.css';
@import './components.css';
@import './utilities.css';
================================================
FILE: docs_src/src/styles/releases/typography.css
================================================
.typography {
--typography-body: theme(colors.gray.600);
--typography-headings: theme(colors.white);
--typography-quotes: theme(colors.gray.500);
--typography-quotes-border: theme(colors.gray.200);
--typography-links: theme(colors.sky.500);
--typography-link-hover: theme(colors.sky.600);
--typography-link-underline: theme(colors.sky.400 / 0.4);
--typography-link-hover-underline: theme(colors.sky.600 / 0.4);
--typography-pre: theme(colors.gray.300);
--typography-pre-shadow: theme(boxShadow.md);
--typography-bold: theme(colors.gray.900);
--typography-kbd: theme(colors.gray.600);
--typography-kbd-border: theme(colors.gray.200);
--typography-kbd-bg: theme(colors.gray.50);
--typography-code: theme(colors.gray.900);
--typography-hr: theme(colors.gray.900 / 0.05);
--typography-th-borders: theme(colors.gray.900 / 0.2);
--typography-td-borders: theme(colors.gray.900 / 0.05);
--shiki-color-text: theme(colors.white);
--shiki-token-constant: theme(colors.orange.300);
--shiki-token-string: theme(colors.orange.300);
--shiki-token-comment: theme(colors.gray.500);
--shiki-token-keyword: theme(colors.sky.300);
--shiki-token-parameter: theme(colors.pink.300);
--shiki-token-function: theme(colors.violet.300);
--shiki-token-string-expression: theme(colors.orange.300);
--shiki-token-punctuation: theme(colors.gray.200);
.dark & {
--typography-body: theme(colors.gray.300);
--typography-headings: theme(colors.white);
--typography-quotes: theme(colors.gray.400);
--typography-quotes-border: theme(colors.gray.800);
--typography-links: theme(colors.sky.400);
--typography-link-hover: theme(colors.white);
--typography-link-underline: theme(colors.sky.400 / 0.4);
--typography-link-hover-underline: theme(colors.white / 0.4);
--typography-pre: theme(colors.gray.400);
--typography-pre-shadow: inset 0 0 0 1px theme(colors.white / 0.1);
--typography-bold: theme(colors.white);
--typography-kbd: theme(colors.white);
--typography-kbd-border: theme(colors.gray.800);
--typography-kbd-bg: theme(colors.gray.900);
--typography-code: theme(colors.white);
--typography-hr: theme(colors.white / 0.1);
--typography-th-borders: theme(colors.white / 0.1);
--typography-td-borders: theme(colors.white / 0.05);
}
color: var(--typography-body);
font-size: theme(fontSize.sm);
line-height: theme(lineHeight.6);
h2 {
font-family: theme(fontFamily.display);
color: var(--typography-headings);
font-weight: theme(fontWeight.semibold);
font-size: theme(fontSize.xl);
line-height: theme(lineHeight.8);
}
/* Headings */
h3 {
color: var(--typography-headings);
font-family: theme(fontFamily.display);
font-weight: theme(fontWeight.semibold);
font-size: theme(fontSize.base);
line-height: theme(lineHeight.6);
display: flex;
align-items: center;
column-gap: theme(gap.3);
}
h3 > svg {
flex: none;
width: theme(width.4);
height: theme(height.4);
}
h4 {
color: var(--typography-headings);
font-family: theme(fontFamily.display);
font-weight: theme(fontWeight.semibold);
font-size: theme(fontSize.sm);
line-height: theme(lineHeight.6);
}
/* Quotes */
blockquote {
border-left: 3px solid var(--typography-quotes-border);
padding-left: theme(padding.6);
color: var(--typography-quotes);
}
/* Links */
a:not(h2 a) {
font-weight: theme(fontWeight.semibold);
color: var(--typography-links);
text-decoration: underline;
text-decoration-color: var(--typography-link-underline);
text-underline-offset: theme(textUnderlineOffset.2);
transition-property: color, text-decoration-color;
transition-duration: theme(transitionDuration.DEFAULT);
transition-timing-function: theme(transitionTimingFunction.DEFAULT);
&:hover {
color: var(--typography-link-hover);
text-decoration-color: var(--typography-link-hover-underline);
}
}
/* Inline text */
strong {
font-weight: theme(fontWeight.semibold);
}
strong:not(a strong) {
color: var(--typography-bold);
}
kbd {
display: inline-block;
border-radius: theme(borderRadius.DEFAULT);
background-color: var(--typography-kbd-bg);
padding: 0 theme(padding[1.5]);
font-family: theme(fontFamily.mono);
font-size: theme(fontSize.xs);
font-weight: 400;
line-height: theme(lineHeight.5);
color: var(--typography-kbd);
box-shadow: inset 0 0 0 1px var(--typography-kbd-border);
}
code {
font-family: theme(fontFamily.mono);
}
code:not(a code, pre code) {
color: var(--typography-code);
}
code:not(pre code) {
font-size: calc(12 / 14 * 1em);
line-height: theme(lineHeight.none);
font-weight: theme(fontWeight.bold);
&::before {
content: '`';
}
&::after {
content: '`';
}
}
/* Code blocks */
pre {
display: flex;
background-color: theme(colors.gray.900);
border-radius: theme(borderRadius.lg);
overflow-x: auto;
box-shadow: var(--typography-pre-shadow);
}
pre code {
flex: none;
padding: theme(padding.6);
font-size: 0.8125rem;
line-height: theme(lineHeight.6);
color: var(--typography-pre);
}
/*
*/
hr {
border-color: var(--typography-hr);
}
/* Lists */
ul,
ol {
padding-left: 1.375rem;
}
ul {
list-style-type: disc;
}
ol {
list-style-type: decimal;
}
li {
padding-left: 0.625rem;
}
li::marker {
color: theme(colors.gray.400);
}
ol > li::marker {
font-size: theme(fontSize.xs);
font-weight: theme(fontWeight.semibold);
}
/* Tables */
table {
width: theme(width.full);
text-align: left;
}
thead {
border-bottom: 1px solid var(--typography-th-borders);
}
thead th {
font-weight: theme(fontWeight.semibold);
padding-top: 0;
padding-bottom: calc(theme(padding.2) - 1px);
color: var(--typography-headings);
}
tbody tr {
border-bottom: 1px solid var(--typography-td-borders);
}
tbody td {
padding-top: calc(theme(padding.2) - 1px);
padding-bottom: theme(padding.2);
}
:is(th, td):first-child {
padding-left: 0;
padding-right: theme(padding.2);
}
:is(th, td):last-child {
padding-left: theme(padding.2);
padding-right: 0;
}
:is(th, td):not(:first-child, :last-child) {
padding-left: theme(padding.2);
padding-right: theme(padding.2);
}
/* Spacing */
> * {
margin-top: theme(margin.6);
}
:is(h2, h3, h4, blockquote, pre, table) {
margin-top: theme(margin.8);
}
hr {
margin-top: calc(theme(margin.16) - 1px);
}
li {
margin-top: theme(margin.4);
}
li > :is(p, ol, ul) {
margin-top: theme(margin.4);
}
:is(h2, h3, h4) + * {
margin-top: theme(margin.4);
}
:is(blockquote, pre, table) + * {
margin-top: theme(margin.8);
}
hr + * {
margin-top: theme(margin.16);
}
> :first-child,
li > :first-child {
margin-top: 0;
}
}
================================================
FILE: docs_src/src/styles/releases/utilities.css
================================================
@tailwind utilities;
================================================
FILE: docs_src/src/styles/tailwind.css
================================================
@import 'tailwindcss/base';
@import 'tailwindcss/components';
@import './prism.css';
@import 'tailwindcss/utilities';
@import './releases/base.css';
@import './releases/components.css';
@import './releases/utilities.css';
================================================
FILE: docs_src/tailwind.config.js
================================================
const defaultTheme = require('tailwindcss/defaultTheme')
/** @type {import('tailwindcss').Config} */
module.exports = {
content: ['./src/**/*.{js,jsx}'],
darkMode: 'class',
plugins: [require('@tailwindcss/typography')],
theme: {
extend: {
fontFamily: {
sans: ['Inter', ...defaultTheme.fontFamily.sans],
display: ['Mona Sans', ...defaultTheme.fontFamily.sans],
},
},
fontSize: {
xs: ['0.8125rem', { lineHeight: '1.5rem' }],
sm: ['0.875rem', { lineHeight: '1.5rem' }],
base: ['1rem', { lineHeight: '1.75rem' }],
lg: ['1.125rem', { lineHeight: '1.75rem' }],
xl: ['1.25rem', { lineHeight: '2rem' }],
'2xl': ['1.5rem', { lineHeight: '2rem' }],
'3xl': ['1.875rem', { lineHeight: '2.25rem' }],
'4xl': ['2rem', { lineHeight: '2.5rem' }],
'5xl': ['3rem', { lineHeight: '3.5rem' }],
'6xl': ['3.75rem', { lineHeight: '1' }],
'7xl': ['4.5rem', { lineHeight: '1' }],
'8xl': ['6rem', { lineHeight: '1' }],
'9xl': ['8rem', { lineHeight: '1' }],
},
typography: (theme) => ({
invert: {
css: {
'--tw-prose-body': 'var(--tw-prose-invert-body)',
'--tw-prose-headings': 'var(--tw-prose-invert-headings)',
'--tw-prose-links': 'var(--tw-prose-invert-links)',
'--tw-prose-links-hover': 'var(--tw-prose-invert-links-hover)',
'--tw-prose-underline': 'var(--tw-prose-invert-underline)',
'--tw-prose-underline-hover':
'var(--tw-prose-invert-underline-hover)',
'--tw-prose-bold': 'var(--tw-prose-invert-bold)',
'--tw-prose-counters': 'var(--tw-prose-invert-counters)',
'--tw-prose-bullets': 'var(--tw-prose-invert-bullets)',
'--tw-prose-hr': 'var(--tw-prose-invert-hr)',
'--tw-prose-quote-borders': 'var(--tw-prose-invert-quote-borders)',
'--tw-prose-captions': 'var(--tw-prose-invert-captions)',
'--tw-prose-code': 'var(--tw-prose-invert-code)',
'--tw-prose-code-bg': 'var(--tw-prose-invert-code-bg)',
'--tw-prose-pre-code': 'var(--tw-prose-invert-pre-code)',
'--tw-prose-pre-bg': 'var(--tw-prose-invert-pre-bg)',
'--tw-prose-pre-border': 'var(--tw-prose-invert-pre-border)',
'--tw-prose-th-borders': 'var(--tw-prose-invert-th-borders)',
'--tw-prose-td-borders': 'var(--tw-prose-invert-td-borders)',
},
},
DEFAULT: {
css: {
'--tw-prose-body': theme('colors.zinc.600'),
'--tw-prose-headings': theme('colors.zinc.900'),
'--tw-prose-links': theme('colors.yellow.500'),
'--tw-prose-links-hover': theme('colors.yellow.600'),
'--tw-prose-underline': theme('colors.yellow.500 / 0.2'),
'--tw-prose-underline-hover': theme('colors.yellow.500'),
'--tw-prose-bold': theme('colors.zinc.900'),
'--tw-prose-counters': theme('colors.zinc.900'),
'--tw-prose-bullets': theme('colors.zinc.900'),
'--tw-prose-hr': theme('colors.zinc.100'),
'--tw-prose-quote-borders': theme('colors.zinc.200'),
'--tw-prose-captions': theme('colors.zinc.400'),
'--tw-prose-code': theme('colors.zinc.700'),
'--tw-prose-code-bg': theme('colors.zinc.300 / 0.2'),
'--tw-prose-pre-code': theme('colors.zinc.100'),
'--tw-prose-pre-bg': theme('colors.zinc.900'),
'--tw-prose-pre-border': 'transparent',
'--tw-prose-th-borders': theme('colors.zinc.200'),
'--tw-prose-td-borders': theme('colors.zinc.100'),
'--tw-prose-invert-body': theme('colors.zinc.400'),
'--tw-prose-invert-headings': theme('colors.zinc.200'),
'--tw-prose-invert-links': theme('colors.yellow.400'),
'--tw-prose-invert-links-hover': theme('colors.yellow.400'),
'--tw-prose-invert-underline': theme('colors.yellow.400 / 0.3'),
'--tw-prose-invert-underline-hover': theme('colors.yellow.400'),
'--tw-prose-invert-bold': theme('colors.zinc.200'),
'--tw-prose-invert-counters': theme('colors.zinc.200'),
'--tw-prose-invert-bullets': theme('colors.zinc.200'),
'--tw-prose-invert-hr': theme('colors.zinc.700 / 0.4'),
'--tw-prose-invert-quote-borders': theme('colors.zinc.500'),
'--tw-prose-invert-captions': theme('colors.zinc.500'),
'--tw-prose-invert-code': theme('colors.zinc.300'),
'--tw-prose-invert-code-bg': theme('colors.zinc.200 / 0.05'),
'--tw-prose-invert-pre-code': theme('colors.zinc.100'),
'--tw-prose-invert-pre-bg': 'rgb(0 0 0 / 0.4)',
'--tw-prose-invert-pre-border': theme('colors.zinc.200 / 0.1'),
'--tw-prose-invert-th-borders': theme('colors.zinc.700'),
'--tw-prose-invert-td-borders': theme('colors.zinc.800'),
// Base
color: 'var(--tw-prose-body)',
lineHeight: theme('lineHeight.7'),
'> *': {
marginTop: theme('spacing.10'),
marginBottom: theme('spacing.10'),
},
p: {
marginTop: theme('spacing.7'),
marginBottom: theme('spacing.7'),
},
// Headings
'h2, h3': {
color: 'var(--tw-prose-headings)',
fontWeight: theme('fontWeight.semibold'),
},
h2: {
fontSize: theme('fontSize.xl')[0],
lineHeight: theme('lineHeight.7'),
marginTop: theme('spacing.20'),
marginBottom: theme('spacing.4'),
},
h3: {
fontSize: theme('fontSize.base')[0],
lineHeight: theme('lineHeight.7'),
marginTop: theme('spacing.16'),
marginBottom: theme('spacing.4'),
},
':is(h2, h3) + *': {
marginTop: 0,
},
// Images
img: {
borderRadius: theme('borderRadius.3xl'),
},
// Inline elements
a: {
color: 'var(--tw-prose-links)',
fontWeight: theme('fontWeight.semibold'),
textDecoration: 'underline',
textDecorationColor: 'var(--tw-prose-underline)',
transitionProperty: 'color, text-decoration-color',
transitionDuration: theme('transitionDuration.150'),
transitionTimingFunction: theme('transitionTimingFunction.in-out'),
},
'a:hover': {
color: 'var(--tw-prose-links-hover)',
textDecorationColor: 'var(--tw-prose-underline-hover)',
},
strong: {
color: 'var(--tw-prose-bold)',
fontWeight: theme('fontWeight.semibold'),
},
code: {
display: 'inline-block',
color: 'var(--tw-prose-code)',
fontSize: theme('fontSize.sm')[0],
fontWeight: theme('fontWeight.semibold'),
backgroundColor: 'var(--tw-prose-code-bg)',
borderRadius: theme('borderRadius.lg'),
paddingLeft: theme('spacing.1'),
paddingRight: theme('spacing.1'),
},
'a code': {
color: 'inherit',
},
':is(h2, h3) code': {
fontWeight: theme('fontWeight.bold'),
},
// Quotes
blockquote: {
paddingLeft: theme('spacing.6'),
borderLeftWidth: theme('borderWidth.2'),
borderLeftColor: 'var(--tw-prose-quote-borders)',
fontStyle: 'italic',
},
// Figures
figcaption: {
color: 'var(--tw-prose-captions)',
fontSize: theme('fontSize.sm')[0],
lineHeight: theme('lineHeight.6'),
marginTop: theme('spacing.3'),
},
'figcaption > p': {
margin: 0,
},
// Lists
ul: {
listStyleType: 'disc',
},
ol: {
listStyleType: 'decimal',
},
'ul, ol': {
paddingLeft: theme('spacing.6'),
},
li: {
marginTop: theme('spacing.6'),
marginBottom: theme('spacing.6'),
paddingLeft: theme('spacing[3.5]'),
},
'li::marker': {
fontSize: theme('fontSize.sm')[0],
fontWeight: theme('fontWeight.semibold'),
},
'ol > li::marker': {
color: 'var(--tw-prose-counters)',
},
'ul > li::marker': {
color: 'var(--tw-prose-bullets)',
},
'li :is(ol, ul)': {
marginTop: theme('spacing.4'),
marginBottom: theme('spacing.4'),
},
'li :is(li, p)': {
marginTop: theme('spacing.3'),
marginBottom: theme('spacing.3'),
},
// Code blocks
pre: {
color: 'var(--tw-prose-pre-code)',
fontSize: theme('fontSize.sm')[0],
fontWeight: theme('fontWeight.medium'),
backgroundColor: 'var(--tw-prose-pre-bg)',
borderRadius: theme('borderRadius.3xl'),
padding: theme('spacing.8'),
overflowX: 'auto',
border: '1px solid',
borderColor: 'var(--tw-prose-pre-border)',
},
'pre code': {
display: 'inline',
color: 'inherit',
fontSize: 'inherit',
fontWeight: 'inherit',
backgroundColor: 'transparent',
borderRadius: 0,
padding: 0,
},
// Horizontal rules
hr: {
marginTop: theme('spacing.20'),
marginBottom: theme('spacing.20'),
borderTopWidth: '1px',
borderColor: 'var(--tw-prose-hr)',
'@screen lg': {
marginLeft: `calc(${theme('spacing.12')} * -1)`,
marginRight: `calc(${theme('spacing.12')} * -1)`,
},
},
// Tables
table: {
width: '100%',
tableLayout: 'auto',
textAlign: 'left',
fontSize: theme('fontSize.sm')[0],
},
thead: {
borderBottomWidth: '1px',
borderBottomColor: 'var(--tw-prose-th-borders)',
},
'thead th': {
color: 'var(--tw-prose-headings)',
fontWeight: theme('fontWeight.semibold'),
verticalAlign: 'bottom',
paddingBottom: theme('spacing.2'),
},
'thead th:not(:first-child)': {
paddingLeft: theme('spacing.2'),
},
'thead th:not(:last-child)': {
paddingRight: theme('spacing.2'),
},
'tbody tr': {
borderBottomWidth: '1px',
borderBottomColor: 'var(--tw-prose-td-borders)',
},
'tbody tr:last-child': {
borderBottomWidth: 0,
},
'tbody td': {
verticalAlign: 'baseline',
},
tfoot: {
borderTopWidth: '1px',
borderTopColor: 'var(--tw-prose-th-borders)',
},
'tfoot td': {
verticalAlign: 'top',
},
':is(tbody, tfoot) td': {
paddingTop: theme('spacing.2'),
paddingBottom: theme('spacing.2'),
},
':is(tbody, tfoot) td:not(:first-child)': {
paddingLeft: theme('spacing.2'),
},
':is(tbody, tfoot) td:not(:last-child)': {
paddingRight: theme('spacing.2'),
},
},
},
}),
},
}
================================================
FILE: examples/agents.py
================================================
#!/usr/bin/env python3
"""Simple Robyn AI Agents Example"""
import os
from robyn import Robyn
from robyn.ai import agent, configure, memory
app = Robyn(__file__)
ai_agent = None
@app.startup_handler
async def startup():
global ai_agent
if not os.getenv("OPENAI_API_KEY"):
print("Set OPENAI_API_KEY to use AI features")
return
user_memory = memory(provider="inmemory", user_id="user")
config = configure(openai_api_key=os.getenv("OPENAI_API_KEY"))
ai_agent = agent(memory=user_memory, config=config)
@app.post("/chat")
async def chat(request):
if not ai_agent:
return {"error": "AI not available"}
query = request.json().get("query")
if not query:
return {"error": "Query required"}
result = await ai_agent.run(query)
return {"response": result.get("response")}
@app.get("/")
def home():
return {"message": "Robyn AI Agent", "endpoint": "/chat"}
if __name__ == "__main__":
app.start(port=8080)
================================================
FILE: examples/mcp.py
================================================
#!/usr/bin/env python3
"""
Robyn MCP Server Example
Simple MCP server demonstrating basic resources and tools.
Run with: python examples/mcp.py
"""
import json
import platform
from datetime import datetime
from robyn import Robyn
app = Robyn(__file__)
# MCP Resources
@app.mcp.resource("time://current")
def current_time() -> str:
return f"Current time: {datetime.now().isoformat()}"
@app.mcp.resource("system://info")
def system_info() -> str:
return json.dumps({"platform": platform.system(), "python_version": platform.python_version(), "timestamp": datetime.now().isoformat()})
# MCP Tools
@app.mcp.tool(
name="calculate",
description="Perform safe mathematical calculations",
input_schema={
"type": "object",
"properties": {"expression": {"type": "string", "description": "Math expression like '2 + 2'"}},
"required": ["expression"],
},
)
def calculate_tool(args):
expression = args.get("expression", "")
allowed_chars = set("0123456789+-*/.() ")
if not all(c in allowed_chars for c in expression):
return "Error: Invalid characters in expression"
try:
result = eval(expression, {"__builtins__": {}}, {})
return f"{expression} = {result}"
except Exception as e:
return f"Error: {str(e)}"
@app.mcp.tool(
name="echo",
description="Echo back text",
input_schema={"type": "object", "properties": {"text": {"type": "string", "description": "Text to echo"}}, "required": ["text"]},
)
def echo_tool(args):
return args.get("text", "")
# MCP Prompts
@app.mcp.prompt(
name="explain_code",
description="Generate code explanation prompt",
arguments=[
{"name": "code", "description": "Code to explain", "required": True},
{"name": "language", "description": "Programming language", "required": False},
],
)
def explain_code_prompt(args):
code = args.get("code", "")
language = args.get("language", "unknown")
return f"""Please explain this {language} code:
```{language}
{code}
```
Include:
1. What it does
2. How it works
3. Key concepts used
"""
@app.get("/")
def home():
return {
"name": "Robyn MCP Server Example",
"mcp_endpoint": "/mcp",
"resources": ["time://current", "system://info"],
"tools": ["calculate", "echo"],
"prompts": ["explain_code"],
}
if __name__ == "__main__":
print("Robyn MCP Server Example")
print("Server: http://localhost:8080")
print("MCP Endpoint: http://localhost:8080/mcp")
app.start(port=8080)
================================================
FILE: examples/sse_example.py
================================================
"""
Server-Sent Events (SSE) Example for Robyn
This example demonstrates how to implement Server-Sent Events using Robyn,
similar to FastAPI's implementation. SSE allows real-time server-to-client
communication over a single HTTP connection.
"""
import asyncio
import time
from robyn import Robyn, SSEMessage, SSEResponse, html
app = Robyn(__file__)
@app.get("/")
def index(request):
"""Serve a simple HTML page to test SSE"""
return html("""
Robyn SSE Example
Robyn Server-Sent Events Demo
""")
@app.get("/events")
def stream_events(request):
"""Basic SSE endpoint that sends a message every second"""
def event_generator():
"""Generator function that yields SSE-formatted messages"""
for i in range(10):
yield SSEMessage(f"Message {i} - {time.strftime('%H:%M:%S')}", id=str(i))
time.sleep(1)
# Send a final message
yield SSEMessage("Stream ended", event="end")
return SSEResponse(event_generator())
@app.get("/events/json")
def stream_json_events(request):
"""SSE endpoint that sends JSON data"""
import json
def json_event_generator():
"""Generator that yields JSON data as SSE"""
for i in range(5):
data = {"id": i, "message": f"JSON message {i}", "timestamp": time.time(), "type": "notification"}
yield SSEMessage(json.dumps(data), event="notification", id=str(i))
time.sleep(2)
return SSEResponse(json_event_generator())
@app.get("/events/named")
def stream_named_events(request):
"""SSE endpoint with named events"""
def named_event_generator():
"""Generator that yields named SSE events"""
events = [
("user_joined", "Alice joined the chat"),
("message", "Hello everyone!"),
("user_left", "Bob left the chat"),
("message", "How is everyone doing?"),
("user_joined", "Charlie joined the chat"),
]
for i, (event_type, message) in enumerate(events):
yield SSEMessage(message, event=event_type, id=str(i))
time.sleep(1.5)
return SSEResponse(named_event_generator())
@app.get("/events/async")
async def stream_async_events(request):
"""Async SSE endpoint demonstrating async generators"""
async def async_event_generator():
"""Async generator for SSE events"""
for i in range(8):
# Simulate async work
await asyncio.sleep(0.5)
yield SSEMessage(f"Async message {i} - {time.strftime('%H:%M:%S')}", event="async", id=str(i))
return SSEResponse(async_event_generator())
@app.get("/events/heartbeat")
def stream_heartbeat(request):
"""SSE endpoint that sends heartbeat messages"""
def heartbeat_generator():
"""Generator that sends heartbeat pings"""
counter = 0
while counter < 20: # Send 20 heartbeats
yield SSEMessage(f"heartbeat {counter}", event="heartbeat", id=str(counter))
counter += 1
time.sleep(0.5)
yield SSEMessage("heartbeat ended", event="end")
return SSEResponse(heartbeat_generator())
@app.get("/help")
def help_page(request):
"""Help page explaining available endpoints"""
return html("""
Robyn SSE Help
Robyn SSE Example Endpoints
GET /
Main demo page with a live SSE client
GET /events
Basic SSE stream with 10 messages sent every second
GET /events/json
SSE stream sending JSON data every 2 seconds
GET /events/named
SSE stream with named events (user_joined, message, user_left)
GET /events/async
Async SSE stream demonstrating async generators
GET /events/heartbeat
Fast heartbeat stream sending messages every 0.5 seconds
Usage: Use curl, browser EventSource API, or any SSE client to connect to these endpoints.
Example with curl:
curl http://localhost:8080/events
Example with JavaScript:
const eventSource = new EventSource('/events');
eventSource.onmessage = function(event) {
console.log('Received:', event.data);
};
""")
if __name__ == "__main__":
print("Starting Robyn SSE Example Server...")
print("Visit http://localhost:8080/ for the main demo")
print("Visit http://localhost:8080/help for endpoint documentation")
app.start(host="0.0.0.0", port=8080)
================================================
FILE: integration_tests/__init__.py
================================================
================================================
FILE: integration_tests/base_routes.py
================================================
import asyncio
import json
import os
import pathlib
import time
from collections import defaultdict
from typing import List, Optional, TypedDict
from integration_tests.subroutes import di_subrouter, static_router, sub_router
from robyn import Headers, Request, Response, Robyn, SSEMessage, SSEResponse, WebSocketDisconnect, jsonify, serve_file, serve_html
from robyn.authentication import AuthenticationHandler, BearerGetter, Identity
from robyn.robyn import QueryParams, Url
from robyn.templating import JinjaTemplate
from robyn.types import Body, JsonBody, JSONResponse, Method, PathParams
try:
from pydantic import BaseModel as PydanticBaseModel
_HAS_PYDANTIC = True
except ImportError:
_HAS_PYDANTIC = False
app = Robyn(__file__)
current_file_path = pathlib.Path(__file__).parent.resolve()
jinja_template = JinjaTemplate(os.path.join(current_file_path, "templates"))
# ===== Websockets =====
# Make it easier for multiple test runs
websocket_state = defaultdict(int)
# --- Regular WebSocket endpoint (new-style with Rust channels) ---
@app.websocket("/web_socket")
async def websocket_endpoint(websocket):
try:
while True:
_ = await websocket.receive_text()
websocket_id = websocket.id
global websocket_state
state = websocket_state[websocket_id]
if state == 0:
await websocket.broadcast("This is a broadcast message")
await websocket.send_text("This is a message to self")
await websocket.send_text("Whaaat??")
elif state == 1:
await websocket.send_text("Whooo??")
elif state == 2:
await websocket.broadcast(websocket.query_params.get("one", ""))
await websocket.send_text(websocket.query_params.get("two", ""))
await websocket.send_text("*chika* *chika* Slim Shady.")
elif state == 3:
await websocket.send_text("Connection closed")
await websocket.close()
break
websocket_state[websocket_id] = (state + 1) % 4
except WebSocketDisconnect:
pass
@websocket_endpoint.on_connect
def websocket_on_connect(websocket):
return "Hello world, from ws"
@websocket_endpoint.on_close
def websocket_on_close(websocket):
return "GoodBye world, from ws"
# --- JSON WebSocket endpoint ---
@app.websocket("/web_socket_json")
async def json_websocket_endpoint(websocket):
try:
while True:
msg = await websocket.receive_text()
websocket_id = websocket.id
response = {"ws_id": websocket_id, "resp": "", "msg": msg}
global websocket_state
state = websocket_state[websocket_id]
if state == 0:
response["resp"] = "Whaaat??"
elif state == 1:
response["resp"] = "Whooo??"
elif state == 2:
response["resp"] = "*chika* *chika* Slim Shady."
websocket_state[websocket_id] = (state + 1) % 3
await websocket.send_json(response)
except WebSocketDisconnect:
pass
@json_websocket_endpoint.on_connect
def json_websocket_on_connect(websocket):
return "Hello world, from ws"
@json_websocket_endpoint.on_close
def json_websocket_on_close(websocket):
return "GoodBye world, from ws"
# --- WebSocket with dependency injection ---
@app.websocket("/web_socket_di")
async def di_websocket_endpoint(websocket, global_dependencies=None, router_dependencies=None):
try:
while True:
_ = await websocket.receive_text()
global_dep = global_dependencies.get("GLOBAL_DEPENDENCY", "MISSING GLOBAL") if global_dependencies else "MISSING GLOBAL"
router_dep = router_dependencies.get("ROUTER_DEPENDENCY", "MISSING ROUTER") if router_dependencies else "MISSING ROUTER"
await websocket.send_text(f"handler: {global_dep} {router_dep}")
except WebSocketDisconnect:
pass
@di_websocket_endpoint.on_connect
async def di_websocket_on_connect(websocket, global_dependencies=None, router_dependencies=None):
global_dep = global_dependencies.get("GLOBAL_DEPENDENCY") if global_dependencies else "MISSING GLOBAL"
router_dep = router_dependencies.get("ROUTER_DEPENDENCY") if router_dependencies else "MISSING ROUTER"
return f"connect: {global_dep} {router_dep}"
@di_websocket_endpoint.on_close
async def di_websocket_on_close(websocket, global_dependencies=None):
global_dep = global_dependencies.get("GLOBAL_DEPENDENCY") if global_dependencies else "MISSING GLOBAL"
return f"close: {global_dep}"
# --- WebSocket echo endpoint for large payload testing (#1269) ---
@app.websocket("/web_socket_echo")
async def echo_websocket_endpoint(websocket):
try:
while True:
msg = await websocket.receive_text()
await websocket.send_text(msg)
except WebSocketDisconnect:
pass
@echo_websocket_endpoint.on_connect
def echo_websocket_on_connect(websocket):
return ""
@echo_websocket_endpoint.on_close
def echo_websocket_on_close(websocket):
return ""
# --- WebSocket with empty returns ---
@app.websocket("/web_socket_empty_returns")
async def empty_websocket_endpoint(websocket):
try:
while True:
await websocket.receive_text()
# No response sent
except WebSocketDisconnect:
pass
@empty_websocket_endpoint.on_connect
async def empty_websocket_on_connect(websocket):
"""Test async handler with no return"""
pass
@empty_websocket_endpoint.on_close
async def empty_websocket_on_close(websocket):
"""Test async handler with explicit None return"""
return None
# ===== Lifecycle handlers =====
async def startup_handler():
print("Starting up")
@app.shutdown_handler
def shutdown_handler():
print("Shutting down")
# ===== Middlewares =====
# --- Global ---
@app.before_request()
def global_before_request(request: Request):
request.headers.set("global_before", "global_before_request")
return request
@app.after_request()
def global_after_request(response: Response):
response.headers.set("global_after", "global_after_request")
return response
@app.get("/sync/global/middlewares")
def sync_global_middlewares(request: Request):
print(request.headers)
print(request.headers.get("txt"))
print(request.headers["txt"])
assert "global_before" in request.headers
assert request.headers.get("global_before") == "global_before_request"
return "sync global middlewares"
# --- Route specific ---
@app.before_request("/sync/middlewares")
def sync_before_request(request: Request):
request.headers.set("before", "sync_before_request")
return request
@app.after_request("/sync/middlewares")
def sync_after_request(response: Response):
response.headers.set("after", "sync_after_request")
response.description = response.description + " after"
return response
@app.get("/sync/middlewares")
def sync_middlewares(request: Request):
assert "before" in request.headers
assert request.headers.get("before") == "sync_before_request"
assert request.ip_addr == "127.0.0.1"
return "sync middlewares"
@app.before_request("/async/middlewares")
async def async_before_request(request: Request):
request.headers.set("before", "async_before_request")
return request
@app.after_request("/async/middlewares")
async def async_after_request(response: Response):
response.headers.set("after", "async_after_request")
response.description = response.description + " after"
return response
@app.get("/async/middlewares")
async def async_middlewares(request: Request):
assert "before" in request.headers
assert request.headers.get("before") == "async_before_request"
assert request.ip_addr == "127.0.0.1"
return "async middlewares"
@app.before_request("/sync/middlewares/401")
def sync_before_request_401():
return Response(401, Headers({}), "sync before request 401")
@app.get("/sync/middlewares/401")
def sync_middlewares_401():
pass
# ===== Routes =====
# --- GET ---
# Hello world
app.inject(RouterDependency="Router Dependency")
@app.get("/", openapi_name="Index")
async def hello_world(r):
"""
Get hello world
"""
return "Hello, world!"
@app.get("/trailing")
def trailing_slash(request):
return "Trailing slash test successful!"
@app.get("/sync/str")
def sync_str_get():
return "sync str get"
@app.get("/async/str")
async def async_str_get():
return "async str get"
@app.get("/sync/str/const", const=True)
def sync_str_const_get():
return "sync str const get"
@app.get("/async/str/const", const=True)
async def async_str_const_get():
return "async str const get"
# dict
@app.get("/sync/dict")
def sync_dict_get():
return Response(
status_code=200,
description="sync dict get",
headers={"sync": "dict"},
)
@app.get("/async/dict")
async def async_dict_get():
return Response(
status_code=200,
description="async dict get",
headers={"async": "dict"},
)
@app.get("/sync/dict/const", const=True)
def sync_dict_const_get():
return Response(
status_code=200,
description="sync dict const get",
headers={"sync_const": "dict"},
)
@app.get("/async/dict/const", const=True)
async def async_dict_const_get():
return Response(
status_code=200,
description="async dict const get",
headers={"async_const": "dict"},
)
# Response
@app.get("/sync/response")
def sync_response_get():
return Response(200, Headers({"sync": "response"}), "sync response get")
@app.get("/async/response")
async def async_response_get():
return Response(200, Headers({"async": "response"}), "async response get")
@app.get("/sync/response/const", const=True)
def sync_response_const_get():
return Response(200, Headers({"sync_const": "response"}), "sync response const get")
@app.get("/async/response/const", const=True)
async def async_response_const_get():
return Response(200, Headers({"async_const": "response"}), "async response const get")
# Binary
@app.get("/sync/octet")
def sync_octet_get():
return b"sync octet"
@app.get("/async/octet")
async def async_octet_get():
return b"async octet"
@app.get("/sync/octet/response")
def sync_octet_response_get():
return Response(
status_code=200,
headers=Headers({"Content-Type": "application/octet-stream"}),
description="sync octet response",
)
@app.get("/async/octet/response")
async def async_octet_response_get():
return Response(
status_code=200,
headers=Headers({"Content-Type": "application/octet-stream"}),
description="async octet response",
)
# JSON
@app.get("/sync/json")
def sync_json_get():
return jsonify({"sync json get": "json"})
@app.get("/async/json")
async def async_json_get():
return jsonify({"async json get": "json"})
# JSON List (auto-serialized without explicit jsonify)
@app.get("/sync/json/list")
def sync_json_list_get():
return [
{"id": 1, "title": "First Post", "published": True},
{"id": 2, "title": "Draft Post", "published": False},
{"id": 3, "title": "Latest Post", "published": True},
]
@app.get("/async/json/list")
async def async_json_list_get():
return [
{"id": 1, "title": "First Post", "published": True},
{"id": 2, "title": "Draft Post", "published": False},
{"id": 3, "title": "Latest Post", "published": True},
]
@app.get("/sync/json/list/empty")
def sync_json_list_empty_get():
return []
@app.get("/async/json/list/empty")
async def async_json_list_empty_get():
return []
@app.get("/sync/json/list/primitives")
def sync_json_list_primitives_get():
return [1, 2, 3, "four", True, None]
@app.get("/async/json/list/primitives")
async def async_json_list_primitives_get():
return [1, 2, 3, "four", True, None]
# JSON Dict (auto-serialized without explicit jsonify)
@app.get("/sync/json/dict")
def sync_json_dict_get():
return {"message": "sync dict", "count": 42, "active": True}
@app.get("/async/json/dict")
async def async_json_dict_get():
return {"message": "async dict", "count": 42, "active": True}
@app.get("/sync/json/const", const=True)
def sync_json_const_get():
return jsonify({"sync json const get": "json"})
@app.get("/async/json/const", const=True)
async def async_json_const_get():
return jsonify({"async json const get": "json"})
# Param
@app.get("/sync/param/:id")
def sync_param(request: Request):
id = request.path_params["id"]
return id
@app.get("/async/param/:id")
async def async_param(request: Request):
id = request.path_params["id"]
return id
@app.get("/sync/extra/*extra")
def sync_param_extra(request: Request):
extra = request.path_params["extra"]
return extra
@app.get("/async/extra/*extra")
async def async_param_extra(request: Request):
extra = request.path_params["extra"]
return extra
# Request Info
@app.get("/sync/http/param")
def sync_http_param(request: Request):
return jsonify(
{
"url": {
"scheme": request.url.scheme,
"host": request.url.host,
"path": request.url.path,
},
"method": request.method,
}
)
@app.get("/async/http/param")
async def async_http_param(request: Request):
return jsonify(
{
"url": {
"scheme": request.url.scheme,
"host": request.url.host,
"path": request.url.path,
},
"method": request.method,
}
)
# HTML serving
@app.get("/sync/serve/html")
def sync_serve_html():
html_file = os.path.join(current_file_path, "index.html")
return serve_html(html_file)
@app.get("/async/serve/html")
async def async_serve_html():
html_file = os.path.join(current_file_path, "index.html")
return serve_html(html_file)
# Template
@app.get("/sync/template")
def sync_template_render():
context = {"framework": "Robyn", "templating_engine": "Jinja2"}
template = jinja_template.render_template(template_name="test.html", **context)
return template
@app.get("/async/template")
async def async_template_render():
context = {"framework": "Robyn", "templating_engine": "Jinja2"}
template = jinja_template.render_template(template_name="test.html", **context)
return template
# File download
@app.get("/sync/file/download")
def sync_file_download():
file_path = os.path.join(current_file_path, "downloads", "test.txt")
return serve_file(file_path)
@app.get("/async/file/download")
async def file_download_async():
file_path = os.path.join(current_file_path, "downloads", "test.txt")
return serve_file(file_path)
# Multipart file
@app.post("/sync/multipart-file")
def sync_multipart_file(request: Request):
files = request.files
file_names = files.keys()
return {"file_names": list(file_names)}
# Queries
@app.get("/sync/queries")
def sync_queries(request: Request):
query_data = request.query_params.to_dict()
return jsonify(query_data)
@app.get("/async/queries")
async def async_query(request: Request):
query_data = request.query_params.to_dict()
return jsonify(query_data)
# Status code
@app.get("/404")
def return_404():
return Response(status_code=404, description="not found", headers={"Content-Type": "text"})
@app.get("/202")
def return_202():
return Response(status_code=202, description="hello", headers={"Content-Type": "text"})
@app.get("/307")
async def redirect():
return Response(
status_code=307,
description="",
headers={"Location": "redirect_route"},
)
@app.get("/redirect_route")
async def redirect_route():
return "This is the redirected route"
@app.get("/sync/raise")
def sync_raise():
raise Exception()
@app.get("/async/raise")
async def async_raise():
raise Exception()
# cookie
@app.get("/cookie")
def cookie():
response = Response(status_code=200, headers=Headers({}), description="test cookies")
response.set_cookie(key="fakesession", value="fake-cookie-session-value")
return response
@app.get("/cookie/multiple")
def multiple_cookies():
response = Response(status_code=200, headers=Headers({}), description="test multiple cookies")
response.set_cookie(key="session", value="abc123")
response.set_cookie(key="theme", value="dark")
return response
@app.get("/cookie/attributes")
def cookie_with_attributes():
response = Response(status_code=200, headers=Headers({}), description="test cookie attributes")
response.set_cookie(
key="secure_session",
value="secret123",
path="/",
http_only=True,
secure=True,
same_site="Strict",
max_age=3600,
)
return response
@app.get("/cookie/overwrite")
def cookie_overwrite():
response = Response(status_code=200, headers=Headers({}), description="test cookie overwrite")
response.set_cookie(key="session", value="first-value")
response.set_cookie(key="session", value="final-value") # Should overwrite
return response
# --- POST ---
# dict
@app.post("/sync/dict")
def sync_dict_post():
return Response(
status_code=200,
description="sync dict post",
headers={"sync": "dict"},
)
@app.post("/async/dict")
async def async_dict_post():
return Response(
status_code=200,
description="async dict post",
headers={"async": "dict"},
)
# Body
@app.post("/sync/body")
def sync_body_post(request: Request):
return request.body
@app.post("/async/body")
async def async_body_post(request: Request):
return request.body
@app.post("/sync/form_data")
def sync_form_data(request: Request):
return request.headers["Content-Type"]
# JSON Request
@app.post("/sync/request_json")
def sync_json_post(request: Request):
try:
return type(request.json())
except ValueError:
return None
@app.post("/async/request_json")
async def async_json_post(request: Request):
try:
return type(request.json())
except ValueError:
return None
@app.post("/sync/request_json/key")
async def request_json(request: Request):
json = request.json()
return json["key"]
# JSON type preservation test
@app.post("/sync/request_json/types")
def sync_json_types(request: Request):
"""Returns the JSON data with Python type names for verification"""
data = request.json()
result = {}
for key, value in data.items():
result[key] = {
"value": value,
"type": type(value).__name__,
}
return result
@app.post("/async/request_json/types")
async def async_json_types(request: Request):
"""Returns the JSON data with Python type names for verification"""
data = request.json()
result = {}
for key, value in data.items():
result[key] = {
"value": value,
"type": type(value).__name__,
}
return result
# JSON top-level array test (Issue #1145)
@app.post("/sync/request_json/array")
def sync_json_array(request: Request):
"""Returns the parsed JSON when the body is a top-level array"""
data = request.json()
return {"parsed": data, "type": type(data).__name__}
@app.post("/async/request_json/array")
async def async_json_array(request: Request):
"""Returns the parsed JSON when the body is a top-level array"""
data = request.json()
return {"parsed": data, "type": type(data).__name__}
# --- PUT ---
# dict
@app.put("/sync/dict")
def sync_dict_put():
return Response(
status_code=200,
description="sync dict put",
headers={"sync": "dict"},
)
@app.put("/async/dict")
async def async_dict_put():
return Response(
status_code=200,
description="async dict put",
headers={"async": "dict"},
)
# Body
@app.put("/sync/body")
def sync_body_put(request: Request):
return request.body
@app.put("/async/body")
async def async_body_put(request: Request):
return request.body
# --- DELETE ---
# dict
@app.delete("/sync/dict")
def sync_dict_delete():
return Response(
status_code=200,
description="sync dict delete",
headers={"sync": "dict"},
)
@app.delete("/async/dict")
async def async_dict_delete():
return Response(
status_code=200,
description="async dict delete",
headers={"async": "dict"},
)
# Body
@app.delete("/sync/body")
def sync_body_delete(request: Request):
print(request.body)
return request.body
@app.delete("/async/body")
async def async_body_delete(request: Request):
return request.body
# --- PATCH ---
# dict
@app.patch("/sync/dict")
def sync_dict_patch():
return Response(
status_code=200,
description="sync dict patch",
headers={"sync": "dict"},
)
@app.patch("/async/dict")
async def async_dict_patch():
return Response(
status_code=200,
description="async dict patch",
# need to fix this
headers={"async": "dict"},
)
# Body
@app.patch("/sync/body")
def sync_body_patch(request: Request):
return request.body
@app.patch("/async/body")
async def async_body_patch(request: Request):
return request.body
# ==== Exception Handling ====
@app.exception
def handle_exception(error):
return Response(status_code=500, description=f"error msg: {error}", headers={})
@app.get("/sync/exception/get")
def sync_exception_get():
raise ValueError("value error")
@app.get("/async/exception/get")
async def async_exception_get():
raise ValueError("value error")
@app.put("/sync/exception/put")
def sync_exception_put(request: Request):
raise ValueError("value error")
@app.put("/async/exception/put")
async def async_exception_put(request: Request):
raise ValueError("value error")
@app.post("/sync/exception/post")
def sync_exception_post(request: Request):
raise ValueError("value error")
@app.post("/async/exception/post")
async def async_exception_post(request: Request):
raise ValueError("value error")
# ===== Authentication =====
@app.get("/sync/auth", auth_required=True)
def sync_auth(request: Request):
assert request.identity is not None
assert request.identity.claims == {"key": "value"}
return "authenticated"
@app.get("/async/auth", auth_required=True)
async def async_auth(request: Request):
assert request.identity is not None
assert request.identity.claims == {"key": "value"}
return "authenticated"
# ===== Main =====
def sync_without_decorator():
return "Success!"
async def async_without_decorator():
return "Success!"
app.add_route("GET", "/sync/get/no_dec", sync_without_decorator)
app.add_route("PUT", "/sync/put/no_dec", sync_without_decorator)
app.add_route("POST", "/sync/post/no_dec", sync_without_decorator)
app.add_route("GET", "/async/get/no_dec", async_without_decorator)
app.add_route("PUT", "/async/put/no_dec", async_without_decorator)
app.add_route("POST", "/async/post/no_dec", async_without_decorator)
# ===== Dependency Injection =====
GLOBAL_DEPENDENCY = "GLOBAL DEPENDENCY"
ROUTER_DEPENDENCY = "ROUTER DEPENDENCY"
app.inject_global(GLOBAL_DEPENDENCY=GLOBAL_DEPENDENCY)
app.inject(ROUTER_DEPENDENCY=ROUTER_DEPENDENCY)
@app.get("/sync/global_di")
def sync_global_di(request, router_dependencies, global_dependencies):
return global_dependencies["GLOBAL_DEPENDENCY"]
@app.get("/sync/router_di")
def sync_router_di(request, router_dependencies):
return router_dependencies["ROUTER_DEPENDENCY"]
# ===== Split request body =====
@app.get("/sync/split_request_untyped/query_params")
def sync_split_request_untyped_basic(query_params):
return query_params.to_dict()
@app.get("/async/split_request_untyped/query_params")
async def async_split_request_untyped_basic(query_params):
return query_params.to_dict()
@app.get("/sync/split_request_untyped/headers")
def sync_split_request_untyped_headers(headers):
return headers.get("server")
@app.get("/async/split_request_untyped/headers")
async def async_split_request_untyped_headers(headers):
return headers.get("server")
@app.get("/sync/split_request_untyped/path_params/:id")
def sync_split_request_untyped_path_params(path_params):
return path_params
@app.get("/async/split_request_untyped/path_params/:id")
async def async_split_request_untyped_path_params(path_params):
return path_params
@app.get("/sync/split_request_untyped/method")
def sync_split_request_untyped_method(method):
return method
@app.get("/async/split_request_untyped/method")
async def async_split_request_untyped_method(method):
return method
@app.post("/sync/split_request_untyped/body")
def sync_split_request_untyped_body(body):
return body
@app.post("/async/split_request_untyped/body")
async def async_split_request_untyped_body(body):
return body
@app.post("/sync/split_request_untyped/combined")
def sync_split_request_untyped_combined(body, query_params, method, url, headers):
return {
"body": body,
"query_params": query_params.to_dict(),
"method": method,
"url": url.path,
"headers": headers.get("server"),
}
@app.post("/async/split_request_untyped/combined")
async def async_split_request_untyped_combined(body, query_params, method, url, headers):
return {
"body": body,
"query_params": query_params.to_dict(),
"method": method,
"url": url.path,
"headers": headers.get("server"),
}
@app.get("/sync/split_request_typed/query_params")
def sync_split_request_basic(query_data: QueryParams):
return query_data.to_dict()
@app.get("/async/split_request_typed/query_params")
async def async_split_request_basic(query_data: QueryParams):
return query_data.to_dict()
@app.get("/sync/split_request_typed/headers")
def sync_split_request_headers(request_headers: Headers):
return request_headers.get("server")
@app.get("/async/split_request_typed/headers")
async def async_split_request_headers(request_headers: Headers):
return request_headers.get("server")
@app.get("/sync/split_request_typed/path_params/:id")
def sync_split_request_path_params(path_data: PathParams):
return path_data
@app.get("/async/split_request_typed/path_params/:id")
async def async_split_request_path_params(path_data: PathParams):
return path_data
@app.get("/sync/split_request_typed/method")
def sync_split_request_method(request_method: Method):
return request_method
@app.get("/async/split_request_typed/method")
async def async_split_request_method(request_method: Method):
return request_method
@app.post("/sync/split_request_typed/body")
def sync_split_request_body(request_body: Body):
return request_body
@app.post("/async/split_request_typed/body")
async def async_split_request_body(request_body: Body):
return request_body
@app.post("/sync/split_request_typed/combined")
def sync_split_request_combined(
request_body: Body,
query_data: QueryParams,
request_method: Method,
request_url: Url,
request_headers: Headers,
):
return {
"body": request_body,
"query_params": query_data.to_dict(),
"method": request_method,
"url": request_url.path,
"headers": request_headers.get("server"),
}
@app.post("/async/split_request_typed/combined")
async def async_split_request_combined(
request_body: Body,
query_data: QueryParams,
request_method: Method,
request_url: Url,
request_headers: Headers,
):
return {
"body": request_body,
"query_params": query_data.to_dict(),
"method": request_method,
"url": request_url.path,
"headers": request_headers.get("server"),
}
@app.post("/sync/split_request_typed_untyped/combined")
def sync_split_request_typed_untyped_combined(
query_params,
request_method: Method,
request_body: Body,
url: Url,
headers: Headers,
):
return {
"body": request_body,
"query_params": query_params.to_dict(),
"method": request_method,
"url": url.path,
"headers": headers.get("server"),
}
@app.post("/async/split_request_typed_untyped/combined")
async def async_split_request_typed_untyped_combined(
query_params,
request_method: Method,
request_body: Body,
url: Url,
headers: Headers,
):
return {
"body": request_body,
"query_params": query_params.to_dict(),
"method": request_method,
"url": url.path,
"headers": headers.get("server"),
}
@app.post("/sync/split_request_typed_untyped/combined/failure")
def sync_split_request_typed_untyped_combined_failure(query_params, request_method: Method, request_body: Body, url: Url, headers: Headers, vishnu):
return {
"body": request_body,
"query_params": query_params.to_dict(),
"method": request_method,
"url": url.path,
"headers": headers.get("server"),
"vishnu": vishnu,
}
@app.post("/async/split_request_typed_untyped/combined/failure")
async def async_split_request_typed_untyped_combined_failure(query_params, request_method: Method, request_body: Body, url: Url, headers: Headers, vishnu):
return {
"body": request_body,
"query_params": query_params.to_dict(),
"method": request_method,
"url": url.path,
"headers": headers.get("server"),
"vishnu": vishnu,
}
@app.get("/openapi_test", openapi_tags=["test tag"])
def sample_openapi_endpoint():
"""Get openapi"""
return 200
class Initial(Body):
is_present: bool
letter: Optional[str]
class FullName(Body):
first: str
second: str
initial: Initial
class CreateItemBody(Body):
name: FullName
description: str
price: float
tax: float
class CreateItemResponse(JSONResponse):
success: bool
items_changed: int
class CreateItemQueryParamsParams(QueryParams):
required: bool
@app.post("/openapi_request_body")
def create_item(request, body: CreateItemBody, query: CreateItemQueryParamsParams) -> CreateItemResponse:
return CreateItemResponse(success=True, items_changed=2)
# ===== JsonBody Routes =====
class TemperatureInput(JsonBody):
fahrenheit: float
@app.post("/sync/json_body/bare")
def sync_json_body_bare(data: JsonBody):
"""Bare JsonBody - receives parsed JSON dict"""
return data
@app.post("/async/json_body/bare")
async def async_json_body_bare(data: JsonBody):
"""Bare JsonBody - receives parsed JSON dict"""
return data
@app.post("/sync/json_body/typed")
def sync_json_body_typed(data: TemperatureInput):
"""Typed JsonBody - receives parsed JSON dict, docs show schema"""
fahrenheit = data.get("fahrenheit", 0)
celsius = (float(fahrenheit) - 32) * 5 / 9
return {"celsius": celsius}
@app.post("/async/json_body/typed")
async def async_json_body_typed(data: TemperatureInput):
"""Typed JsonBody - receives parsed JSON dict, docs show schema"""
fahrenheit = data.get("fahrenheit", 0)
celsius = (float(fahrenheit) - 32) * 5 / 9
return {"celsius": celsius}
@app.post("/openapi_json_body")
def openapi_json_body_endpoint(request: Request, data: TemperatureInput) -> dict:
"""Convert fahrenheit to celsius using JsonBody"""
return {"celsius": (float(data.get("fahrenheit", 0)) - 32) * 5 / 9}
# ===== Server-Sent Events (SSE) Routes =====
@app.get("/sse/basic")
def sse_basic(request):
"""Basic SSE endpoint that sends 3 messages"""
def event_generator():
for i in range(3):
yield f"data: Test message {i}\n\n"
return SSEResponse(event_generator())
@app.get("/sse/formatted")
def sse_formatted(request):
"""SSE endpoint using SSEMessage formatter"""
def event_generator():
for i in range(3):
yield SSEMessage(f"Formatted message {i}", event="test", id=str(i))
return SSEResponse(event_generator())
@app.get("/sse/json")
def sse_json(request):
"""SSE endpoint that sends JSON data"""
def event_generator():
for i in range(3):
data = {"id": i, "message": f"JSON message {i}", "type": "test"}
yield f"data: {json.dumps(data)}\n\n"
return SSEResponse(event_generator())
@app.get("/sse/named_events")
def sse_named_events(request):
"""SSE endpoint with different event types"""
def event_generator():
events = [("start", "Test started"), ("progress", "Test in progress"), ("end", "Test completed")]
for event_type, message in events:
yield SSEMessage(message, event=event_type)
return SSEResponse(event_generator())
@app.get("/sse/async")
async def sse_async(request):
"""Async SSE endpoint with true async generator support"""
async def async_event_generator():
"""True async generator for SSE events"""
for i in range(3):
await asyncio.sleep(0.1) # Simulate async work
yield SSEMessage(f"Async message {i}", event="async", id=str(i))
return SSEResponse(async_event_generator())
@app.get("/sse/streaming_sync")
def sse_streaming_sync(request):
"""SSE endpoint to test real-time sync streaming"""
def streaming_generator():
for i in range(3):
yield SSEMessage(f"Streaming sync message {i} at {time.strftime('%H:%M:%S')}", id=str(i))
time.sleep(0.5) # 500ms delay to test streaming
yield SSEMessage("Streaming test completed", event="end")
return SSEResponse(streaming_generator())
@app.get("/sse/streaming_async")
async def sse_streaming_async(request):
"""SSE endpoint to test real-time async streaming"""
async def streaming_async_generator():
for i in range(3):
await asyncio.sleep(0.3) # 300ms delay
yield SSEMessage(f"Streaming async message {i} at {time.strftime('%H:%M:%S')}", event="async", id=str(i))
yield SSEMessage("Async streaming test completed", event="end")
return SSEResponse(streaming_async_generator())
@app.get("/sse/high_frequency")
def sse_high_frequency(request):
"""SSE endpoint to test high frequency streaming"""
def high_freq_generator():
for i in range(20):
yield SSEMessage(f"Fast message {i}", id=str(i))
time.sleep(0.05) # 50ms = 20 messages per second
yield SSEMessage("High frequency test completed", event="end")
return SSEResponse(high_freq_generator())
@app.get("/sse/single")
def sse_single(request):
"""SSE endpoint that sends a single message and closes"""
def event_generator():
yield "data: Single message\n\n"
return SSEResponse(event_generator())
@app.get("/sse/empty")
def sse_empty(request):
"""SSE endpoint that sends no messages"""
def event_generator():
return
yield # This will never be reached
return SSEResponse(event_generator())
@app.get("/sse/with_headers")
def sse_with_headers(request):
"""SSE endpoint with custom headers"""
headers = Headers({"X-Custom-Header": "custom-value"})
def event_generator():
yield "data: Message with custom headers\n\n"
return SSEResponse(event_generator(), headers=headers)
@app.get("/sse/status_code")
def sse_status_code(request):
"""SSE endpoint with custom status code"""
def event_generator():
yield "data: Message with custom status\n\n"
return SSEResponse(event_generator(), status_code=201)
# ===== Easy Access Query/Path Parameters =====
@app.get("/easy/sync/:id")
def easy_access_sync(id: int, q: str, page: int = 1):
return {"id": id, "q": q, "page": page}
@app.get("/easy/async/:id")
async def easy_access_async(id: int, q: str, page: int = 1):
return {"id": id, "q": q, "page": page}
@app.get("/easy/sync/optional")
def easy_access_optional_sync(name: str, age: Optional[int] = None):
return {"name": name, "age": age}
@app.get("/easy/async/optional")
async def easy_access_optional_async(name: str, age: Optional[int] = None):
return {"name": name, "age": age}
@app.get("/easy/sync/list")
def easy_access_list_sync(tag: List[str]):
return {"tags": tag}
@app.get("/easy/async/list")
async def easy_access_list_async(tag: List[str]):
return {"tags": tag}
@app.get("/easy/sync/bool")
def easy_access_bool_sync(active: bool = False):
return {"active": active}
@app.get("/easy/async/bool")
async def easy_access_bool_async(active: bool = False):
return {"active": active}
@app.get("/easy/sync/mixed/:id")
def easy_access_mixed_sync(request: Request, id: int, q: str = ""):
return {"id": id, "q": q, "method": request.method}
@app.get("/easy/async/mixed/:id")
async def easy_access_mixed_async(request: Request, id: int, q: str = ""):
return {"id": id, "q": q, "method": request.method}
@app.get("/easy/sync/float")
def easy_access_float_sync(price: float):
return {"price": price}
@app.get("/easy/async/float")
async def easy_access_float_async(price: float):
return {"price": price}
# --- WebSocket with easy access query params ---
@app.websocket("/web_socket_easy_access")
async def easy_access_ws_handler(websocket, room: str = "default", page: int = 1):
try:
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"room={room} page={page} msg={msg}")
except WebSocketDisconnect:
pass
@easy_access_ws_handler.on_connect
def easy_access_ws_on_connect(websocket, room: str = "default"):
return f"connected to {room}"
@easy_access_ws_handler.on_close
def easy_access_ws_on_close(websocket, room: str = "default"):
return f"left {room}"
# ===== TypedDict Body Routes =====
class TypedDictRequestBody(TypedDict):
name: str
value: int
class TypedDictResponseBody(TypedDict):
result: str
count: int
@app.post("/sync/typeddict/body", openapi_tags=["typeddict"])
def sync_typeddict_body(data: TypedDictRequestBody) -> TypedDictResponseBody:
"""Accept a TypedDict request body and return a TypedDict response"""
return {"result": data["name"], "count": data["value"]}
@app.post("/async/typeddict/body", openapi_tags=["typeddict"])
async def async_typeddict_body(data: TypedDictRequestBody) -> TypedDictResponseBody:
"""Accept a TypedDict request body and return a TypedDict response"""
return {"result": data["name"], "count": data["value"]}
@app.post("/sync/typeddict/with_request", openapi_tags=["typeddict"])
def sync_typeddict_with_request(request: Request, data: TypedDictRequestBody):
"""TypedDict body alongside Request object"""
return {"method": request.method, "name": data["name"]}
@app.post("/async/typeddict/with_request", openapi_tags=["typeddict"])
async def async_typeddict_with_request(request: Request, data: TypedDictRequestBody):
"""TypedDict body alongside Request object"""
return {"method": request.method, "name": data["name"]}
# ===== Pydantic Integration Routes =====
if _HAS_PYDANTIC:
class UserCreate(PydanticBaseModel):
name: str
email: str
age: int
active: bool = True
class Address(PydanticBaseModel):
street: str
city: str
zip_code: str
class UserWithAddress(PydanticBaseModel):
name: str
email: str
address: Address
@app.post("/sync/pydantic/user", openapi_tags=["pydantic"])
def sync_pydantic_user(user: UserCreate) -> dict:
"""Create a user with Pydantic validation"""
return {"name": user.name, "email": user.email, "age": user.age, "active": user.active}
@app.post("/async/pydantic/user", openapi_tags=["pydantic"])
async def async_pydantic_user(user: UserCreate):
return {"name": user.name, "email": user.email, "age": user.age, "active": user.active}
@app.post("/sync/pydantic/user_with_request")
def sync_pydantic_user_with_request(request: Request, user: UserCreate):
return {"method": request.method, "name": user.name, "email": user.email}
@app.post("/async/pydantic/user_with_request")
async def async_pydantic_user_with_request(request: Request, user: UserCreate):
return {"method": request.method, "name": user.name, "email": user.email}
@app.post("/sync/pydantic/nested", openapi_tags=["pydantic"])
def sync_pydantic_nested(data: UserWithAddress) -> dict:
"""Create a user with nested address"""
return {"name": data.name, "city": data.address.city}
@app.post("/async/pydantic/nested", openapi_tags=["pydantic"])
async def async_pydantic_nested(data: UserWithAddress):
return {"name": data.name, "city": data.address.city}
@app.put("/sync/pydantic/user")
def sync_pydantic_user_put(user: UserCreate):
return {"updated": True, "name": user.name}
@app.put("/async/pydantic/user")
async def async_pydantic_user_put(user: UserCreate):
return {"updated": True, "name": user.name}
@app.patch("/sync/pydantic/user")
def sync_pydantic_user_patch(user: UserCreate):
return {"patched": True, "name": user.name}
@app.patch("/async/pydantic/user")
async def async_pydantic_user_patch(user: UserCreate):
return {"patched": True, "name": user.name}
@app.delete("/sync/pydantic/user")
def sync_pydantic_user_delete(user: UserCreate):
return {"deleted": True, "name": user.name}
@app.delete("/async/pydantic/user")
async def async_pydantic_user_delete(user: UserCreate):
return {"deleted": True, "name": user.name}
@app.post("/sync/pydantic/return_model", openapi_tags=["pydantic"])
def sync_pydantic_return_model(user: UserCreate) -> UserCreate:
"""Return the validated Pydantic model directly"""
return user
@app.post("/async/pydantic/return_model", openapi_tags=["pydantic"])
async def async_pydantic_return_model(user: UserCreate) -> UserCreate:
return user
@app.post("/sync/pydantic/return_list", openapi_tags=["pydantic"])
def sync_pydantic_return_list(user: UserCreate) -> list[UserCreate]:
"""Return a list of Pydantic models"""
return [user, user]
@app.post("/async/pydantic/return_list", openapi_tags=["pydantic"])
async def async_pydantic_return_list(user: UserCreate) -> list[UserCreate]:
return [user, user]
def main():
app.set_response_header("server", "robyn")
app.serve_directory(
route="/test_dir",
directory_path=os.path.join(current_file_path, "build"),
index_file="index.html",
)
# Serving static files at /static from ./integration_tests.
app.serve_directory(
route="/static",
directory_path=str(current_file_path),
)
app.startup_handler(startup_handler)
app.include_router(sub_router)
app.include_router(di_subrouter)
app.include_router(static_router)
class BasicAuthHandler(AuthenticationHandler):
def authenticate(self, request: Request) -> Optional[Identity]:
token = self.token_getter.get_token(request)
if token is not None:
# Useless but we call the set_token method for testing purposes
self.token_getter.set_token(request, token)
if token == "valid":
return Identity(claims={"key": "value"})
return None
app.configure_authentication(BasicAuthHandler(token_getter=BearerGetter()))
# Read port from environment variable if set, otherwise default to 8080
port = int(os.getenv("ROBYN_PORT", "8080"))
app.start(port=port, _check_port=False)
if __name__ == "__main__":
main()
================================================
FILE: integration_tests/build/index.html
================================================
Document
Hello world
================================================
FILE: integration_tests/conftest.py
================================================
import os
import pathlib
import platform
import signal
import socket
import subprocess
import time
from typing import List
import pytest
from integration_tests.helpers.network_helpers import get_network_host
def spawn_process(command: List[str]) -> subprocess.Popen:
if platform.system() == "Windows":
command[0] = "python"
process = subprocess.Popen(command, shell=True, creationflags=subprocess.CREATE_NEW_PROCESS_GROUP)
return process
process = subprocess.Popen(command, preexec_fn=os.setsid)
return process
def kill_process(process: subprocess.Popen) -> None:
if platform.system() == "Windows":
process.send_signal(signal.CTRL_BREAK_EVENT)
process.kill()
return
try:
os.killpg(os.getpgid(process.pid), signal.SIGKILL)
except ProcessLookupError:
pass
def start_server(domain: str, port: int, is_dev: bool = False) -> subprocess.Popen:
"""
Call this method to wait for the server to start
"""
# Start the server
current_file_path = pathlib.Path(__file__).parent.resolve()
base_routes = os.path.join(current_file_path, "./base_routes.py")
command = ["python3", base_routes]
if is_dev:
command.append("--dev")
# Ensure environment variables are properly set for the subprocess
env = os.environ.copy()
env["ROBYN_HOST"] = domain
env["ROBYN_PORT"] = str(port)
process = spawn_process(command)
# Wait for the server to be reachable
timeout = 15 # The maximum time we will wait for an answer
start_time = time.time()
while True:
current_time = time.time()
if current_time - start_time > timeout:
# Robyn didn't start correctly before timeout, kill the process and exit with an exception
kill_process(process)
raise ConnectionError(f"Could not reach Robyn server on {domain}:{port} after {timeout} seconds")
try:
sock = socket.create_connection((domain, port), timeout=2)
sock.close()
break # We were able to reach the server, exit the loop
except Exception:
time.sleep(0.5) # Longer delay before retrying
# Give the server a moment to fully initialize after accepting connections
time.sleep(1)
return process
@pytest.fixture(scope="session")
def session():
domain = "127.0.0.1"
port = 8080
os.environ["ROBYN_HOST"] = domain
process = start_server(domain, port)
yield
kill_process(process)
@pytest.fixture(scope="session")
def default_session():
domain = "127.0.0.1"
port = 8080
process = start_server(domain, port)
yield
kill_process(process)
@pytest.fixture(scope="session")
def global_session():
domain = get_network_host()
port = 8080
os.environ["ROBYN_HOST"] = domain
process = start_server(domain, port)
yield
kill_process(process)
@pytest.fixture(scope="session")
def dev_session():
domain = "127.0.0.1"
port = 8081
os.environ["ROBYN_HOST"] = domain
os.environ["ROBYN_PORT"] = str(port)
# This doesn't test is_dev=True!!!!
process = start_server(domain, port)
yield
kill_process(process)
@pytest.fixture(scope="session")
def test_session():
domain = "127.0.0.1"
port = 8080
os.environ["ROBYN_HOST"] = domain
os.environ["ROBYN_PORT"] = str(port)
process = start_server(domain, port, is_dev=True)
yield
kill_process(process)
# create robyn.env before test and delete it after test
@pytest.fixture
def env_file():
CONTENT = """ROBYN_PORT=8081
ROBYN_URL=127.0.0.1"""
path = pathlib.Path(__file__).parent
env_path = path / "robyn.env"
env_path.write_text(CONTENT)
yield
env_path.unlink()
del os.environ["ROBYN_PORT"]
del os.environ["ROBYN_HOST"]
================================================
FILE: integration_tests/downloads/test.txt
================================================
This is a test file for the downloading purpose
================================================
FILE: integration_tests/helpers/__init__.py
================================================
================================================
FILE: integration_tests/helpers/http_methods_helpers.py
================================================
from typing import Optional
import requests
BASE_URL = "http://127.0.0.1:8080"
def check_response(response: requests.Response, expected_status_code: int):
"""
Raises if the response status code is not the expected one or if one of the global
headers is not present in the response.
"""
assert response.status_code == expected_status_code
assert response.headers.get("global_after") == "global_after_request"
assert "server" in response.headers
assert response.headers.get("server") == "robyn"
def get(
endpoint: str,
expected_status_code: int = 200,
headers: dict = {},
should_check_response: bool = True,
) -> requests.Response:
"""
Makes a GET request to the given endpoint and checks the response.
endpoint str: The endpoint to make the request to.
expected_status_code int: The expected status code of the response.
headers dict: The headers to send with the request.
should_check_response bool: A boolean to indicate if the status code and headers should be checked.
"""
endpoint = endpoint.lstrip("/")
response = requests.get(f"{BASE_URL}/{endpoint}", headers=headers)
if should_check_response:
check_response(response, expected_status_code)
return response
def post(
endpoint: str,
data: Optional[dict] = None,
expected_status_code: int = 200,
headers: dict = {},
should_check_response: bool = True,
) -> requests.Response:
"""
Makes a POST request to the given endpoint and checks the response.
endpoint str: The endpoint to make the request to.
data Optional[dict]: The data to send with the request.
expected_status_code int: The expected status code of the response.
headers dict: The headers to send with the request.
should_check_response bool: A boolean to indicate if the status code and headers should be checked.
"""
endpoint = endpoint.lstrip("/")
response = requests.post(f"{BASE_URL}/{endpoint}", data=data, headers=headers)
if should_check_response:
check_response(response, expected_status_code)
return response
def json_post(
endpoint: str,
json_data=None,
expected_status_code: int = 200,
headers: dict = {},
should_check_response: bool = True,
) -> requests.Response:
"""
Makes a POST request with JSON body to the given endpoint and checks the response.
endpoint str: The endpoint to make the request to.
json_data: The JSON-serializable data to send with the request (dict, list, etc.).
expected_status_code int: The expected status code of the response.
headers dict: The headers to send with the request.
should_check_response bool: A boolean to indicate if the status code and headers should be checked.
"""
endpoint = endpoint.strip("/")
response = requests.post(f"{BASE_URL}/{endpoint}", json=json_data, headers=headers)
if should_check_response:
check_response(response, expected_status_code)
return response
def multipart_post(
endpoint: str,
files: Optional[dict] = None,
expected_status_code: int = 200,
should_check_response: bool = True,
) -> requests.Response:
"""
Makes a POST request to the given endpoint and checks the response.
endpoint str: The endpoint to make the request to.
files Optional[dict]: The files to send with the request.
expected_status_code int: The expected status code of the response.
should_check_response bool: A boolean to indicate if the status code and headers should be checked.
"""
endpoint = endpoint.lstrip("/")
response = requests.post(f"{BASE_URL}/{endpoint}", files=files)
if should_check_response:
check_response(response, expected_status_code)
return response
def put(
endpoint: str,
data: Optional[dict] = None,
expected_status_code: int = 200,
headers: dict = {},
should_check_response: bool = True,
) -> requests.Response:
"""
Makes a PUT request to the given endpoint and checks the response.
endpoint str: The endpoint to make the request to.
expected_status_code int: The expected status code of the response.
headers dict: The headers to send with the request.
should_check_response bool: A boolean to indicate if the status code and headers should be checked.
"""
endpoint = endpoint.lstrip("/")
response = requests.put(f"{BASE_URL}/{endpoint}", data=data, headers=headers)
if should_check_response:
check_response(response, expected_status_code)
return response
def patch(
endpoint: str,
data: Optional[dict] = None,
expected_status_code: int = 200,
headers: dict = {},
should_check_response: bool = True,
) -> requests.Response:
"""
Makes a PATCH request to the given endpoint and checks the response.
endpoint str: The endpoint to make the request to.
expected_status_code int: The expected status code of the response.
headers dict: The headers to send with the request.
should_check_response bool: A boolean to indicate if the status code and headers should be checked.
"""
endpoint = endpoint.lstrip("/")
response = requests.patch(f"{BASE_URL}/{endpoint}", data=data, headers=headers)
if should_check_response:
check_response(response, expected_status_code)
return response
def delete(
endpoint: str,
data: Optional[dict] = None,
expected_status_code: int = 200,
headers: dict = {},
should_check_response: bool = True,
) -> requests.Response:
"""
Makes a DELETE request to the given endpoint and checks the response.
endpoint str: The endpoint to make the request to.
expected_status_code int: The expected status code of the response.
headers dict: The headers to send with the request.
should_check_response bool: A boolean to indicate if the status code and headers should be checked.
"""
endpoint = endpoint.lstrip("/")
response = requests.delete(f"{BASE_URL}/{endpoint}", data=data, headers=headers)
if should_check_response:
check_response(response, expected_status_code)
return response
def head(
endpoint: str,
data: Optional[dict] = None,
expected_status_code: int = 200,
headers: dict = {},
should_check_response: bool = True,
) -> requests.Response:
"""
Makes a HEAD request to the given endpoint and checks the response.
endpoint str: The endpoint to make the request to.
expected_status_code int: The expected status code of the response.
headers dict: The headers to send with the request.
should_check_response bool: A boolean to indicate if the status code and headers should be checked.
"""
endpoint = endpoint.lstrip("/")
response = requests.head(f"{BASE_URL}/{endpoint}", data=data, headers=headers)
if should_check_response:
check_response(response, expected_status_code)
return response
# TODO - at some point this should be the defacto
# and every other method should be replaced with this
def generic_http_helper(
method: str,
endpoint: str,
data: Optional[dict] = None,
expected_status_code: int = 200,
headers: dict = {},
should_check_response: bool = True,
) -> requests.Response:
"""
Makes a request to the given endpoint and checks the response.
endpoint str: The endpoint to make the request to.
expected_status_code int: The expected status code of the response.
headers dict: The headers to send with the request.
should_check_response bool: A boolean to indicate if the status code and headers should be checked.
"""
endpoint = endpoint.lstrip("/")
if method not in ["get", "post", "put", "patch", "delete", "options", "trace"]:
raise ValueError(f"{method} method must be one of get, post, put, patch, delete")
if method == "get":
response = requests.get(f"{BASE_URL}/{endpoint}", headers=headers)
else:
response = requests.request(method, f"{BASE_URL}/{endpoint}", data=data, headers=headers)
if should_check_response:
check_response(response, expected_status_code)
return response
================================================
FILE: integration_tests/helpers/network_helpers.py
================================================
import platform
import socket
def get_network_host():
# windows doesn't support 0.0.0.0
if platform.system() == "Windows":
hostname = socket.gethostname()
ip_address = socket.gethostbyname(hostname)
return ip_address
else:
return "0.0.0.0"
================================================
FILE: integration_tests/index.html
================================================
Document
Hello world. How are you?
================================================
FILE: integration_tests/index.py
================================================
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
async def h():
return "Hello, world!"
app.start()
================================================
FILE: integration_tests/openapi_config.json
================================================
{
"openapi": "3.1.0",
"info": {
"title": "Robyn Test API",
"version": "1.0.0",
"description": null,
"termsOfService": null,
"contact": {
"name": null,
"url": null,
"email": null
},
"license": {
"name": null,
"url": null
},
"servers": [],
"externalDocs": {
"description": null,
"url": null
},
"components": {
"schemas": {},
"responses": {},
"parameters": {},
"examples": {},
"requestBodies": {},
"securitySchemes": {},
"links": {},
"callbacks": {},
"pathItems": {}
}
},
"paths": {
"/": {
"get": {
"summary": "",
"description": "No description provided",
"parameters": [],
"tags": [
"get"
],
"responses": {
"200": {
"description": "Successful Response",
"content": {
"text/plain": {
"schema": {}
}
}
}
}
}
}
},
"components": {
"schemas": {},
"responses": {},
"parameters": {},
"examples": {},
"requestBodies": {},
"securitySchemes": {},
"links": {},
"callbacks": {},
"pathItems": {}
},
"servers": [],
"externalDocs": null
}
================================================
FILE: integration_tests/random_number.rs
================================================
// rustimport:pyo3
use pyo3::prelude::*;
#[pyfunction]
fn say_hello() {
println!("Hello from random_number, implemented in Rust!")
}
// Uncomment the below to implement custom pyo3 binding code. Otherwise,
// rustimport will generate it for you for all functions annotated with
// #[pyfunction] and all structs annotated with #[pyclass].
//
//#[pymodule]
//fn random_number(_py: Python, m: &PyModule) -> PyResult<()> {
// m.add_function(wrap_pyfunction!(say_hello, m)?)?;
// Ok(())
//}
================================================
FILE: integration_tests/subroutes/__init__.py
================================================
from robyn import SubRouter, WebSocketDisconnect, jsonify
from .di_subrouter import di_subrouter
from .file_api import static_router
sub_router = SubRouter(__name__, prefix="/sub_router")
__all__ = ["sub_router", "di_subrouter", "static_router"]
@sub_router.websocket("/ws")
async def ws_handler(websocket):
try:
while True:
await websocket.receive_text()
await websocket.send_text("Message")
except WebSocketDisconnect:
pass
@ws_handler.on_connect
async def connect(websocket):
return "Hello world, from ws"
@ws_handler.on_close
async def close(websocket):
return jsonify({"message": "closed"})
@sub_router.get("/foo")
def get_foo():
return {"message": "foo"}
@sub_router.post("/foo")
def post_foo():
return {"message": "foo"}
@sub_router.put("/foo")
def put_foo():
return {"message": "foo"}
@sub_router.delete("/foo")
def delete_foo():
return {"message": "foo"}
@sub_router.patch("/foo")
def patch_foo():
return {"message": "foo"}
@sub_router.options("/foo")
def option_foo():
return {"message": "foo"}
@sub_router.trace("/foo")
def trace_foo():
return {"message": "foo"}
@sub_router.head("/foo")
def head_foo():
return {"message": "foo"}
@sub_router.post("/openapi_test", openapi_tags=["test subrouter tag"])
def sample_subrouter_openapi_endpoint():
"""Get subrouter openapi"""
return 200
================================================
FILE: integration_tests/subroutes/di_subrouter.py
================================================
from robyn import Request, SubRouter
di_subrouter = SubRouter(__file__, "/di_subrouter")
GLOBAL_DEPENDENCY = "GLOBAL DEPENDENCY OVERRIDE"
ROUTER_DEPENDENCY = "ROUTER DEPENDENCY"
di_subrouter.inject_global(GLOBAL_DEPENDENCY=GLOBAL_DEPENDENCY)
di_subrouter.inject(ROUTER_DEPENDENCY=ROUTER_DEPENDENCY)
@di_subrouter.get("/subrouter_router_di")
def sync_subrouter_route_dependency(r: Request, router_dependencies, global_dependencies):
return router_dependencies["ROUTER_DEPENDENCY"]
@di_subrouter.get("/subrouter_global_di")
def sync_subrouter_global_dependency(global_dependencies):
return global_dependencies["GLOBAL_DEPENDENCY"]
================================================
FILE: integration_tests/subroutes/file_api.py
================================================
"""
Test routes for issue #1251: static files + API routes at same base path.
Notes:
1. No need to test every method, just one is enough to ensure no conflict.
2. The static files are served from ./integration_tests to avoid conflict with the /test_dir route in main app.
3. The static file serving route is defined in a separate SubRouter to isolate it from the main app routes.
4. Serving api & files from the same /static path to test the fix.
"""
from robyn import Request, SubRouter
static_router = SubRouter(__name__, "/static")
@static_router.get("/build")
@static_router.post("/build")
async def build_handler(request: Request):
"""
Test route ensuring no conflict with static file serving at /static.
Although static files are served at /static, this API route should be reached
because /build is not a file, so the request falls through to the API handler.
"""
return f"{request.method}:{request.url.path} works"
================================================
FILE: integration_tests/templates/test.html
================================================
{# templates/test.html #}
Results
{{framework}} 🤝 {{templating_engine}}
================================================
FILE: integration_tests/test_add_route_without_decorator.py
================================================
from collections.abc import Callable
import pytest
from integration_tests.helpers.http_methods_helpers import get, post, put
@pytest.mark.benchmark
@pytest.mark.usefixtures("session")
@pytest.mark.parametrize(
"route,method",
[
("/sync/get/no_dec", get),
("/async/get/no_dec", get),
("/sync/put/no_dec", put),
("/async/put/no_dec", put),
("/sync/post/no_dec", post),
("/async/post/no_dec", post),
],
)
def test_exception_handling(route: str, method: Callable):
r = method(route, expected_status_code=200)
assert r.text == "Success!"
================================================
FILE: integration_tests/test_app.py
================================================
import pytest
from robyn import ALLOW_CORS, Robyn
from robyn.events import Events
from robyn.robyn import Headers
@pytest.mark.benchmark
def test_add_request_header():
app = Robyn(__file__)
app.set_request_header("server", "robyn")
assert app.request_headers.get_headers() == Headers({"server": "robyn"}).get_headers()
@pytest.mark.benchmark
def test_add_response_header():
app = Robyn(__file__)
app.add_response_header("content-type", "application/json")
assert app.response_headers.get_headers() == Headers({"content-type": "application/json"}).get_headers()
@pytest.mark.benchmark
def test_lifecycle_handlers():
def mock_startup_handler():
pass
async def mock_shutdown_handler():
pass
app = Robyn(__file__)
app.startup_handler(mock_startup_handler)
assert Events.STARTUP in app.event_handlers
startup = app.event_handlers[Events.STARTUP]
assert startup.handler == mock_startup_handler
assert startup.is_async is False
assert startup.number_of_params == 0
app.shutdown_handler(mock_shutdown_handler)
assert Events.SHUTDOWN in app.event_handlers
shutdown = app.event_handlers[Events.SHUTDOWN]
assert shutdown.handler == mock_shutdown_handler
assert shutdown.is_async is True
assert shutdown.number_of_params == 0
@pytest.mark.benchmark
def test_allow_cors():
app = Robyn(__file__)
ALLOW_CORS(app, ["*"])
headers = Headers({})
headers.set("Access-Control-Allow-Origin", "*")
headers.set(
"Access-Control-Allow-Methods",
"GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS",
)
headers.set("Access-Control-Allow-Headers", "Content-Type, Authorization")
headers.set("Access-Control-Allow-Credentials", "true")
assert app.response_headers.get_headers() == headers.get_headers()
================================================
FILE: integration_tests/test_authentication.py
================================================
from urllib.parse import urlparse
import pytest
from integration_tests.helpers.http_methods_helpers import get
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_valid_authentication(session, function_type: str):
r = get(f"/{function_type}/auth", headers={"Authorization": "Bearer valid"})
assert r.text == "authenticated"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_valid_authentication_trailing_slash(session, function_type: str):
r = get(f"/{function_type}/auth/", headers={"Authorization": "Bearer valid"})
# Checks whether request is being sent to exact /trailing/ route.
assert urlparse(r.url).path == f"/{function_type}/auth/"
assert r.text == "authenticated"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_invalid_authentication_token(session, function_type: str):
r = get(
f"/{function_type}/auth",
headers={"Authorization": "Bearer invalid"},
should_check_response=False,
)
assert r.status_code == 401
assert r.headers.get("WWW-Authenticate") == "BearerGetter"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_invalid_authentication_token_trailing_slash(session, function_type: str):
r = get(
f"/{function_type}/auth/",
headers={"Authorization": "Bearer invalid"},
should_check_response=False,
)
assert urlparse(r.url).path == f"/{function_type}/auth/"
assert r.status_code == 401
assert r.headers.get("WWW-Authenticate") == "BearerGetter"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_invalid_authentication_header(session, function_type: str):
r = get(
f"/{function_type}/auth",
headers={"Authorization": "Bear valid"},
should_check_response=False,
)
assert r.status_code == 401
assert r.headers.get("WWW-Authenticate") == "BearerGetter"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_invalid_authentication_header_trailing_slash(session, function_type: str):
r = get(
f"/{function_type}/auth/",
headers={"Authorization": "Bear valid"},
should_check_response=False,
)
assert r.status_code == 401
assert r.headers.get("WWW-Authenticate") == "BearerGetter"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_invalid_authentication_no_token(session, function_type: str):
r = get(f"/{function_type}/auth", should_check_response=False)
assert r.status_code == 401
assert r.headers.get("WWW-Authenticate") == "BearerGetter"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_invalid_authentication_no_token_trailing_slash(session, function_type: str):
r = get(f"/{function_type}/auth/", should_check_response=False)
assert r.status_code == 401
assert r.headers.get("WWW-Authenticate") == "BearerGetter"
================================================
FILE: integration_tests/test_base_url.py
================================================
import os
import pytest
import requests
from integration_tests.helpers.network_helpers import get_network_host
@pytest.mark.benchmark
def test_default_url_index_request(default_session):
BASE_URL = "http://127.0.0.1:8080"
res = requests.get(f"{BASE_URL}")
assert res.status_code == 200
@pytest.mark.benchmark
def test_local_index_request(session):
BASE_URL = "http://127.0.0.1:8080"
res = requests.get(f"{BASE_URL}")
assert os.getenv("ROBYN_HOST") == "127.0.0.1"
assert res.status_code == 200
@pytest.mark.benchmark
def test_global_index_request(global_session):
host = get_network_host()
BASE_URL = f"http://{host}:8080"
res = requests.get(f"{BASE_URL}")
assert os.getenv("ROBYN_HOST") == f"{host}"
assert res.status_code == 200
================================================
FILE: integration_tests/test_basic_routes.py
================================================
# Test the routes with:
# - the GET method
# - most common return types
# - sync and async
from typing import Optional
import pytest
from integration_tests.helpers.http_methods_helpers import get
@pytest.mark.benchmark
@pytest.mark.parametrize(
"route,expected_text,expected_header_key,expected_header_value",
[
("/sync/str", "sync str get", None, None),
("/sync/dict", "sync dict get", "sync", "dict"),
("/sync/response", "sync response get", "sync", "response"),
("/sync/str/const", "sync str const get", None, None),
("/sync/dict/const", "sync dict const get", "sync_const", "dict"),
("/sync/response/const", "sync response const get", "sync_const", "response"),
("/async/str", "async str get", None, None),
("/async/dict", "async dict get", "async", "dict"),
("/async/response", "async response get", "async", "response"),
("/async/str/const", "async str const get", None, None),
("/async/dict/const", "async dict const get", "async_const", "dict"),
(
"/async/response/const",
"async response const get",
"async_const",
"response",
),
],
)
def test_basic_get(
route: str,
expected_text: str,
expected_header_key: Optional[str],
expected_header_value: Optional[str],
session,
):
res = get(route)
assert res.text == expected_text
if expected_header_key is not None:
assert expected_header_key in res.headers
assert res.headers[expected_header_key] == expected_header_value
@pytest.mark.benchmark
@pytest.mark.parametrize(
"route, expected_json",
[
("/sync/json", {"sync json get": "json"}),
("/async/json", {"async json get": "json"}),
("/sync/json/const", {"sync json const get": "json"}),
("/async/json/const", {"async json const get": "json"}),
],
)
def test_json_get(route: str, expected_json: dict, session):
res = get(route)
for key in expected_json.keys():
assert key in res.json()
assert res.json()[key] == expected_json[key]
@pytest.mark.benchmark
@pytest.mark.parametrize(
"route, expected_json",
[
(
"/sync/http/param",
{
"method": "GET",
"url": {
"host": "127.0.0.1:8080",
"path": "/sync/http/param",
"scheme": "http",
},
},
),
(
"/async/http/param",
{
"method": "GET",
"url": {
"host": "127.0.0.1:8080",
"path": "/async/http/param",
"scheme": "http",
},
},
),
],
)
def test_http_request_info_get(route: str, expected_json: dict, session):
res = get(route)
for key in expected_json.keys():
assert key in res.json()
assert res.json()[key] == expected_json[key]
================================================
FILE: integration_tests/test_binary_output.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import get
BASE_URL = "http://127.0.0.1:8080"
@pytest.mark.benchmark
@pytest.mark.parametrize(
"route, text",
[
("/sync/octet", "sync octet"),
("/async/octet", "async octet"),
("/sync/octet/response", "sync octet response"),
("/async/octet/response", "async octet response"),
],
)
def test_binary_output(route: str, text: str, session):
r = get(route)
assert r.headers.get("Content-Type") == "application/octet-stream"
assert r.text == text
================================================
FILE: integration_tests/test_delete_requests.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import delete
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_delete(function_type: str, session):
res = delete(f"/{function_type}/dict")
assert res.text == f"{function_type} dict delete"
assert function_type in res.headers
assert res.headers[function_type] == "dict"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_delete_with_param(function_type: str, session):
res = delete(f"/{function_type}/body", data={"hello": "world"})
assert res.text == "hello=world"
================================================
FILE: integration_tests/test_dependency_injection.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import get
@pytest.mark.benchmark
def test_global_dependency_injection():
r = get("/sync/global_di")
assert r.status_code == 200
assert r.text == "GLOBAL DEPENDENCY"
@pytest.mark.benchmark
def test_router_dependency_injection():
r = get("/sync/router_di")
assert r.status_code == 200
assert r.text == "ROUTER DEPENDENCY"
@pytest.mark.benchmark
def test_subrouter_global_dependency_injection():
r = get("/di_subrouter/subrouter_global_di")
assert r.status_code == 200
assert r.text == "GLOBAL DEPENDENCY"
@pytest.mark.benchmark
def test_subrouter_router_dependency_injection():
r = get("/di_subrouter/subrouter_router_di")
assert r.status_code == 200
assert r.text == "ROUTER DEPENDENCY"
================================================
FILE: integration_tests/test_easy_access_params.py
================================================
import os
import pytest
from websocket import create_connection
from integration_tests.helpers.http_methods_helpers import get
WS_BASE_URL = f"ws://127.0.0.1:{os.environ.get('ROBYN_PORT', '8080')}"
# ===== HTTP: Path param + query param with type coercion =====
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_path_and_query_params(session, function_type):
r = get(f"/easy/{function_type}/42?q=hello&page=5")
assert r.json() == {"id": 42, "q": "hello", "page": 5}
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_default_value(session, function_type):
r = get(f"/easy/{function_type}/42?q=hello")
assert r.json() == {"id": 42, "q": "hello", "page": 1}
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_missing_required_param(session, function_type):
"""Missing required 'q' param should return 400."""
r = get(f"/easy/{function_type}/42", should_check_response=False)
assert r.status_code == 400
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_bad_type_coercion(session, function_type):
"""Path param :id declared as int but given 'abc' should return 400."""
r = get(f"/easy/{function_type}/abc?q=hello", should_check_response=False)
assert r.status_code == 400
# ===== HTTP: Optional params =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_optional_present(session, function_type):
r = get(f"/easy/{function_type}/optional?name=bob&age=30")
assert r.json() == {"name": "bob", "age": 30}
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_optional_missing(session, function_type):
r = get(f"/easy/{function_type}/optional?name=bob")
assert r.json() == {"name": "bob", "age": None}
# ===== HTTP: List params =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_list_params(session, function_type):
r = get(f"/easy/{function_type}/list?tag=python&tag=rust&tag=web")
assert r.json() == {"tags": ["python", "rust", "web"]}
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_list_single_value(session, function_type):
r = get(f"/easy/{function_type}/list?tag=python")
assert r.json() == {"tags": ["python"]}
# ===== HTTP: Bool params =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_bool_true(session, function_type):
r = get(f"/easy/{function_type}/bool?active=true")
assert r.json() == {"active": True}
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_bool_false(session, function_type):
r = get(f"/easy/{function_type}/bool?active=false")
assert r.json() == {"active": False}
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_bool_default(session, function_type):
r = get(f"/easy/{function_type}/bool")
assert r.json() == {"active": False}
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_bool_numeric(session, function_type):
r = get(f"/easy/{function_type}/bool?active=1")
assert r.json() == {"active": True}
# ===== HTTP: Mixed (Request object + individual params) =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_mixed_with_request(session, function_type):
r = get(f"/easy/{function_type}/mixed/99?q=search")
assert r.json() == {"id": 99, "q": "search", "method": "GET"}
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_mixed_with_default(session, function_type):
r = get(f"/easy/{function_type}/mixed/99")
assert r.json() == {"id": 99, "q": "", "method": "GET"}
# ===== HTTP: Float params =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_float(session, function_type):
r = get(f"/easy/{function_type}/float?price=19.99")
assert r.json() == {"price": 19.99}
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_easy_access_float_bad_value(session, function_type):
r = get(f"/easy/{function_type}/float?price=notanumber", should_check_response=False)
assert r.status_code == 400
# ===== WebSocket: Easy access query params =====
def test_easy_access_ws_with_params(session):
ws = create_connection(f"{WS_BASE_URL}/web_socket_easy_access?room=chat&page=5")
connect_msg = ws.recv()
assert connect_msg == "connected to chat"
ws.send("hello")
response = ws.recv()
assert response == "room=chat page=5 msg=hello"
ws.close()
def test_easy_access_ws_with_defaults(session):
ws = create_connection(f"{WS_BASE_URL}/web_socket_easy_access")
connect_msg = ws.recv()
assert connect_msg == "connected to default"
ws.send("hello")
response = ws.recv()
assert response == "room=default page=1 msg=hello"
ws.close()
================================================
FILE: integration_tests/test_exception_handling.py
================================================
from collections.abc import Callable
import pytest
from integration_tests.helpers.http_methods_helpers import get, post, put
@pytest.mark.benchmark
@pytest.mark.parametrize(
"route,method",
[
("/sync/exception/get", get),
("/async/exception/get", get),
("/sync/exception/put", put),
("/async/exception/put", put),
("/sync/exception/post", post),
("/async/exception/post", post),
],
)
def test_exception_handling(
route: str,
method: Callable,
session,
):
r = method(route, expected_status_code=500)
assert r.text == "error msg: value error"
================================================
FILE: integration_tests/test_file_download.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import get
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_file_download(function_type: str, session):
r = get(f"/{function_type}/file/download")
assert r.headers.get("Content-Disposition") == "attachment; filename=test.txt"
assert r.text == "This is a test file for the downloading purpose"
================================================
FILE: integration_tests/test_get_requests.py
================================================
import pytest
import requests
from requests import Response
from integration_tests.helpers.http_methods_helpers import get
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_param(function_type: str, session):
r = get(f"/{function_type}/param/1")
assert r.text == "1"
r = get(f"/{function_type}/param/12345")
assert r.text == "12345"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_param_suffix(function_type: str, session):
r = get(f"/{function_type}/extra/foo/1/baz")
assert r.text == "foo/1/baz"
r = get(f"/{function_type}/extra/foo/bar/baz")
assert r.text == "foo/bar/baz"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_serve_html(function_type: str, session):
def check_response(r: Response):
assert r.text.startswith("")
assert "Hello world. How are you?" in r.text
check_response(get(f"/{function_type}/serve/html"))
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_template(function_type: str, session):
def check_response(r: Response):
assert r.text.startswith("\n\n")
assert "Jinja2" in r.text
assert "Robyn" in r.text
check_response(get(f"/{function_type}/template"))
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_queries(function_type: str, session):
r = get(f"/{function_type}/queries?hello=robyn")
assert r.json() == {"hello": ["robyn"]}
r = get(f"/{function_type}/queries")
assert r.json() == {}
@pytest.mark.benchmark
def test_trailing_slash(session):
r = requests.get("http://localhost:8080/trailing") # `integration_tests#get` strips the trailing slash, tests always pass!`
assert r.text == "Trailing slash test successful!"
r = requests.get("http://localhost:8080/trailing/")
assert r.text == "Trailing slash test successful!"
@pytest.mark.benchmark
@pytest.mark.parametrize("key, value", [("fakesession", "fake-cookie-session-value")])
def test_cookies(session, key, value):
response = get("/cookie", 200)
# Cookies should be sent via Set-Cookie header, accessible via response.cookies
assert response.cookies[key] == value
@pytest.mark.benchmark
def test_multiple_cookies(session):
response = get("/cookie/multiple", 200)
assert response.cookies["session"] == "abc123"
assert response.cookies["theme"] == "dark"
@pytest.mark.benchmark
def test_cookie_with_attributes(session):
response = get("/cookie/attributes", 200)
# Check the cookie value
assert response.cookies["secure_session"] == "secret123"
# Check the Set-Cookie header for attributes
set_cookie_header = response.headers.get("Set-Cookie", "")
assert "secure_session=secret123" in set_cookie_header
assert "Path=/" in set_cookie_header
assert "HttpOnly" in set_cookie_header
assert "Secure" in set_cookie_header
assert "SameSite=Strict" in set_cookie_header
assert "Max-Age=3600" in set_cookie_header
@pytest.mark.benchmark
def test_cookie_overwrite(session):
response = get("/cookie/overwrite", 200)
# Same-name cookies should be overwritten, final value should be used
assert response.cookies["session"] == "final-value"
================================================
FILE: integration_tests/test_json_types.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import get, json_post
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_integer_type_preserved(function_type: str, session):
"""Test that integer values in JSON are preserved as integers, not strings"""
json_data = {"lid": 570, "count": 42}
res = json_post(f"/{function_type}/request_json/types", json_data=json_data)
result = res.json()
assert result["lid"]["value"] == 570
assert result["lid"]["type"] == "int"
assert result["count"]["value"] == 42
assert result["count"]["type"] == "int"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_null_type_preserved(function_type: str, session):
"""Test that null values in JSON are preserved as None, not string 'null'"""
json_data = {"start": None, "end": None}
res = json_post(f"/{function_type}/request_json/types", json_data=json_data)
result = res.json()
assert result["start"]["value"] is None
assert result["start"]["type"] == "NoneType"
assert result["end"]["value"] is None
assert result["end"]["type"] == "NoneType"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_boolean_type_preserved(function_type: str, session):
"""Test that boolean values in JSON are preserved as booleans, not strings"""
json_data = {"active": True, "deleted": False}
res = json_post(f"/{function_type}/request_json/types", json_data=json_data)
result = res.json()
assert result["active"]["value"] is True
assert result["active"]["type"] == "bool"
assert result["deleted"]["value"] is False
assert result["deleted"]["type"] == "bool"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_float_type_preserved(function_type: str, session):
"""Test that float values in JSON are preserved as floats"""
json_data = {"price": 19.99, "rate": 0.15}
res = json_post(f"/{function_type}/request_json/types", json_data=json_data)
result = res.json()
assert result["price"]["value"] == 19.99
assert result["price"]["type"] == "float"
assert result["rate"]["value"] == 0.15
assert result["rate"]["type"] == "float"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_string_type_preserved(function_type: str, session):
"""Test that string values in JSON remain strings"""
json_data = {"field_name": "mobile", "field_value": "111000111"}
res = json_post(f"/{function_type}/request_json/types", json_data=json_data)
result = res.json()
assert result["field_name"]["value"] == "mobile"
assert result["field_name"]["type"] == "str"
assert result["field_value"]["value"] == "111000111"
assert result["field_value"]["type"] == "str"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_array_type_preserved(function_type: str, session):
"""Test that array values in JSON are preserved as lists"""
json_data = {"items": [1, 2, 3], "tags": ["a", "b"]}
res = json_post(f"/{function_type}/request_json/types", json_data=json_data)
result = res.json()
assert result["items"]["value"] == [1, 2, 3]
assert result["items"]["type"] == "list"
assert result["tags"]["value"] == ["a", "b"]
assert result["tags"]["type"] == "list"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_nested_object_type_preserved(function_type: str, session):
"""Test that nested object values in JSON are preserved as dicts"""
json_data = {"user": {"name": "John", "age": 30}}
res = json_post(f"/{function_type}/request_json/types", json_data=json_data)
result = res.json()
assert result["user"]["value"] == {"name": "John", "age": 30}
assert result["user"]["type"] == "dict"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_mixed_types_preserved(function_type: str, session):
"""Test the exact scenario from the bug report - mixed types in one request"""
json_data = {
"lid": 570,
"start": None,
"field_name": "mobile",
"field_value": "111000111",
}
res = json_post(f"/{function_type}/request_json/types", json_data=json_data)
result = res.json()
# Integer should remain integer (not become "570")
assert result["lid"]["value"] == 570
assert result["lid"]["type"] == "int"
# None should remain None (not become "null")
assert result["start"]["value"] is None
assert result["start"]["type"] == "NoneType"
# Strings should remain strings
assert result["field_name"]["value"] == "mobile"
assert result["field_name"]["type"] == "str"
assert result["field_value"]["value"] == "111000111"
assert result["field_value"]["type"] == "str"
# ===== Top-level JSON Array Parsing Tests (Issue #1145) =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_top_level_array_of_strings(function_type: str, session):
"""Test that request.json() handles a top-level array of strings (exact scenario from #1145)"""
json_data = ["google_docs", "notion"]
res = json_post(f"/{function_type}/request_json/array", json_data=json_data)
result = res.json()
assert result["type"] == "list"
assert result["parsed"] == ["google_docs", "notion"]
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_top_level_array_of_objects(function_type: str, session):
"""Test that request.json() handles a top-level array of objects"""
json_data = [{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}]
res = json_post(f"/{function_type}/request_json/array", json_data=json_data)
result = res.json()
assert result["type"] == "list"
assert result["parsed"] == [{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}]
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_top_level_empty_array(function_type: str, session):
"""Test that request.json() handles an empty top-level array"""
json_data = []
res = json_post(f"/{function_type}/request_json/array", json_data=json_data)
result = res.json()
assert result["type"] == "list"
assert result["parsed"] == []
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_top_level_array_of_mixed_types(function_type: str, session):
"""Test that request.json() handles a top-level array with mixed types"""
json_data = [1, "two", True, None, {"key": "value"}]
res = json_post(f"/{function_type}/request_json/array", json_data=json_data)
result = res.json()
assert result["type"] == "list"
assert result["parsed"] == [1, "two", True, None, {"key": "value"}]
# ===== JSON List Serialization Tests (Issue #1300) =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_list_response_serialization(function_type: str, session):
"""Test that returning a list from a handler is properly serialized as JSON"""
res = get(f"/{function_type}/json/list")
# Check content type is application/json
assert res.headers["content-type"] == "application/json"
# Check that response is valid JSON (not Python str representation)
result = res.json()
assert isinstance(result, list)
assert len(result) == 3
# Verify the data structure and types are correct
assert result[0] == {"id": 1, "title": "First Post", "published": True}
assert result[1] == {"id": 2, "title": "Draft Post", "published": False}
assert result[2] == {"id": 3, "title": "Latest Post", "published": True}
# Verify booleans are proper JSON booleans (true/false), not Python (True/False)
# This is implicitly tested by res.json() succeeding, but let's verify the raw response too
assert "true" in res.text.lower()
assert "false" in res.text.lower()
assert "True" not in res.text # Python boolean should not appear
assert "False" not in res.text
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_empty_list_response_serialization(function_type: str, session):
"""Test that returning an empty list is properly serialized as JSON"""
res = get(f"/{function_type}/json/list/empty")
assert res.headers["content-type"] == "application/json"
result = res.json()
assert result == []
assert res.text == "[]"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_list_primitives_response_serialization(function_type: str, session):
"""Test that a list of primitives is properly serialized as JSON"""
res = get(f"/{function_type}/json/list/primitives")
assert res.headers["content-type"] == "application/json"
result = res.json()
assert result == [1, 2, 3, "four", True, None]
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_dict_response_auto_serialization(function_type: str, session):
"""Test that returning a dict from a handler is properly auto-serialized as JSON"""
res = get(f"/{function_type}/json/dict")
assert res.headers["content-type"] == "application/json"
result = res.json()
assert result["message"] == f"{function_type} dict"
assert result["count"] == 42
assert result["active"] is True
================================================
FILE: integration_tests/test_middlewares.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import get
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_middlewares(function_type: str, session):
r = get(f"/{function_type}/middlewares")
headers = r.headers
# We do not want the request headers to be in the response
assert not headers.get("before")
assert headers.get("after")
assert r.headers.get("after") == f"{function_type}_after_request"
assert r.text == f"{function_type} middlewares after"
@pytest.mark.benchmark
def test_global_middleware(session):
r = get("/sync/global/middlewares")
headers = r.headers
assert headers.get("global_after")
assert r.headers.get("global_after") == "global_after_request"
assert r.text == "sync global middlewares"
@pytest.mark.benchmark
def test_response_in_before_middleware(session):
r = get("/sync/middlewares/401", should_check_response=False)
assert r.status_code == 401
@pytest.mark.benchmark
@pytest.mark.parametrize(
"route",
[
"/sync/str/const",
"/async/str/const",
"/sync/dict/const",
"/async/dict/const",
"/sync/response/const",
"/async/response/const",
],
)
def test_global_middleware_applied_to_const_routes(route: str, session):
r = get(route)
assert r.headers.get("global_after") == "global_after_request", f"Global after-request middleware was not applied to const route {route}"
================================================
FILE: integration_tests/test_multipart_data.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import multipart_post
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync"])
def test_form_data(function_type: str, session):
res = multipart_post(f"/{function_type}/form_data", files={"hello": "world"})
assert "multipart" in res.text
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync"])
def test_multipart_file(function_type: str, session):
res = multipart_post(f"/{function_type}/multipart-file", files={"hello": "world"})
assert "hello" in res.text
================================================
FILE: integration_tests/test_openapi.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import get, json_post
from robyn import Robyn
@pytest.mark.benchmark
def test_custom_openapi_spec():
app = Robyn(__file__, openapi_file_path="openapi_config.json")
openapi_spec = app.openapi.openapi_spec
assert isinstance(openapi_spec, dict)
assert "openapi" in openapi_spec
assert "info" in openapi_spec
assert "paths" in openapi_spec
assert "components" in openapi_spec
assert "servers" in openapi_spec
assert "externalDocs" in openapi_spec
assert openapi_spec["info"]["title"] == "Robyn Test API"
assert openapi_spec["info"]["version"] == "1.0.0"
@pytest.mark.benchmark
def test_docs_handler():
# should_check_response = False because check_response raises a
# failure if the global headers are not present in the response
# provided we are excluding headers for /docs and /openapi.json
html_response = get("/docs", should_check_response=False)
assert html_response.status_code == 200
@pytest.mark.benchmark
def test_json_handler():
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
assert isinstance(openapi_spec, dict)
assert "openapi" in openapi_spec
assert "info" in openapi_spec
assert "paths" in openapi_spec
assert "components" in openapi_spec
assert "servers" in openapi_spec
assert "externalDocs" in openapi_spec
@pytest.mark.benchmark
def test_add_openapi_path():
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
assert isinstance(openapi_spec, dict)
route_type = "get"
endpoint = "/openapi_test"
openapi_description = "Get openapi"
openapi_tags = ["test tag"]
assert endpoint in openapi_spec["paths"]
assert route_type in openapi_spec["paths"][endpoint]
assert openapi_description == openapi_spec["paths"][endpoint][route_type]["description"]
assert openapi_tags == openapi_spec["paths"][endpoint][route_type]["tags"]
@pytest.mark.benchmark
def test_add_subrouter_paths():
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
assert isinstance(openapi_spec, dict)
route_type = "post"
endpoint = "/sub_router/openapi_test"
openapi_description = "Get subrouter openapi"
openapi_tags = ["test subrouter tag"]
assert endpoint in openapi_spec["paths"]
assert route_type in openapi_spec["paths"][endpoint]
assert openapi_description == openapi_spec["paths"][endpoint][route_type]["description"]
assert openapi_tags == openapi_spec["paths"][endpoint][route_type]["tags"]
@pytest.mark.benchmark
def test_openapi_request_body():
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
assert isinstance(openapi_spec, dict)
route_type = "post"
endpoint = "/openapi_request_body"
assert endpoint in openapi_spec["paths"]
assert route_type in openapi_spec["paths"][endpoint]
assert "requestBody" in openapi_spec["paths"][endpoint][route_type]
assert "content" in openapi_spec["paths"][endpoint][route_type]["requestBody"]
assert "application/json" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]
assert "schema" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]
assert "properties" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]
assert "name" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]
assert "description" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]
assert "price" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]
assert "tax" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]
assert "string" == openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["description"]["type"]
assert "number" == openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["price"]["type"]
assert "number" == openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["tax"]["type"]
assert "object" == openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["name"]["type"]
assert "first" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["name"]["properties"]
assert "second" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["name"]["properties"]
assert "initial" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["name"]["properties"]
assert (
"object"
in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["name"]["properties"]["initial"][
"type"
]
)
assert (
"is_present"
in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["name"]["properties"]["initial"][
"properties"
]
)
assert (
"letter"
in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["name"]["properties"]["initial"][
"properties"
]
)
assert {"type": "string"} in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["name"][
"properties"
]["initial"]["properties"]["letter"]["anyOf"]
assert {"type": "null"} in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]["name"][
"properties"
]["initial"]["properties"]["letter"]["anyOf"]
@pytest.mark.benchmark
def test_openapi_response_body():
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
assert isinstance(openapi_spec, dict)
route_type = "post"
endpoint = "/openapi_request_body"
assert endpoint in openapi_spec["paths"]
assert route_type in openapi_spec["paths"][endpoint]
assert "responses" in openapi_spec["paths"][endpoint][route_type]
assert "200" in openapi_spec["paths"][endpoint][route_type]["responses"]
assert openapi_spec["paths"][endpoint][route_type]["responses"]["200"]["description"] == "Successful Response"
assert "content" in openapi_spec["paths"][endpoint][route_type]["responses"]["200"]
assert "application/json" in openapi_spec["paths"][endpoint][route_type]["responses"]["200"]["content"]
assert "schema" in openapi_spec["paths"][endpoint][route_type]["responses"]["200"]["content"]["application/json"]
assert "properties" in openapi_spec["paths"][endpoint][route_type]["responses"]["200"]["content"]["application/json"]["schema"]
assert "success" in openapi_spec["paths"][endpoint][route_type]["responses"]["200"]["content"]["application/json"]["schema"]["properties"]
assert "items_changed" in openapi_spec["paths"][endpoint][route_type]["responses"]["200"]["content"]["application/json"]["schema"]["properties"]
assert (
"boolean" == openapi_spec["paths"][endpoint][route_type]["responses"]["200"]["content"]["application/json"]["schema"]["properties"]["success"]["type"]
)
assert (
"integer"
== openapi_spec["paths"][endpoint][route_type]["responses"]["200"]["content"]["application/json"]["schema"]["properties"]["items_changed"]["type"]
)
@pytest.mark.benchmark
def test_openapi_query_params():
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
assert isinstance(openapi_spec, dict)
route_type = "post"
endpoint = "/openapi_request_body"
assert endpoint in openapi_spec["paths"]
assert route_type in openapi_spec["paths"][endpoint]
assert "parameters" in openapi_spec["paths"][endpoint][route_type]
assert "required" == openapi_spec["paths"][endpoint][route_type]["parameters"][0]["name"]
assert "query" == openapi_spec["paths"][endpoint][route_type]["parameters"][0]["in"]
assert {"type": "boolean"} == openapi_spec["paths"][endpoint][route_type]["parameters"][0]["schema"]
@pytest.mark.benchmark
def test_openapi_json_body_typed():
"""Test that a typed JsonBody subclass generates a proper requestBody schema in OpenAPI docs."""
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
assert isinstance(openapi_spec, dict)
route_type = "post"
endpoint = "/openapi_json_body"
assert endpoint in openapi_spec["paths"]
assert route_type in openapi_spec["paths"][endpoint]
assert "requestBody" in openapi_spec["paths"][endpoint][route_type]
assert "content" in openapi_spec["paths"][endpoint][route_type]["requestBody"]
assert "application/json" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]
assert "schema" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]
assert "properties" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]
properties = openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]["application/json"]["schema"]["properties"]
assert "fahrenheit" in properties
assert "number" == properties["fahrenheit"]["type"]
@pytest.mark.benchmark
def test_openapi_json_body_bare():
"""Test that a bare JsonBody generates a requestBody with empty properties in OpenAPI docs."""
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
assert isinstance(openapi_spec, dict)
route_type = "post"
# bare JsonBody routes should still have requestBody in the spec
endpoint = "/sync/json_body/bare"
assert endpoint in openapi_spec["paths"]
assert route_type in openapi_spec["paths"][endpoint]
assert "requestBody" in openapi_spec["paths"][endpoint][route_type]
assert "content" in openapi_spec["paths"][endpoint][route_type]["requestBody"]
assert "application/json" in openapi_spec["paths"][endpoint][route_type]["requestBody"]["content"]
try:
import pydantic # noqa: F401
_HAS_PYDANTIC = True
except ImportError:
_HAS_PYDANTIC = False
@pytest.mark.benchmark
@pytest.mark.skipif(not _HAS_PYDANTIC, reason="pydantic not installed")
def test_openapi_pydantic_request_body():
"""Pydantic model on a regular route should produce a full JSON Schema in
requestBody — no dedicated OpenAPI route needed."""
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
endpoint = "/sync/pydantic/user"
route = openapi_spec["paths"][endpoint]["post"]
assert route["tags"] == ["pydantic"]
assert route["description"] == "Create a user with Pydantic validation"
assert "requestBody" in route
schema = route["requestBody"]["content"]["application/json"]["schema"]
assert schema["type"] == "object"
assert schema["title"] == "UserCreate"
props = schema["properties"]
assert props["name"]["type"] == "string"
assert props["name"]["title"] == "Name"
assert props["email"]["type"] == "string"
assert props["email"]["title"] == "Email"
assert props["age"]["type"] == "integer"
assert props["age"]["title"] == "Age"
assert props["active"]["type"] == "boolean"
assert props["active"]["title"] == "Active"
assert props["active"]["default"] is True
assert set(schema["required"]) == {"name", "email", "age"}
assert "active" not in schema["required"]
assert "responses" in route
assert "200" in route["responses"]
assert "application/json" in route["responses"]["200"]["content"]
@pytest.mark.benchmark
@pytest.mark.skipif(not _HAS_PYDANTIC, reason="pydantic not installed")
def test_openapi_pydantic_nested_model():
"""Nested Pydantic models on a regular route should use $ref and populate
components/schemas — no dedicated OpenAPI route needed."""
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
endpoint = "/sync/pydantic/nested"
route = openapi_spec["paths"][endpoint]["post"]
assert route["tags"] == ["pydantic"]
assert route["description"] == "Create a user with nested address"
schema = route["requestBody"]["content"]["application/json"]["schema"]
assert schema["type"] == "object"
assert schema["title"] == "UserWithAddress"
assert schema["properties"]["name"]["type"] == "string"
assert schema["properties"]["email"]["type"] == "string"
assert schema["properties"]["address"]["$ref"] == "#/components/schemas/Address"
assert set(schema["required"]) == {"name", "email", "address"}
assert "Address" in openapi_spec["components"]["schemas"]
address_schema = openapi_spec["components"]["schemas"]["Address"]
assert address_schema["type"] == "object"
assert address_schema["title"] == "Address"
assert address_schema["properties"]["street"]["type"] == "string"
assert address_schema["properties"]["street"]["title"] == "Street"
assert address_schema["properties"]["city"]["type"] == "string"
assert address_schema["properties"]["city"]["title"] == "City"
assert address_schema["properties"]["zip_code"]["type"] == "string"
assert address_schema["properties"]["zip_code"]["title"] == "Zip Code"
assert set(address_schema["required"]) == {"street", "city", "zip_code"}
assert "responses" in route
assert "200" in route["responses"]
assert "application/json" in route["responses"]["200"]["content"]
@pytest.mark.benchmark
@pytest.mark.skipif(not _HAS_PYDANTIC, reason="pydantic not installed")
def test_openapi_pydantic_return_type():
"""When a route has a Pydantic model as return type annotation, the response
schema should reflect the full Pydantic model schema, not just 'object'."""
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
endpoint = "/sync/pydantic/return_model"
route = openapi_spec["paths"][endpoint]["post"]
assert route["tags"] == ["pydantic"]
assert route["description"] == "Return the validated Pydantic model directly"
response_schema = route["responses"]["200"]["content"]["application/json"]["schema"]
assert response_schema["type"] == "object"
assert response_schema["title"] == "UserCreate"
assert "properties" in response_schema
assert response_schema["properties"]["name"]["type"] == "string"
assert response_schema["properties"]["age"]["type"] == "integer"
assert set(response_schema["required"]) == {"name", "email", "age"}
@pytest.mark.benchmark
@pytest.mark.skipif(not _HAS_PYDANTIC, reason="pydantic not installed")
def test_openapi_pydantic_return_list_type():
"""When a route returns list[PydanticModel], the response schema should be
an array with items containing the full Pydantic model schema."""
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
endpoint = "/sync/pydantic/return_list"
route = openapi_spec["paths"][endpoint]["post"]
assert route["tags"] == ["pydantic"]
assert route["description"] == "Return a list of Pydantic models"
response_schema = route["responses"]["200"]["content"]["application/json"]["schema"]
assert response_schema["type"] == "array"
assert "items" in response_schema
items = response_schema["items"]
assert items["type"] == "object"
assert items["title"] == "UserCreate"
assert items["properties"]["name"]["type"] == "string"
assert items["properties"]["age"]["type"] == "integer"
# ===== TypedDict request body tests =====
@pytest.mark.benchmark
def test_openapi_typeddict_request_body():
"""TypedDict subclass used as a parameter annotation should produce a
requestBody schema in OpenAPI docs (issue #1254)."""
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
endpoint = "/sync/typeddict/body"
route = openapi_spec["paths"][endpoint]["post"]
assert route["tags"] == ["typeddict"]
assert "requestBody" in route
schema = route["requestBody"]["content"]["application/json"]["schema"]
assert "properties" in schema
assert "name" in schema["properties"]
assert "value" in schema["properties"]
assert schema["properties"]["name"]["type"] == "string"
assert schema["properties"]["value"]["type"] == "integer"
assert "responses" in route
assert "200" in route["responses"]
response_schema = route["responses"]["200"]["content"]["application/json"]["schema"]
assert "properties" in response_schema
assert "result" in response_schema["properties"]
assert "count" in response_schema["properties"]
@pytest.mark.benchmark
def test_openapi_typeddict_with_request():
"""TypedDict body combined with a Request param should still produce
a requestBody schema (issue #1254)."""
openapi_response = get("/openapi.json", should_check_response=False)
assert openapi_response.status_code == 200
openapi_spec = openapi_response.json()
endpoint = "/sync/typeddict/with_request"
route = openapi_spec["paths"][endpoint]["post"]
assert "requestBody" in route
schema = route["requestBody"]["content"]["application/json"]["schema"]
assert "properties" in schema
assert "name" in schema["properties"]
assert "value" in schema["properties"]
@pytest.mark.benchmark
def test_typeddict_body_injection_sync():
"""TypedDict-annotated parameter should receive the parsed JSON dict
at runtime, not the raw string (issue #1254)."""
response = json_post(
"/sync/typeddict/body",
json_data={"name": "alice", "value": 42},
)
assert response.status_code == 200
data = response.json()
assert data["result"] == "alice"
assert data["count"] == 42
@pytest.mark.benchmark
def test_typeddict_body_injection_async():
"""Async handler with TypedDict body should also receive parsed JSON."""
response = json_post(
"/async/typeddict/body",
json_data={"name": "bob", "value": 7},
)
assert response.status_code == 200
data = response.json()
assert data["result"] == "bob"
assert data["count"] == 7
@pytest.mark.benchmark
def test_typeddict_body_with_request_injection():
"""TypedDict body and Request object should coexist in the same handler."""
response = json_post(
"/sync/typeddict/with_request",
json_data={"name": "charlie", "value": 99},
)
assert response.status_code == 200
data = response.json()
assert data["method"] == "POST"
assert data["name"] == "charlie"
@pytest.mark.benchmark
def test_typeddict_body_invalid_json():
"""Sending invalid JSON to a TypedDict-annotated handler should return 400."""
import requests
response = requests.post(
"http://127.0.0.1:8080/sync/typeddict/body",
data="not valid json",
headers={"Content-Type": "application/json"},
)
assert response.status_code == 400
================================================
FILE: integration_tests/test_patch_requests.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import patch
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_patch(function_type: str, session):
res = patch(f"/{function_type}/dict")
assert res.text == f"{function_type} dict patch"
assert function_type in res.headers
assert res.headers[function_type] == "dict"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_patch_with_param(function_type: str, session):
res = patch(f"/{function_type}/body", data={"hello": "world"})
assert res.text == "hello=world"
================================================
FILE: integration_tests/test_post_requests.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import post
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_post(function_type: str, session):
res = post(f"/{function_type}/dict")
assert res.text == f"{function_type} dict post"
assert function_type in res.headers
assert res.headers[function_type] == "dict"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_post_with_param(function_type: str, session):
res = post(f"/{function_type}/body", data={"hello": "world"})
assert res.text == "hello=world"
================================================
FILE: integration_tests/test_put_requests.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import put
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_put(function_type: str, session):
res = put(f"/{function_type}/dict")
assert res.text == f"{function_type} dict put"
assert function_type in res.headers
assert res.headers[function_type] == "dict"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_put_with_param(function_type: str, session):
res = put(f"/{function_type}/body", data={"hello": "world"})
assert res.text == "hello=world"
================================================
FILE: integration_tests/test_pydantic.py
================================================
import pytest
import requests
from integration_tests.helpers.http_methods_helpers import json_post
BASE_URL = "http://127.0.0.1:8080"
try:
import pydantic
_HAS_PYDANTIC = True
except ImportError:
_HAS_PYDANTIC = False
pytestmark = pytest.mark.skipif(not _HAS_PYDANTIC, reason="pydantic not installed")
def _raw_post(endpoint: str, data: str, content_type: str = "application/json") -> requests.Response:
url = f"{BASE_URL}/{endpoint.lstrip('/')}"
return requests.post(url, data=data, headers={"Content-Type": content_type})
# ===== Valid Pydantic Body =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_valid_user_all_fields(function_type: str, session):
"""All fields provided explicitly — every field value must round-trip correctly."""
json_data = {"name": "Alice", "email": "alice@example.com", "age": 30, "active": False}
res = json_post(f"/{function_type}/pydantic/user", json_data=json_data)
result = res.json()
assert result["name"] == "Alice"
assert result["email"] == "alice@example.com"
assert result["age"] == 30
assert result["active"] is False
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_default_field_applied(function_type: str, session):
"""Omitting 'active' should use the model default (True) and the handler must see it."""
json_data = {"name": "Bob", "email": "bob@example.com", "age": 25}
res = json_post(f"/{function_type}/pydantic/user", json_data=json_data)
result = res.json()
assert result["name"] == "Bob"
assert result["email"] == "bob@example.com"
assert result["age"] == 25
assert result["active"] is True
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_string_to_int_coercion(function_type: str, session):
"""Pydantic v2 in lax mode (default) coerces '30' string to int 30."""
json_data = {"name": "Coerce", "email": "c@test.com", "age": "30"}
res = json_post(f"/{function_type}/pydantic/user", json_data=json_data)
result = res.json()
assert result["name"] == "Coerce"
assert result["age"] == 30
assert isinstance(result["age"], int)
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_extra_fields_ignored(function_type: str, session):
"""Extra fields not in the model should be silently ignored (pydantic v2 default)."""
json_data = {"name": "Eve", "email": "eve@example.com", "age": 28, "extra_field": "should_be_ignored", "another": 99}
res = json_post(f"/{function_type}/pydantic/user", json_data=json_data)
result = res.json()
assert result["name"] == "Eve"
assert result["age"] == 28
assert "extra_field" not in result
assert "another" not in result
# ===== Invalid Pydantic Body — error structure verification =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_missing_single_required_field(function_type: str, session):
"""Missing 'age' should produce exactly one error with correct loc, type, and msg."""
json_data = {"name": "Charlie", "email": "charlie@example.com"}
res = json_post(
f"/{function_type}/pydantic/user",
json_data=json_data,
expected_status_code=422,
should_check_response=False,
)
assert res.status_code == 422
result = res.json()
assert result["error"] == "Validation Error"
errors = result["detail"]
assert isinstance(errors, list)
assert len(errors) == 1
err = errors[0]
assert err["loc"] == ["age"]
assert err["type"] == "missing"
assert "required" in err["msg"].lower()
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_missing_all_required_fields(function_type: str, session):
"""Sending {} should produce errors for all 3 required fields (name, email, age)."""
res = json_post(
f"/{function_type}/pydantic/user",
json_data={},
expected_status_code=422,
should_check_response=False,
)
assert res.status_code == 422
result = res.json()
assert result["error"] == "Validation Error"
errors = result["detail"]
assert isinstance(errors, list)
error_fields = {tuple(e["loc"]) for e in errors}
assert ("name",) in error_fields
assert ("email",) in error_fields
assert ("age",) in error_fields
for err in errors:
assert err["type"] == "missing"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_wrong_type_error_detail(function_type: str, session):
"""Wrong type should produce error with correct loc and a meaningful msg."""
json_data = {"name": "Diana", "email": "diana@example.com", "age": "not_a_number"}
res = json_post(
f"/{function_type}/pydantic/user",
json_data=json_data,
expected_status_code=422,
should_check_response=False,
)
assert res.status_code == 422
result = res.json()
assert result["error"] == "Validation Error"
errors = result["detail"]
age_errors = [e for e in errors if e["loc"] == ["age"]]
assert len(age_errors) == 1
assert "int" in age_errors[0]["type"]
assert "input" in age_errors[0]
assert age_errors[0]["input"] == "not_a_number"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_multiple_type_errors(function_type: str, session):
"""Multiple fields with wrong types should each produce their own error."""
json_data = {"name": 12345, "email": True, "age": "bad"}
res = json_post(
f"/{function_type}/pydantic/user",
json_data=json_data,
expected_status_code=422,
should_check_response=False,
)
assert res.status_code == 422
result = res.json()
error_locs = {tuple(e["loc"]) for e in result["detail"]}
assert ("name",) in error_locs
assert ("email",) in error_locs
assert ("age",) in error_locs
# ===== Malformed / edge-case bodies =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_invalid_json_syntax(function_type: str, session):
"""Completely invalid JSON should return 422 with 'Invalid request body' error."""
res = _raw_post(f"/{function_type}/pydantic/user", data="not json at all {{{")
assert res.status_code == 422
result = res.json()
assert "error" in result
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_empty_body(function_type: str, session):
"""Empty body should return 422."""
res = _raw_post(f"/{function_type}/pydantic/user", data="")
assert res.status_code == 422
result = res.json()
assert "error" in result
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_json_array_body(function_type: str, session):
"""A JSON array instead of an object should return 422."""
res = _raw_post(f"/{function_type}/pydantic/user", data='[{"name": "X"}]')
assert res.status_code == 422
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_null_body(function_type: str, session):
"""JSON null body should return 422."""
res = _raw_post(f"/{function_type}/pydantic/user", data="null")
assert res.status_code == 422
# ===== Pydantic + Request object =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_with_request_object(function_type: str, session):
"""Handler receiving both Request and Pydantic model must see both correctly."""
json_data = {"name": "Frank", "email": "frank@example.com", "age": 35}
res = json_post(f"/{function_type}/pydantic/user_with_request", json_data=json_data)
result = res.json()
assert result["method"] == "POST"
assert result["name"] == "Frank"
assert result["email"] == "frank@example.com"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_with_request_validation_still_works(function_type: str, session):
"""Validation must still trigger 422 even when Request is in the signature."""
json_data = {"name": "Frank"} # missing email and age
res = json_post(
f"/{function_type}/pydantic/user_with_request",
json_data=json_data,
expected_status_code=422,
should_check_response=False,
)
assert res.status_code == 422
result = res.json()
assert result["error"] == "Validation Error"
error_fields = {tuple(e["loc"]) for e in result["detail"]}
assert ("email",) in error_fields
assert ("age",) in error_fields
# ===== Nested Pydantic Models =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_nested_model_valid(function_type: str, session):
"""Valid nested model should be parsed and accessible through the parent."""
json_data = {
"name": "Grace",
"email": "grace@example.com",
"address": {"street": "123 Main St", "city": "Springfield", "zip_code": "62701"},
}
res = json_post(f"/{function_type}/pydantic/nested", json_data=json_data)
result = res.json()
assert result["name"] == "Grace"
assert result["city"] == "Springfield"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_nested_model_missing_nested_fields(function_type: str, session):
"""Missing fields in nested model should produce errors with correct nested loc paths."""
json_data = {
"name": "Grace",
"email": "grace@example.com",
"address": {"street": "123 Main St"}, # missing city and zip_code
}
res = json_post(
f"/{function_type}/pydantic/nested",
json_data=json_data,
expected_status_code=422,
should_check_response=False,
)
assert res.status_code == 422
result = res.json()
assert result["error"] == "Validation Error"
errors = result["detail"]
error_locs = {tuple(e["loc"]) for e in errors}
assert ("address", "city") in error_locs
assert ("address", "zip_code") in error_locs
for err in errors:
assert err["type"] == "missing"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_nested_model_missing_entirely(function_type: str, session):
"""Missing the entire nested object should produce an error at the parent field."""
json_data = {"name": "Grace", "email": "grace@example.com"}
res = json_post(
f"/{function_type}/pydantic/nested",
json_data=json_data,
expected_status_code=422,
should_check_response=False,
)
assert res.status_code == 422
result = res.json()
errors = result["detail"]
address_errors = [e for e in errors if e["loc"] == ["address"]]
assert len(address_errors) == 1
assert address_errors[0]["type"] == "missing"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_nested_model_wrong_type(function_type: str, session):
"""Passing a non-object for the nested model should return 422."""
json_data = {
"name": "Grace",
"email": "grace@example.com",
"address": "not an object",
}
res = json_post(
f"/{function_type}/pydantic/nested",
json_data=json_data,
expected_status_code=422,
should_check_response=False,
)
assert res.status_code == 422
result = res.json()
errors = result["detail"]
address_errors = [e for e in errors if "address" in e["loc"]]
assert len(address_errors) >= 1
# ===== Pydantic with PUT =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_put_valid(function_type: str, session):
"""Pydantic validation must work with PUT method."""
json_data = {"name": "Hank", "email": "hank@example.com", "age": 40}
res = requests.put(f"{BASE_URL}/{function_type}/pydantic/user", json=json_data)
result = res.json()
assert result["updated"] is True
assert result["name"] == "Hank"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_put_invalid(function_type: str, session):
"""PUT with invalid body must also return 422 with proper error structure."""
json_data = {"name": "Hank"} # missing email and age
res = requests.put(f"{BASE_URL}/{function_type}/pydantic/user", json=json_data)
assert res.status_code == 422
result = res.json()
assert result["error"] == "Validation Error"
error_fields = {tuple(e["loc"]) for e in result["detail"]}
assert ("email",) in error_fields
assert ("age",) in error_fields
# ===== Pydantic with PATCH =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_patch_valid(function_type: str, session):
"""Pydantic validation must work with PATCH method."""
json_data = {"name": "Iris", "email": "iris@example.com", "age": 29}
res = requests.patch(f"{BASE_URL}/{function_type}/pydantic/user", json=json_data)
result = res.json()
assert result["patched"] is True
assert result["name"] == "Iris"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_patch_invalid(function_type: str, session):
"""PATCH with invalid body must also return 422."""
json_data = {"name": "Iris"} # missing email and age
res = requests.patch(f"{BASE_URL}/{function_type}/pydantic/user", json=json_data)
assert res.status_code == 422
result = res.json()
assert result["error"] == "Validation Error"
error_fields = {tuple(e["loc"]) for e in result["detail"]}
assert ("email",) in error_fields
assert ("age",) in error_fields
# ===== Pydantic with DELETE =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_delete_valid(function_type: str, session):
"""Pydantic validation must work with DELETE method."""
json_data = {"name": "Zara", "email": "zara@example.com", "age": 33}
res = requests.delete(f"{BASE_URL}/{function_type}/pydantic/user", json=json_data)
result = res.json()
assert result["deleted"] is True
assert result["name"] == "Zara"
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_delete_invalid(function_type: str, session):
"""DELETE with invalid body must also return 422 with proper error structure."""
json_data = {"name": "Zara"} # missing email and age
res = requests.delete(f"{BASE_URL}/{function_type}/pydantic/user", json=json_data)
assert res.status_code == 422
result = res.json()
assert result["error"] == "Validation Error"
error_fields = {tuple(e["loc"]) for e in result["detail"]}
assert ("email",) in error_fields
assert ("age",) in error_fields
# ===== Returning Pydantic models directly =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_return_model_directly(function_type: str, session):
"""Returning a Pydantic model from a handler should auto-serialize to JSON."""
json_data = {"name": "Jack", "email": "jack@example.com", "age": 32}
res = requests.post(f"{BASE_URL}/{function_type}/pydantic/return_model", json=json_data)
assert res.status_code == 200
assert "application/json" in res.headers.get("content-type", "")
result = res.json()
assert result["name"] == "Jack"
assert result["email"] == "jack@example.com"
assert result["age"] == 32
assert result["active"] is True # default field
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_return_model_preserves_all_fields(function_type: str, session):
"""Returned model should include every field, including those with defaults."""
json_data = {"name": "Kate", "email": "kate@example.com", "age": 27, "active": False}
res = requests.post(f"{BASE_URL}/{function_type}/pydantic/return_model", json=json_data)
result = res.json()
assert result["name"] == "Kate"
assert result["email"] == "kate@example.com"
assert result["age"] == 27
assert result["active"] is False
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_return_model_validation_still_works(function_type: str, session):
"""Validation should still trigger 422 even when the route returns a model."""
json_data = {"name": "Kate"} # missing email and age
res = requests.post(f"{BASE_URL}/{function_type}/pydantic/return_model", json=json_data)
assert res.status_code == 422
result = res.json()
assert result["error"] == "Validation Error"
# ===== Returning lists of Pydantic models =====
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_pydantic_return_list_of_models(function_type: str, session):
"""Returning a list of Pydantic models should auto-serialize to a JSON array."""
json_data = {"name": "Leo", "email": "leo@example.com", "age": 45}
res = requests.post(f"{BASE_URL}/{function_type}/pydantic/return_list", json=json_data)
assert res.status_code == 200
assert "application/json" in res.headers.get("content-type", "")
result = res.json()
assert isinstance(result, list)
assert len(result) == 2
assert result[0]["name"] == "Leo"
assert result[1]["name"] == "Leo"
assert result[0]["active"] is True
================================================
FILE: integration_tests/test_request_json.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import post
@pytest.mark.parametrize(
"route, body, expected_result",
[
("/sync/request_json", '{"hello": "world"}', ""),
("/sync/request_json/key", '{"key": "world"}', "world"),
("/sync/request_json", '{"hello": "world"', "None"),
("/async/request_json", '{"hello": "world"}', ""),
("/async/request_json", '{"hello": "world"', "None"),
],
)
def test_request(route, body, expected_result):
res = post(route, body)
assert res.text == expected_result
================================================
FILE: integration_tests/test_split_request_params.py
================================================
import pytest
from integration_tests.helpers.http_methods_helpers import get, json_post, post
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
@pytest.mark.parametrize("type_route", ["split_request_untyped", "split_request_typed"])
def test_split_request_params_get_query_params(session, type_route, function_type):
r = get(f"/{function_type}/{type_route}/query_params?hello=robyn")
assert r.json() == {"hello": ["robyn"]}
r = get(f"/{function_type}/{type_route}/query_params?hello=robyn&a=1&b=2")
assert r.json() == {"hello": ["robyn"], "a": ["1"], "b": ["2"]}
r = get(f"/{function_type}/{type_route}/query_params")
assert r.json() == {}
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
@pytest.mark.parametrize("type_route", ["split_request_untyped", "split_request_typed"])
def test_split_request_params_get_headers(session, type_route, function_type):
r = get(f"/{function_type}/{type_route}/headers")
assert r.text == "robyn"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
@pytest.mark.parametrize("type_route", ["split_request_untyped", "split_request_typed"])
def test_split_request_params_get_path_params(session, type_route, function_type):
r = get(f"/{function_type}/{type_route}/path_params/123")
assert r.json() == {"id": "123"}
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
@pytest.mark.parametrize("type_route", ["split_request_untyped", "split_request_typed"])
def test_split_request_params_get_method(session, type_route, function_type):
r = get(f"/{function_type}/{type_route}/method")
assert r.text == "GET"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
@pytest.mark.parametrize("type_route", ["split_request_untyped", "split_request_typed"])
def test_split_request_params_get_body(session, type_route, function_type):
res = post(f"/{function_type}/{type_route}/body", data={"hello": "world"})
assert res.text == "hello=world"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
@pytest.mark.parametrize("type_route", ["split_request_untyped", "split_request_typed"])
def test_split_request_params_get_combined(session, type_route, function_type):
res = post(
f"/{function_type}/{type_route}/combined?hello=robyn&a=1&b=2",
data={"hello": "world"},
)
out = res.json()
assert out["query_params"] == {"hello": ["robyn"], "a": ["1"], "b": ["2"]}
assert out["body"] == "hello=world"
assert out["method"] == "POST"
assert out["url"] == f"/{function_type}/{type_route}/combined"
assert out["headers"] == "robyn"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_split_request_params_typed_untyped_post_combined(session, function_type):
res = post(
f"/{function_type}/split_request_typed_untyped/combined?hello=robyn&a=1&b=2",
data={"hello": "world"},
)
out = res.json()
assert out["query_params"] == {"hello": ["robyn"], "a": ["1"], "b": ["2"]}
assert out["body"] == "hello=world"
assert out["method"] == "POST"
assert out["url"] == f"/{function_type}/split_request_typed_untyped/combined"
assert out["headers"] == "robyn"
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_split_request_params_get_combined_failure(session, function_type):
# 'vishnu' is an unknown param with no default — now returns 400 (was 500 before easy-access params)
# because unresolved params are treated as missing required query params
res = post(f"/{function_type}/split_request_typed_untyped/combined/failure?hello=robyn&a=1&b=2", data={"hello": "world"}, should_check_response=False)
assert 400 == res.status_code
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_body_bare(session, function_type):
"""Test that bare JsonBody passes the parsed JSON dict to the handler."""
res = json_post(f"/{function_type}/json_body/bare", json_data={"hello": "world", "count": 42})
assert res.json() == {"hello": "world", "count": 42}
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_json_body_typed(session, function_type):
"""Test that typed JsonBody subclass passes the parsed JSON dict to the handler."""
res = json_post(f"/{function_type}/json_body/typed", json_data={"fahrenheit": 212})
result = res.json()
assert result["celsius"] == pytest.approx(100.0)
================================================
FILE: integration_tests/test_sse.py
================================================
import json
import pytest
import requests
from integration_tests.helpers.http_methods_helpers import BASE_URL
from robyn.responses import SSEMessage, SSEResponse, StreamingResponse
@pytest.mark.benchmark
def test_sse_basic_headers(session):
"""Test that SSE endpoints return correct headers"""
response = requests.get(f"{BASE_URL}/sse/basic", stream=True)
assert response.status_code == 200
assert response.headers.get("Content-Type") == "text/event-stream"
# Accept either clean optimized headers or legacy compatibility
cache_control = response.headers.get("Cache-Control")
assert cache_control in ["no-cache, no-store, must-revalidate", "no-cache, no-cache, no-store, must-revalidate"]
@pytest.mark.benchmark
def test_sse_basic_stream(session):
"""Test basic SSE streaming with simple data messages"""
response = requests.get(f"{BASE_URL}/sse/basic", stream=True, timeout=5)
response.raise_for_status()
content = ""
for chunk in response.iter_content(chunk_size=1024, decode_unicode=True):
if chunk:
content += chunk
if content.count("\n\n") >= 3: # Got 3 messages
break
# Parse events
events = []
for line in content.split("\n"):
if line.startswith("data: "):
events.append(line[6:]) # Remove 'data: ' prefix
assert len(events) >= 3
for i in range(3):
assert f"Test message {i}" in events
@pytest.mark.benchmark
def test_sse_formatted_messages(session):
"""Test SSE messages formatted with SSEMessage helper"""
response = requests.get(f"{BASE_URL}/sse/formatted", stream=True, timeout=5)
response.raise_for_status()
content = ""
for chunk in response.iter_content(chunk_size=1024, decode_unicode=True):
if chunk:
content += chunk
if content.count("\n\n") >= 3:
break
# Should contain event and id fields
assert "event: test" in content
assert "id: 0" in content
assert "id: 1" in content
assert "id: 2" in content
# Parse data lines
data_lines = []
for line in content.split("\n"):
if line.startswith("data: "):
data_lines.append(line[6:])
assert len(data_lines) >= 3
for i in range(3):
assert f"Formatted message {i}" in data_lines
@pytest.mark.benchmark
def test_sse_json_data(session):
"""Test SSE streaming with JSON data"""
response = requests.get(f"{BASE_URL}/sse/json", stream=True, timeout=5)
response.raise_for_status()
content = ""
for chunk in response.iter_content(chunk_size=1024, decode_unicode=True):
if chunk:
content += chunk
if content.count("\n\n") >= 3:
break
# Parse data lines
data_lines = []
for line in content.split("\n"):
if line.startswith("data: "):
data_lines.append(line[6:])
assert len(data_lines) >= 3
for i in range(3):
json_data = json.loads(data_lines[i])
assert json_data["id"] == i
assert json_data["message"] == f"JSON message {i}"
assert json_data["type"] == "test"
@pytest.mark.benchmark
def test_sse_named_events(session):
"""Test SSE with different event types"""
response = requests.get(f"{BASE_URL}/sse/named_events", stream=True, timeout=5)
response.raise_for_status()
content = ""
for chunk in response.iter_content(chunk_size=1024, decode_unicode=True):
if chunk:
content += chunk
if content.count("\n\n") >= 3:
break
# Should contain different event types
assert "event: start" in content
assert "event: progress" in content
assert "event: end" in content
# Should contain corresponding data
assert "data: Test started" in content
assert "data: Test in progress" in content
assert "data: Test completed" in content
@pytest.mark.benchmark
def test_sse_async_endpoint(session):
"""Test async SSE endpoint"""
response = requests.get(f"{BASE_URL}/sse/async", stream=True, timeout=5)
response.raise_for_status()
content = ""
for chunk in response.iter_content(chunk_size=1024, decode_unicode=True):
if chunk:
content += chunk
if content.count("\n\n") >= 3:
break
# Parse data lines
data_lines = []
for line in content.split("\n"):
if line.startswith("data: "):
data_lines.append(line[6:])
assert len(data_lines) >= 3
for i in range(3):
assert f"Async message {i}" in data_lines
@pytest.mark.benchmark
def test_sse_single_message(session):
"""Test SSE endpoint that sends only one message"""
response = requests.get(f"{BASE_URL}/sse/single", stream=True, timeout=3)
response.raise_for_status()
content = ""
for chunk in response.iter_content(chunk_size=1024, decode_unicode=True):
if chunk:
content += chunk
if "\n\n" in content: # Got at least one message
break
# Parse data lines
data_lines = []
for line in content.split("\n"):
if line.startswith("data: "):
data_lines.append(line[6:])
assert len(data_lines) == 1
assert data_lines[0] == "Single message"
@pytest.mark.benchmark
def test_sse_empty_stream(session):
"""Test SSE endpoint that sends no messages"""
response = requests.get(f"{BASE_URL}/sse/empty", stream=True, timeout=2)
response.raise_for_status()
content = ""
for chunk in response.iter_content(chunk_size=1024, decode_unicode=True):
if chunk:
content += chunk
# Don't wait forever for empty stream
break
# Parse data lines
data_lines = []
for line in content.split("\n"):
if line.startswith("data: "):
data_lines.append(line[6:])
assert len(data_lines) == 0
@pytest.mark.benchmark
def test_sse_custom_headers(session):
"""Test SSE endpoint with custom headers; SSE responses should not include default CORS headers for cross-origin EventSource support"""
response = requests.get(f"{BASE_URL}/sse/with_headers", stream=True)
assert response.status_code == 200
assert response.headers.get("X-Custom-Header") == "custom-value"
assert response.headers.get("Content-Type") == "text/event-stream"
# SSE responses should not include default CORS headers
assert response.headers.get("Access-Control-Allow-Origin") is None
assert response.headers.get("Access-Control-Allow-Headers") is None
@pytest.mark.benchmark
def test_sse_custom_status_code(session):
"""Test SSE endpoint with custom status code"""
response = requests.get(f"{BASE_URL}/sse/status_code", stream=True)
assert response.status_code == 201
assert response.headers.get("Content-Type") == "text/event-stream"
@pytest.mark.benchmark
def test_sse_middleware_compatibility(session):
"""Test that SSE endpoints work with global middleware"""
response = requests.get(f"{BASE_URL}/sse/basic", stream=True)
# Should have global response headers from middleware
assert response.headers.get("server") == "robyn"
def test_sse_message_formatter():
"""Test the SSEMessage formatter utility function"""
# Test basic message
result = SSEMessage("Hello world")
assert "data: Hello world\n\n" in result
# Test with event type
result = SSEMessage("Hello", event="greeting")
assert "event: greeting\n" in result
assert "data: Hello\n\n" in result
# Test with ID
result = SSEMessage("Hello", id="123")
assert "id: 123\n" in result
assert "data: Hello\n\n" in result
# Test with retry
result = SSEMessage("Hello", retry=5000)
assert "retry: 5000\n" in result
assert "data: Hello\n\n" in result
# Test with all parameters
result = SSEMessage("Hello", event="test", id="456", retry=3000)
assert "event: test\n" in result
assert "id: 456\n" in result
assert "retry: 3000\n" in result
assert "data: Hello\n\n" in result
# Test multiline data
result = SSEMessage("Line 1\nLine 2")
assert "data: Line 1\ndata: Line 2\n\n" in result
def test_sse_message_edge_cases():
"""Test SSEMessage with edge cases"""
# Test empty message
result = SSEMessage("")
assert result == "data: \n\n"
# Test None message (should handle gracefully)
try:
result = SSEMessage(None)
assert "data:" in result
except TypeError:
# This is acceptable behavior
pass
# Test message with special characters
special_message = "Hello\nWorld\r\nWith\tTabs"
result = SSEMessage(special_message)
assert "data: Hello\ndata: World\ndata: With\tTabs\n\n" in result
def test_sse_response_classes():
"""Test that SSE response classes can be imported correctly"""
assert SSEResponse is not None
assert SSEMessage is not None
assert StreamingResponse is not None
# Test basic functionality
def simple_generator():
yield "data: test\n\n"
response = SSEResponse(simple_generator())
assert response.media_type == "text/event-stream"
assert response.status_code == 200
def test_sse_error_handling():
"""Test error handling in SSE streams"""
# Test with a non-existent endpoint
response = requests.get(f"{BASE_URL}/sse/nonexistent", stream=True)
assert response.status_code == 404
def test_sse_http_methods():
"""Test that SSE endpoints only work with GET"""
# GET should work
response = requests.get(f"{BASE_URL}/sse/basic", stream=True)
assert response.status_code == 200
# POST should not work (404 or 405)
response = requests.post(f"{BASE_URL}/sse/basic")
assert response.status_code in [404, 405]
@pytest.mark.benchmark
def test_sse_streaming_sync_real_time(session):
"""Test that sync SSE streaming happens in real-time with timing delays"""
import time
start_time = time.time()
response = requests.get(f"{BASE_URL}/sse/streaming_sync", stream=True, timeout=10)
response.raise_for_status()
messages_received = 0
message_times = []
content = ""
for chunk in response.iter_content(chunk_size=1, decode_unicode=True):
if chunk:
content += chunk
# Check for complete messages
while "\n\n" in content:
message_end = content.find("\n\n") + 2
message = content[:message_end]
content = content[message_end:]
if "data:" in message:
messages_received += 1
message_times.append(time.time() - start_time)
if messages_received >= 3: # Got all 3 data messages
break
if messages_received >= 3:
break
# Verify we got 3 messages
assert messages_received == 3
# Verify timing: each message should arrive ~0.5s after the previous
# Allow some tolerance for processing time (±200ms)
for i in range(1, len(message_times)):
time_diff = message_times[i] - message_times[i - 1]
assert 0.3 <= time_diff <= 0.8, f"Message {i} arrived {time_diff:.2f}s after previous (expected ~0.5s)"
@pytest.mark.benchmark
def test_sse_streaming_async_real_time(session):
"""Test that async SSE streaming happens in real-time with timing delays"""
import time
start_time = time.time()
response = requests.get(f"{BASE_URL}/sse/streaming_async", stream=True, timeout=10)
response.raise_for_status()
messages_received = 0
message_times = []
content = ""
for chunk in response.iter_content(chunk_size=1, decode_unicode=True):
if chunk:
content += chunk
# Check for complete messages
while "\n\n" in content:
message_end = content.find("\n\n") + 2
message = content[:message_end]
content = content[message_end:]
if "data:" in message and "event: async" in message:
messages_received += 1
message_times.append(time.time() - start_time)
if messages_received >= 3: # Got all 3 data messages
break
if messages_received >= 3:
break
# Verify we got 3 messages
assert messages_received == 3
# Verify timing: each message should arrive ~0.3s after the previous
# Allow some tolerance for processing time (±150ms)
for i in range(1, len(message_times)):
time_diff = message_times[i] - message_times[i - 1]
assert 0.15 <= time_diff <= 0.5, f"Async message {i} arrived {time_diff:.2f}s after previous (expected ~0.3s)"
@pytest.mark.benchmark
def test_sse_optimization_headers(session):
"""Test that optimized SSE headers are present"""
response = requests.get(f"{BASE_URL}/sse/streaming_sync", stream=True)
assert response.status_code == 200
# Check for optimization headers
assert response.headers.get("Content-Type") == "text/event-stream"
# Accept either clean optimized headers or legacy compatibility
cache_control = response.headers.get("Cache-Control")
assert cache_control in ["no-cache, no-store, must-revalidate", "no-cache, no-cache, no-store, must-revalidate"]
assert response.headers.get("Pragma") == "no-cache"
assert response.headers.get("Expires") == "0"
assert response.headers.get("X-Accel-Buffering") == "no" # Nginx buffering disabled
# Connection header might be managed by underlying HTTP infrastructure
connection = response.headers.get("Connection")
assert connection is None or connection == "keep-alive"
def test_sse_message_optimization():
"""Test that SSEMessage formatting is optimized"""
import time
# Test single-line fast path
start_time = time.perf_counter()
for _ in range(1000):
result = SSEMessage("Simple message", id="123")
single_line_time = time.perf_counter() - start_time
# Test multi-line path
start_time = time.perf_counter()
for _ in range(1000):
result = SSEMessage("Line 1\nLine 2\nLine 3", id="123")
multi_line_time = time.perf_counter() - start_time
# Single-line should be faster (this is more of a performance regression test)
assert single_line_time < multi_line_time * 2, "Single-line SSEMessage optimization may have regressed"
# Verify correctness
result = SSEMessage("Test", event="test", id="1", retry=1000)
expected_parts = ["event: test\n", "id: 1\n", "retry: 1000\n", "data: Test\n", "\n"]
for part in expected_parts:
assert part in result
================================================
FILE: integration_tests/test_static_files_with_api_routes.py
================================================
"""
Test for issue #1251: Verify that API routes work correctly
when static files are served from the same base path.
This test ensures that non-GET/HEAD HTTP methods properly fall through
to API handlers when a static file service is mounted at the same route.
"""
import pytest
from integration_tests.helpers.http_methods_helpers import get, post
# Notes:
# 1. The /static route serves the integration_tests having files & directories.
@pytest.mark.benchmark
def test_post_api_route_with_root_static_files(session):
"""Test that POST requests reach API handlers (issue #1251).
This ensures that non-GET/HEAD methods are not blocked by static file serving.
"""
response = post("/static/build")
assert response.status_code == 200
assert response.text == f"{response.request.method}:{response.request.path_url} works"
@pytest.mark.benchmark
def test_static_file_still_served_correctly(session):
"""Verify that actual static files are still served correctly."""
response = get("/static/build/index.html", should_check_response=False)
assert response.status_code == 200
# Should serve the index.html file
assert "html" in response.text.lower()
================================================
FILE: integration_tests/test_status_code.py
================================================
import pytest
import requests
from integration_tests.helpers.http_methods_helpers import BASE_URL, get
@pytest.mark.benchmark
def test_404_status_code(session):
get("/404", expected_status_code=404)
@pytest.mark.benchmark
def test_404_not_found(session):
r = get("/real/404", expected_status_code=404)
assert r.text == "Not found"
@pytest.mark.benchmark
def test_202_status_code(session):
get("/202", expected_status_code=202)
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_sync_500_internal_server_error(function_type: str, session):
get(f"/{function_type}/raise", expected_status_code=500)
# ===== Content-Type on error responses =====
@pytest.mark.benchmark
def test_404_not_found_content_type(session):
"""A request to a non-existent route should return Content-Type: text/plain"""
r = get("/real/404", expected_status_code=404)
assert r.text == "Not found"
content_type = r.headers.get("Content-Type", "")
assert "text/plain" in content_type
@pytest.mark.benchmark
@pytest.mark.parametrize("function_type", ["sync", "async"])
def test_500_error_content_type(function_type: str, session):
"""An unhandled exception should return Content-Type: text/plain"""
r = get(f"/{function_type}/raise", expected_status_code=500)
content_type = r.headers.get("Content-Type", "")
assert "text/plain" in content_type
@pytest.mark.benchmark
def test_405_method_not_allowed_content_type(session):
"""An unsupported HTTP method should return 405 with Content-Type: text/plain"""
response = requests.request("NONSTANDARD", f"{BASE_URL}/")
assert response.status_code == 405
content_type = response.headers.get("Content-Type", "")
assert "text/plain" in content_type
================================================
FILE: integration_tests/test_subrouter.py
================================================
import pytest
from websocket import create_connection
from integration_tests.helpers.http_methods_helpers import generic_http_helper, head
@pytest.mark.parametrize(
"http_method_type",
["get", "post", "put", "delete", "patch", "options", "trace"],
)
@pytest.mark.benchmark
def test_sub_router(http_method_type, session):
response = generic_http_helper(http_method_type, "sub_router/foo")
assert response.json() == {"message": "foo"}
@pytest.mark.benchmark
def test_sub_router_head(session):
response = head("sub_router/foo")
assert response.text == "" # response body is expected to be empty
@pytest.mark.benchmark
def test_sub_router_web_socket(session):
BASE_URL = "ws://127.0.0.1:8080"
ws = create_connection(f"{BASE_URL}/sub_router/ws")
assert ws.recv() == "Hello world, from ws"
ws.send("My name is?")
assert ws.recv() == "Message"
================================================
FILE: integration_tests/test_web_sockets.py
================================================
import json
import pytest
from websocket import create_connection
BASE_URL = "ws://127.0.0.1:8080"
@pytest.mark.benchmark
def test_web_socket_raw_benchmark(session):
ws = create_connection(f"{BASE_URL}/web_socket?one=hi&two=hello")
assert ws.recv() == "Hello world, from ws"
ws.send("My name is?")
# Messages may arrive in any order due to WebSocket broadcast behavior
received = sorted([ws.recv() for _ in range(3)])
expected = sorted(["This is a broadcast message", "This is a message to self", "Whaaat??"])
assert received == expected
ws.send("My name is?")
assert ws.recv() == "Whooo??"
ws.send("My name is?")
received = sorted([ws.recv() for _ in range(3)])
expected = sorted(["hi", "hello", "*chika* *chika* Slim Shady."])
assert received == expected
# this will close the connection
ws.send("test")
assert ws.recv() == "Connection closed"
def test_web_socket_json(session):
"""
Not using this as the benchmark test since this involves JSON marshalling/unmarshalling
which pollutes the benchmark measurement.
"""
ws = create_connection(f"{BASE_URL}/web_socket_json")
assert ws.recv() == "Hello world, from ws"
msg = "My name is?"
ws.send(msg)
resp = json.loads(ws.recv())
assert resp["resp"] == "Whaaat??"
assert resp["msg"] == msg
ws.send(msg)
resp = json.loads(ws.recv())
assert resp["resp"] == "Whooo??"
assert resp["msg"] == msg
ws.send(msg)
resp = json.loads(ws.recv())
assert resp["resp"] == "*chika* *chika* Slim Shady."
assert resp["msg"] == msg
def test_websocket_di(session):
"""Test dependency injection in WebSocket connect and handler phases."""
ws = create_connection(f"{BASE_URL}/web_socket_di")
# 1. on_connect should receive both global and router dependencies
assert ws.recv() == "connect: GLOBAL DEPENDENCY ROUTER DEPENDENCY"
# 2. Main handler should also receive both dependencies when processing messages
ws.send("test")
assert ws.recv() == "handler: GLOBAL DEPENDENCY ROUTER DEPENDENCY"
# Send another message to confirm DI is stable across multiple messages
ws.send("test again")
assert ws.recv() == "handler: GLOBAL DEPENDENCY ROUTER DEPENDENCY"
ws.close()
def test_websocket_large_payload(session):
"""Test that WebSocket can handle messages larger than the default 64KB frame size (#1269)"""
ws = create_connection(f"{BASE_URL}/web_socket_echo")
# Consume the empty connect message
ws.recv()
large_message = "A" * (128 * 1024) # 128KB, well above the old 64KB default
ws.send(large_message)
response = ws.recv()
assert response == large_message
assert len(response) == 128 * 1024
ws.close()
def test_websocket_empty_returns(session):
"""Test that WebSocket handlers can return nothing without causing errors"""
ws = create_connection(f"{BASE_URL}/web_socket_empty_returns")
# Connect handler returns None - no message should be received on connection
# We need to send a message to verify the connection is still active
ws.send("test message")
# Message handler returns None - no response should be sent
# The socket should still be open, not crashed
# We can verify this by closing the connection gracefully
ws.close()
# If we got here without exceptions, the test passed
================================================
FILE: llms.txt
================================================
# Robyn
> Robyn is a high-performance, community-driven, and innovator-friendly async web framework for Python with a Rust runtime. It combines Python's ease of use with Rust's performance.
## Quick Facts
- Version: 0.79.0
- Python: >= 3.10
- License: BSD 2.0
- Repository: https://github.com/sparckles/robyn
- Documentation: https://robyn.tech/documentation
- Discord: https://discord.gg/rkERZ5eNU8
## Installation
```bash
pip install robyn
```
## Basic Usage
```python
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
async def index(request):
return "Hello, World!"
app.start(port=8080)
```
## Key Features
- **Rust Runtime**: Core server written in Rust using actix-web for high performance
- **Async/Sync Support**: Both async and sync route handlers supported
- **Multi-Process Scaling**: Built-in multiprocess execution via `--processes` and `--workers`
- **WebSockets**: Native WebSocket support
- **Middlewares**: Before/after request middlewares
- **Dependency Injection**: Built-in DI system
- **OpenAPI/Swagger**: Automatic OpenAPI documentation generation
- **Hot Reloading**: Development mode with `--dev` flag
- **AI Agents**: Built-in AI agent routing via `robyn.ai`
- **MCP Support**: Model Context Protocol server capabilities via `app.mcp`
- **Templating**: Jinja2 templating support (optional)
- **CORS**: Built-in CORS helper via `ALLOW_CORS()`
- **Authentication**: AuthenticationHandler base class for custom auth
- **Static Files**: Directory serving via `app.serve_directory()`
- **SSE**: Server-Sent Events support via `SSEResponse`
- **Easy Access Parameters**: Typed path/query params with automatic coercion in handler signatures
- **Direct Rust Integration**: Embed Rust code directly in routes
## Project Structure
```
robyn/
├── src/ # Rust source code
│ ├── lib.rs # PyO3 module entry point
│ ├── server.rs # Main HTTP server implementation
│ ├── types/ # Request, Response, Headers, Cookie types
│ ├── routers/ # HTTP, WebSocket, middleware routers
│ ├── executors/ # Route execution handlers
│ └── websockets/ # WebSocket implementation
├── robyn/ # Python package
│ ├── __init__.py # Main Robyn and SubRouter classes
│ ├── router.py # Python router implementation
│ ├── authentication.py # AuthenticationHandler
│ ├── dependency_injection.py
│ ├── openapi.py # OpenAPI generation
│ ├── mcp.py # MCP protocol support
│ ├── ai.py # AI agent support
│ ├── responses.py # Response helpers (serve_file, html, SSE)
│ ├── ws.py # WebSocket class
│ └── robyn.pyi # Type stubs
├── integration_tests/ # Integration test suite
├── unit_tests/ # Unit test suite
├── docs_src/ # Documentation (Next.js)
├── granian/ # Bundled Granian server (fork)
└── examples/ # Example applications
```
## Core Classes
### Robyn / SubRouter
Main application class and sub-router for modular routes.
```python
from robyn import Robyn, SubRouter
app = Robyn(__file__)
api = SubRouter(__file__, prefix="/api")
@api.get("/users")
def get_users(request):
return {"users": []}
app.include_router(api)
```
### Request Object
```python
request.method # HTTP method
request.url # Url object (scheme, host, path)
request.headers # Headers dict-like
request.query_params # QueryParams
request.path_params # Dict of URL params
request.body # Raw bytes
request.json() # Parse JSON body
request.form_data # Multipart form data
request.ip_addr # Client IP
request.identity # Identity (if authenticated)
```
### Response Object
```python
from robyn import Response
Response(
status_code=200,
headers={"Content-Type": "application/json"},
description="body content" # or body bytes
)
```
### Decorators
```python
@app.get("/path")
@app.post("/path")
@app.put("/path")
@app.delete("/path")
@app.patch("/path")
@app.head("/path")
@app.options("/path")
@app.before_request("/path") # Middleware before
@app.after_request("/path") # Middleware after
@app.startup_handler # Server startup
@app.shutdown_handler # Server shutdown
```
### WebSockets
```python
from robyn import WebSocketDisconnect
@app.websocket("/ws")
async def handler(websocket):
try:
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
except WebSocketDisconnect:
pass
@handler.on_connect
def on_connect(websocket):
return "Connected"
@handler.on_close
def on_close(websocket):
return "Closed"
```
### Easy Access Parameters
Declare typed path and query parameters directly in handler signatures. Works for both HTTP and WebSocket handlers.
```python
from typing import List, Optional
# HTTP: path params + query params with type coercion
@app.get("/items/:id")
async def get_item(id: int, q: str, page: int = 1):
return {"id": id, "q": q, "page": page}
# Optional, List, and bool params
@app.get("/search")
def search(name: str, tags: List[str], active: bool = False, age: Optional[int] = None):
return {"name": name, "tags": tags, "active": active, "age": age}
# WebSocket: typed query params on handler and callbacks
@app.websocket("/ws")
async def handler(websocket, room: str = "default", page: int = 1):
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"room={room} page={page} msg={msg}")
@handler.on_connect
def on_connect(websocket, room: str = "default"):
return f"connected to {room}"
```
### MCP (Model Context Protocol)
```python
@app.mcp.resource("time://current")
def get_time():
return datetime.now().isoformat()
@app.mcp.tool(name="calc", description="Calculate", input_schema={...})
def calculate(args):
return eval(args["expression"])
@app.mcp.prompt(name="explain", description="Explain code", arguments=[...])
def explain_prompt(args):
return f"Please explain: {args['code']}"
```
## CLI Commands
```bash
python app.py # Start server
python app.py --dev # Development mode (hot reload)
python app.py --processes 4 # Multi-process
python app.py --workers 2 # Workers per process
python app.py --log-level DEBUG # Log level
python app.py --open-browser # Open browser on start
python app.py --create # Create new project scaffold
python app.py --docs # Open documentation
```
## Development Setup
```bash
# Clone
git clone https://github.com/sparckles/robyn.git
cd robyn
# Virtual environment
python3 -m venv .venv && source .venv/bin/activate
# Install tools
pip install pre-commit poetry maturin
# Install dependencies
poetry install --with dev --with test
# Build Rust extension
maturin develop
# Run tests
pytest
```
## Key Dependencies
- **PyO3**: Rust-Python bindings
- **actix-web**: Rust HTTP server (via cookie crate)
- **orjson**: Fast JSON serialization
- **multiprocess**: Multi-process support
- **uvloop**: Fast event loop (non-Windows)
- **watchdog**: File watching for hot reload
## Configuration
Environment variables:
- `ROBYN_HOST`: Server host (default: 127.0.0.1)
- `ROBYN_PORT`: Server port (default: 8080)
- `ROBYN_DEV_MODE`: Enable dev mode
- `ROBYN_BROWSER_OPEN`: Open browser on start
- `ROBYN_CLIENT_TIMEOUT`: Client timeout seconds
- `ROBYN_KEEP_ALIVE_TIMEOUT`: Keep-alive timeout
## Documentation Structure
Main docs at `docs_src/src/pages/documentation/`:
- `api_reference/getting_started.mdx` - Quick start guide
- `api_reference/request_object.mdx` - Request handling
- `api_reference/middlewares.mdx` - Middleware usage
- `api_reference/websockets.mdx` - WebSocket guide
- `api_reference/authentication.mdx` - Auth patterns
- `api_reference/openapi.mdx` - OpenAPI docs
- `api_reference/agents.mdx` - AI agent integration
- `api_reference/mcps.mdx` - MCP server guide
- `example_app/` - Full example application tutorial
================================================
FILE: noxfile.py
================================================
import sys
import nox
@nox.session(python=["3.10", "3.11", "3.12", "3.13", "3.14"])
def tests(session):
session.run("pip", "install", "poetry==1.3.0")
session.run("pip", "install", "maturin")
session.run(
"poetry",
"export",
"--with",
"test",
"--with",
"dev",
"--without-hashes",
"--output",
"requirements.txt",
)
session.run("pip", "install", "-r", "requirements.txt")
session.run("pip", "install", "-e", ".")
args = [
"maturin",
"build",
"-i",
"python",
"--out",
"dist",
]
if sys.platform == "darwin":
session.run("rustup", "target", "add", "x86_64-apple-darwin")
session.run("rustup", "target", "add", "aarch64-apple-darwin")
args.append("--target")
args.append("universal2-apple-darwin")
session.run(*args)
session.run("pip", "install", "--no-index", "--find-links=dist/", "robyn")
session.run("pytest")
@nox.session(python=["3.11"])
def lint(session):
session.run("pip", "install", "black", "ruff")
session.run("black", "robyn/", "integration_tests/")
================================================
FILE: pyproject.toml
================================================
[build-system]
requires = ["maturin>=1.0,<2.0"]
build-backend = "maturin"
[project]
name = "robyn"
version = "0.82.0"
description = "A Super Fast Async Python Web Framework with a Rust runtime."
readme = "README.md"
authors = [{ name = "Sanskar Jethi", email = "sansyrox@gmail.com" }]
license = { file = "LICENSE" }
classifiers = [
"Development Status :: 3 - Alpha",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"License :: OSI Approved :: BSD License",
"Operating System :: OS Independent",
"Topic :: Internet :: WWW/HTTP",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
"Programming Language :: Python :: Implementation :: CPython",
]
dependencies = [
"inquirerpy == 0.3.4",
"multiprocess >= 0.70.18, < 0.71.0",
"orjson >= 3.11.5, < 4.0.0",
"rustimport == 1.3.4",
# conditional
"uvloop~=0.22.1; sys_platform != 'win32' and platform_python_implementation == 'CPython' and platform_machine != 'armv7l'",
"watchdog >= 6.0.0, < 7.0.0",
]
[project.optional-dependencies]
"templating" = ["jinja2 >= 3.1.6, < 4.0.0"]
"pydantic" = ["pydantic >= 2.0.0, < 3.0.0"]
"all" = ["jinja2 >= 3.1.6, < 4.0.0", "pydantic >= 2.0.0, < 3.0.0"]
[project.urls]
Documentation = "https://robyn.tech/"
Repository = "https://github.com/sparckles/robyn"
Issues = "https://github.com/sparckles/robyn/issues"
Changelog = "https://github.com/sparckles/robyn/blob/main/CHANGELOG.md"
[project.scripts]
robyn = "robyn.cli:run"
test_server = "integration_tests.base_routes:main"
[dependency-groups]
dev = [
"black==23.1",
"commitizen==2.40",
"isort==5.11.5",
"maturin==1.7.4",
"pre-commit>=4.5.1,<5.0.0",
"ruff>=0.9.0",
]
test = [
"nox==2023.4.22",
"pytest>=9.0.2",
"pytest-codspeed>=4.2.0",
"requests==2.28.2",
"websocket-client==1.5.0",
]
[tool.poetry]
name = "robyn"
version = "0.82.0"
description = "A Super Fast Async Python Web Framework with a Rust runtime."
authors = ["Sanskar Jethi "]
[tool.poetry.dependencies]
python = "^3.10"
inquirerpy = "0.3.4"
maturin = "1.7.4"
watchdog = "^6.0.0"
multiprocess = "^0.70.18"
uvloop = { version = "0.22.1", markers = "sys_platform != 'win32' and (sys_platform != 'cygwin' and platform_python_implementation != 'PyPy')" }
jinja2 = { version = "^3.1.6", optional = true }
pydantic = { version = "^2.0.0", optional = true }
rustimport = "^1.3.4"
orjson = "^3.11.5"
[tool.poetry.extras]
templating = ["jinja2"]
pydantic = ["pydantic"]
all = ["jinja2", "pydantic"]
[tool.poetry.group.dev]
optional = true
[tool.poetry.group.dev.dependencies]
ruff = ">=0.9.0"
black = "23.1"
isort = "5.11.5"
pre-commit = "^4.5.1"
commitizen = "2.40"
[tool.poetry.group.test]
optional = true
[tool.poetry.group.test.dependencies]
pytest = "^9.0.2"
pytest-codspeed = "^4.2.0"
requests = "2.28.2"
nox = "2023.4.22"
websocket-client = "1.5.0"
[tool.poetry.scripts]
test_server = { callable = "integration_tests.base_routes:main" }
[tool.ruff]
line-length = 160
exclude = ["src/*", ".git", "docs"]
[tool.ruff.lint.mccabe]
max-complexity = 10
[tool.isort]
profile = "black"
line_length = 160
[tool.black]
line-length = 160
target-version = ['py39']
include = '\.pyi?$'
extend-exclude = '''
/(
# directories
\.eggs
| \.git
| \.hg
| \.mypy_cache
| \.tox
| \.venv
| build
| dist
)/
'''
[tool.pytest.ini_options]
markers = [
"benchmark: marks tests as benchmarks for performance measurement (deselect with '-m \"not benchmark\"')",
]
[tool.maturin]
module-name = "robyn"
================================================
FILE: robyn/__init__.py
================================================
import inspect
import logging
import os
import socket
from abc import ABC
from pathlib import Path
from typing import Callable, List, Optional, Union
import multiprocess as mp # type: ignore
from robyn import status_codes
from robyn.argument_parser import Config
from robyn.authentication import AuthenticationHandler
from robyn.dependency_injection import DependencyMap
from robyn.env_populator import load_vars
from robyn.events import Events
from robyn.jsonify import jsonify
from robyn.logger import Colors, logger
from robyn.mcp import MCPApp
from robyn.openapi import OpenAPI
from robyn.processpool import run_processes
from robyn.reloader import compile_rust_files
from robyn.responses import SSEMessage, SSEResponse, StreamingResponse, html, serve_file, serve_html
from robyn.robyn import FunctionInfo, Headers, HttpMethod, Request, Response, WebSocketConnector, get_version
from robyn.router import MiddlewareRouter, MiddlewareType, Router, WebSocketRouter
from robyn.types import Directory, JsonBody
from robyn.ws import WebSocketAdapter, WebSocketDisconnect, create_websocket_decorator
__version__ = get_version()
def _normalize_endpoint(endpoint: Optional[str], treat_empty_as_root: bool = False) -> Optional[str]:
"""
Normalize an endpoint to ensure consistent routing.
Rules:
- Root "/" remains unchanged
- All other endpoints get leading slash added if missing
- Trailing slashes are removed from all endpoints except root
- Empty or blank strings are handled based on treat_empty_as_root flag
- treat_empty_as_root is used for prefixes where empty/blank strings are valid
Args:
endpoint: The endpoint path to normalize.
treat_empty_as_root (used for prefixes):
If True, empty/blank strings are converted to "/" (root).
If False, empty/blank strings return None (invalid endpoint).
Returns:
Normalized endpoint path or None if invalid.
"""
if endpoint is None or (not endpoint and not treat_empty_as_root):
return None
# Remove trailing slashes
endpoint = endpoint.strip().rstrip("/")
# Handle empty result
if not endpoint:
return "/"
# Add leading slash if missing
if not endpoint.startswith("/"):
endpoint = "/" + endpoint
return endpoint
config = Config()
if (compile_path := config.compile_rust_path) is not None:
compile_rust_files(compile_path)
print("Compiled rust files")
class BaseRobyn(ABC):
"""This is the python wrapper for the Robyn binaries."""
def __init__(
self,
file_object: str,
config: Config = Config(),
openapi_file_path: Optional[str] = None,
openapi: Optional[OpenAPI] = None,
dependencies: DependencyMap = DependencyMap(),
) -> None:
directory_path = os.path.dirname(os.path.abspath(file_object))
self.file_path = file_object
self.directory_path = directory_path
self.config = config
self.dependencies = dependencies
self.openapi = openapi
self.init_openapi(openapi_file_path)
if not bool(os.environ.get("ROBYN_CLI", False)):
# the env variables are already set when are running through the cli
load_vars(project_root=directory_path)
self._handle_dev_mode()
logging.basicConfig(level=self.config.log_level)
if self.config.log_level.lower() != "warn":
logger.info(
"SERVER IS RUNNING IN VERBOSE/DEBUG MODE. Set --log-level to WARN to run in production mode.",
color=Colors.BLUE,
)
self.router = Router()
self.middleware_router = MiddlewareRouter()
self.web_socket_router = WebSocketRouter()
self.request_headers: Headers = Headers({})
self.response_headers: Headers = Headers({})
self.excluded_response_headers_paths: Optional[List[str]] = None
self.directories: List[Directory] = []
self.event_handlers: dict = {}
self.exception_handler: Optional[Callable] = None
self.authentication_handler: Optional[AuthenticationHandler] = None
self.included_routers: List[Router] = []
self._mcp_app: Optional[MCPApp] = None
def init_openapi(self, openapi_file_path: Optional[str]) -> None:
if self.config.disable_openapi:
return
if self.openapi is None:
self.openapi = OpenAPI()
if openapi_file_path:
self.openapi.override_openapi(Path(self.directory_path).joinpath(openapi_file_path))
elif Path(self.directory_path).joinpath("openapi.json").exists():
self.openapi.override_openapi(Path(self.directory_path).joinpath("openapi.json"))
else:
logger.debug("No OpenAPI spec file found; using auto-generated documentation only.", color=Colors.YELLOW)
def _handle_dev_mode(self):
cli_dev_mode = self.config.dev # --dev
env_dev_mode = os.getenv("ROBYN_DEV_MODE", "False").lower() == "true" # ROBYN_DEV_MODE=True
is_robyn = os.getenv("ROBYN_CLI", False)
if cli_dev_mode and not is_robyn:
raise SystemExit("Dev mode is not supported in the python wrapper. Please use the Robyn CLI. e.g. python3 -m robyn app.py --dev")
if env_dev_mode and not is_robyn:
logger.error("Ignoring ROBYN_DEV_MODE environment variable. Dev mode is not supported in the python wrapper.")
raise SystemExit("Dev mode is not supported in the python wrapper. Please use the Robyn CLI. e.g. python3 -m robyn app.py")
def add_route(
self,
route_type: Union[HttpMethod, str],
endpoint: str,
handler: Callable,
is_const: bool = False,
auth_required: bool = False,
openapi_name: str = "",
openapi_tags: Union[List[str], None] = None,
):
"""
Connect a URI to a handler
:param route_type str: route type between GET/POST/PUT/DELETE/PATCH/HEAD/OPTIONS/TRACE
:param endpoint str: endpoint for the route added
:param handler function: represents the sync or async function passed as a handler for the route
:param is_const bool: represents if the handler is a const function or not
:param auth_required bool: represents if the route needs authentication or not
"""
""" We will add the status code here only
"""
injected_dependencies = self.dependencies.get_dependency_map(self)
list_openapi_tags: List[str] = openapi_tags if openapi_tags else []
if isinstance(route_type, str):
http_methods = {
"GET": HttpMethod.GET,
"POST": HttpMethod.POST,
"PUT": HttpMethod.PUT,
"DELETE": HttpMethod.DELETE,
"PATCH": HttpMethod.PATCH,
"HEAD": HttpMethod.HEAD,
"OPTIONS": HttpMethod.OPTIONS,
}
route_type = http_methods[route_type]
# Normalize endpoint before adding
normalized_endpoint = _normalize_endpoint(endpoint)
if normalized_endpoint is None:
raise ValueError("Endpoint cannot be blank, do specify '/' for root endpoint")
if auth_required:
self.middleware_router.add_auth_middleware(normalized_endpoint, route_type)(handler)
# Check if this exact route (method + normalized_endpoint) already exists
route_key = f"{route_type}:{normalized_endpoint}"
if not hasattr(self, "_added_routes"):
self._added_routes = set()
if route_key in self._added_routes:
# Route already exists, raise an error
raise ValueError(f"Route {route_type} {normalized_endpoint} already exists")
# Add to our tracking set
self._added_routes.add(route_key)
add_route_response = self.router.add_route(
route_type=route_type,
endpoint=normalized_endpoint,
handler=handler,
is_const=is_const,
auth_required=auth_required,
openapi_name=openapi_name,
openapi_tags=list_openapi_tags,
exception_handler=self.exception_handler,
injected_dependencies=injected_dependencies,
)
logger.info("Added route %s %s", route_type, normalized_endpoint)
return add_route_response
def inject(self, **kwargs):
"""
Injects the dependencies for the route
:param kwargs dict: the dependencies to be injected
"""
self.dependencies.add_router_dependency(self, **kwargs)
def inject_global(self, **kwargs):
"""
Injects the dependencies for the global routes
Ideally, this function should be a global function
:param kwargs dict: the dependencies to be injected
"""
self.dependencies.add_global_dependency(**kwargs)
def before_request(self, endpoint: Optional[str] = None) -> Callable[..., None]:
"""
You can use the @app.before_request decorator to call a method before routing to the specified endpoint
:param endpoint str|None: endpoint to server the route. If None, the middleware will be applied to all the routes.
"""
return self.middleware_router.add_middleware(MiddlewareType.BEFORE_REQUEST, _normalize_endpoint(endpoint))
def after_request(self, endpoint: Optional[str] = None) -> Callable[..., None]:
"""
You can use the @app.after_request decorator to call a method after routing to the specified endpoint
:param endpoint str|None: endpoint to server the route. If None, the middleware will be applied to all the routes.
"""
return self.middleware_router.add_middleware(MiddlewareType.AFTER_REQUEST, _normalize_endpoint(endpoint))
def serve_directory(
self,
route: str,
directory_path: str,
index_file: Optional[str] = None,
show_files_listing: bool = False,
):
"""
Serves a directory at the given route
:param route str: the route at which the directory is to be served
:param directory_path str: the path of the directory to be served
:param index_file str|None: the index file to be served
:param show_files_listing bool: if the files listing should be shown or not
"""
self.directories.append(Directory(route, directory_path, show_files_listing, index_file))
def add_request_header(self, key: str, value: str) -> None:
self.request_headers.append(key, value)
def add_response_header(self, key: str, value: str) -> None:
self.response_headers.append(key, value)
def set_request_header(self, key: str, value: str) -> None:
self.request_headers.set(key, value)
def set_response_header(self, key: str, value: str) -> None:
self.response_headers.set(key, value)
def exclude_response_headers_for(self, excluded_response_headers_paths: Optional[List[str]]):
"""
To exclude response headers from certain routes
@param exclude_paths: the paths to exclude response headers from
"""
self.excluded_response_headers_paths = excluded_response_headers_paths
def add_web_socket(self, endpoint: str, handlers) -> None:
self.web_socket_router.add_route(endpoint, handlers)
def websocket(self, endpoint: str):
"""
Modern WebSocket decorator backed by Rust channels.
Usage:
@app.websocket("/ws")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
@handler.on_connect
def on_connect(websocket):
return "Welcome!"
@handler.on_close
def on_close(websocket):
return "Goodbye"
"""
return create_websocket_decorator(self)(endpoint)
def _add_event_handler(self, event_type: Events, handler: Callable) -> None:
logger.info("Added event %s handler", event_type)
if event_type not in {Events.STARTUP, Events.SHUTDOWN}:
return
is_async = inspect.iscoroutinefunction(handler)
self.event_handlers[event_type] = FunctionInfo(handler, is_async, 0, {}, {})
def startup_handler(self, handler: Callable) -> None:
self._add_event_handler(Events.STARTUP, handler)
def shutdown_handler(self, handler: Callable) -> None:
self._add_event_handler(Events.SHUTDOWN, handler)
def is_port_in_use(self, port: int) -> bool:
try:
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
return s.connect_ex(("localhost", port)) == 0
except Exception:
raise Exception(f"Invalid port number: {port}")
def _add_openapi_routes(self, auth_required: bool = False):
if self.config.disable_openapi:
return
if self.openapi is None:
logger.error("No openAPI")
return
self.router.prepare_routes_openapi(self.openapi, self.included_routers)
self.add_route(
route_type=HttpMethod.GET,
endpoint="/openapi.json",
handler=self.openapi.get_openapi_config,
is_const=True,
auth_required=auth_required,
)
self.add_route(
route_type=HttpMethod.GET,
endpoint="/docs",
handler=self.openapi.get_openapi_docs_page,
is_const=True,
auth_required=auth_required,
)
self.exclude_response_headers_for(["/docs", "/openapi.json"])
def exception(self, exception_handler: Callable):
self.exception_handler = exception_handler
def get(
self,
endpoint: str,
const: bool = False,
auth_required: bool = False,
openapi_name: str = "",
openapi_tags: List[str] = ["get"],
):
"""
The @app.get decorator to add a route with the GET method
:param endpoint str: endpoint for the route added
:param const bool: represents if the handler is a const function or not
:param auth_required bool: represents if the route needs authentication or not
:param openapi_name: str -- the name of the endpoint in the openapi spec
:param openapi_tags: List[str] -- for grouping of endpoints in the openapi spec
"""
def inner(handler):
return self.add_route(HttpMethod.GET, endpoint, handler, const, auth_required, openapi_name, openapi_tags)
return inner
def post(
self,
endpoint: str,
auth_required: bool = False,
openapi_name: str = "",
openapi_tags: List[str] = ["post"],
):
"""
The @app.post decorator to add a route with POST method
:param endpoint str: endpoint for the route added
:param auth_required bool: represents if the route needs authentication or not
:param openapi_name: str -- the name of the endpoint in the openapi spec
:param openapi_tags: List[str] -- for grouping of endpoints in the openapi spec
"""
def inner(handler):
return self.add_route(HttpMethod.POST, endpoint, handler, auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
return inner
def put(
self,
endpoint: str,
auth_required: bool = False,
openapi_name: str = "",
openapi_tags: List[str] = ["put"],
):
"""
The @app.put decorator to add a get route with PUT method
:param endpoint str: endpoint for the route added
:param auth_required bool: represents if the route needs authentication or not
:param openapi_name: str -- the name of the endpoint in the openapi spec
:param openapi_tags: List[str] -- for grouping of endpoints in the openapi spec
"""
def inner(handler):
return self.add_route(HttpMethod.PUT, endpoint, handler, auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
return inner
def delete(
self,
endpoint: str,
auth_required: bool = False,
openapi_name: str = "",
openapi_tags: List[str] = ["delete"],
):
"""
The @app.delete decorator to add a route with DELETE method
:param endpoint str: endpoint for the route added
:param auth_required bool: represents if the route needs authentication or not
:param openapi_name: str -- the name of the endpoint in the openapi spec
:param openapi_tags: List[str] -- for grouping of endpoints in the openapi spec
"""
def inner(handler):
return self.add_route(HttpMethod.DELETE, endpoint, handler, auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
return inner
def patch(
self,
endpoint: str,
auth_required: bool = False,
openapi_name: str = "",
openapi_tags: List[str] = ["patch"],
):
"""
The @app.patch decorator to add a route with PATCH method
:param endpoint str: endpoint for the route added
:param auth_required bool: represents if the route needs authentication or not
:param openapi_name: str -- the name of the endpoint in the openapi spec
:param openapi_tags: List[str] -- for grouping of endpoints in the openapi spec
"""
def inner(handler):
return self.add_route(HttpMethod.PATCH, endpoint, handler, auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
return inner
def head(
self,
endpoint: str,
auth_required: bool = False,
openapi_name: str = "",
openapi_tags: List[str] = ["head"],
):
"""
The @app.head decorator to add a route with HEAD method
:param endpoint str: endpoint for the route added
:param auth_required bool: represents if the route needs authentication or not
:param openapi_name: str -- the name of the endpoint in the openapi spec
:param openapi_tags: List[str] -- for grouping of endpoints in the openapi spec
"""
def inner(handler):
return self.add_route(HttpMethod.HEAD, endpoint, handler, auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
return inner
def options(
self,
endpoint: str,
auth_required: bool = False,
openapi_name: str = "",
openapi_tags: List[str] = ["options"],
):
"""
The @app.options decorator to add a route with OPTIONS method
:param endpoint str: endpoint for the route added
:param auth_required bool: represents if the route needs authentication or not
:param openapi_name: str -- the name of the endpoint in the openapi spec
:param openapi_tags: List[str] -- for grouping of endpoints in the openapi spec
"""
def inner(handler):
return self.add_route(HttpMethod.OPTIONS, endpoint, handler, auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
return inner
def connect(
self,
endpoint: str,
auth_required: bool = False,
openapi_name: str = "",
openapi_tags: List[str] = ["connect"],
):
"""
The @app.connect decorator to add a route with CONNECT method
:param endpoint str: endpoint for the route added
:param auth_required bool: represents if the route needs authentication or not
:param openapi_name: str -- the name of the endpoint in the openapi spec
:param openapi_tags: List[str] -- for grouping of endpoints in the openapi spec
"""
def inner(handler):
return self.add_route(HttpMethod.CONNECT, endpoint, handler, auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
return inner
def trace(
self,
endpoint: str,
auth_required: bool = False,
openapi_name: str = "",
openapi_tags: List[str] = ["trace"],
):
"""
The @app.trace decorator to add a route with TRACE method
:param endpoint str: endpoint for the route added
:param auth_required bool: represents if the route needs authentication or not
:param openapi_name: str -- the name of the endpoint in the openapi spec
:param openapi_tags: List[str] -- for grouping of endpoints in the openapi spec
"""
def inner(handler):
return self.add_route(HttpMethod.TRACE, endpoint, handler, auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
return inner
def include_router(self, router: "SubRouter"):
"""
The method to include the routes from another router.
Merge another SubRouter's routes, middlewares, websocket routes, and dependencies into this router.
Note: This operation mutates the current router's internal collections (route list, middleware lists,
websocket routes, and dependencies) and does not deep-copy the included router. Callers should ensure
there are no path or name conflicts before including a router.
:param router SubRouter: the router object to include the routes from
"""
self.included_routers.append(router)
self.router.routes.extend(router.router.routes)
self.middleware_router.global_middlewares.extend(router.middleware_router.global_middlewares)
self.middleware_router.route_middlewares.extend(router.middleware_router.route_middlewares)
if not self.config.disable_openapi and self.openapi is not None:
self.openapi.add_subrouter_paths(self.openapi)
# extend the websocket routes
prefix = _normalize_endpoint(router.prefix, treat_empty_as_root=True)
if prefix == "/":
prefix = ""
for route, handlers in router.web_socket_router.routes.items():
normalized_route = _normalize_endpoint(route)
new_endpoint = f"{prefix}{normalized_route}"
self.web_socket_router.routes[new_endpoint] = handlers
self.dependencies.merge_dependencies(router)
def configure_authentication(self, authentication_handler: AuthenticationHandler):
"""
Configures the authentication handler for the application.
:param authentication_handler: the instance of a class inheriting the AuthenticationHandler base class
"""
self.authentication_handler = authentication_handler
self.middleware_router.set_authentication_handler(authentication_handler)
@property
def mcp(self):
"""
Get the MCP (Model Context Protocol) interface for this app.
Enables registering MCP resources, tools, and prompts that can be accessed
by MCP clients like Claude Desktop or other AI applications.
Returns:
MCPApp: MCP interface for registering handlers
Example:
@app.mcp.resource("file://documents", "Documents", "Access to document files")
def get_documents(params):
return "Document content here"
@app.mcp.tool("calculate", "Perform calculations", {
"type": "object",
"properties": {
"expression": {"type": "string", "description": "Math expression to evaluate"}
},
"required": ["expression"]
})
def calculate_tool(args):
return eval(args["expression"])
"""
if self._mcp_app is None:
self._mcp_app = MCPApp(self)
return self._mcp_app
class Robyn(BaseRobyn):
def start(self, host: str = "127.0.0.1", port: int = 8080, _check_port: bool = True, client_timeout: int = 30, keep_alive_timeout: int = 20):
"""
Starts the server
:param host str: represents the host at which the server is listening
:param port int: represents the port number at which the server is listening
:param _check_port bool: represents if the port should be checked if it is already in use
:param client_timeout int: timeout for client connections in seconds (default: 30)
:param keep_alive_timeout int: timeout for keep-alive connections in seconds (default: 20)
"""
host = os.getenv("ROBYN_HOST", host)
port = int(os.getenv("ROBYN_PORT", port))
client_timeout = int(os.getenv("ROBYN_CLIENT_TIMEOUT", client_timeout))
keep_alive_timeout = int(os.getenv("ROBYN_KEEP_ALIVE_TIMEOUT", keep_alive_timeout))
open_browser = bool(os.getenv("ROBYN_BROWSER_OPEN", self.config.open_browser))
if _check_port:
while self.is_port_in_use(port):
logger.error("Port %s is already in use. Please use a different port.", port)
try:
port = int(input("Enter a different port: "))
except Exception:
logger.error("Invalid port number. Please enter a valid port number.")
continue
if not self.config.disable_openapi:
self._add_openapi_routes()
logger.info("Docs hosted at http://%s:%s/docs", host, port)
logger.info("Robyn version: %s", __version__)
logger.info("Starting server at http://%s:%s", host, port)
mp.allow_connection_pickling()
run_processes(
host,
port,
self.directories,
self.request_headers,
self.router.get_routes(),
self.middleware_router.get_global_middlewares(),
self.middleware_router.get_route_middlewares(),
self.web_socket_router.get_routes(),
self.event_handlers,
self.config.workers,
self.config.processes,
self.response_headers,
self.excluded_response_headers_paths,
open_browser,
client_timeout,
keep_alive_timeout,
)
class SubRouter(BaseRobyn):
def __init__(self, file_object: str, prefix: str = "", config: Config = Config(), openapi: OpenAPI = OpenAPI()) -> None:
super().__init__(file_object=file_object, config=config, openapi=openapi)
self.prefix = prefix
def __add_prefix(self, endpoint: str):
# Normalize prefix, treating empty as empty (not root)
normalized_prefix = _normalize_endpoint(self.prefix, treat_empty_as_root=True)
# Handle empty endpoint - should just be the prefix
if endpoint in ("", "/"):
return normalized_prefix if normalized_prefix else "/"
# Convert root prefix to empty to avoid double slashes when making endpoint
if normalized_prefix == "/":
normalized_prefix = "" # Empty prefix for root
# Normalize and validate endpoint
normalized_endpoint = _normalize_endpoint(endpoint)
if normalized_endpoint is None:
raise ValueError("Endpoint cannot be blank, do specify '/' for root endpoint")
return f"{normalized_prefix}{normalized_endpoint}"
def get(self, endpoint: str, const: bool = False, auth_required: bool = False, openapi_name: str = "", openapi_tags: List[str] = ["get"]):
return super().get(endpoint=self.__add_prefix(endpoint), const=const, auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
def post(self, endpoint: str, auth_required: bool = False, openapi_name: str = "", openapi_tags: List[str] = ["post"]):
return super().post(endpoint=self.__add_prefix(endpoint), auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
def put(self, endpoint: str, auth_required: bool = False, openapi_name: str = "", openapi_tags: List[str] = ["put"]):
return super().put(endpoint=self.__add_prefix(endpoint), auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
def delete(self, endpoint: str, auth_required: bool = False, openapi_name: str = "", openapi_tags: List[str] = ["delete"]):
return super().delete(endpoint=self.__add_prefix(endpoint), auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
def patch(self, endpoint: str, auth_required: bool = False, openapi_name: str = "", openapi_tags: List[str] = ["patch"]):
return super().patch(endpoint=self.__add_prefix(endpoint), auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
def head(self, endpoint: str, auth_required: bool = False, openapi_name: str = "", openapi_tags: List[str] = ["head"]):
return super().head(endpoint=self.__add_prefix(endpoint), auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
def trace(self, endpoint: str, auth_required: bool = False, openapi_name: str = "", openapi_tags: List[str] = ["trace"]):
return super().trace(endpoint=self.__add_prefix(endpoint), auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
def options(self, endpoint: str, auth_required: bool = False, openapi_name: str = "", openapi_tags: List[str] = ["options"]):
return super().options(endpoint=self.__add_prefix(endpoint), auth_required=auth_required, openapi_name=openapi_name, openapi_tags=openapi_tags)
def websocket(self, endpoint: str):
"""
Modern WebSocket decorator for SubRouter with prefix support.
"""
return create_websocket_decorator(self)(endpoint)
def ALLOW_CORS(app: Robyn, origins: Union[List[str], str], headers: Union[List[str], str] = None):
"""
Configure CORS headers for the application.
Args:
app: Robyn application instance
origins: List of allowed origins or "*" for all origins
headers: List of allowed headers or "*" for all headers
"""
# Handle string input for origins
if isinstance(origins, str):
origins = [origins]
default_headers = ["Content-Type", "Authorization"]
if isinstance(headers, list):
headers = list(set(default_headers + headers))
headers = ", ".join(headers)
@app.before_request()
def cors_middleware(request):
origin = request.headers.get("Origin")
# If specific origins are set, validate the request origin
if origin and "*" not in origins and origin not in origins:
return Response(status_code=403, description="", headers={})
# Handle preflight requests
if request.method == "OPTIONS":
return Response(
status_code=204,
headers={
"Access-Control-Allow-Origin": origin if origin else (origins[0] if origins else "*"),
"Access-Control-Allow-Methods": "GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS",
"Access-Control-Allow-Headers": str(headers) if headers else "Content-Type, Authorization",
"Access-Control-Allow-Credentials": "true",
"Access-Control-Max-Age": "3600",
},
description="",
)
return request
# Set default CORS headers for all responses
if len(origins) == 1:
app.set_response_header("Access-Control-Allow-Origin", origins[0])
else:
# For multiple origins, we'll handle it dynamically in the response
app.set_response_header("Access-Control-Allow-Origin", "*")
app.set_response_header("Access-Control-Allow-Methods", "GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS")
app.set_response_header("Access-Control-Allow-Headers", str(headers) if headers else "Content-Type, Authorization")
app.set_response_header("Access-Control-Allow-Credentials", "true")
__all__ = [
"Robyn",
"Request",
"Response",
"status_codes",
"jsonify",
"serve_file",
"serve_html",
"html",
"StreamingResponse",
"SSEResponse",
"SSEMessage",
"ALLOW_CORS",
"SubRouter",
"AuthenticationHandler",
"Headers",
"WebSocketConnector",
"WebSocketAdapter",
"WebSocketDisconnect",
"JsonBody",
"MCPApp",
]
================================================
FILE: robyn/__main__.py
================================================
from robyn.cli import run
if __name__ == "__main__":
run()
================================================
FILE: robyn/_param_utils.py
================================================
"""
Shared utilities for resolving individual query/path parameters
from handler function signatures, with type coercion.
Used by both robyn/router.py (HTTP handlers) and robyn/ws.py (WebSocket handlers).
"""
import inspect
import logging
from typing import Any, Dict, Optional, Set, Tuple, Union
_logger = logging.getLogger(__name__)
_MISSING = object()
# Values that map to True/False from query string bool params
_BOOL_TRUE_STRINGS = frozenset({"true", "1", "yes", "on"})
_BOOL_FALSE_STRINGS = frozenset({"false", "0", "no", "off", ""})
class QueryParamValidationError(Exception):
"""Raised when a query or path parameter cannot be coerced to the expected type,
or when a required parameter is missing."""
def __init__(self, param_name: str, value: Optional[str], expected_type: type, message: Optional[str] = None):
self.param_name = param_name
self.value = value
self.expected_type = expected_type
if message:
self.detail = message
elif value is None:
self.detail = f"Missing required parameter: '{param_name}'"
else:
self.detail = f"Invalid value '{value}' for parameter '{param_name}': expected {expected_type.__name__}"
super().__init__(self.detail)
def unwrap_optional(annotation) -> Tuple[Any, bool]:
"""
If annotation is Optional[T] (i.e. Union[T, None]), return (T, True).
Otherwise return (annotation, False).
"""
origin = getattr(annotation, "__origin__", None)
if origin is Union:
args = annotation.__args__
non_none_args = [a for a in args if a is not type(None)]
if len(non_none_args) == 1 and type(None) in args:
return non_none_args[0], True
return annotation, False
def is_list_type(annotation) -> bool:
"""Check if annotation is List[T] or list[T]."""
origin = getattr(annotation, "__origin__", None)
return origin is list
def get_list_element_type(annotation) -> type:
"""Get the element type from List[T]. Defaults to str if not specified."""
args = getattr(annotation, "__args__", None)
if args and len(args) > 0:
return args[0]
return str
def coerce_value(value: str, target_type: type, param_name: str):
"""
Convert a string value to the target type.
Raises QueryParamValidationError on failure.
"""
if target_type is str or target_type is inspect.Parameter.empty:
return value
try:
if target_type is int:
return int(value)
if target_type is float:
return float(value)
if target_type is bool:
lower = value.lower()
if lower in _BOOL_TRUE_STRINGS:
return True
if lower in _BOOL_FALSE_STRINGS:
return False
raise ValueError(f"Cannot interpret '{value}' as bool")
# Fallback: try calling the type constructor (covers Enum, UUID, etc.)
return target_type(value)
except (ValueError, TypeError) as e:
raise QueryParamValidationError(param_name, value, target_type) from e
def resolve_individual_params(
unresolved_params: Dict[str, inspect.Parameter],
query_params,
path_params: Optional[Dict[str, str]],
route_param_names: Set[str],
) -> Dict[str, Any]:
"""
Resolve handler parameters as individual path or query parameters.
For each unresolved parameter:
1. If its name matches a route param name (from the endpoint pattern), look it up in path_params.
2. Otherwise, look it up in query_params.
3. Apply type coercion based on the parameter's annotation.
4. Fall back to the parameter's default value, or None for Optional types.
5. Raise QueryParamValidationError if a required parameter is missing.
Args:
unresolved_params: dict of param_name -> inspect.Parameter for params not yet resolved.
query_params: QueryParams object with .get() and .get_all() methods.
path_params: dict of path parameter values (may be None for WebSocket).
route_param_names: set of parameter names declared in the route pattern (e.g. from /:id).
Returns:
dict mapping param names to their resolved values.
"""
resolved = {}
for param_name, param in unresolved_params.items():
annotation = param.annotation
if annotation is inspect.Parameter.empty:
annotation = str
inner_type, is_optional = unwrap_optional(annotation)
is_list = is_list_type(inner_type)
elem_type = get_list_element_type(inner_type) if is_list else inner_type
raw_value = _MISSING
# 1. Check path params first
if path_params is not None and param_name in route_param_names:
pv = path_params.get(param_name)
if pv is not None:
raw_value = pv
# 2. Check query params
if raw_value is _MISSING and query_params is not None:
if is_list:
all_values = query_params.get_all(param_name)
if all_values is not None:
resolved[param_name] = [coerce_value(v, elem_type, param_name) for v in all_values]
continue
else:
qp_value = query_params.get(param_name, None)
if qp_value is not None:
raw_value = qp_value
# 3. Got a value — coerce it
if raw_value is not _MISSING:
resolved[param_name] = coerce_value(raw_value, inner_type, param_name)
continue
# 4. Use default value if available
if param.default is not inspect.Parameter.empty:
resolved[param_name] = param.default
continue
# 5. Optional with no default -> None
if is_optional:
resolved[param_name] = None
continue
# 6. Truly missing required parameter
raise QueryParamValidationError(param_name, None, elem_type)
return resolved
def parse_route_param_names(endpoint: str) -> Set[str]:
"""
Extract parameter names from a route endpoint pattern.
e.g. "/users/:id/posts/:post_id" -> {"id", "post_id"}
Walks the string character by character looking for ':' followed by
word characters (alphanumeric + underscore).
"""
names = set()
i = 0
length = len(endpoint)
while i < length:
if endpoint[i] == ":":
# Start of a param name — collect word characters
i += 1
start = i
while i < length and (endpoint[i].isalnum() or endpoint[i] == "_"):
i += 1
if i > start:
names.add(endpoint[start:i])
else:
i += 1
return names
================================================
FILE: robyn/ai.py
================================================
"""
This is an experimental AI integration module for Robyn framework.
A poc for the blog at https://sanskar.wtf/posts/the-future-of-robyn
Provides agent and memory functionality for building AI-powered applications for the demonstration of the vision mentioned in
"""
import logging
import os
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Union
logger = logging.getLogger(__name__)
class AIConfig:
"""Configuration class for AI providers and settings"""
def __init__(self, **kwargs):
self.config = kwargs
self._load_from_env()
def _load_from_env(self):
"""Load configuration from environment variables"""
env_vars = {
"OPENAI_API_KEY": "openai_api_key",
"ANTHROPIC_API_KEY": "anthropic_api_key",
"GOOGLE_API_KEY": "google_api_key",
"AI_MODEL": "model",
"AI_TEMPERATURE": "temperature",
"AI_MAX_TOKENS": "max_tokens",
}
for env_var, config_key in env_vars.items():
if env_var in os.environ and config_key not in self.config:
value = os.environ[env_var]
# Convert numeric values
if config_key in ["temperature", "max_tokens"]:
try:
value = float(value) if config_key == "temperature" else int(value)
except ValueError:
pass
self.config[config_key] = value
def get(self, key: str, default: Any = None) -> Any:
"""Get configuration value"""
return self.config.get(key, default)
def set(self, key: str, value: Any) -> None:
"""Set configuration value"""
self.config[key] = value
def update(self, **kwargs) -> None:
"""Update configuration with new values"""
self.config.update(kwargs)
def to_dict(self) -> Dict[str, Any]:
"""Get configuration as dictionary"""
return self.config.copy()
class MemoryProvider(ABC):
"""Abstract base class for memory providers"""
@abstractmethod
async def store(self, user_id: str, data: Dict[str, Any]) -> None:
"""Store data in memory"""
pass
@abstractmethod
async def retrieve(self, user_id: str, query: Optional[str] = None) -> List[Dict[str, Any]]:
"""Retrieve data from memory"""
pass
@abstractmethod
async def clear(self, user_id: str) -> None:
"""Clear memory for a user"""
pass
class InMemoryProvider(MemoryProvider):
"""Simple in-memory storage provider"""
def __init__(self):
self._storage: Dict[str, List[Dict[str, Any]]] = {}
async def store(self, user_id: str, data: Dict[str, Any]) -> None:
if user_id not in self._storage:
self._storage[user_id] = []
self._storage[user_id].append(data)
async def retrieve(self, user_id: str, query: Optional[str] = None) -> List[Dict[str, Any]]:
return self._storage.get(user_id, [])
async def clear(self, user_id: str) -> None:
if user_id in self._storage:
del self._storage[user_id]
class Memory:
"""Memory interface for storing and retrieving conversation history and context"""
def __init__(self, provider: Union[str, MemoryProvider], user_id: str, **kwargs):
self.user_id = user_id
if isinstance(provider, str):
if provider == "inmemory":
self.provider = InMemoryProvider()
else:
raise ValueError(f"Unknown memory provider: {provider}")
else:
self.provider = provider
async def add(self, message: str, metadata: Optional[Dict[str, Any]] = None) -> None:
"""Add a message to memory"""
data = {"message": message, "metadata": metadata or {}}
await self.provider.store(self.user_id, data)
async def get(self, query: Optional[str] = None) -> List[Dict[str, Any]]:
"""Get messages from memory"""
return await self.provider.retrieve(self.user_id, query)
async def clear(self) -> None:
"""Clear all memory for this user"""
await self.provider.clear(self.user_id)
class AgentRunner(ABC):
"""Abstract base class for agent runners"""
@abstractmethod
async def run(self, query: str, **kwargs) -> Dict[str, Any]:
"""Execute the agent with the given query"""
pass
class SimpleRunner(AgentRunner):
"""Simple runner with OpenAI integration and fallback responses"""
def __init__(self, **config):
self.config = AIConfig(**config)
self._client = None
def _get_client(self):
"""Get OpenAI client if API key is available"""
if self._client is None and self.config.get("openai_api_key"):
try:
import openai
self._client = openai.OpenAI(api_key=self.config.get("openai_api_key"))
except ImportError:
raise ImportError("openai package not installed. Install with: pip install openai")
return self._client
async def run(self, query: str, **kwargs) -> Dict[str, Any]:
"""Execute with OpenAI (requires API key)"""
client = self._get_client()
if not client:
raise ValueError("OpenAI API key is required. Set 'openai_api_key' in configuration.")
try:
# Use OpenAI
messages = [{"role": "user", "content": query}]
# Add conversation history
context = kwargs.get("context", {})
history = context.get("history", [])
if history:
for item in history[-10:]:
msg = item.get("message", str(item))
if msg.startswith("Query: "):
messages.insert(-1, {"role": "user", "content": msg[7:]})
elif msg.startswith("Response: "):
messages.insert(-1, {"role": "assistant", "content": msg[10:]})
response = client.chat.completions.create(
model=self.config.get("model", "gpt-4o"),
messages=messages,
temperature=self.config.get("temperature", 0.7),
max_tokens=self.config.get("max_tokens", 1000),
)
content = response.choices[0].message.content
metadata = {
"runner_type": "simple_openai",
"model": self.config.get("model", "gpt-4o"),
"usage": {
"prompt_tokens": response.usage.prompt_tokens,
"completion_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
},
}
if self.config.get("debug", False):
metadata["debug_info"] = {"config": self.config.to_dict()}
return {"response": content, "query": query, "metadata": metadata}
except Exception as e:
logger.error(f"Error in SimpleRunner: {e}")
raise e
class Agent:
"""AI Agent interface for handling queries with memory and execution"""
def __init__(self, runner: Union[str, AgentRunner], memory: Optional[Memory] = None, **kwargs):
self.memory = memory
if isinstance(runner, str):
if runner == "simple":
self.runner = SimpleRunner(**kwargs)
else:
raise ValueError(f"Unknown runner type: {runner}")
else:
self.runner = runner
async def run(self, query: str, history: bool = False, **kwargs) -> Dict[str, Any]:
"""Run the agent with the given query"""
context = {}
if self.memory and history:
context["history"] = await self.memory.get()
# Add context to kwargs
if context:
kwargs["context"] = context
# Execute the agent
result = await self.runner.run(query, **kwargs)
# Store the interaction in memory if available
if self.memory:
await self.memory.add(f"Query: {query}")
if "response" in result:
await self.memory.add(f"Response: {result['response']}")
return result
def memory(provider: str = "inmemory", user_id: str = "default", **kwargs) -> Memory:
"""
Create a memory instance with the specified provider
Args:
provider: Memory provider type ("inmemory")
user_id: User identifier for memory isolation
**kwargs: Additional configuration for the provider
Returns:
Memory instance
"""
return Memory(provider=provider, user_id=user_id, **kwargs)
def configure(**kwargs) -> AIConfig:
"""
Create and configure AI settings
Args:
**kwargs: Configuration options including API keys, model settings, etc.
Returns:
AIConfig instance
Example:
config = configure(
openai_api_key="your-key",
model="gpt-4",
temperature=0.7
)
"""
return AIConfig(**kwargs)
def agent(runner: str = "simple", memory: Optional[Memory] = None, config: Optional[AIConfig] = None, **kwargs) -> Agent:
"""
Create an agent instance with the specified runner
Args:
runner: Agent runner type ("simple")
memory: Optional memory instance for context
config: Optional AIConfig instance for configuration
**kwargs: Additional configuration for the runner
Returns:
Agent instance
Example:
# Simple usage
chat = agent()
# With configuration
config = configure(openai_api_key="your-key")
chat = agent(runner="simple", config=config)
# With memory
mem = memory(provider="inmemory", user_id="user123")
chat = agent(runner="simple", memory=mem)
"""
# Merge config if provided
if config:
kwargs.update(config.to_dict())
return Agent(runner=runner, memory=memory, **kwargs)
================================================
FILE: robyn/argument_parser.py
================================================
import argparse
import os
class Config:
def __init__(self) -> None:
parser = argparse.ArgumentParser(description="Robyn, a fast async web framework with a rust runtime.")
self.parser = parser
parser.add_argument(
"--processes",
type=int,
default=None,
required=False,
help="Choose the number of processes. [Default: 1]",
)
parser.add_argument(
"--workers",
type=int,
default=None,
required=False,
help="Choose the number of workers. [Default: 1]",
)
parser.add_argument(
"--dev",
dest="dev",
action="store_true",
default=None,
help="Development mode. It restarts the server based on file changes.",
)
parser.add_argument(
"--log-level",
dest="log_level",
default=None,
help="Set the log level name",
)
parser.add_argument(
"--create",
action="store_true",
default=False,
help="Create a new project template.",
)
parser.add_argument(
"--docs",
action="store_true",
default=False,
help="Open the Robyn documentation.",
)
parser.add_argument(
"--open-browser",
action="store_true",
default=False,
help="Open the browser on successful start.",
)
parser.add_argument(
"--version",
action="store_true",
default=False,
help="Show the Robyn version.",
)
parser.add_argument(
"--compile-rust-path",
dest="compile_rust_path",
default=None,
help="Compile rust files in the given path.",
)
parser.add_argument(
"--create-rust-file",
dest="create_rust_file",
default=None,
help="Create a rust file with the given name.",
)
parser.add_argument(
"--disable-openapi",
dest="disable_openapi",
action="store_true",
default=False,
help="Disable the OpenAPI documentation.",
)
parser.add_argument(
"--fast",
dest="fast",
action="store_true",
default=False,
help="Fast mode. It sets the optimal values for processes, workers and log level. However, you can override them.",
)
args, unknown_args = parser.parse_known_args()
self.fast = args.fast
self.dev = args.dev
self.processes = args.processes
self.workers = args.workers
self.create = args.create
self.docs = args.docs
self.open_browser = args.open_browser
self.version = args.version
self.compile_rust_path = args.compile_rust_path
self.create_rust_file = args.create_rust_file
self.file_path = None
self.disable_openapi = args.disable_openapi
self.log_level = args.log_level
if self.fast:
# doing this here before every other check
# so that processes, workers and log_level can be overridden
cpu_count: int = os.cpu_count() or 1
self.processes = self.processes or ((cpu_count * 2) + 1) or 1
self.workers = self.workers or 2
self.log_level = self.log_level or "WARNING"
self.processes = self.processes or 1
self.workers = self.workers or 1
# find something that ends with .py in unknown_args
for arg in unknown_args:
if arg.endswith(".py"):
self.file_path = arg
break
if self.fast and self.dev:
raise ValueError("--fast and --dev shouldn't be used together")
if self.dev and (self.processes != 1 or self.workers != 1):
raise ValueError("--processes and --workers shouldn't be used with --dev")
if self.dev and self.log_level is None:
self.log_level = "DEBUG"
elif self.log_level is None:
self.log_level = "INFO"
================================================
FILE: robyn/authentication.py
================================================
from abc import ABC, abstractmethod
from typing import Optional
from robyn.robyn import Headers, Identity, Request, Response
from robyn.status_codes import HTTP_401_UNAUTHORIZED
class AuthenticationNotConfiguredError(Exception):
"""
This exception is raised when the authentication is not configured.
"""
def __str__(self):
return "Authentication is not configured. Use app.configure_authentication() to configure it."
class TokenGetter(ABC):
@property
def scheme(self) -> str:
"""
Gets the scheme of the token.
:return: The scheme of the token.
"""
return self.__class__.__name__
@classmethod
@abstractmethod
def get_token(cls, request: Request) -> Optional[str]:
"""
Gets the token from the request.
This method should not decode the token. Decoding is the role of the authentication handler.
:param request: The request object.
:return: The encoded token.
"""
raise NotImplementedError()
@classmethod
@abstractmethod
def set_token(cls, request: Request, token: str):
"""
Sets the token in the request.
This method should not encode the token. Encoding is the role of the authentication handler.
:param request: The request object.
:param token: The encoded token.
"""
raise NotImplementedError()
class AuthenticationHandler(ABC):
def __init__(self, token_getter: TokenGetter):
"""
Creates a new instance of the AuthenticationHandler class.
This class is an abstract class used to authenticate a user.
:param token_getter: The token getter used to get the token from the request.
"""
self.token_getter = token_getter
@property
def unauthorized_response(self) -> Response:
return Response(
headers=Headers({"WWW-Authenticate": self.token_getter.scheme}),
description="Unauthorized",
status_code=HTTP_401_UNAUTHORIZED,
)
@abstractmethod
def authenticate(self, request: Request) -> Optional[Identity]:
"""
Authenticates the user.
:param request: The request object.
:return: The identity of the user.
"""
raise NotImplementedError()
class BearerGetter(TokenGetter):
"""
This class is used to get the token from the Authorization header.
The scheme of the header must be Bearer.
"""
@classmethod
def get_token(cls, request: Request) -> Optional[str]:
if request.headers.contains("authorization"):
authorization_header = request.headers.get("authorization")
else:
authorization_header = None
if not authorization_header or not authorization_header.startswith("Bearer "):
return None
return authorization_header[7:] # Remove the "Bearer " prefix
@classmethod
def set_token(cls, request: Request, token: str):
request.headers["Authorization"] = f"Bearer {token}"
================================================
FILE: robyn/cli.py
================================================
import os
import shutil
import subprocess
import sys
import webbrowser
from pathlib import Path
from typing import Optional
from InquirerPy.base.control import Choice
from InquirerPy.resolver import prompt
from robyn.env_populator import load_vars
from robyn.robyn import get_version
from .argument_parser import Config
from .reloader import create_rust_file, setup_reloader
SCAFFOLD_DIR = Path(__file__).parent / "scaffold"
CURRENT_WORKING_DIR = Path.cwd()
def create_robyn_app():
questions = [
{
"type": "input",
"message": "Directory Path:",
"name": "directory",
},
{
"type": "list",
"message": "Need Docker? (Y/N)",
"choices": [
Choice("Y", name="Y"),
Choice("N", name="N"),
],
"default": Choice("N", name="N"),
"name": "docker",
},
{
"type": "list",
"message": "Please select project type (Mongo/Postgres/Sqlalchemy/Prisma): ",
"choices": [
Choice("no-db", name="No DB"),
Choice("sqlite", name="Sqlite"),
Choice("postgres", name="Postgres"),
Choice("mongo", name="MongoDB"),
Choice("sqlalchemy", name="SqlAlchemy"),
Choice("prisma", name="Prisma"),
Choice("sqlmodel", name="SQLModel"),
],
"default": Choice("no-db", name="No DB"),
"name": "project_type",
},
]
result = prompt(questions=questions)
project_dir_path = Path(str(result["directory"])).resolve()
docker = result["docker"]
project_type = str(result["project_type"])
final_project_dir_path = (CURRENT_WORKING_DIR / project_dir_path).resolve()
print(f"Creating a new Robyn project '{final_project_dir_path}'...")
# Create a new directory for the project
os.makedirs(final_project_dir_path, exist_ok=True)
selected_project_template = (SCAFFOLD_DIR / Path(project_type)).resolve()
shutil.copytree(str(selected_project_template), str(final_project_dir_path), dirs_exist_ok=True)
# If docker is not needed, delete the docker file
if docker == "N":
os.remove(f"{final_project_dir_path}/Dockerfile")
print(f"New Robyn project created in '{final_project_dir_path}' ")
def docs():
print("Opening Robyn documentation... | Offline docs coming soon!")
webbrowser.open("https://robyn.tech")
def start_dev_server(config: Config, file_path: Optional[str] = None):
if file_path is None:
return
absolute_file_path = (Path.cwd() / file_path).resolve()
directory_path = absolute_file_path.parent
if config.dev and not os.environ.get("IS_RELOADER_RUNNING", False):
setup_reloader(str(directory_path), str(absolute_file_path))
return
def start_app_normally(config: Config):
command = [sys.executable]
for arg in sys.argv[1:]:
command.append(arg)
# Run the subprocess
subprocess.run(command, start_new_session=False)
def run():
config = Config()
if not config.file_path:
config.file_path = f"{os.getcwd()}/{__name__}"
load_vars(project_root=os.path.dirname(os.path.abspath(config.file_path)))
os.environ["ROBYN_CLI"] = "True"
if config.dev is None:
config.dev = os.getenv("ROBYN_DEV_MODE", False) == "True"
if config.create:
create_robyn_app()
elif file_name := config.create_rust_file:
create_rust_file(file_name)
elif config.version:
print(get_version())
elif config.docs:
docs()
elif config.dev:
print("Starting dev server...")
start_dev_server(config, config.file_path)
else:
try:
start_app_normally(config)
except KeyboardInterrupt:
# for the crash happening upon pressing Ctrl + C
pass
================================================
FILE: robyn/dependency_injection.py
================================================
"""This is Robyn's dependency injection file."""
from typing import Any
class DependencyMap:
def __init__(self) -> None:
self.global_dependency_map: dict[str, Any] = {}
# {'router': {'dependency_name': dependency_class}
self.router_dependency_map: dict[str, dict[str, Any]] = {}
def add_router_dependency(self, router, **kwargs):
"""Adds a dependency to a route.
Args:
router App Object: The route to add the dependency to.
kwargs (dict): The dependencies to add to the route.
"""
if router not in self.router_dependency_map:
self.router_dependency_map[router] = {}
self.router_dependency_map[router].update(**kwargs)
def add_global_dependency(self, **kwargs):
"""Adds a dependency to all routes.
Args:
kwargs (dict): The dependencies to add to all routes.
"""
for name, element in kwargs.items():
self.global_dependency_map.update({name: element})
def get_router_dependencies(self, router):
"""Gets the dependencies for a specific route.
Args:
router
Returns:
dict: The dependencies for the specified route.
"""
return self.router_dependency_map.get(router, {})
def get_global_dependencies(self):
"""Gets the dependencies for a route.
Args:
route (str): The route to get the dependencies for.
"""
return self.global_dependency_map
def merge_dependencies(self, target_router):
"""
Merge dependencies from this DependencyMap into another router's DependencyMap.
Args:
target_router: The router with which to merge dependencies.
This method iterates through the dependencies of this DependencyMap and adds any dependencies
that are not already present in the target router's DependencyMap.
"""
for dep_key in self.get_global_dependencies():
if dep_key in target_router.dependencies.get_global_dependencies():
continue
target_router.dependencies.get_global_dependencies()[dep_key] = self.get_global_dependencies()[dep_key]
def get_dependency_map(self, router) -> dict:
return {
"global_dependencies": self.get_global_dependencies(),
"router_dependencies": self.get_router_dependencies(router),
}
================================================
FILE: robyn/env_populator.py
================================================
import logging
import os
from pathlib import Path
logger = logging.getLogger(__name__)
# parse the configuration file returning a list of tuples (key, value) containing the environment variables
def parser(config_path=None, project_root=""):
"""Find robyn.env file in root of the project and parse it"""
if config_path is None:
config_path = Path(project_root) / "robyn.env"
if config_path.exists():
with open(config_path, "r") as f:
for line in f:
if line.startswith("#"):
continue
yield line.strip().split("=")
# check for the environment variables set in cli and if not set them
def load_vars(variables=None, project_root=""):
"""Main function"""
if variables is None:
variables = parser(project_root=project_root)
for var in variables:
if var[0] in os.environ:
logger.info(" Variable %s already set", var[0])
continue
else:
os.environ[var[0]] = var[1]
logger.info(" Variable %s set to %s", var[0], var[1])
================================================
FILE: robyn/events.py
================================================
from enum import Enum
class Events(Enum):
STARTUP = "startup"
SHUTDOWN = "shutdown"
================================================
FILE: robyn/exceptions.py
================================================
import http
class HTTPException(Exception):
def __init__(self, status_code: int, detail: str | None = None) -> None:
if detail is None:
detail = http.HTTPStatus(status_code).phrase
self.status_code = status_code
self.detail = detail
def __str__(self) -> str:
return f"{self.status_code}: {self.detail}"
def __repr__(self) -> str:
class_name = self.__class__.__name__
return f"{class_name}(status_code={self.status_code}, detail={self.detail})"
class WebSocketException(Exception):
def __init__(self, code: int, reason: str | None = None) -> None:
self.code = code
self.reason = reason or ""
def __str__(self) -> str:
return f"{self.code}: {self.reason}"
def __repr__(self) -> str:
class_name = self.__class__.__name__
return f"{class_name}(code={self.code}, reason={self.reason})"
__all__ = ["HTTPException", "WebSocketException"]
================================================
FILE: robyn/jsonify.py
================================================
from typing import Any, Dict, List, Union
import orjson
def jsonify(data: Union[Dict[str, Any], List[Any]]) -> str:
"""
This function serializes input data to a json string
Attributes:
data: dict or list to serialize as JSON response
"""
output_binary = orjson.dumps(data)
output_str = output_binary.decode("utf-8")
return output_str
================================================
FILE: robyn/logger.py
================================================
import logging
from enum import Enum
from typing import Optional
class Colors(Enum):
BLUE = "\033[94m"
CYAN = "\033[96m"
GREEN = "\033[92m"
YELLOW = "\033[93m"
RED = "\033[91m"
class Logger:
HEADER = "\033[95m"
ENDC = "\033[0m"
BOLD = "\033[1m"
UNDERLINE = "\033[4m"
def __init__(self):
self.logger = logging.getLogger(__name__)
def _format_msg(
self,
msg: str,
color: Optional[Colors],
bold: bool,
underline: bool,
):
result = msg
if color is not None:
result = f"{color.value}{result}{Logger.ENDC}"
if bold:
result = f"{Logger.BOLD}{result}"
if underline:
result = f"{Logger.UNDERLINE}{result}"
return result
def error(
self,
msg: str,
*args,
color: Optional[Colors] = Colors.RED,
bold: bool = False,
underline: bool = False,
):
self.logger.error(self._format_msg(msg, color, bold, underline), *args)
def warn(
self,
msg: str,
*args,
color: Optional[Colors] = Colors.YELLOW,
bold: bool = False,
underline: bool = False,
):
self.logger.warning(self._format_msg(msg, color, bold, underline), *args)
def info(
self,
msg: str,
*args,
color: Optional[Colors] = Colors.GREEN,
bold: bool = False,
underline: bool = False,
):
self.logger.info(self._format_msg(msg, color, bold, underline), *args)
def debug(
self,
msg: str,
*args,
color: Colors = Colors.BLUE,
bold: bool = False,
underline: bool = False,
):
self.logger.debug(self._format_msg(msg, color, bold, underline), *args)
logger = Logger()
================================================
FILE: robyn/mcp.py
================================================
"""
Model Context Protocol (MCP) implementation for Robyn.
This module provides MCP server functionality following the JSON-RPC 2.0 specification.
It allows Robyn applications to serve as MCP servers, exposing resources, tools, and prompts
to MCP clients like Claude Desktop or other AI applications.
"""
import inspect
import json
import logging
import re
from dataclasses import asdict, dataclass
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
logger = logging.getLogger(__name__)
def _extract_uri_params(uri: str) -> List[str]:
"""Extract parameter names from URI template like 'echo://{message}'"""
return re.findall(r"\{(\w+)\}", uri)
def _generate_schema_from_function(func: Callable) -> Dict[str, Any]:
"""Generate JSON schema from function signature"""
sig = inspect.signature(func)
properties = {}
required = []
for param_name, param in sig.parameters.items():
# Skip 'self' parameter
if param_name == "self":
continue
param_schema = {"type": "string"} # Default to string
# Try to infer type from annotation
if param.annotation != inspect.Parameter.empty:
if param.annotation is str:
param_schema["type"] = "string"
elif param.annotation is int:
param_schema["type"] = "integer"
elif param.annotation is float:
param_schema["type"] = "number"
elif param.annotation is bool:
param_schema["type"] = "boolean"
elif hasattr(param.annotation, "__origin__"):
# Handle generic types like List, Dict, etc.
param_schema["type"] = "object"
properties[param_name] = param_schema
# Add to required if no default value
if param.default == inspect.Parameter.empty:
required.append(param_name)
return {"type": "object", "properties": properties, "required": required}
def _generate_prompt_args_from_function(func: Callable) -> List[Dict[str, Any]]:
"""Generate prompt arguments from function signature"""
sig = inspect.signature(func)
arguments = []
for param_name, param in sig.parameters.items():
if param_name == "self":
continue
arg_def = {"name": param_name, "description": f"Parameter {param_name}", "required": param.default == inspect.Parameter.empty}
arguments.append(arg_def)
return arguments
@dataclass
class MCPResource:
"""Represents an MCP resource"""
uri: str
name: str
description: Optional[str] = None
mimeType: Optional[str] = None
@dataclass
class MCPTool:
"""Represents an MCP tool"""
name: str
description: str
inputSchema: Dict[str, Any]
@dataclass
class MCPPrompt:
"""Represents an MCP prompt template"""
name: str
description: str
arguments: Optional[List[Dict[str, Any]]] = None
@dataclass
class MCPMessage:
"""JSON-RPC 2.0 message structure"""
jsonrpc: str = "2.0"
id: Optional[Union[str, int]] = None
method: Optional[str] = None
params: Optional[Dict[str, Any]] = None
result: Optional[Any] = None
error: Optional[Dict[str, Any]] = None
class MCPError(Exception):
"""MCP-specific error"""
def __init__(self, code: int, message: str, data: Optional[Any] = None):
self.code = code
self.message = message
self.data = data
super().__init__(message)
class MCPHandler:
"""Handles MCP protocol requests and responses"""
def __init__(self):
self.resources: Dict[str, Callable] = {}
self.tools: Dict[str, Callable] = {}
self.prompts: Dict[str, Callable] = {}
self.resource_metadata: Dict[str, MCPResource] = {}
self.tool_metadata: Dict[str, MCPTool] = {}
self.prompt_metadata: Dict[str, MCPPrompt] = {}
self.server_info = {"name": "robyn-mcp-server", "version": "1.0.0"}
def register_resource(self, uri: str, name: str, handler: Callable, description: Optional[str] = None, mime_type: Optional[str] = None):
"""Register a resource handler"""
self.resources[uri] = handler
self.resource_metadata[uri] = MCPResource(uri=uri, name=name, description=description, mimeType=mime_type)
def register_tool(self, name: str, handler: Callable, description: str, input_schema: Dict[str, Any]):
"""Register a tool handler"""
self.tools[name] = handler
self.tool_metadata[name] = MCPTool(name=name, description=description, inputSchema=input_schema)
def register_prompt(self, name: str, handler: Callable, description: str, arguments: Optional[List[Dict[str, Any]]] = None):
"""Register a prompt handler"""
self.prompts[name] = handler
self.prompt_metadata[name] = MCPPrompt(name=name, description=description, arguments=arguments)
async def handle_request(self, request_data: Dict[str, Any]) -> Dict[str, Any]:
"""Handle an MCP JSON-RPC request"""
try:
# Parse the request
method = request_data.get("method")
params = request_data.get("params", {})
request_id = request_data.get("id")
# Handle different MCP methods
if method == "initialize":
result = await self._handle_initialize(params)
elif method == "resources/list":
result = await self._handle_list_resources(params)
elif method == "resources/read":
result = await self._handle_read_resource(params)
elif method == "tools/list":
result = await self._handle_list_tools(params)
elif method == "tools/call":
result = await self._handle_call_tool(params)
elif method == "prompts/list":
result = await self._handle_list_prompts(params)
elif method == "prompts/get":
result = await self._handle_get_prompt(params)
else:
raise MCPError(-32601, f"Method not found: {method}")
# Return successful response
return {"jsonrpc": "2.0", "id": request_id, "result": result}
except MCPError as e:
return {"jsonrpc": "2.0", "id": request_data.get("id"), "error": {"code": e.code, "message": e.message, "data": e.data}}
except Exception as e:
logger.exception("Error handling MCP request")
return {"jsonrpc": "2.0", "id": request_data.get("id"), "error": {"code": -32603, "message": "Internal error", "data": str(e)}}
async def _handle_initialize(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""Handle MCP initialize request"""
return {
"protocolVersion": "2024-11-05",
"capabilities": {"resources": {"subscribe": False, "listChanged": False}, "tools": {}, "prompts": {}},
"serverInfo": self.server_info,
}
async def _handle_list_resources(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""Handle resources/list request"""
resources = []
for uri, metadata in self.resource_metadata.items():
resources.append(asdict(metadata))
return {"resources": resources}
def _match_uri_template(self, requested_uri: str) -> Optional[Tuple[str, Dict[str, str]]]:
"""Match requested URI against registered URI templates"""
for template_uri in self.resources.keys():
# Extract parameter names from template
param_names = _extract_uri_params(template_uri)
if not param_names:
# Exact match for non-templated URIs
if requested_uri == template_uri:
return template_uri, {}
continue
# Create regex pattern from template
pattern = template_uri
for param_name in param_names:
# Use (.+) to match any characters including slashes for paths
# Use ([^/]+) for single segments
if param_name in ["path", "file_path", "directory"]:
pattern = pattern.replace(f"{{{param_name}}}", r"(.+)")
else:
pattern = pattern.replace(f"{{{param_name}}}", r"([^/]+)")
match = re.match(f"^{pattern}$", requested_uri)
if match:
# Extract parameter values
param_values = {}
for i, param_name in enumerate(param_names):
param_values[param_name] = match.group(i + 1)
return template_uri, param_values
return None
async def _handle_read_resource(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""Handle resources/read request"""
uri = params.get("uri")
if not uri:
raise MCPError(-32602, "URI is required")
# Try to match URI template
match_result = self._match_uri_template(uri)
if not match_result:
raise MCPError(-32602, f"Resource not found: {uri}")
template_uri, uri_params = match_result
handler = self.resources[template_uri]
# Call the handler with appropriate parameters based on its signature
try:
sig = inspect.signature(handler)
handler_params = list(sig.parameters.keys())
if inspect.iscoroutinefunction(handler):
if uri_params:
# Use URI parameters for templated resources
content = await handler(**uri_params)
elif handler_params:
# Handler expects parameters, pass the full params dict
content = await handler(params)
else:
# Handler expects no parameters
content = await handler()
else:
if uri_params:
# Use URI parameters for templated resources
content = handler(**uri_params)
elif handler_params:
# Handler expects parameters, pass the full params dict
content = handler(params)
else:
# Handler expects no parameters
content = handler()
except TypeError as e:
# Handle parameter mismatch errors
raise MCPError(-32603, f"Handler parameter error: {str(e)}")
# Determine content type
metadata = self.resource_metadata[template_uri]
mime_type = metadata.mimeType or "text/plain"
return {"contents": [{"uri": uri, "mimeType": mime_type, "text": str(content)}]}
async def _handle_list_tools(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""Handle tools/list request"""
tools = []
for name, metadata in self.tool_metadata.items():
tools.append(asdict(metadata))
return {"tools": tools}
async def _handle_call_tool(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""Handle tools/call request"""
name = params.get("name")
arguments = params.get("arguments", {})
if not name or name not in self.tools:
raise MCPError(-32602, f"Tool not found: {name}")
handler = self.tools[name]
# Call the tool handler
if inspect.iscoroutinefunction(handler):
result = await handler(**arguments)
else:
result = handler(**arguments)
return {"content": [{"type": "text", "text": str(result)}]}
async def _handle_list_prompts(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""Handle prompts/list request"""
prompts = []
for name, metadata in self.prompt_metadata.items():
prompts.append(asdict(metadata))
return {"prompts": prompts}
async def _handle_get_prompt(self, params: Dict[str, Any]) -> Dict[str, Any]:
"""Handle prompts/get request"""
name = params.get("name")
arguments = params.get("arguments", {})
if not name or name not in self.prompts:
raise MCPError(-32602, f"Prompt not found: {name}")
handler = self.prompts[name]
# Call the prompt handler
if inspect.iscoroutinefunction(handler):
result = await handler(**arguments)
else:
result = handler(**arguments)
# Ensure result is in the expected format
if isinstance(result, str):
messages = [{"role": "user", "content": {"type": "text", "text": result}}]
elif isinstance(result, list):
messages = result
else:
messages = [{"role": "user", "content": {"type": "text", "text": str(result)}}]
return {"description": self.prompt_metadata[name].description, "messages": messages}
class MCPApp:
"""MCP application wrapper for Robyn"""
def __init__(self, robyn_app):
self.app = robyn_app
self.handler = MCPHandler()
self._setup_routes()
def _setup_routes(self):
"""Setup MCP routes on the Robyn app"""
@self.app.post("/mcp")
async def handle_mcp_request(request):
"""Handle MCP JSON-RPC requests"""
try:
# Parse JSON request - try multiple approaches
try:
request_data = request.json()
except (ValueError, TypeError, AttributeError):
# Fallback to parsing body as string
body = request.body
if isinstance(body, str):
request_data = json.loads(body)
else:
request_data = json.loads(body.decode("utf-8"))
# Handle case where request.json() returns a string instead of dict
if isinstance(request_data, str):
request_data = json.loads(request_data)
# Handle the request
response = await self.handler.handle_request(request_data)
return response
except json.JSONDecodeError:
return {"jsonrpc": "2.0", "id": None, "error": {"code": -32700, "message": "Parse error"}}
except Exception as e:
logger.exception("Error in MCP request handler")
return {"jsonrpc": "2.0", "id": None, "error": {"code": -32603, "message": "Internal error", "data": str(e)}}
def resource(self, uri: str = None, name: str = None, description: Optional[str] = None, mime_type: Optional[str] = None):
"""
Decorator to register an MCP resource
Args:
uri: Resource URI template (e.g., "echo://{message}")
name: Human-readable name (auto-generated if not provided)
description: Resource description (auto-generated if not provided)
mime_type: MIME type (defaults to "text/plain")
Example:
@app.mcp.resource("echo://{message}")
def echo_resource(message: str) -> str:
return f"Resource echo: {message}"
"""
def decorator(func: Callable):
# Auto-generate metadata if not provided
actual_uri = uri or f"function://{func.__name__}"
actual_name = name or func.__name__.replace("_", " ").title()
actual_description = description or func.__doc__ or f"Resource: {actual_name}"
actual_mime_type = mime_type or "text/plain"
self.handler.register_resource(actual_uri, actual_name, func, actual_description, actual_mime_type)
return func
return decorator
def tool(self, name: str = None, description: str = None, input_schema: Dict[str, Any] = None):
"""
Decorator to register an MCP tool
Args:
name: Tool name (defaults to function name)
description: Tool description (auto-generated if not provided)
input_schema: JSON schema for inputs (auto-generated if not provided)
Example:
@app.mcp.tool()
def echo_tool(message: str) -> str:
return f"Tool echo: {message}"
"""
def decorator(func: Callable):
# Auto-generate metadata if not provided
actual_name = name or func.__name__
actual_description = description or func.__doc__ or f"Tool: {func.__name__}"
actual_schema = input_schema or _generate_schema_from_function(func)
self.handler.register_tool(actual_name, func, actual_description, actual_schema)
return func
return decorator
def prompt(self, name: str = None, description: str = None, arguments: Optional[List[Dict[str, Any]]] = None):
"""
Decorator to register an MCP prompt
Args:
name: Prompt name (defaults to function name)
description: Prompt description (auto-generated if not provided)
arguments: Prompt arguments (auto-generated if not provided)
Example:
@app.mcp.prompt()
def echo_prompt(message: str) -> str:
return f"Please process this message: {message}"
"""
def decorator(func: Callable):
# Auto-generate metadata if not provided
actual_name = name or func.__name__
actual_description = description or func.__doc__ or f"Prompt: {func.__name__}"
actual_arguments = arguments or _generate_prompt_args_from_function(func)
self.handler.register_prompt(actual_name, func, actual_description, actual_arguments)
return func
return decorator
================================================
FILE: robyn/openapi.py
================================================
import inspect
import json
import logging
import re
import typing
from dataclasses import asdict, dataclass, field
from importlib import resources
from inspect import Signature
from pathlib import Path
from typing import Any, Callable, Dict, List, Optional, Tuple, TypedDict, is_typeddict
from robyn.responses import html
from robyn.robyn import QueryParams, Response
from robyn.pydantic_support import get_pydantic_openapi_schema, is_pydantic_model
from robyn.types import Body, JsonBody
_logger = logging.getLogger(__name__)
class str_typed_dict(TypedDict):
key: str
value: str
@dataclass
class Contact:
"""
The contact information for the exposed API.
(https://swagger.io/specification/#contact-object)
@param name: Optional[str] The identifying name of the contact person/organization.
@param url: Optional[str] The URL pointing to the contact information. This MUST be in the form of a URL.
@param email: Optional[str] The email address of the contact person/organization. This MUST be in the form of an email address.
"""
name: Optional[str] = None
url: Optional[str] = None
email: Optional[str] = None
@dataclass
class License:
"""
The license information for the exposed API.
(https://swagger.io/specification/#license-object)
@param name: Optional[str] The license name used for the API.
@param url: Optional[str] A URL to the license used for the API. This MUST be in the form of a URL.
"""
name: Optional[str] = None
url: Optional[str] = None
@dataclass
class Server:
"""
An array of Server Objects, which provide connectivity information to a target server. If the servers property is
not provided, or is an empty array, the default value would be a Server Object with a url value of /.
(https://swagger.io/specification/#server-object)
@param url: str A URL to the target host. This URL supports Server Variables and MAY be relative,
to indicate that the host location is relative to the location where the OpenAPI document is being served.
Variable substitutions will be made when a variable is named in {brackets}.
@param description: Optional[str] An optional string describing the host designated by the URL.
"""
url: str
description: Optional[str] = None
@dataclass
class ExternalDocumentation:
"""
Additional external documentation for this operation.
(https://swagger.io/specification/#external-documentation-object)
@param description: Optional[str] A description of the target documentation.
@param url: Optional[str] The URL for the target documentation.
"""
description: Optional[str] = None
url: Optional[str] = None
@dataclass
class Components:
"""
Additional external documentation for this operation.
(https://swagger.io/specification/#components-object)
@param schemas: Optional[Dict[str, Dict]] An object to hold reusable Schema Objects.
@param responses: Optional[Dict[str, Dict]] An object to hold reusable Response Objects.
@param parameters: Optional[Dict[str, Dict]] An object to hold reusable Parameter Objects.
@param examples: Optional[Dict[str, Dict]] An object to hold reusable Example Objects.
@param requestBodies: Optional[Dict[str, Dict]] An object to hold reusable Request Body Objects.
@param securitySchemes: Optional[Dict[str, Dict]] An object to hold reusable Security Scheme Objects.
@param links: Optional[Dict[str, Dict]] An object to hold reusable Link Objects.
@param callbacks: Optional[Dict[str, Dict]] An object to hold reusable Callback Objects.
@param pathItems: Optional[Dict[str, Dict]] An object to hold reusable Callback Objects.
"""
schemas: Optional[Dict[str, Dict]] = field(default_factory=dict)
responses: Optional[Dict[str, Dict]] = field(default_factory=dict)
parameters: Optional[Dict[str, Dict]] = field(default_factory=dict)
examples: Optional[Dict[str, Dict]] = field(default_factory=dict)
requestBodies: Optional[Dict[str, Dict]] = field(default_factory=dict)
securitySchemes: Optional[Dict[str, Dict]] = field(default_factory=dict)
links: Optional[Dict[str, Dict]] = field(default_factory=dict)
callbacks: Optional[Dict[str, Dict]] = field(default_factory=dict)
pathItems: Optional[Dict[str, Dict]] = field(default_factory=dict)
@dataclass
class OpenAPIInfo:
"""
Provides metadata about the API. The metadata MAY be used by tooling as required.
(https://swagger.io/specification/#info-object)
@param title: str The title of the API.
@param version: str The version of the API.
@param description: Optional[str] A description of the API.
@param termsOfService: Optional[str] A URL to the Terms of Service for the API.
@param contact: Contact The contact information for the exposed API.
@param license: License The license information for the exposed API.
@param servers: list[Server] An list of Server objects representing the servers.
@param externalDocs: Optional[ExternalDocumentation] Additional external documentation.
@param components: Components An element to hold various schemas for the document.
"""
title: str = "Robyn API"
version: str = "1.0.0"
description: Optional[str] = None
termsOfService: Optional[str] = None
contact: Contact = field(default_factory=Contact)
license: License = field(default_factory=License)
servers: List[Server] = field(default_factory=list)
externalDocs: Optional[ExternalDocumentation] = field(default_factory=ExternalDocumentation)
components: Components = field(default_factory=Components)
@dataclass
class OpenAPI:
"""
This is the root object of the OpenAPI document.
@param info: OpenAPIInfo Provides metadata about the API.
@param openapi_spec: dict The content of openapi.json as a dict
"""
info: OpenAPIInfo = field(default_factory=OpenAPIInfo)
openapi_spec: dict = field(init=False)
openapi_file_override: bool = False # denotes whether there is an override or not.
def __post_init__(self):
"""
Initializes the openapi_spec dict
"""
if self.openapi_file_override:
return
self.openapi_spec = {
"openapi": "3.1.0",
"info": asdict(self.info),
"paths": {},
"components": asdict(self.info.components),
"servers": [asdict(server) for server in self.info.servers],
"externalDocs": asdict(self.info.externalDocs) if self.info.externalDocs.url else None,
}
def add_openapi_path_obj(self, route_type: str, endpoint: str, openapi_name: str, openapi_tags: List[str], handler: Callable):
"""
Adds the given path to openapi spec
@param route_type: str the http method as string (get, post ...)
@param endpoint: str the endpoint to be added
@param openapi_name: str the name of the endpoint
@param openapi_tags: List[str] for grouping of endpoints
@param handler: Callable the handler function for the endpoint
"""
if self.openapi_file_override:
return
query_params = None
request_body = None
return_annotation = None
signature = inspect.signature(handler)
openapi_description = inspect.getdoc(handler) or ""
if signature:
parameters = signature.parameters
if "query_params" in parameters:
query_params = parameters["query_params"].default
if query_params is Signature.empty:
query_params = None
if "body" in parameters:
request_body = parameters["body"].default
if request_body is Signature.empty:
request_body = None
# priority to typing
for parameter in parameters:
param_annotation = parameters[parameter].annotation
if inspect.isclass(param_annotation):
if issubclass(param_annotation, JsonBody):
request_body = param_annotation
elif issubclass(param_annotation, Body):
request_body = param_annotation
elif issubclass(param_annotation, QueryParams):
query_params = param_annotation
elif is_pydantic_model(param_annotation):
request_body = param_annotation
elif is_typeddict(param_annotation):
request_body = param_annotation
if signature.return_annotation is not Signature.empty:
return_annotation = signature.return_annotation
modified_endpoint, path_obj = self.get_path_obj(
endpoint, openapi_name, openapi_description, openapi_tags, query_params, request_body, return_annotation
)
if modified_endpoint not in self.openapi_spec["paths"]:
self.openapi_spec["paths"][modified_endpoint] = {}
self.openapi_spec["paths"][modified_endpoint][route_type] = path_obj
def _merge_component_schemas(self, incoming: dict):
"""Merge incoming component schemas into the spec with collision detection.
If an incoming schema name already exists and the schemas differ,
a warning is logged. The incoming schema always wins so that the
most-recently-registered route's models are used (matching the
behaviour of path registration).
"""
existing = self.openapi_spec["components"]["schemas"]
for name, schema in incoming.items():
if name in existing and existing[name] != schema:
_logger.warning(
"OpenAPI component schema '%s' is defined by multiple models with different shapes — the later definition will be used",
name,
)
existing[name] = schema
def add_subrouter_paths(self, subrouter_openapi: "OpenAPI"):
"""
Adds the subrouter paths and component schemas to main router's openapi specs.
@param subrouter_openapi: OpenAPI the OpenAPI object of the current subrouter
"""
if self.openapi_file_override:
return
for path, path_obj in subrouter_openapi.openapi_spec["paths"].items():
self.openapi_spec["paths"][path] = path_obj
subrouter_schemas = subrouter_openapi.openapi_spec.get("components", {}).get("schemas", {})
if subrouter_schemas:
self._merge_component_schemas(subrouter_schemas)
def get_path_obj(
self,
endpoint: str,
name: str,
description: str,
tags: List[str],
query_params: Optional[str_typed_dict],
request_body: Optional[str_typed_dict],
return_annotation: Optional[str_typed_dict],
) -> Tuple[str, dict]:
"""
Get the "path" openapi object according to spec
@param endpoint: str the endpoint to be added
@param name: str the name of the endpoint
@param description: Optional[str] short description of the endpoint (to be fetched from the endpoint definition by default)
@param tags: List[str] for grouping of endpoints
@param query_params: Optional[TypedDict] query params for the function
@param request_body: Optional[TypedDict] request body for the function
@param return_annotation: Optional[TypedDict] return type of the endpoint handler
@return: (str, dict) a tuple containing the endpoint with path params wrapped in braces and the "path" openapi object
according to spec
"""
if not description:
description = "No description provided"
openapi_path_object: dict = {
"summary": name,
"description": description,
"parameters": [],
"tags": tags,
}
# robyn has paths like /:url/:etc whereas openapi requires path like /{url}/{path}
# this function is used for converting path params to the required form
# initialized with endpoint for handling endpoints without path params
endpoint_with_path_params_wrapped_in_braces = endpoint
path_param_names = re.findall(r":(\w+)", endpoint)
if path_param_names:
# Convert param syntax to OpenAPI's {param} syntax
# \w+ matches word characters (letters, digits, underscores) and does not match '/',
# so each :param is captured individually without swallowing intervening path segments.
endpoint_with_path_params_wrapped_in_braces = re.sub(r":(\w+)", r"{\1}", endpoint)
for name in path_param_names:
openapi_path_object["parameters"].append(
{
"name": name,
"in": "path",
"required": True,
"schema": {"type": "string"},
}
)
if query_params:
query_param_annotations = query_params.__annotations__ if query_params is str_typed_dict else typing.get_type_hints(query_params)
for query_param in query_param_annotations:
query_param_type = self.get_openapi_type(query_param_annotations[query_param])
openapi_path_object["parameters"].append(
{
"name": query_param,
"in": "query",
"required": False,
"schema": {"type": query_param_type},
}
)
if request_body:
if is_pydantic_model(request_body):
schema, component_schemas = get_pydantic_openapi_schema(request_body)
if component_schemas:
self._merge_component_schemas(component_schemas)
request_body_object = {"content": {"application/json": {"schema": schema}}}
else:
properties = {}
request_body_annotations = request_body.__annotations__ if request_body is TypedDict else typing.get_type_hints(request_body)
for body_item in request_body_annotations:
properties[body_item] = self.get_schema_object(body_item, request_body_annotations[body_item])
request_body_object = {
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": properties,
}
}
}
}
openapi_path_object["requestBody"] = request_body_object
response_schema: dict = {}
response_type = "text/plain"
if return_annotation and return_annotation is not Response:
response_type = "application/json"
response_schema = self.get_schema_object("response object", return_annotation)
openapi_path_object["responses"] = {"200": {"description": "Successful Response", "content": {response_type: {"schema": response_schema}}}}
return endpoint_with_path_params_wrapped_in_braces, openapi_path_object
def get_openapi_type(self, typed_dict: str_typed_dict) -> str:
"""
Get actual type from the TypedDict annotations
@param typed_dict: TypedDict The TypedDict to be converted
@return: str the type inferred
"""
type_mapping = {
int: "integer",
str: "string",
bool: "boolean",
float: "number",
dict: "object",
list: "array",
}
for type_name in type_mapping:
if typed_dict is type_name:
return type_mapping[type_name]
# default to "string" if type is not found
return "string"
def get_schema_object(self, parameter: str, param_type: Any) -> dict:
"""
Get the schema object for request/response body
@param parameter: name of the parameter
@param param_type: Any the type to be inferred
@return: dict the properties object
"""
properties: dict = {
"title": parameter.capitalize(),
}
type_mapping: dict = {
int: "integer",
str: "string",
bool: "boolean",
float: "number",
dict: "object",
list: "array",
}
for type_name in type_mapping:
if param_type is type_name:
properties["type"] = type_mapping[type_name]
return properties
# Check if it's a generic type (like List[Object])
if hasattr(param_type, "__origin__"):
if param_type.__origin__ is list or param_type.__origin__ is List:
properties["type"] = "array"
# Handle the element type in the list
if hasattr(param_type, "__args__") and param_type.__args__:
item_type = param_type.__args__[0]
properties["items"] = self.get_schema_object(f"{parameter}_item", item_type)
return properties
# check for Pydantic models
if is_pydantic_model(param_type):
schema, component_schemas = get_pydantic_openapi_schema(param_type)
if component_schemas:
self._merge_component_schemas(component_schemas)
return schema
# check for Optional type
if param_type.__module__ == "typing":
properties["anyOf"] = [{"type": self.get_openapi_type(param_type.__args__[0])}, {"type": "null"}]
return properties
# check for custom classes and TypedDicts
elif inspect.isclass(param_type):
properties["type"] = "object"
properties["properties"] = {}
for e in param_type.__annotations__:
properties["properties"][e] = self.get_schema_object(e, param_type.__annotations__[e])
properties["type"] = "object"
return properties
def override_openapi(self, openapi_json_spec_path: Path):
"""
Set a pre-configured OpenAPI spec
@param openapi_json_spec_path: str the path to the json file
"""
with open(openapi_json_spec_path) as json_file:
json_file_content = json.load(json_file)
self.openapi_spec = dict(json_file_content)
self.openapi_file_override = True
def get_openapi_docs_page(self) -> Response:
"""
Handler to the swagger html page to be deployed to the endpoint `/docs`
@return: FileResponse the swagger html page
"""
with resources.open_text("robyn", "swagger.html") as path:
html_file = path.read()
return html(html_file)
def get_openapi_config(self) -> dict:
"""
Returns the openapi spec as a dict
@return: dict the openapi spec
"""
return self.openapi_spec
================================================
FILE: robyn/processpool.py
================================================
import asyncio
import signal
import sys
import webbrowser
from typing import Dict, List, Optional
from multiprocess import Process # type: ignore
from robyn.events import Events
from robyn.logger import logger
from robyn.robyn import FunctionInfo, Headers, Server, SocketHeld
from robyn.router import GlobalMiddleware, Route, RouteMiddleware
from robyn.types import Directory
def run_processes(
url: str,
port: int,
directories: List[Directory],
request_headers: Headers,
routes: List[Route],
global_middlewares: List[GlobalMiddleware],
route_middlewares: List[RouteMiddleware],
web_sockets: Dict[str, dict],
event_handlers: Dict[Events, FunctionInfo],
workers: int,
processes: int,
response_headers: Headers,
excluded_response_headers_paths: Optional[List[str]],
open_browser: bool,
client_timeout: int = 30,
keep_alive_timeout: int = 20,
) -> List[Process]:
socket = SocketHeld(url, port)
process_pool = init_processpool(
directories,
request_headers,
routes,
global_middlewares,
route_middlewares,
web_sockets,
event_handlers,
socket,
workers,
processes,
response_headers,
excluded_response_headers_paths,
client_timeout,
keep_alive_timeout,
)
def terminating_signal_handler(_sig, _frame):
logger.info("Terminating server!!", bold=True)
for process in process_pool:
process.kill()
signal.signal(signal.SIGINT, terminating_signal_handler)
signal.signal(signal.SIGTERM, terminating_signal_handler)
if open_browser:
logger.info("Opening browser...")
webbrowser.open_new_tab(f"http://{url}:{port}/")
logger.info("Press Ctrl + C to stop \n")
for process in process_pool:
process.join()
return process_pool
def init_processpool(
directories: List[Directory],
request_headers: Headers,
routes: List[Route],
global_middlewares: List[GlobalMiddleware],
route_middlewares: List[RouteMiddleware],
web_sockets: Dict[str, dict],
event_handlers: Dict[Events, FunctionInfo],
socket: SocketHeld,
workers: int,
processes: int,
response_headers: Headers,
excluded_response_headers_paths: Optional[List[str]],
client_timeout: int = 30,
keep_alive_timeout: int = 20,
) -> List[Process]:
process_pool: List = []
if sys.platform.startswith("win32") or processes == 1:
spawn_process(
directories,
request_headers,
routes,
global_middlewares,
route_middlewares,
web_sockets,
event_handlers,
socket,
workers,
response_headers,
excluded_response_headers_paths,
client_timeout,
keep_alive_timeout,
)
return process_pool
for _ in range(processes):
copied_socket = socket.try_clone()
process = Process(
target=spawn_process,
args=(
directories,
request_headers,
routes,
global_middlewares,
route_middlewares,
web_sockets,
event_handlers,
copied_socket,
workers,
response_headers,
excluded_response_headers_paths,
client_timeout,
keep_alive_timeout,
),
)
process.start()
process_pool.append(process)
return process_pool
def initialize_event_loop():
if sys.platform.startswith("win32") or sys.platform.startswith("linux-cross"):
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
return loop
else:
# uv loop doesn't support windows or arm machines at the moment
# but uv loop is much faster than native asyncio
import uvloop
uvloop.install()
loop = uvloop.new_event_loop()
asyncio.set_event_loop(loop)
return loop
def spawn_process(
directories: List[Directory],
request_headers: Headers,
routes: List[Route],
global_middlewares: List[GlobalMiddleware],
route_middlewares: List[RouteMiddleware],
web_sockets: Dict[str, dict],
event_handlers: Dict[Events, FunctionInfo],
socket: SocketHeld,
workers: int,
response_headers: Headers,
excluded_response_headers_paths: Optional[List[str]],
client_timeout: int = 30,
keep_alive_timeout: int = 20,
):
"""
This function is called by the main process handler to create a server runtime.
This functions allows one runtime per process.
:param directories List: the list of all the directories and related data
:param headers tuple: All the global headers in a tuple
:param routes Tuple[Route]: The routes tuple, containing the description about every route.
:param middlewares Tuple[Route]: The middleware routes tuple, containing the description about every route.
:param web_sockets list: This is a list of all the web socket routes
:param event_handlers Dict: This is an event dict that contains the event handlers
:param socket SocketHeld: This is the main tcp socket, which is being shared across multiple processes.
:param process_name string: This is the name given to the process to identify the process
:param workers int: This is the name given to the process to identify the process
"""
loop = initialize_event_loop()
server = Server()
# TODO: if we remove the dot access
# the startup time will improve in the server
for directory in directories:
server.add_directory(*directory.as_list())
server.apply_request_headers(request_headers)
server.apply_response_headers(response_headers)
server.set_response_headers_exclude_paths(excluded_response_headers_paths)
for route in routes:
route_type, endpoint, function, is_const, auth_required, openapi_name, openapi_tags = route
server.add_route(route_type, endpoint, function, is_const)
for middleware_type, middleware_function in global_middlewares:
server.add_global_middleware(middleware_type, middleware_function)
for middleware_type, endpoint, function, route_type in route_middlewares:
server.add_middleware_route(middleware_type, endpoint, function, route_type)
if Events.STARTUP in event_handlers:
server.add_startup_handler(event_handlers[Events.STARTUP])
if Events.SHUTDOWN in event_handlers:
server.add_shutdown_handler(event_handlers[Events.SHUTDOWN])
for endpoint in web_sockets:
web_socket = web_sockets[endpoint]
server.add_web_socket_route(
endpoint,
web_socket["connect"],
web_socket["close"],
web_socket["message"],
)
try:
server.start(socket, workers)
loop = asyncio.get_event_loop()
loop.run_forever()
except KeyboardInterrupt:
loop.close()
================================================
FILE: robyn/py.typed
================================================
================================================
FILE: robyn/pydantic_support.py
================================================
"""
Optional Pydantic integration for Robyn.
All pydantic imports are lazy: pydantic is only loaded on the first call
to _ensure_pydantic(), so there is zero import-time overhead when pydantic
is not installed or not used. The module itself is imported at the top
level by router.py and openapi.py, but this is safe because it contains
no pydantic imports at module scope.
"""
import inspect
from typing import Any, Optional, Tuple
import orjson
__all__ = [
"is_pydantic_available",
"is_pydantic_model",
"detect_pydantic_params",
"validate_pydantic_body",
"get_pydantic_openapi_schema",
"serialize_pydantic_response",
"check_pydantic_installed_for_handler",
"PydanticBodyValidationError",
"PydanticNotInstalledError",
"MultiplePydanticBodyError",
]
_BaseModel = None
_ValidationError = None
_pydantic_checked = False
def _ensure_pydantic():
"""Lazy-load pydantic classes. Called at most once."""
global _BaseModel, _ValidationError, _pydantic_checked
if _pydantic_checked:
return
_pydantic_checked = True
try:
from pydantic import BaseModel, ValidationError
_BaseModel = BaseModel
_ValidationError = ValidationError
except ImportError:
_BaseModel = None
_ValidationError = None
def is_pydantic_available() -> bool:
_ensure_pydantic()
return _BaseModel is not None
def is_pydantic_model(annotation) -> bool:
"""Check if an annotation is a pydantic BaseModel subclass.
Returns False if pydantic is not installed or annotation is not a class."""
_ensure_pydantic()
if _BaseModel is None:
return False
return inspect.isclass(annotation) and issubclass(annotation, _BaseModel)
def detect_pydantic_params(handler_params) -> dict:
"""Scan pre-computed handler parameters for Pydantic BaseModel annotations.
Accepts the ``parameters`` OrderedDict from ``inspect.signature(handler)``.
Returns a dict mapping param_name -> model_class for params annotated with
a Pydantic BaseModel subclass. Returns empty dict if pydantic is not
installed or no params use Pydantic models.
"""
_ensure_pydantic()
if _BaseModel is None:
return {}
result = {}
for name, param in handler_params.items():
ann = param.annotation
if ann is inspect.Parameter.empty:
continue
if inspect.isclass(ann) and issubclass(ann, _BaseModel):
result[name] = ann
return result
def _sanitize_errors(errors: list) -> list:
"""Make pydantic error dicts JSON-serializable.
Only copies dicts that actually contain non-serializable values.
Pydantic v2 error dicts can contain bytes, tuples, and other
non-JSON-serializable values in 'input', 'loc', and 'ctx' fields.
"""
sanitized = []
for err in errors:
needs_copy = False
for key, val in err.items():
if (key == "input" and isinstance(val, bytes)) or key == "loc" or (key == "ctx" and isinstance(val, dict)):
needs_copy = True
break
if not needs_copy:
sanitized.append(err)
continue
clean = dict(err)
if "input" in clean and isinstance(clean["input"], bytes):
clean["input"] = clean["input"].decode("utf-8", errors="replace")
if "loc" in clean:
clean["loc"] = list(clean["loc"])
if "ctx" in clean and isinstance(clean["ctx"], dict):
clean["ctx"] = {k: str(v) for k, v in clean["ctx"].items()}
sanitized.append(clean)
return sanitized
def validate_pydantic_body(model_class, body: Any) -> Tuple[Any, Optional[dict]]:
"""Validate request body against a Pydantic model.
Uses model_validate_json for maximum performance — single-pass
parse+validate without an intermediate dict. model_validate_json
accepts str, bytes, and bytearray natively.
This function is only called from the request hot path *after*
_ensure_pydantic() has already been called at registration time,
so we skip the redundant check here.
Returns:
(validated_model_instance, None) on success
(None, error_detail_dict) on failure
"""
try:
return model_class.model_validate_json(body), None
except _ValidationError as e:
return None, {
"detail": _sanitize_errors(e.errors()),
"error": "Validation Error",
}
def get_pydantic_openapi_schema(model_class) -> Tuple[dict, dict]:
"""Get OpenAPI-compatible JSON Schema from a Pydantic model.
Uses ref_template so nested model references point to
#/components/schemas/{ModelName} in the OpenAPI spec.
Returns:
(schema, component_schemas) where:
- schema: the model's JSON Schema (without $defs)
- component_schemas: dict of model_name -> schema for components/schemas
"""
_ensure_pydantic()
if _BaseModel is None or not (inspect.isclass(model_class) and issubclass(model_class, _BaseModel)):
return {}, {}
full_schema = model_class.model_json_schema(ref_template="#/components/schemas/{model}")
component_schemas = full_schema.pop("$defs", {})
return full_schema, component_schemas
def serialize_pydantic_response(res) -> Optional[str]:
"""Serialize a Pydantic model (or list of models) to a JSON string.
Returns None when *res* is not a Pydantic type so the caller can fall
through to other serialisation paths.
This function is only called from the response hot path *after*
_ensure_pydantic() has already been called at registration time,
so we skip the redundant check here.
"""
if _BaseModel is None:
return None
if isinstance(res, _BaseModel):
return res.model_dump_json()
if isinstance(res, list) and res and isinstance(res[0], _BaseModel):
return orjson.dumps([item.model_dump(mode="python") for item in res]).decode("utf-8")
return None
class PydanticBodyValidationError(Exception):
"""Raised at request time when Pydantic body validation fails.
Carries the serializable error dict for the 422 response."""
def __init__(self, error_detail: dict):
self.error_detail = error_detail
super().__init__(error_detail.get("error", "Validation Error"))
class PydanticNotInstalledError(ImportError):
"""Raised at route registration when a handler uses a Pydantic model
but pydantic is not installed."""
def __init__(self, handler_name: str, param_name: str, model_name: str):
super().__init__(
f"Handler '{handler_name}' has parameter '{param_name}' annotated with "
f"Pydantic model '{model_name}', but pydantic is not installed. "
f'Install it with: pip install "robyn[pydantic]" or pip install "robyn[all]"'
)
class MultiplePydanticBodyError(TypeError):
"""Raised at route registration when a handler declares more than one
Pydantic body parameter."""
def __init__(self, handler_name: str, param_names: list):
super().__init__(
f"Handler '{handler_name}' has multiple Pydantic body parameters "
f"{param_names}. Only one Pydantic body parameter per handler is "
f"supported — the entire request body is parsed into that single model."
)
def check_pydantic_installed_for_handler(handler, pydantic_params: dict):
"""Validate Pydantic usage at startup.
Raises PydanticNotInstalledError if pydantic isn't available.
Raises MultiplePydanticBodyError if more than one body param is declared.
"""
if not pydantic_params:
return
if not is_pydantic_available():
first_param = next(iter(pydantic_params))
model = pydantic_params[first_param]
raise PydanticNotInstalledError(handler.__name__, first_param, model.__name__)
if len(pydantic_params) > 1:
raise MultiplePydanticBodyError(handler.__name__, list(pydantic_params.keys()))
================================================
FILE: robyn/reloader.py
================================================
import glob
import os
import signal
import subprocess
import sys
import time
from typing import List, Union
from watchdog.events import FileSystemEventHandler
from watchdog.observers import Observer
from robyn.logger import Colors, logger
def compile_rust_files(directory_path: str) -> List[str]:
rust_files = glob.glob(os.path.join(directory_path, "**/*.rs"), recursive=True)
rust_binaries: list[str] = []
for rust_file in rust_files:
print(f"Compiling rust file: {rust_file}")
result = subprocess.run(
[sys.executable, "-m", "rustimport", "build", rust_file],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
start_new_session=False,
)
if result.returncode != 0:
print(f"Error compiling rust file: {rust_file} \n {result.stderr.decode('utf-8')} \n {result.stdout.decode('utf-8')}")
else:
print(f"Compiled rust file: {rust_file}")
rust_file_base = rust_file.removesuffix(".rs")
# Define the search pattern for the binary file
if sys.platform == "win32":
binary_extension = ".dll"
elif sys.platform == "darwin":
binary_extension = ".so"
elif sys.platform == "linux":
binary_extension = ".so"
else:
raise ValueError(f"Unsupported platform: {sys.platform}")
search_pattern = f"{rust_file_base}.*{binary_extension}"
# Use glob to find matching binary files
matching_binaries = glob.glob(search_pattern)
rust_binaries.extend(matching_binaries)
return rust_binaries
def create_rust_file(file_name: str) -> None:
if file_name.endswith(".rs"):
file_name = file_name.removesuffix(".rs")
rust_file = f"{file_name}.rs"
result = subprocess.run(
[sys.executable, "-m", "rustimport", "new", rust_file],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
start_new_session=False,
)
if result.returncode != 0:
print(
"Error creating rust file : %s %s",
result.stderr.decode("utf-8"),
result.stdout.decode("utf-8"),
)
else:
print("Created rust file : %s", rust_file)
def clean_rust_binaries(rust_binaries: List[str]) -> None:
for file in rust_binaries:
print("Cleaning rust file : %s", file)
os.remove(file)
def setup_reloader(directory_path: str, file_path: str) -> None:
event_handler = EventHandler(file_path, directory_path)
# sets the IS_RELOADER_RUNNING environment variable to True
event_handler.reload()
logger.info(
"Dev server initialized with the directory_path : %s",
directory_path,
color=Colors.BLUE,
)
def terminating_signal_handler(_sig, _frame):
event_handler.stop_server()
logger.info("Terminating reloader", bold=True)
observer.stop()
observer.join()
signal.signal(signal.SIGINT, terminating_signal_handler)
signal.signal(signal.SIGTERM, terminating_signal_handler)
observer = Observer()
observer.schedule(event_handler, path=directory_path, recursive=True)
observer.start()
try:
while observer.is_alive():
observer.join(1)
finally:
observer.stop()
observer.join()
event_handler.process.wait()
class EventHandler(FileSystemEventHandler):
def __init__(self, file_path: str, directory_path: str) -> None:
self.file_path = file_path
self.directory_path = directory_path
self.process: Union[subprocess.Popen[bytes], None] = None # Keep track of the subprocess
self.built_rust_binaries: List = [] # Keep track of the built rust binaries
self.last_reload = time.time() # Keep track of the last reload. EventHandler is initialized with the process.
def stop_server(self) -> None:
if self.process:
os.kill(self.process.pid, signal.SIGTERM) # Stop the subprocess using os.kill()
def reload(self) -> None:
self.stop_server()
print("Reloading the server")
new_env = os.environ.copy()
new_env["IS_RELOADER_RUNNING"] = "True" # This is used to check if a reloader is already running
# IS_RELOADER_RUNNING is specifically used for IPC between the reloader and the server
arguments = [arg for arg in sys.argv[1:] if not arg.startswith("--dev")]
clean_rust_binaries(self.built_rust_binaries)
self.built_rust_binaries = compile_rust_files(self.directory_path)
prev_process = self.process
if prev_process:
prev_process.kill()
self.process = subprocess.Popen(
[sys.executable, *arguments],
env=new_env,
)
self.last_reload = time.time()
def on_modified(self, event) -> None:
"""
This function is a callback that will start a new server on every even change
:param event FSEvent: a data structure with info about the events
"""
# Avoid reloading multiple times when watchdog detects multiple events
if time.time() - self.last_reload < 0.5:
return
time.sleep(0.2) # Wait for the file to be fully written
self.reload()
================================================
FILE: robyn/responses.py
================================================
import asyncio
import mimetypes
import os
from typing import AsyncGenerator, Generator, Optional, Union
from robyn.robyn import Headers, Response
class FileResponse:
def __init__(
self,
file_path: str,
status_code: Optional[int] = None,
headers: Optional[Headers] = None,
):
self.file_path = file_path
self.description = ""
self.status_code = status_code or 200
self.headers = headers or Headers({"Content-Disposition": "attachment"})
def html(html: str) -> Response:
"""
This function will help in serving a simple html string
:param html str: html to serve as a response
"""
return Response(
description=html,
status_code=200,
headers=Headers({"Content-Type": "text/html"}),
)
def serve_html(file_path: str) -> FileResponse:
"""
This function will help in serving a single html file
:param file_path str: file path to serve as a response
"""
return FileResponse(file_path, headers=Headers({"Content-Type": "text/html"}))
def serve_file(file_path: str, file_name: Optional[str] = None) -> FileResponse:
"""
This function will help in serving a file
:param file_path str: file path to serve as a response
:param file_name [str | None]: file name to serve as a response, defaults to None
"""
file_name = file_name or os.path.basename(file_path)
mime_type = mimetypes.guess_type(file_name)[0]
headers = Headers({"Content-Type": mime_type})
headers.append("Content-Disposition", f"attachment; filename={file_name}")
return FileResponse(
file_path,
headers=headers,
)
class AsyncGeneratorWrapper:
"""Optimized true-streaming wrapper for async generators"""
def __init__(self, async_gen: AsyncGenerator[str, None]):
self.async_gen = async_gen
self._loop = None
self._iterator = None
self._exhausted = False
def __iter__(self):
return self
def __next__(self):
if self._exhausted:
raise StopIteration
# Initialize the loop and iterator only once
if self._iterator is None:
self._init_async_iterator()
try:
# Get the next value from the async generator
# This is the key optimization - we don't buffer, we get one value at a time
return self._get_next_value()
except StopIteration:
self._exhausted = True
raise
def _init_async_iterator(self):
"""Initialize the async iterator with proper loop handling"""
try:
# Try to get the running event loop
self._loop = asyncio.get_running_loop()
except RuntimeError:
# No running loop, create a new one
self._loop = asyncio.new_event_loop()
asyncio.set_event_loop(self._loop)
# Create the async iterator
self._iterator = self.async_gen.__aiter__()
def _get_next_value(self):
"""Get the next value from async generator without buffering"""
try:
# Create a coroutine to get the next value
async def get_next():
return await self._iterator.__anext__()
# Run the coroutine to get the next value
return self._loop.run_until_complete(get_next())
except StopAsyncIteration:
# Convert StopAsyncIteration to StopIteration for sync generator protocol
raise StopIteration
except Exception as e:
# Log error and stop iteration
print(f"Error in async generator: {e}")
raise StopIteration
class StreamingResponse:
def __init__(
self,
content: Union[Generator[str, None, None], AsyncGenerator[str, None]],
status_code: Optional[int] = None,
headers: Optional[Headers] = None,
media_type: str = "text/event-stream",
):
# Convert async generator to sync generator if needed
# The Rust implementation detects async generators but falls back to Python wrapper
if hasattr(content, "__anext__"):
# This is an async generator - wrap it with optimized wrapper
self.content = AsyncGeneratorWrapper(content)
else:
# This is a sync generator - use as is
self.content = content
self.status_code = status_code or 200
self.headers = headers or Headers({})
self.media_type = media_type
# Set default SSE headers
if media_type == "text/event-stream":
self.headers.set("Content-Type", "text/event-stream")
# Cache-Control and Connection headers are set by Rust layer with optimized headers
def SSEResponse(
content: Union[Generator[str, None, None], AsyncGenerator[str, None]],
status_code: Optional[int] = None,
headers: Optional[Headers] = None,
) -> StreamingResponse:
"""
Create a Server-Sent Events (SSE) streaming response.
:param content: Generator or AsyncGenerator yielding SSE-formatted strings
:param status_code: HTTP status code (default: 200)
:param headers: Additional headers
:return: StreamingResponse configured for SSE
"""
return StreamingResponse(content=content, status_code=status_code, headers=headers, media_type="text/event-stream")
def SSEMessage(data: str, event: Optional[str] = None, id: Optional[str] = None, retry: Optional[int] = None) -> str:
"""
Optimized SSE message formatting with minimal allocations.
:param data: The message data
:param event: Optional event type
:param id: Optional event ID
:param retry: Optional retry time in milliseconds
:return: SSE-formatted string
"""
# Pre-calculate size to avoid multiple string concatenations
parts = []
# Add optional fields first
if event:
parts.append(f"event: {event}\n")
if id:
parts.append(f"id: {id}\n")
if retry:
parts.append(f"retry: {retry}\n")
# Handle data with optimized multi-line processing
if data:
data_str = str(data)
# Fast path for single-line data (most common case)
if "\n" not in data_str and "\r" not in data_str:
parts.append(f"data: {data_str}\n")
else:
# Multi-line data handling
normalized_data = data_str.replace("\r\n", "\n").replace("\r", "\n")
for line in normalized_data.split("\n"):
parts.append(f"data: {line}\n")
else:
parts.append("data: \n")
# Add the required double newline terminator
parts.append("\n")
# Single join operation for optimal performance
return "".join(parts)
================================================
FILE: robyn/robyn.pyi
================================================
from __future__ import annotations
from dataclasses import dataclass
from enum import Enum
from typing import Callable, Optional, Union
def get_version() -> str:
pass
class SocketHeld:
def __init__(self, url: str, port: int):
pass
def try_clone(self) -> SocketHeld:
pass
class MiddlewareType(Enum):
"""
The middleware types supported by Robyn.
Attributes:
BEFORE_REQUEST: str
AFTER_REQUEST: str
"""
BEFORE_REQUEST: str
AFTER_REQUEST: str
class HttpMethod(Enum):
"""
The HTTP methods supported by Robyn.
Attributes:
GET: str
POST: str
PUT: str
DELETE: str
PATCH: str
OPTIONS: str
HEAD: str
TRACE: str
CONNECT: str
"""
GET: str
POST: str
PUT: str
DELETE: str
PATCH: str
OPTIONS: str
HEAD: str
TRACE: str
CONNECT: str
@dataclass
class FunctionInfo:
"""
The function info object passed to the route handler.
Attributes:
handler (Callable): The function to be called
is_async (bool): Whether the function is async or not
number_of_params (int): The number of parameters the function has
args (dict): The arguments of the function
kwargs (dict): The keyword arguments of the function
"""
handler: Callable
is_async: bool
number_of_params: int
args: dict
kwargs: dict
@dataclass
class Url:
"""
The url object passed to the route handler.
Attributes:
scheme (str): The scheme of the url. e.g. http, https
host (str): The host of the url. e.g. localhost,
path (str): The path of the url. e.g. /user
"""
scheme: str
host: str
path: str
@dataclass
class Identity:
claims: dict[str, str]
class QueryParams:
"""
The query params object passed to the route handler.
Attributes:
queries (dict[str, list[str]]): The query parameters of the request. e.g. /user?id=123 -> {"id": "123"}
"""
def set(self, key: str, value: str) -> None:
"""
Sets the value of the query parameter with the given key.
If the key already exists, the value will be appended to the list of values.
Args:
key (str): The key of the query parameter
value (str): The value of the query parameter
"""
pass
def get(self, key: str, default: Optional[str] = None) -> Optional[str]:
"""
Gets the last value of the query parameter with the given key.
Args:
key (str): The key of the query parameter
default (Optional[str]): The default value if the key does not exist
"""
pass
def empty(self) -> bool:
"""
Returns:
True if the query params are empty, False otherwise
"""
pass
def contains(self, key: str) -> bool:
"""
Returns:
True if the query params contain the key, False otherwise
Args:
key (str): The key of the query parameter
"""
pass
def get_first(self, key: str) -> Optional[str]:
"""
Gets the first value of the query parameter with the given key.
Args:
key (str): The key of the query parameter
"""
pass
def get_all(self, key: str) -> Optional[list[str]]:
"""
Gets all the values of the query parameter with the given key.
Args:
key (str): The key of the query parameter
"""
pass
def extend(self, other: QueryParams) -> None:
"""
Extends the query params with the other query params.
Args:
other (QueryParams): The other QueryParams object
"""
pass
def to_dict(self) -> dict[str, list[str]]:
"""
Returns:
The query params as a dictionary
"""
pass
def __contains__(self, key: str) -> bool:
pass
def __repr__(self) -> str:
pass
@dataclass
class Cookie:
"""
A cookie with optional attributes following RFC 6265.
Attributes:
value (str): The cookie value
path (Optional[str]): Cookie path (e.g. "/")
domain (Optional[str]): Cookie domain
max_age (Optional[int]): Max age in seconds
expires (Optional[str]): Expiry date (deprecated, use max_age instead)
secure (bool): Only send over HTTPS
http_only (bool): Not accessible via JavaScript
same_site (Optional[str]): "Strict", "Lax", or "None" (case-insensitive)
"""
value: str
path: Optional[str] = None
domain: Optional[str] = None
max_age: Optional[int] = None
expires: Optional[str] = None
secure: bool = False
http_only: bool = False
same_site: Optional[str] = None
@staticmethod
def deleted() -> "Cookie":
"""
Create a cookie configured for deletion (expires immediately with max_age=0).
Returns:
Cookie: A cookie that will be deleted by the browser
"""
pass
class Cookies:
"""A collection of cookies keyed by name."""
def __init__(self) -> None:
pass
def set(self, name: str, cookie: Cookie) -> None:
"""
Sets a cookie with the given name.
Args:
name (str): The name of the cookie
cookie (Cookie): The cookie object
"""
pass
def get(self, name: str) -> Optional[Cookie]:
"""
Gets the cookie with the given name.
Args:
name (str): The name of the cookie
"""
pass
def remove(self, name: str) -> None:
"""
Removes the cookie from the collection (does not delete it from the browser).
Args:
name (str): The name of the cookie
"""
pass
def delete(self, name: str) -> None:
"""
Mark a cookie for deletion by setting it to expire immediately.
This sets max_age=0 which tells the browser to delete the cookie.
Args:
name (str): The name of the cookie to delete
"""
pass
def is_empty(self) -> bool:
"""
Returns:
True if there are no cookies, False otherwise
"""
pass
def keys(self) -> list[str]:
"""
Returns:
A list of all cookie names
"""
pass
def __setitem__(self, name: str, cookie: Cookie) -> None:
pass
def __getitem__(self, name: str) -> Optional[Cookie]:
pass
def __contains__(self, name: str) -> bool:
pass
def __len__(self) -> int:
pass
def __iter__(self) -> "CookiesIter":
pass
def __repr__(self) -> str:
pass
class CookiesIter:
"""Iterator for Cookies collection."""
def __iter__(self) -> "CookiesIter":
pass
def __next__(self) -> str:
pass
class Headers:
def __init__(self, default_headers: Optional[dict]) -> None:
pass
def __getitem__(self, key: str) -> Optional[str]:
pass
def __setitem__(self, key: str, value: str) -> None:
pass
def set(self, key: str, value: str) -> None:
"""
Sets the value of the header with the given key.
If the key already exists, the value will be appended to the list of values.
Args:
key (str): The key of the header
value (str): The value of the header
"""
pass
def get(self, key: str) -> Optional[str]:
"""
Gets the last value of the header with the given key.
Args:
key (str): The key of the header
"""
pass
def populate_from_dict(self, headers: dict[str, str]) -> None:
"""
Populates the headers from a dictionary.
Args:
headers (dict[str, str]): The dictionary of headers
"""
pass
def contains(self, key: str) -> bool:
"""
Returns:
True if the headers contain the key, False otherwise
Args:
key (str): The key of the header
"""
pass
def append(self, key: str, value: str) -> None:
"""
Appends the value to the header with the given key.
Args:
key (str): The key of the header
value (str): The value of the header
"""
pass
def is_empty(self) -> bool:
"""
Returns:
True if the headers are empty, False otherwise
"""
pass
@dataclass
class Request:
"""
The request object passed to the route handler.
Attributes:
query_params (QueryParams): The query parameters of the request. e.g. /user?id=123 -> {"id": "123"}
headers Headers: The headers of the request. e.g. Headers({"Content-Type": "application/json"})
path_params (dict[str, str]): The parameters of the request. e.g. /user/:id -> {"id": "123"}
body (Union[str, bytes]): The body of the request. If the request is a JSON, it will be a dict.
method (str): The method of the request. e.g. GET, POST, PUT etc.
url (Url): The url of the request. e.g. https://localhost/user
form_data (dict[str, str]): The form data of the request. e.g. {"name": "John"}
files (dict[str, bytes]): The files of the request. e.g. {"file": b"file"}
ip_addr (Optional[str]): The IP Address of the client
identity (Optional[Identity]): The identity of the client
"""
query_params: QueryParams
headers: Headers
path_params: dict[str, str]
body: Union[str, bytes]
method: str
url: Url
form_data: dict[str, str]
files: dict[str, bytes]
ip_addr: Optional[str]
identity: Optional[Identity]
def json(self) -> Union[dict, list]:
"""
Parse the request body as JSON and return a Python dict or list with preserved types.
JSON types are mapped to Python types as follows:
- null -> None
- bool -> bool
- number -> int or float
- string -> str
- array -> list
- object -> dict
Nested structures are handled recursively up to a maximum depth of 128.
Raises:
ValueError: If the body is not valid JSON.
"""
pass
@dataclass
class Response:
"""
The response object passed to the route handler.
Attributes:
status_code (int): The status code of the response. e.g. 200, 404, 500 etc.
response_type (Optional[str]): The response type of the response. e.g. text, json, html, file etc.
headers (Union[Headers, dict]): The headers of the response or Headers directly. e.g. {"Content-Type": "application/json"}
description (Union[str, bytes]): The body of the response. If the response is a JSON, it will be a dict.
file_path (Optional[str]): The file path of the response. e.g. /home/user/file.txt
cookies (Cookies): The cookies to set in the response.
"""
status_code: int
headers: Union[Headers, dict]
description: Union[str, bytes]
response_type: Optional[str] = None
file_path: Optional[str] = None
cookies: Cookies = None # Initialized automatically
def set_cookie(
self,
key: str,
value: str,
path: Optional[str] = None,
domain: Optional[str] = None,
max_age: Optional[int] = None,
expires: Optional[str] = None,
secure: bool = False,
http_only: bool = False,
same_site: Optional[str] = None,
) -> None:
"""
Sets a cookie in the response. If a cookie with the same key exists,
it will be overwritten.
Args:
key (str): The name of the cookie
value (str): The value of the cookie
path (Optional[str]): Cookie path (e.g. "/")
domain (Optional[str]): Cookie domain
max_age (Optional[int]): Max age in seconds
expires (Optional[str]): Expiry date (RFC 7231 format)
secure (bool): Only send over HTTPS
http_only (bool): Not accessible via JavaScript
same_site (Optional[str]): "Strict", "Lax", or "None"
"""
pass
class Server:
"""
The Server object used to create a Robyn server.
This object is used to create a Robyn server and add routes, middlewares, etc.
"""
def __init__(self) -> None:
pass
def add_directory(
self,
route: str,
directory_path: str,
show_files_listing: bool,
index_file: Optional[str],
) -> None:
pass
def apply_request_headers(self, headers: Headers) -> None:
pass
def apply_response_headers(self, headers: Headers) -> None:
pass
def set_response_headers_exclude_paths(self, excluded_response_headers_paths: Optional[list[str]] = None):
pass
def add_route(
self,
route_type: HttpMethod,
route: str,
function: FunctionInfo,
is_const: bool,
) -> None:
pass
def add_global_middleware(self, middleware_type: MiddlewareType, function: FunctionInfo) -> None:
pass
def add_middleware_route(
self,
middleware_type: MiddlewareType,
route: str,
function: FunctionInfo,
route_type: HttpMethod,
) -> None:
pass
def add_startup_handler(self, function: FunctionInfo) -> None:
pass
def add_shutdown_handler(self, function: FunctionInfo) -> None:
pass
def add_web_socket_route(
self,
route: str,
connect_route: FunctionInfo,
close_route: FunctionInfo,
message_route: FunctionInfo,
use_channel: bool,
) -> None:
pass
def start(self, socket: SocketHeld, workers: int, client_timeout: int, keep_alive_timeout: int) -> None:
pass
class WebSocketConnector:
"""
The WebSocketConnector object passed to the route handler.
Attributes:
id (str): The id of the client
query_params (QueryParams): The query parameters object
async_broadcast (Callable): The function to broadcast a message to all clients
async_send_to (Callable): The function to send a message to the client
sync_broadcast (Callable): The function to broadcast a message to all clients
sync_send_to (Callable): The function to send a message to the client
"""
id: str
query_params: QueryParams
async def async_broadcast(self, message: str) -> None:
"""
Broadcasts a message to all clients.
Args:
message (str): The message to broadcast
"""
pass
async def async_send_to(self, sender_id: str, message: str) -> None:
"""
Sends a message to a specific client.
Args:
sender_id (str): The id of the sender
message (str): The message to send
"""
pass
def sync_broadcast(self, message: str) -> None:
"""
Broadcasts a message to all clients.
Args:
message (str): The message to broadcast
"""
pass
def sync_send_to(self, sender_id: str, message: str) -> None:
"""
Sends a message to a specific client.
Args:
sender_id (str): The id of the sender
message (str): The message to send
"""
pass
def close(self) -> None:
"""
Closes the connection.
"""
pass
================================================
FILE: robyn/router.py
================================================
import inspect
import logging
from abc import ABC, abstractmethod
from functools import wraps
from types import CoroutineType
from typing import Callable, Dict, List, NamedTuple, Optional, Union, is_typeddict
from robyn import status_codes
from robyn._param_utils import QueryParamValidationError, parse_route_param_names, resolve_individual_params
from robyn.authentication import AuthenticationHandler, AuthenticationNotConfiguredError
from robyn.dependency_injection import DependencyMap
from robyn.jsonify import jsonify
from robyn.openapi import OpenAPI
from robyn.pydantic_support import (
PydanticBodyValidationError,
check_pydantic_installed_for_handler,
detect_pydantic_params,
serialize_pydantic_response,
validate_pydantic_body,
)
from robyn.responses import FileResponse, StreamingResponse
from robyn.robyn import FunctionInfo, Headers, HttpMethod, Identity, MiddlewareType, QueryParams, Request, Response, Url
from robyn.types import Body, Files, FormData, IPAddress, JsonBody, Method, PathParams
_logger = logging.getLogger(__name__)
def lower_http_method(method: HttpMethod):
return (str(method))[11:].lower()
class Route(NamedTuple):
route_type: HttpMethod
route: str
function: FunctionInfo
is_const: bool
auth_required: bool
openapi_name: str
openapi_tags: List[str]
class RouteMiddleware(NamedTuple):
middleware_type: MiddlewareType
route: str
function: FunctionInfo
route_type: HttpMethod
class GlobalMiddleware(NamedTuple):
middleware_type: MiddlewareType
function: FunctionInfo
class BaseRouter(ABC):
@abstractmethod
def add_route(*args) -> Union[Callable, CoroutineType, Dict]: ...
class Router(BaseRouter):
def __init__(self) -> None:
super().__init__()
self.routes: List[Route] = []
def _format_tuple_response(self, res: tuple) -> Response:
if len(res) != 3:
raise ValueError("Tuple should have 3 elements")
description, headers, status_code = res
description = self._format_response(description).description
new_headers: Headers = Headers(headers)
if new_headers.contains("Content-Type"):
headers.set("Content-Type", new_headers.get("Content-Type"))
return Response(
status_code=status_code,
headers=headers,
description=description,
)
def _format_response(
self,
res: Union[Dict, List, Response, StreamingResponse, bytes, tuple, str],
) -> Union[Response, StreamingResponse]:
if isinstance(res, Response):
return res
if isinstance(res, StreamingResponse):
return res
pydantic_json = serialize_pydantic_response(res)
if pydantic_json is not None:
return Response(
status_code=status_codes.HTTP_200_OK,
headers=Headers({"Content-Type": "application/json"}),
description=pydantic_json,
)
if isinstance(res, (dict, list)):
return Response(
status_code=status_codes.HTTP_200_OK,
headers=Headers({"Content-Type": "application/json"}),
description=jsonify(res),
)
if isinstance(res, FileResponse):
response: Response = Response(
status_code=res.status_code,
headers=res.headers,
description=res.file_path,
)
response.file_path = res.file_path
return response
if isinstance(res, bytes):
return Response(
status_code=status_codes.HTTP_200_OK,
headers=Headers({"Content-Type": "application/octet-stream"}),
description=res,
)
if isinstance(res, tuple):
return self._format_tuple_response(tuple(res))
return Response(
status_code=status_codes.HTTP_200_OK,
headers=Headers({"Content-Type": "text/plain"}),
description=str(res).encode("utf-8"),
)
def add_route( # type: ignore
self,
route_type: HttpMethod,
endpoint: str,
handler: Callable,
is_const: bool,
auth_required: bool,
openapi_name: str,
openapi_tags: List[str],
exception_handler: Optional[Callable],
injected_dependencies: dict,
) -> Union[Callable, CoroutineType]:
# Pre-compute handler signature ONCE at registration time.
# This avoids calling inspect.signature() on every request.
route_param_names = parse_route_param_names(endpoint)
handler_params = inspect.signature(handler).parameters
handler_param_names = set(handler_params.keys())
unused_route_params = route_param_names - handler_param_names
if unused_route_params:
_logger.warning(
"Route '%s' declares path params %s but handler '%s' doesn't use them",
endpoint,
unused_route_params,
handler.__name__,
)
# Detect Pydantic model params once at registration (zero cost if not used)
pydantic_params = detect_pydantic_params(handler_params)
check_pydantic_installed_for_handler(handler, pydantic_params)
if pydantic_params and route_type in (HttpMethod.GET, HttpMethod.HEAD):
_logger.warning(
"Handler '%s' on %s '%s' uses Pydantic body parameter(s) %s, but %s requests typically do not carry a request body",
handler.__name__,
route_type.name,
endpoint,
list(pydantic_params.keys()),
route_type.name,
)
def wrapped_handler(*args, **kwargs):
request = next(filter(lambda it: isinstance(it, Request), args), None)
if not request or (len(handler_params) == 1 and next(iter(handler_params)) is Request):
return handler(*args, **kwargs)
type_mapping = {
"request": Request,
"query_params": QueryParams,
"headers": Headers,
"path_params": PathParams,
"body": Body,
"method": Method,
"url": Url,
"form_data": FormData,
"files": Files,
"ip_addr": IPAddress,
"identity": Identity,
}
# Phase 1: Type-annotated request components
type_filtered_params = {}
for handler_param in iter(handler_params):
for type_name in type_mapping:
handler_param_type = handler_params[handler_param].annotation
handler_param_name = handler_params[handler_param].name
if handler_param_type is Request:
type_filtered_params[handler_param_name] = request
elif handler_param_type is type_mapping[type_name]:
type_filtered_params[handler_param_name] = getattr(request, type_name)
elif inspect.isclass(handler_param_type):
if issubclass(handler_param_type, JsonBody):
try:
type_filtered_params[handler_param_name] = request.json()
except ValueError as e:
return Response(
status_code=status_codes.HTTP_400_BAD_REQUEST,
headers=Headers({"Content-Type": "application/json"}),
description=jsonify({"error": f"Invalid JSON body: {e}"}),
)
elif issubclass(handler_param_type, Body):
type_filtered_params[handler_param_name] = getattr(request, "body")
elif issubclass(handler_param_type, QueryParams):
type_filtered_params[handler_param_name] = getattr(request, "query_params")
elif is_typeddict(handler_param_type):
try:
type_filtered_params[handler_param_name] = request.json()
except ValueError as e:
return Response(
status_code=status_codes.HTTP_400_BAD_REQUEST,
headers=Headers({"Content-Type": "application/json"}),
description=jsonify({"error": f"Invalid JSON body: {e}"}),
)
# Phase 1.5: Pydantic model body params (only runs if handler uses pydantic)
if pydantic_params:
for param_name, model_class in pydantic_params.items():
if param_name in type_filtered_params:
continue
validated, error = validate_pydantic_body(model_class, request.body)
if error is not None:
raise PydanticBodyValidationError(error)
type_filtered_params[param_name] = validated
# Phase 2: Reserved-name request components
request_components = {
"r": request,
"req": request,
"request": request,
"query_params": request.query_params,
"headers": request.headers,
"path_params": request.path_params,
"body": request.body,
"method": request.method,
"url": request.url,
"ip_addr": request.ip_addr,
"identity": request.identity,
"form_data": request.form_data,
"files": request.files,
"router_dependencies": injected_dependencies["router_dependencies"],
"global_dependencies": injected_dependencies["global_dependencies"],
**kwargs,
}
name_filtered_params = {k: v for k, v in request_components.items() if k in handler_params and k not in type_filtered_params}
filtered_params = dict(**type_filtered_params, **name_filtered_params)
# Phase 3: Individual path/query param resolution
unresolved_names = set(handler_params) - set(filtered_params)
if unresolved_names:
unresolved = {name: handler_params[name] for name in unresolved_names}
individual_params = resolve_individual_params(
unresolved,
request.query_params,
request.path_params,
route_param_names,
)
filtered_params.update(individual_params)
return handler(**filtered_params)
@wraps(handler)
async def async_inner_handler(*args, **kwargs):
try:
response = self._format_response(
await wrapped_handler(*args, **kwargs),
)
except QueryParamValidationError as err:
response = Response(
status_code=status_codes.HTTP_400_BAD_REQUEST,
headers=Headers({"Content-Type": "text/plain"}),
description=str(err),
)
except PydanticBodyValidationError as err:
response = Response(
status_code=status_codes.HTTP_422_UNPROCESSABLE_ENTITY,
headers=Headers({"Content-Type": "application/json"}),
description=jsonify(err.error_detail),
)
except Exception as err:
if exception_handler is None:
raise
response = self._format_response(
exception_handler(err),
)
return response
@wraps(handler)
def inner_handler(*args, **kwargs):
try:
response = self._format_response(
wrapped_handler(*args, **kwargs),
)
except QueryParamValidationError as err:
response = Response(
status_code=status_codes.HTTP_400_BAD_REQUEST,
headers=Headers({"Content-Type": "text/plain"}),
description=str(err),
)
except PydanticBodyValidationError as err:
response = Response(
status_code=status_codes.HTTP_422_UNPROCESSABLE_ENTITY,
headers=Headers({"Content-Type": "application/json"}),
description=jsonify(err.error_detail),
)
except Exception as err:
if exception_handler is None:
raise
response = self._format_response(
exception_handler(err),
)
return response
params = dict(handler_params)
new_injected_dependencies = {}
for dependency in injected_dependencies:
if dependency in params:
new_injected_dependencies[dependency] = injected_dependencies[dependency]
else:
_logger.debug(f"Dependency {dependency} is not used in the handler {handler.__name__}")
if inspect.iscoroutinefunction(handler):
function = FunctionInfo(
async_inner_handler,
True,
len(params),
params,
new_injected_dependencies,
)
self.routes.append(Route(route_type, endpoint, function, is_const, auth_required, openapi_name, openapi_tags))
return async_inner_handler
else:
function = FunctionInfo(
inner_handler,
False,
len(params),
params,
new_injected_dependencies,
)
self.routes.append(Route(route_type, endpoint, function, is_const, auth_required, openapi_name, openapi_tags))
return inner_handler
def prepare_routes_openapi(self, openapi: OpenAPI, included_routers: List) -> None:
for route in self.routes:
openapi.add_openapi_path_obj(lower_http_method(route.route_type), route.route, route.openapi_name, route.openapi_tags, route.function.handler)
# TODO! after include_routes does not immediately merge all the routes
# for router in included_routers:
# for route in router:
# openapi.add_openapi_path_obj(lower_http_method(route.route_type), route.route, route.openapi_name, route.openapi_tags, route.function.handler)
def get_routes(self) -> List[Route]:
return self.routes
class MiddlewareRouter(BaseRouter):
def __init__(self, dependencies: DependencyMap = DependencyMap()) -> None:
super().__init__()
self.global_middlewares: List[GlobalMiddleware] = []
self.route_middlewares: List[RouteMiddleware] = []
self.authentication_handler: Optional[AuthenticationHandler] = None
self.dependencies = dependencies
def set_authentication_handler(self, authentication_handler: AuthenticationHandler):
self.authentication_handler = authentication_handler
def add_route( # type: ignore
self,
middleware_type: MiddlewareType,
endpoint: str,
route_type: HttpMethod,
handler: Callable,
injected_dependencies: dict,
) -> Callable:
params = dict(inspect.signature(handler).parameters)
new_injected_dependencies = {}
for dependency in injected_dependencies:
if dependency in params:
new_injected_dependencies[dependency] = injected_dependencies[dependency]
else:
_logger.debug(f"Dependency {dependency} is not used in the middleware handler {handler.__name__}")
function = FunctionInfo(
handler,
inspect.iscoroutinefunction(handler),
len(params),
params,
new_injected_dependencies,
)
self.route_middlewares.append(RouteMiddleware(middleware_type, endpoint, function, route_type))
return handler
def add_auth_middleware(self, endpoint: str, route_type: HttpMethod):
"""
This method adds an authentication middleware to the specified endpoint.
"""
injected_dependencies: dict = {}
def decorator(handler):
@wraps(handler)
def inner_handler(request: Request, *args):
if not self.authentication_handler:
raise AuthenticationNotConfiguredError()
identity = self.authentication_handler.authenticate(request)
if identity is None:
return self.authentication_handler.unauthorized_response
request.identity = identity
return request
self.add_route(
MiddlewareType.BEFORE_REQUEST,
endpoint,
route_type,
inner_handler,
injected_dependencies,
)
return inner_handler
return decorator
# These inner functions are basically a wrapper around the closure(decorator) being returned.
# They take a handler, convert it into a closure and return the arguments.
# Arguments are returned as they could be modified by the middlewares.
def add_middleware(self, middleware_type: MiddlewareType, endpoint: Optional[str]) -> Callable[..., None]:
"""
This method adds a middleware to the router.
Rules:
If endpoint is None, the middleware is added as a global middleware.
If endpoint is provided, the middleware is added to that specific endpoint.
Only None is supported for global middleware, empty string is not supported.
empty string or "/" is considered as root endpoint.
Args:
middleware_type: The type of middleware to add (before_request, after_request).
endpoint: The endpoint to add the middleware to. If None, the middleware is added as a global middleware.
Returns:
A decorator that takes a handler and adds it as a middleware.
"""
# no dependency injection here
injected_dependencies: dict = {}
def inner(handler):
@wraps(handler)
async def async_inner_handler(*args, **kwargs):
return await handler(*args, **kwargs)
@wraps(handler)
def inner_handler(*args, **kwargs):
return handler(*args, **kwargs)
if endpoint is not None:
if inspect.iscoroutinefunction(handler):
self.add_route(
middleware_type,
endpoint,
HttpMethod.GET,
async_inner_handler,
injected_dependencies,
)
else:
self.add_route(middleware_type, endpoint, HttpMethod.GET, inner_handler, injected_dependencies)
else:
params = dict(inspect.signature(handler).parameters)
if inspect.iscoroutinefunction(handler):
self.global_middlewares.append(
GlobalMiddleware(
middleware_type,
FunctionInfo(
async_inner_handler,
True,
len(params),
params,
injected_dependencies,
),
)
)
else:
self.global_middlewares.append(
GlobalMiddleware(
middleware_type,
FunctionInfo(
inner_handler,
False,
len(params),
params,
injected_dependencies,
),
)
)
return inner
def get_route_middlewares(self) -> List[RouteMiddleware]:
return self.route_middlewares
def get_global_middlewares(self) -> List[GlobalMiddleware]:
return self.global_middlewares
class WebSocketRouter(BaseRouter):
def __init__(self) -> None:
super().__init__()
self.routes: Dict[str, dict] = {}
def add_route(self, endpoint: str, handlers: dict) -> None: # type: ignore
self.routes[endpoint] = handlers
def get_routes(self) -> Dict[str, dict]:
return self.routes
================================================
FILE: robyn/scaffold/mongo/Dockerfile
================================================
FROM python:3.11-bookworm
WORKDIR /workspace
COPY . .
RUN pip install --no-cache-dir --upgrade -r requirements.txt
EXPOSE 8080
CMD ["python3", "app.py", "--log-level=DEBUG"]
================================================
FILE: robyn/scaffold/mongo/app.py
================================================
from pymongo import MongoClient
from robyn import Robyn
app = Robyn(__file__)
db = MongoClient("URL HERE")
users = db.users # define a collection
@app.get("/")
def index():
return "Hello World!"
# create a route
@app.get("/users")
async def get_users():
all_users = await users.find().to_list(length=None)
return {"users": all_users}
# create a route to add a new user
@app.post("/users")
async def add_user(request):
user_data = await request.json()
result = await users.insert_one(user_data)
return {"success": True, "inserted_id": str(result.inserted_id)}
# create a route to fetch a single user by ID
@app.get("/users/{user_id}")
async def get_user(request):
user_id = request.path_params["user_id"]
user = await users.find_one({"_id": user_id})
if user:
return user
else:
return {"error": "User not found"}, 404
if __name__ == "__main__":
app.start(host="0.0.0.0", port=8080)
================================================
FILE: robyn/scaffold/mongo/requirements.txt
================================================
robyn
pymongo
================================================
FILE: robyn/scaffold/no-db/Dockerfile
================================================
FROM python:3.11-bookworm
WORKDIR /workspace
COPY . .
RUN pip install --no-cache-dir --upgrade -r requirements.txt
EXPOSE 8080
CMD ["python3", "app.py", "--log-level=DEBUG"]
================================================
FILE: robyn/scaffold/no-db/app.py
================================================
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
def index():
return "Hello World!"
if __name__ == "__main__":
app.start(host="0.0.0.0", port=8080)
================================================
FILE: robyn/scaffold/no-db/requirements.txt
================================================
robyn
================================================
FILE: robyn/scaffold/postgres/Dockerfile
================================================
# ---- Build the PostgreSQL Base ----
FROM postgres:latest AS postgres-base
ENV POSTGRES_USER=postgres
ENV POSTGRES_PASSWORD=password
ENV POSTGRES_DB=postgresDB
# ---- Build the Python App ----
FROM python:3.11-bookworm
# Install supervisor
RUN apt-get update && apt-get install -y supervisor
WORKDIR /workspace
COPY . .
RUN pip install --no-cache-dir --upgrade -r requirements.txt
# Copy PostgreSQL binaries from the first stage
COPY --from=postgres-base /usr/local/bin /usr/local/bin
COPY --from=postgres-base /usr/lib/postgresql /usr/lib/postgresql
COPY --from=postgres-base /usr/share/postgresql /usr/share/postgresql
COPY --from=postgres-base /var/lib/postgresql /var/lib/postgresql
# Add supervisord config
COPY supervisord.conf /etc/supervisor/conf.d/supervisord.conf
EXPOSE 8080 5455
CMD ["/usr/bin/supervisord"]
================================================
FILE: robyn/scaffold/postgres/app.py
================================================
import psycopg2
from robyn import Robyn
DB_NAME = "postgresDB"
DB_HOST = "localhost"
DB_USER = "postgres"
DB_PASS = "password"
DB_PORT = "5455"
conn = psycopg2.connect(database=DB_NAME, host=DB_HOST, user=DB_USER, password=DB_PASS, port=DB_PORT)
app = Robyn(__file__)
# create a route to fetch all users
@app.get("/users")
def get_users():
cursor = conn.cursor()
cursor.execute("SELECT * FROM users")
all_users = cursor.fetchall()
return {"users": all_users}
@app.get("/")
def index():
return "Hello World!"
if __name__ == "__main__":
app.start(host="0.0.0.0", port=8080)
================================================
FILE: robyn/scaffold/postgres/requirements.txt
================================================
robyn
psycopg2; platform_system=="Windows"
psycopg2-binary; platform_system!="Windows"
================================================
FILE: robyn/scaffold/postgres/supervisord.conf
================================================
[supervisord]
nodaemon=true
[program:python-app]
command=python3 /workspace/app.py --log-level=DEBUG
autostart=true
autorestart=true
redirect_stderr=true
[program:postgres]
command=postgres -c 'config_file=/etc/postgresql/postgresql.conf'
autostart=true
autorestart=true
redirect_stderr=true
================================================
FILE: robyn/scaffold/prisma/Dockerfile
================================================
FROM python:3.11-bookworm
WORKDIR /workspace
COPY . .
RUN pip install --no-cache-dir --upgrade -r requirements.txt
RUN python3 -m prisma generate
RUN python3 -m prisma migrate dev --name init
EXPOSE 8080
CMD ["python3", "app.py", "--log-level=DEBUG"]
================================================
FILE: robyn/scaffold/prisma/app.py
================================================
from prisma import Prisma
from prisma.models import User
from robyn import Robyn
app = Robyn(__file__)
prisma = Prisma(auto_register=True)
@app.startup_handler
async def startup_handler() -> None:
await prisma.connect()
@app.shutdown_handler
async def shutdown_handler() -> None:
if prisma.is_connected():
await prisma.disconnect()
@app.get("/")
async def h():
user = await User.prisma().create(
data={
"name": "Robert",
},
)
return user.json(indent=2)
if __name__ == "__main__":
app.start(host="0.0.0.0", port=8080)
================================================
FILE: robyn/scaffold/prisma/requirements.txt
================================================
robyn
prisma
================================================
FILE: robyn/scaffold/prisma/schema.prisma
================================================
datasource db {
provider = "sqlite"
url = "file:dev.db"
}
generator py {
provider = "prisma-client-py"
}
model User {
id String @id @default(cuid())
name String
}
================================================
FILE: robyn/scaffold/sqlalchemy/Dockerfile
================================================
FROM python:3.11-bookworm
WORKDIR /workspace
COPY . .
RUN pip install --no-cache-dir --upgrade -r requirements.txt
EXPOSE 8080
CMD ["python3", "app.py", "--log-level=DEBUG"]
================================================
FILE: robyn/scaffold/sqlalchemy/__init__.py
================================================
================================================
FILE: robyn/scaffold/sqlalchemy/app.py
================================================
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
def index():
return "Hello World!"
if __name__ == "__main__":
# create a configured "Session" class
app.start(host="0.0.0.0", port=8080)
================================================
FILE: robyn/scaffold/sqlalchemy/models.py
================================================
from sqlalchemy import Boolean, Column, Integer, String, create_engine
from sqlalchemy.orm import declarative_base, sessionmaker
Base = declarative_base()
engine = create_engine("sqlite+pysqlite:///:memory:", echo=True)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
username = Column(String, unique=True, index=True)
hashed_password = Column(String)
is_active = Column(Boolean, default=True)
is_superuser = Column(Boolean, default=False)
if __name__ == "__main__":
Base.metadata.create_all(bind=engine)
================================================
FILE: robyn/scaffold/sqlalchemy/requirements.txt
================================================
robyn
SQLAlchemy
================================================
FILE: robyn/scaffold/sqlite/Dockerfile
================================================
FROM python:3.11-bookworm
WORKDIR /workspace
COPY . .
RUN pip install --no-cache-dir --upgrade -r requirements.txt
EXPOSE 8080
CMD ["python3", "app.py", "--log-level=DEBUG"]
================================================
FILE: robyn/scaffold/sqlite/app.py
================================================
import sqlite3
from robyn import Robyn
app = Robyn(__file__)
@app.get("/")
def index():
# your db name
conn = sqlite3.connect("example.db")
cur = conn.cursor()
cur.execute("DROP TABLE IF EXISTS test")
cur.execute("CREATE TABLE test(column_1, column_2)")
res = cur.execute("SELECT name FROM sqlite_master")
th = res.fetchone()
table_name = th[0]
return f"Hello World! {table_name}"
if __name__ == "__main__":
app.start(host="0.0.0.0", port=8080)
================================================
FILE: robyn/scaffold/sqlite/requirements.txt
================================================
robyn
================================================
FILE: robyn/scaffold/sqlmodel/Dockerfile
================================================
FROM python:3.11-bookworm
WORKDIR /workspace
COPY . .
RUN pip install --no-cache-dir --upgrade -r requirements.txt
EXPOSE 8080
CMD ["python3", "app.py", "--log-level=DEBUG"]
================================================
FILE: robyn/scaffold/sqlmodel/app.py
================================================
from models import Hero
from sqlmodel import Session, SQLModel, create_engine, select
from robyn import Robyn
app = Robyn(__file__)
engine = create_engine("sqlite:///database.db", echo=True)
@app.get("/")
def index():
return "Hello World"
@app.get("/create")
def create():
SQLModel.metadata.create_all(bind=engine)
return "created tables"
@app.get("/insert")
def insert():
hero_1 = Hero(name="Deadpond", secret_name="Dive Wilson")
hero_2 = Hero(name="Spider-Boy", secret_name="Pedro Parqueador")
hero_3 = Hero(name="Rusty-Man", secret_name="Tommy Sharp", age=48)
with Session(engine) as session:
session.add(hero_1)
session.add(hero_2)
session.add(hero_3)
session.commit()
return "inserted"
@app.get("/select")
def get_data():
with Session(engine) as session:
statement = select(Hero).where(Hero.name == "Spider-Boy")
hero = session.exec(statement).first()
return hero
if __name__ == "__main__":
# create a configured "Session" class
app.start(host="0.0.0.0", port=8080)
================================================
FILE: robyn/scaffold/sqlmodel/models.py
================================================
from typing import Optional
from sqlmodel import Field, SQLModel
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
================================================
FILE: robyn/scaffold/sqlmodel/requirements.txt
================================================
robyn
sqlmodel
================================================
FILE: robyn/status_codes.py
================================================
"""
HTTP codes
See HTTP Status Code Registry:
https://www.iana.org/assignments/http-status-codes/http-status-codes.xhtml
And RFC 2324 - https://tools.ietf.org/html/rfc2324
"""
__all__ = (
"HTTP_100_CONTINUE",
"HTTP_101_SWITCHING_PROTOCOLS",
"HTTP_102_PROCESSING",
"HTTP_103_EARLY_HINTS",
"HTTP_200_OK",
"HTTP_201_CREATED",
"HTTP_202_ACCEPTED",
"HTTP_203_NON_AUTHORITATIVE_INFORMATION",
"HTTP_204_NO_CONTENT",
"HTTP_205_RESET_CONTENT",
"HTTP_206_PARTIAL_CONTENT",
"HTTP_207_MULTI_STATUS",
"HTTP_208_ALREADY_REPORTED",
"HTTP_226_IM_USED",
"HTTP_300_MULTIPLE_CHOICES",
"HTTP_301_MOVED_PERMANENTLY",
"HTTP_302_FOUND",
"HTTP_303_SEE_OTHER",
"HTTP_304_NOT_MODIFIED",
"HTTP_305_USE_PROXY",
"HTTP_306_RESERVED",
"HTTP_307_TEMPORARY_REDIRECT",
"HTTP_308_PERMANENT_REDIRECT",
"HTTP_400_BAD_REQUEST",
"HTTP_401_UNAUTHORIZED",
"HTTP_402_PAYMENT_REQUIRED",
"HTTP_403_FORBIDDEN",
"HTTP_404_NOT_FOUND",
"HTTP_405_METHOD_NOT_ALLOWED",
"HTTP_406_NOT_ACCEPTABLE",
"HTTP_407_PROXY_AUTHENTICATION_REQUIRED",
"HTTP_408_REQUEST_TIMEOUT",
"HTTP_409_CONFLICT",
"HTTP_410_GONE",
"HTTP_411_LENGTH_REQUIRED",
"HTTP_412_PRECONDITION_FAILED",
"HTTP_413_REQUEST_ENTITY_TOO_LARGE",
"HTTP_414_REQUEST_URI_TOO_LONG",
"HTTP_415_UNSUPPORTED_MEDIA_TYPE",
"HTTP_416_REQUESTED_RANGE_NOT_SATISFIABLE",
"HTTP_417_EXPECTATION_FAILED",
"HTTP_418_IM_A_TEAPOT",
"HTTP_421_MISDIRECTED_REQUEST",
"HTTP_422_UNPROCESSABLE_ENTITY",
"HTTP_423_LOCKED",
"HTTP_424_FAILED_DEPENDENCY",
"HTTP_425_TOO_EARLY",
"HTTP_426_UPGRADE_REQUIRED",
"HTTP_428_PRECONDITION_REQUIRED",
"HTTP_429_TOO_MANY_REQUESTS",
"HTTP_431_REQUEST_HEADER_FIELDS_TOO_LARGE",
"HTTP_451_UNAVAILABLE_FOR_LEGAL_REASONS",
"HTTP_500_INTERNAL_SERVER_ERROR",
"HTTP_501_NOT_IMPLEMENTED",
"HTTP_502_BAD_GATEWAY",
"HTTP_503_SERVICE_UNAVAILABLE",
"HTTP_504_GATEWAY_TIMEOUT",
"HTTP_505_HTTP_VERSION_NOT_SUPPORTED",
"HTTP_506_VARIANT_ALSO_NEGOTIATES",
"HTTP_507_INSUFFICIENT_STORAGE",
"HTTP_508_LOOP_DETECTED",
"HTTP_510_NOT_EXTENDED",
"HTTP_511_NETWORK_AUTHENTICATION_REQUIRED",
)
HTTP_100_CONTINUE = 100
HTTP_101_SWITCHING_PROTOCOLS = 101
HTTP_102_PROCESSING = 102
HTTP_103_EARLY_HINTS = 103
HTTP_200_OK = 200
HTTP_201_CREATED = 201
HTTP_202_ACCEPTED = 202
HTTP_203_NON_AUTHORITATIVE_INFORMATION = 203
HTTP_204_NO_CONTENT = 204
HTTP_205_RESET_CONTENT = 205
HTTP_206_PARTIAL_CONTENT = 206
HTTP_207_MULTI_STATUS = 207
HTTP_208_ALREADY_REPORTED = 208
HTTP_226_IM_USED = 226
HTTP_300_MULTIPLE_CHOICES = 300
HTTP_301_MOVED_PERMANENTLY = 301
HTTP_302_FOUND = 302
HTTP_303_SEE_OTHER = 303
HTTP_304_NOT_MODIFIED = 304
HTTP_305_USE_PROXY = 305
HTTP_306_RESERVED = 306
HTTP_307_TEMPORARY_REDIRECT = 307
HTTP_308_PERMANENT_REDIRECT = 308
HTTP_400_BAD_REQUEST = 400
HTTP_401_UNAUTHORIZED = 401
HTTP_402_PAYMENT_REQUIRED = 402
HTTP_403_FORBIDDEN = 403
HTTP_404_NOT_FOUND = 404
HTTP_405_METHOD_NOT_ALLOWED = 405
HTTP_406_NOT_ACCEPTABLE = 406
HTTP_407_PROXY_AUTHENTICATION_REQUIRED = 407
HTTP_408_REQUEST_TIMEOUT = 408
HTTP_409_CONFLICT = 409
HTTP_410_GONE = 410
HTTP_411_LENGTH_REQUIRED = 411
HTTP_412_PRECONDITION_FAILED = 412
HTTP_413_REQUEST_ENTITY_TOO_LARGE = 413
HTTP_414_REQUEST_URI_TOO_LONG = 414
HTTP_415_UNSUPPORTED_MEDIA_TYPE = 415
HTTP_416_REQUESTED_RANGE_NOT_SATISFIABLE = 416
HTTP_417_EXPECTATION_FAILED = 417
HTTP_418_IM_A_TEAPOT = 418
HTTP_421_MISDIRECTED_REQUEST = 421
HTTP_422_UNPROCESSABLE_ENTITY = 422
HTTP_423_LOCKED = 423
HTTP_424_FAILED_DEPENDENCY = 424
HTTP_425_TOO_EARLY = 425
HTTP_426_UPGRADE_REQUIRED = 426
HTTP_428_PRECONDITION_REQUIRED = 428
HTTP_429_TOO_MANY_REQUESTS = 429
HTTP_431_REQUEST_HEADER_FIELDS_TOO_LARGE = 431
HTTP_451_UNAVAILABLE_FOR_LEGAL_REASONS = 451
HTTP_500_INTERNAL_SERVER_ERROR = 500
HTTP_501_NOT_IMPLEMENTED = 501
HTTP_502_BAD_GATEWAY = 502
HTTP_503_SERVICE_UNAVAILABLE = 503
HTTP_504_GATEWAY_TIMEOUT = 504
HTTP_505_HTTP_VERSION_NOT_SUPPORTED = 505
HTTP_506_VARIANT_ALSO_NEGOTIATES = 506
HTTP_507_INSUFFICIENT_STORAGE = 507
HTTP_508_LOOP_DETECTED = 508
HTTP_510_NOT_EXTENDED = 510
HTTP_511_NETWORK_AUTHENTICATION_REQUIRED = 511
================================================
FILE: robyn/swagger.html
================================================
Robyn OpenAPI Docs
================================================
FILE: robyn/templating.py
================================================
from abc import ABC, abstractmethod
from jinja2 import Environment, FileSystemLoader
from robyn import status_codes
from .robyn import Headers, Response
class TemplateInterface(ABC):
def __init__(self): ...
@abstractmethod
def render_template(self, *args, **kwargs) -> Response: ...
class JinjaTemplate(TemplateInterface):
def __init__(self, directory, encoding="utf-8", followlinks=False):
self.env = Environment(loader=FileSystemLoader(searchpath=directory, encoding=encoding, followlinks=followlinks))
def render_template(self, template_name, **kwargs) -> Response:
rendered_template = self.env.get_template(template_name).render(**kwargs)
return Response(
status_code=status_codes.HTTP_200_OK,
description=rendered_template,
headers=Headers({"Content-Type": "text/html; charset=utf-8"}),
)
__all__ = ["TemplateInterface", "JinjaTemplate"]
================================================
FILE: robyn/types.py
================================================
from dataclasses import dataclass
from typing import Dict, NewType, Optional, TypedDict
from robyn._param_utils import QueryParamValidationError
@dataclass
class Directory:
route: str
directory_path: str
show_files_listing: bool
index_file: Optional[str]
def as_list(self):
return [
self.route,
self.directory_path,
self.show_files_listing,
self.index_file,
]
PathParams = NewType("PathParams", Dict[str, str])
Method = NewType("Method", str)
FormData = NewType("FormData", Dict[str, str])
Files = NewType("Files", Dict[str, bytes])
IPAddress = NewType("IPAddress", Optional[str])
class JSONResponse(TypedDict):
"""
A type alias for openapi response bodies. This class should be inherited by the response class type definition.
"""
pass
class Body:
"""
A type alias for openapi request bodies. This class should be inherited by the request body class annotation.
"""
pass
class JsonBody:
"""
A type alias for JSON request bodies. When used as a parameter type annotation,
the handler receives the parsed JSON (dict) from request.json() and the OpenAPI
docs will show a generic JSON request body input.
Can be subclassed with annotations to provide a typed schema in the OpenAPI docs:
class MyBody(JsonBody):
name: str
age: int
@app.post("/users")
def create_user(request: Request, data: MyBody):
# data is the parsed JSON dict
...
.. note::
The JSON body is parsed via ``request.json()`` during parameter
resolution, *before* the handler is invoked. If the request body is
not valid JSON, a 400 Bad Request response is returned automatically
with a JSON error message (e.g., ``{"error": "Invalid JSON body: ..."}``)
and the handler is never called. Because parsing happens before
handler invocation, the error **cannot** be caught with a try/except
inside the handler.
If you need custom error handling for malformed JSON, accept the raw
body instead (e.g., ``body: Body``) and call ``request.json()``
yourself inside a try/except block.
"""
pass
__all__ = ["JSONResponse", "Body", "JsonBody", "QueryParamValidationError", "Directory", "PathParams", "Method", "FormData", "Files", "IPAddress"]
================================================
FILE: robyn/ws.py
================================================
from __future__ import annotations
import asyncio
import inspect
import logging
import orjson
from robyn._param_utils import QueryParamValidationError, resolve_individual_params
from robyn.robyn import FunctionInfo, QueryParams, WebSocketConnector
_logger = logging.getLogger(__name__)
class WebSocketDisconnect(Exception):
"""Exception raised when a WebSocket connection is disconnected."""
def __init__(self, code: int = 1000, reason: str = ""):
self.code = code
self.reason = reason
super().__init__(f"WebSocket disconnected with code {code}: {reason}")
class WebSocketAdapter:
"""
Modern WebSocket interface backed by Rust channels.
Wraps a WebSocketConnector and a Rust WebSocketChannel to provide
a clean async API for WebSocket handlers.
"""
def __init__(self, websocket_connector: WebSocketConnector, channel=None):
self._connector = websocket_connector
self._channel = channel
async def receive_text(self) -> str:
"""Receive the next text message. Blocks until a message arrives.
Raises WebSocketDisconnect when the connection is closed."""
if self._channel is None:
raise WebSocketDisconnect(reason="No message channel available")
result = await self._channel.receive()
if result is None:
raise WebSocketDisconnect()
return result
async def receive_bytes(self) -> bytes:
"""Receive binary data (decoded from text)."""
text = await self.receive_text()
return text.encode("utf-8")
async def receive_json(self):
"""Receive and decode JSON data.
Raises WebSocketDisconnect when the connection is closed."""
text = await self.receive_text()
return orjson.loads(text)
async def send_text(self, data: str):
"""Send text data to this WebSocket client."""
await self._connector.async_send_to(self._connector.id, data)
async def send_bytes(self, data: bytes):
"""Send binary data (as text) to this WebSocket client."""
await self._connector.async_send_to(self._connector.id, data.decode("utf-8"))
async def send_json(self, data):
"""Send JSON data to this WebSocket client."""
await self.send_text(orjson.dumps(data).decode())
async def broadcast(self, data: str):
"""Broadcast text data to all connected WebSocket clients on this endpoint."""
await self._connector.async_broadcast(data)
async def close(self):
"""Close the WebSocket connection."""
self._connector.close()
@property
def id(self) -> str:
"""WebSocket connection ID."""
return self._connector.id
@property
def query_params(self):
"""Access query parameters from the connection URL."""
return self._connector.query_params
# Global storage for connection state (per-connection queues and tasks)
_connection_tasks: dict[str, asyncio.Task] = {}
def create_websocket_decorator(app_instance):
"""
Factory function to create a websocket decorator for an app instance.
Returns a decorator that registers a modern WebSocket endpoint
backed by Rust channels.
"""
def websocket(endpoint: str):
"""
Modern WebSocket decorator.
Usage:
@app.websocket("/ws")
async def handler(websocket):
while True:
msg = await websocket.receive_text()
await websocket.send_text(f"Echo: {msg}")
@handler.on_connect
def on_connect(websocket):
return "Welcome!"
@handler.on_close
def on_close(websocket):
return "Goodbye"
"""
def decorator(handler):
_on_connect_fn = None
_on_close_fn = None
def _resolve_ws_params(func_params, adapter):
"""
Resolve all handler params beyond the first positional (websocket).
Handles:
- global_dependencies / router_dependencies (DI)
- query_params (whole QueryParams object, by name or type annotation)
- individual query params (everything else, with type coercion)
"""
injected = app_instance.dependencies.get_dependency_map(app_instance)
resolved = {}
unresolved = {}
for idx, (param_name, param) in enumerate(func_params.items()):
# Skip the websocket adapter (first positional arg, passed separately)
if idx == 0 or param.annotation is WebSocketAdapter:
continue
# DI: global_dependencies
if param_name == "global_dependencies":
resolved[param_name] = injected.get("global_dependencies", {})
continue
# DI: router_dependencies
if param_name == "router_dependencies":
resolved[param_name] = injected.get("router_dependencies", {})
continue
# Whole QueryParams object (by type annotation or reserved name)
if param.annotation is QueryParams or param_name == "query_params":
resolved[param_name] = adapter.query_params
continue
# Everything else: individual query param
unresolved[param_name] = param
if unresolved:
individual = resolve_individual_params(
unresolved,
adapter.query_params,
path_params=None, # WebSocket has no path params yet
route_param_names=set(),
)
resolved.update(individual)
return resolved
# --- Connect handler (called by Rust on connection open) ---
async def connect_handler(ws):
"""Internal connect handler called by Rust.
Creates the adapter, starts the user's handler task,
and calls the user's on_connect callback."""
conn_id = ws.id
channel = ws.message_channel
# Create the adapter with the Rust channel
adapter = WebSocketAdapter(ws, channel)
# Build resolved kwargs for the main handler
try:
handler_params = inspect.signature(handler).parameters
handler_kwargs = _resolve_ws_params(handler_params, adapter)
except QueryParamValidationError as e:
_logger.warning("WebSocket connection rejected for %s: %s", endpoint, e.detail)
return f"Error: {e.detail}"
# Start the user's handler as a long-running asyncio task
async def _run_handler():
try:
await handler(adapter, **handler_kwargs)
except WebSocketDisconnect:
pass
except ConnectionError:
_logger.debug("Connection lost in WebSocket handler for %s", endpoint, exc_info=True)
except Exception:
_logger.exception("Error in WebSocket handler for %s", endpoint)
finally:
_connection_tasks.pop(conn_id, None)
task = asyncio.create_task(_run_handler())
_connection_tasks[conn_id] = task
# Call user's on_connect if defined
if _on_connect_fn is not None:
connect_adapter = WebSocketAdapter(ws, channel)
try:
connect_params = inspect.signature(_on_connect_fn).parameters
connect_kwargs = _resolve_ws_params(connect_params, connect_adapter)
except QueryParamValidationError as e:
_logger.warning("WebSocket on_connect rejected for %s: %s", endpoint, e.detail)
task = _connection_tasks.pop(conn_id, None)
if task is not None and not task.done():
task.cancel()
return f"Error: {e.detail}"
if asyncio.iscoroutinefunction(_on_connect_fn):
result = await _on_connect_fn(connect_adapter, **connect_kwargs)
else:
result = _on_connect_fn(connect_adapter, **connect_kwargs)
return result
return None
# --- Message handler (dummy for new-style; Rust pushes to channel instead) ---
async def message_handler(ws, msg):
"""Dummy message handler. In channel mode, Rust pushes messages
directly to the channel and never calls this."""
return None
# --- Close handler (called by Rust on connection close) ---
async def close_handler(ws):
"""Internal close handler called by Rust.
Waits for the handler task to finish and calls on_close."""
conn_id = ws.id
# Wait for the handler task to finish (it should exit because
# the channel was closed by Rust, triggering WebSocketDisconnect)
task = _connection_tasks.pop(conn_id, None)
if task is not None:
try:
await asyncio.wait_for(task, timeout=5.0)
except (asyncio.TimeoutError, asyncio.CancelledError):
if not task.done():
task.cancel()
except Exception:
_logger.debug("Unexpected error while awaiting handler task for %s", conn_id, exc_info=True)
if not task.done():
task.cancel()
# Call user's on_close if defined
if _on_close_fn is not None:
close_adapter = WebSocketAdapter(ws, None)
try:
close_params = inspect.signature(_on_close_fn).parameters
close_kwargs = _resolve_ws_params(close_params, close_adapter)
except QueryParamValidationError as e:
_logger.warning("WebSocket on_close param error for %s: %s", endpoint, e.detail)
return None
if asyncio.iscoroutinefunction(_on_close_fn):
result = await _on_close_fn(close_adapter, **close_kwargs)
else:
result = _on_close_fn(close_adapter, **close_kwargs)
return result
return None
# --- Build FunctionInfo objects for Rust ---
handlers = {}
# Connect handler FunctionInfo
connect_params = dict(inspect.signature(connect_handler).parameters)
handlers["connect"] = FunctionInfo(
connect_handler,
True, # is_async
len(connect_params),
connect_params,
{}, # no kwargs needed - DI handled in Python
)
# Message handler FunctionInfo (dummy, won't be called in channel mode)
message_params = dict(inspect.signature(message_handler).parameters)
handlers["message"] = FunctionInfo(
message_handler,
True,
len(message_params),
message_params,
{},
)
# Close handler FunctionInfo
close_params = dict(inspect.signature(close_handler).parameters)
handlers["close"] = FunctionInfo(
close_handler,
True,
len(close_params),
close_params,
{},
)
# --- Decorator methods for on_connect / on_close ---
def add_on_connect(connect_fn):
nonlocal _on_connect_fn
_on_connect_fn = connect_fn
return connect_fn
def add_on_close(close_fn):
nonlocal _on_close_fn
_on_close_fn = close_fn
return close_fn
handler.on_connect = add_on_connect
handler.on_close = add_on_close
# Register with the app
app_instance.add_web_socket(endpoint, handlers)
return handler
return decorator
return websocket
================================================
FILE: scripts/format.sh
================================================
#!/bin/bash
set -x
ruff format robyn integration_tests docs_src
================================================
FILE: scripts/release.sh
================================================
#!/bin/bash
set -x
maturin develop
poetry lock
================================================
FILE: setup.py
================================================
import sys
sys.stderr.write(
"""
===============================
Unsupported installation method
===============================
robyn doesn't support installation with `python setup.py install`.
Please use `python -m pip install .` instead.
"""
)
sys.exit(1)
================================================
FILE: src/asyncio.rs
================================================
use pyo3::{prelude::*, sync::PyOnceLock};
use std::convert::Into;
static CONTEXTVARS: PyOnceLock> = PyOnceLock::new();
static CONTEXT: PyOnceLock> = PyOnceLock::new();
fn contextvars(py: Python<'_>) -> PyResult<&Bound<'_, PyAny>> {
Ok(CONTEXTVARS
.get_or_try_init(py, || py.import("contextvars").map(Into::into))?
.bind(py))
}
#[allow(dead_code)]
pub(crate) fn empty_context(py: Python<'_>) -> PyResult<&Bound<'_, PyAny>> {
Ok(CONTEXT
.get_or_try_init(py, || {
contextvars(py)?
.getattr("Context")?
.call0()
.map(std::convert::Into::into)
})?
.bind(py))
}
#[inline(always)]
pub(crate) fn copy_context(py: Python) -> PyResult> {
unsafe {
let ptr = pyo3::ffi::PyContext_CopyCurrent();
Ok(Bound::from_owned_ptr_or_err(py, ptr)?.unbind())
}
}
================================================
FILE: src/blocking.rs
================================================
use crossbeam_channel as channel;
use pyo3::prelude::*;
use std::{
sync::{atomic, Arc},
thread, time,
};
pub(crate) struct BlockingTask {
inner: Box,
}
impl BlockingTask {
#[inline]
pub fn new(inner: T) -> BlockingTask
where
T: FnOnce(Python) + Send + 'static,
{
Self {
inner: Box::new(inner),
}
}
#[inline(always)]
pub fn run(self, py: Python) {
(self.inner)(py);
}
}
pub(crate) enum BlockingRunner {
Empty,
Mono(BlockingRunnerMono),
Pool(BlockingRunnerPool),
}
impl BlockingRunner {
pub fn new(max_threads: usize, idle_timeout: u64) -> Self {
match max_threads {
0 => Self::Empty,
1 => Self::Mono(BlockingRunnerMono::new()),
_ => Self::Pool(BlockingRunnerPool::new(max_threads, idle_timeout)),
}
}
#[inline]
pub fn run(&self, task: T) -> Result<(), channel::SendError>
where
T: FnOnce(Python) + Send + 'static,
{
match self {
Self::Mono(runner) => runner.run(task),
Self::Pool(runner) => runner.run(task),
Self::Empty => Ok(()),
}
}
}
pub(crate) struct BlockingRunnerMono {
queue: channel::Sender,
}
impl BlockingRunnerMono {
pub fn new() -> Self {
let (qtx, qrx) = channel::unbounded();
let ret = Self { queue: qtx };
thread::spawn(move || blocking_worker(qrx));
ret
}
#[inline]
pub fn run(&self, task: T) -> Result<(), channel::SendError>
where
T: FnOnce(Python) + Send + 'static,
{
self.queue.send(BlockingTask::new(task))
}
}
pub(crate) struct BlockingRunnerPool {
birth: time::Instant,
queue: channel::Sender,
tq: channel::Receiver,
threads: Arc,
tmax: usize,
idle_timeout: time::Duration,
spawning: atomic::AtomicBool,
spawn_tick: atomic::AtomicU64,
}
impl BlockingRunnerPool {
pub fn new(max_threads: usize, idle_timeout: u64) -> Self {
let (qtx, qrx) = channel::unbounded();
let ret = Self {
queue: qtx,
tq: qrx.clone(),
threads: Arc::new(1.into()),
tmax: max_threads,
birth: time::Instant::now(),
spawning: false.into(),
spawn_tick: 0.into(),
idle_timeout: time::Duration::from_secs(idle_timeout),
};
// always spawn the first thread
thread::spawn(move || blocking_worker(qrx));
ret
}
#[inline(always)]
fn spawn_thread(&self) {
let tick = self.birth.elapsed().as_micros() as u64;
if tick - self.spawn_tick.load(atomic::Ordering::Relaxed) < 350 {
return;
}
if self
.spawning
.compare_exchange(
false,
true,
atomic::Ordering::Relaxed,
atomic::Ordering::Relaxed,
)
.is_err()
{
return;
}
let queue = self.tq.clone();
let tcount = self.threads.clone();
let timeout = self.idle_timeout;
thread::spawn(move || {
tcount.fetch_add(1, atomic::Ordering::Release);
blocking_worker_idle(queue, timeout);
tcount.fetch_sub(1, atomic::Ordering::Release);
});
self.spawn_tick.store(
self.birth.elapsed().as_micros() as u64,
atomic::Ordering::Relaxed,
);
self.spawning.store(false, atomic::Ordering::Relaxed);
}
#[inline]
pub fn run(&self, task: T) -> Result<(), channel::SendError>
where
T: FnOnce(Python) + Send + 'static,
{
self.queue.send(BlockingTask::new(task))?;
if self.queue.len() > 1 && self.threads.load(atomic::Ordering::Acquire) < self.tmax {
self.spawn_thread();
}
Ok(())
}
}
fn blocking_worker(queue: channel::Receiver) {
Python::attach(|py| {
while let Ok(task) = py.detach(|| queue.recv()) {
task.run(py);
}
});
}
fn blocking_worker_idle(queue: channel::Receiver, timeout: time::Duration) {
Python::attach(|py| {
while let Ok(task) = py.detach(|| queue.recv_timeout(timeout)) {
task.run(py);
}
});
}
================================================
FILE: src/callbacks.rs
================================================
use pyo3::{exceptions::PyStopIteration, prelude::*, IntoPyObjectExt};
use std::sync::{atomic, Arc, OnceLock, RwLock};
use tokio::sync::Notify;
use crate::conversion::FutureResultToPy;
#[pyclass(frozen, freelist = 128, module = "robyn._robyn")]
pub(crate) struct PyEmptyAwaitable;
#[pymethods]
impl PyEmptyAwaitable {
fn __await__(pyself: PyRef<'_, Self>) -> PyRef<'_, Self> {
pyself
}
fn __iter__(pyself: PyRef<'_, Self>) -> PyRef<'_, Self> {
pyself
}
fn __next__(&self) -> Option<()> {
None
}
}
#[pyclass(frozen, module = "robyn._robyn")]
pub(crate) struct PyDoneAwaitable {
result: PyResult>,
}
impl PyDoneAwaitable {
pub(crate) fn new(result: PyResult>) -> Self {
Self { result }
}
}
#[pymethods]
impl PyDoneAwaitable {
fn __await__(pyself: PyRef<'_, Self>) -> PyRef<'_, Self> {
pyself
}
fn __iter__(pyself: PyRef<'_, Self>) -> PyRef<'_, Self> {
pyself
}
fn __next__(&self, py: Python) -> PyResult> {
self.result
.as_ref()
.map_err(|v| v.clone_ref(py))
.map(|v| Err(PyStopIteration::new_err(v.clone_ref(py))))?
}
}
#[pyclass(frozen, module = "robyn._robyn")]
pub(crate) struct PyErrAwaitable {
err: PyErr,
}
impl PyErrAwaitable {
pub(crate) fn new(err: PyErr) -> Self {
Self { err }
}
}
#[pymethods]
impl PyErrAwaitable {
fn __await__(pyself: PyRef<'_, Self>) -> PyRef<'_, Self> {
pyself
}
fn __iter__(pyself: PyRef<'_, Self>) -> PyRef<'_, Self> {
pyself
}
fn __next__(&self, py: Python) -> PyResult<()> {
Err(self.err.clone_ref(py))
}
}
#[pyclass(frozen, module = "robyn._robyn")]
pub(crate) struct PyIterAwaitable {
result: OnceLock>>,
}
impl PyIterAwaitable {
pub(crate) fn new() -> Self {
Self {
result: OnceLock::new(),
}
}
#[inline]
pub(crate) fn set_result(pyself: Py, py: Python, result: FutureResultToPy) {
_ = pyself
.get()
.result
.set(result.into_pyobject(py).map(Bound::unbind));
pyself.drop_ref(py);
}
}
#[pymethods]
impl PyIterAwaitable {
fn __await__(pyself: PyRef<'_, Self>) -> PyRef<'_, Self> {
pyself
}
fn __iter__(pyself: PyRef<'_, Self>) -> PyRef<'_, Self> {
pyself
}
fn __next__(&self, py: Python) -> PyResult>> {
if let Some(res) = self.result.get() {
return res
.as_ref()
.map_err(|err| err.clone_ref(py))
.map(|v| Err(PyStopIteration::new_err(v.clone_ref(py))))?;
}
Ok(Some(py.None()))
}
}
#[repr(u8)]
enum PyFutureAwaitableState {
Pending = 0,
Completed = 1,
Cancelled = 2,
}
#[pyclass(frozen, module = "robyn._robyn")]
pub(crate) struct PyFutureAwaitable {
state: atomic::AtomicU8,
result: OnceLock>>,
event_loop: Py,
cancel_tx: Arc,
cancel_msg: OnceLock>,
py_block: atomic::AtomicBool,
ack: RwLock, Py)>>,
}
impl PyFutureAwaitable {
pub(crate) fn new(event_loop: Py) -> Self {
Self {
state: atomic::AtomicU8::new(PyFutureAwaitableState::Pending as u8),
result: OnceLock::new(),
event_loop,
cancel_tx: Arc::new(Notify::new()),
cancel_msg: OnceLock::new(),
py_block: true.into(),
ack: RwLock::new(None),
}
}
pub fn to_spawn(self, py: Python) -> PyResult<(Py, Arc)> {
let cancel_tx = self.cancel_tx.clone();
Ok((Py::new(py, self)?, cancel_tx))
}
pub(crate) fn set_result(pyself: Py, py: Python, result: FutureResultToPy) {
let rself = pyself.get();
_ = rself
.result
.set(result.into_pyobject(py).map(Bound::unbind));
if rself
.state
.compare_exchange(
PyFutureAwaitableState::Pending as u8,
PyFutureAwaitableState::Completed as u8,
atomic::Ordering::Release,
atomic::Ordering::Relaxed,
)
.is_err()
{
pyself.drop_ref(py);
return;
}
{
let ack = rself.ack.read().unwrap();
if let Some((cb, ctx)) = &*ack {
_ = rself.event_loop.clone_ref(py).call_method(
py,
pyo3::intern!(py, "call_soon_threadsafe"),
(cb, pyself.clone_ref(py)),
Some(ctx.bind(py)),
);
}
}
pyself.drop_ref(py);
}
}
#[pymethods]
impl PyFutureAwaitable {
fn __await__(pyself: PyRef<'_, Self>) -> PyRef<'_, Self> {
pyself
}
fn __iter__(pyself: PyRef<'_, Self>) -> PyRef<'_, Self> {
pyself
}
fn __next__(pyself: PyRef<'_, Self>) -> PyResult>> {
if pyself.state.load(atomic::Ordering::Acquire) == PyFutureAwaitableState::Completed as u8 {
let py = pyself.py();
return pyself
.result
.get()
.unwrap()
.as_ref()
.map_err(|err| err.clone_ref(py))
.map(|v| Err(PyStopIteration::new_err(v.clone_ref(py))))?;
}
Ok(Some(pyself))
}
#[getter(_asyncio_future_blocking)]
fn get_block(&self) -> bool {
self.py_block.load(atomic::Ordering::Relaxed)
}
#[setter(_asyncio_future_blocking)]
fn set_block(&self, val: bool) {
self.py_block.store(val, atomic::Ordering::Relaxed);
}
fn get_loop(&self, py: Python) -> Py {
self.event_loop.clone_ref(py)
}
/// Single-callback optimization: only the most recent callback is stored.
/// This is intentional — this type is internal to the robyn runtime and in
/// practice asyncio registers at most one done-callback per future.
#[pyo3(signature = (cb, context=None))]
fn add_done_callback(
pyself: PyRef<'_, Self>,
cb: Py,
context: Option>,
) -> PyResult<()> {
let py = pyself.py();
let kwctx = pyo3::types::PyDict::new(py);
kwctx.set_item(pyo3::intern!(py, "context"), context)?;
let state = pyself.state.load(atomic::Ordering::Acquire);
if state == PyFutureAwaitableState::Pending as u8 {
let mut ack = pyself.ack.write().unwrap();
*ack = Some((cb, kwctx.unbind()));
} else {
let event_loop = pyself.event_loop.clone_ref(py);
event_loop.call_method(
py,
pyo3::intern!(py, "call_soon"),
(cb, pyself),
Some(&kwctx),
)?;
}
Ok(())
}
/// Clears the single stored callback (see `add_done_callback`).
/// The `cb` argument is accepted for asyncio protocol compatibility but
/// is not used for matching — the sole stored callback is always removed.
#[allow(unused)]
fn remove_done_callback(&self, cb: Py) -> i32 {
let mut ack = self.ack.write().unwrap();
if ack.is_some() {
*ack = None;
1
} else {
0
}
}
#[allow(unused)]
#[pyo3(signature = (msg=None))]
fn cancel(pyself: PyRef<'_, Self>, msg: Option>) -> bool {
if pyself
.state
.compare_exchange(
PyFutureAwaitableState::Pending as u8,
PyFutureAwaitableState::Cancelled as u8,
atomic::Ordering::Release,
atomic::Ordering::Relaxed,
)
.is_err()
{
return false;
}
if let Some(cancel_msg) = msg {
_ = pyself.cancel_msg.set(cancel_msg);
}
pyself.cancel_tx.notify_one();
let ack = pyself.ack.read().unwrap();
if let Some((cb, ctx)) = &*ack {
let py = pyself.py();
let event_loop = pyself.event_loop.clone_ref(py);
let cb = cb.clone_ref(py);
let ctx = ctx.clone_ref(py);
drop(ack);
let _ = event_loop.call_method(
py,
pyo3::intern!(py, "call_soon"),
(cb, pyself),
Some(ctx.bind(py)),
);
}
true
}
fn done(&self) -> bool {
self.state.load(atomic::Ordering::Acquire) != PyFutureAwaitableState::Pending as u8
}
fn result(&self, py: Python) -> PyResult> {
let state = self.state.load(atomic::Ordering::Acquire);
if state == PyFutureAwaitableState::Completed as u8 {
return self
.result
.get()
.unwrap()
.as_ref()
.map(|v| v.clone_ref(py))
.map_err(|err| err.clone_ref(py));
}
if state == PyFutureAwaitableState::Cancelled as u8 {
let msg = self
.cancel_msg
.get()
.unwrap_or(&"Future cancelled.".into_py_any(py).unwrap())
.clone_ref(py);
return Err(pyo3::exceptions::asyncio::CancelledError::new_err(msg));
}
Err(pyo3::exceptions::asyncio::InvalidStateError::new_err(
"Result is not ready.",
))
}
fn exception(&self, py: Python) -> PyResult> {
let state = self.state.load(atomic::Ordering::Acquire);
if state == PyFutureAwaitableState::Completed as u8 {
return self
.result
.get()
.unwrap()
.as_ref()
.map(|_| py.None())
.map_err(|err| err.clone_ref(py));
}
if state == PyFutureAwaitableState::Cancelled as u8 {
let msg = self
.cancel_msg
.get()
.unwrap_or(&"Future cancelled.".into_py_any(py).unwrap())
.clone_ref(py);
return Err(pyo3::exceptions::asyncio::CancelledError::new_err(msg));
}
Err(pyo3::exceptions::asyncio::InvalidStateError::new_err(
"Exception is not set.",
))
}
}
#[pyclass(frozen)]
pub(crate) struct PyFutureDoneCallback {
pub cancel_tx: Arc,
}
#[pymethods]
impl PyFutureDoneCallback {
pub fn __call__(&self, fut: Bound) -> PyResult<()> {
let py = fut.py();
if {
fut.getattr(pyo3::intern!(py, "cancelled"))?
.call0()?
.is_truthy()
}
.unwrap_or(false)
{
self.cancel_tx.notify_one();
}
Ok(())
}
}
#[pyclass(frozen)]
pub(crate) struct PyFutureResultSetter;
#[pymethods]
impl PyFutureResultSetter {
pub fn __call__(&self, target: Bound, value: Bound) {
let _ = target.call1((value,));
}
}
================================================
FILE: src/conversion.rs
================================================
use pyo3::prelude::*;
// Adapted for robyn - returns Py directly
pub(crate) enum FutureResultToPy {
None,
Err(PyResult<()>),
Value(Py),
}
impl<'p> IntoPyObject<'p> for FutureResultToPy {
type Target = PyAny;
type Output = Bound<'p, Self::Target>;
type Error = PyErr;
fn into_pyobject(self, py: Python<'p>) -> Result {
match self {
Self::None => Ok(py.None().into_bound(py)),
Self::Err(res) => Err(res.err().unwrap()),
Self::Value(val) => {
let bound = val.bind(py);
Ok(bound.clone())
}
}
}
}
================================================
FILE: src/executors/mod.rs
================================================
#[deny(clippy::if_same_then_else)]
pub mod web_socket_executors;
use std::sync::Arc;
use anyhow::Result;
use pyo3::prelude::*;
use pyo3::{BoundObject, IntoPyObject};
use pyo3_async_runtimes::TaskLocals;
use crate::types::{
function_info::FunctionInfo,
request::Request,
response::{Response, ResponseType, StreamingResponse},
MiddlewareReturn,
};
#[inline]
fn get_function_output<'a, T>(
function: &'a FunctionInfo,
py: Python<'a>,
function_args: &T,
) -> Result, PyErr>
where
T: Clone + for<'py> IntoPyObject<'py>,
for<'py> >::Error: std::fmt::Debug,
{
let handler = function.handler.bind(py).downcast()?;
// 0-param handlers: skip Request→Python conversion entirely
if function.number_of_params == 0 {
return handler.call0();
}
let kwargs = function.kwargs.bind(py);
let function_args: Py = function_args
.clone()
.into_pyobject(py)
.map_err(|e| {
PyErr::new::(format!(
"Failed to convert args: {:?}",
e
))
})?
.into_any()
.unbind();
match function.number_of_params {
1 => {
if pyo3::types::PyDictMethods::get_item(kwargs, "global_dependencies")
.is_ok_and(|it| !it.is_none())
|| pyo3::types::PyDictMethods::get_item(kwargs, "router_dependencies")
.is_ok_and(|it| !it.is_none())
{
handler.call((), Some(kwargs))
} else {
handler.call1((function_args,))
}
}
_ => handler.call((function_args,), Some(kwargs)),
}
}
// Execute the middleware function
// type T can be either Request (before middleware) or Response (after middleware)
// Return type can either be a Request or a Response, we wrap it inside an enum for easier handling
#[inline]
pub async fn execute_middleware_function(
input: &T,
function: &FunctionInfo,
) -> Result
where
T: Clone + for<'a, 'py> FromPyObject<'a, 'py> + for<'py> IntoPyObject<'py>,
for<'py> >::Error: std::fmt::Debug,
{
if function.is_async {
let output: Py = Python::with_gil(|py| {
pyo3_async_runtimes::tokio::into_future(get_function_output(function, py, input)?)
})?
.await?;
Python::with_gil(|py| -> Result {
// Try response extraction first, then request
match output.extract::(py) {
Ok(response) => Ok(MiddlewareReturn::Response(response)),
Err(_) => match output.extract::(py) {
Ok(request) => Ok(MiddlewareReturn::Request(request)),
Err(e) => Err(e.into()),
},
}
})
} else {
Python::with_gil(|py| -> Result {
let output = get_function_output(function, py, input)?;
match output.extract::() {
Ok(response) => Ok(MiddlewareReturn::Response(response)),
Err(_) => match output.extract::() {
Ok(request) => Ok(MiddlewareReturn::Request(request)),
Err(e) => Err(e.into()),
},
}
})
}
}
// Execute the after_request middleware function with both request and response
// This allows after_request callbacks to access the request object
#[inline]
fn get_function_output_with_two_args<'a, T, U>(
function: &'a FunctionInfo,
py: Python<'a>,
first_arg: &T,
second_arg: &U,
) -> Result, PyErr>
where
T: Clone + for<'py> IntoPyObject<'py>,
U: Clone + for<'py> IntoPyObject<'py>,
for<'py> >::Error: std::fmt::Debug,
for<'py> >::Error: std::fmt::Debug,
{
let handler = function.handler.bind(py).downcast()?;
if function.number_of_params == 0 {
return handler.call0();
}
let kwargs = function.kwargs.bind(py);
let first_arg: Py = first_arg
.clone()
.into_pyobject(py)
.map_err(|e| {
PyErr::new::(format!(
"Failed to convert first arg: {:?}",
e
))
})?
.into_any()
.unbind();
let second_arg: Py = second_arg
.clone()
.into_pyobject(py)
.map_err(|e| {
PyErr::new::(format!(
"Failed to convert second arg: {:?}",
e
))
})?
.into_any()
.unbind();
match function.number_of_params {
1 => {
if pyo3::types::PyDictMethods::get_item(kwargs, "global_dependencies")
.is_ok_and(|it| !it.is_none())
|| pyo3::types::PyDictMethods::get_item(kwargs, "router_dependencies")
.is_ok_and(|it| !it.is_none())
{
handler.call((), Some(kwargs))
} else {
handler.call1((second_arg,))
}
}
2 => {
if pyo3::types::PyDictMethods::get_item(kwargs, "global_dependencies")
.is_ok_and(|it| !it.is_none())
|| pyo3::types::PyDictMethods::get_item(kwargs, "router_dependencies")
.is_ok_and(|it| !it.is_none())
{
handler.call((first_arg, second_arg), Some(kwargs))
} else {
handler.call1((first_arg, second_arg))
}
}
_ => handler.call((first_arg, second_arg), Some(kwargs)),
}
}
// Execute the after_request middleware function with both request and response
#[inline]
pub async fn execute_after_middleware_function(
request: &Request,
response: &Response,
function: &FunctionInfo,
) -> Result {
if function.is_async {
let output: Py = Python::with_gil(|py| {
pyo3_async_runtimes::tokio::into_future(get_function_output_with_two_args(
function, py, request, response,
)?)
})?
.await?;
Python::with_gil(|py| -> Result {
// Try response extraction first, then request
match output.extract::(py) {
Ok(response) => Ok(MiddlewareReturn::Response(response)),
Err(_) => match output.extract::(py) {
Ok(request) => Ok(MiddlewareReturn::Request(request)),
Err(e) => Err(e.into()),
},
}
})
} else {
Python::with_gil(|py| -> Result {
let output = get_function_output_with_two_args(function, py, request, response)?;
match output.extract::() {
Ok(response) => Ok(MiddlewareReturn::Response(response)),
Err(_) => match output.extract::() {
Ok(request) => Ok(MiddlewareReturn::Request(request)),
Err(e) => Err(e.into()),
},
}
})
}
}
#[inline]
pub async fn execute_http_function(
request: &Request,
function: &FunctionInfo,
) -> PyResult {
if function.is_async {
let output = Python::with_gil(|py| {
let function_output = get_function_output(function, py, request)?;
pyo3_async_runtimes::tokio::into_future(function_output)
})?
.await?;
Python::with_gil(|py| extract_response_type(output, py))
} else {
Python::with_gil(|py| {
let output = get_function_output(function, py, request)?;
extract_response_type_bound(output)
})
}
}
#[inline]
fn extract_response_type(output: Py, py: Python) -> PyResult {
// Try Response first (most common case), then StreamingResponse
match output.extract::(py) {
Ok(response) => Ok(ResponseType::Standard(response)),
Err(_) => match output.extract::(py) {
Ok(streaming_response) => Ok(ResponseType::Streaming(streaming_response)),
Err(_) => Err(PyErr::new::(
"Function must return a Response or StreamingResponse",
)),
},
}
}
#[inline]
fn extract_response_type_bound(output: pyo3::Bound<'_, pyo3::PyAny>) -> PyResult {
match output.extract::() {
Ok(response) => Ok(ResponseType::Standard(response)),
Err(_) => match output.extract::() {
Ok(streaming_response) => Ok(ResponseType::Streaming(streaming_response)),
Err(_) => Err(PyErr::new::(
"Function must return a Response or StreamingResponse",
)),
},
}
}
pub async fn execute_startup_handler(
event_handler: Option>,
task_locals: &TaskLocals,
) -> Result<()> {
if let Some(function) = event_handler {
if function.is_async {
Python::with_gil(|py| {
pyo3_async_runtimes::into_future_with_locals(
task_locals,
function.handler.bind(py).call0()?,
)
})?
.await?;
} else {
Python::with_gil(|py| function.handler.call0(py))?;
}
}
Ok(())
}
================================================
FILE: src/executors/web_socket_executors.rs
================================================
use actix::{ActorFutureExt, AsyncContext, WrapFuture};
use actix_web_actors::ws::WebsocketContext;
use pyo3::prelude::*;
use pyo3_async_runtimes::TaskLocals;
use crate::types::function_info::FunctionInfo;
use crate::websockets::WebSocketConnector;
pub fn execute_ws_function(
function: &FunctionInfo,
task_locals: &TaskLocals,
ctx: &mut WebsocketContext,
ws: &WebSocketConnector,
) {
if function.is_async {
let fut = Python::with_gil(|py| {
let handler = function.handler.bind(py).downcast().unwrap();
pyo3_async_runtimes::into_future_with_locals(
task_locals,
handler.call1((ws.clone(),)).unwrap(),
)
.unwrap()
});
let f = async {
let output = fut.await.unwrap();
Python::with_gil(|py| output.extract::>(py).unwrap())
}
.into_actor(ws)
.map(|res, _, ctx| {
if let Some(msg) = res {
ctx.text(msg);
}
});
ctx.spawn(f);
} else {
Python::with_gil(|py| {
let handler = function.handler.bind(py).downcast().unwrap();
if let Some(op) = handler
.call1((ws.clone(),))
.unwrap()
.extract::>()
.unwrap()
{
ctx.text(op);
}
});
}
}
================================================
FILE: src/io_helpers/mod.rs
================================================
use std::fs::File;
use std::io::Read;
use actix_web::HttpResponseBuilder;
use anyhow::Result;
use crate::types::headers::Headers;
// this should be something else
// probably inside the submodule of the http router
#[inline]
pub fn apply_hashmap_headers(response: &mut HttpResponseBuilder, headers: &Headers) {
for iter in headers.headers.iter() {
let (key, values) = iter.pair();
for value in values {
response.append_header((key.clone(), value.clone()));
}
}
}
/// A function to read lossy files and serve it as a html response
///
/// # Arguments
///
/// * `file_path` - The file path that we want the function to read
///
// ideally this should be async
pub fn read_file(file_path: &str) -> Result> {
let mut file = File::open(file_path)?;
let mut buf = vec![];
file.read_to_end(&mut buf)?;
Ok(buf)
}
================================================
FILE: src/lib.rs
================================================
mod asyncio;
mod blocking;
mod callbacks;
mod conversion;
mod executors;
mod io_helpers;
mod routers;
mod runtime;
mod server;
mod shared_socket;
mod types;
mod websockets;
use server::Server;
use shared_socket::SocketHeld;
// pyO3 module
use pyo3::prelude::*;
use types::{
cookie::{Cookie, Cookies, CookiesIter},
function_info::{FunctionInfo, MiddlewareType},
headers::Headers,
identity::Identity,
multimap::QueryParams,
request::PyRequest,
response::{PyResponse, PyStreamingResponse},
HttpMethod, Url,
};
use websockets::{registry::WebSocketRegistry, WebSocketChannel, WebSocketConnector};
#[pyfunction]
fn get_version() -> String {
env!("CARGO_PKG_VERSION").into()
}
#[pymodule]
pub fn robyn(_py: Python, m: &Bound<'_, PyModule>) -> PyResult<()> {
// the pymodule class/function to make the rustPyFunctions available
m.add_function(wrap_pyfunction!(get_version, m)?)?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
// Register awaitable types
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
m.add_class::()?;
Ok(())
}
================================================
FILE: src/routers/const_router.rs
================================================
use actix_http::StatusCode;
use actix_web::{web::Bytes, HttpResponse, HttpResponseBuilder};
use parking_lot::RwLock;
use std::collections::HashMap;
use std::sync::Arc;
use crate::executors::execute_http_function;
use crate::types::cookie::Cookies;
use crate::types::function_info::FunctionInfo;
use crate::types::headers::Headers;
use crate::types::request::Request;
use crate::types::response::Response;
use crate::types::HttpMethod;
use anyhow::Context;
use matchit::Router as MatchItRouter;
use pyo3::{Bound, PyErr, Python};
use anyhow::{Error, Result};
use crate::routers::Router;
/// Pre-built response for const routes — zero per-request allocation.
/// Headers (including global response headers) are baked in at startup.
#[derive(Clone)]
pub struct CachedResponse {
pub status: StatusCode,
pub headers: Arc>,
pub body: Bytes,
route_header_count: usize,
}
impl CachedResponse {
fn from_response(response: &Response) -> Self {
let mut headers = Vec::new();
for entry in response.headers.headers.iter() {
let (key, values) = entry.pair();
for value in values {
headers.push((key.clone(), value.clone()));
}
}
for (name, cookie) in &response.cookies.cookies {
if let Ok(header_value) = cookie.to_header_value(name) {
headers.push(("set-cookie".to_string(), header_value));
}
}
let route_header_count = headers.len();
Self {
status: StatusCode::from_u16(response.status_code)
.unwrap_or(StatusCode::INTERNAL_SERVER_ERROR),
headers: Arc::new(headers),
body: Bytes::from(response.description.clone()),
route_header_count,
}
}
#[inline(always)]
pub fn to_http_response(&self) -> HttpResponse {
let mut builder = HttpResponseBuilder::new(self.status);
for (k, v) in self.headers.as_ref() {
builder.append_header((k.as_str(), v.as_str()));
}
builder.body(self.body.clone())
}
#[inline(always)]
pub fn to_http_response_without_global_headers(&self) -> HttpResponse {
let mut builder = HttpResponseBuilder::new(self.status);
for (k, v) in self.headers.as_ref().iter().take(self.route_header_count) {
builder.append_header((k.as_str(), v.as_str()));
}
builder.body(self.body.clone())
}
}
type RouteMap = RwLock>;
/// Fast const-route lookup table: exact path → CachedResponse.
/// Uses a simple HashMap (no regex, no path params, no RwLock per lookup).
type FastMap = RwLock>;
pub struct ConstRouter {
routes: HashMap>,
fast_routes: HashMap>,
}
impl Router for ConstRouter {
fn add_route<'py>(
&self,
_py: Python,
route_type: &HttpMethod,
route: &str,
function: FunctionInfo,
event_loop: Option>,
) -> Result<(), Error> {
let table = Arc::clone(self.routes.get(route_type).context("No relevant map")?);
let fast_table = Arc::clone(
self.fast_routes
.get(route_type)
.context("No relevant fast map")?,
);
let route = route.to_string();
let event_loop =
event_loop.context("Event loop must be provided to add a route to the const router")?;
pyo3_async_runtimes::tokio::run_until_complete(event_loop, async move {
let output = execute_http_function(&Request::default(), &function)
.await
.unwrap();
match output {
crate::types::response::ResponseType::Standard(response) => {
let cached = CachedResponse::from_response(&response);
table.write().insert(route.clone(), cached.clone()).unwrap();
fast_table.write().insert(route, cached);
}
crate::types::response::ResponseType::Streaming(_) => {
return Err(PyErr::new::(
"Streaming responses are not supported for const routes",
)
.into());
}
}
Ok(())
})?;
Ok(())
}
fn get_route(&self, route_method: &HttpMethod, route: &str) -> Option {
let cached = self.get_cached_route(route_method, route)?;
let mut resp = Response {
status_code: cached.status.as_u16(),
response_type: "text".to_string(),
headers: Headers::new(None),
description: cached.body.to_vec(),
file_path: None,
cookies: Cookies::new(),
};
for (k, v) in cached.headers.as_ref() {
resp.headers.set(k.clone(), v.clone());
}
Some(resp)
}
}
impl ConstRouter {
pub fn new() -> Self {
let mut routes = HashMap::new();
let mut fast_routes = HashMap::new();
for method in [
HttpMethod::GET,
HttpMethod::POST,
HttpMethod::PUT,
HttpMethod::DELETE,
HttpMethod::PATCH,
HttpMethod::HEAD,
HttpMethod::OPTIONS,
HttpMethod::CONNECT,
HttpMethod::TRACE,
] {
routes.insert(method.clone(), Arc::new(RwLock::new(MatchItRouter::new())));
fast_routes.insert(method, Arc::new(RwLock::new(HashMap::new())));
}
Self {
routes,
fast_routes,
}
}
/// Bake global response headers into all cached responses.
/// Called once at server start, after global headers are set.
pub fn bake_global_headers(&self, global_headers: &Headers) {
let mut extra_headers: Vec<(String, String)> = Vec::new();
for entry in global_headers.headers.iter() {
let (key, values) = entry.pair();
for value in values {
extra_headers.push((key.clone(), value.clone()));
}
}
if extra_headers.is_empty() {
return;
}
for (method, fast_table) in &self.fast_routes {
let mut map = fast_table.write();
for cached in map.values_mut() {
let mut combined = cached.headers.as_ref().clone();
combined.extend(extra_headers.iter().cloned());
cached.headers = Arc::new(combined);
}
if let Some(route_table) = self.routes.get(method) {
let mut new_router = MatchItRouter::new();
for (route, cached) in map.iter() {
let _ = new_router.insert(route.clone(), cached.clone());
}
*route_table.write() = new_router;
}
}
}
/// Fast lookup: tries exact HashMap first, falls back to matchit for parameterized/wildcard routes.
#[inline(always)]
pub fn get_cached_route(
&self,
route_method: &HttpMethod,
route: &str,
) -> Option {
let fast_table = self.fast_routes.get(route_method)?;
{
let map = fast_table.read();
if let Some(cached) = map.get(route) {
return Some(cached.clone());
}
}
let route_table = self.routes.get(route_method)?;
let router = route_table.read();
router.at(route).ok().map(|matched| matched.value.clone())
}
}
================================================
FILE: src/routers/http_router.rs
================================================
use parking_lot::RwLock;
use pyo3::{Bound, Python};
use std::collections::HashMap;
use matchit::Router as MatchItRouter;
use anyhow::{Context, Result};
use crate::routers::Router;
use crate::types::function_info::FunctionInfo;
use crate::types::HttpMethod;
type RouteMap = RwLock>;
/// Contains the thread safe hashmaps of different routes
pub struct HttpRouter {
routes: HashMap,
}
impl Router<(FunctionInfo, HashMap), HttpMethod> for HttpRouter {
fn add_route<'py>(
&self,
_py: Python,
route_type: &HttpMethod,
route: &str,
function: FunctionInfo,
_event_loop: Option>,
) -> Result<()> {
let table = self.routes.get(route_type).context("No relevant map")?;
// try removing unwrap here
table.write().insert(route.to_string(), function)?;
Ok(())
}
fn get_route(
&self,
route_method: &HttpMethod,
route: &str,
) -> Option<(FunctionInfo, HashMap)> {
let table = self.routes.get(route_method)?;
let table_lock = table.read();
// Trying route matching just once.
if let Ok(res) = table_lock.at(route) {
let mut route_params = HashMap::new();
for (key, value) in res.params.iter() {
route_params.insert(key.to_string(), value.to_string());
}
let function_info = Python::with_gil(|_| res.value.to_owned());
return Some((function_info, route_params));
}
None
}
}
impl HttpRouter {
pub fn new() -> Self {
let mut routes = HashMap::new();
routes.insert(HttpMethod::GET, RwLock::new(MatchItRouter::new()));
routes.insert(HttpMethod::POST, RwLock::new(MatchItRouter::new()));
routes.insert(HttpMethod::PUT, RwLock::new(MatchItRouter::new()));
routes.insert(HttpMethod::DELETE, RwLock::new(MatchItRouter::new()));
routes.insert(HttpMethod::PATCH, RwLock::new(MatchItRouter::new()));
routes.insert(HttpMethod::HEAD, RwLock::new(MatchItRouter::new()));
routes.insert(HttpMethod::OPTIONS, RwLock::new(MatchItRouter::new()));
routes.insert(HttpMethod::CONNECT, RwLock::new(MatchItRouter::new()));
routes.insert(HttpMethod::TRACE, RwLock::new(MatchItRouter::new()));
Self { routes }
}
}
================================================
FILE: src/routers/middleware_router.rs
================================================
use std::collections::HashMap;
use std::sync::atomic::{AtomicBool, Ordering};
use std::sync::RwLock;
use anyhow::{Context, Error, Result};
use matchit::Router as MatchItRouter;
use pyo3::{Bound, Python};
use crate::routers::Router;
use crate::types::function_info::{FunctionInfo, MiddlewareType};
type RouteMap = RwLock>;
pub struct MiddlewareRouter {
globals: HashMap>>,
routes: HashMap,
has_middleware: AtomicBool,
}
impl Router<(FunctionInfo, HashMap), MiddlewareType> for MiddlewareRouter {
fn add_route<'py>(
&self,
_py: Python,
route_type: &MiddlewareType,
route: &str,
function: FunctionInfo,
_event_loop: Option>,
) -> Result<(), Error> {
let table = self.routes.get(route_type).context("No relevant map")?;
table.write().unwrap().insert(route.to_string(), function)?;
self.has_middleware.store(true, Ordering::Release);
Ok(())
}
fn get_route(
&self,
route_method: &MiddlewareType,
route: &str,
) -> Option<(FunctionInfo, HashMap)> {
let table = self.routes.get(route_method)?;
let table_lock = table.read().ok()?;
let res = table_lock.at(route).ok()?;
let mut route_params = HashMap::new();
for (key, value) in res.params.iter() {
route_params.insert(key.to_string(), value.to_string());
}
let function_info = Python::with_gil(|_| res.value.to_owned());
Some((function_info, route_params))
}
}
impl MiddlewareRouter {
pub fn new() -> Self {
let mut globals = HashMap::new();
globals.insert(MiddlewareType::BeforeRequest, RwLock::new(vec![]));
globals.insert(MiddlewareType::AfterRequest, RwLock::new(vec![]));
let mut routes = HashMap::new();
routes.insert(
MiddlewareType::BeforeRequest,
RwLock::new(MatchItRouter::new()),
);
routes.insert(
MiddlewareType::AfterRequest,
RwLock::new(MatchItRouter::new()),
);
Self {
globals,
routes,
has_middleware: AtomicBool::new(false),
}
}
pub fn add_global_middleware(
&self,
middleware_type: &MiddlewareType,
function: FunctionInfo,
) -> Result<()> {
self.globals
.get(middleware_type)
.context("No relevant map")?
.write()
.unwrap()
.push(function);
self.has_middleware.store(true, Ordering::Release);
Ok(())
}
pub fn get_global_middlewares(&self, middleware_type: &MiddlewareType) -> Vec {
self.globals
.get(middleware_type)
.unwrap()
.read()
.unwrap()
.to_vec()
}
pub fn has_any_middleware(&self) -> bool {
self.has_middleware.load(Ordering::Acquire)
}
}
================================================
FILE: src/routers/mod.rs
================================================
use anyhow::Result;
use pyo3::{Bound, Python};
use crate::types::function_info::FunctionInfo;
pub mod const_router;
pub mod http_router;
pub mod middleware_router;
pub mod web_socket_router;
pub trait Router {
/// Checks if the functions is an async function
/// Inserts them in the router according to their nature(CoRoutine/SyncFunction)
fn add_route<'py>(
&self,
py: Python,
route_type: &U,
route: &str,
function: FunctionInfo,
event_loop: Option>,
) -> Result<()>;
/// Retrieve the correct function from the previously inserted routes
fn get_route(&self, route_type: &U, route: &str) -> Option;
}
================================================
FILE: src/routers/web_socket_router.rs
================================================
use parking_lot::RwLock;
use std::collections::HashMap;
use log::debug;
use crate::types::function_info::FunctionInfo;
/// Contains the thread safe hashmaps of different routes
type WebSocketRoutes = RwLock>>;
pub struct WebSocketRouter {
web_socket_routes: WebSocketRoutes,
}
impl WebSocketRouter {
pub fn new() -> Self {
Self {
web_socket_routes: RwLock::new(HashMap::new()),
}
}
#[inline]
pub fn get_web_socket_map(&self) -> &WebSocketRoutes {
&self.web_socket_routes
}
pub fn add_websocket_route(
&self,
route: &str,
connect_route: FunctionInfo,
close_route: FunctionInfo,
message_route: FunctionInfo,
) {
let table = self.get_web_socket_map();
let insert_in_router = |function: FunctionInfo, socket_type: &str| {
debug!("socket type is {:?} {:?}", table, route);
table
.write()
.entry(route.to_string())
.or_default()
.insert(socket_type.to_string(), function)
};
insert_in_router(connect_route, "connect");
insert_in_router(close_route, "close");
insert_in_router(message_route, "message");
}
}
================================================
FILE: src/runtime.rs
================================================
use futures::FutureExt;
use pyo3::{prelude::*, IntoPyObjectExt};
use std::{future::Future, sync::Arc, sync::OnceLock};
use tokio::{runtime::Builder as RuntimeBuilder, task::JoinHandle};
#[cfg(unix)]
use super::callbacks::PyFutureAwaitable;
#[cfg(windows)]
use super::callbacks::{PyFutureDoneCallback, PyFutureResultSetter};
use super::blocking::BlockingRunner;
use super::callbacks::{PyDoneAwaitable, PyEmptyAwaitable, PyErrAwaitable, PyIterAwaitable};
use super::conversion::FutureResultToPy;
pub trait JoinError {
#[allow(dead_code)]
fn is_panic(&self) -> bool;
}
pub trait Runtime: Send + 'static {
type JoinError: JoinError + Send;
type JoinHandle: Future